




































































































































































































































































Автор: Курейчик В.В. Курейчик В.М. Родзин С.И.
Теги: искусственный интеллект математика математические модели информационные системы эволюционное моделирование издательство физматлит теория вычислений
ISBN: 978-5-9221-1390-8
Год: 2012




В. В. КУРЕИЧИК
В. М. КУРЕИЧИК
С. И. РОДЗИН
эволюционных
ВЫЧИСЛЕНИЙ
ТЕОРИЯ
В. В. КУРЕИЧИК
В. М. КУРЕИЧИК
С. И. РОДЗИН
ТЕОРИЯ
ЭВОЛЮЦИОННЫХ
ВЫЧИСЛЕНИЙ
е
МОСКВА
ФИЗМАТЛИГ8
2012
УДК 004.8 + 5197
ББК 22.18
К 93
Курейчик В. В., Курейчик В.М., Родзин СИ. Теория
эволюционных вычислений. — М.: ФИЗМАТЛИТ, 2012. — 260 с. —
ISBN 978-5-9221-1390-8.
В книге делается попытка решения фундаментальной проблемы
вычислительного интеллекта по разработке общей теории эволюционных
вычислений, инспирированных природными системами, математических моделей
и эффективных форм распределенных алгоритмов эволюционных вычислений;
изучаются когнитивные возможности композиции эволюционных операторов;
предлагаются алгоритмы микро-, макро- и метаэволюционных вычислений,
иллюстрированные решениями экстремальных задач на графах.
Монография адресована магистрам и аспирантам, изучающим теорию
и практику создания интеллектуальных информационных систем и технологий,
а также специалистам по системному анализу, теоретической информатике,
автоматизации проектирования и управления, компьютерному моделированию
и вычислительной математике.
В оформлении обложки использована авторская работа ведущего научного
сотрудника ИППИ РАН д.ф.-м.н. П. П. Николаева.
Научное издание
КУРЕЙЧИК Владимир Викторович
КУРЕЙЧИК Виктор Михайлович
РОДЗИН Сергей Иванович
ТЕОРИЯ ЭВОЛЮЦИОННЫХ ВЫЧИСЛЕНИЙ
Редактор Е.И. Ворошилова
Оригинал-макет: Д.А. Воробьев
Оформление переплета: В.Ф. Киселев
Подписано в печать 19.06.2012. Формат 60x90/16. Бумага офсетная. Печать офсетная.
Усл. печ. л. 16,25. Уч.-изд. л. 17,85. Тираж 100 экз. Заказ № 1023
Издательская фирма «Физико-математическая литература»
МАИК «Наука/Интерпериодика»
117997, Москва, ул. Профсоюзная, 90
E-mail: fizmat@maik.ru, fmlsale@maik.ru;
http://www.fml.ru
Отпечатано с электронных носителей издательства ISBN 978-5-9221-1390-8
в ООО «Чебоксарская типография № 1»
428019, г. Чебоксары, пр. И. Яковлева, 15
Тел.: (8352) 28-77-98, 57-01-87
Сайт: www.volga-print.ru
9"765922" 113906'
© ФИЗМАТЛИТ, 2012
© ВВ. Курейчик, В. М. Курейчик,
ISBN 978-5-9221-1390-8 СИ. Родзин, 2012
ОГЛАВЛЕНИЕ
Предисловие 5
Введение 7
Глава 1. Анализ моделей эволюционных вычислений 11
1.1. Таксономия моделей эволюционных вычислений 11
1.2. Модель генетических алгоритмов 15
1.3. Модель генетического программирования 18
1.4. Модель эволюционных стратегий 22
1.5. Модель эволюционного программирования 24
1.6. Модель роевого интеллекта 26
1.7. Квантовая модель 28
1.8. Другие эвристические модели, основанные на природных аналогиях 31
Глава 2. Общая теория эволюционных вычислений 35
2.1. Гипотезы и закономерности эволюционных вычислений 35
2.2. Основные положения теории эволюционных вычислений 36
2.3. Универсальная феноменологическая модель эволюционных
вычислений 40
2.4. Достоинства и отличительные особенности теории эволюционных
вычислений 43
2.5. Общие правила представления решений в моделях эволюционных
вычислений 44
2.6. Когнитивные возможности универсальной феноменологической
модели эволюционных вычислений 48
2.7. Базовый цикл эволюционных вычислений 65
2.8. Инструментальные средства для поддержки эволюционных
вычислений 69
4 Оглавление
Глава 3. Организация параллельных эволюционных вычислений 72
3.1. Модель глобального параллелизма 72
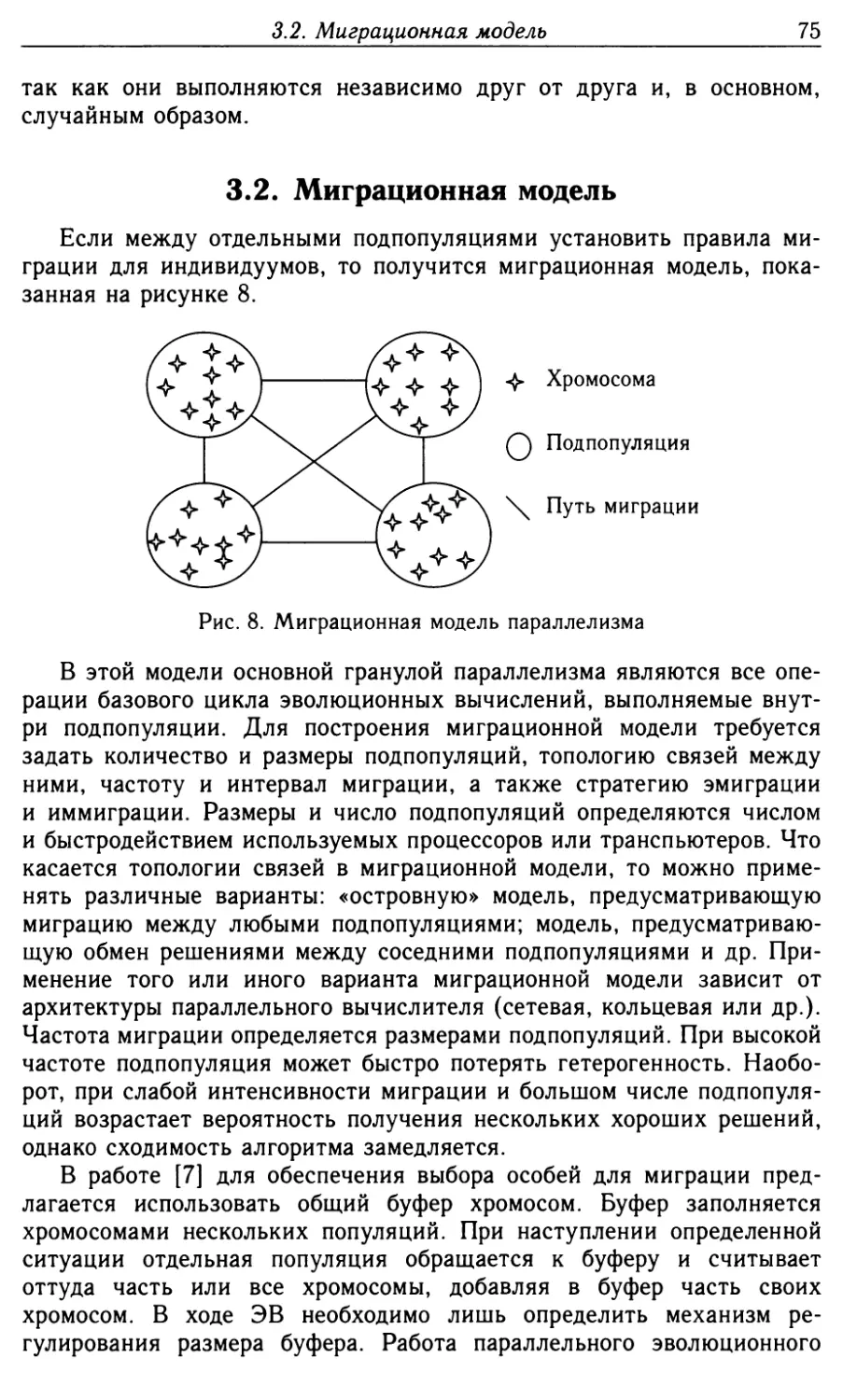
3.2. Миграционная модель 75
3.3. Диффузионная модель 79
3.4. Показатели эффективности работы параллельных алгоритмов .... 81
3.5. Распараллеливание операций базового цикла эволюционных
вычислений 84
Глава 4. Алгоритмы микро-, макро- и метаэволюционных
вычислений 90
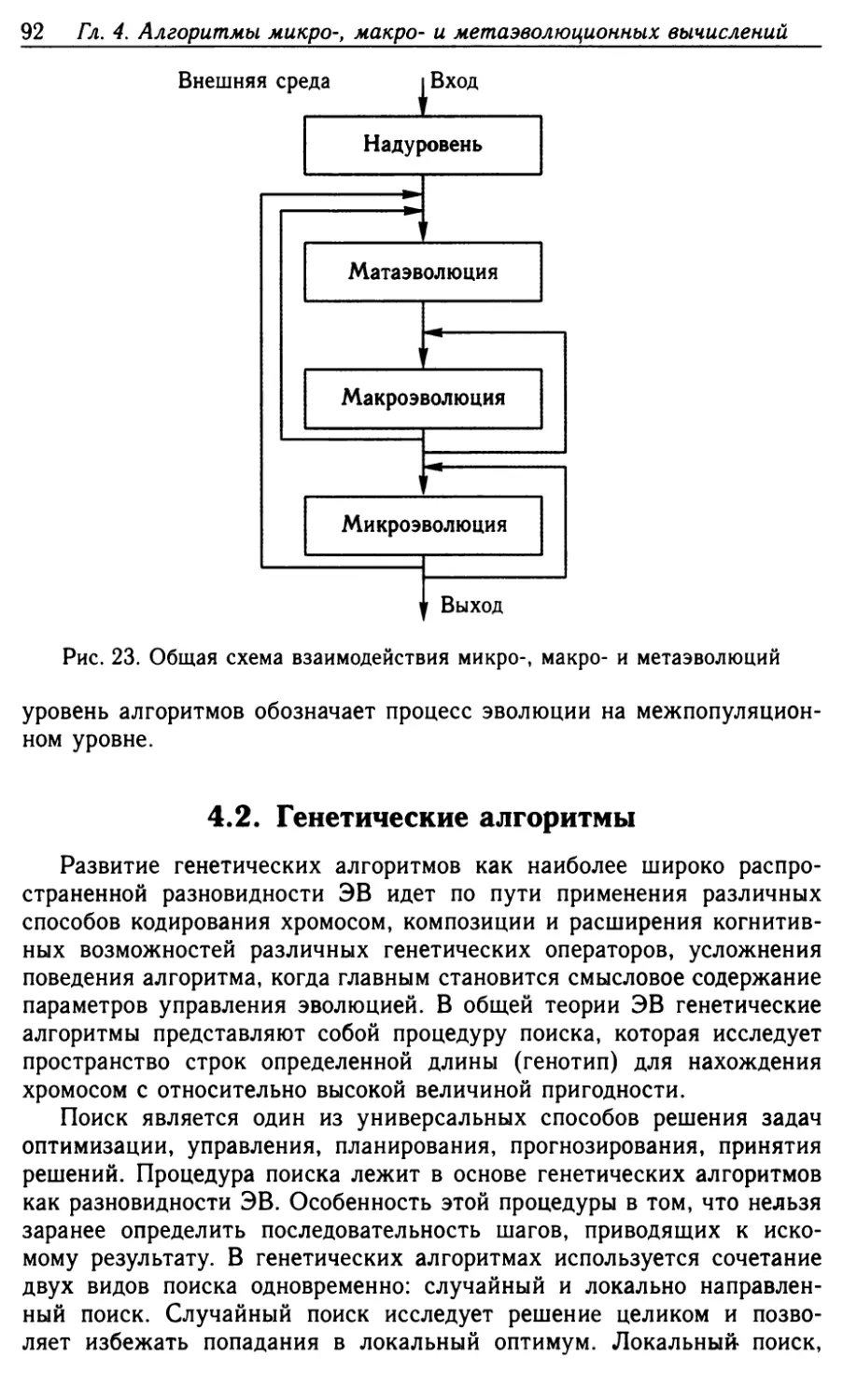
4.1. Теоретические положения микро-, макро- и метауровней
эволюционных вычислений 90
4.2. Генетические алгоритмы 92
4.3. Алгоритмы генетического программирования 109
4.4. Алгоритмы эволюционных стратегий 126
4.5. Алгоритмы эволюционного программирования 132
4.6. Обучающие классификаторы 139
4.7. Алгоритмы роевого интеллекта 142
4.8. Алгоритмы моделирования отжига, пороговые, потоковые и
алгоритмы рекордов 154
4.9. Алгоритмы табуированного поиска 156
4.10. Алгоритмы гармонического поиска 157
4.11. Алгоритмы меметики 159
Глава 5. Эволюционные вычисления и экстремальные задачи на
графах 165
5.1. Разбиение графов 165
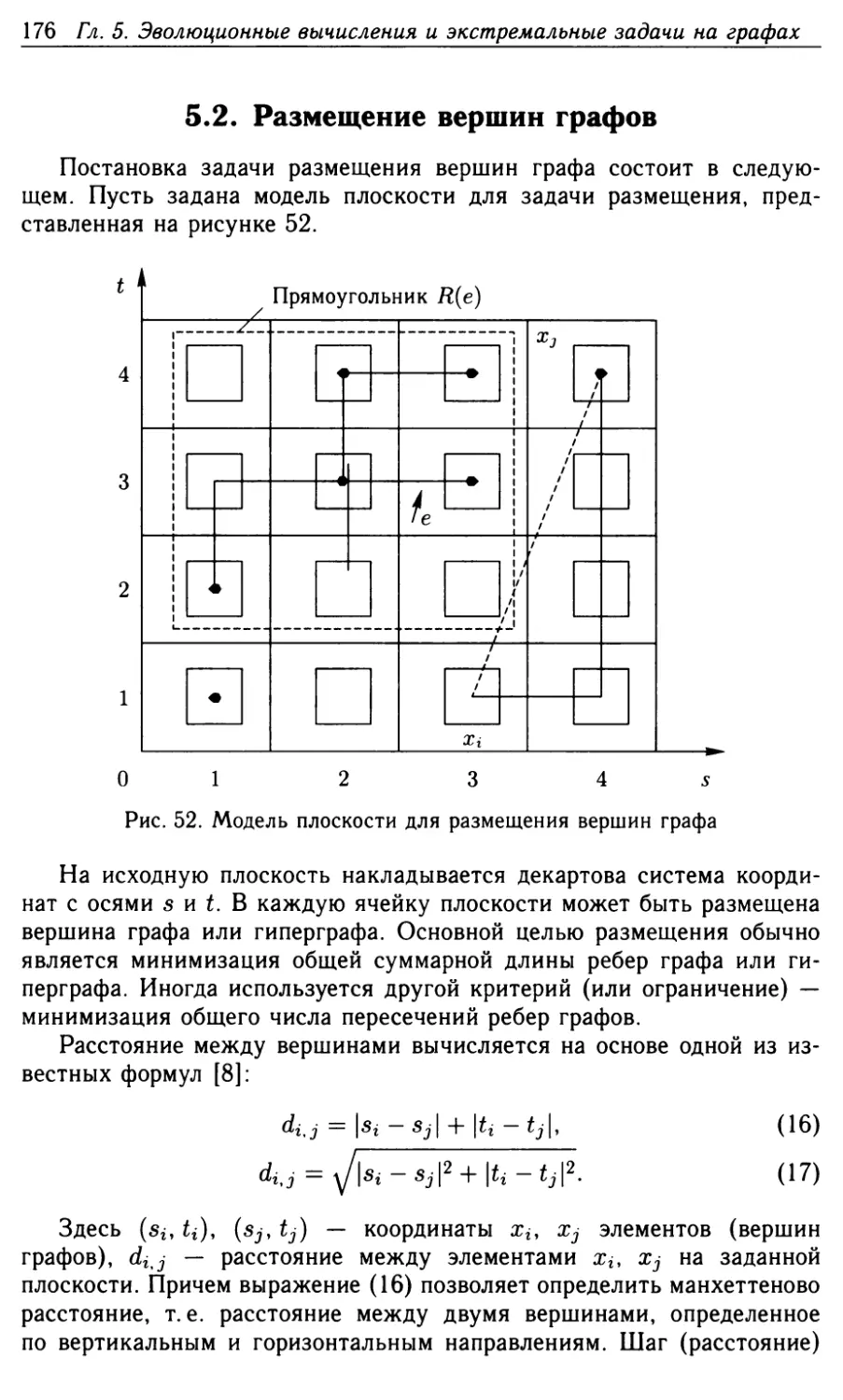
5.2. Размещение вершин графов 176
5.3. Поиск маршрута минимальной длины 183
5.4. Раскраска и изоморфизм графов 199
5.5. Построение клик, независимых и доминирующих множеств 214
5.6. Построение дерева Штейнера 233
5.7. Построение максимальных паросочетаний 242
Заключение 251
Список литературы 253
Список используемых определений и сокращений 257
Предисловие
Идея написания книги возникла у авторов в процессе обсуждения
научных результатов на ежегодных конгрессах по интеллектуальным
системам и технологиям (AIS-IT).
Авторами монографии постоянно проводился поиск
концептуальных подходов, учитывающих проблемное содержание существующих
разновидностей эволюционных вычислений и позволяющих выявлять
перспективу развития различных эволюционных алгоритмов,
направленных, в основном, на создание новых эффективных инструментов
для решения актуальных задач автоматизации проектирования и
синтеза электронных схем. Этот аспект исследования отрабатывался
преимущественно в связи с идеями и методами генетических алгоритмов.
На определенном этапе исследования мы пришли к выводу, что
необходима теория, обобщающая многочисленные разновидности
эволюционных вычислений, которая поможет создавать новые, более
совершенные алгоритмы, которые не только аккумулируют наработки и
