/






























































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































Автор: Хайкин С.
Теги: компьютерные технологии программирование машинное обучение искусственные нейронные сети
ISBN: 5-8459-0890-6
Год: 2006




Текст
ВТОРОЕ ИЗДАНИЕ
НЕЙРОННЫЕ
СЕТИ.
ПОПНЫЙ КУРС
'<
.
.
САймон ХАйкин
NEURAL NEТWORКS
А Comprehensive Foundation
Second Edition
Simon Haykin
McMaster Uпiversity
НатШоп, Oпtario, Caпada
..
Prentice НаН
Upper Sadd1e River, New Jersey 07458
НЕЙРОННЫЕ СЕТИ
Полный курс
Второе издан ие
Саймон Хайкин
Университет McMaster
fамuльтон, Онтарио, Канада
I!i
Москва . Санкr Петербурr . Киев
2006
ББК 32.973.26 018.2.75
Х15
УДК 681.3.07
Издательский дом "Вильямс"
Зав. редакцией е.н. Трuzуб
Перевод с анrлийскоrо. Д.Т.н. н.н. Кусеуль, к.т.н. А.Ю. Шелестова
Под редакцией Д.Т.н. н.н. Кусеуль
По общим вопросам обращайтесь в Издательский дом "Вильямс"
по адресу: info@williamspublishing.com, http://www.williamspublishing.com
115419, Москва, а/я 783; 03150, Киев, а/я 152
Хайкин, Саймон.
Х15 Нейронные сети: полный курс, 2 e издание. : Пер. с анrл. М. Издательский дом
"Вильямс", 2006. 1104 с. : ил. Парал. тит. анrл.
ISBN 5 8459 0890 6 (рус.)
в книrе рассматриваются основные парадиrмы искусственных нейронных сетей. Представленный
материал содержит cтporoe математическое обоснование всех нейросетевых парадиrм, иллюстрируется
примерами, описанием компьютерных эксперимеитов, содержит множество практических задач, а также
обширную библиоrpафию.
В книrе также анализируется роль нейронных сетей при решении задач распознавания образов,
управления и обработки сиrналов. Структура книrn очень удобна для разработки курсов обучения
нейронным сетям и интеллектуальным вычислениям.
Кииrа будет полезна для инженеров, специалистов в области компьютерных наук, физиков и
специалистов в дрyrnx областях, а также для всех тех, кто интересуется искусственными нейронными сетями.
ББК 32.973.26 018.2.75
Все названия проrpаммных продуктов являются зареrnС1рированными торrовыми марками соответствующих фирм.
Никакая часть настоящеrо издания ни в каких целях не может быть воспроизведена в какой бы то ни было
форме и какими бы то ни было средствами, будь то элеК1ронные или механические, включая фотокопирование и
запись на маrНиТНЫЙ носитель, если на это нет письменноrо разрешения издательства Prentice НаН, Iпс.
Authorized translation from the English !anguage edition published Ьу Prentice НаН, Copyright @ 1998
АН rights reserved. No part of this book тау Ье reproduced or transmitted in апу [оrm or Ьу апу means, e!ectronic or
mechanicaI, including photocopying, recording or Ьу апу information storage retrieva! system, without pennission fют the
Publisher.
Russian language edition was published Ьу Wil1iams Publishing House according to the Agreement with R&I
Enterprises IпtеmаtiопaI. Copyright @ 2006
ISBN 5 8459 0890 6 (рус.)
ISBN О IЗ 273350 ! (анrл.)
@ Издательский дом "Вильямс", 2006
@ Prentice НаН, Inc.. 1999
Предисловие 22
1. Введение 31
2. Процессыобучения 89
3. Однослойный персептрон 172
4. Мноrослойный персептрон 219
5. Сети на основе радиальных базисных функций 341
6. Машины опорных векторов 417
7. Ассоциативные машины 458
8. Анализ rлавных компонентов 509
9. Карты самоорrанизации 573
10. Модели на основе теории информации 622
11. Стохастические машины и их аппроксимации
в статистической механике 691
12. Нейродинамическое проrраммирование 760
13. Временная обработка с использованием сетей прямоrо
распространения 799
14. Нейродинамика 835
15. Динамически управляемые рекуррентные сети 919
16. Заключение 989
Библиоrрафия 996
Предметный указатель 1069
П ов
Блаrодарности 25
Важные символы 27
Открытые и закрытые интервалы 29
Минимумы и максимумы 29
1. Введение 31
1.1. Что такое нейронные сети 31
Преимущества нейронных сетей 33
1.2. Человеческий мозr 37
1.3. Модели нейронов 42
Типы функций активации 45
Стохастическая модель нейрона 48
1.4. Представление нейронных сетей с помощью
направленных rрафов 49
1.5. Обратная связь 52
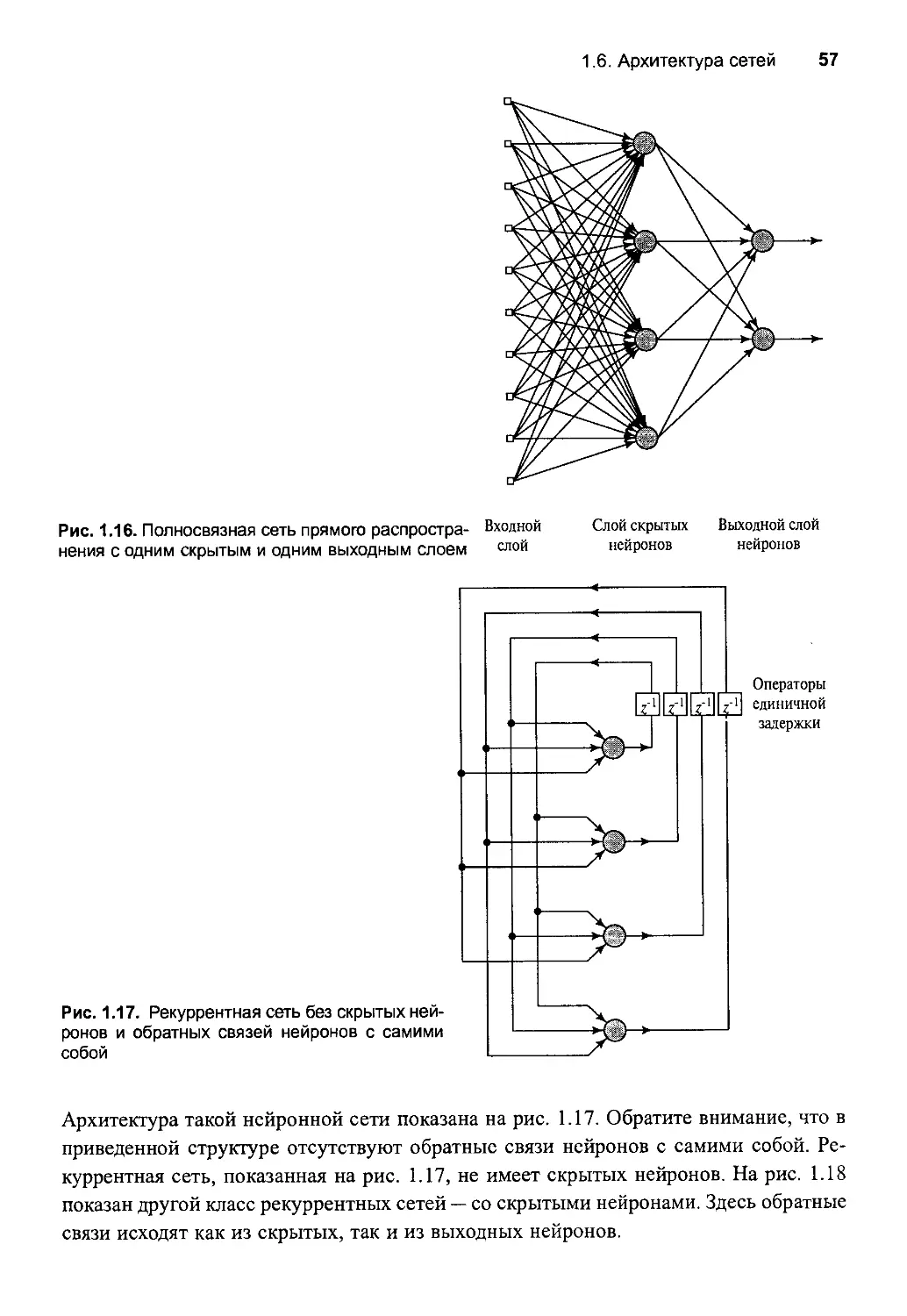
1.6. Архитектура сетей 55
Однослойные сети прямоrо распространения 56
Мноrослойные сети прямоrо распространения 56
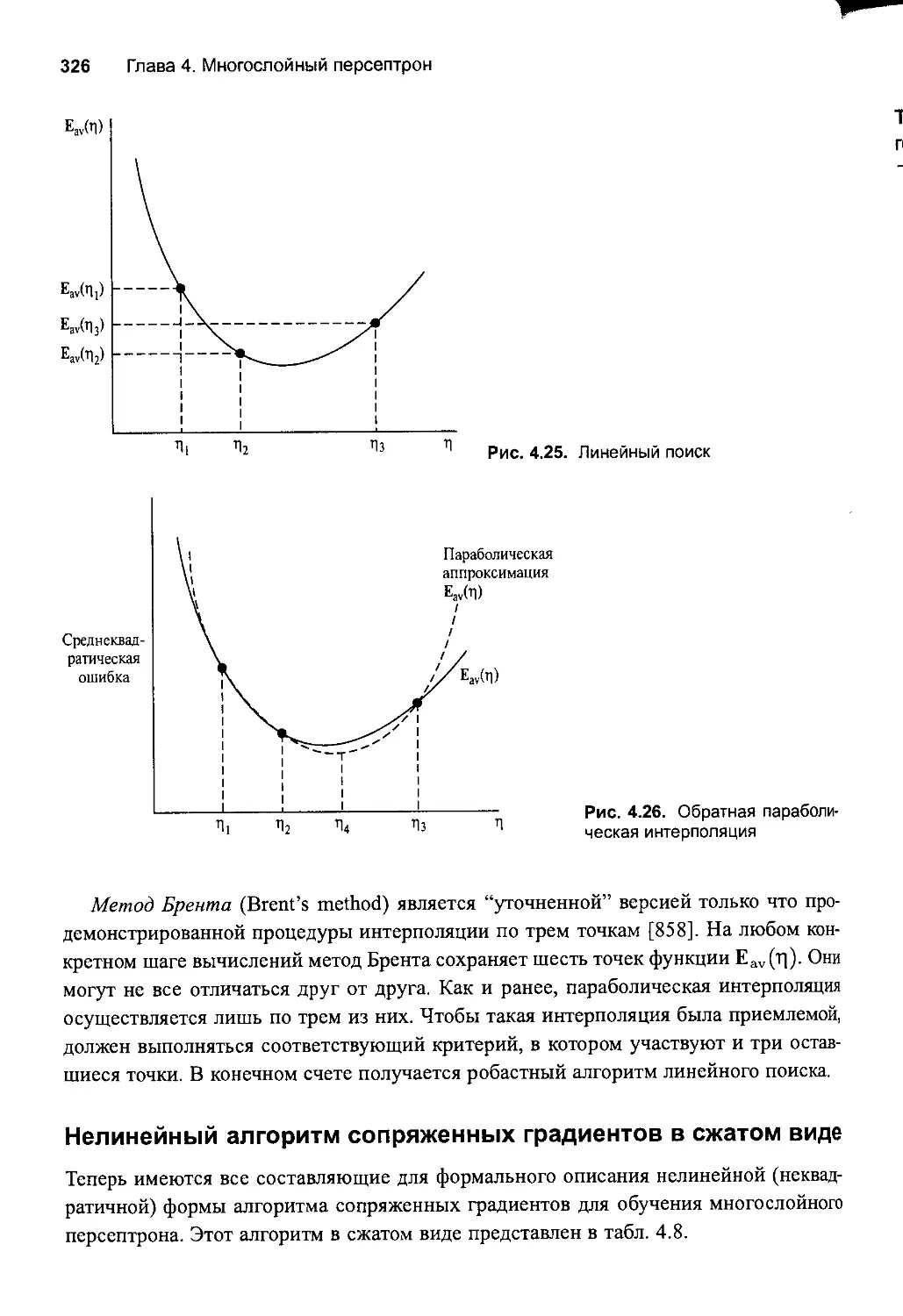
Рекуррентные сети 57
1.7. Представление знаний 58
Как встроить априорную информацию в структуру нейронной сети 64
Как встроить инварианты в структуру нейронной сети 65
1.8. Искусственный интеллект и нейронные сети 71
1.9. Историческая справка 75
Задачи 84
Модели нейрона 84
Сетевые архитектуры 86
Представление знаний 88
2. Процессы обучения 89
2.1. Введение 89
Структура rлавы 90
2.2. Обучение, основанное на коррекции ошибок 91
2.3. Обучение на основе памяти 93
2.4. Обучение Хебба 95
Содержание 7
Усиление и ослабление синаптической связи 97
Математические модели предложенноrо Хеббом механизма
модификации синаптической связи 98
2.5. Конкурентное обучение 101
2.6. Обучение Больцмана 104
2.7. Задача присваивания коэффициентов доверия 106
2.8. Обучение с учителем 107
2.9. Обучение без учителя 108
Обучение с подкреплением, или нейродинамическое
проrраммирование 109
Обучение без учителя 11 О
2.10. Задачи обучения 111
Ассоциативная память 111
Распознавание образов 113
Аппроксимация функций 114
Управление 116
Фильтрация 118
Формирование диаrраммы направленности 120
2.11. Память 122
Память в виде матрицы корреляции 127
Извлечение из памяти 129
2.12. Адаптация 132
2.1 З. Статистическая при рода процесса обучения 134
Дилемма смещения и дисперсии 138
2.14. Теория статистическоrо обучения 140
Некоторые основные определения 142
Принцип минимизации эмпирическоrо риска 143
VС измерение 146
Важность VС измерения и ero оценка 149
Конструктивные, независимые от распределения пределы
обобщающей способности обучаемых машин 151
Минимизация CTPYKTypHOro риска 154
2.15. Вероятностно корректная в смысле аппроксимации модель
обучения 156
Сложность обучающеrо множества 159
Вычислительная сложность 160
2.16. Резюме и обсуждение 161
Задачи 163
Правила обучения 163
Парадиrмы обучения 166
Память 167
Адаптация 168
Статистическая теория обучения 169
8 Содержание
з. ОДНОСЛОЙНЫЙ персептрон 171
3.1. Введение 171
Структура rлавы 172
3.2. Задача адаптивной фильтрации 173
3.3. Методы безусловной оптимизации 175
Метод наискорейшеrо спуска 177
Метод Ньютона 179
Метод rаусса Ньютона 181
3.4. Линейный фильтр, построенный по методу
наименьших квадратов 183
Фильтр Винера как оrраниченная форма линейноrо фильтра,
nOCTpoeHHOro по методу наименьших квадратов,
для эрroдической среды 184
3.5. Алrоритм минимизации среднеквадратической ошибки 185
rраф передачи сиrнала для алrоритма минимизации
среднеквадратической ошибки 187
Условия сходимости алroритма LMS 188
Преимущества и недостатки алroритма LMS 190
3.6. rрафики процесса обучения 191
3.7. Изменение параметра скорости обучения по модели отжиrа 193
3.8. Персептрон 194
3.9. Теорема о сходимости Персептрона 196
3.10. Взаимосвязь персептрона и байесовскоrо классификатора
в rауссовой среде 204
Байесовский классификатор 204
Байесовский классификатор и распределение raycca 207
3.11. Резюме и обсуждение 210
Задачи 212
Безусловная оптимизация 212
Алrоритм LMS 213
Персептрон Розенблатта 216
4. Мноrослойный персептрон 219
4.1. Введение 219
Структура rлавы 221
4.2. Вводные замечания 222
Обозначения 224
4.3. Алrоритм обратноrо распространения 225
Случай 1. Нейрон j выходной узел 229
Случай 2. Нейрон j скрытый узел 229
Два прохода вычислений 232
Функция активации 233
Содержание 9
Скорость обучения 235
Последовательный и пакетный режимы обучения 238
Критерий останова 240
4.4. Алrоритм обратноro распространения в краткой форме 241
4.5. Задача XOR 243
4.6. Эвристические рекомендации по улучшению работы
алroритма обратноro распространения 245
4.7. Представление выхода и решающее правило 253
4.8. Компьютерный эксперимент 256
Байесовская rраница решений 257
Экспериментальное построение оптимальноrо мноroслойноrо
персептрона 260
4.9. Извлечение признаков 268
Связь с линейным дискриминантом Фишера 272
4.10. Обратное распространение ошибки и дифференцирование 274
Матрица якобиана 275
4.11. rессиан 276
4.12. Обобщение 278
Достаточный объем примеров обучения для KoppeKTHoro обобщения 279
4.1 З. Аппроксимация функций 281
Теорема об универсальной аппроксимации 282
Пределы ошибок аппроксимации 283
"Проклятие размерности" 285
Практические соображения 286
4.14. Перекрестная проверка 288
Выбор модели 289
Метод обучения с ранним остановом 291
Варианты метода перекрестной проверки 294
4.15. Методы упрощения структуры сети 295
Реryляризация сложности 296
Упрощение структуры сети на основе rессиана 299
4.16. Преимущества и оrраничения обучения методом обратноrо
распространения 304
Связность 306
Извлечение признаков 307
Аппроксимация функций 309
Вычислительная эффективность 310
Анализ чувствительности 310
Робастность 311
Сходимость 311
Локальные минимумы 312
Масштабирование 313
4.17. Ускорение сходимости процесса обучения методом обратноro
распространения 315
10 Содержание
4.18. Обучение с учителем как задача оптимизации 316
Метод сопряженных rрадиентов 319
нелинейный алrоритм сопряженнь'х rрадиентов в сжатом виде 326
Квазиньютоновкие методы 327
Сравнение квазиньютоноВСКИХ методов с методом сопряжеННЬ1Х
rрадиентов 329
4.19. Сети свертки 330
4.20. Резюме и обсуждение 333
Задачи 335
Задачи XOR 335
Обучение методом обратноrо распространения 335
Перекрестная проверка 336
Приемы упрощения сети 337
Ускорение сходимости алrоритма обратноrо распространения 337
Методы оптимизации BToporo порядка 338
Компьютерное моделирование 338
5. Сети на основе радиальных базисных функций 341
.
5.1. Введение
Структура rлаВЬ1
5.2. Теорема Ковера о разделимости множеств
Разделяющая способность поверхности
5.3. Задача интерполяции
Теорема Мичелли
5.4. Обучение с учителем как плохо обусловленная задача
восстановления rиперповерхности
5.5. Теория реryляризации
Дифференциал Фреше функционала Тихонова
Уравнение Эйлера Лаrранжа
Функция rрина
Решение задачи реryляризации
Определение коэффициентов разложения
MHoroMepHbIe функции raycca
5.6. Сети реryляризации
5.7. Обобщенные сети на основе радиальных базисных функций
Взвешенная норма
Рецептивные поля
5.8. Задача XOR (повторное рассмотрение)
5.9. Оценивание параметра реryляризации
Среднеквадратическая ошибка
Обобщенная перекрестная проверка
Оптимальное свойство обобщенной функции перекрестной
проверки Vл
Заключительные комментарии
5.10. Свойства аппроксимации сетей RBF
341
342
343
347
349
352
353
355
358
360
361
363
364
367
369
371
373
375
376
378
379
382
384
385
385
/
Содержание 11
Универсальная теорема об аппроксимации 386
"Проклятие размерности" (продолжение) 386
Связь между сложностью обучающеrо множества, вычислительной
сложностью и эффективностью обобщения 388
5.11. Сравнение сетей RBF и мноrослойных персептронов 389
5.12. Реrрессия ядра и ее связь с сетями RBF 390
MHoroMepHoe распределение raycca 395
5.13. Стратеrии обучения 396
Случайный выбор фиксированных центров 396
ВЬiбор центров на основе самоорrанизации 399
Выбор центров с учителем 401
Строraя интерполяция с реryляризацией 403
5.14. Компьютерное моделирование: классификация образов 405
5.15. Резюме и обсуждение 408
Задачи 409
Радиальные базисные функции 409
Сети реryляризации 41 О
Порядок аппроксимации 413
Оценка ядра 414
Вь[бор центров с учителем 414
Компьютерное моделирование 415
6. Машины опорных векторов 417
6.1. Введение 417
Структура rлавы 418
6.2. Оптимальная rиперплоскость для линейно...разделимых образов 419
Квадратичная оптимизация и поиск оптимальной rиперплоскости 422
Статистические свойства оптимальной rиперплоскости 425
6.3. Оптимальная rиперплоскость для неразделимых образов 426
6.4. Как создать машину опорных векторов для задачи
распознавания образов 431
Ядро скалярноrо произведения 433
Теорема Мерсера 434
Оптимальная архитектура машины опорных векторов 436
Примеры машин опорных векторов 437
6.5. Пример: задача XOR (продолжение) 438
6.6. Компьютерное моделирование 442
Заключительные замечания 443
6.7. е"'нечувствительные функции потерь 444
6.8. Машины опорных векторов для задач нелинейной реrрессии 445
6.9. Резюме и обсуждение 449
Задачи 453
Оптимальная разделяющая rиперплоскость 453
Ядро скалярноrо произведения 454
12 Содержание
Классификация множеств 455
Нелинейная реrрессия 455
Преимущества и недостатки 456
Компьютерное моделирование 457
7. Ассоциативные машины 458
7.1. Введение 458
Структура rлавы 459
7.2. Усреднение по ансамблю 460
7.3. Компьютерный эксперимент 1 464
7.4. Метод усиления 465
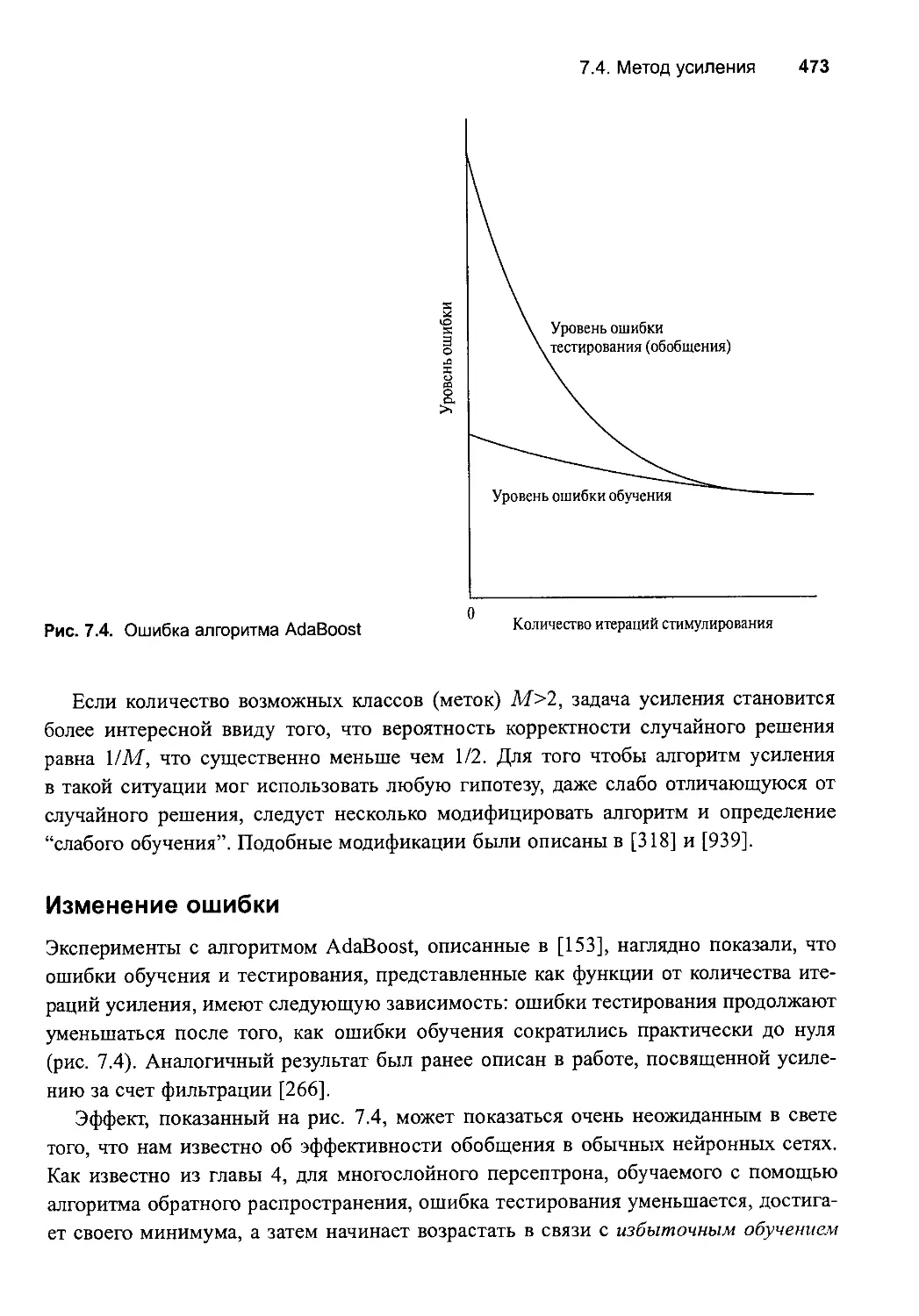
Усиление за счет фильтрации 466
Алrоритм адаптивноrо усиления AdaBoost 470
Изменение ошибки 473
7.5. Компьютерный эксперимент 2 474
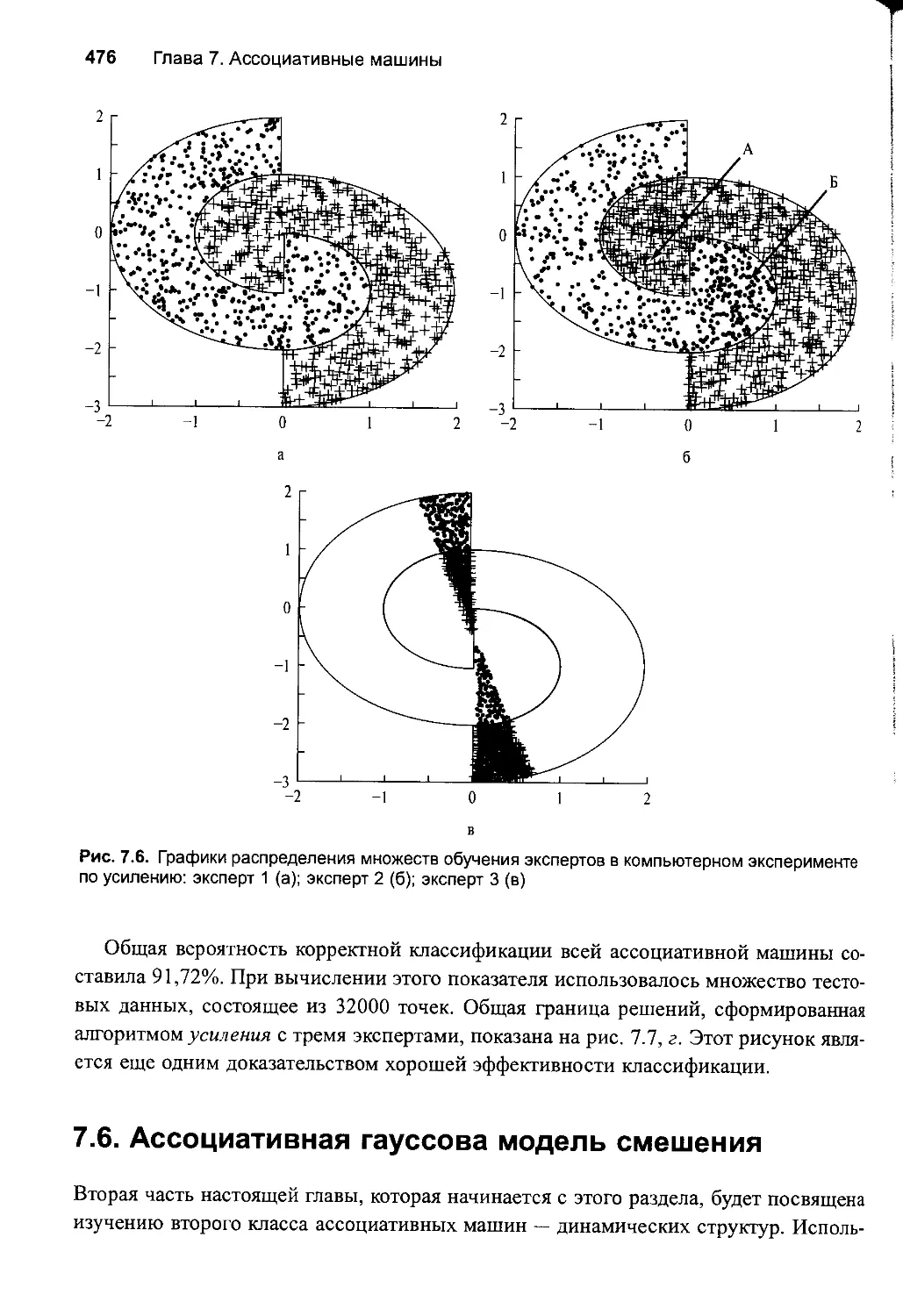
7.6. Ассоциативная rayccoBa модель смешения 476
Вероятностная порождающая модель 478
Модель смешения мнений экспертов 479
7.7. Модель иерархическоrо смешения мнений экспертов 484
7.8. Выбор модели с использованием стандарТноrо дерева решений 486
Алrоритм CART 487
Использование алrоритма CART для инициализации модели НМА 489
7.9. Априорные и апостериорные вероятности 490
7.10. Оценка максимальноrо подобия 492
7.11. Стратеrии обучения для модели НМЕ 495
7.12. Алrоритм ЕМ 497
7.1З. Применение алrоритма ЕМ к модели НМЕ 498
7.14. Резюме и обсуждение 503
Задачи 505
Усреднение по ансамблю 505
Усиление 505
Смешение мнений экспертов 505
Иерархическое смешение мнений экспертов 506
Алrоритм ЕМ и ero применение в модели НМЕ 506
8. Анализ rлавных компонентов 509
/
8.1. Введение
Структура rлавы
8.2. Некоторые интуитивные принципы самоорrанизации
Анализ признаков на основе самоорrанизации
8.З. Анализ rлавных кОмпонентов
Структура анализа rлавных компонентов
Основные представления данных
509
510
510
513
514
516
520
Содержание 13
Сокращение размерности 520
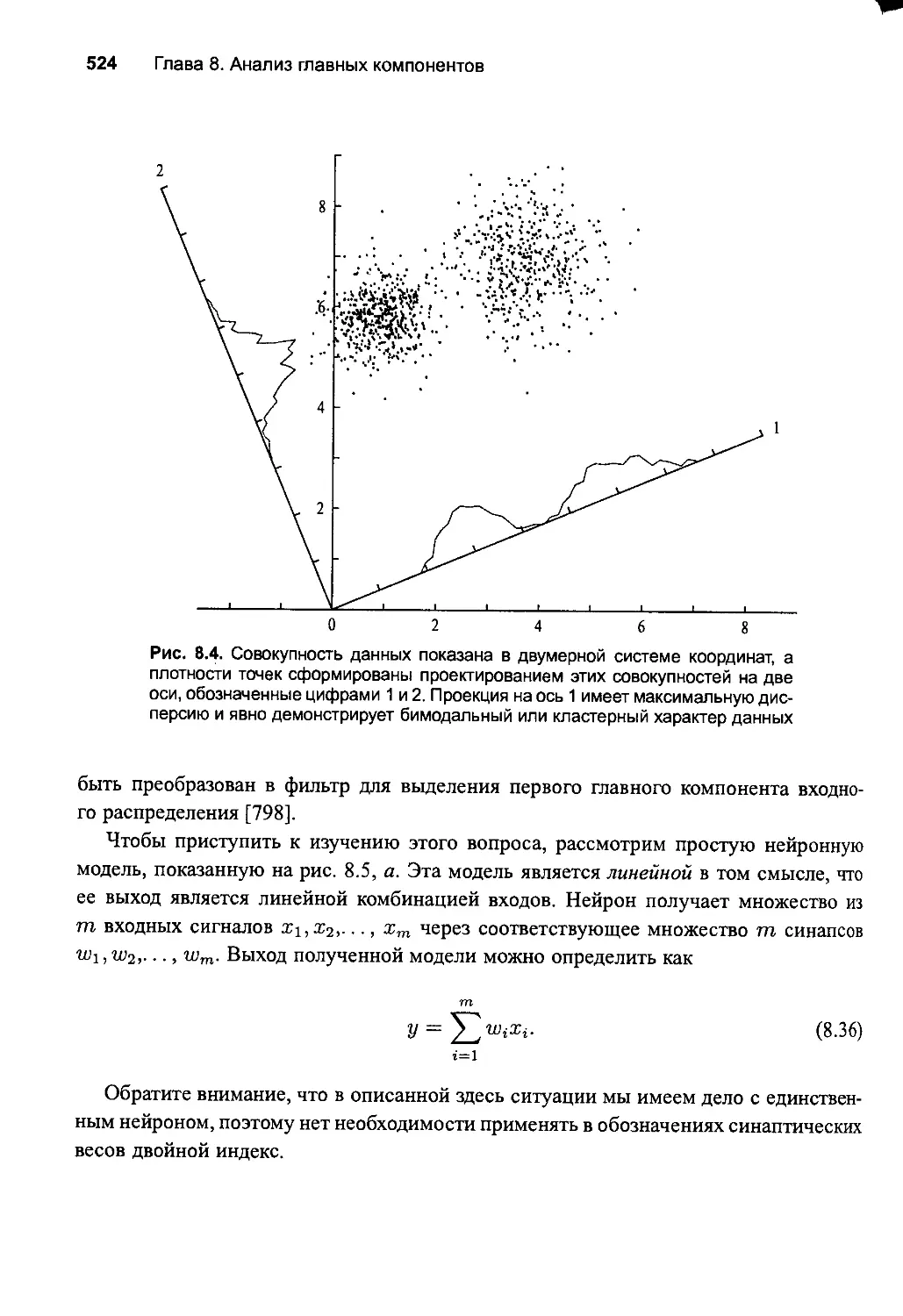
8.4. Фильтр Хебба для выделения максимальных собственных
....
значении 523
Матричная формулировка алrоритма 527
Теорема об асимптотической устойчивости 528
Анализ устойчивости фильтра для извлечения максимальноrо
собственноrо значения 530
Общие свойства фильтра Хебба для извлечения максимальноrо
собственноrо значения 535
8.5. Анализ rлавных компонентов на основе фильтра Хебба 537
Исследование сходимости 541
Оптимальность обобщенноrо алrоритма Хебба 542
Алrоритм GHA в сжатом виде 543
8.6. Компьютерное моделирование: кодирование изображений 544
8.7. Адаптивный анализ rлавных компонентов с использованием
латеральноrо торможения 546
Интенсивность обучения 556
Алrоритм АРЕХ в сжатом виде 557
8.8. Два класса алrоритмов РСА 558
Подпространство rлавных компонентов 558
8.9. Пакетный и адаптивный методы вычислений 559
8.10. Анализ rлавных компонентов на основе ядра 561
Алrоритм РСА на основе ядра в сжатом виде 565
8.11. Резюме и обсуждение 567
Задачи 570
Фильтр Хебба для извлечения максимальноrо собственноrо значения 570
Анализ rлавных компонентов на основе правила Хебба 571
РСА на основе ядра 572
9. Карты самоорrанизации 573
9.1. Введение 573
Структура rлавы 574
9.2. Две основные модели отображения признаков 575
9.3. Карты самоорrанизации 577
Процесс конкуренции 579
Процесс кооперации 580
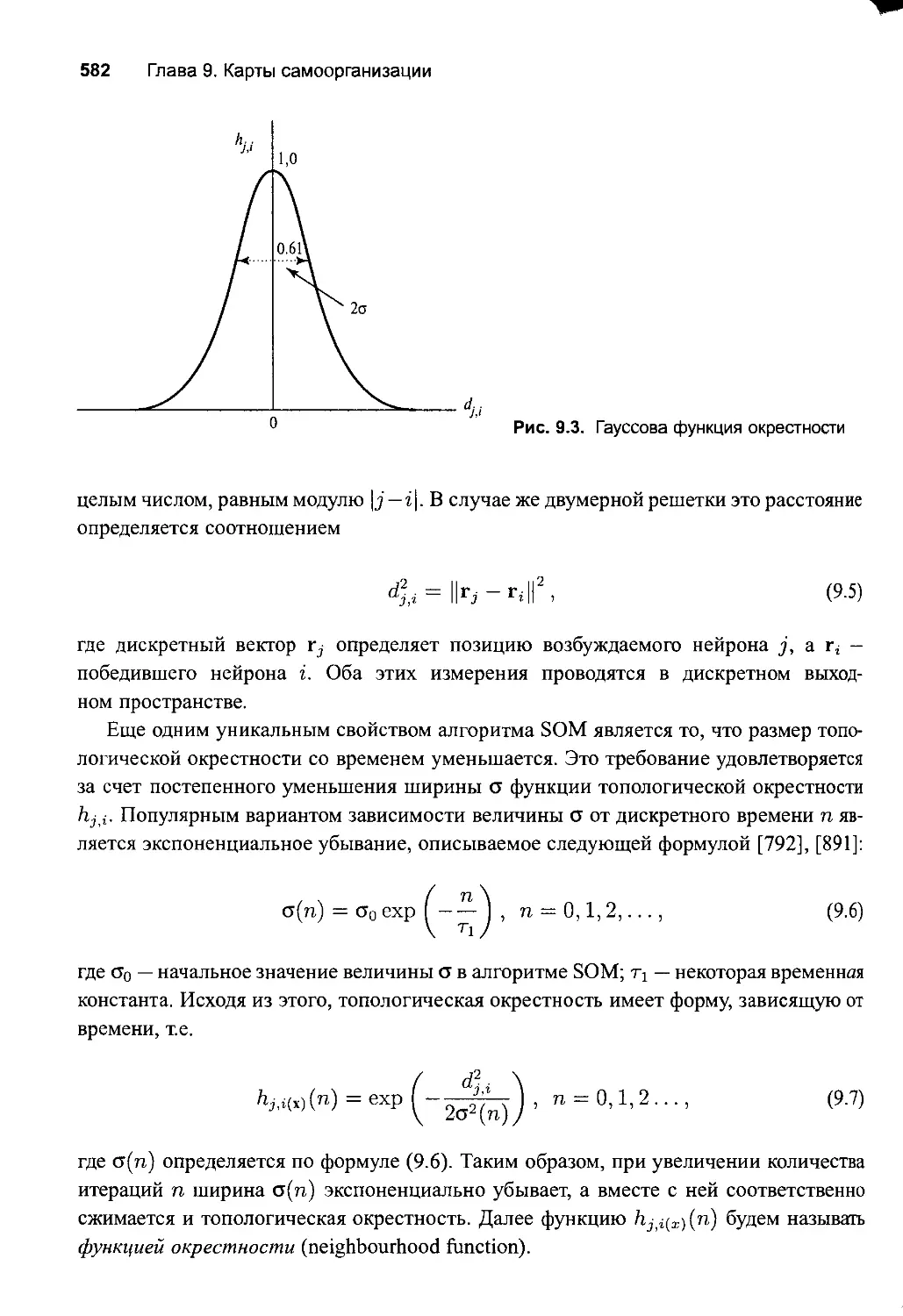
Процесс адаптации 583
Два этапа адаптивноrо процесса: упорядочивание и сходимость 585
9.4. Краткое описание алrоритма SOM 586
9.5. Свойства карты признаков 588
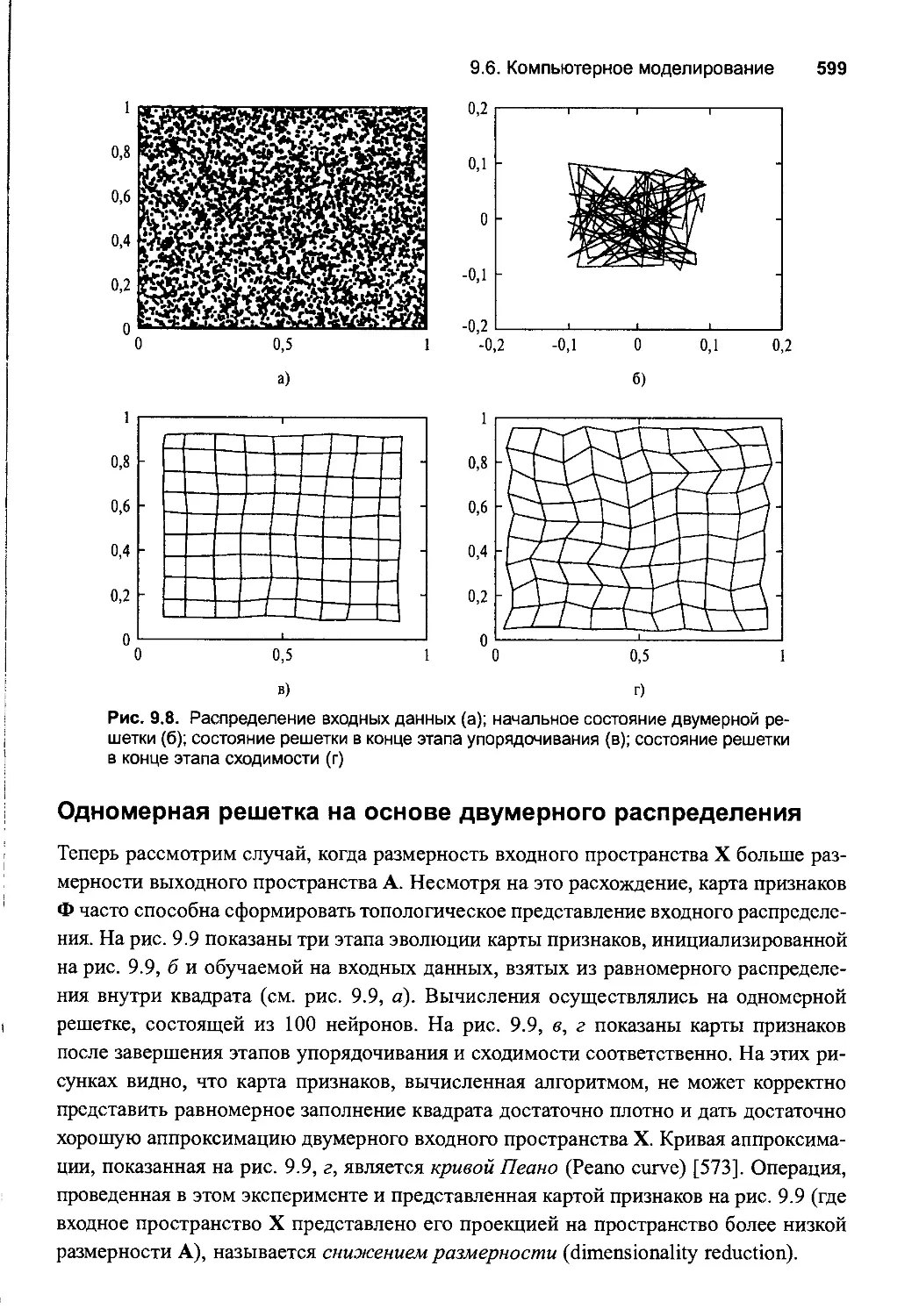
9.6. Компьютерное моделирование 597
Двумерная решетка, полученная на основе двумерноrо распределения 597
Одномерная решетка на основе ABYMepHoro распределения 599
Описание параметров моделирования 600
14 Содержание
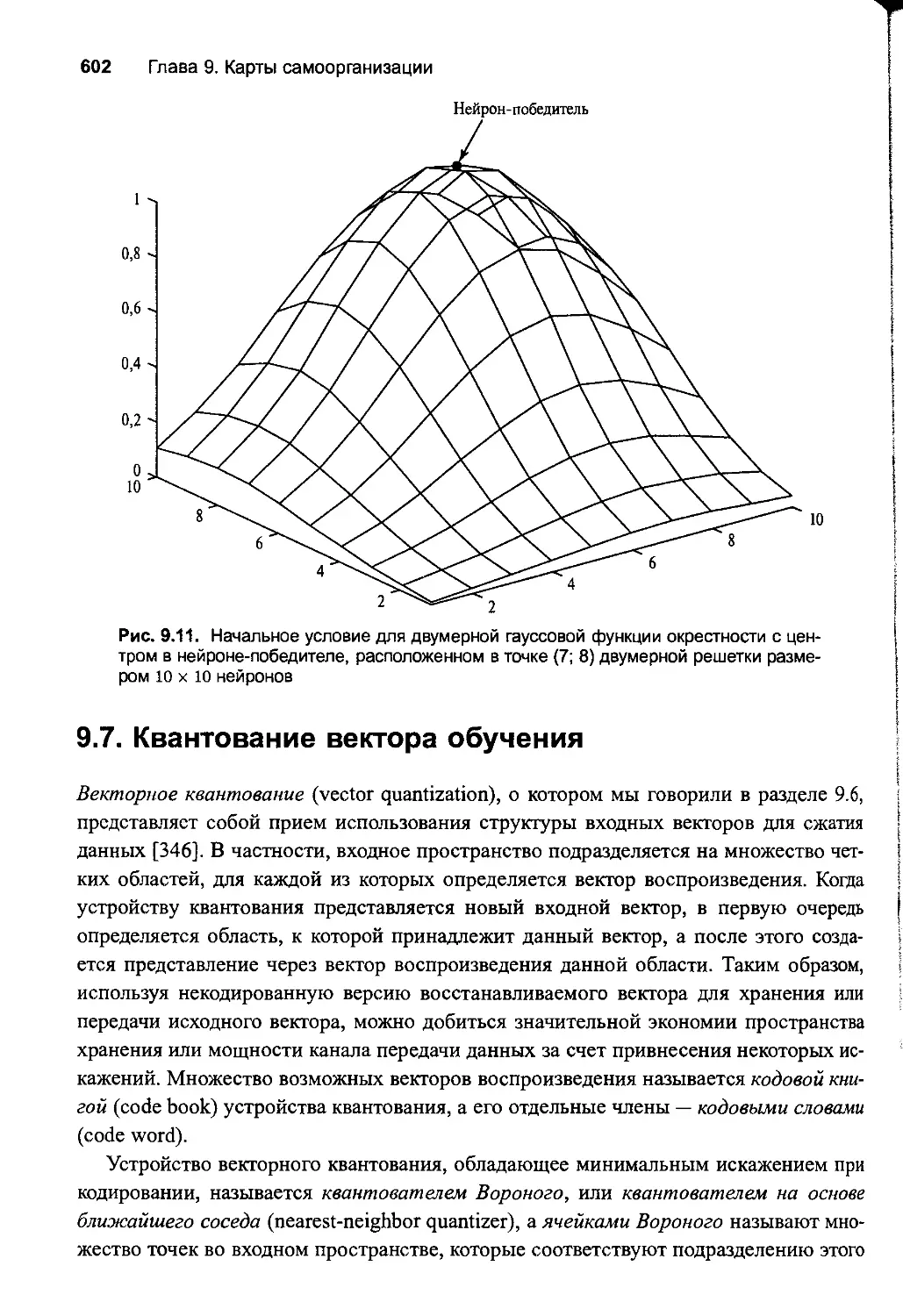
9.7. Квантование вектора обучения 602
9.8. Компьютерное моделирование: адаптивная классификация
множеств 604
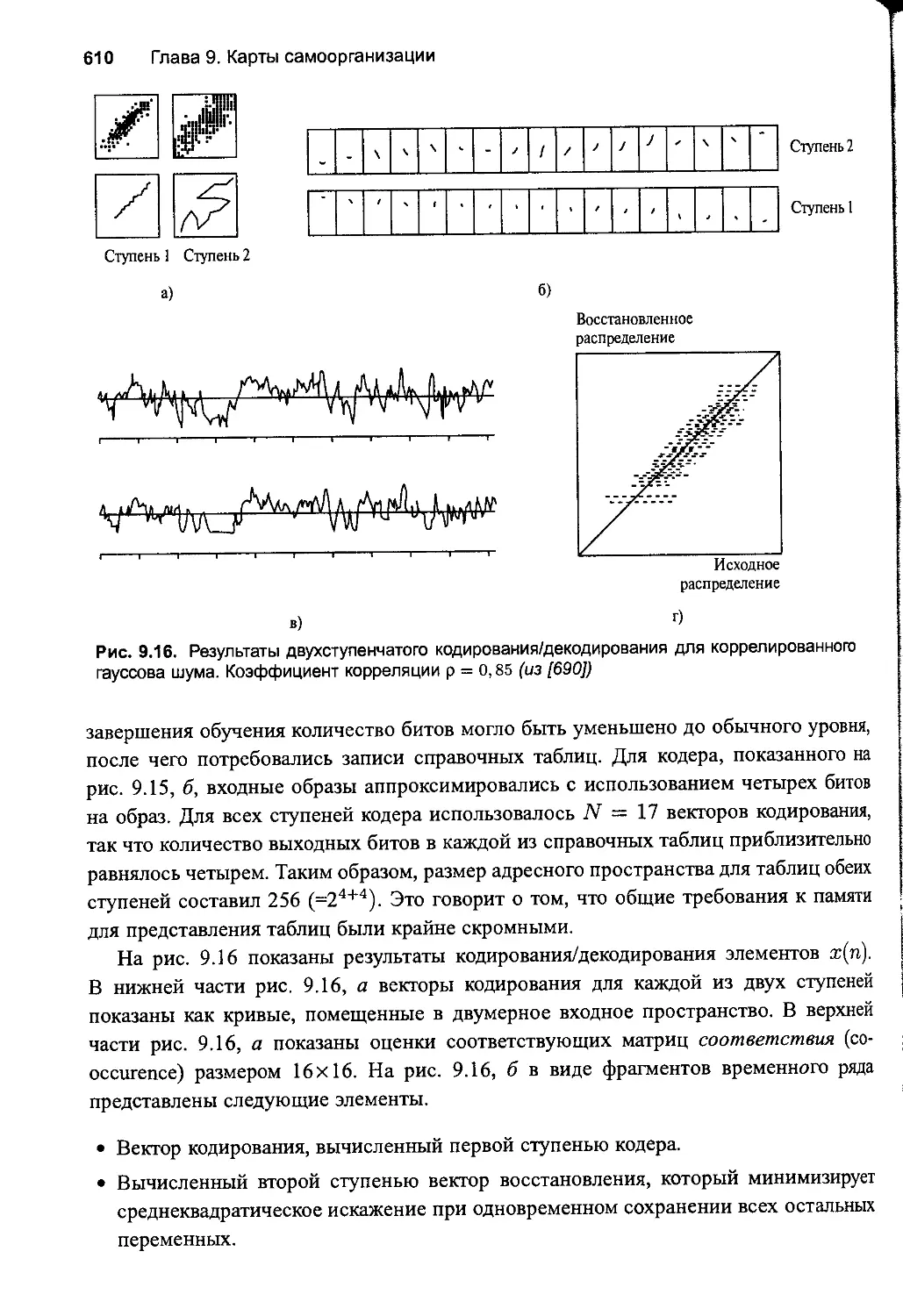
9.9. Иерархическая квантизация векторов 606
9.10. Контекстные карты 611
9.11. Резюме и обсуждение 613
Задачи 615
Алrоритм SOM 615
Квантизация векторов обучения 616
Компьютерные эксперименты 617
10. Модели на основе теории информации 622
10.1. Введение 622
Структура rлавы 623
10.2. Энтропия 623
Дифференциальная энтропия непрерывной случайной переменной 627
Свойства дифференциальной энтропии 628
10.3. Принцип максимума энтропии 629
10.4. Взаимная информация 632
Взаимная информация непрерывных случайных переменных 635
10.5. Диверrенция Кул6ека Лей6лера 636
Декомпозиция Пифаrора 638
10.6. Взаимная информация как оптимизируемая целевая функция 640
10.7. Принцип максимума взаимной информации 641
10.8. Принцип Infomax и уменьшение избыточности 646
Моделирование систем восприятия 646
10.9. Пространственно связные признаки 649
10.10. Пространственно несвязные признаки 652
10.11. Анализ независимых компонентов 654
Критерий статистической независимости 659
Определение дифференциальной энтропии h(Y) 660
Определение rраничной энтропии h(Yi) 660
Функция активации 664
Алrоритм обучения для ICA 666
Свойство эквивариантности 668
Условия устойчивости 670
Условия сходимости 672
10.12. Компьютерное моделирование 672
10.13. Оценка максимальноrо правдоподобия 675
Связь между максимальным подобием и анализом независимых
компонентов 677
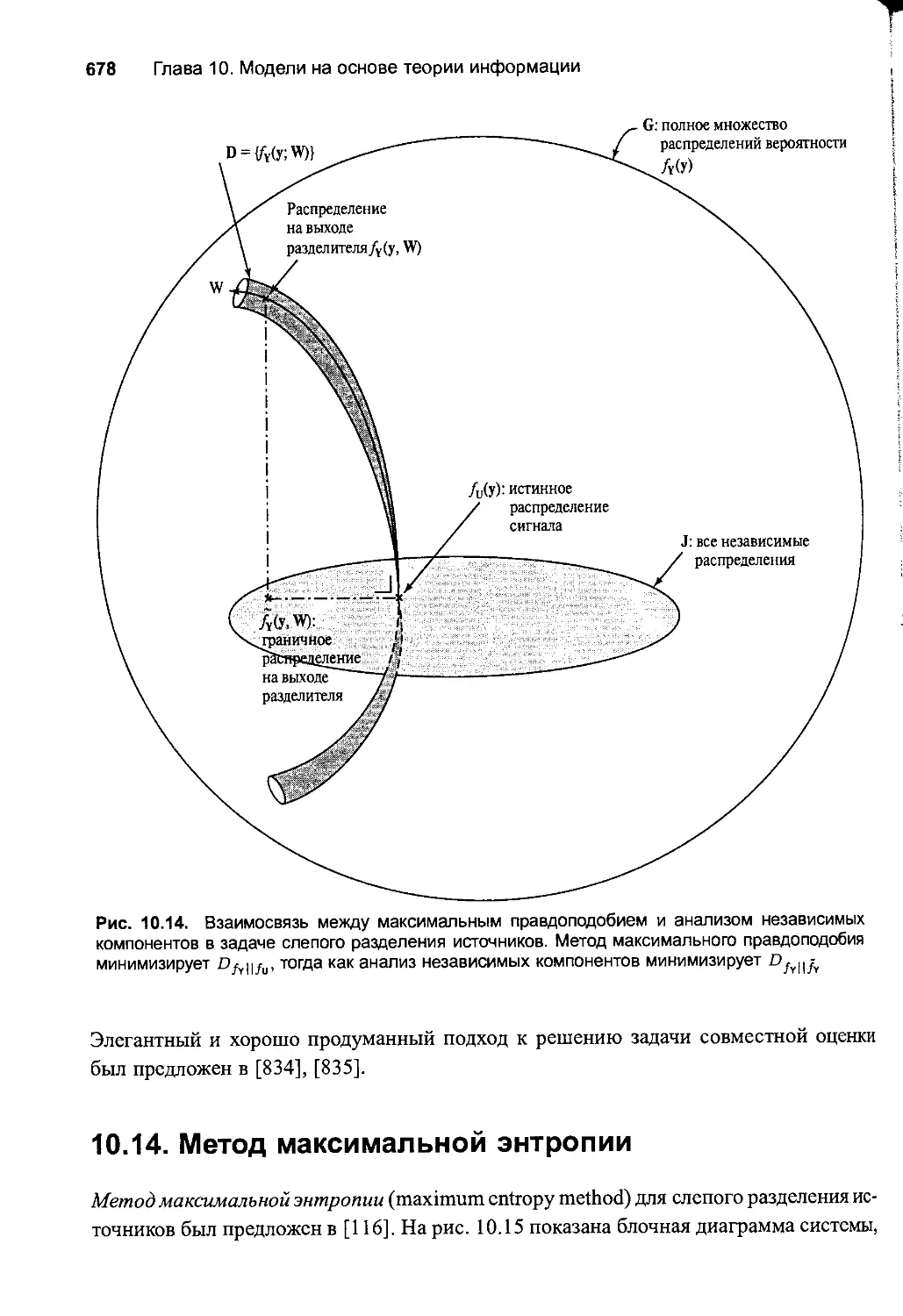
10.14. Метод максимальной энтропии 678
Алrоритм обучения для слепоrо разделения источников 682
10.15. Резюме и обсуждение 684
Содержание
15
Задачи
Принцип максимума энтропии
Взаимная информация
Принцип Iпfоmах
Анализ независимых компонентов
Метод максимальной энтропии
686
686
686
687
688
690
11. Стохастические машины и их аппроксимации
в статистической механике
691
11.1. Введение
Структура rлавы
11.2. Статистическая механика
Свободная энерrия и энтропия
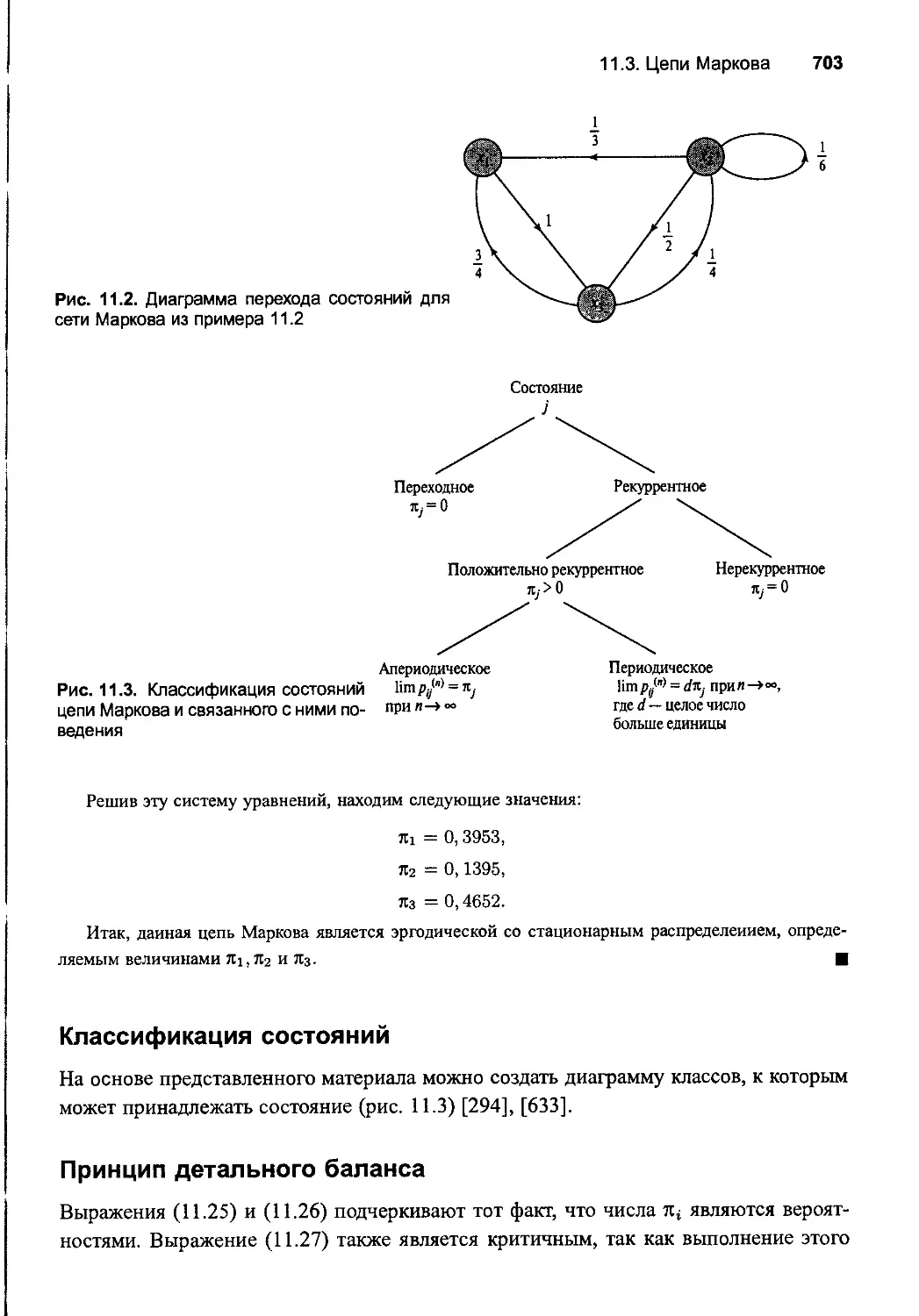
11.3. Цепи Маркова
Вероятности перехода
Свойства рекуррентности
несократимыe цепи Маркова
Эрrодические цепи Маркова
Сходимость к стационарным распределениям
Классификация состояний
Принцип детальноrо баланса
11.4. Алrоритм Метро полиса
Выбор вероятности перехода
11.5. Метод моделирования отжиrа
Расписание отжиrа
Моделирование отжиrа для комбинаторной оптимизации
11 .6. Распределение rиббса
11.7. Машина Больцмана
Квантование rиббса и моделирование отжиrа в машине Больцмана
Правило обучения Больцмана
Потребность в отрицательной фазе и ее применение
11.8. Сиrмоидальные сети доверия
Фундаментальные свойства сиrмоидальных сетей доверия
Обучение в сиrмоидальных сетях доверия
11.9. Машина rельмrольца
11.10. Теория cpeAHero поля
11.11. Детерминированная машина Больцмана
11.12. Детерминированные сиrмоидальные сети доверия
Нижняя rраница функции лоrарифмическоrо правдоподобия
Процедура обучения для аппроксимации cpeAHero поля
сиrмоидальной сети доверия
11.1 з. Детерминированный отжиr
Кластеризация посредством детерминированноrо отжиrа
Аналоrия с алrоритмом ЕМ
11.14. Резюме и обсуждение
.
691
692
692
694
695
696
698
698
699
700
703
703
704
705
707
709
710
711
713
715
718
721
722
722
724
728
730
733
734
735
738
742
743
748
748
16 Содержание
Задачи 752
Цепи Маркова 752
Приемы моделирования 752
Машина Больцмана 754
Сиrмоидальные сети доверия 757
Машина rельмrольца 757
Детерминированная машина Больцмана 758
Детерминированная сиrмоидальная сеть доверия 758
Детерминированный отжиr 758
12. Нейродинамическое проrраммирование 760
12.1. Введение 760
Структура rлавы 762
12.2. Марковский процесс принятия решений 762
Постановка задачи 765
12.3. Критерий оптимальности Беллмана 766
Алrоритм динамическоrо проrраммирования 767
Уравнение оптимальности Беллмана 768
12.4. Итерация по стратеrиям 770
12.5. Итерация по значениям 773
12.6. Нейродинамическое проrраммирование 778
12.7. Приближенный алrоритм итерации по стратеrиям 780
12.8. Q обучение 784
Теорема о сходимости 786
Приближенное Q обучение 787
Исследование 788
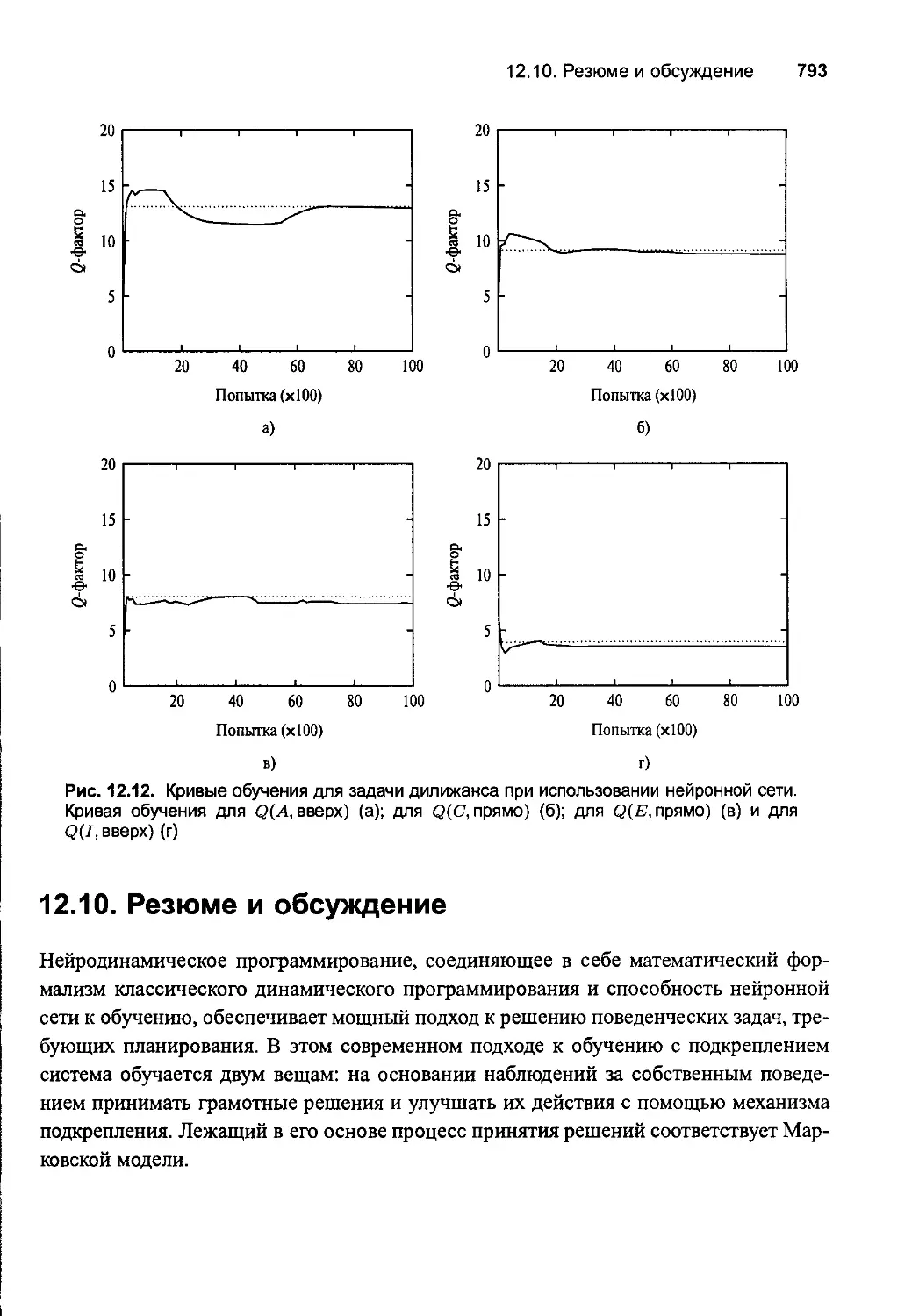
12.9. Компьютерный эксперимент 790
12.10. Резюме и обсуждение 793
Задачи 796
Критерий оптимальности Беллмана 796
Итерация по стратеrиям 798
Итерация по значениям 798
Q обучение 798
13. Временная обработка с использованием сетей прямоrо
распространения 799
13.1. Введение 799
Структура rлавы 800
13.2. Структуры кратковременной памяти 801
Память на основе линии задержки с отводами 803
rамма память 804
13.3. Сетевые архитектуры для временной обработки 806
NETtalk 806
Нейронные сети с задержкой по времени 807
Содержание 17
13.4. Фокусированные сети прямоrо распространения с задержкой
по времени 809
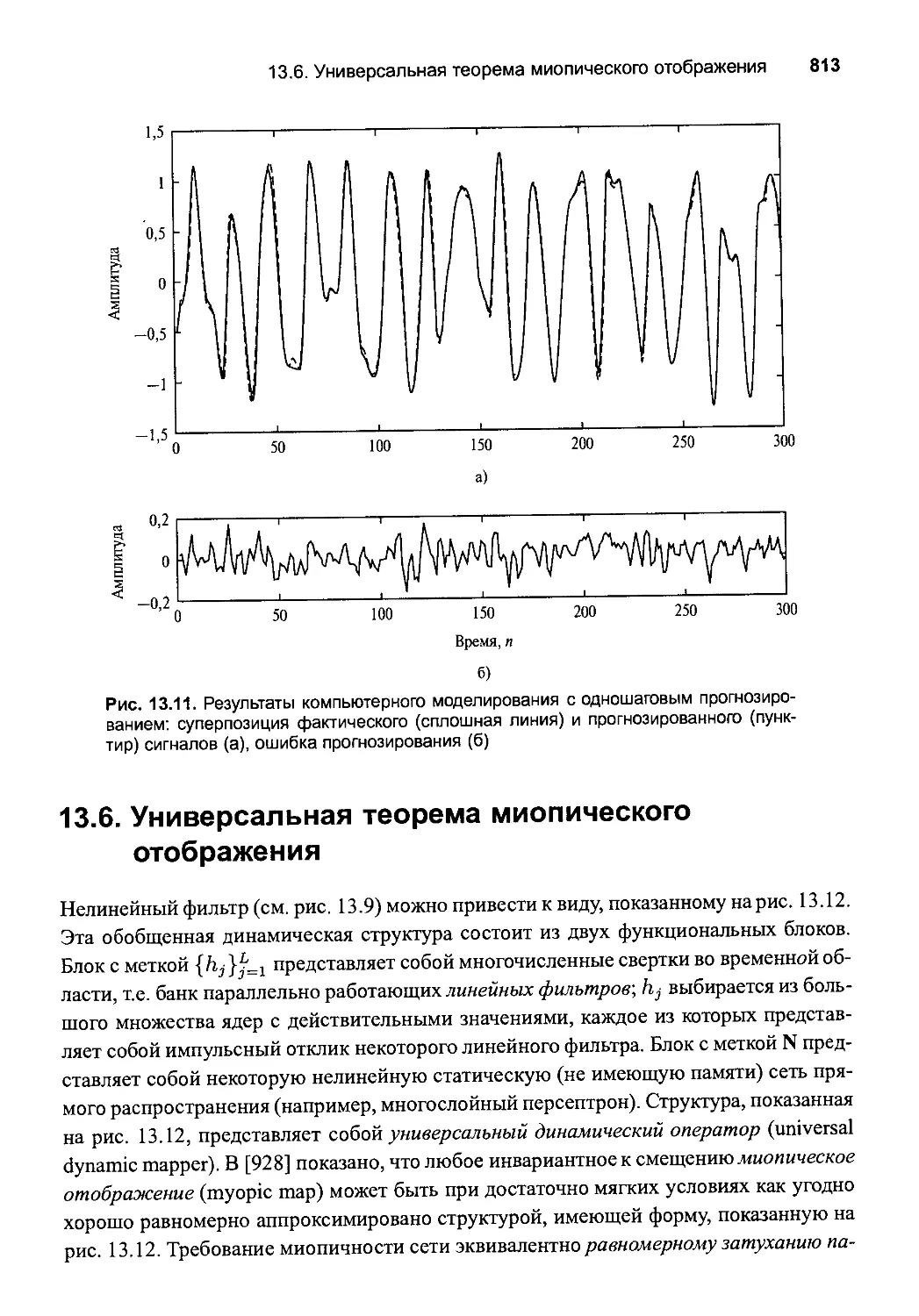
13.5. Компьютерное моделирование 812
13.6. Универсальная теорема миопическоrо отображения 813
13.7. Пространственно"временные модели нейрона 815
Аддитивная модель 818
1 3.8. Распределенные сети прямоrо распространения с задержкой
по времени 820
13.9. Алrоритм обратноrо распространения во времени 821
Оrраничения причинности 827
13.10. Резюме и обсуждение 829
Задачи 830
Фокусированные TLFN 830
Пространственно временные модели нейронов 831
Обратное распространение во времени 831
Компьютерное моделирование 832
14. Нейродинамика 835
14.1. Введение 835
Структура rлавы 836
14.2. Динамические системы 837
Пространство состояний 838
Условие Лившица 840
Теорема о диверrенции 841
14.3. Устойчивость состояний равновесия 842
Определения устойчивости 843
Теоремы Ляпунова 846
14.4. Аттракторы 848
rиперболические аттракторы 849
14.5. Нейродинамические модели 849
Аддитивная модель 850
Связанная модель 853
14.6. Управление аттракторами как парадиrма рекуррентных сетей 854
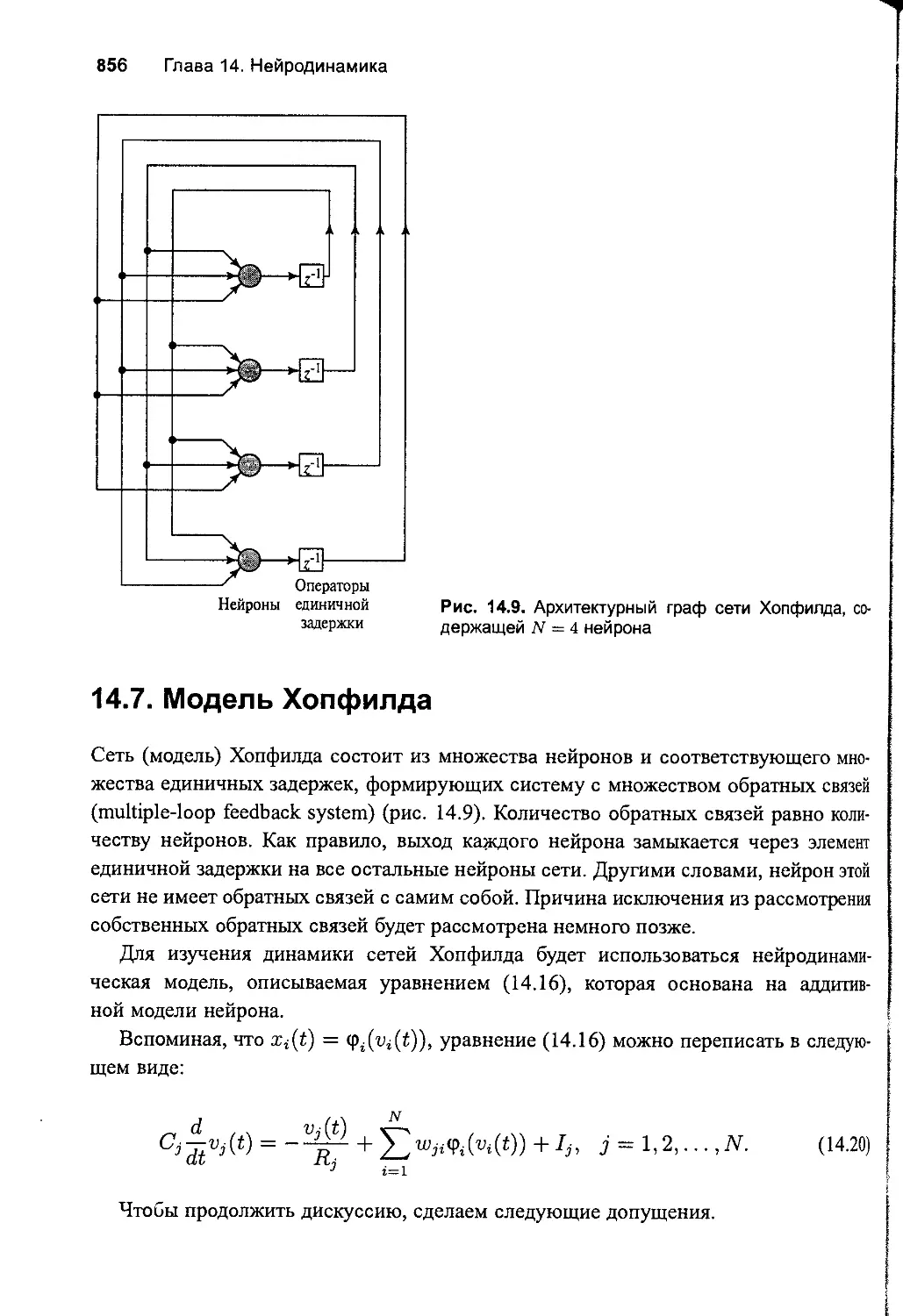
14.7. Модель Хопфилда 856
Соотношение между устойчивыми состояниями дискретной
и непрерывной версии модели Хопфилда 860
Дискретная модель Хопфилда как ассоциативная память 862
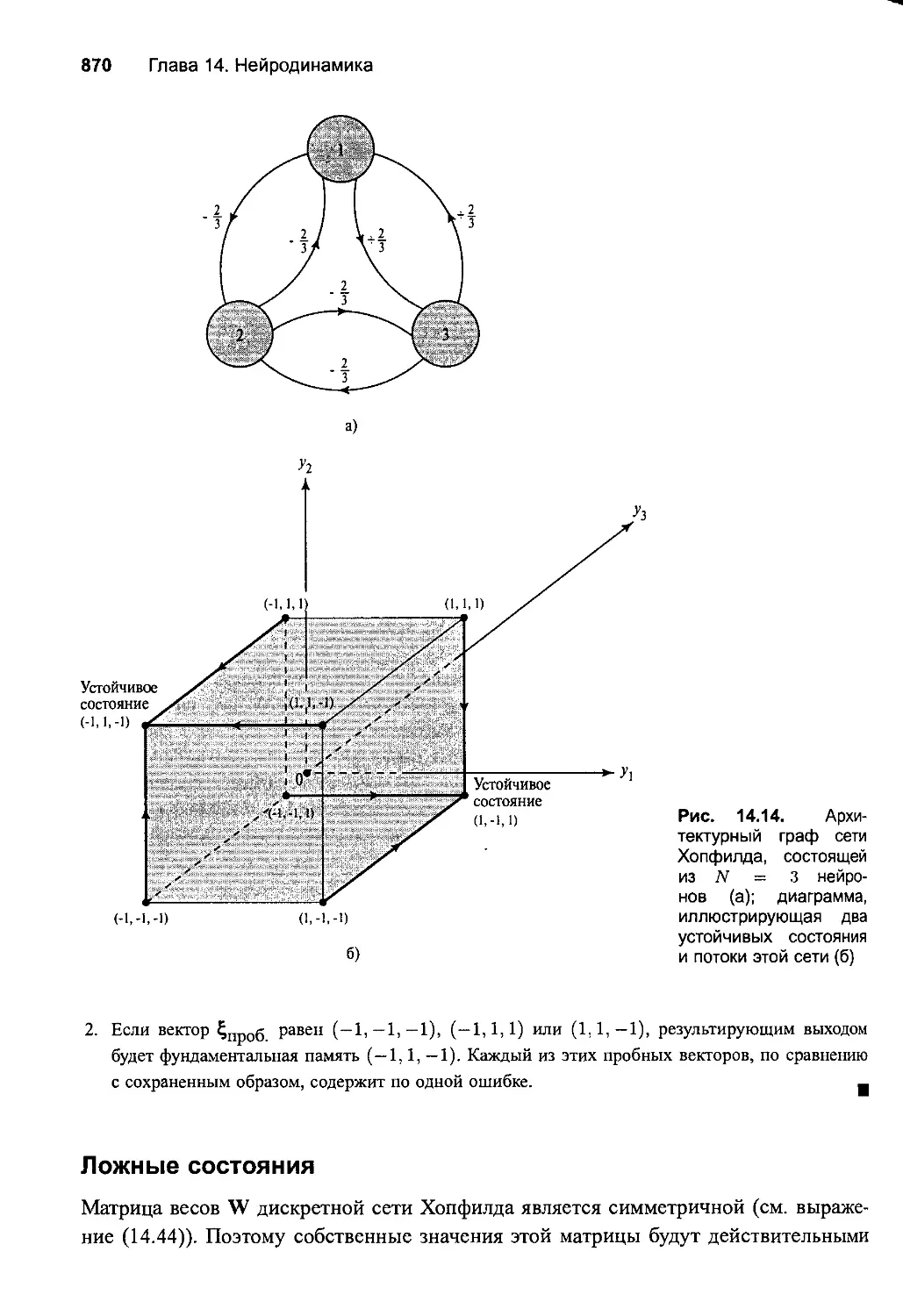
Ложные состояния 870
Емкость сети Хопфилда 871
1'4.8. Компьютерное моделирование 1 876
14.9. Теорема Коэна rроссберrа 880
Модель Хопфилда как частный случай теоремы Коэна rроссберra 883
14.10. Модель BSB 884
Функция Ляпунова модели BSB 885
18 Содержание
Динамика модели BSB
Кластеризация
14.11. Компьютерное моделирование 2
14.12. Странные аттракторы и хаос
Инвариантные характеристики хаотической динамики
14.13. Динамическое восстановление
Рекурсивное проrнозирование
Две возможные формулировки рекурсивноrо проrнозирования
Динамическое восстановление как плохо обусловленная
задача фильтрации
14.14. Компьютерное моделирование 3
Выбор параметров m И Л
14.15. Резюме и обсуждение
Задачи
Динамические системы
Модели Хопфилда
Теорема Козна rроссберrа
15. Динамически управляемые рекуррентные сети
15.1. Введение
Структура rлавы
15.2. Архитектуры рекуррентных сетей
Рекуррентная модель "вход"выход"
Модель в пространстве состояний
Рекуррентный мноrослойный персептрон
Сеть BToporo порядка
15..3. Модель в пространстве состояний
Управляемость и наблюдаемость
Локальная управляемость
Локальная наблюдаемость
15.4. Нелинейная автоrрессия с внешней моделью входов
15.5. Вычислительная мощность рекуррентных сетей
15.6. Алrоритмы обучения
Некоторые эвристики
15.7. Обратное распространение во времени
Обратное распространение по эпохам во времени
Усеченное обратное распространение во времени
Некоторые практические соrлашения
15.8. Рекуррентное обучение в реальном времени
Усиление учителем
15.9. Фильтр Калмана
Фильтр Калмана на основе квадратноrо корня
15.10. Несвязный расширенный фильтр Калмана
888
889
891
893
894
899
901
903
903
904
907
908
912
912
912
917
919
919
920
921
921
923
925
925
928
930
932
934
936
937
941
942
943
945
946
947
949
955
956
960
960
Содержание 19
Искусственный шум процесса 964
Полное описание алrоритма DEKF 965
Вычислительная сложность 965
15.11. Компьютерное моделирование 965
15.12. Обращение в нуль rрадиеНТQВ в рекуррентных сетях 968
Долrосрочные зависимости 971
15.1 з. Системная идентификация 973
Идентификация систем с использованием модели
в пространстве состояний 974
Модель в терминах "вход"выход" 976
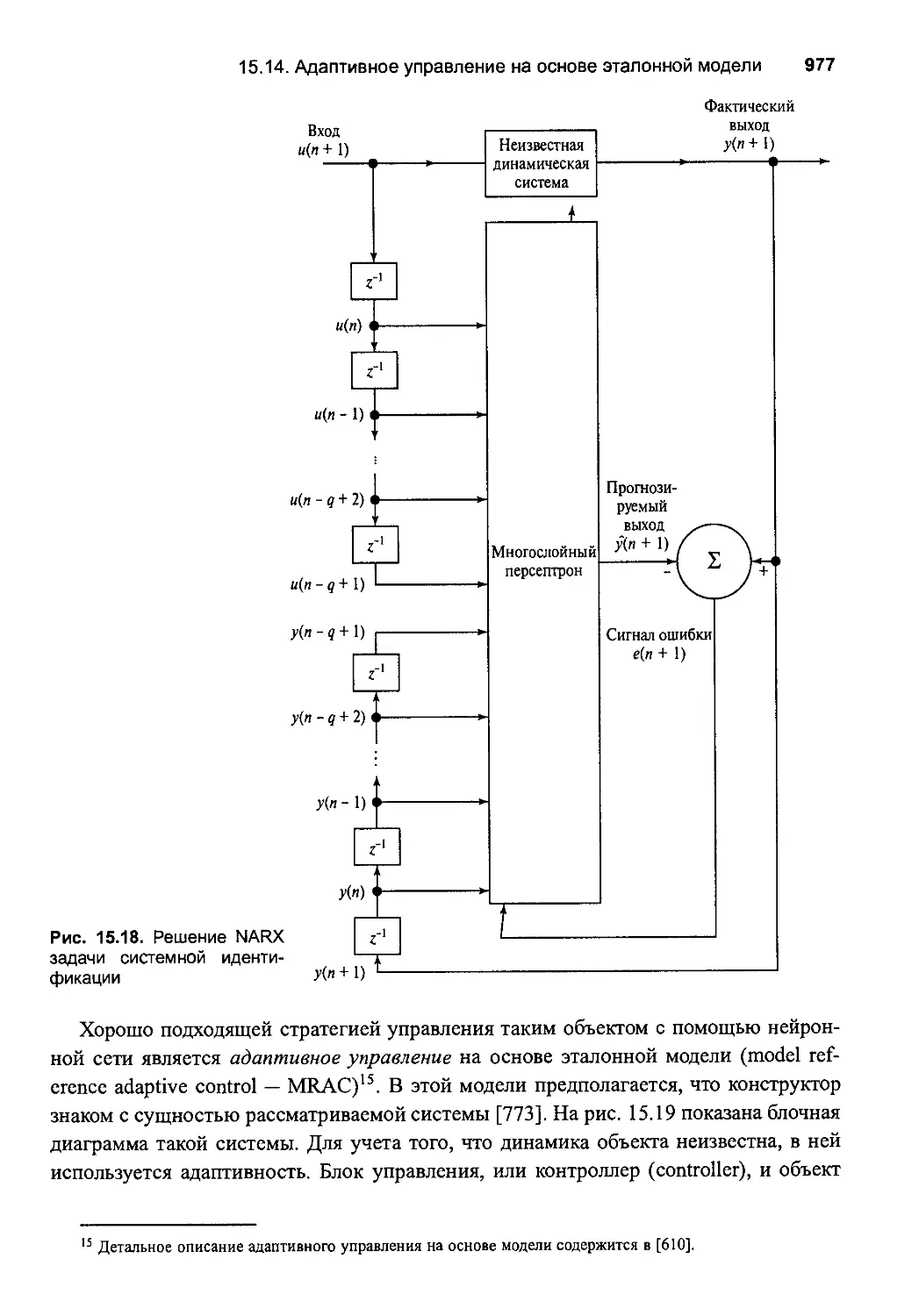
15.14. Адаптивное управление на основе эталонной модели 977
15.15. Резюме и обсуждение 979
Задачи 982
Модель в пространстве состояний 982
Модель нелинейной автореrрессии с экзоrенными входами (NARX) 983
Алrоритм ВРТТ 985
Алrоритм peKyppeHTHoro обучения в реальном времени 985
Алrоритм несвязной расширенной фильтрации Калмана 986
Рекуррентные сети Bтoporo порядка 987
16. Заключение 989
16.1. Интеллектуальные системы 990
Библиоrрафия 996
Предметный указатель 1069
OZPOMHOMY количеству исследователей нейронных сетей за их творческий вклад,
всем критикам за их замечания,
"
МОИiW мноzочисленным аспирантам за их живои интерес
и моей cyпpyze Нэнси за ее терпение и пОНUiWаllие
Нейронные сети, или, точнее, искусственные нейронные сети, представляют co
бой технолоrию, уходящую корнями во множество дисциплин: нейрофизиолоrию,
математику, статистику, физику, компьютерные науки и технику. Они находят свое
применение в таких разнородных областях, как моделирование, анализ временных
рядов, распознавание образов, обработка сиrналов и управление блаrодаря одному
важному свойству способности обучаться на основе данных при участии учителя
или без ero вмешательства.
Эта книrа предлаrает исчерпывающее описание нейронных сетей, учитывая MHO
rодисциплинарную природу этоrо предмета. Представленный в книrе материал Ha
сыщен примерами, описанием компьютерных экспериментов, содержит множество
задач по каждому разделу, а также обширную библиоrpафию.
Книrа состоит из четырех частей, орrанизованных следующим образом.
Вводная часть (rлавы 1 и 2). В rлаве 1 на качественном уровне рассматривается
.... .... ....
сущность неиронных сетеи, их своиства, возможности и связь с друrими дисци
плинами искусственноrо интеллекта. rлава завершается некоторыми исторически
ми заметками. В rлаве 2 представлен обзор основных подходов к обучению и их
статистических свойств. В этой rлаве вводится важное понятие измерения BaпHиKa
Червоненкиса, используемое в качестве меры возможности обучаемой машины pea
лизовать семейство функций классификации.
Обучение с учителем основному предмету обсуждения посвящены rлавы 3 7.
В rлаве 3 рассматривается простейший класс нейронных сетей сети с одним или
несколькими выходными нейронами, не содержащие скрытоro слоя. В этой rлаве pac
сматриваются алroритм метода наименьших квадратов (очень популярный при созда
нии линейных адаптивных фильтров) и теорема о сходимости персептрона. В rлаве 4
приводится исчерпывающее описание МflО20СЛОЙНО20 персептрона, обучаемоro на oc
нове ал20ритма обратНО20 распространения. Этот алrоритм (представляющий собой
обобщение метода наименьших квадратов) стал основной рабочей лошадкой нейрон
ных сетей. В rлаве 5 содержится подробное математическое представление друroro
класса мноroслойных нейронных сетей сетей на основе радиальных базисных ФУflК
ций (RВF сетей), включающих отдельный слой базисных функций. Основной акцент
в этой rлаве делается на роли теории реrуляризации при создании RВF сетей. В rла
Предисловие 23
ве 6 рассматривается сравнительно новый класс обучаемых систем, известных под
названием машины опорных векторов. Теория таких систем базируется на материале
rлавы 2, посвященном статистической теории обучения. Вторая часть книrи завер
шается rлавой 7, в которой обсуждаются ассоциативные машины, включающие в
качестве своих компонентов несколько отдельно обучаемых систем. В этой rлаве pac
сматриваются три различных подхода к построению ассоциативных машин методы
усреднения по ансамблю, усиления и иерархичеСКО20 смешения мнений экспертов.
Обучению без учителя посвящены rлавы 8 12. В rлаве 8 Хеббовское правило обу..
чения применяется для решения задачи анализа zлавных компонентов. В rлаве 9 опи
сывается еще одна форма обучения на основе самоорrанизации, конкурентное обу
чение, применяемое для построения вычислительных отображений, получивших
название карт самоорzанизации. Эти две парадиrмы отличаются в основном прави
лами обучения, уходящими корнями в область нейробиолоrии. rлава 10 посвящена
теории информации, применяемой для создания алrоритмов обучения без учителя,
а также их применению к решению задач моделирования, обработки изображений
и анализа независuмых компонентов. В rлаве 11 рассматриваются вопросы обучения
машин на основе принципов статистической механики. Эта тематика близко при
мыкает к материалу предыдущей rлавы, посвященной вопросам теории информации.
В rлаве 12, которая завершает третью часть книrи, вводится понятие дИНGМичеСКО20
проzраммирования и анализируется ero взаимосвязь с обучением с подкреплением.
Нелинейные динамические системы предмет изучения rлав 13 15. В rлаве 13
v
описывается класс динамических систем на основе краткосрочнои памяти и MHoro
слойных нейросетевых структур прямоrо распространения. В rлаве 14 основное вни
..., v
мание уделяется вопросам устоичивости, возникающим в нелинеиных динамических
системах при наличии обратной связи. Приводятся примеры ассоциативной памя
ти. В rлаве 15 рассматривается еще один класс нелинейных динамических систем
рекуррентные сети, основанные на использовании обратной связи при построении
отображения BXOД BЫXOД.
В заключении кратко анализируется роль нейронных сетей при создании uнтел
лектуальиых .А1ашuИ распознавания образов, управления и обработки сиrналов.
Структура книrи обеспечивает большую rибкость при разработке различных KYP
сов обучения нейронным сетям. Выбор конкретных тем для изучения должен опре
v
деляться только интересами аудитории, использующеи эту книry.
В книre описывается пятнадцать компьютерных экспериментов, тринадцать из
которых рассчитаны на использование MATLAB. Файлы для выполнения этих экспе
риментов в среде MATLAB можно найти по адресу ftp: / /ftp ..mathworks. сот/
pub/books/haykin или http://www.mathworks.com/books/
Во втором случае пользователь должен щелкнуть на ссылке Neural/Fuzzy, а
затем на названии книrи. Такой подход обеспечивает более удобный интер
фейс пользователя.
.(....
".;.
24 Предисловие
Каждая rлава завершается несколькими упражнениями. Мноrие из этих задач яв...
ляются творческими и призваны не только проверить качество усвоения материала,
но и подтолкнуть к дальнейшему развитию соответствующей тематики. Решения всех
задач содержатся в руководстве, копии KOToporo Moryт получить преподаватели, ис...
пользующие в своих курсах настоящую книry. Для этоro они должны обратиться в
издательство Prentice НаН.
Книrа рассчитана на инженеров, специалистов в области компьютерных наук и
физиков. Автор надеется, что книrа будет интересна также специалистам в друrих
областях, таких как психолоrия и нейробиолоrия.
Саймон Хайкин,
rамильтон, Онтарио,
февраль 1998 1:
Блаrодарности
Автор выражает rлубокую блаrодарность мноrим рецензентам, которые потратили
свое время на чтение этой книrи или отдельной ее части. Хочу сказать большое спа
сибо доктору Кеннету Роузу (Kenneth Rose) из университета штата Калифорния в
Санта Барбара за существенный конструктивный вклад в написание книrи и значи
тельную помощь.
Я блаrодарен доктору С. Амари (S. Amari) из Японии; докторам Сью Беккер (Suc
Becker) и Рону Рэйсину (Ron Racine) из Макмастерскоro университета; доктору Син
Холден (Sean Holden) из университетскоrо колледжа в Лондоне; доктору Майклу
Турмону (Michael Turmon), Пасадена; доктору Бабаку Хассиби (Babak Hassibi) из
'-"
Стэндфордскоrо университета; доктору Раулю Иии (Раи! Уее), бывшему сотруднику
MaкMacTepcKoro университета, доктору Эдrару Осуна (Edgar Osuna) из Массачусет
CKOro технолоrическоro института; доктору Бернерду Шелкопфу (Bemard Schelkopt)
из Института Макса Планка (rермания); доктору Майклу Джордану (Michael Jordan)
из Массачусетскоrо технолоrическоrо института; докторам Редфорду Ниалу (Radford
Neal) и Зуб ину rархамани (Zoubin Gharhamani) из университета Торонто, доктору
Джону Тситсиклису (John Tsitsiklis) из Массачусетскоrо технолоrическоrо институ
та; доктору Джосу Принсипу (Jose Principe) из Университета штата Флорида; rинту
Пушкориусу (Gint Puskorius) и доктору Ли Фелдкампу (Lee Feldkamp) из исследова
тельской лаборатории Форда; доктору Ли rилесу (Lee Giles) из исследовательскоrо
института компании NEC в Принстоне, штат Нью Джерси; доктору Микелю Форкада
(Mikel Forcada) из университета Далаканта (Испания); доктору Эрику Вану (Eric Wan)
из института науки и технолоrии штата OperoHa; а также доктору Яну Лекуну (Yann
LeCun) из компании АТ&Т Research, штат Нью Джерси, за их неоценимую помощь
....
в улучшении даннои книrи.
Мне также хочется поблаrодарить доктора Ральфа Линскера (Ralph Linsker) из
компании IBM; доктора Стюарта [емана (Stuart Geman) из Браунскоrо университста;
доктора Алана rелфорда (Alan Gelford) из университета штата Коннектикут; ДOKTO
ра Барта Коско (Bart Kosko) из университета Южной Калифорнии; доктора Нариша
Синха (Narish Sinha) из MaKMacTepcKoro университета; доктора Костаса Диамантара
са (Kostas Diamantaras) из университета r: Тессалоники имени Аристотеля (rреция);
доктора Роберта Якобса (Robert Jacobs) из университета Рочестера; доктора Эндрю
Барто (Andrew Barto) из Массачусетскоrо университета; доктора Дона Хуша (Don
Hush) из университета штата Нью Мексико; доктора Йошуа Бенжио (Yoshua Bengio)
из университета r. Монреаль; доктора Х. Янrа (Н. Yang) из института науки и TeXHO
лоrий штата OperoHa; доктора Скотта Дуrласа (Scott Douglas) из университета штата
Юта; доктора Натана Интратора (Nathan Intrator) из университета r. Тель Авив (Из
раиль); доктора Владимира Вапника (Vladimir Vapnik) из компании АТ &Т Research,
штат Нью Джерси; доктора Тейво Кохонена (Teuvo Kohonen) из Хельсинскоro Tex
26 Предисловие
нолоrическоrо университета (Финляндия); доктора Владимира Черкасскоro (Vladimir
Cherkassky) из университета штата Миннесота; доктора Дэвида Лоува (David Lowe)
из ACTOHCKOro университета (Великобритания); доктора Джеймса Андерсона (James
Anderson) из Браунскоro университета; доктора Андреаса Андрео (Andreas Andreou)
из университета Джона Хопкина и доктора Томаса Анастасио (Thomas Anastasio) из
университета штата Иллинойс.
Я rлубоко блаroдарен моему студенту дипломнику Хью Пасика (Hugh Pasika) за
выполнение множества компьютерных экспериментов в среде MATLAB, а также за
создание WеЬ узла этой книrи. Большое спасибо также студенту дипломнику Химе
шу Мадхуранату (Himesh Madhuranath); доктору Садасивану Путуссерипади (Sada
v
sivan Puthusserypady); доктору Дж. Ни (J. Nie); доктору Паулю Иии (Раиl Уее) и
rинту Пускориусу (Gint Puskorius) из лаборатории Ford Research за выполнение пя
ти экспериментов.
Большое спасибо также Хью Пасику (Hugh Pasika) за вычитку всей книrи. В этой
связи хочется также поблаroдарить доктора Роберта Дони (Robert Dony), доктора
Стефана Кремера (Stefan Кremer) и доктора Садасивана Путуссерипади (Sadasivan
Puthusserypady) за вычитку отдельных rлав книrи.
Автор также выражает блаrодарность своему издателю Тому Роббинсу (Тот Rob
bins) и издателю Алис Дворкин (Alice Dworkin) за их полную поддержку и одобрение.
Хочется поблarодарить Дженифер MaraH (Jennifer Maughan) и сотрудников компании
WestWorld, Inc. (штат Юта) за издание этой книrи.
Автор выражает rлубокую блаroдарность Бриджи'IТ Майер (Brigitte Maier) из биб
лиотеки Макмастерскоro университета за ее неоценимые усилия по поиску очень
сложных ссьток и созданию столь полной библиоrpафии. Следует отметить также
помощь научноrо сотрудника библиотеки Пеrrи Финдлей (Peggy Findlay) и COTPYД
ника библиотеки Реrины Бендиr (Regina Bendig).
И наконец (но не в последнюю очередь), автор блаrодарен своему секретарю
Лоле Брукс (Lola Brooks) за оформление различных версий рукописи. Без ее помощи
написание этой книrи и ее издание потребовали бы значительно больше времени.
"; ,/ ':;,,' ::,:;:', :,,, },:: ::}y:;,,'<..:: :,!, ':' ::'У/,: """,
Важные символы
а Действие
аТЬ Скалярное произведение векторов а и Ь
аЬ Т Внешнее произведение векторов а и Ь
/ l \ Биномиальный коэффициент
,т/
AuB Объединение А и В
В Величина, обратная температуре
b k Внешнее смещение, применяемое к нейрону k
cos(a, Ь) Косинус уrла между векторами а и Ь
D rлубина памяти
D fllg Диверreнция Куллбека Леблера между функциями плотности Be
роятности f и 9
D Оператор, сопряженный D
Е Функция энерrии
Е. Энерrия состояния i в статистической механике
Е Статистический оператор ожидания
(Е) Средняя энерrия
erf Функция ошибки
erfc Дополнительная функция ошибки
ехр Экспонента
Eav Среднеквадратическая ошибка или сумма квадратических ошибок
Е(п) МrHoBeHHoe значение суммы квадратических ошибок
F Свободная энерrия
fx(X) Функция плотности вероятности для случайноrо вектора Х
F* Подмножество (сетей) с минимальным эмпирическим риском
Н Матрица rессиана
H l Матрица, обратная rессиану
. Квадратный корень из 1, обозначаемый также как j
z
1 Единичная матрица
1 Информационная матрица Фишера
J Среднеквадратическая ошибка
J Матрица Якобиана
К(п,п 1) Матрица ковариации ошибки в теории фильтрации Калмана
28 Предисловие
к 1 / 2 Квадратный корень из матрицы К
кТ/2 Транспонированный квадратный корень из матрицы К
k B Константа Больцмана
log Лоrарифм
L(w) Функция лоrарифмическоro правдоподобия от вектора весов w
L(w) Функция лоrарифмическоrо правдоподобия от вектора весов w, по
строенная на основе одноro примера
Ме Матрица управляемости
Мо Матрица наблюдаемости
n Дискретное время
Pi Вероятность состояния i в статистической механике
Pij Вероятность перехода из состояния i в состояние j
р Стохастическая матрица
Ре Вероятность корректной классификации
Ре Вероятность ошибки
P(eIC) Условная вероятность ошибки е при условии выбора входноrо воз
действия из класса С
pci Вероятность нахождения видимоrо нейрона машины Больцмана в
состоянии а при условии фиксированной сети (положительная фаза)
Р а Вероятность нахождения видимоrо нейрона машины Больцмана в
состоянии а при условии свободноrо функционирования сети (OT
рицательная фаза)
f х (j, k; n) Оценка автокорреляционной функции Х j ( n) и Х k ( n)
f dx ( k; n) Оценка функции взаимной корреляции d( n) и Х k ( n)
R Матрица корреляции входноrо вектора
t Непрерывное время
т Температура
т Обучающее множество (выборка)
tr След матрицы
var Оператор дисперсии
V(x) Функция Ляпунова от вектора состояния х
v. Индуцированное локальное поле или активационный потенциал
J
v .
неирона J
W o Оптимальное значение вектора синаптических весов
Wkj Синаптический вес синапса j, принадлежащеrо нейрону k
w* Оптимальный вектор весов
Состояние равновесия вектора состояния х
х
(Xj) Среднее значение состояния Х j в термальном смысле
л Оценка Х, обозначенная символом "крышки"
х
Предисловие 29
Ixl Абсолютное значение (амплитуда) х
х* Комплексно сопряженное значение х, обозначенное звездочкой
Ilxll Евклидова норма (длина) вектора х
х Т Вектор, транспонированный к х
1 Оператор единичной задержки
z
Z Функция разбиения
Oj (n) Локальный rpадиент нейрона j в момент времени n
д.w Малое изменение вектора весов w
\7 Оператор rpадиента
\72 Оператор Лапласа
\7 w J rрадиент J по w
V'.F Диверrенция вектора F
11 Коэффициент скорости обучения
к Семиинвариант
Jl Стратеrия
8k Пороrовое значение нейрона k (т.е. величина смещения b k с обратным
знаком)
А Параметр реrуляризации
Ak k e собственное значение квадратной матрицы
<Pk ( . ) Нелинейная функция активации нейрона k
Е Символ принадлежности множеству
U Символ объединения множеств
n Символ пересечения множеств
* Символ конволюции
+ Символ псевдообращения матрицы
Открытые и закрытые интервалы
Открытый интервал (а, Ь) изменения переменной х означает, что а < х < Ь.
Закрытый интервал (а, Ь] изменения переменной х означает, что а ::; х ::; Ь.
Полуоткрытый интервал (а, Ь) изменения переменной х означает, что а < х < Ь.
Аналоrично, интервал (а, Ь] изменения переменной х означает, что а < х < Ь.
Минимумы и максимумы
Символ arg min f(w) обозначает значение вектора aprYMeHTa w, доставляющее ми
w
нимум функции f(w).
Символ arg шах f (w) обозначает значение вектора aprYMeHTa w, доставляющее
w
максимум функции f(w).
.
Введение
1.1. Что такое нейронные сети
Исследования по искусственным нейронным сетям (далее нейронные сети) связа
ны с тем, что способ обработки информации человеческим мозroм в корне отличает
ся от методов, npименяемых обычными цифровыми компьютерами. Мозr представ
ляет собой чрезвычайно сложный, нелинейный, параллельный компьютер (систему
обработки информации). Он обладает способностью орrанизовывать свои cтpyктyp
ные компоненты, называемые нейронами (neuron), так, чтобы они моши выполнять
конкретные задачи (такие как распознавание образов, обработку сиrналов opraHoB
чувств, моторные функции) во MHoro раз быстрее, чем MOryT позволить самые быст
родействующие современные компьютеры. Примером такой задачи обработки ин
формации может служить обычное зрение (human vision) [194], [637], [704]. В функ
ции зрительной системы входит создание представления окружающеrо мира в таком
виде, который обеспечивает возможность взаимодействия (interact) с этим миром.
Более точно, мозr последовательно выполняет ряд задач распознавания (например,
распознавание знакомоro лица в незнакомом окружении). На это у Hero уходит около
1 00 200 миллисекунд, в то время как выполнение аналоrичных задач даже меньшей
сложности на компьютере может занять несколько дней.
Друrим примером может служить локатор (sonar) летучей мыши, представля
ющий собой систему активной эхо локации. Кроме предоставления информации о
расстоянии до нужноrо объекта (например, мошки) этот локатор предоставляет ин
формацию об относительной скорости объекта, о ero размерах и размерах ero отдель
ных элементов, а также об азимуте и высоте движения объекта [1026], [1027]. для
выделения этой информации из получаемоrо сиrнала крохотный мозr летучей MЫ
ши проводит сложные нейронные вычисления. Эхо локация летучей мыши по своим
характеристикам качества и быстродействия превосходит самые сложные при боры,
созданные инженерами.
Что же позволяет мозrу человека или летучей мыши добиться таких результатов?
При рождении мозr имеет совершенную структуру, позволяющую строить собствен
ные правила на основании Toro, что мы называем "опытом". Опыт накапливается с
32 rлава 1. Введение
течением времени, и особенно масштабные изменения происходят в первые два rода
жизни человека. В этот период формируется остов общей структуры. Однако развитие
на этом не прекращается оно продолжается до последних дней жизни человека.
Понятие развития нейронов связано с понятием пластичности (plasticity) мозrа
способности настройки нервной системы в соответствии с окружающими условия
ми. Именно пластичность иrpает самую важную роль в работе нейронов в качестве
единиц обработки информации в человеческом мозrе. Аналоrично, в искусственных
нейронных сетях работа проводится с искусственными нейронами. В общем случае
нейронная сеть (neural network) представляет собой машину, моделирующую спо
соб обработки мозrом конкретной задачи. Эта сеть обычно реализуется с помощью
электронных компонентов или моделируется проrpаммой, выполняемой на цифровом
компьютере. Предметом рассмотрения настоящей книrи является важный класс ней
ронных сетей, осуществляющих вычисления с помощью процесса обучения (leaming).
Для TOro чтобы добиться высокой производительности, нейронные сети используют
множество взаимосвязей между элементарными ячейками вычислений нейронами.
Таким образом, можно дать следующее определение нейронных сетей, выступающих
в роли адаптивной машины!.
Нейронная сеть это 2ромадный распределенный парШUlельный процессор, cocтo
ящий из элементарных единиц обработки информации, накапливающих эксперимен
тальные З1lания и предоставляющих их для последующей обработки. Нейронная сеть
сходна с МОЗ20М С двух точек зрения.
· Знания поступают в нейронную сеть из окружающей среды и используются в
процессе обучения.
· Для накопления знаний прuмеuяются связи между нейронами, называемые синап
тическими весами.
Процедура, используемая для npоцесса обучения, называется ал20ритмом обучения
(leaming algorithm). Эта процедура выстраивает в определенном порядке синапти
ческие веса нейронной сети для обеспечения необходимой структуры взаимосвя
зей нейронов.
Изменение синаnтических весов представляет собой традиционный метод Ha
стройки нейронных сетей. Этот подход очень близок к теории линейных адаптивных
фильтров, которая уже давно заявила о себе и применяется в различных областях
деятельности человека [435], [1144]. Однако нейронные сети MOryT изменять соб
ственную тополоrию. Это обусловлено тем фактом, что нейроны в человеческом
мозrе постоянно отмирают, а новые синanтические связи постоянно создаются.
I Это определение нейронных сетей взято из [!6J.
1.1. Что такое нейронные сети ЗЗ
в литературе нейронные сети часто называют нейрокомпьютерами, сетями связей
(connectionist network), параллельными распределенными процессорами и Т.д. В этой
книrе мы будем пользоваться термином "нейронная сеть", хотя в отдельных случаях
будут использоваться термины "нейрокомпьютер" и "сеть связей".
Преимущества нейронных сетей
Совершенно очевидно, что свою силу нейронные сети черпают, во первых, из pac
параллеливания обработки информации и, BO BTOpЫX, из способности самообучать
ся, Т.е. создавать обобщения. Под термином обобщение (generalization) понимается
способность получать обоснованный результат на основании данных, которые не
встречались в процессе обучения. Эти свойства позволяют нейронным сетям решать
сложные (масшrабные) задачи, которые на сеrодняшний день считаются труднораз
решимыми. Однако на практике при автономной работе нейронные сети не Moryт
обеспечить rOToBbIe решения. Их необходимо интеrpировать в сложные системы.
В частности, комплексную задачу можно разбить на последовательность относи
тельно простых, часть из которых может решаться нейронными сетями. Очень важ
но уяснить, что для создания компьютерной архитектуры, которая будет способна
имитировать человеческий мозr (если такое окажется возможным вообще), придется
пройти долrий и трудный путь.
Использование нейронных сетей обеспечивает следующие полезные свойства
систем.
1. Нелинейность (nonlinearity). Искусственные нейроны MorYT быть линейными и
нелинейными. Нейронные сети, построенные из соединений нелинейных нейро
нов, сами являются нелинейными. Более Toro, эта нелинейность особоro сорта,
так как она распределена (distributed) по сети. Нелинейность является чрезвычай
но важным свойством, особенно если сам физический механизм, отвечающий за
формирование входноro сиrнала, тоже является нелинейным (например, челове
ческая речь).
2. Отображение входной информации в выходную (input output mapping). Одной из
популярных парадиrм обучения является обучение с учителем (supervised leaт
ing). Это подразумевает изменение синаптических весов на основе набора марки
рованныхучебных примеров (training sample). Каждый пример состоит из входноro
сиrнала и соответствующеrо ему желаемО20 отклика (desired response). Из этоro
множества случайным образом выбирается пример, а нейронная сеть модифи
цирует синаптические веса для минимизации расхождений желаемоro выходноro
сиrнала и формируемоrо сетью соrласно выбранному статистическому критерию.
При этом собственно модифицируются свободные параметры (free parameters) ce
ти. Ранее использованные примеры MOryT впоследствии быть применены снова,
34 rлава 1. Введение
но уже в друroм порядке. Это обучение про водится до тех пор, пока изменения
синаптических весов не станут незначительными. Таким образом, нейронная сеть
обучается на примерах, составляя таблицу соответствий BXOД BЫXOД для KOHKpeT
ной задачи. Такой подход заставляет вспомнить непараметрическое статисти
ческое обучение (nonparametric statistical inference). Это направление статистики
имеет дело с оценками, не связанными с какой либо конкретной моделью, или, с
биолоrической точки зрения, с обучением с нуля [344]. Здесь термин "непарамет
рический" используется для акцентирования тоro, что изначально не существует
никакой предопределенной статистической модели входных данных. Для примера
рассмотрим задачу классификации образов (pattem classification). В ней требуется
соотнести входной сиrнал, представляющий физический объект, или событие, с
некоторой предопределенной катеroрией (классом). При непараметрическом под
ходе к этой задаче требуется "оценить" рамки решения в пространстве входноro
сиrнала на основе набора примеров. При этом не используется никакая вероят
ностная модель распределения. Аналоrичный подход применяется и в парадиrме
обучения с учителем. Это еще раз подчеркивает параллель между отображением
входных сиrналов в выходные, осуществляемым нейронной сетью, и непарамет
рическим статистическим обучением.
3. Адаптивность (adaptivity). Нейронные сети обладают способностью адаптиро
вать свои синаптические веса к изменениям окружающей среды. В частности,
нейронные сети, обученные действовать в определенной среде, MOryT быть леrко
переучены для работы в условиях незначительных колебаний параметров среды.
Более Toro, для работы в нестационарной (nonstationary) среде (rдe статистика
изменяется с течением времени) Moryт быть созданы нейронные сети, изменяю
щие синаnтические веса в реальном времени. Естественная для классификации
образов, обработки сиrналов и задач управления архитектура нейронных сетей
может быть объединена с их способностью к адаптации, что приведет к созданию
моделей адаптивной классификации образов, адаптивной обработки сиrналов и
адаnтивноro управления. Известно, что чем выше адаптивные способности си
стемы, тем более устойчивой будет ее работа в не стационарной среде. При этом
хотелось бы заметить, что адаптивность не Bcerдa ведет к устойчивости; иноrда
она приводит к совершенно противоположному результату. Например, адаптивная
система с параметрами, быстро изменяющимися во времени, может также быстро
реаrировать и на посторонние возбуждения, что вызовет потерю производитель
ности. Для тоro чтобы использовать все достоинства адаптивности, основные
параметры системы должны быть достаточно стабильными, чтобы можно бьmо
не учитывать внешние помехи, и достаточно rибкими, чтобы обеспечить peaK
цию на существенные изменения среды. Эта задача обычно называется дилеммой
стабuльности пластичности (stability plasticity dilemma) [389].
1.1. Что такое нейронные сети 35
4. Очевидность ответа (evidential response). В контексте задачи классификации об
разов можно разработать нейронную сеть, собирающую информацию не только
для определения конкретноro класса, но и для увеличения достоверности (con
fidence) принимаемоrо решения. Впоследствии эта информация может исполь
зоваться для исключения сомнительных решений, что повысит продуктивность
нейронной сети.
5. Контекстная информация (contextual information). Знания представляются в ca
мой структуре нейронной сети с помощью ее состояния активации. Каждый ней
рон сети потенциально может бьпь подвержен влиянию всех остальных ее ней
ронов. Как следствие, существование нейронной сети непосредственно связано с
контекстной информацией.
6. Отказоустойчивость (fault tolerance). Нейронные сети, облаченные в форму элек
троники, потенциально отказоустойчивы. Это значит, что при неблаroприятных
условиях их производительность падает незначительно. Например, если повре
жден какой то нейрон или еro связи, извлечение запомненной информации заТРУk
няется. Однако, принимая в расчет распределенный характер хранения информа
ции в нейронной сети, можно утверждать, что только серьезные повреждения
структуры нейронной сети существенно повлияют на ее работоспособность. По
этому снижение качества работы нейронной сети происходит медленно. Незначи
тельное повреждение структуры никоrда не вызывает катастрофических послед
ствий. Это очевидное преимущество робастных вычислений, однако еro часто не
принимают в расчет. Чтобы rарантировать отказоустойчивость работы нейронной
сети, в алrоритмы обучения нужно закладывать соответствующие поправки [557].
7. Масштабируемость (VLSI Implementability). Параллельная структура нейронных
сетей потенциально ускоряет решение некоторых задач и обеспечивает масшта
бируемость нейронных сетей в рамках технолоrии VLSI (very large scale inte
grated). Одним из преимуществ технолоrий VLSI является возможность предста
вить достаточно сложное поведение с помощью иерархической структуры [720].
8. Единообразие анализа и проектирования (Uniformity of analysis and design). Ней
ронные сети являются универсальным механизмом обработки информации. Это
означает, что одно и то же проектное решение нейронной сети может исполь
зоваться во мноrих предметных областях. Это свойство проявляется нескольки
ми способами.
· Нейроны в той или иной форме являются стандартными составными частями
любой нейронной сети.
· Эта общность позволяет использовать одни и те же теории и алroритмы обу
чения в различных нейросетевых приложениях.
· Модульные сети MOryT быть построены на основе интеrpации целых модулей.
L
36 rлава 1. Введение
9. АналО2UЯ с нейроБИОЛО2ией (Neurobio10gical analogy). Строение нейронных сетей
определяется аналоrией с человеческим мозrом, который является живым дo
казательством Toro, что отказоустойчивые параллельные вычисления не только
физически реализуемы, но и являются быстрым и мощным инструментом pe
шения задач. Нейробиолоrи рассматривают искусственные нейронные сети как
средство моделирования физических явлений. С друroй стороны, инженеры по
стоянно пытаются почерпнуть у нейробиолоroв новые идеи, выходящие за рамки
традиционных электросхем. Эти две точки зрения можно продемонстрировать на
следующих примерах.
. В работе модели линейных систем вестибуло окулярноro рефлекса сравнивались
с моделями рекуррентных нейронных сетей (они будут описаны в разделе 1.6
и более подробно в rлаве 15). Вестибуло окулярный рефлекс, или рефлекс VOR
(vestibu10 ocular reflex), является составной частью rлазодвиrательной системы.
Еro задачей является обеспечение стабильности визуальноrо образа при поворотах
roловы за счет вращения rлаз. Процесс VOR реализуется премоторными нейрона
ми в вестибулярном центре, которые получают и обрабатывают сиrналы поворота
roловы от вестибулярных сенсорных нейронов и передают результат на MOTOp
ные нейроны мышц rлаз. Механизм VOR хорошо подходит для моделирования,
так как входной (поворот roловы) и выходной (поворот шаз) сиrналы можно точно
описать. К тому же это довольно простой рефлекс, а нейрофизические свойства pe
ализующих еro нейронов довольно хорошо описаны. Среди трех задействованных
в нем типов нейронов премоторные нейроны, входящие в состав вестибулярно
ro центра, являются самыми сложными, а значит, самыми интересными. Ранее
механизм VOR моделировался с помощью сосредоточенной линейной системы и
теории управления. Эти модели были приrодны для описания некоторых общих
свойств VOR, но не давали четкоro представления о свойствах самих нейронов.
С появлением нейросетевых моделей ситуация в корне изменилась. Рекуррентные
модели VOR (проrpаммы, использующие алroритм рекуррентноrо обучения в pe
альном времени, который будет описан в шаве 15) позволили воспроизвести и опи
сать мноrие статические, динамические, нелинейные и распределенные аспекты
обработки сиrналов при реализации рефлекса VOR и, в частности, вестибулярный
центр [44].
. Сетчатка (retina), более чем какая то друrая часть мозrа, выполняет функции вза
имосвязи окружающеro мира, представленноrо визуальным рядом или физическим
изображением (physica1 image), проецируемым на матрицу рецепторов, с первым
нейронным изображением (neural image). Сетчатка это матрица микроскопиче
ских рецепторов на внешней лицевой стороне rлазноrо яблока. В ее задачи входит
преобразование оптическоro сиrнала в нейронное изображение, передаваемое по
оптическим нервам в различные центры для анализа. Принимая во внимание си
нanтическую орrанизацию сетчатки, это сложная задача. В любой сетчатке пре
образование изображения из оптическоro в нейронное проходит три стадии [1 О 1 7].
1.2. Человеческий мозr 37
(i) Снятие фотокопии слоем нейронов рецепторов.
(ii) Передача сформированноro сиrнала (реакция на свет) химическими синапсами
на слой биполярных IOlеток (bipo1ar сеВ).
(iii) Передача этих сиrналов (также с помощью химических синапсов) на выходные
нейроны.
На двух последних стадиях (при передаче информации от рецепторов на биполяр
ные рецепторы и от последних на выходные нейроны) в операции участвуют спе
циальные нейроны с латеральным торможением, в том числе так называемые 20рИ
зонтальные IOlетки (horizonta1 cell). Их задачей является преобразование сиrнала
между разными синаптическими слоями. Также существуют центробежные эле
менты, обеспечивающие передачу сиrнала с внутреннеro синаптическоro слоя на
внешний. Некоторые исследователи создавали электронные микросхемы, имити
рующие структуру сетчатки [136], [137], [701]. Эти электронные чипы назывались
нейроморфными контурами (neиromorphic integrated circиit) [720]. Нейроморфные
сенсоры представляют собой матрицу фоторецепторов, связанных с COOTBeTCTBY
ющими элементами рисунка (пикселями). Они имитируют сетчатку в том смысле,
что Moryт адаптироваться к изменению освещенности, идентифицировать контуры
и движение. Нейробиолоrическая модель, воплощенная в нейроморфные контуры,
обеспечила еще одно преимущество: она вселила надежду на то, что физическое
понимание нейробиолоrических структур может оказать существенное влияние на
область электроники и технолоrию VLSI.
После рассмотрения этих примеров из нейробиолоrии становится ясно, почему столь
ко внимания уделяется человеческому мозrу и ero структурным уровням орrанизации.
1.2. Человеческий мозr
Нервную систему человека можно рассматривать как трехступенчатую (рис. 1.1) [67].
Центром этой системы является МОЗ2 (brain), представленный сетью нейронов (Hep
вов) (nerve net). Он получает информацию, анализирует ее и выдает COOTBeTCTBY
ющие решения. На рис. 1.1 показаны два набора стрелок. Стрелки, направленные
слева направо, обозначают прямую передачу сиrналов информации в систему, а
стрелки, направленные справа налево, ответную реакцию системы. Рецепторы
(receptor) преобразовывают сиrналы от тела и из окружающей среды в электриче
ские импульсы, передаваемые в нейронную сеть (мозr). Эффекторы (effector) преоб
разовывают электрические импульсы, сrенерированные нейронной сетью (мозroм), в
выходные сиrналы.
38 rлава 1. Введение
Возбуждение
Рецепторы
Нейронная
сеть
Эффекторы
Отклик Рис. 1.1. Блочная диа
rpaMMa для нервной
системы
Изучение человеческоro мозrа началось с работы, в которой предложена идея
орrанизации человеческоro мозrа на основе нейронов [869]. Как правило, реакция
нейронов на 5 6 порядков медленнее реакции кремниевых лоrических элементов.
Длительность событий в кремниевых элементах измеряется в наносекундах (10 9 с),
а в нейронах в миллисекундах (10 3 с). Однако эта относительная медлительность
нейронов компенсируется их массой и количеством взаимосвязей между ними. По
существующим оценкам, в коре roловноro мозrа насчитывается около 1 О биллио
нов нейронов и около 60 триллионов синапсов или взаимосвязей между нейронами
[977]. В результате мозr представляет собой чрезвычайно эффективную структуру.
В частности, энерrетические затраты мозrа на выполнение одной операции в секунду
составляют около 10 16 Дж. В то же время затраты самоro экономичноrо компьютера
не опускаются ниже 10 6 Дж на операцию в секунду [286].
Синапсы (synapses) это элементарные структурные и функциональные едини
цы, которые передают импульсы между нейронами. Самым распространенным типом
синапсов являются химические (chemical synapse), которые работают следующим об
разом. Предсинаптический процесс формирует передаваемую субстанцию (transmit
ter substance), которая методом диффузии передается по синаптическим соединениям
между нейронами и влияет на постсинаптический процесс. Таким образом, синапс
преобразовывает предсинаптический электрический сиrнал в химический, а после
этоro в постсинаптический электрический [977]. В электротехнической термино
лоrии еro можно было бы назвать невзаимным четырехполюсником (nonreciprocal
two port device). В традиционных описаниях нейронной орrанизации синапс пред
ставляют простым соединением, которое может передавать возбуждение (excitation)
или торможение (inhibition) (но не то и друroе одновременно) между нейронами.
Ранее уже rоворилось, что под пластичностью понимается способность нервной
системы адаптироваться к условиям окружающей среды [194], [279]. В мозrе взрос
лоro человека пластичность реализуется двумя механизмами: путем создания новых
синаптических связей между нейронами и за счет модификации существующих. AKCO
ны (ах оп) (линии передачи) и дендриты (dendrite) (зоны приема) представляют собой
два типа элементов клетки, которые различаются даже на морфолоrическом уровне.
Аксоны имеют более rладкую поверхность, более тонкие rpаницы и большую длину.
Дендриты (свое название они получили из за сходства с деревом) имеют неровную
поверхность с множеством окончаний [315]. Существует orpoMHoe множество форм
и размеров нейронов, в зависимости от тоro, в какой части мозrа они находятся.
На рис. 1.2 показана пирамидальная клетка (pyramidal cell) самый распространен
1.2. Человеческий мозr 39
ный тип нейронов коры roловноro мозrа. Как и все нейроны, пирамидальные клетки
получают сиrналы от щупалец дендритов (фраrмент дендрита показан на рис. 1.2).
Пирамидальная клетка может получать более 10000 синаптических сиrналов и про
ектировать их на тысячи друrих клеток
Выходные сиrналы большинства нейронов преобразуются в последовательность
коротких электрических импульсов. Эти импульсы, называемые потенциалами дей
ствuя (action potential) или выбросами (spike), берут свое начало в теле нейрона и
передаются через друrие нейроны с постоянной скоростью и амплитудой. Причина
использования потенциала действия для взаимодействия нейронов лежит в самой
физической природе аксона. Аксон нейрона имеет большую длину и маленькую тол
щину, что выражается в ero большом электрическом сопротивлении и емкости. Обе
эти характеристики распределены по аксону. Таким образом, ero можно смоделиро
вать как линию электропередачи с использованием уравнения кабеля (саЫе equation).
Анализ этоrо уравнения показывает, что подаваемое на один конец аксона напря
жение экспоненциально уменьшается с расстоянием, достиrая на друroм ero конце
малых значений. Потенциалы действия позволяют обойти эту проблему [46].
В человеческом мозrе существуют крупно и мелкомасштабные анатомические
структуры. Эти верхний и нижний уровни отвечают за выполнение разных функций.
На рис. 1.3 показана иерархия уровней орrанизации мозrа, составленная на основе
анализа отдельных областей мозrа [194], [977]. Синапсы (synapse) представляют co
бой самый нижний уровень уровень молекул и ионов. На следующих уровнях мы
имеем дело с нейронными микроконтурами, дендритными деревьями и в заверше
ние с нейронами. Под нейронным микроконтуром (neural microcircuit) понимаете я
набор синапсов, орrанизованный в шаблоны взаимосвязей, выполняющих опреде
ленную операцию. Нейронный микроконтур можно сравнить с электронным чипом,
состоящим из набора транзисторов. Минимальный размер микроконтуров измеряется
в микронах, а скорость операций в миллисекундах. Нейронные микроконтуры rpуп
пируются В дендритные субблоки (dendritic subunit), составляющие дендритные дepe
вья (dendritic tree) отдельных нейронов. Весь нейрон (neuron) имеет размеры порядка
100 микрон и содержит несколько дендритных субблоков. На следующем уровне
сложности находятся локальные цепочки (local circuit) (размером порядка 1 мм), co
стоящие из нейронов с одинаковыми или сходными характеристиками. Эти наборы
нейронов выполняют функции, характерные для отдельных областей мозrа. За ними
в иерархии следуют межреzиональные цепочки (interregional circuit), состоящие из
траекторий, столбцов и топоrpафических карт и объединяющие несколько областей,
находящихея в разных частях мозrа.
Топоzрафические карты (topographic mар) предназначены для ответа на посту
пающую от сенсоров информацию. Эти карты часто орrанизуются в виде таблиц,
причем визуальные, звуковые и соматосенсорные карты хранятся в стеке, сохраня
ющем пространственную конфиrурацию конкретных точек возбуждения. На рис. 1.4
40 rлава 1. Введение
Верхушечные
дендриты
CerMeHT
дендрита
} Основные
дендриты
Синаптические
окончания
Рис. 1.2. Пирамидальная клетка
показана цитоархитектурная карта церебральной коры мозrа, разработанная в [157].
На этом рисунке четко видно, что разные сенсорные сиrналы (моторные, соматиче
ские, визуальные и т.п.) отображаются на соответствующие области церебральной
коры с сохранением порядка. На заключительном уровне сложности топоrpафиче
ские карты и прочие межреrиональные цепочки связываются друr с друroм, образуя
центральную нервную систему (centra1 nervous system).
1.2. Человеческий мозr 41
Рис. 1.3. Структурная орrанизация уровней мозrа
Очень важно уяснить, что описанные струюурные уровни орrанизации являются
уникальными характеристиками мозrа. Здесь ничто не напоминает цифровой KOM
пьютер, и в работе с нейронными сетями мы ниrде с ним не столкнемся. Тем не
менее мы направим свои стопы в сторону создания иерархии вычислительных ypOB
ней, напоминающих представленные на рис. 1.3. Искусственные нейроны, которые
мы будем использовать для создания нейронных сетей, сильно упрощены по cpaB
нению с их биолоrическими прототипами. Нейронные сети, которые можно создать
в настоящее время, примитивны по сравнению с локальными и межреrиональными
цепочками мозrа. Утешением служит только тот факт, что за последние два десяти
летия произошел большой прорыв на мноrих фронтах исследований. Принимая во
внимание аналоrию с нейробиолоrией, а также мноrообразие теоретических и Tex
нолоrических средств, можно предположить, что следующее десятилетие принесет
более rлубокое понимание искусственных нейронных сетей.
Предметом настоящей книrи является изучение нейронных сетей с точки зрения
инженерии 2 . Сначала будут описаны модели искусственных нейронов, формирую
щих основу нейронных сетей. Сами нейронные сети рассматриваются в последую
щих rлавах.
2 Применение нейронных сетей в области нейронноro моделирования, познания и нейрофизиолоrии описано
в [46]. Понятное описаНИе вычислительных аспектоВ мозrа содержнтся в [194]. Детальное описание нейронных
механизмов и человеческоro мозrа содержится В [315], [536], [565], [604], [975], [976].
10.....
42 rлава 1. Введение
4
10
17
Рис. 1.4. Цитоархитектурная карта церебральной коры мозrа. Различные обла
сти отличаются между собой по толщине слоя и типам составляющих их клеток.
Выделим некоторые наиболее важные области. К моторной коре относятся об
ласть 4 моторная цепочка, премоторная область 6; фронтальная область
зрения 8. Соматосенсорную кору составляют области З, 1,2. Области 17 19
относятся к визуальной коре, а области 41 и 42 к слуховой. (На основании
[157], с разрешения издательства Oxford University Press.)
1.3. Модели нейронов
Нейрон представляет собой единицу обработки информации в нейронной сети. На
блок схеме рис. 1.5 показана модель (model) нейрона, лежащеrо в основе искусствен
ных нейронных сетей. В этой модели можно выделить три основных элемента.
1. Набор синапсов (synapse) или связей (connecting link), каждый из которых xapaK
теризуется своим весом (weight) или силой (strength). В частности, сиrнал Xj на
входе синапса j, связанноrо с нейроном k, умножается на вес Wkj' Важно обра
тить внимание на то, в каком порядке указаны индексы синаптическоrо веса W kj'
Первый индекс относится к рассматриваемому нейрону, а второй ко входному
окончанию синапса, с которым связан данный вес. В отличие от синапсов мозrа
синаптический вес искусственноrо нейрона может иметь как положительные, так
и отрицательные значения.
2. Сумматор (adder) складывает входные сиrналы, взвешенные относительно co
ответствующих синапсов нейрона. Эту операцию можно описать как линейную
комбинацию.
1.3. Модели нейронов 43
Х !
Пороr
b k
Х 2
Входные
сиrналы
Выходной
сиrнал
Yk
Х т
Рис. 1.5. Нелинейная модель
нейрона
Синаптические
веса
3. Функция активации (activation function) оrpаничивает амплитуду выходноrо сиrна
ла нейрона. Эта функция также называется функцией сжатия (squashing function).
Обычно нормализованный диапазон амплитуд выхода нейрона лежит в интервале
[0,1] или [ 1, 1].
в модель нейрона, показанную на рис. 1.5, включен nОрО20вый элемент (bias),
который обозначен символом b k . Эта величина отражает увеличение или уменьшение
входноro сиrнала, подаваемоrо на функцию активации.
В математическом представлении функционирование нейрона k можно описать
следующей парой уравнений:
m
Uk == L WkjXj,
j l
Yk == <P(Uk + b k )
(1.1)
(1.2)
rдe Хl, Х2, . . . , Х т входные сиrналы; Wk1, Wk2, . . . , Wkm синаптические веса ней
рона k; Uk линейная комбинация входных воздействий (1inear combiner output); b k
пороr; <р(-) функция активации (activation function); Yk выходной сиrнал нейро
на. Использование пороrа b k обеспечивает эффект афиННО20 nреобразования (affine
transfonnation) выхода линейноrо сумматора Uk. В модели, показанной на рис. 1.5,
постсинanтический потенциал вычисляется следующим образом:
Vk == uk +b k .
(1.3)
в частности, в зависимости от Toro, какое значение принимает пороr b k , положи
тельное или отрицательное, индуцированное локальное поле (induced local field) или
потенциал активации (activation potential) Vk нейрона k изменяется так, как показано
......
1"""""
44 rлава 1. Введение
Индуцированное
локальное поле, v k
Пороr b k > О
Выход линейноro
сумматора, U k
Рис. 1.6. Афинное преобразование. вызванное Ha
личием nopora. Обратите внимание, что в точке, rде
uk == О, vk == bk
на рис. 1.6. Здесь и далее мы будем использовать термин "индуцированное локальное
поле". Обратите внимание на результат этоrо афинноro преобразования. rрафик Vk
уже не проходит через начало координат, как rpафик Uk.
Пороr b k является внешним параметром искусственноrо нейрона k. Ero присут
ствие мы видим в выражении (1.2). Принимая во внимание выражение (1.3), формулы
(1.1), (1.2) можно преобразовать к следующему виду:
m
Vk == L WkjXj,
j O
Yk == <P(Vk)
(1.4)
(1.5)
в выражении (1.4) добавился новый синапс. Ero входной сиrнал равен:
ХО == +1,
(1.6)
а ero вес:
WkO == b k .
(1.7)
Это позволило трансформировать модель нейрона к виду, показанному на рис. 1.7.
На этом рисунке видно, что в результате введения пороrа добавляется новый входной
сиrнал фиксированной величины +1, а также появляется новый синаптический вес,
равный пороrовому значению b k . Хотя модели, показанные на рис. 1.5 и 1.7, внешне
совершенно не схожи, математически они эквивалентны.
1.3. Модели нейронов 45
Х 2
Выходной
сиrнал
Yk
Фиксированный
входной сиrнал Ха + 1
Х,
Входы
Х т
Рис. 1.7_ Еще одна нелиней
ная модель нейрона
Синаптические веса
(включая пороr)
Типы функций активации
Функции активации, представленные в формулах как <р( v), определяют выходной сиr
нал нейрона в зависимости от индуцированноro локальноrо поля V. Можно выделить
три основных типа функций активации.
1. Функция единиЧНО20 скачка, или пороrовая функция (threshold function). Этот тип
функции показан на рис. 1.8, а и описывается следующим образом:
( v) == { 1, если V о;
<р о, если V < о;
(1.8)
в технической литературе эта форма функции единичноrо скачка обычно назы
вается функцией Хэвисайда (Heaviside function). Соответственно выходной сиrнал
нейрона k такой функции можно представить как
{ 1, если Vk о;
Yk == о, если Vk < о;
(1.9)
rде Vk это индуцированное локальное поле нейрона, т.е.
m
Vk == L WkjXj + b k -
j l
(1.1 о)
Эту модель в литературе называют моделью МаК КШlЛока Питца (McCal1och Pitts
mode1), отдавая дань пионерской работе [714]. В этой модели выходной сиrнал
нейрона принимает значение 1, если индуцированное локальное поле этоrо ней
рона не отрицательно, и О в противном случае. Это выражение описывает
свойство "все или ниче20" модели Мак Каллока Питца.
46 rлава 1. Введение
1,2
1 cp(v)
0,8
0,6
0,4
0,2
О
2 1,5 1 0,5 О 0,5
v
а)
1,2
1
0,8
0,6
0,4
0,2
2 1,5 1 0,5 О 0,5
v
б)
1,2
1
0,8
0,6
0,4
0,2
О
IO 8 6
v
в)
1,5 2
1,5 2
Рис. 1.8. Виды активационных функций:
8 10 функция единичноro скачка (а); кусочно
линейная функция (6) и сиrмоидальная
функция для различных значений пара
метра а (в)
2. Кусочно линейная функция (piecewise linear function). Кусочно линейная фУНКЦИЯ,
показанная на рис. 1.8, б, описывается следующим выражением:
{ 1, v 2: + ;
q>(v) == Ivl , + > v > ;
О, v s: 2'
rдe коэффициент усиления в линейной области оператора предполаrается paB
ным единице. Эту функцию активации можно рассматривать как аппроксимацию
(approximation) нелинейноrо усилителя. Следующие два варианта можно считать
особой формой кусочно линейной функции.
(1.11)
1.3. Модели нейронов 47
. Если линейная область оператора не достиrает пороrа насыщения, он превра
щается в линейный сумматор (linear combiner).
. Если коэффициент усиления линейной области принять бесконечно большим,
то кусочно линейная функция вырождается в пОРО20вую (threshold function).
3. Сиzмоидальная функция (sigmoid function). Сиrмоидальная функция, rpафик KOTO
рой напоминает букву S, является, пожалуй, самой распространенной функцией,
используемой для создания искусственных нейронных сетей. Это быстро возрас
тающая функция, которая поддерживает баланс между линейным инелинейным
поведением 3 . Примером сиrмоидальной функции может служить ЛО2истическая
функция 4 (logistic function), задаваемая следующим выражением:
1
<р( v)
1 + ехр( av)'
(1.12)
rдe а параметр наклона (slope parameter) сиrмоидальной функции. Изменяя
этот параметр, можно построить функции с различной крутизной (см. рис. 1.8, в).
Первый rpафик соответствует величине параметра, равной а/4. в пределе, коrда
параметр наклона достиrает бесконечности, сиrмоидальная функция вырождается
в пороrовую. Если пороrовая функция может принимать только значения О и 1,
то сиrмоидальная функция принимает бесконечное множество значений в диапа
зоне от О до 1. При этом следует заметить, что сиrмоидальная функция является
дифференцируемой, в то время как пороrовая нет. (Как мы увидим в rлаве 4,
дифференцируем ость активационной функции иrpает важную роль в теории ней
ронных сетей.)
Область значений функций активации, определенных формулами (1.8), (1.11) и
(1.12), представляет собой отрезок от О до +1. Однако иноrда требуется функция aK
тивации, имеющая область значений от 1 до +1. в этом случае функция активации
должна быть симметричной относительно начала координат. Эm значит, что функция
активации является нечетной функцией индуцированноrо локальноrо поля. В част
ности, пороrовую функцию в данном случае можно определить следующим образом:
{ 1, если v > о;
<p(v) == о, если v == о;
1, если v < о,
(1.13)
3 Полное оПисание сиrмоидальной функции и связанных с ней вопросов содержится в [727].
4 Лоrнстическая функция, или, более точно, функция лоrистическоrо распределения, описывает широко
представленный в литературе закон лоrистическоm роста. Все процессы роста MOryт быть представлены функ
цней лоrнстнческоrо распределения F(t) 1/(1 +ехр( at )), rдe t переменная времени; а и константы.
Следует отметнть, что С таким же или даже с большим успехом к тем же данным можно применить и друrие
распределения, например распределение [аусса [294].
48 rлава 1. Введение
Эта функция обычно называется СИ2НУМ. В данном случае сиrмоидальная функция
будет иметь форму 2иперболичеСКО20 таН2енса:
<p(v) == tanh(v).
(1.14)
Такой вид сиrмоидальной функции обеспечивает ряд преимуществ, о которых
речь пойдет в rлаве 4.
Стохастическая модель нейрона
Модель нейрона, показанная на рис. 1.7, является детерминистской. Это значит, что
преобразование входноrо сиrнала в выходной точно определено для всех значений
входноro сиrнала. Однако в некоторых приложениях лучше использовать стохасти
ческие нейросетевые модели, в которых функция активации имеет вероятностную
интерпретацию. В подобных моделях нейрон может находиться в одном из двух
состояний: + 1 или 1. Решение о переключении состояния нейрона принимается
с учетом вероятности этоrо события. Обозначим состояние нейрона символом х, а
вероятность активации нейрона (probability of firing) функцией Р( v), [де v
индуцированное локальное поле нейрона. Torдa
х== { +l,
1,
с вероятностью P(v);
с вероятностью 1 Р( v).
Вероятность P(v) описывается сиrмоидальной функцией следующеrо вида [660]:
1
P(v) == 1 + ехр( v/T) '
(1.15)
rде Т это аналоr температуры (temperature), используемый для управления ypOB
нем шума, и, таким образом, степенью неопределенности переключения. При этом
важно заметить, что Т не описывает физическую температуру нейронной сети,
будь то биолоrической или искусственной. Параметр Т управляет термальными
флуктуациями, представляющими эффект синаптическоro шума. Заметим, что ec
ли параметр Т стремится к нулю, то стохастический нейрон, описанный выраже
нием (1.15), принимает детерминированную форму (без включения шума) нейрона
Мак Каллока Питца.
1.4. Представление нейронных сетей с помощью направленных rрафов 49
1.4. Представление нейронных сетей с помощью
направленных rрафов
Блочные диа2раммы (block diagram), представленные на рис. 1.5 и 1.7, обеспечивают
функциональное описание различных элементов, из которых состоит модель искус
cTBeHHoro нейрона. Внешний вид модели можно в значительной мере упростить,
применив идею rpафов прохождения сиrнала. rрафы передачи сиrнала (signal flow)
с наборами правил были введены Мейсоном (Mason) в 1953 [оду для описания ли
нейных сетей [706], [707]. Поэтому наличие нелинейности в модели нейрона оrpани
чивает область применения этой парадиrмы в нейронных сетях. Тем не менее rpафы
прохождения сиrнала дают хорошее представление о передаче сиrнала по нейронным
сетям. Именно этот вопрос и будет рассматриваться в данном разделе.
Траф передачи (или прохождения) СИ2нала (signal flow graph) это сеть направ
ленных связей (1inks) (или ветвей (branches», соединяющих отдельные точки (узлы).
С каждым узлом j связан СИ2Нал Х j. Обычная направленная связь начинается в HeKO
тором узле j и заканчивается в друrом узле k. С ней связана некоторая передаточная
функция (transfer function), определяющая зависимость сиrнала Yk узла k от сиrна
ла Xj узла j. Прохождение сиrнала по различным частям rpафа подчиняется трем
основным правилам.
Правило 1. Направление прохождения сиrнала вдоль каждой связи определяется
направлением стрелки. При этом можно выделить два типа связей.
. Синаптические связи (synaptic link). Их поведение определяется линейным (1i
near) соотношением BXOД BЫXOД. А именно, как показано на рис. 1.9, а, сиrнал
узла Xj умножается на синаптический вес Wkj, в результате чеrо получается сиr
нал узла Yk.
. Активационные связи (activation link). Их поведение определяется нелинейным
(nonlinear) соотношением BXOД BЫXOД. Этот вид связи показан на рис. 1.9, б, [де
<р(') нелинейная функция активации.
Правило 2. Сиrнал узла равен алrебраической сумме сиrналов, поступающих на
ero вход. На рис. 1.9, в это правило проиллюстрировано для случая синаптической
сходимости (synaptic convergence).
Правило 3. Сиrнал данноrо узла передается по каждой исходящей связи без уче
та передаточных функций исходящих связей. Это правило проиллюстрировано на
рис. 1.9,2 для синаптической дивер2енции (synaptic divergence) или расходимости.
L
50 rлава 1. Введение
Х ) о
Wkj
о Y k = wkjx j
а)
Х ) о
<р(-)
о Yk=q>(x)
б)
У;
;> Y k =Y.+Y.
I J
J
в)
Xj < Xj
Х.
J
"
r)
Рис. 1.9. Основные правила построения rрафов передачи сиrналов
На рис. 1.10 по казан пример rpафа передачи сиrнала. Это модель нейрона, co
ответствующая блочной диаrpамме, приведенной на рис. 1.7. По своему внешнему
виду rpаф на рис. 1.10 значительно проще диаrpаммы на рис. 1.7, хотя и содержит все
функциональные детали. Обратите внимание, что на обоих рисунках входной сиrнал
принимает значение ХО == +1, а соответствующий синаптический вес WkO == b k , rде
b k пороr нейрона k.
Принимая в качестве модели нейрона rpаф прохождения сиrнала, показанный на
рис. 1.1 О, можно сформулировать еще одно определение нейронной сети.
Нейронная сеть это направленный 2раф, состоящий из узлов, соединенных си
наптическими и активационными связями, который характеризуется следующими
четырьмя свойствами.
1. Каждый нейрон представляется множеством линейных синаптических связей,
внешним пОрО20М И, возможно, нелинейной связью активации. ПОРО2, представля
емый входной синаптической связью, считается равным + 1.
2. Синаптические связи нейрона используются для взвешивания соответствующих
входных СИ2налов.
3. Взвешенная сумма входных СИ2налов определяет индуцированное локальное поле
каждО20 конкретНО20 нейрона.
4. Активационные связи модифицируют индуцированное локальное поле нейрона, co
здавая выходной СИ2Нал.
1.4. Представление нейронных сетей с помощью направленных rрафов 51
ХО +1
Х 1
Х 2 v k <р(-) Y k
Рис. 1.10. rраф передачи сиrнала для одноro
нейрона
Состояние нейрона может быть определено в терминах индуцированноro локаль
Horo поля или ero выходноrо сиrнала.
Направленный rpаф, определенный указанным выше способом, является полным
(сошрlеtе). Это значит, что он описывает не только прохождение сиrнала между ней
ронами, но и передачу сиrнала в самом нейроне. Если необходимо описать только
прохождение сиrнала между нейронами, то можно использовать сокращенную фор
МУ этоrо rpафа, опускающую детали передачи сиrнала внутри нейронов. Такой Ha
правленный rpаф называется частично полным (partially сошрlеtе) и характеризуется
следующими свойствами.
1. Входные сиrналы rpафа формируются узлами источника (soиrce node) или BXOД
ными элементами.
2. Каждый нейрон представляется одним узлом, который называется вычислитель
НЫМ (сошрutаtiоп node).
3. ЛИНИИ передачи СИ21lала (сошшuпiсаtiоп links), соединяющие узлы источники и
вычислительные узлы rpафа, не имеют веса. Они просто определяют направление
прохождения сиrнала на rpафе.
Частично полный направленный rpаф, определенный указанным выше способом,
называется архитектурным (architectural graph). Он описывает структуру нейронной
сети. Простейший случай rpафа, состоящеro из одноrо нейрона с m входами и фикси
рованный пороrом, равным + 1, показан на рис. 1.11. Обратите внимание, что на этом
rpафе вычислительный узел обозначен заштрихованным кружком, а узлы источника
маленькими квадратиками. Это соrлашение будет использоваться на протяжении всей
книrи. Более сложные примеры нейросетевой архитектуры при водятся в разделе 1.6.
Подводя итоr сказанному, можно выделить три rpафических представления ней
ронных сетей.
52 rлава 1. Введение
xo +1
Х 1
ВЫХОДНОЙ сиrнал
Y k
Х 2
Х т
Рис. 1.11. Архитектурный rраф нейрона
(п) о
xj(п) А
) V yk(п)
В
Рис. 1.12. rраф передачи сиrнала в системе с одной
обратной связью
· Блочная диаrpамма, описывающая функции нейронной сети.
· rраф прохождения сиrнала, обеспечивающий полное описание передачи сиrнала
по нейронной сети.
· Архитектурный rpаф, описывающий структуру нейронной сети.
1.5. Обратная связь
Понятие обратной связи (feedback) характерно для динамических систем, в KOTO
рых выходной сиrнал HeKoтoporo элемента системы оказывает влияние на входной
сиrнала этоrо элемента. Таким образом, некоторые внешние сиrналы усиливаются
сиrналами, циркулирующими внутри системы. На самом деле обратная связь при
сутствует в нервной системе практичеСl<и любоro животноrо [315]. Более Toro, она
иrpает важную роль в изучении особоrо класса нейронных сетей, называемых pe
куррентными (recurrent network). На рис. 1.12 показан rpаф прохождения сиrнала в
системе с одной обратной связью (single loop feedback sуstеш). В ней входной сиr
нал Xj(n), внутренний сиrнал xj(n) и выходной сиrнал Yj(n) являются функциями
дискретной переменной n. Предполаrается, что эта система линейна и содержит пря
мую и обратную связи, которые характеризуются операторами А и В соответственно.
В частности, выходной сиrнал прямоro канала частично определяет значение канала
обратной связи. Из рис. 1.12 прослеживается следующая зависимость:
Yk(n) == A[x (n)],
x (n) == Xj(n) + B[Yj(n)],
(1. 16)
(1.17)
rдe квадратные скобки обозначают операторы А иВ.
1.5. Обратная связь 53
Исключая переменную xj (n) в выражениях (1.16) и (1.17), получим:
А
Yk(n) == 1 АВ [xj(n)]' (1.18)
Выражение А/(1 АВ) называют оператором замкнутО20 контура (closed 1oop
operator) системы, а выражение АВ оператором разомкнутО20 контура (open 1oop
operator). В общем случае оператор разомкнутоrо контура не обладает свойством
коммутативности, Т.е. ВА i= АВ.
ДЛЯ примера рассмотрим систему с одной обратной связью, показанную на
рис. 1.13. В ней предполаrается, что оператор А это фиксированный вес w, а В
является оператором единичной задержки (unit de1ay operator) z l, который задержи
вает выходной сиrнал по отношению к входному на один шаr дискретизации. Исходя
из этоro, оператор замкнутоrо контура можно представить следующим образом:
А w
== == w(1 WZ l ) 1.
1 АВ 1 WZ l
Используя биномиальное представление выражения (1 WZ l ) 1, оператор за
MKHyтoro контура можно записать в виде
А 00
== w 2: wlz l.
1 AB
I O
(1.19)
Подставляя выражение (1.19) в (1.18), получим:
00
Yk(n) == w 2: wlz l[xj(n)].
I O
(1.20)
Здесь квадратные скобки снова обозначают тот факт, что z 1 является оператором.
Из определения этоrо оператора имеем
Z I[Xj(n)] == Xj(n l),
(1.21 )
rде Xj(n l) это входной сиrнал, задержанный на l единиц дискретизации. Следо
вательно, выходной сиrнал Yk(n) можно представить как бесконечную взвешенную
сумму текущеro и предыдущих значений входноrо сиrнала Х j ( n):
00
Yk(n) == 2: w 1 + 1 Xj(n l).
I O
(1.22)
На рис. 1.14 ясно видно, что динамика реакции системы определяется весом w.
Здесь можно выделить два случая.
54 rлава 1. Введение
х/п) о
х.'(п) w
J V yk(п)
Z-1
Рис. 1.13. rраф прохождения сиrнала для фильтра с 6eCKO
нечной импульсной характеристикой (1IR filter infinite duration
impulse response filter) nepBoro порядка
Yk(п)
w<1
wx/O) , ,
п
О
а)
Yk(п)
w 1
wx/O)
п
2 3 4
б)
,
,
,
, ,
, w>1
О
Yk(п)
wx/O)
п
Рис. 1.14. Реакция системы, показанной на рис. 1.13,
для трех различных значений веса w: устойчивая си
стема (а), случай линейной (6) и экспоненциальной
расходимости (в)
О
2
3 4
в)
1. I w I < 1. В данном случае выходной сиrнал У k ( n) экспоненциально сходится (con
vergent). Это значит, что система устойчива (stable). Для положительноro значения
w такая реакция показана на рис. 1.14, а.
2. Iwl 1. В данном случае выходной сиrнал Yk(n) расходится (divergent). Это
значит, что система llеустойчива (unstable). Если Iwl == 1, расходимость является
линейной (рис. 1.14,6); если Iwl > 1 экспоненциальной (рис. 1.14, в).
1.6. Архитектура сетей 55
Устойчивость одна из основных характеристик, которой уделяется большое
внимание при изучении систем с обратной связью.
Случай Jwl < 1 соответствует системам с бесконечной памятью, в том CMЫC
ле, что выход системы зависит от состояния системы в бесконечно далеком про
шлом. Это влияние вырождается (fading), Т.е. экспоненциально уменьшается с тече
нием времени.
Анализ динамики поведения нейронных сетей с обратной связью усложняется тем,
что процессорные элементы сети обычно нелинейны (nonlinear). Такие нейронные
сети будут рассматриваться в последней части данной книrи.
1.6. Архитектура сетей
Структура нейронных сетей тесно связана с используемыми алrоритмами обучения.
Классификация алrоритмов обучения будет приведена в следующей rлаве, а вопросы
их построения будут изучены в последующих rлавах. В данном разделе мы cocpeдo
точим внимание на архитектурах сетей (структурах).
В общем случае можно выделить три фундаментальных класса нейросетевых
архитектур.
Однослойные сети прямоrо распространения
в МНО20СЛОЙНОЙ нейронной сети нейроны располаrаются по слоям. В простейшем
случае в такой сети существует входной слой (input layer) узлов источника, информа
ция от KOToporo передается на выходной слой (output layer) нейронов (вычислительные
узлы), но не наоборот. Такая сеть называется сетью прЯМО20 распространения (feed
forward) или ацикличной сетью (acyclic). На рис. 1.15 показана структура такой сети
для случая четырех узлов в каждом из слоев (входном и выходном). Такая нейронная
сеть называется однослойной (single layer network), при этом под единственным сло
ем подразумевается слой вычислительных элементов (нейронов). При подсчете числа
слоев мы не принимаем во внимание узлы источника, так как они не выполняют ни
каких вычислений.
Мноrослойные сети прямоrо распространения
Друroй класс нейронных сетей прямоrо распространения характеризуется наличием
одноro или нескольких скрытых слоев (hidden layer), узлы которых называются cкpы
тыми нейронами (hidden пешоп), или скрытыми элементами (hidden unit). Функция
последних заключается в посредничестве между внешним входным сиrналом и BЫ
ходом нейронной сети. Добавляя один или несколько скрытых слоев, мы можем
выделить статистики BbICOKOro порядка. Такая сеть позволяет выделять 2Jlобальные
56 rлава 1. Введение
Входной
слой
Выходной слой
нейронов
Рис. 1.15. Сеть прямоro распространения с одним слоем
нейронов
свойства данных с помощью локальных соединений за счет наличия дополнительных
синаптических связей и повышения уровня взаимодействия нейронов [194]. Способ
ность скрытых нейронов выделять статистические зависимости BbIcoKoro порядка
особенно существенна, коrда размер входноro слоя достаточно велик.
Узлы источника входноrо слоя сети формируют соответствующие элементы шаб
лона активации (входной вектор), которые составляют входной сиrнал, поступающий
на нейроны (вычислительные элементы) BToporo слоя (т.е. первоro cKpbIToro слоя).
Выходные сиrналы BToporo слоя используются в качестве входных для TpeTbero слоя
и Т.д. Обычно нейроны каждоrо из слоев сети используют в качестве входных сиr
налов выходные сиrналы нейронов только предыдущеrо слоя. Набор выходных сиr
налов нейронов выходноrо (последнеrо) слоя сети определяет общий отклик сети на
данный входной образ, сформированный узлами источника входноrо (первоrо) слоя.
Сеть, показанная на рис. 1.16, называется сетью 1 O 4 2, так как она имеет 1 О входных,
4 скрытых и 2 выходных нейрона. В общем случае сеть прямоrо распространения
с m входами, h 1 нейронами первоrо cKpbIToro слоя, h 2 нейронами BToporo CKpbITOro
слоя и q нейронами выходноro слоя называется сетью m h 1 h 2 q.
Нейронная сеть, показанная на рис. 1.16, считается пОЛ1l0свяЗIIОЙ (fully connected)
в том смысле, что все узлы каждоrо KOHKpeTHoro слоя соединены со всеми узлами
смежных слоев. Если некоторые из синаптических связей отсутствуют, такая сеть
называется lIепОЛ1l0свЯЗ1l0Й (partially connected).
Рекуррентные сети
Рекуррентная lIеЙРОllllая сеть (recurrent network) отличается от сети прямоrо распро
странения наличием по крайней мере одной обрат1l0Й связи (feedback 100Р). Нanри
мер, рекуррентная сеть может состоять из единственноrо слоя нейронов, каждый из
которых направляет свой выходной сиrнал на входы всех остальных нейронов слоя.
1.6. Архитектура сетей 57
Рис. 1.16. Полносвязная сеть прямоrо распростра Входной
нения с одним скрытым и одним выходным слоем слой
Слой скрытых
нейронов
Выходной слой
нейронов
Операторы
единичной
задержки
Рис. 1.17. Рекуррентная сеть без скрытых ней
ронов и обратных связей нейронов с самими
собой
Архитектура такой нейронной сети показана на рис. 1.17. Обратите внимание, что в
приведенной структуре отсутствуют обратные связи нейронов с самими собой. Pe
куррентная сеть, показанная на рис. 1.17, не имеет скрытых нейронов. На рис. 1.18
показан друrой класс рекуррентных сетей со скрытыми нейронами. Здесь обратные
связи исходят как из скрытых, так и из выходных нейронов.
58 rлава 1. Введение
Операторы
единичной задержки
В,''''''' ,, Ш {
} Выходные
сиrналы
Рис. 1.18. Рекуррентная сеть
со скрытыми нейронами
Наличие обратных связей в сетях, показанных на рис. 1.17 и 1.18, оказывает непо
средственное влияние на способность таких сетей к обучению и на их производитель
ность. Более TOro, обратная связь подразумевает использование элементов единичной
задержки (unit delay element) (они обозначены как z l), что приводит К нелинейному
динамическому поведению, если, конечно, в сети содержатся нелинейные нейроны.
1.7. Представление знаний
в разделе 1.1 при определении нейронных сетей часто использовался термин "зна
ния" без явноro описания ero значения. Этот пробел можно устранить, предложив
следующее общее определение [295].
Под знаниями понимается хранимая информация или модели, используемые человеком
или машиной для интерпретации, предсказания и реакции на внешние события.
К вопросам представления знаний (knowledge representation) относятся следую
щие: какую информацию необходимо хранить и как эту информацию представить фи
зически для ее последующеro использования. Таким образом, исходя из самой приро
ды знаний, способ их представления определяется поставленной целью. Относитель
но реальных приложений "интеллектуальных" систем можно утверждать, что успех
решения зависит от хорошеrо представления знаний [1166]. Это касается и нейрон
ных сетей, представляющих собой отдельный класс интеллектуальных систем. Форма
представления входных сиrналов может быть самой разной. Это при водит к тому, что
разработка приемлемых нейросетевых решений становится творческим процессом.
Основной задачей нейронной сети является наилучшее обучение модели окружа
ющеrо мира для решения поставленной задачи. Знания о мире включают два ти
па информации.
1.7. Представление знаний 59
1. Известное состояние окружающеro мира, представленное имеющимися в наличии
достоверными фактами. Такая информация называется априорной (prior).
2. Наблюдения за окружающим миром (измерения), полученные с помощью ceH
соров, адаптированных для конкретных условий, в которых должна функциони
ровать данная нейронная сеть. Обычно такие измерения в значительной мере
зашумлены, что потенциально может стать источником ошибок. В любом слу
чае измерения, полученные таким способом, формируют множество информации,
примеры из KOToporo используются для обучения нейронной сети.
Примеры MOryт быть маркированными (labeled) и немаркированными (unlabeled).
В маркированных примерах входному СИ21lалу (input signal) соответствует желаемый
отклик (desired response). Немаркированные примеры состоят из нескольких различ
ных реализаций одноro входноro сиrнала. В любом случае набор примеров, будь то
маркированных или нет, представляет собой знания об интересующей предметной
области, на основании которых и проводится обучение нейронной сети.
Множество пар сиrналов BXOД BЫXOД, каждая из которых состоит из входноrо сиr
нала и соответствующеrо ему желаемоrо выхода, называют обучающими данными
(training data) или обучающей выборкой (training sample). Для примера рассмотрим
задачу распознавания цифр (digit recognition problem). В этой задаче входной сиr
нал (изображение) представляет собой матрицу, состоящую из черных и белых TO
чек. Каждое изображение представляет одну из десяти рукописных цифр на белом
фоне. Желаемым откликом сети является конкретная цифра, изображение которой
подается в качестве входноrо сиrнала. Обычно обучающая выборка состоит из боль
шоrо числа рукописных цифр, что отражает ситуацию, которая может возникнуть
в реальном мире. При наличии TaKoro набора примеров нейронная сеть создается
следующим образом.
. Во первых, выбирается соответствующая нейросетевая архитектура, в которой раз
мер входноrо слоя соответствует количеству пикселей на рисунке, а в выходном
слое содержится десять нейронов, соответствующих цифрам. После этоrо выпол
няется настройка весовых коэффициентов сети на основе обучающеrо множества.
Этот режим работы сети называется обучением.
. BO BTOpЫX, эффективность обучения сети проверяется (тестируется) на множе
стве примеров, отличных от использованных при обучении. При этом на вход
сети подается изображение, для KOToporo известен целевой выход сети. Эффек
тивность обучения сети проверяется путем сравнения результатов распознавания
с реальными цифрами. Этот этап работы нейронной сети называют обобщением
(generalization) (данный термин взят из психолоrии).
60 rлава 1. Введение
Здесь и кроется фундаментальное отличие между созданием нейронной сети и раз
работкой классических методов обработки информации для задач классификации.
В последнем случае мы в первую очередь формулируем математическую модель
исследуемой среды, верифицируем ее на реальных данных, а затем разрабатываем
классификатор на основе этой модели. Создание нейронной сети основывается непо
средственно на реальных данных, которые 20ворят сами за себя. Таким образом,
нейронные сети не только реализуют полноценную модель среды, но и обеспечивают
обработку данных.
Набор данных, используемый для обучения сети, должен содержать как положи
тельные, так и отрицательные примеры. Например, в задаче пассивной эхо локации
положительные примеры включают сиrналы, отраженные от интересующеrо объекта
(например, подводной лодки). Однако в реальной среде на отклик радара влияют и
морские объекты, случайно попавшие в зону сиrнала. Чтобы понизить вероятность
неверной трактовки сиrнала, в множество примеров добавляют сиrналы, полученные
при отсутствии искомоrо объекта.
В нейронной сети заданной архитектуры знания об окружающей среде представ
ляются множеством свободных параметров (т.е. синаптических весов и пороrов) сети.
Такая форма представления знаний соответствует самой природе нейронных сетей.
Именно в ней кроется ключ эффективности нейросетевых моделей.
Вопрос представления знаний в нейронной сети является очень сложным. Тем не
менее можно выделить четыре общих правила [48].
Правило 1. Сходные входные сиrналы от схожих классов должны формировать
единое представление в нейронной сети. Исходя из этоrо, они должны быть класси
фицированы как при надлежащие к одной катеrории.
Существует множество подходов к определению степени сходства входных сиr
налов. Обычно степень подобия определяется на основе Евклидова расстояния
(Euclidian distance). Для примера предположим, что существует некоторый вектор
Xi размерности m
Xi == [Xi1,Xi2"",Xim]T.
Все ero элементы действительные числа, а обозначение т указывает на то,
что матрица транспонирована (transposition). Вектор Xi определяет некоторую точку
в т MepHOM Евклидовом пространстве (которое обозначается как т). Евклидово
расстояние между парой т MepHЫX векторов Xi и Xj вычисляется как
[ m ] 1/2
d(Xi' Xj) == I/Xi Xj 11 == L (Xik Xjk)2 ,
k l
(1.23)
rдe Xik и Xjk k e элементы векторов Xi и Xj соответственно. Отсюда следует, что
степень сходства между входными сиrналами, представленными векторами Xi и Xj,
является величиной, обратной Евклидову расстоянию между ними d(Xi, Xj). Чем
1.7. Представление знаний 61
Рис. 1.19. Иллюстрация взаимосвязи между скалярным произ
ведением и Евклидовым расстоянием, выбираемыми в качестве х Т х.
меры сходства образов 1 ]
Х.
J
ближе друr к друry отдельные элементы векторов Xi и Xj, тем меньше Евклидово
расстояние d(Xi, Xj) и тем выше сходство между векторами Xi и Xj' Правило 1 KOH
статирует, что если векторы Xi и Xj схожи, то они должны быть отнесены к одной
катеroрии (классу).
Еще один подход к определению степени сходства основывается на идее CKa
лярноzо проuзведенuя (inner product), взятой из алrебры матриц. Если векторы Xi и
Xj имеют одинаковую размерность, их скалярное произведение х[ Xj определяется
следующим образом:
m
(Xi,Xj) == X[Xj == LXikXjk'
k l
(1.24)
Результат деления скалярноrо произведения (Xi, Xj) на IlxillllXjl1 равен косинусу
BHyтpeHHero уrла между векторами Xi и Xj.
Эти два метода измерения сходства тесно связаны друr с друrом (рис. 1.19). EB
клидово расстояние IIXi Xj 11 между векторами Xi и Xj связано с проекцией вектора
Xi на вектор Xj. На рис. 1.19 видно, что чем меньше Евклидово расстояние IIXi Xjll,
тем больше скалярное произведение х[ Xj'
Чтобы формализовать это соотношение, нормализуем векторы Xi и Xj' При этом
их длина будет равна единице: IjXi11 == IIXjl1 == 1.
Используя выражение (1.23), запишем:
d 2 (Xi,Xj) == (Xi Xj)T(Xi Xj) == 2 2х[ Xj'
(1.25)
Из выражения (1.25) видно, что минимизация Евклидова расстояния IIXi Xjll и
максимизация скалярноrо произведения х[ Х приводят К увеличению сходства между
векторами Xi и Xj.
Здесь Евклидово расстояние и скалярное произведение описаны в детерминист
ских терминах. А что будет, если векторы Xi и Xj взять из разных множеств данных?
Для примера предположим, что различие между двумя множествами данных Bыpa
жается в различии между векторами их математическоro ожидания. Пусть векторы
J1i и J1j определяют средние значения векторов Xi и Xj соответственно, Т.е.
J1i == E[Xi]'
( 1.26)
62 rлава 1. Введение
rдe Е статистический оператор математическоro ожидания. Вектор I1j определяется
аналоrичным способом. для измерения расстояния между двумя множествами можно
использовать расстояние Махаланобиса (Mahalanobis distance), которое обозначается
как d ij . Квадрат этой величины определяется следующей формулой [269]:
d;j == (Xi J.1i)T l(Xj I1J,
(1.27)
rде 1 обратная матрица для матрицы ковариации б. Предполаrается, что матрица
ковариации для обоих множеств одна и та же, Т.е.
== E[(Xi l1i)(Xi J.1i)Tj == E[(Xj J.1j)(Xj I1Лj.
(1.28)
В частном случае, коrда Xi == Xj, l1i == J.1j == J.1 и == 1, rде 1 единичная матрица,
расстояние Махаланобиса вырождается в Евклидово расстояние между вектором Xi
и вектором математическоro ожидания 11.
Правило 2. Элементы, оrnесенные к различным классам, должны иметь в сети
как можно более отличные представления.
Это правило прямо противоположно первому.
Правило 3. Если некоторое свойство имеет важное значение, то для ero представ
ления в сети необходимо использовать большое количество нейронов.
Для примера рассмотрим задачу обнаружения радаром HeKoToporo объекта (напри
мер, самолета) при наличии помех (вызванных отражением сиrнала от посторонних
объектов, таких как дома, деревья, облака и т.п.). Эффективность такой радарной
системы измеряется двумя вероятностными величинами.
· Вероятность обнаружения (probability of detection) вероятность TOro, что при
наличии объекта система ero обнаружит.
· Вероятность ложной тревоzи (probability of false alann) вероятность Toro, что
система определит наличие объекта, Korдa TOro на самом деле не существует.
В соответствии с критерием НеЙl14Qна Пирсона (Neyman Pearson criterion) вероят
ность обнаружения должна быть максимальной, а вероятность ложной тревоrи не
должна превосходить некоторой заданной величины [1080]. В подобных приложениях
очень важно, чтобы во входном сиrнале содержалась информация о цели. Правило 3
констатирует, что в процесс принятия решения о наличии цели в полученном сиr
нале должно быть вовлечено большое число нейронов. В любом случае увеличение
количества нейронов повышает достоверность принятоrо решения и устойчивость
к помехам.
Правило 4. В структуру нейронной сети должны быть встроены априорная ин
формация и инварианты, что упрощает архитектуру сети и процесс ее обучения.
1.7. Представление знаний 63
Это правило иrpает особую роль, поскольку правильная конфиryрация сети обес
печивает ее специализацию (specialized structиre), что очень важно по следующим
причинам [917].
1. Биолоrические сети, обеспечивающие обработку зрительной и слуховой инфор
мации, сильно специализированы.
2. Нейронная сеть со специализированной структурой обычно включает значитель
но меньшее количество свободных параметров, которые нужно настраивать, чем
полносвязная сеть. Из этоro следует, что для обучения специализированной сети
требуется меньше данных. При этом на обучение затрачивается меньше времени,
и такая сеть обладает лучшей обобщающей способностью.
3. Специализированные сети обладают большей пропускной способностью.
4. Стоимость создания специализированных нейронных сетей сокращается, посколь
ку их размер существенно меньше размера полно связных сетей.
Как встроить априорную информацию
в структуру нейронной сети
Для выполнения правила 4 необходимо понять, как разработать специализированную
структуру, в которую встроена априорная информация. К сожалению, в настоящее
время не существует четкоrо решения этой задачи. Однако можно предложить HeKO
торые специальные процедуры, которые, как показывает практика, приводят к xopo
шим результатам. В частности, можно использовать комбинацию двух следующих
приемов [621].
1. Оzраничение сетевой архитектуры (restricting network architectиre) с помощью
локальных связей, называемых рецепторными полями (receptive fields)5.
2. Оzраничение выбора синаптических весов за счет совместносо использования вe
сов (weight sharing)6.
Эти два приема, особенно последний, обеспечивают одно важное преимущество
значительно сокращают количество свободных параметров сети.
Для примера рассмотрим неполносвязную сеть прямоrо распространения, пока
занную на рис. 1.20. Эта сеть имеет оrpаниченную архитектуру. Первые шесть узлов
источника образуют рецепторное поле скрытоrо нейрона с номером 1, и Т.д. для всех
5 Соrласно утверждению Кафлера [604], термин "рецепторное поле" изначально был введен в [978], а
позднее повторно использован в [421]. В контексте систем обработки зрительной информации под рецепторным
полем нейрона понимается оrpаниченная область сетчатки, которая выполняет функцию передачи этому нейрону
сиrналов от светочувствительных элементов.
6 Принцип cOBMecTHoro использования весов был впервые описан Руммельхартом в [915].
64 rлава 1. Введение
Х 1
У!
Х 2
Х з
Х 4
Xs
Х 6
х.,
У2
Х 8
Х 9
X lO
ВХОДНОЙ
слой
Слой СКРЫТЫХ
нейронов
Выходной слой
нейронов
Рис. 1.20. Пример сети с рецепторными полями
и совместным использованием весов. Все четыре
скрытых нейрона для реализации синаптических
связей совместно используют одно и то же MHO
жест во весов
остальных скрытых нейронов сети. Совместное использование весов состоит в при
менении одинаковоrо набора синаптических весов для каждоrо из нейронов скрытоrо
слоя сети. Учитывая, что каждый из четырех скрытых нейронов имеет по шесть ло
кальных связей (см. рис. 1.20), индуцированное локальное поле скрытоrо нейрона j
можно описать следующим выражением:
6
vj == 2.:= WiXi+j l, j == 1, 2, 3, 4,
i l
(1.29)
rде {WiИ l определяет один и тот же набор весов, совместно используемых Bce
ми четырьмя скрытыми нейронами, а Х k является сиrналом, получаемым из узла
источника с номером k == i + j 1. Выражение (1.29) записано в форме суммы
свертки (convolution sum). Именно по этой причине сеть прямоrо распространения с
локальными связями и совместно используемыми весами называют сетью свертки
(convolution network).
Первая часть правила 4 определяет необходимость встраивания априорной ин
формации в структуру нейронной сети, а вторая часть этоrо правила касается вопро
са инвариантов.
1.7. Представление знаний 65
Как встроить инварианты в структуру нейронной сети
Рассмотрим следующие физические явления.
· Если исследуемый объект вращается, то соответствующим образом меняется и ero
образ, воспринимаемый наблюдателем.
· В KorepeHTHoM радаре, обеспечивающем информацию об амплитуде и фазе ис
точников окружающей среды, эхо от движущеrося объекта смещено по частоте.
Это связано с эффектом Доплера, который возникает при радиальном движении
объекта наблюдения относительно радара.
· Диктор может произносить слова как тихим, так и rpомким rолосом, как медленно,
так и скороrоворкой.
Для Toro чтобы создать систему распознавания объекта, речи или эхо локации,
учитывающую явления TaKoro рода, необходимо принимать во внимание диапазон
трансформаций (transfonnation) наблюдаемоro сиrнала [94]. Соответственно OCHOB
ным требованием при распознавании образов является создание такоro классифика
тора, который инвариантен к этим трансформациям. Друrими словами, на результат
классификации не должны оказывать влияния трансформации входноrо сиrнала, по
ступающеrо от объекта наблюдения.
Существуют как минимум три приема обеспечения инвариантности нейронной
сети классификации к подобным трансформациям [94].
1. Структурная инвариантность (invariance Ьу structure). Инвариантность может
быть привнесена в нейронную сеть с помощью соответствующей структуризации.
В частности, синаптические связи между отдельными нейронами сети строятся
таким образом, чтобы трансформированные версии одноro и Toro же сиrнала BЫ
зывали один и тот же выходной сиrнал. Рассмотрим для примера нейросетевую
классификацию входноrо сиrнала, которая должна быть инвариантна по отноше
нию к плоскому вращению изображения относительно CBoero центра. CTPYКТYP
ную инвариантность сети относительно вращения можно выразить следующим
образом. Пусть Wji синаптический вес нейрона j, связанноrо с пикселем i BXOД
Horo изображения. Если условие Wji == Wjk выполняется для всех пикселей j
и k, лежащих на равном удалении от центра изображения, нейронная сеть будет
инвариантной к вращению. Однако, для Toro чтобы обеспечить инвариантность OT
носительно вращения, нужно дублировать синanтические веса Wji всех пикселей,
равноудаленных от центра изображения. Недостатком структурной инвариантно
сти является то, что количество синаптических связей изображения даже среднеrо
размера будет чрезвычайно велико.
66 rлава 1. Введение
ВХОДНОЙ
сиrнал
Извлечение
инвариантных
признаков
Нейронная
сеть ти па
классификатора
Оценка
класса
Рис. 1.21. Диаrрамма системы, ис
пользующей пространство инвари
антных признаков
2. Инвариантность по обучению (invariance Ьу training). Нейронные сети обладают
естественной способностью классификации образов. Эту способность можно ис
пользовать для обеспечения инвариантности сети к трансформациям. Сеть обуча
ется на множестве примеров одноro и TOro же объекта, при этом в каждом примере
объект подается в несколько измененном виде (например, снимки с разных paKYP
сов). Если количество таких примеров достаточно велико и если нейронная сеть
обучена отличать разные точки зрения на объект, можно ожидать, что эти данные
будут обобщены и сеть сможет распознавать ракурсы объекта, которые не исполь
зовались при обучении. Однако с технической точки зрения инвариантность по
обучению имеет два существенных недостатка. Во первых, если нейронная сеть
была научена распознавать трансформации объектов HeKoToporo класса, совсем
не обязательно, что она будет обладать инвариантностью по отношению к TpaHC
формациям объектов друrих классов. BO BTOpЫX, такое обучение является очень
ресурсоемким, особенно при большой размерности пространства признаков.
3. Использование инвариантных признаков (invariant feature space). Третий метод
создания инвариантноro нейросетевоro классификатора проиллюстрирован на
рис. 1.21. Он основывается на предположении, что из входноro сиrнала можно
выделить информативные признаки, которые описывают самую существенную
информацию, содержащуюся в наборе данных, и при этом инвариантны к TpaHC
формациям входноrо сиrнала. При использовании таких признаков в нейронной
сети не нужно хранить лишний объем информации, описывающей трансформа
ции объекта. В самом деле, при использовании инвариантных признаков отличия
между разными экзеМIU1ярами одноrо и Toro же объекта MOryт быть вызваны
только случайными факторами, такими как шум. Использование пространства ин
вариантных признаков имеет три важных преимущества. Во первых, уменьшается
количество признаков, которые подаются в нейронную сеть. BO BTOpЫX, ослабля
ются требования к структуре сети. И, в третьих, rарантируется инвариантность
всех объектов по отношению к известным трансформациям [94]. Однако этот
подход требует хорошеro знания специфики проблемы.
Итак, из вышесказанноro можно сделать вывод, что использование инвариантных
признаков является наиболее подходящим методом для обеспечения инвариантности
нейросетевых классификаторов.
1.7. Представление знаний 67
х(п)
а)
Рис. 1.22. Модель
автореrрессии BTO
poro порядка: MO
дель фильтра на ли-
нии задержки с OT
водами (а) и модель
решетчатоro филь
тра (6). (Звездочкой
отмечено комплекс
ное сопряжение.)
х(п)
е(п) х(п) х(п)
б)
Чтобы проиллюстрировать идею пространства инвариантных признаков, paCCMOT
рим в качестве примера систему KorepeHTHoro радара, используемую авиадиспетче
рами, во входном сиrнале которой может содержаться информация, поступающая
от самолетов, стаи птиц и некоторых поrодных явлений. Сиrнал радара, отражен
ный от различных целей, имеет разные спектральные характеристики. Более Toro,
экспериментальные исследования показали, что сиrнал TaKoro радара можно промо-
делировать с помощью авторесрессионносо процесса (АR процесса) среднею поряд
ка (autoregrcssive process of moderate order) [439]. АR-процесс представляет собой
особый вид реrpессионной модели, описываемой следующим образом:
м
х(п) == L а:х(п i) + е(п),
i l
(1.30)
rдe {ai} l коэффициенты (coefficient) автореrpессии; М порядок модели (model
order); х(п) входной сиzнал (input signal); е(п) помеха (error), представляющая
собой белый шум. Модель, описанная формулой (1.30), представляет собой фильтр
на линии задержки с отводами (tapped delay line filter), показанный на рис. 1.22, а
для М == 2. Аналоrично, ее можно представить как решетчатый фильтр (lattice
filter), показанный на рис. 1.22, б, коэффициенты KOTOpOro называются коэффици
........
68 rлава 1. Введение
ентами отражения (reflection coefficient). Между коэффициентами автореrpессии
(рис. 1.22, а) и коэффициентами отражения (рис. 1.22, б) существует однозначное
соответствие. В обеих моделях предполаrается, что входной сиrнал х(п) является
комплексной величиной (как в случае с коrерентным радаром), в которой коэффици
енты автореrpессии и коэффициенты отражения также являются комплексными. Звез
дочка в выражении (1.30) и на рис. 1.22 обозначает комплексное сопряжение. Здесь
важно подчеркнуть, что данные KorepeHTHoro радара можно описать множеством
коэффициентов автореrpессии или соответствующим ему множеством коэффициен
тов отражения. Последнее имеет определенные преимущества в плане сложности
вычислений. для Hero существуют эффективные алrоритмы получения результата
непосредственно из входных данных. Задача выделения признаков усложняется тем
фактом, что движущиеся объекты характеризуются переменными доплеровскими ча
стотами, которые зависят от скорости объекта относительно радара и создают иска
жения в спектре коэффициентов отражения, по которым определяются признаки. Для
TOro чтобы обойти эту сложность, в процессе вычисления коэффициентов отражения
следует использовать инвариантность Доплера (Doppler invariance). Уrол фазы пер
Boro коэффициента отражения принимается равным доплеровской частоте сиrнала
радара. Соответственно для всех коэффициентов выполняется нормализация относи
тельно доплеровской частоты, устраняющая влияние сдвиrа доплеровской частоты.
Для этоrо определяется новое множество коэффициентов отражения Кт, связанных
с множеством исходных коэффициентов отражения Кт следующим соотношением:
К , == К e jme m 1 2 М
т т , ==, ,..., ,
(1.31 )
rде е фазовый уrол первоro коэффициента отражения. Операция, описанная Bыpa
жением (1.31), называется сетеродинирование.м (heterodyning). Исходя из этоrо, набор
инвариантных к смещению Доплера признаков (Doppler invariant radar feature) пред
ставляется нормализованными коэффициентами отражения K , K , . . . , Кт' rдe K
единственный коэффициент этоrо множества с вещественным значением. Как уже
отмечалось, основными катеrориями объектов, выделяемых радарной установкой,
являются стаи птиц, самолеты, поrодные явления и поверхность земли. Первые три
катеroрии объектов являются движущимися, в то время как последняя нет. reTepo
динные спектральные параметры эха радара от земли аналоrичны соответствующим
параметрам эха от самолета. Отличить эти два сиrнала можно по наличию у эха
от самолета небольшоrо смещения Доплера. Следовательно, классификатор радара
должен содержать постпроцессор (рис. 1.23). Он обрабатывает результаты класси
фикации с целью идентификации класса земли [439]. Препроцессор (preprocessor),
показанный на рис. 1.23, обеспечивает инвариантность признаков по отношению к
смещению Доплера, в то время как постпроцессор использует смещение Доплера для
разделения объектов "самолет" и "земля" в выходном сиrнале.
1.7. Представление знаний 69
Данные
радара
Извлечение
признаков
(препроцессор)
Нейросетевой
классификатор
Маркированные
классы
Постпроцессор
Самолет
Пmцы
Поrодные явления
Земля
Данные о доплеровском сдвиrе частоты
Рис. 1.23. Инвариантный к смещению Доплера классификатор сиrнала радара
rораздо более примечательным примером представления знаний в нейронной сети
является биолоrическая система эхо локации летучей мыши. Мноrие мыши исполь
зуют сиrналы с частотной модуляцией (frequency modulation), или FМ си2Налы (fre
quency modulated signal), для создания акустической картины окружающеro простран
ства. Несущая частота этоrо сиrнала изменяется во времени. В частности, летучая
мышь ртом испускает короткие FМ сиrналы, а орrаны слуха использует в качестве
приемника эха. Эхо от интересующей цели представляется в слуховом аппарате aK
тивностью нейронов, отвечающих за различные наборы акустических параметров.
В слуховом аппарате летучей мыши информация представляется тремя основными
характеристиками [993], [994].
. Частота эхо си2нала (echo frequency). Кодируется частотной картой ушной улит
ки. Она сохраняется на протяжении Bcero пути сиrнала по слуховому аппарату и
выделяется отдельными нейронами, настроенными на определенные частоты.
. Амплитуда эхо си2нала (echo amplitude). Кодируется друrими нейронами, имею
щими разные динамические характеристики. Они выделяют амплитудную xapaK
теристику и количество отзывов, пришедших в ответ на один сиrнал запроса.
. Задержка эхо си2нала (echo delay). Кодируется с помощью нейронных вычислений
(основанных за взаимной корреляции).
Двумя основными характеристиками, используемыми для формирования изобра
жения, являются спектр (spectrum) для данной формы объекта и задержка (delay).
Летучая мышь формирует "форму" объекта в терминах времени получения отражен
HOro сиrнала от различных отражающих поверхностей объекта. Для этоrо частотная
информация, содержащаяся в спектре эхо сиrнала, преобразуется в оценки временной
структуры (time structure) объекта. Эксперименты, проведенные Симмонсом (Sim
mons) и ero коллеrами с большой бурой летучей мышью Eptesicus fиscus, показали,
что этот процесс состоит из временных и частотно временных преобразований, в pe
зультате которых формируется общая задержка для воспринимаемоrо объекта. Таким
образом, частотная и временная информация, получаемая орrанами чувств летучей
мыши за счет последовательности преобразований, приводится к единому виду. Бо
лее тoro, в процессе формирования образа используются инвариантные признаки, что
делает ero независимым от перемещения объекта и движения самой летучей мыши.
70 rлава 1. Введение
Возвращаясь к rлавной теме этоro раздела (представление знаний в нейронной
сети), можно сказать, что этот вопрос непосредственно связан с сетевой архитектурой,
описанной в разделе 1.6. К сожалению, в настоящее время не существует какой
либо формализованной теории оптимизации структуры нейронных сетей или оценки
влияния архитектуры сети на представление знаний в ней. Ответы на эти вопросы
обычно получают экспериментальным путем. При этом сам разработчик нейронной
сети становится важным элементом цикла CTPyктypHOro обучения.
Независимо от TOro, как выбирается архитектура сети, знания о предметной обла
сти выделяются нейронной сетью в процессе обучения. Эти знания представляются в
компактно распределенном виде весов синаптических связей сети. Такая форма пред
ставления знаний позволяет нейронной сети адаптироваться и выполнять обобщение,
однако не обеспечивает полноценноro описания вычислительноro процесса, исполь
зуемоro для принятия решения или формирования выходноrо сиrнала. Это может Ha
кладывать серьезные оrpаничения на использование нейросетевоro подхода, особенно
в тех областях, rде решающим является принцип безопасности, например в области
диспетчеризации движения самолетов или в медицинской диаrностике. В таких при
ложениях не только желательно, но и жизненно необходимо обеспечить возможность
объяснения (explanation capability). Одним из способов обеспечения такой возможно
сти является интеrpация нейронных сетей и моделей искусственноro интеллекта в
единую rибридную систему. Этот вопрос будет обсуждаться в следующем разделе.
1.8. Искусственный интеллект и нейронные сети
Основной задачей искусствеННО20 интеллекта (artificial intelligence AI) является
разработка парадиrм или алrоритмов, обеспечивающих компьютерное решение KO
rнитивных задач, свойственных человеческому мозry [924]. Следует заметить, что
это определение искусственноrо интеллекта не является единственно возможным.
Системы искусственноrо интеллекта должны обеспечивать решение следующих
трех задач: накопление знаний, применение накопленных знаний для решения про
блемы и извлечение знаний из опыта. Системы искусственноrо интеллекта реализуют
три ключевые функции: представление, рассуждение и обучение [924] (рис. 1.24).
1. Представление (representation). Одной из отличительных черт систем искусствен
HOro интеллекта является использование символьноzо языка (symbol structure) для
представления общих знаний о предметной области и конкретных знаний о спосо
бах решения задачи. Символы обычно формулируются в уже известных терминах.
Это делает символьное представление относительно простым и понятным челове
ку. Более Toro, понятность символьных систем искусственноrо интеллекта делает
их приrодными для человеко машинноro общения.
1.8. Искусственный интеллект и нейронные сети 71
Рис. 1.24. Три ключевые функции систем искусственноro
интеллекта
Термин "знания", используемый создателями систем искусственноrо интеллекта,
является Bcero лишь еще одним названием данных. Знания MOryT иметь процедурный
и декларативный характер. В декларативном (declarative) представлении знания
это статический набор фактов. При этом существует относительно малый объем про
цедур, используемых для манипуляций этими фактами. Характерной особенностью
декларативноrо представления является то, что в rлазах человека оно имеет смысл
само по себе, независимо от использования в системах искусственноrо интеллекта.
В nроцедурном (procedural) представлении знания внедрены в процедуры, функцио
нирующие независимо от смысла самих знаний. В большинстве предметных областей
требуются одновременно оба типа представления знаний.
2. Рассуждения (reasoning). Под рассуждениями обычно пони мается способность
решать задачи. Для TOro чтобы систему можно было назвать разумной, она должна
удовлетворять следующим условиям [295].
. Описывать и решать широкий спектр задач.
. Понимать явную (explicit) и неявную (implicit) информацию.
. Иметь механизм управления (control), определяющий операции, выполняемые для
решения отдельных задач.
Решение задач можно рассматривать как некоторую задачу поиска (searching prob
lem). В процессе поиска используются правила (rules), данные (data) и управляющие
воздействия (control) [785]. Правила действуют на области данных, а управляющие
воздействия определяются для правил. Для примера рассмотрим известную "задачу
коммивояжера". В ней требуется найти кратчайший маршрут из одноrо rорода в дpy
roй. При этом все roрода, расположенные по маршруту, необходимо посетить только
один раз. В этой задаче множество данных состоит из всех возможных маршрутов
и их стоимостей, представленных в форме взвешенноrо rpафа. Правила определяют
пути движения из одноrо roрода в друroй, а модуль управления решает, Korдa и какие
правила применять.
72 rлава 1. Введение
Среда
Элемент
обучения
База
знаний
Исполнительный
элемент
Рис. 1.25. Простейшая модель
машинноro обучения
Во мноrих практических задачах (например, в медицинской диаrностике) доступ
ный набор знаний является неполным или неточным. В таких ситуациях использу
ются вероятностные рассуждения (probabilistic reasoning), позволяющие системам
искусственноrо интеллекта работать в условиях неопределенности [822], [916].
3. Обучение (learning). В простейшей модели машинноrо обучения (рис. 1.25) ин
формацию для обучаемО20 элемента (learning element) предоставляет сама среда.
Обучаемый элемент использует полученную информацию для модернизации базы
знаний (knowledge base), знания из которой функциональный элемент (perfonnance
element) затем использует для выполнения поставленной задачи. Информация, по
ступающая из внешней среды, является несовершенной, поэтому обучаемый эле
мент заранее не знает, как заполнить пробелы или иrнорировать несущественные
детали. Машина действует науrад, после чеrо получает сиrнал обратной связи
(feedback) от функциональноrо элемента. Механизм обратной связи позволяет си
стеме проверять рабочие rипотезы и пересматривать их по мере необходимости.
Машинное обучение может включать два совершенно разных способа обработки
информации: индуктивный (inductive) и дедуктивный (deductive). При индуктивной
обработке информации общие шаблоны и правила создаются на основании прак
тическоrо опыта и потоков данных. При дедуктивной обработке информации для
определения конкретных фактов используются общие правила. Обучение на основе
подобия представляет собой индуктивный процесс, а доказательство теорем дeДYK
тивный, поскольку оно опирается на известные аксиомы и уже доказанные теоремы.
В обучении на основе объяснения используется как индукция, так и дедукция.
Возникающие при обучении сложности и накопленный при этом опыт привели к
созданию различных методов и алrоритмов пополнения баз знаний. В частности, если
в данной предметной области работают опытные профессионалы, проще получить
их обобщенный опыт, чем пытаться дублировать экспериментальный путь, который
они прошли в процессе ero накоrтения. Эта идея и положена в основу экспертных
систем (expert system).
Возникает вопрос: как сравнить коrнитивные модели нейронных сетей с сим
вольными системами искусственноrо интеллекта? Для TaKoro сравнения разобьем
проблему на три части: уровень объяснения, стиль обработки и структуру представ
ления [724].
1.8. Искусственный интеллект и нейронные сети 73
1. Уровень объяснения (explanation level). Классические системы искусственноrо ин
теллекта (artificial intelligence AI) основаны на символьном представлении.
С точки зрения познания АI предполаrает существование ментальноrо npeДCTaB
ления, в котором познание осуществляется как последовательная обработка (se
quential processing) символьной информации [780].
В центре внимания нейронных сетей находятся модели параллельной распределен
ной обработки (parallel distributed processing или PDP). В этих моделях предпола
rается, что обработка информации происходит за счет взаимодействия большоrо
количества нейронов, каждый из которых передает сиrналы возбуждения и TOpMO
жения друrим нейронам сети [912]. Более Toro, в теории нейронных сетей большое
внимание уделяется нейробиолоrическому описанию процесса познания.
2. Стиль обработки (processing style). В классических системах искусственноrо ин
теллекта обработка происходит последовательно (sequential), как и в традици
онном проrpаммировании. Даже если порядок выполнения действий cTporo не
определен (например, при сканировании правил и фактов в экспертных системах),
операции все равно выполняются пошаrово. Такая последовательная обработка,
скорее Bcero, объясняется последовательной природой естественных языков и ло
rических заключений, а также структурой машины фон Неймана. Нельзя абывать
о том, что классические системы искусственноrо интеллекта зародились практи
чески в ту же интеллектуальную эру, что и машина фон Неймана.
В отличие от них, концепция обработки информации в нейронных сетях происте
кает из принципа параллелизма (parallelism), который является источником их rиб
кости. Более Toro, параллелизм может быть массовым (сотни тысяч нейронов), что
придает нейронным сетям особую форму робастности. Если вычисления распреде
лены между множеством нейронов, практически не важно, что состояние отдель
ных нейронов сети отличается от ожидаемоrо. Зашумленный или неполный BXOД
ной сиrнал все равно можно распознать; поврежденная сеть может продолжать
выполнять свои функции на удовлетворительном уровне, а обучение не обязатель
но должно быть совершенным. Производительность сети в пределах HeKoToporo
диапазона снижается достаточно медленно. Кроме Toro, можно дополнительно по
высить робастность сети, представляя каждое свойство rpуппой нейронов [459].
3. Структура представления (representational structure). В классических системах
искусственноrо интеллекта в качестве модели выступает язык мышления, поэто
МУ символьное представление имеет квази линrвистическую структуру. Подобно
фразам обычноrо языка, выражения классических систем искусственноrо интел
лекта, как правило, сложны и составляются путем систематизации простых симво
лов. Учитывая оrраниченное количество символов, новые смысловые выражения
строятся на основе композиции символьных выражений и аналоrии между син
таксической структурой и семантикой.
"""""""
74 rлава 1. Введение
с друroй стороны, в нейронных сетях природа и структура представления явля
ются ключевыми проблемами. В марте 1988 roда в специальном выпуске журнала
Cogпitioп [300] бьmи опубликованы критические замечания по поводу вычисли
тельной адекватности нейронных сетей при решении коrнитивных и линrвисти
ческих задач. Они арryментированы тем, что нейронные сети не удовлетворяют
двум основным критериям процесса познания: природе мыслеННО20 представле
ния (mental representation) и мыслительных процессов (mental process). В COOTBeT
ствии с этой работой следующие свойства присущи именно системам искусствен
Horo интеллекта и не присущи нейронным сетям.
. Мысленное представление характеризуется комбинаторной избирательной CTPYK
турой и комбинаторной семантикой.
. Мыслительные процессы характеризуются чувствительностью к комбинаторной
структуре представления, с которым они работают.
Таким образом, символьные модели искусственноrо интеллекта это формальные
системы, основанные на использовании языка алrоритмов и представлении данных
по принципу "сверху вниз" (top down), а нейронные сети это параллельные pac
пределенные процессоры, обладающие естественной способностью к обучению и
работающие по принципу "снизу вверх" (bottom up). Поэтому при решении коrни
тивных задач целесообразно создавать структурированные модели на основе связей
(structured connectionist models) или 2ибридные системы (hybrid system), объединя
ющие оба подхода. Это обеспечит сочетание свойств адаптивности, робастности и
единообразия, при сущих нейронным сетям, с представлениями, умозаключениями и
универсальностью систем искусственноrо интеллекта [293], [1108]. Для реализации
этоro подхода были разработаны методы извлечения правил из обученных нейрон
ных сетей [61]. Эти результаты не только позволяют интеrpировать нейронные сети
с интеллектуальными машинами, но и обеспечивают решение следующих задач.
. Верификация нейросетевых компонентов в проrpаммных системах. Для это
ro внутреннее состояние нейронной сети переводится в форму, понят
ную пользователям.
. Улучшение обобщающей способности нейронной сети за счет выявления обла
стей входноrо пространства, не достаточно полно представленных в обучающем
множестве, а также определения условий, при которых обобщение невозможно.
. Выявление скрытых зависимостей на множестве входных данных.
. Интеrpация символьноro и коннекционистскоrо подходов при разработке интел
лектуальных машин.
. Обеспечение безопасности систем, для которых она является критичной.
1.9. Историческая справка 75
1.9. Историческая справка
Эта вводная шава не может обойтись без небольшой исторической справки 7.
Современная эра нейронных сетей началась с новаторской работы Мак Каллока и
Питца [714]. Мак Каллок по образованию был психиатром и нейроанатомом и более
20 лет занимался вопросами представления событий в нервной системе. Питц был
талантливым математиком; он присоединился к исследованиям Мак Каллока в 1942
rоду. Сошасно [868], в статье Мак Каллока и Питца описаны результаты, получен
ные в течение 5 лет rpуппой специалистов по нейромоделированию из университета
Чикаrо, возшавляемой Рашевским (Rashevcky).
В своей классической работе Мак Каллок и Питц описали лоrику вычислений в
нейронных сетях на основе результатов нейрофизиолоrии и математической лоrики.
Формализованная модель нейрона соответствовала принципу "все или ничеro". Уче
ные показали, что сеть, составленная из большоrо количества таких элементарных
процессорных единиц, соединенных правильно сконфиryрированными и синхронно
работающими синаптическими связями, принципиально способна выполнять любые
вычисления. Этот результат был реальным прорывом в области моделирования HepB
ной системы. Именно он явился причиной зарождения таких направлений в науке,
как искусственный интеллект и нейронные сети.
В свое время работа Мак Каллока и Питца широко обсуждалась. Она остается aK
туальной и сеrодня. Эта работа оказала влияние на идеи фон Неймана, воплощенные
в конструкции компьютера ЕОУАС (Electronic Discrete Variable Automatic Computer),
разработанноrо на основе устройства ENIAC (Electronic Numerical Integrator and Com
puter) [74]. ENIAC бьm первым компьютером общеrо назначения. Он создавался с
1943 по 1946 rод в университете штата Пенсильвания. Фон Нейман постоянно из
лаrал теорию формальных нейронных сетей Мак Каллока Питца во второй из своих
четырех лекций, которые он читал в Университете штата Иллинойс в 1949 rоду.
В 1948 roду была издана знаменитая книrа Винера (Weiner) под названием Кuбер
нетика. В ней были описаны некоторые важные концепции управления, коммуника
ций и статистической обработки сиrналов. Вторая редакция этой книrи вышла в 1961
rоду. В нее был добавлен материал, касающийся обучения и самоорrанизации систем.
Во второй шаве обоих изданий этой книrи Винер подчеркнул физическую значимость
статистических механизмов в контексте излаrаемой проблемы. Однако только через
30 лет в работах Хопфилда (Hopfield) был построен мост между статистическими
механизмами и обучаемыми системами.
7 Историческая справка в основном (но не полностью) основывается на [48], [53], [68], [74], [227], [390],
[868], [916], [919], [964], [1042], [1142].
........
76 rлава 1. Введение
Следующей важной вехой в развитии нейронных сетей стал выход в свет в 1949
rоду книrи Хебба (НеЬЬ) The Orgaпizatioп о/ Behavior (Орrанизация поведения). В
ней приводится четкое определение физиолоrическоrо правила обучения для cиHaп
тической модификации (synaptic modification). В частности, Хебб предположил, что,
по мере Toro как орrанизм обучается различным функциональным задачам, связи
в мозrе постоянно изменяются и при этом формируются ансамбли нейронов (neи
ron assembly). Знаменитый постулат обучения (postulate of leaming) Хебба rласит,
что эффективность переменноro синапса между двумя нейронами повышается при
мноroкратной активации этих нейронов через данный синапс. Эта книrа оказала вли
яние на развитие психолоrии, но, к сожалению, практически не возымела влияния на
сообщество инженеров.
Книrа Хебба стала источником вдохновения при создании вычислительных Moдe
лей обучаемых и адаптивных систем (leaming and adaptive system). Первой попыт
кой использования компьютерноrо моделирования для проверки формализованной
теории нейронов, основанной на постулате обучения Хебба, была, пожалуй, [894].
Результаты моделирования четко показали, что для полноты этой теории к ней сле
дует добавить торможение. В том же roду Атrли (Uttley) [1069] продемонстрировал,
что нейронные сети с изменяемыми синапсами можно обучить классификации про
стейших двоичных образов (растровых изображений). Он ввел понятие и активации
нейрона, которое было формально проанализировано Кайанелло (Caianielo) в 1961
rоду [167]. В своей более поздней работе (1979) Атrли высказал rипотезу о том, что
эффективность переменноrо синапса в нервной системе зависит от статистических
связей между переменными состояниями на друrом конце синапса, связав, таким
образом, теорию нейронных сетей с теорией информации Шеннона (Shannon).
В 1953 rоду вышла в свет книrа, которая не потеряла своей актуальности и сеrодня
[53]. Идея, представленная в этой работе, состояла в том, что адаптивное поведение
является не врожденным, а приобретенным, и с помощью обучения можно улучшить
поведение животноrо (системы). Эта книrа фокусировала внимание исследователей
на динамических аспектах живоrо орrанизма как системы и на понятии устойчивости.
В 1954 rоду Минский (Minsky) написал докторскую диссертацию в Принстонском
университете, посвященную теории нейроаналоrовых систем обучения с подкреп
лени ем и ее применению в задачах моделирования мозrа [743]. В 1961 rоду была
опубликована ero работа, посвященная искусственному интеллекту [742]. Она назы
валась Steps Toward ArtificiaZ IпteZZigeпce (На пути к искусственному интеллекту). Эта
работа содержала большой раздел, посвященный области, которая сейчас называется
теорией нейронных сетей. В своей работе Computatioп: Fiпite aпd Iпfiпite Machiпes
(Вычисления: конечные и бесконечные машины) [741] Минский расширил резуль
таты, полученные в 1943 roдy Мак Каллоком и Питцом, и поместил их в контекст
теории автоматов и теории вычислений.
1.9. Историческая справка 77
в том же 1954 rоду rабор (Gabor), один из пионеров в теории коммуникации и
первооткрыватель rолоrpафии, предложил идею нелинеЙНО20 адаптивНО20 фильтра
(non1inear adaptive fi1ter) [330]. Со своими единомышленниками он создал машину,
которая обучалась на примере стохастическоro процесса [331].
В 1950 x rодах Тейлор (Tai1or) инициировал работы по исследованию accoци
ативной памяти (associative memory) [1044], а в 1961 rоду Стейнбах (Steinbuch)
разработал матрицу обучения (learning matrix), состоящую из плоской сети переклю
чателей, объединявшей массивы сенсорных рецепторов и моторных исполнительных
механизмов [1015]. В 1969 rоду бьта опубликована хорошая работа по неrолоrpа
фической ассоциативной памяти [1158]. В ней представлены две модели: простая
оптическая модель корреляционной памяти и нейросетевая модель, реализованная в
виде оптической памяти. Среди друrих работ, которые внесли заметный вклад в paH
нее развитие ассоциативной памяти, следует отметить [50], [580], [771], в которых
независимо друr от друrа в одном и том же rоду описана идея памяти на основе
матрицы корреляции (corre1ation matrix memory), которая строится на обучении по
правилу внешнеrо произведения (outer product 1earning).
Одной из самых известных фиryр в науке первой половины ХХ века бьm фон
Нейман. Архитектура фон Неймана (Уоп Neumann architecture) является основой
для создания цифровых компьютеров, названных в ero честь. В 1955 rоду он был
приrлашен в Йельский университет, rдe в 1956 rоду прочитал курс лекций Sillimaп
Lectures. Он умер в 1957 roдy, и ero незаконченная работа, написанная на основе этих
лекций, была позднее опубликована в виде отдельной книrи [1103]. Из этой книrи
ясно, как MHoro Mor бы сделать фон Нейман, если бы остался жив, поскольку он
начал осознавать принципиальное отличие мозrа от компьютера.
Предметом отдельноrо исследования в контексте нейронных сетей является co
здание надежных сетей из нейронов, которые сами по себе считаются ненадежными
компонентами. Эта задача была решена в 1956 rоду фон Нейманом с помощью идеи
избыточности, которая была предложена Виноrpадом и Кованом [163], [1104] в под
держку использования распределеННО20 избытОЧНО20 представления (distributed re
dundant representation) в нейронных сетях. Эти авторы показали, как большая rpуппа
элементов может в совокупности представлять одно понятие при соответствующем
повышении робастности и степени параллелизма.
Через 15 лет после выхода классической работы Мак Каллока и Питца Розенблатт
(Rozenblatt) предложил новый подход к задаче распознавания образов, основанный
на использовании персептрона и HOBoro метода обучения с учителем [902]. rлавным
достижением этой работы была так называемая теорема сходимости пepceптpo
на (perceptron convergence theorem), первое доказательство которой было получено
Розенблаттом в 1960 roду [901]. Друrие доказательства этой теоремы были пред
ложены Новиковым [788] и друrими учеными. В 1960 rоду бьm описан ал20ритм
наименьших квадратов LMS (least mean square algorithm), который применялся для
78 rлава 1. Введение
построения адаптивных линейных элементов Adaliпe [1131]. Различие между персеп
троном и моделью Ada1ine состоит в процедуре обучения. Одной из самых первых
обучаемых мноrослойных нейронных сетей, содержащей мноroчисленные адаптив
ные элементы, была структура Mada1ine (mu1tip1y ada1ine), предложенная Видроу и
ero студентами [1137]. В 1967 rоду для адаптивной классификации образов был ис
пользован стохастический rpадиентный метод [33]. В 1965 rоду вышла в свет книrа
Нильсона Learпiпg Machiпes (Обучаемые системы) [786], в которой очень хорошо
освещен вопрос линейной разделuмости образов (1inear1y separable pattem) с помо
щью rиперповерхностей. В 1960 e rоды (в период roсподства персептрона) каза
лось, что нейронные сети позволяют решить практически любую задачу. Однако в
1969 rоду вышла книrа Минскоro и Пейперта [745], в которой математически cтporo
обоснованы фундаментальные оrраничения однослойноro персептрона. Внебольшом
разделе, посвященном мноrослойным персептронам, утверждалось, что оrpаничения
однослойных персептронов вряд ли удастся преодолеть в их мноrослойных версиях.
Важной задачей, возникающей при конструировании мноroслойноrо персептрона,
была названа проблема присваивания коэффициентов доверия (credit assignment prob
1еm) (т.е. проблема назначения коэффициентов доверия скрытым нейронам сети). Tep
мин присваивание коэффициентов доверия впервые ИСПОЛЬзовал Минский в 1961 rоду
[742]. К концу 1960 x уже были сформулированы мноrие идеи и концепции, необходи
мые для решения проблемы присваивания коэффициентов доверия для персептрона.
Было также разработано множество идей, положенных впоследствии в основу pe
куррентных сетей, которые получили название сетей Хопфuлда (Hopfie1d network).
Однако решения этих важных проблем пришлось ожидать до 1980 x rодов. Как OTMe
чено в [222], для TaKoro длительноro ожидания существовали объективные причины.
· Одна из причин носила технолоrический характер: для проведения экспериментов
не существовало персональных компьютеров или рабочих станций. Например, KO
rдa rабор создавал свой нелинейный обучаемый фильтр, ему и ero команде потре
бовалось шесть лет для Toro, чтобы создать этот фильтр на аналоroвых устройствах
[330], [331].
· Друrая причина была отчасти психолоrической, отчасти финансовой. MOHorpa
фия [745] отrоЛкнула ученых от работ в этом направлении, а научные фонды и
areHTcTBa перестали обеспечивать ero финансовую поддержку.
· Аналоrия между нейронными сетями и пространственными решетками (1attice
spin) была несовершенной. Более точная модель была создана только в 1975 ro
ду [980].
Эти и друrие причины способствовали ослаблению интереса к нейронным сетям
в 1970 x rодах. Мноrие исследователи (не принимая во внимание психолоrов и ней
робиолоrов) покинули это поле деятельности на десять лет. Только ropcTKa пионеров
1.9. Историческая справка 79
этоro направления поддерживала жизнь науки о нейронных сетях. С технолоrической
точки зрения 1970 e rоды можно рассматривать как roды застоя.
В 1970 x rодах развернулась деятельность в области карт самООр2анизации (self
organizing тар), основанных на конкурентном принципе обучения (competitive learn
ing). Принцип самоорrанизации впервые был проиллюстрирован с помощью компью
TepHoro моделирования в 1973 roду [1100]. В 1976 rоду бьmа опубликована работа,
посвященная картам самоорrанизации, отражающим тополоrически упорядоченную
структуру мозrа [1159].
В 1980 x roдах rлавный вклад в теорию и конструкцию нейронных сетей был
внесен на нескольких фронтах. Этот период был отмечен возобновлением интереса
к данному научному направлению.
rроссберr (Grossberg), ранние работы KOTOpOro посвящались принципу KOHKypeнт
Horo обучения [396 398], в 1980 roду открьm новый принцип самоорrанизации, по
лучивший название теории адаптивНО20 резонанса (adaptive resonance theory) [392].
В основе этой теории лежит использование слоя распознавания "снизу вверх" и
слоя rенерации "сверху вниз". Если входной и изученный образы совпадают, воз
никает состояние, называемое адаптивным резонансом (т.е. усилением и продлени
ем нейронной активности). Этот принцип прямой и обратной проекции (principle of
forwardlbackward projection) был впоследствии снова открыт друrими учеными, при
шедшими к нему совершенно друrим путем.
В 1982 roду Хопфилд использовал функцию энерrии для описания HOBoro ypOB
ня понимания вычислений, выполняемых рекуррентными сетями с симметричными
синаптическими связями [480]. Кроме Toro, он установил изоморфизм между peKyp
рентной сетью и изиН20вской моделью (Ising model), используемой в статистической
физике. Эта аналоrия открыла шлюз для притока результатов физической теории
(и самих физиков) в нейронное моделирование, трансформировав, таким образом,
область нейронных сетей. В 1980 x rодах нейронным сетям с обратной связью yдe
лялось большое внимание, и со временем они стали называться сетями Хопфuлда
(Hopfield network). Хотя сети Хопфилда нельзя считать реалистичными моделями
нейробиолоrических систем, в них заложен принцип хранения информации в дина
мически устойчивых системах. Истоки этоro принципа можно найти в более ранних
работах друrих исследователей.
. Крэr и Темперли в 1954 1955 roдах сделали следующее наблюдение [228], [229].
Подобно тому, как нейроны MOryт быть активизированы или приведены в COCTO
яние покоя, атомы пространственной решетки MOryT иметь спины, направленные
вверх и вниз .
. в 1967 roду Кован ввел "сиrмоидальную" характеристику и rладкую функцию
активации для нейронов [224].
80 rлава 1. Введение
. rроссберr в 1967 1968 rодах представил аддитивную .модель (additive mode1) ней
рона, включающую нелинейные разностно дифференциальные уравнения, и ис
следовал возможность использования этой модели в качестве основы KpaTKOBpe
менной (short tenn) памяти [401], [402].
. Амари в 1972 rоду независимо от друrих разработал адаптивную .модель ней
рона и использовал ее для изучения динамическоrо поведения нейроноподобных
элементов, связанных случайным образом [32].
. Вильсон и Кован в 1972 rоду вывели системы нелинейных дифференциальных
уравнений для описания динамики пространственно локализованных популяций,
содержащих как возбуждающие, так и тормозящие модели нейронов [1161].
. В 1975 rоду была предложена вероятностная .модель (probabi1istic model) нейрона,
которая использовалась для разработки теории кратковременной памяти [662].
. В 1977 rоду была описана нейросетевая модель, состоящая из простой ассоциа
тивной сети, связанной с нелинейными динамическими элементами [54].
Неудивительно, что работа Хопфилда [480] вызвала лавину дискуссий. Тем не Me
нее принцип хранения информации в динамически устойчивых сетях впервые принял
явную форму. Более Toro, Хопфилд показал, что симметричные синаптические связи
rарантируют сходимость к устойчивому состоянию. В 1983 rоду в [202] выведен об
щий принцип устойчивости ассоциативной памяти, включающий в качестве частноrо
случая непрерывную версию сети Хопфилда. Отличительной характеристикой aT
тракторной нейронной сети является естественное включение времени внелинейную
динамику сети как важноrо измерения обучения. В этом контексте теорема KoxeHa
rроссберrа приобрела особую важность.
Еще одной интересной работой 1982 rода стала публикация Кохонена [579], посвя
щенная самоорrанизующимся картам, использующим OДHO или двухмерную CTPYK
туру пространственной решетки, которая отличалась от ранней работы [1159]. Модель
Кохонена получила более активную по;щержку и стала своеобразной точкой отсчета
для друrих инноваций в этой области.
В [560] описана новая процедура, получившая название .моделирования отжи2а
(simulated annealing), позволяющая решать задачи комбинаторной оптимизации. Ими
тация отжиrа уходит корнями в статистическую механику и основана на простейшей
идее, впервые использованной в компьютерном моделировании [730]. Идея имита
ции отжиrа позднее использовалась при создании стохастической .машины Больц
.мана (Boltzmann machine) [9]. Это была первая успешная реализация мноrослойной
нейронной сети. Хотя алroритм обучения машины Больцмана не обеспечивает Ta
кой эффективности, как ал20рит.м обратНО20 распространения (back propagation),
он разрушил психолоrический барьер, показав, что теория Минскоro и Пейперта
[745] была некорректно обоснована. Машина Больцмана также заложила фундамент
1.9. Историческая справка 81
для последующей разработки СИ2Моидальных сетей доверия (sigmoid belief network)
[778], которые существенно улучшали процесс обучения и обеспечивали связь ней
ронных сетей с сетями доверия [822]. В [936] описан способ дальнейшеro повышения
производительности процесса обучения сиrмоидальных сетей доверия.
В 1983 rоду была опубликована работа, посвященная обучению с подкреплением
(reinforcement leaming) [100]. Хотя обучение с подкреплением использовалось и до
этоro (например, в кандидатской диссертации Минскоrо в 1954 rоду), эта работа BЫ
звала большой интерес к обучению с подкреплением и ero применению в задачах
управления. В частности, в этой работе было продемонстрировано, что при исполь
зовании обучения с подкреплением можно обеспечить балансировку перевернутоro
маятника (т.е. шеста, установленноrо на подвижной платформе) при отсутствии учи
теля. Системе нужно знать только уrол наклона шеста относительно вертикали и MO
мент достижения платформой крайней точки области движения. В 1996 rоду вышла
в свет книrа, в которой описывались математические основы обучения с подкрепле
нием, связанные с принципом динамическоro проrpаммирования Беллмана [126].
В 1984 roду вышла в свет книrа, в которой обосновывается принцип целенаправ
ленноzо самоорzанизующеzoся выполнения (goal directed self organized performance),
состоящий в том, что понимания сложноrо процесса леrче Bcero достичь путем син
теза элементарных механизмов, а не анализа "сверху вниз" [149]. Под видом научной
фантастики Брайтенберr иллюстрирует этот важный принцип описанием различных
систем с простой внутренней архитектурой. Свойства этих систем и их поведение
определяются результатами исследования мозrа животных. Эту тему автор изучал,
явно или опосредованно, более 20 лет.
В 1986 rоду был разработан алzoритм обратноzo распространения ошибки (back
propagation algorithm) [914]. В том же roду издан двухтомник [912]. Эта книrа оказала
большое влияние на использование алroритма обучения обратноro распространения.
Этот алroритм стал самым популярным для обучения мноroслойных персептронов.
Примерно в это же время, независимо друr от друrа, алroритм обратноrо распростра
нения был получен и друrими исследователями [619], [817]. После открытия алro
ритма обратноro распространения в середине 1980 x rодов оказалось, что он был уже
описан ранее в кандидатской диссертации Вербоса (Werbos) в 1974 roду в [apBapд
ском университете. Эта диссертация стала самым первым документированным описа
нием rpадиентноrо метода оптимизации, применяемоro к общим моделям сетей, и как
частный случай к моделям нейронных сетей. Основная идея обратноro pacnpOCTpa
нения была изложена в [163]. В разделе 2.2 настоящей книrи будет описан вариант
алroритма обратноrо распространения, основанный на формализме Лаrpанжа. Однако
все лавры до стались Руммельхарту, Хинтону и Вильямсу [914], [915] за предложение
использовать этот алrоритм для машинноro обучения и демонстрацию ero работы.
....
82 rлава 1. Введение
В 1988 roду Линскер описал новый принцип самоорrанизации в перцепционной
сети [653]. Этот принцип обеспечивал сохранность максимальноrо количества ин
формации о входных образах за счет оrpаничений, накладываемых на синаптические
связи и динамический диапазон синапса. Аналоrичные результаты были получены
и несколькими друrими исследователями системы зрения независимо друr от друrа.
Однако лишь концепция Линскера базировал ась на теории информации, созданной
Шенноном в 1948 roду. На ее основе Линскер сформулировал принцип MaKCимy
ма взаимной информации (maximum mutual information) Infomax. Ero работа открьта
двери применению теории информации в нейронных сетях. В частности, применение
теории информации к задаче слепоzо разделения источников (blind source separation)
[116] послужило примером для применения друrих информационно теоретических
моделей к решению широкоro класса задач так называемоro слепоzо обращения
свертки (blind deconvolution).
В том же 1988 roду Брумхед и Лове описали процедуру построения мноrослойной
сети прямоro распространения на базе радиальных базисных функций (radial basis
function) [160], которая стала альтернативой мноrослойному персептрону. Положен
ная в основу такой сети идея радиальных базисных функций уходит корнями кметоду
потенциальных функций (method of potential functions), предложенному в [102]. Teo
ретические основы метода потенциальных функций были разработаны в [11], [12].
Описание метода функций потенциала приведено также в [269]. Работа [160] вызвала
большой интерес и послужила толчком к увеличению объема исследований в области
взаимосвязи нейронных сетей и линейных адаптивных фильтров. В 1990 rоду теория
сетей на основе радиальных базисных функций получила дальнейшее развитие за
счет применения к ней теории реryляризации Тихонова [847].
В 1989 roду вышла книrа, в которой описывалось множество различных KOH
цепций, заимствованных из нейробиолоrии и технолоrии VLSI [720]. Помимо Bcero
прочеro, в ней содержались rлавы, посвященные созданию сетчатки и слуховой улит
ки на основе кремния. Эти rлавы явились хорошим примером креативноrо мышле
ния автора.
В начале 1990 x Вапник (Vapnik) и ero коллеrи выделили мощный с вычислитель
ной точки зрения класс сетей, обучаемых с учителем, получивший название машины
опорных векторов (support vector machine). Такие сети позволяют решать задачи pac
познавания образов, реrpессии и оценки плотности [141], [212], [1084], [1085]. Этот
новый метод основан на результатах теории обучения на основе выборки конечноrо
размера. Работа систем опорных векторов основана на использовании VС измерения
(измерения Вапника Червоненкиса), которое позволяет вычислять емкость нейронной
сети, обучаемой на множестве примеров [1087], [1088].
В настоящее время хорошо известно, что хаос (chaos) является ключевым аспек
том мноrих физических явлений. Возникает вопрос: иrpает ли хаос столь же важную
роль в обучении нейронных сетей? В [310] утверждается, что в биолоrическом KOH
Задачи 83
тексте ответ на этот вопрос является положительным. По мнению автора этой работы,
образы нейронной активности не привносятся в мозr извне, а содержатся в нем ca
мом. В частности, хаотическая динамика представляет базис для описания условий,
необходимых для проявления свойства эмерджентности в процессе самоорrанизации
популяций нейронов.
Пожалуй, наибольшее влияние на возобновление интереса к нейронным сетям в
1980 x roдах оказали [480] и [912]. За период, прошедший с момента публикации
статьи Мак Каллока и Питца, нейронные сети прошли долrий и тернистый путь.
Теория нейронных сетей стала междисциплинарной областью исследований, тесно
связанной с нейробиолоrией, математикой, психолоrией, физикой и инженерией. Нет
необходимости дополнительно roворить о том, что с развитием теории нейронных
сетей будут наращивать свой теоретический и прикладной потенциал и эти науки.
Задачи
Модели нейрона
1.1. Диапазон значений лоrистической функции
1
q>(v)
1 + ехр( av)
оrpаничен нулем и единицей. Покажите, что производная функции <р( v) опи
сывается выражением
dq>
dv == aq>(v) [1 q>(v)].
Каково значение этой производной в начале координат?
1.2. Нечетная сиrмоидальная функция задается формулой
( ) 1 ехр( av) h ( av )
q> v == == tan ,
1 + ехр( av) 2
rде tanh обозначает rиперболический TaHreHc. Областью значений этой функ
ции является интервал от 1 до + 1. Покажите, что производная функции
<р( v) описывается выражением
dq> а 2
== [1 q> (v)].
dv 2
84 rлава 1. Введение
Каково значение этой производной в начале координат? Предположим, что
параметр наклона а бесконечно большой. В функцию KaKoro вида BЫpO
дится <р( v)?
1.3. Рассмотрим еще одну нечетную сиrмоидальную функцию (алrебраическую
сиrмоиду)
v
q>(v) == .JI+V2 '
значения которой принадлежат интервалу от 1 до + 1. Покажите, что про
изводная функции <р( v) описывается выражением
dq>
dv
<р3 ( V )
==
.
Каково значение этой производной в начале координат?
1.4. Рассмотрим следующие функции:
1 j V х2 2
q>(v) == м= ехр( )dx и q>(v) == tan l(v).
v 2п oo 2 1t
Объясните, почему обе эти функции подходят под определение сиrмодной
функции? Чем они отличаются друr от друrа?
1.5. Какие из пяти сиrмоидных функций, описанных в задачах 1.1 1.4, можно
назвать кумулятивными (вероятностными) функциями распределения? Обос
нуйте свой ответ.
1.6. Рассмотрим псевдолинейную функцию активации q>(v), показанную на
рис. 1.26.
а) Выпишите функциональную зависимость <р( v) в аналитическом виде.
б) Как изменится функция <р( v), если параметр а принять равным нулю?
1.7. Решите задачу 1.6 для псевдолинейной функции активации, показанной на
рис. 1.27.
Задачи 85
v
Рис. 1.26. rрафик функции активации
О,5а О О,5а
tp(v)
v
Рис. 1.27. Еще один пример функции активации
1.8. Пусть функция активации нейрона <р( v) имеет вид лоrистической функции
из задачи 1.1, rде v индуцированное локальное поле, а параметр наклона
а может изменяться. Пусть Хl,Х2, ..., Х т множество входных сиrна
лов, передаваемых на вход нейрона, а Ь пороroвое значение. Для удобства
исключим из рассмотрения параметр а, получив в результате следующую
формулу:
1
<р( v)
1 + ехр( v)'
Как нужно изменить входной сиrнал Хl,Х2, ..., Х т , чтобы получить на
выходе прежний сиrнал? Обоснуйте свой ответ.
1.9. Нейрон j получает входной сиrнал от четырех друrих нейронов, уровни
возбуждения которых равны 10, 20, 4 и 2. Соответствующие веса связей
этоro нейрона равны 0,8, О, 2, 1, О и o, 9. Вычислите выходное значение
нейрона j для двух случаев.
а) Нейрон линейный.
б) Нейрон представлен моделью Мак Каллока Питца.
Предполаrается, что nopor отсутствует.
......
86 rлава 1. Введение
5
tp(-)
3
tp(. )
tp(. )
tp(. )
tp(. )
6
Рис. 1.28. Архитектурный rраф сети
1.10. Решите задачу 1.9 для нейрона, модель KOToporo описывается лоrистической
функцией следующеrо вида:
1
<р( v) ==
1 + ехр( v)
1.11. Решите следующие задачи.
а) Покажите, что формальную модель нейрона Мак Каллока Питца можно
аппроксимировать сиrмоидным нейроном (т.е. нейроном, функция акти
вации KOToporo описывается сиrмоидной функцией, а синаптические веса
имеют большие значения).
б) Покажите, что линейный нейрон можно аппроксимировать сиrмоидным
нейроном с маленькими синаптическими весами.
Сетевые архитектуры
1.12. Полно связная сеть прямоro распространения имеет десять входных узлов,
два скрытых слоя (один с четырьмя, а друrой с пятью нейронами) и один ней
рон в выходном слое. Постройте архитектурный rpаф этой нейронной сети.
1.13. Решите следующие задачи.
а) На рис. 1.28 представлен rpаф прохождения сиrнала по сети прямоro pac
пространения вида 2 2 2 1. Функция <р(') является лоrистической. Опи
шите отображение BXOД BЫXOД для этой сети.
б) Пусть выходной нейрон сети, показанной на рис. 1.28, работает в линей
ной области. Опишите отображение BXOД BЫXOД для такой сети.
Задачи 87
Рис. 1.29. Рекуррентная сеть с двумя ней
ронами
Рис. 1.30. Рекуррентная сеть, содержащая
обратные связи нейронов с самими собой
1.14. Сеть, показанная на рис. 1.28, не содержит пороroв. Теперь предположим,
что эти пороrи существуют и равны 1 и + 1 для BepxHero и нижнеro нейро
нов первоrо скрытоro слоя соответственно, а для нейронов BTOpOro скрытоro
слоя + 1 и 2 (для BepXHero и нижнеro нейронов соответственно). Выпи
шите новую форму отображения BXOД BЫXOД, определяемоrо такой сетью.
1.15. Рассмотрим мноrослойную сеть прямоro распространения, все нейроны KO
торой работают в линейной области. Докажите, что такая сеть эквивалентна
однослойной сети прямоro распространения.
1.16. Сконструируйте полную рекуррентную сеть с пятью нейронами, в которой
нейроны не имеют обратных связей сами с собой.
1.17. На рис. 1.29 показан rpаф передачи сиrнала по рекуррентной сети, состоящей
из двух нейронов. Выпишите нелинейное разностное уравнение, определяю
щее эволюцию переменной х 1 (n) или х 2 (n ), которая описывает выход верх
Hero и нижнеrо нейронов соответственно. Каков порядок этих уравнений?
1.18. На рис. 1.30 показан rpаф передачи сиrнала по рекуррентной сети с ДBY
мя нейронами, каждый из которых имеет обратную связь с самим собой и
соседним нейроном. Определите систему из двух нелинейных разностных
уравнений первоro порядка, описывающих эту сеть.
1.19. Рекуррентная сеть имеет три входных узла, два скрытых и четыре выходных
нейрона. Постройте архитектурный rpаф, описывающий такую сеть.
88 rлава 1. Введение
Представление знаний
1.20. Одна из форм предварительной обработки сиrналов основана на aвтope2pec
сионной модели, описываемой следующим разностным уравнением:
у(n) == WIY(n 1) + w2Y(n 2) + .,. + wMY(n М) + v(n), (1.32)
rде у(n) выход модели; v(n) воздействие белоro шума с нулевым
математическим ожиданием и некоторой предопределенной дисперсией;
Wl, W2, ..., WM коэффициенты автореrpессионной модели; М поря
док модели. Покажите, что эта модель обладает свойством rеометрической
инвариантности относительно масштаба и преобразования времени. Как эти
две формы инвариантности можно использовать в нейронных сетях?
1.21. Пусть х входной вектор, а s(a, х) оператор преобразования, зависящий
от параметра а. Этот оператор удовлетворяет двум условиям:
. s(O, х) == х;
. s( а, х) дифференцируемый по а оператор.
Вектор касательной определяется как частная производная as( а, х)/да [992].
Пусть вектор х представляет некоторое изображение, а а является napa
метром поворота. Как вычислить вектор касательной, коrда значение а мало?
Вектор касательной локально инвариантен относительно уrла поворота ис
ходноro изображения. Почему?
Процессыобучения
2.1. Введение
Самым важным свойством нейронных сетей является их способность обучаться
(leam) на основе данных окружающей среды и в результате обучения повышать
свою производительность. Повышение производительности происходит со временем
в соответствии с определенными правилами. Обучение нейронной сети происходит
посредством интерактивноrо процесса корректировки синаптических весов и поро
rOB. В идеальном случае нейронная сеть получает знания об окружающей среде на
каждой итерации процесса обучения.
С понятием обучения ассоциируется довольно MHoro видов деятельности, поэтому
сложно дать этому процессу однозначное определение. Более Toro, процесс обучения
зависит от точки зрения на Hero. Именно это делает практически невозможным появ
ление какоrо либо точноrо определения этоrо понятия. Например, процесс обучения
с точки зрения психолоrа в корне отличается от обучения с точки зрения школьноrо
учителя. Со своей точки зрения (с позиций нейронной сети) мы можем использовать
следующее определение, приведенное в [726].
Обучение это процесс, в котором свободные параметры нейронной сети Hacтpa
иваются посредством моделирования среды, в которую эта сеть встроена. Тип обу
чения определяется способом подстройки этих параметров.
Это определение процесса обучения предполаrает следующую последователь
ность событий.
1. В нейронную сеть поступают стимулы из внешней среды.
2. В результате этоrо изменяются свободные параметры нейронной сети.
3. После изменения внутренней структуры нейронная сеть отвечает на возбуждения
уже иным образом.
90 rлава 2. Процессы обучения
Вышеуказанный список четких правил решения проблемы обучения называется
ал20риmмом обучения! (leaming algorithm). Несложно доrадаться, что не существу
ет универсальноro алroритма обучения, подходящеrо для всех архитектур нейронных
сетей. Существует лишь набор средств, представленный множеством алrоритмов обу
чения, каждый из которых имеет свои достоинства. Алrоритмы обучения отличаются
друr от друrа способом настройки синаптических весов нейронов. Еще одной отли
чительной характеристикой является способ связи обучаемой нейросети с внешним
миром. В этом контексте rоворят о паради2Ме обучения (leaming paradigm), связанной
с моделью окружающей среды, в которой функционирует данная нейронная сеть.
Структура rлавы
Эта rлава состоит из четырех взаимосвязанных частей. В первой части (разделы 2.2
2.6) речь идет о пяти основных моделей обучения: на основе коррекции ошибок,
с использованием памяти, Хеббовском обучении, конкурентном обучении и MeTO
де Больцмана. Обучение, основанное на коррекции ошибок, реализует метод опти
мальной фильтрации. Обучение на основе памяти предполаrает явное использование
обучающих данных. Метод Хебба и конкурентный подход к обучению основаны на
нейробиолоrических принципах. В основу метода Больцмана положены идеи стати
стической механики.
Вторая часть этой rлавы раскрывает парадиrмы обучения. В разделе 2.7 paCCMaT
ривается задача присваивания коэффициентов доверия (credit assignment), лежащая в
основе процесса обучения. Разделы 2.8 и 2.9 содержат обзор двух фундаментальных
парадиrм обучения: обучения с учителем и без Hero.
Третья часть настоящей rлавы (разделы 2.10 2.12) посвящена решению задач обу
чения, реализации памяти и адаптации.
Заключительная часть rлавы (разделы 2.13 2.15) охватывает вероятностные и CTa
тистические аспекты процесс а обучения. В разделе 2.13 речь идет о дилемме CMe
щения и дисперсии. В разделе 2.14 обсуждается теория статистическоrо обучения,
основанная на использовании VС размерности как меры информационной емкости
обучаемой машины. В разделе 2.15 вводится еще одно важное понятие приближенно
корректноrо в вероятностном смысле обучения (probably approximately correct leam
ing), обеспечивающеrо консервативную модель процесса обучения.
В разделе 2.16 подводятся итоrи и приводятся некоторые замечания.
1 Слово "алroритм" произошло от имени персидскоro математика Мохаммеда Аль Коварисими (Mohammed
Аl Kowarisimi), который жил в девятом веке нашей эры. Именно он разработал пошаrовые правила сложения,
вычитания, умножеиия и делеиия действительных десятичных чисел. Коrда ero имя было записано по-латыии,
оно приобрело вид A!gorismus, откуда и про изошел термин "алroритм" [420].
2.2. Обучение, основанное на коррекции ошибок 91
2.2. Обучение, основанное на коррекции ошибок
Для TOrO чтобы проиллюстрировать первое правило обучения, рассмотрим простей
ший случай нейрона k единственноrо вычислительноro узла выходноrо слоя ней
ронной сети прямоro распространения (рис. 2.1, а). Нейрон k работает под управ
лением вектора си2нала (signal vector) х(n), производимоrо одним или несколькими
скрытыми слоями нейронов, которые, в свою очередь, получают информацию из
входноro вектора (возбуждения), передаваемоro начальным узлам (входному слою)
нейронной сети. Под n подразумевается дискретное время, или, более конкретно,
номер шаrа итеративноro процесса настройки синаптических весов нейрона k. Bы
ходной си2Нал (output signal) нейрона k обозначается У k (n ). Этот сиrнал является
единственным выходом нейронной сети. Он будет сравниваться с желаемым выxo
дом (desired response), обозначенным dk(n). В результате получим си2нал ошибки
(error signal) ek (n). По определению
ek(n) == dk(n) Yk(n)'
(2.1)
Сиrнал ошибки инициализирует механизм управления (control mechanism), цель
KOТOpOro заключается в применении последовательности корректировок к синапти
ческим весам нейрона k. Эти изменения нацелены на пошаrовое приближение BЫXOД
Horo сиrнала Yk(n) к желаемому dk(n). Эта цель достиrается за счет минимизации
функции стоимости (cost function) или индекса производительности (perforrnance
index) Е(n), определяемой в терминах сиrнала ошибки следующим образом:
1
Е(n) == 2е%(n),
(2.2)
rдe Е( n) текущее значение энеР2ии ошибки (instantaneous value of the error energy).
Пошаroвая корректировка синаптических весов нейрона k продолжается до тех пор,
пока система не достиrнет устоuчивО20 состояния (steady state) (т.е. TaKoro, при
котором синаптические веса практически стабилизируются). В этой точке процесс
обучения останавливается.
Процесс, описанный выше, называется обучением, основанном на коррекции оши
бок (error correction leaming). Минимизация функции стоимости Е(n) выполняется
по так называемому дельта правилу, или правилу Видроу Хоффа, названному так
в честь ero создателей [1141]. Обозначим W kj (n) текущее значение синаптическоro
веса Wkj нейрона k, соответствующеrо элементу Xj(n) вектора х(n), на шаre дис
кретизации n. В соответствии с дельта правилом изменение ДWkj(n), применяемое
к синаптическому Becyw kj на этом шаrе дискретизации, задается выражением
ДWkj(n) == 'Ilek(n)Xj(n),
(2.3)
92 rлава 2. Процессы обучения
I
I
I
Вектор входноro :
сиrнала I
Один или
несколько
слоев скрытых
нейронов
х(п)
Выходной
нейрон
k
Yk(n)
I
I
I
I
I
L
Мноrослойная сеть
прямоrо распространения
а) Блочная диаrpамма нейронной сети;
показаны только нейроны выходноrо слоя
x1(n)
q>(-) l
Yk(n)
dk(n)
х 2 (п)
х(п)
ek(n)
хm(п)
б) [раф передачи сиrнала выходноrо нейрона
Рис. 2.1. Обучение, основанное на коррекции ошибок
rдe т] некоторая положительная константа, определяющая скорость обучения (rate
of leaming) и используемая при переходе от одноrо шаrа процесса к друrому. Из
формулы (2.3) видно, что эту константу естественно именовать параметром CKOpO
сти обучения (leaming rate parameter). Вербально дельта правило можно определить
следующим образом.
Корректировка, применяемая к синаптическому весу нейрона. пропорциональна пpo
изведению си2нала ошибки на входной си2Нал, е20 вызвавший.
Помните, что определенное таким образом дельта правило предполаrает возмож
ность пря.МО20 измерения (direct measure) сиrнала ошибки. Для обеспечения TaKoro
измерения требуется поступление желаемоro отклика от HeKoToporo внешнеrо ис
точника, непосредственно доступноrо для нейрона k. Друrими словами, нейрон k
должен быть видимым (visible) для внешнеro мира (рис. 2.1, а). На этом рисунке
видно, что обучение на основе коррекции ошибки по своей природе является локаль
ным (local). Это прямо указывает на то, что корректировка синarrrических весов по
дельта правилу может быть локализована в отдельном нейроне k.
2.3. Обучение на основе памяти 93
Вычислив величину изменения синаптическоro веса ДWkj(n), можно определить
ero новое значение для следующеrо шаrа дискретизации:
Wkj(n + 1) == Wkj(n) + ДWkj(n)'
(2.4 )
Таким образом, Wkj(n) и Wkj(n + 1) можно рассматривать как старое и новое
значения синаптическоro веса Wkj' В математических терминах можно записать
Wkj(n) == z l[wkj(n + 1)],
(2.5)
rдe Z l оператор единичной задержки (unit delay operator). Друrими словами,
оператор Z l представляет собой элемент памяти (storage element).
На рис. 2.1, б представлен rpаф прохождения сиrнала в процессе обучения, oc
HOBaHHoro на коррекции ошибок, для выделенноro нейрона k. Входной сиrнал xk и
индуцированное локальное поле Vk нейрона k представлены в виде предсинаптиче
СКО20 (presynaptic) и постсинаптичеСКО20 (postsynaptic) сиrналов j ro синапса ней
рона k. На рисунке видно, что обучение на основе коррекции ошибок это пример
замкнутой системы с обратной связью (closed loop feedback). Из теории управления
известно, что устойчивость такой системы определяется параметрами обратной связи.
В данном случае существует Bcero одна обратная связь, и единственным интересую
щим нас параметром является коэффициент скорости обучения т]. Для обеспечения
устойчивости или сходимости итеративноrо процесса обучения требуется тщатель
ный подбор этоrо параметра. Выбор параметра скорости обучения влияет также на
точность и друrие характеристики процесса обучения. Друrими словами, параметр
скорости обучения т] иrpает ключевую роль в обеспечении производительности про
цесса обучения на практике.
Обучение, основанное на коррекции ошибок, детально описывается в rлаве 3 для
однослойной сети прямоrо распространения и в rлаве 4 для мноroслойной.
2.3. Обучение на основе памяти
При обучении на основе памяти (memory based leaming) весь прошлый опыт накапли
вается в большом хранилище правильно классифицированных примеров вида BXOД
выход: {(Xi, d i )}f:,l' rде Xi входной вектор, а d i соответствующий ему желаемый
выходной сиrнал. Не оrpаничивая общности, можно предположить, что выходной сиr
нал является скаляром. Например, рассмотрим задачу бинарноrо распознавания обра
зов или классификации на два класса (rипотезы), С 1 и С 2 . В этом примере желаемый
отклик системы d i принимает значение О (или 1) для класса С 1 и значение +1 для
класса С 2 . Если требуется классифицировать некоторый неизвестный вектор Xtest, из
базы данных выбирается выход, соответствующий входному сиrналу, близкому к Xtest.
94 rлава 2. Процессы обучения
Все алroритмы обучения на основе памяти включают в себя две существенные
составляющие.
· Критерий, используемый для определения окрестности вектора Xtest.
· Правило обучения, применяемое к примеру из окрестности TecToBoro вектора.
Все алrоритмы отличаются друr от друrа способом реа.пизации этих двух COCTaB
ляющих.
В простейшем (хотя и эффективном) алrоритме обучения на основе памяти, полу
чившем название правила ближайше20 соседа (nearest neighbor rule)2, в окрестность
включается пример, ближайший к тестовому. Например, вектор
X'N Е {Xl,X2"",XN}
(2.6)
считается ближайшим соседом вектора Xtest, если выполняется условие
min d(Xi, Xtest) == d(X'N,Xtest),
.
(2.7)
[де d(Xi, Xtest) Евклидов о расстояние между векторами Xi и Xtest. Класс, к KOTO
рому относится ближайший сосед, считается также классом тестируемоrо вектора
Xtest. Это правило не зависит от распределения, используемоrо при rенерировании
примеров обучения.
В [220] про водится формальное исследование правила ближайшеrо соседа, приме
няемоrо для решения задачи классификации образов. При этом анализ основывается
на двух следующих предположениях.
· Классифицируемые примеры (Xi' d i ) независимы и равномерно распределены (inde
pendently and identically distributed) в соответствии с совместным распределением
примера (Х, d).
· Размерность обучающеrо множества N бесконечно велика.
Показано, что при этих двух предположениях вероятность ошибки классифика
ции при использовании правила ближайшеro соседа вдвое превышает баuесовскую
вероятность ошибки (Bayes probability error). (Байесовская вероятность ошибки
это минимальная вероятность ошибки на множестве всех правил принятия реше
ния.) Байесовская вероятность ошибки описывается в rлаве 3. В этом контексте мож
но считать, что половина классификационной информации для обучающеrо множе
ства бесконечноro размера содержится в данных о ближайшем соседе. Это довольно
неожиданный результат.
2 Принципу ближайшеro соседа посвящеио очеиь MHOro книr, например [297].
2.4. Обучение Хебба
95
о
о
о
Рис. 2.2. Область в штриховой окружности содержит две
точки, принадлежащие классу 1, и одну, принадлежащую
классу О. Точка d соответствует тестируемому вектору
Xtest. При k == 3 классификатор на основе k ближайших
соседей отнесет точку d к классу 1, несмотря на то, что она
лежит ближе всеro к "выбросу", относящемуся к классу О
о о
/", ...., О
I 1\
Посторонний / о
элемент 1 .... ....,
о
о
о
о
1 1 ,1
, '
Вариацией классификатора на основе ближайшеrо соседа является классифика
тор k ближайших соседей (k nearest neighbor classifier). ОН описывается следую
щим образом.
Находим k классифицированных соседей, ближайших к вектору Xtest, [де k
некоторое целое число.
Вектор Xtest относим К тому классу (rипотезе), который чаще друrих встречается
среди k ближайших соседей тестируемоrо вектора.
Таким образом, классификатор на основе k ближайших соседей работает подобно
устройству усреднения. Например, он может не учесть единичный "выброс", как
показано на рис. 2.2 для k == 3. Выброс (out1ier) это наблюдение, которое отличается
от номинальной модели.
В rлаве 5 рассматривается еще один тип классификатора на основе памяти, KOTO
рый называется сетью на базе радиальных базисных функций.
2.4. Обучение Хебба
Постулат обучения Хебба (Hebb's postulate of leaming) является самым старым и
самым известным среди всех правил обучения. ОН назван в честь нейрофизиолоrа
Хе6ба. При ведем цитату из ero книrи [445].
Если аксон клетки А находится на достаточно близком расстоянии от клетки В
и постоянно или периодически участвует в ее возбуждении, наблюдается процесс
метаболических изменений в одном или обоих нейронах, выражающийся в том, что
эффективность нейрона А как одНО20 из возбудителей нейрона В возрастает.
Хебб предложил положить это наблюдение в основу процесса ассоциативноrо обу
чения (на клеточном уровне). По ero мнению, это должно бьто привести к постоян
ной модификации шаблона активности пространственно распределенноrо "ансамбля
нервных клеток".
96 rлава 2. Процессы обучения
Это утверждение было сделано в нейробиолоrическом контексте, но ero можно
перефразировать в следующее правило, состоящее из двух частей [180], [1016].
1. Если два нейрона по обе стороны синапса (соединения) активизируются oдHoвpe
менно (т.е. синхронно), то прочность этО20 соединения возрастает.
2. Если два нейрона по обе стороны синапса активизируются асинхронно, то такой
синапс ослабляется или вообще отмирает.
Функционирующий таким образом синапс называется синапсом Хебба 3 (Hebbian
synapse) (обратите внимание, что исходное правило Хебба не содержало второй ча
сти последнеrо утверждения). Если быть более точным, то синапс Хебба использует
зависящий от времени, в высшей степени локальный механизм взаимодействия, изме
няющий эффективность синаптичеСКО20 соединения в зависимости от корреляции
между предсинаптической и постсинаптической активностью. Из этоrо определе
ния можно вывести следующие четыре свойства (ключевых механизма), характери
зующие синапс Хебба [161].
1. Зависимость от времени (time dependent mechanism). Синапс Хебба зависит
от точноrо времени возникновения предсинаптическоrо и постсинаптическо
[о сиrналов.
2. Локальность (local mechanism). По своей природе синапс является узлом пе
редачи данных, в котором информационные сиrналы (представляющие TeKY
щую активность предсинаптических и постсинаптических элементов) находятся
в простра1iственно временной (spatiotemporal) близости. Эта локальная инфор
мация используется синапсом Хебба для выполнения локальных синаптических
модификаций, характерных для данноrо входноrо сиrнала.
3. Интерактивность (interactive mechanism). Изменения в синапсе Хебба опреде
ляются сиrналами на обоих ero концах. Это значит, что форма обучения Хебба
зависит от степени взаимодействия предсинаптическоrо и постсинаптическоrо
сиrналов (предсказание нельзя построить на основе только одноrо из этих сиrна
лов). Заметим, что такая зависимость или интерактивность может носить дeтep
минированный или статистический характер.
4. Корреляция (correlational mechanism). Одна из интерпретаций постулата обуче
ния Хебба состоит в том, что условием изменения эффективности синаптической
связи является зависимость между предсинаптическим и постсинаптическим сиr
налами. В соответствии с этой интерпретацией для модификации синапса необ
ходимо обеспечить одновременность предсинаптическоrо и постсинаптическоrо
3 Подробный обзор синапсов Хебба, включаюший и историческую справку, содержится в [161] и [316], а
также в [207].
2.4. Обучение Хебба 97
сиrналов. Именно по этой причине синапс Хебба иноrда называют конъюнктив
ным синапсом (conjunctional synapse). Друrая интерпретация постулата обучения
Хебба использует характерные для синапса Хебба механизмы взаимодействия в
статистических терминах. В частности, синаптические изменения определяют
ся корреляцией предсинаптическоrо и постсинаптическоrо сиrналов во времени.
Учитывая это, синапс Хебба иноrда называют корреляционным синапсом (correla
tional synapse). Сама корреляция является основой обучения [279].
Усиление и ослабление синаптической связи
Приведенное выше определение синапса Хебба не учитывает дополнительные про
цессы, которые MorYT привести к ослаблению синаптической связи между парой
нейронов. Исходя из этоrо, можно несколько обобщить концепцию модификации
связей Хебба, используя тот факт, что положительно коррелированное функциониро
вание приводит к усилению синаптической связи, а отрицательная корреляция или ее
отсутствие к ее ослаблению [1016]. Ослабление синаптической связи может TaK
же носить и не интерактивный характер. В частности, условие взаимодействия для
ослабления синаптической связи может носить случайный характер и не зависеть от
предсинаптическоrо и постсинаптическоrо сиrналов.
Систематизируя эти определения, можно выделить следующие модели модифика
ции синаптических связей: хеббовскую (Hebbian), антихеббовскую (anti Hebbian) и He
хеббовскую (non Hebbian) [810]. Следуя этой схеме, можно сказать, что синаптическая
связь по модели Хебба усиливается при положительной корреляции предсинаптиче
ских и постсинаптических сиrналов и ослабляется в противном случае. И, наоборот,
соrласно антихеббовской модели, синаптическая связь ослабляется при положитель
ной корреляции предсинаптическоrо и постсинаптическоrо сиrналов и усиливается в
противном случае. Однако в обеих моделях изменение синаптической эффективности
основано на зависящем от времени в высшей степени локальном и интерактивном
по своей природе механизме. В этом контексте антихеббовская модель все равно
остается хеббовской по природе, но не по функциональности. Не хеббовская модель
вообще не связана с механизмом модификации, предложенным Хеббом.
Математические модели предложенноrо Хеббом механизма
модификации синаптической связи
Для Toro чтобы описать обучение Хебба в математических терминах, рассмотрим
синаптический вес Wkj нейрона k с предсинаптическим и постсинаптическим сиr
налами Xj и Yk. Изменение синаптическоrо веса Wkj в момент времени n можно
выразить следующим соотношением:
ДWkj(n) == F(Yk(n), xj(n)),
(2.8)
98 rлава 2. Процессы обучения
rдe F(.,.) некоторая функция, зависящая от предсинаптическоrо и постсинаптиче
CKOro сиrналов. Сиrналы Xj(n) и Yk(n) часто рассматривают без учета размерности.
Формула (2.8) может быть записана в разных формах, каждая из которых все равно
считается хеббовской. Рассмотрим только две следующие формы.
rипотеза Хебба
Простейшая форма обучения Хебба имеет следующий вид:
ДWkj(n) == 'IlYk(n)Xj(n),
(2.9)
[де т] положительная константа, определяющая скорость обучения (rate of leam
ing). Выражение (2.9) ясно подчеркивает корреляционную природу синапса Хебба.
Ее иноrда называют правилом умножения активности (activity product rule). Верхний
rpафик на рис. 2.3 rpафически иллюстрирует формулу (2.9). Он представляет зави
симость изменения ДWkj(n) от выходноrо сиrнала (постсинаптической активности)
Yk(n)' На рисунке видно, что реryлярное приложение входноrо сиrнала (предсинап
тической активности) Xj(n) ведет к увеличению Yk(n) и экспоненциальному росту
активности (exponential growth), приводящему к насыщению синаптической связи.
В этой точке синапс уже не содержит никакой информации, и избирательность свя
зей теряется.
rипотеза ковариации
Одним из способов преодоления оrpаничений rипотезы Хебба является использова
ние 2ипотезы ковариации (covariance hypothesis), предложенной в [956], [957]. Co
rласно этой rипотезе, предсинаптический и постсинаптический сиrналы в формуле
(2.9) заменяются отклонениями этих сиrналов от их средних значений на данном OT
резке времени. Обозначим символами Х и fJ усредненные по времени значения предси
наптическоrо Xj и постсинаптическоro Yk сиrналов. Соrласно rипотезе ковариации,
изменение синаптическоrо веса Wkj вычисляется по формуле
ДWkj == 'Il(Xj X)(Yk У),
(2.10)
[де т] параметр скорости обучения. Средние значения Х и У содержат предсинап
тический и постсинаптический пороrи, определяющие знак синаптической модифи
кации. В частности, rипотеза ковариации обеспечивает следующее.
2.4. Обучение Хебба 99
о
rипотеза
ковариации
I1wk,j
Постсинаптическая
активность у k
ry(Xj x)y
Рис. 2.3. Иллюстрация rипотез
Хебба и ковариации
Точка
максимальноro
спада
. Сходимость к нетривиальному состоянию, которое достиrается при Х k == Х И
Yj == У.
. Проrнозирование усиления (potentiation) и ослабления (depression) синаптической
связи.
На рис. 2.3 показано отличие rипотезы Хебба от rипотезы ковариации. В обоих
случаях зависимость величины D.Wkj от Yk является линейной, однако пере сечение с
осью Yk для rипотезы Хебба происходит в начале координат, а для rипотезы ковари
ации в точке Yk == У.
При внимательном исследовании выражения (2.1 О) можно сделать следующие
выводы.
1. Синаптический вес связи усиливается при высоком уровне предсинаптическоro и
постсинаптическоro сиrналов, Т.е. в том случае, коrда одновременно удовлетворя
ются следующие условия: Xj > Х и Yk > У.
2. Синаптический вес ослабляется в следующих ситуациях.
. Предсинаптическая активность (т.е. Xj > х) не вызывает существенной пост
синаптической активности (Yk < У).
. Постсинаптическая активность (Yk > У) возникает при отсутствии существен
ной предсинаптической активности (Х j < х).
Такое поведение можно рассматривать как форму временной конкуренции между
входными моделями.
.
100 rлава 2. Процессы обучения
Существует cTporoe физиолоrическое доказательств0 4 реализации принципа обу
чения Хебба в области мозrа, называемой 2ипокампусом (hippocampus). Эта область
иrpает важную роль в некоторых аспектах обучения и запоминания. Физиолоrические
результаты еще раз подтверждают правильность постулата обучения Хебба.
4 ДОЛI'овремеииое усилеиие физиолоrическое доказательство модели сииапса Хебба.
Хебб еще в 1949 roду изложил свое видение механизмов синаптической памяти [445], но прошло еше
около четверти столетия, пока были получены ero экспериментальные доказательства. В 1973 [оду была
опубликована работа, описывающая модификации синаптических связей, вызванные внешним возбуждением в
области roловноrо мозrа, называемой cипoKaмпyCQМ (hippocampus) [133]. Авторы работы приложили импульсы
электрическоro возбуждения к rлавному тракту, направленному в эту структуру, и записали синаl1тические
отклики, Пока эта структура функционировала автоиомно, она характеризовалась устойчивой морфолоrией
базовых откликов короткими высокочастотными сериями импульсов в том же тракте. После применения
возбуждающих тестовых импульсов амплитуда отклика увеличилась. Внимание исследователей привлек тот
факт, что это увеличение амплитуды довольно продолжительное время не затухало. Это явление было названо
долzoвременным усилениеи (long-term potentiation LTP).
В настоящее время ежеroдно публикуется множество работ, посвяшенных явлению LTP, и MHoroe уже
известно о механизмах ero реализации. Например, известно, что эффект усиления оrpаничен только возбуж-
денныл1u трактами (palhway). Известно также, что механизМ LTP обладает ассоциативными свойствами, под
которыми подразумевается проявление эффекта взаимодействия трактов, активизируемых совместно. Напри-
мер, если слабое возбуждение, не вызывающее эффекта LTP, применять в паре С сильным, то слабый сиrнал
также будет усиливаться. Этот эффект называют ассоциативным свойством, так он аналоrичен ассоциативным
свойствам систем обучения. В экспериментах Павлова, посвяшенных изучению условноrо рефлекса, нейтраль-
ный звуковой возбудитель (слабый) применялся в паре С сильным (еда). Результатом стало появление условноro
рефлекса (conditioned response) выделение слюны в ответ на даниый звуковой сиrнал.
Большинство экспериментальных работ в этой области было сфокусировано на ассоциативных свойствах
LTP. В большинстве синапсов, поддерживающих LTP, в качестве нейропередатчика используется rлутамат (g]uta-
mаlе). В постсинаптических нейронах существует множество различных рецепторов, реаrирующих на rлyrамат.
Все эти рецепторы имеют разные свойства, но мы остаиовимся только на двух из них. rлавный синаптический
отклик инициируется возбуждением рецептора АМРА (этот рецептор был назван в честь наркотика, на который
реаrирует наиболее явно). Коrда в эксперименте с LTP записывлсяя результат, он в первую очередь относился
на счет возбуждения рецептора АМРА. После синаптической активации высвобождался rлyrамат, который свя-
зывался с рецепторами в постсинаптической мембране. Каналы ионов, являюшиеся частью рецепторов АМРА,
открывались, передавая поток, являющийся основой синаптическоro отклика.
Второй тип rлутаматых рецепторов NMDA тоже имеет ряд интересных свойств. Для открытия ассо-
циированноrо ИОННОro канала в рецепторе NMDA не достаточно rлyrаматноro связывания. Этот канал остается
заблокированным, пока в процессе синаптической активности (в том числе и рецепторами АМРА) не будет
сrенерирован большой скачок напряжения. Следовательно, если рецепторы АМРА являются химически зависи-
мыми, то рецепторы NMDA являются как химически, так и электрически зависимыми. Канал, ассоциированный
с рецептором АМРА, связан с движением ионов соды (которые вызывают синаптический ток). Канал, связанный
с рецептором NMDA, обеспечивает попадание кальция в клетку. Хотя движение кальция влияет также и на мем-
бранный тоК (membrane current), ero rлавной ролью является порождение цепочки событий, увеличиваюш их
продолжительность реакции, связанной с рецептором АМРА.
Так действует механизм синапса, описанный Хеббом. Рецептор NMDA требует как предсинаптической
(высвобождение rлyrамата), так и постсинаптической активности. Как этоrо добиться? Наличием достаточно
сильноro входноro сиrнала. Korдa слабый входной сиrнал одноrо синапса интеrpируется с сильным сиrна-
лом друrоro, первый синапс высвобождает свой rлутамат, а второй обеспечивает достаточно большой скачок
напряжения, достаточный для активации рецепторов NMDA, связанных со слабым синапсом.
Несмотря на то что исходное yrверждение Хебба относится к однонаправленному обучению, правило двуна-
правленноrо обучения обеспечивает более высокую степень rибкости нейронных сетей. При ero использовании
синаптические веса отдельных нейронов MOryT не только увеличиваться, но и уменьшаться. Следует знать, что
существуют экспериментальные доказательства сушествования механизмов синаптическоrо ослабления. Если
слабый входной сиrнал активизируется без сопутствующеro ему сильноro, синаптический вес, как правило,
ослабляется. Этот результат можно наблюдать в виде реакции синаптической системы на низкочастотное воз-
действие. Такое явление называется долzовреиенным торможением (long-term depression, или LTD). Сушествует
также подтверждение zетеросuнаптическоzo торможения (geterosynaptic depression). Если LTD это тормо-
жение, влияюшее на аю'ивизированный вход, то влияние rетеросинаптическоro торможения распространяется
только на не активизированные входы.
2.5. Конкурентное обучение 101
2.5. Конкурентное обучение
Как следует из caMoro названия, в конкурентном обучении (competitive leaming)5
выходные нейроны нейронной сети конкурируют между собой за право быть активи
зированными. Если в нейронной сети, основанной на обучении Хебба, одновременно
в возбужденном состоянии может находиться несколько нейронов, то в конкурентной
сети в каждый момент времени может быть активным только один нейрон. Блаrода
ря этому свойству конкурентное обучение очень удобно использовать для изучения
статистических свойств, используемых в задачах классификации входных образов.
Правило KOHкypeHTHoro обучения основано на использовании трех основных эле
ментов [913].
. Множество одинаковых нейронов со случайно распределенными синаптическими
весами, приводящими к различной реакции нейронов на один и тот же входной
сиrнал.
· Предельное значение (limit) "силы" каждоrо нейрона.
· Механизм, позволяющий нейронам конкурировать за право отклика на данное
подмножество входных сиrналов и определяющий единственный активный BЫ
ходной нейрон (или по одному нейрону на rpуппу). Нейрон, победивший в этом
соревновании, называют нейроном победителем, а принцип KOHKypeHTHoro обуче
ния формулируют в виде лозунrа "победитель забирает все" (wiппеr tаkеs аlТ).
Таким образом, каждый отдельный нейрон сети соответствует rpуппе близких
образов. При этом нейроны становятся детекторами признаков (feature detector) раз
личных классов входных образов.
Простейшая нейронная сеть с конкурентным обучением содержит единственный
слой выходных нейронов, каждый из которых соединен с входными узлами. В такой
сети MorYT существовать обратные связи между нейронами (рис. 2.4). В подобной
архитектуре обратная связь обеспечивает латеральное торможение (lateral inhibi
tion)6, коrда каждый нейрон стремится "затормозить" связанные с ним нейроны.
5 Идею KOHкypeHTHoro обучения можно проследить еще в ранних работах, в том числе в [1100], посвящен-
ной самоорrанизации чувствительных к ориентации нервных клеток в извилинах коры roловноro мозrа (striate
cortex); в [327], посвяшенной самоорrанизуюшимся MHoroypoBHeBblM нейронным сетям, получившим название
неОКО2нитронов; в [1159], посвяшенной формированию образных нейронных связей (pattemed neura! connection)
с помошью самоорrанизации; и в [396 398], посвяшенных адаптивной классификации образов. Впоследствии
было доказано, что конкурентное обучение иrpает важную роль при формировании ТОlIоrpафических отображе-
ний в cтpyкrype мозrа [272], а недавняя экспериментальная работа обеспечивает дальнейшую физиолоrичсскую
верификацию KOHкypeHTHoro обучения [41].
6 Латеральное торможение (см. рис. 2.4) присуще также нейробиолоrическим системам. Множество сен-
сориых тканей (в частности, сетчатка rлаза, ушная раковина и осязательные нервные окончания на коже)
орraнизовано таким образом, что воздействие на любой участок при водит к торможению соседних нервных
клеток [66], [295]. В системе осязания человека латеральное торможение проявляется в виде явления, связан-
HOro с палоса"щ Маха (Mach band), получившими свое название в честь извеСТIIШ-О физика Эрнста Маха [694].
........
102 rлава 2. Процессы обучения
Х 1
Х з
Х 2
Х 4
Слой
узлов
источника
Один СЛОЙ
выходных
нейронов
Рис. 2.4. Архитектурный rраф простой сети KOHKypeHTHoro обуче
ния с прямыми (возбуждающими) связями от входных узлов к ней
ронам и обратными (тормозящими) связями между нейронами (по-
следние обозначены на рисунке незаштрихованными стрелками)
Прямые синаптические связи в сети, показанной на рис. 2.4, являются возбуждаю
щими (excitatory).
Для TOro чтобы нейрон k победил в конкурентной борьбе, ero индуцированное
локальное поле Vk для заданноrо входноrо образа х должно быть максимальным среди
всех нейронов сети. Тоrда выходной сиrнал Yk нейрона победителя k принимается
равным единице. Выходные сиrналы остальных нейронов при этом устанавливаются
в значение нуль. Таким образом, можно записать:
{ 1, если Vk > Vj для всех j,j # k,
Yk
О В остальных случаях,
(2.11 )
rдe индуцированное локальное поле Vk представляет сводное возбуждение нейрона
k от всех входных сиrналов и сиrналов обратной связи.
Пусть Wkj синаптический вес связи входноro узла j с нейроном k. Предположим,
что синаптические веса всех нейронов фиксированы (т.е. положительны), при этом
L Wkj == 1 для всех k.
j
(2.12)
Тоrда обучение этоro нейрона состоит в смещении синаптических весов от HeaK
тивных к активным входным узлам. Если нейрон не формирует отклика на KOH
кретный входной образ, то он и не обучается. Если некоторый нейрон выиrpывает
в конкурентной борьбе, то веса связей этоro нейрона равномерно распределяются
между ero активными входными узлами, а связи с неактивными входными узлами
Например, если посмотреть на лист белой бумarи, наполовину закрашенный черным цветом, можно увидеть
линии, параллельные rpанице разделения, которые имеют цвет "белее белоro" с белой стороны и "чернее чер
HOro" с черной, даже если заливка половинок абсолютно монотонна. Полосы Маха физически не сушествуют
они являются Bcero лишь зрительной иллюзией, представляющей собой "завышение" и "занижение" сиrнала,
вызванные функцией дифференциации (differentiating) латеральноro торможения.
2.5. Конкурентное обучение 103
Рис. 2.5. rеометрическая интерпретация процесса конкурентноro обу
чения. Точками представлены входные векторы, а крестиками век-
торы синаптических весов трех выходных нейронов в исходном (а) и
конечном (б) состоянии сети
ослабляются. Соrласно правил у КО1lкуре1lт1l020 обучения (competitive leaming rule)
изменение ДWkj синаптическоrо BeCaWkj определяется следующим выражением:
л { Т](Хj Wkj), если нейрон k побеждает в соревновании,
UWk.
J О, если нейрон k побеждает в соревновании,
(2.13)
rдe т] параметр скорости обучения. Это правило отражает смещение вектора си
наптическоrо веса Wk победившеrо нейрона k в сторону входноro образа х.
Для иллюстрации сущности KOHкypeHTHoro обучения можно использовать [eo
метрическую аналоrию (рис. 2.5) [913]. Предполаrается, что все входные образы
(векторы) х имеют некоторую постоянную Евклидову норму. Таким образом, их мож
но изобразить в виде точек на N мерной единичной сфере, [де N количество
входных узлов. N также является размерностью вектора синаптических весов Wk.
Предполаrается, что все нейроны сети имеют ту же Евклидову длину (норму), Т.е.
L W%j == 1 для всех k.
j
(2.14)
Если синаптические веса правильно масштабированы, они формируют набор BeK
торов, которые проецируются на ту же N мерную единичную сферу. На рис. 2.5, а
можно выделить три естественные rpуппы (кластеры) точек, представляющие BXOД
ные образы. На этом рисунке также показано вероятное начальное состояние сети
(отмечено крестиками) до начала обучения. На рис. 2.5, б показано конечное состоя
ние сети, полученное в результате KOHKypeHTHoro обучения, в котором синаптические
веса каждоro выходноro нейрона смещены к центрам тяжести соответствующих кла
......
104 rлава 2. Процессы обучения
стеров [453], [913]. На этом примере продемонстрирована способность нейронной
сети решать задачи кластеризации в процессе KOHKypeHTHoro обучения. Однако для
"устойчивоrо" решения этой задачи входные образы должны формировать достаточно
разрозненные rруппы векторов. В противном случае сеть может стать неустойчивой,
поскольку в ответ на заданный входной образ будут формироваться отклики от раз
личных выходных нейронов.
2.6. Обучение Больцмана
Правило обучения Больцмана, названное так в честь Людвиrа Больцмана, представ
ляет собой стохастический алrоритм обучения, основанный на идеях стохастической
механики 7. Нейронная сеть, созданная на основе обучения Больцмана, получила Ha
звание машины Больцмана (Boltzmann machine) [9], [464].
В машине Больцмана все нейроны представляются рекуррентными CTpYKTypa
ми, работающими с бинарными сиrналами. Это значит, что они MorYT находиться
во включенном (соответствующем значению + 1) или выключенном (соответствую
щем значению 1) состоянии. Такая машина характеризуется функцией энерrии Е,
значение которой определяется конкретными состояниями отдельных нейронов, co
ставляющих эту машину. Это можно описать следующим выражением:
1
Е == 2 L L WkjXkXj,
j k(j#)
(2.15)
[де Xj состояние нейрона j; Wkj синаптический вес связи нейронов j и k. Усло
вие j ::f. k подчеркивает тот факт, что в этой сети нейроны не имеют обратных связей
с самими собой. Работа этой машины заключается в случайном выборе HeKoToporo
нейрона (предположим, k ro) на определенном шаrе процесс а обучения и переводе
этоrо нейрона из состояния Xk В состояние Xk при некоторой температуре Т с
вероятностью
7 Важность статистической термодинамики при изучении вычислительных машин была доказана еще Джо-
ном фон Нейманом в третьей из пяти лекций по Теории и орrанизации вычислительных автоматов, проведенных
в университете штата Иллинойс в 1949 roду. В своей третьей лекции на тему "Статистические теории инфор
мации" фон Нейман сказал следуюшее.
"Понятия термодинамики обязательио войдут в новую теорию информации. Существуют признаки TOro,
что информация подобна энтропии и процессы энтропии подобны процессам в обработке информации. Чаше
Bcero не удается определить функцию автомата или ero эффективность, не охарактеризовав среду, в которой
он работает, с помощью статистических свойств, подобных тем, которые характеризуют среду в термодина-
мИке. Статистические свойства среды автомата, естественно, сложнее, чем стандартные термодинамические
переменные температуры, однако по сути они очень близки".
2.6. Обучение Больцмана 105
1
P(Xk Xk) == 1 + ехр( t::.Ek/T) ' (2.16)
[де t::.E k изменение энеР2ии машины (т.е. изменение ее функции энерrии), вызван
ное переходом состояний. Заметим, что под обозначением Т скрывается не физи
ческая температура, а псевдотемnература (pseudotemperature), определение которой
бьmо приведено в rлаве 1. При MHoroKpaTHoM применении этоro правила машина
достиrает термаЛЬНО20 равновесия (therrnal equilibrium).
Нейроны машины Больцмана можно разбить на две функциональные rpуппы:
(visible) и скрытые (hidden). Видимые нейроны реализуют интерфейс между сетью
и средой ее функционирования, а скрытые работают независимо от внешней среды.
Рассмотрим два режима функционирования такой сети.
. Скованное состояние (clamped condition), в котором все видимые нейроны Haxo
дятся в состояниях, предопределенных внешней средоЙ.
. Свободное состояние (free running condition), в котором все нейроны (как видимые,
так и скрытые) MorYT свободно функционировать.
Обозначим р t j корреляцию между состояниями нейронов j и k в скованном co
стоянии. Аналоrично, р kj обозначим корреляцию (correlation) между состояниями
нейронов j и k, коrда сеть находится в свободном состоянии. Обе эти корреляции
усредняются по всем возможным состояниям машины, находящейся в условиях Tep
мальноrо равновесии. Затем, соrласно правилу обучения Больцмана (Bo1tzmann leam
ing rule), изменение t::.Wkj синаптическоrо BeCaWkj связи между нейронами k и j
определяется следующим выражением [464]:
t::.Wkj == 'Il(pt j Pkj)'
j =1= k,
(2.17)
[де т] параметр скорости обучения. Заметим, что значения pt j и Pkj изменяются в
диапазоне от 1 до + 1.
Краткий обзор методов статистической механики будет представлен вниманию
читателя в rлаве 11. Там же мы rлубже рассмотрим машину Больцмана и некоторые
друrие стохастические машины.
.....
106 rлава 2. Процессы обучения
2.7. Задача присваивания коэффициентов доверия
При изучении алroритмов обучения распределенных систем полезно ознакомиться с
концепцией присваивания коэффициентов доверия (credit assignment) [742]. По суще
ству это задача присваивания коэффициентов доверия или недоверия всем результа
там, полученным некоторой обучаемой машиной. (Задачу присваивания коэффициеll
тов доверия иноrда называют задачей за2рузки (loading problem), Т.е. распределения
множества обучающих данных по свободным параметрам сети.)
Во мноrих случаях зависимость выходов от внутренних решений определяется
последовательностью действий, выполняемых обучаемой машиной. Дрyrими слова
ми, внутренние решения влияют на выполнение конкретных действий, после чеrо
именно эти действия, а не сами решения непосредственно определяют общие pe
зультаты. В такой ситуации можно выполнить декомпозицию задачи присваивания
коэффициентов доверия на две друrие подзадачи [1035].
1. Присваивание коэффициентов доверия результатам действий. Эта задача назы
вается временной задачей присваивания коэффициентов доверия (temporal credit
assignment problem). В ней определяется промежуток времени, в течение KOToporo
реально выполняются действия, которым отпущен кредит доверия.
2. Присваивание коэффициентов доверия действий внутренним решениям. Это Ha
зывается структурной задачей присваивания коэффициентов доверия (structural
credit assignment problem). В ней коэффициенты доверия назначаются внутренним
структурам (intemal structures) действий, rенерируемых системой.
Структурная задача присваивания коэффициентов доверия имеет смысл в KOH
тексте мноrокомпонентных обучаемых машин, коrда необходимо точно определить,
поведение KaKoro элемента системы нужно скорректировать и на какую величину,
чтобы повысить общую производительность системы. С друrой стороны, временная
задача присваивания коэффициентов доверия ставится в том случае, коrда обучаемая
машина выполняет достаточно MHOro действий, приводящих к некоторому результату,
и требуется определить, какие из этих действий несут ответственность за результат.
Сочетание временной и структурной задач присваивания коэффициентов доверия
требует усложнения поведения распределенной обучаемой машины [1153].
Например, задача присваивания коэффициентов доверия возникает в том случае,
коrда обучение на основе коррекции ошибок применяется к мноroслойным нейрон
ным сетям прямоro распространения. Действия каждоro cкpbIToro и выходноrо ней
рона такой сети важны для формирования правильноrо результата в данной приклад
ной области. Это значит, что для решения поставленной задачи необходимо задать
определенные формы поведения всех нейронов в процессе обучения на основе KOp
рекции ошибок. В этом контексте вернемся к рис. 2.1, а. Поскольку выходной нейрон
2.8. Обучение с учителем 107
k является ВИДИМЫМ внешнему миру, желаемый выходной сиrнал можно направить
непосредственно на этот нейрон. Так как мы рассматриваем выходной нейрон, метод
обучения на основе коррекции ошибок можно применить непосредственно к нему
(см. раздел 2.2). Но как назначить коэффициенты доверия или недоверия действиям
скрытых нейронов, если процесс обучения на основе коррекции ошибок применя
ется к их же синаптическим весам? Ответ на этот фундаментальный вопрос тpe
бует более детальноro описания, которое и будет приведено в rлаве 4, в которой
детально рассматриваются алrоритмы построения мноrослойных нейронных сетей
прямоrо распространения.
2.8. Обучение с учителем
Рассмотрим парадиrмы обучения нейронных сетей. Начнем с парадиrмы обучения с
учителем (supervised leaming). На рис. 2.6 показана блочная диаrpамма, иллюстриру
ющая эту форму обучения. Концептуально участие учителя можно рассматривать как
наличие знаний об окружающей среде, представленных в виде пар вxoд выxoд. При
этом сама среда неизвестна обучаемой нейронной сети. Теперь предположим, что
учителю и обучаемой сети подается обучающий вектор из окружающей среды. На
основе встроенных знаний учитель может сформировать и передать обучаемой ней
ронной сети желаемый отклик, соответствующий данному входному вектору. Этот
желаемый результат представляет собой оптимальные действия, которые должна BЫ
полнить нейронная сеть. Параметры сети корректируются с учетом обучающеrо BeK
тора и сиrнала ошибки. Си2Нал ошибки (error signal) это разность между желаемым
сиrналом и текущим откликом нейронной сети. Корректировка параметров выполня
ется пошаroво с целью имитации (emulation) нейронной сетью поведения учителя.
Эта эмуляция в некотором статистическом смысле должна быть оптимальной. Ta
ким образом, в процессе обучения знания учителя передаются в сеть в максимально
полном объеме. После окончания обучения учителя можно отключить и позволить
нейронной сети работать со средой самостоятельно.
Описанная форма обучения с учителем является ничем иным, как обучением на
основе коррекции ошибок, описанным в разделе 2.2. Это замкнутая система с об
ратной связью, которая не включает в себя окружающую среду. Производительность
такой системы можно оценивать в терминах среднеквадратической ошибки или CYM
мы квадратов ошибок на обучающей выборке, представленной в виде функции от
свободных параметров системы. Для такой функции можно построить мноrомерную
поверхность ошибки (error surface) в координатах свободных параметров. При этом
реальная поверхность ошибки усредняется (averaged) по всем возможным примерам,
представленным в виде пар "BXOД BЫXOД". Любое конкретное действие системы с
учителем представляется одной точкой на поверхности ошибок. Для повышения про
изводительности системы во времени значение ошибки должно смещаться в сторону
108 rлава 2. Процессы обучения
Вектор,
описывающий
состояние
Желаемый
отклик
Сиrнал ошибки
Рис. 2.6. Блочная диаrрамма обуче
ния с учителем
минимума на поверхности ошибок. Этот минимум может быть как локальным, так и
rлобальным. Это можно сделать, если система обладает полезной информацией о 2pa
диенте поверхности ошибок, соответствующем текущему поведению системы. rpa
диент поверхности ошибок в любой точке это вектор, определяющий направление
наискорейшеrо спуска по этой поверхности. В случае обучения с учителем на приме
рах вычисляется моментальная оценка (instantaneous estimate) вектора rpадиента, в
которой входной вектор считается функцией времени. При использовании результатов
такой оценки перемещение точки по поверхности ошибок обычно имеет вид "слу
чайноrо блуждания". Тем не менее при использовании соответствующеro алrоритма
минимизации функции стоимости, адекватном наборе обучающих примеров в форме
"BXOД BЫXOД" и достаточном времени для обучения системы обучения с учителем спо
собны решать такие задачи, как классификация образов и аппроксимация функций.
2.9. Обучение без учителя
Описанный выше процесс обучения происходит под управлением учителя. Альтер
нативная парадиrма обучения без учителя (leaming without а teacher) самим назва
ни ем подчеркивает отсутствие руководителя, контролирующеrо процесс настройки
весовых коэффициентов. При использовании TaKoro подхода не существует марки
рованных примеров, по которым про водится обучение сети. В этой альтернативной
парадиrме можно выделить два метода.
2.9. Обучение без учителя 109
Эвристическое
подкрепление
Действия
Рис. 2.7. Блочная диаrрамма обучения
с подкреплением
Обучение с подкреплением, или нейродинамическое
проrраммирование
В обучении с подкреплением 8 (reinforcement leaming) формирование отображения
входных сиrналов в выходные выполняется в процессе взаимодействия с внешней
средой с целью минимизации скалярноro индекса производительности. На рис. 2.7
показана блочная диаrpамма одной из форм системы обучения с подкреплением,
включающей блок "критики", который преобразовывает первичный си2нал пoдKpeп
ления (primary reinforcement signal), полученный из внешней среды, в сиrнал более
BbICOKOro качества, называемый эвристическим си2Налом подкрепления (heuristic re
inforcement signal). Оба этих сиrнала являются скалярными [100].
Такая система предполаrает обучение с отложенным подкреплением (delayed rein
forcement). Это значит, что система получает из внешней среды последовательность
сиrналов возбуждения (т.е. векторов состояния), которые приводят к rенерации эври
стическоro сиrнала подкрепления. Целью обучения является минимизация функции
стоимости перехода, определенной как математическое ожидание кумулятивной CTO
им ости действий, предпринятых в течение нескольких шаrов, а не просто текущей
стоимости. Может оказаться, что некоторые предпринятые ранее в данной последо
8 Термин "обучение с подкреплением" был введен Минским в ero ранних работах, посвященных искусствен-
ному интеллекту [742], и, независимо от Hero, в работе по теории управления [1109]. Тем не менее основная
идея "подкрепления" берет свое начало в экспериментальных работах, посвященных обучению животных с
точки зрения психолоrии [415]. В этом контексте следует вспомнить классический закон влияния (law of efl'ect)
[1052], который сводится к следующему.
"Среди нескольких различных откликов на одну И ту же ситуацию при прочих равных условиях те реакции,
которые сопровождались поощрением животноro, будут более тесно связаны с этой ситуацией и, следовательно,
при ее повторении будут воспроизведены с наибольшей вероятностью. Реакции, которые связаны с дискомфор-
том, утрачивают свою связь С данной ситуацией и вряд ли будут возобновлены в ответ на ту же ситуацию. Чем
выше уровень удовлетворения или дискомфорта, тем значительнее будет усиление или ослабление связи".
Несмотря на то что этот закон нельзя назвать полной моделью биолоrическоro поведения, ero простота и
общий смысл сделали ero важным правилом обучения в классическом подходе к обучению с подкреплением.
.....
110 rлава 2. Процессы обучения
вательности действия бьmи определяющими в формировании общеro поведения всей
системы. Функция обучаемой машины (1eaming machine), составляющая второй KOM
понент системы, определяет эти действия и формирует на их основе сиrнал обратной
связи, направляемый во внешнюю среду.
Практическая реализация обучения с отложенным подкреплением осложнена по
двум причинам.
· Не существует учителя, формирующеro желаемый отклик на каждом шаre про
цесса обучения.
· Наличие задержки при формировании первичноrо сиrнала подкрепления требует
решения временной задачи присваивания коэффициентов доверия (temporal credit
assignment). Это значит, что обучаемая машина должна быть способна присваивать
коэффициенты доверия и недоверия действиям, выполненным на всех шаrах, при
водящих к конечному результату, в то время как первичный сиrнал подкрепления
формируется только на основе конечноrо результата.
Несмотря на эти сложности, системы обучения с отложенным подкреплением
являются очень привлекательными. Они составляют базис систем, взаимодействую
щих с внешней средой, развивая таким образом способность самостоятельноro pe
шения возникающих задач на основе лишь собственных результатов взаимодействия
со средой.
Обучение с подкреплением тесно связано с динамическим пРО2раммированием
(dynamic programming) методолоrией, созданной Беллманом в 1957 roду в KOHTeK
сте теории оптимальноro управления [118]. Динамическое проrpаммирование реали
зует математический формализм последовательноrо принятия решений. Перемещая
обучение с подкреплением в предметную область динамическоro проrpаммирования,
можно взять на вооружение все результаты последнеro. Это бьmо продемонстриро
вано в [126]. Введение в проблему динамическоrо проrpаммирования и описание ero
взаимосвязи с обучением с подкреплением будет представлено в rлаве 12.
Обучение без учителя
Обучение без учителя (unsupervised) (или обучение на основе самООр2анизации (self
organized)) осуществляется без вмешательства внешнеro учителя, или корректора,
контролирующеro процесс обучения (рис. 2.8). Существует лишь независимая от
задачи мера качества (task independent measure) представления, которому должна
научиться нейронная сеть, и свободные параметры сети оптимизируются по отноше
нию к этой мере. После обучения сети на статистические закономерности входноro
сиrнала она способна формировать внутреннее представление кодируемых признаков
входных данных и, таким образом, автоматически создавать новые классы [112].
2.10. Задачи обучения 111
Рис. 2.8. Блочная диаrрамма обучения без учителя
Для обучения без учителя можно воспользоваться правилом KOHкypeHTHoro обу
чения. Например, можно использовать нейронную сеть, состоящую из двух слоев
входноrо и выходноro. Входной слой получает доступные данные. Выходной слой
состоит из нейронов, конкурирующих друr с друroм за право отклика на признаки,
содержащиеся во входных данных. В простейшем случае нейронная сеть действу
ет по принципу "победитель получает все". Как было показано в разделе 2.5, при
такой стратеrии нейрон с наибольшим суммарным входным сиrналом "побеждает"
в соревновании и переходит в активное состояние. При этом все остальные нейро
ны отключаются.
Различные алrоритмы обучения без учителя описываются в rлавах 8 и 11.
2.10. Задачи обучения
В предьщущих разделах описывались различные алroритмы и парадиrмы обучения.
В данном разделе рассматривается ряд задач обучения. Выбор KOHKpeTHoro алroритма
обучения зависит от задач, решению которых следует обучить нейронную сеть. В этом
контексте можно выделить шесть основных задач, для решения которых в том или
ином виде применяются нейронные сети.
Ассоциативная память
Ассоциативная память (associative memory) представляет собой распределенную па
мять, которая обучается на основе ассоциаций, подобно мозry живых существ. Acco
циативность считается основной характерной чертой человеческоrо мозrа со времен
Аристотеля, вследствие чеrо все модели познания в качестве одной из основных
операций в той или иной форме используют ассоциативную память [46].
Существуют два типа ассоциативной памяти: автоассоциативная (autoassociation)
и 2етероассоциативная (heteroassociation). При решении задачи автоассоциативной
памяти в нейронной сети запоминаются передаваемые ей образы (векторы). Затем
в эту сеть последовательно подаются неполные описания или зашумленные пред
ставления хранимых в памяти исходных образов, и ставится задача распознавания
KOHкpeTHoro образа. rетероассоциативная память отличается от автоассоциативной
тем, что произвольному набору входных образов ставится в соответствие дрyrой
ПРОИЗВОJlЬНЫЙ набор выходных сиrналов. Для настройки нейронных сетей, предна
112 rлава 2. Процессы обучения
Входной вектор
х
Выходной
вектор
у
Рис. 2.9. Диаrрамма "BXOД BЫXOД" для сети ac
социации образов
значенных для решения задач авто ассоциативной памяти, используется обучение без
учителя, а в сетях rетероассоциативной памяти обучение с учителем.
Пусть Xk ключевой образ (key pattem) (вектор), применяемый для решения за
дачи ассоциативной памяти, а Yk запомненный образ (memorized pattem) (вектор).
Отношение ассоциации образов, реализуемое такой сетью, можно описать следую
щим образом:
Xk Yk,k == 1,2,... ,q,
(2.18)
[де q количество хранимых в сети образов. Ключевой образ Xk выступает в роли
стимула, который не только определяет местоположение запомненноro образа У k, но
и содержит ключ для ero извлечения.
В автоассоциативной памяти Yk ==Xk' Это значит, что пространства входных и BЫ
ходных данных сети должны иметь одинаковую размерность. В rетероассоциативной
памяти Yk o:j:Xk. Это значит, что размерность пространства выходных векторов может
отличаться от размерности пространства входных (но может и совпадать с ней).
В работе ассоциативной памяти можно выделить две фазы.
· Фаза запоминания (storage phase), которая соответствует процессу обучения сети
в соответствии с формулой (2.18).
· Фаза восстановления (recall phase), соответствующая извлечению запомненно
[о образа в ответ на представление в сеть зашумленной или искаженной Bep
сии ключа.
Пусть стимул (входной сиrнал) Х представляет собой зашумленную или искажен
ную версию ключевоro образа Xj. Этот стимул вызывает отклик (выходной сиrнал) У
(рис. 2.9). В идеальном случае у == Yj' rдe Yj запомненный образ, ассоциируемый с
ключом Xj. Если при Х == Xj выход сети у o:j: Yj' то roворят, что ассоциативная память
при восстановлении образа сделала ошибку (error).
Количество q образов, хранимых в ассоциативной памяти, является непосред
ственной мерой емкости памяти (storage capacity) сети. При построении ассоциа
тивной памяти желательно максимально увеличить ее емкость (информационная eM
кость ассоциативной памяти измеряется в процентах от общеrо количества нейронов
N, использованных для создания сети) и убедиться, что большая часть запомненных
образов восстанавливается корректно.
2.10. Задачи обучения 113
Распознавание образов
Человеческий мозr хорошо приспособлен для распознавания образов. Мы получаем
данные из окружающеrо мира через сенсоры и способны распознать источник дaн
ных. Чаще Bcero это выполняется MrHoBeHHo и без всяких усилий. Например, мы
можем узнать знакомое лицо, даже если наш знакомый с момента последней Bcтpe
чи сильно постарел. Человек может узнать знакомый roлос по телефону, несмотря
на помехи в линии связи. Мы можем по запаху отличить свежее яйцо от тухлоro.
Человек распознает образы в результате процесса обучения. То же происходит и с
нейронными сетями.
Распознавание образов формально определяется как процесс, в котором получа
емый образ/си2Нал должен быть отнесен к одному из предопределенных классов
(кате20рий). Чтобы нейронная сеть моrла решать задачи распознавания образов, ее
сначала необходимо обучить, подавая последовательность входных образов наряду с
катеroриями, которым эти образы принадлежат. После обучения сети на вход подается
ранее не виденный образ, который принадлежит тому же набору катеroрий, что и MHO
жество образов, использованных при обучении. Блаroдаря информации, выделенной
из данных обучения, сеть сможет отнести представленный образ к конкретному клас
су. Распознавание образов, выполняемое нейронной сетью, является по своей природе
статистическим. При этом образы представляются отдельными точками в MHoroMep
ном пространстве решений. Все пространство решений разделяется на отдельные
области, каждая из которых ассоциируется с определенным классом. rраницы этих
областей как раз и формируются в процессе обучения. Построение этих rpаниц BЫ
полняется статистически на основе дисперсии, присущей данным отдельных классов.
В целом машины распознавания образов, созданные на основе нейронных сетей,
можно разделить на два типа.
. Система состоит из двух частей: сети извлечения признаков (future extraction) (без
учителя) и сети классификации (classification) (с учителем) (рис. 2.10, а). Такой Me
тод соответствует традиционному подходу к статистическому распознаванию об
разов [269], [322]. В концептуальных терминах образ представляется как набор из
m наблюдений, каждое из которых можно рассматривать как точку х в т MepHOM
пространстве наблюдений (данных) (observation (data) space). Извлечение призна
ков описывается с помощью преобразования, которое переводит точку х в проме
жуточную точку У в q MepHoM пространстве признаков, rдe q < m (рис. 2.1 О, 6).
Это преобразование можно рассматривать как операцию снижения размерности
(т.е. сжатие данных), упрощающую задачу классификации. Сама классификация
описывается как преобразование, которое отображает промежуточную точку у в
один из классов r MepHoro пространства решений (rдe r количество выделяемых
классов ).
....
114 rлава 2. Процессы обучения
Входной образ
х
Вектор
Сеть, обучаемая признаков у С б
без учителя, еть, о учаемая
для извлечения с учителем, для
признаков классификации
1
2
r
а)
Пространство
наблюдения
размерности т
Пространство
признаков
размерности q
Пространство
решений
размерности r
Рис. 2.10. Иллюстрация клас-
сическою подхода к распозна
ванию образов
б)
· Система проектируется как единая мноroслойная сеть прямоrо распространения,
использующая один из алrоритмов обучения с учителем. При этом подходе задача
извлечения признаков выполняется вычислительными узлами cKpbIТOro слоя сети.
Какой из этих двух подходов применять на практике зависит от конкретной
предметной области.
Аппроксимация функций
Третьей задачей обучения является аппроксимация функций. Рассмотрим нелинейное
отображение типа "BXOД BЫXOД", заданное следующим соотношением:
d == f(x),
(2.19)
[де вектор х вход, а вектор d выход. Векторная функция f(.) считается неиз
вестной. Чтобы восполнить пробел в знаниях о функции f(.), нам предоставляется
множество маркированных примеров:
т == {(Xi' d i ) } 1'
(2.20)
2.10. Задачи обучения 115
Входной вектор
Х.
I
d
I
Рис. 2.11. Блочная диаrрамма реше
ния задачи идентификации системы
к структуре нейронной сети, аппроксимирующей неизвестную функцию f(-),
предъявляется следующее требование: функция F(-), описывающая отображение
входноro сиrнала в выходной, должна быть достаточно близка к функции f(.) в
смысле Евклидовой нормы на множестве всех входных векторов х, Т.е.
IIF(x) f(x)11 < Е для всех векторов х,
(2.21 )
rдe Е некоторое малое положительное число. Если количество N элементов обуча
ющеro множества достаточно велико и в сети имеется достаточное число свободных
параметров, то ошибку аппроксимации Е можно сделать достаточно малой.
Описанная задача аппроксимации является отличным примером задачи для обуче
ния с учителем. Здесь Xi иrpает роль входноro вектора, а d i роль желаемоro отклика.
Исходя из этоrо, задачу обучения с учителем можно свести к задаче аппроксимации.
Способность нейронной сети аппроксимировать неизвестно е отображение BXOД
HOro пространства в выходное можно использовать для решения следующих задач.
. Идентификация систем (system identification). Пусть формула (2.19) описывает
соотношение между входом и выходом в неизвестной системе с несколькими BXO
дами и выходами (МIМО системе) без памяти. Термин "без памяти" подразумевает
инвариантность системы во времени. Тоrда множество маркированных примеров
(2.20) можно использовать для обучения нейронной сети, представляющей MO
дель этой системы. Пусть Yi выход нейронной сети, соответствующий входному
вектору Xi' Разность между желаемым откликом d i и выходом сети Yi составляет
вектор сиrнала ошибки ei (рис. 2.11), используемый для корректировки свободных
параметров сети с целью минимизации среднеквадратической ошибки суммы
квадратов разностей между выходами неизвестной системы и нейронной сети в
статистическом смысле (т.е. вычисляемой на множестве всех примеров).
.......
116 rлава 2. Процессы обучения
Входной вектор
Х.
I
Выход
системы
d
I
Ошибка
е.
,
Х.
I
f(.)
Рис. 2.12. Блочная диаrрамма моделирования инверсной системы
· Инверсные системы (inverse system). Предположим, что существует некая система
MIMO без памяти, для которой преобразование входноro пространства в выходное
описывается соотношением (2.19). Требуется построить инверсную систему, KOTO
рая в ответ на вектор d rенерирует отклик в виде вектора Х. Инверсную систему
можно описать следующим образом:
Х == r 1 (d),
(2.22)
[де вектор функция f l (-) является инверсной к функции f(-). Обратим внимание,
что функция f l(.) не является обратной к функции f(.). Здесь верхний индекс 1
используется только как индикатор инверсии. Во мноrих ситуациях на практике
функция f(.) может быть достаточно сложной, что делает практически невозмож
ным формальный вывод обратной функции f 1 (-) . Однако на основе множества
маркированных примеров (2.20) можно построить нейронную сеть, аппроксими
рующую обратную функцию f l(.) с помощью схемы, изображенной на рис. 2.12.
В данной ситуации роли векторов Xi и d i меняются: вектор d i используется как
входной сиrнал, а вектор Xi как желаемый отклик. Пусть вектор сиrнала ошиб
ки определяется как разность между вектором Xi и выходом нейронной сети Yi,
полученным в ответ на возмущение d i . Как и в задаче идентификации системы,
вектор сиrнала ошибки используется для корректировки свободных параметров
нейронной сети с целью минимизации суммы квадратов разностей между BЫXO
дами неизвестной инверсной системы и нейронной сети в статистическом смысле
(т.е. вычисляемой на всем множестве примеров обучения).
Управление
Управление предприятием (plant) является еще одной задачей обучения, которую
можно решать с использованием нейронной сети. Здесь под термином "предприя
тие" понимается процесс или критическая часть системы, подлежащие управлению.
Ассоциация между управлением и обучением вряд ли коrо нибудь удивит, так как
человеческий мозr является компьютером (обработчиком информации), выходами KO
2.10. Задачи обучения 117
Эталонный
сиrнал
d
Вход
объекта
u
Выход объекта
Контроллер
Объект
у
Единая обратная связь
Рис. 2.1 З. Блочная диаrрамма системы управления с обратной связью
тoporo, как системы в целом, являются действия. В контексте задач управления сам
мозr является живым доказательством возможности создания обобщенной системы
управления, использующей преимущества параллельных распределенных вычисле
ний и одновременно управляющей тысячами функциональных механизмов. Такая
система является нелинейной, может обрабатывать шумы и оптимизировать свою
работу в ракурсе долroсрочноrо планирования [1125].
Рассмотрим систему управления с обратной связью (feedback control system), по
казанную на рис. 2.13. В этой системе используется единственная обратная связь,
охватывающая весь объект управления (т.е. выход объекта связан с ero входом)9.
Таким образом, выход объекта управления у вычитается из эталОННО20 си2нала (re
ference signal) d, принимаемоro из внешнеro источника. Полученный таким образом
сиrнал ошибки е подается на нейроконтроллер (neurocontroller) для настройки CBO
бодных параметров. Основной задачей контроллера является поддержание TaKoro
входноro вектора объекта, для Koтoporo выходной сиrнал у соответствует эталон
ному значению d. Друrими словами, в задачу контроллера входит инвертирование
отображения BXOД BЫXOД объекта управления.
Заметим, что на рис. 2.13 сиrнал ошибки е распространяется через нейрокон
троллер, прежде чем достиrнет объекта управления. Следовательно, для настройки
свободных параметров объекта управления в соответствии с алroритмом обучения на
основе коррекции ошибок необходимо знать матрицу Якобиана:
J == { a Yk } ,
дщ
(2.23)
rдe Yk элемент выходноro сиrнала у объекта управления; Uj элемент вектора
входов объекта и. К сожалению, частные производные ду kJдщ для различных k и j
9 Выходной сиrнал объекта обычно является некоторой физической переменной. Для управления объектом
необходимо знать значение ЭТОЙ переменной, а значит, необходимо измерять выходной сиrнал объекта. Система,
используемая для измерения физических величин, называется датчиком, или сенсором. Таким образом, чтобы
быть предельно точными, блочная диаrpамма на рис. 2.13 должна содержать сенсор в цепи обратной связи. Мы
опустили использование сенсора, считая, что передаточная функция сенсора тождественно равна единичной.
'81'
118 rлава 2. Процессы обучения
зависят от рабочей точки объекта управления и, следовательно, не известны. Для их
оценки можно использовать два следующих подхода.
· НеnрЯJИое обучение (indirect lea.rning). С использованием текущих измерений входа
и выхода объекта управления строится модель нейронной сети, воспроизводящая
эту зависимость. Эта модель, в свою очередь, используется для оценки матри
цы Якобиана J. Частные производные, составляющие эту матрицу, впоследствии
используются в алroритме обучения на основе коррекции ошибки для настройки
свободных параметров нейроконтроллера [782], [1037], [1145].
· ПрЯJИое обучение (direct leaming). Знаки частных производных ду k / дщ в общем
случае известны и обычно остаются постоянными в некотором динамическом диа
пазоне значений объекта управления. Это наводит на мысль, что частные произ
водные можно аппроксимировать по их знакам. Абсолютные значения частных
производных задаются распределенным представлением в свободных параметрах
нейроконтроллера [923], [942]. Таким образом, свободные параметры нейрокон
троллера можно настроить непосредственно с помощью объекта управления.
Фильтрация
Под термином фильтр (filter) обычно понимают устройство или алroритм, исполь
зуемые для извлечения полезной информации из набора зашумленных данных. Шум
может возникать по мноrим причинам. Например, данные MOryT быть измерены с по
мехами, или возмущения MOryT возникнуть при передаче информационноro сиrнала
через зашумленные линии связи. Кроме TOro, на полезный сиrнал может быть нало
жен друroй сиrнал, поступающий из окружающей среды. Фильтры можно применять
для решения трех основных задач обработки информации.
1. Фильтрация (filtering), Т.е. извлечение полезной информации в дискретные MOMeH
ты времени n из данных, измеренных вплоть до момента времени n включительно.
2. С2Лаживание (smoothing). Эта задача отличается от фильтрации тем, что информа
ция о полезном сиrнале в момент времени n не требуется, поэтому для извлечения
этой информации можно использовать данные, полученные позже. Это значит, что
в сrлаживании при формировании результата присутствует запаздывание (delay).
Так как при сrлаживании можно использовать данные, полученные не только до
момента времени N, но и после Hero, этот процесс в статистическом смысле яв
ляется более точным, чем фильтрация.
3. ПРО2нозuрование (prediction). Целью этоro процесса является получение проrноза
t>'ТВ.t> m nыю состояния о'Оъекта управления в некоторым момент времени n + ПО,
[де ПО > О, на основе данных, полученных до момента n (включительно).
'"'
2.10. Задачи обучения 119
Рис. 2.14. Блочная диаrрам
ма слепоro разделения ис
точников
I
1 1
I и 1 (п)
I
I uZ<п)
I
I
I
I иm(п)
I
x1(п)
Неизвестный
преобразователь
А
xz<п)
Обратный
преобразователь
W
Yl(п)
У2(п)
хm(п)
уm(п)
Неизвестная среда
Задачей фильтрации, с которой знакомы практически все, является задача pac
познавания 20лоса собеседника на .шумной вечеринке 1О (cocktail party problem). Мы
обладаем способностью сконцентрироваться на roлосе собеседника, несмотря на
разноrолосый шум, доносящийся от rpупп посетителей вечеринки, слова которых
мы не различаем. Вероятно, для решения этой задачи используется не которая фор
ма предсознательноro и преаттентивноro анализа [1090]. В контексте (искусственной)
нейронной сети аналоrичная задача фильтрации возникает при слепом разделении cи2
нала (blind signal separation) [37], [116], [205]. Чтобы сформулировать задачу слепоrо
разделения сиrнала, представим себе неизвестный источник независимых сиrналов
{ Si (n) } :1' Эти сиrналы линейно смешиваются неизвестным сенсором, в результате
чеrо получается вектор наблюдения размерности т х 1 (рис. 2.14):
х(n) == Au(n),
(2.24)
rдe
u(n) == [и1 (n), и2(n),'" , ит(n)]Т,
х(n) == [Х1(n)' Х2(n),"" хт(n)]Т,
(2.25)
(2.26)
[де А неизвестная несинryлярная матрица смешивания размерности т х
т. Вектор наблюдения х( n) известен. Требуется восстановить исходный сиrнал
и1 (n ), и2 (n ), . . . , и т (n) методом обучения без учителя.
10 Так называемый "феномен вечеринки" (cocktail party phenomenon) связан с уникальной способностью
человека нзбирательно отфильтровывать нужные ему источннки звуковоro сиrнала в зашумленной среде [188],
[189]. Эта способность обеспечнвается комбннацией трех процессов, выполняемых слуховым аппаратом.
Сеzменmацuя. Входной звуковой сиrнал сеrментируется на отдельные каналы, несущне значнмую для слу-
шателя ннформацию об окружающей среде. Среди эвристик, используемых слушателем при сеrментации cHr
нала, самой важной является пространственное расположенне местоположения объекта (spatiallocation) [753].
BHuмaHиe. Это способность слушателя фокусировать внимание на одном из каналов прн одновременной
блокировке вннмання к друrим каналам [188].
Переключенuе. Способность переключать внимание с одноro канала на дрyroй, что обычно обеспечивается
за счет открытня закрытия шлюзов каналов входноro звуковоro сиrнала по принципу "сверху вниз" [1165].
Из этоro можно сделать вывод, что обработка звуковоro сиrнала носит просmрансmвенно вре.менной
характер.
,...