позволят интенсифицировать труд инженеров и программистов, но будут
ориентированы на фундаментальный анализ способов решения задач
вычислительного интеллекта.
Результатами исследований в этом направлении стали
установленные авторами гипотезы и закономерности эволюционных вычислений,
а также формирование общей таксономии и построение
феноменологической модели эволюционных вычислений; разработка основных
положений общей теории эволюционных вычислений и установление
когнитивных возможностей универсальной феноменологической
модели эволюционных вычислений; изучение моделей организации
параллельных эволюционных вычислений и разработка новых
алгоритмов эволюционных вычислений; решения конкретных математических
и научно-технических задач, основанные на предлагаемой общей
теории эволюционных вычислений.
Пришло понимание того, что спектр моделей и алгоритмов
эволюционных вычислений имеет целостный смысл, что создание
алгоритмического и программного обеспечения эволюционных вычислений,
включая средства их проектирования, моделирования и использования,
требует выработки фундаментального подхода, в котором ключевое
значение имеет содержательное понимание и модельное представление
эволюции. Само понятие «эволюционные вычисления» получило при
этом новое, более широкое значение, а выработка подхода
приобрела характер проблемы, находящейся на стыке нескольких областей:
6
Предисловие
математики, искусственного интеллекта, компьютерных технологий
и программирования.
Ограниченный объем монографии не позволил охватить многие
практические аспекты эволюционных вычислений, однако, некоторые
из них присутствуют в последних публикациях авторского коллектива,
представленных в списке литературы. Авторы монографии исходили
из своих представлений о важности тех или иных разделов, а также
опирались на свой многолетний научно-исследовательский опыт
проведения теоретических и экспериментальных исследований в области
эволюционного моделирования, распределенного интеллекта, биоин-
спирированных методов оптимизации и механизмов принятия решений.
Насколько удачно это удалось сделать — судить читателям, и мы
заранее благодарны тем, которые укажут на замеченные недостатки
и недоработки.
Для чтения книги требуются знания в объеме стандартных
университетских курсов по дискретным структурам, моделированию систем,
методам оптимизации и теории принятия решений. По мнению одного
из авторов, а именно В.М. Курейчика, желательно, чтобы читатели
ознакомились с его монографией «Генетические алгоритмы» (Таганрог:
ТРТУ, 2002), в которой популярно изложены основные понятия
эволюционного моделирования, а также описаны генетические алгоритмы.
Как бы то ни было, в книге представлены все основные понятия
эволюционной теории.
Материал книги распределен между авторами следующим образом.
В.М. Курейчик подготовил предисловие, §§ 1.2, 1.7, 4.2, 4.10; глава 5
написана совместно В.М. Курейчиком и В.В. Курейчиком, который
изложил также §§ 1.6, 4.1, 4.7, 4.11 и заключение. СИ. Родзин написал
введение, главы 1 (кроме §§ 1.2, 1.6, 1.7), 2, 3, а также §§ 4.3-4.6,
4.8, 4.9.
Таганрог, декабрь 2011
В.М. Курейчик
Природа любит скрываться
Гераклит
Введение
Интерес исследователей к решению математических проблем
искусственного интеллекта возрастает, особенно в области разработки
алгоритмов и компьютерных программ, использующих простые
механизмы изменчивости и отбора по аналогии с эволюцией в природе.
Идеи теории эволюции не бесспорны, однако они объясняют
широкий спектр наблюдаемых явлений, а их потенциал не ограничивается
только генетическими алгоритмами, эффективность которых известна
давно.
Разновидностями эволюционных вычислений, наряду с
генетическими алгоритмами, являются алгоритмы генетического
программирования, эволюционных стратегий, эволюционного программирования,
обучающие классификаторы, алгоритмы Монте-Карло, роевого
интеллекта, меметики, гармоничного поиска и др. Замысел авторов состоит
в попытке создания общей теории эволюционных вычислений,
инспирированных природными системами, построения математических
моделей и эффективных форм распределенных алгоритмов эволюционных
вычислений для решения трудных задач оптимизации и структурного
синтеза в области автоматизации проектирования, исследования
операций, поддержки принятия решений и др.
Проблема является фундаментальной ввиду ее теоретической
и практической важности, а также вследствие ее направленности на
комплексное исследование эволюционных вычислений как
математических преобразований, трансформирующих входной поток информации
в выходной, основанных на правилах имитации механизмов
эволюционного синтеза, на статистическом подходе к исследованию ситуаций
и итерационном приближении к искомому решению. Используя
компьютерное моделирование на основе эволюционных вычислений,
можно создавать сложные системы, для которых не существует
аналитического описания.
Эволюционные вычисления способствуют решению не только
оптимизационных проблем, но также представлению сложного
поведения в виде результата взаимодействия относительно простых
структур. Они демонстрируют целенаправленное, устойчивое к флуктуа-
циям и почти оптимальное поведение, не являясь инструктивным
процессом, вполне подходят в качестве основы когнитивной
обработки данных при решении задач обучения без учителя. Это мощный
метод, особенно в контексте параллельных и распределенных средств
поиска. Однако возникают вопросы. Каковы ограничения алгоритмов
8
Введение
эволюционных вычислений? Как сочетаются разнообразные модели
эволюционных вычислений? Как управлять мощным и гибким
механизмом эволюционного поиска в пространстве параметров задачи,
сохранив с помощью композиции эволюционных операторов важные
аспекты родительской информации для последующих поколений,
компромисс между разнообразием и постоянством? Чтобы ответить на эти
и некоторые другие вопросы, необходима теория, обобщающая
различные парадигмы эволюционных вычислений, инспирированных
природными системами, опирающаяся на единую концепцию и когнитивные
механизмы алгоритмов эволюционных вычислений, на возможности
их распараллеливания.
Эта задача представляется фундаментальной, поскольку прогресс
в вычислительном интеллекте сводится к синтезу все более
высокоорганизованных вычислительных методов. Эволюционные вычисления
являются одним из важных направлений исследования и
совершенствования методов вычислительного интеллекта. Однако до сих пор
не выработано общего концептуального подхода к целенаправленному
синтезу алгоритмов эволюционных вычислений. В монографии именно
эта задача является основной.
До настоящего времени выдвигаемая проблема не представлена
в явном виде в отечественной и зарубежной монографической
литературе.
Известной мировой школой, представляющей новое направление
в эволюционном моделировании, является школа С. Ferreira в
Великобритании (www.gene-expression-programming.com). Основное
направление исследований сосредоточено в программировании
генетических выражений. Новые алгоритмы, разрабатываемые представителями
школы, используют специфичные операторы комбинаторного поиска,
которые увеличивают их эффективность. Сами авторы определяют
программирование генетических выражений как мультигенное
генотип/фенотип кодирование деревьев выражений, связанных частным
взаимодействием. Известно, что в простейшем случае при единичной
длине хромосомы программирование генетических выражений
эквивалентно генетическим алгоритмам.
Наиболее известной школой, в которой исследуют генетические
алгоритмы, эволюционные стратегии, генетическое программирование
и эволюционное программирование, является лаборатория
эволюционных вычислений Департамента компьютерных наук в университете
Дж. Мейсона в США (http://www.cs.gmu.edu). Руководство школой
осуществляет К. де Йонг, ученик Дж. Холланда. Лаборатория
работает над проектами и приложениями моделей эволюции. Такие
модели необходимы для лучшего понимания эволюционных систем; они
используются для обеспечения робастности, гибкости и адаптивности
вычислительных систем. Главное внимание специалисты лаборатории
Введение
9
уделяют решению сложных научных и технических проблем, таких как
инновационное проектирование, оптимизация и машинное обучение.
В аналогичном направлении, но с акцентом на генетические алгоритмы,
работает под руководством Д. Голдберга лаборатория генетических
алгоритмов в Иллинойском университете (http://www.illigal.ge.uiuc.edu).
Большой вклад в развитие алгоритмов эволюционных вычислений
внесли российские ученые Д. Батищев, И. Букатова, В. Емельянов,
В.М. Курейчик, И. Норенков, В. Редько.
Главная трудность при построении эволюционных вычислений,
инспирированных природными системами, и применении этих
вычислений в прикладных задачах состоит в том, что природные системы
довольно хаотичные, а все наши действия, фактически, носят
четкую направленность. Использование компьютера как инструмента для
решения определенных задач предполагает максимально быстрое их
выполнение при минимальных затратах. Природные системы не имеют
таких целей или ограничений, во всяком случае, нам они не известны.
Неполнота знаний о внешнем мире, непредсказуемость реальных
ситуаций заставляет исследователей использовать модели,
инспирированные природными системами, способные подстраиваться к изменению
внешней среды и самостоятельно ориентироваться в сложных
условиях. Эволюция в природе не направлена к фиксированной цели, вместо
этого эволюция делает шаг вперед в любом доступном направлении.
В качестве ожидаемых результатов алгоритмов, инспирированных
природными системами, указываются требования целенаправленного
перехода системы в заданное состояние, а в качестве критерия
эффективности — число шагов решения. При этом традиционные модели
теории управления, оптимизации, системного анализа из-за
размерности становятся на практике реальным сдерживающим фактором.
Когнитивная адаптация алгоритма в процессе динамического
моделирования — едва ли не единственный способ поиска решения задач в
таких случаях. Это определяет практическую актуальность исследований
когнитивных принципов принятия решений на основе эволюционных
алгоритмов, инспирированных природными системами и
моделирующих бионические принципы.
Книга состоит из пяти глав.
В первой главе представлена таксономия моделей эволюционных
вычислений, а также анализ моделей генетических алгоритмов,
генетического программирования, эволюционных стратегий, эволюционного
программирования, роевого интеллекта, квантовой и других эвристик,
основанных на природных аналогиях.
Во второй главе обсуждаются гипотезы и закономерности
эволюционных вычислений, представлены основные положения теории
эволюционных вычислений, приводится феноменологическая модель
эволюционных вычислений, ее когнитивные возможности и общие правила
10
Введение
представления решений в моделях эволюционных вычислений,
анализируется базовый цикл эволюционных вычислений.
Третья глава посвящена вопросам организации параллельных
эволюционных вычислений. В ней рассмотрены различные модели
параллелизма и показатели эффективности работы параллельных
эволюционных алгоритмов.
Четвертая глава содержит теоретические положения микро-, макро-
и метауровнеи эволюционных вычислений, а также описание
разновидностей алгоритмов эволюционных вычислений.
В пятой главе приводятся примеры эволюционных вычислений для
решения экстремальных задач на графах.
Математик строит модели,
совершенные сами по себе
(то есть совершенные по своей
точности), но он не знает,
модели чего он создает.
Станислав Лем
Глава 1
АНАЛИЗ МОДЕЛЕЙ ЭВОЛЮЦИОННЫХ
ВЫЧИСЛЕНИЙ
1.1. Таксономия моделей эволюционных вычислений
Вычисления — это физический процесс. В природе действуют
эволюционные процессы, поэтому естественно говорить об
эволюционных вычислениях, инспирированных природными системами, которые
на практике доказали свою непримитивность.
Эволюционные вычисления как математические преобразования,
трансформирующие, согласно принятой модели, входной поток
информации в выходной, основаны на правилах имитации механизмов
эволюционного синтеза, а также на статистическом подходе к исследованию
ситуаций и итерационном приближении к искомому решению.
Математические и компьютерные вычисления, человеческие
размышления, логические построения и умозаключения обычно связывают
с понятием алгоритма. Выполнение алгоритма — это и есть модель
вычислений, размышлений и других физических процессов. Как
известно, различают понятия строгого (детерминированного) и
нестрогого (недетерминированного) алгоритма. Строгий алгоритм за конечное
число шагов выдаст один и тот же результат, в отличие от нестрогого
алгоритма. Существует множество свидетельств того, что
интеллектуальная деятельность, решение интеллектуальных задач нельзя описать
в виде строгих алгоритмов и формальных систем. Известная теорема
Гёделя говорит, что формальная система не может быть одновременно
полной и непротиворечивой [1]. Полнота означает, что формальная
система знает о своей области знаний всё и может судить об
истинности самой себя. Если же система сможет судить о полноте самой
себя, то у такой системы будут внутренние противоречия и результаты
ее деятельности необязательно правильные, потому что вопрос
самопроверки относится к разряду «вечных» вычислений.
12 Гл. 1. Анализ моделей эволюционных вычислений
Эволюционные вычисления изначально нацелены на
недетерминированность. Для их реализации лучше подходят не
однопроцессорные, а более эффективные архитектуры, допускающие большое
количество параллельных и взаимодействующих процессов. Программная
поддержка эволюционных вычислений на современных процедурных
или предикатных языках также представляется малопродуктивной.
В частности, недостаток предикатных языков заключается в том,
что область применения правил очень узкая и выстраиваются они
в слишком длинные цепочки. В интеллекте же наоборот, преобладают
короткие цепочки вывода, в которых логическая единица оценивает
весьма широкий массив входных условий, причем по нечетким и
нелинейным критериям.
Малопригодной для реализации эволюционных вычислений
является и существующая нечеткая логика, поскольку она не имеет дела
ни с распараллеливанием операций, ни с обратным их объединением.
Всё, с чем оперирует нечеткая логика в ходе вычислений, сводится
к обработке логических выражений, только вместо логических нуля
и единицы в ней применяются арифметические операции для сочетания
чисел из вещественного диапазона от нуля до единицы.
При параллельном выполнении эволюционных вычислений поиск
решения ведется параллельно, сами решения постоянно сравниваются
и обмениваются информацией друг с другом. Поэтому эволюционные
вычисления способны выдать фантастический скачок
производительности по сравнению со случайным поиском и «перемолоть» самые
трудные задачи. Казалось бы, типичное случайное решение в среднем
ничего интересного из себя не представляет, его эффективность крайне
низка. Но стоит только множеству решений в процессе
эволюционных вычислений начать взаимодействовать между собой, как хорошее
решение быстро появляется и прогрессирует.
Конечно, ход естественной эволюции гораздо сложнее и
эффективнее, нежели любой эволюционный алгоритм. Тем не менее,
эволюционный алгоритм может находить эффективные решения в самых
разных областях, когда даже неизвестно как искать правильное
решение. В пользу эволюционных вычислений говорит то обстоятельство,
что жизнь на Земле (и разум), вероятно, появилась именно по таким
принципам [2, 3]. Эволюционные вычисления становятся еще более
эффективными, если популяция решений и преобразующие их
операторы учитывают внешние данные и внутреннее состояние системы
в текущий момент. Поскольку оценка и принятие решения при
эволюционных вычислениях производится на каждом шаге эволюции, то это
выгодно отличает их от процедурных алгоритмов поиска оптимального
решения.
Несмотря на кажущуюся хаотичность, процедура эволюционного
поиска является очень устойчивой. Главное, чтобы у нас был хоть
какой-то критерий оценки качества получаемых решений, т.е. лучше
ли одно решение, чем другое. Этого достаточно, чтобы эволюционный
/./. Таксономия моделей эволюционных вычислений 13
алгоритм заработал. Для реальных практических задач такой критерий
обычно имеется.
Оценка решений в процессе эволюционных вычислений должна
быть кумулятивной, т. е. накапливаться, давая каждому решению
некоторую отсрочку, чтобы эволюционировать. Хорошие решения в ходе
эволюции обычно с большей вероятностью клонируются. Эта
особенность присуща любой разновидности эволюционных вычислений.
Разновидностями моделей эволюционных вычислений являются
модели поведения роя, модели отжига, табуированного поиска, меметики
и некоторые другие. Предлагаемая таксономия является обобщением
существующих разновидностей эволюционных вычислений,
инспирированных природными системами, включает алгоритмы Монте-Карло,
эволюционные алгоритмы, алгоритмы меметики, гармоничного поиска,
роевого интеллекта (колонии муравьев, стаи птиц, пчелиного роя) и др.
Алгоритмы Монте-Карло представляют собой общее название
группы численных методов, основанных на получении большого числа
реализаций случайного процесса, который формируется таким образом,
чтобы его вероятностные характеристики совпадали с аналогичными
величинами решаемой задачи. Они используются для решения задач
в различных областях физики, математики, экономики, оптимизации,
теории управления и включают в себя моделирование отжига, табуиро-
ванный поиск, пороговые и потоковые алгоритмы, алгоритмы
рекордных оценок, слепой случайный поиск и др.
Эволюционные алгоритмы также представляют собой общее
название группы методов, которые моделируют базовые положения теории
биологической эволюции — процессы отбора, мутации и
воспроизводства. Согласно этой теории поведение особей, множество которых
принято называть популяцией, определяется окружающей средой,
правилами отбора в соответствии с целевой функцией пригодности,
причем размножаются только наиболее пригодные виды, а рекомбинация
и мутация позволяют особям изменяться и приспособляться к среде.
К таким алгоритмам с адаптивным поисковым механизмом относятся
генетические алгоритмы, генетическое программирование,
эволюционные стратегии и эволюционное программирование.
Алгоритмы меметики представляют собой подход к
эволюционным моделям передачи информации, который основывается на
концепции мемов, рассматривающей идеи как единицы культурной
информации, распространяемые между людьми посредством имитации,
обучения и др.
Алгоритмы гармоничного поиска также основаны на универсальных
законах природных систем, характеризуют их структурную
организацию и включают метод золотого сечения, Фибоначчи и некоторые
другие.
Алгоритмы роевого (группового) интеллекта основаны на
моделировании поведения социальных насекомых (муравьев, птиц, пчел).
Они, в отличие от людей, обходятся без руководящего центра, причем
14
Гл. 1. Анализ моделей эволюционных вычислений
групповой интеллект роя часто превосходит умственные способности
одной особи и позволяет решать задачи, немыслимые для одной особи:
находить кратчайший путь к источнику пищи, распределять
обязанности, защищать территорию, строить, собирать ресурсы и т. п.