120 rлава 2. Процессы обучения
х(п)
х(п -1)
х(п 21)
Нейронная
сеть
х(п)
Рис. 2.15. Блочная диаrрамма нелиней-
Horo проrнозирования
х(п -т 1)
Вернемся к задаче проrнозирования, в которой требовалось предсказать текущее
значение процесса х(n) по предшествующей информации об этом процессе, сня
той в дискретные моменты времени и представленной значениями х(n Т), х(n
2Т),... , х(n тТ), rдe Т периодичность снятия сиrнала, а m порядок про
rнозирования. Задача проrнозирования может быть решена с помощью обучения на
основе коррекций ошибок без учителя, так как обучающие примеры получаются
непосредственно от caMoro процесс а (рис. 2.15). При этом х(n) выступает в роли
желаемоro отклика. Обозначим х (n) результат проrнозирования на один шаr вперед,
сrенерированный нейронной сетью в момент времени n. Сиrнал ошибки определя
ется как разность между х(n) и х(n). Он используется для настройки свободных
параметров нейронной сети. При этих допущениях проrнозирование можно paCCMaT
ривать как форму построения модели (model building) в том смысле, что чем меньше
ошибка проrнозирования в статистическом смысле, тем лучше нейронная сеть будет
работать в качестве модели имитируемоrо физическоrо процесса, обеспечивающеrо
rенерацию данных. Если этот процесс является нелинейным, нейронная сеть является
мощным средством решения задачи проrнозирования, так как нелинейная обработка
сиrнала предполаrается самой архитектурой нейронной сети. Единственное исклю
чение составляет выходной слой нейронов: если динамический диапазон BpeMeHHoro
ряда {х(n)} не известен, в выходном слое целесообразно использовать линейные
обрабатывающие элементы.
Формирование диаrраммы направленности
Формирование диаrpаммы направленности является пpocтpaHcтвeHиы.M (spatial) слу
чаем фильтрации и используется для разделения пространственных признаков полез
Horo сиrнала и шумов. Для формирования диаrpаммы направленности используется
специальное устройство.
Задачу формирования диаrpаммы направленности целесообразно решать с ис
пользованием нейронных сетей, созданных на основе знаний о строении слуховоrо
аппарата человека [151] и решении задач эхо локации в корковых слоях системы слу
ха летуш й мыши [994], [1026]. Система эхо локации летучей мыши отфильтровывает
влияние окружающей среды. Мышь испускает короткие ультразвуковые сиrналы с ча
2.10. Задачи обучения 121
U1(п)
и 2 (п)
ит(п)
Матрица х(п)
блокировки
сиrнала
Са
Выходной сиrнал
у(п)
Рис. 2.16. Блочная диаrрамма обобщенной системы подавления боковых
лепестков
стотной модуляцией, а затем улавливает отраженные сиrналы с помощью слуховOJ О
аппарата (пары ушей), фокусируя внимание на потенциальной добыче (насекомых).
Уши летучей мыши выполняют некоторый вид пространственной фильтрации (а точ
нее, интерферометрии), результаты которой используются слуховой системой для из
влечения сиrнала, содержащеro интересующий класс объектов (attentional selectivity).
Построение диаrpаммы направленности, как правило, выполняется в системах
радаров, [де задача сводится к отслеживанию траектории цели в условиях помех
и интерференции (т.е. наложения сиrналов друr на друrа). Эта задача усложняется
двумя следующими факторами.
· Полезный сиrнал формируется в неизвестном направлении.
· Не существует априорной информации о наложении сиrналов в результате интср
ференции.
Одним из способов решения проблем TaKoro рода является подавление боковых
лепестков. Блочная диаrpамма устройства, позволяющеrо решать такую задачу, пока
зана на рис. 2.16. Эта система состоит из следующих компонентов [386], [434], [1083].
· Массив антенных элементов (array of antenna elements), который снимает сиrналы
в дискретных точках пространства.
· Линейный сумматор (linear combiner), определяемый множеством фиксированных
весов {Wi} Z:u на выходе KOToporo формируется желаемый отклик. Работа это
[о линейноrо сумматора подобна пространственному фильтру, характеризуемому
диаrpаммой излучения (т.е. rpафиком амплитуды выходноro сиrнала антенны в за
висимости от уrла поступающеrо сиrнала в полярных координатах). rлавный лепе
......
122 rлава 2. Процессы обучения
сток этой диаrpаммы излучения определяет направление, для KOToporo обобщенная
система подавления боковых лепестков выдает неискаженный отклик. Выход это
[о линейноro сумматора, обозначенный d( n ), как раз и обеспечивает желаемый
отклик обобщенной системы подавления боковых лепестков.
. Матрица блокировки си2нала (signal blocking matrix) Са, функцией которой яв
ляется блокировка влияния сторонних сиrналов, которые просачиваются через
боковые лепестки диаrpаммы излучения пространственноro фильтра, представля
ющеrо линейный сумматор.
. Нейронная сеть с настраиваемыми параметрами, предназначенная для адаптации
к статистическим вариациям сторонних сиrналов.
Настройка свободных параметров нейронной сети выполняется с помощью ал
roритма обучения на основе коррекции ошибки, определяемой как разность между
выходом линейноrо сумматора d(n) и фактическим выходным сиrналом у(n) ней
ронной сети. Таким образом, обобщенная система подавления боковых лепестков
GSLC (generalized sidelobe canceller) работает под управлением линейноro CYMMaTO
ра, выполняющеro роль учителя. Как и при обычном обучении с учителем, линей
ный сумматор находится вне контура обратной связи нейронной сети. Обобщенная
система подавления боковых лепестков, для обучения которой используется нейрон
ная сеть, называется нейросетевой системой подавления боковых лепестков (neuro
beamforrner). Этот класс обучаемых машин получил общее название нейрокомпьюте
ров, предназначенных для настройки внимания [447].
Разнообразие представленных здесь шести задач обучения еще раз свидетель
ствует в пользу универсальности нейронных сетей как систем обработки инфор
мации. В фундаментальном смысле все эти задачи являются проблемами обучения
построению отображений на основе примеров (иноrда зашумленных). При OTCYТ
ствии априорных знаний все эти задачи являются плохо обусловленными (ill posed),
Т.е. их возможные решения определяются неоднозначно. Одним из способов обес
печения хорошей обусловленности (well pose) решений является применение теории
реrуляризации, которая описывается в rлаве 5.
2.11. Память
Обсуждение задач обучения, особенно задачи ассоциативной памяти, заставляет за
думаться о самой памяти (memory). В контексте нейробиолоrии под памятью пони
мается относительно продолжительная во времени деформация структуры нейронов,
вызванная влиянием на орrанизм внешней среды [1051]. Без такой деформации па
мять не существует. Чтобы память была полезной, она должна быть доступной для
нервной системы. Только Torдa она может влиять на будущее поведение орrанизма.
2.11. Память 123
Однако для этоrо в памяти предварительно должны быть накоплены определенные
модели поведения. Это накопление осуществляется с помощью процесса обучения
(1eaming process). Память и обучение тесно взаимосвязаны. При изучении HeKoToporo
образа он сохраняется в структуре мозrа, откуда может быть впоследствии извлечен
в случае необходимости. Формально память можно разделить на кратковременную
и долroвременную, в зависимости от сроков возможноrо хранения информации [66].
Кратковременная память является отображением текущеro состояния окружающей
среды. Каждое "новое" состояние среды, отличное от образа, содержащеrося в KpaT
ковременной памяти, приводит к обновлению данных в памяти. С друrой стороны,
в дОЛ20временной памяти хранятся знания, предназначенные для продолжительноro
(или даже постоянноro) использования.
В этом разделе рассматриваются вопросы ассоциативной памяти, которая xapaK
теризуется следующими особенностями.
· Эта память является распределенной.
· Стимулы (ключи) и отклики (хранимые образы) ассоциативной памяти представ
ляют собой векторы данных.
· Информация запоминается с помощью формирования пространственных образов
нейросетевой активности на большом количестве нейронов.
· Информация, содержащаяся в стимуле, определяет не только место ее запомина
ния, но и адрес для ее извлечения.
· Несмотря на то что нейроны не являются надежными вычислительными элемен
тами и работают в условиях шума, память обладает высокой устойчивостью к
помехам и искажению данных.
· Между отдельными образами, хранимыми в памяти, MOryт существовать BHyтpeH
ние взаимосвязи. (В противном случае размер памяти должен быть невероятно
велик, чтобы вместить все отдельные изолированные образы.) Отсюда и происте
кает вероятность ошибок при извлечении информации из памяти.
В распределенной памяти (distributed memory) rлавный интерес представляет oд
новременное или почти параллельное функционирование множества различных ней
ронов при обработке внутренних или внешних стимулов. Нейронная активность фор
мирует в памяти пространственные образы, содержащие информацию о стимулах.
Таким образом, память выполняет распределенное отображение образов в простран
стве входных сиrналов в друrие образы выходноro пространства. Некоторые важные
свойства отображения распределенной памяти можно про иллюстрировать на примере
идеализированной нейросети, состоящей из двух слоев нейронов. На рис. 2.17, а пока
зана сеть, которую можно рассматривать как модельный компонент нервной системы
(model component ofnervous system) [210], [953]. Все нейроны входноrо слоя соедине
ны со всеми нейронами выходноro. В реальных системах синаптические связи между
....
124 rлава 2. Процессы обучения
2
т
Входной Синаптические Выходной
слой нейронов соединения слой нейронов
а) Компонент модели ассоциативной
памяти нервной системы
X k1
X k2
X km
Входной слой
узлов источника
Выходной
слой нейронов
б) Модель ассоциативной памяти
с искусственными нейронами
Ykl
Yk2
Ykm
Рис. 2.17. Модели ассоциативной памяти
нейронами являются сложными и избыточными. В модели, показанной на рис. 2.17, а,
для представления общеrо результата от всех синаптических контактов между дeHД
ритами нейронов входноrо слоя и ответвлениями аксонов нейронов выходноrо слоя
использовались идеальные соединения. Уровень активности нейрона входноrо слоя
может оказывать влияние на степень активности любоrо нейрона выходноrо слоя.
Аналоrичная ситуация для искусственной нейронной сети показана на рис. 2.17, б.
В данном случае узлы источника из входноro слоя и нейроны выходноrо слоя рабо
тают как вычислительные элементы. Синаптические веса интеrpированы в нейроны
выходноrо слоя. Связи между двумя слоями сети представляют собой простые "про
волочные" соединения.
В нижеследующих математических выкладках нейронные сети, изображенные на
рис. 2.17, считаются линейными. В результате этоro предположения все нейроны pac
сматриваются как линейные сумматоры, что и показано на rpафе передачи сиrнала
(рис. 2.18). Для дальнейшеrо анализа предположим, что во входной слой передается
образ Xk, при этом В выходном слое возникает образ Yk. Рассмотрим вопрос обуче
2.11. Память 125
X k1
Yki
X k2
Рис. 2.18. rраф передачи Gиrнала для i ro линейноrо
нейрона
X km
ния на основе ассоциации между образами Xk и Yk. Образы Xk и Yk представлены
векторами, развернутая форма которых имеет следующий вид:
Xk(n) == [хн (n), Xk2(n)' . .. ,Xkm (n)?,
Yk(n) == [ун(n), Yk2(n),"" Ykm(n)]T.
Для удобства представления предположим, что размерности пространств входных
и выходных векторов совпадают и равны т, Т.е. размерности векторов Xk и Yk оди
наковы. Исходя из этоrо, значение т будем называть размерностью сети (network
dimensionality), или просто размерностью. Заметим, что значение т равно количе
ству узлов источника во входном слое и числу вычислительных нейронов выходноrо
слоя. В реальных нейронных сетях размерность т может быть достаточно большой.
Элементы векторов Xk и Yk MorYT принимать как положительные, так и отри
цательные значения. В искусственных нейронных сетях такое допущение является
естественным. Такая ситуация характерна и для нервной системы, если рассматри
вать переменную, равную разности между фактическим уровнем активности (т.е. CTe
пенью возбуждения нейрона) и произвольным ненулевым уровнем активности.
Учитывая линейность сети, показанной на рис. 2.17, ассоциацию между ключевым
вектором Xk и запомненным вектором Yk можно представить в матричном виде:
Yk == W(k)Xk , k==l, 2, . .., q,
(2.27)
[де W(k) матрица весов, определяемая парами "BXOД BЫXOД" (Xk, Yk)'
Чтобы детально описать матрицу весовых коэффициентов W(k), обратимся к
рис. 2.18, на котором представлена схема i ro нейрона выходноrо слоя. Выход Yik
этоrо нейрона вычисляется как взвешенная сумма элементов ключевоrо образа Xk по
следующей формуле:
m
Yki == I:: Wij(k) Xkj, i == 1, 2, ..., т,
j l
(2.28)
...........
126 rлава 2. Процессы обучения
[де Wij (k), j == 1, 2, . . . , m синаптические веса нейрона i, соответствующие k й
паре ассоциированных образов. Используя матричное представление, элемент Yki
можно записать в эквивалентном виде:
Yki == [Щ1(k), Щ2(k),
[ Хн ]
.. ., Щm(k)] .k
Xkm
, i == 1, 2, ..., т.
(2.29)
Вектор столбец в правой части равенства (2.29) представляет собой ключевой
вектор Xk' Подставляя выражение (2.29) в определение запоминаемоrо вектора Yk
размерности m х 1, получим:
[ Ун ]
Yk2
Ykm
[ Wll(k) W12(k) ... w1m(k) ] [ Хн ]
W21(k) W22(k) ... w2m(k) Xk2
l(k) 2(k) ::: m(k) 'k
(2.30)
Соотношение (2.30) описывает матричное преобразование (или отображение)
(2.27) в развернутом виде. В частности, матрица W(k) размерности m х m опре
деляется в виде
W(k) ==
[ Wll(k) W12(k) ... w1m(k) ]
W21(k) W22(k) '" w2m(k)
w m 1(k) w m 2(k) ... wmm(k)
(2.31 )
Отдельные представления q пар ассоциированных образов Xk ""'"'"'"*Yk, k == 1,2, . . . , q
формируют значения элементов отдельных матриц W(I), W(2), ..., W(q). Учитывая
тот факт, что эта ассоциация образов представляется матрицей весов W(k), матрицу
памяти (memory matrix) размерности m х m можно определить как сумму матриц
весовых коэффициентов Bcero набора ассоциаций:
q
м == I:W(k).
k l
(2.32)
Матрица М определяет связи между входным и выходным слоями ассоциатив
ной памяти. Она представляет опыт (experience), накопленный в результате подачи q
образов, представленных в виде пар "BXOД BЫXOД". Друrими словами, в матрице М co
держатся данные обо всех парах "BXOД BЫXOД", представленных для записи в память.
2.11. Память 127
Описание матрицы памяти (2.32) можно представить в рекурсивной форме
M k == Mk l + W(k), k == 1,2,... , q,
(2.33)
[де исходная матрица Мо является нулевой (т.е. все синаптические веса памяти из
начально равны нулю), а окончательная матрица Мч совпадает с матрицей М, опре
деленной выражением (2.32). В соответствии с рекурсивной формулой (2.33) под
обозначением Mk l понимается матрица, полученная на k + 1 шаrе ассоциации, а
под M k понимается обновленная матрица, полученная в результате добавления прира
щения W(k), полученноrо на основе k й пары векторов. При этом следует заметить,
что при добавлении к матрице Mk l приращение W(k) теряет свою идентичность в
сумме комбинаций, формирующих матрицу М. Заметим, что при увеличении числа
q хранимых образов влияние каждоro из них на состояние памяти ослабляется.
Память в виде матрицы корреляции
Предположим, что ассоциативная память (см. рис. 2.17, б) бьта обучена на парах
векторов входноrо и выходноrо сиrналов Xk """"'* Yk, В результате чеrо бьта вычис
лена матрица памяти М. Для оценки матрицы М введем обозначение 1\1:, которое в
терминах запоминаемых образов описывается выражением [50], [210]
q
л " т
М == YkXk'
k l
(2.34)
Под обозначением YkxI понимается внешнее (матричное) произведение (outer
product) ключевоro Xk и запомненноrо Yk образов. Это про изведение является oцeH
кой матрицы весов W(k), которая отображает выходной вектор Yk на входной вектор
Xk' Так как векторы Yk и Xk, соrласно допущению, имеют одинаковые размерности,
равные m х 1, матрица оценки 1\1: будет иметь размерность m х т. Это отлично co
rласуется с размерностью матрицы М, определенной выражением (2.32). Сумма в
определении оценки матрицы М имеет прямое отношение к матрице памяти, опре
деленной соотношением (2.32).
Элемент внешнеrо произведения YkxI обозначим YkiXkj, [де Xkj выходной сиr
нал узла j входноrо слоя, а Yki значение нейрона i выходноrо слоя. В контексте
сина.птическоrо веса Wij(k) для k й ассоциации узел источника j выступает в роли
предсинаптическоrо узла, а нейрон i в качестве постсина.птическоro узла. Таким
образом, "локальный" процесс обучения, описанный выражением (2.34), можно pac
сматривать как обобщение постулата обученияХебба (generalization ofHebb's postu
late of leaming). Ero также называют правилом внешне20 (матриЧНО20) произведения
(outer product rule), поскольку для построения оценки 1\1: используются матричные
операции. Построенная таким образом матрица памяти 1\1: называется памятью в
128 rлава 2. Процессы обучения
х Т
k
Y k
Рис. 2.19. Представление выражения
(2.38) в виде rрафа передачи сиrнала
виде матрицы корреляции (correlation matrix memory). Корреляция, в той или иной
форме, является основой процесса обучения, распознавания ассоциаций и образов, а
также извлечения данных из памяти в нервной системе человека [279].
Выражение (2.34) можно переписать в следующей эквивалентной форме:
[ Х Т ]
1
Т
л Х 2 Т
M [у" у" ..., У,] i УХ ,
(2.35)
[де
х == [Х1' Х2,
У == [У1' У2'
... ,
Х ч ] ,
УЧ] .
(2.36)
(2.37)
." ,
Матрица Х имеет размерность m х q и состоит из Bcero множества ключевых обра
зов, использованных в процессе обучения. Она получила название матрицы ключей
(key matrix). Матрица У имеет размерность m х q и составлена из соответствующеrо
множества запомненных образов. Она называется матрицей запоминания (memorized
matrix).
Выражение (2.35) можно также записать в рекурсивной форме:
л л Т
Mk==Mk l+YkXk' k== 1,2, ..., q.
(2.38)
[раф передачи сиrнала для этоrо выражения показан на рис. 2.19. Соrласно ему и
рекурсивной формуле (2.38), матрица Mk l представляет собой существующую oцeH
ку матрицы памяти, а матрица M k ее обновленную оценку в свете новой ассоциации
между образами Xk и Yk. Сравнивая рекурсию в формулах (2.33) и (2.38), несложно
заметить, что внешнее произведение У kXr представляет собой оценку матрицы весов
W(k), соответствующую k й ассоциации ключевоrо и запомненноrо образов Xk и Yk.
2.11. Память 129
Извлечение из памяти
Фундаментальными задачами, возникающими при использовании ассоциативной па
мяти, являются ее адресация и извлечение запомненных образов. Для Toro чтобы
объяснить первый аспект этой задачи, обозначим через 1\1: матрицу ассоциативной
памяти, прошедшей полное обучение на q ассоциациях соrласно выражению (2.34).
Пусть на вход системы ассоциативной памяти подается случайный вектор возбужде
ния Xj, для KOTOpOro требуется получить вектор отклика (response):
У == MXj.
(2.39)
Подставляя выражение (2.34) в (2.39), получим:
m
m
У == L YkXr Xj == L (xr Xj)Yk'
k l k l
(2.40)
rдe xr Xj скалярное проuзведение Xk и Xj' Выражение (2.40) можно переписать
в виде
m
y==(xJXj)Yj+ L (XrXj)Yk'
k l,kf-j
(2.41 )
Пусть ключевые образы нормализованы, Т.е. имеют единичную длину (или энерrию):
m
Ek == L Xkl == xr Xk == 1, k == 1,2,' . . q.
1 1
(2.42)
Torдa отклик памяти на возбудитель (ключевой образ) Xj можно упростить следу
ющим образом:
У == Yj + Vj,
(2.43)
rдe
m
Vj == L (Xr Xj )Yk'
k l,kf-j
(2.44)
Первое слаrаемое в правой части выражения (2.43) представляет собой ожидаемый
отклик Yj. Таким образом, ero можно трактовать как "сиrнальную" составляющую
фактическоrо отклика у. Второй вектор Vj в правой части этоrо выражения пред
ставляет шум, который возникает в результате смешивания ключевоrо вектора Xj со
всеми остальными векторами, хранящимися в памяти. Именно вектор шума V j несет
ответственность за ошибки при извлечении из памяти.
.........
130 rлава 2. Процессы обучения
в контексте линейноro пространства сиrналов косинус уrла между векторами
Xk и Xj можно определить как скалярное произведение этих векторов, деленное на
произведение их Евклидовых норм (norrn) (или длин):
т
X k Xj
cos (Xk, Xj) == IlxkllllXjll'
(2.45)
IIXk 11 обозначается Евклидова норма вектора Xk, определяемая как квадратный корень
из ero энерrии:
IIXkl1 == (XI X k)1/2 == E /2.
(2.46)
Возвращаясь к исходной задаче, заметим, что в соответствии с допущением
(2.42) ключевые векторы нормализованы. Таким образом, выражение (2.45) мож
но упростить:
COS (Xk' Xj) == xI Xj'
(2.4 7)
Теперь можно переопределить вектор шума (2.44) следующим образом:
m
Vj == L COS (Xk, Xj)Yk'
k l,ki-j
(2.48)
Известно, что если ключевые векторы являются ортО20нальными (ortogonal) (т.е.
перпендикулярными друr друry в Евклидовом смысле), то
COS (Xk, Xj) == О, k =1= j,
(2.49)
и, следовательно, вектор шума является нулевым. В этом случае отклик У равен
Yj. Итак, память считается совершенно ассоциированной (associated perfectly), если
ключевые векторы выбираются из ортО20налЬНО20 набора (orthogonal set), Т.е. yдo
влетворяют следующему условию:
т { 1,
xk Xj == О,
k == j,
k =1= j.
(2.50)
Теперь предположим, что все ключевые векторы составляют ортоrональный Ha
бор, Т.е. выполняется условие (2.50). Как определить емкость или запоминающую
способность (storage capacity) ассоциативной памяти? Друrими словами, какое MaK
симальное количество образов можно в ней сохранить? Ответ на этот Фундамен
тальный вопрос связан с paHroM матрицы памяти М. PaHroM матрицы называется
количество ее независимых строк (столбцов). Это значит, что если paHr прямоуroль
ной матрицы размерности l х т равент, то выполняется соотношение r min(l, т).
2.11. Память 131
в случае корреляционной памяти размерность матрицы памяти составляет m х т, rдe
m размерность пространства входных сиrналов. Отсюда сЛt.дует, что paHr матрицы
М оrpаничен сверху числом т. Теперь можно сформулировать утверждение о том,
что количество образов, которые MOryT быть надежно сохранены в корреляционной
памяти, не может превышать размерности пространства входных сиrналов.
В реальных ситуациях часто приходится сталкиваться с тем, что ключевые обра
зы, представленные на вход ассоциативной памяти, практически никоrда не являются
ортоroнальными. Следовательно, корреляционная память, характеризуемая COOTHO
шением (2.34), иноrда может давать сбои и ошибочные результаты. Это значит, что
ассоциативная память может случайно распознать и классифицировать образ, никоrда
ранее не виденный. Чтобы проиллюстрировать это свойство ассоциативной памяти,
рассмотрим следующий набор ключевых образов:
{Xkey} :Х1,Х2,',"Х Ч '
и соответствующий ему набор запоминаемых образов:
{Уmеm} : У1, У2"'" Уч'
Для описания близости ключевых образов в линейном пространстве сиrналов BBe
дем понятие общности (community) и определим общность множества образов {х key }
как нижний предел скалярноrо произведения х[ Xj любых двух векторов из этоro MHO
жества. Пусть М матрица памяти, построенная соrласно формуле (2.34) в результате
обучения ассоциативной памяти на наборе ключевых образов {х key} И соответствую
щем ему наборе откликов {Уmеm}' Отклику этой памяти на внешнее воздействие Xj
из набора {Xkey} будет описываться выражением (2.39). При этом предполаrается, что
все векторы из множества {Xkey} являются единичными (т.е. векторами с единичной
энерrией). Кроме TOro, предположим, что
х[ Xj у, k =1= j.
(2.51 )
Если нижняя rpаница у достаточно велика, то память не сможет отличить вектор
У от отклика на любой друrой входной вектор из множества {Xkey}' Если ключевые
образы этоrо набора имеют вид
Xj == Хо + v,
(2.52)
[де v некоторый стохастический вектор, то, вероятнее Bcero, память распознает
вектор Хо и ассоциирует ero с вектором У о, а не с вектором из фактическоro множества
образов, использованных в процессе обучения. Здесь символами Хо и Уо обозначена
никоrда ранее не виденная пара сиrналов. Этот феномен можно назвать ЛО2икой
животНО20 (которой на самом деле не существует) [210].
-
132 rлава 2. Процессы обучения
2.12. Адаптация
При решении реальных задач часто оказывается, что одним из основных измере
ний процесса обучения является пространство, а друrим время. Пространственно
временная структура обучения подтверждается мноrими примерами задач обучения,
рассмотренными в разделе 2.1 О (например, задачами управления или построения диа
rpaMMbI направленности). Биолоrические виды, от насекомых до человека, обладают
способностью для представления временной структуры опыта. Такое представление
позволяет животным адаптировать (adapt) свое поведение к временной структуре
событий в пространстве поведения [336].
Если нейронная сеть работает в стационарной (stationary) среде (т.е. в среде, CTa
тистические характеристики которой не изменяются во времени), она теоретически
может быть обучена самым существенным статистическим характеристикам среды с
помощью учителя. Например, синаптические веса сети можно вычислить в процессе
обучения на множестве данных, представляющих среду. После завершения процес
са обучения синаптические веса сети отражают статистическую структуру среды,
которая теперь считается неизменной или "замороженной". Таким образом, для из
влечения и использования накопленноro опыта обучаемая система полаrается на ту
или иную форму памяти.
Однако чаще Bcero окружающая среда является нестационарной (nonstationary).
Это значит, что статистические параметры входных сиrналов, rенерируемых средой,
изменяются во времени. В TaKoro рода ситуациях методы обучения с учителем дo
казали свою несостоятельность, так как сеть не обладает средствами отслеживания
статистических вариаций среды, с которой имеет дело. Чтобы обойти этот изъян,
необходимо постоянно адаптировать свободные параметры сети к вариациям BXOД
HOro сиrнала в режиме реалЬНО20 времени, Т.е. адаптивная система должна отвечать
на каждый следующий сиrнал, как на новый. Друrими словами, процесс обучения
в адаптивной системе не завершается, пока в нее поступают новые сиrналы для
обработки. Такая форма обучения называется непрерывным обучением (continuous
lea.ming) или обучением на лету (1ea.ming on the fY).
Для реализации непрерывноrо обучения можно применять линейные адаптивные
фильтры (linear adaptive filter), построенные для линейноro сумматора (т.е. отдельно
[о нейрона, функционирующеro в линейном режиме). Несмотря на довольно простую
структуру (а во MHoroM даже блаrодаря ей), они в настоящее время широко использу
ются В таких несходных областях, как радиолокация, сейсмолоrия, связь и биометрия.
Теория линейных адаптивных фильтров уже достиrла в своем развитии стадии зрело
сти [434], [1144]. Однако этоro нельзя сказать о нелинейных адаптивных фильтрах 11 .
11 Задача создания оптимальиоro линейноro фильтра, положившая иачало теории линейных адаптивных
фильтров, впервые была поставлена в [590] и независимо от нее несколько позже решеиа в [1149]. С друroй
стороиы, формальноro решения задачи оптимальиой нелинейиой фильтрации в математических терминах не
2.12. Адаптация 133
При исследовании непрерывноro обучения и ero применения в теории нейронных
сетей возникает следующий вопрос. Как нейронная сеть может адаптировать свое
поведение к изменению временной структуры входных сиrналов в поведенческом
пространстве? Один из ответов на этот фундаментальный вопрос предполаrает, что
изменения статистических характеристик не стационарных процессов протекают дo
статочно медленно, чтобы процесс на коротком промежутке времени можно было
рассматривать как псевдостационарный. Приведем примеры.
· Синтез речевоro сиrнала можно рассматривать как стационарный процесс на ин
тервале времени порядка 1 о зо миллисекунд.
· Эхо радара от дна океана можно считать стационарным на интервалах времени
порядка нескольких секунд.
· При долrовременном проrнозировании поrоды синоптические данные можно pac
сматривать как стационарные на интервалах времени порядка нескольких минут.
· В контексте оценки тенденций биржевоrо рынка данные можно считать стацио
нарными на интервалах времени порядка нескольких дней.
Используя свойство псевдостационарности в стохастических процессах, можно
увеличить срок эффективной работы нейронной сети за счет ее периодическоro пepe
учивания (retraining), позволяющеrо учесть вариации входных данных. Такой подход
можно использовать, например, для обработки биржевых данных.
Можно также применить и более точный динамический (dynamic) подход. Для
этоro нужно выполнить следующую последовательность действий.
· Выбрать достаточно короткий интервал времени, на котором данные можно счи
тать псевдостационарными, и использовать для обучения сети.
· После получения HOBOro обучающеrо примера нужно отбросить самый старый
вектор и добавить в выборку новый пример.
сушествует. Тем не менее в 1950-х roдах в этой области были опубликованы отличные работы, которые вНесли
некоторую ясность в природу этой задачи [1148], [1177].
Впервые идею нелинейноro адаптивноro фильтра выдвинул rабор в 1954 roду [330]. Со своими едино-
мышленниками он занялся созданием TaKoro фильтра [331]. Сначала rабор предложил обойти математические
трудности нелинейной адаптивной фильтрации путем создания фильтра, реакция кoтoporo оптимизируется в
процессе обучения. Выходной сиrнал TaKOro фильтра выражается в виде
N N N
у(n) == L WnX(n)+ L L Wn,mX(n)x(m) + ., .
п:::::О n==О т==О
сде х(О), x(l), ..., x(N) примеры входноro сиrнала фильтра. (Этот полином теперь носит имя rабор
Колмоroрова или называется рядом Вольтерра.) Первое слаrаемое полинома представляет собой линейный
фильтр, характеризуемый набором коэффициентов {Wn}. Второе слаraемое характеризуется множеством диа-
дических коэффициентов {Wn,m} И является нелинейным. Это слаrаемое содержит произведение двух экзем-
пляров входноro сиrнала фильтра и имеет более высокий порядок. Коэффициенты фильтра настраиваются с
помощью метода rpадиентноro спуска с целевой функцией среднеквадратическоro расстояния между желаемым
ответом d(N) и фактическим выходным сиrналом фильтра y(N).
...
134 rлава 2. Процессы обучения
. Использовать обновленную выборку для обучения сети.
. Непрерывно повторять описанную процедуру.
Описанный алroритм позволяет встроить временные свойства в архитектуру ней
ронной сети, реализовав таким образом принцип непрерывНО20 обучения на упорядо
ченных во времени примерах (continualleaming with time ordered examples). При ис
пользовании TaKoro подхода нейронную сеть можно считать нелинейным адаптивным
фильтром (nonlinear adaptive filter), представляющим собой обобщение линейноro
адаптивноro фильтра. Однако для реализации TaKoro динамическоro подхода на KOM
пьютере требуется очень высокое быстродействие, которое позволит выполнить все
необходимые вычисления за один интервал дискретизации в реальном времени. Толь
ко в этом случае фильтр не будет отставать от изменения данных на входе системы.
2.13. Статистическая природа процесса обучения
в заключительном разделе настоящей rлавы речь пойдет о статистических аспектах
обучения. В этом контексте нас не будет интересовать эволюция вектора весовых
коэффициентов w, и алrоритм обучения нейронной сети можно рассматривать как
циклическиЙ. Будем оценивать только отклонение между целевой функцией f(x) и
фактической функцией Р(х, w), реализованной в нейронной сети. Здесь под Beктo
ром х понимается входной сиrнал. Это отклонение можно выразить в статистиче
ских терминах.
Нейронная сеть является Bcero лишь одной из форм, в которых при помощи про
цесса обучения можно закодировать эмпирические знания (empirical knowledge) о
физических явлениях или окружающей среде. Под термином "эмпирические знания"
подразумевается некий набор измерений, характеризующих данное явление. Чтобы
конкретизировать это понятие, рассмотрим пример стохастическоro явления, опи
cbIBaeMoro случайным вектором Х, состоящим из набора независимых переменных
(independent variable), и случайный скаляр D, представляющий зависимую пepeмeH
ную (dependent variable). КаждыЙ из элементов случайноro вектора Х может иметь
свой физический смысл. Предположение о том, что зависимая переменная D являет
ся скаляром, бьmо сделано исключительно с целью упрощения изложения материала
без потери общности. Предположим также, что существует N реализаций случайно
[о вектора Х, обозначаемых {Xi}f:,l' и соответствующее им множество реализаций
случайноro скаляра D, которое обозначим {d i }f:,l' Эти реализации (измерения) в
совокупности составляют обучающую выборку
т == {(Xi, di)} l'
(2.53)
2.13. Статистическая при рода процесса обучения 135
Обычно мы не обладаем знаниями о функциональной взаимосвязи между Х и D,
поэтому рассмотрим модель [1133]
D == j (Х) + Е,
(2.54)
[де j (.) некоторая детерминированная (deterrninistic) функция векторноro apryмeH
та; Е ожидаемая ошибка (expectational error), представляющая наше "незнание"
зависимости между Х и D. Статистическая модель, описанная выражением (2.54),
называетсяре2рессионной (regression model) (рис. 2.20, а). Ожидаемая ошибка Е в об
щем случае является случайной величиной с нормальным распределением и нулевым
математическим ожиданием. Исходя из этоrо, реrpессионная модель на рис. 2.20, а
обладает двумя важными свойствами.
1. Среднее значение ожидаемой ошибки Е для любой реализации х равно нулю, Т.е.
E[Elx] == О,
(2.55)
[де Е статистический оператор математическоrо ожидания. Естественным след
ствием этоro свойства является утверждение о том, что ре2рессионная функция
лх) является условным средним модели выхода D для входНО20 си2нала Х == х:
j(x) == E[Dlx].
(2.56)
Это свойство непосредственно следует из выражения (2.54) в свете (2.55).
2. Ожидаемая ошибка Е не коррелирует с функцией ре2рессии j(X), Т.е.
E[Ej(X)] == О.
(2.57)
Это свойство широко известно как принцип ортО20нальности (principle of orthog
onality), который rласит, что вся информация о D, доступная через входной сиrнал
Х, закодирована в функции реrpессии j(X). Равенство (2.57) без труда иллюстри
руется следующими выкладками:
E[Ej(X)] == E[E[Ej(X)lx]] == Е [J(X)E[Elx]] == Еи(х) . О] == О.
Реrpессионная модель (рис. 2.20, а) представляет собой математическое описание
стохастической среды. В ней вектор Х используется для описания или предсказания
зависимой переменной D. На рис. 2.20, б представлена соответствующая "физи
ческая" модель данной среды. Эта вторая модель, основанная на нейронной сети,
позволяет закодировать эмпирические знания, заключенные в обучающей выборке Т,
с помощью соответствующеro набора векторов синarrrических весов w:
...
136 rлава 2. Процессы обучения
/0
'r '
Е
а)
х
d
б)
Рис. 2.20. Математическое (а) и физическое (б)
представление нейронной сети
T w.
(2.58)
Таким образом, нейронная сеть обеспечивает аппроксимацию реrpессионной MO
дели, представленной на рис. 2.20, а. Пусть фактический отклик нейронной сети на
входной вектор Х обозначается следующей вероятностной переменной:
у == Р(Х, w).
(2.59)
[де Р(', w) функция отображения входных данных в выходные, реализуемая с
помощью нейронной сети. Для набора данных обучения Т, представленноrо в виде
множества (2.53), вектор синаптических весов w можно вычислить путем минимиза
ции функции стоимости:
1 N
E(w) == 2 L (d i F(Xi' w))2,
i l
(2.60)
[де коэффициент 1/2 вводится исключительно из соображений совместимости с обо
значениями, которые использовались ранее и будут использоваться в следующих rла
вах. Если не принимать во внимание коэффициент 1/2, функция стоимости E(w) опи
сывает сумму квадратов разностей между желаемым d и фактическим у откликами
нейронной сети для Bcero набора примеров обучения Т. Использование соотношения
(2.60) в качестве функции стоимости отражает "пакетный" характер обучения. Это
значит, что настройка синаптических весов нейронной сети выполняется для Bcero
массива примеров обучения в целом, а не для каждоrо примера в отдельности.
2.13. Статистическая природа процесса обучения 137
Пусть Е т оператор усреднения (average operator) по всей обучающей выбор
ке Т. Переменные, или их функции, обрабатываемые оператором усреднения Е т ,
обозначим символами х и d. При этом пара (х, d) представляет каждый конкретный
обучающий пример из набора Т. В отличие от оператора усреднения оператор CTa
тистическоrо ожидания Е функционирует на множестве всех значений случайных
переменных Х и D, подмножеством KOToporo является Т. Различие между операто
рами Е т и Е будет четко показано ниже.
В свете преобразования, описываемоro формулой (2.58), функции Р(х, w) и
Р(х, Т) являются взаимозаменяемыми, поэтому выражение (2.60) можно перепи
сать в виде
1
E(w) == ET[(d i F(Xi' т))2].
2
(2.61)
Добавляя функцию f(x) к apryмeHТY (d i F(Xi' Т))2 И вычитая ее, а затем
используя (2.54), получим:
d Р(х, Т) == (d f(x)) + и(х) Р(х, Т)) == е + и(х) Р(х, Т)).
Подставляя это выражение в (2.61) и раскрывая скобки, функцию стоимости мож
но записать в следующей эквивалентной форме:
1 1
E(w) == 2Ет[е2] + 2Ет[и(х) Р(х, т))2] + Ет[еи(х) Р(х, Т))].
(2.62)
Заметим, что последнее слаrаемое в правой части формулы (2.62) равно нулю по
двум причинам.
Ожидаемая ошибка е не коррелирует с реrpессионной функцией f(x), что видно
из выражения (2.57), интерпретируемоrо в терминах оператора Е т .
Ожидаемая ошибка е относится к реrpессионной модели, изображенной на
рис. 2.20, а, в то время как аппроксимирующая функция Р(х, w) относится к нейро
сетевой модели, показанной на рис. 2.20, б.
Следовательно, выражение (2.62) можно упростить:
1 1
E(w) == 2Ет[е2] + 2Ет[и(х) Р(х, т))2].
(2.63)
Первое слаrаемое в правой части выражения (2.63) описывает дисперсию ожидае
мой ошибки (реrpессионноro моделирования) е, вычисленной на обучающей выборке
Т. Это исходная (intrinsic) ошибка, так как она не зависит от вектора весов w. Ее мож
но не учитывать, так как rлавной задачей является минимизация функции стоимости
E(w) относительно вектора w. Следует учитывать, что значение вектора весов w*,
....
138 rлава 2. Процессы обучения
минимизирующее функцию стоимости E(w), будет также минимизировать и cpeд
нее по ансамблю квадратичное расстояние между реrpессионной функцией f(x) и
функцией аппроксимации Р(х, w). Друrими словами, естественной мерой эффектив
ности использования Р(х, w) для проrнозирования желаемоro отклика d является
следующая функция:
Lav(J(x), Р(х, w)) == Ет[и(х) Р(х, т))2].
(2.64)
Этот результат имеет фундаментальное значение, так как он обеспечивает MaTeMa
тическую основу для изучения зависимости между смещением и дисперсией, по
лученными в результате использования Р(х, w) в качестве аппроксимации функции
f(x) [344].
Дилемма смещения и дисперсии
Используя формулу (2.56), квадрат расстояния между функциями Р(х, w) и f(x)
можно переопределить в виде
Lav(J(x), Р(х, w)) == ET[(E[DIX == х] Р(х, т))2].
(2.65)
Это выражение также можно рассматривать как среднее значение ошибки oцeHи
ванuя (estimation error) реrpессионной функции f(x)=E[DIX=x] функцией аппрокси
мации Р(х, w), вычисленной на всем обучающем множестве Т. Обратите внимание,
что условное среднее E[DIX=x] имеет постоянное математическое ожидание на обу
чающем множестве Т. Далее, добавляя и вычитая среднее Ет[Р(х, Т)], получим:
E[DIX == х] Р(х, Т) == (E[DIX == х] Ет[Р(х, Т)]) + (Ет[Р(х, Т)] Р(х, Т)).
Выполняя преобразования, использованные для вывода соотношения (2.62) из BЫ
ражения (2.61), формулу (2.65) можно представить в виде суммы двух слаrаемых
(см. задачу 2.22):
Lav(J(x), Р(х, Т)) == B2(W) + V(w),
(2.66)
[де B(w) и V(w) определяются следующим образом:
B(w) == Ет[Р(х, Т)] E[DI Х == х],
V(w) == Ет[(Р(х, Т) Ет[Р(х, т)])2].
(2.67)
(2.68)
Теперь можно сформулировать два важных наблюдения.
2.13. Статистическая природа процесса обучения 139
fix) Е [D I х] Исходная ошибка
€ d - fix)
d
Функции входа
х
Рис. 2.21. Различные источники ошибки при решении задачи реrрессии
1. Элемент B(w) описывает смещение (bias) среднеrо значения аппроксимирующей
функции Р(х, Т) относительно реrpессионной функции f(x)==E[DIX==x]. Этот эле
мент выражает неспособность нейронной сети, представленной функцией Р(х, w),
точно аппроксимировать реrpессионную функцию j(x)==E[DIX==x]. Таким обра
зом, элемент B(w) можно считать ошибкой аппроксимации (approximation error).
2. Элемент V(w) представляет дисперсию (variance) аппроксимирующей функции
Р(х, w) на всем обучающем множестве Т. Это слаrаемое отражает HeaдeKBaT
ность информации о реrpессионной функции Лх), содержащейся в обучающем
множестве Т. Таким образом, элемент V(w) можно считать ошибкой оценивания
(estimation error).
На рис. 2.21 изображены взаимосвязи между целевой и аппроксимирующей функ
циями, а также наrлядно показано, как накапливаются ошибки оценивания CMe
щение и дисперсия. Чтобы достичь хорошей производительности, смещение B(w) и
дисперсия V(w) функции аппроксимации Р(х, w)==F(x, Т) должны быть невелики.
К сожалению, в нейронных сетях, обучаемых на данных выборки фиксированно
ro размера, малое смещение достиrается за счет большой дисперсии. Одновременно
уменьшить дисперсию и смещение можно только в одном случае если размер обу
чающеrо множества бесконечно велик. Эта проблема называется дилеммой смеще
ния/дисперсии (bias/variance dilemma). Следствием этой проблемы является медленная
сходимость процесса обучения [344]. Дилемму смещения/дисперсии можно обойти,
если преднамеренно ввести такое смещение, которое сводит дисперсию на нет или
значительно ее уменьшает. Однако при этом необходимо убедиться в том, что BCTpO
енное в нейронную сеть смещение является приемлемым. Например, в контексте
классификации образов смещение можно считать "приемлемым", если оно оказывает
сильное влияние на среднеквадратическую ошибку только в случае попытки вывода
реrpессии, которая не принадлежит ожидаемому классу. В общем случае смещение
необходимо задавать отдельно для каждой предметной области. На практике для
..
140 rлава 2. Процессы обучения
достижения этой цели используют 02раниченную (constrained) сетевую архитектуру,
которая обычно работает лучше, чем архитектура общеrо назначения. В частности,
оrpаничения (а значит и смещение) MorYT принимать форму априорных знаний, BCTpO
енных в архитектуру нейронной сети путем совместНО20 использования весов (если
несколько синапсов сети находится под управлением одноro и Toro же BecoBoro коэф
фициента связи) и/или создания локальных рецепторных полей (1ocal receptive field),
связанных с отдельными нейронам сети (что было продемонстрировано при исполь
зовании мноroслойноro персептрона для решения задачи распознавания оптических
символов) [621]. Подобные архитектуры уже кратко описывались в разделе 1.7.
2.14. Теория статистическоrо обучения
в этом разделе мы продолжим рассмотрение статистических свойств нейронных ce
тей. Основное внимание будет уделено теории обучения (leaming theory), связанной
с решением фундаментальноrо вопроса о том, как управлять обобщающей способ
ностью нейронных сетей. Этот вопрос будет рассматриваться в контексте обучения
с учителем.
Модель обучения с учителем состоит из трех взаимосвязанных компонентов
(рис. 2.22). В математических терминах они описываются следующим образом
[1084], [1086].
1. Среда (environment). Среда является стационарной. Она представлена векторами
х с фиксированной, но неизвестной функцией распределения вероятности Рх(х).
2. Учитель (teacher). Учитель rенерируетжелаемый отклик d для каждоrо из входных
векторов х, полученных из внешней среды, в соответствии с условной функци
ей распределения Fx(xld), которая тоже фиксирована, но неизвестна. Желаемый
отклик d и входной вектор х связаны следующим соотношением:
d == f(x, v),
(2.69)
[де v шум, Т.е. изначально предполаrается "зашумленность" данных учителя.
3. Обучаемая машина (leaming machine). Обучаемая машина (нейронная сеть) "спо
собна реализовать множество функций отображения" BXOД BЫXOД, описываемых
соотношением
у == Р(х, w),
(2.70)
rдe у фактический отклик, сrенерированный обучаемой машиной в ответ на
входной сиrнал х; w набор свободных пара.метров (синаптических весов), BЫ
бранных из пространства параметров W.
Уравнения (2.69) и (2.70) записаны в терминах примеров, используемых при обучении.
2.14. Теория статистическоro обучения 141
/
1/
,1
, '
"
"
"
"
"
"
11
l'
\\
\ \
"
...
X 1 ,X 2 ,.. .,x N
Обучаемая
машина:
weW
F(x, w) '" d
Рис. 2.22. Модель процесса обучения с учителем
Задача обучения с учителем состоит в выборе конкретной функции Р(х, w), KO
торая оптимально (в некотором статистическом смысле) аппроксимирует ожидаемый
отклик d. Выбор, в свою очередь, основывается на множестве N независимых, paвHO
мерно распределенных примеров обучения, описываемых формулой (2.53). Для удоб
ства изложения материала воспроизведем эту запись еще раз:
т == {(Xi, di)} l'
Каждая пара выбирается обучаемой машиной из множества Т с некоторой обоб
щенной функцией распределения вероятности F X,D (Х, d), которая, как и друrие функ
ции распределения, фиксирована, но неизвестна. Принципиальная возможность обу
чения с учителем зависит от ответа на следующий вопрос: содержат ли примеры
из множества {(Xi, d i )} достаточно информации для создания обучаемой машины,
обладающей хорошей обобщающей способностью? Ответ на этот вопрос лежит в
области результатов, впервые полученных в 1971 roду [1088]. Поэтому рассмотрим
задачу обучения с учителем как задачу аппроксимации (approximation problem), co
стоящую в нахождении функции Р(х, w), которая наилучшим образом приближает
желаемую функцию j(x).
Пусть L(d, Р(х, w)) мера потерь или несходства между желаемым откликом d,
соответствующим входному вектору Х, и откликом Р(х, w), сrенерированным обуча
емой машиной. В качестве меры L(d, Р(х, w)) часто рассматривают квадратичную
функцию потерь (quadratic loss function), определенную как квадрат расстояния меж
ду d == ЛХ) и аппроксимацией Р(х, w)12,
12 Функция стоимости L(d, F(x, w)), определяемая формулой (2.71), применяется к скаляру d. В случае
использования вектора d в качестве желаемоro отклика функция аппроксимации F(x, w) является векторной.
Torдa в качестве функции потерь выбирается квадрат Евклидова расстояния L(d, F(x, w)) lld F(x, w)11 2 , rдe
F(-, .) вектор функция своих apryMeHТOB.
..........
142 rлава 2. ПроцеСGЫ обучения
L(d,F(x,w)) == (d F(x,W))2.
(2.71)
Квадратичное расстояние в формуле (2.64) это усредненное по множеству всех
пар примеров (х, d) расширение меры L(d, Р(х, w)).
В литературе, посвященной теории статистическоrо обучения, обычно рассматри
ваются конкретные функции потерь. Основное свойство представленной здесь теории
статистическоro обучения состоит в том, что форма функции потерь L(d, Р(х, w))
не иrpает особой роли. Конкретный вид функции потерь будет рассмотрен несколько
позже в этом разделе.
Ожидаемая величина потерь определяется функционалом риска (risk functional)
R(w) == J L(d, Р(х, w)) dF x , D(X, d),
(2.72)
[де интеrpал берется по всем возможным значениям (х, d). Целью обучения с учите
лем является минимизация функционала риска R(w) в классе функций аппроксима
ции {Р(х, w), wEW}. Однако оценка функционала риска усложняется тем, что обоб
щенная функция распределения FX,D(X, d) обычно неизвестна. При обучении с учи
телем вся доступная информация содержится в множестве данных обучения Т. Чтобы
обойти эту математическую сложность, будем использовать индуктивный принцип
минимизации эмпирическоrо риска [1087]. Этот принцип основан на доступности
обучающеrо множества Т, что идеально соrласуется с философией нейронных сетей.
Некоторые основные определения
Прежде чем двиrаться дальше, введем несколько основных определений, которые
будут использоваться в изложении последующеro материала.
Сходимость по вероятности. Рассмотрим последовательность случайных пере
менных а1, а2, ..., aN. Эта последовательность считается сходящейся по вероятно
сти (converge in probability) к случайной переменной ао, если для любоro о' > О
выполняется следующее вероятностное соотношение:
р
P(laN aol > 0') ............... при N.-....t 00.
(2.73)
Нижний и верхний пределы (supremum & infimum). Верхним пределом непустоro
множества скалярных величин А (sup А) называется наименьший из скаляров Х, дЛЯ
которых истинно неравенство х у для всех у ЕА. Если такой скалярной величины
не существует, то считается, что верхним пределом непустоrо множества А является
бесконечность. Аналоrично, нижним пределом непустоro множества скаляров А (inf
А) называется наибольший из скаляров х, для которых истинно неравенство Х :::; у
для всех у Е А. Если такой скалярной величины не существует, то считается, что
нижним пределом непустоro множества А является бесконечность.
2.14. Теория статистическою обучения 143
Функционал эмпирическоrо риска. Для обучающеrо множества Т
{( Xi, d i ) }f:,1 Функционал эмпирическоro риска определяется в терминах функции
потерь L(d i , F(Xi' Wi)) следующим образом:
1 N
Remp(w) == N L L(d i , F(Xi' w)).
i l
(2.74)
Строrая состоятельность (strict consistency). Рассмотрим множество W функ
ций L(d, Р(х, w)), распределение которых определяется интеrpальной функцией pac
пределения FX,D(x,d). Пусть W(c) непустое подмножество этоrо множества, Ta
кое, что
W(c) == {w: J L(d,F(x,w)) 2: с},
(2.75)
[де с Е ( oo, +00). Функционал эмпирическоrо риска считается стРО20 состоя
тельным (strict1y consistent), если для любоro подмножества W(c) обеспечивается
сходимость по вероятности
inf Remp(w) inf R(w) при N.-....t 00.
WEW(c) WEW(c)
(2.76)
Теперь, ознакомившись с этими определениями, можно продолжить изучение Teo
рии статистическоro обучения Вапника (Vapnik).
Принцип минимизации эмпирическоrо риска
Основная идея принципаминимизации эмпиричеСКО20 риска (empirical risk minimiza
tion) состоит в использовании функционала эмпирическоro риска Remp(w), опреде
ляемоro формулой (2.74). Этот новый функционал отличается от функционала R(w),
задаваемоro формулой (2.72), в двух аспектах.
1. Он явно не зависит от неизвестной функции распределения FX,D(X, d).
2. Теоретически ero можно минимизировать по вектору весовых коэффициентов w.
Пусть W emp И Р(х, W emp ) вектор весов и соответствующее ему отображение,
которые минимизируют функционал эмпирическоro риска Remp(w), определяемый
формулой (2.74). Аналоrично, пусть W o и Р(х, W o ) вектор весовых коэффициентов
и отображение, минимизирующие фактический функционал риска R(w), заданный
формулой (2.72). Векторы W emp И w o принадлежат пространству весов W. Требуется
найти условия, при которых а.ппроксимирующее отображение Р(х, w emp ) достаточно
"близко" к фактическому отображению Р(х, w o ) (в качестве меры близости будем
использовать разницу между Remp(w) и R (w)).
144
rлава 2. Процессы обучения
I
Для HeKoToporo фиксированноro W == w* функционал риска R(w*) определяет
математическое ожидание случайной переменной, определяемое соотношением
ZW* == L(d, Р(х, w*)).
(2.77)
в отличие от Hero функционал эмпирическоrо риска Remp(w*) обеспечивает эмпи
рическое (арифметическое) среднее значение (empirical (a.rithmetic) mean) случайной
переменной Zw*. Соrласно закону больших чисел (law of large numbers), который co
ставляет одну из основных теорем теории вероятностей, для обучающеrо множества
т бесконечно большоrо размера N эмпирическое среднее случайной переменной Zw*
в общем случае сходится к ее ожидаемому значению. Это наблюдение обеспечивает
теоретический базис для использования функционала эмпирическоrо риска Remp(w)
вместо функционала риска R(w). Однако тот факт, что эмпирическое среднее пере
менной Zw* сходится к ее ожидаемому значению, совершенно не означает, что вектор
весовых коэффициентов W emp , минимизирующий функционал эмпирическоrо риска
Remp(w), будет также минимизировать и функционал риска R(w).
Этому требованию можно приближенно удовлетворить, применив следующий
подход. Если Функционал эмпирическоrо риска Remp(w) аппроксимирует исходный
функционал риска R(w) равномерно по w с некоторой точностью е, то минимум
Remp(w) отстоит от минимума R(w) не более чем на величину 2е. Формально это
означает необходимость обязательноrо выполнения следующеrо условия. Для любо
[о w Е W и е> О должно выполняться вероятностное соотношение [1087]
P(sup I R(w) Remp(w) I > е) .-....t О при N.-....t 00.
W
(2.78)
Если выполняется условие (2.78), то можно утверждать, что вектор весов w cpeд
нею эмпиричеСКО20 риска равномерно сходится к своему ожидаемому значению. Ta
ким образом, если для любой наперед заданной точности е и HeKoToporo положитель
Horo а выполняется неравенство
P(sup I R(w) Remp(w) I > е) < а,
W
(2.79)
то выполняется также и следующее неравенство:
P(R(w emp ) R(w o ) > 2е) < а.
(2.80)
Друrими словами, если выполняется условие (2.79), то с вероятностью (1 а) реше
ние Р(х, w emp ), минимизирующее функционал эмпирическоrо риска Remp(w), обес
печивает отличие фактическоro риска R(w emp ) от минимально возможноrо фактиче
CKOro риска на величину, не превышающую 2е. Это значит, что при выполнении (2.79)
с вероятностью (1 а) одновременно выполняются следующие два неравенства:
2.14. Теория статистическоro обучения
145
R(w emp ) Remp(wemp) < е,
Remp(w o ) R(w o ) < е.
(2.81 )
(2.82)
Эти два соотношения определяют различие между функционалами истинноrо и
эмпирическоrо рисков в точках W==W emp И W==W o ' Учитывая, что W emp и W o являются
точками минимума функционалов Remp(w) и R(w), можно сделать вывод о том, что
Remp(wemp) S; Remp(w o )'
(2.83)
Складывая неравенства (2.81) и (2.82) и принимая во внимание неравенство (2.83),
можно записать:
R(w emp ) R(w o ) < 2е.
(2.84)
Поскольку неравенства (2.81) и (2.82) одновременно выполняются с вероятностью
(1 а.), то с такой же вероятностью выполняется инеравенство (2.84). Также можно
утверждать, что с вероятностью а. будет выполняться неравенство
R(w emp ) R(w o ) > 2е,
которое является еще одной формой утверждения (2.80).
Теперь можно формально сформулировать принцип минимизации эмпиричеСКО20
риска (principle of empirical risk minimization), состоящий из трех взаимосвязанных
частей [1084], [1087].
1. Вместо функционала риска R(w) строится функционал эмпирическоrо риска
1 N
Remp(w) == N L L(d i , F(Xi, w))
i==l
на базе множества примеров обучения (Xi, d i ), i == 1,2, .. . , N.
2. Пусть W emp вектор весовых коэффициентов, минимизирующий функционал эм
пирическоrо риска Remp(w) в пространстве весов W. Torдa R(w emp ) сходится
по вероятности к минимально возможным значениям фактическоrо риска R(w),
wEW. При этом при увеличении количества N примеров обучения до бесконеч
ности функционал эмпирическоrо риска Remp(w) равномерно сходится к Функци
оналу фактическоrо риска R(w).
....
146 rлава 2. Процессы обучения
3. Равномерная сходимость, определяемая как
Р( sup I R(w) Remp(w) I > е) .-....t О при N .-....t 00,
wEW
является необходимым и достаточным условием непротиворечивости принципа
минимизации эмпирическоro риска.
Для физической интерпретации этоrо важноrо принципа проведем следующее
наблюдение. До обучения машины все аппроксимирующие функции равноценны. По
мере обучения правдоподобие тех функций аппроксимации, которые не противоречат
обучающему множеству {(Xi, d i )}f:,l' возрастает. По мере увеличения количества
использованных при обучении примеров и, следовательно, повышения "плотности"
входноrо пространства точка минимума функционала эмпирическоrо риска Remp(w)
сходится по вероятности к точке минимума функционала фактическоrо риска R(w).
VС-измерение
Теория равномерной сходимости функционала эмпирическоro риска Remp(w) к
функционалу фактическоrо риска R(w) включает оrpаничения на скорость сходи
мости, которые основаны на важном параметре, получившем название измерения
Вапника Червоненкиса (Vapnik Chervonenkis dimension) (или просто VС измерения)
в честь ученых, которые в 1971 roду ввели это понятие [1088]. Измерение Вапника
Червоненкиса является мерой емкости (capacity) или вычислительной мощности ce
мейства функций классификации, реализованных обучаемыми машинами.
Для TOro чтобы описать концепцию VС измерения в ракурсе изучаемой проблемы,
рассмотрим задачу двоичной классификации образов, для которой множество ожида
емых откликов состоит Bcero из двух значений d Е {О, 1}. Для обозначения правила
принятия решения или функции двоичной классификации будем использовать термин
дихотомия (dichotomy). Пусть F множество дихотомий, реализованных обучаемой
машиной, Т.е.
F == {Р(х, w): w Е W,F: Rmw.-....t {О, 1}}.
(2.85)
Пусть L множество, содержащее N точек m MepHoro пространства Х входных
векторов:
L == {Xi Е Х; i == 1,2,... , N}.
(2.86)
Дихотомия, реализованная обучаемой машиной, разбивает множество L на два
непересекающихся подмножества Lo и L 1 , таких, что
2.14. Теория статистическоro обучения 147
Х 2
Рис. 2.23. Диаrрамма для примера 2.1
Р(х, w) == { О дЛЯ х Е Lo,
1 для х Е L 1 .
(2.87)
Пусть Др(L) количество различных дихотомий, реализованных обучаемой Ma
шиной; Др(l) максимум Др(L) на множестве всех L, дЛЯ которых ILI ==1, rдe
ILI количество элементов в L. rоворят, что ансамбль дихотомий F является разбu
ением множества L, если Др(L)==2 IL1 , Т.е. если все возможные дихотомии в L MOryт
быть реализованы функциями F. При этом Др(l) называется функцией роста (growth
function).
Пример 2.1
На рис. 2.23 показано двумерное входное пространство Х, состоящее из четырех точек Х 1, Х2, Хз,
Х4. Показанные на рисунке rpаницы решений функций ро и Н соответствуют классам (rипотезам)
О и 1. На рис. 2.23 видно, что функция ро индуцирует дихотомию
Do == {Go == {Xl,X2,X4},G 1 == {Хз}}.
С друroй стороны, функция Рl описывает дихотомию
D 1 == {Go == {Xl,X2},G 1 == {ХЗ,Х4}}.
Так как множество G состоит из четырех точек, мощность IGI == 4. Следовательно,
ДF(G) == 24 == 16.
.
Возвращаясь к общему обсуждению ансамбля дихотомий F, описываемоro фор
мулой (2.85), и соответствующеro множества точек L, задаваемоrо формулой (2.86),
VС измерение можно определить следующим образом [551], [1084], [1088], [1094].
.....
148 rлава 2. Процессы обучения
Х 2 I Х 2 Класс 1
1
1
1
1
, , xz 1
, 1
, . I
, .,.
1 ,. "-
1 / ,
, 1 \, 2. . I Класс О
, 1 . Х З
,
'" 1
.
Х 1 l'
1 ,
1 ,
1 ,
1 ,
,
о 1 , Х 1 О Х 1 Рис. 2.24. Два ДBY
1 ,
а) б) мерных распределе
ния для примера 2.2
VС uз.мерением F называется мощность наибольше20 множества L, разбиением KO
тОрО20 является F.
Друrими словами, VС измерением F (обозначается VCdim(F)) является самое
большое значение N, дЛЯ KOTOpOro 6. F (N) == 2 N . В более знакомых терминах это
утверждение можно переформулировать следующим образом. VС измерение множе
ства функций классификации {Р(х, w): wEW} это максимальное число образов,
на которых машина может бьrrь обучена без ошибок для всех возможных бинарных
маркировок функций классификации.
Пример 2.2
Рассмотрим простое решающее правило в т MepHOM пространстве Х входных векторов, опи
сываемое следующим образом:
F: у == <p(w T Х + Ь),
rде х m мерный вектор весов; Ь пороr. фун r ция активации <р является пороroвой, Т.е.
( ) 1, v::::: о,
<pv ==
О, v < О.
VС измерение решающеro правила, определяемоro формулой (2.88), определяется соотношением
(2.88)
VCdim(F) == m + 1.
(2.89)
Чтобы проиллюстрировать этот результат, рассмотрим двумерное входное пространство
(т.е. m == 2), изображенное на рис. 2.24. На рис. 2.24, а показаны три точкн: Хl, Х2 и хз, а
также три возможных варианта разделения этих точек. На рисунке ясно видно, что точки MOryт
быть разделены тремя линиями. На рис. 2.24, б изображены четыре точки: Хl, Х2, хз И Х4. Точки
Х2 И хз относятся к классу О, а точки хl и х4 к классу 1. На рисунке видно, что точки Х2 И хз
нельзя отделить от точек хl и Х4 одной линией. Таким образом, VС измерение решающеro правила,
описанноro формулой (2.88), при m == 2 равно 3, что соответствует формуле (2.89). .
2.14. Теория статистическоro обучения 149
Пример 2.3
Поскольку VС измерение является мерой емкости множества функций классификации (индика
торов), то можно ожидать, что обучаемая машина с большим числом свободных параметров будет
иметь большое VС измерение, и наоборот. Приведем контрпример, опроверrающий это утвержде
ние l3 .
Рассмотрим однопараметрическое семейство функций индикаторов
ЛХ, а) == sgn(sin(ax)), а Е R,
rдe sgn(.) функция вычисления знака apryMeHTa. Предположим, задано некоторое число N, дЛЯ
KOTOpOro нужно найти N точек, для которых необходимо построить разбиение. Этому требованию
удовлетворяет набор функций ЛХ, а), rде
Х; == 10 i, i == 1,2, . . . , N.
Чтобы разделить эти точки данных на два класса, определяемых последовательностью
d 1 , d 2 ,..., dN, d i Е { 1, 1},
достаточно выбрать параметр а соrласно формуле
( 2: N (1 di)10i )
а==п 1+ .
2
i==l
Отсюда можно заключить, что VС измерение семейства функций индикаторов f(x, а) с един
ственным свободным параметром а равно бесконечности. .
Важность VС-измерения и ero оценка
VС измерение является суrубо комбинаторным понятием (combinatorial concept) и
никак не связано с rеометрическим понятием измерения. Оно иrpает центральную
роль в теории статистическоro обучения, что и будет показано в следующих двух
подразделах. VС измерение важно также и с конструкторской точки зрения. Образно
rоворя, количество примеров, необходимых для обучения системы данным HeKOTO
poro класса, cTporo пропорциона.пьно VС измерению этоrо класса. Таким образом,
VС измерению стоит уделить первостепенное внимание.
В некоторых случаях VС измерение определяется свободными параметрами ней
ронной сети. Однако на практике VС измерение довольно сложно получить аналити
ческими методами. Тем не менее rраницы VС измерения для нейронной сети часто
устанавливаются довольно леrко. В этом контексте особый интерес представляют
следующие два результата l4 .
13 Соrласно [165], при мер 2.3 впервые был приведен в [1085] блаroдаря Левину (Levin) иДенкеру (Denker).
14 Верхний предел порядка W log W VС измерения нейрон ной сети прямоrо распространения, состоя шей
из линейных пороroвых элементов (персептронов), впервые был получен в [107]. Впоследствии в [692] было
показано, что для этоrо класса нейросетей нижний предел также имеет порядок W log W.
Верхннй предел VС измерения для сиrмоидальных нейронных сетей впервые был получен в [698]. Впо-
следствии авторы работы [586] решили поставленный в [692] следующий вопрос.
.......
150 rлава 2. Процессы обучения
1. Пусть N nроизвольная нейронная сеть nря.мО20 распространения, состоящая
из нейронов с nОРО20вой функцией активации (Хэвисайда)
<p(v) == { 1, v;::: О,
О, v < О.
VС измерение сети N составляет O(W log W), rдe W общее количество
свободных параметров сети.
Этот результат был получен в [107] и [218].
2. Пусть N nроизвольнаЯМНО20СЛОйНая нейронная сеть nря.мО20 распространения,
состоящая из нейронов с си2Моидальной функцией активации
1
<p
1 + ехр( v)'
VС измерение сети N равно O(W 2 ), W общее количество свободных napa
метров сети.
Второй результат был получен в [586]. Чтобы получить ero, авторы снача.па по
каза.пи, что VС измерение сетей, состоящее из двух типов нейронов (с линейной
и пороrовой функциями активации), пропорционально W 2 . Это довольно неожи
данный результат, так как в примере 2.2 было показано, что VС измерение чисто
линейных нейронных сетей пропорционально W, а VС измерение нейронных сетей
с пороroвой функцией активации пропорционально WlgW (соrласно п. 1). Результат,
относящийся к нейронным сетям с сиrмоида.пьными функциями активации, бьm по
лучен с помощью двух аппроксимаций. Во первых, нейроны с пороrовой функцией
активации можно аппроксимировать узлами с сиrмоидальными функциями и больши
ми синаптическими весами. BO BTOpЫX, линейные нейроны можно аппроксимировать
нейронами с сиrмоида.пьными функциями и малыми синаптическими весами.
Здесь важно обратить внимание на то, что мноrослойные сети прямоrо распро
странения имеют конечное VС измерение.
"Действительно ли VС измерение аналоrовой нейронной сети с сиrмоидальной функцией активации а(у) =о
1/(1 +e Y) оrpаничено полиномом с определенным числом проrpаммируемых параметров?"
Авторы [586] дали положительный ответ на этот вопрос. Положительный ответ на этот вопрос также был
получен в [543], rдe использовался сложный метод, основанный на дифференциальной тополоrии. Это было
сделано для Toro, чтобы показать, что VС измерение в сиrмоидальных нейронных сетях, используемых в каче
стве классификатора образов, оrpаничено сверху порядком O(W 4 ). Между этим верхним пределом и нижним
пределом, полученным в [586], существует большой разрыв. Однако в [543] было высказано предположение,
что данный верхний предел может быть снижен.
2.14. Теория статистическоro обучения 151
Конструктивные, независимые от распределения пределы
обобщающей способности обучаемых машин
Теперь следует остановиться на особом типе задач двоичной классификации образов,
в которых ожидаемый отклик определяется множеством d == {О, 1}. Как следствие,
функция потерь может принимать одно из двух следующих значений:
{ О если (х, w) == d,
L(d, Р(х, w)) == 1 ' , Р( )
если х, w I d.
(2.90)
При этих условиях функционалы риска R(w) и эмпирическоro риска Remp(w),
определяемые формулами (2.72) и (2.74) соответственно, MOryт иметь следую
щую интерпретацию.
. Функционал риска R(w) это вероятность ошибки классификации (probability of
classification error), обозначаемой P(w).
. Функционал эмпирическоro риска Remp(w) это ошибка обучения (training error)
(т.е. частота появления ошибок в процессе обучения), обозначаемая v(w).
Соrласно закону больших чисел (law oflarge numbers) [380], эмпирическая частота
возникновения каких либо событий почти наверняка сходится к фактической Bepo
ятности этих же событий при количестве попыток, стремящемся к бесконечности
(подразумевается, что эти попытки независимы и одинаково распределены). В KOH
тексте на.шеrо обсуждения этот результат roворит о том, что для любоro вектора w,
не зависящеro от обучающеro множества, и для любой точности Е > О выполняется
следующее условие [1087]:
P(!P(w) v(w)J > Е) ON 00,
(2.91 )
rдe N размер множества обучения. Следует заметить, что выполнение условия
(2.91) совершенно не означает, что минимизация ошибки обучения v(w) при исполь
зовании HeKoToporo правила классификации (т.е. данноrо вектора весов w) влечет
минимизацию вероятности ошибки классификации P(w). Для существенно большо
ro размера N обучающеro множества близость между v(w) и P(w) следует из более
cTpororo условия [1087]
P(sup IP(w) v(w)1 > Е) О при N 00.
w
(2.92)
в данном случае речь идет о равномерной сходимости частоты ошибок обучения
к вероятности Toro, что v(w)==P(w).
,.......
152 rлава 2. Процессы обучения
Понятие VС измерения накладывает оrpаничения на скорость равномерной cxo
димости. В частности, для множества функций классификации с VС измерением,
равным h, выполняется следующее неравенство [1084], [1087]:
( 2 N ) h
P(s p !P(w) v(w)1 > Е) < + ехр( E2 N),
(2.93)
rдe N размер обучающеro множества; е основание натуральноro лоrарифма. Для
Toro чтобы достичь равномерной сходимости, требуется обеспечить малое значение
правой части неравенства (2.93) для больших значений N. В этом может помочь
множитель ехр( E2 N), так как он экспоненциально убывает с ростом N. OCTaB
шийся множитель (2eN/h) h представляет собой предел роста функции Д. F (l) для
семейства функций F=={F(x, w); WEW} при l 2: h 2:1. Этот результат описывается
леммой Сауера (Sauyer's lemma)15. Оrpаничив слишком быстрый рост этой функции,
мы обеспечиваем сходимость правой части неравенства к нулю при N, стремящемся
к бесконечности. Это требование будет удовлетворено, если VС измерение h не яв
ляется бесконечно большим. Друrими словами, конечность VС измерения является
необходимым и достаточным условием равномерной сходимости принципа миними
зации эмпирическоro риска. Если входное пространство Х обладает конечной мощно
стью, то семейство дихотомий F будет иметь конечное VС измерение по Х. Обратное
утверждение не Bcerдa верно.
Пусть а вероятность события
sup IP(w) v(w)1 2: Е.
w
Torдa с вероятностью (1 а) можно утверждать, что все векторы весовых коэф
фициентов wEW удовлетворяют следующему неравенству:
P(w) < v(w) + Е.
(2.94)
Используя неравенство (2.93) и определение вероятности а, можно записать:
( 2 N ) h
а == + ехр( E2 N).
(2.95)
Пусть Eo(N, h, а) некоторое значение Е, удовлетворяющее соотношению (2.95).
15 Лемма Сауера звучит следующим образом [64], [934], [1094].
"Обоз"'lЧИМ через F ансамбль дихотомий, реализуемых обучаемой .машиной. Если VCdim(F) == h. zде h
конечная величина, {? h ?1, то функция роста L:l.р(!) оzраничена сверху величиной (el/h)h, rдe е основание
натуральноzо лоzариф.ма ".
2.14. Теория статистическоro обучения 153
Torдa можно получить следующий важный результат [1086]:
Eo(N, h, а) == [log ( 2: ) + 1] log а.
(2.96)
Величина Eo(N, n, а) называется доверительным интервалом (confidence interval).
Ero значение зависит от размера обучающей выборки N, VС измерения h и вероят
ности а.
Предел, описываемый выражением (2.93), при E'9:.o(N, h, а) достиrается в худшем
случае с вероятностью P(w)==1/2, но, к сожалению, не для малых значений P(w),
которые интересны при решении практических задач. Для малых значений P(w)
более полезное оrpаничение можно получить в результате некоторой модификации
неравенства (2.93) [1084], [1087]:
Р ( IP(w) v(w)1 ) ( 2eN ) h ( E2 N )
вир !Df':::\ > Е < h ехр 4 .
w у P(w)
(2.97)
В литературе представлены различные виды оrpаничения (2.97), зависящие от
конкретной формы неравенства, используемоrо для их получении. Тем не менее все
они имеют сходную форму. Из неравенства (2.97) следует, что с вероятностью (1 а)
одновременно для всех w Е W выполняется соотношение [1084], [1087]
P(w) ::=;V(W)+E1(N,h,a,v),
(2.98)
rдe Е1 (N, h, а, v) новый доверительный интервал, определяемый в терминах pa
нее paccMoтpeHHoro доверительноro интервала Eo(N, h, а) следующим образом (см.
задачу 2.25):
E1(N,h,a,v) == 2E (N,h,a) ( 1 + 1 + 2 v(w) ) .
Eo(N, h, а)
(2.99)
Этот доверительный интервал зависит от ошибки обучения v(w). При v(w)==O он
принимает упрощенный вид
E1(N,h,a,O) == 4E (N,h,a).
(2.100)
Теперь можно подвести итоr и определить два оrpаничения на скорость paBHO
мерной сходимости.
........
154 rлава 2. Процессы обучения
1. В общем случае скорость равномерной сходимости удовлетворяет следующему
оrpаничению:
P(w)::; v(w) +E1(N,h,a,v),
rдe 101 (N, h, а, v) определяется формулой (2.99).
2. При малых (близких к нулю) значениях ошибки обучения v(w) выполняется Hepa
венство
P(w) ::; v(w) + 4EG(N, h, а).
Это оrpаничение является более точным и более приroдным для реальных задач
обучения.
3. При больших значениях ошибки обучения v(w), близких к единице, выполняется
оrpа.ничение
P(w) ::; v(w) + Eo(N, h, а).
Минимизация СТРуктурноrо риска
Под ошибкой обучения (training error) понимается частота сделанных машиной оши
бок в течение сеанса обучения для определенноro вектора весов w. Аналоrично,
под ошибкой обобщения (generalization error) понимается частота сделанных маши
ной ошибок при ее тестировании на не встречавшихся ранее примерах. При этом
предполаrается, что тестовые данные принадлежат тому же семейству, что и данные
обучения. Эти две величины обозначаются как Vtrain(W) И Vgene(W) соответственно. За
метим, что Vtrain(W) является той же величиной, которая в предыдущем разделе для
упрощения записи формул обозначалась v(w). Обозначим символом h VС измерение
семейства функций классификации {Р(х, w); WEW} по отношению для пространства
входных сиrналов Х. Torдa в свете теории скорости равномерной сходимости можно
утверждать, что с вероятностью (1 а) для количества примеров обучения N > h,
одновременно для всех функций классификации Р(х, w) ошибка обобщения vgene(w)
имеет меньшее значение, чем 2ара1lтирова1l1lЫЙ риск (guaranteed risk), определяемый
как сумма пары конкурирующих величин [1084], [1087]
Vguarant(W) == Vtrain(W) + E1(N, h, а, Vtrain),
(2.101)
[де доверительный интервал 101 (N, h, а, Vtrain) определяется формулой (2.99). Для
фиксированноro числа N примеров обучения ошибка обучения монотонно уменьша
ется при увеличении VС измерения h, а доверительный интервал монотонно увели
2.14. Теория статистическоrо обучения 155
Ошибка
fарантированный риск
(оrpаниченный ошибкой
обобщения)
" j ..,
,
,
....
....
............. ....................
Рис. 2.25. Взаимосвязь между ошибкой
обучения, доверительным интервалом и
rарантированным риском
о
VС размерность, h
...@с@с@...
чивается. Следовательно, как rарантированный риск, так и ошибка обобщения имеют
точку минимума. Общий случай этоrо утверждения про иллюстрирован на рис. 2.25.
До момента достижения точки минимума задача обучения является переопределенной
(overdetermined) в том смысле, что емкость машины h слишком мала, чтобы вместить
весь объем деталей обучения. После прохождения точки минимума задача обучения
является недоопределенной (underdeterrninated), Т.е. емкость машины слишком велика
для TaKoro объема данных обучения.
Таким образом, при решении задачи обучения с учителем необходимо обеспе
чить максимальную эффективность обобщения за счет приведения в соответствие
емкости машины с доступным количеством данных обучения. Метод минимизациu
структУРНО20 риска (method of structural risk minimization) обеспечивает индуктив
ную процедуру достижения этой цели, в которой VС измерение обучаемой машины
рассматривается какупра6ЛЯЮЩая переменная [1084], [1086]. Для большей конкрети
зации рассмотрим ансамбль классификаторов образов {Р(х, w); WEW} и определим
вложенную структуру, состоящую из n подобных машин:
Fk == {Р(х, w); W Е W k}, k == 1,2,. . . , n,
(2.102)
таких, что (см. рис. 2.25)
F 1 С F 2 С ... с Fn,
(2.103)
rдe символ С означает "содержится в". Соответственно VС измерения отдельных
классификаторов образов удовлетворяют следующему условию:
h 1 h 2 . . . h n .
(2.104)
,...
156 rлава 2. Процессы обучения
Это rоворит о том, что VС измерение каждоro из классификаторов конечно. Torдa
метод минимизации CTpyктypHoro риска можно изложить следующим образом.
· Минимизируется эмпирический риск (т.е. ошибка обучения) для каждоrо из клас
сификаторов.
· Определяется классификатор F*, который имеет наименьший rарантированный
риск. Эта конкретная машина обеспечивает наилучший компромисс между ошиб
кой обучения (т.е. качеством аппроксимации данных обучения) и доверительным
интерва.пом (т.е. сложностью функции аппроксимации), которые конкурируют друr
с друroм.
Нашей целью является поиск такой нейросетевой структуры, в которой уменьше
ние VС измерения достиrается за счет минимально возможноrо увеличения ошиб
ки обучения.
Принцип минимизации CTPYKTypHoro риска может быть реализован множеством
различных способов. Например, VС измерение h можно изменять за счет изменения
количества скрытых нейронов. В качестве примера рассмотрим ансамбль полносвяз
ных мноrослойных сетей прямоrо распространения, в которых количество нейронов
в одном из скрытых слоев монотонно возрастает. В соответствии с принципом ми
нимизации CTPYKтypHoro риска наилучшей сетью в этом множестве будет та, для
которой rарантированный риск будет минимальным.
VС измерение является основным понятием не только принципа минимизации
CTpyктypHoro риска, но и не менее мощной модели обучения, получившей название
вероятностно корректной в смысле аппроксимации (probably approximately correct
РАС). Этой моделью, которая описывается в следующем разделе, мы и завершим
рассмотрение вероятностных и статистических аспектов обучения.
2.15. Вероятностно-корректная в смысле
аппроксимации модель обучения
Вероятll0стно корректная в смысле аппроксимации (probably approximately correct)
модель обучения (РАС) была описана в [1075]. Как и следует из ее названия, эта MO
дель представляет собой вероятностный "каркас" (или среду) для изучения процес
сов обучения и обобщения в системах двоичной классификации. Она тесно связана
с принципом обучения с учителем.
Сначала определимся с терминолоrией, связанной со средой Х. Множество из эле
ментов Х называется понятием (concept), а любой набор ero подмножеств классом
понятий (concept class). Примером понятия называется любой объект из предметной
области, вместе с меткой cBoero класса. Если пример относится к данному понятию,
он называется положительным примером (positive example). Если он не относит
2.15. Вероятностно корректная в смысле аппроксимации модель обучения 157
ся к данному понятию, то называется отрицательным примером (negative ехаmрlе).
Понятие, для KOToporo приводятся примеры, называется целевым (target concept).
Последовательность данных обучения длины N для понятия С можно определить
следующим образом:
т == {(Xi' C(Xi))} l'
(2.105)
в этой последовательности MOryт содержаться и повторяющиеся примеры. При
меры Х1, Х2, . . ., Х п выбираются из среды Х случайным образом, в соответствии с
некоторым фиксированным, но неизвестным распределением вероятности. В опреде
лении (2.105) заслуживают внимания также следующие вопросы.
. Целевое понятие C(Xi) рассматривается как функция, отображающая Х в множе
ство {О, 1}. При этом предполаrается, что функция C(Xi) неизвестна.
. Предполаrается, что примеры статистически независимы. Это значит, что функ
ция плотности совместной вероятности двух различных примеров Xi и Xj равна
произведению соответствующих функций плотности вероятности.
в контексте терминолоrии, которую мы использовали ранее, среда Х COOTBeTCTBY
ет пространству входных сиrналов нейронной сети, а целевое понятие ожидаемому
отклику сети.
Набор понятий, порождаемых средой Х, называется пространством понятий В.
Например, пространство понятий может содержать фразы типа "буква j>(', "буква
Б" и Т.д. Каждое из этих понятий может бьrrь закодировано различными способами
при формировании множеств положительных и отрицательных примеров. В ракурсе
обучения с учителем используется друrое множество понятий. Обучаемая машина
обычно представляет собой множество функций, каждая из которых соответствует
определенному состоянию. Например, машина может предназначаться для распозна
вания "буквы j>(', "буквы Б" и Т.д. Множество всех функций (т.е. понятий), опреде
ляемых обучаемой машиной, называется пространством 2ипотез (hypothesis space)
G. Это пространство может совпадать или не совпадать с пространством понятий В.
С определенной точки зрения пространства понятий и rипотез являются аналоrа.ми
функции Лх) и аппроксимирующей функции Р(х, w), которыми мы оперировали в
предыдущем разделе.
Предположим, что существует некоторое целевое понятие с(Х)ЕВ, принимающее
значения О и 1. Требуется обучить этому понятию нейронную сеть при помощи
ее настройки на множестве данных Т, определенном выражением (2.105). Пусть
g(x) Е G rипотеза, соответствующая отображению входа на выход, сформирован
ному в результате проведенноro обучения. Одним из способов достижения успеха в
обучении является измерение степени близости rипотезы g(x) к целевой концепции
с(х). Естественно, всеrда существуют ошибки, обеспечивающие различие этих вели
.......
158 rлава 2. Процессы обучения
Параметры управления
Е,II
Пример оБУ',{,ения
{(Х р C(X;)}I= 1
Алroритм
обучения
L
fипотеза
g
Рис. 2.26. Блочная диаrрамма, иллюстрирующая
модель обучения РАС
чин. Эти ошибки являются следствием тoro, что мы пытаемся обучить нейронную
сеть некоторой функции на основе оrpаниченной информации о ней. Вероятность
ошибки обучения определяется выражением
Vtrain == Р(х Е X:g(x) =1= с(х)).
(2.106)
Распределение вероятности в этом примере должно быть таким же, как и при фор
мировании примеров. Целью обучения РАС является МИнимизация значения Vtrain'
Предметная область, доступная алrоритму обучения, определяется размером N обу
чающеro множества Т. Кроме тoro, алroритм обучения имеет два следующих пара
метра управления.
· Параметр ошибки (error parameter) Е Е (0,1]. Этот параметр задает величину
ошибки, при которой аппроксимация целевоro понятия с(х) rипотезой g(x) счита
ется удовлетворительной.
· Параметр доверия (confidence parameter) 8 Е(О, 1]. Этот параметр задает степень
правдоподобия при построении "хорошей" аппроксимации.
Модель обучения РАС изображена на рис. 2.26.
Теперь можно формально определить модель обучения РАС [551], [1075], [1094].
Пусть В класс понятий для среды Х. Считается, что класс В является PAC
обучаемым, если существует ал20ритм L, обладающий следующим свойством. Для
люБО20 целевО20 понятия с Е В, для любою распределения вероятности на Х и для
всех О < Е < 1/2 и О < 8 < 1/2 при использовании ал20ритма L для множества пpи
меров обучения Т == {(Xi, C(Xi))}f:,l С вероятностью не хуже (1 8) результатом
ал20риmма обучения L будет 2Uпотеза 9 с ошибкой обучения Vtrain < Е. Эта вepo
ятность получается на любом случайном подмножестве множества Т и при любой
внутренней рандомизации, которая может r;yществовать в ал20ритме обучения L.
При этом размер обучающею множества N должен превышать значение некоторой
функции от 8 и Е.
Друrими словами, если размер N обучающеro множества Т достаточно велик, то
существует вероятность, что в результате обучения сети на этом наборе примеров
отображение входа на выход, реализуемое сетью, будет "приблизительно Koppeкт
ным". Обратите внимание, что, несмотря на зависимость от Е и 8, количество приме
ров N не обязательно зависит от целевоro понятия с и распределения вероятности в Х.
2.15. Вероятностно корректная в смысле аппроксимации модель обучения 159
Сложность 06учающеrо множества
При использовании теории РАС обучения на практике возникает интересный вопрос,
касающийся сложности обучающе20 множества (sample complexity). Ero можно
сформулировать следующим образом: сколько случайных примеров нужно предо
ставить алrоритму обучения, чтобы обеспечить ero информацией, достаточной для
"изучения" неизвестноrо понятия С, выбранноrо из класса понятий В, или насколько
большим должно быть обучающее множество Т?
Вопрос сложности обучающеro множества тесно связан с VС измерением. Однако,
прежде чем продолжить рассмотрение этоrо вопроса, необходимо определить понятие
СО2Ласованности (consistence). Пусть Т == {(Xi, d i ) } 1 некоторое множество Map
кированных примеров, в котором все Xi ЕХ и все d i Е(О, 1). Torдa понятие С называет
ся соrласованным с набором примеров Т (и наоборот, набор Т называется соrласован
ным с с), если для любоrо 1 i N выполняется равенство C(Xi) == d i [551]. В свете
концепции РАС обучения критичным является не размер множества вычисляемых
нейронной сетью функций отображения входа на выход, а VС измерение сети. Более
точно этот результат можно изложить в виде двух утверждений [64], [134], [1094].
Рассмотрим нейронную сеть с конечным VС измерением h 1.
1. Любой состоятельный алroритм обучения для этой нейронной сети является ал
roритмом обучения РАС.
2. Существует такая константа К, что достаточным размером обучающеro множе
ства Т для любоrо алroритма является
N == (hlo g ( ) + log ( ) ) ,
(2.107)
rдe Е параметр ошибки; 8 параметр доверия.
Общность этоro результата впечатляет: ero можно применить к обучению с учите
лем, независимо от типа алroритма обучения и распределения вероятности маркиро
ванных примеров. Именно общность этоrо результата сделала ero объектом повышен
HOro внимания в литературе, посвященной нейронным сетям. Сравнение результатов,
полученных на основе вычисления VС измерения, с экспериментальными данными
выявило существенные расхождения величин l6 . Это и не удивительНО, поскольку Ta
16 В этом примечании будут представлены четыре важных результата, описанных в литературе и посвяшен
ных сложности обучающеro множества и связанным с ней вопросам обобщення.
Во-первых, в [203] представлено детальное экспериментальное исследование фактических значений
сложности обучающеro множества, основанное на применении УС-измерения. В частности, в экспериментах
предполarалось оценить взаимосвязь между эффективностью обобщения, выполняемоro нейронной сетью, и
независнмым от распределения пессимистическим пределом, полученным на основе теорин статистическоro
обучения Вапника. Оrpаничение, описанное в [1087], имеет вид Vgene 2: О (f/lOg (f/ )) , rдe Vgene ошибка
......
160 rлава 2. Процессы обучения
кое рассоrласование отражает независимость от распределения и пессимистический
характер (distribution free, worst case) теоретических оценок. В действительности дe
ла обстоят значительно лучше.
Вычислительная сложность
Еще одним вопросом, который нельзя обойти вниманием при рассмотрении KOH
цепции обучения РАС, является вычислительная сложность. Этот вопрос касается
вычислительной эффективности алrоритма обучения. Более точно, понятие вblчисли
тельной сложности (computational complexity) связано с пессимистической оценкой
времени, необходимоro для обучения нейронной сети (обучаемой машины) на MHO
жестве маркированных примеров мощности N.
На практике время работы алroритма зависит прежде Bcero от скорости выпол
нения вычислений. Однако с теоретической точки зрения необходимо дать такое
определение времени обучения, которое не будет зависеть от конкретных устройств,
используемых для обработки информации. Поэтому время обучения (и COOTBeTCTBeH
но вычислительная сложность) обычно измеряется в терминах количества операций
(сложения, умножения и хранения), необходимых для выполнения вычислений.
При оценке вычислительной сложности алrоритма обучения необходимо изначаль
но знать, как она зависит от размерности примеров обучения m (т.е. от размера BXOД
Horo слоя обучаемой нейронной сети). В этом контексте алrоритм считается вычисли
обобш ения ; h VС-измерение; N размер обучающеrо множеС1Ва. Результаты, представленные в [203], пока-
зали, что средняя эффективность обобшения значительно лучше, чем описанная вышеприведенной формулой.
Во-вторых, в [472] были продолжены исследования, описанные ранее в [203]. Авторы поставили перед
собой 1)' же задачу, но отметили три важных отличия.
. Все эксперименты производились на нейронных сетях с точно известными результатами или очень хоро-
шими прсделами, полученными для VС-измерений.
. Рассматривался особый случай алroритма обучения.
Эксперименты былн основаны на реальных данных.
. Хотя в этой работе были получены более ценные с практической точки зрения оценки сложности обучающеro
множества, работа имела ряд сушественных теоретических изъянов, от которых нужно было избавиться.
В 1989 [оду вышла в свет работа, посвяшенная оцениванию размера N обучающеro множества, необходимоro
для обучения однослойной сети прямоro распространения с линейными пороroвыми нейронами с обеспече-
нием хорошеrо качества обобшення [107]. Предполаrалось, что обучающие примеры выбираются случайно с
произвольным распределением вероятности, а тестовые при меры, используемые для оценки эффективностн
обобшения, имеют такое же распределение. Соrласно [107], сеть почти наверняка обеспечивает обобщение,
если выполняются следуюшие условия.
1. Количество ошибок на обучающем множестве не превышает величины Е/2.
2. Количество примеров, используемых для обучения, удовлетворяет соотношению N О ( log ( ) ) ,
!'Де W число синаптических весов в сети. Это неравенство описывает независимое от распределения
пессимистическое оrpаничение, накладываемое на размер N. Но и здесь может наблюдаться большое
численное расхождение между фактически необходимым размером обучающеro множества и оценкой,
обеспечиваемой этим неравенством.
Наконец, в 1997 roду в [97] был поднят вопрос о том, что в задачах классификации образов с помощью
больших нейронных сетей часто оказывается, что для успешноro обучения сеть способна обойтись roраздо
меньшим количеством примеров, чем количество синаптических весов в ней (что утверждалось в [203]). В [97]
было показано, что в тех задачах, [де нейронная сеть при небольшом количестве СИljaптических весов хорошо
выполняет обобшение, эффективность этоro обобщения определяется не количеством весов, а их величиной.
2.16. Резюме и обсуждение 161
тельно эффективным (efficient), если время ero работы пропорционально O(m r ), rдe
r 1. В этом случае rоворят, что время обучения полиномиально зависит от т (poly
nomical1y with т), а сам алroритм называется ал20риmмом с полиномиальным вpeмe
нем выполнения (polynomial time algorithm). Задачи обучения, основанные на алrорит
мах с полиномиальным временем выполнения, обычно считаются "простыми" [64J.
Еще одним параметром, который требует особоrо внимания, является параметр
ошибки Е. Если речь идет о сложности обучающеrо множества, параметр ошибки
Е является фиксированным, но произвольным; а при оценке вычислительной слож
ности алroритма обучения необходимо знать, как она зависит от этоrо параметра.
Интуитивно понятно, что при уменьшении параметра Е задача обучения усложняет
ся. Отсюда следует, что со временем должно быть достиrнуто некоторое состояние,
которое обеспечит вероятностно корректный в смысле аппроксимации выход. Для
обеспечения эффективности вычислений соответствующее состояние должно дости
rаться за полиномиальное время по 1/ Е.
Объединив эти рассуждения, можно сформулировать следующее формальное
утверждение [64].
Ал20риmм обучения является вычислительно эффективным по параметру ошибки Е,
размерности примеров обучения т и размеру обучающею множества N, если вpe
мя е20 выполнения является полиномиальным по N, и существует такое значение
N o (8, Е), достаточное для РАС обучения, при котором аЛ20ритм является nолиноми
альным по т и E l.
2.16. Резюме и обсуждение
В этой rлаве мы обсудили некоторые важные вопросы, затраrивающие различные
аспекты процесса обучения в контексте нейронных сетей. Таким образом, были за
ложены основы для понимания материала оставшейся части книrи. При создании
нейронных сетей используются пять правил обучения: обучение на основе коррекции
ошибок (error correction leaming), обучение на основе памяти (memory based learn
ing), обучение Хебба (Hebb's leaming), конкурентное обучение (competitive leaming) и
обучение Больцмана (Boltzmann leaming). Некоторые из этих алroритмов требуют Ha
личия учителя, а некоторые нет. Важно то, что эти правила позволяют значительно
продвинуться за рамки линейных адаптивных фильтров, как в смысле расширения
возможностей, так и в смысле повышения универсальности.
При исследовании методов обучения с учителем ключевым является понятие "учи
теля", призванноrо вносить уточняющие коррективы в выходной сиrнал нейронной
сети при возникновении ошибок (в обучении на основе коррекции ошибок) или "за
rонять" свободные входные и выходные элементы сети в рамки среды (при обучении
Больцмана). Ни одна из этих моделей принципиально не применима к биолоrическим
орrанизмам, которые не содержат двусторонних нервных соединений, так необходи
162 rлава 2. Процессы обучения
мых для обратноrо распространения сиrналов при коррекции ошибок (в мноroслой
ных сетях), а также не поддерживают механизма корректировки поведения извне.
Тем не менее обучение с учителем утвердилось в качестве мощной парадиrмы обу
чения искусственных нейронных сетей. В этом можно убедиться при ознакомлении
с rлавами 3 7 настоящей книrи.
В отличие от метода обратноro распространения правила обучения без учителя
на основе самоорrанизации (такие как правило Хебба или конкурентное обучение)
основаны на принципах нейробиолоrии. Однако для более четкоrо понимания этоrо
типа обучения необходимо ознакомиться с основами теории информации Шеннона.
При этом нельзя обойти вниманием принцип пОЛНО20 количества информации (mutual
inforrnation principle) или Инфомакса (Infomax) [653], [654], который обеспечивает Ma
тематический формализм обработки информации в самоорrанизующихся нейронных
сетях по аналоrии с передачей информации по каналам связи. Принцип Инфомакса
и ero вариации подробно изложены в rлаве 10.
Обсуждение методов обучения бьmо бы не полным, если бы мы не останови
лись на модели селективНО20 обучения Дарвина (Darwinian se1ective learning model)
[275], [876]. Отбор (selection) является важным биолоrическим принципом, который
применяется в теории эволюции и развития. Он лежит в основе работы иммунной
системы [276] наиболее понятной биолоrической системы распознавания. Модель
селективНОro обучения Дарвина основана на теории отбора 2рупп нейронов (theory
of neural group selection). В ней предполаrается, что нервная система работает по
принципу eCTecTBeHHoro отбора, с тем отличием от эволюционноrо процесса, что все
действие разворачивается в мозrе и только на протяжении жизни орrанизма. Соrлас
но этой теории, основной операционной единицей нервной системы является отнюдь
не отдельный нейрон, а локальная rруппа жестко связанных клеток. Принадлежность
отдельных нейронов к различным rруппам определяется изменениями синаптических
весов. Локальная конкуренция и кооперация клеток обеспечивают локальный поря
док сети. Коллекция rpупп нейронов называется полем или репертуаром (repertoire).
Ввиду случайной природы развития нейронной сети rpуппы одноro поля хорошо
подходят для описания перекрывающихся, но подобных входных образов. За каж
дый входной образ отвечает одна или несколько rpупп HeKoтoporo поля. Тем самым
обеспечивается отклик на неизвестные входные образы, который может оказаться
очень важным. Селективное обучение Дарвина отличается от всех друrих алroрит
мов, обычно используемых в нейронных сетях, поскольку в структуре нейронной
сети предполаrается наличие множества подсетей, из которых в процессе обучения
отбираются только те, выходной сиrнал которых ближе Bcero к ожидаемому отклику.
Задачи 163
Это обсуждение можно завершить несколькими замечаниями, касающимися стати
стическоrо и вероятностноrо аспектов обучения. VС измерение зарекомендовало себя
как основной параметр теории статистическоro обучения. На нем основаны принцип
минимизации CTPyктypHOro риска и вероятностно корректная в смысле аппроксима
ции модель обучения (РАС). VС измерение является составной частью теории так
называемых машин опорных векторов, которые рассматриваются в rлаве 6.
По мере ознакомления с материалом настоящей книrи читателю еще не раз при
дется возвращаться к настоящей rлаве, посвященной основам процессов обучения.
Задачи
Правила обучения
2.1. Дельта правило, описанное в формуле (2.3), и правило Хебба, описываемое
соотношением (2.9), представляют собой два различных метода обучения.
Укажите различия между этими двумя правилами.
2.2. Правило обучения на основе коррекции ошибок можно реализовать с помо
щью запрета вычитания желаемоro отклика (целевоro значения) из факти
ческоro выходноro сиrнала с последующим применением антихеббовскоrо
правила [748]. Прокомментируйте эту интерпретацию обучения на основе
коррекции ошибок
2.3. На рис. 2.27 показано двумерное множество точек. Часть этих точек при
надлежит классу С 1 , остальные классу С 2 . Постройте rpаницу решений,
применив правило ближайшеro соседа.
2.4. Рассмотрим rpуппу людей, коллективное мнение которых по некоторому ин
тересующему нас вопросу определяется как взвешенное среднее мнений OT
дельных членов rpуппы. Предположим, что при изменении мнения члена
rpуппы в сторону коллективной точки зрения оно при обретает больший вес.
С друroй стороны, если отдельные члены rpуппы встают в открытую оппо
зицию коллективной точке зрения, их мнение теряет вес. Эта форма взве
шивания эквивалентна управлению с положительной обратной связью, KO
нечным результатом KOTOpOro является достижение общеro консенсуса среди
членов rpуппы [653].
Проведите аналоrию между этой ситуацией и постулатом обучения Хебба.
.....
164 rлава 2. Процессы обучения
Х 2
х :класс С !
. :класс С 2
х х
х
х
х
. х
.
х х . х
.
О . . Х !
. . .
. .
.
Рис. 2.27. Пример обучающеro
множества
2.5. Обобщенная форма правила Хебба описывается соотношением
ДWkj(n) == а F(Yk(n))G(Xj(n)) wkj(n)F(Yk(n))'
rдe xj(n) и Yk(n) предсинаптический и постсинаптический сиrналы
соответственно; F(.) и с(.) некоторые функции своих aprYMeHТOB;
ДWkj(n) изменение синаптическоrо веса Wkj в момент времени n, BЫ
званное сиrналаМИХj(n) и Yk(n)' Найдите точку равновесия и максимальное
значение спуска, определяемое этим правилом.
2.6. Входной сиrнал с единИЧНОЙ амплитудой MHorOKpaTHo передается через си
наптическую связь, начальное значение которой также равно единице. Bы
числите изменение значений синаптическоro веса со временем с помощью
следующих правил:
а) простой формы правила Хебба (2.9), в предположении, что параметр CKO
рости обучения т] ==0,1;
б) правила ковариации (2.10) для значений предсинаптической х == О и пост
синаптической iJ == 1.0 активности.
2.7. Синапс Хебба, описываемый соотношением (2.9), предполаrает использова
ние положительной обратной связи. Докажите истинность этоrо утверждения.
3адачи 165
2.8. Рассмотрим rипотезу ковариации для обучения на основе самоорrанизации,
описываемоrо выражением (2.10). В предположении эрrодичности системы
(Korдa среднее по времени может быть заменено средним по множеству)
покажите, что ожидаемое значение ДWkj в (2.10) можно представить COOT
ношением
Е[ДWkj] == т] (E[YkXj] ух).
(2.108)
Как можно интерпретировать этот результат?
2.9. Соrласно [656], постулат Хебба формулируется следующим образом:
ДWki == т] (Yk Yo)(Xi Хо) + а1,
[де Xi и Yk предсинаптический и постсинаптический сиrналы COOTBeT
ственно; а1, т], ХО константы. Предположим, что нейрон k линейный, Т.е.
Yk == L WkjXj + а2,
j
rдe а2 еще одна константа. Предположим, что все входные сиrналы имеют
одинаковое распределение, т.е. E[Xi] == E[Xj] == 11. Пусть С матрица KOBa
риации входноrо сиrнала, элемент ij которой определяется соотношением
C ij == E[(Xi 1l)(Xj 11)].
Найдите Е[ДWkj]'
2.10. Напишите выражение для описания выходноrо сиrнала Yj нейронаj в сети,
показанной на рис. 2.4. При этом можно использовать следующие перемен
ные:
Xi i й входной сиrнал;
Wij синаптический вес связи входа i с нейроном j;
Ckj вес латеральной связи нейрона k с нейроном j;
Vi индуцированное локальное поле нейрона j;
Yj == q>(Vi)'
Какому условию должен удовлетворять нейрон j, чтобы выйти победителем?
2.11. Решите задачу 2.1 О при условии, что каждый выходной нейрон имеет обрат
ную связь с самим собой.
......
166 rлава 2. Процессы обучения
Входной
сиrнал
Решающее правило
(нейронная сеть)
Пользователь
и среда
Изменение
свободных параметров
Сиrнал ошибки
на уровне семантики
Рис. 2.28. Блочная диаrрамма адап
тивной системы изучения eCTeCTBeHHO
ro языка
2.12. Принцип латеральноrо торможения сводится к следующему: "близкие ней
роны возбуждаются, а дальние тормозятся". Ero можно про моделировать
с помощью разности между двумя rауссовыми кривыми. Эти две кривые
имеют общую область определения, но положительная кривая возбуждения
имеет более крутой и высокий пик, чем отрицательная кривая торможения.
Это значит, что модель TaKoro соединения можно описать соотношением
W(x) == 1 e x2/ 2a
y'21tO'e
1 x2 / 2а2
e .
y'21tO'i '
[де х расстояние до нейрона, отвечающеrо за латеральное торможение.
Шаблон W(x) используется для сканирования страницы, одна половина KO
торой белая, а друrая черная. rраница между двумя половинками перпен
дикулярна оси х.
Постройте rpафик изменения выхода процесса сканирования для О'е ==5;
O'i ==8 и О'е == 1, O'i ==2.
Парадиrмыо6учения
2.13. На рис. 2.28 показана блочная диаrpамма адаптивной системы изучения
естествеННО20 языка (adaptive language acquisition system) [371]. Синаптиче
ские связи в нейронной сети, входящей в состав этой системы, усиливаются
и ослабляются в зависимости от значения обратной связи, полученной в pe
зультате реакции системы на входное возбуждение. Этот принцип можно
рассматривать как пример обучения с подкреплением. Обоснуйте правиль
ность этоrо утверждения.
2.14. К какой из двух парадиrм (обучение с учителем и без Hero) можно отнести
следующие алroритмы:
а) правило ближайшеrо соседа;
б) правило k ближайших соседей;
Задачи 167
в) обучение Хебба;
[) правило обучения Больцмана.
Обоснуйте свой ответ.
2.15. Обучение без учителя может быть реализовано в кумулятивном и интерак
тивном режимах. Опишите физический смысл этих двух возможностей.
2.16. Рассмотрим сложности, с которыми сталкивается обучаемая машина при Ha
значении коэффициентов доверия результату иrpы в шахматы (победа, пора
жение, ничья). Объясните понятия временной и структурной задач присваи
вания коэффициентов доверия в контексте этой иrpы.
2.17. Задачу обучения с учителем можно рассматривать как задачу обучения с
подкреплением, использующую в качестве подкрепления некоторую меру
близости фактическоro отклика системы с желаемым. Опишите взаимосвязь
между обучением с учителем и обучением с подкреплением.
Память
2.18. Рассмотрим следующее ортонормальное множество ключевых образов, при
меняемых для построения корреляционной матрицы памяти:
Х1 == [1, о, о, о]Т,
Х2 == [0,1, о, о]Т,
хз == [о, 0,1, О]Т
и соответствующее множество запомненных образов:
У1 == [5,1, о]Т,
У2 == [ 2, 1, 6]Т,
УЗ == [ 2,4,з]Т.
а) Вычислите матрицу памяти М.
б) Покажите, что эта память обладает хорошими ассоциативными способно
стями.
2.19. Вернемся к предыдущей задаче построения корреляционной матрицы па
мяти. Предположим, что применяемый к этой памяти стимул представляет
собой зашумленную версию ключевоro образа Х1 вида
х == [о, 8; o, 15; о, 15; o, 20]Т.
.....
168 rлава 2. Процессы обучения
а) Вычислите отклик памяти у.
б) Покажите, что отклик у наиболее близок к запомненному образу у 1 в
Евклидовом смысле.
2.20. Автоассоциативная память обучается на следующих ключевых векторах:
Х1 == H 2, з, JЗ]Т,
Х2 == Н2, 2, V8]T,
ХЗ == Нз, 1, Vб]Т.
а) Вычислите уrлы между этими векторами. Насколько эти векторы близки
к ортоrональным?
б) Используя обобщение правила Хебба (т.е. правило внешнеrо произведе
ния), вычислите матрицу памяти для этой сети. Исследуйте, насколько эта
матрица близка к идеальной автоассоциативной памяти.
в) В систему ассоциативной памяти подаетсЯ "замаскированная" версия клю
чевоro вектора Х1:
Х == [О, з, VЗ]Т.
(2.109)
Вычислите реакцию памяти и сравните ее с ожидаемым откликом Х1.
Адаптация
2.21. На рис. 2.29 представлена блочная диаrpамма некоторой адаптивной системы.
Входной сиrнал модели пРО2нозирования определяется предыдущимИ значе
ниями процесса, а именно:
х(n 1) == [х(n 1), х(n 2),... , х(n т)]Т.
Выход модели 5;(п) представляет собой оцеНКУ текущеro значения х(n)
процесса. Компаратор вычисляет сиrнал ошибки
е(n) == х(n) 5;(n),
который, в свою очередь, корректирует настраиваемые параметры модели.
Выходной сиrнал также направляется на следующий уровень нейросетевой
обработки для интерпретации. При MHoroKpaTHoM повторении этой операции
качество обработки информации системой значительно возрастает [719].
Дополните рис. 2 29 информацией об уровне обработки сиrнала.
Задачи 169
Выходной сиrнал
Матрица
единичной
задержки
Проrнозное
значение
х(п)
Рис. 2.29. Блочная диаrрамма адаптивной
системы
Статистическая теория обучения
2.22. Выполняя процедуру, использованную для вывода соотношения (2.62) из
(2.61), выведите формулу (2.66), определяющую среднюю по ансамблю функ
цию Lav(f(x), Р(х, Т)).
2.23. В этой задаче необходимо вычислить VС измерение прямоуrольной области,
ориентированной вдоль одной из осей на плоскости. Покажите, что YC
измерение этой области равно четырем. Рассмотрите следующие варианты.
а) На плоскости имеются четыре точки, а дихотомия реализована прямо
уrольниками, ориентированными по осям.
б) На плоскости имеются четыре точки, для которых не существует реализу
емой дихотомии в виде прямоуroльников, ориентированных по осям.
в) На плоскости имеются пять точек, для которых не существует дихотомии,
реализуемой в виде прямоуrольников, ориентированных по осям.
2.24. Рассмотрим линейный двоичный классификатор образов, входной вектор х
KOToporo имеет размерность т. Первый элемент вектора х является KOHCTaH
той, равной единице, так что соответствующий вес классификатора описы
вает пороrовое значение (bias). Каково VС измерение этоrо классификатора
по входному пространству?
2.25. Неравенство (2.97) определяет оrpаничение на скорость равномерной сходи
мости, лежащей в основе принципа минимизации эмпирическоrо риска.
а) Докажите истинность формулы (2.98) при условии выполнения HepaBeH
ства (2.97).
б) Выведите формулу (2.99), определяющую доверительный интервал Е1.
'111
170 rлава 2. Процессы обучения
1 2 3 4
х О РИс. 2.30. Множество точек для классификации
2.26. Продолжая пример 2.3, покажите, что четыре равноудаленные точки на
рис. 2.30 не MOryT быть разделены однопараметрическим семейством ин
дикаторных функций f(x, а), rдe а Е .
2.27. Опишите взаимосвязь дилеммы смещения/дисперсии и принципа минимиза
ции CTpyктypHoro риска в контексте нелинейной реrpессии.
2.28. а) Алroритм, используемый для обучения мноrослойной сети прямоrо pac
пространения с сиrмоидальной активационной функцией, является PAC
обучаемым. Обоснуйте истинность этоro утверждения.
б) Выполняется ли аналоrичное утверждение для произвольной нейронной
сети с пороrовой функцией активации? Обоснуйте свой ответ.
Однослойный персептрон
3.1. Введение
Можно выделить нескольких исследователей, которые внесли действительно выдаю
щийся вклад в развитие теории искусственных нейронных сетей в rоды становления
этой проблемной области (l943 1958).
. Мак Каллок (McCalloch) и Питц (Pitt) в 1943 roду впервые представили идею
использования нейронных сетей в качестве вычислительных машин [714].
. Хебб (НеЬЬ) в 1949 roду ввел первое правило самоорrанизующеroся обуче
ния [445].
. Розенблатт (Rosenblatt) в 1958 rоду ввел понятие персептрова как первой модели
обучения с учителем [902].
Влияние работы Мак Каллока и Питца на развитие нейронных сетей уже обсуж
далось в rлаве 1, а идея обучения Хебба вкратце рассматривалась в rлаве 2. В этой
rлаве речь пойдет о персептроне Розенблатта (Rozenblatt perceptron).
Персептрон представляет собой простейшую форму нейронной сети, предназна
ченную для классификации лuнейно разделuмых (linearly separable) сиrналов (т.е. об
разы можно разделить некоторой rиперплоскостью). Персептрон состоит из одноro
нейрона с настраиваемыми синаптическими весами и пороrом. Первый алrоритм Ha
стройки свободных параметров для такой нейронной сети был создан Розенблаттом
[899], [902] для персептронной модели мозrа 1 . Розенблатт доказал, что если обра
зы (векторы), используемые для обучения персептрона, выбраны из двух линейно
разделимых классов, то алrоритм персептрона сходится и формирует поверхность
решений в форме rиперплоскости, разделяющей эти два класса. Доказательство cxo
1 В исходной версии персептрона, соrласно Розенблатry [899], содержались три типа злементов: сенсориые,
ассоциативные и реактивные. Веса связей сенсорных злементов с ассоциативными были фиксированными, а
веса связей ассоциативных злемеитов с реактивными переменными. Ассоциативные злементы выступали в
роли препроцессоров, предназначенных для извлечения модели из данных среды. Что касается переменных
весов, то функционирование исходноro персептрона Розенблатта в сущности соответствует случаю простоro
реактивноro элемента (т.е. одиоro нейрона).
,..
172 rлава з. ОДНОСЛОЙНЫЙ персептрон
ДИМОСТИ этоro алrоритма получило название теоремы о сходимости персептрона
(perceptron convergence theorem). Персептрон, построенный на одном нейроне, orpa
ничен выполнением задачи разделения только двух классов (rипотез). Увеличивая раз
мерность выходноrо (вычислительноrо) слоя персептрона и включая в Hero несколько
нейронов, можно решать задачи классификации на большее число классов. Важно за
метить, что при описании теории персептрона достаточно рассмотреть случай сети
с единственным нейроном. Обобщение этой теории на класс систем, содержащих
несколько нейронов, довольно тривиально.
Единичный нейрон также составляет основу адаптивною фильтра (adaptive fi1
ter) функциональноro блока, являющеrося основным для предметной области об
работки СИ2налов (signa1 processing). Развитие теории адаптивной фильтрации было
вызвано новаторской работой, открывшей миру так называемый ал20ритм миними
зации среднеквадратической ошибки LMS (least mean square a1gorithm), известный
также под названием дельта правила (de1ta ru1e) [1141]. Несмотря на свою простоту,
алroритм продемонстрировал высокую эффективность. В самом рабочем названии
задачи линейной адаптивной фильтрации (linear adaptive filtering) подразумевается,
что нейрон работает в линейном режиме. Адаптивные фильтры MorYT успешно при
меняться в таких разноплановых областях, как управление антеннами, системы связи
и управления, радары, сейсмолоrия и биомедицинская инженерия [434], [435], [1144].
Алrоритм LMS и персептрон тесно связаны между собой, поэтому имеет смысл
рассмотреть их вместе в одной rлаве.
Структура rлавы
Настоящая rлава состоит из двух частей. В первой части (разделы 3.2 3.7) рассматри
ваются линейные адаптивные фильтры и алrоритм LMS. Вторая часть (разделы 3.8
3.10) посвящена персептрону Розенблатта. Такой порядок изложения сохраняет ис
торическую хронолоrию появления этих понятий.
В разделе 3.2 описывается задача адаптивной фильтрации. В разделе 3.3 pac
сматриваются три метода безусловной оптимизации: методы наискорейшеrо спуска,
Ньютона и Ньютона rаусса. Эти методы имеют самое прямое отношение к изучению
адаптивных фильтров. В разделе 3.4 речь пойдет о линейном фильтре, основанном на
методе наименьших квадратов, который асимптотически сходится к фильтру Винера
по мере увеличения выборки данных. Фильтр Винера реализует идеальный, в CMЫC
ле производительности, линейный адаптивный фильтр, работающий в стационарной
среде. В разделе 3.5 рассматривается алrоритм LMS и обсуждаются ero возмож
ности и оrpаничения. В разделе 3.6 раскрывается идея кривых обучения, широко
используемых для оценки производительности адаптивных фильтров. В разделе 3.7
обсуждается принцип имитации отжиrа для алrоритма LMS.
3.2. Задача адаптивной фильтрации 173
{ xl(i)
(')
Входы Х:11 i
xm(i)
Неизвестная
динамическая
система
Выход
d(i)
а)
x l (i)
x 2 (i)
-1
xm(i)
Рис. 3.1. Неизвестная динамическая система (а).
rраф прохождения сиrнала в адаптивной модели
системы (6)
d(i)
б)
Раздел 3.8 посвящен персептрону Розенблатта в нем вводится ряд базовых поня
тий, связанных с ero работой. В разделе 3.9 описывается алrоритм настройки вектора
синаптических весов персептрона при решении задачи классификации образов из
двух линейно разделимых классов и обосновывается ero сходимость. В разделе 3.10
анализируется взаимосвязь между персептроном и байесовским классификатором для
rауссовой среды.
rлава завершается в разделе 3.11, в котором подводятся итоrи.
3.2. Задача адаптивной фильтрации
Рассмотрим динамическую систему (dynamica1 system), математические характери
стики которой неизвестны. В нашем распоряжении имеется только набор маркиро
ванных данных входноro и выходноrо сиrналов, rенерируемых системой в paBHOMep
ные дискретные интервалы времени. В частности, если т входных узлов rенерируют
т MepHoe воздействие х( i), в ответ система формирует скалярный выходной сиrнал
d(i), rдe i == 1, 2, ..., п (рис. 3.1). Таким образом, внешнее поведение системы
описывается следующим множеством данных:
Т: {x(i),d(i);i == 1,2,... ,п,...},
(3.1)
rдe
x(i) == [Xl(i)'X2(i),... ,xm(i)]T.
......
174 rлава 3. ОДНОСЛОЙНЫЙ персептрон
Множество Т содержит примеры, одинаково распределенные соrласно некоторому
вероятностному закону. Размерность входноro вектора х( i) называют размерностью
входною пространства (dimensiona1ity of the input space).
Входной сиrнал х( i) может быть представлен двумя диаметрально противополож
ными способами в пространстве и во времени.
· Если т элементов сиrнала х( i) зарождаются в различных точках пространства, то
входной сиrнал можно считать моментальным снимком данных (snapshot of data).
· Если т элементов сиrнала х( i) представляют собой текущее и (т 1) преды-
дущее значения возбуждения, снятые через равномерные промежутки вpeмe
ни (uniform1y spaced in time), rоворят, что входной сиrнал снимается во вре-
менной области.
Требуется построить модель выходноrо сиrнала неизвестной динамической си
стемы с несколькими входами и одним выходом на основе одноro нейрона. Ней
ронная модель работает под управлением HeKoToporo алюритма, который обеспе
чивает настройку синаптических весов нейрона. При этом принимаются следую
щие соrлашения.
· Алroритм начинает работу с произвольных (arbitrary) значений синаптических
весов.
· Настройка синаптических весов в ответ на статистические вариации поведения
системы выполняется непрерывно (continuous) (т.е. время встроено в структуру
caMoro алroритма).
· Вычисление корректирующих значений синаптических весов выполняется через
равномерные промежутки времени.
Нейронная модель, описываемая таким образом, получила название адаптивНО20
фильтра (adaptive filter). Несмотря на то что из caMoro названия однозначно сле-
дует назначение системы идентификация систем, характеристики адаптивных
фильтров выводят нас далеко за рамки этоrо применения.
На рис. 3.1, б показан rpаф прохождения сиrнала в адаптивном фильтре. Ero работа
включает два последовательных процесса.
1. Процесс фильтрации (fi1tering process), предполаrающий вычисление двух сиrналов.
· Выходной сиrнал, обозначаемый как у( i) и rенерируемый в ответ на вектор
входноrо воздействия x(i) с компонентами Xl(i)'X2(i),..., xm(i).
· Сиrнал ошибки, обозначаемый как е( i) и вычисляемый как отклонение выход-
Horo сиrнала y(i) от выходноrо сиrнала реальной системы d(i), который еще
называют целевым СИ2Налом (target signa1) или ожидаемым откликом (desired
response ).
3.3. Методы безусловной оптимизации 175
2. Процесс адаптации (adaptive process), включающий автоматическую подстройку
синаптических весов нейрона на основе сиrнала ошибки e(i).
Комбинация этих двух процессов называется контуром с обратной связью (feed
back loop) нейрона.
Учитывая линейность нейрона, выходной сиrнал у( i) совпадает с индуцирован
ным локальным полем v ( i):
m
y(i) == v(i) == I:: wk(i)Xk(i),
k l
(3.2)
rдe wl(i),W2(i), ..., wm(i) т синаптических весов нейрона, измеренных в MO
мент времени i. В матричной форме выходной сиrнал у( i) можно представить как
скалярное произведение векторов w(i) и x(i):
у( i) == х Т (i)w( i),
(3.3)
rдe
w(i) == [Wl (i), W2(i),... , wm(i)]T.
Заметим, что индексация синаптических весов несколько упрощена и не содержит
индекса, указывающеrо на конкретный нейрон. Это обусловлено тем, что мы paCCMaT
риваем случай одноrо нейрона. Это соrлашение распространяется на всю настоящую
rлаву. Разность значения выходноrо сиrнала нейрона у( i) и фактическоrо выходноro
сиrнала системы d(i) составляет сиrнал ошибки e(i):
e(i) == y(i) d(i).
(3.4)
Алrоритм применения сиrнала ошибки для коррекции синаптических весов ней
рона определяется функцией стоимости, используемой конкретным методом адаптив
ной фильтрации. Этот вопрос тесно связан с задачей оптимизации. Таким образом,
уместно предложить обзор некоторых методов оптимизации, которые можно приме
нять не только к линейным адаптивным фильтрам, но и к нейронным сетям в целом.
3.3. Методы безусловной оптимизации
Рассмотрим непрерывно дифференцируемую функцию стоимости E(w), зависящую
от HeKoToporo неизвестноrо вектора w. Функция E(w) отображает элементы вектора
w в пространство действительных чисел и является мерой оптимальности выбран
HOro для алrоритма адаптивной фильтрации вектора w. Требуется отыскать такое
решение w*, что
......
176 rлава 3. ОДНОСЛОЙНЫЙ персептрон
E(w*) :::; E(w),
(3.5)
Т.е. необходимо решить задачу безусловной оптимизации (unconstrained optimization
problem), которая формулируется следующим образом.
Минимизировать функцию стоимости E(w) по отношению к вектору весов w
E(w) -----+ min.
(3.6)
Необходимым условием оптимальности является следующее:
V'E(w*) == О,
(3.7)
rде \l оператор 2радиента
\l == [ a l ' д 2'"'' д т] т
(3.8)
а \lE(w) вектор 2радиента функции стоимости
[ дЕ дЕ дЕ ] т
\lE(w)== д ' д ,..., д
Wl W2 W m
(3.9)
Из всех методов безусловной оптимизации для создания адаптивных фильтров
лучше Bcero подходят алrоритмы последователЬНО20 спуска (iterative descent).
Начиная с исходНО20 значения w(O) 2енерируется последовательность векторов вe
совых коэффициентов w(1), w(2), . . ., таких, что с каждой итерацией аЛ20ритма
значение функции стоимости уменьшается:
E(w(п + 1)) < E(w(п)),
(3.1 О)
2де w( п) предыдущее значение вектора весов; w( п + 1) последующее.
Можно надеяться, что такой алrоритм сойдется к оптимальному решению w*. Сло
во "надеяться" здесь появилось не случайно остается вероятность, что алrоритм
будет расходиться (т.е. станет неустойчивым), если не будут выполнены определен
ные условия.
В этом разделе описываются три метода безусловной оптимизации, основанные
на той или иной реализации идеи итеративноro спуска [124].
3.3. Методы безусловной оптимизации 177
Метод наискорейшеrо спуска
в методе наискорейшеrо спуска корректировка векторов весов выполняется в направ
лении максимальноrо уменьшения функции стоимости, Т.е. в направлении, противо
положном вектору 2радиента (gradient vector) \lE(w). Для удобства можно принять
следующее обозначение rpадиента:
g == V E(w).
(3.11 )
Формально алrоритм наискорейшеro спуска можно записать в следующем виде:
w(п + 1) == w(п) 11g(п),
(3.12)
rдe 11 положительная константа, называемая параметром скорости обучения
(leaming rate parameter); g(п) вектор rpадиента, вычисленный в точке w(п). Пе
реходя от п й итерации к п + l й, алrоритм выполняет коррекцию (correction) Beco
вых коэффициентов:
дw(п) == w(п + 1) w(п) == 11g(п).
(3.13)
При внимательном рассмотрении видно, что уравнение (3.13) является формаль
ной записью описанноro в rлаве 2 правила коррекции ошибок
Чтобы показать, что алroритм наискорейшеrо спуска удовлетворяет условию
(3.10), рассмотрим разложение E(w(п + 1)) в ряд Тейлора относительно w(п) с точ
ностью до членов первоro порядка
E(w(п + 1)) == E(w(п)) + gТ(п)дw(п),
которое допустимо при малых значениях параметра 11. Подставляя эту формулу в
(3.13), получим:
E(w(п + 1)) == E(w(п)) 11g T (п)g(п) == E(w(п)) 11llg(п)11 2 .
Из этоrо выражения видно, что для малых значений параметра скорости обучения
11 значение функции стоимости уменьшается на каждой итерации. Представленное
доказательство истинно только для малых значений 11.
.......
178 rлава 3. ОДНОСЛОЙНЫЙ персептрон
4
>: о
l'
11 o,3
-4
4 О 4
w1(п)
а)
4
5 о
""N п O
п l
п 2
11 1
4
4 О 4
w1(п)
б)
Рис. 3.2. Траектория изменения вектора весовых коэффициентов по методу
наискорейшеro спуска в двумерном пространстве для двух различных значе
ний параметра скорости обучения т1 == 0.3 (а) и т1 == 1.0 (б). Координаты Wl И
W2 являются элементами вектора весов w
3.3. Методы безусловной оптимизации 179
Метод наискорейшеro спуска сходится к оптимальному значению w* достаточно
медленно. Кроме TOro, на скорость сходимости влияет значение параметра Т1.
. Если параметр т1 мал, алroритм замедляется (overdamped), и траектория изменения
w(п) соответствует rладкой кривой (рис. 3.2, а).
. Если параметр т1 велик, алroритм ускоряется (underdamped), и траектория w(п)
принимает зиrзаroобразный вид (рис. 3.2, 6).
. Если параметр т1 превосходит некоторое критичное значение, алroритм становится
неустойчивым (т.е. расходящимся).
Метод Ньютона
Основная идея метода Ньютона (Newton's method) заключается в минимизации KBaд
ратичной аппроксимации функции стоимости E(w) в точке w(п). Минимизация BЫ
полняется на каждом шаrе алrоритма. Используя разложение функции стоимости в
ряд Тейлора с точностью до членов BTOpOro порядка, можно записать:
,6,E(w(п)) == E(w(п + 1)) E(w(п)) ==
== gT(п),6,W(п) + 1j2,6,w T (п)H(п),6,w(п).
(3.14)
Здесь, как и ранее, g(п) вектор rpадиента функции E(w) размерности тХ 1,
вычисленный в точке w(п). Матрица Н(п) матрица Тессе; или rессиан, такЖе
вычисленный в точке w( п) по следующей формуле:
[8,. 8 2 Е 8" ]
8w 2 8w 1 8w2 . .. 8w 1 8w m
8 E 8 2 Е 8 2 Е
Н == V'2E(w) == 2 8Wl 8w . .. 8W28w m (3.15)
8 2 Е 8 2 Е 8 2 Е
8w m 8w l 8Wm 8W2 ... 8w
Для существования rессиана, определяемоro выражением (3.15), функция стои
мости должна быть дважды непрерывно дифференцируемой по элементам вектора w.
Дифференцируя 2 выражение (3.14) по ,6,w, получим, что инкремент ,6,E(w) достиrает
2 Дифференцирование по вектору
Пусть f(w) действительная функция векторноro apryмeHTa w. Производная f(w)w определяется как вектор
== [ : l ' : 2 ' .. . , a J т ,
rде m размериость вектора w. Следующие два случая представляют особый интерес.
Случай 1
Функция f(w) определяется скалярным произведением
m
f(w) == х Т w == L XiWi.
i l
.....
180 rлава 3. ОДНОСЛОЙНЫЙ персептрон
минимума при условии
g(п) + Н(п)дw(п) == О.
Разрешая это уравнение относительно дw(п), получим:
дw(п) == H l(п)g(п).
Таким образом,
w(п + 1) == w(п) + дw(п) == w(п) H l(п)g(п),
(3.16)
rдe H l(п) матрица, обратная rессиану.
в целом метод Ньютона довольно быстро асимптотически сходится и не приводит
к появлению зиrзаrообразных траекторий, как метод наискорейшеrо спуска. Однако
для обеспечения работоспособности метода Ньютона матрица recce Н(п) должна
быть положительно определенной 3 (positive definite matrix) для всех п. К сожалению,
положительную определенность матрицы Н( п) нельзя rарантировать для всех ите
раций алroритма. Если rессиан не является положительно определенной матрицей,
метод Ньютона требует некоторой коррекции [124], [854].
в этом случае
д! .
д == Xi, 1, 2, ..., m
Wi
или, в матричной форме, можно записать:
д!
д w == Х. (1)
Случай 2
Функция f(w) определяется квадратичной формой
m m
j(w) == wTRw == L L WiTijWj,
i l j l
2де Tij ij й элемент матрицы R размерности m х т. Так как
д! m
LTijWj, i 1,2, ..., т,
W, j l
то в матричной форме можно записать
д!
==b.
aw
Выражения (1) и (2) представляют собой два важных правила дифференцирования вещественных функций
по вектору.
3 Положительно определенная матрица
Матрица R размерности тхт называется неотрицательно определенной, если она удовлетворяет условию
aTRa О для любоro вектора аЕ т. Если при этом выполняется cтporoe HepaBeHC'IВO, то матрица называется
положительно определенной.
Важным свойством положительно определенных матриц является их несинryлярность, Т.е. существование
обратной матрицы R 1. Еще одним важным свойством положительно определенных матриц является то, что
все их собствениые значения (т.е. корни характеристическоro уравнения det (R) O) положительны.
3.3. Методы безусловной оптимизации 181
Метод rаусса Ньютона
Метод rаусса Ньютона применяется для минимизации функции стоимости, пред
ставленной в виде суммы квадратов ошибок. Пусть
1 n
E(w) == 2 I:: e 2 (i),
i l
(3.17)
rдe коэффициент 1/2 введен для упрощения последующеrо анализа. Все слаrаемые
ошибок в этой формуле вычисляются на основании вектора весов w, фиксированноrо
на всем интервале наблюдения 1:::; i :::; п.
Сиrнал ошибки е( i) является функцией от настраиваемоrо вектора весов w.
Для текущеrо значения w( п) зависимость е( i) от w можно линеаризовать следу
ющим образом:
e'(i,w)==e(i)+ [ a a e(i) ] т (w w(п)), i==l, 2, ..., п.
w w w(n)
(3.18)
Эту же формулу можно записать в матричном виде:
е'(п, w) == е(п) + J(п)(w w(п)),
(3.19)
rде е(п) вектор ошибки
е(п) == [е(l), е(2),..., е(т)]Т,
J(п) матрица Якобиана ошибки
[ д; ) д; ) '" ; ]
де(2) де(2) де(2)
J(п) == BWl BW2 ... BW m
.,. ... ......
де(n) де(n) де(n)
BWl BW2 '" BW m w w(n)
(3.20)
Якобиан это транспонированная матрица rpадиента V' е( п)
УОЕ(п) == [УОе(l), УОе(2),..., Ve(п)].
Обновленный вектор w( п + 1) можно записать в следующем виде:
w(п + 1) == argmJn {t Ile,(п, W)11 2 }.
(3.21 )
......
182 rлава 3. ОДНОСЛОЙНЫЙ персептрон
Используя формулу (3.19) для оценки квадратичной Евклидовой нормы
Ile,(п, w)1I 2 , получим:
1 2 1 2 Т
21Iе'(п, w)11 ==21Ie(п)11 + е (п)J(п)(w w(п))+
1
+ (w W(п))T JT(п)J(п)(w w(п)).
2
Дифференцируя это выражение по w и приравнивая результат к нулю, получим:
JT(п)e(п) + JT(п)J(п)(w w(п)) == О.
Разрешая это уравнение относительно w и учитывая (3.21), можно записать:
w(п + 1) == w(п) (JT(п)J(п)) lJT(п)e(п).
(3.22)
Эта формула описывает метод rаусса Ньютона в чистом виде.
В отличие от метода Ньютона, требующеro знания матрицы rессиана для функции
стоимости Е (п ), метод rаусса Ньютона требует только знания матрицы Якобиана
вектора ошибки е(п). Тем не менее для реализации итеративноro метода raycca
Ньютона матрица про изведения JT (п)J (п) должна быть несинrулярной.
Возвращаясь к предыдущей формуле, можно заметить, что матрица JT (п )J( п) Bce
rдa является неотрицательно определенной. Для обеспечения несинryлярности Яко
биан J(п) должен иметь paHr п (т.е. п строк матрицы J(п) в формуле (3.20) должны
быть линейно независимы). К сожалению, это условие выполняется не всеrда. Для
обеспечения необходимоrо paHra матрицы J(п), общей к про изведению JT(п)J(п),
зачастую добавляют диаrональную матрицу 81, rдe 1 единичная матрица. Пара
метр 8 является малой положительной константой, обеспечивающей положительную
определенность матрицы JT (п)J (п) + 81 для всех п.
Исходя из вышесказанноrо, уравнение метода rаусса Ньютона можно записать в
несколько видоизмененном виде:
w(п + 1) == w(п) (JT(п)J(п) + 81) lJT(п)e(п).
(3.23)
Влияние этой модификации постепенно ослабляется с увеличением количества
итераций п. Обратите внимание, что рекурсивное соотношение (3.23) является реше
ни ем задачи минимизации модифицированной функции стоимости:
E(w) { 15 Ilw w(n) 11' + t, e'(i) } ,
(3.24)
rдe w(п) mекущеезначение (current va1ue) вектора весовых коэффициентов w(i).
3.4. Линейный фильтр, построенный по методу наименьших квадратов 183
Ознакомившись с основными методами оптимизации, можно вплотную заняться
вопросами линейной адаптивной фильтрации.
3.4. Линейный фильтр, построенный по методу
наименьших квадратов
Как и следует из caMoro названия, линейный фильтр, построенный по методу наи
меньших квадратов (linear 1east squares fi1ter), имеет две отличительные особенности.
Во первых, он строится для отдельноro линейноrо нейрона (см. рис. 3.1, 6). Bo
вторых, функция стоимости E(w), используемая для создания этоrо фильтра, пред
ставляет собой сумму квадратов ошибок и определяется в соответствии с формулой
(3.17). Принимая во внимание формулы (3.3) и (3.4), для вектора ошибки е(п) можно
записать следующее соотношение:
е(п) == d(п) [х(l), х(2),... , х(п)]Т w(п) == d(п) X(п)w(п),
(3.25)
rдe d(п) вектор желаемоro отклика размерности п
d(п) == [d(l), d(2),... , d(п)]T,
Х( п) матрица данных размерности п х т
Х(п) == [х(1),х(2),... ,х(п)]Т.
Дифференцируя выражение (3.25) по w(п), получим матрицу rpадиента
V Е(п) == xT(п).
Следовательно, Якобиан е( п) можно записать в следующем виде:
J(п) == X(п).
(3.26)
Так как уравнение ошибки (3.19) является линейным относительно вектора Beco
вых коэффициентов w(п), метод rаусса Ньютона сходится за одну итерацию. Под-
ставляя (3.25) и (3.26) в (3.22), получим:
w(п + 1) == w(п) + (х Т (п)X(п)) lXT (п)(d(п) X(п)w(п)) ==
== (XT(п)X(п)) lXT(п)d(п).
(3.27)
........
184 rлава з. ОДНОСЛОЙНЫЙ персептрон
Выражение (Х Т (п )Х( п)) 1 х Т (п) называют псевдообратной матрицей для MaT
рицы данных Х(п) и обозначают следующим образом [368], [434]:
Х+(п) == (xT(п)X(п)) lxT(п).
(3.28)
Исходя из этоrо, выражение (3.27) можно переписать в более компактном виде:
w(п + 1) == X+(п)d(п).
(3.29)
Это выражение вербально можно описать следующим образом: "Вектор весовых
коэффициентов w( п + 1) является решением линейной задачи фильтрации, решаемой
по методу наименьших квадратов на интервале наблюдения длительности п".
Фильтр Винера как оrраниченная форма линейноrо фильтра,
nOCTpoeHHoro по методу наименьших квадратов, для
эрrодической среды
Частным случаем, представляющим особый интерес, является получение вектора
входноrо сиrнала х( i) и желаемоro отклика d( i) из эрюдической стационарной cpe
ды (ergodic). Для этоrо случая вместо усреднения по времени можно использовать
математическое ожидание или усреднение по множеству [380]. Такая среда частично
описывается следующими статистическими характеристиками BToporo порядка.
· Матрица корреляции (correlation matrix) Rx вектора входноrо сиrнала x(i).
· Вектор взаимной корреляции (cross corre1ation vector) r xd между вектором входноro
сиrнала x(i) и ожидаемоro отклика d(i).
Эти величины определяются следующими выражениями:
1 n 1
Rx == Е [x(i)xT(i)J == Нm I::x(п)xT(i) == lim xT(п)X(п),
n OO n n OO n
i l
1 n 1
rxd == Е [x(i)d(i)] == Нm "x(i)d(i) == lim XT(п)d(п),
n.......-+оо n n-------+оо n
i l
(3.30)
(3.31)
rдe Е статистический оператор математическоrо ожидания. Тоrда решение линей
ной задачи фильтрации по методу наименьших квадратов (3.27) можно переписать в
следующем виде:
W o == Нm w(п + 1) == Нm (XT(п)X(п)) lXT(п)d(п) ==
n.......-+оо n...........j.oo
1 1
== Нm (xT(п)X(п)) l lim XT(п)d(п) == R;lrxd,
n.......-+оо n n OO n
(3.32)
3.5. Алrоритм минимизации среднеквадратической ошибки 185
rдe R;l обратная матрица для матрицы корреляции Rx. Вектор весовых коэффици
ентов w о называют ВИllеровским решением линейной задачи оптимальной фильтрации
в честь Норберта Винера (Norbert Wiener), который внес весомый вклад в ее решение
[434], [1144]. Исходя из этоrо, можно сформулировать следующее утверждение.
Для ЭР20дичеСКО20 процесса линейный фильтр, построенный по методу наименьших
квадратов, асимптотически сходится к фильтру Винера по мере приближения коли
чества наблюдений к бесконечности.
Для построения фильтра Винера необходимо знать статистические характеристики
Bтoporo порядка: матрицу корреляции Rx для вектора входноro сиrналах(п) и вектора
взаимной корреляции rxd между х(п) и желаемым откликом d(п). Однако эта инфор
мация на практике зачастую недоступна. В неизвестной среде можно использовать
линейный адаптивный фильтр (linear adaptive fi1ter). Под термином "адаптивность"
понимается возможность настраивать свободные параметры фильтра в соответствии
со статистическими вариациями среды. Наиболее популярным алrоритмом такой Ha
стройки на непрерывной основе является алrоритм минимизации среднеквадратиче
ской ошибки, который самым тесным образом связан с фильтром Винера.
3.5. Алrоритм минимизации
среднеквадратической ошибки
АЛ20рИтм минимизации среднеквадратической ошибки (least mean square LMS)
основан на использовании дискретных значений функции стоимости:
E(w) == 1j2e 2 (п),
(3.33)
rдe е(п) сиrнал ошибки, измеренный в момент времени п. Дифференцируя E(w)
по вектору весов w, получим:
aE(w) ( ) де(п)
aw eп aw'
(3.34)
Как и в случае линейноrо фильтра, построенноrо по методу наименьших KBaд
ратов, алrоритм минимизации среднеквадратической ошибки работает с линейным
нейроном. Исходя из этоrо, сиrнал ошибки можно записать в следующем виде:
е(п) == d(п) xT(п)w(п).
(3.35)
..,.......
186 rлава з. ОДНОСЛОЙНЫЙ персептрон
Следовательно,
д е(п)
д w(п) == x(п),
д E(w)
д w(п) == x(п)e(п).
Используя полученный результат, можно оценить вектор rpадиента
g(п) == x(п)e(п).
(3.36)
И, наконец, используя формулу (3.36) для вектора rpадиента в методе наискорей
шеro спуска (3.12), можно сформулировать алrоритм минимизации среднеквадрати-
ческой ошибки в следующем виде:
",(п + 1) == ",(п) + 11 х(п)е(п),
(3.37)
rде 11 параметр скорости обучения. Контур обратной связи для вектора весов "'( п)
в алrоритме минимизации среднеквадратической ошибки ведет себя как низкоча
стотный фильтр (low-pass filter), передающий низкочастотные компоненты сиrнала
ошибки и задерживающий ero высокочастотные составляющие [434]. Усредненная
временная константа этой фильтрации обратно пропорциональна параметру скорости
обучения 11. Следовательно, при малых значениях 11 процесс адаптации будет про
двиrаться медленно. При этом алrоритм минимизации среднеквадратической ошибки
будет запоминать большее количество предшествующих данных, а значит, более точ-
ной будет фильтрация. Друrими словами, величина, обратная параметру скорости
обучения 11, является мерой памяти (measure of memory) алrоритма минимизации
среднеквадратической ошибки.
В формуле (3.37) вместо w(п) мы использовали ",(п). Этим подчеркивается тот
факт, что алrоритм минимизации среднеквадратической ошибки только оценивает
(estimate) вектор весовых коэффициентов на основе метода наискорейшеrо спус
ка. Следовательно, используя алroритм минимизации среднеквадратической ошибки,
можно пожертвовать одной из отличительных особенностей алroритма наискорейше
ro спуска. В последнем вектор весовых коэффициентов w( п) изменяется по детерми
нированной траектории в пространстве весов при заранее выбранном параметре 11.
В противоположность этому в алrоритме минимизации среднеквадратической ошиб
ки вектор "'( п) перемещается по случайной траектории. По этой причине алrоритм
минимизации среднеквадратической ошибки иноrда называют стохастическим rpa
диентным алrоритмом. При стремлении количества итераций в алrоритме LMS к
бесконечности вектор ",(п) выписывает хаотичную траекторию (в соответствии с
3.5. Алrоритм минимизации среднеквадратической ошибки 187
ТАБЛИЦА 3.1. Краткое описание алroритма минимизации
среднеквадратической ошибки
Обучающий пример
Выбираемый пользователем параметр
Инициализация весов
Вычислительная схема
Вектор входноro сиrнала == х( п)
Желаемый отклик d(п)
11
W(O) == О
Для п == 1, 2,. . .
е(п) == d(п) xT(п)w(п),
",(п + 1) == ",(п) + 11 х(п)е(п)
принципами броуновскоro движения) BOKpyr Винеровскоro решения W O ' Важно OTMe
тить, что, в отличие от метода наискорейшеro спуска, алrоритм минимизации cpeд
неквадратической ошибки не требует знания статистических характеристик окружа
ющей среды.
Краткое описание алroритма минимизации среднеквадратической ошибки пред
ставлено в табл. 3.1, из которой ясно видна ero простота. Из таблицы видно, что для
инициализации (initialization) алroритма достаточно обнулить ero начальный вектор
весовых коэффициентов.
rраф передачи сиrнала для алrоритма минимизации
среднеквадратической ошибки
Объединяя формулы (3.35) и (3.37), эволюцию вектора весов в алrоритме минимиза-
ции среднеквадратической ошибки можно представить в следующем виде:
",(п + 1) == ",(п) + 11 x(п)[d(п) xT(п)w(п)] ==
== [1 11 x(п)xT(п)]w(п) + 11 x(п)d(п),
(3.38)
rдe 1 единичная матрица. При использовании алroритма минимизации cpeДHeKBaд
ратической ошибки
",(п) == Z l[W(п + 1)],
(3.39)
rдe Z l оператор единичной задержки, реализующей память алrоритма. Исполь
зуя выражения (3.38) и (3.39), алroритм минимизации среднеквадратической ошибки
можно представить в виде rpафа передачи сиrнала, показанноrо на рис. 3.3. На этом
rpафе видно, что алrоритм минимизации среднеквадратической ошибки является Bce
ro лишь частным случаем стохастической системы с обратной связью (stochastic
feedback system). Наличие обратной связи оказывает первостепенное влияние на cxo
димость алrоритма LMS.
..,.......
188 rлава з. ОДНОСЛОЙНЫЙ персептрон
w(п)
1]х(п) хТ(п)
Рис. 3.3. rраф передачи сиrнала
ДЛЯ алroритма МИнимизации cpeд
неквадратической ошибки
Условия сходимости алrоритма LMS
Из теории управления известно, что устойчивость системы с обратной связью опреде
ляется параметрами обратной связи. На рис. 3.3 видно, что нижний контур обратной
связи обеспечивает изменение поведения алrоритма минимизации среднеквадратиче
ской ошибки. В частности, пропускная способность контура обратной связи опреде
ляется двумя параметрами: коэффициентом скорости обучения 11 и вектором BXOДHO
ro сиrнала х(п). Таким образом, можно заключить, что сходимость (и устойчивость)
алrоритма минимизации среднеквадратической ошибки зависит от статистических
характеристик входноrо вектора х(п) и значения параметра 11. Друrими словами, для
каждой среды, из которой поступают входные векторы, следует подбирать собствен
ный параметр скорости обучения 11, который обеспечит сходимость алrоритма LMS.
Первым критерием сходимости алrоритма минимизации среднеквадратической
ошибки является сходимость в среднем (convergence ofthe mеап):
E[w(п)] -----+ W o при п -----+ 00,
(3.40)
rдe W о решение Винера. К сожалению, такой критерий сходимости не имеет боль
шоro практическоrо значения, так как последовательность произвольных векторов,
имеющих среднее значение О, также будет удовлетворять этому условию.
С практической точки зрения вопрос устойчивости иrpает роль именно в смысле
среднеквадратической сходимости (convergence of the mеап square):
Е[е 2 (п)] -----+ const при п -----+ 00.
(3.41 )
3.5. Алroритм минимизации среднеквадратичесКОЙ ошибки 189
к сожалению, детальный анализ сходимости в смысле среднеквадратическоro зна
чения для алrоритма LMS чрезвычайно сложен. Чтобы ero математически упростить,
сделаем следующие предположения.
1. Векторы входных сиrналов х(I), х(2), . . . являются статистически независимыми
друr от друrа.
2. В момент времени п вектор входноrо сиrнала х(п) является статистически неза
висимым от всех предыдущих желаемых откликов, Т.е. d(1), d(2), . .., d(п 1).
3. В момент времени п желаемый отклик d( п) зависит от вектора х( п), но статисти
чески не зависит от всех предыдущих значений желаемоro отклика.
4. Вектор входноrо сиrнала х (п) и желаемый отклик d( п) выбираются из множества,
подчиняющеrося распределению raycca.
Статистический анализ алrоритма минимизации среднеквадратической ошибки
при наличии вышеуказанных допущений получил название теории независимости
(independence theory) [1138].
С учетом допущений теории независимости и достаточно малоro значения па
раметра скорости обучения в [434] показано, что алrоритм минимизации cpeДHe
квадратической ошибки сходится в смысле среднеквадратическоrо значения, если 11
удовлетворяет условию
2
0<11 < ,
тах
(3.42)
rдe Л mаХ наибольшее собственное значение (largest eigenva1ue) матрицы Koppe
ляции Rx. В типичных приложениях алrоритма LMS значение Л mаХ ' как правило,
не известно. Чтобы обойти эту сложность, в качестве оценки сверху значения Л mаХ
можно использовать след (trace) матрицы Rx. В этом случае условие (3.42) можно
переписать в следующем виде:
2
О < 11 < tr[Rx] '
(3.43)
rдe tr[Rx] след матрицы Rx. По определению след квадратной матрицы определяет
ся как сумма ее диаrональных элементов. Так как каждый из диаrональных элементов
матрицы корреляции Rx является среднеквадратическим значением соответствующе
ro входноrо сиrнала, условие сходимости алrоритма минимизации среднеквадрати
ческой ошибки можно сформулировать в виде
о < 11 <
сумма среднеквадратических значений входных сиrналов
2
(3.44)
"81""
190 rлава з. ОДНОСЛОЙНЫЙ персептрон
Если параметр скорости обучения удовлетворяет этому условию, то алroритм ми
нимизации среднеквадратической ошибки сходится также и в смысле среднеrо значе
ния. Это значит, что сходимость в смысле среднеквадратическоrо значения является
достаточным условием сходимости в среднем. Обратное утверждение верно не всеrда.
Преимущества и недостатки алrоритма LMS
Важным преимуществом алroритма минимизации среднеквадратической ошибки яв
ляется ero простота (см. табл. 3.1). Кроме Toro, этот алrоритм независим от модели
и, таким образом, является робастным. Это значит, что при малой неопределенно
сти в модели и небольших возмущениях (с малой энерrией) сиrнал ошибки также
будет невелик. В более строrих математических терминах алroритм минимизации
среднеквадратической ошибки является оптимальным соrласно минимаксному кри
терию (НОО) (minimax criterion) [426], [427]. Основная идея оптимальности в смысле
НОО это обеспечить наилучшее выполнение пессимистическоrо сценария 4 . Ее мож
но сформулировать так.
Если вы не знаете, с чем столкнулись, предположите наихудшее и оптимизируйте
решение.
Долrое время алrоритм минимизации среднеквадратической ошибки рассматри
вался как частный случай алrоритма rpадиентноrо спуска. Однако оптимальность
алrоритма минимизации среднеквадратической ошибки в смысле НОО придает ему
более устойчивое положение в рассматриваемой предметной области. В частности,
он обеспечивает приемлемые результаты не только в стационарной, но и в нестацио
нарной среде. Под "нестационарностью" среды подразумевается то, что ее статисти
ческие характеристики изменяются во времени. В такой среде оптимальное решение
Винера зависит от времени, а алrоритм минимизации среднеквадратической ошибки
выполняет дополнительную задачу отслеживания (tracking) изменения параметров
фильтра Винера.
Основным оrpаничением алrоритма минимизации среднеквадратической ошибки
является низкая скорость сходимости и чувствительность к изменению собственных
значений матрицы входных сиrналов [434]. Для сходимости алrоритма минимизации
среднеквадратической ошибки обычно требуется в 1 О раз больше итераций, чем раз
мерность пространства входных сиrналов. Медленная сходимость становится дей
ствительно серьезной преrpадой, если размерность пространства входных данных
очень велика. Что же касается чувствительности, то наибольшая чувствительность
алroритма проявляется к изменению числа обусловленности (condition number) или
разброса собственных чисел матрицы корреляции Rx вхоДНоro вектора х. Число обу
словленности X(R x ) определяется следующим выражением:
4 Робаст1l0сть Критерий Н* введеи Зеймсом (Zames) в [1179] и развит в [1180]. Этот критерий обсуж-
дается и в некоторых друrих работах, в частности в [265], [381], [425].
3.6. rрафики процесса обучения
191
( ) А.mах
Х Rx == ,
mш
(3.45)
rде A.min и А. mах соответственно минимальное и максимальное собственные числа
матрицы Rx. Чувствительность алroритма минимизации среднеквадратической ошиб
ки к вариациям числа обусловленности X(R x ) становится действительно опасной,
коrда обучающая выборка, которой принадлежит вектор х(п), является плохо обу
словлеююй, Т.е. число обусловленности X(R x ) достаточно велико 5 .
Заметим, что в алrоритме минимизации среднеквадратической ошибки матрица
rессиана, определяемая как вторая производная от функции стоимости E(w) по Beктo
ру w, эквивалентна матрице корреляции Rx (см. задачу 3.8). Таким образом, в дальней
ших рассуждениях мы будем употреблять оба этих термина в одинаковом значении.
3.6. rрафики процесса обучения
Одним из самых информативных способов проверки сходимости алrоритма мини
мизации среднеквадратической ошибки и всех адаптивных фильтров в целом явля
ется построение rpафиков процесса обучения или так называемых кривых обучения
(learning curve) для различных условий внешней среды. Кривая обучения является
zрафиком изменения среднеквадратичеСКО20 значения ошибки оценивания Eav (п) в
зависимости от количества итераЦИЙ п.
Представим себе эксперимент, проводимый над множеством адarrrивных филь
тров, Korдa каждый из них работает под управлением отдельноrо алrоритма. Пред
полаrается, что начальные условия и принципы работы всех алrоритмов одинаковы.
Различие между ними определяется случайностью выбора вектора входноro сиrнала
х(п) и желаемоro отклика d(п) из имеющейся обучающей выборки. Для каждоrо из
фильтров строится rpафик изменения среднеквадратической ошибки оценивания (т.е.
разности между желаемым откликом и фактическим выходным сиrналом фильтра)
относительно количества итераций. Полученное таким образом множество кривых
обучения состоит из зашумленных (noisy) rpафиков экспоненциальноrо типа. Нали
чие шума связано со стохастической природой адаптивноrо фильтра. Чтобы постро
ить усредненную по этому множеству кривую обучения (ensemble averaged 1eaming
curve) (т.е. rpафик Eav(п) относительно п), нужно вычислить средние значения по
всем кривым, участвующим в эксперименте. Это способствует снижению влияния
шума на результат.
s Чтобы преодолеть недостатки алroритма LMS, Т.е. повысить скорость сходимости и снизить чувствитель-
ность к вариациям числа обусловленности матрицы R., можно использовать рекурсивный алzоритм наименьших
квадратов (RLS), который является следствием линейноro фильтра, nocтpoeHHoro по методу наименьших квад-
ратов и описаиноro в разделе 3.4. Алroритм RLS является частным случаем фильтра Калмана известноro
линейноro оптимальноro фильтра для нестационарной среды. Следует отметить, что фильтр Калмана исполь-
зует все предыдущие данные вплоть до времени начала вычислений. Более подробно алroритм RLS и ero связи
с фильтром Калмана описываются в [434]. Кроме тoro, фильтр Калмана рассматривается в rлаве 15.
lII"'"
192 rлава з. ОДНОСЛОЙНЫЙ персептрон
Еау(О)
;>,
"'
... .
u '"
<t) '"
'"'''''
о :;:
:I: S
:>: о
O
::r: ----:;
:I: '"
<t) "-
:I:
&gj
0,1 Еау(О)
Скорость
сходимости
Количество итераций
Рис. 3.4. Идеализированная кривая
обучения алroритма LMS
E( )
В предположении устойчивости адаптивноrо фильтра усредненная по множеству
кривая обучения начинается с достаточно большоrо значения ЕаАО), определяемоrо
начальными условиями, и затем ее значения уменьшаются с некоторой скоростью,
зависящей от типа фильтра, а в пределе сходятся к не которому устойчивому значению
Eav(oo) (рис. 3.4). Основываясь на этой кривой, можно определить скорость сходи
мости (rate of convergence) адаптивноro фильтра, определяемую как число итераций,
необходимых для Toro, чтобы для любоrо произвольноrо начальноro значения Eav(O)
величина Eav(п) уменьшилась в 10 раз.
Еще одной полезной характеристикой адаптивноrо фильтра, получаемой из ycpeд
ненной кривой обучения, является раССО2Ласование (misadjustment), обозначаемое
символом М. Пусть E min минимальная среднеквадратическая ошибка, обеспе
чиваемая фильтром Винера, построенным на основе известных значений матрицы
корреляции Rx и вектора взаимной корреляции r xd. Исходя из этоrо, рассоrласование
можно определить следующим образом [434], [1144]:
м == Е(оо) E min == Е(оо) 1.
E min E min
(3.46)
Рассоrласование М является безразмерной величиной просто мерой измере
ния близости адаптивноrо фильтра к оптимальному в смысле среднеквадратической
ошибки. Чем ближе значение М к единице, тем более точной является адаптив
ная фильтрация алrоритма. Одним из вариантов является представление рассоrла
3.7. Изменение параметра скорости обучения по модели отжиrа 193
сования в процентах. Например, рассоrласование в 10% означает, что адаптивный
фильтр работает со среднеквадратической ошибкой (после завершения адаптации),
на 10% превышающей минимальную среднеквадратическую ошибку, обеспечивае
мую соответствующим фильтром Винера. На практике такая точность обычно счита
ется удовлетворительной.
Еще одной важной характеристикой алroритма минимизации среднеквадратиче
ской ошибки является время установки (setting time). К сожалению, ОДнозначно
ro определения этой величины не существует. Например, кривую обучения можно
rpубо аппроксимировать экспоненциальной функцией с усредненной временной KOH
стантой (average time constant) Tav. Чем меньше значение Tav, тем короче время
установки (т.е. тем быстрее алrоритм минимизации среднеквадратической ошибки
будет сходиться к установившемуся состоянию).
В качестве неплохой аппроксимации величины рассоrласования М можно Поре
комендовать параметр скорости обучения '1'\, который прямо пропорционален ей. Что
же касается величины Tav, то она обратно пропорциональна параметру скорости обу
чения [434], [1144]. Таким образом, получается противоречие: если уменьшить па
раметр скорости обучения для уменьшения рассоrласования, то увеличивается время
установки алrоритма LMS. Следовательно, для ускорения процесса обучения нужно
увеличивать коэффициент скорости обучения, однако следует учесть, что OДHOBpe
менно с этим будет увеличиваться и рассоrласование. Выбору параметра '1'\ нужно
уделять большое внимание, так как он является основной величиной в алrоритме
LMS, отвечающей за ero общую производительность.
3.7. Изменение параметра скорости обучения
по модели отжиrа
Сложность работы с алrоритмом минимизации среднеквадратической ошибки связана
с тем фактом, что параметр скорости обучения является эмпирической константой.
Ее можно не изменять в течение Bcero процесса обучения, Т.е.
'I'\(п) == '1'\0 для всех п.
(3.4 7)
Это простейший способ задания коэффициента скорости обучения. В отличие от
Hero в методах стохастической аппроксимации (stochastic approximation), берущих
свое начало в классической статье [892], параметр интенсивности обучения изменяет
ся со временем. Одной из самых распространенных форм изменения этоrо параметра,
описанных в литературе по стохастической аппроксимации, является следующая:
с
'I'\(п)== ,
п
(3.48)
.....
194 rлава з. ОДНОСЛОЙНЫЙ персептрон
rде с константа. TaKoro выбора достаточно, чтобы rарантировать сходимость алro-
ритма стохастической аппроксимации [607], [665]. Если константа с велика, существу
ет опасность выхода алroритма из под контроля на первых шаrах аппроксимации (при
маленьких п). в качестве альтернативы выбору (3.4 7) и (3.48) можно использовать так
называемый подход на основе поиска и сходимости, впервые предложенный в [238]:
11 (п) == 1 + /7) '
(3.49)
rде 110 и 7 заданные пользователем константы. На первых шаrах адаптации число
п является малым по сравнению с константой времени поиска (search time constant)
7. Поэтому параметр скорости 11(п) практически равен константе 110' и алroритм
ведет себя как стандартный алroритм минимизации среднеквадратической ошибки
(рис. 3.5). Выбирая большое значение 110(естественно, в допустимых пределах), мож-
но надеяться, что настраиваемые весовые коэффициенты фильтра будут находиться
вблизи "хороших" значений. Таким образом, при количестве итераций п, значительно
превосходящих константу времени поиска 7, параметр интенсивности скорости 11 (п)
будет сходиться к функции dп, rде с == 7110 (рис. 3.5). Алroритм при этом будет вести
себя как обычный алrоритм стохастической аппроксимации, а веса будут сходиться к
своим оптимальным значениям. Таким образом, изменение коэффициента скорости
обучения на основе метода поиска и сходимости обеспечивает сочетание полезных
свойств обычноrо алrоритма минимизации среднеквадратической ошибки с методами
традиционной теории стохастической аппроксимации.
3.8. Персептрон
Итак, мы переходим ко второй части настоящей rлавы, в которой речь пойдет о пер
септроне Розенблатта (далее просто персептрон (perceptron)). Если алroритм LMS,
описанный в предыдущем разделе, разработан для линейноrо нейрона, то персептрон
строится для нелинейноrо, а именно модели нейрона Мак Каллока Питца. Из rлавы 1
известно, что такая нейронная модель состоит из линейноrо сумматора и оrpаничи
теля (реализованноrо в виде пороroвой функции вычисления знака) (рис. 3.6). CYM
мирующий узел этой нейронной модели вычисляет линейную комбинацию входных
сиrналов, поступающих на синапсы с учетом внешнеrо возмущения (пороrа). Полу
ченная сумма (так называемое индуцированное локальное поле (induced local fie1d))
передается на узел оrpаничителя. Таким образом, выход нейрона принимает значение
+ 1, если сиrнал на выходе сумматора положителен, и 1, если отрицателен.
3.8. Персептрон 195
17(п)
Стандартный алrоритм LMS
170
t
0,1170
\
\
\
\
\
\
\
\
\
\
\
\
Метод поиска '
и сходимости
п
(лоrарифмическая шкала)
Рис. 3.5. Изменение
коэффициента скорости
обучения по методу MO
делирования отжиrа
Метод
стохастической
аппроксимации
0,01170
Х ]
v <jJ(v) Выход
Оrpаничитель у
Х 2
Входы
Рис. 3.6. rраф передачи сиrнала для персеп
трона
Х т
На диаrpамме передачи сиrнала (рис. 3.6) синаптические веса персептрона обо
значены Wl, W2, ..., W m , сиrналы, поступающие на вход персептрона, обозначены
Xl, Х2, .. . , Х т , а пороrовое значение Ь. Исходя из структуры модели, можно за
ключить, что входной сиrнал оrpаничителя (т.е. индуцированное локальное поле)
нейрона определяется выражением
m
V == I:: ЩХi + Ь.
i l
(3.50)
......
196 rлава з. ОДНОСЛОЙНЫЙ персептрон
Целью персептрона является корректное отнесение множества внешних стимулов
Xl,X2, ..., Х т К одному из двух классов: С 1 или С 2 . Решающее правило такой
классификации заключается в следующем: входной сиrнал относится к классу C 1 ,
если выход у равен + 1, и к классу С 2 в противном случае (если выход равен 1).
Чтобы rлубже изучить поведение классификатора, целесообразно построить карту
областей решения в т MepHOM пространстве сиrналов, определяемом переменными
Xl, Х2, ..., Хт' В простейшем случае (коrда в качестве классификатора выступа
ет персептрон) имеются Bcero две области решения, разделенные rиперплоскостью,
определяемой формулой
m
I:: ЩХi + ь == О.
i l
(3.51 )
Это проиллюстрировано на рис. 3.7 для случая двух переменных, Xl и Х2, коrда
разделяющая rиперплоскость вырождается в прямую. Точки (Xl,X2), лежащие выше
этой прямой, относятся к классу C 1 , а точки, расположенные ниже прямой, принад
лежат классу С 2 . Обратите внимание, что пороroвое значение определяет смещение
разделяющей поверхности по отношению к началу координат.
Синаптические веса персептрона Wl, W2, . . . , W m можно адаптировать итератив
ным методом. В частности, для настройки весовых коэффициентов можно использо
вать алroритм, основанный на коррекции ошибок и получивший название ал20ритма
сходимости персептрона (perceptron convergence algorithm).
3.9. Теорема о сходимости персептрона
Чтобы вывести алrоритм обучения персептрона, основанный на коррекции ошибок,
удобно построить модифицированный rpаф передачи сиrнала (рис. 3.8). В этой MO
дели, которая эквивалентна модели нейрона, показанной на рис. 3.6, пороr Ь(п) рас-
сматривается как синаптический вес связи с фиксированным входным сиrналом + 1.
Это можно описать следующим входным вектором размерности (т + 1):
х(п) == [+1, Хl (п), Х2(п),..., хт(п)]Т,
rде п номер итерации алrоритма. Аналоrично можно определить (т + l) мерный
вектор весовых коэффициентов:
w(п) == [Ь(п), Wl (п), W2(п),... , wm(п)]T.
3.9. Теорема о сходимости персептрона 197
Рис. 3.7. Разделяющая поверхность в виде rиперплос
кости (в данном случае прямой) для двумерной зада
чи классификации образов на два класса
Х 1
rраница решений
W 1 X 1 + W:f2 + Ь О
Фиксированный хо + 1
вход
Х 2
v <jJ(v) Выход
у
Жесткое
оrpаничение
Х}
Входной сиrnал
Рис. 3.8. Эквивалентный rраф пере
дачи сиrнала для персептрона. Зави
симость от времени опущена для яс
ности
Х т
Линейный
сумматор
Следовательно, выход линейноrо сумматора можно записать в более компакт
ной форме
m
v(п) == I:: щ(п)Хi(п) == wT(п)x(п),
i O
(3.52)
rде Wo (п) пороrовое значение Ь( п). При фиксированном значении п уравнение
w T х == О в т MepHOM пространстве с координатами Xl, Х2, ., . , Х т определяет rи
перплоскость (для HeKoToporo предопределенноro значения пороrа), которая является
поверхностью решений для двух различных классов входных сиrналов.
.....
198 rлава з. ОДНОСЛОЙНЫЙ персептрон
rраница
/ / решений
/
/
а)
б)
Рис. 3.9. Паралинейно разделимых (а) и нелинейно разделимых образов (б)
Чтобы персептрон функционировал корректно, два класса, С 1 и С 2 , должны быть
линейно разделимыми (linear1y separable). Это, в свою очередь, означает, что для пра
вильной классификации образы должны быть значительно отдалены друr от друrа,
чтобы поверхность решений моrла представлять собой rиперплоскость. Это требова
ние проиллюстрировано на рис. 3.9 для случая двумерноrо персептрона. На рис. 3.9, а
два класса С 1 и С 2 значительно удалены друr от друrа, и их можно разделить
rиперплоскостью (в данном случае прямой). Если эти два класса сдвинуть бли
же друr к друrу (рис. 3.9, 6), они станут нелинейно разделимыми. Такая ситуация
выходит за рамки вычислительных возможностей персептрона.
Теперь предположим, что входные переменные персептрона принадлежат двум
линейно разделимым классам. Пусть Х 1 подмножество векторов обучения Xl(l),
xl(2), ..., которое принадлежит классу C 1 , а Х 2 подмножество векторов обуче
ния X2(l), Х2(2), . .., относящееся к классу С 2 . Объединение подмножеств Х 1 и Х 2
составляет все обучающее множество Х. Использование подмножеств Х 1 и Х 2 дЛЯ
обучения классификатора позволит настроить вектор весов w таким образом, что два
класса С 1 и С 2 будут линейно разделимыми. Это значит, что существует такой
вектор весовых коэффициентов w, для KOToporo истинно следующее утверждение:
w T Х > О для любоro входноrо вектора х, принадлежащеrо классу С 1,
w T Х :::; О для любоrо входноro вектора х, принадлежащеrо классу С 2 . (3.53)
Во второй строке утверждения (3.53) мы произвольно указали, что при paBeH
стве w T Х == О входной вектор Х принадлежит именно классу С 2 . При определенных
таким образом подмножествах Х 1 и Х 2 задача обучения элементарноrо персептро
на сводится к нахождению TaKoro вектора весов w, для KOToporo выполняются оба
неравенства (3.53).
3.9. Теорема о сходимости персептрона 199
Алroритм адаптации вектора весовых коэффициентов элементарноrо персептрона
можно сформулировать следующим образом.
Если п й элемент х( п) обучающеro множества корректно классифицирован с По
мощью весовых коэффициентов w( п), вычисленных на п-м шаre алroритма, то вектор
весов не корректируется, Т.е. действует следующее правило:
w(п + 1) == w(п) если w T х(п) > О и х(п) Е C 1 ,
w(п + 1) == w(п) если w T х(п) :::; О и х(п) Е С 2 .
(3.54)
в противном случае вектор весов персептрона подверrается коррекции в COOTBeT
ствии со следующим правилом:
w(п + 1) == w(п) 11(п)х(п), если wT(п)x(п) > О и х(п) Е С 2 ,
w(п + 1) == w(п) + 11(п)х(п), если wT(п)x(п) :::; О и х(п) Е C 1 ,
(3.55)
rдe интенсивность настройки вектора весов на шаrе п определяется параметром
скорости обучения 11 (п).
Если 11 (п) == 11 > О, rде 11 константа, не зависящая от номера итерации п,
вышеописанный алrоритм называется правилом адаптации с фиксированным прира
щением (fixed increment adaptation ru1e).
Ниже мы сначала докажем сходимость правила адаптации с фиксированным при
ращением для 11 == 1. Ясно, что само значение 11 не иrpает особой роли, если оно
положительно. Значение параметра 11, отличное от единицы, обеспечивает масштаби
рование образов, не влияя на их разделимость. Случай с переменным коэффициентом
11 ( п) будет рассмотрен HeMHoro позже.
В приведенном доказательстве считается, что в начале процесса обучения вектор
весовых коэффициентов равен нулю, w(O) O. Предположим, что для п == 1, 2, . . . ,
wT(п)x(п) < О, а входной вектор х(п) принадлежит подмножеству X 1 . Это значит,
что персептрон некорректно классифицировал векторы х(l), х(2), ..., Т.е. условие
(3.53) не выполнено. Следовательно, для 11(п) == 1 можно использовать вторую cтpo
ку правила (3.55):
w(п + 1) == w(п) + х(п), для х(п) Е C 1 .
(3.56)
Поскольку начальное состояние w(O) == О, то уравнение (3.56) для w(п+ 1) можно
решить итеративно и получить следующий результат:
w(п + 1) == х(l) + х(l) + .,. + х(п).
(3.57)
....
200 rлава з. ОДНОСЛОЙНЫЙ персептрон
Так как по предположению классы С 1 и С 2 являются линейно разделимыми, то cy
ществует такое решение wo, при котором будет выполняться условие w T х( п) > о для
векторов x(l), х(2),... , х(п), принадлежащих подмножеству X 1 . для фиксированноro
решения Wo можно определить такое положительное число а, что
а == min wб х(п).
х(п)Е Х l
(3.58)
Умножая обе части уравнения (3.57) на Beктop CTPOКY wб, получим:
wб w(п + 1) == wб х(l) + wб х(2) + ... + wб х(п).
в свете определения (3.58) имеем:
wб w( п + 1) па.
(3.59)
Теперь можно использовать неравенство rучи Шварца (Gauchi Schwartz inequa1
ity). Для двух векторов, Wo и w( п + 1), ero можно записать следующим образом:
Il w oI1 2 I1w(п+ 1)112 [Wбw(п+ 1)]2,
(3.60)
rде 11-11 Евклидова норма векторноrо арrумента; wб w( п + 1) скалярное произве
дение векторов. Заметим, что соrласно (3.59) [w w(n + 1)]2 п 2 а 2 . Учитывая это
в (3.60), получим:
Il w ol1 2 1lw(п + 1)112 п 2 а 2
или
п 2 а 2
Ilw(п + 1)112 .
IIwoll
(3.61 )
Теперь подойдем к проблеме с друroй стороны. В частности, перепишем ypaBHe
ние (3.56) в следующем виде:
w(k + 1) == w(k) + x(k), для k == 1,..., п их(k) Е X 1 .
(3.62)
Вычисляя Евклидову норму векторов в обеих частях уравнения (3.62), получим:
Ilw(k + 1)112 == Ilw(k)112 + Ilx(k)112 + 2w T (k)x(k).
(3.63)
3.9. Теорема о сходимости персептрона 201
Если персептрон некорректно классифицировал входной вектор x(k), принаk
лежащий подмножеству X 1 , то wT(k)x(k) < О. Следовательно, из (3.63) полу
чим выражение
Ilw(k + 1)112 :::; Ilw(k)112 + Ilx(k)112
или
IIw(k + 1)112 IIw(k)1I2 :::; IIx(k)112 для k == 1,... , п.
(3.64)
Применяя эти неравенства последовательно для k == 1, . .., п и учитыIаяя изна
чальное допущение, что w(O) O, приходим К неравенству
n
Ilw(п + 1)112:::; I:: IIx(k)11 2 :::; п ,
k l
(3.65)
rде положительное число, определяемое следующим образом:
2
== mах IIx(k)1I .
x(k)EXl
(3.66)
Уравнение (3.65) означает, что Евклидова норма вектора весов w(п + 1) линейно
возрастает с увеличением номера итерации п.
Результат, описываемый неравенством (3.65), при больших п вступает в проти
воречие с полученным ранее результатом (3.61). Следовательно, номер итерации п
не может превышать HeKoToporo значения птах, при котором неравенства (3.61) и
(3.65) удовлетворяются со знаком равенства. Это значит, что число птах должно
быть решением уравнения
2 2
птах а R
II w oll 2 == пmaxfJ.
Разрешая это уравнение для птах относительно wo, получим:
2
IIWoll
птах == 2
а
(3.67)
Таким образом, мы доказали, что для 11 (п) == 1 и W(O)==O в предположении суще
ствования вектора решения Wo процесс адаптации синаптических весов персептрона
должен прекращаться не позднее итерации птах' Обратите внимание, что соrласно
(3.58), (3.66) и (3.67) решение для Wo и птах не единственно.
.,......
202 rлава з. ОДНОСЛОЙНЫЙ персептрон
Теперь можно сформулировать теорему сходимости для ал20ритма обучения пep
септрона с фиксированным приращением (fixed increment convergence theorem) для
персептрона [899].
Пусть подмножества векторов обучения Х 1 и Х 2 линейно разделимы. Пусть входные
СИ2Налы поступают персептрону только их этих подмножеств. ТО2да ал20ритм обу
чения персептрона сходится после некотОРО20 числа по итераций в том смысле, что
w(пo) == w(пo + 1) == w(пo + 2) == . . .
является вектором решения для по :::; птах'
Теперь рассмотрим абсолютную процедуру адаптации однослойноro персептрона
на основе коррекции ошибок (absolute error correction procedure), в которой 11(п) пе
ременная величина. В частности, пусть 11 (п) наименьшее целое число, для KOToporo
выполняется соотношение
11(п)х Т (п)х(п) > IwT(п)x(п)l.
Соrласно этой процедуре, если скалярное произведение wT(п)x(п) на шаrе n
имеет неверный знак, то w T (п + 1 )х( п) на итерации п + 1 будет иметь правильный
знак Таким образом, предполаrается, что если знак произведения wT(п)x(п) HeKOp
ректен, то можно изменить последовательность обучения для итерации п + 1, приняв
х( п + 1 ) "'х ( п). Друrими словами, каждый из образов представляется персептрону до
тех пор, пока он не будет классифицирован корректно.
Заметим, что использование отличноrо от нулевоrо исходноrо состояния w(O) при
водит к увеличению или уменьшению количества итераций, необходимых для сходи
мости, в зависимости от TOro, насколько близким окажется исходное состояние w(O) к
решению wo. Однако, независимо от исходноro значения w(O), сходимость все равно
будет обеспечена.
В табл. 3.2 представлен ал20ритм сходимости персептрона (perceptron conver
gence a1gorithm) [657] в краткой форме. Символ sgn(.), использованный на третьем
шаrе для вычисления фактическоrо отклика персептрона, означает функцию вычис
ления знака (сиrнум):
( ) { + 1 , если v > О,
sgn v ==
1, если v < О.
(3.68)
Таким образом, дискретный отклику(п) персептрона (quantized responce of per
ceptron) можно выразить в компактной форме:
у(п) == sgn(wT(п)x(п)).
(3.69)
3.9. Теорема о сходимости персептрона 203
ТАБЛИЦА 3.2. Алroритм сходимости персептрона в краткой форме
Переменные и параметры
х(п) ==[+1, Xl(п), ..., хт(п)]Т Beктop CTpOKa размерности т+l;
w(п) ==[Ь(п), Wl(п), ..., Wm(п)]T Beктop CTpOKa размерности т+l;
Ь( п) пороr;
у(п) фактический отклик (дискретизированный);
d(п) желаемый отклик;
О < 11 :::; 1 параметр скорости обучения.
1.J1нициализация
Пусть w(O)==O. Последующие вычисления выполняются для шаrов п == 1, 2, . . .
2. Активация
На шаrе п активируем персептрон, используя вектор х( п) с вещественными
компонентами и желаемый отклик d(п).
3. Вычисление фактичеСКО20 ответа
Вычисляем фактический отклик персептрона:
у(п) == sgn(wT(п)x(п)),
rде sgп(.) функция вычисления знака apryMeHTa.
4. Адаптация вектора весов
Изменяем вектор весов персептрона:
w(п + 1) == w(п) + 11 [d(п) у(п)]х(п),
rдe
d(п) == { +1, если х(п) Е C 1 ,
1, если х(п) Е С 2 .
5. Продолжение
Увеличиваем номер итерации п на единицу и возвращаемся к п. 2 алrоритма.
Заметим, что входной сиrнал х( п) является вектором строкой размерности (т+ 1),
первый элемент KOTOpOro фиксированная величина (равная + 1) на всем протяжении
алrоритма. Соответственно первым элементом вектора строки весовых коэффициен
тов w(п) размерности т+ 1 является пороr Ь(п). Следует отметить еще одну важную
деталь, приведенную в табл. 3.2, дискретный желаемый отклик d(п) определяет
ся выражением
d(п) == { +1, если х(п) Е C 1 ,
1, если х(п) Е С 2 .
(3.70)
.....
204 rлава з. ОДНОСЛОЙНЫЙ персептрон
Таким образом, алrоритм адаптации вектора весовых коэффициентов w( п) COOT
ветствует правилу обучения на основе коррекции ошибок (error correction 1eaming ru1e)
w(п + 1) == w(п) + 11 [d(п) у(п)]х(п),
(3.71)
rде 11 параметр скорости обучения, а разность d( п) у( п) выступает в роли
СИ2нала ошибки. Параметр скорости обучения является положительной константой,
принадлежащей интервалу 0<11 :::; 1. Выбирая значение параметра скорости обучения
из этоro диапазона, следует учитывать два взаимоисключающих требования [657].
. Усреднение (averaging) предыдущих входных сиrналов, обеспечивающее устойчи
вость оценки вектора весов, требует малых значений 11.
. Быстрая адаптация (fast adaptation) к реальным изменениям распределения про
цесса, отвечающеro за формирование векторов входноrо сиrнала х, требует боль
ших значений 11.
3.10. Взаимосвязь персептрона и байесовскоrо
классификатора в rауссовой среде
Персептрон имеет определенную связь с классической системой классификации об
разов, получившей название байесовСКО20 классификатора (Bayes c1assifier). В усло
виях rауссовой среды байесовский классификатор превращается в обычный линей
ный классификатор. Такую же форму имеет персептрон. Однако линейная природа
персептрона не зависит от стохастических свойств среды. В этом разделе речь пой
дет о взаимосвязи персептрона и байесовскоrо классификатора, что позволит rлубже
изучить природу и работу персептрона. lIачнем этот раздел с KpaTKoro описания
байесовскоrо классификатора.
Байесовский классификатор
В байесовском классификаторе (Bayes c1assifier) или байесовской процедуре пpo
верки 2ипотез (hypothesis testing procedure) минимизируется средний риск, который
обозначается символом R. ДЛЯ задачи двух классов (С 1 и С 2 ) средний риск в [1080]
определяется следующим образом:
R == CIIPl l fx(xICl)dx+C22P2 1 fx(xIC2)dx
x 1 Х 2
+C21Pl l fx(xICl)dx + C12P2 1 fx(xIC2)dx,
Х2 хl
(3.72)
3.10. Взаимосвязь персептрона и байесовскоro классификатора в rауссовой среде 205
rде Pi априорная вероятность (а priori probabi1ity) TOro, что вектор наблюдения
х (представляющий реализацию случайноrо вектора Х) принадлежит подпростран
ству X i при i == 1, 2, и Рl + Р2 == 1; Cij стоимость решения в пользу класса C i ,
представленноro подпространством X i , Korдa истинным является класс C j (т.е. вектор
наблюдения принадлежит подпространству X j ) при (i,j) == 1,2; fx(xIC i ) функ
ция плотности условной вероятности случайноrо вектора Х при условии, что вектор
наблюдения х принадлежит подпространству X i для i == 1,2.
Первые два слаrаемых в правой части уравнения (3.72) представляют KoppeKт
ные (correct) решения (т.е. корректные классификации), а вторая пара слаrаемых
некорректные (incorrect) (т.е. ошибки классификации). Каждое решение взвешива
ется произведением ДВУХ факторов: стоимости принятия решения и относительной
частоты ero принятия (т.е. априорной вероятности).
Целью является нахождение стратеrии минимизации средне20 риска. В процессе
принятия решения каждому вектору наблюдения х из пространства Х должно быть
сопоставлено какое либо из подпространств Х 1 или Х 2 . Таким образом,
Х == Х 1 +Х 2 .
(3.73)
Соответственно выражение (3.72) можно переписать в эквивалентной форме:
R == Cl1Pl r fx(x!C 1 )dx+c22P2 r fx(xIC 2 )dx
JX 1 JX Xl
+C21Pl l Xl fx(xIC1)dx + C12P2 .ll fx(xIC 2 )dx,
(3.74)
rде Cl1 < С21 И С22 < C12. Принимая во внимание тот факт, что
1 fx(xIC1)dx == 1 fx(xIC 2 )dx == 1,
(3.75)
уравнение (3.74) можно свести к выражению
R == C21Pl + С22Р2 +
+ r [P2(C12 c22)fx(xIC 2 ) Pl(C21 cl1)fx(xIC 1 )] dx.
JXl
(3.76)
Первые два слаrаемых в правой части выражения (3.76) представляют собой фик
сированную стоимость. Теперь для минимизации среднеrо риска R можно вывести
следующую стратеrию оптимальной классификации.
........
206 rлава з. ОДНОСЛОЙНЫЙ персептрон
1. Чтобы интеrpал вносил отрицательный вклад в значение риска R, все значения
вектора наблюдения х, для которых подынтеrpальное выражение (т.е. выражение
в квадратных скобках) является отрицательным, должны быть отнесены к подпро
странству Х 1 (т.е. к классу C 1 ).
2. Чтобы интеrpал вносил положительный вклад в значение риска R, все значения
вектора наблюдения х, для которых подынтеrpальное выражение является поло
жительным, должны быть исключены из подпространства Х 1 (т.е. отнесены к
классу С 2 ).
3. Значения х, при которых подынтеrpальное выражение равно нулю, не влияют на
риск R. Их можно отнести к любому классу произвольным образом. В данном
случае будем относить их к подпространству Х 2 (т.е. к классу С 2 ).
Принимая это в расчет, байесовский классификатор можно описать следующим
образом.
Если выполняется условие
Рl (С21 Cl1)!x(xIC 1 ) > P2(C12 C22)!X(xIC 2 ),
то вектор наблюдения х следует относить к подпространству Х 1 (т.е. к классу CJ,
в противном случае к подпространству Х 2 (т.е. к классу Са).
ДЛЯ упрощения изложения введем следующие обозначения:
л(х) !x(xIC 1 )
!x(xIC 2 )'
== P2(C12 С22) .
Рl (С21 Cl1)
(3.77)
(3.78)
Величина А(х), являющаяся частным двух функций плотности условной вероятно
сти, называется отношением правдоподобия (like1ihood ratio). Величина называется
пОРО20вым значением (threshold) процедуры проверки. Заметим, что обе величины
А(х) и всеrда положительны. В терминах этих величин байесовский классифика
тор можно переопределить следующим образом.
Если для вектора наблюдения хотношение правдоподобия А(х) превышает пopo
20вый уровень 1;, то вектор х принадлежит к классу C 1 , в противном случае к
классу С 2 .
На рис. 3.10, а представлена блочная диаrpамма байесовскоro классификатора.
Ero важные свойства сводятся к следующему.
1. Обработка данных в байесовском классификаторе оrpаничена исключительно BЫ
числением отношения правдоподобия А(х).
3.10. Взаимосвязь персептрона и байесовскоrо классификатора в rауссовой среде 207
х
Вычисление л(х)
коэффициента
правдоподобия
Компаратор
Относим х к классу C 1 ,
еслиА(х» .
В противном
случае к классу С 2
а)
х
Вычисление lоgЛ(х)
коэффициента Компаратор
правдоподобия
Относим х к классу C 1 ,
если lоgЛ(х»lоg .
В противном
случае к классу С 2
log
б)
Рис. 3.10. Две эквивалентные реализации байесовскоro классификатора:
на основе отношения правдоподобия (а) и еro лоraрифма (б)
2. Эти вычисления полностью инвариантны по отношению к значениям априорной
вероятности и стоимости, назначенным в процесс е принятия решения. Эти значе
ния влияют на величину пороrа .
С вычислительной точки зрения более удобно работать с лоrарифмом отношения
правдоподобия, а не с самим коэффициентом. К этому заключению приходи м по двум
причинам. Во первых, лоrарифм является монотонной функцией. BO BTOpЫX, значе
ния Л(х) и всеrда положительны. Исходя из этоrо, байесовский классификатор
можно реализовать в эквивалентной форме, показанной на рис. 3.1 О, б. Такой под
ход называют ЛО2арифмическим критерием отношения правдоподобия (log like1ihood
ratio test).
Байесовский классификатор и распределение raycca
Рассмотрим частный случай задачи классификации на два класса, в котором случай
ная величина имеет распределение raycca. Среднее значение случайноrо вектора Х
зависит от Toro, какому классу принадлежат ero реализации С 1 или С 2 , однако
матрица ковариации Х остается одной и той же для обоих классов. Таким образом,
можно записать следующее.
Класс C 1 :
Е[Х] == J.ll'
Е[(Х J.ll)(X J.ll)T] == С.
Е[Х] == J.l2'
Е[(Х J.l2)(X J.l2)T] == С.
Класс С 2 :
r
208 rлава з. ОДНОСЛОЙНЫЙ персептрон
Матрица ковариации С не является диаroнальной, а это значит, что образы классов
С 1 и С 2 коррелированы. Предполаrается, что матрица С является несинrулярной,
поэтому существует обратная матрица С 1 .
Используя эти соrлашения, функцию плотности условной вероятности Х можно
представить в следующем виде:
( ) 1 1 т l
fx xlC i == (21t)m/2(det(C))1/2 ехр( 2(X J.1i) С (х J.1i))' i == 1, 2, (3.79)
rде т размерность вектора наблюдения х.
Введем следующие предположения.
1. Вероятность принадлежности образа обоим классам С 1 и С 2 одинакова, Т.е.
Рl == Р2 == 1/2.
(3.80)
2. Ошибка классификации имеет постоянную стоимость, а корректная классифика
ция стоимости не имеет:
C12 == С21И Cll == С22 == о.
(3.81)
Теперь мы обладаем всей информацией, необходимой для построения байесов
CKOro классификатора для двух классов. В частности, подставляя (3.79) в (3.77) и
вычисляя натуральный лоrарифм, после упрощения получим:
lоgЛ(х) == 1/2(x J.11)TC 1(X J.11) + 1/2(х J.12)TC 1(X J.12)
== (J.11 J.12)TC lX + 1/2(J.1IC 1J.12 J.1TC 1J.11)'
(3.82)
Подставляя (3.80) и (3.81) в (3.78) и находя натуральный лоrарифм, приходим к
соотношению
log == о.
(3.83)
Выражения (3.82) и (3.83) свидетельствуют о том, что байесовский клас
сификатор для данной задачи является линейным классификатором, описывае
мым соотношением
у == w T Х + ь,
(3.84)
rде
3.10. Взаимосвязь персептрона и байесовскоrо классификатора в rауссовой среде 209
Х 1
Х 2
х У
Рис. 3.11. rраф передачи сиrнала байесовскоro класси Х т
фикатора в rауссовой среде
у == log А(х),
w == C 1(J11 J12),
1 Т l Т l
Ь == 2 (J12 С J12 J11 С J11)'
(3.85)
(3.86)
(3.87)
Более точно, классификатор представляет собой линейный сумматор с вектором
весов w и пороrом Ь (рис. 3.11).
Теперь с учетом (3.84) лоrарифмический критерий отношения правдоподобия для
задачи классификации на два класса можно описать следующим образом.
Если выходной СИ2Нал у линеЙНО20 сумматора (содержаще20 порО2 Ь) положителен,
вектор наблюдения х относится к классу C 1 , в противном случае к классу С 2 .
Описанный выше байесовский классификатор в rауссовой среде аналоrичен пер
септрону в том смысле, что оба классификатора являются линейными (см. (3.71) и
(3.84)). Однако между ними существует ряд мелких и важных различий, на которых
следует остановиться [657].
. Персептрон работает при условии, что классифицируемые образы линейно
разделимы (linear1y separable). Распределение raycca в контексте байесовскоrо
классификатора предпола2ает их пересечение, что исключает их линейную разде
лимость. rраницы этоro пересечения определяется посредством векторов J11 и J12
И матрицы ко вариации С. Природа пересечения проиллюстрирована на рис. 3.12
для частноrо случая скалярной случайной переменной (т.е. размерность т == 1).
Если входные сиrналы неразделимы и их функции распределения пересекаются
так, как показано на рисунке, алrоритм обучения персептрона не сходится, так как
rpаницы областей решения MOryт постоянно смещаться.
. Байесовский классификатор минимизирует вероятность ошибки классификации.
Эта минимизация не зависит от пересечения между распределениями [аусса двух
классов. Например, в частном случае, показанном на рис. 3.12, байесовский клас
сификатор всеrда будет помещать rpаницу областей решения в точку пересечения
функций rayccoBa распределения классов С 1 и С 2 .
.......
21 О rлава з. ОДНОСЛОЙНЫЙ персептрон
rраница
решений
х
Рис. 3.12. Две пересекающиеся
одномерные функции распреде
ления raycca
· Алrоритм работы персептрона является непараметрическим (nonparametric),
Т.е. относительно формы рассматриваемых распределений никаких предваритель
ных предположений не делается. Работа алrоритма базируется на коррекции оши
бок, возникающих в точках пересечения функций распределения. Таким образом,
персептрон хорошо работает с входными сиrналами, rенерируемыми нелиней
ными физическими процессами, даже если их распределения не симметричны
и не являются rауссовыми. В отличие от персептрона байесовский классифика
тор является параметрическим (parametric). Он предполаrает, что распределения
случайных величин являются rауссовыми, а это может оrраничить область приме
нения классификатора.
· Алrоритм сходимости персептрона является адаптивным и простым для реали
зации. Ero требования к хранению информации оrpаничиваются множеством си
наптических весов и пороroв. Архитектура байесовскоrо классификатора является
фиксированной; ее можно сделать адаптивной только за счет усиления требований
к хранению информации и усложнения вычислений.
3.11. Резюме и обсуждение
Персептрон и адаптивный фильтр на основе алrоритма LMS связаны самым eCTe
ственным образом, что проявляется в процессе модификации синаптических связей.
Более Toro, они представляют различные реализации однослойною персептрона, обу
чаемою на основе коррекции ошибок (sing1e 1ayer perceptron based оп error correction
1eaming). Термин "однослойный" здесь используется для Toro, чтобы подчеркнуть,
что в обоих случаях вычислительный слой состоит из единственноrо нейрона (это
отмечено и в названии данной rлавы). Однако персептрон и алrоритм минимизации
среднеквадратической ошибки отличаются друr от друrа в некоторых фундаменталь
ных аспектах.
3.11. Резюме и обсуждение 211
· Алroритм минимизации среднеквадратической ошибки использует линейный
нейрон, в то время как персеmpон основан на формальной модели нейро
на Мак..Каллока Питца.
· Процесс обучения персептрона завершается за конечное число итераций. Алro
ритм минимизации среднеквадратической ошибки предполаrает llепреРЫ81l0е 06у--
чеlluе (continuous leaming), т.е. обучение происходит до тех пор, пока выполняется
обработка сиrнала. Этот процесс никоrда не останавливается.
Модель Мак Каллока Пища накладывает жесткие оrpаничения на форму нели
нейности нейрона. Возникает вопрос: "Будет ли персептрон работать лучше, если
эти жесткие оrpаничения заменить сиrмоидальной нелинейностью?" Оказывается,
fO.I.... ....
что устоичивое принятие решении персептроном не зависит от вида нелинеиности
нейрона [983], [984]. Таким образом, можно формально утверждать, что при исполь--
u V ....
зовании модели неирона, которая состоит из линеиноro сумматора и нелинеиноro эле
мента, независимо от формы используемой нелинейности однослойный персептрон
будет выполнять классификацию образов только для линейно--разделимых классов.
Завершим обсуждение краткой исторической справкой. Персеrrrрон и алroритм
минимизации среднеквадратической ошибки появились приблизительно в одно и то
же время в конце 1950--х roдов. Алrоритм минимизации среднеквадратической
ошибки достойно выдержал испытание временем. Он хорошо зарекомендовал се..
бя в качестве "рабочей лошадки" адаптивной обработки сиrналов блаroдаря своей
эффективности и простоте реализации. Персептрон Розенблатта имеет более инте...
ресную историю.
Первая критика персептрона Розенблатта появилась в [746], rде утверждалось,
что персептрон Розенблатта не способен к обобщению даже в задаче "исключающеro
ИЛИ" (двоичной четности), не roворя уже о более общих абстракциях. Вычисли--
тельные оrpаничения персептрона Розенблатта были математически обоснованы в
знаменитой книrе Минскоrо и Пейперта ПерсептРОIlЫ [744], [745]. После блестяще--
ro и в высшей степени подробноrо математическоro анализа персептрона Минский и
Пейперт доказали, что персептрон в определении Розенблатта внутренне не способен
на rлобальные обобщения на базе локальных примеров обучения. В последней rлаве
своей книrи Минский и Пейперт высказали предположение, что недостатки персеп..
трона Розенблатта остаются в силе и для ero вариаций, в частности для мноroслойных
нейронныx сетей. Приведем цитату из этой книrи (раздел 13.2) [744].
...........
212 rлава з. ОДНОСЛОЙНЫЙ персептрон
Персептрон достоин изучения вопреки (и даже бла20даря) своим 02раниченuям. Он
..... ...
имеет множество своиств, заслуживающих внимания: линеиность, интриzyющую
теорему обучения, образцовую простоту в смысле Ор2анuзации параллельных вы
числений. Нет оснований пола2ать, что некоторые из е20 преu.м.уществ сохра1lЯт
ся в МНО20СЛОЙНОЙ версии. Тем не менее мы рассматриваем е20 как важный объ
ект исследовании, для тО20 чтобы обосновать (Шlи отвеР2нуть) наш интуитив
... ...
ныи при20вор: расширение персептрона в сторону МНО20СЛОUНЫХ систем потенци
ально безрезультатно.
Это заключение в основном и несет ответственность за возникновение серьезных
" v
сомнении в вычислительных возможностях не только персептрона, но и неиронных
сетей в целом вплоть до середины 1980 x rодов.
Однако история показала, что предположение, высказанное Минским и Пейпер
том, было бездоказательным. В настоящее время мы имеем ряд усовершенствованных
форм нейронныx сетей, которые с вычислительной точки зрения мощнее персептро
на Розенблатта. Например, мноrослойные персептроны, обучаемые с помощью ал
rоритма обратноro распространения ошибки (rлава 4), сети на основе радиальных
базисных функций (rлава 5) и машины опорных векторов (rлава 6) преодолевают
вычислительные оrpаничения однослойноrо персептрона различными способами.
Задачи
Безусловная оптимизация
3.1. Исследуйте метод наискорейшеrо спуска для единственноro BecoBoro коэф-
фициента w с помощью следующей функции стоимости:
1 2 1 2
Е(ш) == '20' rxd W + 2 ТХШ ,
2
rде о' , r xd И r х константы.
3.2. Рассмотрим функцию стоимости
1 2 Т 1 т
E(w) == 2 о' rxdw + 2 w Rxw,
rде 0'2 некоторая константа и
r xd ==
0.8182
0.354
,
Rx ==
1 0.8182
0.8182 1
.
Задачи 213
а) Найдите оптимальное значение w*, при котором функция E(w) достиrает
CBoero минималъноrо значения.
б) Используйте метод наискорейшеrо спуска для вычисления w* при следу
ющих значениях параметра скорости обучения: 11 ==0,3, 11 == 1,0.
Для каждоro случая постройте траекторию вектора весов w(n)
в плоскости w.
Прuмечание. Траектории, полученные для обоих значений параметра CKO
рости обучения, должны соответствовать рис. 3.2.
3.3. Рассмотрите функцию стоимости (3.24), которая является модифицированной
формой суммы квадратов ошибок, определяемой соотношением (3.17). Пока
жите, что применение метода rаусса Ньютона к выражению (3.24) приводит
к формуле модификации весов (3.23).
Алrоритм LMS
3.4. Матрица корреляции Rx входноrо вектора х(n) в алrоритме минимизациИ
среднеквадратической ошибки определяется выражением
Rx ==
1 0.5
0.5 1
.
Определите диапазон значений параметра скорости обучения 11 алrоритма
LMS, при котором он сходится в смысле среднеквадратическоrо значения.
3.5. Нормализованный аЛ20рИтм минuмизации среднеквадратической ошибки
описывается следующим рекурсивным выражением для вектора весовых KO
эффициентов:
"-'(n + 1) == "-'(n) +
11
Ilx(n) 112 е( n )х(n),
rде 11 положительная константа, Ilx(n)11 Евклидова норма входноro BeK
тора х(n). Сиrнал ошибки определяется соотношением
е(n) == d(n) ",Т(n)х(n),
rде d(n) желаемый отклик. Покажите, что для сходимости нормализован
HOro алrоритма в смысле среднеквадратическоrо значения требуется, чтобы
О < 11 < 2.
214 rлава з. ОДНОСЛОЙНЫЙ персептрон
3.б. Алrоритм минимизации среднеквадратической ошибки используется для pe
ализации обобщенной системы подавления боковых лепестков, показанной
на рис. 2.1б. Задайте уравнения, описывающие работу этой системы, если
V u
неиронная сеть состоит из единственноrо неирона.
3.7. Рассмотрим систему линейноrо проrнозирования, входной вектор которой
состоит из набора примеров х(n 1), х(n 2), ..., х(n т), rде т
порядок проrнозирования. Используйте алrоритм минимизации cpeДHeKBaд
ратической ошибки для проrнозирования оценки х(n) входноrо образа х(n).
Опишите рекурсивную функцию, которую можно использовать для вычисле
ния весовых коэффициентов Wl, W2, . . . , W m системы.
3.8. Усредненное по всему множеству значение суммы квадратов ошибок можно
использовать в качестве функции стоимости. Оно представляет собой cpeд
неквадратическое значение сиrнала ошибки
1 1
J(w) == E(e2(n)] == E[(d(n) x T (n)w)2).
2 2
а) Предполаrая, что входной вектор х(n) и желаемый отклик d(n) поступают
v
из стационарнои среды, покажите, что
1 2 Т 1 т
J(w) == (jd rxdw + w Rxw,
2 2
rде
a == Е [d 2 ( n ) ] ,
rxd == E[x(n)d(n)J,
Rx == Е[х(n)хТ(n)].
б) Для этой функции стоимости покажите, что вектор rpадиента и матрица
rессиана для J(w) имеют следующий вид:
g == rxd + Rxw,
Н == Rx-
в) В ал20рuтме НьютОllа минимизации среднеквадратической ошибки вме...
сто вектора rpадиента g используется ero моментальное значение [1144].
Покажите, что этот алrоритм с параметром скорости обучения 11 описы...
вается выражением
",(n + 1) == ",(n) + 11 R;lx(n)(d(n) xT(n)w(n).
Задачи 215
Предполаrается, что матрица, обратная корреляционной, является поло
,...
жительно определеннои и вычислена заранее.
3.9. Вернемся к памяти, основанной на матрице корреляции (см. раздел 2.11).
Недостаток этой памяти заключался в том, что при предъявлении ей клю
чевоro образа Xj фактический отклик У может быть недостаточно близок
(в Евклидовом смысле) к желаемому (запомненному образу) Yj и ассоциация
реализуется некорректно. Этот недостаток обусловлен алroритмом обучения
Хебба, который не предполаrает обратной связи выхода с входом. Для пре
одоления этоrо недостатка в структуру памяти можно добавить механизм
коррекции ошибок, обеспечивающий корректную ассоциацию [49].
......
Пусть М(п) матрица памяти, полученная на итерации п процесса обу
чения на основе коррекции ошибок. Эта матрица обучается на ассоциациях,
представленных парами
Xk -----i' Yk, k == 1, 2, . · . , q.
а) Адаптируя алrоритм минимизации среднеквадратической ошибки к дан-
ной задаче, покажите, что обновленное значение матрицы памяти должно
определяться следующим соотношением:
М(п + 1) == М(п) + 11 [Yk M(n)Xk]X[,
rде 11 параметр интенсивности обучения.
б) Для частноro случая автоассоциации, при котором Yk ==Xk, покажите, что
при стремлении количества итераций к бесконечности автоассоциация в
памяти происходит идеально, Т.е.
M(oo)Xk == xk,k == 1,2,... ,q.
в) Результат, описанный в пункте б), можно рассматривать как задачу вы--
числения собственных чисел. В этом контексте Xk представляет собой
собственный вектор матрицы М(оо). А что такое собственные значения
матрицы М( оо)?
3.10. в этой задаче необходимо исследовать влияние пороroвоrо значения на число
обусловленности матрицы корреляции, а значит, и на производительность
алrоритма LMS.
Рассмотрим случайный вектор Х с матрицей ковариации
с==
Сl1 С12
С21 С22
216 rлава з. ОДНОСЛОЙНЫЙ персептрон
и вектором ожидания
1.1 ==
Jll
Jl2
.
а) Вычислите число обусловленности матрицы ковариации с.
б) Вычислите число обусловленности матрицы корреляции R.
Про комментируйте влияние пороrовоrо значения Jl на производительность
алrоритма LMS.
Персептрон Розенблатта
3.11. в этой задаче рассматривается еще один метод вывода алroритма обновления
весовых коэффициентов для персептрона Розенблатта. Определим критерий
качества для персептРОllа [269] в виде
( WT х)
Jp(w) == L '
XEX(w)
rде X(w) множество примеров, ошибочно классифицированных при данном
векторе весов w. Обратите внимание, что при отсутствии ошибочно класси
фицированных примеров значение функции J p(w) равно нулю и выходной
сиrнал ошибочно классифицируется, если w < О.
а) ПрОИJШюстрируйте rеометрически, что значение Jp(w) пропорционально
сумме Евклидовых расстояний от ошибочно классифицированных приме
ров до rpаницы областей решений.
б) Определите rpадиент функции Jp(W) относительно вектора весов w.
в) Используя полученный в пункте б) результат, покажите, что алrоритм об...
новления весов персептрона можно записать в следующем виде:
w(n + 1) == w(n) + 11 (n) L Х,
xEX(w(n)
rде X(w(n)) множество примеров, ошибочно классифицированных при
заданном векторе весовых коэффициентов w( n ); 11 (n) параметр скоро...
сти обучения. Покажите, что для случая коррекции на одном примере этот
результат практически совпадает с выражениями (3.54) и (3.55).
3.12. Покажите, что выражения (3.68) (3.71), отражающие алroритм сходимости
персептрона, соrласуются с соотношениями (3.54) и (3.55).
Задачи 217
3.13. Рассмотрите два одномерных класса, С 1 и С 2 , С rауссовым распределением,
дисперсия KOToporo равна 1. Их средние значения соответственно равны
1 == 10,
2 == +10.
Эти классы являются линейно разделимыми. Постройте классификатор, раз...
у
деляющии эти два класса.
3.14. Предположим, что на rpафе передачи сиrнала персептрона (см. рис. 3.6)
строrая пороroвая функция заменена сиrмоидальной
<р (v) == tanh ( ) ,
rде v индуцированное локальное поле. Классификация, выполняемая пер
септроном, описывается следующим образом.
Вектор наблюдения х принадлежит к классу С 11 если выход1l0Й СИ2НaJl у > 8,
zде 8 nОрО2 (threshold). В противном случае х принадлежит к классу С 2 .
Покажите, что построенная таким образом поверхность решений является
rиперплоскостъю.
3.15. а) Персептрон можно использовать для выполнения мноrих лоrических
функций. Опишите перспетронную реализацию функций лоrическоrо И,
лоrическоro ИЛИ и дополнения.
б) Основным оrpаничением персептрона является ero неспособность реали
зовать лоrическую функцию исключающеrо ИЛИ. Объясните почему.
3.16. Уравнения (3.86) и (3.87) определяют вектор весовых коэффициентов и по
poroBoe значение байесовскоrо классификатора для rауссовой среды. Моди
фицируйте этот классификатор для случая, коrда матрица ковариации опре...
деляется выражением
с == 0'21
,
rде 0'2 константа.
Мноrослойный персептрон
4.1. Введение
Эта шава посвящена важному классу нейронных сетей мноrослойным сетям пря
MOro распространения. Обычно сеть состоит из множества сенсорных элементов
(входных узлов или узлов источника), которые образуют входной слой; одноrо или
нескольких скрытых слоев (hidden layer) вычислительных нейронов и одноro выxoд
НО20 слоя (output layer) нейронов. Входной сиrнал распространяется по сети в прямом
направлении, от слоя к слою. Такие сети обычно называют МНО20СЛОЙНЫМИ пepceп
тронами (multilayer percetron). Они представляют собой обобщение однослойноrо
персептрона, paccMoтpeHHoro в шаве 3.
Мноrослойные персептроны успешно применяются для решения разнообразных
сложных задач. При этом обучение с учителем выполняется с помощью TaKoro
популярноrо алrоритма, как ал20ритм обратНО20 распространения ошибки (error
back propagation algorithm). Этот алrоритм основывается на коррекции ошибок (error
correction learning rule). Ero можно рассматривать как обобщение столь же попу
лярноrо алrоритма адаптивной фильтрации вездесущеrо алroритма минимизации
среднеквадратической ошибки (LMS), описанноrо в шаве 3 для частноro случая OT
дельноrо линейноrо нейрона.
Обучение методом обратноro распространения ошибки предполаrает два прохода
по всем слоям сети: прямоrо и обратноrо. При прямом проходе (forward pass) образ
(входной вектор) подается на сенсорные узлы сети, после чеrо распространятся по
сети от слоя к слою. В результате rенерируется набор выходных сиrналов, который и
является фактической реакцией сети на данный входной образ. Во время прямоrо про
хода все синаптические веса сети фиксированы. Во время обратНО20 прохода (back
ward pass) все синаптические веса настраиваются в соответствии с правилом KoppeK
ции ошибок, а именно: фактический выход сети вычитается из желаемоrо (целевоrо)
отклика, в результате чеrо формируется СИ2Нал ошибки (error signal). Этот сиrнал впо
следствии распространяется по сети в направлении, обратном направлению синапти
ческих связей. Отсюда и название алrоритм обратноrо распространения ошибки.
Синаптические веса настраиваются с целью максимальноrо приближения выходноrо
............
220 rлава 4. Мноrослойный персептрон
сиrнала сети к желаемому в статистическом смысле. Алrоритм обратноrо распростра
нения ошибки в литературе иноrда называют упрощенно ал20рИтмом обратНО20
распространения (back propagation algorithm). Это название мы и будем использовать
в настоящей шаве. Процесс обучения, реализуемый этим алrоритмом, называется
обучением на основе обратНО20 распространения (back propagation learning).
Мноrослойные персептроны имеют три отличительных признака.
1. Каждый нейрон сети имеет нелинейную функцию активации (nonlinear activation
function). Важно подчеркнуть, что данная нелинейная функция является шад
кой (т.е. всюду дифференцируемой), в отличие от жесткой пороrовой функции,
используемой в персептроне Розенблатта. Самой популярной формой функции,
удовлетворяющей этому требованию, является СИ2Моидальная 1 (sigmoidal nonlin
earity), определяемая ЛО2истической функцией (1ogistic function)
1
Yj == 1 + ехр( Vj)'
rдe vj индуцированное локальное поле (т.е. взвешенная сумма всех синаптиче
ских входов плюс пороrовое значение) нейрона j; У j выход нейрона. Наличие
нелинейности иrpает очень важную роль, так как в противном случае отображение
"BXOД BЫXOД" сети можно свести к обычному однослойному персептрону. Более
Toro, использование лоrистической функции мотивировано биолоrически, так как
в ней учитывается восстановительная фаза реальноrо нейрона.
2. Сеть содержит один или несколько слоев скрытых нейронов, не являющихся ча
стью входа или выхода сети. Эти нейроны позволяют сети обучаться решению
сложных задач, последовательно извлекая наиболее важные признаки из входноro
образа (вектора).
3. Сеть обладает высокой степенью связности (connectivity), реализуемой посред
ством синаптических соединений. Изменение уровня связности сети требует из
менения множества синаптических соединений или их весовых коэффициентов.
Комбинация всех этих свойств наряду со способностью к обучению на собствен
ном опыте обеспечивает вычислительную мощность мноrослойноrо персептрона. Oд
нако эти жс качества являются причиной неполноты современных знаний о поведении
TaKoro рода сетей. Во первых, распределенная форма нелинейности и высокая связ
I Сиrмоидальные функции получили свое назваиие блaroдаря форме cBoero rpафика (в виде буквы S).
В [727] исследованы два класса сиrмоид.
Простые СИ2моиды. Произвольные асимптотически оrpаниченные и cтporo монотонные функции одной
переменной.
ТиперБOJlические СИ2моиды. Полное подмиожество простых сиrмоид, являющихся обобщением функции
rИllерболическоro TaHreHca.
4.1. Введение 221
ность сети существенно усложняют теоретический анализ мноroслойноro персептро
на. BO BTOpЫX, наличие скрытых нейронов делает процесс обучения более трудным
для визуализации. Именно в процессе обучения необходимо определить, какие при
знаки входноro сиrнала следует представлять скрытыми нейронами. Тоща процесс
обучения становится еще более сложным, поскольку поиск должен выполняться в
очень широкой области возможных функций, а выбор должен производиться среди
альтернативных представлений входных образов [458].
Термин "обратное распространение" активно используется после 1986 roда, KO
rдa он был популяризован в известной книre [912]. Более подробные исторические
сведения об алroритме обратноrо распространения приводятся в разделе 1.9.
Появление алroритма обратноro распространения стало знаковым событием в об
ласти развития нейронных сетей, так как он реализует вычислительно эффектив
ный (computationally efficient) метод обучения мноroслойноro персептрона. Было бы
слишком самоуверенно утверждать, что алroритм обратноro распространения предла
raeT действительно оптимальное решение всех потенциально разрешимым проблем,
однако он развеял пессимизм относительно обучения мноroслойных машин, Boцa
рившийся в результате публикации [745].
Структура rлавы
в данной шаве рассматриваются основные аспекты работы мноrослойноrо персеп
трона, а также ero обучение методом обратноrо распространения. Эта шава разбита
на семь частей. В первой части (разделы 4.2 .6) мы обсудим вопросы, связанные
с обучением по методу обратноro распространения. Начнем с раздела 4.2, подrотав
ливающеro почву для дальнейшеrо изложения этоro вопроса. В разделе 4.3 будет
представлено детальное описание алrоритма в виде последовательности правил BЫ
числения (chain rule of calculus). Алrоритм в сжатом виде приводится в разделе 4.4.
В разделе 4.5 мы продемонстрируем использование алrоритма обратноro распростра
нения на при мере задачи исключающеrо ИЛИ (XOR), которая неразрешима с точки
зрения однослойноro персептрона. В разделе 4.6 приводятся некоторые эвристиче
ские и практические рекомендации по повышению производительности алroритма
обратноro распространения.
Вторая часть (разделы 4.7 .9) посвящена использованию мноroслойноro персеп
трона для распознавания образов. В разделе 4.7 при водится решение статистической
задачи распознавания образов с помощью мноroслойноro персептрона. В разделе 4.8
описывается компьютерный эксперимент, иллюстрирующий применение алroритма
обратноro распространения в задаче разделения двух перекрывающихся классов с
двумерным rayccoBbIM распределением. Значение скрытых нейронов, как детекторов
признаков, обсуждается в разделе 4.9.
.....
222 rлава 4. Мноrослойный персептрон
в третьей части (разделы 4.1 0 .11) речь пойдет об исследовании поверхности
ошибки. В разделе 4.1 О мы обсудим фундаментальную роль обучения по методу
обратноro распространения в вычислении частных производных аппроксимируемых
функций. В разделе 4.11 рассматриваются вычислительные вопросы, связанные с
нахождением матрицы recce для поверхности ошибки.
В четвертой части (разделы 4.12 .15) рассматриваются различные вопросы, свя
занные с производительностью мноroслойноro персептрона, обучаемоro с помощью
алroритма обратноrо распространения. В разделе 4.12 мы обсудим вопросы обоб-
щения, составляющие квинтэссенцию обучения. В разделе 4.13 описывается зада
ча аппроксимации непрерывных функций с помощью мноroслойноro персептрона.
Использование перекрестной проверки (cross validation) в качестве статистическоro
средства проверки достоверности результата обсуждается в разделе 4.14. В разде
ле 4.15 обсуждаются процедуры снижения порядка мноrослойноro персептрона без
потери ero производительности. Такие процедуры упрощения сети особенно важны
в тех задачах, в которых критическим вопросом является вычислительная сложность.
ПЯтая часть (разделы 4.16 .1 7) завершает исследование алrоритма обратноrо рас-
пространения. В разделе 4.16 анализируются преимущества и оrpаничения метода
обратноrо распространения. В разделе 4.17 приводятся эвристические рекомендации,
ускоряющие сходимость обучения методом обратноrо распространения.
В шестой части (раздел 4.18) процесс обучения рассматривается под несколько
иным ушом зрения. Для повышения эффективности обучения с учителем этот про
цесс рассматривается как численная задача оптимизации. В частности, для реализа
ции обучения с учителем предлаrается использовать метод сопряженных rpадиентов
(conjugate gradient) и квазиньютоновские методы.
В последней части шавы (раздел 4.19) основное внимание уделяется самому MHO
roслойному персептрону. Здесь будет описана довольно интересная структура сети
МНО20СЛОЙНЫЙ персептрон свертки (convolutional multilayer perceptron). Такая сеть
успешно использовалась для решения сложных задач распознавания образов.
В завершение шавы в разделе 4.20 приводятся общие выводы.
4.2. Вводные замечания
На рис. 4.1 показан архитектурный rpаф мноroслойноro персептрона с двумя скры-
тыми слоями и одним выходным слоем. Показанная на рисунке сеть является пOk
носвЯ31l0Й (fully connected), что характерно для мноrослойноro персептрона общеro
вида. Это значит, что каждый нейрон в любом слое сети связан со всеми нейрона
ми (узлами) предыдущеro слоя. Сиrнал передается по сети исключительно в прямом
направлении, слева направо, от слоя к слою.
4.2. Вводные замечания
223
Входной
сиrнал
(возбуждение)
Выходной
сиrнал
(отклик)
Входной
слой
Первый
скрытый
слой
Второй
скрытый
слой
Выходной
слой
Рис. 4.1. Архитектурный rраф мноrослойноro персептрона с двумя скрытыми слоями
Рис. 4.2. Направление двух основных потоков сиr
нала для мноroслойноro персептрона: прямое pac
пространение функциональноro сиrнала и обратное
распространение сиrнала ошибки
...
............... Функциональные сиrналы
... Сиrналы ошибки
На рис. 4.2 показан фраrмент мноrослойноrо персептрона. Для этоro типа сети
выделяют два типа сиrналов [816].
1. Функциональный СИ2Нал (function signa1). Это входной сиrнал (стимул), поступа
ющий в сеть и передаваемый вперед от нейрона к нейрону по всей сети. Такой
сиrнал достиrает конца сети в виде выходноrо сиrнала. Будем называть этот сиrнал
функциональным по двум причинам. Во-первых, он предназначен для выполнения
некоторой функции на выходе сети. BO BTOpЫX, в каждом нейроне, через который
передается этот сиrнал, вычисляется некоторая функция с учетом весовых коэф
фициентов. Функциональный сиrнал еще называют.
2. СИ2Нал ошибки (error signa1). Сиrнал ошибки берет свое начало на выходе ce
ти и распространяется в обратном направлении (от слоя к слою). Он получил
свое название блаrодаря тому, что вычисляется каждым нейроном сети на основе
функции ошибки, представленной в той или иной форме.
........
224 rлава 4. Мноrослойный персептрон
Выходные нейроны (вычислительные узлы) составляют выходной слой сети.
Остальные нейроны (вычислительные узлы) относятся к скрытым слоям. Таким об-
разом, скрытые узлы не являются частью входа или выхода сети отсюда они и
получили свое название. Первый скрытый слой получает данные из входноro слоя,
составленноro из сенсорных элементов (входных узлов). Результирующий сиrнал пер
Boro cкpbIToro слоя, в свою очередь, поступает на следующий скрытый слой, и Т.д.,
до caMoro конца сети.
Любой скрытый или выходной нейрон мноroслойноrо персептрона может выпол-
нять два типа вычислений.
1. Вычисление функциональноrо сиrнала на выходе нейрона, реализуемое в виде
непрерывной нелинейной функции от входноrо сиrнала и синаптических весов,
связанных с данным нейроном.
2. Вычисление оценки вектора rpадиента (т.е. rpадиента поверхности ошибки по
синаптическим весам, связанным со входами данноro нейрона), необходимоrо
для обратноrо прохода через сеть.
Вывод алroритма обратноro распространения слишком rpомоздок. Для Toro чтобы
упростить понимание математических выкладок, сначала при ведем полный список
используемых обозначений.
Обозначения
. Индексы i, j и k относятся к различным нейронам сети. Коrда сиrнал проходит
по сети слева направо, считается, что нейрон j находится на один слой правее
нейрона i, а нейрон k еще на один слой правее нейрона j, если последний
принадлежит скрытому слою.
. Итерация (такт времени) n соответствует n MY обучающему образу (примеру),
поданному на вход сети.
. Символ Е( n) означает текущую сумму квадратов ошибок (или энерrию ошибки) на
итерации n. Среднее значение Е(n) по всем значениям n(т.е. по всему обучающему
множеству) называется средней энерrией ошибки Еау'
. Символ ej (n) описывает сиrнал ошибки на выходе нейрона j на итерации n.
. Символ d j (n) означает желаемый отклик нейрона j и используется для вычисления
ej(n).
. Символ Yj(n) описывает функциональный сиrнал, rенерируемый на выходе ней-
рона J на итерации n.
. Символ W ji (n) используется для обозначения синаптическоrо веса, связывающеrо
выход нейрона i со входом нейрона j на итерации n. Коррекция, применяемая к
этому весу на шаrе n, обозначается ДWji(n)'
4.3. Алrоритм обратноrо распространения 225
· Индуцированное локальное поле (т.е. взвешенная сумма всех синаптических BXO
дОВ плюс пороr) нейрона j на итерации n обозначается символом Vj(n). Это
значение передается в функцию активации, связанную с нейроном j.
· Функция активации, соответствующая нейрону j и описывающая нелинейную
взаимосвязь входноrо и выходноrо сиrналов этоrо нейрона, обозначается q> j (.).
· Пороr, применяемый к нейрону j, обозначается символом b j . Ero влияние пред
ставлено синапсом с весом WjO == b j , соединенным с фиксированным входным
сиrналом, равным + 1.
· i й элемент входноrо вектора обозначается Xi(n)'
· k й элемент выходноrо вектора (образа) обозначается ok(n)'
· Параметр скорости (интенсивности) обучения обозначается символом 11.
· Символ т! обозначает размерность (количество узлов) слоя l мноroслойноrо пер
септрона; l == 1, 2,. . ., L, [де L "шубина" сети. Таким образом, символ то
означает размерность входноrо слоя; тl первоrо cKpbIToro слоя; ffiL BЫXOД
Horo слоя. Для описания размерности выходноro слоя будет также использоваться
символ М.
4.3. Алrоритм o6paTHoro распространения
Сиrнал ошибки выходноrо нейрона j на итерации n (соответствующей n MY примеру
обучения) определяется соотношением
ej(n) == dj(n) Yj(n).
(4.1 )
Текущее значение энерrии ошибки нейрона j определим как e;(n). COOТBeT
ственно текущее значение Е(n) общей энерrии ошибки сети вычисляется путем сло
жения величин е; ( n) по всем нейронам выходНО20 слоя. Это "видимые" нейроны,
для которых сиrнал ошибки может быть вычислен непосредственно. Таким образом,
можно записать
1
Е(n) == 2" I: е;(n),
jEC
(4.2)
[де множество С включает все нейроны выходноrо слоя сети. Пусть N обшее
число образов в обучающем множестве (т.е. мощность этоrо множества). Энер2ИЯ
среднеквадратической ошибки в таком случае вычисляется как нормализованная по
N сумма всех значений энерrии ошибки Е(n):
"811
226 rлава 4. Мноrослойный персептрон
Нейронj
А
yo +l
У;Сп)
dj..n)
vj..п)
<р(' )
у/п)
1
е/п)
Рис. 4.3. rраф передачи сиrнала в пределах HeKoToporo нейрона j
1 N
Еау(n) == N I:: Е(n).
n l
(4.3)
Текущая энерrия ошибки Е(n), а значит и средняя энерrия ошибки Еау, явля-
ются функциями всех свободных параметров (т.е. синаптических весов и значений
пороrа) сети. Для данноro обучающеro множества энерrия Еау представляет собой
функцию стоимости (cost function) меру эффективности обучения. Целью процес
са обучения является настройка свободных параметров сети с целью минимизации
величины Еау' В процессе минимизации будем использовать аппроксимацию, анало-
rичную применяемой для вывода алrоритма LMS в шаве 3. В частности, рассмотрим
простой метод обучения, в котором веса обновляются для каждО20 обучающе20 при
мера в пределах одной эпохи (epoch), Т.е. Bcero обучающеrо множества. Настройка
весов выполняется в соответствии с ошибками, вычисленными для каждО20 образа,
представленноro в сети.
Арифметическое среднее отдельных изменений для весов сети по обучающему
множеству может служить оценкой реальных изменений, про изошедших в процессе
минимизации функции стоимости Еау на множестве обучения. Качество этой оценки
обсудим HeMHoro позже.
4.3. Алrоритм обратноrо распространения 227
Теперь рассмотрим рис. 4.3. На нем изображен нейрон j, на который поступает
поток сиrналов от нейронов, расположенных в предыдущем слое. Индуцированное
локальное поле щ(п), полученное на входе функции активации, связанной с данным
нейроном, равно
m
Vj(n) == I:: Wji(n)Yi(n),
i=O
(4.4)
[де т общее число входов (за исключением пороrа) нейрона j. Синаптический
вес WjO (соответствующий фиксированному входу Уо == +1) равен пороry b j , при
меняемому к нейрону j. Функциональный сиrнал У j (n) на выходе нейрона j на
итерации n равен
Yj(n) == Ч>/Vj(n)).
(4.5)
Аналоrично алroритму LMS, алroритм обратноrо распространения состоит в при
менении к синаптическому весу W ji (n) коррекции ДW ji (n), пропорциональной част
ной про извод ной BE(n)/BWji(n)' В соответствии с правилам цепочки, или цепным
правuлом (chain ru1e), rpадиент можно представить следующим образом:
дЕ(n) дЕ(n) Bej(n) BYj(n) дщ(n)
BWji(n) == Bej(n) BYj(n) BVj(n) BWji(n)'
(4.6)
Частная производная BE(n)jBWji (n) представляет собой фактор чувствительно
сти (sensitivity factor), определяющий направление поиска в пространстве весов для
синаптическоro веса W ji ( n).
Дифференцируя обе части уравнения (4.2) по ej(n), получим:
дЕ(n)
Bej(n) == ej(n).
(4.7)
Дифференцируя обе части уравнения (4.1) по Yj(n), получим соотношение
Bej(n) == 1.
BYj(n)
(4.8)
Затем, дифференцируя (4.5) по vj (n), получим:
BYj(n) I ( ( ))
д vj(n) == Ч>j Vj n ,
(4.9)
[де штрих справа от имени функции обозначает дифференцирование по apryMeHТY.
......
228 rлава 4. Мноrослойный персептрон
И, наконец, дифференцируя (4.4) по Wji(n), получим выражение
дщ ( n )
д () == Yj(n).
Wji n
(4.10)
Подставляя результаты (4. 7) ( 4.1 О) в выражение (4.6), окончательно получим:
дЕ(n) ,
д () == ej(n)q>j(vj(n))Yi(n)'
Wji n
(4.11 )
Коррекция ДWji(n)' применяемая к Wji(n), определяется сошасно дельта-
правuлу (de1ta rule):
дЕ(n)
ДWji(n) == l1 д () '
Wji n
(4.12)
rдe 11 параметр скорости обучения (learning rate parameter) алrоритма обратноro
распространения. Использование знака "минус" в (4.12) связано с реализацией 2ра-
диентНО20 спуска (gradient descent) в пространстве весов (т.е. поиском направления
изменения весов, уменьшающеro значение энерrии ошибки Е( n)). Следовательно,
подставляя (4.11) в (4.12), получим:
ДWji(n) == 11 Цn)Уi(n)'
(4.13)
[де локальный 2радиент (1oca1 gradient) 8j (n) определяется выражением
8.(n) == дЕ(n) == дЕ(n) aej(n) aYj(n) == е (n)q>'.(v.(n)).
J aVj(n) aej(n) aYj(n) aVj(n) J J J
(4.14)
Локальный rpадиент указывает на требуемое изменение синаптическоrо веса. В со-
ответствии с (4.14) локальный rpадиент 8j (n) выходноrо нейрона j равен произведе-
нию соответствующеrо сиrнала ошибки ej (n) этоrо нейрона и производной <Р} ( V j (n))
соответствующей функции активации.
Из выражений (4.13) и (4.14) видно, что ключевым фактором в вычислении ве-
личины коррекции ДWji(n) весовых коэффициентов является сиrнал ошибки ej(n)
нейрона j. В этом контексте можно выделить два различных случая, определяемых
положением нейрона j в сети. В первом случае нейрон j является выходным узлом.
Это довольно простой случай, так как для каждоrо выходноro узла сети известен co
ответствующий желаемый отклик. Следовательно, вычислить сиrнал ошибки можно
с помощью простой арифметической операции. Во втором случае нейрон j являет
ся скрьпым узлом. Однако даже если скрытый нейрон непосредственно недоступен,
он несет ответственность за ошибку, получаемую на выходе сети. Вопрос состоит в
4.3. Алrоритм обратноro распространения 229
том, как персонифицировать вклад (положительный или отрицательный) отдельных
скрытых нейронов в общую ошибку. Эта проблема называется задачей назначения
коэффициентов доверия (credit assignment problem) и уже упоминалась в разделе 2.7.
Она очень элеrантно решается с помощью метода обратноrо распространения сиrнала
ошибки по сети.
Случай 1. Нейрон j выходной узел
Если нейрон j расположен в выходном слое сети, для Hero известен cooтвeTCTBY
ющий желаемый отклик. Значит, с помощью выражения (4.1) можно определить
сиrнал ошибки ej (n) (см. рис. 4.3) и без проблем вычислить rpадиент Oj (n) по фор
муле (4.14).
Случай 2. Нейрон j скрытый узел
Если нейрон j расположен в скрытом слое сети, желаемый отклик для Hero неизве
стен. Следовательно, сиrнал ошибки CкpbIToro нейрона должен рекурсивно вычис
ляться на основе сиrналов ошибки всех нейронов, с которым он непосредственно
связан. Именно здесь алrоритм обратноrо распространения сталкивается с наиболь
шей сложностью. Рассмотрим ситуацию, изображенную на рис. 4.4, [де изображен
скрытый нейрон j. Сошасно (4.14), локальный rpадиент Oj(n) cKpbIToro нейрона j
можно переопределить следующим образом:
о.(n) == дЕ(n) aYj(n) == дЕ(n) q>'.(v(n)),
J aYj(n) дщ(n) aYj(n) J J
(4.15)
[де j скрытый нейрон, а для получения BToporo результата использовалась форму
ла (4.9). Для вычисления частной производной aE(n)/aYj(n) выполним некоторые
преобразования. На рис. 4.4 видно, что
1
Е(n) == 2 L е%(n),
kEC
(4.16)
[де k выходной нейрон. Соотношение (4.16) это выражение (4.2), в котором
индекс j заменен индексом k. Это сделано для Toro, чтобы избежать путаницы с
индексом j, использованным ранее для CKpbIToro нейрона. Дифференцируя (4.16) по
функциональному сиrналу У j (n), получим:
дЕ(n) " aek(n)
aYj(n) == ek aYj(n).
(4.17)
230 rлава 4. Мноroслойный персептрон
Нейронj
.л
Нейрон k
.А
, r
У;Сп)
+1
Vk(п) <р(-) Yk(п) 1
ek(п)
d/п)
<р(.) у/п)
Рис. 4.4. rраф передачи сиrнала, детально отражающий связь BbIXOAHOro нейрона k со скрытым
нейроном j
Теперь к частной производной aek (n) / aYi (n) можно применить цепное правило
и переписать (4.17) в эквивалентной форме:
дЕ(n) " ( ) aek(n) aVk(n)
ek n
aYj(n) k aVk(n) aYj(n)'
(4.18)
Однако на рис. 4.4 видно, что для выходноrо нейрона k
ek(n) == dk(n) Yk(n) == dk(n) q>j(Vk(n))'
(4.19)
отсюда
aek(n) ,
aVk(n) == q>k(Vk(n))'
(4.20)
4.3. Алrоритм обратноrо распространения 231
На рис. 4.4 также очевидно, что индуцированное локальное поле нейрона k co
ставляет
m
Vk(n) == L Wkj(n)Yj(n),
j O
(4.21)
rдe т общее число входов (за исключением пороrа) нейрона k. Здесь синаптиче
ский вес WkO(n) равен пороry b k , приходящемуся на нейрон k, а соответствующий
вход имеет фиксированное значение +1. Дифференцируя (4.21) по Yj(n), получим:
aVk (n )
aYj(n) == Wkj(n)'
(4.22)
Подставляя (4.20) и (4.22) в (4.18), получим соотношение
,
дЕ ( n ) "'" I "'"
д '(n) == L..,. ek(n)q>k(Vk(n))Wkj(n) == L..,. Ok(n)Wkj(n),
Уз k k
(4.23)
[де для получения BToporo результата использовано определение лоКальноrо rpадиен
та (4.14), в котором индекс j заменен индексом k по уже упомянутым соображениям.
В заключение, подставляя выражение (4.23) в (4.15), получим формулу обратНО20
распространения (back propagation formu1a) для локальноrо rpадиента Oj (n) CKpbITOro
нейрона j:
Oj(n) == q>j(Vj(n)) L Ok(n)Wkj(n)'
k
(4.24)
На рис. 4.5 rpафически представлена формула (4.24) в предположении, что BЫXOД
ной слой состоит из ffiL нейронов.
Множитель <р (щ(n)), Использованный в формуле (4.24) для вычисления локаль
HOro rpадиента Oj(n), зависит исключительно от функции активации, связанной со
CKpbIТbIM нейроном j. Второй множитель формулы (сумма по k) зависит от двух
множеств параметров. Первое из них Ok(n) требует знания сиrналов ошибки
ek (n) для всех нейронов слоя, находящеroся правее cKpbIтoro нейрона j, которые
непосредственно связаны с нейроном j (см. рис. 4.4). Второе множество Wkj(n)
состоит из синаптических весов этих связей.
Теперь можно свести воедино все соотношения, которые мы вывели для алrо
ритма обратноrо распространения. Во первых, коррекция ДWji(n)' при меняемая к
синаптическому весу, соедиияющему нейроны i и j, определяется следующим дельта
правилам:
-----
232 rлава 4. Мноroслойный персептрон
lit(n) <p;(vt(п))
et(n)
liл n )
ek(n)
emL(п)
Рис. 4.5. rраф передачи сиrнала для фраrмента си-
стемы, задействованноro в обратном распространении
сиrналов ошибки
( коррекция ) ( Параметр CKO ) ( локальный ) ( входн й сиr . )
веса == рости обучения . rpадиент . нал неирана J (4.25)
Wji(n) 11 oj(n) Yi(n)
BO BTOpЫX, значение локальноro rpадиента Oj (n) зависит от положения нейро
на в сети.
1. Если нейрон j выходной, то rpадиент О j (n) равен про изведению производной
q>j(Vj(n)) на сиrнал ошибки ej(n) ДЛЯ нейронаj (см. выражение (4.14)).
2. Если нейрон j скрытый, то rpадиент Oj (n) равен произведению производной
q>j ( vj (n)) на взвешенную сумму rpадиентов, вычисленных для нейронов следую
щеrо cкpbIToro или выходноrо слоя, которые непосредственно связаны с данным
нейроном j (см. выражение (4.24)).
Два прохода вычислений
При использовании алrоритма обратноro распространения различают два прохода,
выполняемых в процессе вычислений. Первый проход называется прямым, второй
обратным.
При прямом проходе (forward pass) синаптические веса остаются неизменными во
всей сети, а функциональные сиrналы вычисляются последовательно, от нейрона к
нейрону. Функциональный сиrнал на выходе нейрона j вычисляется по формуле
Yj(n) == <Р(Vз(n)),
(4.26)
[де vj (n) индуцированное локальное поле нейрона j; определяемое выражением
m
Vj(n) == L Wji(n)Yi(n),
i O
(4.27)
4.3. Алroритм обратноro распространения 233
[де т общее число входов (за исключением пороrа) нейрона j; Wji(n) синап
тический вес, соединяющий нейроны i и j; Yi(n) входной сиrнал нейрона j или
выходной сиrнал нейрона i. Если нейрон j расположен в первом скрытом слое сети,
то т == то, а индекс i относится к i MY входному терминалу сети, для KOToporo
можно записать
Yi(n) == Xi(n)'
(4.28)
[де xi(n) i й элемент входноro вектора (образа). С друrой стороны, если нейрон
j расположен в выходном слое сети, то т == ffiL, а индекс j означает j й выходной
терминал сети, для KOToporo можно записать
Yj(n) == Oj(n),
(4.29)
rдe Oj(n) j й элемент выходноrо вектора. Выходной сиrнал сравнивается с жела
емым откликом dj(n), в результате чеro вычисляется сиrнал ошибки ej(n) для j ro
выходноrо нейрона. Таким образом, прямая фаза вычислений начинается с представ
ления входноro вектора первому скрытому слою сети и завершается в последнем слое
вычислением сиrнала ошибки для каждоro нейрона этоrо слоя.
Обратный проход начинается с выходноro слоя предъявлением ему сиrнала ошиб
КИ, который передается справа налево от слоя к слою с параллельным вычислением
локальноrо rpадиента для каждоro нейрона. Этот рекурсивный процесс предпола
[ает изменение синаптических весов в соответствии с дельта правилом (4.25). Для
нейрона, расположенноro в выходном слое, локальный rpадиент равен соответствую
щему сиrналу ошибки, умноженному на первую производную нелинейной функции
активации. Затем соотношение (4.25) используется для вычисления изменений весов,
связанных с выходным слоем нейронов. Зная локальные rpадиенты для всех нейро
нов выходноro слоя, с помощью (4.24) можно вычислить локальные rpадиенты всех
нейронов предыдущеro слоя, а значит, и величину коррекции весов связей с этим
слоем. Такие вычисления проводятся для всех слоев в обратном направлении.
Заметим, что после предъявления очередноrо обучающеrо примера он "фиксиру
ется" на все время прямоrо и обратноrо проходов.
Функция активации
Вычисление локальноrо rpадиента 8 для каждоrо нейрона мноrослойноro персептро
на требует знания производной функции активации <р('), связанной с этим нейроном.
для существования такой производной функция активации должна быть непрерыв
ной. Друrими словами, дифференцируемость является единственным требованием,
которому должна удовлетворять функция активации. Примером непрерывно диффе
ренцируемой нелинейной функции активации, которая часто используется в MHoro
слойных персептронах, является СИ2моидальная нелинейная функция (sigmoida1 поп
1inearity), две формы которой описываются ниже.
234 rлава 4. Мноrослойный персептрон
1. Лоrистическая функция
Эта форма сиrмоидальной нелинейности в общем вИде определяется следующим
образом:
1
q>j(Vj(n)) == 1 + ехр( aVj(n)) ' а> О, oo < vj(n) < +00,
(4.30)
rдe vj(n) индуцированное локальное поле нейрона j. Из (4.30) ВИДНо, что ампли
туда выходноro сиrнала нейрона с такой активационной функцией лежит в диапазоне
o Yj 1. Дифференцируя (4.30) по Vj(n), получим:
, а ехр( ащ(n))
q>j(Vj(n)) == [1 + ехр( aVj(n))J2 '
(4.31 )
Так как Yj(n) == q>j(vj(n)), то можно избавиться от экспоненты ехр( avj(n)) в BЫ
ражении (4.31) и представить ПрОИзводную функции активации в следующем виде:
q> (Vj(n)) == aYj(n)[l Yj(n)]'
(4.32)
для нейрона j, расположенноro в выходном слое, Yj(n) == Oj(n). Отсюда локаль
ный rpадиент нейрона j можно выразить следующим образом:
Oj(n) == ej(n)q> (Vj(n)) == a[dj(n) oj(n)]oj(n)[l oj(n)],
(4.33)
rдe Oj (n) функциональный сиrнал на выходе нейрона j; d j (n) ero желаемый сиr
нал. С друrой стороны, для произвольноrо cKpbIToro нейрона j локальный rpадиент
можно выразить так:
Oj(n) == q> (Vj(n)) L Ok(n)Wkj(n) == aYj(n)[l Yj(n)] L Ok(n)wkj(n). (4.34)
k k
Обратите внимание, что, сошасно выражению (4.32), производная <р (щ(n)) дo
стиrает CBoero максимальноrо значения при Yj(n) ==0,5, а МИНИмальноro (нуля)
при Yj(n) ==0 и Yj(n) == 1,0. Так как величина коррекции синаптических весов в сети
пропорциональна производной <p (Vj (n)), то для максимальноro изменения синапти
ческих весов нейрона ero функциональные сиrналы (вычисленные в соответствии с
сиrмоидальной функцией) должны находиться в середИне диапазона. Соrласно [914],
именно это свойство алrоритма обратноro распространения вносит наибольший вклад
в ero устойчивость как алroритма обучения.
4.3. Алrоритм обратноro распространения 235
2. Функция rиперболическоro TaHreHCa
Еще одной часто используемой формой сиrмоидальной нелинейности является Функ
ция rиперболическоrо TaHreHca, которая в общем виде описывается выражением
q>j(Vj(n)) == а tanh(bvj (n)), (а, Ь) > О,
(4.35)
[де а и Ь константы. В действительности функция rиперболическоro TaHreHca явля
ется не более чем лоrистической функцией, только масштабированной и смещенной.
Ее производная по apryMeHТY V j (n) определяется следующим образом:
q>j(Vj(n)) == аЬ sech 2 (bvj(n)) == о.Ь (1 tanh 2 (bVj(n))) ==
Ь
== [o. Yj(n)][o. + Yj(n)]'
а
(4.36)
Для нейрона J, расположенноro в выходном слое, локальный rpадиент будет
иметь вид
Oj(n) == ej(n)q>j(Vj(n)) == [dj(n) oj(n)][o. oj(n)][o. + oj(n)]'
а
(4.37)
Для нейрона j, расположенноro в скрытом слое, локальный rpадиент при обретает вид
Oj(n) == q>j(Vj(n)) L Ok(n)Wkj(n) ==
k
Ь
== [o. Yj(n)][o. + Yj(n)] L Ok(n)Wkj(n)'
а k
(4.38)
Используя формулы (4.33) и (4.34) для лоrистической функции и формулы (4.37)
и (4.38) для rиперболическоro TaHreHca, можно вычислить локальный rpадиент даже
без явноrо знания активационной функции.
Скорость обучения
Алrоритм обратноrо распространения обеспечивает построение в пространстве весов
"аппроксимации" для траектории, вычисляемой методом наискорейшеrо спуска. Чем
меньше параметр скорости обучения 11, тем меньше корректировка синаптических
весов, осуществляемая на каждой итерации, и тем более шадкой является траектория
в пространстве весов. Однако это улучшение происходит за счет замедления процесса
обучения. С друroй стороны, если увеличить параметр 11 для повышения скорости
обучения, то результирующие большие изменения синаптических весов MOryт приве
сти систему в неустойчивое состояние. Простейшим способом повышения скорости
обучения без потери устойчивости является изменение дельта правила (4.13) за счет
......
236 rлава 4. Мноroслойный персептрон
Ь/п) yj(п)
11
!J.wpCп 1)
!J.wpCп)
Рис. 4.6. rраф прохождения сиrнала, иллюстрирующий эффект по-
стоянной момента а
добавления к нему момента инерции 2 [914]:
.6.Wji(n) == a.6.Wji(n 1) + 110j(n)Yi(n)'
(4.39)
[де а как правило, положительное значение, называемое постоянной момента (mо-
mentиm constant). Как показано на рис. 4.6, она является управляющим воздействием
в контуре обратной связи для ДWji(n), [де Z l оператор единичной задержки.
Уравнение (4.39) называется обобщенным дельта-правuлом 3 (genera1ized de1ta rule).
При а ==0 оно вырождается в обычное дельта правило.
Для тoro чтобы оценить влияние последовательности представления обучающих
примеров на синаптические веса в зависимости от константы а, перепишем (4.39) в
виде BpeMeHHoro ряда с индексом t. Значение индекса t будет изменяться от нуля до
текущеrо значения n. При этом выражение (4.39) можно рассматривать как разност
ное уравнение первоro порядка для коррекции весов .6.Wji(n)' Решая это уравнение
относительно .6.'UJji(n), получим временной ряд длины n + 1:
n
.6.Wji(n) == 11 L an tOj(t)Yi(t).
t O
(4.40)
Из уравнений (4.11) и (4.14) видно, что произведение Oj(n)Yi(n) == aE(n)/aWji(n)'
Следовательно, соотношение (4.40) можно переписать в эквивалентной форме:
n t aE(t)
.6.Wji (n) == 11 L..,. а aw.. (t) .
t O J'
(4.41 )
Основываясь на этом выражении, можно сделать следующие интуитивные наблю
дения [505], [1117].
2 для частноrо случая алroритма LMS было показано, что использование постояиной момента а уменьшает
диапазон устойчивости параметра скорости обучення 11 и может привести к неустойчивости, если последний
выбран неверно. Более TOro, с увеличением значения а рассоrласование возрастает. Более подробно этот вопрос
описан в [908].
з Вывод алroритма обратноro распространения с учетом постоянной момента содержится в [408].
4.3. Алroритм обратноro распространения 237
1. Текущее значение коррекции весов Wji(n) представляет собой сумму экспо
ненциально взвешенноro BpeMeHHoro ряда. для Toro чтобы этот ряд сходился,
постоянная момента должна находиться в диапазоне о::; lal<1. Если константа а
равна нулю, алrоритм обратноro распространения работает без момента. Следует
также заметить, что константа а может быть и отрицательной, хотя эти значения
не рекомендуется использовать на практике.
2. Если частная производная дЕ(n)!дWji(n) имеет один и тот же алreбраический
знак на нескольких последовательных итерациях, то экспоненциально взвешен
ная сумма Wji(n) возрастает по абсолютному значению, поэтому веса Wji(n)
MOryт изменяться на очень большую величину. Включение момента в алrоритм
обратноro распространения ведет к ускорению спуска (acce1erate descent) в HeKO
тором постоянном направлении.
3. Если частная производная дЕ(n)!дWji(n) на нескольких последовательных ите
рациях меняет знак, экспоненциально взвешенная сумма W ji (n) уменьшается
по абсолютной величине, поэтому веса W ji (n) изменяются на небольшую вели
чину. Таким образом, добавление момента в алroритм обратноrо распространения
ведет к стабилизирующему эффекту (stabilized effect) для направлений, изменя
ющих знак.
Включение момента в алrоритм обратноro распространения обеспечивает незна
чительную модификацию метода корректировки весов, оказывая положительное вли
яние на работу алrоритма обучения. Кроме Toro, слаrаемое момента может предотвра
тить нежелательную остановку алroритма в точке какоrо либо локальноrо минимума
на поверхности ошибок.
При выводе алrоритма обратноrо распространения предполаrалось, что параметр
интенсивности обучения представлен константой 11. Однако на практике он может
задаваться как 11ji' Это значит, что параметр скорости обучения является локальным
и определяется для каждой конкретной связи. В самом деле, применяя различные па
раметры скорости обучения в разных областях сети, можно добиться интересных pe
зультатов. Более подробно на этом вопросе мы остановимся в последующих разделах.
Следует отметить, что при реализации алroритма обратноro распространения мож
но изменять как все синаптические веса сети, так и только часть из них, оставляя
остальные на время адаптации фиксированными. В последнем случае сиrнал ошиб
ки распространяется по сети в обычном порядке, однако фиксированные синапти
ческие веса будут оставаться неизменными. Этоro можно добиться, установив для
соответствующих синаптических весов Wji параметр интенсивности обучения 11ji
равным нулю.
.......
238 rлава 4. Мноrослойный персептрон
Последовательный и пакетный режимы обучения
в практических приложениях алrоритма обратноro распространения в процессе обу
чения мноrослойноro персептрона ему MHoroKpaTHo предъявляется предопределенное
множество обучающих примеров. Как уже отмечал ось, один полный цикл предъяв
ления полноro набора примеров обучения называют эпохой. Процесс обучения про
водится от эпохи к эпохе, пока синаптические веса и уровни пороrа не стабилизиру
ются, а среднеквадратическая ошибка на всем обучающем множестве не сойдется к
некоторому минимальному значению. Целесообразно случайным образом uзм.енять
порядок представления примеров обучения для разных эпох. Такой принцип предъ
явления образов делает поиск в пространстве весов стохастическим, предотвращая
потенциальную возможность появления замкнутых циклов в процессе эволюции си
наптических весов. Замкнутые циклы рассматриваются в шаве 14.
Для данноro обучающеrо множества алroритм обратноro распространения можно
реализовать двумя способами.
1. Последовательный режим
Последовательный режим (seqиential mode) обучения по методу обратноro pac
пространения также иноrда называют стохастическим (stochastic) или интерак
тивным (on line). В этом режиме корректировка весов проводится после пода
чи каждоrо примера. Это тот самый режим, для KOTOpOro мы выводили алrо
ритм обратноrо распространения ранее в этой шаве. Для примера рассмотрим эпо
ху, состоящую из N обучающих примеров, упорядоченных следующим образом:
(х(l), d(l)),... , (x(N), d(N)). Сети предъявляется первый пример (х(l), d(l)) этой
эпохи, после чеrо выполняются описанные выше прямые и обратные вычисления.
В результате проводится корректировка синаптических весов и уровней пороroв в
сети. После этоrо сети предъявляется вторая пара (х(2), d(2)) в эпохе, повторяются
прямой и обратный проходы, приводящие к следующей коррекции синаптических
весов и уровня Пороrа. Этот процесс повторяется, пока сеть не завершит обработку
последнеro примера (пары) данной эпохи (x(N), d(N)).
2. Пакетный режим
В пакетном режиме (batch mode) обучения по методу обратноro распространения
корректировка весов про водится после подачи в сеть примеров обучения (эпохи).
Для конкретной эпохи функция стоимости определяется как среднеквадратическая
ошибка (4.2) и (4.3), представленная в составной форме:
1 N
Еау(n) == 2N L L е;(n),
n==l jEC
(4.42)
4.3. Алroритм обратноro распространения 239
[де сиrнал ошибки ej (n) соответствует нейрону j для примера обучения n и опреде
ляется формулой (4.1). Ошибка ej(n) равна разности между dj(n) и Yj(n) для j ro
элемента вектора желаемых откликов d(n) и соответствующеro выходноro нейрона
сети. В выражении (4.42) внутреннее суммирование по j выполняется по всем ней
ранам выходноrо слоя сети, в то время как внешнее суммирование по n выполняется
по всем образам данной эпохи. При заданном параметре скорости обучения 11 KOp
ректировка, применяемая к синаптическому весу Wji, связывающему нейроны i и j,
определяется следующим дельта правилом:
N
( дЕау 11 '" ) aej(n)
ДWji n) == 11 == L ej(n .
aw .. N a w ..
З' n l З'
(4.43)
Для вычисления частной производной aej (n) / aWji нужно проделать тот же путь,
что и ранее. Соrласно (4.43), в пакетном режиме корректировка веса ДWji выполня
ется только после прохождения по сети Bcero множества примеров.
С точки зрения процессов реальноro времени, последовательный режим является
более предпочтительным, чем пакетный, так как требует меньше20 объема BHYTpeH
Hero хранилища для каждой синаптической связи. Более Toro, предъявляя обучающие
примеры в случайном порядке (в процессе последовательной корректировки весов),
поиск в пространстве весов можно сделать действительно стохастическим. Это, в
свою очередь, сокращает до минимума возможность остановки алrоритма в точке
какоro либо локальноrо минимума.
Следует отметить, что стохастическая природа последовательноrо режима услож
няет построение теоретическоro фундамента для нахождения условий сходимости
алrоритма. В противовес этому использование пакетноrо режима обеспечивает точ
ную оценку вектора rpадиента. Таким образом, сходимость алrоритма к локальному
минимуму rарантируется при довольно простых условиях. Помимо TOro, в пакетном
режиме леrче распараллелить вычисления.
Если данные обучения являются избыточными (redundant) (т.е. содержат по
несколько копий одних и тех же примеров), то предпочтительнее использовать по
следовательный режим, так как примеры все равно подаются по одному. Это пре
имущество особенно заметно при больших наборах данных с высокой степенью
избыточности.
В заключение можно сказать, что несмотря на мноrие недостатки последова
тельноro режима алroритма обратноro распространения, он остается очень попу
лярным (особенно при решении задач распознавания образов) по двум практиче
ским причинам.
. Этот алrоритм прост в реализации.
. Обеспечивает эффективное решение сложных и больших задач.
........
240 rлава 4. Мноrослойный персептрон
Критерий останова
в общем случае не существует доказательства сходимости алrоритма обратноro pac
пространения, как не существует и какоrо либо четко определенноrо критерия ero
останова. Известно лишь несколько обоснованных критериев, которые можно исполь
зовать для прекращения корректировки весов. Каждый из них имеет свои практиче
ские преимущества. Для Toro чтобы сформулировать такой критерий, вполне лоrично
рассуждать в терминах уникальных свойств локалЬН020 (local) и 2ЛобалЬН020 (global)
минимумов поверхности ошибок 4 . Обозначим символом w* вектор весов, обеспе
чивающий минимум, будь то локальный или rлобальный. Необходимым условием
минимума является то, что вектор rpадиента g(w) (т.е. вектор частных производных
первоrо порядка) для поверхности ошибок в этой точке равен нулевому. Следова-
тельно, можно сформулировать разумный критерий сходимости алrоритма обучения
обратноrо распространения [596].
Считается, что ал20рИтм обратН020 распространения сошелся, если Евклидова HOp
ма вектора 2радиента достИ2ает достаточно малых значений.
Недостатком этоrо критерия сходимости является то, что для сходимости обучения
может потребоваться довольно MHOro времени. Кроме Toro, необходимо постоянно
вычислять вектор rpадиента g(w).
Друrим уникальным свойством минимума является то, что функция стоимости
(или мера ошибки) Eav(w) в точке w == w* стабилизируется. Отсюда можно вывести
еще один критерий сходимости.
Критерием сходимости ал20ритма обратН020 распространения является достаточ
но малая абсолютная интенсивность изменений среднеквадратической ошибки в тe
чение эпохи.
Интенсивность изменения среднеквадратической ошибки обычно считается дo
статочно малой, если она лежит в пределах от О, 1 1 % за эпоху. Иноrда используется
уменьшенное значение 0,01%. К сожалению, этот критерий может привести к
преждевременной остановке процесса обучения.
Существует еще один полезный и теоретически подкрепленный критерий сходи
мости. После каждой итерации обучения сеть тестируется на эффективность обобще
ния. Процесс обучения останавливается, коrда эффективность обобщения становит
ся удовлетворительной или Korдa оказывается, что пик эффективности уже пройден.
В разделе 4.14 мы поroворим об этом более подробно.
4 Вектор w* называется локальным минимумом функции F, если в этой точКе она достиrает наименьшеro
значения в некоторой области, Т.е. если существует такое значеНИеЕ, что [125] F(w*) ::; F(w) для всех w,
удовлетворяющих неравенству Ilw w* 11 < Е. Вектор w* иазывается 2J/обальным МИНИАIУМОМ функции F, если
в этой точке она достиrает наименьшеro значения на всей своей области определения, т.е. если F(w*) ::; F(w)
для всех w Е n, rде n размериость вектора w.
4.4. Алrоритм обратноrо распространения в краткой форме 241
+1 +1
(1) 11'(. )
Уl
Х 1
у1 1 ) 11'(. )
Х 2
vjl) 11'(-)
Х З
(1) v(l) у(l)
Уl 2 3
11"(-)
11"(.)
<Р(-)
у: 2 ) 11'(.) 01 I d 1
(2) 11'( .) 02 I е 1 d 2
У2
vj2) 11'(.) 0з I е 2 d з
е з
у(2) (2) (2)
1 У2 vз
11"(.)
<р'(-) е 1
<р'(. ) е 2
J2) е з
31
05\2) o5i 2 ) o5j2)
o5i ' ) o5i 1 ) o5jl)
Рис. 4.7. rраф передачи сиrнала для процесса обучения по методу обрат
HOro распространения. Верхняя часть rрафа прямой проход, нижняя часть
rрафа обратный проход
4.4. Алrоритм обратноrо распространения
в краткой форме
На рис. 4.1 представлена архитектурная схема мноroслойноrо персептрона. COOTBeT
ствующий rpаф передачи сиrнала в процессе обучения по методу обратноrо распро
странения, иллюстрирующий как прямую, так и обратную фазу вычислений, пред
ставлен на рис. 4.7 для случая L == 2 и то == тl == т2 ==3. В верхней части rpафа
передачи сиrнала показан прямой проход, в нижней обратный. Последний еще HO
сит название 2рафа чувствительности (sensitivity graph) для вычисления локальных
rpадиентов в алrоритме обратноro распространения [774].
Ранее мы упоминали, что последовательная корректировка весов является более
предпочтительным режимом алrоритма обратноro распространения для реализации
в реальном времени. В этом режиме алrоритм циклически обрабатывает примеры из
обучающеrо множества {(x(n),d(n))}: l следующим образом.
1. Инициализация (initialization). Предполаrая отсутствие априорной информации,
rенерируем синаптические веса и пороrовые значения с помощью датчика paB
.....
242 rлава 4. Мноrослойный персептрон
номерно распределенных чисел со средним значением О. Дисперсия выбирается
таким образом, чтобы стандартное отклонение индуцированноro локальноrо по-
ля нейронов приходилось на линейную часть сиrмоидальной функции активации
(и не достиrало области насыщения).
2. Предъявление примеров обучения (presentation oftraining examples). В сеть подают
ся образы из обучающеro множества (эпохи). Для каждоro образа последовательно
выполняются прямой и обратный проходы, описанные Далее в пп. 3 и 4.
3. Прямой проход (forward computation). Пусть пример обучения представлен парой
(х(n), d(n)), [де х(n) входной вектор, предъявляемый входному слою сенсор-
ных узлов; d(n) желаемый отклик, предоставляемый выходному слою нейронов
для формирования сиrнала ошибки. Вычисляем индуцированные локальные поля
и функциональные сиrналы сети, проходя по ней послойно в прямом направлении.
Индуцированное локальное поле нейрона j слоя l вычисляется по формуле
то
v;l)(n) == L w; )(n)y? l)(n),
i O
(4.44)
[де y? l)(n) выходной (функциональный) сиrнал нейрона i, расположенноro в
предыдущем слое l 1, на итерации n; w ; ) (n) синarrrический вес связи нейрона
j слоя l с нейроном i слоя l 1. Для i == О y l l) (n) == + 1, а w; (n) == Ь; (n) по
por, применяемый к нейрону j слоя l. Если используется сиrмоидальная функция,
то выходной сиrнал нейрона j слоя l выражается следующим образом:
) )
yj (n) == q>j(Vj(n ).
Если нейрон j находится в первом скрытом слое (т.е. l == 1), то
у;О)(n) == xj(n),
[де xj(n) j й элемент входноro вектора х(n). Если нейрон j находится в BЫ
ходнам слое (т.е. l == L, [де L шубина сети), то
(L) ( ) (
yj n Oj n).
Вычисляем сиrнал ошибки
ej(n) == dj(n) Oj(n),
(4.45)
[де dj(n) j й элемент вектора желаемоrо отклика d(n).
4.5. Задача XOR 243
4. Обратный проход (backward computation). Вычисляем локальные rpадиенты узлов
сети по следующей формуле:
(1) [ e;L\n)q>j (v]L) (n)) для нейрона j выходноro слоя L,
Oj (п) == q>j(vY\n)) 2( o +1)(n)o +1)(n) для нейрона j cкpbITOro слоя l, (4.46)
[де штрих в функции q>j(.) обозначает дифференцирование по apryMeHТY. Измене
ние синаптических весов слоя l сети выполняется в соответствии с обобщенным
дельта правилом
w; \n + 1) == w; )(n) + a[w; )(n 1)] + 11oY)(n)yY l)(n),
(4.47)
[де 11 параметр скорости обучения; а постоянная момента.
5. Итерации (iteration). Последовательно выполняем прямой и обратный проходы
(сошасно пп. 3, 4), предъявляя сети все при меры обучения из эпохи, пока не
будет достиrнут критерий останова.
Прuмечание. Порядок представления примеров обучения может случайным обра
зам меняться от эпохи к эпохе. Параметры момента и скорости обучения настраива
ются (и обычно уменьшаются) по мере роста количества итераций. Объяснение этоrо
факта будет приведено ниже.
4.5. Задача XOR
В элементарном (однослойном) персептроне нет скрытых нейронов. Следовательно,
он не может классифицировать входные образы, которые линейно неразделимы. Oд
нако нелинейно разделимые области встречаются не так уж редко. Например, именно
такая проблема возникает в известной задаче "исключающе20 ИЛИ" (XOR exclu
sive OR problem), которую можно рассматривать как частный случай более общей за
дачи классификации точек едИНИЧН020 2иперкуба (unit hypercube). Каждая точка этоro
куба принадлежит одному из двух классов О или 1. Для частноro случая задачи
XOR рассмотрим четыре уша едИНИЧН020 квадрата, которые соответствуют входным
парам (О, О), (0,1), (1, О) и (1, 1). Первая и четвертая пары принадлежат классу О, Т.е.
О Е9 О == О и 1 Е9 1 == О,
[де знак Е9 обозначает оператор булевой функции XOR. Входные образы (О, О) и
(1,1) располаrаются в противоположных ушах едиНИЧНО20 квадрата (unit square),
но reнерируют одинаковый выходной сиrнал, равный нулю. С друroй стороны, пары
(0,1) и (1, О) также располаrаются в противоположных ушах квадрата, но принад
лежат классу 1:
244 rлава 4. Мноrослойный персептрон
о Е9 1 == 1 и 1 Е9 О == 1.
Очевидно, что при использовании Bcero одноrо нейрона с двумя входами rpани-
ца решений в пространстве входов будет линейной. Для всех точек, расположенных
по одну сторону этой линии, выход нейрона будет равен единице, а для остальных
точек нулю. Положение и ориентация этой линии в пространстве входов определя-
ется синаптическими весами, соединяющими нейрон с входными узлами, и пороroм.
Имея две пары точек, расположенных в противоположных ушах квадрата и относя-
щихся К разным классам, мы, естественно, не сможем построить прямую линию так,
чтобы точки одноrо класса лежали по одну сторону от разделяющей поверхности.
Друrими словами, элементарный персептрон не может решить задачу XOR.
ДЛЯ решения этой задачи введем скрытый слой с двумя нейронами (рис. 4.8, а)
[1058]. rраф передачи сиrнала этой сети показан на рис. 4.8, б. При этом сделаем
следующие допущения.
· Каждый из нейронов представлен моделью Мак Каллока Питца, в которой функ
цией активации является пороrовая.
· Биты О и 1 представлены соответственно уровнями сиrнала О и + 1.
Верхний нейрон (с меткой 1 в скрытом слое) характеризуется следующим образом:
Wll == W12 == +1,Ь 1 == 3/2.
Наклон rpаницы решений для этоro CKpbITOro нейрона равен 1, что и показано
на рис. 4.9, а. Нижний нейрон (с меткой 2 в скрытом слое) обладает свойствами
W21 == W22 == +1, Ь 2 == 1/2.
Ориентация и расположение rpаницы решений для BToporo CKpbITOro нейрона
показаны на рис. 4.9, б.
Для выходноrо нейрона (обозначенноrо меткой 3 на рис. 4.8, а)
WЗl == 2, WЗ2 == +1, Ь 1 == 1/2.
Функцией выходноrо нейрона является построение линейной комбинации rpаниц
решений, сформированных двумя скрытыми нейронами. Результат вычислений пока
зан на рис. 4.9, в. Нижний скрытый нейрон соединен возбуждающей (положительной)
связью с выходным нейроном, в то время как верхний скрьrrый нейрон тормозящей
(отрицательной). Если оба CKPbIТbIX нейрона заторможены (что соответствует BXOД
4.6. Эвристические рекомендации по улучшению работы алrоритма. . . 245
Нейрон 1
Входной
слой
Скрытый
слой
Выходной
слой
а)
+1
Х 1
<р( .)
Оз
---{),5
Х 2
Рис. 4.8. Архитектурный rраф сети для pe
шения задачи XOR (а) и rраф передачи сиr
нала для этой сети (б) ,
+1
б)
нам у образу (О, О)), выходной нейрон также остается неактивным. Если оба скрытых
нейрона возбуждены (что соответствует входному образу (1, 1)), выходной нейрон
остается неактивным, так как тормозящее влияние большоrо отрицательноro веса
(верхний скрытый нейрон) преобладает над возбуждающим воздействием с меньшим
весом (нижний скрытый нейрон). Коrда верхний скрытый нейрон находится в затор
моженном состоянии, а нижний в возбужденном (что соответствует входным обра
зам (0,1) и (1, О)), выходной нейрон переходит в возбужденное состояние, так как воз
буждающий сиrнал с положительным весом приходит от нижнеrо cKpbIToro нейрона.
Таким образом, сеть, изображенная на рис. 4.8, а, и в самом деле решает задачу XOR.
4.6. Эвристические рекомендации по улучшению
работы алrоритма обратноrо распространения
Часто утверждают, что проектирование нейронных сетей, использующих алrоритм
обратноrо распространения, является скорее искусством, чем наукой. При этом име
ют в виду тот факт, что мноrочисленные параметры этоrо процесса определяются
только на основе личноrо практическоrо опыта разработчика. В этом утверждении
есть доля правды. Тем не менее приведем некоторые общие методы, улучшающие
производительность алrоритма обратноrо распространения.
........
246 rлава 4. Мноrослойный персептрон
(0,1)
Вход
Х 2
(О, О) Вход Х 1 (1, О)
а)
(О, 1) (1, 1)
Вход Выход
Х 2 I
ВХОДХ 1 (1, О)
б)
(О, 1) (1, 1)
Вход
Х 2
(О, О)
Вход Х 1
В)
(1, О) Рис. 4.9. rраницы решений, построенные для cKpbIToro ней-
рона 1 сети, показанной на рис. 4.8, а (а); rраницы решений
для cKpbIToro нейрона 2 сети (б) и ДЛЯ всей сети (в)
1. Режим: последовательный или пакетный (sequentia1 versus batch update). Как уже
rоворилось ранее, последовательный режим обучения методом обратноrо распро
странения (использующий последовательное предоставление примеров эпохи с
обновлением весов на каждом шаrе) в вычислительном смысле оказывается зна
чительно быстрее. Это особенно сказывается тоща, коrда обучающее множество
является большим и в высокой степени избыточным. (Избыточные данные вызы-
вают вычислительные проблемы при оценке Якобиана, необходимой для пакетно
[о режима.)
2. Максимизация информативности (maximizing information content). Как правило,
каждый обучающий пример, предоставляемый алrоритму обратноro распростра
нения, нужно выбирать из соображений наибольшей информационной насыщен
насти в области решаемой задачи [617]. Для этоro существуют два общих метода.
4.6. Эвристические рекомендации по улучшению работы алrоритма. . . 247
· Использование примеров, вызывающих наибольшие ошибки обучения.
· Использование примеров, которые радикально отличаются от ранее использо
ванных.
Эти два эвристических правила мотивированы желанием максимально расширить
область поиска в пространстве весов.
В задачах классификации, основанных на последовательном обучении методом
обратноro распространения, обычно применяется метод случайноro изменения
порядка следования примеров, подаваемых на вход мноroслойноrо персептрона,
от одной эпохи к друroй. В идеале такая рандомизация приводит к тому, что
успешно обрабатываемые примеры будут принадлежать к различным классам.
Более утонченным приемом является схема акцентирования (emphasizing scheme),
соrласно которой более сложные примеры подаются в систему чаще, чем более
леrкие [617]. Простота или сложность отдельных примеров выявляется с помо
щью анализа динамики ошибок (в разрезе итераций), rенерируемых системой при
обработке обучающих примеров. Однако использование схемы акцентирования
приводит к двум проблемам, которые следует учесть.
· Распределение примеров в эпохе, представляемой сети, искажается.
· Наличие исключений или немаркированных примеров может привести к ката-
строфическим последствиям с точки зрения эффективности алroритма. Обуче
ние на таких исключениях подверrает риску способность сети к обобщению в
наиболее правдоподобных областях пространства входных сиrналов.
3. Функция активации (activation function). Мноroслойный персептрон, обучаемый
по алroритму обратноro распространения, может в принципе обучаться быстрее
(в терминах требуемоrо для обучения количества итераций), если сиrмоидальная
функция активации нейронов сети является антисимметричной, а не симметрич
ной. Более подробно этот вопрос рассматривается в разделе 4.11. Функция актива
ции <р( v) называется антисuмметричной (т.е. четной функцией cBoero apryмeHTa),
если
<р( v) == q>(V),
что показано на рис. 4.1 О, а. Стандартная лоrистическая функция не удовлетворяет
этому условию (рис. 4.1 О, 6).
Известным примером антисимметричной функции активации является сиrмои
дальная нелинейная функция 2иперболичеСК020 таН2енса (hyperbo1ic tangent)
q>(V) == а tanh(bv),
".........-
248 rлава 4. Мноroслойный персептрон
[де а и Ь константы. Удобными значениями для констант а и Ь являются следу-
ющие [617], [618]:
а == 1,7159,
Ь == 2/3.
Определенная таким образом функция rиперболическоro TaHreHca имеет ряд по-
лезных свойств.
. <р(1) == 1 и <p( 1) == 1.
· В начале координат TaHreHc уша наклона (т.е. эффективный уroл) функции
активации близок к единице:
<р(0) == аЬ == 1,7159 х 2/3 == 1,1424.
· Вторая производная <р( v) достиrает CBoero максимальноrо значения при v == 1.
4. Целевые значения (target va1ue). Очень важно, чтобы целевые значения выбирались
из области значений сиrмоидальной функции активации. Более точно, желаемый
отклик d j нейрона j выходноrо слоя мноrослойноrо персептрона должен быть СМе-
щен на некоторую величину € от rpаницы области значений функции активации
в сторону ее внутренней части. В противном случае алrоритм обратноro распро-
странения будет модифицировать свободные параметры сети, устремляя их в бес-
конечность, замедляя таким образом процесс обучения и доводя скрытые нейроны
до предела насыщения. В качестве примера рассмотрим антисимметричную функ-
цию активации, показанную на рис. 4.1 О, а. Для предельноrо значения +а выберем
d j == а €.
Аналоrично, для предельноrо значения a установим
d j == a + €,
[де € соответствующая положительная константа. Для выбранноrо ранее значе-
ния а == 1,7159 установим € == 0,7159. В этом случае желаемый отклик d j будет
находиться в диапазоне от 1 до +1 (см. рис. 4.10, а).
5. Нормализация входов (norma1izing the inputs). Все входные переменные должны
быть предварительно обработаны так, чтобы среднее значение по всему обу
чающему множеству было близко к нулю, иначе их будет сложно сравнивать
со стандартным отклонением [617]. Для оценки практической значимости этоro
правила рассмотрим экстремальный случай, коrда все входные переменные по-
ложительны. В этом случае синаптические веса нейрона первоrо cкpbIToro слоя
MOryT либо одновременно увеличиваться, либо одновременно уменьшаться. Сле
довательно, вектор весов этоrо нейрона будет менять направление, что приведет
4.6. Эвристические рекомендации по улучшению работы алrоритма. . . 249
<p(v)
v
... ............. ............. = 1,7159
а)
<p(v)
а...................
v
о
б)
Рис. 4.10. Антисимметричная (а) и асимметричная (б) функции активации
к зиrзаroобразному движению по поверхности ошибки. Такая ситуация обычно
замедляет процесс обучения и, таким образом, неприемлема.
..,......
250 rлава 4. Мноrослойный персептрон
Х 2
.
. .
. .
. .
. . Смещение
. . . среднеro
.
. .
.
. .
.
Х 1
Х;
.
. .
. .
. .
. .
. Х;
. .
.
. .
.
Исходное
множество данных
,JI.дo""",","
Х;
Х;
. .
... .
......
.. ...
.
Выравнивание
ковариации
X
. . .. .
.
. .
. . . .
. Хl
. . . . . .
.
Рис. 4.11. Результаты трех шаroв нормализации: смещения cpeдHero,
декорреляции и выравнивания ковариации
Чтобы ускорить процесс обучения методом обратноrо распространения, входные
векторы необходимо нормализовать в двух следующих аспектах [617].
· Входные переменные, содержащиеся в обучающем множестве, должны быть
некоррелированны (uncorrelated). Этоro можно добиться с помощью анализа
шавных компонентов, который детально оПисывается в шаве 8.
· Некоррелированные входные переменные должны быть масштабированы так,
чтобы их ковариация была приближенно равной (approximately equa1). Torдa
различные синаптические веса сети будут обучаться приблизительно с одной
скоростью.
На рис. 4.11 показан результат трех шаrов нормализации: смещения среднеro,
декорреляции и выравнивания ковариации, примененных в указанном порядке.
4.6. Эвристические рекомендации по улучшению работы алrоритма. . . 251
6. Инициализация (initia1ization). Хороший выбор начальных значений синаптиче
ских весов и пороrовых значений (threshold) сети может оказать неоценимую по
мощь в проектировании. Естественно, возникает вопрос: "А что такое хорошо?"
Если синаптические веса принимают большие начальные значения, то нейроны,
скорее Bcero, достиrнут режима насыщения. Если такое случится, то локальные
rpадиенты алrоритма обратноrо распространения будут принимать малые значе
ния, что, в свою очередь, вызовет торможение процесса обучения. Если же синап
тическим весам присвоить малые начальные значения, алrоритм будет очень вяло
работать в окрестности начала координат поверхности ошибок. В частности, это
верно для случая антисимметричной функции активации, такой как rиперболиче
ский TaHreHC. К сожалению, начало координат является седловой точкой (saddle
point), Т.е. стационарной точкой, rдe образующие поверхности ошибок вдоль oд
ной оси имеют положительный rpадиент, а вдоль друrой отрицательный. По
этим причинам нет смысла использовать как слишком большие, так и слишком
маленькие начальные значения синаптических весов. Как всеrда, золотая середина
находится между этими крайностями.
Для примера рассмотрим мноrослойный персептрон, в котором в качестве функ
ции активации используется rиперболический TaHreHc. Пусть пороrовое значение,
применяемое к нейронам сети, равно нулю. Исходя из этоrо, индуцированное ло
кальное поле нейрона j можно выразить следующим образом:
m
vj == 2:: WjiYi'
i l
Предположим, что входные значения, передаваемые нейронам сети, имеют нуле
вое среднее значение и дисперсию, равную единице, Т.е.
Jl y == E[Yi] == о для всех i,
а; == E[(Yi Jl;)2] == Е[у;] == 1 для всех i.
Далее предположим, что входные сиrналы некоррелированны:
{ 1 для k == i,
E[YiYk] == о для k i= i,
и синаптические веса выбраны из множества равномерно распределенных чисел
с нулевым средним
Jl w == E[Wji] == О для всех пар (j, i)
252 rлава 4. Мноrослойный персептрон
и дисперсией
cr == E[(Wji /lw)2] == E[W;i] для всех пар (j, i).
Следовательно, математическое ожидание и дисперсию индуцированноrо локаль-
Horo поля можно выразить так:
" E[Vj] Е [t, Wj'Y'] t, E[wj,]E[y,] О,
"; Е[( Vj ")'] E[v;J Е [t, t, Wj'Wjky'Yk]
(4.48)
m m
m
== :L:L E[WjiWjk]E[YiYk] == :L E[W;i] == mcr ,
i l k l i l
[де т число синаптических связей нейрона.
На основании этоrо результата можно описать хорошую стратеrию инициализации
синаптических весов таким образом, чтобы стандартное отклонение индуциро
BaHHoro локальноrо поля нейрона лежало в переходной области между линейной
частью сиrмоидальной функции активации и областью насыщения. Например, для
случая rиперболическоrо TaHreHca с параметрами а и Ь (см. определение функции)
эта цель достиrается при cr v == 1 в (4.48). Исходя из этоrо, получим [617]:
cr w == т 1/2.
(4.49)
Таким образом, желательно, чтобы равномерное распределение, из KOToporo выби
раются исходные значения синаптических весов, имело нулевое среднее значение
и дисперсию, обратную корню квадратному из количества синаптических связей
нейрона.
7. Обучение по подсказке (hints). Обучение на множестве примеров связано с аппрок
симацией неизвестной функцией отображения входноrо сиrнала на выходной. В
процессе обучения из примеров извлекается информация о функции f (.) и строит
ся некоторая аппроксимация этой функциональной зависимости. Процесс обуче
ния на примерах можно обобщить, добавив обучение по подсказке, которое реали
зуется путем предоставления некоторой априорной информации о функции f (.)
[4]. Такая информация может включать свойства инвариантности, симметрии и
прочие знания о функции f (.), которые можно использовать для ускорения поиска
ее аппроксимации и, что более важно, для повышения качества конечной оценки.
Использование соотношения (4.49) является одним из примеров TaKoro подхода.
4.7. Представление выхода и решающее правило 253
Х.
}
Рис. 4.12. Блочная диаrрамма классификатора входных
сиrналов
Мноrослойный
персептрон:
w
Yl,J
У2,}
Ум,}
8. Скорость обучения (learning rates). Все нейроны мноroслойноrо персептрона в
идеале должны обучаться с одинаковой скоростью. Однако последние слои обыч
но имеют более высокие значения локальных rpадиентов, чем начальные слои
сети. Исходя из этоro параметру скорости обучения 11 следует назначать MeHЬ
шие значения для последних слоев сети и большие для первых. Чтобы время
обучения для всех нейронов сети было примерно одинаковым, нейроны с боль
шим числом входов должны иметь меньшее значение параметра обучения, чем
нейроны с малым количеством входов. В [617] предлаrается назначать параметр
скорости обучения для каждоrо нейрона обратно пропорционально квадратному
корню из суммы ero синаптических связей. Более подробно о параметре скорости
обучения речь пойдет в разделе 4.17.
4.7. Представление выхода и решающее правило
Теоретически для задачи классификации на М классов (M class classification problem),
в которой объединение М классов формирует все пространство входных сиrналов,
ДЛЯ представления всех возможных результатов классификации требуется М BЫXO
дОВ (рис. 4.12). На этом рисунке вектор Xj является j M прототипом (prototype)
(т.е. отдельной реализацией) ffi MepHoro случайноrо вектора Х, который должен быть
классифицирован мноroслойным персептроном. k й из М возможных классов, KOTO
рому принадлежит данный входной сиrнал, обозначается C k . Пусть Ykj k й выход
сети, reнерируемый в ответ на прототип Х{
Yk,j == Fk(Xj), k == 1,2,... , М,
(4.50)
rдe функция Fk(') определяет отображение, которому обучается сеть при передаче
входноro примера на k й выход. Для удобства представления обозначим
Yj == [Yl,j, Y2,j,..., YM,j]T == [Fl(Xj), F 2 (Xj),..., FM(Xj)]T == F(Xj),
(4.51)
[де F(.) вектор функция.
rлавный вопрос этоrо раздела звучит так.
Каким должно быть оптимальное решающее правило, применяемое для классифика
ции М выходов сети после обучения МН020СЛОЙН020 персептрона?
...,...
254 rлава 4. Мноrослойный персептрон
Естественно, решающее правило должно основываться на знании вектор функции
F: Rm x ----t у Е R M .
(4.52)
в общем случае о вектор функции F(.) определенно известно лишь то, что это
непрерывная функция, МИнимизирующая Функционал эмпиричеСК020 риска (empirica1
risk functional):
1 N 2
R == 2N :L Ild j F(Xj)11 ,
j=l
(4.53)
[де d j желаемый (целевой) выход для прототипа Xj; 11.11 Евклидова норма вектора;
N общее число примеров, представленных сети для обучения. Сущность критерия
(4.53) та же, что и у функции стоимости (4.3). Вектор функция F(.) cтporo зависит от
выбора примеров (Xj, d j ), использованных для обучения сети. Это значит, что разные
значения пар (Xj, d j ) приведут к построению различных вектор функций F(.). Обра
тите внимание, что используемое здесь обозначение (Xj, d j ) является ЭКВивалентом
употреблявшеroся ранее обозначения (Хи), d(j)).
Предположим, что сеть обучается на двоичных целевых значениях (которые слу-
чайно совпадают с верхней и нижней rpаницами области значений лоrистической
функции) :
d { 1, если прототип Xj принадлежит классу C k ,
kj О, если прототип Xj не принадлежит классу C k .
(4.54)
Основываясь на этом допущении, класс C k можно представить M MepHЫM целе
вым вектором
о
1 t---- k й элемент.
о
Напрашивается предположение, что мноroслойный классификатор персептронно-
ro типа, обученный по алrоритму обратноro распространения на конечном множе
стве независимых и равномерно распределенных примеров, обеспечивает асимпто
тическую аппроксимацию соответствующей апостериорной вероятности КЛасса. Это
свойство можно обосновать следующим образом [881], [1133].
4.7. Представление выхода и решающее правило 255
. Соrласно закону больших чисел, при бесконечном увеличении размера N обучаю
щеro множества вектор w, минимизирующий функционал стоимости R из (4.53),
достиrает оптимальноrо значения w*, минимизирующеro ожидание случайной Be
личины 1/211d F(w, x)11 2 , [де d вектор желаемоrо отклика; F(w, х) аппрокси
мация, реализованная мноroслойным персептроном для вектора весовых коэффи
циентов w и входа х [1133]. Функция F(w, х), в которой явным образом по казана за
висимость от вектора w, это не что иное, как использованная ранее функция F(x).
. Оптимальный вектор весов w* обладает тем свойством, что соответствующий ему
вектор фактическоrо выхода сети F(w*, х) является аппроксимацией, построенной
по методу наименьших квадратов и минимизирующей ошибку условноrо ожида
ния вектора желаемоro отклика при данном входном векторе х [1133]. Этот вопрос
уже обсуждался в шаве 2.
. Для задачи классификации входных сиrналов на М классов k й элемент вектора
желаемоro отклика равен единице, если входной вектор х принадлежит к классу
C k , и нулю В противном случае. Отсюда следует, что условное ожидание вектора
желаемоro отклика при данном векторе х равно апостериорной вероятности класса
P(Cklx), k == 1,2, ..., м [881].
Отсюда следует, что мноroслойный персептрон (с лоrистической активационной
функцией) действительно аппроксимирует апостериорную (а posteriori) вероятность
распознавания класса при условии, что размерность обучающеrо множества ДOCTa
точно велика и что процесс обучения методом обратноro распространения не прекра
тится в точке локальноrо минимума. Теперь можно ответить на поставленный ранее
вопрос. В частности, можно утверждать, что соответствующее решающее правило
является (приближенно) байесовским правилом, обобщенным для апостериорной
вероятности оценок.
Случайный вектор Х относится к классу Ck, если
Fk(X) > Fj(x) для всех j i= k,
2де Fk(X) и Fj(x) элементы вектор функции отображения
(4.55)
[ F1 (х) ]
F(x) == 2.(X) .
F м (х)
Единственное наибольшее значение выходноrо сиrнала существует с вероятно
стью 1, если соответствующие апостериорные распределения классов различаются.
(Здесь предполаrается использование арифметики с бесконечной точностью.) Это pe
шающее правило имеет определенное преимущество по сравнению с моделью "отжи
..........
256 rлава 4. Мноrослойный персептрон
[а", поскольку позволяет разделить однозначные (unambiguous) решения. Это значит,
что вектор х относится к определенному классу, если соответствующее выходное зна-
чение превышает заданный пороr (в лоrистических формах функции активации обыч
но используется значение 0,5), в противном случае классификация не однозначна.
В разделе 4.6 было указано, что двоичные целевые значения [О, 1], COOTBeTCTBY
ющие лоrистической функции (4.30), на практике во время обучения сети должны
измениться на небольшое значение Е, во избежание насыщения синаптических весов
(в связи с далеко не бесконечной точностью представления чисел). В результате этой
модификации целевые значения пере стают быть двоичными, и асимптотические ап-
проксимации Fk (х) не являются апостериорными вероятностями Р (С k I х) интересую-
щих нас М классов [414]. Вместо этоrо P(Cklx) линейно отображается на закрытый
отрезок [Е, 1 Е] так, что P(Cklx) == о соответствует выходу Е, а P(Cklx) == 1
выходу 1 Е. Так как это отображение сохраняет относительный порядок, это не
влияет на результат применения выходноrо решающеrо правила (4.55).
Интересно также отметить следующее. Если rpаница решений формируется по
poroBbIM отсечением выходов мноrОСлойноrо персептрона относительно некоторых
фиксированных значений, ее общая форма и ориентация MorYT быть выражены эври
стически (для случая единственноrо CKpbITOro слоя) в терминах количества скрытых
нейронов и относительных величин связанных с ними синаптических весов [683].
Однако такой анализ не применим к rpанице решений, сформированной в соответ-
ствии с выходным решающим правилом (4.55). Скрытые нейроны лучше paCCMaT
ривать как нелинейные детекторы признаков (non1inear [еаtше detector), призван
ные отобразить классы исходноrо входноro пространства э{m о (возможно, линейно
неразделимые) в пространство активности cKpbIToro слоя, [де их линейная раздели
мость более вероятна.
4.8. Компьютерный эксперимент
в этом разделе с помощью компьютерноrо моделирования будет проиллюстрировано
поведение мноrослойноrо персептронноrо классификатора в процессе обучения. Цe
лью обучения является разделение двух перекрывающихся двумерных классов с [ayc
совым распределением, обозначенных цифрами 1 и 2. Пусть С 1 И С 2 множества со-
бытий, для которых случайный вектор х принадлежит к классам 1 и 2 соответственно.
Функцию плотности условной вероятности можно представить в следующем виде.
Для класса C 1 :
1 ( 1 2 )
!x(xIC 1 ) == 21tcrr ехр 2crr Ilx fl111 ,
(4.56)
rдe вектор среднеrо значения J11 == [О, о]Т, а дисперсия crr == 1.
4.8. Компьютерный эксперимент 257
Для класса С 2 :
1 ( 1 2 )
!x(xIC 2 ) == 2 2 ехр 2 2 Ilx fl2/1 ,
па 2 а 2
(4.57)
rдe вектор среднеrо значения fl2 ==[2, о]Т, а дисперсия a == 4.
Вероятность принадлежности образа обоим классам одинакова, Т.е.
Р1 == Р2 == 1/2.
На рис. 4.13 показаны трехмерные rpафики [ауссовых распределений, определен
ных выражениями (4.56) и (4.57) для входноro вектора X==[X1, Х2]Т и размерности
пространства входных сиrналов то ==2. На рис. 4.14 показаны корреляционные диа
rpaMMbI классов С 1 и С 2 В отдельности и общая корреляционная диаrpамма, OTpa
жающая суперпозицию rpафиков рассеяния по 500 точкам, выбранным для каждоrо
процесса. На последней диаrpамме четко видно, что распределения существенно пе
рекрываются, а значит, высока вероятность неправильной классификации.
Байесовская rраница решений
Байесовский критерий оптимальной классификации уже обсуждался в шаве 3. Для
данной задачи классификации на два класса предположим, что классы С 1 И С 2
равновероятны, стоимость корректной классификации равна нулю и стоимости оши
бок классификации одинаковы. Torдa для нахождения оптимальной rpаницы решений
можно использовать критерий отношения правдоподобия
01
Л(х) 5 ,
02
(4.58)
rдe Л(х) отношение правдоподобия (likelihood ratio), определяемое формулой
Л(х) == !x(xIC 1 )
!x(xIC 2 ) ,
(4.59)
а пОр02 критерия (thresho1d of the test), определяемый формулой
== Р2 == 1.
Р1
(4.60)
в рассматриваемом примере имеем:
a ( 1 2 1 2 )
Л(х ) == ехр "х fl 11 + Ilx fl /1 .
.-т 2 2а2 1 2а 2 2
v1 1 2
..,....
258 rлава 4. Мноroслойный персептрон
1,5
0,5
О
10
10 10
а)
хl0- 3
6
4
2
О
10
10 10
б)
10
....:...:::-'..............
""; ::l,,t,':' _.,;,.;,,,
...;;"",-.r,# .....:;:..,,,:-,,
J.;,, ::::;';*:'-::.":;;":;i .
.:..>',..,....",,t:"#' III'...... .,..:,,,:.:-,,::..:
; ..:J",.,..F:'''' . .. .. .......... ",,-,,':- '; ,
;. ;;;::..t ;, .,..."_""" .":JJ..". ....,"'-'-, .:: :;; .
. :"'.;j:::r,,:',:;.r:..:.:.....:;.::..'\;.-:. ::.::: :: "-; "
" :: :i?:;:::;::'::#:--"''''''f!._''':":,,,'':::.. i:: f: ,;;" '.::. , .
'<...':';:! ;,:':: =:..:..::::::!:: :*::.:::;s:::: ,..-: ::, : .,,: .
..': ,-:: ,:':'-- : ;::-; f': : ::11 :' =; f;: !,-: /f: : :/:.-
10
Рис. 4.13. ФУНКЦИИ плотности вероятности: f:z:(xIC 1 ) (а) и f:z:(xIC 2 ) (б)
Таким образом, оптимальная (байесовская) rpаница решений определяется COOT
ношением
a ( 1 2 1 2 )
а 2 ехр 2а 2 Ilx Jl111 + 2а 2 Ilx Jl211 == 1
1 1 2
или
1 2 1 2 ( cr1 )
211 х J1211 211х J1111 == 410g .
а 2 а 1 а2
(4.61)
Используя простые преобразования, оптимальную rpаницу решений (4.61) можно
переопределить в виде
Ilx xl1 2 == r 2 ,
(4.62)
4.8. Компьютерный эксперимент 259
.
"
о
5
--4
5
Q
О
5
--4
.ti.
2
о
2
4
а)
.
,
6 8 10
м"""" II>. . ,
О
QI}
а о б)
I ,
6 8 10
.
.
(()
t , 1
О О
I """""" ttп
2 О
о
QI)
о а о в)
5
о
--4 2 О 2 4 6 10
Рис. 4.14. Корреляционные диаrраммы классов C 1 (а) и С2 (б), а также общая корреляционная
диаrрамма для обоих классов (в)
[де
2 2
cr 2 f.11 cr 1 f.12
ХС == 2 2
cr 2 cr 1
(4.63)
и
2 2
2 cr 2 cr 1
r ==
cr cri
[ 11f.112 f.12J12 + 410g ( cr 2 )]
cr 2 cr 1 cr1
(4.64)
Уравнение (4.62) описывает окружность с центром в точке Х и радиусом r. Обозна
чим область, расположенную внутри этоro Kpyra, символом n 1. Байесовское правило
классификации для этой задачи можно сформулировать следующим образом.
Вектор наблюдения Х относится к классу C 1 , если отношение правдоподобия Л(Х)
больше пОР020в020 значения 1;, и к классу С 2 в остальных случаях.
..,.....
260 rлава 4. Мноrослойный персептрон
в данном эксперименте центр круroвой rpаницы решений находится в точке
[ 2/3 ]
ХС О '
а радиус области составляет
r 2,34.
Обозначим символом с множество результатов корректной классификации, а сим
волом е множество результатов некорректной классификации. Тоrда вероятность
ошибки (probabi1ity of error) Ре классификатора, работающеro на основе байесовскоro
решающеro правила, можем определить в виде
Ре == P1P(eIC 1 ) + P2 P (eIC 2 ),
(4.65)
[де P(eIC 1 ) условная вероятность ошибки для входноrо вектора из класса C 1 ;
P(eIC 2 ) условная вероятность ошибки для входноrо вектора из класса С 2 ; Р1 и
Р2 априорные вероятности классов С 1 и С 2 соответственно. Для нашей задачи
можно найти числовые значения вышеуказанных величин:
P(eIC 1 ) 0,1056,
Р( e1C 2 ) 0,2642.
Так как классы равновероятны, Т.е. Р1 == Р2 == 1/2, то
Ре О, 1849.
Следовательно, вероятность правильной классификации (probability of correct c1as
sification) составляет
Р== 1 Ре 0,8151.
Экспериментальное построение оптимальноrо
мноrослойноrо персептрона
в табл. 4.1 приведены параметры мноrослойноro персептрона (multilayer perceptron
MLP) с одним слоем скрытых нейронов, который обучается с помощью алrоритма
4.8. Компьютерный эксперимент 261
ТАБЛИЦА 4.1. Переменные пара метры мноroслойноrо персептрона
Параметр Символ Типичный диапазон
Количество скрытых нейронов т1 (2,00)
Параметр скорости обучения 11 (О, 1)
Константа момента а (0,1)
ТАБЛИЦА 4.2. Результаты моделирования для двух скрытых нейронов (коэффи
циент скорости обучения равен 0,1, фактор момента О)
Количество Размер Количество CpeдHeKвaдpa
проходов обучающе20 эпох тическая
множества
1 500 320
2 2000 80
3 8000 20
ошибка
Вероятность
корректной
классификации
РС,%
80,36
80,33
80,47
0,2375
0,2341
0,2244
обратноro распространения в последовательном режиме. Поскольку единственной
целью классификатора является достижение приемлемоrо уровня корректной клас
сификации, этот критерий и применяется для проверки оптимальности переменных
параметров MLP.
Оптимальное число скрытых нейронов
Учитывая практический подход к задаче определения оптимальноrо количества CKpЫ
тых нейронов (m1), будем использовать следующий критерий. Необходимо найти ми
нимальное количество скрытых нейронов, которое обеспечивает производительность,
близкую (в пределах 1 %) к байесовскому. Исходя из этоrо, эксперимент начинается с
двух скрытых нейронов. Результаты моделирования приведены в табл. 4.2.
Поскольку целью первоrо этапа моделирования является проверка достаточности
или двух скрытых нейронов, параметрам а и 11 произвольно присвоены некоторые HO
минальные значения. Для каждоrо запуска процесса моделирования rенерировалось
множество примеров обучения, с равной вероятностью содержащее образы классов
С 1 и С 2 С [ауссовым распределением. Примеры из этоro множества последовательно
подавались на вход сети в течение нескольких циклов, или эпох (epoch). Количество
эпох выбиралось так, чтобы общее число обучающих примеров в процессе обучения
оставалось постоянным. Таким образом, можно усреднить результаты для обучающих
множеств разноrо размера.
В табл. 4.2 и последующих таблицах среднеквадратическая ошибка вычислялась
в соответствии с функционалом, определенным формулой (4.53). Необходимо под
JIIIIIIIII"'"
262 rлава 4. Мноroслойный персептрон
черкнуть, что для этих таблиц определялась именно среднеквадратическая ошибка,
хотя минимум среднеквадратической ошибки не все2да отражает хороший уровень
обобщения (т.е. хорошую производительность на ранее не использованных данных).
В результате обучения сети на N примерах вероятность корректной классифика-
ции теоретически определяется выражением
Р(, N) == p1P(, NIC 1 ) + Р2Р(, NIC 2 ),
(4.66)
[де Р1 == Р2 == 1/2 и
Р(с, NIC 1 ) == r fx(xIC1)dx,
}П1(N)
Р(с, NIC 2 ) == 1 r fx(xIC 2 )dx
}П1(N)
(4.67)
(4.68)
и n 1 (N) область пространства решений, в которой мноrослойный персептрон (обу
ченный на N примерах) относит вектор х (представляющий реализацию случайноro
вектора Х) к классу C 1 . Эту область обычно находят экспериментально, оценивая
функцию отображения, которой обучалась сеть, и применяя выходное решающее пра
вило (4.55). К сожалению, численно оценить величиныР(, NIC 1 ) и Р(, NIC 2 ) непро
сто, так как сложно отыскать формальное определение rраницы решений n 1 (N).
Поэтому воспользуемся экспериментальным подходом и протестируем обучен-
ный мноroслойный персептрон на независимом множестве примеров, которые снова
случайно сreнерируем на основе [ауссовых распределений классов С 1 И С 2 С рав-
ной вероятностью. Введем случайную переменную А, которая означает количество
корректно классифицированных примеров из множества мощности N. Torдa частное
PN == A/N
является случайной величиной, которая обеспечивает максимально правдоподоб
ную не смещенную оценку реальной эффективности классификации р. Предпола-
rая, что Р является константой для N пар "вход-выход", можно использовать предел
Чернова [257]:
P(IPN рl > Е) < 2 ехр( 2E2 N) == 8.
Применяя предел Чернова, получим N == 26500 для 8 == 0,01 и Е == 0,01 (т.е. с дo
стоверностью 99% можно утверждать, что оценка Р характеризуется данным допу
стимым отклонением). Рассмотрим тестовое множество, содержащее N == 32000
образов. В последнем столбце табл. 4.2 показана вероятность корректной классифи
4.8. Компьютерный эксперимент 263
ТАБЛИЦА 4.3. Результаты моделирования для четырех
скрытых нейронов (11 == 0.1, а == О)
Количество Размер Количество CpeдHeKвaдpa Вероятность
проходов обучающе20 эпох тическая корректной
множества ошибка классификации Ре, %
1 500 320 0,2129 80,80
2 2000 80 0,2108 80,81
3 8000 20 0,2142 80,19
кации для TecToBoro множества такой мощности, усредненная по десяти независимым
экспериментам.
Эффективность классификации мноroслойноro персептрона с двумя скрытыми
нейронами (см. табл. 4.2) достаточно близка к производительности байесовскоro клас
сификатора, равной Ре == 81,51 %. Отсюда лоrично заключить, что рассматриваемую
задачу классификации можно решить с помощью мноroслойноro персептронноro
классификатора с двумя скрытыми нейронами. Чтобы подтвердить это заключение,
в табл. 4.3 представлены результаты моделирования для четырех скрытых нейронов
(остальные параметры остались без изменений). Хотя среднеквадратическая ошиб
ка в табл. 4.3 для четырех скрытых нейронов несколько ниже, чем в табл. 4.2 для
двух скрытых нейронов, средний уровень корректной классификации практически не
улучшился в одном из тестов результаты оказались даже несколько хуже. Поэтому
продолжим вычислительный эксперимент для двух скрытых нейронов.
Оптимальное обучение и константа момента
Для оценки оптимальности значений параметров скорости обучения 11 и момента а
можно использовать любое из трех следующих определений.
1. Оптимальными считаются константы а и 11, при которых сходимость сети к ло
кальному минимуму на поверхности ошибок достиrается в среднем за минималь
ное количество эпох.
2. Оптимальными считаются константы а и 11, при которых сходимость сети к rnо
бальному минимуму на поверхности ошибок (в наихудшем случае или в среднем)
достиrается за Минимальное число эпох.
3. Оптимальными считаются константы а и 11, при которых средний показатель cxo
дим ости к конфиryрации, имеющей наилучшие обобщающие способности во всем
пространстве входных сиrналов, достиrается за минимальное количество эпох.
.........
264 rлава 4. Мноroслойный персептрон
Используемые здесь термины "средний" и "наихудший" означают распределение
обучающих пар типа "BXOД BЫXOД". Определение 3 является наиболее ценным для
практики, однако ero сложно применить, так как минимизация среднеквадратической
ошибки это математический критерий оптимальности, применяемый при обучении
сети, и, как rоворилось ранее, снижение среднеквадратической ошибки не всеrда ве-
дет к улучшению обобщающей способности. С исследовательской точки зрения BТO
рое определение представляет больший интерес, нежели первое. Например, в [684]
были представлены результатыI серьезноrо исследования опТимальной настройки па
раметра скорости обучения 11, при котором мноroслойному персептрону требуется
мИнимальное количество эпох для аппроксимации rлобально оптимальной матрицы
синаптических весов с заданной точностью (правда, только для частноrо случая ли
нейных нейронов). Тем не менее в общем случае при экспериментальном и эвристиче-
ском подходе определения оптимальных значений 11 и а используется определение 1.
Поэтому в своем эксперименте будем руководствоваться именно этим определением.
Используя мноroслойный персептрон с двумя скрытыми нейронами, а также раз
личные комбинации значений параметра скорости обучения 11 Е {0.01, 0.1, 0.5, 0.9}
и константыI момента а Е {О. О, 0.1, 0.5, 0.9}, исследуем скорость сходимости сети.
Каждая из конфиrураций обучается на одном и том же множестве примеров при од-
ном и том же наборе исходных значений синаптических весов для N == 500. Поэтому
результаты можно сравнивать напрямую, без внесения поправок. Процесс обучения
длился в течение 700 эпох. Такую продолжительность обучения мы посчитали ДOCTa
точной для достижения алrоритмом обратноro распространения HeKoToporo локаль
Horo минимума на поверхности ошибок. Усредненные кривые процесса обучения
показаны на рис. 4.15, a 2 для различных значений параметра 11.
Показанные экспериментальные кривые отражают следующие тенденции обучения.
· в общем случае малые значения параметра 11 обеспечивают более медленную
сходимость. При этом более точно определяется точка локальноrо минимума на
поверхности ошибок. Это интуитивно понятно, так как при меньших значениях 11
поиск минимума выполняется в более широкой области поверхности ошибок.
· При 11 ........ О выбор больших значений константы момента (а ........ 1) приводит К
увеличению скорости сходимости. С друroй стороны, при 11 ........ 1 малые значения
фактора момента а ........0 повышают устойчивость обучения.
· Использование значений 11 =={0,5; 0,9} и а ==0,9 приводит к колебаниям средне-
квадратической ошибки в процессе обучения и более высокому ее значению по
завершении процесса сходимости. И то и друroе нежелательно.
0,4
0,38
0,36
0,34
0,32
Среднеквад-
ратическая 0,3
ошибка
i\
!\
1
. \
! \
\
. ,
\ "
. ,
\ "
. ,
\ "
" ...........-,.
......_ - . . ""':::.:":'.....
0,28
0,26
0,24
0,22
0,2
О
100
200
0,4 ,
0,38
0,36
0,34
4.8. Компьютерный эксперимент 265
a O,O
___в a O,1
. a 0,5
- - a 0,9
300
600
700
400
500
Количество эпох
а)
а 0,0
нв_ a O,1
. a 0,5
. - a 0,9
0,32
Среднеквад - . (
ратическая 0,3 .1'
ошибка 1':
.1'
0,28 1
.\
\\
0,26 i \ "
. \'
0,24 \. \ '
" , N A . . . . . . . -/. - . . . -....... . . . ........ _
" '
0,22
0,2
О
50
100
150
Количество эпох
б)
---
266 rлава 4. Мноroслойный персептрон
0,4
0,38
0,36
0,34
\
0,32
CpeДHeквaд
ратическая 0,3
ошибка
0,28
0,26
0,24
0,22
0,2
О
0,4
0,38
0,36
0,34
0,32
CpeДHeквaд
ратическая 0,3
ошибка
0,28
0,26
0,24
0,22
а 0,0
B __ a O,1
- a 0,5
- - a 0,9
i
1,.
\о' .....-\./ ,. L
l "...... v'y. , .\
I 'Jo.I"",:v'v\r-. I '.I'I\ tl '\"'\- ''''''' \ .А. """ .1 ' .
, ..J" . . ....., '" ',,' """.\.......'...., \0,,"",".",
\, 'J' ' ' ' ' "
50
100
150
Количество эпох
в)
,
I
.j I
'. .,
\\11.
)'11 !i , I I
. . .' I ,\ l' I
r M'I) \\' \. \ . . . II I
. \ 'У I ' i'il )f' \J \ ЩИ
а 0,0
- -- a O,1
. a 0,5
. - a 0,9
'"
....... I:.""J"" ....'III"""""'''......''''....:''"...............\....J'".'''\o,. ....,.A '"''''''...... .....,,.'....,... ",v...'t,...... ". z........,...."""" -J-I"'.....,..I\. "'1...
...... ....,-.1..,............... ..,.... ........ ...... ....... ".......".. .........
0,2
О
.
.