Эволюционные вычисления пока не включают модели и
системы, которые, возможно, являются биологически более реалистичными,
но которые не оказались полезными в прикладном смысле. Речь идет
о системах так называемой искусственной жизни (термин чаще всего
применяется к компьютерному моделированию жизненных процессов).
Они больше похожи на биологические системы и менее направлены на
решение технических задач, они обладают сложным и интересным
поведением и, видимо, в будущем получат практическое применение [4].
Классификационная схема (таксономия) существующих
разновидностей эволюционных вычислений, инспирированных природными
системами, имеет вид, представленный на рисунке 1.
Мягкие
вычисления
Вычислительный
интеллект
Искусственный
интеллект
1 ЭВОЛЮЦИОННЫЕ ВЫЧИСЛЕНИЯ
>
i
Алгоритмы Монте-Карло
Моделирование отжига
Табуированный поиск
Пороговые алгоритмы
Потоковые алгоритмы
Алгоритмы рекордов
Случайный поиск
А
Эволюционные
алгоритмы
Генетические алгоритмы
Обучающие
классификаторы
Эволюционное
програмирование
Эволюционные
стратегии
Генетическое
прогрг
1ММИрОЕ
*ание
i
k i
i i
i
Рис. 1. Классификационная схема (таксономия) эволюционных вычислений
В свою очередь эволюционные вычисления являются одной из
основ для научных направлений, называемых «мягкими вычислениями»
и «вычислительным интеллектом», сформировавшихся в последние
1.2. Модель генетических алгоритмов
15
20 лет, включающих также нечеткую логику, искусственные нейронные
сети и ряд примыкающих областей.
1.2. Модель генетических алгоритмов
Д. Холланд для объяснения механизмов адаптации систем
предложил использовать так называемые репродуктивные планы, которые
в дальнейшем стали называть генетическими алгоритмами (ГА),
поскольку они были основаны на идеях биологической эволюции,
инспирированных природными системами [5]. В настоящее время развитие
ГА как разновидности ЭВ идет по пути непрерывного усложнения их
поведения, когда главным становится смысловое содержание
параметров управления эволюцией [6].
Формализуем модель генетических алгоритмов.
Формализованная модель генетических алгоритмов включает
следующую систему отношений, имитирующих эволюцию
исследуемого объекта [7]. ГА работает с множеством (популяцией)
искусственных хромосом (индивиды, или стринги). Каждая хромосома а состоит
из L бит (генов): а = (а\, a<i, ..., а^), где а^ G {0, 1} — аллель.
Хромосомы могут состоять из п отдельных сегментов (п ^ L), каждому
из которых может соответствовать некоторая переменная в
рассматриваемой задаче. Сегмент j (j= 1, 2, ..., п) содержит при двоичном
способе кодирования значение переменной, причем длина сегментов
может различаться.
Предположим, что в рассматриваемой задаче необходимо
максимизировать целевую функцию F(U), где U = (u\t щ, ..., ип) —
переменные, от которых зависит функция. При двоичном кодировании стринги
имеют конечную длину, так как каждая переменная Uj (j = \,2, ..., п)
принимает значения в интервале [i/jmin, Ujmax]y что делает
пространство поиска решения ограниченным, т. е.
п
11 l4?rmn> ^.7 max] * ■** »
j = l
где i?+ — множество положительных вещественных чисел. Тогда при
заданной функции декодирования вида
п
uj min) Uj max J
.7 = 1
можно получить декодируемое значение переменной й = Т(а) из
двоичного стринга.
Действительно, рассмотрим j-й сегмент. Его длина равна Lj бит,
он кодирует переменную Uj. Обозначим через a,jZ бит с номером z
16 Гл. L Анализ моделей эволюционных вычислений
(z = 1, 2, ..., Lj), принадлежащий j-ому сегменту стринга. Тогда
декодирование происходит следующим образом:
Tj(ajU ...,ajL.) =
„, | 47 max Щmin / \ ^ c%z—\ \ _ „,
-Ujmin + ^—— \^(Lj{Lj_z+{)-2 I ~^'
при этом вещественные числа в двоичном коде можно представить
с ограниченной точностью. Например, для двоичного представления
вещественных переменных в интервале — 1 ^ и ^ 2 с шагом 0,1
требуется не менее L = 5 бит. Числу и = -1 будет соответствовать стринг
00000, числу и = 2 — стринг 11111, а стрингу 0^2030405 = 11001 будет
соответствовать декодируемое значение
В ГА это служит одной из причин того, что при поиске
оптимального значения функций от вещественных переменных оптимум
достигается лишь приблизительно.
Таким образом, формализованная модель ГА включает в себя
следующие элементы:
— инициализация. Случайно генерируется исходная популяция
P(t = 0), состоящая из /i хромосом а* (г = 1, 2, ...,//), где обычно
30 ^ fi ^ 500. Это означает, что двоичные значения битов отдельных
хромосом, входящих в популяцию, устанавливаются равновероятно
и независимо друг от друга;
— оценка хромосом, которая необходима для оценки качества
хромосом, входящих в популяцию, и последующей их селекции.
Хромосомы декодируются и оценивается их функция качества (фитнесс-
функция) Ф исходя из целевой функции F и функции декодирования
Г:Ф(о<) = ^оГ(а<);
— стохастическая селекция и репликация. Вычисляется
вероятность селекции хромосомы a^ G Р,
/ м
ps(ai) = Ф(сц) / £ Ф(а,-).
i=i
Это — пропорциональная (не дискриминационная или рулеточная)
селекция, так как все родительские хромосомы имеют отличную от 0
вероятность потенциального участия в производстве потомков.
Выбранная таким образом хромосома копируется в первоначально пустой
список родителей, предназначенных для производства потомства.
Селекция проводится /х раз, при этом математическое ожидание того, как
часто хромосома Щ выбирается в качестве родительской хромосомы,
равно iiops(ai). Результатом является список родительских хромосом;
1.2. Модель генетических алгоритмов
17
— генерация потомков, когда, например /х/2 раз производятся
следующие действия:
1) случайный выбор с вероятностью 1//х пары партнеров а\
и Щ для кроссинговера (скрещивания) и мутации;
2) кроссинговер (в ГА обычно применяется одноточечный
оператор кроссинговера с вероятностью р&, например, из двух
родителей вида 00 | 000 и 11 | 111 образуются два потомка
вида 00111 и 11000, где символ «|» обозначает точку
скрещивания);
3) мутация (в ГА обычно применяется оператор мутации с
вероятностью рт от 0,01 до 0,001, например, из родителя вида
01 | 011 образуется потомок вида 00111);
4) оценка потомков Ф(а^) = F(T(a[)) и формирование новой
популяции путем выбора /х лучших хромосом;
— переход на повторное выполнение стохастической селекции и
репликации до тех пор, пока не будет выполняться условие останова
алгоритма (заданное число шагов эволюции tmax, качество решения,
время работы алгоритма и т.п.).
Представим нотацию формализованной модели ГА на псевдокоде,
который имеет следующий вид:
выбор
*:=0
параметров ГА (/х,
Uj min» Uj max» L, pK, Pm)
инициализация Щ (г = 1, 2, ..., /х) —► P(t)
определение Ф(йг) Для всех a* G P(t)
repeat
t:=t+l
P(t) :=
P{t)pa6
for г =
begin
end
for г =
begin
end
-- 0
:=0
1 to /i
стохастическая селекция хромосом из P(t — 1) с
вероятностью ps(cii)
репликация P(t)pa6 := P(t)?a6Uai
1 to /i/2
стохастическая селекция двух хромосом из множества
P{t)?a6 с вероятностью ps = 1//х
кроссинговер выбранной пары с вероятностью рк
мутация выбранной пары с вероятностью рш
определение функции качества Ф полученных потомков
формирование популяции P(t) из лучших потомков и
родителей
проверка условий останова алгоритма.
2 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
18 Гл. I. Анализ моделей эволюционных вычислений
С целью упрощения можно использовать следующее представление
формализованной модели генетического алгоритма [8]:
ГА = (ff, N, ff, fc, Г, Lj9 А, ЩФ, ОГР, ГУ),ГО, t),
где Р° — исходная популяция хромосом (альтернативных
решений), Р? = (Р?и Р°2, ...,i?„), Р°\ £ Р? - хромосома
(альтернативное решение), принадлежащая г-ой исходной популяции; N —
мощность популяции, т.е. число входящих в нее хромосом, N — \Р?\\
P?k £ Р? — к-я хромосома, принадлежащая г-ой популяции,
находящейся в Т поколении эволюции (иногда число поколений
связывают с числом генераций генетического алгоритма, обозначаемых
буквой G); Lj — длина г-ой хромосомы (альтернативного решения),
т. е. число генов (элементов, входящих в закодированное решение,
представленное в заданном алфавите) (например, \Р?\ = Lj, A —
произвольный абстрактный алфавит, в котором, кодируются хромосомы);
ЩФ, ОГР, ГУ) — целевая функция, ограничения и граничные
условия, которые определяются на основе модели ЭВ; ГО — генетические
операторы, t — критерий окончания работы ГА.
1.3. Модель генетического программирования
Проблемы компьютерного синтеза программ стали одним из
направлений искусственного интеллекта примерно в конце 50-х годов.
Первые попытки автоматизации программирования привели к достаточно
скромным результатам, что вполне объяснимо тогдашним состоянием
компьютерной техники. Начиная с середины 80-х годов, интерес
исследователей к данной проблематике резко возрос благодаря работам по
ГП, представленным в рамках первой и последующих международных
конференций по ЭВ. Наиболее значительными следует признать работы
Д. Коза [9].
Формализуем модель генетического программирования.
Формализованная модель генетического программирования
включает следующую систему отношений, имитирующих эволюцию
исследуемого объекта, которым является программа. Поскольку
ГП ориентировано, в основном, на решение задач автоматического
синтеза программ на основе обучающих данных путем индуктивного
вывода, то хромосомы или структуры ГП являются математическими
выражениями, представляющими компьютерные программы различной
величины и сложности. Эти программы автоматически генерируются
с помощью генетических операторов, имеют древовидную структуру,
узлами которой являются функции, переменные и константы.
1.3. Модель генетического программирования 19
Исходная популяция Р(0) хромосом в ГП образуется случайно и
состоит из программ, которые включают в себя элементы множества
проблемно-ориентированных элементарных функций (function set), а
также проблемно-ориентированные переменные и константы (terminal
set). Множества function set и terminal set являются основой для
эволюционного синтеза программы, способной наилучшим образом решать
поставленную задачу. Одновременно устанавливаются правила выбора
элементов из указанных множеств в пространстве всех потенциально
синтезируемых программ. Множества terminal set и function set, а
также правила их обработки оказывают серьезное влияние на размерность
пространства поиска наилучшего решения и на качество результатов,
получаемых алгоритмом ГП.
Для описания древовидных структур обычно применяется язык
Лисп, обладающий для этого всеми необходимыми свойствами:
• Лисп является синтаксически простым функциональным языком,
программа на котором представляет собой рекурсивную функцию
символьных выражений, состоящих из элементарных функций,
условных операторов и операторов суперпозиции;
• обработка данных в программе на Лисп сводится к объединению,
делению и перегруппировке информации;
• языковые конструкции Лисп представляются древовидной
структурой, форма и величина которой может динамически
изменяться.
Однако применение ГП нельзя связывать лишь с языком Лисп,
существует немало примеров, когда для целей ГП применяются другие
языки, например С, Smalltalk, C++.
Настройка модели ГП предусматривает выполнение следующих
действий:
• установка множества terminal set,
• установка множества function set;
• определение подходящего вида функции качества;
• установка параметров эволюции;
• определение критерия остановки ГП и правил декодирования
результатов эволюции.
Поскольку основой моделирования эволюции в ГП являются
элементы множеств terminal set и function set, то выбор пользователем
языка программирования определяет вид получаемых решений. Что
касается установки функции качества, параметров эволюции и критериев
остановки процесса моделирования, то они совпадают с аналогичными
этапами в моделях ГА.
В качестве элементов function set могут фигурировать следующие:
• арифметические операции (например +, -, *, %-деление);
• математические функции (например sin, cos);
2*
20
Гл. 1. Анализ моделей эволюционных вычислений
• булевы операции (например if-then-else)\
• циклы (например for, do-until)\
• некоторые специальные функции для быстрого поиска хороших
решений.