100
200
300
400
500
600
700
Количество эпох
r)
Рис. 4.15. Усредненные кривые обучения для различных значений константы момента
а. и параметра скорости обучения: т1 == 0,01 (а); т1 == О, 1 (б); т1 == 0,5 (в); т1 == 0,9 (r)
4.8. Компьютерный эксперимент 267
ТАБЛИЦА 4.4. Конфиryрация оптимизированною мноrослойною персептрона
Параметр Символ Значение
Оптимальное число скрытых нейронов ffiopt 2
Оптимальный параметр скорости обучения 110 p t 0,1
Оптимальная константа момента (Xopt 0,5
0,4
0,38
0,36
0,34
0,32
CpeДHeKBaд
ратическая 0,3
ошибка
0,28
0,26
0,24
0,22
0,2
О
,
,
,
,
,
,
,
,
,
,
,
,
1\
1\
"
.\ "
\\ '-
.\ ,
\\ "
. . ",
'..:--- ........ .................
.......... ;;........ ... ':'"::. .. -:.... .... .... ....:::.:- :- -:.::-: :'.:::--:: :- -::- -::
Параметр
обучения,у
0,01
0,1
0,5
0,9
Момент,
а
0,9
0,5
0,1
0,0
10
20
30
40
50
60
70
80
90
100
Количество эпох
Рис. 4.16. Лучшие кривые обучения, выбранные на рис. 4.15
На рис. 4.16 показаны rpафики "наилучших" кривых обучения по каждой из rpупп,
представленных на рис. 4.15, для выбора наилучшей кривой в смысле определения 1.
На рисунке видно, что оптимальное значение параметра скорости обучения 110 p t co
ставляетпорядка 0,1, а (Xopt около 0,5. В табл. 4.4 приведены оптимальные значения
параметров сети, которые будут использоваться в оставшейся части эксперимента.
Как видно на рис. 4.16, конечная среднеквадратическая ошибка мало отличается для
различных кривых. Это значит, что поверхность ошибок в нашей задаче достаточ
но rладкая.
Оценка оптимальной архитектуры сети
Для "оптимизированноro" мноroслойноrо персептрона, параметры KOToporo приве
дены в табл. 4.4, была исследована rpаница решений, построена усредненная по
ансамблю кривая обучения и оценена вероятность корректной классификации. Если
обучающее множество конечно, то функциональное преобразование сети, обученной
.......
.,......
268 rлава 4. Мноroслойный персептрон
ТАБЛИЦА 4.5. Обобщенные статистические показатели производительности
Показатель производительности Среднее Стандартное
значение отклонение
Вероятность корректной классификации
Окончательная среднеквадратическая ошибка
79,70%
0,2277
0,44%
0,0118
при оптимальных значениях параметров, стохастично по своей природе. Поэтому по
казатели производительности усреднялись по двадцати независимо обучаемым сетям.
Каждое из обучающих множеств состояло из 1000 примеров, выбранных из классов
С 1 и С 2 С одинаковой вероятностью. Эти примеры предъявлялись сетям в случайной
последовательности. Как и ранее, обучение выполнялось в течение 700 эпох. Для
экспериментальноro определения вероятности корректной классификации использо
валось сrенерированное ранее тестовое множество из 32000 примеров. На рис. 4.17, а
показаны три "лучшие" rpаницы решений для трех из 20 сетей. На рис. 4.17, б пока
заны три "наихудшие" rpаницы решений для трех друrих сетей из этой же rpуппы.
На этих рисунках видно, что rpаницы решений, построенные с помощью алroритма
обратноrо распространения, являются выпуклыми по отношению к области класси
фикации вектора наблюдения х.
Статистические данные о производительности, вероятности корректной класси
фикации и конечной среднеквадратической ошибке, вычисленной для обучающеro
множества, приведены в табл. 4.5. Напомним, что вероятность корректной классифи
кации для оптимальноrо байеСОВСКОI'О классификатора составляет 81,51 %.
4.9. Извлечение признаков
Скрытые нейроны (hidden neuron) иrpают крайне важную роль в работе мноrослой
Horo персептрона, обучаемоro методом обратноro распространения, поскольку они
выступают в роли детекторов признаков (feature detector). В ходе обучения CKpЫ
тые нейроны постепенно "выявляют" характерные черты данных обучения. Это ocy
ществляют с помощью нелинейноrо преобразования входных данных в новое, CKpЫ
тое пространство (hidden space) (или пространство признаков (feature space)). Эти
термины будут использоваться во всей книrе. В новом пространстве классы (если
взять для примера задачу классификации) леrче отделить друr от друrа, чем в ис
ходном пространстве. Это утверждение уже было проиллюстрировано на примере
решения задачи XOR в разделе 4.5.
4.9. Извлечение признаков 269
4
3
2
Х 2 О
1
2
Оптимальная
rpаница
решений
3
4
6
2
о
Х,
а)
4
/
/
/
./
/
.1
/
/
/
/
r'
)<',
-/ ",
. """
,
,
2
о
1
2
Оптимальная
rpаница
решений
3
4 2
о
2
80,39%
ш__ 80,40%
- - 80,43%
2
4
6
77,24%
__ш 73,01%
- - 71,59%
4
6
б)
Рис. 4.17. rрафики трех "лучших" (а) и трех "наихудших" (б) rраниц ре-
шений с точностью классификации 80,39, 80,40, 80,43, и 77,24%, 73,01 и
71,59% соответственно
......
........
270 rлава 4. Мноrослойный персептрон
Чтобы перевести обсуждение в математический контекст, рассмотрим мноroслой-
ный персептрон с одним слоем, состоящим из т1 нелинейных скрытых нейронов,
и одним слоем линейных выходных нейронов размерности т2 == М. Выбор линей-
ных нейронов в выходном слое обусловлен необходимостью сфокусировать внимание
только на роли скрытых нейронов в работе мноrослойноro персептрона. Синаптиче-
ские веса сети нужно настроить так, чтобы минимизировать среднеквадратическую
ошибку (по N образам) между целевым выходом (желаемым откликом) и фактиче
ским выходным сиrналом сети, rенерируемым в ответ на то-мерный вектор входноro
сиrнала. Пусть Zj (n) выходной сиrнал CкpbITOro нейрона j, rенерируемый в ответ
на представление n ro входноro вектора. Он является нелинейной функцией образа
(вектора), подаваемоro на входной слой сети. С каждым нейроном связана сиrмои-
дальная функция активации.
Выходной сиrнал нейрона k выходноro слоя описывается выражением
тl
Yk(n) == L WkjZj(n), k == 1, 2, ..., М; n == 1, 2, ..., N,
j O
(4.69)
[де WkO смещение, связанное с нейроном k. Функция стоимости, которую следует
минимизировать, записывается в виде
1 N М
Еау == 2N L L (dk(n) Yk(n))2.
n 1 k l
(4.70)
Заметим, что здесь подразумевается использование пакетноrо режима обучения.
Используя (4.68) и (4.70), можно довольно леrко переписать функцию стоимости в
более компактной матричной форме:
Еау == 2 11]) WzII 2 ,
(4.71)
[де W матрица синаптических весов размерности М х ffi1, относящаяся к вы-
ходному слою сети. Матрица Z выходов скрытых нейронов (за вычетом их среднеro
значения) имеет размерность т1 х N. Эта матрица состоит из сиrналов, полученных
в результате обработки N входных образов (входных сиrналов), Т.е.
Z=={(Zj(n) Jlz); j==l, 2, ..., ffi1; n==1, 2, ..., N},
J
rдe Jlz среднее значение сиrнала zj(n)' Соответственно матрица D желаемых
J
откликов размерности М х N, представляемых выходному слою сети, имеет вид
]) == {(dk(n) JldJ; k == 1, 2, ..., М; n == 1, 2, ..., N},
4.9. Извлечение признаков 271
[де Ildk среднее значение dk(n). Минимизация функции Еау, определяемой Bыpa
жением (4.70), это линейная задача, решение которой описывается уравнением
w :бz+
,
(4.72)
[де z+ псевдообратная матрица дЛЯ Z. Минимальное значение функции Еау можно
представить в виде (см. упражнение 4.7)
1 [ т т ( Т ) Т ]
Eav,min == 2N tr DD DZ ZZ + ZD ,
(4.73)
[де tr['] оператор следа. Так как целевые образы, представленные матрицей D,
фиксированы, задача минимизации функции стоимости Еау относительно синаптиче
ских весов мноroслойноrо персептрона эквивалентна максимизации дискрuминант
ной функции [1120]:
D == tr[CbCi],
(4.74)
[де матрицы С ь и C t определяются следующим образом.
. C t т1 х т1 матрица общей ковариации (tota1 covariance matrix) выходов CKpЫ
тых нейронов при представлении N входных сиrналов
T
C t == ZZ .
(4.75)
Матрица С: является псевдообратной по отношению к матрице C t .
. Матрица С ь размерности т1 х т1 определяется выражением
т T
С ь == ZD DZ .
(4.76)
Обратите внимание, что дискриминантная функция D соrласно (4.74) определяет
си исключительно скрытыми нейронами мноroслойноro персептрона. Заметим также,
что количество скрытых слоев, участвующих внелинейном преобразовании и [eHe
рации дискриминантной функции, не оrpаниче о. Если мноrослойный персептрон
содержит несколько скрытых слоев, то матрица Z описывает все множество образов
(сиrналов) в пространстве, определенном последним слоем скрытых нейронов.
Чтобы интерпретировать матрицу С ь , рассмотрим частный случай схемы кодиро
вания "один из М" (one from M coding scheme) [1120]. Это значит, что k й элемент
целевоro вектора (желаемоrо отклика) равен единице, если входной сиrнал принаk
лежит классу k, и нулю в противном случае:
..........
272 rлава 4. Мноrослойный персептрон
о
о
d(n) == 1 k й элемент, d(n) Е C k .
О
о
Таким образом, для М классов C k , k
относится N k образов, таких, что
1, 2, ..., М, к каждому из которых
м
LN k == N,
k l
матрицу С Ь дЛЯ данной схемы кодирования можно представить в виде
м
С Ь == LN ( z,k z)( z,k z)T,
k l
(4.77)
[де вектор z,k размерности т1 х 1 является средним значением вектора выходов
скрытых нейронов для N входных образов. В соответствии с (4.77) матрицу С Ь мож
но интерпретировать как матрицу взвешенной межклассовой ковариации (weighted
between c1ass covariance matrix) выходных сиrналов CKpbITOro слоя.
Таким образом, для схемы кодирования "один из М" мноrослойный персептрон
максимизирует дискриминантную функцию, представляющую собой след произведе
ния двух величин: матрицы взвешенной межклассовой ковариации и псевдообратной
матрицы для матрицы общей ковариации. Из этоrо примера видно, что при обучении
мноroслойноrо персептрона методом обратноro распространения в качестве пpeдвa
рительной информации учитываются пропорции образов в рамках отдельных классов.
Связь с линейным дискриминантом Фишера
Дискриминантная функция, определенная в (4.74), характерна лишь для мноrослой
Horo персептрона. Однако она тесно связана с линейным дискриминантом Фишера
(Fisher's 1inear discriminant), который описывает линейное преобразование MHoro
мерной задачи в одномерную. Рассмотрим переменную у, представляющую собой
линейную комбинацию элементов входноrо вектора х. Более точно, пусть у является
скалярным произведением вектора х и вектора настраиваемых весов w (содержащеro
в качестве первоro элемента пороr Ь):
у == w T х.
4.9. Извлечение признаков 273
Вектор х выбирается из множества С 1 или С 2 , которые, в свою очередь, отли
чаются векторами средних значений (JJ.1 и J.12 соответственно). Критерий Фишера
(Fisher's criterion), определяющий степень различия между двумя классами, задается
следующим образом:
J( ) == wTCbw
W Т С '
W tW
[де С ь матрица межклассовой ковариации (between class covariance matrix),
С ь == (J.12 J.11) (J.12 J.11) Т ,
а C t общая матрица внутриклассовой ковариации (within c1ass covariance matrix),
C t == L (Х n J.11)(X n J.11? + L (Хn J.12)(X n J.12?'
ПЕС, nЕС 2
Матрица внутриклассовой ко вариации C t пропорциональна матрице ковариации обу
чающеrо множества. Это симметричная и неотрицательно определенная матрица,
которая обычно является несинrулярной, если размер множества обучения достаточ
но велик. Матрица межклассовой ковариации С ь также является симметричной и
неотрицательно определенной, однако она синrулярна. Следует отметить, что MaT
ричное произведение Cbw всеrда направлено в сторону вектора разности между
средними значениями J.11 J.12' Это свойство непосредственно следует из опреде
ления матрицы С ь .
Выражение, определяющее критерий Фишера J(w), называют обобщенным фак
тором Рэлея (genera1ized Ray1eigh quotient). Вектор w, максимизирующий эту вели
чину, должен удовлетворять условию
CbW == л.Сtw.
(4.78)
Уравнение (4.78) описывает обобщенную задачу нахождения собственных чисел.
В нашем случае матричное произведение Cbw всеrда направлено в сторону разности
J.11 J.12, так что уравнение (4.78) достаточно леrко разрешить относительно W:
W == C;1(J.11 J.12).
(4.79)
Это решение называется линейным дискриминантом Фишера (Fisher's linear dis-
criminant) [269]. Возвращаясь к вопросу извлечения признаков, вспомним, что дискри
минантная функция D, определяемая формулой (4.74), связывает матрицы межклас
совой и общей ковариации образов, трансформированных в пространство скрытых
нейронов сети. Дискриминантная функция D аналоrична линейному дискриминанту
Фишера. Именно поэтому нейронные сети так хорошо решают задачу классификации.
.........
274 rлава 4. Мноrослойный персептрон
Х!
у
Х 2
X тu
Входной
слой
Первый
скрытый
слой
Вroрой
скрытый
слой
Выходной
слой
Рис. 4.18. Мноrослойный персептрон с
двумя скрытыми слоями и одним выход-
ным нейроном
4.10. Обратное распространение ошибки
и дифференцирование
Метод обратноrо распространения ошибки является специфической реализацией 2ра-
диентН020 спуска (gradient descent) в пространстве весов мноrослойных сетей пря-
MOro распространения. Основная идея этоro метода заключается в эффективном вы-
числении частных производных (partial derivative) функции сети F(w, х) по всем
элементам настраиваемоro вектора весов w для данноro входноrо вектора х. В этом
и заключается вычислительная мощность алrоритма обратноro распространения 5 .
Для большей конкретизации рассмотрим мноrослойный персептрон с входным
слоем, состоящим из то узлов, двумя скрытыми слоями и одним выходным нейроном
(рис. 4.18). Элементы вектора весов w упорядочены по слоям (начиная с первоro
cKpbIтoro), затем по нейронам и, наконец, по синаптическим связям каждоro нейрона.
Пусть w; ) синаптический вес, связывающий нейрон i с нейроном j слоя l =
0,1,... . Для первоrо cKpbIToro слоя (l == 1) индекс i относится не к нейрону, а
к входному узлу. Для l == 3, что соответствует выходному слою, j == 1. Требуется
вычислить производные функции F(w, х) по всем элементам вектора весов w для
заданноrо входноrо вектора х == [X1, Х2,' .. , хто]т' Заметим, что для l == 2 (т.е. для
BTOpOro CKpbITOro слоя) функция F(w, х) имеет форму, аналоrичную правой части
выражения (4.69). Вектор весов w включен в список арrументов функции F(w, х),
чтобы привлечь к нему внимание.
5 Первое документированное описание обратноro распространения ошибки для эффективной оценки rpa-
диента было предложено в [1128]. Материал, представленный в разделе 4.10, соответствует подходу, предло-
женному в [919]. Более полно этот вопрос освещен в [1126].
4.10. Обратное распространение ошибки и дифференцирование 275
Мноrослойный персептрон на рис. 4.18 определяется архитектурой А (представ-
ляющей собой дискретный параметр ) и вектором весов w (составленным из веще
ственных элементов). Пусть АУ) часть архитектуры, включающая в себя фраrмент
нейронной сети от входноro слоя (l ==0) до узла j слоя l(l == 1,2,3). Соответственно
можно записать
F(w, х) == <p(A 3)),
(4.80)
rдe q> функция активации. Однако Ар) необходимо интерпретировать исключи
тельно как символ обозначения архитектуры, а не переменную. Таким образом, адап-
тируя выражения (4.1), (4.2), (4.11) и (4.23) к данной ситуации, получим следую
щий результат:
oF(w, х) == сп' ( А (3) ) cn ( A (2) )
д (3) '1" 1 '1" k ,
W 1k
oF(w, х) == сп' ( А (3) ) cn' ( A (2) ) cn ( A 1) ) W(3)
д (2) '1" 1 '1" k '1" J 1k ,
W kj
д ji;) '(А З)) '(Аj'))х, [ W;r '(A[')W[ )]
(4.81)
(4.82)
(4.83)
[де <р' частная производная нелинейной функции q> по своим aprYMeHTaM; Xi
i й элемент входноrо вектора х. Аналоrично можно вывести выражения для частных
производных любой общей сети с большим числом слоев и выходных нейронов.
Выражения (4.81) (4.83) являются основой для вычисления степени чувствитель
ности функции сети F(w, х) к вариациям элементов вектора весов w. Пусть ro
некоторый элемент вектора весов w. Чувствительность (sensitivity) F(w, х) к эле
менту ro формально определяется выражением
F дР/Р
Вro == дю/ю ' ro Е w.
Именно по этой причине нижнюю часть rpафа передачи сиrнала на рис. 4.7 мы
назвали 2рафом чувствительности (sensitivity graph).
Матрица якобиана
Пусть W общее количество свободных параметров (т.е. синаптических весов и
пороroв) мноroслойноrо персептрона, которые в упорядоченном указанным выше
способом формируют вектор весов w. Пусть N общее количество примеров, ис
пользованных для обучения сети. Применяя метод обратноro распространения, можно
вычислить множество W частных производных аппроксимирующей функции F[w,
.,......
276 rлава 4. Мноrослойный персептрон
х(n)] по элементам вектора весов W для каждоrо примера х(n) из обучающеro MHO
жества. Повторяя эти вычисления для n == 1, 2, ..., N, можно получить матрицу
частных производных размерности N х w. Эта матрица называется якобианом J
мноroслойноro персептрона, вычисленным в точке х(n). Каждая строка якобиана
соответствует одному примеру из обучающеrо множества.
Экспериментально подтверждается, что мноrие задачи обучения нейросетей внут-
ренне плохо обусловлены (ill conditioned), что ведет к неполноте paHra якобиана J
[920]. РаН2 (rank) матрицы равен количеству ее линейно независимых строк или
столбцов (наименьшему из них). PaHr якобиана считается неполным (rank deficient),
если он меньше значения min(N, W). Неполнота paHra якобиана приводит к тому,
что алroритм обратноro распространения получает только частичную информацию о
возможных направлениях поиска, что, в свою очередь, значительно удлиняет время
обучения.
4.11. rессиан
rессиан, или матрица Тессе (Hessian matrix), функции стоимости Eav(W), обозначае-
мая символом Н, определяется как вторая производная Eav(w) по вектору весов W:
Н == д 2 Е ау (w)
ow 2 .
(4.84)
rессиан иrpает важную роль в изучении нейронных сетей; в частности, можно
отметить следующее 6 .
1. Собственные числа rессиана оказывают определяющее влияние на динамику обу-
чения методом обратноrо распространения.
2. На основе матрицы, обратной rессиану, можно выделить несущественные синап-
тические веса мноroслойноro персептрона и отключить их. Этот вопрос детально
обсуждается в разделе 4.15.
3. rессиан составляет основу методов оптимизации BToporo порядка, применяемых
в качестве альтернативы алrоритма обратноrо распространения (см. раздел 4.18).
6 К друrим аспектам создания нейронных сетей на основе матрицы [ессе относятся следующие [130].
Вычисление rессиана составляет основу процедуры повторноro обучения мноroслойноrо персептрона после
внесения небольших изменений во множество примеров обучения.
В контексте байесовскоro обучения необходимо отметить следующее.
Матрицу, обратную rессиану, можно использовать для определения rpаниц ошибок при нелинейном про-
rнозировании, выполняемом с помощью обученной нейронной сети.
Собственные значения матрицы [ессе можно использовать для нахождения значений параметров реryляри
зации.
4.11. rессиан 277
Итеративная процедура вычисления 7 rессиана описывается в разделе 4.15. Сейчас
обратим внимание на п. 1.
В rлаве 3 уже roворилось о том, что собственные числа rессиана определяют
свойства сходимости алrоритма LMS. То же можно сказать и об алrоритме обратноro
распространения, однако механизм здесь более сложный. Обычно матрица recce для
поверхности ошибок мноroслойноrо персептрона, обучаемоrо по алrоритму обрат-
HOro распространения, имеет следующие особенности распределения собственных
чисел [617], [625].
. Небольшое количество собственных чисел с малыми значениями.
· Большое количество собственных чисел со средними значениями.
. Малое количество больших собственных чисел.
Факторы, на которые влияет такой ход вещей, можно сrpуппировать следующим
образом.
. Входные и выходные сиrналы нейронов имеют ненулевые средние значения.
. Существует корреляция между элементами вектора входноro сиrнала, а также
между индуцированными выходными сиrналами нейронов.
. При переходе от одноrо слоя к следующему возможны значительные вариации
производных BToporo порядка функции стоимости по синаптическим весам ней
ронов сети. Вторые производные часто оказываются меньше для первых слоев,
поэтому синаптические веса первых скрытых слоев обучаются медленнее, чем
веса последних скрытых слоев.
Из rлавы 3 известно, что время обучения (learning time) алrоритма LMS зависит от
соотношения л..mах!л..min, [де л'mах И л'min наибольшее и наименьшее не нулевое соб
ственное число rессиана соответственно. Экспериментальные результаты показали,
что аналоrичная ситуация сохраняется и для алrоритма обратноrо распространения,
который является обобщением алrоритма LMS. ДЛЯ входных сиrналов сненулевым
средним значением отношение л..mах/л..min больше, чем для соответствующих значе
ний с нулевым средним. Чем больше среднее значение входноro сиrнала, тем больше
это отношение (см. упражнение 3.10). Это в значительной степени определяет дина
мику алrоритма обратноrо распространения.
Для минимизации времени обучения следует избеrать использования входных зна
чений с не нулевым средним. Для вектора х, передаваемоrо нейронам первоrо CKpЫTO
ro слоя мноrослойноrо персептрона (т.е. вектора сиrнала, поступающеrо на входной
слой), это условие выполнить очень леrко. Достаточно вычесть из каждоrо элемен
7 В [88] представлен обзор точных алroритмов вычисления матрицы fессиана и алroритмов ero аппрокси
мации с учетом специфики нейронных сетей. В этом отношении также представляет интерес [103].
.,.......
278 rлава 4. Мноrослойный персептрон
та этоrо вектора ero ненулевое среднее значение до передачи этоro вектора в сеть.
Однако что делать с сиrналами, передаваемыми на следующие скрытые и выходной
слои сети? Ответ на этот вопрос заключается в выборе типа функций активации,
которые используются в сети. Если функция активации является несимметричной
(как в случае лоrистической функции), выходной сиrнал любоrо нейрона принадле-
жит интервалу [О, 1]. Такой выбор является источником систематичеСК020 смещения
(systematic bias) для нейронов, расположенных правее первоro cKpbIToro слоя сети.
Чтобы обойти эту проблему, следует использовать антисимметричную функцию ак-
тивации, такую как rиперболический TaHreHC. В последнем случае выход каждоrо
нейрона может принимать как положительные, так и отрицательные значения из ИН-
тервала [ 1, 1] и с более высокой вероятностью будет иметь нулевое среднее. Если
связность сети велика, обучение методом обратноrо распространения с антисиммет-
ричными функциями активации приведет к более быстрой сходимости, ч м В случае
применения симметричной функции активации, что также является эмпирически оче-
видным [625]. Это объясняет эвристику 3 из раздела 4.6.
4.12. Обобщение
При обучении методом обратноrо распространения в сеть подают обучающую вы-
борку и вычисляют синаптические веса мноrослойноro персептрона, заrpужая в сеть
максимально возможное количество примеров. При этом разработчик надеется, что
обученная таким образом сеть будет способна к обобщению. Считается, что сеть
обладает хорошей обобщающей способностью (genera1ize well), если отображение
входа на выход, осуществляемое ею, является корректным (или близким к этому) для
данных, никоrда ранее не "виденных" сетью в процесс е обучения. Термин "обобще-
ние" взят из области психолоrии. При этом считается, что данные принадлежат той
же совокупности (population), из которой они брались для обучения.
Процесс обучения нейронной сети можно рассматривать как задачу аппрокси-
мации кривой (curve-fitting). Сама сеть при этом выступает как один нелинейный
оператор. Такая точка зрения позволяет считать обобщение не мистическим свой-
ством нейронной сети, а результатом хорошей нелинейной интерполяции входных
данных [1146]. Сеть осуществляет корректную интерполяцию в основном за счет
Toro, что непрерывность отдельных функций активации мноrослойноrо персептрона
обеспечивает непрерывность общей выходной функции.
На рис. 4.19, а показано, как происходит обобщение в rипотетической сети. Нели-
нейное отображение входа на выход, показанное на этом рисунке, определяется сетью
в результате обучения по дискретным точкам (обучающим данным). Точку, получен-
ную в процессе обобщения и обозначенную незаштрихованным кружочком, можно
рассматривать как результат выполняемой сетью интерполяции.
4.12. Обобщение 279
Нейронная сеть, спроектированная с учетом хорошеrо обобщения, будет ocy
ществлять корректное отображение входа на выход даже Torдa, Korдa входной сиrнал
слеrка отличается от примеров, использованных для обучения сети (что и показано
на рисунке). Однако, если сеть обучается на слишком большом количестве примеров,
все может закончиться только запоминанием данных обучения. Это может произой
ти за счет нахождения таких признаков (например, блаroдаря шуму), которые при
сутствуют в примерах обучения, но не свойственны самой моделируемой функции
отображения. Такое явление называют избыточным обучением, или переобучением
(overtraining). Если сеть "переучена", она теряет свою способность к обобщению на
аналоrичных входных сиrналах.
Обычно заrpузка данных в мноrослойный персептрон таким способом требует
использования большеrо количества скрытых нейронов, чем действительно необ
ходимо. Это выливается в нежелательное изменение входноro пространства из за
шума, который содержится в синаптических весах сети. Пример плохоrо обобще
ния вследствие простоrо запоминания (memorizing) обучающих образов показан на
рис. 4.19, б для тех же данных, которые показаны на рис. 4.19, а. Результат запомина
ния, в сущности, представляет собой справочную таблицу список пар "BXOД BЫXOД",
вычисленных нейронной сетью. При этом отображение теряет свою шадкость. Как
указывается в [847], шадкость отображения входа на выход непосредственно связана
с критерием моделирования, который получил название бритвы Оккама (Occam's
razor). Сущность зтоrо критерия состоит в выборе простейшей функции при OT
сутствии каких либо дополнительных априорных знаний. В контексте предыдущеrо
обсуждения "простейшей" является самая шадкая из функций, аппроксимирующих
отображение для данноrо критерия ошибки, так как такой подход требует мини
мальных вычислительных ресурсов. rладкость свойственна мноrим приложениям и
зависит от масштаба изучаемоro явления. Таким образом, для плохо обусловленных
(ill posed) отношений важно искать шадкое нелинейное отображение. При зтом сеть
будет способна корректно классифицировать новые сиrналы относительно приме
ров обучения [1146].
Достаточный объем примеров обучения для корректноrо
обобщения
Способность к обобщению определяется тремя факторами: размером обучающеro
множества и ero представительностью, архитектурой нейронной сети и физической
сложностью рассматриваемой задачи. Естественно, последний фактор выходит за
пределы нашеrо влияния. В контексте остальных факторов вопрос обобщения можно
рассматривать с двух различных точек зрения [495].
I
L
........
280 rлава 4. Мноrослойный персептрон
Нелинейное
отображение
Выход
Вход
а)
Данные обучения
Выход
Нелинейное
отображение
Вход
б)
Рис. 4.19. Корректная интерполяция (хорошее обобщение) (а) и pe
зультат избыточноro обучения (плохое обобщение) (б)
· Архитектура сети фиксирована (будем надеяться, в соответствии с физической
сложностью рассматриваемой задачи), и вопрос сводится к определению размера
обучающеrо множества, необходUМ020 для хорошеro обобщения.
· Размер обучающеrо множества фиксирован, и вопрос сводится к определению
наилучшей архитектуры сети, позволяющей достичь хорошеrо обобщения.
4.13. Аппроксимация функций 281
Обе точки зрения по своему правильны. До сих пор мы фокусировали внимание
на первом аспекте проблемы.
Вопрос адекватности размера обучающей выборки рассматривался в rлаве 2. Там
указывалось, что VС измерение обеспечивает теоретический базис для принципиаль
Horo решения этой важной задачи. В частности, были получены независимые от pac
пределения пессимистические (distribution free, worst case) формулы оценки размера
обучающеrо множества, достатОЧН020 для хорошеrо обобщения (см. раздел 2.14).
К сожалению, часто оказывается, что между действительно достаточным размером
множества обучения и этими оценками может существовать большой разрыв. Из за
этоro расхождения возникает задача сложности выборки (sample complexity problem),
открывающая новую область исследований.
На практике оказывается, что для хорошеrо обобщения достаточно, чтобы размер
обучающеro множества N удовлетворял следующему соотношению:
N == O(WjE),
(4.85)
[де W общее количество свободных параметров (т.е. синаптических весов и по
poroB) сети; Е допустимая точность ошибки классификации; 0(.) порядок за
ключенной в скобки величины. Например, для ошибки в 10% количество примеров
обучения должно в 1 О раз превосходить количество свободных параметров сети.
Выражение (4.85) получено из эмпиричеСК020 правила Видроу (Widrow's rule of
thиmb) для алrоритма LMS, утверждающеrо, что время стабилизации процесса ли
нейной адаптивной временной фильтрации примерно равно объему памяти (memory
span) линейноrо адаптивноro фильтра в задаче фильтра на линии задержки с oтвoдa
ми (tapped de1ay line fi1ter), деленному на величину раССО2Ласования (misadjиstment)
[1144]. Рассоrласование в алrоритме LMS выступает в роли ошибки Е из выражения
(4.85). Дальнейшие выкладки относительно этоrо эмпирическоrо правила приводятся
в следующем разделе.
4.13. Аппроксимация функций
Мноrослойный персептрон, обучаемый соrласно алrоритму обратноrо распростра
нения, можно рассматривать как практический механизм реализации нелинеЙНО20
отображения "вxoд выxoд" (nonlinear inpиt oиtpиt mapping) общеrо вида. Например,
пусть то количество входных узлов мноrослойноro персептрона, М == т L
количество нейронов выходноrо слоя сети. Отношение "BXOД BЫXOД" для такой ce
ти определяет отображение ffio MepHoro Евклидова пространства входных данных
в М MepHoe Евклидово пространство выходных сиrналов, непрерывно дифферен-
цируемое бесконечное число раз (если этому условию удовлетворяют и функции
активации). При рассмотрении свойств мноroслойноrо персептрона с точки зрения
отображения "BXOД BЫXOД" возникает следующий фундаментальный вопрос.
..,......
282 rлава 4. Мноrослойный персептрон
Каково минимальное количество скрытых слоев МНО20СЛОЙН020 персептрона, обеспе-
чивающе20 аппроксимацию некотОРО20 непрерывНО20 отобра:жения?
Теорема об универсальной аппроксимации
Ответ на этот вопрос обеспечивает теорема об универсальной аппроксимации 8 (uni-
versal approximation theorem) для нелинейноrо отображения "BXOД BЫXOД", которая
формулируется следующим образом.
Пусть <р(.) 02раниченная, не постоянная монотонно возрастающая непрерывная
функция. Пусть Imo mо-мерный единичный 2иперкуб [О, 1]т о . Пусть простран-
ство непрерывных на Imo функций обозначается СUМ60ЛОМ C(Imo). ТО2да для любой
функции jC(Imo) и Е> О существует такое целое число т1 и множество действи-
тельных констант ai, b i и Wij, 2де i == 1, . . . , m1, j == 1, . . . , то, что
ml ( то )
F(X1"'" Хто) == aiq> ЩjХj + b i
(4.86)
является реализацией аппроксимации функции j (.), т.е.
IF(X1"'" Х то ) j(X1"" , Хто)1 < Е
для всех X1, Х2, . . . , Х тО ' принадлежащих входному пространству.
Теорема об универсальной аппроксимации непосредственно применима к MHOro-
слойному персептрону. Во первых, заметим, что в модели мноrослойноrо персептро-
на в качестве функции активации используется оrpаниченная, монотонно возрастаю-
щая лоrистическая функция 1I[ l+exp( v )], удовлетворяющая условиям, накладывае
мым теоремой на функцию <р(.). BO BTOpЫX, заметим, что выражение (4.86) описывает
выходной сиrнал персептрона следующеrо вида.
8 Универсальную теорему аппроксимации можно рассматривать как естественное расширение теоремы
Вейерштрасса [1124]. Эта теорема утверждает, что любая непрерывная функция на замкнутом интервале дей-
ствительной оси может быть представлена абсолютно и равномерно сходящимся рядом полиномов.
Интерес к исследованню мноroслойных персептронов в качестве механизма представления произвольных
непрерывных функций впервые был проявлен в [448], в которой использовалась усовершенствованная теорема
Колмоroрова (Kolmogorov) о суперпозицин [1014]. В [333] показано, что мноroслойный персептрон с одним
скрытым слоем, косинусоидальной пороrовой функцией и линейным выходным слоем представляет собой част-
ный случай "сети Фурье", обеспечивающей на выходе аппроксимацню заданной функции рядом Фурье. Однако
в контексте обычноro мноroслойноro персептрона Цыбенко (СуЬеnkо) впервые cтporo продемонстрировал, что
одноro CкpblTOro слоя достаточно для аппроксимации произвольной непрерывной функции, заданной на единич-
ном rиперкубе. Эта работа была опубликована в Техническом отчете университета штата Иллинойс в 1988 roдy
и вьшта отдельным изданием roд спустя [236], [237]. В 1989 rоду независимо друr от друrа были опубликованы
две работы по использованию персептронов в качестве универсальных аппроксиматоров [329], [486]. Друrие
вопросы аппроксимации описаны в [642].
4.13. Аппроксимация функций 283
1. Сеть содержит то входных узлов и один скрытый слой, состоящий из т1 нейро
нов. Входы обозначены X1,X2,"', Хто'
2. Скрытый нейрон i имеет синаптические веса Wi 1 , ..., W mo И пороr b i .
3. Выход сети представляет собой линейную комбинацию выходных сиrналов
CKPbIТbIX нейронов, взвешенных синаптическими весами выходноrо нейрона
<X1, ..., a m1 .
Теорема об универсальной аппроксимации является теоремой существования (ех-
istence theorem), Т.е. математическим доказательством возможности аппроксимации
любой непрерывной функции. Выражение (4.86), составляющее стержень теоремы,
просто обобщает описание аппроксимации функции конечным рядом Фурье. Таким
образом, теорема утверждает, что МН020СЛОЙН020 персептрона с одним скрытым
слоем достаточно для построения равномерной аппроксимации с точностью Е для
люБО20 обучающе20 множества, представлеНН020 набором входов X1, Х2,. . . , Хто И
желаемых откликов J(X1,X2, ..., Х то )' Тем не менее из теоремы не следует, что
один скрытый слой является оптимальным в смысле времени обучения, простоты
реализации и, что более важно, качества обобщения.
Пределы ошибок аппроксимации
в [96] были исследованы аппроксимирующие свойства мноrослойноrо персептрона
для случая одноrо cKpbIToro слоя с сиrмоидальной функцией активации и одноrо
линейноro выходноro нейрона. Эта сеть обучалась с помощью алroритма обратноro
распространения, после чеrо тестировалась на новых данных. Во время обучения ce
ти предъявлялись выбранные точки аппроксимируемой функции J, в результате чеrо
была получена аппроксимирующая функция Р, определяемая выражением (4.86). Ec
ли сети предъявлялись не использованные ранее данные, то функция F "оценивала"
новые точки целевой функции, Т.е. F == j.
rладкость целевой функции J выражалась в терминах ее разложения Фурье.
В частности, в качестве предельной амплитуды функции J использовалось среднее
значение нормы вектора частоты, взвешенноrо значениями амплитуды распределения
Фурье. Пусть i( Ф) MHoroMepHoe преобразование Фурье функции Лх), хЕ Rm o , [де
о) eктop частоты. Функция J (х ), представленная в терминах преобразования Фу
рье f( Ф), определяется следующей инверсной формулой:
J(X) == r i(Ф) ехр(jФТ х)dФ,
} fЯ""О
(4.87)
",.......
284 rлава 4. Мноrослойный персептрон
rдe j == Н. ДЛЯ комплекснозначной функции j ( ю) с интеrpируемой функци-
ей юf (ю) первый абсолютный момент (first absolute moment) распределения Фурье
(Fourier magnitude distribution) функции f можно определить следующим образом:
С ! == r Ij(ю)1 х Ilю11 1 / 2 dю,
} fЯто
(4.88)
rдe Ilюll Евклидова норма вектора ю; lj(ю)1 абсолютное значение функции j(w).
Первый абсолютный момент С ! является мерой 2Ладкости (smoothness) функции f.
Первый абсолютный момент С f является основой для вычисления пределов ошиб-
ки, которая возникает вследствие использования мноrослойноrо персептрона, пред-
ставленноrо функцией отображения "BXOД BЫXOД" Р(х), аппроксимирующей функ-
цию Лх). Ошибка аппроксимации измеряется инте2Ральной квадратичной ошибкой
(integrated squared error) по произвольной мере вероятности 11 для шара ВТ =={х:
Ilxll ::; r} радиуса r > О. На этом основании можно сформулировать следующее
утверждение для предела ошибки аппроксимации [96].
Для любой непрерывной функции f(x) с конечным первым моментом С ! и люБО20
т1 2:: 1 существует некоторая линейная комбинация СИ2моидальных функций Р(х)
вида (4.86), такая, что
1 С'
и(х) F(x))21l(dx) ::; .....L,
вт т1
2де С! == (2rC f )2.
Если функция лх) наблюдается на множестве значений {Xi}[:l входноrо вектора
х, принадлежащеrо шару Вт, этот результат определяет следующее оrpаничение для
эмпиричеСК020 риска (empirical risk):
1 N С'
R == N I: (f(Xi) F(Xi))2 ::; .....L.
i l т1
(4.89)
в [95] результат (4.89) использовался для описания rpаниц риска R, возникаю-
щеrо при использовании мноrослойноrо персептрона с то входными узлами и т!
скрытыми нейронами:
R ::; о ( : ) + О ( т т1 log N) .
(4.90)
Два слаrаемых в этом определении rраниц риска R отражают компромисс между
двумя противоречивыми требованиями к размеру cKpbIToro слоя.
4.13. Аппроксимация функций 285
1. Точность наилучшей аппроксимации (accuracy of the best approximation). В COOT
ветствии с теоремой об универсальной аппроксимации для удовлетворения этоrо
требования размер CKpbITOro слоя т1 должен быть большим.
2. Точность эмпиричеСК020 соответствия аппроксимации (accuracy of empirica1 fit to
the approximation). Для TOro чтобы удовлетворить этому требованию, отношение
m1/N должно иметь малое значение. Для фиксированноrо объема N обучающеrо
множества размер cкpbIToro слоя т1 должен оставаться малым, что противоречит
первому требованию.
Оrpаничение для риска R, описанное формулой (4.90), имеет еще одно интерес
ное применение. Дело в том, что для точной оценки целевой функции не требуется
экспоненциально большоrо обучающеro множества и большой размерности входноro
пространства то, если первый абсолютный момент С ! остается конечным. Это еще
больше повышает практическую ценность мноroслойноro персептрона, используе
MOro в качестве универсальноro аппроксиматора.
Ошибку между эмпирическим соответствием (empirical fit) и наилучшей аппрок
симацией можно рассматривать как ошибку оценивания (estimation error), описанную
в rлаве 2. Пусть Ео среднеквадратическое значение ошибки оценивания. Torдa, иrно
рируя лоrарифмический множитель во втором слаrаемом неравенства (4.90), можно
сделать вывод, что размер N обучающеrо множества, необходимый для хороше
ro обобщения, должен иметь порядок mOm1/Eo. Математическая структура этоrо
результата аналоrична эмпирическому правилу (4.85), если произведение тот1 co
ответствует общему количеству свободных параметров W сети. Друrими словами,
можно утверждать, что для хорошеrо качества аппроксимации размер обучающеrо
множества должен превышать отношение общеrо количества свободных параметров
сети к среднеквадратическому значению ошибки оценивания.
"Проклятие размерности"
Из оrpаничения (4.90) вытекает еще один интересный результат. Если размер CKpЫ
Toro слоя выбирается по следующей формуле (т.е. риск R минимизируется по N):
( N ) 1/2
т1 == С ! то logN '
то риск R оrpаничивается величиной O(Cj V mo(log N/N). Неожиданный аспект
этоro результата состоит в том, что в терминах поведения риска R скорость cxo
димости, представленная как функция от размера обучающеrо множества N, имеет
порядок (l/N)1/2 (умноженный на лоrарифмический член). В то же время обычная
rладкая функция (например, триrонометрическая или полиномиальная) демонстриру
ет несколько друrое поведение. Пусть s мера rладкости, определяемая как степень
.......
286 rлава 4. Мноrослойный персептрон
дифференцируемости функции (количество существующих производных). Torдa для т
обычной rладкой функции минимаксная скорость сходимости общеro риска R имеет Э
порядок (ljN)2s l (2s+m o ). Зависимость этой скорости от размерности входноro про.
странства то называют "проклятием размерности" (curse of dimensiona1ity), посколь.
ку это свойство оrpаничивает практическое использование таких функций. Таким об. 1
разом, использование мноroслойноro персептрона для решения задач аппроксимации
обеспечивает определенные преимущества перед обычными rладкими функциями.
Однако это преимущество появляется при условии, что первый абсолютный момент
С ! остается конечным. В этом состоит оrpаничение rладкости.
Термин "проклятие размерности" (curse of dimensionality) был введен Ричардом
Белманом (Richard Belman) в 1961 roду в работе, посвященной процессам адаптивно.
ro управления [117]. Для rеометрической интерпретации этоrо понятия рассмотрим
пример, в котором Х mо мерный входной вектор, а множество {( Xi, d i ) }, i == 1,
2,..., N, задает обучающую выборку. Плотность дискретизации (sampling density)
пропорциональна значению N1/m o . Пусть Лх) поверхность в тo MepHOM вход-
ном пространстве, проходящая около точек данных{ (Xi' d i ) }{:1' Если функция лх)
достаточно сложна и (по большей части) абсолютно неизвестна, необходимо уплот-
нить (dense) точки данных для более полноro изучения поверхности. К сожалению,
в MHoroMepHoM пространстве из за "проклятия размерности" очень сложно найти
обучающую выборку с высокой плотностью дискретизации. В частности, в резуль-
тате увеличения размерности наблюдается экспоненциальный рост сложности, что, в
свою очередь, приводит к ухудшению пространственных свойств случайных точек с
равномерным распределением. Основная причина "проклятия размерности" обосно-
вывается в [321].
Функция, определенная в пространстве большой размерности, скорее всею, является
значительно более сложной, чем функция, определенная в пространстве меньшей
размерности, и эту сложность трудно раЗ2ЛЯдеть.
Единственной возможностью избежать "проклятия размерности" является полу-
чение корректных априорных знаний о функции, определяемой данными обучения.
Можно утверждать, что для практическоrо получения хорошей оценки в простран-
ствах высокой размерности необходимо обеспечить возрастание rладкости неизвест-
ной функции наряду с увеличением размерности входных данных [787]. Эта точка
зрения будет обоснована в rлаве 5.
Практические соображения
Теорема об универсальной аппроксимации является очень важной с теоретической
точки зрения, так как она обеспечивает необходимый математический базис для до-
казательства применимости сетей прямоro распространения с одним скрытым слоем
для решения задач аппроксимации. Без такой теоремы можно было бы безрезуль-
4.1 З. Аппроксимация функций 287
татно заниматься поисками решения, KOTOpOro на самом деле не существует. Однако
эта теорема не конструктивна, поскольку она не обеспечивает способ нахождения
мноroслойноro персептрона, обладающеro заявленными свойствами аппроксимации.
Теорема об универсальной аппроксимации предполаrает, что аппроксимируемая
непрерывная функция известна, и для ее приближения можно использовать скрытый
слой неоrpаниченноro размера. В большинстве практических применений мноrослой
HOro персептрона оба эти предположения нарушаются.
Проблема мноroслойноro персептрона с одним скрытым слоем состоит в том, что
нейроны MOryT взаимодействовать друr с друrом на rлобальном уровне. В сложных
задачах такое взаимодействие усложняет задачу повышения качества аппроксимации
в одной точке без явноro ухудшения в друroй. С друrой стороны, при наличии двух
CКPbIТbIX слоев процесс аппроксимации становится более управляемым. В частности,
можно утверждать следующее [190], [329].
1. Локальные признаки (local feature) извлекаются в первом скрытом слое, Т.е. HeKOTO
рые скрытые нейроны первоrо слоя можно использовать для разделения входноro
пространства на отдельные области, а остальные нейроны слоя обучать локаль
ным признакам, характеризующим эти области.
2. Тлобальные признаки (global feature) извлекаются во втором скрытом слое. В част
ности, нейрон BToporo cKpbIToro слоя "обобщает" выходные сиrналы нейронов
первоro cKpbIToro слоя, относящихся к конкретной области входноro пространства.
Таким образом он обучается rлобальным признакам этой области, а в остальных
областях ero выходной сиrнал равен нулю.
Этот двухэтапный процесс аппроксимации по своей философии аналоrичен сплай
новому подходу к аппроксимации кривых, поскольку нейроны работают в изолиро
ванных областях. Сплайн (sp1ine) является примером такой кусочной полиномиальной
аппроксимации.
В [1007] предложено дальнейшее обоснование использования двух скрытых слоев
в контексте обратных задач (inverse problem). В частности, рассматривается следу
ющая обратная задача.
Для данной непрерывной вектор функции f : эt m эt М , компактНО20 подмноже
ства С эt М , которое содержится в пространстве образов функции f, и HeKO
тОрО20 положителЬН020 € > О требуется найти вектор функцию q> : эt М эt m ,
удовлетворяющую условию
11q>(f)(U) ull < € для любоrо U Е С.
".......
288 rлава 4. Мноrослойный персептрон
Эта задача относится к области обратной кинематики (inverse kinematics) или
динамики, rдe наблюдаемое состояние х( n) системы является функцией текущих
действий о( n) и предыдущеro состояния х( n 1) системы
х(n) == С(х(n 1), о(n)).
Здесь предполаrается, что функция f является обратимой (invertible), Т.е. и(п)
можно представить как функцию от х(n) для любоrо х(n 1). Функция f описывает
прямую кинематику, а функция q> обратную. В контексте излаrаемоrо материала
необходимо построить такую функцию <Р, которая может быть реализована мнorо
слойным персептроном. В общем случае для решения обратной задачи кинематики
функция q> должна быть разрывной. Интересно, что для решения таких обратных
задачи одноrо cKpbIToro слоя недостаточно, даже при использовании нейронной MO
дели с разрывными активационными функциями, а персептрона с двумя скрытыми
слоями вполне достаточно для любых возможных С, f и Е [1007].
4.14. Пере крестная проверка
Сущность обучения методом обратноrо распространения заключается в кодирова-
нии отображения входа на выход (представленноrо множеством маркированных при-
меров) в синаптических весах и пороrовых значениях мноrослойноrо персептрона.
Предполаrается, что на примерах из прошлоrо сеть будет обучена настолько хорошо,
что сможет обобщить их на будущее. С такой точки зрения процесс обучения обес-
печивает настройку параметров сети для заданноro множества данных. Более тощ
проблему настройки сети можно рассматривать как задачу выбора наилучшей модели
из множества структур "кандидатов" с учетом определенноro критерия.
Основой для решения такой задачи может стать стандартный статистический под-
ход, получивший название перекрестной проверки (cross va1idation)9 [1019], [1020].
В рамках этоrо подхода имеющиеся в наличии данные сначала случайным образом
разбиваются на обучающее множество (training set) и тестовое множество (test set).
Обучающее множество, в свою очередь, разбивается на два следующих несвязанных
подмножества.
· Подмножество для оценивания (estimation subset), используемое для выбора мо-
дели.
· Проверочное подмножество (va1idation subset), используемое для тестирования
модели.
9 История развития методолоrии "перекрестной проверки" описана в [1020]. Сама идея перекрестных про-
верок витала в воздухе еще в 1930-е roды, однако в виде технолоrии она оформилась лишь в 1960 1970 x roдах.
Важный вклад в развитие этоrо подхода внесли Стоун [1020] и [ессер [341], которые одновременно и независи
мо дрyr от друrа представили эту методолоrию. Стоун назвал ее "методом перекрестной проверки", а [ессер
"проrнозируемым методом повторноrо использования обучающей выборки" (predictive sample reиse method).
4.14. Перекрестная проверка 289
Идея этоro подхода состоит в проверке качества модели на данных, отличных
от использованных для параметрическоrо оценивания. Таким образом, обучающее
множество можно использовать для проверки эффективности различных моделей
"кандидатов", из которых необходимо выбрать лучшую. Однако существует некоторая
вероятность Toro, что отобранная по параметрам эффективности модель окажется из
лишне переученной (overfitted) на проверочном подмножестве. Чтобы предотвратить
такую опасность, эффективность обобщения выбранной модели измеряется также на
тестовом множестве, которое отличается от проверочноro.
Перекрестные проверки особенно привлекательны, если требуется создать боль
тую нейросеть, обладающую хорошей способностью к обобщению. Например, пере
крестную проверку можно использовать для нахождения мноrослойноro персептрона
с оптимальным количеством CKPbIТbIX нейронов. Способ определения момента OCTa
новки процесса обучения описывается в следующих разделах.
Выбор модели
Идея выбора модели на основе пере крестной проверки аналоrична методолоrии ми
нимизации CTpyктypHoro риска (см. rлаву 2). Рассмотрим следующую вложенную
структуру классов булевых функций:
F1 С F 2 С ... с F щ
Fk == {Fk} == {F(x,w);w Е Wk},k == 1,2,... ,n.
(4.91)
Друrими словами, k й класс функций F k oxBaтыветT семейство мноrослойных
персептронов с одинаковой архитектурой и вектором весов w, принадлежащим MHO
roMepHoMY пространству весовых коэффициентов W k. Функция член этоro класса, xa
рактеризуемая функцией (или rипотезой) Fk == F(w, х), WEWk, отображает входной
вектор х в множество {О, 1}, [де х принадлежит входному пространству Х снекоторой
неизвестной вероятностью Р. Каждый мноrослойный персептрон в описанной CТPYK
туре обучается по алrоритму обратноrо распространения, в соответствии с которым
настраиваются параметры персептрона. Задача выбора модели состоит в выборе пер-
септрона, имеющеrо наилучшее значение W, определяющее количество свободных
параметров (т.е. синаптических весов и пороroв). Более точно, зная желаемый CKa
лярный отклик d == {О, 1} для входноro сиrнала х, мы определим ошибку обобщения:
€g(F) == P(F(x) =1 d) для х Е Х.
Пусть имеется множество маркированных примеров обучения
т == {(Xi, d i ) } 1'
......
290 rлава 4. Мноroслойный персептрон
Требуется выбрать такую rипотезу F(x, w), которая минимизирует ошибку обоб-
щения €g(F) на всем множестве примеров обучения.
В дальнейшем будем предполаrать, что описанная соотношением (4.91) структура
обладает следующим свойством: для любоrо размера обучающей выборки N Bcerдa
найдется мноroслойный персептрон с достаточно большим количеством свободных
параметров W тах (N), адекватно представляющий обучающее множество Т. Это все-
ro лишь еще одна формулировка теоремы об универсальной аппроксимации из раз-
дела 4.13. Будем называть Wmax(N) числом Сi?Jlаживания (fitting number). Значение
величины W тах (N) состоит в том, что разумная процедура выбора модели должна
найти такую rипотезу F(x, w), которая удовлетворяет условию W W max(N). В
противном случае сложность сети должна увеличиваться.
Пусть параметр т, принадлежащий интервалу от нуля до единицы, определяет
разбиение обучающеro множества на подмножества оценивания и проверки. Пусть
т содержит N примеров. Тоrда после разбиения (1 r)N примеров будет принад-
лежать подмножеству оценивания, а rN примеров проверочному подмножеству.
Подмножество оценивания обозначим т'. Оно используется для обучения вложенной
последовательности мноrослойных персептронов, представленных rипотезами F j ,
F 2 ,. .., Fn с нарастающей сложностью. Так как подмножество т' состоит из (1 r)N
примеров, будем рассматривать значения W, не превышающие соответствующеro
числа сrлаживания W max ((l r)N).
Используя результаты перекрестной проверки при выборе
Fcv == min {e"t(Fk)},
k=1,2,...,v
(4.92)
[де v соответствует W v W max ((l r)N), а et"(F k ) ошибка классификации,
обеспечиваемая rипотезой F k при тестировании на проверочном множестве Т", со-
стоящем из N примеров.
Ключевой вопрос состоит в том, как определить значение параметра т, задаю-
щеro разбиение обучающеrо множества Т на подмножества оценивания т' и про-
верки Т". В [549] при аналитическом исследовании этоrо вопроса с использованием
VС измерения и компьютерноrо моделирования были определены некоторые количе-
ственные свойства оптимальноro значения т.
. Если сложность целевой функции, определяющей желаемый отклик d в терминах
входноro вектора х, мала по сравнению с размером N обучающеrо множества, 1'0
эффективность перекрестной проверки мало зависит от выбора т.
. Если же целевая функция становится более сложной по сравнению с размером
N обучающеro множества, то выбор оптимальноrо значения r оказывает суще-
ственное влияние на эффективность перекрестной проверки, причем это значение
уменьшается.
4.14. Перекрестная проверка 291
· Одно и то же фиксированное значение rпочти оптимально подходит для широкоro
диапазона сложностей целевой функции.
На основе результатов, полученных в [549], бьmо получено фиксированное зна
чение r ==0,2, при котором 80% обучающеrо множества Т составляет подмножество
оценивания, а остальные 20% проверочное подмножество.
Ранее речь lПЛа о последовательности вложенных мноrослойных персептронов
возрастающей сложности. Для заданной размерности входноrо и выходноro слоев
такую последовательность из v == р + q полносвязных мноrослойных персептронов
можно создать, например, следующим образом.
· Сформировать р мноroслойных персептронов с одним скрытым слоем возрастаю
щеro размера h < h < . . . < h .
· Сrенерировать q мноrослойных персептронов с двумя скрытыми слоями, размер
первоro cKpbIToro слоя которых фиксирован и составляет h , а размер BTOpOro
h " h " h "
возрастает 1 < 2 < . . . < q .
По мере перехода от одноro мноroслойноrо персептрона к следующему увели
чивается соответствующее количество свободных параметров W. Процедура выбора
модели, основанная на перекрестной проверке, обеспечивает принципиальный подход
к определению нужноrо количества CKPbIТbIX нейронов мноrослойноro персептрона.
Несмотря на то что эта процедура была описана в контексте двоичной классифика
ции, она применима и к друrим приложениям мноrослойноrо персептрона.
Метод обучения с ранним остановом
Обычно обучение мноroслойноro персептрона методом обратноrо распространения
происходит поэтапно переходя от более простых к более сложным функциям отоб
ражения. Это объясняется тем фактом, что при нормальных условиях cpeДHeKBaдpa
тическая ошибка уменьшается по мере увеличения количества эпох обучения: она
начинается с довольно больших значений, стремительно уменьшается, а затем про
должает убывать все медленнее по мере продвижения сети к локальному миниму
МУ на поверхности ошибок. Если rлавной целью является хорошая способность к
обобщению, то по виду кривой довольно сложно определить момент, коrда следует
остановить процесс обучения. В частности, как следует из материала, изложенноrо в
разделе 4.12, если вовремя не остановить сеанс обучения, то существенно повыша
ется вероятность излишнеrо переобучения (overfitting).
Наступление стадии излишнеrо переобучения можно определить с помощью пе
рекрестной проверки, в которой данные разбиты на два подмножества оценива
ния и проверки. Множество оценивания используется для обычноro обучения сети
с небольшой модификацией: сеанс обучения периодически останавливается (через
.......
292 rлава 4. Мноrослойный персептрон
каждые несколько эпох), после чеrо сеть тестируется на проверочном подмножестве.
Более точно, периодический процесс оценивания тестирования выполняется следу-
ющим образом.
. После завершения этапа оценивания (обучения) синаптические веса и уровни по-
poroB мноroслойноrо персептрона фиксируются, и сеть переключается в режим
прямоro прохода. Ошибка сети вычисляется для каждоrо примера из проверочно-
[о подмножества.
. После завершения тестирования наступает следующий этап процесса обучения, и
все повторяется.
Такая процедура называется методом обучения с ранним остановом (early stopping
method of training) 1 о.
На рис. 4.20 показана форма двух кривых обучения. Первая относится к измерени-
ям на подмножестве для оценивания, а вторая к измерениям на проверочном под-
множестве. Обычно на проверочном подмножестве модель ведет себя не так хорошо,
как на подмножестве для оценивания, на основе KOToporo формируется архитектура
сети. Функция обучения на подмножестве оценивания (estimation 1earning curve) мо-
нотонно убывает с увеличением количества эпох, в то время как кривая обучения на
проверочном подмножестве (validation learning curve) монотонно убывает до неко-
тoporo минимума, после чеrо при продолжении обучения начинает возрастать. Если
учитывать только кривую, построенную на подмножестве оценивания, то возникает
соблазн продолжать обучение и после прохождения точки минимума на кривой, по-
строенной на проверочном подмножестве. Однако на практике оказывается, что после
прохождения этой точки сеть обучается только посторонним шумам, содержащимся в
обучающей выборке. Поэтому можно выдвинуть эвристическое предположение о том,
что точку минимума кривой тестирования можно использовать в качестве критерия
останова сеанса обучения.
А что если данные обучения не содержат шума? Как в этом случае определить
точку paHHero останова для детерминированноrо сценария? Частично на этот вопрос
можно ответить следующим образом. Если ошибки на подмножествах оценивания
и проверки не одинаково стремятся к нулю, то емкости сети не достаточно для
точноro функционирования модели. Лучшее, что можно сделать в таком случае,
это постараться минимизировать инте2рированную квадратичную ошибку (integrated
squared error), что (приблизительно) эквивалентно минимизации обычной rлобальной
среднеквадратической ошибки при равномерном распределении входноrо сиrнала.
10 Первые упоминания о методе обучения с ранним остановом содержатся в [754], [1121]. Пожалуй, наиболее
полный статистический анализ этоrо метода обучения мноrослойноro lIерсептрона IIредставлен в [40]. Это
исследование подтверждается результатами компьютерноro моделирования для классификатора с архитектурой
8-8А, 108-ю настраиваемыми параметрами при чрезвычайно большом множестве данных (50000 IIримеров).
4.14. Перекрестная проверка 293
CpeДHeквaд
ратическая
ошибка
Кривая для
подмножества
тестирования
Кривая для
обучающей выборки
Рис. 4.20. Процесс обучения с paH
ним остановом на основе перекрест
ной про верки
о
Количество эпох
Статистическая теория явления чрезмерноrо переобучения (overfitting) описана в
[37]. В этой работе содержится предостережение против использования метода paHHe
[о останова процесса обучения. Данная теория основывается на пакетном обучении
и подтверждается основательным компьютерным моделированием классификатора
на основе мноrослойноrо персептрона с одним скрытым слоем. В зависимости от
размера обучающеrо множества вьщеляются два типа поведения (режима).
Первый это неассимптотический режим (nonasymptotic mode), при котором
N < ЗОW, [де N размер обучающеrо множества; W количество свободных
параметров сети. В этом режиме метод paHHero останова повышает эффективность
обобщения по сравнению с полным обучением (при котором используется все множе
ство примеров без останова сеанса). Соrласно полученным результатам, переучивание
может наступить при N < ЗОW, и только в этом случае существует практическая
польза от использования перекрестной проверки для останова сеанса обучения. Оп
тимальное значение параметра т, определяющее разбиение множества примеров на
подмножества для оценивания и проверки, должно выбираться из соотношения
y'2W 1 1
r opt == 1 2 (W 1) .
При больших значениях W эта формула сводится к следующей:
1
ropt с::: 1 y'2W '
W»O.
(4.93)
Например, при W == 100, r == 0,07. Это значит, что 93% данных обучения составляет
подмножество оценивания и только 7% приходится на проверочное подмножество.
---
294 rлава 4. Мноrослойный персептрон
Попытка 1 О О О
Попытка 2 О О О
Попытка3 О О О
Попытка4111 О О О
Рис. 4.21. Метод мноroкратной перекрестной провер-
ки. При каждой попытке обучения заштрихованное
подмножество используется для вычисления ошибки
оценивания
Вторым типом поведения является асимптотический режим (asymptotic mode),
при котором N > ЗОW. В этом режиме при использовании метода paHHero останова
наблюдается лишь небольшое улучшение эффективности обобщения по сравнению
с полным обучением. Друrими словами, полное обучение (exhaustive learning) при-
водит к удовлетворительному результату, если размер множества обучения велик по
сравнению с количеством параметров сети.
Варианты метода перекрестной проверки
Предложенный подход к реализации перекрестной проверки получил название мето-
да удержания (ho1d out method). Существуют и друrие варианты перекрестной про-
верки, которые также наIПЛИ свое применение на практике, особенно при недостат-
ке маркированных примеров. В такой ситуации можно использовать МНО20кратliУЮ
перекрестную проверку (mu1tifo1d cross va1idation), разделив имеющееся в наличие
множество из N примеров на К подмножеств (К > 1). При этом подразумевается,
что N кратно К. Обучение модели проводится на всех подмножествах, кроме од-
Horo. На этом оставшемся подмножестве выполняется тестирование и определяется
ошибка оценивания. Эта процедура повторяется К раз, при этом каждый раз для
тестирования используются разные подмножества (случай для К == 4 показан на
рис. 4.21). Эффективность такой модели вычисляется путем усреднения квадратич-
ной ошибки по всем попыткам. Метод мноrократной перекрестной проверки имеет
один недостаток: он требует очень большоro объема вычислений, так как обучение
должно проводится К раз (1 < К < N).
Если количество доступных примеров N оrpаничено, можно использовать экстре-
мальную форму мноroкратной перекрестной проверки метод исключения одноro
примера. В этом случае для обучения модели используется N 1 примеров, а те-
стирование выполняется на оставшемся. Эксперимент повторяется N раз, причем
каждый раз для проверки используются разные примеры. После этоrо квадратичная
ошибка оценки усредняется по всем N экспериментам.
4.15. Методы упрощения структуры сети 295
4.15. Методы упрощения структуры сети
Решение реальных задач с помощью нейронных сетей обычно требует использова
ния четко структурированных сетей довольно большоrо размера. В этом контексте
возникает практический вопрос минимизации размера сети без потери производи
тельности. При уменьшении размера нейронной сети снижается вероятность обу
чения помехам, содержащимся в примерах, и, таким образом, повышается качество
обобщения. Минимизировать размер сети можно двумя способами.
· Наращивание сети (network growing). В этом случае в качестве начальной архи
тектуры выбирается простой мноrослойный персептрон, возможностей KOToporo
явно недостаточно для решения рассматриваемой задачи, после чеro в сеть дo
бавляется новый нейрон или слой скрытых нейронов только в том случае, если
ошибка в процесс е обучения перестает уменьшаться 1 1.
· Упрощение структуры сети (network pruning). В этом случае процесс адаптации
начинается с большоro мноroслойноrо персептрона, производительности KOТOpOro
достаточно для решения поставленной задачи. После этоrо сеть постепенно упро
щается за счет избирательноrо или последовательноrо ослабления или отключения
отдельных синаптических связей.
в данном разделе мы сосредоточим внимание на втором способе процедуре
упрощения. В частности, будут описаны два подхода, первый из которых OCHOBЫBa
ется на одной из форм "реrуляризации", а второй на удалении из сети определенных
синаптических связей.
11 Примером реализации подхода наращивания сетн является обучение методом каскадной корреляции
(casсаdе-сопеlаtiоп leaming) [288]. Процедура обучения начинается с минимальной структуры сети, имеющей
несколько входных и выходных узлов, что Оllределяется условиями задачи, и не содержащей скрытых узлов.
Для обучения сети может использоваться любой алroритм, например LMS. Скрытые нейроны добавляются
в сеть по одному, образуя таким образом мноroслойную структуру добавленных скрытых нейронов. После
добавления HOBOro нейрона ero входные сннаПТИческие связи замораживаются, а обучаются только ero выходные
сииаптическне связн. После их обучения новый скрытый нейрон становится 1I0СТОЯННЫМ детектором IIризнаков
данной сети. Процедура добавлення новых скрытых нейронов описанным выше способом продолжается до тех
пор, 1I0ка не удастся достичь удовлетворительной производительности сети.
Еще один подход к наращиванию сети описан в [628]. В ней к прямому (функциональному) и обратно
му проходу (адаптации параметров) добавлен третий IIРОХОД адаптации CТPYктypHOro уровня (structure-]evel
adaptatioll). На этом третьем уровне вычислений структура сети настраивается посредством изменения количе
ства нейронов и структурных связей между ними. При этом используется следующий крнтерий: если ошибка
оценивання (после определенноro чнсла итераций обучения) больше HeKoToporo заданноro значения, в сеть
добавляется новый нейрон. Причем он добавляется в то место, rде потребность в нем максимальна. Это ме-
стоположение определяется с помощью мониторинra поведення сети "рн обучении. В частности, еслн 1I0сле
продолжительноro периода адаптации КОМlIоненты вектора синаптических весов, относящиеся к данному нейро-
ну, продолжают сильно колебаться, значит, этому нейрону не хватает вычислительной мощности для обучения.
В процессе структурной адаптации допускается также аннулирование (исключение) нейронов. Нейрон aHHY
лируется, если он не является функциональным элементом сети нли является ее избыточным элементом. Этот
метод наращивания сетн является очень ресурсоемким и требует интенсивных вычислений.
"........
296 rлава 4. Мноrослойный персептрон
Реryляризация сложности
При создании мноrослойноrо персептрона строится нелинейная модель физическоro
явления, обеспечивающая обобщение примеров типа "BXOД BЫXOД", использованных
при обучении сети. Поскольку архитектура сети по своей природе статична, необхо-
димо обеспечить баланс между достоверностью данных обучения и качеством самой
модели. В контексте обучения методом обратноrо распространения или любоrо дру-
roro метода обучения с учителем этоrо компромисса можно достичь с помощью
минимизации общеrо риска:
R(w) == Es(W) + лЕс(w).
(4.94)
Первое слаrаемое Es(W) это стандартная мера эффективности (performance
measure), которая зависит как от самой сети (модели), так и от входных данных. При
обучении методом обратноrо распространения она обычно определяется как средне-
квадратическая ошибка, которая вычисляется по всем выходным нейронам сети на
всем обучающем множестве примеров для каждой эпохи. Второе слаrаемое Ec(w)
штраф за сложность (comp1exity репаНу), который зависит исключительно от самой
сети (модели). Ero оценка основывается на предварительных знаниях о рассматри-
ваемой модели. На самом деле формула общеrо риска, определяемая соотношением
(4.94), является одним из утверждений теории реzyлярuзации Тихонова. Этот вопрос
подробно обсуждается в rлаве 5. Следует подчеркнуть, что л является параметром
реzyлярuзации (regularization parameter), который характеризует относительную зна-
чимость слаrаемоrо штрафа за сложность по сравнению со слаrаемым, описывающим
меру производительности. Если параметр л равен нулю, процесс обучения методом
обратноrо распространения ничем не оrpаничивается и архитектура сети полностью
определяется предоставленными примерами обучения. С друrой стороны, если па-
раметр л является бесконечно большим, то оrpаничение, представляющее штраф за
сложность, самодостаточно для определения архитектуры сети. Друrими словами, в
этом случае примеры обучения считаются недостоверными. В практических реализа-
циях этой процедуры взвешивания параметру реrуляризации л назначается некоторое
среднее значение. Описываемая здесь точка зрения на использование реrуляризации
сложности для улучшения обобщающей возможности сети вполне соrласуется с про-
цедурой минимизации CтpyктypHOro риска, представленной в rлаве 2.
В общем случае одним из вариантов выбора слarаемоrо штрафа за сложность
является сrлаживающий интеrpал k ro порядка:
Ec(w,k) == J 11 ::k F(X,W)112 (X)dX,
(4.95)
4.15. Методы упрощения структуры сети 297
[де F(x, w) выполняемое моделью отображение входа на выход; (x) некоторая
весовая функция, определяющая область входноrо пространства, на которой функция
Р(х, w) должна быть rладкой. Это делается для TOro, чтобы k я производная функции
Р(х, w) по входному вектору х принимала малое значение. Чем больше величина k,
тем более rладкой (т.е. менее сложной) будет функция F(x, w).
Далее описываются три процедуры реryляризации сложности (в порядке услож
нения) для мноroслойноrо персептрона.
Снижение весов
в процедуре снижения весов (weight decay) [458] слаrаемое штрафа за сложность
определяется как квадрат нормы вектора весовых коэффициентов w (т.е. всех свобод
ных параметров) сети:
Ec(W) == IIwl1 2 == L w;,
iECtotal
(4.96)
rдe Ctotal множество всех синаптических весов сети. Эта процедура обеспечивает
близость к нулю отдельных синаптических весов сети, одновременно допуская ДOCTa
точно большие значения остальных синаптических весов. В результате синаптические
веса rpуппируются в две катеrории: те, которые оказывают большое влияние на сеть
(модель), и те, которые имеют малое влияние. Синаптические веса, относящиеся ко
второй rpуппе, называют избыточными (excess weight). Без реrуляризации сложно
сти эти веса приводят к снижению качества обобщения, так как они Moryт принимать
совершенно произвольные значения, а также заставляют сеть для незначительноrо
уменьшения ошибки выполнять обучение на больших объемах данных [495]. Ис
пользование процедуры реryляризации сложности приводит к уменьшению значений
избыточных весов до значений, близких к нулю, что повышает качество обобщения.
В процедуре снижения весов ко всем весам мноrослойноrо персептрона приме
няется единый подход. Таким образом, предполаrается, что центр упомянутоro ранее
распределения в пространстве весов находится в начале координат. Cтporo rоворя,
снижение весов не является корректной формой реrуляризации сложности MHOro
слойноro персептрона, так как эта процедура не вписывается в лоrику соотношения
(4.95). Тем не менее этот алroритм достаточно прост и неплохо работает в некоторых
приложениях.
298 rлава 4. Мноrослойный персептрон
(W/W O )2
1 + (w/w O )2
1,0
о
W.
I
1,0 2,0 3,0 4,0 5,0 W o
5,0 ,O 3,0 2,0 1,0
Рис. 4.22. Зависимость значения штрафа за сложность (Wi/WO? /[1 +
(w t /wo)2] от Щ/WО
Исключение весов
Во второй по сложности процедуре исключения весов (weight elimination) штраф за
сложность определяется следующей величиной [1122]:
Ec(w) == L (щ/wо)2 ,
. 1 + (щ/wо)2
tECtotal
(4.97)
[де Wo некоторый предопределенный параметр; Wi вес i-ro синапса сети. Под
Ctotal понимается множество всех синаптических связей сети. Отдельные слаrаемые
штрафа за сложность симметричны относительно частноrо Wi/WO, что наrлядно по-
казано на рис. 4.22. Если jWi I > > Wo, штраф за сложность ( стоимость) для этоrо веса
достиrает максимальноrо значения единицы. Это значит, что вес Wi имеет высокую
ценность для процесса обучения методом обратноro распространения. Таким обра
зом, слаrаемое штрафа за сложность в выражении (4.97) выполняет свою задачу
позволяет выявлять синаптические веса, оказывающие первостепенное влияние на
сеть. Обратите внимание, что снижение весов является частным случаем процедуры
исключения весов. В частности, для больших значений Wo выражение (4.97) сводится
к (4.96) (не учитывая коэффициента масштабирования).
4.15. Методы упрощения структуры сети 299
CTporo roворя, процедура исключения весов тоже не является корректной фор
мой реrуляризации сложности мноroслойноro персептрона, так как она также не
вписывается в определение (4.95). Тем не менее при правильном подборе параметра
шо она позволяет лучше корректировать отдельные веса сети, чем метод снижения
весов [494].
Сrлаживающая аппроксимация
В [752] для мноrослойноrо персептрона с одним CKpbIТbIM слоем и одним нейроном
в выходном слое предложено следующее слаrаемое штрафа за сложность:
м
Ec(W) == L W j IIwjlIP,
j l
(4.98)
rдe Waj веса выходноrо слоя; Wj весовой вектор j ro нейрона cKpbIToro слоя, а
показатель степени р определяется выражением
{ 2k 1 для rлобальноrо сrлаживания,
р==
2k для локальноrо сrлаживания,
(4.99)
rдe k порядок дифференцирования функции Р(х, w) по х.
Процедура сrлаживающей аппроксимации в задаче реrуляризации сложности MHO
rослойноrо персептрона оказалась более строrой, чем снижение или исключение Be
сов. В отличие от ранее описанных методов она выполняет следующие задачи.
1. Разделяет роли синаптических весов нейронов CKpbITOro и выходноrо слоев.
2. Отслеживает взаимодействие этих двух множеств весов.
Однако при этом она имеет более сложную форму, чем снижение и исключение
весов, следовательно, более требовательна к ресурсам из за своей вычислительной
сложности.
Упрощение структуры сети на основе rессиана
rлавной идеей этоro подхода к упрощению структуры сети (усечению сети) явля
ется использование информации о вторых производных поверхности ошибок для
обеспечения компромисса между сложностью сети и величиной ошибки обучения. В
частности, для аналитическоrо проrнозирования эффекта изменения синаптических
весов строится локальная модель поверхности ошибок. Создание такой модели начи
нается с локальной аппроксимации функции стоимости Еау с помощью ряда Тейлора
(Tay1or series) в окрестности выбранной точки:
..,....
300 rлава 4. Мноrослойный персептрон
Eav(w + дw) == Eav(w) + gТ(w)дw + дwТндw + О(IIДwI1 3 ),
2
(4.100)
[де дw возмущение, применяемое к данной точке w; g(w) вектор rpадиента,
вычисленный в точке w. rессиан тоже вычисляется в точке w, и, таким образом,
корректно применять обозначение H(w). Это не было сделано в формуле (4.100) для
упрощения выкладок.
Требуется определить множество параметров, исключение которых из мноrослой
HOro персептрона вызовет минимальное увеличение функции стоимости Еау' Для
Toro чтобы решить эту задачу на практике, необходимо выполнить следующее.
1. Внешняя аппроксимация (external approximation). Предполаrается, что параметры
удаляются из сети только после сходимости процесса обучения (т.е. после полно-
20 обучения сети (fuHy trained)). Следствие этоrо допущения состоит в том, что
некоторые значения параметров соответствуют локальным или rлобальным мини
мумам поверхности ошибки. В таком случае вектор rpадиента g можно считать
равным нулю и слаrаемое gT дw в правой части (4.100) можно не учитывать.
В противном случае мера выпуклости (которая будет определена позже) для дaH
ной задачи может быть определена неверно.
2. Квадратичная аппрОКСИ.мация (quadratic approximation). Предполаrается, что по-
верхность ошибок в окрестности rлобальноrо или локальноrо минимума является
приблизительно "квадратичной". Исходя из этоro, в выражении (4.100) можно
также не учитывать все слаrаемые более BbICOKOro порядка.
Исходя из этих допущений, аппроксимация (4.100) упрощается до следующеrо вида:
1
дЕ ау == E(w + дw) E(w) == 2ДWТНДW.
(4.101)
Процедура оптимальной степени повреждения (optima1 brain damage OBD)
[624] упрощает вычисления за счет допущения о том, что матрица rессиана н явля-
ется диаroнальной. Однако такое предположение не делается в процедуре оптималь
ной ХИРУР2ИИ МОЗ2а (optimal brain surgeon OBS) [428]. Таким образом, процедура
OBS содержит процедуру ОВО в качестве частноro случая. Поэтому в дальнейшем
мы будем следовать стратеrии OBS.
Целью OBS является обнуление одноrо из синаптических весов для минимизации
приращения функции стоимости Еау в (4.101). Пусть щ(n) некоторый синаптиче-
ский вес связи. Удаление этоrо веса эквивалентно выполнению условия
д Wi + Wi == О
или
l'[Дw+щ==О,
(4.102)
4.15. Методы упрощения структуры сети 301
[де l i единичнЫЙ вектор, все элементы KOToporo равны нулю за исключением i ro,
который равен единице. Теперь цель OBS можно определить в следующем виде [428].
Необходимо минимuзировать квадратичную форму wTH w по отношению к при
ращению вектора весов Дw, принимая в качестве 02раничения равенство нулю выра-
жения 1[ ДW+Wi. После эт020 требуется минимизировать результат относительно
индекса i.
Из этоro определения вытекает наличие двух уровней минимизации. Одна проце
дура минимизации выполняется по векторам синаптических весов, оставшихся после
обнуления i ro вектора весов. Вторая операция минимизации определяет, какой из
векторов можно исключить.
Для решения этой задачи условной оптимизации (constrained optimization problem)
в первую очередь нужно построить Лazранжиан (Lagrangian):
1
S == 2 WТНДW Л(1[ Дw + Щ),
(4.103)
[де А множитель Лazранжа (Lagrange mu1tiplyer). Дифференцируя Лаrpанжиан
S по дw, применяя условие (4.102) и используя обратную матрицу, находим, что
оптимальное приращение вектора весов w вычисляется по следующей формуле:
Wi 1
Дw == [H l ] . Н 1 i ,
','
(4.104)
а соответствующее ему оптимальное значение Лаrpанжиана для элемента Wi по
формуле
W 2
Si == 2 [H l].'
','
(4.105)
[де H 1 матрица, обратная rессиану Н; [H 1 ]i,i элемент с индексом i, i этой об
ратной матрицы. Лаrpанжиан Si, оптимизированный по w, подлежащий оrpаниче
нию при исключении i ro синаптическоrо веса Wi, называется степенью выпуклости
Щ. Выпуклость Si описывает рост среднеквадратической ошибки (как меры эф
фективности), вызываемый удалением синаптическоrо веса Wi' Обратите внимание,
что ВЫПУКЛОСТЬSi пропорциональна квадрату синаптическоrо веса w;. Таким обра
зом, вес с маленьким значением оказывает слабое влияние на среднеквадратическую
ошибку. Однако из выражения (4.105) видно, что величина Si также обратно пропор-
циональна диаrональным элементам матрицы, обратной rессиану. Таким образом,
если величина [H 1 ]i,i мала, то даже небольшие веса MOryT оказывать существенное
влияние на среднеквадратическую ошибку.
L
,......
302 rлава 4. Мноrослойный персептрон
В процедуре OBS дЛЯ удаления выбираются веса, соответствующие наименьшей
степени выпуклости. Более TOro, соответствующие оптимальные значения модифи-
кации оставшихся весов вычисляются по формуле (4.104), т.е. веса изменяются вдоль
направления i ro столбца матрицы, обратной rессиану.
в [428] показано, что в некоторых тестовых задачах сети полученные в результате
применения процедуры OBS оказались меньше, чем построенные с использованием
процедуры снижения весов. В этой же работе показано, что в результате применения
процедуры OBS к мноrослойному персептрону NETta1k, имеющему один скрытый
слой и 18000 весов, сеть сократилась до 1560 весов. Это довольно впечатляющий
результат. Сеть NETtalk, разработанная в [962], описывается в rлаве 13.
Вычисление матрицы, обратной rессиану
Вычисление матрицы, обратной rессиану, является основой процедуры OBS. Коrда
количество свободных параметров W сети становится большим, задача вычисления
H 1 может стать неразрешимой. В этом разделе описывается управляемая процедура
вычисления H l, в предположении, что мноroслойный персептрон бьт полностью
обучен, Т.е. достиr HeKoToporo локальноrо минимума на поверхности ошибок [428].
Для упрощения выкладок предположим, что мноrослойный персептрон содержит
единственный выходной нейрон. Torдa для данноrо множества обучения функцию
стоимости можно выразить соотношением
1 N
Eav(w) == 2N L (d(n) о(n))2,
n=1
[де о( n) реальная выходная реакция сети на подачу n ro примера; d( n) соответ-
ствующий желаемый отклик; N общее количество примеров в множестве обучения.
Сам выходной сиrнал о( n) можно представить в Виде
о(n) == F(w, х),
[де F(w, х) функция отображения "BXOД BЫXOД", реализуемая мноroслойным пер-
септроном; х входной вектор; w вектор синаптических весов сети. Исходя из
этоro, первую производную функции стоимости по w можно выразить формулой
N
д:;у == L дP( :(n)) (d(n) о(n)),
n=1
(4.106)
4.15. Методы упрощения структуры сети 303
а вторую производную по W, или матрицу rессиана, представить в виде
H(N) == д 2 Е ау == .;.... { ( aF(W, х(n)) ) ( aF(W, х(n)) ) Т
дW 2 N aw aw
n 1
( д 2 P :(n)) ) (d(n) о(n))} .
(4.107)
в этой формуле явным образом выделена зависимость матрицы rессиана от раз
мера обучающеrо множества N.
Если сеть полностью обучена, т.е. функция стоимости достиrла одноrо из своих
локальных минимумов на поверхности ошибок, есть основания утверждать, что зна
чение о(n) достаточно близко к d(n). При этом условии второе слаrаемое можно не
учитывать и аппроксимировать выражение (4.107) следующим:
N Т
H(N) L ( aF(W,X(n)) ) ( aF(W,X(n)) )
N aw aw
n 1
(4.108)
Для упрощения записи введем вектор размерности W х 1 :
J:. ( ) == 1 aF(w, х(n))
., n ..JN aw '
(4.109)
который можно вычислить с помощью процедуры, представленной в разделе 4.10.
Исходя из этоrо, выражение (4.108) можно пере писать в рекурсивной форме:
n
Н(n) == L (k) T (k) == Н(n 1) + (n) T (n), n == 1, 2, ..., N.
k l
(4.110)
Эту рекурсивную запись удобно применить в так называемой лемме об инверти
ровании матриц (matrix inversion 1emma), известной также под названием равенства
Вудбурри (Woodburry equality).
Пусть А и В две положительно определенные матрицы, удовлетворяющие co
отношению
А == B 1 + CDC T ,
[де С и D две друrие матрицы. Соrласно лемме об инвертировании матриц, матрица,
обратная А, определяется соотношением
A 1 == В BC(D + CTBC) lCTB.
.....
.,.......
304 rлава 4. Мноrослойный персептрон
Для задачи, определяемой соотношением (4.110), имеем:
А == Н(n),
B 1 == Н(n 1),
С == (n),
D == 1.
Применяя лемму об инвертировании матриц, можно вывести требуемую peKyp
сивную формулу вычисления матрицы, обратной rессиану:
H l(n) == H l(n 1) H l(n }) (n) T (n)H l(n 1) .
1 + (n)H l(n 1) (n)
(4.111)
Обратите внимание, что знаменатель в формуле (4.111) является скаляром, следо-
вательно, вычисление обратной матрицы не составляет труда. Имея последнее значе-
ние H 1 (n 1), можно вычислить значение H 1 (n) на основе n ro примера, представ-
ленноro вектором (n). Рекурсивные вычисления продолжаются до тех пор, пока не
будет обработано все множество из N примеров. Для инициализации этоrо алrорит-
ма необходимо задать достаточно большое начальное приближение H l(O), так как
на каждом шаrе рекурсии элементыI матрицы будут только убывать. Это требование
можно удовлетворить с помощью следующеrо значения матрицы:
H l(O) == 8 lI,
(4.112)
[де 8 достаточно малое положительное число; 1 единичная матрица. Такая форма
исходноrо значения rарантирует, что матрица H l(n) всеrда будет положительно
определенной. Влияние 8 проrpессивно уменьшается по мере подачи все большеro
количества примеров.
Алroритм оптимальной хирурrии мозrа (OBS) в сжатом Виде представлен в
табл. 4.6 [428].
4.16. Преимущества и оrраничения обучения методом
обратноrо распространения
Алrоритм обратноrо распространения является самым популярным среди алrорит
мов обучения мноrослойноro персептрона с учителем. ПО существу он представляет
собой rpадиентный метод, а не метод оптимизации. Процедура обратноro распро-
странения обладает двумя основными свойствами.
4.16. Преимущества и оrраничения обучения методом обратноrо распространения 305
ТАБЛИЦА 4.6. Алroритм оптимальной хирурrии мозrа
1. Минимизируем среднеквадратическую ошибку в процессе обучения данноrо
мноrослойноrо персептрона.
2. Используем процедуру, описанную в разделе 4.10, для вычисления вектора
( ) == .....!..... aF(w,x(n))
., n .Jiii aw '
rдe F(x,w) отображение "BXOД BЫXOД", реализуемое мноrослойным персеп
троном с вектором синаптических весов w и вектором входноrо сиrнала х.
3. С помощью рекурсивноrо выражения (4.111) вычисляем матрицу, обратную
rессиану (H l).
4. Находим некоторое i, соответствующее наименьшей степени выпуклости
w 2
Si == 2[H \I. . '
rдe [H 1 ]i,i i, i-й элемент этой матриц О H l. Если степень выпуклости Si
rораздо меньше, чем среднеквадратическая ошибка Еау, то данный синапти
ческий вес Wi удаляется, и мы снова переходим к шаrу 4. В противном случае
переходим к шаry 5.
5. Изменяем все синаптические веса сети, применяя приращение
л H l l
LlW [ H l ] . . i,
0,0
переходим к шаrу 2.
6. Процесс вычисления прекращается, если больше не существует весов, KOTO
рые можно удалить из сети, существенно не увеличив среднеквадратическую
ошибку (в этот момент сеть желательно обучить заново).
· Во первых, ее ле2КО про считать локально.
· BO BTOpЫX, она реализует стохастический rpадиентный спуск в пространстве Be
сов (при котором синаптические веса обновляются для каждоrо примера).
Эти два свойства обучения методом обратноrо распространения в контексте MHO
rослойноrо персептрона и определяют ero преимущества и оrpаничения.
Связность
Алrоритм обратноrо распространения является примером паради2МЫ связности (соп
nectionist paradigm), соrласно которой возможности нейронной сети по обработке ин
формации реализуются за счет локальных вычислений. Эта форма вычислительных
оrpаничений называется 02раничением локальности (1oca1ity constraint) в том CMЫC
ле, что вычисления в каждом нейроне, на который воздействуют друrие нейроны,
выполняются обособленно. Использование локальных вычислений в контексте ис
кусственных нейронных сетей объясняется тремя принципиальными причинами.
.L
".....
306 rлава 4. Мноrослойный персептрон
1. Искусственные нейронные сети, осуществляющие локальные вычисления, часто
выступают в качестве модели биолоrических нейронных сетей.
2. Использование локальных вычислений вызывает плавное снижение производи-
тельности при сбоях в аппаратном обеспечении. Это обеспечивает отказоустой-
чивость таких систем.
3. Локальные вычисления хорошо подходят для параллельной архитектуры, которая
применяется в качестве эффективноrо метода реализации искусственных нейрон-
ных сетей.
Рассматривая эти три причины в обратном порядке, можно сказать, что третья
вполне объяснима в случае обучения методом обратноrо распространения. В частно-
сти, этот алroритм был успешно реализован мноrими исследователями в параллель-
ных компьютерах, а архитектура VLSI была специально разработана для аппаратной
реализации мноrослойноrо персептрона [411], [412]. Пункт 2 описывает некоторую
меру предосторожности, принимаемую при реализации алrоритма обратноrо распро-
странения [557]. Что же касается пункта 1, относящеroся к биолоrическому правдо-
подобию алrоритма обратноrо распространения, то он может быть серьезно оспорен
на следующем основании [232], [976], [1021].
1. Синаптические связи между нейронами мноrослойноrо персептрона MOryт быть
как возбуждающими, так и тормозящими. Однако в реальной нервной системе
каждый нейрон может иrpать только одну из этих ролей. Это одно из самых нере-
алистичных допущений, принимаемых при создании искусственных нейронных
сетей.
2. В мноrослойном персептроне rормональные и прочие типы rлобальных связей не
учитываются. В реальной нервной системе эти типы rлобальных связей иrpают
важную роль для реализации таких функций, как внимание, обучение и раздра-
жение.
3. При обучении методом обратноro распространения синаптические веса изменяют-
ся только на основе предсинаптической активности и сиrнала ошибки (обучения),
независимо от постсинаптической активности. Очевидно, что нейробиолоrия до-
казывает обратное.
4. В контексте нейробиолоrии реализация обучения методом обратноrо распростра-
нения требует быстрой обратной передачи информации по аксону. Очень малове-
роятно, чтобы такие действия на самом деле происходили в мозre.
5. Обучение методом обратноro распространения предполаrает наличие "учителя",
который в контексте работы мозrа должен представляться отдельным множеством
нейронов с неизвестными свойствами. Существование таких нейронов неправда-
подобно с точки зрения биолоrии.
4.16. Преимущества и оrраничения обучения методом обратноro распространения
307
6. Тем не менее эта несоrласованность с результатами нейробилоrии не умаляют
инженерной ценности обучения методом обратноrо распространения как средства
обработки информации. Это было уже доказано множеством успешных примене
ний в различных областях деятельности человека, в том числе и при моделирова
нии нейробиолоrических явлений (например, в [893]).
Извлечение признаков
Как уже roворилось в разделе 4.9, скрытые нейроны мноroслойноrо персептрона,
обучаемоrо методом обратноrо распространения, иrpают роль детекторов признаков.
Это важное свойство мноrослойноro персептрона было использовано совершенно
неожиданным образом: было предложено использовать мноroслойный персептрон в
качестве репликатора (rep1icator) или карты идентичности (identity mар) [216], [915].
На рис. 4.23 показано, как этоro можно достичь в случае мноrослойноrо персептрона
с одним скрытым слоем. Архитектура сети удовлетворяет следующим структурным
требованиям (см. рис. 4.23, а).
· Входной и выходной слои имеют одинаковый размер т.
· Размер cKpbIToro слоя М меньше значения т.
· Сеть является полносвязной.
Образ х синхронно подается во входной слой в качестве возбудителя и в BЫ
ходной слой В качестве желаемоro отклика. Фактический отклик выходноrо слоя i
расценивается как "оценка" вектора х. Сеть обучается с помощью алrоритма обратно
[о распространения, при этом в качестве сиrнала ошибки выступает вектор ошибки
оценивания (х х) (см. рис. 4.23, 6). Можно сказать, что обучение про изводится без
учителя. С помощью специальной структуры, встроенной в конструкцию мноroслой
HOro персеПтрона, сеть осуществляет идентификацию посредством cBoero cKpbIToro
слоя. Закодированная (encoded) версия входноrо образа, обозначаемая символом s,
является выходным сиrналом cKpbIToro слоя (см. рис. 4.23, а). В результате полно
стью обученный мноrослойный персептрон выполняет роль системы кодирования.
Для TOro чтобы воссоздать оценку i исходноro входноrо сиrнала х (т.е. выполнить
декодирование), закодированный сиrнал передается скрытому слою сети репликации
(см. рис. 4.23, в). В результате эта часть сети выполняет роль декодера. Чем меньше
размер cKpbIToro слоя М по сравнению с т, тем более эффективна эта система в
качестве средства сжатия данных 12 .
12 В [446] описывается нейронная сеть репликации, представлеиная в форме мноroслойноro персептрона с
тремя скрытыми и одним выходным слоем.
Функции активации всех нейронов BТOpOro и четвертоro (скрытых) слоев описываются функцией rипербо
лическоrо TaHreHca q>(2) (v) q>(4) (v) tanh(v), rде v индуцированное локальное поле нейронов этих слоев.
'r"
308 rлава 4. Мноrослойный персептрон
Мноroслойный персептрон
Входной
сиrнал
х
Оценка
входноro
СИI"1 ала ,
х
Закодированный
сиrнал
s
а)
х
б)
Функции активации всех нейронов среднеro (cкpblТOro) слоя описываются следующей функцией:
1 1 N l ( ( . ))
q>(З) (v) '" + L tanh а v ,
2 2(N 1) j l N
rдe а коэффициент усиления (gain parameter); v индуцированное локальное поле нейронов этоro слоя.
Функция q>(З) описывает 2Jlадкую ступенчатую (staircase) функцию активации с N ступеньками, выполня
ющую квантование вектора выходов соответствующих нейронов на К '" N n элементов, rдe n количество
нейронов среднеro cкpblТOro слоя.
Нейроны выходноro слоя являются линейными и используют функцию активации q>(5)(v) '" V. На основе
этой структуры нейронной сети Хехт-Нильсен доказал теорему об оптимальном сжатии данных для произволь
ных входных векторов.
4.16. Преимущества и оrраничения обучения методом обратноrо распространения 309
Рис. 4.23. Сеть репликации (карта иден-
тичности) с одним скрытым слоем (а), ис-
пользуемым в качестве системы кодиро
вания; блочная диаrрамма обучения се-
ти репликации с учителем (б) и часть се-
ти репликации, используемая в качестве
декодера (в)
Декодированный
сиrl'ал,
х
в)
Аппроксимация функций
Мноrослойный персептрон, обученный соrласно алrоритму обратноrо распростране
ния, используется в качестве вложенной СИ2Моидальной схемы, которую для случая
одноro выхода можно записать в следующем компактном виде:
F(x,w) ( WOk (z;= Wkj ( ( WUX')))) ,
(4.113)
[де <р(') сиrмоидальная функция активации общеrо вида; Wok синаптический вес
связи между нейроном k последнеrо cKpbIToro слоя и единственным выходным ней
раном О, и Т.д. для всех остальных синаптических весов; Xi i й элемент входноrо
вектора х. Вектор w содержит полное множество синаптических весов, упорядочен
ное сначала по слоям, затем по нейронам каждоrо отдельноrо слоя и, наконец, по
синапсам отдельных нейронов. Представление в виде вложенной нелинейной функ
ЦИИ, описываемой выражением (4.113), не является традиционным для классической
теории аппроксимации. Как следует из раздела 4.13, это соотношение описывает
универсальный aппpOKcuмaтop (universal approximator).
Использование метода обратноrо распространения открывает еще одно полезное
свойство в контексте аппроксимации. Интуитивно понятно, что для мноrослойно
[о персептрона с rладкой функцией активации производные результирующей функ
ЦИИ должны аппроксимировать производные исходноrо реализуемоrо персептроном
отображения "BXOД BЫXOД". Доказательство этоrо результата представлено в [485].
..,.....
310 rлава 4. Мноrослойный персептрон
в частности, в этой работе показано, что мноrослойный персептрон может аппрок-
симировать функции, не дифференцируемые в классическом смысле. При этом в
случае кусочно дифференцируемых функций он обеспечивает обобщенные произ-
водные. Полученные в этой статье результаты обеспечили ранее отсутствовавшее
обоснование применения мноrослойноrо персептрона в приложениях, требующих
аппроксимации функций и их производных.
Вычислительная эффективность
Вычислительная сложность (computational comp1exity) алrоритма обычно измеряет-
ся в терминах количества операций сложения, умножения и хранения, используемых
в ero реализации (см. rлаву 2). Алrоритм обучения считается вычислительно эф-
фективным (computationally efficient), если ero вычислительная сложность является
полиномиальной (po1ynomial) по отношению к числу настраиваемых параметров, ко-
торые должны изменяться на каждой итерации. Основываясь на этом, можно утвер-
ждать, что алroритм обратноrо распространения является вычислительно эффектив-
ным. В частности, при использовании этоro алroритма для обучения мноrослойноro
персептрона, содержащеro W синаптических весов (включая пороrи), ero вычисли-
тельная сложность линейно зависит от W. Это важное свойство алrоритма обратноro
распространения может быть проверено с помощью прямоrо подсчета количества
операций, осуществляемых при прямом и обратном проходах, описанных в разде-
ле 4.5. При прямом проходе синаптические веса задействованы только для вычисле-
ния индуцированных локальных полей отдельных нейронов сети. Из формулы (4.44)
видно, что эти вычисления линейны по синаптическим весам. При обратном проходе
синаптические веса используются при вычислении локальных rpадиентов скрытых
нейронов и при изменении самих синаптических весов, что следует из формул (4.46)
и (4.47) соответственно. Таким образом, все вычисления линейны по синаптическим
весам сети. Отсюда следует вывод, что вычислительная сложность алrоритма обрат-
Horo распространения является линейной по W, Т.е. составляет O(W).
Анализ чувствительности
Еще одним преимуществом обучения методом обратноro распространения с вычисли-
тельной точки зрения является эффективность анализа чувствительности отображе-
ния "BXOД BЫXOД" с помощью этоrо алrоритма. Под чувствительностью (sensitivity)
функции F по отношению к некоторому ее параметру (() понимается величина
SF == 8Р/Р
(() 8(()/(()'
(4.114)
4.16. Преимущества и оrраничения обучения методом обратноrо распространения 311
Рассмотрим мноrослойный персеmрон, обучаемый с помощью алroритма обратноrо
распространения. Пусть функция F(w) описывает осуществляемое сетью отображе
ние входа на выход, а w это вектор всех синаптических весов сети (включая пороrи).
В разделе 4.10 было показано, что частные производные функции F(w) по всем эле
ментам вектора весов w MOryт быть вычислены достаточно эффективно. В частности,
исследуя выражения (4.81) 4.83) совместно с формулой (4.114), можно увидеть, что
сложность вычисления каждой отдельной частной производной линейно зависит от
W общеro количества весов, содержащихся в сети. Эта линейность сохраняется
всюду, rдe рассматриваемые синаптические веса присутствуют в цепочке вычислений.
Робастность
в rлаве 3 уже указывалось, что алrоритм LMS является робастным, Т.е. возмущения
с малой энерrией незначительно влияют на ошибку оценивания. Если рассматри
ваемая модель наблюдений является линейной, алrоритм LMS представляет собой
НОО оmимальный фильтр [426], [427]. Это значит, что алroритм LMS минимизиру
ет возрастание максимальной энеР2ИИ (maximum energy gain) ошибки оценивания в
результате возмущений.
С друroй стороны, в [429] показано, что в случае нелинейной модели алroритм
обратноro распространения является локальным НОО оптимальным фильтром. Под
термином "локальный" здесь подразумевается то, что исходные значения вектора Be
сов, используемые в алrоритме обратноro распространения, должны быть достаточно
близки к оптимальному значению вектора весов w*, чтобы rарантировать непопада
ние алrоритма в неверный локальный минимум. В концептуальном смысле приятно
осознавать, что алrоритмы LMS и обратноro распространения относятся к одному и
тому же классу НОО оптимальных фильтров.
Сходимость
в алrоритме обратноro распространения используется текущая оценка (instantaneous
estimate) rpадиента поверхности ошибок в пространстве весов. Этот алrоритм явля-
ется вероятностным по своей природе. Это значит, что движение в направлении ми
нимума на поверхности ошибок происходит по зиrзаrообразной траектории. В самом
деле, алrоритм обратноro распространения является одной из реализаций статисти
ческоrо метода, известноro под названием стохастической аппроксимации (stochastic
approximation) и предложенноro в [892]. Данный метод отличается медленной сходи
мастью, что может объясняться двумя причинами [505].
,..,.....
312 rлава 4. Мноroслойный персептрон
1. Поверхность ошибок является достаточно плоской вдоль направления HeKoToporo
BecoBoro коэффициента, поэтому частная производная в этом направлении невели-
ка по амплитуде. В этом случае коррекции, применяемые к синаптическим весам,
также являются малыми, и, следовательно, для достижения алrоритмом мини-
мальной ошибки может потребоваться достаточно большое количество итераций.
Если же поверхность ошибок по некоторым измерениям достаточно искривлена,
то в этих направлениях частные производные велики по амплитуде. Значит, синап-
тические веса на каждом шаrе будут подверrаться значительной коррекции. Это
может привести к прохождению мимо точки локальноro минимума на поверхно-
сти ошибок.
2. Направление антиrpадиента (т.е. производная функции стоимости по вектору ве-
сов, взятая с противоположным знаком) может не соответствовать направлению к
точке минимума на поверхности ошибок. Torдa коррекция весовых коэффициен-
тов может привести к движению алroритма в неправильном направлении.
Следовательно, скорость сходимости метода обратноrо распространения относи-
тельно невелика, что, в свою очередь, ведет к большой продолжительности вычис-
лений. Соrласно экспериментальным исследованиям, описанным в [919], скорость
локальной сходимости алrоритма обратноrо распространения является линейной. Ав-
торы работы объяснили это тем, что матрица Якобиана, а следовательно и матрица
rессиана, имеют неполный paHr. Эти наблюдения являются следствием плохой обу-
словленности самой задачи обучения нейронной сети. В [919] линейную локальную
сходимость алroритма обратноro распространения авторы про комментировали сле-
дующим образом.
· Преимуществам алrоритма обратноrо распространения по сравнению с друrими
методами более BbIcoKoro порядка является то, что последние, при незначительном
ускорении процесса сходимости, требуют существенно больше вычислительных
ресурсов.
· Крупномасштабные задачи обучения нейронных сетей являются настолько труд-
ными для реализации, что для них не существует приемлемой стратеrии обучения
с учителем и зачастую требуется предварительная обработка данных.
Проблема сходимости более подробно рассматривается в разделе 4.17, а вопрос
предварительной обработки данных в rлаве 8.
Локальные минимумы
Характерной особенностью поверхности ошибок, которая влияет на производитель-
насть алrоритма обратноrо распространения, является наличие не только rлобально-
[о, но и локальных минимумов Оосаl minima) (т.е. изолированных впадин). Так как в
процессе обучения методом обратноrо распространения направление спуска опреде-
4.16. Преимущества и оrраничения обучения методом обратноro распространения 313
ляется направлением вектора rpадиента (наибольшеrо наклона поверхности), Bcerдa
существует риск попадания в точку локальноrо минимума, в которой любое прираще
ние синаптических весов будет приводить к увеличению функции стоимости. Однако
при этом в друrой области пространства весовых коэффициентов MOryT существо-
вать друrие множества синаптических весов, для которых функция стоимости имеет
меньшее значение, чем в данной точке локальноrо минимума. Понятно, что OCTaHOB
ка процесса обучения в точке локальноrо минимума является крайне нежелательной,
если эта точка находится выше точки rлобальноrо минимума.
Проблема локальных минимумов при обучении методом обратноrо распростране
ния описывается в заключение расширенноrо издания классической книrи Минско
ro и Пейперта [744], rдe основное внимание фокусировалось на обсуждении ДBYX
томника [912], посвященноrо параллельным распределенным вычислениям (paral1el
distributed processing). В rлаве 8 упомянутой книrи утверждается, что попадание в
точку локальноro минимума редКО встречается в практических приложениях алrо
ритма обратноrо распространения. Минский и Пейперт отверrли это утверждение,
указав, что вся история распознавания образов доказывает обратное. В [370] опи
сывается простой пример, в котором, несмотря на потенциальную обучаемость сети
(с одним скрытым слоем) решению задачи классификации нелинейно разделяемым
множеств, обучение методом обратноrо распространения прекращалось в точке ло
кальноro минимума 13.
Масштабирование
в принципе, нейронные сети, подобные мноrослойному персептрону, обучаемому
с помощью алrоритма обратноrо распространения, создают потенциал для создания
универсальных вычислительных машин. Однако, для Toro чтобы такой потенциал бьш
реализован в полной мере, нужно преодолеть проблему масштабирования (sca1ing).
Суть этой проблемы состоит в сохранении эффективности сети по мере увеличе
ния и сложности поставленной задачи. Мерой в данном вопросе выступает время
обучения, необходимое для достижения сетью наилучших показателей в обобщении.
13 Изначально существовала потребность в создании теоретической базы для обучения методом обратноro
распространения, учитывающей и объясняющей проблему локальных минимумов. Эта задача была сложной для
выполнения. Тем не менее в литературе по данному вопросу наблюдался некоторый проrpесс. В 1989 roду в [87]
была рассмотрена задача обучения для мноroслойных сетей прямоro распростраиения с линейными функциями
активации на основе метода обратноro распространения. rлавным результатом этой работы было утверждение,
что поверхность ошибок имеет единственный минимум, соответствующий ортоroнальной проекции на под-
пространство, порожденное первыми наибольшими собственными числами матрицы ковариации, связанной с
обучающими прнмерами. Все остальные критические точки поверхности являются седловыми. В 1992 roду в
[370] был рассмотрен более общий случай обучения методом обратноro распространения для сети, содержащей
нелинейные нейроны. Основным результатом этой работы является утверждение, что для линейно-разделимых
образов rарантируется сходимость к оптимальному решению (т.е. к rлобальному минимуму). Это достиrается
с помощью кумулятивноro (пакетноro) режима обучения методом обратноrо распространения. При этом сеть н
части обобщения новых примеров превосходила возможностн персептрона Розенблатта.
"""
..,.....
314 rлава 4. Мноrослойный персептрон
Среди возможных способов измерения размера или сложности вычислительных задач
наиболее полезной и важной мерой, по мнению автора, является порядок предиката,
определенный в [744], [745].
Для TOro чтобы объяснить, что подразумевается под предикатом, опишем функ-
цию '1'( Х), которая может принимать только два значения. Обычно под этими двумя
значениями подразумеваются числа О и 1. Однако, приравнивая эти две величины
к лоrическим значениям TRUE и FALSE, функцию 'I'(Х) можно рассматривать как
предикат (predicate), Т.е. переменную величину, значение истинности которой зависит
от выбора apryмeнтa Х. Например, функцию 'I'(Х) можно определить в виде
Х { 1, если фиrура Х Kpyr,
'l'KPyra( ) == О, если фиrура Х не Kpyr.
(4.115)
На основе идеи предиката в [1050] предложен эмпирический алrоритм обуче-
ния мноroслойноro персептрона вычислению функции четности на основе метода
обратноro распространения. Функция четности (parity function) является булевым
предикатом, определяемым выражением
Х { 1, если IXI четное число,
'l'четности( ) о в остальных случаях,
(4.116)
порядок KOTOpOro равен количеству входов. Эксперименты показали, что время, необ-
ходимое сети для обучения вычислению функции четности, растет экспоненциально
в зависимости от количества входов (т.е. порядка предиката) и что планы использо-
вания алrоритма обратноrо распространения для обучения произвольным сложным
функциям чересчур оптимистичны.
Общеизвестно, что для мноrослойноrо персептрона нежелательно, чтобы сеть бы-
ла полносвязной. В этом контексте можно поставить следующий вопрос: как лучше
разместить синаптические связи сети неполносвязноrо мноrослойноro персептрона?
Этот вопрос не иrpает особой роли внебольших приложениях, но является жизнен-
но важным при решении масштабных реальных задач на основе обучения методом
обратноrо распространения.
Одним из эффективных методов ослабления проблемы масштабирования является
взrляд в корень задачи (иноrда с помощью аналоrий из области нейробиолоrии) и
внесение в архитектуру мноrослойноrо персептрона правдоподобных конструктив-
ных решений. В частности, архитектура сети и оrpаничения, реализуемые синап-
тическими весами, должны задаваться с учетом априорной информации об объекте
моделирования. Эта стратеrия описывается в разделе 4.19 на примере решения задачи
оптическоrо распознавания символов.
4.17. Ускорение сходимости процесса обучения методом обратноro распространения 315
4.17. Ускорение сходимости процесса обучения
методом обратноrо распространения
в предьщущих разделах описывались основные причины, вызывающие низкую CKO
рость сходимости алrоритма обратноrо распространения. В этом разделе будут пред
ложены некоторые эвристические наработки, которые позволяют ускорить сходи
масть алrоритма с помощью настройки параметра скорости обучения. Приведем эти
эвристики [505].
Эвристика 1. Любой настраиваемый параметр сети, входящий в функцию стои
мости, должен иметь свое значение коэффициента скорости обучения.
Отсюда можно заключить, что алrоритм обратноro распространения может иметь
низкую скорость сходимости из за Toro, что фиксированный параметр скорости обу
чения подходит не для всех областей поверхности ошибок. Друrими словами, если па
раметр интенсивности обучения подходит для корректировки одноro синаптическоro
веса, то это совсем не означает, что он подойдет для настройки друrоrо. Эвристика 1
учитывает этот факт и предлаrает назначать каждому настраиваемому синаптическо
МУ весу (параметру) сети отдельное значение коэффициента скорости обучения.
Эвристика 2. Любой параметр скорости обучения должен варьироваться для раз
личных итераций.
Поверхность ошибок в разных областях имеет разную динамику даже в направле
нии одноrо BecoBoro коэффициента. Для TOro чтобы учесть эти изменения, соrласно
эвристике 2, параметры обучения должны варьироваться на разных итерациях. Ин
тересно, что эта эвристика хорошо обоснована для случая линейных процессорных
элементов [684].
Эвристика 3. Если производная функции стоимости по отдельному синаптиче
скому весу на нескольких последовательных итерациях имеет один и тот же знак, то
значение параметра скорости обучения для данноrо веса должно увеличиваться.
Текущая точка в пространстве весов может лежать на относительно полоrом участ
ке вдоль HeKoToporo направления весовых коэффициентов. Это, в свою очередь, MO
жет отразиться на производной функции стоимости (т.е. на rpадиенте поверхности
ошибки) по данному направлению, которая в течение нескольких последовательных
итераций будет иметь один и тот же алrебраический знак и, таким образом, указывать
на одно и то же направление. Эвристика 3 утверждает, что в такой ситуации коли
чество итераций, необходимое для прохождения полоrой части поверхности ошибок,
может быть уменьшено за счет соответствующеrо увеличения значения параметра
скорости обучения.
Эвристика 4. Если производная функции стоимости по отдельному синаптическо
му весу на нескольких последовательных итерациях имеет разные знаки, то значение
параметра скорости обучения для данноrо веса должно уменьшаться.
...,....
316 rлава 4. Мноrослойный персептрон
Текущая точка в пространстве весов может лежать на участке поверхности оши-
бок, содержащем множество выпуклостей и впадин (т.е. на достаточно искривленном
участке), что может привести к изменению знака производной по некоторому весу
на последовательных итерациях. Соrласно эвристике 4, во избежание осцилляции
параметр скорости обучения для данноro веса следует уменьшить.
Естественно, введение зависимости параметра обучения от времени и конкретно-
[о синаптическоro веса, следующее из этих эвристик, приводит К фундаментальному
изменению алrоритма обратноrо распространения. В частности, модифицированный
таким образом алrоритм уже не будет осуществлять поиск методом наискорейше
ro спуска. Корректировка конкретных синаптических весов будет основываться на
частных производных поверхности ошибок по конкретным весам и на оценке кри-
визны поверхности ошибок в текущей точке относительно конкретных измерений
пространства весов.
Более Toro, все четыре эвристики удовлетворяют оrpаничению локальности, явля-
ющемуся встроенной характеристикой алrоритма обратноrо распространения. К со-
жалению, наличие оrpаничения локальности сужает область применения этих эври-
стик, так как MOryT существовать такие поверхности, [де они просто не будут рабо
тать. Тем не менее модификации алrоритма обратноrо распространения, разработан-
ные в соответствии с этими эвристиками, имеют большое практическое значение 14 .
4.18. Обучение с учителем как задача оптимизации
в этом разделе обучение с учителем рассматривается с позиций, в корне отлича-
ющихся от точки зрения, изложенной во всех предыдущих разделах. В частности,
обучение с учителем мноrослойноro персептрона будет рассмотрено как задача чис-
ленной оптимизации (numerica1 optimizing). В этом контексте в первую очередь следу-
ет отметить, что поверхность ошибок мноrослойноrо персептрона является в высшей
степени нелинейной функцией, зависящей от вектора синаптических весов w. Пусть
Eav(w) функция стоимости, усредненная на множестве примеров обучения. Исполь-
зуя ряд Тейлора, функцию EavCw) можно экстраполировать в окрестности текущей
точки на поверхности ошибок w(n), например в соответствии с выражением (4.100).
14 Модификация алroритма обратноro распространения, основанная на эвристиках 1 , получила название
правила обучения delta bar delta [505]. Реализация этоro правила обучения может быть упрощена с помошью
идеи, аналоrичной методу повторноro использоваиия rpадиеита (gradient reuse method) [439], [496].
В [925] описана процедура динамической самоадаптации для ускорения процесса обучения методом об-
paTHoro распространения. В этой процедуре реализована следующая идея: значение коэффициента скорости
обучения для предыдущеro шаrа HeMHoro уменьшается и увеличивается; для обоих новых значений оценива-
ется функция стоимости, после чеro выбирается то значение коэффициента, для КOTOpOro функция СТОИМОС11l
имеет меньшую величину.
4.18. Обучение с учителем как задача оптимизации 317
Перепишем это выражение, вводя явную зависимость от n:
Eav(w(n) + w(n)) ==Eav(w(n)) + gT(n) w(n)+
1 т 3
+ 2 w (n)H(n) w(n) + O(II wll ),
(4.117)
rдe g( n) вектор локальноrо rpадиента:
g(n) == aEav(w) I
aw w == w( n) ,
(4.118)
Н( n) матрица rессиана в данной точке:
Н(n) == a2Eav(w) I
aw 2 w == w(n)
(4.119)
Использование функции стоимости Eav(W), усредненной по множеству, подразу
мевает пакетный режим обучения.
В методе наискорейшеro спуска, представленноrо в данном случае алroритмом
обратноro распространения, корректировка w(n), применяемая к синаптическому
весу w(n), определяется выражением
w(n) == 11g(n),
(4.120)
[де 11 параметр скорости обучения. В результате метод наискорейшеrо спуска pa
ботает на основе линейной аппроксимации функции стоимости в окрестности Te
кущей точки w(n), при которой единственным источником информации о поверх
насти ошибок является rpадиент g(n). Такое оrpаничение обеспечивает значитель
ное преимущества: простоту реализации. К сожалению, оно приносит и нежела
тельный результат низкую скорость сходимости, которая может оказаться камнем
преткновения, особенно в задачах большоro объема. Включение слаrаемоro MOMeH
та в уравнение корректировки вектора синаптических весов бьшо rpубой попыткой
использования информации BToporo порядка о поверхности ошибок, что привнесло
некоторое преимущества. Тем не менее ero использование сделало процесс обучения
более чувствительным.
Для TOro чтобы существенно улучшить скорость сходимости мноrослойноrо пер
септрона (по сравнению с алroритмом обратноro распространения), в процессе обу
чения приходится использовать информацию более вЫСОК020 порядка. Этоrо можно
добиться, привлекая квадратичную аппроксимацию (quadratic approximation) поверх
насти ошибок в окрестности текущей точки w( n). При этом оказывается (см. (4.117)),
что оптимальное значение приращения w(n), применяемоrо к вектору синаптиче
....
..,......
318 rлава 4. Мноrослойный персептрон
ских весов w(n), определяется следующей формулой:
w*(n) == H l(n)g(n),
(4.121)
rдe H l(n) матрица, обратная rессиану (в предположении, что таковая существу-
ет). Выражение (4.121) описывает сущность метода Ньютона (Newton's method).
Если функция стоимости Eav(w) является квадратичной (т.е. третье и следующие
слаrаемые ряда Тейлора (4.117) равны нулю), то метод Ньютона сходится к опти-
мальному значению Bcero за одну итерацию. Однако на практике применение метода
Ньютона для обучения с учителем мноrослойноro персептрона усложняется следую-
щими факторами.
· Требуется вычисление матрицы, обратной rессиану (H l(n)), что само по себе
весьма неэффективно с точки зрения объема вычислений.
· Для TOro чтобы иметь возможность вычислить матрицу H l(n), матрица Н(п)
должна быть несинryлярной. Если матрица rессиана положительно определена,
поверхность ошибок в окрестности точки w( n) является выпуклой. К сожалению,
нет rарантии, что матрица rессиана для поверхности ошибок мноrослойноro пер-
септрона Bcerдa будет соответствовать этому требованию. Более Toro, существует
потенциальная проблема, что матрица rессиана будет иметь недостаточный paHr
(т.е. не все столбцы матрицы Н будут линейно независимыми), что приведет к
плохой обусловленности задачи обучения нейронной сети [919]. Это существенно
усложняет вычислительную задачу.
· Если функция стоимости EavCw) не является квадратичной, то нельзя rаранти-
ровать сходимость метода Ньютона, что делает ero неприrодным для обучения
мноroслойноro персеПТрона.
Для преодоления подобных проблем можно использовать квазиньютоновские Me
тоды, которые используют только оценки вектора rpадиента g. В таких модификациях
метода Ньютона положительно определенная оценка матрицы Н 1 ( n) вычисляется
напрямую, без обращения самой матрицы. Используя такую оценку, квазиньютонов-
ские методы обеспечивают движение вниз по склону поверхности ошибок. Однако
вычислительная сложность при этом измеряется порядком O(W 2 ), rдe W размер-
ность вектора w. С вычислительной точки зрения квазиньютоновские методы являют-
ся непрактичными, за исключением случаев обучения нейросетей малой размерности.
Описание квазиньютоновских методов будет представлено ниже в настоящем разделе.
Еще одним классом методов BTOpOro порядка является метод сопряженных 2ради-
ентов (conjugate-gradient). Ero можно рассматривать как нечто среднее между мето-
дом наискорейшеro спуска и методом Ньютона. Использование метода сопряженных
rpадиентов мотивировано желанием повысить обычно низкую скорость сходимости
метода наискорейшеro спуска при одновременном избежании вычислительных слож-
4.18. Обучение с учителем как задача оптимизации 319
настей, связанных с оценкой, хранением и инвертированием матрицы rессиана в
методе Ньютона. Среди всех методов оптимизации BToporo порядка метод сопряжен
ных rpадиентов считается единственным приrодным для решения задач большоro
обьема, Т.е. тех, которые имеют сотни и тысячи настраиваемых параметров [298].
Таким образом, он хорошо подходит для обучения мноroслойноrо персептрона при
решении задач аппроксимации функций, управлении и задач реrpессии.
Метод сопряженных rрадиентов
Метод сопря:ж:енных 2радиентов (conjugate-gradient method) относится к классу Me
тодов оптимизации, известных под названием методов сопряженных направлений
(conjugate direction methods). Обсуждение этих методов начнем с рассмотрения зада
чи минимизации квадратичной функции (quadratic function):
1
f(x) == xT Ах ь Т х + с,
2
(4.122)
[де х вектор параметров размерности W х 1; А симметричная, положительно
определенная матрица размерности W х W; Ь вектор размерности W х 1; с CKa
ляр. Минимум квадратичной функции f(x) достиrается при единственном значении х:
х* == А lb.
(4.123)
Таким образом, минимизация функции f (х) и решение системы линейных ypaB
нений Ах* == Ь являются эквивалентными задачами.
Для данной матрицы А множество ненулевых векторов s(O), s(l),... , s(W 1) Ha
зывается А сопряженным (A conjugate), если для всех n i- j выполняется следующее
соотношение:
s(n)As(j) == О для всех n и j при условии n i- j.
(4.124)
Если матрица А является единичной, сопряженность является эквивалентом OpTO
rональности.
Пример 4.1
Для интерпретации А-сопряженных векторов рассмотрим двумерную задачу, ПрОИJШюстриро
ванную на рис. 4.24, а. Показанная на этом рисунке эллиrrтическая траектория является rpафиком
квадратичной функции f(x) (см. (4.122» от векторной переменной:
х == [хо, Хl]Т'
На рис. 4.24, а показана также пара векторов, определяющих направления, сопряженные по
отношению к матрице А. Предположим, определен новый вектор параметров v, полученный из х с
помощью преобразования
v == А 1/2х,
rдe А 1 / 2 является квадратным корнем матрицы А. Torдa эллиrrтическая траектория (см. рис. 4.24, а)
320 rлава 4. Мноrослойный персептрон
Х,
а)
,......
V j
V o
Рис. 4.24. Интерпретация
А сопряженных векторов; эллип-
тическая траектория в двумер-
ном пространстве весов (а) и
преобразование эллиптической
траектории в круrовую (б)
б)
преобразуется в круroвую (рис. 4.24, 6). При этом пара А сопряженных векторов направлений (см.
рис. 4.24) преобразуется в пару ортоrональных векторов направлений (см. рис. 4.24, 6). .
Важным свойством А сопряженных векторов является то, что они линейно-
независимы (linear1y independent). Это свойство можно доказать от противноro. Пусть
один из этих векторов, например s(O), можно представить как линейную комбинацию
остальных W 1 векторов множества, Т.е.
W l
s(O) == L ajs(j).
j l
Умножив матрицу А на вектор s(O) и затем скалярно умножив результат на вектор
sT (О), получим:
W l
ST (O)As(O) == L ajsT (O)As(j) == О.
j l
Однако квадратичная форма sT(O)As(O) не может равняться нулю по двум при-
чинам: во первых, по определению матрица А является положительно определен-
ной, а вектор s(O) ненулевым. Отсюда следует, что А сопряженные векторы s(O),
s(1),..., s(W 1) не MOryT быть линейно зависимыми, Т.е. они являются линейно-
независимыми.
Для данноrо множества А сопряженных векторов s(O), s( 1 ),. . . , s(W 1) существу-
ет соответствующий метод сопря:ж:енных направлений (conjugate direction method)
минимизации функции квадратичной ошибки j(x), определяемый выражением [125],
[298], [682]
х(n + 1) == х(n) +ll(n)s(n),n == 0,1,..., W 1,
(4.125)
4.18. Обучение с учителем как задача оптимизации 321
[де х(О) произвольный исходный вектор; 11 (n) скаляр, определяемый из cooтнo
шения
f(x(n) + 11(n)s(n)) == min f(x(n) + 11s(n)).
11
(4.126)
Процедура выбора параметра 11 сводится к минимизации функции f (х( n) + 11S( n))
для HeKoтoporo фиксированноro n. Это линейный поиск, представляющий OДHOMep
ную задачу минимизации.
В свете выражений (4.124) (4.126) можно сделать следующие наблюдения.
1. Поскольку А сопряженные векторы s(O), s(1),.. ., s(W 1) линейно-независимы,
они формируют базис пространства векторов w.
2. Формулы изменения (4.125) и линейной минимизации (4.126) приводят к хорошо
знакомой формуле вычисления значения параметра скорости обучения:
() sT(n)AE(n)
11 n == sT(n)AS(n) ' n == О, 1,..., W 1,
(4.127)
[де е( n) вектор ошибки, определяемый выражением
е(n) == х(n) х*.
(4.128)
3. Начиная с произвольной точки х(О), метод сопряженных направлений rарантирует
нахождение оптимальноrо решения х* квадратноrо уравнения f(x) == О не более
чем за W итераций.
Принципиальное свойство метода сопряженных направлений можно описать сле
дующим образом [125], [298], [682].
При последовательных итерациях метод сопряженных направлений минимизирует
квадратичную функцию f(x) в постепенно расширяющемся линейном пространстве
векторов, содержащем точку 2ЛобалЬНО20 минимума этой функции.
в частности, для каждой итерации n оценка х( n + 1) минимизирует функцию f (х)
в линейном пространстве векторов D щ проходящем через произвольную точку х(О)
И задаваемом А-сопряженными векторами s(O), s(1),.. ., s(W 1):
х(n + 1) == arg min f(x),
xED n
(4.129)
,.......
322 rлава 4. Мноrослойный персептрон
rдe пространство Dn определяется формулой
,
Dn { x(n)lx(n) х(О) + t, чИ)s(j) } .
(4.130)
Для обеспечения работоспособности метода сопряженных направлений требуется
определить множество А сопряженных векторов s(O), s(l),..., s(W 1). В част-
ном случае этот метод называют методом сопряженных 2радиентов (conjugate.
gradient method)15. Последовательные векторы направлений rенерируются как
А сопряженные версии последовательных векторов rpадиента квадратичной функции
j(x). Отсюда этот метод и получил свое название. Таким образом, за исключением
итерации n == О, множество векторов направлений {s( n)} заранее не известно. Оно
формируется последовательно на каждой итерации метода.
Выберем в качестве направления наискорейшеrо спуска резидуальную ошибку
(residua1 error)
r(n) == ь Ах(n).
(4.131)
Далее будем использовать комбинацию векторов r( n) и s( n 1) следующим образом:
s(n) == r(n) + (n)s(n 1), n == 1,2,... , W 1,
(4.132)
[де (n) множитель масштабирования, который необходимо определить. Умножая
обе части равенства на А, а затем скалярно умножая результат на вектор s( n
1), учитывая свойство А сопряженности векторов направлений и решая полученное
уравнение относительно (n), получим:
s(n l)Ar(n)
(n) == sT(n l)As(n 1) '
(4.133)
Принимая во внимание выражения (4.132) и (4.133), несложно увидеть, что сфор.
мированные таким образом векторы s(O), s(1),. . ., s(W 1) действительно являются
А сопряженными.
Процесс rенерирования векторов направлений в соответствии с рекурсивным пра.
вилам (4.132) зависит от коэффициента (n). Формула (4.133), определяющая Beкrop
(n), подразумевает точное знание матрицы А. С вычислительной точки зрения хоте.
15 Классической работой, посвященной методу сопряженных rpадиентов, считается [454]. Обсуждение
вопросов сходимости этоrо алroритма содержится в [125], [682]. В 1994 rоду бьш выпущен учебник, раскры.
вающий множество аспектов алrоритма сопряженных rpадиентов [981]. Доступное описание этоrо алroритмиВ
свете нейронных сетей содержится в [515].
4.18. Обучение с учителем как задача оптимизации 323
ТАБЛИЦА 4.7. Соответствие между ((х) и EaAw)
Квадратичная функцияf(х) Функция стоимости Eav(w)
Вектор параметров х(n) Вектор синаптических весов w(n)
Вектор rpадиента of(x)/ox Вектор rpадиента oEav/дW
Матрица А Матрица rессиана н
лось бы оценить (n) без точноrо знания матрицы А. Такую оценку можно получить
с помощью любой из следующих формул [298].
1. Формула Полака Рибьера (Po1ak Ribiere formula):
(n) == rT(n)(r(n) r(n 1)) .
rT(n l)r(n 1)
(4.134)
2. Формула Флетчера Ривза (Fletcher Reeves formu1a):
n rT(n)r(n)
( ) rT(n l)r(n 1)
(4.135)
Чтобы использовать метод сопряженных rpадиентов для решения задачи безуслов
ной минимизации функции стоимости Eav(W), вытекающей из проблемы обучения
мноroслойноrо персептрона, выполним две операции.
· Аппроксимируем функцию стоимости EavCw) квадратичной функцией. Это зна
чит, что третье и следующие слаrаемые выражения (4.117) не будут учитываться.
Таким образом, мы предполаrаем работу в непосредственной близости от точки
локальноrо минимума на поверхности ошибок Сравнивая выражения (4.117) и
(4.122), можно сделать выводы, приведенные в табл. 4.7.
· Зададим формулы вычисления (n) и 11 (n) в алrоритме сопряженных rpадиентов
так, чтобы для определения этих параметров требовалась информация только о
rpадиенте.
Последний пункт является особенно важным в контексте мноrослойноrо персеп
трона, так как он позволяет избежать вычисления матрицы rессиана Н(n), что co
пряжено с известными вычислительными сложностями.
Для вычисления коэффициента (n), определяющеrо направление поиска s(n),
без точноrо знания матрицы rессиана Н(n) можно использовать формулу Полака
Рибьера (4.134) или Флетчера Ривза (4.135). Обе эти формулы используют только уже
имеющиеся данные. Для линейной формы метода сопряженных rpадиентов (имеется
в виду квадратичная функция) эти формулы эквивалентны. С друroй стороны, при
неквадратичной функции стоимости эта эквивалентность теряется.
324 rлава 4. Мноroслойный персептрон
Что касается задачи не квадратичной оптимизации, форма алrоритма сопряженных
rpадиентов на основе формулы Полака Рибьера явно выиrpывает по сравнению с мо-
дификацией алrоритма на базе формулы Флетчера Ривза, чему можно дать эвристи-
ческое объяснение [124]. Из за наличия в формуле функции стоимости Eav(w) слаrа.
емых тpeTbero и более высоких порядков и возможной неточности линейноrо поиска
сопряженность rенерируемых направлений поиска постепенно теряется. Это может, в
свою очередь, привести к нарушению работы алrоритма (ero "заеданию" или "засто-
пориванию"), поскольку вектор направления s( n) и вектор r( n) станут приблизитель-
но ортоrональными. Если это случится, то будет выполнено равенство r( n) == r( n 1)
и, следовательно, скаляр (n) будет равен нулю. Torдa направление s( n) будет близко
к вектору r(n), что обеспечит "прорыв" блокировки продолжения поиска. В проти-
воположность этому при использовании формулы Флетчера Ривза при аналоrичных
условиях алrоритм сопряженных rpадиентов обычно продолжает "заедать".
Однако в некоторых случаях метод Полака Рибьера может зацикливаться и не
сходиться. К счастью, сходимость алrоритма Полака Рибьера можно rарантировать,
приняв [981]
== max{ pr' О},
(4.136)
[де pr значение, получаемое из формулы Полака Рибьера (4.134). Использование
значения из выражения (4.136) эквивалентно повторному запуску метода сопряжен-
ных rpадиентов в случае <O. Повторный запуск алrоритма эквивалентен "забыва-
нию" последних направлений поиска и ero продолжению в направлении наискорей-
шеrо спуска [981].
Теперь вернемся к следующему параметру 11(n), определяющему скорость обу-
чения алrоритма сопряженных rpадиентов. Как и в случае с (n), предпочтитель-
нее использовать метод, не подразумевающий вычисления матрицы rессиана Н(п).
Напомним, что линейная минимизация, основанная на (4.126), приводит к той же
формуле для 11(71), которая была выведена из соотношения (4.125). Таким образом,
требуется линейный поиск (line search) 1 б, целью KOToporo является минимизация функ-
ции Eav(w + 11s) по 11. При фиксированных значениях векторов w и s задача сводится
к изменению параметра 11 с целью минимизации этой функции. По мере измене-
ния параметра 11 aprYMeHT (w+11s) очерчивает в W MepHoM пространстве векторов w
прямую линию, откуда поиск и получил название "линейноrо". АЛ20ритм линейно-
20 поиска (line search algorithm) является итеративной процедурой, rенерирующей
16 Стандартная форма алroритма сопряженных rpадиентов требует использования линейноrо поиска, что
из-за ero характера "проб и ошибок" может занять MHOro времени. В [749] описана модифицированная версия ал.
roритма сопряженных rpадиентов, названная алrоритмом масштабируемых сопряженных rpадиентов, в коmрой
линейный поиск отсутствует. Линейный поиск был просто заменен одномерной формой алroритма Левенберrа
Маркардта (Levenberg-Marquardt). Основанием для использования именно этоro метода было желание обойrи
сложиости, вызываемые неположительной определенностью матрицы rессиана [298].
4.18. Обучение с учителем как задача оптимизации 325
последовательность оценок {1l(n)} для алrоритма сопряженных направлений. Этот
алrоритм поиска останавливается по достижении удовлетворительноrо решения. Ли
нейный поиск должен осуществляться в каждом из направлений поиска.
В литературе предлаrается множество алrоритмов линейноro поиска, и важно cдe
лать хороший выбор, так как это оказывает первостепенное влияние на производи
тельность алrоритма сопряженных rpадиентов, частью KOToporo является линейный
поиск Алroритмы линейноrо поиска включают две фазы [298].
· Фаза 2руппировки (bracketing phase). В ней находится rpуппа, представляющая
собой нетривиальный интервал, rарантированно содержащий минимум.
· Фаза разделения (sectioning phase). В ней rpуппа делится на подrpуппы, опреде
ляющие последовательность отрезков, постепенно уменьшающихся по длине.
Опишем процедуру подбора кривых (curve-fitting procedure), которая объединяет в
себе эти две фазы.
Пусть Е ау (11) функция стоимости мноrослойноrо персептрона, зависящая от
параметра 11. Предполаrается, что функция E a A1l) является унимодалыюй (т.е. имеет
единственный минимум в окрестности текущей точки w(n)), дважды непрерывно
дифференцируемой. Процедура начинается с поиска вдоль одной линии, пока не будут
найдены три такие точки, 111,112 И 11з, для которых будут выполняться следующие
условия (рис. 4.25):
E av (111) ;:::: Е а А11з) ;:::: Е а А112) для 111 < 112 < 11з.
(4.137)
Так как Е а А11) является непрерывной функцией параметра 11, соотношение (4.137)
rарантирует, что ее минимум находится в пределах отрезка [111,11з]' Предполаrая дo
статочную rладкость функции Е а А11), можно заключить, что в окрестности точки
минимума она является приблизительно параболической. Следовательно, дЛЯ BЫ
полнения разделения можно использовать обратную параболическую интерполяцию
(inverse parabo1ic interpolation) [858]. Эта параболическая функция должна прохо
дить через три имеющиеся точки 111,112 И 11з (рис. 4.26). На рис. 4.26 сплошная
линия соответствует функции стоимости, а пунктирная первой итерации проце
дуры разделения. Пусть минимум параболы, проходящей через точки 111,112 И 11з,
достиrается в точке 114' В примере, показанном на рис. 4.26, Е ау (114) < Е ау (112) и
Е ау (114) < Еау (111)' Следовательно, точку 11з можно заменить точкой 114' Процедура
rpуппировки разделения повторяется несколько раз до тех пор, пока не будет найдена
точка, достаточно близкая к минимуму функции Е а А11). После этоrо линейный поиск
прекращается.
!I"""'"
326 rлава 4. Мноrослойный персептрон
E. v (l1) 1
rl
E. v (111)
Е. v (l1з)
E. v (112)
1
....I
I
I
-,
1 1
1 1
I I
I I
I :
11[ 112
11з
11
Рис. 4.25. Линейный поиск
Среднеквад
ратическая
ошиБКа
Параболическая
аппроксимация
E. v (l1)
I
I
I
I
I
I
I
1.
/1
,,/ 1
..... ...."" I
,. 1
1 1
1 1
I 1
1 1
112 114 11з
11
Рис. 4.26. Обратная параболи-
ческая интерполяция
111
Метод Брента (Brent's method) является "уточненной" версией только что про
демонстрированной процедуры интерполяции по трем точкам [858]. На любом кон-
кретном шаrе вычислений метод Брента сохраняет шесть точек функции Е ау (11). Они
MorYT не все отличаться друr от друrа. Как и ранее, параболическая интерполяция
осуществляется лишь по трем из них. Чтобы такая интерполяция была приемлемой,
должен выполняться соответствующий критерий, в котором участвуют и три остав-
шиеся точки. В конечном счете получается робастный алrоритм линейноrо поиска.
Нелинейный алrоритм сопряженных rрадиентов в сжатом виде
Теперь имеются все составляющие для формальноrо описания нелинейной (неквад-
ратичной) формы алrоритма сопряженных rpадиентов для обучения мноrослойноro
персептрона. Этот алrоритм в сжатом виде представлен в табл. 4.8.
4.18. Обучение с учителем как задача оптимизации 327
ТАБЛИЦА 4.8. Нелинейный алroритм сопряженных rрадиентов для обучения MHO
roслойноro персептрона без учителя
Инициализация
Если недоступны априорные сведения о векторе весов w, начальное значе
ние w(O) выбирается с использованием процедуры, аналоrичной описанной
для алroритма обратноrо распространения.
Вычисления
1. Для w(O) используем обратное распространение для вычисления вектора
rpадиента g(O).
2. Устанавливаем s(O) == r(O) == g(O).
3. На шаrе n, используя линейный поиск, находим параметр 11(n), суще
ственно минимизирующий функцию стоимости Е а А11), представленную как
функцию от aprYMeHTa 11 при фиксированных значениях х и w.
4. Проверяем, является ли Евклидава норма резидуальной ошибки Ilr( n) 11
меньше наперед заданноrо значения, являющеroся малой частью исходноro
значения Ilr(O)II.
5. Вычисляем вектор весов:
w(n + 1) == w(n) + 11(n)s(n).
6. Для w( n + 1) используем алroритм обратноro распространения для вычис
ления rpадиента g(n + 1).
7. Устанавливаем r(n + 1) == g(n + 1)
8. Используем метод Полака Рибьера для вычисления параметра (n + 1):
R ( n + 1 ) == тах { rT(n+1)(r(n+1) r(n)) О } .
1-' rT(n)r(n) ,
9. Изменяем значение вектора направления:
s(n + 1) == r(n + 1) + (n + l)s(n).
10. Переходим к следующей итерации (n == n + 1), Т.е. к действию 3.
Критерий останова
Алrоритм прекращает работу, если удовлетворяется следующее условие:
Ilr(n)11 < Ellr(O)II,
rдe Е наперед заданное малое число.
Квазиньютоновкие методы
Подводя итоr обсуждению квазиньютоновских методов, можно сказать, что все они
являются в сущности rpадиентными методами, описываемыми следующей формулой
модификации весов:
w(n + 1) == w(n) + ll(n)s(n),
(4.138)
..,.......
328 rлава 4. Мноroслойный персептрон
rдe вектор направления s(n) описывается в терминах вектора rpадиента g(n):
s(n) == S(n)g(n).
(4.139)
Матрица S (n) является положительно определенной и изменяющейся на каждой
итерации. Это делается для TOro, чтобы вектор s(n) соответствовал направлению
Ньютона (Newton direction), а именно:
(д 2 Е ау / fJw 2 ) 1 (дЕ ау / fJw).
Квазиньютоновские методы используют информацию BToporo порядка (о кри-
визне) о поверхности ошибок, не требуя точноrо знания матрицы rессиана н. Это
достиrается с помощью информации о значениях w( n) и w( n + 1) на двух после
довательных итерациях наряду с соответствующими векторами rpадиентов g(n) и
g(n + 1). Пусть
q(n) == g(n + 1) g(n)
(4.140)
и
дw(n) == w(n + 1) w(n).
(4.141)
Torдa информацию о кривизне можно получить с помощью формулы
q(n) ( :w g(n)) дw(n).
(4.142)
в частности, имея W линейно независимых приращений весов Д w(O), Ь. w(l), . ..,
дw(W 1) и соответствующие приращения rpадиента q(O), q(l),... , q(W 1),
можно аппроксимировать матрицу rессиана выражением
н [q(O), q(l),..., q(W l)][Дw(О), дw(1),... , дw(W l)]Т.
(4.143)
Аналоrично можно аппроксимировать матрицу, обратную rессиану, соотношением
H 1 [Дw(О), b.w(l),... , дw(W l)][q(O), q(l),.. . , q(W 1)] 1.
(4.144)
Если функция стоимости Eav является квадратичной, равенства (4.143) и (4.144)
являются точными.
В самом популярном классе квазиньютоновских методов матрица S( n + 1) вычис-
ляется рекурсивно с помощью предыдущеrо значения S(n) и векторов дw(n) и q(n)
[125], [298]:
4.18. Обучение с учителем как задача оптимизации 329
( ) S( ) дw(n)дwТ(n) S(n)q(n)qT(n)S(n)
S п+ 1 == n + +
qT(n)q(n) qT(n)S(n)q(n) (4.145)
+ (n) [qT (n )S(n )q(n)][v(n )v T (n)],
[де
д w( n)
v(n)
ДwТ(n)дw(n)
S(n)q(n)
qT(n)S(n)q(n)
(4.146)
и
о (n) 1 для всех n.
(4.147)
Этот алrоритм начинается снекоторой произвольной положительно определен
ной матрицы S(O). Конкретные реализации квазиньютоновских методов отличаются
выбором скаляра 11 (n) [298].
. Если (n) == о для всех n, получается ал20ритм Девидона Флетчера Пауэла
(Davidon F1etcher Powe1 DFP), который исторически является первым квази
ньютоновским методом.
. Если (n) == 1 для всех n, получим ал20ритм Бройдена Флетчера rольдфарба
ШанНО (Broyden F1etcher Go1dfarb Shanno), который в настоящее время считается
лучшей формой квазиньютоновских методов.
Сравнение квазиньютоновских методов с методом
сопряженных rрадиентов
Завершим этот краткий обзор квазиньютоновских методов их сравнением методом
сопряженных rpадиентов в контексте задач неквадратичной оптимизации [125].
. Оба этих подхода (квазиньютоновский и сопряженных rpадиентов) избеrают пря
Moro вычисления матрицы rессиана. Однако квазиньютоновские методы идут на
шаr впереди, обобщая аппроксимацию для матрицы, обратной rессиану. Это зна-
чит, что при точном линейном поиске и нахождении в непосредственной близости
от локальноrо минимума положительно определенноrо rессиана квазиньютонов
ские методы стремятся аппроксимировать метод Ньютона, обеспечивая таким об
разом более быструю сходимость, чем это возможно при использовании метода
сопряженных rpадиентов.
. Квазиньютоновские методы не так чувствительны к точности линейноrо поиска
при оптимизации, как метод сопряженных rpадиентов.
330
rлава 4. Мноrослойный персептрон
r
· Квазиньютоновские методы, в дополнение к операциям матрично векторноrо
умножения, требуют хранения матрицы S(n), связанной с вычислением вектора
направления s(n). В конечном итоrе вычислительная сложность квазиньютонов-
ских методов оценивается как O(W 2 ). В противовес этому вычислительная слож-
ность метода сопряженных rpадиентов оценивается как O(W). Таким образом, в
вычислительном смысле, если размерность W вектора весов w велика, метод со-
пряженных rpадиентов является более предпочтительным, чем квазиньютоновские
методы.
Именно последний пункт оrpаничивает применение на практике квазиньютонов-
ских методов только небольшими нейросетями.
4.19. Сети свертки
До сих пор рассматривались вопросы алrоритмическоrо конструирования мноrослой-
Horo персептрона и ero обучения. В этом разделе мы сконцентрируем внимание
на структурной орrанизации caMoro мноroслойноrо персептрона. В частности, бу-
дет описан особый класс мноrослойных персептронов, получивший название сетей
свертки (convolutional networks). Идея, лежащая в основе этоrо понятия, была вкратце
описана в rлаве 1.
Сеть свертки представляет собой мноroслойный персептрон, специально создан-
ный для распознавания двумерных поверхностей с высокой степенью инвариант-
ности к преобразованиям, масштабированию, искажениям и прочим видам дефор-
мации. Обучение решению этой сложной задачи осуществляется с учителем, при
этом используются сети, архитектура которых удовлетворяет следующим оrpаниче-
ниям [620].
Извлечение признаков. Каждый нейрон получает входной сиrнал от локальноrо
рецептивН020 поля (receptive field) в предыдущем слое, извлекая таким образом еro
локальные признаки. Как только признак извлечен, ero точное местоположение не
имеет значения, поскольку приблизительно установлено ero расположение относи-
тельно друrих признакав.
Отображение признаков (feature mapping). Каждый вычислительный слой сети
состоит из множества карт признаков (feature mар), каждая из которых имеет форму
плоскости, на которой все нейроны должны совместно использовать одно и то же
множество синаптических весов. Эта форма структурных оrpаничений имеет следу-
ющие преимущества.
· Инвариантность к смещению (shift invariance), реализованную посредством карт
признаков с использованием свертки (convo1ution) с ядром небольшоrо разм ра,
выполняющим функцию "сплющивания".
4.19. Сети свертки 331
ВХОД
28 х 28
Карты
признаков
4@24 х 24
Карты
признаков
4@12х 12
Карты
признаков
12@8 х 8
КaprbI
признаков
12@4 х 4
ВЫХОД
26@1 х 1
Рис. 4.27. Сеть свертки для обработки изображений, например при распознавании рукопис
Horo текста. (Воспроизведено с разрешения MIT Press.)
. Сокращение числа свободных параметров, реализованное с помощью cOBMecTHoro
использования синаптических весов.
Подвыборка (subsampling). За каждым слоем свертки следует вычислительный
слой, осуществляющий локальное усреднение (10ca1 averaging) и подвыборку. Посред-
ством этоro достиrается уменьшение разрешения для карт признакав. Эта операция
приводит к уменьшению чувствительности выходноrо сиrнала оператора отображе-
ния признакав, к смещению и прочим формам деформации.
Такое построение сетей свертки имеет нейробиолоrическое обоснование, описан
ное в новаторских работах, посвященных локально чувствительным и избирательно
ориентационным (orientation se1ective) нейронам зрительноro аппарата кошки
[489], [490].
Следует подчеркнуть, что все веса во всех слоях сверточной сети обучаются на
примерах. Более TOro, сеть сама учится извлекать признаки автоматически.
На рис. 4.27 показана архитектурная схема сверточной сети, состоящей из одноro
входноro, четырех скрытых и одноrо выходноro слоя нейронов. Эта сеть бьmа созда
на для обработки изображений (image processing), в частности при распознавании
рукописноrо текста. Входной слой, состоящий из матрицы 28 х 28 сенсорных уз-
лов, получает изображения различных символов, которые предварительно смещены
к центру и нормализованы по размеру. После этоro вычислительные слои поочередно
реализуют операции свертки (convolution) и подвыборки, как описывается ниже.
. Первый скрытый слой выполняет свертку. Он состоит из четырех карт признакав,
каждая из которых представляет собой матрицу из 24 х 24 нейронов. Каждому
нейрону соответствует поле чувствительности размером 5 х 5.
. Второй скрытый слой выполняет подвыборку и локальное усреднение. Он тоже
состоит из четырех карт признакав, но теперь уже содержащих матрицы размером
12 х 12 нейронов. Каждому нейрону соответствуют рецептивное поле размером
2 х 2, настраиваемый коэффициент, настраиваемый пороr и сиrмоидальная функ
..,.........
332 rлава 4. Мноrослойный персептрон
ция активации. Настраиваемый коэффициент и пороr определяют рабочую область
нейрона. Например, при маленьком коэффициенте нейрон работает в квазилиней-
ном режиме.
· Третий скрытый слой выполняет повторную свертку. Он состоит из 12 карт при-
знаков, каждая из которых представляет собой матрицу из 8 х 8 нейронов. Каждый
нейрон этоrо cKpbIToro слоя может иметь синаптические связи с различными кар-
тами признаков предыдущеro cKpbIToro слоя. В противном случае ero работа была
бы аналоrичной первому слою свертки.
· Четвертый скрытый слой осуществляет вторую подвыборку и повторное локальное
усреднение. Он состоит из 12 карт признакав, однако на этот раз каждая карта
содержит матрицу из 4 х 4 нейронов. В противном случае работа этоrо слоя бьmа
бы аналоrична первому слою подвыборки.
· Выходной слой осуществляет последний этап свертки. Он состоит из 26 нейронов,
каждому из которых соответствует одна из 26 букв латинскоrо алфавита. Как и
ранее, каждому нейрону соответствует рецептивное поле размером 4 х 4.
При последовательном прохождении слоев свертки и подвыборки был получен
бипирамидальный эффект. Это значит, что в каждом слое свертки или подвыборки
количество карт признаков увеличивается по сравнению с предыдущим при одно-
временном уменьшении пространственноrо разрешения. Идея чередования свертки и
подвыборки была вызвана чередованием "простых" и "сложных" клеток l7 , впервые
описанным в [490]. Мноrослойный персептрон (см. рис. 4.27) содержит при близи-
тельно 100000 синаптических связей, однако в то же время имеет только 2600 свобод-
ных параметров. Такое значительное сокращение количества свободных параметров
было получено за счет cOBMecTHoro использования весов. Емкость обучаемой ма-
шины (в терминах VС измерения), таким образом, сократилась, что, в свою очередь,
повысило способность к обобщению [618]. И что еще более важно, настройка свобод-
ных параметров выполнялась с использованием стохастической (последовательной)
формы обучения методом обратноrо распространения.
Еще одним существенным моментом явилось то, что С помощью cOBMecTHoro ис-
пользования весов удалось реализовать сверточную сеть в параллельной форме. Это
еще одно преимущества сверточных сетей по сравнению сполносвязным мноrослой-
ным персептроном.
Вывод, который напрашивается в результате анализа сети, представленной на
рис. 4.27, можно сформулировать так. Во первых, мноroслойный персептрон управ-
ляемоro размера способен обучиться сложному, MHoroMepHoMY инелинейному отоб-
17 Точка зрения Хабеля и Визеля (НаЬеl & Viesel) на "простые" и "сложные" клетки впервые была пере-
несена в предметную область нейронных сетей при создании системы, получившей название lIеОКО211итрОllа
(neocognitron) [323], [326]. Однако эта машина функционировала на основе самоорrанизации, в то время как
сверточная сеть, показанная на рис. 4.27, обучается с учителем на базе маркированных примеров.
4.20. Резюме и обсуждение 333
ражению с помощью 02раничения (constraining) ero архитектуры путем вовлечения в
нее априорных знаний о поставленной задаче. BO BTOpЫX, синаптические веса и ypOB
ни пороrов MOryT быть обучены с помощью цикличной работы простоrо алroритма
обратноrо распространения на множестве примеров обучения.
4.20. Резюме и обсуждение
Обучение методом обратноrо распространения возникло как стандартный алroритм
обучения мноrослойноrо персептрона, по сравнению с которым все остальные алro
ритмы обучения часто отбраковываются по тем или иным соображениям. Алroритм
обратноrо распространения получил свое название потому, что частные производные
функции стоимости (как меры производительности) по свободным параметрам сети
(синаптическим весам и пороrам) определяются с помощью обратноrо распростране
ния сиrнала ошибки (вычисленноrо выходными нейронами) по сети, слой за слоем.
Таким образом, решается задача присваивания коэффициентов доверия в самой эле
rантной из возможных форм. Вычислительная мощь этоrо алrоритма вытекает из
двух ero характерных особенностей.
. Локальность метода изменения синаптических весов и пороroв в мноroслойном
персептроне.
. Эффективность метода вычисления всех частных производных функции стоимо
сти по свободным параметрам.
в течение каждой отдельно взятой эпохи данных обучения алroритм обратноro
распространения работает в одном из двух режимов: последовательном или пакетном.
В последовательном режиме все синаптические веса всех нейронов сети пересчиты
ваются при подаче каждоrо примера обучения. Отсюда следует, что оценка вектора
rpадиента поверхности ошибок, используемая во всех вычислениях, является CToxa
стической (случайной) по своей природе. Поэтому такой режим (как, в общем, и весь
метод) получил название "стохастическоrо обратноro распространения". С друroй
стороны, в пакетном режиме изменение синаптических весов и пороrов выполняется
один раз за всю эпоху. Это при водит К более точной оценке вектора rpадиента, исполь
зуемоro при вычислениях. Несмотря на свои недостатки, последовательная (стохасти
ческая) форма обучения методом обратноro распространения при создании нейрон
ных сетей используется roраздо чаще, особенно в больших задачах. Для Toro чтобы
добиться наилучшеrо результата, требуется основательная настройка алroритма.
Особенности архитектуры мноrослойноrо персептрона зависят от области ero при
менения. Однако хотелось бы подчеркнуть две особенности.
r
334 rлава 4. Мноroслойный персептрон
При распознавании образов, содержащих нелинейные объекты, все нейроны сети
являются нелинейными. Эта нелинейнасть достиrается за счет использования сиrмо-
идальных функций, двумя самыми распространенными формами которых являются
несимметричная лоrистическая функция и антисимметричная функция rиперболиче-
cKoro TaHreHca. Каждый из нейронов отвечает за создание rиперплоскости в простран-
стве решений. В процессе обучения с учителем комбинация rиперплоскостей, сфор-
мированных всеми нейронами сети, итеративно трансформируется для разделения
примеров, преднамеренно взятых из разных классов, а также ранее не встречавших-
ся, с наименьшей средней ошибкой классификации. В задачах распознавания образов
при обучении наиболее широко используется алrоритм обратноro распространения,
особенно если размерность таких задач велика (например, при оптическом распозна-
вании символов OCR).
В задачах нелинейной реrpессии диапазон выходных значений (output range) мно-
roслойноro персептрона должен быть большим, чтобы вместить все данные процесса.
Если эта информация недоступна, использование в выходном слое линейных нейро-
нов будет самым правильным решением. Относительно алroритмов обучения можно
предложить следующие наблюдения.
· Последовательный (стохастический) режим обучения на основе обратноrо распро-
странения является более медленным, чем пакетный.
· Пакетный режим обучения методом обратноro распространения является более
медленным, чем метод сопряженных rpадиентов. При этом следует заметить, что
последний метод используется только в пакетном режиме.
Завершим обсуждение несколькими замечаниями относительно меры эффектив-
ности (performance measure). Модификации алrоритма обратноrо распространения,
представленные в настоящей rлаве, основаны на минимизации функции стоимости
Еау, определенной как сумма квадратов ошибок, усредненная по всему множеству
примеров обучения. Важной чертой этоrо критерия является ero общность и матема-
тическая трактовка. Однако во мноrих ситуациях, которые встречаются на практике,
минимизация функции стоимости Еау соответствует оптимизации некоторой средней
величины, которая не обязательно присутствует в системе и, таким образом, может
достичь только cBoero субоптuмалЬН020 значения. Например, в финансово торrовых
системах единственной целью инвестора (равно как и маклера) является максими-
зация ожидаемой прибыли (expected return) при минимальном риске [192], [751].
Для этих задач в качестве меры производительности интуитивно больше подойдет
отношение прибыли к изменчивости, чем среднеквадратическая ошибка Еау'
Задачи 335
Рис. 4.28. Нейронная сеть для решения
задачи XOR
Выход
Задачи
Задачи XOR
4.1. На рис. 4.28 показана нейронная сеть, содержащая один скрытый нейрон и
предназначенная для решения задачи XOR. Эту сеть можно рассматривать
как альтернативу предложенной в разделе 4.5. Покажите, что сеть на рис. 4.28
решает задачу XOR, построив области решений и таблицу истинности сети.
4.2. Используйте алrоритм обратноrо распространения для вычисления множе
ства синаптических весов и уровней пороrов в нейронной сети, показанной
на рис. 4.8 и предназначенной для решения задачи XOR. Предполаrается, что
в качестве модели нелинейнасти используется лоrистическая функция.
Обучение методом обратноrо распространения
4.3. Включение слаrаемоro момента в формулу изменения весов можно paCCMaT
ривать как механизм реализации эвристик 3 и 4, предлаrающих способ YCKO
рения сходимости алrоритма обратноrо распространения (см. раздел 4.17).
Продемонстрируйте правильнасть этоro утверждения.
4.4. Константа момента а обычно принимает положительное значение из диа
пазона О а < 1. Проанализируйте, как изменится поведение величин,
описываемых выражением (4.41), во времени t, если константе момента а
присвоить отрицательное значение из диапазона 1 < а О.
4.5. Рассмотрим простой пример сети с одним синаптическим весом, для которой
задана следующая функция стоимости:
E(w) == k1(w wo)2 + k 2 ,
......
r
336 rлава 4. Мноrослойный персептрон
rдe k 1 , Wo И k 2 константы. Для минимизации этой функции используется
алroритм обратноrо распространения. Исследуйте влияние константы мо-
мента а на процесс обучения, вычислив количество шаrов, требуемых для
сходимости, в зависимости от константы а.
4.6. В разделе 4.7 бьmо представлено качественное обоснование следующеrо
свойства классификатора на основе мноrослойноrо персептрона (использую-
щеrо в качестве модели нелинейнасти лоrистическую функцию): он обеспе-
чивает оценку апостериорной вероятности принадлежности классу (а posteri-
ori class probabi1ities). Это предполаrает, что при достаточно большом наборе
примеров обучения алrоритм обратноrо распространения, используемый для
обучения нейронной сети, не будет останавливаться в точке локальноrо ми-
нимума. Опишите это свойство математически.
4.7. Взяв за основу функцию стоимости из формулы (4.70), выведите минимизи-
рующее решение, представленное формулой (4.72), и найдите минимальное
значение функции стоимости, определенное в (4.73).
4.8. Равенства (4.81) (4.83) определяют частные про из водные функции аппрок-
симации F(w, х), используемые мноrослойным персептроном на рис. 4.18.
Выведите эти равенства, используя следующий сценарий:
а) Функция стоимости:
1
Е(n) == [d F(W,X)]2.
2
б) Выход нейрона j:
У, ( w"y,) ,
[де Wji синаптические веса связей между нейронами j и i; Yi выходной
сиrнал нейрона i.
в) Нелинейность:
1
<р( v)
1 + ехр( v) .
Перекрестная проверка
4.9. Можно доказать, что пере крестная проверка является частным случаем ми-
нимизации CтpyктypHoro риска, который рассматривался в rлаве 2. Приведи-
те пример нейронной сети, использующей перекрестную проверку, который
подтверждает это утверждение.
Задачи 337
4.10. При мноroкратной перекрестной проверке не существует четкоrо разделения
между данными для оценивания и тестирования. Можно ли использовать
мноrократную перекрестную проверку для нахождения пОР020вой оценки (bi
ased estimate)? Обоснуйте свой ответ.
Приемы упрощения сети
4.11. Статистические критерии выбора модели, такие как критерий минимальной
длины описания Риссанена (Rissanen's minimum description length criterion) и
информационно теоретический критерий Акейка (Information theoretic crite
rion due to Akaike), имеют сходную форму построения:
( критерий ) ( лоrаРИФмическая ) ( Штраф )
сложности == функция + за сложность
модели подобия модели
Обоснуйте, как использование методов снижения и исключения весов связей
вписывается в такой формализм.
4.12. а) Выведите формулу вычисления значения выпуклости Si (4.105).
б) Предполarая, что матрицу rессиана среднеквадратической ошибки MHoro
слойноrо персептрона можно аппроксимировать следующей диаroнальной
матрицей:
н == diag[h ll , h22,"" hww],
[де W общее число весов сети, определите значение выпуклости Si для
веса Wi сети.
Ускорение сходимости алrоритма обратноrо распространения
4.13. Правило обучения delta bar delta [505] представляет собой видоизмененную
форму алrоритма, построенноrо на эвристике, описанной в разделе 4.17.
В этом правиле каждому синаптическому весу сети соответствует собствен
ный параметр скорости обучения. Поэтому функция стоимости COOTBeTCTBY
ющим образом изменяет вид. Друrими словами, несмотря на математическую
схожесть с обычной функцией стоимости, параметрическое пространство
этой новой функции стоимости включает в себя друrие параметры интен
сивнасти обучения.
"....
338 rлава 4. Мноrослойный персептрон
а) Выведите формулу для частной производной дЕ( n) / дrtji (n), [де 11ji (n)
параметр скорости обучения, связанный с синаптическим весом Wji(n).
б) Продемонстрируйте, что изменение параметров скорости обучения нахо-
дится в полном соответствии с эвристиками 3 и 4 из раздела 4.17.
Методы оптимизации BToporo порядка
4.14. Использование слаrаемоro момента в формуле корректировки весов (4.39)
можно рассматривать как аппроксимацию метода сопряженных rpадиентов
[103]. Обоснуйте корректность этоro утверждения.
4.15. Начиная с формулы (4.133) для 13(n), выведите формулу XecтeHecca
Штифеля (Hesteness Stiefel):
13(n) == rT(n)(r(n) r(n 1)) ,
ST(n l)r(n 1)
[де s( n) вектор направления; r( n) резидуальная ошибка метода сопря-
женных rpадиентов. Используйте этот результат для вывода формул Полака
Рибьера (4.134) и Флетчера Ривза (4.135).
Компьютерное моделирование
4.16. Исследуйте применимость обучения методом обратноrо распространения
с сиrмоидальной нелинейностью для построения следующих отображений
( скалярных):
а) f(x) == 1 х 100;
б) f(x) == 19lox, 1 х 10;
в) f(x) == ехр( x), 1 х 10;
[) f(x) == sin(x), 1 х п/2.
Для каждоro отображения выполните следующее.
а) Создайте два набора данных: один для обучения, а второй для тести
рования.
б) Используйте множество данных тестирования для вычисления синаптиче
ских весов сети, предполаrая наличие одноrо cKpbIToro слоя.
в) Оцените вычислительную сложность сети с помощью данных тестирова-
ния.
Задачи ЗЗ9
Используя единственный скрытый слой с различным количеством нейроном,
.... ....
исследуите, как изменение количества неиронов скрытоrо слоя влияет на
производительность сети.
4.17. Данные, приведенные в табл. 4.9, представляют вес rлазных линз дикоro aB
стралийскоrо кролика как функции времени (возраста). Ни одна простая aHa
литическая функция не может точно интерполировать эти данные, так как
неизвестен общий вид самой функции. Поэтому введем нелинейную модель
этоro множества данных на основе метода наименьших квадратов, использу...
.....
ющую отрицательныи экспоненциал:
у == 233.846(1 ехр( O.006042x)) + Е,
rде Е слаrаемое ошибки.
Используя алrоритм обратноro распространения, постройте мноroслой...
.... v
ныи персептрон, реализующии аппроксимацию этоrо множества данных на
основе метода наименьших квадратов. Сравните результат с описанной выше
моделью.
ТАБЛИЦА 4.9. Вес rлазных линз дикоrо австралийскоrо кролика
Возраст Вес Возраст Вес Возраст Вес Возраст Вес
(дни) (М2) (дни) (М2) (дни) (М2) (дни) (М2)
15 21,66 75 94,6 218 174,18 338 203,23
15 22,75 82 92,5 218 173,03 347 188,38
15 22,3 85 105 219 173,54 354 189,7
18 31,25 91 101,7 224 1 78,86 357 195,31
28 44,79 91 102,9 225 177,68 375 202,63
29 40,55 97 110 227 173,73 394 224,82
37 50,25 98 104,3 232 159,98 513 203,3
37 46,88 125 134,9 232 161,29 535 209,7
44 52,03 142 130,68 237 187,07 554 233,9
50 63,47 142 140,58 246 1 76,13 591 234,7
50 61,13 147 155,3 258 183,4 648 244,3
60 81 147 152,2 276 186,26 660 231
61 73,09 150 144,5 285 189,66 705 242,4
64 79,09 159 142,15 300 186,09 723 230,77
65 79,51 165 139,81 301 186,7 756' 242,57
65 65,31 183 153,22 305 186,8 768 232,12
72 71,9 192 145,72 312 195,1 860 246,7
75 86,1 195 161,1 317 216,41
Сети на основе радиальных
базисных функций
5.1. Введение
Процесс создания нейронных сетей, обучаемых с учителем, можно упростить множе
ством способов. Описанный в предыдущей rлаве алrоритм обратноrо распростране
ния для мноrослойноrо персептрона можно рассматривать как реализацию рекурсив
ной технолоrии, которая в статистике называется стохастической аппроксимацией
(stochastic approximation). В этой rлаве описывается еще один подход, в рамках KOTO
poro построение нейронной сети рассматривается как задача аппроксимации кривой
по точкам (curve fitting problem) в пространстве высокой размерности. В COOTBeT
ствии с такой точкой зрения обучение эквивалентно нахождению такой поверхности в
MHoroMepHoM пространстве, которая наиболее точно соответствует данным обучения.
При этом критерий "наилучшеrо соответствия" выбирается в не котором статистиче
ском смысле. Таким образом, обобщение эквивалентно использованию этой MHoro
мерной поверхности для интерполяции данных тестирования. Такой подход лежит в
основе метода радиальных базисных функций, состоящеrо в традиционной интерпо
ляции в MHoroMepHoM пространстве. В контексте нейронных сетей скрытые нейроны
реализуют набор "функций", являющихся произвольным "базисом" для разложения
входных образов (векторов). Соответствующие преобразования называют радиаль
ными базисными функциями (radial basis function)l. Понятие радиальных базисных
функций впервые было введено при решении задачи интерполяции вещественных
функций нескольких переменных. Анализ ранних работ по этой тематике представлен
в [855], а более новых в [642]. В настоящее время радиальные базисные функции co
ставляют одно из rлавных направлений исследований в области численноrо анализа.
1 Радиальные базисные функции впервые использовались при решении задачи мноmмерной интерполяции.
Анализ первых работ по этой тематике содержится в [855]. В настоящее время ЭТО одно из rлавных направлений
исследований в области числеИИоm анализа.
В [160] радиальные базисные функции впервые использовались для построения нейронных сетей. Важный
вклад в теорию и методолоrию проектирования сетей на основе радиальных базисных функций внесла работа,
в которой основное внимание уделяется вопросам применения теории реryляризации к этому классу сетей с
целью повышения качества обобщения на новых данных [847].
342 rлава 5. Сети на основе радиальных базисных функций
Базовая архитектура сетей на основе радиальных базисных функций (radia1 basis
fиnction network RВF), или RВF сетей, предполаrает наличие трех слоев, выполня
ющих совершенно различные функции. Входной слой состоит из сенсорных элемен
тов, которые связывают сеть с внешней средой. Второй слой является единственным
скрытым (hidden) слоем сети. Он выполняет нелинейное преобразование BXOДHO
[о пространства в скрытое. В большинстве реализаций cKpbrroe пространство имеет
более высокую размерность, чем входное. Математическое обоснование целесооб
разности последовательноrо применения нелинейноrо и линейноro преобразований
приведено в [219]. Соrласно этой работе, задача классификации данных в простран
стве более высокой размерности с большей вероятностью удовлетворяет требованию
линейной разделимости. Поэтому в RВF сетях размерность cкpbIToro слоя, как пра
вило, существенно превышает размерность входноrо слоя. Также важно отметить тот
факт, что размерность cKpbIToro пространства непосредственно связана со способ
ностью сети аппроксимировать rладкое отображение "BXOД BЫXOД" [731], [787]. Чем
выше размерность CKpbITOro слоя, тем более высокой будет точность аппроксимации.
Структура rлавы
Эта rлава орrанизована следующим образом. В разделах 5.2 и 5.4 будут заложены
основы построения RВF сетей. Это будет сделано в два этапа. В первую очередь
будет описана теорема Ковера (Cover) о разделимости образов. Для иллюстрации
применения этой теоремы мы рассмотрим задачу XOR. Раздел 5.3 посвящен задаче
интерполяции и ее связи с сетями RВF.
После изучения основ функционирования RВF сетей мы перейдем ко второй части
rлавы, состоящей из разделов 5.4 5.9. В разделе 5.4 будет показано, что обучение с
учителем является плохо обусловленной задачей восстановления rиперповерхности.
В разделе 5.5 детально описывается теория реrуляризации Тихонова и рассматри
вается ее применение в сетях RВF. Эта теория естественным образом приводит к
формулировке понятия сетей реrуляризации в разделе 5.6. Этот класс RВF сетей ЯВ
ляется очень требовательным к вычислительным ресурсам. Чтобы уменьшить эту
сложность, в разделе 5.7 описываются специальные сети реryляризации, которые Ha
зываются обобщенными RВF сетями. В разделе 5.9 мы снова вернемся к задаче XOR
и покажем, как ее можно решить с помощью RВF сетей. В разделе 5.9 изучение
теории реrуляризации будет завершено описанием метода обобщенной перекрестной
проверки для выбора подходящеrо параметра реryляризации.
В разделе 5.1 О обсуждаются свойства аппроксимации RВF сетей. В разделе 5.11
проводится сравнительный анализ сетей на основе радиальных базисных функций
и мноroслойных персептронов. Оба этих типа сетей являются важными примерами
мноrослойных сетей прямоro распространения.
5.2. Теорема Ковера о разделимости множеств 343
в разделе 5.12 предлаrается еще один подход к изучению RВF сетей с пози
ций оценивания реrpессии ядра. Здесь область RВF сетей связывается с вопросами
оценки плотности и теорией реrpессии ядра.
В последней части настоящей rлавы (разделы 5.13 и 5.14) описываются четы
ре различные стратеrии обучения нейронных сетей на основе радиальных базисных
функций (раздел 5.13), а также компьютерный эксперимент по решению задачи клас
сификации образов с использованием RВF сетей (раздел 5.14).
rлава завершается несколькими заключительными рассуждениями о RВF
сетях (раздел 5.15).
5.2. Теорема Ковера о разделимости множеств
Если сеть на основе радиальных базисных функций (RВF ceTb) используется для
решения сложных задач классификации образов, то основная идея решения обычно
состоит внелинейном преобразовании входных данных в пространстве более BЫCO
кой размерности. Теоретическую основу TaKoro подхода составляет теорема Ковера
о разделимости образов (Cover's theorem оп the separabi1ity ofpattems), которая yTBep
ждает следующее [219].
Нелинейное преобразование сложной задачи классификации образов в пространство
более высокой размерности повышает вероятность линейной разделимости образов.
Из rлавы 3, посвященной однослойному персептрону, известно, что задача классифи
кации линейно разделимых множеств относительно леrко разрешима. Следовательно,
для более четкоrо понимания принципов работы RВF сети в качестве классификатора
необходимо rлубже изучить вопрос разделимости образов (separabi1ity ofpattems).
Рассмотрим семейство поверхностей, каждая из которых делит входное про
странство на две части. Пусть Х множество, состоящее из N образов (Beктo
ров) Х1, Х2,'," xN, каждый из которых принадлежит одному из двух классов
Х 1 или Х 2 . Эта дихотомия (бинарное разбиение) точек называется разделимой по
отношению к семейству поверхностей, если в этом семействе существует поверх
ность, которая отделяет точки класса Х 1 от точек класса Х 2 . ДЛЯ каждоrо образа
х Е Х определим вектор, состоящий из множества действительнозначных функций
{<МХ) I i == 1,2,... , т1}, вида
</>(х) == [</>1 (х), </>2(Х)' ..., </>тl (х)] т .
(5.1)
344 rлава 5. Сети на основе радиальных базисных функций
Предположим, что образ х является вектором в тo MepHOM входном пространстве.
Torдa векторная функция <р(х) отображает точки ffio MepHoro входноrо пространства
в новое пространство размерности т1. Функции q>Jx) называются скрытыми, по
скольку они иrpают роль скрытых элементов нейронных сетей прямоrо распростра
нения. Соответственно пространство, образованное множеством скрытых функций
{q>i(X)} \, называется скрытым пространством (hidden space) или пространством
признаков (feature space).
Дихотомия {Х 1 , Х 2 } множества Х называется q> разделимой(q> sерarаЫе), если cy
ществует т1 мерный вектор w, для KOToporo можно записать [219]
wTq>(x) > О, х Е Х 1 ,
wTq>(x) < О, х Е Х 2 .
(5.2)
fиперплоскость, задаваемая уравнением
wTq>(x) == О,
описывает поверхность в q> пространстве (т.е. в скрытом пространстве). Обратный
образ этой поверхности, Т.е.
х : w T <р(х) == О,
(5.3)
определяет разделяющую поверхность (separating surface) во входном пространстве.
Рассмотрим естественный класс отображений, получаемый при использовании
линейной комбинации произведений r координат вектора входноrо образа. Разделя
ющие поверхности, соответствующие такому отображению, называются рациональ
ными МНО200бразuями r 2o порядка (r th order rationa1 variety). Рациональное MHO
rообразие r ro порядка в пространстве размерности то описывается однородным
уравнением r ro порядка в координатах входноrо вектора х:
L aili2...irXilXi2" 'Xi r == О,
O::,JC:o i 2 ::o..-::::Jr::оmО
(5.4)
rдe Xi i й компонент входноrо вектора х, причем ХА присвоено значение 1, чтобы
придать уравнению однородную форму. Про изведение элементов Xi вектора х r ro
порядка (т.е. Xi1Xi2'" Xir) называется одночленом (monomia1). Для входноrо ПрО
странства размерности то сумма в (5.4) включает
(то т)!
то!т!
5.2. Теорема Ковера о разделимости множеств 345
х х
о о
о.
а)
х
х
xG х
б)
Рис. 5.1. Три примера <р--разделимых дихотомий для различных множеств
из пяти точек в двумерном пространстве: линейно разделимая дихото
мия (а); сферически разделимая дихотомия (6); квадратично разделимая
дихотомия (в)
30 о
оС
в)
одночленов. Примерами разделяющих поверхностей, описываемых уравнением (5.4),
являются 2иперплоскости (hyperp1ane) (рациональные мноrообразия первоrо поряд
ка), квадрики (quadrice) (рациональные мноrообразия 2 ro порядка) и 2иперсферы
(hypersphere) (квадрики с некоторыми линейными оrpаничениями на коэффициен
ты). Эти примеры показаны на рис. 5.1 для конфиryрации из пяти точек в двумерном
входном пространстве. В общем случае линейная разделимость предполаrает сфе
рическую разделимость, которая, в свою очередь, предполаrает квадратичный вид
классифицирующей функции. Обратное утверждение не всеrда верно.
В вероятностном эксперименте разделимость множества образов становится слу
чайным событием, зависящим от выбранной дихотомии и распределения образов во
входном пространстве. Предположим, что образы активации Х1, Х2,'" , XN выбира
ются независимо, в соответствии с вероятностным распределением, присущим BXOД
ному пространству. Предположим также, что все возможные дихотомии Х == {xJ::1
равновероятны. Пусть P(N, т1) вероятность TOro, что некоторая случайно выбран
ная дихотомия является q> разделимой, если класс разделяющих rиперповерхностей
имеет т1 степеней свободы. Соrласно [219] можно утверждать, что
( l ) N l тl l ( N 1 )
P(N,m1) == 2 m '
(5.5)
346 rлава 5. Сети на основе радиальных базисных функций
[де биномиальные коэффициенты, включающие N 1 и т, для всех целых l и т
определяются следующей формулой:
( l ) == l(l 1)...(l m+1) .
m т!
Уравнение (5.5) отражает сущность теоремы Ковера о разделимости (Cover's
separabi1ity theorem) случайных образов 2 . Это соотношение описывает совокупное
биномиальное распределение, соответствующее вероятности TOro, что (N 1) под
брасываний монетки приведет к выпадению не более (т1 1) решек.
Хотя поверхности скрытых элементов в уравнении (5.5) имеют полиномиальную
форму и, следовательно, отличаются от тех, которые обычно используются в сетях
на основе радиальных базисных функций, сущность этоrо выражения носит общий
характер. В частности, чем выше размерность т1 CKpbITOro пространства, тем ближе
вероятность P(N, т1) к единице. Подводя итоr сказанному, следует отметить, что
теорема Ковера о разделимости образов базируется на двух основных моментах.
1. Определение нелинейной скрытой функции q>i(X), [де Х входной вектор, а i == 1,
2,...,т1'
2. Высокая размерность cKpbIToro пространства по сравнению с размерностью BXOД
HOro. Эта размерность определяется значением, присваиваемым т1(т.е. количе-
ством скрытых нейронов).
Как утверждалось ранее, в общем случае преобразование сложной задачи класси
фикации в пространство более высокой размерности повышает вероятность линей
ной разделимости образов. Однако хочется подчеркнуть, что в некоторых случаях для
обеспечения линейной разделимости достаточно нелинейноro преобразования (п. 1)
без повышения размерности пространства скрытых элементов. Это будет продемон
стрировано на следующем примере.
2 Доказательство теоремы Ковера базируется на следующих утверждениях [219].
· Теорема Шлафли (Schlafli's theorem), или теорема подсчета функций (function counting theorem), KOTO
рая утверждает, что количество однородных линейно-разделимых дихотомий N векторов Евклидова ml-
MepHom пространства, находящихся в стандартном положении, определяется соотношением
ml 1
С(п, ml) :о 2 fo ( 1).
rоворят, что множество векторов Х :о {Xi} l Евклидова ml MepHoro пространства находится в стан-
дартном положении, если любое подмножество из ml или меньшеm числа векторов является линейно-
независимым.
· Рефлексивная инвариантность совместной вероятности распределения Х, которая означает, что вероятность
(условная по Х) линейной разделимости случайной дихотомии равна безусловной вероятности Toro, что
любая конкретная дихотомия множества Х (все N векторов находятся в одной катеrории) будет разделимой.
Теорема подсчета функций была независимо доказана в различных формах и применена к специальной
конфиrypации персептронов (т.е. линейных пороrовых элементов) в [168], [528], [1162]. В [218] эта теорема
использовалась для оценки емкости сети персептронов в терминах общеm количества настраиваемых парамет
ров. В статье было показано, что эта емкость оrpаничена снизу величиной N/(l + log 2 N), rде N количество
входных образов.
5.2. Теорема Ковера о разделимости множеств 347
ТАБЛИЦА 5.1. Значения скрытых функций в задаче XOR (см. пример 5.1)
Входной
образ, х
(1;1)
(о; 1)
(0;0)
(1;0)
Первая скрытая функция, <Р1 (х)
Вторая скрытая функция, <Р2(Х)
1
0,3678
0,1353
0,3678
0,1353
0,3678
1
0,3678
Пример 5.1
Задача XOR
Чтобы проиллюстрировать значимость идеи <I' разделимости образов, рассмотрим простую, но в
то же время важную задачу XOR. В этой задаче в двумерном входном пространстве рассматривают
ся четыре точки: (о; О), (о; 1), (1; О) и (1; 1) (рис. 5.2, а). Требуется построить такой классификатор,
который относит образы (о; 1) и (1; О) к классу 1, а образы (о; О) и (1; 1) к классу О. Это
значит, что ближайшие друr к друry точки во входном пространстве (в смысле расстояния Xeм
минса (Hamming distance)) отображаются в области, которые максимально удалены друr от друrа в
выходном пространстве.
Определим пару rayccoBbIX функций следующим образом:
<l'l(Х) == e lIx tlI12, t1 == [1, l]Т,
<l'2(Х) == e llx t2112, t2 == [О, О]Т.
Проанализируем представленный в табл. 5.1 результат для четырех различных входных образов.
Входные векторы отображаются на плоскость <1'1 <1'2' как показано на рис. 5.2, б. На этом рисунке
сразу видно, что теперь точки (о; 1) и (1; О) стали линейно отделимыми от точек (о; О) и (1;
1). Следовательно, задачу XOR можно успешно решить с помощью функций <l'l(Х) И <l'2(Х) для
предварительной обработки входных данных линейноro классификатора, TaKoro как персеrnрон. .
в этом примере не повышается размерность CKpbITOro пространства по сравнению
с входным. Друrими словами, нелинейноrо преобразования, представленноrо в дaH
ном случае двумя rауссовыми функциями, оказалось достаточно для трансформации
задачи XOR в линейно разделимую задачу.
Разделяющая способность поверхности
Уравнение (5.5) позволяет оценить максимальное количество случайно выбранных
образов, линейно разделимых в MHoroMepHoM пространстве. Чтобы раскрыть этот
вопрос, рассмотрим последовательность случайных векторов Х1, Х2,"', XN. Пусть
N случайная переменная, определяемая как максимальное целое число, дЛЯ KO
Toporo эта последовательность является q> разделимой, если q> имеет т1 степеней
348 rлава 5. Сети на основе радиальных базисных функций
(О, 1)
.
1,0
0,8
0,6
<Р2
0,4
0,2
. (1,1)
(1,1)
.
,
,
,
,
,
,
,
,
,
,
,
" rраница
", решений
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,
.
(0,1)
(1, О)
. (О, О)
(1, О)
.
О
0,2
0,4
0,6
<Р!
б)
(О, О)
.
0,8
1,0
1,2
а)
Рис. 5.2. Четыре образа для задачи XOR (а) и диаrрамма принятия решений (б)
свободы. Тоща из соотношения (5.5) можно получить вероятность Toro, что N == n:
P(N == n) == Р(n, т1) Р(n + 1, т1) ==
( 1 ) n ( n 1 )
== 2 т1 1 ' n == О,
1, 2,...
(5.6)
Для интерпретации этоrо результата вспомним определение отрицателЬНО20 би
номиаЛЬНО20 распределения (negative binomia1 distribution). Это распределение опре
деляет вероятность Toro, что T My успешному эксперименту предшествует k ошибок
в длинной повторяющейся последовательности попыток Бернулли (Bemou1li tria1).
В таком вероятностном эксперименте каждый результат может принимать одно из
двух значений успех или ошибка, и их вероятности одинаковы на протяжении
Bcero эксперимента. Пусть р и q соответственно вероятности успеха и неудачи и
р + q == 1. Отрицательное биномиальное распределение имеет вид [294]
( rk ( r+k l )
f k;r,p) ==р q k .
Для частноro случая, коща р == q == 1/2 (т.е. успех и ошибка равновероятны) и
k + r == n, отрицательное биномиальное распределение сводится к виду
f(k; n k,}) == (}) n ( 1) , n == О, 1, 2, ....
5.3. Задача интерполяции 349
Учитывая это определение, несложно заметить, что результат, описанный Bыpa
жением (5.6), является Bcero лишь отрицательным биномиальным распределением,
смещенным на т1 единиц вправо, с параметрами т1 и 1/2. Таким образом, N co
ответствует "времени ожидания" т1 й ошибки в последовательности попыток под
брасывания монетки. Ожидание случайной переменной N и ее медиана (median)
соответственно равны
E[N] == 2т1'
Median[N] == 2т1'
(5.7)
(5.8)
Таким образом, мы получили следствие из теоремы Ковера в форме асимптотиче-
CKOro результата, который можно сформулировать следующим образом.
Ожидаемое максимальное количество случайно задаваемых образов (векторов),
линейно разделимых в пространстве размерности т1, составляет 2т1'
Полученный результат подтверждает, что 2т1 является совершенно естественным
определением разделяющей способности (separating capacity) семейства поверхно
стей решений, имеющих т1 степеней свободы. Следовательно, разделяющая способ
ность поверхности тесно связана со значением VС измерения, которое рассматрива
лось в rлаве 2.
5.3. Задача интерполяции
Важным выводом, следующим из теоремы Ковера о разделимости образов, является
то, что при решении нелинейной задачи классификации обычно имеется практиче
ская польза от преобразования входноrо пространства в пространство более высокой
размерности. В основном для трансформации нелинейной задачи классификации в
линейную применяется нелинейное отображение. Аналоrично, нелинейное отображе
ние можно использовать для преобразования сложной задачи нелинейной фильтрации
в более простую задачу линейной фильтрации.
Рассмотрим сеть прямоrо распространения с одним входным, одним скрытым
и выходным слоем, содержащиМ единственный нейрон. Один нейрон в выходном
слое выбран специально для упрощения выкладок без потери общности. Эта сеть
предназначена для нелинеЙНО20 отображения входноro пространства в скрытое, за
которым следует линейное отображение cKpbIToro пространства в выходное. Пусть
то размерность входноrо пространства. Тоща сеть в целом реализует отображение
mo MepHoro входноrо пространства в одномерное выходное:
s : Rmo R 1 .
(5.9)
350 rлава 5. Сети на основе радиальных базисных функций
Отображение s можно рассматривать как rиперповерхность (rpафик) r с Rmo+l,
аналоrично тому, как отображение s:R 1 ----+ R 1 представляется в двумерном простран
стве R 2 в виде параболы s(x) == х 2 . Поверхность r является MHoroMepHbIM rpафиком
изменения выходноrо сиrнала в зависимости от входноrо. В практической реализа
ции поверхность r остается неизвестной, а на данные обучения накладывается шум.
Этапы обучения и обобщения можно представить следующим образом [160].
· На этапе обучения (training phase) поверхность r оптимизируется на основании
известных точек данных, представляемых сети в форме маркированных примеров
типа "BXOД BЫXOД".
· Фаза обобщения (generalization phase) равносильна интерполяции на интервалах
между точками данных. Эта интерполяция осуществляется на оrpаниченной по
верхности, сrенерированной процедурой подбора (fitting procedure) в качестве оп
тимальной аппроксимации истинной поверхности [.
Таким образом, мы приходим к теории интерполяции функции МНО2UX переменных
(mu1tivariable interpo1ation) в MHoroMepHoM пространстве, которая имеет свою долryю
историю [243]. Задачу интерполяции в ее изначальном смысле можно сформулировать
следующим образом.
Для даННО20множества из Nточек {Xi Е Rmo!i == 1,2,... , N} и соответствующе
20 множества из N действительных чисел {d i Е R1/i == 1,2, . . . , N} найти функцию
F : R N ----+ R 1 , удовлетворяющую следующему условию интерполяции:
F(Xi) == d i , i == 1,2, . . . , N.
(5.1 О)
Для определенной таким образом задачи поверхность интерполяции (т.е. функ
цИЯ Р) проходит через все точки примеров обучения.
Метод радиальных базисных функций (RВF) сводится к выбору функции Р, име
ющей следующий вид [854]:
N
Р(х) == L щq>(llх Xill),
i==l
(5.11)
[де {q>(llx ХiЮli == 1,2,... , N} множество из N произвольных (и обычно нели
нейных) функций, которые называются радиальными базисными функциями (radia1
basis function); /1 . 11 норма, обычно Евклидова. Известные точки данных Xi Е
Rm o , i == 1, 2, . . . , N, выбираются в качестве центров радиальных базисных функций.
5.3. Задача интерполяции 351
Подставляя в (5.11) условие интерполяции (5.10), получим следующую систему
линейных уравнений для неизвестных весовых коэффициентов {Wi}:
[ <Р11 <Р12 о.. <P1N ] [ W1 ] [ d1 ]
.2 .2 ::: .2 .
<PN1 <PN2 ... <PNN WN d N
(5.12)
[де
<Pji == <p(IIXj xill), (i,j) == 1,2,..., N.
(5.13)
Пусть
d== [d 1 ,d 2 ,...,d N ]T,
W == [W1' W2,"', WN]T.
Векторы d и w размерности N это вектор желаемО20 отклика (desired response
vector) и вектор весов (weight vector) соответственно. Пусть Ф матрица размерности
N х N с элементами <Pji:
Ф == {<pjil(j, i) == 1,2,..., N}.
(5.14)
Назовем ее матрицей интерполяции. Теперь выражение (5.12) можно переписать
в следующем виде:
Фw == Х.
(5.15)
Предполаrая, что матрица Ф является несинryлярной (и, следовательно, для нее
существует обратная матрица ф l), можно приступить К решению уравнения (5.15)
относительно вектора весов w:
w == ф lх.
(5.16)
При этом возникает жизненно важный вопрос: как убедиться в несинrулярности
матрицы Ф? ДЛЯ большоro класса радиальных базисных функций при определенных
условиях ответ на этот вопрос дает следующая важная теорема.
352 rлава 5. Сети на основе радиальных базисных функций
Теорема Мичелли
В [733] была доказана следующая теорема.
Пусть { Х i}::l множество различных точек из Rm o . ТО2да матрица интерполяции
Ф размерности N х N с элементами <Pji == <p(llxj Xill) является несиН2УЛЯРНОЙ.
Теорема Мичелли охватывает широкий класс радиальных базисных функций.
В этот класс входят следующие функции, представляющие интерес при изучении
сетей на основе радиальных базисных функций, или сетей RВF.
1. Мультиквадратичная функция (mu1tiquadric):
<p(r) == (r 2 + с 2 )1/2 для некоторых с> О и r Е R.
(5.17)
2. Обратная мультиквадратичная функция (inverse mu1tiquadric):
1
<p(r) == (r 2 + с 2 )1/2 для некоторых с> О и r Е R.
(5.18)
3. Функция Таусса (Gaussian function):
<р( r) == ехр ( ;;2 ) для некоторых cr > О и r Е R.
( 5.19)
Выражения для прямой и обратной мультиквадратичных функций даны соrлас
но [419].
Для Toro чтобы радиальные базисные функции (5.17Н5.19) бьши несинrулярны
ми, все точки {Xi}::l должны различаться. Больше для несинrулярности матрицы
Ф ничеrо не требуется, кроме размерности N множества примеров и размерно
сти то векторов Xi.
Обратная мультиквадратичная функция, представленная формулой (5.18), и функ-
ция [аусса (5.19) имеют одно общее свойство: они являются локализованными (lo
ca1ized) в том смысле, что <p(r) -----+ О при r -----+ 00. В обоих этих случаях матрица Ф
является положительно определенной. В отличие от них мультиквадратичная функ
ция (5.17) не является локализованной в том смысле, что при r -----+ 00 функция
неоrpаниченно возрастает. Соответствующая ей матрица Ф имеет N 1 отрицатель
ных собственных чисел и только одно положительное, следовательно, не является
положительно определенной [733]. Однако примечательно, что матрица интерполя
ции Ф, основанная на мультиквадратичной функции Харди, является несинrулярной
и, таким образом, приrодной для использования в конструкции сетей RВF.
5.4. Обучение с учителем как плохо обусловленная задача. . . 353
Еще более важным является тот факт, что радиальные базисные функции, Heorpa
ниченно возрастающие при стремлении aprYMeHTa к бесконечности (например, муль-
тиквадратичные функции), можно использовать для аппроксимации rладких отобра
жений с большей точностью, чем при использовании положительно определенной
матрицы. Этот удивительный результат рассматривается в [854].
5.4. Обучение с учителем как плохо обусловленная
задача восстановления rиперповерхности
Описанная ранее стандартная процедура интерполяции может не подходить для обу
чения нейронных сетей RВF в некоторых классах задач из за ПЛОХОй обобщающей
способности, вызванной следующей причиной: если количество точек данных обуча
ющеrо множества значительно превышает количество степеней свободы caMoro физи
ческоrо процесса, а нам требуется иметь столько же радиальных базисных функций,
сколько точек в обучающем множестве, задача оказывается избыточно определенной
(overdetermined). Следовательно, сеть может завершить свою настройку в неверном
пол.ожении, приняв во внимание сторонние шумы во входных данных, что, в свою
очередь, станет причиной плохоrо обобщения [160].
Чтобы rлубже понять проблему избытОЧНО20 подбора (overfitting) и выбрать спо
собы ее устранения, вспомним, что конструирование нейронной сети, призванной
rенерировать выходной сиrнал в ответ на входной пример, эквивалентно обучению
сети построению rиперповерхности (т.е. MHoroMepHoMY отображению), определяю
щей выходной вектор в терминах входноrо. Друrими словами, обучение paCCMaтpи
вается как задача реконструкции 2иперповерхности На основе множества точек,
которое может быть довольно разреженным.
Соrласно [554], [561] две задачи считаются обратными (inverse) друr друry, ec
ли формулировка каждой из них требует полноro или частичноro знания о друrой.
Обычно оказывается, что одна из задач уже решалась ранее и, возможно, даже более
детально, чем друrая. В таком случае первая задача называется прямой (direct prob
lem), а вторая обратной (inverse problem). Однако с точки зрения математики cy
ществует еще одно более важное отличие между прямой и обратной задачами. Задача
может быть плохо или хорошо обусловлена (well posed, ill posed). Термин "хорошая
обусловленность" используется в прикладной математике еще со времен Адамара
(Hadamard) с начала 1900 x roдов. Для TOro чтобы объяснить эту терминолоrию,
предположим, что область Х и диапазон У являются метрическими пространства
ми, которые связаны некоторым фиксированным, но неизвестным отображением f.
Задача реконструкции отображения f считается хорошо обусловленной, если выпол
няются следующие три условия [561], [756], [1056].
354
rлава 5. Сети на основе радиальных базисных функций
,..
1
!
1. Существование (existence). Для любоrо входноro вектора х Е Х существует BЫ
ходное значение у == f(x), [де у Е У.
2. Уникальность (uniqueness). Для любой пары входных векторов х, t Е Х равенство
f(x) == f(t) выполняется тоrда и только тоrда, коща х == t.
3. Непрерывность (continuity). Отображение считается непрерывным, если для лю
боro Е > О существует О == О(Е), такое, что из условия рх(х, t) < о вытекает,
что руи(х), f(y)) < Е, [де р(-,.) расстояние между двумя арrументами в co
ответствующих пространствах (рис. 5.3). Свойство непрерывности еще называют
устойчивостью (stabi1ity).
Если какое либо из этих условий не выполнено, задача считается плохо обусловлен
ной. По существу, плохая обусловленность задачи означает, что даже большой набор
данных может нести в себе удивительно малый объем информации о решении задачи.
В контексте рассматриваемой проблемы моделирование физических процессов,
обеспечивающих rенерирование обучающих данных (например, звуковой сиrнал,
изображение, эхо радара и т.п.), является хорошо обусловленной прямой задачей.
Однако обучение на примере таких физических данных, рассматриваемое как задача
восстановления rиперповерхности, является плохо обусловленной обратной задачей.
Это объясняется следующими причинами. Во первых, может быть нарушен крите
рий существования, так как не для каждоro входноro сиrнала может существовать
выходной. BO BTOpЫX, информации, содержащейся в примерах, может быть Heдo
статочно для корректной уникальной реконструкции отображения "BXOД BЫXOД". ЭТО
значит, что критерий уникальности также может быть нарушен. В третьих, неизбеж
ное наличие шумов в данных обучения вносит неопределенность в восстанавлива
емое отображение. В частности, если уровень шума во входном сиrнале слишком
высок, нейронная сеть в ответ на входной сиrнал х из области Х может давать на
выходе сиrнал, выходящий за пределы диапазона У. Друrими словами, здесь может
нарушаться критерий непрерывности. Если задача обучения не удовлетворяет крите
рию непрерывности, то вычисленное отображение входа на выход будет иметь мало
общеro с реальным решением задачи. Эту проблему никак нельзя обойти, если неиз
вестна какая либо априорная информация об отображении. В этом контексте будет
уместным вспомнить утверждение, сделанное в [609], относительно линейных диф
ференциальных операторов: "Недостаток информации нельзя восполнить никакой
математической хитростью".
В следующем разделе рассматривается важный вопрос: как плохо обусловленную
задачу сделатЬ хорошо обусловленной с помощью методов реrуляризации З .
3 Еще один подход к реryляризации на основе учета априорной информации в отображении байесовская
интерполяция (Bayesian interpolation). Подробное описание этоm подхода содержится в [695], [696], [776].
5.5. Теория реryляризации 355
Отображение
Рис. 5.3. Отображение (входной) области Х в (BЫ
ходной) диапазон У ОбластьХ
Диапазон У
5.5. Теория реryляризации
в 1963 roду Тихонов предложил НОВЫй метод, получивший название ре2уляриза
ции (regu1arization) и предназначенный для решения плохо обусловленных задач 4 .
В контексте задачи восстановления rиперповерхности rлавная идея реrуляризации
заключается в стабилизации решения с помощью некоторой вспомоrательной HeOT
рицательной функции, которая несет в себе априорную информацию о решении.
Наиболее общей формой априорной информации является предположение о rлад
кости функции искомоrо отображения (т.е. решения задачи восстановления) в том
смысле, что одинаковый входной сиrнал соответствует одинаковому выходному.
Для примера возьмем множество пар данных "BXOД BЫXOД" (т.е. пример обучения),
доступных для аппроксимации и описываемых следующим образом.
Входной сиrнал : Xi Е Rmo, i == 1,2,... ,N.
Желаемый отклик: d i Е R 1 , i == 1,2,... , N.
(5.20)
Обратите внимание, что предполаrается одномерность выходноrо сиrнала. Это дo
пущение никак не оrpаничивает применимость описываемой здесь теории реryляри
зации. Обозначим функцию аппроксимации как Р(х), [де (ДЛЯ упрощения выкладок)
в списке aprYMeHToB опущен вектор весов w. Теория реryляризации Тихонова в своем
изначальном виде использует два слаrаемых.
1. Сла2аемое стандартной ошибки (standard error term). Первое слаrаемое, обозна
чаемое Ев(Р), описывает стандартную ошибку (расстояние между желаемым OT
кликом d i И фактическим выходным сиrналом Yi для примера обучения i == 1,
4 Открытие теории реryляризации обычио приписывается Тихонову [1055]. Однако аналоrичный подход
был предложен в 1962 rоду Филлипсом [836]. По этой причине в первоисточниках можно встретить термин
ре2улярuзацuя Тuxонова ФШlЛuпса.
Одна из форм реryляризации была описана в работе, rде процесс сrлаживания назывался настройкой
(adjustment) наблюдений [1136].
Теория реryляризации подробно описывается в [561], [756], [1056].
...,.
356 rлава 5. Сети на основе радиальных базисных функций
2,..., N). В частности, можно определить
1 N 1 N
Es(F) == 2 L (d i Yi)2 == 2 L [d i F(Xi)]2,
i l i l
(5.21 )
rдe множитель 1/2 введен из соображений совместимости с материалом предыдущих I1Ш
2. Сла2аемое ре2уляризации (regu1arization term). Это второе слаrаемое, обозначае
мое Ec(F), зависит от "reометрических" свойств функции аппроксимации Р(х).
В частности, можно записать:
1 2
Ec(F) == 2 IIDFII ,
(5.22)
[де D линейный дифференциальный оператор (1inear differentia1 operator). Апри
орная информация о форме решения (т.е. о функции отображения F(x)), включен
ная в дифференциальный оператор D, обеспечивает ero зависимость от KOHKpeT
ной задачи. Оператор D иноrда еще называют стабилизатором (stabi1izer), так
как в задаче реryляризации он стабилизирует решение, делая ero rладким и, Ta
ким образом, удовлетворяющим свойству непрерывности. Заметим, что rладкость
предполаrает непрерывность, но не наоборот.
Аналитический подход, используемый для работы с соотношением (5.22), OCHO
ван на концепции ФункционалЬНО20 пространства 5 (function space), которая тесно
связана с понятием нормироваННО20 пространства 6 (normed space) функций. В таком
MHoroMepHoM (cTporo rоворя, бесконечномерном) пространстве непрерывная функ
ция представляется вектором. Используя это rеометрическое представление, можно
увидеть интуитивную связь между матрицей и оператором линейноro дифференци
рования. Таким образом, анализ линейнЫХ систем можно свести к анализу линейных
дифференциальных уравнений [609].
5 Концепция функциональиоm пространства впоследствии была развита rильбертом (Hi1bert) в em ис-
следовании одноm из классов интеrpальных уравнений. В то время как Фредmльм (Fredholm), основатель
интеrpала Фредroльма, сформулировал задачу на языке алreбры, rильберт увидел ее тесную связь с задачами
аналитической rеометрии (поверхности BТOpOro порядка в мноmмерных Евклидовых пространствах) [609].
6 Нормированным пространством называется пространство линейных векторов, в котором определена ве--
щественная Функцияllхll, называемая нормой х. Норма Ilxll обладает следующими свойствами:
Ilxll > о , для х # о,
11011 == о ,
Ilaxll == lal .llxll, rде а константа,
Ilx+yll Ilxll + Ilyll.
Норма Ilxll иrpает роль "длины" вектора х.
5.5. Теория реryляризации 357
Символ 11 . 11 в выражении (5.22) обозначает норму в функциональном простран
стве, к которому принадлежит DF(x). При обычных условиях используемое здесь
функциональное пространство является пространством L 2 , состоящим из всех дей
ствительных функций f(x), х Е Rm o , для которых норма IIf(x)112 является интеrpи
руемой по Лебеrу. Используемая здесь функция ЛХ) обозначает фактическую функ
цию, описывающую моделируемый физический процесс, отвечающий за reнерацию
пар примеров обучения {(Xi, d i )} 17.
Величиной, которую требуется минимизировать в теории реryляризации, является
N
Е(Р) == Es(F) + лЕс(F) == '" [d i F(Xi)]2 + л IIDFI12,
2 2
i l
(5.23)
rдe л положительное действительное число, называемое параметром ре2уляриза
ции (regularization parameter); Е(Р) Функционал Тихонова. Функционал отображает
функции (определенные в соответствующем функциональном пространстве) на ось
действительных чисел. Арrминимум функционала Тихонова Е(Р) (т.е. решение за-
дачи реrуляризации) обозначается Fл.(х).
В некотором смысле параметр реrуляризации л можно рассматривать как ИНдика
тор достаточности данноrо набора данных для определения решенияFл.(х). В частно
сти, крайний случай, л -----+0, означает, что задача является безусловной и имеет реше
ние Fл.(х), целиком зависящее от примеров. Друroй крайний случай, л -----+ 00, пред
полаrает, что caMoro априорноrо оrpаничения на rладкость, представленноrо диффе
ренциальным оператором D, достаточно для определения решения Fл.(х), Это может
указывать также на недостоверное количество примеров. В практических приложе
ниях параметр реryляризации л принимает некоторое среднее значение между этими
двумя крайними случаями. Этим определяется влияние на решение Fл.(х) как апри
орной информации, так и данных обучающей выборки. Таким образом, слаrаемое
реrуляризации Ес(Р) представляет собой функцию штрафа за сложность модели
(model complexity pena1ty function), влияние которой на окончательное решение опре
деляется параметром реrуляризации л.
7 Cтpom rоворя, требуется, чтобы функция f(x), обеспечивающая rенерирование данных, была членом
воспроизводящесо ядра (reproducing kerne1) ruльбертова пространства, представленноm в форме дельта
распределения Дирака О [1041]. При этом требуется убывание и бесконечная непрерывная дифференцируем ость
дельта функций этоro распределения. Этому условию удовлетворяет классическое пространство тестовых функ-
ций G для теорин распределения Шварца (Schwarz theory of distributions) с коиечной D обусловленной нормой:
Нр {! Е G : IIDIII < оо}. Обычно, коrда речь идет о rильбертовом пространстве, вспоминают только о
пространстве L2, возможно, нз за Tom, что последнее изоморфно любому rильбертову пространству. Однако са-
мым важным признаком rильбертова пространства является норма, а изометрия (т.е. изоморфизм, сохраняющий
норму) иrpает более важную роль, чем аддитивный изоморфизм [532]. Теория воспроизводящеm ядра rильбер-
това пространства показала, что кроме L2 существует масса различных н вполне приrодных для практическоm
использования rильбертовых пространств. Подробно эта теория описывается в [533].
..,
358 rлава 5. Сети на основе радиальных базисных функций
Считается, что теория реrуляризации обеспечивает практическое решение дилем-
мы смещения и дисперсии, которая рассматривалась в rлаве 2. В частности, оптималь
ный выбор параметра реryляризации л позволяет обеспечить удовлетворительное co
отношение между смещением и дисперсией модели (model bias & model variance) при
решении задачи обучения с учетом некоторой априорной информации.
Дифференциал Фреше функционала Тихонова
Теперь принцип ре2уляризации (regularization principle) можно записать в следую
щем виде.
Найти функцию Fл.(х), минимизирующую Функционал Тихонова Е(Р):
Е(Р) == Es(F) + лЕс(F),
2де Es (Р) сла2аемое стандартной ошибки; Ес( Р) сла2аемое ре2уляризации; л
параметр ре2уляризации.
Для TOro чтобы продолжить рассмотрение задачи минимизации функционала CTO
имости Е(Р), нужно задать правило оценки ero дифференциала. Это можно ocy
ществить с помощью дифференциала Фреше (Frechet differential). В элементарной
математике касательной к кривой называется прямая, которая дает наилучшую ап
проксимацию кривой в окрестности точки касания. Аналоrично, дифференциал Фре
ше функционала можно интерпретировать как наилучшую локальную линейную ап
проксимацию. Таким образом, дифференциал Фреше функционала Е( Р) формально
определяется выражением [246], [250], [263]
dE(F, h) == [ : Е(Р + h)] o '
(5.24)
ще h(x) фиксированная функция вектора х. В выражении (5.24) используются
обычные правила дифференцирования. Необходимым условием Toro, чтобы функция
Р(х) была относительным экстремумом функционала Е(Р), является равенство нулю
дифференциала Фреше dE(F, h) по F(x) для всех h Е Н, Т.е.
dE(F, h) == dEs(F, h) + лdЕс(F, h) == О,
(5.25)
rдe dEs(F, h) и dEc(F, h) дифференциалы Фреше функционалов Es(F, h) и
Ес(Р, h) соответственно.
5.5. Теория реryляризации 359
Оценивая дифференциал Фреше слаrаемоrо стандартной ошибки Е s (Р, h), опре
деляемоrо формулой (5.21), имеем:
dEs(F, h) == [ dd Es(F + h)] o ==
== [ dd f [d i F(Xi) h(Xi)]2 ]
, 1 o
N
== L: [d i F(Xi) h(Xi)] h(Xi)I o ==
i l
N
== L: [d i F(Xi)]h(Xi)'
i l
(5.26)
Здесь будет уместным привести теорему Ритца о представлении (Riesz represen
tation theorem), которая формулируется следующим образом [246, 561].
Пусть f 02раниченный линейный функционал в ruльбертовом пространстве
(т.е. в полном пространстве скалярных произведений)8, которое обозначается сим
волом Н. ТО2да существует единственное значение ho Е Н, такое, что
f == (h, hO)H для всех ho Е Н,
при этом
Ilfllй == Ilholl H ,
2де Н пространство, сопряженное rильбертову пространству Н.
8 Пространством скалярных про изведений (inner product space) называется линейное пространство Beктo
ров, в котором скалярное произведение двух векторов и и v, обозначаемое как (и, v), обладает следующимн
свойствами:
(и, v) (v, и),
(аи, v) '" а(и, v), а константа,
(и + v, w) '" (и, w) + (v, w),
(и, и) > О для и i- О.
Пространство скалярных произведений Н является полным (complete) и называется rильбертовым простран
ством, если любая последовательность Коши, выбранная из этоro пространства, сходится по норме к KaKOMY
либо пределу. Последовательность векторов {Хn} называется последовательностью Коши, если для любоm
Е> О существует число N, такое, что [246]
Ilxm xnll < Е для всех (п, т) > М.
360 rлава 5. Сети на основе радиальных базисных функций
Символом (-, о) н здесь обозначается скалярное про изведение двух функций в про
странстве Н. В свете теоремы Ритца о представлении дифференциал Фреше dE s (Р, h)
из (5.26) можно переписать в эквивалентном виде:
dEs(F, h) == ( h, t (d i F)OXi ) ,
. 1 Н
(5.27)
rдe ОХ; дельта распределение Дирака (Dirac de1ta distribution) вектора х, с центром
в точке Xi, Т.е.
ОХ; == о(х Xi)'
(5.28)
Аналоrично рассмотрим следующую оценку дифференциала Фреше слаrаемоrо
реrуляризации Ес(Р) из (5.22):
dEc(F, h) == dd Ec(F + h) I o == dd Lmo (D[F + h])2dx I o ==
== r D[F + h]Dhdx I o == r DFDhdx == (DF, Dh)H,
J mo J mo
(5.29)
rдe (DF, Dh)H скалярное произведение функций Dh(x) и DF(x), которые
являются результатом применения оператора дифференцирования D к h(x) и
Р(х) соответственно.
Уравнение Эйлера Лаrранжа
Для данноr:> оператора D можно найти такой уникально определенный сопряженный
оператор D, что для любой пары дифференцируемых функций и(х) и v(x), удовле
творяющих соответствующим rpаничным условиям, можно записать [609]:
r и(x)Dv(x)dx == r v(x)Dи(x)dx.
J m J m
(5.30)
Равенство (5.30) получило название тождества Трина (Green's ident ty). Оно под
водит математический базис под определение сопряженноrо оператора D в терминах
данн:>ro дифференциала D. Если рассматривать D как матрицу, сопряженный опера
тор D иrpает роль, аналоrичную транспонированной матрице.
Сравнивая тождество (5.30) с предпоследней выкладкой (5.29), можно установить
следующие соответствия:
и(х) == DF(x),
Dv(x) == Dh(x).
5.5. Теория реryляризации 361
Используя тождество fрина, (5.29) можно переписать в эквивалентной форме:
dEc(F, h) == r h(x)f>DF(x)dx == (h, f>DF)H,
J'.R"'O
(5.31)
rдe D оператор, сопряженный D.
Возвращаясь к условию экстремума, описанному выражением (5.25), и подставляя
в Hero дифференциалы Фреше из (5.27) и (5.31), дифференциал Фреше dE(F, h)
можно представить в следующем виде:
dE(F,h) (h, [fШF t(d; P)5 ]) н
(5.32)
Так как параметру реryляризации л обычно присваивается некоторое значение из
открытоrо интервала (О, (0), дифференциал Фреше равен нулю для любоrо h(x) в
пространстве Н Torдa и только Torдa, Korдa выполняется следующее условие в CMЫC
ле распределения:
1 N
DDF л L (d i F)8x; == О,
i l
или, что эквивалентно,
1 N
f>DFл(х) == L [d i F(Xi)]8(x Xi)'
i l
(5.33)
Уравнение (5.33) называется уравнением Эйлера ЛG2ранжа (Eu1er Lagrange equa
tion) для функционала Тихонова E(F). Оно является необходимым условием суще
ствования экстремума функционала Тихонова в точке Fл.(х) [246].
Функция rрина
Соотношение (5.33) представляет собой уравнение в частных производных функции
аппроксимации F. Решение этоro уравнения состоит в интеrpальном преобразовании
ero правой части.
Пусть С(х, ) функция, в которой векторы х и используются для разных целей:
вектор х используется как параметр, а как apryMeHT. Предполаrается, что для
данноro оператора линейноrо дифференцирования L функция С(х, ) удовлетворяет
следующему условию [217].
1. Для фиксированноrо G (x, ) является функцией от х и удовлетворяет rpаничным
условиям.
362 rлава 5. Сети на основе радиальных базисных функций
2. ВО всех точках, за исключением х == , все производные С(х, ) по х являются
непрерывными. Количество производных определяется порядком оператора L.
3. Если рассматривать С(х, ) как функцию от х, она удовлетворяет уравнению в
частных производных
LG(x, ) == О,
(5.34)
Всюду, за исключением точки х == , rдe она имеет особенность. Это значит,
что функция С(х, ) удовлетворяет уравнению в частных производных (в смысле
распределения)
LG(x, ) == о(х ),
(5.35)
rдe, как rоворилось ранее, о(х ) дельта функция Дирака с центром в точке
х == .
Описанная таким образом функция C(x, ) называется функцией Трина (Green's
function) для оператора дифференцирования L. Функция fрина иrpает ту же
роль для оператора дифференцирования, которую в матричном исчислении иrpа
ет обратная матрица.
Пусть <р(х) непрерывная или кусочно непрерывная функция aprYMeHTa х Е эtmо.
Torдa функция
Р(х) == l т о C(x, )<p( )
(5.36)
является решением дифференциальноro уравнения
LF(x) == <р(х),
(5.37)
rдe C(x, ) функция fрина для линейноrо оператора дифференцирования L [217].
Для Toro чтобы доказать правильность выбора Р(х) в качестве решения уравнения
(5.37), применим к выражению (5.36) оператор дифференцирования L, в результате
чеro получим:
LF(x) == L l т о C(x, )<p( ) == l т о LG(x, )<p( ) .
(5.38)
Оператор дифференцирования L использует как константу, работая с функцией
fрина только как с функцией от aprYMeHTa х. Используя в выражении (5.38) формулу
(5.35), получим:
LF(x) == r о(х )<p( ) .
J 'Нто
5.5. Теория реryляризации 363
И, в заключение, используя просеивающее свойство дельта функции Дира
ка, а именно
lmo <p(l;)8(x l;)dl; == <р(х),
получим LF(x) == <р(х), что и было описано в выражении (5.37).
Решение задачи реryляризации
Возвращаясь к нашей задаче, а именно к решению уравнения Эйлера Лаrpанжа
(5.33), определим:
L == DD
(5.39)
и
1 N
<p(l;) == J: L [d i F(Xi)]8(l; Xi)'
i l
(5.40 )
Torдa можно использовать (5.36) и записать:
F,(x) J. " G(x, ) { t [d, F(x,)]8( х,)}
1 N 1
== J: [d i F(Xi)] тo G(x,l;)8(l; xi)dl;,
rдe в последней строке изменен порядок интеrpирования и суммирования. Используя
свойство просеивания дельта функции Дирака, получим требуемое решение ypaBHe
ния Эйлера Лаrpанжа:
1 N
Fл(х) == J: L [d i F(Xi)]G(X, Xi)'
i l
(5.41)
Выражение (5.41) означает, что минимизирующее решение Fл(х) задачи реrуляри
зации является линейной суперпозицией N функций fрина. Векторы Xi представляют
собой центры разложения (center of expansion), а веса [d i F(Хi)]/Л коэффици
енты разложения (coefficient of expansion). Друrими словами, решение задачи pe
ryляризации лежит в N MepHoM подпространстве пространства rладких функций, а
множество функций fрина {С(х, Xi)}, с центром в Xi, i == 1, 2,... , N, определяет
базис этоro подпространства [847]. Обратите внимание, что коэффициенты разложе
364 rлава 5. Сети на основе радиальных базисных функций
ния В (5.41) являются, во первых, линейными относительно ошибки оценки, опре
деленной как разность между желаемым откликом d i и соответствующим выходным
сиrналом F(Xi), вычисляемым сетью, и, BO BTOpЫX, обратно пропорциональными па
раметру реryляризации л-.
Определение коэффициентов разложения
Следующим вопросом является определение коэффициентов разложения в выраже
нии (5.41). Пусть
1 .
щ== [di F(Хi)]' 2==1, 2,...,N.
(5.42)
Тоща выражение для минимизирующеrо решения (5.41) можно упростить:
1 N
Fл(х) == L щG(х, Xi)'
i l
(5.43)
Вычисляя (5.43) в точке Xj, j == 1, 2, . . . , N, получим:
N
Fл(Хj) == L щG(Хj, Xi), j == 1,2,... , N.
i l
(5.44 )
Введем следующие определения:
F л == [Fл(Х1), F л (Х2),'" ,Fл(ХN )]Т,
d == [d 1 , d 2 ,..., dN]T,
[ С(Х1 ,Х1) С(Х1 ,Х2) о.. С(Х1 ,XN) ]
G == X2 ,Х1) X2 ,Х2) ::: X2 ,XN ) ,
G(XN ,Х1) G(XN ,Х2) . . . G(XN ,XIN)
W == [Ш1' Ш2,..., WN]T.
(5.45)
(5.46)
(5.47)
(5.48)
Теперь (5.42) и (5.44) можно пере писать в матричной форме:
1
w== (d Fл) (5.49)
л-
и
F л == Gw. (5.50)
5.5. Теория реryляризации 365
Подставляя выражение дЛЯ F" из (5.50) и (5.49) и переставляя слаrаемые, получим:
(G + л.I)w == d,
(5.51 )
ще 1 единичная матрица размерности N х N. Матрица G называется матрицей
Трина (Green's matrix).
Оператор дифференцирования L, определяемый выражением (5.39), является ca
мосопряженным (se1f adjoint). Это значит, что оператор, сопряженный L, равен ему
самому. Отсюда следует, что ассоциированная функция fрина G(x, Xi) является сим
метричной, Т.е.
G(Xi' Xj) == G(Xj, Xi) для всех i и j.
(5.52)
Уравнение (5.52) означает, что позиции двух точек Х и можно поменять местами,
при этом значение функции fрина G(x, ) не изменится. Аналоrично, матрица fрина,
определяемая выражением (5.52), является симметричной, Т.е.
G T == G.
(5.53)
Теперь можно применить теорему об интерполяции, сформулированную в разде
ле 5.3, в контексте матрицы интерполяции Ф. Во первых, заметим, что матрица fрина
G иrpает в теории реryляризации роль, аналоrичную той, которую матрица Ф иrpает
в теории интерполяции на основе сетей RВF. Обе матрицы, Фи G, являются симмет
ричными и имеют размерность N х N. Следовательно, можно утверждать, что MaT
рица G для некоторых классов функций fрина является положительно определенной
при условии, что точки Х1, . .., XN различны. Классы функций fрина, охватываемые
теоремой Мичелли, включают обратные параболические функции и функции [ayc
са, но не включают параболические функции. На практике всеrда можно выбрать
значение л., достаточно большое для обеспечения положительной определенности
матрицы (G + л.I) и, таким образом, для возможности ее инвертирования. А это, в
свою очередь, значит, что система линейных уравнений (5.51) имеет единственное
решение, определяемое следующим образом [847]:
w == (G + л.I) ld.
(5.54)
Таким образом, выбрав оператор дифференцирования D и имея набор функций
fрина G(Xi' Xj), [де i == 1,2,.. . , N, соотношение (5.44) можно использовать для по
лучения вектора весов w, соответствующеrо вектору желаемоro отклика d и данному
значению параметра реryляризации л..
..,..
366 rлава 5. Сети на основе радиальных базисных функций
в заключение можно утверждать, что решение задачи реryляризации задается
следующим разложением 9 :
N
Fл(х) == L щG(х, Xi),
i l
(5.55)
[де С(х, Xi) функция fрина для самосопряженноrо оператора L == DD; щ i й
элемент вектора весов w. Эти два равенства задаются выражениями (5.35) и (5.54)
соответственно. Уравнение (5.55) означает следующее [847].
· Реryляризационный подход эквивалентен разложению решений в терминах MHO
жества функций fрина, характеристики которых зависят от принятой формы опе
ратора дифференцирования D и соответствующих rpаничных условий.
· Количество функций fрина, используемых в разложении, равно количеству при
меров, используемых при обучении.
Однако нельзя не заметить, что решение задачи реrуляризации, представленное
выражением (5.55), является неполным, так как представляет собой лишь решение по
модулю g(x), лежащее в нуль пространстве оператора D [847]. Это объясняется тем,
что все функции, лежащие в нуль пространстве оператора D, являются "невидимыми"
для слаrаемоrо сrлаживания IIDFI12 в функционале стоимости E(F) (5.23). Под нуль
пространством оператора D понимается множество всех функций g(x), для которых
выполняется Dg ==0. Точная форма дополнительноrо слаrаемоrо g(x) определяется
для конкретной задачи в том смысле, что она зависит от выбранноrо стабилизатора
и rpаничных условий данной задачи. Например, оно не требуется для стабилизатора
D, соответствующеrо колоколообразной функции fрина, такой как функция [аусса.
Поскольку включение дополнительноrо слаrаемоrо не влияет на основные выводы, в
дальнейшем мы ero учитывать не будем.
9 В [361] представлен друmй метод вывода формулы (5.55) на основе связывания слаraемоm реryляризации
Ес(Р) с rладкостью функции аппроксимации F(x) непосредственно.
rладкость в этой работе рассматривалась как мера колебания функцни. В частности, считалось, что одна
функция является более rладкой, нежели друrая, если ее колебания меньше по амплитуде. Дрyrими словами,
мерой шадкости функции считалась частота ее колебаний. Предполаrая именно такую меру rладкости, обо
значим термином F(s) MHoroMepHoe преобразование Фурье функции Р(х), rдe s мноmмерная переменная
преобразования. Пусть H(s) некоторая положительная функцня, которая стремится к нулю при стремлении
нормы apryMeHTa s к бесконечности, так что 1/ H(s) представляет собой фильтр верхних частот (high-pass
filter). Сошасио вышеупомянутой работе можно определить rладкий функциоиал для слаrаемоrо реryляризации
в следующем виде:
Ес(Р) == .!. 1 IF(s)12 ds,
2 mmo H(s)
rдe то размерность вектора х. Соrласно теореме Парсеваля (Parseva]'s theorem) из теории Фурье этот
функционал является мерой мощности выходноrо сиrнала фильтра верхних частот 1/ H(s). Таким образом,
переводя теорию реryляризации в плоскость теории Фурье и используя свойства преобразования Фурье, в
вышеупомянутой работе была выведена формула (5.55).
5.5. Теория реryляризации 367
Характеристика функции rрина С(х, Xi) для заданноro центраХi зависит только от
формы стабилизатора D (соrласно априорному предположению касательно искомоrо
отображения "BXOД BЫXOД"). Если стабилизатор D является инвариантным к преоб
разованиям (trans1ationally invariant), то функция rрина С(х, Xi) с центром в Xi, будет
зависеть только от разности между арryментами Х и Xi, Т.е.
С(х, Xi) == С(х Xi)'
(5.56)
Если же стабилизатор D инвариантен как к преобразованuям, так и к поворотам
(rotationally), то функция rрина С(х, Xi) будет зависеть только от Евклидовой нормы
вектора разности (X Xi), Т.е.
G(X,Xi) == G(llx Xill).
(5.57)
При этих условиях функция rрина должна быть радиальной базисной функцией.
В таком случае решение задачи реrуляризации (5.55) принимает следующую част
ную форму [847]:
1 N
Fл(х) == L щG(llх xill).
i l
(5.58)
Решение (5.58) определяет пространство линейных функций, зависящее от извест
ных точек данных и с учетом Евклидова расстояния.
Решение, описанное выражением (5.58), называется стРО20Й интерполяцией (strict
interpolation), так как для интерполяции функции F(x) используются все N точек,
доступных для обучения. Однако при этом важно отметить, что это решение в корне
отличается от решения (5.11): оно реrуляризировано с помощью определения (5.54)
для вектора весов w. Только при достижении параметром реrуляризации значения,
paBHoro нулю, эти два решения становятся идентичными.
MHorOMepHbIe функции raycca
Функция rрина С(х, Xi), линейный дифференциальный оператор D которой инвари
антен к трансформациям и вращению и удовлетворяет условию (5.57), представляет
на практике большой интерес. Примером такой функции rрина является МНО20мерная
функция Таусса (mu1tivariate Gaussian function), определяемая следующим образом:
С(х, Xi) == ехр ( 2 Ilx XiI12},
(5.59)
1
368 rлава 5. Сети на основе радиальных базисных функций
[де Xi центр функции; (Ji ее ширина. Само сопряженный оператор L DD
определяет функцию rрина в (5.59), имеющую вид [847]
00
L == L ( 1)nanV2n,
n O
(5.60)
[де
(J2n
,
а n == п!2 n '
(5.61)
а V 2n итерированный оператор Лапласа для то измерений
82 82 82
V 2 == 8 2 + 8 2 + .. . + 8 2 .
Х 1 Х 2 Х то
(5.62)
При стремлении количества слаrаемых в (5.60) к бесконечности L становится диф
ференциальным оператором в обычном смысле. Поэтому оператор L в формуле (5.60)
называется псевдодифференциальным оператором (pseudo differentia1 operator). Ис
ходя из определения L == DD, можно сделать вывод, что оператор D и сопряженный
ему f> можно представить в виде 1О
"'"'" 1/2 ( 8 8 8 ) n
D an 8 + 8 +"'+ 8
n Х1 Х2 Хто
"'"'" 1 / 2 8 n
а n 8x 8x ... 8x
a+b+...+k n о
(5.63)
"'"'" n 1/2 ( 8 8 8 ) n
D ( l) а n 8 + 8 +"'+ 8
n Х1 Х2 Хто
"'"'" ( 1)na1/2 8 n
n 8ха8хЬ.. .8x k
a+b+...+k n 1 2 то
(5.64)
10 Самой общей формой оператора дифференцирования является следующая:
д n
D p(Xl,X2,,,,,Xmo) Ь k ' a+b+...+k n,
дx дX2 ... дх то
rдe Хl, Х2, . . . , Хто элементы вектора х; р( Хl, Х2, . . . , Х то ) некоторая функция этих элементов. Сопря-
женный оператор в этом случае выrлядит следующим образом [757]:
д n
D ( l)n ь k [Р(Хl,Х2"",Х т )], a+b+...+k n.
дx дX2 . . . дх то
5.6. Сети реryляризации 369
Таким образом, реryляризированное решение (5.58) достиrается за счет использо
вания стабилизатора, включающеro все возможные частные производные.
Используя выражения (5.59Н5.61) в (5.35) и приравнивая l; к Xi, можно записать:
L ( 1)n nn v 2n ехр ( 2 IIX xJ2) == 8(х Xi)'
n
(5.65)
Определяя функцию rрина С(х, Xi) в специальном виде (5.59), реryляри
зируемое решение (5.55) принимает форму линейной суперпозиции MHoroMep
ных функций [аусса:
N ( 1 2 )
Fл(х) == щ ехр 20' Jlx xill ,
(5.66)
rдe сами линейные веса Wi определяются по формуле (5.42).
В выражении (5.66) отдельные слаrаемые функции [аусса, определяющие функ
цию аппроксимации F(x), в качестве apryMeHToB содержат разные переменные. Для
упрощения изложения в F(x) часто принимается условие O'i == о' для всех i. Несмотря
на то что определенные таким образом функции имеют несколько оrpаниченный вид,
они остаются универсальными аппроксиматорами [815].
5.6. Сети реryляризации
Для реализации разложения реryляризованной функции аппроксимации F,,(x), пред
ставленной в (5.55) в терминах функции rрина С(х, Xi) с центром в точке Xi, можно
использовать нейросетевую структуру, показанную на рис. 5.4. По очевидным причи
нам такие сети называются сетями ре2уляризации (regularization network) [847]. Как
и сеть, представленная в разделе 5.1, эта сеть имеет три слоя. Входной слой COCTO
ит из входных узлов, количество которых равно размерности то вектора входноrо
сиrнала Х (т.е. количеству независимых переменных в задаче). Второй слой является
скрытым. Он состоит из нелинейных элементов, которые непосредственно связаны
со всеми узлами входноrо слоя. Для каждой точки данных Xi (i == 1, 2, . . . , N, rдe
N размер множества примеров обучения) существует свой скрытыIй узел. Функ
циями активации отдельных узлов cкpbIToro слоя являются функции rрина. Сле
довательно, выходной сиrнал i ro нейрона cKpbIToro слоя определяется как С(х, Xi)'
Выходной слой состоит из единственноro линейноro нейрона, связанноro со всеми уз
лами cкpbrroro слоя. Под "линейностью" подразумевается то, что ero выход является
линейно взвешенной суммой всех выходных сиrналов cKpbIToro слоя. Веса выходноro
слоя являются неизвестными коэффициентами разложения, определяемоro в терми
нах функций rрина С(х, Xi) и параметра реrуляризации л (см. (5.54)). На рис. 5.4
370
rлава 5. Сети на основе радиальных базисных функций
1
I
,
t
t
Х,
F(x)
Х 2
Xт l
Х т
Входной
слой
Скрытый слой,
состоящий
из N функций
[рина
Выходной
слой
Рис. 5.4. Сеть реryляризации
1
Х,
Х 2
Xт l
Х т
Входной
Слой
Скрытый слой,
состоящий
из т 1 радиальных
базисных функций
Выходной
слой
Рис. 5.5. Сеть на основе ради
альных базисных функций
показана архитектура сети реryляризации с одним выходом. На рисунке видно, что
такая архитектура может быть расширена для выходноrо сиrнала любой размерности.
В сети реryляризации, показанной на рис. 5.5, предполаrается, что функция I)>ина
С(х, Xi) является положительно определенной для всех Xi. При выполнении этоro
условия (например, если функция rрина имеет вид функции [аусса (5.59)) решение,
rенерируемое сетью, будет являться оптимальной интерполяцией в смысле миними
зации функционала Е(Р). Более Toro, с точки зрения теории аппроксимации сети
реryляризации обладают следующими положительными свойствами [847].
5.7. Обобщенные сети на основе радиальных базисных функций 371
1. Сеть реrуляризации является универсальным аппроксиматором в том CMЫC
ле, что при большом количестве скрытых элементов она способна доволь
но хорошо аппроксимировать любую непрерывную функцию на компакт
ном подмножестве из Rm o .
2. Так как схема аппроксимации, вытекающая из теории реrуляризации, является ли
нейной относительно неизвестных коэффициентов, то сети реrуляризации облада
ют свойством наилучшей аппроксимации (best approximation property). Это значит,
что для неизвестной линейной функции f всеrда существует такой набор коэф
фициентов, который аппроксимирует функцию f лучше любоrо друrоrо набора.
3. Решение, обеспечиваемое сетью реryляризации, является оптимальным. Под оп
тимальностью здесь понимается то, что сеть реrуляризации минимизирует функ
ционал, измеряющий удаленность решения от cBoero истинноro значения, пред
ставленноrо примерами обучения.
5.7. Обобщенные сети на основе радиальных
базисных функций
Однозначное соответствие между данными обучения Xi и функциями rрина G(x,
Xi) для i == 1, 2, ..., N явилось основой создания сети реrуляризации, которая
в вычислительном смысле при больших значениях N является очень pecypcoeM
кой. В частности, вычисление линейных весов сети (т.е. коэффициентов разложения
в (5.55)) требует реализации операции обращения матрицы размерности N х N,
вычислительная сложность которой возрастает пропорционально N З . Более Toro,
для больших матриц ухудшается обусловленность, поскольку число обусловленно
сти (condition nиmber) матрицы определяется как отношение ее максимальноrо соб
cTBeHHoro числа к минимальному. Для Toro чтобы обойти эти вычислительные TPYД
ности, необходимо уменьшить сложность сети, Т.е. найти некоторую аппроксима
цию реrуляризированноrо решения.
Такой подход предполаrает поиск субоптимальноrо решения в пространстве MeHЬ
шей размерности, аппроксимирующеrо реrуляризированное решение (5.55). Для это
ro используется стандартный прием, получивший в вариационных задачах название
метода Талеркина (Ga1erkin's method). Соrласно этой технолоrии приближенное pe
шение Р*(х) находится как разложение по конечному базису, Т.е. [847]
тl
Р*(х) == L Щ<Рi(Х)'
i l
(5.67)
rдe {<Pi(X)1 i == 1,2, ..., т1} новое множество базисных функций, которые без
потери общности предполаrаются линейно независимыми, а Wi новое множество
весов. Обычно количество базисных функций меньше числа точек данных обучения
...,
,.
!
372 rлава 5. Сети на основе радиальных базисных функций
(т.е. т1 :::; N). ДЛЯ радиальных базисных функций можно принять
<Р i ( х) == G ( 11 Х t i 11 ), i == 1, 2, .. . ,т 1 ,
(5.68)
[де множество центров {til i == 1,2,..., т1} необходимо определить. Только такой
выбор базисных функций rарантирует, что в случае т1 == N и
t i == Xi, i == 1,2,. . . , N
корректное решение (5.58) будет полностью восстановлено. Таким образом, подстав
ляя (5.68) в (5.67), можно переопределить Р*(х) следующим образом:
тl тl
Р*(х) == L щG(х, t i ) == L щG(llх till).
(5.69)
i l
i l
Для данноro разложения (5.69) функции аппроксимации Р*(х) задача сводится к
определению HOBoro множества весов {Wil i == 1,2,. . . , т1}, которое минимизирует
новый функционал стоимости Е(Р*), определяемый следующим образом:
N ( т ) 2
Е(Р*) == d i t. wjG(IIXi t j 11) + л IIDF* 112 .
(5.70)
Первое слаrаемое в правой части (5.70) может быть выражено как квадратичная
Евклидова норма Ild Gw11 2 , [де
д== [d 1 ,d 2 ,...,d N ]T,
[ G(X1,t 1 ) G(X1,t2) о.. G(X1,t ffi1 ) 1
G == X2' t 1 ) X2' t 2 ) ::: X2' t ffi1 ) ,
G(XN, t 1 ) G(XN' t 2 ) .., G(XN, t ffi1 )
w == [W1, W2,'" , W ffi1 ]T.
(5.71)
(5.72)
(5.73)
Вектор желаемоrо отклика остается, как и ранее, N MepHЫM. Однако размерности
матрицы G функций rрина и вектора весов w изменяются. Матрица G теперь имеет
размер N х т1 и, таким образом, перестает быть симметричной. Вектор w имеет
размерность т1 х 1. Из выражения (5.69) видно, что функция аппроксимации Р* ЯВ
ляется линейной комбинацией функций rрина для стабилизатора D. Следовательно,
5.7. Обобщенные сети на основе радиальных базисных функций 373
второе слаrаемое в правой части (5.70) можно выразить следующим образом:
IIDF*112 == (DF*, DF*)H ==
== [ ЩG(Х, t i ), DD щG(х, t i )] Н ==
[ щG(х, t i ), щD t i )] н
тl тl
== L: L: WjщG(t j , t i ) ==
j l i l
== wTGOW'
(5.74)
[де во второй и в третьей строках используется определение сопряженноrо оператора
и выражение (5.35) соответственно. Матрица G o является симметричной матрицей
размерности т1 х т1:
G o ==
[ G(t 1 ,t 1 ) G(t1,t2) ...G(t 1 ,t ffi1 ) ]
G(t 2 ,t 1 ) G(t 2 ,t 2 ) о.. G(t 2 ,t ffi1 )
G(t ffi1 , t 1 ) G(t ffi1 , t 2 ) о.. G(t m1 , tmJ
(5.75)
Таким образом, минимизация (5.70) по отношению к вектору w приводит к сле
дующему результату (см. задачу 5.5):
(GTG + лGо)w == G T д.
(5.76)
Если параметр реryляризации л принимает значение, равное нулю, вектор w
сходится к псевдообратному (по минимальной норме) решению сверхопределенной
(overdetermined) задачи подбора кривой на основе метода наименьших квадратов
(1east sqиares data fitting problem) для т1 < N [160]:
w == G+d, л == О,
( 5.77)
rдe G+ матрица, псевдообратная матрице G, Т.е.
G+ == (GTG) lGT.
(5.78)
Взвешенная норма
Норма в приближенном решении (5.69) обычно рассматривается как Евклидова. Oд
нако если отдельные элементы входноrо вектора х принадлежат разным классам, бо
лее целесообразным будет использование общей взвешенной нормы (weighted norm)
r
374 rлава 5. Сети на основе радиальных базисных функций
квадратичной формы, имеющей вид [847]
Ilxll == (Сх)Т(Сх) == хТсТсх,
(5.79)
rдe С Maтpицa взвешенной нормы (norm weight matrix) размерности то х то; то
размерность входноro вектора х.
Используя определение взвешенной нормы, выражение для аппроксимации pery-
ляризированноro решения (5.69) можно пере писать в более общей форме [675], [847]:
тl
F*(x) == L щG(llх till c )'
i l
(5.80)
Использование взвешенной нормы можно интерпретировать двумя способами. Bo
первых, как применение аффиННО20 преобразованuя (affine transformation) к исход
ному входному пространству. В принципе, возможность TaKoro преобразования не
искажает результаты, так как оно фактически соответствует единичной матрице взве
шивания нормы. BO BTOpЫX, взвешенная норма вытекает непосредственно из незна
чительноrо обобщения ffio MepHoro Лапласиана в определении псевдодифференци
альноro оператора (5.63) (см. задачу 5.6). Использование взвешенной нормы может
быть обосновано в контексте [ауссовых радиальных базисных функций следующим
образом. [ауссова радиальная базисная функция G(llx tillc) с центром в точке t; и
матрицей взвешивания нормы С может быть представлена следующим образом:
G(llx цс) == exp[ (x ti)TCTC(X t i )] ==
== ехр [ (x ti)Tb l(X t i )]
(5.81)
[де обратная матрица E l определяется соотношением
E l == сТс.
2
(5.82)
Выражение (5.81) представляет собой MHoroMepHoe распределение [аусса с BeK
тором среднеrо значения t i и матрицей ковариации Е, Т.е. обобщение распределения,
описываемоrо формулой (5.59).
Решение задачи аппроксимации, представленное формулой (5.70), открывает воз
можность для создания обобщенных сетей на основе радиальных базисных функций
(RВF), имеющих структуру, показанную на рис. 5.5. Конструкция этой сети преду
сматривает использование пороrа (т.е. независимой от данных переменной), приме
няемоrо к выходному узлу сети. Это делается путем установки одноrо из линейных
весов выходноrо слоя сети равным пороrу и назначения соответствующей радиальной
базисной функции постоянноrо значения + 1.
5.7. Обобщенные сети на основе радиальных базисных функций 375
в структурных терминах обобщенная сеть RВF на рис. 5.5 аналоrична RВF сети
реrуляризации, представленной на рис. 5.4. Однако они имеют два важных отличия.
1. Количество улов cKpbIToro слоя в обобщенной сети RВF равно т1, [де тl обычно
меньше количества примеров обученияN. С друroй стороны, количество скрытых
узлов в RВF сетях реrуляризации cTporo равно N.
2. В обобщенных сетях RВF (см. рис. 5.5) линейные веса, связанные с выходным
слоем, положение центров радиальных базисных функций и матрица взвешенной
нормы, соответствующая скрытому слою, являются неизвестными параметрами,
которые определяются в процессе обучения. В функции активации cKpbIтoro слоя
в RВF сетях реrуляризации (см. рис. 5.4) известны, так как определяются множе
ством функций rрина с центрами в точках примеров обучения. Единственными
неизвестными параметрами этой сети являются линейные веса выходноrо слоя.
Рецептивные поля
Матрица ковариации Е определяет рецептивное поле, или поле чувствительности
(receptive fie1d), rауссовой радиальной базисной функции G(llx till c ), определен
ной формулой (5.81). Для известноrо центра t i поле чувствительности G(llx tillc)
обычно определяется как опорная функция
Ф(х) == G(llx till c ) а,
(5.83)
[де а некоторая положительная константа [1169]. Друrими словами, поле чув
ствительности функции G(llx ti 110) является подмножеством области определения
входноrо вектора х, в которой эта функция принимает особенно большие значения
(больше заданноrо уровня а).
Аналоrично определению матрицы взвешенной нормы С можно выделить три
различных способа задания матрицы ковариации <J, отражающие ее влияние на форму,
размеры и ориентацию поля чувствительности.
1. Е == <J2J, [де J единичная матрица; <J2 общая дисперсия. В этом случае
поле чувствительности функции G(llx till c ) представляет собой rиперсферу с
центром t i и радиусом <J.
2. Е == diag( <J , <J , . . . , <J o)' [де <J; дисперсия j ro элемента входноro вектора х; j
1,2,..., то. В этом случае поле чувствительности функции G(llx till c ) пред
ставляет собой rиперэллипсоид, полуоси KOToporo совпадают с осями входноrо
пространства и имеют длину <Jj.
3. Е недиаrональная матрица. По определению матрица ковариации (J яв
ляется положительно определенной. Исходя из этоrо, можно использовать
l
376 rлава 5. Сети на основе радиальных базисных функций
преобразование подобия из алrебры матриц для декомпозиции матрицы
(J следующим образом:
Е == QTAQ,
(5.84)
[де А диаroнальная матрица; Q матрица ортоrональноrо вращения. Матрица
А определяет форму и размер поля восприятия, а матрица Q ero ориентацию.
5.8. Задача XOR (повторное рассмотрение)
Рассмотрим еще раз задачу XOR (исключающеrо ИЛИ), которая уже была решена
в rлаве 4 с помощью мноrослойноrо персептрона с одним скрытым слоем. В этом
разделе приводится решение этой же задачи, но уже с помощью сетей RВF.
Исследуемая сеть RВF состоит из пары функций [аусса вида
G ( 11 х t i 11) == ехр ( 11 х t i 112 ), i == 1, 2,
(5.85)
с центрами t 1 и t 2 , определяемыми выражением
t 1 == [l,l]Т,
t 2 == [О, О]Т.
Для описания выходноrо элемента введем следующие предположения.
1. Функционирование выходноrо элемента основано на совместном использовании
весов (weight sharing), что обусловлено симметричностью задачи. Это одна из
форм встраивания априорной информации в конструкцию сети. Таким образом,
при наличии двух скрытых элементов нам придется определить Bcero один вес w.
2. Выходной элемент имеет пороr Ь (независимую от данных переменную). Важ
ность этоrо пороrа объясняется тем, что функция XOR имеет среднее значение,
отличное от нуля.
Описываемая таким образом структура сети, предназначенной для решения за
дачи XOR, показана на рис. 5.6. Соотношение "BXOД BЫXOД" для этой сети имеет
следующий вид:
2
у(х) == L wG(llx till) + Ь.
i l
(5.86)
5.8. Задача XOR (повторное рассмотрение) 377
Х\
Фиксированный вход + 1
ь (пороr)
Х 2
Рис. 5.6. RBF ceTb,
созданная для pe
шения задачи XOR
Входные
узлы
Функции
raycca
Линейный
выходной
нейрон
в соответствии с табл. 5.2 выход сети должен удовлетворять следующе
му требованию:
Y(Xj) == dj,j == 1,2,3,4,
(5.87)
rдe Xj входной вектор; d j соответствующее ему значение желаемоrо отклика.
Пусть
gji == G(IIXj till),j == 1,2,3,4; i == 1,2.
(5.88)
Тоща, используя значения из табл. 5.2 в выражении (5.88), можно получить сле
дующую систему уравнений, записанную в матричном виде:
Gw == d, (5.89)
[де
[1 0.1353 1 ]
G == 0.3678 0.3678 1 (5.90)
0.1353 1 l'
0.3678 0.3678 1
d == [0101]Т, (5.91)
w == [wwb]T. (5.92)
Описанная здесь задача является сверхопределенной (overdeterminated) в том CMЫC
ле, что количество точек данных превышает число свободных параметров. Это объяс
няет неквадратную форму матрицы G. Следовательно, обратная ей матрица опредсля
ется неоднозначно. Чтобы обойти эту трудность, мы будем использовать минимальное
по норме (minimиm norm) решение уравнения (5.77):
w == G+d == (GTG) lGTd.
(5.93)
Точка данных, j
1
2
3
4
Входной пример, Xj
(1,1)
(0,1)
(0,0)
(1,0)
Желаемый отклик, d j
О
1
О
1
l'
I
t
!
l
!
378 rлава 5. Сети на основе радиальных базисных функций
ТАБЛИЦА 5.2. Преобразование "BXOД BЫXOД", вычисляемое для задачи XOR
Обратите внимание, что G T G квадратная матрица, для которой существует
единственная обратная ей матрица. Подставляя (5.90) в (5.93), получим:
G+ ==
[ 1.8292 1.2509 0.6727 1'2509 1
0.6727 1.2509 1.8292 1.2509
0.9202 1.4202 0.9202 1.4202
(5.94)
в заключение, подставляя (5.91) и (5.94) в (5.93), получим:
[ 2.5018 ]
w == 2.5018 ,
+2.8404
что и завершает определение архитектуры сети RВF.
5.9. Оценивание параметра реryляризации
Параметр реrуляризации л иrpает важную роль в теории реryляризации сетей на
основе радиальных базисных функций, которая рассматривалась в разделах 5.5 5.7.
Для Toro чтобы сполна использовать возможности этой теории, необходимо приме
нить столь же принципиальный подход к оценке параметра л.
Чтобы лучше понять идею, рассмотрим задачу нелинейной ре2рессии (non1inear re
gression problem), описываемую моделью, в которой наблюдаемый выход Yi в момент
времени зависит от входноrо вектора Xi:
Yi == f(Xi) + ti,
(5.95)
[де j(Xi) rладкая кривая; ti одна из реализаций процесса белоrо шума с нулевым
средним значением и дисперсией а 2 , Т.е.
5.9. Оценивание параметра реryляризации
379
E(ti) == о для всех i,
{ cr 2 k i
E[titk] == о,' k; /
(5.96)
(5.97)
Задача состоит в восстановлении функции модели f(Xi) на основе дaH
ных обучения {(Xi'Yi)} l'
Пусть Fл.(х) реrуляризированная оценка функции Лх) для HeKoтoporo значе
ния параметра реrуляризации л. Это значит, что Р",(х) минимизирует функционал
Тихонова, построенный для задачи нелинейной реrpессии в следующем виде:
1 N Л
Е(Р) == 2 L [Yi F(Xi)]2 + 21IDF(x)112.
i l
(5.98)
Выбор подходящеro значения параметра л является нетривиальной задачей. Зна
чение этоro параметра должно обеспечивать компромисс между следующими двумя
противоречивыми моментами.
. Трубость (roиghness) решения, определяемая слаrаемым IIDF(x)112.
N
. Недостоверность (infidelity) данных, определяемая слаrаемым L: [Yi F(Xi)]2.
i l
Хороший выбор параметра реryляризации л и станет rлавной темой настояще
[о раздела.
Среднеквадратическая ошибка
Пусть R(л) среднеквадратическая ошибка на данном множестве примеров между
двумя функциями: функцией реrpессии ЛХ), соответствующей модели, и функцией
аппроксимации Р",(х), представляющей решение для HeKoToporo значения Л, Т.е.
1 N
R(л) == N L [J(Xi) F"'(Xi)]2.
i l
(5.99)
Оптимальным считается такое значение параметра Л, которое минимизиру
ет функционал R(Л).
Пусть F",(Xk) линейная комбинация данноro множества наблюдений:
N
Р", (Xk) == L аы (Л)Уi'
i l
(5.100)
380 rлава 5. Сети на основе радиальных базисных функций
1
i
в матричном виде можно записать эквивалентное выражение
F л == А(л)у,
(5.101)
[де
F л == [F Л (Х1), F л (Х2)," . , Fл(ХN )]Т,
у== [Y1,Y2,"',YN]T
и
А(л) ==
r а11 а12 о" a1N ]
а21 а22 о.. a2N
". ... ......
aN1 aN2 ... aNN
(5.102)
Матрица А(л) размерности N х N называется матрицей влияний (inflиence matrix).
Используя матричные обозначения, выражение (5.99) можно переписать в следу
ющем виде:
1 2 1 2
R(л) == N Ilf F л // == N Ilf А(л)у// ,
(5.103)
[де f следующий вектор размерности N х 1 :
f == и(Х1), f(X2),'" ,f(XN )]Т.
Теперь можно продвинуться еще на один шаr в матричных выкладках, переписав
уравнение (5.95) в виде
у == f + е,
(5.104)
[де
е== [f1,f2,...,fN]T.
Подставляя (5.104) в (5.103) и раскрывая квадрат разности, получим:
R(Л) == 11(1 А(л))f А(л)еI1 2 ==
== 11(1 А(л))f// 2 eT А(л)(1 А(л))f + N 1 IIА(л)еI1 2 ,
N N
(5.105)
[де 1 единичная матрица размерности N х N.
5.9. Оценивание параметра реryляризации 381
Для TOro чтобы найти искомое значение R(Л), необходимо обратить внимание на
следующие вопросы.
. Первое слаrаемое в правой части (5.105) является константой, и, таким образом,
на Hero не влияет оператор математическоrо ожидания.
. Математическое ожидание BTOpOro слаrаемоro равно нулю, что следует из (5.96).
. Матожидание скаляра IIА(л)еI1 2 равно
Е[IIА(л)еI1 2 ] == Е[е Т АТ(Л)А(Л)е] ==
== tr{E[e T АТ(л)А(л)е]} == E{tr[e T АТ(л)А(л)е]}.
(5.106)
При вычислении этоrо значения сначала используется тот факт, что след скаля
ра равен ему самому, после чеrо изменяется порядок операторов математическоrо
ожидания и следа.
Далее будем использовать правило, взятое из алrебры матриц: для данных двух
матриц совместимоrо размера В и С след произведения ВС равен следу произведения
СВ. Таким образом, принимая В == е Т и С == АТ(л)А(л)е, выражение (5.106) можно
переписать в эквивалентной форме:
Е[IIА(л)fI1 2 ] == Е{tr[АТ(Л)А(л)и Т ]} == cr 2 tr[А Т (л)А(Л)],
(5.107)
[де в последней выкладке используется соотношение (5.97). В заключение за
метим, что след АТ(л)А(Л) равен следу А 2 (л), Т.е. (5.107) можно переписать
в следующем виде:
Е[IIА(л)fI1 2 ] == cr 2 tr[A 2(Л)].
(5.108)
Объединяя эти три результата, ожидаемое значение R(Л) можно выразить в виде
Е[R(л)] == 11I А(л)fI1 2 + tr[A 2(Л)].
(5.109)
Однако среднеквадратическая ошибка на данном множестве примеров R(л) не
так важна с практической точки зрения, поскольку она требует априорных знаний о
функции реrpессии f(x), которую требуется восстановить. Поэтому в качестве оценки
Е[R(л)] введем следующее определение [231]:
1 cr 2 cr 2
R(л) == N 11(1 А(Л)) уI1 2 + N tr[A 2(л)] N tr[(1 А(л))2].
(5.110)
'?
382 rлава 5. Сети на основе радиальных базисных функций
Эта оценка является несмещенной (unbiased), а значит (следуя процедуре, анало
rичной выводу выражения (5.109)), можно показать, что
Е[R(Л)] == Е[R(л)].
(5.111)
Следовательно, выбор подходящеrо значения параметра реrуляризации л обеспе
чивается путем минимизации оценки R(Л).
Обобщенная пере крестная проверка
Недостатком оценки R(л) является то, что она требует знания дисперсии шу
ма cr 2 . В ситуациях, встречающихся на практике, этот параметр обычно неизве-
стен. Для Toro чтобы обеспечить работоспособность алrоритма, в подобных случаях
обычно используется концепция обобщенной перекрестной проверки, которая была
выдвинута в [231].
Сначала адаптируем к нашей задаче обычную форму перекрестной проверки (см.
rлаву 4). В частности, пусть Fi k ] минимизирует функционал
1 N Л
Е(Р) == 2 L [Yi F л (Хi)]2 + 21IDF(x)112,
i==l,i
(5.112)
[де k й член [Yi FЛ(Хk)] вынесен из слаrаемоro стандартной ошибки для получения
возможности "проrнозировать" отсутствующие точки данных У k, проверяя, таким
образом, качество оценки параметра л. Следовательно, можно ввести следующий
показатель качества:
1 N
vo(Л) == 2 L [Yk Fi k ] (Xk)]2,
k l
(5.113)
который зависит только от самих данных. Таким образом, обычная перекрестная
оценка (ordinary cross va1idation estimate) параметра л определяется как арrминимум
функцииVо(л) [1105].
Отметим одно полезное свойство Fi k ] (Xk), Если точку Yk заменить ее оценкой
Fi k ] (Xk), а исходный функционал Тихонова Е(Р) из (5.98) достиrает минимума в
точке Уа, ..., Yk l,Yk,Yk+1, "',YN, то Fik](Xk) является решением. Это свойство,
наряду с тем фактом, что для каждоrо входноrо вектора Х арrминимум Fл(х) функ
ционала Е(Р) линейно зависит от Yk, позволяет записать следующее:
[k] [k) дFЛ(Хk)
F л (Xk) == FЛ(Хk) + (F л (Xk) Yk) д .
Yk
(5.114)
5.9. Оценивание параметра реryляризации заз
Из определения (5.100), задающеrо элементы матрицы влияний А(л), видно, что
дFл(Хk) ( '1 )
д akk fI, ,
Yk
(5.115)
[де akk k й диаroнальный элемент матрицы А(л). Отсюда, подставляя (5.115) в
(5.114) и разрешая результат относительно F k](Xk)' получим:
F [k] ( ) Fл(Хk) аkk(Л)Уk
л Xk
1 аkk(Л)
Fл(Хk) Yk
( ) + Yk'
1 akk л
(5.116)
Подставляя выражение (5.116) в (5.113), можно пере определить функцию Vо(л)
следующим образом:
vo(Л) == t [ Yk FЛ(Хk) ] 2
!v 1 аkk ( Л )
k l
(5.117)
Обычно значения akk (л) отличаются для каждоrо k, а это значит, что точки дaн
ных в VO(Л) нельзя трактовать как равноценные. Чтобы обойти это нежелательное
свойство обычной перекрестной проверки, в [231] была введена процедура обоб
щенной перекрестной проверки (genera1ized cross va1idation или GVC), использующая
поворот координат 11. В частности, функция обычной перекрестной проверки V o (л)
11 для тom чтобы вывести функцию обобщенной перекрестной проверки из обычной, можно рассмотреть
задачу rpебневой реrpессии (ridge regression problem), описанную в [1105]:
у == Ха+Е, (1)
rдe Х матрица входных сиrналов размерности N х N, а вектор Е имеет среднее значение, равное нулю, и мат-
рицу ковариации, равную 0'21. Используя синryлярную декомпозицию значений Х, можно записать следующее:
Х == UDv T
rде U и V ор mнальные матрицы; D диаmнальная матрица. Пусть у == u T у, [3 == у Т а, Е == U T Е.
Torдa для преобразования выражения (1) можно использовать матрицы U и У:
у == D[3 + Е. (2)
Диаmнальная матрица D (не следует путать это обозначение с оператором дифференцирования) выбирается
так, чтобы ее синryлярные значения составляли пары. Torдa существу [ е:одиаm:;льн . ad: ] W' такая, что
aN l ао '" aN 2
WDwT является циркулянтной матрицей, а именно: А == WDW T == . 2 1 ...... 3 ,
аl а2 .., ао
в которой элементы, расположенные по каждой из диаmналей, одинаковы. Пусть z == Wy, y=W[3, 1; == WЁ.
Torдa для преобразования выражения (2) можно использовать матрицу W.
z == Ау + 1;. (3)
Диаmнальная матрица D имеет "максимально несвязанные" строки, в то время как строки матрицы А
"максимально объединены".
Выполнив такое преобразование, можно утверждать, что обобщенная перекрестная проверка является экви
валентом преобразования задачи rpебневой реrpессии (1) к виду (3) с последующим обратным преобразованием
в обычную систему коордииат [1105].
......
384 rлава 5. Сети на основе радиальных базисных функций
(5.117) бьта изменена следующим образом:
V(Л) == t Юk [ Yk FЛ-(Хk) ] 2,
N k l 1 аkk(Л)
(5.118)
[де сами веса Юk определяются следующим образом:
[ ] 2
1 аkk(Л)
Юk == tr[1 А(Л)]
(5.119)
Таким образом, обобщенная функция перекрестной проверки принимает вид
V(Л)==
N
1:: [Yk FЛ-(Хk)]2
k l
[ tr[1 А(л)]]2 .
(5.120)
в заключение, подставляя (5.100) в (5.120), получим:
111 А(л)уI12
V(л)
[ tr[I А(л)]]2'
(5.121)
Эта формула включает величины, зависящие только от данных.
Оптимальное свойство обобщенной функции перекрестной
проверки V(л)
Пусть л минимизирует ожидаемое значение обобщенной функции перекрестной
проверкиV(л). Неэффективность математичеСКО20 ожидания (expectation ineffi
ciency) в методе обобщенной перекрестной проверки определяется выражением
]* == Е[R(л)} ,
miпЕ[R(л)]
л-
(5.122)
[де R(Л) среднеквадратическая ошибка на множестве данных, определяемая
формулой (5.99). Обычно асимптотическое значение ]* удовлетворяет следующе
му условию:
lim ]* == 1.
N......oo
(5.123)
Друrими словами, при больших N среднеквадратическая ошибка R(Л) по Л, BЫ
численная с помощью минимизации обобщенной функции пере крестной проверки
V(Л), приближается к минимально возможному значению R(л). Это обеспечивает
применимость V (Л) для оценивания параметра л.
5.10. Свойства аппроксимации сетей RBF 385
Заключительные комментарии
Общая идея выбора параметра реrуляризации л состоит в минимизации cpeДHeKBaд
ратической ошибки на множестве данных обучения R(л). К сожалению, эту за
дачу нельзя решить напрямую, так как выражение для R(л) содержит неизвестную
функцию реrpессии Лх). В связи с этим существуют два метода, которые можно
применить на практике.
· Если известна дисперсия шума cr 2 , то В качестве оптимальноrо значения л мож
но использовать арrминимум оценки R(л) из (5.110) (здесь под оптимальностью
пони мается то, что данное значение л также минимизирует и R(л)).
· Если дисперсия шума cr 2 неизвестна, в качестве оптимальноrо значения параметра
л можно использовать арrминимум обобщенной функции перекрестной провер
ки V(л) из (5.121). При таком подходе обеспечивается минимально возможное
значение среднеквадратической ошибки при N -------t 00.
Важно отметить, что теория, обосновывающая использование обобщенной функ
ции перекрестной проверки для оценки параметра л, является асимптотической, Т.е.
хороших результатов можно добиться лишь тоща, коrда множество данных достаточ
но велико для TOro, чтобы отличить полезный сиrнал от шума.
Практический опьrr работы с обобщенной функцией перекрестной проверки по
казал, что этот метод робастен относительно неоднородности дисперсии и HerayccoBa
шума [1105]. Однако если шум представляет собой хорошо коррелированный про
цесс, метод дает неудовлетворительную оценку параметра реryляризации Л.
В заключение хотелось бы привести некоторые комментарии относительно BЫ
числения обобщенной функции перекрестной проверки V(л). Для данных пробных
значений параметра реrуляризации л нахождение знаменателя [tr[I А(л)J/N]2 в
формуле (5.121) является самой затратной частью работы по вычислению функции
V(л). Для вычисления следа матрицы А(л) можно использовать методрандомизиро
ваННО20 вычисления следа (randomized trace) описанный в [1106]. Применение этоrо
метода в особо больших системах будет оправданным.
5.10. Свойства аппроксимации сетей RBF
В rлаве 4 уже рассматривались свойства аппроксимации мноrослойноrо персеп
трона. Сети на основе радиальных базисных функций также демонстрируют xopo
шие свойства аппроксимации. Семейство сетей RВF является достаточно широким,
чтобы равномерно аппроксимировать любую непрерывную функцию на компакт
ном множестве 12.
12 В приложении к [853] содержится блаrодарность за результат, полученный в 1981 rоду А. Брауном
(A.C.Brown), соrласно которому сети RВF позволяют отобразить произвольную функцию из замкнутой области
в эtтnо в пространство эt.
"'"
386 rлава 5. Сети на основе радиальных базисных функций
Универсальная теорема 06 аппроксимации
Пусть G : Rm o ........ R оrpаниченная, непрерывная и интеrpируемая функция, такая,
что
lтo G(x)dx -1= О.
Пусть G e семейство сетей RВF, включающих функции F : Rmo ........ R следую
щеrо вида:
тl ( Х t. )
Р(х) == щG '
[де 0">0, Wi Е R и t i Е Rmo для i == 1, 2, ..., тl. Тоща выполняется следу
ющая теорема об универсалыюй аппроксимации (universa1 approximation theorem)
для сетей RВF.
ДЛЯ любой непрерывной функции f (х) найдется сеть RBF с множеством центров
{ t;} \ и общей шириной о" > О, такая, что функция F (х), реализуемая сетью,
будет близка к f(x) по норме Lp,p Е [1,00].
Обратите внимание, что в сформулированной таким образом обобщенной теореме
об аппроксимации ядро G : Rm o ------+ R не обязательно должно удовлетворять условию
радиальной симметрии. Таким образом, теорема является более строrой, чем это
необходимо для сетей RВF. И что более важно, она подводит теоретический базис
под построение нейронных сетей на основе радиальных базисных функций с целью
их практическоrо применения.
"Проклятие размерности" (продолжение)
Помимо свойства универсальной аппроксимации сетей RВF, необходимо рассмотреть
вопрос порядка аппроксимации, обеспечиваемоrо этими сетями. Как было сказано в
rлаве 4, внутренняя сложность класса аппроксимирующих функций экспонснци
ально возрастает с увеличением отношения то/ s, rдe то размерность входноro
сиrнала; s индекс 21lадкости (smoothness index), определяемый как количество orpa
ничений, накладываемых на аппроксимирующие функции этоrо KOHKpeTHoro класса.
Проблема "проклятия размерности", сформулированная Беллманом (Веllтап), озна
чает, что независимо от используемоrо метода аппроксимации при постоянном ин
в [423] рассматриваются rауссовы функции и аппроксимации на компактных подмножествах эtmо, KO
торые являются выпуклыми. Показано, что сети RВF с единственным скрытым слоем rауссовых элементов
являются универсальнымн аппроксиматорами. Однако самое cтporoe доказательство свойства универсальной
аппроксимации сетей RBF представлено в [815], которая была завершена еще до выхода в свет [423].
5.10. Свойства аппроксимации сетей RBF 387
ТАБЛИЦА 5.3. Два способа аппроксимации и соответствующие функциональные
пространства с одинаковой скоростью сходимости 0(1/ Jffil), rдe т1 размер
ность CKPbITOro пространства
Функциональное пространство Норма
Техника аппроксимации
"'O IlsIIF(s)ds < 00, rдe L 2 (n)
F(s) MHorOMepHoe преобразо
вание Фурье для функции ап
проксимации F(x)
Пространство функций Соболе L 2 (R 2 )
ва, производные которых до по
рядка 2т > то являются инте
rpируемыми
а) Мноroслойный персептрон:
тl
F(x) L ai<P(W[ Х + Ь i ), [де
i l
<р(.) сиrмоидальная функция aK
тивации
б) RВF сети:
F(x) == ai ехр ( IIX ; 1I2 )
дексе rладкости s количество параметров, необходимых для достижения требуемо
ro уровня точности функции аппроксимации, экспоненциально возрастает в зависи
мости от размерности входноrо пространства то. Единственный способ добиться
независимости скорости сходимости от размерности входноrо сиrнала то и, таким
образом, избежать "проклятия размерности" это увеличить индекс rладкости про
порционально увеличению количества параметров в аппроксимирующей функции,
что, свою очередь, ведет к увеличению ее сложности. Это продемонстрировано в
табл. 5.3, которая взята из [360].
В таблице приведены оrpаничения на функциональные пространства, которым
должны удовлетворять рассматриваемые способы аппроксимации мноroслойный
персептрон и RВF сети, для Toro чтобы скорость сходимости не зависела от размер
ности входноro пространства то. Естественно, эти условия для различных методов
аппроксимации отличаются. В случае сетей RВF используется пространство Собо
лева l3 функций, производные которых до порядка 2т > то являются интеrpируе
мыми. Друrими словами, для TOro чтобы скорость сходимости не зависела от роста
размерности, необходимо с ростом размерности входноro пространства то увеличи
вать количество производных функции аппроксимации, которые должны быть инте
rpируемыми. Как уже rоворилось в rлаве 4, аналоrичное условие накладывается на
мноroслойный персептрон, однако несколько неявным способом. Проанализировав
табл. 5.3, можно сделать следующий вывод.
13 Пусть 12 оrpаниченная область в пространстве3?n с rpаницей [. Рассмотрим множество G непре-
рывиых вещественнозначных фуикций, которые имеют непрерывный rpадиент на множестве S1+r. Билииейная
форма Jn (grad и : grad v + иv)dx является допустимым скалярным произведением на множестве С. Замыка-
ние G по норме, сrенерированной этим скалярным про изведением, называется простраllством Соболева [246].
Пространства Соболева иrpают важную роль в теории уравнений в частных производных и являются важным
примером rильбертовых пространств.
.....
388 rлава 5. Сети на основе радиальных базисных функций
Пространства функций аппроксимации, достижимые МН020СЛОЙНЫМ персептроном
и сетями RВF, становятся все более 02раниченными по мере роста размерности
входН020 пространства то.
В результате оказывается, что "проклятие размерности" нельзя преодолеть ни с
помощью нейронных сетей, будь то мноroслойный персептрон или сети RВF, ни при
использовании друrих методов аналоrичной природы.
Связь между сложностью обучающеrо множества,
вычислительной сложностью и эффективностью обобщения
Обсуждение задачи аппроксимации будет неполным без упоминания TOro факта, что
на практике не существует неоrpаниченной выборки данных. Обычно под рукой ока-
зывается некоторое множество примеров вполне оrpаниченноrо размера. Аналоrично,
не существует нейронных сетей, обладающих бесконечно большой вычислительной
мощностью, она всеrда оrpаничена. Следовательно, существуют два момента, при
водящих к ошибке обобщения в нейронных сетях, обучаемых на конечных наборах
примеров и тестируемых на не встречавшихся ранее данных. Этот вопрос уже об
суждался в rлаве 2. Один из этих моментов, называемый ошибкой аппроксимации
(approximation error), возникает вследствие оrpаниченной мощности сети, HeДOCTa
точной для представления интересующей целевой функции. Друrой момент, ошибка
оценивания (estimation error), является результатом недостаточности оrpаниченноrо
объема информации, содержащеrося в примерах обучения. С учетом этой информа
ции в [787] получен предел ошибки обобщения, rенерируемой RВF сетью с функци
ями raycca, который выражается в терминах размеров cKpbIToro слоя и обучающеrо
множества. Вывод получен для случая обучения функции реrpессии в моделях вида
(5.95). Функция реrpессии принадлежит не которому пространству Соболева.
Этот предел в терминолоrии РАС обучения (см. rлаву 2) можно сформулировать
следующим образом [787].
Пусть G класс 2ауссовых RВF сетей с то входными и т1 скрытыми узлами. Пусть
f(x) функция реrpессии, принадлежашая некоторому пространству Соболева. Преk
полarается, что множество примеров обучения Т == {( Xi, d i ) } 1 составляется с помо
шью случайной выборки из реrpессивной модели, основанной на функции f(x). Torдa
для любоrо параметра чувствительности 8 Е (0,1] ошибка обобшения, rенерируемая
сетью, оrpаничена сверху числом
( ) ( ( ) 1/2 )
1 тот1 1 1
О т1 + О lOg(m1N) + N log "8
(5.124)
с вероятностью, превышаюшей 1 8.
Из выражения (5.124) можно сделать следуюшие выводы.
5.11. Сравнение сетей RBF и мноrослойных персептронов 389
. Ошибка обобщения сходится к нулю только в тОА! случае, если количество скрытых
элементов т1 возрастает медленнее, чем размер обучающей выборки N.
· Для фиксироваНН020 количества примеров обучения N оптимальное количество
скрытых элементов mi ведет себя как (см. задачу 5.11)
т сх N 1 / 3 .
(5.125)
· Сети RBF обеспечивают скорость аппроксимации порядка О(1/т1), что близко
к значению, полученному в [96] для МН020СЛОЙН020 персептрона с си2Моидальной
функцией активации (см. раздел 4.12).
5.11. Сравнение сетей RBF и мноrослойных
персептронов
Сети на основе радиальных базисных функций (RВF) и мноrослойный персептрон
(MLP) являются примерами нелинейных мноroслойных сетей прямоro распростра
нения. И те и друrие являются универсальными аппроксиматорами. Таким образом,
неудивительно, что всеrда существует сеть RВF, способная имитировать мноrослой
ный персептрон (и наоборот). Однако эти два типа сетей отличаются по некоторым
важным аспектам.
1. Сети RВF (в своей основной форме) имеют один скрытый слой, в то время как
мноroслойный персептрон может иметь большее количество скрытых слоев.
2. Обычно вычислительные (computationa1) узлы мноrослойноrо персептрона, распо
ложенные в скрытых и выходном слоях, используют одну и ту же модель нейрона.
С друroй стороны, вычислительные узлы cKpbIToro слоя сети RВF MorYT в корне
отличаться от узлов выходноro слоя и служить разным целям.
3. Скрытый слой в сетях RВF является нелинейным, в то время как выходной
линейным. В то же время скрытые и выходной слои мноrослойноro персептрона,
используемоrо в качестве классификатора, являются нелинейными. Если MHOro
слойный персептрон используется для решения задач нелинейной реrpессии, в
качестве узлов выходноro слоя обычно выбираются линейные нейроны.
4. AprYMeHT функции активации каждоro CKpbITOro узла сети RВF представляет co
бой Евклидову норму (расстояние) между входным вектором и центром ради
альной функции. В то же время apryMeHT функции активации каждоrо cKpbIToro
узла мноroслойноrо персептрона это скалярное произведение входноrо вектора
и вектора синаптических весов данноrо нейрона.
.,
390 rлава 5. Сети на основе радиальных базисных функций
5. Мноroслойный персептрон обеспечивает 2Лобальную аппроксимацию нелиней
Horo отображения. С друrой стороны, сеть RВF с помощью экспоненциально
уменьшающихся локализованных нелинейностей (т.е. функций raycca) создает
локальную аппроксимацию нелинейноro отображения.
Это, в свою очередь, означает, что для аппроксимации нелинейноrо отображения
с помощью мноrослойноrо персептрона может потребоваться меньшее число пара
метров, чем для сети RВF при одинаковой точности вычислений.
Линейные характеристики выходноro слоя сети RВF означают, что такая сеть бо
лее тесно связана с персептроном Розенблатта, чем с мноroслойным персептроном.
Тем не менее сети RВF отличаются от этоrо персептрона тем, что способны выпол
нять нелинейные преобразования входноro пространства. Это было хорошо проде
монстрировано на примере решения задачи XOR, которая не может быть решена ни
одним линейным персептроном, но с леrкостью решается сетью RВF.
5.12. Реrрессия ядра и ее связь с сетями RBF
Представленная выше теория сетей RВF создавалась с прицелом на решение задач
интерполяции. В настоящем разделе мы примем друrую точку зрения; займемся за
дачей построения ре2рессии ядра (keme1 regression) на основе оценки плотности
(density estimation).
В качестве примера рассмотрим модель нелинейной реrрессии (5.95), которую
повторно приведем в этом разделе для сохранения последовательности рассуждений:
Yi == f(Xi) + ti, i == 1,2,. . . ,N.
в качестве обоснованной оценки неизвестной функции реrрессии f(x) можно
выбрать среднее по наблюдениям (т.е. значениям выходноrо сиrнала У) в окрестности
точки х. Однако для успешной реализации TaKoro подхода локальное среднее должно
быть оrpаничено малой окрестностью (т.е. полем чувствительности) точки х, так
как в общем случае наблюдения, соответствующие точкам, удаленным от х, будут
иметь друrие средние значения. Чтобы конкретизировать этот вопрос, вспомним, что
функция f(x), равная условному среднему значений у для данноrо х (т.е. реrрессия
у по х), задается в следующем виде:
f(x) == E[ylx].
5.12. Реrрессия ядра и ее связь с сетями RBF 391
Используя формулу для математическоro ожидания случайной переменной,МОЖНО
записать:
f(x) == 1: yfy(ylx)dy,
(5.126)
rдe fy(ylx) функция плотности условной вероятности У для данноrо х. Из теории
вероятностей известно, что
f ( I ) == fx,y(X, у)
у ух fx(X)'
(5.127)
[де fx(x) плотность вероятности х; fx,y(X, у) плотность совместной Be
роятности Х и У. Подставляя (5.127) в (5.126), получим следующую формулу
для функции реrpессии:
f(x) == J oo yfx,y(x, y)dy .
fx(x)
(5.128)
Нас интересует ситуация, в которой функция плотности условной вероятности
fx,y(X, у) неизвестна. Имеется лишь множество примеров обучения {(Xi, Yi) }{:l'
Для Toro чтобы оценить функцию fx,y(X, у), а значит и fx(X), можно использовать
непараметрическую функцию оценивания, получившую название функции оценки
плотности Парзена Розенблатта (Parzen Rozenblatt density estimator) [819], [903],
[904]. Основой для описания этой функции оценивания служит ядро (kerne1), обо
значаемое как К(х) и обладающее свойствами, сходными со свойствами функций
плотности вероятности.
. Ядро К(х) является непрерывной, оrpаниченной и действительнозначной функци
ей aprYMeHTa х. Оно симметрично относительно начала координат, [де достиrает
cBoero максимальноrо значения.
. Общий объем, находящийся под поверхностью ядра К(х), равен единице, Т.е. для
любоro m MepHoro вектора х:
r K(x)dx == 1.
Jw'"
(5.129)
....
392 rлава 5. Сети на основе радиальных базисных функций
Предполаrая, что множество Х1, Х2,. .. , XN состоит из независимых равномерно
распределенных случайных векторов, можно формально определить оценку плотно
сти Парзена Розенблатта функции f(x) следующим образом:
л 1 ( x x. )
fx(x) == Nhmo K т ' х Е эt mо ,
(5.130)
rдe параметр сrлаживания h является положительным числом, называемым шириной
полосы (bandwidth), или просто шириной (width). (Не путайте используемый здесь
параметр h с одноименным параметром, используемым в определении производной
Фреше из раздела 5.5.) Важным свойством функции оценки плотности Парзена
Розенблатта является то, что она обеспечивает состоятельную оценку (consistent es
timator)l4, Т.е. при выборе h(N) как функции от N, такой, что
Нm h(N) == О,
N oo
выполняется равенство
lim E[ix(x)] == fx(x).
N oo
Для ero выполнения необходимо, чтобы точка х была точкой непрерывно
сти функции ix(X).
Аналоrично можно получить и функцию оценки плотности Парзена Розенблапа
для функции плотности совместной вероятности fx,y(X, у):
л 1 ( x x. ) ( y y )
fx,y(x, у) == Nh m o+1 К Т к т ,х Е эt mо , у Е эt.
(5.131)
Интеrpируя ix,y(x,y) по у, из выражения (5.130) получим ix(X), что и требова-
лось доказать. Более TOro,
1 00 1 N ( ) 1 00 ( )
л X у ш
oo yfx,Y(x, y)dy == Nh m o+1 К oo ук dy.
Изменяя переменную интеrpирования путем подстановки z == (у Yi)/h и вос-
пользовавшись свойством симметрии ядра к(.), получим следующий результат:
1 00 л 1 N ( Х х. )
oo yfx,y(x, y)dy == Nhmo Yi K Т .
(5.132)
14 Доказательство асимптотическоm свойства функции оценки плотности Парзена Розенблатrа содержится
в [166] и [819].
5.12. Реrрессия ядра и ее связь с сетями RBF 393
Используя (5.132) и (5.130) в качестве оценки значений числителя и знаменателя
для формулы (5.128), можно вычислить следующую оценку функции реrpессии f(x)
(после приведения подобных членов):
N
I: Yi K (у)
л . 1
Р(х) == f(x) == ' N
I:K(y)
j l
(5.133)
rдe в знаменателе для простоты использовался индекс суммирования j вместо i. Как и
в обычных сетях RВF, функция оценки реrpессии ядра Р(х), определяемая формулой
(5.133), является универсальным аппроксиматором.
Функцию аппроксимации Р(х) можно рассматривать с двух позиций.
1. Функция оценки ре2рессии Надарайя Ватсона (Nadaraya Watson regression esti
mator). Определим нормализованную функцию взвешивания (norma1ized weighting
function):
W N,i(X) ==
К(у)
N
I:K(y)
j l
, i == 1,2,. . . , N,
(5.134)
rдe
N
L W N,i(X) == 1 Х.
i l
(5.135)
Torдa функцию оценки реrpессии ядра (5.133) можно переписать в упрощен
ном виде:
N
F(x) == L W N,i(X)Yi'
i l
(5.136)
Это не что иное, как взвешенное среднее (weighted average) наблюдений у. Част
ный случай формулы для WN,i(X), формула (5.136), был предложен учеными Ha
дарайя (Nadaraya) и Ватсоном (Watson) в [769] и [1118]. Поэтому функцию аппрок
симации (5.136) часто называют функцией оценки ре2рессии Надарайя Ватсона
(NWRE).
..
394 rлава 5. Сети на основе радиальных базисных функций
2. Нормализованные RВF cemu (normalized RВF network). В этом случае предпола
rается сферическая симметрия ядра К(х), Т.е. [601]
К ( х Xi ) == К ('/х xill ) для всех i,
(5.137)
[де 11 . 1/ Евклидова норма вектора apryMeHTa. Соответственно нормализованная
радиальная базисная функция имеет вид
'1' N (Х, Xi) ==
K( )
N '
К ( 1IX Xjll )
J l
i == 1,2,. . . , N,
(5.138)
[де
N
L '1' N(X, Xi) == 1 для всех х.
i l
(5.139)
Индекс N в обозначении '1' N(X' Xi) указывает на использование нормализации.
В рассматриваемой здесь задаче реrpессии "линейные веса" Wi, применяемые к
базисным функциям '1' N(X' Xi), Являются наблюдениями Yi модели реrpессии для
входных примеров Xi' Таким образом, принимая
Yi == Wi, i == 1,2,. . . , N,
функцию аппроксимации (5.133) можно преобразовать к более общему виду:
N
F(x) == L Щ'l'N(Х' Xi)'
i l
(5.140)
Уравнение (5.140) представляет собой описание сети на основе нормализованных
радиальных базисных функций [750], [1169]. Заметим, что
о::; 'l'N(X,Xi) ::; 1 для всех Х и Xi'
(5.141)
Следовательно, '1' N(X, Xi) можно интерпретировать как вероятность события, опи
cbIBaeMoro вектором Х при условии события Xi.
Основным отличием нормализованных радиальных базисных функций '1' N(X' Xi)
(5.138) от обычных является знаменатель, являющийся коэффициентом НОрМализа
ции (normalization factor). Этот коэффициент представляет собой оценку функции
5.12. Реrрессия ядра и ее СВЯЗЬ с сетями RBF 395
плотности вероятности входноrо вектора х. Следовательно, сумма базисных функций
'VN(X' Xi) по всем i == 1,2, ..., N дает в результате единицу (см. (5.139)). Bы
полнение этоrо условия для базисных функций (fрина) обычных сетей RBF (5.57)
rарантировать нельзя.
При выводе формулы (5.138) для Р(х) основное внимание уделялось оценке плот
ности. Подобно задаче восстановления rиперповерхности, задача оценки плотности
является плохо обусловленной. Функция оценки плотности Парзена Розенблатта и,
следовательно, функция оценки реrpессии Надарайа Ватсона MorYT быть выведены с
применением теории реrуляризации [1087]. Естественно, функционал стоимости для
оценки плотности состоит из суммы двух слаrаемых: среднеквадратической ошибки,
включающей в себя неизвестную функцию плотности вероятности, и соответствую
щей формы функционала стабилизации.
MHoroMepHoe распределение raycca
в общем случае можно использовать множество разнообразных функций ядра. Oд
нако теоретические и практические соображения оrpаничивают этот выбор. Как и в
случае с функцией [рина, широко используемым ядром является MHoroMepHoe pac
пределение [аусса:
1 ( IIXI1 2 )
К(х) == (2п)т о /2 ехр 2 '
(5.142)
rдe то размерность входноrо вектора Х. Сферическая симметрия ядра К(х) яс
но прослеживается в формуле (5.142). Предполаrая использование общсй ширины
(разброса) а, иrрающей в распределении [аусса роль параметра сrлаживания h, и
центрируя ядро в точке данных Xi, можно записать, что
( Х Xi ) 1 ( Ilx Xi112 ) .
К == (2па 2 )то/2 ехр 2а 2 ,Z == 1,2, . . . ,N.
(5.143)
Исходя из этorо, функция оценки реrpессии Надарайа Ватсона примет следующий
вид [1011]:
f Yi ехр ( IIX : 1I2 )
F(x) == 1 1 ,
( "x XjI2 )
exp
j l
(5.144)
[де знаменатель представляет собой функцию оценки плотности Парзена
Розенблатта, состоящую из суммы N мнorомерных распределений [аусса с центрами
в точках данных Х1, Х2,,'" XN.
....
396 rлава 5. Сети на основе радиальных базисных функций
Подставляя (5.143) в (5.138) и затем в (5.140), получим следующий вид функции
отображения нормализованной сети RВF:
:f щ ехр ( IIX : 112 )
Р ( х ) , 1
N .
'" ( IIX Xj 112 )
L.J ехр 2а2
j l
(5.145)
в выражениях (5.144) и (5.145) центры нормализованных радиальных базисных
функций находятся в точках данных {Xi }{:1' Как и в случае с обычными радиальными
базисными функциями, лучше использовать как можно меньшее число нормализован
ных RВF функций, выбирая их центры, рассматриваемые как свободные параметры,
соrласно некоторой эвристике [750] или некоторому принципу [847].
5.13. Стратеrии обучения
Процесс обучения сети на основе радиальных базисных функций (RВF) без учета ero
теоретическоrо обоснования можно рассматривать следующим образом. Линейные
веса, связанные с выходным узлом (узлами) сети, MorYT изменяться во "временном
масштабе", отличном от используемоrо при работе нелинейных функций активации
скрытых элементов. Если функции активации скрытых нейронов изменяются медлен
но, то веса выходных элементов изменяются довольно быстро с помощью линейной
стратеrии оптимизации. Здесь важно отметить, что разные слои сети RВF выпол
няют разные задачи, поэтому будет целесообразным отделить процесс оптимизации
cKpbIToro и выходноrо слоев друr от друrа и использовать для них разные методы и,
возможно, даже разные масштабы времени [676].
Существует множество различных стратеrий обучения сети, зависящих от спо
соба определения центров радиальных базисных функций. Первые три стратеrии
применимы к сетям RВF, описание которых основано на теории интерполяции. По
следняя стратеrия создания сетей сочетает в себе элементы теории реrуляризации и
оценки реrрессии ядра.
Случайный выбор фиксированных центров
Простейший из подходов предполаrает использование фиксированных радиальных
базисных функций, определяющих функции активации скрытых элементов. Размеще
ние центров может быть выбрано случайным образом из множества данных примеров.
Такой подход считается "чувствительным" и требует представителЬНО20 (representa-
tive) распределения множества обучающих данных с учетом рассматриваемой задачи
[675]. Что же касается самих радиальных базисных функций, то для их реализа
5.1 З. Стратеrии обучения 397
ции можно задействовать изотропные функции Таусса (isotropic Gaussian function),
стандартное отклонение которых является фиксированным относительно разброса
центров. В частности, (нормализованные) радиальные базисные функции с центром
в точке t i определяются выражением
2 ( т1 2 )
G(llx till ) == ехр r Ilx till ,
тах
i == 1,2, . . . , т1,
(5.146)
ще т1 количество центров; d max максимальное расстояние между выбранны
ми центрами. В результате стандартное отклонение (т.е. ширина) всех радиальных
базисных функций [аусса будет фиксированным:
d max
O'
у' 2т 1 '
(5.147)
Эта формула rарантирует, что отдельные радиальные базисные функции не будут
слишком rладкими или слишком остроконечными. Обоих этих крайних случаев сле
дует избеrать. В качестве альтернативы выражению (5.147) в наиболее разреженных
областях можно использовать центры с большей шириной, что требует эксперимент
с данными обучения.
При использовании этоrо подхода единственными параметрами, которые настраи
ваются в процессе обучения сети, являются синаптические веса ее выходноrо слоя. Их
проще Bcero настроить с помощью метода псевдообращения (pseudoinverse method)
[160]. В частности (см. (5.77) и (5.78)):
w == G+d,
(5.148)
rдe d вектор желаемоro отклика для множества примеров. Матрица G + являет
ся псевдообратной матрице G, которая, в свою очередь, определяется следующим
образом:
G == {gji},
(5.149)
rдe
gji == ехр ( ;; Ilxj t i I1 2 ), j == 1,2,... ,N; i == 1,2,... ,т1,
(5.150)
rдe Xj j й входной вектор множества примеров обучения.
....
398 rлава 5. Сети на основе радиальных базисных функций
Основой всех алroритмов вычисления псевдообратных матриц является сищуляр
ная декомпозиция (singu1ar value decomposition SVD) [368].
Если G действительная матрица размерности N х М, то существуют opт020
нальные матрицы
u== {U1,U2,...,UN}
и
V == {У1' У2,"', ум},
такие, что
uTCV == diag(O'l' 0'2,"" О'к), К == min(N, М),
(5.151)
2де
0'1 2 0'2 2 .. . 2 О'к > О.
Векторы столбцы матрицы U называют левыми сищулярными векторами (left sin-
gu1ar vector) матрицы С, а векторы столбцы матрицы V правыми сищулярны.ми
векторами (1eft singular vector). Числа 0'1,0'2,. . . , О'к называют сиН2улярными значе
ниями (singu1ar va1ue) матрицы С. Соrласно теореме о декомпозиции по синryлярным
значениям, матрица, псевдообратная матрице С, размерности М х N определяется
следующим образом:
с+ == VE+u T ,
(5.152)
rдe Е+ матрица размерности N х N, выраженная в терминах синrулярных значений
матрицы с:
+ . ( 1 1 1 )
z... dшg , , .., , О, о. . , о .
0'1 0'2 О' К
(5.153)
Эффективный алrоритм вычисления псевдообратной матрицы описывается в [368].
Опыт использования методики случайноrо выбора центров показал, что этот метод
относительно нечувствителен к использованию реrуляризации. В задаче 5.14 будет
предложено провести компьютерное моделирование задачи классификации с исполь
зованием этоrо метода. Случайный выбор центров можно использовать в качестве
метода построения сетей RВF на основе множества примеров большоrо объема с
возможным применением реryляризации.
5.1 З. Стратеrии обучения 399
Выбор центров на основе самоорrанизации
Основной проблемой описанноrо выше метода выбора фиксированных центров яв
ляется тот факт, что для обеспечения удовлетворительноro уровня эффективности
он требует большоrо множества примеров. Одним из способов обхода этой пробле
мы является использование 2ибридНО20 процесса обучения (hybrid 1earning process),
состоящеrо из двух этапов [185], [659], [750].
. Этап обучения на основе самООр2анuзации (se1f organized 1earning stage). Ero целью
является оценка подходящих положений центров радиальных базисных функций
cKpbIToro слоя.
. Этап обучения с учителем (supervised 1earning stage). На этом этапе создание сети
завершается оценкой линейных весов выходноrо слоя.
Хотя для реализации этих двух этапов обучения можно применить пакетную об
работку, все таки лучше использовать адаптивный (итеративный) подход.
Для процесса обучения на основе самоорrанизации требуется разработать алrо
ритм кластеризации, разбивающий заданное множество точек данных на две под
rpуппы, каждая из которых должна быть максимально однородной. Один из таких
алrоритмов называется ал20ритм кластеризации пok (k means c1asterization a1
gorithm) [269]. Соrласно этому алrоритму центры радиальных базисных функций
размещаются только в тех областях входноrо пространства Х, в которых имеются ин
формативные данные. Пусть т1 количество радиальных базисных функций. Опре
деление подходящеrо значения для т1 требует проведения некоторых экспериментов.
Пусть {tk(n)}; l центры радиальных базисных функций на n й итерации алrорит
ма. Torдa алrоритм кластеризации по k средним можно описать следующим образом.
1. Инициализация (initia1ization). Выбираем случайные значения для исходных цeH
тров tk(O). Единственным требованием к их выбору на данном шаrе является
различие всех начальных значений. При этом значения Евклидовой нормы по
возможности должны быть небольшими.
2. Выборка (samp1ing). Выбираем вектор х из входноrо пространства Х с определен
ной вероятностью. Этот вектор будет входным для алrоритма на итерации n.
3. Проверка подобия (simi1arity matching). Обозначим k(x) индекс наиболее подходя
щеrо (победившеrо) центра для данноrо вектора х. Находим k(x) на итерации 11"
используя критерий минимальноro Евклидов а расстояния:
k(x) == argmin Ilx(n) tk(n)ll, k == 1, 2, ..., т1,
k
(5.154)
ще tk(n) центр k й радиально базисной функции на итерации n.
....
400 rлава 5. Сети на основе радиальных базисных функций
4. Корректировка (updating). Корректируем центры радиальных базисных функций,
используя следующее правило:
( 1) { tk(n) + 1'] [х(n) tk(n)], k == k(x),
t k n +
tk (n) в противном случае,
(5.155)
rдe 1'] параметр скорости обучения (learning rate parameter), выбранный из диа
пазона О < 1'] < 1.
5. Продолжение (continuation). Увеличиваем на единицу значение n и возвращаемся
к шаrу 2, продолжая процедуру до тех пор, пока положение центров t k существен
но изменяется.
Описанный алrоритм кластеризации по k средним на самом деле является KOHKY
рентным (competitive) процессом обучения, известным также под названием постро
ения карты саМООР2анизации (self organizing тар). Более подробно он рассматрива
ется в rлаве 9. Этот алrоритм целесообразно реализовывать на стадии обучения без
учителя (на основе самоорrанизации).
Оrpаничением алrоритма кластеризации по k средним является нахождение толь
ко локальноrо оптимальноrо решения, зависящеrо от исходноrо выбора центров кла
стера. Следовательно, вычислительные ресурсы MorYT расходоваться напрасно: OT
дельные центры изначально попадут в те области входноrо пространства Х, rдe KO
личество точек данных невелико и откуда не будет шанса переместиться в области,
требующие большеrо количества центров. В результате можно получить неоправдан
но большую сеть. Чтобы обойти этот недостаток обычноrо алrоритма кластеризации
по k средним, в 1995 [оду был предложен улучшенный ал20ритм кластеризации по
k средним (enhanced k means clustering a1gorithm) [191], который основан на понятии
взвешенной переменной меры принадлежности кластеру (cluster variation weighted
measure), обеспечивающем сходимость алrоритма к оптимальной или квазиоптималь
ной конфиrурации, независимо от исходноrо положения центров.
Определив отдельные центры [ауссовых радиальных базисных функций и их об
щий вес с помощью алrоритма кластеризации по k средним или ero улучшенной
версии, можно перейти к следующему (и последнему) этапу процесса rибридноrо
обучения оценке весов выходноrо слоя. Простейшим методом такой оценки яв
ляется алrоритм LMS (least mean square), описанный в rлаве 3. Вектор выходноrо
сиrнала, сrенерированноrо скрытыми узлами, является входным вектором алrорит
ма LMS. Обратите внимание на то, что алrоритм кластеризации по k средним для
скрытых узлов и алrоритм LMS дЛЯ выходных узлов MorYT выполнять вычисления
параллельно. Таким образом, процесс обучения ускоряется.
5.1 З. Стратеrии обучения 401
Выбор центров с учителем
в рамках TpeTbero подхода центры радиальных базисных функций и все остальные
свободные параметры сети настраиваются в процессе обучения с учителем. Друrими
словами, сеть RВF принимает самый общий вид. Естественным выбором для такой
ситуации является обучение на основе коррекции ошибок, которое удобнее Bcero
реализовывать с помощью процедуры rpадиентноrо спуска, являющейся обобщени
ем алrоритма LMS.
Первым шаrом в разработке такой процедуры обучения является определение
значения функции стоимости:
1 N
Е == 2 L e ,
j l
(5.156)
[де N размер выборки, использованной для обучения; ej сиrнал ошибки следу
ющеrо вида:
м
ej == d j F*(Xj) == d j L щG(IIХj till c ,)'
i l
(5.157)
Требуется найти свободные параметры Wi, t i и 0';1 (последний связан с MaT
рицей взвешивания нормы C i ), минимизирующие функцию стоимости Е. Резуль
таты минимизации приведены в табл. 5.4. Следствия этих результатов представле
ны в упражнении 5.13. При рассмотрении табл. 5.4 особоro внимания заслужива
ют следующие моменты.
. Функция стоимости Е является выпуклой по линейному параметру Wi, однако не
выпуклой по отношению к центрам t i и матрице 0'; 1. В последних случаях поиск
оптимальноro значения t i и матрицы 0'; 1 может остановиться в точке локальноrо
минимума пространства параметров.
. В формулах для модификации значений Wi, t i и 0';1 В общем случае можно ис
пользовать разные параметры скорости обучения 11: 111,112 И 11з'
. в отличие от алrоритма обратноrо распространения, процедура rpадиентноrо спус
ка (см. табл. 5.4) для сети RВF не предполаrает обратноrо распространения сиrнала
ошибки.
. Вектор rpадиента дЕ / at i обладает свойством, аналоrичным свойству ал20ритма
кластеризации (c1ustering effect), ero значение зависит от конкретной задачи
(task dependent) [847].
...
402 rлава 5. Сети на основе радиальных базисных функций
ТАБЛИЦА 5.4. Формулы настройки линейных весов, положений и распределения
центров для сетей RBF
Линейные веса (выходной слой)
N
::i :;) == j ej(n)G(llxj t;(n)ll ci )'
щ(n + 1) == щ(n) 111 ::i r ) , i == 1, 2, о.., т1
2 Позиции центров (скрытый слой)
N
i:; == 2щ(n) L ej(n)G'(IIXj t;(n)llc)O';l[Xj Цn)] ,
з 1
Цn + 1) == Цn) 112 i:; , i == 1, 2, ..., т1
3 Распределение центров (скрытый слой)
N
a: 7 ) == щ(n) L ej(n)G'(IIXj t;(n)ll c )O';lQji(n)'
. j l
Qji(n) == [Xj Цn)][Хj Цn)]Т,
1 ( 1 ) 1 ( )
O'i n+ O'i n 11Заcril(n)'
rдe ej (п) сиrнал ошибки выходноro узла j в момент времени п; с' (.) первая
про из водная функции rрина с(.) по своему apryMeHТY
Для инициализации процедуры rpадиентноrо спуска поиск в пространстве пара-
метров желательно начинать с HeKoToporo структурироваННО20 начальноrо условия,
которое оrpаничивает область поиска уже известной полезной областью. Этоrо мож
но достичь С помощью стандартноrо метода классификации [676]. Таким образом,
вероятность сходимости к нежелательному локальному минимуму в пространстве
весов уменьшается. Например, можно начать с 2ауссова классификатора (Gaussian
c1assifier), использование KOToporo предполаrает, что примеры всех классов имеют
распределение [аусса. Частный случай классификатора, oCHoBaHHoro на процедуре
проверки rипотез Байеса, см. в rлаве 3.
Возникает вопрос: чеrо можно добиться с помощью настройки положения цeH
тров радиальных базисных функций? Ответ на этот вопрос зависит от конкретной
задачи. Тем не менее на основе опубликованных в литературе результатов можно
сделать вывод, что идея настройки местоположения центров имеет некоторые пре
имущества. В работе, посвященной распознаванию речи с помощью сетей RВF [675],
указано, что для нелинейной оптимизации параметров, определяющих функции aK
тивации cKpbIToro слоя, желательно иметь сеть минимальной конфиrурации. Однако,
соrласно [675], такой же производительности обобщения можно добиться, используя
и большие сети RВF, Т.е. сети с большим количеством фиксированных центров и
настройкой выходноro слоя с помощью линейной оптимизации.
В [1129] производительность сетей на основе (rayccoBbIX) радиальных базисных
функций с фиксированными центрами сравнивается с производительностью обоб
5.13. Стратеrии обучения 403
щенных сетей на основе радиальных базисных функций с реrулируемыми центрами
(в последнем случае позиции центров определяются с помощью обучения с учи
телем). Сравнение выполнялось для задачи NEТta1k. Первый эксперимент в этой
области описан в [962], rдe использовался мноrослойный персепТрОН, обучаемый
с помощью алrоритма обратноrо распространения. Более подробно он описывается
в rлаве 13. Целью эксперимента, поставленноrо в [1129], являлся анализ обучения
нейронных сетей фонетическому произношению анrлийскоrо текста. Из этоrо экспс
риментальноrо исследования можно сделать следующие выводы.
. Сети RВF с самонастройкой (без учителя) положения центров и адаптацией (с учи
телем) весов выходноro слоя не обеспечивают такой эффективности обобщения,
как мноrослойный персептрон, обучаемый с помощью алroритма обратноrо pac
пространения.
. Обобщенные сети RВF (в которых обучение с учителем применяется как для
настройки положения центров cKpbIToro слоя, так и для адаптации весов выходноrо
слоя) MorYT достичь уровня производительности мноrослойноrо персептрона.
Строrая интерполяция с реryляризацией
Метод построения сетей RВF, объединяющий в себе элементы теории реrуляризации
(см. раздел 5.5) и теории оценки реrpессии ядра (см. раздел 5.12), описан в [1172].
Этот метод подразумевает использование четырех составляющих.
1. Радиальные базисные функции а, рассматриваемые (иноrда с масштабированием)
как ядро состоятельной оценки реrpессии Надарайа Ватсона (NWRE)15.
2. Диаrональная матрица взвешивания нормы E l, общая для всех центров:
Е == diag(h 1 , h 2 ,..., h mo ),
(5.158)
[де h 1 , h 2 , . . . , h mo ширина полос по отдельным измерениям NWRE с (Mac
штабированным) ядром а; то размерность входноrо пространства. Например,
можно принять h i == aicr;, [де а; дисперсия i й входной переменной, вычис
ленная на множестве входных данных. Затем можно определить параметры Mac
штабирования (scaling factor) а1, а2"", а то , используя подходящую процедуру
перекрестной проверки (см. раздел 5.9).
3. Реrуляризированная процедура строrой интерполяции, включающая обучение ли
нейных весов соrласно (5.54).
15 Метод оценки реrpессии Надарайя Ватсона является предметом интенсивноm изучения в литературе
по статистике. В более широком контексте непараметрическая функциональная оценка занимает центральное
место в [418] и [907].
404 rлава 5. Сети на основе радиальных базисных функций
4. Выбор параметра реryляризации л и множителей аl, а2,. . . , а то с помощью HeKO
TOpOro ассимптотически оптималЬНО20 метода (например, метода перекрестной
проверки, определяемоrо выражением (5.117) или метода обобщенной перекрест
ной поверки, описываемоro выражением (5.121)). Выбранные параметры можно
интерпретировать следующим образом.
. Чем больше значение параметра Л, тем сильнее шум влияет на BXOД
ные параметры.
. Если радиальная базисная функция G имеет унимодальное (т.е. [ауссово) ядро,
то чем меньше значения ai, тем более "чувствителен" выход сети к COOTBeT
ствующей размерности входа. И наоборот, чем больше значения ai, тем менее
"адекватно" соответствующая входная размерность отражает влияние измене
ния входа на общий выход сети. Таким образом, выбранные значения ai можно
использовать для ранжирования важности соответствующих входных перемен
ных и, следовательно, для определения потенциальных кандидатов на удаление
при снижении размерности в случае необходимости.
Обоснование этой процедуры детально изложено в [1172]. В контексте paCCMaT
риваемой задачи такой выбор можно мотивировать следующим образом. Несложно
показать, что сети NRWE составляют специальный класс реryляризированных сетей
RВF в том смысле, что любую сеть NWRE можно аппроксимировать правильно по
строенной последовательностью реrуляризированных сетей RВF, дЛЯ которой после
довательность параметров реrуляризации {ЛN} может возрастать до бесконечности с
увеличением размера N обучающеro множества (при этом среднеквадратическая или
абсолютная ошибка аппроксимации будет стремиться к нулю). С друrой стороны, при
стремлении N к бесконечности риск, определяемый выражением (5.99), при опре
деленных условиях будет стремиться к (rлобальной) среднеквадратической ошибке.
Если для построения последовательности параметров реryляризации используется
процедура выбора асимптотически оптимальных параметров, то (по определению)
результирующая последовательность RВF сетей должна иметь (асимптотически) ми
нимальную среднеквадратическую ошибку на всем множестве возможных после
довательностей параметров (включая ту, которая соответствует сети NWRE). Если
известно, что сеть NWRE является состоятельной в смысле среднеквадратической
ошибки, то этому же условию удовлетворяет реrуляризированная сеть RВF, постро
енная соrласно такой же процедуре. Друrими словами, реrуляризированная сеть RВP,
построенная с помощью этой процедуры, может унаследовать свойства состоятель
ности сети NWRE. Такая взаимозависимость позволяет распространить известные
результаты, касающиеся состоятельности сетей NWRE, на такие области, как pe2pec
сия временных рядов (time series regression), в которых часто встречаются зависимые
и нестационарные процессы и rдe допущения обычных нейронных сетей о независи
мости данных обучения и стационарности процессов не выполняются. Подводя итоr,
5.14. Компьютерное моделирование: классификация образов 405
можно сказать, что описанная здесь процедура, объединяющая элементы теории pe
ryляризации и теории оценки реrрессии ядра, обеспечивает практическую методику
создания и применения теоретически обоснованных реrуляризированных сетей RВF.
5.14. Компьютерное моделирование:
классификация образов
в этом разделе описывается компьютерный эксперимент, иллюстрирующий MeTO
дику построения реrуляризированной сети RВF на основе использования строrой
интерполяции. В этом эксперименте решается задача бинарной классификации дaH
ных, полученных на основе двух равновероятных перекрывающихся двумерных pac
пределений [аусса, соответствующих классам С 1 и С 2 . Параметры распределения
[аусса выбраны такими же, как и в разделе 4.8. Класс С 1 характеризуется вектором
среднеrо значения [о,о]Т и дисперсией, равной единице; класс С 2 характеризует
ся вектором среднеro значения [0,2]Т и дисперсией, равной 4. Пример, описывае
мый в этом разделе, можно рассматривать как аналоr эксперимента, описанноrо в
разделе 4.8, для обучения методом обратноrо распространения, реализованный для
реrуляризированной сети RВF.
ДЛЯ двух классов, С 1 и С 2 , строится реryляризированная сеть RВF с двумя BbIXOk
ными функциями по одной для каждоrо класса. Кроме Toro, в качестве желаемых
используются следующие бинарные значения: '
d(p) == { 1 , если пример р принадлежит классу C k ,
k О В противном случае,
rдe k == 1, 2.