Элементами множества terminal set являются переменные и
константы, среди которых могут быть случайные, с коротким временем
жизни константы, а также булевы константы, принимающие значения
из множества {Т, Nil), и вещественные константы, принимающие
значения на отрезке [-1,000; 1,000] с шагом 0,001. Множества function
set и terminal set должны быть достаточными для нахождения решения
задачи, а любая функция или операция — быть корректно
выполнимыми при любых допустимых аргументах.
Форма функции качества имеет большое значение для
эффективности ГП. Общепризнанным способом оценки ее качества является
такой показатель, как среднеквадратичная ошибка (чем она меньше,
тем лучше программа). Иногда используется критерий «выигрыша»,
согласно которому выигрыш определяется в зависимости от степени
близости к корректному значению целевой функции. Функцию
качества в ГП называют rohfitness и обозначают через Фго. Однако на
практике обычно используется стандартное значение ФзЬ.
Обозначим через а* некоторую программу из популяции
размером \х. Тогда
( Фго(аг), если наименьшее значение ФГО
I является подходящим,
| Фтах - Фго(йг)> если наибольшее значение Фго
I является подходящим,
причем юстируемое значение равно
Интервал изменения Фju(ai) равен (0, 1). Размер популяции /i в ГП
обычно составляет несколько тысяч программ. Для максимального
числа генераций tmax рекомендации отсутствуют. Коза в своих
экспериментах использовал значение tmax = 51.
Таким образом, формализованная модель ГП представляет
следующий набор элементов.
— Инициализация модели предусматривает случайную генерацию
популяции Р(0), состоящей из /х древовидных программ. Причем
корневой вершиной дерева всегда является функция, аргументы
которой выбираются случайно из множеств function set или terminal set.
1.3. Модель генетического программирования
21
Концевыми вершинами дерева должны быть переменные или
константы, в противном случае процесс генерации необходимо рекурсивно
продолжить. Если структура дерева становится сложной, то заранее
устанавливается максимальная глубина дерева. Она равна числу ребер
дерева, которое содержит самый длинный путь от корневой вершины
до некоторой концевой вершины. Обычно в экспериментах
максимальная глубина дерева колеблется от шести (для популяции Р(0)) до 17
(в более поздних популяциях P(t)). Для обеспечения многообразия
популяции Р(0) в ходе инициализации может применяться, так
называемый, half-ramping способ, согласно которому деревья разной высоты
генерируются с одинаковой частотой. Правда, этот способ не лишен
недостатка, связанного с не совсем случайным характером
генерируемых деревьев. Поэтому существуют альтернативные методы
псевдослучайной генерации деревьев начальной популяции Р(0), причем
дупликация идентичных хромосом в Р(0) считается недопустимой.
— Оценка решений по значению функции качества для каждой
программы, например, по разнице между лучшим и худшим значением
функции или по величине среднеквадратичной ошибки (чем ошибка
меньше, тем лучше программа).
— Генерация новой популяции предусматривает следующие шаги:
1) выбор операторов эволюции, основными из которых для
ГП являются репродукция и кроссинговер, применяемые
с вероятностью рг и pk соответственно, причем рг +рк = 1
(чаще всего рТ = 0,1, pk = 0,9);
2) селекция и репликация, выполняемая по аналогии с ГА;
3) образование новой популяции; если к некоторой программе
применяют оператор репродукции, то эта программа
копируется в новую популяцию; для проведения кроссингове-
ра выбираются две родительские хромосомы; случайным
образом определяются точки кроссинговера и путем
обмена образуются два потомка; при программной реализации
на языке Лисп кроссинговер сводится к обмену списками
между двумя программами при сохранении синтаксической
корректности вновь получаемых программ.
— Проверка критерия остановки. Процедура ГП является
итерационной, и критерии ее остановки аналогичны критериям для ГА:
достижение максимального числа шагов эволюции, достижение заданного
уровня качества (значения целевой функции всех программ в
популяции превысило порог), достижение заданного уровня сходимости
(хромосомы подобны, улучшение функции замедляется).
Представим нотацию модели ГП на псевдокоде, который имеет
следующий вид:
22 Гл. 1. Анализ моделей эволюционных вычислений
выбор параметров ГП (/х = 4000 ч- 16000, tmax = 51, рк = 0,9,
Рг = 0,1)
t:=0
инициализация программ а» (г = 1, 2, , /х) —► P(t)
определение Ф(а{) для всех а; G Р(£)
repeat
*:=*+ 1
P(t) := 0
repeat (г < /x)
выбор оператора кроссинговера с вероятностью pk или
оператора репродукции с вероятностью рг,
если выбрана репродукция, то выполняется
соревновательная селекция индивидуума а из популяции P(t — 1),
формирование P(t) := Р(£) U {a}
i :=г + 1
иначе (если выбран кроссинговер), то в популяции
P(t- 1) выполняется соревновательная селекция двух
родительских хромосом ар\ и аР2, получаются два потомка
flni и ^п2» Для которых определяются функции Ф(аП1)
и Ф(ап2),
P(t):=P(t)U{anl,an2},
г := г -h 2
если (г > /i), то размер популяции Р(£) сокращается до /х
проверка условий останова алгоритма.
1.4. Модель эволюционных стратегий
Как одна из основных форм ЭВ, эволюционные стратегии (ЭС)
рассматривают ход эволюции на уровне фенотипа [10, 11], в
отличие от генетических алгоритмов, которые акцентируют внимание на
генетическом механизме наследственности на уровне хромосом. ЭС
анализируют эволюцию на уровне целой популяции. В ЭС оператор
мутации применяется с частотой, соответствующей нормальному
закону распределения. Это является оправданным для выбранного уровня
моделирования, в отличие от мутации на генном уровне, где она
проявляется как редкое событие и практически не влияет на фенотип.
Решение многих реальных задач сопровождается множеством
технических деталей, которые трудно учесть в ГА. Существует
астрономическое число возможных популяций. Большинство из них имеют
несущественные отличия, выявить которые ГА не могут, поскольку
они не способны уловить семантические и прагматические различия
между ними и теми изменениями, которые, наоборот, существенно
влияют на ход эволюции. Именно поэтому перспективным
выглядит подход, состоящий в разработке ЭС. Эволюционные стратегии
1.4. Модель эволюционных стратегий
23
вырабатывают решения (фенотипы) из параметров (генотипов). К тому
же многие практические задачи являются задачами не только
дискретной, но и непрерывной оптимизации, поэтому имеет смысл провести
формализацию принципов и особенностей построения ЭС.
Используя базовые гипотезы ЭВ, формализуем модель
эволюционных стратегий.
Формализованная модель эволюционных стратегий включает
следующую систему отношений, имитирующих эволюцию
исследуемого объекта. Без ограничения общности будем считать, что задача
ЭС в терминах математического программирования состоит в
минимизации целевой функции F(x\,X2, ...,xn), где Х{ —
вещественные переменные (г = 1,2, ...,п). Каждому индивиду ЭС
соответствует вектор в n-мерном пространстве, который представляет собой
некоторое решение поставленной задачи. Кроме того, каждый
индивид характеризуется некоторым среднеквадратичным отклонением Gj
(j = 1, 2, ..., m; 1 < га ^ п), которое для оператора мутации означает
среднюю величину наследственной изменчивости. Величина Gj
является параметром, характеризующим адаптивные свойства ЭС. Будем
считать, что если 1 < га < п, то сгь сг2, ..., Gm-\ жестко связаны с
переменными х\, Х2, ..., хт-\, а величина Gj для остальных переменных
xm,xm+i, ...fxn является свободной. Отметим, что в большинстве
практических приложений га = 1 или т = п.
Модель ЭС представляют следующие элементы:
— инициализация модели, которая предусматривает генерацию
начальной популяции P(t = 0) из \х индивидов вида Sk = (#ь Gk), где
к= 1,2, ...,/х;
— оценка решения: для каждого индивида Sk устанавливается
функция качества Ф(а^), будем считать ее идентичной целевой
функцией F(ffc), т.е. Ф(а^) = F(xk)\
— генерация потомков: задача состоит в получении А потомков
из /z родителей, для этого необходимо выбрать родителей, провести
их рекомбинацию и репликацию (копирование и передача фенотипа
родителей потомкам), а затем мутацию потомков;
— оценка потомков: производится оценка каждого потомка S' =
= (х7, <?'); Ф(а') = F(x') и ограничивается размер промежуточной
популяции;
— селекция;
— проверка условий остановки алгоритма ЭС: критериями
остановки алгоритма ЭС являются максимальное число шагов эволюции tmax,
отсутствие прогресса в смысле заметного улучшения значений целевой
функции, малая разница между лучшим и худшим значением функции
для текущей популяции и т. п.
Представим нотацию формализованной модели ЭС на псевдокоде,
который имеет следующий вид:
24 Гл. 1. Анализ моделей эволюционных вычислений
выбор начальных значений параметров ЭС (/х, Л, га, a0k> Ч, ^2» £)
t:=0
инициализация Щ (г = 1, 2, ..., /i) —► Р(£)
определение F(Si)y Va» Е Р(£)
repeat
t:=t+ 1
P(t) := 0
Рраб := 0
for 2 = 1 to Л repeat
begin
если родители выбираются случайно, то случайная
селекция двух родителей из популяции P(t - 1) с вероятностью
р8 = l/fi для V5i e P(t - 1);
если производится варьирование с репликацией, то
рекомбинация родителей и образование потомка а2, а также
мутация потомка az и образование a!z\
если размеры промежуточной популяции ограничены,
то определение Ф(3£), Рраб = Рраб U {a'z}
end
если селекция ведется детерминировано, то лучшие
индивиды ИЗ ПОПУЛЯЦИИ Рраб —► Р(£)
проверка условий останова алгоритма.
1.5. Модель эволюционного программирования
Другим классом задач, расширяющим границы применения
концепции ЭВ, является компьютерный синтез клеточных автоматов,
способных инновационным образом реагировать на стимулы, поступающие
из внешней среды. Наиболее подходящим инструментом для решения
подобного рода задач является эволюционное программирование (ЭП).
Модель ЭП представляется актуальной с позиций теории многоагент-
ных систем, искусственной жизни, коллективного поведения, потому
что она помогает лучше понять феномен взаимодействия между
искусственными программными агентами (артефактами) [12, 13].
В ЭП популяция рассматривается как центральный объект
эволюции. ЭП исходит из предположения о том, что биологическая эволюция
является, в первую очередь, процессом приспособления на
поведенческом уровне, а не на уровне таких генетических структур, как
хромосомы. Популяция особей в ЭП отражает характер поведения, вид
общения и пр. Этот уровень абстракции в природе не предусматривает
рекомбинации [14]. Поэтому в ЭП отсутствует оператор кроссинговера,
также как и некоторые другие операторы, используемые в ГП.
Мутация в ЭП является единственным оператором поиска альтернативных
решений на уровне фенотипа, а не на уровне генотипа, как в ГП.
1.5. Модель эволюционного программирования
25
Рассмотрим эволюционную программу на примере задачи
минимизации функции F(a\, . ..,ап), зависящей от п непрерывных
переменных, которые представляются в виде вектора А = (аь ..., ап). Вектор
А в ЭП соответствует отдельному артефакту. Используя базовые
гипотезы эволюционных вычислений, формализуем модель ЭП.
Формализованная модель эволюционного программирования
представима следующей системой отношений, имитирующих эволюцию
исследуемого объекта:
— инициализация: на этапе инициализации случайным образом
генерируется популяция Р(0), состоящая из // артефактов А* (г =
= 1,2, ...,/х);
— оценка решения: каждая особь А* определяет фитнесс-функцию
Ф(Аг), которая зачастую равна значению целевой функции (Ф = F,
хотя в общем случае они могут и не совпадать). В общем случае
считаем, что Ф(А*) = Q(F(Ai), &);
— генерация потомков;
— случайная селекция;
— проверка критерия останова.
Параметры ЭП выбираются таким образом, чтобы обеспечить
скорость работы алгоритма и поиск лучшего решения.