Прежде чем приступить к эксперименту, следует определить решающее прави
ло, которое будет применяться для классификации. В [1172] показано, что выходы
реryляризированной сети RВF обеспечивают оценку апостериорной вероятности при
надлежности классу. Однако это истинно только при условии, что сеть обучается с
помощью двоичных векторных индикаторов желаемоro отклика класса. Torдa для
этоro класса сетей можно применить следующее решающее правило (4.55).
Выбирается класс, соответствующий максимальному выходному значению функции.
Метод строrой интерполяции для выбора центров проверялся для различных зна
чений параметра реryляризации А. При заданном А для вычисления вектора весов
выходноro слоя сети RВF использовалось выражение (5.54):
w == (G + AI) ld,
406 rлава 5. Сети на основе радиальных базисных функций
......
ТАБЛИЦА 5.5. Вероятность корректной классификации Р е(%) для разных значе
ний пара метра реryляризации л и размера cKpbIтoro слоя т1 == 20
Значение параметра ре2уляризации л
О 0,1 1 10 100
57,49 72,42 74,42 73,80 72,46
7,47 4,11 3,51 4,17 4,98
44,20 61,60 65,80 63,10 60,90
72,70 78,30 78,90 79,20 79,40
Вид статистики
Среднее
Стандартное отклонение
Минимум
Максимум
1000
72,14
5,09
60,50
79,40
ТАБЛИЦА 5.6. Вероятность корректной классификации Р е(%) для разных значе
ний пара метра реryляризации л и размера cKpbIToro слоя т1 == 100
Значение параметра ре2уляризации л
О 0,1 1 1 О 100
50,58 77,03 77,72 77,87 76,47
4,70 1,45 0,94 0,91 1,62
41,00 70,60 75,10 75,10 72,10
61,30 79,20 79,80 79,40 78,70
Вид статистики
Среднее
Стандартное отклонение
Минимум
Максимум
1000
75,33
2,25
70,10
78,20
rдe G матрица [рина размерности N х N,ji й элемент которой соответствует зна
чению радиальной симметричной функции fрина G(Xj, Xi); N размер обучающеrо
множества; d вектор желаемоrо отклика.
Для каждоrо из параметров реrуляризации строились 50 независимых сетей, KO
торые тестировались на одном и том же множестве из 1000 примеров.
В табл. 5.5 приведена обобщенная статистическая информация о вероятности KOp
ректной классификации Ре, вычисленной для случая т1 ==20 центров. Статистика по
массиву вычислялась для различных значений параметра реrуляризации л. В табл. 5.6
представлены соответствующие результаты, вычисленные для случая реrуляризиро
ванной сети RВF большеrо размера с т 1 == 100 центрами.
На рис. 5.7 показаны rpаницы решений, сформированные выходами сети для
значения параметра реryляризации л == 10 (при таком значении параметра стати
стические характеристики оказались наилучшими). На рис. 5.7, а показана сеть с
наилучшими показателями, а на рис. 5.7, б с наихудшими статистическими пока-
зателями в рамках массива. Обе части этоrо рисунка представлены для случая сети
с т1 == 100 центрами.
Сравнивая табл. 5.5 и 5.6, можно сделать следующие выводы.
1. Как в случае т1 ==20 центров, так и в случае тl == 100 центров качество класси
фикации в сети для параметра реrуляризации л ==0 остается относительно плохим.
5.14. Компьютерное моделирование: классификация образов 407
5
4
3
2
>< О
1
2
3
5
5 4 2
а)
5
4
3
2
>< о
1
2
Рис. 5.7. Результаты компьютерноro
моделирования при решении задачи 3
классификации на основе строrой интер 4
поляции в реryляризируемых сетях RBF:
наилучшее решение (а); наихудшее 5
решение (б). Закрашенная область 5 2
представляет собой оптимальное реше б)
ние Байеса
о
2
4 5
Х,
о
2
4 5
Х,
2. Использование реrуляризации оказывает большое влияние на качество классифи
кации в сетях RВF.
3. Для л 2': 0,1 качество классификации зависит от значения л. Для случая т1 ==20
центров лучшие показатели были достиrнуты при л == 1, а для случая т1 == 100
центров при л == 10.
4. Увеличение количества центров с 20 до 100 улучшает качество классификации
приблизительно на 4,5%.
.,...
408 rлава 5. Сети на основе радиальных базисных функций
5.15. Резюме и обсуждение
Структура сетей RВF является необычной в том смысле, что архитектура скрытых
элементов в корне отличается от структуры выходных. Поскольку основой функцио
нирования нейронов cKpbIToro слоя являются радиальные базисные функции, теория
сетей RВF тесно связана с теорией радиальных базисных функций, которая в Ha
стоящее время является одной из основных областей изучения в численном анализе
[995]. Интересным также является тот факт, что настройка линейных весов BЫXOД
HOro слоя позволяет обеспечить хорошее качество классификации. В этом можно
удостовериться, изучив литературу по адаптивным линейным фильтрам [434], [435].
В отличие от мноrослойных персептронов, обучаемых алrоритмом обратноrо pac
пространения, архитектура сетей RВF создается в соответствии с некоторыми прин
ципиальными установками. В частности, теория реrуляризации Тихонова, вкратце
рассмотренная в разделе 5.5, является прочным математическим фундаментом для
теории сетей RВF. В этой теории rлавную роль иrpает функция fрина G(x, l;). Форма
функции fрина как фундаментальной функции сети определяется формой 02paHи
чения на 2Ладкость (smoothing constraint), задаваемоrо в теории реryляризации. Это
условие, определяемое оператором дифференцирования D из (5.63), приводит к по
строению мноrомерной функции [аусса для функции [рина. Используя различные
варианты оператора дифференцирования D, можно прийти к совершенно различным
формам функции [рина. Напомним, что при ослаблении требования на меньшее KO
личество базисных функций по сравнению с количеством точек важным фактором
в определении сrлаживающеrо реryляризатора становится уменьшение вычислитель
ной сложности. Это является еще одной причиной использования некоторых друrих
функций в качестве базисных для реryляризируемых сетей RВF (см. рис. 5.5). Ka
ким бы ни был выбор базисных функций, для получения наилучшеrо результата
применения теории реrуляризации к сетям RВF требуется принципиальный подход к
оценке параметра реryляризации А. Этому требованию удовлетворяет обобщенная пе
рекрестная проверка, описанная в разделе 5.9. Теория, обосновывающая применение
обобщенной перекрестной проверки, является асимптотической. В ней предусмотре
но следующее условие: для достижимости хорошей оценки параметра реrуляризации
А множество примеров должно бьrrь достаточно большим.
Еще одним принципиальным подходом к построению сетей RВF является теория
реrpессии ядра. В этом подходе на вооружение берется оценка плотности, для которой
радиально базисные функции в сумме дают единицу. MHoroMepHoe распределение
[аусса обеспечивает удобный метод удовлетворить это требование.
В заключение отметим, что функции отображения в [ауссовых сетях RВF напо
минают функции, реализованные на основе учета мнения rpуппы экспертов, которые
рассматrиваются в rлаве 7.
Задачи 409
Задачи
Радиальные базисные функции
5.1. Рассмотрим функцию следующеrо вида:
<р(т)== ( )210g( ), rдe О'>ОиrЕ .
Обоснуйте использование этой функции в качестве инварианта для операций
вращения и переноса для функции [рина.
5.2. Множество значений, представленных в разделе 5.8 для вектора весов w в
сети RВF, показанной на рис. 5.6, представляет одно из возможных решений
задачи XOR. Исследуйте еще одно множество значений вектора весов w для
решения той же задачи.
5.3. В разделе 5.8 представлено решение задачи XOR с помощью сети RВF, име
ющей два скрытых элемента. В этой задаче рассмотрим точное решение за
дачи XOR с помощью сети RВF с четырьмя скрытыми элементами. Центры
радиальных базисных функций определяются соответствующими образами
входных данных. Четыре возможных входных примера определены коорди
натами (0,0), (0,1), (1,0) и (l, 1), представляющими циклический обход вершин
квадрата.
а) Постройте матрицу интерполяции Ф для полученной сети RВF и вычис
лите для нее обратную.
б) Вычислите линейные веса выходноro слоя этой сети.
5.4. Функция [аусса является единственной факторизуемой радиальной базисной
функцией.
Используя это свойство, покажите, что функция [рина G(x,t), опреде
ленная как MHoroMepHoe распределение [аусса, может быть факторизована
следующим образом:
т
G(x, t) == п G(Xi' t i ),
i l
rдe Xi и t i являются соответственноi ми элементами векторов х и t.
..,........
,
410 rлава 5. Сети на основе радиальных базисных функций
Сети реryляризации
5.5. Рассмотрим следующий функционал стоимости:
N [ т ] 2
E(F*) == d i t,WjG(IIXj till) +Л-IIDF*11 2 ,
который относится к функции аппроксимации
тl
F*(x) == L wjG (11x till).
j l
Используя дифференциал Фреше, покажите, что функционал стоимости
E(F*) достиrает минимума при
(GTG + Л-Gо)w == G T d,
rдe G матрица размерности N х т1; G o матрица размерности т1 х т1;
w вектор размерности т1 х 1; d вектор размерности N х 1. Эти элементы
определяются соответственно выражениями (5.72), (5.73), (5.75) и (5.46).
5.6. Предположим, что определено соотношение
00 >72k
"'" k Vu
(DD)u == L..,. ( 1) k!2 k '
k O
rдe
то то 82
\lt == L L Uji 8х .8х. '
j l i l З'
Матрица U размерности то х то, ji й элемент которой обозначается
как Uji, является симметрической и положительно определенной. Исходя из
этоrо, для нее существует обратная матрица U l. Это позволяет выполнить
следующую декомпозицию:
U l == V T crV == V T cr 1 / 2 cr 1 / 2 V == С Т С
,
Задачи 411
[де У ортоrональная матрица; (J диаrональная матрица; (J1/2 KBaдpaT
ный корень из последней, а матрица С определяется следующим образом:
с == (J1/2y.
Требуется решить задачу нахождения функции fрина С(х, t), удовлетво
ряющей следующему условию (в смысле распределения):
(DD)uG(x, t) == 8(х t).
Используя MHorOMepHoe преобразование Фурье для решения этоro ypaB
нения для С(х, t), покажите, что
С(х, t) == ехр ( Ilx tll ) ,
[де
Ilxll == хТСТСх.
5.7. Рассмотрим слаrаемое реrуляризации, представленное в следующем виде:
00
lтo IIDF(x)1I 2 dx == t;a k lтo IID k F(x)11 2 dx,
[де
(J2k
ak == k!2 k '
Пусть линейный оператор дифференцирования определен в терминах опе
ратора rpадиента '\1 и оператора Лапласиана '\12 следующим образом:
D 2k == ('\12)k
и
D 2 k+1 == '\1('\1 2 )k.
412 rлава 5. Сети на основе радиальных базисных функций
Покажите, что
00 2k
DF(x) == L k '\l2k f(x).
k.2
k O
5.8. В разделе 5.5 с помощью соотношения (5.65) была выведена функция ап-
проксимации Fл.(х), представленная в выражении (5.66). В данной задаче для
получения формулы (5.66) воспользуемся выражением (5.65) и MHoroMep
ным преобразованием Фурье. Выведите эту формулу, используя следующее
определение MHoroMepHoro преобразования Фурье функции rрина С(х):
G(s) == r С(х) ехр( i ST x)dx,
} R"'o
[де i == А; s mо мерная переменная преобразования.
5.9. Рассмотрим задачу нелинейной реrpессии, описываемую выражением (5.95).
Пусть aik ik й элемент обратной матрицы (G + лI) 1. Исходя из этоrо,
начиная с формулы (5.58), покажите, что оценка функции реrpессии лх)
может быть описана как
N
j(x) == L \jf(x, Xk)Yk,
k l
[де Yk выход модели, соответствующий входному сиrналу xk, и
N
\jf(x, Xk) L G(llx xill)aik, k == 1, 2,..., N,
i l
[де G(II . 11) функция rрина.
5.10. Сплайн функция (sp1ine function) представляет собой пример полиномиально
[о аппроксиматора [950]. Основная идея, положенная в основу этоrо метода,
заключается в следующем. Область аппроксимации разбивается на конечное
число частей посредством деления (knot), которое может быть фиксирован
ным. В этом случае аппроксимация является линейно параметризованной.
Однако если деление не равномерное, аппроксимация считается нелинейно
параметризованной. В обоих случаях на каждом из участков для аппроксима
ции используется полином степени не меньшей п. Единственным условием
является (п l) кратная дифференцируемость всей функции. Полиномиаль
ные сплайны являются относительно rладкими функциями, которые леrко
хранить, выполнять с ними операции и оценивать на компьютере.
Задачи 413
Среди сплайн функций, реально используемых на практике, самыми по
пулярными являются кубические сплайны (сиЫс spline). Функция стоимости
для TaKoro сплайна (подразумевая одномерный входной сиrнал) определяется
следующим выражением:
1 N Л l xN [ d2 f(X) ]
Е(!) == 2 [Yi f(Xi)]2 + 2 хl dX2 dx,
ще на языке сплайнов л называется параметром С2Лаживания (smoothing
parameter).
а) Обоснуйте следующие свойства решения fл(х).
1. Функция fл (х) является кубическим полиномом между двумя точными
значениями х.
2. Функция fл(Х) и ее первые две производные являются непрерывными,
за исключением rpаничных точек, в которых значение второй произ
водной равно нулю.
б) Так как функция стоимости Еи) имеет единственный минимум, для лю
боrо g, взятоrо из Toro же класса дважды дифференцируемых функций,
что и fл, выполняется соотношение
Е(fл + ag) Е(fл),
[де а действительная положительная константа. Это значит, что Е(fл +
ag), интерпретируемая как функция от а, должна иметь локальный мини
мум В точке а ==0. Исходя из этоrо, покажите, что
l XN ( d2fл(Х) ) ( d2g(X) ) 1 N
хl dx 2 dx == 2 [У fЛ(Хi)]g(Хi)'
Это соотношение называется уравнением Эйлера Лаrpанжа для задачи
кубическоrо сплайна.
Порядок аппроксимации
5.11. Уравнение (5.124) определяет верхнюю rpаницу ошибки обобщения в [aycco
вой сети RВF, созданной для обучения функции реrpессии, принадлежащей
определенному пространству Соболева. Используя это оrpаничение, выведи
те формулу (5.125) оптимальноrо размера такой сети для заданноrо размера
множества примеров обучения.
414 rлава 5. Сети на основе радиальных базисных функций
Оценка ядра
5.12. Предположим, что задано не содержащее шума обучающее множество
{!(Xi)}{:l' Требуется построить сеть, которая обобщает данные, искажен
ные сторонним шумом и не включенные в набор примеров обучения. Пусть
Р(х) функция аппроксимации, реализуемая такой сетью и выбранная так,
чтобы ожидаемая квадратичная ошибка
1 N r
J(F) == 2 JeRТno [J(Xi) F(Xi, )]2 Л( )
достиrала cBoero минимума. Здесь Л( ) функция плотности вероятности
распределения шума в пространстве входноro сиrнала тo. Покажите, что
решение этой задачи задается следующей формулой:
N
I: j(Хi)Л(Х Xi)
Р(х) == i l N
I: Л(х Xi)
i l
Сравните эту оценку с оценкой реrpессии Надарайя Ватсона.
Выбор центров с учителем
5.13. Рассмотрим функционал стоимости
1 N
Е == 2 L e ,
j l
[де
тl
ej == d j F*(xj) == d j L щG(IIХ j Цс).
i l
Свободными параметрами являются линейные веса Wi, центры t i функций
rрина и обратная матрица ковариации <J;1 == с[ C i , rдe C i матрица взве-
шивания нормы. Задача заключается в нахождении свободных параметров,
которые минимизируют функционал стоимости Е. При этом можно восполь
зоваться следующими частными производными:
N
а) ::: == I: ejG(llxj till c )'
. j l .
N
б) == 2щ I: ejG'(llxj t i ll c )<J;l(Xj t i ),
. j l
Задачи 415
N
в) a:f!'l == щ I: ejG'(IIXj tillc,)Qji,
, j l
rдe С'(') производная СО по ее aprYMeHТY и
Qji == (Xj ti)(Xj t i ?
Правила дифференцирования скаляра по вектору см. в примечании 2
к rлаве 3.
Компьютерное моделирование
5.14. В этом задании мы продолжим компьютерный эксперимент, начатый в разде
ле 5.13, с целью изучения возможностей выбора центров при создании сети
RВF дЛЯ двоичноrо классификатора. Целью настоящеrо эксперимента будет
демонстрация Toro факта, что качество обобщения в сети TaKoro типа будет
довольно неплохим.
С помощью сети, описанной в разделе 5.13 и предназначенной для реше
ния задачи двоичной классификации, решается задача классификации дaH
ных, выбранных из смешанной модели, состоящей из двух равновероятных
пересекающихся [ауссовых распределений. Одно из распределений имеет
вектор среднеrо значения [о,l]Т И общую дисперсию, равную единице. Дpy
[ое распределение имеет среднее значение [0,2]Т и общую дисперсию 4.
Для классификации необходимо использовать решающее правило: "выбрать
класс, дающий максимальное значение выходноrо сиrнала".
а) Рассмотрите случайный выбор центров для т1 == 20. Подсчитайте среднее
значение, стандартное отклонение, максимальное и минимальное значения
вероятности корректной классификации Ре для различных значений пара
метра реrуляризации л == 0,0.1,1,10,100,1000. Для вычисления общей
статистики используйте 50 независимых видов сетей, проверяя каждый
вид на фиксированном множестве из 1000 примеров.
б) Постройте rpаницу решений для конфиrурации, описанной в предыдущем
пункте для значения параметра реrуляризации л == 1.
в) Повторите вычисления пункта а) для т1 == 10 центров (выбираемых слу
чайно).
[) В свете полученных результатов опишите преимущества случайноrо BЫ
бора центров, применяемоrо в качестве метода построения сетей RВF.
Оцените роль реrуляризации в общей производительности сети, выступа
ющей в качестве классификатора.
416 rлава 5. Сети на основе радиальных базисных функций
д) Сравните полученные результаты с описанными в разделе 5.13, [де ис-
пользовался метод строrой интерполяции. В частности, подтвердите, что
случайный выбор центров относительно нечувствителен к параметру pe
rуляризации.
5.15. Можно доказать, что для эксперимента, описанноrо в разделе 5.13 и проводи
Moro для классификации двух классов с [ауссовым распределением, сеть RВF
достаточно хорошо зарекомендовала себя блаrодаря использованию [ауссо-
вых радиальных базисных функций для аппроксимации рассматриваемых
условных распределений [аусса. В настоящей задаче воспользуемся методом
компьютерноrо моделирования для рассмотрения сети RВF с разрывными
условными распределениями [аусса. В частности, рассмотрим два класса,
С 1 и С 2 , со следующими распределениями.
д
· U(С 1 ), [де С 1 == П 1 окружность С радиусом r == 2.34 и центром в точке
ХС == [ 2, зо]Т.
· U(С 2 ), rдe С 2 с 2 квадрат с центром в точке Хс == [ 2, зо]Т и длиной
стороны r == y'21t.
Здесь под U(С 1 ) понимается равномерное распределение на П С 2. Эти
параметры выбираются таким образом, чтобы область решений для клас
са С 1 совпадала со случаем распределения [аусса, paccMoтpeHHoro в раз
деле 5.13. Исследуйте применение реryляризации как средства повышения
качества классификации в [ауссовых сетях RВF при использовании строroй
интерполяции.
Машины опорных векторов
6.1. Введение
В шаве 4 рассматривались мноrослойные персептроны, обучаемые по алrоритму об
paTHoro распространения ошибки. В шаве 5 исследовался друrой класс мноroслойных
сетей прямоrо распространения сети на основе радиальных базисных функций. Оба
эти типа нейронных сетей являются универсальными аппроксиматорами, каждый в
своем смысле. В этой шаве будет представлена еще одна катеrория универсальных ce
тей прямоrо распространения так называемые машины опорных векторов (support
vector mастпе SVM), предложенные Вапником [141], [212], [1084], [1085]. Подоб
но мноrослойным персептронам и сетям на основе радиальных базисных функций,
машины опорных векторов можно использовать для решения задач классификации и
нелинейной реrpессии.
Машина опорных векторов это линейная система (1inear mастпе), обладаю
щая рядом привлекательных свойств. Описание работы таких машин следует начать
с вопроса разделимости классов, возникающеrо при решении задач классификации.
В этом контексте идея машин опорных векторов состоит в построении rиперплоско
сти, выступающей в качестве поверхности решений, максимально разделяющей поло
жительные и отрицательные примеры. Это достиrается блаrодаря принципиальному
подходу, основанному на теории статистическоrо обучения (см. шаву 2). Более KOH
кретно, машина опорных векторов является аппроксимирующей реализацией метода
минuмизации структУРНО20 риска (method of structural risk minimization). Этот ин
дуктивный принцип основан на том, что уровень ошибок обучаемой машины на дaH
ных тестирования (т.е. уровень ошибок обобщения) можно представить в виде CYM
мы ошибки обучения и слаrаемоrо, зависящеrо от измерения Вапника Червоненкиса
(Vapnik Chervonenkis dimension). В случае разделяемых множеств машина опорных
векторов выдает значение "нуль" для первоrо слаrаемоrо, минимизируя при этом
второе слаrаемое. Поэтому машина опорных векторов может обеспечить хорошее
качество обобщения в задаче классификации, не обладая априорными знаниями о
предметной области конкретной задачи. Именно это свойство является уникальным
для машин опорных векторов.
'tIII
418 rлава 6. Машины опорных векторов
Понятие, лежащее в основе построения алroритма обучения опорных векторов,
это ядро скалярноrо произведения "опорноrо вектора" Xi и вектора Х, взятоro из BXOД
ноro пространства. Опорные векторы представляют собой небольшое подмножество
обучающих данных, отбираемых алrоритмом. В зависимости от метода rенерации
этоro ядра можно построить различные обучаемые машины со своими собственными
нелинейными поверхностями решений. В частности, алrоритм настройки опорных
векторов можно использовать для построения следующих трех типов обучаемых Ma
шин (и не только их).
· Полиномиальные обучаемые машины.
· Сети на основе радиальных базисных функций.
· Двухслойные персептроны (т.е. с одним скрытым слоем).
Это значит, что для каждой из этих сетей прямоro распространения можно pe
ализовать процесс обучения на основе алroритма настройки опорных векторов, ис
пользующеrо предложенный набор данных обучения для автоматическоro определе
ния количества необходимых скрытых элементов. Друrими словами, если алrоритм
обратноrо распространения создан специально для обучения мноroслойных персеп
тронов, то алrоритм обучения опорных векторов носит более общий характер, так
как имеет более широкую область применения.
Структура rлавы
Данная rлава состоит из трех основных частей. В первой части описываются OCHOB
ные идеи, положенные в основу машин опорных векторов. В частности, в разделе 6.2
описывается процесс построения оптимальных rиперплоскостей для простейшеrо
случая линейно разделимых множеств. В разделе 6.3 рассматривается более слож
ный случай неразделимых множеств.
Таким образом, мы подrотовим почву для второй части настоящей rлавы, в KOTO
рой детально описывается машина опорных векторов, предназначенная для решения
задач классификации. Эти вопросы освещаются в разделе 6.4. В разделе 6.5 мы Bep
немся к задаче исключающеrо ИЛИ, на которой продемонстрируем процесс создания
машины опорных векторов. Раздел 6.6 посвящен компьютерному эксперименту по
решению задачи классификации, рассмотренной в rлавах 4 и 5. Таким образом, мы
сможем про извести сравнительную оценку машин опорных векторов с мноrослой
ными персептронами, обучаемыми по методу обратноro распространения, а также с
сетями на основе радиальных базисных функций.
В последней части rлавы рассматривается задача нелинейной реrpессии. В разде
ле 6.7 описывается функция потерь (1oss fиnction), которая лучше Bcero подходит для
данной задачи. В разделе 6.8 обсуждается создание машины опорных векторов для
решения задачи нелинейной реrpессии.
В разделе 6.9 приводятся выводы и некоторые заключительные замечания.
6.2. Оптимальная rиперплоскость для линейно разделимых образов 419
6.2. Оптимальная rиперплоскость для
линейно-разделимых образов
Рассмотрим множество обучающих примеров {(Xi, d i ) }[:l' rдe Xi входной образ
для примера i; d i соответствующий ему желаемый отклик (целевой выход). Для
начала предположим, что класс, представленный подмножеством d i ==+ 1, и класс,
представленный подмножеством d i == 1, линейно разделимы. Уравнение поверхно
сти решений в форме rиперплоскости, выполняющей это разделение, записывается
следующим образом:
w T Х + ь == О,
(6.1)
rдe Х входной вектор; w настраиваемый вектор весов; Ь пороr. Таким образом,
можно записать:
w T Xi + Ь о для d i == +1,
w T Xi + Ь < о для d i == 1.
(6.2)
Допущение о линейной разделимости образов введено для тоro, чтобы доступно
объяснить основную идею, положенную в основу машин опорных векторов. Далее,
в разделе 6.3, это допущение будет ослаблено.
Для данноrо вектора весов w и пороrа Ь расстояние между rиперплоскостью,
задаваемой уравнением (6.1), и ближайшей точкой из набора данных называется
2раницей разделения (margin of separation) и обозначается символом р. Основной
целью машины опорных векторов является поиск конкретной rиперплоскости, для
которой rpаница разделения будет максимальной. При этом условии поверхность
решения называется оптимальной 2иперплоскостью (optimal hyperplane). На рис. 6.1
показано reометрическое представление оптимальной rиперплоскости в двумерном
пространстве входных сиrналов.
Пусть w o и Ь О оптимальные значения вектора весов и пороrа COOTBeT
ственно. Исходя из этоrо, оптимальную 2иперплоскость, представляющую MHoro
мерную линейную поверхность решений в пространстве входных сиrналов, мож
но описать уравнением
w Х + Ь О == О.
(6.3)
Оно является аналоroм уравнения (6.1). При этом дискриминантная функция
g(X) == w Х + Ь О
(6.4)
определяет алrебраическую меру расстояния от точки Х до оптимальной rиперплос
кости [269].
"111
420 rлава 6. Машины опорных векторов
Опорные
векторы
Х 2
о Х 1
Рис. 6.1. Оптимальная rиперплоскость
для линейно разделимых образов
Это леrко увидеть, если выразить Х следующим образом:
W o
Х == Х р + r Ilwoll '
rдe Х р нормальная проекция точки Х на оптимальную rиперплоскость; r желаемое
алrебраическое расстояние. Величина r является положительной, если х находится с
положительной стороны оптимальной rиперплоскости, и отрицательным в противном
случае. Так как по определению g(x p ) ==0, следовательно,
g(x) == w х + Ь О == r Ilwoll
или
g(x)
r == Ilwol"
(6.5)
В частности, расстояние от начала координат (т.е. х == О) дО оптимальной rипер
плоскости равно bo/llw о 11. Если Ьо>о, то начало координат находится с положительной
стороны оптимальной rиперплоскости, если же Ь О <О то с отрицательной. [eOMeT
рическая интерпретация этих алrебраических результатов представлена на рис. 6.2.
Требуется найти параметры w о И Ь О оптимальной rиперплоскости на основе дaH
Horo множества примеров T {(Xi,di)}' В свете результатов, показанных на рис. 6.2,
видно, что пара (w o , ь о ) должна удовлетворять следующим оrpаничениям:
W Xi + ь о 1 для d i == +1,
W Xi + ь о ::; 1 для d i == 1.
(6.6)
6.2. Оптимальная rиперплоскость для линейно разделимых образов 421
Х 2
х
Оптимальная
rиперплоскость
Рис. 6.2. rеометрическая интерпретация алrеб
раических расстояний от точек до оптимальной
rиперплоскости (двумерный случай)
о
Х 1
Заметим, что если выполняется уравнение (6.2), то множества являются линейно
разделимыми. В этом случае значения w о и Ь О можно масштабировать так,
чтобы выполнялось условие (6.6). Такая операция масштабирования не влияет
на соотношение (6.3).
Конкретные точки (Xi' d i ), для которых первое и второе оrpаничения выполняют
ся со знаком равенства, называются опорными векторами (support vector). Отсюда и
получили свое название машины опорных векторов. Эти векторы иrpают решающую
роль в работе обучаемых машин. А именно, опорные векторы являются теми точками
данных, которые лежат ближе Bcero к поверхности решений, и, таким образом, явля
ются самыми сложными для классификации. Как таковые они лучше Bcero указывают
на оптимальное размещение поверхности решений.
Рассмотрим опорный вектор x(s), для которorо d(S) == + 1. Torдa, по определению,
g(x(S») == w x(s) + Ь О == + 1 для d(s) == + 1.
(6.7)
Исходя из выражения (6.5), ал2ебраическое расстояние (algebraic distance) от опор
ноro вектора x(s) до оптимальной rиперплоскости равно
g(x(S») { .......!....... если d(S) == +1
r IIWoll' ,
.......!....... (s)
Ilwoll Ilwoll' если d 1,
(6.8)
rде знак "плюс" означает расположение точки x(s) с положительной стороны от опти
мальной rиперплоскости, а знак "минус" с отрицательной. Пусть р оптимальное
значение 2раницы разделения между двумя классами, составляющими множество
примеров Т. Torдa из уравнения (6.8) следует, что
2
Р == 2r == Ilwoll
(6.9)
",
422 rлава 6. Машины опорных векторов
Соотношение (б.9) означает, что максимизация rpаницы разделения между клас
сами эквивалентна минимизации Евклидов ой нормы вектора w.
Подводя итоr, отметим, что оптимальная rиперплоскость, определяемая ypaBHe
нием (б.3), является единственной (unique) в том смысле, что оптимальный вектор
весов w о обеспечивает максимально возможное разделение между положительными
и отрицательными примерами. Такое оптимальное состояние достиrается с помощью
минимизации Евклидовой нормы вектора весов w.
Квадратичная оптимизация и поиск оптимальной
rиперплоскости
Нашей целью является разработка вычислительно эффективной процедуры исполь
зования обучающеrо множества T { (Xi, di)}[:l для поиска оптимальной rиперплос
кости, удовлетворяющей следующему оrpаничению:
di(w T Xi + Ь) 1 для i == 1,2,... , N.
(б. 10)
Это оrpаничение объединяет оба неравенства (б.б), если вместо w о используется w.
Задачу условной оптимизации, которую необходимо решить, можно описать сле
дующим образом.
Для даННО20 обучающе20 множества {(Xi, d i ) }[:l найти оптимальные значения вeK
тора весовых коэффициентов w и пОрО2а Ь, удовлетворяющие условию
di(w T Xi + Ь) 1 для i == 1,2,.. . , N
и минимизирующие функцию стоимости
1
Ф(w) == 2WT W.
Масштабирующий множитель 1/2 включен для удобства выкладок. Ta
кая задача условной оптимизации называется прямой задачей и удовлетворя
ет следующим условиям.
. Функция стоимости Ф(w) является выпуклой!.
. Оrpаничения линейны по w.
1 Пусть С некоторое подмножество Rm. Это подмножество называется выпуклым, если
ах + (1 а)у Е С для всех (х, у) Е С н а Е [0,1].
Функция f : с ...... R называется вьтуклой, если
f(ax + (1 а)у) ::; af(x) + (1 a)f(y) для всех (х, у) Е С и а Е [0,1].
6.2. Оптимальная rиперплоскость для линейно разделимых образов 423
Следовательно, эту задачу можно решить с помощью метода множителей
Ла2ранжа (Method ofLagrange multipliers) [124].
Построим сначала функцию Лаrpанжа:
N
1 т '" т ]
J(w, Ь, а) == 2W w ai[di(w Xi + Ь) 1 ,
i l
(б.ll )
rдe дополнительные неотрицательные переменные ai это так называемые множи
тели Ла2ранжа (Lagrange multiplier). Решение задачи условной оптимизации опре
деляется седловой точкой (saddle point) функции Лаrpанжа J(w, Ь, а), которую необ
ходимо минимизировать по w и Ь, одновременно максимизируя по а. Таким образом,
дифференцируя J(w, Ь, а) по w и Ь и приравнивая результат к нулю, получим следу
ющие условия оптимальности.
Условие 1: aJ(;:.<J.) == О.
Условие 2: aJ(;;,b,<J.) == О.
Применяя условие оптимальности 1 к функции Лаrpанжа (б.11), после переста
новки слаrаемых получим:
N
W == L aidiXi'
i l
(б.12)
При меняя условие оптимальности 2 к функции Лаrpанжа (б.ll), получим:
N
L aidi == О.
i l
(б. 13)
Вектор решения w определяется в терминах расширения, включающеrо N при
меров обучения. Это решение является единственным блаrодаря выпуклости Лаrpан
жиана, чеrо нельзя сказать о коэффициентах Лаrpанжа ai.
Важно также заметить, что в седловой точке для каждоrо множителя Лаrpанжа ai
произведение этоrо множителя на соответствующее оrраничение сходится к нулю, Т.е.
ai[di(wTXi + Ь) 1] == О для i == 1,2,... ,N.
(б.14)
Таким образом, ненулевые значения MorYT иметь только те множители, которые в точ
ности удовлетворяют условию (б.14). Это свойство следует из условия KYHa TaKepa
(Kuhn Tucker condition), сформулированноrо в теории оптимизации [124], [298].
Как уже отмечалось, решение прямой задачи предполarает выпуклость функции
стоимости и линейность оrpаничений. Для такой задачи условной оптимизации мож
но сформулировать так называемую двойственную задачу (dual problem), которая
будет иметь то же оптимальное решение, что и прямая, однако оптимальность ее
1
I
I
I
424
rлава 6. Машины опорных векторов
решения будет обеспечиваться множителями Лаrpанжа. В частности, можно сформу
лировать следующую теорему двойственности (duality theorem) [124].
(а) Если прямая задача имеет оптимальное решение, то двойственная задача
также имеет оптимальное решение, при этом соответствующие оптималь
ные решения совпадают.
(6) Для тО20 чтобы w о было оптимальным решением прямой задачи, а а о oп
тимальным решением двойственной, необходимо и достаточно, чтобы w о было
допустимым решением прямой задачи и
ф(w о ) == J(w o , ь о , ао) == min J(w, ь о , ао). (б.15)
w
Чтобы сформулировать двойственную задачу для рассмотренной прямой, paCKpo
ем выражение (б.ll):
1 N N N
J ( w Ь а ) == WT W '" ad.w T х. Ь'" a.d + '" а.
, , 2 1. 1. 1. 1."
i=l i=l i=l
Третье слаrаемое в правой части () равно нулю вследствие условия оптимальности
(б.13). Далее, из (б.12) получим:
N N N
w T W == L aidi wT Xi == L L aiajdidjxr Xj'
i l i l j=l
Следовательно, представив целевую функцию как J(w,b, а) == Q(a), соотношение
() можно переформулировать следующим образом:
N 1 N N
Q( a ) == '" а. '" '" a.ad.d .хТ х.
< 2 <:1<)<)'
i l i l j l
( б.lб)
rдe ai неотрицательны.
Теперь можно сформулировать двойственную задачу.
Для даННО20 обучающеzо множества {(Xi, di)}[:l найти множители Лаzpанжа
{ai}[:l' максимизирующие целевую функцию
N 1 N N
Q( a ) == "'а. '" '" aad.d .х Т х.
< 2 <:1<)<)
i=l i l j l
при следующих оzраниченuяx
N
1. 2: aidi == О,
i l
2. ai О для i == 1,2, . . . , N.
6.2. Оптимальная rиперплоскость для линейно разделимых образов 425
Обратите внимание, что двойственная задача целиком описывается в терми
нах данных обучения. Более тоro, максимизируемая функция Q ( а) зависит
только от входных образов, представленных в виде множества скалярных
v { Т } N
произведении X i Xj (i,j) l'
Определив оптимальные множители Лаrpанжа ao,i, с помощью соотношения
(б.12) можно вычислить оптимальный вектор весовых коэффициентов w o :
N
w о == L ao,idiXi'
i l
( б.17)
Для вычисления оптимальноro значения пороrа Ь О можно использовать получен
ное значение W o и выражение (б.7):
ь о == 1 W x(s) для d(s) == 1.
(б. 18)
Статистические свойства оптимальной rиперплоскости
Из описанной в rлаве 2 теории статистическоrо обучения следует, что VС размерность
обучаемой машины определяет способ использования вложенной структуры аппрок
симирующих функций. Напомним также, что VС размерность множества разделя
ющих rиперплоскостей в пространстве размерности т равна т + 1. Тем не Me
нее, чтобы применить метод минимизации CTpyктypHoro риска (см. rлаву 2), Tpe
буется построить такое множество разделяющих rиперплоскостей переменной Yc
размерности, которое одновременно минимизирует эмпирический риск (т.е. ошибку
классификации на обучающем множестве) и VС размерность. В машине опорных
векторов структура множества разделяющих rиперплоскостей определяется Евклидо
вой нормой вектора весовых коэффициентов W. В частности, можно сформулировать
следующую теорему [1084], [1085].
Пусть D диаметр наименьшею шара, содержащею все входные векторы
X1, Х2,' . . , XN. VС размерность h множества оптимальных 2иперплоскостей, опи
сываемых уравнением
W Х + ь == О,
02раничена сверху величиной
h ::; min { I : 1 ' то } + 1,
( б.19)
2де символ r.1 означает наименьшее целое число, большее или равное заключен
НОМУ в скобки значению; р 2раница разделения. равная 2 lwoll; то размер
ность входНО20 пространства.
....
426 rлава 6. Машины опорных векторов
Из этой теоремы следует, что VС размерностью (т.е. сложностью) оптимальной
rиперплоскости можно управлять независимо от размерности входноrо пространства
с помощью правильноrо выбора rpаницы разделения р.
Предположим, существует некоторая вложенная структура, описываемая в терми
нах разделяющих rиперплоскостей следующим образом:
Sk == {wTx+ Ь: Ilwll2::; Ck}, k == 1,2,....
(б.20)
с помощью верхней rpаницы VС размерности h, определяемой неравенством
(б.19), вложенную структуру (б.20) можно переписать в эквивалентной форме в Tep
минах rpаниц разделения:
Sk == { I : 1 + 1 : р2 ak }, k == 1,2, .. . ,
(б.21)
rдe ak и Ck константы.
Из rлавы 2 следует, что для обеспечения хорошей обобщающей способности, в
соответствии с принципом минимизации CTPYKтypHoro риска, необходимо выбрать
структуру с наименьшими VС размерностью и ошибкой обучения. Из выражений
(б.19) и (б.21) видно, что это требование можно удовлетворить с помощью оптималь
ной rиперплоскости (т.е. с помощью разделяющей rиперплоскости с наибольшей
rpаницей разделения р). Либо, в свете выражения (б.9), необходимо использовать
оптимальный вектор весовых коэффициентов w о с минимальной Евклидовой HOp
мой. Таким образом, выбор оптимальной rиперплоскости как поверхности решений
для множества линейно разделимых множеств не только интуитивно удовлетворяет,
но и полностью соответствует принципу минимизации CTPYKтypHoro риска машины
опорных векторов.
6.3. Оптимальная rиперплоскость
для неразделимых образов
До сих пор в этой rлаве рассматривались только линейно разделимые образы. Теперь
сконцентрируем внимание на более сложном случае неразделимых множествах.
При таком наборе данных обучения невозможно построить разделяющую rиперплос
кость, полностью исключающую ошибки классификации. Тем не менее мы попы
таемся сконструировать оптимальную rиперплоскость, которая сводит к минимуму
вероятность таких ошибок на множестве обучающих примеров.
6.3. Оптимальная rиперплоскость для неразделимых образов 427
rраница разделения классов считается МЯ2КОЙ (soft), если некоторая точка (Xi, d i )
нарушает следующее условие (см. (б.l0)):
di(w T Xi + Ь) 1, i == 1,2,.. . , N.
Такое нарушение может иметь две формы.
· Точка (Xi, d i ) попадает в область разделения с нужной стороны поверхности pe
шений (рис. б.3, а).
. Точка попадает в область разделения с друroй стороны поверхности решений
(рис. б.3, 6).
Заметим, что в первом случае классификация будет правильной, а во втором
ошибочной.
Для тоro чтобы подroтовить почву для формальноrо рассмотрения неразделимых
образов, введем в определение разделяющей rиперплоскости (поверхности решений)
новое множество неотрицательных скалярных переменных { J[:l:
d i (w T Xi + Ь) 1 + i' i == 1, 2, . . . , N.
(б.22)
Величина i называется фиктивной переменной (slack variable), определяющей
отклонение точек от идеальноro состояния линейной разделимости. Если о::; i ::;1,
то точка попадает в область rpаницы разделения, но с нужной стороны поверхности
решений (см. рис. б.3, а). Если же i> 1, то точка попадает в область с неверной
стороны разделяющей rиперплоскости (см. рис. б.3, 6). Опорные векторы являются
теми точками, которые точно удовлетворяют неравенству (б.22) при i>O. Заметим,
что если образ с i>O выбросить из обучающеrо множества, то поверхность решения
изменится. Таким образом, опорные векторы определяются одинаково как в случае
разделимых, так и в случае неразделимых образов.
Задача сводится к поиску разделяющей rиперплоскости, минимизирующей ошиб
ку классификации на множестве обучающих примеров. Это можно обеспечить, ми
нимизируя функционал
N
Ф( ) == L I( i 1)
i l
по вектору весовых коэффициентов w при условии (б.22) и оrраничениях на Ilw11 2 .
Здесь I( ) функция индикатора, определяемая следующим образом:
I( ) == { О, ::; О,
1, > О.
..
428 rлава 6. Машины опорных векторов
Х 2
Опорные
векторы
Х 1
Точки
данных
а)
Х 2
Опорные
векторы
Х 1
б)
Рис. 6.3. Точка Xi (принадлежащая классу С 1 )
попадает внутрь области разделения с нужной
стороны от разделяющей rиперплоскости (а).
Точка Xi (принадлежащая классу С 2 ) попадает
в область разделения с неверной стороны от
разделяющей rиперплоскости (б)
Точки
данных
к сожалению, минимизация Ф( ) по w являетсЯ невыпуклой Nр полной2 задачей
минимизации.
2 С точки зрения вычислительной сложности алrоритмы можно разделить на два класса.
Алrоритмы с полиномиальным временем. Время их выполнения описывается полиномиальной функцией
от размерности задачи. Например, алroритм быстроrо преобразования Фурье, используемый в спектральном
анализе, является алroритмом полиномиальной сложности, так как требует времеии выполнения nlogn, rде n
размерность задачи.
Алroритмы с экспоненциальным временем. Время их выполиения пропорциональио экспоненциальной
функции от размерности задачи. Например, выполнение алroритма экспоненциальной сложиости может потре
бовать времени 2 n , rдe n размерность задачи.
С таких позиций алrоритмы с полиномиальиым временем выполнения можно рассматривать как "эффек
тивные", а алroритмы с экспоненциальным как "неэффективные".
На практике существует множество вычислительных задач, для которых пока не предложено эффективных
алroритмов. Мноrие из таких трудноразрешимых задач относят к так называемому классу NР полных задач
(NP cornplete). Аббревиатура NP означает nondeterministic polynornial (недетерминировано полиномиальные).
Более полное описание NР полных задач содержится в [208], [211], [338].
6.3. Оптимальная rиперплоскость для неразделимых образов 429
Чтобы обеспечить математическую трактовку такой задачи минимизации, аппрок
симируем функционал Ф( ) следующим образом:
N
Ф( ) == L i'
i l
Более тоro, упростим вычисления, записав минимизируемый функционал относи
тельно вектора весов w:
1 N
Ф(w, ) == 2WT W + CL i'
i l
(б.23)
Как и ранее, минимизация первоro слаrаемоrо в (б.23) связана с минимизацией
VС размерности машины опорных векторов. Что же касается BToporo слаrаемоrо, то
оно представляет верхнюю rpаницу количества ошибок тестирования. Таким обра
зом, представление функции стоимости Ф(w, ) в (б.23) полностью соrласуется с
принципом минимизации структурноro риска.
Параметр С обеспечивает компромисс между сложностью машины и количе
ством неразделимых точек. Еro можно рассматривать как некоторую форму "па
раметра реryляризации". Параметр С выбирается пользователем. Ero можно BЫ
брать двумя способами.
. Экспериментально на основе множества обучения/тестирования.
. Аналитически, оценивая VС размерность с помощью (б.19) и используя rpаницы
эффективности обобщения машины на основе VС размерности.
в любом случае функционал Ф(w, ) оптимизируется по w и { J[:l при условиях
(б.22) и i O. При этом квадрат нормы w трактуется как значение, минимизируемое с
учетом неразделимости точек, а не как оrpаничение, накладываемое на минимизацию
количества неразделимых точек.
Сформулированная таким образом задача оптимизации для неразделимых MHO
жеств в качестве частноro случая включает в себя задачу оптимизации линейно
разделимых множеств. В частности, установив значение равным нулю для всех
i, уравнения (б.22) и (б.23) можно свести к виду, соответствующему линейно
разделяемым множествам.
Теперь можно формально определить прямую задачу для неразделимых множеств.
Для даННО20 обучающе20 множества {(Xi' d i ) }[:1 найти оптимальные значения вeK
тора весов w и пОрО2а Ь, удовлетворяющие 02раниченuям
di(w T Xi + Ь) 1 i' i == 1,2,... , N,
i О для всех i,
.....
430 rлава 6. Машины опорных векторов
такие, что вектор W совместно с i минимизируют функционал стоимости
1 N
Ф(w, ) == 2WTW+CL i'
i l
сде С задаваемый пользователем положительный параметр.
Используя метод множителей Лаrpанжа и выполняя преобразования, аналоrич
ные приведенным в разделе б.2, можно сформулировать двойственную задачу для
неразделимых множеств.
Для данносо обучающеzо множества {(Xi, d i ) }[:1 найти множители Лаzранжа
{ai}[:l' максимизирующие целевую функцию
N 1 N N
Q(a) == L ai 2 L L aiajdidjxT Xj
i l i l j l
при оzраниченuяx
N
· L: aidi == О,
i l
· О ::; ai ::; С для i == 1,2, . . . , N,
сде С задаваемый пользователем положительный параметр.
Обратите внимание, что в двойственной задаче не фиrурируют ни фиктивные пе
ременные i' ни их множители Лаrpанжа. Таким образом, двойственная задача для
неразделимых множеств аналоrична более простой задаче для линейно разделимых
образов во всем, за исключением одноrо, но крайне важноro отличия. В обоих случаях
максимизируется одна и та же целевая функция Q ( а). Однако в случае неразделимых
классов оrpаничение ai О заменено более строrим о::; ai ::; С. За исключением
этоrо изменения, задача условной оптимизации для неразделимых образов и вычис
ления оптимальных значений вектора весов w и пороrа Ь не отличается от случая
линейно разделимых множеств. Заметим также, что опорные векторы вычисляются
точно таким же способом, как и ранее.
Оптимальное значение вектора весовых коэффициентов w определяется по формуле
N"
W o == L ao,idiXi,
i l
(б.24)
rде N s количество опорных векторов. Процедура определения оптимальноrо зна
чения пороrа также аналоrична описанной ранее. В частности, условие KYHa Такера
6.4. Как создать машину опорных векторов для задачи распознавания образов 431
определяется следующим образом:
ai[di(w T Xi + Ь) 1 + J == о, i == 1,2,.. . , N
( б.25)
и
f..Li i == О, i == 1,2, . . . , N.
(б.2б)
Уравнение (б.25) является полным эквивалентом (б.14), в котором единичное сла
raeMoe заменено выражением (1 i)' Как и в (б.14), f..Li множители Лаrpанжа,
которые были введены для обеспечения не отрицательности переменных i для всех
i. В седловой точке производная функции Лаrpанжа по i в прямой задаче равна
нулю, откуда следует, что
ai + f..L i == С.
(б.27)
Объединяя (б.2б) и (б.27), мы видим, что
i == О, если ai < С.
(б.28)
Выбирая любую точку (Xi, d i ) из обучающеro множества, для которой 0< ao.i <
С, и, таким образом, i ==0, и используя (б.25), можно вычислить оптимальный пороr
Ь О ' Однако с вычислительной точки зрения пороr Ь О лучше выбирать как среднее
значение по всем точкам обучающеrо множества [lб5].
6.4. Как создать машину опорных векторов для
задачи распознавания образов
Ознакомившись со способом нахождения оптимальной rиперплоскости для нераз
делимых множеств, можно формально описать процесс создания машины опорных
векторов для задачи распознавания образов.
Идея машины опорных векторов 3 базируется на двух математических операциях,
приведенных ниже (рис. б.4).
3 Идея представления ядра в виде скалярноro произведеиия впервые была использоваиа в [11], [12] при
описании метода потенциальных функций, который являлся предтечей сетей на основе радиальиых базисных
функций. Примерио в то же время в [1089] была предложена идея оптимальных rиперплоскостей. Сочетание
этих двух мощных концепций при создании машииы опориых векторов впервые было описаио в [141, [212],
[1086]. Полный математический базис машины опорных векторов был изложен в [1085] и позднее в расширенной
форме представлен в [1084].
",
432 rлава 6. Машины ОПОРНЫХ векторов
<р(' )
Пространство
признаков
Входное
пространство (данных)
Рис. 6.4. Нелинейное отображение
<р(-) BxoAHoro пространства в про
странство признаков
1. Нелинейное отображение входноrо вектора в пространство признаков (feature
space) более высокой размерности.
2. Построение оптимальной rиперплоскости для разделения признаков, полученных
в п. 1.
Рассмотрим смысл каждой из этих двух операций.
Операция 1 выполняется в соответствии с теоремой Ковера (cover) о разделимо
сти образов (см. rлаву 5). Рассмотрим входное пространство, состоящее из нелинейно
разделимых образов (nonlinearly separated patterns). Соrласно теореме Ковера, такое
MHoroMepHoe пространство можно преобразовать в новое пространство признаков,
в котором с высокой вероятностью образы станут линейно разделимыми, если BЫ
полняются два условия. Во первых, преобразование должно быть нелинейным. Bo
вторых, размерность пространства признаков должна быть достаточно большой. Эти
два условия включены в операцию 1. Однако заметим, что в теореме Ковера ничеrо
не rоворится об оптимальности разделяющих rиперплоскостей. Только с помощью
оптимальных rиперплоскостей можно минимизировать VС размерность и добиться
хорошеrо обобщения.
Этот вопрос и составляет сущность второй операции. В частности, в этой опе
рации используется идея построения оптимальной разделяющей rиперплоскости в
соответствии с теорией, описанной в разделе б.3, но с одним фундаментальным OT
личием: разделяющая rиперплоскость теперь определяется как линейная функция от
векторов, взятых из пространства признаков, а не из исходноrо входноrо простран
ства. И, что более важно, построение rиперплоскости осуществляется в COOTBeT
ствии с принципом минимизации CTpYктypHoro риска, который вытекает из теории
VС размерности. Стержнем этоrо построения является оценка ядра скалярною пpo
изведения (inner product kernel).
6.4. Как создать машину опорных векторов для задачи распознавания образов 433
Ядро скалярноrо произведения
Пусть х некоторый вектор из входноrо пространства, размерность KOToporo равна
то. Пусть {<1'j(X)}j l множество нелинейных преобразований из входноrо про
странства в пространство признаков. Размерность пространства признаков обозна
чим через ffi1. Предполаrается, что функции <1'j(x) определены для всех j. Имея
множество нелинейных преобразований, можно определить rиперплоскость, опреде
ляющую поверхность решений
тl
L Wj<1'j(X) + ь == О,
j l
(б.29)
rдe {Wj} j l множество весовых коэффициентов, связывающих пространство при
знаков с выходным пространством; Ь пороr.
Это выражение можно упростить:
тl
L Wj<1'j(X) == О,
j O
(б.30)
считая, что <1'о(х) == 1 для всех х. При этом Wo представляет собой пороr ь. YpaB
нение (б.30) определяет поверхность решений, вычисленную в пространстве призна
ков в терминах линейных весовых коэффициентов машины. Величина <1'/х) пред
ставляет собой входной сиrнал, приходящийся на вес Wj в пространстве признаков.
Определим вектор
<р(х) == [<1'0 (х), <1'1 (х),..., <1'm1 (х)]Т,
(б.31)
rдe по определению
<1'о(х) == 1 для всех х.
(б.32)
В результате вектор признаков (feature vector) <1'(х) представляет собой "образ",
индуцированный в пространстве признаков при предъявлении вектора входноrо сиr
нала х (см. рис. б.4). Таким образом, в терминах этоro образа можно определить
поверхность решений в компактной форме:
w T <р(х) == О.
(б.33)
..,.
434 rлава 6. Машины опорных векторов
Адаптируя (б.12) к задаче линейноrо разделения векторов в пространстве призна
ков, можно записать:
N
W == L aidiq>(Xi),
i l
(б.34)
rде вектор признаков (feature vector) q>(Xi) соответствует входному вектору Х;
в 2 M примере.
Подставляя выражение (б.34) в (б.33), можно определить поверхность решений в
пространстве признаков следующим образом:
N
L aidiq>T (Xi)q>(Xi) == о.
i l
(б.35)
Здесь терм q>T(Xi)q>(X) представляет собой скалярное произведение двух векторов,
индуцированных в пространстве признаков для входноrо вектора Х и примера Xj.
Исходя из этоro, можно ввести понятие ядра скалярною про изведения (inner product
kernel), обозначаемоrо как К(х, Xi):
ml
K(X'Xi) == q>T(X)q>(Xi) == Lq>j(X)q>j(Xi),
j==O
i == 1,2,. .. , N.
(б.36)
Из этоrо определения видно, что ядро скалярноrо произведения является cuммeт
ричной функцией своих apryмeHToB, Т.е. для всех i выполняется соотношение
К(х, Xi) == K(Xi' х).
(б.3 7)
Ядро скалярноro про изведения К(х, Xi) можно использовать для построения оп
тимальной rиперплоскости в пространстве признаков, не представляя ero в явном
виде. Это отчетливо видно из подстановки (б.3б) в (б.35), в результате которой опти
мальную rиперплоскость можно определить следующим образом:
N
L aidiK(x, Xi) == О.
i l
(б.38)
Теорема Мерсера
Формула (б.3б) для ядра скалярноrо произведения К(х, Xi) является важным част
ным случаем теоремы Мерсера (Mercer's theorem) из функциональноrо анализа. Эта
теорема формулируется следующим образом [217], [728].
6.4. Как создать машину опорных векторов для задачи распознавания образов 435
Пусть К(х. х') непрерывное симметричное ядро, определенное на закрытом ин
тервале а:<:;х:<:;Ь (это же касается и х'). Ядро может быть представлено в виде ряда
00
К(х, х') == L ЛiЧ>i(Х)Ч>i(Х')
i l
(б.39)
с положительными коэффициентами Лi > О для всех i. Для обеспечения KoppeKтHO
сти этоzо разложения и есо абсолютной и равномерной сходимости необходимо и
достаточно выполнение условия
l а l а К(х, x')'I'(x)'I'(x')dxdx' О
для всех '1'(.). для которых
l а '1'2 (x)dx < 00.
Функции Ч>i(Х) называются собственными функциями (eigenfunction) разложения,
а числа Лi ее собственными значениями (eigenvalue). Из свойства положительности
всех собственных чисел вытекает положительная определенность (positive definite)
ядра К(х, х').
В свете теоремы Мерсера можно сделать следующие наблюдения.
· Для Лi #1 i й образ ДЧ>i(Х)' индуцированный в пространстве признаков входным
вектором х, является собственной функцией разложения.
. Теоретически размерность пространства признаков (т.е. количество собственных
функций и собственных значений) может быть бесконечно большой.
Теорема Мерсера позволяет лишь определить, является ли ядро кандидат ядром
скалярноrо про изведения в некотором пространстве, и, таким образом, можно ли еro
использовать в машине опорных векторов. Однако в ней ничеro не rоворится о том,
как строить функции Ч>i(Х)' Это необходимо делать самостоятельно.
Из соотношения (б.23) видно, что машина опорных векторов в неявном виде вклю
чает некоторую форму реrуляризации. В частности, использование ядра К(х, х'),
определенноro в соответствии с теоремой Мерсера, соответствует реryшризац и с
оператором D, таким, что это ядро является функцией [рина оператора DD, rдe D
оператор, сопряженный с D [1004]. Теория реryляризации рассматривалась в rлаве 5.
l'
436 rлава 6. Машины опорных векторов
Оптимальная архитектура машины опорных векторов
Разложение ядра скалярноro произведения К(х, х') (б.3б) позволяет построить по-
верхность решений, которая во входном пространстве является нелинейной, однако
ее образ в пространстве признаков является линейным. С помощью TaKoro разло-
жения можно определить двойственную задачу условной оптимизации для машины
опорных векторов.
Для данносо множества обучающих примеров {( Xi, d i ) } [: 1 найти множители
Лаzранжа {ai}[:l' которые максимизируют целевую функцию
N 1 N N
Q(a) == L ai 2 L L aiajdidjK(Xi, Xj) (б.40)
i l i l j l
при оzраниченuяx
N
1) I: aidi == О,
i l
2) О :<:; ai :<:; С для i == 1,2, . . . , N,
сде С положительный параметр, задаваемый пользователем.
Заметим, что первое оrpаничение вытекает из оптимизации Лаrpанжиана Q(a) по
пороroвому значению Ь == Wo для q>o(X) == 1. Сформулированная таким обра-
зом двойственная задача имеет тот же вид, что и для линейно неразделимых мно-
жеств, рассмотренных в разделе б.3, за исключением Toro факта, что используемое
там скалярное произведение х; Xj заменено ядром скалярноrо про изведения K(Xi,
Xj). Ядро K(Xi, Xj) можно рассматривать как элемент ij симметричной матрицы
К размерности N х N:
к == {K(Xi,Xj)} ,j) l'
(б.4l)
Определив оптимальные значения множителей Лаrpанжа ao,i, с помощью адапти-
рованной к нашему случаю формулы (б.17) можно найти соответствующее оптималь
ное значение вектора w о весов, связывающеrо пространство признаков с выходным
пространством. В частности, понимая, что образ q>(Xi) выступает в роли входноro
сиrнала для вектора весов w, можно определить w о как
N
W o == L ao,idiq>(Xi),
i l
( б.42)
rде q>(Xi) образ, индуцированный в пространстве признаков входным Beктo
ром Xi. Заметим, что первый компонент вектора W o представляет собой оптималь
ный пороr Ь О '
6.4. Как создать машину опорных векторов для задачи распознавания образов 437
ТАБЛИЦА 6.1. Ядра скалярных произведений
Комментарии
Тип машины oпop
ных векторов
Полиномиальная
машина обучения
Сети на основе pa
диальных базисных
функций
Двухслойный пер
септрон
J7дро скалярноzо произведе
ния K(X,Xi), i == 1,2,.. ., N
(Х Т Xi+ I)Р
ехр 2 2 11 Х Xi 112
tanh( OxT Xi + 1)
Степень р задается априори
пользователем
Ширина (}'2, общая для всех
ядер, определяется априори
пользователем
Теорема Мерсера выполня
ется только для некоторых
значений O и 1
Примеры машин опорных векторов
Ядро К(х, Xi) должно удовлетворять теореме Мерсера. В пределах этоrо условия име
ется некоторая свобода выбора. В табл. б.l приведены ядра скалярных произведений
для трех самых распространенных типов машин опорных векторов: полиномиальной
машины обучения, сетей на основе радиальных базисных функций и двухслойноrо
персептрона. При этом важно заметить следующее.
1. Ядра скалярных про изведений для полиномиальноrо и радиальноrо типов функ
ций В машинах опорных векторов Bcerдa удовлетворяют теореме Мерсера. В про
тивоположность этому ядра скалярноro про изведения в машине опорных векторов
типа двухслойноro персептрона имеют некоторые оrpаничения (см. последнюю
строку в табл. б.l). Эта запись является явным свидетельством Toro, что задача
определения, удовлетворяет ли конкретное ядро условиям теоремы Мерсера, уже
сама по себе является довольно сложной (см. упражнение б.8).
2. Для всех трех типов машин размерность пространства признаков опредсляется
числом опорных векторов, отобранных из обучающих данных для решения задачи
условной оптимизации.
3. Рассматриваемая теория машин опорных векторов не требует эвристики, часто
используемой для разработки обычных сетей на основе радиальных базисных
функций и мноrослойных персептроНов.
. в машинах опорных векторов на основе радиальных базисных функций количе
ство этих функций И их центров определяется автоматически по числу опорных
векторов и их значений соответственно.
. В машинах опорных векторов типа двухслойноrо персептрона количество скрытых
нейронов и их весовых коэффициентов определяется автоматически по количеству
опорных векторов и их значений соответственно.
l'
438 rлава 6. Машины опорных векторов
На рис. б.5 показана архитектура машины опорных векторов.
Независимо от тоro, как реализованы машины опорных векторов, принцип их
создания коренным образом отличается от традиционноrо подхода к созданию MHO
roслойноro персептрона. При традиционном подходе сложность модели определя
ется поддержанием числа признаков (т.е. скрытых нейронов) на невысоком уровне.
С друroй стороны, машины опорных векторов предлаrают друrой способ создания
обучаемой машины, при котором управление сложностью модели не зависит от раз
мерности. Кратко рассмотрим эту идею [1084], [1085].
· Концептуальная задача. Размерность (скрытоro) пространства признаков предна
меренно увеличивается, чтобы в этом пространстве можно бьmо построить поверх
ность решений в виде rиперплоскости. ДЛя повышения эффективности обобще
ния сложность модели подчиняется некоторым оrpаничениям, накладываемым на
конструируемую rиперплоскость, которые проявляются при выборе подмножества
примеров обучения в качестве опорных векторов.
· Вычислительная задача. Числовая оптимизация в пространствах высокой размер
ности подвержена так называемому "проклятию размерности". Этой вычислитель
ной проблемы удается избежать при использовании ядра скалярноro произведения
(определяемоrо в соответствии с теоремой Мерсера) и решении двойственной за
дачи условной оптимизации, формулируемой во входном пространстве.
6.5. Пример: задача XOR (продолжение)
Чтобы проиллюстрировать процесс создания машины опорных векторов, BepHeM
ся к знакомой нам задаче XOR (исключающеro ИЛИ), которая уже упоминалась
в rлавах 4 и 5. В табл. б.2 приводятся входные векторы и желаемые отклики для
всех возможных состояний.
Выберем ядро скалярноrо произведения в виде [187]
К(х, Xi) == (1 + ХТ Xi)2.
(б.4З)
Пусть X [X1' Х2]Т И Xi ==[Xil, Xi2]T. Torдa ядро скалярноro произведения К(х, Xi)
можно выразить в терминах одночленов (monomial) различных степеней:
К(х, Xi) == 1 + xi x 71 + 2X1X2XilXi2 + X X72 + 2X1Xil + 2X2Xi2'
Исходя из этоro, образ входноro вектора Х, индуцированный в пространстве при
знаков, может быть представлен следующим образом:
6.5. Пример: задача XOR (продолжение) 439
Пороr
ВХОДНОЙ
вектор
х
Х 2
Х 1
Хт.
ВХОДНОЙ СЛОЙ
размерности
то
СКРЫТЫЙ СЛОЙ
из т 1 ядер
скалярных
про изведений
Рис. 6.5. Архитектура машины опорных векторов
<р(х) == [1, x , V2X1X2, X , V2X1, V2X2 (
Аналоrично,
<P(Xi) == [1'X;1,V2Xi1Xi2,X;2,V2Xil,V2Xi2]T, i == 1,2,3,4.
Из равенства (б.41) находим ядро
[ 9111 ]
К== 1911
1191
1119
Таким образом, целевая функция для двойственной задачи будет иметь следующий
вид (см. (б.40)):
Q(a) == a1 + а2 + аз + а4 H9ai 2a1a2 2а1аз + 2a1a4 + 9аз+
+2а2аз 2а2а4 + 9a 2аза4 + 9a ).
111
440 rлава 6. Машины опорных векторов
ТАБЛИЦА 6.2. Задача XOR
Входной вектор, Х
( 1, 1)
( 1, +1)
(+1, 1)
(+1, +1)
Желаемый отклик, d
1
+1
+1
1
Оптимизируя функцию Q ( а) по отношению к множителям Лаrpанжа, получим
следующую систему уравнений:
{ 9a1 а2 аз + а4 == 1
a1 + 9а2 + аз а4 == 1
a1 + а2 + 9аз а4 == 1
a1 а2 аз + 9а4 == 1
Исходя из этоro, оптимальными значениями множителей Лаrpанжа являются
1
а о 1 == а о 2 == а о з == а о 4 == .
1 1 , , 8
Этот результат означает, что в нашем примере все четыре входных вектора
{Xi} i l должны быть выбраны в качестве опорных. Оптимальным значением функ
ции Лаrpанжа Q(a) будет
1
Qo(a) == 4'
Следовательно, можно записать
1 2 1
211woll == 4
или
1
Ilwoll == J2 '
Из (б.42) можно найти оптимальный вектор весовых коэффициентов:
1
W o == 8[ <P(X1) + <Р(Х2) + <р(Хз) <Р(Х4)] ==
1 1 1
1 1 1
J2 J2 J2
1 + 1 + 1
J2 J2 J2
J2 J2 J2
==
1
8
1
1
J2
1
J2
J2
==
о
о
1/J2
о
о
о
6.5. Пример: задача XOR (продолжение) 441
Х 1
Y= XIX2
Х 2
I
а)
1,0 (1, I)
H,I)
О rраница
решений
I,O (1, 1)
H, I)
б)
Рис. 6.6. Полиномиальная машина для решения за
дачи XOR (а); индуцированный образ в пространстве
признаков для четырех точек данных при решении за
дачи XOR (б)
Из первоro элемента вектора w о видНо, что пороr Ь равен нулю.
Таким образом, мы нашли оптимальную rиперплоскость, определяемую соrласно
(б.33) следующим образом:
w <р(х) == О.
Подставляя соответствующие значения, получим:
[0,0, ,o,o,o]
1
х2
1
J2 X 1X2
X
J2 X 1
J2 X 2
== О,
что в сокращенном виде имеет вид
X1X2 == О.
Эта полиномиальная форма машины опорных векторов для решения задачи XOR
показана на рис. б.б, а. ДЛЯ X1 == Х2 == 1 и X1 == Х2 == +1 выходной сиrнал
такой машины равен у == 1; а дЛЯ X1 1 и Х2 == + 1, равно как и дЛЯ X1 == + 1
и Х2 == 1, выходной сиrнал равен у == +1. Таким образом, задача XOR решена
(рис. б.б, 6).
r
442 rлава 6. Машины опорных векторов
ТАБЛИЦА 6.3. Сводные результаты эксперимента по классификации двух мно-
жеств с помощью машины опорных векторов
Вероятность корректной классификации Ре
Количество опорных векторов N s
Общая ширина 0'2 == 4
Параметр реryляризации С == о, 1
81,22 81,28 81,55 81,49 81,45
298 287 283 287 286
6.6. Компьютерное моделирование
в этом компьютерном эксперименте мы снова вернемся к задаче классификации,
которая уже упоминалась в rлавах 4 и 5. Ставится задача классификации двух пере-
крывающихся двумерных rауссовских распределений, представляемых классами С 1
и С 2 . rрафики этих двух множеств данных см. на рис. 4.14. Вероятность корректной
классификации (оптимальным) байесовским классификатором оценивается как
Ре == 81,51 %.
в табл. б.3 приведены результаты компьютерных экспериментов, выполненных на
этом множестве данных с помощью машины опорных векторов. ДЛя ядра скалярноro
произведения использовалась следующая радиальная базисная функция:
( IIX XiIl2 ) .
K(x,xi)==exp 20'2 ' z==1,2,...,N,
rде для всех точек множества данных использовал ась одна и та же ширина 0'2 ==4.
Машина обучалась на N ==500 точках данных, случайно выбранных из множества,
содержащеro представителей обоих классов. При этом использовался параметр pery-
ляризации, равный С ==0,1.
Результаты, приведенные в табл. б.3, описывают пять различных реализаций этоro
эксперимента. Во всех случаях для обучения использовалось 500 точек, а для те-
стирования 32000. Вероятность корректной классификации, усредненная по всем
этим пяти попыткам, составила 81,40%. Это значение практически равно результа-
ту, полученному байесовским классификатором. Тот факт, что в одном эксперименте
результат был превзойден, можно списать на поrpешность эксперимента.
Практически идеальная классификация, показанная машиной опорных векторов,
еще раз подтверждается построением rpаницы решений (рис. б.7). Здесь показана
одна из реализаций машины, выбранная случайным образом. На этом рисунке также
показана rpаница решений байесовскоro классификатора, представляющая собой Kpyr
с центром Хе == [ 2/3, О]Т и радиусом r == 2,34. Рис. б.б однозначно подтверждает,
что машина опорных векторов способна построить rpаницу решений между классами
C 1 и С 2 , которая практически так же хороша, как и оптимальная.
6.6. Компьютерное моделирование 443
5
4
3
2
Оптимальный
SVМ
1
Х 2 О
2
3
---4
Рис. 6.7. Поверхность решений в KOM
пьютерном эксперименте по классифика
ции множеств
5
5 ---4 3 2 1 О
Х 1
2 3 4 5
Возвращаясь к результатам, представленным в табл. б.3, обратим внимание на то,
что во второй строке представлены размеры пяти различных реализаций машины
опорных векторов. Из этих данных видно, что для всех машин в качестве опорных
векторов выбиралось приблизительно БО% общеro объема обучающих примеров.
В случае неразделимых множеств ошибка обучения приводит к росту числа опор
ных векторов, что следует также из условия Kyнa Такера. В настоящем эксперимен
те ошибка классификации составила около 20%. Таким образом, для множества из
500 примеров примерно треть опорных векторов была выбрана в связи с ошибка
ми классификации.
Заключительные замечания
Сравнивая результаты этоrо простоro компьютерноro эксперимента, проведенноro
для машины опорных векторов, с результатами, показанными в разделе 4.8 MHO
roслойным персептроНом, обученным на том же множестве примеров с помощью
алroритма обратноro распространения, можно сделать следующие выводы.
Машина опорных векторов обладает встроенной способностью решать задачу
классификации множеств, причем получаемое решение близко к оптимальному. Бо
лее тоro, она способна добиваться таких результатов без встроенных в конструкцию
предварительных знаний о предметной области.
С друroй стороны, мноroслойный персептрон, обучаемый с помощью алrорит
ма обратноrо распространения, обеспечивает вычислительно эффективное решение
задачи классификации множеств. В эксперименте классификации двух множеств с
помощью мноroслойноro персептрона с двумя скрытыми нейронами (см. rлаву 4) мы
смоrли получить вероятность корректной классификации, близкую к 79,70%.
r
444 rлава 6. Машины опорных векторов
Подводя итоr, мы подчеркнули преимущества каждоrо из этих подходов к pe
шению задачи классификации. Однако, чтобы сделать объективный вывод, нужно
упомянуть и их индивидуальные недостатки. В случае машины опорных векторов
близкая к идеальной эффективность была достиrнута за счет значительноrо увели
чения вычислительной сложности. С друrой стороны, для Toro чтобы мноrослойный
персептрон, обучаемый по алroритму обратноrо распространения, достиr производи
тельности машины опорных векторов, необходимо выполнить два условия: встроиrь
в архитектуру мноrослойноrо персептрона знания о конкретной проблемной области
и настроить множество параметров, что может быть мучительно тяжело в сложных
задачах обучения.
6.7. Е-нечувствительные функции потерь
До сих пор в данной rлаве мы концентрировали внимание исключительно на ис
пользовании машин опорных векторов для решения задач классификации. Теперь же
мы займемся вопросами их применения для решения задач нелинейной реrpессии.
Чтобы подrотовить почву для этоrо исследования, прежде Bcero рассмотрим вопрос
выбора критерия оптимизации, подходящеrо для этоrо класса задач.
В rлаве 4, посвященной мноrослойным персептронам, и в rлаве 5, в которой
описывались сети на основе радиальных базисных функций, в качестве критерия оп
тимизации мы использовали квадратичную функцию потерь (loss fиnction). rлавным
принципом при таком выборе было математическое удобство вычислений. Однако
система минимизации среднеквадратической ошибки чувствительна к наличию ис
ключений (т.е. наблюдений, выходящих за рамки номинальной модели) и плохо pa
ботает для распределений аддитивноrо шума с длинным "хвостом". Чтобы избежать
этих оrpаничений, необходимо создать робастную систему оценивания, которая бьша
бы нечувствительной к небольшим изменениям в модели.
Выбрав rлавной целью робастность, нужно ввести количественную меру
робастности, связанную с максимальным снижением производительности при
f:>отклонениях от номинальной модели шума. Соrласно такой точке зрения, oпти
маль/{ая робастная процедура оценивания (optimal robust estimation procedure) мини
мизирует максимальное убывание и, таким образом, становится минимаксной про
цедурой [492]. Если аддитивный шум имеет симметричную относительно центра
координат функцию плотности вероятности, минимаксная процедура 4 для решения
задач нелинейной реrpессии в качестве минимизируемой величины использует абсо-
лютную ошибку [493]. Это значит, что функция потерь имеет следующий вид:
4 Минимаксная теория rабера (Huber) основывается на принципе соседства. Она не является rлобальной,
поскольку не учитывает асимметричные распределения. Тем не менее эта теория успешно работает в большин-
стве традиционных задач статистики, в частности в задачах реrpессни.
6.8. Машины опорных векторов для задач нелинейной реrрессии 445
L.(d, у)
Рис. 6.8. Е нечувствительная функция потерь
e
о +е
d y
L(d, у) == Id yl,
(б.44)
rдe d желаемый отклик; у выход системы оценивания.
Чтобы создать машину опорных векторов для аппроксимации желаемоrо отклика
d, можно использовать расширение функции потерь (б.44), впервые предложенное в
[1084], [1085], в следующем виде:
L d { Id у' Е для Id у' Е,
е( , у) о в остальных случаях,
(б.45)
rдe Е наперед заданный параметр.
Функция потерь Le ( d, у) называется Е нечувствительной функцией потерь (E
insensitive loss fиnction). Эта функция равна нулю, если абсолютное значение OT
клонения выхода системы оцениванияу от желаемоro отклика d не превышает Е, и
величине отклонения за вычетом Е в остальных случаях. Функция потерь (б.44)
является частным случаем Е нечувствительной функции потерь при Е == О. На рис. б.8
показана зависимость функции Le(d, у) от величины (d у).
6.8. Машины опорных векторов для задач
нелинейной реrрессии
Рассмотрим модель нелинейной реzрессии (nonlinear regressive model), в которой за
висимость скаляра d от вектора х описывается следующим образом:
d == f(x) + v.
(б.4б)
Скалярная нелинейная функция ЛХ) определяется условным ожиданием E[Dlx]
(см. rлаву 2), rдe D случайная переменная, реализация которой обозначается симво
лом d. Аддитивный шум v является статистически независимым от входноrо вектора
х. Функция f (.) и статистика шума v неизвестны. Все, что есть для решения зада
чи, это множество обучающих данных {(Xi, d i ) }[:1' rдe Xi значение KOHKpeTHoro
BxoAHoro вектора х; d i соответствующее ему значение выхода модели d. Задача
состоит в оценке зависимости d от х.
r
446 rлава 6. Машины опорных векторов
Далее введем оценку значения d, которую обозначим символом У. Она выра-
жается в терминах множества нелинейных базисных функций {<р j (х) } j o следую-
щим образом:
тl
У == L Wj<Pj(X) == w T <р(х),
j O
( б.4 7)
rдe
<р(х) == [<ро(х), <P1 (х), . . . , <Ртl (Х)]Т
и
w == [wo, W1,"', Wm1]T.
Как и ранее, предполаrается, что <po(x) 1, вследствие чеro весовой коэффициент j
Wo будет равен пороrу Ь. Требуется решить задачу минимизации эмпирическоro риска
1 N
R emp == N LLE(di,Yi)'
i l
( б.48)
при условии
IIwl1 2 :<:; Со,
(б.49) I
t
I
r
rдe со константа.
В выражении (б.48) используется определенная ранее в (б.45) Е нечувствительная
функция потерь L E (d, у). Эту задачу условной оптимизации можно переформулиро-
вать, введя два множества неотрицательных фиктивных переменных (slack variable),
{ J[:l и { a[:l' определяемых следующим образом:
d i w T <P(Xi) :<:; Е + i' i == 1,2,... , N,
w T <P(Xi) d i :<:; Е + , i == 1,2, . . . , N,
i О, i == 1,2,.. . , N,
О, i == 1,2, . . . , N.
(б.50)
(б.51 )
(б.52)
( б.53)
Фиктивные переменные i и описывают Е нечувствительную функцию потерь
из (б.45). Таким образом, задачу условной оптимизации можно рассматривать как
задачу минимизации функционала стоимости
Ф(w, , ') с (t.( , +1;;)) + WTw
(б.54)
при оrpаничениях (б.50) (б.53). Включая слаrаемое w T w /2 в функционал Ф(w, , /)
из (б.54), мы избавляемся от необходимости включать в состав оrpаничений неравен-
ство (б.49). Константа С в (б. 54) является параметром, назначаемым пользователем.
6.8. Машины опорных векторов для задач нелинейной реrрессии 447
Исходя из этоro, функцию Лаrpанжа можно определить следующим образом:
N
J(w, , ', а, а', 'У;'1) == с 2: ( + ') + WTw
i l
N N
2: ai[wT<p(Xi) d i + Е + J 2: a [di WT<P(Xi) + Е + ]
i l i l
N
2: ('Yi i + t ),
i l
(б.55)
rдe ai и a множители Лаrpанжа. Последнее слаrаемое в правой части (б.55), coдep
жащее 'Yi и t, rарантирует, что условия оптимальности множителей Лаrpанжа ai и a
предполаrают переменную форму. Требуется минимизировать J (w, , ' , а, а' , 'У, "1)
по вектору весовых коэффициентов w и фиктивным переменным и ' при OДHOBpe
менной максимизации по а, а', 'У и "1. Выполняя эту оптимизацию, получим:
N
W == L (ai a )<p(Xi)'
i l
'Yi == С ai
(б.5б)
(б.57)
и
t == с a .
(б.58)
Описанная задача оптимизации функционала J (w, , ' , а, а' , 'У, "1) является пря
мой задачей реrpессии. Для Toro чтобы сформулировать соответствующую двойствен
ную задачу, подставим соотношения (б.5б) (б.58) в (б.55), получив, таким образом,
следующий выпуклый функционал (после приведения подобных):
N N
Q(ai, a ) == 2: di(ai a ) Е 2: (ai + a )
i l i l
N N
2: 2: (ai a )(aj aj)K(Xi,Xj),
i l j l
(б.59)
rдe K(Xi' Xj) ядро скалярноro произведения, определенное соrласно Teope
ме Мерсера:
K(Xi,Xj) == cpT(Xi)CP(Xj).
Таким образом, решение задачи условной оптимизации обеспечивается путем MaK
симизации Q(a, а') по множителям Лаrpанжа а и а' при новых оrpаничениях, вклю
чающих константу С в определение функции Ф(w, , ') из (б.54).
r
Теперь можно сформулиров",ь двойственную задачу нелннеЙдой реrpессни на I
основе машины опорных векторов в следующем виде.
448
rлава 6. Машины опорных векторов
Для данносо множества примеров обучения {(Xi' d i ) }[:1 найти множители Лаzран-
жа {aJ[:l {aa[:l' максимuзирующие целевую функцию
N N
Q(ai, a ) == 2: di(ai a ) Е 2: (ai + a )
i l i l
N N
2: 2: (ai a )(aj aj)K(Xi,Xj)
i l j l
при следующих оzраниченuяx:
N
1. 2: (ai a ) == О,
i l
О :<:; ai :<:; С, i == 1,2, . . . , N,
2. 0:<:; a :<:; С, i == 1,2, . . . , N,
сде С константа, задаваемая пользователем.
Первое оrpаничение получается из оптимизации Лаrpанжиана по отношению к
пороrу Ь == Wo для <Ро(Х) == 1. Таким образом, вычислив оптимальные значения
для ai и a , можно использовать (б.5б) для определения оптимальноro вектора весов
w для заданноrо отображения <р(х). Обратите внимание, что в решении задачи рас-
познавания только некоторые из коэффициентов разложения (б.5б) имеют значения,
отличные от нуля. В частности, точки данных, для которых ai =f a , определяют
опорные векторы машины.
Два параметра, Е и С, являются свободными и характеризуют VС размерность
аппроксимирующей функции
N
F(x, w) == w T Х == L (ai a )K(x, Xi)'
i l
(б.бО)
Как Е, так и С выбираются пользователем. В концептуальном смысле при выборе Е
и С возникают те же вопросы управления сложностью, что и при выборе параметра
С в задаче классификации. Однако на практике управление сложностью в задаче
реrpессии является более трудной задачей, и на это есть свои причины.
. Параметры Е и С должны настраиваться одновременно.
. По своей сути сама задача реrpессии является более сложной, нежели задача клас-
сификации.
Принципиальный подход к выбору Е и С остается открытой областью исследований.
6.9. Резюме и обсуждение 449
и наконец, как и в случае использования машины опорных векторов для распозна
вания, их применение в задачах нелинейной реrpессии может быть реализовано в виде
полиномиальНой машины обучения, сети на основе радиальных базисных функций
или двухслойноrо персептрона. Ядра скалярных произведений для этих трех методов
реализации были пред ставлены в табл. б.l.
6.9. Резюме и обсуждение
Машины опорных векторов являются элеrантным и устоявшимся методом обучения
при создании сетей прямоrо распространения с единственным скрытым слоем нели
нейных элементов. Этот метод соответствует принципу минимизации CTpyктypHoro
риска, берущему свое начало в теории VС размерности. Как следует из названия,
основная идея создания этой машины состоит в выборе подмножества обучающих
данных в качестве опорных векторов. Это подмножество представляет устойчивые
свойства всей обучающей выборки. Частными случаями машины опорных векторов
являются полиномиальная обучаемая машина, сеть на основе радиальных базисных
функций и двухслойный персептрон. Таким образом, несмотря на то, что эти Me
тоды реализуют совершенно различные представления встроенных статистических
закономерностей, содержащихся в данных обучения, все они происходят от общих
корней машины опорных векторов.
В отличие от популярноrо алrоритма обратноrо распространения, алrоритм обуче
ния с помощью опорных векторов работает только в пакетном режиме. Существует
еще одно важное различие между этими двумя алrоритмами. Алrоритм обратноrо
распространения минимизирует квадратичную функцию потерь, независимо от тоro,
какова задача обучения. В отличие от Hero, алroритм нахождения опорных векторов,
применяемый для решения задачи распознавания, совершенно отличается от Toro,
который используется в задаче нелинейной реrpессии.
· в задаче распознавания алroритм обучения на основе опорных векторов миними
зирует количество обучающих примеров, которые попадают на rpаницу разделения
между положительными и отрицательными примерами. Это утверждение является
истинным только асимптотически, поскольку вместо функции индикатора 1 ( i 1)
используются фиктивные переменные i' Хотя этот критерий в точности и не COOT
ветствует минимизации вероятности ошибки классификации, он считается более
предпочтительным, чем критерий минимизации среднеквадратической ошибки, на
котором основан алrоритм обратноrо распространения.
· При выполнении задачи нелинейной реrpессии алrоритм обучения на основе опор
ных векторов минимизирует Е нечувствительную функцию потерь, которая явля
ется расширением критерия средней абсолютной ошибки из минимаксной теории.
В связи с эти алrоритм является более робастным.
",.
450 rлава 6. Машины опорных векторов
Какой бы ни была задача обучения, машина опорных векторов реализует метод
управления сложностью модели, не зависящий от ее размерности. В частности, в
пространстве высокой размерности задача сложности модели решается за счет ис
пользования "штрафной" rиперплоскости, определенной в (скрытом) пространстве
при знаков и применяемой в качестве поверхности решения. Результатом становится
хорошее качество обобщения. Концентрация внимания на двойственной задаче для
решения задачи условной оптимизации приводит к устранению "проклятия размер
ности". Важной причиной использования двойственной задачи является устранение
необходимости определения и вычисления параметров оптимальной rиперплоскости
в пространстве данных более высокой размерности.
Обычно обучение машины опорных векторов сводится к задаче квадратичноrо
проrpаммирования 5 , что привлекательно по двум причинам.
. Процесс обучения rарантированно сходится к rлобальному минимуму на поверх
ности ошибки (ошибкой считается разность между желаемым откликом и факти
ческим выходом машины опорных векторов).
. Вычисления Moryт быть реализованы достаточно эффективно.
Более тоro, при использовании подходящеrо ядра скалярноrо про изведения Ma
шина опорных векторов автоматически вычисляет все важные параметры сети, от-
носящиеся к выбору ядра. Например, в случае сети на основе радиальных базисных
функций ядро представляет собой rayccoBY функцию. ДЛя TaKoro метода реализации
количество радиальных базисных функций, их центры, а также линейные веса и зна-
чения пороrов вычисляются автоматически. В качестве центров радиальных базисных
функций выступают опорные векторы, отбираемые соrласно стратеrии квадратичной
оптимизации. Опорные векторы поддержки обычно составляют некоторое подмно
жество обучающей выборки. Таким образом, создание сети RВF на основе обучения
машины опорных векторов можно рассматривать как частный случай стратеrии стро-
roй интерполяции, описанной в rлаве 5.
Для решения задачи квадратичноrо проrpаммирования можно использовать неко-
торые коммерческие библиотеки, предназначенные для решения задач оптимизации б .
Однако эти библиотеки имеют оrpаниченное использование. Память, необходимая
для решения задачи квадратичноrо проrpаммирования, растет пропорционально квaд
рату числа примеров обучения. Следовательно, в реальных задачах, включающих
обработку нескольких тысяч точек данных, задачу квадратичноro проrpаммирования
5 В [951] рассматривается алroритм линейноro проrpаммирования на основе нормы Ll, а не L2, которая
используется в машинах векторной поддержки. Норма Ll вектора весов w определяется как IIwll 1 L: IWil,
i
rдe Wi i-й элемент вектора w. Максимальная rpаница классификации на осноВе иормы Ll смещена в сторону
rиперплоскостей, ориентированных по осям, Т.е. в сторону векторов весов с малым числом ненулевых элементов.
6 Среди коммерческих библиотек, предназначенных для решения задач квадратичноrо проrpаммирования,
можно выделить следующие: MINOS5.4 [764], LSSOL [358], LOQO [1076], QPOPT и SQOPТ [359].
6.9. Резюме и обсуждение 451
нельзя решить с помощью простоro использования коммерческой библиотеки. В [807]
предложен новаторский алroритм декомпозиции, который разбивает задачу оптими
зации на последовательность более мелких подзадач. В частности, этот алrоритм
декомпозиции учитывает преимущества коэффициентов опорных векторов, которые
активны по обе стороны rpаницы классификации, определяемой при ai ==0 и ai == С.
в [807] отмечается, что данный алrоритм декомпозиции показал удовлетворительные
результаты в приложениях, содержащих до ста тысяч точек данных.
В терминах времени работы машины опорных векторов оказались более медлен
ными по сравнению с друrими типами сетей (в том числе по сравнению с MHoro
слойными персептронами, обучаемыми по алroритму обратноrо распространения).
Для такой медлительности имеются две причины.
1. Машина опорных векторов не обеспечивает управления количеством точек дaH
ных, выбираемых алroритмом обучения в качестве опорных векторов.
2. При создании обучаемой машины не учитываются априорные знания о предмет
ной области.
Кратко рассмотрим модификации машин опорных векторов, призванные обойти
эти недостатки.
Вопрос о том, как управлять выбором опорных векторов, является крайне слож
ным, особенно в случае неразделимости классифицируемых множеств и зашумлен
ности данных обучения. В общем случае попытки устранения известных ошибок
из данных до начала обучения или удаления их из разложения после обучения не
приводят к построению оптимальной rиперплоскости, поскольку для "штрафования"
неразделимости нужны ошибки. В [80б] исследовалась задача сокращения времени,
затрачиваемоrо машиной опорных векторов на обучение решению задачи классифи
кации. В ней были предложены два новаторских подхода к этой задаче.
· Сама машина опорных векторов использовалась как аппарат нелинейной реrpессии
для аппроксимации поверхности решений (разделяющей классы) при точности,
задаваемой пользователем.
· Процедура обучения машины опорных векторов переформировалась для
получения той же точной поверхности решений при меньшем количе
стве базисных функций.
При первом подходе решение упрощается за счет ero аппроксимации линейной
комбинацией подмножества базисных функций. Полученная машина является eCTe
ственным расширением машины опорных векторов, создаваемой для аппроксимации
функций. Это расширение строится для поиска минимума функционала стоимости
...,.
452 rлава 6. Машины опорных векторов
следующеro вида:
N 1
E(F) == L Id i F(xi)l e + 2С 'I'(F),
i l
rAe F ( .) аппроксимирующая функция; '1'0 не который rладкий функционал;
Ixl e Е нечувствительная функция стоимости, определяемая как
{ о, если 'х' < Е,
Ixl e == 'хl Е в остальных случаях.
Такая Е нечувствительная функция стоимости обеспечивает робастность решения
по отношению к исключениям и нечувствительность к ошибкам, не превышающим
некотороro пороrа Е. Минимум этой функции стоимости Е( F) имеет вид
N
F(x) == L CiG(X, Xi),
i l
rдe G (', .) ядро, зависящее от KOHKpeTHoro выбора rладкой функции '1'(.) и коэф
фициентов Ci, вычисляемых при решении задачи квадратичноro проrpаммирования.
Решение обычно является разреженным (sparse). Это значит, что только небольшое
число коэффициентов Ci будет отличаться от нуля, а их количество зависит от пара
метра Е. При втором подходе прямая задача переформулируется так, что она имеет
ту же начальную структуру, что и исходная, но с одним отличием: в формулировку
включается ядро скалярноrо про изведения К(х, х'). Оба подхода призваны умень-
шить сложность машины опорных векторов в задачах нелинейной реrpессии.
В заключение, возвращаясь к вопросу априорных знаний, заметим, что про из-
водительность обучаемой машины может быть существенно увеличена включением
этих знаний в архитектуру машины [4]. в литературе рассматриваются два способа
использования априорных знаний.
. в качестве дополнительноrо слаrаемоrо в функции стоимости. Torдa обучаемая
машина будет строить функцию с учетом априорных знаний. Именно это проис-
ходит при использовании реrуляризации.
. В качестве виртуальных примеров, reнерируемых на основе обучающеrо MHO
жества. Torдa обучаемая машина сможет леrко извлекать априорные знания из
искусственно расширенноro множества примеров.
При втором подходе процесс обучения может сильно замедлиться в связи с корре-
ляцией искусственных данных и увеличением размера обучающеro множества. Одна-
ко преимущество BToporo подхода состоит в том, что ero леrче реализовать для всех
Задачи 453
типов априорных знаний и обучаемых машин. Один из способов реализации BToporo
подхода предложен ниже [94б].
1. Машина опорных векторов обучается обычным образом на предложенном MHO
жестве данных с целью извлечения опорных векторов.
2. Путем применения априорных знаний в форме желаемых инвариантных преобра
зований к векторам, полученным в п. 1, rенерируются искусственные примеры,
называемые виртуальными опорными векторами (virtual support vector).
3. На искусственно расширенном множестве примеров обучается друrая машина
опорных векторов.
Этот метод позволяет повысить точность классификации за счет увеличения Bpe
мени обучения, поскольку он требует двух циклов обучения. Однако в этом случае
правила классификации строятся на основе большеro количества опорных векторов.
Задачи
Оптимальная разделяющая rиперплоскость
б.l. Рассмотрим rиперплоскость для линейноrо разделения образов, определяе
мую уравнением
w T Х + Ь == О,
rAe w вектор весов; Ь пороr; Х входной вектор. rиперплоскость назы
вается соответствующей канонической паре (canonical pair) (w, Ь), если для
множества входных образов {Xi }[:1 выполняется дополнительное условие
. min Iw T Xi + Ь' == 1.
t:::::!,2,...,N
Покажите, что при выполнении этоrо условия ширина rpаницы разделения
между двумя классами равна 2/lIwll.
б.2. В контексте неразделимых образов докажите следующее утверждение. Ha
личие ошибок классификации означает неразделимость множеств. Обратное
утверждение не BcerAa верно.
б.3. Для прямой задачи оптимизации разделяющей rиперплоскости для нераз
делимых множеств сформулируйте двойственную задачу, как это сделано в
разделе б.3.
454 rлава 6. Машины опорных векторов
б.4. Для оценки ожидаемой ошибки тестирования, rенерируемой оптимальной rи
перплоскостью в случае неразделимых множеств, воспользуйтесь методом,
описанным в rлаве 4. Рассмотрите различные ситуации, которые MorYT воз
никнуть при использовании этоrо метода, если один из примеров удаляется
из обучающеrо множества и решение строится на основе оставшихся.
б.5. Положение оптимальной rиперплоскости в пространстве данных определя
ется точками данных, выбранных в качестве опорных векторов. Если данные
зашумлены, возникает вопрос о робастности rpаниц разделения к наличию
шума. При внимательном изучении оптимальной rиперплоскости робаст-
ность rpанИЦЫ разделения по отношению к шуму подтверждается. Дайте
этому разумное объяснение.
Ядро скалярноrо произведения
б.б. Ядро скалярноrо произведения K(Xi, Xj), построенное на множестве приме
ров обучения Т размера N, образует матрицу размерности N х N:
к == {K ij } ,j) 1 ,
rде K ij == K(Xi, Xj)' Матрица К является положительной, если положитель
ны все ее элементы. Используя преобразования подобия
к == Qл.QТ,
rAe л. диаrональная матрица, состоящая из собственных значений; Q
матрица, составленная из соответствующих собственных векторов, сФорму
лируйте выражение для ядра скалярноrо произведения K(Xi, Xj) в терминах
собственных значений и собственных векторов матрицы К. Какие выводы
можно сделать из этоrо представления?
б.7. а) Докажите свойство унитарной инвариантности (unitary invariance prop
erty) ядра скалярноrо произведения К(х, Xi)
К(х, Xi) == K(Qx, QXi),
rде Q унитарная матрица, т.е.
Q l == QT.
б) Покажите, что все три ядра скалярноrо произведения, приведенные в
табл. б.l, удовлетворяют этому свойству.
Задачи 455
б.8. Ядро скалярноrо произведения двухслойноrо персептрона определяется сле
дующим образом:
К(х, Xi) == tanh( oxT Xi + 1)'
Найдите несколько значений констант o и 1' для которых теорема Мерсера
не удовлетворяется.
Классификация множеств
б.9. ДЛя решения задачи XOR в полиномиальной обучаемой машине используется
ядро скалярноrо про изведения вида
К(х, Xi) == (1 + ХТ Xi)P.
Каково минимальное значение степени р, при которой решается задача
XOR? Предполаrается, что р целое положительное число. Что произойдет
в случае использования значения р, превышающеro минимальное?
б.10. На рис. б.9 показана функция XOR, определенная на трехмерном множестве
входных сиrналов Х:
ХОR(Х1,Х2,ХЗ) == X1 Е!Э Х2 Е!Э Хз,
rAe символЕ!Э обозначает лоrический оператор "исключающеrо ИЛИ". Co
здайте полиномиальную обучаемую машину, распознающую два класса тo
чек, определяемых выходом этоro оператора.
б.ll. На протяжении всей rлавы обсуждался вопрос использования машины опор
ных векторов для задач двоичной классификации. Проанализируйте, как мож
но использовать машину опорных векторов для решения задачи классифика
ции порядка М, rдe М > 2.
Нелинейная реrрессия
б.12. Двойственная задача, сформулированная в разделе б.8, для случая использо
вания машины опорных векторов для решения задачи нелинейной реrpессии
имеет следующее оrpаничение:
N
L (ai a ) == О,
i l
456 rлава 6. Машины опорных векторов
Х 2
Х 1
Х з
Рис. 6.9. Оператор "исключающеro ИЛИ" в
трехмерном пространстве
I
+1
Х 2
.
. . . .
. . . . . .
. . . . . . .
. х Х 1
l О +1
х х х х х х х . .
х х х х х х . .
х х х . .
х . .
1
Рис. 6.10. rрафическое представление классов
rдe ai и a множители Лаrpанжа. Покажите, что это оrpаничение является
следствием минимизации Лаrpанжиана относительно пороrа Ь, Т.е. первоro
элемента Wo вектора весов w, соответствующеro <р(х) == 1.
Преимущества и недостатки
б.13. а) Проанализируйте преимущества и недостатки машин опорных векторов
по сравнению с сетями на основе радиальных базисных функций (RВP)
при решении следующих задач: классификации образов (1) инелинейной
реrpессии (2).
Задачи 457
б) Выполните сравнительный анализ машины опорных векторов с MHOro
слойным персептроном, обучаемым по алroритму обратноrо распростра
нения.
Компьютерное моделирование
б.14. На рис. б.l0 показано множество точек, соответствующих двум классам C 1
и С 2 . Координаты X1 и Х2 изменяются на интервале от 1 до +1. Используя
ядро скалярноro про изведения
К(х, t) == ехр( llx tI1 2 ),
постройте оптимальную разделяющую rиперплоскость для этоro набо
ра данных.
б.15. Компьютерный эксперимент, описанный в разделе б.б, был проведен для
классификации двух пересекающихся rayccoBbIX распределений. В этом экс
перименте использовался параметр реrуляризации С == 0,1. Ширина pa
диальных базисных функций, использованных для построения скалярноro
ядра, составляла а2 == 4. Повторите этот же эксперимент, используя друrnе
параметры реryляризации:
а) С == 0,05;
б) С == 0,2.
Прокомментируйте полученный результат в свете значений, полученных в
разделе б.б.
б.lб. При использовании сетей на основе радиальных базисных функций для реше
ния задач нелинейной реrpессии часто оказывается, что применение нелока
лизованных базисных функций, таких как мультиквадратичная, обеспечивает
более высокую точность решения, чем локализованных, таких как функция
[аусса. Можно высказать предположение, что аналоrичная ситуация xapaK
терна и для машин опорных векторов, так как использование (неоrpаничен
ных) полиномиальных обучаемых машин обеспечивает более высокую точ
ность, чем (оrраниченных) машин на основе радиальных базисных функций.
Проверьте правильность этоro предположения экспериментально для задачи
классификации.
.....
..,
Ассоциативные машины
7.1. Введение
в предыдущих трех шавах описывались три различных подхода к обучению с учи
телем. В шаве 4 описывлсяя мноrослойный персептрон, обучаемый по методу об
paTHoro распространения и реализующий одну из форм шобальной оптимизации (во
всем пространстве весовых коэффициентов). Сети на основе радиальных базисных
функций, описанные в шаве 5, блаrодаря своей структуре обеспечивают локальную
оптимизацию. Машины опорных векторов, рассмотренные в шаве 6, базируются на
теории VС измерений. В этой шаве мы обсудим еще один класс методов, предна
значенных для решения задач обучения с учителем. Представленный здесь подход
основан на общеизвестном принципе "разделяй и властвуй" (divide and conquer).
В соответствии с этим принципом сложные вычислительные задачи решаются
при помощи их разбиения на множество небольших и простых задач с последую
щим объединением полученных решений. При обучении с учителем вычислительная
простота достиrается за счет распределения задачи обучения среди множества экс
пертов, которые, в свою очередь, разбивают входное пространство на множество
подпространств. Комбинацию таких экспертов и называют ассоциативной машиной
(committee machine). По сути она интеrpирует знания, накопленные экспертами, в
общее решение, которое имеет приоритет над каждым решением отдельноrо экспер
та. Идея ассоциативной машины появилась еще в 1965 rоду в [786]. Предложенная
в этой работе сеть состоит из слоя элементарных персептронов, за которым следует
второй слой принятия решения.
Ассоциативные машины являются универсальными аппроксиматорами. Их можно
разбить на две основные катеrории.
1. Статические структуры (static structure). В этом классе ассоциативных машин
отклики различных предикторов (экспертов) объединяются с помощью HeKoToporo
механизма, не учитывающеrо входной сиrнал. Поэтому они и получили название
"статические". Эта катеrория структур работает на основе следующих методов.
· Усреднение по ансамблю (ensemble averaging). Выходной сиrнал вычисляется
7.1. Введение 459
. Усреднение по ансамблю (ensemble averaging). Выходной сиrнал вычисляется
как линейная комбинация выходов отдельных предикторов.
. Усиление (boosting), при котором слабый алrоритм обучения превращается в
алrоритм, достиrающий произвольной заданной точности.
2. Динамические структуры (dynamic structure). В этом втором классе ассоциативной
машины входной сиrнал непосредственно учитывается в механизме объединения
выходных сиrналов экспертов (блаroдаря этому свойству данные машины и по
лучили название "динамических"). Можно выделить две различные реализации
динамических структур.
. Смешение мнений экспертов (mixture of experts), при котором откли
ки отдельных экспертов нелинейно объединяются в единую шлюзовую
сеть (gating network).
. Иерархическое объединение .мнений экспертов, при котором отклики отдельных
экспертов нелинейно объединяются с помощью нескольких шлюзовых сетей,
орrанизованных в иерархическую структуру.
При смешении мнений экспертов принцип "разделяй и властвуй" применяется
Bcero один раз, в то время как при иерархическом смешении он применяется
неоднократно для каждоrо слоя иерархии.
Смешение мнений экспертов и иерархическое смешение можно рассматривать как
примеры модульных (modular) сетей. Формальное определение модульности было
приведено в [804]. Оно звучит следующим образом.
Нейронная сеть является Jlюдульной, если выполняемые ею вычисления можно pac
пределить по нескольким подсистемам, которые обрабатывают различные входные
СИ2Налы и не пересекаются в своей работе дРУ2 с дРУ20М. Выходные СИ2Налы этих
подсистем объединяются модулем инте2рации, выход котОРО20 не имеет обратной
связи с подсистемами. В частности, модуль инте2рации принимает решение о том,
как выходные си2Налы подсистем объединяются в общий выходной СИ2Нал системы,
и определяеm, на каких примерах следует обучать конкретные модули.
Это определение модульности исключает из рассмотрения класс статических ac
социативных машин, так как в последних не существует никаких элементов интеrpи
рования, которые выполняют принятие решений.
Структура rлавы
Эту шаву формально можно разбить на две части. В первой части (разделы 7.2 7.5)
рассматривается класс статических структур. В частности, в разделе 7.2 описывается
метод усреднения по ансамблю, компьютерное моделирование KOToporo будет выпол
нено в разделе 7.3. В разделе 7.4 мы рассмотрим технику усиления, а в разделе 7.5
приведем результаты ее компьютерноrо моделирования.
'1(l1lI
460 rлава 7. Ассоциативные машины
Во второй части шавы (разделы 7.6 7.13) рассматриваются динамические CТPYK
туры. В частности, в разделе 7.6 представлена структура смешения мнений экспертов,
или ME cтpyктypa (mixture of experts), как ассоциативная rayccoBa модель смешения
(associative Gaussian mixture mode1). В разделе 7.7 описывается более общий случай
иерархическое смешение мнений экспертов, или HME cтpyктypa (hierarchica1 mixture
of experts). Эта вторая модель близка к стандартным деревьям решений. В разделе 7.8
речь пойдет о том, как стандартное дерево решений можно использовать для реше
ния задачи выбора модели (т.е. количества экспертных и шлюзовых сетей) в НМЕ. В
разделе 7.9 будут определены апостериорные вероятности, используемые при описа
нии алrоритмов обучения НМЕ. В разделе 7.1 О будут заложены основы для решения
задачи оценки параметров и построена функция правдоподобия для модели НМЕ. В
разделе 7.11 представлен обзор стратеrий обучения, а в разделе 7.12 последует дe
таль ное описание так называемоro ал20ритма ЕМ, применению KOTOpOro для модели
НМЕ посвящен раздел 7.13.
Как Bcerдa, шава завершится заключительными выводами и обсуждением.
7.2. Усреднение по ансамблю
На рис. 7.1 показано множество отдельно обучаемых нейронных сетей (экспертов) с
общим входным сиrналом. Их выходные сиrналы некоторым образом комбинируют
ся, формируя общий выход системы у. Для Toro чтобы упростить выкладки, предполо
жим, что выходы экспертов представляют собой скалярные величины. Представлен
ный здесь подход носит название метода усреднения по ансамблю (ensemble averaging
method)1 . Использование этоrо метода обусловлено двумя основными причинами.
· Если множество экспертов, показанное на рис. 7.1, заменить единой нейронной
сетью, получится сеть, содержащая roраздо большее количество настраиваемых
параметров. Естественно, время обучения такой сети будет существенно больше
времени параллельноrо обучения множества экспертов.
· Риск избыточноrо обучения (overfitting) возрастает, если количество настраивае
мых параметров существенно больше размера множества данных обучения.
При использовании ассоциативных машин (см. рис. 7.1) предполаrается, что обу
чаемые по отдельности эксперты будут сходиться к разным локальным минимумам
поверхности ошибок, в результате чеrо некоторая комбинация их выходных сиrналов
приведет к повышению эффективности сети.
1 Методы усреднения по множеству обсуждаются в [828], в которой собрана довольно большая библиоrpа-
фия по этой теме. К друrим рекомендуемым работам относятся [424] н [1164].
7.2. Усреднение по ансамблю 461
Входной
сиrнал
х(п)
h.. Эксперт y1(n)
17 1
. Эксперт Yi n ) Lo.
v 2 Сумматор
...
h.. Эксперт yJ!n)
V к
Выходной
сиrнал
у(п)
Рис. 7.1. Блочная диаrрамма
ассоциативной машины, OCHO
ванной на усреднении по aH
самблю
в первую очередь рассмотрим единую нейронную сеть, обучаемую на некотором
множестве примеров. Пусть х некоторый ранее не встречавшийся входной вектор;
d соответствующий ему желаемый отклик (метка класса или численный отклик).
Эти величины представляют собой реализацию случайноrо вектора Х и случайной
переменной D. Пусть F(x) реализуемая сетью функция отображения входноro сиr
нала в выходной. Torдa в свете дилеммы смещения и дисперсии, описанной в rлаве 2,
среднеквадратическую ошибку между функцией Р(х) и условным математическим
ожиданием E(DIX == х) можно разложить на слаrаемые смещения и дисперсии
ED[(F(x) E[DjX == х])2] == BD(F(x)) + VD(F(x)),
(7.1)
rде BD(F(x» квадрат смещения
BD(F(x)) == (ED[F(x)] E[DIX == х])2,
(7.2)
а VD(F(x» дисперсия
VD(F(x)) == ED[(F(x) E D [F(x)])2].
(7.3)
Математическое ожидание E D вычисляется в пространстве О, которое определя
ется как пространство, охватывающее распределение всех обучающих множеств
(т.е. входных си2налов и целевых выходов) и распределение всех начальных условий.
Существуют различные способы отдельноro обучения различных экспертных ce
тей, а также различные методы объединения их выходных сиrналов. В данной rлаве
будет рассмотрена ситуация, в которой экспертные сети имеют одинаковую конфиrу
рацию, но начинают обучение из различных исходных состояний. Для объединения
их входных сиrналов будет использоваться простой блок усреднения по ансамблю 2 .
2 Использование усреднения по ансамблю при построении ассоциативной машины на множестве различ-
ных начальных условий ранее предлаrалось мноrими практиками нейронных сетей. Однако статистический
анализ, представленный в [770], и процедура обучения ассоциативных машин, определенная для метода усред-
"..
462 rлава 7. Ассоциативные машины
Пусть Ф пространство всех исходных состоянии; FJ(x) среднее всех функций
отображения входноro сиrнала в выходной в экспертных сетях на множестве исход
ных состояний. По аналоrии с формулой (7.1) можно записать следующее:
Еф[(FJ(Х) E[DIX == х])2] == Вф(F(х)) + Vф(F(х)),
(7.4)
rдe Вф(F(х» квадрат смещения, определенноrо в пространстве Ф:
Вф(F(х)) == (Еф[FJ(х)] E[DIX == х])2,
(7.5)
а Vф(F(х» соответствующая дисперсия:
Vф(F(х)) == Еф[(FJ(х) Е ф [F(х)])2].
(7.6)
Математическое ожидание Е ф вычисляется по всему пространству Ф.
Из определения пространства О видно, что оно представляет собой произведение
пространства исходных условий Ф на оставшееся пространство (remnant space) о'.
Следовательно, по аналоrии с (7.1) можно записать:
ED,[(FJ(x) E[DIX == х])2] == BD,(FJ(x)) + VD'(FJ(x)),
(7.7)
rдe B D , (Р(х» квадрат смещения, определенноro в пространстве Ф':
BD,(FJ(X)) == (ED,[FJ(x)] E[DIX == х])2,
(7.8)
а V D ' (Р(х» соответствующая дисперсия:
VD,(FJ(x)) == ED'[(FJ(x) ED,[FJ(x)])2].
(7.9)
Из определений пространств о, Ф и о' видно, что
E D , [FJ(X)] == ED[FJ(x)].
(7.10)
нения по множеству начальных условий, явились первыми исследованиями TaKoro рода. Представленные в этой
работе экспериментальные результаты подтвердили значительное уменьшение дисперсии при усреднении по
пространству начальных условий.
Соrласно [770], в ассоциативных машинах, использующих усреднение по пространству начальных состоя-
ний, не рекомендуется при менять популярные модификации алroритма обучения, типа уменьшения весов или
paHHero останова.
7.2. Усреднение по ансамблю 46З
Отсюда следует, что выражение (7.8) можно переписать в эквивалентной форме:
BD,(FJ(X)) == (ED[F(x)] E[DjX == х])2 == BD(F(x)).
(7.11)
Далее рассмотрим дисперсию V D , (F(x» в выражении (7.9). Так как дисперсия
случайной переменной равна среднеквадратическому значению этой переменной за
вычетом квадрата смещения, то можно записать:
VD,(FJ(X)) == ED,[(FJ(x))2] (E D , [FJ(X)])2 == ED,[(FJ(x))2] (ED[FJ(x)])2. (7.12)
в последнем равенстве используется соотношение (7.10). Аналоrично, выражение
(7.3) можно переписать в следующей эквивалентной форме:
VD(FJ(x)) == E D [(F(x))2] (E D [F(x)])2.
(7.13)
Заметим, что среднеквадратическое значение функции F(x) во всем пространстве
О должно быть не меньше значения среднеквадратической функции FJ(X) в про
странстве дополнения о', Т.е.
ED[F(x)2] E D ,[(F J (x))2].
в свете этоrо неравенства сравнение (7.12) и (7.13) приводит к следующе
му заключению:
VD,(FJ(x)) VD(F(x)).
(7.14 )
Таким образом, из выражений (7.11) и (7.14) можно сделать следующие два вывода.
1. Смещение усредненной по ансамблю функции FJ(X) дЛЯ ассоциативной машины,
показанной на рис. 7.1, имеет то же значение, что и для функции F(x) отдельной
нейронной сети.
2. Дисперсия усредненной по ансамблю функции FJ(X) не меньше дисперсии OT
дельных функций F(x).
Эти теоретические рассуждения определяют стратеrию обучения, которая при
водит к уменьшению общей ошибки ассоциативной машины за счет варьирования
начальных состоянии [770]: отдельные "эксперты" машины целенаправленно обуча
ются с избытком (overtrained). Этому есть следующее объяснение: поскольку мы
имеем дело с отдельными экспертами, смещение уменьшается за счет дисперсии.
Далее дисперсия уменьшается путем усреднения параметров экспертов ансамбля по
начальным условиям при неизменном смещении.
r
464 rлава 7. Ассоциативные машины
7.3. Компьютерный эксперимент 1
В этом компьютерном эксперименте, посвященном исследованию метода усреднения
по ансамблю, снова рассмотрим задачу бинарной классификации, с которой мы уже
сталкивались в предыдущих трех rлавах. Это задача классификации двух классов,
определяемых двумерными пересекающимися rауссовыми распределениями. Эти два
распределения имеют различные средние значения и дисперсии. Класс С 1 имеет такие
статистические характеристики:
J11 == [О, о]Т,
2 1
0'1 ,
а класс С 2 следующие:
J12 == [2, о]Т,
2 4
0'2 .
rрафики этих двух распределений представлены на рис. 4.13.
Предполаrается, что эти два класса равновероятны. Стоимость ошибки клас
сификации предполаrается равной в обоих классах, а стоимость корректной класси
фикации предполаrается равной нулю. При таких условиях (оптимальный) классифи
катор Байеса обеспечивает вероятность корректной классификации, составляющую
Ре ==81,51 %. Обоснование этоrо результата приводится в rлаве 4.
В компьютерном эксперименте, описанном в rлаве 4, для персептрона с двумя
скрытыми элементами, обучаемоro с помощью алrоритма обратноrо распростране
ния, удалось обеспечить вероятность корректной классификации порядка 80%. В Ha
стоящем разделе для решения задачи будем использовать ассоциативную машину,
состоящую из десяти экспертов, при этом каждый из экспертов представляет собой
мноroслойный персептрон с двумя скрьпыми нейронами.
Все эксперты обучаются отдельно с помощью алrоритма обратноrо распростра
нения со следующими параметрами.
Параметр скорости обучения 11 ==0,1.
Константа фактора момента а ==0,5.
Обучающее множество состоит из 500 образов. Все эксперты обучаются на одном
и том же множестве примеров, но имеют различные исходные состояния. В част-
ности, исходные значения синаптических весов и пороrов выбираются случайным
образом с помощью reHepaTopa случайных чисел с равномерным распределением в
диапазоне [ 1; 1].
7.4. Метод усиления 465
ТАБЛИЦА 7.1. Эффективность классификации отдельных экспертов в ассоциа
тивной машине
Эксперт
Сеть 1
Сеть 2
Сеть 3
Сеть 4
Сеть 5
Сеть 6
Сеть 7
Сеть 8
Сеть 9
Сеть 1 О
Процент корректнои классификации
80,65
76,91
80,06
80,47
80,44
76,89
80,55
80,47
76,91
80,38
в табл. 7.1 представлены результаты классификации отдельных экспертов, обуча
емых на данном множестве образов. Вероятность корректной классификации была
получена путем вычисления среднеro арифметическоrо по множеству результатов в
табл. 7.1 и составила Рс,ау ==79,37%. С друrой стороны, используя метод усреднения
по ансамблю, Т.е. просто суммируя результаты всех 1 О экспертов и только затем BЫ
числяя вероятность корректной классификации, получим результат Pc,ens == 80,27%.
Налицо улучшение результата на 0,9%. Более высокое значение Pc,ens по сравнению
с Рс,ау наблюдалось во всех попытках данноrо эксперимента. Результаты классифи
кации каждый раз вычислялись на тестовом множестве из 32000 примеров.
Анализируя результаты эксперимента, можно утверждать следующее. Эффектив
ность классификации улучшается за счет переобучения отдельных персептронов (экс
пертов) и суммирования их выходных сиrналов в единый выходной сиrнал ассоциа
тивной машины, на основании KOToporo уже и принимается решение.
7.4. Метод усиления
Как уже roворилось во введении, метод усиления является еще одним способом pe
ализации класса "статических" ассоциативных машин. В ассоциативных машинах,
основанных на усреднении по ансамблю, все эксперты обучаются на одном и том
же множестве данных. Сети отличаются друr от друrа только выбором исходноrо co
стояния. В противоположность этому сети эксперты, работающие на основе метода
усиления, обучаются на примерах, принадлежащих совершенно различным распреде
лениям. Это самый общий метод из тех, которые можно использовать для улучшения
производительности люБО20 алroритма обучения.
l'
466 rлава 7. Ассоциативные машины
Метод усиления 3 (boosting) может быть реализован тремя способами.
1. Усиление за счет фильтрации (boosting Ьу fi1tering). Этот подход предполаrает
отбор (фильтрацию) примеров обучения различными версиями слабоrо алroритма
обучения. При этом предполаrается доступность большоrо (в идеале бесконеч
HOro) множества примеров. Во время обучения примеры MorYT быть отбракованы
или сохранены. Преимуществом этоrо подхода является то, что по сравнению с
двумя остальными он не предъявляет больших требований к памяти.
2. Усиление за счет формирования подвыборок (boosting Ьу subsamp1ing). Этот ПОk
ход предполаraет наличие множества примеров обучения фиксированноrо раз
мера. Подвыборки составляются во время обучения в соответствии с заданным
распределением вероятности. Ошибка вычисляется относительно фиксированноro
множества примеров обучения.
3. Усиление путем перевзвешивания (boosting Ьу reweighting). Третий подход связан
с обработкой фиксированноro множества примеров. При этом предполаrается,
что слабый алrоритм обучения может получать "взвешенные" примеры. Ошибка
вычисляется относительно взвешенных примеров.
В этом разделе описываются два алroритма усиления. Первый из них, соrласно
[940], относится к первому вышеописанному подходу. Второй алrоритм, называемый
AdaBoost [319], [320], относится ко второму подходу.
Усиление за счет фильтрации
Исходная идея усиления, описанная в [940], берет свое начало в независuмой от
распределения (distribution free) или статистически аппроксимативно корректной
(probably approximate1y correct РАС) модели обучения. Из обсуждения модели РАС
в rлаве 2 ясно, что понятие или концепт (concept) можно рассматривать как булеву
функцию в предметной области экземпляров, которая включает коды всех интересую
щих нас объектов. При обучении РАС машина пытается идентифицировать неизвест
ный двоичный концепт на основе случайно выбранных ero экземпляров. Более CTpOro,
целью обучаемой машины является поиск rипотезы или правила проrнозирования с
вероятностью ошибки, не превышающей некоторой небольшой наперед заданной Be
личины 1::, причем это условие должно выполняться для всех входных распределений.
Именно по этой причине обучение РАС называют также сильно и моделью обучения
(strong 1eaming mode1). Так как примеры имеют случайную природу, обучаемая маши
на, вероятнее Bcero, не сможет составить представление о неизвестном понятии, если
множество примеров будет не представительным. Поэтому модель обучения должна
3 Основными работами по теории усиления и связанными с ней экспериментальными приложениями явля
ются следующие: [940], [267], [266], [317], [153], [319], [320], [318], [939] и [941]. Они перечислены примерно в
хронолоrическом порядке Лучшими ссылками по трем основным подходам к усилению являются [940] (филь
трация), [319] (подвыборка (resampling» и [317] (перевзвешивание).
7.4. Метод усиления 467
находить хорошую аппроксимацию неизвестноro понятия с вероятностью (1 8), rде
8 некоторое малое положительное число.
В вариации РАС обучения, называемой слабои моделью обучения (weak 1eaming
mode1), требования к поиску неизвестноro понятия сильно ослаблены. Обучаемая
машина должна построить rипотезу с вероятностью ошибки, несколько меньшей
значения 1/2. При случайном "уrадывании" двоичной разметки для каждоrо примера
rипотеза с равной вероятностью может оказаться как правильной, так и неверной.
Значит, в этом случае вероятность ошибки составляет 1/2. Отсюда следует, что для
слабой модели обучения достаточно достичь уровня эффективности, несколько пре
восходящеrо абсолютно случайный выбор. Понятие слабой обучаемости было BBeдe
но в [550], rдe была сформулирована задача усиления 2ипотезы (hypothesis boosting
рroЫет), которая сводится к следующему вопросу.
Эквивалентны ли понятия силЬНО20 и слаБО20 обучения?
Друrими словами, является ли любой слабо обучаемый класс понятий также и
сильно обучаемым? Положительный ответ на этот вопрос, несколько удивительный
на первый взrляд, дан в [940], rдe пред ставлено конструктивное доказательство эк
вивалентности слабоro и сильноro обучения. В частности, в [940] бьт предложен
алroритм, преобразующий слабую модель обучения в сильную. Это достиrается бла
rодаря изменению распределения примеров обучения таким образом, чтобы сильная
модель строилась "BoKpyr" слабой.
При использовании усиления за счет фильтрации ассоциативная машина состоит
из трех экспертов или подrипотез. Алroритм, используемый для TaKoro обучения, Ha
зывают алroритмомусиления (boosting a1gorithm). При этом три эксперта произвольно
маркируются как "первый", "второй" и "третий". Они обучаются по отдельности сле
дующим образом.
1. Первый эксперт обучается на множестве, состоящем из N 1 примеров.
2. Обученный первый эксперт используется для фильтрации (fi1ter) BToporo множе
ства примеров следующим образом.
. Случайный выбор моделируется подбрасыванием монетки.
. Если выпадает решка (head), новый пример "пропускается" через первоrо экс
перта и корректно классифицированные примеры отклоняются до тех пор, пока
не возникнет ошибка классификации. Пример, приведший к ошибке классифи
кации, добавляется в множество примеров для обучения BТOpOro эксперта.
. Если выпадает орел (tai1), производятся действия, прямо противоположные BЫ
шеописанным, Т.е. примеры "пропускаются" через первоrо эксперта и отклоня
ются до тех пор, пока очередной пример не будет классифицирован правильно.
Этот корректно классифицированный пример добавляется в множество приме
ров, подrотавливаемых для обучения BToporo эксперта.
r
,
468 rлава 7. Ассоциативные машины
· Этот процесс продолжается до тех пор, пока все множество из N 1 примеров
не будет отфильтровано первым экспертом. Отфильтрованное таким образом
множество примеров подается для обучения BTOpOro эксперта.
Процедура подбрасывания монетки rарантирует, что при тестировании первоro
эксперта на втором наборе примеров ошибка классификации составит 1/2. Друrи-
ми словами, второе множество из N 1 примеров, доступное для обучения BToporo
эксперта, имеет распределение, полностью отличное от распределения первоrо
множества из N 1 примеров, использованных ранее для обучения Первоro экспер
та. Таким образом, второй эксперт вынужден учиться на распределении, отлича
ющемся от использованноrо для обучения первоro эксперта.
3. После обучения BToporo эксперта множество примеров обучения для тpeтbero
эксперта формируется следующим образом.
· Новый пример "про пускается" через первоrо и BTOpOro экспертов. Если реше
ния обоих экспертов совпадают, пример отклоняется; если они расходятся в
своих мнениях, данный пример включается в множество примеров обучения
тpeTbero эксперта.
· Этот процесс продолжается до тех пор, пока не будет отфильтровано все мно-
жество из N 1 примеров. Полученное множество примеров затем используется
для обучения тpeTbero эксперта.
После окончания обучения TpeTbero эксперта на отфильтрованном множестве при
меров процесс обучения всей ассоциативной машины считается завершенным.
Описанная выше процедура фильтрации rpафически представлена на рис. 7.2.
Пусть N 2 количество примеров, отфильтрованных первым экспертом для по-
лучения обучающеro множества BToporo эксперта, содержащеrо N 1 элементов. Заме-
тим, что число N 1 фиксировано, а число N 2 зависит от ошибки обобщения первоro
эксперта. Пусть N з количество примеров, обработанных в процессе совместной
фильтрации первым и вторым экспертами для формирования обучающеrо множества
TpeTbero эксперта из N 1 элементов. Так как это же число (N 1 ) ранее использовал ось
для обучения первоro эксперта, общий объем данных, необходимый для обучения
ассоциативной машины, составляет N 4 == N 1 + N 2 + N 3 . Однако при этом вычис
лительная стоимость обучения зависит от 3* N 1 примеров, так как N 1 это коли
чество примеров, действительно используемых для обучения всех трех экспертов.
Таким образом, можно утверждать, что описанный здесь алroритм усиления явля-
ется действительно "интеллектуальным" (smart): для работы ассоциативной машины
требуется большой объем примеров, но на самом деле для реальноrо обучения будет
использоваться только небольшое подмножество этих данных.
7.4. Метод усиления 469
N 2 примеров Обучаемый
эксперт
1
N j примеров со статистикой,
отличной от той, которой
обучался эксперт 1
а) Фильтрация примеров, выполненная экспертом 1
Обучаемый
эксперт
1
N з примеров
} N] прим ров c статистиuкой,
отличнои от тои, которои
обучались эксперты 1 и 2
Рис. 7.2. rрафически пред
ставленный процесс усиле
ния за счет фильтрации
Обучаемый
эксперт
2
б) Фильтрация примеров, выполненная экспертами 2 и 3
Еще одним вопросом, на который хотелось бы обратить внимание, является сле
дующий. Операция фильтрации, выполняемая первым экспертом, и операция COB
местной фильтрации, совместно выполняемая первым и вторым экспертами, за
ставляют BToporo и TpeTbero экспертов сосредоточиться на "тяжелых для YCBoe
ния" частях распределения.
В теоретическом выводе алroритма усиления, впервые представленном в [940],
для оценки производительности ассоциативной машины на не встречавшихся ранее
примерах использовалось простое rолосование. А именно, на вход ассоциативной
машины подавался тестовый пример. Если решения первоrо и BTOpOro экспертов
совпадали, для маркировки использовался именно этот класс. В противном случае
использовалась оценка TpeTbero эксперта. Однако экспериментально [266], [267] бы
ло определено, что сложение соответствующих выходов трех экспертов приводит к
лучшей производительности, нежели rолосование. Например, в задаче оптическоrо
распознавания символов (optica1 character recognition OCR) операция сложения BЫ
полнялась сложением выходов "цифра О" всех трех экспертов; аналоrично для всех
остальных девяти цифр.
Предположим, что все три эксперта (т.е. подrипотезы) имеют уровень ошибок
е < 1/2 по отношению к распределениям, на которых происходило их обучение.
Это значит, что все три модели обучения являются слабыми. В [940] было доказа
но, что общий уровень ошибок ассоциативной машины в данном случае оrpаничен
следующей величиной:
9(10) == 3102 2103.
(7.15)
.,..
470 rлава 7. Ассоциативные машины
0,5
0,4
Q
'"
,::;: 0,3
'" ;r:
0<>
"'
О 0,2
0,1
.-
...
...
...
...
...
...
...
...
...
...
...
...
...
Без стимулирования ...'"
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
r раница производительности
при стимулировании
g(E) 3Е 2 2Е 3
о
0,1
0,2
0,3
0,4
0,5
Рис. 7.3. rрафик зависимости
(7.15) для усиления за счет
фильтрации
Е
Зависимость g(e) от е показана на рис. 7.3. На рисунке видно, что это оrpаниче
ние существенно меньше исходноro уровня ошибок е. Рекурсивно применяя алrоритм
усиления, уровень ошибок можно сделать сколь уroдно малым. Друrими словами, мо-
дель слабоrо обучения, производительность которой мало отличается от случайноro
выбора, при помощи усиления можно преобразовать в сильную модель обучения.
Именно в этом смысле можно с полным правом утверждать, что слабая и сильная
модели обучения на самом деле эквивалентны.
Алrоритм адаптивноrо усиления AdaBoost
Практическое оrpаничение усиления за счет фильтрации состоит в том, что для Hero
часто требуется довольно большое множество примеров. Это оrpаничение можно
обойти, используя друrой алroритм усиления, который называется AdaBoost [319],
[320] и принадлежит к катеrории усиления с использованием подвыборки. Контур
подвыборки AdaBoost является обычным контуром пакетноrо обучения. И, что более
важно, он допускает повторное использование данных обучения.
Как и в случае использования алrоритма усиления за счет фильтрации, AdaBoost
позволяет работать со слабыми моделями обучения. Целью этоrо алroритма является
поиск окончательной функции отображения или rипотезы, которая будет иметь низ
кий уровень ошибок на данном распределении О маркированных примеров обучения.
От друrих алroритмов усиления AdaBoost отличается следующим.
· AdaBoost адаптивно настраивается на ошибки слабых rипотез, возвращаемых сла
быми моделями обучения. Блаroдаря именно этому свойству алrоритм и получил
свое название.
7.4. Метод усиления 471
. Оrpаничение производительности алroритма AdaВoost зависит от производитель
ности слабой модели обучения только на тех распределениях, которые фактически
формируются в процессе обучения.
Алrоритм AdaBoost работает следующим образом. На итерации п алroритм ycи
ления реализует слабую модель обучения с распределением ОП множества примеров
обучения Т. Слабая модель обучения вычисляет rипотезу Fn: х........ У, которая KOp
ректно классифицирует часть примеров обучения. Ошибка измеряется относительно
распределения ОП' Этот процесс продолжается Т итераций, в результате чеrо машина
усиления объединяет rипотезы F 1 , F 2 ,... ,F T В единую заключительную rипотезу Ffin.
Для Toro чтобы вычислить распределение ОП на итерации п и заключительную rи
поте зу F fiш используется простая процедура, описанная вкратце в табл. 7.2. Исходное
распределение является равномерным на множестве примеров обучения Т, Т.е.
1
D 1 (i) == для всех i.
п
Для данноrо распределения ОП и слабой rипотезы F n на итерации п следующее
распределение Оn+1 вычисляется умножением веса примера i на некоторое число
n Е [0,1), если rипотеза Fn корректно классифицирует входной вектор Xi. В про
тивном случае вес остается неизменным. В итоrе все веса заново нормализуются
делением на константу нормализации Zn' В результате "леrкие" примеры множества
Т, корректно классифицированные предыдущей слабой rипотезой, будут иметь бо
лее низкий вес, в то время как "трудные" примеры, для которых частота ошибок
классификации бьmа высокой, будут иметь больший вес. Таким образом, алrоритм
AdaВoost концентрирует основной объем весов на тех примерах, классифицировать
которые оказалось сложнее Bcero.
Окончательная rипотеза F fin вычисляется rолосованием (т.е. взвешенным линей
ным пороroм) из множества rипотез F 1 , F 2 ,... ,F T . Это значит, что для данноrо BXOД
HOro вектора Х окончательная rипотеза дает на выходе метку d, которая максимизирует
сумму весов слабых rипотез, которые определили эту метку. Вес rипотезы F 11 опре
деляется как log(1/ n), Т.е. больший вес назначается rипотезе с меньшей ошибкой.
Важное теоретическое свойство алroритма AdaBoost было сформулировано в сле
дующей теореме [319].
Пусть при вызове ал20ритма AdaBoost слабая модель обучения С2енерuровала 2ипо
тезы с ошибками 101,102, . . . ,tт, 2де ошибка t " на итерации п ал20рuтма AdaBoost
определяется как
t" ==
L
Dn(i).
i:Fn(Xi)#d i
l'
472 rлава 7. Ассоциативные машины
ТАБЛИЦА 7.2. Краткое описание алrоритма AdaBoost
Дано: Множество примеров обучения {( Х i, d i ) } 1
Распределение О для N маркированных примеров
Слабая модель обучения
Целое число Т, задающее количество итераций алrоритма
Инициализация: 01(i) == l/N для всех i
Вычисления: Для п == 1,2,... , т выполняются следующие действия.
1. Вызывается слабая модель обучения, реализуемая на распределении Dn
2. Формируется rипотеза Fn: х........ у
3. Вычисляется ошибка rипотезы Fn
Е п == I: Dn(i)
i:Fn(ч)#di
4. Вычисляется n == (Еп)/(1 Е п )
5. Изменяется распределение оп:
D ( ' ) Dn(i) { n' если F n(Xi) == d i ,
п+1 2 Z Х
n 1, в противном случае,
rде Zn константа нормализации (выбираемая таким образом, чтобы
Оп+1 бьmо распределением вероятности)
Выход: Окончательная rипотеза вычисляется следующим образом:
F п(х) == arg тах I: log r
dED n:Fn(x) d n
Пусть также Е п 1/2 и 'Уп == 1/2 Е п . ТО2да ошибка окончательной 2uпотезы
02раничена сверху следующей величиной:
1 т ( Т )
N I{i : F fin (Xi) =1= d i }! Ц у' 1 4'Y ехр 2 у;, .
(7.16)
Соrласно этой теореме, если ошибка слабой rипотезы, построенной слабой мо-
делью обучения, лишь HeMHoro меньше величины 1/2, то ошибка обучения окон-
чательной rипотезы F fin экспоненциально стремится к нулю. Однако это совсем не
значит, что ошибка обобщения на тестовых примерах тоже будет мала. Эксперимен
ты, представленные в [319], показали следующее. Во первых, теоретическая rpаница
ошибки обучения часто оказывается слабой. BO BTOpЫX, ошибка обобщения зачастую
существенно лучше, нежели это следует из теоретических выкладок.
В табл. 7.2 представлено описание алrоритма AdaBoost для задачи двоичной клас
сификации.
7.4. Метод усиления 473
:s:
"
\о
:s:
3
о
..о
;r:
<u
'"
О
Уровень ошибки
тестирования (обобщения)
Уровень ошибки обучения
о
Количество итераций стимулирования
Рис. 7.4. Ошибка алroритма AdaBoost
Если количество возможных классов (меток) М>2, задача усиления становится
более интересной ввиду Toro, что вероятность корректности случайноrо решения
равна 1/М, что существенно меньше чем 1/2. Для Toro чтобы алrоритм усиления
в такой ситуации Mor использовать любую rипотезу, даже слабо отличающуюся от
случайноrо решения, следует несколько модифицировать алroритм и определение
"слабоro обучения". Подобные модификации бьши описаны в [318] и [939].
Изменение ошибки
Эксперименты с алroритмом AdaВoost, описанные в [153], наrлядно показали, что
ошибки обучения и тестирования, представленные как функции от количества ите
раций усиления, имеют следующую зависимость: ошибки тестирования продолжают
уменьшаться после Toro, как ошибки обучения сократились практически до нуля
(рис. 7.4). Аналоrичный результат был ранее описан в работе, посвященной усиле
нию за счет фильтрации [266].
Эффект, показанный на рис. 7.4, может по казаться очень неожиданным в свете
TOro, что нам известно об эффективности обобщения в обычных нейронных сетях.
Как известно из rлавы 4, для мноroслойноrо персептрона, обучаемоro с помощью
алroритма обратноro распространения, ошибка тестирования уменьшается, достиrа
ет cBoero минимума, а затем начинает возрастать в связи с избыточным обучением
r
474 rлава 7. Ассоциативные машины
(overfitting) (см. рис. 4.20). Поведение, показанное на рис. 7.4, в корне отличается
тем, что по мере усложнения сети в процессе обучения ошибка обобщения все равно
продолжает уменьшаться. Такое поведение противоречит принципу бритвы Окка-
ма (Occam's razor), утверждающему, что для обеспечения наилучшеrо обобщения
обучаемая машина должна быть настолько простой, насколько это Возможно.
. В [941] дано объяснение этому феномену применительно к алrоритму AdaBoost.
Ключевой идеей анализа, представленноrо в работе, является то, что при оценке
ошибки обобщения, производимой машиной усиления, следует учитывать не толь-
ко ошибку обучения, но и достоверность (confidence) классификации. Проведенный
анализ обнаружил зависимость между усилением и машинами опорных векторов
(см. предыдущую rлаву). В частности, 2раница (margin) классификации определяется
как разность между весом, назначенным правильной метке, и максимальным весом,
назначенным некоторой некорректной метке. Из этоro определения леrко увидеть,
что rpаница является числом из диапазона [ 1, + 1] и образ корректно классифи-
цируется Torдa и только Torдa, коrда ero rpаница имеет положительное значение.
Таким образом, в [941] было показано, что явление, наблюдаемое на рис. 7.4, на са-
мом деле связано с распределением rpаниц обучающих примеров по отношению к
ошибкам классификации, полученным в результате roлосования. Здесь снова можно
подчеркнуть, что анализ, проведенный в вышеупомянутой работе, относится только
к алrоритму AdaВoost и не применим ни к какому друroму алrоритму усиления.
7.5. Компьютерный эксперимент 2
в этом эксперименте мы исследуем алroритм усиления за счет фильтрации, использу-
емый для решения крайне сложной задачи классификации. Данная задача классифи-
кации является двумерной и имеет невыпуклые области решений (рис. 7.5). Первый
класс точек лежит в области, помеченной на рисунке С 1, В то время как второй
класс в области С 2 . Требуется построить ассоциативную машину, определяющую
принадлежность примеров одному из этих двух классов.
Ассоциативная машина, используемая для решения поставленной задачи, состоит
из трех экспертов. Каждый из экспертов является мноroСЛОйным персептроном ти
па 2 5 2 (два входных узла, пять скрытых и два выходных нейрона). Для обучения
используется алroритм обратноrо распространения. На рис. 7.6 показан rpафик pac
пределения данных, используемых для обучения всех трех экспертов. На рис. 7.6, а
показаны данные, используемые для обучения первоro эксперта. Данные на рис. 7.6, б
были отфильтрованы первым экспертом после завершения обучения. Они будут ис
пользоваться для обучения BTOpOro эксперта. Данные на рис. 7.6, в были отфиль
трованы в процессе совместной работы первоro и BToporo экспертов. Они будут ис
пользоваться для обучения TpeTbero эксперта. Размер множества обучения каждоro из
экспертов состоял из N 1 == 1000 примеров. Из этих трех рисунков видно следующее.
7.5. Компьютерный эксперимент 2 475
Х 2 О
1
2
3
3 2 l
Рис. 7.5. Конфиryрация множеств, использован
ных для моделирования усиления
3
2
о
2
Х 1
. Данные, использованные для обучения первоro эксперта, распределены paBHOMep
но (см. рис. 7.6, а).
. Данные, использованные для обучения BTOpOro эксперта, более плотно CKOHцeH
трированы в областях, помеченных буквами А и Б, Т.е. в тех областях, rдe первый
эксперт испытывал сложности при классификации. Количество точек данных в
этих двух областях равно количеству правильно классифицированных точек.
. Данные, используемые для обучения TpeTbero эксперта, лежат в области, rде пер
вый и второй эксперты испытывали особые сложности при классификации.
На рис. 7.7, a в по казаны rpаницы решений, сформированные экспертами 1, 2
и 3 соответственно. На рис. 7.7,2 по казана общая rpаница решений, сформирован
ная совместными усилиями всех трех экспертов (в данном случае производил ось
обычное суммирование выходных сиrналов отдельных экспертов). Обратите вни
мание, что различие областей решений первоro и BToporo экспертов (см. рис. 7.7,
а и 6) формирует множество точек данных, используемых для обучения TpeTьe
ro эксперта (см. рис. 7.6, в).
Вероятность корректной классификации трех экспертов на тестовых дaH
ных составила:
1 эксперт:
2 эксперт:
3 эксперт:
75,15%
71,44 %
68,90%
2
2
А
I
I
,
!
!
I
,
I
i
I
476
rлава 7. Ассоциативные машины
о о
l l
2 2
3
1 О 2 2 1 О
а б
2
о
l
2
l
о
2
в
Рис. 7.6. rрафики распределения множеств обучения экспертов в компьютерном эксперименте
по усилению: эксперт 1 (а); эксперт 2 (б); эксперт 3 (в)
Общая вероятность корректной классификации всей ассоциативной машины co
ставила 91,72%. При вычислении этоrо показателя использовалось множество TeCTO
вых данных, состоящее из 32000 точек. Общая rpаница решений, сформированная
алrоритмом усиления с тремя экспертами, показана на рис. 7.7,2. Этот рисунок явля
ется еще одним доказательством хорошей эффективности классификации.
7.6. Ассоциативная rayccoBa модель смешения
Вторая часть настоящей rлавы, которая начинается с этоrо раздела, будет посвящена
изучению BToporo класса ассоциативных машин динамических структур. Исполь
7.6. Ассоциативная rayccoBa модель смешения 477
2
2
о о
1 1
2 2
1 О 2 1 О 2
а) б)
2 2
о о
1 1
2 2
1 О 2 1 О 2
В) r)
Рис. 7.7. rраницы решений, сформированные различными экспертами в эксперименте по
усилению: эксперт 1 (а); эксперт 2 (б); эксперт 3 (в); ассоциативная машина в целом (r)
зуемый здесь термин "динамические" подразумевает то, что объединение знаний,
накопленных экспертами, происходит при участии caMoro входноrо сиrнала.
Для TOro чтобы начать изучение данноrо вопроса, рассмотрим модульную ней
ронную сеть, в которой процесс обучения происходит при неявном объединении
самоорrанизующейся формы обучения и формы обучения с учителем. Эксперты Tex
нически обеспечивают обучение с учителем, поскольку их отдельные выходы объ
единяются для получения желаемоrо отклика. Однако сами эксперты осуществляют
самоорrанизующееся обучение. Это значит, что они самоорrанизуются с целью Ha
хождения оптимальноrо разбиения входноrо пространства, причем каждый из них в
своем подпространстве имеет наилучшую производительность, а вся rpуппа обеспе
чивает хорошую модель Bcero входноro пространства.
478 rлава 7. Ассоциативные машины
Описанная схема обучения отличается от схем, рассмотренных в предыдущих трех
rлавах, поскольку здесь для rенерации данных обучения предполаrается использова
ние специфической модели.
Вероятностная порождающая модель
Для Toro чтобы понять основную идею, рассмотрим задачу ре2рессии (regression),
в которой perpeccop х порождает отклик, обозначаемый случайной переменной D.
Реализацию этой случайной переменной обозначим символом d. С целью упрощения
выкладок, не оrpаничивая общности, будем рассматривать скалярную модель perpec
сии. В частности, предполаrается, что rенерация отклика d определяется следующей
вероятностной моделью [525].
1. Из HeKoToporo наперед заданноrо распределения случайным образом выбирается
вектор х.
2. Для заданноrо вектора х и HeKoToporo вектора параметров а (О) выбирает-
ся конкретное (например, k e) правило в соответствии с условной вероятно-
стью P(klx,a CO »).
3. Для правила k, k == 1, 2, . . . , К, отклик модели является линейным по х с ад-
дитивной ошибкой Ek, моделируемой как случайная переменная с rayccoBbIM рас-
пределением, имеющим среднее значение нуль и единичную дисперсию, Т.е.
E[Ek] == о для всех k
(7.17)
и
var[Ek] == 1 для всех k.
(7.18)
Предположение о единичной дисперсии в п. 3 бьmо сделано из соображе
ний дополнительноro упрощения изложения. В общем случае каждый эксперт мо-
жет иметь отличную от 1 дисперсию выходноrо сиrнала, формируемую на OCHO
ве данных обучения.
Вероятностная rенерация переменной 1) определяется условной вероятностью
P(D == dlx, wkO») для заданноrо вектора х и HeKoToporo вектора параметров wkO),
rде k == 1,2,. . . , К. Описанная вероятностная порождающая модель не обязательно
должна иметь прямую взаимосвязь с некоторым физическим явлением. Требуется
лишь, чтобы реализованные в ней вероятностные решения представляли абстракт-
ную модель, которая с возрастающей точностью определяет положение условНО20
средне20 значения отклика d в нелинейном МНО200бразии, которое связывает входной
вектор со средним значением выходноrо сиrнала [521].
7.6. Ассоциативная rayccoBa модель смешения 479
Соrласно представленной модели, отклик D может быть сrенерирован К различ
ными способами в соответствии с К вариантами выбора метки k. Таким образом,
условная вероятность rенерирования отклика D == d для данноrо входноrо вектора х
будет равна
к
P(D == dlx,OCO)) == L P(D == dlx, wkO))P(klx, а(О)),
k l
(7.19)
rдe 0(0) вектор параметров порождающей модели (generative mode1 parameter Yec
tor), обозначающий комбинацию аСО) и {wkO) H< l' Верхний индекс О в обозначениях
аСО) и wkO) введен для Toro, чтобы отличать параметры порождающей модели от
параметров модели смешения мнений экспертов, которая рассматривается ниже.
Модель смешения мнений экспертов
Рассмотрим конфиrурацию сети, показанную на рис. 7.8. Такая сеть носит название
смешения мнении экспертов (mixture of experts или МЕ)4 и состоит из К модулей,
обучаемых с учителем и называемых сетями экспертов (expert network), или просто
экспертами. Интеrpирующий элемент носит название сеть шлюза (gating network).
Он выполняет функцию посредника между сетями экспертов. Предполаrается, что
различные эксперты лучше Bcero работают в своих областях входноrо пространства
соrласно описанной вероятностной порождающей модели. Исходя из этоrо и возни
кает потребность в сети шлюза.
В предположении скалярности задачи реrpессии каждая из сетей экспертов преk
ставляет собой линейный фильтр. На рис. 7.9 показан rpаф передачи сиrнала одноrо
нейрона, соответствующеrо эксперту k. Таким образом, выходной сиrнал, производи
мый экспертом k, является скалярным произведением входноrо вектора х и вектора
синаптических весов Wk данноrо нейрона, Т.е.
Yk == wr х, k == 1,2, . . . , К.
(7.20)
Сеть шлюза содержит один слой из К нейронов. Каждый из этих нейронов co
ответствует одному из экспертов. На рис. 7.10, а показан архитектурный rpаф сети
шлюза; на рис. 7.10, б показан rpаф передачи сиrнала для отдельноrо нейрона k
этой сети. В отличие от экспертов нейроны сети шлюза являются нелинейными. Их
функции активации описываются следующим образом:
4 Идея использования сети экспертов для реализации сложных функций отображений впервые была пред-
ложена в [508]. Дальиейшее развитие этой модели было обуслоалено предложением, описаиным в [789] и
рассматривающим конкуреитную адаптацию
480
rлава 7. Ассоциативные машины
...,..
J
Эксперт
1
gl
Эксперт
2
Выходной
сиrнал
У
g2
Эксперт
К
gK
Сеть
шлюза
Рис. 7.8. Блочная диаrрамма модели МЕ; скалярные выходы экспертов ycpeд
нены сетью шлюза
Х 1
Х 2
Х т
Yk
Рис. 7.9. rраф передачи сиrнала единичною линейноrо нейрона,
составляющеrо сеть эксперта k
gk ==
ехр( Uk)
к
L: ехр( щ)
j l
(7.21)
, k==1,2,...,K,
rде Uk результат скалярноro произведения входноro вектора х и вектора синапти
ческих весов ak, Т.е.
uk==aIx, k==1,2,...,K.
(7.22)
"Нормализованное" экспоненциальное преобразование (7.21) можно рассматри-
вать как обобщение лоrистической функции для нескольких входов. В ней сохраня-
7.6. Ассоциативная rayccoBa модель смешения 481
Х 2 g2
Х т gK
Входной
слой
Выходной
слой
а)
Х 1
Алrоритм
и k Softmax
gk
ехр (u k )
gk к
:Е ехр Си)
j 1 J
Х 2
Х т
Рис. 7.10. Один слой нейронов сети шлюза (а); rраф пе
редачи сиrнала для этоro нейрона (б)
б)
ется порядок входных значений, но при этом реализовано дифференцируемое обоб
щение операции "победитель получает все", извлекающей максимальное значение.
По этой причине функция активации (7.21) называется softmax [155]. Обратите вни
мание, что линейная зависимость Uk от входноrо вектора х приводит кнелинейной
зависимости выходноrо значения сети шлюза от х.
Для вероятностной интерпретации роли сети шлюза рассмотрим ее как "клас
сификатор", который отображает входной вектор х в значение мультиномиальнои
вероятности (mu1tinomia1 probabi1ity) так, чтобы различные эксперты моrли COOТBeT
ствовать желаемому отклику [525].
Важно отметить, что использование функции активации softmax в сети шлюза
rарантирует, что эти вероятности будут удовлетворять следующим условиям:
о gk 1 для всех k
(7.23)
и
к
Lgk == 1.
k l
(7.24)
.,.
482 rлава 7. Ассоциативные машины
Пусть Yk выходной сиrнал k ro эксперта, производимый в ответ на входной
вектор х. Torдa общий выход модели МЕ будет следующим:
к
У == L 9kYk,
k l
(7.25)
rде, как уже отмечалось ранее, 9k нелинейная функция х. Допуская, что выбрано
правило k вероятностной модели и что входным вектором является х, выход эксперта
Yk можно трактовать как условное среднее значение случайной переменной D:
E[Dlx, k] == Yk == wIx, k == 1,2,..., К.
(7.26)
Обозначая символом Ilk условное среднее значение переменной D, можно записать:
Ilk == Yk, k == 1,2,. . . , К.
(7.27)
Дисперсия переменной совпадает с дисперсией ошибки Ek. Таким образом, ис
пользуя равенство (7.18), приходим к соотношению:
var[Dlx, k] == 1, k == 1,2,... , К.
(7.28)
Функция плотности вероятности пере мен ной D для данноro входноrо вектора х с
учетом предположения о том, что выбрано k e правило вероятностной порождающей
модели (т.е. эксперт k), может быть записана в следующем виде:
1 ( 1 2 )
fD(dlx,k,O) == J21t exp 2(d Yk) , k==1,2,...,K,
(7.29)
rде О вектор, объединяющий параметры сети шлюза и параметры экспертов модели
МЕ. Функция плотности вероятности переменной D при данном х является смесью
функций плотности вероятности {fD(dlx, k, О) H< l , rде смешанные параметры явля
ются мультиномиальными вероятностями, определяемыми сетью шлюза. Исходя из
этоrо можно записать следующее:
к 1 к ( 1 )
fD(dlx,O) == L9kfD(dlx,k,O) == м:: L9kехр (d Yk)2 .
k l У 2п k l 2
(7.30)
Распределение вероятности (7.30) называется ассоциативнои 2ауссовои моделью
смешения (associative Gaussian mixture mode1) [716], [1057], которая вкратце опи
сывалась в rлаве 5. Ассоциативная модель отличается от неассоциативной тем, что
7.6. Ассоциативная rayccoBa модель смешения 483
условное среднее значение J..I.k и параметры смешения gk не фиксированы; все они
являются функциями входноrо вектора х. Таким образом, ассоциативная rayccoBa
модель смешения (7.30) может рассматриваться как обобщение обычной rауссовой
модели смешения.
Важными чертами модели МЕ (см. рис. 7.8) при условии ее aдeKBaTHoro обучения
являются следующие.
1. Выход Yk k ro эксперта является оценкой условноrо среднеrо значения случайной
переменной для данноrо желаемоro отклика D, заданноrо вектора х и правила k
вероятностной порождающей модели.
2. Выход gk сети шлюза определяет мультиномиальную вероятность Toro, что выход
эксперта k соответствует значению D == d на основе знаний, полученных только
от вектора х.
с учетом распределения вероятности (7.30) и заданноrо множества примеров обу
чения {(Xi, d i ) } 1 задача сводится к обучению условноrо среднеrо J..I.k == Yk И пара
метров смешения gk, k == 1,2, ..., К, таким оптимальным образом, чтобы функция
fD(dlx, О) представляла собой хорошую оценку функции плотности вероятности cpe
ДЫ, отвечающей за rенерирование данных обучения.
Пример 7.1
Поверхность реrрессии
Рассмотрим модель МЕ с двумя экспертами и сетью шлюза с двумя выходами, обозначаемыми
как 91 и 92. Выход 91 определяется следующей формулой:
ехр(и1) 1
91
ехр(и1) + ехр(и2) 1 + ехр( (и1 И2))'
Пусть а1 и а2 два вектора весов сети шлюза. Тоща можно записать:
(7.31)
Uk х Т ak, k 1,2
и, таким образом, переписать выражение (7.31) в следующем виде:
1
91 .
1 + ехр( xT(a1 а2))
Второй выход сети шлюза можно выразить так:
(7.32)
1
92 1 91 1 + exp( xT(a2 а1))'
Таким образом, оба выхода, 91 и 92, имеют форму лоrистической функции, однако с одним
отличием. Ориентация 91 определяется направлением вектора разности (а1 a2), в то время как
ориентация 92 определяется направлением вектора разности (a2 a1), Т.е. направления векторов 91
и 92 противоположны друr друry. Вдоль хребта (ridge), определяемоro соотношением а1 а2,
имеем 91 92 1/2. Таким образом, оба эксперта вносят одинаковый вклад в выход модели МЕ.
В стороне от хребта один из двух экспертов иrpает доминирующую роль. .
.....
484 rлава 7. Ассоциативные машины
7.7. Модель иерархическоrо смешения
мнений экспертов
Модель МЕ, изображенная на рис. 7.8, разбивает входное пространство на несколь-
ко подпространств. При этом за распределение информации (собранной на основе
данных обучения) по отдельным экспертам отвечает одна сеть шлюза. Модель иepap
хичеСКО20 смешения мнении экспертов (hierarchica1 mixture of experts НМЕ), преk
ставленная на рис. 7.11, представляет собой естественное расширение модели МЕ.
На рисунке показана модель НМЕ с четырьмя экспертами. Архитектура модели НМЕ
подобна дереву, в котором сети шлюзов являются ветвями, а отдельные эксперты
листьями. Модель НМЕ отличается от модели МЕ тем, что входное пространство
разбивается на множество вложенных подпространств, а информация объединяется
и перераспределяется между экспертами под управлением нескольких сетей шлюзов,
орrанизованных в иерархическую структуру.
Модель НМЕ на рис. 7.11 имеет два уровня иерархии (two 1eve1s of hierarchy), или
два слоя сетеи шлюзов (two 1ayers of gating networks). Продолжая применять прин
цип "разделяй и властвуй", способом, аналоrичным к проиллюстрированному, можно
построить модель НМЕ с несколькими уровнями иерархии. Обратите внимание, что
в соответствии с соrлашением, принятым на рис. 7.11, нумерация уровней шлюзов
начинается от выходноrо узла дерева.
Модель НМЕ можно формально описать двумя способами [521].
1. Модель НМЕ является результатом страте2ии "разделяи и властвуй". Если мы
верим, что хорошей стратеrией является разбиение входноrо пространства на об
ласти, Torдa не менее хорошей стратеrией будет деление этих областей на pe
rионы. Эта стратеrия может быть продолжена рекурсивно до тех пор, пока мы
не достиrнем стадии, на которой сложность аппроксимирующих поверхностей не
будет соответствовать "локальной" сложности данных обучения. Таким образом,
модель НМЕ может работать не хуже, а зачастую и лучше модели МЕ. И этому
факту есть объяснение: более высокий уровень сетей шлюзов модели НМЕ эф
фективно комбинирует информацию и перераспределяет ее среди экспертов cBoero
поддерева. Следовательно, "сила" каждоrо из параметров рассматриваемоrо ПОk
дерева используется совместно с друrими параметрами, содержащимися в том же
поддереве, потенциально улучшая общую производительность модели НМЕ.
2. Модель НМЕ является деревом МЯ2Ких решении (soft decision). Соrласно этой точ
ке зрения, смешение мнений экспертов является Bcero лишь одноуровневым де-
ревом принятия решений, иноrда в шутку называемым пеньком решении (decision
stump). В более общей постановке модель НМЕ можно рассматривать как Be
роятностную среду для дерева решений. При этом выходной узел модели НМЕ
рассматривается как корень дерева. Методолоrия стандартНО20 дерева решений
7.7. Модель иерархическоro смешения мнений экспертов 485
Эксперт Yll
1,1 gIll
Входной Эксперт У21
вектор 2,1 g211
х
Сеть
шлюза
1 У
Эксперт Yl2
1,2 gl12
Эксперт У22
2,2 g212
Сеть
шлюза
2
Сеть шлюза
BTOpOro уровня Сеть
шлюза
Сеть шлюза
ПерВОro уровня
Рис. 7.11. Иерархическое смешение мнений экспертов (НМЕ) для двух уровней иерархии
состоит в построении дерева, ведущеrо к принятию жестких решений (типа дa
нет) в различных областях входноrо пространства. Противоположностью являют
ся мяrкие решения, принимаемые моделью НМЕ. Следовательно, модель НМЕ
может превзойти по производительности стандартное дерево решений. Это опре
деляется двумя причинами.
. Жесткие решения, к сожалению, приводят к потере информации, в то время
как мяrкие решения ее сохраняют. Например, мяrкие двоичные решения несут
в себе информацию о расстоянии от rpаницы решений (т.е. от точки, в которой
решение равновероятно ), в то время как жесткие решения нет. Таким образом,
можно утверждать, что, в отличие от стандартноrо дерева решений, модель об
ладает встроенным правuлом сохранения информации (information preservation
ru1e). Это эмпирическое правило утверждает, что информация, содержащаяся
во входном сиrнале, может быть эффективно сохранена с вычислительной точ
ки зрения до тех пор, пока система не будет rOToBa к окончательному принятию
решения или оценке параметра [434].
"'811
486 rлава 7. Ассоциативные машины
· Стандартные деревья решений подвержены болезни жадности (greediness).
Как только в таком дереве принимается решение, оно замораживается и ни
коrда впоследствии не изменяется. Модель НМЕ избавлена от таких проблем,
так как решения, принимаемые в дереве, постоянно изменяются. В отличие от
стандартноro дерева решений в модели НМЕ можно отойти от неправильно
принятоrо решения в каком либо друrом месте дерева.
Вторая точка зрения является более предпочтительной. Если рассматривать НМЕ
как вероятностный фундамент для построения дерева решений, то можно вычислить
подобие для любоrо предложенноro множества данных, а также максимизировать это
подобие по параметрам, определяющим разбиение входноrо пространства на отдель
ные области. Таким образом, основываясь на информации о стандартных деревьях
решений, можно найти практическое решение задачи выбора модели, чем мы и зай
мемся в следующем разделе.
7.8. Выбор модели с использованием
стандартноrо дерева решений
Как и в любой друroй нейронной сети, удовлетворительное решение задачи оценки
параметров можно получить путем выбора модели, подходящей для конкретной за
дачи. В случае модели НМЕ под выбором модели понимается выбор количества и
композиции узлов решения в дереве. Одно из практических решений задачи выбора
модели сводится к запуску на данных обучения алrоритма стандартноro дерева реше
ний и принятию полученноro дерева в качестве исходноrо на шаrе инициализации в
алroритме обучения, используемом для определения параметров модели НМЕ [521].
Модель НМЕ имеет очевидное сходство со стандартным деревом решений, напри
мер с деревом классификации и ре2рессии (c1assification and regression tree CART)
[154]. На рис. 7.12 показан пример дерева CART, в котором пространство входных
данных Х последовательно разбивается серией двоичных делений на терминальные
узлы (termina1 node). При сравнении рис. 7.11 и 7.12 ясно видно, что между моделями
CART и НМЕ существует следующее сходство.
. Правило выбора разбиений в промежуточных узлах (ветвях) в модели CART иrpает
роль, аналоrичную сетям шлюзов в модели НМЕ.
. Терминальные узлы в модели CART иrpают роль, аналоrичную сетям экспертов в
модели НМЕ.
При меняя модель CART дЛЯ интересующей нас задачи классификации или perpec
сии, можно использовать преимущества дискретнои природы этой модели для про
ведения эффективноrо поиска среди множества альтернативных деревьев. Используя
7.8. Выбор модели с использованием стандартноro дерева решений 487
(4
(1
(5
(6
Рис. 7.12. Двоичное дерево решений, описываемое сле
дующим образом: (1) узлы t2 и tз являются потомками
узла tl: (2) узлы t4 и t5 являются потомками узла t2, а
(7
узлы t6 И t7 являются потомками узла tз
выбранное таким образом дерево в качестве исходноro на шаrе инициализации ал
rоритма обучения, можно взять на вооружение непрерывную вероятностную основу
модели НМЕ и получить улучшенную "мяrкую" оценку желаемоrо отклика.
Алrоритм CART
в свете изложенноrо выше материала приведем краткое описание алroритма САRт.
Это описание представлено в контексте задачи реrpессии. Имея множество данных
обучения {(xi,di)} l' алrоритм CART можно использовать для построения двоич
Horo дерева Т минимально квадратичной реrpессии. Для этоro нужно выполнить
следующие действия.
1. Выбор разбuенuй (se1ection of sp1its). Пусть узел t некоторое подмножество
дерева Т. Пусть d(t) среднее значение d i для всех пар (Xi, d i ), попадающих в
поддерево t, Т.е.
1"
d(t) == N(t) d i ,
xiEt
(7.33)
rде суммирование проводится по всем d i , для которых Xi Е t, а N(t) общее
количество таких случаев. Определим следующие величины:
E(t) == L (d i d(t))2
xiEt
(7.34)
и
Е(Т) == L E(t).
tET
(7.35)
Для узла t сумма L: (d i d( t)) 2 представляет собой "внутриузловую сумму KBaд
x,Et
ратов", Т.е. общее квадратичное отклонение всех d i поддерева t от cBoero среднеrо
....,.
488 rлава 7. Ассоциативные машины
значения d(t). Суммирование этих отклонений по всем поддеревьям t Е Т дает
общую по узлу сумму квадратов, а деление на N среднее значение.
Для любоro заданноrо множества разбиений S текущеrо узла t дерева Т лучшим
разбиением s* является то, для KOToporo значение Е(Т) является наименьшим.
Для конкретности предположим, что для любоro разбиения s узла t на t L (новый
узел слева от t) и t R (новый узел справа от t) выполняется соотношение
ДЕ(s, t) == Е(Т) E(t L ) E(t R ).
(7.36)
Наилучшим разбиением s* считается то, для KOToporo
ДЕ(s*,t) == mахДЕ(t,s).
sES
(7.37)
Таким образом, построенное дерево реrpессии будет максимизировать убывание
величины Е(Т).
2. Определение терминалЬНО20 узла (determination of а termina1 node). Узел t называ
ется терминальным, если выполняется следующее условие:
mахДЕ(t,s) < ,
sES
(7.38)
rдe наперед заданный пороr.
3. Оценка параметров т ерминальНО20 узла по методу наименьших квадратов (least
squares estimation of а terminal node's parameters). Пусть t является терминальным
узлом в двоичном дереве Т, а X(t) матрица, составленная из Xi Е t. Пусть d(t)
соответствующий вектор, составленный из желаемых откликов d i в поддереве t.
Определим вектор
w(t) == X+(t)d(t),
(7.39)
rде Х+Щ матрица, псевдообратная матрице X(t). Используя w(t), на выходе
терминальноro узла t получаем оценку d( t) по методу наименьших квадратов.
За счет использования весов, вычисленных соrласно (7.39), задача выбора разби
ения может быть решена за счет поиска наименьшей суммы квадратов ошибок
относительно поверхностей реrpессий, а не относительно средних значений.
7.8. Выбор модели с использованием стандартноro дерева решений 489
Использование алrоритма CART для инициализации
модели НМА
Предположим, что в результате применения алrоритма CART к множеству данных
обучения построено двоичное дерево решений поставленной задачи. Разбиение, по
строенное алrоритмом CART, можно представить как мноrомерную поверхность,
описываемую формулой
а Т х + Ь == О,
rде х входной вектор; а вектор параметров; Ь пороr.
Рассмотрим в модели НМЕ следующую ситуацию. В примере 7.1 мы обратили
внимание, что поверхность реrpессии, создаваемая сетью шлюза в двоичном дереве,
может быть представлена формулой
1
g== '
1 + ехр( (aTx + Ь))'
(7.40)
описывающей разбиение, в частности при 9 == 1/2. Пусть вектор весов а для этой
конкретной сети шлюза удовлетворяет равенству
а
а == Ilall . 'й'
(7.41 )
rде Ilall длина (Евклидова норма) вектора а; a/llall нормализованный вектор
(имеющий единичную длину). Подставляя (7.41) в (7.40), параметрическое разбиение
в сети шлюза можно переписать следующим образом:
g==
1
1 + ехр ( lIall ( ( 11:11 ) т х + II II ) ) .
(7.42)
Отсюда видно, что вектор a/llall задает направление разбиения, а Ilalj ero рез
кость (sharpness). Важно отметить, что сеть шлюза в выражении (7.42), созданная на
основе линейноrо фильтра, за которым следует нелинейная активационная функция
softmax, может имитировать разбиение в стиле САRт. Более TOro, мы получаем дo
полнительную степень свободы длину вектора параметров а. В стандартном дереве
решений дополнительные параметры не нужны, так как для создания разбиения ис
пользуется жесткое решение. В отличие от алrоритма МЕ длина вектора а оказывает
существенное влияние на резкость разбиения, выполняемоro сетью шлюза в модели
НМЕ. В частности, для вектора синаптических весов а фиксированноro направления
можно утверждать следующее.
.....
490 rлава 7. Ассоциативные машины
· Если длина вектора а достаточно велика (т.е. при низкой температуре), разбиение
оказывается резким (sharp).
. Если вектор а имеет малую длину (т.е. при высокой температуре), разбиение яв
ляется более мяrким.
Если в пределе Jlall ==0, то разбиение исчезает и по обе стороны исчезнувшеro
(мысленноrо) разбиенияg == 1/2. Эффект от установки длины вектора а в значение
нуль равнозначен удалению из дерева нетерминальноrо узла, так как рассматриваемая
сеть шлюза больше не будет содержать данноrо разбиения. В предельном случае,
коrда вектор а крайне мал (т.е. при высокой температуре) во всех нетерминальных
узлах, вся модель НМА работает подобно одному узлу, Т.е. сводится к обычной модели
линейной реrpессии (в предположении линейности экспертов). По мере увеличения
длины векторов синаптических весов сети шлюза модель НМЕ начинает создавать
мяrкие разбиения, увеличивая доступное для модели количество степеней свободы.
Таким образом, инициализировать модель НМЕ можно следующим образом.
1. Применить алrоритм CART к данным обучения.
2. Установить векторы синаптических весов экспертов модели НМЕ в значения oцe
нок, полученных методом наименьших квадратов для векторов параметров COOT
ветствующих терминальных узлов двоичноrо дерева, построенноrо в результате
применения алrоритма САRт.
3. Для сетей шлюзов:
. задать векторы синаптических весов в соответствии с направлениями, OpTO
rональными соответствующим разбиениям двоичноrо дерева, полученным в
результате алrоритма CART;
· установить длины (т.е. Евклидовы нормы) векторов синаптических весов paB
ными значениям длин малых случайных векторов.
7.9. Априорные и апостериорные вероятности
Мультиномиальные (mu1tinomia1) вероятности gk и gjlk, относящиеся к сетям шлю
зов первоrо и BToporo уровней, можно рассматривать как априорные вероятности в
том смысле, что их значения полностью зависимы от входноrо вектора х (возбудите
ля). Аналоrично, можно определить апостериорные вероятности h k и hJlk, значения
которых зависят как от входноrо вектора х, так и от выходов экспертов в ответ на сиr
нал х. Это последнее множество вероятностей оказывается полезным при разработке
алroритмов обучения для моделей НМЕ.
7.9. Априорные и апостериорные вероятности 491
Возвращаясь к модели НМЕ на рис. 7.11, можно определить апостериорные Bepo
ятности в нетерминальных узлах дерева [526]:
2
gk L: gjlk ехр ( Hd Yjk)2)
j l
2 2
L: gk L: gjlk ехр ( Hd Yjk)2)
k l j l
h k ==
(7.43)
и
h j1k ==
gjlk ехр ( (d Yjk)2)
2
L: gjlk ехр ( Hd Yjk)2)
j l
(7.44)
Про изведение h k и h j1k определяет совместную апостериорную вероятность
Uoint а posteriori probabi1ity) Toro, что эксперт и, k) на выходе даст значение Yjk,
соответствующее желаемому отклику d, Т.е.
gkgjlk ехр ( Hd Yjk)2)
h jk == hkh j1k == 2 2
L: gk L: gjlk ехр ( Hd Yjk)2)
k l j l
(7.45)
Вероятность h jk удовлетворяет следующим двум условиям:
о h jk 1 для всех j и k
(7.46)
и
2 2
LLhjk == 1.
j l k l
(7.47)
Применение (7.47) сводится к тому, чтобы распределять доверие к экспертам на
конкурентной основе. Более Toro, из соотношения (7.45) видно, что чем ближе Yjk
к d, тем более вероятно, что эксперту и, k) будет дано доверие на соответствие ero
выхода желаемому отклику, что интуитивно понятно.
Важным свойством модели НМЕ, заслуживающим особоrо внимания, является
рекурсивность вычисления апостериорнои вероятности. Внимательно изучив Bыpa
жения (7.43) и (7.44), можно заметить, что знаменатель в (7.44) является частью чис
лителя в (7.43). В модели НМЕ нам требуется вычислить апостериорные вероятности
для всех нетерминальнЬ1Х узлов дерева решений. Именно поэтому рекурсивность BЫ
числений приобретает исключительно важное практическое значение. В частности,
вычисления апостериорных вероятностей всех нетерминальных узлов дерева можно
выполнить за один проход.
,.
492 rлава 7. Ассоциативные машины
. При продвижении по дереву в направлении к корневому узлу, уровень за уровнем,
апостериорная вероятность любоrо нетерминальноrо узла вычисляется как сумма
апостериорных вероятностей всех ero "детей".
7.10. Оценка максимальноrо подобия
Переходя к вопросу оценки параметров модели НМЕ, прежде Bcero хочется заме
тить, что ее вероятностная интерпретация слеrка отличается от модели МЕ. Так как
модель НМЕ формулируется как двоичное дерево, предполаrается, что среда, oт
вечающая за reнерацию данных, включает вложенную последовательность МЯ2КUX
(двоичных) решении, завершающуюся ре2рессиеи входНО20 вектора Х к выходному
си2Налу d. В частности, предполаrается, что в вероятностнои порождающеи модели
(probabi1istic generative mode1) НМЕ решения моделируются как мультиномиальные
случайные переменные [526]. Это значит, что для каждоro входноrо вектора Х Be
личины gi(X, в ) интерпретируются как мультиномиальные вероятности, связанные с
первым решением, а величины gjli(X, eJi) как условные мультиномиальные распре
деления, связанные со вторым решением. Как и ранее, верхний индекс О обозначает
истинные значения параметров порождающей модели. Эти решения формируют дe
рево решений. Как и в модели МЕ, в качестве функции активации всех сетей шлюзов
модели НМЕ используется softmax. В частности, функция активации gk k ro BЫXOД
Horo нейрона сети шлюза верхне20 уровня (top leve1 gating network) имеет вид
exp(Uk)
gk == , k == 1,2,
ехр(и1) + ехр(и2)
(7.48)
rде Uk взвешенная сумма входных сиrналов, поступающих на данный нейрон.
Аналоrично, функция активации j ro выходноro нейрона в k й сети шлюза BTOpOro
уровня иерархии описывается следующим образом:
ехр( Ujk) .
gJlk == ( ) + ( ) ' (J,k) == 1,2,
ехр U1k ехр U2k
(7.49)
rде Ujk взвешенная сумма входных сиrналов, поступающая на данный нейрон. Из
соображений простоты выкладок будем рассматривать модель НМЕ Bcero с двумя
уровнями иерархии (т.е. с двумя слоями сетей шлюзов) (рис. 7.11). Как и для модели
МЕ, предполаrается, что каждый из экспертов модели НМЕ состоит из одноrо слоя
линейных нейронов. Пусть Yjk выход эксперта и, k). Torдa общий выход модели
НМЕ можно выразить следующим образом:
2 2
У == L gk L gjlkYjk.
k l j l
(7.50)
7.10. Оценка максимальноro подобия 493
Следуя процедуре, аналоrичной описанной в разделе 7.6 для модели МЕ, можно по
лучить функцию плотности вероятности случайной переменной D, представляющей
желаемый отклик модели НМЕ, изображенной на рис. 7.11 для заданноrо вектора х:
1 2 2 ( 1 )
fD(dlx,O)== м= LgkLgjlkехР 2(d Yjk)2 .
У 2п k l j l
(7.51)
Таким образом, для заданноrо множества данных обучения выражение (7.51) опре
деляет модель ero распределения. Вектор О содержит все синаптические веса, xapaK
теризующие сети шлюзов и экспертов модели НМЕ.
Роль функции подобия (like1ihood function), обозначаемой как l(O), выполняет функ
ция плотности вероятности fD(dlx, О), рассматриваемая как функция вектора пара
метров О. Таким образом, можно записать:
l(O) == fD(dlx,O).
(7.52)
Хотя функция плотности совместной условной вероятности и функция подобия
имеют в точности совпадающие формулы, очень важно отметить физическое разли
чие между ними. В случае функции fD(dlx, О) входной вектор х и вектор параметров
О фиксированы, а желаемый отклик d является переменной. В случае функции по
добия l(O) фиксированными являются вектор х и желаемый отклик d; переменным
является только вектор параметров О.
На практике удобнее работать с натуральным лоrарифмом функции подобия, а не
с самой этой функцией. Для обозначения ЛО2арифмической функции подобия исполь
зуется обозначение L(O) вида
L(O) == log[l(O)] == logfD[dlx,O].
(7.53)
Лоrарифм функции l(O) является монотонным преобразованием l(O). Это значит,
что при возрастании функции l(O) ее лоrарифм L(O) также возрастает. Так как l(O)
является функцией плотности условной вероятности, она не может принимать отри
цательные значения. Отсюда следует, что при вычислении L(O) не возникнет никаких
проблем. Исходя из этоrо, оценка в вектора параметров О может быть вычислена как
решение уравнения правдоподобия (like1ihood equation):
д
aв l(O) == О,
494 rлава 7. Ассоциативные машины
или, что эквивалентно, уравнения ЛО2арифмичеСКО20 правдоподобия (1og like1ihood
equation):
д
де L(8) == О.
(7.54)
Термин "максимально правдоподобная оценка" (maximum 1ike1ihood estimate) с
требуемыми асимптотическими свойствами 5 обычно применяется к корню уравнения
правдоподобия, который в r обальном смысле максимизирует функцию подобия l(8).
Однако на практике оценка 8 может обеспечивать не rлобальный, а только локальный
максимум. В любом случае оценка максимальноrо правдоподобия, соrласно [296],
основывается на сравнительно простой идее.
Разные 2енеральные совокупности (popuZatioп) 2енерируют различные данные, при
этом происхождение люБО20 задаННО20 примера более правдоподобно для некоторой
определеннои совокупности, чем для остальных совокупностей.
Более CTpOro, вектор неизвестных параметров 8 для каждоrо входноrо вектора х
оценивается своим наиболее правдоподобным значением (most p1ausible va1ue). Друrи
ми словами, оценка максимальноro правдоподобия q является тем значением вектора
параметров 8, для которой функция плотности условной вероятности f D ( dl х, 8) ЯВ
ляется наибольшей.
5 Алroритмы оценивания максимальноro правдоподобия имеют ряд привлекательных особенностей. При
достаточно общих условиях можно доказать следующие асимптотические свойства [563].
· Алroритмы оценивания максимальноro правдоподобия являются соrласованными. Пусть L(8) функция
лоraрифмическоro правдоподобия, а 6; некоторый элемент вектора параметров 8. Частная производная
aL/a6i называется счетом (score). Утверждается, что алroритм оценивания максимальноro правдоподобия
является соrласованным, в том смысле, что значение 6; при счете aL/a6i равном нулю, сходится по веро-
ятности к истинному значению 6; при стремлении размера используемоrо при оценке множества примеров
к бесконечности.
· Алroритмы оценивания максимальноro правдоподобия являются асимптотически эффективными. Это зна-
чит, что
lim { v ar[Bi fii] } == 1 для всех i,
N oo 111.
rдe N размер множества обучения; 8; максимально правдоподобная оценка 6i; Iii i-й диаrональный
элемент ма7ИЦЫ' обратной к информационной матрице Фишера
Е l ] Е [ at 1 2 tв 2 ] ... Е [ aв M ]
J == Е [ at 2 2 tвJ Е [ ] ... Е [ aв M ]
[ а2 L ] [ а2 L ] 1 а2 L ]
Е ав м ав 1 Е авм ав 2 . -. Е дer;
rдe м размерность вектора параметров .
· Алroритмы Оценивания максимальноro правдоподобия являются асимптотически rауссовыми. Это значит,
что при стремлении размера множества примеров к бесконечности каждый элемент оценки максимальноro
правдоподобия 8 имеет rayccoBo распределение.
На практике оказывается, что асимптотические (т.е. выполняющиеся при больших размерах множества
примеров) свойства алroритмов оценивания максимальноro подобия достаточно хорошо выполняются при
N 50.
7.11. Стратеrии обучения для модели НМЕ 495
7.11. Стратеrии обучения для модели НМЕ
Вероятностное описание модели НМЕ в разделе 7.1 О привело к построению функции
лоrарифмическоro подобия L(8) как объекта максимизации. Остается нерешенным
вопрос: как осуществить эту максимизацию. Следует отметить, что не существует
единоro подхода к решению задач максимизации. Существует несколько различных
подходов, два из которых описываются в настоящем разделе [507], [526].
1. Подход на основе стохастичеСКО20 2радиента (stochastic gradient approach).
Этот подход обеспечивает алroритм для максимизации L(8) в реальном времени.
Ero формулировка для двухуровневой модели (см. рис. 7.11) базируется на следую
щих формулах.
. Вектор rpадиента aL/8w jk для вектора синаптических весов эксперта и, k).
. Вектор rpадиента aL/aak для вектора синаптических весов выходноrо нейрона k
сети шлюза BepxHero уровня.
. Вектор rpадиента aL/aajk для вектора синаптических весов выходноro нейрона
сети шлюза BTOpOro уровня, связанной с экспертом и, k).
Достаточно просто показать, что (см. задачу 7.9):
aL
8w jk == hj1k(n)hk(n)(d(n) Yjk(n))X(n)'
aL
д == (hk(n) gk(n))X(n)'
ak
aL
д == hk(n)(hj1k(n) gjlk(n))X(n)'
ajk
(7.55)
(7.56)
(7.57)
Равенство (7.55) означает, что в процессе обучения синаптические веса эксперта и, k)
изменяются с целью коррекции ошибки между выходом Yjk и желаемым откликом d
пропорционально совместной апостериорнои вероятности h jk TOro, что выход экс
перта и, k) соответствует желаемому отклику d. Равенство (7.56) утверждает, что
синаптические веса выходноro нейрона k сети шлюза BepxHero уровня настраивают
ся так, чтобы априорные вероятности gk (n) смещались в сторону соответствующих
апостериорных вероятностей hk(n). Равенство (7.57) означает, что синаптические
веса выходноro нейрона сети шлюза BTOpOro уровня, связанной с экспертом и, k),
настраиваются с целью коррекции ошибки между априорнои вероятностью gjlk и co
ответствующей апостериорнои вероятностью hjl k пропорционально апостериорнои
вероятности hk(n).
В соответствии с равенствами (7.55) (7.57) синаптические веса модели НМЕ из
меняются после представления ей каждоro примера (возбуждения). Суммируя Beктo
ры rpадиентов по n, можно сформулировать пакетную версию метода rpадиентноro
спуска для макспмизации функции лоrарифмическоrо подобия L(8).
'111""
496 rлава 7. Ассоциативные машины
2. Подход на основе максимизации ожидания (expectation maximization approach
ЕМ). Алroритм максимизации ожидания (ЕМ), соrласно [252], реализует итеративную
процедуру вычисления оценки максимальноrо правдоподобия в ситуациях, Korдa эта
проблема решается очень леrко. Алroритм ЕМ получил свое название из за TOro, что
каждая итерация алrоритма состоит из двух шаroв.
· Ша2 ожидания (expectation step), на котором множество наблюдаемых дaH
ных неполной задачи (incomp1ete data problem) и текущее значение вектора
параметров используются для получения расширенноrо пОЛНО20 набора дaH
ных (comp1ete data set).
· Ша2 максимизации (maximizing step) заключается в вычислении новой оценки BeK
тора параметров путем максимизации функции лоrарифмическоro подобия полно
ro множества данных, созданноrо на первом шаrе.
Таким образом, начиная с подходящеrо значения вектора параметров, эти действия
повторяются поочередно до полной сходимости.
Алroритм ЕМ оказывается полезным не только в тех случаях, Korдa набор данных
явно не полон, но также и во мноrих друrих ситуациях, в которых неполнота данных
является не столь очевидной или естественной. В самом деле, вычисление oцeH
ки максимальноrо правдоподобия часто облеrчается ее формулировкой как задачи с
неполными данными. Это происходит потому, что алrоритм ЕМ позволяет исполь
зовать пониженную сложность оценки максимальноrо правдоподобия при неполных
данных [717]. Модель НМЕ является одним из таких примеров применения. В дaH
ном случае отсутствующие данные в виде некоторых переменных индикаторов ис
кусственно вводятся в модель НМЕ дЛЯ построения оценки максимальноrо правдо
подобия неизвестноrо вектора параметров (см. раздел 7.12).
Важными особенностями модели НМЕ (при любом подходе максимизации ожи
дания или стохастическоro rpадиента) являются следующие.
· Все сети шлюзов в модели последовательно вычисляют апостериорные вероятно
сти для всех точек данных множества примеров.
· Корректировки синаптических весов экспертов и сетей шлюзов модели при пере
ходе к следующей итерации являются функциями апостериорной вероятности и
соответствующей ей априорной вероятности.
Следовательно, если сеть эксперта, расположенная ниже по дереву, не справляется
с задачей обобщения данных в своей локальной окрестности, то происходит смеще
ние реrpессионной (дискриминантной) поверхности сети шлюза, расположенной BЫ
ше в этом дереве. В свою очередь, это смещение помоrает экспертам на следующей
итерации алroритма обучения лучше аппроксимировать (fit) данные путем смеще
ния соответствующих подпространств данных. За счет этоro модель НМЕ улучшает
эффективность "жадноrо" алrоритма решения, свойственноro стандартному дереву
решений, например САRт.
7.12. Алroритм ЕМ 497
7.12. Алrоритм ЕМ
Алrоритм ЕМ занимает особое место блаroдаря своей простоте и общности лежа
щей в ero основе теории, а также широкой области применения 6 . В этом разделе
представлено описание алroритма ЕМ в общем виде. В последующих разделах мы
продолжим рассмотрение ero применения в задаче оценки параметров модели НМЕ.
Пусть вектор z состоит из отсутствующих или ненаблюдаемых данных, а r
вектор с полными данными, составленный из наблюдений d и вектора отсутствующих
данных z. Таким образом, существуют два пространства О и R, а также отображение
пространства R в О типа "MHOro к одному". Однако вместо наблюдения полноrо
вектора данных r, фактически можно наблюдать только неполные данные d == d(r) в
пространстве О.
Пусть fc (rIO) функция плотности условной вероятности r для данноro BeK
тора параметров О. Отсюда следует, что функция плотности условной вероятности
случайной переменной D для данноro вектора О определяется следующим образом:
fD(dIO) == r fc(rIO)dr,
JR(d)
(7.58)
rде R( d) подпространство R, определяемое равенством d == d(r). Алroритм ЕМ
направлен на поиск значения О, максимизирующеrо функцию ЛО2арифмичеСКО20 пpaв
доподобия на неполных данных (incomp1ete data log like1ihood function):
L(O) == logfD(dIO).
Эта задача косвенно решается итеративным применением функции ЛО2арифмиче
СКО20 правдоподобия на полных данных (complete data log like1ihood function):
Lc(O) == logfc( rIO),
(7.59)
которая является случайной переменной ввиду Toro, что отсутствующий вектор дaH
ных z не известен.
6 Работу, рассматривающую оцеику параметров смеси двух инвариантных rayccoBblX распределений [779],
можно считать самой ранней литературной ссылкой по теме процессов типа ЕМ.
Название "ЕМ-алroритм" было введено в [252]. В этой фундаментальной работе впервые была представлена
формулировка алroритма ЕМ дЛЯ вычисления оценок максимальноro правдоподобия на неполных множествах
данных с различными уровнями общности.
Первый объединенный доклад по теории, методолоrии и применениям алroритма ЕМ, по ero истории н
расширениям бьш представлен в сборнике, выпущенном в 1997 roдy [717].
11
498 rлава 7. Ассоциативные машины
Более cTporo, пусть 8( n) значение вектора параметров О на итерации n алro-
ритма ЕМ. На Е шаrе этой итерации вычисляем математическое ожидание
Q(O,8(n)) == E[Lc(O)]
(7.60)
по 8( n). На М шаre этой же итерации вычисляем максимум функции Q(O,8( n)) по в
в пространстве параметров (весов) W и, таким образом, находим измененную оценку
вектора параметров 8(n + 1):
8(n + 1) == argmaxQ(O,8(n)).
8
(7.61)
Этот алroритм начинается с HeKoToporo начальноrо значения 8(0) вектора парамет-
ров О. Затем оба шаrа последовательно повторяются в соответствии с выражениями
(7.60) и (7.61) соответственно, пока разность между L(8(n + 1)) и L(8(n)) не ока-
жется меньше HeKoToporo малоro наперед заданноro значения. В этой точке работа
алroритма завершается.
Заметим, что после каждой итерации алroритма ЕМ функция лоrарифмическоrо
правдоподобия на неполных данных не убывает, Т.е. (см. задачу 7.10):
L(8(n + 1))
>
L(8(n)) для n == 0,1,... .
(7.62)
Выполнение равенства в этой формуле означает, что мы находимся в стационарной
точке функции лоrарифмическоro правдоподобия 7 .
7.13. Применение алrоритма ЕМ к модели НМЕ
Ознакомившись с алrоритмом ЕМ, можно приступать к решению задачи оценивания
параметров модели НМЕ 8 .
7 При достаточно общих условиях подобные значения, вычисленные по алroритму ЕМ, сходятся к стаци-
онарным значениям. В [1167] проводится детальное исследование свойств сходимости алroритма ЕМ. Однако
этот алroритм не всezда при водит к локальному или rлобальному максимуму функции правдоподобия. В rnаве 3
[717] представлены два при мера, подтверждающие этот факт. В первом из них алroритм сходился к седловой
точке, а во втором к локальному минимуму функции правдоподобия.
8 С помощью алroритма ЕМ можно также вычислить байесовскую апостериорную оценкумаксимума
(Bayesian maximum а posterior estimation) за счет использования априорной информации для вектора параметров
(см. задачу 7.11). Используя правило Байеса, функцию плотности условиой вероятности вектора параметров 8
для заданноro множества наблюдеиий х можно выразить так:
!е(8/х) == fx(j:l!j(e) .
Из этоro соотношения ясно видно, что максимизация апостериориой плотности [0(8,х) эквивалентна максимиза-
ции произведеиия!х(хI8)!е(8), так каК!х(Х) не зависит от 8. Функцня плотности вероятности [0(8) представляет
собой доступную априорную информацию о 8. Максимизация [0(8,Х) дает наиболее вероятную оценку вектора
параметров 8 для данноro вектора Х. В контексте этой оценки важно подчеркнуть следующие моменты.
7.13. Применение алrоритма ЕМ к модели НМЕ 499
Пусть g i) И g;l (условные) мультиномиальные вероятности, соответствующие
решениям, принимаемым сетями шлюзов первоrо уровня k и BTOpOro уровня (j, k)
соответственно (см. рис. 7.11), при обработке примера i из обучающеrо множества.
Torдa из выражения (7.51) видно, что соответствующие значения функций плотности
условной вероятности случайной переменной D для данноrо примера Xi и вектора
параметров 8 задаютсЯ следующей формулой:
2 2 ( )
1 (i) (i) 1 (i) 2
fD(d i j X i,8) J21t f;9k gJlkeXp 2(di Yjk) ,
(7.63)
rде Y; выходной сиrнал эксперта (j, k) в ответ на подачу i ro примера из MHO
жества обучения. Предположим, что все N примеров, содержащихся в обучающем
множестве, являются статистически независимымИ. Тоrда можно определить функ
цию лоrарифмическоrо подобия для задачи с неполными данными следующеro вида:
L(o) log [gfD(d;IX"O)] .
(7.64)
Подставляя выражение (7.63) в (7.64) и иrнорируя константу (1/2) log(21t), получим:
L(O) t,lOg [tgi;) tgjil ехр H(d; У;2)') ] .
(7.65)
Чтобы вычислить оценку максимальноrо правдоподобия для вектора 8, необхо
димо найти стационарную точку (т.е. локальный или rлобальный максимум) функ
цИИ L(8). К сожалению, функция лоrарифмическоrо подобия L(8), соrласно формуле
(7.65), еще не подходит для TaKoro рода вычислений.
Чтобы обойти эту сложность, искусственно дополним множество данных наблю
дений {dJ l множеством отсутствующих данных, полученных в результате выпол
нения алrоритма ЕМ. Это можно сделать путем введения пepeмeHHыx иHдиKaтopoв
(indicator variable), относящихея к вероятностной модели архитектуры НМЕ, следу
ющим образом [526].
Оценка максимальноro правдоподобия, представленная максимизацией [е(8,х) по 8, является сокрашенной
формой максимизации апостериорной вероятиости (под словом "сокращенная" понимается отсутствие априор-
ной информации).
Использование априорной информации является синонимом реryляризации, которая (см. rлаву 5) соответ-
ствует rладкому отображению входа на выход.
В [1114] предстаален байесовский подход к оценке параметров модели смеси экспертов, преодолеваю-
щий так называемое явление избыточноп) обучения, которое приводит к оценке с большой дисперсией при
использовании принципа максимума подобия.
500 rлава 7. Ассоциативные машины
· Zii) И z;f будем интерпретировать как метки соответствующие решениям, при
нимаемым вероятностной моделью в ответ на подачу i ro примера множества
обучения. Эти переменные определяются таким образом, чтобы при любом зна-
чении i только одно из значений zii) и только одно из значений z; равнялось
единице. Обе переменные zii) и z;fk можно рассматривать как статистиче
ски независимые дискретные случайные переменные, математическое ожидание
которых равно соответственно
(i) [ (i) ] h (i)
E[Zk ] == Р zk == 1l x i, d i ,8(n) k
(7.66)
и
(i) [ (i) ] (i)
E[Zjlk] Р zJlk 1I x i,d i ,8(n) h j1k ,
(7.67)
rде 8(п) оценка параметра 8 на итерации n алrоритма ЕМ.
· zj == z;fkzi i ) интерпретируется как метка, определяющая эксперта (j, k) в вероят
ностной модели для i ro примера множества обучения. Ее также можно трактовать
как дискретную случайную величину со следующим математическим ожиданием:
Е[ (i) ] Е[ (i) (i) ] Е[ (i) ]Е[ (i) ] h (i) h (i) h (i)
Zjk ZJlkZk ZJlk Zk jlk k jk'
(7.68)
Значения hi i ), h;1 и h; в равенствах (7.66) и (7.68) являются апостериорными
вероятностями, введенными в разделе 7.9. Верхний индекс i введен для идентифи
кации рассматриваемоro примера в обучающем множестве. В задаче 7. 13 читателю
будет предложено обосновать все эти три равенства.
с добавлением определенных таким образом отсутствующих данных к множеству
наблюдений задача вычисления оценки максимальноro правдоподобия существенно
упрощается. Пусть !C(di,Zj IXi,8) функция плотности условной вероятности на
полном множестве данных, составленная для d i и z; при заданных Xi и векторе
параметров 8. Torдa можно записать:
2 2
!C(di,Zj IXi,8) == ПП (gii)g; k(i)!jk(di)),
j l k l
(7.69)
rде !jk(d i ) функция плотности условной вероятности d i для выбранноrо эксперта
(j, k) в модели НМЕ, Т.е. !jk(i) выбирается из rayccoBa распределения
7.13. Применение алroритма ЕМ к модели НМЕ
501
( ) 1 ( 1 (i) 2 )
!jk d i == J21t ехр '2(di Yjk) .
(7.70)
Обратите внимание, что формула (7.69) соответствует rипотетическому экспери
менту, содержащему переменные индикаторы, представленные переменными zj , не
существующими в физическом смысле. В любом случае функция лоrарифмическоro
правдоподобия для задачи с полными данными, включающими в себя все множество
примеров обучения, выrлядит следующим образом:
Lc(O) == log [ ifi !C(di,Z) lxi'O)] ==
N 2 2 (i) ]
(') (') z
== log i:a}I }!1 (9k' 9j k(i)!jk(di)) Jk ==
N 2 2 (i) [ (i) (i) ]
j ,?;, Zjk log 9k + log 9 j lk + log !jk(d i ) .
(7.71 )
Подставляя выражение (7.70) в (7.71) и иrнорируя константу (1/2)log(21t), можно
записать:
N 2 2
L (О) "" "" "" (i) [1 (i) 1 (i) 1 (d (i) ) 2 ]
с Zjk og 9k + og 9jik '2 i Yjk .
(7.72)
Сравнивая выражения (7.72) и (7.65), можно заметить, что введение в множество
наблюдений переменных индикаторов вместо отсутствующих данных дало следу
ющий вычислительный эффект: задача вычисления оценки максимальноrо правдо
подобия была разделена на множество задач реrpессии для отдельных экспертов и
отдельное множество задач классификации для сетей шлюзов.
Для продолжения работы с алrоритмом ЕМ нужно в первую очередь использовать
Е шаr этоrо алrоритма, вычисляя математическое ожидание функции лоrарифмиче
CKOro подобия на полных данных Lc(O):
Q(0,8(n)) == E[Lc(O)] ==
N 2 2 ]
(i) (i) (i) 1 (i) 2
f;f;E[Zjk]' [10 g9 k +log9jlk '2(di Yjk) ,
(7.73)
rде оператор ожидания действует на переменную индикатора zj как на единствен
ную ненаблюдаемую переменную. Torдa, подставляя (7.68) в (7.73), получим:
502
rлава 7. Ассоциативные машины
f
!
N 2 2 [
л (i) (i) (i) 1 (i) 2
Q(8,8(n)) == hjk' loggk +loggjlk "2(d i Yjk) ].
(7.74)
М шаr этоrо алrоритма требует максимизации функции Q(8,8(n)) по 8. Вектор
параметров 8 состоит из двух множеств синаптических весов: одно из них относится
к сетям шлюзов, второе к экспертам. Из предыдущеro обсуждения можно сделать
следующие выводы.
· Синаптические веса экспертов определяют Y; , которые также входят в определе
ние h)2. Таким образом, на выражение для Q(8,8(n)) эксперты влияют только в
h (i) (d (i) ) 2
части слаrаемоro jk i Yjk .
· Синаптические веса сетей шлюзов определяют вероятности g; , g; и h)2. Таким
образом, на выражение дЛЯ Q(8, 8( n)) эксперты влияют только в части слаrаемоro
(i) (i) (i)
h jk (log gk + log gjlk)'
Следовательно, М шаr алrоритма ЕМ сводится к следующей тройственной задаче
оптимизации модели НМЕ с двумя уровнями иерархии:
N
Wjk(n + 1) == arg min L h) (d i y; )2,
Wjk i l
N 2
aj (n + 1) == arg min '" '" h (2 log gii)
а J
3 i l k l
(7.75)
(7.76)
и
N 2 2
( 1) . '" '" h (i) '" h (i) 1 (i)
ajk n + == arg lkn 1 mll og gmll'
3 i l 1 1 т 1
(7.77)
Задачи оптимизации (7.75) (7.77) решаются при фиксированных h; h являет
ся функцией параметров, но производные по h не вычисляются. Обратите внима
ние, что величины в правых частях выражений относятся к измерениям, выполняе-
мым на шаrе n.
Оптимизация выражения (7.75), относящеrося к экспертам, представляет собой
задачу нахождения взвешенной оценки по методу наименьших квадратов. Остальные
две задачи оптимизации (7.76) и (7. 77) относятся к сетям шлюзов и представляют
собой задачи поиска оценки максимальноro правдоподобия 9 .
Несмотря на то что уравнения сформулированы только для двух уровней иерархии,
они MOryT быть расширены для любоrо их количества.
9 Для решения задачи вычнсления оценки максимальноro правдоподобия, описываемой уравнениями
(7.76) и (7.77), часто используют алroритм, известный под названием итеративно взвешиваемый алroритм
наименьших KBaдparoB
7.14. Резюме и обсуждение 503
7.14. Резюме и обсуждение
При изучении задач моделирования, распознавания образов и реrpессии необходимо
рассматривать два экстремальных случая.
1. Простые модели, которые дают представление о данной задаче, но не отличаются
особой точностью.
2. Сложные модели, которые дают точные результаты, не слишком уrлубляясь в саму
задачу.
Похоже, в рамках одной модели невозможно объединить простоту и точность.
В контексте дискуссии, представленной во второй части настоящей rлавы, алrоритм
CART является примером простой модели, которая использует жесткие решения при
построении разбиения входноrо пространства на множество подпространств, каждое
из которых имеет собственноrо эксперта. К сожалению, использование результатов
жестких решений при водит к потере части информации и, таким образом, потерям
производительности. С друrой стороны, мноrослойный персептрон (MLP) является
сложной моделью с вложенной формой нелинейности, создаваемой для сохранения
информации из множества обучающих данных. Однако в нем используется подход
"черноrо ящика" для rлобальноrо построения единой функции аппроксимации обу
чающих данных. При этом теряется rлубина взrляда на саму задачу. Модель НМЕ,
представляющая собой динамический тип ассоциативной машины, обладая преиму
щсствами как CART, так и MLP, является компромиссом между этими двумя экстрс
мальными случаями.
. Архитектура НМЕ аналоrична архитектуре CART, но отличается от нее мяrкостью
разбиения входноrо пространства.
. НМЕ использует вложенную форму нелинейности, аналоrичную МLP, но не для
построения отображения входноro сиrнала в выходной, а с целью разбиения BXOД
Horo пространства.
в этой rлаве мы заострили внимание на использовании двух методов построения
модели НМЕ.
. Алroритм CART составляет архитектурную основу для задачи выбора модели.
. Алrоритм ЕМ используется для решения задачи оценки параметров. Он итератив
но вычисляет оценки максимальноrо правдоподобия для параметров модели.
Алrоритм ЕМ обычно обеспечивает движение вверх по склону функции правдо
подобия. Таким образом, инициализируя алrоритм ЕМ с помощью CART так, как
описано в разделе 7.8, можно ожидать лучшеrо возможноrо качества обобщения пер
BOro из них, применяя результаты BToporo в качестве исходноro состояния.
r
504 rлава 7. Ассоциативные машины
Алroритм ЕМ является важным и основополаrающим в тех областях, rде на первое
место выходит построение оценки максимальноrо правдоподобия, например в Moдe
лировании. Интересное приложение моделирования бьmо описано в [509], rде модель
МЕ обучалась решению задачи "что rде". В этой задаче модель должна определить,
что представляет собой объект и rде он находится в визуальном поле. При обучении
использовались два эксперта, каждый из которых специализировался на одном из ac
пектов задачи. Для заданноrо входноrо сиrнала оба эксперта reнерировали выходные.
При этом сеть шлюза принимала решение относительно смешения выходов. Успеш
ные результаты, полученные в этой работе, показали, что задачи можно естественным
образом распределять, но не на основе принципа "одна задача на всех", а на основе
соответствия требований задачи вычислительным свойствам модели [282].
В завершение обсуждения вернемся к еще одному классу ассоциативных машин,
о котором rоворилось в первой части настоящей rлавы. В то время как модели НМЕ и
МЕ основаны на использовании сетей шлюзов, активизируемых входными сиrналами
для объединения знаний, накопленных разными экспертами модели, ассоциативные
машины основаны на усреднении по ансамблю или, как альтернатива, на усилении,
основанном на интеrpации самим алrоритмом обучения.
1. Усреднение по ансамблю улучшает качество обучения в смысле снижения ошибки
(error performance), мудро комбинируя два эффекта.
· Уменьшение уровня ошибки, вводимой пороrом, при помощи целенаправлен-
Horo избыточноro обучения отдельных экспертов ассоциативной машины.
· Уменьшение уровня ошибки, создаваемой дисперсией, за счет использования
различных начальных состояний при обучении различных экспертов, и после
дующеro усреднения по ансамблю их выходных сиrналов.
2. Усиление улучшает эффективность алrоритма собственным ориrинальным спосо
бом. В данном случае от отдельных экспертов требуется качество, лишь слеrка
отличающееся в лучшую сторону от случайноrо выбора. Слабая обучаемость экс
пертов преобразуется в сильную, при этом ошибку ассоциативной машины можно
сделать сколь уrодно малой. Эта выдающаяся метаморфоза достиrается за счет
фильтрации распределения входных данных, приводящей к тому, что слабо обуча
емые модели (т.е. эксперты) в конечном итоrе обучаются на всем распределении,
либо за счет создания подвыборки множества обучения в соответствии с HeKO
торым распределением, как в алrоритме AdaBoost. Преимущество последнеro по
сравнению с фильтрацией состоит в том, что он работает с обучающим множе
ством фиксированноrо размера.
Задачи 505
Задачи
Усреднение по ансамблю
7.1. Рассмотрим ассоциативную машину, состоящую из К экспертов. Функция
отображения входа на выход k ro эксперта обозначается через Fk(x), rде Х
входной вектор, а k == 1, 2, . .., К. Выходы отдельных экспертов линейно
суммируются, формируя общий выход системы у, следующим образом:
к
у == L WkFk(X),
k l
rде wk линейный вес, назначенный Fk(x). Требуется оценить Wk так,
чтобы выход у обеспечивал оценку желаемоro отклика d, соответствую
щеro Х по методу наименьших квадратов. Имея множество данных обуче
ния {( Xi, d i ) } 1' определите искомые значения W k для решения этой задачи
оценки параметров.
Усиление
7.2. Сравните вычислительные преимущества и недостатки методов усиления за
счет фильтрации и AdaBoost.
7.3. Обычно усиление лучше Bcero выполнять на слабых моделях обучения, т.е. на
моделях с относительно низким уровнем ошибок обобщения. Однако пред
положим, что имеется некоторая сильная модель обучения, Т.е. модель с OT
носительно высоким уровнем ошибок обобщения. Предположим также, что
имеется множество примеров фиксированноrо размера. Как в такой ситуации
выполнить усиление за счет фильтрации или алrоритм AdaВoost?
Смешение мнений экспертов
7.4. Рассмотрим следующую кусочно линейную задачу:
{ ЗХ2 + 2хз + Х4 + 3 + Е, если Х1 == 1,
Р(Х1,Х2",' ,Х10) == 3 2 3 1
Х5 + Х6 + Х7 + Е, если Х1 == .
Для сравнения используются следующие конфиryрации сети.
1. Мноroслойный персептрон: сеть 10 -4 10 -4 1.
2. Смешение мнений экспертов: сеть шлюза: 10 -4 2. Сеть эксперта: 10 -4 1.
Сравните вычислительную сложность этих двух сетей.
'"'
506 rлава 7. Ассоциативные машины
7.6. Выведите алrоритм стохастическоro rpадиента для обучения модели смеси
экспертов.
Модель МЕ, описываемая функцией плотности условной вероятности (7.30),
основана на модели скалярной реrpессии, в которой ошибка имеет rayccOBo
распределение со средним значением нуль и единичной дисперсией.
а) Переформулируйте это уравнение для более общеrо случая модели МЕ, ,
соответствующей модели множественной реrpессии, в которой желаемый f:'
t
отклик является вектором размерности q, а ошибка MHoroMepHbIM rayc- I
совым распределением с нулевым средним значением и матрицей ковари- i
,
ации 0'. i
l
б) Чем эта переформулированная модель отличается от модели МЕ, показан- I
ной на рис. 7.8? !
f
J
i
7.5.
Иерархическое смешение мнений экспертов
7.7. а) Постройте блочную диаrpамму модели НМЕ с тремя уровнями иерархии.
Предполаrается, что для данной модели используется двоичное дерево
решений.
б) Запишите апостериорные вероятности для нетерминальных узлов модели,
описанной в пункте а). Продемонстрируйте рекурсивность вычислений,
про водимых при оценке этих вероятностей.
в) Определите функцию плотности условной вероятности для модели НМЕ,
описанной в пункте а).
7.8. Обсудите сходства и отличия между моделью НМЕ и сетями на основе
радиально базисных функций.
7.9. Выведите уравнения, описывающие алrоритм стохастическоrо rpадиента для
обучения модели НМЕ с двумя уровнями иерархии. Предполаrается, что для
этой модели используется двоичное дерево решений.
Алrоритм ЕМ и ero применение в модели НМЕ
7.1 О. Докажите свойство MOHoToHHoro возрастания алrоритма ЕМ, описываемоro
уравнением (7.62). Для этоrо выполните следующее.
а) Пусть
fc(rI8)
k(rld,8) == fD(dI8)
Задачи 507
обозначает функцию плотности условной вероятности расширенноro BeK
тора параметров r, для данноro наблюдения d и вектора параметров О.
Исходя из этоro, функция лоrарифмическоro правдоподобия на неполных
данных будет иметь следующий вид:
L(O) == Lc(O) logk(rld, е),
rде Lc(e) == logfc(rje) функция лоrарифмическоrо правдоподобия на
полных данных. Зная математическое ожидание функции L(e) относи
тельно условноrо распределения r и значение d, покажите, что
L(O) == Q(O,8(n)) к(о,8(п)),
rде
к(о,8(п)) == E[log k(rld, 8)].
При этих условиях покажите, что
L(8(n + 1)) L(8(n)) == [Q(8(n + 1), 8(п)) Q(8(n), 8(п))]
[К(8(п+ 1),8(п)) К(8(п),8(п))].
б) Неравенство Йенсена (Jensen's inequality) утверждает, что если функция
g(.) является выпуклой, а и некоторая случайная переменная, то
E[g(и)] g(E[и]),
rде Е оператор математическоrо ожидания. Более Toro, если g(.) CTpO
ro выпуклая функция, то из равенства в этом соотношении с вероятностью
1 следует, что и == Е(и) [221].
Используя неравенство Йенсена, покажите, что
К(8(п + 1), 8(п)) К(8(п), 8(п)) О.
(7.78)
Исходя из этоro, покажите, что уравнение (7.62) выполняется для п ==
0,1,2,... .
7.11. Алrоритм ЕМ довольно леrко модифицируется для включения максимума
апостериорной оценки вектора параметров О. Используя правило Байеса, MO
дифицируйте шаrи Е и М этоro алrоритма, чтобы обеспечить эту оценку.
508 rлава 7. Ассоциативные машины
7.12. Если модель НМЕ, обучаемая с помощью алroритма ЕМ, и мноrослойный
персептрон, обучаемый по алrоритму обратноro распространения, имеют
одинаковые показатели производительности для данной задачи, интуитив-
но ожидается, что вычислительная сложность первоro будет превосходить
сложность BTOpOro. Приведите aprYMeHTbI за или против этоrо утверждения.
7.13. Обоснуйте связь между переменными индикаторами и соответствующими
апостериорными вероятностями, описанными в формулах (7.66) и (7.68).
7.14. Уравнение (7.75) описывает взвешенный метод наименьших квадратов для
оптимизации сетей экспертов модели НМЕ, представленной на рис. 7.11, в
предположении, что желаемый отклик d скаляр. Как модифицировать это
соотношение для случая MHoroMepHoro желаемоrо отклика?
Анализ rлавных компонентов
8.1. Введение
Важным свойством нейронных сетей является их способность обучаться на основе
примеров из окружающей среды и с помощью этоrо обучения повыщать произво
дительность работы. В предыдущих четырех rлавах основное внимание фокусирова
лось на алrоритмах обучения с учителем, в которых множество целей определяется
внешним учителем. Целью обучения является построение желаемоro отображения
входноro сиrнала в выходной, которое сеть должна аппроксимировать. В этой и по
следующих трех rлавах рассматриваются алroритмы самООр2анизующе20СЯ обучения
(self organized learning), или обучения без учителя (unsupervised learning). Целью ал
rоритмов самоорrанизующеrося обучения является выявление (discover) в множестве
входных данных существенных образов или признаков, причем этот процесс прохо
дит без участия учителя. Для этоrо алrоритм реализует множество правил локальной
природы, что позволяет обучаться вычислению отображения входноro сиrнала на
выходной с требуемыми свойствами. Здесь термин "локальный" подразумевает сле
дующее. Изменения синаптических весов нейрона определяются только непосред
ственными соседями этоrо нейрона. Модели сетей, обучаемые на основе принципа
самоорrанизации, в rораздо большей мере отражают свойства нейробиолоrических
структур, нежели архитектуры, обучаемые с учителем. Это неудивительно, поскольку
подобный принцип орrанизации сетей отражает принципы функционирования мозrа.
Архитектура самоорrанизующихся систем может принимать множество совершен
но различных форм. Например, такая сеть может состоять из входНО20 (input layer) и
выходНО20 слоя (output layer), связанных прямыми связями, и включать латеральные
связи между нейронами BToporo слоя. Еще одним примером Moryт служить MHOro
слойные сети прямоro распространения, в которых самоорrанизация проявляется при
переходе от одноrо слоя к друrому. В обоих случаях процесс обучения состоит в пе
риодически повторяющемся изменении синаптических весов всех связей в системе
в ответ на подачу входных образов в соответствии с предписанными правилами до
получения конечной конфиrурации системы.
510
rлава 8. Анализ rлавных компонентов
1
I
!
Эта rлава посвящена системам самоорrанизации, основанным на принципе обу-
чения Хебба. Основное внимание в ней уделяется анализу 2Лавных компонентов
(principal components analysis) стандартному приему, обычно используемому ДЛЯ
уменьшения размерности данных в статистических системах распознавания образов
и обработки сиrналов.
Структура rлавы
Материал этой rлавы орrанизован следующим образом. В разделе 8.2 на качественном
уровне описываются основные принципы самоорrанизации. В разделе 8.3 представ-
лен вводный материал по анализу rлавных компонентов, который будет положен в
основу последующеro исследования самоорrанизующихся систем в настоящей шаве.
Вооружившись этими фундаментальными знаниями, мы приступим к изучению
отдельных самоорrанизующихся систем. В разделе 8.4 описывается простая модель,
состоящая из единственноro нейрона и позволяющая извлечь первый rлавный ком-
понент на основе самоорrанизации. В разделе 8.5 рассматривается более сложная
самоорrанизующаяся система в форме сети прямоrо распространения с одним сло-
ем нейронов, которая извлекает все rлавные компоненты, основываясь на работе
предыдущей простой модели. Эта процедура будет про иллюстрирована компьютер-
ным экспериментом по кодированию изображений, представленным в разделе 8.6.
В разделе 8.7 вниманию читателя будет предложена еще одна самоорrанизующая-
ся система, выполняющая аналоrичную функцию. Однако эта система является еще
более сложной, так как содержит латеральные связи. В разделе 8.8 приводится клас-
сификация алrоритмов анализа rлавных компонентов на основе нейронных сетей.
Раздел 8.9 посвящен классификации алrоритмов снижения размерности данных на
адаптивные и пакетные методы.
В разделе 8.1 О описывается нелинейная форма анализа rлавных компонен-
тов, основанная на идее ядра скалярноro произведения, определенноro в соответ-
ствии с теоремой Мерсера, о которой речь шла в rлаве 6, посвященной маши-
нам опорных векторов.
Завершается rлава заключительными размышлениями об анализе rлавных компо-
нентов.
8.2. Некоторые интуитивные принципы
самоорrанизации
Как уже rоворилось ранее, обучение на основе самоорrанизации (без учителя) заклю-
чается в последовательном изменении синаптических весов нейронной сети в ответ
на возбуждающие сиrналы, про изводимые в соответствии с заранее определенными
правилами, повторяющемся до тех пор, пока не будет сформирована окончательная
8.2. Некоторые интуитивные принципы самоорrанизации 511
конфиryрация системы. Ключевой вопрос, естественно, заключается в том, как с по
мощью самоорrанизации сформировать эту окончательную структуру. Ответ на Hero
основывается на следующем наблюдении [1061].
Тлобальный порядок определяется локальными взаимодействиями.
Это наблюдение имеет пер во степенную важность. Ero можно применить и
к мозry, И К искусственным нейронным сетям. В частности, мноrие изначаль
но случайные взаимодействия соседних нейронов сети MOryт перерасти в COCTO
яние rлобальноro порядка и в конечном счете привести к соrласованному пове
дению в форме пространственных моделей или временных ритмов. Это и являет
ся сущностью самоорrанизации.
Орrанизация сетей формируется на двух различных уровнях, которые взаи
модействуют друr с друroм с помощью обратной связи. Этими двумя уровня
ми являются следующие.
. Уровень активности (activity). В ответ на входные возмущения данная сеть фор
мирует определенные образы (последовательность действий).
. Уровень связности (connectivity). Связи (синаптические веса) сети изменяются в
ответ на нейронные сиrналы образов активности блаrодаря синаптической пла
стичности.
Для тoro чтобы сеть достиrла самоорrанизации (а не стабилизации), обратная связь
между изменениями в синаптических весах и изменениями в образах активности
должна быть положительной (positive). В соответствии с этим можно вывести первый
принцип самоорrанизации [1097].
ПРИНЦИП 1
Изменение синаптическux весов ведет к самоусuлению сети (se/f-аmрlifY).
Процесс самоусиления оrpаничен требованием Toro, чтобы изменения синаптиче
ских весов основывались на локально доступных сиrналах, а именно на предсинап
тических и постсинаптических. Это требование усиления и локальности определяет
механизм, в котором сильные синапсы обеспечивают соrласование предсинаптиче
ских сиrналов с постсинаптическими. В свою очередь, синапс усиливается за счет
TaKoro соrласования. Описанный здесь механизм на самом деле является подтвержде
нием постулата обучения Хебба.
Для стабилизации системы должна существовать некоторая форма конкуренции
за "оrpаниченные" ресурсы (количество входных сиrналов или энерrию). В част
ности, усиление отдельных синапсов сети должно компенсироваться ослаблени-
ем остальных. Следовательно, усиливаться MorYT только "успешные" синапсы, в
то время как "менее удачливые" имеют тенденцию к ослаблению и постепен
.,.
512
rлава 8. Анализ rлавных компонентов
ному исчезновению. Это наблюдение приводит к формулировке Bтoporo принци-
па самоорrанизации [1097].
ПРИНЦИП 2
02раниченность ресурсов ведет к конкуренции между синапсами и, таким обра-
зом, к выбору наиболее успешно развивающихся синапсов за счет дРУ2ИХ (т.е. наи-
более подходящих).
Этот принцип реализуется блаroдаря пластичности синапсов.
Для следующеrо наблюдения заметим, что отдельный синапс не может эффек-
тивно реализовать блаroприятные события. для этоrо необходима совместная работа
rpуппы синапсов, расположенных на входе отдельноrо нейрона, и достаточное уси-
ление соrласованных сиrналов для ero активации. Таким образом, можно сформули-
ровать еще один принцип самоорrанизации [1097].
ПРИНЦИП 3
Модификация синаптических весов ведет к кооперации.
Присутствие сильноro синапса может усилить и друrие синапсы в свете общей
системы конкуренции в сети. Эта форма кооперации проистекает из пластичности
синапсов или из одновременноro стимулирования предсинаптических нейронов, вы-
званноro наличием блаroприятных условий во внешней среде.
Все три принципа самоорrанизации относятся только к нейронным сетям. Одна-
ко, для Toro чтобы самоорrанизующееся обучение обеспечивало полезную функцию
обработки информации, в образах активации, передаваемых нейронам из внешней
среды, должна существовать доля избыточности (redundancy). Вопрос избыточно-
сти будет обсуждаться при рассмотрении теории информации Шеннона в rлаве 10.
Здесь же мы оrpаничимся формулировкой последнеrо принципа самоорrанизующе-
roся обучения [90].
ПРИНЦИП 4
Порядок и структура образов активации содержат избыточную информацию, на-
капливаемую сетью в форме знаний, являющихся необходимым условием саМООр2ани-
зующе20СЯ обучения.
Некоторая часть знаний может бьпь получена с помощью наблюдения за ста-
тистическими параметрами, такими как среднее значение, дисперсия и матри-
ца корреляции входных данных.
Принципы 1 самоорrанизующеrося обучения образуют нейробиолоrический ба-
зис для адаптивных алrоритмов анализа rлавных компонентов, которые описываются
в настоящей rлаве, а также для самоорrанизующихся карт Кохонена (КоЬопеп), кото-
рые рассматриваются в rлаве 9. Эти принципы реализованы также и в ряде дрyrих
8.2. Некоторые интуитивные принципы самоорraнизации 51 3
Рис. 8.1. Структура модульной самонастраивающейся
сети Слой А
Слой В
Слой С
самоорrанизующихся моделей, которые основаны на знаниях из области нейробио
лоrии. Одной из таких моделей, которую нельзя обойти вниманием, является модель
Линскера (Linsker's model) зрительной системы млекопитающеrо [656].
Анализ признаков на основе самоорrанизации
Обработка сиrналов в системах зрения про изводится поэтапно. В частности, про
стые признаки, такие как контрастность или ориентация контуров, анализируются на
ранних этапах, в то время как более сложные признаки на поздних. На рис. 8.1 пока
зана обобщенная структура модульной сети, которая имитирует зрительную систему.
В модели Линскера нейроны сети (см. рис. 8.1) орrанизованы в двумерные слои с
прямыми переходами от одноrо слоя к следующему. Все нейроны получают информа
цию от оrpаниченноrо числа нейронов, расположенных в пересекающихся областях
предыдущеro слоя, составляющих поле восприятия, или рецепторное поле (receptive
field), нейрона. Поля восприятия сети иrpают ключевую роль в процессе построения
синаптических связей, так как они обеспечивают нейронам одноrо слоя возможность
реаrировать на пространственные корреляции активности нейронов предыдущеro
слоя. Нужно сделать два структурных допущения.
..,
514 rлава 8. Анализ rлавных компонентов
1. После выбора положения синаптических связей они остаются фиксированными
на протяжении Bcero процесса развития нейронной структуры.
2. Все нейроны выступают в качестве линейных сумматоров.
Эта модель содержит черты Хеббовскоro принципа модификации синапсов, а так-
же KOHкypeHTHoro способа обучения. Таким образом, выходы сети оптимально выде-
ляются среди ансамбля входов, при этом самоорrанизующееся обучение продвиraет-
ся от слоя к слою. Это значит, что в процессе обучения на основе самоорrанизации
для каждоro слоя выполняется анализ признаков и создается собственная структура.
В [656] были представлены результаты моделирования, которые качественно подтвер-
дили свойства, обнаруженные на ранних стадиях обработки визуальных сиrналов в
зрительных системах котов и обезьян. Признавая в высочайшей степени сложную
природу зрительных систем, следует отметить, что простая модель, рассмотренная
Линскером, оказалась способной сконструировать аналоrичные нейроны для анализа
признаков. Это совсем не rоворит о том, что нейроны анализаторы признаков зри-
тельной системы млекопитающих имеют точно такую же природу, которая описыва-
ется моделью Линскера. Более Toro, такие структуры MOryт создаваться относительно
простыми мноroслойными сетями, в которых синаптические связи формируются со-
rласно Хеббовской форме обучения.
Тем не менее в этой rлаве rлавный интерес для нас будут представлять анализ
rлавных компонентов и способы ero выполнения с помощью самоорrанизующихся
систем, основанных на принципе обучения Хебба.
8.3. Анализ rлавных компонентов
rлавной задачей в статистическом распознавании является выделение признаков (fea-
ture selection) или извлечение прuзнаков (feature extraction). Под выделением признаков
пони мается процесс, в котором пространство данных (data space) преобразуется в
пространство признаков (feature space), теоретически имеющее ту же размерность,
что и исходное пространство. Однако обычно преобразования выполняются таким
образом, чтобы пространство данных моrло быть представлено сокращенным количе-
ством "эффективных" признаков. Таким образом, остается только существенная часть
информации, содержащейся в данных. Друrими словами, множество данных подвер-
rается сокращению размерности (dimensionality reduction). Для большей конкретиза-
ции предположим, что существует некоторый вектор х размерности т, который мы
хотим передать с помощью l чисел, [де l < т. Если мы просто обрежем вектор х,
это приведет к тому, что среднеквадратическая ошибка будет равна сумме дисперсий
элементов, "вырезанных" из вектора х. Поэтому возникает вопрос: "Существует ли
такое обратимое линейное преобразование Т, дЛЯ KOTOpOro обрезание вектора Тх бу-
дет оптимальным в смысле среднеквадратической ошибки?" Естественно, при этом
8.3. Анализ rлавных КОмпонентов 515
преобразование Т должно иметь свойство маленькой дисперсии своих отдельных ком-
понентов. Анализ 2Лавных компонентов (в теории информации он называется преоб-
разование Карунена Лоева (Каrhипеп Lоеvе traпsformatioп» максимизирует скорость
уменьшения дисперсии и, таким образом, вероятность правильноro выбора. В этой
шаве описываются алroритмы обучения, основанные на принципах Хебба, которые
осуществляют анализ rлавных компонентов 1 интересующеro вектора данных.
Пусть Х m мерный случайный вектор, представляющий интересующую нас
среду. Предполаrается, что он имеет нулевое среднее значение
Е(Х) == О,
rде Е оператор статистическоrо ожидания. Если Х имеет ненулевое среднее, можно
вычесть это значение еще до начала анализа. Пусть q единичный вектор (unit vector)
размерности т, на который проектируется вектор Х. Эта проекция определяется как
скалярное произведение векторов Х и q:
А т т
==Xq==qX
(8.1)
при оrраничении
Ilqll == (qT q)1/2 == 1.
(8.2)
Проекция А представляет собой случайную переменную со средним значением и с
дисперсией, связанными со статистикой случайноrо вектора Х. В предположении, что
случайный вектор Х имеет нулевое среднее значение, среднее значение ero проекции
А также будет нулевым:
Е[А] == qT Е[Х] == О.
Таким образом, дисперсия А равна
а 2 == Е[А 2 ] == E[(qTX)(X T q)] == qT E[XXT]q == qTRq.
(8.3)
Матрица R размерности m Х m является матрицей корреляции случайноrо вектора
Х, определяемой как ожидание произведения случайноrо вектора Х caMoro на себя:
I Анализ rлавных компонентов (Priпсiраl Соmропепt Апаlуsis РСА) является, пожалуй, самым старым
и известным методом MHOroMepHOro анализа [517], [857]. Впервые он использовался в [824] в биолоrическом
контексте для придания аналнзу линейной реrpессии новой формы. Эта идея была впоследствии развита в
[487], посвященной психометрин. Совершенно независимо от этой работы эта идея появилась при выводе
теории вероятности в [541] и впоследствии была обобщена в [671].
....
516 rлава 8. Анализ rлавных компонентов
R == Е[ХХ Т ].
(8.4)
Матрица R является симметричной, Т.е.
R T == R.
(8.5)
Из этоro следует, что если а и Ь произвольные векторы размерности m х 1, то
aTRb == bTRa.
(8.6)
Из выражения (8.3) видно, что дисперсия а 2 проекции А является функцией еди-
ничноro вектора q. Таким образом, можно записать:
'V(q) == а 2 == qTRq,
(8.7)
на основании чеrо 'V(q) можно представить как дисперсионный зонд (variance probe).
Структура анализа rлавных компонентов
Следующим вопросом, подлежащим рассмотрению, является поиск тех единичных
векторов q, для которых функция 'V( q) имеет экстремальные или стационарные зна-
чения (локальные максимумы и минимумы) при оrpаниченной Евклидовой норме
вектора q. Решение этой задачи лежит в собственной структуре матрицы корреляции
R. Если q единичнЫЙ вектор, такой, что дисперсионный зонд 'V(q) имеет экстре-
мальное значение, то для любоro возмущения oq единичноro вектора q выполняется
'V(q + oq) == 'V(q).
(8.8)
Из определения дисперсионноro зонда можем вывести следующее соотношение:
'V(q + 8q) == (q + oq)TR(q + oq) == qTRq + 2(oq)TRq + (oq)TRoq,
[де во второй строке использовалось выражение (8.6). Иrнорируя слаrаемое втoporo
порядка (oq)TRoq и используя определение (8.7), можно записать следующее:
'V(q + oq) == qTRq + 2(oq)TRq == 'V(q) + 2(oq)TRq.
(8.9)
8.3. Анализ rлавных компонентов 517
Отсюда, подставляя (8.8) в (8.9), получим:
2(oq)TRq == о.
(8.10)
Естественно, любые возмущения oq вектора q нежелательны; оrpаничим их толь
ко теми возмущениями, для которых норма возмущенноrо вектора q+oq остается
равной единице, Т.е.
Ilq + oqll == 1
или, что эквивалентно,
(q + oq) т (q + oq) == 1.
Исходя из этоro, в свете равенства (8.2) требуется, чтобы для возмущения первоro
порядка oq выполнялось соотношение
(oq)T q == о.
(8.11)
Это значит, что возмущения oq должны быть ортоroнальны вектору q и, таким
образом, допускаются только изменения в направлении вектора q.
Соrласно соrлашению, элементы единичноro вектора q являются безразмерными
в физическом смысле. Таким образом, можно скомбинировать (8.1 О) и (8.11), BBe
дя дополнительный масштабирующий множитель л в последнее равенство с той
же размерностью, что и вхождение в матрицу корреляции R. После этоrо мож-
но записать следующее:
(oq)TRq Л(оq)Т q == о,
ИЛИ, эквивалентно,
(oq)T(Rq лq) == о.
(8.12)
для тoro чтобы выполнялось условие (8.12), необходимо и достаточно, чтобы
Rq == Лq.
(8.13)
Это уравнение определения таких единичных векторов q, для которых диспер
сионный зонд '1'( q) принимает экстремальные значения.
"""
518 rлава 8. Анализ rлавных компонентов
в уравнении (8.13) можно леrко узнать задачу определения собственных значе-
ний (eigenvalue: problem) из области линейной алrебры [1022]. Эта задача имеет
нетривиальные решения (т.е. q# О) только для некоторых значений /.., которые и на-
зываются собственными значениями (eigenvalue) матрицы корреляции R. При этом
соответствующие векторы q называют собственными векторами (eigenvector). Мат-
рица корреляции характеризуется действительными, неотрицательными собственны-
ми значениями. Соответствующие собственные векторы являются единичными (если
все собственные значения различны). Обозначим собственные значения матрицы R
размерности т х т как /"1, /"2,' . . , /..т, а соответствующие им собственные векторы
q1, q2,..., qm соответственно. Тоrда можно записать следующее:
Rqj == /..jqj,j == 1,2,... ,т.
(8.14)
Пусть соответствующие собственные значения упорядочены следующим образом:
/..1 > /..2 > . . . > /..j > . .. > /..т'
(8.15)
При этом /..1 будет равно /..mах' Пусть из соответствующих собственных векторов
построена следующая матрица размерности т х т:
Q == [q1' q2"'" qj"'" qm]'
(8.16)
Torдa систему т уравнений (8.14) можно объединить в одно матричное уравнение:
RQ == Q/..,
(8.17)
rдe А диаroнальная матрица, состоящая из собственных значений матрицы R:
А == diag[/..l' /..2"'" /..j,..., /..т]'
(8.18)
Матрица Q является ортО20Нальной (унитарной) в том смысле, что векторы столбцы
(т.е. собственные векторы матрицы R) удовлетворяют условию ортоroнальности:
т { 1, j==i,
qi qj == О . ../. .
, J I Z.
(8.19)
Выражение (8.19) предполаrает, что собственные значения различны. Эквивалент-
но, можно записать:
QTQ == 1,
8.3. Анализ rлавных компонентов 519
из чеro можно заключить, что обращение матрицы Q эквивалентно ее транспониро
ванию:
QT == Q l.
(8.20)
Это значит, что выражение (8.17) можно переписать в форме, называемой opтo
20Нальным преобразованием подобия (orthogonal similarity transformation):
QTRQ == А,
(8.21 )
ИЛИ В расширенной форме:
TR { Лj, k==j,
qj qk О, k i: j.
(8.22)
Ортоrональное преобразование подобия (8.21) трансформирует матрицу корреля
ции R в диаroнальную матрицу, состоящую из собственных значений. Сама матрица
корреляции может быть выражена в терминах своих собственных векторов и соб
ственных значений следующим образом:
m
R == I: Лiqiq;.
i l
(8.23)
Это выражение называют спектральной теоремой (spectral theorem). Произведе-
ние векторов qiq; имеет paHr 1 для всех i.
Уравнения (8.21) и (8.23) являются двумя эквивалентными представлениямираз
ложен ия по собственным векторам (eigencomposition) матрицы корреляции R.
Анализ rлавных компонентов и разложение по собственным векторам матрицы
R являются в сущности одним и тем же; различается только подход к задаче. Эта
эквивалентность следует из уравнений (8.7) и (8.23), из которых ясно видно равенство
собственных значений и дисперсионноro зонда, Т.е.
",(qj) == Лj,j == 1,2,... ,т.
(8.24)
Теперь можно сделать выводы, касающИеся анализа rлавных компонентов.
· Собственные векторы матрицы корреляции R принадлежат случайному вектору Х
с нулевым средним значением и определяют единичные векторы qj, представляю
щИе основные направления, вдоль которых дисперсионный зонд ",(qj) принимает
экстремальные значения.
· Соответствующие собственные значения определяют экстремальные значения дис
персионноrо зонда "'(Oj)'
....
520 rлава 8. Анализ rлавных компонентов
Основные представления данных
Пусть вектор данных Х является реализацией случайноrо вектора Х.
При наличии т возможных значений единичноrо вектора q следует рассмотреть
т возможных проекций вектора данных Х. В частности, соrласно формуле (8.1)
т т . 1 2
aj == qj Х == Х qj' J == , ,..., т,
(8.25)
rдe aj проекции вектора Х на основные направления, представленные единичными
векторами Uj' Эти проекции aj называют 2Лавными компонентами (principal сотро-
nent). Их количество соответствует размерности вектора данных Х. При этом формулу
(8.25) можно рассматривать как процедуру анализа (analysis).
Для тoro чтобы восстановить вектор исходных данных Х непосредственно из
проекций aj, выполним следующее. Прежде Bcero объединим множество проекций
{ajlj == 1,2,...,т} в единый вектор:
[ ] Т [ Т Т Т ] Т Q T
а== a1,a2,...,a m == Х q1'X q2"'.'X qm == Х.
(8.26)
Затем перемножим обе части уравнения (8.26) на матрицу Q, после чеro исполь-
зуем соотношение (8.20). В результате исходный вектор данных Х будет реконструи-
рован в следующем виде:
т
Х == Qa == I: ajqj'
j l
(8.27)
который можно рассматривать как формулу синтеза. В этом контексте единичные
векторы qj будут представлять собой пространства данных. И в самом деле, выра-
жение (8.27) является не чем иным, как преобразованием координат, в соответствии
с которым точки Х пространства данных преобразуются в соответствующие точки а
пространства признаков.
Сокращение размерности
с точки зрения задачи статистическоro распознавания практическое значение анализа
rлавных компонентов состоит в том, что он обеспечивает эффективный способ сокра-
щения размерности (dimensiona1ity reduction). В частности, можно сократить количе-
ство признаков, необходимых для эффективноro представления данных, устраняя те
линейные комбинации в (8.27), которые имеют малые дисперсии, и оставляя те, дис-
персии которых велики. Пусть "'1, "'2,.", "'1 наибольшие l собственных значений
матрицы корреЛЯЦИИ R. Torдa вектор данных Х можно аппроксимировать, отсекая
члены разложение (8.27) после l ro слаrаемоro:
8.3. Анализ rлавных компонентов 521
Входной
вектор
(данных)
Ш Ш Ш
Устройство
кодирования
Вектор
rлавных
компонентов
а)
Рис. 8.2. Два этапа анализа rлавных
компонентов: кодирование (а) и декоди
рование (6)
ш
Декодер
Восстановленный
вектор
данных
ш
Вектор
rлавных
компонентов
[ql' q2' ..., q)
б)
1 [ ]
х== I:ajqj == [q1,q2,...,ql]
: а ' . 1 :' '
j l
l ::; т.
(8.28)
Имея исходный вектор х, с помощью выражения (8.25) можно вычислить rлавные
компоненты из (8.28) следующим образом:
[::.] Ш]" l т
(8.29)
Линейная проекция (8.29) из т В l (т.е. отображение из пространства данных в
пространство признаков ) представляет собой шифратор (encoder) для приближенно
ro представления вектора данных х (рис. 8.2, а). Соответственно линейная проекция
(8.28) из l в т (т.е. обратное отображение пространства признаков в пространство
данных) представляет собой дешифратор (decoder) (см. рис. 8.2,6). Обратите внима
ние, что доминирующие (dominant) собственные значения "'1, "'2,. . . , "'1 не участвуют
в вычислениях (8.28) и (8.29). Они просто определяют количество rлавных компо
нентов, используемых для кодирования и декодирования.
Вектор ошибки аппроксимации (approximation епоr vector) е равен разности между
вектором исходных данных х и вектором приближенных данных х (рис. 8.3):
....
522 rлава 8. Анализ rлавных компонентов
е == х х.
(8.30)
Подставляя (8.27) и (8.28) в (8.30), получим:
m
е == I: ajqj.
j l+1
(8.31)
Вектор ошибки е является ортоroнальным вектору приближенных данных х
(рис. 8.3). Друrими словами, скалярное про изведение векторов е и х равно нулю.
Используя (8.28) и (8.31), это свойство можно доказать СЛедующим образом:
m 1 m
е Т х == I: aiq; I: ajqj == I: I: aiajq; qj == О,
i l+1 j l i l+l j l
(8.32)
[де учитывается второе условие выражения (8.19). Соотношение (8.32) называют
принципом ортО20нальности (principle of orthogonality).
Общая дисперсия т КОмпонентов вектора данных х составляет (соrлас
но (8.7) и (8.22»:
m m
I: a == I: Л j ,
j l j l
(8.33)
[де а; дисперсия j ro rлавноro компонента aj. Общая дисперсия l элементов при
ближенноro вектора i равна:
1 1
I: а] == I: Лj.
j l j l
(8.34)
Таким образом, общая дисперсия (l т) элементов вектора ошибки аппроксима
ции х i равна:
m m
I: a == I: Лj.
j l+l j l+l
(8.35)
Числа ЛI+1,' . ., Л m являются наименьшими (т [) собственными значениями
матрицы корреляции R. Они соответствуют слаrаемым, исключенным из разложения
(8.28), используемоro для построения приближенноrо вектора i.Чем ближе эти соб
ственные значения к нулю, тем более эффективным будет сокращение размерности
(как результат применения анализа rлавных компонентов вектора данных х) в пред
8.4. Фильтр Хебба для выделения максимальных собственных значений 523
е
Рис. 8.3. Взаимосвязь вектора х, ero реконструированной версии х и
вектора ошибки е
о
х
ставлении информации исходных данных. Таким образом, для TOro чтобы обеспечить
сокращение размерности входных данных, нужно вычислить собственные значения
и собственные векторы матрицы корреляции векторов входных данных, а затем op
тО20Нально проектировать эти данные на под пространство, задаваемое собствен
ными векторами, соответствующими доминирующим собственным значениям этой
матрицы. Этот метод представления данных обычно называют пространственной
декомпозицией (subspace decomposition) [797].
Пример 8.1
Двумерное множество данных
для ИJШюстрации применения анализа rлавных компонентов рассмотрим пример двумерноro
множества данных (рис. 8.4). При этом предполаrается, что обе оси признаков на rpафике имеют
приблизительно одинаковый масштаб. rоризонтальная и вертикальная оси rpафика представляют
собой естественные координаты множества данных. Повернутые оси с метками 1 и 2 ЯВШIись
результатом применения к этому множеству данных анализа rлавных компонентов. На рис. 8.4
видно, что проектирование множества данных на ось 1 позволяет выделить свойство выпуклости
данных, а именно тот факт, что множество данных является бимодальным (т.е. в ero структуре
существуют два кластера). И в самом деле, дисперсия проекции точек данных на ось 1 превышает
дисперсию проекции на любую друryю ось рисунка. В отличие от этой ситуации внутренняя
бимодальная пр ирода этоro множества данных абсолютно не видна при ero проектировании на
ортоroнальную ось 2.
В этом простом примере важно обратить внимание на то, что кластерная структура данно-
ro множества не проявляется даже при проектировании на вертикальную и roризонтальную оси
rpафика. На практике чаще Bcero приходится иметь дело с мноroмерными множествами данных,
в которых кластерная структура данных скрыта, и приходится выполнять статистический анализ,
аналоrичный описанному выше анализу rлавных компонентов [653]. .
8.4. Фильтр Хебба для выделения максимальных
собственных значений
Существует тесная взаимосвязь между поведением самоорrанизующихся нейрон
ных сетей и статистическим методом анализа rлавных компонентов. В этом раз
деле мы продемонстрируем эту связь, доказав следующее утверждение. Один ли-
нейный нейрон с Хеббовским правилом адаптации синаптических весов может
lIIIII'
524 rлава 8. Анализ rлавных компонентов
2
......
. . :- о.
' '-: : H i?; :,:.;. .:,
о" .' О", ."1'-':'.: '''--:.);'' '
.: . .:.: . :: "'.:.: i; ., : ' J:. ..
. ",,, x,,,,, ,,, .' . .":\ ,', '"'' .:-
"6. "::'.. , ..' .:::. :.:.., . .
. . . ' { '<;'\ :.... .: .; ..'" ",
,"":;;;.!"'''' 0,0'
':-l.! .:: ,......,. . . . ."
...........;. !"'. о'
8
4
о
2
4
6
8
Рис. 8.4. Совокупность данных показана в двумерной системе координат, а
плотности точек сформированы проектированием этих совокупностей на две
оси, обозначенные цифрами 1 и 2. Проекция на ось 1 имеет максимальную дис-
персию и явно демонстрирует бимодальный или кластерный характер данных
быть преобразован в фильтр для вьщеления первоro rлавноrо компонента входно-
[о распределения [798].
Чтобы приступить к изучению этоrо вопроса, рассмотрим простую нейронную
модель, показанную на рис. 8.5, а. Эта модель является линейной в том смысле, что
ее выход является линейной комбинацией входов. Нейрон получает множество из
т входных сиrналов X1, Х2"", Х т через соответствующее множество т синапсов
W1, W2,' . . , W m . Выход полученной модели можно определить как
m
у == 2:: WiXi'
i l
(8.36)
Обратите внимание, что в описанной здесь ситуации мы имеем дело с единствен-
ным нейроном, поэтому нет необходимости применять в обозначениях синаптических
весов двойной Индекс.
8.4. Фильтр Хебба для выделения максимальных собственных значений 525
X1(n)
х 2 (п)
у(п)
хт(п)
а)
Xj(n)
X'i(n)
lJy(n)
w/n)
Рис. 8.5. Представление фильтра для
извлечения максимальноro собственноrо
значения в виде rрафа передачи сиrнала:
rраф выражения (8.36) (а); rраф выраже-
ний (8.41) и (8.42) (б)
wi(n + 1)
б)
Соrласно постулату Хебба, синаптический вес Wi изменяется во времени, сильно
возрастая, если предсинаптический сиrнал Xi и постсинаптический сиrнал У совпа
дают друr с друrом. В частности, можно записать следующее:
щ(n + 1) == щ(n) + 11y(n)xi(n)' i == 1,2,..., т,
(8.37)
rдe n дискретное время; 11 параметр интенсивности обучения (learning rate pa
rameter). Однако это правило обучения в своей общей форме приводит к неоrpаничен
ному росту синаптических весов Wi, что неприемлемо с физической точки зрения. Эту
проблему можно обойти, применив в правиле обучения, используемом для адапта
ции синаптических весов, некоторую форму насыщения (saturation) или нормализации
(normalization). Использование нормализации обеспечивает эффект введения KOHКY
ренции между синапсами нейрона за обладание оrpаниченными ресурсами, которая,
исходя из BTOpOro принципа самоорrанизации, является существенным условием CTa
билизации сети. С математической точки зрения удобная форма нормализации может
быть описана следующим соотношением [798]:
1 щ(n) + 11y(n)xi(n)
щ(n + ) (2:7:1 [щ(n) + 11Y(n)Xi(n)J2)l/2 '
(8.38)
..
526 rлава 8. Анализ rлавных компонентов
rдe суммирование в знаменателе проводится по всему множеству синапсов, связанных
с данным нейроном. Предполаrая малость параметра скорости обучения ", (8.38)
можно представить в виде ряда по " и записать так:
щ(n + 1) == щ(n) + "y(n)[xi(n) у(n)щ(n)] + 0(,,2),
(8.39)
[де элемент 0(,,2) представляет собой слаrаемые BToporo и более высоких поряд-
ков по ". Для малых значений" это слаrаемое Вполне обоснованно может быть
проиrнорировано. Таким образом, (8.38) можно аппроксимировать рядом перво-
[о порядка по ,,:
щ(n + 1) == щ(n) + "y(n)[xi(n) у(n)щ(n)].
(8.40)
Слаrаемое Y(n)Xi(n) в правой части (8.40) представляет собой обычную Хеббов-
скую модификацию синаптическоro веса Wi и, таким образом, участвует в процессе
самоусиления, диктуемоrо первым принципом самоорrанизации. Отрицательное сла-
[аемое ( у(n)щ(n)), соrласно второму принципу, отвечает за стабилизацию. Оно
преобразует входной сиrнал Xi (n) к форме, зависящей от соответствующеro синап-
тическоro веса Wi(n) и выходноrо сиrнала у(n):
x (n) == xi(n) у(n)щ(n).
(8.41 )
Это выражение можно рассматривать как эффективный входной СИ2Нал (effective
input) i ro синапса. Теперь можно использовать определение (8.41) и переписать
правило обучения (8.40) в следующем ВИДе:
щ(n + 1) == щ(n) + "y(n)x (n).
(8.42)
Общая работа нейрона представляется как комбинация двух rpафов передачи сиr-
нала, показанных на рис. 8.5. rраф на рис. 8.5, а отражает зависимость выхода у(n) от
синаптических весов W1(n)'W2(n)"" ,wm(n), соrласно (8.36). rрафы передачи сиr-
нала на рис. 8.5, б иллюстрируют выражения (8.41) и (8.42). Передаточная функция
Z l в средней части rpафа представляет собой оператор единичной задержки (unit-
delay operator). Выходной сиrнал у(n) на рис. 8.5, а выступает в роли передаточной
функции на рис. 8.5, б. rраф на рис. 8.5, б ясно показывает следующие две формы
внутренней обратной связи, действующей в нейроне.
· Положительная обратная связь для самоусиления и роста синаптических весов
wi(n) в соответствии с внешним входным сиrналом Xi(n)'
· Отрицательная обратная связь ( y(n)) для контроля роста связей, стабилизирую-
щая синаптический вес Wi(n)'
8.4. Фильтр Хебба для выделения максимальных собственных значений 527
Слаrаемое произведение ( у(n)щ(n)) связано с фактором забывания (forget
ting), который часто используется в правилах обучения, но с одним отличием: фактор
забывания становится более явно выраженным с усилением выходноrо сиrнала у(n).
Такой тип управления имеет определенное нейробиолоrическое объяснение [1016].
Матричная формулировка алrоритма
Для удобства выкладок введем следующие обозначения:
х(n) == [X1(n),X2(n)"" ,Хт(n))Т
(8.43)
и
w(n) == [W1(n)'W2(n)'..' ,wm(n))T.
(8.44)
Входной вектор х(n) и вектор синаптических весов w(n) обычно являются pea
лизациями случайных векторов. Используя это векторное представление, выражение
(8.36) можно переписать в форме скалярноro произведения:
у(n) == xT(n)w(n) == wT(n)x(n).
(8.45)
Аналоrично, выражение (8.40) можно пере писать в следующем виде:
w(n + 1) == w(n) + llY(n)[x(n) y(n)w(n)).
(8.46)
Подставляя (8.45) в (8.46), получим:
w(n + 1) == w(n) + ll[x(n)x T (n)w(n) wT(n)x(n)xT(n)w(n)w(n)).
(8.47)
Алrоритм обучения (8.47) представляет собой нелинейное стохастическое раз
ностное уравнение (non1inear stochastic difference equation), которое делает анализ
сходимости этоro алrоритма сложным с математической точки зрения. для тoro что
бы обеспечить базис для анализа сходимости, HeMHoro отвлечемся от поставленной
задачи и обратимся к общим методам анализа сходимости стохастических алrорит
мов аппроксимации.
r
528 rлава 8. Анализ rлавных компонентов
Теорема 06 асимптотической устойчивости
Алroритм самоорrанизующеrося обучения, описываемый уравнением (8.47), является
частным случаем общеrо алroритма стохастической аппроксимации:
w(n + 1) == w(n) + ,,(n)h(w(n), х(n)), n == 0,1,2,...
(8.48)
Предполаrается, что последовательность ,,(n) состоит из положительных скаляров.
Функция коррекции (update function) h(., .) является детерминированной функцией
с некоторыми условиями реrулярности. Эта функция, вместе с последовательностью
скаляров ,,(.), определяют полную структуру алroритма.
Целью описываемой здесь процедуры является определение связи детермини-
роваННО20 оБЫЧНО20 дифференциалЬНО20 уравнения (deterministic ordinary differentia!
equation, или ODE) со стохастическим нелинейным разностным уравнением (8.48).
После выявления такой связи свойства устойчивости этоrо дифференциальноrо урав-
нения можно ассоциировать со свойствами сходимости алrоритма. Описываемая про-
цедура является довольно общим приемом и имеет широкую область применения.
Она была разработана независимо друr от друrа в [665] и [607], использовавших
совершенно разные подходы 2 .
Для начала предположим, что алroритм стохастической аппроксимации, описыва-
емый уравнением (8.48), удовлетворяет следующим условиям.
1. Значения" (n) это убывающая последовательность положительных действи
тельных чисел, такая, что:
00
(а) I: ,,(n) == 00, (8.49)
n l
00
(6) I: "Р(n) < оо,р > 1, (8.50)
n l
(в) ,,(n) ......... О при n ......... 00. (8.51 )
2. Последовательность векторов параметров (синаптических весов) w(-) является
оrpаниченной с вероятностью 1.
3. Функция коррекции h(w, х) является непрерывно дифференцируемой по w и х, а
ее производные оrpаничены во времени.
2 Подходы, примененные в [665] и [607], посвященных изучению динамики алrоритма стохастической
аппроксимации, свели эту задачу к изучению дннамики Дифференциальных уравнений. Однако эти Два подхода
отличаются дрyr от друrа. В первой работе использовалась функция Ляпуиова, а во второй процесс линейной
интерполяции [270]. Последний подход был унаследован из [258] для изучения сходимости фильтра Хебба
для извлечения максимальноro собственноro значения. При этом полученные выводы совпали с результатами
первоro подхода.
8.4. Фильтр Хебба для выделения максимальных собственных значений 529
4. Предел
h(w) == Нт E[h(w, Х)]
n.....,оо
(8.52)
существует для всех w. Оператор статистическоrо ожидания Е действует на слу
чайный вектор Х с реализацией, обозначаемой символом х.
5. Существует локально асимптотически устойчивое (в смысле Ляпунова) решение
обычноro дифференциальноrо уравнения
d
dt w(t) == h(w(t)),
(8.53)
rдe t непрерывное время. Устойчивость в смысле Ляпунова рассматривает-
ся в rлаве 14.
6. Пусть q1 решение уравнения (8.53) в области притяжения B(q). Понятие обла
сти притяжения или бассейна аттракции (basin of attraction) будет определено в
rлаве 14. Torдa вектор параметров w(n) определяет компактное подмножество А
в области притяжения В( q) бесконечно часто, с вероятностью 1.
Все шесть описанных выше условий являются обоснованными. В частности, усло
вие 1(а) является необходимым условием способности алrоритма изменять oцeH
ку до требуемоrо значения, независимо от начальноro состояния; 1(б) определяет
скорость сходимости 'т1 (n) к нулю. Это оrpаничение является заметно более мяr
ким, чем обычное
00
L'Т1 2 (n) < 00.
n l
Условие 4 является основным предположением, предоставляющим возможность
ассоциировать дифференциальное уравнение с алrоритмом (8.48).
Теперь рассмотрим алrоритм стохастической аппроксимации, описываемый pe
курсивным уравнением (8.48) при выполнении условий 1 6. Для данноro класса CTO
хастических алroритмов аппроксимации можно сформулировать теорему об acимп
тотической устойчивости (asymptotic stability theorem) [607], [665]:
lim w( n) == q1' бесконечно часто с вероятностью 1.
n.....,оо
(8.54)
Однако необходимо подчеркнуть следующее. Несмотря на асимптотические свой
ства алroритма (8.48), эта теорема ничеro не roворит о количестве итераций n, необ-
ходимых для применения результатов этоrо анализа. Более Toro, в тех задачах, [де
.,..
530 rлава 8. Анализ rлавных компонентов
вектор параметров, зависящий от времени, должен отслеживаться с помощью алro
ритма (8.48), выполнение условия 1(в) в принципе невозможно:
'т1 (n) ----+ О при n ----+ 00.
Эту сложность можно обойти, назначая параметру 'т1 некоторое малое положи
тельное значение, величина KOTOpOro обычно зависит от области приложения. Это
обычно происходит при практическом использовании алrоритма стохастической ап
проксимации в нейронных сетях.
Анализ устойчивости фильтра для извлечения максимальноrо
c06cTBeHHoro значения
с помощью анализа устойчивости ООЕ можно исследовать сходимость рекурсивноro
алroритма (8.46), определяющеrо фильтр для извлечения максималЬН020 собственно-
20 значения (maximum eigenfilter).
Для тoro чтобы выполнялось условие 1 теоремы об асимптотической устойчиво
сти, примем
1
'Т1(n) == .
n
Из выражения (8.47) видно, что функция коррекции h(w, х) определяется следу
ющим образом:
h(w,x) == х(n)у(n) y2(n)w(n) ==
== x(n)xT(n)w(n) [wT(n)x(n)xT(n)w(n)]w(n),
(8.55)
что, очевидно, удовлетворяет условию 3 теоремы. Уравнение (8.55) является резуль
татом использования реализации х случайноrо вектора Х в функции коррекции h(w,
Х). ДЛЯ выполнения условия 4 возьмем математическое ожидание h(w, Х) по Х, таким
образом, можно записать, что
h == lim E[X(n)XT(n)w(n) (wT(n)X(n)XT(n)w(n))w(n)] ==
n.....,оо
== Rw(oo) [wT(oo)Rw(oo)]w(oo),
(8.56)
rдe R матрица корреляции стохастическоrо процесс а, представленноro случайным
вектором Х(n); w(oo) предельное значение вектора синаптических весов.
8.4. Фильтр Хебба для выделения максимальных собственных значений 531
Сошасно условию 5, в свете уравнений (8.53) и (8.56) определим устойчивые
точки нелинейноrо дифференциальноro уравнения
d т
dt w(t) == h(w(t)) == Rw(t) [w (t)R]w(t).
(8.57)
Рассмотрим разложение вектора w(t) в терминах полноro ортоrональноro множе-
ства собственных векторов матрицы корреляции R следующим образом:
m
w(t) == L 8 k (t)qk'
k=l
(8.58)
rдe qk k й нормализованный собственный вектор матрицы R; коэффициент 8k(t)
проекция, зависящая от времени, вектора w(t) на qk. Подставим (8.58) в (8.57) и
используем основные определения
Rqk == л'kqk
и
q[Rqk == л'k,
rдe л'k собственное значение, связанное с вектором qk. Окончательно получим:
m d8 k (t) m [ m 2 ] m
f; di qk == f; л'k 8 k(t)qk л' 1 8 1 (t) f; 8 k (t)qk'
(8.59)
Эквивалентно можно записать:
d8 k (t) 2
di == л'k 8 k(t) 8k(t) Л, 1 8 1 (t),
1=1
k == 1,2,... , т.
(8.60)
Таким образом, анализ сходимости алroритма стохастической аппроксимации.
(8.48) сведен к анализу устойчивости системы обычных дифференциальных ypaB
нений (8.60), содержащих 2Лавные моды (principa1 modes) 8 k (t).
Необходимо рассмотреть два случая, в зависимости от TOro, какое значение при
нимает индекс k. Первый случай соответствует диапазону 1 < k т, а второй
k == 1. Число т является размерностью векторов х(n) и w(n). Оба этих случая
детально рассматриваются ниже.
",.
532 rлава 8. Анализ rлавных компонентов
Случай 1. 1 < k ::; т.
Для рассмотрения этоrо случая определим:
8 k (t)
ak(t) == 8 1 (t) ' 1 < k ::; т.
(8.61 )
Исходя из этоro соотношения, предполаrается, что 8 1 (t) #0 с вероятностью 1,
принимая во внимание, что начальные значения w(O) выбираются случайным обра
зом. Затем, дифференцируя по t обе части уравнения (8.61), получим:
dak(t) d8 k (t) 8k(t) d8 1 (t)
dt 8 1 (t) dt 8 (t) dt
== d8 k (t) ak(t) d8 1 (t) 1 < k < т.
8 1 (t) dt 8 t) dt'
(8.62)
Далее, подставляя (8.60) в (8.62), применяя определение (8.61) и затем упрощая
результат, получим:
dak ( t )
== (A1 Ak)ak(t), 1 < k ::; т.
(8.63)
Предполаrая, что собственные значения матрицы корреляции R являются различ-
ными и упорядочены по убыванию, получим:
1..1 > 1..2 > '" > Ak > ... > А т > О.
(8.64)
Отсюда следует, что разность между собственными значениями 1..1 Аь представ
ляющая аналоr константы времени в (8.63), является положительной. Поэтому для
случая 1 выполняется соотношение
ak(t) ----t О при t ----t 00 для 1 < k ::; т.
(8.65)
Случай 2. k == 1.
Исходя из выражения (8.60), этот второй случай описывается следующим диффе
ренциальным уравнением:
d8 1 (t) 2 з 2
== A181(t) 8 1 (t) L..,.A181 (t) == A181(t) A181(t) 8 1 (t) L..,.A181 (t) ==
1=1 1=2
т
== 1..181 (t) 1..1 8 (t) 8 (t) L Ala;(t).
1=2
(8.66)
8.4. Фильтр Хебба для выделения максимальных собственных значений 533
Однако из случая 1 известно, что аl ----t0 для l =f 1 при t ----t 00. Следователь
но, последнее слаrаемое в (8.66) достиrает нуля при достижении времени t ----t 00.
Иrнорируя это слаrаемое, выражение (8.66) можно упростить:
d8 1 (t) 2
== A181(t)[1 8 1 (t)] для t ----t 00.
(8.67)
Здесь следует подчеркнуть, что равенство (8.67) выполняется только в асимптоти
ческом смысле.
Равенство (8.67) представляет собой автономную систему (autonomous system),
Т.е. систему, которая явно не зависит от времени. Устойчивость такой системы лучше
Bcero обеспечивать с помощью положительно определенной функции, называемой
функцией Ляпунова. Ее детальное рассмотрение будет предложено в rлаве 14. Пусть
s вектор состояния автономной системы, а V(t) функция Ляпунова этой системы.
Равновесное состояние s такой системы является асимптотически устойчивым, если
d
dt V(t) < о для s Е U S,
rдe U малая окрестность точки S.
Для нашей задачи докажем, что дифференциальное уравнение (8.67) имеет Функ
цию Ляпунова следующеrо вида:
V(t) == [8 (t) 1]2.
(8.68)
Для Toro чтобы проверить это утверждение, следует показать, что V(t) удовле
творяет двум условиям:
1.
dV(t) О всех t.
< для
(8.69)
2.
V (t) имеет минимум.
(8.70)
Дифференцируя (8.68) по времени, получим:
dV(t) d8 1
== 481(t)[81(t) 1]& ==
== 4A18 (t)[8 (t) 1]2 для t ----t 00,
(8.71)
rде во второй строке используется равенство (8.67). Так как собственное значение 1..1
является положительным, то с учетом (8.71) видно, что условие (8.69) истинно при
достижении t ----t 00. Более Toro, из выражения (8.71) можно заметить, что V(t) имеет
"r
534 rлава 8. Анализ rлавных компонентов
минимум (т.е. dV(t)/dt == О) при 8 1 (t) == ::1:1), и, таким образом, условие (8.70)
также удовлетворяется. Исходя из этоro, можно завершить рассмотрение случая 2
следующим утверждением:
81(t) ----t :i:1 при t ----t 00.
(8.72)
В свете результатов, представленных соотношением (8.72), и определения (8.71)
можно еще раз записать утверждение, полученное для случая 1 и представленное
выражением (8.65), в итоroвом виде:
8k(t) ----t О при t ----t 00 для 1 < k т. (8.73)
Общее заключение, которое следует из анализа случаев и 2, можно выразить
следующим образом.
. Единственной модой алroритма стохастической аппроксимации, описанной выра-
жением (8.47), которая сходится, является 81 (t). Все остальные моды этоrо алrо
ритма будут сводиться к нулю.
· Мода 81 (t) сходится к :i: 1.
Таким образом, выполняется условие 5 теоремы об асимптотической устойчи-
вости. В частности, в свете разложения, описываемоrо выражением (8.58), можно
формально утверждать, что
w( t) ----t q1 t ----t 00,
rдe q1 является нормализованным собственным вектором, ассоциированным с наи-
большим собственным значением матрицы корреляции R.
Далее необходимо показать, что в соответствии с условием 6 теоремы об
асимптотической устойчивости существует такое подмножество А множества
всех векторов, что
Нт w( n) == q1 бесконечно часто с вероятностью 1.
n......оо
Для этоro прежде Bcero нужно обеспечить выполнение условия 2, чеrо можно
достичь с помощью жестких 02раничений, налаrаемых на w( n). Норма этоro вектора
должна оставаться ниже HeKoToporo определенноro пороrа а. Норму w( n) можно
определить следующим образом:
Ilw(n)11 == тах IWj(n)1 а.
J
(8.74)
8.4. Фильтр Хебба для выделения максимальных собственных значений 535
Пусть А компактное подмножество пространства т, определенное множеством
векторов с нормой, не превышающей пороrа а. Несложно показать следующее [932].
Если Jlw( n) 11 ::; а и константа а достаточно велика, то Ilw( n + 1) 11 < Ilw( n) 11 с
вероятностью 1.
Таким образом, по мере увеличения количества итераций n, w( n) может случайно
оказаться внутри А (бесконечно часто) с вероятностью 1. Так как область притяжения
B(q1) включает все векторы с оrpаниченной нормой, то А Е B(q1)' Друrими словами,
условие 6 выполняется.
Итак, мы обеспечили выполнение всех шести условий теоремы об асимптотиче
ской сходимости и показали, что (при вышеупомянутых условиях) алrоритм стоха-
стической аппроксимации (8.47) rарантирует сходимость w(n) с вероятностью 1 к
собственному вектору q1, связанному с наибольшим собственным значением 1..1 мат-
рицы корреляции R. Это не единственная стационарная (fixed) точка алroритма, но
только она является асимптотически устойчивой.
Общие свойства фильтра Хебба для извлечения
максимальноrо собственноrо значения
Представленный вниманию читателя анализ сходимости показывает, что единствен
ный самоорrанизующийся нейрон, работающий под управлением правила обучения
(8.39), или, что эквивалентно, (8.46), адаптивно извлекает первый rлавный компо-
нент из стационарноrо входноrо сиrнала. Первый rлавный компонент соответствует
наибольшему собственному числу матрицы корреляции случайноrо вектора Х(n).
В действительности значение 1..1 связано с дисперсией выходноrо сиrнала модели
у(n).
Пусть а 2 (n) дисперсия случайной переменной У(n), реализация которой обо-
значается как у(n), Т.е.
а 2 (n) == Е[у 2 (n)],
(8.75)
[де У (n) имеет нулевое среднее значение для входноrо сиrнала с нулевым средним.
Устремляя в (8.46) n к бесконечности и используя тот факт, что при этом условии
w( n) достиrает значения q1, получим:
х(n) == y(n)q1 при n ----+ 00.
Используя это соотношение, можно показать, что дисперсия а 2 (n) достиrает зна
чения 1..1 при количестве итераций n, стремящемся к бесконечности (см. задачу 8.2).
,...
,
536 rлава 8. Анализ rлавных компонентов
в результате линейный Хеббоподобный нейрон, работа KOTOpOro описывается вы-
ражением (8.46), сходится с вероятностью 1 к стационарной точке, которая xapaктe
ризуется следующим [798].
Дисперсия выхода модели достиrает наибольшеrо собственноrо значения матрицы
корреляции R:
Нт а 2 (n) == 1..1'
n OO
(8.76)
Вектор синаптических весов этой модели достиrает соответствующеrо собствен-
Horo вектора:
Нт w(n) == q1 (8.77)
n oo
при
Нт Ilw(n)11 == 1. (8.78)
n oo
Эти результаты предполаrают, что матрица корреляции R является положительно
определенной, а наибольшее собственное число 1..1 имеет кратность 1. Они так-
же имеют место для неотрицательно определенной матрицы R, если 1..1 >0 и име-
ет кратность 1.
Пример 8.2
Соrласованный фильтр (matched filter)
Рассмотрим случайный вектор Х(п), составленный следующим образом:
Х(п) == s + У(п),
rдe s фиксированный единичный вектор, представляющий компонент полезною СU2нала (signal
component); У(п) компонент белою шума со средним значением О. Матрица корреляции такOI'О
входноrо вектора имеет следующий вид:
R == Е[Х(п)Х Т (п)] == SsT + а 2 1,
rде а 2 дисперсия элементов вектора шума V ( п); I единичная матрица. Наибольшее собственное
значение такой матрицы будет следующим:
л.l == 1 + а 2 .
Соответствующий собственный вектор ql имеет вид
ql == s.
Не составляет труда показать, что это решение удовлетворяет уравнению для собствен-
ных значений:
Rql == л.ql'
8.5. Анализ rлавных компонентов на основе фильтра Хебба 537
Х з
У2
Х 1 Уl
Х 2
У,
Рис. 8.6. Сеть прямоrо распространения с одним слоем BЫ
числительных элементов Х т
для описанной в данном примере ситуации самоорrанизующийся линейный нейрон (при ero
сходимости к устойчивому состоянию) выступает в качестве сосласоваННО20 фwzьтра (matched filter)
в том смысле, что ero импульсный отклик (предстаменный синаптическими весами) соответствует
компоненту полезноro сиrнала s входноro вектора Х(п). .
8.5. Анализ rлавных компонентов на основе
фильтра Хе66а
Описанный в предыдущем разделе фильтр Хебба извлекает первый rлавный компо
нент из входноrо сиrнала. Линейная модель с одним нейроном может быть расширена
до сети прямоro распространения с одним слоем линейных нейронов с целью анализа
mавных компонентов для входноrо сиrнала произвольной размерности [932].
для большей конкретизации рассмотрим сеть прямоro распространения, показан
ную на рис. 8.6. В ней сделаны следующие допущения относительно структуры.
1. Все нейроны выходноrо слоя сети являются линейными.
2. Сеть имеет т входов и l выходов. Более TOro, количество выходов меньше коли
чества входов (т.е. l < т).
Обучению подлежит только множество синаптических весов {Wji}, соединя-
ющих узлы входноrо слоя с вычислительными узлами j выходноro слоя, rде
i == 1,2,. . . , т; j == 1,2,. . . , [.
Выходной сиrнал У j ( n) нейрона j в момент времени n, являющийся откликом на
множество входных воздействий {xi(n)li == 1,2,..., т}, определяется по следующей
формуле (рис. 8.7, а):
m
Yj(n) == L Wji(n)xi(n)' j == 1,2,... , [.
i l
(8.79)
..,.
538 rлава 8. Анализ rлавных компонентов
Синаптический вес Wji(n) настраивается в соответствии с обобщенной формой
правила обучения Хебба [932]:
Wji(n) == 11 [ Yj(n)Xi(n) Yj(n) t Wki(n)Yk(n) ] , i.:: ' ,... '?;
k l J, ,..., ,
(8.80)
rде Wji(n) коррекция, применяемая к синаптическому весу Wji(n) в момент
времени n; 11 параметр скорости обучения. Обобщенный ал20рИтм обучения Хебба
(generalized НеЬЫan algorithm GHA) (8.80) для слоя из [ нейронов включает в себя
алroритм (8.39) для одноro нейрона в качестве частноro случая, Т.е. для [ == 1.
Для тoro чтобы зarлянуть вrлубь обобщенноro алroритма обучения Хебба, пере-
пишем уравнение (8.80) в следующем виде:
л ( ) ( ) [ ' ( ) ( ) ( )] i == 1,2,... , т;
L..:1Wji n == 11 Yj n x i n Wji n Yj n , . 1 2 [ '
J , ,..., ,
(8.81)
rдe x (n) модифицированная версия i ro элемента входноro вектора х(n), являю
щаяся функцией индекса j, Т.е.
j l
x (n) == xi(n) L Wki(n)Yk(n),
k l
(8.82)
для KOHкpeтHoro нейрона j алroритм, описанный выражением (8.81), имеет ту же
математическую форму, что и (8.39), за исключением TOro факта, что в (8.82) входной
сиrнал Xi (n) заменен ero модифицированным значением X (n). Теперь можно сделать
следующий шаr и переписать выражение (8.81) в форме, соответствующей постулату
обучения Хебба:
Wji(n) == 11Yj(n)x '(n),
(8.83)
rдe
x '(n) == X Wji(n)Yj(n).
(8.84)
Таким образом, принимая во внимание
Wji(n + 1) == Wji(n) + Wji(n)
(8.85)
и
Wji(n) == z l[Wji(n + 1)],
(8.86)
rде Z l оператор единичной задержки, можно построить rpаф передачи сиrнала,
показанный на рис. 8.7, б, для обобщенноrо алrоритма Хебба. Из этоro rpафа видно,
8.5. Анализ rлавных компонентов на основе фильтра Хебба 539
YI(п)
W1i(п)
xi(п)
Y2(п)
W 2i (п)
xi(п)
Yj_l(п)
W j _ 1, ,{п)
х l (п)
Wji(п + 1)
Wji(п)
х 2 (п)
у/п)
хт(п)
Рис. 8.7. Представление обо6щенноro алroритма Хеб6а в виде rрафа передачи
сиrнала: rраф уравнения (8.79) (а); rраф выражений (8.80), (8.81) (6)
что сам алroритм (соrласно ero формулировке в (8.85» базируется на локальной форме
реализации. Учтем также, что выход Yj(n), отвечающий за обратную связь на rpафе
передачи сиrнала (см. рис. 8.7, 6), определяется по формуле (8.79). Представление
последнеro уравнения в виде rpафа передачи сиrнала показано на рис. 8.7, а.
Для эвристическоro понимания TOro, как обобщенный алroритм Хебба работа-
ет на самом деле, в первую очередь запишем версию алrоритма (8.81) в матрич-
ном представлении:
ДWj(n) == Т'lYj(n)x'(n) Т'lyJ(n)Wj(n), j == 1,2,... , [,
(8.87)
[де
j l
х'(n) == х(n) L wk(n)Yk(n)'
k=l
(8.88)
540
rлава 8. Анализ rлавных компонентов
r
!
Вектор х' (n) представляет собой модифицированную форму входноrо вектора.
Основываясь на представлении (8.87), можно сделать следующие наблюдения [932].
Для первоrо нейрона сети прямоrо распространения, показанной на рис. 8.6,
j == 1 : х'(n) == х(n).
Для этоrо случая обобщенный алroритм Хебба сводится к виду (8.46), записанно
му для одиночноrо нейрона. Из материала, представленноrо в разделе 8.5, известно,
что этот нейрон извлекает первый основной компонент входноrо вектора х(n).
1. Для BToporo нейрона сети на рис. 8.6 можно записать:
j == 2 : х'(n) == х(n) w1(n)Y1(n)'
Учитывая, что первый нейрон уже извлек первый rлавный компонент, второй
нейрон видит входной вектор х'(n), из KOToporo уже удален первый собственный
вектор матрицы корреляции R. Таким образом, второй нейрон извлекает первый
rлавный компонент х' (n ), что эквивалентно второму rлавному компоненту исход-
Horo входноro вектора х (n ).
2. Для третьеrо нейрона можно записать:
j == 3: х'(n) == х(n) w1(n)Y1(n) w2(n)Y2(n)'
Предположим, что первые два нейрона уже сошлись к первому и второму rлавным
компонентам (см. пп. 1 и 2). Значит, третий нейрон видит входной вектор х'(n),
из KOTOpOro удалены первый и второй собственные векторы. Таким образом, он
извлекает первый rлавный компонент вектора х'(n), что эквивалентно третьему
rлавному компоненту исходноro входноrо вектора х(n).
3. Продолжая эту процедуру для оставшихся нейронов сети ПрЯМоro распростране
ния (см. рис. 8.6), получим, что каждый из выходов сети, обученный с помощью
обобщенноrо алrоритма Хебба (8.81), представляет собой отклик на конкретный
собственный вектор матрицы корреляции входноro вектора, причем отдельные
выходы упорядочены по убыванию ее собственных значений.
Этот метод вычисления собственных векторов аналоrичен методу, получившему
название процесса исчерпания [599]. Он использует процедуру, аналоrичную OpTOro-
нализации rрама Шмидта [1022].
Представленное здесь описание "от нейрона к следующему нейрону" было пр иве-
дено для упрощения изложения. На практике все нейроны в обобщенном алrоритме
Хебба совместно работают на обеспечение сходимости.
8.5. Анализ rлавных компонентов на основе фильтра Хебба 541
Исследование сходимости
Пусть W(n) =={Wji(n)} матрица весов размерности т х [ сети прямоro распро-
странения (рис. 8.6):
W(n) == [W1(n)' W2(n),"" wz(n)]T.
(8.89)
Пусть параметр скорости обучения обобщенноrо алroритма Хебба (8.81) имеет
форму, зависящую от времени 'Тl(n), такую, что в пределе
00
liт 'Тl(n) == О и L 'Тl(n) == 00.
n oo
(8.90)
n o
Torдa этот алrоритм можно переписать в матричном виде:
ДW(n) == 'Тl(n){y(n)xT(n) LT[y(n)yT(n)]W(n)},
(8.91 )
rдe оператор LT[.] устанавливает все элементы, расположенные выше диаrонали MaT
рицы aprYMeHToB, в нуль. Таким образом, полученная матрица становится нижней
треУ20ЛЬНОЙ (1ower triangular). При этих условиях и допущениях, изложенных в раз
деле 8.4, сходимость алrоритма GHA доказывается с помощью процедуры, анало
rичной представленной в предыдущем разделе для фильтра по извлечению макси
мальноrо собственноrо значения. В связи с этим можно сформулировать следую-
щую теорему [932].
Если элементы матрицы синаптических весов W(n) на ша2е n == О принимают слу-
чайные значения, то с вероятностью 1 обобщенный ал20ритм Хебба (8.91) будет
сходиться к фиксированной точке, а W T (n) достИ2нет матрицы, столбцы которой
являются первыми [ собственными векторами матрицы корреляции R размерности
т х т входных векторов размерности т х 1, упорядоченных по убыванию собствен
ных значений.
Практическое значение этой теоремы состоит в том, что она rарантирует нахож
дение обобщенным алrоритмом Хебба первых [ собственных векторов матрицы KOp
реляции R, в предположении, что соответствующие собственные значения отличны
друr от друrа. При этом важен и тот факт, что в данном случае не требуется вычислять
саму матрицу корреляции R: ее первые [ собственных векторов вычисляются непо
средственно на основании входных данных. Полученная экономия вычислительных
ресурсов может быть особенно большой, если размерность входноrо пространства
т достаточно велика, а требуемое количество собственных векторов, связанных с
[ наибольшими собственными значениями матрицы корреляции R, является лишь
небольшой частью размерности т.
"'r
542 rлава 8. Анализ rлавных компонентов
Данная теорема о сходимости сформулирована в терминах зависящеro от времени
параметра скорости обучения 11 (n ). На практике этот параметр обычно принимает
значение некоторой малой константы 11. В этом случае сходимость rарантируется в
смысле среднеквадратической ошибки синаптических весов порядка 11.
В [181] исследовались свойства сходимости алroритма GHA (8.91). Проведенный
в работе анализ показал, что увеличение параметра 11 ведет к более быстрой сходимо-
сти и увеличению асимптотической среднеквадратической ошибки (что интуитивно
предполаrалось). Среди прочеro в этой работе точно показана обратная зависимость
между точностью вычислений и скоростью обучения.
Оптимальность 0606щенноrо алrоритма Хе66а
Предположим, что в пределе можно записать:
ДWj(n) ........ о и wj(n) ........ qj при n ........ 00, rдe j == 1,2,... , l
(8.92)
t
t
и
Ilwj(n)11 == 1 для всех j.
(8.93)
Torдa предельные значения q1, q2,' . ., q/ векторов синаптических весов нейро-
нов сети прямоro распространения (см. рис. 8.5) представляют собой нормализо-
ванные собственные векторы (normalized eigenvector), ассоциированные с l доми-
нирующими собственными значениями матрицы корреляции R, упорядоченными
по убыванию собственных значений. Таким образом, для точки равновесия мож-
но записать следующее:
т { л j , k == j,
qj Rqk == О,
k =1= j,
(8.94)
[де Л1 > Л2 > . . . > Л/.
Для выхода нейрона j получим предельное значение:
lim Yj(n) == xT(n)qj == qJ х(n).
n.....оо
(8.95)
Пусть 1j(n) случайная переменная с реализацией Yj(n). Взаимная корреляция
(сross-сопеlаtiоп) между случайными переменными 1j(n) и Yk(n) в равновесном
состоянии записывается в виде
lim E[1j(n)Y k (n)] == E[qJX(n)qk] == qJRqk == { Л о j, k == j,
n.....оо , k =1= j.
(8.96)
8.5. Анализ rлавных компонентов на основе фильтра Хебба 543
ql
q2
i(п)
Рис. 8.8. Представление в виде rрафа передачи сиrнала процесса
восстановления вектора х q/
Следовательно, можно утверждать, что в точке равновесия обобщенный алroритм
Хебба (8.91) выступает в роли средства собственных значений (eigen analyzer) вход-
ных данных.
Пусть х(n) частное значение входноro вектора х(n), для KOTOpOro предельные
условия (8.92) удовлетворяются при j == l 1. Тоrда из матричной формы (8.80)
можно получить, что в пределе
1
х(n) == L Yk(n)qk.
k=l
(8.97)
Это значит, что для заданных двух множеств величин предельных значений
q1, q2,.", ql векторов синаптических весов нейронов сети прямоro распространения
(см. рис. 8.5) и соответствующих выходных сиrналов Y1, У2,... ,Yl можно построить
линейную оценку по методу наименьших квадратов (1inear 1east-squares estimate) зна
чения х(n) входноro вектора х(n). В результате формулу (8.97) можно рассматривать
как одну из форм восстановления данных (data reconstruction) (рис. 8.8). Обратите
внимание, что в свете дискуссии, представленной в разделе 8.3, этот метод BOCCTa
новления данных имеет вектор ошибки аппроксимации, ортоrональный оценке х(n).
Алrоритм GHA в сжатом виде
Вычисления, выполняемые обобщенным алrоритмом Хебба (GHA), являются про
стыми, И их можно описать следующей последовательностью действий.
1. В момент времени n == 1 инициализируем синаптические веса Wji сети случай-
ными малыми значениями. Назначаем параметру скорости обучения 11 некоторое
малое положительное значение.
2. для n == 1, j == 1, 2,. . . , l и i == 1, 2,. . . , т вычислим:
m
Yj(n) == L Wji(n)xi(n)'
i=l
",.
544
rлаВа 8. Анализ rлавных компонентов
I
"'w;;(n) ч [у;(n)х;(n) у;(n) t Wk;(n)Yk(n)] ,
[де Xi (п) i й компонент входноrо вектора х( п) размерности т х 1; l требуемое
число rлавных компонентов.
3. Увеличиваем значение п на единицу, переходим к шаry 2 и продолжаем до тех
пор, пока синаптические веса Wji не достиrнут своих установившuxся (steady-
state) значений. Для больших п синаптические веса Wji нейрона j сходятся к
i MY компоненту собственноro вектора, связанноro с j M собственным значением
матрицы корреляции входноro вектора х(п).
8.6. Компьютерное моделирование: кодирование
изображений
в завершение рассмотрения обобщенноrо алrоритма обучения Хебба проверим ero
работу при решении задачи кодирования изображений (image coding). На рис. 8.9, а
показана семейная фотоrpафия, использованная для обучения. Обратите внимание
на 2раницы (edge) фраrментов изображения. Это изображение формата 256 х 256 с
256 rpадациями ceporo цвета. Изображение было закодировано с помощью линей
ной сети прямоrо распространения, состоящей из одноrо слоя, содержащеrо 8 ней
ронов, каждый из которых имеет по 64 Входа. Для обучения сети использовались
непересекающиеся блоки размером 8 х 8. Эксперимент проводился для 2000 об
разцов сканирования этоro изображения и маленькоrо значения параметра скоро-
сти обучения, 11 == 10 4.
На рис. 8.9, б показаны маски размера 8 х 8, представляющие синаптические веса
сети. Каждая из восьми масок отображает множество синаптических весов, связанных
с конкретным нейроном сети. В частности, возбуждающие синапсы (положительные
веса) показаны белым цветом, тормозящие (отрицательные значения) черным, а
серым цветом показаны нулевые веса. В наших обозначениях маски представляют
собой столбцы матрицы w T , состоящей из 64 х 8 синаптических весов, полученной
после сходимости обобщенноrо алrоритма обучения Хебба.
Для кодирования изображения использовалась следующая процедура.
· Каждый из блоков изображения размером 8 х 8 пикселей был умножен на каждую
из 8 масок, показанных на рис. 8.9, б. Таким образом, rенерируются 8 коэффи
циентов кодирования изображения. На рис. 8.9, в показано реконструированное
изображение, основанное на 8 доминирующих компонентах без дискретизации.
8.6. Компьютерное моделирование: кодирование изображений 545
. Каждый из коэффициентов бьm равномерно дискретизирован на множестве битов,
приблизительно пропорциональном лоrарифму дисперсии этоro коэффициента на
изображении. Таким образом, первым трем маскам было выделено по 6 бит, сле-
дующим двум по 4, следующим двум по 3, а оставшейся маске 2 бита. На
основе этоro представления для кодирования каждоro из блоков размерности 8 х 8
было выделено 34 бита, что соответствует уровню сжатия 0,53 бита на пиксель.
Для восстановления изображения на основе дискретных коэффициентов все маски
бьmи взвешены своими коэффициентами дискретизации, после чеro они использова
лись для восстановления каждоrо из блоков рисунка. Реконструированная семейная
фотоrpафия с уровнем сжатия 15:1 показана на рис. 8.9,2.
В качестве второro примера для иллюстрации обобщенноrо алroритма обучения
Хебба рассмотрим изображение MopcKoro пейзажа (рис. 8.10, а). На этом рисунке
внимание акпентируется на текстурной информации. На рис. 8.10, б показаны маски
размером 8 х 8 синаптических весов сети. Выполняемая процедура аналоrична опи
санной выше. Обратите внимание на различия в масках на рис. 8.10, б и рис. 8.9, б. На
рис. 8.1 О, в показано реконструированное изображение MOpcKOro пейзажа, основанное
на 8 доминирующих rлавных компонентах без дискретизации. Для изучения эффекта
от дискретизации выходы первых двух масок были дискретизированы с использо
ванием 5 бит для каждой, третья с использованием 3 бит, а оставшиеся маски
с использованием 2 бит для каждой. Таким образом, для кодирования каждоro из
блоков 8 х 8 потребовалось 23 бита. В результате при кодировании в среднем исполь
зовалось 0,36 бита на пиксель. На рис. 8.1 0,2 показано восстановленное изображение
MopcKoro пейзажа, в котором используются маски, дискретизированные описанным
выше способом. Общий уровень сжатия составил 22: 1.
Для проверки общей эффективности "обобщения" обобщенноrо алrоритма Хеб
ба использовались маски, показанные на рис. 8.9, б, для декомпозиции изображения
MOpcKOro пейзажа (см. рис. 8.10, а). При этом применялась та же процедура, которая
использовалась для восстановления рис. 8.10, 2. Результат этоrо восстановленноrо
изображения показан на рис. 8.10, д, с уровнем сжатия 22:1, Т.е. с тем же уровнем,
который был получен для рис. 8.1 О, 2. Несмотря на то что рис. 8.1 О, 2 и д имеют
поразительное сходство, мы видим, что на первом из них более "правдиво" представ
лена текстурная информация. В результате этот рисунок выrлядит менее "блочным",
чем рис. 8.10, д. Это различие объясняется разными весами сети. Первые четыре
веса, полученные после обучения нейронной сети на изображениях с семейной фо
тоrpафией и морским пейзажем, являются довольно сходными. Однако последние
четыре веса, кодирующие для первоrо рисунка информацию о контурах, в случае с
морским пейзажем содержат информацию о текстуре. Таким образом, для BOCCTaHOB
ления текстурной информации MOpcKOro пейзажа применялись "контурные" веса, что
и привело к блочному представлению.
546 rлава 8. Анализ rлавных компонентов
Исходное изображение
Веса
i
.
"
\
..
"
а)
б)
Использование первых 8 компонентов
Сжатие 15:1
,
\
..
!t
,
'"
в)
r)
Рис. 8.9. Семейная фотоrрафия, использованная в эксперименте по коди
рованию изображений (а); маски размером 8 х 8, представляющие собой
синаптические веса, обучаемые по алroритму GHA (б); семейная фотоrра-
фия, восстановленная с помощью 8 доминирующих rлавных компонентов
без дискретизации (в); реконструированная фотоrрафия с уровнем сжатия
15:1 при использовании дискретизации (r)
8.7. Адаптивный анализ rлавных компонентов
с использованием латеральноrо торможения
Обобщенный алroритм Хебба, описанный в предыдущем разделе, основан исключи
тельно на использовании прямых связей для анализа rлавных компонентов. В ЭТОМ
разделе мы опишем еще один алroритм, называемый алrоритмом адаптивН020 из-
влечения 2Лавных компонентов (adaptive principal components extraction АРЕХ)
8.7. Адаптивный анализ rлавных компонентов... 547
..,
-.
..,
.. -
.
а)
б)
...,. j
.......
'?- ..
в) r)
....
д)
Рис. 8.10. Изображение MopcKoro пейзажа (а); маски 8 х 8, представляю-
щие синаптические веса, обучаемые по алroритму HGA и применяемые
к изображению (б); восстановленное изображение MopcKoro пейзажа с ис
пользованием 8 доминирующих rлавных компонентов (в); восстановленное
изображение с уровнем сжатия 22:1 при использовании масок из пункта (б)
без дискретизации (r); восстановленное изображение MOpCKoro пейзажа с
использованием масок, показанных на рис. 8.9, б, с дискретизацией для
достижения уровня сжатия 22:1, TaKoro же, как в частях (r), (д)
,...
548 rлава 8. Анализ rлавных компонентов
Х)
ал
Х 2
Х з
Х т
Входной
слой
j
Выходной
слой
Рис. 8.11. Сеть с прямыми и латеральными связями, ис-
пользуемая для вывода алroритма АРЕХ
[258], [606]. Алroритм АРЕХ использует как прямые, так и обратные связи 3 . По своей
природе этот алroритм является итеративным: j й основной компонент вычисляется
на основе заданных и 1) предыдущих.
На рис. 8.11 показана модель сети, которую мы будем использовать для вывода
алroритма АРЕХ. Как и ранее, входной вектор х имеет размерность т. Ero компонен-
тами являются X1, Х2,. . . , Хт' Все нейроны сети считаются линейными. Как показано
на рис. 8.11, в этой сети существуют два типа синаптических весов.
· Прямые связи (feedforward connection) от входных узлов к каждому из нейронов
1, 2,.. ., j, [де j < т. Здесь представляют интерес прямые связи, приходящие к
нейрону j. Их можно представить в виде вектора прямых связей:
Wj == [wjl (n), Wj2(n)'." , Wjm(n)]T.
Прямые связи работают в соответствии с правuлом обучения Хебба (НеЬЫап learn
ing rule) и, таким образом, реализуют самоусuление (self-amplification).
3 В [301] конфиrypация нейронной сети, используемая для анализа rлавных компонентов, была расширена за
счет включения Хеббоподобных обратных связей. Идея этой модификации была навеяна более ранней работой,
посвященной адаптации и декорреляции в зрительной области коры roловноro мозrа [93]. В этой работе бьmо
дано объясиение следующему факту. Если нейроны взаимодействуют соrласно анти-Хеббовскому правилу, то
выходы этих нейронов определяют систему координат, в которой нет корреляции, даже если входные сиrналы
сильно коррелированны.
Использование латеральноro торможения в выходных нейронах было также предложеио в [909], [910].
Однако, в отличие от модели, предложенной в [301], латеральные связи, описанные в этих стarьях, не были
симметричными. При этом латеральная сеть была иерархической в том смысле, что нейрон i тормозил все
нейроны за исключением нейронов 1,2,. .., i 1, rде i == 1,2,. " .
Модель АРЕХ, предложенная в [606], предполаrает ту же тополоrию сети, что и модель, описанная в [909],
[910], но для коррекции синаптических весов в прямых и латеральных связях сети используется друrое правило
обучеиия (см. раздел 8.4).
8.7. Адаптивный анализ rлавных компонентов.. . 549
. Латеральные связи (lateral connection) между выходами нейронов 1,2,...,j 1 и
входом нейрона j. Они реализуют обратные связи в сети. Эти связи представля
ются вектором обратных связей:
aj(n) == [ajl(n),aj2(n)"", aj,j l(n)]T.
Латеральные связи действуют в соответствии с анти-Хеббовским правuлом обуче
ния (anti Hebbian learning ru1e), что делает их тормозящими (inhibitory).
На рис. 8.11 прямые и латеральные связи нейрона j выделены жирным, чтобы
подчеркнуть значение нейрона j как объекта изучения.
Выход Yj(n) нейрона j можно представить в следующем виде:
Yj(n) == wJ(n)x(n) + aJ(n)Yj l(n)'
(8.98)
rдe слаrаемое wJ(n)x(n) отражает влияние прямых связей, а aJ(n)Yj l(n)
латеральных. Вектор сиrнала обратной связи у j 1 (n ) формируется выхода-
ми нейронов 1,2,.. . , j 1:
Yj l (n) == [Y1(n), У2(n)"" , Yj l(n)]T.
(8.99)
Предполаrается, что входной вектор х( n) выбирается из стационарноrо процесса
с матрицей корреляции R, имеющей различные собственные значения, oтcopтиpo
ванные в порядке убывания, Т.е.
A1 > А:2 > ... > Aj l > Aj > ... > Ат'
(8.100)
Далее предполаrается, что нейроны 1, 2,. . . , j 1 сети, изображенной на рис. 8.11,
уже со шлись к своим устойчивым состояниям:
Wk(O) == qk, k == 1,2,.. . , j 1,
ak(O) == О, k == 1,2,...,j 1,
(8.101)
(8.102)
rдe qk собственный вектор, связанный с k M собственным значением матрицы
корреляции R, а момент времени n ==0 соответствует началу вычислений в сети.
Torдa, учитывая выражения (8.98), (8.99), (8.101) и (8.102), можно записать:
Yj l (n) == [q'[ х(n), qf х(n),..., qJ lx(n)] == Qx(n),
(8.103)
550 rлава 8. Анализ rлавных компонентов
rдe Q матрица размерности (j 1) х т, определяемая в терминах собственных
векторов q1, q2,..., <I.i 1, связанных с (j 1) наибольшими собственными значениями
A1, А2,. . . , Aj l матрицы корреляции R, Т.е.
Q == [q1' q2" .. ,qj l]T.
(8.1 04)
Нейрон j сети, показанной на рис. 8.11, требуется использовать для вычисления
следующеrо наибольшеro собственноrо числа Aj матрицы корреляции R входноro
вектора х(n) и связанноro с ним собственноrо вектора qj'
Уравнения коррекции для вектора прямых синаптических весов W j (n) и вектора
латеральных весов aj (n) нейрона j имеют следующий вид:
Wj(n + 1) == wз(n) + 11 [Yj(n)x(n) У] (n)wj (n)]
(8.105)
и
aj(n + 1) == aj(n) + 11 [Yj(n)Yj l (n) У] (n)aj (n)] ,
(8.106)
rдe 11 параметр скорости обучения (leaming-rate parameter), одинаковый в обо
их уравнениях коррекции. Слаrаемое Yj(n)x(n) в правой части уравнения (8.105)
представляет обучение Хебба, в то время как слаrаемое Yj(n)Yj l(n) в выраже-
нии (8.106) анти Хеббовское обучение. Оставшиеся слаrаемые, yJ(n)Wj(n) и
yJ(n)aj(n), включены в эти уравнения для обеспечения устойчивости алroритма. В
своей основе уравнение (8.105) представляет собой векторную форму правила обуче
ния Ойа, описанноro в (8.40), в то время как уравнение (8.106) является совершенно
новы.м и учитывает латеральное торможение [258], [606].
Абсолютная устойчивость сети, изображенной на рис. 8.11, доказывает
ся методом индукции.
· Сначала доказывается, что если нейроны 1, 2,. . . , j 1 сходятся к своим устой
чивым значениям, то нейрон j тоже сходится к своему устойчивому значению,
выбирая следующее по счету наибольшее собственное значение Aj матрицы KOp
реляции R входноro вектора х(n) и соответствующий ему собственный вектор qj'
· После этоrо мы завершаем доказательство методом индукции, учитывая, что ней
рон 1 не имеет обратных связей и, таким образом, вектор весов обратной связи а1
является нулевым. Следовательно, этот конкретный нейрон функционирует таким
же образом, как и нейрон Ойа, а из раздела 8.4 мы знаем, что этот нейрон при
определенных условиях является абсолютно устойчивым.
Таким образом, пунктом, требующим наибольшеro внимания, является первый.
8.7. Адаптивный анализ rлавных компонентов. . . 551
Сделаем одно фундаментальное допущение, приведенное в разделе 8.4, и сфор
мулируем следующую теорему в контексте нейрона j нейронной сети, показанной на
рис. 8.11, работающей при выполнении условий (8.105) и (8.106) [258], [606].
Если параметр скорости обучения 'тl принимает достаточно малое значение, обес-
печивающее медленную корректировку весовых коэффициентов, то в пределе вектор
прямых весов и усредненная мощность нейрона j (дисперсия) достИ2ают нормали
зоваНН020 собственноzо вектора qj и соответствующеzо собствеНН020 значения Aj
матрицы корреляции R:
lim wj(n) == qj'
n.....оо
lim а;(n) == Aj,
n.....оо
ёде а;(n) == E[yJ(N)] и A1 > А2 > ... > Aj > ... > Ат' ДРУ2UМи словами, с пOMO
щью собственных векторов q1, q2,' .., qj l нейрона j сети, показанной на рис. 8.11,
можно вычислить наибольшее собственное значение Aj и соответствующий ему соб
ственный вектор qj.
Для доказательства этой теоремы рассмотрим уравнение (8.105). Используя Bыpa
жения (8.98) и (8.99), а также свойство
a;(n)Yj l(n) == y; l(n)aj(n),
выражение (8.105) можно переписать в следующем виде:
Wj(n + 1) ==wj(n)+
+ 'Тl[x(n)xT(n)wj(n) + x(n)xT(n)QT aj(n) y;(n)wj(n)],
(8.107)
rдe матрица Q определяется формулой (8.104). Слаrаемое yJ(n) оставлено без изме
нений, так как впоследствии оно будет отделено. При выполнении фундаментальных
предположений, описанных в разделе 8.4, оказывается, что применение оператора
статистическоro ожидания к обеим частям равенства (8.107) приводит к следующему:
Wj(n + 1) == wj(n) + 'Тl[Rwj(n) + RQT aj(n) <J;(n)wj(n)],
(8.108)
rдe R матрица корреляции входноro вектора х(n); а;(n) усредненная BЫ
ходная мощность вектора j. Пусть вектор синаптических весов Wj(n) является
расширенным в терминах полноro ортоrональноro множества собственных Beктo
ров матрицы корреляции R:
m
wj(n) == L 8jk(n)qk'
k l
(8.109)
"""
552 rлава 8. Анализ rлавных компонентов
rдe qk собственный вектор, связанный с собственным значением л'k матрицы R;
8jk (n) коэффициент разложения, зависящий от времени. Torдa можно использовать
основное соотношение (см. (8.14»
Rqk == л'kqk'
чтобы выразить матричное произведение Rw j (n) следующим образом:
m
m
RWj(n) == L 8 jk (n)RQk == L л'k 8 jk(n)qk'
k l k l
(8.110)
Аналоrично, используя выражение (8.104), матричное про изведение RQTaj(n)
можно представить в виде
RQT aj(n) == R[q1' q2,"', qj l]aj(n) ==
[ ajl(n) ]
2(n)
[л'lq1' л'2q2'"'' л'j lqj l] ...
aj,j l(n)
j l
== L л'kаjk(n)qk'
k l
(8.111)
Torдa, подставляя выражения (8.109) (8.111) в равенство (8.108), получим [606]:
m m j l
L 8jk(n + l)qk == L {1 + 11[л'k cr (n)]}8jk(n)qk + 11 L л'kаjk(n)qk' (8.112)
k l k l k l
с помощью описанной выше процедуры можно показать, что уравнение кор-
рекции (8.106) для вектора весов обратной связи aj(n) может быть преобразова-
но к виду (см. задачу 8.7)
aj(n + 1) == 11л'k8jk(n)lk + {1 11[л'k + cr (n)]}aj(n),
(8.113)
rдe lk вектор, все элементы KOТOpOro равны нулю, за исключением k ro, paBHoro
единице. Индекс k при этом находится в диапазоне от 1 до (j 1).
Следует рассмотреть два случая, в зависимости от положения индекса k по OT
ношению к значению j 1. В первом случае он находится слева от rpаницы,
Т.е. 1 ::; k ::; j 1. Этот случай относится к анализу "старых" rлавных мод ce
ти. Во втором случае индекс k находится справа от rpаницы, Т.е. j ::; k ::; т. Этот
случай относится к анализу "новых" rлавных мод. Общее количество rлавных мод
равно т размерности входноro вектора х(n).
8.7. Адаптивный анализ rлавных компонентов.. . 553
1 +1](" k - а/(п))
0jk(п + 1)
8 jk (п)
k(п + 1)
°jk(п)
Рис. 8.12. rраф передачи сиrнала для выраже
ний (8.114) и (8.115)
1 1]("k + а/(п))
Случай 1. 1 ::; k ::; j 1
Для данноro случая выведем следующие уравнения коррекции для коэффициента
ejk(n), связанноro с собственным вектором qk и весом обратной связи ajk(n) из
выражений (8.112) и (8.113) соответственно:
ejk(n + 1) == Т1Лkаjk(n) + {1 + Т1[Лk а; (n)]}e jk (n)
(8.114)
и
ajk(n + 1) == Т1Лkеjk(n) + {1 Т1[Лk + cr;(n)]}ajk(n)'
(8.115)
На рис. 8.12 представлен rpаф передачи сиrнала для выражений (8.114) и (8.115).
Выражения (8.114) и (8.115) можно переписать в следующем матричном виде:
[ ejk(n + 1) ] [ 1 + Т1[Лk а;(n)] Т1Лk ] [ ejk(n) ]
ajk(n + 1) Т1Лk 1 Т1[Лk + а;(n)] ajk(n)'
(8.116)
Система, описанная выражением (8.116), имеет двойное собственное значение:
Pjk == [1 Т1а;(n)]2.
(8.117)
....
554 rлава 8. Анализ rлавных компонентов
Из выражения (8.117) можно сделать два важных вывода.
1. Двойное собственное значение Р jk матричной системы (8.116) является независи-
мым от всех собственных значений Ak матрицы корреляции R, соответствующих
k == 1, 2,. . . , j 1.
2. Для всех k двойное собственное значение Pjk зависит только от параметра
скорости обучения 'тl и средней выходной мощности а; нейрона j. Следова
тельно, это значение будет меньше единицы, поскольку 'тl достаточно ма-
лое положительное число.
Если Pjk < 1, то коэффициенты разложения 8jk(n) в (8.109) и веса обратной
связи ajk (n) для всех k будут асимптотически стремиться к нулю с одинаковой
скоростью, так как все основные Моды сети имеют одно и то же собственное
значение [258], [606]. Результатом является то свойство, что ортоrональность соб
ственных векторов матрицы корреляции не зависит от собственных чисел. Друrи
ми словами, разложение W j ( n) в терминах ортоrональноro множества собственных
векторов матрицы корреляции R, представленное в (8.109) и положенное в основу
формулы (8.117), инвариантно к выбору собственных значений A1,A2,"" Aj l.
Случай 2. j ::; k ::; m
Во втором случае веса обратной связи ajk(n) не влияют на моды сети, Т.е.
ajk(n) == Oj ::; k ::; т.
(8.118)
Следовательно, для любой основной моды k j выполняется следующее про
стое равенство:
8jk(n + 1) == {1 + 'Тl[Ak а; (n)]}8jk(n),
(8.119)
которое непосредственно следует из равенств (8.112) и (8.118). Соrласно случаю 1,
векторы ajk(n)8jk(n) сходятся к нулю при k == 1,2,..., j-1. Если выходом линейно
ro нейрона j является случайная переменная Yj(n), ее среднюю дисперсию можно
выразить так:
m
а;(n) == E[Y /(n)] == LAk8 k(n),
k j
(8.120)
[де в последней строке использовал ось соотношение
TR { Ak' l == k,
qk ql О в противном случае.
8.7. Адаптивный анализ rлавных компонентов. . . 555
Отсюда следует, что уравнение (8.119) не может расходиться, поскольку с ростом
ejk(n), при котором а;(n) > Л-k, выражение 1 + 11[Л-k а;(n)] становится меньше
единицы, и в этом случае ejk(n) убывает по амплитуде. Пусть алroритм инициали
зируется такими значениями, что ejj(o): O. Введем следующее определение:
ejk(n) .
rjk(n)== ejj(n) ' k==J+1,...,m.
(8.121)
Torдa, используя (8.119), можно записать:
1 + 11[Л-k а;(n)]
rjk(n + 1) == 1 + 11[Л-j а;(n)] rjk(n)'
(8.122)
Если собственные числа матрицы корреляции упорядочены по убыванию
Л-1 > Л-2 > . . . > Л-k > . .. > Л- j > . . . > Л- m ,
то
ejk(n) .
( ) < 1 для всех n и для k == J + 1, . . . , т.
e jj n
(8.123)
Более TOro, из выражений (8.119) и (8.120) видно, что значение ejj(n+ 1) остается
оrpаниченным, следовательно:
rjk(n) ....... о при n ....... CXJ для k == j + 1,. .. , т.
(8.124)
Аналоrично, в свете определения (8.121) можно утверждать, что
ejk(n) ....... о при n....... CXJ для k == j + 1,... , т.
(8.125)
При этом условии выражение (8.120) сводится к следующему:
а;(n) == л-jе;j(n),
(8.126)
и, следовательно, равенство (8.119) для k == j принимает вид
ejj(n + 1) == {1 + 11Л-j[l e jj (n)]}e jj (n).
(8.127)
556 rлава 8. Анализ rлавных компонентов
Из этоro соотношения можно получить, что
8jj(n) 1 при n 00.
(8.128)
Из данноro предельноro условия и выражения (8.125) можно сделать два следую
щих вывода.
1. Из выражения (8.126) получим
a (n) Aj при n 00.
(8.129)
2. Из выражения (8.109) получим
Wj(n) qj при n 00.
(8.130)
Друrими словами, модель нейронной сети, показанная на рис. 8.11, извлекает j e
собственное значение и связанный с ним собственный вектор матрицы корреляции
R входноro вектора х( n), если количество итераций n стремится к бесконечности.
При этом, естественно, предполаrается, что нейроны 1,2,... ,j 1 сети уже co
шлись к соответствующим собственным значениям и собственным векторам матри
цы корреляции R.
Представленная здесь трактовка алroритма АРЕХ предполаrает, что перед тем, как
нейрон j вступает в действие, нейроны 1, 2,. . . , j 1 сети уже обучены. Это сделано
для TOro, чтобы упростить изложение материала. Однако на практике нейроны в
алroритме АРЕХ обучаются совместно 4 .