Нотация формализованной модели ЭП, представленная на
псевдокоде, имеет следующий вид:
выбор начальных значений параметров ЭП (/х, ft, ljy r3
t:=0
инициализация а* (г = 1, 2, ..., /i) —► P(t)
определение функции качества Ф(а-), Va* E P(t)
repeat
Рраб := P{t)
t:=t+l
P(t) := 0
for г = 1 to /i repeat
begin
копирование а* из P(t — 1);
мутация потомка а!{\
определение Ф(а^);
Рраб = Рраб U {(*>{}
end
for г = 1 to 2/i repeat
for z = 1 to h
попарное сравнение функций Ф(<2г) и случайно
контрагента из Рраб.
end
сортировка особей в Рраб по возрастанию числа побед
нии функций
формирование P(t) из // лучших особей Рраб
проверка условий останова алгоритма.
, kjy Zj)
выбранного
при сравне-
26 Гл. 1. Анализ моделей эволюционных вычислений
1.6. Модель роевого интеллекта
Моделирование самоорганизации общественных насекомых
составляет основу роевых алгоритмов. Рой рассматривается как многоагент-
ная система, в которой каждый агент функционирует автономно по
довольно примитивным правилам. В противовес почти примитивному
поведению агентов поведение всей системы получается на удивление
разумным.
Роевые модели исследуются с середины 90-х годов. На сегодняшний
день уже получены неплохие результаты для решения таких сложных
комбинаторных задач, как задача коммивояжера, задача оптимизации
транспортных маршрутов, задача раскраски графа, задача о
назначениях, задача оптимизации сетевых графиков, задача календарного
планирования и многие другие. Особенно эффективны роевые модели
при динамической оптимизации процессов в распределенных
нестационарных системах, например, трафиков в телекоммуникационных сетях.
Основу поведения роя составляет самоорганизация, обеспечивающая
достижения общих целей роя на основе низкоуровневого
взаимодействия. Рой не имеет централизованного управления. Его особенностями
являются прямой и непрямой обмен локальной информацией между
отдельными особями.
Совокупность сравнительно простых агентов конструирует
стратегию своего поведение без наличия глобального управления.
Например, модель муравьиной колонии, по аналогии с биологической
моделью, базируется на непрямом обмене информацией колонии агентов,
называемых искусственными муравьями, использующих феромонные
следы как коммуникационное средство. Феромонные следы служат
распределенной численной информацией. Она наряду с эвристической
информацией о задаче используется муравьями для
недетерминированного конструирования решений задачи и отражает опыт, накопленный
муравьями в процессе поиска решения.
Модель роевого интеллекта может быть применена практически
к любой задаче, которая допускает следующее представление:
• дан конечный набор компонент решений X = {х\, #2, ••• ,#п};
• определены состояния проблемы, множество их возможных
последовательностей и множество последовательностей, которые
удовлетворяют ограничениям задачи;
• с теми состояниями, которые не являются решениями, можно
ассоциировать стоимость или ее оценку;
• определен конечный набор возможных соединений U между
элементами Х\
• с компонентами и их соединениями ассоциируются феромонные
следы, представляющие долговременную память муравьев.
При подобном представлении задачи каждый муравей колонии
имеет следующие свойства:
1.6. Модель роевого интеллекта
27
• он использует граф G = (X,U) для поиска оптимального
решения, передвигаясь по соединениям из U;
• он имеет память, которую использует для хранения информации
о пройденном пути; память может использоваться для
нахождения допустимых решений, для оценки найденного решения или
для возвращения назад с целью размещения феромона;
• ему может быть присвоено начальное состояние, а также одно
или более конечных состояний;
• муравей, находясь в некотором состоянии, может переместиться
в любой узел графа из множества допустимых соседних узлов;
• переход осуществляется с помощью вероятностного правила;
правило является функцией значений, которые хранятся в структуре
данных (таблица муравьиных маршрутов); эти значения
получаются путем функциональной композиции локально доступных
для вершины феромонных следов, а также памяти муравья,
которая хранит его предысторию и ограничения задачи;
• муравей может обновить феромонный след на компоненте или
соответствующем соединении;
• найдя решение, муравей может пройти этот же путь назад и
обновить феромонный след на использованных соединениях или
компонентах.
Важной особенностью модели является то, что муравьи
передвигаются одновременно и независимо. Хорошие решения обычно
появляются только в результате коллективного взаимодействия между
муравьями, которое достигается путем непрямого общения посредством
информации, которую муравьи записывают/считывают в переменные,
содержащие значения феромонных следов.
В известном смысле, это является распределенным процессом
обучения, в котором отдельные агенты-муравьи не адаптируются, а
наоборот, адаптивно изменяют вид и восприятие задачи другими агентами.
Кроме описания деятельности муравьев роевые алгоритмы обычно
включают еще процедуры испарения феромонного следа. Испарение
феромона — это процесс, с помощью которого интенсивность
феромонного следа на соединениях автоматически уменьшается со временем.
Процесс испарения является полезной формой «забывания», он
содействует исследованию новых областей в пространстве поиска, позволяет
избежать быстрой сходимости алгоритма в субоптимальной области.
Следует ли выполнять этот процесс параллельно и независимо для
каждого муравья, необходима ли какая-то форма их синхронизации —
эти вопросы оставляются на усмотрение разработчика конкретного
алгоритма, допуская свободу в определении способа взаимодействия
этих процессов.
В общем случае в роевых моделях многомерное пространство
поиска населяется роем частиц [15]. Помимо координат каждая частица
обладает скоростью перемещения и ускорением.
28
Гл. 1. Анализ моделей эволюционных вычислений
Формализованная модель роя включает следующую систему
отношений, имитирующих эволюцию исследуемого объекта:
• создается исходная «случайная» популяция частиц;
• рассчитывается целевая функция для каждой частицы;
• лучшая частица (с точки зрения целевой функции) объявляется
«центром притяжения»: векторы скоростей всех частиц, за
исключением «сумасшедших», устремляются к этому центру, чем
дальше частица находится от центра, тем большим ускорением
она обладает;
• рассчитываются новые координаты частиц в пространстве
решений;
• три предыдущих шага итерационно повторяются заданное
число раз;
• последний «центр тяжести» соответствует найденному
локальному оптимуму.
Рой не знает, где именно находится цель, но на каждой итерации
рой знает, как далеко она находится. Эффективной стратегией будет
следование за особью, которая на данный момент находится к цели
ближе всего.
Эта модель определенно может считаться одной из самых
перспективных для построения распределенных алгоритмов, инспирированных
природными системами.
1.7. Квантовая модель
Квантовая модель вычислений предполагает, что вычисления
выполняются на гипотетическом вычислительном устройстве (квантовом
компьютере) по следующей схеме:
• задается система кубитов, на которой записывается начальное
состояние;
• посредством базовых квантовых операций изменяется состояние
системы или ее подсистем;
• измеряется результирующее состояние системы.
Идея квантовых вычислений была впервые высказана Ю.И. Ма-
ниным [16] и Р. Фейнманом [17]. Она состоит в том, что квантовая
система из L двухуровневых квантовых частиц (квантовых битов,
кубитов) имеет 2L линейно независимых состояний. Вследствие
принципа квантовой суперпозиции пространством состояний такого
квантового регистра является 2ь-мерное гильбертово пространство. Операция
в квантовых вычислениях соответствует повороту вектора состояния
регистра в этом пространстве. Таким образом, квантовое
вычислительное устройство размером L кубит может выполнять параллельно
2L операций.
В ноябре 2009 года физикам из Национального института
стандартов и технологий в США впервые удалось собрать программируемый
1.7. Квантовая модель
29
квантовый компьютер, состоящий из двух кубит. Наиболее известными
алгоритмами квантовых вычислений являются [18]:
• алгоритм Гровера, позволяющий найти решение уравнения f(x) =
= 1, где 0 ^ х < 7V, за время 0(\/]V);
• алгоритм Шора, позволяющий разложить натуральное число п на
простые множители за полиномиальное от log(n) время;
• алгоритм Дойча-Джоза, который позволяет «за одно
вычисление» определить, является ли функция двоичной переменной f(n)
постоянной (/i(n) = 0, /2(72) = 1 независимо от п) или
«сбалансированной» (/3(0) = 0, /3(1); /4(0) = 1, /4(1) = 0).
Суть квантовых вычислений сводится к следующему. Исходные
данные наносятся на небольшое количество элементарных частиц.
В процессе решения данные начинают обрабатываться одновременно
огромным количеством разных способов, между которыми происходит
обмен информацией о лучших или худших решениях. Происходит это
за счет того, что при запуске квантовых вычислений каждая частица
«знает» о состоянии всех остальных частиц, участвующих в
вычислении. У каждой частицы нет четкого физического состояния, она
находится одновременно в нескольких состояниях и может участвовать
в нескольких параллельных процессах. То, что происходит в
промежутке между заданием входных данных и снятием результата решения,
остается загадкой.
Получается, что небольшой объем входных данных в процессе
решения порождает на многие порядки более сложное внутреннее
состояние, которое непонятно как эволюционирует, не поддается
исследованию и, тем не менее, выдает правильное решение. Это состояние
носит вероятностный характер, и при правильном составлении
квантового алгоритма можно сделать так, чтобы вероятность снятия
правильного решения намного превышала вероятность снятия неправильного
решения.
Таким образом, можно получить практически бесплатно огромные
вычислительные мощности [19]. Однако у квантовых вычислений
имеется серьезная проблема: частицы решения должны быть полностью
изолированы от внешнего мира, иначе внешний мир будет сбивать
правильность хода решения (нарушать когерентность). Очевидно, что
полная изоляция невозможна, поскольку (как гласит квантовая физика)
каждая частица, каждый квант изначально «размазаны» в
пространстве и тесно связаны между собой. Отсюда следует, что квантовые
вычисления на высоких мощностях не смогут нас обеспечить
абсолютно истинными вычислениями, но вполне пригодны для правдоподобных
решений в искусственном интеллекте [20].
Неопределенность квантовых вычислений — это фактически
прямое следствие теоремы Гёделя [1], гласящей, что формальная система
не может с абсолютно истинной точностью познать саму себя.
Именно эта особенность квантовых вычислений позволяет причислить их
к классу эволюционных вычислений, считать одним из проявлений
30 Гл. 1. Анализ моделей эволюционных вычислений
более общего класса процессов, инспирированных природными
системами.
Приведем в качестве примера алгоритм квантового поиска,
ориентированный на решение задачи определения гамильтонова цикла (ГЦ)
в графе [8].
1. Начало.
2. Ввод исходных данных.
3. Проверка необходимых условий существования ГЦ в графе.
4. Анализ математической модели и на его основе построение
дерева частичных решений.
5. Суперпозиция частичных решений на основе жадной стратегии
и квантового поиска.
6. В случае наличия тупиковых решений — последовательный поиск
с пошаговым возвращением.
7. Если набор полных решений построен, то переход к п. 8, если
нет, то к п. 5.
8. Лексикографический перебор полных решений и выбор из него
оптимального или квазиоптимального решения.
9. Конец работы алгоритма.
Приведем псевдокод алгоритма квантового поиска гамильтонова
цикла в графе, используя операторные конструкции языка Паскаль.
begin {основная программа}
generation := 0 {установка}
initialize;
repeat {основной цикл}
gen := gen + 1
generation;
cycle;
return;
statistics (max, avg, min, sumfitness, newsol)
report (gen)
oldsol := newsol
until (gen ^ maxgen)
end {конец основной программы}.
Здесь generation (gen) — генерации (итерации) алгоритма; max, avg,
min, sumfitness — максимальное, среднее, минимальное, суммарное
значение целевой функции соответственно; oldsol, newsol — старое
и новое решение соответственно. Алгоритм квантового поиска
выполняется в блоке repeat.
Работа алгоритма начинается с чтения данных, инициализации
случайных решений, вычисления статистических данных и их вывода.
Процедура report представляет полный отчет обо всех параметрах
алгоритма. На основе анализа данных из процедуры report строится
график зависимости значений целевой функции от числа генераций.
Если функция имеет несколько локальных оптимумов и мы попали
1.8. Другие эвристические модели, основанные на природных аналогиях 31
в один из них, то увеличение числа генераций может не привести
к улучшению значений целевой функции. В этом случае наступила
предварительная сходимость алгоритма.
Операция return предусматривает пошаговый возврат до
выхода из тупика. Алгоритмы квантового поиска весьма чувствительны
к изменениям и перестановкам входных параметров исходной модели.