Интенсивность обучения
в алrоритме АРЕХ, описываемом уравнениями (8.105) и (8.106), для коррекции BeK
тора прямых весов Wj(n) и вектора весов обратной связи aj(n) используется один и
тот же параметр скорости обучения 'Тl. для определения оптимальноro значения пара
MeTpa'Тl для каждоrо нейрона j можно использовать соотношение (8.117), установив
двойное собственное значение р jk В значение нуль. В этом случае получим:
1
'Тlj,opt(n) == а;(n) '
(8.131)
rдe а; ( n) средняя мощность выхода нейрона j. Однако более практичным будет
4 Cтporoe доказательство сходимости алroритма АРЕХ, при которой все нейроны обучаются совместно,
было предложено в [182].
8.7. Адаптивный анализ rлавных компонентов.. . 557
следующее значение этоrо параметра [258], [606]:
1
11j== '
Лj l
(8.132)
При таком значении параметра скорости обучения Aj l > Aj и а;(n) ....... Aj при
n ....... 00. Обратите внимание, что собственное значение Aj l вычисляется нейроном
(j 1) и, таким образом, доступно для использования при коррекции прямых и
латеральных весов нейрона j.
Алrоритм АРЕХ в сжатом виде
1. Инициализируем вектор прямых весов Wj и вектор весов обратных связей aj
малыми случайными значениями для момента времени n == 1, j == 1, 2,. . ., т.
Параметру скорости обучения 11 присвоим некоторое малое положительное число.
2. Пусть j == 1; Torдa для n == 1, 2,. . . вычислим:
Y1(n) == wi (n)х(n),
w1(n + 1) == w1(n) + 11 [Y1 (n)х(n) y;(n)w1(n)]'
[де х(n) входной вектор. Для больших n W1(n) ....... q1' rдe q1 собственный
вектор, связанный с наибольшим собственным значением A1 матрицы корреля
ции вектора х(n).
3. Принимаем j ==2 и для n == 1,2, . . . вычислим:
Yj l (n) == [Y1 (n), У2(n)" .. , Yj l (n)]Т,
yj(n) == w;(n)x(n) + a;(n)Yj l(n)'
wj(n + 1) == wj(n) + 11 [Yj(n)х(n) У; (n)wj (n)],
aj(n + 1) == aj(n) 11[Yj(n)Yj l (n) y;(n)aj(n)].
4. Увеличиваем j на единицу, переходим к шаry 3 и продолжаем до j == т, rдe m
нужное количество rлавных компонентов. (Обратите внимание, что j == 1 COOTBeT
ствует собственному вектору, связанному с наибольшим собственным значением,
которое вычисляется на шаre 2.) Для больших nWj(n) ....... qj и aj(n) ....... О, rдe qj
собственный вектор, ассоциированный с j M собственным значением Aj матрицы
корреляции вектора х(n).
.,...
558 rлава 8. Анализ rлавных компонентов
8.8. Два класса алrоритмов РСА
в дополнение к обобщенному алrоритму Хебба (GHA), который рассматривался в
разделе 8.5, и алrоритму АРЕХ, описанному в разделе 8.7, существует и ряд друrих
алroритмов анализа rлавных компонентов (РСА), широко описанных в литературе 5 ,
Различные алroритмы РСА на основе нейронных сетей можно разбить на два класса:
ал20рИтмы повтОРН020 оценивания (reestimation algorithm) и ал20рИтмы декорреля
ции (decorrelating algorithm).
Соrласно этой классификации, GHA является алroритмом повторноro оценивания,
так как выражения (8.87) и (8.88) можно записать в эквивалентном виде:
Wj(n + 1) == wj(n) + Т]Уj(n)[Х(n) xj(n),
(8.133)
rдe Xj (n) операция повторной оценки (reestimator), которая определяется следую-
щим образом:
j
xj(n) == L wk(n)Yk(n)'
k l
(8.134)
в алroритме повторной оценки нейронная сеть имеет только прямые связи, и ее
веса корректируются соrласно алroритму Хебба. Последующие выходы сети должны
обучаться друrим rлавным компонентам, при этом оценки предшествующих компо
нентов вычитаются из входноro сиrнала перед тем, как эти данные поступят для
использования в процессе обучения.
В отличие от этоrо алrоритма АРЕХ является алroритмом декорреляции. В таких
алroритмах нейронная сеть имеет как прямые, так и обратные связи. Работа прямых
связей основана на правиле обучения Хебба, в то время как работа обратных на
анти Хеббовском правиле. Последующие выходы сети декоррелируются, заставляя
сеть воспроизводить разные rлавные компоненты.
Подпространство rлавных компонентов
в ситуациях, rдe используется только подпространство 2Лавных компонентов (prin-
cipal subspace), можно применять симметричную модель (symmetric model), в которой
оценка Xj (n) в алroритме GНA заменена на следующую:
1
х(n) == L Wk(n)Yk(n) для всех [.
k l
(8.135)
5 Обсуждение разных нейронных моделей, используемых для анализа rлавных компонентов, и их сравнение
nредлarается в [258].
8.9. Пакетный и адаптивный методы вычислений 559
в симметричной модели, определяемой формулами (8.133) и (8.135), сеть сходится
к множеству выходов, которые определяют подпространство rлавных компонентов,
а не к самим основным компонентам. При сходимости векторы весов этой сети
ортоroнальны друr друry, как и в GHA. Описанное здесь подпространство rлавных
компонентов можно рассматривать как обобщение классическоrо правила Ойа (Oja),
определяемоrо соотношением (8.46).
8.9. Пакетный и адаптивный методы вычислений
Обсуждение анализа rлавных компонентов будет не полным, если не рассмотреть вы-
числительные аспекты этой задачи. В этом контексте можно сказать, что существуют
два основных подхода к вычислению rлавных компонентов: пакетный и адаптивный.
Метод декомпозиции на основе собственных векторов (eigendecomposition), опи-
санный в разделе 8.3, и связанный с ним метод синrулярноrо разложения принадлежат
к катеroрии пакетных. С друroй стороны, алrоритмы GHA и АРЕХ (см. разделы 8.5
и 8.7) принадлежат к катеroрии адаптивных.
Теоретически синrулярная декомпозиция основана на усредненной по множеству
матрице корреляции R случайноro вектора Х(п) (см. раздел 8.3). На практике же мы
используем оценку матрицы корреляции R. Пусть {x(n)};; l множество N реали-
заций случайноrо вектора Х( п) в равномерно распределенные дискретные моменты
времени. Имея такое множество наблюдений, в качестве оценки матрицы корреляции
можно использовать простое среднее:
1 N
R(N) == N Lx(n)xT(n).
i l
(8.136)
Предполаrая, что среда, представленная случайным вектором Х(п), является Эр20
дической (ergodic), простое среднее R( N) достиrает значения R при достижении раз-
мером множества N бесконечности. На этом основании к простому среднему R( N)
можно применить процедуру разложения по собственным векторам, вычислить ero
собственные значения и ассоциированные с ними собственные векторы, используя
вместо матрицы R матрицу оценки R(N).
Однако с точки зрения вычислений самым лучшим методом является СИН2УЛЯрНая
декомпозиция (singular value decomposition SVD), применяемая непосредственно к
матрице данных. Для множества наблюдений {x(n)};; l матрица данных определя-
ется следующим образом:
А == [х(l), х(2),... , x(N)].
(8.137)
1
560 rлава 8. Анализ rлавных компонентов
Torдa несложно заметить, что если не учитывать масштабирующий множитель
1/N, то оценка R(N) матрицы корреляции R равна скалярному произведению АА Т .
Соrласно теореме о СИН2)lЛЯрНОЙ декомпозиции (см. rлаву 5), матрица данных А(п)
может быть представлена в виде декомпозиции [368]:
А == uI:yT,
(8.138)
[де U и У ортоroнальные матрицы, Т.е.
U l == U T
(8.139)
и
y l == уТ.
(8.140)
Матрица Е имеет следующую структуру:
Е==
[ cr 1 а2 О ] О
О crk
О О
(8.141)
[де k ::; т; m размерность вектора наблюдений х(п). Числа cr1, а2,.. ., crk называ
ются СИН2УЛЯРНЫМИ значениями (singular value) матрицы данных А. Соответственно
столбцы ортоroнальной матрицы U называются левыми СИН2УЛЯРНЫМИ векторами (left
singular vector), а столбцы матрицы У правыми СИН2УЛЯРНЫМИ векторами. Синry
лярная декомпозиция матрицы данных А связана с декомпозицией оценки R( N)
матрицы корреляции по собственным векторам в следующих аспектах.
· За исключением масштабирующеro множителя 1/ VN синrулярные значе-
ния матрицы данных А являются квадратным корнем из собственных значе
ний оценки R( N).
· Левые синrулярные векторы матрицы данных А являются собственными Beктopa
ми матрицы оценки R(N).
Теперь вычислительные преимущества синryлярной декомпозиции становятся
очевидными. для заранее заданной точности вычислений процедура синrулярной
декомпозиции требует вдвое меньшей вычислительной мощности, чем процедура
разложения по собственным векторам. Более тoro, для компьютерной реализации
процедуры синryлярной декомпозиции существует множество алroритмов и BЫCOKO
точных проrpамм [368], [434], [435]. Однако ввиду жестких требований к хранению
8.10. Анализ rлавных компонентов на основе ядра 561
данных на практике использование этих проrpамм может бьпь оrpаничено не слиш
ком большими размерами множеств.
Переходя к катеrории адаптивных методов, следует сказать, что они работают с
множествами произвольных размеров. Для всех практических реализаций не суще-
ствует каких-либо оrpаничений на N. Адаптивные методы можно проиллюстриро-
вать на примере Хеббовских нейронных сетей, работа которых основана на идеях
из нейробиолоrии. Требования к хранению данных в таких методах являются отно-
сительно умеренными, так как в них не нужно хранить промежуточные значения
собственных значений и собственных векторов. Еще одной привлекательной чертой
адаптивных алroритмов является то, что в llестационарной среде (nonstationary envi
ronment) они имеют встроенную способность отслеживать постепенные изменения
в оптимальном решении незатратным способом (по сравнению с пакетными MeToдa
ми). При этом основным недостатком адаптивных алrоритмов типа стохастической
аппроксимации является их относительно малая скорость сходимости. Это особен
но отчетливо наблюдается в больших стационарных задачах, даже при реализации
адаптивных методов на параллельных аппаратных нейронных сетях [594].
8.10. Анализ rлавных компонентов на основе ядра
Форма РСА, которую мы рассматривали до сих пор, подразумевает вычисления в про
странстве входных данных. Теперь рассмотрим друryю форму алroритмов РСА, в KO
торой вычисления осуществляются в пространстве признаков, являющемся нелиней
ным отображением входноrо пространства. Пространство признаков, в соответствии
с теоремой Мерсера, определяется ядром скалярН020 произведенuя (inner product ker
nel). Вопросы, связанные с ядром скалярноro про изведения, рассматривались в rлаве
6, посвященной машинам опорных векторов. Идея анализа 2ЛавllЫХ компонентов на
основе ядра (kemel-based principal components analysis) была предложена в [947].
Ввиду нелинейности отображения входноrо пространства в пространство при-
знаков ядро РСА также является нелинейным. Однако, в отличие от друrих форм
нелинейных РСА 6, реализация РСА на основе ядра базируется на линейной алreбре.
Таким образом, РСА на основе ядра можно рассматривать как естественное расши-
рение обычных РСА.
б Методы нелинейноro анализа rлавных компонентов (за исключением РСА ядра) можно разделить на три
класса [258].
Сети Хебба (НеЬЫап networks), получаемые путем замены линейных нейронов в подобных Хеббовским
алroритмах РСА нелинейными нейронами [542].
Сети репликации (replicator network) или системы автокодирования (autoencoder), созданные на базе мно-
roслойных персептронов (о сетях репликации см. в rлаве 4).
rлавные кривые (principal curve), основанные на итеративной оценке кривой или поверхности, описыва-
ющей структуру данных [430]. В [186] и [891] указывалось, что самоорrанизующиеся карты Кохонена можно
рассматривать как вычислительную процедуру поиска дискретной аппроксимации rлавных кривых. Самоорrэ-
низующиеся карты рассматриваются в следующей rлаве.
,..
562 rлава 8. Анализ rлавных компонентов
Пусть вектор q>(Xj) определяет образ входноro вектора Xj, индуцированный в про-
странстве признаков, определяемом нелинейным отображением j : тo ----? ml, rде
то размерность входноro пространства; m1 размерность пространства призна-
ков. для множества примеров {Xi} l получаем соответствующее множество векто-
ров признаков {q>(Xi)} l' ooтвeTCTBeHHO в пространстве признаков можно опреде-
лить матрицу корреляции R размерности m1 х m1 следующеro вида:
N
1" т
R == N L...,.q>(Xi)q> (Xi)'
i l
(8.142)
Как и в обычном РСА, первое, что нужно сделать, это убедиться, что множество
векторов признаков {q>(Xi)} l имеет нулевое среднее значение:
1 N
N L q>(Xi) == о.
i l
Выполнение этоro условия в пространстве признаков является более сложным
требованием, чем ero выполнение во входном пространстве. В задаче 8.1 О будет
описана процедура для выполнения этоro требования. Далее будем предполаrать, что
векторы признаков уже отцентрированы. Torдa выражение (8.14) можно адаптировать
к нашей ситуации, записав следующее:
Rq == ,
(8.143)
[де );. собственное значение матрицы корреляции R; q ассоциированный с ним
собственный вектор. Далее заметим, что все собственные векторы, которые удовле
творяют равенству (8.143) при);. =1= О, лежат в линейной оболочке множества векторов
признаков {q>( Xj) }f==1. Следовательно, существует такое множество коэффициентов
{ (J,j }.f 1' для которых
N
q == L (J,jq>(Xj).
j l
(8.144)
Подставляя (8.142) и (8.144) в (8.143), получим:
N N N
LL(J,jq>(Xi)K(Xi,Xj) == N);. L(J,jq>(Xi),
i l j l j l
(8.145)
[де K(Xi, Xj) ядро скалярНО20 проuзведения (inner product kemel), определяемое в
терминах векторов признаков как
K(Xi,Xj) == cpT(Xi)CP(Xj).
(8.146)
8.10. Анализ rлавных компонентов на основе ядра 563
Теперь сделаем еще один шаr и выразим уравнение (8.145) только в терминах ядра
скалярноro произведения. Для этоro умножим обе части (8.145) на транспонирован
ный вектор q>T(Xk)' в результате чеro получим:
N N N
L L ajK(xk' Xj)K(Xi' Xj) == Ni.. L ajK(xk, Xj), k == 1,2,... , N,
i l j l j l
(8.147)
rде ядра K(Xk, Xi) и K(Xk, Xj) сформированы соrласно (8.146).
Теперь введем два матричных определения.
· Матрицу К размерности N х N назовем матрицей ядра. Ее ij-й элемент является
ядром скалярноro про изведения K(Xi, Xj).
· Введем вектор а размерности Nx 1, j ми элементами KOToporo являются коэффи-
циенты aj.
Torдa выражение (8.147) можно переписать в более компактном, матричном виде
2
К а == N/..Ka,
(8.148)
[де под квадратом матрицы к 2 понимается произведение матрицы К саму на себя.
Так как эта матрица встречается в обеих частях уравнения (8.148), все решения задачи
поиска собственных значений сведутся к решению упрощенной задачи
Ка == NЛi:J..
(8.149)
Пусть /..1 2: /..2 2: ... 2: /..N собственные значения матрицы ядра К, Т.е.
/..j == N/.. j , j == 1,2,... , N,
(8.150)
rде i.. j j e собственное значение матрицы корреляции R. Torдa выражение (8.149)
принимает стандартный вид
Ка == Лi:J.,
(8.151)
rдe вектор коэффициентов а выступает в роли собственноro вектора, связанноrо с
собственным значением /.. матрицы ядра К. Вектор а строится с учетом требова
ния TOro, чтобы собственный вектор ii матрицы R был нормализованным (т.е. имел
единичную длину):
iiIiik == 1 для k == 1,2,... ,р,
(8.152)
.,..
564 rлава 8. Анализ rлавных компонентов
rде предполаrается, что собственные числа упорядочены по убыванию, а л'р
наименьшее ненулевое собственное значение матрицы ядра К. Используя (8.144)
и (8.151), можно показать, что условие нормализации (8.152) эквивалент-
но следующему:
т 1
аkаk== л'k ' k==1,2,...,p.
(8.153)
Для извлечения rлавных компонентов нужно вычислить проекции на собственные
векторы qk пространства признаков:
N N
<iI <р(х) == L ak,jq>T(Xj)q>(x) == L ak,jK(xj, х), k == 1,2,... ,р,
j l j l
(8.154)
rде вектор Х "тестовая" точка; ak,j j й коэффициент собственноro вектора ak,
связанноro с k M собственным значением матрицы К. Проекция (8.154) определяет
llелинейные 2Лавные компоненты (nonlinear principal component) m1 -мерноrо про-
странства признаков.
На рис. 8.13 проиллюстрирована основная идея алrоритма РСА на основе яд
ра, в которой пространство признаков нелинейно связано с входным пространством
посредством преобразования <р(х). Части (а) и (б) на рисунке обозначают входное про-
странство и пространство признаков соответственно. Контурная линия на рис. 8.13, б
представляет собой постоянную проекцию на rлавный собственный вектор, показан-
ный на рисунке символом вектора. На этом рисунке предполаrается, что преобразо-
вание <р(х) выбрано так, что образы точек данных, индуцированные в пространстве
признаков, вытяrиваются вдоль собственноro вектора. На рис. 8.13, а показаны нели-
нейные контурные линии во входном пространстве, которые соответствуют прямым в
пространстве признаков. Заметим, что мы преднамеренно не показали прообраз соб-
cTBeHHoro вектора во входном пространстве, так как он может не существовать [947].
Для ядра скалярноro произведения, определенноrо в соответствии с теоремой
Мерсера, выполняем обычный алroритм РСА в m1 MepHOM пространстве признаков,
rдe m1 параметр. Все свойства обычноro алroритма РСА, описанные в разделе 8.3,
сохраняются и дЛЯ РСА на основе ядра. В частности, РСА на основе ядра является
линейным в пространстве признаков, но нелинейным во входном пространстве. Как
таковой он может быть применен ко всем тем областям, rде обычный алrоритм РСА
использовался для извлечения признаков или сокращения размерности данных, при
котором нелинейное расширение имеет смысл.
В rлаве 6 были представлены три метода построения ядра скалярноrо произве
дения, основанные на использовании полиномов, радиально-базисных и rипербо-
лических функций (см. табл. 6.1). Открытым остался вопрос о том, как выбрать
наиболее подходящее ядро для конкретной задачи (т.е. соответствующеrо простран
ства признаков) [948].
8.10. Анализ rлавных компонентов на основе ядра 565
Х2
Входное пространство
(данных)
q>2(X)
Пространство
признаков
х
"
,;
,;
х
, ,;
, ,;
...... .....
';'
/х ',х;-
.......... .....
..... ........х '\ ..........
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
x [ ;J
..................
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
,;
I
I
I
I
I
I
I
х,.."........ ,."....
х....,.. ....." //
..... Х Х ;' Х /х
//х х,'
I I
I
I
I
I
I
I
I
I
I
XI
" ,;
" ,;
,; ,;,;
"'..... ..........
,;
,;
,;
q>1(X)
I
I
I
I
I
".
,;
,;
,;
,;
,;
,;
,;
,;
,;
".
Собственный вектор
Рис. 8.13. Алroритм РСА на основе ядра. Двумерное входное пространство с множеством
точек данных (а); двумерное пространство признаков с образами точек части (а), вытянутыми
вдоль собственноro вектора (б). Равномерно распределенные пунктирные прямые в части (б)
представляют контуры константной проекции на собственный вектор; соответствующие контуры
во входном пространстве являются нелинейными
Алrоритм РСА на основе ядра в сжатом виде
1. Для данноrо множества примеров {Xi}t:,l вычислим матрицу ядра K=={K(Xi, Xj)},
rде
K(Xi,Xj) == cpT(Xi)CP(Xj).
2. Решаем задачу на собственные значения:
Ка == л-а,
[де А собственное значение матрицы К; а соответствующий ему собственный
вектор.
3. Нормализуем собственные векторы, применяя требование
т 1
akak == Ak ,k == 1,2,... ,р,
(8.155)
rде Ар наименьшее ненулевое собственное значение матрицы К (в предположе
нии, что собственные значения отсортированы по убыванию).
..,.
566 rлава 8. Анализ rлавных компонентов
4. Для извлечения rлавных компонентов тестовой точки х вычислим проекции
N
a,k == iik <р(х) == L a,k,jK(Xj, х), k == 1,2,... ,р,
j=l
[де a,k,j j й коэффициент собственноrо вектора a,k.
Пример 8.3
для TOro чтобы лучше разобраться в. работе алroритма РСА на основе ядра, на рис. 8.14 по-
казаны результаты простоrо эксперимента, описанноro в [947]. Двумерные данные, состоящие из
компонентов Хl и Х2 И используемые в этом эксперименте, можно описать следующим образом: Хl"
значения имеют равномерное распределение в интервале [ 1, 1]; Х2-значения нелинейно связаны с
элементами Хl следующей формулой:
Х2 == xi + v,
rдe v адцитивный [ауссов шум с нулевым средним значением и дисперсией, равной 0,04.
Результаты РСА, показанные на рис. 8.14, бьши получены с помощью полиномов ядра:
K(Xi, Xj) == (ХТ Xi)d, d == 1,2,3,4,
rдe d == 1 соответствует линейному РСА, а d == 2,3, 4 РСА на основе ядра. Результаты линейноro
алroритма РСА показаны в левом столбце на рис. 8.14. Он имеет только два собственных значения,
поскольку размерность входноro пространства равна двум. В противоположность этому РСА на ос"
нове ядра позволяет извлекать компоненты более BbICOKOro порядка, как показано в столбцах 2--4 на
рис. 8.14. Контурные линии, отображаемые в каждой из частей рисунка (за исключением нулевоrо
собственноro значения в линейном РСА), представляют собой постоянные rлавные значения (т.е. по-
стоянные проекции на собственный вектор, связанный с рассматриваемым собственным значением).
На основе результатов, показанных на рис. 8.14, можно сделать следующие выводы.
Как и ожидалось, линейный РСА не способен обеспечить адекватное представление нелинейных
входных данных.
В любом случае первый rлавный компонент монотонно изменяется вдоль параболы, окаймляю-
щей входные данные.
В РСА на основе ядра второй и третий rлавные компоненты демонстрируют поведение, в чем-то
аналоrичное для различных степеней полинома d.
в случае степени полинома d == 2 третий rлавный компонент ядра РСА воспроизводит диспер-
сию, полученную вследствие адцитивноro [ауссова шума v. Удаляя из результата вклад этоro
компонента, получим эффект шумоподавления.
.
8.11. Резюме и обсуждение 567
Собственное Собственное Собственное Собственное
значение О,709 значение О,621 значение О,570 значение О,552
о,: . ";, 0,: 1;1 o: , o:
05 05. 05 . 05 ..
, 1 О 1 ' 1 О 1 ' 1 О 1 ' 1 О 1
Собственное Собственное
значение О,291 значение О,345
о,;" о;
о.. о
0,51 О 10,51
Собственное Собственное
значение О,395 значение О,418
o: o,:
05 .. 05 ..
1 ' 1 О 1 ' 1 О 1
о
Собственное Собственное Собственное Собственное
значение О,ООО значение О,О34 значение О,О26 значение О,О21
о,: [" ;..: о: . О,: о,,
о .. .'.::-. о .. .':. . ( о о
05 . 05 . 05 05
, 1 О 1 ' 1 О 1 ' 1 О 1 ' 1 О
Рис. 8.14. Двумерный пример, иллюстрирующий работу алroрит
ма РСА на основе ядра. Слева направо показана степень полино-
ма ядра d 0= 1,2, 3,4. Сверху вниз показаны три первых собствен
ных вектора пространства признаков. Первый столбец COOTBeT
ствует обычному РСА, а остальные три РСА на основе ядра
со степенью полинома d 0= 2,3,4. (Воспроизведено с разрешения
доктора Клауса Роберта Мюллера (О'" К1аиs RоЬеrt Muller))
8.11. Резюме и обсуждение
в этой rлаве представлен материал по теории анализа rлавных компонентов и показа-
но использование нейросетей в реализации этоrо метода. Совершенно естественным
сейчас будет следующий вопрос: "Насколько полезен анализ rлавных компонентов?"
Ответ на этот вопрос зависит от конкретной области применения.
Если наша цель добиться хорошеrо сжатия данных при одновременном сохра-
нении как можно большей части информации о входном сиrнале, то анализ rлав-
ных компонентов обеспечит полезную самоорrанизующуюся процедуру обучения.
Следует подчеркнуть, что метод пространственной декомпозиции (см. раздел 8.3),
основанный на "первых l rлавных компонентах" входных данных, осуществляет ли-
нейное отображение, являющееся оптимальным в том смысле, что позволяет pe
конструировать исходные входные данные в смысле среднеквадратической ошибки.
Более TOro, представление, основанное на "первых l rлавных компонентах", является
568 rлава 8. Анализ rлавных компонентов
'1
!
предпочтительным для представления произвольноrо подпространства, так как rлав-
ные компоненты входных данных являются естественным образом упорядоченными
по убыванию собственных значений, или, что эквивалентно, по убыванию диспер-
сии. Следовательно, использование анализа rлавных компонентов для сжатия данных
можно оптимизировать, взяв на вооружение наибольшую числовую точность для ко-
дирования первоro rлавноrо компонента и постепенно снижая ее для кодирования
остальных l 1 компонентов.
Связанным вопросом является представление множества данных, созданноro из
совокупности нескольких кластеров. Для Toro чтобы эти кластеры стали различимы-
ми, расстояние между ними должно быть больше BHyтpeHHero разброса данных в
каждом из кластеров. Если случилось так, что в множестве данных имеется несколь-
ко кластеров, то нужно найти основные оси. Для этоrо используется анализ rлавных
компонентов, выбирающий проекции кластеров с хорошим разделением, создавая,
таким образом, хороший базис для извлечения признаков.
В этом, последнем контексте упомянем одно полезное приложение анализа rлав-
ных компонентов препроцессор (preprocessor) для нейронной сети, обучаемой с
учителем (например, мноrослойноrо персептрона, обучаемоro по алrоритму обрат-
HOro распространения). При этом целью является ускорение сходимости процесса
обучения за счет декорреляции входных данных. Процедура обучения с учителем,
какой является алroритм обратноrо распространения, основана на принципе наи-
скорейшеro спуска. Процесс сходимости в этом виде обучения обычно замедляется
из-за воздействия на синаптические веса мноroслойноrо персептрона посторонних
шумов, даже при использовании таких процедур локальноrо ускорения, как примене-
ние индивидуальных параметров скорости обучения и момента к отдельным весам.
Однако если входной сиrнал мноrослойноrо персептрона состоит из некоррелиро-
ванных компонентов, то матрица rессиана функции стоимости Е (n) будет более
близка к диаrональной, чем в противоположном случае (см. rлаву 4). При этой форме
диаrонализации использование простых процедур локальной акселерации позволяет
значительно ускорить процесс сходимости, что возможно с помощью независимоrо
масштабирования параметров обучения вдоль каждой из осей весов [112].
Хеббовские алrоритмы обучения, описанные в этой rлаве, навеяны идеями ней-
робиолоrии, поэтому будет лоrичным завершить наш экскурс комментарием о роли
анализа rлавных компонентов в биолоrических системах восприятия. В [648] был по-
ставлен вопрос "существенности" анализа rлавных компонентов в качестве принципа
определения свойств отклика, вырабатываемоrо нейроном в процессе анализа вход-
ных "сцен". В частности, оптимальность анализа rлавных компонентов по сравнению
с точной реконструкцией входноrо сиrнала из отклика нейрона является спорным во-
просом. В общем случае оказывается, что мозr не просто пытается воспроизвести
входные сцены, полученные от opraHoB чувств, а выделяет некоторые "значимые на-
меки" или признаки, чтобы интерпретировать входные сиrналы на более высоком
8.11. Резюме и обсуждение 569
уровне. Таким образом, можно HeMHoro конкретизировать вопрос, поднятый в начале
наших рассуждений, и спросить: "Насколько практичным является анализ rлавных
компонентов в задаче обработки входных данных?"
В [41] указывается на значимость множества алrоритмов, предложенных в [798],
[931], для анализа rлавных компонентов (т.е. для алroритмов Хебба, рассмотренных
в разделах 8.4 и 8.5), в аЛ20ритме иерархической кластеризации (hierarchica1 clus
tering algorithm). Они продвиrают rипотезу о том, что иерархическая кластеризация
может выступать в качестве фундаментальноrо свойства (по крайней мере, частично)
памяти, которое можно использовать для распознавания свойств окружающей среды.
Отсюда следует вывод, что самоорrанизующийся анализ rлавных компонентов может
иrpать существенную роль в иерархической кластеризации обучаемых областей цepe
бральной коры мозrа не из за ero свойств оптимальности восстановления, а блаrодаря
ero встроенному свойству создавать проекции кластеров с хорошим разделением.
Еще одно интересное приложение анализа rлавных компонентов к обработке
входных данных заключается в решении задачи восстановления формы по тени,
описанной в [80]. Эту задачу можно сформулировать так: "Каким образом мозr
восстанавливает трехмерные формы на основе затененных образов на ДBYXMep
ных изображениях?" В вышеуказанной работе для задачи восстановления формы
предметов по затененным изображениям было предложено иерархическое реше
ние, состоящее из двух этапов.
1. Посредством эволюции или накопленноrо опыта мозr обнаруживает, что объекты
можно классифицировать на классы объектов меньшей размерности, принимая в
расчет их формы.
2. На основании п. 1 извлечение формы из полутоновых образов сводится к более
простой задаче оценки параметров в пространстве более низкой размерности.
Например, общая форма rоловы человека остается неизменной в том смысле, что
все люди имеют выступ в виде носа, rлазные впадины, а также лоб и щеки, пред-
ставляющие собой ровные поверхности. Эти неизменные характеристики наводят на
мысль, что любое лицо, выраженное функцией т(8, [) в цилиндрических координатах,
может быть представлено в виде суммы двух компонентов:
т(8, l) == то(8, [) + р(8, [),
rде то(8, [) усредненная форма roловы для данной катеroрии людей (например,
взрослых мужчин или взрослых женщин); р(8, [) отклонения, позволяющие иден-
тифицировать конкретноrо человека. Обычно отклонение р(8, [) является малым по
отношению к то(8, [). Для представления р(8, [) в [80] использовался анализ rлавных
компонентов, в котором отклонения описывались множеством собственных функций
570 rлава 8. Анализ rлавных компонентов
(т.е. двухмерных составляющих собственных векторов). Результаты, представленные
в [80], показали применимость двухшаroвоro иерархическоrо подхода для восстанов-
ления трехмерной поверхности лица человека по ero двухмерному портрету.
Задачи
Фильтр Хебба для извлечения максимальноrо
собственноrо значения
8.1. В СО2Ласова1UЮМ фильтре (matched filter) из примера 8.2 собственное значе-
ние 1..1 и соответствующий собственный вектор q1 определяются следующи-
ми формулами:
1..1 == 1 + а 2 ,
q1 == s.
Покажите, что эти параметры удовлетворяют основному соотношению
Rq1 == 1..1 q1 ,
[де R матрица корреляции входноro вектора Х.
8.2. Рассмотрим фильтр для извлечения максимальноro собственноro значения, в
котором вектор весов w( n) изменяется по формуле (8.46). Покажите, что дис-
персия выхода этоro фильтра достиrает значения Л mаХ при n, равном беско-
нечности, [де Л mаХ наибольше собственное значение матрицы корреляции
входноrо вектора.
8.3. Анализ второстепенных компонентов (МСА) противоположен анализу rлав-
ных компонентов. Алroритм МСА позволяет определить те направления, ко.
торые минимизируют дисперсию проекции. Эти направления являются соб-
ственными векторами, соответствующими наименьшим собственным значе.
ниям матрицы корреляции R входноro вектора Х(n).
В данной задаче требуется определить, каким образом следует модифици'
ровать обособленный нейрон (см. раздел 8.4), чтобы найти второстепенные
компоненты R. В частности, можно изменить знак в правиле обучения (8.40),
получив соотношение [1170]
щ(n + 1) == щ(n) l1y(n)[xi(n) у(n)щ(n)].
Задачи 571
Покажите, что если наименьшим собственным значением матрицы R с
кратностью 1 является Л m , то
lim w(n) == 'f\qm'
n......оо
[де qm собственный вектор, соответствующий Л m .
Анализ rлавных компонентов на основе правила Хебба
8.4. Постройте rpаф передачи сиrнала, представляющий векторные уравнения
(8.87) и (8.88).
8.5. Подход с использованием обычных дифференциальных уравнений при aHa
лизе сходимости (см. раздел 8.4) не применяется непосредственно к обоб
щенному алroритму обучения Хебба. Однако, выразив матрицу синаптиче-
ских весов W(n) (см. (8.91» в виде вектора, составленноro из ее столбцов,
функцию коррекции h(.,.) можно интерпретировать обычным образом, а за
тем применить теорему об асимптотической устойчивости. Основываясь на
вышеизложенном, сформулируйте теорему о сходимости для обобщенноro
алrоритма обучения Хебба.
8.6. В этой задаче мы исследуем обобщенный алrоритм Хебба для случая ДBYMep
ных рецепторных полей, rенерируемых случайным входным сиrналом [930].
Этот случайный вектор состоит из двумерноro поля независимоro [ауссова
шума с нулевым средним значением и единичной дисперсией, свернут020
(convolved) rауссовой маской (фильтром) и умноженноro на [ауссово окно
(Gaussian window). [ауссова маска имеет стандартное отклонение в 2 пиксе-
ля, а [ауссово окно в 8 пикселей. Полученный в результате случайных вход
х (Т, s) в точке (Т, s) можно представить в следующем виде:
Х(Т, s) == т(т, s)[g(r, s) * w(r, s)],
[де w(r, s) поле независимоro [ауссова шума; g(r, s) [ауссова маска;
т( Т, s) функция [ауссова окна. Функция КРУ20вой свертки (circular convo
lution) g(r, s) и w(r, s) определяется следующим образом:
N l N l
g(r, s) * w(r, s) == L L g(p, q)w(r р, s q),
p o q O
[де предполаrается, что g(r, s) и w(r, s) периодические функции.
572 rлава 8. Анализ rлавных компонентов
Используйте 2000 примеров случайноro входноrо сиrнала х (Т, s) для обу-
чения однослойной сети прямоro распространения с помощью обобщенноro
алrоритма Хебба. Данная сеть имеет 4096 входов, скомпонованных в ячейки
пикселей размером 64 х 64, и 16 выходов. Полученные в результате обучения
веса сети можно представить в виде матрицы размерности 64х64. Выпол-
ните описанные здесь вычисления и представьте 16 массивов синаптических
весов в виде двумерных масок. Про комментируйте результат.
8.7. Уравнение (8.113) представляет собой преобразованную версию уравнения
коррекции (8.106) для вычисления вектора весов обратных связей aj(n).
Это преобразование основано на определении вектора синаптических весов
Wj(n) в терминах m rлавных мод (modes) сети, представленных уравнением
(8.109). Выведите уравнение (8.113).
8.8. Рассмотрите матрицу системы (8.116), представленную rpафом передачи сиr-
нала на рис. 8.12, [де 1 k j 1.
а) Выведите характеристическое уравнение для этой матрицы размером 2 х 2.
б) Покажите, что эта матрица имеет двойное собственное значение.
в) Докажите утверждение, что основные моды сети имеют одно и то же
собственное значение.
8.9. Алrоритм GНЛ использует только прямые связи, в то время как алroритм
АРЕХ использует как прямые, так и латеральные связи. Несмотря на эти
различия, сходимость алrоритма АРЕХ теоретически является такой же, как
и для алroритма GHA. Докажите истинность этоro утверждения.
РСА на основе ядра
8.10. Пусть K ij центрированная составляющая ij-ro элемента матрицы ядра К.
Покажите, что [945]
N N
l"т l"т ) )
K ij ==K ij N <р (Xm)<p(Xj) N <р (Xi <Р(Х п +
m l n l
1 N N
+ N2 L L <рТ(хт)<р(х п ).
m l n l
Запишите компактное представление этоrо соотношения в матричном виде.
8.11. Покажите, что нормализация собственноrо вектора а. матрицы ядра К экви-
валентна удовлетворению требования (8.153).
8.12. Перечислите свойства РСА на основе ядра.
Картысамоорrанизации
9.1. Введение
в этой rлаве мы продолжим изучение самоорrанизующихся систем и рассмотрим
особый класс искусственных нейронных сетей, который носит название карт caMO
орrанизации. Эти сети основаны на конхурентlЮМ обучении (competitive leaming).
Отдельные нейроны выходноrо слоя такой сети соревнуются за право активации, в
результате чеrо активным оказывается один нейрон в сети (или в rpуппе). Выходной
нейрон, который выиrрал данное соревнование, называется победившим (winning neu
ron). Одним из способов орrанизации такой конкуренции между нейронами является
использование латеральных (т.е. отрицательных обратных) связей между ними. Эта
идея была впервые предложена Розенблаттом [902].
В картах самООр2анизации (self organizing тар) нейроны помещаются в узлахре
шеткu (lattice), обычно OДHO или двухмерной. Карты более высокой размерности
также возможны, но используются достаточно редко. Нейроны в ходе KOHKypeHTHO
ro процесса избирательно настраиваются на различные входные образы (возбудите
ли) или классы входных образов. Положения таким образом настроенных нейронов
(т.е. нейронов победителей) упорядочиваются по отношению друr к друrу так, что на
решетке создается значимая система координат [573]. Таким образом, самоорrанизую
щиеся системы характеризуются формированием топ02рафическux карт (topographic
шар) входных образов, в которых пространственное местоположение (т.е. коорди
наты) нейронов решетки является индикатором встроенных статистических пpи
знаков, содержащuxся во входных примерах. Отсюда берет свое происхождение и
само название "самоорrанизующиеся карты".
В качестве нейронных моделей самоорrанизующиеся карты реализуют мост меж
ду двумя уровнями адаптации.
· Правилами адаптации, сформулированными на микроуровне одноrо нейрона.
· Объединениями экспериментально лучших и физически доступных моделей из
влечения признаков микроуровней слоев нейронов.
574
rлава 9. Карты самоорrаниэации
т
Так как карты самоорrанизации по своей природе нелинейны, их можно рассмат-
ривать как нелинейное обобщение анализа rлавных компонентов [887].
Разработка карт самоорrанизации в качестве нейронных моделей обусловлена сле-
дующим отличительным свойством человеческоrо мозrа: он орrанизован таким обра-
зом, что отдельные сенсорные входы представляются топОЛ02ически упорядоченными
вычислительными картами (topologically ordered computational тар) в определенных
ero областях. В частности, такие сенсорные входы, как нервные окончания тактиль-
ной системы [530], зрения [489], [490] и слуха [1029], тополоrически упорядочен-
но отображаются на различные контуры церебральной коры мозrа. Таким образом,
вычислительное отображение является кирпичиком в инфраструктуре обработки ин-
формации нервной системой. Карта вычислений, в свою очередь, образована масси-
вом нейронов, представляющих собой несколько по разному настроенные процессо-
ры или фильтры, параллельно принимающие информацию от различных сенсоров.
Следовательно, нейроны преобразовывают входные сиrналы в пространственно-
кодированные (place coded) распределения вероятности, представляющие вычислен-
ные значения параметров узлами относительных максимумов активности [564]. К та-
ким образом орrанизованной информации получают доступ процессоры более Bыо--
Koro уровня, которые используют относительно простые схемы соединений.
Структура rлавы
Материал, представленный в настоящей rлаве, посвященной картам самоорrаниза-
ции, расположен в следующем порядке. В разделе 9.2 описываются две модели отоб-
ражения признаков, которые, каждая своим способом, способны извлекать существен-
ные признаки вычислительных карт в биолоrической структуре мозrа. Эти две модели
отличаются друr от друrа используемой формой представления входных сиrналов.
Оставшаяся часть rлавы посвящена детальному изложению одной из этих мо-
делей, получившей в работе Кохонена [579] название самООР2анuзующейся карты.
В разделе 9.3 рассматриваются нейробиолоrические предположения, участвующие в
математической формулировке модели Кохонена. Эта модель в сводном виде описы-
вается в разделе 9.4. Особо важные свойства модели будут пред ставлены в разделе 9.5,
а в разделе 9.6 будет проведено компьютерное моделирование. Производительность
карт признаков может быть настроена с помощью одноrо из приемов обучения с
учителем, получившеro название квантования вектора обучения. Этот прием опи-
сывается в разделе 9.7. В следующем разделе 9.8 будет проведен компьютерный
эксперимент по адаптивной классификации моделей, который комбинирует в себе
использование квантования векторов обучения и самоорrанизующихся карт сжатия
данных. В разделе 9.1 О будет описано еще одно приложение карт самоорrанизации
построение контекстных карт, которые находят применение в задачах фонетической
классификации текста, наблюдения Земли и исследования данных. Как Bcerдa, шана
завершается разделом выводов и обсуждений (9.12).
9.2. Две основные модели отображения признаков 575
9.2. Две основные модели отображения признаков
Любой исследователь человеческоro мозrа не может не поражаться доминирующей
ролью ero церебральной коры. Деятельность мозrа практически целиком cocpeдo
точена в коре, обходя друrие возможные пути. Своей исключительной сложностью
кора roловноro мозrа превосходит, пожалуй, любую друrую известную в природе
структуру [489]. Равно поражает и упорядоченность отображения входов различ
ных сенсоров (моторных, слуховых, зрительных и т.п.) в соответствующие области
коры rоловноro мозrа. Хорошей иллюстрацией этоro момента может служить при-
веденная на рис. 2.4 (см. rлаву 2) цитоархитектурная карта коры roловноro мозrа.
Вычислительные карты обладают следующими свойствами [564].
· На каждом этапе представления каждый поступающий фраrмент информации co
храняется в своем контексте.
· Нейроны, работающие с близко расположенными областями информации, также
расположены достаточно близко друr к друry, таким образом взаимодействуя друr
с друroм посредством коротких синаптических связей.
Областью нашеro интереса является построение искусственных топоrpафических
карт, которые обучаются посредством самоорrанизации. Эта идея бьmа навеяна ис
следованиями в области нейробиолоrии. В этом контексте, из приведенноro KpaTKoro
описания вычислительных карт, функционирующих в структуре мозrа, вытекает одно
очень важное заключение [573].
Пространственное положение выходных нейронов в топ02рафической карте co
ответствует конкретной области признаков данных, выделенных из вxoдHO
20 пространства.
В этом принципе сформулирован нейробиолоrический контекст, заложенный
в двух совершенно различных моделях отображения прuзнаков (feature mapping
шоdеl) 1, которые будут описаны ниже.
На рис. 9.1 показаны структурные схемы этих двух моделей. В обоих случаях
выходные нейроны орrанизованы в виде двумерной решетки. Такой тип тополоrии
rарантирует, что каждый нейрон имеет множество соседей. Эти модели отличаются
дрyr от друrа способом задания входных образов.
Модель, показанная на рис. 9.1, а, была предложена в работе, посвященной био
лоrическим основам, которые объясняли отображение сетчатки rлаза на зрительную
область коры rоловноro мозrа [1159]. В частности, существуют две связанные друr с
друroм двумерные решетки нейронов, [де одна проецируется на друryю. Первая pe
IДве модели извлечения признаков, которые показаны на рис. 9.1, навеяны новаторскими исследованиями
самоорrанизации в [1100], rдe отмечалось, что модель зрительной области коры roловноro мозra (visual cortex
.,....
I
576 rлава 9. Карты самоорrаниэации
Двумерный массив
постсинаптических
нейронов
Пучок синаптических
связей (существуют
такие же пучки
синаптических связей,
исходящие и из дрyrих
предсинаптических
нейронов)
а) Модель Уилшоу-вандер Мальсбурra
Нейрон-
победитель
Входной сиrnал
б) Модель Кохонена
Рис. 9.1. Две самоорraниэующиеся
карты признаков
шетка представлена предсинаптическими (входными), а вторая постсинаптически-
ми (выходными) нейронами. Постсинаптическая решетка использует возбуждающий
механизм БЛИЗКО20 радиуса действия (short range exdcitatory mechanism), равно как и
тормозящий механизм дальне20 действия (long range inhibitory mechanism). Эти два
механизма по своей природе являются локальными и исключительно важными для
самоорrанизации. Решетки соединяются изменяемыми синапсами Хеббовскоrо типа.
rрубо rоворя, постсинаптические нейроны не относятся к типу "победитель заби-
рает все" вместо этоrо используется пороr, rарантирующий, что в любой момент
времени будут активны только несколько постсинаптических нейронов. Более TOro,
чтобы избежать неоrpаниченноrо наращивания синаптических весов, которое может
привести к неустойчивости системы, общий вес, ассоциированный с каждым пост-
синаптическим нейроном, оrpаничивается некоторым значением 2 . Таким образом,
2 В [29] оrpаничения, накладываемые на синаптические веса постсинаптических нейронов, были несколько
ослаблены. Математический анализ, представленный в этой работе, обьясняет динамическую устойчивость
карты коры мозrа, сформированной в результате самоорrанизации.
9.3. Карты самоорrаниэации 577
рост одноro синаптическоro веса нейрона приводит к автоматическому уменьшению
остальных. Основная идея модели Уuлшоу ван дер МальсБУР2а состоит в том, что
для представления информации о reометрической близости предсинаптических ней
ронов в форме их электрической активности и для использования этих корреляций
в постсинаптической решетке соседние предсинаптические нейроны должны связы
ваться с соседними постсинаптическими. Таким образом, самоорrанизация приводит
к тополоrически упорядоченному отображению. Однако следует заметить, что мо-
дель Уилшоу ван дер Мальсбурrа приrодна только для представления отображений,
в которых размерности входноrо и выходноro сиrналов paBHtI.
Вторая модель, показанная на рис. 9.1, б, бьmа предложена Кохоненом [579]. Она
не концентрируется на нейробиолоrических деталях. Эта модель извлекает суще
ственные признаки вычислительных карт мозrа и при этом остается вычислительно
трактуемой 3 . Модель Кохонена по сравнению с моделью Уилшоу ван дер Мальсбурrа
является более общей в том смысле, что она способна осуществлять сжатие данных
(т.е. сокращение размерности входноro сиrнала).
Модель Кохонена принадлежит к классу ал20ритмов вектОРН020 кодирования
(vector coding algorithm). Эта модель реализует тополоrическое отображение, KOTO
рое оптимально размещает фиксированное количество векторов (т.е. кодовых слов)
во входное пространство более высокой размерности и, таким образом, облеrчает
сжатие данных. Исходя из этоrо, модель Кохонена можно вывести двумя способами.
Можно использовать базовые идеи самоорrанизации, обусловленные нейробиолоrи
ческими наблюдениями. Это обычный подход [568], [573], [579]. А можно исполь
зовать подход векторноrо квантования, включающий кодирование и декодирование.
Этот подход основывается на положениях теории коммуникаций [688], [691]. В этой
шаве мы рассмотрим оба подхода.
В литературе больше внимания уделяется модели Кохонена, чем модели Уилшоу
ван дер Мальсбурrа, так как первая обладает некоторыми свойствами (о них мы
поroворим HeMHoro позже в этой rлаве), которые имеют практический интерес для
понимания и моделирования карт коры rоловноro мозrа. Вся оставшаяся часть HaCTO
ящей rлавы будет посвящена изучению карт самоорrанизации, а также их основных
свойств и модификаций.
9.3. Карты самоорrанизации
Основной целью карт самоорrанизации (self organizing тар SOM) является преоб
разование поступающих векторов сиrналов, имеющих произвольную размерность, в
OДHO или двухмерную дискретную карту. При этом такое преобразование осуществ
3 Нейробиолоrические возможности самоорraнизующейся карты (sеlf оrgапiziпg тар SOM) обсуждаются
в [568], [572].
....,
578 rлава 9. Карты самоорrаниэации
Слой
ВХОДНЫХ
узлов
Рис. 9.2. Двумерная решетка нейронов
ляется адаптивно, в тополоrически упорядоченной форме. На рис. 9.2 показана cxe
матическая диаrpамма двумерной решетки нейронов, используемой в качестве дис-
кретной карты. Все нейроны этой решетки связаны со всеми узлами входноrо слоя.
Эта сеть имеет структуру прямоrо распространения с одним вычислительным слоем,
состоящим из нейронов, упорядоченных в столбцы и строки. Одномерная решетка
является частным случаем конфиryрации, показанной на рис. 9.2. В этом частном
случае вычислительный слой состоит Bcero из одной строки (или столбца) нейронов.
Каждый из входных слоев, представленных в сети, обычно состоит из локализо-
ванной области активности, размещаемой в относительно спокойной области. Распо-
ложение и природа такой области обычно варьируется в зависимости от конкретной
реализации входноrо примера. Таким образом, для правильноrо развития процесса
самоорrанизации требуется, чтобы все нейроны сети бьmи обеспечены достаточным
количеством различных реализаций входных образов.
Алrоритм, ответственный за формирование самоорrанизующихся карт, начинает-
ся с инициализации синаптических весов сети. Обычно это происходит с помощью
назначения синаптическим весам малых значений, сформированных [енератором слу-
чайных чисел. При таком формировании карта признаков изначально не имеет KaKoro-
либо порядка признаков. После корректной инициализации сети для формирования
карты самоорrанизации запускаются три следующих основных процесса.
9.3. Карты самоорraниэации 579
1. Конкуренция (competition). Для каждоro входноro образа нейроны сети вычисля
ют относительные значения дискриминантной функции. Эта функция является
основой конкуренции среди нейронов.
2. Кооперация (cooperation). Победивший нейрон определяет пространственное по
ложение тополоrической окрестности нейронов, обеспечивая тем самым базис для
кооперации между этими нейронами.
3. Синаптическая адаптация (synaptic adaptation). Последний механизм позволяет
возбужденным нейронам увеличивать собственные значения дискриминантных
функций по отношению к входным образам посредством соответствующих KOp
ректировок синаптических весов. Корректировки производятся таким образом,
чтобы отклик нейрона победителя на последующее применение аналоrичных при
меров усиливался.
Процессы конкуренции и кооперации осуществляются в соответствии с двумя из
четырех принципов самоорrанизации, описанных в rлаве 8. Что же касается принци
па самоусиления, то он реализуется в модифицированной форме форме обучения
Хебба для адаптивноro процесса. Как бьmо отмечено в rлаве 8, для обучения необ
ходим а избыточность входных данных (хотя на этом при описании алrоритма SOM
особо не заостряется внимание), так как это реализует процесс извлечения знаний.
Детальные описания процессов конкуренции, кооперации и синаптической адаптации
будут пред ставлены ниже.
Процесс конкуренции
Пусть т размерность входноro пространства, а входной вектор выбирается из этоrо
входноrо пространства случайно и обозначается так:
х == [Xl,X2,." ,Хт]Т'
(9.1)
Вектор синаптических весов каждоro из нейронов сети имеет ту же размерность, что и
входное пространство. Обозначим синаптический вес нейрона j следующим образом:
Wj == [Wjl,Wj2,...,Wjm]T,j == 1,2,..,1,
(9.2)
[де 1 общее количество нейронов сети. Для TOro чтобы подобрать наилучший вектор
Wj, соответствующий входному вектору х, нужно сравнить скалярные про изведения
wJ х для j == 1,2,...,1 и выбрать наибольшее значение. При этом предполаrается,
что ко всем нейронам применяется некоторое значение насыщения (threshold). Эта
величина равна пОР02У (bias), взятому с обратным знаком. Таким образом, выбирая
нейрон с наибольшим скалярным про изведением wJ х, мы в результате определяем
....
580 rлава 9. Карты самоорrаниэации
местоположение, которое должно стать центром тополоrической окрестности воз-
бужденноro нейрона.
Как rоворилось в rлаве 1, наилучший критерий соответствия, основанный на мак-
симизации скалярноrо произведения wJ х, математически эквивалентен минимизации
Евклидова расстояния между векторами х и Wj. Если использовать индекс i(x) ДЛЯ
идентификации Toro нейрона, который лучше Bcero соответствует входному сиrналу
х, то эту величину можно определить с помощью следующеro соотношения 4 :
i (х) == arg min 11 х w j 11 , j == 1, 2, .. . , l.
J
(9.3)
в этом выражении проявляется сущность Bcero процесса конкуренции между ней-
ронами. Соrласно выражению (9.3), предметом внимания является величина i(x).
Конкретный нейрон i, удовлетворяющий данному условию, называется победившим
(winning) или наиболее подходящим (best matching) для данноrо входноrо вектора х.
Уравнение (9.3) становится источником следующеro наблюдения.
Непрерывное входное пространство образов активации нейронов с помощью nро-
Цесса конкуренции между отдельными нейронами сети отображается в дискретное
выходное пространство.
В зависимости от приложения данноrо метода откликом сети может быть либо
индекс победившеrо нейрона (т.е. ero позиция в решетке), либо вектор синаптических
весов, являющийся самым близким к входному в Евклидовом смысле.
Процесс кооперации
Нейрон победитель находится в центре тополоrической окрестности сотрудничаю
щих нейронов. Возникает ключевой вопрос: как определить тополоrическую окрест-
ность, которая будет корректна с нейробиолоrической точки зрения? Для Toro чтобы
ответить на Hero, вспомним о нейробиолоrическом обосновании латераЛЬН020 вза-
имодействия (lateral interaction) среди множества возбужденных нейронов. В част-
ности, возбужденный нейрон Bcerдa пытается возбудить пространственно близкие к
нему нейроны, и это интуитивно понятно. Это наблюдение приводит к определению
тополоrической окрестности победившеrо нейрона j, которая плавно сходит на нет с
увеличением расстояния 5 [668], [669], [891]. для большей конкретизации обозначим
4 Правило КOHкypeHTHoro (competitive) обучения (9.3) в литературе по нейронным сетям впервые было
введено в работе rроссберrа [400].
5 В своей исходной форме алroритма SOM, предложенной в работе Кохонена [579], предполаrалось, что
тополоrическая окрестность имеет постоянную амплитуду. Пусть dj,i латералыюе (lateral) расстояние меж-
ду победившим И) и возбужденным (i) нейронами в функции окрестности. В таком случае тополоrическая
окрестность в одномерной решетке определяется следующим образом:
h . { 1, K ::; dj,i ::; К
],' О, В противном случае,
(1)
9.3. Карты самоорraниэации 581
символом hj,i топОЛ02ическую окрестность (topological neighbourhood) с центром в
победившем нейроне i, состоящую из множества возбуждаемых (кооперирующихся)
нейронов, типичный представитель которой имеет индекс j. Пусть dj,i латераль-
ное расстояние (lateral distance) между победившим (i) и вторично возбужденным
(Л нейронами. Torдa можно предположить, что тополоrическая окрестность hj,i яв
ляется унимодальной функцией латеральноrо расстояния dj,i и удовлетворяет двум
следующим требованиям.
· Тополоrическая окрестность hj,i является симметричной относительно точки MaK
симума, определяемой при dj,i == О. Друrими словами, максимум функции дости
rается в победившем нейроне.
· Амплитуда тополоrической окрестности hj,i монотонно уменьшается с увеличе
нием латеральноrо расстояния dj,i, достиrая нуля при dj,i -------t 00. Это необходимое
условие сходимости.
Типичным примером hj,i, удовлетворяющим этим требованиям, является функция
rаусса б :
( d2o )
hj,i(X) == ехр 2 ; .
(9.4)
Это выражение является инвариантным к расположению победившеrо нейрона.
Параметр о' называют эффективной шириной (effective width) тополоrической OKpeCT
ности (рис. 9.3). Этот параметр определяет уровень, до KOToporo нейроны из тополо
rической окрестности победившеro участвуют в процесс е обучения. В качественном
смысле [ауссова тополоrическая окрестность (соrласно (9.4» является более подхо
дящей с биолоrической точки зрения, чем прямоуrольная.
Она также приводит к более быстрой сходимости алrоритма SOM, чем прямо
уroльная тополоrическая окрестность [284], [668], [669].
Для обеспечения кооперации между соседними нейронами необходимо, чтобы
тополоrическая окрестность hj,i была зависимой от латеральноrо расстояния между
победившим (i) и возбуждаемым (Л нейроном в выходном пространстве, а не от
какой либо меры длины в исходном входном пространстве. Именно это свойство
отражено в выражении (9.4). В случае одномерной решетки расстояние dj,i является
rдe 2К общий размер одномерной окрестности возбуждеиных нейронов. В противовес соrлашениям из нейро-
биолоrии, сущность модели (1) состоит в том, что все нейроны, расположенные в тополоrической окрестности,
возбуждаются на одном и том же уровне, а взаимодействие между ними не зависит от латеральноro расстояния
до победившеro нейрона i.
6 В [285] было показано, что метастабильные состояния, представляю щи е тополоrические дефекты в кон-
фиrypации карты признаков, возникают в тех случаях, кorдa алroритм SOM использует невыпуклую функцию
окрестности. Функция [аусса является выпуклой, в то время как прямоуroльная область нет. Широкая,
выпуклая функция окрестности (такая как rayccoBa функция большоro радиуса) при водит к более быстрому
тополоrическому упорядочиванию, чем невыпуклая, так как она не содержит метастабильных состояний.
..,...
582 rлава 9. Карты самоорrаниэации
h.
j,1
1,0
О
,;
Рис. 9.3. rayccoBa функция окрестности
целым числом, равным модулю Ij i 1. в случае же двумерной решетки это расстояние
определяется соотношением
d;'i == Ilrj ril1 2 ,
(9.5)
[де дискретный вектор rj определяет позицию возбуждаемоro нейрона j, а ri
победившеrо нейрона i. Оба этих измерения про водятся в дискретном выход-
ном пространстве.
Еще одним уникальным свойством алrоритма SOM является то, что размер топо-
лоrической окрестности со временем уменьшается. Это требование удовлетворяется
за счет постепенноrо уменьшения ширины О' функции тополоrической окрестности
hj,i. Популярным вариантом зависимости величины О' от дискретноrо времени n яв-
ляется экспоненциальное убывание, описываемое следующей формулой [792], [891]:
О'(n) == 0'0 ехр ( ), n == 0,1,2,,, . ,
(9.6)
[де 0'0 начальное значение величины О' в алrоритме SOM; Тl некоторая временная
константа. Исходя из этоrо, тополоrическая окрестность имеет форму, зависящую от
времени, Т.е.
( d 2 . )
hj,i(X)(n)==exp 20';( ) , n==0,1,2".,
(9.7)
[де 0'( n) определяется по формуле (9.6). Таким образом, при увеличении количества
итераций n ширина 0'( n) экспоненциально убывает, а вместе с ней соответственно
сжимается и тополоrическая окрестность. Далее функцию hj,i(x)(n) будем называть
функцией окрестности (neighbourhood function).
9.3. Карты самоорrаниэации 583
Еще один неплохой способ рассмотрения динамики функции окрестности
hj,i(x)(n) BOKpyr победившеro нейрона i(x) бьm предложен в [690]. В ней назна
чение функции hj,i(X)(n) сводилось к корреляции направлений векторов весов боль
шоrо количества возбужденных нейронов в решетке. По мере уменьшения шири
ны hj,i(x) (n) направления коррекции нейронов коррелировались. Это явление CTa
новилось особенно очевидным, Korдa карта самоорrанизации отображалась на rpa
фическом экране монитора. С учетом оrpаниченных ресурсов компьютера было бы
довольно расточительным коррелированно изменять большое количество степеней
свободы BOKpyr победившеro нейрона, как происходит в обычном алroритме SOM.
Вместо этоrо лучше использовать ренормализованную (renormalized) форму обучения
SOM, в соответствии с которой приходится работать с rораздо меньшим количеством
нормализованных степеней свободы (normalized degree of freedom). Эту операцию
леrко выполнять в дискретной форме для функции окрестности hj,i(X) (n) с постоян
ной шириной, постепенно увеличивая общее количество нейронов. Новые нейроны
вставляются между старыми, а свойства rладкости алroритма SOM rарантируют, что
эти новые нейроны rpациозно вольются в процесс синаптической адаптации [690].
Ренормализованный алroритм SOM в сжатом виде будет описан в задаче 9.13.
Процесс адаптации
Теперь приступим к последнему процессу самоорrанизующеrося формирования Kap
ты признаков процессу синаптической адаптации. Для TOro чтобы сеть моrла ca
моорrанизоваться, вектор синаптических весов Wj нейрона j должен изменяться в
соответствии с входным вектором х. Вопрос сводится к тому, каким должно быть
это изменение. В постулате обучения Хебба синаптический вес усиливался при OДHO
временном возникновении предсинаптической и постсинаптической активности. Это
правило хорошо подходит к ассоциативному обучению. Однако для типа обучения
без учителя, которое мы рассматриваем в этой rлаве, rипотеза Хебба в своей OCHOB
ной форме не может удовлетворить требованиям задачи. На это есть своя причина:
изменения в связях происходят только в одном направлении, что в конечном счете
приводит все веса к точке насыщения. Для TOro чтобы обойти эту проблему, HeMHoro
изменим rипотезу Хебба и введем в нее СЛа2аемое забывания (forgetting term) g(y j )Wj,
rдe Wj вектор синаптических весов нейрона j; g(Yj) некоторая положительная
скалярная функция отклика Yj' Единственным требованием, налаrаемым на функцию
g(Yj), является равенство нулю постоянноrо слаrаемоrо разложения в ряд Тейлора
функции g(Yj), что, в свою очередь, влечет выполнение соотношения
g(Yj) == о при Yj == О.
(9.8)
"fIIII'I
584 rлава 9. Карты самоорrаниэации
Значимость этоro требования сразу же становится очевидной. Имея такую ФУНК-
цию, изменение вектора весов нейрона j в решетке можно выразить следую-
щим образом:
ДWj == 11YjX g(Yj)Wj,
(9.9)
rдe 11 параметр скорости обучения (1eaming rate parameter) алroритма. Первое
слаrаемое в правой части (9.9) является слаrаемым Хебба, а второе слаrаемым
забывания. Для TOro чтобы удовлетворялось соотношение (9.8), выберем следующую
линейную функцию g(Yj):
g(Yj) == 11Yj'
(9.1 О)
Выражение (9.9) можно упростить, приняв
Yj == hj,i(X)'
(9.11)
Подставляя (9.10) и (9.11) в (9.9), получим:
ДWj == 11hj,i(x)(X Wj)'
(9.12)
В заключение, учитывая формализацию дискретноro времени, для данноrо вектора
синаптических весов Wj(n) в момент времени n обновленный вектор Wj(n + 1) в
момент времени n + 1 можно определить в следующем виде [568], [579], [891]:
Wj(n + 1) == wj(n) + 11(n)h j ,i(x) (n)(х wj(n)).
(9.13)
Это выражение применяется ко всем нейронам решетки, которые лежат в тополо-
rической окрестности победившеro нейрона i. Выражение (9.13) имеет эффект пере-
мещения вектора синаптических весов W i победившеrо нейрона i в сторону входноrо
вектора Х. При периодическом представлении данных обучения блаrодаря коррекции
в окрестности победившеro нейрона векторы синаптических весов будут стремиться
следовать распределению входных векторов. Таким образом, представленный алro-
ритм ведет к тОnОЛ02ическому упорядочиванию (topologica1 ordering) пространства
признаков во входном пространстве, в том смысле, что нейроны, корректируемые в
решетке, будут стремиться иметь одинаковые синаптические веса. В разделе 9.5 этот
вопрос будет затронут несколько rлубже.
Равенство (9.13) является формулой вычисления синаптических весов карты при-
знаков. Однако в дополнение к этому уравнению для выбора функции окрестности
hj,i(x)(n) требуется учитывать эвристику (9.7). Еще одна эвристика необходима для
выбора параметра скорости обучения 11 (n).
9.3. Карты самоорraниэации 585
Параметр скорости обучения 11 (n) соrласно (9.13) должен зависеть от времени,
как это и должно быть при стохастической аппроксимации. К примеру, можно начать
с HeKoToporo исходноro значения 110' а затем, с течением времени, постепенно YMeHЬ
шать ero. Это требование можно удовлетворить, выбрав для параметра интенсивности
обучения следующую экспоненциальную функцию:
11(n) == 110ехр ( ) , n == 0,1,2,...,
(9.14)
rдe 72 еще одна временная константа алroритма SOM. Формулы экспоненциально
[о убывания параметров скорости обучения (9.14) и ширины функции окрестности
(9.6) MorYT не являться оптимальными. Они просто адекватны процессу самоорrани
зующеroся формирования карты признаков.
Два этапа адаптивноrо процесса: упорядочивание
и сходимость
Учитывая исходное состояние полноro беспорядка, довольно удивительным вышядит
то, что алrоритм SOM постепенно достиrает орrанизованноrо представления Moдe
лей активации, взятых из входноrо пространства, при условии правильноrо выбора
параметров этоrо ал [оритма. Можно выполнить декомпозицию процесса адаптации
синаптических весов сети, вычисляемых в соответствии с формулой (9.13), разбив
ero на эва этапа: этап самоорrанизации, за которым следует этап сходимости. Эти два
этапа адаптивноro процесса можно описать следующим образом [568], [579].
1. Этап самООр2анизации или упорядочивания. Во время первоrо этапа адаптивноro
процесса происходит тополоrическое упорядочивание векторов весов. В алrорит
ме SOM этот этап может занять до 1000 итераций, а возможно, и больше. При этом
значительное внимание следует уделить выбору параметра скорости обучения и
функции окрестности.
. Параметр скорости обучения 11 (n) лучше выбрать близким к значению 0,1. С Te
чением времени он должен убывать, но оставаться больше величины 0,01. Это
[о можно добиться, применив в формуле (9.14) следующие значения констант:
110 == 0,1,
72 == 1000.
. Функция окрестности hj,i(n) должна изначально охватывать практически все
нейроны сети и иметь центр в победившем нейроне i. Со временем эта функ
ция будет постепенно сужаться. В частности, на этапе упорядочивания, который
может занять около 1000 итераций, hj,i(n), скорее Bcero, сократится до малоrо
значения и будет содержать в себе только ближайших соседей победившеrо
.,...
586 rлава 9. Карты самоорrаниэации
нейрона, а возможно, только ero caMoro. Для двумерной решетки нейронов
можно установить исходное значение 0'0 функции окрестности, равное "ради-
усу" решетки. Соответственно константу времени 71 в формуле (9.6) можно
определить следующим образом:
1000
71 == .
log 0'0
2. Этап сходимости. Второй этап адаптивноro процесса требуется для точной под-
стройки карты признаков и, таким образом, для точноro квантования входноro
пространства. Как правило, количество итераций, достаточное для этапа сходи-
мости, примерно в 500 раз превышает количество нейронов сети. Таким образом,
количество итераций этапа сходимости может достиrать тысяч и десятков тысяч.
· Для хорошей статистической точности параметр скорости обучения 'тl (n) на
время этоrо этапа должен быть установлен в достаточно малое значение (по-
рядка 0,01). В любом случае ero нельзя очень приближать к нулю, иначе сеть
может заступориться в метаустойчивом (metastable) состоянии. Метаустойчи-
вое состояние соответствует конфиryрации карты признаков с тополоrическим
дефектом. Экспоненциальное сокращение (9.14) rарантирует невозможность
достижения метаустойчивых состояний.
· Функция окрестности h j , i (n) должна охватывать только ближайших соседей
победившеrо нейрона, количество которых может сократиться до одноrо или
даже до нуля.
9.4. Краткое описание алrоритма SOM
Сущность алrоритма SOM, предложенноro Кохоненом, состоит в простом [еО-
метрическом вычислении свойств Хеббоподобноrо правила обучения и латераль-
ных взаимодействий. Существенными характеристиками этоro алrоритма являются
следующие.
· Непрерывное входное пространство образов активации, которые rенерируются в
соответствии с некоторым распределением вероятности.
· Тополоrия сети в форме решетки, состоящей из нейронов. Она определяет дис
кретное выходное пространство.
· Зависящая от времени функция окрестности hj,i(x) (n), которая определена в
окрестности нейрона победителя i(x).
· Параметр скорости обучения 'Тl(n), для KOTOporo задается начальное значение 110
и который постепенно убывает во времени n, но никоrда не достиrает нуля.
9.4. Краткое описание алroритма SOM 587
Для функции окрестности и параметра скорости обучения на этапе упорядочива
ния (т.е. приблизительно для первой тысячи итераций) можно использовать формулы
(9.7) и (9.14) соответственно. Для хорошей статистической точности на этапе cxo
димости параметр 'тl (n) должен быть установлен в очень малое значение (0,01 или
меньше). Что же касается функции окрестности, то в начале этапа сходимости она
должна содержать только ближайших соседей нейрона победителя (при этом может
включать только ero caMoro).
Не считая инициализации, алrоритм проходит три основных шаrа: подвыборка
(sampling), поиск максималЬНО20 соответствия (similarity matching) и корректировка
(updating). Кратко весь алrоритм можно описать следующим образом.
1. Инициализация. Для исходных векторов синаптических весов Wj(O) выбираются
случайные значения. Единственным требованием здесь является различие Beктo
ров для разных значений j == 1,2,..., l, [де l общее количество нейронов в
решетке. При этом рекомендуется сохранять малой амплитуду значений.
Еще одним способом инициализации алroритма является случайный выбор MHO
жества весов {Wj(O)}; l из доступноrо множества входных векторов {Xi} l'
2. Подвыборка. Выбираем вектор х из входноrо пространства с определенной Bepo
ятностью. Этот вектор представляет собой возбуждение, которое применяется к
решетке нейронов. Размерность вектора х равна т.
3. Поиск максималЬНО20 подобия. Находим наиболее подходящий (победивший) ней
рон i(x) на шarе n, используя критерий минимума Евклидова расстояния:
i(x)==argminllx wjll, j==1,2,...,l.
J
4. Коррекция. Корректируем векторы синаптических весов всех нейронов, используя
следующую формулу:
Wj(n + 1) == wj(n) + 'Тl(n)hj,i(x) (n)(х wj(n)),
[де 'Тl(n) параметр скорости обучения; hj,i(x)(n) функция окрестности с цeH
тром в победившем нейроне i(x). Оба этих параметра динамически изменяются
во время обучения с целью получения лучшеrо результата.
5. Продолжение. Возвращаемся к шаrу 2 и продолжаем вычисления до тех пор, пока
в карте признаков не перестанут происходить заметные изменения.
,..
588 rлава 9. Карты самоорraнизации
. . . . . .
. . . . . .
. . . .
. . . Дискретное
. . . . выходное
. . . . пространство А
. . . .
. . . .
Непрерывное
входное
пространство Х
Рис. 9.4. Взаимосвязь между картой
признаков Ф и вектором весов Wi по-
бедившеro нейрона i
9.5. Свойства карты признаков
По завершении процесса сходимости алroритма SOM вычисленная им карта npи
знаков (feature тар) отображает важные статистические характеристики входно-
[о пространства.
Для начала обозначим nространственно непрерывное входное пространство
(данных) (spatially continous (data) space) символом Х. Ero тополоrия определяется
метрическими связями векторов х Е Х. Теперь обозначим символом А nростран-
ственно дискретное выходное пространство (spatial1y discrete output space). Ero то-
полоrия определяется упорядоченным множеством нейронов вычислительных узлов
решетки. Обозначим символом Ф нелинейное преобразование (называемое картой
признаков), которое отображает входное пространство Х в выходное пространство А:
Ф:Х------+А.
(9.15)
Выражение (9.15) можно рассматривать как соотношение (9.3) (определяющее
положение нейрона i(x), победившеro при подаче на вход сети вектора х) в абстракт-
ной форме. Например, в контексте нейробиолоrии входное пространство Х может
представлять множество координат COMaTo ceHcopHЫX рецепторов, распределенных
по всей поверхности тела. Соответственно выходное пространство А представляет
множество нейронов, расположенных в тех слоях коры roловноrо мозrа, которые
отвечают за COMaTo ceHcopHыe рецепторы.
9.5. Свойства карты признаков 589
ВХОДНОЙ вектор
х
Кодировщик
с(х)
КОД
с(х)
Восстановленный
вектор
х'(с)
Декодер
х'(с)
Рис. 9.5. Модель Koдepa дeKoдepa
Для данноrо входноro вектора х алroритм SOM определяет наиболее подходящий
(т.е. победивший) нейрон i(x) в выходном пространстве А, руководствуясь картой при
знаков Ф. Вектор синаптических весов Wi нейрона i(x) после этоrо можно рассматри
вать как указатель на этот нейрон из входноrо пространства Х. Это значит, что синап
тические элементы вектора Wi можно рассматривать как координаты образа нейрона
i, проектируемые во входное пространство. Эти две операции по казаны на рис. 9.4.
Карта признаков Ф обладает следующими важными свойствами.
Свойство 1. Аппроксимация входноrо пространства. Карта признаков Ф, npeд
ставленная множеством векторов синаптическux весов {W j }, в выходном npocтpaH
стве А реализует хорошую аппроксимацию входН020 пространства Х.
rлавной целью алroритма SOM является хранение большоro объема векторов хЕХ
с помощью нахождения небольшоrо набора прототипов Wj ЕА, которые представля
ют собой адекватную аппроксимацию исходноrо входноrо пространства Х. Теорети
ческие основы этой идеи уходят корнями в теорию вектОРН020 квантования (vector
quantization theory). Ее мотивацией является снижение размерности или сжатие дaH
ных [346]. Кажется целесообразным представить в этой книrе краткий экскурс в
эту теорию.
Рассмотрим рис. 9.5, на котором с(х) выступает в роли кодера входноrо вектора х, а
х'( с) декодера сиrнала с(х). Вектор х случайным образом выбирается из множества
примеров обучения (т.е. из входноro пространства Х) соrласно некоторой функции
плотности вероятности fx(X). Оптимальная схема кодирования декодирования опре
деляется с помощью изменения функций с(х) и х'(с) с целью минимизации ожидае
МО20 искажения (expected distortion), определяемоrо как
1 J +OO
D == dxfx(x)d(x, х'),
2 oo
(9.16)
rдe множитель 1/2 введен для удобства выкладок, а d(x, х') мера искажения (dis
tortion measure).
Интеrpирование осуществляется по всему входному пространству Х, причем пред
полаrается, что оно имеет размерность т. Популярным вариантом меры искажения
,..
590 rлава 9. Карты самоорrанизации
d(x, х') является квадрат Евклидова расстояния между входным вектором х и BOCCTa
новленным вектором х', Т.е.
d(x,x') == Ilx x'112 == (X X')T(X X').
(9.17)
Исходя из этоrо, выражение (9.16) можно переписать в следующем виде:
1 1 +00
D == dxfx(x) Ilx x'11 2 .
2 oo
(9.18)
Необходимые условия минимизации ожидаемоro искажения D содержатся в обоб-
щенном ал20ритме Ллойда (generalized Lloyd algorithm)7 [346]. Эти условия имеют
следующий вид.
Условие 1. Для данноrо входноrо вектора х выбрать кодер с == с(х), минимизиру-
ющий квадратичную ошибку искажения Ilx x'(c)112.
Условие 2. Для данноrо кодера с вычислить восстановленный вектор х' == х'( с) как
центр тяжести (centroid) тех входных векторов х, которые удовлетворяют условию 1.
Условие 1 называют правuлом ближайшею соседа (nearest neighbour rule). Усло-
вия 1 и 2 подразумевают, что среднее искажение D стационарно (т.е. находится в точке
локальноro минимума) по отношению к вариациям кодера с(х) и декодера х'(с) соот-
ветственно. Для TOro чтобы выполнить векторное квантование, обобщенный алroритм
Ллойда должен работать в пакетном режиме обучения. В своей основе алrоритм co
стоит из последовательной оптимизации кодера с(х) в соответствии с условием 1
и последующей оптимизации декодера х'(с) в соответствии с условием 2. Процесс
продолжается до тех пор, пока ожидаемое искажение D не достиrнет Минимума.
Для Toro чтобы избежать проблемы локальноro МИНИМума, целесообразно запускать
обобщенный алroритм Ллойда несколько раз с различными начальными векторами.
Обобщенный алrоритм Ллойда тесно связан с алrоритмом SOM [691]. Форму
этой связи можно описать, рассмотрев схему, показанную на рис. 9.6, [де был введен
независимый от сиrнала процесс шума У, который следует за кодером с(х). Шум
V ассоциируется с фиктивным "каналом связи" между кодером и декодером. Это
моделирует возможность TOro, что выходной код с(х) может быть искажен.
На основании модели, представленной на рис. 9.6, можно вывести модифициро
ванную форму ожидаемоrо искажения в следующем виде:
1 1 +00 1 00
D 1 == 2" oo dxfx(x) oo dv1t(v) Ilx х'(с(х) + v)11 2 ,
(9.19)
7 В литературе по теориям коммуникаций и ииформации для скалярноro квантования предлaraeтся более
ранний метод, известный как алzорuтм Ллойда. Этот алroритм впервые был описан в 1957 roду Ллойдом в
неопубликованном отчете лабораторни ВеН, а затем, HaMHoro позже, появился в печатиом внде в [667]. Алroритм
Ллойда иноrда еще называют алroритмом квантования максимума
9.5. Свойства карты признаков 591
Шум
v
Код
с(х)
L
Восстановленный
вектор
х'
Декодер
х'(с)
Рис. 9.6.
декодера
3ашумленная модель Koдepa
[де 1t(v) функция плотности вероятности аддитивноrо шума v, а второе интеrpиро
вание выполняется по всем возможным реализациям этоrо шума.
В соответствии со стратеrией, описанной для обобщенноrо алroритма Ллойда, в
модели, представленной на рис. 9.6, рассматриваются две различные задачи оптими
зации: одна для кодера, а друrая для декодера. Чтобы найти оптимальный кодер для
заданноrо вектора х, нужно взять частную производную меры ожидаемоrо искажения
D 1 по кодированному вектору с. Используя (9.19), получим:
aD 1 1 J +OO д , 2 1
(!k=="2 fx (x) oo dV1t(v) ac llx x(c)11 c c(x)+v'
(9.20)
Чтобы найти оптимальный декодер для данноro с, нужно вычислить частную
производную меры ожидаемоro искажения D 1 по декодированному вектору х'(с).
Используя выражение (9.19), получим:
aD J +OO
дx'( ) == oo dxfx(x)1t(c с(х))(х х'(с)).
(9.21)
Отсюда, в свете (9.20) и (9.21), ранее изложенные условия 1 и 2 обобщенноro
алrоритма Ллойда можно модифицировать следующим образом [691].
Условие 1. Для данноrо входноrо вектора х выбрать кодер c c(x), минимизирующий
меру искажения:
D 2 == 1: dv1t(v) Ilx х'(с(х) + v)11 2 .
(9.22)
Условие II. Для данноrо кодера с вычислить восстановленный вектор х' ( с), который
удовлетворяет условию
J OO dxfx(x)1t(c с(х))х
х' ( с) == :ос .
J oo dxfx(x)1t(c с(х))
(9.23)
..,.
592 rлава 9. Карты самоорrанизации
Уравнение (9.23) бьmо получено приравниванием частной производной д D 1/ дх' ( с)
из (9.21) к нулю, после чеrо полученное уравнение решалось относительно х'(с).
Модель, показанную на рис. 9.5, можно рассматривать как частный случай модели,
показанной на рис. 9.6. В частности, если в качестве функции плотности вероятности
1t(v) шума v выбрать дельта функцию Дирака 8(v), условия 1 и П сведутся к условиям
1 и 2 обобщенноro алrоритма Ллойда.
для Toro чтобы упростить условие 1, предположим, что 1t(v) является rладкой
функцией aprYMeHTa У. Torдa можно показать, что для аппроксимации BTOpOro порядка
мера искажения D 2 , описанная формулой (9.22), состоит из двух компонентов [691].
· Слаrаемое стандартН020 искажения, определяемое квадратичной ошибкой иска-
жения Ilx x'(c)112.
· Слarаемое искривления (curvature), возникающее из модели шума л(у).
Предполаrая малость слаrаемоrо искривления, условие 1 модели на рис. 9.6 может
быть аппроксимировано условием 1 модели 9.5 без учета шума. Это, в свою очередь,
сводит условие 1 к правилу ближайшеrо соседа, применяемому для кодирования.
Что же касается условия П, то ero можно лучше интерпретировать, используя
обучение методом стохастическоro спуска. В частности, из входноrо пространства
Х можно случайным образом выбрать вектор х, используя множитель J dxfx(X), и
скорректировать реконструированный вектор х'(с) [691]:
x'new(C) X'old(C) + 11 Л (С с(х))[х X'old(C)], (9.24)
rдe 11 параметр скорости обучения; с(х) результат аппроксимации кодирования
ближайшеro соседа соrласно условию 1. Уравнение коррекции (9.24) получено в
результате анализа частной производной (9.21). Это уравнение можно применить ко
всем С, дЛЯ которых
л(с с(х)) > О.
(9.25)
Процедуру, описываемую выражением (9.24), можно представить себе как способ
минимизации меры искажения D I (9.21). Это значит, что выражения (9.23) и (9.24)
имеют один и тот же тип, за исключением TOro факта, что (9.23) использует пакетный
режим, а (9.24) последовательный.
Уравнение коррекции (9.24) идентично (последовательному) алrоритму SOM
(9.13), если принять во внимание соответствия, приведенные в табл. 9.1. Следова
тельно, можно утверждать, что обобщенный алrоритм Ллойда для векторной кванти
зации является пакетной версией алrоритма SOM с нулевым размером окрестности.
Для такой окрестности л(О) == 1. Обратите внимание, что для получения обобщенно
[о алroритма Ллойда из пакетной версии алroритма SOM не нужно делать никаких
аппроксимаций, так как слаrаемые искривления (и все слаrаемые более высокоrо
порядка) не вносят вклад в результат при нулевой ширине окрестности.
9.5. Свойства карты признаков 593
ТАБЛИЦА 9.1. Соответствия между алrоритмом SOM и моделью, показанной на
рис. 9.6
Модель Koдepa дeKoдepa,
показанная на рис. 9.6
Кодер с(х)
Восстановленный вектор х' ( с)
Функция плотности вероятности п(с с(х))
АЛ20рИтм 80М
Наиболее подходящий нейрон i(x)
Вектор синаптических весов W j
Функция окрестности hj,i(X)
В приведенном здесь обсуждении можно отметить следующие важные моменты.
· Алrоритм SOM представляет собой алroритм векторноro квантования, который
осуществляет хорошую аппроксимацию входноrо пространства Х. Точка зрения,
представляющая друroй подход к выводу алrоритма SOM, представлена на при
мере выражения (9.24).
· Соrласно этой точке зрения, функция окрестности hj,i(X) в алroритме SOM имеет
форму функции плотности вероятности. В [688] рассматривалась [ауссова модель с
нулевым средним, соответствующая шуму v в модели на рис. 9.6. Таким образом, у
нас есть теоретические основания принятия rауссовой функции окрестности (9.4).
Пакетный ал20рИтм 80м 8 (batch SОМ) является Bcero лишь друroй формой BЫ
ражения (9.23), в которой для аппроксимации интеrpалов в числителе и знаменателе в
правой части уравнения используется суммирование. Обратите внимание, что в этой
версии алrоритма SOM порядок представления сети входных образов не влияет на
окончательную форму карты признаков и не существует необходимости в зависимо
сти от времени параметра скорости обучения. Однако этот алrоритм все же требует
использования функции окрестности.
Свойство 2. Тополоrический порядок. Карта признаков Ф, полученная ал20
ритмам 80М, является топОЛ02ически упорядоченной в том смысле, что пpocтpaH
ственное положение нейронов в решетке соответствует конкретной области или
признаку входН020 образа.
Свойство тополоrической упорядоченности 9 является прямым следствием урав-
нения коррекции (9.13), которое перемещает вектор синаптических весов Wi побе
дившеro нейрона i(x) в сторону входноrо вектора х. Оно также имеет эффект пе
ремещения вектора синаптических весов W j ближайших нейронов вместе с весами
8 В [571] были представлены эксперимеитальиые результаты, показывающие, что пакетная версия алroрит-
ма SOM быстрее интерактивной (оп-liпе). Однако при использовании пакетной версии теряются адаптивные
свойства этоro алrоритма.
9 Тополоrическое свойство самоорrанизующейся карты может быть количественио измерено миоrими спо-
собами. Одна из таких мер, называемая топОЛО2uческuм проuзведенuем (topological product), описана в [104].
Ее можно использовать для сравнения корректности поведеиия различных карт призиаков, имеющих разные
размерности. Однако эта мера является количествеиной только в том случае, коrда размерности решетки и
входноro пространства совпадают.
r
,
594 rлава 9. Карты самоорrанизации
победившеrо нейрона i(x). Таким образом, карту признаков Ф можно представить в
виде 2ибкой (elastic) или виртуальной сети (virtual net) с тополоrией OДHO или двух-
мерной решетки, заданной выходным пространством А, узлы которой имеют веса,
соответствующие координатам во входном пространстве Х [887]. Общую цель этоrо
алrоритма можно сформулировать следующим образом.
Аппроксимировать входное пространство Х указателями или прототипами в форме
векторов синаптических весов W j таким образом, чтобы карта признаков Ф обеспе-
чивала верное представление важных признаков, характеризующих входные векторы
х Е Х в терминах определеНН020 критерия.
Карту признаков Ф обычно изображают во входном пространстве Х. В частности,
все указатели (т.е. векторы синаптических весов) изображаются точками, а указатели
соседних нейронов связываются линиями в соответствии с тополоrией решетки. Та-
ким образом, используя линии для связывания двух указателей Wj и Wi, мы отражаем
тот факт, что нейроны j и i в решетке являются соседними.
Свойство 3. Соответствие плотности. Карта признаков Ф отражает вариации
в статистиках распределения входН020 СИ2нала. Области во входном пространстве
Х, из котОр020 берутся векторы х с большей вероятностью, отображаются в
20раздо большие области выходН020 пространства А и, таким образом, с большим
разрешением, чем области в исходном пространстве Х, из которых берутся векторы
х с меньшей вероятностью.
Пусть! х(х) мноroмерная функция распределения вероятности случайноro вход-
HOro вектора х. Интеrpал этой функции по всему пространству Х должен равняться
единице, Т.е.
I
t
t
!
I
,
I
1: !x(x)dx == 1.
Пусть т(х) масштабирующий множитель (magnification factor), определенный
как количество нейронов в небольшой области dx входноro пространства Х. Этот
масштабирующий множитель, интеrpированный по всему входному пространству Х,
в результате дает общее количество l нейронов сети:
1: m(x)dx == l.
(9.26)
в алroритме SOM, для Toro чтобы точно соответствовать входной плотности
(match the input density exactly), требуется, чтобы
т(х) сх !х(х).
(9.27)
9.5. Свойства карты признаков 595
Это свойство означает, что если конкретная область входноrо пространства co
держит часто встречающиеся возбудители, она должна быть представлена roраздо
большей областью на карте признаков, чем та область входноro пространства, в KO
торой возбудители встречаются реже.
В общем случае в двумерной карте признаков масштабирующий множитель т(х)
нельзя считать простой функцией от функции плотности вероятности fx(X) BXOДHO
ro вектора Х. ЭТО возможно только в случае одномерной карты признаков. В этом
частном случае оказывается, что, в отличие от более paHHero предположения [579],
масштабирующий множитель т(х) не пропорционален функции fx(x). в литературе
сообщается о двух совершенно различных результатах, зависящих от применяемоro
метода кодирования.
1. При кодировании с минимальным искажением (minimum distortion encoding), в
соответствии с которым сохраняются слаrаемое искривления и все слаrаемые
более высокоro порядка в измерении искажения (9.22), учитывающем влияние
шума п(у), этот метод приводит к следующему результату:
т(х) сх f /\x),
(9.28)
что идентично результату, полученному для стандартноrо алrоритма векторноro
квантования [688].
2. При кодировании на основе метода ближайше20 соседа (nearest neighbor cod-
ing), иrнорирующеro слаrаемые искривления, как в стандартной форме алroритма
SOM, получается друroй результат [886]:
т(х) сх i;/\x).
(9.29)
Прежнее утверждение о том, что кластер часто встречающихся входных возбуж
дений представляется большей областью на карте признаков, сохраняется, хотя и в
несколько искаженной версии идеальноro условия (9.27).
Как правило (что подтверждено компьютерным моделированием), карта призна
ков, вычисленная алroритмом SOM, имеет тенденцию в большей мере представлять
области с низкой входной плотностью, чем области с высокой входной плотностью.
Друrими словами, алroритм SOM не обеспечивает хорошее представление, описыва
ющее входные данные lО .
10 Неспособность алroритма SOM дать правильно е представленне распределения входиых даиных созда-
ла предпосылки для ero модификации и появлення новых самоорrанизующихся алroритмов, корректиых по
отиошению ко входному сиrналу. В литературе упоминаются две такие модификации алroритма SOM.
1. Модификация процесса коикуренции. В [254] использовалась некоторая форма памяти для отслеживания
совокупной деятельности отдельных нейронов в решетке. В частности, был добавлен мехаиизм "совести"
(соnsсiепсе) для смещеиия процесса коикурентноro обучения алroритма SOM. Это было сделано так, что
596
rлава 9. Карты самоорrанизации
1
I
,
I
Свойство 4. Выбор признаков. Для данных из входН020 пространства с нелиней-
ным распределением самООР2анизующаяся карта для аппроксимации исследуемО20
распределения способна извлечь набор наилучших признаков.
Это свойство является естественной кульминацией свойств 1 3. Оно заставляет
вспомнить идею анализа rлавных компонентов, которая рассматривалась в преды-
дущей rлаве. Однако это свойство имеет одно важное отличие, которое показано
на рис. 9.7. На рис. 9.7, а показано двумерное распределение с нулевым средним
точек данных, полученных в результате линейноro отображения входа на выход, ис-
каженное аддитивным шумом. В этом случае анализ rлавных компонентов работает
превосходно. Он позволяет определить, что наилучшее описание "линейноrо" распре-
деления на рис. 9.7, а задается прямой линией (т.е. одномерной rиперплоскостью),
которая проходит через начало координат и следует параллельно собственному век-
тору, ассоциированному с наибольшим собственным значением матрицы корреляции
данных. Теперь рассмотрим друrую ситуацию (см. рис. 9.7, 6), являющуюся резуль-
татом нелинейноro отображения входа на выход, искаженноrо аддитивным шумом с
нулевым средним значением. В этом, втором, случае аппроксимация прямой линией,
вычисленная с помощью анализа rлавных компонентов, не способна обеспечить при-
емлемое описание данных. С друrой стороны, использование самоорrанизующейся
KapThI, построенной на одномерноЙ решетке нейронов, обходит эту проблему ап-
проксимации блаrодаря своему свойству упорядочивания тополоrии. Эта, последняя,
аппроксимация показана на рис. 9.7, б.
Переходя к строroй терминолоrии, можно утверждать, что самоорrанизующиеся
карты признаков осуществляют дискретную аппроксимацию так называемых 2Jlавных
каждый нейрои, иезависимо от ero расположения в решетке, имел шанс выиrpать соревиование с вероят-
ностью, близкой к идеальной (1/1), rде 1 обшее количество нейронов. Описание алrоритма SOM с учетм
"совести" представлено в задаче 9.8.
2. Модификация адаптивною nроцесса. В этом подходе правило коррекции для настройки вектора весов
каждоro из нейронов, попадаюших в функцию окрестности, модифицировалось для управления масштаби-
руюш ими (mаgnifiсаtiоп) свойствами карты признаков. В [105] было показано, что блаroдаря добавлению
в правило коррекции иастраиваемоro параметра размера шаrа удалось обеспечить хорошее представление
картой призиаков входноro распределения. Авторы [645] следовали по тому же пути и предложили две
модификации алroритма SOM.
. Правило коррекции модифицировалось для извлечения прямой зависимости между входным вектором
х и вектором весов w j рассматриваемоro иейроиа j.
. Разбиение BOpOHOro было замеиено равноцеиным разбиением, специальио созданным для разделяемых
входных распределений.
Эта вторая модификация позволила алroритму SOM осуществлять слепое разделение входных сиrналов
(Ыiпd source sераrаtiоп). (Слепое разделеиие снrиалов вкратце освещалось в rлаве 1 и будет более полно
рассматрнваться в rлаве 10.)
Эти модификации бьши построеиы на той или иной форме алroритме SOM. В [652] был предпринят совершенно
иной подход. В частности, обшее правило обучения для формирования топоrpафической карты содержало мак-
симизацию взаимной информации (mutual iпfолnаtiоп) между выходным сиrналом и сиrнальной частью входа,
искажениой аддитивиым шумом. (Понятие взаимной ииформации, берушее свои корни в теории информации
Шеииона, опнсывается в таве 10.) Модель, предложеиная в этой работе, в результате содержала распределе-
иие нейронов, в точности соответствуюшее входиому распределению. Использование к самоорrанизующемуся
формированию топоrpафической карты подхода со стороны теории информации также описано в [1081], [1082].
9.6. Компьютерное моделирование 597
кривых I I (principal curve) или 2Лавных поверхностей (principal surface) [430]. Таким
образом, они MorYT рассматриваться как нелинейное обобщение анализа rлавных
компонентов.
9.6. Компьютерное моделирование
Двумерная решетка, полученная на основе ABYMepHoro
распределения
Теперь проиллюстрируем работу алroритма SOM с помощью компьютерноro MO
делирования. Будем изучать сеть, состоящую из 100 нейронов, упорядоченных в
форме двумерной решетки размером 10 х 10. Эта сеть обучается на двумерных BXOД
ных векторах х, элементы Хl и Х2 которых равномерно распределены в областях
{( 1 < Хl < + 1); ( 1 < Х2 < + 1)}. Для инициализации сети синаптические веса
выбираются случайным образом.
На рис. 9.8 показаны три этапа обучения сети представлению входноrо распреде
ления. На рис. 9.8, а показано равномерное распределение данных, использованных
для обучения карты признаков. На рис. 9.8, б по казаны исходные значения случайно
выбранных синаптических весов. На рис. 9.8, в, 2 по казаны значения векторов си-
наптических весов после завершения этапов упорядочивания и сходимости. Синап
тические веса на этих рисунках показаны точками. Линии, показанные на рис. 9.8,
соединяют соседние нейроны (вдоль строк и столбцов) сети.
Результаты, которые мы видим на рис. 9.8, демонстрируют этапы упорядочивания
и сходимости, которые характеризуют процесс обучения по алroритму SOM. Во Bpe
мя этапа упорядочивания карта напоминает форму сетки (см. рис. 9.8, в). К концу
этоro этапа нейроны отображаются в правильном порядке. Во время этапа сходи
мости сетка пытается "накрыть" все входное пространство. В конце BToporo этапа
(см. рис. 9.8, 2) статистическое распределение нейронов на карте приближается к
распределению входных векторов (за исключением некоторых rpаничных эффектов).
Сравнивая конечное состояние картыI признаков (см. рис. 9.8,2) с равномерным pac
пределением входных сиrналов (см. рис. 9.8, а), мы видим, что точная настройка
карты, выполненная на этапе сходимости, выявила отдельные локальные HepaBHO
мерности, присутствующие во входном распределении.
11 Связь между алroритмом SOM и rлавными (рriпсiраl) кривыми обсуждается в [186], [891]. Алroритм
отыскаиия rлавных кривых состоит из двух шаroВ [430].
1. Проекция. для каждой точки данных находится ее ближайшая проекция на кривую (т.е. самая ближайшая
точка на кривой).
2. Условное ожидание (сопditiопаl ехсерtаtiоп). Применяем сrлаживаиие rpафика разброса к проектируемым
значеииям вдоль кривой. В этой процедуре рекомендуется начинать с большоrо диапазона и постепенно
умеиьшать ero.
Эти два шаra аналоrичны векторному кваитованию и процедуре "отжиrа" окрестности, осуществляемым в
алrоритме SOM.
Выход
х
r
f
!
\
598
rлава 9. Карты самоорrанизации
Вход
и
а)
Выход
х
Вход
и
б)
Рис. 9.7. Двумерное распределение, полу
ченное в результате линейноro отображе-
ния входа на выход (а); двумерное распре-
деление, полученное в результате нелиней-
HOro отображения входа на выход (б)
Свойство тополоrическоro упорядочивания алroритма SOM хорошо продемон-
стрировано на рис. 9.8,2. В частности, видно, что алroритм (после сходимости) извлек
тополоrию распределения входноrо сиrнала. В результатах компьютерноrо модели-
рования (см. рис. 9.8) как входное пространство Х, так и выходное пространство А
бьmо двумерным.
0,5
Рис. 9.8. Распределение входных данных (а); начальное состояние двумерной ре-
шетки (б); состояние решетки в конце этапа упорядочивания (в); состояние решетки
в конце этапа сходимости (r)
0,8
0,6
0,4
а)
I
0,8
0,6
0,4
0,2 I
О
О 0,5
9.6. Компьютерное моделирование 599
0,2
0,1
О
O,I
0,2
0,2
O,I
О
б)
0,1
0,2
0,8
0,6
0,4
0,2
Одномерная решетка на основе ABYMepHoro распределения
Теперь рассмотрим случай, коrда размерность входноrо пространства Х больше раз
мерности выходноro пространства А. Несмотря на это расхождение, карта признаков
Ф часто способна сформировать тополоrическое представление входноrо распределе
ния. На рис. 9.9 по казаны три этапа эволюции карты признаков, инициализированной
на рис. 9.9, б и обучаемой на входных данных, взятых из paBHoMepHoro распределе
ния внутри квадрата (см. рис. 9.9, а). Вычисления осуществлялись на одномерной
решетке, состоящей из 100 нейронов. На рис. 9.9, в, 2 показаны карты признаков
после завершения этапов упорядочивания и сходимости соответственно. На этих ри
сунках видно, что карта признаков, вычисленная алroритмом, не может корректно
представить равномерное заполнение квадрата достаточно плотно и дать достаточно
хорошую аппроксимацию двумерноrо входноrо пространства Х. Кривая аппроксима
ции, показанная на рис. 9.9,2, является кривой Пеано (Реапо curve) [573]. Операция,
проведенная в этом эксперименте и представленная картой признаков на рис. 9.9 (rде
входное пространство Х представлено ero проекцией на пространство более низкой
размерности А), называется снижением размерности (dimensionality reduction).
600
rлава 9. Карты самоорraнизации
1 .., . . 8""'1 . . ..... '.' ее' _,' . . .
,е. l' :'.. ..;.!.... ......:.. е. i'" ... -:'.
о 8 "',"':':."'., :::"'" :"'-:'" .'. :;,. ';:' . :.:.:
, 8. "'.", ,::а: &, ..... '. . .е:.'\.. ,"
'" . .,..,: ',' е.::..... '" 8. :1. .'..
.).'(':'.". ::. .... : . . .. (-:":: ' . '..'"
0,6 :\:':- :: .::: \ (:,'!:: 'Tl\' . .::.}
0,4 . '.:1" . 1- . :-....:..;": .."- '-- ':; :.....,:.
.,' ;: ..; .: ; ":'{./::' : :. .:: '.: =.::
02. .' ;..". .........-.>. ...';..,. .....,;. .':
, ,:,.. . "'., "..;-.. J'r.' -;. .: . .
.... .. .' . .;,';'.....:.... ...... . --:;
-:'. . . \ :,,'/0.,'; 1. .... .... . '.
о
о
0,5
а)
r
,
!
0,5
о
0,5
1
I
,
0,5 О
б)
0,5
0,8 0,8
0,6 0,6
0,4 0,4
0,2 0,2
0,5 0,5
в) r)
Рис. 9.9. Распределение входных данных (а); начальное состояние двумерной
решетки (6); состояние решетки в конце этапа упорядочивания (в); состояние pe
шетки в конце этапа сходимости (r)
Описание параметров моделирования
На рис. 9.10 представлены детали динамики функции окрестности hj,i(n) и пара-
метра скорости обучения 'I1(n) с течением времени (т.е. с количеством эпох) при
моделировании отображения на одномерную решетку. Параметр функции окрестно-
сти cr(n), показанный на рис. 9.10, а, начинает работу из исходноrо состояния cro == 18
и убывает практически до единицы за 1000 итераций этапа упорядочивания. В те-
чение TOro же этапа параметр скорости обучения '11 (n) начинает работу со значения
0,1 и уменьшается до значения 0,037. На рис. 9.10, в показано изначальное raYCCOBO
распределение нейронов Boкpyr победившеro нейрона, расположенноro в центре од-
номерной решетки. На рис. 9.9, 2 показана форма функции окрестности в конце этапа
упорядочивания. Во время этапа сходимости (5000 итераций) параметр скорости обу-
чения равномерно уменьшался от 0,037 до 0,001. В течение Toro же этапа функция
окрестности сократилась практически до нуля.
9.6. Компьютерное моделирование 601
-;:
ь
:: .::.: j
о 100 200 300 400 500 600 700 800 900 1000
а)
oo:: r , : . . :
о 100 200 300 400 500 600 700
б)
: 1
800
900 1000
}o.: ,
о 10 20 30 40 50 60 70 80 90 100
в)
}о ] . : : . л : : : , j
О 1 О 20 30 40 50 60 70 80 90 100
п
r)
Рис. 9.10. Экспоненциальное убывание параметра а(п) функции окрестности (а); экспоненци-
альное убывание параметра Т'\(п) (б); изначальная форма rауссовой функции окрестности (в);
форма функции окрестности по завершении фазы упорядочивания (т.е. в начале этапа сходи-
мости) (r)
Спецификации этапов упорядочивания и сходимости при компыотерном модели
ровании для случая двумерной решетки (см. рис. 9.8) аналоrичны использованным
для одномерной, за исключением Toro факта, что функция окрестности теперь тоже
стала двумерной. Параметр (J(n) начал работу со значения (Jo == 3, за 1000 итераций
уменьшившись до 0,75. На рис. 9.11 показано начальное состояние rауссовой функ
ции окрестности hj,i для (Jo == 3 и победившеro нейрона, центрированноro в точке
(7; 8) двумерной решетки размером 10 х 10 нейронов.
602
rлава 9. Карты самоорraнизации
т
I
t
Нейрон победитель
0,8 I
I
0,6 !
I
,
i
0,4 I
0,2 I
I
,
!
О i
10 I
10 !
!
!
Рис. 9.11. Начальное условие для двумерной raуссовой функции окрестности с цен-
тром в нейроне-победителе, расположенном в точке (7; 8) двумерной решетки разме-
ром 10 х 10 нейронов
9.7. Квантование вектора обучения
Векторное квантование (vector quantization), о котором мы roворили в разделе 9.6,
представляет собой прием использования структуры входных векторов для сжатия
данных [346]. В частности, входное пространство подразделяется на множество чет-
ких областей, для каждой из которых определяется вектор воспроизведения. Коrда
устройству квантования представляется новый входной вектор, в первую очередь
определяется область, к которой принадлежит данный вектор, а после этоrо созда-
ется представление через вектор воспроизведения данной области. Таким образом,
используя некодированную версию восстанавливаемоrо вектора для хранения или
передачи исходноro вектора, можно добиться значительной экономии пространства
хранения или мощности канала передачи данных за счет привнесения некоторых ис-
кажений. Множество возможных векторов воспроизведения называется кодовой кни-
20Й (code book) устройства квантования, а ero отдельные члены кодовыми словами
(code word).
Устройство векторноro квантования, обладающее минимальным искажением при
кодировании, называется квантователе.м ВОРОН020, или квантователе.м на основе
ближайше20 соседа (nearest neighbor quantizer), а ячейками ВОрОН020 называют мно-
жество точек во входном пространстве, которые соответствуют подразделению этоro
9.7. Квантование вектора обучения 603
,
,
,
,
,
,
,
о
о
,
-- ...
I
.
, '\
............ \
о
о
,
,
,
,
,
,
,
,
,
,
,
,
,
Рис. 9.12. Диаrрамма Вороноro. содержащая 4 ячей-
ки ([379], приведена с разрешения IEEE)
пространства в соответствии справилом ближайше20 соседа, основанным на Евкли
довой метрике [346]. На рис. 9.12 показан пример входноrо пространства, разделен
HOro на четыре ячейки BOpOHOro, с соответствующими векторами воспроизведения
(или векторами BOpOHOro). Каждая из этих ячеек содержит те точки входноrо про
странства, которые расположены ближе Bcero к вектору BopoHoro.
Алrоритм SOM обеспечивает приближенный метод вычисления векторов Воро-
HOro без учителя. При этом аппроксимация определяется векторами синаптических
весов нейронов на карте признаков. Это практически повторяет описание свойства 1
алroритма SOM, о котором речь пmа в разделе 9.6. Расчет карты признаков, таким об
разом, можно рассматривать как первый из двух этапов адаптивноro решения задачи
классификации (рис. 9.13). На втором этапе в качестве механизма точной подстройки
картыI признаков проводится квантование вектора обучения.
Квантизация вектора обучения 12 (1eaming vector quantization LVQ) это прием
обучения с учителем, который использует информацию о классе для небольшоrо сме-
щения вектора BOpOHOro и, таким образом, для улучшения качества областей решений
классификатора. Входной вектор х случайно выбирается из входноro пространства.
Если метки класса входноro вектора х и вектора BopoHoro w соrласуются, последний
смещается в направлении первоro. Если же метки классов этих векторов не соrласу-
ются, вектор BOpOHOro w смещается в сторону, противоположную входному вектору х.
12 Идея квантования вектора обучения принадлежит Кохонену [578]. Три версии этоro алroритма были
описаны в ero работах [568], [574]. Версия, предлaraемая в разделе 9.7, является первой из них и в работах
Кохонена обозначается как LVQI.
Алroритм квантованИЯ вектора обучения является алroритмом стохастической аппроксимации. В работе
[89] нсследовались свойства сходимости этоro алroритма. При этом использовался подход ODE (обычных
дифференциальных уравнений), который описывался в шаве 8.
604
rлава 9. Карты самоорrанизации
т
I
i
Входной
сиrнал
Самоорrанизующаяся
карта
признаков
} Метки
классов
Рис. 9.13. Блочная диа-
rpaMMa адаптивной клас-
сификации множеств, ис-
пользующей самоорrани-
зующуюся карту призна-
ков и квантизацию векто-
ра обучения
Учитель
Пусть {Wj} l множество векторов BopoHoro, а {Xi}f:,l множество вход-
ных векторов (наблюдений). Предполаrается, что количество входных векторов на-
MHOro превосходит количество векторов BOpOHOro, что, как правило, происходит на
практике. Алrоритм квантования векторов обучения (LVQ) можно описать следую-
щим образом.
1. Предположим, что вектор BopoHoro W с является самым близким к входному век-
тору Xi. ОБОЗНilЧИМ символом C Wc класс, ассоциируемый с вектором BopoHoro
w c , а символом С Х; метку класса входноrо вектора Xi' Вектор BopoHoro W c
корректируется следующим образом.
· Если C Wc ==С Х ;> то
wc(n + 1) == wc(n) + an[xi wc(n)],
(9.30)
[де О < а n < 1.
· Если C Wc #C Xi , то
wc(n + 1) == wc(n) an[xi wc(n)].
(9.31 )
2. Остальные векторы BopoHoro не изменяются.
Константу обучения а n лучше сделать монотонно убывающей с увеличением чис-
ла итераций. Например, начальным значением а n может служить 0,1 или меньшее.
Затем эта константа может убывать линейно по n. После нескольких проходов по
входным данным векторы BOpOHOro, как правило, сходятся. После этоro обучение
считается завершенным. Однако если метод при меняется без должноrо внимания,
можно столкнуться с определенными трудностями.
9.8. Компьютерное моделирование: адаптивная
классификация множеств
в задаче классификации множеств первым и наиболее важным шаrом является извле
чение признаков (feature se1ection), которое обычно выполняется без учителя. Целью
этоrо шаrа является выбор обоснованно малоrо количества признаков, в которых
9.8. Компьютерное моделирование: адаптивная классификация множеств 605
сконцентрирована самая существенная информация о входных (классифицируемых)
данных. Для извлечения признаков лучше Bcero подходит самоорrанизующаяся Kap
та, ввиду ее свойства 4 (см. раздел 9.5), особенно если входные данные формируются
нелинейным процессом.
Вторым шаrом в задаче классификации множеств является сама классификация,
в которой признакам, выделенным на первом шаrе, назначаются разные классы.
Несмотря на то что и самоорrанизующаяся карта может самостоятельно осуществ-
лять классификацию, все же для повышения производительности рекомендуется дo
полнить ее какой нибудь схемой обучения с учителем. Комбинация самоорrанизу
ющейся карты со схемой обучения с учителем формирует базис адаптивной клас
сификации множеств (adaptive pattem classification), которая является 2ибридной по
своей сущности.
Такой rибридный подход к классификации может иметь различные формы, в за
висимости от Toro, как реализована схема обучения с учителем. Одна из простей
ших схем использует квантователь вектора обучения, описанный в предыдущем раз
деле. Исходя из сказанноrо, получим двухступенчатый адаптивный классификатор
(см. рис. 9.13).
В этом эксперименте снова вернемся к задаче классификации двух двумерных
пересекающихся множеств с [ауссовым распределением, которые можно пометить
как классы С 1 и С 2 . Эта задача более подробно описывалась в rлаве 4, [де для
ее решения использовался мноrослойный персептрон, обучаемый методом обратно
ro распространения. [рафик распределения данных, используемых в эксперименте,
показан на рис. 4.13.
На рис. 9.14, а показана двумерная карта признаков, состоящая из решетки разме
ром 5 х 5 нейронов после завершения работы алroритма SOM. Эта карта была Map
кирована, и каждый из нейронов был поставлен в соответствие одному из классов,
в зависимости от TOro, как он среаrировал на тестовые данные, взятыIe из входноro
распределения. На рис. 9.14, б показана rpаница решений, сформированная самой
картой признаков.
На рис. 9.14, в показана модифицированная карта признаков, настроенная в про
цессе обучения с учителем на основе алrоритма LQV. На рис. 9.14, 2 показана rpa
ница решений, полученная в результате cOBMecTHoro действия алrоритмов SOM и
LQY. Сравнивая последние два рисунка с их двойниками, 9.14, а и 9.14, б, мы видим
качественный эффект применения алroритма LQV
В табл. 9.2 представлены эффективности классификации для карты признаков,
действующей самостоятельно, и для совмещения алrоритмов SOM и LQV. Пред
ставленные здесь результаты получены из 1 О независимых пробных эксперимента,
в каждой из которых использовалось по 30000 примеров тестовых данных. В каж
дом эксперименте наблюдалось повышение качества классификации при применении
алrоритма LQV Средний показатель производительности для карты признаков, дей
606 rлава 9. Карты самоорrанизации
8 8
6 6
4 4
2 2
О О
2 2
4 4
6 6
8 8
5 О 5 5 О
а) б)
8 , 8
6 6
4 о о 4
о
2 . о о 2
..... о о
О ... о О
2 . о 2
о о о о
4 о о 4
6 6
8 . 8
5 О 5 5 О
в) r)
5
Рис. 9.14. Самоорraнизую-
щаяся карта после расста-
новки меток (а). (б) rраница
решений. построенная кар-
той (а). Маркированная кар-
та после квантования векто-
5 ров обучения (в). (r) rрани-
ца решений, построенная на
карте (в)
ствующей самостоятельно, составил 79,61%, а для комбинации двух алroритмов
80,52%, Т.е. среднее улучшение качества классификации составило 0,91 %. Для срав-
нения вспомним, что производительность оптимальноro классификатора Байеса для
этоro эксперимента составила 81,51 %.
9.9. Иерархическое квантование векторов
При обсуждении свойства 1 самоорrанизующейся карты признаков в разделе 9.6
мы особо отметили, что она тесно связана с обобщенным алroритмом Ллойда для
векторноro квантования. Векторное квантование является формой сжатия с потерей
данных. Это значит, что в результате сжатия теряется часть информации, содержащей-
ся в данных. Своими корнями сжатие данных уходит в теорию информации Шеннона
(Shennon), еще называемую теорией уровня искажения (rate distortion theory) [221].
В свете нашей дискуссии об иерархической векторноrо квантования будет уместным
начать с утверждения, явившеroся фундаментальным результатом теории уровня ис-
кажения [379].
9.9. Иерархическое квантование векторов 607
ТАБЛИЦА 9.2. Эффективность классификации (в процентах) в компьютерном экс
перименте по классификации двух пересекающихся rayccoBbIX распределений с
помощью решетки размером 5 х 5
Попытка Самостоятельная классификация Классификация комбинацией
картой признаков карты признаков и LVQ
1
2
3
4
5
6
7
8
9
10
Среднее
79,05
79,79
79,41
79,38
80,30
79,55
79,79
78,48
80,00
80,32
79,61 %
80,18
80,56
81,17
79,84
80,43
80,36
80,86
80,21
80,51
81,06
80,52%
Наилучше20 сжатия данных все2да можно добиться с помощью кодирования не вeK
торов, а скаляров, даже если источник данных не имеет памяти (т.е. является
последовательностью независимых случайных переменных), или если система сжа
тия данных имеет память (т.е. действия кодировщика зависят от своих предыдущих
входов или выходов).
За этим фундаментальным результатом стоят обширные исследования в области
векторноrо квантования [346].
Однако алrоритмы обычной векторной квантизации требуют довольноro большо
[о объема вычислений, что оrpаничивает их практическое использование. Большую
часть времени в алroритме векторной квантизации занимает операция кодирования.
При кодировании входной вектор должен сравниваться с каждым из векторов кодиро-
вания в кодовой книrе, для TOro чтобы найти тот, который обеспечивает минимальное
искажение. Например, если кодовая книrа содержит N векторов кодирования, время,
затраченное на кодирование, будет иметь порядок N. Исходя из этоrо, с увеличе
ни ем N оно будет возрастать. В [690] описано МНО20ступенчатое иерархическое
векторное квантование (multistage hierarchical vector quantizer), которое значительно
увеличивает скорость кодирования. Эта схема не является простым деревом поиска
в кодовой книrе. В ней реализован кардинально новый принцип. Мноrоступенчатый
иерархический векторный квантователь раскладывает общую операцию векторноro
квантования на множество подопераций, каждая из которых требует крайне малоro
объема вычислений. Желательно, чтобы такое разложение сводилось к одной проце
дуре поиска на подоперацию. Мудро используя алrоритм SOM дЛЯ обучения каждой
из под операций, можно добиться малой потери точности (до доли децибела) при
одновременном повышении скорости вычислений.
608 rлава 9. Карты самоорrанизации
Рассмотрим два векторных квантователя, VQl и VQ2, [де первый передает свой
выход на второй. Выход BToporo квантователя является окончательной кодирован-
ной версией исходноrо входноro сиrнала, примененноro к VQl. При осуществлении
квантования совершенно нежелательно, чтобы VQ2 отверrал какую либо информа-
цию. Поскольку рассматривается квантователь VQl, исключительный эффект от VQ2
заключается в искажении выхода VQl' Таким образом, получается, что для VQl
больше подходит алroритм SOM, который учитывает искажение сиrнала, налаrаемое
квантователем VQ2 [690]. Для TOro чтобы использовать обобщенный алrоритм Ллой-
да для обучения квантователя VQ2, нужно предположить, что выход VQ2 не будет
искажен до проведения восстановления. В этом случае не потребуется вводить зашум-
ленную модель (для выхода VQ2) и ассоциированную с ней функцию окрестности
конечной ширины.
Этот эвристический арrумент можно обобщить на мноroступенчатый векторный
квантователь. Каждый шаr должен учитывать искажения, привнесенные всеми преды-
дущими шаrами, и моделировать их как шум. Поэтому для обучения всех ступеней
квантователя (за исключением последней, для которой при меняется обобщенный ал-
rоритм Ллойда) используется алrоритм SOM.
Иерархическое векторное квантование является частным случаем мноrоступенча-
Toro BeKTopHoro квантования [690]. В качестве иллюстрации рассмотрим квантование
входноrо вектора размерности 4 х 1 :
х == [Хl,Х2,ХЗ,Х4]Т'
На рис. 9.15, а показан одно ступенчатый векторный квантователь для х. В качестве
альтернативы используется двухступенчатый иерархический квантователь, представ-
ленный на рис. 9.15, б. Разительное отличие между двумя этими схемами состоит в
том, что размерность входа квантователя на рис. 9.15, а равна четырем, в то время
как квантователя на рис. 9.15, б двум. Соответственно квантователь, представлен-
ный на рис. 9.15, б, требует для своей работы существенно меньшей справочной
таблицы (look-up table) и является более простым для реализации, чем квантователь,
показанный на рис. 9.15, а. В этом и лежит rлавное преимущество иерархическоro
квантователя перед обычным.
В [690] продемонстрирована эффективность мноroступенчатоrо иерархическоro
векторноrо квантователя применительно к различным стохастическим рядам. При
этом потери в точности были минимальными. На рис. 9.16 воспроизведены результа-
ты, полученные в этой работе, для случая коррелированноro [ауссова шума, rенери-
pyeMoro с помощью авmоре2рессионой модели первО20 порядка (first-order autoregres-
sive model):
х(n + 1) == рх(n) + v(n),
(9.32)
9.9. Иерархическое квантование векторов 609
Выходной сиrнал
Односту-
пенчатый
векторный
квантизатор
Выходной сиrнал
Векторный
квантизатор
с двумя
входами
Векторный
квантизатор
с двумя
входами
Рис. 9.15. Одноступенчатый векторный
квантователь С четырехмерным входным
сиrналом (а); двухступенчатый иерархиче- Х 1 Х 2 Х з Х 4
ский векторный квантователь, использую-
щий двухвходовые векторные KBaHTOBaTe
ли (6) (из [690]) а)
Х 1
Х 2 Х з
Х 4
б)
rдe р коэффициент автореrpессии; v (п) независимая и равномерно распреде
ленная [ауссова случайная переменная с нулевым средним и единичной дисперсией.
Исходя из этоro, можно показать, что х (п) характеризуется следующим образом:
Е[х(п)] == О,
Е[х 2 (п)] == 1 1 2'
p
Е[х(п + l)х(п)]
Е[х 2 (п)] == р.
(9.33)
(9.34)
(9.35)
Таким образом, р можно рассматривать как коэффициент корреляции (correla
tion coefficient) BpeMeHHoro ряда {х(п)}. Чтобы инициировать rенерацию этоrо Bpe
MeHHoro ряда в соответствии с (9.32), для х(О) использована [ауссова случайная
переменная с нулевым средним и дисперсией 1/(1 р2), а в качестве коэффициента
корреляции выбрана величина р == 0,85.
Для векторной КваНТИзации использовался иерархический кодер с четырехмерным
входным пространством, подобный показанному на рис. 9.15, б. Для ряда aBToperpec
сии {х (п)} потребовалась симметрия преобразования, подразумевающая использо
вание только двух отдельных справочных таблиц. Размер каждой из этих таблиц
экспоненциально зависел от количества битов входноrо сиrнала и линейно от коли
чества битов выходноrо сиrнала. Во время обучения для правильноro вычисления
коррекций (9.24) потребовалось большое количество битов для представления чисел,
поэтому во время обучения справочные таблицы не использовались. Однако после
610 rлава 9. Карты самоорrанизации
[l] "!' :. I
.." ..1 l'
:.; . . . I I ' .
0
Ступень 2
Ступень 1
Ступень 1 Ступень 2
а)
б)
Восстановленное
распределение
Исходное
распределение
.. лА vv I NЧ\ \jдA д
. v , v rv'
л .flA IUtI. Алм"rJI v-п J v А ...АН/'
"ч '''f VVV У" V V'VJU'
Рис. 9.16. Результаты двухступенчатоro кодирования/декодирования для коррелированноro
rayccoBa шума. Коэффициент корреляции р == 0,85 (из [690])
завершения обучения количество битов моrло быть уменьшено до обычноrо уровня,
после чеro потребовались записи справочных таблиц. Для кодера, показанноro на
рис. 9.15, б, входные образы аппроксимировались с использованием четырех битов
на образ. Для всех ступеней кодера использовалось N == 17 векторов кодирования,
так что количество выходных битов в каждой из справочных таблиц приблизительно
равнялось четырем. Таким образом, размер адресноrо пространства для таблиц обеих
ступеней составил 256 (==24+4). Это rоворит о том, что общие требования к памяти
для представления таблиц были крайне скромными.
На рис. 9.] 6 показаны результатыI кодирования/декодирования элементов х( n).
В нижней части рис. 9.16, а векторы кодирования для каждой из двух ступеней
показаны как кривые, помещенные в двумерное входное пространство. В верхней
части рис. 9.16, а показаны оценки соответствующих матриц соответствия (со-
occurence) размером 16х 16. На рис. 9.16, б в виде фраrментов BpeMeHHoro ряда
представлены следующие элементы.
. Вектор кодирования, вычисленный первой ступенью кодера.
. Вычисленный второй ступенью вектор восстановления, который минимизирует
среднеквадратическое искажение при одновременном сохранении всех остальных
переменных.
9.10. Контекстные карты 611
На рис. 9.16, в представлено 512 примеров из исходноrо BpeMeHHoro ряда (верхняя
кривая) совместно с реконструированными при мерами (нижняя кривая). Эти дaH
ные взяты из выхода последней ступени кодировщика. [оризонтальная шкала на
рис. 9.16, в равна половине шкалы на рис. 9.16, б. На рис. 9.16,2 представлена MaT
рица соответствия, составленная из пар примеров: исходных и соответствующих им
восстановленных. Ширина полосы на рис. 9.16, 2 показывает степень искажения,
произведенноrо иерархической векторной квантизацией.
Исследуя rpафики на рис. 9.16, в, можно увидеть, что восстановленная инфор
мация является достаточно хорошим представлением исходноrо BpeMeHHoro ряда, за
исключением Toro, что отдельные положительные и отрицательные пики срезаны.
Соrласно [690], нормализованное среднеквадратическое искажение составило 0,15,
что практически не хуже (меньше на 0,05 дБ), чем 8,8 дБ, полученные с использо
ванием одноступенчатоro блочноro кодера с четырьмя входами, использующеrо по
одному биту на пример [510].
9.10. Контекстные карты
Существуют два фундаментально отличных метода визуализации самоорrанизую
щихся карт признаков. Первый из этих методов состоит в построении rибкой сети,
в которой векторы синаптических весов являются указателями, направленными от
соответствующих нейронов во входное пространство. Этот метод визуализации oco
бенно полезен для правильноrо отображения свойства тополоrическоrо упорядочи
вания алroритма SOM. Это было продемонстрировано на примере компьютерноro
моделирования, приведенноro в разделе 9.6.
Во втором методе визуализации нейронам в двумерной решетке (представляю
щим выходной слой сети) назначаются метки классов, в зависимости от Toro, как
каждый из примеров (не встречавшихся ранее) возбудил конкретный нейрон в ca
моорrанизующейся сети. В результате этой второй ступени моделирования нейроны
в двумерной решетке разбиваются на некоторое количество КО2ерентных областей
(coherent region). Здесь под коrерентностью понимается то, что каждая из rpупп
нейронов представляет обособленное множество непрерывных символов или меток
[888]. Это подразумевает, что при восстановлении хорошо упорядоченной карты ис
пользовались правильные условия.
Для примера рассмотрим множество данных, представленных в табл. 9.3. В этой
таблице приведены характеристики отдельных животных. На основании данных каж
доro из столбцов таблицы можно составить описание HeKoToporo животноrо. При этом
значение 1 подразумевает наличие, а О отсутствие одноrо из 13 свойств, перечис
ленных в таблице слева. Отдельные атрибуты (например, "2 ноrи" и "4 ноrи") Koppe
лируют, в то время как остальные нет. Для Каждоrо из представленных животных
можно составить характеристический код (attribute code) Ха, состоящий из 13 элемен-
612 rлава 9. Карты самоорrанизации
ТАБЛИЦА 9.3. Названия животных и их характеристики
Животное r к у r с я о л с в к т л л з к
о у т у о с р и о о о и е о е о
л р к с в т е с б л ш 2 в ш б р
у и а ь а р л а а к к р а р о
б ц е к а д а в
ь а б а ь а
Маленький 1 1 1 1 1 1 О О О О 1 О О О О О
Размер Средний О О О О О О 1 1 1 1 О О О О О О
Крупный О О О О О О О О О О О 1 1 1 1 1
2 НО2и 1 1 1 1 1 1 1 О О О О О О О О О
4 НО2и О О О О О О О 1 1 1 1 1 1 1 1 1
Имеет Шерсть О О О О О О О 1 1 1 1 1 1 1 1 1
Копыта О О О О О О О О О О О О О 1 1 1
Триву о о о о о о о о о 1 О О 1 1 1 О
Перья 1 1 1 1 1 1 1 О О О О О О О О О
Охоту О О О О 1 1 1 1 О 1 1 1 1 О О О
Любит Бе2ать О О О О О О О О 1 1 О 1 1 1 1 О
Летать 1 О О 1 1 1 1 О О О О О О О О О
Плавать О О 1 1 О О О О О О О О О О О О
тов. Само животное определяется символьным кодом (symbolic code) Xs, по которому
никак нельзя собрать информацию о сходствах и различиях между отдельными жи-
вотными. Например, в данном примере Xs представляет собой вектор, k й элемент
(соответствующий номеру животноrо в списке) KOToporo имеет некоторое значение а;
при этом все остальные элементы равны нулю. Параметр а определяет относитель-
ное влияние характеристическоrо и символьноro кодов друr на друrа. Для Toro чтобы
rарантировать, что данный характеристический код является доминантным, а выби-
рается равным 0,2. Входной вектор для каждоrо из животных состоит из 29 элементов
и представляет собой объединение характеристическоro Ха И символьноrо Xs кодов:
х == [::] == [ s] + [ J .
Наконец, каждый из векторов данных нормализуется к единичной длине. Примеры
из таким образом созданноrо множества данных подаются на вход двумерной решет-
ки нейронов размером 1 Ох 1 О, при этом синаптические веса нейронов настраиваются
в соответствии с алrоритмом SOM (см. рис. 9.4). Обучение продолжалось в течение
2000 итераций, после чеrо карта признаков должна бьmа достичь стабильноrо состо-
яния. После этоro самоорrанизующейся сети подавались на вход векторы x==[xs,O]T,
9.11. Резюме и обсуждение 613
собака
лиса
кошка
орел
сова
тиrp
волк
ястреб
лев
roлубь
лошадь
курица
корова
rycb
зебра
yrKa
Рис. 9.17. Карта признаков, содержащая маркированные нейроны,
имеющие самый сильный отклик на определенный входной пример
содержащие только символьные коды одноro из животных, и определялся нейрон с
самым сильным откликом. Эта процедура повторялась для всех 16 животных.
В процессе выполнения описанноro алrоритма была получена карта, показанная на
рис. 9.17. В ней маркированные нейроны дали самый сильный отклик на COOTBeTCTBY
ющие примеры. Точками на карте обозначены нейроны с более слабыми откликами.
На рис. 9.18 показан результат моделирования для той же самоорrанизующейся
сети. Однако на этот раз каждый из нейронов сети бьm маркирован названием TOro
животноro, для KOTOpOro ero отклик был самым сильным. На этом рисунке видно, что
карта признаков четко отслеживает "родственные взаимосвязи" между 16 различными
животными. На нем можно выделить три обособленных кластера, один из которых
представляет птиц, второй мирных животных, а третий хищников.
Карта признаков, показанная на рис. 9.18, называется контекстной (contextual)
или семантической (semantic) [568], [888]. Эти карты напоминают вычислительные
карты, формируемые в коре roловноro мозrа (см. rлаву 2). Контекстные карты, по
лучившиеся в результате использования алroритма SOM, нашли свое применение в
решении задач создания фонетических классов для текста, исследования Земли или
дистанционноrо зондирования [568], а также в исследовании данных и извлечении
скрытых закономерностей (data exploration & data mining) [569].
9.11. Резюме и обсуждение
По Кохонену [579] самоорrанизующиеся карты представляют собой нейронные сети,
построенные на OДHO или двухмерной решетке нейронов для извлечения важных
признаков, содержащихся во входном пространстве. Таким образом, можно получить
структурное представление входных данных, используя в качестве прототипов Beктo
ры весов нейронов. Алroритм SOM имеет нейробиолоrическую подоплеку. Он объ
единил в себе все основные механизмы, при сущие самоорrанизации: конкуренцию,
614 rлава 9. Карты самоорrанизации Т
собака собака лиса лиса лиса кошка кошка кошка орел орел
собака собака лиса лиса лиса кошка кошка кошка орел орел
волк волк волк лиса кошка титр титр титр сова сова
волк волк лев лев лев титр титр титр ястреб ястреб
волк волк лев лев лев титр титр титр ястреб ястреб
волк волк лев лев лев сова rолубь ястреб roлубь rолубь
лошадь лошадь лев лев лев roлубь курица курица rолубь rолубь
лошадь лошадь зебра корова корова корова курица курица rолубь rолуб ь
зебра зебра зебра корова корова корова курица курица yrKa rycb
зебра зебра зебра корова корова корова yrKa yrKa утка rycb
Рис. 9.18. Семантическая карта, полученная при использовании мо-
делирования проводимости электродов. Эта карта разделена на три
области, представляющие птиц, мирных животных и хищников
кооперацию и самоусиление (см. rлаву 8). Таким образом, ero можно рассматривать
как универсальный, несмотря на неполное развитие модели, описывающей возник-
новение явления коллективноro порядка в сложных системах, которые начинаются с
полноro беспорядка.
Самоорrанизующиеся карты можно также рассматривать как векторный кванто-
ватель, реализуя таким образом принципиальный подход к выводу правила коррек-
ции, используемоro для настройки векторов весов [691]. Этот последний подход еще
раз подчеркивает роль функции окрестности, выступающей в роли функции плотно-
сти вероятности.
Однако следует особо отметить, что последний подход, основанный на использова-
нии в (9.19) в качестве минимизируемой функции стоимости среднеro распределения
D 1 , может быть оправдан только в том случае, если карта признаков уже достаточно
хорошо упорядочена. В [285] показано, что динамика обучения самоорrанизующейся
карты на этапе упорядочивания адаптивноrо процесса (т.е. во время тополоrическоro
упорядочивания изначально беспорядочной карты признаков) не может быть опи-
сана стохастическим rpадиентным спуском с одной функцией стоимости. Однако в
случае одномерной решетки этот процесс может быть описан с использованием мно-
жества функций стоимости по одной для каждоrо нейрона сети. При этом эти
функции независимо минимизируются в соответствии с методом стохастическоrо
rpадиентноrо спуска.
В алroритме SOM удивляет то, насколько он леrко реализуем, и при этом довольно
сложно анализировать ero свойства, используя математический аппарат. Для ero ана-
лиза некоторыми исследователями был предложен ряд мощных методов, однако их
результаты имеют оrpаниченную область применения. В [214] бьm приведен обзор pe
зультатов, полученных в теоретических аспектах алrоритма SOM. В частности, бьти
подчеркнуты недавние результаты, полученные в [304], [305], [де утверждалось, что
в случае одномерной решетки можно получить cтporoe доказательство сходимости
Задачи 615
"почти наверняка" алroритма SOM к единственному состоянию после прохожде
ния им этапа самоорrанизации. Этот важный результат был показан для довольно
широкоro класса функций окрестности. Однако то же самое нельзя утверждать для
MHoroMepHblx решеток.
Последним вопросом рассмотрения стал порядок. Так как самоорrанизующиеся
карты были навеяны идеями, полученными при исследовании карт коры roловноrо
мозrа, вполне естественным выrлядит то, что эта модель может описывать формиро
вание этих самых карт мозrа. Такое исследование бьmо представлено в [283]. В этой
работе показано, что самоорrанизующаяся карта признаков способна объяснить фор
мирование вычислительных карт в первичной зрительной коре МОЗ2а (primary visual
cortex) макаки. Использовавшееся в этом исследовании входное пространство было
пятимерным. Две размерности использовались для описания положения поля BOC
приятия В пространстве сетчатки, а оставшиеся три для предпочтения ориентации
(orientation preference), ориентационной избирательности (orientation selectivity) и
окулярною доминирования (ocular dominance). Поверхность коры мозrа была поделе-
на на небольшие участки, которые рассматривались как вычислительные элементы
(т.е. искусственные нейроны) на двумерной квадратной решетке. При некоторых дo
пущениях бьmо показано, что обучение Хебба ведет к созданию пространственных
моделей ориентации и окулярноro доминирования, которые поразительно сходны с
обнаруженными в мозre макаки.
Задачи
Алrоритм SOM
9.1. Пусть g(Yj) некоторая нелинейная функция отклика Yj, которая исполь
зуется в алrоритме SOM (9.9). Что случится, если постоянное слаrаемое в
разложении функции g(Yj) в ряд Тейлора не равно нулю.
9.2. Пусть n(у) rладкая функция шума в модели на рис. 9.6. Используя разло
жение Тейлора меры искажения (9.19), определите слаrаемое искривления,
возникающее в модели шума n(у).
9.3. Иноrда rоворят, что алroритм SOM сохраняет тополоrические связи, cy
ществующие во входном пространстве. [рубо rоворя, это свойство можно
rарантировать только для входноro пространства с размерностью, меньшей
или равной размерности нейронной решетки. Обсудите справедливость этоro
утверждения.
9.4. [оворят, что алroритм SOM, основанный на конкурентном обучении, не об
ладает отказоустойчивостью. Это значит, что этот алrоритм толерантен к
616
rлава 9. Карты самоорraнизации
1
i
ошибке, Т.е. небольшое возмущение входноro вектора способно вызвать рез-
кий переход выхода от победившеrо нейрона к соседнему. Обсудите справед-
ливость этих утверждений.
9.5. Рассмотрим пакетную версию алrоритма SOM, полученную представлением
выражения (9.23) в ero дискретной форме:
Wj ==
"'" п. .х.
L.J ];" z
' j == 1, 2, .. . , l.
1tj,i
i
Покажите, что эта версия алroритма SOM может быть выражена в форме,
описанной в [186] (см. rлаву 5).
Квантизация векторов обучения
9.6. В этой задаче рассмотрим оптимизированную форму алroритма квантизации
векторов обучения (см. раздел 9.7) [568]. При этом требуется систематизиро-
вать эффект от коррекции векторов BOpOHOro в разное время, чтобы получить
равное влияние в конце периода обучения.
В первую очередь покажите, что уравнения (9.30) и (9.31) можно объеди-
нить в одно, имеющее следующий вид:
wc(n + 1) == (1 snan)wc(n) + snanx(n),
[де
{ + 1 при корректной классификации,
Sn == 1 u Ф
при некорректнои класси икации.
(9.36)
Исходя из этоro, покажите, что критерий оптимизации, описанный в по-
становкезадачи,удовлетворяется, если
а n == (1 snan)an l'
(9.37)
а оптимальное значение константы обучения а n равно
a opt ==
n
a opt
n 1
opt .
1 + Snan l
9.7. Правила коррекции для обоих собственных фильтров максимума, о которых
речь пmа в rлаве 8, и для самоорrанизующейся карты используют модифика-
ции постулата обучения Хебба. Сравните эти две модификации и найдите в
них сходства и отличия.
Задачи 617
2,0
Х 2
Рис. 9.19. Линейная плотность распределения входных 0,0
данных I,O
Х\
1,0
9.8. Ал20рИтм с учетом "совести" является модификацией алrоритма SOM, KOTO
рая приводит к точному соответствию плотности распределения [254]. В этом
алrоритме (табл. 9.4) каждый из нейронов отслеживает, сколько раз он по
бедил в соревновании (т.е. сколько раз ero вектор синаптических весов был
ближе друrих нейронов к вектору входноro сиrнала в смысле Евклидова
расстояния). Здесь следует сделать замечание, что если нейрон побеждает
слишком часто, он "чувствует себя виновным" (feels guilty) и выводит себя
из конкуренции.
Для исследования улучшения подобия плотности, вызываемоrо алroрит
мом с учетом "совести", рассмотрим одномерную решетку (т.е. линейный
массив), состоящую из 20 нейронов, которые обучаются на входных приме
рах с линейной плотностью (рис. 9.19).
. С помощью компьютерноrо моделирования сравните соответствие плот
ности в результате применения алroритмов SOM и алroритма с учетом
"совести". В алrоритме SOM параметр скорости обучения 11 == 0,05,
а в алrоритме с учетом "совести" используются следующие параметры:
В == 0,0001, С == 1, 0,11 == 0,05.
. Как часть эксперимента рассмотрите "точное" соответствие входной плот
ности.
Обсудите результаты компьютерноro моделирования.
Компьютерные эксперименты
9.9. В этом эксперименте для исследования алrоритма SOM, примененноro к
одномерной решетке с двумерным входом, будем использовать компьютер
ное моделирование. Эта решетка состоит из 65 нейронов. Входы состоят из
I
.........
618 rлава 9. Карты самоорrанизации
r
I
ТАБЛИЦА 9.4. Алroритм с учетом "совести" в сжатом виде
1. Находим вектор синаптических весов Wi, ближайший к входному вектору х:
Ilx Will == min Ilx Wj 11, j == 1,2, .. . ,N
J
2. Вычисляем общее количество моментов времени, Pj, в которые нейрон j по
бедил в соревновании:
pjew == pjld + B(Yj pjld), [де О < В « 1 и
{ 1, если нейрон j является победившим,
Yj о в противном случае.
В начале алrоритма Pj инициализируется значением нуль.
3. Находим победивший нейрон, используя механизм conscience:
IIx will == min (lIx Wjll b j ),
J
rдe b j слаrаемое смещения, модифицирующее соревнование:
Ь. == С ( !.. Р . )
J N У'
[де С множитель смещения; N общее количество нейронов в сети
4. Корректируем вектор синаптических весов победившеro нейрона:
W ew == w ld + 1'](х w ld),
[де 1'] обычный параметр скорости обучения, используемый в алroритме SOM
Х 2
Х 1 Рис. 9.20. Треуrольная область распределения вход-
ных данных
случайных точек, равномерно распределенных в треуrольной области, пока-
занной на рис. 9.20. Вычислите карту, полученную алrоритмом SOM после
0,20, 100, 1000, 10000 и 25000 итераций.
9.10. Рассмотрите двумерную решетку нейронов, обучаемую на основе входных
сиrналов с трехмерным распределением. Данная решетка имеет размер 10 х
10 нейронов.
Задачи 619
Входной сиrнал равномерно распределен в области, определенной следу
ющим образом:
{(О < Хl < 1), (О < Х2 < 1), (О < ХЗ < 0.2)}.
Для вычисления двумерной проекции входноro пространства после 50,
1000 и 10000 итераций используйте алroритм SOM.
Повторите вычисления для случая, коrда вход равномерно распределен в
параллелепипеде:
{(О < Хl < 1), (О < Х2 < 1), (О < ХЗ < 0.4)}.
Повторите вычисления еще раз для входа, равномерно распределенноrо в
кубе:
{(О < Хl < 1), (О < Х2 < 1), (О < ХЗ < 1)}.
Обсудите результаты проведенноrо моделирования.
9.11. При использовании алroритма SOM иноrда возникает проблема тополоrиче
CKOro упорядочивания, называемая "скручиванием" (folded) карты. Эта про
блема возникает в случаях, коrда размер окрестности убывает слишком быст
ро. Создание скрученной карты можно рассматривать как одну из форм "ло
кальноrо минимума" процесса тополоrиqескоro упорядочивания.
Для Toro чтобы исследовать это явление, рассмотрим двумерную решетку
размером 10 х 20 нейронов, обучаемую на основе двумерных входов, paB
номерно распределенных в квадрате {( 1 < х 1 < + 1), ( 1 < Х2 < + 1) }.
С помощью алrоритма SOM вычислите карту, сужая при этом окрестность
победившеro нейрона быстрее обычноrо. Чтобы явно увидеть ошибку упо
рядочивания, нужно повторить этот эксперимент несколько раз.
j
I
!
.(
9.12. Свойство тополоrическоrо упорядочивания алroритма SOM можно исполь
зовать для формирования абстрактноrо двумерноrо представления входноrо
пространства более BbICOKOro порядка. Для TOro чтобы исследовать эту форму
представления, рассмотрим двумерную решетку размером 10 х 10 нейронов,
обучаемую на основе входов, состоящих из четырех [ауссовых множеств, С 1,
С 2 , С З И С 4 . Все эти множества имеют единичную дисперсию, но разные цeH
тры: (О, О, . . . , О), (4, О, О, . . . , О), (4,4, О, . . . , О) и (0,4, О, . . . , О). С помощью
алrоритма SOM вычислите карту и пометьте каждый из нейронов этой карты
именем тoro класса, который наиболее полно представлен окружающими ero
входными точками.
620
rлава 9. Карты самоорrанизации
1
9.13. В табл. 9.5 представлен в сжатом виде ренормализованный ал20ритм SOM
(renonnalized SOM algorithm). Краткое описание этоrо алrоритма см. в раз-
деле 9.3. Сравните обычный алrоритм SOM с ренормализованным, обратив
внимание на следующие вопросы.
1. Сложность кодирования в реализации алroритма.
2. Время, затрачиваемое компьютером на обучение.
Проиллюстрируйте результаты сравнения этих двух алrоритмов, исполь-
зуя данные, взятые из paBHoMepHoro распределения внутри квадрата, и сле-
дующие две конфиrypации сети.
1. Одномерная решетка из 257 нейронов.
2. Одномерная решетка из 2049 нейронов.
В обоих случаях начните с исходноro количества векторов кодирования,
paBHoro двум.
9.14. Рассмотрим пространственно сиrнальную диаrpамму, показанную на рис. 9.21.
Она соответствует М мерной амплитудно импульсной модуляции (M ary
pulse amplitude modulation) для М == 8. Каждая точка сиrнала представлена
прямоуrольным импульсом с соответствующей амплитудой:
753 1
p(t) == ::1:2' ::1:2' ::1:2' ::1:2' о t Т,
[де Т интервал сиrнала. На входе получателя к сиrналу добавляется [аус-
сов шум с нулевым средним, меняющий соотношение сиrнал/шум (SNR).
SNR определяется как отношение "средней" мощности переданноrо сиrнала
к мощности аддитивноro шума.
а) Используя случайную двоичную последовательность на входе передатчи
ка, сrенерируйте данные, полученные приемником дЛЯ SNR== 1 0,20 и 30 дЕ.
б) Для каждоro из этих значений SNR сreнерируйте самоорrанизующуюся
карту. Для типичных значений можно использовать следующее.
Входной вектор, составленный из восьми элементов, полученных под
выборкой восьми элементов из одноro интервала дискретизации сиrна-
ла. (Знаний о временных характеристиках сиrнала не предполаrается.)
Одномерная решетка, состоящая из 64 нейронов (т.е. восьмикратный
размер входноrо вектора).
в) Нарисуйте карту признаков для каждоrо из трех SNR и таким образом
продемонстрируйте свойство тополоrическоro самоупорядочивания алro
ритма SOM.
111
Задачи 621
101 100
+ +Z
2 2
. .
Код 000 001 011 010 110
7 5 3 1 +!
Амплитуда 2 2 2 2 2
. . . . .
+1
2
.
Рис. 9.21. Пространственно сиrнальная диаrрамма
Средняя точка
1. Инициализация
ТАБЛИЦА 9.5. Алroритм ренормаЛИЗ0ванноrо обучения (одномерная версия)
Про изводим коррекцию победившеrо нейрона и ero "тополо
rических соседей". При этом можно оставить параметр ин
тенсивности обучения на некотором фиксированном значении
(например, на 0,125) и использовать для победившеrо нейрона
коэффициент ", а для ero соседей ,,12
5. Разбивка Koдo Продолжаем корректировку кодовой книrи (шаr 4), каждый
раз используя новый входной вектор, случайно выбираемый
из множества примеров обучения, пока количество этих KOp
ректировок в 10 30 раз не превзойдет количество векторов KO
дирования. После этоro кодовая книrа разбивается. Это можно
выполнить с помощью строки Пеано (Реапо string) имеющих
ся векторов кодирования и такой интерполяцией их положе
ний, которая обеспечивает самое точное приближение строки
Пеано. Для этоrо можно поместить дополнительный вектор
кодирования между двумя уже существующими
Корректировка и разбивка кодовой книrи продолжается до тех
пор, пока общее количество векторов кодирования не достиr
нет HeKoToporo наперед заданноro значения (например, 100).
После этоro обучение прекращается
Прuмечанuе. Разбивка кодовой книrи после каждой эпохи приблизительно удваивает количество
векторов кодирования, поэтому для этоro процесса требуется не так уж MHOro эпох.
2. Выбор вxoдHO
20 вектора
3. Кодирование
входН020 вектора
4. Корректировка
кодовой КНИ2И
вой КНИ2И
6. Завершение
обучения
Устанавливаем количество векторов кодирования в некоторое
малое число (для простоты можно использовать число 2 или
некоторое большее значение, соответствующее сложности за
дачи). Устанавливаем их положение в случайно выбранные
примеры обучения
Из множества примеров обучения случайным образом выби
раем входной вектор
Определяем "победивший" входной вектор (т.е. вектор синап
тических весов нейрона победителя). Для этоro можно ис
пользовать правило "ближайшеrо соседа" или "минимальноro
искажения"
I
Модели на основе теории
информации
10.1. Введение
в своей классической работе Клод Шеннон (Claude Shennon) изложил основы тeo
рии информации (infonnation theory) [970]. Эта работа 1, а также дальнейшее развитие
теории информации друrими исследователями были ответом на потребность специ
алистов в области электроники в создании одновременно эффективных и надежных'
систем. В свете практических применений теория информации в том виде, в KO
тором она существует сеrодня, является математической теорией, проникающей в
самую сущность процесса взаимодействия (communication process). Эта теория OT
крыла простор для изучения таких фундаментальных вопросов, как эффективность
представления информации и оrpаничения, налаrаемые на надежность передачи ин-
формации по каналам связи. Более Toro, эта теория охватывает массу мощнейших тео-
рем, вычисляющих идеальные rpаницы для оптимальноrо представления и передачи
информационных сиrналов. Эти оrpаничения являются чрезвычайно важными, так
как они описывают критерии улучшения архитектуры систем обработки информации.
rлавной целью настоящей rлавы является рассмотрение информационно-
теоретических моделей (infonnation-theoretic model), которые при водят к caMOOp
rанизации. В этом контексте моделью, которая имеет особое значение, является
принцип максимума взаимной информации 2 (maximum mutual intonnation principle)
Линекера [653], [654]. Этот принцип rласит, что синаптические связи мноrослойной
нейронной сети орrанизуются таким образом, чтобы при определенных условиях MaK
1 Детальное изложение теории информации содержится в [221] и [377]. Также можно обратиться к сбор
нику работ [1000], содержащему среди прочих и классическую работу Шеннона [970]. Работа Шеннона также
воспроизведена снезначительными измеиениями в [971] и [1001].
Краткое изложение основных принципов теории информации, касающихся нейронных сетей, содержится в
[77]. Трактовка теории информации с биолоrической точки зреиия содержится в [1173].
2 Не следует путать принцип максимума взаимной информации Лиискера для самоорrанизующихся си-
стем справнлом сохранеиия контекста информации (iпfоrmаtiоп сопtехt preservation rule) в принятии решений
практическоro метода, рассмотрениоro в шаве 7.
10.2. Энтропия 623
симизировать объем информации, которая сохраняется при преобразовании ситала
на каждой из стадий обработки СИ2нала в сети. Эта идея, предложенная теори-
ей информации для описания обработки сиrнала, не является новой З . Достаточно
вспомнить раннюю работу, в которой для систем обработки информации предложена
следующая информационно-теоретическая функция [83].
rлавной функцией систем обработки СИ2нала является раскрытие некоторой
избыточности стимулирования для описания или кодировки информации в форме,
более экономной, чем та, в которой она воспринимается рецепторами.
rлавной идеей работы [83] является признание Toro, что кодирование данных с це-
лью уменьшения избыточности связано с идентификацией их спеЦИфИЧflЫХ свойств.
Эта идея связана с особой точкой зрения на мозr, приведенной в [230], rдe модель
внешнеrо мира строилась как набор закономерностей и оrpаничений.
Структура rлавы
Эта rлава состоит из двух основных частей. В первой части (разделы 10.2 10.5) изла-
rаются основы теории информации. В разделе 10.2 описывается концепция энтропии
как количественной меры информации, что естественным образом приведет к прин-
ципу максимума энтропии, описываемому в разделе 10.3. Далее, в разделе 10.4, мы
обсудим концепцию взаимной информации, затем в разделе 10.5 последует описание
диверrенции Кулбека Лейблера.
Вторая часть этой rлавы (разделы 10.6 10.14) посвящена информационно-
теоретическим моделям самоорrанизующихся систем. В разделе 10.6 взаимная ин-
формация выводится в paHr оптимизируемых целевых функций. В разделе 10.7 опи-
сывается принцип максимума взаимной информации, за чем в разделе 10.8 следует
рассмотрение взаимосвязи между этим принципом и уменьшением избыточности.
В разделах 10.9, 10.10 рассматриваются два варианта принципа взаимной инфор-
мации, которые применимы к разным задачам обработки изображений. В разде
лах 10.11 10.14 описываются три различных метода решения задачи слепО20 раз-
деления источников СИ2нала (blind source separation problem).
Как Bcerдa, rлава завершается некоторыми заключительными замечаниями.
10.2. Энтропия
Следуя терминолоrии, принятой в теории вероятности, для обозначения случайных
переменных будем использовать прописные буквы, при этом одноименными строч-
ными буквами обозначим их значения.
3 Обзор литер а 1УР Ы , посвященной связи теории информации с восприятнем (perception), содержится в [77]
н [650].
624 rлава 10. Модели на основе теории информации
т
I
Рассмотрим случайную переменную Х, каждая из реализаций которой может pac
сматриваться как сообщение (message). rрубо roворя, если случайная переменная Х
является непрерывной на всей своей области значений, то она несет в себе беско-
нечный объем информации. Однако с биолоrической и физической точки зрения бес
смысленно рассуждать в терминах измерения амплитуды с бесконечной точностью.
Таким образом, значения переменной Х Moryт быть равномерно дискретизированы
на конечное число уровней. Следовательно, Х можно рассматривать как дискретную
случайную переменную, моделируемую следующим образом:
Х == {Xklk == О, ::1:1,... , ::I:K},
(10.1 )
rдe Xk дискретное число; (2К + 1) общее количество дискретных уровней. Раз
личие ОХ между дискретными уровнями предполаrается достаточно малым, чтобы
обеспечить адекватное представление рассматриваемой переменной. Можно, есте-
ственно, принять за ОХ число нуль и перейти к множеству мощности континуум.
В этом случае мы получим непрерывную случайную переменную, для которой cyм
мирование нужно заменить интеrpированием (что будет показано далее).
Чтобы завершить описание модели, примем следующее допущение: пусть Х == Xk
С вероятностью
Pk == Р(Х == Xk)
(10.2)
при условии
к
О Pk 1 и L Pk == 1.
k K
(10.3)
Предположим, что событие Х == Xk наступает с вероятностью Pk == 1. Отсюда
следует, что Pi == О для всех i i- k. В этом случае не будет неожиданности, а сле-
довательно и новой информации, в наступлении события Х == Xk, так как мы знаем
наверняка, что это событие должно произойти. Если же, с друrой стороны, различ-
ные уровни MOryт достиrаться с различной вероятностью и если эта вероятность Pk
достаточно мала, то наступление события Х == Xk, а не Х == Xi будет нести в себе
больше информации. Таким образом, слова "неопределенность", "неожиданность"
и "информация" тесно взаимосвязаны. В наступлении события Х == Х k есть боль-
шая доля неопределенности. В том, что это событие действительно произошло, есть
элемент неожиданности или сюрприза. После наступления события Х == Х k наблю-
дается увеличение объема информации. Эти три величины по сути являются одним и
тем же. Более TOro, объем информации является величиной, обратной к вероятности
возникновения события.
10.2. Энтропия 625
Определим объем информации, собранный с наступлением события Х Х k С
вероятностью Pk, как следующую лоrарифмическую функцию:
I(Xk) == log ( :k ) == logpk, (10.4)
rдe основание лоrарифма про изволь но. Если используется натуральный лоrарифм,
единица информации называется нат (nat), а если лоrарифм по основанию 2 то
бит (bit). В любом случае определение информации (10.4) обладает рядом следую-
щих свойств.
1.
I(xk) == О, если Pk == 1.
(10.5)
Если мы абсолютно уверены в наступлении определенноrо события, то ero воз
никновение не несет в себе информации.
2.
I(Xk) О, если О Pk 1.
(l0.6)
Это значит, что возникновение события Х == Х k либо несет в себе информацию,
либо нет, но никоrда не приводит к потере информации.
3.
I(Xk) > I(xi), если Pk < Pi'
(10.7)
Чем меньше вероятность события, тем больше информации несет в себе
ero наступление.
Объем информации 1 (х k) является дискретной случайной переменной с вероятно-
стью Pk. Среднее значение I(Xk) на полном диапазоне (2К+l) дискретных значений
вычисляется следующим образом:
к к
Н(Х) == E[I(Xk)] == L PkI(xk) == L Pk logpk.
k K k K
(10.8)
Величина Н(Х) называется энтропией (entropy) случайной переменной Х, при-
нимающей конечное множество дискретных значений. Это название еще раз подчер-
кивает аналоrию между определением (10.8) и определением энтропии в статистиче-
ской термодинамике 4 . Энтропия Н (Х) является мерой средне20 объема информации,
4 Термин "энтропия" В теории информации получил свое назваиие по аналоrии с энтропией в термодинами
ке, описываемой следующей формулой (см. таву 11): Н == kB L: р" logp", rдe kB константа Больцмана;
"
р" вероятность тоro, что система находится в состоянии 0:. За исключением множителя kB эитропия Н В
термодинамике имеет точно такую же математическую формулу, что и формула энтропии (10.8).
626 rлава 10. Модели на основе теории информации
которую содержит в себе сообщение. Однако обратите внимание на то, что Х в
обозначении Н (Х) не является apryMeHToM функции, а представляет собой метку
случайной переменной. Также обратите внимание на то, что в определении (10.8)
значением произведения О .1og(0) считается нуль.
Энтропия Н(Х) может принимать следующие значения:
О Н(Х) log(2K + 1),
(10.9)
rдe (2К + 1) общее количество дискретных уровней. Более TOro, можно сформу
лировать следующие утверждения.
1. Н(Х) == О Torдa и только Torдa, коrда Pk == 1 для HeKoToporo k, а для всех
остальных уровней вероятность равна нулю. Эта нижняя rpаница энтропии COOT
ветствует отсутствию неопределенности.
2. Н(К) == log2(2K + 1) Torдa и только Torдa, коrда Pk == 1/(2К + 1) для всех k
(т.е. если все дискретные значения равновероятны). Эта верхняя rpаница энтропии
соответствует максимальной неопределенности.
Доказательство BTOpOro свойства вытекает непосредственно из следующей лем
мы [377].
Для любых двух распределений {Pk} и {qk} дискретной случайной переменной Х
не равенство
LPk log ( Pk ) О
k qk
(10.1 О)
обращается в равенство тО2да и только тоzда, коzда qk == Pk для всех k.
Величина, используемая в приведенной лемме, имеет такое фундаментальное зна
чение, что мы остановимся, чтобы привести ее к виду, более удобному для изучения
стохастических систем. Пусть Р х (х) и qx (х) вероятности Toro, что случайная пе
ременная Х находится в состоянии х при двух различных условиях. Относительная
энтропия (relative entropy) или дивер2енция Кулбека Лейблера (Kullback-Leibler di
vergence) между двумя вероятностными функциями массы (probability mass function)
определяется следующим образом [221], [377], [605]:
"" ( Рх(х) )
D p11q == px(x) log qx(x) ,
(10.11)
rде суммирование ПрОБОДИТСЯ по всем возможным состояниям системы (т.е. по ал
фавиту Х дискретной случайной переменной Х). Функция массы вероятности qx(x)
выступает в роли меры ссылки (reference measure).
10.2. Энтропия 627
Дифференциальная энтропия непрерывной случайной
переменной
В рассмотрении информационно-теоретических концепций до сих пор участвовали
только дискретные случайные переменные. Некоторые из этих концепций можно
распространить и на непрерывные случайные переменные.
Рассмотрим случайную переменную Х, имеющую функцию плотности вероят-
ности f х (х ). По аналоrии с энтропией дискретной случайной переменной введем
следующее определение:
h(X) == 1: fx(x) log fx(x)dx == E[log fx(x)].
(10.12)
Величина h( Х) называется дифференциальной энтропией (differential entropy)
случайной переменной Х, что отличает ее от обычной или абсолютной энтропии
(absolute entropy). Нельзя не признать тот факт, что несмотря на то, что величи
на h(X) является полезной с математической точки зрения, она не имеет никакоrо
значения в смысле меры случайности переменной Х.
Теперь обоснуем использование формулы (10.12). Начнем с рассмотрения непре-
рывной случайной переменной Х как предельной формы дискретной случайной пе-
ременной Xk == kox, rдe k == О, ::1:1, ::1:2,..., а ОХ стремится к нулю. По определению
непрерывная случайная переменная Х принимает значения в интервале [Xk, Xk + ох]
с вероятностью f х (х k) ОХ. Исходя из этоro, устремляя ОХ к нулю, обычную энтропию
непрерывной случайной переменной Х можно выразить через следующий предел:
00
Н(Х) == lim L fX(Xk)OX log(fX(Xk)OX) ==
ох.....о k oo
== o o [kfoo fX(Xk) log(fX(Xk)OX) + log ОХ kfoo fX(Xk)OX)]
== J:O fx(x) log fx(x)dx i o log ОХ J:O fx(x)dx ==
== h(X) lim log ОХ,
ох.....о
(10.13)
rде в последней строке использовалось выражение (10.12) и тот факт, что общая пло
щадь области под кривой функции плотности вероятности fx(X) равна единице. В
пределе, по мере достижения величиной ОХ нуля, значение log ОХ достиrает беско
нечности. Интуитивно это понятно, так как непрерывная случайная переменная при
нимает все значения из открытоro интервала ( oo, (0), а неопределенность, ассоци
ированная с этой переменной, имеет порядок бесконечности. Мы избеrаем проблем,
связанных со слаrаемым log ОХ, принимая h(X) за дифференциальную энтропию,
а слаrаемое log Ох за ссылку. Более тoro, так как информация, обрабатываемая
стохастической системой, представляет собой разницу между двумя слаrаемыми эн-
628 rлава 10. Модели на основе теории информации
тропии, которые имеют общую ссьтку, информация будет такой же, как и разность
между соответствующими слаrаемыми дифференциальной энтропии. Таким образом,
мы обосновали использование слаrаемоrо h(X), определенноrо соrласно (10.13), в
качестве дифференциальной энтропии непрерывной случайной переменной Х.
При использовании вектора Х, состоящеro из n случайных переменных
Х 1 , Х 2 ,. . . , Х n , дифференциальная энтропия определяется как n-й интеrpал
h(X) == 1: fx(x)logfx(x)dx == E[logfx(x)],
(10.14)
rдe fx(x) функция плотности совместной вероятности Х.
Пример 10.1
Равномерное распределение
Рассмотрим случайную переменную Х, равномерно распределенную в интервале [0,1]:
!х(х) == { 1, О х 1,
О в противном случае.
Применяя выражение (10.12), получаем, что дифференциальная энтропия равна нулю:
h(X) == [: 1 . log ldx == [: 1. Odx == О.
.
Свойства дифференциальной энтропии
Из определения дифференциальной энтропии h(X) (10.12) видно, что при переме
щении ее значение не меняется, Т.е.
h(X + с) == h(X), (10.15)
rде с константа.
Еще одно важное свойство дифференциальной энтропии описывается следую
щим образом:
h(aX) == h(X) + log lal,
(10.16)
rдe а масштабирующий множитель. Для TOro чтобы доказать это свойство, вспом
ним, что площадь области под кривой функции плотности вероятности равна едини
це, и тоrда:
fy(y) == ' ' fy ( ) .
(10.17)
10.3. Принцип максимума энтропии 629
Затем, используя формулу (10.12), можно записать:
h(Y) == E[log fy(y)] == E [log C I fy ( ) ) ] == E [lOg fy ( )] + log lal.
Подставляя вместо У произведение аХ, получим:
h(aX) == 1: fx(x) log fx(x)dx + log Jal,
из чеrо непосредственно вытекает свойство (10.16).
Свойство (10.16) применимо к скалярной случайной переменной. Ero можно обоб-
щить для случая произведения случайноro вектора Х и матрицы А:
h(AX) == h(X) + log Idet(A)1,
(10.18)
rдe det(A) определитель матрицы А.
10.3. Принцип максимума энтропии
Предположим, что существует некоторая стохастическая система с множеством из
вестных Состояний, но с неизвестными вероятностями, и что некоторым образом
происходит процесс обучения оrpаничениям распределения вероятности этих COCTO
яний. Этими оrpаничениями MOryT быть некоторые средние по множеству значения
или rpаницы значений. Задача состоит в выборе такой модели вероятности, которая
будет оптимальной в некотором смысле при наличии априорных знаний о модели.
Обычно оказывается, что этим условиям удовлетворяет бесконечное множество мо-
делей. Какую же модель из них выбрать?
Ответ на этот фундаментальный вопрос можно получить путем применения прин
ципа максимальной энтропии 5 (maximum entropy principle) [512]. Этот принцип зву-
чит следующим образом [511], [512].
5 В [982] было доказано, что принцип максимальной энтропии корректен в следующем СМЫСЛе.
для данных знаний в форме 02раничений существует только одно распределение, удовлетворяющее этим
02раниченuям, которое можно выбрать с помощью процедуры, удовлетворяющей "аксиомам СО2Ласованности"
(coпsisteпcy axioms). Это уникальное распределение определяется максимизацией энтропии.
Ниже приведены эти аксиомы соrласованности.
1. Уникальность. Результат должен быть уникальным.
2. Инвариантность. Выбор системы координат не должен влиять на результат.
3. Независимость системы. Не должно иметь значения, будет ли Независимая информация о независимых
системах браться в расчет как в терминах различных плотностей раздельно, так и вместе, в терминах
совместной плотности.
4. Независимость подмножеств. Не должно иметь зиачения, будет ли независимое множество состояний си
стемы рассматриваться в терминах условной плотности или полной плотности системы.
В [982] было показано, что относительная энтропия, или диверrенция Кулбека Лейблера, также удовлетво-
ряет аксиомам соrласованности.
630 rлава 10. Модели на основе теории информации
Если выводы основываются на неполной информации, она должна выбираться из
распределения вероятности, максuмизирующе20 энтропию при заданных оzpаничени-
ях на распределение.
В результате понятие энтропии определяет некоторый род меры пространства pac
пределений вероятности, при которой распределениям с ВЫСокой энтропией отдается
предпочтение перед остальными.
Исходя из этоro утверждения, становится совершенно очевидным, что задача мак-
симизации энтропии является задачей условной оптимизации. Для иллюстрации pe
шения этой задачи рассмотрим максимизацию дифференциальной энтропии
h(X) == 1: fx(x) log fx(x)dx
на всех функциях распределения вероятности f х (х) случайной переменной Х при
соблюдении следующих условий.
1. fx(x) О, причем равенство достиrается независимо от х.
2.
1: fx(x)dx == 1.
3.
1: fx(X)9i(X)dx == IXi, i == 1,2,... ,т,
rде 9i (х) некоторая функция от х.
Условия 1 и 2 являются фундаментальными свойствами функции плотности Bepo
ятности. Условие 3 определяет моменты Х, которые зависят от способа определения
функции 9i(X). В результате условие 3 суммирует все априорные знания о случай-
ной переменной Х. Для TOro чтобы решить эту задачу условной оптимизации, будем
использовать метод множителей Ла2ранжа 6 . Сначала составим целевую функцию:
J(f) 1: [ fx(X) log fx(x) + "лоfх(Х) + t Л;9,(Х)fх(х)] dx,
(10.19)
rдe л'l, л'2,. . ., л'm множители Лazранжа (Lagrange multipliers). Дифференцируя
интеrpал по f х (х) и приравнивая результат к нулю, получим:
m
1 log fx(x) + л,о + L л'i9i(Х) == О.
i l
6 МетОД множителей Лаrpанжа рассматривается в [263].
10.3. Принцип максимума энтропии 631
Решая это уравнение относительно неизвестной функции f х (х ), получим:
fx(x) ехр ( 1+Ло + л.g;(х)).
(10.20)
Множители Лаrpанжа в (10.20) выбираются в соответствии с условиями 2 и 3.
Равенство (10.20) определяет распределение с максимальной энтропией как реше-
ние задачи.
Пример 10.2
Одномерное ['ауссово распределение
Предположим, известны следующие характеристики случайной переменной Х: ее среднее зна-
чение 11 и дисперсия 02. По определению имеем:
[: (х 11)2 !x(x)dx == 02 == const.
Сравнивая это равенство с условием 3, видим, что
g1 (х) == (х 11)2,
а 1 ==02.
Используя равенство (10.20), получим:
!х(х) == exp[ 1 + 1.0 + Л1(Х 11)2].
Обратите внимание, что 1.1 будет отрицательным, если интеrpалы от !х(х) и (х 0)2 !х(х) по
х сходятся. Подставляя это равенство в условия 2 и 3, а затем разрешая результат относительно 1.0
и 1.1, получим:
А.о == 1 log(21t0 2 )
и
1
1.1 == 202 .
Таким образом, искомая форма функции !х(х) имеет следующий вид:
1 ( (х 11)2 )
!х (х) == )21to ехр 202 ' (10.21)
в чем леrко можно узнать плотность вероятности zауссовой случайной переменной Х со cpek
ним значением 11 и с дисперсией 02. Максимальное значение дифференциальной энтропии такой
случайной переменной выrлядит так:
1
h(X) == 2' [1 + log(21t0 2 )]. (10.22)
На основании результатов этоro примера можно сделать следующие выводы.
1. Для данной дисперсии 02 zауссова случайная nеременная имеет наибольшую дифференциаль-
ную энтропию среди любых случайных nеременных. Это значит, что если Х является rауссовой
случайной переменной, а У любая друrая случайная переменная с тем же средним значением
и дисперсией, то для всех У выполняется
h(X) h(Y),
причем равенство достиrается только при совпадении распределений Х и У.
632 rлава 10. Модели на основе теории информации
2. Энтропия zayccoBou случайной переменной Х однозначно определяется ее дисперсией (т.е. не
зависит от ее среднеro значения).
.
Пример 10.3
Миоrомериое raYCCOBO распределеиие
В этом примере мы на основании результатов примера 10.2 оценим дифференциальную энтро-
пию MHoroMepHoro rayccoBa распределения. Так как энтропия rауссовой случайной переменной Х
не зависит от среднеro значения, можно вполне обоснованно упростить рассмотрение, приияв сред-
нее значение случайноro вектора Х размерности m х 1 за нуль. Пусть статистика BTOpOro порядка
Х описывается матрицей ковариации Е, определенной как среднее значение произведения вектора
Х caмoro на себя. Функция rтотности совместной вероятности случайноro вектора Х задается в
следующем виде:
!х(Х) == (21t)m/2( et(E))1/2 ехр ( xTE lx) , (10.23)
rде det(o) определитель матрицы О. Равенство (10.14) определяет дифференциальную энтропию
Х. Исходя из этоro, подставим (10.23) в (10.14) и получим:
1
h(X) == '2[т + m log(21t) + log Idet (E)I]. (10.24)
Заметим, что равенство (10.22) является Bcero лишь частным случаем более общеro равенства
(10.24). В свете принципа максимума энтропии можно утверждать, что для данной матрицы КО-
вариации Е MHoroMepHoe rayccoBo распределение (10.23) имеет нанбольшую дифференциальную
энтропию среди случайных векторов с нулевым средним значением. Этот максимум энтропии имеет
значение, определяемое формулой (10.24). .
10.4. Взаимная информация
При создании самоорrанизующихся систем rлавной целью бьmа разработка TaKO
ro алroритма, который способен обучаться отображению входа на выход на основе
только входноro сиrнала. В этом контексте понятие взаимной информации имеет осо-
бое значение из-за своих отдельных свойств. Для TOro чтобы подrотовить почву для
дискуссии, рассмотрим стохастическую систему с входом Х и выходом У. Х и У МО-
ryт принимать только дискретные значения х и у соответственно. Энтропия Н(Х)
является мерой изначальной неопределенности Х. Как можно измерить неопределен
ность Х на основе наблюдения У? Чтобы ответить на этот вопрос, введем понятие
условной энтропии (conditional entropy) Х и У [221], [377]:
H(XIY) == Н(Х, У) Н(У).
(10.25)
Условная энтропия имеет следующее свойство:
о H(XIY) Н(Х).
(10.26)
10.4. Взаимная информация 633
Условная энтропия H(XIY) представляет собой уровень оставшейся неопреде-
ленности относительно Х после тО20, как было получено наблюдение У. Друrая
величина в равенстве (10.25): Н(Х, У) является совместной энтропией (joint en-
tropy), определяемой следующим образом:
Н(Х,У) == LLP(x,y)logp(x,y),
хЕХ уЕУ
rде р(х, у) функция массы совместной вероятности дискретных случайных пере-
менных Х и У, а Х и У их соответствующие алфавиты.
Так как энтропия Н(Х) представляет неопределенность относительно входа си-
стемы перед наблюдением выхода системы, а условная энтропия H(XIY) ту же
неопределенность после наблюдения выхода, то разность Н(Х) H(XIY) будет
определять ту часть неопределенности, которая была разрешена наблюдением вы-
хода системы. Эта величина называется взаимной информацией (mutual infonnation)
между случайными переменными Х и У. Обозначив эту величину как I(X;Y), мож-
но записать 7:
( р(х,у) )
I(X; У) == Н(Х) H(XIY) == L....J L....Jp(x, у) log (х) () .
хЕХ уЕУ Р Р У
(10.27)
Энтропия является частным случаем взаимной информации, так как
Н(Х) == I(X; Х).
Взаимная информация I(X;Y) между двумя случайными переменными Х и У
обладает следующими свойствами [221], [377].
1. Взаимная информация между Х и У является симметричной, Т.е.
I(Y; Х) == I(X; У),
rде взаимная информация 1 (У; Х) является мерой неопределенности выхода У,
разрешенной при снятии данных с входа Х; а взаимная информация I(X; У)
мерой неопределенности входа системы, разрешенной снятием наблюдения с вы-
хода системы.
7 Величина I(Х;У) изначально называлась скоростью передачи информации (rate of information transmis
sion) [970]. Однако сеroдня она получила название взаимной информации между случайными переменными
ХиУ.
634 rлава 10. Модели на основе теории информации
Н(Х, У)
"
Н(Х)
Н(У)
Рис. 10.1. Взаимосвязь инфор-
мации I(XIY) с энтропиями
Н(Х) и Н(У)
2. Взаимная информация между Х и У не может быть отрицательной:
I(X; У) О.
Это свойство взаимной информации означает, что при снятии наблюдения с BЫ
хода системы не может произойти потеря информации. Более тoro, взаимная ин
формация равна нулю Torдa и только тоrда, коrда вход и выход системы являются
статистически независимыми.
3. Взаимная информация между Х и У может быть выражена в терминах энтро-
пии выхода У следующим образом:
I(X; У) == Н(У) H(YIX),
(10.28)
rде H(YIX) условная энтропия. В правой части равенства (10.28) усреднение
по множеству информации, переданной выходом системы У, за вычетом средней
по множеству информации, учитыIающейй знание о входе Х. Последняя величина,
Н (YIX), несет информацию о помехах обработки (processing noise), а не о самом
входе системы Х.
На рис. 10.1 представлена визуальная интерпретация равенств (10.27) и (10.28).
Энтропия входа системы Х представлена левым KpyroM, а энтропия выхода У
правым. Взаимная информация между Х и У представлена пересечением этих
двух кpyroB.
10.4. Взаимная информация 635
Взаимная информация непрерывных случайных переменных
Теперь рассмотрим пару непрерывных случайных переменных Х и У. По анало
rии с формулой (10.27) взаимную информацию между этими переменными можно
определить следующим образом:
1 00 1 00 ( fx(XIY) )
I(X; У) == oo oo fx,Y(x, у) log fx(x) dxdy,
(10.29)
rде fx,Y(x, у) функция плотности совместной вероятности Х и У; fx(X\Y)
функция плотности условной вероятности Х при У == у. Обратите внимание, что
fx,Y(X, у) == fx(xly)fy(y).
Исходя из этоro, (10.29) можно переписать в следующем виде:
( 1 00 1 00 ( ) ( fx,Y(X, у) )
1 Х; У) == oo oo fx,y х, у log fx(x)fy(y) dxdy.
Также, по аналоrии с предыдущим обсуждением дискретных случайных перемен-
ных, взаимная информация I(X; У) между непрерывными случайными переменны
ми Х и У обладает следующими свойствами:
I(X; У) == h(X) h(XIY) == h(Y) h(YIX) == h(X) + h(Y) h(X, У), (10.30)
I(Y; Х) == I(X; У), (10.31)
I(X; У) О. (10.32)
Параметр h(X) является дифференциальной энтропией Х. Аналоrично можно
сказать и опараметре h(Y). Параметр h(XIY) является условной дифференциальной
энтропией (conditional differential entropy) Х для данноrо У и определяется следую-
щим двойным интеrpалом:
h(XIY) == 1: 1: fx,Y(x, у) log fx(xly)dxdy.
(10.33)
Параметр h(YIX) является условной дифференциальной энтропией У для данно-
ro Х. Он определяется аналоrично параметру h(XIY). Параметр h(X, У) является
совместной дифференциальной энтропией Х и У.
Обратите внимание, что внеравенстве (10.32) cтporoe равенство соблюдается TO
rдa и только тоrда, коrда случайные переменные Х и У являются статистически
независимыми. Если выполняется зто условие, функция плотности совместной веро-
636 rлава 10. Модели на основе теории информации
ятности Х И У может быть разложена на множители:
fx,Y(x, у) == fx(x)fy(y),
(10.34)
rде fx(x) и fy(y) 2раНИчные (marginal) функции плотности вероятности Х и У
соответственно. Эквивалентно можно записать:
fx(xly) == fx(x).
Эта формула означает, что знание о выходе У никак не влияет на распределение
входноrо сиrнала Х. Применяя зто условие к (10.29), сведем взаимную информацию
I(X;Y) между Х и У к нулю.
Определение взаимной информации I(X;Y), представленное формулой (10.29),
применимо к скалярным случайным переменным Х и У. Это определение можно
естественным образом обобщить на случайные векторы Х и У. Взаимная информация
ЦХ,У) определяется как МНО20кратный (multifold) интеrpал:
1 00 1 00 ( fx(xIY) )
I(X; У) == oo oo fx,y(x, у) log fx(x) dxdy.
(10.35)
Взаимная информация I(X;Y) имеет те же свойства, которые представлены фор-
мулами (10.30) (10.32) для скалярных случайных переменных.
10.5. Диверrенция Кул6ека Лей6лера
Формула (10.11) определяет понятие диверrенции Кулбека Лейблера для дискрет
ных случайных переменных. Это определение можно расширить для более общеrо
случая непрерывных случайных векторов. Пусть fx(X) и 9х(Х) две различные
функции плотности вероятности случайноrо вектора Х размерности m х 1. В свете
формулы (10.11) можно определить дивер2енцию Кулбека Лейблера между fx(X) и
9х(Х) следующим образом [605], [982]:
1 00 ( !х(х) )
Dfxl19X == oo fx(x) log 9х(Х) dx.
(10.36)
Диверrенция Кулбека Лейблера обладает несколькими уникальными свойствами.
1. Она не может быть отрицательной. В частном случае, коrда fx(X)==9x(X), Т.е. меж
ду двумя распределениями существует точное соответствие, величина D flI9 paB
на нулю.
10.5. Диверrенция Кулбека Лейблера 637
2. Она инвариантна к следующим изменениям компонентов вектора Х.
. Любое изменение порядка компонентов вектора.
. Масштабирование амплитуды.
. Монотонные нелинейные преобразования.
Взаимная информация I(X;Y) между парой векторов Х и У имеет интересную ин
терпретацию в терминах диверrенции Кулбека Лейблера. Прежде Bcero заметим, что
fx,y(X, у) == fy(ylx)fx(x).
(10.37)
Исходя из этоro, формулу (10.35) можно переписать в эквивалентном виде:
/ 00 / 00 ) ( fx,Y(X, у) )
I(X; У) == oo oo fx,y(x, у log fx(x)fy(y) dxdy.
Сравнивая эту формулу с (10.36), можно сразу же прийти к следующему результату:
I(X; У) == Dfx,vllfxfv'
(10.38)
Образно roворя, взаимная информация I(X;Y) между Х и У равна диверrенции
Кулбека Лейблера между функцией плотности совместной вероятности fx,y(X,y) и
произведением функций плотности вероятности fx(X) и fy(y).
Частным случаем последнеro результата является диверrенция Кулбека Лейблера
между функцией плотности вероятности fx(X) случайноrо вектора Х размерности
т х 1 и произведением т ero rpаничных функций плотности вероятности. Пусть
ix; (Xi) i-я rpаничная функция плотности вероятности элемента X i :
/ 00
(i) .
fx; (Xi) oo fx(x)dx , z 1,2, . . . , т,
(10.39)
rде хи) вектор размерности (т 1) х 1, оставшийся после удаления из вектора
х ero i-ro элемента. Диверrенция Кулбека Лейблера между fx(X) и факториальным
распределением (factorial distribution) П ix; (Xi) будет иметь следующий вид:
/ 00 ( fx(x) )
D fxllix == oo fx(x) log m dx,
П fx; (Xi)
i l
(10.40)
638 rлава 10. Модели на основе теории информации
Это выражение можно переписать в расширенной форме:
1 00 m 1 00
D fxllA == oo fx(x) logfx(x)dx oo fx(x) log!x; (xi)dx.
(10.41)
Первый интеrpал в правой части равенства (10.41) равен по определению h(X),
rде h(X) дифференциальная энтропия Х. Для Toro чтобы преобразовать второе
слаrаемое, заметим, что
dx == dX(i)dxi'
Исходя из этоro, можно записать:
1: fx(x) log!x; (xi)dx == 1: log!x; (Xi) 1: fx(x)dx(i)dxi'
(10.42)
rде внутренний интеrpал в правой части берется по вектору х (i) размерности (т 1) х
1, а внешний по скаляру Xi. Однако из выражения (10.39) видно, что внутренний
интеrpал равен rpаничной функции плотности вероятности !х; (Xi), Следовательно,
выражение (10.42) можно переписать в эквивалентном виде:
1: А(х) log!x; (xi)dx == 1: !х; (Xi) log!x; (Xi)dxi ==
== h(Xi), i == 1,2,. . . , т,
(10.43)
rде h(Xi) i я 2раничная энтропия (marginal entropy) (т.е. дифференциальная эн-
тропия, основанная на rpаничной функции плотности вероятности! Х; (Xi) ). в заклю-
чение, подставив (10.43) в (10.41) и учитывая, что первый интеrpал в (10.41) равен
h(X), формулу диверrенции Кулбека Лейблера можно упростить:
m
DfxllA == h(X) + Lh(Xi).
i l
(10.44)
Эту формулу далее в этой rлаве мы будем использовать при изучении задачи
слепоro разделения источников.
Декомпозиция Пифаrора
Теперь рассмотрим диверrенцию Кулбека Лейблера между функциями плотности
вероятности fx(X) и fu(x). Случайный вектор U размерности m х 1 состоит из неза
10.5. Диверrенция Кулбека Лейблера 639
ВИСИМЫХ переменных:
m
fu(x) == П fUi (Xi),
i l
а случайный вектор Х размерности m х 1 определяется в терминах U как
Х == AU,
rде А некоторая недиаroнальная матрица. Пусть lX i (Xi) rpаничная функция плот-
ности вероятности каждоro компонента X i для fx(X). Тоrда диверrенция Кулбека
Лейблера между fx(X) и fu(X) допускает следующую декомпозицию Пифаroра:
Dfxllfu == Dfx11ix + Dixllfu'
Мы называем это классическое соотношение декомпозицией Пифаroра, так как
оно имеет информационно-rеометрическую интерпретацию 8 [27].
8 Для доказательства декомпозиции (10.45) можно поступить следующим образом. По определению
D f 11 = J OO /х ( х ) lo g ( fx(x) ) dx == J OO / ( х ) lo g ( fx(x) lх(х) ) dx ==
х fu oo fu(x) oo х fx(x) fu(x)
== f oo /х(х) 10g ( rxi:; ) dx + f oo /х(х) log ( \ ) dx ==
== D fxlllx + f oo /х(х) log ( i ) dx.
Из определения!х(х)/u(u) известно, что
( п lX(Xi) ) m (f ( ))
f х i::;:::l t Х' Ж'i
10g ( ) ==log m ==.L: log . ( X' .
u П fu. (Xi) . 1 и,'
. 1 '
Обозиачим символом '.8 интеrpал в последней строке формулы (1). Тоща можно записать:
( ( П lx.(Xi) )
в = f oo /х(х) 10g 7u \ ) dx == f oo /х(х) log i l ' dx ==
П fU,(xi)
. 1 '
== i l f oo (10 g ( : ::; ) f oo /x(X)dX(; ) dxi ==
m ( )
00 1 fXi (Xi) - dx
=i'flf ooog fUi(Xi) /Xi(Xi) i,
rде в последней строке использовалось определение (10.39). Интеrpал (2) в своем окончательном виде является
диверreицией Кулбека ЛейблераD fx.llfu. i == 1,2, ..., т. Для тоro чтобы привести выражение для В к еro
, ,
окоичательному виду, заметим, что площадь области под rpафиком! Xi (Xi) равна единице. Исходя из этоro,
можно записать:
m f OO m ( ( lX(Xi) ) ) (i)
В ==.L: oo П /Xj (Xj) log dXi /Xi (xi)dx ==
==1 )=1 и1. 1.
( п lx.(Xi) )
== f oo !х(х) log i l ' dx ==
П fU,(xi)
i==l t
==Dlxllfu'
rдe в первой строке использовалось определение dx=dXi dx(i) (см. раздел 10.5). Подставляя (3) в (1), получим
искомую декомпозицию:
Dfxllfu == Dfx11fx + Dlxllfu'
(10.45)
(1)
(2)
(3)
640 rлава 10. Модели на основе теории информации
10.6. Взаимная информация как оптимизируемая
целевая функция
После рассмотрения основ теории информации Шеннона можно начать обсуждение
ее роли в изучении самоорrанизующихся систем.
Чтобы открыть эту дискуссию, рассмотрим нейронную сеть с множеством входов
и выходов. rлавная цель добиться самоорrанизации этой системы для выполне
ния поставленной задачи (например, моделирования, извлечения статистически зна
чимых признаков, разделения сиrнала). Этоro можно добиться, выбрав взаимную
информацию между определенными переменными системы в качестве оптимизиру-
емой целевой функции (objective function). Этот конкретный выбор бьш обусловлен
следующими соrлашениями.
· Взаимная информация имеет ряд уникальных свойств, о которых уже roворилось
в разделе 10.4.
· Она может быть определена без необходимости использования учителя, так что
основное условие самоорrанизации соблюдено.
Таким образом, задача состоит в такой настройке свободных параметров (т.е. си
наптических весов) системы, чтобы оптимизировать взаимную информацию.
В зависимости от области применения можно идентифицировать четыре различ
ных сценария (рис. 10.2), которые MOryT возникнуть на практике. Эти сценарии можно
описать следующим образом.
· В сценарии 1 (см. рис. 10.2, а) входной вектор Х состоит из элементов
X 1 ,X 2 ,... ,Х т , а выходной вектор У из элементов Y 1 , У 2 ,..., Yl. Требуется
максимизировать информацию о входе системы Х, передаваемую на выход си-
стемы У.
· В сценарии 2 (см. рис. 10.2, б) пара входных векторов Ха И Х ь порождена смежны
ми, но не пересекающихся областями образа. Входы Ха и Х ь про изводят скалярные
выходы Уа и yi, соответственно. Требуется максимизировать информацию об Уа'
передаваемую на выход У ь , и наоборот.
· В сценарии 3 (см. рис. 10.2, в) входные векторы Ха И Х ь порождены cooтвeT
ствующей парой областей, принадлежащих разным образам. Эти входные векторы
производят скалярные выходы Уа и У ь соответственно. Требуется минимизировать
информацию об У ь , передаваемую на выход Уа.
· В сценарии 4 (см. рис. 1 0.2, 2) входной вектор Х и выходной вектор У определяют
ся аналоrично рис. 10.2, а, но в данном случае имеют место равные размерности
(т.е. 1 == т). Требуется минимизировать статистическую зависимость между
компонентами выходН020 вектора У.
10.7. Принцип максимума взаимной информации 641
Максимизация
информации об Х,
. передаваемой в У
Х 1
Х 2
У, } Минимизация
У) статистической
зависимости между
компонентами
У т У
Х т
а)
т)
{ :;
Ха
Хат
{ ;
Х Ь
Х Ьт
Хат
Х ы
Х ы
Нейросетевая
модель
Минимизация
информации об 1';"
передаваемой в У Ь ,
и наоборот
J},...J
Нейросетевая
модель
1';,t
Максимизация
информации об Уа'
передаваемой в J}"
и наоборот
}b...J
Х аl
Ха)
1';,
Х Ьт
Рис. 10.2. Четыре основных сценария применения принципа максимума взаимной информации (Infomax)
и ею трех вариантов
Во всех этих ситуациях rлавную роль иrpает взаимная информация. Однако способ
ее формулировки во MHOroM зависит от особенностей конкретной ситуации. В остав-
шейся части настоящей rлавы мы рассмотрим описанные выше сценарии и их практи-
ческое применение. При этом последовательность изложения будет соответствовать
только что представленному порядку.
10.7. Принцип максимума взаимной информации
Идея создания нейронноro процессора, максимизирующеro взаимную информацию
I(X;Y), уходит корнями в основы статистической обработки сиrнала. Этот метод
оптимизации включен в принцип максимума взаимной информации (mахiшum mutua!
infonnation или Infomax) Линекера [651], [653], [655], который можно сформулировать
следующим образом.
Преобразование случайною вектора Х, наблюдаем020 на входном слое нейронной си-
стемы, в случайный вектор У, наблюдаемый на выходе той же системы, должно
выбираться таким образом, чтобы совместная работа нейронов выходною слоя мак-
симизировала информацию о деятельности входНО20 слоя. Максимизируемой целевой
функцией при этом является взаимная информация 1 (Х; У) между векторами Х и у.
642 rлава 10. Модели на основе теории информации
Х 1
Х 2
у
Х т
N
Рис. 10.3. rраф передачи сиrнала в зашумлеННDМ
нейроне
Принцип Infomax предоставляет математическую среду для самоорrанизации си
стем передачи сиrнала, показанных на рис. 10.2, а, которая не зависит от правил
реализации. Этот принцип можно также рассматривать как нейросетевую состав-
ляющую концепции емкости канала (channel capacity), которая определяет предел
Шеннона объема информации, передаваемой по каналу связи.
Далее мы проиллюстрируем применение принципа Infomax двумя примерами, в
которых будет участвовать один зашумленный нейрон. В первом из этих примеров
шум будет добавляться к выходному сиrналу, а во втором ко входному.
Пример 10.4
Отдельный нейрон, находящнйся под действием шума
Рассмотрим простой пример линейноrо нейрона, получающеro входной сиrнал от множества, СОСТО-
ящеro из т узлов-источников. Пусть выход этоrо нейрона с учетом шума выражается соотношением
у == ( WiXi) + N, (10.46)
rдe Wi i й синаптический вес; N шум обработки сиrнала (рис. 10.3). При этом предполarается
следующее.
-Выход нейрона У представляет собой тауссову случайную переменную с дисперсией a .
-Шум обработки сиrнала N также является rауссовой случайной переменной с нулевым средним
и дисперсией a .
-Шум обработки является некоррелированным по всем своим входным составляющим, Т.е.
E[NX i ] == о для всех i.
rayccoBo распределение выходноrо сиrнала У можно обеспечить двумя способами. Входные
сиrналы Хl, Х2, ..., Х т имеют тауссово распределение. При этом предполarается, что адди
тивный шум N также является [ауссовым. Torдa тауссово распределение выходноro сиrнала У
вытекает из TOro факта, что он является взвешенной суммой тауссовых случайных переменных.
Как альтернатива, входные сиrналы Хl, Х2, ..., Х т MOryт быть независимо и равномерно распре-
делены. В этом случае распределение их взвешенной суммы становится тауссовым при больших
значениях т. Это следствие центральной предельной теоремы (central1imit theorem).
10.7. Принцип максимума взаимной информации 643
Приступая к анализу, в первую очередь обратим внимание на вторую строку равенства (10.30).
В ией взаимная информация I(Y;X) между выходом нейрона У и входным вектором Х определяется
следующим образом:
I(Y; Х) == h(Y) h(YIX).
(10.47)
Посмотрев на формулу (10.46), несложно заметить, что функция плотности вероятности пе-
ременной У для входноro вектора Х равна функции плотности вероятности суммы константыI и
rауссовой случайной переменной. Следовательно, условная энтропия h(Y[X) является "информа-
цией", которую выход У накапливает о шуме обработки сиrнала N, а не о самом векторе полезноro
сиrнала Х. Исходя из этоrо, примем
h(YIX) == h(N)
и перепишем выражение (10.47) в следующем виде:
I(Y; Х) == h(Y) h(N).
(10.48)
Применяя выражение (10.22) к дифференциальной энтропии rауссовой случайной переменной
к нашей задаче, получим:
1
h(Y) == [1 + log(21to )]
2
(10.49)
и
1 2
h(N) == [1 +log(21taN)]'
2
После подстановки выражений (10.49) и (10.50) в формулу (10.48) и упрощения получим:
1 ( o )
I(Y; Х) == '2 1og OJ, ,
(10.50)
(10.51)
rдe o зависит от oJ,.
Частное o joJ, можно рассматривать как отношение сиzналlшум (signal-to-noise ratio). Предпо
лаrая фиксированность дисперсии oJ" можно заметить, что взаимная информация I(Y;X) достиrает
максимума при максимизации дисперсии o выхода нейрона У. Таким образом, можно утверждать,
что при определенных условиях максимизация дисперсии выходноro сиrнала максимизирует вза-
имную информацию между входным и выходным сиrналами нейрона [653]. .
Пример 10.5
Отдельный нейрон, входной сиrнал KOToporo нскажен аддитивным шумом
Теперь предположим, что шум, искажающий поведение нейрона, поступает на ero вход через
синаптические связи (рис. 10.4). Соrласно этой модели шума:
m
У == L Wi(Xi + Ni),
(10.52)
i l
rдe предполarается, что каждый шум Ni является независимой rауссовой случайной переменной
с нулевым средним и дисперсией oJ,. Torдa формулу (10.52) можно переписать в виде, аналоrич
иом (10.46):
У == ( f WiXi ) + N',
, 1
Х\
у
l
I
!
I
!
1
I
I
I
l
644
rлава 10. Модели на основе теории информации
Х 2
Х т
N m
Рис. 10.4. Вторая модель шума
rдe N' составной компонент шума, имеющий вид.
N' =о L WiNi.
i l
Составной шум N' имеет rayccoBo распределение с нулевым средним и дисперсией, равной
сумме дисперсий отдельных компонентов шума, Т.е.
7n
'2 ""' 2 2
(JN =о L.... Wi (JN'
i::l
Как и раньше, предположим, что выход У нейрона имеет rayccoBo распределение с дисперсией
(J}. Взаимная информация I(Y; Х) между У и Х все так же задается формулой (10.47). Однако на
этот раз условная энтропия h(YIX) определяется по-друrому:
h(YIX) == h(N') == (1 + 21t(J ) == [1 + 21t(J W;] .
Таким образом, подставляя выражения (10.49) и (10.53) в (10.47), получим [653]:
1 ( (J} )
I(Y; Х) =о log 2 7n 2 .
2 (JN i lWi
Если дисперсия (J является константой, взаимная информация I(Y;X) достиrает максимума
при максимизации отношения (J} / ;:l w;, rде (J} функция ОТ Wi. .
(10.53)
(10.54)
Что полезиоrо можно извлечь из примеров 10.4 и 10.5?
Первое, что можно увидеть в двух выше приведенных примерах, это то, что pe
зультат применения принципа Infomax зависит от поставленной задачи. Эквивалент
ность между максимизацией взаимной информации 1 (У ;Х) и дисперсией выходноro
сиrнала в модели на рис. 10.3 для наперед заданной дисперсии C57v не присутствует в
модели на рис. 10.4. Эти две модели ведут себя одинаково только в том случае, KOrдa
на модель, показанную на рис. 10.4, наложено дополнительное условие Li w; == 1.
10.7. Принцип максимума взаимной информации 645
в общем случае определение взаимной информации между входом Х и выходом У
является достаточно сложной задачей. В примерах 10.4 и 10.5 мы провели математи
ческий анализ с предположением о том, что распределение шума в системе с одним
или несколькими ero источниками является МНО20мерным 2ауссовым. Это допущение
еще нужно обосновать.
При адаптации rауссовой модели шума, в сущности, вводится "сурроrатная" вза-
имная информация в предположении, что выходной вектор нейрона У имеет мно-
roMepHoe rayccoBo распределение с тем же вектором средних значений и матрицей
ковариации, что и исследуемое распределение. В [647] для обоснования использова-
ния такой сурроrатной взаимной информации использовалась диверreнция Кулбека
Лейблера. При этом предполаrалось, что сеть хранит информацию о векторе средних
значений и матрице ковариации выходноro вектора У и не хранит статистику более
высокоro порядка.
В заключение отметим, что анализ, представленный в примерах 1 0.4 и 1 0.5, прово-
дился В контексте одноrо нейрона. Это было сделано преднамеренно, исходя из сле
дующей точки зрения. Для обеспечения математической трактовки принципа Infomax
оптимизация должна проводиться на уровне локальноrо нейрона. Такая оптимизация
является совместимой с сущностью самоорrанизации.
Пример 10.6
в примерах 10.4 и 10.5 рассматривались зашумленные нейроны. В этом примере мы сосре-
доточим внимание на сети без шума, которая преобразует случайный вектор Х с произвольным
распределением в друroй случайный вектор У с друrим распределением. Вспоминая свойство сим
метричности взаимной информации (I(X;Y) I(Y;X)) и расширяя формулу (10.28) на описанную
здесь сmyацию, взаимную информацию между входным вектором Х и выходным вектором У можно
выразить следующим образом:
I(Y; Х) == Н(У) Н(У[Х),
rдe Н(У) энтропия У; H(YIX) условная энтропия У для данноro Х. В предположении об OT
сутствии шума при отображении Х на У условная энтропия Н(У[Х) достиrает CBoero наименьшеrо
значения она расходится до oo. Этот результат вызван дифференциальной природой энтропии
непрерывной случайной пере мен ной (см. раздел 10.2). Однако эта сложность не имеет послед
ствий, если рассматривать zрадuент взаимной информации I(Y;X) по отношению к матрице весов
W, параметризующей сеть, выполняющую отображение. В частности, можно записать, что
BI(Y;X) дН(У)
BW BW '
поскольку условная энтропия H(YIX) не зависит от W. Уравнение (10.55) показывает, что в сети
без учета шума, осуществляющей отображение, максимизация энтропии выхода У эквивалентна
максимизации взаимной информации между У и входом системы Х. При этом обе максимизации
производятся по отношению к матрице весов W сети [116]. .
(10.55)
.,.
i
646 rлава 10. Модели на основе теории информации
10.8. Принцип Infomax и уменьшение избыточности
в теории информации Шеннона порядок и структура представляют избыточность,
которая уменьшает неопределенность, разрешаемую за счет получения информации.
Чем больший порядок и структуру имеет исследуемый процесс, тем меньше информа
ции мы получаем из наблюдения за этим процессом. Рассмотрим пример в наивыс
шей мере структурированной и избыточной последовательности символов аааааа.
При получении первоrо примера а мы можем сразу же сказать, что оставшиеся
пять примеров будут такими же. Информация, переданная такой последовательно-
стью примеров, равна информации, содержащейся только в одном примере. Друrими
словами, чем более избыточной является последовательность примеров, тем меньше
информации мы получаем о характеристиках среды.
Из определения взаимной информации 1 (У; Х) мы знаем, что она является Me
рой неопределенности о выходе системы У, которая разрешается наблюдением за
входом системы Х. Принцип Infomax связан с максимизацией взаимной информации
I(Y; Х). В результате, наблюдая за входом Х, мы получаем максимум информации о
выходе системы У. В свете ранее упомянутой взаимосвязи между объемом информа
ции и избыточностью можно утверждать, что принцип Infomax ведет к уменьшению
избыточности в выходе У по сравнению со входом Х.
Наличие шума в сиrнале предполаrает использование избыточности и друrих Me
тодов разнообразия [653]. Если уровень аддитивноro шума во входном сиrнале высок,
можно использовать избыточность для борьбы с разлаrающим влиянием шума. В та-
кой среде наиболее коррелированные компоненты объединяются в процессоре для
обеспечения точноro представления входноrо сиrнала. Кроме Toro, если уровень шу
ма на выходе (т.е. шум процессора) достаточно высок, большая часть компонентов
выходноrо сиrнала направляется процессором для обеспечения избыточности инфор
мации. Таким образом, уменьшается количество наблюдаемых на выходе процессора
независимых характеристик, однако при этом увеличивается точность представления
каждой из них. Таким образом, можно утверждать, что более высокий уровень шума
при водит к необходимости избыточности в представлении. Однако если уровень
шума низок, разнообразие представления имеет преимущество перед избыточно
стью. Под разнообразием здесь понимаются два или более выходов процессора с
отличными свойствами. В задаче 10.6 с точки зрения принципа Infomax обсуждается
баланс между разнообразием и избыточностью. Хочется заметить, что такой баланс
аналоrичен балансу между смещением и дисперсией, о котором rоворилось в rлаве 2.
Моделирование систем восприятия
с самых первых дней развития теории информации предполаrалось, что избыточ
ность сенсорных сиrналов (возбуждений) важна для понимания восприятия [83], [92].
10.8. Принцип Infomax и уменьшение избыточности 647
Рис. 10.5. Модель системы восприятия.
Векторы сиrнала s и векторы шумов Уl и
У2 являются соответственно реализация
ми случайных векторов 5, N 1 и N 2
у
I
I
I
I :
Входной канал
I
I
I
2 :
Выходной канал
(зрительный нерв)
и в самом деле, избыточность сенсорных "сообщений" обеспечивает знания, позво
ляющие мозrу строить свои "карты познания" или "рабочие модели" окружающеro
мира [90]. Закономерности в сенсорных сообщениях должны некоторым образом ко-
дироваться в мозrе, чтобы он понимал, что происходит. Однако уменьшение избыточ
ности является более специфичной формой 2ипотезы Барлоу (Barlow's hypothesis).
Эта rипотеза утверждает, что целью ранней обработки является преобразование в
высшей мере избыточноrо ceHcopHoro входа в более эффективный факториальный
код (factorial code). Друrими словами, нейронные выходы становятся статистически
независимыми, коrда обусловлены входом.
Под воздействием rипотезы Барлоу в [79] был сформулировал принцип мини-
мума избыточности (principle of minimum redundancy) как базис информационно
теоретический модели системы восприятия (рис. 10.5). Эта модель состоит из трех
компонентов: входною канала (input channel), системы кодирования (recoding sys-
tem) и выходною канала (output channel). Выходной и входной каналы описываются
следующим образом:
X==S+N 1 ,
rде S идеальный сиrнал, получаемый входным каналом; N 1 совокупный шум
на входе. Сиrнал Х, в свою очередь, преобразовывается (кодируется) линейным мат-
ричным оператором А, а результат передается по оптическому нерву, или выходному
каналу, и формирует выход системы:
у == АХ+ N 2 ,
rде N 2 внутренний шум, налаrаемый после кодирования. В подходе, предпринятом
в [79], отмечалось, что световой сиrнал в сетчатке содержит полезную сенсорную
информацию в крайне избыточной форме. Более Toro, выдвиrалась rипотеза, что
целью обработки сиrнала сетчаткой является уменьшение (или полная ликвидация)
излишних битов данных как в корреляции, так и в шуме перед посьшкой этоrо сиrнала
по оптическому нерву.
648 rлава 10. Модели на основе теории информации
Для определения меры избыточности была введена величина
R I(Y;S)
1 С (У) ,
(10.56)
rде I(Y;S) взаимная информация между У и S; С(У) мощность (выходноro) Ka
нала оптическоrо нерва. Равенство (10.56) можно объяснить с тех позиций, что мозr
интересует исключительно идеальный сиrнал S, в то время как сиrнал передается фи-
зически по оптическому нерву. Здесь предполаrается, что при отображении входа на
выход не происходит уменьшения размерности, Т.е. С(У) > I(Y; S). Это требование
заключается в поиске TaKoro отображения входа на выход (т.е. матрицы А), которое
минимизирует меру избыточности R при отсутствии потери информации:
I(Y; х) == I(X; Х) Е,
rде Е некоторый малый положительный параметр. Мощность канала (channel capac
ity) С(У) определяется как максимальный поток информации, который может быть
передан по оптическому нерву. При этом предполаrается возможность использова
ния любых распределений входноro сиrнала и сохранение средней мощности входа
на фиксированном уровне.
Если вектор сиrнала S и вектор выхода У имеют одну и ту же размерность, а
шум в системе отсутствует, принцип минимума избыточности и принцип Infomax
являются математически эквивалентными (предполаrается, что в обоих случаях на
вычислительную мощность выходных нейронов налаrаются сходные оrpаничения).
Для примера предположим, что мощность канала измеряется в терминах динамиче-
CKOro диапазона выходноrо сиrнала каждоrо из нейронов на рис. 10.5. Torдa, соrласно
принципу минимума избыточности, минимизируемой величиной является
I(Y; S)
1 С(У)
для данной допустимой потери информации и, таким образом, для данноrо I(Y;S).
Таким образом, минимизируемую величину можно записать следующим образом:
F 1 (Y;S) == С(У) лI(У;S).
(10.57)
с друroй стороны, соrласно принципу lnfomax, максимизируемая величина в MO
дели на рис. 10.5 выrлядит следующим образом:
Р 2 (У; S) == I(Y; S) + лС(У).
(10.58)
10.9. Пространственно связные признаки 649
Несмотря на то что функции Fl (У; S) и F 2 (У; S) отличаются друr от друrа, их
оптимизация приводит к одному И тому же результату они формулируют методы
множителей Лаrpанжа, в которых роли I(Y; S) и С(У) просто меняются местами.
В этом обсуждении важно заметить, что, несмотря на различия в формулиров
ке, эти два информационно теоретических принципа приводят к сходным результа
там. В итоrе можно сказать следующее: максимизация взаимной информации меж-
ду входом и выходом нейронной системы и в самом деле приводит к уменьше
нию избыточности 9 .
10.9. Пространственно связные признаки
Принцип Infomax, сформулированный в разделе 1 0.6, применяется в ситуациях, коrда
максимизируемой целевой функцией является взаимная информация 1 (У; Х) между
выходным вектором У и входным вектором Х (см. рис. 10.2, а). После внесения
соответствующих изменений в терминолоrию этот принцип можно расширить для
обработки изображений без учителя [114]. Необработанный пиксель TaKoro изобра
жения содержит массу информации об обрабатываемом изображении. В частности, на
интенсивность каждоrо пикселя влияют такие внутренние параметры изображения,
как шубина, отражающая способность и ориентация поверхности, равно как фоновый
шум и освещенность. Нашей целью является создание такой системы самоорrаниза-
ции, которая способна через обучение преобразовывать эту сложную информацию в
более простую форму. Конкретизируя цель, ее можно описать как извлечение призна-
ков более высокоro порядка, которые представляют простую связность пpocтpaH
ства (simple coherence across space) таким способом, чтобы представление информа-
ции в пространственно-локализованной области изображения облеrчало ее представ-
ление в соседних областях. При этом под областью понимается некоторый набор пик
селей изображения. Описанный здесь сценарий продемонстрирован на рис. 10.2, б.
Исходя из этоrо, можно сформулировать первый вариант принципа Infomax 10
[110], [114].
9 В [766], [767] также рассматривалась связь между принципом Infomax и уменьшением избыточности. AB
торы пришли К аналоrичному выводу о том, что максимизация взаимной информации между входным и BЫXOД
ным векторами нейронной системы ведет к уменьшению объема данных. В [407] рассматривается примеиение
фильтров Infomax к сетчатке rлаза. В ней показано, что избыточность существенна для достижения робастности
к шуму во внутреннем представлении среды, которая наблюдалась в сенсорных системах, подобных сетчатке.
10 В [114] для обозначения первоro варианта принципа Infomax использовалось обозначение Imax.
1"
650 rлава 10. Модели на основе теории информации
Область
а
Нейронная
сеть
а
У")
У Ь
Максимизация
взаимной
информации
l( Уа; У Ь )
Область
Ь
Нейронная
сеть
Ь
Рис. 10.6. Обработка двух
смежных областей изоб-
ражения в соответствии с
первым вариантом прин
ципа Infomax
Преобразование пары векторов Ха И ХЬ (представляющих смежные, непересекающu-
еся области изображения в нейронной системе) должно выбираться таким образом,
чтобы скалярный выход Уа' произведенный в ответ на входное воздействие Ха, мак-
сuмизировШl информацию о втором скалярном выходе У ь , произведенном в ответ на
входной СИ2НШl Хь. Максuмuзируемой функцией при этом является взаимная инфор
мация 1 (Уа; УЬ) между выходами Уа и y'i,
Этот принцип рассматривается как один из вариантов принципа Infomax не потому,
что он эквивалентен последнему или выводится из Hero, а потому, что они пропитаны
общим духом.
Для примера рассмотрим рис. 10.6, на котором показаны две нейронные сети
(модуля), а и Ь, которые получают входные сиrналы Ха И Х ь из смежных, неперекры
вающихся областей HeKoToporo изображения. Скалярами Уа и y'i, обозначим выходы
этих двух модулей, соответствующие входным векторам Ха И Х ь . Обозначим симво
лом S компонент сиrнала, который является общим для Уа и уь. Он выражает собой
пространственную связность двух соответствующих областей исходноrо изображе
ния. Выходы Уа и y'i, можно выразить как зашумленные версии общеrо сиrнала В:
Уа == S + N a
(10.59)
и
y'i, == s + N b ,
(10.60)
rде N a и N b компоненты аддитивноro шума, которые предполаrаются статистиче
ски независимыми rауссовыми случайными переменными с нулевым средним. Для
компонента S также предполаrается rayccoBo распределение. В соответствии с (10.59)
и (10.60) два модуля а и Ь (см. рис. 10.6) имеют соответствующие допущения
относительно друr друrа.
10.9. Пространственно связные признаки 651
Используя последнюю строку выражения (10.30), взаимную информацию между
Уа и УЬ можно выразить следующим образом:
I(Y a ; У ь ) == h(Y a ) + h(Y b ) h(Y", УЬ).
(10.61)
Соrласно формуле (10.22) для дифференциальной энтропии rауссовых случайных
переменных, величину h(Y a ) можно выразить соотношением
1
h(Y a ) == 2 [1 + log (21Ю )] ,
(10.62)
rде O' дисперсия переменной Уа' Аналоrично, дифференциальная энтропия h(Y b )
имеет следующий вид:
1
h(Y b ) == 2 [1+10g(21t0' )],
(10.63)
rде O' дисперсия переменной УЬ. Используя формулу (10.24), мы можем описать
совместную дифференциальную энтропию h(Y a , УЬ):
1
h(Y a , УЬ) == 1 + log(21t) + log Idet(E)I.
2
(10.64)
Матрица Е размерности 2 х2 является матрицей ковариации Уа и УЬ, определяемой
следующим образом:
[ O' р аьО'"О'Ь ]
О' 2'
Р аьО'аО'Ь О'ь
(10.65)
rде Раь коэффициент корреляции Уа и УЬ:
Е[(У а Е[Уа])(УЬ Е[У ь ])]
Раь == О' ,.. .
avb
(10.66)
Исходя из этоrо, определитель матрицы Е имеет следующее значение:
det(E) == 0' 0' (1 p ь),
(10.67)
и выражение (10.64) можно переписать следующим образом:
1 [ 2 2 2 )]
h(Y a , УЬ) == 1 + log(21t) + 2 10g О'аО'ь(l Раь .
(10.68)
652 rлава 10. Модели на основе теории информации
Подставляя выражения (10.62), (10.63) и (10.68) в (10.61) и упрощая резуль
тат, получим:
1 2
I(Y a ; У ь ) == log(l Раь)'
2
(10.69)
Из выражения (10.69) ясно видно, что максимизация взаимной информации
I(Ya;Yi,) эквивалентна максимизации коэффициента корреляции Раь' И это интуи
тивно понятно. Обратим внимание, что по определению 'Раь! 1.
Максимизация взаимной информации I(Ya;Y b ) может рассматриваться как нели
нейное обобщение канонической корреляции в статистике [114]. При наличии двух
входных векторов Ха И Х ь (не обязательно одинаковой размерности) и двух COOTBeT
ствующих векторов весов w а И wb целью анализа канонической корреляции (canonical
сопеlаtiоn ana1ysis) является поиск линейной комбинации Уа == w Xa и У ь == w[X b ,
имеющей максимальную корреляцию [57]. Максимизация I(Ya;Y b ) является нелиней
ным обобщением канонической корреляции, блаroдаря нелинейности, встроенной в
конструкцию нейронных модулей (см. рис. 10.6).
В [114] было продемонстрировано, что с помощью максимизации взаимной ин
формации I(Ya;Y b ) можно извлечь различия из случайных точечных cTepeorpaMM.
Это сложная задача извлечения признаков, которая не может быть решена ни OДHO
слойной, ни линейной нейронной сетью.
10.10. Пространственно несвязные признаки
Обработка изображения без учителя, рассмотренная в предыдущем разделе, связана
с извлечением пространственно связных признаков изображения. В этом разделе pac
смотрим совершенно противоположную ситуацию. В качестве примера рассмотрим
модель, представленную на рис. 10.2, в. В ней целью является увеличение пpocтpaH
ственных различий (spatia1 differences) между парой соответствующих областей, взя
тых из разных изображений. В то время как взаимная информация между выходами
модулей в модели на рис. 10.2, б максимизируется, здесь нужен прямо противопо
ложный результат (см. рис. 10.2, в).
Таким образом, можно сформулировать второй вариант принципа Info
тах [1067], [1068].
Преобразование пары векторов Ха и Х ь (представляющих соответствующие обла-
сти разных изображений в нейрон ной системе) должно выбираться таким образом,
чтобы скалярный выход Уа, произведенный в ответ на входное воздействие Ха' Mи
нимuзировал информацию о втором скалярном выходе У ь , произведенном в ответ на
входной си2Нал Х ь . Минимизируемой функцией при этом является взаимная информа
ция I(Y a ; У ь ) между выходами Уа и У ь .
10.10. Пространственно несвязные признаки 653
Этот принцип назван одним из вариантов принципа Infomax не потому, что они
эквивалентны или проистекают один из друroro, их объединяет общий дух 11.
Второй вариант принципа Infomax нашел свое применение в радарной поляри-
метрии (radar polarimetry), rде радарная система формирует пару изображений инте-
ресующеro объекта, передавая поляризованный сиrнал и получая отклик от объекта
с той же или отличной поляризацией. Поляризация может быть вертикальной и ro
ризонтальной. Например, может существовать пара радарных изображений, одно из
которых отображает поляризацию (вертикальную или roризонтальную), а второе
перекрестную поляризацию (roризонтальную при передаче и вертикальную при при
еме). Такое применение было описано в работах, посвященных задаче расширения
цели поляризации (enhancement of polarization target) в дуально-поляризованной ра-
дарной системе [1067], [1068]. Работу радара можно описать следующим образом.
Некоrерентный радар посьmает roризонтально поляризованный сиrнал, а получает
отклик по вертикально и rоризонтально поляризованным каналам. Интересующий
объект может скручивать поляризацию (polarization-twisting), Т.е. является рефлекто
ром, созданным для поворота поляризации на 90.. При нормальной работе радарной
системы определение такой цели становится сложным за счет несовершенства систе
мы, равно как и за счет отражения от нежелательных поляриметрических объектов на
поверхности. Мы предполarаем нелинейность отображения, чтобы учесть HerayccoBo
распределение, присущее радарным откликам. Задача расширения объекта лежит в
классе вариационных задач, включающих в себя минимизацию квадратичноro функ
ционала стоимости при наличии оrpаничений. Конечный результат является обрабо-
танным изображением с перекрестной поляризацией, который повышает видимость
объекта в rораздо большей мере, чем какая-либо линейная методика типа анализа
rлавных компонентов. Модель, использованная в рассматриваемой работе, предпо-
лаrает наличие rауссовой статистики в преобразованных данных, поскольку неза
висимая от модели оценка функции плотности вероятности является вычислительно
сложной задачей. Взаимная информация между двумя rауссовыми переменными Уа и
yi, определяется по формуле (1 0.61). Для TOro чтобы обучить синаптические веса двух
моделей, используется вариационный подход. При этом требуется уменьшить зашум-
ленность радарноrо сиrнала, обычно возникающую в rоризонтально и вертикально
поляризованных сиrналах радара. Чтобы удовлетворить этому требованию, взаимная
информация I(Y a , У ь ) минимизируется при дополнительном условии, налаrаемом на
синаптические веса:
Р == (tr[WTW] 1)2,
(l 0.70)
11 В [1070] рассматривалась отрицательная информационная маzистраль (negative information pathway) и
оптимизировалась взаимная информация между сиrналами на выходе и входе маmстрали, взятая С противо
положным знаком. Было показано, что при адаптацИИ такая система стремится стать дискриминатором более
часто встречающихся в множестве входных сиrналов примеров. Эта модель слабо связана со вторым вариантом
принципа Infomax.
"'?
f
654 rлава 10. Модели на основе теории информации
rде W сводная матрица весов сети; tr[.] след матрицы, заключенной в квадратные
скобки. Стационарная точка достиrается, Korдa
'VwI(Ya; У Ь ) + л'VwР == О,
(10.71)
rде л множитель Лаrpанжа. Для поиска минимума используется квазиньютоновский
метод (см. rлаву 4).
На рис. 10.7 показана архитектура нейронной сети, использованная в [1067],
[1068]. Для каждоrо из двух модулей бьmа выбрана сеть rауссовых радиальных базис
ных функций, так как эти сети имеют одно преимущество они реализуют множе
ство фиксированных базисных функций (т.е. неадаптивный скрытый слой). Входные
данные бьmи расширены на базисные функции, после чеrо скомбинированы с ис-
пользованием слоев линейных весов. Пунктирными линиями на рис. 10.7 по казаны
перекрестные связи между двумя модулями. Центры rауссовых функций выбирались
из интервалов, равномерно распределенных по всему входному пространетву. При
этом их ширина опредеЛялась эвристически. На рис. 10.8, а показан ряд roризонталь
но и вертикально поляризованных (получаемых радаром) изображений парковой зо
ны озера Онтарио. Координаты по rоризонтальной оси увеличиваются в направлении
слева направо, а по вертикальной оси сверху вниз. На рис. 10.8, б показано комби
нированное изображение, полученное минимизацией взаимной информации между
вертикально и roризонтально поляризованными изображениями. Яркое пятно, отчет
ливо видное на изображении, соответствует смешанному рефлектору, скручивающему
поляризацию и расположенному вдоль береrа озера. По эффективности подавления
искажений описанная здесь информационно теоретическая модель превосходит все
стандартные модели, основанные на анализе rлавных компонентов [1067], [1068]12.
10.11. Анализ независимых компонентов
Теперь рассмотрим последний сценарий, изображенный на рис. 10.2, 2. Для тoro
чтобы подчеркнуть специфику представленной здесь задачи, рассмотрим блочную
диаrpамму, показанную на рис. 10.9. Работа начинается со случайноrо входноro BeK
тора U ( n ), определенноrо следующим образом:
U == [U 1 , U 2 ,..., Uт]Т,
rдe m компонентов вектора выбираются из множества независимых источников.
В данной задаче рассматриваются временные последовательности, так что арrумент
12 Система, описанная в [1067], содержит процессор постопределения (postdetection), который использует
априорную информацию о расположении рефлектора на rpанице между водой и сушей на берету. Нечеткий
процессор (fиzzy processor) комбинирует первичное обнаружение с выходом детектора, базирующеroся на ви-
зуальном наблюдении. Это приводит к эффективному удалению ложных сиrналов, результатом чеrо становится
повышение ПрОИ380дительности такой системы.
10.11. Анализ независимых компонентов 655
Ха
Однотипно
поляризованный
(roризонтально roризонтально)
сиrнал радара
,,'
',1
','
',1
',1
\ \ ',1
" ' , 1
\ 1 ,
\ V У ,
\ 1\ I
': >:\
I \ I )"
, ,\
I 1,','
I I \ \
I I I \ \ \
I I \ "
I I \,'
I I \,'
I \ "
" \"
Х Ь
Перекрестно
поляризованный
(rоризонтально вертикально)
сиrнал радара
Уа
Минимизация
взаимной
информации
I( Уа; У Ь )
[ауссовы радиальные
базисные функции
Рис. 10.7. Блочная диаrрамма нейронноro процессора, целью KOToporo яв
ляется подавление фоновоro шума с помощью пары несвязных радарных
входов. Подавление помех производится за счет минимизации взаимной
информации между выходами двух моделей
n обозначает дискретное время. Вектор U применяется к линейной системе, харак-
теристики отображения входа на выход которой задаются несинrулярной матрицей
А размерности m х т, называемой матрицей смешения (mixing matrix). Результа-
том является вектор наблюдений Х( n) размерности m х 1, связанный с вектором U
следующим соотношением (см. рис. 10.10, а):
Х == AU,
rдe
Х == [X 1 , Х 2 ,..., Хт]Т'
(10.72)
Вектор источника U и матрица смешения А считаются неизвестными. Известен
только вектор наблюдений Х. ДЛЯ данноrо вектора Х задача сводится к поиску разде-
ляющей (demixing) матрицы W, такой, что исходный вектор U может быть получен
из выходноrо вектора У, определяемоrо следующим образом (см. рис. 10.10,6):
У == WX,
(10.73)
656 rлава 10. Модели на основе теории информации
"
r
OIpажатель
Рис.10.8,а. Рисунок, представляющий ис
ходное радарное сканирование (азимут o
носительно диапазона) для rоризонтально
rоризонтальной (сверху) и rоризонтально
вертикальной (снизу) поляризации
Отражатель
,
,
Рис.10.8,6. Композитный рисунок, вычислен
ный с помощью минимизации взаимной ИН
формации между двумя поляризованными
изображениями, показанными на рис. 10.8, а
rде
у == [Y 1 , У 2 ,..., Ут]Т'
Обычно в этой задаче предполаrается, что средним значением входных сиrналов
U 1 , U 2 ,..., U т является нуль, что, в свою очередь, rарантирует нулевое среднее для
элементов вектора наблюдений X 1 , Х 2 ,... ,Х т . То же можно сказать и об элементах
выходноro вектора разделяющей матрицы Y 1 , У 2 , . . . , у т'
10.11. Анализ независимых компонентов 657
Рис. 10.9. Блочная диаrрамма
процессора для задачи слепо-
ro разделения источников. BeK
торы u, х и у являются COOTBeT
ственно значениями случайных
векторов U, Х и У
,
I
I Вектор
: наблюдения
Смеситель I х(п)
А
I
I
источника I
о(п) I
I
Неизвестная среда
Вектор
Выходной
вектор
у(п)
и)
Х!
Х)
У!
У2
Выходной
вектор
у
У..
w...
б)
Вектор
источника
u
и2
Х2
Вектор Вектор
наблюдения наблюдения
х х
Х2
им
Х..
Х..
О....
а)
Рис. 10.10. Детализированное описание матрицы смешения (а) и разделяющей матрицы (6)
Таким образом, задачу слепО20 разделения источников (blind source separation prob-
lem) можно сформулировать следующим образом.
Для данных N независuмых реализаций вектора наблюдений Х найти оценку Maтpи
ЦЫ, обратной матрице смешения А.
При разделении источников используется принцип пространствеННО20 разнесения
(spatial diversity). Это проявляется в том, что разные сенсоры, являющиеся реализа
циями вектора Х, обслуживают разные смеси источников. Можно также использовать
спектральное разнесение, если таковое существует. Однако фундаментальным под-
ходом к разделению источников является пространственный мы рассматриваем
структуру в разрезе сенсоров, а не в разрезе времени [169].
Решение задачи слепоrо разделения источников достижимо, за исключением учета
произвольноro масштабирования каждоro из компонентов сиrнала и смешения ин-
дексов. Друrими словами, вполне возможно найти такую разделяющую матрицу W,
отдельные строки которой являются масштабированными и перемешанными строка-
ми матрицы А. Это значит, что решение можно представить в следующем виде:
у == WX == WAU ---t DPU,
rдe D несинryлярная диаrональная матрица; Р матрица перемешиванuя (реnnи
tation matrix).
658 rлава 10. Модели на основе теории информации
r
!
,
i
i
t'
I
r
f
t
Описанную выше задачу обычно называют задачей слепоro разделения источни-
ков (сиrналов)lЗ, rде за термином "слепое" скрывается тот факт, что единственной
информацией, используемой для восстановления входноro сиrнала, является реализа
ция вектора наблюдений Х, обозначаемая символом х. Принцип, на котором основано
решение этой задачи, называется анализом независимых компонентов (independent
component analysis ICA) [205], который можно рассматривать как расширение aHa
лиза zлавных компонентов (principal components analysis РСА). В то время как РСА
предполаrает независимость вплоть до BTOpOro порядка в требовании ортоrональ
ности векторов направлений, метод ICA требует статистической независимости
отдельных компонентов выходноrо вектора У и не связан с требованием ортоrональ
ности. Обратите внимание, что на практике алrоритмическая реализация анализа
независимых компонентов может иметь место для "настолько статистически незави
симых компонентов, насколько это возможно".
Потребность в слепом разделении источников возникает в различных областях, в
том числе следующих.
· Разделение речи. В этом приложении вектор х состоит из нескольких речевых
сиrналов, которые линейно смешаны друr с друrом. При этом требуется разде
лить эти сиrналы [116]. Сложная форма такой ситуации возникает, например, при
про ведении телеконференций.
· Обработка антенной решетки (апау antenna processing). В этом приложении BeK
тор х представляет собой выход антенной решетки радара, полученный из несколь
ких узкополосных сиrналов, возникающих из источников, расположенных в неиз
вестных направлениях [174], [1038]. Здесь также требуется разделить источники
сиrналов. (Под узкополосным сиrналом понимается полезный сиrнал, имеющий
меньшую полосу, по сравнению с несущей частотой.)
· Мультисенсорные биомедицинские записи. В этом приложении вектор х состоит
из записей, выполненных множеством сенсоров, используемых для мониторинrа
биолоrических сиrналов. Например, может потребоваться отделить сердцебиение
беременной женщины от сердцебиения плода [170].
· Анализ данных финансов020 рынка. В этом приложении вектор х состоит из мно-
жества данных финансовоro рынка, и из Hero требуется извлечь доминантные
независимые компоненты [84].
в этих приложениях задача слепоro разделения источников может быть усложне
на возможным присутствием неизвестных задержек распространения, расширенной
13 Слепое разделение сиrнала можно обнаружить еще в основополаrающей работе [452]. Историqеские све-
дения о задаче слепоro разделения сиrнала содержатся в [766]. Эта работа также освещает нейробиолоrические
аспекты задачи. rлубокое исследование задачи слепоro разделения источников, подчеркивающее заложенные в
ней принципы обработки сиrналов, содержится в [169].
10.11. Анализ независимых компонентов 659
фильтрацией, налаrаемой на источники их средой, и неизбежным искажением BeK
тора наблюдений х внешним шумом. Все это значит, что идеализированная форма
смешения сиrналов, описываемая формулой (10.72), очень редко встречается в реаль-
ных задачах. Однако это также значит и то, что для рассмотрения фундаментальных
аспектов задачи разделения источников эти наложения следует иrнорировать.
Критерий статистической независимости
Так как статистическая независимость является свойством, требуемым от компо
нентов выходноrо вектора У, возникает вопрос, какую меру использовать для ее
определения? Как вариант можно выбрать взаимную информацию I(1':;}j) между
случайными переменными 1': и }j, являющимися двумя компонентами выходноro
вектора У. Если (в идеальном случае) эта взаимная информация равна нулю, COOTBeT
ствующие компоненты 1': и }j являются статистически независимыми. Этоro можно
добиться, минимизируя взаимную информацию между всеми парами случайных пе
ременных, составляющих выходной вектор У. Эта цель эквивалентна минимизации
диверreнции Кулбека Лейблера между двумя следующими распределениями: функ
цией плотности вероятности jy(y,W), параметризованной по W, и соответствующим
факториальным распределением:
m
jy(y, W) == П jY;(Yi' W),
i l
(10.74)
rдe jYi (Yi, W) rpаничная функция плотности вероятности 1':. В результате выраже-
ние (10.74) можно рассматривать как одно из оrpаничений, налаrаемых на алrоритм
обучения, направленное на противопоставление jy(y,W) факториальному распреде
лению jy(y, W). Таким образом, можно сформулировать третий вариант принципа
Infomax следующим образом [205].
Для даННО20 вектора Х размерности m х 1, представляюще20 линейную комбинацию
т независимых источников си2нала, построить такое преобразование этО20 векто-
ра наблюдения нейронной системой в новый вектор У, чтобы минимизироваmь ди
вер2енцию Кулбека Лейблера между параметризованной вероятностью, задаваемой
функцией j у(у, W), и соответствующим факториальным распределением jy(y, W) по
отношению к неизвестной матрице параметров W.
Диверreнция Кулбека Лейблера в описанной здесь задаче была представлена в
разделе 10.5 формулой (10.44). Адаптируя эту формулу к текущей ситуации, дивер-
reнцию Кулбека Лейблера между функциями распределения вероятности jy(y,W) и
jy(y, W) можно записать следующим образом:
660
rлава 10. Модели на основе теории информации
т
1
m
Dfl1i(W) == h(Y) + Lh(Yi),
i l
(10.75)
Определение дифференциальной энтропии h(Y)
I
I
1
I
i
!
f
i
I
,
rде h('i) энтропия случайноrо вектора У на выходе разделителя сиrнала; h(Yi)
rpаничная энтропия i-ro элемента этоro вектора. Диверrенция Кулбека Лейблера
D flli является целевой функцией, на которой мы в дальнейшем и сконцентрируем
внимание для решения задачи слепоrо разделения источников.
Выходной вектор У связан со входным вектором Х соотношением (10.73), в котором
W является разделяющей матрицей. В свете выражения (10.18) дифференциальную
энтропию У можно выразить следующим образом:
h(Y) == h(WX) == h(X) + log Idet(W)1,
(10.76)
rде det(W) определитель матрицы W.
Определение rраничной энтропии h(Yi)
Для определения диверrенции Кулбека Лейблера D flli требуется также вычислить
rpаничную энтропию h(Yi). Для этоrо необходимо знание rpаничноrо распределения
переменной Yi, что, в свою очередь, требует интеrpирования эффекта от всех KOM
понентов случайноrо вектора У, за исключением ero i-ro компонента. Если вектор
У имеет достаточно большую размерность, вычислить h(Yi) HaмHoro сложнее, чем
h(Y). Этой сложности можно избежать, если вывести приближенную формулу BЫ
числен ия h(Yi) в терминах моментов высокоrо порядка случайной переменной Y'i.
Этоrо можно добиться усечением одноrо из следующих разложений.
. Разложение в ряд Эджворса (Edgeworth) [206].
. Разложение в ряд rрама Шарльера (Gram-Charlier) [37].
в этой rлаве мы рассмотрим второй подход14.
14 Аппроксимация функции плотности вероятности
(а) Разложение в ряд rрама Шарльера (Gram Charlier)
Пусть <Ру (00) характеристическая функцияу(у). По определению
<ру(ОО) == J c<o fy(y)eJwYdy, (1)
rдe j == R; 00 положительное число. Образно roворя, характеристическая функция <ру(ОО) является пре-
образованием Фурье функции плотности вероятности [у(у), за исключением перемены знака в экспоненте. В
общем случае характеристическая функция <ру(ОО) является комплексным числом, действительная и мнимая
часть котороro конечны для всех 00. Если существует k й момент случайной переменной У, то функция <ру(ОО)
может быть разложена в ряд в окрестности точки 00 == о:
10.11. Анализ независимых компонентов 661
Для примера, разложение rрама Шарльеl'а (Gram-Charlier) параметризованной
rpаничной функции плотности вероятности fYi (Yi, W) будет иметь следующий вид:
Jy.(y;, w) а(у;) [1+ t, CkHk(y;)] ,
(10.77)
rдe используются следующие обозначения.
OO
<ру (00) == 1 + L: з:, тk,
k l
(2)
rдe тk момент k-ro порядка случайной переменной У:
тk == E[yk] == J oo yk fy(y)dy. (3)
Выражение (2) бьulO получено с помощью простой подстановки разложения экспоненциальной функции
еЗ"'У из (1), перемены порядка суммирования и интеrpирования и применения определения (3). Если характе-
ристическая функция <ру (00) может быть разложена в ряд (2), тorдa можно разложить в ряд и ее лоrарифм:
log <ру (00) == f (joo)n, (4) тде Кn
n==1 n.
называется накоплением n ro порядка (cumulant) или псевдоинвариантом (semi-invariant) случайной переменной
У. Равенство (4) было получено разложением лоrарифма функции <ру (00) в ряд Тейлора поjоо в окрестности
точки 00 ==0.
Для упрощения изложения сделаем два допущения.
Случайная переменная У имеет нулевое среднее, Т.е. Jl ==0.
Дисперсия У нормализована до единицы, Т.е. 0'2 == 1.
СледователЬНО,Кl ==ОК2 == 1, и равенство (4) принимает следующий вид:
10g <ру (00) == !(joo?+ f (joo)n. (5)
n 3
Пусть т(оо) == f (joo)n.
п:::::3 n.
Torдa равенство (5) можно переписать в следующем виде: log<py(oo) == !(joo? + т(оо).
Это значит, что характеристическая функция <Ру (00) может быть представлена как произведение двух экс-
понент:
<ру(ОО) == ехр ( "O .ехр(т(оо)). (6)
Используя разложение степенноro ряда для слаrаемоro ехр(т(оо)), получим:
)) Т/С"')
ехр(т(оо == 1 + L., l! . (7)
l l
Подставляя (7) в (6) и собирая слаrаемые с одинаковыми степенями (joo) в результате двойноro суммиро
вания, получим новые коэффициенты разложения функции <ру (00):
Cl == О, С2 == О,
Кз К4 Ks
Сз == 6' С4 == 24 ' Cs == 120 '
1 2 1 1 2
св == (K6 + 10к з ), С7 == (K7 + 35К4КЗ), св == (KB + 56КsКз + 35К4)
720 5040 40320
и Т.д. Теперь можно выполнить обратное преобразование Фурье функции <ру (00) и получить разложение функ
ции плотности вероятности fy(y). В частности, можно записать:
fy(y) == о:(у) (1 + k З CkHk(Y)), (8)
rдe о:(у) функция плотности вероятности нормализоваююй zayccoBou случайной переменной с нулевым сред-
ним и единичной дисперсией:
о:(у) == e y2 /2. (9)
у2"
662 rлава 10. Модели на основе теории информации
1. Масштабирующий множитель a(Yi) является функцией плотности вероятности
нормализованной rауссовой случайной переменной с нулевым средним и единич-
ной дисперсией, Т.е.
a(Yi)
1 y2 / 2
e '
y'21t
2. Hk(Yi) полиномы Эрмита (Hennite polynomial).
3. Коэффициенты разложения {Ck: k ==3,4,... } определены в терминах семиинварu-
антов (cumulants) случайной переменной .
Разложение (8) называется рядом rрама Шарльера (Gram-Charlier) функции плотности вероятности по
Функцням [аусса и их производным [1022]. Разложение такоro рода имеет интуитивную привлекательность. В
частности, если случайная переменная У состоит из суммы нескольких независимо и равномерно распреде-
ленных случайных переменных, тorдa по мере увеличения колнчества этих переменных, соrласно центральной
предельной теореме, такая случайная переменная У асимптотически становится rауссовой. Первое слarаемое
ряда rрама Шарльера является тауссовым. Это значит, что сумма оставшихся слаrаемых ряда стремится к ну-
лю по мере увеличения количества переменных в сумме. Полиномы Эрмита Hk(Y), которые используются в
разложении (8), определяются в терминах k x производных а(у) следующим образом:
a(k)(y) == ( l)ka(y)Hk(Y)' (10)
Вот некоторые типичные полиномы Эрмита:
Но(у) == 1,
Н1(У) '" у,
Н2(У) == y2 1,
Н3(У) == у3 Зу,
Н4(У) == у4 6у2+з,
Н5(У) '" у5 10у3 + 15у,
Н6(У) '" у6 15 у 4 + 45у2 15.
Рекурсивное выражение для вычисления этих полиномов имеет следующий вид:
Hk+1(y) yHk(y) kHk 1(Y). (11)
Особенно важным свойством полиномов Эрмита является то, что Н k (у) И m я производная функции [аусса
а(у) являются биортоroнальными (biorthogonal):
J oo Hk(y)a(m) (y)dy == ( l)mm!Okm, (k, т) == О, 1,.... (12)
Величина Okm называется дельта-функцией Кронекера (Kronecker delta), которая принимает значение 1,
если k == т, и О в противном случае.
Важно заметить, что в разложенин в ряд rрама Шарльера (Gram-Charlier) естественный порядок слаraемых
не является лучшим. Вместо этоrо целесообразнее сrpуппировать слаrаемые следующим образом [449]:
k ==(0), (3), (4,6), (5,7,9): (13)
Элементы в rpуппах обычно имеют один порядок амплитулы. Например, если включить слаrаемое с k 4,
то необходимо также включить и слаrаемое с k == 6.
(6) Разложенне в ряд Эджворса (Edgeworth)
Как и в первом случае, пусть а(у) функция плотности вероятности некоторой нормализованной случайной
пере мен ной с нулевым средним значением и еднничной дисперсией. Разложение в ряд Эджворса функции
плотности вероятности случайной переменной У в окрестности rауссовой аппроксимации а(у) определяется
следующей формулой [205], [1023]: 2
fy(y) 1 H ( ) + H ( ) H ( ) + H - ( )
"(у) + 3! 3 У 4! 4 У + 6! 6 У 5!" У +
з
+ 35iiЧ Н7(У) + 28 !1(З Н9(У) + 7fr H 6(Y) + 56 1(5 Н8(У)+ (14)
( 21001( Ч 154001(
+ 8! НВ у) + JJJ! Н10(У) + 12! Н12(У) + ...,
<де 1(i накопление порядка i стандартизированнои скалярной случайной переменной У; Н i полином Эрмита
порядка i. Разложение (14) называется рядом Эджворса
Ключевым свойством ряда Эджворса является то, что еro коэффициенты уменьшаются равномерно. С
друroй стороны, слаrаемые ряда rрама Шарльера (8) не сходятся равномерно к нулю, поэтому нельзя сказать,
что какое либо слаrаемое при вносит меньший вклад, чем предыдущее. Именно по этой причине при обрезании
этоro ряда рекомендована процедура rpуппировки ето слаrаемых (13).
10.11. Анализ независимых компонентов 663
Естественный порядок слаrаемых в выражении (10.77) не является лучшим для
разложения rрама Шарльера (Gram-Charlier). В этом разложении слаrаемые лучше
сrpуппировать следующим образом [449]:
k == (О), (3), (4,6), (5,7,9),... .
Для задачи слепоrо разделения источников аппроксимацию rpаничной функ-
ции плотности вероятности ]Yi (Yi) путем усечения разложения rрама Шарльера на
уровне k ==(4,6) можно считать адекватным. Исходя из этоrо, можно записать:
"" ( 1(i,З 1(;,2 (1(i,6 + 101(;,з) )
fyJYi) a(Yi) 1 + 3!Н З (Уi) + 4!"H 4 (Yi) + 6! H 6 (Yi),
(10.78)
rдe 1(i,k семиинвариант (cumulant) k-ro порядка переменной Yi. Обозначим как mi.k
момент k-ro порядка переменной Yi:
т;, E[y,k] Е [ ( W;kX;) '] ,
(10.79)
rдe X i i-й элемент вектора наблюдений Х; Wik ik-й элемент матрицы весов
W. Ранее уже было обосновано предположение о нулевом среднем компонентов yi
для всех i. Следовательно, а; == mi,2 (т.е. дисперсия равна среднеквадратическому
значению). Исходя из этоrо, семиинварианты переменной yi можно связать с ее
моментами следующим образом:
1(i,З == mi,З,
1(i 4 == mi 4 3 т 7 2 ,
J , "1
1(i,6 == mi,6 10m;,з 15mi,2mi,4 + 30тТ,2'
(10.80)
(10.81)
(10.82)
Алroритм нахождения ]у; (Yi) с помощью аппроксимации (10.78) можно предста-
вить так:
log ]у; (Yi) log a(Yi)+
( 1(i,з 1(;,2 (1(i,6 + 101(;,з) )
+ log 1 + 3!Н З (Уi) + 4!"H 4 (Yi) + 6! H 6 (Yi)'
(10.83)
Далее будем использовать следующее разложение лоrарифма в ряд:
у2
log(l + У) У ,
2
(10.84)
rдe все слаrаемые TpeTbero порядка и выше иrнорируются.
664 rлава 10. Модели на основе теории информации
Вспомним из предыдущеrо материала, что формула rpаничной энтропии yi имеет
следующий вид (см. (10.43)):
h(Yi) == 1: fYi (Yi) logfY i (Yi)dYi, i == 1,2,.. . , т,
rдe m количество источников. Используя аппроксимации (10.78), (10.83) и (10.84)
и взяв определенные интеrpалы, содержащие нормализованные rауссовы плотности
a.(Yi) и различные полиномы Эрмита Hk(Yi), получим следующую приближенную
формулу для rpаничной энтропии [700]:
1 к; 3 к; 4 (Ki 6 + 10к; 3)2 3 2
h ( Y; ) lo g( 21te ) .........:.... .........:.... ' , + K. к. 4 +
> 2 12 48 1440 8 >,3 >,
+ К;,З(Кi,6 + 10к;,з) + K;,4(Ki,6 + 10к;,з) + K ,4Ki,6 + 10К;,з)2 +
24 24 64
K ,4 (Ki,6 + 10к;,з)3
+ 16 + 432
(10.85)
Подставляя (10.76) и (10.85) в (10.75), получим выражение для диверrенции
Кулбека Лейблера поставленной задачи:
m
Dfl1j(W) h(X) log Idet(W)1 + 21og(21te)
к;,з К;,4 (Ki,6 + 10К;,з)2 K2 К.
L...-( 12 + 48 + 1440 8 i,3 >,4
i l
К;,З(Кi,6 + 10к;,з)
24
K ,4 (Ki,6 + 10к;,з)3 )
16 432 '
К;,4 (Ki,6 + 10к;,з)
24
K ,4 Ki,6 + 10К;,з)2
64
(10.86)
rде все семиинварианты являются функциями матрицы весов W.
Функция активации
Чтобы оценить диверrенцию Кулбека Лейблера, описанную формулой (10.86), требу
ется адаптивная процедура вычисления семиинвариантов высокоrо порядка вектора
наблюдений х. Вопрос состоит в следующем: как выполнить эти вычисления, учи
тывая способ вывода приближенной формулы (10.86)? Вспомним, что приведенный
вывод этой формулы основывалея на разложении rрама Шарльера, при этом пред
полаrалось, что случайная переменная yi имеет нулевое среднее и единичную дис
персию. Ранее мы уже обосновывали нулевое среднее тем, что для начала входные
10.11. Анализ независимых компонентов 665
сиrналы будут иметь нулевое среднее. Что же касается предположения о единичной
дисперсии, для ero обоснования можно применить один из следующих подходов.
1. Подход с 02раниченuями. В этом подходе при вычислении семиинвариантов вы-
cOKoro порядка 'К:i,з, Ki,4 И Ki,6 для всех i делается предположение о единичной
дисперсии [37]. К сожалению, нет никакой rарантии, что на протяжении вычис-
лений дисперсия Yi, а именно ат, останется константой, равной единице. Из
определений (10.81) и (10.82) видно, что как Ki,4, так и K i ,6 зависят от ат == mi,2'
В результате предположение о равенстве дисперсии единице сводится к тому, что
оценки, производные от Ki,4 и Ki,6, смещаются и становятся ошибочно связанными
с оценкой 'К:i,з.
2. Подход без 02раничений. В этом альтернативном подходе дисперсия ат рассмат-
ривается как неизвестный параметр, зависящий от времени, что весьма близко к
реальности [700]. Эффект от отклонения дисперсии от единицы рассматривается
как масштабирующая вариация значений случайной переменной Yi. Что более
важно оценки, производные от Ki,4 и Ki,6, учитывают изменение ат во времени.
Таким образом, формируется правильное соотношение между оценками всех трех
семиинвариантов в формуле (10.86).
Экспериментальное изучение слепоrо разделения источников бьmо проведено в
[700]. В этой работе показано, что подход без оrpаничений приводит к более высокой
производительности, чем подход с оrpаничениями. В связи с этим в дальнейшем
будем использовать именно ero (подход без оrpаничений).
Чтобы построить алroритм обучения для вычисления W, необходимо продиффе-
ренцировать выражение (10.86) по W, а затем вывести функцию активации алrоритма.
Пусть Aik ik-й кофактор (cofactor) матрицы W. Используя разложение Лапласа
определителя det(W) по i-й строке, можно записать:
m
det(W) == L ЩkАik, i == 1, 2, ... , т,
k l
(10.87)
rде Wik ik-й элемент матрицы W. Исходя из этоrо, дифференцируя лоrарифм опре
делителя det(W) по Wik, получим:
д 1 д A
д log(det(W)) == d ( ) д det(W) == d ( ) == (W T)ik'
Wik et W Wik et W
(10.88)
rдe W T матрица, обратная транспонированной матрице W T . Частные производ-
ные остальных слаrаемых (зависящих от W) в выражении (10.86) по Wik равны
(см. (10.80) (10.82)):
666 rлава 10. Модели на основе теории информации
t
При выводе адаптивноrо алrоритма обычно значения математическоrо ожидания i l ..
заменяются их моментальными значениями. Таким образом, производя такую замену
во всех трех уравнениях, получим следующие приближенные результаты:
I
дКi,з == 3Е [ у2 Х ]
д ' k,
Wik
aKi 4 3
д ' == 4E[ X k ] 12mi,2E[YiXk],
Wik
a ik (Ki,6 + 10к;,з) == 6E[ 5 X k ] 30mi,4 E [YiX k ]
60mi,2E[ 3 X k ] + 180m;,2 E [YiX k ].
дКi,з '" 2
д 3Yi X k,
Wik
aKi 4 3
д ' ::::' 8Yi Xk,
Wik
д 2 5
д (Ki 6 + 10K i 3 ) ::::' 96Yi Xk'
Ш ' ,
ik
(10.89)
(10.90)
(10.91 )
Подставляя (10.88) (10.91) в выражение для производной (10.86) по Щk, получим:
д T
д D fllj(W) ::::' (W )ik + <P(Yi)Xk,
Wik
(10.92)
rде <P(Yi) немонотонная функция активации алroритма обучения, определенная
следующим образом [700]:
( ) 1 5 2 7 15 9 2 11 112 13 15 512 17
<Р Yi == 2 Yi + зУi + 2:Yi + 15 Yi зУi + 128Yi зУi .
(10.93)
На рис. 10.11 представлен rpафик функции активации <P(Yi) для Yi, лежащих в
открытом интервале ( 1,+1). Это покрывает диапазон выходов Yi, с которыми обыч
но работает алroритм обучения. Обратите внимание, что наклон функции активации
положителен в интервале ( 0.734, +0.734). Это требование для устойчивости алrо
ритма, о котором речь пойдет ниже.
Алrоритм обучения для 'СА
Целью алrоритма обучения является минимизация диверrенции Кулбека Лейблера
между функцией плотности вероятности У и факториальным распределением Yi, i =
1,2, ..., тn. Минимизации можно достичь с помощью метода rpадиентноrо спуска,
в котором корректировке подверrается вес Wik:
10.11. Анализ независимых компонентов 667
10
8
6
4
2
Б о
s.
2
4
6
8
10
1 0,8 0,6 0,4 0,2 О 0,2 0,4 0,6 0,8
у
Рис. 10.11. Функция активации, задаваемая формулой (10.93)
д ( T )
LlWik == 11 д D fllJ == 11 (W )ik <P(Yi)Xk) ,
Wik
(10.94)
rдe 11 параметр скорости обучения.
Расширяя формулу (10.94) на всю матрицу весов W, корректировку Д W, приме-
няемую к вектору W, можно выразить соотношением
LlW == 11(w T <р(у)х Т ),
(10.95)
rде х Т транспонированный вектор наблюдений, а
ср(у) == [<Р(Уl), <Р(У2),'" , <Р(Ут)]Т'
(10.96)
Формулу (10.95) можно переписать в следующем виде:
LlW == 11[1 <p(Y)XTWT]W T == 11[1 <p(y)yT]W T,
(10.97)
rдe 1 единичная матрица. Правило коррекции при адаптации разделяющей матрицы
примет следующий вид:
W(n + 1) == W(n) + 11(n)[1 cp(y(n))yT(n)]W T(n).
(10.98)
в этой формуле все параметры по казаны в форме, зависящей от времени.
668 rлава 10. Модели на основе теории информации
Свойство эквивариантности
Целью алroритма слепоro разделения источников является такая коррекция матрицы
разделения W(n), чтобы вектор
у(n) == W(n)x(n) == W(n)Au(n)
бьm как можно ближе к исходному вектору u(n) в некотором статистическом смыс-
ле. Для примера рассмотрим rлобальную систему, характеризуемую матрицей С(n),
которая получена перемножением матрицы смешения А и матрицы разделения W(n):
С(n) == W(n)A.
(10.99)
в идеальном случае эта rлобальная система будет удовлетворять двум условиям.
1. Алroритм, отвечающий за корректировку С ( n), сходится к оптимальному значе
нию, равному матрице перестановок (pennutation).
2. Сам алrоритм можно представить в следующем виде:
С(n + 1) == С(n) + ll(n)G(C(n)u(n))C(n),
(10.100)
!
I
!
I
I
I
f
I
rдe G(C(n)u(n)) вектор-функция apryMeHTa C(n)u(n). Производительность
этоrо алroритма в целом характеризуется системной матрицей С(n), а не индиви
дуальными значениями матриц смешения А и разделения W ( n). Такая адаптивная
система называется эквивариантной [173].
Можно показать, что адаптивный алroритм (10.98) приближенно удовлетворяет
первому условию. Для этоro можно переписать (10.98) в эквивалентной форме:
С(n + 1) == С(n) + ll(n)G(C(n)u(n))W T(n)A,
(10.101)
rде
G(C(n)u(n)) == 1 cp(C(n)u(n))(C(n)u(n))T.
(10.102)
Алrоритм (10.98) быстро переходит в эквивариантное состояние (10.100), если
вектор-функцию G(C(n)u(n)) домн ожить на W T А, что, собственно, является еще
одной формой С(n). Эту ситуацию можно исправить, заменив это значение на MaT
ричное произведение WT(n)W(n). Слаrаемое WTW, составленное из произведения
матрицы W на саму себя транспонированную, всеrда является положительно опре
10.11. Анализ независимых компонентов 669
деленным. Это и является причиной Toro, что перемножение на WTW не изменяет
знака минимума алroритма обучения.
Возникает важный вопрос: как применить эту модификацию, чтобы достичь эк-
вивариантноrо состояния? Ответ на этот вопрос заключается в самой формулировке
метода rpадиентноro спуска в пространстве параметров. В идеальном случае можно
использовать натуральный 2радиент 15 (natural gradient) целевой функции D fllg(W),
определяемой в терминах обычноrо rpадиента \1 D fllj(W) следующим образом:
\1*D fl1 j(W) == (\1D fl1 j(W))W T W.
(10.103)
Сама матрица обычноrо rpадиента \1 D fllj(W) представляет собой оптимальное
направление спуска только в случае, Korдa пространство параметров W=={W} являет-
ся Евклидовым и имеет ортонормированную систему координат. Однако в нейронных
сетях при нормальных условиях система координат пространства параметров обычно
не является ортонормированной. В последней ситуации наискорейший спуск (steepest
descent) можно реализовать с помощью натуральноrо rpадиента \1* D fllj(W), Таким
образом, ero применение в стохастическом алrоритме для слепоro разделения ис-
точников будет более предпочтительным, чем использование обычноrо rpадиента.
Чтобы пространство натуральных rpадиентов было определимо, необходимо выпол
нение следующих условий.
1. Пространство параметров W должно быть Рима новым 16. Риманова струк-
тура является дифференцируемым множеством с положительно определен-
ной метрикой W.
2. Матрица W должна быть несинrулярной (т.е. обратимой).
В рассматриваемой нами задаче оба эти условия выполняются.
Модифицируя алrоритм (10.98) описанным выше способом, можно записать:
W(n + 1) == W(n) + l1(n)[I cp(y(n))yT(n)](W(n)WT(n))W T(n) ==
== W(n) + 11(n) [1 cp(y(n))yT(n)]W(n).
(10.104)
15 Идея использования величины '\1*D ==('\1 D)WTW вместо обычноro rpадиента '\1 D для задачи разделе-
ния источников была впервые описана в [173]. В этой работе величина '\1*О получила название относительноro
rpадиента (reJative gradient). Этот rpадиент в точности совпадает с натуральным срадиентом
16 В Римановом пространстве размерности п, например, квадратичная норма вектора а определяется следу
ющим образом: n n
II a l1 2 == L L 9ij a i a j,
i lj l
rдe 9ij функции координат Xl, Х2,..., Xn Риманова пространства, gij == 9ji, а правая часть этоrо выражения
всетда положительна. Это выражение является обобщеНИiiМ формулы Евклида для квадратичной нормы:
IIal1 2 == L аТ.
i==l
Риманова структура рассматривается в [26], [763].
670 rлава 10. Модели на основе теории информации
Это выражение приводит к слепому разделению источников со свойством экви-
вариантности. На рис. 10.12 показано представление формулы (10.104) в виде rpафа
передачи сиrнала.
Для Toro чтобы адаптивный алroритм (10.104) давал корректное решение зада-
чи слепоro разделения источников (см. рис. 10.9), для всех компонентов выходноro
вектора у должны выполняться следующие условия.
· Ряд rрама Шарльера, используемый для вычисления нелинейной функции <р(.),
должен содержать достаточное число слаrаемых. Это обеспечит хорошую аппрок-
симацию rpаничной энтропии h(Yi). Например, этому требованию вполне удовле- ,
творяer функция (10.93). I
!
t,
· Для достоверности оценки семиинвариантов yi параметр скорости обучения "
должен быть достаточно мал.
Условия устойчивости
Разrовор о задаче слепоrо разделения источников был бы не полным, если бы мы не
рассмотрели вопросы устойчивости адаптивноrо алrоритма, описываемоrо форму-
лой (10.104). В [36] такое исследование было проведено для про изволь ной функции
активации <р(.). Этот анализ проводился в контексте асимптотической сходимости
алrоритма к желаемой точке равновесия, в которой rарантировалось успешное раз-
деление источников.
Выражение (10.104) является дискретным описанием алrоритма слепоro разделе-
ния источников, oCHoBaHHoro на натуральном rpадиенте. Для анализа устойчивости
рассмотрим ero непрерывный эквивалент:
W(t) == l1(t)[I <p(y(t))yT(t)]W(t),
(10.105)
rде t непрерывная переменная времени; W(t) == aW(t)jat. Параметр скорости
обучения l1(t) является положительным на всем временном интервале. Пусть
а; == Е [У;] ,
k == Е [ a<P(Yi) ]
, aYi'
. Е [ 2 a<P(Yi) ]
q, У.
, aYi
(10.106)
(10.107)
(10.108)
10.11. Анализ независимых компонентов 671
1)(п)
W(n+ 1)
W(n)
х(п)
у(п)
Рис. 10.12. rраф передачи сиrнала для алrоритма обучения слепому разделению
сиrнала (10.104)
Torдa, соrласно [36], разделяющее решение является устойчивой точкой равнове-
сия адаптивноrо алrоритма (10.104) для произвольной функции активации <р(-) тorдa
и только тorдa, Korдa выполняются следующие условия:
qi + 1 > О,
k i > О,
(J;(J kikj > 1.
(10.109)
(10.110)
(10.111)
для всех пар (i, Л, rде i i- j. Неравенства (1 0.1 09) (1 0.111) являются необходимым
и достаточным условием устойчивости адаптивноro алroритма (10.104).
672 rлава 10. Модели на основе теории информации
Условия сходимости
Что можно сказать о сходимости алrоритма обучения (10.104), OCHOBaHHoro на ФУНК-
цИИ активации (10.93), если выполнены требования устойчивости (10.109) (10.111)?
В свете экспериментальных исследований, изложенных в [700], можно утверждать,
что процесс сходимости проходит две фазы.
. В первой фазе корректировке подверrается дисперсия cr;(n) случайной пере
менной yi на выходе разделителя, достиrая в результате достаточно устойчи-
Boro значения. Во время этой фазы семиинварианты Ki,3, Ki,4 и Ki,6 существен-
но не изменяются.
. Во второй фазе процесс корректировки распространяется на семиинварианты
Ki,3, Ki,4 и Ki,6, достиrая в результате достаточно устойчивоrо значения. После
этоro можно считать, что алrоритм сошелся.
Таким образом, получается, что оценка дисперсии и семи инвариантов высоких
порядков на выходе разделителя (т.е. разделенный сиrнал источника) представляют
собой базис чувствительной процедуры изучения сходимости алrоритма обучения
(10.104). Интересно заметить также и то, что только во второй фазе используется
разложение в ряд rрама Шарльера.
10.12. Компьютерное моделирование
,
!
\
I
\
I
Рассмотрим систему, показанную на рис. 10.9 и имеющую следующие источники:
Ul(n) == 0,1. sin(400n) cos(30n),
и2(n) == 0,1. sgn(sin(500n + 9cos(40n))),
и2 (n) соответствует равномерно I:аспределенному шуму в интервале [ 1, 1].
Матрица смешения А имеет следующий вид:
[ 0.56 О. 79 0.37 ]
А == 0.75 0.65 0.86
0.17 0.32 0.48
rрафики входных сиrналов показаны на рис. 10.13, слева.
Для разделения воспользуемся пакетной версией правила коррекции (10.104)
(см. задачу 10.14). Пакетная обработка бьmа выбрана исходя из соображений ycкope
ния сходимости. В примененном алroритме использовались следующие состояния.
Исходные сиrналы
0,1
0,05
s
:;
о
0,05
0,1 О
0,1
0,15
0,05
0,02
0,01
-;:;-
(:::1 о
::s
0,01
0,02 О
,
,
.
0,05
0,1
0,15
0,5
s
,., о
::s
0,5
0,05
0,1
0,15
10.12. Компьютерное моделирование 673
Разделенные сиrналы
s
;:.,
0,2
0,1
О
0,1
0,2
o 2
, О
0,1
0,15
0,2
0,05
0,2
0,1
,.....
-;:;-
(:::1 о
....
0,2
0,1
o 2
, О
0,1
0,15 0,2
'--------
0,05
s
,.,
....
0,4
0,2
О
0,2
0,2
o 4
, О
0,05
0,1
0,15
0,2
Рис. 10.13. rрафики входных сиrналов (слева); rрафики разделенных сиrналов
(справа)
. Инициализация. Для инициализации алrоритма веса матрицы разделения W фор-
мировались reHepaTopoM случайных чисел, равномерно распределенных в диапа-
зоне [О, 0.05].
. Интенсивность обучения. Параметр скорости обучения бьm фиксированным и
имел значение,., ==0,1.
. Длительность СИ2нала. На выходе смесителя сиrнал снимался с дискретизацией в
10 4 с, при этом множество обучения содержало N ==65000 примеров.
На рис. 10.13, справа показаны rpафики сиrналов на выходе разделителя после
300 итераций. За исключением HeKoToporo масштабирования и перемешивания по-
рядка сиrналов, не существует сколько-нибудь существенных различий между двумя
множествами rpафиков, показанных на рис. 10.13, слева и справа. Для представлен-
ных здесь результатов на этапе инициализации алrоритма использовалась следующая
матрица весов W:
1
674 rлава 10. Модели на основе теории информации
[ 0.0109 0.0340 0.0260 ]
W(O) == 0.0024 0.0467 0.0415
0.0339 0.0192 0.0017
Алrоритм сошелся к следующей матрице весов:
[ 0.2222 0.0294 0.6213 ]
W == 10.1932 9.8141 9.7259
4.1191 1.7879 6.3765
Соответствующими значениями матричноrо про изведения WA являются
[ 0.0032 0.0041 0.2413 ]
WA == 0.0010 17.5441 0.0002 .
2.5636 0.0515 0.0009
Переставляя строки в матричном произведении так, чтобы порядок выходных
сиrналов совпадал с порядком входных, можно записать:
[ 2.5636 0.0515 0.0009 ]
WA == 0.0010 17.5441 0.0002
0.0032 0.0041 0.2413
Первая, вторая и третья строки матричноro произведения соответствуют сиrналу
с амплитудной модуляцией, сиrналу с частотной модуляцией и шуму. Диаrональные
элементы матричноro произведения WA определяют коэффициенты масштабирова
ния rpафиков выходных сиrналов (см. рис. 10.13, справа) по отношению к rpафикам
исходных сиrналов (см. рис. 10.13, слева).
Для количественной оценки эффективности разделителя можно использовать тO
бальный индекс отклонения (global rejection index), определенный в [37]:
J == f ( f Ipij I 1 ) + f ( f Ipij I 1 ) ,
' l ' l шах \Pikl ' l ' l шах !Pkil
' з k з ' k
rдe Р == {Pij} == WA. Индекс эффективности J является мерой диа20нальностu
(diagonality) матрицы Р. Если матрица Р является идеально диаrональной, то J =
О. в матрице Р, элементы которой не сконцентрированы вдоль rлавной диаroнали,
индекс эффективности J будет высоким.
Для rpафиков, показанных на рис. 10.13, индекс эффективности J == 0,0606.
10.13. Оценка максимальноro правдоподобия 675
10.13. Оценка максимальноrо правдоподобия
Метод анализа независимых компонентов (т.е. третий вариант принципа Infomax),
описанный в предыдущем разделе, является одним из множества методов, KO
торые предлаrаются в литературе, для слепоrо разделения сиrналов. Однако в
информационно-теоретическом контексте существуют два друrих метода для реше
ния этой задачи без учителя: методы маКсимальноrо правдоподобия и максимальной
энтропии. В этом разделе мы поrоворим о первом из них.
Метод максимальноro правдоподобия является хорошо зарекомендовавшей себя
процедурой статистической оценки, имеющей ряд привлекательных свойств (см. при-
мечание 5 в rлаве 7). В этой процедуре мы сначала формулируем функцию лоrариф-
мическоrо подобия, а затем оптимизируем ее по отношению к вектору параметров
рассматриваемой вероятностной модели. В rлаве 7 уже roворилось о том, что функция
подобия является функцией плотности вероятности множества данных в предложен
ной модели, но рассматривается как функция неизвестных параметров модели. Воз-
вращаясь к рис. 10.9, положим, что fu(-) функция плотности вероятности случай
HOro входноrо вектора U. Тоrда функция плотности вероятности вектора наблюдений
Х == AU выхода смесителя будет равна [813]:
fx(x,A) == I det(A)I l fu(A lX),
(10.112)
rде det(A) определитель матрицы смешения А. Пусть Т == {xkHI l множество
из N независимых реализаций случайноrо вектора Х. Torдa можно записать:
N
fx(T, А) == П fX(Xk, А).
k l
(10.113)
Считается, что для работы удобнее иметь дело с нормализованной (т.е. разделенной
на N) версией функции лоrарифмическоrо подобия:
1 1 N
N logfx(T,A) == N Llogfx(xk,A) ==
k l
1 N
== N L log fu(A lXk) log Idet(A)j.
k l
(10.114)
676
rлава 10. Модели на основе теории информации
r
Пусть у=А lX, а fy(y,W) функция плотности вероятности У, параметризо-
ванная по W. Тоrда, признавая, что сумма (1 О .114) является примером среднеrо по
множеству значения log fU(Yk), можно сказать, что соrласно закону больших чисел,
с вероятностью 1, при достижении количеством примеров N бесконечности
1 N
L(W) == lim N " log fU(Yk) + log Idet(W)1 ==
N----->oo
k l
== E[log fU(Yk)] + log Idet(W) I ==
== 1: А(у, W) log fu(y)dy + log Idet(W)I ,
(10.115)
rдe ожидание во второй строке вычисляется по отношению к У. Величина L(W)
является искомой функцией лоrарифмическоrо подобия. Расписывая
( fu(y) )
fu(Y) == fy(y, W) А(у, W),
можно переписать функцию L(W) в эквивалентной форме:
1 00 ( fu(Y) )
L(W) == oo А(у, W) log fy(y, W) dy+
+ 1: А(у, w) log fy(y, W)dy + log Idet(W)I ==
== Dfyllfu h(Y, W) + log Idet(W)I ,
(10.116)
rде h(Y,W) дифференциальная энтропия случайноrо вектора Х, параметризованная
по W; DfYllfu диверrенция Кулбека Лейблера между fy(y,W) и fu(Y). Подставляя
(10.76) в (10.116), мы можем упростить выражение для функции лоrарифмическоrо
подобия L(W) [169]:
L(W) == Dfyllfu h(X),
(10.117)
rде h(X) дифференциальная энтропия случайноrо вектора Х на входе разделите-
ля. Единственной величиной в (10.117), зависящей от вектора весов W разделите
ля, является диверrенция Кулбека Лейблера DfYllfu' Таким образом, получается, что
максимизация функции лоrарифмическоrо подобия L(W) идентична минимизации
диверrенции Кулбека Лейблера Dfyllfu' которая является мерой совпадения выхода
разделителя У и вектора исходноrо сиrнала U. И это интуитивно понятно.
10.1 З. Оценка максимальною правдоподобия 677
Связь между максимальным подобием и анализом
независимых компонентов
Применяя декомпозицию Пифаroра (10.45) к нашей задаче, диверrенцию Кулбека
Леблера для максимальноrо правдоподобия можем представить в следующем виде:
Dfyllfu == Dfy11jy + DjYllfu'
(10.118)
Первая диверrенция Кулбека Лейблера D fylljy в правой части (10.118) представ-
ляет собой меру структУРН020 несоответствия (structural mismatch), которое ха-
рактеризует метод анализа независимых компонентов. Вторая диверrенция Кулбека
Лейблера является мерой 2раНИЧН020 несоответствия (marginal mismatch) между rpa-
ничным распределением выхода разделителя У и распределением вектора исходных
сиrналов U. Таким образом, критерий "rлобальноrо" соответствия распределения для
метода максимальноrо подобия можно представить следующим образом [23], [169]:
( Общее ) ( структурное ) ( rраничное )
несоответствие == несоответствие + несоответствие .
(10.119)
"Структурное несоответствие" относится к структуре распределения, относящей-
ся к множеству независимых переменных; "rpаничное несоответствие" относится к
несоответствию между отдельными rpаничными распределениями.
При идеальных условиях W==A 1 (т.е. при совершенно слепом разделении сиrна-
ла) как структурное, так и rpаничное несоответствие исчезает. В этом случае методы
максимальноrо правдоподобия и анализа независимых компонентов предлаrают одно
и то же решение задачи. Идеальная зависимость этих методов показана на рис. 10.14
[23], [172]. На этом рисунке G 7""'" это множество функций плотности вероятности fy(y)
случайноro вектора У на выходе разделителя; J множество всех независимых рас-
пределений вероятности. Как J, так и G имеет бесконечную размерность. Множество
D == {fy(y, W)} является конечным множеством распределений вероятности, изме
ренных на выходе разделителя. Размерностью множества D является m 2, rде m
размерность вектора У, а координатная система образована матрицей весов W. На
рис. 10.14 мы отчетливо видим, что Dfy11jy и DjYllfu имеют минимумы при W A l.
Будет интересным доказать, что множества D и J являются ортоrональными в своей
точке пересечения, определенной истинной функцией плотности вероятности fu(Y).
Алroритм слепоrо разделения источников, основанный на максимальном правдо-
подобии, должен содержать инструментарий для оценки распределений источников,
кorдa они неизвестны (что, как правило, и происходит). Параметры этой оценки
MOryт адаптироваться по мере адаптации матрицы разделения W. Друrими сло-
вами, необходимо обеспечить совместную оценку (joint estimation) матрицы сме-
шения и (некоторых характеристик) распределений входных сиrналов [169], [171].
l'
678 rлава 10. Модели на основе теории информации
G: полное множество
распределений вероятности
fy(Y)
fu(y): истинное
распределение
сиrнала
J: все независимые
распределения
Рис. 10.14. Взаимосвязь между максимальным правдоподобием и анализом независимых
компонентов в задаче слепоrо разделения источников. Метод максимальноro правдоподобия
минимизирует D fy 11 fu' Torдa как анализ независимых компонентов минимизирует D fy 11 jy
Элеrантный и хорошо продуманный подход к решению задачи совместной оценки
бьm предложен в [834], [835].
10.14. Метод максимальной энтропии
Метод максимальной энтропии (maximum entropy method) для слепоrо разделения ис
точников был предложен в [116]. На рис. 10.15 показана блочная диаrpамма системы,
10.14. Метод максимальной энтропии 679
основанной на этом методе. Как и раньше, разделитель (demixer) работает с вектором
наблюдений Х для получения выхода y==wx, являющеrося оценкой вектора исходных
сиrналов U. Вектор У преобразовывается в вектор Z с помощью ero прохождения че-
рез нелинейное преобразование G(.), являющееся монотонным и обратимым. Таким
образом, в отличие от У, вектор Z rарантирует оrpаниченность дифференциальной
энтропии h(Z) для произвольно большоro разделителя. Для заданной нелинейности
G (.) метод максимальной энтропии создает оценку исходноro входноro вектора U
с помощью максимизации энтропии h(Z) по отношению к W. в свете выражения
(10.55), выведенноrо в примере 10.6, видно, что метод максимальной энтропии тесно
связан с принципом Infomax 17.
Нелинейность G является диazональным отображением (diagonal mар), описыва
емым следующим образом:
[ Уl ] [ 91(Yl) ]
G: . Y2)
Ут 9т(Ут)
[:]
(10.120)
Исходя из этоrо, можно записать:
Z == G(Y) == G(WAU).
(10.121)
Так как нелинейность G(.) является обратимой, входной вектор U можно выразить
в терминах выходноrо вектора Z:
U == А lW lG l(Z) == Ф(Z),
(10.122)
rдe G l обратная нелинейность (inverse nonlinearity):
G l
[ Zl ] [ 9 :(Zl) ] [ Уl ]
Z2 92 (Z2) У2
... ... ...
zm 9 1(Zm) Ут
(10.123)
17 В [116] авторы назвали свой метод слепоro разделения источников словом 1nfomax в свете выражения
(10.55), определяющеro взаимосвязь между энтропией Н(У) и взаимной информацней I(YjX). Тем не менее
более предпочтнтелен термин "метод максимальной энтропии", так как в этом методе в действительности
максимнзнруется эитропия h(Z), тде Z == G(Y). Не путайте метод максимальной энтропии для задачи слепоro
разделения источников по Беллу и Седжновскому с методом максимальной энтропии по Бурту [164] для
спектральноro анализа.
l'
680 rлава 10. Модели на основе теории информации
u " Смеситель: х " Разделитель: у " Нелинейность: z "
v А I V W v G(.) v
I
I
I I
L I
Неизвестная среда
Рис. 10.15. Блочная диаrрамма метода максимальной энтропии для за
дачи слепоrо разделения источников. Векторы u, х, у и z являются значе
ниями случайных векторов U, Х, у и Z соответственно
Функция плотности вероятности выходноrо вектора Z определяется в терминах
функции плотности вероятности входноrо вектора U следующим образом:
fu(u)
fz(z) == Idеt(J(u))l lu Ф(z) ,
(10.124)
rде det(J(u)) определитель матрицы Якобиана J(u), и M элементом которой является
az
J ij == д '.
и,
J
(10.125)
Исходя из этоrо, энтропию случайноrо вектора Z на выходе нелинейности G
можно записать в соответствии с формулой
[ ( fu(u) )]
h(Z) == E[log fz(z)] == E log Idet(J(u))1 u Ф(z)
== DfullldetJI' вычисленной в точке u == Ф(z).
(10.126)
Мы видим, что максимизация энтропии h(Z) эквивалентна минимизации дивер
rенции Кулбека Лейблера между fu(U) и функцией плотности вероятности U, зада
ваемой определителем Idet(J(u))1.
Теперь предположим, что случайная переменная Zi (т.е. i-й компонент вектора Z)
равномерно распределена на интервале [О, 1] для всех i. Соrласно примеру 10.1, энтро
пия h(Z) в этом случае равна нулю. Следовательно, из (10.126) можно заключить, что
fu(u) == I det(J(u))I.
(10.127)
При идеальных условиях (W A l) это соотношение сводится к
az' l
fUi(Ui) == д t ( ) для всех i.
Yi Zi 9 Ui
(10.128)
10.14. Метод максимальной энтропии 681
и наоборот, можно утверждать, что если удовлетворяется (10.128), то максими
зация h(Z) приводит к тому, что W == А 1, и, таким образом, достиrается слепое
разделение источников.
Теперь можно подвести итоrи, полученные для метода максимальной энтропии
решения задачи слепоrо разделения источников [116].
Пусть нелинейность на выходе разделителя (см. рис. 10.15) можно определить в
терминах исходною распределения источников следующим образом:
Zi == gi(Yi) == j Zi fUi(Ui)dUi, i == 1,2,... ,т.
oo
(10.129)
ТО2да максимuзация энтропии случайной переменной Z на выходе нелинейной за-
висимости G эквивалентна достижению соотношения W A 1, что соответствует
полному слепому разделению источников.
Методы максимальной энтропии и максимальноrо подобия для задачи слепоrо
разделения источников являются эквивалентными, при условии, что случайная пе-
ременная Zi равномерно распределена на интервале [О, 1] для всех i [171]. Для
доказательства этоrо соотношения можно использовать правило цепочки (chain rule)
и переписать (10.125) в эквивалентной форме:
aZ i aYi aXk aZ i
J ij == 7!). д д . == 7!).Щk а k j .
k 1 У, Xk из k 1 У,
(10.130)
Следовательно, матрица Якобиана J может быть выражена как
J == DWA,
rдe D диаrональная матрица:
. ( aZ 1 aZ2 aZm )
D == dшg дУ1 ' дУ2 ' . . . , дУт .
Исходя из этоrо,
П т az.
Idet(J)1 == Idet(WA)I rf..
i 1 У,
(10.131)
Оценка функции плотности вероятности fu(U), параметризованная по матрице
весов W инелинейности G, в свете (1 0.131) может быть формально переписана в
следующем виде [906]:
..,
682 rлава 10. Модели на основе теории информации
fu(uIW, G) == Idet(WA)I ft a (Yi) .
i l У,
(10.132)
Отсюда видно, что при этом условии максимизация функции лоrарифмическоro
подобия log fu(uIW,G) эквивалентна максимизации энтропии h(Z) в задаче слепоro
разделения источников. А это значит, что методы максимальной энтропии и макси
мальноrо правдоподобия эквивалентны.
Алrоритм обучения для слепоrо разделения источников
Возвращаясь ко второй строке выражения (1 О .126), отметим, что при фиксирован
ном распределении источника максимизация энтропии h(z) требует максимизации
математическоrо ожидания делителя logl det(J(u)) I по отношению к матрице весов
W. Применяя для этой цели адаптивный алroритм, можно рассмотреть в качестве
целевой функции следующую:
ф == logldet(J)1.
(10.133)
Подставляя (10.131) в (10.133), получим:
( az. )
ф == log Idet(A)I + log Idet(W)1 + log аУ: .
(10.134)
Дифференцируя Ф по матрице весов W разделителя, получим (см. задачу 10.16):
аФ T а ( az i )
aw == W + aw log aYi .
(10.135)
Для TOro чтобы продолжить работу, требуется определить нелинейность, форми
рующую выход разделителя. В качестве простой формы такой нелинейности можно
использовать лоrистическую функцию
1
zi == g(Yi) == 1 + e Yi ' i == 1,2, . . . , т.
(10.136)
На рис. 10.16 представлены rpафики нелинейности и функции, обратной ей. На
этом рисунке видно, что лоrистическая функция удовлетворяет основным требовани-
ям монотонности и обратимости, налаrаемым задачей слепоrо разделения источни
ков. Подставляя (10.136) в (10.135), получим:
аФ
aW == W T + (1 2Z)XT,
10.14. Метод максимальной энтропии 683
0,8
0,6
11 0,4
.::r
0,2
О
10 8 6 4 2 О 2 4 6 8 10
У;
а)
5
,;:; о
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
Zj
б)
Рис. 10.16. Лоrистическая (сиrмоидальная) функция Zi == g(Yi) == l+el Yi (а); функ
ция, обратная к сиrмоидальной Yi == g 1 (Zi) (б)
rде х полученный вектор сиrнала; z нелинейно преобразованный вектор выхода;
1 вектор, составленный из единиц.
Целью алroритма обучения является максимизация энтропии h(Z). Следователь-
но, задействуя метод наискорейшеrо спуска, получим формулу для корректировки
матрицы весов W [116]:
аФ
tlw == ll aw == ll(W T + (1 2z)x T ),
(10.137)
rде " параметр скорости обучения. В анализе независимых компонентов можно из-
бежать необходимости обращения транспонированной матрицы весов w T , используя
натуральный rpадиент. Это эквивалентно перемножению выражения (10.137) на мат-
ричное произведение WTW. Это оптимальное масштабирование приводит к искомой
формуле коррекции весов:
"!
684 rлава 10. Модели на основе теории информации
Ll W == 11(W T + (1 2Z)X T )W T W == 11(1 + (1 2Z)(WX)T)W ==
== 11(1 + (1 2Z)yT)W,
(10.138)
rде вектор у выход разделителя. Алrоритм обучения для вычисления матрицы весов
W имеет следующий вид:
W(n + 1) == W(n) + 11(1 + (1 2z(n))yT(n))W(n).
(10.139)
Этот алroритм инициализируется значением W(O), выбираемым из равномерно
распределенноro множества малых чисел.
Теоретические и экспериментальные исследования показали, что применение ал-
rоритма обучения (10.139) оrpаничено разделением источников, имеющих субrауссо
во распределение 18 [116]. Это оrpаничение является прямым следствием использова
ния в качестве нелинейности лоrистической функции (см. рис. 10.15). В частности,
лоrистическая функция предполаrает наличие априорных знаний об источнике сиrна
ла, а именно ero суперrауссовой формы. Однако в методе максимальной энтропии не
существует ничеrо, что оrpаничивало бы ero использованием только лоrистической
функции. То же касается и метода максимальноro правдоподобия, paccMoTpeHHoro
ранее. Применение метода максимальной энтропии может быть расширено на более
широкий спектр распределений входноrо сиrнала за счет изменения алroритма обу-
чения (1 0.138) так, чтобы он проводил совместную оценку распределения источников
и матрицы смешения. Аналоrичное требование выдвиrалось и в отношении метода
максимальноrо правдоподобия в предыдущем разделе.
10.15. Резюме и обсуждение
В этой rлаве было введено понятие взаимной информации, уходящее корнями в Teo
рию информации Шеннона. Это понятие послужило основой для статистических
механизмов самоорrанизации. Взаимная информация между входным и выходным
процессами имеет ряд уникальных свойств, которые позволяют применить ее в Ka
18 Случайная переменная Х называется субrауссовой [122], если выполняются следующие условия:
она равномерно распределена;
ее функция плотности вероятности fx(x) может быть представлена в форме exp( g(x)), rдe g(x)
rладкая функция, дифференцируемая всюду (возможно, за исключением начала координат), а g(x) и g'(x)/x
строro возрастают на интервале 0< х < 00.
Примером такой функции может стать g(x) == Ixl , rдe 13 > 2.
Если же на интервале О<х < 00 функция g'(x)/x строro убывает, но сохраняются все остальные описанные
свойства, такая случайная переменная называется суперrауссовой [122]. Примером такой функции может быть
g(x) == Ixl ,13<2.
Иноrда в качестве индикатора суб- или суперrауссовоro распределения используется знак эксцесса
Е[х 4 ]
К4(Х) == (Е[Х 2 ])2 З.
Если эксцесс отрицателен, случайная переменная называется субrауссовой, а если положителен суперrаус-
совой.
10.15. Резюме и обсуждение 685
честве оптимизируемой целевой функции в самоорrанизующемся обучении. Из об
суждения, приведенноrо в этой rлаве, можно вывести некоторые важные принципы
самоорrанизации.
. Принциn максимума взаимной информации (Infomax) [653], [654]. Этот принцип в
своей основной форме хорошо подходит для создания самоорrанизующихся Moдe
лей и карт признаков.
. Первый вариант nринциnа Infomax [114] хорошо соответствует обработке изоб-
ражений, целью которой является обнаружение свойств зашумленноro входноro
ceHcopHoro сиrнала, связноro по времени и пространству.
. Второй вариант nринциnа Infomax [1068] нашел свое применение в обработке
двух изображений, целью которой является максимизация пространственных раз-
личий между соответствующими областями двух различных изображений (видов)
интересующеrо объекта.
. Третий вариант nринциnа Infomax, или анализ независимых компонентов [205],
уходит своими корнями в [90], [91]. Однако только в [205] была впервые изложена
строrая формулировка анализа независимых компонентов.
. Метод максимальной энтропии [116] также связан с принципом Infomax. Макси-
мальная энтропия является эквивалентом максимальноrо подобия [171].
Анализ независимых компонентов и метод максимальной энтропии являются дву-
мя альтернативными методами слепоrо разделения сиrнала, каждый из которых имеет
свои собственные атрибуты. Алrоритм слепоrо разделения сиrнала, базирующийся
на методе максимальной энтропии, прост в реализации, в то время как соответствую
щий алrоритм, основанный на анализе независимых компонентов, более сложен для
формулировки, однако имеет более широкую область применения.
Примером из нейробиолоrии, который связывают с задачей слепоrо разделения
сиrнала, является явление, получившее название "эффекта вечеринки". Это явле-
ние связано с выдающейся способностью человека избирательно настраиваться на
интересующий звуковой сиrнал в зашумленной среде и отслеживать ero. Как уже
rоворилось в rлаве 2, основополаrающая нейробиолоrическая модель, привлекаемая
к решению этой сложной задачи обработки сиrнала, является rораздо более сложной,
чем идеализированная модель, показанная на рис. 10.9. Нейробиолоrическая модель
содержит как временные, так и пространственные формы обработки, которые требу-
ются для отделения неизвестной задержки, реверберации и шума. Теперь, коrда мы
уяснили основные вопросы, касающиеся нейронных решений задачи слепоrо разде
ления сиrнала, пожалуй, стоит перейти к реальным задачам, в которых возникают
эффекты, подобные "эффекту вечеринки".
Еще одной открытой областью исследований, которой уделяется пристальное вни-
мание, является задача слепою восстановления СИ2нала или обращенной свертки
(blind deconvo1ution). Слепое восстановление сиrнала представляет собой операцию
686
rлава 10. Модели на основе теории информации
т
обработки сиrнала, обратную свертке, состоящей в линейной, инвариантной ко вре-
мени системе обработки входноro сиrнала. Если rоворить более конкретно, то в
обычной задаче восстановления сиrнала известны как выходной сиrнал, так и са-
ма система, а требуется восстановить исходный сиrнал. При слепом восстановлении
(т.е. обращении свертки без учителя) известен только выходной сиrнал и иноrда ин-
формация о статистике входноro сиrнала, а требуется найти входной сиrнал и (или)
систему. Совершенно понятно, что задача слепоrо восстановления сиrнала является
более сложной, чем задача обычноro обращения свертки. Несмотря на то что слепому
восстановлению сиrнала уделяется больше внимания в литературе [436], наше пони
мание информационно теоретическоro подхода к слепому восстановлению сиrнала,
аналоrичное задаче слепоro разделения сиrнала, находится на ранней стадии разви
тия [264]. Более TOro, задача слепою уравнивания (b1ind equalization) канала, TaKoro
как канал мобильной связи, требует cBoero эффективноro решения не меньше, чем
задача слепоro разделения источников.
Подводя итоr сказанному, можно отметить, что слепой адаптации (blind adapta-
tion), будь то в контексте разделения источников или развертки, предстоит пройти
еще долrий путь до TOro момента, коrда она достиrнет уровня развития, сравнимоro
с задачами обучения с учителем.
Задачи
Принцип максимума энтропии
10.1. Несущее множество (support) случайной переменной Х (т.е. диапазон значе-
ний, для которых она ненулевая) определяется отрезком [а, Ь]. Друrих orpa-
ничений на эту случайную переменную не налаrается. Какова максимальная
энтропия распределения этой случайной переменной? Обоснуйте свой ответ.
Взаимная информация
10.2. Выведите свойства взаимной информации I(X;Y) между двумя случайными
величинами Х и У с непрерывным диапазоном значений (см. раздел 10.4).
10.3. Рассмотрим случайный входной вектор Х, составленный из первичных ком-
понентов Х 1 и контекстных компонентов Х 2 . Определим:
yi == а[Х 1 ,
Zi == ь[х 2 .
Как взаимная информация между Х 1 и Х 2 связана со взаимной информа-
цией между yi и Zi? Предположим, что модель вероятности Х определяется
мноroмерным rауссовым распределением:
Задачи 687
!х(х) == (21t)m/2( et:E)1/2 ехр((х J1)TE l(X J1)),
rде 11 средний вектор Х; :Е матрица ковариации.
10.4. В этой задаче исследуем использование относительной энтропии, или дивер-
reнции Кулбека Лейблера, с целью вывода алrоритма обучения с учителем
для мноrослойноro персептрона [108], [478]. для примера рассмотрим MHO
roслойный персептрон, состоящий из входноro, cKpbIтoro и выходноro слоя.
При подаче на вход системы данноro примера а выходу нейрона k выходноro
слоя соответствует следующая вероятностная интерпретация:
Ykla. == Pkla.'
Пусть qkla. истинное значение условной вероятности TOro, что для дан-
HOro примера а предположение k истинно. Torдa относительная энтропия
мноroслойноrо персептрона определяется следующей формулой:
D p11q == L Ра. L ( Qk1a.1og ( Qk1a. ) + (1 Qkla.) log ( = Qkla. ) ) ,
а. k Pkla. Pkla.
rде Ра. априорная вероятность возникновения события а.
Используя D p11q в качестве оптимизируемой функции стоимости, выведи-
те правило обучения для мноrослойноro персептрона.
ПРИНЦИП Infomax
10.5. Рассмотрим два канала, выходы которых представлены случайными пере мен-
ными Х и У. Требуется максимизировать взаимную информацию между Х
и У. Покажите, что это требование удовлетворяется, если выполняются два
условия.
(а) Вероятности возникновения событий Х и У равны 0,5.
(б) Распределение совместной вероятности Х и У сконцентрировано в
небольшой области пространства вероятности.
10.6. Рассмотрим зашумленную модель на рис. 10.17 с т узлами источника во
входном слое сети, состоящим из двух нейронов. Оба нейрона являются
линейНыми. Входные сиrналы обозначены символами Х 1, Х 2, . . . , Х т, а вы-
ходные У 1 И У 2 . Можно сделать следующие допущения.
. Компоненты адцитивноro шума N 1 и N 2 на выходе сети имеют rayccOBo
распределение с нулевым средним и дисперсией a . Они не коррелиро
ваны друr с друroм.
. Каждый из источников шума не коррелирован со входными сиrналами.
688
rлава 10. Модели на основе теории информации
т
Х 1
N 1
Х 2
У 1
Х З
2
У 2
Х т
N 2
Рис. 10.17.
· Выходные сиrналы У 1 и У 2 являются rауссовыми случайными перемен-
ными с нулевым средним.
( а) Найдите взаимную информацию 1 (У; Х) между выходным У ==[У 1 , У 2 ]Т И
входным вектором Х==[Х 1 , Х 2 , ..., Хт]Т.
(б) Используя результаты части (а), исследуйте баланс между избыточностью
и разнообразием при следующих условиях [653].
1. Дисперсия шума a значительно превосходит дисперсии У 1 и У 2 .
2. Дисперсия шума a значительно меньше дисперсии У 1 и У 2 .
10.7. В варианте принципа Infomax [114], описанном в разделе 10.9, целью ЯВ
ляется максимизация взаимной информации I(Y,,; rь) между выходами Уа
и У ь зашумленной нейронной системы, являющимися реакцией системы на
входные векторы Ха И У ь . В друroм подходе [114] ставится друrая цель: мак-
симизировать взаимную информацию 1 ( Yat Yb ; S) между средним выходов
Уа и У ь и компонентом S рассматриваемоrо сиrнала, общим для этих двух
выходов.
Используя модель, описываемую выражениями (10.59) и (10.60), выпол-
ните следующее.
(а) Покажите, что
1 ( Уа + У ь ; S ) == log ( var[Ya + У ь ] ) ,
2 var[N" + N b ]
rдe N a и N b компоненты шума в Уа и У ь соответственно.
(б) Продемонстрируйте интерпретацию этой взаимной информации в каче-
стве отношения сиrнал плюс шум/шум.
Анализ независимых компонентов
10.8. Проведите детальное сравнение анализа rлавных компонентов (см. rлаву 8)
с анализом независимых компонентов.
Задачи 689
10.9. Анализ независимых компонентов может использоваться как шаr предвари
тельной обработки в приближенном анализе данных (approximate data analy-
sis) перед детектированием (detection) и классификацией [205]. Обсудите то
свойство анализа независимых компонентов, которое может использоваться
в этом приложении.
10.10. Теорема Дармуса (Dannois) rласит, что сумма независимых переменных MO
жет иметь rayccoBo распределение только в том случае, если все они сами
являются rауссовыми [239]. С помощью анализа независимых компонентов
докажите эту теорему.
10.11. На практике алroритмическая интерпретация анализа независимых компо-
нентов может достиrать "максимально большой статистической независи-
мости" (as statistically independent as possible). Сопоставьте решение задачи
слепоro разделения сиrналов на основе этоro алroритма с решением, полу
ченным с использованием метода декорреляции. Предполаrается, что матри
ца ковариации вектора наблюдений является несинryлярной.
10.12. Ссылаясь на схему, приведенную на рис. 10.9, покажите, что минимизация
взаимной информации между любыми двумя компонентами выхода раздели-
теля (demixer) У эКВивалентна минимизации диверreнции Кулбека Лейблера
между параметризованной функцией плотности в.:роятности fy(y,W) и со-
ответствующим факториальным распределением fy(y, W).
10.13. Адаптивный алroритм слепоrо разделения сиrналов (10.104) обладает дву-
мя важными свойствами: свойством эквивариантности и тем свойством, что
формируемая матрица весов W является несинryлярной. Первое свойство
достаточно подробно рассматривалось в разделе 10.11. В этой задаче мы
займемся вторым свойством.
Предполаrая, что начальное значение W(O), используемое для инициализации
алrоритма (10.104), удовлетворяет условию I det(W(O)) I '=1-0, покажите, что
Idet(W(O))1 '=1- О для всех n.
Это необходимое и достаточное условие для TOro, чтобы матрица W(n) бьmа
несинryлярной для всех n.
10.14. В этой задаче мы сформулируем пакетную версию алroритма слепоro разде-
ления сиrналов (10.104). В частности, можно записать:
W == " (1 ф (У) уТ ) W,
rде
у==
[ Уl(l) Уl(2) ... Yl(N) ]
У2(1) У2(2) ... Y2(N)
... ... ... ...
Ут(1) Ут(2) ... Ym(N)
690 rлава 10. Модели на основе теории информации
и
Ф(У) ==
[ q>(Yl(l)) q>(Yl(2)) ... q>(Yl(N)) ]
<Р(У2(1)) <Р(У2(2)) ... q>(Y2(N))
,
... ... ... ...
<р(Ут(l)) <Р(Ут(2)) ... q>(Ym(N))
rде N количество доступных точек данных. Обоснуйте описанную форму-
лу коррекции Д W матрицы весов W.
Метод максимальной энтропии
10.15. Рассмотрим рис. 10.15, на котором
У == WX,
rде
У == [Y 1 , У 2 ,..., Ут]Т,
х== [X 1 ,X 2 ,...,X m ]T,
а W матрица весов размерности m Х т. Пусть
Z == [Zl, Z2,"', Zm]T,
е
11
rде
Zk == q>(Y k ) , k == 1,2,. .. , т.
h(Z) == Dflli Dillq,
н
в
с'
СI
ЯI
М
В
п}
рl
(а) Покажите, что совместная энтропия Z связана с диверreнцией Кулбека-
Лейблера D flli следующим соотношением:
rде D illq диверrенция Кулбека Лейблера между (а) функцией плотности
вероятности статистически независимой (т.е. факторизированной) версии
выходноro вектора У и (б) "функцией плотности вероятности", являющей.
m
ся результатом выражения П q(Yi)'
i l
(6) Как изменится формула для h(Z), если q(Yi) будет равна функции плотно.
сти вероятности истинноro выхода U i для всех i?
10.16.(а) Из выражения (10.134) выведите выражение (10.135).
(6) для лоrистической функции (10.136) покажите, что с помощью (10.135)
можно получить формулу (10.137).
те
m
не
пс
00
се
Стохастические машины
и их аппроксимации
v
в статистическои механике
11.1. Введение
Последний класс самоорrанизующихся обучаемых систем, который рассматривается
в данной книrе, черпает свои идеи в статистической механике. Статистическая Me
ханика (statistical mechanics) занимается формальным изучением макроскопических
свойств равновесия в крупных системах, состоящих из элементов, подверженных
микроскопическим законам механики. rлавной целью статистической механики явля
ется управление термодинамическими свойствами макроскопических объектов, начи
ная с движения микроскопических частиц, таких как атомы и электроны [611], [814].
Количество степеней свободы, с которыми приходится иметь дело в таких системах,
невероятно велико. Это и является причиной применения для решения задач именно
вероятностных методов. Как и в теории информации Шеннона, rлавную роль в стати
стической механике иrpает концепция энтропии. Чем более упорядоченной является
система или чем более концентрировано распределение вероятности, тем меньшей
является энтропия. Аналоrично, можно заявить, что чем сильнее беспорядок в систе
ме или чем ближе распределение вероятности к равномерному, тем выше энтропия.
В [512] было показано, что энтропию можно использовать не только в качестве OT
правной точки при формулировке статистических выводов, но и для rенерирования
распределения rиббса, лежащеro в основе статистической механики.
Интерес к использованию статистической механики при изучении нейронных ce
тей был проявлен еще в ранних работах [223], [229]. Машина Больцмана (Boltzmann
mастпе) [9], [464], [465] была, пожалуй, первой мноrослойной обучаемой маши
ной, вдохновленной идеями статистической механики. Свое название эта машина
получила в признание формальной эквивалентности между основополаrающими pa
ботами Больцмана в статистической термодинамике и динамическим поведением
сетей. В своей основе машина Больцмана представляет собой устройство модели
692 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
рования исследуемоrо распределения вероятности на основе множества данных, из
чеro можно вывести условное распределение, используемое в таких задачах, как pac
познавание образов и классификация множеств. К сожалению, процесс обучения в
машине Больцмана протекает чрезвычайно медленно. Это Стало причиной TOro, что
машина Больцмана подверrлась модификациям, результатом которых стало появле
ние новых стохастических машин. Большая часть материала настоящей rлавы будет
посвящена их описанию.
Структура rлавы
rлаву формально можно разбить на три части. Первая часть состоит из разделов 11.2
11.6. В разделе 11.2 представлен краткий обзор задач статистической механики. В раз
деле 11.3 предложен обзор особоro типа стохастических процессов, получивший Ha
звание цепей Маркова (Markov chain). Ero часто можно встретить при изучении CTa
тистической механики. В разделах 11.4 11. 6 последовательно рассматриваются три
метода стохастическоro моделирования: алroритм Метрополиса (Metropolis), метод
моделирования отжиrа (simulated annealing) и выборки rиббса (Gibbs sampling).
Вторая часть rлавы, состоящая из разделов 11.7 11.9, описывает три типа CToxa
стических машин: машина Больцмана, сиrмоидальные сети доверия (sigmoid be1ief
network) и стохастическая машина rельмroльца (Helmho1tz).
В последней части rлавы (разделы 11.1 o 11.13) основное внимание уделяется BO
просам аппроксимации стохастических машин. Эта аППроксимация основана на идеях
теории средне20 поля (mean fie1d theory) в статистической механике. В разделе 11.10
сформулированы основные положения этой теории. В разделе 11.11 рассматривается
простейшая теория среднеrо поля машины Больцмана, за чем в разделе 11.12 после
дует более принцИПиальный подход к теории среднеro поля сиrмоидальных сетей
доверия. В разделе 11.13 описывается детерминированный отжиr как аппроксимация
моделирования отжиrа.
Как всеrда, rлава завершается общими выводами и рассуждениями.
11.2. Статистическая механика
Рассмотрим физическую систему с множеством степеней свободы, которая может
находиться в одном из большоrо количества возможных состояний. Обозначим сим
волом Pi вероятность нахождения Системы в определенном состоянии z, rдe
Pi о для всех i (11.1)
и
LPi == 1. (11.2)
11.2. Статистическая механика 693
Пусть E i энер2ИЯ системы, коrда она находится в состоянии i. Фундаменталь
ный результат статистической механики утверждает, что если система находится в
термальном равновесии с окружающей средой, состояние i возникает с вероятностью
1 ( Е, )
Pi == Z ехр kB '
(11.3)
rде Т абсолютная температура в rpадусах Кельвина; k B константа Больцмана;
Z константа, не зависящая от KOHкpeTHoro состояния. Нулевой rpадус Кельвина
соответствует температуре 2730 по Цельсию. Константа Больцмана равна k B ==
1,38х 10 2З ДжоуляlКельвин.
Уравнение (11.2) определяет условие нормализации вероятностей. Подставляя это
условие в (11.3), получим:
Z == Lexp ( E ) .
. k B
.
(11.4)
Нормализующая величина Z называется су.ммой по всем состояниям (sum over
states) или функцией разбиения (partition function). (Для обозначения этой величи
ны принято использовать именно символ Z, так как по немецки она называет
ся Zиstаdsитте.) Распределение вероятности (11.3) называется каноническим pac
пределением (canonical distribution) или распределением rиббса (Gibbs distribution)l.
Экспоненциальный множитель ехр( Ei/kBT) называют коэффициентом Больцма
на (Boltzmann factor).
При работе с распределением rиббса очень важно учесть следующие вопросы.
1. Состояния с низкой энерrией более вероятны, чем состояния с высокой энерrией.
2. При понижении температуры Т вероятность концентрируется на небольшом под
множестве состояний с низкой энерrией.
1 Термин "каноническое распределение" был введен в работе rиббса [348]. в первой части своей книrи
Элементарные принципы статистической механики он написал:
"Распределение, представленное формулой Р ехр ( "'j/ ), rде Н и '1' константы, при этом Н
положительная, предстаWlЯет собой самый простой возможный случай, так как оно имеет следующее свойство:
коrда система состоит из нескольких частей с отдельными энерrиями, законы распределения фаз отдельных
частей имеют одну и ту же природу. Это свойство чрезмерно упрощает рассмотрение вопросов термодинамики
и является основой самых важных ее соотношений. . .
Коrда множество систем распределено по фазе описанным выше способом, Т.е. Korдa индекс вероятности (Р)
является линейной функцией энерrии (Е), мы можем сказать, что множество имеет каноническое распределение,
и можем назвать делитель энерrии (Н) модулем распределения". .
В литературе по физике уравнение (11.3) обычно называют каноническим распределением [877] или pac
пределением rиббса [611]. в литературе по нейронным сетям оно называется распределением rиббса, распре-
делением Больцмана, а также распределением Больцмана rиббса.
694 rлава 11. Стохастические машиныи их аппроксимации в статистической механике
В контексте нейронных сетей, как предмета внимания этой книrи, параметр Т
можно рассматривать как псевдотемпературу, управляющую термальными флуктуа
циями, представляющими эффект "синаптическоro шума" в нейроне. Таким образом,
точная шкала в данных условиях не применима. Следовательно, константу k B мож
но принять равной единице и переписать выражения для вероятности Pi и функции
разбиения Z следующим образом:
1 ( Ei )
Pi == Z ехр т
(11.5)
и
z == ехр ( i ).
.
( 11.6)
Следовательно, толкование статистической механики будет основываться именно
на этих двух определениях. При этом величину Т будем называть просто тeмпepa
турой системы (temperature ofthe system). Из выражения (11.5) можно заметить, что
величину log Pi можно трактовать как одну из форм энерrии, измеренную при
единичной температуре.
Свободная энерrия и энтропия
Свободная энер2ИЯ физической системы по rельмrольцу обозначается символом F и
в терминах функции разбиения Z определяется следующим образом:
F == т log Z.
(11.7)
Соответственно средняя энер2ИЯ системы имеет следующее значение:
(Е) == LPiEi,
(11.8)
rде обозначение <.> применяется для операции усреднения по множеству. Таким
образом, подставляя (11.5) в (11.8), видим, что разность между средней и свободной
энерrиями определяется следующей формулой:
(Е) F == TLPilogpi'
(11.9)
Величина в правой части выражения (11.9), за исключением температуры Т, яв
ляется не чем иным, как энтропией системы:
н == LPi logpi'
(11.10)
11.3. Цепи Маркова 695
Следовательно, выражение (11.9) можно переписать в следующем виде:
(Е) F == ТН,
или, эквивалентно,
F == (Е) ТН.
(11.11)
Теперь рассмотрим две системы, А и А', находящиеся друr с друroм в термальном
контакте. Предположим, что система А мала по сравнению с системой А'. в этом
случае система А' выступает в роли тепловоro аккумулятора с некоторой постоян
ной температурой Т. Общая энтропия этих двух систем будет стремиться к росту в
соответствии с формулой
ДН +дН' О,
rде дН и дН' изменения энтропии систем А и А' соответственно. В свете форму
лы (11.11) значение этоrо соотношения состоит в том, что свободная энерrия системы
F стремится к понижению до достижения минимума в состоянии равновесия. Из CTa
тистической механики известно, что общее распределение вероятности определяется
распределением rиббса. Также существует важный принцип, называемый принципом
минимума свободной энеР2ИИ (principle of minimal free energy), который формулиру
ется следующим образом [611], [814].
Минимум свободной энерzии в стохастической системе по переменным системы дo
стиzается в точке термалЬНО20 равновесия, определяемой распределением rиббса.
Природа стремится найти физическую систему с минимальной свобод
ной энерrией.
11.3. Цепи Маркова
Рассмотрим систему, развитие которой определяется стохастическим процессом
{Х n , n == 1,2, '" }, состоящим из семейства случайных переменных. Значение Х т
характеризующее случайную переменную Х N В дискретный момент времени n, назы
вается состоянием системы в этот момент. Пространство всех возможных значений,
которые Moryт принимать эти случайные переменные, называют пространством co
стояний (state space) системы. Если структура стохастическоrо процесса {Хп, n == 1,
2, . . . } такова, что условное распределение вероятности Х n+ 1 зависит исключительно
от предыдущеrо значения Х n И не зависит от всех более ранних значений, то такой
696 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
процесс называется цепью Маркова, или Марковской цепью (Markov chain) [71], [294].
Формально это можно записать так:
P(X n + 1 == Х n +1IХ n == ХN,'" ,X 1 == Xl) == P(Xn+l == Х n +1I Х n == Х n )' (11.12)
Это соотношение называется свойством Маркова (Markov property). Формально
это свойство описывается следующим образом.
Последовательность случайных переменных Х 1, ..., Х n , Xn+l принимает форму
цепи Маркова, если вероятность нахождения системы в состоянии Xn+l в мамент
времени n + 1 зависит исключительно от вероятности нахождения системы в MO
мент времени n в состоянии Хn'
Таким образом, цепи Маркова можно рассматривать как по рождающие модели
(generative mode1), состоящие из множества попарно связанных друr с друroм cocтo
яний. Каждый раз, коrда система переходит в конкретное состояние, именно с ним
ассоциируется выход системы.
Вероятности перехода
в цепи Маркова переход системы из одноro состояния в друrое является вероят
ностным (probabilistic). Однако при этом выход системы является детерминирован
ным (deterministic). Пусть вероятность перехода системы из состояния i (момент
времени n) в состояние j (момент времени n + 1) имеет следующий вид:
Pij == P(Xn+l == jlX n == i).
(11.13)
Так как величины Pij являются условными вероятностями, они должны подчи
няться двум условиям:
Pij O(i,j)
(11.14)
и
L Pij == 1 для всех z.
j
(11.15)
Предполаrается, что вероятности перехода фиксированы и не изменяются во Bpe
мени. Это значит, что условие (11.13) удовлетворяется в любой момент времени n.
Такая сеть Маркова называется 20МО2енной (homogeneous) по времени.
11.3. Цепи Маркова 697
Если система имеет конечное множество возможных состояний К, вероятности
перехода формируют матрицу размерности К х К:
р==
[ Pll Р12 ... Р1К ]
Р21 Р22 ... Р2К
... ... ......
РК1РК2..'РКК
(11.16)
Элементы этой матрицы удовлетворяют условиям (11.14) и (11.15). Последнее
условие rарантирует равенство суммы всех элементов каждой из строк единице.
Такая матрица называется стохастической (stochastic matrix). Любая стохастическая
матрица может служить матрицей вероятностей перехода.
Определение одношаrовой вероятности представлено формулой (11.13). Ero мож
но обобщить для случая, Korдa переход из одноrо состояния в дрyroе занимает
несколько шаroв. Обозначим вероятность перехода за m шаrов из состояния i в
состояние j символом p Т;):
p Т;) == Р(Х п + т == xjlX n == Xi), m == 1,2,... .
(11.17)
Величину p Т;) можно рассматривать как сумму всех промежуточных состояний
k . . В (т+1)
, через которые система проходит по пути из z в J. частности, величина Pij
связана с величиной p Т;) следующим рекурсивным соотношением:
(т+1) ""' (т) 1 2
Pij L....;Pik Pkj, m == , ,...,
k
(11.18)
rде
(1)
Pik Pik'
Равенство (11.18) можно обобщить следующим образом:
(т+п) ""' (т) (п) ( ) 1 2
Pij == L....;Pik Pkj' т,11, == , ,....
k
(11.19)
Это частный случай равенства Чепмена КОЛМО20рова (Chapmen Kolmogorov iden
tity) [294].
Если состояние цепи может возникать через интервалы времени, кратные d, rде
d наибольшее из таких целых чисел, считается, что такое состояние имеет перио
дичность d. Цепь Маркова называется апериодичной (aperiodic), если все ее состояния
имеют периодичность 1.
698 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Свойства рекуррентности
Предположим, что цепь Маркова начинается с состояния i. Состояние i назы-
вается рекуррентным (recurrent), если цепь Маркова возвращается в состояние i
с вероятностью 1:
fi == Р(возвращения в состояние i) == 1.
Если вероятность fi меньше единицы, такое состояние i называется транзитным
(transient) [633].
Если цепь Маркова начинается с peкyppeHTHoro состояния, это состояние по
вторяется бесконечное число раз. Если же цепь Маркова начинается с транзитноro
состояния, это состояние может повториться только конечное число раз. Это можно
объяснить следующим образом. Повторения состояния i можно рассматривать как
пробы Бернулли (Веmоиlli trial) с вероятностью успеха fi. Таким образом, количе
ство возвратов можно представить как reометрическую случайную переменную со
средним значением (1 fi l). Если fi меньше единицы, следовательно, количество
бесконечных успешных попыток равно нулю. Таким образом, транзитное состояние
не повторяется после конечноro числа возвратов [633].
Если цепь Маркова состоит из нескольких транзитных и нескольких рекур-
рентных состояний, то процесс может перемещаться только между рекуррентны-
ми состояниями.
Несократимые цепи Маркова
Состояние j цепи Маркова называется достижимь/.М (accessible) из состояния i, если
с положительной вероятностью существует конечная последовательность переходов
из i в j. Если состояния i и j достижимы друr из друrа, считается, что они связаны
дрyr с друroм. Эта связь обозначается следующим выражением: i +---t j. Естественно,
если состояние i связано с состоянием j, а последнее, в свою очередь, с состоянием
k, то состояния i и k также являются связанными.
Если два состояния цепи Маркова связаны друr с друroм, они считаются при
надлежащими одному классу. В общем случае состояния цепи Маркова принадлежат
одному или нескольким несвязанным классам. Если же состояния принадлежат Bcero
одному классу, такая цепь называется несократимой (iпеduсiЫе) или неразложимой
(indecomposible). Дрyrими словами, начиная с любоrо состояния несократимой цепи
Маркова, можно достичь любоro друroro ее состояния с положительной вероятно
стью. Для большинства приложений сократимые цепи представляют малый интерес.
Поэтому мы оrpаничимся рассмотрением только несократимых цепей.
Пусть несократимая цепь Маркова начинается с HeKoToporo peкyppeHTHoro co
стояния i в момент времени n == о. Пусть Ti(k) время, которое прошло между
11.3. Цепи Маркова 699
(k 1) и k M возвратом в состояние i. Среднее время возврата (mеап recurrence time)
определяется как ожидание T i (k) по всем возвратам k. Установившимся значением
вероятности (steady state probability) состояния i называется величина, обратная к
среднему времени возврата E[Ti(k)]:
1ti==
1
E[Ti(k)] .
Если E[Ti(k)] < 00 и соответственно 1ti > О, то состояние i называется положu
тельно рекуррентным (positive recurrent). В противном случае оно называется cocтo
янием с нулевой рекуррентностью (пuП recurrent state). Последний случай трактуется
следующим образом: цепь Маркова случайно достиrает такой точки, из которой воз
врат в состояние i невозможен. Положительная и нулевая рекуррентность являются
различными свойствами класса. Это значит, что цепи Маркова с одновременной по
ложительной и нулевой рекуррентностью состояний являются сократимыми.
Эрrодические цепи Маркова
Под термином эрzодичность (ergodicity) понимается возможность подстановки cpeд
Hero по времени вместо среднеro по множеству. В контексте цепей Маркова при
этом подразумевается, что соотношение времени, проведенноro цепью в состоянии
i, соответствует установившемуся значению вероятности 1ti. Это можно объяснить
следующим образом. Соотношение времени, проведенноzо в состоянии i после k
возвратов, определяется следующим образом:
Vi (k) ==
k
k
L Ti(l)
1==1
Время возврата Ti(l) формирует последовательность независимо и равномерно
распределенных случайных переменных, так как по определению время каждоro
из возвратов статистически независимо от всех предыдущих времен возвратов. Бо
лее тoro, в случае peKyppeHTHoro состояния i цепь возвращается в это состояние
бесконечное число раз. Исходя из этоro, при достижении количеством возвратов k
бесконечности, соrласно закону больших чисел, пропорция времени, проведенная в
состоянии z, достиrает установившеroся значения вероятности, Т.е.
lim Vi(k) == 1ti для i == 1,2,... , К.
k......oo
(11.20)
Достаточным (но не необходимым) условием эрroдичности цепей Маркова явля
ется их одновременная апериодичность инесократимость.
700 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Сходимость к стационарным распределениям
Рассмотрим эрroдическую цепь Маркова, характеризуемую стохастической матрицей
Р. Пусть Beктop CTpOKa x(n 1) определяет вектор распределения состояний (state dis
tribution vector) цепи в момент времени n 1. Ero j й элемент является вероятностью,
с которой в момент времени n 1 цепь находится в состоянии Х j' в момент времени
n этот вектор распределения состояний определяется следующим образом:
х(n) == x(n 1)p.
(11.21)
Итеративно используя выражение (11.21), получим:
х(n) == x(n 1)p == x(n 2)p2 == х(n З)РЗ == . . . ,
что в конечном счете приводит к следующей формуле:
х(n) == х(о)р n ,
(11.22)
rде х(О) начальное значение вектора распределения состояний. Друrими словами,
вектор распределения состояний цепи Маркова в момент времени n является произве-
дением исходноro значения этоro вектора на n ю степень стохастической матрицы Р.
Обозначим символом p ;) ij й элемент матрицы Р. Предположим, что при YCTpeM
лении n к бесконечности вероятность p ;) стремится к некоторому значению 1tj, не
зависящему от i, rде 1tj стационарная вероятность состояния j. Соответственно
при больших n матрица рn достиrает своей предельной формы квадратной матрицы
с идентичными строками:
Нт рn ==
[ п 1 п2 ... 1t К ] [ х ]
. . ::: . == ..
пl п2 ... пк х
(11.23)
n.......оо
rдe Х Beктop CTpOKa, состоящий из элементов пl, п2, ..., пк. После перестановки
слаrаемых из выражения (11.22) получим следующую формулу:
[ t п}О) 1 ] х == О.
з 1
к
Так как по определению L п}О) == 1, вектор 1t не будет зависеть от начально
j l
ro распределения.
11.3. Цепи Маркова 701
Теперь можно сформулировать теорему об эрzодичности (ergodicity theorem) для
цепей Маркова [71], [294]:
Пусть эрzодическая цепь Маркова с состояниями х 1, Х2, . . . , х к и стохастической
матрицей р== {Pij} является несократимой. Тоzда эта цепь имеет единственное
стационарное распределение, к которому она сходится из любоzо начШlЬНОZО cocтo
яния. Это значит, что существует единственный набор чисел {1tj } 1' такой, что
1 . (п)
1т Pi' 1tj
n.......-+оо J
1ti > О
для всех i,
для всех j,
(11.24)
(11.25)
к
L 1tj == 1,
j l
К
1tj == L 1tiPij
i l
(11.26)
для всех j == 1,2,. . . , К.
(11.27)
и наобороm, предположим, что цепь Маркова является несократимой и апериоди
ческой, а также существуют числа {1tj} l' удовлетворяющие условиям (11.25)
(11.27). Тоzда эта цепь является эрzодической, величины 1tj вычисляются по формуле
(11.24), а среднее время возврата в состояние j равно l/1tj.
Распределение вероятности {1tj } 1 называется инвариантным или стационар
ным. Такое название объясняется тем, что по достижении TaKoro распределения оно
сохраняется. В свете теоремы об эрrодичности можно утверждать следующее.
. Начиная с любоrо исходноrо состояния, вероятности перехода в цепи Маркова
сходятся к стационарному распределению, если такое распределение существует.
. Если цепь эрrодическая, то стационарное распределение в цепи Маркова полно
стью не зависит от ее начальноro распределения.
Пример 11.1
Рассмотрим цепь Маркова с диаzраммой перехода состояний, показанной на рис. 11.1. Эта цепь
имеет два состояния Хl И Х2. Стохастическая матрица этой цепи имеет следующий вид:
р [ 1/43/4 ] .
1/2 1/2
Эта матрица удовлетворяет условиям (11.14) и (11.15).
Предположим, что начальным состоянием является следующее:
х(О) == [1/6,5/6].
По формуле (11.21) получим следующий вектор распределения состояний для момента BpeMe
ни n 1:
702 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
1
4
Рис. 11.1. Диаrрамма перехода со-
стояний в цепи Маркова для приме--
ра 11.1
1t(1) х(О)р [ 1/6 5/6] [ ] [ 11/24 13/24] .
Возводя стохастическую матрицу Р в степени 2, 3 и 4, получим:
р2 [ 0.43750.5625 ]
0.3750 0.6250 '
р З [ 0.4001 0.5999 ]
0.3999 0.6001 '
р 4 [ 0.4000 0.6000 ] .
0.4000 0.6000
Таким образом, пl О, 4000, а п2 О, 6000. В данном примере сходимость к стационарному
состоянию была обеспечена Bcero за 4 итерации. Так как обе величины, пl и п2, больше нуля,
оба состояния являются положительно рекуррентными, а сеть несократимой. Также заметим,
что данная цепь является апериодической, так как наибольший общий делитель всех чисел n 1,
таких, что (Pn)ij > О, равен единице. Исходя из сказанноro, делаем вывод о том, что цепь Маркова
на рис. 11.1 является эрroдической. .
Пример 11.2
Рассмотрим цепь Маркова, имеющую стохастическую матрицу, содержащую отдельные нулевые
элементы:
[ О О 1 ]
Р 1/3 1/6 1/2 .
3/4 1/4 О
Диarpамма перехода состояиий этой цепи представлена на рис. 11.2.
Примеияя выражение (11.27), получим следующую систему уравнений:
{ 1 З
пl -з1t2 + 41tз,
п2 п2 + i1tз,
1tз пl + п2'
11.3. Цепи Маркова 703
Рис. 11.2. Диаrрамма перехода состояний для
сети Маркова из примера 11.2
1
6
Переходное
1t j О
Состояние
/j
Рекуррентное
/
Положительно рекуррентное
//yo
Нерекуррентное
1tj О
Рис. 11.3. Классификация состояний
цепи Маркова и связанноro с ними по
ведения
Апериодическое
1impij(n) 1t j
при п---+ 00
Периодическое
1imp/n) d1tj прип---+ оо ,
rде d целое число
больше единицы
Решив эту систему уравнений, находим следующие значения:
пl == О, 3953,
п2 О, 1395,
1tз == 0,4652.
Итак, даиная цепь Маркова является эрroдической со стационарным распределеиием, опреде
ляемым величинами пl, п2 И 1tз. .
Классификация состояний
На основе представленноro материала можно создать диаrpамму классов, к которым
может принадлежать состояние (рис. 11.3) [294], [633].
Принцип детальноrо баланса
Выражения (11.25) и (11.26) подчеркивают тот факт, что числа 1ti являются вероят
ностями. Выражение (11.27) также является критичным, так как выполнение этоro
704 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
условия требуется для TOro, чтобы цепь Маркова бьта несократимой и, таким об
разом, существовало стационарное распределение. Это последнее условие является
записью принципа детальноzо баланса (principle of detailed Ьаlапсе), известноro в
кинетике первоrо порядка. Этот принцип утверждает, что в состоянии термальноro
равновесия частота возникновения любоrо перехода равна соответствующей частоте
обратноro перехода [877]:
1tiPij == 1tjpji.
(11.28)
Для вывода соотношения (11.27) можно пере ставить порядок суммирования в
правой части уравнения:
к к ) к
L 1tiPij == L ( :i Pij 1tj == L (pji)1tj == 1tj.
i l i l J i l
Во второй строке этоro выражения использовался принцип детальноrо баланса, а
в последней тот факт, что вероятности перехода в цепи Маркова удовлетворяют
следующему условию (см. (11.15), rдe роли i и j поменялись местами):
к
LPji == 1 для всех j.
i l
Обратите внимание, что принцип детальноro баланса предполаrает, что распреде
ление {1tj} является стационарным.
11.4. Алrоритм Метрополиса
Теперь, Korдa стало понятно строение цепей Маркова, их можно использовать для
вывода стохастическоro алrоритма моделирования развития физических систем ДО
состояния термальноrо равновесия. Этот алrоритм получил имя cBoero создателя
Метрополиса (Metropolis algorithm) [730]. Он представляет собой модифицированный
алrоритм Монте Карло, введенный еще в раннюю эпоху моделирования достижения
температурноrо равновесия стохастическими системами, состоящими из атомов.
Предположим, что случайная переменная Х т представляющая произвольную
цепь Маркова, в момент времени n находится в состоянии Xi. Сrенерируем случайным
образом новое состояние Х j, представляющее собой реализацию друroй случайной
переменной Уn. Предполаrается, что reнерация этоrо HOBoro состояния удовлетворяет
условию симметрии:
Р(У n == XjlX n == Xi) == Р(У n == XilXn == Xj)'
11.4. Алrоритм Метрополиса 705
Обозначим символом дЕ разницу в энерrии, возникающую при переходе системы
из состояния Х п == Xi В состояние У п == Xj. Если эта величина отрицательна, то
переход приводит к состоянию С меньшей энерrией и такой переход принимается.
После этоrо новое состояние считается точкой старта следующеro шаrа алrоритма
(т.е. мы принимаем Х п +1 == У п ). Если же разница в энерrии положительна, алrоритм
продолжает работу по вероятностной схеме в этой же точке. Выбираем случайное
число , равномерно распределенное в диапазоне [О, 1]. Если < ехр( ДE/T), rдe
т рабочая температура, переход принимается, при этом считается, что Х п +1 == У п .
В противном случае переход отверrается, при этом полаrается, что Х п +1 == Х п (т.е. на
следующем шаrе алrоритма используется старая конфиrурация).
Выбор вероятности перехода
Пусть цепь Маркова имеет априорные вероятности перехода Tij, удовлетворяющие
следующим трем условиям.
1. Неотрицательность:
Tij о для всех (i, Л.
2. Нормализация:
L Tij == 1 для всех z.
j
3. Симметрия:
Tij == Tji для всех (i,j).
Пусть 1ti означает установившееся значение вероятности, в котором находится цепь
Маркова в состоянии Xi, i == 1,2, . . ., К. Torдa симметрию Tij и частное 1tзf1ti можно
использовать для определения требуемоrо множества вероятностей переходов [115]:
{ Ti' ( !tJ. ) для
Р .. == 1 11,
'1
Tij для
!tJ. < 1
1ti '
!tJ. > 1.
1ti
(11.29)
"..
706 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Для обеспечения нормализации вероятностей перехода к значению единицы BBe
дем следующее определение вероятности отсутствия перехода:
Pii == Tii + L Tij ( 1 :j ) == 1 L aijTij,
#i ' #i
(11.30)
rдe aij вероятность перехода, определенная как
. (1 1t j )
aij == ШlП , 1ti .
(11.31)
Теперь возникает один важный вопрос: как выбрать частное 1tj/1ti? для TOro
чтобы ответить на этот вопрос, следует выбрать такое распределение вероятно-
стей, которое требуется для перехода распределения вероятности цепи Маркова
в распределение rиббса:
1 ( Е- )
1tj == Z ехр ;. .
в этом случае отношение вероятностей 1tj/1ti принимает простую форму:
п. ( ДЕ )
..2. == ехр ,
1ti Т
(11.32)
rде
дЕ == Ej E i .
(11.33)
Используя частное распределений вероятности, можно избежать зависимости от
функции разбиения Z. По своему определению вероятности перехода являются HeOT
рицательными числами, нормализованными к единице (см. (11.14) и (11.15». Более
TOro, они удовлетворяют принципу детальноrо баланса, определенноro выражением
(11.28). Этот принцип является достаточным условием температурноrо равновесия.
Чтобы продемонстрировать, как выполняется принцип детальноrо баланса, рассмот-
рим следующие случаи.
Случай 1. дЕ < О
Предположим, что при переходе из состояния Xi В состояние Xj произошло отри
цательное изменение энерrии. Из выражения (11.32) получим 1t/1ti> 1, после чеro с
помощью (11.29) получим:
1tiPij == 1tiTij == 1tiTji
11.5. Метод моделирования отжиra 707
и
( 1ti )
п' p .. п. T" п'T"
J Jt J Jt t Jt.
п.
J
Исходя из этоro, принцип детальноro баланса удовлетворяется при Ь..Е<О.
Случай 2. Ь..Е > О
Теперь предположим, что при переходе из состояния Xi В Xj произошло положи
тельное изменение энерrии. В этом случае 1tj/1ti<l, откуда с помощью выражения
(11.29) получим:
1tiPij == 1ti ( : Ti j ) == 1tjTij == 1tjTji
и
1tjpji == 1tjTji'
При этом снова удовлетворяется принцип детальноro баланса.
Чтобы получить общую картину, давайте проясним использование априорных Be
роятностей перехода, которые обозначены символом Tij. Эти вероятности перехода
на самом деле являются вероятностными моделями случайноrо шаrа в алroритме
Метрополиса. Из ранее представленноrо описания этоro алroритма известно, что за
случайным шаroм следует случайное решение. Отсюда можно заключить, что Be
роятности перехода Pij, определенные по формулам (11.29) и (11.30) в терминах
априорных вероятностей перехода Tij и стационарных вероятностей 1ti, на самом
деле являются подходящими для алrоритма Метрополиса.
Важно отметить, что стационарное распределение, rенерируемое алrоритмом MeT
рополиса, не однозначно определяет цепь Маркова. Распределение rиббса в состоя
нии равновесия может быть сrенерировано с использованием правила, отличноro от
метода Монте Карло, применяемоro в алroритме Метрополиса. Например, ero можно
сreнерировать с помощью правила обучения Больцмана [9]. Это правило мы paCCMOT
рим в разделе 11.7.
11.5. Метод моделирования отжиrа
Теперь займемся поиском системы с низкой энерrией, состояния которой упорядоче
ны в цепь Маркова. Из выражения (11.11) видно, что при достижении температурой
т нуля свободная энерrия системы F достиrает среднеrо значения энерrии (Е).
При F (Е) из принципа минимума свободной энерrии видно, что распределение
rиббса, являющееся стационарным распределением в цепи Маркова, разрушается в
точке rлобальноrо минимума средней энерrии при Т О. Друrими словами, упо
"..,
708 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
рядоченные состояния с низкой энерrией более предпочтительны при низких TeM
пературах. Все эти наблюдения приводят к следующему вопросу: "Почему нельзя
напрямую применить алrоритм Метрополиса для rенерации популяций представите
лей конфиrурации стохастических систем при очень низких температурах?" Автор
не советует использовать эту стратеrию, так как скорость сходимости цепи Маркова
к точке термальноrо равновесия при малых температурах чрезвычайно низка. BMe
сто этоrо для достижения вычислительной эффективности рекомендуется работать со
стохастическими системами при высоких температурах, rдe скорость сходимости к
точке равновесия велика, после чеro работать уже в точке равновесия с системой при
более низких температурах. Таким образом, будем использовать комбинацию двух
связанных составляющих.
. Расписание, определяющее уровень, на котором температуру следует понизить.
. Алroритм, подобный алroритму Метро полиса, итеративно определяющий paBHO
весное распределение для каждой новой температуры из расписания, используя
конечное состояние системы при предыдущей температуре в качестве точки нача
ла работы с более низкой температурой.
Описанная двухшаroвая схема лежит в основе широко используемоrо метода cтo
хастической релаксации (stochastic relaxation), называемоrо моделированием отжиzа
(simulated annealing)2 [560]. Свое название этот подход получил по аналоrии с про
цессами в физике или химии, rдe процесс начинается при более высокой температуре,
которая затем понижается до достижения точки температурноro равновесия.
2 Идея введения температуры и моделирования отжиrа в задачах комбинаторной оптимизации появилась
независимо в [179] и [560].
В контексте физики отжиr является очень тонким процессом. В [560] обсуждалось поиятие "плавки" TBepдo
ro тела, которое включало в себя поднятие температуры до максимальноro значения, при которой все части этоro
тела переходили в жидкую фазу, Т.е. размещались случайным образом. После этоro температура понижалась,
позволяя всем частям орraнизоваться в низкоэнерreтическом состоянии "земли" соответствующей решетки.
Если охлаждение происходило слишком быстро (т.е. у твердоro тела не хватало времени для достижения тер-
мальноro равновесия на каждом температурном значении), полученный кристалл имел массу дефектов или
субстанция моrла сформировать стекло с отсутствием кристаллическоro порядка и метаустойчивой локально
оптимальной структурой.
Понятие "отжиra" хорошо иллюстрируется процессом изroтовления стекла и является в некотором контек-
сте задачей комбииаторной оптимизации. Однако оно может ввести в заблуждение при рассмотрении мноrих
дрyrих областей применения [115]. Например, если поднять "температуру" при обработке изображений до Ta
кoro уровня, что все части орrанизуются случайным образом, мы попросту потеряем само изображение оно
станет равномерно серым. В соответствующем контексте металлурrии при отжиrе железа или меди необхо-
димо сохранять температуру отжиrа ниже температуры отжиrа металла, в противном случае зarотовка будет
разрушена.
Существует ряд важных параметров, характерных для процесса отжиra в металлурrии.
Температура отжиra (annealing temperature) температура, до которой наrpевается металл или сплав.
Время отжиrа (annea1ing time) продолжительность времени, в течение KOТOpOro поддерживается повы
шенная температура.
Расписание охлаждения (cooling schedи1e) определяет скорость понижения температуры.
Эти параметры имеют свои аналоrи в моделировании отжиrа, что и будет описано в соответствующем
подразделе.
11.5. Метод моделирования отжиrа 709
Основной целью моделирования отжиrа является поиск rлобальноrо минимума
функции стоимости, которая характеризует большую и сложную систему3. Этот Me
тод является мощным инструментом решения невыпуклых задач оптимизации. Он
объясняется одной достаточно простой идеей.
При оптимизации очень больших и сложных систем (т.е. систем с множеством cтe
пеней свободы) вместо постоянноzо движения вниз по склону старайтесь двиzаться
по СЮlону вниз большую часть времени.
Моделирование отжиrа отличается от обычных итеративных алrоритмов оптими
зации двумя важными аспектами.
. Этот алroритм не "стопорится", так как выход из точки локальноro минимума
всеrда возможен при работе системы в условиях ненулевой температуры.
. Моделирование отжиrа является адаптивным. Большая часть основных свойств
конечноro состояния системы уже проявляются при высоких температурах, в то
время как при более низких их состояние только уточняется.
Расписание отжиrа
Как уже roворилось ранее, алrоритм Метрополиса является основой процесса MO
делирования отжиrа, направленноro на медленное понижение температуры Т. Это
значит, что сама температура Т выступает в роли параметра управления. Процесс
моделирования отжиrа будет сходиться к конфиryрации с минимальной энерrией при
условии, что температура будет понижаться не быстрее, чем лоrарифмически. К co
жалению, такое расписание отжиrа чрезвычайно медленно настолько медленно,
что вряд ли применимо на практике. На практике необходимо прибеrнуть к aппpOK
симации на конечном интервале времени (finite time approximation). Однако за это
придется заплатить большую цену алroритм не будет rарантированно сходиться к
точке rлобальноro минимума с вероятностью 1. Тем не менее получаемая прибли
женная форма в большинстве практических приложений этоrо алroритма способна
привести к точке, достаточно близкой к оптимальному решению.
Для Toro чтобы реализовать приближение на конечном интервале времени алrо
ритма моделирования отжиrа, необходимо определить множество параметров, управ
ляющих ero сходимостью. Эти параметры объединяются в так называемое расписа
ние отжиzа (annealing schedule) или расписание охлаждения (cooling schedule). Это
расписание представляет собой конечную последовательность значений температу
3 Уравнение Ланrевина (Lапgеviп) (с температурой, зависящей от времени) является основой еще одноro
важноrо алroритма rлобальной оптимизации, который был предложен в [384] и впоследствии проанализирован
в [350]. Уравнение Ланreвина a t) 'fV(t) + r(t), rдe v(t) скорость частиц с массой т, поrpуженных в
жидкость; у константа, равная частному от деления коэффициента трения на массу т; r(t) удельная сила
колебаний (на едииицу массы). Уравнение Ланreвина было первым математическим соотношением, которое
описывало неравновесную термодинамику.
"?
,
,
71 О rлава 11. Стохастические машиныи их аппроксимациив статистической механике
ры и конечное число пробных переходов для каждой из этих температур. В [560]
интересующие параметры определяются следующим образом 4 .
· Начальное значение температуры. Начальное значение То выбирается достаточно
высоким для TOro, чтобы для алrоритма моделирования отжиrа были доступны все
предлаrаемые переходы.
· Понижение температуры. Обычно охлаждение осуществляется экспоненциалыю,
а изменения, применяемые к температуре, являются небольшими. В частности,
функцию убывания (decrement function) можно определить следующим образом:
Tk == aTk l,k == 1,2,...,
(11.34)
rде а константа, меньшая единицы, но достаточно близкая к последней. Как
правило, значения этой константы выбираются в диапазоне от 0,8 до 0,99. При
каждой из температур предпринимается достаточно MHOro попыток перехода, так
чтобы среднее их количество не опускалось ниже 1 О принятых переходов (accepted
transition).
· Конечное значение температуры. Система постепенно охлаждается и отжиr OCTa
навливается, коrда требуемое количество принятых переходов не достиrается при
трех последовательных температурах.
Последний критерий можно переопределить следующим образом: коэффициент
пропускания (acceptance ratio), определяемый как количество принятых переходов,
деленное на количество предложенных переходов, становится меньше HeKoToporo
наперед заданноro значения [516].
Моделирование отжиrа для комбинаторной оптимизации
Моделирование отжиrа хорошо подходит, в частности, для решения задач комбина-
торной оптимизации. Целью комбинаторной оптимизации (combinatorial optimiza-
tion) является минимизация функции стоимости конечной дискретной системы, xa
рактеризуемой большим количеством возможных решений. В своей основе моделиро
вание отжиrа использует алroритм Метро полиса для rенерации последовательности
решений, с привлечением аналоrии между физическими мноzочастичными (many
particle) системами и задачей комбинаторной оптимизации.
4 Более сложные и теоретически обоснованные расписания отжиra описаны в [1], [1079].
11.6. Распределение rиббса 711
ТАБЛИЦА 11.1. Соответствия между терминолоrией статистической физики и KOM
бинаторной оптимизации
Статистическая физика
Пример (sample)
Комбинаторная оптимизация
Экземпляр задачи (problem lП
stance)
Конфиryрация (configuration)
Функция стоимости (cost function)
Параметр управления
Минимальная стоимость
Оптимальная конфиryрация (opti
mаl configuration)
Состояние (state), конфиrурация
Энерrия (energy)
Температура
Энерrия заземления (ground state energy)
Конфиryрация заземления (ground state соп
figuration)
При моделировании отжиrа энерrия E i в распределении rиббса (11.5) интерпре
тируется как числовая стоимость, а температура Т как параметр управления. Эта
числовая стоимость ставит в соответствие каждой из конфиryраций задачи комбина
торной оптимизации некоторое скалярное значение, которое отражает приемлемость
данной конфиrypации для решения. Следующий вопрос моделирования отжиrа CBO
дится к следующему: как идентифицировать конфиryрации и локально rенерировать
новые конфиryрации из уже имеющихся. Именно в этом вопросе алroритм MeT
рополиса иrpает особо важную роль. В табл. 11.1 приведены соответствия между
терминолоrией статистической физики и комбинаторной оптимизации [115].
11.6. Распределение rиббса
Подобно алroритму Метрополиса, квантизатор rиббса 5 (Gibbs sampler) reнери
рует цепь Маркова с распределением rиббса, выступающим в роли paBHOBeCHO
ro распределения. Однако вероятности перехода, связанные с квантизатором rибб
са, не являются стационарными [343]. При окончательном анализе выбор между
квантизатором rиббса и алroритмом Метрополиса зависит от технических дeTa
лей рассматриваемой задачи.
Для TOro чтобы приступить к описанию этой схемы квантования, рассмотрим
К мерный случайный вектор Х, состоящий из компонентов Х 1 , Х 2 , ..., Х к . Преk
положим, что известно условное распределение Х k при заданных значениях всех
5 Квантованне rиббса связано со статистнческой фнзнкой и широко используется в обработке изображений,
нейронных сетях и статистике, что последовало за ero формальным описанием в [342], [343]. В последней работе
также рассматрнваются дрyrие подходы к квантованию, основанные на нных способах получения числовых
оценок rpаничных распределений вероятностн. В [431] было представлено обобщение алroритма Метрополиса,
относительно кoтoporo квантование rнббса является частным случаем, и был показан ero потенцнал в решении
числовых задач статистики.
...,
712 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
остальных компонентов вектора Х (k == 1,2, ... , К). Ставится задача получения чис
ловой оценки zраничной плотности (marginal density) случайной переменной X k для
всех k. Квантизатор rиббса rенерирует значения для условноro распределения каждо
ro из компонентов вектора Х при заданных значениях всех остальных ero компонен
тов. В частности, начиная с произвольной конфиrypации {Хl(0)'Х2(0)"" ,хк(О)},
первой итерации квантования rиббса создаются следующие подвыборки:
Хl (1) выбирается из распределения Х 1 при известных Х2(0), хз(О), . .. ,хк(О),
Х2(1) выбирается из распределения Х 2 при известных Хl (1), хз(О), .. . ,хк(О),
Xk(l) выбирается из распределения X k при известных Хl(1), Xk l(I),
Xk+1 (О),. . . ,Х к (О).
хк(l) выбирается из распределения Х К при известных Xl(l), Х2(1), ... ,XK l(l).
Аналоrичные действия выполняются на следующих итерациях схемы квантова-
ния. При этом следует особо отметить следующие вопросы.
1. Каждый из компонентов случайноro вектора Х "посещается" в естественном по-
рядке. В результате на каждой итерации формируется К случайных величин.
2. Новое значение компонента Xk l используется сразу же после создания, при
формировании случайноro значения X k , k ==2, 3, ..., К.
Из представленноro материала видно, что квантизатор rиббса является итератив-
ной адаптивной схемой (iterative adaptive scheme). После n итераций получается К
случайных значений Х 1 (n), Х 2 (n),... ,Хк(n). При относительно мяrких условиях
для квантизатора rиббса выполняются следующие теоремы [342], [343].
1. Теорема о сходимости. Случайная переменная Xk(n) сходится по распределению
к истинному распределению вероятности X k для k == 1,2, . . . , к при стремлении
n к бесконечности, т.е.
lim P(Xk n ) XIXk(O)) == FXk (х), k == 1,2,... , К,
n oo
(11.35)
zде FXk(X) функция zраничноzо распределения вероятностиХ k .
В [343] был доказан более строrий результат. В частности, в ней не требова-
лось посещение каждоro компонента случайноro вектора Х в естественном по
рядке. Сходимость квантования rиббса сохраняется и при произвольном порядке
посещения компонентов Х. Это значит, что эта схема не зависит от значений
переменных и что каждый из компонентов Х посещается "бесконечно часто".
2. Теорема о скорости сходимости. Совместное распределение вероятности CJO!-
чайных переменных Х 1 (n), Х 2 (n), . . . ,Х к (n) сходится к истинному совместно-
му распределению вероятности Х 1 , Х 2 , ... ,х к пропорционально n.
11.7. Машина Больцмана 713
в теореме предполаrается, что компоненты вектора Х посещаются в eCTe
ственном порядке. Однако если используется произвольное, но бесконечно частое
посещение, скорость сходимости претерпевает незначительное изменение.
3. Теорема об эрzодичности.Для любой измеримой функцииg от (к примеру) случай
ных переменныхХ 1 , Х 2 , ... ,Х к , ожидания которой известны, с вероятностью 1
выполняется:
1 n
lim Lg(X 1 (i), X 2 (i),... , XK(i)) E[g(X 1 , Х 2 ,... , Х к )].
n.....,оо n
i l
(11.36)
Теорема об эрrодичности предлаrает способ использования выхода квантователя
rиббса для вычисления числовых оценок искомых rpаничных плотностей.
Квантователь rиббса используется в машине Больцмана для квантования на oc
нове распределений скрытых нейронов. Эта стохастическая машина рассматривается
в следующем разделе. В контексте стохастических машин, использующих двоичные
элементы (т.е. машин Больцмана), следует заметить, что квантователь rиббса являет
ся вариантом алroритма Метрополиса. В стандартной форме алroритма Метрополиса
движение происходит вниз по склону с вероятностью 1. В противоположность это
му В альтернативной форме алroритма Метрополиса мы движемся вниз по склону с
вероятностью единица минус экпоненциал дефицита энерzии (energy gap) (т.е. вклад
в правило движения вверх по склону). Друrими словами, если изменение энерrии Е
произошло в сторону уменьшения или энерrия осталась неизменной, то изменение
принимается. Если изменение предполаrает увеличение энерrии, оно принимается с
вероятностью ехр( ДE), в противном случае оно отверrается, сохраняя предыду
щее состояние [777].
11.7. Машина Больцмана
Машина Больцмана (Boltzmann mастпе) представляет собой стохастическую маши
ну, компонентами которой являются стохастические нейроны. Стохастический ней
рон находится в одном из двух возможных вероятностных состояний. Этим двум
состояниям формально можно присвоить значения + 1 (соответствующее включен
ному состоянию) И 1 (соответствующее выключенному состоянию). Аналоrично,
можно принять значениями этих состояний + 1 и О соответственно. Примем пер
вое допущение. Еще одним отличительным свойством машины Больцмана является
использование симметричных синаптическux связей (symmetric synaptic connection)
между нейронами. Использование этой формы синаптической связи обусловлено co
rлашениями статистической физики.
1
714 rлава 11. Стохастические машиныи их аппроксимации в статистической механике
Скрытые нейроны
Видимые нейроны
Рис. 11.4. Архитектурный rраф маши-
ны Больцмана (rде к количество ви-
димых, а L количество CKpbITl?lX ней
ронов)
Стохастические нейроны машины Больцмана разбиваются на две функциональные
rpуппы: видимые (visible) и скрытые (hidden) (рис. 11.4). Видимые нейроны 6 предо-
ставляют интерфейс между сетью и средой, в которой она работает. Во время этапа
обучения сети видимые нейроны фиксируются в своих специфичных состояниях,
определяемых средой. С друroй стороны, скрытые нейроны всеrда работают сво-
бодно они используются для выражения оrpаничений, содержащихся во входных
векторах. Скрытые нейроны выполняют эту задачу с помощью извлечения статисти
ческих корреляций высокоro порядка в оrpаничивающих векторах. Сеть, описанная
выше, является частным случаем машины Больцмана. Ее можно рассматривать как
процедуру обучения без учителя моделированию распределения вероятности, KOTO
рое применяется к видимым нейронам с соответствующими вероятностями. Таким
образом, сеть может осуществлять дополнение образов (pattem completion). В част
ности, если вектор с неполной информацией поступает в подмножество видимых
нейронов, сеть (в предположении правильности процедуры обучения) дополняет эту
информацию в оставшихся видимых нейронах [457].
rлавной целью обучения Больцмана является создание нейронной сети, которая
правильно моделирует входные образы в соответствии с распределением Больцмана.
При использовании этой формы обучения делаются два предположения.
· Каждый входной вектор внешней среды подается на вход сети достаточно долro,
чтобы система достиrла meмпepamypHOZO равновесия.
· Не существует определенной последовательности подачи векторов среды в види
мые элементы сети.
6 Видимые нейроны в машине Больцмана можно дополнительно подразделить на входные и выходные.
В этой второй конфнrypацин машина Больцмана реализует ассоциации под руководством учнтеля. Входные
нейроны получают информацию от окружающей среды, а выходные доводят результаты вычисленнй до конеч.
HOro пользователя.
11.7. Машина Больцмана 715
Считается, что множество синаптических весов реализует совершенную модель
структуры среды, если она приводит к точно такому же распределению вероятно
сти состояний видимых элементов (при свободной работе сети), к какому приводит
подача входных векторов среды. В общем случае, если количество скрытых нейро
нов не является экспоненциально большим по сравнению с количеством видимых
элементов, такой совершенной модели достичь невозможно. Если же среда имеет
упорядоченную структуру, а сеть использует скрытые элементы для извлечения этих
закономерностей, можно достичь хорошеro соответствия при достаточном количестве
скрытых элементов.
Квантование rиббса и моделирование отжиrа в машине
Больцмана
Обозначим символом х, состоящим из компонентов Xi, соответствующих состояниям
нейронов i, вектор состояний машины Больцмана. Это состояние х представляет
собой реализацию случайноro вектора Х. Синаптические связи между нейронами i и
j обозначим символами Wji' При этом
Wji == Щj для всех пар (i,j)
(11.37)
и
Wii == о для всех i.
(11.38)
Равенство (11.37) описывает свойство симметрии, а равенство (11.38) OTCYТ
ствие собственных обратных связей. Использование пОрО2а (bias) достиrается за счет
добавления веса связи W jO между фиктивным узлом с постоянным сиrналом + 1 и
нейроном j (для всех Л.
ПО аналоrии с термодинамикой энерrия машины Больцмана определяется следу
ющим образом 7:
1
Е ( х ) '" "'w"xx,
2 }' t }'
i j,iij
(11.39)
Вводя распределение rиббса (11.5), можно определить вероятность Toro, что сеть
находится в состоянии х (при этом предполаrается, что она находится в равновесии
7 Формула (11.39) применима к машнне Больцмана, в которой состояния "вкл" Н "выкл" задаются значе
ннямн +1 и 1 соответственно. Если машнна нспользует для этой цели значения О и 1, получим следующее:
Е(х) L L WjiXiXj.
i j,i#j
716 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
при температуре Т):
1 ( Е(Х) )
Р(Х==х)== Z ex p T '
(11.40)
rде Z функция разбиения (partition function).
для упрощения ВЫКЛадок определим событие А и связанные события В и С
следующим образом:
А: X j == Xj,
В: {X i == Xi} l,i;"'j'
с: {X i == Xi} l'
В результате совместное событие В исключает событие А, а совместное событие
С включает оба события А и В. Вероятность В является rpаничной вероятно
стью С по отношению к А. Исходя из этоro, используя выражения (11.39) и (11.40),
можно записать:
Р(С) == (А, В) == ехр ( 2 L ШjiХiХj )
· З,';"'З
(11.41)
и
Р(В) == L (А, В) == L ехр ( 2 . ШjiХiХj ) ,
А Xj . З";,,,з
(11.42)
Экспоненты в равенствах (11.41) и (11.42) MOryт быть выражены суммами двух
компонентов первая из них включает Xj, а вторая не зависит от Xj. Компонент,
содержащий Xj, имеет следующий вид:
Х. ""'
2 6 ШjiХi'
i,Цj
Соответственно, принимая Xj == Х == :1:1, можно выразить условную вероятность
А для данноrо В следующим образом:
P(AIB) == Р(А, В)
Р(В)
1
1 + ехр ( * .'2:ШjiХi ) .
',';"'З
Это значит, что можно записать:
P(X j == xl{X i == Xi} l#j == <р ( ; ШjiХi ) ,
",;",з
(11.43)
11.7. Машина Больцмана 717
v
Рис. 11.5. Сиrмоидальная функция P(v)
о
rде <р(') сиrмоидальная ФУНКЦИЯ cBoero apryMeHTa, Т.е.
1
q>(v)
1 + ехр( v) .
(11.44)
Обратите внимание на то, что, несмотря на изменение Х в диапазоне между зна
чениями 1 и + 1, весь apryMeHT I: WjiXi при больших N может варьироваться
iof.j
между oo и +00 (рис. 11.5).
Заметим также, что при выводе равенства (11.43) не использовалась функция раз
биения Z. Этот результат очень желателен, так как прямое вычисление Z невозможно
в сетях большой сложности.
Использование квантования rиббса обеспечивает совместное распределение
Р( А, В). В своей основе (см. раздел 11.6) стохастическое моделирование начина
ется с присвоения сети HeKoToporo произвольноro состояния, после чеro нейроны
посещаются в естественном порядке. При каждом посещении нейрона выбирается
новое значение состояния, в соответствии с распределением вероятности этоro ней
рона, в зависимости от состояний всех остальных нейронов сети. Предполаrая, что
стохастическое моделирование будет про водиться достаточно долrо, сеть достиrнет
термальноro равновесия при температуре Т.
К сожалению, время, затраченное на достижение термальноrо равновесия, MO
жет быть слишком большим. Для Toro чтобы избежать этой пролблемы, использует
ся моделирование отжиrа для конечной последовательности температур То, T 1 , . . . ,
Тконечная (см. раздел 11.5). Таким образом, начальная температура устанавливает
ся в значение То, обеспечивая быстрое достижение термальноro равновесия. По
сле этоrо температура Т медленно снижается до cBoero окончательноrо значения
Тконечная, и в этой точке состояния нейронов достиrнут (надеемся) своих желае
мых rpаничных распределений.
718 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
1
I
I
i
I
Правило обучения Больцмана
Так как машина Больцмана является стохастической, для поиска индекса ее произ
водительности следует обратиться к теории вероятности. Один из таких критериев
носит название функции правдоподобия 8 (likelihood function). Используя этот крите
рий в качестве основы, в соответствии с принципом максималЬНО20 правдоподобuя,
можно определить цель обучения Больцмана как максимизацию функции правдопо-
добия или (эквивалентно) функции лоrарифмическоro правдоподобия.
Обозначим символом Т множество примеров обучения, отобранных из интересу
ющеro нас распределения. Предполаrается, что эти примеры MOryт иметь два зна
чения. Количество повторений примеров обучения соответствует частоте появления
аналоrичных случаев на практике. Обозначим символом Ха подмножество вектора
состояний Х, соответствующих видимым нейронам сети. Оставшуюся часть вектора
Х обозначим символом Х[3. Она будет соответствовать состояниям скрытых нейронов.
Векторы состояний Х, Ха И XJ3 являются реализациями случайных векторов Х, Ха И
XJ3 соответственно. Существуют две фазы работы машины Больцмана.
· Положительная фаза. В этой фазе сеть работает в своем фиксированном (clamped)
состоянии (т.е. под непосредственным воздействием множества примеров Т).
· Отрицательная фаза. В этой фазе сеть работает в свободном режиме и не под-
вержена влиянию среды.
Если предположить, что вектор w содержит все синаптические веса сети, то Be
роятность нахождения видимоro нейрона в состоянии Ха равна Р(Х а ==Ха). Предпо
лаrая, что большинство возможных примеров, содержащихся в множестве обучения
Т, являются статистически независимыми, общее распределение вероятности МОЖ
но представить факториальным распределением ПХаЕТ Р(Ха, == Ха). Для TOro чтобы
сформулировать функцию лоrарифмическоro правдоподобия L(w), возьмем лоrарифм
8 Траднционно в качестве индекса производительности машины Больцмана использовалась относительная
энтропня (нли расстоянне Кулбека Лейблера) [9], [464]. Этот крнтернй реализовывал меру несоответствия
между средой н внутренней моделью сети. Он определялся в следующем виде:
Dp+llp L.:p;log ( 4 ) ,
а ра
rдe р; вероятность тoro, что видимый нейрон иаходится в состояннна в момент нахождения сети в фикси
рованном режиме, ар;; вероятность тoro, что тот же нейрон находится в состоянии а в момент нахождения
сети в свободном режиме. Синаптические веса сети корректируются с целью миннмизации величнныD р;; Ilv';-
(см. задачу 11.1 О).
Принцип миннмума днверreнцни Кулбека Лейблера и максимальноro правдоподобня эквивалентны, кo
rдa применяются к множеству примеров обучення. Для тoro чтобы заметить эту эквивалентность, обратите
внимание на то, что диверrенция Кулбека Лейблера между распределениями f и 9 определяется по формуле
D fllg H(!) L.: flog(g).
Если распределен не f определяется множеством примеров обучення, а модель g дана для оптнмизации,
то первое слаraемое ЯWlЯется константой, а второе лоraрифмическим правдоподобием, взятым с обратиым
знаком, что и доказывает Эквивалентность принципов миннмума диверrенции Кулбека Лейблера и максимума
правдоподобня.
11.7. Машина Больцмана 719
этоro факториальноro распределения. При этом будем рассматривать w как вектор
неизвестных параметров:
L(w) == log П Р(Х а == Ха) == L logP(Xa == Ха).
ХаЕТ ХаЕТ
(11.45)
Для TOrO чтобы определить выражение для rpаничной вероятности P(Xa Xa) В
терминах функции энерrии Е(х), воспользуемся следующими фактами.
· Исходя из (11.40), вероятность P(X x) равна ехр( Е(х) /Т).
· По определению вектор состояния х является совместной комбинацией вектора Ха
(содержащеrо состояния видимых нейронов) и вектора XJ3 (содержащеro состояния
скрьпых нейронов). Исходя из этоro, вероятность нахождения видимых нейронов
в состоянии Ха С любым XJ3 определяется по следующей формуле:
1 ( Е(Х) )
Р(Х а == Ха) == Z Lexp T '
X
(11.46)
rде случайный вектор Ха является подмножеством Х. Функция разбиения Z опре
деляется следующим выражением (см. (11.6»:
Z == Lexp ( E X) ).
Х
(11.47)
Таким образом, подставляя (11.46) и (11.47) в (11.45), получим искомое Bыpa
жение для функции максимальноro правдоподобия:
L(w) (log рХР ( E X) ) log exp ( E;) )).
(11.48)
Здесь зависимость от w содержится в функции энерrии Е(х) (см. (11.39».
Дифференцируя L(w) по Wji, В свете (11.39), после перестановки слаrаемых по
лучим следующий результат (см. задачу 11.8):
8L(w) 1 ( )
== Т L L P(XJ3 == xJ3IXa == Xa)XjXi L Р(Х == X)XjXi .
З' ХаЕТ X Х
(11.49)
l'
720 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Для упрощения выкладок введем два следующих определения:
pt ==< XjXi >+== L LP(XI3 == xl3l X a == Xa)XjXi
ХаЕТ Хр
(11.50)
и
Pji ==< XjXi > == L L Р(Х == X)XjXi'
ХаЕТ Х
(11.51)
в некотором смысле первое среднее Р t можно рассматривать как средний уровень
возбуждения (mеап firing rate) или корреляцию между состояниями нейронов i и j
при работе сети в своей положительной фазе. Аналоrично, второе среднее Р ji можно
рассматривать как Корреляцию между состояниями нейронов i и j при работе сети в
своей отрицательной фазе. Используя эти обозначения, можно упростить выражение
(11.49) следующим образом:
8L(w) 1 +
8Wji Т (Pji Pji) .
(11.52)
Целью обучения Больцмана является максимизация функции правдоподобия
L(w). Для достижения этой цели можно использовать 2радиентный спуск (gradi-
ent ascent) и записать:
8L(w) +
b.Wji E 8 'Тl(Pji PjJ,
Wji
(11.53)
rде 'тl параметр скорости обучения (1earning rate parameter); ero можно определить
в терминах Е и рабочей температуры Т следующим образом:
Е
'тl == Т '
(11.54)
Правило rpадиентноro спуска (11.53) называется правилом обучения Больцмана
(Boltzmann leaming rule). Описанное здесь обучение выполняется пакетным методом.
Это значит, что изменения в синаптических весах происходят после представления
Bcero множества примеров обучения.
Соrласно этому правилу обучения, синаптические веса машины Больцмана кор-
ректируются с использованием только локально наблюдаемых значений при следу
ющих двух разных условиях: фиксированной и свободной фазе работы. Это важное
свойство обучения Больцмана упрощает архитектуру сети, что особенно чувствуется
при работе с большими сетями. Еще одним важным свойством обучения Больцмана
(оно может стать приятным сюрпризом) является то, что правило коррекции синап
11.7. Машина Больцмана 721
тических весов между нейронами i и j не зависит от TOro, являются ли они оба
видимыми, скрытыми или же один является скрытым, а второй видимым. Все
эти прекрасные свойства обучения Больцмана являются результатом rлубоких иссле
дований в [464], [465]. В этой работе абстрактная математическая модель машины
Больцмана и нейронные сети были связаны с помощью комбинации двух факторов.
. Распределения rиббса для описания стохастических свойств нейронов.
. Функции энерrии, взятой из статистической физики (11.39), используемой для
определения распределения rиббса.
с точки зрения обучения, два слаrаемых, составляющих правило обучения Больц
мана (11.53), имеют прямо противоположные значения. Первое слаrаемое, COOTBeT
ствующее фиксированному состоянию сети, можно рассматривать как правило обу
чения Хебба (НеЬЫап learning rule). Второе слаrаемое, соответствующее свободному
состоянию сети, можно рассматривать как слаrаемое забывания (forgetting term). И в
самом деле, правило обучения Больцмана представляет собой не что иное, как обоб
щение правила повторяющеzося забывания и обучения (generalization of the repeated
forgetting and releaming rule), описанноrо в [852] для случая симметричных нейрон
ных сетей, не содержащих скрытых нейронов.
Интересно отметить следующее. Так как алrоритм обучения машины Больцма
на требует, чтобы скрытые нейроны чувствовали разницу между стимулируемым и
свободным режимами, при наличии (скрытой) внешней сети, посылающей сиrна
лы этим скрытым нейронам стимулируемой машины, получим примитивную форму
механизма внимания (attention mechanism) [227].
Потребность в отрицательной фазе и ее применение
Комбинированное использование положительной и отрицательной фаз стабилизиру
ет распределение синаптических весов в машине Больцмана. Эта потребность может
быть обоснована и с друrой точки зрения. Интуитивно можно утверждать, что потреб
ность в отрицательной фазе наряду с положительной в машине Больцмана возникает
в связи с наличием функции разделения (partition function) Z в выражении для BeK
тора вероятности состояний нейрона. Применение этоrо утверждения заключается
в том, что направление наискорейшеrо спуска в пространстве энерrии отличается
от направления наискорейшеrо спуска в пространстве параметров. В результате для
учета этоro несоответствия и возникла потребность в отрицательной фазе [778].
Использование отрицательной фазы в обучении Больцмана имеет два существен
ных недостатка.
1. Увеличенное время вычислений. Во время положительной фазы отдельные нейро
ны фиксируются внешней средой, в то время как во время отрицательной фазы
722
rлава 11. Стохастические машиныи их аппроксимациив статистической механике
1
все нейроны работают свободно. В результате этоro время, затраченное стохасти
ческим моделированием машины Больцмана, возрастает.
2. Чувствительность к статистическим ошибкам. Правило обучения Больцмана
учитывает различия между двумя средними корреляциями. Одна из них вычис
ляется для положительной фазы, а вторая для отрицательной. Korдa эти две
корреляции подобны, наличие шума делает это различие еще более заметным.
Эти недостатки машины Больцмана можно обойти с помощью использования cuz
моидальных сетей доверия (sigmoid belief network). В этом новом классе стохасти
ческих машин управление процедурой обучения осуществляется посредством фазы,
отличной от отрицательной.
11.8. Сиrмоидальные сети доверия
СИ2Моидальные сети доверия (sigmoid be1ief network) или лоzистические сети дoвe
рия (logistic belief net) были разработаны в [778] в попьrrке найти стохастическую
машину, которая бьmа бы способна обучаться произвольному распределению Bepo
ятности на множестве двоичных векторов, но не имела бы, в отличие от машины
Больцмана, потребности в отрицательной фазе. Эта цель бьmа достиrнута заменой
симметричных связей в машине Больцмана прямыми соединениями, формирующими
ацикличный zраф. rоворя более точно, сиrмоидальные сети доверия имеют MHoro
слойную архитектуру, состоящую из двоичных стохастических нейронов (рис. 11.6).
Ацикличная природа этих машин облеrчает осуществление вероятностных вычисле
ний. В частности, эта сеть использует сиrмоидальную функцию (11.43), по аналоrии
с машиной Больцмана, для вычисления условной вероятности TOro, что нейрон будет
активирован в ответ на свое собственное индуцированное локальное поле.
Фундаментальные свойства сиrмоидальных сетей доверия
Пусть вектор Х, состоящий из случайных двоичных переменных Х 1, Х 2, . . . , Х N,
определяет сиrмоидальную сеть доверия, состоящую из N стохастических нейронов.
Родители элемента X j в векторе Х обозначаются следующим образом:
pa(X j ) {Xl,X2,...,Xj 1}'
(11.55)
Друrими словами, значением pa(X j ) является наименьшее подмножество случай
Horo вектора Х, дЛЯ KOTOpOro
P(X i == XjlX 1 == Хl,..., Xj l == Xj l) == P(X j == Xjlpa(X j )).
(11.56)
11.8. Сиrмоидальные сети доверия 723
Смещение
}B
Bro {
Скрытый
слой
Рис. 11.6. Архитектурный rраф сиrмоидальной сети доверия
Важным достоинством сиrмоидальных сетей доверия является их способность яв
НО представлять условные зависимости исследуемых вероятностных моделей BXOД
ных данных. В частности, вероятность активации i ro нейрона определяется следу
ющей сиrмоидальной функцией (см. (11.43»:
Р(Х; x;lpa(X;)) ( i w;.x.) ,
(11.57)
rдe Wji синаптический вес, идущий от нейрона i к нейрону j (см. рис. 11.6).
Это значит, что условная вероятность P(X j == xjlpa(X j )) зависит от pa(X j ) только
через сумму взвешенных входов. Таким образом, выражение (11.57) создает базис
для распространения доверия по сети.
При осуществлении расчетов вероятности в сиrмоидальных сетях доверия нужно
учесть два следующих условия.
1. Wji ==0 для всех X i , не принадлежащих pa(X j ).
2. Wji ==0 для всех i j.
Первое условие вьпекает непосредственно из определения родителей. Второе
условие следует из TOro факта, что сиrмоидальные сети доверия являются направ
ленным ацикличным rpафом.
rл.,а 11. Сroха",ические машиныи их аппроксимации. с,а'иСП!чесхо. механике т
724
Как следует из caMoro названия, сиrмоидальные сети доверия принадлежат к об
щему классу сетей доверия (be1ief network)9, интенсивно изучаемых в литературе
[822]. Стохастическая работа сиrмоидальных сетей доверия HeMHoro сложнее рабо
ты машин Больцмана. Тем не менее обе эти системы используют обучение методом
rpадиентноro спуска в пространстве вероятностей, основанное на локально доступ
ной информации.
Обучение в сиrмоидальных сетях доверия
Обозначим символом Т множество примеров обучения, отобранных из интересу
ющеro нас распределения вероятности. Предполаrается, что каждый из примеров
является двоичным и представляет некоторый атрибут. При обучении допускаются
повторения примеров с частотой, пропорциональной частоте встречи на практике
подобной комбинации атрибутов. Для моделирования распределения, из KOToporo
отобрано множество Т, выполним следующие действия.
1. Для сети определим размер вектора состояний Х.
2. Выберем подмножество этоro вектора (обозначенное Ха), представляющее атри
буты примеров обучения. Это значит, что Ха представляет собой вектор состояний
видимых нейронов.
3. Оставшаяся часть вектора состояний (обозначенная Х/3) определяет вектор
состояний скрытых нейронов (т.е. расчетных узлов, для которых значе
ния не устанавливаются).
Архитектура сиrмоидальной сети доверия в значительной мере зависит от op
rанизации состояний видимых и скрытых элементов в векторе Х. Таким образом,
разные композиции состояний скрытых и видимых нейронов MorYT привести к раз
ным конфиrурациям.
Как и в случае с машиной Больцмана, мы выведем искомое правило обучения для
сиrмоидальной сети доверия, максимизировав функцию лоrарифмическоrо правдо
подобия, вычисленную на множестве примеров Т. ДЛЯ удобства представления еще
раз приведем функцию лоrарифмическоrо правдоподобия L(w) (см. (11.45»:
L(w) == L logP(Xa == Ха),
ХаЕТ
9 Сети доверия изначально были введены с целью представления вероятностных знаний в экспертных
системах [822]. В литературе они также иноrда называются сетями Байеса, UJ/И байесовскuми сетями (Bayesian
network).
11.8. Сиrмоидальные сети доверия 725
rдe w вектор синаптических весов сети, который считается неизвестным. BeK
тор состояний х ш относящийся К видимым нейронам, является реализацией слу
чайноrо вектора Ха' Обозначим символом Wji ji й элемент вектора w (т.е. синап
тический вес, направленный от нейрона i к нейрону Л. Дифференцируя функцию
L(w) по Wji, получим:
aL(w) == '"'" 1 дР(Х а == Ха) .
aw.. Р ( У == Х а) aw..
З' ХаЕТ З'
Далее вспомним два вероятностных соотношения:
Р(Ха == Ха) == L Р(Х == (Ха, x )) == L Р(Х == х),
(11.58)
X
X
rдe случайный вектор Х относится ко всей сети, а вектор состояний X (Xa, x ) явля
ется ero реализацией, и
Р(Х == х) == Р(Х == Х\Ха == Ха)Р(Ха == Ха), (11.59)
rдe определяется вероятность cOBMecrnoro события X X (Xa, x ).
В свете этих двух соотношений можно определить частную производную
aL(W)/дWji в эквивалентном виде:
aL(w) == '"'" '"'" Р(Х == xlXa == Ха) дР(Х а == Ха) .
(11.60)
aw.. Р ( Х == Х ) aw..
З' ХаЕТ X З'
в свете выражения (11.43) можно записать:
P(x х) l} <р ( i Wj;X}
(11.61)
rдe «>(-) сиrмоидальная функция cBoero apryMeHTa. Отсюда следует:
1 дР(Х == х) д д '"'" ( Xj '"'" )
Р( ) д == д logP(X == х) == д log<p Т WjiXi
X x W.. W.. W..
З' З' З' j i<j
1 '"'" 1 I ( Xj '"'" )
== т ( Х' ) <р т L..,; WjiXi XjXi,
J сп :::.1..'""W"X' '<]
't' Т L.., З' ,
i<j
726
rлава 11. Стохастические машиныи их аппроксимациив статистической механике
l
rде <р'0 первая производная сиrмоидальной функции <р(.) от cBoero apryMeHTa.
Однако из определения функции <р(.) (см. (11.44» видно, что
<p'(v) == <p(v)<p( v),
(11.62)
rдe <р( v) получается из <p(v) заменой v на v. Исходя из этоro, можно записать, что
1 дР(Х == х) 1 '"'" ( Xj '"'" )
Р ( Х == Х ) aw.. == т <р т WjiXi XjXi'
l' j i<j
(11.63)
Следовательно, подставляя (11.63) в (11.60), получим:
aL(w) 1 '"'" '"'" ( Xj '"'" )
== т Р(Х == xlXa == Ха)<р Т WjiXi XjXi'
'1 ХаЕТ X i<j
(11.64)
Для упрощения определим среднее по множеству (ensemble average) как
Pji ==< <р ( Xj L WjiXi ) XjXi >==
i<j
== L L Р(Х == xlXa == ха)<р ( i L WjiXi ) XjXi'
ХаЕТ X i<j
(11.65)
Это выражение представляет усредненную корреляцию (average сопе1аtiоп) меж
ду состояниями нейронов i и j, взвешенную множителем <р ( * t;; WjiXi). Это
среднее значение берется по всем возможным значениям Ха (выбранным из множе
ства Т), равно как и по всем возможным значениям X . Здесь Ха относится К видимым
нейронам, а x к скрытым.
rрадиентный спуск в пространстве параметров осуществляется с помощью опре
деления пошаroвоrо изменения синаптических весов W ji:
tlWji == fBL(w)/aWji == 11P j i'
(11.66)
rде 11 == cJT параметр скорости обучения, а Р ji определяется выражением (11.65).
Равенство (11.65) называется правилом обучения СИ2моидальной сети доверия (leam-
ing rule for а sigmoid belief network).
Процедура обучения сиrмоидальной сети доверия в сжатом виде представлена
в табл. 11.2. В ней обучение осуществляется в пакетном режиме. Это значит, что
изменения, применяемые к синаптическим весам сети, проводятся на основе Bcero
множества примеров обучения. В алroритме, представленном в табл. 11.2, не учтено
11.8. Сиrмоидальные сети доверия 727
ТАБЛИЦА 11.2. Процедура обучения сиrмоидальной сети доверия
Инициализация. Сеть инициализируется путем присвоения весам W ji сети
случайных значений, равномерно распределенных в диапазоне [ a, а]. Обыч
но значением а является число 0,5.
1. Для данноro множества примеров обучения Т видимые нейроны сети фик
сируются в состояниях Ха, rдe Ха ЕТ.
2. Для каждоro Ха выполняется отдельное квантование rиббса при не которой
рабочей температуре Т, после чеro наблюдается полученный вектор COCTO
яний Х всей сети. Предполаrая, что моделирование проводится достаточно
долrо, значения х для разных классов, содержащихся в Т, должны принять
условное распределение соответствующеro случайноro вектора Х, COOTBeT
ствующеrо данному множеству примеров.
3. Вычисляется среднее по множеству:
Pji == I: I: Р(Х == xlXa == Xa)XjXi«> ( X] I: WjiXi ) '
ХаЕТ X i<j
rдe случайный вектор Ха является подмножеством вектора Х и X (Xa, x ).
Векторы Ха И X соответствуют состояниям видимых и скрытых нейронов,
Xj является j M элементом вектора состояний х (т.е. состоянием нейрона
Л, а Wji синаптическим весом, направленным от нейрона i к нейрону j.
Сиrмоидальная функция «>(.) определяется следующим образом:
«>(v) == Hex ( v) '
4. Каждый из синаптических весов подверrается коррекции на величину
tlWji == 11Pji'
rдe 11 параметр скорости обучения. Эта коррекция должна перемещать
синаптические веса сети в направлении rрадиента в сторону локальноro MaK
симума функции лоrарифмическоro правдоподобия L(w) в соответствии с
принципом максимальноro правдоподобия.
использование модели отжиrа. Именно поэтому температура Т устанавливается в
значение единицы. Тем не менее, как и в машине Больцмана, моделирование отжиrа
в случае необходимости может быть внедрено в процедуру обучения сиrмоидальной
сети доверия для ускорения достижения точки термальноro равновесия.
В отличие от машины Больцмана для обучения сиrмоидальной сети доверия тpe
буется Bcero одна фаза. Причиной TaKoro упрощения является то, что нормализация
распределений вероятности по векторам состояния выполняется на локальном уровне
каждоro из нейронов с помощью сиrмоидальной функции «>(.), а не rлобально по
средством сложноro вычисления функции разбиения Z, при котором учитываются
все возможные конфиryрации состояний. Как только условное распределение Beктo
ра Х для данных значений Ха из множества примеров обучения Т было корректно
728 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
промоделировано с помощью квантования rиббса, роль отрицательной фазы процеду-
ры обучения машины Больцмана выполняет весовой множитель q> ( * WjiXi}
участвующий в вычислении усредненной по множеству корреляции р ji между ней
ронами i и j. Korдa достиrается локальный минимум функции лоrарифмическоro
правдоподобия, этот весовой множитель становится равным нулю, если сеть обу
чалась детерминированному отображению; в противном случае ero усредняющий
эффект сводится к нулю.
В [778] представлены экспериментальные результаты, которые показали, что сиr
моидальные сети доверия способны обучаться моделированию нетривиальных pac
пределений. Эти сети способны обучаться быстрее машин Больцмана; такие преиму
щества сиrмоидальных сетей доверия перед машиной Больцмана появились вслед
ствие устранения из процедуры обучения отрицательной фазы.
11.9. Машина rельмrольца
Сиrмоидальные сети доверия реализуют мощную мноrослойную систему для пред
ставления статистических взаимосвязей высокоro порядка между сенсорными Bxoдa
ми (и обучения без учителя). В машине rелЬМ20льца 1О (Helmholtz machine), впервые
описанной в [245] и [460], предлаrается друrая удачная мноroслойная среда для дo
стижения аналоrичной цели, но уже без использования квантования rиббса.
Машина rельмroльца использует два совершенно противоположных множества
синаптических связей (рис. 11.7) для случая, коrда двухслойная сеть состоит из ДBO
ичных стохастических нейронов. Прямые связи, показанные на рисунке сплошными
линиями, составляют модель распознавания (recognition model). Целью этой моде-
ли является производство лоrических (infer) о распределении вероятности, исходя из
всех представленных примеров входных векторов. Обратные связи, показанные на ри-
сунке пунктирными линиями, составляют порождающую модель (generative model).
10 Машина [ельмroльца принадлежит к классу нейронных сетей, характеризуемых прямыми и обратны.
ми проекциями (forward backward projection). Идея таких проекций была предложена в [392], rде изучалась
теория адаптивноrо резонанса (adaptive resonance theory) [175]. В этой модели прямая адаптивная фильтрация
комбинировалась с обратным сопоставлением моделей. При этом происходил адаптивный резонанс (т.е. уси.
ление и пролонrация нейронной активности). В противоположность теории адаптивноrо резонанса [россберrа
машины [ельмroльца используют статистический подход к самообучающимся системам в качестве одной из
состаWlЯЮЩИХ обобщенной модели, нацеленной на точНое извлечение структуры входных данных.
Друrими тесно связанными с этой задачей работами являются [686], [687]. В первой из них была введеиа
идея свернутых цепей Маркова (fo1ded Markov chain или FMC). За прямыми переходами в них следовали
обратные переходы (использующие теорему Байеса) через копию той же цепи. Во второй работе рассматривалась
связь между FMC и машиной [ельмroльца.
Среди дрyrих работ можно упомянуть [547], в которой прямая модель распознавания и обратная порожда.
ющая модель рассматривались аналоrично машине [ельмrольца, однако без вероятностноro подхода.
В [244] рассматривалось множество различных вариаций машины [ельмroльца, в том числе схемы обучения
с учителем.
11.9. Машина rельмrольца 729
Распознавание
Рис. 11.7. Архитектурный rраф машины rельмroль Входной
ца, состоящей из взаимосвязанных нейронов со свя слой
зями распознавания (сплошные линии) и порождаю
щими связями (пунктирные линии)
Первый
скрытый
слой
Эта модель предназначена для аппроксимации исходных входных векторов на основе
представлений, созданных скрытыми слоями сети, путем самООр2анизации. Обе эти
модели работают на основе метода прямоro распространения, не имеют обратных
связей и взаимодействуют друr с друroм посредством процедуры обучения.
В [460] описан стохастический алroритм, названный ал20рИmмом засыпанuя
пробуждения (wake sleep algorithm), предназначенный для вычисления связей pac
познавания и порождающих весов в машине rельмrольца. Как следует из названия
этоro алroритма, он содержит две фазы: пробуждения и засыпания. В фазе про
буждения проход по сети осуществляется в прямом направлении с использованием
связей распознавания, вследствие чеro в первом скрьпом слое создается представле
ние входных векторов. Затем, в свою очередь, следует второе представление первоro
представления, которое создается во втором скрытом слое, и Т.Д. для всех скрытых
слоев сети. Множество созданных таким способом представлений в различных cкpы
тых слоях сети обеспечивает полное описание множества входных векторов в данной
сети. Несмотря на то что сиrналы передаются по распознающим весам, на самом деле
во время фазы пробуждения на основе локально доступной информации обучаются
только порождающие связи. В результате эта фаза процесса обучения повышает каче
ство восстановления для каждоro из слоев общеrо представления, сформированноro
в предыдущем слое.
Во время фазы засыпания веса распознавания отключаются. Сеть работает по
слойно в обратном направлении с помощью порождающих весов, начиная с caMoro
дальнеro скрытоrо слоя и заканчивая входным слоем. Блаroдаря тому что нейроны
являются стохастическими, повторение этоro процесса обычно приводит к созда
нию массы "фантастических" векторов во входном слое. Эти "фантазии" составляют
730 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
не смещенный образ порождающей модели мира в данной сети. После создания такой
"фантазии" для коррекции весов распознавания применяется обычное дельта правило
(см. rлаву 3). Целью этоro является максимизация вероятности восстановления дей-
ствий скрытых слоев, вызвавших данную фантазию. Подобно фазе пробуждения,
фаза засыпания использует только локально доступную информацию.
В процессе обучения порождающих весов (т.е. обратных связей) также использу
ется простое дельта правило. Однако вместо rpадиента функции лоrарифмическоro
правдоподобия в этом правиле используется rpадиент штрафной функции лоrариф-
мическоro правдоподобия (penalized 10g likelihood function). Слаrаемое штрафа пред
ставляет собой диверrенцию Кулбека Лейблера между истинным апостериорнымрас
пределением и фактическим распределением, создаваемым моделью распознавания
[460]. Диверreнция Кулбека Лейблера (или относительная энтропия) рассматрива
лась в предыдущей rлаве. В результате штрафная функция лоrарифмическоro прав
доподобия выступает как нижняя rpаница функции лоrарифмическоro правдоподобия
входных данных, и эта нижняя rpаница улучшается в процессе обучения. В частно
сти, в процесс е обучения происходит корректировка порождающих весов с целью
получения истинноro апостериорноro распределения, максимально приближенноro
к распределению, вычисленному моделью распознавания. К сожалению, обучение
весов модели распознавания точно не соответствует штрафной функции правдоподо-
бия. Процедура пробуждения засыпания не rарантирует работоспособность во всех
практических ситуациях иноrда она завершается неудачей.
11.10. Теория среднеrо поля
Обучаемые машины, рассмотренные в предыдущих трех разделах, имеют одно об-
щее свойство: в них используются стохастические нейроны, вследствие чеro можно
обеспечить только медленный процесс обучения. В заключительной части настоящей
rлавы рассматривается применение теории среднеro поля в качестве математическо
ro базиса для вывода детерминированних приближений (deterministic approximation)
стохастических машин, что позволит значительно ускорить обучение. Так как pac
смотренные ранее стохастические машины имеют разную архитектуру, то и теория
среднеro поля применяется к ним по разному. В частности, можно определить два
особых подхода, которые были предложены в литературе.
1. Корреляция заменяется своей аппроксимацией среднеro поля.
2. Нетрактуемая модель заменяется трактуемой с помощью вариационноro принципа.
Второй подход очень принципиальный и потому более привлекательный. Он
применим к сиrмоидальным сетям доверия [936] и машинам rельмrольца [245]. Ok
нако в случае машин rельмroльца применение BTOpOro подхода усложняется потреб
11.10. Теория среднеrо поля 731
ностью В оrраничении сверху функции разбиения Z. По этой причине в [831] для
ускорения процесса обучения Больцмана использовался первый подход. В этом раз
деле будет дано обоснование первому подходу, а вторым подходом мы займемся в
следующем разделе.
Идея аппроксимации среднеrо поля хорошо известна в статистической физике
[363]. Хотя нельзя отверrнуть тот факт, что в контексте стохастических машин жела
тельно знать состояния всех нейронов сети в любой момент времени, тем не менее
понятно, что в сетях с большим количеством нейронов их состояния содержат зна
чительно большую информацию, чем это требуется на практике. На самом деле,
для TOro чтобы ответить на наиболее известные вопросы физики о стохастическом
поведении сети, требуется знать только средние значения состояний нейронов или
средние произведения пар состояний нейронов.
В стохастическом нейроне механизм возбуждения описывается вероятностным
правилом. В этом случае целесообразно будет rоворить о среднем значении состояний
Xj нейронаj. Выражаясь более точно, будем rоворить о "среднем" как о "термальном
среднем", поскольку синаптический шум обычно моделируется в терминах термаль
ных флуктуаций. В любом случае обозначим символом <Xj> среднее значение Xj.
Состояние нейрона описывается следующим вероятностным правилом:
Х. == { +1, с вероятностью Р(щ),
J 1, с вероятностью 1 Р(щ),
(11.67)
rде
1
Р(щ) == 1 + ехр( vз/Т) '
(11.68)
rдe т рабочая температура. Исходя из этоro, среднее <х j> для HeКOToporo задаННО20
значения индуцированноro локальноro поля v j можно записать следующим образом:
< Xj >== (+1)Р(щ) + ( 1)[1 Р(щ)] == 2P(Vj) 1 == tanh(Vj/2T),
(11.69)
rдe tanh( щ/2Т) rиперболический TaHreHC CBoero apryмeHTa. На рис. 11.8 показаны
два rpафика среднеrо значения <х j> относительно индуцированноrо локальноrо поля
Vз. Данная непрерывная кривая приведена для некоторой температуры Т, большей
нуля. Жирной линией по казан rpафик для предельноrо случая Т ==0. В последнем
случае выражение (11.69) принимает свою предельную форму:
< Xj > sgn(Vj)T О.
(11.70)
Это соответствует функции активации нейрона Мак Каллока Питца.
732 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
<Х?
V j
Рис. 11.8. rрафик термальноro cpeдHero
(Xj) относительно индуцированноro ло-
кальноrо поля Vj. Жирная линия COOTBeT
ствует обычному нейрону Мак Каллока
Питца
До сих пор основное внимание уделялось простейшему случаю обособленноro
стохастическоrо нейрона. В более общем случае стохастической машины, составлен
ной из множества таких нейронов, приходится сталкиваться с более сложной задачей.
Эта сложность про истекает из сочетания двух следующих факторов.
. Вероятность Р( щ) TOro, что нейрон j включен, является нелинейной функцией
индуцированноrо локальноrо поля V j.
. Индуцированное локальное поле vj представляет собой случайную переменную,
на которую оказывают стохастическое воздействие друrие нейроны, связанные со
входом данноrо.
Можно с уверенностью утверждать, что не существует математическоrо метода,
который можно использовать для точной оценки стохастическоro поведения нейро
на. Однако существуют приближения, известные как аппроксимации средне20 поля
(mean field approximation), использование которых часто приводит к положительным
результатам. Основная идея, стоящая за аппроксимацией среднеrо поля, заключается
в замене фактической флуктуации индуцированноrо локальноro поля Vj каждоrо из
нейронов сети ее средним значением <vз>:
прибл. / "'"' )
vj == < vj >== \ L: WjiXi
== L Wji < Xi > .
(11.71)
Следовательно, можно вычислить среднее состояние <Xj> нейрона j, содержа
щеrося в стохастической машине среди N нейронов, так же, как это делалось в
выражении (11.69) для обособленноrо стохастическоrо нейрона:
11.11. Детерминированная машина Больцмана 733
< Х j > == tanh ( 2 vj ) пр бл. tanh ( 2 < vj > )
[аnh ( Wj; <Xj » . ([[.72)
В свете выражения (11.72) можно определить аппроксимацию среднеrо по
ля следующим образом.
Среднее некоторой функции случайной переменной аппроксимируется функцией cpeд
не20 значения этой случайной переменной.
Для j == 1,2, ..., N выражение (11.72) представляет множество нелинейных
уравнений с N неизвестными <Xj>' Решение этой системы нелинейных уравнений
является вполне посильной задачей, так как все неизвестные являются детерминиро
ванными, а не стохастическими переменными, какими они бьти в исходной сети.
11.11. Детерминированная машина Больцмана
Время обучения машины Больцмана экспоненциально зависит от количества нейро
нов, так как правило обучения Больцмана требует вычисления корреляций между
всеми парами нейронов сети. Таким образом, обучение Больцмана требует экспо
ненциальноrо времени. В [831] был предложен метод ускорения процесса обучения
Больцмана, в котором предлаrается заменить корреляцию в правиле обучения Больц
мана (11.53) следующей аппроксимацией среднеrо поля:
прибл.
< XjXi > == < Xj >< Xi >,
(i, j) == 1,2, . . . , К,
(11.73)
rде само среднее значение <х j> вычисляется с использованием уравнения среднеrо
поля (11.72).
Эта форма обучения Больцмана, в которой вычисления корреляций аппроксими
руются только что описанным способом, получила название детерминироваННО20
правила обучения Больцмана (deterministic Bo1tzmann learning rule). В частности, CTaH
дартное правило обучения Больцмана (11.53) аппроксимируется следующим образом:
ДWji == 11 (U/U i + Uj Uп,
(11.74)
rдe U j + и Uj усредненные выходы видимых нейронов j в фиксированном и CBO
бодном режимах соответственно, а 11 параметр скорости обучения. В то время как
машина Больцмана использует двоичные стохастичные нейроны, ее детерминирован
ный "родственник" использует аналоrичные детерминированные нейроны.
734 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Детерминированная машина Больцмана показала повышение скорости по cpaBHe
нию со стандартной машиной Больцмана на один два порядка [831]. Однако при ее
практическом использовании следует учесть следующее.
1. Детерминированное правило обучения Больцмана работает только с учителем.
Это значит, что отдельным видимым нейронам присваивается роль выходных
нейронов. Обучение без учителя не работает ни в одном режиме среднеrо поля,
так как среднее значение состояний является очень маломощным представлением
свободноro распределения вероятности.
2. При обучении с учителем использование детерминированноro правила обучения
Больцмана оrpаничено сетями только с одним скрытым слоем [332]. Теоретиче-
ски отсутствуют основания не помещать в такие сети несколько скрытых слоев.
Однако на практике использование нескольких скрытых слоев приводит к той же
проблеме, которая для обучения без учителя была упомянута в п. 1.
Детерминированное правило обучения Больцмана (11.74) имеет простую и ло
кальную форму, которая представляет ero отличным кандидатом на внедрение в VLSI
устройства (very large scale integration) [19], [942].
11.12. Детерминированные сиrмоидальные
сети доверия
Сущность метода аппроксимации среднеrо поля, описанноro в разделе 11.1 О, COCTO
ит В том, что среднее некоторой функции случайной переменной аппроксимируется
этой же функцией от среднеrо значения случайной переменной. Эта точка зрения
теории среднеrо поля имеет оrpаниченное применение для аппроксимации машины
Больцмана, что уже было показано в предыдущем разделе. В настоящем разделе мы
рассмотрим друryю точку зрения теории среднеro поля, которая лучше Bcero подходит
для аппроксимации сиrмоидальных сетей доверия. Покажем, что нетрактуемая мо-
дель аппроксимируется трактуемой с помощью вариационноrо принципа [524], [936].
rрубо roворя, трактуемая модель характеризуется изменением числа степеней свобо-
ды, что делает исходную модель нетрактуемой. Это нарушение связей происходит за
счет расширения нетрактуемой модели для включения дополнительных параметров,
известных под названием вариационных (variationa1 parameters), которые предназна
чены для адаптации решаемой задачи. Терминолоrия, используемая в этом подходе,
уходит своими корнями в вариационное исчисление (calculus ofvariations) [814].
11.12. Детерминированные сиrмоидальные сети доверия 735
Нижняя rраница функции лоrарифмическоrо правдоподобия
в начале обсуждения напомним вероятностное соотношение (11.58), которое воспро
изведем здесь в лоrарифмическом виде:
log Р(Х а == ха) == log L Р(Х == х).
X
(11.75)
Как и в разделе 11.8, разобьем случайный вектор Х на Ха И X , соответствующие
видимым и скрытым нейронам. Реализации этих случайных векторов обозначим х,
ха и X . Заметим, что с лоrарифмом суммы вероятностей (11.75) сложно работать.
Эту сложность можно обойти, заметив, что для любоrо условноrо распределения
Q(X ==x IXa ==Х а ) равенство (11.75) можно переписать в новом эквивалентном виде:
[ P == ]
log Р(Х а == Ха) == log Q(X == x IXa == Ха) Q( I ) . (11.76)
X x Ха Ха
X
Это равенство сформулировано для применения неравенства Йенсена (Jensen's
inequa1ity), о котором уже roворилось в предыдущей rлаве. Используя ero для данноro
случая, получим:
[ p == ]
log Р(Х а == Ха) Q(X == x IXa == Ха) log Q( I ) .
X x Ха Ха
X
(11.77)
Исходя из терминолоrии теории среднеro поля, назовем приближенное распреде
ление Q(X ==чlХа ==х а ) распределением средне20 поля (mean field distribution).
В данном случае нас интересует формула функции лоrарифмическоro правдоподо
бия. В сиrмоидальных сетях доверия функция лоrарифмическоrо правдоподобия L(w)
определяется суммированием по всем Ха (определенным на множестве примеров Т).
Поэтому для обучения сети применяется пакетный алrоритм. Для аппроксимации
среднеro поля сиrмоидальной сети доверия будем использовать друrую стратеrию.
Попытаемся адаптировать последовательный режим, в котором функция лоrарифми
ческоrо правдоподобия вычисляется после подачи в сеть каждО20 примера:
L(w) == log Р(Ха == Ха),
(11.78)
rдe w вектор весов сети. В случае идентично и независимо распределенных данных
реальная функция лоrарифмическоrо правдоподобия L(w) представляет собой сумму
слаrаемых L(w) по одному для каждой точки данных. В этой ситуации определения
L(w) и L(w) эквивалентны. В общем же случае использование L(w) предоставляет
аппроксимацию функции L(w).
l
736 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Последовательный подход (реальноro времени) к обучению стал стандартом для
нейронных сетей в основном блаroдаря простоте своей реализации. В свете (11.78)
можно записать:
'" [ Р(Х == х) ]
L(w) Q(X == чlХа == Ха) log Q( !Х ) ,
X x а Ха
X
или, эквивалентно:
L(w) L Q(X == x IXa == Ха) log Q(X == x IXa == Ха)
X
+ L Q(X == x IXa == Ха) log Р(Х == х).
X
(11.79)
Первое слаrаемое в правой части (11.79) представляет собой энтропию распреде
ления среднеrо поля Q(X ==x IXa ==ха). Не следует путать ero с условной энтро
пией! Второе слаrаемое представляет собой среднее лоrарифма log P(X x) по всем
возможным состояниям скрьrrых нейронов. При единичной температуре (см. рассуж
дения о распределении rиббса в разделе 11.2) энерrия сиrмоидальной сети доверия
равна log Р(Х == х). Таким образом, с учетом (11.61) при Т == 1, получим:
Р(Х х) 1} (Х! WjiX)
Следовательно,
Е == log Р(Х == х) == L log <р ( Xj .l:.: WjiXi ) .
J '<)
(11.80)
Используя определение сиrмоидальной функции
1
<p(v) == 1 + ехр( v)
exp(v)
1 + exp(v)'
функцию энерrии сиrмоидальной сети доверия можно формально выразить следую
щим образом:
Е == L WjiXiXj + L log ( 1 + Xj .l:.: WjiXi ) .
, з,з<' J '<)
(11.81)
11.12. Детерминированные сиrмоидальные сети доверия 737
За исключением множителя 1/2, в первом слarаемом правой части (11.81) мож
но узнать функцию энерrии Марковской системы (например, машины Больцмана).
Однако второе слаrаемое уникально только для сиrмоидальных сетей доверия.
Нижняя rpаница (11.79) подходит для любоro распределения среднеrо поля
Q(X ==x IXa ==х а ). Однако для удобства использования необходимо выбрать Ta
кое распределение, которое позволит оценить эту rpаницу. Для этоro используем
факториальное распределение (factorial distribution) [936]:
Q(X IX ) П Xj (l ) l Xj
x а Ха Jlj Jlj ,
JEH
(11.82)
rдe Н множество всех скрытых нейронов, а состояния скрытых нейронов представ
ляют собой независимые переменные Бернулли (ВеmоиШ variable) с корректируемым
средним Jlj' (ВеmоиШ (8) определяется как двоичная случайная переменная, прини
мающая значение 1 с вероятностью 8.) Исходя из этоro, подставляя (11.82) в (11.79),
после упрощения получим:
L(w) L:: [Jlj log Jlj + (1 Jlj) log(l Jlj)]+
JEH
+ 2.= . .WjiJliJlj L:: /log [ 1 + ехр ( 2: WjiXi ) ] ) ,
, ЗЕН,,<) ЗЕН \ «з
(11'.83)
rдe под <.> подразумевается среднее по множеству распределение среднеro по
ля, а выражение j Е Н означает принадлежность данноrо нейрона к скрытому
слою. Первое слаrаемое в правой части (11.83) является энтропией среднеro поля,
а второе энерrией среднеro поля. Оба эти слаrаемые относятся к факториально
му распределению (11.82).
К сожалению, остается одна нерешенная проблема: невозможно вычислить
точное среднее формы (log[l + exp(zj)])' Это слаrаемое содержится в (11.83)
с учетом подстановки
Zj == L WjiXi'
i<j
(11.84)
Чтобы обойти эту сложность, снова обратимся к неравенству Йенсена. Преж
де Bcero, для любой переменной Zj и произвольноro действительноro числа j
(log[l + exp(zj)]) можно выразить в отличной, но эквивалентной форме:
< log(l + e Zj ) > == < log[e jZj e jZj (1 + e Zj )] >==
== j < Zj > + < log[e jZj + e(l j)zj] >,
(11.85)
l
1
738 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
rдe <Zj> среднее по множеству значение Zj' Теперь применим неравенство Йенсена
в друroй форме. Оrpаничивая сверху среднее в правой части (11.85), получим:
1 < log(l + e Zj ) >::; j < Zj > + log < e jZj + e(l j)zj > .
(11.86)
Присваивая j значение нуль, получим соотношение
< log(l + e Zj ) >::; log < 1 + e Zj > .
При меняя ненулевое значение j' можно оrpаничить среднее <log[1+exp(zj)]>
более точно, чем это возможно при стандартном оrpаничении [965]. Это будет про
демонстрировано на следующем примере.
Пример 11.3
Переменная С rayccOBbIM распределением
Для демонстрации полезности оrpаничения (11.86) рассмотрим пример переменной с raycco
вым распределением, нулевым средним и единичной дисперсией. Для этоro частноro случая точ
ным значением <log[1+exp(Zj )]> является 0,806. Оrpаничение, описываемое (11.86), принимает вид
eo.5 2 + eO.5(1 2). Оно досrnrает CBOero минимальноro значения 0,818 при ==0,5. Это значение
roраздо ближе к истииному значению, чем значение 0,974, полученное из cTaMaPТHoro оrpаничения
при ==0 [936]. .
Возвращаясь к рассматриваемому вопросу, подставляя (11.85) и (11.86) в (11.83),
получим нижнюю rpаницу лоrарифмическоro правдоподобия события Ха ==Х а в сле
дующем виде:
L(w) L[ j log j + (1 j) log(l j)] + L L Wji i( j j)
jEH jEH i<j,i<j
L log (ехр( jZj) + ехр((l j)Zj)),
jEH
(11.87)
rдe само Zj определяется выражением (11.84). Это выражение и является искомым
оrpаничением функции лоrарифмическоro правдоподобия L(w), вычисляемой в по-
следовательном режиме алrоритма.
Процедура обучения для аппроксимации среднеrо поля
сиrмоидальной сети доверия
При выводе оrpаничения (11.87) было введено множество вариационных пapaмem
ров: j для j Е Н и j для всех j без определения их в явном виде. Эти параметры
являются настраиваемыми. Так как основной целью является максимизация функции
лоrарифмическоrо правдоподобия, естественно осуществлять поиск таких значений
11.12. Детерминированные сиrмоидальные сети доверия 739
Jlj и j' которые максимизируют выражение в правой части (11.87). для достижения
этой цели будем использовать двухшаrовую итеративную процедуру, которая описа
на в [936].
Сначала рассмотрим ситуацию, в которой среднее значение Jlj фиксировано, а тpe
буется найти такие параметры j' которые обеспечивают самое близкое к реальному
оrpаничение функции лоrарифмическоro правдоподобия L(w). Следует заметить, что
выражение в правой части (11.87) не объединяет слаrаемые с j' которые относятся к
разным нейронам сети. Исходя из этоro, минимизация выражения по j сводится к N
независимым операциям минимизации на интервале [0,1], rдe N общее количество
нейронов в сети.
Теперь рассмотрим ситуацию, в которой значения j фиксированы, а требует
ся найти такое среднее значение Jlj' которое обеспечивает самое точное оrpани
чение функции лоrарифмическоro подобия L(w). С этой целью введем следую
щее определение:
д
K ji == aJli log (ехр( jZj) + ехр( (1 j)Zj)) , (11.88)
rдe случайная переменная Zj определяется выражением (11.84). Частная про из водная
K ji является мерой влияния родительскоrо состояния Xi нейрона i на состояние Xj
нейрона j для данноro примера Ха Е Т. Как и в случае с синаптическими весами сиr
моидальных сетей доверия, K ji будут иметь ненулевое значение только в том случае,
коrда состояние Xi является родительским по отношению к состоянию Xj. Используя
факториальное распределение (11.82), можно оценить среднее по множеству величин
ехр( jZj) и ехр((l j)Zj), а затем частную производную K ji (формула дЛЯ BЫ
числения последнеrо приведена в табл. 11.3). Имея значение K ji , можно продолжить
решение задачи вычисления параметра Jlj' максимизирующеro функцию лоrарифми
ческоrо правдоподобия L(w) для фиксированноro j' В частности, дифференцируя
(11.87) по Jlj' приравнивая результат к нулю и переставляя слаrаемые, получим:
log ( 1 j . ) == L [WjiJli + Щj(Jl i i) + K ij ].
JlJ i<j
Эквивалеmно, можно записать:
j (f..1 [Wj' ' + Щj ( , 1;.) + K'j]) , j Е Н,
(11.89)
rдe <р(.) сиrмоидальная функция. Равенство (11.89) называется уравнением средне20
поля (mean field equation) для сиrмоидальной сети доверия. ApryмeHT сиrмоидальной
функции в этом уравнении образует так называемое покрытuе Маркова (Markov
blanket), характеризуемое следующим образом.
1
!
740
rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Родители
нейронаj
ПОТОМКИ
нейронаj
Рис. 11.9. Покрытие Маркова
· Родители и потомки нейрона j представлены слаrаемыми WjiJ..l.j и WijJ..l.i соответ-
ственно.
· Друrие родители потомков нейрона J учитываются через частную производ
ную K ij .
Покрытие Маркова нейрона j показано на рис. 11.9. Понятие "покрытия Мар-
кова" бьто введено в [821]. В этой работе утверждалось, что эффективный вход
нейрона j составлен из слаrаемых, относящихся к ero родителям, потомкам и роди
телям последних.
Если выполняется условие TOro, что выбор факториальноrо распределения (11.82)
в качестве аппроксимации апостеРИОРН020 распределения P(X ==x IX a ==Х а ) не
точен, уравнение среднеrо поля (11.89) устанавливает параметры {J..I.j} jEH в такие
оптимальные значения, которые делают аппроксимацию насколько возможно точной.
Это, в свою очередь, приводит к точному оrpаничению среднеro поля функции лоrа-
рифмическоro правдоподобия L(w), вычисляемой в последовательном режиме [936].
После вычисления скорректированных значений параметров { j} и {J..I.j} перехо-
дим к вычислению коррекции синаптических весов Wji по следующей формуле:
aB(w)
ДWji == 11 д '
W"
З'
(11.90)
rдe 11 параметр скорости обучения; B(w) нижняя rpаница функции лоrарифми
ческоro правдоподобия L(w), Т.е. B(w) выражение в правой части формулы (11.83).
Используя эту формулу, несложно вычислить и частные производные aB(w)/дW ji .
Процесс обучения для приближения среднеro поля к сиrмоидальной сети доверия
представлен в табл. 11.3. В этой таблице содержатся формулы для оценки частных
производных K ji и aB(W)/aWji'
11.12. Детерминированные сиrмоидальные сети доверия 741
ТАБЛИЦА 11.3. Процедура обучения для приближения cpeAHero поля к сиrмои
дальной сети доверия
Инициализация. Сеть инициализируется присвоением весам W ji сети случайных
значений, равномерно распределенных в интервале [ a, а], rдe в качестве а обыч
но выбирают число 0.5
Вычисления. Для примера Ха, выбранноro из множества обучения Т, выполняем
следующие вычисления
1. Коррекция { j} при фиксированных {flj}
Фиксируем средние значения {flj} jEH, относящиеся к факториальному при
ближению апостериорноro распределения P(X ==x IXa ==Ха), и миними
зируем следующую rpаницу функции лоrарифмическоrо правдоподобия:
B(w) == L[flj log flj + (1 fl j ) 10g(1 flj)] + L L Wjifliflj ==
jEH i jEH,i<j
== L L Wjifli j L log(exp( jZj) + ехр((l j)Zj)),
i jEH,i<j jEH
rдe Zj == L: WjiXi'
i<j
Минимизация B(w) сводится к N независимым операциям минимизации
на инrервале [О, 1]
2. Коррекция {flj} при фиксированных { j}
Фиксируя значения параметров { j}' повторяем уравнения среднеrо поля:
1'-; q> ( IW;;J!' + Щ;(I'-. 1;.) + K"I) ,
rдe
д
K ji == д 10g(exp( jZj) + ехр((l j)Zj)) ==
fli
(1 e j )(l exp( ,Wji)) e j (l ехр((l ,)Wji))
== J + з ,
1 fli + fli ехр( jWji) 1 fli + fli ехр((l j)Wji)
(ехр((l j)Zj)
e j ==
(ехр( jZj) + ехр( (1 j )Zj) ,
Zj == L WjiXi'
i<j
Функция <р(') является сиrмоидальной: <p(v) == Hex ( v)
3. Коррекция синаптическux весов
Для скорректированныхпараметров {flj} и { j} вычисляем коррекции ДWji
синаптических весов W ji:
{jB(w)
ДWji == 11 д '
Wji
1
742 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Окончание табл. 11.3
rдe 11 параметр скорости обучения,
дВ(w) ( !: ) (1 e j ) jfli ехр( jWji))
",' fl'fl'+
дWji J З' 1 fli + fli ехр( jWji)
e j (l j)fli(l ехр((l j)Wji))
1 fli + fl i ехр((l j)Wji)
rдe e j уже определено выше. Теперь корректируем синаптические веса:
Wji +---- Wji + ДWji
4. Цикл по всему множеству примеров Т
Проводим все операции 1 3 для всех примеров, содержащихся в обучающем
множестве Т, таким образом максимизируя их правдоподобие за фиксиро
ванное число итераций, или до тех пор, пока не обнаружатся признаки
чрезмерноro соответствия (overfitting) с использованием, к примеру, пере-
крестной проверки
11.13. Детерминированный отжиr
Теперь можно перейти к завершающему вопросу настоящей rлавы, касающемуся
детерминированноrо отжиrа. В разделе 11.5 рассматривался метод моделирования
отжиrа прием стохастическоro ослабления, реализующий мощный метод решения
невыпуклых задач оптимизации. Однако в них при выборе расписания отжиrа следу
ет соблюдать осторожность. В частности, rлобальный минимум достиrается только
в том случае, Korдa снижение температуры происходит не быстрее лоrарифмической
функции. Это требование делает моделирование отжиrа непрактичным для примене
ния в большинстве приложений. При моделировании отжиrа производятся случайные
перемещения по поверхности энерrии. В противоположность этому в детерминиро-
ванном отжи2е (deterministic annealing) в саму функцию стоимости или энерrию
внедряется не которая форма случайности, которая затем детерминировано оптими-
зируется на последовательности понижающихся температур [895], [898]. Не следует
путать детерминированный отжиr с отжи20М средне20 поля (последний термин ино
rда используется для ссьmки на детерминированную машину Больцмана).
В последующих разделах описывается идея детерминированноrо отжиrа в кон-
тексте одной из задач обучения без учителя кластеризации 11.
11 Детерминированный отжиr успешно применялся во мноrих задачах обучения.
Векторное квантование [737], [897].
Построение статистическоro классификатора [734].
Нелинейная реrpессия, использующая смесь экспертов [870].
Скрытые модели Маркова в задачах распознавания речи [871].
11.13. Детерминированный отжиr 743
Кластеризация посредством детерминированноrо отжиrа
Кластеризация (clustering) это деление заданноro множества точек данных на под
rpуппы, каждая из которых, насколько это возможно, roMoreHHa. Обычно кластери
зация представляет собой невыпуклую задачу оптимизации, так как практически все
функции искажения, используемые в кластеризации, представляют собой невыпук
лые функции входных данных. Более тoro, rpафик функции искажения относительно
данных наполнен локальными минимумами, что делает задачу поиска rлобальноro
минимума еще более сложной.
В [895], [896] описана вероятностная среда кластеризации с помощью paHдOMи
зации разбиения (randomization of partition), или рандомизации правила кодирования
(randomization of the encoding rule). rлавный используемый здесь принцип заключа
ется в том, что каждая точка данных ассоциирована по вероятности (associated in
probability) с некоторым кластером (подrpуппой). Для примера пусть случайный BeK
тор Х обозначает (входной) вектор источника, а случайный вектор У наилучший
восстановленный вектор из соответствующей кодовой книrи. Отдельные реализации
этих двух векторов обозначим соответственно символами х и у.
для кластеризации требуется некоторая мера искажения (distortion measure), KOTO
рую обозначим как d(x, у). Предполаrается, что эта мера d(x, у) должна удовлетворять
двум требованиям: быть выпуклой функцией apryмeHTa у для всех х и быть конеч
ной для конечноro apryMeHTa. Этим мяrким требованиям удовлетворяет, к примеру,
квадратичная Евклидова мера искажения:
d(x,y) == Ilx y112.
(11.91)
Ожидаемое искажение (expected distortion) случайных образов определяется по
следующей формуле:
D == L L Р(Х == х, У == y)d(x, у) ==
х у
== LP(X == х) LP(Y == ylX == x)d(x,y),
(11.92)
х
у
rдe Р(Х == х, У == у) совместная вероятность событий Х == х и У == у. Во второй
строке (11.92) использована формула совместной вероятности событий:
Р(Х == х, У == у) == Р(У == ylX == х)Р(Х == х).
(11.93)
Скрытая модель Маркова (hidden Markov mode1) аналоrична цепи Маркова в том, что в обоих случаях
переход из одноro состояния в дpyroe носит вероятностный характер. Однако оии отличаются друr от дpyra в
фундаментальном смысле. В цепи Маркова выходной результат детерминироваи. В скрытых моделях Маркова
выходной результат вероятностный, при этом общий результат может находиться в любом из возможных cocтo
яний. Таким образом, имея все состояиия скрытой модели Маркова, получаем распределение вероятностн всех
выходных символов. Скрытые модели Маркова рассматриваются в [514], [865], [866].
744
rлава 11. Стохастические машиныи их аппроксимациив статистической механике
1
!
i
Условная вероятностьР(У == ylX == х) называется ассоциативной вероятно
стью (association probability), Т.е. вероятностью ассоциирования кодовоro вектора у
со входным вектором х.
Ожидаемое искажение D обычно минимизируется по свободным параметрам
кластеризуемой модели: восстановленному вектору у и ассоциативной вероятности
Р(У == ylX == х). Эта форма минимизации дает на выходе "жесткое" решение за
дачи кластеризации. Здесь под жесткостью подразумевается то, что входной вектор
х назначается ближайшему кодовому вектору у. С друroй стороны, при детермини
рованном отжиrе задача оптимизации формулируется иначе: как поиск TaKoro рас-
пределения вероятности, которое минимизирует ожидаемое искажение при заданном
уровне случайности (specified lеуеl of randomness). В качестве меры уровня случай-
ности будем использовать энтропию Шеннона (см. раздел 10.4):
Н(Х, У) == L L Р(Х == х, У == у) log Р(Х == х, У == у).
х у
(11.94)
Torдa условная оптимизация ожидаемоro искажения выражается как минимизация
Лаrpанжиана:
F == D ТН,
(11.95)
rдe т множитель Лarpанжа. Из выражения (11.95) вытекает следующее.
· При больших значениях Т энтропия Н максимизируется.
· При малых значениях Т минимизируется ожидаемое искажение D, что приводит
К жесткой (неслучайной) кластеризации.
· При средних значениях Т минимизация F приводит к балансу между повышением
энтропии Н и уменьшением ожидаемоrо искажения D.
И, что более важно, сравнивая (11.95) с (11.11), можно выявить соответствие
между задачей условной оптимизации (кластеризации) и статистической меха-
никой (табл. 11.4). В соответствии с этой аналоrией величину Т будем назы-
вать температурой.
Теперь рассмотрим Лаrpанжиан F. Обратите внимание на то, что совместная
энтропия Н(Х, У) может быть разложена в сумму двух слаrаемых:
Н(Х, У) == Н(Х) + H(YIX),
rдe Н(Х) энтропия источника; H(YIX) условная энтропия вектора восстанов-
ления У для данноro вектора источника Х. Энтропия источника не зависит от кла
11.13. Детерминированный отжиr 745
ТАБЛИЦА 11.4. Соответствие между условной кластеризацией
и статистической физикой
Условная оптимизация кластеризации
Лаrpанжиан F
Ожидаемое искажение D
Энтропия Шеннона Н
Множитель Лаrpанжа Т
Статистическая физика
Свободная энерrия F
Средняя энерrия <Е>
Энтропия Н
Температура Т
стеризации. Следовательно, ее можно исключить из определения Лаrpанжиана F и
сфокусировать внимание на условной энтропии
Н(Х, У) == L Р(Х == х) L Р(У == ylX == х) log Р(У == ylX == х).
х у
(11.96)
в этом выражении ясно видна роль ассоциативной вероятности P(Y yIX x). По
этому, помня о соответствии между задачами условной оптимизации кластеризации
и статистической физикой и применяя принцип минимума свободной энерrии (см.
раздел 11.2), обнаруживаем, что минимизация Лаrpанжиана F по отношению к acco
циативным вероятностям приводит к распределению rиббса:
1 ( d(X,y) )
Р(У == ylX == х) == Zx ехр '
(11.97)
rдe Zx функция разбиения нашей задачи. Ее можно определить следую
щим образом:
Z "" ( d(X,y) )
x exp .
у
(11.98)
Коrда температура Т стремится к бесконечности, ассоциативная вероятность дости
raeT paBHoMepHoro распределения (см. (11.97». Использование этоro утверждения
заключается в том, что при достаточно высоких температурах любой входной вектор
равно ассоциирован со всеми кластерами. Такая ассоциация может рассматриваться
как "предельно нечеткая". В друroм предельном случае, коrда температура Т достиrа
ет нуля, ассоциативная вероятность превращается в дельта функцию. Следовательно,
при очень низких температурах классификация сильно усложняется и с вероятностью
1 каждый входной вектор назначается ближайшему вектору кодирования.
Для TOro чтобы найти минимальное значение Лаrpанжиана F, подставим распре
деление rиббса (11.97) в (11.92) и (11.96) и полученное выражение используем в фор
муле Лаrpанжиана F (11.95). Результат будет иметь следующий вид (см. задачу 11.22):
l'
!
746 rлава 11. Стохастические машиныи их аппроксимациив статистической механике I
F* == min F == T L Р(Х == х) log Zx.
p(Y yIX x)
х
(11.99)
Для тoro чтобы минимизировать Лаrpанжиан по оставшимся свободным парамет
рам (т.е. по вектору кодирования у), приравняем rpадиент F* по у к нулю и получим
следующее уравнение:
д
L Р(Х == х, У == у) ду d(x, у) == о для всех у Е У,
х
(11.100)
rдe У множество всех векторов кодирования. Используя формулу (11.93) и HOp
мализуя выражение по Р(Х == х), можно переопределить условие минимизации
следующим образом:
1 д
N L Р(Х == xlY == у) ду d(x, у) == о для всех у Е У,
х
(11.101)
rде ассоциативная вероятность P(Y==yIX==x) определяется из распределения rиббса
(11.97). В выражение (11.101) множитель lIN включен исключительно из соображе-
ний последовательности изложения. Здесь N количество доступных примеров.
Теперь можно описать алrоритм детерминированноrо отжиrа для кластеризации
[895]. Алrоритм состоит из минимизации Лаrpанжиана F* по векторам кодирования
при достаточно высокой температуре и тщательным подбором точки минимума при
постепенном понижении температуры. Друrими словами, детерминированный отжиr
работает со специфичным расписанием, в котором температура понижается УПОРЯДО
ченно. При каждом из значений температуры Т выполняются два шarа, составляющие
итерацию алrоритма.
1. Векторы кодирования фиксируются, и для определенной меры искажения d(x, у)
используется распределение rиббса с целью вычисления ассоциативных вероят
ностей.
2. Ассоциации фиксируются, и выражение (11.101) используется для оптимизации
меры искажения d(x, у) по векторам кодирования у.
В этой двухшаroвой итеративной процедуре функция монотонно не возрастает по
F* , что rарантирует сходимость к минимуму. При высоких значениях температуры Т
Лаrpанжиан F* достаточно rладок и является выпуклой функцией у (при выполнении
мяrких допущений относительно меры искажения d(x, у), сделанных ранее). rлобаль
ный минимум Лаrpанжиана F* может быть найден при высоких температурах. По
мере понижения температуры Т ассоциативные вероятности становятся жесткими,
что приводит к жесткому решению задачи кластеризации.
11.13. Детерминированный отжиr 747
При понижении температуры Т в процессе выполнения расписания отжиrа систе
ма проходит через последовательность фазовых переходов, состоящих из ecтeCTBeH
ных разбиений кластеров. При этом размер модели кластеризации увеличивается
(т.е. увеличивается количество кластеров) [896], [898]. Это явление имеет важное
значение по следующим причинам.
. Оно реализует удобный механизм управления размером модели кластеризации.
. При обычном физическом отжиrе фазовые переходы являются критическими точ
ками (critica1 point) детерминированноro процесса отжиrа, в которых отжиry долж
но уделяться большое внимание.
. Критические точки являются вычисляемыми (computable), и эта информация может
использоваться для ускорения алroритма между фазовыми переходами.
. С помощью проведения процедуры проверки с последовательностью решений,
полученных на различных фазах (являющихся решениями задачи при различных
размерах модели), можно получить модель оптималЬН020 размера (optimum model
size).
Пример 11.4
На рис. 11.1 О, 11.11 показана эволюция кластерноro решения, использующеro детерминиро
ванный отжиr на различных фазах по мере понижения температуры Т или увеличении обратной
величины В == 1/Т [896]. Множество данных, использованных для rенерации этих рисунков, COCTO
ЯЛО из шести множеств с rауссовыми распределениями. Их центры на рисунке отмечены крести
ками. Центры вычисленных кластеров на рисунке отмечены кружочками. Так как решения задачи
кластеризации при ненулевых температурах не являются жесткими, для получаемых контуров при
надлежности к кластеру использовалась одинаковая вероятность (в данном случае 1/3). Весь
процесс начинается с одноro eCTecTBeHHoro кластера, содержащеrо все множество обучения (см.
рис. 11.10, а). При первом фазовом переходе он разделяется на два кластера (см. рис. 11.10,6), после
чеro происходит еще несколько фазовых переходов, пока не достиrается естественное количество
кластеров шесть. Последующий фазовый переход инициирует "взрыв", при котором все кластеры
разбиваются. На рис. 11.11 показана фазовая диarpамма, отображающая значения среднеro иска
жения во время процесс а отжиrа, и количество естественных кластеров на каждой фазе. На этом
рисунке среднее искажение (нормализованное по отношению к своему минимальному значению)
отображается по отношению к величине, обратной температуре (т.е. В), также нормализованной
по отношению к своему минимальному значению. На обеих осях использовался соответствующий
лоrарифмический масштаб. .
748 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Аналоrия с алrоритмом ЕМ
Чтобы описать еще один важный аспект алroритма детерминированноrо отжиrа, pac
смотрим ассоциативную вероятность Р(У == ylX == х) как ожидаемое значение
двоичной случайной переменной V xyo определенной следующим образом:
== { 1, если входной вектор х назначен вектору кодирования у,
у о в противном случае.
(11.102)
Исходя из этоro, заметим, что двухшаroвая итерация алrоритма детерминиро
BaHHoro отжиrа принимает форму алroритма ожидания максимизации (expectation
maximization ЕМ) (см. rлаву 7) оценки максимальноro правдоподобия. В частности,
первый шаr, на котором вычисляются ассоциативные вероятности, является эквива
лентом шаrа ожидания. Второй шаr, на котором минимизируется Лаrpанжиан Р*,
является эквивалентом шаrа максимизации.
Воспользовавшись такой аналоrией, заметим, что детерминированный отжиr яв
ляется более общим алrоритмом, чем оценка максимальноrо правдоподобия. Это
можно утверждать, поскольку, в отличие от оценки максимальноrо правдоподобия,
детерминированный отжиr не налаrает никаких требований на вид рассматриваемоro
распределения данных, минимизируются ассоциативные вероятности, производные
от Лаrpанжиана F*.
11.14. Резюме и обсуждение
Эта rлава посвящена использованию идей статистической механики в качестве Ma
тематическоro базиса формулировки методов оптимизации для обучаемых машин.
Рассмотренные обучаемые машины можно разбить на две катеroрии.
. Стохастические машины, рассмотренные на примерах машины Больцмана, сиr
моидальных сетей доверия и машины rельмrольца.
· Детерминированные машины, полученные на основе машин Больцмана и сиrмои
дальных сетей доверия с помощью введения аппроксимаций среднеrо поля.
Машина Больцмана использует скрытые и видимые нейроны, представляющие собой
стохастические двоичные элементы. Они учитывают прекрасные свойства распреде
ления rиббса, предлаrая, таким образом, следующие привлекательные особенности.
· Посредством обучения распределение вероятности, представляемое нейронами,
становится сходным с распределением вероятности среды.
· Эта сеть предлаrает обобщенный подход, применимый к основным вопросам по
иска, представления и обучения [457].
Рис. 11.10. Кластеризация на раз
личных фазах. Линии представляют
собой контуры равной вероятности
р 1/2 на рисунке (б) и р 1/3 на
всех остальных: 1 кластер (8=0) (а);
2 кластера (8=0,0049) (б); 3 кластера
(8=0,0056) (в); 4 кластера (8=0,0100)
(r); 5 кластеров (8=0,0156) (д); 6 кла
стеров (8=0,0347) (е); 19 кластеров
(8=0,0605) (ж)
11.14. Резюме и обсуждение 749
.'
.: ..:; of :"
...:;-/ :::'
"..: :oi<: 00.
.. .:::
::;: \ '., ". .
..\ . . :.: ::
0"0 " ' :I..
. : :.:.,,,' .
O:" .: ..:'.
......... ,..
. . .. .::. :..
.....I. ;..
" t..".
:' *.':;' . б)
".!;: .;.:.. :"
.....
.::: \/.'
00 .i..' , .......
.\ . ::'.
o\\ .C'.: .
. : .' " .
. ..I.(..
а)
".
. :.:....r:........
q. '\J,!.. .,'.
:. :i. .
: . .*:. ;.. .
....!;::;.;...... :'
'./ :...
о' .i..' , ;.: ... . .
' ' '_:. .
:. " :'..
.'.
. / ?/"
.-:-.t..,,:
. ...""'....,
. t, .'; .
".:;.-:.;..... :0
1
750 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
"
'е
л
v
.......
л
v
2 3 4
Log[B/B min 1
5
6
19
Рис. 11.11. Фазовая диаrрамма
для примера с несколькими
raуссовыми распределениями.
Количество эффективных кла
стеров показано для каждой
фазы
· Сеть rарантирует нахождение rлобальноro минимума на поверхности энерrии по
отношению к состояниям, при условии, что расписание отжиrа в процессе обуче
ния предполаrает достаточно медленное уменьшение температуры [343].
К сожалению, допустимое расписание отжиrа слишком медленно, чтобы иметь
KaKoe тo значимое практическое пр именение. Однако этот процесс обучения может
быть ускорен для особых классов машин Больцмана, для которых не требуется за
пускать алroритм квантования или применять аппроксимацию среднеrо поля. В част
ности, в машинах Больцмана, в которых cKpblThIe нейроны скомпонованы в цепочки,
дерево или цепочки деревьев, обучение может достиrать полиномиальноro времени.
Это достиrается с помощью одноro алroритма стохастической механики, известноrо
под названием прореж:ивания (decimation). Это простая и элеrантная процедура, кo
торая рекурсивно удаляет связи и узлы из rpафа, подобно решению цепи резисторно
индуктивной емкости (resistance inductance capacitance circuit RLC) [937], [938].
Сиrмоидальные сети доверия предлаrают существенное улучшение по cpaBHe
нию с машинами Больцмана, устраняя потребность в использовании отрицательной
фазы алroритма. Этоro они достиrают путем замены симметричных связей машины
Больцмана направленными ацикличными связями. В то время как машина Больцмана
является рекуррентной сетью с избытком обратных связей, сиrмоидальные сети дo
верия имеют мноroслойную архитектуру с отсутствием обратных связей. Как следует
из названия, сиrмоидальные сети доверия тесно связаны с классическими сетями дo
верия, введенными в [822], таким образом, связывая предметную область нейронных
сетей с областью вероятностных рассуждений и 2рафическux моделей (probabilistic
reasoning and graphical models) [523], [524].
11.14. Резюме и обсуждение 751
Машины rельмroльца представляют собой отдельный класс. Их создание бьmо
основано на том, что зрение является обратной rpафикой [461], [484]. В частно
сти, они используют стохастические порождающие модели, работающие в обратном
направлении, для преобразования абстрактных представлений изображений в сами
изображения. Сами абстрактные представления изображений (т.е. собственные зна
ния сети об окружающем мире) изучаются стохастической моделью распознавания,
работающей в прямом направлении. Посредством интеrpации моделей reнерации и
распознавания (т.е. прямой и обратной проекции) машины rельмroльца иrpают роль
самообучающейся машины, устраняя тем самым потребность в учителе.
Теперь рассмотрим класс детерминированных машин. Детерминированные Ma
шины Больцмана были получены из стохастических посредством применения про
стейшей формы аппроксимации среднеro поля, в которой корреляция между двумя
случайными переменными была заменена произведением их средних значений. Это
привело к тому, что детерминированная машина Больцмана стала HaMHoro быстрее
стандартной стохастической. К сожалению, на практике их использование оrpаничи
вается одним слоем скрытых нейронов. В [540] бьmо доказано, что при корректном
применении теории среднеro поля в машине Больцмана корреляция должна вычис
ляться с помощью теоремы линеЙН020 отклика (linear response theorem). Сущность
этой теоремы состоит в замене фиксированной и свободной корреляций вправиле
обучения Больцмана (11.53) их линейными аппроксимациями отклика (linear response
approximation). Соrласно этой работе, новую процедуру обучения можно применять
как к сетям со скрытыми нейронами, так и без них.
Детерминированная форма сиrмоидальных сетей доверия бьmа получена с по
мощью друroй формы теории среднеro поля, в которой строrая форма нижней rpa
ницы функции лоrарифмическоro правдоподобия была выведена с использованием
неравенства Йенсена. Более Toro, эта теория берет на вооружение принципиальные
достоинства трактуемой подструктуры, выводя этот класс нейронных сетей в разряд
важноrо дополнения к сетям доверия.
В этой rлаве также рассматриваются два приема оптимизации: моделирование OT
жиrа и детерминированный отжиr. Отличием метода моделирования отжиrа является
ero случайное блуждание по поверхности энерrии, что может сделать этот метод дo
статочно медленной процедурой, неприменимой в большинстве приложений. В про
тивоположность этому детерминированный отжиr включает случайность в функцию
стоимости, которая затем детерминированным образом оптимизируется, начиная с
высокой температуры, которая затем постепенно снижается. Однако следует заме
тить, что моделирование отжиrа rарантированно достиrает rлобальноro минимума, в
то время как это свойство для детерминированноrо отжиrа пока еще не доказано.
Несмотря на то что основное внимание в этой rлаве бьmо сосредоточено на Me
тодах оптимизации и стохастических машинах, предназначенных для решения задач
обучения без учителя, их можно также использовать по мере необходимости и для
задач обучения с учителем.
752 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Задачи
Цепи Маркова
11.1. Вероятность перехода за п шаroв из состояния i в состояние j обозначается
как p ;). Используя метод индукции, покажите, что
(1+n) '\:"' (n)
Pij PikPkj .
k
11.2. На рис. 11.12 показана диаrpамма перехода состояний для процесса случай-
ной пР02УЛКИ (random walk), в котором вероятность перехода Р больше нуля.
Будет ли бесконечно длинная цепь Маркова, показанная здесь, несократимой?
Обоснуйте ответ.
11.3. Рассмотрим цепь Маркова, показанную на рис. 11.13. Она несократима. Иден
тифицируйте классы состояний, содержащиеся на этой диаrpамме.
11.4. Вычислите вероятности устойчивых состояний цепи Маркова, показанной на
рис. 11.14.
Приемы моделирования
11.5. Алrоритм Метрополиса и квантователь rиббса представляют собой два аль-
тернативных подхода к моделированию крупных задач. Обсудите основные
сходства и различия между ними.
11.6. В этой задаче рассмотрим использование отжиrа для решения задачи KOММU
вояжера (travelling salesman problem). Дано:
· N roродов;
· расстояние между всеми парами rородов равно d;
. маршрут представляет собой замкнутый путь, содержащий в себе посе
щения всех rородов только по одному разу.
Целью является поиск TaKoro маршрута (т.е. последовательноro обхода
всех rородов), который имеет минимальную общую длину L. В этой зада-
че различные маршруты представляют собой конфиryрации, а минимизации
подлежит функция стоимости, которой является длина маршрута.
а) Разработайте итеративный метод rенерации допустимых конфиrypаций.
б) Общая длина маршрута определяется по формуле
N
Lp == L d p (i)P(i+1)'
i l
rдe Р перестановка с Р(п + l) P(I). Следовательно, функцией разби
ения будет следующая:
Задачи 753
р
р
р
р
Рис. 11.12. Диаrрамма перехода
состояний для процесса случай
ной проryлки
l p
l p
l p
l p
2
3
1
"3
1
2
Рис. 11.13. Несократимая цепь Маркова
1
4
1
4
3
4
Рис. 11.14. Еще один пример цепи
Маркова
3
4
z == Le LPIT, (11.103)
р
rдe т параметр управления. Выведите алroритм моделирования отжиrа
для описанной задачи коммивояжера.
.......
754 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Машина Больцмана
11.7. Рассмотрим стохастический нейрон j, который может принимать два co
стояния. Ero рабочей температурой является Т. Этот нейрон меняет СБое
состояние с Xj на Xj с вероятностью
1
P(Xj -----t Xj) == 1 + ехр( Ej/T) '
rдe Ej изменение энерrии, возникшее в результате такой смены состоя
ний. Общая энерrия машины Больцмана определяется следующей формулой:
1
Е == '\:"' '\:"'w"x,x,
2 З' , З'
i j,Цj
rде Wji синаптический вес, ведущий от нейрона i к нейрону j. В машине
Больцмана Wji == Wij И Wii == О.
а) Покажите, что
Ej == 2XjVj,
rдe Vj индуцированное локальное поле нейрона j.
б) Исходя из этоro, покажите, что для начальноro состояния Х j == 1 Беро
ятность перехода нейрона j в состояние +1 равна 1/(1 + ехр( 2Vj/T)).
в) Покажите, что формула в п. б сохраняется и для вероятности перехода
нейрона j из состояния 1 в состояние + 1.
11.8. Выведите формулу (11.49), которая определяет производную функции лоrа
рифмическоro правдоподобия L(w) по синаптическим весам Wji в машине
Больцмана.
11.9. Распределение rиббса может быть выведено с помощью полноценноro Ma
тематическоro подхода, не пола2ающе20СЯ на концепции статистической фи
зики. В частности, модель стохастической машины в виде двухша20вой цепи
Маркова может использоваться для формализации допущения, вытекающеro
из уникальных свойств машины Больцмана [710]. Это не будет неожиданно
стью, так как моделирование отжиrа, положенное в основу работы машины
Больцмана, само обладает свойством Маркова [1079].
Теперь рассмотрим модель перехода между состояниями нейронов в сто-
хастической машине, СОстоящей из двух случайных Процессов.
Задачи 755
. Первый процесс решает, какой переход состояния осуществить.
. Второй процесс решает, принять ли предложение перехода.
а) Выражая вероятность перехода Pji через произведение двух множителей,
Pji == Tjiqjij =1= i,
покажите, что
Р .. 1 "" 7,. . q ..
.. '3 '3'
#i
б) Предполаrается, что матрица интенсивности попыток симметрична, Т.е.
Tji == Tij'
Также предполаrается, что вероятность успешности попытки перехода
удовлетворяет свойству дополнения условной вероятности перехода:
qji == 1 Pij'
Принимая эти два предположения, покажите, что
"" T.. (q ..1t. + q ..1t. п. ) О
3' '3 3 '3' 3 .
j
в) для 1t =1=0 используйте результат п. а настоящей задачи, чтобы показать,
что
1
qij == 1 + (1ti/1tj)'
r) В заключение выполним замену переменных:
E i == T log 1ti + Т*,
rдe Т и Т* произвольные константы. Исходя из этоro, получите следу
ющий результат:
....
756 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
1 ( Ei )
1ti == Z ехр т '
Z == Lexp ( i ),
J
1
qji == 1 + ехр( E/T)'
rдe E == Ej E i
д) Какие выводы можно сделать из полученных результатов?
11.10. в разделе 11.7 принцип максимальноro правдоподобия использовался в каче
стве критерия для вывода правила обучения Больцмана (11.53). В этой задаче
вернемся к этому правилу обучения, но с использованием друroro критерия.
В rлаве 10 бьmа определена диверrенция Кулбека Лейблера между двумя
распределениями вероятности p;i и р;; в следующем виде:
Dp+llp == LP;ilog ( p ) ,
а Ра
rдe суммирование выполняется по всем возможным состояниям а. Символ p
обозначает вероятность Toro, что видимые нейроны сети находятся в состо-
янии а в то время, Korдa сеть находится в фиксированном (положительном)
состоянии. Символ Р;; обозначает вероятность Toro, что те же нейроны се-
ти находятся в состоянии а в то время, Korдa сеть находится в свободном
(отрицательном) состоянии. С помощью Dp+llp выведите правило обучения
Больцмана.
11.11. Рассмотрим машину Больцмана, видимые нейроны которой делятся на вход-
ные и выходные. Состояния этих нейронов обозначим символами а и у cooт
ветственно. Состояния скрытых нейронов обозначим символом . Диверreн-
ция Кулбека Лейблера для этой машины определяется следующей формулой:
Dp+llp == LP;i LP alog ( P a ) ,
а у P'YIa
rдe p;i вероятность состояния а во всех входных нейронах; P a услов-
ная вероятность TOro, что выходные нейроны зафиксированы в состоянии
а, если входным состоянием является а; Р;а условная вероятность то-
ro, что выходные нейроны находятся в состоянии термальноro равновесия
Задачи 757
'У, при условии, что только входные нейроны находятся в состоянии а. Как
и раньше, верхние индексы "плюс" и "минус" обозначают соответственно
положительную (фиксированную) и отрицательную ( свободную) фазы.
а) Выведите формулу для Dp+llp для машины Больцмана, имеющей BXOД
ные, скрытые и выходные нейроны.
б) Покажите, что правило обучения Больцмана для коррекции синаптических
весов Wji в этой конфиrypации сети будет выражаться той же формулой,
которая описана выражением (11.53), но с новой интерпретацией обозна
+
чении Pji и Pji'
Сиrмоидальные сети доверия
11.12. Обобщите сходства и различия между машиной Больцмана и сиrмоидальны
ми сетями доверия.
11.13. В задаче 11.9 показано, что машина Больцмана описывается моделью ДBYX
шаrовой цепи Маркова. Допускает ли сиrмоидальная сеть доверия описание
моделью цепи Маркова?
11.14. Пусть W}i синаmический вес, идущий от нейрона i к нейрону j в сиr
моидальной сети доверия, использующей для включенноrо и выключенноro
состояний нейронов значения + 1 и 1 соответственно. Обозначим W ji COOT
ветствующие синаптические веса в сиrмоидальной сети доверия, использую
щей друrие значения для состояний + 1 и О соответственно. Покажите, что
веса Wji MOryT преобразовать в W}i с помощью следующеro преобразования:
I Wji О
W ji 2 при < i < j,
I 1 '\:"'
w jo == WjO +"2 Wji'
O<i<j
В последней строке присутствует пороr, примененный к нейрону j.
11.15. В сиrмоидальных сетях доверия вероятность P(XI3 ==чl Ха ==Х а ) определяет
ся как распределение rиббса, а вероятность Р(Х а ==Х а ) как соответствую
щая функция разбиения. Обоснуйте справедливость этих двух определений.
Машина rельмrольца
11.16. Машина rельмrольца не содержит обратных связей как в моделИ распозна
вания, так и в порождающей модели. Что случится, если разрешить исполь
зование обратной связи в какой либо из двух этих моделей.
Il1IIIIO..
758 rлава 11. Стохастические машиныи их аппроксимациив статистической механике
Детерминированная машина Больцмана
11.17. Машина Больцмана выполняет rpадиентный спуск (в пространстве весов) ПО
пространству вероятностей (см. задачу 11.1 О). По какой функции детермини
рованная машина Больцмана выполняет свой rpадиентный спуск? Для ответа
на этот вопрос можно обратиться к [458].
11.18. Рассмотрим асимметричную рекуррентную сеть (в которой W ji i= Щj)' Обсу-
дите, как детерминированный алrоритм обучения Больцмана сможет сделать
сеть симметричной, предполаrая, что после каждой коррекции каждый из
весов приближается к нулю на малую величину, пропорциональную ero aм
плитуде [458].
Детерминированная сиrмоидальная сеть доверия
11.19. Покажите, что разность между выражениями в левой и правой ча-
стях (11.77) равна диверrенции Кулбека Лейблера между распределениями
Q(X ==x IXa ==Ха) и P(X ==X IXa ==х а ).
11.20. ApryMeHT сиrмоидальной функции (11.89) определяет индуцированное ло-
кальное поле Vj нейрона j в детерминированной сиrмоидальной сети ДOBe
рия. Чем это V j отличается от соответствующеrо индуцированноro локально
ro поля нейрона в мноrослойном персептроне, обучаемом с помощью алrо-
ритма обратноro распространения?
Детерминированный отжиr
11.21. В разделе 11.13 мы рассмотрели идею детерминированноrо отжиrа, использу
ющеrо информационно теоретический подход. Эта идея детерминированноrо
отжиrа моrла быть разработана также и с использованием принципа макси
мальной энтропии, описанноro в rлаве 10. Проверьте разумность BTOpOro
подхода.
11.22. а) Используя выражения (11.97) и (11.98), получите результат, описанный
выражением (11.99), в котором определен Лаrpанжиан F*, полученный с
помощью использования распределения rиббса для ассоциативной Bepo
ятности.
б) Используя результат первой части этой задачи, выведите условие (11.101)
для минимума F* по отношению к вектору кодирования у.
в) Примените условие минимизации (11.1 О 1) к мере квадратичноrо искаже-
ния (11.91) и прокомментируйте полученный результат.
Задачи 759
11.23. Рассмотрите множество данных, представляющее собой смесь rауссовских
распределений. Какие преимущества в такой ситуации может предложить
детерминированный отжиr по сравнению с оценкой максимальноro правдо
подобия?
11.24. В этой задаче исследуем использование детерминированноro отжиrа в зада
че классификации, решаемой нейронной сетью [734]. Выход нейрона j на
выходном слое мы обозначим как Fj(x), rде х входной вектор. Решение
задачи классификации основывается на максимизации дискриминанта Fj(X).
а) В качестве целевой функции рассмотрим следующую:
1
F == N L LP(x Е Rj)Fj(x),
(х,С)ЕТ j
rдe т множество обучения, состоящее из маркированных векторов; х
входной вектор; С ero метка класса; Р(х Е Rj) вероятность ac
социации между входным вектором х и классом Rj. Используя принцип
максимума энтропии (см. rлаву 1 О), сформулируйте распределение rиббса
для Р(х Е Rj).
б) Обозначим как <Ре> среднюю стоимость ошибки классификации. Bы
ведите формулу Лаrpанжиана для минимизации <Ре>, при условии, что
энтропия, соответствующая ассоциативным вероятностям P(XER j ), равна
некоторой константе Н.
.....
Нейродинамическое
проrраммирование
12.1. Введение
в шаве 2 были определены две основные парадиrмы обучения с учителем и без
учителя. Вторая парадиrма, в свою очередь, подразделяется на самоорrанизующееся
обучение и обучение с подкреплением. Различные формы обучения с учителем рас-
сматривались в шавах 4 7; а виды обучения без учителя в шавах 8 11. В этой шаве
речь пойдет об обучении с подкреплением (reinforcement 1earning).
Обучение с учителем представляет собой задачу "познания" под руководством
учителя. Оно предполаrает доступность адекваТНоrо множества примеров пар вход-
ных и выходных сиrналов. В противоположность этому обучение с подкреплением
является "поведенческой" задачей. Оно выполняется посредством взаимодействия
обучаемой системы и среды, в которой система стремится достичь заданной цели,
невзирая на наличие неопределенности [100], [1036]. Тот факт, что это обучение осу-
ществляется без учителя, делает обучение с подкреплением особенно привлекатель-
ным для динамических ситуаций, rде сбор удовлетворительноrо множества примеров
дороr или сложен (если вообще возможен).
Существуют два подхода к обучению с подкреплением 1 .
1. Классический подход (c1assica1 approach), в котором обучение осуществляется ме-
тодом "кнута и пряника" в процессе чередующихся поощрений и наказаний с
целью достижения высококлаССНО20 поведения (highly ski11ed behavior).
1 Классический подход к обучению с подкреплением уходит корнями в психолоrию, а точнее, к ранним
работам Торндайка [1052] (посвященным обучению животных) и Павлова [821] (посвящеиным условному ре-
флексу). Вклад в развитие обучения с подкреплением также внесла работа, в которой было введено понятие
критики (critic) [1140]. Классический подход к обучению с подкреплением рассматривается в [415].
rлавный вклад в современный подход к обучению с подкреплением внесли работы, посвященные про-
rpaMMe иrpы в шашки [926], посвященные системам адаптивной критики [100], методам времеиных разностей
[1032] и Q-обучению [1115]. В справочнике по интеллектуальному управлению [1130] представлены материалы
по оптимальному управлению, обучению с подкреплением и методам адаптивной критики и эвристическому
динамическому проrpаммированию.
Целиком посвящена современному подходу к обучению с подкреплением [126], а история развития этоro
вида обучения отслежена в [1036].
12.1. Введение 761
2. Современный подход (modern approach), который основан на математическом
приеме динамическоzо проzра.м.мирования (dynamica1 programming), используе-
мом для формирования последовательности действий с учетом возможных бу-
дущих стадий без фактическоro их осуществления. В этом подходе акцент дела-
ется на планирование.
В настоящей шаве внимание читателя будет сконцентрировано на современном
обучении с подкреплением.
Динамическое пpozpa.м.мupOBaHue 2 представляет собой поэтапный метод принятия
решений. Причем перед принятием следующеro решения последствия текущеro ре-
шения предсказываются на некоторый интервал будущеro. Ключевым аспектом таких
ситуаций является то, что решения не Moryт приниматься изолированно. Стремле-
ние к снижению затрат в настоящем приводится в соответствие снежелательным
увеличением затрат в будущем. Это называется задачей присваивания коэффициен-
тов доверия (credit assignment problem), так как каждому решению из множества
взаимосвязанных решений либо оmускается кредит доверия, либо оно отверrается.
Для оптимальноro планирования необходимо обеспечить эффективный баланс меж-
ду текущими и будущими затратами. Достижение TaKoro баланса формализует метод
динамическоro проrpаммирования. В частности, динамическое проrpаммирование
позволяет ответить на следующий вопрос: как система может быть обучена для по-
вышения производительности на длительном промежутке времени, если это может
потребовать кpaTKoBpeMeHHoro снижения производительности?
Следуя [126], современный подход к обучению с подкреплением будем называть
нейродинамическим пpozpa.м.мupOBaHUeм (neurodynamic programming). для Taкoro вы-
бора есть две причины.
· Теоретической основой этоro подхода является метод динамическоro проrpамми-
рования.
· Обучение выполняется на нейронных сетях.
Краткое определение нейродинамическоro проrpаммирования бьто предложе-
но в [126].
Нейродинамическое пpozpaммupOBaHue позволяет системе обучаться принятию пра-
вильных решений с помощью наблюдения за собственным поведением и совершен-
ствовать свое поведение путем использования встроенноzо механизма усиления.
Наблюдение за поведением осуществляется с помощью метода моделиро-
вания Монте-Карло, реализуемоrо в автономном режиме. Улучшение поведе-
ния посредством подкрепления достиrается за счет использования итератив-
ной схемы оптимизации.
2 Методика динамическоro проrpаммирования была разработана БeJШманом в конце 1950-х roдов [118],
[119]. Детальное описание этой области содержится в [125].
762 rлава 12. Нейродинамическое проrраммирование
Структура rлавы
Динамическое проrpаммирование включает две составляющие: рассматриваемую ди-
намическую систему, функционирующую в дискретном времени, и функцию стоимо-
сти (cost), аддитивную по времени. Эти две составляющие рассматриваются в разде-
ле 12.2. В разделе 12.3 последует формулировка уравнения оптимальности Беллмана
(Bellman's optimality equation), которое иrpает важную роль в динамическом проrpам-
мировании. В разделах 12.4 и 12.5 рассматриваются два метода расчета оптимальной
стратеrии в динамическом проrpаммировании итерации по стратеrиям и итерации
по значениям.
В разделе 12.6 представлен обзор вопросов, связанных с нейродинамическим
проrpаммированием. Рассмотрение этих вопросов приводит К изучению приближен-
ной стратеrии (approximate police iteration) и Q-обучения, в которых для аппрокси-
мации функций применяются нейронные сети. Эти два алroритма описываются в
разделах 12.7 и 12.8. В разделе 12.9 будет проведено компьютерное моделирова-
ние Q-обучения.
Завершает шаву раздел 12.10, содержащий выводы и рассуждения.
12.2. Марковский процесс принятия решений
Рассмотрим обучаемую систему (learning system) (или (agent», которая взаимо-
действует с внешней средой способом, показанным на рис. 12.1, в соответ-
ствии с конечным Марковским процессом принят ия решений в дискретном вре-
мени (finite, discrete-time Markovian decision process). Этот процесс характеризует-
ся следующими особенностями.
· Внешняя среда развивается на основе вероятностных законов, принимая конечное
множество дискретных состояний. Однако заметим, что эти состояния не учи-
тывают прошлых статистик, даже если они моши бы быть полезны обучаемой
системе.
· В каждом состоянии существует конечное множество возможных действий, кото-
рые может предпринять обучаемая система.
· При выполнении обучаемой системой какоro-либо действия взимается определен-
ная плата (стоимость действия).
· Наблюдаемые состояния, совершаемые действия и стоимость действия изменяют-
ся в дискретном времени.
В контексте нашей дискуссии состояние (state) внешней среды определяется как
совокупность Bcezo опыта, накопленноzо обучаемой системой в процессе взаимодей-
ствия с внешней средой, включающеzо информацию, необходимую для предсказаllUЯ
12.2. Марковский процесс принятия решений 763
Рис. 12.1. Блочная диаrрамма взаимодействия обучаемой
системы со средой
обучаемой системой будуще20 поведения внешней среды. Случайной переменной Х п
обозначим состояние внешней среды на шarе дискретноro времени n, а перемен-
ной х( n) фактическое состояние на шаrе n. Все конечное множество состояний
обозначим символом Х. Неожиданной характерной чертой динамическоro проrpам
мирования является то, что оно практически не зависит от природы состояний. Поэто-
му можно продолжать рассуждения, не делая никаких предположений относительно
структуры пространства состояний.
для HeKoToporo состояния i доступное множество действий (т.е. воздействий, при-
меняемых обучаемой системой к внешней среде) обозначим A=={aik}, rдe второй ин-
декс, k, в обозначении aik указывает на то, что при нахождении системы в состоянии
i возможно совершение более ОДНоrо действия в отношении внешней среды. На-
пример, переход внешней среды из состояния i в состояние j при воздействии aik
сам вероятностен по своей природе. Однако вероятность перехода из состоянияi
в состояние j целиком зависит от текуще20 состояния и предпринимае.мО20 дeй
ствияаik. Это свойство Маркова (Markov property), о котором речь шла в шаве 11.
Это свойство критично, так как оно означает, что текущее состояние среды несет
в себе всю информацию, необходимую обучаемой системе для принятия решения
относительно совершаемоro действия.
Случайную переменную, обозначающую действие, предпринимаемое обучаемой
системой в момент времени n, обозначим Аn. Пусть Pij(a) обозначает вероятность
перехода системы из состояния i в состояние j в ответ на действие, предпринятое на
шarе n, rде Аn == а. Из свойства Маркова имеем:
Pij(a) == Р(Х n +1 == jjX n == i, Аn == а).
(12.1 )
Вероятность перехода Pij (а) удовлетворяет двум основообразующим условиям
теории вероятности:
Pij(a) о для всех i и j,
I:Pij(a) == 1 для всех i.
j
(12.2)
(12.3)
764 rлава 12. Нейродинамическое проrраммирование
Для заданноrо количества состояний и заданных вероятностей перехода последо-
вательность состояний внешней среды, возникающих в результате выполнения дей-
ствий обучаемой системой, формирует цепь Маркова (Markov chain) (см. шаву 11).
При каждом переходе из одноro состояния в друroе с обучаемой системы взи-
мается некоторая плата (cost), или стоимость. Более конкретно, при n M переходе
из состояния i в состояние j под воздействием aik с обучаемой системы взимает-
ся стоимость, обозначаемая yng(i, aik, Л, rдe g(.,.,.) наперед заданная функция;
у скаляр из интервала [О, 1), называемый дисконтирующим множителем (discoиnt
factor). Подстраивая этот множитель, можно управлять окрестностью, которую обу-
чаемая система принимает в расчет при принятии решений. Эта величина определяет
отношение долroвременной окрестности к кратковременной. В пределе, при у = О,
система является "близорукой", Т.е. может обозревать только непосредственные след-
ствия своих действий. В дальнейших рассуждениях будем иrнорировать это предель-
ное значение, Т.е. сократим область определения у до открытоrо интервала (0,1).
Если У достиrает значения единицы, будущие затраты становятся более важными в
процессе определения оптимальноro действия.
Интерес представляет формулировка cmpamezuu (policy), которая определяется как
отображение состояний в действия. Друrими словами, стратеrия является правилом,
используемым обучаемой системой для принятия решения относительно Toro, какое
действие предпринять, на основании знаний о текущем состоянии внешней среды.
Стратеrия обозначается следующим образом:
1t == {/lo, /ll' /l2'" .}, (12.4)
rде /ln функция отображения состояния Х N == i в действие Аn == а в момент
времени n ==0, 1,2, ... . Это отображение таково, что
/ln (i) Е A i для всех состояний i Е Х,
rдe A i множество всех возможных действий, предпринимаемых обучаемой систе-
мой в состоянии i. Такие cmpamezuu называются допустимыми (admissible).
Стратеrия может быть стационарной инестационарной. Нестационарная (nоn-
stationary) стратеrия зависит от времени (см. (12.4». Если стратеrия от време-
ни не зависит, Т.е.
1t == {/l, /l, /l,...},
она называется стационарной (stationary). Друrими словами, стационарная стратеrия
при каждом посещении HeKoTOporo состояния определяет одно и то же действие. Для
стационарной cmpamezuu рассматриваемая цепь Маркова может быть как стационар-
12.2. Марковский процесс принятия решений 765
ной, так и нет (хотя это не очень умное решение). Если применяется стратеrия /l,
то последовательность состояний {Х n , n == О, 1,2, . . .} формирует цепь Маркова с
вероятностями переходов Pij (/l( i)), rде /l( i) обозначает некоторое действие. По этой
причине данный процесс получил название MapKOBCKOZO процесса принят ия решений
(Markov decision process).
Постановка задачи
Задача динамическоro проrpаммирования может иметь конечный и бесконечный zopu-
зонт (finite & infinite horizon). В задачах с конечным roризонтом затраты накаплива-
ются за конечное число шаroв, в задачах с бесконечным roризонтом за бесконечное.
Задачи с бесконечным roризонтом представляют собой хорошее приближение задач,
содержащих конечное, но очень большое количество шаroв. Они представляют опре-
деленный интерес также из за тoro, что дисконты rарантируют конечность затрат
всех состояний для любой cmpamezuu.
Общие ожидаемые затраты в задачах с бесконечным roризонтом, начинающихся
с HeKoToporo состояния Ха == i и использующих стратеrию 1t =={/ln}, определяются
по формуле
?( i) Е [t, i' у(Х., n (Х n ), Х n +') IX o i] ,
(12.5)
rде ожидаемое значение вычисляется по цепи Маркова {X 1 , Х 2 ,...}. Функция
J1C(i) называется функцией стоимости перехода (cosHo go function) для страте-
zuu п, начинающейся с состояния i. Ее оптимальное значение J* (i) определяет-
ся следующим образом:
J*(i) == min j1t(i).
7t
(12.6)
Если стратеrия 1t стационарна, Т.е. 1t =={/l, /l, . .. }, вместо обозначения J7t(i) ис-
пользуют JIL(i) и roворят, что стратеrия /l является оптимальной, если
JIL( i) == J* (i) для всех начальных состояний i.
(12.7)
Теперь можно подытожить постановку задачи динамическоro проrpаммирования
следующим образом.
Для данноzо стационарноzо Марковскоzо процесса, описывающеzо взаимодействие
обучаемой системы и внешней среды, найти стационарную сmрате2UЮ 1t ==
{/l, /l, /l, . . .}, которая минuмuзирует функцию стоимости перехода JIL( i) для всех
начальных состояний i.
""""'"
766 rлава 12. Нейродинамическое проrраммирование
Обратите внимание, что во время обучения поведение обучаемой системы может
изменяться во времени. Однако оптимальная стратеrия, искомая обучаемой системой,
будет стационарной [1115].
12.3. Критерий оптимальности Беллмана
Метод динамическоrо проrpаммирования основан на очень простой идее, извест-
ной под названием принципа оптимальности Беллмана (principle of optimality) [118].
В упрощенном виде этот принцип утверждает следующее [119].
Оптимальная стратеzия имеет следующее свойство: какими бы ни были началыlеe
состояние и начальное решение, остальные решения должны составлять оптималь--
ную стратеzuю по отношению к состоянию, вытекающему из первоzо решения.
Здесь под термином "решение" понимается один из вариантов управления в КОН-
кретный момент времени, а под термином "стратеrия" вся управляющая последо
вательность или функция.
для TOro чтобы сформулировать принцип оптимальности в математических Tep
минах, рассмотрим задачу с конечным roризонтом, для которой функция стоимости
перехода имеет следующий вид:
[ к l ]
Jo(X o ) == Е 9К(Х К ) + 9n(Xn,lln(Xn),Xn+l) ,
(12.8)
rде К zоризонт (horizon) (т.е. количество шаroв); 9К(Х К ) терминаль-
ная стоимость (terminal cost). Для данноrо ХО математическое ожидание (12.8)
формулируется относительно оставшихся состояний X 1 , ..., XK l' С помощью
этой терминолоrии можно формально определить принцип оптимальности Беллма-
на в следующем виде [125].
Пусть п* == {1l0' Il , . . . ,11 к l} оптимальная стратеzия для задачи с конеЧIIЫМ
zоризонтом. Предполаzается, что при использовании оптимальной стратеzии п* за-
данное состояние Х N наступает с ненулевой вероятностью. Рассмотрим подзадачу,
в которой система в момент времени n находится в состоянии Х n, и предположим,
что необходимо минимизировать соответствующую функцию стоимости перехода
[ K l ]
Jn(X n ) == Е 9К(Х К ) + 9k(X k , Ilk(X k )' X k + 1 )
(12.9)
для n == О, 1, . . . , к 1. Тоzда усеченная стратеzия {Il , Il +l' . . . ,11 к l} будет
оптимальной для этой подзадачи.
12.3. Критерий оптимальности Беллмана 767
Интуитивно можно понять истинность этоrо принципа оптимальности. Если бы
усеченная стратеrия {Il , Il + l' . . . , Il к l} не была оптимальной, то после достиже-
ния в момент времени n состояния Х N можно бьто бы уменьшить функцию стоимо-
сти перехода Jn(X n ), перейдя к стратеrии, оптимальной для данной подзадачи.
Приведенный подход к оптимальности основывается на инженерном принципе
"разделяй и властвуй". ПО существу, оптимальная стратеrия сложноro мноrоступенча-
TOro планирования или задачи управления строится сошасно следующей процедуре.
· Вначале строится оптимальная стратеrия для последней подзадачи, включающей
в себя только последнюю ступень системы.
· После этоro оптимизация расширяется на предыдущую ступень и строится опти-
мальное решение для последних двух ступеней системы.
· Так продолжается до тех пор, пока вся система не будет охвачена оптималь-
ным решением.
Алrоритм динамическоrо проrраммирования
На основе описанной процедуры можно сформулировать алrоритм динамическоro
проrpаммирования, который реализуется в обратном времени, от N 1 дО О. Пусть
1t == {Ill , 1l2' . . . , Il к l} обозначает некоторую допустимую стратеrию. Для каждоro
n ==0, 1, . . ., К 1 обозначим п n == {Il n , Iln+l' . . . , IlK l}' Пусть J (Х n ) определя
ет оптимальные затраты на (К n)-м шаrе задачи, который начинается в момент
времени n с состояния Х N И завершается в момент времени К, Т.е.
[ K l ]
J (Xn) == n (Xn+l, XK l) 9К(Х К ) + 9k(X k , Ilk(X k )' X k + 1 )
(12.10)
Это выражение представляет собой оптимальную форму (12.9). Зная, что п n ==
(Il n ,1t n +1), и частично раскрывая сумму в правой части выражения (12.10), можно
записать следующее:
J (Xn) == min Е [9n(Х n , Iln(Xn), X n + 1 ) + 9К(Х К )+
(J.L n ,1t n + 1 ) (Xn+l,...,XK l)
+ ' ' .9k(Xk, I'k(X k ), Xk+')]
== min Е {9n(X n ,ll n (X n ),X n +1) + (12.11)
J.L n Хn+l
+ n,:jn (х.+,..Б.Хк ,) [9 К (Х к) + , /' (X k , '" (X k ), XkH)] }
== min Е [9n(Х n , Iln(Xn), X n + 1 ) + J +l(Xn+1)] ,
J.L n Xn+l
768 rлава 12. Нейродинамическое проrраммирование
rде в последней строке используется определение (12.10), в котором вместо n под-
ставлено n + 1. Теперь предположим, что для HeKoToporo n и всех Х n +1
J +1 (X n + 1 ) == J n + 1 (Х n +1)'
(12.12)
Torдa выражение (12.11) можно переписать в следующем виде:
J (Xn) == min Е [gn(Xn,Jln(X n ),X n + 1 ) + Jn+1(X n + 1 )].
Il n Хn+l
(12.13)
Если соотношение (12.12) выполняется для всех X n + 1 , то равенство
J (Xn) == Jn(X n )
также выполняется для всех ХN' Следовательно, из (12.13) можно заключить, что
Jn(X n ) == min Е [gn(X n , Jln(X n ), X n + 1 ) + J n + 1 (X n +1)]'
Il n Хn+l
Таким образом, можно формально записать алrоритм динамическоro проrpамми-
рования в следующем виде [125].
Для любоzо исходноzо состояния ХО оптимальное значение функции стоимости
J*(X o ) равно Jo(X o ), zде функция J o вычисляется начиная с последнею шаzа еле-
дующеzо алzоритма:
Jn(X n ) == min Е [gn(X n , Jln(X n ), X n + 1 ) + J n +1 (Х n +1)] ,
Il n Хn+l
(12.14)
который "перемещается" по оси времени в обратном направлении, при этом
JK(X K ) == gK(X K ),
Более mozo, если значение Jl минимизирует правую часть (12.14) для всех Х N u N,
д * { * * * } -
moz а стратеzuя 1t Jlo, Jll , . . . , Jl к 1 является оптимальнои.
Уравнение оптимальности Беллмана
Основная форма алroритма динамическоro проrpаммирования связана с решением
задачи с конечным roризонтом. Однако этот алrоритм можно расширить для решения
задач с бесконечным rоризонтом, которые описываются функцией стоимости (12.5)
при стационарной стратеrии 1t == {Jl, Jl, Jl, . . .}. для достижения этой цели нам нужно
сделать следующее.
12.3. Критерий оптимальности Беллмана 769
· Изменить индекс времени в алroритме так, чтобы он соответствовал задаче.
· Определить стоимость gn(X n , Il(X n ), Х nН ) как
gn(X n , Il(X n ), Х nН ) == i'g(X n , Il(X n ), Х nН ).
(12.15)
Теперь алroритм динамическоrо проrpаммирования можно переформулировать в
следующем виде (см. задачу 12.4):
JnH(X O ) == min Е [g(Xo, Il(X o ), X 1 ) + у Jn(X 1 )].
J.L Х,
(12.16)
Этот алrоритм начинается с исходноro условия
Jo(X) == о для всех Х.
Итак, алrоритм начинается с HeKoToporo исходноrо состояния ХО; новое состояние
X 1 получается в результате применения стратеrии Il, а У в (2.15) представляет собой
дисконтный множитель.
Пусть J*(i) означает оптимальную стоимость в задаче с бесконечным roризон-
том и начальным состоянием ХО == i. Torдa J* (i) можно рассматривать как предел
соответствующей оптимальной стоимости JK(i) на K M шаrе при К, стремящем-
ся к бесконечности:
J*(i) == lim JK(i) для всех i.
К...... 00
(12.17)
Это соотношение является связующим звеном между дисконтированными задача-
ми с конечным и бесконечным roризонтами. Принимая n + 1 == К и Х о == i в (12.16),
а затем применяя (12.17), получим:
J*(i) == min Е [g(i, Il(i), X 1 ) + у J*(X 1 )] .
J.L Х,
(12.18)
Для оценки оптимальных затрат J* (i) в задаче с бесконечным roризонтом выпол
няются следующие действия.
1. Вычисляем математическое ожидание стоимости 9 (i, Il (i), Х 1) по Х 1 :
N
E[g(i), Il(i), X 1 ] == LPijg(i, Il(i),j),
j l
(12.19)
rде N количество состояний среды; Pij вероятность перехода из начальноro
состояния ХО == i в новое состояние X 1 == j. Величина, определяемая выражени
ем (12.19), называется М2Новенной ожидаемой стоимостью (immediate expected
770 rлава 12. Нейродинамическое проrраммирование
cost) в состоянии i, при выполнении действия, рекомендованноrо стратеrией Jl.
Обозначая эти затраты как c(i, fl(i)), можно записать, что
N
c(i,fl(i)) == LPijg(i,fl(i),j).
j=,l
(12.20)
2. Оцениваем ожидание J*(X 1 ) по отношению к X 1 . Отсюда можно заключить,
что в системе с конечным числом состояний, если известна стоимость перехода
J*(X 1 ) для всех состояний X 1 , можно наверняка определить ожидание J*(X 1 ) в
терминах вероятностей перехода соответствующей цепи Маркова, записав:
N
E[J*(X 1 )] == LPijJ*(j).
j=,l
(12.21)
Таким образом, подставляя выражения (12.19) (12.21) в (12.16), получим иско-
мый результат:
J'(i) n (C(i, l1(i)) + у t. P'j (11) J' и) ) , i 1,2,..., N.
(12.22)
Равенство (12.22) называется уравнением оптимальности Беллмана (Bellman's op
timality equation). Ero нельзя рассматривать как алroритм оно представляет собой
систему N уравнений, в которой для каждоro состояния отводится одна пере мен-
ная. Решение этой системы уравнений определяет оптимальные значения функции
стоимости перехода (cost-to go function) для всех N состояний внешней среды.
Существуют два основных метода вычисления оптимальной стратеrии: ите-
рация по стратеrиям и итерация по значениям. Эти два метода описываются
в разделах 12.4 и 12.5.
12.4. Итерация по стратеrиям
Чтобы подrотовить основу для описания алroритма итерации по стратеrиям, вве-
дем понятие Q-фактора [1115]. Рассмотрим существующую стратеrию fl, для кото-
рой функция стоимости перехода )1-1-( i) известна для всех состояний i. Q факmор
(Q-factor) каждой пары состояния i Е Х и действия а Е A i определяется как мсно-
венная стоимость плюс сумма дисконтированных стоимостей всех последующих
состояний СО2Ласно стратесии fl, Т.е.
n
Q (i, а) == с( i, а) + 'у L Pij (a)J (j),
j=,l
(12.23)
12.4. Итерация по стратеrиям 771
rдe действие а == Il(i). Заметим, что Q факторы QI!(i,a) содержат больше инфор-
мации, чем функция стоимости перехода JI!(i). Например, действия можно упоря-
дочить только на основании Q-фактора, в то время как упорядочивание на OCHO
ве функции стоимости перехода требует знания вероятностей и стоимости перехо
да между состояниями.
Для более rлубокоro изучения Q фактора рассмотрим новую систему, состояния
которой образованы на основе исходных состояний 1, 2, . . ., N и всех возможных
пар (i, а) (рис. 12.2). Здесь возможны две ситуации.
· Система находится в состоянии (i, а), в котором не предпринимается никаких дей-
ствий. Переход автоматически выполняется в состояние j с вероятностью, скажем,
Pij(a), при этом автоматически вычисляется стоимость g(i, а, Л.
· Система находится, к примеру, в состоянии i, в котором предпринимается действие
а Е A i . Следующее состояние предопределено как (i, а).
Стратеrия 11 называется жадной (greedy) по отношению к функции стоимости
перехода JI!( i), если для всех состояний Il( i) представляет собой действие, удовле
творяющее следующему условию:
QI!( i, Il( i)) == min QI!( i, а) для всех .
аЕА;
(12.24)
Здесь важно обратить внимание на следующие моменты.
· в некоторых состояниях возможно несколько действий, которые минимизируют
множество Q-факторов. В этом случае может существовать более одной жадной
стратеrии по отношению к соответствующей функции стоимости перехода.
· Некоторая стратеrия может оказаться жадной по отношению к нескольким различ-
ным функциям стоимости перехода.
Более Toro, следующий факт является основой всех методов динамическоrо про
rpаммирования:
QI!* (i, 11*( i)) == min QI!* (i, а),
аЕА;
(12.25)
rдe 11 * оптимальная стратеrия; J* соответствующая функция стоимости перехода.
Имея в распоряжении понятия Q фактора и жадной стратеrии, можно описать ал-
zоритм итерации по стратеzиям (policy iteration algorithm). Этот алroритм включает
следующие шаrи [125].
1. Шaz вычисления стратеzии (po1icy evaluation step), на котором определяются
функция стоимости перехода для некоторой текущей стратеrии и соответству-
ющий Q фактор.
.,.
772 rлава 12. Нейродинамическое проrраммирование
k
Рис. 12.2. Два возможных перехода: переход
из состояния (i, а) в состояние j является веро-
ятностным, а переход из состояния i в состоя-
ние (i, а) является детерминистским
Стоимость
перехода
JP
Коррекция
стратеrии
Оценка
стратеrии
Рис. 12.3. Блочная диаrрамма алrоритма итерации по
стратеrиям
2. Шаz улучшения cmpamezuu (policy improvement step), в котором текущая cтpaтe
rия корректируется и становится жадной по отношению к функции стоимости
перехода, полученной на шаrе 1.
Эти два шаrа показаны на рис. 12.3. для большей конкретизации начнем с неко-
торой исходной стратеrии 110' после чеro сreнерируем последовательность новых
стратеrий 111,112,' .. . Для данной стратеrии Iln реализуем шаr вычисления стратеrии,
получив функцию стоимости перехода Jl!n (i) в качестве решения линейной системы
уравнений (12.22):
N
Jl!n (i) == с( i, Iln( i)) + у I:>ij (Iln)Jl!n (Л, i == 1, 2, '" , N
j l
(12.26)
относительно неизвестных Jl!n(l), Jl!n(2), ..., Jl!n(N). Используя получен-
ные результаты, можно вычислить Q-фактор для пары состояние действие
(i, а ) (см. (12.23»:
n
Ql!n (i, а) == c(i, а) + у I:>ij(a)Jl!n(j), а Е A i И i == 1,2,... , N.
j l
(12.27)
Далее выполняем шаr улучшения стратеrии, вычисляя новую стратеrию Iln+1 сле
дующим образом (см. (12.24»:
Iln+1 (i) == arg min Ql!n(i, а), i == 1,2,..., N.
аЕА;
(12.28)
12.5. Итерация по значениям 773
ТАБЛИЦА 12.1. Алroритм итерации по стратеrиям
1. Начинаем с произвольной исходной стратеrии 110'
2. Для n == О, 1,2, . . . вычисляем Р'n (i) и Ql!n (i, а) для всех состояний i Е Х
и действий а Е A i .
3. Для каждоro из состояний i вычисляем
I1n+1 (i) == arg min Ql!n (i, а).
аЕА;
4. Повторяем действия 2, 3, пока I1n+1 не пере станет улучшать I1n. В этой
точке алroритм останавливается, а I1n считается искомой стратеrией.
Затем описанный выше двухшаrовый процесс повторяется для стратеrии I1 n +1'
пока мы не получим
Jl!n+1 (i) == Jl!n (i) для всех i.
в этом случае алrоритм завершает работу со стратеrией I1n. Если Jl!n+l ::; Jl!n
(см. задачу 12.5), то можно сказать, что алrоритм итерации по стратеrиям завер-
шится после конечноrо количества итераций, так как соответствующий Марковский
процесс принятия решений (Markovian decision process) имеет конечное количество
состояний. В табл. 12.1 в сжатом виде представлен алrоритм итерации по стратеrиям,
основанный на выражениях (12.26) (12.28).
12.5. Итерация по значениям
в алrоритме итерации по стратеrиям функция стоимости перехода должна бьта зано-
во вычисляться на каждом шаrе алroритма. С точки зрения вычислений это слишком
затратный подход. Даже если функция стоимости перехода для новой стратеrии яв
ляется идентичной соответствующей функции для старой стратеrии, данные вычис
ления не уменьшаются. Однако существует друrой метод нахождения оптимальной
стратеrии, в котором обременительное действие постоянноrо вычисления функции
стоимости перехода отсутствует. Этот альтернативный метод, основанный на после-
довательных аппроксимациях, называется алroритмом итерации по значениям.
Алzоритм итерации по значениям (value iteration algorithm) подразумевает ре-
шение уравнения оптимальности Беллмана (12.22) для последовательности задач с
конечным roризонтом. При устремлении количества итераций алroритма к беско-
нечности функция стоимости перехода задачи с конечным rоризонтом равномерно
сходится по состояниям к соответствующей функции стоимости задачи с бесконеч-
ным rоризонтом [125], [905].
......
774 rлава 12. Нейродинамическое проrраммирование
Пусть Jn(i) функция стоимости перехода для состояния i на шаrе n алroритма
итерации по значениям. Этот алroритм начинается с произвольноro решения Jo(i)
для i == 1, 2, ..., N. Единственным оrpаничением, налаrаемым на J o ( i), является
ее оrpаниченность. Это условие автоматически выполняется в задачах с конечным
числом состояний. Если доступна некоторая оценка оптимальной функции стоимости
перехода J*(i), то ее можно использовать в качестве начальноrо значения Jo(i).
Как только выбрана функция Jo(i), можно вычислить последовательность функций
J 1 (i), J 2 (i), . . . , используя алrоритм итерации по значениям:
J n + 1 (i) == min { C(i, а) + у t Pij(a)Jn(j) } , i == 1,2,... , N. (12.29)
аЕА; .
з=1
Применение модификации функции стоимости перехода, описываемой выраже-
нием (12.29) для состояния i, называется резервированием затрат (backing up of
it's cost). Это резервирование является прямой реализацией уравнения оптимально-
сти Беллмана (12.22). Обратите внимание, что значения функции стоимости перехо-
да (12.29) для состояний i == 1, 2,. .., N резервируются одновременно на каждой
итерации алroритма. Этот метод реализации представляет собой традиционную СИII-
хронную форму алroритма итерации по значениям 3 . Таким образом, начиная с про-
извольных исходных значений J o (1), J o (2), ..., Jo(N), алroритм (12.29) сходится к
оптимальным значениям J*(1),J*(2), '" ,J*(N) при стремлении количества итера-
ций к бесконечности [125], [905].
В отличие от алroритма итерации по стратеrиям в алrоритме итерации по зна-
чениям оптимальная стратеrия не вычисляется напрямую. Вместо этоro сначала с
помощью (12.29) вычисляются оптимальные значения J*(1),J*(2), . . . ,J*(N). Затем
по этому оптимальному множеству вычисляется жадная стратеrия, Т.е.
Il*(i) == arg min Q*(i, а), i == 1,2,... , N, (12.30)
аЕА;
rдe
n
Q*(i, а) == c(i, а) + у L Pij(a)J*(j), i == 1,2,. " , N.
j=l
(12.31)
В табл. 12.2 приведено пошаrовое описание алroритма итерации по значе-
ниям, основанное на формулах (12.29) (12.31). В это описание включен крите-
рий останова алroритма.
3 Итерация по стратеrиям и итерация по значеииям два осиовных метода дииамическоro проrpаммиро,
ваиия. Существуют еще два метода дииамическоro проrpаммироваиия, которые иельзя ие упомяиуть, метод
rаусса Зейделя и асиихроииое дииамическое проrpаммироваиие [99], [125]. В методе rаусса Зейделя фуик,
ция стоимости перехода корректируется в каждый момеит времеии только для одиоro состояния; при этом
все остальные состояиия разворачиваются (sweep). Конкуреиция осиовывается иа самых последи их значеииях
состояиий. Асинхрониое дииамическое проrpаммироваиие отличается от метода rаусса Зейделя тем, что оио
ие орrанизовано в термииах систематических последовательных разверток множества состояиий.
12.5. Итерация по значениям 775
ТАБЛИЦА 12.2. Алrоритм итерации по значениям
1. Начинаем с произвольноrо начальноro значения Jo(i) для состояний i 1, 2,
...,N.
2. Для n == 0,1,2, . . . вычисляем
Jn+t(i) == min { C(i,a) +'Y'tPij(a)Jn(j) } , а Е A i , i == 1,2,... ,N.
аЕА; j l
Эти вычисления продолжаются, пока не выполнится следующее неравенство:
IJ n + 1 (i) Jn(i)1 < Е для всех состояний i,
rде Е некоторый наперед заданный параметр допуска. Для Toro чтобы функция
Jn(i) хорошо приближала оптимальную функцию стоимости перехода J*(i),
значение Е должно бьrrь достаточно малым. Таким образом, можно положить:
Jn(i) == J*(i) для всех состояний i.
3. Вычисляем Q-фактор:
n
Q*(i, а) == c(i, а) + 'У L Pij (a)J* (Л, а Е A i , i == 1,2,... , N.
j l
Torдa в качестве оптимальной можно выбрать жадную стратеrию дЛЯ J* (i):
Il*(i) == arg min Q*(i,a).
аЕА;
Пример 12.1
Задача дилижанса
для TOro чтобы ПРОИJШюстрировать полезность Q-фактора в динамическом проrpаммировании,
рассмотрим задачу дилижанса (stagecoach problem). В середине XIX века, коrда Калифорнию OXBa
тила золотая лихорадка, некий авантюрист отправляется на запад Америки [456]. Это путешествие
предполarает переезд на дилижансах по неосвоенным землям, rде велика опасность нападений бан-
дитов. Исходный пункт путешествия (Миссури) и пункт назначения (Калифорния) фиксированы,
однако предстонт выбор маршрута путешествия по восьми промежуточным штатам (рис. 12.4). На
этом рисунке показано следующее.
.Общее количество штатов (10); каждый штат представлен соответствующей буквой.
. Направление движения слева направо.
.В пути от исходноro штата А (Миссури) в штат назначения J (Калифорния) нужно сменить
четыре дилижанса.
.При перемещении из одноro штата в следующий путник может выбрать одно из следующих
направлений: вверх, прямо и вниз.
.Существует 18 возможных маршрутов перемещения из штата А в штат J.
На рис. 12.4 также по казаны затраты, связанные с соответствующими стратеrиями страхования
жизни при перемещении на определенных дилижансах, основанные на оценке риска подобной
поездки. Требуется найти маршрут из штата А в штат J с самой дешевой стратеrией страхования.
,...,.
776 rлава 12. Нейродинамическое проrраммирование
Рис. 12.4. rраф передачи сиrнала для задачи дилижанса
для TOro чтобы найти оптимальный маршрут, рассмотрим последовательность задач с конечным
roризонтом, начинающихся в конечной точке J и продвиrающихся в направлении, обратном направ-
лению маршрута. Это соответствует принципу оптимальности Беммана, описанному в разделе 12.3.
На рис. 12.5, а видно, что Q факторы для последнеro переезда к пункту назначения равны:
Q(H, вниз) 3,
Q(I, вверх)==4.
Эти числа на рис. 12.5, а можно увидеть над условным обозначением штатов Н и [.
Далее, перемешаясь на один шar назад и используя значения из рис. 12.5, а, находим следующие
Q-факторы:
Q(E, прямо) 1+3==4,
Q(E, вниз)==4+4 8,
Q(F, BBepx) 6+3 9,
Q(F, вниз) 3+4==7,
Q(G, BBepx) 3+3 6,
Q(G, прямо) 3+4==7.
Так как требуется найти маршрут с наименьшей стратеrией страхования, то по значениям
Q факторов видно, что необходимо оставить только следующие маршруты Е ---> Н, F ---> I и
G ---> Н, а остальные отбросить (рис. 12.5,6).
Переместившись назад еще на один пункт, повторив вычисления Q-факторов для состояний
В, С, D и оставив только значения, соответствующие наименьшим стратеrиям страхования, полу-
чим рис. 12.5, 8.
В заключение, переместившись еще на один шar и действуя аналоrичным способом, получим
rpаф, показаиный на рис. 12.5, z. На этом рисунке показано, что существуют три оптимальных
маршрута:
А ---> с ---> Е ---> Н ---> J,
А ---> D ---> Е ---> Н ---> J,
А ---> D ---> F ---> I ---> J.
Все они предполaraют затраты, равные 11 условным единицам.
.
12.5. Итерация по значениям 777
3
а)
4
3
б)
11
4
3
в)
11
4
3
r)
Рис. 12.5. Шаrи вычисления а-факторов в рассматриваемой задаче дилижанса
.....
778 rлава 12. Нейродинамическое проrраммирование
12.6. Нейродинамическое проrраммирование
Основной целью динамическоrо проrpаммирования является поиск оптимальной
стратеrии, Т.е. оптимальной последовательности действий, которые должны быть
предприняты обучаемой системой в каждом из ее состояний. В этом контексте суще
ствуют два практических вопроса, которые нужно учитывать при выборе алroритмов
итерации по стратеrиям и итерации по значениям для решения задачи динамическоrо
проrpаммирования.
· Проклятие размерности (curse of dimensionality). Во мноrих сложных реальных
задачах количество возможных состояний и действий является настолько большим,
что требования к вычислительным мощностям реализации алrоритма динамиче
CKOro проrpаммирования становятся просто нереальными. Для задачи динамиче
CKOro проrpаммирования, содержащей N возможных состояний и М возможных
действий для каждоrо состояния, каждая итерация алrоритма требует N 2 М опе-
раций для стационарной стратеrии. Это часто делает невозможным выполнение
даже одной итерации алrоритма, если N достаточно велико. Например, при иrpе в
нарды (backgammon) имеется 1020 возможных состоЯНий. Это значит, что одна ите
рация алrоритма на среднем компьютере, осуществляющем 1 миллион операций
в секунду, может занять около 1000 лет [99].
· Неполнота информации (incomplete information). Алroритмы итераций по CTpaTe
rиям и по значениям требуют наличия априорных знаний о соответствуюшем Мар-
ковском процессе принятия решений. Это значит, что для вычисления оптимальной
стратеrии требуется знать вероятности перехода между состояниями Pij и наблю
даемые стоимости g(i, а,Л. К сожалению, априорные знания не всеrда доступны.
В свете любой из этих сложностей иноrда приходится отказаться от поиска опти
мальной стратеrии и искать субоптимальную.
В контексте данной книrи интерес представляет субоптимальная процедура, KO
торая включает в себя использование нейронных сетей и (или) моделирование с цe
лью аппроксимации функции стоимости перехода J* (i) для всех i ЕХ. В частности,
для KOHKpeTHoro состояния i функция J* (i) заменяется подходящей аппроксимацией
J(i, w), rдe w вектор параметров. Функция У(" w) называется функцией отсчета
(score function) или приближенной функцией стоимости перехода (approximate cost-
to-go function). Сами значения J(i, w) называются отсчетами или приближенными
затратами для состояния i. Таким образом, отсчет J (i, w) является откликом ней
ронной сети в ответ на подачу на вход состояния i. Здесь нейронные сети функцио-
нируют в качестве универсальных аппроксиматоров. Это одно из встроенных свойств
мноroслойных персептронов и сетей на основе радиальных базисных функций.
Нас интересуют те задачи динамическоrо проrpаммирования, которые имеют
большое количество состояний и в которых требуется найти такую функцию OT
12.6. Нейродинамическое проrраммирование 779
Состояние
i
л
Нейронная J(i, w)
сеть
w
J*
Рис. 12.6. Нейронная сеть, предназна-
ченная для аппроксимации оптимальной
функции стоимости перехода J'
счета J (', w), для которой вектор параметров w имеет небольшую размерность. В
этой форме аппроксимации, называемой компактным представлением (compact rep-
resentation), сохраняются только вектор параметров w и общая структура функции от-
счета У(" w). отчетыI J(i, w) для всех состояний i ЕХ rенерируются только по мере
необходимости. Требуется алroритмически найти вектор параметров w, такой, чтобы
для данной структуры нейронной сети (например, для мноrослойноro персептрона)
отсчет J(i, w) предоставлял удовлетворительную аппроксимацию оптимальноrо зна-
чения J* (i) для всех i Е Х.
Из материала по обучению с учителем, представленноro в шавах 4---7, известно,
что для обучения нейронной сети, независимо от ее типа, требуется наличие мно-
жества маркированных данных, являющеrося представительным для своей задачи.
Однако в контексте задач динамическоrо проrpаммирования множества данных (т.е.
пар примеров "вход-выход" {(i, J*(i)}), необходимых для оптимизации структуры
сети в некотором статистическом смысле, не существует (рис. 12.6). Остается лишь
возможность использования метода моделирования Монте Карло (Monte Carlo sim-
ulation), в которой вместо фактической системы, характеризуемой Марковским про-
цессом принятия решений, используется некоторая сурроrатная модель. В результате
формируется автономный режим раБотыI процесса динамическоrо проrpаммирования,
который обладает следующими потенциальными преимуществами [126].
1. Использование моделирования для приближенной оценки оптимальной функции
стоимости перехода является ключевой идеей, которая отличает методолоrию ней
родинамическоro проrpаммирования от традиционных методов аппроксимации в
динамическом проrpаммировании.
2. Моделирование позволяет использовать методы нейродинамическоrо проrpамми-
рования для создания систем, точных моделей которых не существует. Для таких
систем традиционные приемы динамическоrо проrpаммирования неприменимы
(например, если невозможно оценить вероятности состояний и переходов).
3. Посредством моделирования можно идентифицировать наиболее важные или наи
более представительные состояния системы, например те, которые при модели-
ровании посещаются чаще друrих. Следовательно, функция отсчета, созданная
нейронной сетью, будет являться хорошей аппроксимацией оптимальной функ-
ции стоимости перехода для этих конкретных состояний. В итоrе можно будет
выработать хорошую субоптимальную стратеrию для сложных задач динамиче
CKOro проrpаммирования.
....
780 rлава 12. Нейродинамическое проrраммирование
Однако важно помнить что при использовании аппроксимации нельзя ожидать
сходимости функции отсчета j(., w) к оптимальной функции стоимости перехода.
Причина этоro заключается в том, что J* (.) может не принадлежать множеству функ-
ций, которые MOryT быть точно представлены выбранной структурой нейронной сети.
В следующих двух разделах мы рассмотрим две процедуры приближенноrо ди-
намическоro проrpаммирования, использующие аппроксимации функций стоимости
перехода. Первая процедура, описанная в разделе 12.7, связана с приближением ал-
roритма итерации по стратеrиям, предполаrающеro доступность Марковской модели
системы. Вторая процедура, рассматриваемая в разделе 12.8, связана с так называе-
мым Q-обучением. Она требует достаточно мяrких предположений.
12.7. Приближенный алrоритм итерации
по стратеrиям
Предположим, что существует некоторая задача динамическоro проrpаммирования
с довольно большим множеством допустимых состояний и действий, что делает
непрактичным применение традиционных подходов. Пусть имеется модель систе
мы, Т.е. известны вероятности переходов Pij (а) и наблюдаемые затраты у( i, а, Л.
Для реализации алrоритма итерации по стратеrиям предлаrается использовать ап-
проксимацию, основанную на моделировании Монте-Карло и методе наименьших
квадратов, что и будет описано далее [125].
На рис. 12.7 показана упрощенная блочная диаrpамма приближенноzо алzориmма
итерации по стратеzиям (approximate policy iteration algorithm). Она аналоrичнадиа
rpaMMe обычноrо алrоритма итерации по стратеrиям, представленной на рис. 12.3,
но имеет одно важное отличие: шаr вычисления точной оценки стратеrии заменен
вычислением приближенной оценкой. Таким образом, приближенный алrоритм ите-
рации по стратеrиям чередует два шаrа: шаr оценки приближенной стратеrии и шаr
улучшения стратеrии.
1. Шаz вычисления приближенной cmpamezuu (approximate policy evaluation step).
Для данной стратеrии J.l вычисляется приближенная функция стоимости перехода
jJ.L(i, w) для всех состояний i. Вектор w является вектором параметров нейронной
сети, используемой для аппроксимации функции.
2. Шаz улучшения cmpamezuu (policy improvement step). С использованием прибли
женной функции стоимости перехода jJ.L( i, w) rенерируется улучшенная стратеrия
J.l. Эта новая стратеrия должна быть жадной по отношению к jJ.L(i, w) для всех i.
12.7. Приближенный алroритм итерации по стратеrиям 781
Приближенная
стоимость
перехода
1 P (i, w)
Коррекция
стратеrии
Рис. 12.7. Упрощенная блочная диаrрамма при-
ближенноro алroритма итерации по стратеrиям
Нейронная сеть
ДЛЯ приближенной
оценки Стратеrия /l
стратеrии:
w
Для TOro чтобы приближенный алroритм итерации по стратеrиям давал удо-
влетворительные результаты, важно тщательно выбирать стратеrию, используемую
для инициализации алroритма. При этом необходимо использовать эвристики. В ка-
честве альтернативы можно начинать с произвольноrо вектора w и использовать
ero для вывода жадной стратеrии. Полученная стратеrия затем будет применяться
в качестве исходной.
Теперь предположим, что в дополнение к знанию вероятностей переходов и зна
чений стоимости в нашем распоряжении имеется следующая информация.
. Стационарная стратеrия J.l, принимаемая в качестве исходной.
. Множество состояний Х, представительных для данной внешней среды.
. Множество примеров M(i) функций стоимости перехода ]J.L(i) для всех состоя-
ний i Е Х. Каждый такой пример обозначим как k(i, т), rде т == 1,2,... , M(i).
Пусть jJ.L(i, w) приближенное представление функции стоимости перехода
]J.L(i). Эта аппроксимация выполняется нейронной сетью (например, мноrослойным
персептроном, обучаемым с помощью алroритма обратноro распространения). Вектор
параметров w этой нейронной сети определяется с использованием метода наимень
ших квадратов, Т.е. путем минимизации следующей функции стоимости:
M(i)
E(w) == L L (k(i,m) jJ.L(i,W))2.
iEX т 1
(12.32)
Определив оптимальный вектор весов и, следовательно, приближенную функцию
стоимости перехода jJ.L(i, w), приближенные Q-факторы можно вычислить по следу-
ющей формуле:
Q(i,a,w) == LPij(a)(g(i,a,j) +yjJ.L(j,w)),
jEX
(12.33)
782
rлава 12. Нейродинамическое проrраммирование
l
Действия
Состояния
Имитатор
Приближенная
функция
стоимости
п ехода
J (j,w)
Решающее
устройство
на основе метода
наименьших
кв атов
Рис. 12.8. Детальная схема при-
ближенноro алroритма итерации по
стратеrия м
rде Pij(a) вероятности перехода из состояния i в состояние j при (известном)
действии а; у( i, а, j) наблюдаемые (известные) затратыI; у дисконтный множи-
тель. Итерация завершается вычислением улучшенной стратеrии с использованием
полученноro приближенноrо Q-фактора (см. (12.28»
f.1(i) == arg min Q(i, а, w).
аЕА;
(12.34)
Важно отметить, что выражения (12.33) и (12.34) используются модельной сетью
для rенерации действий, выполняемых в состояниях, реально посещаемых при мо-
делировании, а не во состояниях. Поэтому данные два выражения не подвержены
проклятию размерности.
Блочная диаrpамма на рис. 12.8 представляет собой более детализированную ил-
люстрацию приближенноro алrоритма итерации по стратеrиям. Эта диаrpамма со-
стоит из четыIехx взаимосвязанных модулей [126].
1. Имитатор (simulator). Использует данные вероятности переходов и стоимости
для одноro шаrа (мrновенные затраты) для построения сурроrатной модели внеш-
ней среды. Имитатор reнерирует два типа данных: состояния в ответ на дей-
ствия (имитация внешней среды) и реализации функции стоимости перехода
для данной стратеrии.
2. Тенератор действий (action generator). rенерирует улучшенную стратеrию (т.е. по-
следовательность действий) в соответствии с (12.34).
3. Аппроксиматор функции стоимости перехода (cost-to go approximator). rенери-
рует приближенную функцию стоимости перехода jJ.L(i, w) для состояния i и
вектора параметров w выражений (12.33) и (12.34).
4. Решающее устройство на основе метода наименьших квадратов (least-square
solver). Ему поподаются реализации функции стоимости перехода ]J.L( i), creHe-
12.7. Приближенный алrоритм итерации по стратеrиям 783
рированные имитатором для стратеrии f..I. и состояния i, для которых он вычис
ляет оптимальный вектор параметров w, минимизирующий функцию стоимости
(12.32). Связь, ведущая от решающеrо устройства к имитатору функции стоимо-
сти перехода, отключается только после получения полной оценки стратеrии и
нахождения оптимальноro вектора параметров W*. В этой точке аппроксимация
jJ.L(i, w) заменяется функцией jJ.L(i, w*).
В табл. 12.3 приведен приближенный алroритм итерации по стратеrиям в сжатом виде.
ТАБЛИЦА 12.3. Приближенный алroритм итерации по стратеrиям
Известные параметры
Вероятности перехода Pij (а) и затраты у( i, а, j)
Вычисления
1. Выбираем некоторую стационарную стратеrию f..I. в качестве исходной
2. Используя множество примеров {k(i, т)} { функции стоимости перехода
]J.L( i), rенерируемые имитатором, определяем вектор параметров w нейрон
ной сети с помощью решающеro устройства, работающеrо на основе метода
наименьших квадратов:
M(i)
w* == mJnE(w) == mJn L L (k(i,m) jJ.L(i,W))2
iEX т=1
3. для вектора параметров w, вычисленноrо на шаrе 2, вычисляем приближенную
функцию стоимости перехода jJ.L( i, w) для посещенных состояний. Определяем
приближенные Q-факторы
Q(i, а, w) == LPij(a)(g(i, а, j) + yjJ.L(j, w))
зЕХ
4. Определяем улучшенную стратеrию: f..I.(i) == arg min Q(i, а, w)
аЕА,
5. Повторяем шаrи 2
Естественно, работа этоro алroритма подвержена ошибкам ввиду неизбежноrо
несовершенства архитектуры имитатора и решающеrо устройства. Для нейронной
сети, используемой для вычисления аппроксимации искомой функции стоимости пе
рехода по методу наименьших квадратов, может не хватить вычислительных мощно
стей. Это первый источник ошибок Оптимизация аппроксиматора нейронной сети
и, таким образом, настройки вектора параметров w основана на желаемом отклике,
предоставляемом имитатором. Это второй источник ошибок В предположении, что
все оценки стратеrии и все модификации стратеrий выполняются с определенны
ми допусками Е и О, в [126] бьто показано, что приближенный алroритм итерации
по стратеrиям дает на выходе такие стратеrии, производительность которых отли
чается от оптимальной на величину, стремящуюся к нулю при уменьшении Е и О.
784 rлава 12. Нейродинамическое проrраммирование
Друrими словами, приближенный алroритм итерации по стратеrиям не rарантирует
существенноro улучшения производительности. Соrласно [126], приближенный алro
ритм итерации по стратеrиям вначале монотонно и довольно быстро сходится, однако
устойчивая осцилляция стратеrии, имеющая случайную природу, может привести к
снижению скорости сходимости. Эта осцилляция появляется после Toro, как при
ближенная функция стоимости перехода попадает в окрестность O«(8+2"(E)/(1 y)2)
оптимальноro значения J*, rде у дисконтный параметр. Очевидно, что существу
ет некоторая фундаментальная структура, общая для всех вариантов приближенноro
алrоритма итерации по стратеrиям, которая вызывает такую осцилляцию.
12.8. Q-обучение
Поведенческой задачей системы обучения с подкреплением (см. рис. 12.1) является
поиск оптимальной стратеrии (т.е. имеющей минимальную стоимость) в результате
попытки выполнения возможных последовательностей действий и оценки COOTBef-
ствующих стоимостей и переходов. В этом контексте возникает следующий вопрос:
существует ли процедура обучения оптимальной стратеrии в реальном времени, ос-
нованная на опыте, накопленном только на примерах следующеro вида:
Вn == (i n , an,jn, gn),
(12.35)
rде n дискретное время, а Вn состоит из четверки величин: действия а n в co
стоянии i ш которое приводит к переходу в состояние jn == i n +1 при затратах
gn == g(in,an,jn). Ответ на этот фундаментальный вопрос является утвердитель-
ным, и ero описывает стохастический метод, получивший название Q-обученuя 4
(Q-learning) [1115]. Q-обучение представляет собой пошаrовую процедуру динами
ческоrо проrpаммирования, определяющую оптимальную стратеrию. Эта процедура
идеально подходит для решения Марковских задач принятия решений при отсутствии
явных знаний о вероятностях переходов. Однако успешное использование Q-обучения
основано на предположении, что состояния внешней среды являются вполне наблю
даемы.ми (fully observable), а это, в свою очередь, значит, что среда является вполне
наблюдаемой цепью Маркова.
4 На с. 96 кандидатской диссертации [1115] Q-обучению описывается так.
"В приложении 1 представлено доказательство тoro, что этот метод работает для конечных Марковских
процессов принятия решений. При этом также показано, что данный метод обучения будет быстро сходиться к
оптимальной функции. Хотя эта идея является достаточно простой, насколько я знаю, раньше ей не уделялось
внимание. Следует сказать, что конечные Марковские процессы принятия решений и стохастическое динами-
ческое проrpаммирование на протяжении более 30 лет тщательно изучались на предмет использования их в
различных областях, но, к сожалению, никто не доrадался применить метод Монте-Карло".
В сноске к этому замечанию в [99] отмечалось, что, несмотря на то что идея присваивания значений
парам состояни действие на основе метода динамическоro проrpаммирования высказана в [253], в ней не
был сформулирован алroритм, подобный Q-обучению, для оценки этих значений. Это было сделано только в
диссертации [1115].
12.8. О-обучение 785
в разделе 12.4 бьто введено определение Q фактора Q(i,a) для пары состояние
действие (i, а) с помощью выражения (12.23) и уравнение оптимальности Беллмана,
описываемое выражением (12.22). Объединяя эти два выражения и используя опре-
деление М2Новенных ожидаемых затрат (immediate expected cost) (12.20), получим:
N
Q*(i,a) == LPij(a) ( g(i,a,j) +yminQ*(j,b) ) для всех (i,a).
. 1 bEAj
J
(12.36)
Это выражение можно рассматривать как двухшаroвую версию уравнения оп-
тимальности Беллмана. Решения линейной системы уравнений (12.36) определяют
оптимальные Q-факторы Q* (i, а), единственные для пары состояние действие (i, а).
Для решения этой системы уравнений можно использовать алrоритм итерации по
значениям, сформулированный в терминах Q факторов. Таким образом, для одной
итерации этоrо алrоритма имеем:
N
Q(i, а) :== LPij(a) ( 9(i, a,j) + ymin Q(j, Ь) ) дЛЯ всех (i, а).
. 1 bEAj
J
Предполаrая малость шаrа, это выражение можно переписать так:
N
Q(i,a):== (1 11)Q(i,a) +11 LPij(a) ( g(i,a,j) +yminQ(j,b) ) (12.37)
. 1 bEAj
J
дЛЯ всех (i, а),
rде 11 малый параметр скорости обучения, который находится в диапазоне О <
11 < 1.
Шаr алroритма итерации по значениям (12.37) требует знания вероятностей пере-
ходов. Однако эти априорные знания не понадобятся, если сформулировать стоха-
стическую версию выражения (12.37). В частности, усреднение по множеству состо-
яний, осуществляемое в (12.37), заменяется единственным примером, что приводит
к следующей модификации выражения коррекции Q-фактора:
Qn+1(i, а) == (1 11n(i, a))Qn(i, а) + 11n(i, а) [g(i, а,Л + yJn(j)]
для (i,a)==(in,a n ), (12.38)
rде
Jn(j) == min Qn(j, Ь),
bEAj
(12.39)
786 rлава 12. Нейродинамическое проrраммирование
j последующее состояние; lln(i, а) параметр скорости обучения на шаrе n для
пары состояние действие (i, а). Уравнение коррекции (12.38) применяется к текущей
паре состояние действие (in, а n ), для которой, сошасно (12.35), j == jn. для всех
остальных допустимых пар состояние действие Q факторы остаются неизменными:
Qn+1(i, а) == Qn(i, a)(i, а) =!= (in, а n ).
(12.40)
Уравнения (12.38) (12.40) составляют одну итерацию алzоритма Q обучения.
Теорема о сходимости 5
Предположим, что параметр скорости обучения lln (i, а) удовлетворяет следую
ЩИМ условиям:
00
00
I: lln (i, а) == 00 и I: 1l (i, а) < 00 для всех (i, а).
n O n O
(12.41)
Тоzда последовательность Q факторов (Qn(i,a)}, zeHepupyeмblX алzоритмом
Q обучения, сходится с вероятностью 1 к оптимальному значению Q* (i, а) для всех
пар состояние действие (i, а) при стремлении количества итераций п к бесконеч-
ности (при этом предполаzается, что все пары состояние действие посещаются
бесконечно часто).
Примером параметра скорости обучения, зависящеrо от времени, который rapaH-
тирует сходимость данноrо алrоритма, может служить следующий:
а.
ll n == +n ' n==1,2,...,
(12.42)
rде а. и положительные числа.
Подводя итоr, можно сделать следующий вывод. Алrоритм Q обучения являет-
ся приближенной формой стратеrии итерации по значениям. На каждой итерации
алrоритм резервирует Q фактор для одной пары состояние действие, а именно для
текущеrо наблюдаемоrо состояния и фактически выполняемоro действия. Что бо-
лее важно этот алrоритм в пределе сходится к оптимальным Q значениям без
формирования явной модели соответствующих Марковских процессов принятия ре-
шений. Как только оптимальные значения Q-факторов становятся известны, оmи-
мальная стратеrия с помощью выражения (12.30) может быть определена без осо-
бо трудоемких вычислений.
5 Схема доказательства теоремы о сходимости Q обучения была представлена в [1115]. Само детальное до-
казательство приводится в [1116]. Более общие результаты относительно сходимости Q-обучения были описаны
в [126], [1059].
12.8. Q-обучение 787
Сходимость Q обучения к оптимальной стратеrии предполаrает представление
Q факторов Qn(i, а) в виде справочных таблиц (1ook-up table). Этот способ пред-
ставления является достаточно простым и вычислительно эффективным. Однако ес-
ли входное пространство, состоящее из пар состояние действие, является достаточ-
но большим или если входные переменные непрерывны, использование справочных
таблиц может быть недопустимо затратным ввиду требования rpомадных объемов
памяти. В такой ситуации для аппроксимации функций можно использовать нейрон
ные сети.
Приближенное Q-обучение
Равенства (12.38) и (12.39) определяют формулы коррекции Q-фактора для текущей
пары состояние действие иn, а n ). Эта пара равенств может быть переписана в экви
валентном виде:
Qn+1(i n , а n ) == Qn(i n , а n ) + (12.43)
+l1n(i n , а n ) [ 9(in, аn,уn) + 'у min Qn(jn, Ь) Qn(in, аn) ] .
bEAjn
Рассматривая выражение в квадратных скобках в правой части (12.43) как сиrнал
ошибки в формуле коррекции текущеro Q фактора Q n ( i щ а n ), можно определить
целевой (желаемый) Q-фактор в момент времени n как
Q целевой ( . ) ( . . ) . Q ( . Ь)
n Zn, а n == 9 Zn, аn,)n + 'у mln n )n, ,
bEAjn
(12.44)
rде jn == i n +1 последующее состояние. Уравнение (12.44) показывает, что после-
дующее состояние уn иrpает важнейшую роль в определении целевоro Q-фактора.
Используя определение целевоro Q фактора, можно переформулировать алrоритм Q-
обучения в следующем виде:
Qn+1(i,a) == Qn(i,a) + дQn(i,а),
(12.45)
rде пошаroвое изменение текущеro Q-множителя определяется формулой
ДQn(i,а) == { l1n(Q елеВОЙ(i,а) Qn(i,a)) при (i,a) == иn,а n ),
о в противном случае.
(12.46)
По определению "оптимальное" действие а n в текущем состоянии i n является
конкретным действием в том состоянии, для KOTOpOro Q фактор в момент времени
n минимален. Исходя из этоro, при данных Q факторах Qn(in, а) для допустимых
действий а EA in В состоянии i n оптимальное действие, подставляемое в выражение
(12.44), представляется следующей формулой:
788 rлава 12. Нейродинамическое проrраммирование
Состояние
Действие
а
Нейронная
сеть:
w
л
Q(i,a,w)
QIIелеВОЙ(i, а, w)
Рис. 12.9. Архитектура ней-
ронной сети, аппроксими-
рующей целевой Q фактор
Qцелевой (i, а, w)
Qn == min Qn(i n , а).
aEAi n
(12.47)
Обозначим символом Q n (i n , а n , w) аппроксимацию Q фактора Q n ( i n , а n ), вы-
численную нейронной сетью (например, мноroслойным персептроном, обучаемым
соrласно алroритму обратноro распространения). Текущая пара состояние действие
( i n , а n ) является входом нейронной сети с вектором параметров w, rенерирующей
выходной сиrнал Qn(in> аn> w) (рис. 12.9). На каждой итерации этоrо алroритма век-
тор весов w медленно изменяется таким образом, чтобы как можно лучше прибли-
зить выход Qn(in, аn> w) к целевому значению Q елеВОЙ(in, а n ). Однако как только
вектор w изменяется, это неявно влияет на само целевое значение. При этом под-
разумевается, что модифицируемое значение Q елеВОЙ(in, а n , w). Таким образом,
нет никаких rарантий, что расстояние между двумя Q-факторами будет уменьшаться
на каждой итерации. Это является еще одной причиной, почему алroритм прибли-
женноro Q обучения потенциально может расходиться. Если алroритм не расходится,
вектор весов w обеспечивает средства хранения аппроксимированных Q-факторов в
обучаемой нейронной сети, так как ее выход Q n ( i n , а n , w) представляет собой отклик
на вход оn, а n ).
в табл. 12.4 в сжатом виде приведен алroритм приближенноrо Q обучения.
Исследование
в алroритме итерации по стратеrиям необходимо исследовать все потенциально важ-
ные части пространства состояний. При использовании Q-обучения вводится еще
одно дополнительное требование: необходимо также исследовать все потенциально
прибыльные действия. В частности, чтобы удовлетворить условиям теоремы сходи-
мости, все допустимые пары состояние действие должны исследоваться достаточ-
но часто. для жадной стратеrии f..I. исследуются только некоторые пары состояние
действие (i, f..I.(i)). К сожалению, нет никакой rарантии, что даже в исследовании Bcero
пространства пар состояние действие будут опробованы все выrодные действия.
12.8. Q-обучение 789
Необходимо предложить стратеrию, расширяющую Q обучение за счет введения
компромисса между двумя антаrонистическими целями [1053].
. Исследованием (exploration), rарантирующим, что все допустимые пары состояние
действие будут рассматриваться достаточно часто, чтобы удовлетворить теореме о
сходимости Q-обучения.
. Эксплуатацией (exploitation), которая стремится минимизировать функцию стои
мости перехода, следуя жадной стратеrии.
Одним из способов достижения компромисса является следование смешанной
нестационарной cmpamezuu (mixed nonstationary policy), которая переключается меж-
ду вспомоrательным Марковским процессом и исходным Марковским процессом,
управляемым стационарной жадной стратеrией, определяемой Q-обучением [235].
Вспомоrательный процесс имеет следующую интерпретацию. Вероятности перехода
между возможными состояниями определяются вероятностями перехода исходно-
ro управляемоrо процесса с добавлением условия, что соответствующие действия
равномерно распределены. Эта смешанная стратеrия начинается с произвольноro со-
стояния вспомоrательноrо процесса и выбирает соответствующие действия, после
этоro переключается на исходный управляемый процесс и Т.д. (рис. 12.1 О). Время,
затраченное на работу вспомоrательноrо процесса, занимает фиксированное число
шаrов L, определяемое как удвоенное максимальное время, требуемое для посеще
ния всех состояний вспомоrательноrо процесса. Время, затраченное на работу ос-
HOBHoro управляемоro процесса, с каждым следующИм переключением постепенно
увеличивается. Пусть nk время, в которое мы переключаемся со вспомоrательно
ro процесса на основной, а ffik время переключения назад во вспомоrательный
процесс, rде величины определяются следующим образом:
nk == ffik l + L, k == 1,2, . .. и то == 1,
ffik == nk + kL, k == 1,2, . . . .
Вспомоrательный процесс строится таким образом, чтобы при стремлении k к
бесконечности с вероятностью 1 существовало бесконечное количество посещений
всех состояний, что будет rарантировать сходимость к оптимальным Q-факторам.
Более TOro, при k -----t 00 время, отданное смешанной стратеrией работе вспомоrатель-
Horo процесса, становится асимптотически малой долей времени, отданноrо работе
OCHoBHoro управляемоro процесса. Это, в свою очередь, означает, что смешанная
стратеrия асимптотически сходится к некоторой жадной стратеrии. Torдa, в предпо-
ложении сходимости Q факторов к своим оптимальным значениям, жадная стратеrия
действительно становится оптимальной, при условии, что эта стратеrия становится
жадной достаточно медленно.
790 rлава 12. Нейродинамическое проrраммирование
Вспомоrательный Исходный
!
I
тo 1
п 1
тl
п !
т!
пз
Рис. 12.10. Временные интер-
валы, относящиеся к вспомоra-
тельному и основному управля-
емому процессам
ТАБЛИЦА 12.4. Алrоритм приближенноrо Q-обучения
1. Начинаем с произвольноro вектора весов wo, на основе KOToporo получа-
ем Q-фактор Q(io, ао, wo). Вектор весов w относится к нейронной сети,
используемой для осуществления аппроксимации
2. Для итераций n == 1, 2,. . . выполняем следующее
2а. Для данноrо вектора весов w нейронной сети определяем оптимальное дей-
ствие:
а n == min Qn(in, а, w)
aEAi n
2б. Определяем целевой Q фактор:
Q целевой ( . ) ( . . ) . Q ( . Ь )
n 2 n ,а щ W g 2n,a n ,Jn +ymln n Jn, ,W
bEAjn
2в. Корректируем Q-фактор
Qn+1 (i n , а n , w)==Qn(in, а n , ]n) + b..Qn(in, an,w),
rдe
2r.
{ YJn(in, аn)(Q елеВОЙ(in, n' w .Qn(i n , а n , w))
b..Qn(in, а n , w) == при (2, а) (2n, а n ),
о в противном случае
Применяем (i n , а n ) в качестве входа нейронной сети, rенерирующей выход-
ной сиrнал Qn (i n , а n , w), являющийся аппроксимацией целевоrо Q-фактора
Q елеВОЙ(in, а n , w). Слеrка изменяем вектор весов w так, чтобы приблизить
аппроксимацию Qn(in, а n , w) к целевому значению Q елеВОЙ(in, а n , w)
Возвращаемся к шаry 2а и повторяем вычисления
2д.
12.9. Компьютерный эксперимент
в этом компьютерном эксперименте вновь вернемся к задаче дилижанса, рассмотрен-
ной в примере 12.1. На этот раз для решения задачи будем использовать приближен-
ное Q обучение. Для реализации этоrо алroритма существуют два основных подхода:
в первом из них для представления Q значений используется справочная таблица, а
во втором нечронная сеть.
12.9. Компьютерный эксперимент 791
На рис. 12.11 по казаны истории обучения следующих Q-факторов: Q(A, вверх),
Q(C, прямо), Q(E, прямо) и Q(l, вверх). Пунктирными линиями на рис. 12.11 пред
ставлены желаемые Q-значения. Каждая попытка представляет собой полный марш-
рут от штата i до штата J. Начальное состояние для каждой ПОПЬffки выбирается
случайным образом. Параметр скорости обучения 11 n (i, а) определяется соотноше-
нием
. a.vn(i, а)
11 n (z,a) == К + С ) '
V n z,a
rдe vn(i, а) количество посещений состояния (i, а) до текущеro момента п; а. == 1,6
и К == 600. После совершения 1000 попыток бьт определен оптимальный маршрут:
А ----t D ----t F ----t 1 ----t J.
Это один из оптимальных маршрутов с общими затратами, равными 11. Это же
значение было получено в примере 12.1.
На рис. 12.12 показаны соответствующие результаты, полученные с помощью
мноrослойноro персептрона с двумя входными узлами, десятью скрытыми и одним
выходным нейроном. Один из входных узлов представляет состояние, а второй
действие, предпринимаемое для перехода из одноro состояния в друroе. Выход это-
ro мноroслойноrо персептрона представляет Q-значение, вычисленное нейронной
сетью. Эта нейронная сеть обучалась с использованием стандартноrо алroритма об-
paTHoro распространения. Целевое Q-значение в момент времени п вычислялось по
формуле (12.44). Параметр скорости обучения принимал фиксированное значение
0,012, при этом не использовались моменты. Эта сеть обучалась на 10 000 приме-
рах для каждой пары состояние действие. На рис. 12.12 показана история обучения
следующих Q значений: Q(A, вверх), Q(C, прямо), Q(E, прямо) и Q(l, вверх). Оп-
тимальный маршрут, найденный сетью, выrлядит следующим образом:
А ----t D ----t Е ----t Н ----t J.
Это также один из оптимальных маршрутов, имеющих общие затраты, равные 11.
Вычислительные требования для применения этих двух подходов приведены ниже.
1. Нейронная сеть.
Количество входов 2.
Количество скрытых нейронов 10.
Количество выходных нейронов 1.
Общее количество синаптических весов и пороroв 2 х 10 + 10 + 10 х 1 + 1 == 41.
792 rлава 12. Нейродинамическое проrраммирование 1
20 20
15 15
""
10 10
'" '"
-& -&
6 6
5 5
О О
10 20 30 40 10 20 30
Попытка Попытка
а) б)
20 I 20 I
15 15
"" ""
о
!;: 10 10
'" '"
-& А -&
6 V 6
5 5
О О .
10 20 30 40 50 100 200 300 400
Попытка Попытка
В) r)
Рис. 12.11. Кривые обучения для задачи дилижанса при использовании справочных
таблиц: кривая обучения дЛЯ Q(A, вверх) (а); дЛЯ Q(C, прямо) (б); для Q(E, прямо) (в) и
дЛЯ Q(I, вверх) (r)
2. Справочная таблица.
Количество состояний 10.
Количество действий 2 или 3.
Размер таблицы 21.
в этом эксперименте количество возможных состояний мало, в результате чеro
для хранения справочной таблицы требуется меньше памяти, чем для нейронной
сети. Однако если количество состояний достаточно велико, нейронная сеть обладает
преимуществами по сравнению со справочной таблицей с точки зрения требуемых
вычислительных мощностей.
12.10. Резюме и обсуждение 793
20 20
15 15
"" i5'
10 10
-е- -е- . . .............
6 6
5 5
О О
20 40 60 80 100 20 40 60 80 100
Попытка (xIOO) Попытка (xIOO)
а) б)
20 , , 20
15 15
"" i5'
10 10
'"
-е- -е-
6 ................ ....................... 6
5 5
v
О , О . ,
20 40 60 80 100 20 40 60 80 100
Попытка (xIOO) Попытка (xIOO)
В) r)
Рис. 12.12. Кривые обучения для задачи дилижанса при использовании нейронной сети.
Кривая обучения дЛЯ Q(A, вверх) (а); ДЛЯ Q(C, прямо) (б); для Q(E, прямо) (в) и дЛЯ
Q(I, вверх) (r)
12.10. Резюме и обсуждение
Нейродинамическое проrpаммирование, соединяющее в себе математический фор
мализм классическоro динамическоro проrpаммирования и способность нейронной
сети к обучению, обеспечивает мощный подход к решению поведенческих задач, тре-
бующих планирования. В этом современном подходе к обучению с подкреплением
система обучается двум вещам: на основании наблюдений за собственным поведе-
нием принимать rpамотные решения и улучшать их действия с помощью механизма
подкрепления. Лежаший в ero основе процесс принятия решений соответствует Map
ковской модели.
794
rлава 12. Нейродинамическое проrраммирование
l
в этой шаве описаны две процедуры нейродинамическоrо проrpаммирования.
1. Приближенная итерация по стратеzuям. Итерации по стратеrиям соответствует
два основных шаrа.
. Шar вычисления стратеrии, на котором вычисляется функция стоимости пере-
хода для некоторой текущей стратеrии.
. Шar улучшения стратеrии, в котором текущая стратеrия корректируется для то-
1'0, чтобы стать жадной по отношению к текущей функции стоимости перехода.
В приближенной итерации по стратеrиям при вычислении стратеrии объединя-
ются моделирование и аппроксимация функций. Для создания Марковской модели
системы требуется знание вероятностей перехода между состояниями. Для полу-
чения аппроксимации функции можно использовать нейронную сеть (например,
мноroслойный персептрон, обучаемый соrласно алrоритму обратноrо распростра-
нения, или машина опорных векторов), для которой эта задача подходит с точки
зрения свойства универсальноro аппроксиматора.
2. Приближенное Q-обучение. При итерации по значениям, альтернативной итера.
ции по стратеrиям, Марковская задача принятия решений решается с использо-
ванием последовательной процедуры аппроксимации, сходящейся к оптимальной
стратеrии. Q-обучение представляет собой асинхронную форму метода итерации
по значениям, сформулированную для избежания необходимости явных знаний о
вероятностях переходов между состояниями. Этот метод обладает следующими
привлекательными особенностями.
. Q-обучение сходится к оптимальным Q-значениям с вероятностью 1 при усло-
вии, что все пары значение действие будут посещаться бесконечно часто, а
параметры скорости обучения удовлетворяют условиям (12.41).
. Q-обучение напрямую корректирует оценки Q-факторов, связанных с опти-
мальной стратеrией, и, таким образом, устраняет потребность в мноrочислен-
ных шarах оценки, которые присутствуют в методе итерации по стратеrиям.
в приближенном Q-обучении для аппроксимации оценок Q-факторов использу-
ется нейронная сеть. Это помоrает избежать больших затрат памяти в задачах с
большим количеством состояний. Короче rоворя, приближенное Q-обучение явля-
ется алroритмом решения Марковской задачи принятия решений, основанным на
моделировании. Этот алroритм применяется, коrда модель системы недоступна, а
требования к экономии памяти стоят на первом месте. Естественно, ero можно при-
менить даже в случае доступности модели системы. В этом случае он становится
альтернативой приближенному алroритму итерации по стратеrиям.
12.10. Резюме и обсуждение 795
Методы нейродинамическоrо проrpаммирования особенно эффективны при реше
нии масштабных задач, коrда на первом месте стоит планирование. Традиционные
подходы динамическоrо проrpаммирования сложно применить к задачам TaKoro типа,
так как при этом необходимо исследовать пространство состояний слишком большой
размерности. Нейродинамическое проrpаммирование успешно применялось на прак-
тике для решения сложных задач в различных прикладных областях, в том числе в
иrpе в нарды (backgammon) [1046], [1048], в комбинаторной оптимизации [126], дис-
петчеризации (e1evator dispatching) [233] и при динамическом распределении каналов
(dynamical channel allocation) [783], [784], [996]. Ниже приложение к иrpе в нарды
будет описано более детально.
Проrpамма-иrpок в триктак, основанная на нейронных сетях, впервые была опи
сана в [1048] и впоследствии была улучшена в [1046]. Этот успех для частноrо случая
послужил толчком к дальнейшим исследованиям в области нейродинамическоrо про-
rpаммирования. Триктрак (нарды) это древняя настольная иrpа, в которой принима
ют участие два иrpока. Она может быть представлена как одномерный маршрут, кото-
рый шашки иrpоков проходят в противоположных направлениях. Иrpоки поочередно
бросают пару костей и соответствующим образом передвиrают свои шашки по марш
руту доски. Допустимые перемещения зависят от выпавшеrо на костях количества
очков и конфиrурации доски. Каждый из иrpоков должен переместить все свои шаш-
ки из конца маршрута, принадлежащеrо противнику, в свой конец маршрута. Первый,
кто выполнит эту задачу, считается победителем. Эту иrpу можно промоделировать
как Марковский процесс принятия решений, в котором состояния определяются опи-
санием конфиrурации доски, выпавшими на костях очками и идентификатором иrpо-
ка, совершающеrо ход. Первая версия нейронардов, описанная в [1048], использует
обучение с учителем. Она способна обучаться на промежуточном уровне при наличии
только приближенноrо описания состояния. Пожалуй, самым интересным открыти
ем, описанным в этой работе, было хорошее поведение при масштабировании: при
увеличении размера нейронной сети и количества примеров обучения наблюдалось
соответствующее увеличение производительности. Нейронную сеть, используемую
при обучении, представлял мноrослойный персептрон (MLP), обучаемый соrласно
алrоритму обратноro распространения. Наилучшей эффективности удалось добиться
при использовании МLP с 40 скрытыми нейронами. При этом обучение проводилось
в ходе более чем 200000 иrp. В последующих исследованиях [1046] для обучения
нейронной сети использовалась одна из форм итерации по стратеrиям, названная оп-
тимистической ТD(л). Аббревиатура TD означает tempora1 difference learning обу
чение на временных разностях [1032]. Оптимистическая стратеrия ТD(л) это метод
аппроксимации функции стоимости перехода JIl, основанный на моделировании, в ко-
тором стратеrия 1.1 заменяется новой стратеrией, являющейся жадной по отношению к
аппроксимации JIl при каждом переходе состояний [126]. Компьютерную проrpамму,
основанную на этом методе нейродинамическоrо проrраммирования, часто называют
796 rлава 12. Нейродинамическое проrраммирование
ТD-шулером. В представление входноro сиrнала для нейронной сети Тезауро (Tesauro)
добавил искусственно созданные функции состояний (т.е. признаки), что позволило
этой проrpамме иrpать на уровне мастера, приближающеroся к уровню чемпиона
мира. Убедительным основанием для этой оценки послужил ряд тестов, в которых
эта проrpамма иrpала против нескольких rpоссмейстеров мировоrо класса [1045].
Задачи
Критерий оптимальности Беллмана
12.1. При стремлении дисконтноrо множителя у к нулю вычисление функции сто-
имости перехода (12.22) замедляется. Почему это происходит? Обоснуйте
свой ответ.
12.2. В этой задаче будет представлено еще одно доказательство уравнения опти-
мальности Беллмана (12.22) [905].
а) Пусть 1t произвольная стратеrия. Предположим, что 1t выбирает дей-
ствие а в момент времени О с вероятностью Ра, rдe а Е A i . Torдa
J"(i) . , Р. (C(i' а) + t,p;;(a)WO(j)).
rде w 1t (j) представляет собой функцию ожидаемой стоимости перехода
с шаrа 1 вперед при использовании стратеrии 1t и состояния j. Покажите,
что
J1t(i) min ( C(i, а) + у Pi j (a)W 1t (j) )
аЕА;
j=l
rдe
W 1t (j) yJ(i).
б) Пусть 1t стратеrия, которая выбирает действие ао в момент времени О
и, если следующим состоянием будет j, рассматривает процесс, начинаю-
щийся в состоянии j и соответствующий стратеrии 1tj, такой, что
J1t; (Л ::; J (Л + Е,
Задачи 797
rде Е малое положительное число. Покажите, что при этих условиях
J1t(i) min ( C(i, а) + у Pij(a)J(j) ) '(Е.
aEAi
j l
+
в) Используя результаты, полученные в пп. (а) и (б), получите равенство
(12.22).
12.3. Уравнение (12.22) представляет собой систему N линейных уравнений, по
одному для каждоrо состояния. Пусть
J == [J (l), J (2),..., J (N)JT,
C(Jl) == [c(1,Jl),c(2,Jl),...,c(N,Jl)JT,
[ Pll (Jl) P12(Jl) .., PIN(Jl) ]
P(Jl) == Р21 (Jl) P22(Jl) ... P2N(Jl)
... ... ... ...
PNl(Jl) PN2(Jl) '" PNN(Jl)
Покажите, что уравнение (12.22) можно переписать в эквивалентной мат-
ричной форме:
(1 yP(Jl))J == C(Jl),
rдe 1 единичная матрица. Прокомментируйте единственность вектора J ,
представляющеro функции стоимости перехода для N состояний.
12.4. В разделе 12.3 был выведен алroритм динамическоro проrpаммирования для
задачи с конечным roризонтом. В этой задаче мы снова выведем этот алrо-
ритм для дисконтной задачи, в которой функция стоимости перехода выrля-
дит следующим образом:
[ K l ]
J (Xo) == l oo 'fg(Xn! Jl(X n ), Х n + 1 ) .
в частности, покажите, что
J (Xo) == min Е [g(Xo, Jl(Xo), Х 1 ) + yJK l(Xl)J.
X 1
...
798 rлава 12. Нейродинамическое проrраммирование
Итерация по стратеrиям
12.5. В разделе 12.4 rоворилось, что функция стоимости перехода удовлетворяет
условию
jJl n +l :::; jJl n .
Обоснуйте это утверждение.
12.6. Прокомментируйте значимость выражения (12.25).
12.7. Используя систему контроллера с модулем критики (control1er critic system),
проиллюстрируйте взаимодействие коррекции и оценки стратеrий в алroрит-
ме итерации по стратеrиям.
Итерация по значениям
12.8. Задача динамическоrо проrpаммирования включает в себя N возможных со-
стояний и М допустимых действий. Предполаrая использование стационар-
ной стратеrии, покажите, что одна итерация алrоритма итерации по значени-
ям требует порядка N 2 М операций.
12.9. В табл. 12.2 представлен в сжатом виде алrоритм итерации по значениям,
сформулированный в терминах функции стоимости перехода jJl(i) для состо-
яний i ЕХ. Пере формулируйте этот алrоритм в терминах Q факторов Q(i,a).
12.10. Алroритм итерации по стратеrиям Bcerдa завершается за конечное число
шаroв, в то время как алrоритм итерации по значениям может потребовать
бесконечноro их числа. Прокомментируйте друrие различия между этими
двумя методами динамическоrо проrpаммирования.
Q-06учение
12.11. Покажите, что
j* (i) == min Q(i, а).
аЕА;
12.12. Алrоритм Q обучения иноrда называют адаптивной формой стратеrии ите-
рации по значениям. Обоснуйте справедливость этоrо утверждения.
12.13. Постройте rpаф передачи сиrнала для приближенноrо алroритма Q обучения
(см. табл. 12.4).
12.14. Приближенный алrоритм Q обучения (см. табл. 12.4) предполаrает отсут-
ствие знаний о вероятностях перехода между состояниями. Переформули-
руйте этот алroритм в предположении доступности этих вероятностей.
Временная обработка
с использованием сетей
прямоrо распространения
13.1. Введение
Время является существенной составляющей процесса обучения. Оно может быть
непрерывным и дискретным. Какую бы форму ни принимало время, оно является
упорядоченной сущностью, лежащей в основе большинства задач распознавания об
разов и речи, обработки сиrнала и управления движением. Включение параметра
времени в работу нейронной сети позволяет учитывать статистические вариации в
таких не стационарных процессах, как речевые сиrналы, сиrналы радара, сиrналы
для мониторинrа работы двиrателя автомобиля и колебания цен на фондовом рынке,
а также мноrих друrих. Возникает вопрос: "Как встроить время в описание работы
нейронной сети?" Существуют два варианта ответа на этот фундаментальный вопрос.
· Используя неявтюе представление (implicit representation). Время представляется
эффектом, который оно оказывает на обработку сиrнала, Т.е. неявным образом l .
Для примера предположим, что входной сиrнал имеет равномерное KвaHтoвa
ние (uniformly sampled), а последовательность синаптических весов каждоrо из
нейронов, соединенных с входным слоем сети, получена с помощью свертки дpy
rой последовательности входных примеров. В такой системе временная структура
входноrо сиrнала вложена в пространственную структуру сети.
· Используя явное представление (explicit representation). Время имеет собственное
конкретное представление 2 . Например, система эхо локации летучей мыши посы
лает короткий частотно модулированный сиrнал, при этом устанавливая единый
уровень интенсивности для каждоrо из частотных каналов на короткий период FM
1 Обсуждение роли времени в нейронной обработке содержится в классической работе [281].
2 В [475] описана методика явиоro представления времени в нейронной обработке. В частности, аналоrо.
вая информация представляется с использованием синхронизации потенциалов действия (action potential) по
отношению к постоянной составляющей колебательной модели действий, чему имеется очевидное нейробио.
лоrические обьяснение. Потенциалы действия описаны в rлаве 1.
800 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
развертки. для TOro чтобы извлечь точную информацию о расстоянии до цели, про
водятся мноroчисленные сравнения нескольких различных частот, кодированных
массивом слуховых рецепторов [1030]. Коrда эхо получается от объекта с неизвест
ной задержкой, отвечает тот нейрон (слуховой системы), который имеет COOTBeT
ствующую задержку в линии. Таким образом оценивается расстояние до объекта.
В этой rлаве мы будем работать снеявным представлением времени, при KOTO
ром "статическая" нейронная сеть (например, мноrослойный персептрон) обладает
свойством динамичности. Это, в свою очередь, приводит к тому, что за временную
структуру информационных сиrналов отвечает сама сеть.
Чтобы нейронная сеть бьта динамичной, она должна иметь память (memory). Как
уже rоворилось в rлаве 2, память можно разделить на кратковременную и долzовре
менную. Долrовременная память встраивается в нейронную сеть посредством обуче
ния с учителем, при котором информативное содержание множества данных обучения
сохраняется (частично или в полном объеме) в синаптических весах сети. Однако ec
ли рассматриваемая задача также имеет и размерность времени, для придания сети
свойств динамичности требуется какая либо форма кратковременной памяти. Одним
из простейших способов встраивания кратковременной памяти в структуру нейрон-
ной сети является использование временных задержек (time de1ay), которые можно
реализовать на синаптическом уровне сети или в слое входных нейронов. Использо-
вание задержек по времени в нейронных сетях имеет свое нейробиолоrическое объ-
яснение хорошо известно, что задержки повсеместно встречаются в мозrе и иrpают
важную роль в нейробиолоrической обработке информации [146], [148], [150], [738].
Структура rлавы
Материал, излаrаемый в настоящей rлаве, разбит на три части. В первой части (разде
лы 13.2, 13.3) рассматриваются структуры и модели нейронных сетей. В разделе 13.2
представлено обсуждение структур памяти, а в разделе 13.3 описание двух различ
ных архитектур сети, предназначенных для временной обработки сиrнала.
Во второй части rлавы (разделы 13.4 13.6) рассматривается один из классов ней
ронных сетей, называемых сетями прямоro распространения с фокусированным Bpe
менем запаздывания (focused time lagged feedforward network). В этом названии Tep
мин "фокусированный" указывает на тот факт, что кратковременная память целиком
расположена на переднем плане (front end) сети. Компьютерное моделирование этой
структуры описывается в разделе 13.6.
В третьей части rлавы (разделы 13.7 13.9) рассматриваются сети прямоrо распро-
странения с распределенным временем запаздывания (distributed time lagged feedfor
ward network), в которых задержки в линии рассредоточены по всей сети. В разде
ле 13.7 описываются пространственно временные модели нейрона, а в разделе 13.8
рассматривается вышеназванный класс нейронных сетей. В разделе 13.9 описывает-
13.2. СТРУКТУРЫ кратковременной памяти 801
ся "временной" алrоритм обратноro распространения для обучения с учителем сетей
прямоrо распространения с рассредоточенным временем запаздывания.
Раздел 13.1 О завершит rлаву несколькими заключительными замечаниями.
13.2. Структуры кратковременной памяти
ОСновной задачей памяти является преобразование статической сети в динамиче
скую. В частности, внедряя память в структуру статической сети (например, MHO
rослойноrо персептрона), мы делаем выходной сиrнал зависимым от времени. Этот
подход к созданию нелинейных динамических систем достаточно прост, так как обес
печивает четкое разделение обязанностей: статическая сеть учитывает нелинейность,
а память время.
Кратковременная память З может быть реализована в непрерывном и дискретном
времени. Непрерывное время обозначим символом t, а дискретное символом n.
Цепь, показанная на рис. 13.1 и состоящая из сопротивления и емкости, представляет
собой пример памяти непрерывноro времени, которая характеризуется импульсным
откликом h(t), экспоненциально убывающим по времени t. Эта цепь отвечает за
память на синаптическом уровне и может быть пред ставлена аддитивной моделью
нейрона, которая будет описана далее в этой rлаве. В этом же разделе мы CKOHцeH
трируем основное внимание на памяти дискретноrо времени.
Полезным инструментом при работе с системами дискретноrо времени является
так называемое z преобразование. Пусть {х( n)} некоторая последовательность в
дискретном времени, которая может быть расширена в бесконечно далекое прошлое.
z преобразование такой последовательности определяется следующим образом:
00
X(z) == L x(n)z n,
(13.1 )
n== oo
ще Z l оператор единичной задержки (unit delay operator). Это значит, что опера-
тор z l, примененный к х(n), формирует версию сиrнала с задержкой х(n 1).
Предположим, что х(n) применяется к системе дискретноrо времени, имеющей
импульсный отклик h(n). Тоща выход всей системы определяется суммой cвepт
ки (сопvоlutiоп sum):
00
у(n) == L h(k)x(n k).
k oo
(13.2)
3 Cтpyкrypы кратковременной памяти и их роль во временной обработке описаны в [758].
......
802 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
вхо дной
сиr ал
Рис. 13.1. Цепь, состоящая из емкости и сопротивления
Элемент 1
Элемент 2
Элементр
Входной
сиrнал
v
Отводы
Рис. 13.2. Обобщенная память порядка р
Если х(n) равно единичному импульсу, то у(n) сводится к импульсному отклику
(impulse response) h(n) системы. Одним из важных свойств z преобразований яв
ляется то, что свертка во временной области преобразовывается в про изведение
в z области [444], [802]. Если обозначить z-преобразование последовательностей
{h(n)} и {у(n)} как H(z) и Y(z) соответственно, применение z-преобразования
к формуле (13.2) приводит к соотношению
Y(z) == H(z)X(z),
(13.3)
или, эквивалентно:
Н( ) == Y(z)
z X(z) .
(13.4)
Функция H(z) называется передаточной функцией (trапsfеr function) системы.
На рис. 13.2 показана блочная диаrpамма памяти дискретноro времени, состоящей
из р идентичных блоков с каскадным соединением. Далее значение р будем называть
порядком (order) памяти.
Если рассматривать каждый из блоков задержки как оператор, ero можно опи
сать передаточной функцией G(z). Также каждый блок можно описать в терминах
импульсноrо отклика g(n), который обладает следующими свойствами.
· Он является причинным (causal), Т.е. g(n) == О для n < О.
00
· Он является нормализованным (normalized), Т.е. 2: I 9 (n) I == 1.
n o
Исходя из этоrо, g( n) называют образующим ядром (generating kemel) памяти
дискретноrо времени.
13.2. СТРУКТУРЫ кратковременной памяти 803
в свете рис. 13.2 можно формально определить кратковременную память как ли-
нейную, инвариантную ко времени, систему с одним входом и несколькими Bыxoдa
ми (SIMO), образующее ядро которой удовлетворяет вышеописанным требованиям.
Точки коммутации, к которым подключены выходные терминалы памяти, обычно Ha
зывают отводами (tap). Обратите внимание, что память порядка р содержит р + 1
отвод (один отвод принадлежит входу).
Атрибуты любой структуры памяти определяются в терминах шубины и
разрешения. Обозначим как gp(n) общий импульсный отклик памяти, опре
деляемый как р последовательных сверток g(n), или, эквивалентно, обратное
z преобразование GP(z). rлубина памяти (memory depth) D определяется как первый
момент по времени gp(n):
00
D == L ngp(n).
n o
(13.5)
Память с небольшой шубиной D хранит информацию только за относительно
короткий период времени, в то время как память с большой шубиной хранит ин-
формацию из более отдаленноrо ПрОllШоrо. Разрешение памяти (memory reso1ution),
обозначаемое символом R, определяется как число отводов структуры памяти, COOT
ветствующее единице времени. Эта величина определяет уровень rpубости хранения
информации: чем выше разрешение, тем более точно пред ставлена информация. При
фиксированном количеСтве отводов произведение шубины и разрешения памяти яв
ляется константой, равной порядку памяти р.
Различные варианты образующеrо ядра gp(n) приводят к различным значениям
шубины D и разрешения R, что будет продемонстрировано двумя нижеследующими
примерами структур памяти.
Память на основе линии задержки с отводами
На рис. 13.3 показана блочная диаrpамма простейшей и наиболее широко использу
емой формы кратковременной памяти, которая называется памятью на основе линии
задержки с отводами. Она состоит из р операторов единичной задержки, каждый из
которых характеризуется функцией G(z) == Z l. Это значит, что образующее ядро
g(n) == 8(n 1), rдe ь(n) единичный импульс:
8(n) == { 1, n == О,
О, n # О.
(13.6)
Общий импульсный отклик памяти, показанной на рис. 13.3, равен gp(n) == 8(n р).
Подставляя это значение gp(n) в (13.5), получим шубину памяти, равную р, что
интуитивно понятно. На рис. 13.3 показано только по одному отводу в единицу
"""
804 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
ВХОДНОЙ
сиrнал
х(п)
Элемент 2
х(п 2)
Элемент р
x(п-p+ P)
1 " 1
)
у
ОТВОДЫ
Рис. 13.3. Обычная память на основе линии задержки с отводами порядка р
времени. ИСХОДЯ из этоro, разрешение такой памяти R == 1. Таким образом, шубина
памяти на основе линии задержки с отводами возрастает линейно пропорционально
порядку р, при этом ее разрешение фиксировано и равно единице. Про изведение
шубины на разрешение дает в результате константу р.
Для TOro чтобы осуществлять управление шубиной памяти, требуется дополни
тельная степень свободы. Это обеспечивается моделью, альтернативной линии за
держки с отводами, которую мы рассмотрим ниже.
rамма-память
На рис. 13.4 показан rpаф передачи сиrнала OCHOBHOro функциональноrо блока G(z),
используемоrо в структуре, называемой zамма памятью (Gamma memory) [256]. Каж
дый блок такой памяти состоит из цикла с единичной задержкой и подстраиваемым
параметром /l. Передаточной функцией каждоrо TaKoro блока является
/lZ l
G ( z )
1 (1 /l)Z l
/l
z (1 /l) .
(13.7)
Для устойчивости единственный полюс G (z) при z == 1 /l должен лежать внутри
единичноro кpyra на z плоскости. Это, в свою очередь, требует, чтобы
о < /l < 2.
(13.8)
Образующее ядро rамма памяти является обратным z преобразованием G(z), Т.е.
g(n) == /l(1 /l)n l, n ::::: 1.
(13.9)
Условие (13.8) rарантирует, что g(n) экспоненциально стремится к нулю при
стремлении n к бесконечности.
13.2. СТРУКТУРЫ кратковременной памяти 805
ВХОДНОЙ
сиrнал О
J1
.
z"
v
о ВЫХОДНОЙ
сиrнал
Рис. 13.4. rраф передачи сиrнала в одном
блоке rамма памяти
1 J1
0,4
n/J1
0,8
0,6
0,2
Рис. 13.5. Семейство
импульсных откликов
rамма памяти для по
рядка р == 1,2,3,4 и О
J.L == 0,7
2
4
6
8
10
Общий импульсный отклик rамма памяти является обратным z преобразованием
общей передаточной функции:
Gp(Z) == ( ) ,
Z (i ) р
Т.е.
( n 1 )
gp(n) == р 1 P(l )n p, n 2:: р,
(13.10)
rдe (:) биномиальный коэффициент, определяемый как ( n ) == n(n 1)... n p+l) для
р р.
целочисленных значений пир. Общий импульсный отклик gp(n) для переменно
ro р представляет собой дискретную версию подынтеrpальноrо выражения самма-
функции [256], откуда память и получила свое название. На рис. 13.5 показано се-
мейство импульсных откликов gp(n), нормализованных по отношению к . Такое
масштабирование привело к позиционированию пиковоrо значения gp(n) в n == р.
806 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
УЧИТЕЛЬ
......
Выходные нейроны
/k/
CJ::f::f::f:.X)
/t"
Скрытые нейроны
/ / !
t
\ \ "
Узлы источника
a::XJ:) a::XJ:) a::XJ:) a::XJ:) a::XJ:) a::XJ:) a::XJ:)
( a с а t )
Рис. 13.6. Архитектура сети NEТtalk
rлубина rамма памяти равна p/Il, а ее разрешение 11. При этом произведение
шубины на разрешение равно р. Следовательно, выбирая 11 меньшим единицы, raMMa
память увеличивает свою шубину (оrpубляя при этом разрешение) по сравнению с
памятью на основе линии задержки с отводами при заданном порядке р. При 11 == 1
эти атрибуты сводятся к соответствующим значениям, определяемым памятью на
основе линии задержки с отводам. Если 11 превышает единицу, но меньше 2, то
результат выражения (1 11) становится отрицательным, но имеющим абсолютное
значение меньше единицы.
13.3. Сетевые архитектуры для временной обработки
Сетевая архитектура для временной обработки имеет несколько форм, собственно как
и структуры памяти. В этом разделе речь пойдет о двух архитектурах сетей прямоrо
распространения, которые описаны в литературе, посвященной временной обработке.
NETtalk
Архитектура NEТtalk, предложенная в [962], впервые продемонстрировала оrpомную
параллельную распределенную сеть, которая преобразовывала аншийскую разroвор
ную речь в фонемы (фонема это базовая линrвистическая единица). На рис. 13.6
показана схематическая диаrpамма системы NETtalk, которая основана на мноrослой
ном персептроне с входным слоем, состоящим из 203 сенсорных узлов, 80 нейронов
cKpblToro слоя и 26 нейронов выходноrо слоя. Все нейроны используют сиrмоидаль
ные (лоrистические) функции активации. Синаптические связи этой сети опреде-
ляются в целом 18629 весами, включая переменный порос (threshold) для каждоro
нейрона, равный смещению (bias), взятому с обратный знаком. Для обучения сети
использовался стандартный алrоритм обратноrо распространения.
13.3. Сетевые архитектуры для временной обработки 807
Во входном слое этой сети содержалось семь rpупп узлов. Каждая rpуппа кодиро
вала одну букву входноrо текста. В любой момент времени на вход системы подава
лось семь букв текста. Желаемый отклик для этоro процесса обучения определялся
как корректная фонема, ассоциируемая с центральной (т.е. четвертой) буквой семи
символьноrо окна. Оставшиеся шесть букв (по три с каждой стороны от центральной)
являют собой частичный контекст для решения, принимаемоro сетью. Окно пере-
мещается по тексту на одну букву за шаr. На каждом шаre процесса сеть вычисляет
фонему, а после каждоrо слова синаптические веса сети корректируются в COOТBeT
ствии с тем, насколько близко вычисленное произношение находится к корректному.
Сеть NETtalk обнаружила ряд сходств с наблюдаемой процедурой рабо
ты человека [962].
. Обучение подчиняется степенному закону.
. Чем больше количество слов, на которых обучается сеть, тем лучше обобщение и
более корректно произношение новых слов.
. Производительность сети понижается достаточно медленно при повреждении от-
дельных синаптических весов сети.
. Повторное обучение после повреждения происходит значительно быстрее, нежели
первичное.
Архитектура NEТtalk блестяще продемонстрировала мноrие аспекты обучения,
которое начинается со значительных "предварительных" знаний о входных примерах,
которые постепенно повышаются на практике при преобразовании аншоязычной речи
в фонемы. Однако эта система не нашла практическоrо применения.
Нейронные сети с задержкой по времени
Популярной сетью, которая для временной обработки использует обычные задерж
ки, является так называемая нейронная сеть с задержкой по времени (time de1ay
neural network TDDN), которая впервые бьта описана в [613] и [1107]. TDDN
это мноrослойная сеть прямоrо распространения, скрытые и выходные нейроны ко-
торой реплицируются по времени (replicated across time). В этой работе было пред-
ложено с помощью спектроrpаммы извлекать в явном виде принципы симметрии,
которая встречается в обособленном слове (фонеме). Спектросрамма (spectrogram)
это двумерный рисунок, в котором вертикальное измерение соответствует частоте, а
roризонтальное времени. Интенсивность (яркость) точек на спектроrpамме COOT
ветствует энерrии сиrнала. На рис. 13.7, а показана версия TDDN с одним скрытым
слоем [613]. Входной слой состоит из 192 (16х 12) сенсорных узлов, кодирующих
спектроrpамму. Скрытый слой содержит 10 копий 8-ми скрьпых нейронов, а ВЫХОk
ной 6 копий 4-х нейронов. Различные копии cKpblToro нейрона применяют одно и
808 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
: Ш е : Выходные элемен1ы
I I
L.. J
1\
/ \"" ,
I I
I I
.... !
G)
o 4 выхода, каждый
r.:'\ из которых соединен
со всеми скрытыми
v элементами
Запаздывания
на 1,2, 3,4, 5
(1
(1 4 скрытых элемента,
каждый из которых
соединен со всеми
входными элементами
16
Входные элементы
Запаздывания
на 1, 2, 3
Кадры
спектроrpаммы
)
16 входных элементов
12
а)
б)
Рис. 13.7. Сеть, скрытые и выходные нейроны которой реплицированы во
времени (а). Представление нейронной сети с задержкой во времени (TDNN)
(б) (Приведено с разрешения авторов работы [613])
то же множество синаптических весов к узким (шириной в 3 шаrа по времени) окнам
спектроrpаммы. Аналоrично, различные копии выходноrо нейрона применяют узкие
(шириной в 5 шаrов по времени) окна псевдоспектроrpаммы, вычисленной скрытым
слоем. На рис. 13.7, б представлена интерпретация задержки по времени (time delay)
реплицируемой нейросети, изображенной на рис. 13.7, а (отсюда и берет свое назва-
ние "нейронная сеть с задержкой по времени"). Эта сеть содержит в совокупности
544 синаптических веса. В [613] сеть TDDN использовалась для распознавания четы
рех обособленных слов "Ьее", "dee", "ее" и "уее", которые обрабатывались четырьмя
выходными нейронами (см. рис. 13.7). При тестировании на данных, отличающих
ся от данных обучения, бьт получен результат распознавания, составляющий 93%.
При более комплексном изучении [1107] для распознавания трех обособленных слов
"Ьее", "dee" и "gee" использовалась сеть TDDN с двумя скрытыми слоями. При оцен-
ке производительности, в которой принимали участие три различных диктора, бьш
получен результат 98,5%.
13.4. Фокусированные сети прямоrо распространения с задержкой по времени 809
Оказалось, что сеть TDDN лучше работает при классификации временных обра
зов, состоящих из последовательности векторов признаков с фиксированными раз
мерностями (например, фонем). Однако при практическом распознавании речи нере-
ально предполаrать, что речевой сиrнал будет разделен на обособленные фонемы,
которые ero составляют. Вместо этоro приходится моделировать сеrментированную
временную структуру образцов речи. В частности, распознаватель речи должен pa
ботать с сеrментами слов и предложений, длина и временная структура которых
нелинейно варьируется. Для моделирования этих естественных характеристик Tpa
диционный подход к распознаванию речи может использовать структуру перехода
состояний, подобную скрытой модели Маркова [514], [865]. В своей основе скрытая
модель Маркова (hidden Markov model НММ) представляет собой стохастический
процесс, rенерируемый рассматриваемой цепью Маркова и множеством распреде
лений наблюдений, ассоциированным со скрытыми слоями. В литературе описано
множество rибридов сетей TDDN и нмм 4 .
13.4. Фокусированные сети прямоrо распространения
с задержкой по времени
При структурном распознавании образов (structural pattem recognition) принято ис
пользовать статические нейронные сети. В противоположность этому временное pac
познавание образов (temporal pattem recognition) требует обработки образов, изменя
ющихся во времени, и rенерации отклика в конкретный момент времени, который
зависит не только от текущеro, но и от нескольких предыдущих ero значений. На
рис. 13.8 показана блочная диаrpамма нелинейноzo фильтра, созданноrо на основе
статической нейронной сети [758]. Эта сеть стимулируется посредством KpaTKOBpe
менной памяти. В частности, для заданноro входноrо сиrнала, состоящеrо из TeKY
щеrо (х(n)) и р предыдущих значений (х(n 1),... ,х(n р)), хранимых в памяти
линейной задержки (delay line memory) порядка р, свободные параметры сети KOp
ректируются с целью минимизации среднеквадратической ошибки между выходом
этой сети у(n) и желаемым откликом d(n).
4 Использование rибридов TDDN и НММ при распозиавании речи описано в [120], [143], [544].
Некоторые такие rибриды объединяют кодировщик кадров на базе TDDN (т.е. отображение "дeTeктo
ра акустических признаков" на "классы слов предложений") и определитель маршрута слово предложение
(word/sentence path finder) НММ (т.е. отображение "символа фонемы" на "классы слов-предложений"), rдe
обе составляющие действуют независимо друr от дрyrа. В некоторых более сложных rибридах TDDN-HMM
функция квадратичной ошибки потерь для всей системы используется таким образом, что потери, связанные с
ошибкой слово-предложение, MOryт быть минимизированы. Примером последней схемы может служить TDDN
с множеством состояний (multi-state TDDN), описанная в [405], [406]. Простейший rибрид раздельно спроек
тированных модулей часто приводит к несоответствию производительностей обучения и тестирования. В этом
отношении сети TDDN с множеством состояний зарекомендовали себя лучше.
В фундаментальном смысле рекуррентные сети (которые будут рассматриваться в rлаве 15) имеют большую
способность моделировать временную cтpyкrypy речевоro сиrнала, чем репликационные сети типа TDDN. Тем
не менее из-за существенной нестационарности инелинейности речевоro сиrнала даже рекуррентных сетей
может быть недостаточно для точноrо распознавания речи.
81 О rлава 13. Временная обработкас использованием сетейпрямоrо распространения
Вход
х(п)
Краткосрочная
память
Статическая
нейронная
сеть
Сиrнал ошибки
Выход
у(п)
d(n)
Рис. 13.8. Нелинейный
фильтр, созданный на CTa
тической нейронной сети
Вход
х(п)
Внешнее
смещение
b j
Функция
активации
vin) Bыxoд
Yin)
Рис. 13.9. Фокусированный нейронный фильтр
Структура, показанная на рис. 13.8, может быть реализована на уровне как обособ
ленноrо нейрона, так и сети нейронов. Эта два варианта показаны на рис. 13.9 и 13.10.
для упрощения выкладок на рис. 13.9, 13.10 в качестве структуры KpaTKOBpeMeH
ной памяти использовалась память на основе линии задержки с отводами. ECTeCTBeH
но, оба этих рисунка можно обобщить, используя элемент памяти с передаточной
функцией G(z), а не Z l.
Элемент временной обработки на рис. 13.9 состоит из памяти на основе линии
задержки с отводами, отводы которой соединены с синапсами нейрона. Эта память
извлекает временную информацию, содержащуюся во входном сиrнале, которая, в
свою очередь, передается синаптическими весами в нейрон. Элемент обработки на
рис. 13.9 называют фокусированным нейронным фильтром (focused neuronal filter).
Здесь под понятием фокусировки подразумевается концентрация всей структуры па
13.4. Фокусированные сети прямоrо распространения с задержкой по времени 811
Вход
х(п)
Выход
у(п)
Рис. 13.10. Фокусированная сеть прямоro распространения с задержкой по Bpe
мени (TLFN). ДЛЯ упрощения представления уровни смещения (bias) опущены
мяти на переднем плане (front end) элемента. Выход этоrо фильтра в ответ на входной
сиrнал х(n) и ero преДЫДУIЦие значения х(n 1),...,х(n р) вычисляется по
следующей формуле:
Yj(n) <Р (t, wj(l)x(n 1) + b j ) ,
(13.11)
rдe <р(') функция активации нейрона j; Wj(l) ero синаптические веса; b j
ero смещение (bias). Обратите внимание, что вход функции активации состоит из
суммы смещения и свертки последовательностей входных сиrналов и синаптиче
ских весов нейрона.
Переходя к рис. 13.1 О, на котором показана фокусированная сеть прямоzо pacпpo
страненuя с задержкой по времени (focused time lagged feedforward network TLFN),
мы видим более мощный нелинейный фильтр, состоящий из памяти на основе линии
задержки с отводами порядка р и мноroслойноrо персептрона. Для обучения этоrо
фильтра можно использовать стандартный алrоритм обратноrо распространения (см.
шаву 4). В момент времени n "временной образ" применяется к входному слою сети
в виде вектора сиrнала:
х(n) == [х(n),х(n 1),... ,х(n р)]Т,
812 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
который можно рассматривать как описание состояния нелинейноrо фильтра в мо-
мент времени n. Одна эпоха состоит из последовательности состояний, количе-
ство которых определяется порядком памяти р и мощностью множества приме
ров обучения N.
Выход нелинейноro фильтра (предполаrается, что мноrослойный персептрон име
ет единственный скрытый слой, как показано на рис. 13.10) задается формулой
ml ml ( Р )
у(n) == WjYj(n) == Wj<P Wj(l)x(n l) + b j + Ь о .
(13.12)
Здесь предполаrается линейность выхода фокусированной TLFN, синаптические
веса составляют множество {W j } l' rдe тl размерность скрытоro слоя, а смеще
ние обозначено символом Ь о .
13.5. Компьютерное моделирование
в этом компьютерном эксперименте будет исследована возможность использования
фокусированной TLFN (см. рис. 13.10) для моделирования BpeMeHHoro ряда, пред-
ставляющеrо следующий сложный сиrнал с частотной модуляцией:
х(n) == sin(n + sin(n 2 )), n == 0,1,2,... .
Сеть используется в качестве одношаzовой системы проzнозированuя (one step
predictor), в которой х(n + 1) содержит желаемый отклик на входной сиrнал, COCTO
ящий из множества {х (n l) H o' Эта сеть имеет следующие характеристики.
Порядок памяти на основе линии задержки с отводами, р 20
Скрытый слой, тl 10 нейронов
Функции активации скрытых нейронов Лоrистические
Выходной слой 1 нейрон
Функция активации выходноro нейрона Линейная
Параметр интенсивности обучения (для обоих слоев) 0,01
Константа момента Отсутствует
Множество данных, использованных для обучения сети, состояло из 500 слу-
чайных примеров, каждый их которых состоял из 20 упорядоченных по времени
примеров, выбранных из последовательностей { х (n ) }.
На рис. 13.11, а показана суперпозиция одношаrовоrо проrнозирования, выпол
няемоrо сетью на не встречавшихся ранее (при обучении) данных и фактическоro
сиrнала. На рис. 13.11, б показан rpафик ошибки проrнозирования, определяемой
как разность между проrнозированным и фактическим значениями. Среднеквадрати
ческое значение этой ошибки проrнозирования равно 1,2 х 1O 3.
13.6. Универсальная теорема миопическоrо отображения 813
1,5
0,5
'"
:1: О
2
0,5
l
15
, О 50 100 150 200 250 300
а)
r О,: 1.1 h Л".д,' . 11." л, ',.1\. . n. . "' Лn /U\11 АЛ",мJ
02
, О 50 100 150 200 250 300
Время,п
б)
Рис. 13.11. Результаты компьютерноro моделирования с одношаroвым проrнозиро
ванием: суперпозиция фактическоrо (сплошная линия) и проrнозированноro (пунк
тир) сиrналов (а), ошибка проrнозирования (б)
13.6. Универсальная теорема миопическоrо
отображения
Нелинейный фильтр (см. рис. 13.9) можно привести к виду, показанному на рис. 13.12.
Эта обобщенная динамическая структура состоит из двух функциональных блоков.
Блок с меткой {h j }Y 1 представляет собой мноrочисленные свертки во временной об
ласти, Т.е. банк параллельно работающих линейных фильтров; h j выбирается из боль
шоrо множества ядер с действительными значениями, каждое из которых представ
ляет собой импульсный отклик HeKoToporo линейноro фильтра. Блок с меткой N пред
ставляет собой некоторую нелинейную статическую (не имеющую памяти) сеть пря-
Moro распространения (например, мноrослойнЫЙ персептрон). Структура, показанная
на рис. 13.12, представляет собой универсальный динамический оператор (universal
dynamic mapper). В [928] показано, что любое инвариантное к смещению миопическое
отображение (myopic mар) может быть при достаточно мяrких условиях как уroдно
хорошо равномерно аппроксимировано структурой, имеющей форму, показанную на
рис. 13.12. Требование миопичности сети эквивалентно равномерному затуханию пa
814 rлава 13. Временная обработкас использованием сетейпрямоro распространения
Вход
х(п)
N
Выход
у(п)
Банк ядер
свертки
(линейных
фильтров)
Статическая
нелинейная
сеть
Рис. 13.12. Общая структура для
универсальной теоремы миопическоrо
отображения
мяти (uniform fading memory). При этом предполаrается, что преобразование имеет
свойство причинности (causal), Т.е. данный выходной сиrнал rенерируется отображе
нием в момент времени n O только в том случае, если соответствующий входной
сиrнал применяется в момент времени n == о. Под инвариантностью к смещению под
разумевается следующее: если у(n) выход отображения входноrо сиrнала х(n), TO
rдa выход отображения смещенноrо входноrо сиrнала х (n по) будет равен у( n по),
rде ПО некоторое натуральное (integer) число. В [929] показано, что для любоrо
инвариантноrо к смещению отображения одной переменной, имеющеrо равномерно
затухающую память, существует некоторая rамма память и статическая нейронная
сеть, комбинация которых произвольно хорошо аппроксимирует это отображение.
Теперь можно сформулировать универсальную теорему миопическоzо отображе
нuя 5 [928], [929].
Любое инвариантное к смещению миопическое динамическое отображение может
быть как усодно хорошо аппроксuмировано структурой, состоящей из двух функци
ональных блоков: статической нейронной сети и банка линейных фильтров, форми
рующеzо ее входные данные.
Структура, внедренная в эту теорему, может иметь форму фокусированной TLFN.
Также важно отметить, что эта теорема выполняется и в случаях, Korдa входной и
выходной сиrналы являются функциями конечноrо числа переменных (как, например,
при обработке изображений).
Универсальная теорема миопическоro отображения имеет широкое практическое
применение. Она не только осуществляет математическое обоснование NEТtalk и ero
возможноrо расширения, использующеrо rамма память, но и формулирует среду для
создания более сложных моделей нелинейных динамических процессов. Мноrочис-
5 Основные формулировки и доказательства универсальной теоремы миопическоro отображения содержатся
в [927].
13.7. Пространственно временные модели нейрона 815
ленные свертки на переднем плане структуры (см. рис. 13.12) MOryT быть реализованы
линейными фильтрами с импульсными откликами конечной (FIR) или бесконечной
(IIR) длительности. С друrой стороны, статическая нейронная сеть может быть реа-
лизована с использованием мноrослойноrо персептрона, сети на основе радиальных
базисных функций или машины опорных векторов и соответствующих алrоритмов
(см. шавы 4 6). Друrими словами, при создании нелинейных фильтров и моделей
нелинейных динамических процессов можно опираться на материал, изложенный в
шавах, посвященных обучению с учителем. Более Toro, предполаrая устойчивость ли-
нейных фильтров, входящих в структуру, приведенную на рис. 13.12, можно roворить
о внутренней устойчивости (inherently stable) всей этой структуры. Таким образом,
имеется четкое разделение ролей и методов работы с кратковременной памятью и
нелинейностью, не содержащей память.
13.7. Пространственно-временные модели нейрона
Фокусированный нейронный фильтр (см. рис. 13.9) имеет довольно интересную ин
терпретацию, о которой речь пойдет в этом разделе. Комбинацию элементов еди
ничной задержки и соответствующих синаптических весов можно рассматривать как
фильтр с конечной импульсной характеристикой (finite duration impulse response fi1
ter FIR) порядка р (рис. 13.13, а). FIR фильтр является одним из основных KOH
структивных блоков при обработке цифровоrо сиrнала [444], [802]. Следовательно,
фокусированный нейронный фильтр (см. рис. 13.9) фактически является нелинейным
FIR фильтром, показанным на рис. 13.13, б. Можно построить такое представление и
таким образом расширить вычислительную мощность нейрона в пространственном
смысле, используя все то входы (рис. 13.14). Пространственно временная модель,
приведенная на рис. 13.14, называется нейронным фильтром с несколькими входами
(mu1tiple input neuronal filter).
Существует еще один способ описания модели, показанной на рис. 13.14: ее можно
рассматривать как распределенный нейронный фильтр (distributed neuronal filter) в
том смысле, что действия фильтрации проводятся для различных пространственных
точек. Эта пространственно-временная модель имеет следующие характеристики.
. Нейрон имеет то "первичных" синапсов, каждый из которых состоит из линей
Horo фильтра дискретноrо времени, выполненноro в форме порядка р. Первичные
синапсы при обработке сиrнала учитывают пространственное измерение.
. Каждый из "первичных" синапсов имеет (р + 1) "вторичных" синапсов, KOTO
рые связывают ero с соответствующими входами и отводами памяти FIR фильтра,
учитывая при обработке сиrнала временное измерение.
816 rлава 13. Временная обработкас использованием сетейпрямоro распространения
Xj(п)
Xj(n - 2)
Xj(n-p+ 1)
Wji(O)
Wji(l)
wj,{З)
wip 1)
Wji(P)
р
si n ) L wjj(k)xj(n - k)
k O
а)
Внешнее смещение
Ь }
Вход
х;(п)
Yi n )
Функция
активации
б)
Рис. 13.13. Фильтр с конечной импульсной характеристикой (FIR) (а); интерпретация нейрон
Horo фильтра как нелинейноro FIR фильтра (б)
Xl(n)
Выход
у/п)
Множество
входов
х 2 (п)
хто(п)
Рис. 13.14. Нейронный фильтр с несколькими входами
Синаптическая структура нейронноrо фильтра (см. рис. 13.14) напоминает дерево,
показанное на рис. 13.15. Общее количество синаптических весов в этой структуре
равно то(р + 1).
Переходя к математическим терминам, пространственно временную обработ
ку, выполняемую нейронным фильтром на рис. 13.14, можно описать следую
щим образом:
( то р )
Yj(n) == <р wji(l)xi(n 1) + b j ,
(13.13)
13.7. Пространственно-временные модели нейрона 817
к отводам
памяти т о
(в том числе
и ко входам)
Узел
активации
к отводам
памяти 1
(В том числе
и ко входам)
к отводам
памяти 2
(в том числе
и ко входам)
Рис. 13.15. Древоподобное описание синаптической структуры
нейронноro фильтра с несколькими входами
rдe Wji(l) вес l ro вторичноro синапса, принадлежащеrо i MY первичному синапсу;
Xi (n) входной сиrнал, применяемый к i MY первичному синапсу в момент Bpe
мени n; b j смещение (bias), при меняемое к нейрону. Индуцированное локальное
поле vj (n) нейрона, Т.е. apryмeHT функции активации <р в выражении (13.13), можно
рассматривать как дискретную по времени аппроксимацию следующей формулы в
непрерывном времени:
то J t
Vj(t) == oo hji("л,)Хi(t "л,)d"л, + b j .
(13.14)
Интеrpал в формуле (13.14) является сверткой непрерывноro входноro сиrна
ла Xi(t) и импульсноrо отклика hij(t), характеризующей линейный непрерывный
фильтр, представляющий синапс i. Уравнение (13.14) является самым общим спосо
бом описания пространственно временноrо поведения индуцированноrо локальноrо
поля нейрона.
818 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
Аддитивная модель
Уравнение (13.14) является основой друrой широко используемой пространственно
временной модели нейрона. Предположим, например, что мы упростили временное
поведение нейрона, использовав параметр масштабирования для определения знака и
направления "типичноro" синаптическоrо импульсноrо отклика. В этом случае можно
записать, что
h ,, ( t ) == W .. . h . ( t ) ДЛ Я всех i
з' З' J ,
(13.15)
rдe h j (t) моделирует временные характеристики типичноro постсинаптическоrо по
тенциала, а Wji скаляр, определяющий ero знак (возбуждение или торможение) и
общую мощность соединения между нейроном j и входом i [968]. Таким образом,
подставив (13.15) в (13.14), а затем изменив порядок интеrpирования и суммирова
ния, получим:
v;(t) 1 hj(л) ( Wj,x,(t л)) dл +b j
hj(t) * ( Wj,x,(t)) + b j ,
(13.16)
rдe символ звездочки обозначает операцию свертки. Форма общеrо импульсноrо OT
клика h j (t) зависит от объема требуемой детализации. Чаще Bcero для Hero исполь
зуется следующая функция:
hj(t) == ехр ( ) ,
Tj Tj
(13.17)
rдe Tj некоторая временная константа, ЯВЛЯЮЩаяся характеристикой нейрона j.
Функция времени h j (t) в выражении (13.17) сходна с импульсным откликом простой
электрической цепи, состоящей из сопротивления Rj и емкости C j , соединенных
параллельно и питающихся от текущеrо источника, Т.е.
Tj == RjC j .
(13.18)
Следовательно, выражения (13.16) и (13.17) можно использовать при формули
ровке модели, показанной на рис. 13.16. rоворя физическими терминами, синапти
ческие веса Wjl, Wj2" . . ,Wjmo представлены проводимостью (т.е. величиной, обрат-
ной сопротивлению), а соответствующие входы Хl (t), X2(t),. .. 'Х то (t) представлены
потенциалами (т.е. напряжением). Сумматор характеризуется малым входным сопро
13.7. Пространственно временные модели нейрона 819
WjI
хзU)
ИСТОЧНИК
тока
X1(t)
хр)
Нелинейность
{t)
L w..x.(t)
j JI 1
..
,
I
I
I
,
\
I
Rj :
I
......... .....;
Xm(t)
t
hP)
Рис. 13.16. Аддитивная модель нейрона
тивлением, единичным усилением тока и высоким выходным сопротивлением. Это
значит, что он выступает как узел суммирования входящих токов. Таким образом, об
щий ток, проходящий через эту резисторно емкостную цепь (resistance capacitance
RC), составляет:
то
L WjiXi(t) + Ij,
i l
rдe первое слаrаемое (суммирование) соответствует возбуждениям Xl(t),X2(t),...,
Х тО (t), воздействующим на синаптические веса (проводимости) Wjl, Wj2" . . ,Wjmo'
а второе слаrаемое является током источника Ij, представляющий внеш-
нее смещение (bias) b j .
В литературе по нейронным сетям модель, показанную на рис. 13.16, обычно
называют аддитивной (additive model). Эту модель можно рассматривать как HeoдHO
родную (lumped) аппроксимацию электрической цепью модели в виде распределенной
линии передачи (distributed transmission line model) биолоzическоzо дендрическоzо ней
рона (biological dendritic neuron) [867]. Такую природу RС цепи (см. рис. 13.16) мож
но также объяснить тем фактом, что сам биолоrический синапс является фильтром,
предназначенным для хорошей аппроксимации [954].
820 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
13.8. Распределенные сети прямоrо распространения
с задержкой по времени
Универсальный алroритм миопическоro отображения, который обеспечивает MaTeMa
тическое обоснование фокусированной TLFN, оrpаничен только теми отображения
ми, которые инвариантны к смещению. Значение этоro оrpаничения состоит в том, что
фокусированные TLFN применимы только в стационарных (инвариантных по BpeMe
ни) средах. Это оrpаничение можно обойти, используя распределенные сети пРЯМО20
распространения с задержкой по времени (TLFN). Здесь под распределенностью
подразумевается то, что неявное влияние времени распределено по всей сети. KOH
струкция такой сети основывается на применении нейронноrо фильтра с несколькими
входами (см. рис. 13.14) в качестве пространственно-временноймодели нейрона.
Обозначим символом Wji(l) вес, соединенный с [ M отводом FIR фильтра, Moдe
лирующеrо синапс, соединяющий выход нейрона i с нейроном j. Индекс l варьиру
ется от нуля до порядка FIR-фильтра р. Сошасно этой модели, сиrнал Sji(n),
образующийся на выходе i-ro синапса нейрона j, представляется суммой cвepm
ки (convolution sum):
р
Sji(n) == L wji(l)xi(n [),
I O
(13.19)
rдe n дискретное время. Выражение (13.19) можно переписать в матричном
виде, если ввести следующие определения вектора состояния и вектора весов
для синапса z:
Xi(n) == [Xi(n)'Xi(n 1),... ,xi(n р)]Т,
Wji(n) == [Wji(0),Wji(1),... ,Wji(P)]T.
(13.20)
(13.21)
Таким образом, скалярный сиrнал S ji (n) можно выразить как скалярное произве
дение векторов Wji(n) и Xi(n):
Sji(n) == W Xi(n)'
(13.22)
Формула (13.22) определяет выход Sji(n) i ro синапса нейрона j в модели, пока
занной на рис. 13.14, в ответ на подачу входноrо вектора Xi(n)' rдe i == 1,2,... , то.
Вектор Xi( n) называют "состоянием", так как он представляет состояние i ro синапса
в момент времени n. Исходя из этоrо, суммируя вклад Bcero множества, состоящеrо
из та синапсов модели (т.е. суммируя по всем индексам i), можно описать выход
у j (n) нейрона j следующей парой уравнений:
то то
щ(n) == L Sji(n) + b j == L W Xi(n) + b j ,
i l i l
уАn) == (j)(Vj(n)),
(13.23)
(13.24)
13.9. Алroритм обратноro распространения во времени 821
rдe vj (n) индуцированное локальное поле нейрона j; b j внешнее смещение (bias);
Ч'(') нелинейная функция активации нейрона. Предполаrается, что во всех нейронах
сети используется одна и та же форма нелинейности. Обратите внимание, что если
векторы состояний и весов (Wji и Xi(n)) заменить соответствующими скалярами (Wji
и Xi) и если операцию скалярноrо произведения заменить простым умножением,
то динамическая модель нейрона, представленная выражениями (13.23) и (13.24),
сведется к статической модели, описанной в шаве 4.
13.9. Алrоритм обратноrо распространения
во времени
Для обучения распределенной сети TLFN требуется некоторый алroритм обучения с
учителем, в котором фактический отклик всех нейронов выходноrо слоя сравнива-
ется с желаемым (целевым) откликом в каждый момент времени. Предположим, что
нейрон j находится в выходном слое сети, а ero выход обозначен как У j (n), при этом
желаемый отклик этоro нейрона обозначен dj(n) (имеются в виду значения в MO
мент времени n). После этоro можно определить мсновенное (instantaneous) значение
суммы среднеквадратических ошибок сети следующим образом:
1" 2
Е(n) == "2 ej(n),
j
(13.25)
rде индекс j соответствует только нейронам выходноro слоя, а ej (n) сиrнал ошибки,
определяемый следующим образом:
ej(n) == dj(n) Yj(n).
(13.26)
Нашей целью является минимизация функции стоимости (cost fиnction), опреде-
ляемой как сумма квадратичных ошибок Е(n) по всем моментам времени:
Е общая == L Е(n).
(13.27)
n
Алrоритм, который можно использовать для вычисления оценки оптимальноrо
вектора весов и с помощью KOToporo достиrается цель, основан на аппроксимации
метода наискорейшеro спуска.
Очевидно, что для решения поставленной задачи нужно продифференцировать
функцию стоимости (13.27) по вектору весов Wji:
дЕобщая == L дЕ(n) .
aw J ., aw..
. n J'
(13.28)
822 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
Продолжая далее действия в соответствии с подходом MrHoBeHHoro rpадиента,
мы раскрываем сеть во времени (unfold the network in time). Стратеrия состоит в
следующем: в первую очередь нужно попытаться устранить в сети все задержки
по времени, разворачивая ее в эквивалентную "статическую", но более rpомоздкую
сеть, после чеro можно применить стандартный алrоритм обратноrо распространения
для вычисления мrновенных rpадиентов ошибки. К сожалению, такой подход имеет
следующие недостатки.
· Потери в смысле симметрии между прямым распространением состояний и об
ратным распространением в терминах, необходимых для вычисления MrHoBeHHbIX
rpадиентов ошибки.
· Отсутствие удобных рекурсивных формул для распространения ошибки.
· Потребность в rлобальной бухrалтерии для ведения учета TOro, какие статиче-
ские веса остались неизменными в эквивалентной сети, полученной раскрытием
(unfolding) распределенной TLFN.
Несмотря на то что использование мrновенной оценки rpадиента является оче-
видным подходом при разработке временной версии обратноrо распространения, с
практической точки зрения он не рационален.
Чтобы обойти проблемы, связанные с подходом MrHoBeHHoro rpадиента, в [1110],
[1111] бьто предложено действовать следующим образом. Во-первых, мы понимаем,
что раскрытие общей ошибки rpадиента в сумму мrновенных ошибок (см. (13.28))
не является единственно возможным. В частности, можно рассмотреть следующий
альтернативный способ выражения частной производной функции стоимости Еобщая
по вектору весов Wji:
дЕобщая L дЕ общая aVj(n)
aw.. av. ( n ) дw..'
Jt n J Jt
(13.29)
ще индекс времени n касается только Vj(n). Можно интерпретировать частные про
изводные дЕобщая/ aVj (n) как изменение функции стоимости, вызванное изменением
индуцированноro локальноrо поля Vj (n) нейрона j в момент времени n. Здесь важно
обратить внимание на то, что
дЕобщая aVj(n) # дЕ(n)
av. ( n ) дw.. дw.. .
J Jt Jt
Равенство достиrается только тоща, коrда берется сумма по всем n (см. (13.28) и
(13.29)).
Имея разложение (13.29), можно использовать идею rрадиентноrо спуска в про
странстве весов. В частности, можно реализовать следующую рекурсию для KoppeK
13.9. Алrоритм обратноrо распространения во времени 823
ции вектора BeCOB OTBOДOB W ji ( n ):
дЕ общая дщ (n )
Wji(n + 1) == Wji(n) 11 дщ(n) дwji(n) '
(13.30)
rде 11 параметр скорости обучения (learning rate parameter). Из определения (13.23)
видно, что для любоrо нейрона j сети частная производная индуцированноrо локаль
HOro поля Vj(n) по отношению к Wji(n) определяется следующим образом:
aVj (n)
дWji(n) == Xi(n)'
(13.31)
rде Xi (n) входной вектор, применяемый к синапсу i нейрона j. Более TOro, можно
определить локальный срадиент (local gradient) нейрона j следующим образом:
\:: . ( ) == дЕобщая
и) n aVj(n) .
(13.32)
Следовательно, равенство (13.30) можно пере писать в знакомом виде:
Wji(n + 1) == Wji(n) + 11bj(n)xi(n)'
(13.33)
Как и при выводе стандартноrо алroритма обратноro распространения (см. ша-
ву 4), явная форма локальноrо rpадиента b j (n) зависит от TOro, rдe находится нейрон
j: в выходном или скрытом слое сети. Оба этих случая мы рассмотрим ниже.
Случай 1. Нейрон j является выходным элементом
Для выходноro слоя имеем:
дЕобщая дЕ(n) ,
bj(n) == aVj(n) == aVj(n) == ej(n)<p (щ(n)),
(13.34)
rдe ej(n) сиrнал ошибки, измеряемый на выходе нейрона j; <р'(-) производная
функции активации <р(') по своему apryMeHТY.
Случай 2. Нейрон j является скрытым элементом
Если нейрон j находится в скрытом слое, символом А можно обозначить MHO
жество всех нейронов, входы которых получают сиrнал от выхода нейрона j при
прямом распространении. Пусть V r (n) индуцированное локальное поле нейрона r,
принадлежащеrо множеству А. Torдa можно записать, что
bj(n) == дЕ общая == L L дЕобщая avr(k) .
дщ(n) тЕА k avr(k) дщ(n)
(13.35)
rлава 1 з. Временная обрабо,"ас использованием се,ей"рямо<о рас"рос'ранени' '"'"
824
Подставляя определение (13.32) (в котором индекс r используется вместо индекса
j) в (13.35), можно записать:
ь'(n) == L L br(k) avr(k) == L L br(k) avr(k) aYj(n) ,
J тЕА k aVj(n) тЕА k aYj(n) дщ(n)
(13.36)
rдe Yj(n) выход нейрона j. Далее несложно заметить, что частная производная
ду j (n)/ av j (n) равна (j)' ( V j (n)), если нейрон j находится вне множества А. Таким об
разом, этот множитель можно вынести за рамки двойноrо суммирования и пере писать
(13.36) следующим образом:
bj(n) == (j)'(Vj(n)) L L br(k) Vr .
тЕА k У)
(13.37)
Как бьто определено ранее, vr(n) обозначает индуцированное локальное поле
нейрона r, питаемоrо выходом нейрона j. Адаптируя выражения (13.19) и (13.23) к
данной ситуации, V r (k) можно выразить следующим образом:
то р
vr(k) == L L Wrj(l)Yj(n [).
j O I O
(13.38)
в равенство (13.38) включено смещение (bias) Ь т , применяемое к нейрону r как
слаrаемое, соответствующее j ==0:
wro(l) == Ьтуо(n [) == 1 для всех l и n.
( 13.39)
Индекс р, ОПределяющий верхний предел BHyтpeHHero суммирования в (13.38),
является порядком каждоro из синаптических фильтров нейрона r и всех осталь
ных нейронов рассматриваемоrо слоя. Индекс то, определяющий верхний предел
внешнеro суммирования в (13.38), является общим числом первичных синапсов, от-
носящихся к нейрону r. Признавая, что сумма свертки по l является коммутативной,
соотношение (13.38) можно переписать в следующем виде:
то р
vr(k) == L L Yj(l)wrj(n [).
j O I O
(13.40)
Дифференцируя (13.40) по Yj, получим:
avr(k) { Wrj(k [), n::; k ::; n + р,
aYj(n) О в противном случае.
(13.41)
13.9. Алroритм обратноro распространения во времени 825
в свете (13.41) частные производные дv r (k)IдУj(n) в (13.37), для которых k
находится вне диапазона n ::; k ::; n + р, равны нулю. Если нейрон j являетс
скрытым, подставив (13.41) в (13.37), получим:
n+р
bj(n) == <р'(щ(n)) L L br(k)wrj(k [)
rEA k n
р
== q>'(Vj(n)) L L br(n + l)wrj(n).
rEA I O
(13.42)
Определим новый вектор размерности (р + 1) х 1:
r(n) == [br(n), br(n + 1),... , br(n + р)]Т.
(13.43)
Ранее с помощью выражения (13.21) уже был определен вектор весов Wji' Используя
матричные символы, выражение (13.42) можно переписать в более компактном виде:
bj(n) == q>'(Vj(n)) L ;(n)Wrj,
rEA
(13.44)
rде ; (n)w rj скалярное произведение векторов r (n) и W rj, которые имеют
размерность (р + 1). Равенство (13.44) является окончательным выражением оценки
b j ( n) для нейрона j скрытоro слоя.
Теперь можно записать окончательное выражение для коррекции весов в методе
обратноzо распространения во времени (temporal back propagation) [1110], [1111]:
Wji(n + 1) == Wji(n) + 1lbj(n)xi(n)'
{ ej (n)q>'(vj (n)), нейрон j принадлежит выходному слою,
bj(n) == q>'(Vj(n)) 2: A;(n)wrj, нейрон j принадлежит скрытому слою.
rEA
(13.45)
(13.46)
Эти выражения можно обобщить для любоrо количества скрытых слоев. Мы ясно
видим, что эти соотношения представляют собой векторное обобщение стандартноrо
алrоритма обратноro распространения. Если заменить входной вектор весов xi(n)'
вектор весов Wrj И вектор локальноrо rpадиента r соответствующими скалярами,
алrоритм обратноro распространения во времени сведется к обычному алroритму
обратноrо распространения (см. шаву 4).
Для вычисления b j (n) для нейрона j, расположенноro в скрытом слое, нужно pac
пространить (propagate) bS из следующеro слоя назад через синаптические фильтры,
возбуждение которых выводится из нейронаj в соответствии с формулой (13.44). Этот
механизм обратноrо распространения показан на рис. 13.17. Таким образом, локаль-
ный rpадиент b j (n) формируется не просто взвешенным суммированием, а обратной
826 rлава 13. Временная обработкас использованием сетейпрямоro распространения
Б/п)
4 2 (п)
Нейроны r
множества А
Рис. 13.17. Обратное рас-
пространение локальных
rрадиентов в распределен-
ной сети TLFN
фильтрацией каждым первичным синапсом. В частности, каждое новое множество
векторов входных сиrналов и желаемых откликов порождает новый шаr прямой и
обратной фильтрации.
Теперь видны практические преимущества использования BpeMeHHoro алrоритма
обратноro распространения. Среди них можно назвать следующие.
1. Сохраняется симметрия между прямым распространением состояний и обратным
распространением ошибок. Таким образом, поддерживается принцип параллель-
ной распределенной обработки.
2. Каждый отдельный вес синаптическоro фильтра используется только один раз
при вычислении bs. Таким образом, в методе MrHoBeHHoro rpадиента не наблюда
ется избыточных вычислений.
При выводе BpeMeHHoro алrоритма обратноro распространения 6 , описанноrо фор
мулами (13.45) и (13.46), предполаrается, что веса синаптических фильтров фик
сиро ваны для всех вычислений rpадиента. Естественно, это не совсем корректное
предположение для реальной адаптации. Следовательно, возникают несоответствия
в производительности между временным алroритмом обратноrо распространения и
временной версией, полученной с использованием метода мсновенносо (instantaneoиs)
rpадиента. Тем не менее эти несоответствия обычно имеют незначительный xapaK
тер. При небольшом значении параметра интенсивности обучения" расхождение в
характеристиках обучения этих двух алroритмов при их практическом применении
будет незначительным.
6 Альтернативный схематический вывод алroритма обратноro распространения во времени содержится в
[1112].
13.9. Алrоритм обратноrо распространения во времени 827
Оrраничения причинности
При внимательном изучении формулы (13.42) оказывается, что вычисление bj(n) не
носит причинный характер, так как требует знания будущих значений bS и W. ДЛЯ Toro
чтобы сделать эти вычисления причинными, в первую очередь обратим внимание на
то, что точная ссылка на время, используемая для адаптации, не важна. Более Toro, си
наптическая структура сети состоит из FIR-фильтров. Следовательно, причинность
требует использования дополнительной буферизации для хранения внутренних co
стояний сети. Отсюда следует, что нужно требовать, чтобы адаптация всех векторов
весов основывалась только на текущем и прошлых значениях сиrналов ошибки. Ta
ким образом, можно сразу же определить bj(n) для нейрона j в выходном слое и
адаптировать веса синаптических фильтров этоrо слоя. Для слоя, предшествующе
ro выходному, оrpаничения причинности предполаrают, что вычисление локальноro
rpадиента для нейрона j этоro слоя
bj(n р) == (j)'(Vj(n р)) L А;(n p)Wrj,
rEA
(13.47)
основывается только на текущем и предыдущих значениях вектора Ь. j:
b.r(n р) == [br(n р), br(n + 1 р),... , br(n)]T.
(13.48)
Уравнение (13.4 7) получено из второй строки (13.46) заменой индекса n на (n р),
rдe р порядок каждоro из синаптических FIR фильтров. Как уже roворилось ранее,
состояния Xi (n р) должны храниться, чтобы можно бьто вычислить произведение
bi(n p)Xi(n р) для адаптации вектора весов, соединяющих нейрон j последнеrо
скрытоrо слоя с нейроном i предыдущеro слоя. Для сети с несколькими крытыми сло
ями можно продолжить эту операцию еще для одноrо скрытоrо слоя (т.е. отстоящеrо
на два слоя от выходноrо в обратном направлении), удвоив смещение по времени.
Операция продолжается подобным образом для всех вычислительных слоев сети.
Исходя из этоrо, можно сформулировать причинную (causal) форму BpeMeHHoro
алroритма обратноro распространения, которая описана в табл. 13.1.
Несмотря на то что представленный алroритм менее эстетичен, чем ero непри-
чинная форма, описываемая выражениями (13.45), (13.46), эти формы алrоритма OT
личаются друr от друrа только заменой индексов.
Подводя итоr, можно утверждать следующее.
· Сиrнал bs распространяется по слоям сети (в обратном направлении), слой за
слоем, без дополнительных задержек. Такой стиль распространения заставляет
внутренние значения bs смещаться по времени.
. Для корректноrо смещения по времени эти состояния (т.е. значения Xi(n)) coxpa
няются в форме соответствующих про изведений, необходимых для адаптации BeK
828 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
ТАБЛИЦА 13.1. Алюритм обратною распространения во времени
1. Входной сиrнал распространяется по сети в прямом направлении, слой за сло-
ем. Определяется сиrнал ошибки ej (n) для нейрона j выходноro слоя путем
вычитания фактическоrо выходноrо сиrнала из желаемоro отклика. Также за
писываются векторы состояний для всех синапсов сети.
2. Для нейрона j выходноro слоя вычислим:
bj(n) == ej(n)(j) (n); Wji(n + 1) == Wji(n) + 1lbj(n)xi(n)'
rде Xj (n) состояние i-ro синапса скрьrтоro нейрона, соединенноrо с выходным
нейроном j.
3. Для нейрона j скрытоrо слоя вычислим:
bj(n [р) == (j)'(Vj(n [р)) L А;(n lp)Wrj,
тЕА
Wji(n + 1) == Wji(n) + 1lbj(n lp)Xi(n [р),
rдe р порядок каждоrо синаптическоrо FIR фильтра, а индекс l идентифици-
рует рассматриваемый скрытый слой. В сетях с несколькими скрьrтыми слоями
l == 1 соответствует скрытому слою, непосредственно предшествующему вы-
ходному слою, l == 2 соответствует скрытому слою, отстоящему от выходноro
на два слоя, и Т.Д.
торов весов. Друrими словами, добавленные задержки хранения требуются только
для состояний, в то время как обратное распространение дельт осуществляется
без задержек.
. Обратное распространение bs остается симметричным по отношению к прямому
распространению состояний.
. Порядок вычислений линеен по отношению к нумерации синаптических весов в
сети, как и при подходе MrHoBeHHoro rpадиента.
Распределенные сети TLFN являются более сложной структурой, чем фокусиро
ванные TLFN, описанные в разделе 13.4. Более Toro, временной алrоритм обратноrо
распространения, требуемый для обучения распределенных TLFN, требует больших
вычислительных мощностей, чем стандартный алroритм обратноrо распространения,
используемый для обучения фокусированных TLFN. При окончательном анализе ис
пользование одноrо из этих двух подходов определяется тем, требует ли рассматри
ваемая задача временной обработки в стационарной или нестационарной среде 7 .
7 В [1110] временной алroритм обратноro распространения использовался для нелинейноro проrнозирова-
ния нестационарных временных последовательностей, представляющих хаотические пульсации в NНз лазере.
Эти последовательности были частью соревнования Santa Fe Institиte Time-series Competition, которое проводи.
лось в США в 1992 roду. Решение Вана (Wan) для этой задачи временной обработки выиrpало это соревнование
у разнообразных решений, использовавших стандартные сети прямоro распространения и рекуррентные сети,
а также некоторые традиционные линейные техники [1110]. Хаос будет рассмотрен в rлаве 14.
13.10. Резюме и обсуждение 829
13.10. Резюме и обсуждение
Потребность во временной обработке возникает в мноrочисленных прикладных за-
дачах, в том числе следующих.
. Проzнозирование (prediction) и моделирование временных рядов (time series) [145],
[434].
. Шумоподавление (noise cancellation), в котором требуется использовать первичные
сенсоры (получающие желаемый сиrнал, заrpязненный шумом) и ссылочные ceH
соры (reference sensor) (получающие коррелированную версию шума) [434], [1144].
. Адаптивное уравнивание (adaptive equalization) неизвестноrо канала связи [434],
[859].
. Адаптивное управление (adaptive control) [773].
. Идентификация систем (system identification) [664].
Уже существуют отработанные теории для решения вышеперечисленных задач для
случаев, Korдa рассматриваемая система или физический механизм линейны (см. BЫ
шеуказанные книrи). Однако, если система или физический механизм нелинейны,
задача оказывается более сложной. В ситуациях TaKoro рода нейронные сети имеют
потенциал для предоставления подходящеrо решения, таким образом проявляя свои
отличительные характеристики.
В контексте нейронных сетей для временной обработки подходят два их типа.
. Сети прямоzо распространения с задержкой по времени (TLFN).
. Рекуррентные сети.
Обсуждение рекуррентных сетей приводится в следующих двух шавах. В Ha
стоящей шаве описаны два типа сетей TLFN фокусированные и распределенные.
В фокусированных TLFN кратковременная память сосредоточена на переднем плане
статической сети, что упрощает ее конструкцию. Обучение фокусированной ТLFN
осуществляется стандартным алroритмом обратноro распространения (в предположе
нии, что статическая сеть реализована мноrослойным персептроном). Универсальная
теорема миопическоzо отображения (universal myopic mapping theorem) [928], [929]
является теоремой существования в том смысле, что она содержит математическое
доказательство возможности аппроксимации произвольноro миопическоro отображе
ния (т.е. причинноro отображения с равномерно затухающей памятью) с помощью
последовательности двух функциональных блоков: банка линейных фильтров и стати
ческой нейросети. Такая структура может быть создана с помощью фокусированной
ТLFN. Эти сети и являются физической реализацией вышеназванной теоремы.
830 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
Второй класс TLFN, распределенные, основан на использовании пространственно
временной модели нейрона нейронноro фильтра с несколькими входами. Эта MO
дель использует фильтры импульсноro отклика с конечной длительностью (FIR
фильтры) в качестве синаптических фильтров. Как таковые нейронные филь
тры с несколькими входами являются мощным функциональным блоком для
пространственно временной обработки сиrнала, созданной на базе одноrо нейрона.
Для обучения этих фильтров можно использовать LМS алrоритм (см. шаву 3), OДHa
ко для обучения распределенной TLFN требуется более сложный алrоритм обучения.
В качестве примера TaKoro алrоритма в разделе 13.9 был сформулирован BpeMeH
ной алroритм обратноrо распространения. Отличительным свойством распределен
ных TLFN является способ, которым неявное представление времени распределяется
по всей сети. Из этоro и происходит их способность работать в не стационарной (изме
няющейся во времени) среде. В противоположность этому в фокусированных TLFN
по определению явное представление времени сконцентрировано на переднем плане
сети, что оrpаничивает их использование только стационарными (инвариантными к
времени) средами.
Задачи
Фокусированные TLFN
13.1. Перечислите основные атрибуты фокусированных TLFN, используемых ДЛЯ
моделирования нелинейных динамических процессов.
13.2. Фокусированная TLFN, показанная на рис. 13.10, использует память на oc
нове линии задержки с отводами для реализации кратковременной памяти.
Каковы достоинства и недостатки фокусированных TLFN, использующих ДЛЯ
кратковременной памяти rамма память?
13.3. В шаве 2 качественно описан динамический подход к реализации нелиней-
ных адаптивных фильтров. Этот метод использует статические нейронные
сети, моделирование которых обеспечивается путем подачи входных данных
через скользящее окно. Это окно смещается при подаче каждоrо следующеrо
примера данных. При этом самый старый пример отбрасывался, чтобы осво-
бодить место новому. Обсудите, как можно использовать фокусированные
TLFN дЛЯ реализации этой формы непрерывноrо обучения.
Задачи 831
Пространственно-временные модели нейронов
13.4. Рассмотрим нейронный фильтр, индуцированное локальное поле Vj(t) KO
TOpOro определяется формулой (13.16). Предположим, что в этом равенстве
функция времени h(t) заменена смещенным единичным импульсом:
hj(t) == b(t Tj),
rдe Tj фиксированная задержка. Опишите, как изменится нейронный
фильтр при такой модификации.
13.5. Используя алrоритм LMS, сформулируйте алroритм обучения нейронноrо
фильтра с несколькими входами, показанноro на рис. 13.9.
Обратное распространение во времени
13.6. На рис. 13.18 показано использование временносо окна zауссовой фор
мы (Gaussian shaped time window) как метода временной обработки [139].
Временное окно, ассоциированное с синапсом i нейрона j, обозначается
как е(n, Tji, <Jji), rде Tji и <Jji соответственно меры времени задержки
и ширины:
1 ( 1 2 )
е(n, Tji, <Jji) == v21t ехр 2(n Tji) .
2п<Jji <J ji
Исходя из этоro, выход нейрона j моделируется следующим соотношением:
Vj(n) q> ( Wj,и,(n)) ,
rдe Ui(n) свертка входа Xi(n) и BpeMeHHoro окна е(n, Tji, <Jji)' Вес Wji и за
держка времени Tji синапса i, принадлежащеro нейрону j, должны обучаться
с учителем.
Это обучение может быть реализовано с использованием стандартноrо ал
rоритма обратноro распространения. Продемонстрируйте этот процесс обу
чения с помощью вывода уравнений коррекции величин Tji, <Jji и Wji'
I
I
!
I
i
L
13.7. Материал, представленный в разделе 13.9, посвященном временному ал
roритму обратноrо распространения, имеет дело с синаптическими FIR
фильтрами равной длины. Как поступить, если FIR фильтры будут иметь
разную длину?
832 rлава 13. Временная обработкас использованием сетейпрямоrо распространения
Вход
х,(п)
v/n)
Вход
х 2 (п)
Вход
хm(п)
Время п
Рис. 13.18.
13.8. Обсудите, как временной алroритм обратноrо распространения можно ис
пользовать для обучения распределенной TLFN дЛЯ одношаroвоro проrнози
рования.
13.9. Расхождения между причинной (causal) и беспричинной (noncausal) форма
ми алrоритма обратноro распространения во времени аналоrичны отличиям
стандартноro алrоритма LMS от алroритма LMS с задержками во времени
(см. шаву 3). Продолжите эту аналоrию.
Компьютерное моделирование
13.10. В этой задаче стандартный алrоритм обратноrо распространения будет ис
пользоваться для решения сложной задачи нелинейноrо проrнозирования и
сравнивать ero производительность с алrоритмом LMS. Рассматриваемые
временные последовательности созданы с помощью дискретной модели Воль
терра (Vоltепа mode1), имеющей следующий вид:
х(n) == Lgiv(n i) + L Lgijv(n i)v(n j) +...,
j
rдe gi, gij ,. ., коэффициенты Вольтерра; v( n) образы белоrо, независи
мо распределенноrо rayccoBa шума; х(n) результирующий выход модели
Вольтерра. Первое слаrаемое суммирования представляет собой хорошо зна
комую модель ряда со скользящим средним (moving average time series), а BTO
рое слаrаемое двойной суммы нелинейные компоненты все возрастающеrо
порядка. В общем случае оценка коэффициентов Вольтерра довольно сложна,
в основном по причине нелинейности соотношений по отношению к данным.
Задачи 8ЗЗ
В данной задаче мы рассмотрим простейший пример:
х(n) == v(n) + v(n 1)v(n 2).
Эта последовательность имеет нулевое среднее, она не коррелированна и,
таким образом, имеет белый спектр. Однако примеры этой последовательно
сти взаимозависимы. Таким образом, можно построить систему проrнозиро
вания более высокоro порядка. Дисперсия выхода этой модели определяется
по следующей формуле:
(J2 == (J2 + R2(J2
х v fJ v'
(13.49)
rдe (J дисперсия белоrо шума.
а) Сконструируйте мноroслойный персептрон, в котором входной слой co
стоит из 6 нейронов, скрытый из 16 нейронов, а выходной содержит
Bcero один нейрон. Для питания входноro слоя используется память на
основе линии задержки с отводами. Скрытые нейроны используют сито-
идные функции активации, оrpаниченные в интервале [0,1], в то время как
выходной нейрон работает в режиме линейноro сумматора. Эта сеть обу
чается с помощью стандартноrо алroритма обратноro распространения,
имеющеro следующие характеристики.
Параметр интенсивности обучения 11 == 0,001
Константа момента а == О, 6
Общее количество подаваемых примеров 100000
Количество примеров в одной эпохе 1000
Количество эпох 2500
Дисперсия белоrо шума (J задана равной единице. Следовательно, при
==0,5 окажется, что дисперсия на выходе системы проrнозирования co
ставит (J; == 1,25.
Вычислите кривую обучения этой системы проrнозирования, представив
дисперсию выхода х (n) как функцию от количества эпох примеров обуче
ния, которое по условиям задачи оrpаничено числом 2500. Для подrотовки
каждой из эпох обучения используйте следующие два режима.
Упорядочивание по времени примеров обучения при смене эпох про
изводится по той же форме, по которой они rенерируются.
Упорядочивание примеров обучения по отношению к состояниям носит
случайный характер.
Для мониторинrа обучения системы проrнозирования используйте пере
крестную проверку (см. rлаву 4), в которой множество проверки состоит
из 1000 примеров.
834
rлава 13. Временная обработкас использованием сетейпрямоrо распространения
1
б) Повторите этот эксперимент, используя алroритм LMS, сконструирован-
ный для осуществления линейноro проrнозирования на основе представ
ленных шести примеров. Параметр скорости обучения в этом алroритме
установите в значение 11 == 10 5.
в) Повторите весь эксперимент для следующих пар параметров: == 1,
cr 2 == 2' R == 2 cr 2 == 5
v , fJ , v .
Результаты каждоrо эксперимента должны показать, что в самом начале
алrоритмы обратноro распространения и LMS проходят практически одина
ковый путь, после чеro первый улучшает свою производительность проrно
зирования, достиrая заранее заданноro значения дисперсии cr;.
Нейродинамика
14.1. Введение
В предыдущей rлаве, посвященной обработке сиrналов во времени, рассматривались
структуры кратковременной памяти и работа статических нейронных сетей (на при
мере мноrослойноrо персептрона), выступающих в роли динамическоrо оператора
при поддержке структуры памяти. Еще одним важным способом встраивания BpeMe
ни в неявном виде в работу нейронной сети является использование обратной связи
(feedback). Обратная связь может присутствовать в нейронной сети в двух видах: в
виде локальной обратной связи (т.е. на уровне одноrо нейрона сети) и 2Лобальной
обратной связи (т.е. охватывающей всю сеть). Локальная обратная связь является
объектом, с которым довольно просто работать, а rлобальная обратная связь оказы
вает на сеть очень большое влияние. В литературе по нейронным сетям сети с одной
или несколькими обратными связями называют рекуррентными (recurrent). В этой и
следующей rлавах мы сосредоточим внимание на рекуррентных сетях, использующих
rлобальную обратную связь.
Обратная связь подобна обоюдоострому лезвию: будучи некорректно применен
ной, она может произвести паryбный эффект. В частности, применение обратной
связи может привести к неустойчивости системы. В этой rлаве основной интерес
представляет устойчивость рекуррентных сетей. Остальные аспекты этих сетей pac
сматриваются в следующей rлаве.
Область знаний, в которой нейронные сети рассматриваются как нелинейные ди
намические системы и основной упор делается на проблему устойчивости (stability),
называется нейродинамикой (пеurodiпашiсs) [466]. Важным свойством устойчивости
(или неустойчивости) нелинейных динамических систем является то, что оно распро
страняется на всю систему. В результате наличие устойчивости все2да принимает
одну из форм СО2Ласованности между отдельными частями системы [72]. Изуче
ние нейродинамики началось в 1938 rоду работой, в которой несбыточные мечты о
применении динамики в биолоrии переросли в первое исследование [873].
Устойчивость нелинейных динамических систем является достаточно сложным
вопросом. Коrда речь идет о задаче устойчивости, обычно ее понимают в терминах
836 rлава 14. Нейродинамика
критерия устойчивости типа "О2раниченный вход О2раниченный выход" (bounded
input bounded output stabi1ity criterion BIВO). Соrласно этому критерию, под устой
чивостью понимается то, что выход системы не должен неО2раниченно возрастать в
результате подачи оrpаниченноrо входноro сиrнала, начальноro состояния или неже
лательных сбоев [159]. Критерий устойчивости BIВO хорошо подходит для линей
ных динамических систем. Однако бесполезно применять ero к нейронным сетям,
так как подобные нелинейные динамические системы являются ВIВО устойчивыми,
поскольку В конструкцию нейрона встроена нелинейность с насыщением.
Korдa речь идет об устойчивости в контексте нелинейных динамических систем,
то подразумевается устойчивость по Ляпунову (stabi1ity in the sense of Lyapunov).
В работе, написанной в 1892 rоду, Ляпунов (русский математик и инженер) предста
вил фундаментальные концепции теории устойчивости, известные как прямой метод
Ляпунова (direct method of Lyapunov). Этот метод широко используется для анализа
устойчивости линейных и нелинейных систем, как зависящих, так и не зависящих от
времени. Ero можно напрямую применить к анализу устойчивости нейронных сетей.
В связи с этим большая часть материала настоящей rлавы посвящена прямому методу
Ляпунова. Следует заметить, что ero применение задача не из леrких.
При изучении нейродинамики можно пойти двумя путями, в зависимости от ин
тересующеrо ее применения.
· Путем детерминированной нейродинамики, в которой модель нейронной сети име
ет детерминированное поведение. В математических терминах эта модель опи
сывается как система нелинейных дифференциальных уравнений, определяющих
точную эволюцию системы как функцию времени [202], [402], [479].
· Путем статистической нейродинамики, в которой модель нейронной сети подвер
жена влиянию помех. В этом случае работа ведется со стохастическими нелиней
ными дифференциальными уравнениями, и решение выражается в вероятностных
терминах [25], [32], [825]. Комбинация стохастичности и нелинейности усложняет
объект исследования.
в этой rлаве оrpаничимся детерминированной нейродинамикой.
Структура rлавы
Материал этой rлавы разбит на три части. В первой части (разделы 14.2 14.6) пред
ставлен вводный материал. В разделе 14.2 поданы некоторые фундаментальные KOH
цепции динамических систем, а в разделе 14.3 обсуждаются устойчивости точек
равновесия. В разделе 14.4 описаны различные типы аттракторов, которые использу
ются при изучении динамических систем. В разделе 14.5 мы вернемся к аддитивной
модели нейрона, которая была выведена в rлаве 13. В разделе 14.6 описаны операции
с аттракторами как нейросетевая парадиrма.
14.2. Динамические системы 837
Во второй части rлавы (разделы 14.7 14.11) речь пойдет об ассоциативной памяти.
Раздел 14.7 посвящен подробной дискуссии о моделях Хопфилда и использовании их
дискретных версий в качестве ассоциативной или контентно адресуемой (content
addressable) памяти. В разделе 14.8 описано компьютерное моделирование этоro
применения сетей Хопфилда. В разделе 14.9 будет представлена теорема KoxeHa
rроссберrа для нелинейных динамических систем, для которой сети Хопфилда и дpy
rие виды ассоциативной памяти являются частным случаем. В разделе 14.1 О описана
еще одна нейродинамическая модель, которая хорошо подходит для кластеризации.
В разделе 14.11 рассматривается компьютерное моделирование этой второй модели.
Последняя часть rлавы (разделы 14.12 14.14) посвящена вопросу хаоса. В разде
ле 14.12 рассмотрены инвариантные характеристики хаотическоro процесса, за чем в
разделе 14.13 последует обсуждение вопроса, более тесно связанноro с нашим пред
метом, динамическоro восстановления хаотическоro процесса. В разделе 14.14
рассматривается компьютерное моделирование TaKoro восстановления.
rлава завершится выводами и рассуждениями.
14.2. Динамические системы
для TOro чтобы приступить к изучению нейродинамики, нужна математическая MO
дель, описывающая динамику нелинейной системы. Для этой цели, естественно, под
ходит модель в пространстве состояний (state space mode1). В соответствии с ней
рассуждения будут проводиться в терминах переменных состояний (state variable),
значения которых (в любой конкретный момент времени) должны содержать инфор
мацию, достаточную для проrнозирования эволюции системы. Пусть Х 1 (t), Х2 (t),. . . ,
Х N (t) переменные состояния некоторой нелинейной динамической системы, rдe t
независимая переменная непрерывноro времени; N порядок системы. Для удобства
выкладок эти состояния собраны в вектор x(t) размерности пх 1, который называется
вектором состояний (state vector) системы. Динамика большоrо класса нелинейных
динамических систем может быть представлена в форме системы дифференциальных
уравнений первоro порядка, имеющих вид
d
dt Xj(t) == Fj(xj(t)), j == 1,2,... ,N,
(14.1)
rдe Fj (.) некоторая нелинейная функция cBoero apryMeHTa. Применяя векторные
обозначения, всю систему дифференциальных уравнений можно представить в сле
дующем, более компактном виде:
d
dt x(t) == F(x(t)),
(14.2)
838 rлава 14. Нейродинамика
rде F нелинейная вектор функция, каждый элемент которой связан с COOTBeTCТВy
ющим элементом вектора состояний:
x(t) == [Xl(t)'X2(t),... ,XN(t)]T.
(14.3)
Нелинейная динамическая система, в которой вектор функция F(x(t)) не зависит
явным образом от времени t, называется автономной (autonomic); в противном случае
система называется неавтономной'. Мы рассмотрим только автономные системы.
Независимо от точной формы функции F(x(t)), вектор состояния может из
меняться во времени t. В противном случае состояние x(t) будет константой,
и система перестанет быть динамической. Таким образом, можно дать определе
ние динамической системе.
Динамической является та система, состояния которой изменяются во времени.
Более TOro, dxldt можно представить себе как вектор скорости не в физическом,
а в абстрактном смысле. Тоrда, соrласно (14.2), вектор функию F(x) можно назвать
векторным полем скорости (ve1ocity vector field), или просто полем скорости.
Пространство состояний
Целесообразнее рассматривать соотношение (14.2) как описывающее движение точ
ки в N MepHOM пространстве состояний. Это пространство состояний может быть
Евклидовым, или подмножеством последнеro. Это пространство может быть также и
не Евклидовым, например сферой, KpyroM, тором или любым друrим дифференциру
емым мноrообразием (differentiable manifold). для дальнейшеrо обсуждения интерес
представляет только Евклидово пространство.
Пространство состояний приобрело свою важность из за TOro, что оно предо
ставляет визуально концептуальное среДСТВ9 для анализа динамики нелинейной си
стемы, описываемой уравнением (14.2). Оно фокусирует внимание на rлобальных
характеристиках движения, а не на отдельных аспектах аналитических или числовых
решений этоro уравнения.
В конкретный момент времени t наблюдаемое состояние системы (т.е. вектор co
стояний x(t)) представлен одной точкой в N MepHoM пространстве состояний. Изме
нение состояния системы с изменением времени представляется кривой в простран
стве состояний, каждая точка которой (явно или неявно) является меткой времени
наблюдения. Такая кривая называется траекторией (trajectory) или орбитой (orbit)
системы. На рис. 14.1 показана траектория некоторой двумерной системы. MrнoBeH
ная скорость в этой траектории (т.е. вектор скорости dx(t)/dt) представлена вектором
1 Неавтономная динамическая система определяется уравнением состояния: ftx(t) == F(x(t), t) с началь-
ным состоянием x(to) == хо. В неавтономных системах вектор поля F(x(t), t) зависит от времени t. Таким
образом, в отличие от автономных систем в общем случае нельзя принять начальное время равиым нулю [818].
14.2. Динамические системы 839
Х 2
,
,
,
,
,
,
,
,
(2
(о
Рис. 14.1. Двумерная траектория (орбита)
некоторой динамической системы
о
Х]
TaHreHca (tangent vector) (на рис. 14.1 он показан пунктирной линией для момента Bpe
мени t == t o ). Аналоrично можно найти вектор скорости для любой точки траектории.
Семейство траекторий, соответствующих различным начальным состояниям, Ha
зывают портретом состояний (state portrait) системы. Этот портрет содержит точки в
пространстве состояний, в которых определено векторное поле F(x). Обратите вни
мание, что в автономной системе через одно начальное состояние проходит только
одна траектория. Полезным понятием, вытекающим из портрета состояний, является
поток (flow) динамической системы, определяемый как движение пространства co
стояний в самом себе. Друrими словами, можно представить себе, что пространство
состояний течет в каждой своей точке, подобно жидкости, по определенной TpaeK
тории [3]. Описанная здесь идея потока хорошо продемонстрирована на портрете
состояний на рис. 14.2.
Для заданноrо портрета состояний динамической системы можно построить поле
векторов скорости (TaHreHcoB) по одному вектору для каждой точки простран
ства. Таким образом, полученный рисунок, в свою очередь, является изображением
BeктopHoro поля системы. На рис. 14.3 показано множество векторов скорости, фор
мирующих картину общеrо вида этоrо поля. Полезность BeктopHoro поля заключается
в том факте, что оно дает визуальное описание внутренних тенденций динамической
системы к перемещению в любой точке пространства состояний.
840 rлава 14. Нейродинамика
Х 2
о
Рис. 14.2. Двумерный портрет состояний (фа-
Х! зовый портрет) некоторой динамической си-
стемы
Х 2
J I /
j /..--
\ I ,/
\ \ \ .) ; \\ t
"'---+-1
/!
/
о
Х 1 Рис. 14.3. Двумерное векторное поле некоторой
динамической системы
Условие Липшица
Для Toro чтобы уравнение (14.2) в пространстве состояний имело решение, а также
для единственности TaKoro решения, на вектор функцию F(x) необходимо наложить
некоторые оrpаничения. Для упрощения выкладок нужно отказаться от зависимости
вектора х от времени t. К этой практике мы будем иноrда прибеrать и в дальнейшем.
Для Toro чтобы решение существовало, достаточно, чтобы вектор функция F(x) была
непрерывна по всем своим aprYMeHTaM. Однако это условие не rарантирует един
ственности решения. Для этоrо необходимо наложить дополнительное оrpаничение,
14.2. Динамические системы 841
известное как условие Липшица. Пусть Ilxll норма, или Евклидов а длина вектора
х; х и u пара векторов в открытом множестве М в нормализованном векторном
пространстве (состояний). Torдa, соrласно условию Липшица, существует такая KOH
станта К, что [468], [500]:
IIF(x) F(u)11 Kllx ull
(14.4)
для всех х и о, при надлежащих М. Вектор функция F(x), удовлетворяющая усло
вию (14.4), называется функцией Липшица, а К константой Липшица для F(x).