Это говорит о том, что для одного вида модели объекта, например
представленного матрицей, можно получить решение с одним
локальным оптимумом. А для этой же матрицы с переставленными строками
и столбцами можно получить другое решение с лучшим локальным
оптимумом. Следует отметить, что, изменяя параметры, алгоритмы
и схему квантового поиска, в некоторых случаях можно выходить
из локальных оптимумов. Эта проблема продолжает оставаться одной
из важнейших в методах поисковой оптимизации.
1.8. Другие эвристические модели, основанные
на природных аналогиях
Существуют и другие эвристические модели, основанные на
природных аналогиях, конкурирующие с моделями ЭВ и роевыми
алгоритмами: модель отжига, пороговая и потоковая модели, модель рекордных
оценок [21].
В модели отжига в качестве природного аналога берется процесс
кристаллизации эмалевой субстанции. В ходе ее охлаждения степень
свободного движения молекул постепенно становится ограниченной,
достигая точки равновесия с минимальным энергетическим уровнем
в кристаллической структуре. Важной особенностью данного процесса
является скорость охлаждения.
Обозначим через S множество состояний системы, через Т
температуру системы при термическом равновесии. Тогда рт(о) является
вероятностью того, что система при температуре Т находится в
состоянии а, независимо от энергетического уровня Еа этого состояния.
Согласно распределению Больцмана
^(a) = E/U)exp(*r^)-
bes
где к является константой Больцмана. Предположим, что система
находится в момент времени t в состоянии а с энергетическим
уровнем Еа. Путем небольшого случайного изменения в момент времени
t + 1 система переходит в состояние Ь с энергетическим уровнем Еъ.
Если разница АЕ = Еъ — Еа ^ 0, то актуальным становится
состояние 6; если АЕ > О, то состояние b запоминается и выбирается
с вероятностью ехр((£а - ЕЬ)/(к • Г)). При достаточно большом t
32 Гл. 1. Анализ моделей эволюционных вычислений
данное правило обеспечивает переход системы в состояние равновесия.
Аналогия с физическим процессом здесь заключается в следующем:
• решения оптимизационной задачи соответствуют состояниям
системы в процессе охлаждения физической субстанции;
• целевая функция F соответствует энергетическому уровню
субстанции;
• процедура поиска оптимального решения аналогична поиску
состояния системы с минимальным энергетическим уровнем;
• температура Т является параметром для управления процедурой
оптимизации.
Формализованная модель отжига включает в себя следующие
элементы [21]:
выбирается начальная температура Го
>0;
устанавливается начальное число итераций /о*>
t := 0;
выбирается начальное решение х\
вычисляется F[x)\
for г = 1 to It
begin
выполняется копирование (репликация) х\
переход в
копии х\
соседнюю точку х
вычисляется F{x)\
если АЕ =
если ехр(-
бирается с
end
t:=t+ l
установка Ttl It\
проверка условий
= F(x') - F(x) < 0,
-AE/Tt) > rnd(0, 1)
вероятностью ехр(-
останова.
путем мутации
то замена х на
(вариации)
х'. Иначе,
, то х1 запоминается и вы-
- AE/Tt)
Пороговая модель близка к модели отжига. Однако имеются
отличия. Основное отличие состоит в стремлении упростить реализацию
и параметризацию алгоритма, сократить время поиска и повысить
качество получаемых решений. В частности, пороговый алгоритм
предусматривает иное, нежели метод отжига, правило принятия решения.
По методу отжига, если новое решение приводит к ухудшению целевой
функции, то рассчитывается вероятность его использования в ходе
дальнейшего поиска. Согласно пороговому алгоритму каждое новое
решение должно быть «не намного хуже, чем предыдущее», причем
мера ухудшения устанавливается в качестве некоторого порогового
значения, которое в процессе моделирования уменьшается до нуля.
Для сравнения представим на псевдокоде процедуру поиска
максимума целевой функции пороговым алгоритмом в терминах
эволюционного моделирования [21]:
1.8. Другие эвристические модели, основанные на природных аналогиях 33
выбор начального порогового значения То > 0;
выбор конечного порогового значения Тш\п ^ 0;
установка начального числа итераций /о;
*:=0
г:=0
выбор начального решения х\
вычисление F{x)\
повторять до тех пор, пока Tt ^ Tmm;
копирование (репликация) х\
переход в соседнюю точку х' путем мутации (вариации) копии я;
вычисление F(x')\
если AF = F(x) — F(x) > —Tt, то замена х на х'. Иначе, если
долго не наблюдается улучшения или г = 1и то г := 0, t := t + 1,
определить Ttj It\
stop.
Выбор нового решения из множества соседних точек можно
осуществлять либо случайно, либо по определенному плану. Это же
относится и к установке порогового значения на каждом этапе
моделирования.
Потоковая модель может рассматриваться как дальнейшее
упрощение пороговой модели. Метафорой для потоковой модели является
поведение путешественника при наводнении в гористой местности.
При медленно растущем уровне воды W новое решение принимается,
если значение целевой функции для этого решения выше, нежели W.
От скорости подъема потока воды V зависит, сумеет или нет
путешественник найти лучшее решение оптимизационной задачи. В этом
состоит отличие данной модели от пороговой модели.
Программа на псевдокоде для поиска решения с помощью потоковой
модели имеет следующий вид:
задание начального уровня воды W > 0;
задание скорости подъема уровня воды V > 0;
задание конечного значения tmax\
t:=0
выбор начального решения х\
вычисление F(x)\
repeat
t:=t+ 1
копирование (репликация) х\
переход в соседнюю точку х' путем мутации копии х;
вычисление F(xf)\
если F{x') > W, то замена х на х', W := W + V до тех
пор, пока либо долго не наблюдается улучшения решения,
либо достигнуто значение £тах;
stop.
3 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
34
Гл. 1. Анализ моделей эволюционных вычислений
Модель рекордных оценок аналогична потоковой модели.
Описание этой модели на псевдокоде имеет следующий вид:
задание отклонения AW > 0;
задание конечного значения tmax;
\ t:=0
выбор начального решения х;
вычисление F(x);
record := F(x);
repeat
t:=*+l
копирование (репликация) х\
переход в соседнюю точку х' путем мутации копии х\
вычисление F(x')\
если F(x') > record — AW, то замена х на х'\
если F(x') > record, то record := F(x'). Повторять до тех
пор, пока либо долго не наблюдается улучшения решения,
либо достигнуто значение tmax\
stop.
Отличие данной модели, также инспирированной природными
системами, состоит в том, что сохраняется каждое новое решение,
которое не намного хуже, чем лучшее из уже полученных решений.
Истинная теория рождается
как ересь, а умирает как
предрассудок.
Гегель
Глава 2
ОБЩАЯ ТЕОРИЯ ЭВОЛЮЦИОННЫХ
ВЫЧИСЛЕНИЙ
2.1. Гипотезы и закономерности эволюционных
вычислений
Предлагаемая общая теория эволюционных вычислений
основывается на следующих гипотезах [23]:
• в отличие от точных методов математического программирования
методы эволюционных вычислений позволяют находить решения,
близкие к оптимальным, за приемлемое время;
• в отличие от других методов оптимизации алгоритмы
эволюционных вычислений характеризуются существенно меньшей
зависимостью от особенностей приложения, являются более
универсальными и обеспечивают лучшую степень приближения к
оптимальному решению;
• универсальность эволюционных вычислений определяется их
применимостью к решению разнообразных прикладных задач,
у которых фазовое пространство переменных не обязательно
является метрическим;
• алгоритмы эволюционных вычислений, с точки зрения
преобразования информации, представляют собой не просто случайный
поиск, а последовательное преобразование множества решений,
поскольку используют информацию, накопленную в процессе
эволюции;
• моделирование эволюции представляет собой экспериментальный
способ решения задач, в которых связь оптимизируемых
параметров объектов с управляемыми и наблюдаемыми параметрами
сложна и не всегда может быть выражена аналитически;
• применение эволюционных вычислений эффективно в задачах,
где необходимо получить всю историю поведения системы, ее
эволюцию в целом.
3*
36
Гл. 2. Общая теория эволюционных вычислений
Сопоставительный анализ различных базовых моделей
эволюционных вычислений, гипотез, лежащих в основе этих моделей, и
формализованных способов их описания позволяет говорить о следующих
закономерностях эволюционных вычислений [24]:
• ключевым элементом формализованных моделей эволюционных
вычислений является построение начальной модели, правил, по
которым она эволюционирует, а также подходов к представлению
(кодированию) решений;
• модели эволюционных вычислений применимы к решению
трудных задач проектирования, оптимизации, прогнозирования
и управления, у которых переменные могут быть
лингвистическими и не иметь количественного выражения;
• эволюционные вычисления моделируют процесс поиска
оптимальных решений посредством эволюционных операторов
селекции, репродукции, мутации и др., поддерживают популяцию
структур, которая эволюционируют в окружающей среде.
Селекция фокусирует внимание на отборе индивидуумов с более
высокими значениями целевой функции, а репродукция, мутация
и другие операторы генерируют новых индивидуумов;
• все базовые модели эволюционных вычислений представляют
собой итерационные эвристические процедуры, не имеют
ограничений на вид целевой функции;
• популяция в моделях эволюционных вычислений играет роль
памяти о структуре пространства поиска решений. Память не
обязательно ограничивается лишь последними лучшими решениями;
• используя различные механизмы, инспирированные природными
системами, можно эффективно управлять скоростью сходимости
процесса поиска, однако, эти процедуры не всегда обладают
свойством параллелизма;
• модели эволюционных вычислений являются инструментом
исследования, способным конкурировать с другими методами
поиска оптимальных решений по качеству получаемых решений
в сочетании с трудоемкостью их получения;
• различия в базовых моделях эволюционных вычислений не носят
методологический характер и не затрагивают фундаментальные
принципы, присущие эволюции независимо от формы и уровня
абстракции модели.
2.2. Основные положения теории эволюционных
вычислений
Основные положения общей теории эволюционных вычислений
представляют собой систему идей, сформулированных ниже.
а) Моделирование эволюции популяции индивидуальных структур
происходит посредством процессов циклического вычисления и оценки
2.2. Основные положения теории эволюционных вычислений 37
функции качества синтезируемых решений с последующей их
селекцией и репродукцией. Поведение этих процессов определяется
окружающей средой индивидуальных структур и зависит от их текущих
характеристик. Другими словами, модели эволюционных вычислений
поддерживают популяции структур, которые эволюционируют в
соответствии с правилами отбора и операторами поиска (рекомбинация,
мутация). Каждому индивидууму популяции присваивается значение
его приспособленности (пригодности) к окружающей среде.
Воспроизводство фокусирует внимание на индивидуумах с более высокими
значениями пригодности. Рекомбинация и мутация влияют на
индивидуумов, предоставляя тем самым базовую эвристику, разнообразные
когнитивные возможности и механизмы поиска.
б) В любых природных системах процессы роста и снижения
энтропии системы могут иметь различную скорость, хотя в целом, согласно
второму закону термодинамики, энтропия растет неизбежно
(природные процессы необратимы и система не может однозначно вернуться
в предыдущее состояние). В информационных системах и моделях
эволюционных вычислений все процессы характеризуются тенденцией
к росту информации, однако, информацию нельзя отождествлять с
энтропией: процесс роста энтропии необратим и относится к окружающей
среде, а информация — к объекту или системе.
в) Баланс самоорганизации в природных системах может
склоняться к снижению энтропии под влиянием фундаментальных процессов
в случае возникновения детерминированного алгоритма, состоящего
из последовательности реакций системы на разнообразные условия
внешней среды. Таким образом, по аналогии в процессе эволюционных
вычислений могут спонтанно возникать замкнутые алгоритмы [25].
г) Рано или поздно спонтанно образовавшийся алгоритм
эволюционных вычислений неизбежно прерывается (вследствие предпосылки
о неизбежном росте энтропии). Следовательно, эволюционировать
может только комплекс из многих систем (популяций), которые содержат
в себе процессы репродукции и подвержены изменчивости. Процессы
репродукции и отбора можно обобщить на любые самоорганизующиеся
системы. Например, эти процессы автоматически действуют в
социальных системах: люди, машины, технологии, системы управления и т. д.
всегда сравниваются и отбираются в этих системах и невозможно
найти хотя бы один факт, когда эволюционировали бы системы, которые
не имеют этого алгоритма [26].