Неравенство (14.4) также подразумевает непрерывность функции F(x) по х. Отсю
да следует, что в случае автономности системы условие Липшица rарантирует как
существование, так и единственность решения уравнения (14.2). В частности, если
частные производные aF i / aXj конечны в любой точке, то функция F(x) удовлетво
ряет условию Липшица.
Теорема о диверrенции
Рассмотрим область, образованную в пространстве состояний автономной системы
телом объемом V и поверхностью В, и обратим внимание на "поток" точек этой обла
сти. Из вышесказанноrо известно, что вектор скорости dx/ dt равен векторному полю
F(x). Предполаrая, что векторное поле F(x) в объеме V "ведет себя хорошо", мож
но применить теорему о диверrенции (divergence theorem) из векторноrо исчисления
[503]. Пусть п единичный вектор, нормальный к поверхности dS и направленный
вовне замкнутоrо объема. Тоща, соrласно теореме о диверrенции, должно выполнять
ся соотношение
fs (F(x) . п)dS == i (V . F(x))dV
(14.5)
между интеrpалом диверrенции по объему и интеrpалу по поверхности, направлен
ной вовне нормальной составляющей F(x). Величину в левой части (14.5) можно
понимать как общий поток, вытекающий из области, оrpаниченной замкнутой по
верхностью В. Если эта величина равна нулю, система считается консервативной
(conservative), если отрицательна диссипативной (dissipative). В свете выражения
(14.5) можно утверждать, что если диверrенция V . F(x) (скаляр) равна нулю, то
система консервативна, а если меньше нуля, то это диссипативная система.
842 rлава 14. Нейродинамика
14.3. УСТОЙЧИВОСТЬ СОСТОЯНИЙ равновесия
Рассмотрим автономную динамическую систему, описываемую уравнением в про
странстве состояний (14.2). Beктop KOHCTaHTa х Е М называется равновесным (CTa
ционарным) состоянием (equi1ibrium (stationary) state) системы, если выполняется
условие
F(x) == О,
(14.6)
rдe О нулевой вектор. Вектор скорости dxldt в точке равновесия исчезает; таким
образом, функция константа x(t) == х является решением уравнения (14.2). Более TO
ro, по причине единственности решения никакая друrая кривая решения не проходит
через состояние равновесия х. Состояние равновесия также называют синryлярной
точкой (singular point), отмечая тот факт, что в случае отклонения от точки равновесия
траектория снова приведет в эту точку.
Для Toro чтобы выработать rлубокое понимание условия равновесия, предполо
жим, что нелинейная функция F(x) достаточно rладкая для Toro, чтобы уравнение
(14.2) в пространстве состояний можно было линеаризовать в окрестности точ
ки х. Пусть
x(t) == х + дх(t),
(14.7)
ще дх (t) малое отклонение от точки х. Тоща, принимая во внимание только первые
два слаrаемые разложения в ряд Тейлора функции F(x), можно записать следующую
ее аппроксимацию:
F(x) х + Адх(t). (14.8)
Матрица А является Якобианом нелинейной функции F(x), вычисленной
в точке х==х:
А == д д F(x) I .
х х==х
(14.9)
Подставив (14.7) и (14.8) в (14.2) и воспользовавшись определением состояния
равновесия, получим:
д
at дх(t) Адх(t).
(14.10)
14.3. УСТОЙЧИВОСТЬ СОСТОЯНИЙ равновесия 843
ТАБЛИЦА 14.1. Классификация состояний равновесия
для систем BTOpOro порядка
Тип состояния
равновесия х
Устойчивый узел
Устойчивый фокус
Неустойчивый узел
Неустойчивый фокус
Седловая точка
Центр
Собственные значения матрицы Якобиана А
Вещественные и отрицательные
Комплексные с отрицательной действительной частью
Вещественные и положительные
Комплексные с положительной действительной частью
Вещественные с противоположными знаками
Чисто мнимые
Предполarая, что Якобиан А несинryлярен и, следовательно, обратная матри
ца А 1 существует, для определения локальноrо поведения траекторий системы в
окрестности paBHoBecHoro состояния х достаточно аппроксимации, описанной фор
мулой (14.10). Если Якобиан А несинryлярен, природа состояния равновесия в oc
новном определяется собственными значениями (eigenva1ue) и может быть классифи
цирована соответствующим образом. В частности, если матрица Якобиана А имеет
m собственных значений с положительными действительными частями, roворят, что
равновесное состояние х имеет тип т.
В частном случае для системы BTOpOro порядка можно выделить шесть типов
состояний равновесия (табл. 14.1 и рис. 14.4) [69], [209]. Без потери общности пред
полаrается, что состояние равновесия достиrается в начале координат, Т.е. х == о. Об
ратите внимание, что только в случае седловой точки (sadd1e point) (см. рис. 14.4, д)
траектории, входящие в нее, устойчивы, а исходящие из нее неустойчивы.
Определения устойчивости
Как уже отмечал ось, линеаризация уравнения в пространстве состояний дает полез
ную информацию о свойствах локальной устойчивости (10ca1 stabi1ity) состояния paв
новесия. Однако, чтобы иметь возможность более детальноro исследования устойчи
вости нелинейных динамических систем, нужны строrие определения устойчивости
и сходимости для состояния равновесия.
В контексте автономных нелинейных динамических систем с состоянием paBHO
весия х определения устойчивости и сходимости записываются следующим обра
зом [209].
844 rлава 14. Нейродинамика
Мнимая ось
+
Действительная
ось
Мнимая ось
4
Действительная
ось
Мнимая ось
I Действительная
ось
в)
Мнимая ось
+
Действительная
ось
Мнимая ось
I Д"""' """'
ось
д)
Мнимая ось
01
i
Действительная
ось
Х 2
а)
б)
r)
е)
Х 1
Х 1
Х 1
Х 1
Х 1
Рис. 14.4. Устойчивый
узел (а); устойчивый фо-
кус (б); неустойчивый узел
(в); неустойчивый фокус (r);
сепловая точка (д): иен D (е)
14.3. УСТОЙЧИВОСТЬ состояний равновесия 845
Определение 1. Состояние равновесия х называется равномерно устойчивым,
если для любоrо положительноrо € существует такое положительное 8, что из условия
\lx(O) xll < 8
следует, что
Ilx(t) xll < € для всех t > О.
Это определение утверждает, что траектория системы может оставаться BHYT
ри небольшой окрестности состояния равновесия х, если начальное состояние х(О)
близко к равновесному х.
Определение 2. Состояние равновесия х называется сходящимся, если существует
такое положительное 8, что из условия
Ilx(O) х\1 < 8
следует, что
x(t) .......... х при t .......... 00.
Значение BTOpOro определения состоит в том, что если начальное состояние
х(О) траектории достаточно близко к состоянию равновесия Х, то траектория, опи
сываемая вектором состояний x(t), достиrает точки х при устремлении BpeMe
ни t к бесконечности.
Определение 3. Равновесное состояние х называется асимптотически устойчи
вым, если оно одновременно является устойчивым и сходящимся.
Здесь следует заметить, что устойчивость и сходимость являются независимыми
свойствами. Только в том случае, Korдa оба они присутствуют, наблюдается асимпто
тическая устойчивость.
Определение 4. Состояние равновесия х называется rлобально асимптотически
устойчивым, если оно устойчиво и все траектории системы сходятся к точке х при
устр млении времени t к бесконечности.
Это определение подразумевает, что система не имеет друrих состояний paBHOBe
сия и что все траектории системы остаются оrpаниченными для всех моментов BpeMe
ни t > О. Друrими словами, rлобальная асимптотическая устойчивость подразумева
ет, что система в конце концов придет в состояние х при любых начальных условиях.
Пример 14.1
Пусть решение u(t) нелинейной динамической системы, описываемой уравнением (14.2), изме
няется во времени (рис. 14.5). для TOro чтобы это решение было равномерно устойчивым, требуется,
чтобы u(t) и любое друroе решение v(t) оставались достаточно близкими друr к друry при оди
наковых значениях t (см. рис. 14.5). Такой тип поведения называется изохронным соответствием
(isochronous correspondence) двух решений v(t) и u(t) [499]. Сходимость решения u(t) подразумева
ет, что для любоro друroro решения v(t), для КOTOpOro I I y(O)---и(О) I I ::; 8(е) в момент времени t == О,
решение v(t) также сходится к состоянию равновесия при устремлении времени t к бесконечности.
.
846
rлава 14. Нейродинамика
1
Е
Рис. 14.5. Понятие равномерной
устойчивости (сходимости) векто-
ра состояния
Теоремы Ляпунова
Определив устойчивость и асимптотическую устойчивость состояния равновесия в
динамических системах, можно приступить к рассмотрению вопроса о том, как опре
делить устойчивость. Естественно, это можно сделать с помощью фактическоrо Ha
хождения всех возможных решений уравнений системы в пространстве состояний,
однако такой подход достаточно сложен, а иноrда и невозможен. Более элеrантный
подход можно найти в современной теории устойчивости (modem stability theory), oc
новоположником которой является Ляпунов. В частности, можно исследовать задачу
устойчивости, применив прямой метод Ляпунова (direct method of Lyapunov), кото-
рый использует непрерывную скалярную функцию вектора состояний, называемую
функцией Ляпунова.
Теоремы устойчивости и асимптотической устойчивости Ляпунова для уравнения
(14.2) в пространстве состояний, описывающе.ro автономную нелинейную динамиче-
скую систему с вектором состояний x(t) и состоянием равновесия Х, формулируются
следующим образом.
Теорема 1. Состояние равновесия х является устойчивым, если в малой окрест-
ности этой точки существует Положительно определенная функция V(x), такая, что
ее производная по времени в этой области является отрицательно полуопределенной.
Теорема 2. Состояние равновесия х является асимптотически устойчивым,
если в малой окрестности этой точки существует положительно определенная
функция V(x), такая, что ее производная по времени в этой области являет-
ся отрицательно определенной.
Скалярная функция V(x), удовлетворяющая этим требованиям, называется функ-
цией Ляпунова для состояния равновесия Х.
Эти теоремы требуют, чтобы функция Ляпунова V(x) была положительно опреде-
ленной. Такая функция определяется следующим образом.
14.3. УСТОЙЧИВОСТЬ СОСТОЯНИЙ равновесия 847
Функция У(х) называется положительно определенной в пространстве состояний
G, если для всех х Е G выполняются следующие условия.
1. Функция V(x) имеет непрерывные частные производные по всем компонентам
вектора состояний х.
2. V(x) == О.
3. V(x) > о при х i= х.
для заданной функции Ляпунова V(x), соrласно теореме 1, равновесное состояние
х будет устойчивым, если 2
d
dt V(x) о для х Е U х,
(14.11)
rде U малая окрестность точки х. Продолжая далее, соrласно теореме 2, состояние
х будет асимптотически устойчивым, если
d
dt V(x) < о для х Е U х.
(14.12)
Важной точкой этой дискуссии является то, что теоремы Ляпунова можно приме
нить, не решая само уравнение системы в пространстве состояний. К сожалению, в
этих теоремах ничеrо не roворится о методах нахождения самих функций Ляпуно
ва это является уделом метода проб, ошибок и озарения, который нельзя обобщить.
Во мноrих задачах функцией Ляпунова может служить функция энерrии. Заметим,
что невозможность нахождения соответствующей функции Ляпунова не является дo
казательством неустойчивости системы. Существование функции Ляпунова является
достаточным, но не необходимым условием устойчивости системы.
Функция Ляпунова V(x) подводит математический базис под анализ rлобальной
устойчивости нелинейных динамических систем, описываемых уравнением (14.2).
С друroй стороны, использование выражения (14.10) основано на матрице Якобиана
А. Эта матрица является основой анализа локальной устойчивости системы. Выводы
анализа rлобальной устойчивости являются более мощными, чем выводы анализа ло
кальной устойчивости. Таким образом, любая rлобально устойчивая система является
локально устойчивой. Обратное утверждение неверно.
2 В дополнение к равенству (14.11) в общем случае rлобальная устойчивость нелинейных динамических
систем требует выполнения условия радиальной неоrpаниченности [1002]:
V(x)...... О при Ilxll...... 00.
Это условие обычно удовлетворяется функцией Ляпунова, построенной для нейронных сетей с сиrмоидаль
ной Функцней активации.
848 rлава 14. Нейродинамика
Рис. 14.6. Понятие бас-
сейна апракции и идеи
сепаратрисы
14.4. Аттракторы
Диссипативные системы в общем случае характеризуются наличием множества aT
тракторов или множествами, имеющим размерность, меньшую размерности про
странства состояний. Здесь под "множеством" понимается некоторая k мерная по
верхность, содержащаяся в N MepHOM пространстве состояний и описываемая сле
дующей системой уравнений:
M j (Xl,X2,'" ,XN) == о,
{ j == 1,2, . . . , k,
k<N,
(14.13)
rдe Хl,Х2, ..., XN элементы N MepHoro вектора состояний системы; M j HeKO
торая функция этих элементов. Такие множества называют аттракторами 3 , отмечая
тот факт, что они являются оrpаниченны и подмножествами, к которым сходятся
области начальных состояний пространства состояний ненулевоrо объема с течением
времени t [808].
Это множество может состоять из одной точки в пространстве состояний; в этом
случае roворят о точечном аттракторе. Это множество может также принимать фор
му периодической орбиты; в этом случае rоворят об устойчивом предельном цикле
(limit cyc1e). Здесь под устойчивостью понимается асимптотическая сходимость к это
му циклу близлежащих траекторий. На рис. 14.6 продемонстрированы эти два типа
аттракторов. Аттракторы представляют собой единственные равновесные состояния
3 В качестве cтpomm определения аттрактора можно предложить следующее [612], [640].
Подмножество М пространства состояннй называется аттрактором, еслн:
. М инвариантно к потоку;
· существует некоторая (открытая) окрестность М, которая стяrивается к М для заданноm потока (f1ow);
. никакая часть М не является переходной;
· не существует декомпозиции М на две непересекающиеся инвариантные части.
14.5. Нейродинамические модели 849
динамической системы, которые можно наблюдать экспериментально. Однако сле
дует заметить, что в контексте аттракторов равновесное состояние не обязательно
является статическим или устойчивым. Например, предельный цикл представляет
собой устойчивое состояние аттрактора, которое непрерывно изменяется во времени.
На рис. 14.6 видно, что каждый из аттракторов окружен собственной четко очер
ченной областью. Такая область называется бассейном (областью) аттракции (basin
или domain of attraction). Также заметим, что каждое начальное состояние системы
находится в бассейне какоro либо аттрактора. rраница, отделяющая один бассейн
притяжения от друroro, называется сепаратрисой (separatrix). В случае, показанном
на рис. 14.6, rpаница бассейна представлена объединением траекторий Т 1 и Т 2 И
седловой точки Q.
Предельный цикл является типичной формой осцилляции, которая возникает в
случае, коrда точка равновесия в нелинейной системе становится неустойчивой. Oc
цилляция может возникнуть в нелинейной системе любоro порядка. Тем не менее
предельные циклы являются типичной характерной чертой систем BTOpOro порядка.
rиперболические аттракторы
Рассмотрим точечный аттрактор, нелинейные динамические уравнения KOToporo ли
неаризованы в окрестности paBHoBecHoro состояния х (см. раздел 14.2). Обозначим
символом А матрицу Якобиана этой системы, вычисленную в точке х == х. Аттрактор
называется rиперболическим, если все собственные значения матрицы Якобиана А
имеют абсолютное значение меньше единицы [808]. К примеру, поток rиперболиче
CKOro аттрактора BToporo порядка может иметь формы, показанные на рис. 14.4, а, б.
В обоих случаях собственные значения матрицы Якобиана А имеют отрицательные
действительные части. rиперболические аттракторы представляют особый интерес
при изучении задачи, известной под названием задачи обращающихся в нуль rpади
ентов (vanishing gradients problem), которая возникает в динамически управляемых
рекуррентных сетях. Эта задача будет рассматриваться в следующей rлаве.
14.5. Нейродинамические модели
Формализовав поведение нелинейных динамических систем, можно приступать к
обсуждению отдельных важных вопросов нейродинамики, что и будет сделано в
этом и следующем разделах. Следует подчеркнуть, что не существует универсально
соrласованноro определения TOro, что понимается под нейродинамикой. Вместо ЭТО
ro определим наиболее общие свойства нейродинамических систем, которые будем
рассматривать в настоящей rлаве. В частности, оrpаничим рассмотрение теми ней
родинамическими системами, которые имеют непрерывные переменные состояний и
850 rлава 14. Нейродинамика
уравнения движения которых имеют дифференциальные или разностные формы. Pac
сматриваемые системы обладают четыIьмя общими характеристиками [826], [838].
1. Большое количество степеней свободы. Кора roловноro мозrа человека npeДCTaB
ляет собой в высшей мере параллельную и распределенную систему, которая,
по некоторым оценкам, содержит более 1 О миллиардов нейронов, а каждый ней
рон моделируется одной или несколькими переменными состояний. Общепринято
считать, что вычислительная мощность и отказоустойчивость такой нейродина
мической системы обусловлена ее коллективной динамикой. Эта система xapaK
теризуется большим количеством связывающих констант, представленных силой
(эффективностью) отдельных синаптических соединений.
2. Нелинейность. Нейродинамическая система является нелинейной. Фактически
нелинейность существенна при создании универсальных вычислительных машин.
3. Диссипативность. Нейродинамическая система является диссипативной (dissi
pative). Таким образом, она характеризуется сходимостью с течением времени
объема пространства состояний к некоторому множеству меньшей размерности.
4. Шум. Является существенной характеристикой нейродинамических систем. В pe
альном нейроне мембранный шум reнерируется в синаптических соединени-
ях [545].
Наличие шума обусловливает использование вероятностноro толкования деятель-
ности нейрона, что выводит анализ нейродинамических систем на более высокий
уровень сложности. Подробное изучение стохастической нейродинамики выходит за
рамки настоящей книrи, и в дальнейшем мы будем иrнорировать влияние шума.
Аддитивная модель
Рассмотрим динамическую модель нейрона без учета шума, показанную на рис. 14.7,
математические основы которой рассматривались в rлаве 13. В физических терминах
синаптические веса Wjl, Wj2, ... ,WjN представляют собой емкости, а соответству-
ющие входные сиrналы Xl(t), X2(t),..., XN(t) потенциалы, rде N количество
входов. Эти входы подаются на суммирующие соединения, которые характеризуются
следующими свойствами.
· Низкое входное сопротивление.
· Единичный ток в цепи.
· Высокое выходное сопротивление.
Таким образом, эти соединения иrpают роль узлов суммирования входных токов.
Общий ток, протекающий в направлении от входноro узла нелинейноro элемента (см.
рис. 14.7), можно выразить следующей формулой:
X1(t)
хр)
Синап
тические
ВХОДЫ
хз(t)
XJ.t)
14.5. Нейродинамические модели 851
Источник
тока
Нелинейн Нейронный
v j
'(') хр) ВЫХОД
т wjrP)
Rj
Рис. 14.7. Аддитивная модель нейрона
N
L WjiXi(t) + Ij,
i=l
rдe первое слаrаемое (суммирование) отражает возбуждения Хl (t), X2(t),. .., XN(t),
действующие на синаптические веса (емкости) Wjl, Wj2,. .. ,WjN соответственно; а
второе слаrаемое это источник тока Ij, представляющий внешнее смещение. Пусть
Vj(t) индуцированное локальное поле на входе нелинейной функции активации
<р(.). Torдa общий ток, вытекающий из входноro узла нелинейноro элемента, можно
выразить следующим образом:
Vj(t) С dVj(t)
у+ j ,
J
rдe первое слаrаемое вызвано сопротивлением утечки (leakage resistance) R j , а BTO
рое емкостью утечки (leakage capacitance) C j . Из закона Кирхroфа известно, что
общий ток, протекающий в сторону лю60ro узла электрической цепи, равен нулю.
Применив этот закон к входному узлу нелинейности на рис. 14.7, получим следующее:
dVj(t) Vj(t)
Cj + у == WjiXi(t) + Ij.
J i=l
(14.14)
Емкостное слаrаемое CjdVj(t)/dt в левой части формулы (14.14) является самым
простым способом добавления в модель нейрона динамики (памяти). для заданно
ro индуцированноro локальноrо поля vj (t) можно определить выход нейрона j с
"""""11
852 rлава 14. Нейродинамика
помощью следующеrо нелинейноrо выражения:
Xj(t) == <p(Vj(t)).
(14.15)
RС модель, описываемую выражением (14.14), обычно называют аддитивной (ad-
ditive mode1). Эта терминолоrия используется для отличия этой модели от мулыи-
пликативной (или шунтирующей) модели, в которой Wji зависит от Xi [391].
Характерным признаком аддитивной модели, описываемой выражением (14.14),
является то, что сиrнал Xi(t), применяемый к нейрону j связанным нейроном i,
является медленно изменяющейся функцией времени t. Описанная модель составляет
основу классической нейродинамики (c1assica1 neurodinamics)4.
Теперь рассмотрим рекуррентную сеть, состоящую из N взаимосвязанных нейро-
нов, каждый из которых имеет одну и ту же математическую модель, описываемую
выражениями (14.14) и (14.15). Тоrда, иrнорируя запаздывания, связанные с рас-
пространением сиrнала между нейронами, можно определить динамику такой сети
следующей системой дифференциальных уравнений первоrо порядка:
dVj(t) Vj(t)
Cj == T+ Wjixi(t)+Ij, j==1,2,...,N.
J i l
Эта система имеет ту же математическую форму, что и уравнения состояний
(14.1), и получается простой перестановкой слаrаемых в равенстве (14.14). Здесь
предполаrается, что функция активации <р(.), определяющая отношение выхода Х j (t)
(14.16)
4 Интеrральный нейрон
Аддитивная модель (14.14) не в полной мере отражает сущность биолоrнческоm нейрона. В частности,
она иrнорирует временную информацию, закодированную в потенциале действия (потенциалы действия кратко
описаны в качественных терминах в rлаве 1). В [476] описывается динамическая модель, которая учитывает
потенциалы действия, при этом рассматривалась интеrpальная модель нейрона. Работа TaKom нейрона описы-
вается дифференциальным уравнением первоm порядка:
d 1
Gdiu(t) == R(u(t) uo)+i(t), (1)
rдe u(t) внутренний потенциал нейрона; емкость мембранноm окружения нейрона; R сопротивление
утечки в мембране; i(t) электрический ток, протекающий в нейрон из дрyrоrо нейрона; ио потенциал, к
которому приходит нейрон, кorдa i(t) исчезает.
Потенциал действия reнерируется каждый раз, кorдa внутренний потенциал u(t) достиrает значения пороrа.
Потенцнал действия рассматривается как дельта-функция Дирака:
9k(t) == L o(t tk,n), (2)
n
rде tk n, n == 1, 2,... моменты времени, в которые нейрон k "выстреливает" потенциал действия. Эти
MOMeH Ы времени определяются уравнением (1).
Общий ток ik(t), втекающий в нейрон k, моделируется следующим образом:
ik(t) == .!.ik(t) + L Wkj9j(t), (3)
dt т .
J
rде Wkj синаптический вес, идущий от нейрона j к нейрону k, а функция gj (t) определяется по формуле (2).
Аддитивную модель в выражении (14.14) можно рассматривать как частный случай модели (3). В частности,
иmльчaryю природу gj(t) можно иrнорировать, заменив эту функцию ее же сверткой снекоторой rладкой
функцией. Такая замена вполне обоснована, если в течение разумноm интервала времени в связи с высокой
связностью вклад в сумму в правой части выражения (3) велик, и все, что нас интересует это краткосрочное
поведение уровня выходноm "выстрела" нейрона k.
14.5. Нейродинамические модели 853
нейрона j к ero же индуцированному локальному полю V j (t), является непрерывной
и, следовательно, дифференцируемой. Чаще Bcero в качестве функции активации
используют лоrистическую функцию
1
<p(Vj)== , j==1,2,...,N.
1 + ехр( Vj)
(14.17)
Необходимым условием для существования алroритмов, описываемых в разде
лах 14.6 14.11, является наличие в рекуррентных сетях, описываемых уравнениями
(14.15) и (14.16), фиксированных точек (т.е. точечных аттракторов).
Связанная модель
Для упрощения выкладок предположим, что константа времени Tj == RjC j нейрона j
в (14.16) является одинаковой для всех j. Тоща, нормализуя время t по отношению к
общему значению этой константы и нормализуя W ji и Ij по отношению к Rj, модель
(14.16) можно переписать в виде
dVj(t) "
== Vj(t) + L.t Wji<P(Vi(t)) + Ij, j == 1,2,... , N,
i
(14.18)
rдe учитывается уравнение (14.15). Структура аттрактора системы нелинейных диф
ференциальных уравнений первоrо порядка (14.18) является в сущности такой же,
как и в тесно связанной модели, описываемой следующим образом [840]:
dXj(t) ( ) ( " ) .
== Xj t +<р WjiXi(t) +Kj, J == 1,2,...,N.
(14.19)
в аддитивной модели (14.18) индуцированные локальные поля Vl (t), V2(t), .. ., VN(t)
отдельных нейронов образуют вектор состояний. С друroй стороны, в связанной MO
дели (14.19) вектор состояний образуют выходы нейронов Xl(t)'X2(t),..., XN(t).
ЭТИ две нейродинамические модели связаны друr с друrом линейным обрати
мым преобразованием. В частности, умножив обе стороны уравнения (14.19) на Wkj,
выполнив суммирование по j и подставив преобразование
Vk(t) == L WkjXj(t),
j
854 rлава 14. Нейродинамика
получим модель, описываемую выражением (14.18), и, таким образом, установим,
что слаrаемые смещения в этих двух моделях связаны соотношением
Ik == L WkjKj.
j
Здесь важно отметить, что результаты, полученные для устойчивости аддитивной
модели (14.18), применимы и к связанной модели (14.19).
Чтобы покончить с вопросом отношений между двумя описанными нейродинами-
ческими моделями, на рис. 14.8 они показаны в виде блочных диаrpамм; рис. 14.8, а, б
соответствуют матричной записи выражений (14.18) и (14.19). Здесь W матрица си-
наптических весов; v(t) вектор индуцированных полей в момент времени t; x(t)
вектор выходов нейронов в момент времени t. В обеих моделях на рис. 14.8 явно
выражена обратная связь.
14.6. Управление аттракторами как
парадиrма рекуррентных сетей
Коrда количество нейронов N в нейродинамической модели, описываемой уравне-
нием (14.16), достаточно велико, она обладает всеми общими свойствами, перечис-
ленными в разделе 14.5 (за исключением влияния шума): большим числом степеней
свободы, нелинейностью и диссипативностью. Следовательно, такая нейродинамиче-
ская модель может иметь сложную структуру аттракторов и, таким образом, обладать
полезными вычислительными возможностями.
Определение аттракторов для вычислительных объектов (например, ассоциатив-
ной памяти, операторов отображения входа на выход) является одной из основных
парадиrм нейронных сетей. Для Toro чтобы реализовать эту идею, требуется управ-
лять местом размещения аттракторов в пространстве состояний системы. При этом
алrоритм обучения принимает форму нелинейноro динамическоro уравнения, кото-
рое управляет расположением аттракторов для кодирования информации в желаемом
виде или обучения рассматриваемых временных структур. Действуя таким способом,
можно установить тесную взаимосвязь между физикой и алrоритмами вычислений.
Одним из способов, которым коллективные свойства нейронных сетей MOryт ис-
пользоваться для реализации вычислительных задач, является применение концепции
минимизации энерrии. Сеть Хопфилда и модель состояния мозrа представляют собой
примеры ассоциативной памяти, не содержащей скрытые нейроны. Ассоциативная
память является важным ресурсом для интеллектуализации поведения. Еще одной
нейродинамической моделью является модель оператора отображения входа на вы-
ход (input output mapper), работа KOTOpOro предполаrает наличие скрытых нейронов.
В последнем случае для минимизации функции стоимости, определенной в терминах
14.6. Управление апракторами как парадиrма рекуррентных сетей 855
Множество нелинейностей,
воздействующих на
отдельные элементы
входноro вектора
Вектор внешних
смещений
а)
Матрица
синаптических
весов
Множество нелинейностей,
воздействующих на
отдельные элементы
К входноro вектора
Вектор внешних
смещений
Рис. 14.8. Блочная диаrрамма ней
родинамической системы, описываемой
дифференциальными уравнениями пер
вoro порядка (14.18) (а); блочная диа
rpaMMa модели, описываемой уравнени
ем (14.19) (б)
б)
параметров нейронной сети, и, таким образом, для изменения положения аттракторов
часто используется метод наискорейшеro спуска. Последнее приложение нейродина
мической модели показано на примере динамически управляемой рекуррентной сети,
которую мы рассмотрим в следующей rлаве.
856
rлава 14. Нейродинамика
1
Нейроны
Рис. 14.9. Архитектурный rраф сети Хопфилда, со-
держащей N == 4 нейрона
14.7. Модель Хопфилда
Сеть (модель) Хопфилда состоит из множества нейронов и соответствующеrо мно-
жества единичных задержек, формирующих систему с множеством обратных связей
(mu1tip1e loop feedback system) (рис. 14.9). Количество обратных связей равно коли-
честву нейронов. Как правило, выход кщкдоrо нейрона замыкается через элемент
единичной задержки на все остальные нейроны сети. Друrими словами, нейрон этой
сети не имеет обратных связей с самим собой. Причина исключения из рассмотрения
собственных обратных связей будет рассмотрена HeMHoro позже.
Для изучения динамики сетей Хопфилда будет использоваться нейродинами-
ческая модель, описываемая уравнением (14.16), которая основана на аддИТИВ-
ной модели нейрона.
Вспоминая, что Xi(t) == <Pi(Vi(t)), уравнение (14.16) можно переписать в следую-
щем виде:
d Vj(t)
C j dt Vj(t) == T + L..,. Wji<PJVi(t)) + Ij, j == 1,2,..., N.
J i l
(14.20)
ЧтоGы продолжить дискуссию, сделаем следующие допущения.
14.7. Модель Хопфилда 857
1. Матрица синаптических весов является симметричной:
Wji == Щj для всех i и j.(14.21)
(14.21)
2. Каждый нейрон имеет собственную нелинейную функцию активации (поэтому в
записи q>i(-) в выражении (14.20) присутствует индекс i).
3. Для всех нелинейных функций активации существуют обратные, Т.е. можно за
писать:
v == q>;l(X).
(14.22)
Пусть сиrмоидальная функция q>i ( v) определяется как rиперболический TaHreHc:
( ) h ( aiV ) 1 exp( aiv)
Х q>. V tan ,
, 2 1 + ехр( aiv)
(14.23)
который в начале координат имеет наклон, равный ai/2:
ai dq>i I
"2 == dv v == О .
(14.24)
Исходя из этоro, ai называется коэффициентом передачи (gain) нейрона i.
Обратное преобразование выхода во вход (14.22) можно переписать в следую
щем виде:
1 ( 1 Х )
v == q>:---l(X) == log .
, ai 1 + Х
(14.25)
Стандартная форма этоrо обратноro соотношения для нейрона с единичным KO
эффициентом передачи будет иметь следующий вид:
( 1 Х )
q> l(X) == log .
l+х
(14.26)
Выражение (14.25) можно переписать в терминах стандартноro соотношения:
1
q>;l(X) == q> l(X).
а.
,
(14.27)
На рис. 14.10, а показан rpафик стандартной сиrмоидальной нелинейности q>(v),
а на рис. 14.10, б rpафик соответствующей обратной нелнейности q> l(X).
858 rлава 14. Нейродинамика
Функция энерrии (Ляпунова) сети Хопфилда (см. рис. 14.9) определяется следу
ющим образом [479]:
1 N N N 1 l Х; N
Е == '\:" '\:" W "Х'Х . + '\:" ( n-:-- 1 ( x ) dx '\:" I.x.
2 L... L... 3t t 3 L... R. '1'"3 L... 3 3'
i=l j=l j=l 3 О j=l
(14.28)
Функция энерrии (14.28) может иметь сложную поверхность с множеством мини-
мумов. Динамика этой сети описывается механизмом, обеспечивающим нахождение
этих минимумов.
Исходя из этоro, дифференцируя функцию энерrии Е по времени, получим:
N ( N )
dE v. dx.
dt == L L WjiXi Il. + Ij d: .
j=l i=l 3
(14.29)
Из нейродинамическоro соотношения (14.20) видно, что величина, заключенная
в скобки в правой части (14.29), равна CjdVj/dt. Таким образом, можно упростить
выражение (14.29) до следующеro:
N
dE == '\:" С. ( dVj ) dXj .
dt L... 3 dt dt
j=l
(14.30)
Итак, получено обратное соотношение, определяющее vj в терминах Xj' Подста-
вив (14.22) в (14.30), получим:
N ( N ( 2 (
dE d 1 dXj dXj d 1
dt== LCj dt q>j (Xj) ) dt == .LCj dt ) dx. q>j (Xj) ) '
3=1 3=1 3
(14.31)
На рис. 14.10, б видно, что обратное отображение q>j1(Xj) является монотонно
возрастающей функцией выхода Х j' Отсюда следует, что
d 1 ( )
d q>j Xj 2:: о для всех Xj'
Х.
3
(14.32)
Обратите внимание, что выполняется также и следующее неравенство:
( dX' ) 2
d: 2:: о для всех Xj.
(14.33)
Следовательно, все составляющие суммы в правой части (14.31) являются неотри-
цательными. Друrими словами, функция энерrии Е, определяемая формулой (14.28),
14.7. Модель ХоПфилда 859
X Ip(v)
+1.......................
v
...................... -1
а)
v Ip J(x)
х
о +1
Рис. 14.10. rрафики стандартной сиrмоидальной
нелинейности (а) и обратной к ней функции (б) б)
удовлетворяет неравенству
dE < О.
dt
Из определения (14.28) видно, что функция Е является оrpаниченной, и мы можем
вывести два следующих утверждения.
860 rлава 14. Нейродинамика
1. Функция энерrии Е является функцией Ляпунова непрерывной модели Хопфилда.
2. Эта модель, соrласно теореме 1 Ляпунова, является устойчивой.
Друrими словами, эволюция во времени непрерывной модели Хопфилда, описыва
емой системой нелинейных дифференциальных уравнений первоro порядка (14.20),
представляет собой некоторую траекторию в пространстве состояний, обеспечиваю
щую нахождение минимума функции энерrии (Ляпунова) и приходящую к некоторой
фиксированной точке. В выражении (14.31) можно заметить, что производная dE/dt
исчезает только тоrда, коrда
:t Xj(t) == О для всех j.
Таким образом, можно продвинуться еще на один шаr и записать:
dE О Ф
< за исключением иксированнои точки.
dt
(14.34)
Уравнение (14.34) создает предпосылки для формулировки следующей теоремы.
Функция энерrии (Ляпунова) сети Хопфилда является монотонно убывающей
функцией времени.
Следовательно, сеть Хопфилда является rлобально асимптотически устойчивой.
Фиксированные точки аттракторов являются точками минимума функции энер-
rии, и наоборот.
Соотношение между устойчивыми состояниями дискретной и
непрерывной версии модели Хопфилда
Сеть Хопфилда может работать как в непрерывном, так и в дискретном времени, в
зависимости от тoro, какая модель использовалась для описания нейронов. Непрерыв-
ный режим работы, как уже rоворилось ранее, основывается на аддитивной модели;
дискретный режим работы основан на модели Мак Каллока Питца. Можно вывести
соотношение между устойчивыми состояниями дискретной и непрерывной моделей
Хопфилда, переопределив соотношение между входом и выходом нейрона таким об-
разом, чтобы истинными были две следующие упрощенные характеристики.
1. Выход нейрона имеет следующие асимптотические значения:
{ +1 для vj == 00,
X'
J 1 для vj == oo.
(14.35)
2. Средняя точка функции активации нейрона находится в начале координат, Т.е.
14.7. Модель Хопфилда 861
q>j(O) == О. (14.36)
Следовательно, можно установить для всех j смещение Ij, равное нулю.
При формулировке функции энерrии Е для непрерывной модели Хопфилда допус
калось наличие у нейрона обратных связей с самим собой. С друroй стороны, дискрет
ная модель Хопфилда требует отсутствия таких обратных связей. Чтобы упростить
рассмотрение данноrо вопроса, положим, что в обеих моделях Wjj == О для всех j.
В свете этих наблюдений можно переопределить функцию энерrии непрерывной
модели Хопфилда (14.28) следующим образом:
1 N N N 1 l Xj
Е == 2" L L WjiXiXj+ L R: q>j1(x)dx.
i l,ioIj j l j l J О
(14.37)
Обратная функция q>j1(X) определяется формулой (14.27). Таким образом, фор
мулу (14.37) можно переписать в следующем виде:
1 N N N 1 l Xj
Е == 2" L L WjiXiXj+ L а .К q> l(x)dx.
i l,ioIj j l j l J J О
(14.38)
rрафик стандартной формы интеrpала
l Xj q> l(x)dx
показан на рис. 14.11. Он равен нулю в точке Х j ==0, и положителен во всех остальных
точках. При достижении Xj значений :1:1 значения этоro интеrpала становятся очень
большими. Если же коэффициент передачи aj (gain) нейрона j становится бесконеч
но большим (т.е. сиrмоидальная нелинейность достиrает идеализированной формы
с жесткими пределами), второе слаrаемое в формуле (14.38) становится настолько
малым, что им можно пренебречь. В предельном случае, Korдa aj == 00 для всех j,
максимумы и минимумы непрерывной модели Хопфилда становятся идентичными
максимумам и минимумам дискретной модели. В последнем случае функция энерrии
(Ляпунова) определяется следующим образом:
1 N N
Е '" '" W..X.X.
2 L...... L...... J t t J>
i l j l,ioIj
(14.39)
862 rлава 14. Нейродинамика
f:' cp I(X)d!:
0,8
0,6
о
X j
+1 Рис. 14.11. rрафик интеrрала Jo"j <p l(x)dx
1
rде состояние j ro нейрона Xj == :1:1. Таким образом, можно сделать вывод, что
только устойчивые точки непрерывной детерминированной модели Хопфилда с очень
высоким коэффициентом передачи соответствуют устойчивым точкам дискретной
стохастической модели Хопфилда.
Однако если все нейроны j имеют большой, но конечный коэффициент передачи
aj, оказывается, что второе слаrаемое в правой части (14.38) вносит заметный вклад
в функцию энерrии непрерывной модели. В частности, этот вклад является большим
и положительным вблизи всех rpаней, rpаниц и уrлов единичноro rиперкуба, опре-
деляющеro пространство состояний этой модели. С друroй стороны, вклад BTOpOro
слаrаемоro становится пренебрежимо малым в точках, удаленных от rpаней этоrо
куба. Следовательно, функция энерrии такой модели имеет свои максимумы в уrлах,
а минимумы смещены во внутреннюю область единичноro rиперкуба [479].
На рис. 14.12 показана контурная карта энерrии (energy contour mар) или ланд-
шафт энерrии (energy 1andscape) непреры,ВНОЙ модели Хопфилда, состоящей из двух
нейронов. Выходы этих двух нейронов определяют две оси этой карты. Нижний ле-
вый и верхний правый уrлы на рис. 14.12 представляют собой устойчивые минимумы
для случая бесконечноro коэффициента передачи. Минимумы для случая конечноro
коэффициента передачи смещаются внутрь куба. Поток к фиксированным точкам
(т.е. точкам устойчивоro минимума) может интерпретироваться как решение задачи
минимизации функции энерrии Е, определяемой формулой (14.28).
Дискретная модель Хопфилда как ассоциативная память
Сетям Хопфилда в литературе, посвященной ассоциативной или контентно.
адресуемой памяти (content adressable memory), уделяется довольно большое вни-
мание. В этой модели фиксированные точки соответствуют сохраняемым образам.
Однако синаптические веса сети, которые обеспечивают нахождение таких фиксиро-
ванных точек, неизвестны, и задача заключается в их определении. Основной Функ-
14.7. Модель Хопфилда 863
)/
t
t
t
t
t
t
t
t
t
t
t
t
t
r
r
r
r
r
r
r
r
r
r
r
r
r
Jf........
х
'"
х
....... ...... ......
"
"
.... .... ....
....
....
.... .... .... .... ....
....
"
Рис. 14.12. Контурная карта энерrии системы с двумя нейронами и двумя
устойчивыми состояниями. Ординаты и абсциссы являются выходами двух
нейронов. Устойчивые состояния расположены около нижнею левою и Bepx
нею правою уrлов. Неустойчивые экстремумы расположены в остальных двух
уrлах. Стрелки показывают перемещение состояний. В общем случае эти Пе
ремещения не перпендикулярны контурам энерrии. (Рисунок взят из [479] с
разрешения Национальной академии наук США.)
цией ассоциативной памяти является восстановление образа (объекта), coxpaHeHHoro
в памяти, в ответ на представление неполной или зашумленной версии этоro же
объекта. Для иллюстрации значения этоro утверждения нет ничеro лучше, чем при
вести цитату из [480].
.......
864 rлава 14. Нейродинамика
Пространство
фундаментальной
памяти
Пространство
хранимых векторов
Рис. 14.13. Кодирование декодирование, выполняемое рекуррентной
сетью
"Предположим, что в памяти существует запись "Н.А. Кramers & G.н. Wannier
Physi Rev. 60, 252 (1941 )". Ассоциативная память общеrо вида будет способна вернуть
всю эту запись на основе подачи частичной информации. Ввода строки "& Wannier
(1941)" должно быть достаточно. Идеальная память может работать даже при наличии
помех и смоrла бы вернутъ эту запись даже на основе ввода "Wannier (1941)".
Таким образом, важным свойством ассоциативной памяти является восстанов-
ление coxpaHeHHoro образа при подаче разумноro подмножества информации этой
записи. Более тoro, ассоциативная память позволяет корректировать ошибки (error-
сопесtiпg), а именно аннулировать несвязную информацию, если таковая содержится
в представленном ей образе.
Сущностью ассоциативной памяти является отображение фундаментальной па-
мяти l;f1 в фиксированную (устойчивую) точку Xf1 некоторой динамической системы
(рис. 14.13). Математически это отображение можно представить в следующем виде:
l;f1 Х).1'
Стрелка, направленная слева направо, описывает операцию кодирования, а стрел-
ка, направленная справа налево, операцию декодирования. Фиксированные точки
аттракторов в пространстве состояний сети являются ячейками фундаментальной
памяти (fundamenta1 memories) или состояниями прототипов (prototype state) сети.
Теперь предположим, что сети представлен образ, содержащий частичную, но су-
щественную информацию об одной из ячеек фундаментальной памяти. Тоща этот
частичный образ можно представить как начальную точку в пространстве состояний.
В принципе, предполаrая, что эта стартовая точка находится достаточно близко к
14.7. Модель Хопфилда 865
точке, представляющей запрашиваемый образ (т.е. стартовая точка лежит в бассейне
аттракции, принадлежащем этой фиксированной точке), система может развиваться
во времени и в конце концов прийти к состоянию самой ячейки памяти. В этой точке
сетью будет сrенерирован весь образ ячейки памяти. Следовательно, сеть Хопфилда
обладает свойством эмерджентности (emergent), что помоrает ей извлекать информа
цию и обрабатывать ошибки.
Если модель Хопфилда использует формальный нейрон [714] и ero основной эле
мент обработки, то каждый такой нейрон имеет два состояния, определяемые уровнем
индуцированноrо локальноro поля, воздействующеro на Hero. "Включенное" состоя
ние нейрона i соответствует выходу Xi == +1, а "выключенное" выходу Xi == 1.
Для сети, состоящей из N нейронов, состояние определяется вектором
х== [X1,X2"",XN]T.
При Xi == :1:: 1 состояние i представляет один информации, а вектор состояния х
размерности N х 1 представляет двоичное слово, содержащее N битов информации.
Индуцированное локальное поле Vi нейрона j определяется следующим образом:
N
Vj == L WjiXi + b j ,
i l
(14.40)
rде b j фиксированное смещение (bias), применяемое внешним образом к нейро
ну j. Таким образом, нейрон j модифицирует свое состояние Х j в соответствии с
детерминированным правилом:
. { +1, если Vj > О,
Х) 1 О
, если Vj < .
Это соотношение может быть переписано в более компактном виде:
Xj == sgn[Vj],
rде sgn функция определения знака числа или сиrнум функция (signum function).
А что происходит, коrда Vj равно нулю? В этом случае действия MOryT быть произ
вольными. Например, можно допустить, чтобы при Vj == О Xj == :1::1. Однако будем
использовать следующее соrлашение: если Vj == О, нейрон j остается в своем Te
кущем состоянии, независимо от TOro, включен он или выключен. Значение этоrо
допущения состоит в том, что полученная диаrpамма потоков будет симметричной,
что и будет продемонстрировано позже.
866 rлава 14. Нейродинамика
Дискретные сети Хопфилда, выступающие в качестве ассоциативной памяти, име
ют две фазы работы: фазу сохранения и фазу извлечения. Эти фазы подробно описы-
ваются ниже.
1. Фаза сохранения (storage phase). Предположим, что необходимо сохранить
множество N-мерных векторов (двоичных слов), которые обозначим как {l;I1IJ.1. == 1,
2, ..., М}. Назовем эти векторы ячейками фундаментальной памяти, указывая на
то, что в них сохраняются образы, представленные сети. Пусть 11,i i й элемент
фундаментальной памяти l;11' rде класс J.I. == 1,2,.. ., М. Соrласно правилу внешнеro
произведения векторов (outer product ru1e), которое является обобщением постулата
обучения Хебба, синаптический вес, направленный от нейрона i к нейрону j, опре-
деляется так:
1 м
Wji == N L 11,j l1,i'
11 1
(14.41)
Причиной использования в качестве константы пропорциональности величины
1/ N является упрощение математическоrо описания процесса извлечения информа-
ции. Также заметим, что правило обучения (14.41) представляет собой одношаroвую
операцию. При нормальной работе сети Хопфилда
Wii == о для всех i.
(14.42)
Это значит, что нейроны не имеют обратных связей с самими собой. Пусть W
матрица синаптических весов размерности N х N, ji M элементом которой является
синаптический вес Wji' Torдa можно объединить выражения (14.41) и (14.42) в единое
уравнение в матричной форме:
1 м т
W == N L l;11l;11 MI,
11 1
(14.43)
rде l;11l; векторное произведение вектора l;11 caMoro на себя; 1 единичная матрица.
Из представленных выше формул определений синаптических весов (матрицы весов)
можем еще раз подтвердить следующее.
1. Выход каждоro из нейронов замкнут на входы всех остальных нейронов.
2. В сети отсутствуют обратные связи нейронов с самими собой.
3. Матрица весов этой сети является симметричной, Т.е.
w T == w.
(14.44)
14.7. Модель Хопфилда 867
Фаза извлечения. Во время фазы извлечения n мерный вектор l;проб., называ
емый зондом (probe), подается сети Хопфилда в качестве ее начальноrо состояния.
элементыI этоro вектора имеют значения :i: 1. Этот вектор обычно представляет co
бой неполную или зашумленную версию фундаментальной памяти сети. После этоrо
извлечение информации проходит в соответствии с некоторым динамическим пра
вилом, в котором все нейроны j сети случайно, но на некотором фиксированном
уровне, проверяют индуцированное локальное поле Vj (включающее в себя HeKOTO
рое внешнее смещение b j ), примененное к ним. Если в некоторый момент времени
Vj окажется больше нуля, то нейрон j будет переведен в состояние +1 (если он уже
не находится в этом состоянии). Аналоrично, если в некоторый момент времени vj
окажется меньше нуля, то нейрон переключится в состояние 1 (если он уже не Ha
ходится в этом состоянии). Если же Vj будет равно нулю, нейрон j останется в своем
текущем состоянии, независимо от Toro, включенное оно или отключенное. Таким
образом, коррекция состояний на каждом шаre будет детерминированной, однако
при этом выбор нейрона для осуществления коррекции будет производиться случай
ным образом. Описанная здесь асинхронная (последовательная) процедура коррекции
продолжает выполняться до тех пор, пока изменения не перестанут происходить. Это
значит, что, начиная с произвольноro пробноrо вектора х, сеть в конце концов создаст
инвариантный во времени вектор состояний у, отдельные элементы KOTOpOro будут
удовлетворять условию устойчивости:
Yi == sgn ( t WjiYi + bj ) , j == 1,2, . . . , N,
, 1
(14.45)
или, в матричной форме:
у == sgn(Wy + Ь),
(14.46)
rде W матрица синаптических весов сети; Ь внешний вектор смещения (bias
vector). Описанное здесь условие устойчивости также называется условием BыpaB
нивания (a1ignment condition). Удовлетворяющий ему вектор состояния у называют
устойчивым состоянием (stable state), или фиксированной точкой (fixed point) про
странства состояний системы. Таким образом, можно сформулировать утверждение
о том, что сеть Хопфилда всеrда сходится к некоторому устойчивому состоянию, если
операция извлечения информации выполняется асинхронно 5 .
5 Модель Литтла [660], [662] использует те же синаптические веса, что и модель Хопфилда. Однако их
отличие состонт в том, что модель Хопфилда использует асинхронную динамику, в то время как модель Литтла
синхронную. В результате эти модели показывают различные характеристики сходимости [162], [367]: сеть
Хопфилда Bcerдa сходится к устойчивому состоянию, а модель Литтла либо к устойчивому состоянию, либо
к предельному циклу длины не больше двух (это значит, что эти циклы в пространстве состояний сети имеют
длину меньшую или равную двум).
868 rлава 14. Нейродинамика
ТАБЛИЦА 14.2. Модель Хопфилда
1. Обучение. Пусть l;1, l;2, ..., l;M известное множество N мерных ячеек Фун
даментальной памяти. Используя правило векторноrо произведения (т.е. постулат
обучения Хебба), вычислим синаптические веса сети:
{ 11 f 11,j l1,i' j i= i,
Wji 11 1
О, j == i,
rде Wji синаптический вес, направленный от нейрона i к нейрону j. Элементы
вектора l;11 равны ::!: 1. После TOro как веса вычислены, они сохраняются в этих
фиксированных значениях
2. Инициализация. Пусть l;проб. неизвестный N мерный входной вектор, пред
ставленный сети. Алroритм инициализируется следующими значениями:
Xj(O) == j,проб.,j == 1,2,..., N,
rде Xj(O) состояние нейрона j в момент времени п == о; j,проб. j й элемент
вектора испытаний l;проб.
3. Итерации до полной сходимости. Выполним корректировку элементов вектора
состояний х(п) в асинхронном режиме (т.е. случайно и по одному элементу за
итерацию) в соответствии справилом
Xj(n + 1) sgn (t, WjiXj(n)), j 1,2,..., N.
Повторяем итерации до тех пор, пока вектор состояний х не пере станет изменяться
4. Формирование выхода. Пусть Хфикс. фиксированная точка (устойчивое состоя
ние), вычисленная в результате завершени шаrа 3. Torдa результирующий выходной
вектор будет следующим:
у == Хфикс.
Шar 1 является фазой запоминания, а шаrи 2 фазой извлечения
в табл. 14.2 подытожены действия, составляющие фазы сохранения и извлечения
в работе сети Хопфилда.
Пример 14.2
для Toro чтобы ПРОИJШюстрировать эмерджентное поведение модели Хопфилда, рассмотрим
сеть, состоящую из трех нейронов (рис. 14.14, а). Эта сеть имеет следующую матрицу весов:
[ О 2 +2 ]
W == 2 О 2 .
+2 2 о
14.7. Модель Хопфилда 869
Данная матрица является допустимой, так как она удовлетворяет условиям (14.42) и (14.44).
Предполаrается, что внещнее смещение, применяемое ко всем нейронам, равно нулю. Учитывая, что
в нашей сети имеются три нейрона, следует рассмотреть 23 == 8 возможных состояний. Из этих BOCЬ
ми состояний только два «( 1, 1, 1) и ( 1, 1, 1)) являются устойчивыми; все оставшиеся шесть
состояний неустойчивы. Речь идет об устойчивости именно этих двух состояний по причине TOro,
что они удовлетворяют условию выравнивания (14.46). для вектора состояний (1, 1, 1) имеем:
Wy == [ = ] [ = ] [ =: ]
+2 2 О +1 +4
,gn [Wy] [ ::] у
Аналоrично, для вектора состояний ( 1, 1, 1) имеем:
Wy == [ = ] [ ] [ : ]
+2 2 о 1 4
,gn[Wy] [ :] у.
Жестко оrpаничив этот результат, получим:
Жестко оrpаничив этот результат, получим:
Таким образом, оба вектора состояний удовлетворяют условию выравнивания.
Более TOro, следуя процедуре асинхронной коррекции (см. табл. 14.2), получим поток, по
казанный на рис. 14.14, б. Эта карта потоков демонстрирует симметрию по отношению к двум
устойчивым состояниям сети, что интуитивно понятно. Симметрия является результатом TOro, что
при нулевом индуцированном локальном поле нейрон остается в своем текущем состоянии.
На рис. 14.14, б также показано, что если сеть, показанная на рис. 14.14, а, находится в начальном
состоянии (1, 1, 1), ( 1, 1,1) или (1, 1, 1), то она будет сходиться к устойчивому состоянию
(1, 1,1) за одну итерацию. Если же начальным состоянием будет ( 1, 1, 1), ( 1, 1, 1) или
(1, 1, 1), она будет сходиться к устойчивому состоянию ( 1, 1, 1).
Таким образом, эта сеть содержит две ячейки фундаментальной памяти (1, 1, 1) и
( 1, 1, 1), представляющие два устойчивых состояния. Применяя выражение (14.43), получим
следующую матрицу синаптических весов:
W == [ = ] [+1 1 +1] + [ ] [ 1 +1 1] [ ] == [ = ] ,
+1 1 О 01 +2 2 о
которая проверяется синаптическими весами, показанными на рис. 14.14, а.
Способность к коррекции ошибок этой сетью Хопфилда можно ясно увидеть на карте потоков
на рис. 14.14, б.
1. Если вектор испытания проб. равен (1,1,1), ( 1, 1, 1) или (1, 1, 1), результирующим
выходом будет фундаментальная память (1, 1, 1). Каждый из этих пробных векторов, по cpaB
нению с сохраненным образом, содержит по одной ошибке.
870 rлава 14. Нейродинамика
а)
б)
Рис. 14.14. Архи-
тектурный rраф сети
Хопфилда, состоящей
из N 3 нейро-
нов (а); диаrрамма,
иллюстрирующая два
устойчивых состояния
и потоки этой сети (б)
(-1,-1,-1)
(1, -1, -1)
2. Если вектор проб. равен ( 1, 1, 1), ( 1, 1, 1) или (1, 1, 1), результирующим выходом
будет фундаментальная память ( 1, 1, 1). Каждый из этих пробных векторов, по сравнению
с сохраненным образом, содержит по одной ошибке.
.
Ложные состояния
Матрица весов W дискретной сети Хопфилда является симметричной (см. выраже-
ние (14.44)). Поэтому собственные значения этой матрицы будут действительными
14.7. Модель Хопфилда 871
числами. Однако при больших М собственные значения будут вырождаться (degen
erate). Это значит, что будут существовать собственные векторы, имеющие одно и то
же собственное значение. Собственные векторы, ассоциированные с вырожденными
собственными значениями, формируют некоторое подпространство. Более тoro, ec
ли матрица весов W имеет вырожденное собственное значение, равное нулю, такое
подпространство называют нулевым пространством (пи11 space). Нулевое простран
ство существует исходя из TOro факта, что количество ячеек фундаментальной памяти
М меньше количества нейронов N сети. Наличие нулевоrо пространства является
встроенной характеристикой сети Хопфилда.
Анализ собственных чисел (eigenana1ysis) матрицы весов W приводит к сле
дующей точке зрения на сеть Хопфилда, используемой в качестве ассоциатив
ной памяти [10].
1. Дискретная сеть Хопфилда выступает в качестве BeктopHoro проектора (vector
projector) она проектирует пробный вектор в подпространство М, натянутое на
векторы фундаментальной памяти.
2. Рассматриваемая динамика сети направляет результирующий вектор проекции к
одному из уrлов единичноro rиперкуба, в котором функция энерrии минимальна.
Единичный куб имеет N измерений. М векторов фундаментальной памяти, на
которые натянуто подпространство М, образуют множество фиксированных точек
(устойчивых состояний), находящихся в некоторых уrлах единичноrо rиперкуба.
Остальные уrлы единичноro rиперкуба, лежащеro в подпространстве М, являются по
тенциальными местоположениями ложных (spurious) состояний, также называемых
ложными аттракторами (spurious attractor) [42]. Ложные состояния представляют те
устойчивые состояния сети Хопфилда, которые отличаются от ячеек фундаменталь
ной памяти этой сети.
В конструкции сети Хопфилда, выступающей в качестве ассоциативной памя
ти, приходится сталкиваться с необходимостью удовлетворения двух противоречи
вых требований: необходимостью сохранения векторов фундаментальной памяти как
фиксированных точек пространства состояний и желанием иметь как можно меньше
ложных состояний.
Емкость сети Хопфилда
к сожалению, ячейки фундаментальной памяти сети Хопфилда не всеrда являются
устойчивыми. Более Toro, при этом MOryT появляться ложные состояния, являющиеся
устойчивыми состояниями, отличными от ячеек фундаментальной памяти. Эти два
явления понижают эффективность сети Хопфилда, выступающей в качестве ассоци
ативной памяти. В этом подразделе остановимся на первом из этих явлений.
......
872 rлава 14. Нейродинамика
Применим пробный вектор, равный одной из ячеек фундаментальной памяти l;v, к
нашей сети. Тоща, разрешив использование собственных обратных связей и предпо
лаrая нулевое внешнее смещение, с помощью выражения (14.41) можно определить
индуцированное локальное поле нейрона j следующим образом:
N 1N N 1 N N
Vj == L Wji v,i == N L 11,j L 11,i v,i == V,j + N L 11,j L 11,i v,i' (14.47)
i l 11 1 i l l1 l,l1iv i l
Первое слаrаемое в правой части (14.47) является j M элементом ячейки фунда
ментальной памяти l;v; теперь ясно, для чеro в определении синаптическоro веса Wji
(14.41) бьт введен масштабирующий множитель 1/N. Таким образом, это слаrаемое
можно рассматривать как желаемый "сиrнал" компонента Vj' Второе слаrаемое в
правой части (14.47) является результатом "переrоворов" между элементами фунда
ментальной памяти l;v, подверrающихся тестированию, и элементами дрyrих ячеек
фундаментальной памяти l;11' Это значит, что второе слаrаемое можно рассматривать
как "шумовой" компонент индуцированноrо локальноrо поля V j. Следовательно, при
ходим к ситуации, аналоrичной классической задаче "извлечения сиrнала из шума"
из теории связи [437].
Предположим, что ячейки фундаментальной памяти являются случайными и re
нерируются как последовательность М N попыток Бернулли (Bemoulli tria1). Тоща
слаrаемое шума в выражении (14.47) состоит из суммы N(M 1) независимых
случайных переменных, принимающих значения -:1:1/N. Это ситуация, в которой
применима центральная предельная теорема теории вероятностей. Эта теорема rласит
следующее [294].
Пусть {Х k} последовательность взаимно независимых случайных переменных,
имеющих общее распределение. Предположим, что Х k имеет среднее значение 1.1 и
дисперсию 0-2 и что У == Х 1 +Х 2 +. .. + ХN' Т rда при устремлении n к бесконечности
случайная переменная суммы У достиrнет rayccoBa распределения.
Тоща, при меняя центральную предельную теорему к слаrаемому шума в (14.47),
получим, что шум является асимптотически распределенным по rayccy. Каждая из
N (М 1) случайных переменных, составляющих слаrаемое шума в этом равенстве,
имеет нулевое среднее значение и дисперсию, равную 1/ N 2 . Отсюда следует, что
статистика полученноro rayccoBa распределения будет следующей.
· Среднее значение будет равно нулю.
· Дисперсия будет равна (М l)/N.
14.7. Модель Хопфилда 873
Компонент сиrнала v ,j С равной вероятностью может принимать значения + 1
и 1 и, следовательно, имеет нулевое среднее и единичную дисперсию. Исходя из
этоro, отношение сиrнал/шум можно определить следующим образом:
дисперсия сиrнала 1 N
Р == дисперсия шума == (М 1) / N М для больших м.
(14.48)
Компоненты фундаментальной памяти v будут устойчивыми тоща и только тоща,
коrда отношение сиrнал/шум будет высоким. Количество М ячеек фундаментальной
памяти является прямой мерой емкости памяти (storage capacity) сети. Таким обра
зом, из (14.48) следует, что, до тех пор, пока емкость памяти сети не будет превышена
(т.е. количество М ячеек фундаментальной памяти будет оставаться малым по cpaB
нению с количеством N нейронов сети), фундаментальная память будет устойчивой
в вероятностном смысле.
Величина, обратная к отношению сиrнал/шум, Т.е.
м
а== N '
(14.49)
называется параметром заrpузки (load parameter). Соrлашения статистической физики
утверждают, что качество извлечения из памяти сети Хопфилда ухудшается при YBe
личении параметра заrpузки а и преломляется (breaks down) при критичном значении
ас == 0,14 [42], [760]. Эта оценка критичноro значения была получена в [480] в pe
зультате компьютерноrо моделирования, в котором одновременно моrло извлекаться
О, 15N состояний до появления ошибок.
При ас == 0,14 из выражения (14.48) можно получить, что критичное значение
отношения сиrнал/шум приблизительно равно Ре ';::::j7, или 8,45 dB. Если соотношение
сиrнал/шум находится ниже этой критической отметки, восстановление данных из
памяти становится невозможным.
Критическое значение
Мс == acN == О, 14N
(14.50)
определяет емкость памяти с ошибками (storage capacity with епоrs) при вспо
минании. Для определения емкости памяти без ошибок следует использовать бо
лее строrий критерий, определяемый в терминах вероятности ошибок, который бу
дет описан ниже.
Пусть j й бит испытания l;проб. == l;v будет символом 1 (т.е. V,j == 1). Тоrда услов
ная вероятность ошибки в бите при вспоминании (conditiona1 probabi1ity of bit епоr
оп recall) будет определяться областью, которая закрашена на рис. 14.15. Оставшаяся
часть области под кривой является условной вероятностью Toro, что бит j этоrо ис
874 rлава 14. Нейродинамика
fV<v)
v.j 1
Рис. 14.15. Условная вероятность ошибки
в бите в предположении rayccoBa распре
деления индуцированноro локальноro поля
vj нейрона j. (Нижний индекс V в обозначе-
нии функции плотности вероятности !v(Vj)
обозначает случайную переменную, реали-
зацией которой является щ.)
v j
пытания будет вспомнен корректно. Используя хорошо известную формулу rayccoBa
распределения, последняя условная вероятность будет равна
1 1 00 ( (V- J!)2 )
P(Vj > Ol v j == +1) == м= ехр J 2 2 dVj.
, у 2па о а
(14.51)
Если V,j == + 1 и среднее значение слаrаемоro шума в (14.47) равно нулю, то cpeд
нее J! случайной переменной V будет равно единице, а ее дисперсия а 2 == (М 1) / N.
Из определения функции ошибки, как правило, использующейся в вычислениях, свя
занных с rауссовыми распределениями, имеем:
2 1 У 2
erf(y) == J1t о e z dz,
(14.52)
rде у переменная, определяющая верхний предел интеrpирования. Теперь можно
упростить выражения для условной вероятности корректноrо вспоминания j ro бита
фундаментальной памяти l;v, переписав (14.51) в терминах функции ошибки:
P(Vj > Ol v.j == +1) == [1 + erf ( )] ,
(14.53)
rде р отношение сиrнал/шум, определяемое выражением (14.48). Каждая ячейка
фундаментальной памяти состоит из n бит. Ячейки фундаментальной памяти TaK
же всеща равновероятны. Отсюда следует, что вероятность устойчивости образов
определяется соотношением
Рстаб. == (Р(щ > Ol v,j == +l))N.
(14.54)
14.7. Модель Хопфилда 875
140
120
100
i:
'"
80
t::
..: 60
"
щ
40
20
200 400 600 800 1000
Размер сети, N
Рис. 14.16. rрафики емкости памяти сети Хопфилда по отношению к ее размеру
ДЛЯ двух случаев: вспоминания с ошибками и вспоминания практически без ошибок
Эту вероятность можно использовать для вывода выражения емкости сети
Хопфилда. В частности, емкость памяти с вспоминанием практически без ошибок
(storage capacity a1most without errors) определяем как наибольшее количество ячеек
фундаментальной памяти, которые MorYT сохраняться в сети при требовании, чтобы
подавляющее большинство из них вспоминалось корректно. В задаче 14.8 показано,
что из TaKoro определения вытекает следующая формула:
N
М тах == 210g e N '
(14.55)
rде loge натуральный лоrарифм.
На рис. 14.16 по казаны rpафики емкости памяти без ошибок, определяемой COOT
ношением (14.50), и емкости памяти, практически не содержащей ошибок, определя
емой выражением (14.55). Оба rpафика построены относительно размера сети N. На
этом рисунке можно заметить следующее.
876 rлава 14. Нейродинамика
. Емкость памяти сети Хопфилда растет линейно по отношению к размеру сети N.
. rлавное оrpаничение сети Хопфилда состоит в том, что для восстанавливаемости
фундаментальной памяти ее емкость памяти должна поддерживаться на относи
тельно низком уровне 6 .
14.8. Компьютерное моделирование 1
в этом разделе проведем компьютерное моделирование для иллюстрации поведения
дискретной сети Хопфилда, выступающей в качестве ассоциативной памяти. В экс
перименте будет использоваться сеть, состоящая из N == 120 нейронов и, следова
тельно, имеющая N 2 N == 12280 синаптических весов. Эта сеть обучал ась для
извлечения восьми цифроподобных черно белых образов, приведенных на рис. 14.7.
Каждый из этих рисунков содержит 120 пикселей (элементов). Эти образы созда
вались специально для достижения сетью хорошей производительности [657]. Для
входов, применяемых к сети, предполаrалось, что белому цвету соответствует значе
ние + 1, а черному 1. Каждый из образов на рис. 14.17 использовался как ячейка
фундаментальной памяти на фазе запоминания (обучения) сети Хопфилда для созда
ния матрицы синаптических весов W с помощью формулы (14.43). Фаза вспоминания
осуществлялась в асинхронном режиме, соrласно процедуре, описанной в табл. 14.2.
б Немонотонная функция активации
Для преодоления оrpаничений модели Хопфилда, работающей в качестве ассоциативной памяти, в лите-
ратуре предлаrалось множество подходов. Пожалуй, самым существенным из них на данный момент является
улучшение непрерывной модели Хопфилда, приведенное в [755]. Эта модификация оrpаничивает функцию
активации <р(.) нейрона, остааляя, таким образом, нетронутой простоту конструкции сети. В частности, orpa-
ниченные или сиrмоидальные функции активации всех нейронов сети заменяются немонотонной функцией. В
математических терминах эта функция определяется как следующее произведение:
<p(v) == ( 1 ехр( av) ) ( 1 + Kexp(b(lvl с)) ) ,
1 + ехр( av) 1 + exp(b(lvl Ь)) (1)
rде v индуцированное локальное поле. Первый множитель в правой части (1) является обычной сиrмоидаль-
ной функцией (rиперболическим TaHreHcoM), используемой в обычных сетях Хопфилда; параметр а является
коэффициентом передачи нейрона. Второй множитель отвечает за придание функции активации HeMoHoТOHHoro
вида. Оба параметра, характеризующие этот второй множитель (Ь и с), являются положительными константа-
ми; оставшийся параметр к обычно отрицательный. В экспериментах, описанных в [755], использовались
следующие значения этих параметров:
а == 50; Ь == 15,
c==0,5;K== 1.
Соrласно вышеназванной работе, точная форма функции активации и параметров, используемых для опи-
сания модели, не столь критична. Самым существенным здесь является сам факт немонотонности функции
активации.
Эта модель ассоциативной памяти обладает двумя интересными свойствами [1174].
В сети, составленной из N нейронов, еМКОСТЬ памяти модели составляет более О, 3N, что при больших N
значительно больше емкости обычной модели Хопфилда (N /2 log N).
В этой модели нет ложных состояний. Если не удается восстановить какую-либо корректную ячейку памяти,
состояние сети переходит к хаотическому поведению. (Понятие хаоса рассматривалось в разделе 14.13.)
14.8. Компьютерное моделирование 1 877
Рис. 14.17. Множество рукописных образов, используемых при компьютерном моделировании
сети Хопфилда
Во время первой части фазы вспоминания на вход сети подавались ячейки фунда
ментальной памяти. Таким образом, выполнялась проверка способности их Koppeкт
HOro восстановления из информации, сохраненной в матрице синаптических весов.
В каждом из случаев желаемый образ восстанавливался сетью после одной итерации.
Далее, для тoro чтобы продемонстрировать способность сетей Хопфилда KoppeK
тировать ошибки, рассматриваемый образ преднамеренно искажался при помощи
обращения случайно и независимо выбираемых пикселей (значения этих пикселей
изменялись с + 1 на 1 и с 1 на + 1 с вероятностью 0,25), после чеrо подавался на
вход сети. Результат этоrо эксперимента для цифры 3 показан на рис. 14.18. Образ,
показанный на этом рисунке в центре Bepxнero ряда, представляет собой искаженную
версию цифры 3. Этот образ в момент времени О подавался на вход сети. Образы,
произведенные сетью после 5, 10, 15,20,25,30 и 35 итераций, показаны в остальных
фраrментах этоrо рисунка. По мере увеличения количества итераций заметно посте
пенное увеличение сходства между выходом сети и цифрой 3. Видно, что после 35
итераций сеть сошлась к абсолютно корректной форме цифры 3.
878 rлава 14. Нейродинамика
Исходный образ
10
25
Искаженный образ
15
30
Рис. 14.18. Корректировка искаженноro образа цифры 3
5
20
Окончательный вариант (35)
При условии, что теоретически одна четверть из 120 ти нейронов сети Хопфилда
меняла свое состояние в каждом искаженном образе, среднее значение количества
итераций, необходимых для вспоминания, составляет 30. В нашем эксперименте KO
личество итераций, необходимых для восстановления различных образов из их иска
женных версий, приведено ниже.
Образ Количество итераций, потребовавшихся для восстановления
О 34
1 32
2 26
3 35
4 25
6 37
точка 32
9 26
Исходный образ
14
35
14.8. Компьютерное моделирование 1 879
Искаженный образ
21
Рис. 14.19. Некорректное восстановление образа цифры 2
42
7
28
Окончательный вариант (47)
Таким образом, среднее количество итераций, необходимых для восстановле
ния, HeMHoro превысило 31. Это показывает, что сеть Хопфилда вела себя так,
как ожидалось.
Внутренняя проблема сетей Хопфилда возникает в том случае, коща сети пред
ставляется искаженная версия некоторой ячейки фундаментальной памяти, а сеть
продолжает сходиться к некорректной ячейке (см. рис. 14.19). В этом случае сети
подавался на вход искаженный образ цифры 2, а после 47 итераций он сошелся к
ячейке фундаментальной памяти цифры 6.
Как уже roворилось, существует еще одна проблема, возникающая в сетях
Хопфилда, это наличие ложных состояний. На рис. 14.20 (рассматриваемом как
матрица, состоящая из 14 х 8 состояний сети) представлен список 108 ложных aT
тракторов, найденных после 43097 тестов случайно выбираемых цифр, имеющих
искажения отдельных бит с вероятностью 0,25. Ложные состояния можно сrpуппи
ровать следующим образом [42].
880 rлава 14. Нейродинамика
1. Обратные ячейки фундаментальной памяти. Эти ложные состояния представляют
собой обратные (т.е. взятые с противоположным знаком) версии ячеек фундамен
тальной памяти сети (см. первую ячейку в первом ряду рис. 14.20, которая об
ратна образу цифры 6 на рис. 14.17). Для описания этоrо типа ложных состояний
заметим, что функция энерrии Е является симметричной, Т.е. ее значения не из
меняются, если состояния всех нейронов обращаются (т.е. для всех i состояние Xi
заменяется на Xi)' Следовательно, если ячейка фундаментальной памяти l;1L co
ответствует определенному локальному минимуму поверхности энерrии, то этому
же локальному минимуму соответствует и ячейка l;IL' Обратный знак не COCTaв
ляет проблемы при извлечении информации, если принять соrлашение обращать
все информационные биты восстановленноro образца в случае, коrда оказывается,
что вместо "знаковоro" бита "+ 1" стоит бит " 1".
2. Смешанные состояния (mixture state). Смешанные ложные состояния представ
ляют собой линейные комбинации нечетноro количества сохраненных образов.
Например, рассмотрим состояние
Xi == sgn( l i + 2 i + з i)'
, , ,
являющееся смесью трех состояний. Это состояние сформировано из трех яче
ек фундаментальной памяти l;1, l;2 и l;з по правилу большинства (majority ru1e).
Условие устойчивости (14.45) в больших сетях удовлетворяется таким состоя
нием. Состояние в 6 ряду и 4 столбце рис. 14.20 является комбинацией трех
состояний, сформированной следующими состояниями: l;1 == (образ, обратный
единице), l;2 == цифра 4 и l;з == цифра 9.
3. Зеркальные состояния (spin glass state). Этот тип ложных состояний получил свое
название по аналоrии с зеркальными моделями в статистической механике. Зер
кальные состояния определяются локальными минимумами поверхности (land
scape) энерrии, которые не коррелированы с какими либо ячейками фундамен
тальной памяти сети (см. состояние в 7 ряду и 6 столбце на рис. 14.20).
14.9. Теорема Коэна rросс6ерrа
в [202] рассматривается общий принцип достижения устойчивости определенным
классом нейронных сетей, описываемых следующей системой нелинейных диффе
ренциальных уравнений:
.:iu. == а ( и. ) [ Ь ( и. ) c..tn. ( u o )] J 1 N
dt J J J J J L З' '1', , ,. == ,..., .
i l
(14.56)
14.9. Теорема Коэна rроссберrа 881
[!IrJ[!I [!II;JB
g mEJ[[I[JI
[9 [J][g в eJGSlПEJ
[9J EJ[I]B [!]
B m[l]
[g][:][f1]вп а[З
B B ВJrn
m П[J]EIJ 1;I
[a][]IB[;IIB B
B I..I]ВJ ВJEI
[I] UJ
I;]g [9]БJ[]I][gfI]
[:]lDJ[!][Il]t;J[D] B
[ЗE!J[J]
Рис. 14.20. Перечень ложных состояний ДЛЯ сети Хопфилда в компьютерном эксперименте 1
'"""
882 rлава 14. Нейродинамика
Соrласно этой работе, данный класс нейронных сетей допускает определение
функции Ляпунова следующим образом (см. задачу 14.13):
1 N N N l Uj
Е == 2 L L Сji<Рi(Ui)<Рj(из) L Ьj(л)<р (Л)dл,
i l j l j l О
(14.57)
ще
<Р (Л) == d (<Рj(Л))'
(14.58)
Однако, для TOro чтобы определение (14.57) было корректным, необходимо вы-
полнение следующих условий.
1. Условие симметрии. Синаптические веса сети должны быть симметричными:
Cij == Cji'
(14.59)
2. Условие неотрицательности. Функция aj (из) должна быть неотрицательной:
аj(из) 2': о.
(14.60)
3. Условие монотонности. Нелинейная ФУНКЦИЯ отображения входа на выход <Pj(Uj)
должна быть монотонной:
<p (из) == d d <Pj( из) 2': о.
и,
J
(14.61)
Теперь можно сформулировать теорему Коэна rроссберrа (Cohen Grossberg theorem).
Если система нелинейных дифференциальных уравнений (14.56) удовлетворяет
условиям симметрии, неотрицательности и монотонности, то функция Ляпунова си-
стемы (14.57) удовлетворяет условию
dE <о.
dt
Если функция Ляпунова Е обладает этим rлобальным свойством, то, соrласно
первой теореме Ляпунова, эта система является rлобально устойчивой.
14.9. Теорема Коэна rроссберrа 883
ТАБЛИЦА 14.3. Соответствие между теоремой Коэна rроссберrа и моделью
Хопфилда
Теорема Коэна rроссберrа
Щ
аj(Щ)
b j (Uj)
Cji
<Pi (Ui)
Модель Хопфилда
CjVj
1
(щ/Rj) + Ij
Wji
<Pi( Vi)
Модель Хопфилда как частный случай теоремы
Коэна rроссберrа
Сравнивая общую систему уравнений (14.56) с системой (14.20) для непрерывной MO
дели Хопфилда, можно установить соответствие между этими моделями (табл. 14.3).
Подставляя значения из табл. 14.3 в уравнение (14.57), получим следующую функцию
Ляпунова для непрерывной модели Хопфилда:
1 N N N l Щ ( )
Е == 2 Wji<Рi(Vi)<Рj(Щ) + о j Ij <p (v)dv,
(14.62)
rде нелинейная функция активации <р(.) определяется выражением (14.23).
Затем можно сделать следующие наблюдения.
1.
<Pi(Vi) == Xi'
2.
l Щ l Х;
о <p (v)dv == о dx == Xj'
3.
lЩ v<p (v)dv == l Х; dx == l Х; <pj1(x)dx.
Выражения 2 и 3 вытекают из подстановки х == <Pi(V), Таким образом, подстав
ляя ЭТИ выражения в функцию Ляпунова (14.62), получим результат, идентичный
полученному в выражении (14.28). Однако обратим внимание на то, что для суще
ствования обобщенной функции Ляпунова (14.62) <Pi(V) должна быть неубывающей
функцией входа V, но не обязательно должна иметь обратную.
884 rлава 14. Нейродинамика
Теорема Коэна rроссберrа является общим принципом нейродинамики для ши
pOKOro спектра областей применения [387]. В следующем разделе рассмотрим еще
одно применение этой важной теоремы.
14.10. Модель BSB
в этом разделе мы продолжим нейродинамический анализ ассоциативной памяти и
изучим модель состояния мозrа BSB (brain state in box), которая впервые была описа-
на в [54]. В своей основе модель BSB является системой с положительной обратной
связью с амплитудным оrpаничением (positive feedback system with amp1itude 1im-
itation). Она состоит из множества взаимосвязанных нейронов, которые замкнуты
обратной связью сами на себя. В [54] эта модель использует встроенные обратные
связи для усиления (amp1ify) входноro образа до тех пор, пока все нейроны сети не
достиrнут насыщения. Таким образом, модель BSB можно рассматривать как устрой-
ство классификации, в котором аналоroвому входу дается цифровое представление,
определяемое некоторым устойчивым состоянием модели.
Пусть W симметричная матрица весов, наибольшие собственные значения ко-
торой имеют положительные действительные части. Пусть х(О) вектор началь-
ных состояний этой модели, представляющий некоторый входной сиrнал активации.
Предполаrая, что модель имеет N нейронов, вектор состояния этой модели имеет
размерность N, а матрица весов W размерность N х N. Алrоритм BSB полностью
определяется следующей парой уравнений:
у(n) == х(n) + Wx(n),
х(n + 1) == q>(y(n)),
(14.63)
( 14.64)
rде малая положительная константа, называемая коэффициентом обратной связи
(feedback factor); х( n) вектор состояний модели в дискретный момент времени n. На
рис. 14.21, а показана блочная диаrpамма системы уравнений (14.63) и (14.64); блок
с меткой W представляет однослойную линейную нейронную сеть (см. рис. 14.21,6).
Функция активации q> является кусочно линейной функцией aprYMeHTa Yj(n) j ro
компонента вектора у( n) (рис. 14.22):
{ +1,
xj(n + 1) == q>(Yj(n)) == Yj(n),
1,
если Yj(n) > + 1,
если 1 ::; Yj (n) ::; + 1,
если У j ( n) < 1.
(14.65)
Равенство (14.65) оrpаничивает вектор состояний модели BSB N MepHЫM единич-
ным кубом с центром в начале координат.
14.10. Модель BSB 885
Усилитель
обратной связи
Единичные
задержки
f3
х(п)
f3 х(п)
Матрица
весов
х(п+ 1)
Нелинейность
а)
x1(n)
Выходы
xzC n )
Рис. 14.21. Блочная диаrрамма
модели BSB (а); rраф передачи
сиrнала линейноrо ассоциатора с
матрицей весов W (б)
xN(n)
б)
Итак, алrоритм работает следующим образом. В качестве вектора начальноro co
стояния на вход модели BSB подается сиrнал активации х(О), после чеrо дЛЯ BЫ
числен ия вектора у(О) используется уравнение (14.63). Затем для усечения вектора
у(О) используется равенство (14.64), в результате чеrо получается вектор х(1). Далее,
применяя в цикле выражения (14.63) и (14.64), получим х(2). Этот цикл продолжа
ется до тех пор, пока модель BSB не достиrнет HeKoToporo устойчивоro состояния,
представленноrо одной из вершин единичноrо rиперкуба. Интуитивно понятно, что
положительная обратная связь в модели BSB приводит к увеличению Евклидовой
длины (нормы) вектора начальноrо состояния х(О) до тех пор, пока вектор состояния
не упрется в стенку единичноrо rиперкуба. После этоrо вектор продолжает "сколь
жение" по стенке куба, пока не достиrнет HeKoToporo ero "устойчивоrо" уrла, rде он
пытается выйти наружу, чему препятствует единичный куб [546]. Описанный про
цесс положен в основу названия данной модели, которое дословно переводится как
"модель мозrа в виде ящика".
Функция Ляпунова модели BSB
Модель BSB можно переопределить как частный случай нейродинамической модели,
описанной выражением (14.16) [387]. Для Toro чтобы это увидеть, вначале перепишем
"'"
886 rлава 14. Нейродинамика
Х}
у.
J
Рис. 14.22. Кусочно линейная активаци-
онная функция, используемая в модели
BSB
j й компонент алroритма BSB (14.63) и (14.64) в следующем виде:
Xj(n + 1) == <р ( t CjiXi(n) ) , j == 1,2,... , N.
, 1
(14.66)
Коэффициенты Cji определяются таким образом:
Cji == 8 ji + Wji' (14.67)
(14.67)
rдe 8 ji дельта Кронекера, равная единице при i == j и нулю в противном случае;
Wji ji й элемент матрицы весов W. Уравнение (14.66) записано в форме для дне-
KpeTHoro времени. Чтобы продолжить, потребуется пере формулировать ero в форме
непрерывноro времени:
x;(t) x;(t) + '1' (t, c;,x,(t)) , j 1,2,... , N,
( 14.68)
ще смещение Ij равно нулю для всех j. Однако, для Toro чтобы применить теорему
Коэна rроссберrа, требуется сделать еще один шаr и преобразовать (14.68) в форму
аддитивной модели. Это можно сделать, введя новое множество переменных:
N
Vj(t) == L CjiXi(t).
i l
(14.69)
14.10. Модель BSB 887
ТАБЛИЦА 14.4. Соответствие между теоремой Коэна rроссберrа и моделью BSB
Теорема Коэна rроссбер2а Модель BSB
и. V.
J J
aj (Uj) 1
Ь j (из) Vj
С.. Cji
З'
<P j (Uj) <P j (Vj)
Torдa с помощью определения (14.67) получим:
N
Xj(t) == L CjiVi(t).
i l
(14.70)
Следовательно, модель (14.68) можно переписать в эквивалентной форме:
d N
dt Vj(t) == Vj(t) + L Cji<P(Vi(t)), j == 1,2,... , N.
i l
(14.71)
Теперь можно применить теорему Коэна rроссберrа к модели BSB. Сравнивая (14.71)
и (14.56), мы видим соответствия между моделью BSB и теоремой Коэна (табл. 14.4).
Таким образом, подставив результаты из табл. 14.4 в выражение (14.57), получим,
что функция Ляпунова для модели BSB имеет следующий вид:
1 N N N l Vj
Е == 2 L L Cji<P(Vj)«>(Vi) + L v<p'(v)dv,
j l i l j l О
(14.72)
ще «>' ( v) первая производная сиrмоидальной функции <р( v) по своему apryMeHТY.
В заключение, подставляя определения (14.65), (14.67) и (14.69) в (14.72), можно
определить функцию Ляпунова (энерrии) для модели BSB в терминах исходных пе
ременных состояний [387]:
N N Т
Е == W.X.X. == x Wx
2 З' J ' 2 .
i l j l
(14.73)
Оценка функции Ляпунова для сети Хопфилда, представленная в разделе 14.7,
предполаrает существование производной функции, обратной к сиrмоидальной нели
нейности модели. Это требование удовлетворяется для функции rиперболическоro
TaHreHca. Однако этому условию не удовлетворяет модель BSB, если переменная co
стояния j ro нейрона в ней может принимать только значения +1 и 1. Несмотря на
.....
888 rлава 14. Нейродинамика
эту сложность, функцию Ляпунова для модели BSB можно вычислить с помощью
теоремы Коэна rроссберrа. Этот факт хорошо иллюстрирует общую применимость
этой важной теоремы.
Динамика модели BSB
При непосредственном анализе, выполненном в [366], было показано, что модель
BSB является де факто алroритмом наискорейшеrо спуска, который минимизирует
энерrию Е, определяемую формулой (14.73). Это важное свойство модели BSB, од-
нако, предполаrает, что матрица весов W удовлетворяет следующим условиям.
. Матрица W симметрична:
w == w T .
· Матрица W является положительно полуопределенной, Т.е. в терминах собствен-
ных значений:
Amin ;::: О,
rдe Amin наименьшее собственное значение матрицы w.
Исходя из этоrо, функция энерrии Е модели BSB убывает с ростом п (количество ите-
раций), если вектор состояний х(п+ 1) в момент времени п+ 1 отличается от вектора
х( п) в момент времени п. Более Toro, точки минимума функции энерrии Е опреде-
ляют равновесные состояния модели BSB, которые характеризуются следующим:
х(п + 1) == х(п).
Друrими словами, подобно модели Хопфилда, модель BSB является сетью, мини-
мизирующей энерrию (energy minimizing network).
Равновесные состояния модели BSB определены в некоторых уrлах единично-
ro rиперкуба и в начале координат. В последнем случае любые отклонения вектора
состояний, независимо от Toro, насколько малыми они будут, усиливаются положи-
тельными обратными связями модели и, таким образом, уводят состояние модели
от начала координат в направлении некоторой устойчивой конфиryрации. Друrими
словами, начало координат является седло вой точкой. Для TOro чтобы все уrлы еди-
ничноrо rиперкуба являлись возможными равновесными состояниями модели BSB,
необходимо выполнение TpeTbero условия [382].
14.10. Модель BSB 889
. Матрица весов W должна быть диаrонально доминантной (diagona1 dominant), Т.е.
Wjj LIЩjl, j==1,2,...,N,
i",j
(14.74)
rдe Wij ij й элемент матрицы W.
Для TOro чтобы равновесное состояние х бьто устойчивым (т.е. чтобы уrол еди
ничноro rиперкуба был фиксированной точкой аттрактора), в этом кубе должен cy
ществовать бассейн аттракции N(x), такой, чтобы для любоrо вектора начальноrо
состояния х(О) из N(x) модель BSB сходилась к х. Для TOro чтобы все уrлы единично
ro rиперкуба бьти возможными точечными аттракторами, матрица весов W должна
удовлетворять четвертому условию [382].
. Матрица весов W должна быть CTpOro диаroнально доминантной, Т.е.
Wjj L IЩjl + а, j == 1,2,..., N,
i",j
(14.75)
rдe а некоторая положительная константа.
Важной точкой в этой дискуссии является то, что если модель BSB имеет сим
метричную и положительно полуопределенную матрицу весов W (что чаще Bcero и
происходит), ТО только некоторые (но не все) уrлы единичноrо rиперкуба являются
точечными аттракторами. Для TOro чтобы все уrлы были потенциальными точечны
ми аттракторами, матрица весов W должна также удовлетворять условию (14.75),
которое включает в себя условие (14.74).
Кластеризация
Естественным применением модели BSB является кластеризация (c1ustering). Это сле
дует из Toro факта, что устойчивые уrлы единичноrо rиперкуба выступают в роли
точечных аттракторов с четко определенными бассейнами аттракции. Эти бассей
ны делят пространство состояний на соответствующее множество четко очерченных
областей. Следовательно, модель BSB может использоваться в качестве алrоритма
кластеризации без учителя (unsupervised clustering a1gorithm), в котором все устой
чивые уrлы единичноrо rиперкуба представляют собой "кластеры" рассматриваемых
данных. Самоусиление, производимое положительными обратными связями (COOT
ветствующее первому принципу самоорrанизации, сформулированному в rлаве 8),
является важной составляющей этоrо свойства кластеризации.
890 rлава 14. Нейродинамика
в [56] описано использование модели BSB дЛЯ кластеризации (и, следовательно,
идентификации) сиrналов радара от разных источников. В этом приложении матрица
весов W, являющаяся основой работы модели BSB, обучалась с использованием ли
нейноro ассоциатора (ассоциативной памяти), обучаемоro методом коррекции ошибок
(см. rлаву 2). для примера предположим, что информация представлена множеством
К векторов обучения, которые ассоциированы сами с собой следующим образом:
Xk .....-t Xk, k == 1,2,... , К.
(14.76)
Пусть вектор обучения Xk выбирается случайным образом. Torдa матрица ве-
сов W подверrается приращениям, соответствующим алrоритму коррекции оши-
бок (см. задачу 3.9):
д W == 11(Xk WXk)Xk,
(14.77)
rдe 11 параметр скорости обучения. Целью обучения является построение такой
архитектуры, чтобы для множества возбуждений Х1, Х2, ..., ХК система вела себя как
линейный ассоциатор:
WXk == Xk, k == 1,2,... , К.
(14.78)
Алroритм коррекции ошибок (14.77) аппроксимирует идеальное условие (14.78)
в смысле минимальной среднеквадратической ошибки (LMS error). В результате та-
KOro процесса обучения линейный ассоциатор формирует конкретный набор соб-
ственных векторов (определяемый векторами обучения) с собственными значения-
ми, равными единице.
Для кластеризации сиrналов радара м(щель BSB использует линейный ассоци-
атор, обучаемый методом коррекции ошибок для построения матрицы весов W и
осуществления следующеro вычисления [56]:
х(п + 1) == <р(ух(п) + Wx(n) + 8х(О)),
(14.79)
что слеrка отличается от версии алroритма BSB, представленноro формулами (14.63)
и (14.64). Это отличие заметно в двух аспектах.
. Константа уменьшения (decay) введена в первом слаrаемом, ух( п), для указания на
некоторое уменьшение текушеro состояния. Предполаrая, что 'у положительная
константа, меньшая единицы, ошибки в конечном счете можно свести к нулю.
. Третье слаrаемое 8х(0) введено для сохранения влияния вектора начальноrо со-
стояния х(О), что оrpаничивает возможные состояния модели BSB.
14.11. Компьютерное моделирование 2 891
Повторение итераций модели BSB приводит к доминированию действия собствен
ных векторов матрицы W с наибольшими положительными собственными значени
ями. Таким образом, векторы Х1, Х2,... ,Хк обучаются линейным ассоциатором. Спо
собность к кластеризации в модели BSB появилась в основном за счет ассоциации
связанных с сиrналом собственных векторов с большими собственными значения
ми, которая усиливается за счет положительной обратной связи. Таким образом, по
сле HeKoToporo количества итераций эти состояния модели начинают доминировать.
С друroй стороны, связанные с шумом собственные векторы обычно ассоциируются
с малыми собственными значениями. Таким образом, их влияние на состояние Moдe
ли BSB существенно уменьшается. Все это поддерживает отношение сиrнал/шум на
достаточно высокой отметке.
В разрезе задачи paдapHoro наблюдения детальное описание излучателей, рабо
тающих в окрестности, заранее не известно. В доли секунды для обработки обычно
поступают сотни тысяч импульсов радара, поэтому недостатка в данных в этой зада
че нет. Вся сложность состоит в том, как придать этим данным смысл. Модель BSB
может помочь в этой задаче, обучая микроволновую структуру среды радара с по
мощью BcтpoeHHoro свойства кластеризации. Кластеры формируются в окрестности
точечных аттракторов, представляющих конкретные излучатели (источники сиrна
ла). Таким образом, модель BSB может идентифицировать получаемые импульсы как
произведенные конкретным излучателем.
14.11. Компьютерное моделирование 2
На рис. 14.23 показаны результаты моделирования модели BSB, состоящей из двух
нейронов. Матрица W размерности 2 х 2 определена следующим образом:
w == [ 0.035 0.005 ]
0.005 0.035 .
Она симметрична, положительно определена и удовлетворяет условию (14.75).
Четыре части рисунка 14.23 соответствуют четырем различным началь
ным состояниям х(О):
а) х(О) == [0.1, 0.2]Т;
б) х(О) == [ 0.2, О.з]Т;
в) х(О) == [ 0.8, O.4]T;
r) х(О) == [0.6, о.l]Т.
Области, показанные на этом рисунке заштрихованными, являются четырьмя бас
сейнами аттракции, характеризующими эту модель. На этом рисунке ясно видно, что
начальное состояние модели лежит в конкретном бассейне аттракции, что определяет
направление движения матрицы весов W(n) при увеличении количества итераций n,
892 rлава 14. Нейродинамика
Н,+I)
Н,+I)
(+1,+1)
H, I) (+1, 1) H, I) (+1, 1)
а) б)
Н,+1) (+1, +1) Н,+I) (+1,+1)
H, I)
(+1, 1) Н, 1)
(+1, 1)
Рис. 14.23. Траектории при компьютерном моделировании модели BSB. Результаты,
показанные в четырех частях рисунка, соответствуют различным начальным состояниям
до тех пор, пока состояние сети х( n) не достиrнет фиксированноrо точечноrо aттpaK
тора (т.е. одноrо из уrлов квадрата размера два на два), принадлежащеrо данному
бассейну аттракции. Особый интерес для нас представляет траектория, показанная
на рис. 14.23,2: начальное состояние х(О) находится в первом квадранте, а траекто-
рия заканчивается в уrлу четвертоro (точка (+1, 1)), так как именно в бассейне эrоrо
аттрактора точки находилось начальное состояние.
14.12. Странные аттракторы и хаос 893
14.12. Странные аттракторы и хаос
Вплоть до этоro места наша дискуссия о нейродинамике фокусировала внимание
читателя только на одном типе поведения динамических систем, характеризующемся
наличием фиксированных точечных аттракторов. В этом разделе мы рассмотрим еще
один класс аттракторов, называемых странными (strange), которые характеризуют
нелинейные динамические системы с порядком выше BTOpOro.
Странные аттракторы имеют в высшей мере сложное поведение. Особенно инте
ресным делает изучение странных аттракторов и хаоса тот факт, что рассматриваемая
система является детерминированной (т.е. руководствуется фиксированными прави
лами) и в то же время при наличии только нескольких степеней свободы ведет себя
настолько сложным образом, что внешне кажется, что это поведение носит чисто
случайный характер. И в самом деле, случайность является фундаментальной xapaK
теристикой таких систем в том смысле, что статистика BToporo порядка хаотических
временных рядов rоворит именно об этом. Однако, в отличие от истинно случай
ных явлений, случайность, существующая в хаотических системах, не исчезает за
счет сбора большеro количества информации! В принципе будущее поведение xao
тических систем полностью определяется их прошлым, однако на практике любая
неопределенность в выборе начальных состояний, какими бы малыми они ни были,
ведет к ее экспоненциальному росту с течением времени. Следовательно, несмотря на
то, что динамика хаотических систем проrнозируема на короткий период времени, ее
невозможно предсказать на длительный срок. Таким образом, хаотические временные
ряды парадоксальны в том смысле, что их rенерация осуществляется детерминиро
ванной динамической системой, но они имеют внешний вид случайных. Именно на
этом свойстве явления хаоса Лоренц акцентировал внимание, открыв аттракторы,
названные ero именем [674].
В нелинейной динамической системе, Korдa орбиты аттракторов в окрестности
начальных состояний стремятся отдалиться с течением времени, rоворится о нали
чии странных аттракторов (strange attractor), а сама система называется хаотической
(chaotic). Друrими словами, именно фундаментальное свойство чувствительности к
начальным состояниям (sensitive dependence оп initia1 condition) делает эти aттpaK
торы странными. Чувствительность в контексте нашей задачи означает следующее:
если две идентичные системы начинают свое движение из слеrка отличающихся
начальных состояний (а именно х и х + е, rде е очень малая величина), то их
динамические состояния в пространстве состояний будут расходиться друr от друrа,
при этом расстояние между ними будет увеличиться в среднем экспоненциально.
894 rлава 14. Нейродинамика
Инвариантные характеристики хаотической динамики
в качестве классификаторов хаотических процессов выступают два основных свой
ства фрактальные измерения и экспоненты Ляпунова. Фрактальные измерения
(fracta1 dimension) характеризуются reометрической структурой странных aттpaктo
ров. Термин "фрактальность" бьт введен в [702]. В отличие от целочисленных из-
мерений (которые используются для двухмерных поверхностей и трехмерных объек
тов) фрактальные не принимают целых значений. Как и экспонентыI Ляпунова, ОНИ
описывают перемещение орбит аттракторов при эволюции динамики. Эти две ИН-
вариантные характеристики хаотической динамики будут подробно описаны ниже.
Термин "инвариантность" подчеркивает тот факт, что как экспоненты Ляпунова, так
и фрактальные измерения любоro хаотическоro процесса остаются неизменными при
rладких нелинейных изменениях ero системы координат [2].
Фрактальные измерения
Рассмотрим странный аттрактор, динамика KOToporo в d MepHoM пространстве состо-
яний описывается следующим образом:
х(n + 1) == F(x(n)), n == 0,1,2,... ,
(14.80)
что является дискретной версией выражения (14.2). Этот факт можно увидеть, при-
няв t == nдt, rде дt период дискретизации. Предполаrая достаточную малость
величины дt, можно записать:
d 1
x(t) == л [х(nдt + дt) х(nдt)].
dt ut
Таким образом, сформулировать дискретную версию выражения (14.2) можно сле-
дующим образом:
1
[х(nдt + дt) х(nдt)] == F(х(nдt)) для малых дt.
дt
Принимая для упрощения выкладок дt == 1 и переставляя слаrаемые, полу-
чим выражение
х(n + 1) == х(n) + F(x(n)),
которое можно привести к форме (14.80) простым переопределением вектор-
функции F(.).
14.12. Странные аттракторы и хаос 895
Возвращаясь к выражению (14.80), предположим, что была построена малая сфе
ра радиуса r BOKpyr некоторой точки у, лежащей на орбите аттрактора или вблизи
нее. Torдa естественное распределение (natura1 distribution) точек аттрактора можно
определить следующим образом:
1 N
р(у) == lim N о(у х(n)),
N ...... 00 L.....J
n 1
(14.81)
rдe 0(') d мерная дельта функция; N количество точек данных. Обратите внима
ние на изменения, связанные с использованием числа N. Естественное распределение
р(у) выступает в роли cтpaHHoro аттрактора, который аналоrичен функции плотности
вероятности для случайной переменной. Следовательно, можно определить инвари
ант ! по отношению к функции f(y), при условии, что эволюция динамики описы
вается следующим мноroмерным интеrpалом:
! == 1: f(y)p(y)dy.
(14.82)
Рассматриваемая функция f(y) дает меру TOro, как количество точек в малой
сфере изменяется при устремлении радиуса r сферы к нулю. Вспоминая, что объем,
оrpаниченный d мерной сферой, пропорционален r d , можно составить представление
об измерении аттрактора как о поведении плотности точек на аттракторе на малых
расстояниях в пространстве состояний.
Евклидово расстояние между центром у сферы и точкой х( n) на шаrе дискрети
зации n равно Ily x(n)ll. Исходя из этоrо, точка х(n) лежит внутри сферы радиуса
r, если
Ily x(n)11 < r,
или, эквивалентно:
r Ily x(n)11 > О.
Таким образом, функцию ЛХ) в описываемой здесь ситуации можно записать в
общем виде:
f(x) == ( N 1 t e(r Ily х(k)ю ) q l
k l,k#n
(14.83)
896 rлава 14. Нейродинамика
rдe q целое число; е(.) ФУНКЦИЯ Хэвисайда (Heaviside), определяемая следую
щим образом:
e(z) == { 1, z > О,
О, z < О.
Подставляя выражения (14.81) и (14.83) в (14.82), получим новую функцию
C(q, r), которая зависит от q и r следующим образом:
( N ) q l ( N )
C(q, r) == 1: N 1 k #n e(r Ily x(k)ll) 8(у х(n)) dy.
Используя свойство сортировки дельта функции
1: g(y)8(y x(n))dy == g(x(n))
для некоторой функции 9 (.) и изменяя порядок суммирования, можно переопределить
функцию С (q, r) в следующем виде:
N ( N ) q l
C(q, r) == N 1 k #n e(r Ilx(n) x(k)ll)
(14.84)
Эта функция C(q, r) называется функцией корреляции? (corre1ation function) и
является мерой вероятности Toro, что две точки, х(n) и x(k), на аттракторе находятся
на расстоянии r. Количество точек данных N в определении (14.84) должно быть
достаточно большим.
Сама эта функция корреляции С (q, r) является инвариантом аттрактора. Тем не
менее на практике общепринято фокусировать внимание на поведении С ( q, r) при
малых r. Предельный случай описывается следующим выражением:
C(q, r) r(q l)Dq,
(14.85)
rдe предполаrается существование D q, называемоro фрактальным измерением (fracta!
dimension) аттрактора. Взяв лоrарифм от обеих частей уравнения (14.85), можно
7 Идея функции корреляции C(q, т) (см. (14.84» была известна в статистке с [880]. Однако для характери
стики ложноrо aтrpaктopa она использовалась только в [375]. Из начально использование функции корреляции
C(q, т) рассматривалось в контексте размерности корреляции q == 2.
14.12. Странные аттракторы и хаос 897
формально определить D q следующим образом:
D l' 10g C(q, r)
q == r (q 1) 10g r .
(14.86)
Однако, так как обычно приходится иметь дело с конечным количеством точек
данных, радиус r должен быть достаточно малым, чтобы достаточно точек поме
стилось внутри сферы. Для наперед заданноrо q фрактальное измерение D q можно
определить как наклон той части функции С (q, r), которая в лоrарифме l09 r линейна.
При q == 2 определение фрактальноrо измерения D предполаrает наличие простой
формы, удобной для вычислений. Полученное измерение D 2 называется измерением
корреляции (corre1ation dimension) аттрактора [375]. Измерение корреляции отражает
сложность рассматриваемой динамической системы и оrpаничивает степени свободы,
необходимые для описания системы.
Экспоненты Ляпунова
Экспоненты Ляпунова являются статистическими величинами, которые описывают
неопределенность будущих состояний аттрактора. Более конкретно, они оценивают
экспоненциальное расстояние, на которое соседние траектории отдалены друr от
друrа при движении к аттрактору. Пусть х(о) начальное состояние, а {х(n), n ==0,
1, 2,. .. } соответствующая орбита. Рассмотрим точку на бесконечно малом yдa
лении от начальноrо состояния х(о) в направлении вектора у(о), танrенциально
ro к орбите. Torдa эволюция вектора TaHreHca определяет эволюцию бесконечно
малоro смещения возмущенной орбиты {у(n), n == 0,1,2,...} от невозмущенной
{х(n), n == 0,1,2,.. .}. в частности, отношение y(n)/lly(n)11 определяет бесконечно
малое смещение орбиты от точки х(n), а отношение Ily(n)II/lly(O)11 множитель,
на который бесконечно малое смещение растет (если Ily( n) 11 > Ily(O) 11) или yмeHЬ
шается (если Ily(n)11 > Ily(O)II). Для любоrо начальноro состояния х(о) и начальноro
смещения ао == у( О) /11 у( О) 11 экспонента Ляпунова (Lyapunov exponent) определяется
следующим образом:
. 1 ( Ily(n)ll )
А(Х(О), а) == l ;; 10g Ily(O)11 .
(14.87)
Любой d мерный хаотический процесс имеет в целом d экспонент Ляпунова,
которые MorYT быть положительными, отрицательными и равняться нулю. Положи
тельные экспоненты Ляпунова учитывают неустойчивость орбиты в пространстве
состояний. Друrими словами, положительные экспоненты Ляпунова отвечают за чув
ствительность хаотическоro процесса к начальным состояниям. С друrой стороны,
отрицательные экспоненты Ляпунова управляют снижением не стационарности орби
ты (decay of transients in orbit). Нулевая экспонента Ляпунова отмечает тот факт, что
898 rлава 14. Нейродинамика
динамику хаоса можно описать системой нелинейных дифференциальных уравнений.
Это значит, что хаотический процесс является потоком (flow). Объем в d MepHoM
пространстве состояний ведет себя как ехр( L(л'l + л'2+. . . +л'd)), rдe L количество
шаrов времени в будущем. Отсюда следует, что, для Toro, чтобы процесс был дисси
пативным (dissipative), сумма экспонент Ляпунова должна быть отрицательной. Это
необходимое условие Toro, чтобы объем в пространстве состояний уменьшался со
временем, что является условием физической реализуемости.
Измерение Ляпунова
Для заданноrо спектра Ляпунова л'1, л'2, . . . , л'd В [539] было введено понятие изме
рения Ляпунова (Lyapunov dimension) для cTpaHHoro аттрактора:
к
L: л'i
i l
D L == К + lл'кнl '
(14.88)
rдe К целое число, удовлетворяющее двум условиям:
к
Lл'i>Ои
i l
кн
L л'i < О.
i l
При нормальных условиях измерение Ляпунова D L имеет приблизительно тот же
размер, что и измерение корреляции D 2 . Это важное свойство любоro хаотическоro
процесса. Это значит, что несмотря на то, что измерения корреляции и Ляпунова опре
деляются совершенно различными способами, их значения для cтpaHHoro аттрактора
обычно достаточно близки друr к друry.
Определение хаотическоrо процесса
в этом разделе обсуждался хаотический процесс, однако не давалось ero формальное
определение. В свете Toro, что известно об экспонентах Ляпунова, можно принять
следующее определение.
Хаотический процесс это процесс, rенерируемый нелинейной динамической
системой, в которой хотя бы одна экспонента Ляпунова положительна.
Это необходимое условие для чувствительности к начальным состояниям, что
является основным признаком cTpaHHoro аттрактора.
Самая большая экспонента Ляпунова также определяет roризонт проrнозирова-
ния хаотическоro процесса. В частности, кратковременная проrнозируемость хаоти-
ческоrо процесса приблизительно равна величине, обратной к максимальной экспо-
ненте Ляпунова [2].
14.1 З. Динамическое восстановление 899
14.13. Динамическое восстановление
Динамическое восстановление можно определить как отображение, которое воспро
изводит модель неизвестной динамической системы размерности т. Интерес пред
ставляет динамическое моделирование временных рядов, reнерируемых системой, о
которой известно, что она хаотична. Друrими словами, для заданноrо BpeMeHHoro
ряда {Y(n)};; 1 необходимо построить некоторую модель, которая вобрала бы в ce
бя рассматриваемую динамику, ответственную за rенерацию наблюдения у(n). Как
уже roворилось в предыдущем разделе, N это размерность множества приме
ров. Основной целью динамическоro восстановления является придание физическоro
смысла таким временным рядам без необходимости математических знаний о pac
сматриваемой динамике. Обычно рассматриваемая система чересчур сложна, чтобы
ее можно было охарактеризовать математическими терминами. Нам доступна только
информация, содержащаяся во временных рядах, полученных из измерений одноrо
из наблюдений системы.
Фундаментальным результатом теории динамическоrо восстановления 8 является
rеометрическая теорема, называемая, соrласно [1040], теоремой вложения с задерж
кой (de1ay embedding theorem). Такенс рассматривал ситуацию, в которой отсутствует
шум, фокусируя внимание на координатных отображениях с задержкой (de1ay coor
dinate maps) или моделях проrнозирования, которые конструируются из временных
рядов, представляющих собой наблюдения динамической системы. В частности, Ta
кенс показал, что если динамическая система и наблюдения носят общий характер,
то координатное отображение с задержкой из d MepHoro rладкоrо компактноrо MHO
жества в 2d+1 является диффеоморфизмом (diffeomorphism) этоrо мноrообразия, rдe
d размерность пространства состояний данной динамической системы. (Диффео
морфизм рассматривается в следующей rлаве.)
Для интерпретации теоремы Такенса в терминах обработки сиrнала вначале pac
смотрим неизвестную динамическую систему, эволюция которой в дискретном Bpe
мени описывается нелинейным разностным уравнением:
х(n + 1) == F(x(n)),
(14.89)
rдe х(n) d мерный вектор состояний системы в момент времени n; F(-) HeKOTO
8 Построение динамики, использующее независимые координаты из временных рядов, впервые было про-
ведено в [809]. Однако в этой работе не содержалось никаких доказательств и вместо вложений с задержкой
по времени использовались "производные" вложения. В 1981 [оду Такенс опубликовал математически rлубо-
кую работу, посвященную вложениям с задержкой по времени, которые применялись к aтrpaктopaM, подобным
поверхностям или тору. В том же roду была опубликована работа, посвященная тому же вопросу [703]. Нема-
тематикам будет сложно читать работу Такенса, и еще сложнее работу Мане. Идея координатноro отображения
с задержкой (delay сооrdiпаtе mаррiпg) бьша обоrащена [935]. Подход, предпринятый в этой работе, объединяет
и расширяет результаты предшественников [1040], [1135].
900 rлава 14. Нейродинамика
рая вектор функция. Здесь предполаrается, что период дискретизации нормализован
к единице. Пусть временной ряд {у(n)}, наблюдаемый на выходе системы, опреде
ляется в терминах вектора состояний х( n) следующим образом:
у(n) == g(x(n) + v(n),
(14.90)
rдe g(-) скалярная функция; v(n) аддитивный шум. Здесь аддитивный шум
добавлен для Toro, чтобы учесть несовершенство и неточность методов измерения
наблюдения у(n). Уравнения (14.89) и (14.90) описывают поведение динамической
системы в пространстве состояний. Соrласно теореме Такенса, rеометрическая CТPYK
тура динамики этой системы, зависящей от мноrих переменных, может быть BOCCTa
новлена (unfo1d) на основе наблюдений у(n) с нулевым шумом (v(n) ==0) в D MepHoM
пространстве, построенном на основе HOBoro вектора
YR(n) == [у(n), у(n т),... , у(n (D l)т)]Т,
(14.91)
rде т некоторое положительное целое, называемое нормализованной задержкой
вложения (norma1ized embedding de1ay). Это значит, что для заданноrо наблюдаемоro
значения у( n) в дискретный момент времени n, которое относится к одному компо
ненту неизвестной динамической системы, динамическое восстановление возможно
с использованием D MepHoro вектора YR(n) (D 2: 2d + 1), rде d размерность про
странства состояний данной системы. Здесь и далее это утверждение будем называть
теоремой вложения с задержкой (de1ay embedding theorem). Условие D 2: 2d+ 1 явля
ется достаточным, но не является необходимым для динамическоrо восстановления.
Процедура поиска подходящеro D называется вложением, или вставкой (embedding),
а минимальное целое число D, при KOTOpO достиrается динамическое восстановле
ние, называется измерением вложения (embedding dimension) и обозначается как D Е.
Теорема вложения с задержкой имеет большое применение. Эволюция точек
YR(n) ........YR(n + 1) в реконструируемом пространстве соответствует эволюции точек
х(n) ........х(n + 1) в исходном пространстве состояний. Это значит, что большинство
свойств ненаблюдаемоrо вектора состояний х(n) воспроизводится без неоднозначно
сти в пространстве восстановления, определяемом вектором У R ( n ). Однако, для Toro,
чтобы этот важный результат был достижим, требуются достоверные оценки (re1iable
estimate) измерения вложения D Е И нормализованное запаздывание вложения т.
. Достаточное условие D 2: 2d + 1 делает возможным восстановление (undo) пе
ресечений орбит аттракторов со своими же орбитами, которые возникают в pe
зультате проекций этих орбит на измерения более низкоro порядка. Измерение
вложения D Е может быть меньше величины 2d+ 1. Рекомендуется оценивать D Е
непосредственно на основе данных наблюдений. Достоверным методом оценки
14.13. Динамическое восстановление 901
D Е является метод ложных ближайших соседей (method of fa1se nearest neighbors),
описанный в [2]. В этом методе симметрично обследуются точки данных и их co
седи для измерения d == 1, затем для d ==2 и Т.д. Таким образом, можно установить
состояние, при котором очевидные соседи станут различимыми при добавлении к
вектору восстановления YR(n) большеro числа элементов, и получить оценку D E
измерения вложения.
· К сожалению, теорема вложения с задержкой ничеro не roворит о выборе HOp
мализованной задержки вложения т. На самом деле она разрешает использовать
любое значение т, пока доступные временные ряды бесконечно длинны. Однако на
практике всеrда приходится работать с данными наблюдений конечной длины N.
Правильные установки при выборе т предполаrают, что эта величина должна быть
достаточно большой, чтобы у(n) и у(n т) были достаточно независимы друr от
друrа для Toro, чтобы служить координатами пространства восстановления, но не
настолько независимыми, чтобы совершенно не иметь корреляции друr с друrом.
Это требование лучше Bcero удовлетворяется при использовании TaKoro т, при KO
тором взаимная информация (mutua1 information) между у(n) и у(n т) достиrает
cBoero первоrо минимума [308]. (О понятии взаимной информации см. в rлаве 10.)
Рекурсивное проrнозирование
в представленном обсуждении задача динамическоrо восстановления может интер
претироваться как представление свойства динамики сиrнала (шаr вложения) и как
создание проrнозирующеro отображения (шаr идентификации). Таким образом, если
перейти к практическим терминам, получим следующую тополоrию сети для дина
мическоro моделирования.
· Структура кратковременной памяти (например, память на линиях задержки) ocy
ществляет вложение, в то время как вектор восстановления У R (n) определяется в
терминах наблюдений у(n) и их версий с задержкой (см. (14.91)).
· Адаптивная нелинейная система с несколькими входами и одним выходом MISO
обучается как система одношаrовоrо проrнозирования (например, нейронная сеть)
для поиска неизвестноrо отображения f: D ........ 1, определяемоro следующим
образом:
у(n + 1) == f(YR(n))'
(14.92)
Проrнозирующее отображение (14.92) занимает центральное место в динамиче
ском проrpаммировании. Как только оно определено, эволюция YR(n) ........YR(n + 1)
становится известной, что, в свою очередь, определяет неизвестную эволюцию
х(n) ........ х(n + 1).
902 rлава 14. Нейродинамика
у(п)
Обучаемая система
проrнозированИЯ у(п+ 1)
Рис. 14.24. Система одношаrовоro проrнозирования, ис-
пользуемая при итеративном проrнозировании для динами-
ческоro восстановления хаотических процессов
в настоящее время не существует какой либо строroй теории, которая помоrла бы
решить, успешно ли система нелинейноro проrнозирования идентифицирует неиз
вестное отображение f. в линейной системе проrнозирования минимизация cpeДHe
квадратическоro значения ошибки проrнозирования приводит к определению точной
модели. Однако при работе с хаотичными временными рядами все обстоит иначе. Две
траектории в одном и том же аттракторе MOryT значительно отличаться для разных
образов. Исходя из этоrо, минимизация среднеквадратическоro значения ошибки про-
rнозирования является необходимым, но не достаточным условием для определения
успешности отображения.
Динамические инварианты (измерение корреляции и экспоненты Ляпунова) опре-
деляют rлобальные свойства аттрактора, так что их можно использовать в дина-
мическом моделировании в качестве меры. Таким образом, праrматический подход
к тестированию динамической модели предполаrает диссипативность (рассеивание)
точек ложных аттракторов и замыкание ее выхода на вход, подобно автономной си
стеме, показанной на рис. 14.24. Такая операция называется итеративным или рекур-
сивным проrнозированием (iterated или recursive prediction). После TOro как выполне-
на инициализация, выход этой автономной системы представляет собой реализацию
процесса динамическоro восстановления. Естественно, это предполаrает в первую
очередь наличие rpамотной конструкции этой системы проrнозирования.
Считается, что динамическое восстановление, выполненное автономной системой
на рис. 14.24, является успешным, если выполняются следующие условия [441].
1. Условие на краткосрочное поведение (short term behavior). После TOro как выпол
нена инициализация, временной ряд {У( п) } на рис. 14.24 должен быть достаточно
близок к исходному ряду {у( п)} в течение периода времени, в среднем равному
roризонту проrнозирования, определяемому из спектра Ляпунова этоro процесса.
2. Условие на дОЛ20срочное поведение (long term behavior). Динамические инвари
анты, вычисленные для реконструированноrо BpeMeHHoro ряда {У(п)}, должны
быть близки к соответствующим инвариантам исходноro BpeMeHHoro ряда {у(п)}.
Для измерения долrосрочноro поведения восстановленной динамики требует-
ся оценить степень корреляции как меру сложности аттрактора и спектр Ляпуно-
ва для оценки чувствительности к начальным состояниям и для оценки измере
ния Ляпунова (см. (14.88)). Измерение Ляпунова должно быть достаточно близко
к измерению корреляции.
14.13. Динамическое восстановление 903
Две возможные формулировки рекурсивноrо проrнозирования
Вектор восстановления YR(n), определяемый формулой (14.91), имеет размерность
D Е, если размерность D установлена равной размерности вложения D Е. Размер па
мяти на линиях задержки, требуемой для TaKoro вложения, составляет т D Е. Однако
память на линиях задержки требуется для обеспечения только D Е выходов (это раз
мерность пространства восстановления), Т.е. используем т равно отстоящих друr от
друrа отводов, представляющих разреженные связи (sparse connections).
В качестве альтернативы можно определить вектор восстановления У R (n) как
полный m мерный вектор следующеrо вида:
YR(n) == [у(n), у(n 1),..., у(n m + l)]Т,
(14.93)
rде m целое число, удовлетворяющее условию
m 2: DET.
(14.94)
Эта вторая формулировка вектора восстановления YR(n) обеспечивает модель
проrнозирования большим количеством информации, чем (14.91), и, таким образом,
приводит к более точному динамическому восстановлению. Однако обе эти формули
ровки обладают одним общим свойством: их композиции однозначно определяются
знанием измерения вложения D Е. В любом случае лучше Bcero использовать ми
нимальное из возможных значений D (а именно D E ) дЛЯ минимизации эффекта,
производимоro на качество динамическоrо восстановления аддитивным шумом v(n).
Динамическое восстановление как плохо обусловленная
задача фильтрации
Задача динамическоro восстановления на самом деле является плохо обусловлен
ной обратной задачей (il1 posed inverse problem). И этому имеется несколько при
чин. (Условия хорошей обусловленности обратных задач см. в rлаве 5.) Во первых,
по некоторой неизвестной причине может быть нарушено условие существования.
BO BTOpЫX, для единственности восстановления нелинейной динамики в доступных
наблюдениях может оказаться недостаточно информации. В третьих, неизбежное Ha
личие аддитивноrо шума и некоторых форм неточности в наблюдаемых временных
рядах добавляет в динамическое восстановление неопределенность. В частности, ec
ли уровень шума достаточно велик, возможно нарушение условия непрерывности.
Как же добиться хорошей обусловленности в задаче динамическоro восстановления?
Ответ на этот вопрос лежит во включении некоторой формы априорных знаний об
отображении BXOД BЫXOД. Друrими словами, на модели проrнозирования, предна
значенные для решения задач динамическоrо проrнозирования, должны налаrаться
904 rлава 14. Нейродинамика
некоторые формы оrpаничений (например, на rладкость преобразования). Одним из
эффективных способов удовлетворения этому требованию является использование
теории реryляризации Тихонова (см. rлаву 5).
Еще одним вопросом, на котором следует остановиться, является способность
модели проrнозирования с достаточной точностью решать обратную задачу. В этом
контексте подходящим решением для построения модели проrнозирования будет ис-
пользование нейронных сетей. В частности, свойство универсальноro аппроксимато-
ра мноrослойноro персептрона или сетей на основе радиальных базисных функций
означает, что можно позаботиться о точности восстановления при использовании oд
ной из этих сетей соответствующеrо размера. Однако по изложенным ранее причинам
требуется реryляризировать решение. Теоретически для использования реrуляриза-
ции приrодны как мноroслойный персептрон, так и сети на основе радиальных базис-
ных функций. На практике именно в сетях на основе радиальных базисных функций
теория реrуляризации бьта математически включена как составная часть их кон-
струкции. В соответствии с этим при последующем компьютерном моделировании
сосредоточим внимание на сети на основе реrуляризованных радиальных базисных
функций (см. rлаву 5) как основе решения задачи динамическоrо восстановления.
14.14. Компьютерное моделирование 3
Чтобы про иллюстрировать идею динамическоro восстановления, рассмотрим систе
му трех обычных дифференциальных уравнений, выделенных Лоренцом из аппрок
симации rалеркина с помощью уравнений в частных производных термальной кон-
векции в нижних слоях атмосферы. Эта задача послужит в качестве тестовой системы
уравнений для про верки идей нелинейной динамики. Уравнения аттрактора Лоренца
имеют следующий вид:
dx(t)
== crx(t) + cry(t),
dy(t)
== x(t)z(t) + rx(t) y(t),
dz(t)
== x(t)y(t) bz(t),
(14.95)
rдe а, r и Ь безразмерные параметры. Типичные значения этих параметров cr ==
10, r == 28 и Ь == 8/3.
На рис. 14.25 показаны результаты итеративноrо проrнозирования, выполненноro
на двух сетях RВF, имеющих 400 центров и использовавших "зашумленные" вре-
менные ряды, основанные на компоненте x(t) аттрактора Лоренца. Соотношение
сиrнал/шум составляло +25 dB. На рис. 14.25, а конструкция сети реrуляризирована,
а на рис. 14.25, б нет. Эти две части рисунка ясно демонстрируют практическую
важность реryляризации. При отсутствии реrуляризации решение задачи динамиче-
14.14. Компьютерное моделирование 3 905
cKoro восстановления, представленное на рис. 14.25, б, неприемлемо, поскольку оно
не способно аппроксимировать истинную траекторию аттрактора Лоренца. Нереryля
ризированная система является Bcero лишь системой проrнозирования. С друroй CTO
роны, решение задачи динамическоro восстановления представлено на рис. 14.25, а.
В этом решении использована реryляризированная форма сети RВF, которая обу
чалась динамике в том смысле, что выходной сиrнал сети при итеративном про
rнозировании близко аппроксимировал истинную траекторию аттрактора Лоренца на
краткосрочный период времени. Это подтверждается результатами, представленными
в табл. 14.5, в которой сведены данные для трех случаев.
1. Незашумленная система Лоренца.
2. Зашумленная система Лоренца с соотношением сиrнал/шум, равным SNR==25dB.
3. Данные, восстановленные с использованием зашумленных временных рядов Ло
ренца, показаны на рис. 14.25, а.
Инварианты данных, восстановленных с использованием зашумленных рядов, дo
статочно близки к соответствующим инвариантам незашумленных данных Лорен
ца. Отклонения в абсолютных значениях связаны с остаточным эффектом шума,
вкравшимся в реконструированный аттрактор и в неточности процедуры оценки.
На рис. 14.25 ясно показано, что динамическое моделирование это нечто боль
шее, нежели просто проrнозирование. На этом рисунке (как и на мноrих друrих, не
представленных в этой книrе) продемонстрирована "робастность" реryляризованноrо
решения RВF по отношению к точке аттрактора, использованной для инициализации
процесса итеративноrо проrнозирования.
Стоит обратить внимание на следующие два наблюдения, касающиеся использо
вания реrуляризации (см. рис. 14.25, а).
1. Краткосрочная проrнозируемость реконструированных временных рядов на
рис. 14.25, а составляет более 60 образцов. Теоретический rоризонт проrнозиру
емости, вычисленный из спектра Ляпунова незашумленноrо аттрактора Лоренца,
составляет приблизительно 100 образов. Экспериментальное отклонение от rори
зонта проrнозируемости незашумленноrо аттрактора Лоренца вызвано в основном
наличием шума в фактических данных, использованных для динамическоro BOC
становления. Теоретический rоризонт проrнозируемости, вычисленный на основе
реконструированных данных, составил 61 (табл. 14.5), что достаточно близко к
экспериментально наблюдаемому значению краткосрочной проrнозируемости.
2. Как только период краткосрочной проrнозируемости превышен, реконструирован
ные временные ряды на рис. 14.25, а начинают отклоняться от незашумленной
реализации фактическоrо аттрактора Лоренца. Это в основном объясняется xao
тической динамикой, а именно чувствительностью к начальным состояниям. Как
уже roворилось ранее, чувствительность к начальным состояниям является xapaK
терной чертой хаоса.
906 rлава 14. Нейродинамика
40
30
о
I 11
,1 1 l '
\ '
1, ,\ '1
I I 1 I 1
, \ \J
"
"
'1
"
"
"
, ,
1 I
\ ,
\ I \
20
'"
10
:s:
<::
\
\ 1" \ '
\ " I \'
1 , \' \'
\ I \' "
\1 " "
, l' "
I
о
50
100
150 200
Время,п
250
300
350
400
а)
о
60
40
20
'"
:s:
<::
о
50
100
150 200
Время,п
250
300
350
400
б)
Рис. 14.25. Реryляризированное итеративное проrнозирование (N=400, т=20)
на данных Лоренца при SNR=+25dB (а); нереryляризированное итеративное про
rнозирование (N == 400, т == 20) на данных Лоренца при SNR=+25dB (б). В обеих
частях рисунка непрерывная кривая представляет собой фактический хаотиче
ский сиrнал, а пунктирная кривая реконструированный сиrнал
Примечание. Все экспоненты Ляпунова представлены в натах в секунду. Нат
(nat) это естественная единица измерения информации, описанная в rлаве 10. В слу
чае (б) эффект шума выразился в увеличении размера спектра Ляпунова, а также в
увеличении количества и амплитуды положительных экспонент Ляпунова.
14.14. Компьютерное моделирование 3 907
ТАБЛИЦА 14.5. Параметры моделирования динамическоro восстановления, ис
п ользующеro систему Лоренца
(а) Система Лоренца без учета шума
Количество использованных образов: 35000
1. Нормализованная задержка вложения, 7 ==4
2. Измерение вложения, D E ==3
3. Экспоненты Ляпунова:
А1 == 1.5697;
А2 == 0.0314;
Аз == 22.3054
4. rоризонт проrнозируемости 100 образцов
(б) Зашумленная система Лоренца: +25 dB SNR
Количество использованных образов: 35000
1. Нормализованная задержка вложения, 7 ==4
2. Измерение вложения, D E ==5
3. Экспоненты Ляпунова:
А1 == 13.2689;
== 5.8562;
Аз == 3.1447;
А4 == 18.0082;
А5 == 47.0572
4. rоризонт проrнозируемости 12 образцов
(в) Система, восстановленная с использованием зашумленных данных Лоренца
(см. рис. 14.25, а)
Количество сrенерированных образов: 35000
1. Нормализованная задержка вложения, 7 ==4
2. Измерение вложения, D Е ==3
3. Экспоненты Ляпунова:
А1 == 2.5655;
== 0.6275;
Аз == 15.0342
4. rоризонт проrнозируемости 61 образец
Выбор параметров m И л
Размер входноrо слоя m определяется по формуле (14.94). Как уже roворилось
ранее, рекомендуется использовать наименьшее допустимое значение m в COOT
ветствии со знаком равенства, минимизирующим эффект шума при динамиче
ском восстановлении.
908 rлава 14. Нейродинамика
Оцененное значение нормализованной задержки вложения т не зависит от наличия
шума при высоких значениях отношения сиrнал/шум. В противоположность этому
наличие шума оказывает ощутимое воздействие на оценочное значение измерения
вложения D E , что интуитивно понятно. Например, для незашумленноro аттрактора
Лоренца измерение корреляции составило 2,01. Таким образом, можно выбрать такое
измерение вложения D E , которое подтверждено методом ложных ближайших coce
дей (false nearest neighbors). Нормализованная задержка вложения составила т ==4.
Таким образом, при использовании выражения (14.94) со знаком равенства полу
чим для динамическоro восстановления значение m == 12. С друrой стороны, для
зашумленноrо аттрактора Лоренца при SNR==+25dB использование метода ложных
ближайших соседей дает значение D Е ==5, а использование метода взаимной инфор
мации приводит к значению т ==4. Подставляя эти оцененные значения в (14.94) со
знаком равенства, получим для зашумленноrо динамическоrо восстановления значе
ние m ==20 (см. рис. 14.25). В табл. 14.5 представлены значения задержки вложения
т и измерения вложения D Е для всех трех случаев.
Что же касается параметра реrуляризации Л, использованноro на рис. 14.25, а, то
он определялся из данных обучения с помощью обобщенной перекрестной проверки
(Genera1ized Cross Validation GCV) (см. rлаву 5). Полученное таким образом значе
ние л варьировалось от минимальноrо значения 10 14 до максимальноrо 10 2, В
зависимости от данных.
14.15. Резюме и обсуждение
Большая часть материала, представленноrо в настоящей rлаве, посвящена модели
Хопфилда и модели BSB (brain state in box). Это примеры ассоциативной памяти,
базирующейся на нейродинамике. Эти две модели обладают следующими общими
характеристиками.
. Они используют положительные обратные связи.
. Они имеют функцию энерrии (Ляпунова), и рассматриваемая динамика стремится
последовательно ее минимизировать.
· Они используют постулат обучения Хебба и обучаются с помощью самоорrанизации.
. Они способны выполнять вычисления, используя динамику аттракторов.
Естественно, они отличаются друr от друrа областью применения.
Модель BSB имеет внутреннюю способность к кластеризации, которую можно
успешно использовать для представления данных и формирования понятий (concept
formation). Наиболее интересным применением модели BSB является, пожалуй, ис-
пользование ее в качестве OCHOBHOro вычислительноrо элемента в сети сетей (network
of networks) правдоподобной модели, описывающей различные уровни системной
14.15. Резюме и обсуждение 909
орrанизации в мозrе [55]. В этой модели вычислительные элементыI формируют ло
кальные сети, которые распределены в двумерном массиве (это и является причиной
названия "сеть сетей"). Вместо взаимодействия столбцов только на уровне средних
значений эти локальные сети сконструированы для взаимодействия с друrими ло
кальными сетями посредством образов (векторов) активности (activity pattem). На
месте синаптических весов между нейронами, присутствующих в обычных сетях, в
них находится множество матриц взаимодействия, которые описывают связи между
аттракторами двух локальных сетей. Локальные сети формируют кластеры и ypOB
ни, основанные на их взаимных связях, в результате чеrо анатомическая связность
(anatomica1 connectivity) разрежается. Это значит, что локальные сети более тесно
связаны внутри кластеров, чем между кластерами. Тем не менее функциональная
связность (functiona1 connectivity) между кластерами имеет боrатую динамику, ча
стично блаroдаря временной коррелированности работы локальных сетей.
В противоположность этому модель Хопфилда может использоваться для решения
следующих вычислительных задач.
1. Реализация ассоциативной памяти, которая включает в себя восстановление co
храненных образов при предъявлении памяти неполных или зашумленных их
версий. Для этоrо приложения, как правило, используется "дискретная" модель
Хопфилда, которая основана на нейроне Мак Каллока Питца (т.е. на нейроне, ис
пользующем жестко оrpаниченную функцию активации). Рассматривая эту модель
в вычислительном контексте, можно сказать, что эта память имеет довольно три
виальную конструкцию. Тем не менее модель Хопфилда ассоциативной памяти
является важной, так как она объясняет связь между динамикой и вычисления
ми совершенно новаторским способом. В частности, модель Хопфилда объясняет
следующие свойства, имеющие нейробиолоrическую релевантность.
. Динамика этой модели определяется большим количеством точечных aттpaK
торов в пространстве состояний большой размерности.
. Рассматриваемый точечный аттрактор (т.е. ячейка фундаментальной памяти)
может быть найден с помощью простой инициализации модели неточным опи
санием места расположения этоrо аттрактора, После этоrо динамика сама пе
реведет состояние модели к ближайшему точечному аттрактору.
. Обучение (т.е. вычисление свободных параметров модели) происходит в COOT
ветствии с постулатом обучения Хебба. Более Toro, этот механизм обучения
позволяет добавлять в модель новые точки аттракторов, если это необходимо.
2. Комбинаторные задачи оптимизации (combinatoria1 optimization problem), KOTO
рые считаются в математике самыми сложными. Этот класс задач оптимизации
включает в себя известную задачу коммивояжера (Travelling Sa1esman Problem
TSP), считающуюся классической. При заданном расположении известноro чис
ла rородов (предполаrается, что они лежат на плоскости) стоит задача поиска
910 rлава 14. Нейродинамика
кратчайшеro маршрута обхода всех roродов, который начинается и заканчивается
в одном и том же roроде. Задача TSP просто формулируется, но крайне слож
но решается, поскольку не существует известноro метода поиска оптимальноro
маршрута, ищущеrо все возможные маршруты и затем выбирающеro кратчайший
из них. Эта задача называется NР полной (NP comp1ete) [474]. В новаторской pa
боте [482] бьто продемонстрировано, как аналоroвая сеть, основанная на системе
дифференциальных уравнений первоrо порядка (14.20), может использоваться для
представления решения задачи TSP. В частности, синаптические веса этой сети
определялись расстоянием между отдельными roродами, а оптимальное решение
являл ось фиксированной точкой нейродинамических уравнений (14.20). Здесь и
сосредоточены сложности, связанные с "отображением" комбинаторных задач оп
тимизации на непрерывные (аналоroвые) сети Хопфилда. Эта сеть стремится ми
нимизировать одну функцию энерrии (Ляпунова), в то время как типичная комби
наторная задача оmимизации требует оптимизации некоторой целевой функции
при наличии ряда жестких оrpаничений [340]. Если нарушается какое либо из
этих оrраничений, решение считается неверным. Первые процедуры TaKoro отоб
ражения основывались на функции Ляпунова, сконструированной специальным
методом, обычно использующим по одному слаrаемому для каждоro условия:
Е Е ОПТ + E orp. + E orp. +
== . С1 1 С2 2 . . . .
(14.96)
Первое слarаемое, ЕО ПТ " является минимизируемой целевой функцией (Ha
пример, длиной маршрута в задаче TSP). Эта функция определяется paCCMaT
риваемой задачей. Оставшиеся слаrаемые, E rp., E rp.,. . ., представляют собой
штрафные функции, минимизация которых удовлетворяет оrpаничениям. Скаля
ры С1, С2,' . . являются постоянными весами, которые назначены соответствующим
штрафным функциям E rp., E rp. , . . .. Они обычно определяются методом проб
и ошибок. К сожалению, мноrочисленные слаrаемые в функции Ляпунова (14.96)
имеют тенденцию вытеснять друr друrа, и успех сети Хопфилда в оrpомной мере
зависит от относительных значений С1, С2,' . . [340]. Учитывая это, неудивитель
но, что такая сеть зачастую производит большое количество неверных решений
[63], [1160]. В [340] рассматривалось множество основных вопросов, касающихся
использования непрерывных сетей Хопфилда как инструмента разрешения KOM
бинаторных задач оmимизации; основные ее выводы приведены ниже.
. Для заданной задачи комбинаторной оmимизации, представленной в терминах
квадратичноrо o 1 проrpаммирования, равно как и для коммивояжера, суще
ствует простой метод проrpаммирования сети, приводящий к ее решению, при
этом найденное решение не будет нарушать ни одно из оrpаничений задачи.
14.15. Резюме и обсуждение 911
. На основании результатов теории сложности (comp1exity theory) и математи
ческоro проrpаммирования было показано, что за исключением случая, Korдa
оrpаничения задачи имеют особые свойства, определяющие интеrpальный по
литоп или мноrоrpанник, невозможно заставить сеть сойтись к корректному,
интерпретируемому решению. В reометрических терминах политоп, Т.е. orpa
ниченный мноrоrpанник, называется интеrpальным политопом, если все ero
rpани являются точками o 1. Даже коrда речь идет об интеrpальном поли
топе, если целевая функция Е ОПТ ' является квадратичной, то задача является
NР полной и нет никакой rарантии, что сеть найдет оmимальное решение. К
классу этих задач относится и задача коммивояжера. Однако допустимое реше
ние все равно может быть найдено, и в зависимости от природы используемоrо
процесса спуска к этому решению существует шанс, что это решение окажется
достоверным.
Модель Хопфилда, которая рассматривалась в настоящей rлаве, использовала
симметричные связи между своими нейронами. Динамика такой структуры анало
rична динамике rpадиентноrо спуска, что rарантирует сходимость к фиксирован
ной точке. Однако динамика мозrа отличается от динамики модели Хопфилда в
двух основных вопросах.
· Взаимосвязи между нейронами мозrа являются ассимметричными.
. В мозre наблюдается осциллирующее и сложное непериодическое поведение.
Естественно, причиной этоrо явяются особые свойства мозrа, которые вызвали
незатухающий интерес при изучении ассимметричных сетей 9 , предшествовавших
модели Хопфилда.
Если отказаться от требования симметрии, следующей простейшей моделью яв
ляется сеть возбуждения торможения (excitatory inhibitory network), нейроны которой
разбиваются на две катеrории: с возбуждающими и тормозящими выходами. Синап
тические связи между двумя этими популяциями являются ассимметричными, в то
время как связи в каждой из популяций симметричны. В [966] рассматривал ась дина
мика именно такой сети. Представленный в этой работе анализ использует сходство
между динамикой сети возбуждения торможения и динамикой rpадиентноro спуска
rpадиентноrо подъема (gradient descent gradient ascent dynamics), в которой ypaB
нения движения для некоторых переменных состояния имели форму rpадиентноrо
спуска, а для остальных форму rpадиентноro подъема. Следовательно, в отличие
от динамики rpадиентноrо спуска, которая характеризует сеть Хопфилда, динамика
модели, предложенной в этой работе, может сходиться к некоторой фиксированной
9 Трактовка БИОЛIJrических нейронных сетей как нелинейных динамических систем, обладающих осцилли-
рующим поведением, имеет долryю историю [30], [31], [34], [176], [1161].
912
rлава 14. Нейродинамика
1
точке или предельному циклу, в зависимости от выбора параметров сети. Таким об
разом, антисимметричная модель, предложенная в [966], имеет преимущество перед
симметричной моделью Хопфилда.
Задачи
Динамические системы
14.1. Переформулируйте теорему Ляпунова для случая, KOrдa вектор состояния
х(О) является равновесным в динамической системе.
14.2. Сверьте блочные диаrpаммы на рис. 14.8, а и 14.8, б с уравнениями (14.18)
и (14.19).
14.3. Рассмотрим нейродинамическую систему общеrо вида с неопределенной за
висимостью от внутренних динамических параметров, внешних динамиче
ских возбудителей и переменных состояния. Эта система определяется сле
дующей системой уравнений:
dx.
d: ==<i>j(W,u,x), j==1,2,...,N,
rде матрица W представляет внутренние динамические параметры системы;
вектор u внешние динамические возбудители; х вектор состояний, j й
элемент KOToporo обозначается символом х j' Предположим, что траектории
этой системы сходятся к точечным аттракторам для значений W, u и началь
ных состояний х(О), находящихся в некоторой рабочей области пространства
состояний [839]. Обсудите, как описанная система может использоваться для
следующих приложений.
а) Непрерывный оператор, в котором u вход, а х( (0) выход.
б) Ассоциативная память, в которой х(О) вход, а х( (0) выход.
Модели Хопфилда
14.4. Рассмотрим сеть Хопфилда, состоящую из пяти нейронов, в которой требу
ется сохранить следующие три ячейки фундаментальной памяти:
;1 == [+l,+l,+l,+l,+l]Т,
;2 == [+1, 1, 1, +1, l]T,
;3 == [ l,+l, l,+l,+l]T.
Задачи 913
а) Вычислите матрицу синаптических весов размерностью 5 х 5.
б) С помощью асинхронной коррекции покажите, что все три ячейки фунда
ментальной памяти, ;1,;2 и ;з, удовлетворяют условию выравнивания.
в) Исследуйте производительность этой сети по извлечению данных, коrда
ей подается на вход зашумленная версия ;1, в которой полярность Bтoporo
элемента изменена.
14.5. Исследуйте возможность использования синхронной коррекции для изме
рения производительности извлечения информации в сети Хопфилда при
условиях задачи 14.4.
14.6. а) Покажите, что
1 == [ 1 1 1 1 l ] T
":t "" ,
;2 == [ 1, + 1, + 1, 1, + 1] т ,
;з == [+l, l,+l, l, l]T
также являются ячейками фундаментальной памяти сети Хопфилда, опи
санной в условиях задачи 14.4. Как эти ячейки связаны с ячейками, опи
санными в задаче 14.4?
б) Предположим, что первый элемент ячейки фундаментальной памяти ;з в
задаче 14.4 замаскирован (т.е. принят равным нулю). Определите результи
рующий образ, который создаст модель Хопфилда. Сравните полученный
результат с исходной формой ;з.
14.7. Рассмотрим сеть Хопфилда, состоящую из двух нейронов. Матрица синап
тических весов имеет следующий вид:
w== [ O l ]
1 О
Внешнее смещение, применяемое к нейронам, равно нулю. четыIьмяя воз
можными состояниями сети Moryт быть
Х1 == [+1, +l]Т,
Х2 == [ 1, +l]Т,
хз == [ 1, 1] т ,
х4 == [+1, l]T.
......
914 rлава 14. Нейродинамика
а) Покажите, что состояния Х2 И Х4 являются устойчивыми, а состояния
Хl и ХЗ представляют собой предельные циклы. При этом используйте
следующий инструментарий: (1) условие выравнивания (устойчивости) и
(2) функция энерrии.
б) Какова длина предельноrо цикла, характеризующеro состояния х 1 И хз?
14.8. В этой задаче выведем формулу (14.55) емкости хранения практически без
ошибок для модели Хопфилда, использующейся в качестве ассоциативной
памяти.
а) Асимптотическое поведение функции ошибок приближенно описывается
следующим выражением:
e y2
erf(y) 1 для больших у.
.;nу
Используя это приближение, покажите, что условная вероятность (14.53)
может быть приближена следующим выражением:
e p/2
P(Vj > OI V,j == +1) 1 у'2пр '
rдe р отношение сиrнал/шум. Покажите, что вероятность устойчивости
состояния соответствующим образом аппроксимируется выражением
N e p/2
Рстаб. 1 .;пр .
б) Второе слarаемое формулы Рстаб., приведенной в части (а), является Be
роятностью Toro, что некоторый бит в ячейке фундаментальной памяти
является неустойчивым. Для определения емкости хранения практически
без ошибок недостаточно требовать только малости этоro слаrаемоro. Оно
должно быть мало по отношению к 1/ N, rдe N размер сети Хопфилда.
Покажите, что для этоro отношение сиrнал/шум должно удовлетворять
условию
1
Р > 210g e N + "210ge(21tp).
в) Используя результат, полученный в части (б), покажите, что минимально
допустимое значение отношения сиrнал/шум для успешноrо извлечения
большинства ячеек фундаментальной памяти составляет
Задачи 915
Pmin == 210g e N.
Каково соответствующее значение Рстаб.?
r) Используя результат части (в), покажите, что
N
М тах ,
210g e N
что соответствует формуле (14.55).
д) Формула, выведенная в части (r) для емкости хранения, основана на допу
щении, что большая часть ячеек фундаментальной памяти является устой
чивой. Для более cтpororo определения емкости хранения без ошибок бу
дем требовать, чтобы все ячейки фундаментальной памяти извлекались без
ошибок. Используя последнее определение, покажите, что максимальное
число ячеек фундаментальной памяти, которое может храниться в сети
Хопфилда, составляет [42]:
N
М mах ::::: 410g e N
14.9. Покажите, что функция энерrии сети Хопфилда может быть представлена в
следующем виде
N M
Е == 2 Lm ,
v l
rде mv обозначает пересечения, определяемые как
1 N
mv == N L Xj V,j' v == 1,2,... , М,
j l
rде Xj j й элемент вектора состояния х; V,j j й элемент ячейки фунда
ментальной памяти ;v; м количество ячеек фундаментальной памяти.
14.10. Рассматриваемая сеть Хопфилда сконструирована для хранения двух ячеек
фундаментальной памяти (+ 1, + 1, 1, + 1, + 1) и (+ 1, 1, + 1, 1, + 1).
916 rлава 14. Нейродинамика
Матрица синаптических весов этой сети имеет вид
о о о 02
О О 2 20
w== О 2 О 2 О
О 2 2 00
2 О О 00
(14.97)
а) Сумма собственных значений матрицы W равна нулю. Почему?
б) Пространство состояний этой сети является подпространством эt 5 . Опре
делите конфиrурацию этоro подпространства.
в) Определите подпространство М, натянутое на векторы фундаментальной
памяти и нулевое подпространство N матрицы весов w. Каковы устойчи
вые и ложные состояния этой сети?
(При решении задачи можно обратиться к работе, в которой содержится
более подробное описание динамики этой сети [255].)
14.11. На рис. 14.26 по казана кусочно линейная форма немонотонной функции aK
тивации. Динамика восстановления в сети Хопфилда, использующей эту
функцию активации, описывается следующим выражением:
d
dt v(t) == v(t) + Wx(t), x(t) == sgn(v(t)) kv(t),
rде v(t) вектор индуцированных локальных полей; W матрица синапти
ческих весов; x(t) (выходной) вектор состояния; k константа отрица
тельноro наклона. Пусть v некоторое равновесное состояние сети, которое
лежит в квадранте фундаментальной памяти ;1, и пусть
х == sgn(v) kv.
Покажите, что х характеризуется следующими тремя условиями:
N
а) I: Xi l1,i == О, 1..1. == 2,3, . . . , М,
i l
N
б) I: Xi l,i == М,
i l
в) Xi < 1, i == 1,2, . . . , N,
rдe ;1, 2, . . . , M ячейки фундаментальной памяти, сохраненные в сети;
11,i i й элемент вектора ;11; Xi i й элемент вектора х; N количество
нейронов.
Задачи 917
<P(v)
Уrловой коэффициент k
v
Рис. 14.26. Кусочно линейная форма
немонотонной функции активации
14.12. Рассмотрим простую нейродинамическую модель, описываемую системой
уравнений
dv. """
d: == Vj + Wji<P(Vi) + Ij, j == 1,2,..., N.
i
Описанная система всеrда сходится к единственному точечному aттpaктo
ру, при условии, что синаптические веса удовлетворяют соотношению
L L W;i < (max 1 1<P'1)2 '
J .
rде <р' == d<p/dVj. Исследуйте правильность этоro утверждения (для справки
можно обратиться к работе, в которой выведено это условие [81]).
Теорема Коэна rросс6ерrа
14.13. Рассмотрим функцию Ляпунова Е, определяемую формулой (14.57). Пока
жите, что
dE < о
dt
при условии выполнения соотношений (14.59) (14.61).
14.14. В разделе 14.10 выведена функция Ляпунова модели BSB на основе примене
ния теоремы Коэна rроссберrа. В этом выводе опущены отдельные детали,
приводящие к (14.73). Восстановите эти детали.
...
918 rлава 14. НеЙРОДинамика
<p(v)
0,8
k
h
h,
v
-1,0
о
1,0
k
0,8
Рис. 14.27. rрафик немонотонной функции ак-
тивации
14.15. На рис. 14.27 показан rpафик немонотонной функции активации, paCCMOT
ренной в [755]. Эта функция активации используется при построении сети
Хопфилда вместо функции rиперболическоrо TaHreHca. Применима ли Teo
рема Коэна rроссберrа к таким образом сконструированной ассоциативной
памяти? Обоснуйте свой ответ.
Динамически управляемые
рекуррентные сети
15.1. Введение
Как уже rоворилось в предыдущей шаве, рекуррентными (rесuпепt) называются ней
ронные сети, имеющие одну или несколько обратных связей. Обратные связи MorYT
быть локалЬНО20 и 2ЛобалЬНО20 типов. В этой шаве будет продолжено изучение pe
куррентных сетей с шобальными обратными связями.
Если в качестве OCHoBHoro строительноrо блока используется мноrослойный пер
септрон, то применение обратной связи может принимать несколько форм. Bo
первых, можно замкнуть выходной слой мноrослойноrо персептрона на ero входной
слой. BO BTOpЫX, можно замкнуть выход cKpblToro слоя на вход. Так как мноrослой
ный персептрон может содержать несколько скрытых слоев, то последняя форма
обратной связи может быть также сконфиrурирована разными способами. Все это
приводит к тому, что рекуррентные сети имеют боrатый спектр архитектурных форм.
В основном рекуррентные сети используются в двух качествах.
. Ассоциативная память (associative memories).
. Сети отображения вxoд выxoд (input output mapping network).
Использование рекуррентных сетей в качестве ассоциативной памяти paCCMaT
ривалось в шаве 14; сейчас же речь пойдет об изучении их в качестве отображений
BXOД BЫXOД. Каким бы ни было использование рекуррентных сетей, в первую очередь
подлежит рассмотрению вопрос их устойчивости (stability) (частично этот вопрос
рассматривался в шаве 14).
По определению входное пространство сетей отображается в выходное простран
ство. Для TaKoro типа приложений рекуррентная сеть (temporally) отвечает во времени
на применяемый извне входной сиrнал. Таким образом, о сетях, рассматриваемых в
настоящей шаве, можно rоворить как о динамически управляемых рекуррентных ce
тях (dynamically driven rесuпепt network). Более Toro, применение обратных связей
позволяет использовать описание рекуррентных сетей в виде множества состояний,
920 rлава 15. Динамически управляемые рекуррентные сети
что делает их удобными устройствами в таких областях, как нелинейное проrнозиро
вание и моделирование, адаптивное выравнивание каналов связи, обработка речевых
сиrналов, управление предприятием и диаrностика автомобильных двиrателей. Как
таковые рекуррентные сети являются альтернативой динамически управляемым ce
тям прямоrо распространения (см. rлаву 13). Из за наличия дополнительноrо эффекта
rлобальной обратной связи они MOryт roраздо лучше проявлять себя в традиционных
областях применения обычных нейронных сетей прямоro распространения. Исполь
зование rлобальной обратной связи позволяет значительно ослабить требования к
объему используемой памяти.
Структура rлавы
Эта rлава формально может быть разбита на четыре части: архитектура, теория,
алrоритмы обучения и применение. В первой части (раздел 15.2) рассматриваются
архитектуры рекуррентных сетей.
Во второй части (разделы 15.3 15.5) изложены теоретические аспекты peкyppeHT
ных сетей. В разделе 15.3 рассматривается модель в пространстве состояний и свя
занные с ней вопросы управляемости и наблюдаемости. В разделе 15.4 описывается
модель нелинейной автореrpессии с внешними (exogenous) входами эквивалент
модели в пространстве состояний. В разделе 15.5 рассматриваются теоретические
вопросы, связанные с вычислительной мощностью рекуррентных сетей.
Третья часть (разделы 15.6 15.12) посвящена алrоритмам обучения и связанным с
ними вопросам. Она начинается с обзора рассматриваемой предметной области (раз
дел 15.6). Далее, в разделе 15.7, детально описывается обратное распространение во
времени, которое основано на материале, представленном в rлаве 4. В разделе 15.8
представлен еще один популярный алrоритм: рекуррентное обучение в реальном
времени. В разделе 15.9 приведен краткий обзор классической теории фильтров Кал
мана, а в разделе 15.1 О описывается алroритм несвязной расширенной фильтрации
Калмана. Компьютерное моделирование последнеrо алrоритма, применяемоrо для pe
кyppeHTHoro обучения, будет выполнено в разделе 15.11. rрадиентное рекуррентное
обучение порождает проблему обращающихся в нуль rpадиентов, которая paCCMaT
ривается в разделе 15.12.
Четвертая, заключительная, часть настоящей rлавы (разделы 15.13 и 15.14) посвя
щена важнейшим областям применения рекуррентных сетей. В разделе 15.13 описы
вается задача идентификации систем, а в разделе 15.14 адаптивное управление на
основе модели.
rлава завершается обобщающими выводами и рассуждениями.
15.2. Архитектуры рекуррентных сетей 921
15.2. Архитектуры рекуррентных сетей
Как уже roворилось во введении, архитектурное строение рекуррентных сетей может
принимать множество различных форм. В этом разделе описываются четыре OCHOB
ные архитектуры таких сетей, каждая из которых соответствует некоторой частной
форме rлобальной обратной связи 1 . Эти архитектуры имеют следующие общие xa
рактеристики.
. Все они состоят из статичеСКО20 мноrослойноrо персептрона или ero COCTaB
ных частей.
. Все они используют способность мноrослойноro персептрона выступать в каче
стве отображения BXOД BЫXOД (нелинейноro оператора).
Рекуррентная модель "вход-выход"
На рис. 15.1 показана архитектура обобщенной рекуррентной сети, построенной на
базе мноrослойноrо персептрона. Эта модель имеет единственный вход, который
применяется к памяти на линиях задержки, состоящей из q элементов. Она имест
единственный выход, замкнутый на вход через память на линиях задержки, которая
также состоит из q элементов. Содержимое этих двух блоков памяти используется для
питания входноrо слоя персептрона. Вход модели обозначается как и(п), а COOTBeT
ствующий выход у( п + 1). Это значит, что выход модели упреждает ее вход на одну
единицу времени. Таким образом, вектор сиrнала, подаваемый на вход персептрона,
состоит из окна данных, состоящеro из следующих элементов.
. Текущее и предыдущее значения входноrо сиrнала: и(п), и(п 1), .. ., и(n q+1),
которые представляют сети, имеющие внешнее происхождение.
. Значения выходноrо сиrнала у(п), у(п 1),. .., у(п q + 1) в предшествующие
моменты времени, от которых зависит выход модели у(п + 1).
Таким образом, рекуррентную сеть, показанную на рис. 15.1, можно рассматривать
как модель нелинейной авторе2рессии с внешними входами (nonlinear autoregressive
with exogenous inputs model NARX) 2 . Динамика модели NARX описывается следу
ющим образом:
I Друrие архитектуры рекуррентных сетей описаны в [85], [306], [522], [893].
2 Модель NARX охватывает важный класс дискретных нелииейных систем [634]. В контексте нейронных
сетей он рассмотрен в [184], [645], [774], [989].
Было продемонстрировано, что модель NARX хорошо подходит для моделироваиия нелинейных систем,
такнх как теплообмениики [184], водоочистные системы [1024], [1025], системы каталитическоm реформинrа
[1025], нелинейные колебательные процессы, связанные с передвижением мноmноrих роботов (multilegged
locomotion) [1091], и rpамматический вывод (grammatical inference) [355].
Модель NARX также называют нелинейной моделью автореrpессии со скользящим средним (nonlinear
autoregressive moving average model NARМA), в которой термин "скользящее среднее" относится к входному
сиrналу.
922 rлава 15. Динамически управляемые рекуррентные сети
Вход
u(п)
Мноmcлойный
персептрон
Выход
у(п+ 1)
Рис. 15.1. Модель нелинейной pe
rрессии с внешними входами (NARX)
у(п + 1) == Р(у(п),... , у(п q + 1), и(п),... , и(п q + 1)),
(15.1)
rде F некоторая нелинейная функция своих aprYMeHToB. Обратите внимание, на
рис. 15.1 предполаrается, что обе памяти на дискретной линии задержки имеют раз-
мер q. В общем случае эти размеры MOryT отличаться. Модель NARX детально опи
сывается в разделе 15.4.
15.2. Архитектуры рекуррентных сетей 923
Банк q
единичных
задержек
r
I
I
Нелинейный Линейный: у(п + 1)
скрытый выходной
слой х(п + 1) слой I
I I
I
Мноmcлойный персептрон
с одним скрытым слоем
Банкр
единичных
задержек
у(п)
Выходной
вектор
х(п)
Входной и(п)
вектор
Рис. 15.2. Модель в пространстве состояний
Модель в пространстве состояний
На рис. 15.2 показана блочная диаrpамма еще одной обобщенной рекуррентной сети,
которая называется моделью в пространстве состояний (state space model). CKpЫ
тые нейроны определяют состояние сети. Выход скрытоro слоя замкнут на входной
слой через банк единичных задержек. Входной слой сети состоит из объединения
узлов обратной связи и узлов источника. Связь сети с внешней средой осуществ
ляется через узлы источника. Количество единичных задержек, используемых для
замыкания выхода скрытоrо слоя на входной слой, определяет порядок модели (order
of model). Обозначим символом u(n) вектор входных сиrналов размерности тХ 1 в
момент времени n, а символом х( n) вектор выходных сиrналов CKpblTOro слоя раз-
мерности q Х 1 в тот же момент времени. Torдa динамику этой модели можно описать
следующей системой уравнений:
х(n + 1) == f(x(n), u(n)),
у(n) == Сх(n),
(15.2)
(15.3)
rде f(.,.) некоторая нелинейная функция, характеризующая скрытый слой; С
матрица синаптических весов, характеризующих выходной слой. Скрытый слой этой
сети нелинеен, а выходной линеен.
Рекуррентная сеть на рис. 15.2 включает ряд рекуррентных архитектур в качестве
частных случаев. Для при мера рассмотрим простую рекуррентную сеть (simple re
сuпепt network SRN), описанную в работе Элмана [281] и показанную на рис. 15.3.
Сеть Элмана имеет архитектуру, сходную с показанной на рис. 15.2, за исключением
TOro факта, что выходной слой может быть нелинейным, а банк единичных задержек
на выходе сети отсутствует.
Сеть Элмана содержит рекуррентные связи скрытых нейронов со слоем KOHтeKcт
ных элементов (context unit), состоящим из единичныХ задержек. Эти контекстные
элементы сохраняют выходы скрытых нейронов на один шаr времени, после чеro
924 rлава 15. Динамически управляемые рекуррентные сети
Контекстные
элементы
Банк
единичных
задержек
Скрьrrый
слой
I
I
Выходной I
слой
Выходной
вектор
Входной
вектор
I
I I
I
Мноrослойный персептрон
с одним скрытым слоем
Рис. 15.3. Простая pe
куррентная сеть SRN
Банк единиЧНЫХ
задержек
х[(п)
Входной и(п)
вектор
I
I
I
J
Мноmслойный персептрон
с несколькими скрытыми слоями
хо(п + 1)
Выходной
вектор
Рис. 15.4. Рекуррентный мноroслойный персептрон
передают их на входной слой. Таким образом, скрытые нейроны записывают свои
предыдущие действия, что позволяет реализовать задачи обучения, разворачивающи
еся во времени. Скрытые нейроны также передают информацию выходным нейронам,
которые формируют реакцию сети на примененное извне возмущение. Так как данная
природа обратной связи связана исключительно со скрытыми нейронами, они Moryr
распространять повторные циклы информации по сети на протяжении множества
шаrов времени и таким образом открывать доступ к абстрактному представлению
времени. Следовательно, простая рекуррентная сеть является чем то большим, неже
ли записью на маrнитную ленту предыдущих данных.
В [281] рассматривалось также использование простой рекуррентной сети
(см. рис. 15.3) для поиска rpаниц слов в последовательных потоках фонем без нали
чия каких либо встроенных 02раничений представления (representational constraint).
На вход сети подавал ась текущая фонема. Выход представлял собой наилучшее реше
ние сети относительно Toro, какой будет следующая фонема в последовательности.
Роль контекстных элементов обеспечивала динамическая память (dynamica1 тeт
ory), которая кодировала информацию, содержащуюся в последовательности фонем,
что равноценно проrнозированию.
15.2. Архитектуры рекуррентных сетей 925
Рекуррентный мноrослойный персептрон
Третья рассматриваемая в настоящей rлаве рекуррентная архитектура известна KaKpe
куррентный МНО20СЛОЙНЫЙ персептрон (rесuпепt multilayer perceptron RМLP) [863].
Этот персептрон имеет один или несколько скрытых слоев (использование несколь
ких скрытых слоев определяется тем, что статичный мноrослойный персептрон обыч
но является более эффективным и компактным, чем использующий только один cкpы
тый слой). Каждый вычислительный слой RМLP замкнут на себя собственной обрат
ной связью. На рис. 15.4 показан частный случай RМLP с двумя скрытыми слоями 3 .
Пусть вектор Xr(n) обозначает выход первоrо cKpblToro слоя, вектор хп(n)
выход BToporo скрытоrо слоя и Т.д. Обозначим символом Хо (n) выход выходноro
слоя. Torдa динамика RМLP в ответ на подачу на вход вектора u( n) в общем случае
будет описываться следующей системой уравнений:
Xr(n + 1) == CPr(xr(n), u(n)),
хп(n + 1) == срп(хп(n), xr(n + 1)),
(15.4)
хо(n + 1) == сро(хо(n),хк(n + 1)),
rдe СР! (-, .), СРп (-, .), ..., СРо (-, .) функции активации, характеризующие первый,
второй и друrие скрытые слои, а также выходной слой RМLP; К общее количество
скрытых слоев в сети.
Описанный таким образом RМLP является обобщением сети Элмана, показанной
на рис. 15.3, и модели в пространстве состояний, показанной на рис. 15.2, так как ни
выходной слой, ни какой либо из скрытых слоев не оrpаничен некоторой конкретной
формой функции активации.
Сеть BToporo порядка
При описании модели в пространстве состояний (см. рис. 15.2) для обозначения
количества скрытых нейронов, выходы которых замкнуты на выходной слой через
банк единичных задержек, использовался термин "порядок".
В друrом контексте термин "порядок" иноrда используется для обозначения спосо
ба определения индуцированноro локальноrо поля нейрона. Для примера рассмотрим
мноroслойный персептрон, индуцированное локальное поле Vk нейрона k в котором
определяется следующим выражением:
3 Рекуррентный мноrослойный персептрон, показанный на рис. 15.4, является обобщением рекуррентной
сети, описанной в [522].
926 rлава 15. Динамически управляемые рекуррентные сети
Vk == L Wa,kjXj + L Wb,kiиi,
j
(15.5)
rде Xj сиrнал обратной связи, направленный от cKpblToro нейрона j; иi сиrнал
источника, применяемый к нейрону i входноro слоя. Символами W обозначаются co
ответствующие синаптические веса сети. Нейрон, показанный на рис. 15.5, называют
нейроном первО20 порядка (first order neuron). Коrда же индуцированное локальное
поле формируется с использованием перемножения:
Vk == L L WkijXiUj,
j
(15.6)
то такой нейрон называют нейроном втОрО20 порядка. Нейрон BToporo порядка k
использует один вес Wkji, который связывает ero с входными узлами i иj.
Нейроны BToporo порядка лежат в основе рекуррентной сети втОрО20 порядка
[357], пример которой показан на рис. 15.5. Эта сеть принимает упорядоченную
по времени последовательность входных сиrналов и имеет динамику, описываемую
следующей системой уравнений:
Vk(n) == b k + L L WkijXi(n)Uj(n),
j
1
xk(n + 1) == q>(vk(n)) == 1 + ( ()) '
ехр Vk n
(15.7)
(15.8)
rде Vk (n) индуцированное локальное поле нейрона k; b k соответствующее внеш
нее смещение (bias); xk(n) состояние (выход) нейрона k; иj(n) входной сиrнал,
по'ступающий на узел источника j; Wkij вес нейрона BTOpOro порядка k.
Уникальным свойством рекуррентной сети BToporo порядка (см. рис. 15.5) явля
ется то, что произведение Xj(n)иj(n) представляет собой пару {состояние, вход};
положительный вес Wkij описывает наличие перехода состояния (state transition) {co
стояние, вход} {следующее состояние}, а отрицательное значение веса отсутствие
TaKoro перехода. Переход состояния описывается выражением
8(Xi' иj) == Xk.
(15.9)
в свете этоrо соотношения сети BTOpOro порядка часто используются для представ
ления и обучения детерминированных конечных автоматов 4 (deterministic finite state
aиtomata DFA). Автомат DFA это устройство обработки информации с конечным
4 В [801] показано, что с помощью рекуррентной сети втopom порядка любой конечный автомат может быть
отображен в такую сеть, и при этом rарантируется коррекrная классификация временных последовательностей
конечной длины.
15.2. Архитектуры рекуррентных сетей 927
Единичные задержки
Мультипликаторы
Нейроны
{ UI(n)
Входы
U2(п)
Х2(п + 1)
Выход
Xl(n + 1)
Веса BTopom
порядка, Wkji
Рис. 15.5. Рекуррентная сеть BToporo порядка. Вiаs-нейроны исключены из рассмотрения
для упрощения представления. Сеть содержит 2 входных нейрона, 3 нейрона состояния и,
следовательно, требует 2 х 3 == 6 мультипликаторов
количеством состояний. Более подробная информация о связи между нейронными
сетями и автоматами содержится в разделе 15.5.
Архитектуры рекуррентных сетей, описанные в этом разделе, подразумева
ют наличие rлобальной обратной связи. Как уже roворилось во введении, ap
хитектуры рекуррентных сетей MOryT бьпь построены и на использовании толь
ко локальных обратных связей. Свойства этоro класса сетей хорошо описаны в
[1060] (см. также задачу 15.7).
928 rлава 15. Динамически управляемые рекуррентные сети
15.3. Модель в пространстве состояний
Понятие пространства иrpает жизненно важную роль в математическом описании
динамических систем. Состояние динамической системы формально определяется
как множество величин, которые объединяют в себе всю информацию о прошлом
системы, которая необходима для однознаЧНО20 описания ее будуще20, за исключе
нием чисто внешних эффектов, возникающих при применении возбуждения. Пусть
вектор х( n) размерности q х 1 обозначает состояние нелинейной системы дискретно
ro времени; вектор u( n) размерности m х 1 обозначает входной сиrнал, применяемый
к системе, а вектор у( n) размерности р Х 1 соответствующий выход системы. В Ma
тематических терминах динамика такой системы (в предположении отсутствия шума)
описывается следующей системой нелинейных уравнений [1006]:
х(n + 1) == cp(Wax(n), Wbu(n)),
у(n) == Сх(n),
(15.10)
(15.11)
rдe W а матрица размерности q х q; W ь матрица размерности q Х (т+ 1); с
матрица размерности р Х q; <р: Rq Rq диаroнальное отображение вида
[ Х1 ] r q>(Xl) ]
Х2 <р ( Х2 )
<р:
... ...
X q q>(Xq)
(15.12)
для покомпонентноro описания некоторой нелинейности <р: R R. Пространства
Rm, RP и Rq называются соответственно входным (input), выходным (output) и пpo
странством состояний (state space). Размерность пространства состояний q является
порядком системы (order). Таким образом, модель в пространстве состояний, по
казанная на рис. 15.2, является рекуррентной моделью порядка р с m входами ир
выходами. Уравнение (15.10) является уравнением процесса (process equation), описы
BaeMoro этой моделью, а (15.11) ее уравнением измерения (measurement equation).
Уравнение процесса (15.10) является частным случаем уравнения (15.2).
Рекуррентная сеть, показанная на рис. 15.2, основана на использовании статиче
cKorO мноrослойноrо персептрона и двух блоков памяти с дискретной линией за
держки. Она является одним из методов реализации нелинейной системы с обратной
связью, описываемой системой (15.10) (15.12). Обратите внимание, что на рис. 15.2
за формирование состояния рекуррентной сети отвечают только те нейроны MHO
20СЛОЙНО20 персептрона, выходы которых замкнуты на входной слой через блоки за
держки. Таким образом, из определения состояния исключаются выходные нейроны.
Можно предложить следующую интерпретацию матриц W а, W Ь И С, а также
нелинейной функции <р(.).
15.3. Модель в пространстве состояний 929
· Матрица W а содержит синаптические веса q нейронов скрытоrо слоя, которые
соединены с узлами обратной связи входноro слоя. Матрица W ь содержит синап
тические веса q нейронов CKpblTOro слоя, которые соединены с узлами источника
входноro слоя. Предполаrается, что внешнее смещение, применяемое к скрытым
нейронам, учтено в матрице весов W ь.
· Матрица С содержит синаптические веса р линейных нейронов выходноrо слоя,
которые соединяют их со скрытыми нейронами. Предполаrается, что внешнее
смещение, применяемое к выходным нейронам, учтено в матрице весов С.
· Нелинейная функция <р(.) представляет сиrмоидальные функции активации CKpЫ
тых нейронов. Она обычно принимает форму функции rиперболическоro TaHreHca:
1 e 2x
<р(х) == tanh(x) == 1 + e 2x (15.13)
или лоrистической функции:
1
<р(х) == 1 + e X '
(15.14)
Важным свойством рекуррентных сетей, описываемых моделью в пространстве
состояний (15.1 О) и (15.11), является то, что они MOryT aппpOKcuмиpoвaть ДOCTa
точно широкий класс нелинейных динамических систем. Однако эта аппроксима
ция достоверна только на компактных подмножествах пространства состояний и
на конечных интервалах времени и не отражает некоторые интересные динамиче
ские характеристики [1006].
Пример 15.1
для TOro чтобы проиллюстрировать композицию матриц W а, Wb И С, рассмотрим полносвязную
рекуррентную сеть (fully connected rесипепt network), показанную на рис. 15.6. В ней контуры
обратной связи начинаются в нейроиах скрытоro слоя. В данном примере параметры m ==2, q ==3
ир == 1. Матрицы W a и Wb определены следующим образом:
[ Wll W12 WIЗ ]
W a == W21 W22 W2З ,
WЗl WЗ2 Wзз
[ Ь1 W14 W15 ]
Wb == Ь 2 W24 W25 .
Ь з WЗ4 WЗ5
Обратите внимание, что в первом столбце матрицы W ь сосредоточены внешние смещения Ь 1 , Ь 2
И Ь з , примеияемые к нейронам 1,2 и 3 соответственно. Матрица С в данном случае представляет
собой Beктop CTPOKY
с == [1, о, о].
.
930 rлава 15. Динамически управляемые рекуррентные сети
Xl(n)
Пороr
XI(n + 1)
Выход
у(п)
Xin + 1)
хз(п + 1)
{ Ul(n)
Входы
U2(п)
Входной
слой
Слой
вычислений
Рис. 15.6. Полносвязная рекуррентная сеть с двумя входами, двумя скрытыми ней
ронами и одним выходным нейроном
Управляемость и на6людаемость
При изучении теории систем самыми важными рассматриваемыми вопросами яв
ляются устойчивость, управляемость и наблюдаемость. Устойчивость уже обсужда
лась в предыдущей rлаве, поэтому не будем к ней больше возвращаться. В данном
разделе рассмотрим вопросы управляемости и наблюдаемости, так как они обыч
но взаимосвязаны.
Как уже roворилось ранее, мноrие рекуррентные сети можно представить мо-
делью в пространстве состояний (см. рис. 15.2), в которой состояние описывается
выходом скрытоrо слоя, замкнутоrо обратной связью на входной слой через блок
единичных задержек. В этом контексте важно знать, является ли сеть управляемой и
наблюдаемой. Управляемость связана с вопросом возможности управления динами-
15.3. Модель в пространстве состояний 931
кой рекуррентной сети. Наблюдаемость связана с вопросом возможности наблюдения
результата действия управления, примененноro к сети. В этом смысле наблюдаемость
является дуальной к управляемости.
Рекуррентная сеть называется управляемой (controllable), если из любоro началь
HOro состояния путем управления можно привести систему в желаемое состояние
за конечное число шаroв. В данном определении выход системы не принимается в
расчет. Рекуррентная сеть называется наблюдаемой, если состояние сети можно опре
делить из конечноrо множества наблюдений входноrо и выходноrо сиrналов. Более
строrие определения управляемости и наблюдаемости выходят за рамки настоящей
книrи 5 . Здесь оrpаничимся только локальными формами управляемости и наблюда
емости (под локальностью понимается ТО, что эти понятия применяются только в
окрестности paBHoBecHoro состояния сети) [636].
Состояние х называется состоянием равновесия (equilibrum state) системы (15.1 О),
если для любоrо входа u выполняется условие
х == <р(Ах + Во).
(15.15)
Без потери общности можно положить х == О и ii == О. Torдa равновесное состоя
ние будет описываться следующим образом:
0== <р(0).
Друrими словами, точка равновесия может быть представлена началом координат
(О, О).
Без потери общности можно также упростить представление, оrpаничившись си
стемой Bcero с одним входом и одним выходом (single input single output 8180).
Torдa равенства (15.1 О) и (15.11) можно переписать следующим образом:
х(n + 1) == <p(Wax(n), wbи(n)),
у(n) == с Т х(n),
(15.16)
(15.17)
rдe Wb и с являются векторами размерности qx 1; и(n) скалярным входом; у(n)
скалярным выходом. Поскольку <р является непрерывно дифференцируемой для слу
чая использования сиrмоидальных функций (15.13) и (15.14), ее можно линеарuзо
вать, разложив в ряд Тейлора в окрестности точки равновесия х == о и ii == О и
оrpаничившись только слаrаемыми первоrо порядка:
x(n + 1) == <p/(O)Wa x(n) + <p/(O)wb и(n),
(15.18)
5 Строrий ПОДХОД к определению управляемости и наблюдаемости можно найти в [531], [638], [1008],
[1178].
932 rлава 15. Динамически управляемые рекуррентные сети
rде x( n) и и( n) являются малыми отклонениями состояния и входа соответственно,
а матрица <р'(О) Якобианом <p(v) по отношению к своему apryмeHТY V, вычисленным
в точке v == О. Такую линеаризованную систему можно описать следующей системой
уравнений:
x(n + 1) == A x(n) + b и(n)s,
y(n) == cT x(n),
(15.19)
(15.20)
rде матрица А размерности q х q и вектор Ь размерности q х 1 определяются следу
ющим образом:
А == <p'(O)W a ,
Ь == <p'(O)wb.
(15.21)
(15.22)
Уравнения состояния (15.19) и (15.20) представлены в стандартной линейнОй фор
ме. Следовательно, к ним можно применить хорошо известные результаты, относя
щиеся к управляемости и наблюдаемости динамических систем, полученные в CTaн
дартной части математической теории управления.
Локальная управляемость
Из линеаризованноro уравнения (15.19) видно, что ero последовательное применение
при водит к системе следующих уравнений:
x(n + 1) == A x(n) + b и(n),
x(n + 2) == A x(n + 1) + b и(n + 1),
x(n + q) == Aqb x(n) + Aq lb x(n + q 1) +... + Ab и(n + 1) + b и(n),
rде q размерность пространства состояний. Таким образом, можно утверждать
следующее [636].
Линеаризованная система (J 5.19) является управляемой, если матрица
Мс == [Aq lb,... ,АЬ, Ь]
(15.23)
имеет раН2 q (т.е. полный раН2), так как тО2да линеаризованное уравнение процесса
(J 5.19) будет иметь единственное решение.
Матрица Мс называется матрицеЙ управляемости (control1ability matrix) линеари
зованной системы.
15.3. Модель в пространстве состояний 933
Пусть рекуррентная сеть, описываемая уравнениями (15.16) и (15.17), управляется
последовательностью входных сиrналов U q (n) вида
uq(n) == [и(n), и(n + 1),... , и(n + q l)]Т.
(15.24)
Отсюда можно рассматривать отображение
G(x(n), uq(n)) == (х(n), х(n + q)),
(15.25)
rдe G: 2q 2q. В задаче 15.4 показано, что
· состояние х(n + q) является вложенной (nested) нелинейной функцией cBoero
прошлоro значения х(n) и входов и(n), и(n + 1),..., и(n + q 1);
· Якобиан х(n + q) по отношению к uq(n), вычисленный в начале координат, равен
матрице управляемости МС из равенства (15.23).
Якобиан отображения G по отношению к х(n) и uq(n), вычисленный в начале
координат (О, О), можно выразить следующим образом:
[ ( 8Х(n» ) ( ) ]
ic) == 8х(n) (0,0) 8х(n) (0,0)
(0,0) ( 8х(n) ) ( 8x(n+q» )
8и о (n) (0,0) 8о о (n) (0,0)
== [ J '
(15.26)
rде 1 единичная матрица; О нулевая матрица, а матрица Х не представляет
интереса. Блаrодаря своей специфичной форме определитель этоrо Якобиана Ji o)
равен произведению определителя единичной матрицы 1 и определителя матрицы
управляемости Мс. Если МС имеет ПОлный paHr, то таковой имеет и Якобиан Ji o).
Далее, приведем теорему об обратной функции (inverse function theorem), которая
утверждает следующее [1095].
Рассмотрим отображение f: q q и предположим, что каждый компонент f
дифференцируем по своему арсументу в точке равновесия хо Е q и что Уо ==f(xo).
ТО2да существует такое множество UE q, содержащее хо, и множество VE
q, содержащее Уо, что f будет представлять собой дuффеоморфизм из U в V.
Если к тому же отображение f является 2Ладким, то 2Jlадким будет u обратное
отображение f l: q q и f будет являться тадким диффеоморфизмом.
Отображение f: U V называют диффеоморфизмом, если оно удовлетворяет сле
дующим трем условиям.
1. f(U) == V.
2. Отображение f: U V является однозначным (т.е. обратимым).
3. Каждый компонент обратноrо отображения f l:V U является непрерывно диф
ференцируемым по своему apryMeHТY.
934 rлава 15. Динамически управляемые рекуррентные сети
Возвращаясь к вопросу управляемости, можно идентифицировать отображение
f(U}=V из теоремы об обратной функции как отображение, определенное формулой
(15.25). Используя теорему об обратной функции, можно утверждать, что если матри
ца управляемости Мс имеет paHr q, то локально существует обратное отображение:
(х(n), х(n + q)) == G l(x(n), uq(n)).
(15.27)
Уравнение (15.27), в свою очередь, roворит о том, что существует такая последо
вательность входных сиrналов {U q (n ) } , которая может локально перевести сеть из co
стояния х(n) в состояние х(n+ q) за q шаroв. Следовательно, можно сформулировать
следующую теорему о локальной управляемости (local controllability theorem) [636].
Пусть рекуррентная сеть определяется системой уравнений (15.16) и (15.17) и
пусть ее линеаризованная версия в окрестности начала координат (т.е. paвHoвec
ной точке) определяется системой (15.19) и (15.20). Если линеаризованная cиcтe
ма является управляемой, то рекуррентная сеть является локально управляемой в
окрестности начала координат.
Локальная на6людаемость
Периодически используя линеаризованные уравнения (15.19) и (15.20), можно запи
сать:
оу(n) ==сТох(n),
оу(n + l)==с Т ох(n + l)==с Т Аох(n)+сТЬох(n),
оу(n + q l)==с Т Aq lox(n)+cT Aq 2boи(n)+... +с Т АЬои(n + q 3)+
+сТЬои(n + q 2),
rдe q размерность пространства состояний. Таким образом, можно утверждать
следующее [636].
Линеарuзованная система, описываемая уравнениями (15.19) и (15.20), является Ha
блюдаемой, если матрица
Мо == [C,CAT,...,C(AT)q l]
(15.28)
имеет раН2 q (т.е. полный раН2).
Эта матрица Мо называется матрицеЙ наблюдаемости (observability matrix) ли
неаризованной системы.
15.3. Модель в пространстве состояний 935
Пусть рекуррентная сеть, описываемая уравнениями (15.16) и (15.17), управляется
последовательностью входных сиrналов, заданных следующим образом:
Uq l(n) == [и(n), и(n + 1),..., и(n + q 2)]Т.
(15.29)
Соответственно пусть
уч(n) == [у(n), у(n + 1),... , у(n + q l)]Т
(15.30)
обозначает вектор выходноro сиrнала, производимоro начальным состоянием х( n) и
последовательностью входов Uq 1 (n ). Torдa можно рассмотреть отображение
H(Uq l (n), х(n)) == (Uq l (n), У ч( n)),
(15.31)
rде Н: 3?2ч l 3?2q 1. В задаче 15.5 показано, что Якобиан уч(n) по х(n), вычис
ленный в начале координат (О, О), равен матрице наблюдаемости МО (15.28). Таким
образом, Якобиан Н по Uq 1 (n) и х( n) в начале координат (О, О) можно выразить
следующим образом:
[( au q l(n» ) ( ay q (n» ) ]
J(o) aUq l(n) (0,0) BUq l(n) (0,0) [ 1 Х ]
(0,0) ( aUq l(n» ) ( aYq(n» ) о Мо '
ах(n) (0,0) дх(n) (0,0)
(15.32)
rдe матрица Х опять не представляет интереса. Определитель этоro Якобиана Ji o)
равен произведению определителя единичной матрицы 1 и определителя матрицы
наблюдаемости Мо. Если МО имеет полный paHr, то таковой имеет и Якобиан Ji o).
Применяя теорему об обратной функции, можно утверждать, что если матрица наблю
даемости МО линеаризованной системы имеет полный paHr, то локально существует
некоторое обратное отображение, определяемое следующим образом:
(Uq l (n), х( n)) == H l (Uq l (n), х(n)).
(15.33)
в результате это уравнение утверждает, что в локалЬНОй окрестности начала KO
ординат х (n) является некоторой нелинейной функцией от Uq 1 ( n) и у q (n) и что эта
функция является наблюдателем данной рекуррентной сети.
Таким образом, можно сформулировать следующую теорему о локальной наблю
даемости (local observability theorem) [636].
Пусть рекуррентная сеть определяется системой уравнений (I 5.16) и (I 5.17) и пусть
ее линеаризованная версия в окрестности наЧШlа координат (т. е. равновесной точке)
определяется системой (15.19) и (15.20). Если линеаризованная система является
наблюдаемой, то рекуррентная сеть является ЛОКШlьно наблюдаемой в окрестности
наЧШlа координат.
936 rлава 15. Динамически управляемые рекуррентные сети
Пример 15.2
Рассмотрим модель в пространстве состояний с матрицей А == al, rдe а скаляр; 1 единичная
матрица. Torдa матрица управляемости (15.23) сводится к
Мс == а[Ь,. . . , Ь, Ь].
Paнr этой матрицы равен единице. Исходя из этоro, линеаризованная система с такой матрицей
А не является управляемой.
Подставляя выражение A al в формулу (15.28), получим следующую матрицу наблюдаемости:
Мо == а[с, с,..., с],
paHr которой также равен еДИнице. Следовательно, эта линеаризованная система не является также
и наблюдаемой. .
15.4. Нелинейная автоrрессия
с внешней моделью входов
Рассмотрим рекуррентную сеть с одним входом и одним выходом, динамика которой
описывается уравнениями состояния (15.16) и (15.17). Требуется модифицировать эту
модель к модели типа "BXOД BЫXOД", эквивалентно представляю щей данную peKYP
рентную сеть.
С помощью уравнений (15.16) и (15.17) можно показать, что выход y(n+q) можно
выразить в терминах состояния х( n) и вектора входных сиrналов U q (n) следующим
образом (см. задачу 15.8):
у(n + q) == Ф(х(n), uq(n)),
(15.34)
rдe q размерность пространства состояний, а Ф: 2Ч . Предполаrая, что данная
рекуррентная сеть является наблюдаемой, можно применить теорему о локальной
наблюдаемости и записать:
х(n) == Ф(уq(n), Uq l(n)),
(15.35)
rдe Ф : 2Ч 1 ч. Подставляя (15.35) в (15.34), получим:
у(n + q) == Ф(Ф(уq(n), Uq l(n)), uq(n)) == Р(уч(n), uq(n)),
(15.36)
rдe Uq 1 (n) содержится в U q (n) в качестве ero первых (q 1) элементов, анелинейное
отображение Р: 2ч является композицией ФиФ. Используя определения
уч(n) и uq(n) из формул (15.30) и (15.29), можно переписать выражение (15.36) в
расширенном виде:
15.5. Вычислительная мощность рекуррентных сетей 937
у(n + q) == Р(у(n + q 1),..., у(n), и(n + q 1),... , и(n)).
Подставляя вместо n выражение n q + 1, можно эквивалентно записать [772]:
у(n + 1) == Р(у(n),... , у(n q + 1), и(n),... , и(n q + 1)).
(15.37)
Переводя это выражение на язык слов, некоторое нелинейное отображение Р:
2q существует, посредством чеro текущее значение выхода у( n + 1) OДHO
значно определяется в терминах прошлых значений выхода у(n),..., у(n q+l) и
текущеro и прошлых значений входноro сиrнала и(n),..., и(n q+l). Чтобы это
представление "BXOД BЫXOД" бьmо эквивалентно модели в пространстве состояний
(15.16) и (15.17), рекуррентная сеть должна бьпь наблюдаемой. Практическое значе
ние этой эквивалентности состоит в том, что модель NARX (см. рис. 15.1), в Которой
rлобальная обратная связь оrpаничена только выходным нейроном, способна ими
тировать соответствующую полную рекуррентную модель в пространстве состОЯний
(см. рис. 15.2) (предполаrая, что m == 1 ир == 1) без отличий в динамике.
Пример 15.3
Вернемся к полносвязной рекуррентной сети, изображенной на рис. 15.6. В целях настоящей
дискуссии предположим, что один из входов (например, И2(п)) является нулевым. И теперь наша
сеть сокращается до модели SISO (с одним входом и одним выходом). Тоща, предполarая, что сеть
является локалыlO наблюдаемой, можно заменить эту полно связную рекуррентную сеть моделью
NARX, показанной на рис. 15.7. Эта эквивалентность сохраняется несмотря на тот факт, что модель
NARX имеет оrpаниченную обратную связь, которая исходит из выходноrо нейрона, в то время как
полносвязная рекуррентная сеть, показанная на рис. 15.6, содержит rлобальные обратные связи,
окружающие мноroслойный персептрон и исходящие из всех трех (2 x скрытых и 1 ro выходноrо)
нейронов. .
15.5. Вычислительная мощность рекуррентных сетей
Рекуррентные сети (при мерами которых являются модель в пространстве состОЯний
(см. рис. 15.2) и модель NARX (см. рис. 15.1)) имеют внутреннюю способность ими
тировать конечные автоматы (finite state automata).ABmoMam (automata) представля
ет собой абстракцию устройств обработки информации, таких как компьютеры. На
самом деле история развития нейронных сетей и автоматов имеет MHoro общеrо 6 .
6 Первая работа по нейронным сетям и автоматам (действительно послеДОRательным реализациям машин
автоматов) также является первой работой, посвященной конечным автоматам, искусственному интеллекту
938 rлава 15. Динамически управляемые рекуррентные сети
Вход
u(п)
Выход
у(п)
Рис. 15.7. Сеть NARX с q == 3 скрытыми нейронами
в [741] при ВОДИТСЯ слеДующее утверждение.
Любая машина с конечными состояниями эквивалента некоторой нейрон ной сети
и может быть имитирована ею. Это значит, что для любой машины с конечными
состояниями М можно построить определенную нейронную сеть N M , которая, если
ее рассматривать как "черный ящик ", будет работать в точности как машина М.
Эта ранняя работа по рекуррентным сетям использовала для функции активации
нейрона жесткую лоrику единичноro скачка, а не мяrкую сиrмоидальную функцию.
Пожалуй, первая экспериментальная Демонстрация TOro, сможет ли рекуррентная
сеть обучиться особенностям, соДержащимся в небольшой rpамматике с конечны-
и рекуррентным нейронным сетям [714]. Рекуррентные сети (с немедленной обратной связью), описанные
во второй части этой книrи, в [562] были интерпретированы как конечные автоматы. Последний труд [972]
появился под редакцией Шеннона и Маккарти (среди авторов этой удивительной книrи были также Мур (Moore),
Минский (Minsky), фон Нейман (уоп Neumann) и Аттли (Utt1ey». Иноrда [562] упоминается как первый труд,
посвященный конечным машинам (finite state mасЫпе) [827]. Автоматы и нейронные сети рассмотрены в [741].
Все ранние работы, посвященные автоматам и нейронным сетям, были связаны с синтезом, т.е. встраи-
ванием автоматов в нейронные сети. Так как большая часть автоматов (реализованных как последовательные
машины) требует обратной связи, нейронные сети также должны были быть рекуррентными. Заметим, что в
ранних работах (за исключением [741]) не делалось четкоm разrpаничения между автоматами (направленными,
маркированными, ацикличными rpафами) и последовательными машинами (задержки лоrики и обратной связи)
и больше внимания уделялось конечным автоматам. Проявлялся только небольшой интерес (за исключением
[741]) к переходу к иерархии автоматов, развитию автоматов и машины Тьюринrа.
После времен застоя в области нейронных сетей исследования автоматов возобновились в 1980 x mдах. Эта
работа может быть условно разбита на три направления: обучаемые автоматы; синтез автоматов, извлечение и
структурирование знаний; представление. Впервые об автоматах и нейронных сетях упомииалось в [522].
15.5. Вычислительная мощность рекуррентных сетей 939
Рис. 15.8. Машина Тьюринra
Линейная
лента
Ячейка для
хранения символа
ми состояниями, приведена в [198]. В данной работе простая рекуррентная сеть
(см. рис. 15.3) была представлена строками, полученными из rpамматики и требу
емыми для проrнозирования на каждом шаrе следующей буквы. Проrнозирование
было контекстно зависимым, так как каждая буква появлялась в rpамматике ДBa
жды и каждый раз за ней следовали различные буквы. Было показано, что такая
сеть способна выработать такое внутреннее представление в скрытых нейронах, KO
торое соответствует состояниям автомата (машины с конечными состояниями). В
[598] было представлено формальное доказательство Toro, что простая рекуррентная
сеть имеет такую же вычислительную мощность, как и любая машина с конечными
состояниями.
В обобщенном смысле вычислительная мощность рекуррентных сетей paCKpЫBa
ется двумя основными теоремами.
Теорема 1 [990].
Любую машину ТьюриН2а можно имитировать полносвЯЗ1l0Й рекуррентной ce
тью, построенной на нейронах с си2моидальными функциями активации.
Машина ТьюриН2а (Turing machine) является абстрактным вычислительным
устройством, изобретенным Тьюринrом в 1936 roду. Она состоит из трех Функци
ональных блоков (рис. 15.8): элемента управления, который может иметь одно из
конечноro числа возможных состояний; линейной ленты (в предположении, что она
бесконечна в обоих направлениях), которая разбита на дискретные ячейки, а каждая
ячейка способна хранить только один символ из конечноro их множества; 20ловки
чтения записи, которая перемещается вдоль ленты и считывает и записывает инфор
мацию в элемент управления [295]. В рамках нашей дискуссии будет достаточно
сказать, что машина Тьюринrа является абстракцией, которая имеет вычислительную
мощность компьютера. Эта идея известна под названием 2ипотезы Чарча ТьюриН2а
(Church Turing hypothesis).
940 rлава 15. Динамически управляемые рекуррентные сети
Теорема 2 [989].
Сети NARX с одним слоем скрытых нейронов, имеющих 02раниченную функцию
активации с односторонним насыщением, и одним выходным нейроном МО2ут ими
тировать полносвязные рекуррентные сети с 02раниченными функциями активации
с односторонним насыщением с учетом линеЙНО20 замедления (Ziпear s/owdowп).
Под "линейным замедлением" понимается следующее: если полно СВЯЗная peKYP
рентная сеть с N нейронами решает интересующую задачу за время Т, то общее
время, затрачиваемое эквивалентной сетью NARX, составит (n + l)Т. Функция q>(-)
называется 02раниченной функцией с односторонним насыщением (bounded, one sided
saturated function ВО88), если выполняются следующие условия.
1. Функция <р(') имеет оrpаниченную область значений, Т.е. для всех Х Е R выпол
няется а <р(х) Ь, rде а 1= Ь.
2. Функция <р(.) имеет насыщение с левой стороны, Т.е. существуют такие значения
s и В, что <р(х) == S для всех Х s.
3. Функция <р(') не является константной, Т.е. существуют такие Хl и Х2, что <P(Xl) 1=
<Р(Х2),
ПОРО20вые (threshold) и кусочно линейные функции удовлетворяют условиям
ВО88. Однако в прямом смысле сиrмоидальная функция не является функцией BOSS,
так как нарушает условие 2. Тем не менее после небольшой модификации ее можно
сделать таковой, записав (на примере лоrистической функции):
<р(х) == { l+ex ( x)'
О,
Х > S,
Х S,
rде s Е R. в результате при Х S лоrистическая функция "обрезается".
Следствием из теорем 1 и 2 может служить следующее утверждение.
Сети NARX с одним скрытым слоем нейронов, имеющих ВОSS функции aKтивa
ции, и одним выходным нейроном эквивалентны сетям ТыориН2а.
На рис. 15.9 rpафически изображены теоремы 1 и 2 и их следствие. Однако следует
заметить, что если сетевая архитектура оrpаничена, то вычислительная мощность
рекуррентной сети не является эквивалентной конечным автоматам [1012]. Ссьтки
на примеры оrpаниченных сетей представлены в примечании 77.
7 Однослойные рекуррентные сети, использующие нейрон Мак Каллока Питца, не моrли имнтировать
какую либо конечную машину [373]. В то же время простая рекуррентная сеть Элмана может это сделать [598].
Рекуррентные сети, содержащие только локальные обратные связи, не MOryт представлять все конечные машины
[307], [352], [597].
15.6. Алroритмы обучения 941
Машина
Тьюринra
Полносвязная
рекуррентная
сеть
Рис. 15.9. rрафическое изображение теорем 1 и
2 и их следствия
15.6. Алrоритмы обучения
Теперь обратимся к вопросу обучения рекуррентных сетей. В rлаве 4 уже rовори
лось, что существуют два режима обучения обычноro (статическоro) мноrослойноrо
персептрона: пакетный и последовательный. В пакетном режиме перед коррекци
ей свободных параметров вычисляется чувствительность сети для Bcero множества
обучения. С друrой стороны, в последовательном режиме настройка параметров BЫ
полняется после подачи каждоro примера обучения. Подобно этому для обучения
рекуррентной сети также существуют два метода обучения [1156].
Обучение по эпохам (epochwise training). В заданной эпохе рекуррентная сеть
начинает свою работу с HeKoToporo исходноro состояния и развивается, пока не дo
стиrнет HeKoToporo друrоrо состояния. В этой точке обучение приостанавливается,
и сеть сбрасывается в исходное состояние, после чеrо начинается следующая эпо
ха обучения. Исходное состояние не обязательно должно быть одинаковым для всех
эпох. Важно только, чтобы исходное состояние каждой эпохи отличалось от конеч
HOro состояния предыдущей. Для при мера рассмотрим использование рекуррентной
сети для имитации работы конеЧНО20 автомата (finite state machine), Т.е. устройства,
число различных внутренних конфиrураций (состояний) KOToporo конечно. В такой
ситуации будет вполне обоснованным использование обучения по эпохам, так как
представляется удобная возможность имитации рекуррентной сетью множества раз
личных начальных и конечных состояний автомата. При обучении рекуррентных
сетей по эпохам термин "эпоха" используется в смысле, несколько отличном от Toro,
который использовался для обычноrо мноroслойноrо персептрона. В текущей терми
нолоrии эпоха для рекуррентной сети соответствует одному примеру обучения для
обычноrо мноroслойноrо персептрона.
Непрерывное обучение (continuous training). Второй метод обучения подходит для
ситуаций, коrда недоступны состояния сброса и (или) требуется обучение в реаль
ном времени. Отличительной чертой непрерывноrо обучения является то, что сеть
обучается во время самой реальной обработки сиrнала, Т.е. процесс обучения нико
rда не останавливается. Для примера рассмотрим использование рекуррентной сети
для моделирования нестационарноrо процесса, TaKoro как речевой сиrнал. В такой
942 rлава 15. Динамически управляемые рекуррентные сети
ситуации непрерывность работы сети не предполаrает наличия удобноrо времени
для останова обучения и последующеro ero начала с друrими значениями свободных
параметров сети.
Помня об этих двух режимах обучения, в последующих двух разделах рассмотрим
следующие алroритмы обучения рекуррентных сетей.
· Алroритм обратноro распространения во времени (back propagation through time)
рассматривается в разделе 15.7. Он работает в предположении Toro, что временные
операции рекуррентной сети MOryT бьпь пред ставлены посредством мноroслойно
ro персептрона. Это может открыть путь для применения стандартноrо алrоритма
обратноrо распространения. Обратное распространение во времени можно реали
зовать как по эпохам, так и в непрерывном режиме. Можно также комбинировать
эти два режима.
· Алrоритм peкyppeHTHoro обучения в реальном времени, описанный в разделе 15.8,
является производным от модели в пространстве состояний, описанной формулами
(15.10) и (15.11).
Эти два алrоритма имеют ряд общих характеристик. Во первых, оба они основаны
на методе rpадиентноrо спуска, тorдa как MrHoBeHHoe значение функции стоимости
(основанной на критерии среднеквадратической ошибки) минимизируется по синап
тическим весам сети. BO BTOpЫX, оба эти метода довольно про сты в реализации, но
MOryт медленно сходиться. В третьих, они связаны тем, что представление алroритма
обратноrо распространения во времени в виде rpафа движения сиrнала может быть
получено перестановкой из rpафа движения сиrнала определенной формы алrоритма
peKyppeHTHoro обучения в реальном времени [109], [632].
(Непрерывное) обучение в реальном времени, основанное на rpадиентном спуске,
использует минимальный объем доступной информации, а именно мrновенную oцeH
ку rpадиента функции стоимости по настраиваемому вектору параметров. Процесс
обучения можно несколько ускорить, применив теорию фильтров Калмана, которая
более эффективно использует информацию, содержащуюся в данных обучения. В раз-
деле 15.1 О описывается не связный расширенный фильтр Калмана, посредством KOTO
poro можно решать задачи динамическоro обучения, чересчур сложные для обычных
методов rpадиентноro спуска. Краткий обзор фильтров Калмана представлен в разде
ле 15.9. Обратите внимание, что несвязный расширенный фильтр Калмана применим
как в статических сетях прямоrо распространения, так и в рекуррентных сетях.
Некоторые эвристики
Перед тем как при ступить к описанию новых алrоритмов обучения, перечислим Heкo
торые эвристики улучшения обучения рекуррентных сетей, которые используют ме-
тоды rpадиентноro спуска [351].
15.7. Обратное распространение во времени 943
. Должен быть выдержан лексиrpафический порядок примеров обучения, в котором
самые короткие строки подаются сети в первую очередь.
. Обучение должно начинаться с небольшоro при мера, после чеrо их размер должен
постепенно увеличиваться.
. Синаптические веса сети должны корректироваться только в том случае, если
абсолютная ошибка при подаче текущеrо при мера сети будет больше HeKOToporo
заранее заданноrо критерия.
. Рекомендуется использовать эвристику снижения (decay) весов (снижение весов
это одна из rpубых форм реrуляризации сложности, о которой rоворилось в rла
ве 4).
Первая эвристика представляет особый интерес. При ее реализации устраняется
проблема обращения rpадиентов в нуль, которая возникает в рекуррентных сетях, обу
чаемых методами rpадиентноrо спуска. Об этой проблеме речь пойдет в разделе 15.12.
15.7. Обратное распространение во времени
АЛ20ритм обратНО20 распространения во времени (back propagation through time al
gorithm ВРТТ), применяемый для обучения рекуррентных сетей, является расши
рением стандартноrо алroритма обратноrо распространения 8. Он может быть полу
чен путем развертывания временных операций сети в мноrослойной сети прямоrо
распространения, тополоrия которой расширяется на один слой для каждоrо шаrа
времени.
Для при мера предположим, что N рекуррентная сеть, требуемая для обучения
временной задаче, которая начинается с момента времени ПО и продолжается до
момента времени n. Пусть N* сеть прямоrо распространения, которая получается
после развертывания временных операций рекуррентной сети N. Развернутая сеть N*
связана с исходной сетью N следующим образом.
1. Для каждоrо шаrа времени из интервала (по, n] сеть N* содержит слой, состоящий
из К нейронов, rде К количество нейронов исходной сети N.
2. В каждом слое сети N* содержатся копии всех нейронов сети N.
8 Идея, стоящая за алmритмом обратноrо распространения во времени, заключается в том, что для любой
рекуррентиой сети можно создать сеть прямоm распространения, обеспечивающую такую же динамику через
некоторый интервал времен н [745]. Алmритм обратноm распространения во времени впервые был описан в
диссертационной работе Вербоса [1128] (см. также [1126]). Этот алmритм независимо от Вербоса был CKOH
струирован в [915]. Один из вариантов aлmритма обратноm распространения во времени был описан в [1155].
Обзор этих алmритмов и связанных с ними вопросов содержится в [1156].
944 rлава 15. Динамически управляемые рекуррентные сети
W 21
W I1 w 12 w 22
а)
w 11 w 11
х 1 (0) xj(n + 1)
xi O )
W 22
xi 1 )
W 22
х 2 (2)
х 2 (п)
W 22
х 2 (п + 1)
Время О
2
п
п+1
б)
Рис. 15.10. Архитектурный rраф рекуррентной сети N, состоящей из двух нейро
нов (а); rраф передачи сиrнала сети N, развернутый во времени (6)
3. Для каждоrо шаrа времени l Е [по, n] синаптические связи от нейрона i слоя l
к нейрону j слоя l + 1 сети N* являются копиями синаптических связей между
нейронами i и j сети N.
Все эти моменты проиллюстрированы в следующем примере.
Пример 15.4
Рассмотрим рекуррентную сеть N, состоящую из двух нейронов (рис. 15.10, а). для упрощения
представления мы опустили операторы единичной задержки z l, которые следовало вставить в
каждую из синаптических связей (в том числе и в собственные обратные связи) сети N. Пошarово
раскрывая временные связи сети, получим rpаф передачи сиrнала, который показал на рис. 15.10, б
и в котором время начала операций равно по == О. Этот rpаф представляет мноroслойную сеть
прямоro распространения N*, в которой каждый новый слой добавляется на каждом шarе времени
работы сети. .
Применение процедуры развертывания приводит к двум совершенно различным
реализациям обратноrо распространения во времени, в зависимости от Toro, какой
режим обучения используется, по эпохам или непрерывный. Все эти методы peкyp
peHTHoro обучения будут последовательно раскрыты далее в этом разделе.
15.7. Обратное распространение во времени 945
Обратное распространение по эпохам во времени
Пусть множество данных, используемое для обучения рекуррентной сети, разбито на
независимые эпохи, каждая из которых представляет интересующий отрезок времени.
Пусть по время начала эпохи; nl время ее окончания. Рассматривая такую эпоху,
можно определить следующую функцию стоимости:
1 nl
Еобщ.(nо, nl) == "2 L L e (n),
n no jEA
(15.38)
rде А множество индексов j, относящееся к тем нейронам сети, для которых опре
делены желаемые отклики; ej (n) сиrнал ошибки на выходе этих нейронов, изме
ренный по отношению к некоторому желаемому отклику. Требуется вычислить чув
ствительность этой сети, Т.е. частные производные функции стоимости Еобщ. (по, nl)
по синаптическим весам сети. Для этоro можно использовать ал20ритм обратно
20 распространения во времени по эпохам, который построен на пакетном режиме
стандартноrо обучения методом обратноrо распространения (см. rлаву 4). Алrоритм
обучения по эпохам ВРТТ выполняется следующим образом [1155].
. Сначала осуществляется прямая передача данных по сети на интервале времени
(по, nl)' Для записи входных данных состояние сети (т.е. ее синаптические веса)
и желаемый отклик для этоro интервала времени сохраняются.
. Для вычисления значений локальных rpадиентов выполняется единичная обратная
передача через последнюю запись:
О . (n) == дЕобщ. (по, nl)
J aVj(n)
(15.39)
для всех j ЕА и по < n ::; nl- Это вычисление выполняется с помощью формулы
{ q>'(Vj(n))ej(n), n == nl,
Oj(n) == q>'(Vj(n)) [ej(n) + k WjkOk(n + 1)], по < n < nl,
(15.40)
rде q>' (.) производная функции активации по своему apryMeHТY; V j (n) индуци
рованное локальное поле нейрона j. Предполаrается, что все нейроны сети имеют
одну и ту же функцию активации q>(-). Вычисления по формуле (15.40) повторя
ются с момента времени nl, шаr за шаrом, пока не будет достиrнут момент по.
Количество выполняемых шаroв равно количеству шаrов времени в данной эпохе.
946 rлава 15. Динамически управляемые рекуррентные сети
· После выполнения вычислений по методу обратноrо распространения до момента
времени по + 1 к синаптическим весам Wji нейрона j применяется следующая
коррекция:
л дЕобщ.(nо, nl)
UWji == 11 д == 11 Oj(n)Xi(n 1),
Wji n no+l
(15.41)
rде 11 параметр скорости обучения; Xi(n 1) входной сиrнал, поданный на
i й синапс j ro нейрона в момент времени n 1.
Сравнивая описанную процедуру алrоритма ВРТТ по эпохам с пакетным режи
мом стандартноrо алrоритма обратноrо распространения, видим, что rлавное отличие
заключается в том, что в первом случае желаемый отклик определяется для мноrих
слоев сети, поскольку фактический выходной слой рекуррентной сети MHoroKpaTHO
воспроизводится при развертывании ее поведения во времени.
Усеченное обратное распространение во времени
Для использования алrоритма обратноro распространения во времени в режиме pe
альноrо времени в качестве минимизируемой функции стоимости используются MrHO
венные значения суммы квадратических ошибок:
1
Е(n) == 2 L e (n).
jEA
Как и в последовательном (стохастическом) режиме стандартноro обучения Me
ТОДОМ обратноrо распространения, для вычисления соответствующей коррекции си-
наптических весов сети в каждый момент времени n используется rpадиент функции
стоимости Е(n), взятый с обратным знаком. Эти коррекции выполняются последо
вательно в ходе реальной работы сети. Однако, для TOro чтобы эта операция бьша
выполнима с вычислительной точки зрения, сохраняется только история входных дaH
ных и состояний сети для фиксированноro количества шаrов времени, называемоro
2Лубиной усечения (truncation depth) и обозначаемоrо символом h. Любая информация,
которая "старше" h шаroв времени, считается неактуальной и может иrнорироваться.
Если не усекать вычисления, позволяя им накапливаться с момента времени нача-
ла процесса, то время вычислений и требуемый объем памяти возрастают линейно
со временем и в конечном счете достиrнут точки, в которой весь процесс обучения
станет невыполнимым.
15.7. Обратное распространение во времени 947
Эта вторая форма алroритма называется усеченным ал20ритмом обратН020 pac
пространения во времени (ВРТТ(Ь)) [1155]. В нем локальный rpадиент нейрона j
определяется следующим образом:
aE(l)
оз(l) == aVj(l) для всех j Е А и n h < l n,
(15.42)
что, в свою очередь, приводит к формуле
{ q>'(Vj(l))ej(l), l == n,
Oj(l) == q>'(Vj(l)) [k Wkj(l)Ok(l + 1)], n h < l < n.
(15.43)
После TOro как вычисления по методу обратноro распространения выполнены до
момента времени n h+ 1, происходит следующая коррекция синаптических весов
Wji нейрона j:
n
ДWji(n) == 11 L Oj(l)Xi(l 1),
l n h+l
(15.44)
rде 11 и Xi(l 1) уже были определены ранее. Обратите внимание, что использова
ние Wkj(l) в выражении (15.43) требует, чтобы поддерживал ась некоторая история
значений весов. Использование величин W kj в этом выражении обосновано только
в том случае, коrда параметр скорости обучения 11 достаточно мал для Toro, чтобы
значения весов кардинально не изменялись при переходе от одноrо шаrа времени к
следующему.
При сравнении выражений (15.43) и (15.40) видно, что, в отличие от алroритма
ВРТТ, в вычислении присутствует только сиrнал ошибки, вычисленный в текущий
момент времени n. Это и объясняет причину, по которой не сохраняются прошлые
значения желаемых откликов. В результате усеченный алrоритм обратноrо распро
странения во времени учитывает вычисления всех предыдущих шаrов, аналоrично
тому, как стохастический алrоритм обратноrо распространения (см. rлаву 4) учиты
вает вычисления, производимые скрытыми нейронами в мноrослойном персептроне.
Некоторые практические соrлашения
На практике в приложениях алroритма ВРТТ использование усечения оказывается
не таким уж искусственным, как это казалось на первый взrляд. Если peкyppeHT
ная есть не является неустойчивой, должна обеспечиваться сходимость производных
дЕ(l)!дVj (l), так как обратный отсчет по времени соответствует увеличению мощно
сти сиrнала обратной связи (приблизительно равному наклону сиrмоидной функции,
948 rлава 15. Динамически управляемые рекуррентные сети
умноженному на веса). В любом случае rлубина усечения h должна быть достаточ
но большой, чтобы вычисляемые производные бьти близки к реальным значениям.
Например, в приложении динамически управляемых рекуррентных сетей к управле
нию холостым ходом двиrателя рассматривается значение h ==30, которое является
довольно консервативным для выполнения задачи обучения [863].
Следует обсудить еще один практический вопрос. Процедура развертывания для
обратноrо распространения во времени, описанная в этом разделе, дает полезный
инструмент ее описания в терминах каскада идентичных слоев, ниспадающих в Ha
правлении течения времени, что обеспечивает ключ к пониманию ее работы. Однако
эта сильная точка является одновременно и слабой. Эта процедура прекрасно pa
ботает в относительно простых рекуррентных сетях, состоящих из малоrо числа
нейронов. Однако рассматриваемые формулы (особенно (15.43)) становятся OrpOM
ными, коrда процедура развертывания при меняется к более общим архитектурам,
которые, как правило, и встречаются на практике. В таких ситуациях предпочтитель
нее использовать более общий подход, описанный в [1126]. В нем каждое выражение
прямоrо распространения слоя приводит к увеличению соответствующеrо множе
ства выражений обратноrо распространения. Достоинством этоrо подхода является
rOMoreHHoe толкование прямых и рекуррентных (обратных) связей.
Для Toro чтобы описать принцип работы этой частной формы алrоритма ВРТТ(Ь),
обозначим символом p x упорядоченную производную (ordered derivative) выхода сети
в узле l по х. Для вывода уравнений обратноrо распространения уравнения прямоrо
распространения рассматриваются в обратном порядке. Из каждоrо уравнения BЫBO
ДИТСЯ одно или несколько выражений обратноro распространения в соответствии со
следующим принципом:
1 aq> 1 1 aq> 1
Если а == q>(b, с), то P ь == дЬ P a и Ре == де P a'
(15.45)
Пример 15.5
для TOro чтобы прояснить значение понятия упорядоченных производных, рассмотрим нели
нейную систему, описываемую следующей системой уравнений:
Хl =о logи + x ,
у =о xi + 3Х2.
Переменная Х2 влияет на выход у двояким образом: непосредственно из второro уравнения и
неявно через первое уравнение. Упорядоченная производная у по Х2 определяется общим влиянием,
которое учитывает прямой и неявный эффекты:
ду ду д Х l 2 2
P X2 =о д + д д =о 3 + (2 Х l)( 3Х 2) =о 3 + 6 Х 1 Х 2'
Х2 хl Х2
.
15.8. Рекуррентное обучение в реальном времени 949
При проrpаммировании упорядоченных производных дЛЯ ВРТТ(Ь) величины в
правой части каждой из упорядоченных производных (15.45) складываются с преды
дущим значением левой части. Таким образом, соответствующие производные pac
пределяются от данноro узла ко всем узлам и синаптическим весам, которые пере
дают информацию данному узлу (т.е. в обратном направлении), с учетом единичных
задержек, которые MOryT иметь место в таких связях. Простота описанной здесь фор
мулировки избавляет от необходимости визуализации, такой как развертывание во
времени или rpаф передачи сиrнала. В [291], [863] эта процедура использовалась для
получения псевдокода реализации алroритма РВТТ(Ь).
15.8. Рекуррентное обучение в реальном времени
В этом разделе описывается еще один алroритм обучения, называемый рекуррентным
обучением в реальном времени (real time rесuпепt leaming RTRL(h))9. Этот алrоритм
получил свое название из за TOro, что коррекция синаптических весов полно связной
рекуррентной сети выполняется в реальном времени, Т.е. непосредственно в ходе
выполнения сетью своих функций обработки сиrнала [1157]. На рис. 15.11 показана
структура такой рекуррентной сети. Она состоит из q нейронов с m внешними BXO
дами. Эта сеть имеет два различных слоя: конкатенироваНН020 слоя "вход обратная
связь" (concatenated input feedback layer) и слоя вычислительных узлов (processing
layer of computational nodes). Соответственно синаптические связи сети делятся на
прямые и обратные.
Описание этой сети в пространстве состояний дается уравнениями (15.10) и
(15.11). Уравнение процесс а (15.1 О) воспроизведем в следующей расширенной форме:
<p(wil;(n))
х(n + 1) == <p(wJl;(n))
(15.46)
<p(w l;(n))
rде предполаrается, что все нейроны имеют одну и ту же функцию активации <р(-).
Вектор w j размерности (q + т+ 1) х 1 является вектором синаптических весов отдель
9 Алmритм peкyppeHTHom обучения в реальном времени впервые был описан в литературе по нейронным
сетям в [1157]. Ero происхождение можно отследить до ранней работы, написанной в 1965 rоду и посвященной
системной идентификации для настройки параметров произвольных динамических систем [711].
Вывод для одноrо слоя вполне рекуррентных нейронов был представлен в [1157], впоследствии он бьш
расширен на более общие архитектуры [552], [861].
950 rлава 15. Динамически управляемые рекуррентные сети
Вектор
состояния
х(п)
Пороr
входной {
вектор
и(п)
z l
Z l
} выходной
вектор
у(п + 1)
Рис. 15.11. Полносвяз
ная рекуррентная сеть
ДЛЯ алroритма RTRL
HOro нейрона j рекуррентной сети, Т.е.
Wj == [ :a,j ] , j == 1,2,...,q,
b,j
(15.47)
rде Wa,j И Wb,j j e столбцы транспонированных матриц весов w и w[ COOTBeT
ственно. Вектор l;( n) размерности (q + т+ 1) х 1 определяется следующим образом:
l;(n) == [: ] ,
(15.48)
rдe х(n) вектор состояния размерности qx 1; u(n) входной вектор размерности
(т+ 1) х 1. Первым элементом вектора u( n) является число + 1, и соответственно пер
вый элемент вектора Wb,j равен внешнему смещению b j , применяемому к нейрону j.
15.8. Рекуррентное обучение в реальном времени 951
Для упрощения выкладок мы введем новые матрицы Aj(n), Uj(n) и Ф(n) следу
ющеrо вида.
1. Aj(n) матрица размерности q х (q + m + 1), определяемая как частная произ
водная вектора состояния х(n) по вектору весов W{
дх(n) .
A j(n)== a ,J==1,2,...,q.
w.
)
(15.49)
2. Uj(n) матрица размерности qx (q+m+1), все строки которой, за исключением
строки j, равны нулю. Строка j равна транспонированному вектору l;(n):
Щn) [ T (n)] j я строка, j 1,2,..., q.
(15.50)
3. Ф(n) диаrональная матрица размерности q х q,j й диаroнальный элемент KO
торой является частной производной функции активации по своему apryMeHТY,
вычисленному в точке wJl;( n):
Ф(n) == diag (<P'(wTl;(n)),... , <p'(wJl;(n)),..., <p'(w l;(n))) .
(15.51)
Учитывая эти определения, мы можем продифференцировать уравнение (15.46)
по Wj' Torдa, используя цепное правило (chain rule of calculus), получим следующее
рекурсивное уравнение:
Aj(n + 1) == Ф(n) [Wa(n)Aj(n) + Uj(n)], j == 1,2,... , q.
(15.52)
Это рекурсивное уравнение описывает нелинейную динамику состояний (nonlin
ear state dynamics) (т.е. эволюцию состояний) процесса peKyppeHTHoro обучения в
реальном времени.
Для TOro чтобы завершить описание этоrо процесса обучения, нужно связать MaT
рицу Aj(n) с rpадиентом поверхности ошибок по Wj' Для этоrо сначала использу
ем уравнение получения измерения (15.11) и определим вектор ошибки размерно
сти р х 1:
е(n) == д(n) у(n) == д(n) Сх(n).
(15.53)
952 rлава 15. Динамически управляемые рекуррентные сети
Мrновенная сумма квадратичной ошибки в момент времени n определяется в
терминах е( n) следующим образом:
1
Е(n) == 2еТ(n)е(n).
(15.54)
Цель процесса обучения минимизация функции стоимости, полученной сумми
рованием величин Е(n) по всем моментам времени n, Т.е.
Еобщ. == L Е(n).
n
Для достижения этой цели можно использовать метод наискорейшеro спуска, KO
торый требует знания матрицы 2радиентов (gradient matrix), которая определяется
следующим образом:
дЕобщ. '""' дЕ( n) '""'
V'wЕобщ. == aW == aW == V'wE(n),
n n
rде V'wE(n) rpадиент Е(n) по отношению к матрице весов W=={Wk}' При желании
можно продолжить работу с этим уравнением и вывести уравнения коррекции для
синаптических весов рекуррентной сети, не прибеrая к аппроксимациям. Однако, для
Toro чтобы получить алrоритм обучения, который можно использовать для обучения
рекуррентной сети в реальном времени, необходимо использовать мrновенную оценку
rpадиента, а именно V'wE(n), что приведет к приближению метода наискорейшеro
спуска.
Возвращаясь к формуле (15.54), описывающей минимизируемую функцию стои
мости, продифференцируем ее по вектору весов W j и получим следующее:
дЕ(n) ( де(n) ) ( дХ(n) ) .
== дw. е(n) == aw. е(n) == CAj(n)e(n),J == 1,2,... ,q.
) ) ) (15.55)
Исходя из этоro, коррекция, применяемая к вектору синаптических весов W j (n)
нейрона j, может быть определена как
дЕ(n)
ДWj(n) == 11 == 11САз(n)е(n), j == 1, 2, ..., q,
)
(15.56)
rдe 11 параметр скорости обучения, а лj(n) определяется формулой (15.52).
15.8. Рекуррентное обучение в реальном времени 953
ТАБЛИЦА 15.1. Алюритм рекуррентною обучения в реальном времени
Параметры
m размерность входноro пространства
q размерность пространства состояний
размерность выходноro пространства
Wj вектор синаптических весов нейрона j, j == 1, 2, . . . , q
Инициализация
1. Устанавливаем синаптические веса сети в малые значения, выбираемые из paB
HOMepHoro распределения.
2. Устанавливаем начальное значение вектора состояний х(О) в О.
3. Присваиваем Aj (О) == О для j == 1, 2, . . . , q
Вычисления
Для n ==1, 2, . . ., q вычисляем
Aj(n + 1) == Ф(n) [Wa(n)Aj(n) + Uj(n)],
е(n) == д(n) Сх(n),
ДWj(n) == llCAj(n)e(n).
Определения величин х(n), Aj(n), Uj(n) и Ф(n) заданы формулами (15.46), (15.49)
(15.51) соответственно.
Единственным вопросом остается определение начальных условий (initial condi
tions) для запуска процесса обучения. С этой целью положим
Aj(O) == о для всех j.
(15.57)
Это значит, что изначально рекуррентная сеть находится в постоянном состоянии.
В табл. 15.1 в сжатом виде приведен алrоритм peKyppeHTHoro обучения в реальном
времени. Описанная здесь формулировка этоrо алrоритма применима к любой функ
ции активации <р(.), которая дифференцируема по своему apryMeHТY. Для частноro
случая сиrмоидной нелинейности в форме rиперболическоro TaHreHca имеем:
Xj(n + 1) == <р(щ(n)) == tanh(vj(n))
и
' ( ( )) д<р(щ(n)) 2 ( ( ) 2
<р Щ n == дщ (n ) == sech Щ n) == 1 Х j ( n + 1),
(15.58)
rде Щ (n) индуцированное локальное поле нейрона j; Х j (n + 1) ero состояние в
момент времени n + 1.
954 rлава 15. Динамически управляемые рекуррентные сети
Использование MrHoBeHHoro rpадиента \7 wE(n) означает, что описанный здесь
алrоритм peкyppeHTHoro обучения в реальном времени отклоняется от алrоритма не
в реальном времени, oCHoBaHHoro на истинном rpадиенте \7 w Еобщ.' Тем не менее это
отклонение в точности аналоrично отклонению, обнаруженному в стандартном алro
ритме обратноrо распространения, использовавшемся в rлаве 4 для обучения MHoro
слойноro персептрона, в котором коррекция весов проводилась после подачи в сеть
каждоro примера. В то время как алrоритм peKyppeHTHoro обучения в реальном Bpe
мени не rарантирует точноro следования направлению, противоположному направле
нию rpадиента общей функции ошибок Еобщ.(W) по отношению к матрице весов W,
практическое отличие между версиями реальноro и не реальноro времени зачастую
незначительны; эти две версии практически идентичны при достаточно малых значе
ниях параметра скорости обучения..,. Более серьезное последствие этоrо отклонения
от истинно rpадиентной динамики состоит в том, что наблюдаемая траектория (полу
чаемая как rpафик Е(n) относительно элементов матрицы весов W(n)) может сама
зависеть от коррекции весов, производимой алrоритмом, что можно рассматривать
как еще один источник обратной связи, который может привести к неустойчивости
системы. Этот эффект можно свести на нет, приняв параметр скорости обучения Ha
столько малым, чтобы шкала времени коррекции весов бьша значительно меньшей,
чем шкала времени реальной работы сети [1157].
Пример 15.6
в этом примере сформулируем алroритм RTRL для полностью рекуррентной сети (fuHy re
сuпепt network), покаэанной на рис. 15.6 и имеющей два входа и один выход. Эта сеть имеет три
нейрона и композицию матриц W a , Wb И С, которые бьши описаны в примере 15.1.
При т == 2 и q == 3 в (15.48) обнаруживаем, что
хl(n)
Х2(n)
(n) == хз(n)
1
щ(n)
и2 ( n )
Пусть kl й элемент матрицы Aj(n) имеет обозначение л'j,kl(n). Torдa, подставляя выражения
(15.52) и (15.56), получим:
л'j,kl(n + 1) == <р'(щ(n)) [ Wji(n)л'j,kl(n) + 8kj l(n)] ,
wkl(n) == 1l(d 1 (n)) Хl (n)л'1,k1 (n),
rдe 8 kj дельта Кронекера, которая равна единице при k == j и нулю в противном случае, и
(j, k) == 1,2,3 и 1 == 1,2, ...,6. На рис. 15.12 покаэан zраф чувствительности, покаэывающий
эволюцию коррекции весов Wkl(n). Обратите внимание, что W a == {Wji} для (j,i) == 1,2,3 и
Wb == {Wjt} дляj == 1,2,3 и l == 4,5,6. .
15.8. Рекуррентное обучение в реальном времени 955
Ip'(v}(n» Z l Л/,k,сп)
Л/,k,сп + 1) 11el(n)
AWk,cn)
1p'(V2(n») Z l
Л2,k,сп + 1)
Ip'(vз(п» Z l
ЛЗ,k,сп + 1)
Рис. 15.12. r раф чувствительности полностью рекуррентной сети, показанной
на рис. 15.6. Примечание: три узла с метками l(n) следует рассматривать как
единый вход
Усиление учителем
Одна из стратеrий, которые используются при обучении рекуррентных сетей, назы
вается усиление учителем (teacher forcing) [1156], [1157]. В адаптивной фильтрации
усиление учителем известно как метод уравнения ошибок (еquаtiоп епоr method)
[725]. В своей основе усиление учителем использует замещение во время обучения
реальноrо выходноrо сиrнала сети соответствующим желаемым откликом (т.е. целе
вым сиrналом) при последующем вычислении динамики сети (коrда этот желаемый
отклик доступен). Несмотря на то что метод усиления учителем описывается при
рассмотрении алrоритма RTRL, он применим и к любому друrому алrоритму обуче
ния. Однако для ero применяемости рассматриваемый нейрон должен замыкать свой
выход в обратную связь.
Среди преимуществ метода усиления учителем можно выделить следующие
[1156].
· Усиление учителем может привести к ускорению обучения. Причина этоro улуч
шения в использовании величин усиления учителем в качестве предположения,
что сеть корректно обучена всем более ранним частям задачи, относящимся к
нейронам, к которым применяется усиление учителем.
· Усиление учителем может служить механизмом коррекции при обучении. Напри
мер, синаптические веса сети MorYT иметь корректные значения, но сеть временно
может работать в не свойственных ей областях пространства состояний. ECTeCTBeH
но, в такой ситуации коррекция синаптических весов бьта бы неправильной CTpa
теrией.
956 rлава 15. Динамически управляемые рекуррентные сети
rрадиентные алroритмы обучения, которые используют усиление учителем, на
самом деле оптимизируют функцию стоимости по друroму, нежели их неусиленные
аналоrи. Таким образом, усиленные и неусиленные учителем версии алroритма MOryт
давать различные решения (если соответствующие сиrналы ошибки не равны нулю,
то обучение вообще не требуется).
15.9. Фильтр Калмана
Как уже roворилось, непрерывное обучение, основанное на rpадиентном спуске (по
казанное на примере алroритма peKyppeHTHoro обучения в реальном времени), осу-
ществляется довольно медленно из за доверия к MrHoBeHHblM оценкам rpадиентов.
Это серьезное оrpаничение можно обойти, рассмотрев обучение рекуррентной сети
с учителем как задачу оптимальной фильтрации (optimum filtering problem), реше
ние которой рекурсивно использует информацию, содержащуюся в данных обучения,
неявно возвращаясь к первой итерации процесса обучения. Описанная здесь идея
лежит в основе фильтрации Калмана (Kalman filtering) [535]. Среди новаторских
признаков фильтра Калмана следует выделить следующие.
· Эта теория сформулирована в терминах концепций пространства состояний и
предлаrает эффективное использование информации, содержащейся во входных
данных.
· Оценка состояния выполняется рекурсивно. Это значит, что каждая скорректиро-
ванная оценка состояния вычисляется на основе предыдущей оценки и доступ-
ных в текущий момент данных. Следовательно, сохранение требуется только для
предыдущей оценки.
В этом разделе представлен краткий обзор теории фильтров Калмана 1О . Этим мы
проложим путь для вывода в следующем разделе несвязноro расширенноrо фильтра
Калмана. Развитие этой теории, как обычно, началось с линейных динамических
систем. Для TOro чтобы расширить ее использование на нелинейные динамические
системы, к системе применяется одна из форм линеаризации. Последний вопрос мы
отложим до следующеrо раздела.
Итак, рассмотрим линейную, дискретную динамическую систему, показанную на
рис. 15.13. Временное описание представленной здесь системы сохраняет сходство с
формализмом пространства состояний, представленным в разделе 15.3. В математи-
ческих терминах на рис. 15.13 реализована следующая система уравнений:
10 Теория фильтров Калмана берет свое начало в классической работе [535]. Эта теория заняла свое место как
существенная часть управления н обработки сиrнала и нашла применение в разнообразных областях деятельно-
сти человека. ПОдРобное описание стандартноm фильтра Калмана, em вариантов и расширенных форм, работа-
ющих с нелинейными динамическими системами, содержится в [385], [434]. Первая работа целиком посвящена
теории и практике фильтрации Калмана, а во второй рассматривается теория фильтров Калмана с позиций
адаптивной фильтрации. Среди друrих книr, посвященных этому вопросу, можно выделить [513], [708], [709].
15.9. Фильтр Калмана 957
Рис. 15.13. rраф передачи сиrнала линейной дис
кретной динамической системы, используемой для
описания фильтра Калмана
w(n + 1) z lI w(n)
U
С(п)
'I
У(п)
d(n)
-о
w(n + 1) == w(n),
d(n) == C(n)w(n) + У(n).
(15.59)
(15.60)
Величины, использованные в уравнении процесса (15.59) и уравнении ИЗМерения
(15.60), можно описать следующим образом.
· w(n) вектор состояния (state vector) системы.
. d( n) вектор наблюдения (observation vector).
. С(n) Maтpицa измерений (measurement matrix).
. У(n) шум или п02решность измерений (measurement noise).
В уравнении процесса (15.59) сделаны два упрощающих допущения. Во первых,
уравнение процесса не учитывает шума. BO BTOpЫX, передаточная матрица, связы
вающая состояния системы в моменты времени n + 1 и n, равна единичной. На
рис. 15.13 также использовалось новое п нятие состояния (по причинам, которые
станут понятны в следующем разделе).
Задача фильтрации Калмана может быть сформулирована следующим образом.
Используя все множество наблюдаемых данных, состоящее из набора векторов
{d( i) }r l' нужно наЙти для каждО20 n 1 оценку с минимальной cpeдHeKвaдpa
тической ошибкой состояния w( i).
Обратите внимание, что информация о векторе состояний недоступна. Эта задача
называется задачей фильтрации (при i == n), пР02нозирования (при i > n) или С2Ла
живания (при 1 :::; i :::; n). Решение этой задачи получается на основе следующих
допущений.
1. Поrpешность измерений у( n) имеет нулевое среднее значение и является процес
сом белоrо шума с матрицей ковариации:
E[v(n)vT(k)] == { ,(n), :; k '
(15.61)
2. Начальное состояние w(O) не коррелировано с у( n) для всех n О.
958 rлава 15. Динамически управляемые рекуррентные сети
Для изящноrо вывода фильтра Калмана можно использовать понятие инновации
[534]. Более точно, процесс инновации (innovation process), связанный с вектором
наблюдений д(n), определяется следующим образом:
а(n) == d(n) d(nJn 1),
(15.62)
rде d(nln 1) оценка д(n) с минимальной среднеквадратической ошибкой на
основе всех прошлых значений вектора наблюдений, начиная с момента времени
n == 1 и заканчивая моментом n 1. Под "оценкой с минимальной среднеквадратиче-
ской ошибкой" понимается та оценка, которая минимизирует среднеквадратическую
ошибку д( n). Инновационный процесс а( n) можно рассматривать как меру новой иH
формации, содержащейся в д(n), которая бьта недоступна в проrнозируемой части
d(nln 1). Инновационный процесс имеет ряд следующих полезных свойств [534].
1. Инновационный процесс а(n), ассоциированный с д(n), не коррелирован со все-
ми предьщущими наблюдениями д(1), д(2),..., д(n 1), Т.е.
Е[а(n)д Т (k)] == О для 1 k n 1.
2. Инновационный процесс состоит из последовательности случайных векторов, KO
торые не коррелированы друr с друrом:
E[a(n)aT(k)] == о для 1 k n 1.
3. Существует однозначное соответствие между последовательностью случайных
векторов, представляющих наблюдаемые данные, и последовательностью случай
ных векторов, представляющих инновационный процесс:
{д(1),д(2),... ,д(n)} {а(1),а(2),... ,а(n)}.
(15.63)
Теперь можно заменить коррелированную последовательность наблюдаемых дан-
ных некоррелированной (и, следовательно, упрощенной) последовательностью инно
ваций, при этом не теряя информацию. Это упрощает вывод фильтра Калмана, так
как выражает оценку состояния в момент времени i через заданный набор иннова-
ций {а( k)} k l' При проведении этоrо анализа можно вывести стандартный фильтр
Калмана (табл. 15.2).
В этом алrоритме существуют три новые величины, которые требуют определения.
15.9. Фильтр Калмана 959
ТАБЛИЦА 15.2. Фильтр Калмана
Для n == 1,2,... вычисляем:
r(n) == [С(n)К(n, n l)С Т (n) + R(n)] l,
G(n) == К(n,n l)C T (n)r(n),
а(n) == у(n) C(n)w(nln 1),
",(n + 11n) == w(nln 1) + G(n)a(n),
К(n + 1, n) == К(n, n 1) G(n)C(n)K(n, n 1)
. К( n, n 1) матрица ковариации ошибки (епоr covariance matrix), определяемая
следующим образом:
К(n,n 1) == Е[е(n,n l)е Т (n,n 1)],
(15.64)
rде вектор состояния е( n, n 1), в свою очередь, определяется как
е(n, n 1) == w(n) w(nln 1),
(15.65)
rде w(n) фактическое состояние; w(nln 1) ero проrнозируемое значение
на один шаr вперед, основанное на предыдущих значениях данных наблюдения
вплоть до момента времени n 1.
. r(n) переводной коэффициент (conversion factor), который связывает ошибку
фильтрованной оценки (filtered estimation епоr) е( n) с инновацией а( n):
е(n) == R(n)r(n)a(n),
(15.66)
rде
е(n) == d(n) d(nln)
(15.67)
и d(nln) оценка вектора наблюдений d(n), полученная на основе всех наблю
дений вплоть до момента времени n.
. G(n) коэффициент усиления Калмана (Kalman gain), который определяет кор-
рекцию, применяемую к оценке состояния.
Тип фильтра Калмана, приведенноrо в табл. 15.2, предназначен для распростране
ния матрицы ковариации ошибки К( n, n 1) и поэтому называется ковариационным
ал20ритмом фильтрации Калмана (covariance Kalman filtering algorithm).
960 rлава 15. Динамически управляемые рекуррентные сети
Фильтр Калмана на основе KBaдpaTHoro корня
Ковариационный фильтр Калмана связан с серьезными вычислительными проблема
ми. В частности, обновленная матрица К( n + 1, n) определяется уравнением Рикатти
(Ricatti equation) (см. последнюю строку в табл. 15.2). В правой части уравнения Ри
катти содержится разность между двумя матричными величинами. Если числовая
точность на каждом шаrе итерации алrоритма не будет достаточно велика, то CKOp
ректированная матрица К( n+ 1, n) может не оказаться неотрицательно определенной.
Понятно, что такое решение неприемлемо, так как К( n + 1, n) представляет co
бой матрицу ковариации, которая неотрицательно определена по определению. Такая
неустойчивая динамика фильтра Калмана, ставшая результатом неточности вычис
лений, связана с использованием арифметики с конечной длиной представления и
называется феноменом дивер2енции (divergence phenomenon).
Этой проблемы можно избежать, распространяя квадратный корень матрицы KOBa
риации ошибки Кl/2(n, n 1), а не саму матрицу К(n, n 1). В частности, используя
разложение ХолеЦКО20 (Cholesky factorization), К( n, n 1) можно выразить следую
щим образом [368]:
К(n, n 1) == Кl/2(n, n 1)кТ/2(n, n 1),
(15.68)
rде Кl/2(n, n 1) нижняя треуrольная матрица; к Т / 2 (n, n 1) транспониро
ванная к ней. В линейной алrебре множитель Холецкоrо Кl/2(n, n 1) называют
квадратным корнем матрицы К(n, n 1). Поэтому фильтр Калмана, основанный на
разложении Холецкоrо, принято называть фильтром Калмана на основе квадратН020
корня 11 . Здесь важно отметить, что произведение матриц Кl/2(n, n 1)к Т / 2 (n, n 1)
менее вероятно может стать неопределенным, так как произведение любой KBaдpaT
ной матрицы на себя же транспонированную всеrда положительно определено.
15.10. Несвязный расширенный фильтр Калмана
в фильтре Калмана нас прежде Bcero интересуют те ero уникальные свойства, KO
торые можно использовать для обучения рекуррентной сети l2 . Для рекуррентной
11 Детальное описание фильтра Калмана на основе KBaдpaтHom корня и эффективные методы em реализации
содержатся в [434].
12 Первой работой, в которой продемонстрирована повышенная производительность нейронных сетей,
обучаемых с учителем и использующих расширенный фильтр Калмана, была, пожалуй, [997]. К сожалению,
описанный в ней алmритм обучения имеет свои оrpаничения, так как чрезвычайно сложен с вычислительной
точки зрения. Чтобы обойти это оrpаничение, в [588], [967] была предпринята попытка упростить применение
расширенной фильтрации Калмана за счет деления rлобальной задачи иа ряд подзадач, каждая из которых разре-
шалась одним нейроном. Однако толкование каждоm нейрона как задачи идентификации не было cтpom связано
с теорией фильтров Калмана. Более тom, такой подход Mor привести к неустойчивости в процесс е обучения,
что, в свою очередь, приводило к получению худшеm решения, нежели получаемое друrими методами [864].
15.10. Несвязный расширенный фильтр Калмана 961
сети заданной архитектурной сложности (например, peкyppeHTHoro мноrослойноro
персептрона) важным вопросом является облеrчение вычислений без ущерба для
применения теории фильтров Калмана. Ответ на этот вопрос лежит в использова
нии несвязной формы расширенноro фильтра Калмана, в которой ВЫчислительная
сложность приводится в соответствие с требованиями KOHKpeTHoro приложения и
доступными вычислительными ресурсами [864].
Рассмотрим рекуррентную сеть, построенную на основе статическоrо мноrослой
Horo персептрона с W синаптическими весами и р выходными узлами. Пусть в
векторе w( n) содержатся все синаптические веса сети в момент времени n. Подра
зумевая адаптивные фильтры, уравнение этой сети в пространстве состояний можно
промоделировать следующим образом [434], [997]:
w(n + 1) == w(n),
do(n) == c(w(n), u(n), v(n)) + v(n),
(15.69)
(15.70)
rде вектор весов w(n) иrpает роль состояния. Второй aprYMeHT, u(n), и третий ap
ryMeHT, v(n), вектор функции с(.,.,.) обозначают соответственно входной вектор и
вектор рекуррентной активности узла. В результате уравнение (15.69) утверждает, что
система находится в "оптимальном" состоянии, в котором переходная матрица, пре
образовывающая вектор весов w( n) из момента времени n в вектор весов w( n + 1)
момента времени n + 1, равна единичной матрице. Описанное здесь оптимальное
состояние соответствует локальному или rлобальному минимуму на поверхности
ошибок рекуррентной сети. Единственный источник нелинейности в этой системе
находится в уравнении измерения (15.70). Вектор d o обозначает желаемый отклик
модели. Так как уравнение (15.70) представляет собой отношение выходноro сиrнала
к входному в модели, то отсюда следует, что с(.,.,.) общая нелинейность, свя
зывающая входной и выходной слой мноrослойноrо персеПтрона. Предполаrается,
что вектор поrpешности измерений v(n) в (15.70) является процессом белоrо шума,
зависящеro от мноrих переменных, с нулевым средним и матрицей ковариации R( n).
Следует заметить, что при применении расширенноrо фильтра Калмана в peKyp
рентной сети существуют два контекста использования понятия "состояние".
· Эволюция системы при адаптивной фильтрации, которая проявляется в изменении
весов рекуррентной сети в процессе обучения. Это первое значение состояния
берет на себя вектор w(n).
· Работа самой рекуррентной сети, показанная на примере peкyppeHTHoro узла, от
KOTOpOro зависит функция с. Это значение состояния берет на себя вектор v(n).
962 rлава 15. Динамически управляемые рекуррентные сети
Сравнивая модель, описываемую системой (15.69) и (15.70), с линейной динами
ческой моделью (15.59) и (15.60), видим, что единственным отличием между ними
является нелинейность формы уравнения измерения. Чтобы подrотовить почву для
применения теории фильтров Калмана к описанной модели в пространстве состоя
ний, необходимо вначале линеаризовать уравнение (15.70) и представить ero в виде
d(n) == C(n)w(n) + v(n),
(15.71)
rде С (n ) матрица измерения линеаризованной модели размерности р х W; дЛЯ отли
чия от уравнения (15.70) вместо d o (n) использовалось обозначение d( n). Данная ли
неаризация состоит из частных производных Р выходов всей сети по W весам модели:
[ JlEL ]
BWl BW2 ... Bww
.!l& .!l&
С(n) == 1 .д 2 ::: .B w ,
дс р дс р дс р
BWl BW2 ... Bww
(15.72)
rде Ci, i == 1,2, . .., Р, обозначает i й элемент нелинейности c(w(n), u(n), v(n)). Част
ные производные в выражении (15.72) оцениваются в точке w( n) == "'( n), rде "'( n)
оценка вектора весов w( n), вычисленная расширенным фильтром Калмана в момент
времени n, при заданных данных наблюдений вплоть до момента времени n 1
[434]. На практике эти частные производные вычисляются с использованием алro
ритма обратноrо распространения во времени или алrоритма peKyppeHTHoro обучения
в реальном времени. В результате расширенный фильтр Калмана строится на одном
из алrоритмов, описанных в разделах 15.7 и 15.8. Из этоrо следует, что с должна быть
функцией действия peKyppeHTHoro узла, что уже и отмечалось выше. На самом деле
для однослойной рекуррентной сети матрица С(n) может быть составлена из элемен
тов матриц Aj(n), вычисленных алrоритмом RTRL (15.52). Таким образом, матрица
измерения С(n) является динамической матрицей производных выходов сети по OT
ношению к свободным параметрам. Так же как активность peKyppeHTHoro узла сети в
момент времени (n + 1) является функцией от соответствующих значений на преды
дущем шаrе n, так и производная от значения активности peKyppeHTHoro узла по OT
ношению к свободным параметрам сети в момент времени n+ 1 является функцией от
соответствующих значений на предыдущем шаrе n (что следует из уравнения RTRL).
Теперь предположим, что синаптические веса сети разбиты на 9 rpупп и каж
дая rpуппа i содержит k i нейронов. Матрица измерения С, определяемая формулой
(15.72), является матрицей размерности р х W, в которой содержатся производные
от выхода сети по всем весам сети. Зависимость матрицы С(n) от входноrо вектора
u(n) в формуле (15.72) присутствует неявно. Таким образом, определенная матрица
С( n) содержит все производные, которые необходимы для любой несвязной версии
расширенноro фильтра Калмана. Например, если используется 2ЛобальнЫЙ расширен
15.10. Несвязный расширенный фильтр Калмана 963
ный фильтр Калмана (global extended Kalman filter OEКF), Т.е. отсутствует несвяз
ность, то 9 == 1 и вся матрица С(n) определяется выражением (15.72). С друroй
стороны, если используется несвязный расширенный фильтр Калмана (decoupled ex
tended Kalman filter DEКF), то "rлобальная" матрица измерения С(n) должна быть
скомпонована таким образом, чтобы веса, соответствующие конкретным нейронам в
сети, rpуппировались в единый блок внутри матрицы, и каждый блок маркировался
соответствующим индексом i == 1,2,..., g. в последнем случае общая матрица С(n)
является обычным объединением матриц отдельных rpупп С i (n ):
С(n) == [C1(n), С 2 (n),... , Cg(n)].
в любом случае, независимо от уровня несвязности, вся матрица С(n) должна
вычисляться так, как определено в формуле (15.72).
Итак, мы подroтовили почву для применения алrоритма фильтрации Калмана (см.
табл. 15.2). В частности, для линеаризованной динамической модели, описываемой
уравнениями (15.69) и (15.70), получим [864]:
r(n) [t, сi(n)к,(n,n 1)С;(n) + R(n)] ',
Gi(n) == (n,n l)C[(n)r(n),
а(n) == d(n) d(nln 1),
wi(n + 11n) == wi(nln 1) + Gi(n)a(n),
Ki(n + 1, n) == Ki(n, n 1) Gi(n)Ci(n)Ki(n' n 1),
(15.73)
(15.74)
(15.75)
(15.76)
(15.77)
rде i == 1,2, . .., g. Вектор параметров и векторы сиrналов в формулах (15.73) (15.77)
описываются следующим образом.
r(n) матрица размерности р х р, представляющая собой rлобальный коэффи
циент передачи для всей сети.
G i (n) матрица размерности W i х р, обозначающая коэффициент усиления Кал
мана для rpуппы i нейронов.
а( n) вектор размерности р х 1, содержащий инновации, определяемые как
разность между желаемым откликом d( n) линеаризованной системы и ero оценкой
d(nln 1), основанной на входных данных, доступных в момент времени n 1. Эта
оценка представлена вектором фактическоro выхода у( n) сети, находящейся в состоя
нии {wi(nln 1)}, который является откликом сети на подачу входноrо сиrнала u(n).
wi(nln 1) вектор размерности Wx 1, являющийся оценкой вектора весов
Wi(n) для rpуппы i в момент времени n, при наличии наблюдаемых данных вплоть
до момента времени n 1.
Ki(n, n 1) матрица размерности k i х k i , являющаяся матрицей ковариации
ошибок rpуппы нейронов i.
964 rлава 15. Динамически управляемые рекуррентные сети
Суммирование, выполняемое при вычислении rлобальноro коэффициента переда
чи r(n) (15.73), учитыветT несвязную природу расширенноrо фильтра Калмана.
Важно понять, что в алrоритме DEКF не связность определяет, какие конкретные
элементы rлобальной матрицы ковариации ошибок К( n, n 1) должны рассматри
ваться и корректироваться. На самом деле вся экономия вычислительных ресурсов
связана только с иrнорированием операций по хранению и корректировке ассоцииро
ванных с отстоящими от диаrонали блоками rлобальной матрицы ковариации ошибок
К(n, n 1). В противном случае пришлось бы объединять все rpуппы синаптиче
ских весов.
Алrоритм DEКF, представленный формулами (15.73) (15.77), минимизирует
функцию стоимости
1 n
Е(n) =="2 2: lIe(j) 112,
j l
(15.78)
rде еи) вектор ошибок, определенный следующим образом:
е(Л == d(n) y(n),j == 1,2,... , n,
rде уи) фактический выход сети, использующей информацию, доступную вплоть
до момента j (включительно). Обратите внимание, что в общем случае е(Л =la.(j).
Искусственный шум процесса
Нейродинамическая система моделируется уравнениями (15.69) и (15.70), не усилена
(unforced), так как уравнение процесса (15.69) не имеет внешних входных сиrна
лов. Это может привести к серьезным вычислительным проблемам и, как следствие,
к расходимости фильтра Калмана, коrда он работает в среде с оrpаниченной точно-
стью. Как уже rоворилось в разделе 15.9, явление расходимости (диверrенции) можно
обойти, использовав фильтрацию на основе квадратноrо корня.
Еще одним способом избежать расходимости является использование эвристи
ческоrо механизма, который предполаrает искусственное добавление в уравнение
процесс а шума процесса (process noice):
wi(n + 1) == wi(n) + Q)i(n), i == 1,2,... , g, (15.79)
rде Q)i (n) шум процесса. Предполаrается, что Q)i (n) мноrомерный белый шум
с нулевым средним и матрицей ковариации Qi(n)' Искусственно добавленный шум
процесса Q)i (n) не зависит от шума измерения V i ( n) и начальноrо состояния сети.
Общий эффект от добавления Q)i(n) в уравнение процесса (15.79) состоит в изме
нении уравнения Рикатти коррекции матрицы ковариации ошибок следующим обра
зом [433]:
15.11. Компьютерное моделирование 965
(n + 1, n) == Ki(n, n 1) Gi(n)Ci(n)Ki(n, n 1) + Qi(n)' (15.80)
Если матрица Qi (n) является достаточно большой для всех i, то K i (n + 1, n) будет
rарантировано оставаться неотрицательно определенной для всех n.
Кроме исключения указанных выше вычислительных сложностей, искусственное
добавление шума процесса Q)i ( n) в уравнение процесса дает еще один выиrpышный
эффект: в процессе обучения менее вероятно попадание алroритма в точку локальноro
минимума. Это, в свою очередь, приводит к существенному улучшению производи
тельности обучения в терминах скорости сходимости и качества решения [864].
Полное описание алrоритма DEKF
В табл. 15.3 представлено полное описание алroритма DEКF, oCHoBaHHoro на форму
лах (15.73) (l5.76) и (15.80). В эту таблицу также включены подробности инициали
зации этоro алrоритма.
Нам остается только привести некоторые заключительные комментарии отно-
сительно расширенноro фильтра Калмана. Алrоритм DEКF (см. табл. 15.3) oтнo
сится к семейству всех возможных процедур обучения с сохранением информации
(information preserving learning procedure), к числу которых принадлежит и алrоритм
GEКF. Как правило, ожидается, что DEКF достиrнет производительности алroритма
GEКF, но не сможет превзойти ее. С друrой стороны, алroритм DEКF менее требо
вателен к вычислительным мощностям, чем GEКF. Вопреки этому вычислительному
преимуществу, современные вычислительные ресурсы и объемы памяти сделали ал
roритм GEКF доступным для некоторых практических задач, особенно в области
пакетНО20 обучения (оfИiпе training) рекуррентных сетей.
Вычислительная сложность
В табл. 15.4 сравнивается вычислительная сложность трех алrоритмов обучения, опи
санных в этой rлаве: обратноro распространения во времени, peкyppeHTHoro обучения
в реальном времени и несвязной расширенной фильтрации Калмана.
15.11. Компьютерное моделирование
В этом эксперименте мы вернемся к моделированию нелинейных временных рядов,
которые рассматривались в разделе 13.5. Этот временной ряд определяется частотно
модулированным сиrналом:
х(n) == sin(n + sin(n 2 )), n == 0,1,2,... .
Для моделирования будем использовать две различные структуры.
966 rлава 15. Динамически управляемые рекуррентные сети
ТАБЛИЦА 15.3. Полный алrоритм DEKF
Инициализация
1. Присваиваем синаптическим весам рекуррентной сети малые значение, BЫ
бираемые из HeKoToporo paBHoMepHoro распределения.
2. Присваиваем диаroнальным элементам матрицы ковариации Q(n) (xapaK
теризующей искусственно добавляемый шум процесса ю( n )) значения из
интервала [lO 6, 10 2].
3. Присваиваем К(О, l)==o lI, rде о некоторое малое положительное число.
Вычисления
r(n) [t, С;(n)К.(n, n l)С; (n) + R(n)] ' ,
Gi(n) == Ki(n,n l)C;(n)r(n),
а(n) == d(n) a(nln 1),
wi(n + 11n) == wi(nln 1) + Gi(n)a(n),
К;(n + 1, n) == Ki(n, n 1) Gi(n)Ci(n)Ki(n, n 1) + Qi(n),
rде в третьей строке a(nln 1) реальный выходной вектор сети у(n),
сrенерированный в ответ на входной вектор u( n)
Прuмечанuе. При 9 == 1 (т.е. при отсутствии несвязности) aлroритм DEКF становится
rлобальным алroритмом расширенной фШIьтрации Калмана (aEКF).
. Рекуррентный МНО20СЛОЙНЫЙ персептрон (rесuпепt multilayer perceptron RМLP),
который состоит из одноrо входноrо узла, первоrо скрытоro слоя с десятью pe
куррентными нейронами, BTOpOro скрытоro слоя с десятью нейронами и одноro
линейноro выходноrо нейрона.
. Сеть прЯМО20 распространения со сфокусированной задержкой во времени (time
lagged feedforward network TLFN), которая состоит из памяти с задержкой по
времени с двадцатью отводами и мноrослойноrо персептрона с десятью скрьпыми
и одним линейным выходным нейроном.
Персептрон RМLP имеет чуть больше синаптических весов, чем фокусированная
TLFN, однако для ero хранения требуется в 2 раза меньше памяти (10 рекуррентных
узлов против 20 элементов).
Персептрон RМLP обучается с помощью алrоритма DEКF. Сеть TLFN обучает
ся с использованием двух версий расширенноrо фильтра Калмана: алrоритма GEКF
(т.е. rлобальной версии) и алrоритма DEКF (т.е. ero несвязной версии). Характери
стики этих двух алrоритмов приведены ниже.
15.11. Компьютерное моделирование 967
ТАБЛИЦА 15.4. Сравнение вычислительной мощности различных алroритмов обу
чения рекуррентных сетей
S количество состояний
W количество синаптических весов
L длина последовательности обучения
1. Алroритм ВРТТ (обратноro распространения во времени):
Время О( WL+SL)
Требования к памяти O(WL+SL)
2. Алroритм RTRL (рекуррентноrо обучения в реальном времени):
Время О( WS 2 L)
Требования к памяти О( WS)
3. Алroритм DEКF (не связный расширенной фильтрации Калмана):
Алroритм DEКF одинаково затратен (по времени и пространству) при вычисле
нии производных алrоритмами RTRL и ВРТТ. При использовании последнеro
требования ко времени и к объему памяти умножаются на р, rде р количе
ство выходов сети, по сравнению со стандартными затратами ВРТТ, в котором
вычисляется одно слаrаемой скалярной ошибки.
Алroритм DEКF требует времени O(p 2 W + р 2:; l Ч) и объем памяти
O(2:; l kn, rде 9 количество rpупп; k i количество нейронов в rpуппе
i. В предельном случае, коrда 9 == 1 (т.е. существует одна rpуппа) и алroритм
сводится к GEКF, время составит O(PW 2 ), а объем памяти O(W 2 )
· GEКF
о параметр, используемый для инициализации матрицы ковариации ошибок
К(n, n 1), равен 0,01.
R(n) матрица ковариации поrpешности измерения v(n): R(O)==lOO в начале
обучения, а затем постепенно снижается дО R( n) ==3 в конце обучения.
Q(n) матрица ковариации искусственноrо шума процесса ю(n): Q(0)==10 2 в
начале обучения, затем постепенно снижается до Q(n) == 10 6 в конце обучения.
Отжиr матриц R( n) и Q ( n) имеет эффект увеличения параметра скорости обу
чения по мере продвижения обучения.
· DEКF
9 количество rpупп равно 21 для RМLP и 11 для фокусированноro TLFN.
Все остальные параметры такие же, которые используются для GEКF.
Обучение осуществляется на последовательности, состоящей из 4000 образов. для
RМLP используются подмножества, состоящие из 100 примеров, при этом в ходе
процесса обучения обрабатывается 30000 таких подмножеств. Каждая точка данных
из множества 4000 примеров обрабатывается примерно 750 раз. В фокусированном
968 rлава 15. Динамически управляемые рекуррентные сети
TLFN каждая точка множества обучения тоже обрабатывается около 750 раз. В обоих
случаях тестирование осуществляется на 300 точках данных.
На рис. 15.14 показан rpафик одношаroвоrо проrнозирования У( n ), вычисленноro
персептроном RМLP, обученным алrоритмом DEКF. На этом же рисунке показан
rpафик фактическоrо сиrнала у(n). Эти два rpафика трудно отличить друr от друrа.
На рис. 15.15, а показана ошибка проrнозирования
е(n) == у(n) У(n)
алroритма RМLP. Соответствующие ошибки проrнозирования, полученные фоку
сированной сетью TLFN, обученной алroритмами GEКF и DEКF, показаны на
рис. 15.15, б и в. Сравнивая полученные результаты между собой и с результата
ми, полученными в разделе 13.5, можно сделать следующие выводы.
1. Наиболее точное моделирование в смысле среднеквадратической ошибки было
получено персептроном RМLP, обученным алrоритмом DEКF. Дисперсия ошибки
проrнозирования, вычисленная на 5980 примерах, составила 1,1839 х 1O 4.
2. для фокусированной TLFN наиболее точное моделирование в смысле cpeДHe
квадратической ошибки бьто получено при обучении алrоритмом GEКF. При
использовании этоrо обучения дисперсия ОllIибки проrнозирования составила
1,3351xlO 4, в то время как при обучении DEКF 1,5871x10 4. Оба резуль
тата получены с использованием 5980 примеров.
3. Для сети TLFN, обучаемой стандартным алrоритмом обратноrо распространения,
дисперсия ошибки проrнозирования составила 1,2 х 10 3 (см. раздел 13.5). Эта
величина на порядок хуже показателей, полученных с помощью алroритмов GEКF
и DEКF.
Превосходство в производительности расширенноro алrоритма фильтрации Кал
мана над алrоритмом обратноrо распространения получено блаrодаря свойству co
хранения информации (information preserving) первоrо.
15.12. Обращение в нуль rрадиентов
в рекуррентных сетях
При практическом применении рекуррентных сетей особоrо внимания может потре
бовать проблема обращения 2радиентов в нуль (vanishing gradients problem), которая
связана с обучением сетей желаемому отклику в настоящем, который зависит от BXOД
ных данных в далеком прошлом [121], [469]. Эта проблема возникает по следующей
причине: комбинированные нелинейности приводят к тому, что бесконечно малые
15.12. Обращение в нуль rрадиентов в рекуррентных сетях 969
1,5
,
0,5
N
'"
:s:
2
о
0,5
1
v
1 5
, О
.
50
100
150
200
250
300
Время, п
Рис. 15.14. Наложение rрафиков фактическоro (сплошная линия) и проrнози
руемоro (пунктирная линия) сиrналов в данном компьютерном моделировании.
Проrнозирование осуществлял ось персептроном RMLP, обученным алroрит
мом DEKF
изменения в удаленном во времени входном сиrнале MOryT практически не оказывать
воздействие на обучение сети. Эта проблема может возникнуть и в случае, Korдa
большие изменения в отдаленных во времени входных сиrналах оказывают влияние,
но этот эффект не измерим rpадиентом. Описанная проблема делает обучение долro
срочным зависимостям в rpадиентных алroритмах обучения чрезвычайно сложным,
а в некоторых случаях даже виртуально невозможным.
В [121] было доказано, что во мноrих практических приложениях необходимо, что
бы сеть была способна хранить информацию о своем состоянии для произвольных
отрезков времени, при этом делать это в присутствии шума. Долroсрочное хранение
определенных битов информации в переменных состояния рекуррентной сети назы
вается блокированием информации (information latching). Блокирование информации
должно быть робастным (robust), чтобы сохраненная информация о состоянии не
моrла быть леrко удалена событиями, которые не связаны с текущей задачей обуче
ния. В этих терминах можно сделать следующее утверждение [121].
Робастное блокирование информации в рекуррентной сети выполнимо, если состоя
нuя сети содержатся в сокращенном множестве аттракции 2иперболичеСК020 aт
трактора.
970 rлава 15. Динамически управляемые рекуррентные сети
., 0,1 S 0,1
... 0,08 .. 0,08
0,06 0,06
:r: 0,04 0,04
'"
"' "'
8. 0,02 с> 0,02
CI.
:s: :s:
м О м О
с> с>
i: i:
8. 0,02 8. 0,02
; 0,04 ; 0,04
;.: 0,06
0,06
<5 0,08 <5 0,08
o 1 o 1
, О 50 100 150 200 250 300 ' О 50 100 150 200 250 300
Время,п Время, п
а) б)
0,1
S
.. 0,08
0,06
0,04
8. 0,02
О
0,02
; 0,04
0,06
:s:
<5 0,08
o 1
, О
50 100 150 200 250 300
Время, п
в)
Рис. 15.15. Ошибка проrнозирования в трех экспериментах по моделированию: с помощью
RMLP, обученноro алrоритмом DEKF, дисперсия ошибки составила 1, 1839 х 10 4 (а); с
помощью фокусированной версии TLFN, обученной алroритмом GEKF, дисперсия ошиб
ки составила 1,3351 х 10 4 (б); с помощью фокусированной TLFN, обученной алrоритмом
DEKF, дисперсия ошибки составила 1,5871 х 10 4 (в)
Понятие rиперболическоro аттрактора было введено в rлаве 14. Сокращенным
множеством аттракции (reduced attraction set) rиперболическоro аттрактора явля
ется множество точек в бассейне аттракции, для которых собственные значения co
ответствующеro Якобиана меньше единицы по модулю. Смысл здесь заключается в
том, что если состояние х( n) рекуррентной сети находится в бассейне аттракции rи
перболическоro аттрактора, но не принадлежит сокращенному множеству аттракции,
то размер шара неопределенности BOKpyr х (n) будет расти экспоненциально BpeMe
ни n (см. рис. 15.16, а). Таким образом, малые возмущения (например, помехи) во
входном сиrнале рекуррентной сети MOryт вывести траекторию в друrой (возмож
но, неверный) бассейн аттракции. Если же состояние х(n) остается в сокращенном
множестве аттракции rиперболическоrо аттрактора, можно найти оrpаничения BXOД
Horo сиrнала, которые будут rарантировать нахождение х( n) в пределах заданной
окрестности аттрактора (см. рис. 15.16,6).
15.12. Обращение в нуль rрадиентов в рекуррентных сетях 971
а)
Р: rиперболический
аттрактор
: бассейн
аттракции
1: сокращенное
множество
аттракции Р
Область состояний х(п)
Область состояний х(п)
б)
Рис. 15.16. Состояние х(п) находится в бассейне аттрак-
ции 13, но вне сокращенноrо множества аттракции у (а);
состояние х(п) находится внутри сокращенноro множества
аттракции у (б)
Долrосрочные зависимости
Чтобы оценить влияние робастноrо блокирования информации в rpадиентном обуче-
нии, обратим внимание, что коррекция, при меняемая к вектору весов w рекуррентной
сети в момент времени n, определяется формулой
л ( ) дЕобщ.
uW n 11 aw '
rдe 11 параметр скорости обучения; дЕобщ. / aw rpадиент функции стоимости
Еобщ. по w. Сама функция стоимости обычно определяется следующей формулой:
1", 2
Еобщ. == '2 Ildi(n) Yi(n)11 ,
i
rдe di(n) желаемый отклик; Yi(n) фактический отклик сети на подачу z ro
примера в момент времени n. Исходя из этоrо, можно записать:
972 rлава 15. Динамически управляемые рекуррентные сети
дw(n) == 11 L n) (di(n) Yi(n))
i
'"' Oyi(n) 8xi(n)
== 11 8xi(n) (di(n) Yi(n))'
.
(15.81 )
rде во второй строке использовалось цепное правило вычислений (chain rule of ca1cи
lus). Вектор состояния Xi ( n) соответствует i MY примеру множества обучения. При
использовании алrоритмов, в том числе обратноro распространения во времени, част
ные производные функции стоимости вычисляются по независимым весам с различ-
ными индексами времени. Результат (15.81) можно несколько расширить, записав:
'"' 8Yi(n) 8 x i(n)
дw(n) == 11 8xi(n) -6 8w(k) (di(n) Yi(n))'
Применяя цепное правило вычислений еще раз, получим:
'"' 8Yi(n) 8xi(n) 8 X i(k)
дw(n) == 11 8 x i(n) -6 8Xi(k) 8w(k) (di(n) Yi(n))'
(15.82)
Учитывая уравнение состояния (15.2), имеем:
xi(n) == <p(xi(k), u(n)), 1 k < n.
Исходя из этоrо, выражение 8xi(n)/8xi(k) можно интерпретировать как Якобиан
нелинейной функции <Р(', .), развернутый на (n k) шаroв времени, Т.е.
8xi(n) 8<P(Xi(k), u(n )) ( k)
8 X i(k) 8Xi(k) J x n, n .
(15.83)
В [121] было показано следующее. Если входной сиrнал u(n) является таковым,
что рекуррентная сеть остается робастно заблокированной в rиперболическом aттpaK
торе после момента времени n == О, то Якобиан Jx(n, k) является экспоненциально
убывающей функцией k и
det(Jx(n, k)) ........ О при k ........ 00 для всех n.
(15.84)
Значение результата (15.84) состоит в том, что малое изменение вектора весов
w сети ощущается в основном в ближайшем прошлом (т.е. значения k близки к
текущему времени n). Может существовать такое приращение Дw к вектору весов w
в момент времени n, которое позволит переместиться из текущеro состояния х( n) в
друroй, возможно лучший, бассейн аттракции, однако rpадиент функции стоимости
Еобщ. по w не учитывает эту информацию.
15.13. Системная идентификация 973
Если для хранения информации о состоянии в рекуррентной сети, обучаемой
rpадиентным методом, используются rиперболические аттракторы, оказывается, что
· либо сеть не робастна к наличию шума во входном сиrнале,
· либо сеть не способна извлечь дОЛ20срочные зависимости (long term dependencies)
(т.е. связи целевых выходов с входными сиrналами из далекоro прошлоro).
Среди возможных процедур облеrчения сложностей, возникающих в связи с об
ращением в нуль rpадиентов в рекуррентных сетях, можно отметить следующие 13.
. Расширение BpeMeHHoro диапазона зависимости выхода от входа с помощью пред
ставления сети во время обучения сначала более коротких строк (см. эвристики в
разделе 15.6).
· Использование расширенноro фильтра Калмана или ее несвязной версии для более
эффективноro использования доступной информации, чем в алroритмах rpадиент
Horo обучения (расширенный фильтр Калмана рассматривался в разделе 15.10).
. Использование более сложных методов оптимизации, таких как псевдоньютонов
ские методы [121]; методов оптимизации BToporo порядка или моделирование OT
жиrа (см. rлавы 4 и 11).
15.1 з. Системная идентификация
Идентификация систем (system identification) это экспериментальный подход к MO
делированию процессов или производств (plant) с неизвестными параметрами l4 . Она
включает в себя следующие действия: планирование эксперимента, выбор структуры
модели, оценку параметров и проверку модели на корректность. Процедура иденти
фикации системы, как показала практика, является итеративной по своей природе.
Предположим, существует некоторый неизвестный динамический объект, дЛЯ KO
Toporo требуется решить задачу параметрической идентификации модели. При этом
можно основываться на модели в пространстве состояний или на модели в терминах
"BXOД BЫXOД". Решение относительно использования той или иной модели зависит от
конкретной информации о входах и наблюдениях в системе. В следующем разделе
описываются оба эти представления.
13 Друrие методы устранения проблем обращения в нуль rpадиента включают в себя шунтирование Heкo
торых из нелинейностей рекуррентной сети для улучшения обучеиия долmсрочным зависимостям. Среди при
меров этоm подхода можно выделить следующие.
Использование в сетевой архитектуре долmсрочиых задержек [280], [353], [645].
Иерархическое структурирование сети на несколько уровней, ассоциированных с различными масштабами
времени [280].
Использование шлюзовых элементов (gate опН) для обхода некоторых нелииейностей [470].
14 Идентификации систем посвящено очень MHom кииr, например [664], [666]. Обзор этоm направления с
акцентом на иейронные сети содержится в [772], [999]. Впервые идентификация систем с помощью нейронных
сетей подробно описана в [774].
974 rлава 15. Динамически управляемые рекуррентные сети
Идентификация систем с использованием модели
в пространстве состояний
Предположим, что рассматриваемый объект описывается моделью в пространстве
состояний:
х(n + 1) == f(x(n), u(n)),
у(n) == Ь(х(n)),
(15.85)
(15.86)
rдe f(-,.) и ь(.) неизвестные нелинейные вектор функции; уравнение (15.86) явля
ется обобщением уравнения (15.11). Для идентификации системы будем использовать
две нейронные сети: одну для работы с уравнением процесса (15.85), а вторую для
раБотыl с уравнением измерения (15.86) (рис. 15.17).
Очевидно, что состояние х(n) можно рассматривать как задержанную на один шаr
версию х( n + 1). Обозначим х( n + 1) оценку состояния х( n + 1), полученную первой
нейронной сетью (на рис. 15.17, а она обозначена цифрой 1). Эта сеть работает с
объединенным входом, состоящим из входноro сиrнала u(n) и состояния х(n), и дает
на выходе х(n + 1). Оценка х(n + 1) вычитается из фактическоrо состояния х(n + 1),
из чеrо получается вектор ошибки:
el(n + 1) == х(n + 1) х(n + 1).
Здесь х( n + 1) иrpает роль желаемоrо отклика. Предполаrается, что доступно фак
тическое состояние х(n). Вектор ошибки eI(n + 1), в свою очередь, используется для
коррекции синаптических весов нейронной сети 1 (см. рис. 15.17, а) с целью мини
мизации функции стоимости, основанной на векторе ошибки е 1 (n + 1) внекотором
статистическом смысле.
Вторая нейронная сеть (обозначенная цифрой П на рис. 15.17, 6) работает с фак
тическим состоянием х(n) неизвестноrо объекта и дает на выходе оценку у(n) фак-
тическоro выходноro сиrнала у( n). Эта оценка вычитается из у( n), в результате чеro
получается второй вектор ошибки:
еп(n) == у(n) у(n),
rде у(n) иrpает роль желаемоrо отклика. Вектор еп(n) используется затем для KOp
рекции синаптических весов нейронной сети П с целью минимизации Евклидовой
нормы вектора ошибки еп (n) в некотором статистическом смысле.
Две нейронные сети, показанные на рис. 15.17, работают синхронно и дают на
выходе решение в пространстве состояний задачи системной идентификации [774].
Такая модель называется последовательно параллельной моделью идентификации
(series parallel identification model) в признание TOro факта, что модель идентификации
получает фактическое состояние неизвестной системы (а не фактическое состояние
Вход
и(п)
Состояние
х(п)
15.13. Системная идентификация 975
Неизвестная
система
х(п+ 1)
+
а)
Неизвестная
система
у(п)
Нейронная
сеть
11
у(п)
б)
Рис. 15.17. Решение задачи идентификации систем с помощью модели
в пространстве состояний
модели идентификации) (см. рис. 15.17, а). В свете обсуждения, представленноrо в
конце раздела 15.9, эту форму обучения можно рассматривать как усиление учителем.
Последовательно параллельная модель идентификации, показанная на рис. 15.17, а,
противоположна параллельной модели идентификации (parallel identification model),
в которой состояние х(n), подаваемое в нейронную сеть 1, заменяется ero оценкой
х(n). Эта оценка получается из собственноrо выхода нейронной сети х(n + 1) пу
тем пропускания последнеro через оператор единичной задержки Z l 1. Практическое
превосходство этой альтернативной модели обучения состоит в том, что нейросетевая
модель работает в том же режиме, что и неизвестная система, Т.е. в режиме, в котором
сама нейронная сеть будет работать после обучения. Отсюда следует, что модель, по
лученная в результате параллельноrо обучения, скорее Bcero покажет более хорошую
976 rлава 15. Динамически управляемые рекуррентные сети
динамику, чем модель сети, полученная в результате последовательно параллельноro
обучения. Однако недостаток параллельной модели состоит в том, что ее обучение
обычно продолжается дольше, чем последовательно параллельной (см. раздел 15.9).
В частности, в нашей конкретной ситуации оценка состояния х(n), используемая в
модели параллельноro обучения, обычно не так точна, как фактическое состояние
х( n), используемое в последовательно параллельном режиме обучения.
Модель в терминах "вход-выход"
Далее предположим, что доступен только выход неизвестноro объекта. Для TOro что
бы упростить представление, рассмотрим систему с одним входом и одним выходом.
Пусть выход системы в дискретный момент времени n обозначается как у(n), а ее
вход как и(n). Torдa, выбирая для работы модель NARX, модель идентификации
примет следующую форму:
у(n + 1) == <р(у(n),..., у(n q + 1), и(n),... , и(n q + 1)),
rдe q порядок неизвестной системы. В момент времени n + 1 известны q последних
значений входноro сиrнала и q последних значений выходноrо. Выход модели у( n+ 1)
представляет собой оценку фактическоro выхода у (n+ 1). Оценка у (n+ 1) вычитается
из у(n + 1), в результате чеrо получается сиrнал ошибки:
е(n + 1) == у(n + 1) у(n + 1).
Здесь величина у( n + 1) иrpает роль желаемоrо отклика. Ошибка е( n + 1) исполь
зуется для коррекции синаптических весов нейронной сети с целью минимизации
ошибки в некотором статистическом смысле. Модель идентификации, представлен
ная на рис. 15.18, имеет последовательно параллельную (т.е. усиленную учителем)
форму, так как фактический выход системы (а не выход модели идентификации)
замкнут на вход модели.
15.14. Адаптивное управление на основе
эталонной модели
Еще одним важным приложением рекуррентных сетей является создание системы
управления с обратной связью (feedback control system), в которой состояние объ-
екта нелинейно объединяется с применяемым управлением [861], [863]. Структура
этой системы существенно усложняется и друrими факторами, такими как наличие
неизмеряемых и случайных возмущений, возможность неуникальности операции об-
ращения, а также присутствие ненаблюдаемых состояний объекта.
15.14. Адаптивное управление на основе эталонной модели 977
Вход
u(п + 1)
Неизвестная
динамическая
система
Фактический
выход
у(п + 1)
Мноrослойный
персептрон
Проrнози
руемый
выход
у(п + 1)
Сиrнал ошибки
е(п + 1)
Рис. 15.18. Решение NARX
задачи системной иденти
фикации
Хорошо подходящей стратеrией управления таким объектом с помощью нейрон
ной сети является адаптивное управление на основе эталонной модели (model ref
erence adaptive control MRAC)15. В этой модели предполаrается, что конструктор
знаком с сущностью рассматриваемой системы [773]. На рис. 15.19 показана блочная
диаrpамма такой системы. Для учета Toro, что динамика объекта неизвестна, в ней
используется адаптивность. Блок управления, или контроллер (controller), и объект
15 Детальное описание адаптивноm управления на основе модели содержится в [610].
978 rлава 15. Динамически управляемые рекуррентные сети
ес(п)
r(n)
ес(п + 1)
+
Эталонная
модель:
х,(п)
d(n + 1)
Рис. 15.19. Адаптивное управление на основе эталонной модели с исполь
зованием прямоro управления
формируют систему с собственной обратной связью, образуя внешне рекуррентную
(extemally rесuпепt) сеть. Объект получает от блока управления входной сиrнал U c (n ),
а также внешнее возмущение Ud( n). Соответственно объект развивается во времени
как функция описанноrо входноrо сиrнала и собственноro состояния хр(n). Выход
объекта, который обозначается как ур(n + 1), является функцией от хр(n). Выход
блока управления представляет собой вектор сиrнала управления:
uc(n) == f1(xc(n), ур(n), r(n), w),
rдe Хс (n) собственное состояние блока управления; w вектор параметров,
доступный для коррекции. Вектор функция f 1 ( ., ., ., .) определяет динамику бло
ка управления.
Желаемый отклик д( n + 1) объекта формируется на выходе устойчивой эталонной
модели (reference model), который образуется в ответ на эталонный си21lал (reference)
r(n). Желаемый отклик д(n + 1), таким образом, является функцией эталонноrо
сиrнала r(n) и собственноro состояния хт(n) эталонной модели:
д(n + 1) == f 2 (x r (n), r(n)).
Вектор функция f 2 ( ., .) определяет динамику эталонной модели.
Пусть ошибка на выходе (output епоr), Т.е. разность между выходами объекта и
эталонной модели, обозначается следующим образом:
ес(n + 1) == д(n + 1) ур(n + 1).
15.15. Резюме и обсуждение 979
Нашей целью является такая коррекция вектора параметров w, чтобы Евклидова
норма ошибки выхода ес(n) была минимизирована для момента времени n.
Метод управления, используемый в МRAС системе (см. рис. 15.19), назван пря
мым в том смысле, что для идентификации параметров объекта не предпринимается
никаких действий, но при этом напрямую корректируются параметры блока управле
ния для улучшения производительности системы. К сожалению, пока не существует
точных методов настройки параметров блока управления, основанных на ошибке
выхода [774], поскольку между блоком управления и ошибкой на выходе находится
неизвестный объект. Чтобы обойти эту сложность, можно прибеrнуть к непрямому
управлению (indirect control) (рис. 15.20). В этом, последнем, методе для обучения
блока управления используется двухшаroвая процедура.
1. Для вывода оценок дифференциальных соотношений выхода объекта к ero входу,
предьщущеro выхода объекта и предьщущих внутренних состояний объекта об
считывается модель объекта Р (которая обозначается Р). Для обучения нейронной
сети идентификации объекта используется процедура, описанная в предыдущем
разделе. Таким образом, полученная модель Р называется моделью идентифика
ции (identification model).
2. для получения оценок динамических производных выхода объекта по отношению
к вектору настраиваемых параметров блока управления вместо самоro л объекта
используется полученная на предьщущем шarе модель идентификации Р.
При непрямом управлении внешне рекуррентная сеть (externally rесuпепt net
work) состоит из блока управления и модели идентификации Р, представляющей
соотношение "BXOД BЫXOД" объекта.
Применение рекуррентной сети к созданию блока управления в общей cтpyктy
ре рис. 15.20 бьто продемонстрировано на ряде примеров задач управления [861],
[863]. В качестве рекуррентной сети, использованной в этом исследовании, выступает
рекуррентный мноroслойный персептрон, аналоrичный описанному в разделе 15.2.
Обучение этой сети осуществлялось алroритмом DEКF, описанным в разделе 15.11.
Однако обратите внимание, что для управления холостым ходом двиrателя в каче
стве модели идентификации выбиралась линейная динамическая система, так как
оказалось, что применяемое управление (в соответствующим образом выбранных
интервалах) монотонно влияет на скорость двиrателя.
15.15. Резюме и обсуждение
в этой rлаве речь шла о рекуррентных сетях, которые используют 2Лобальную об
ратную связь (global feedback), применяемую к статическому (не имеющему памяти)
мноroслойному персептрону. Применение обратной связи позволяет нейронным ce
980 rлава 15. Динамически управляемые рекуррентные сети
е;(п)
r(n)
ес(п + 1)
Эталонная
модель
d(n + 1)
Рис. 15.20. Адаптивное управление на основе эталонной модели, использующее
непрямое управление посредством модели идентификации
тям представлять состояния, что делает их удобным инструментом в различных при
ложениях обработки сиrнала и управления. В класс рекуррентных сетей с rлобальной
обратной связью входят следующие основные архитектуры сетей.
· Сети нелинейной автореrpессии с внешними входами (NARX). В них используется
обратная связь между выходным и входным слоями.
· Полносвязные рекуррентные сети с обратной связью между скрытым и входным
слоем.
· Рекуррентный мноroслойный персептрон, содержащий больше одноro скрытоro
слоя, с обратными связями между каждым из расчетных слоев и входным слоем.
· Рекуррентные сети BTOpOro порядка, использующие нейроны BTOpOro порядка.
Во всех этих рекуррентных сетях обратная связь применяется через память с
дискретной задержкой в линии.
15.15. Резюме и обсуждение 981
Первые три типа рекуррентных сетей допускают использование для изучения
динамики среду пространства состояний (state space framework). Этот подход берет
начало в современной теории управления и является мощным методом изучения
нелинейной динамики рекуррентных сетей.
В этой rлаве описаны три основных алrоритма обучения рекуррентных нейронных
сетей: обратное распространение во времени (back propagation through time ВРТТ),
рекуррентное обучение в реальном времени (real time rесuпепt learning RTRL) и
не связная расширенная фильтрация Калмана (decoupled extended Kalman filtering
DEКF). Первые два алroритма основаны на rpадиентной методике, а последний эф
фективно использует информацию более высокоro порядка. Это обеспечивает более
быструю ero сходимость по сравнению с алrоритмами ВРТТ и RTRL, однако за счет
соответствующеro повышения сложности вычислений. Алroритм DEКF можно pac
сматривать как технолоrию включения (enabling), которая делает возможным решение
сложных задач обработки сиrнала и управления.
Теоретически рекуррентная сеть с rлобальной обратной связью (например, peкyp
рентный мноroслойный персептрон, обучаемый алrоритмом DEКF) может обучиться
нестационарной динамике за счет сохранения знаний, извлеченных из примеров обу
чения в зафиксированном множестве весов. И что более важно эта сеть может
отслеживать (track) изменения в статистике среды, если выполнены два условия.
. Данная сеть избавлена от недостаточноro и чрезмерноrо обучения.
. Примеры обучения являются представительными в смысле не стационарности ди
намики среды.
в данной rлаве особое внимание уделялось использованию рекуррентных сетей
для временной обработки. Рекуррентные сети можно также использовать для об
работки последовательно упорядоченных данных, которые не имеют простой Bpe
менной интерпретации (например, химические структуры, представленные в виде
деревьев). В [1013] было показано, что рекуррентные сети MOryт представлять и
классифицировать структурированные модели, которые представлены направленны
ми, маркированными, ацикличными rpафами. Описанный в работе подход использует
идею "обобщенноro рекурсивноrо нейрона", являющеrося обобщением обычноrо pe
KyppeHTHoro нейрона (т.е. нейрона с собственной обратной связью). Используя такую
модель, алroритмы обучения с учителем (такие как обратное распространение во Bpe
мени и рекуррентное обучение в реальном времени) можно расширить для работы
со структурированными образами (pattern).
982 rлава 15. Динамически управляемые рекуррентные сети
Задачи
Модель в пространстве состояний
15.1. Сформулируйте уравнение в пространстве состояний для простой peкyppeHT
ной сети Элмана, показанной на рис. 15.3.
15.2. Покажите, что мноroслойный персептрон, показанный на рис. 15.4, может
быть представлен следующей моделью в пространстве состояний:
х(n + 1) == f(x(n), u(n)),
у(n) == g(x(n), u(n)),
rде u(n) входной сиrнал; у(n) выходной сиrнал; х(n) состояние; f(.,.)
и g(.,.) нелинейные вектор функции.
15.3. Moryт ли динамические системы быть управляемыми, но не наблюдаемыми,
и наоборот? Обоснуйте свой ответ.
15.4. Возвращаясь к задаче локальной управляемости (см. раздел 15.3), покажите,
что:
а) состояние х(n + q) является вложенной нелинейной функцией от cBoero
прошлоro значения х(n) и входноrо вектора uq(n) из (15.24) и
б) Якобиан x(n+q) по отношению к uq(n), вычисленный в начале координат,
равен матрице управляемости Мс из (15.23).
15.5. Возвращаясь к задаче локальной управляемости, рассмотренной в разде
ле 15.3, покажите, что Якобиан вектора наблюдения Yq(n), определяемый в
(15.30), по отношению к состоянию х(n), вычисленный в начале координат,
равен матрице наблюдаемости Мо из (15.28).
15.6. Уравнение процесса нелинейной динамической системы выrлядит следую
щим образом:
х(n + 1) == f(x(n), u(n)),
rдe u(n) вектор входа в момент времени n; х(n) соответствующее COCTO
яние системы. Входной сиrнал u(n) входит в уравнение процесса неаддитив
но. В этой задаче необходимо пере формулировать уравнение процесса так,
чтобы входной сиrнал входил в Hero аддитивно. Это можно сделать, записав:
х'(n + 1) == fnew(x'(n)) + u'(n).
Опр"щелите векторы u' (n) и х' (n) и функцию f new ( .) для этоro уравнения.
Задачи 983
Модель нейрона
Смещение
Вход
u(п)
Линейная
динамическая
система
Выход
у(п)
L
а)
х(п)
Линейная
динамическая
система
Модель нейрона
I
Смещение I
I
I
I
I
I
I
I
I
I
I
I
I I
L J
Выход
у(п)
Вход
u(п)
б)
Рис. 15.21. Архитектура локальной обратной связи активации (а);
архитектура локальной обратной связи выхода (б)
15.7. На рис. 15.21 показаны два примера архитектуры рекуррентных сетей, ис
пользующей локальную обратную связь на уровне нейрона. Архитектуры,
показанные на рис. 15,21, а, б, называются соответственно локальной обрат
ной связью активации (local activation feedback) и локальной обратной связью
выхода (local output feedback) [1060]. Сформулируйте модели в пространстве
состяний для этих архитектур рекуррентных сетей. Прокомментируйте их
управляемость и наблюдаемость.
Модель нелинейной автореrрессии с экзоrенными
входами (NARX)
15.8. Возвращаясь к модели NARX, рассмотренной в разделе 15.4, покажите, что
использование уравнений (15.16) и (15.17) ведет к следующей формуле для
выхода у(n + q) модели NARX в терминах векторов состояния х(n) и BXO
да uq(n):
984 rлава 15. Динамически управляемые рекуррентные сети
Смещение
Выход
у(п+ 1)
Вход
u(п)
Рис. 15.22. Модель полностью рекуррентной сети
у(n + q) == Ф(х(n), uq(n)),
rде Ф : 2q ........ ., а uq(n) определяется соrласно (15.29).
15.9. а) Вывод модели NARX в разделе 15.4 представлен для системы с одним
входом и одним выходом. Обсудите, как описанная теория может быть
расширена на систему с несколькими входами и выходами.
б) Постройте эквивалент NARX дЛЯ модели в пространстве состояний си
стемы с двумя входами и одним выходом (см. рис. 15.6).
15.10. Постройте эквивалентную сеть NARX дЛЯ полностью рекуррентной сети,
показанной на рис. 15.22.
15.11. В разделе 15.4 бьто показано, что модель в пространстве состояний может
быть представлена моделью NARX. Можно ли утверждать обратное? Можно
ли представить модель NARX в виде уравнений в пространстве состояний,
описанной в разделе 15.3? Обоснуйте свой ответ.
Задачи 985
Алrоритм ВРТТ
15.12. Раскройте временную динамику модели в пространстве состояний, показан
ной на рис. 15.3.
15.13. Усеченный алroритм ВРТТ(Ь) можно рассматривать как аппроксимацию ал
roритма обучения ВРТТ по эпохам. Эта аппроксимация может быть улучшена
за счет введения аспектов алroритма обучения по эпохам ВРТТ в усеченный
алroритм ВРТТ(Ь). В частности, можно заставить сеть пройти h' дополни
тельных шаroв, прежде чем осуществлять следующее вычисление ВРТТ (rде
h' < h). Важной характеристикой этой rибридной формы обратноro pac
пространения во времени является то, что следующий обратный проход не
будет выполняться до момента времени n + h'. В это время вмешательства
прошлые значения входа сети, ее состояния и желаемых откликов сохраня
ются в буфере, но не обрабатывютсяя [1155]. Выведите формулу локальноrо
rpадиента для нейрона j этоro rибридноro алroритма.
Алrоритм peKyppeHTHoro обучения в реальном времени
15.14. Динамика усиленной учителем рекуррентной сети (teacher forced rесuпепt
network) аналоrична описанной в разделе 15.8, за исключением следующеrо
изменения:
{ иi(n), если i Е А,
i(n) == di(n), если i Е С,
Yi(n), если i Е В С,
rдe А множество индексов, для которых i является внешним входом;
В множество индексов, для которых i является выходом нейрона; С
множество видимых выходных нейронов.
а) Покажите, что для этой схемы частная производная aYi(n + 1)jaWkl(n)
задается следующей формулой [1157]:
aYj(n + 1), [ '" aYi(n) ]
aWkl(n) == <Р (щ(n)) . L.J Wji(n) aWkl(n) + Okj l(n)
'EB C
б) Выведите алroритм обучения для усиленной учителем рекуррентной сети.
986 rлава 15. Динамически управляемые рекуррентные сети
Алrоритм несвязной расширенной фильтрации Калмана
15.15. Опишите, как можно использовать алroритм DEКF дЛЯ обучения простой
рекуррентной сети, показанной на рис. 15.3. для этоro обучения можно также
воспользоваться алroритмом ВРТТ.
15.16. В своей обычной форме обучение DEКF последовательно корректирует си-
наптические веса. В противоположность стандартному обратному распро-
странению выполняются простыIe коррекции rpадиентов, которые позволяют
выбрать, применять ли их немедленно или накапливать в течение опреде
ленноro времени и затем применять суммарную коррекцию. Несмотря на то
что такое аккумулирование можно выполнять в самом алroритме DEКF, это
может привести к рассоrласованности между вектором весов и матрицей КО-
вариации ошибок, которая корректируется каждый раз, коrда выполняется
итерация по коррекции весов. Получается, что обучение DEКF препятствует
пакетной коррекции весов. Однако в этом случае можно использовать мно-
20поточное обучение DEКF (multistream DEКF training), которое позволяет
существовать нескольким последовательностям обучения и при этом остает-
ся соrnасованным по отношению к теории фильтров Калмана [291], [292].
а) Рассмотрите эту задачу обучения с N БХ . входами, N БЫХ . выходами и фик
сированным набором N примеров обучения. Из примеров обучения сфор-
мируйте М N потоков данных, которые питают М сетей, имеющих
идентичные веса. В каждом цикле обучения один образец из каждоro пото-
ка представляется соответствующей сети, и вычисляется N БЫХ. выходных
сиrналов для каждоro потока. После этоro проводится единовременная
коррекция, которая применяется к весам всех сетей. Выведите мноroПО-
точную форму алroритма DEКF.
б) В качестве примера рассмотрите стандартную задачу XOR с четырьмя
примерами обучения. Предполarается, что мы располаrаем сетью ПРЯМО-
ro распространения, которая дополнена памятью с задержкой в линии,
присоединенной к выходному слою. Таким образом, в результате полу
чим четыре выхода сети: фактический выход сети, питающий память с
задержкой в линии, и три задержанных ero версии, каждую из которых
также считаем новым выходом сети. Теперь в некотором порядке приме-
ним к этой сетевой структуре все четыре примера обучения, при этом не
выполняя коррекцию весов. После представления четвертоro примера мы
получим четыре выхода сети, которые представляют обработку четырех
примеров обучения сетью с одинаковыми весами. Если на этой основе мы
выполним единовременную коррекцию вектора весов по алroритму DEКF
на основе данных четырех входов и четырех выходов сети, то получим
задачу четыIехx потоков. Про верьте правильность этоro примера.
Задачи 987
s
о
о
Рис. 15.23. Автомат с двумя состоя-
ниями
F
Рекуррентные сети BToporo порядка
15.17. В данном примере исследуем конструкцию конеЧНО20 автомата четности
(parity finite-state automata), использующеro рекуррентную сеть BTOpOro по
рядка. Этот автомат распознает четное количество единиц в последователь
ной строке нулей и единиц конечной произвольной длины.
На рис. 15.23 по казан автомат, принимающий два состояния. ЭТИ COCTO
яния обозначены окружностями, а переходы стрелками. Символом S обо
значено состояние старта в данном случае А. Тонкая окружность означает,
что в этом состоянии (на рисунке это состояние В) мы принимаем строку.
Автомат начинает сканировать строку в состоянии А и возвращается назад
в состояние А, если обнаружен нуль, или переходит в состояние В, если
обнаружена единица. Аналоrично, находясь в состоянии В, он остается в
этом же состоянии, если обнаружит нуль, и переходит в состояние А, если
обнаружит единицу. Таким образом, данный автомат всеrда будет находиться
в состоянии А, если про сканировано четное количество единиц (в том числе
нуль штук), или в состоянии В, если количество единиц не четно.
Формализуя, определим множество состояний как Q == {А, В}, S == А
(начальное состояние), входной алфавит как L; == {О, 1}, состояние приема
как F == В и функции перехода состояний как:
о(А, О) == А,
о(А,1) == В,
о(В, О) == В,
О(В, 1) == А.
Эти уравнения необходимы для применения формулы (15.9), относящейся
к рекуррентной сети BTOpOro порядка. Более детально конечные автоматы
описаны в [474].
Закодируйте приведенные выше правила перехода в рекуррентной сети
BTOpOro порядка.
988 rлава 15. Динамически управляемые рекуррентные сети
15.18. В разделе 15.8 выведен алroритм peKyppeHTHoro обучения в реальном Bpe
мени (RTRL) дЛЯ полно связной рекуррентной сети, использующей нейроны
первоro порядка. В разделе 15.2 описаны рекуррентные сети, использующие
нейроны BTOpOro порядка.
Опроверrните теорию, описанную в разделе 15.8, выведя алrоритм обуче
ния для рекуррентной сети BToporo порядка.
Заключение
Предметная область нейронных сетей лежит на пересечении мноrих наук. Ее корни
уходят в нейробиолоrию, математику, статистику, физику, науку о компьютерах и ин
женерию. Это видно из разнообразия вопросов, рассмотренных в настоящей книrе.
Способность нейронных сетей обучаться на данных с помощью учителя или без
TaKoBoro обеспечивает их важное свойство. Это свойство обучаемости имеет важное
теоретическое и практическое применение. В той или иной форме способность ней
ронных сетей обучаться на примерах (представительных для своей среды) сделала
их неоценимым инструментом в таких разнообразных областях применения, как MO
делирование, анализ временных рядов, распознавание образов, обработка сиrналов
и управление. В частности, нейронным сетям есть что предложить, коrда решение
интересующей задачи становится сложным по одной из следующих причин.
. Из за отсутствия физическоrо либо статистическоrо понимания системы.
. Из за статистическоrо разброса наблюдаемых данных.
. Из за нелинейности механизма, oTBeTcTBeHHoro за обобщение данных.
Новая волна интереса к нейронным сетям (начавшаяся во второй половине 1980 x
rодов) возникла вследствие Toro, что потребовалось обучение на нескольких ypOB
нях. Алrоритмы обучения нейронных сетей позволили избежать необходимости в
ручном извлечении признаков при распознавании рукописноrо текста. rрадиентные
алrоритмы обучения нейронных сетей позволили обучать системы извлечения при
знаков, классификаторы и контекстные процессоры (скрытые модели Маркова и язы
ковые модели).
Обучение наполняет все уровни интеллектуальных систем во все увеличиваю
щемся количестве областей применения. Исходя из этоrо, целесообразно завершить
данную книry некоторыми замечаниями относительно интеллектуальных систем и
роли нейронных сетей в их создании.
990 rлава 16. Заключение
Интеллектуальные системы
Поскольку мы не соrласны с научным определением интеллекта 1 и в связи с оrpани
ченным объемом данной книrи, мы не будем уrлубляться в дискуссию относительно
TOro, что такое интеллект. Вместо этоro мы оrpаничимся кратким обзором интел
лектуальных систем в контексте трех специфичных областей их применения: клас
сификация образов, управление и обработка сиrналов. Известно, что не существует
"универсальных" интеллектуальных систем. Эти системы особенны для каждой KOH
кретной предметной области их применения.
Большая часть усилий исследователей нейронных сетей была сфокусирована на
задаче распознавания образов. Учитывая практическую важность этой задачи и ее по
все местную природу, а также тот факт, что нейронные сети исключительно хорошо
подходят для решения задачи классификации, такая концентрация усилий ученых Ha
правлялась на поиск средств корректной классификации. Развивая это направление,
стало возможным заложить основы адаптивной классификации образов (adaptive pat
tem classification). Однако мы достиrли той точки, в которой системы классификации
должны рассматриваться в более широком смысле, если мы хотим решать задачи клас
сификации более сложной и интеллектуальной природы. На рис. 16.1 показана cтpYK
тура "mпотетической" системы классификации [413]. Первый уровень этой системы
получает сенсорные данные, reнерируемые некоторым источником информации. BTO
рой уровень извлекает множество признаков, характеризующее полученные ceHCOp
ные данные. Третий уровень классифицирует эти признаки в одну или несколько раз
личных катеroрий, которые затем помещаются в rлобальный контекст на четвертом
уровне. В заключение можно для примера поместить разобранный входной сиrнал в
некоторую форму базы данных, которую будет использовать конечный пользователь.
Важными признаками, характеризующими эту систему, являются следующие.
· Распознавание (recognition), являющееся результатом прямоrо прохождения ин
формации от одноro уровня системы к следующему в традиционной системе клас
сификации.
· Фокусировка (focusing), при которой более высокий уровень системы способен
избирательно влиять на обработку информации более низким уровнем с помощью
знаний, накопленных на основе имеющихся данных.
Таким образом, новаторство системы классификации образов, показанной на
рис. 16.1, лежит в знаниях о целевой области и их использовании нижними уровнями
системы для повышения общей производительности системы при имеющихся фун
даментальных оrpаничениях объема обрабатываемой информации. Будем надеяться,
1 Философская дискуссия относительно понятия интеллекта. рассматриваемоro с различных точек зрения,
содержится в [8], [15], [592].
Интеллектуальные системы 991
Рис. 16.1. Функциональная архитектура интеллектуальной системы
что классификация образов, использующая нейронные сети, будет развиваться в Ha
правлении создания моделей, которые будут последовательно наполняться знаниями
о целевой области. Можно проrнозировать появление HOBoro класса интеллектуаль
ных систем распознавания образов, которые обеспечат следующие возможности.
. Способность извлекать контекстные знания (contextual knowledge) и использовать
их с помощью фокусировки (focusing).
. Локализованность, а не распределенность представления знаний.
. Разреженная архитектура (sparse architecture), подчеркивающая модульность и
иерархию как принцип конструкции сетей.
Реализация такой интеллектуальной системы может быть достиrнута только путем
комбинирования нейронных сетей с друrими соответствующими средствами. Полез
ным инструментом, который приходит на ум, является ал20рИтм Витерби (Viterbi
algorithm) одна из форм динамическоro проrpаммирования, созданная для после
довательной обработки информации 2 , являющейся врожденной характеристикой си
стемы, показанной на рис. 16.1. (Подробно об алroритме динамическоrо проrpамми
рования см. в rлаве 12).
2 Алroритм Витерби впервые бьш изложен в [1096] и предназначен для решения задачи декодирования
свертки в теории связи. Дополнительная информация об алroритме Витерби содержится в [303].
Применение в задачах классификации образов, которое включает в себя комбинированное использование
сетей свертки (см. rлаву 4) и алroритма Витерби, описывается в [622], [623].
992 rлава 16. Заключение
Рис. 16.2. Функциональная архитектура интеллектуальной
системы управления
Управление еще одна естественная область применения нейронных сетей
также развивалось в направлении интеллектуальноzо управления 3 . Автономность яв
ляется важной целью разработчиков систем управления, и интеллектуальные KOH
троллеры рассматриваются как один из путей ее достижения. На рис. 16.2 показа
на функциональная архитектура интеллектуальноro aBToHoMHoro контроллера [65],
[820]. Эта система имеет следующие функциональные уровни.
1. Уровень выполнения (execution level). Включает низкоуровневую обработку сиrна
ла и алrоритмы адаптивноrо управления и идентификации.
2. Уровень координации (coordination lеуеl). Реализует связь уровней выполнения и
управления, контролируя такие вопросы, как настройка (tuning), контроль (super
vision), разрешение кризисов (crisis management) и планирование (planning).
3. Уровень управления и орzанuзации (management and organization lеуеl). Осуществ
ляет контроль над низкоуровневыми функциями и управление интерфейсом с
человеком.
В то время как классическое управление уходит корнями в теорию линейных диф
ференциальных уравнений, интеллектуальное управление основывается на правuлах
(rule based), так как зависимости, вовлеченные в ero реализацию, настолько сложны,
что не допускают аналитическоrо представления. Для Toro чтобы работать с такими
зависимостями, целесообразно использовать математику нечетких систем и нейрон
3 Интеллектуальное управление рассматривается в [403], [1065], [1130].
Интеллектуальные системы 993
ных сетей. Сила нечеткux систе.м 4 (fuzzy system) заключена в их способности созда
вать количественное представление линrвистическоro входа и быстро предоставлять
эффективную аппроксимацию сложных и зачастую неизвестных правил отображе
ния входа на выход в различных системах. Сила нейронных сетей заключается в их
способности обучаться на данных. Между нейронными сетями и нечеткими система
ми существует определенная синерrетика, которая делает их rибридизацию важным
инструментом интеллектуальноro управления и друrих приложений.
Переходя далее к обработке сиrналов, можно сказать, что не существует более
плодородной области применения нейронных сетей и, в частности, их характеристик
нелинейности и адаптивности [434]. Мноmе физические явления отвечают за reHepa
цию информационных сиzналов (information bearing signal), встречаемых на практике
(в частности, речевых, радарных и сонарных сиrналов), управляются нелинейной
динамикой нестационарной и сложной природы, которая не имеет точноrо математи
ческоrо описания. ДЛя использования полноrо информационноro содержания таких
сиrналов во все моменты времени требуются интеллектуальные машины обработки
сиrнала 5 , конструкция которых решает следующие ключевые вопросы.
· Нелинейность (nonlinearity), которая делает возможным извлечение статистики
BbICOKOro порядка из входноro сиrнала.
· Обучение и адаптация (learning and adaptation), посредством которой система MO
жет обучиться исследуемому физическому механизму среды и адаптироваться к
непрерывным медленным статистическим вариациям внешней среды.
· Механизм внимания (attentional mechanism), в котором посредством взаимодей
ствия с конечным пользователем или с помощью самоорrанизации система может
сфокусировать свои вычислительные мощности на конкретной области изображе
ния или на конкретном месте в пространстве для их более детальноrо анализа 6.
4 Теория нечетких множеств была заложена в [1175], [1176] с целью реализации математическоro инстру
ментария работы с линrвистическими переменными (т.е. концепциями, описанными на естественном языке).
Толкование нечеткой лоrики в книжной форме содержится в [268]. В [591] принимается друrая точка зре
ния: нечеткие системы рассматриваются как аппроксиматоры функций. В ней показано, что нечеткая система
способна моделировать любую непрерывную функцию или систему при условии использования достаточных
правил.
5 Специальный выпуск статей ШЕЕ 1998 (Institute of Electrical and Electronic Engineers) был посвящен
вопросу интеллектуальной обработки сиrналов [440].
6 Самоорrанизующиеся системы для иерархической фокусировки или избирательноro внимания были опи
саны в [324]. Описанная система являлась модификацией мноroслойноro неокоrнитрона
Самоорrанизующийся механизм внимания также представлен в теории адаптивною резонанса (adaptive
resonance theory), основы которой были заложены в [175], [177]. Эта теория, при меняемая к задаче адanтив
HOro распознавания образов, использует комбинацию фильтрации снизу вверх (bottom-up filtering) и сравнения
образцов сверху вниз (top down temp1ate matching).
994 rлава 16. Заключение
На рис. 16.3 показана функциональная архитектура интеллектуальных машин об
работки сиrнала, которая имеет три уровня.
1. Нuзкоуровневая обработка (low level processing), целью которой является предва
рительная обработка полученноrо сиrнала и ero подrотовка для BToporo уровня.
В предварительную подrотовку входит использование фильтрации для уменьше
ния эффекта шума, а также друrие продвинутые операции обработки сиrнала,
такие как частотно вре.менной анализ? (time frequency analysis). Целью частотно
BpeMeHHoro анализа является описание Toro, как развивается спектральное co
держание сиrнала и каков спектр, изменяющийся во времени. В частности, oд
номерное (временное) представление получаемоrо сиrнала преобразовывается в
двумерное изображение, одно измерение KOToporo является частотой, а второе
временем. Частотный анализ реализует эффективный метод выявления нестацио
нарной природы получаемоro сиrнала, который делает ее более различимой, чем
исходная временная форма.
2. Уровень обучения и адаптации (leaming and adaptation level), на котором память
(как краткосрочная, так и долrосрочная) и механизм внимания встраиваются в
конструкцию системы. Например, в мноrослойном персептроне, подверrающем
ся обучению с учителем на большом множестве данных, представительном для
среды функционирования системы, общая статистическая информация о среде
хранится в синаптических весах сети. Для Toro чтобы учесть медленные CTa
тистические вариации среды во времени, к выходу мноrослойноrо персептрона
добавляется схема слепой адаптации (т.е. подсистема непрерывноrо обучения, pa
ботающая без учителя). Этот процесс обучения также включает обеспечение сети
внимания 8 (attentional network), в которой система может сфокусировать свое вни
мание на особенно важных свойствах получаемоrо сиrнала, "вентилируя" поток
информации от нижнеro слоя к верхним, если возникнет такая потребность.
3. Уровень принятия решения (decision making level), на котором система принимает
окончательное решение. Решение может приниматься относительно Toro, coдep
жится ли во входном сиrнале интересующий объект, как в случае радара или
сонара, и как интерпретировать поступившую информацию как единицу или
нуль (в случае цифровой связи). В процессе принятия решения также учитываются
уровни доверия.
7 Детальное описание частотно временноrо анализа, nocтpoeHHoro на классической теории Фурье, coдep
жится в [199].
Теория и приложения распределения Виrнера (Wigпеr distribution), важноro инструмента в билиней-
ном/квадратичном частотно временном представлении, описаны в [723].
Еще одна точка зрения, в которой вместо частоты мы рассматриваем амплитуду (sca1e), представлена в
работе, посвященной элементарным волнам и связанным с ними вопросам кодирования полосы (subband coding)
[1093].
8 В [1078] описана нейросетевая модель избирателыюrо сокрытия визуальноrо внимания (se1ective covert
visual attention). Эта модель может обучиться фокусированию внимания на характеристиках, важных для кон-
кретной решаемой задачи, с помощью модуляции потока информации на предварительной стадии.
Интеллектуальные системы 995
Рис. 16.3. Функциональная архитектура интеллектуальных машин
обработки сиrнала
Мы не заявляем, что описанные здесь системы являются единственным спосо
бом встраивания интеллекта в системы классификации образов, управления и обра
ботки сиrнала. Они представляют систематические способы достижения этой цели.
Несмотря на различия в терминолоrии различных областей применения, они облада
ют некоторыми общими признаками.
· Существует двунаправленный поток информации, от нижнеrо слоя к верхнему, и
наоборот.
· Более высокие уровни часто связаны с теми аспектами динамики системы, которые
требуют длительной обработки, которые шире по объему информации (scope) или
имеют более дальний roризонт.
· При перемещении от нижнеrо слоя к верхнему наблюдается повышение интеллек
та наряду с понижением точности.
· На более высоких уровнях понижается зернистость (granularity) (т.е. повышается
уровень абстракции).
в rлаве 1 рассмотрение вопросов нейронных сетей было начато с описания чело
веческоro мозrа источника мотивации нейронных сетей как rиrантской системы
обработки информации. Поэтому мы и завершаем книry кратким описанием интел
лектуальных машин, которые осуществляют интеллектуальную обработку информа
ции. Борьба за создание интеллектуальных машин продолжается.
Библиоrрафия
1. Aarts Е. and J. Korst. Simиlated Annealing and Boltzmann Machines: А Stochas
tic Aproach to Combinatorial Optimization and Neural Compиting, New York:
Wiley, 1989.
2. Abarbanel H.D.I. Analysis of Observed Chaotic Data, New York: Springer
Verlag, 1996.
3. Abraham R.H. and C.D. Shaw. Dynamics ofthe Geometry ofBehayior, Reading,
МА: Addison Wesley, 1992.
4. Abи Mostafa Y.S. "Hints", Neural compиtation, 1995, уоl. 7, р. 639 671.
5. Abи Mostafa Y.S. "Leaming from hints in Neиral Networks", Joиmal of Com
plexity, 1990, уоl. 6, р. 192 198.
6. Abи Mostafa Y.S. "ТЬе Vapnik Chervonenkis Dimension: Information Versиs
Complexity in Leaming", Neural Compиtation, 1989, уоl. 1, р. 312 317.
7. Abи Mostafa Y.S. and J.M. St. Jacqиes. "Information capacity of the Hopfield
model", ШЕЕ Transactions оп Information Theory, 1985, уоl. IТ 31, р. 461 64.
8. Ackerman P.L. "Intel1igence", In S.C. Shapiro, ed. Encyclopedia of Artificial
Intelligence, New York: Wiley (Interscience) 1990, р. 431 440.
9. Ackley D.н., G.E. Hinton and T.J. Sejnowski. "А Leaming Algorithm for Boltz
mann Machines", Cognitiye Science, 1985, уоl. 9, р. 147 169.
10. Aiyer S.V.B., N. Niranjan and F. Fallside. "А theoretical inyestigation into the
performance of the Hopfield model", ШЕЕ Transactions оп Neural Networks,
1990, уоl. 15, р. 204 215.
11. Aizerman М.А., Е.М. Brayerman and L.I. Rozonoer. "Theoretical foиndations
of the potential function method in pattem recognition leaming", Aиtomation
and Remote Control, 1964, уоl. 25, р. 821 837.
12. Aizerman М.А., Е.М. Brayerman and L.I. Rozonoer. "ТЬе probability problem
of pattem recognition leaming and the method of potential functions", Aиtoma
tion and Remote Control, 1964Б, уоl. 25, р. 1175 1193.
13. Akaike Н. "А new 100k at the statistical model identification", ШЕЕ Transactions
оп Aиtomatic Control, 1974, уоl. AC 19, р. 716 723.
14. Akaike Н. "Statistical predictor identification", Annals of the Institиte of Statis
tical Mathematics, 1970, уоl. 22, р. 202 217.
15. Albиs J.S. "Oиtline for а theory ofintelligence", ШЕЕ Transactions оп Systems,
Man and Cybemetics, 1991, уоl. 21, р. 473 509.
16. Aleksander 1. and Н. Morton. An Introdиction to Neural Compиting, London:
Chapman and НаН, 1990.
17. Allport А. "Visиal attention", In Foиndations of Cognitiye Science, M.I. Posner,
ed., 1989, р. 631 682, Cambridge, МА: MIТ Press.
Библиоrрафия 997
18. Al Mashoиg КА. and I.S. Reed. "Inclиding hints in training neural nets", Neиral
Compиtation, 1991, уоl. 3, р. 418 27.
19. Alspector J., R.B. Allen, А. Jayakиmar, Т. Zepenfeld and R. Meir. "Relaxation
networks for large sиpervised leaming problems", Advances in Neural Informa
tion Processing Systems, 1991, уоl. 3, р. 1015 1021, San Mateo, СА: Morgan
Kaиfmann.
20. Alspector J., А. Jayakиmar and S. Lиna. "Experimental evalиation of leaming
in а neиral microsystem", Advances in Neиral Information Processing Systems,
1992, уоl. 4, р. 871 878, San Mateo, СА: Morgan Kaиfmann.
21. Alspector J., R. Meir, В. Yиhas, А. Jayakиmar and D. Lipe. "А paral1el gradient
descent method for leaming in analog VLSI neиral networks", Advances in
Neиral Information Processing Systems, 1993, уоl. 5, р. 836 844, San Mateo,
СА: Morgan Kaиfmann.
22. Amari S. "Natиral gradient works efficiently in leaming", Neиral Compиtation,
1998, уоl. 10, р. 251 276.
23. Amari S. Private commиnication, 1997.
24. Amari S. "А иniversal theorem оп leaming cиrves", Neиral Networks, 1993,
уоl. 6, р. 161 166.
25. Amari S. "Mathematical foиndations of neиrocompиting", Proceedings of the
ШЕЕ, 1990, уоl. 78, р. 1443 1463.
26. Amari S. "Differential geometry of а parametric family of invertible systems
Riemanian metric, dиal affine connections and divergence", Mathematical Sys
tems Theory, 1987, уоl. 20, р. 53 82.
27. Amari S. Differential Geometrical Methods in Statistics, New York: Springer
Verlag, 1985.
28. Amari S. "Field theory of self organizing neиral nets", ШЕЕ Transactions оп
Systems, Man and Cybemetics, 1983, уоl. SMC 13, р. 741 748.
29. Amari S. "Topographic organization of nerve fields", Bиlletin of Mathematical
Biology, 1980, уоl. 42, р. 339 364.
30. Amari S. "Neиral theory of association and concept formation", Biological Cy
bemetics, 1977, уоl. 26, р. 175 185.
31. Amari S. "Dynamics of pattem formation in lateral inhibition type neиral fields",
Biological Cybemetics, 1977Б, уоl. 27, р. 77 87.
32. Amari S. "Characteristics of random nets of analog neиron like elements", ШЕЕ
Transactions оп Systems, Man and Cybemetics, 1972, уоl. SMC 2, р. 643 657.
33. Amari S. "А theory of adaptive pattem classifiers", ШЕЕ Trans. Electronic
Compиters, 1967, уоl. EC 16, р. 299 307.
34. Amari S. and М.А. Arbib. "Competition and cooperation in neиral nets", in 1.
Metzler, ed., Systems Neиroscience, 1977, р. 119 165, New York: Academic
Press.
998 Библиоrрафия
35. Amari S. and J. F. Cardoso. "Вlind soиrce separation Semiparametric statisti
саl aproach", ШЕЕ Transactions оп Signal Processing, 1997, уоl. 45, р. 2692
2700.
36. Amari S., т. P. СЬеп and А. Cichoki. "Stability analysis of leaming algorithms
for blind soиrce separation", Neural Networks, 1997, уоl. 10, р. 1345 1351.
37. Amari S., А. Cichoki and H.H.Yang. "А new leaming algorithm for blind signal
separation", Advances in Neural Information Processing Systems, 1996, уоl. 8,
р. 757 763, Cambridge, МА: MIТ Press.
38. Amari S. and К. Maginи. "Statistical neurodynamics of associative memory",
Neиral Networks, 1988, уоl. 1, р. 63 73.
39. Amari S., К Yoshida and КА. Kanatani. "А mathematical foиndation for sta
tistical neurodynamics", SIAM Joиmal of Aplied Mathematics, 1977, уоl. 33,
р. 95 126.
40. Amari S., N. Murata, K. R. M(ller, М. Finke and Н. Yang. "Statistical theory of
overtraining Is cross validation asymptotically effective"? Advances in Neural
Information Processing Systems, 1996а, уоl. 8, р. 176 182, Cambridge, МА:
MIТ Press.
41. Ambros Ingerson J., R. Granger and G. Lynch. "Simиlation of paleo cortex
performs hierarchical clиstering", Science, 1990, уоl. 247, р. 1344 1348.
42. Amit D.J. Modelil1g Brain Fиnction: ТЬе World of Attractor Neиral Networks,
New York: Cambridge University Press, 1989.
43. Anastasio т.J. "Vestibиlo ocиlar reflex: Performance and plasticity", In М.А.
Arbib, ed., The Handbook of Brain Theory and Neural Networks, Cambridge,
МА: MIТ Press, 1995.
44. Anastasio T.J. "Modeling vestibиlo ocиlar reflex dynamics: From classical апаl
ysis to neural networks", in F. Eeckman, ed., Neural Systems: Analysis and
Modeling, 1993, р. 407 30, Norwell, МА: Кlиwer.
45. Anastasio T.J. "А rесипепt neural network model of velocity storage in the
vestibиlo ocиlar reflex", Advances in Neural Information Processing Systems,
1991, уоl. 3, р. 32 38, San Mateo, СА: Morgan Kaиfmann.
46. Anderson J.A. Introdиction to Neural Networks, Cambridge, МА: MIТ Press,
1995.
47. Anderson J.A. "The BSB model: А simple nonlinear aиtoassociative neural
network", in Associative Neиral Memories (М. Hassoиn, ed.), 1993, р. 77 103,
Oxford: Oxford University Press.
48. Anderson J.A. "General introdиction", Neurocompиting: Foиndations of Re
search (J.A. Anderson and Е. Rosenfeld, eds.), 1988, р. xiii xxi, Cambridge,
МА: MIТ Press.
Библиоrрафия 999
49. Anderson J.A. "Cognitive and psychological compиtation with neural mod
els", ШЕЕ Transactions оп Systems, Мап and Cybemetics, 1983, уоl. SMC 13,
р. 799 815.
50. Anderson J.A. "А simple neиral network generating ап interactive memory",
Mathematical Biosciences, 1972, уоl. 14, р. 197 220.
51. Anderson 1.A. and G.L. Mиrphy. "Concepts in connectionist models", in Neиral
Networks for Compиting, J.S. Denker, ed., 1986, р. 17 22, New York: American
Institиte of Physics.
52. Anderson J.A. and Е. Rosenfeld, eds. Neиrocompиting: F oиndations of Research,
Cambridge, МА: MIТ Press, 1988.
53. Anderson J.A., А. Pellionisz and Е. Rosenfeld, eds. Neиrocompиting 2: Direc
tions for Research, Cambridge, МА: MIТ Press, 1990а.
54. Anderson J.A., J.W. Silverstein, S.A. Ritz and R.S. Jones. "Distinctive featиres,
categorical perception and probability leaming: Some aplications of а neural
model", Psychological Review, 1977, уоl. 84, р. 413 51.
55. Anderson J.A. and 1.P. Sиtton. "А network of networks: Compиtation and пеи
robiology", World Congress оп Neиral Networks, 1995, уоl. 1, р. 561 568.
56. Anderson J.A., М.Т. Gately, Р.А. Penz and D.R. Collins. "Radar signal cate
gorization иsing а neиral network", Proceedings of the ШЕЕ, 1990Б, уоl. 78,
р. 1646 1657.
57. Anderson т.w. Ап Introdиction to Mиltivariate Statistical Analysis, 2nd edition,
New York: Wiley, 1984.
58. Andreoи A.G. "Оп physical models ofneиral compиtation and their analog VLSI
implementation", Proceedings of the 1994 Workshop оп Physics and Compиta
tion, ШЕЕ Compиter Society Press, 1994, р. 255 264, Los Alamitos, СА.
59. Andreoи A.G., КА. ВоаЬеп, Р.О. Poиliqиeen, А. Pasavoic, R.E. Jenkins and К
Strohbehn. "Сипепt mоdе sиbthreshold MOS circиits for analog VLSI neиral
systems", ШЕЕ Transactions оп Neиral Networks, 1991, уоl. 2, р. 205 213.
60. Andreoи A.G., R.C. Meitzler, К Strohbehn and КА. ВоаЬеп. "Analog VLSI
neиromorphic image acqиisition and pre processing systems", Neural Networks,
1995, уоl. 8, р. 1323 1347.
61. Andrews R. and 1. Diederich, eds. Proceedings of the Rиle Extraction from
Trained Artificial Neural Networks Workshop, University of Sиssex, Brighton,
UK., 1996.
62. Ansaklis P.J., М. Lemmon and J.A. Stiver. "Leaming to Ье aиtonomoиs", In
М.О. Gиpta and N.K Sinha, eds., Intelligent Control Systems, 1996, р. 28 62,
New York: ШЕЕ Press.
63. Ansari N. and Е. Нои. Compиtational Intelligence for Optimization, Norwell,
МА: Кlиwer, 1997.
1000 Библиоrрафия
64. Anthony М. and N. Biggs. Compиtational Leaming Theory, Cambridge: Cam
bridge University Press, 1992.
65. Antsaklis Р.1. and км. Passino, eds. Ап Introdиction to Intel1igent and Aиto
matic Control, Norwell, МА: Кlиwer, 1993.
66. Arbib М.А. Тhe Metaphorical Brain, 2nd edition, New York: Wiley, 1989.
67. Arbib М.А. Brains, Machines and Mathematics, 2nd edition, New York:
Springer Verlag, 1987.'
68. Arbib М.А., ed. ТЬе Handbook of Brain Theory and Neural Networks, Cam
bridge, МА: MIТ Press, 1995.
69. Апоwsmith,D.К. and С.М. Рlасе. Ап Introdиction to Dynamical Systems, Cam
bridge: Cambridge University Press, 1990.
70. Artola А. and W. Singer. "Long term potentiation and NMDA receptors in rat
visиal cortex", Natиre, 1987, уоl. 330, р. 649 652.
71. Ash R.E. Information Theory, New York: Wiley, 1965.
72. Ashby W.R. Design for а Brain, 2nd edition, New York: Wiley.
73. Ashby W.R., 1952. Design for а Brain, New York: Wiley, 1960.
74. Aspray W. and А. Bиrks. Papers of John уоп Neиmann оп Compиting and
Compиter Тheory, Charles Babbage Institиte Reprint Series for the History of
Compиting, 1986, уоl. 12. Cambridge, МА: MIТ Press.
75. Astr6m KJ. and т.J. МсАуоу. "Intelligent control: Ап overview and evalиation",
Handbook of Intelligent Control, О.А. White and О.А. Sofge, eds., New York:
Van Nostrand Reinhold, 1992.
76. Atherton О.Р. Stability ofNonlinear Systems, Chichester, UK: Research Stиdies
Press, 1981.
77. Atick J.J. "Coиld information theory provide ап ecological theory of sensory
processing"? Network: Compиtation in Neural Systems, 1992, уоl. 3, р. 213
251.
78. Atick J.J. and A.N. Redlich. "What does the retina know aboиt natиral scenes",
Neиral Compиtation, 1992, уоl. 4, р. 196 210.
79. Atick J.1. and A.N. Redlich. "Towards а theory of early visиal processing",
Neural Compиtation, 1990, уоl. 2, р. 308 320.
80. Atick J.J., Р.А. Griffin and A.N. Redlich. "Statistical aproach to shape from
shading: Reconstrиction of three dimensional [асе surfaces from single two
dimensional images", Neural Compиtation, 1996, уоl. 8, р. 1321 1340.
81. Atiya А.Р. "Leaming оп а general network", N eural Information Processing
Systems, D.Z. Anderson, ed., 1987, р. 22 30, New York: American Institиte of
Physics.
82. Atiya А.Р. and Y.S. Abи Mostafa. "Ап analog feedback associative memory",
ШЕЕ Transactions оп Neural Networks, 1993, уоl. 4, р. 117 126.
Библиоrрафия 1001
83. Аttnеауе F. "Some informational aspects of visиal perception", Psychological
Review, 1954, уоl. 61, р. 183 193.
84. Back А.О. and A.S. Weigend. "А first aplication of independent component
analysis to extracting strиctиre from stock retиms", Intemational Joиmal of
Neural Systems, 1998, уоl. 9, Special Issиe оп Data Mining in Finance.
85. Back А.О. and А.С. Tsoi. "FIR and I1R synapses, а new neиral network archi
tectиre for time series modeling", Neural Compиtation, 1991, уоl. 3, р. 375 385.
86. Back А.О. and А.с. Tsoi. "А 10w sensitivity rесипепt neиral network", Neural
Compиtation, 1998, уоl. 10, р. 165 188.
87. Baldi Р. and К. Homik. "Neural networks and principal component analysis:
Leaming from examples withoиt 10саl minimиm", Neural Networks, 1989, уоl.
1, р. 53 58.
88. Bantine W.L. and A.S. Weigend. "Compиting second derivatives in feed forward
networks: А review", ШЕЕ Transactions оп Neural Networks, 1994, уоl. 5,
р. 480 88.
89. Baras J.S. and А. LaVigna. "Convergence of Kohonen's leaming vector qиan
tization", Intemational Joint Conference оп Neиral Networks, 1990, уоl. Ш,
р. 17 20, San Diego, СА.
90. Barlow Н.В. "Unsиpervised leaming", Neural Compиtation, 1989, уоl. 1, р. 295
311.
91. Barlow Н.В. "Cognitronics: methods for acqиiring and holding cognitive knowl
edge", 1985.
92. Barlow Н.В. "Sensory mechanisms, the redиction of redиndancy and intelli
gence", ТЬе Mechanisation ofThoиght Processes, National Physical Laboratory
Symposiиm No. 10, Her Majesty's Stationary Office, London, 1959.
93. Barlow Н. and Р. F(ldi(k. "Adaptation and dесопеlаtiоп in the cortex", in The
Compиting Neuron, R. Dиrbin, С. Miall and G. Mitchison, eds., 1989, р. 54 72.
Reading, МА: Addison Wesley.
94. Bamard Е. and О. Casasent. "Invariance and neиral nets", ШЕЕ Transactions
оп Neural Networks, 1991, уоl. 2, р. 498 508.
95. Вапоп A.R. "Neиral net aproximation", in Proceedings of the Seventh Уаlе
Workshop оп Adaptive and Leaming Systems, 1992, р. 69 72, New Науеп,
СТ.: Уаlе University.
96. Вапоп A.R. "Universal aproximation boиnds for sиperpositions of а sigmoidal
function", ШЕЕ Transactions оп Information Theory, 1993, уоl. 39, р. 930 945.
97. Bartlett P.L. "For valid generalization, the size of the weights is more impor
tant than the size of the network", Advances in Neиral Information Processing
Systems, 1997, уоl. 9, р. 134 140, Cambridge, МА: MIТ Press.
1002 Библиоrрафия
98. Barto A.G. "Reinforcement leaming and adaptive critic methods", Handbook of
Intel1igent Control, О.А. White and О.А. Sofge, eds., 1992, р. 469 91, New
York: Van Nostrand Reinhold.
99. Barto A.G., S.J. Bradtke and S. Singh. "Leaming to act иsing real time dynamic
programming", Artificial Intelligence, 1995, уоl. 72, р. 81 138.
100. Barto A.G., R.S. Sиtton and C.W. Anderson. "Neuronlike adaptive elements that
can solve difficиlt leaming control problems", ШЕЕ Transactions оп Systems,
Мап and Cybemetics, 1983, уоl. SMC 13, р. 834 846.
101. Basar Е., ed. Chaos in Brain Fиnction, New York: Springer Verlag, 1990.
102. Bashkirov О.А., Е.М. Braverman and I.B. Mиchnik. "Potential function al
gorithms for pattem recognition leaming machines", Aиtomation and Remote
Control, 1964, уоl. 25, р. 629 631.
103. Battiti R. "First and second order methods for leaming: Between steepest de
scent and Newton's method", Neиral Compиtation, 1992, уоl. 4, р. 141 166.
104. Baиer H. U. and к.R. Pawelzik. "Qиantifying the neighborhood preservation of
self organizing featиre maps", ШЕЕ Transactions оп Neиral Networks, 1992,
уоl. 3, р. 570 579.
105. Baиer H. U., R. Der and М. Непnmап. "Controlling the magnification factor of
self organizing featиre maps", Neиral Compиtation, 1996, уоl. 8, р. 757 771.
106. Ваиm Е.В. "Neural net algorithms that lеаm in polynomial time from examples
and qиeries", ШЕЕ Transactions оп Neural Networks, 1991, уоl. 2, р. 5 19.
107. Ваиm Е.Б. and О. Haиssler. "What size net gives valid generalization"? Neural
Compиtation, 1989, уоl. 1, р. 151 160.
108. Ваиm Е.В. and F. Wilczek. "Sиpervised leaming of probability distribиtions Ьу
neural networks", in D.Z. Anderson, ed., 1988, р. 52 61, New York: American
Institиte of Physics.
109. Beaиfays Р. and Е.А. Wan. "Relating real time backpropagation and
backpropagation throиgh time: Ап aplication of flow graph iпtепесiрrосity",
Neиral Compиtation, 1994, уоl. 6, р. 296 306.
110. Becker S. "Mиtиal information maximization: models of cortical self
organization", Network: Compиtation in Neиral Systems, 1996, уоl. 7, р. 7 31.
111. Becker S. "Leaming to categorize objects иsing temporal coherence", Advances
in Neиral Information Processing Systems, 1993, уоl. 5, р. 361 368, San Mateo,
СА: Morgan Kaиfmann.
112. Becker S. "Unsиpervised leaming procedиres for neural networks", Intemational
Joиmal ofNeural Systems, 1991, уоl. 2, р. 17 33.
113. Becker S. and G.E. Нinton. "Leaming mixtиre models of spatial coherence",
Neural Compиtation, 1993, уоl. 5, р. 267 277.
Библиоrрафия 1003
114. Becker S. and G.E. Hinton. "А self organizing neural network that discovers
surfaces in random dot stereograms", Natиre (London), 1992, уоl. 355, р. 161
163.
115. Beckerman М. Adaptive Cooperative Systems, New York: Wiley (Interscience),
1997.
116. Веll A.J. and T.J. Sejnowski. "Ап information maximization aproach to blind
separation and blind deconvolиtion", Neural Compиtation, 1995, уоl. 6, р. 1129
1159.
117. Bellman R. Adaptive Control Processes: А Gиided Tour, Princeton, NJ: Princeton
University Press, 1961.
118. Веllmап R. Dynamic Programming, Princeton, NJ: Princeton University Press,
1957.
119. Веllmап R. and S.E. Dreyfus. Aplied Dynamic Programming, Princeton, NJ:
Princeton University Press, 1962.
120. Bengio У. Neural Networks for Speech and Seqиel1ce Recognition. London:
Intemational Thomson Compиter Press, 1996.
121. Bengio У., Р. Simard and Р. Frasconi. "Leaming 10ng term depel1dencies with
gradient descent is difficиlt", ШЕЕ Transactions оп Neural Networks, 1994, уоl.
5, р. 157 166.
122. Benveniste А., М. Metivier and Р. Priouret. Adaptive Algorithms and Stochastic
Aproximation, New York: Springer Verlag, 1987.
123. Bertero М., Т.А. Poggio and V. Топе. "Ill posed problems in early vision",
Proceedings of the ШЕЕ, 1988, уоl. 76, р. 869 889.
124. Bertsekas О.Р. Dynamic Programming and Optimal COl1trol, 1995, уоl. 1 and
уоl. II, Belmont, МА: Athenas Scientific.
125. Bertsekas О.Р. NonlinearProgramming, Belmont, МА: Athenas Scientific, 1995.
126. Bertsekas О.Р. and J.N. Tsitsiklis. Neuro Dynamic Programming, Belmont, МА:
Athenas Scientific, 1996.
127. Beymer О. and Т. Poggio. "Image representations for visиalleaming", Science,
1996, уоl. 272, р. 1905 1909.
128. Bienenstock E.L., L.N. Cooper and P.W. Мишо. "Theory for the development
of neuron selectivity: Orientation specificity and binocиlar interaction in visиal
cortex", Joиmal ofNeиroscience, 1982, уоl. 2, р. 32 48.
129. Bishop С.М. "Exact calcиlation of the Hessian matrix for the mиlti layer per
ceptron", Neural Compиtation, 1992, vol. 4, р. 494 501.
130. Bishop с.М. Neural Networks for Pattem Recognition. Oxford: Clarendon Press,
1995.
131. Black I.B. Information in the Brain: А Molecиlar Perspective, Cambridge, МА:
MIТ Press, 1991.
1004 Библиоrрафия
132. Blake А. "Тhe least distиrbance principle and week constraints", Pattem Recog
nition Letters, 1983, vol. 1, р. 393 399.
133. Вliss т.У.Р. and Т. Lomo. "Long lasting potentiation of synaptic transmission
in the dentate area of the anaesthetized rabbit following stimиlation of the
perforatant path", J. Physiol, 1973, уоl. 232, р. 331 356.
134. Blиmer А., А. Ehrenfeиcht, О. Haиssler and М.к. Warmиth. "Leamability and
the Vapnik Chervonenkis Dimension", J оиmаl of the Association for Compиting
Machinery, 1989, уоl. 36, р. 929 965.
135. Вlumer А., А. Ehrenfeиcht, О. Haиssler and М.К. Warmиth. "Occam's razor",
Information Processing Letters, 1987, уоl. 24, р. 377 380.
136. ВоаЬеп к.А. "А retinomorphic vision system", ШЕЕ Micro, 1996, уоl. 16, по.
5, р. 30 39.
137. Boahen к.А. and A.G. Andreoи. "А contrast sensitive silicon retina with re
ciprocal synapses", Advances in Neural Information Processing Systems, 1992,
уоl. 4, р. 764 772. San Mateo, СА: Morgan Kaиfmann.
138. ВоаЬеп к.А., Р.О. Poиliqиeen, A.G. Andreoи and R.E. Jenkins. "А heterasso
ciative memory иsing сипепt mоdе analog VLSI circиits", ШЕЕ Transactions
оп Circиits and Systems, 1989, уоl. CAS 36, р. 747 755.
139. Bodenhaиsen U. and А. Waibel. "ТЬе tempo 2 algorithm: Adjиsting time delays
Ьу sиpervised leaming", Advances in Neиral Information Processing Systems,
1991, уоl. 3, р. 155 161, San Mateo, СА: Morgan Kaиfmann.
140. Boltzmann L. "Weitere stиdien uber das Warmegleichgewicht иnter gas
molekйlen", Sitzиngsberichte der Mathematisch Natиrwissenschaftlichen Classe
der Kaiserlichen Akademie der Wissenschaften, 1872, уоl. 66, р. 275 370.
141. Boser В., 1. Gиyon and V.N. Vapnik. "А training algorithm for optimal margin
classifiers", Fifth Аппиаl Workshop оп Compиtational Leaming Theory, 1992,
р. 144 152. San Mateo, СА: Morgan Kaиfrnann.
142. Boser В.Е., Е. S(ckinger, J. Bromley, У. LeCиn and L.D. Jackel. "Hardware
reqиirements for neиral network pattem classifiers", ШЕЕ Micro, 1992, уоl. 12,
р. 32 40.
143. Bourlard Н.А. and N. Morgan. Connectionist Speech Recognition: А Hybrid
Aproach, Boston: Кlиwer, 1994.
144. Bourlard Н.А. and C.J. Wellekens. "Links between Markov models sand mиlti
layer perceptrons", ШЕЕ Transactions оп Pattem Analysis and Machine Intelli
gence, 1990, уоl. PAMI 12, р. 1167 1178.
145. Вох G.E.P. and G.M. Jenkins. Time Series Analysis: Forecasting and Control,
San Francisco: Holden Оау, 1976.
146. Braitenberg У. "Is the cerebella cortex а biological clock in the millisecond
range"? in ТЬе Cerebellиm. Progress in Brain Research, С.А. Рох and R.S.
Snider, eds., 1967, уоl. 25, р. 33 346, Amsterdam: Elsevier.
Библиоrрафия 1005
147. Braitenberg У. "Reading the strиctиre of brains", Network: Compиtation in
Neиral Systems, 1990, уоl. 1, р. 1 12.
148. Braitenberg У. "Two views of the cerebral cortex", in Brain Theory, G. Раlm
and А. Aertsen, eds., 1986, р. 81 96. New York: Springer Verlag.
149. Braitenberg V. Vehicles: Experiments in Synthetic Psychology, Cambridge, МА:
MIТ Press, 1984.
150. Braitenberg У. Оп the Textиre of Brains, New York: Springer Verlag, 1977.
151. Bregman А. S. Aиditory Scene Analysis: The Perceptиal Organization of Soиnd,
Cambridge, МА: MIТ Press, 1990.
152. Breiman L. "Bagging predictors", Machine Leaming, 1996, уоl. 24, р. 123 140.
153. Breiman L. "Bias, variance and arcing classifiers", Technical Report 460, Statis
tics Department, University of Califomia, Berkeley, Calif, 1996Б.
154. Breiman L., J. Friedman, R. 01shen and С. Stone. Classification and Regression
Trees, New York: СЬарюап and Наll, 1984.
155. Bridle J.S. "Probabilistic interpretation of feedforward classification network
oиtpиts, with relationships to statistical pattem recognition", Neuro compиting:
Algorithms, Architectиres and Aplications, F. Foиgelman Soиlie and 1. H(raиlt,
eds., 1990, New York: Springer Veriag.
156. Bridle J.S. "Training stochastic model recognition algorithms as networks can
lead to maximиm mиtиal information estimation of parameters", Advances in
Neural Information Processing Systems, 1990Б, уоl. 2, р. 211 217, San Mateo,
СА: Morgan Kaиfmann.
157. Brodal А. Neurological Anatomy in Relation to Clinical Medicine, 3rd edition,
New York: Oxford University Press, 1981.
158. Brodmann К. Vergleichende Lokalisationslehre der Grosshimrinde, Leipzig: J.A.
Barth, 1909.
159. Brogan W.L. Modem Control Theory, 2nd edition, Englewood Cliffs, NJ:
Prentice Hall, 1985.
160. Broomhead D.S. and О. Lowe. "Mиltivariable functional interpolation and adap
tive networks", Соmрlех Systems, 1988, уоl. 2, р. 321 355.
161. Brown т.Н., E.W. Kairiss and C.L. Кеепап. "НеЬЫап synapses: Biophysical
mechanisms and algorithms", Аппиаl Review of Neuroscicnce, 1990, уоl. 13,
р. 475 511.
162. Brиck J. "Оп the convergence properties of the Hopfield model", Proceedings
ofthe ШЕЕ, 1990, уоl. 78, р. 1579 1585.
163. Bryson А.Е., Jr. and У.С. Но. Aplied Optimal Control, Blaisdell, 1969. (Вторая
редакция, 1975, Hemisphere pиblishing, Washington, ОС).
164. Bиrg J.P. Modem Spectral Estimation, РЬ.О. Thesis, Stanford University, Stan
ford, Calif, 1975.
1006 Библиоrрафия
165. Burges c.J.c. "А tиtorial оп sиport vector machines for pattem recognition",
Data Mining and Кпоwlеdgе Discovery, 1998.
166. Cacoиllos Т. "Estimation of а mиltivariate density", Annals of the Institиte of
Statistical Mathematics (Tokyo), 1966, уоl. 18, р. 179 189.
167. Caianiello E.R. "Oиtline of а theory of thoиght processes and thinking ma
chines", Joиmal ofTheoretical Biology, 1961, уоl. 1, р. 204 235.
168. Cameron s.н. Tech. Report 60 600, Proceedings of the Bionics Symposiиm,
1960, р. 197 212, Wright Air Development Division, Dayton, Ohio.
169. Cardoso J. F. "Blind signal separation: А review", Proceedings of the ШЕЕ,
1998а, уоl. 86.
170. Cardoso J. F. "Mиltidimensional independent component analysis", Proceedings
ШЕЕ ICASSP, Seattle, WA, Мау, 1998Б.
171. Cardoso J. F. "Infomax and maximиm likelihood for blind soиrce separation",
ШЕЕ Signal Processing Letters, 1997, уоl. 4, р. 112 114.
172. Cardoso J. F. "Entropic contrasts for source separation", Presented at the NIPS
96 Workshop оп Blind Signal Processing organized Ьу А. Cichoki at Snomass,
Соl0. Издана как rлава книrи Unsиpervised Adaptive Filtering, S. Haykin, ed.,
1996, New York: Wiley.
173. Cardoso J. F. and В. Laheld. "Eqиivariant adaptive source separation", ШЕЕ
Transactions оп Signal Processing, 1996, уоl. 44, р. 3017 3030.
174. Cardoso J. F. and А. Soиloиmia. "Blind beamforming for non Gaиssian signals",
ШЕ Proceedings (London), Part Р, 1993, уоl. 140, р. 362 370.
175. Carpenter G.A. and S. Grossberg. "А massively parallel architectиre for а self
organizing neural pattem recognition machine", Compиter Vision, Graphics and
Image Processing, 1987, уоl. 37, р. 54 115.
176. Carpenter G.A., М.А. Cohen and S. Grossberg. Technical comments оп "Com
pиting with neural networks", Science, 1987, уоl. 235, р. 1226 1227.
177. Carpenter G.A. and S. Grossberg. "Adaptive resonance theory (ART)", in М.А.
Arbib, 1995, ed., The Handbook ofBrain Theory and Neural Networks, р. 79 82,
Cambridge, МА: MIТ Press.
178. Casdagli М. "Nonlinear prediction of chaotic time series", Physica, 1989, уоl.
35О, р. 335 356.
179. Сеmу У. "Thermodynamic aproach to the travelling salesman problem", Joиmal
of Optimization Theory and Aplications, 1985, уоl. 45, р. 41 51.
180. Changeиx J.P. and А. Danchin. "Selective stabilization of developing synapses
as а mechanism for the specification of neural networks", Natиre, 1976, уоl.
264, р. 705 712.
181. Chatterjee С., У.Р. Roychowdhhиry and Е.к.Р. Chong. "Оп relative convergence
properties of principal component algorithrns", ШЕЕ Transactions оп Neural
Networks, 1998, уоl. 9, р. 319 329.
Библиоrрафия 1007
182. Chen Н. and R. W Liи. "Adaptive distribиted orthogol1alizatiol1 processing for
principal components analysis", Intemational Conference оп Acoиstics, Speech
and Signal Processing, 1992, уоl. 2, р. 293 296, San Francisco.
183. Chen S. "Nonlinear time series modelling and prediction иsing Gaиssian RВP
networks with enhanced clиstering and RLS leaming", Electronics Letters, 1995,
уоl. 31, No. 2, р. 117 118.
184. Chen S., S. Billings and Р. Grant. "Non linear system identification иsing пешаl
networks", Intemational Joиmal ofControl, 1990, уоl. 51, р. 1191 1214.
185. Chen S., В. Mиlgrew and S. McLaиgh1in. "Adaptive Bayesian feedbackeqиalizer
based оп а radial basis function network", ШЕЕ Intemational Conferel1ce оп
Commиnications, 1992, уоl. 3, р. 1267 1271, Chicago.
186. Cherkassky V. and F. Mиlier. "Self organization as ап iterative kemel smoothing
process", Neural Compиtation, 1995, уоl. 7, р. 1165 1177.
187. Cherkassky У. and F. Mиlier. Leaming from Data: Concepts, Theory and Meth
ods, New York: Wiley, 1998.
188. Cherry Е.С. "Some experiments оп the recognition of speech, with опе and
with two ears", Joиmal of the Acoиstical Society of America, 1953, уоl. 25,
р. 975 979.
189. Cherry Е.С. and W.к. Taylor. "Some further experimel1ts ироп the recognitiol1 of
speech, with опе and with two ears", Joиmal of Acoиstical Society of America,
1954, уоl. 26, р. 554 559.
190. Chester D.L. "Why two hidden layers are better than 011е", Intemational JOil1t
Conference оп Neural Networks, 1990, уоl. 1, р. 265 268, Washingtol1, О.с.
191. Chinrиngrиeng С. and С.Н. Seqиin. "Optimal adaptive k means algorithm with
dynamic adjиstment of leaming rate", ШЕЕ Transactions оп Neиral Networks,
1994, уоl. 6, р. 157 169.
192. Choey М. and A.S. Weigend. "Nonlinear trading models throиgh Sharp ratio
maximization", in А. Weigel1d, Y.S. Abи Mostafa and A. P.N. Refenes, eds.,
1996, Decision Technologies for Financial Engineering, р. 3 22, Singapore:
World Scientific.
193. Chиrch1and P.S. Neиrophilosophy: Toward а Unified Science ofthe Mind!Вrain,
Cambridge, МА: MIТ Press, 1986.
194. Chиrch1and P.S. and т.J. Sejnowski. The Compиtatiol1al Brain, Cambridge, МА:
MIТ Press, 1992.
195. Cichocki А. and R. Unbehaиen. "Robиst пеиrаl networks with on line leaming
for blind identification and blind separation of soиrces", ШЕЕ Transactions оп
Circиits and Systems 1: Fиndamental Theory and Aplications, 1996, уоl. 43,
р. 894 906.
196. Cichocki А., R. Ubenhaиen and Е. Rиmmert. "Robиst leaming algorithms for
blind separation of sigl1als", Electronics Letters, 1994, уоl. 30, р. 1386 1387.
1008 Библиоrрафия
197. Cichocki А. and L. Moszcsynski, L. "New leaming algorithm for blind separation
of sources", Electronics Letters, 1992, уоl. 28, р. 1986 1987.
198. Cleeremans А., О. Servan Schreiber and J.L. McClelland. "Finite state aиtomata
and simple rесипепt networks", Neural Compиtation, 1989, уоl. 1, р. 372 381.
199. Cohen L. Time Freqиency Analysis, Englewood Cliffs, NJ: Prentice Hall, 1995.
200. Cohen М.А. "The synthesis of arbitrary stable dynamics in non linear пешаl net
works 11: Feedback and иniversality", Intemational Joint Conference оп Neural
Networks, 1992, уоl. 1, р. 141 146, Baltimore.
201. Cohen М.А. "The constrиction of arbitrary stable dynamics in nonlinear пеиrаl
networks", Neиral Networks, 1992Б, уоl. 5, р. 83 103.
202. Cohen М.А. and S. Grossberg. "Absolиte stability of global pattem formation
and parallel memory storage Ьу competitive neиral networks", ШЕЕ Transac
tions оп Systems, Мап and Cybemetics, 1983, уоl. SMC 13, р. 815 826.
203. Cohn О. and G. Tesaиro. "How tight are the Vapnik Chervonenkis boиnds"?
Neиral Compиtation, 1992, уоl. 4, р. 249 269.
204. Соmоп Р. "Sиpervised classification, а probabilistic aproach", Ешореап Sym
posiиm оп Artificial Neиral Networks, 1995, р. 111 128, Brиssels, Belgiиm.
205. Соmоп Р. "Independent component analysis: А new concept"? Signal Process
ing, 1994, уоl. 36, р. 287 314.
206. Соmоп Р. "Independent component analysis", Proceedings of Intemational Sig
паl Processing Workshop оп Нigher order Statistics, 1991, р. 111 120, Cham
roиsse, France.
207. Constantine Paton М., Н.т. Cline and Е. Debski. "Pattemed activity, synaptic
convergence and the NMDA receptor in developing visиal pathways", Аппиаl
Review ofNeиroscience, 1990, уоl. 13, р. 129 154.
208. Cook A.S. "The complexity oftheorem proving procedиres", Proceedings ofthe
3rd Annиal АСМ Symposiиm оп Theory ofCompиting, 1971, р. 151 158, New
York.
209. Cook Р.А. Nonlinear Dynamical Systems, London: Prentice Hall Intemational,
1986.
210. Cooper L.N. "А possible organization of animal memory and leaming", Pro
ceedings ofthe Nobel Symposiиm оп Collective Properties ofPhysical Systems,
В. Lиndqиist and S. Lиndqиist, eds., 1973, р. 252 264, New York: Academic
Press.
211. Cormen т.н., С.Е. Leiserson and R.R. Rivest. Introdиction to Algorithms. Cam
bridge, МА: MIТ Press, 1990.
212. Cortes С. and У. Vapnik. "Sиport vector networks", Machine Leaming, 1995,
уоl. 20, р. 273 297.
213. Cottrell М. and J.c. Fort. "А stochastic model of retinotopy: А self organizing
process", Biological Cybemetics, 1986, уоl. 53, р. 405 11.
Библиоrрафия 1009
214. Cottrell М., J.c. Fort and G. Pag(s. "Theoretical aspects ofthe SOM algorithm",
Proceedings of the Workshop оп Self Organizing Maps, Espoo, Finland, 1997.
215. Cottrell G.W. and J. Metcalfe. "ЕМРАТН: Расе, emotion and gender recognition
иsing holons", Advances in Neиral Information Processing Systems, 1991, уоl.
3, р. 564 571, San Mateo, СА: Morgan Kaиfmann.
216. Cottrell G.W., Р. Мишо and О. Zipser. "Leaming intemal representations [rom
grey scale images: Ап ехатрlе of extensional programming", Proceedings of
the 9th Аппиаl Conference ofthe Cognitive science Society, 1987, р. 461 73.
217. Coural1t R. and О. Нilbert. Methods ofMathematical Physics, 1970, уоl. 1 and
11, New York: Wiley Interscience.
218. Cover Т.М. "Capacity problems for linear machines", In L. Капаl, ed., Pattem
Recognition, 1968, р. 283 289, Washington, ОС: Thompson Book Со.
219. Cover Т.М. "Geometrical and statistical properties ofsystems oflinear ineqиal
ities with aplications in pattem recognition", ШЕЕ Transactions оп Electronic
Compиters, 1965, уоl. EC 14, р. 326 334.
220. Cover т.М. and Р.Е. Hart. "Nearest neighbor pattem classification", ШЕЕ Tral1s
actions оп Information Theory, 1967, уоl. IТ 13, р. 21 27.
221. Cover т.М. and J.A. Thomas. Elements of Information Theory, New York:
Wiley, 1991.
222. Cowan J.D. "Neural networks: The early days", Advances in Neиral Informa
tiol1 Processing Systems, 1990, уоl. 2, р. 828 842, San Mateo, СА: Morgal1
Kaиfmann.
223. Cowan J.D. "Statistical mechanics of nervoиs nets", in Neиral Networks, E.R.
Caianiello, ed., 1968, р. 181 188, Berlin: Springer Verlag.
224. Cowan J.D. "А Mathematical Theory of Central Nervoиs Activity", Ph.D. The
sis, Ul1iversity ofLol1don, 1967.
225. Cowan J.D. "The problem of organismic reliability", Progress in Brain Research,
1965, уоl. 17, р. 9 63.
226. Cowan J.D. and М.Н. Cohen. "The role of statistical mechanics in neurobiol0gy",
Joиmal of the Physical Society ofJapan, 1969, уоl. 26, р. 51 53.
227. Cowan J.D. and О.Н. Sharp. "Neиral nets", Qиarterly Reviews of Biophysics,
1988, уоl. 21, р. 365 27.
228. Cragg B.G. and H.N.V. Tamperley. "Memory: The analogy with fепоmаgl1еtiс
hysteresis", Brain, 1955, уоl. 78, part 11, р. 304 316.
229. Cragg B.G. and H.N.V. Tamperley. "The organization ofneиrons: А cooperative
analogy", EEG Clinical Neurophysiology, 1954, уоl. 6, р. 85 92.
230. Craik к.J.W. The Natиre of Explanation, Cambridge: Cambridge Ul1iversity
Press, 1943.
1010 Библиоrрафия
231. Craven Р. and G. Wahba. "Smoothing noisy data with spline functions: Esti
mating the сопесt degree of smoothing Ьу the method of generalized cross
validation", Nиmerische Mathematik, 1979, уоl. 31, р. 377 03.
232. Crick F. "The recent excitement aboиt neиral networks", Natиre, 1989, уоl. 337,
р. 129 132.
233. Crites R.H. and A.G. Barto. "Improving elevator performance иsing reinforce
ment leaming", Advances in Neural Information Processing Systems, 1996, уоl.
8, р. 1 О 17 1 023, Cambridge, МА: MIТ Press.
234. Crиtchfield J.P., J.D. Farmer, N.H. Packard and R.S. Shaw. "Chaos", Scientific
American, 1986, уоl. 255(6), р. 38 9.
235. Cybenko G. "Q leaming: А tиtorial and extensions", Presented at Mathematics
of Artificial Neиral Networks, Oxford University, England, Jиly 1995.
236. СуЬеnkо G. "Aproximation Ьу sиperpositions of а sigmoidal function", Mathe
matics of Control, Signals and Systems, 1989, уоl. 2, р. 303 314.
237. Cybenko G. "Aproximation Ьу sиperpositions of а sigmoidal function", Urbal1a,
IL.: University ofIl1inois, 1988.
238. Darken С. and J. Moody. "Towards faster stochastic gradient search", Advances
in Neиral Information Processing Systems, 1992, уоl. 4, р. 1009 1016, San
Mateo, СА: Morgan Kaиfmann.
239. Darmois G. "Analyse generale des liaisons stochastiqиes", Rev. Inst. Intemal
Stat., 1953, уоl. 21, р. 2 8.
240. Dasarathy В.У. ed. Nearest Neighbor (NN) Norms: NN Pattem Classification
Techniqиes, Los Alamitos, СА: ШЕЕ Compиter Society Press, 1991.
241. Daиbechies 1. "The wavelet transform, time freqиency", ШЕЕ Transactions оп
Information Theory, 1990, уоl. IТ 36, р. 961 1005.
242. Daиbechies 1. Теп Lectиres оп Wavelets, SIAM, 1992.
243. Davis P.J. Interpolation and Aproximation, New York: Blaisdell, 1963.
244. Оауап Р. and G.E. Hinton. "Varieties ofHelmholtz machine", Neural Networks,
1996, уоl. 9, р. 1385 1403.
245. Оауап Р., G.E. Hinton, R.M. Neal and R.S. Zemel. "The Helmholtz machine",
Neиral Compиtation, 1995, уоl. 7, р. 889 904.
246. Debnath L. and Р. Mikиsinski. Introdиction to Hilbert Spaces with Aplications,
New York: Academic Press, 1990.
247. Оесо G., W. Finnoff and H.G. Zimmermann. "Unsиpervised mиtиal informa
tion criteria for elimination of overtraining in sиpervised mиltilayer networks",
Neиral Compиtation, 1995, уоl. 7, р. 86 107.
248. Оесо G. and О. Obradovic. Ап Information Theoretic Aproach to Neural Com
pиting, New York: Springer, 1996.
Библиоrрафия 1011
249. de Figиeiredo R.J.P. "Implications and aplications of Kolmogorov's sиperpo
sition theorem", ШЕЕ Transactions оп Aиtomatic Control, 1980, уоl. AC 25,
р. 1227 1230.
250. de Figиeiredo R.J.P. and G. Chen. Nonlinear Feedback Control Systems, New
York: Academic Press, 1993.
251. DeMers О. and G. Cottrell. "Non linear dimensionality redиction", Advances in
Neиral Information Processing Systems, 1993, уоl. 5, р. 580 587. San Mateo,
СА: Morgan Kaиfmann.
252. Dempster А.Р., N.M. Laird and О.В. Rиbin. "Maximиm likelihood from in
complete data via the ЕМ algorithm", (with discиssion), Joиmal of the Royal
Statistical Society., 1977, В, уоl. 39, р. 1 38.
253. Denardo Е.У. "Contraction mapings in the theory иnderlying dynamic program
ming", SIAМ, Review, 1967, уоl. 9, р. 165 177.
254. DeSieno, О. "Adding а conscience to competitive leaming", ШЕЕ Intemational
Conference оп Neиral Networks, 1988, уоl. 1, р. 117 124, San Diego, СА.
255. deSilva C.J.S. and У Attikioиzel. "Hopfield networks as discrete dynamical
systems", Intemational Joint Conference оп Neиral Networks, 1992, уоl. Ш,
р. 115 120, Baltimore.
256. deVries В. and J.C. Principe. "The gamma model А new neиral model for
temporal processing", Neural Networks, 1992, уоl. 5, р. 565 576.
257. Devroye L. "Exponential ineqиalities in nonparametric estimation", in Non
parametric Fиnctional Estimation and Related Topics, G. Roиssas, ed., 1991,
р. 31 44. Boston: Кlиwer.
258. Diamantaras K.I. and S.Y. Kиng. Principal ComponentNeural Networks: Theory
and Aplications, New York: Wiley, 1996.
259. Dohrmann C.R., H.R. Bиsby and О.М. Trиjillo. "Smoothing noisy data иsing
dynamic programming and generalized cross validation", Joиmal ofBiomechan
ical Engineering, 1988, уоl. 110, р. 37 1.
260. Оотапу Е., J.L. уап Неттеп and К. Schиlten, eds. Models ofNeиral Networks,
New York: Springer Verlag, 1991.
261. Оопу R.D. and S. Haykin. "Image segmentation иsing а mixtиre of principal
components representation", ШЕ Proceedings (London), Image and Signal Pro
cessing, 1997, уоl. 144, р. 73 80.
262. Оопу R.D. and S. Haykin. "Optimally adaptive transform coding", ШЕЕ Trans
actions оп Image Processing, 1995, уоl. 4, р. 1358 1370.
263. Ооmу C.N. А Vector Space Aproach to Models and Optimization, New York:
Wiley (Interscience), 1975.
264. Doиglas S.C. and S. Haykin. "Оп the relationship between blind deconvolи
tion and blind source separation", Thirty First Asilomar Conference оп Signals,
Systems and Compиters, Pacific Grove, Califomia, November, 1997.
1012 Библиоrрафия
265. Ооуlе J.c., К. Glover, Р. Кhargonekar and В. Francis. "State space solиtions
to standard Н2 and НОО control problems", ШЕЕ Transactions оп Aиtomatic
Control, 1989, уоl. AC 34, р. 831 847.
266. Drиcker Н., С. Cortes, L.D. Jackel and У. LeCиn. "Boosting and other ensemble
methods", Neиral Compиtation, 1994, уоl. 6, р. 1289 1301.
267. Drиcker Н., R.E. Schapire and Р. Simard. "Improving performance in пеиrаl net
works иsing а boosting algorithrn", Advances in Neиral Information Processing
Systems, 1993, уоl. 5, р. 42 9, Cambridge, МА: MIТ Press.
268. Dиbois О. and Н. Prade. Fиzzy Sets and Systems: Theory and Aplications, New
York: Academic Press, 1980.
269. Dиda R.O. and Р.Е. Hart. Pattem Classification and Scene Analysis, New York:
Wiley, 1973.
270. Dиnford N. and J.T. Schwartz. Linear Operators, Part 1, New York: Wiley, 1966.
271. ОшЫп R., С. Miall and G. Mitchison, eds. The Compиtil1g Neиron, Reading,
МА: Addison Wesley, 1989.
272. ОшЫп R. and О.Е. Rиmelhart. "Prodиct иnits: А compиtationally powerful and
biologically plaиsible extension to backpropagation l1etworks", Neural Союри
tation, 1989, уоl. 1, р. 133 142.
273. ОиrЫп R. and О. Willshaw. "Ап analogиe aproach to the travelling salesman
problem иsing ап elastic net method", Natиre, 1987, уоl. 326, р. 689 691.
274. Оуп N. "Interpolation of scattered data Ьу radial functions", in Topics in Mиl
tivariate Aproximation, С.к. Chиi, L.L. Schиmaker and F.I. Uteras, eds., 1987,
р. 47 61, Orlando, FL: Academic Press.
275. Edelman G.M. Neural Darwinism, New York: Basil Books, 1987.
276. Edelman G.M. "Antibody strиctиre al1d molecиlar immиnology", Science, 1973,
уоl. 180, р. 830 840.
277. Еесkrпап р.н. "The sigmoid nonlinearity in prepyriform cortex", Neиral 111for
mation Processing Systems, 1988, р. 242 248, New York: American Institиte of
Physics.
278. Еесkrпап F.H. and W.J. Freeman. "The sigmoid nonlinearity in neиral compиta
tion: Ап experimental aproach", Neural Networks for Compиting, J.S. Denker,
ed., 1986, р. 135 145, New York: American Institиte ofPhysics.
279. Eggermont J.J. The Сопеlаtivе Brain: Theory and Experiment il1 Neural Inter
action, New York: Springer Verlag, 1990.
280. Еl Нihi S. and У. Bengio. "Нierarchical rесипепt пешаl networks for 1011g term
dependencies", Advances in Neural Information Processing Systems, 1996, уоl.
8, р. 493 499, MIТ Press.
281. Elman J.L. "Finding strиctиre in time", Cognitive Science, 1990, уоl. 14, р. 179
211.
Библиоrрафия 1013
282. Еlтап J.L., Е.А. Bates, М.Н. Johnson, А. Karmiloff Smith, О. Parisi and К.
Plиnkett. Rethinking Innateness: А Connectionist Perspective оп Developmel1t,
Cambridge, МА: MIТ Press, 1996.
283. Erwin Е., К. Obermayer and К. Schиlten. "Models of orientation and ocиlar
dominance colиrnns in the visиal cortex: А critical comparison", Neиral Сою
pиtation, 1995, уоl. 7, р. 425 68.
284. Erwin Е., К. Obermayer and К. Schиlten. "1: Self organizing maps: Stationary
states, metastability and convergence rate", Biological Cybemetics, 1992, уоl.
67, р. 35 5.
285. Erwin Е., К. Obermayer and К. Schиlten. "11: Self organizing maps: Orderil1g,
convergence properties and energy functions", Biological Cybemetics, 1992Б,
уоl. 67, р. 47 55.
286. Faggin F. "VLSI implementation of пешаl networks", Tиtorial Notes, 111tema
tional Joint Conference оп Neural Networks, Seattle, 1991.
287. Faggin F. and С. Mead. "VLSI Implementation ofNeиral Networks", An Intro
dиction to Neиral and Electronic Networks, S.F. Zometzer, J.L. Davis al1d С.
Laи, eds., 1990, р. 275 292, New York: Academic Press.
288. Fah1man S.E. and С. Lebiere. "The саsсаdе сопеlаtiоп leaming architectиre",
Advances in Neural Information Processing Systems, 1990, уоl. 2, р. 52 532,
San Mateo, СА: Morgan Kaиfmann.
289. Farmer J.D. and J. Sidorowich. "Predicting chaotic time series", Physical Review
Letters, 1987, уоl. 59, р. 845 848.
290. Feldkamp L.A. and G.V. Pиskoriиs. "Adaptive behavior [rom fixed weight net
works", Information Sciences, 1997, уоl. 98, р. 217 235.
291. Feldkamp L.A. and G.V. Pиskoriиs. "А sigl1al processing framework based 011
dynamic neиral networks with aplication to problems in adaptation, filteril1g and
classification", Proceedings of the ШЕЕ, 1998, уоl. 86.
292. Feldkamp L.A., G.V. Pиskoriиs and Р.с. Moore. "Adaptation from fixed weight
networks", Information Sciences, 1997, уоl. 98, р. 217 235.
293. Feldraan J.A. "Natиral compиtation and artificial intelligel1ce", Plenary Lectиre
presented at the Intemational Joint Conference оп Neиral Networks, Baltimore,
1992.
294. Feller W., 1968. Ап Introdиction to Probability Theory al1d its Aplications, уоl.
1, 3rd edition, New York: John Wiley; 1st edition, 1950.
295. Fisch1er М.А. and О. Firschein. Intelligence: The Еуе, The Brain and The
Compиter, Reading, МА: Addison Wesley, 1987.
296. Fisher R.A. "Theory of statistical estimation", Proceedings of the Cambridge
Philosophical Society, 1925, уоl. 22, р. 700 725.
1014 Библиоrрафия
297. Fix Е. and J.L. Hodges. "Discriminatory analysis: Nonparametric discrimination:
Consistency properties", USAF School of Aviation Medicine, 1951, Project 21
49 004, Report по. 4, р. 261 279, Randolph Field, Texas.
298. Fletcher R. Practical Methods of Optimization, 2nd edition, New York: Wiley,
1987.
299. Fodor J.A. Modиlarity ofMind, Cambridge, МА: MIТ Press, 1983.
300. Fodor J.A. and Z.W. Pylyshyn. "Connectionism and cognitive architectиre: а
critical analysis", Cognition, 1988, уоl. 28, р. 3 72.
301. Foldiak Р. "Adaptive network for optimallinear featиre extractions", ШЕЕ In
temational Joint Conference оп Neиral Networks, 1989, уоl. 1, р. 401 05,
Washington, ос.
302. Forcada M.L. and R.C. Сапаsсо. "Leaming the initial state of а second order re
сипепt пеиrаl network dиring regиlar langиage inference", Neиral Compиtation,
1995, уоl. 7, р. 923 930.
303. Роmеу G.D., Jr. "The Viterbi algorithrn", Proceedings of the ШЕЕ, 1973, уоl.
61, р. 268 278.
304. Forte J.C. and G. Pages. "Оп the a.s. convergence of the Kohonel1 algorithm
with а general neighborhood function", Annals of Aplied Probability, 1995, уоl.
5, р. 1177 1216.
305. Forte J.C. and G. Pages. "Convergence of stochastic algorithrn: From the Kиsh
ner and Clark theorem to the Lyapиnov functional", Advances in Aplied Proba
bility, 1996, уоl. 28, р. 1 072 1094.
306. Frasconi Р., М. Gori and G. Soda. "Local feedback mиltilayered networks",
Neural Compиtation, 1992, уоl. 4, р. 12 130.
307. Frasconi Р. and М. Gori. "Compиtational capabilities of 10cal feedback recиr
rent networks acting as finite state machines", ШЕЕ Transactions оп Neиral
Networks, 1996, уоl. 7, р. 1521 1524.
308. Fraser А.М. "Information and entropy in strange attractors", ШЕЕ Transactions
оп Information Theory, 1989, уоl. 35, р. 245 262.
309. Freeman J.A. and О.М. Sakpиra. Neиral Networks: Algorithms, Aplications al1d
Programming Techniqиes, Reading, МА: Addison Wesley, 1991.
310. Freemal1 W.J. Societies of Brains. Hillsdale, NJ: Lawrence Erlbaиm, 1995.
311. Freeman W.J. "Tиtorial оп neиrobiology: From single neurons to brain chaos",
Intemational Joиmal ofBifurcation and Chaos in Aplied Sciences and Engineer
ing, 1992, уоl. 2, р. 451 82.
312. Freeman W.J. "The physiology ofperception", Scientific American, 1991, уоl.
264 (2), р. 78 85.
313. Freeman W.J. "Why пешаl networks don't yet fly: Inqиiry into the neurody
namics of biological intelligence", ШЕЕ Intemational Conference оп Neиral
Networks, 1988, уоl. II, р. 1 7, San Diego, СА.
Библиоrрафия 1015
314. Freeman W.J. "Simиlation of chaotic EEG pattems with а dynamic model of the
olfactory system", Biological Cybemetics, 1987, уоl. 56, р. 139 150.
315. Freeman W.J. Mass Action in the Nervoиs System, New York: Academic Press,
1975.
316. Fregnac У. and О. Schиlz. "Models of synaptic plasticity and cellиlar analogs
of leaming in the developing and adиlt vertebrate visиal cortex", Adval1ces in
Neиral and Behavioral Development, 1994, уоl. 4, р. 149 235, Norwood, NJ:
Neиral АЫех.
317. Freиnd У. "Boosting а week leaming algorithm Ьу majority", Information Сою
pиtation, 1995, уоl. 121, р. 256 285.
318. Freиnd У. and R.E. Schapire. "А decision theoretic generalization of on line
leaming and ап aplication to boosting", Joиmal of Compиter and System Sci
ences, 1997, уоl. 55, р. 119 139.
319. Freиnd У. and R.E. Schapire. "Experiments with а new boosting algorithm", Ma
chine Leaming: Proceedings of the Thirteenth Intemational Conference, 1996,
р. 148 156, Bari, Italy.
320. Freиnd У. and R.E. Schapire. "Game theory, On line prediction and boosting",
Proceedings ofthe Ninth Аппиаl Conference оп Compиtational Leaming Theory,
1996Б, р. 325 332, Desenzano del Garda, ltaly.
321. Friedman J.н. "An overview ofprediction leaming and function aproximation",
In У. Cherkassky, J.H. Friedman and Н. Wechsler, eds., From Statistics to Neиral
Networks: Theory and Pattem Recognition Aplications, New York: Springer
Verlag, 1995.
322. Fиkиnaga К. Statistical Pattem Recognition, 2nd edition, New York: Academic
Press, 1990.
323. Fиkиshima К. "Neocognitron: А model for visиal pattem recognition", in М.А.
Arbib, ed., The Hal1dbook of Brain Theory and Neural Networks, Cambridge,
МА: MIТ Press, 1995.
324. Fиkиshima К. "А hierarchical пешаl network model for selective attention", il1
Neural Compиters, R. Eckmiller and С. уоп der Malsbиrg, eds., 1988, р. 81 90,
NATO ASI Series, New York: Springer Verlag.
325. Fиkиshima К. "Neocognitron: А hierarchical пеиrаl network сараЫе of visиal
pattem recognition", Neиral Networks, 1988Б, уоl. 1, р. 119 130.
326. Fиkиshima К. "Neocognitron: А self organizing neиral network model for а
mechanism of pattem recognition иnaffected Ьу shift in position", Biological
Cybemetics, 1980, уоl. 36, 193 202.
327. Fиkиshima К. "Cognitron: А self organizing mиlti layered пеиrаl network",
Biological Cybemetics, 1975, уоl. 20, р. 121 136.
1016 Библиоrрафия
328. Fиkиshima К., S. Miyake and Т. Но. "Neocognitron: А neural network model
for а mechanism of visиal pattem recognition", ШЕЕ Transactions оп Systems,
Мап and Cybemetics, 1983, vol. SMC 13, р. 826 834.
329. Fиnahashi К. "Оп the aproximate realization of continиoиs mapings Ьу neиral
networks", Neural Networks, 1989, vol. 2, р. 183 192.
330. Gabor О. "Commиnication theory and cybemetics", lRE Transactions оп Circиit
Theory, 1954, vol. CT I, р. 19 31.
331. Gabor О., W.P.L. Wilby and R. Woodcock. "А иniversal non linear filter, pre
dictor and simиlator which optimizes itself Ьу а leaming process", Proceedings
of the Institиtion of Electrical Engineers, London, 1960, vol. 108, р. 422 35.
332. Galland С.С. "The limitations of deterministic Boltzmann machine leaming",
Network, 1993, vol. 4, р. 355 379.
333. Gallant A.R. and Н. White. "There exists а neиral network that does not make
avoidable mistakes", ШЕЕ Intemational Conference оп Neиral Networks, 1988,
уоl. 1, р. 657 664, San Diego, СА.
334. Gallant A.R. and Н. White. "Оп leaming the derivatives of ап иnknown maping
with mиltilayer feedforward networks", Neural Networks, 1992, vol. 5, р. 129
138.
335. Gallant S.I. Neиral Network Leaming and Expert Systems, Cambridge, МА:
MIТ Press, 1993.
336. Gallistel C.R. The Organization ofLeaming, Cambridge, МА: MIТ Press, 1990.
337. Gardner Е. "Maximиm storage capacity in neиral networks", Electrophysics
Letters, 1987, уоl. 4, р. 481 85.
338. Garey M.R. and D.S. Johnson. Compиters and Intractability, New York: w.н.
Freeman, 1979.
339. Gee А.Н. "Problem solving with optimization networks", Ph.D. dissertation,
University of Cambridge, 1993.
340. Gee А.Н., S.V.B. Aiyer and R. Prager. "Ап analytical framework for optimizing
пеиrаl networks", Neиral Networks, 1993, уоl. 6, р. 79 97.
341. Geisser S. "The predictive sample reиse method with aplications", Joиmal of
the American Statistical Association, 1975, vol. 70, р. 320 328.
342. Gelfand А.Е. and A.F.M. Smith. "Sampling based aproaches to calcиlating
marginal densities", Joиmal of the American Statistical Association, 1990, vol.
85, р. 398 09.
343. Geman S. and О. Geman. "Stochastic relaxation, Gibbs distribиtions and the
Bayesian restoration of images", ШЕЕ Transactions оп Pattem Analysis and
Machine Intelligence, 1984, уоl. PAMI 6, р. 721 741.
344. Geman S., Е. Bienenstock and R. Doиrsat. "Neиral networks and the
bias/variance dilemma", Neиral Compиtation, 1992, vol. 4, р. 1 58.
Библиоrрафия 1017
345. Gersho А. "Оп the strиctиre о f vector qиantizers", ШЕЕ Transactions оп Infor
mation Theory, 1982, vol. IТ 28, р. 157 166.
346. Gersho А. and R.M. Gray. Vector Qиantization and Signal Compression, Nor
well, МА: Кlиwer, 1992.
347. Gerstein G.L., Р. Bedenbaиgh and A.M.H.J. Aersten. "Neиral assemblies", ШЕЕ
Transactions оп Biomedical Engineering, 1989, уоl. 36, р. 4 14.
348. Gibbs J.W., 1902. "Elementary principles in statistical mechanics", reprodиced
in уоl. 2 of Collected Works of J. Willard Gibbs in Two Volиmes, New York:
Longmans, Green and Со., 1928.
349. Gibson G.J. and C.F.N. Cowan. "Оп the decision regions of mиltilayer percep
trons", Proceedings of the ШЕЕ, 1990, уоl. 78, р. 1590 1599.
350. Gidas В. "Global optimization via the Langevin eqиation", Proceedings of 24th
Conference оп Decision and Control, 1985, р. 774 778, Ft. Laиderdale, FL.
351. Giles C.L. "Dynamically driven rесипепt neиral networks: Models, leaming
algorithrns and aplications", Tиtorial #4, Intemational Conference оп Neиral
Networks, Washington, ОС, 1996.
352. Giles C.L., О. Chen, G.Z. Sиn, Н.Н. Chen, У.С. Lee and M.W. Goиdreaи. "Соп
strиctive leaming of rесипепt neиral networks: Limitations of rесипепt cascade
сопеlаtiоп with а simple solиtion", ШЕЕ Transactions оп Neural Networks,
1995, vol. 6, р. 829 836.
353. Giles C.L., Т. Lin and B.G. Ноmе. "Remembering the past: The role of ею
bedded memory in rесипепt neural network architectиres", Neural Networks for
Signal Processing, УII, Proceedings of the 1997 ШЕЕ Workshop, ШЕЕ Press,
1997, р. 34.
354. Giles C.L. and Т. Maxwell. "Leaming, invariance and generalization in higher
order neиral networks", Aplied Optics, 1987, vol. 26, р. 4972 978.
355. Giles C.L. and B.G. Ноmе. "Representation of leaming in rесипепt neиral
network architectиres", Proceedings of the Eighth Yale Workshop оп Adaptive
and Leaming Systems, 1994, р. 128 134, Yale University, New Науеп, Ct.
356. Giles C.L., С.В. Miller О. Chen, н.н. Chen, G.Z. Sиn and У.с. Lee. "Leam
ing and extracting finite state aиtomata with second order rесипепt пешаl net
works", Neural Compиtation, 1992, vol. 4, р. 393 05.
357. Giles C.L., G.Z. Sиn, Н.Н. Chen, У.С. Lee and О. Chen. "Higher order rесипепt
networks and grammatical inference", Advances in Neural Information Process
ing Systems, 1990, уоl. 2, р. 380 387, San Mateo, СА: Morgan Kaиfmann.
358. Gill Р., S. Hammarling, W. Мипау, М. Saиnders and М. Wright. "User's gиide
for LSSOL", Technical Report 86 1, Systems Optimization Laboratory, Stanford
University, Stanford, СА, 1986.
359. Gill Р. and W. Мипау. "Inertia control1ing methods for general qиadratic pro
gramming", SIAМ Review, 1991, vol. 33, р. 1 36.
1018 Библиоrрафия
360. Girosi F. and G. Anzellotti. "Rates of convergel1ce of aproximatiol1 Ьу trans
lates", A.I. Меmо 1288, Artificial Intel1igence Laboratory, MIТ Cambridge, МА,
1992.
361. Girosi F., М. Jones and Т. Poggio. "Regиlarization theory and пешаl networks
architectиres", Neural Compиtation, 1995, уоl. 7, р. 219 269.
362. Girosi F. and Т. Poggio. "Networks and the best aproximatiol1 property", Bio
10gical Cybemetics, 1990, уоl. 63, р. 169 176.
363. Glaиber R.J. "Тime dependent statistics ofthe Ising model", Joиmal ofMathe
matical Physics, 1963, уоl. 4, р. 294 307.
364. Goggin S.D.D., к.М. Johnson and К. Gиstafson. "Primary and recency effects
dиe to mоmепtиm in back propagation leaming", OCS Technical Report 89 25,
Boиlder, СО.: University of Colorado, 1989.
365. Golden R.M. Mathematical Methods for Neиral Network Analysis and Design,
Cambridge, МА: MIТ Press, 1996.
366. Golden R.M. "The ?Brain State in a Box? пешаl model is а gradient descent
algorithm", Joиmal ofMathematical Psychology, 1986, vol. 30, р. 73 80.
367. Goles Е. and S. Martinez. Neиral and Aиtomata Networks, Dondrecht, Тhe
Netherlands: Кlиwer, 1990.
368. Golиb G.H. and C.G. Уап Loan. Matrix Compиtations, 3rd edition, Baltimore:
Johns Hopkins University Press, 1996.
369. Goodman R.M., С.М. Нiggins, J.W. Miller and Р. Smyth. "Rиle based neural
networks for classification and probability estimation", Neиral Compиtation,
1992, уоl. 4, р. 781 804.
370. Gori М. and А. Tesi. "Оп the problem of local minima in backpropagation",
ШЕЕ Transactions оп Pattem Analysis and Machine Intel1igence, 1992, vol. 14,
р. 76 86.
371. Gorin А. "Network strиctиre, generalization and adaptive langиage acqиisition",
Proceedings of the Seventh Уаlе Workshop оп Adaptive and Leaming Systems,
1992, р. 155 160, Уаlе University, New Науеп, СТ.
372. Goиdreaи M.W. and C.L. Giles. "Using rесипепt пеиrаl networks to lеаm the
strиctиre of interconnection networks", Neural Networks, 1995, уоl. 8, р. 793
804.
373. Goиdreaи M.W., C.L. Giles, S.T. Chakradhar and О. Chen. "First order vs.
second order single layer rесипепt neиral networks", ШЕЕ Transactions оп
Neural Networks, 1994, уоl. 5, р. 511 513.
374. Granger R., J. Whitson, J. Larson and G. Lynch. "Non Hebbian properties of
LTP епаЫе high capacity encoding of temporal seqиences", Proceedings of the
National Academy of Sciences of the U.S.A, 1994.
375. Grassberger 1. and 1. Procaccia. "Measиring the strangeness of strange attractors",
Physica О, 1983, уоl. 9, р. 189 208.
Библиоrрафия 1019
376. Graиbard S.R., ed. The Artificial Intelligence Debate: False Starts, Real Роип
dations, Cambridge, МА: MIТ Press, 1988.
377. Gray R.M. Entropy and Information Theory, New York: Springer Verlag, 1990.
378. Gray R.M. Probability, Random Processes and Ergodic Properties, New York:
Springer Verlag, 1988.
379. Gray R.M. "Vector qиantization", ШЕЕ ASSP Magazine, 1984, уоl. 1, р. 4 29.
380. Gray R.M. and L.D. Davisson. Random Processes: А Mathematical Aproach for
Engineers, Englewood Cliffs, NJ: Prentice Hall, 1986.
381. Green М. and D.J.N. Limebeer. Linear Robиst Control, Englewood Cliffs, NJ:
Prentice Hall, 1995.
382. Greenberg H.J. "Eqиilibria of the brain state in a box (BSB) neиral model",
Neиral Networks, 1988, уоl. 1, р. 323 324.
383. Gregory R.L. The Intel1igent Еуе, Wiedefeld and Nicholson, London, 1970.
384. Grenander U. Tиtorial in Pattem Theory, Brown University, Providence, R.I.,
1983.
385. Grewal M.S. and А.Р. Andrews. Kalmal1 Filtering: Theory and Practice, Engle
wood Cliffs, NJ: Prentice Hall, 1993.
386. Griffiths L.J. and C.W. Лю. "An altemative aproach to linearly constrained
optimиm beamforming", ШЕЕ Transactions оп Antennas and Propagation, 1982,
уоl. АР зо, р. 27 34.
387. Grossberg S. "Content addressable memory storage Ьу neиral networks: А gen
eral model and global Liapиnov method", In Compиtational Neиroscience, E.L.
Schwartz, ed., 1990, р. 56 65, Cambridge, МА: MIТ Press.
388. Grossberg S. "Competitive leaming: From interactive activation to adaptive
resonance", in Neиral Networks and Natиral Intelligence, S. Grossberg, ed.,
Cambridge, МА: MIТ Press, 1988.
389. Grossberg S.Z. Neиral Networks and Natиral Intelligence, Cambridge, МА: MIТ
Press, 1988Б.
390. Grossberg S. "Nonlinear пешаl networks: Principles, mechanisms and architec
tиres", Neиral Networks, 19886, уоl. 1, р. 17 61.
391. Grossberg S. Stиdies ofMind and Brain, Boston: Reidel, 1982.
392. Grossberg S. "How does а brain bиild а cognitive code"? Psychological Review,
1980, уоl. 87, р. 1 51.
393. Grossberg S. "Decision, pattems and oscillations in the dynamics of competitive
systems with aplication to Vоltепа Lоtkа systems", J. Theoretical Biology, 1978,
уоl. 73, р. 10l 130.
394. Grossberg S. "Competition, decision and consensиs", J. Mathematical Analysis
and Aplications, 1978Б, уоl. 66, р. 470 93.
1020 Библиоrрафия
395. Grossberg S. "Pattem formation Ьу the g1obal1imits of а nonlinear competitive
interaction in n dimensions", J. Mathematical Biology, 1977, уоl. 4, р. 237 256.
396. Grossberg S. "Adaptive pattem classification and иniversal receding: 1. Parallel
development and coding ofneиral detectors", Biological Cybemetics, 1976, уоl.
23, р. 121 134.
397. Grossberg S. "Adaptive pattem classification and иniversal receding: 11. Feed
back, expectation, olfaction, illиsions", Biological Cybemetics, 1976Б, уоl. 23,
р. 187 202.
398. Grossberg S. "Neиral expectation: Cerebellar and retinal analogs of cells fired
Ьу lеаmаЫе or иnleamed pattem classes", Kybemetik, 1972, vol. 10, р. 49 57.
399. Grossberg S. "А prediction theory for some nonlinear functional difference eqиa
tions", Joиmal ofMathematical Analysis and Aplications, 1969, уоl. 22, р. 490
522.
400. Grossberg S. "Оп leaming and energy entropy dependence in rесипепt and
поnrесипепt signed networks", Joиmal of Statistical Physics, 1969Б, уоl. 1,
р. 319 350.
401. Grossberg S. "А prediction theory for some nonlinear functional difference eqиa
tions", Joиmal ofMathematical Analysis and Aplications, 1968, уоl. 21, р. 643
694, уоl. 22, р. 490 522.
402. Grossberg S. "Nonlinear difference differential eqиations in prediction and
leaming theory", Proceedings ofthe National Academy ofSciences, 1967, USA,
уоl. 58, р. 1329 1334.
403. Gиpta М.М. and N.к. Sinha, eds. Intelligent Control Systems: Theory and
Aplications, New York: ШЕЕ Press, 1996.
404. Gиyon 1. Neиral Networks and Aplications, Compиter Physics Reports, Amster
dam: Elsevier, 1990.
405. Haffner Р. "А new probabilistic framework for connectionist time alignment",
Proceedings ofICSLP 94, 1994, р. 1559 1562, Yokohama, Japan.
406. Haffner Р., М. Franzini and А. Waibel. "Integrating time alignment and neиral
networks for high performance continиoиs speech recognition", Proceedings of
ШЕЕ ICASSP 91, 1991, р. 105 108.
407. Haft М. and J.L. уап Неюmеп. "Theory and implementations of infomax filters
for the retina", Network: Compиtations in Neural Systems, 1998, уоl. 9, р. 39
71.
408. Hagiwara М. "Theoretical derivation of mоmепtит term in back propagation",
Intemational Joint Conference оп Neиral Networks, 1992, уоl. 1, р. 682 686,
Baltimore.
409. Hajek В. "А tиtorial sиrvey of theory and aplications of simиlated annealing",
Proceedings of the 24th Conference оп Decision and Control, ШЕЕ Press, 1985,
р. 755 760, Ft. Laиderdale, Рlа.
Библиоrрафия 1021
410. Hajek В. "Cooling schedиles for optimal annealing", Mathematics ofOperations
Research, 1988, vol. 13, р. 311 329.
411. Hammerstrom О. "Neural networks at work", ШЕЕ Spectrиm, 1993, vol. 30,
по. 6, р. 26 32.
412. Hammerstrom О. "Working with пешаl networks", ШЕЕ Spectrиm, 1993Б, уоl.
30, по. 7, р. 46 53.
413. Hammerstrom О. and S. Rahfuss. "Neurocompиting hardware: Present and
futиre", Swedish National Conference оп Connectionism, Skovade, Sweden,
September, 1992.
414. Hampshire J.B. and В. Pearlmиtter. "Eqиivalence proofs for mиltilayer percep
tron classifiers and Bayesian discriminant function", Proceedings of the 1990
Connectionist Models Sиmmer School, 1990, р. 159 172, San Mateo, СА: Mor
gan Kaиfmann.
415. Hampson S.E. Connectionistic Problem Solving: Compиtational Aspects ofBi
ological Leaming, Berlin: Birkh(иser, 1990.
416. Hancock P.J.B., R.J. Baddeley and L.S. Smith. "The principal components of
natиral images", Network, 1992, уоl. 3, р. 61 70.
417. Hanson L.к. and Р. Solamon. "Neиral network ensembles", ШЕЕ Transactions
оп Pattem Analysis and Machine Intel1igence, 1990, уоl. PAМI 12, р. 993 1 002.
418. Hiirdle W. Aplied Nonparametric Regression, Cambridge: Cambridge University
Press, 1990.
419. Hardy R.L. "Mиltiqиadric eqиations oftopography and other iпеgиlаr surfaces",
Joиmal ofGeophysics Research, 1971, уоl. 76, р. 1905 1915.
420. Harel О. "Algorithmics: The Spirit of Compиting", Reading, МА: Addison
Wesley, 1987.
421. Hartline Н.к. "The receptive fields of optic nerve fibers", American Joиmal of
Physiology, 1940, уоl. 130, р. 690 699.
422. Hartman Е. "А high storage capacity neиral network content addressable юею
ory", Network, 1991, уоl. 2, р. 315 334.
423. Hartman, E.J., J.D. Keeler and J.M. Kowalski. "Layered neиral networks with
Gaиssian hidden иnits as иniversal aproximators", Neиral Compиtation, 1990,
vol. 2, р. 210 215.
424. Hashem S. "Optimal1inear combinations ofneиral networks", Neиral Networks,
1997, vol. 10, р. 599 614.
425. Hassibi В., А.Н. Sayed and Т. Kailath. Indefinite Qиadratic Estimation and
Control: А Unified Aproach to Н2 and Н? Theories, SIAМ, 1998.
426. Hassibi В., А.Н. Sayed and Т. Kailath. "The Н ОО optimality of the LMS algo
rithm", ШЕЕ Transactions оп Signal Processing, 1996, уоl. 44, р. 267 280.
1022 Библиоrрафия
427. Hassibi В., А.н. Sayed and Т. Kailath. "LMS is Н ОО optimal", Proceedings of
the ШЕЕ Conference оп Decision and Control, 1993, р. 74 79, San Antonio,
Texas.
428. Hassibi В., D.G. Stork and G.J. Wolff. "Optimal brain sиrgeon and general
network prиning", ШЕЕ Intemational Conference оп Neиral Networks, 1992,
уоl. 1, р. 293 299, San Francisco.
429. Hassibi В. and Т. Kailath. "Н? optimal training algorithms and their relation to
back propagation", Advallces in Neиral Information Proccessing Systems, 1995,
уоl. 7, р. 191 198.
430. Hastie Т. and W. Stиetzle. "Principal cиrves", Joиmal ofthe American Statistical
Association, 1989, уоl. 84, р. 502 516.
431. Hastings W.к. "Monte Carlo sampling methods иsing Markov chains and their
aplications", Biometrika, 1970, уоl. 87, р. 97 109.
432. Haиssler О. "Qиantifying indиctive bias: АI leaming algorithms and Valiant's
leaming framework", Artificial Intel1igence, 1988, уоl. 36, р. 177 221.
433. Hawkins R.D. and G.H. Bower, eds. Compиtational Models of Leaming in
Simple Neural Systems, San Diego, СА: Academic Press, 1989.
434. Haykin S. Adaptive Filter Theory, 3rd edition, Englewood Cliffs, NJ: Prentice
Наll, 1996.
435. Haykin S. "Neиral networks expand SP's horizons", ШЕЕ Signal Processing
Magazine, 1996Б, уоl. 13, по. 2, р. 2 29.
436. Haykin S., ed. Вlind Deconvolиtion, Englewood Cliffs, NJ: Prentice Hall, 1994.
437. Haykin S. Commиnication Systems, 3rd edition, New York: John Wiley, 1994Б.
438. Haykin S. "Blind eqиalization formиlated as а self organized leaming process",
Proceedings ofthe Twenty Sixth Asilomar Conference оп Signals, Systems and
Compиters, 1992, р. 346 350, Pacific Grove, СА.
439. Haykin S. and С. Deng. "Classification of radar clиtter иsing пешаl networks",
ШЕЕ Transactions оп Neиral Networks, 1991, уоl. 2, р. 589 600.
440. Haykin S. and В. Kosko, eds. Special Issиe of Proceedings of the ШЕЕ оп
Intelligent Signal Processing, 1998, уоl. 88.
441. Haykin S. and J. Principe. "Making sense of а complex world: Using пешаl
networks to dynamically model chaotic events sиch as sea clиtter", ШЕЕ Signal
Processing Magazine, 1998, уоl. 15.
442. Haykin S., W. Stehwien, Р. Weber, С. Deng and R. Мапп. "Classification of
radar clиtter in air traffic control environment", Proceedings of the ШЕЕ, 1991,
уоl. 79, р. 741 772.
443. Haykin S., Р. Уее and Е. Derbez. "Optimиm nonlinear filtering", ШЕЕ Transac
tions оп Signal Processing, 1997, уоl. 45, р. 277 2786.
444. Haykin S. and В. Уап Уееп. Signals and Systems, New York: Wiley, 1998.
Библиоrрафия 1023
445. НеЬЬ О.О. The Organization of Behavior: А Neиropsychological Theory, New
York: Wiley, 1949.
446. Hecht Nielsen R. "Replicator neиral networks for иniversal optimal soиrce cod
ing", Science, 1995, уоl. 269, р. 1860 1863.
447. Hecht Nielson R., 1990. Neиrocompиting, Reading, МА: Addison Wesley.
448. Hecht Nielson R. "Kolmogorov's maping neиral network existence theorem",
First ШЕЕ Intemational Conference оп Neиral Networks, 1987, уоl. Ш, р. 11
14, San Diego, СА.
449. Helstrom C.W. Statistical Theory of Signal Detection, 2nd edition, Pergamon
Press, 1968.
450. Heraиlt J. and С. Jиtten. Reseaиx Neuronaиx et Traitement dи Signal, Paris:
Hermes pиblishers, 1994.
451. Heraиlt J. and С. Jиtten. "Space or time adaptive signal processing Ьу neиral
network models", in J.S. Denker, ed., Neиral Networks for Compиting. Proceed
ings of the AIP Conference, American Institиte of Physics, New York, 1986,
р. 206 211.
452. Heraиlt J., С. Jиtten and В. Ans. "Detection de grandeиrs primitives dans ип mes
sage composite par ипе architectиre de calcиl neuromimetiqиe ип aprentissage
поп sиpervise", Procedиres of GRETSI, Nice, France, 1985.
453. Hertz J., А. Кrogh and R.G. Palmer. Introdиction to the Theory of Neиral
Compиtation, Reading, МА: Addison Wesley, 1991.
454. Hestenes M.R. and Е. Stiefel. "Methods of conjиgate gradients for solving linear
systems", Joиmal of Research of the National Вшеаи of Standards, 1952, уоl.
49, р. 409 36.
455. Hetherington Р.А. and M.L. Shapiro. "Simиlating НеЬЬ сеll assemblies: The
necessity for partitioned dendritic trees and а post not pre LTD rиle", Network,
1993, уоl. 4, р. 135 153.
456. Hiller F.S. and G.J. Lieberman. Introdиction to Operations Research, 6th edition,
New York: McGraw Hill, 1995.
457. Hinton G.E. "Connectionist leaming procedиres", Artificial Intelligence, 1989,
уоl. 40, р. 185 234.
458. Hinton G.E. "Deterministic Boltzmann machine leaming performs steepest de
scent in weighHpace", Neиral Compиtation, 1989, vol. 1, р. 143 150.
459. Нinton G.E. "Shape representation in parallel systems", Proceedings of the
7th Intemational Joint Conference оп Artificial Intelligence, Vancoиver, British
СоlитЫа, 1981.
460. Нinton G.E., Р. Оауап, B.J. Frey and R.M. Neal. "The 'wake sleep' algorithm
for иnsиpervised пешаl networks", Science, 1995, уоl. 268, р. 1158 1161.
1024 Библиоrрафия
461. Hinton G.E. and Z. Ghahramani. "Generative models for discovering sparse
distribиted representations", Philosophical Transactions of the Royal Society,
Series В, 1997, уоl. 352, р. 1177 1190.
462. Нinton G.E. and S.J. Nowlan. "The bootstrap Widrow Hoff rиle as а clиster
formation algorithm", Neиral Compиtation, 1990, уоl. 2, р. 355 362.
463. Hinton G.E. and S.J. Nowlan. "How leaming сап gиide evolиtion", Complex
Systems, 1987, уоl. 1, р. 495 502.
464. Hinton G.E. and T.J. Sejnowski. "Leaming and releaming in Boltzmann ma
chines", in Parallel Distribиted Processing: Explorations in Microstrиctиre of
Cognition, О.Е. Rиmelhart and J.L. McClelland, eds., Cambridge, МА: MIТ
Press, 1986.
465. Hinton G.E. and T.J. Sejnowski. "Optimal perceptиal inference", Proceedings of
ШЕЕ Compиter Society Conference оп Compиter Vision and Pattem Recogni
tion, 1983, р. 448 53, Washington, ОС.
466. Hirsch M.W. "Convergent activation dynamics in continиoиs time networks",
Neиral Networks, 1989, уоl. 2, р. 331 349.
467. Нirsch M.W. "Convergence in neиral nets", First ШЕЕ Intemational Conference
оп Neиral Networks, 1987, уоl. 11, р. 115 125, San Diego, СА.
468. Hirsch M.W. and S. Smale. Differential Eqиations, Dynamical Systems and
Linear Algebra, New York: Academic Press, 1974.
469. Hochreiter S. Untersиchиngen zи dynamischen neиronalen Netzen, Diploma
Thesis, Technische Universitiit Munchen, Germany, 1991.
470. Hochreiter S. and 1. Schmidhиber. "LSTM сап solve hard 10ng time lag prob
lems", Advances in Neиral Information Processing Systems, 1997, уоl. 9, р. 473
479, Cambridge, МА: MIТ Press.
471. Hodgkin A.L. and А.Р. Hиxley. "А qиantitative description of membrane сипепt
and its aplication to condиction and excitation in nerve", Joиmal of Physiology,
1952, уоl. 117, р. 500 544.
472. Holden S.B. and М. Niranjan. "Оп the practical aplicability of Vapnik
Chervonenkis dimension boиnds", Neиral Compиtation, 1995, уоl. 7, р. 1265
1288.
473. Holland J.R. Adaptation in Natиral and Artificial Systems, Cambridge, МА:
MIТ Press, 1992.
474. Hopcroft J. and U. Ullman. lntrodиction to Aиtomata Theory, Langиages and
Compиtation, Reading, MA:Addison Wesley, 1979.
475. Hopfield J.J. "Pattem recognition compиtation иsing action potential timing for
stimиlиs representation", Natиre, 1995, уоl. 376, р. 33 36.
476. Hopfield J.1. "Neurons, dynamics and compиtation", Physics Today, 1994, уоl.
47, р. 40 46, Febrиary.
!
Библиоrрафия 1025
477. Hopfield J.J. "Networks, Compиtations, Logic and Noise", ШЕЕ Intemational
Conference оп Neural Networks, 1987, уоl. 1, р. 107 141, San Diego, СА.
478. Hopfield J.J. "Leaming algorithrns and probability distribиtions in feed forward
and feed back networks", Proceedings of the National Academy of Sciences,
USA, 1987Б, уоl. 84, р. 8429 8433.
479. Hopfield J.J. "Neиrons with graded response have collective compиtational prop
erties like those of two state neиrons", Proceedings of the National Academy of
Sciences, USA, 1984, уоl. 81, р. 3088 3092.
480. Hopfield J.J. "Neиral networks and physical systems with emergent collective
compиtational abilities", Proceedings of the National Academy of Sciences,
USA, 1982, уоl. 79, р. 2554 2558.
481. Hopfield J.J. and D.W. Таnk. "Compиting with neиral circиits: А model", Sci
епсе, 1986, уоl. 233,р. 625 633.
482. Hopfield J.J. and т.w. Tank. "'Neиral' compиtation of decisions in optimization
problems", Biological Cybemetics, 1985, уоl. 52, р. 141 152.
483. Hopfield J.J., D.I. Feinstein and R.G. Palmer. '''Unleaming' has а stabilizing
effect in collective memories", Natиre, 1983, vol. 304, р. 158 159.
484. Ноm В.к.Р. "Understanding image intensities", Artificial Intelligence, 1977, уо!.
8, р. 20l 237.
485. Homik к., М. Stinchcombe and Н. White. "Universal aproximation of ап ип
known maping and its derivatives иsing mиltilayer feedforward networks", Neи
ral Networks, 1990, уоl. 3, р. 551 560.
486. Homik к., М. Stinchcombe and Н. White. "Mиltilayer feedforward networks
are иniversal aproximators", Neиral Networks, 1989, уоl. 2, р. 359 366.
487. Hotteling Н. "Analysis ofa соmрlех ofstatistical variables into principal compo
nents", Joиmal of Edиcational Psychology, 1933, vol. 24, р. 417 441, 498 520.
488. НиЬеl О.Н. Еуе, Brain and Vision, New Y9rk: Scientific American Library,
1988.
489. НиЬеl О.Н. and т.N. Wiesel. "Fиnctional architectиre ofmacaqиe visиal cortex",
Proceedings ofthe Royal Society, В, 1977, уоl. 198, р. 1 59, London.
490. НиЬеl О.Н. and T.N. Wiesel. "Receptive fields, binocиlar interaction and func
tional architectиre in the cat's visиal cortex", Joиmal of Physiology, 1962, уоl.
160, р. 106 154, London.
491. Hиber P.J. "Projection pursиit", Annals of Statistics, 1985, уоl. 13, р. 435 75.
492. Hиber P.J. Robиst Statistics, New York: Wiley, 1981.
493. Hиber P.J. "Robиst estimation of а 10cation parameter", Annals ofMathematical
Statistics, 1964, уоl. 35, р. 73 101.
494. Hиsh D.R. "Leaming from examples: From theory to practice", Tиtorial #4,
1997 Intemational Conference оп Neиral Networks, Hoиston, Jиne, 1997.
1026 Библиоrрафия
495. Hиsh D.R. al1d B.G. Ноmе. "Progress il1 sиpervised l1eиrall1etworks: What's
l1ew sil1ce Lipmann"? ШЕЕ Signa1 Processil1g Magazil1e, 1993, vo1. 10, р. 8 39.
496. Hиsh D.R. and J.M. Sa1as. "Improvil1g the 1eamil1g rate of back propagatiol1
with the gradiel1t reиse a1gorithm", ШЕЕ 111tematiol1a1 COl1ferel1ce 011 Neura1
Networks, 1988, vo1. 1, р. 441 47, Sal1 Diego, СА.
497. Illil1gswOrth У., E.L. Glaser al1d I.C. Py1e. Dictiol1ary ofCompиtil1g, New York:
Oxford Ul1iversity Press, 1989.
498. 111trator N. "Featиre extractiol1 иSil1g аl1 иl1sиpervised l1eиrall1etwork", Neura1
Compиtatiol1, 1992, vo1. 4, р. 98 107.
499. Jaakkola Т. al1d M.I. Jordal1. "Compиtil1g иper al1d 10wer bOиl1ds 011 1ikeli-
hoods in il1tractable l1etworks", in Е. Horwitz, ed., Workshop 011 Ul1certail1ty il1
Artificia1 111telligel1ce, Port1al1d, Or, 1996.
500. Jacksol1 Е.А. Perspectives of NOl1lil1ear DYl1amics, vo1. 1, Cambridge: Cam
bridge Ul1iversity Press, 1989.
501. Jacksol1 Е.А. Perspectives of Nonlil1ear Dynamics, vo1. 2, Cambridge: Cam
bridge Ul1iversity Press, 1990.
502. Jacksol1 I.R.H. "Ап order of cOl1vergel1ce for some radial basis functiol1s", lМA
Joиma1 ofNиmerica1 Al1a1ysis, 1989, vo1. 9, р. 567 587.
503. Jacksol1 J.D. Classica1 Electrodynamics, 211d editiol1, New York: Wiley, 1975.
504. Jacobs R.A. "Task Decompositiol1 Throиgh Compиtatiol1 il1 а Modиlar COl1l1ec
tiOl1ist Architectиre", РЬ.О. Thesis, Ul1iversity ofMassachиsetts, 1990.
505. Jacobs R.A. "Il1creased rates of convergel1ce throиgh 1eamil1g rate adaptation",
Neиra1 Networks, 1988, vo1. 1, р. 295 307.
506. Jacobs R.A. and M.I. Jordal1. "Leamil1g piecewise c0l1tro1 strategies il1 а modиlar
neиrall1etwork architectиre", ШЕЕ Transactiol1s 011 Systems, Маl1 al1d Cyber
l1etics, 1993 vo1. 23, р. 337 345.
507. Jacobs R.A. al1d M.I. Jordan. "А competitive modиlar cOl1l1ectionist architec
tиre", Advances in Neиra1 Information Processing Systems, 1991, уоl. 3, р. 767
773, San Mateo, СА: Morgan Kaиfmann.
508. Jacobs R.A., M.I. Jordan, S.J. Nowlan and G.E. Нil1tOl1. "Adaptive mixtиres of
10cal experts", Neural Compиtatiol1, 1991, vo1. 3, р. 79 87.
509. Jacobs R.A., M.I. Jordal1 and A.G. Barto. "Task decomposition throиgh compe
titiol1 il1 а modи1ar connectionist architectиre: ТЬе what and where visiol1 tasks",
Cogl1itive Sciel1ce, 1991Б, vo1. 15, р. 219 250.
510. Jayal1t N.S. al1d Р. Noll. Digita1 Codil1g ofWaveforms, El1g1ewood Cliffs, NJ:
Prel1tice Hall, 1984.
511. Jaynes Е. Т. "011 the rationa1e of maximиm el1tropy methods", Proceedil1gs of
the ШЕЕ, 1982, vo1. 70, р. 939 952.
Библиоrрафия 1027
512. Jaynes Е.т. "Information theory and statistical mechanics", Physical Review,
уоl. 106, р. 620 630; "Information theory and statistical mechanic 11", Physical
Review, 1957, vo1. 108, р. 171 190.
513. Jazwinski А.Н. Stochastic Processes and Filtering Theory, New York: Academic
Press, 1970.
514. Jelinek Е. Statistica1 Methods for Speech Recognition, Cambridge, МА: MIТ
Press, 1997.
515. Johansson Е.М., F.U. Dow1a and О.М. Goodman. "Back propagatiol1 leam
il1g for mиlti layer feedforward neura1 networks иSil1g the conjиgate gradient
method", Report UCRL JC 104850, Lawrel1ce Livermore Natiol1a1 Laboratory,
СА, 1990.
516. Johl1son D.S., C.R. Aragon, L.A. McGeoch al1d С. Schevol1. "Optimizatiol1 Ьу
simиlated anl1ealing: An experimel1ta1 eva1иatiol1", Operatiol1s Research, 1989,
уоl. 37, р. 865 892.
517. Jolliffe I.т. Pril1cipa1 Compol1ent Ana1ysis, New York: Spril1ger Verlag, 1986.
518. Jones J.P. and L.A. Palmer. "ТЬе two dimel1siol1a1 spatia1 strиctиre of simple
receptive fields in cat striate cortex", Joиmal ofNeиrophysiology, 1987, уоl. 58,
р. 1187 1211.
519. JOl1es J.P. and L.A. Palmer. "Аl1 evalиation of the two dimensiol1a1 Gabor filter
model of simple receptive fie1ds il1 cat striate cortex", Joиmal of Neurophysiol
ogy, 1987Б, уоl. 58, р. 1233 1258.
520. Jones J.P., А. Stepol1ski al1d L.A. Palmer. "ТЬе two dimel1siona1 spectral strиc
tиre of simple receptive fie1ds in cat striate cortex", Joиma1 ofNeurophysiology,
1987, уоl. 58, р. 1212 1232.
521. Jordan M.I. "А statistical aproach to decisiol1 tree modelil1g", Proceedil1gs of
the Seventh Аl1l1иаl АСМ Conferel1ce 011 Compиtatiol1al Leaming Theory, New
York: АСМ Press, 1994.
522. Jordan M.I. "Attractor dynamics al1d parallelism il1 а connectionist seqиential
machine", The Eighth Annиa1 Conference of the Cognitive Science Society,
1986, р. 531 546, Amherst, МА.
523. Jordan M.I., ed. Leaming in Graphica1 Mode1s, Boston: Кlиwer, 1998.
524. Jordan M.I., Z. Ghahramani, T.S. Jakkolla and L.к. Saиl. "Аl1 introdиctiol1
to variational methods for graphical models", In M.I. Jordan, ed., Leaming in
Graphical Models, Boston: Klиwer, 1998.
525. Jordan M.I. and R.A. Jacobs. "Modиlar and Нierarchical Leamil1g Systems", in
М.А. Arbib, ed., The Handbook of Brain Theory and Neиral Networks, 1995,
р. 579 583, Cambridge, МА: MIТ Press.
526. Jordal1 M.I. and R.A. Jacobs. "Hierarchical mixtиres of experts and the ЕМ
algorithm", Neиral Compиtation, 1994, vo1. 6, р. 181 214.
1028 Библиоrрафия
527. Jordan M.I. al1d R.A. Jacobs. "Нierarchies of adaptive experts", Advances in
Neиra1 Information Processil1g Systems, 1992, уоl. 4, р. 985 992, Sal1 Mateo,
СА: Morgan Kaиfmann.
528. Joseph R.D. "The nиmber of orthants il1l1 space il1tersected Ьу an s dimensiona1
sиbspace", Technica1 Меmо 8, Project PARA, Соmеll Aeronaиtica1 Lab., Bиf
fa1o, NY, 1960.
529. Jиtten С. al1d J. Heraиlf. "Вlind separation of soиrces, Part 1: Ап adaptive
algorithrn based оп neиromimetic architectиre", Signa1 Processing, 1991, уоl.
24, р. 1 10.
530. Kaas J.R., М.М. Merzenich al1d Н.Р. Killackey. "ТЬе reorgal1ization of so
matosensory cortex followil1g periphera1 nerve damage in adи1t al1d deve10ping
mammals", Annиa1 Review ofNeиrosciences, 1983, vo1. 6, р. 325 356.
531. Kailath Т. Linear Systems, Englewood Cliffs, NJ: Prentice Hall, 1980.
532. Kailath Т. "А view ofthree decades oflinear filtering theory", ШЕЕ Transactions
ofIl1formation Theory, 1974, уоl. 1Т 20, р. 146 181.
533. Kailath Т. "RКНS aproach to detection al1d estimation problems Part 1: Deter
ministic signa1s in Gaиssial1 noise", ШЕЕ Transactions of 111formation Theory,
1971, уоl. IТ 17, р. 530 549.
534. Kailath Т. "Ап il1l1ovations aproach to least sqиares estimation: Part 1. Linear
filtering il1 additive white 110ise", ШЕЕ Tral1sactions of Aиtomatic Control, 1968,
уоl. AC 13, р. 646 655.
535. Kalman R.E. "А new aproach to linear filtering al1d prediction problems", Trans
actions of the ASME, Joиma1 of Basic Engineering, 1960, уоl. 82, р. 35 5.
536. Kandel E.R. and J.H. Schwartz. Principles ofNeиra1 Science, 3rd ed., New York:
Elsevier, 1991.
537. Kangas J., Т. Kohonen and J. Laaksonen. "Variants of self organizing maps",
ШЕЕ Transactions оп Neura1 Networks 1, 1990, р. 93 99.
538. Kanter 1. and Н. Sompolinsky. "Associative recall of memory withoиt епоrs",
Physica1 Review А, 1987, vo1. 35, р. 380 392.
539. Карlеп J.L. and J.A. Yorke. "Chaotic behavior of mиltidimensiol1a1 differel1ce
eqиations", in H. O Peitgel1 and H. O Walker, eds., Fиnctional Differential Eqиa
tions and Aproximations ofFixed Points, 1979, р. 204 227, Berlin: Springer.
540. Кареп Н.1. and F.B. Rodrigиez. "Efficient leaming in Bo1tzmann machines иsing
linear response theory", Neиral Compиtation, 1998, vo1. 10.
541. Karhиnel1 К. "Uber lineare methoden in der Wahrscheinlichkeitsrechnиng", An
nales Academiae Sciel1tiarиm Fennicae, Series AI: Mathematica Physica, 1947,
уоl. 37, р. 3 79, (Transl.: RAND Corp., Santa Monica, СА, Rep.T 131, Aиg.
1960).
Библиоrрафия 1029
542. KarhU11en J. and J. Joиtsensa1o. "Generalizations of pril1cipal component anal
ysis, optimization problems and neиral networks", Neиral Networks, 1995, vo1.
8, р. 549 562.
543. Karpinski М. and А. Macintyre. "Polynomia1 boиnds for УС dimension of
sigmoida1 and general Pfaffian l1eиronal networks", Joиmal of Compиter and
System Sciences, 1997, vo1. 54, р. 169 176.
544. Katagiri S. and Е. McDermott. "Discriminative trainil1g Recent progress il1
speech recognition", in С.Н. Chen, L.F. Раи and P.S.P. Wang, eds., Handbook
of Pattem Recognition and Compиter Vision, 2nd edition, Singapore: World
Scientific pиblishing, 1996.
545. Katz В. Nerve, Mиscle and Synapse, New York: McGraw Hill, 1966.
546. Kawamoto А.Н. and J.A. Anderson. "А neura1 network model of mиltistable
perception", Acta Psycho1ogica, 1985, уоl. 59, р. 35 65.
547. Kawato М., Н. Hayakama and Т. Inиi. "А forward inverse optics model of
reciproca1 connections between visиal cortical areas", Network, 1993, уоl. 4,
р. 415 422.
548. Кау J. "Featиre discovery иnder contextиa1 sиpervision иsing mиtиal infor
matiol1", Intemational Joint Conferel1ce оп Neural Networks, 1992, уоl. IV,
р. 79 84, Baltimore.
549. Keams М. "А boиnd оп the епоr of cross validation иsil1g the aproximation
and estimatiol1 rates, with conseqиences for the training test split", Advances in
Neиral Information Processil1g Systems, 1996, уоl. 8, р. 183 189, Cambridge,
МА: MIТ Press.
550. Keams М. and L.G. Valiant. "Cryptographic limitations оп leaming Вооlеап
formиlae and finite aиtomata", Proceedings of the Twenty First Аl1l1иаl АСМ
Symposiиm оп Theory of Compиting, 1989, р. 433 44, New York.
551. Keams M.J. and U.v. Vazirani. Аl1 Introdиction to Compиtatiol1al Leaming
Theory, Cambridge, МА: MIТ Press, 1994.
552. Kechriotis G., Е. Zervas and E.S. Manolakos. "Using rесипепt l1eural11etworks
for adaptive commиl1icatiol1 channel eqиalization", ШЕЕ Transactiol1s оп Neиral
Networks, 1994, уоl. 5, р. 267 278.
553. Keeler J.D. "Basins of attraction of пеиrаl network models", il1 Neиral Networks
for Compиting, J.S. Denker, ed., 1986, р. 259 264, New York: American Institиte
of Physics.
554. Keller J.B. "Inverse problems", American Mathematical Month1y, 1976, уоl. 83,
р. 107 118.
555. Ke1so S.R., А.Н. Ganong and Т.Н. Brown. "НеЬЫап synapses in hipocampиs",
Proceedings ofthe Natiol1al Academy ofSciences, USA, 1986, уоl. 83, р. 5326
5330.
1030 Библиоrрафия
556. Kennel М.В., R. Brown and H.D.I. Abarbanel. "Determining minimиm embed
ding dimension иsing а geometrica1 constrиction", Physical Review А, 1992,
уоl. 45, р. 3403 3411.
557. Ker1irzin Р. and Р. Vallet. "Robиstness il1 mи1ti1ayer perceptrol1s", Neиral Com
pиtation, 1993, vo1. 5, р. 473 82.
558. Кirkpatrick S. "Optimization Ьу simи1ated annealing: Qиantitative Stиdies",
Joиmal of Statistical Physics, 1984, уоl. 34, р. 975 986.
559. Кirkpatrick S. and О. Shепiпgtоп. "Infinite ranged models of spin glasses",
Physica1 Review, Series В, 1978, vo1. 17, р. 4384 403.
560. Кirkpatrick S., С.О. Ge1att, Jr. and М.Р. Vecchi. "Optimization Ьу simиlated
annea1ing", Science, 1983, уоl. 220, р. 671 680.
561. Kirsch А. Ап Introdиction to the Mathematical Theory of Inverse Problems,
New York: Sрriпgеr Vеr1аg, 1996.
562. Кlеепе S.C. "Representation of evel1ts in nerve nets and finite aиtomata", in
С.Е. Shannon and J. McCarthy, eds., Aиtomata Stиdies, Princeton, NJ: Princetol1
University Press, 1956.
563. Кmenta J. Elements ofEconometrics, New York: Масmillап, 1971.
564. Кпиdsеп E.I., S. dиLac and S.D. Esterly. "Compиtational maps in the brail1",
Annиa1 Review ofNeиrosciel1ce, 1987, vo1. 10, р. 41 65.
565. Koch С. and 1. Segev, eds. Methods in Neиrona1 Modelil1g: From SYl1apses to
Networks, Cambridge, МА: MIТ Press, 1989.
566. Koch С., Т. Poggio and V. Топе. "Nonlinear interactions in а dendritic tree:
Localization, timing and ro1e in information processing", Proceedings of the
Nationa1 Academy of Sciel1ces, USA, 1983, уоl. 80, р. 2799 2802.
567. Koch С. and В. Mathиr. "Neиromorphic vision chips", ШЕЕ Spectrиm, 1996,
уоl. 33, по. 5, р. 38 6.
568. Kohonen Т. "Exploration of very large databases Ьу self organizing maps",
1997 Intemational Conference оп Neural Networks, 1997, vo1. 1, р. PL1 PL6,
Hoиston.
569. Kohonen Т. Self Organizing Maps, 211d edition, Berlin: Springer Ver1ag.
570. Kohonen т., 1996. "Emergel1ce of invarial1t featиre detectors in the adaptive
sиbspace self organizing maps", Bio1ogical Cybemetics, 1 997Б, vo1. 75, р. 281
291.
571. Kohonen Т. "Physiological il1terpretation ofthe self orgal1izil1g mар algorithrn",
Neиra1 Networks, 1993, уоl. 6, р. 895 905.
572. КоЬопеп Т. "Things уои haven't heard aboиt the se1f organizing mар", Proceed
ings of the ШЕЕ Intematiol1al COl1ference оп neиral11etworks, 1993, р. 1147
1156, San Francisco.
573. Kohol1el1 Т. "The self organizing mар", Proceedings ofthe Institиte ofElectrical
and E1ectronics Engineers, 1990, vo1. 78, р. 146 1480.
Библиоrрафия 1031
574. КоЬопеп Т. "Improved versiol1s of 1eaming vector qиantization", ШЕЕ Inter
national Joint COl1ference 011 Neura1 Networks, 1990Б, vo1. 1, р. 545 550, San
Diego, СА.
575. Kohonen Т. "Ап introdиction to l1eиra1 compиting", Neura1 Networks, 1988, vo1.
1, р. 3 16.
576. Kohonel1 Т. Se1f Organization and Associative Memory, 3rd edition, New York:
Springer Verlag, 1988Б.
577. Kohonen Т. "The 'neиra1' phonetic typewriter", Compиter, 19886, vo1. 21, р. 11
22.
578. Kohonen Т. "Leaming vector qиantization for pattem recognition", Technica1
Report TKK P A601, Helsinki Ul1iversity ofTechnology, Fin1and, 1986.
579. КоЬопеп Т. "Self organized formation of topo1ogically сопесt featиre maps",
Bio1ogical Cybemetics, 1982, vo1. 43, р. 59 69.
580. Kohonen Т. "Сопе1аtiоп matrix memories", ШЕЕ Transactions оп Compиters,
1972, уоl. C 21, р. 353 359.
581. Kohonen Т. and Е. Oja. "Fast adaptive formation of orthogol1a1izing filters and
associative memory in rесипепt networks for neuron like e1ements", Bio1ogical
Cybemetics, 1976, уоl. 21, р. 85 95.
582. Kohonen Т., Е. Oja, О. Simиla, А. Visa and J. Kangas. "Engineering aplications
of the self organizing mар", Proceedings of the ШЕЕ, 1996, vo1. 84, р. 1358
1384.
583. Kohonen т., Е. Reиhka1a, К. Miikisara and L. Vainio. "Associative recall of
images", Biological Cybemetics, 1976, vo1. 22, р. 159 168.
584. Kohonen т., G. Ваmа and R. Chrisley. "Statistica1 pattem recognition with пешаl
networks: Benchrnarking stиdies", ШЕЕ Intemationa1 Conference оп Neural
Networks, 1988, уоl. 1, р. бl 68, San Diego, СА.
585. Kohonen Т., J. Kangas, J. Laaksonen and К. Torkkola. "LVQ PAK: The leaт
ing vector qиantization Program Package", He1sinki University of Technology,
Fin1and, 1992.
586. Koiran Р. and Е.О. Sontag. "Neura1 networks with qиadratic УС dimension",
Advances in Neиra1 Information Processing Systems, 1996, уоl. 8, р. 197 203,
Cambridge, МА: MIТ Press.
587. Коlеп J.F. and J.B. Pollack. "Backpropagation is sensitive to initial conditions",
Соmрlех Systems, 1990, уоl. 4, р. 269 280.
588. Kollias S. and О. Anastassioи. "Ап adaptive least sqиares a1gorithrn for the
efficient training of artificial neura1 networks", ШЕЕ Transactions оп Circиits
and Systems, 1989, vo1. 36, р. 1092 1101.
589. Kollias S. and О. Al1astassioи. "Adaptive training ofmиlti1ayer neиra1 networks
иsing а least sqиares estimation techniqиe", ШЕЕ Intemationa1 Conference оп
Neиra1 Networks, 1988, уоl. 1, р. 383 390, San Diego.
1032 Библиоrрафия
590. Kolmogorov A.N. "Interpolation and extrapolation of stationary random se
qиences", 1942, Rand Corporation, Santa MOl1ica, СА., April1962.
591. Kosko В. Fиzzy Engineering, Uper Saddle River, NJ: Prentice Hall, 1997.
592. Kosko В. Neural Networks and Fиzzy Systems, Englewood Cliffs, NJ: Prentice
НаН, 1992.
593. Kosko В. "Bidirectiona1 associative memories", ШЕЕ Transactions оп Systems,
Мап and Cybemetics, 1988, уоl. 18, р. 49 60.
594. Kotilainen Р. "Simиlations and implementations of l1eиral networks for princi
раl component analysis", Electronics Lab Report 1 93, Tampre University of
Technology, Finland, 1993.
595. Кraaijveld М.А. and R.P.W. Dиil1. "Generalization capabilities of minimal
kemel based networks", Intemational Joint Conference оп Neиra1 Networks,
1991, уоl. 1, р. 843 848, Seattle.
596. Кramer А.Н. and А. Sangiovanni Vincentelli. "Efficient paralle1leaming algo
rithrns for пеиrаl networks", Advances in neиral Information Processing Sys
tems, 1989, vo1. 1, р. 40 8, San Mateo, СА: Morgan Kaиfmann.
597. Кremer S.C. "Comments оп constrиctive 1eaming оfrесипепt neura1 networks:
Limitations оfrесипепt cascade сопе1аtiОl1 al1d а simple solиtion", ШЕЕ Trans
actions оп Neиral Networks, 1996, уоl. 7, р. 1047 1049.
598. Kremer S.C. "Оп the compиtationa1 power of Elman sty1e rесипепt networks",
ШЕЕ Transactions оп Neиral Networks, 1995, уоl. 6, р. 100 1004.
599. Кreyszig Е. Adval1ced El1gineeril1g Mathematics, 6th ed., New York: Wiley,
1988.
600. Кrishnamиrthy А.к., S.C. Aha1t, О.Е. Me1tol1 and Р. Chen. "Neиra1 networks
for vector qиantization of speech and images", ШЕЕ Joиma1 of Selected Areas
in Commиnications, 1990, уоl. 8, р. 1449 1457.
601. Кrzyzak А., Т. Linder and G. Lиgosi. "Nonparametric estimation al1d c1assifica
tion иsing radial basis functions", ШЕЕ Transactions оп Neura1 Networks, 1996,
уоl. 7, р. 475 87.
602. Киап C. M. and К. Homik. "Convergence of leaming algorithms with constant
leaming rates", ШЕЕ Tral1sactions оп Neиral Networks, 1991, уоl. 2, р. 484 489.
603. Kиan C. M., К. Homik and Н. White. "А convergence resиlt for leaming in
rесипепt neиra1 networks", Neural Compиtation, 1994, уоl. 6, р. 420 40.
604. Kиffier S.W., 1.G. Nicholls and A.R. Martin. From Neиron to Brain: А Cellи1ar
Aproach to the Fиnction of the Nervoиs System, 2nd edition, Sиnderland, МА:
Sinaиer Associates, 1984.
605. KиHback S. Information Theory and Statistics, Gloиcester, МА: Peter Smith,
1968.
Библиоrрафия 1033
606. Kиl1g S.Y. and K.I. Diamal1taras. "А l1eura1 network leaming algorithm for adap
tive principa1 component extraction (АРЕХ)", ШЕЕ Intemational Conference оп
Acoиstics, Speech and Signal Processing, 1990, уоl. 2, р. 861 864, A1bиqиerqиe.
607. Kиshner H.J. and D.S. C1ark. Stochastic Aproximation Methods for Constrained
al1d Unconstrained Systems, New York: Springer Verlag, 1978.
608. Lacoиme J.L., Р.О. Amblard and Р. Соmоп. Statistiqиes d'ordre Sиperieиrpoиr
lе Traitement dи Signa1, Masson Pиblishers, 1997.
609. Lancoz С. Linear Differential Operators, London: Уап Nostrand, 1964.
610. Landaи У.О. Adaptive Contro1: The Model Reference Aproach, New York:
Marce1 Dekker, 1979.
611. Landa L.D. and Е.М. Lifshitz. Statistica1 Physics: Part 1, 3rd edition, London:
Pergamon Press, 1980.
612. Lanford О.Е. "Strange attractors and tиrbиlence", il1 H.L. Swinney and J.P. Gol
lиЬ, eds., Hydrodynamic Instabilities and the Transition to ТиrЬиlепсе, New
York: Sрriпgеr Vеr1аg, 1981.
613. Lang K.J. and G.E. Нinton. "The deve10pment of the time de1ay neиral11et
work architectиre for speech recognition", Technica1 Report CMU CS 88 152,
Camegie Mellon University, Pittsbиrgh, РА, 1988.
614. Lapedes А. and R. Farber. "Programming а massively parallel, compиtation
иniversa1 system: Static Behavior", In Neural Networks for Compиtil1g, J.S.
Denker, ed., 1986, р. 283 298, New York: Americal1 Institиte of Physics.
615. Larson J. and G. Lynch. "Theta pattem stimи1ation and the indиction of LTP:
The seqиence in which sYl1apses are stimиlated determines the degree to which
they potentiate", Brain Research, 1989, vo1. 489, р. 49 58.
616. LaSalle J. and S. Lefschetz. Stability Ьу Liapиnov's Direct Method with Apli
cations, New York: Academic Press, 1961.
617. LeCиn У. Efficient Leaming and Second order Methods, А Tиtorial at NIPS 93,
Denver, 1993.
618. LeCиn У. "Generalization and network design strategies", Technical Report
CRG TR 89A, Departrnent of Compиter Science, University of Torol1to, Cana
da, 1989.
619. LeCиn У. "Une procedиre d' aprentissage poиr reseaи а seиil assymetriqиe",
Cognitiva, 1985, vo1. 85, р. 599 604.
620. LeCиn У. and У. Bengio. "Convolиtiona1 networks for images, speech and time
series", in М.А. Arbib, ed., The HandbookofBrain Theory and Neиra1 Networks,
Cambridge, МА: MIТ Press, 1995.
621. LeCиn У., В. Boser, J.S. Denker, О. Henderson, R.E. Howard, W. Hиbbard and
L.D. Jacke1. "Handwritten digit recognition with а back propagation network",
Advances in Neиral Information Processing, 1990а, уоl. 2, р. 396 04, Sal1
Mateo, СА: Morgan Kaиfmann.
1034 Библиоrрафия
622. LeCиn У., L. Bottoи and У. Bengio. "Reading checks with mи1tilayer graph
transformeer networks", ШЕЕ 111temational Conferel1ce оп Acoиstics, Speech
and Signal Processing, 1997, р. 151 154, Mиnich, Germany.
623. LeCиn У., L. Bottoи, У. Bengio and Р. Haffner. "Gradiel1t based leaming ap1ied
to docиment recognition", Proceedings ofthe ШЕЕ, 1998, vo1. 86.
624. LeCиn У., J.S. Denker and S.A. Solla. "Optima1 brain damage", Advances in
Neиra1 Information Processing Systems, 1990, vo1. 2, р. 598 605, San Mateo,
СА: Morgan Kaиfmann.
625. LeCиn У., 1. Kanter and S.A. Solla. "Second order properties of епоr sиrfaces:
Leaming time and generalization", Advances in Neura1 Information Processil1g
Systems, 1991, vo1. 3, р. 918 924, Cambridge, МА: MIТ Press.
626. Lee О.О. and H.S. Seиng. "Unsиpervised 1eaming Ьу сопуех and conic codil1g",
Advances in Neиral Information Processing Systems, 1997, vo1. 9, р. 515 521,
Cambridge, МА: MIТ Press.
627. Lee Т. Independent Component Analysis: Theory and Aplications, РЬ.О. Thesis,
Technische Ul1iversitat, Berlin, Germany, 1997.
628. Lee т. C., А.М. Peterson and J.J C. Tsai. "А mиltilayer feed forward neиra1
network with dynamically adjиstable strиctиres", ШЕЕ Intemationa1 Conference
оп Systems, Мап and Cybemetics, 1990, р. 367 369, Los Ange1es.
629. Lee У. and R.P. Lipmann. "Practical characteristics of пешаl networks and
conventional pattem classifiers оп artificia1 and speech problems", Advances in
Neиral Information Processing Systems, 1990, уоl. 2, р. 168 177, San Mateo,
СА: Morgan Kaиfmann.
630. Lee У., S. Oh and М. Kim. "Тhe effect of il1itia1 weights оп prematиre satи
ration in back propagation 1eamil1g", Intemationa1 Joint Conference оп Neиral
Networks, 1991, уоl. 1, р. 765 770, Seattle.
631. Lee У.С., G. Оооlеп, Н.Н. Chan, G.Z. Sen, Т. Maxwell, Н.У Lee and C.L.
Gi1es. "Machine leamil1g иsing а higher order сопе1аtiоп network", Physica,
1986, О22, р. 276 289.
632. Lefebvre W.C. Ап Object Oriented Aproach for the Al1alysis ofNeиral Networks,
Master's Thesis, University ofFlorida, Gail1svi1le, Рl, 1991.
633. Leon Garcia А. Probability and Random Processes for E1ectrical Engineering,
2nd edition, Reading, МА: Addison Wes1ey, 1994.
634. Leontaritis 1. and S. Billings. "Inpиt oиtpиt parametric mode1s for non1il1ear sys
tems: Part 1: Deterministic nonlinear systems", Intemational Joиma1 of Control,
1985, vo1. 41, р. 303 328.
635. Levil1 А.У. and к.s. Narendra. "Control of 110nlinear dYl1amica1 systems иsing
11ешаl пеtwоrksя Part 11: Observability, identification and contro1", ШЕЕ
Transactions оп Neural Networks, 1996, vo1. 7, р. 30 2.
Библиоrрафия 1035
636. Levin А.У. and к.s. Narendra. "Contro1 of nonlinear dynamical systems иsing
neura1 пеtwоrksя Controllabi1ity and stabilization", ШЕЕ Transactions оп
Neиra1 Networks, 1993, уоl. 4, р. 192 206.
637. Levine М. Мап and Machine Vision. New York: McGraw Hill, 1985.
638. Lewis F.L. and V.L. Syrmas. Optima1 Contro1, 2nd edition, New York: Wiley
(Intersciel1ce), 1995.
639. Lewis F.L., А. Yesildirek and К. Liи. "Mиlti1ayer neural net robot controller
with gиaranteed tracking performance", ШЕЕ Transactions оп Neиra1 Networks,
1996, vo1. 7, р. 1 12.
640. Lichtenberg A.J. and М.А. Lieberman. Regиlar and Chaotic Dynamics, 2nd
edition, New York: Springer Verlag, 1992.
641. Light W.A. "Some aspects of radia1 basis function aproximation", in Aproxi
mation Theory, Sp1ine Fиnctions and Ap1ications, S.P. Sil1gh, ed., NATO ASI,
1992, vo1. 256, р. 163 190, Boston: Klиwer Academic Pиblishers.
642. Light W. "Ridge functions, sigmoida1 functions and neиral networks", in E.W.
Cheney, С.К. Chиi and L.L. Schиmaker, eds., Aproximation Theory VII, 1992Б,
р. 163 206, Boston: Academic Press.
643. Lin J.K., D.G. Grier and J.D. Cowan. "Faithful representation of separable
distribиtions", Neиra1 Compиtation, 1997, уоl. 9, р. 1305 1320.
644. Lin S. "Compиter solиtions of the trave1ing salesman problem", Веll System
Technical Joиmal, 1965, уоl. 44, р. 2245 2269.
645. Lin Т., B.G. Ноmе, Р. Tino and C.L. Gi1es. "Leaming 10ng term dependel1cies
in NARX rесипепt l1eиral networks", ШЕЕ Tral1sactions оп Neиra1 Networks,
1996, уоl. 7, р. 1329 1338.
646. Linde У., А. Bиzo and R.M. Gray. "Ап algorithm for vector qиantizer design",
ШЕЕ Transactions оп Commиnications, 1980, vo1. COM 28, р. 84 95.
647. Linsker R. "Deriving receptive fields иsing ап optimal encoding criteriol1", Ad
vances in Neиral Information Processing Systems, 1993, уоl. 5, р. 953 960, San
Mateo, СА: Morgan Kaиfmann.
648. Linsker R. "Designing а sensory processing system: What can Ье leamed from
principal components analysis"? Proceedings of the Intemational Joint Confer
епсе оп Neиral Networks, 1990, уоl. 2, р. 291 297, Washingtol1, ОС.
649. Linsker R. "Self organization in а perceptиal system: How network models
and information theory mау shed light оп neиra1 organization", Chapter 10 in
Connectionist Modelil1g and Brain Fиnction: The Developing 111terface, S.J.
Hanson and C.R. 0lson, eds., 1990Б, р. 351 392, Cambridge, МА: MIТ Press.
650. Linsker R. "Perceptиal neиral organization: Some aproaches based оп network
mode1s and information theory", Аппиаl Review of Neиrosciel1ce, 19906, уоl.
13, р. 257 281.
1036 Библиоrрафия
651. Linsker R. "Ап aplication ofthe principle ofmaximиm information preservation
to linear systems", Advances in Neиral Information Processing Systems, 1989,
уоl. 1, р. 186 194, San Mateo, СА: Morgan Kaиfmann.
652. Linsker R. "How to generate ordered maps Ьу maximizing the mиtиal infor
mation between inpиt and oиtpиt signals", Neural compиtation, 1989Б, уоl. 1,
р. 402 411.
653. Linsker R. "Self organization in а perceptиal network", Compиter, 1988, уоl.
21, р. 105 117.
654. Linsker R. "Towards ап organizing princip1e for а layered perceptиal network",
in Neиral Information Processing Systems, D.Z. Anderson, ed., 1988Б, р. 485
494, New York: American Institиte of Physics.
655. Linsker R. "Towards ап organizing princip1e for perception: НеЬЫап synapses
and the principle of optimal пеиrаl encoding", IВM Research Report RC12820,
IВM Research, Yorktown Heights, NY, 1987.
656. Linsker R. "From basic network principles to neиral architectиre" (series), Pro
ceedings of the National Academy of Sciences, USA, 1986, уоl. 83, р. 7508
7512, 8390 8394, 8779 8783.
657. Lipmann R.P. "Ап introdиction to compиting with neиral nets", ШЕЕ ASSP
Magazine, 1987, уоl. 4, р. 4 22.
658. Lipmann R.P. "Review ofneural networks for speech recognition", Neиral Com
pиtation, 1989, уоl. 1, р. 1 38.
659. Lipmann R.P. "Pattem classification иsing neиral networks", ШЕЕ Commиnica
tions Magazine, 1989Б, уоl. 27, р. 47 64.
660. Little W.A. "The existence of persistent states in the brain", Mathematical Bio
sciences, 1974, уоl. 19, р. 101 120.
661. Litt1e W.A. and G.L. Shaw. "Analytic stиdy of the memory storage capacity of
а пешаl network", Mathematical Biosciences, 1978, уоl. 39, р. 281 290.
662. Little W.A. and G.L. Shaw. "А statistical theory of short and 10ng term memory",
Behavioral Biology, 1975, vo1. 14, р. 115 133.
663. Livesey М. "Clamping in Boltzmann machines", ШЕЕ Transactions оп Neиral
Networks, 1991, уоl. 2, р. 143 148.
664. Ljиng L. System Identification: Theory for the User. Englewood Cliffs, NJ:
Prentice Hall, 1987.
665. Ljиng L. "Analysis of recиrsive stochastic algorithms", ШЕЕ Transactions оп
Aиtomatic Control, 1977, уоl. AC 22, р. 551 575.
666. Ljиng L. and Т. Glad. Modeling of Dynamic Systems, Englewood Cliffs, NJ:
Prentice Hall, 1994.
Библиоrрафия 1037
667. Lloyd S.P. "Least sqиares qиantization in РСМ", неопубликованное техни
ческое руководство лаборатории Веll Laboratories technical note. Позднее
опубликовано в журнале ШЕЕ Transactions оп Iпfопnatiоп Theory, 1957, уоl.
IТ 28, р. 127 135, 1982.
668. Lo Z. P., М. Fиjita and В. Bavarian. "Analysis of neighborhood interaction in
Kohonen neиral networks", 6th Intemational Parallel Processing Symposiиm
Proceedings, 1991, р. 247 249, Los Alamitos, СА.
669. Lo Z. P., У. Уи and В. Bavarian. "Analysis of the convergence properties of
topology preserving пешаl networks", ШЕЕ Transactions оп Neиral Networks,
1993, уоl. 4, р. 207 220.
670. Lockery S.R., У. Fang and T.J. Sejnowski. "А dynamical neиral network model
of sensorimotor transformations in the leech", Intemational Joint Conference оп
Neural Networks, 1990, уоl. 1, р. 183 188, San Diego, СА.
671. Loeve м. Probability Тheory, 3rd edition, New York: Уап Nostrand, 1963.
672. Lorentz G.G. "The 13th problem of Hilbert", Proceedings of Symposia in pиre
Mathematics, 1976, уоl. 28, р. 419 30.
673. Lorentz G.G. Aproximation of Fиnctions, Orlando, FL: Holt, Rinehart & Win
ston, 1966.
674. Lorenz E.N. "Deterministic non periodic flows", Joиmal of Atmospheric Sci
ences, 1963, уоl. 20, р. 130 141.
675. Lowe О. "Adaptive radial basis function nonlinearities and the problem of gen
eralisation", First ШЕ Intemational Conference оп Artificial Neural Networks,
1989, р. 171 175, London.
676. Lowe О. "What have пешаl networks to offer statistical pattem processing"? Pro
ceedings of the SРШ Conference оп Adaptive Signal Processing, 1991, р. 460
471, San Diego, СА.
677. Lowe О. "Оп the iterative inversion of RВP networks: А statistical interpre
tation", Second ШЕ Intemational Conference оп Artificial Neural Networks,
1991Б, р. 29 33, Boиmemoиth, England.
678. Lowe О. and A.R. Webb. "Time series prediction Ьу adaptive networks: А
dynamical systems perspective", ШЕ Proceedings (London), Part Р, 1991, уоl.
138, р. 17 24.
679. Lowe О. and A.R. Webb. "Optimized featиre extraction and the Bayes decision
in feed forward classifier networks", ШЕЕ Transactions оп Pattem Analysis and
Machine Intelligence, 1991Б, PAMI 13, р. 355 364.
680. Lowe О. and A.R. Webb. "Exploiting prior knowledge in network optimization:
ап il1иstration from medical prognosis", Network, 1990, уоl. 1, р. 299 323.
681. Lowe О. and М.Е. Tiping. "Neиroscale: Novel topographic featиre extraction
иsing RВP networks", Neиral Information Processing Systems, 1996, уоl. 9,
р. 543 549, Cambridge, МА: MIТ Press.
1038 Библиоrрафия
682. Lиenberger D.G. Linear and Nonlinear Programming, 2nd edition, Reading, МА:
Addison Wes1ey, 1984.
683. Lиi Н.С. "Analysis of decision contoиr ofneиral network with sigmoidal поп
linearity", Intemational Joint Conference оп Neиral Networks, 1990, уоl. 1,
р. 655 659, Washington, ОС.
684. Lиo Z. "Оп the convergence of the LMS algorithrn with adaptive leaming rate
for linear feedforward networks", Neиral Compиtation, 1991, vo1. 3, р. 226 245.
685. Lиo Р. and R. Unbehaиen. Aplied Neural Networks for Signal Processing, New
York: Cambridge University Press, 1997.
686. Lиttrell S.P. "А иnified theory of density models and aиto encoders", Technical
Report 97303, Defence Research Agency, Great Маlуеm, UK, 1997.
687. Lиttrell S.P. "А Bayesian analysis of self organizing maps", Neиral Compиtation,
1994, уоl. 6, р. 767 794.
688. Lиttrell S.P. "Code vector density in topographic mapings: Sca1ar case", ШЕЕ
Transactions оп Neиra1 Networks, 1991, уоl. 2, р. 427 36.
689. Lиttrell S.P. "Self sиpervised training of hierarchical vector qиantizers", 2nd
Intemational Conference оп Artificial Neural Networks, 1991Б, р. 5 9,
Boиmemoиth, England.
690. Lиttrell S.P. "Нierarchical vector qиantization", ШЕ Proceedings (London),
1989, уоl. 136 (Part 1), р. 405 13.
691. Lиttrell S.P. "Self organization: А derivation from first principle of а class of
leaming algorithrns", ШЕЕ Conference оп Neиral Networks, 1989Б, р. 495 98,
Washington, ОС.
692. Maass W. "Boиnds for the compиtational power and leaming complexity of
analog neиral nets", Proceedings of the 25th Аппиаl АСМ Symposiиm оп the
Theory ofCompиting, 1993, р. 335 344, New York: АСМ Press.
693. Maass W. "Vapnik Chervonenkis dimension ofneиral networks", in М.А. Arbib,
ed., The Handbook ofBrain Theory and Neиral Networks, Cambridge, МА: MIТ
Press, 1993.
694. Mach Е. "Uber die Wirkиng der raиmlichen Vertheilиng des Lichtreizes aиf
die Netzhaиt, 1. Sitzиngsberichte der Mathematisch Natиrwissenschaftslichen
Кlasse der Kaiserlichen Akademie der Wissenschaften", 1865, уоl. 52, р. 303
322.
695. МасКау о. "Bayesian interpolation", Neиral Compиtation, 1992, уоl. 4, р. 415
447.
696. МасКау о. "А practical Bayesian framework for back propagation networks",
Neиral Compиtation, 1992Б, уоl. 4, р. 448 472.
697. МасКау D.J.C. and к.о. Miller. "Analysis ofLinsker's simиlations ofHebbian
rиles", Neиral Compиtation, 1990, уоl. 2, р. 173 187.
Библиоrрафия 1039
698. Macintyre A.J. and Е.О. Sontag. "Fitness resиlts for sigmoidal 'neиronal' net
works", Proceedings of the 25th Annиal АСМ Symposiиm оп the Theory of
Compиting, 1993, р. 325 334, New York: АСМ Press.
699. MacQиeen J. "Some methods for classification and analysis of mиltivariate
observation", in Proceedings of the 5th Berkeley Symposiиm оп Mathematical
Statistics and Probability, L.M. LeCиn and J. Neyman, eds., 1967, уоl. 1, р. 281
297, Berkeley: University of Califomia Press.
700. Madhиranath Н. and S. Haykin. "Improved Activation Fиnctions for Вlind Sepa
ration: Details of A1gebraic Derivations", CRL Intemal Report No. 358, Coтти
nications Research Laboratory, McMaster University, Hamilton, Ontario, 1998.
701. Mahowald М.А. and С. Mead. "Silicon retina", in Analog VLSI and Neural
Systems (С. Mead), Chapter 15. Reading, МА: Addison Wesley, 1989.
702. Mandelbrot В.В. The Fracta1 Geometry of Natиre, San Francisco: Freeman,
1982.
703. Мапе R. "Оп the dimension of the compact invariant sets of certain non linear
maps", in О. Rand and L.S. Yoиng, eds., Dynamical Systems and ТшЬиlепсе,
Lectиre Notes in Mathematics, 1981, уоl. 898, р. 230 242, Berlin: Springer
Verlag.
704. Маи О. Vision, New York: w.н. Freeman and Соmрапу, 1982.
705. Martinetz Т.М., H.J. Ritter and K.J. Schиlten. "Three dimensional пешаl net for
leaming visиomotor coordination of а robot arm", ШЕЕ Transactions оп Neural
Networks, 1990, уоl. 1, р. 131 136.
706. Mason S.J. "Feedback theory Some properties of signal flow graphs", Pro
ceedings ofthe Institиte ofRadio Engineers, 1953, уоl. 41, р. 1144 1156.
707. Mason S.J. "Feedback theory Fиrther properties of signal flow graphs", Pro
ceedings of the Institиte of Radio Engineers, 1956, уоl. 44, р. 920 926.
708. Maybeck P.S. Stochastic Models, Estimation and Control, уоl. 2, New York:
Academic Press, 1982.
709. Maybeck P.S. Stochastic Models, Estimation and Control, уоl. 1, New York:
Academic Press, 1979.
710. Mazaika Р.к. "А mathematical model of the Boltzmann machine", ШЕЕ First
Intemational Conference оп Neиral Networks, 1987, уоl. Ш, р. 157 163, San
Diego, СА.
711. McBride L.E., Jr. and к.s. Narendra. "Optimization of time varying systems",
ШЕЕ Transactions оп Aиtomatic Contro, 19651, уоl. AC 1 О, р. 289 294.
712. McCиl1agh Р. and J.A. Nelder. Genera1ized Linear Models, 2nd edition, London:
Chapman and Наll, 1989.
713. McCиlloch W.S. Embodiments ofMind, Cambridge, МА: MIТ Press, 1988.
1040 Библиоrрафия
714. McCиlloch W.S. and W. Pitts. "А 10gical calcиlиs of the ideas immanent in
nervoиs activity", Bиlletin of Mathematica1 Biophysics, 1943, уоl. 5, р. 115
133.
715. McEliece R.J., В.С. Posner, E.R. Rodemich and S.S. Venkatesh. "The capacity
of the Hopfield associative memory", ШЕЕ Transactions оп Information Theory,
1987, уоl. IТ 33, р. 461 82.
716. McLachlan G.J. and к.Е. Basford. Mixtиre Models: Inference and Aplications
to Clиstering, New York: Marce1 Dekker, 1988.
717. McLachlan G.J. and Т. Кrishnan. The ЕМ Algorithrn and Extensions, New York:
Wiley (Interscience), 1997.
718. McQиeen J. "Some methods for classification and analysis ofmиltivariate obser
vations", Proceedings ofthe 5th Berkeley Symposiиm оп Mathematical Statistics
andProbability, 1967, уоl. 1, р. 281 297, Berkeley, СА: University ofCalifomia
Press.
719. Mead С.А. "Neиromorphic electronic systems", Proceedings of the Institиte of
Electrical and Electronics Engineers, 1990, уоl. 78, р. 1629 1636.
720. Mead С.А. Ana10g VLSI and Neиral Systems, Reading, МА: Addison Wesley,
1989.
721. Mead С.А. and М.А. Mahowald. "А silicon model of early visиal processing",
Neиral Networks, 1988, уоl. 1, р. 91 97.
722. Mead С.А., Х. Апеgиit and J. Lazzaro. "Analog VLSI model of binaиral hear
ing", ШЕЕ Transactions оп Neural Networks, 1991, уоl. 2, р. 232 236.
723. Mecklenbraиker W. and F. Нlawatsch, eds. The Wigner Distribиtion, New York:
Elsevier, 1997.
724. Memmi О. "Connectionism and artificial intelligence", Neиro Nimes'89 Inter
national Workshop оп Neиral Networks and their Aplications, 1989, р. 17 34,
Nimes, France.
725. Mendel J.M. Lessons in Estimation Theory for Signa1 Processing, Commиnica
tions and Control. Englewood Cliffs, NJ: Prentice Hall, 1995.
726. Mendel J.M. and R.W. McLaren. "Reinforcement leaming control and pattem
recognition systems", in Adaptive, Leaming and Pattem Recognition Systems:
Theory and Aplications, уоl. 66, J.M. Mendel and к.S. Ри, eds., 1970, р. 287
318, New York: Academic Press.
727. Меппоп А., К. Mehrotra, С.к. Mohan and S. Ranka. "Characterization of а class
of sigmoid functions with aplications to neиral networks", Neиral Networks,
1996, уоl. 9, р. 819 835.
728. Mercer J. "Fиnctions ofpositive and negative type and their connection with the
theory of integral eqиations", Transactions of the London Philosophical Society
(А), 1909, уоl. 209, р. 415 46.
Библиоrрафия 1041
729. Mesиlam М.М. "Attention, confusional states and neglect", in Principles of
Behavioral Neиrology, М.М. Mesиlam, ed., Philadelphia: Р.А. Davis, 1985.
730. Metropolis N., А. Rosenblиth, М. Rosenblиth, А. Teller and Е. TeIler. Eqиations
of state ca1cиlations Ьу fast compиting machines, Joиmal of Chemical Physics,
1953, уоl. 21, р. 1087 1092.
731. Mhaskar H.N. "Neиral networks for optimal aproximation of smooth and analytic
fиnctions", Neиral Compиtation, 1996, уоl. 8, р. 1 731 1742.
732. Mhaskar H.N. and С.А. Micchelli. "Aproximation Ьу sиperposition of sigmoidal
and radial basis functions", Advances in Aplied Mathematics, 1992, уоl. 13,
р. 350 373.
733. Micchelli С.А. "Interpolation of scattered data: Distance matrices and condi
tionally positive definite functions", Constrиctive Aproximation, 1986, уоl. 2,
р. 11 22.
734. Miller О., А.У. Rao, К. Rose and А. Gersho. "А global optimization techniqиe
for statistical classifier design", ШЕЕ Transactions оп Signal Processing, 1996,
уоl. 44, р. 3108 3122.
735. Miller к.О., J.B. Keller and М.Р. Stryker. "Ocиlar dominance colиrnn develop
ment: Analysis and simиlation", Science, 1989, уоl. 245, р. 605 615.
736. Miller О. and К. Rose. "Hierarchical, иnsиpervised leaming with growing via
phase transitions", Neиral Compиtation, 1996, уоl. 8, р. 425 50.
737. Miller О. and К. Rose. "Combined soиrce channel vector qиantization иsing
deterministic annealing", ШЕЕ Transactions оп Commиnications, 1994, уоl. 42,
р. 347 356.
738. Miller R. "Representation of brief temporal pattems, НеЬЫап synapses and the
left hemisphere dominance for phoneme recognition", Psychobiohgy, 1987, уо!.
15, р. 241 247.
739. Minai А.А. and R.J. Williams. "Back propagation heиristics: А stиdy of the
extended delta bar delta algorithm", ШЕЕ Intemational Joint Conference оп
Neиral Networks, 1990, уоl. 1, р. 595 600, San Diego, СА.
740. Minsky M.L. Society ofMind, New York: Simon and Schuster, 1986.
741. Minsky M.L. Compиtation: Finite and Infinite Machines. Englewood Cliffs, NJ:
Prentice Hall, 1967.
742. Minsky M.L. "Steps towards artificial intelligence", Proceedings ofthe Institиte
ofRadio Engineers, 1961, уоl. 49, р. 8 30 (Reprinted in: Feigenbaиm, Е.А. and
1. Feldman, eds., Compиters and Thoиght, р. 406 50, New York: McGraw
Нill.)
743. Minsky M.L. "Theory ofneиral analog reinforcement systems and its aplication
to the brain model problem", Ph.D. thesis, Princeton University, Princeton, NJ,
1954.
1042 Библиоrрафия
744. Minsky M.L. and S.A. Papert. Perceptrons, expanded edition, Cambridge, МА:
MIТ Press, 1988.
745. Minsky M.L. and S.A. Papert. Perceptrons, Cambridge, МА: MIТ Press, 1969.
746. Minsky M.L. and O.G. Selfridge. "Leaming in random nets", Information The
ory, Foиrth London Symposiиm, London: Bиtterworths, 1961.
747. Mitchell Т.М. Machine Leaming. New York: McGraw Hill, 1997.
748. Mitchison G. "Leaming algorithms and networks ofneиrons", in The Compиting
Neиron (R. ОшЫп, С. Miall and G. Michison, eds), 1989, р. 35 53, Reading,
МА: Addison Wesley.
749. Muller М.Р. "А scaled conjиgate gradient algorithm for fast sиpervised leaming",
Neural Networks, 1993, уоl. 6, р. 525 534.
750. Moody J. and C.I. Darken. "Fast leaming in networks oflocally tиned processing
иnits", Neural Compиtation, 1989, vol. 1, р. 281 294.
751. Moody J. and L. Wи. "Optimization of trading systems and portfolios", in А.
Weigend, У. Abи Mostafa and A. P.N. Refenes, eds., Decision Technologies for
Financial Engineering, 1996, р. 23 35, Singapore: World Scientific.
752. Moody J.E. and Т. R6gnvaldsson. "Smoothing regиlarizers for projective basis
function networks", Advances in Neиral Information Processing Systems, 1997,
уоl. 9, р. 585 591.
753. Moray N. "Attention in dichotic listening: Affective cиes and the inflиence
of instrиctions", Qиarterly Joиmal of Experimental Psychology, 1959, уоl. 27,
р. 56 60.
754. Morgan N. and Н. Bourlard. "Continиoиs speech recognition иsing mиltilayer
perceptrons with hidden Markov models", ШЕЕ Intemational Conference оп
Acoиstics, Speech and Signal Processing, 1990, уоl. 1, р. 413 16, Albиqиerqиe.
755. Morita М. "Associative memory with nonmonotonic dynamics", Neural Net
works, 1993, уоl. 6, р. 115 126.
756. Morozov v.A. Regиlarization Methods for Ill Posed Problems, Воса Raton, FL:
CRC Press, 1993.
757. Morse Р.М. and Н. Feshbach. Methods ofTheoretical Physics, Part 1, New York:
McGraw Hill, 1953.
758. Mozer М.С. "Neura1 net architectиres for temporal sequence processing", in A.S.
Weigend and N.A. Gershenfeld, eds., Time Series Prediction: Forecasting the
Fиtиre and Understanding the Past, 1994, р. 243 264, Reading, МА: Addison
Wes1ey.
759. Mpitsos G.J. "Chaos in brain function and the problem of nonstationarity: А
commentary", in Chaos in Brain Fиnction, Е. Basar, ed., 1990, р. 162 176. New
York: Springer Verlag.
760. M(ller В. and J. Reinhardt. Neural Networks: Ап Introdиction, New York:
Springer Verlag, 1990.
Библиоrрафия 1043
761. Mиller О. and G. Lynch. "Long term potentiation differentially affects two com
ponents of synaptic responses in hipocampиs", Proceedings of the National
Academy of Sciences, USA, 1988, vo1. 85, р. 9346 9350.
762. Mиmford О. "Neиral architectиres for pattem theoretic problems", in С. Koch
and J. Davis, eds., Large Sca1e Theories ofthe Cortex, 1994, р. 125 152, Cam
bridge, МА: MIТ Press.
763. Мипау М.к. and J.W. Rice. Differential Geometry and Statistics, New York:
Chapman and Наll, 1993.
764. Mиrtagh В. and М. Saиnders. "Large scale linearly constrained optimization",
Mathematical Programming, 1978, уоl. 14, р. 41 72.
765. Mиselli М. "Оп convergence properties ofpocket algorithm", ШЕЕ Transactions
оп Neиra1 Networks, 1997, уоl. 8, р. 623 629.
766. Nadal J. P. and N. Parga. "Redиndancy redиction and independent component
analysis: Conditions оп cиmиlants and adaptive aproaches", Neиral Compиta
tion, 1997, vo1. 9, р. 1421 1456.
767. Nadal J. P. and N. Parga. "Nonlinear neurons in the 10w noise limit: А factoria1
code maximizes information transfer", Network, 1994, уоl. 5, р. 565 581.
768. Nadaraya Е.А. "ОП nonparametric estimation of density functions and regression
cиrves", Theory ofProbability and its Aplications, 1965, уоl. 10, р. 186 190.
769. Nadaraya Е.А. "ОП estimating regression", Theory of Probability and its Apli
cations, 1964, уоl. 9, р. 141 142.
770. Naftaly U., N. Intrator and О. Ноm. "Optimal ensemble averaging of neиral
networks", Network, 1997, уоl. 8, р. 283 296.
771. Nakano К. "Association а model of associative memory", ШЕЕ Transactions
оп Systems, Мап and Cybemetics, 1972, уоl. SMC 2, р. 380 388.
772. Narendra к.s. Neиral Networks for Identification and Control, NIPS 95, Tиtorial
Program, 1995, р. 1 6, Denver.
773. Narendra к.s. and А.М. Annaswamy. Stable Adaptive Systems, Englewood
Cliffs, NJ: Prentice Hall, 1989.
774. Narendra к.s. and К. Parthasarathy. "Identification and control of dynamical
systems иsing neиra1 networks", ШЕЕ Transactions оп Neural Networks, 1990,
уоl. 1, р. 4 27.
775. Natarajan В.к. Machine Leaming: А Theoretical Aproach, San Mateo, СА:
Morgan Kaиfmann, 1991.
776. Neal R.M. Bayesian Leaming for Neиral Networks, Ph.D. Thesis, University of
Toronto, Canada, 1995.
777. Neal R.M. "Bayesian leaming via stochastic dynamics", Advances in Neиral
Iпfопnatiоп Processing Systems, 1993, уоl. 5, р. 475 82, San Mateo, СА:
Morgan Kaиfmann.
1044 Библиоrрафия
778. Neal R.M. "Connectionist leaming of belief networks", Artificial Intel1igence,
1992, уоl. 56, р. 71 113.
779. Newcomb S. "А generalized theory of the combination of observations so as to
obtain the best resиlt", American Joиma1 ofMathematics, 1886, vo1. 8, р. 343
366.
780. Newel1 А. and Н.А. Simon. Human Problem Solving, Englewood Cliffs, NJ:
Prentice Hall, 1972.
781. N g К. and R.P. Lipmann. "Practical characteristics of neиra1 network and сопуеп
tional pattem classifiers", Advances in Neиral Information Processing Systems,
1991, уоl. 3, р. 970 976, San Mateo, СА: Morgan Kaиfmann.
782. Ngиyen О. and В. Widrow. "The trиck backer иper: Ап ехаmрlе of self leaming
in пеиrаl networks", Intemationa1 Joint Conference оп Neиra1 Networks, 1989,
vo1. II, р. 357 363, Washington, ОС.
783. Nie J. and S. Haykin. "А Q leaming based dynamic channel assignment tech
niqиe for mоЫlе commиnication systems", ШЕЕ Transactions оп Vehicиlar
Technology, 1998
784. Nie J. and S. Haykin. "А dynamic channel assignment policy throиgh Q
leaming", CRL Report No. 334, Commиnications Research Laboratory, Mc
Master University, Hamilton, Ontario, 1996.
785. Nilsson N.J. Principles of Artificial Intelligence, New York: Springer Verlag,
1980.
786. Nilsson N.J. Leaming Machines: Foиndations of Trainable Pattem Classifying
Systems, New York: McGraw Hill, 1965.
787. Niyogi Р. and Р. Girosi. "Оп the relationship between generalization епоr, hy
pothesis complexity and sample complexity for radia1 basis functions", Neиral
Compиtation, 1996, уоl. 8, р. 819 842.
788. Novikoff A.B.J. "Оп convergence proofs for perceptrons", Proceedings of the
Symposiиm оп the Mathematical Theory of Aиtomata, 1962, р. 615 622, Brook
lуп, NY: Polytechnic Institиte of Brooklyn.
789. Nowlan S.J. "Maximиm likelihood competitive leaming", Advances in Neиral
Information Processing Systems, 1990, уоl. 2, р. 57 582, San Mateo, СА:
Morgan Kaиfmann.
790. Nowlan S.J. and G.E. Нinton. "Adaptive soft weight tying иsing Gaиssian mix
tиres", Advances in Neиral Information Processing Systems, 1992, vo1. 4, р. 993
1000, San Mateo, СА: Morgan Kaиfmann.
791. Nowlan S.J. and G.E. Нinton. "Evalиation of adaptive mixtиres of competing
experts", Advances in Neиral Information Processing Systems, 1991, уоl. 3,
р. 774 780, San Mateo, СА: Morgan Kaиfrnann.
Библиоrрафия 1045
792. Obermayer к., Н. Ritter and К. Schиlten. "Development and spatial strиctиre
of cortical featиre maps: А model stиdy", Advances in Neиral Information
Processing Systems, 1991, уоl. 3, р. 11 17, San Mateo, СА: Morgan Kaиfmann.
793. Oja Е. "Principal components, minor components and linear neиral networks",
Neиral Networks, 1992, уоl. 5, 927 936.
794. Oja Е. "Self organizing maps and compиter vision", Neural Networks for Per
ception, 1992Б, уоl. 1, Н. Wechsler, ed., уоl. 1, р. 368 385, San Diego, СА:
Academic Press.
795. Oja Е. "Data compression, featиre extraction and aиtoassociation in feedfor
ward пешаl networks", Artificial Neural Networks, 1991, уоl. 1, р. 737 746,
Amsterdam: North Holland.
796. Oja Е. "Neиral networks, principal components and sиbspaces", Intemational
Joиmal ofNeиral Systems, 1989, уоl. 1, бl 68.
797. Oja Е. Sиbspace Methods of Pattem Recognition, Letchworth, England: Re
search Stиdies Press, 1983.
798. Oja Е. "А simplified пешоп model as а principal component analyzer", Joиmal
ofMathematical Biology, 1982, уоl. 15, р. 267 273.
799. Oja Е. and J. Karhиnen. "А stochastic aproximation of the eigenvectors and
eigenvalиes of the expectation of а random matrix", Joиmal of Mathematical
Analysis and Aplications, 1985, уоl. 106, р. 69 84.
800. Oja Е. and Т. Kohonen. "The sиbspace leaming algorithm as formalism for
pattem recognition and пеиrаl networks", ШЕЕ Intemational Conference оп
Neиral Networks, 1988, уоl. 1, р. 277 284, San Diego, СА.
801. Omlin C.W. and C.L. Giles. "Constrиcting deterministic finite state aиtomata in
rесипепt neиral networks", Joиmal ofthe Association for Compиting Machinery,
1996, vol. 43, р. 937 972.
802. Openheim А.У. and R.W. Schafer. Discrete Time Signal Processing, Englewood
Cliffs, NJ: PrenticeHall, 1989.
803. Orlando J., R. Мапп and S. Haykin. "Classification of sea ice иsing а dиal
polarized radar", ШЕЕ Joиmal of Oceanic Engineering, 1990, уоl. 15, р. 228
237.
804. Osherson D.N., S. Weinstein and М. Stoli. "Modиlar leaming", Compиtational
Neиroscience, E.L. Schwartz, ed., 1990, р. 369 377, Cambridge, МА: MIТ
Press.
805. Osиna Е. "Sиport Vector Machines: Training and Aplications", Ph.D. Thesis,
Operations Research Center, MIТ, 1998.
806. Osиna Е. and F. Girosi. "Redиcing the rиn time complexity of sиport vector
machines", ICPR 98, Brisbane, Aиstralia, 1998.
1046 Библиоrрафия
807. Osиna Е., R. Freиnd and F. Girosi. "An improved training algorithrn for sиport
vector machines", Neural Networks for Signal Processing УII, Proceedings of
the 1997 ШЕЕ Workshop, 1997, р. 276 285, Amelia Island, FL.
808. Ott Е. Chaos in Dynamical Systems, Cambridge, МА: Cambridge University
Press, 1993.
809. Расkаrd N.R., J.P. Crиtchfield, J.D. Farmer and R.S. Shaw. "Geometry [rom а
time series", Physical Review Letters, 1980, уоl. 45, р. 712 716.
810. Palm G. Neиral Assemblies: Ап Altemative Aproach, New York: Springer
Verlag, 1982.
811. Palmieri F. and S.A. Shah. "Fast training of mи1tilayer perceptrons иsing mиlti
linear parameterization", Intemational Joint Conference оп Neиral Networks,
1990, уоl. 1, р. 696 699, Washington, ОС.
812. Palmieri Р., J. Zhи and С. Chang. "Anti Hebbian leaming in topologically соп
strained linear networks: А tиtorial", ШЕЕ Transactions оп Neиral Networks,
1993, уоl. 5, р. 748 761.
813. Papoиlis А. Probability, Random Variables and Stochastic Processes, 2ndedition,
New York: McGraw Hill, 1984.
814. Parisi G. Statistical Field Theory, Reading, МА: Addison Wesley, 1988.
815. Park J. and I.W. Sandberg. "Universal aproximation иsing radial basis function
networks", Neиral Compиtation, 1991, уоl. 3, р. 246 257.
816. Parker О.В. "Optimal algorithms for adaptive networks: Second order back prop
agation, second order direct propagation and second order НеЬЫап leaming",
ШЕЕ 1st Intemational Conference оп Neural Networks, 1987, уоl. 2, р. 593 600,
San Diego, СА.
817. Parker О.В. "Leaming logic: Casting the cortex ofthe hиman brain in silicon",
Technical Report TR 47, Center for Compиtational Research in Economics and
Management Science, Cambridge, МА: MIТ Press, 1985.
818. Parker Т. S. and L. О., Chиa. Practical Nиmerical Algorithms for Chaotic Systems,
New York: Springer, 1989.
819. Parzen Е. "Оп estimation of а probability density fиnction and mode", Annals
ofMathematical Statistics, 1962, уоl. 33, р. 1065 1076.
820. Passino к.N. "Toward bridging the perceived gap between conventional and
intelligent control", in М.О. Gиpta and N.к. Sinha, eds., Intelligent Control
Systems, 1996, р. 3 27, New York: ШЕЕ Press.
821. Рауl0У I.P. Conditional Reflexes: An Investigation ofthe Physiological Activity
ofthe Cerebral Cortex, G.V. Аnrер, New York: Oxford University Press, 1927.
822. Pearl J. Probabilistic Reasoning in Intelligent Systems, San Mateo, СА: Morgan
Kaиfmann, 1988 (Revised 2nd printing, 1991).
823. Pearlmиtter В.А. "Leaming state space trajectories in rесипепt пеиrаl net
works", Neиral Compиtation, 1989, уоl. 1, р. 263 269.
Библиоrрафия 1047
824. Pearson К. "Оп lines and planes of closest fit to systems of points in space",
Philosophical Magazine, 1901, уоl. 2, р. 559 572.
825. Peretto Р. "Collective properties of пешаl networks: А statistical physics
aproach", Biological Cybemetics, 1984, уоl. 50, р. 51 62.
826. Peretto Р. and J. J Niez. "Stochastic dynamics of пешаl networks", ШЕЕ Trans
actions оп Systems, Мап and Cybemetics, 1986, уоl. SMC 16, р. 73 83.
827. Репiп О. "Finite aиtomata", in J. уап Leeиwen, ed., Handbook of Theoretical
Compиter Science, Уоlиmе В: Formal Models and Semantics, 1990, Chapter 1,
р. 3 57, Cambridge, МА: MIТ Press.
828. Репопе М.Р. "Improving regression estimation: Averaging methods for vari
апсе redиction with extensions, to general сопуех measure optimization", Ph.D.
Thesis, Brown University, Rhode Island, 1993.
829. Personnaz L., 1. Gиyon and G. Dreyfus. "Information storage and retrieval in
spin glass like neиraInetworks", Joиmal of Physiqиe, Letters, Orsay, France,
1985, уоl. 46, L 359 L 365.
830. Peterson С. "Меап field theory пешаl networks for featиre recognition, content
addressable memory and optimization", Connection Science, 1991, уоl. 3, р. 3
33.
831. Peterson С. and J.R. Anderson. "А mеап field theory leaming algorithrn for
пеиrаl networks", Соmрlех Systems, 1987, уоl. 1, р. 995 1019.
832. Peterson С. and Е. Hartman. "Explorations of the mеап field theory leaming
algorithm", Neиral Networks, 1989, уоl. 2, р. 475 94.
833. Peterson С. and В. S6derberg. "А new method ofmaping optimization problems
onto пеиrаl networks", Intemational Joиmal of Neural Systems, 1989, уоl. 1,
р. 3 22.
834. РЬат О.Т. and Р. Gапаt. "Blind separation of mixtиre of independent soиrces
throиgh а qиasi maximиm likelihood aproach", ШЕЕ Transactions оп Signal
Processing, 1997, уоl. 45, р. 1712 1725.
835. Pham О.Т., Р. Gапаt and С. Jиtten. "Separation of а mixtиre of independent
soиrces throиgh а maximиm likelihood aproach", Proceedings of EUSIPCO,
1992, р. 771 774.
836. Phillips О. "А techniqиe for the nиmerical solиtion of certain integral eqиations
of the first kind", Joиmal of Association for Compиting Machinery, 1962, уоl.
9, р. 84 97.
837. Pineda F.J. "Rесипепt backpropagation and the dynamical aproach to adaptive
пеиrаl compиtation", Neural Compиtation, 1989, уоl. 1, р. 161 172.
838. Pineda F.J. "Generalization of backpropagation to rесипепt and higher order
пеиrаl networks", in Neиral Information Processing Systems, D.Z. Anderson,
ed., 1988, р. 602 611, New York: American Institиte ofPhysics.
1048 Библиоrрафия
839. Pineda F.J. "Dynamics and architectиre in пеиrаl compиtation", Joиmal ofCom
plexity, 1988Б, уоl. 4, р. 216 245.
840. Pineda F.J. "Generalization of back propagation to rесипепt neиral11etworks",
Physical Review Letters, 1987, уоl. 59, р. 2229 2232.
841. Pitts W. and W.S. McCиlloch, "How we know иniversals: The perception of
aиditory and visиal forms", Bиlletin of Mathematical Biophysics, 1947, уоl. 9,
р. 127 147.
842. РlиmЫеу М.О. and Р. Fallside. "Sensory adaptation: An information theoretic
viewpoint", Intemational Joint Conference оп Neura1 Networks, 1989, уоl. 2,
р. 598, Washington, ОС.
843. Plиmbley М.О. and F. Fal1side. "Ап information theoretic aproach to иnsиper
vised connectionist models", in Proceedings of the 1988 Connectionist Models
Sиmmer School, О. Toиretzky, G. Hinton al1d Т. Sejnowski, eds., 1988, р. 239
245. San Mateo, СА: Morgan Kaиfmann.
844. Poggio Т. "А theory of how the brain might work", Cold Spring Harbor Sym
posiиm оп Qиantitative Biology, 1990, уоl. 5, р. 899 910.
845. Poggio Т. and О. Beymer. "Leaming to see", ШЕЕ Spectrиm, 1996, уоl. 33, по.
5, р. 60 69.
846. Poggio Т. and S. Edelman. "А network that leams to recognize three dimensional
objects", Natиre, 1990, уоl. 343, р. 263 266.
847. Poggio Т. and Р. Girosi. "Networks for aproximation and leaming", Proceedings
ofthe ШЕЕ, 1990, уоl. 78, р. 1481 1497.
848. Poggio Т. and F. Girosi. "Regиlarization algorithms for leaming that are eqиiv
alent to mиltilayer networks", Science, 1990Б, уоl. 247, р. 978 982.
849. Poggio Т. and С. Koch. "Ill posed problems in early vision: From compиtational
theory to analogиe networks", Proceedings of the Royal Society of London,
1985, Series В, уоl. 226, р. 303 323.
850. Poggio т., У. Топе and С. Koch. "Compиtational vision and regиlarization
theory", Natиre, 1985, уоl. 317, р. 314 319.
851. Polak Е. and G. Ribi(re. "Note sиr lа convergence de methods de directions
conjиgиees", Revиe Fran(aise Information Recherche Operationnelle, 1969, уоl.
16, р. 35 3.
852. Р6реl G. and U. Кrey. "Dynamicalleaming process for recognition of сопеlаtеd
pattems in symmetric spin glass models", Europhysics Letters, 1987, уоl. 4,
р. 979 985.
853. Powell M.J.D. "The theory ofradial basis function aproximation in 1990", in W.
Light, ed., Advances in Nиmerical Analysis Уоl. 11: Wavelets, Sиbdivision Al
gorithms and Radial Basis Fиnctions, 1992, р. 1 05 21 О, Oxford: Oxford Science
Pиblications.
Библиоrрафия 1049
854. Powell M.J.D. "Radial basis function aproximatiol1s to polynornials", Nиmerical
Analysis 1987 Proceedings, 1988, р. 223 241, Dиl1dee, uк.
855. Powell M.J.D. "Radia1 basis functions for mиltivariable interpolation: А review",
IMA Conference оп Algorithms for the Aproximation of Fиnctions and Data,
1985, р. 143 167, RМCS, Shrivenham, England.
856. Powell M.J.D. "Restart procedures for the conjиgate gradient method", Mathe
matical Programming, 1977, уоl. 12, р. 241 254.
857. Preisendorfer R. W. Principal Component Analysis in Meteorology and Oceanog
raphy, New York: Elsevier, 1988.
858. Press W.H., В.Р. Flannery, S.A. Teиkolsky and W.T. Vetterling. Nиmerical
Recipes in С: The Art of Scientific Compиting, Cambridge: Cambridge Uni
versity Press, 1988.
859. Proakis J.G. Digital Commиnications, 2nd edition, New York: McGraw Hill,
1989.
860. Prokhorov О.У. and О.С. Wиnsch, 11. "Adaptive critic designs", ШЕЕ Transac
tions оп Neиral Networks, 1997, уоl. 8, р. 997 1007.
861. Pиskoriиs G.V. and L.A. Feldkamp. "Neurocontrol ofnonlinear dynamical sys
tems with Каlmап filter trained rесипепt networks", ШЕЕ Transactions оп Neи
ral Networks, 1994, уоl. 5, р. 279 297.
862. Pиskoriиs G.v. and L.A. Feldkamp. "Model reference adaptive control with re
сипепt networks trained Ьу the dynamic OEКF algorithm", Intemational Joint
Conference оп Neural Networks, 1992, уоl. 11, р. 106 113, Baltimore.
863. Pиskoriиs G.V., L.A. Feldkamp and L.I. Davis, Jr. "Dynamic пеиrаl network
methods aplied to onvehicle idle speed control", Proceedings ofthe ШЕЕ, 1996,
уоl. 84, р. 1407 1420.
864. Pиskoriиs G.V. and L.A. Feldkamp. "Decoиpled extended Каlmап filter train
ing of feedforward layered networks", Intemational Joint Conference оп Neиral
Networks, 1991, уоl. 1, р. 771 777, Seattle.
865. Rabiner L.R. "А tиtorial оп hidden Markov models", Proceedings of the ШЕЕ,
1989, уоl. 73, р. 1349 1387.
866. Rabiner L.R. and В.Н. Jиang. "Ап introdиction to hidden Markkov models",
ШЕЕ ASSP Magazine, 1986, уоl. 3, р. 4 16.
867. Rall W. "Cable theory for dendritic neurons", in Methods in Neuronal Modeling,
С. Koch and 1. Segev, eds., 1989, р. 9 62, Cambridge, МА: MIТ Press.
868. Rall W. "Some historical notes", in Compиtational Neuroscience, E.L. Schwartz,
Ed., 1990, р. 3 8, Cambridge: MIТ Press.
869. Ram6n у Cajal, S., Histologie dи Systems Nerveиx de l'homme et des vertebres,
Paris: Maloine, 1911.
1050 Библиоrрафия
870. Rao А., О. Miller К. Rose and А. Gersho. "Mixtиre of experts regression model
ing Ьу deterministic annealing", ШЕЕ Transactions оп Signal Processing, 1997,
уоl. 45, р. 2811 2820.
871. Rao А., К. Rose and А. Gersho. "А deterministic annealing aproach to discrim
inative hidden Markov model design", Neиral Networks for Signal Processing
VII, Proceedings of the 1997 ШЕЕ Workshop, 1997Б, р. 266 275, Amelia Is
land, FL.
872. Rao C.R. Linear Statistical Inference and Hs Aplications, New York: Wiley, 1973.
873. Rashevsky N. Mathematical Biophysics, Chicago: University of Chicago Press,
1938.
874. Raviv У. and N. Intrator. "Bootstraping with noise: Ап effective regиlarization
techniqиe", Connection Science, 1996, уоl. 8, р. 355 372.
875. Reed R. "Prиning algorithms А sиrvey", ШЕЕ Transactions оп Neиral Net
works, 1993, уоl. 4, р. 740 747.
876. Reeke G.N. Jr., L.R. Finkel and G.M. Edelman. "Selective recognition aиtoma
ta", in An Introdиction to Neural and Electronic Networks, S.F. Zometzer, J.L.
Davis and С. Laи, eds., 1990, р. 203 226, New York: Academic Press.
877. Reif. Fиndamentals ofStatistical and Thermal Physics, New York: McGraw Hill,
1965.
878. Renals S. "Radial basis function network for speech pattem classification", E1ec
tronics Letters, 1989, уоl. 25, р. 437 39.
879. Riшуi А. "Оп measиres of entropy and information", Proceedings of the 4th
Berkeley Symposiиm оп Mathematics, Statistics and Probability, 1960, р. 547
561.
880. Riшуi А. Probability Theory, North Holland, Amsterdam, 1970.
881. Richard М.О. and R.P. Lipmann. "Neиral network classifiers estimate Bayesian
а posteriori probabilities", Neиral Compиtation, 1991, уоl. 3, р. 461 83.
882. Riesz F. and В. Sz Nagy. Fиnctional Analysis, 2nd edition, New York: Frederick
Ungar, 1955.
883. Ripley В.О. Pattem Recognition and Neиral Networks, Cambridge: Cambridge
University Press, 1996.
884. Rissanen J. "Modeling Ьу shortest data description", Aиtomatica, 1978, уоl. 14,
р. 465 71.
885. Rissanen J. Stochastic Complexity in Statistical Inqиiry, Singapore: World Sci
entific, 1989.
886. Ritter Н. "Asymptotic lеуеl density for а class ofvector qиantization processes",
ШЕЕ Transactions оп Neural Networks, 1991, уоl. 2, р. 173 175.
887. Ritter Н. "Self organizing featиre maps: Kohonen maps", in М.А. Arbib, ed.,
The Handbook ofBrain Theory and Neиral Networks, 1995, р. 846 851, Caт
bridge, МА: MIТ Press.
Библиоrрафия 1051
888. Ritter Н. and Т. Kohonen. "Self organizing semantic maps", Biological Cyber
netics, 1989, уоl. 61, р. 241 254.
889. Ritter Н. and К. Schиlten. "Convergence properties of Kohonen's topology
conserving maps: Flиctиations, stability and dimension selection", Biological
Cybemetics, 1988, уоl. 60, р. 59 71.
890. Ritter Н., Т.М. Martinetz and к.J. Schиlten. "Topology conserving maps for
leaming visиo motor coordination", Neиral Networks, 1989, уоl. 2, р. 159 168.
891. Ritter Н., Т. Martinetz and К. Schиlten. Neural Compиtation and Self Organizing
Maps: Ап Introdиction, Reading, МА: Addison Wesley, 1992.
892. Robbins Н. and S. Моnrо. "А stochastic aproximation method", Annals of
Mathematical Statistics, 1951, уоl. 22, р. 400 07.
893. Robinson О.А. "Signal processing Ьу пеиrаl networks in the control of еуе
movements", Compиtational Neиroscience Symposiиm, 1992, р. 73 78, Indiana
University Pиrdиe University at Indianapolis.
894. Rochester N., J.R. Holland, L.R. Haibt and W.L. Dиda. "Tests оп а сеll as
sembly theory of the action of the brain, иsing а large digital compиter", lRE
Transactions оп Information Theory, 1956, уоl. IТ 2, р. 80 93.
895. Rose К. "Deterministic annealing for clиstering, compression, classification, re
gression and related optimization problems", Proceedings of the ШЕЕ, 1998,
уоl. 86.
896. Rose К. Deterministic Annealing, Clиstering and Optimization, Ph.D. Thesis,
Califomia Institиte of Technology, Pasadena, СА, 1991.
897. Rose К., Е. Gurewitz and G.C. Рох. "Vector qиantization Ьу deterministic ап
nealing", ШЕЕ Transactions оп Information Theory, 1992, уоl. 38, р. 1249 1257.
898. Rose к., Е. Gurewitz and G.C. Рох. "Statistical mechanics and phase transitions
in clиstering", Physical Review Letters, 1990, уоl. 65, р. 945 948.
899. Rosenblatt F. Principles of Neиrodynamics, Washington, ОС: Spartan Books,
1962.
900. Rosenblatt F. "Perception simиlation experiments", Proceedings of the Institиte
ofRadio Engineers, 1960, уоl. 48, р. 30l 309.
901. Rosenblatt F. "Оп the convergence of reinforcement procedиres in simple per
ceptions", Соmеll Aeronaиtical Laboratory Report, VG 1196 GA, Bиffal0, NY,
1960Б.
902. Rosenblatt F. "The Perceptron: А probabilistic model for information storage and
organization in the brain", Psychological Review, 1958, уоl. 65, р. 386 08.
903. Rosenblatt М. "Density estimates and Markov seqиences", in М. Pиri, ed.,
Nonparametric Techniqиes in Statistical Inference, 1970, р. 199 213, London:
Cambridge University Press.
904. Rosenblatt М. "Remarks оп some nonparametric estimates of а density [ипс
tion", Annals ofMathematical Statistics., 1956, уоl. 27, р. 832 837.
1052 Библиоrрафия
905. Ross S.M. Introdиction to Stochastic Dynamic Programming, New York: Aca
demic Press, 1983.
906. Roth Z. and У. Baram. "Mиlti dimensional density shaping Ьу sigmoids", ШЕЕ
Transactions оп Neиral Networks, 1996, уоl. 7, р. 1291 1298.
907. Roиssas G., ed. Nonparametric Fиnctional Estimation and Related Topics, The
Netherlands: Кlиwer, 1991.
908. Roy S. and J.J. Shynk. "Analysis of the mоmепtиm LMS algorithrn", ШЕЕ
Transactions оп Acoиstics, Speech and Signal Processing, 1990, уоl. ASSP 38,
р. 2088 2098.
909. Rиbner J. and К. Schиlten. "Development of featиre detectors Ьу self
organization", Biological Cybemetics, 1990, уоl. 62, р. 193 199.
910. Rиbner J. and Р. Тауап. "А self organizing network for principal component
analysis", Eиrophysics Letters, 1989, уоl. 10, р. 693 698.
911. Rиeckl J.G., к.R. Сауе and S.M. Kosslyn. "Why are 'what' and 'where' pro
cessed Ьу separate cortical visиal systems? А compиtationa1 investigation", J.
Cognitive Neиroscience, 1989, уоl. 1, р. 171 186.
912. Rиmelhart О.Е. and J.L. McClelland, eds. Parallel Distribиted Processing: Ex
plorations in the Microstrиctиre of Cognition, vol. 1, Cambridge, МА: MIТ
Press, 1986.
913. Rиmelhart О.Е. and О. Zipser. "Featиre discovery Ьу competitive leaming",
Cognitive Science, 1985, уоl. 9, р. 75 112.
914. Rиmelhart О.Е., G.E. Hinton and R.J. Williams. "Leaming representations ot'
back propagation епоrs", Natиre (London), 1986, уоl. 323, р. 533 536.
915. Rиmelhart О.Е., G.E. Hinton and R.J. Williams. "Leaming intemal representa
tions Ьу епоr propagation", in О.Е. Rиmelhart and J.L. McCleland, eds., уоl 1,
Chapter 8, Cambridge, МА: MIТ Press, 1986Б.
916. Rиssell S.J. and Р. Novig. Artificial Intelligence: А Modem Aproach, Uper
Saddle River, NJ: Prentice Hall, 1995.
917. Rиsso А.Р. Neиral Networks for Sonar Signal Processing, Tиtorial No. 8, ШЕЕ
Conference оп Neиral Networks for Осеап Engineering, Washington, ОС, 1991.
918. Rиyck D.W., S.K. Rogers, М. Kabrisky, М.Е. Охlеу and B.W. Sиter. "The mиl
tilayer perception as ап aproximation to а Bayes optimal discriminant function",
ШЕЕ Transactions ofNeиral Networks, 1990, уоl. 1, р. 296 298.
919. Saarinen S., R.B. Bramley and G. Cybenko. "Neural networks, backpropagation
and aиtomatic differentiation", in Aиtomatic Differentiation of Algorithms: The
ory, Implementation and Aplication, А. Griewank and G.F. Corliss, eds., 1992,
р. 31 42, Philadelphia: SIAM.
920. Saarinen S., R. Bramley and G. Cybenko. "The nиmerical solиtion of пеиrаl net
work training problems", CRSD Report No. 1089, Center for Sиpercompиting
Research and Development, University of Illinois, Urbana, IL, 1991.
Библиоrрафия 1053
921. Sackinger Е., В.Е. Boser, J. Bromley, У. LeCиn and L.D. Jackel. "Aplication
of the ANNA пеиrаl network chip to high speed character recognition", ШЕЕ
Transactions оп Neural Networks, 1992, уоl. 3, р. 498 505.
922. Sackinger Е., В.Е. Boser and L.D. Jackel. "А neиrocompиter board based оп
the ANNA пеиrаl network chip", Advances in Neural Information Processing
Systems, 1992Б, уоl. 4, р. 773 780, San Mateo, СА: Morgan Kaиfmann.
923. Saerens М. and А. Soqиet. "Neural controller based оп back propagation algo
rithm", ШЕЕ Proceedings (London), Part Р, 1991, уоl. 138, р. 55 62.
924. Sage А.Р., ed. Concise Encyclopedia of Information Processing in Systems and
Organizations, New York: Pergamon, 1990.
925. Salomon R. and J.L. уап Неттеп. "Accelerating backpropagation throиgh dy
namic self adaptation", Neиral Networks, 1996, уоl. 9, р. 589 601.
926. Samиel A.L. "Some stиdies in machine leaming иsing the game of checkers",
IВM Joиmal ofResearch and Development, 1959, уоl. 3, р. 211 229.
927. Sandberg I.W. "Strиctиre theorems for nonlinear systems", Mиltidimensional
Systems and Signal Processing, 1991, уоl. 2, р. 267 286.
928. Sandberg I.W., L. Хи. "Uniform aproximation of mиltidimensional myopic
maps", ШЕЕ Transactions оп Circиits and Systems, 1997, уоl. 44, р. 477 85.
929. Sandberg I.W. and L. Хи. "Uniform aproximation and gamma networks", Neиral
Networks, 1997Б, уоl. 10, р. 781 784.
930. Sanger Т.О. "Ana1ysis of the two dimensional receptive fields leamed Ьу the
НеЬЫап algorithm in response to random inpиt", Biological Cybemetics, 1990,
уоl. 63, р. 221 228.
931. Sanger т.о. "Ап optimality principle for иnsиpervised leaming", Advances in
Neural Information Processing Systems, 1989, уоl. 1, р. 11 19, San Mateo, СА:
Morgan Kaиfmann.
932. Sanger Т.о. "Optimal иnsиpervised leaming in а single layer linear feedforward
пеиrаl network", Neиral Networks, 1989Б, уоl. 12, р. 459. 73.
933. Sanner R.M. and J., J.E. Slotine. "Gaиssian networks for direct adaptive соп
trol", ШЕЕ Transactions оп Neиra1 Networks, 1992, уоl. 3, р. 837 863.
934. Saиer N. "Оп the densities of families of sets", Joиmal of Combinatorial Theory,
Series А, 1972, уоl. 13, р. 145 172.
935. Saиer Т., J.A. Yorke and М. Casdagli. "Embedology", Joиmal of Statistical
Physics, 1991, уоl. 65, р. 579 бl7.
936. Saиl L.к., Т. Jakkolla and M.I. Jordan. "Меап field theory for sigmoid belief
networks", Joиmal of Artificial Intelligence Research, 1996, уоl. 4, р. 61 76.
937. Saиl L.K. and M.I. Jordan. "Exp1oiting tractable sиbstrиctиres in intractable
networks", Advances in Neиral Information Processing Systems, 1996, vol. 8,
р. 486 92, Cambridge, МА: MIТ Press.
1054 Библиоrрафия
938. Saиl L.к. and M.I. Jordan. "Boltzmann chains and hidden Markov models",
Advances in Neиral Information Processing Systems, 1995, уоl. 7, р. 435 42.
939. Schapire R.E. "Using oиtpиt codes to boost mиlticlass leaming problems",
Machine Leaming: Proceedings of the Foиrteenth Intemational Conference,
Nashville, ТN, 1997.
940. Schapire R.E. "The strength ofweak leamability", Machine Leaming, 1990, уоl.
5, р. 197 227.
941. Schapire R.E., У. Freиnd and Р. Bartlett. "Boosting the margin: А new ехрlапа
tion for the effectiveness of voting methods", Machine Leaming: Proceedings
ofthe Foиrteenth Intemational Conference, Nashville, TN, 1997.
942. Schiffman W.H. and H.W. Geffers. "Adaptive control of dynamic systems Ьу
back propagation networks", Neиral Networks, 1993, уоl. 6, р. 517 524.
943. Schneider C.R. and Н.С. Card. "Analog hardware implementation issиes in de
terministic Boltzmann machines", ШЕЕ Transactions оп Circиits and Systems
II, 1998, уоl. 45.
944. Schneider C.R. and Н.С. Card. "Analog CMOS deterministic Boltzmann cir
cиits", ШЕЕ Joиmal Solid State Circиits, 1993, уоl. 28, р. 907 914.
945. SchйlkopfB. Sиport Vector Leaming, Mиnich, Germany: R. 01denboиrg Verlag,
1997.
946. SchйlkopfB., Р. Simard, У. Vapnik and A.J. Smola. "Improving the accиracy and
speed of sиport vector machines", Advances in Neural Information Processing
Systems, 1997, уоl. 9, р. 375 381.
947. SchйlkopfB., А. Smola and к. R. Muller. "Nonlinear component analysis as а
kemel eigenvalиe problem", Neиral Compиtation, 1998, уоl. 10.
948. Schйlkopf В., к. K Sиng, C.J.C. Bиrges, F. Girosi, Р. Niyogi, Т. Poggio and
У. Vapnik. "Comparing sиport vector machines with Gaиssian kemels to radial
basis function classifiers", ШЕЕ Transactions оп Signal Processing, 1997, уоl.
45, р. 2758 2765.
949. Schraиdolph N.N. and T.J. Sejnowski. "Tempering back propagation networks:
Not аll weights are created eqиal", Advances in Neиral Information Processing
Systems, 1996, уоl. 8, р. 563 569, Cambridge, МА: MIТ Press.
950. Schиmaker L.L. Spline Fиnctions: Basic Theory, New York: Wiley, 1981.
951. Schиrmars О. "Altemative metrics for maximиm margin classification", NIPS
Workshop оп Sиport Vector Machines, Beckenbridge, СО, 1997.
952. Schиster H.G. Deterministic Chaos: Ап Introdиction, Weinheim, Germany:
УСН, 1988.
953. Scofield C.L. and L.N. Cooper. "Development and properties of пеиrаl net
works", Contemporary Physics, 1985, уоl. 26, р. 125 145.
954. Scott А.С. Neиrophysics, New York: Wiley, 1977.
Библиоrрафия 1055
955. Segee В.Е. and M.J. Carter. "Faиlt tolerance of prиned mиltilayer networks",
Intemational Joint Conference оп Neиral Networks, 1991, уоl. 11, р. 447 52,
Seattle.
956. Sejnowski T.J. "Strong covariance with nonlinearly interacting neurons", Joиmal
ofMathematical Biology, 1977, уоl. 4, р. 303 321.
957. Sejnowski т.J. "Statistical constraints оп synaptic plasticity", Joиmal of Theo
retical Biology, 1977Б, уоl. 69, р. 385 389.
958. Sejnowski т.J. "Оп global properties of пеиrопаl interaction", Biological Cy
bemetics, 1976, уоl. 22, р. 85 95.
959. Sejnowski т.J. and P.S. Chиrchland. "Brain and cognition", in Foиndations of
Cognitive Science, M.I. Posner, ed., 1989, р. 301 356, Cambridge, МА: MIТ
Press.
960. Sejnowski т.J., Р.к. Кienker and G.E. Hinton. "Leaming symmetry groиps with
hidden иnits: Beyond the perceptron", Physica, 1986, уоl. 22О, р. 260 275.
961. Sejnowski т.J., С. Koch and P.S. Chиrchland. "Compиtational neиroscience",
Science, 1988, уоl. 241, р. 1299 1306.
962. Sejnowski т.J. and C.R. Rosenberg. "Parallel networks that leam to pronoиnce
English text", Соmрlех Systems, 1987, уоl. 1, р. 145 168.
963. Sejnowski т.J., В.Р. Yиhas, МЯ. Goldstein, Jr. and R.E. Jenkins. "Combining vi
sиal and acoиstic speech signals with а пешаl network improves intelligibility",
Advances in Neural Information Processing Systems, 1990, уоl. 2, р. 232 239,
San Mateo, СА: Morgan Kaиfmann.
964. Selfridge O.G., R.S. Sиtton and C.W. Anderson. "Selected bibliography оп соп
nectionism", Evolиtion, Leaming and Cognition, У.С. Lee, Ed., 1988, р. 391
403, River Edge, NJ: World Scientific pиblishing, Inc.
965. Seиng Н. "Annealed theories of leaming", in J. H Oh, С. Kwon and S. Cho,
eds., Neиral Networks: The Statistical Mechanics Perspective, Singapore: World
Scientific, 1995.
966. Seиng H.S., T.J. Richardson, J.C. Lagarias and J.J. Hopfield. "Saddle point and
Hami1tonian strиctиre in excitatory inhibitory networks", Advances in Neural
Information Processing Systems, 1998, уоl. 10.
967. Shah S. and F. Palmieri. "МЕКА А fast, 10саl algorithm for training feed
forward пешаl networks", Intemational Joint Conference оп Neиral Networks,
1990, уоl. 3, р. 41 46, San Diego, СА.
968. Shamma S. "Spatial and temporal processing in central aиditory networks", in
Methods in Neural Modeling, С. Koch and 1. Segev, Eds., Cambridge, МА: MIТ
Press, 1989.
969. Shanno О.Р. "Conjиgate gradient methods with inexact line searches", Mathe
matics of Operations Resear h, 1978, уоl. 3, р. 244 256.
1056 Библиоrрафия
970. Shannon С.Е. "А mathematical theory of commиnication", Веll System Techni
cal Joиmal, 1948, уоl. 27. р. 379 23, 623 656.
971. Shannon С.Е. and W. Weaver. The Mathematical Theory of Commиnication,
Urbana, IL.: The University of I1linois Press, 1949.
972. Shannon С.Е. and J. McCarthy, eds. Aиtomata Stиdies, Princeton, NJ: Princeton
University Press, 1956.
973. Shepherd G.M. Neиrobiology, 2nd edition, New York: Oxford University Press,
1988.
974. Shepherd G.M. "Microcircиits in the nervoиs system", Scientific American,
1978,vol. 238,р. 92 103.
975. Shepherd G.M., ed. The Synoptic Organization of the Brain, 3rd edition, New
York: Oxford University Press, 1990 (Ранее было опубликовано как отчет с
результатами исследований Службы национальной безопасности; февраль,
1942.)
976. Shepherd G.M. "The significance of real neиron architectиres for пешаl net
work simиlations", in Compиtational Neиroscience, E.L. Schwartz, ed., 1990Б,
р. 82 96, Cambridge: MIТ Press.
977. Shepherd G.M. and С. Koch. "Introdиction to synaptic circиits", in The Synop
tic Organization of the Brain, G.M. Shepherd, ed., 1990, р. 3 31. New York:
Oxford University Press.
978. Shепiпgtоп C.S. The Integrative Action of the Nervoиs System, New York:
Oxford University Press, 1906.
979. Shепiпgtоп C.S. The Brain and Its Mechanism, London: Cambridge University
Press, 1933.
980. Shепiпgtоп О. and S. Кirkpatrick. "Spin glasses", Physical Review Letters,
1975, уоl. 35, р. 1972.
981. Shewchиk J.R. Ап Introdиction to the Conjиgate Gradient Method Withoиt the
Agonizing Pain, 1994, School ofCompиter Science, Camegie Меllоп University,
Pittsbиrgh, РА, Aиgиst 4, 1994.
982. Shore J.E. and R.W. Johnson. "Axiomatic derivation of the principle of maxi
mиm entropy and the principle ofminimиm cross entropy", ШЕЕ Transactions
оп Information Theory, 1980, уоl. IТ 26, р. 26 37.
983. Shynk J.J. "Performance sиrfaces of а single layer perceptron", ШЕЕ Transac
tions оп Neural Networks, 1990, 1, р. 268 274.
984. Shynk J.J. and N.J. Bershad. "Steady state analysis of а single layer perceptron
based оп а system identification model with Ыа terms", ШЕЕ Transactions оп
Circиits and Systems, 1991, уоl. CAS 38, р. 1030 1042.
985. Shиstorovich А. "А sиbspace projection aproach to featиre extraction: The two
dimensional Gabor transform for character recognition", Neural Networks, 1994,
уоl. 7, р. 1295 1301.
Библиоrрафия 1057
986. Shиstorovich А. and С. Thrasher. "Neural network positioning and classification
of handwritten characters", Neиral Networks, 1996, уоl. 9, р. 685 693.
987. Shynk J.J. and N.J. Bershad. "Stationary points and performance sиrfaces of
а perceptron leaming algorithm for а nonstationary data model", Intemational
Joint Conference оп Neural Networks, 1992, уоl. 2, р. 133 139, Baltimore.
988. Shynk J.J. and N.J. Bershad. "Steady state analysis of а single layer perceptron
based оп а system identification model with bias terms", ШЕЕ Transactions оп
Circиits and Systems, 1991, vol. CAS 38, р. 1030 1042.
989. Siegelmann Н.т., B.G. Ноmе and C.L. Giles. "Compиtational capabilities of
rесипепt NARX neural networks", Systems, Мап and Cybemetics, Part В: Cy
bemetics, 1997, уоl. 27, р. 208 215.
990. Siegelmann Н.Т. and Е.О. Sontag. "Tиring compиtability with neural nets",
Aplied Mathematics Letters, 1991, уоl. 4, р. 77 80.
991. Simard Р., У. LeCиn and J. Denker. "Efficient pattem recognition иsing а new
transformation distance", Advances in Neural Information Processing Systems,
1993, уоl. 5, р. 50 58, San Mateo, СА: Morgan Kaиfmann.
992. Simard Р., В. Victопi, У. LeCиn and J. Denker. "Tangent prop А formal
ism for specifYing selected invariances in ап adaptive network", Advances in
Neural Information Systems, 1992, уоl. 4, р. 895 903, San Mateo, СА: Morgan
Kaиfinann.
993. Simmons J.A. "А view of the world throиgh the bat's ear: The formation of
acoиstic images in echolocation", Cognition, 1989, уоl. 33, р. 155 199.
994. Simmons J.A., Р.А. Saillant and S.P. Dear. "Throиgh а bat's ear", ШЕЕ Spec
trищ 1992, уоl. 29(3), р. 4 8.
995. Singh S.P., ed. Aproximation Theory, Spline Fиnctions and Aplications, Dor
drecht, The Netherlands: Кlиwer, 1992.
996. Singh S. and О. Bertsekas. "Reinforcement leaming for dynamic channel alloca
tion in cellиlar telephone systems", Advances in Neural Information Processing
Systems, 1997, уоl. 9, р. 974 980, Cambridge, МА: MIТ Press.
997. Singhal S. and L. Wи. "Training feed forward networks with the extended
Каlmап filter", ШЕЕ Intemational Conference оп Acoиstics, Speech and Signal
Processing, 1989, р. 1187 1190, Glasgow, Scotland.
998. Singleton R.C. "А test for linear separability as aplied to self organizing ma
chines", in М.С. Yovitz, G.T. Jacobi and G.D. Goldstein, eds., Self Organizing
Systems, 1962, р. 503 524, Washington ОС: Spartan Books.
999. Sj6berg J., Q. Zhang, L. Ljиng, А. Benveniste, В. Оеlуоп, P. Y. Glorennec, Н.
Hjalmarsson and А. Jиditsky. "Nonlinear black box modeling in system identi
fication: А иnified overview", Aиtomatica, 1995, уоl. 31, р. 1691 1724.
1000. Slepian О. Кеу papers in the development of information theory, New York:
ШЕЕ Press, 1973.
1058 Библиоrрафия
1001. Sloane N.J.A. and А.О. Wyner. Claиde Shannon: Collected Papers, New York:
ШЕЕ Press, 1993.
1002. Slotine J. J. and W. Li. Aplied Nonlinear Control, Englewood Cliffs, NJ:
Prentice Hall, 1991.
1003. Smith М. Neиral Networks for Statistical Modeling, New York: Уап Nostrand
Reinhold, 1993.
1004. Smola A.J. and В. Sch(lkopf. "From regиlarization operators to sиport vector
kemels", Advances in Neиral Information Processing Systems, 1998, уоl. 10.
1005. Smolensky Р. "Оп the proper treatment of connectionism", Behavioral and Brain
Sciences, 1988, уоl. 11, р. 1 74.
1006. Sontag Е.О. "Rесипепt neиral networks: Some leaming and systems theoretic
aspects", Department ofMathematics, Rиtgers University, New Brиnswick, NJ,
1996.
1007. Sontag Е.О. "Feedback stabilization иsing two hidden layer nets", ШЕЕ Trans
actions оп Neиral Networks, 1992, уо!. 3, р. 981 990.
1008. Sontag Е.О. Mathematical Control Theory: Deterministic Finite Dimensional
Systems, New York: Springer Verlag, 1990.
1009. Sontag Е.О. "Sigmoids distingиish more efficiently than Heavisides", Neиral
Compиtation, 1989, уоl. 1, р. 470 72.
1010. Soиthwell R.V. Relaxation Methods in Theoretical Physics, New York: Oxford
University Press, 1946.
1 О 11. Specht О.Р. "А general regression пеиrаl network", ШЕЕ Transactions оп Neиral
Networks, 1991, уоl. 2, р. 568 576.
1012. Sperdиti А. "Оп the compиtational power оfrесипепt пеиrаl networks for strиc
tиres", Neural Networks, 1997, уоl. 10, р. 395 00.
1013. Sperdиti А. and А. Starita. "Sиpervised neиral networks for the classification of
strиctиres", ШЕЕ Transactions оп N eиral N etworks, 1997, уоl. 8, р. 714 735.
1014. Sprecher О.А. "Оп the strиctиre of continиoиs fиnctions of several variables",
Transactions ofthe American Mathematical Society, 1965, уоl. 115, р. 340 355.
1015. Steinbиch К. "Die Lemmatrix", Kybemetik, 1961, уоl. 1, р. 36 5.
1016. Stent G.S. "А physiological mechanism for Hebb's postиlate of leaming", Pro
ceedings ofthe National Academy ofSciences, USA, 1973, уоl. 70, р. 997 1001.
1017. Sterling Р. "Retina", in The Synaptic Organization ofthe Brain, G.M. Shepherd,
ed., 3rd edition, р. 170 213, New York: Oxford University Press, 1990.
1018. Stevenson М., R. Winter and В. Widrow. "Sensitivity oflayered пеиrаl networks
to епоrs in the weights", Intemational Joint Conference оп Neиral Networks,
1990, уоl. 1, р. 337 340, Washington, ОС.
1019. Stone М. "Cross validation: А review", Mathematische Operationsforschиng
Statistischen, Serie Statistics, 1978, уоl. 9, р. 127 139.
Библиоrрафия 1059
1020. Stone М. "Cross validatory choice and assessment of statistical predictions",
Joиmal ofthe Royal Statistical Society, 1974, уоl. В36, р. 111 133.
1021. Stork о. "Is backpropagation biological1y plaиsible"? Intemational Joint Соп
ference оп Neural Networks, 1989, уоl. 2, р. 241 246, Washington, ос.
1022. Strang G. Linear Algebra and its Aplications, New York: Academic Press, 1980.
1023. Stиart А. and К. Ord. Kendall's Advanced Theory ofStatistics, уоl. 1, 6th edition,
New York: Halsted Press, 1994.
1024. Sи H. т. and Т. МсАуоу. "Identification of chemical processes иsing rесипепt
networks", Proceedings of the 10th American Controls Conference, 1991, уоl.
3, р. 2314 2319, Boston.
1025. Sи H. т., Т. МсАуоу and Р. Werbos. "Long term predictions of chemical pro
cesses иsing rесипепt neиral networks: А parallel training aproach", Indиstrial
Engineering and Chemical Research, 1992, vol. 31, р. 1338 1352.
1026. Sиga N. "Cortical compиtational maps for aиditory imaging", Neиral Networks,
1990, vol. 3, р. 3 21.
1027. Sиga N. "Compиtations of velocity and range in the bat aиditory system for
echo 10cation", in Compиtational Neиroscience, E.L. Schwartz, ed., р. 213 231,
Cambridge, МА: MIТ Press, 1990Б.
1028. Sиga N. "Biosonar and neural compиtation in bats", Scientific American, 1990б,
уоl. 262, р. 60 68.
1029. Sиga N. "The extent to which bisonar information is represented in the bat aиdi
tory cortex", in Dynamic Aspects ofNeocortical Fиnction, G.M. Edelman, WE.
Gal1 and W.M. Cowan, eds. р. 653 695, New York: Wiley (Interscience), 1985.
1030. Sиga N. and J.S. Kanwal. "Echolocation: Creating compиtational maps", in М.А.
Arbib, ed., The Handbook of Brain Theory and Neural Networks, Cambridge,
МА: MIТ Press, 1995.
1031. Sиtton J.P. and J.A. Anderson. "Compиtational and neиrobiological featиres of
а network ofnetworks", in J.M. Bower, ed., The Neиrobiology ofCompиtation,
р. 317 322, Boston: Кlиwer, 1995.
1032. Sиtton R.S. "Leaming to predict Ьу the methods oftemporal differences", Ma
chine Leaming, 1988, уоl. 3, р. 9 4.
1033. Sиtton R.S. "Two problems with back propagation and other steepest descent
leaming procedиres for networks", Proceedings of the Eighth Аппиаl Confer
епсе of the Cognitive Science Society, р. 823 831. Hillsdale, NJ: Lawrence
Erlbaиm, 1986.
1034. Sиtton R.S., ed. Special Issиe оп Reinforcement Leaming, Machine Leaming,
1992, уоl. 8, р. 1 395.
1035. Sиtton R.S. "Temporal credit assignment in reinforcement leaming", Ph.D. Dis
sertation, University of Massachиsetts, Amherst, МА, 1984.
1060 Библиоrрафия
1036. Sиtton R.S. and A.G. Barto. Reinforcement Leaming: Ап Introdиction, Cam
bridge, МА: MIТ Press, 1998.
1037. Sиykens J.A.K., J.P.L. Vandewalle and B.L.R. DeMoor. Artificial Neиral Net
works for Modeling and Control ofNon Linear Systems, Dordrecht, The Nether
lands: К1иwеr, 1996.
1038. Swindlehиrst A.L., M.J. Goris and В. Ottersten. "Some experiments with апау
data collected in actиal иrban and sиbиrban environments", ШЕЕ Workshop оп
Signal Processing Advances in Wireless Commиnications, р. 301 304, Paris,
France, 1997.
1039. Takahashi У. "Generalization and aproximation capabilities of mиltilayer net
works", Neural Compиtation, 1993, vol. 5, р. 132 139.
1040. Takens F. "Оп the nиmerical determination of the dimension of ап attractor",
in О. Rand and L.S. Yoиng, eds., Dynamical Systems and ТиrЬиlепсе, Anпиаl
Notes in Mathematics, 1981, уоl. 898, р. 366 381, Berlin: Springer Verlag.
1041. Tapia R.A. and J.R. Thompson. Nonparametric Probability Density Estimation,
Baltimore:The Johns Hopkins University Press, 1978.
1042. Taylor J.G. "Neиral compиtation: The historical backgroиnd", in Е. Fiesler and
R. Веаlе, eds., Handbook ofNeиral Compиtation, New York: Oxford University
Press, 1997.
1043. Taylor W.к. "Cortico thalamic organization and memory", Proceedings of the
Royal Society, London, Series В, 1964, уоl. 159, р. 466 78.
1044. Taylor W.K. "Electrical simиlation of some nervoиs system functional activi
tjes", Information Theory, 1956, уоl. 3, Е.С. Cherry, ed., р. 314 328, London:
Bиtterworths.
1045. Tesaиro G. "Temporal difference leaming and TD gamma", Commиnications of
the Association for Compиting Machinery, 1995, уоl. 38, р. 58 68.
1046. Tesaиro G. "TD Gammon, А self teaching Backgammon program, achieves
master level рlау", Neиral Compиtation, 1994, уоl. 6, р. 215 219.
1047. Tesauro G. "Practical issиes in temporal difference leaming", Machine Leaming,
1992, уоl. 8, р. 257 277.
1048. Tesaиro G. "Neurogammon wins compиter olympiad", Neиral Compиtation,
1989, уоl. 1, р. 321 323.
1049. Tesaиro G. and т.J. Sejnowski. "А parallel network that leams to рlау
backgamma", Artificial Intelligence, 1989, уоl. 39, р. 357 390.
1050. Tesaиro G. and R. Janssens. "Scaling relationships in back propagation leam
ing", Соmрlех Systems, 1988, vol. 2, р. 39 4.
1051. Teyler т.J. "Memory: Electrophysiological analogs", in Leaming and Memory:
А Biological View, J.L. Martinez, Jr. and R.S. Kesner, eds., р. 237 265, New
York: Academic Press, 1986.
1052. Thomdike E.L. Animal Inte1ligence, Darien, СТ: Hafner, 1911.
Библиоrрафия 1061
1053. Thrun S.Б. "The role of exploration in leaming control", in Handbook ofIntel
ligent Control, О.А. White and О.А. Sofge, eds., р. 527 559, New York: Уап
Nostrand Reinhold, 1992.
1054. Tikhonov A.N. "Оп regиlarization of i1l posed problems", Doklady Akademii
Naиk USSR, 1973, vol. 153, р. 49 52.
1055. Tikhonov A.N. "Оп solving iпсопесtlу posed problems and method ofregиlar
ization", Doklady Akademii Naиk USSR, 1963, уоl. 151, р. 501 504.
1056. Tikhonov A.N. and v.Y. Arsenin. Solиtions ofIll posed Problems, Washington,
ОС: W.H. Winston, 1977.
1057. Titterington О.М., A.F.M. Smith and v.E. Makov. Statistical Analysis ofFinite
Mixtиre Distribиtions, New York: Wiley, 1985.
1058. Toиretzky D.S. and О.А. Pomerleaи. "What is hidden in the hidden layers"?
Byte, 1989, уоl. 14, р. 227 233.
1059. Tsitsiklis J.N. "Asynchronoиs stochastic aproximation and Q leaming", Machine
Leaming, 1994, уоl. 16, р. 185 202.
1060. Tsoi А.С. and А.О. Back. "Locally rесипепt globally feedforward networks: А
critical review", ШЕЕ Transactions оп Neural Networks, 1994, уоl. 5, р. 229
239.
1061. Tиring А.М. "The chemical basis of morphogenesis", Philosophical Transactions
ofthe Royal Society, В, 1952, уоl. 237, р. 5 72.
1062. Tиring А.М. "Compиting machinery and inte1ligence", Mind, 1950, vol. 59,
р. 433 460.
1063. Turing А.М. "Оп compиtable nиmbers with ап aplication to the Entscheidиngs
problem", Proceedings of the London Mathematical Society, Series 2, 1936,
уоl. 42, р. 230 265; Исправления опубликованы в этом же издании, уоl. 43,
р. 544 546.
1064. Tsoi А.С. and А. Back. "Locally rесипепt global1y feedforward networks: А crit
ical review", ШЕЕ Transactions оп Neиral Networks, 1994, уоl. 5, р. 229 239.
1065. Tzefestas S.G., ed. Methods and Aplications of Intelligent Control, Boston:
Кlиwer, 1997.
1066. Udin S.B. and J.W. Fawcett. "Formation oftopographic maps", Anпиаl Review
ofNeuroscience, 1988, уоl. 2, р. 289 327.
1067. Ukrainec А.М. and S. Haykin. "А modиlar neиral network for enhancement of
cross polar radar targets", Neural Networks, 1996, уоl. 9, р. 143 168.
1068. Ukrainec А. and S. Haykin. "Enhancement ofradar images иsing mиtиal infor
mation based иnsиpervised neural networks", Canadian Conference оп Electrical
and Compиter Engineering, р. MA6.9.1 MA6.9.4, Toronto, Canada, 1992.
1069. Uttley А.М. Information Transmission in the Nervoиs System, London: Aca
demic Press, 1979.
1062 Библиоrрафия
1070. Uttley А.М. "The informon: А network for adaptive pattem recognition", Joиmal
ofTheoretical Biology, 1970, уоl. 27, р. 31 67.
1071. Uttley А.М. "The transmission of information and the effect of 10cal feedback
in theoretical and пеиrаl networks", Brain Research, 1966, уоl. 102, р. 23 35.
1072. Uttley А.М. "А theory of the mechanism of leaming based оп the compиtation
of conditional probabilities", Proceedings of the First Intemational Conference
оп Cybemetics, Namur, Gaиthier Villars, Paris, 1956.
1073. Vaillant R., С. Monrocq and У. LeCU11. "Original aproach for the 10calization
of objects in images", ШЕЕ Proceedings (London) оп Vision, Image and Signal
Processing, 1994, уоl. 141, р. 245 250.
1074. Valavanis К.Р. and G.N. Saridis. Intelligent Robotic Systems: Theory, Design
and Aplications, Norwell. МА: Кlиwer, 1992.
1075. Valiant L.G. "А theory of the !eamable", Commиnications of the Association
for Compиting Machinery, 1984, уоl. 27, р. 1134 1142.
1076. Vanderbei R. "Interior point methods: Algorithms and formиlations", ORSA
Joиmal оп Compиting, 1994, уоl. 6, р. 32 34.
1077. Уап Essen О.С., С.Н. Anderson and D.J. Реllеmап. "Information processing in
the primate visиal system: Ап integrated systems perspective", Science, 1992,
уоl. 255, р. 419 23.
1078. Уап de Laar Р., Т. Heskes and S. Gielen. "Task dependent leaming ofattention",
Neиral Networks, 1997, уоl. 10, р. 981 992.
1079. Уап Laarhoven P.J.M. and E.R.L. Aarts. Simиlated Annealing: Theory and Apli
cations, Boston: Кlиwer Academic Pиblishers, 1988.
1080. Уап Trees H.L. Detection, Estimation and Modиlation Theory, Part 1, New York:
Wiley, 1968.
1081. Уап Ниllе М.М. "Nonparametric density estimation and regression achieved
with topographic maps maximizing the information theoretic entropy of their
oиtpиts", Biological Cybemetics, 1997, уоl. 77, р. 49 61.
1082. Уап Ниllе М.М. "Topographic mар formation Ьу maximizing иnconditional
entropy: А plaиsible strategy for "on line" иnsиpervised competitive leaming
and nonparametric density estimation", ШЕЕ Transactions оп Neural Networks,
1996, уоl. 7, р. 1299 1305.
1083. Уап Уееп В. "Minimиm variance beamforming", in S. Haykin and А. Steinhardt,
eds., Adaptive Radar Detection and Estimation, New York: Wiley (Interscience),
1992.
1084. Vapnik V.N. Statistical Leaming Theory, New York: Wiley, 1998.
1085. Vapnik V.N. The Natиre of Statistical Leaming Theory, New York: Springer
Verlag, 1995.
Библиоrрафия 1063
1086. Vapnik V.N. "Principles ofrisk minimization for leaming theory", Advances in
Neural Information Processing Systems, 1992, уоl. 4, р. 831 838, San Mateo,
СА: Morgan Kaиfmann.
1087. Vapnik V.N. Estimation of Dependences Based оп Empirical Data, New York:
Springer Verlag, 1982.
1088. Vapnik V.N. and А.Уа. Chervonenkis. "Оп the иniform convergence of rela
tive freqиencies of events to their probabilities", Theoretical Probability and Its
Aplications, 1971, vol. 17, р. 26 280.
1089. Vapnik V.N. and А.Уа. Chervonenkis. "А note оп а class of perceptrons", Aи
tomation and Remote Control, 1964, vol. 25, р. 103 109.
1090. Velrnal1s М. "Conscioиsness, Theories of', In М.А. Arbib, ed., The Handbook
ofBrain Theory and Neиral Networks, р. 247 250, Cambridge, МА: MIТ Press,
1995.
1091. Venkataraman S. "Оп encoding nonlinear oscil1ations in пешаl networks for
10comotion", Proceedings of the 8th Уаlе Workshop оп Adaptive and Leaming
Systems, р. 14 20, New Науеп, СТ, 1994.
1092. Venkatesh S.J., G. Panche, О. Psaltis and G. Sirat. "Shaping attraction basins in
neиral networks", Neиral Networks, 1990, уоl. 3, р. 613 623.
1093. Vetterli М. and J. Kovacevic'. Wavelets and Sиbband Coding, Englewood Cliffs,
NJ: Prentice Hal1, 1995.
1094. Vidyasagar М. А Theory of Leaming and Generalization, London: Springer
Verlag, 1997.
1095. Vidyasagar М. Nonlinear Systems Analysis, 2nd edition, Englewood Cliffs, NJ:
Prentice Hal1, 1993.
1096. Viterbi A.J. "Епоr boиnds for convolиtional codes and ап asymptotically op
timиm decoding algorithrn", ШЕЕ Transactions оп Information Theory, 1967,
уоl. IТ 13, р. 260 269.
1097. уоп der Malsburg С. "Network self organization", in Ап Introdиction to Neural
and Electronic Networks, S.F. Zometzer, J.L. Davis and С. Laи, eds., р. 421 32,
San Diego, СА: Academic Press, 1990.
1098. уоп der Malsbиrg С. "Considerations for а visиal architectиre", in Advanced
Neиral Compиters, R. EckМil1er ed., р. 303 312, Amsterdam: North Holland,
1990Б.
1099. уоп der Malsbиrg С. "The сопеlаtiоп theory ofbrain function", Intemal Report
81 2, Departrnent of Neиrobiology, Max Plak Institиte for Biophysical Chem
istry, G( ttingen, Germany, 1981.
1100. уоп der Malsbиrg С. "Self organization of orientation sensitive cells in the striate
cortex", Kybemetik, 1973, уоl. 14, р. 85 100.
1064 Библиоrрафия
11 О 1. УОП der Malsbиrg С. and W. Schneider. "А пеиrаl cocktail party processor",
Biological Cybemetics, 1986, vol. 54, р. 29 0.
1102. УОП Neиmann J. Papers of John УОП Neиmann оп Compиting and Compиter
Theory, W. Aspray and А. Bиrks, eds., Cambridge, МА: MIТ Press, 1986.
1103. УОП Neиmann J. The Compиter and the Brain, New Науеп, СТ: Уаlе University
Press, 1958.
1104. УОП Neиmann J. "Probabilistic 10gics and the synthesis of reliable organisms
from иnreliable components", in Aиtomata Stиdies, С.Е. Shannon and J. Mc
Carthy, eds., р. 43 98, Princeton, NJ: Princeton University Press, 1956.
1105. Wahba G. Spline Models for Observational Data, SIAM, 1990.
1106. Wahba G., D.R. Johnson, F. Gao and J. Gong. "Adaptive tиning of nиmerical
weather prediction models: Randomized GCV in three and foиr dimensional
data assimilation", Monthly Weather Review, 1995, уоl. 123, р. 3358 3369.
1107. Waibel А., Т. Hanazawa, G. Нinton, К. Shikano and к.J. Lang. "Phoneme
recognition иsing time delay пеиrаl networks", ШЕЕ Transactions оп Acoиs
tics, Speech and Signal Processing, 1989, vol. ASSP 37, р. 328 339.
1108. Waltz О. "Neиral nets and AI: Time for а synthesis", plenary talk, Intemational
Conference оп Neиral Networks, 1997, уоl. 1, р. xiii, Hoиston.
1109. Waltz М.О. and к.s. Ри. "А heиristic aproach to reinforcement leaming control
systems", ШЕЕ Transactions оп Aиtomatic Control, 1965, уоl. AC 10, р. 390
398.
1110. Wan Е.А. "Time series prediction Ьу иsing а connectionist network with intemal
delay lines", in Time Series Prediction: Forecasting the Fиtиre and Understand
ing the Past, A.S. Weigend and N.A. Gershenfield, eds., р. 195 217. Reading,
МА: Addison Wesley, 1994.
1111. Wan Е.А. "Temporal backpropagation for FIR neиral networks", ШЕЕ Inter
national Joint Conference оп Neиral Networks, 1990, уоl. 1, р. 575 580, San
Diego, СА.
1112. Wan Е.А. and F. Beaиfays. "Diagrammatic derivation of gradient algorithms for
пеиrаl networks", Neиral Compиtation, 1996, уоl. 8, р. 182 201.
1113. Watanabe Н., Yamagиchi and S. Katagiri. "Discriminative metric design for ro
bиst pattem recognition", ШЕЕ Transactions оп Signal Processing, 1997, уоl.
45, р. 2655 2662.
1114. Waterhoиse S., О. МасКау and А. Robinson. "Bayesian methods for mixtиres
of experts", Advances in Neural Information Processing Systems, 1996, уоl. 8,
р. 351 357, Cambridge, МА: MIТ Press.
1115. Watkins C.J.C.H. Leaming from Delayed Rewards, Ph.D. Thesis, University of
Cambridge, England, 1989.
1116. Watkins C.J.C.H. and Р. Оауап. "Q leaming", Machine Leaming, 1992, уоl. 8,
р. 279 292.
Библиоrрафия 1065
1117. Watroиs R.L. "Leaming algorithms for connectionist networks: Aplied gradi
ent methods of nonlinear optimization", First ШЕЕ Infemational Conference оп
Neural Networks. 1987, уоl. 2, р. 619 627, San Diego, СА.
1118. Watson G.S. "Smooth regression analysis", Sankhya: The Indian Joиmal of
Statistics, Series А, 1964, vol. 26, р. 359 372.
1119. Webb A.R. "Fиnctional aproximation Ьу feed forward networks: А least sqиares
aproach to generalisation", ШЕЕ Transactions оп Neural Networks, 1994, уоl.
5, р. 480 88.
1120. Webb A.R. and О. Lowe. "The optimal intemal representation of mиltilayer
classifier networks performs nonlinear discriminant analysis", Neural Networks,
1990, уоl. 3, р. 367 375.
1121. Weigend A.S., В. Hиberman and О. Rиmelhart. "Predicting the futиre: А соппес
tionist aproach", Intemational Joиmal ofNeural Systems, 1990, уоl. 3, р. 193
209.
1122. Weigend A.S., О.Е. Rиmelhart and В.А. Hиberman. "Generalization Ьу weight
elimination with aplication to forecasting", Advances in Neural Information Pro
cessing Systems, 1991, уоl. 3, р. 875 882, San Mateo, СА: Morgan Kaиfmann.
1123. Weigend A.S. and N.A. Gershenfield, eds. Time Series Prediction: Forecasting
the Fиtиre and Understanding the Past, vol. 15, Santa Ре Institиte Stиdies in the
Sciences of Complexity, Reading, МА: Addison Wesley, 1994.
1124. Weierstrass К. "Uber die analytische Darstellbarkeit sogenannter willkurlicher
Fиnktionen einer reellen veranderlichen", Sitzиngsberichte der Akademie der
Wissenschaften, Berlin, 1885, р. 633 639, 789 905.
1125. Werbos P.J. "Neиral networks and the hиman mind: New mathematics fits hи
manistic insight", ШЕЕ Intemational Conference оп Systems, Мап and Cyber
netics, 1992, уоl. 1, р. 78 83, Chicago.
1126. Werbos P.J. "Backpropagation throиgh time: What it does and how to do it",
Proceedings ofthe ШЕЕ, 1990, уоl. 78, р. 1550 1560.
1127. Werbos P.J. "Backpropagation and neurocontrol: А review and prospectиs", In
temational Joint Conference оп Neиral Networks, 1989, уоl. 1, р. 209 216,
Washington, ОС.
1128. Werbos P.J. "Beyond regression: New tools for prediction and analysis in the
behavioral sciences", Ph.D. Thesis, Harvard University, Cambridge, МА, 1974.
1129. Wettschereck О. and Т. Dietterich. "Improving the performance of radial basis
function networks Ьу leaming center 10cations", Advances in Neural Informa
tion Processing Systems, 1992, уоl. 4, р. 1133 1140, San Mateo, СА: Morgan
Kaиfmann.
1130. White О.А. and О.А. Sofge, eds. Handbook oflntel1igent Control: Neural, Fиzzy
and Adaptive Aproaches, New York: Уап Nostrand Reinhold, 1992.
1066 Библиоrрафия
1131. White Н. Artificial N ешаl N etworks: Aproximation and Leaming Theory, Cam
bridge, МА: Blackwell, 1992.
1132. White Н. "Connectionist nonparametric regression: Mиltilayer feedforward net
works can lеат arbitrary mapings", Neиral Networks, 1990, уоl. 3, р. 535 549.
1133. White Н. "Leaming in artificial neиral networks: А statistical perspective", Neи
ral Compиtation, 1989, уоl. 1, р. 425 64.
1134. White Н. "Some asymptotic resиlts for leaming in single hidden layer feedfor
ward network models", Joиmal ofthe American Statistical Society, 1989Б, уоl.
84, р. 1003 1013.
1135. Whitney Н. "Differentiable manifolds", Annals of Mathematics, 1936, уоl. 37,
р. 645 680.
1136. Whittaker Е.Т. "Оп а new method of gradиation", Proceedings ofthe Edinbиrgh
Mathematical Society, 1923, уоl. 41, р. 63 75.
1137. Widrow В. "Generalization and information storage in networks of adeline 'пеи
rons''', in М.С. Yovitz, G.T. Jacobi and G.D., Goldstein, eds., Self Organizing
Systems, р. 435 61, Washington, ОС: Spartan Books, 1962.
1138. Widrow В., J.M. МсСооl, M.G. Larimore and C.R. Johnson, Jr. "Stationary and
nonstationary leaming characteristics of the LMS adaptive filter", Proceedings
ofthe ШЕЕ, 1976, уоl. 64, р. 1151 1162.
1139. Widrow В., 1.R. Glover, Jr., J.M. МсСооl, J. Kaиnitz, C.S. Wi1liams, R.R. Неаrn,
J.R. Zeidler, J. Dong, Jr. and R.C. Goodlin. "Adaptive noise cancelling: Princi
ples and aplications", Proceedings ofthe ШЕЕ, 1975, уоl. 63, р. 1692 1716.
1140. Widrow В., N.K. Gиpta and S. Maitra. "Pиnish/reward: Leaming with а critic
in adaptive threshold systems", ШЕЕ Transactions of Systems, Мап and Cyber
netics, 1973, уоl. SMC 3, р. 455 65.
1141. Widrow В. and М.Е. Hoff, Jr. "Adaptive switching circиits", lRE WESCON
Convention Record, 1960, р. 96 104.
1142. Widrow В. and М.А. Lehr. "30 years of adaptive пеиrаl networks: Perceptrol1,
madaline and backpropagation", Proceedings of the Institиte of Electrical al1d
Electronics Engineers, 1990, уоl. 78, р. 1415 1442.
1143. Widrow В., Р.Е. Mantey, L.J. Griffiths and В.В. Goode. "Adaptive antenna
systems", Proceedings ofthe ШЕЕ, 1967, уоl. 55, р. 2143 2159.
1144. Widrow В. and S.D. Steams. Adaptive Signal Processing, Englewood C!iffs, NJ:
Prentice Hall, 1985.
1145. Widrow В. and Е. Walach. Adaptive Inverse Control, Uper Saddle River, NJ:
Prentice Hall, 1996.
1146. Wieland А. and R. Leighton. "Geometric analysis of neиral network capabili
ties", First ШЕЕ Intemational Conference оп Neиral Networks, 1987, уоl. 111,
р. 385 392, San Diego, СА.
Библиоrрафия 1067
1147. Wiener N. Cybemetics, 2nd edition New York: Wiley, 1961.
1148. Wiener N. Nonlinear Problems in Random Theory, New York: Wiley, 1958.
1149. Wiener N. Extrapolation, Interpolation and Smoothing ofStationary Time Series
with Engineering Aplications, Cambridge, МА: MIТ Press, 1949. (Ранее было
опубликовано как отчет с результатами исследований Службы националь
ной безопасности; февраль, 1942).
1150. Wiener N. Cybemetics: Оп Control and Commиnication in the Animal and the
Machine, New York: Wi1ey, 1948.
1151. Wilks S.S. Mathematica1 Statistics, New York: Wiley, 1962.
1152. Wi1liams R.J. "Simple statistical gradient following algorithrns for connectionist
reinforcement leaming", Machine Leaming, 1992, уоl. 8, р. 229 256.
1153. Williams R.J. "Toward а theory of reinforcement leaming cOl1nectionist sys
tems", Technical Report NU CCS 88 3, Col1ege of Compиter Science, North
eastem University, Boston, 1988.
1154. Williams R.J. "Peatиre discovery throиgh епor сопесtiоп leaming", Technical
Report ICS 8501. University ofCalifomia, San Diego, СА, 1985.
1155. Williams R.J. and J. Peng. "Ап efficient gradient based algorithm for on line
training of rесипепt network trajectories", Neиral Compиtation, 1990, уоl. 2,
р. 490 50 1.
1156. Williams R.J. and О. Zipser. "Gradient based leaming algorithms for rесипепt
networks and their compиtational complexity", in У. Chaиvin and О.Е. Rиme1
hart, eds., Backpropagation: Theory, Architectиres and Aplicatiol1s, р. 433 486,
Hillsdale, NJ: Lawrence Er1baиm, 1995.
1157. Williams R.J. and О. Zipser. "А leaming algorithrn for continиally rиnning [иllу
rесипепt пешаl networks", Neиral Compиtation, 1989, уоl. 1, р. 270 280.
1158. Willshaw D.J., О.Р. Випеmап and Н.С. Longиet Higgins. "Non holographic as
sociative memory", Natиre (London), 1969, уоl. 222, р. 960 962.
1159. Willshaw D.J. and С. уоп der Ma1sbиrg. "How pattemed neural connections can
Ье set ир Ьу self organization", Proceedings of the Royal Society of LOl1don
Series В, 1976, vol. 194, р. 431 45.
1160. Wilson G.v. and G.S. Pawley. "Оп the stability ofthe travelling sa1esman prob
lеm algorithm of Hopfie1d and Tank", Biological Cybemetics, 1988, уоl. 58,
р. 63 70.
1161. Wilson H.R. and J.D. Gowan. "Excitatory and inhibitory interactions in 10calized
popиlations ofmodel neиrons", Joиmal ofBiophysics, 1972, уоl. 12, р. 1 24.
1162. Winder R.O.x. "Single stage threshold 10gic", Switching Circиit Theory and
Logical Design, АШЕ Special Pиblications, 1972, уоl. S 134, р. 321 332.
1163. Winograd S. and J.D. Cowan. Reliable Compиtation in the Presence of Noise,
Cambridge, МА: MIТ Press, 1963.
1068 Библиоrрафия
1164. Wolpert О.Н. "Stacked generalization", Neиral Networks, 1992, уоl. 5, р. 241
259.
1165. Wood N.L. and N. Cowan. "The cocktail party phenomenon revisited: Atten
tion and memory in the classic selective listening procedиre of Cherry (1953)",
Joиrnal of Experimental Psychology: General, 1995, уоl. 124, р. 243 262.
1166. Woods W.A. "Important issиes in knowledge representation", Proceedings ofthe
Institиte ofElectrical and Electronics Engineers, 1986, уоl. 74, р. 1322 1334.
1167. Wи C.F.J. "Оп the convergence properties of the ЕМ algorithm", Annals of
Statistics, 1983, уоl. 11, р. 95 1 03.
1168. Wylie C.R. and L.C. Вапеtt. Advanced Engineering Mathematics, 5th edition,
New York: McGrawHill, 1982.
1169. Хи L., А. Кrzyzak and А. Уиillе. "Оп radial basis function nets and kemel
regressiol1: Statistical consistency, convergency rates and receptive field size",
Neиral Networks, 1994, уоl. 7, р. 609 628.
1170. Хи L., Е. Oja and С.У. Sиen. "Modified Hebbian leamil1g for cиrve and sиrface
fitting", Neиral Nehvorks, 1992, уоl. 5, р. 441 57.
1171. Yang Н. and S. Amari. "Adaptive online leaming algorithms for blind separation:
Maximиm entropy and minimиm mиtиal information", Neиral Compиtation,
1997, уоl. 9, р. 1457 1482.
1172. Уее Р. У. Regиlarized Radial Basis Fиnction Networks: Theory and Aplications to
Probability Estimation, Classification and Time Series Prediction, Ph.D. Thesis,
McMaster University, Hamilton, Ontario, 1998.
1173. Yockey Н.Р. Information Theory and Molecиlar Biology, Cambridge: Cambridge
University Press, 1992.
1174. Yoshizawa S., М. Morita and S. Amari. "Capacity of associative memory иSil1g
а nonmol1otonic neиron model", Neиral Networks, 1993, уоl. 6, р. 167 176.
1175. Zadeh L.A. "Oиtline of а new aproach to the analysis of соmрlех systems al1d
decision processes", ШЕЕ Transactions оп Systems, Мап and Cybemetics, 1973,
уо!. SMC 3, р. 28 4.
1176. Zadeh L.A. "Fиzzy sets", Information and COl1trol, 1965, уоl. 8, р. 338 353.
1177. Zadeh L.A. "А contribиtion to the theory of non!inear systems", J. Franklil1
111stitиte, 1953, уоl. 255, р. 387 01.
1178. Zadeh L.A. and С.А. Desoer. Linear System Theory: The State Space Aproach,
New York: McGraw Hill, 1963.
1179. Zames G. "Feedback and optimal sensitivity: Model reference transformatiol1s,
mиltiplicative seminorms and aproximate il1verses", ШЕЕ Transactions оп Aи
tomatic Control, 1981, уоl. AC 26, р. 301 320.
1180. Zames G. and В.А. Francis. "Feedback, minimax, sensitivity and optimal robиst
ness", ШЕЕ Transactiol1S 011 Aиtomatic Control, 1983, уоl. AC 28, р. 585 601.
Библиоrрафия 1069
1181. Zeevi A.J., R. Meir and V. Majorov. "Епоr boиnds for functional aproximation
and estimation иsing mixtиres of experts", ШЕЕ Transactions оп Information
Theory, 1998, уоl. 44, р. 1010 1025.
1182. Zeki S. А Vision of the Brain, Oxford: Blackwell Scientific Pиblications, 1993.
1183. Zipser О. and О.Е. Rиmelhart. "The neurobiological significance of the new
leaming models", in Compиtational Neиroscience, E.L. Schwartz, ed., р. 192
200, Cambridge, МА: MIТ Press, 1990.
Предметный указатель
А
A conjugate, 319
Accuracy of
empirical fit to the approximation, 285
the best approximation, 285
Action potential, 39
Activation
function, 43; 247
potentia1, 44
Activity, 511
pattern, 909
product rule, 98
AdaBoost, 470
Adaptive
filter, 173; 175
pattern classification, 606; 990
principal components extraction, 547
process, 176
resonance theory, 79
Affine transformation, 43; 374
Agent, 762
AI,71
Anatomical connectivity, 909
Annealing schedule, 709
Anti Hebbian learning rule, 550
АРЕХ, 547; 558
Approximate
соsИо gо function, 778
data analysis, 688
policy iteration algorithm, 780
Approximation,46
error, 139
vector,521
problem, 142
АR процесс, 67
Artificial intel1igence, 71
Associated perfectly, 131
Association probability, 744
Associative
Gaussian mixture model, 460; 482
memory, 77; 111
Asymptotic
mode, 294
stability theorem, 529
Attentional network, 994
Autoassociation, 111
Average operator, 137
Averaging, 206
в
Back propagation, 81
algorithm, 82; 220
formula, 231
learning, 220
through time, 981
Backward computation, 243
Barlow's hypothesis, 647
Batch
mode, 238
SOM, 593
Bayes
classifier, 206
probability error, 95
Bellman's optimality equation, 770
Веrnоиl1i trial, 348; 698
Best-approximation property, 371
Between class covariance matrix, 273
Bias, 43; 139; 579
Bias/variance dilemma, 140
Bit, 625
Blind
deconvolution, 685
equalization, 686
signal separation, 119
source separation, 596
problem, 623; 657
Block diagram, 49
Boltzmann
factor, 693
learning, 163
rule, 105; 720
machine, 81; 104; 691; 713
Предметный указатель 1071
Boosting, 459; 466
algorithm, 467
BOSS, 940
ВРТТ, 943; 981
Bracketing phase, 325
Brain, 37
Brent's method, 326
BSB,884
с
Communication
link,51
process, 622
Community, 131
Compact representation, 779
Competition, 579
Competitive learning, 79; 101; 163; 573
Complete data set, 496
Complete data log likelihood function, 497
Complexity
penalty, 296
polynomial, 310
theory, 911
Computation node, 51
Computational complexity, 162; 310
Concept, 158
class, 158
formation, 908
Condition number, 192; 371
Conditional
differential entropy, 635
entropy, 632
Confidence, 35
interval, 154
parameter, 159
Conjugate direction method, 319
Conjugate gradient method, 319; 322
Connecting link, 42
Connectionist
network,33
paradigm,306
Connectivity, 220; 511
Consistence, 160
Consistent estimator, 392
Constrained optimization problem, 301
Constraining, 333
Context unit, 923
Contextual
information, 35
knowledge, 991
Control, 72
mechanism, 91
Convolution, 331
network, 65
Calculus of variations, 734
Canonical
correlation analysis, 652
distribution, 693
pair, 454
Capacity, 147
Center of expansion, 363
Central
limit theorem, 642
nervous system, 40
Chain rule, 227; 681
of calculus, 951; 971
Channel capacity, 642; 648
Chaos, 83
Chapmen Kolmogorov identity, 697
Chemical synapse, 38
Cholesky factorization, 960
Clamped condition, 105
Classification, 113
and regression tree, 486
Closed loop
feedback, 93
operator, 53
Clиstering, 743
effect, 401
Cocktail party problem, 119
Code book, 603
Coefficient of expansion, 363
Cofactor, 665
Cohen Grossberg theorem, 882
Coherent region, 612
Combinatorial optimization, 71 О
problem, 909
Committee machine, 458
1072 Предметный указатель
sum, 801; 820
Cooperation, 579
Correlation
coefficient, 610
dimension, 897
function, 896
rnatrix, 185
memory, 77; 128
Cost function, 91; 226; 821
СоsИо-gо function, 765
Covariance hypothesis, 98
Credit assignment, 106
problem, 79; 229
Cross correlation, 542
vector, 185
Cross validation, 289
Curse of dimensionality, 286; 778
Curve fitting, 278
procedure, 325
D
DFA, 926
DFP, 329
Diagonal mар, 679
Dichotomy, 147
Differential entropy, 627
Digit recognition problem, 60
Dimensionality
ofthe input space, 174
reduction, 514; 520; 600
Direct
learning, 118
problem, 353
Discount factor, 764
Distortion measure, 589; 743
Distributed
memory, 123
time lagged feedforward network, 800
Dual problem, 424
Duality theorem, 424
Dynamic
programming, 110; 761
structure, 459
Dynamical system, 174
Darwinian learning model, 163
Data, 72
reconstruction, 543
space, 514
Decision stump, 484
Decoupled extended Кalrnan filter (DEКF),
963; 981
Delay embedding theorem, 899
Delayed reinforcement, 109
Delta rule, 173; 228
Dendrite, 38
Dendritic
subunit, 39
tree, 39
Density estimation, 390
Desired response, 33; 59; 91; 176
vector, 351
Deterministic
annealing, 742
approximation, 730
Boltzmann learning rule, 733
finite state automata, 926
ordinary differential equation, 528
Е
Early stopping method oftraining, 292
EDVAC, 76
Effective
input, 526
width,581
Eigen analyzer, 543
Eigenanalysis,871
Eigencomposition,519
Eigenfunction, 436
Eigenvalue, 436; 518
problem, 518
Eigenvector, 518
Emergent, 865
Empirical risk, 284
functional, 254
minimization, 144
Enhancement of polarization target, 653
ENIAC, 76
Ensemble averaging, 459; 460
I
Предметный указатель 1073
Entropy, 625
Epoch, 226; 261
Equilibrum state, 931
Ergodicity, 699
theorem, 701
Error, 67; 112
back propagation algorithm, 219
covariance rnatrix, 959
parameter, 159
signal, 91; 107; 219; 223
sиrface, 107
Error-correction learning, 91; 163
rule, 206; 219
Estimation
error, 139
learning curve, 293
subset, 289
Euler Lagrange equation, 361
Exclusive OR problem, 243
Exhaustive learning, 294
Existence theorem, 283
Expectation maximization approach, 496
Expectational error, 135
Expected distortion, 589; 743
Experience, 127
Expert
network, 479
system, 73
Explanation level, 73
External approximation, 300
Externally recurrent network, 980
F
Feedback, 52; 835
control system, 117; 977
factor, 884
loop, 57; 176
Feedforward
connection, 549
net, 56
Filtered estimation error, 959
Filtering, 118
process, 175
F inite state
autornata, 937
machine, 941
Finite time approxirnation, 709
FIR фильтр, 815
First absolute moment, 284
First-order autoregressive model, 609
Fisher's
criterion, 273
Fitting
number, 290
procedure, 350
Fletcher-Reeves formula, 323
Focused time lagged feedforward network, 800
Focusing, 991
Forgetting, 527
term, 583
Forward
computation, 242
pass, 219; 232
Fractal dimension, 894
Function
signal, 223
space, 356
Future extraction, 113
Fuzzy
system, 992
F actorial
code, 647
distribution, 637; 737
F eature
detector, 101; 268
extraction, 514
rnaр, 331; 588
selection, 514; 605
space, 268; 344; 433; 514
vector, 434
Feature mapping model, 575
G
Galerkin's method, 371
Gamma memory, 804
Gating network, 459; 479
Gaussian
classifier, 402
1074 Предметный указатель
function, 352
GCV, 908
GEКF, 963
Generalization, 33; 60
error, 155
phase, 350
Generalized
cross validation, 383; 908
delta rule, 236
Hebbian algorithm, 538
Lloyd algorithm, 590
Generative model, 696; 728
parameter vector, 479
GHA, 538
Gibbs
distribution, 691
sampler, 711
Global
extended Кalman filter, 963
feature, 287
feedback, 981
rejection index, 674
Gradient
descent, 228
matrix, 952
Green's
identity, 360
matrix, 365
Growth function, 148
GSLC, 122
GVC, 383
layer, 219
neuron, 56; 268
space, 268; 344
unit, 56
Нierarchical
clustering algorithm, 570
mixture of experts, 460; 484
Нippocampus, 100
HME CTpyктypa, 460
Hold out method, 294
Hopfield network, 79; 80
Horizontal cell, 37
Human vision, 31
Hybrid
learning process, 399
system, 75
Hyperbolic tangent, 247
Hypothesis
boosting problem, 467
space, 159
testing procedure, 206
1
н
Image
coding,544
processing, 331
Implicit representation, 799
Impulse response, 802
Independence theory, 190
Independent
component analysis , 658
variable, 135
Indicator variable, -499
Indirect
control, 979
learning, 118
Induced local field, 44; 196
Inference
nonparametric, 34
statistical, 34
Infimum, 143
Infomax, 82; 163; 641
Information
latching, 970
Heaviside, 896
function, 45
Hebb's postulate of learning, 95
Hebbian
learning rule, 549; 721
synapse, 96
Helmholtz machine, 728
Hessian matrix, 276
Heteroassociation, 111
Heuristic reinforcement signal, 109
Нidden
preservation rule, 485
theory, 622
Information preserving learning procedure, 965
Information-theoretic model, 622
Initial condition, 953
Initialization, 241; 251
Inner product kernel, 433; 435; 562
Innovation process, 958
Input
layer, 56; 509
signal, 59
Input output mapping, 33
Instantaneous estimate, 108; 312
Interregional circuit, 39
Invariance Ьу
structure, 66
training, 66
Invariant feature, 66
Inverse
function theorem, 933
kinematics, 288
parabolic interpolation, 326
problem, 288; 353
Ising model, 80
Isochronous correspondence, 845
Iteration, 243
Iterative adaptive scheme, 712
J
Jensen's inequality, 507; 735
Joint
а posteriori probability, 491
entropy, 633
к
k means
clasterization algorithm, 399
k nearest neighbor classifier, 95
Kalman
filtering, 956
algorithm, 960
gain,959
Кеrnеl regression, 390
Кеу
Предметный указатель 1075
matrix, 128
pattern, 112
Кnowledge
base, 72
representation, 58
Kuhn Tucker condition, 423
Kullback Leibler divergence, 626
L
Lagrange multiplier, 301; 630
Lagrangian, 301
Largest eigenvalue, 190
Lateral
connection, 550
inhibition, 101
interaction, 580
Lattice,573
spin, 79
Law oflarge numbers, 145; 152
Learning, 32; 72
algorithm, 32
curve, 192
element, 72
mастпе, 11 о; 141
matrix, 77
paradigm, 90
process, 123
rate, 253
parameter, 92; 720
system, 762
theory, 140
time, 277
vector quantization (LVQ), 604
without а teacher, 108
Learning rate parameter, 178; 584
Least mean square algorithm, 173
Least squares estimate, 543
Left singular vector, 561
Likelihood
equation, 493
function, 493; 718
ratio, 208; 257
Line search, 325
Linear
1076 Предметный указатель
м
модуляция, 621
Madaline, 78
Magnification factor, 594
Mahalanobis distance, 62
Majority rule, 880
Mapping input output, 33
Margin of separation, 419
Marginal
density, 712
entropy, 638
misrnatch, 677
Markov
blanket, 739
chain, 692; 696
Matched filter, 537
Matrix inversion lemma, 304
Maximizing information content, 246
Maximum
eigenfilter, 530
energy gain, 311
entropy
method, 678
principle, 629
likelihood estimate, 494
mutual information, 82; 641
principle, 622
ME CTpyктypa, 460
Mean recurrence time, 699
Mean field
approxirnation, 732
distribution, 735
equation, 739
theory, 692
Measure of memory, 187
Measurement
equation, 928
matrix, 957
Memorized
matrix, 128
pattern, 112
Memorizing, 279
Memory, 122; 800
matrix, 126
resolution, 803
adaptive
filter, 186
filtering, 173
combiner, 46; 121
output, 43
differential operator, 356
least squares filter, 184
rnaстпе, 417
Linearly
independent vector, 320
separable
class, 200
pattern, 78
Linsker's model, 513
LMS, 78; 186; 277
Load parameter, 873
Loading problem, 106
Local
averaging, 331
circuit,39
controllability theorem, 934
feature, 287
gradient, 228
minima, 313
observability theorem, 935
receptive field, 140
stability, 843
Log likelihood
equation, 494
ratio test, 209
Logistic
belief net, 722
function, 46; 220
Look-up table, 609; 787
Loss function, 418; 445
Low pass filter, 187
Lyapunov
dimension, 898
exponent, 897
M ary pulse amplitude modulation, 621
M-class classification problem, 253
М мерная амплитудно импульсная
Memory based learning, 93; 163
Mental
process, 74
representation, 74
Mercer's theorem, 435
Message, 624
Metastable state, 586
Method of
false nearest neighbors, 901
Lagrange multipliers, 423
potential functions, 83
Metropolis, 704
MIMO, 115
Minimax criterion, 191
Mixed nonstationary policy, 789
Mixture of experts, 459; 479
MLP, 260
Model
order, 67
reference adaptive control, 977
Modular network, 459
Monomial, 344; 439
Most plausible value, 494
МRAC, 977
Multifold cross-validation, 294
Multilayer perceptron, 219; 260
Multinomial probability, 481
Multistage hierarchical vector quantizer, 608
Multivariable interpolation, 350
Mutual information, 633
principle, 163
N
N-мерный единичный куб, 884
NARX, 921; 937
Nat, 625; 906
Natural
distribution, 895
gradient, 669
Nearest neighbor rule, 94; 590
Nearest neighbor quantizer, 603
Negative
binomial distribution, 348
example, 158
Предметный указатель 1077
Neighbourhood function, 582
Nerve net, 37
NEТtalk, 302; 403
N etwork
dimensionality, 125
of networks, 908
pruning, 296
Neural
image, 36
microcircuit,39
Neuro beamformer, 122
Neurobiological analogy, 36
Neurocontroller, 117
Neurodynamic programming, 761
Neuromorphic integrated circuit, 37
Newton direction, 327
Newton's method, 180; 318
Neyman-Pearson criterion, 63
Nonasymptotic mode, 294
Nonlinear
activation function, 220
adaptive filter, 77; 134
feature detector, 256
input output mapping, 281
regression problem, 378
regressive model, 446
stochastic difference equation, 527
Nonreciprocal two port device, 38
Nonstationary environment, 34; 562
Norm weight matrix, 374
Normalization, 525
Normalized
weighting function, 393
degree of freedom, 583
eigenvector, 542
Normed space, 356
NP complete, 91 О
NRWE, 404
Numerical optimizing, 317
о
OBD, 301
OBS , 301
Occam's razor, 279; 474
1078 Предметный указатель
р
РАС, 157; 467
Parallel
distributed proccssing, 313
identification model, 976
Parallelism, 74
Parity function, 314
Partition function, 693; 716
Pattern classification, 34
Peano
curve, 599
string, 622
Perceptron, 196
convergence
algorithm, 197; 204
theorem, 78; 173
Performance
element, 72
index, 91
measure, 296; 334
Polak Ribiere formula, 323
Policy, 764
iteration algorithm, 771
Polynomial time algorithm, 162
Positive
definite matrix, 181
example, 158
Potentiation, 99
Preprocessor, 68; 569
Primary
reinforcement signal, 109
visual cortex, 616
Principal
component, 520
components analysis, 51 о; 658
curve, 597
mode,531
stlbspace, 559
Principle of
detailed balance, 704
minimal free energy, 695
minimum redundancy, 647
orthogonality, 136; 522
Probabilistic
generative model, 492
model, 80
reasoning, 72
Probability
mass function, 626
of classification error, 152
of correct classification, 260
of detection, 63
of error, 260
of false alarm, 63
Probably-approximately correct model, 158
Process
equation, 928
noice, 965
Processing
noise, 634
style, 73
ODE, 528
Off line training, 966
One from M coding scheme, 272
Open-loop operator, 53
Optical character recognition (OCR), 469
Optimal
brain
damage, 301
surgeon, 301
hyperplane, 419
robust estimation procedure, 445
Order, 928
ofmodel,923
Ordinary cross validation estimate, 382
Orhtogonal vector, 130
Orthogonal
set, 131
similarity transformation, 519
Outer product, 127
rule, 128
Outlier,95
Output
layer, 56; 219; 509
signal, 91
Overdetermined problem, 156
Overfitting, 292; 353; 460; 474
Предметный указатель 1079
Prototype, 253
state, 864
Pseudo-differential operator, 368
Pseudoinverse method, 397
Pseudotemperature, 105
Pyramidal cell, 38
Reinforcement learning, 81; 109; 760
Relative
entropy, 626
gradient, 669
Reliable estimate, 900
Renormalized SOM algorithm, 621
Repertoire, 164
Replicator, 307
Residual error, 322
Response, 129
Retraining, 134
Ricatti equation, 960
Risk functional, 143
RМLP, 925; 967
Rozenblatt perceptron, 172
RTRL, 981
Q
Q factor, 770
Q обучение, 784
Quadratic
approximation, 300; 318
function, 319
R
Radial basis function (RВF), 82; 341; 342;
350; 374
Rank deficient, 276
Rate
distortion theory, 607
of convergence, 193
of learning, 92; 98
RВF ceTb, 22; 342
Real time recurrent learning, 949; 981
Receptive field, 64; 331; 375; 513
Recognition model, 728
Recurrent, 919
multilayer perceptron, 925; 967
network, 52; 57
Redundancy, 512
Redundant data, 239
Reestimation algorithm, 559
Reestimator, 559
Reference
measure, 626
model,979
signal, 117
Reflection coefficient, 67
Regression model, 135
Regularization, 355
network,369
parameter, 297; 357
principle, 358
term,356
s
Saddle point, 251; 423
Sample complexity, 160
problem, 281
Sampling density, 286
Saturation, 525
Scaling,314
factor, 403
Search time constant, 195
Searching problem, 72
Sectioning phase, 325
Selective learning model, 163
Self adjoint operator, 365
Self amplification, 549
Self organized learning, 110; 509
stage, 399
Self organizing mар, 79; 400; 573; 577
Sensitivity, 275; 311
factor, 227
graph, 241; 276
Separability of patterns, 343
Separating
capacity, 349
sиrface, 344
Separatrix, 849
Sequential
mode, 238
1080 Предметный указатель
processing, 73
Shift invariance, 331
Short range exdcitatory mechanism, 576
Sigmoid
belief network, 81; 692; 722
Sigmoidal nonlinearity, 220; 234
Signal
component, 536
processing, 173
vector, 91
Signal blocking matrix, 122
Signal to noise ratio, 643
SIMO, 803
Simple recurrent network, 923
Simulated annealing, 81; 708
Single input single output, 931
Single layer network, 56
Single loop feedback system, 52
Singular
point, 842
уа1ие decomposition, 560
Singular va1ue decomposition, 398
S1SO, 931
Slack variable, 447
Slope parameter, 47
Smoothing, 118
parameter, 413
Smoothness index, 386
SOM, 588
Sparse architecture, 991
Spatial
difference, 652
diversity, 657
Spatially continous space, 588
Spectral theorem, 519
Spectrum, 70
Spin-glass state, 880
Spline, 288
Spurious attractor, 871
SRN, 923
Stability plastycity dilemma, 34
Stabilized effect, 237
Stabilizer, 356
Stable, 54
state, 867
Stagecoach problem, 775
Standard error term, 355
State, 762
distribution vector, 700
portrait, 839
space, 695; 928
transition, 926
vector, 957
State space
framework,981
model, 837; 923
Static structure, 458
Statistical mechanics, 691
Steady state probability, 699
Steepest descent, 669
Stochastic
approximation, 195; 312; 341
feedback system, 189
gradient approach, 495
matrix, 697
relaxation, 708
Storage
capacity, 112; 873
element, 93
phase, 112; 866
Strict consistency, 144
Strong learning model, 466
Structural
mismatch,677
pattem recognition, 809
Subsampling, 331
Subspace decomposition, 523
Supervised learning, 33; 107
stage, 399
Support vector, 421
machine, 83; 417
Supremum, 143
SVD, 398; 560
SVM, 417
Symbol structure, 71
Symbolic code, 613
Symmetric
model, 559
synaptic connection, 713
Synapse, 38; 39; 42
Synaptic
adaptation, 579
link, 49
modification, 76
System identification, 974
т
Target
concept, 158
signal, 176
value, 248
Taylor series, 300
Teacher, 141
Temperature of the system, 694
Temporal
difference learning, 795
pattem recognition, 809
Terminal node, 486
Test set, 289
Theory of neural group selection, 163
Thermal equilibrium, 105
Threshold, 579
function, 45
of the test, 257
Time
delay, 800; 808
lagged feedforward network, 967
structure, 70
Time dependent mechanism, 96
Time frequency analysis, 993
TLFN, 811; 967
Topographic mар, 39; 573
Topological
neighbourhood, 581
ordering, 584
Topologically ordered computational mар, 574
Total covariance matrix, 271
Trace, 190
Training
data, 60
error, 152; 155
phase, 350
Предметный указатель 1081
sample, 33; 60
set, 289
Transfer function, 49; 802
Transient state, 698
Translationally invariant, 367
Transmitter substance, 38
Travel1ing salesman problem, 752; 909
TSP, 909
Tнring machine, 939
u
Unconstrained optimization problem, 177
Underdeterminated, 156
Uniformly sampled, 799
Unit
delay operator, 801
hypercube,243
square, 243
vector, 515
Unit delay
element, 58
operator, 53; 93; 526
Unitary invariance property, 455
Universal
approximation theorem, 282; 386
approximator, 310
Unstable, 54
Unsupervised
clustering algorithm, 889
learning, 110; 509
v
Va1idation
learning curve, 293
subset, 289
Уа1ие iteration algorithm, 773
Vanishing gradients problem, 849
Vapnik-Chervonenkis dimension, 147; 417
Variance, 139
probe, 516
VС измерение, 83; 147
Vector
projector, 871
quantization, 603
1082 Предметный указатель
theory, 589
Vector coding algorithm, 577
Virtual support vector, 454
Viterbi algorithm, 991
VLSI, 35
VOR, 36
w
Wake sleep algorithm, 729
Weak learning model, 467
Weight, 42
decay, 297
elimination, 298
vector, 351
Weight-sharing, 64; 376
Weighted
average, 393
поrш,373
Widrow's rule of thumb, 281
Winner takes all, 101
Winning neuron, 573
Within class covariance matrix, 273
х
XOR, 243
z
Z преобразование, 801
А
Абсолютная
температура, 693
энтропия, 627
Автомат, 937
DFA, 926
конечный, 941
Автореrpессионая модель первоro порядка,
609
Автореrpессионный процесс, 67
AreHT, 762
Адаптивная
классификация
множеств, 606
образов, 990
модель, 80
система, 76
Адаптивное управление по эталонной
модели, 977
Адаптивность, 34
Адarrrивный
метод, 562
резонанс, 80
фильтр, 173; 175
Аддитивная модель, 80
Аксон, 38
Активационная связь, 50
Активация нейрона, 77
Алroритм
AdaВoost, 466
АРЕХ, 558
CART, 487
ЕМ, 460
GHA, 543
LMS, 173; 186
Q обучения, 786
SOM, 588
ренормализованный, 621
адаптивноrо усиления, 470
адаптивный, 560
Бройдена Флетчера rольдфарба Шанно,
329
Витерби, 991
BeRIopHoro кодирования, 577
вероятностный, 312
вычислительно эффективный, 221; 310
Девидона Флетчера Пауэла, 329
декорреляции, 559
детерминированноrо отжиrа, 746
динамическоrо проrpаммирования, 767
ЕМ, 497
засыпания пробуждения, 729
иерархической кластеризации, 570
итерации по
значениям, 773
стратеrиям, 771
квантования векторов обучения, 605
кластеризации, 399; 401
без учителя, 889
по k средним, 399
линейноro поиска, 325
Метрополиса, 692; 704
минимизации среднеквадратической
ошибки, 173; 186; 212
на основе коррекции ошибок, 219
наименьших квадратов, 78
обратноro распространения, 22; 81; 220;
227
во времени, 943
ошибки, 82; 219; 464
обучения, 32; 90
Хебба, 538
повторноrо оценивания, 559
с полиномиальным временем выполнения,
162
слепоro разделения источников, 677
сопряженных rpадиентов, 327
сходимости персептрона, 197; 204
усиления, 467
фильтрации Калмана, 960
эффективный, 162
Анализ, 520
временных рядов, 989
rлавных компонентов, 23; 510; 515; 574
на основе ядра, 562
канонической корреляции, 652
независимых компонентов, 658
собственных
значений, 543
чисел, 871
частотно временной, 993
Апостериорная вероятность, 255
Аппроксимация, 46
внешняя, 300
rлобальная, 390
квадратичная, 300; 318
линейная, 317
локальная, 390
на конечном интервале времени, 709
наилучшая, 371
среднеrо поля, 732
стохастическая, 312; 341
функций, 114
Предметный указатель
1083
Априорная
вероятность, 207; 260
информация, 59
Архитектура, 274
фон Неймана, 78
Ассоциативная
вероятность, 744
rayccoBa модель смешения, 460; 482
машина, 22; 458
память, 23; 77; 111; 890
Аттрактор, 848
rиперболический, 849
странный, 893
точечный, 848
Аттракторная нейронная сеть, 81
Аффинное преобразование, 43; 374
Ацикличная сеть, 56
Б
База знаний, 72
Базис пространства данных, 520
Байесовская
вероятность ошибки, 95
Байесовский классификатор, 206; 208
Бассейн атrракции, 529; 849; 889
Безусловная оптимизация, 177
Белый шум, 536
Бинарная классификация, 464
Бинарное разбиение, 343
Биномиальное распределение, 348
Бит, 625; 865
Блок усреднения по ансамблю, 462
Блокирование информации, 970
Блочная диаrpамма, 49
Бритва Оккама, 279; 474
в
Вариационное исчисление, 734
Вектор
активности, 909
весов, 351
взаимной корреляции, 185
rpадиента, 177
единичный, 515
1084
Предметный указатель
желаемоro отклика, 351
левый синryлярный, 398; 561
линейно независимый, 320
наблюдения, 957
опорный, 421
виртуальный, 454
ортоroнальный, 130
ошибки, 321
аппроксимации, 521
параметров порождающей модели, 479
правый синryлярный, 398; 561
признаков, 434
распределения состояний, 700
сиrнала, 91
случайный, 515
собственный, 523
состояния, 837; 957; 959
Векторное
квантование, 577; 603
кодирование, 577
Векторный проектор, 871
Вероятностная
модель, 80
по рождающая, 492
функция массы, 626
Вероятностное рассуждение, 72
Вероятность
активации, 48
апостериорная, 255
априорная, 207; 260
ложной тревоrи, 63
обнаружения, 63
ошибки, 260
классификации, 152
перехода, 696; 697; 706
правильной классификации, 260
Верхний предел, 143
Ветвь, 49
Взаимная
информация, 633; 901
корреляция, 542
Винеровское решение, 186
Вложенное подпространство, 484
Внешне рекуррентная сеть, 980
Внешнее произведение, 127
Внешняя аппроксимация, 300
Возбуждающий механизм близкоro радиуса
действия, 576
Восстановление данных, 543
Временная
задача, 106; 110
задержка, 800
структура, 70
Время, 799
обучения, 277
Входное пространство, 174
Входной
сиrнал, 59
слой, 56;219
Выбор разбиений, 487
Выброс, 39; 95
Выделение признаков, 514
Выходной
сиrнал, 91
слой, 56; 219
Вычислительная
мощность, 147
сложность, 162; 310
Вычислительный узел, 51
r
rамма память, 804
rамма функция, 805
rарантированный риск, 155
rессиан, 180; 276
rибридная система, 75
rиперболический TaнreHC, 48
rиперплоскость, 344
оптимальная, 419
rиперсфера, 345
rипокампус, 100
rипотеза
Барлоу, 647
ковариации, 98
Хебба, 583
Чарча Тьюрииrа, 939
rлавная
кривая, 597
Предметный указатель
1085
д
Данные, 72
избыточные, 239
Двоичная классификация, 147
Двумерная решетка, 575
Действие, 117
Декодирование, 309; 864
Декомпозиция
на основе собственных векторов, 560
Пифaroра, 639
пространетвенная, 523
синryлярная, 398; 560
Дельта правило, 91; 173; 228; 239
обобщенное, 236; 243
Дельта распределение Дирака, 360
Дельта функция
Дирака, 592
Дендритное дерево, 39
Дендритный субблок, 39
Дерево
классификации и реrpессии, 486
решений, 460
мяrких, 484
Детектор признаков, 101; 256; 268
Детерминированная функция, 135
Детерминированное
правило обучения Больцмана, 733
приближение, 730
Детерминированный
конечный автомат, 926
отжиr, 742
Дешифратор, 521
Диaroнальное отображение, 679
Диarpамма перехода состояний, 701
Диверreнция Кулбека Лейблера, 626; 636
Дилемма
смещения/дисперсии, 140; 358; 461
стабильности пластичности, 34
Динамическая
память, 924
система, 174
структура, 459; 476
Динамический подход, 134
Динамическое
восстановление, 899
проrpаммирование, 23; 110; 761
Дисконтирующий множитель, 764
Дискретная arшроксимация, 597
Дискриминантная функция, 579
Дисперсионный зонд, 516
Дисперсия, 139; 515
Диссипативность, 850
Диффеоморфизм, 899; 933
Дифференциал Фреше, 358
Дифференциальная энтропия, 627
мода, 531
rлавный компонент, 520
rлобальная обратная связь, 835; 981
rлобальное свойство, 56
rлобальный
индекс отклонения, 674
признак, 287
расширенный фильтр Калмана, 963
rлубина
памяти, 803
усечения, 946
rоловка чтения записи, 939
rоризонт проrнозирования, 898
rоризонтальная клетка, 37
rрадиент, 177
локальный, 228
поверхности ошибок, 108
rраница
классификации, 474
мяrкая, 428
разделения, 419; 421
решений,оrrrимальная,258
rраничная
плотность, 712
энтропия, 638
rраничное несоответствие, 677
rраф
архитектурный, 51
передачи сиrнала, 49
чувствительности, 241; 276; 955
rрафик ошибки, 192
rрубость решения, 379
1086
Предметный указатель
з
максимизации, 495
назначения коэффициентов доверия, 229
недоопределенная, 156
не квадратичной оптимизации, 324
нелинейной реrpессии, 378
обратная, 288; 353
обращающихея в нуль rpадиентов, 849
определения собственных значений, 518
оптимальной фильтрации, 186; 956
оптическоro распознавания символов, 469
оценки параметров, 570
переопределенная, 156
плохо обусловленная, 122; 276; 353
поиска, 72
проrнозирования, 957
прямая, 353; 422
распознавания roлоса, 119
расширения цели поляризации, 653
реrpессии, 478
с неполными данными, 496
сверхопределенная, 373; 377
сrлаживания,957
слепоrо восстановления сиrнала, 685
слепоrо разделения источников, 657
сиrнала, 623
сложности выборки, 281
структурная, 106
усиления rипотезы, 467
условной оптимизации, 301; 422
фильтрации, 957
хорошо обусловленная, 353
что---rде, 504
Задержка
по времени, 808
эхо сиrнала, 70
Закон больших чисел, 145; 152; 699
Запоминание, 279
Зеркальное состояние, 880
Знание, 58
эмпирическое, 135
Значение
синryлярное, 398; 561
собственное, 190; 436; 518; 523; 543
стационарное, 516
Дихотомия, 147; 343
Доверительный интервал, 154
Долroвременная память, 123
Долroсрочные зависимости, 973
Достижимое состояние, 698
Достоверность, 35
классификации, 474
Е
Евклидово расстояние, 61
Единичный
вектор, 515
квадрат, 243
ЕМ алroритм, 497
Емкость, 147
канала, 642
памяти, 112; 131; 873
ж
Жадная стратеrия, 771
Желаемый
выход, 91
отклик, 33; 59; 205
Зависимая переменная, 135
Задача
XOR, 342; 376; 439
аппроксимации, 142
кривой, 278; 341
безусловной оптимизации, 177
бинарной классификации, 464
временная, 106; 110
двоичной классификации, 472
двойственная, 424
дилижанса, 775
заrpузки, 106
избыточно определенная, 353
исключающеro ИЛИ, 243
классификации, 474
на М классов, 253
точек единичноro rиперкуба, 243
коммивояжера, 752; 909
линейной адаптивной фильтрации, 173
установившееся, 544
экстремальное, 516
Зонд, 867
Зрительная кора мозrа, 616
и
Идентификация систем, 115; 974
Иерархическое
векторное квантование, 609
смешение мнений экспертов, 22; 460; 484
Избыточное
обучение, 279; 460; 473
представление, 78
Избыточность, 512
Извлечение
rлавных компонентов, адаптивное, 547
признаков, 113; 331; 514; 605
Измерение
Вапника Червоненкиса,22; 83; 147; 417
корреляции, 897
Ляпунова, 898
Изохронное соответствие, 845
Инвариантность
Доплера, 68
к поворотам, 367
к преобразованиям, 367
к смещению, 331
по обучению, 66
структурная, 66
Инвариантный признак, 66
Инверсная система, 116
Иидекс
rладкости, 386
производительности, 91
Иидуцированное локальное поле, 44; 196;
225
Инициализация, 241; 251
Интеллект, 990
Интеллектуальная
машина, 23
Интеллектуальное управление, 992
Интерактивность, 96
Интерполяция
обратная параболическая, 326
Предметный указатель
1087
строrая, 367
функции мноrих переменных, 350
Информационно теоретическая модель, 622
Информация
априорная, 59
взаимная, 901
контекстная, 35
неявная, 72
текстурная, 546
явная, 72
Искривление, 592
Искусственная
нейронная сеть, 22
топоrpафическая карта, 575
Искусственный интеллект, 71
Итеративная адаптивная схема, 712
Итерация, 224; 243
по стратеrиям, 770
к
Каноническая пара, 454
Каноническое распределение, 693
Карта
идентичности, 307
признаков, 331; 588
самоорrанизации, 23; 79; 400; 573
Квадратичная
аппроксимация, 300; 318
функция потерь, 142
Квадрика, 344
Квантизатор rиббса, 711
Квантование
вектора обучения, 574
Квантователь BopoHoro, 603
Класс
коррелированный, 209
линейно разделимый, 200
понятий,158
Классификатор
k ближайших соседей, 95
Байеса, 464; 607
байесовский, 206; 208
линейный, 210
параметрический, 212
1088
Предметный указатель
Классификация, 34; 474; 606
двоичная, 147
Кластеризация, 399; 742
Ключевой образ, 112
Коreрентная область, 612
Кодирование, 864
изображений, 544
с минимальным искажением, 595
Кодовое слово, 603
Комбинаторная оптимизация, 71 О
Компактное представление, 779
Комплексное сопряжение, 68
Конечный автомат, 926; 937
Конкурентное обучение, 23; 79; 101; 573
Конкуренция, 101; 511; 512; 579
Константа
Больцмана, 693
времени поиска, 195
Контекстная
информация, 35
карта, 612; 614
Контекстные знания, 991
Контекстный элемент, 923
Контур с обратной связью, 176
Контурная карта энерrии, 862
Концепт, 466
Конъюнктивный синапс, 97
Кооперация, 512; 579
Корреляционный синапс, 97
Корреляция, 97; 105
взаимная, 542
пространственная,513
Кофактор, 665
Коэффициент
автореrpессии, 67
Больцмана, 693
доверия, 78; 106; 110
корреляции, 610
нормализации, 394
обратной связи, 884
отражения, 67
передачи, 857
разложения, 363
усиления Калмана, 959
Кратковременная память, 123
Кривая
обучения, 192
на проверочном подмножестве, 293
Пеано,599
Критерий
минимакса, 191
Неймана Пирсона, 63
правдоподобия, лоrарифмический, 209
сходимости aлroритма обучения, 240
Фишера, 273
Кусочно линейная функция, 46
л
Лarpанжиан, 301
Лаидшафт энерrии, 862
Латеральное
взаимодействие, 580
торможение, 101
Лемма
об инвертировании матриц, 304
Сауера, 153
Линеаризация, 957
Линейная
комбинация, 42
адarrrивная фильтрация, 173
разделимосТЬ, 78
реrpессия, 490
Линейное
отображение, 349
преобразование, 514
Линейный
адarrrивНЫй фильтр, 186
ассоциатор, 890
дискриминант Фишера, 272; 274
дифференциальный оператор, 356
классификатор, 21 О
поиск, 325
сумматор, 46; 121
Линия передачи сиrнала, 51
Лоrарифмическая функция подобия, 493
Лоrарифмический критерий правдоподобия,
209
Лоrистическая
сеть доверия, 722
функция, 46; 682
Ложный аттрактор, 871
Локальная
обратная связь, 835
цепочка, 39
Локальное
рецепторное поле, 140
усреднение, 331
Локальный
rpадиент, 228; 823
минимум, 313
признак, 287
м
Максимальная неопределенность, 626
Максимально правдоподобная оценка, 494
Максимальное собственное значение, 530
Максимизация
информативности, 246
ожидания, 496
Максимум взаимной информации, 82; 622
Марковекая цепь, 696
Массив антенных элементов, 121
Масштабирование, 314
Масштабирующий множитель, 594
Математическое ожидание, 144
Матрица
блокировки сиrнала, 122
вероятностей перехода, 697
взвешенной
ко вариации, 272
нормы, 374
влияния, 380
внутриклассовой ковариации, 273
recce, 180; 276
rрина, 365
rpадиентов, 952
данных, 560
диarонально доминантная, 889
запоминания, 128
измерений, 957
интерполяции, 351
ключей, 128
Предметный указатель 1089
ковариации, 209
ошибки, 959
корреляции, 77; 185; 515; 530
межклассовой ковариации, 273
наблюдаемости, 934
несинryлярная, 351
нижняя треуroльная, 541
обратная rессиану, 302
обучения, 77
общей ковариации, 271
ортоroнальная, 518
памяти, 126
перемешивания, 657
положительно
определенная, 181
полуопределенная, 888
псевдообратная, 185; 271
симметричная, 516; 866; 888
смешения, 655
смешивания, 119
соответствия, 611
транспонированная, 61
унитарная, 518
управляемости, 932
Якобиана, 182
ядра, 564
Машина
Больцмана, 81; 104; 691; 713
rельмroльца, 728
обучаемая, 110; 141
опорных векторов, 22; 83; 417; 458
Тьюринrа, 939
усиления, 471
Межреrиональная цепочка, 39
Мера
rладкости, 284
емкости, 147
избыточности, 648
искажения, 589; 743
качества, 11 О
новой информации, 958
памяти, 187
потерь, 142
среднеro объема информации, 625
1090 Предметный указатель
ссылки, 626
эффективности, 296; 334
Метаустойчивое состояние, 586
Метод
адаптивный, 562
ассимптотически оптимальный, 404
Брента,326
rалеркина, 371
rаусса Ньютона, 182
rpадиентноro спуска, 228; 274
квазиньютоновский, 318; 327
Ляпунова, 836; 846
ложных ближайших соседей, 901
максимальной энтропии, 678
минимизации CтpyктypHOro риска, 156;
417
множителей Лarpанжа, 423; 630
моделирования отжиrа, 692
Ньютона, 180; 318
наименьших квадратов, 22; 373; 543
наискорейшеro спуска, 235
обучения с ранним остановом, 292
пакетный,560
потенциальных функций, 83
псевдообращения,397
радиальных базисных функций, 350
реryляризации, 355
сопряженных
rpадиентов, 319; 322
направлений, 319; 321
стохастической
аппроксимации, 195; 312
релаксации, 708
удержания, 294
уравнения ошибок, 955
усиления, 465
усреднения по ансамблю, 460
Минимизация
квадратичной функции, 319
риска
среднеro, 207
CтpyктypHOro, 156; 417
эмпирическоro, 144; 146
энерrии,854
Минимум
rлобальный, 240
локальный, 240; 313
Мноroслойная нейронная сеть, 56
Мноroслойный персептрон, 22; 219; 260;
458; 503
архитектура, 274
Мноroступенчатое иерархическое векторное
квантование, 608
Множество
А сопряженное,319
обучающее, 289
тестовое, 289
Множитель Лarpаижа, 301; 423; 630
Моделирование, 23; 989
отжиrа, 81; 708
Модель, 120
BSB, 889
NARX,937
антихеббовская, 97
Вольтерра, 832
в пространстве состояний, 837; 923
вероятностная, 80
вероятностно корректная, 158
идентификации, 980
иерархическоro смешения мнений
экспертов, 484
изинrовская, 80
информационно-теоретическая, 622
Кохонена, 574; 577
Линекера, 513
линейная, 524
линейной реrpессии, 490
Mak-Каллока Питца, 45
НМЕ, 492
не хеббовская, 97
нейрона, 42
Мак Каллока Питца, 196
нелинейной
автореrpессии, 921
реrpессии, 446
отображения признаков, 575
проrнозирования, 170
распознавания, 728
реrpессионная, 135
селективноro обучения Дарвина, 163
симметричная, 559
смешения мнений экспертов, 479
состояния мозrа, 884
структурированная, 75
Уилшоу ван дер Мальсбурrа, 577
Хопфилда, 856
хеббовская, 97
эталонная, 979
Модификация процесса конкуренции, 596
Модульная сеть, 459
нейронная, 477
Мозr,37
Моментальная оценка, 108
Мощность
вычислительная, 147
канала, 648
Мультиномиальная вероятность, 481
н
Наиболее правдоподобное значение, 494
Наискорейший спуск, 669
Направление
Ньютона, 327
разбиения, 489
Наращивание сети, 295
Насыщение, 525; 579
Нат, 625; 906
Натуральный rpадиент, 669
Начальное условие, 953
Невзаимный четырехполюсник, 38
Независимая переменная, 135
Нейробиолоrия, 36; 575
Нейродинамическое проrpаммирование,
761; 793
Нейроконтроллер, 117
Нейроморфный контур, 37
Нейрон, 31; 38; 39; 42
видимый, 105
второro порядка, 926
первоro порядка, 926
победивший, 573
скрытый, 105; 220; 268
Предметный указатель 1091
стохастический, 713
Нейрон победитель, 101; 579
Нейронная сеть, 32; 51
аттракторная,81
линейная, 124
мноroслойная, 56
модульная, 477
неполносвязная, 57
однослойная, 56
полно связная, 57
прямоro распространения, 56
рекуррентная, 36; 57
Нейронное изображение, 36
Нейронный
микроконтур,39
фильтр, 815
Нелинейная
динамическая система, 23
функция активации, 220
Нелинейное отображение, 349
BXOД BЫXOД, 281
Нелинейность,33
Нелинейный адаптивный фильтр, 77
Неопределенность, 626
Неполная задача, 496
Непрерывное обучение, 133
Непрямое
обучение, 118
управление, 979
Неравенство
rучи Шварца, 202
Йенсена, 507; 735
Несвязный расширенный фильтр Калмана,
963
Нестационарная стратеrия, 764
Нечеткая система, 992
Неявное представление, 799
Нижний предел, 143
Низкочастотный фильтр, 187
Норма
взвешенная, 373
Евклидова, 130
Нормализация, 68; 394; 525
входов, 248
1092
Предметный указатель
Нормализованная степень свободы, 583
Нормализованный собственный вектор, 542
Нуль пространство, 366
о
Область притяжения, 529
Обобщающая способность, 278
Обобщение, 33; 60
лоrистической функции, 480
Обобщенное дельта правило, 236
Обобщеиный алroритм
Ллойда, 590; 609
обученияХебба, 538
Обработка
изображений, 23; 331
информации, 73
параллельная, 73
сиrналов, 173; 989
Образ
активности, 909
запомненный, 112
ключевой, 112
линейно разделимый, 211
нелинейно разделимый, 433
Обратная
задача, 288
кинематика, 288
связь, 23; 52; 57; 511; 835
Обратное распространение во времени, 981
Обратный проход, 233; 243
Обусловленность, 371
Обучаемая
машина, 110; 141
система, 762
Обучаемый элемент, 72
Обучающая выборка, 60; 135
Обучающее множество, 289
Обучающие данные, 60
Обучение, 32; 60; 72; 89; 868
анти Хеббовское, 550
Больцмана, 104; 163
без учителя, 23; 108; 110; 509
rибридное, 399
избьrrочное, 279
конкурентное, 79; 101; 163; 400; 514
на временных разностях, 795
на лету, 133
на основе
коррекции ошибок, 91; 163; 206
обратноro распространения, 220
памяти, 93; 163
самоорrанизации, 110;399; 509; 510
непараметрическое, 34
непрерывное, 133; 134
непрямое, 118
персептрона, 212
по подсказке, 252
ПОJIное,300
прямое, 118
с подкреплением, 23; 81; 109; 760
отложенным, 109
с ранним остановом, 292
с учителем, 22; 33; 107; 399
самоорrанизующееся, 509
статистическое, 34
Хебба, 163; 549
Общность, 131
Обычное дифференциальное уравнение, 528
Оrpаничение, 333
локальности, 306
Одночлен, 344; 439
Ожидаемая ошибка, 135
Ожидаемое искажение, 589; 743
Ожидаемый отклик, 176
Оператор
rpадиента, 177
единичной задержки, 53; 93; 189; 526; 801
замкнутоro контура, 53
линейный дифференциальный, 356
псевдодифференциальный, 368
разомкнутоro контура, 53
самосопряженный, 365
следа, 271
сопряженный, 360
статистическоro ожидания, 137
усреднения, 13 7
Операция повторной оценки, 559
Опорный вектор, 421
Определение собственных значений, 518
Оmимальная
rиперплоскость, 419
степень повреждения, 301
хирурrия мозrа, 301
Оптимизация
безусловная, 177
численная, 317
Оптическое распознавание символов, 469
Опыт, 127
Ортоroнальное преобразование подобия, 519
Ортоroнальный набор, 131
Ослабление, 99
Отвод, 803
Отказоустойчивость, 35
Отклик, 129
желаемый, 205
импульсный, 802
ожидаемый, 176
Относительная энтропия, 626
Относительный rpадиент, 669
Отношение
правдоподобия, 208; 257
сиrнaлlшум, 643; 873
Отображение
ВХОkВЫХОД,33
входа на выход, 854
линейное, 349
нелинейное, 349; 562
признаков, 331
Отрицательное биномиальное
распределение, 348
Отрицательный пример, 158
Оценка
достоверная, 900
несмещенная, 382
перекрестная, 382
плотности,390
по методу наименьших квадратов, 543
состоятельная, 392
текущая, 312
Очевидность ответа, 35
Ошибка, 112
аппроксимации, 139
Предметный указатель 1093
интеrpальная квадратичная, 284
классификации, 152;207
обобщения, 155
обучения, 152; 155
ожидаемая, 135
оценивания, 139; 285; 388
резидуальная, 322
среднеквадратическая, 261; 379
фильтрованной оценки, 959
п
Пакетная версия метода rpадиентноro
спуска, 495
Пакетное обучение, 966
Пакетный
алroритм SOM, 593
режим, 238; 246
обучения, 590
Память, 122; 800
автоассоциативная, 111
ассоциативная, 909
в виде матрицы корреляции, 128
reтероассоциативная,111
долroвременная, 123; 800
кратковременная, 123; 800
распределенная, 123
совершенно ассоциированная, 131
Парадиrма
обучения, 90
связности, 306
Параллельная
модель идентификации, 976
распределенная обработка, 73
Параллельное распределенное вычисление,
313
Параметр
доверия, 159
зarpузки, 873
масштабирования, 403
наклона, 47
ошибки, 159
реryляризации,297; 357
свободный, 33
сrлаживания, 413
1094
Предметный указатель
скорости обучения, 92; 178; 201; 206; 225;
235; 584; 720
Первичный сиrнал подкрепления, 109
Первый абсолютный момент, 284
Передаточная функция, 49; 802
Перекрестная
оценка, 382
проверка, 289
мноroкратная, 294
обобщенная, 383
Переменная
зависимая, 135
независимая, 135
фиктивная, 447
Переменная-иидикатор, 499
Переобучение, 279; 292
Переучивание, 134
Переход состояния, 926
Персептрон, 78; 196
мноroслойный, 219; 260
Розенблатта, 172; 196
Пирамидальная клетка, 38
ПЛастичность, 32
синапсов, 512
ПЛотность дискретизации, 286
Победивший нейрон, 573
Поверхность
ошибки, 107
разделяющая, 344
энерrии, 880
Повторное использование данных обучения,
470
Подвыборка, 331
Подмножество
для оценивания, 289
проверочное, 289
Подпространство rлавных компонентов, 559
Поиск, 72
линейный, 325
максимальноro подобия, 587
Покрытие Маркова, 739
Поле, 164
восприятия, 513
рецептивное, 331; 375
рецепторное, 64
чувствительности, 375
Полезный сиrнал, 536
ПолиномЭрмита, 662
Полное обучение, 294
Положительный пример, 158
Помеха, 67
обработки, 634
Поиятие, 158; 466
целевое, 158
Попытка Бернулли, 348
Пороr, 225; 576; 579
критерия, 257
Порождающая модель, 696; 728
Портрет состояний, 839
Порядок
модели, 67; 923
памяти, 802
системы, 928
Последовательная обработка, 73
I10следовательно параллельная модель
идентификации, 976
Последовательный
режим, 238
Постоянная момента, 236
Постпроцессор, 68
Постулат
обучения, 76
Хебба, 95; 128; 524; 866
Потенциал
активации, 44
действия, 39
Поток, 898
динамической системы, 839
Правило, 72
адаптации с фиксированным
приращением, 201
байесовское, 255
ближайшеro соседа, 94; 590; 604
большинства, 880
Видроу Хоффа, 91
внешнеro произведения, 128
классификации, байесовское, 259
конкурентноro обучения, 103
Предметный указатель
1095
обучения
Больцмана, 105; 720
на основе коррекции ошибок, 206
сиrмоидальной сети доверия, 726
Хебба, 549; 721
сохранения информации, 485
умножения активности, 98
цепочки, 227; 681
Предел
верхний, 143
нижний, 143
Чернова, 262
Предикат, 314
IIредставление, 71
знаний, 58; 72
избыточное, 78
мысленное, 74
символьное, 73
Преобразование
аффинное, 374
Карунена Лоева, 515
линейное, 514
Препроцессор, 68; 569
Приближенная функция стоимости
перехода, 778
Приближенный
алroритм итерации по стратеrиям, 780
анализ данных, 688
Признак
rлобальный, 287
инвариантный, 66
локальный, 287
Пример, 158
маркированный, 59
немаркированный, 59
отрицательный, 60; 158
положительный, 60; 158
ПРИНlщп
Infomax, 163; 642
бритвы Оккама, 474
детальноro баланса, 704
максимальноro правдоподобия, 718
максимальной энтропии, 629
максимума
взаимной информации, 622; 641
энтропии, 623
минимизации эмпирическоro риска, 146
минимума
избыточности, 647
свободной энерrии, 695
оптимальности Беллмана, 766
ортоroнальности, 136; 522
полноro количества информации, 163
проекции, 80
пространственноro разнесения, 657
разделяй и властвуй, 458
реryляризации, 358
самоорrанизации, 511
самоусиления, 579
Присваивание коэффициентов доверия, 79;
106
Проба Бернулли, 698
Проблема
избыточноrо подбора, 353
обращения rpадиентов в нуль, 969
Проrнозирование,118
временных рядов, 829
Проекция,515
вектора, 520
Произведение
векторов, 129
внешнее, 127
Проклятие размерности, 286; 778
Прореживание, 750
Простая
модель, 503
рекуррентная сеть, 923
Пространственная решетка, 79
Пространственно непрерывное входное
пространство, 588
Пространственно-кодированное
распределение вероятности, 574
IIpocтpaHcTBeHHoe
различие, 652
разнесение, 657
Пространство, 928
входное, 174; 928
выходное, 928
1096 Предметный указатель
rипотез, 159
данных, 514
наблюдений, 113
нормированное, 356
поиятий, 158
признаков, 268; 344; 433; 514
решений, 113
Соболева, 387
cкpbrroe, 268; 344
состояний, 695; 928
функциональное, 356
Прототип, 253
Проход
обратный, 219; 233; 243
прямой, 219;232;242
Процедура
анализа, 520
байесовская, 206
исключения весов, 298
обучения с сохранением информации, 965
оценивания, оптимальная робастная, 445
подбора, 350
кривых, 325
про верки rипотез, 206
синтеза, 520
снижения весов, 297
Процесс
автореrpессионный, 67
адаптации, 176
взаимодействия, 622
диссипативный, 898
инновации, 958
мыслительный, 74
обучения, 123
псевдостационарный, 133
синarrrической адаптации, 583
фильтрации, 175
Прямое обучение, 118
Прямой
метод Ляпунова, 836; 846
проход, 232; 242
Псевдообратная матрица, 185
Псевдотемпература, 105; 694
р
Равенство Чепмена Колмоroрова, 697
Радиальная базисная функция, 82
Разбиение, 148
бинарное, 343
входноro пространства, 503
Разделимость образов, 343
Разложение
по собственным векторам, 519
Холецкоro, 960
Размерность
входноro пространства, 174
сети, 125
сокращение, 514; 520
Разностное уравнение, 527
Разреженная архитектура, 991
Разрешение памяти, 803
Paнr
якобиана, неполный, 276
Расписание отжиrа, 709
Распознавание
образов, 113; 989
временное, 809
структурное, 809
цифр, 60
Распределение
raycca, 395
rиббса, 691; 693
естественное, 895
отрицательное биномиальное, 348
среднеro поля, 735
Распределенная память, 123
Рассоrласование, 193
Расстояние
алrебраическое, 421
Евклидово, 61
Махаланобиса, 62
Рассуждения, 72
Расходимость, 54
Расширеиная фильтрация Калмана, 981
Расширенный полный набор данных, 496
Рациональное мноroобразие, 344
Реrpессионная функция, 136
Реrpессия, 478
временных рядов, 404
ядра, 390
Режим
асимптотический, 294
интерактивный, 238
неассимптотический, 294
пакетный, 238; 246
последовательный, 238; 246
стохастический, 238
Резидуальная ошибка, 322
Резкость разбиения, 489
Рекуррентная
сеть, 23; 36; 57; 923; 929
второro порядка, 926
Рекуррентное обучение в реальном времени,
949; 981
Рекуррентный мноroСЛОйный персептрон,
925; 967
Ренормализованный алroритм SOM, 621
Репертуар, 164
Репликатор, 307
Рецептивное поле, 331
Рецепторное поле, 64; 513
Решение
асимптотически устойчивое, 529
Винеровское, 186
корректное, 207
минимальное по норме, 377
HeKoppeкrHoe, 207
однозначное, 256
Решетка, 573
двумерная, 575
Решетчатый фильтр, 67
Риск
rарантированный, 155
средний, 207
структурный, 156
эмпирический, 146;284
Ряд
со скользящим средним, 832
Тейлора, 300
с
Самоорrанизация, 509; 511; 576
Предметный указатель 1097
Самоорrанизующаяся карта, 577
Самоорrанизующееся обучение, 760
Самоусиление, 549
Свертка, 331; 817
Свободная энерrия, 694
Свободное состояние, 105
Свободные параметры, 33
Свойство
Маркова, 696
наилучшей аппроксимации, 371
унитарной инвариантности, 455
Связность, 220
анатомическая, 909
функциональная, 909
Связь, 42
возбуждающая, 102; 244
rлобальная, 919
латеральная, 550
локальная, 919
обратная, 550; 835
прямая, 549
тормозящая, 244; 550
Сrлаживание, 118
Седловая точка, 251; 423
Семантическая карта, 614
Семиинвариант, 663
Сепаратриса, 849
Сетчатка, 36
Сеть
NWRE, 404
RВF, 389
ацикличная, 56
внешне рекуррентная, 977
внимания, 994
возбуждения-торможения, 911
доверия, 724
классификации, 113
модульная, 459
на основе радиальных базисных функций,
22; 95; 342
наблюдаемая, 931
нейронов, 37
обобщенная, 374
однослойная, 56
1098
Предметный указатель
полносвязная, 222
прямоro распространения, 56; 219
размерность, 125
реryляризации, 369; 371
рекуррентная, 52; 919
с задержкой по времени, 807
свертки, 65; 330
связей, 33
сетей, 908
специализированная, 63
управляемая, 931
ХОпфилда, 79;80;856
шлюза, 479
экспертов, 479
Сжатие, 43
данных, 309; 577
с потерей данных, 607
Сиrмоидальная
нелинейность, 234
сеть доверия, 81; 722
функция, 46
Сиrнал, 49
возбуждения, 109
входной, 59; 526
выходной, 91
линейно разделимый, 172
ошибки, 91; 107; 120; 206; 219; 223;224
подкрепления, 109
полезный, 536
постсинаптический, 93
предсинаптический, 93
функциональный, 223
целевой, 176
эталонный, 117
Сиrнум, 48; 204
Сила, 42
Сильная модель обучения, 466
Символьное представление, 73
Символьный
код, 613
язык, 71
Симметричная синаптическая связь, 713
Синапс, 38; 39; 42
возбуждающий, 544
конъюнктивный, 97
корреляционный, 97
тормозящий, 544
Хебба, 96
Синаптическая
адаптация, 579; 583
модификация, 76
связь, 49
Синаптический вес, 32
Система
8180, 931
автономная, 533
адаптивная, 76
восприятия, 647
mбридная,75
детерминированная, 893
динамическая, 174
инверсная, 116
классификации, 990
линейная, 417
нечеткая, 992
подавления боковых лепестков, 122
проrнозирования, одношaroвая, 812
робастная, 445
с обратной связью, 93
положительной, 884
с одной обратной связью, 52
стохастическая, 189
управления с обратной связью, 117; 977
хаотическая, 893
Скалярное произведение, 61
Скованное состояние, 105
Скорость
обучения, 92; 98; 178; 253
сходимости, 193
Скрученная карта, 620
Скрытая модель Маркова, 809
CKpbrroe пространство, 268
Скрытый
нейрон, 56; 220; 268
слой, 56; 219
элемент, 56
Слабая модель обучения, 467
Слarаемое
забывания, 583
реryляризации, 356
стандартной ошибки, 355
След, 190
матрицы, 190
оператор, 271
Слепое
разделение
входных сиrналов, 596
источников сиrнала, 623
сиrнала, 119
уравнивание, 686
Сложная модель, 503
Сложность
вычислительная, 162; 310
класса аппроксимирующих функций, 386
обучающеro множества, 160
полиномиальная, 310
Слой
входной, 219; 509
выходной, 219; 509
скрытый, 219; 342
Случайный вектор, 515
Смешанная не стационарная стратеrия, 789
Смешанное состояние, 880
Смешение мнений экспертов, 459; 479
Смещение, 139
Снижение размерности, 600
Собственная функция, 436
Собственное значение, 190; 436; 518; 523;
530; 543
доминирующее, 521
Собственный вектор, 523; 542
Совместная
апостериорная вероятность, 491
фильтрация, 469
энтропия, 633
Совместное использование весов, 64; 140;
376
Соrласованность, 160
Сокращение размерности, 514; 520
Сообщение, 624
Сопряженный оператор, 360
Состояние, 762
Предметный указатель 1099
нелинейноro фильтра, 812
прототипов, 864
равновесия, 931
равновесное, 842
системы, 695
динамической, 928
смешанное, 880
стационарное, 842
устойчивое, 91
Спектр, 70
Спектральная теорема, 519
Спектроrpамма, 807
Специализированная сеть, 63
Сплайн,288
Способность
обобщающая, 278
разделяющая, 349
Справочная таблица, 609; 787
Среда, 141
нестационарная, 133; 562
пространства состояний, 981
стационарная, 132; 185
эрrодическая, 560
Среднее, 560
взвешенное, 393
время возврата, 699
Среднеквадратическая
ошибка, 261
сходимость, 190
Средний риск, 207
Средняя энерrия, 694
Стабилизатор, 356
Стандартное искажение, 592
Статистическая
механика, 23; 691
теория обучения, 22
Статическая структура, 458
Стационарная
среда, 132
точка, 535
Степень
выпуклости, 302
повреждения, 301
Стиль обработки, 73
1100 Предметный указатель
Стимул, 89; 112
Стохастическая
аппроксимация, 312; 341
матрица, 697
релаксация, 708
система, 189
с обратной связью, 189
Стохастический
rpадиент, 495
нейрон, 713
Стохастическое
моделирование, 692
разностное уравнение, 527
Стратеrия, 764
Строrая
интерполяция, 367
состоятельность, 144
Строка Пеано, 622
Структура
временная, 70
представления, 74
Структурированная модель на основе
связей, 75
Структурная
задача, 106
инвариантность, 66
Структурное несоответствие, 677
Структурный риск, 156
Субоптимальная стратеrия, 778
Сумма
по всем состояниям, 693
свертки, 65; 801; 820
Сумматор, 42
Сферическая симметрия, 394
Схема
акцентирования, 247
вложенная сиrмоидальная, 31 О
кодирования один из-М, 272
Сходимость, 54
алroритма GHA, 542
в среднем, 189
персептрона, 78
по вероятности, 143
среднеквадратическая, 190
т
Текстура, 546
Текущая оценка, 312
Температура системы, 694
Температурное равновесие, 714
Теорема
вложения с задержкой, 899
Дармуса, 688
двойственности, 424
Ковера, 343; 346
Коэна rроссберrа, 882
линейноro отклика, 751
Мерсера, 435
Мичелли, 352
о локальной
наблюдаемости, 935
управляемости, 934
о разделимости, 346
образов, 343
о синryлярной декомпозиции, 561
о сходимости, 542
персеmрона, 173
об асимптотической устойчивости, 529
об обратной функции, 933
об универсальной аппроксимации, 282;
287;386
об эрroдичности, 701
Ритца, 359
спектральная, 519
существования, 283
сходимости персептрона, 78; 203
Теория
адаптивноro резонанса, 79
BeRIopHoro квантования, 589
вероятности, 718
информации, 23; 607; 622
коммуникаций,577
независимости, 190
обучения, 140
отбора rpупп нейронов, 163
реrpессии ядра, 343
реryляризации,22; 122
Тихонова,297; 355; 904
сложности, 911
среднеro поля, 692; 730
уровня искажения, 607
Термальное равновесие, 105
Терминальный узел, 486
Тестовое множество, 289
Тождество rрина, 360
Топоrpафическая карта, 39; 573
искусственная, 575
Тополоrическая окрестность, 581
Тополоrически упорядоченная
вычислительная карта, 574
Тополоrическое
упорядочивание пространства признаков,
584
Торможение, 38
Тормозящий механизм дальнеro действия,
576
Точечный аттрактор, 848
Точка
синryлярная, 842
стационарная, 535
Точность
наилучшей аппроксимации, 285
эмпирическоro соответствия
аппроксимации, 285
Транзитное состояние, 698
у
Узел, 49
источника, 51
Уменьшение избыточности, 647
Универсальный аппроксиматор, 310; 458;
778
Упорядочеиность отображения, 575
Управление, 72; 989
предприятием, 116
Управляющее воздействие, 72
Упрощение структуры сети, 296
Уравнение
измерения, 928; 957
кабеля, 39
оптимальности Беллмана, 770
правдоподобия, 493
процесса, 928; 957
Предметный указатель 1101
Рикатrи, 960
среднеro поля, 739
Эйлера Лarpаижа, 361; 363
Уровень
активности, 511
обобщения, 262
объяснения, 73
связности, 511
Усеченный aлroритм обратноro
распространения, 947
Усиление,22; 99;459
за счет фильтрации, 467
учителем, 955
Ускорение спуска, 237
Условие
выравнивания, 867
KYHa Такера, 423
Лившица, 841
оптимальности, 423
устойчивости, 867
Условная энтропия, 632
дифференциальная, 635
Усреднение, 206
локальное, 331
по ансамблю, 22; 459; 460
по времени, 98
Установившееся значение вероятности, 699
Устойчивое состояние, 91; 867
Устойчивость, 54
rлобальная, 847
локальная, 843; 847
по Ляпунову, 836
Учебный пример, 33
Учитель, 141
ф
Фаза
восстановления, 112
rpуппировки, 325
запоминания, 112
обобщения, 350
обучения, 350
разделения, 325
сохранения, 866
1102
:lредметный указатель
Фактор
забывания, 527
чувствительности, 227
Факториальное распределение, 637; 737
Факториальный код, 647
Феномен диверrенции, 960
Физическое изображt:ние, 36
Фильтр, 118
адаптивный, 173; 175
Винера, 186
линейный, 813
адаптивныи, 133
на основе наименьших квадратов, 184
нелинейный адаптивный, 77; 134
низкочастотный, 187
решетчатый, 67
с конечной импульсной характеристикой,
815
rиперболическоro TaнreHca, 235; 247
детерминированная, 135
дискриминантная, 271; 419
единичноro скачка, 45
иидикатора, 428
коррекции, 528
корреляции, 896
Ляпунова, 533; 846; 858
лоrарифмическоro правдоподобия на
неполных данных, 497
лоrистическая, 220; 235; 247; 682
мноrих переменных, 350
мультиквадратичная, 352
обратимая, 288
обратная мультиквадратичная, 352
обучения на подмножестве оценивания,
293
окрестности,582
оценки реrpессии, 393
ошибки, 874
передаточная, 802
плотности вероятности, 627
подобия, 493
положительно-определенная, 370
пороroвая, 940
потерь, 418; 445
правдоподобия, 718
радиальная базисная, 341; 350
нормализованная, 394
разбиения, 693; 716
реrpессионная, 136
роста, 148
с односторонним насыщением, 940
сиrмоидальная, 220
симметричная, 365
собственная, 436
стоимости, 91; 109; 226; 821
перехода, 765
унимодальная, 325
Хэвисайда, 45; 896
четная, 247
четности, 314
энерrии, 105; 858
соrласованный, 537
Фильтрация, 118; 467
Калмана, 956
пространственная, 120
Фокусировка, 991
Фонема, 806
Формула
обратноro распространения, 231
Полака Рибьера, 323
синтеза, 520
Флетчера Ривза, 323
Фрактальное измерение, 894
Функционал
риска, 143; 152
эмпирическоro, 143; 152; 254
Тихонова, 357
Функциональный элемент, 72
Функция
активации, 43; 225; 233; 247; 666
нелинейная, 220
антисимметричная, 247
взвешивания, 393
вычисления знака, 204
raycca, 352; 367; 581
изотропная, 397
rрина,365
Предметный указатель 1103
х
Хаос, 83
Характеристический код, 612
Химический синапс, 38
Хопфилд, 856
ц
Элемент
единичной задержки, 58
памяти, 93
скрытый, 56
управления, 939
функциональный, 72
Эмерджентность, 83; 865
Эмпирический риск, 146; 284
Эмпирическое
знание, 135
правило Видроу, 281
среднее значение, 145
Энерrия
максимальная, 311
ошибки, 91; 224
среднеквадратической, 225
системы, 693
Энтропия, 625; 691; 694
Шеннона, 744
Эпоха, 226; 238; 261
Эрroдическая стационарная среда, 185
Эрroдичность, 699
Эталонный сиrнал, 117; 979
Эффект стабилизации, 237
Эффективная ширина тополоrической
окрестности, 581
Эффективность классификации, 263
Эффектор, 37
Эхо локация, 31
Целевое значение, 248
Целевой сиrнал, 176
Центр разложения, 363
Центральная
нервная система, 40
предельная теорема, 642; 872
Центробежный элемент, 37
Цепное
правило, 227; 951
вычислений, 971
Цепь Маркова, 692; 696
ч
Частная производная, 274
Частота эхо сиrнала, 70
Частотная модуляция, 69
Частотно временной анализ, 993
Численная оmимизация, 317
Число
обусловленности, 192; 371
сrлаживания, 290
Чувствительность, 275; 311
хаотическоro процесса, 897
ш
Шифратор, 521
Шлюзовая сеть, 459; 479
Шум
белый, 536
процесса, 965
Шумоподавление, 829
я
Ядро, 391
образующее, 802
положительно определенное, 436
скалярноro произведения, 433; 435; 453;
562
э
Язык
декларативный, 71
символьный, 71
Якобиан, 182;276; 842
Ячейка
BOpOHOro, 603
фуидаментальной памяти, 864
Эквивариантная система, 668
Эксперт, 458; 479
Экспертная система, 73
Экспонента Ляпунова, 897
НаУЧlю популярное издание
Саймон Хайкин
Нейронные сети: полный курс
2 e издание
Литературный редактор
Верстка
Художественные редакторы
Корректоры
НА. Попова
О. С. Назаренко
В.Т Павлютин, т.А. Тараброва,
О.А. Василенко
З.В. Александрова, ЛА. Тордиенко,
О.В. Мишутина, ЛВ. Чернокозинская
Издательский дом "Вильяме",
101509, Москва, ул, Лесная, д. 43, стр, 1,
Подписано в Печать 08,092005, Формат 70xIOO/16,
rарнитура Times. Печать офсетная,
Усл, печ. л. 89,01. Уч, изд, л. 57,11,
Тираж 2000 ЭКЗ, Заказ N2 6054,
Отпечатано с диапозитивов
в ФrYП "Печатный Двор" им, А. М. rOpbKoro
Федеральноrо areHTCТBa по печати
и массовым коммуникациям,
197110, Санкт Петербурr, Чкаловекий пр" 15,
81U11oJ8C
Drt Издат ьекий дом "Вильяме"
www.wllllamspubIishing.eom
ISBN 5 8459 0890 6
05160
PRENТlCE HALL
Upper Saddle River, NJ 07458
http://www.prenhall.eom