д) Изменчивость различных структур природных систем не
одинакова. Имеются как практически неизменные элементы, так и элементы,
которые постоянно меняются, например, в такт с изменениями
окружающей среды. Иными словами, наследственная информация защищена
от изменчивости в разной степени, в зависимости от ее ценности для
выживания [27]. Если в системе произошли изменения и они
благоприятны или безразличны для нее, то они остаются в ней и с течением
времени становятся все менее и менее доступными для последующих
38
Гл. 2. Общая теория эволюционных вычислений
изменений. Это объясняет необратимость и направленность
эволюции — большую вероятность усложнения, чем упрощения
организмов, изменения в которых происходят одновременно с изменениями во
внешней среде, причем в соответствующем направлении. Если условия
окружающей среды не меняются, то для изменчивости нет причин
(природа нашла выход из этого затруднения, «перемешивая» некоторую
часть наследственной информации при размножении организмов) [28].
Суть общей теории эволюционных вычислений сводится к
следующему.
Фиксируется множество объектов X (популяция решений),
обладающих некоторыми параметрами и связанных друг с другом
посредством определенной структуры. Среди этих объектов необходимо
выбрать наилучшие в смысле некоторого критерия качества
(оптимальности) F. Критерий оптимальности формируется на основе свойств
объектов и не обязательно существует в виде аналитических
выражений. Важно, что существует отображение вида
F.X -^Я,
где R — множество действительных чисел и каждому объекту х Е X
из множества X сопоставляется значение критерия F(x).
Фенотипическая природа исследуемого множества объектов
произвольна, поэтому необходимо построить кодированное представление
исходного множества объектов в другом, конечном множестве,
обладающем структурой, например векторного пространства S (генотип).
Отображение вида
ip: X —> S
описывает связь между исследуемыми объектами, которые
выступают в качестве потенциальных решений задачи поиска, и объектами,
управление и манипулирование которыми осуществляет алгоритм
эволюционных вычислений.
Существует обратное отображение вида
(p~l:S-+X,
где каждому вновь сгенерированному элементу представления s Е 5
соответствует элемент во множестве X.
Тогда, например, процесс оптимизации с помощью алгоритма
эволюционных вычислений состоит в построении множества объектов-
решений Xopt Е X, для которых выполняются следующие условия:
Xopt = argmaxF[(^_1(s)], s Е 5.
Таким образом, в процессе оптимизации множество X развивается
и эволюционирует к оптимальному состоянию, изменяя свой состав
и параметры входящих в него объектов. Способ построения множества
объектов s Е S определяется алгоритмом эволюционных вычислений.
2.2. Основные положения теории эволюционных вычислений 39
Особенностью моделей эволюционных вычислений является то, что
в качестве множества S строится так называемое кодовое
пространство — множество представлений объектов х в виде кодов (хромосом).
Эволюция множества X задается эволюцией представления S. На
множестве S определяется подмножество Р$ — случайная начальная
популяция. Решение на каждом шаге эволюции определяется следующей
разностной вычислительной схемой:
Pt+i = A(Pt),
где А — композиция различных эволюционных операторов. Критерий
оптимальности вычисляется на каждом шаге в процессе отбора
решений по критерию, реализуемому в композиции операторов А.
Другая идея, положенная в основу общей теории эволюционных
вычислений, относится к реализации системы эволюционного
моделирования, оптимизации и эволюционного синтеза. Она применима к
широкому кругу прикладных задач и состоит в следующем. Алгоритмы
эволюционных вычислений работают не в исходном множестве
решений, а в его представлении в кодовом пространстве. Замысел состоит
в том, что оптимизируемая (синтезируемая) модель и эволюционный
алгоритм разделены, а система эволюционных вычислений и
моделирования представляет собой систему с обратной связью. На рисунке 2
приведена структура системы эволюционных вычислений.
Инициализация
параметров
и настройка
алгоритма
i
i
F(J
Алгоритм
эволюционных
вычислений
<р = Х —>S
St+l=A(St)
<) <P~l:S-
Модель
эволюционных
вычислений
Хор\
+х
—
Рис. 2. Структура системы эволюционных вычислений
В данном случае математическая природа прикладной модели
не имеет значения. Модель получает от алгоритма очередной набор
значений параметров, характеризующих решения X = (хь хг, •••» #п)»
и выдает соответствующее значение функции качества F(X). Данное
значение используется алгоритмом эволюционных вычислений при
отборе и формировании новых решений. Процесс останавливается, когда
текущий набор значений решений удовлетворяет заданному критерию,
40
Гл. 2. Общая теория эволюционных вычислений
то есть найдено оптимальное решение
-^opt = (^lopb ^2opt» • • • » ^noptj-
Представленная структура системы эволюционных вычислений,
вытекающая из общей теории, является адаптивной, так как в ней
предусмотрена возможность системы модифицировать свое поведение
для достижения лучших результатов. Это возможно, в том числе
за счет расширения когнитивных возможностей композиции
различных эволюционных операторов А в разностной вычислительной схеме
Рж = A(Pt).
Простой эволюционный поиск решения может оказаться более
эффективным для некоторых задач, чем обучение и адаптивная настройка
эволюционных операторов, так как обучение и адаптация имеет ряд
промежуточных шагов, а эволюция идет к поиску оптимума более
прямым путем. Тем не менее, хотя обучение и несовершенно, оно
способствует более быстрому нахождению оптимума по сравнению со
случаем чистой эволюции, поэтому в разработанной общей теории ЭВ
важную роль играют когнитивные возможности операторных
конструкций алгоритмов эволюционных вычислений.
Общая теория эволюционных вычислений позволяет по-новому
взглянуть на оптимизационные задачи и процессы принятия решений
и попробовать дать ответы на многочисленные вопросы. Каковы
необходимые и достаточные условия сходимости каждого из эволюционных
алгоритмов? Насколько инвариантными являются эволюционные
алгоритмы по отношению к виду функции качества, структуре
представления решений и виду начальных данных? Какие виды эволюционных
алгоритмов более эффективно использовать для решения известных
задач оптимизации?
Ответы на эти вопросы являются актуальными, поскольку
большинство современных исследований ориентированы, в основном, на
решение конкретных задач и содержат исключительно
экспериментальные подтверждения эффективного использования того или иного ЭА.
2.3. Универсальная феноменологическая модель
эволюционных вычислений
Общая теория эволюционных вычислений опирается на
фундаментальные принципы, присущие природным системам, базовые гипотезы
и закономерности. Одним из основных принципов эволюции в природе
является поиск оптимального состояния [26]. Принцип состоит в том,
что любая природная система стремится к оптимальному состоянию,
к функционированию в оптимальном режиме. Это обеспечивает ее
существование, максимальную устойчивость и длительность жизни,
конечно, при условии слаженности функционирования составляющих
системы.
2.3. Универсальная феноменологическая модель эволюционных вычислений\\
Эволюция — не случайна. Она направляется принципом
оптимальности природы (принципом наименьшего действия, экономии
энергетических затрат и т.п.). Эволюционные вычисления, в отличие от
традиционных вычислений, нацелены на поиск наилучших решений
«приспособленных» к существованию и «выживанию» в реальном мире.
Они включают выявление состояния системы, принятие решения на
изменение состояния и собственно эволюцию. Эволюционные
вычисления как разновидность математических преобразований предоставляют
удобные средства для алгоритмического решения различных задач
проектирования, оптимизационного синтеза, прогнозирования и
управления, для эффективного вычисления функций, обладают робастностью,
невысокой стоимостью решения.
С математической точки зрения процесс эволюции представляет
собой движение по ландшафту целевой функции в направлении поиска
ее экстремума.
Пусть Xj — переменные, описывающие состояние природной
системы и ее реакцию на внешние воздействия Мк. Обозначим через
Ьт параметры структуры, определяющие функционирование природной
системы. Тогда ее функционирование определяется системой из
уравнений вида
U{xjtMk,bm) = 0.
В системе с целью упрощения время не учитывается. При
заданных значениях Мк и Ьт можно определить состояние системы и ее
реакцию на внешние воздействия. В процессе эволюции производится
отбор наиболее приспособленных систем. Это означает, что отбираются
системы с такими параметрами структуры, которые являются наиболее
приспособленными (поиск экстремума целевой функции F(xj)). Этому
препятствуют ограничения, свойственные любой природной системе.
Реальные параметры всегда ограничены по величине. Таким образом,
процесс эволюции системы можно представить как задачу поиска
экстремума некоторой функции при наличии ограничений. В качестве
аналога модели эволюции предлагается использовать функцию
следующего вида:
Y(X9 Л) = F(Xj) + £ XiUtixj, Mkl Ьт). (1)
г
В формуле (I) Ui — ограничения в задаче, взятые с
коэффициентами Аь Л = (Ai, Аг, ..., Ап), г = 1,2, ..., тг, где п — число ограничений.
Эволюционная модель (1) является идеализированной
феноменологической моделью. Она так же нереальна, как и множество других,
весьма полезных моделей. Например, в информатике и физике
используется множество идеализированных моделей: «машина Тьюринга»,
«клеточные автоматы», «материальная точка», «идеальная жидкость»,
«абсолютно твердое тело» и т. п. С вычислительной точки зрения
разница между этими моделями состоит лишь в том, что вычисления,
42
Гл. 2. Общая теория эволюционных вычислений
соответствующие процессу эволюции, неприводимы (исход эволюции
непредсказуем).
Недетерминированность эволюции связана с тем, что требуемая для
наилучшей приспособленности системы функция может реализовы-
ваться разными эволюционно возникшими структурами.
Следовательно, одной из причин непредсказуемости пути и исхода эволюции
является неоднозначность отношений «структура-функция», «фенотип-
генотип» в эволюционно возникших системах.
С точки зрения эффективности (вычислительной мощности),
согласно NFL-теореме [29], все эвристические, в том числе
эволюционные, алгоритмы «в среднем» (по всем возможным функциям (1))
являются идентичными. Рисунок 3 иллюстрирует эту теорему.
Вычислительная мощность
(качество решения в соче- Эволюционные алгоритмы
тании с трудоемкостью
Специальные
алгоритмы
Случайный поиск
или перебор
(все возможные
оптимизационные задачи)
Рис. 3. Иллюстрация NFL-теоремы Вольперта-Макрида
Таким образом, эволюционные вычисления с точки зрения качества
получаемых решений в сочетании с трудоемкостью занимают
промежуточное положение между специальными алгоритмами,
ориентированными на достаточно узкий класс задач, и алгоритмами случайного
поиска или перебора.
Моделью эволюции может быть любая природная система,
меняющая свою структуру в соответствии с некоторым принципом
оптимальности. Эволюционный эвристический алгоритм требует теоретического
обоснования. Он является формальной процедурой. Однако эта
процедура должна соответствовать формальному описанию модели системы,
где этот алгоритм применяется. Это означает, что модель и алгоритм
должны адекватно описывать структуру системы, функциональный
принцип оптимальности, быть тесно связанными с целесообразностью
системы и ее эволюции.
2.4. Достоинства эволюционных вычислений
43
2.4. Достоинства и отличительные особенности
теории эволюционных вычислений
При традиционных подходах не принято разделять модель как
систему зависимостей, имитирующей структуру или
функционирование исследуемого объекта, и алгоритм оптимизации или структурного
синтеза модели. Структура предлагаемой системы ЭВ, изображенная
на рисунке 2, представляет собой, по сути, автоматизированный
объект управления, в котором устройство управления — алгоритм ЭВ,
а объект управления — модель ЭВ. Сложность программирования
существующих алгоритмов, инспирированных природными системами,
состоит в том, что им приходится выполнять операции, для которых
они не приспособлены. Между тем их основное предназначение —
управление.
Другой недостаток традиционных подходов — это использование
только одного алгоритма ЭВ, которого достаточно для проведения
теоретических исследований, но бывает недостаточно при практическом
применении.
Переход от традиционного программирования различных
разновидностей эволюционных алгоритмов к новой концепции ЭВ,
инспирированных природными системами, осуществляется за счет усложнения
модели ЭВ. Модель может описывать сколь угодно сложную систему
зависимостей и структур, основанных на природных аналогиях.
Главное требование к модели — ее адекватность исследуемому объекту.
Модель не обязательно должна быть формальной (например, в виде
логических, алгебраических, дифференциальных и т.п. уравнений).
Модель может эволюционировать во времени. Цели моделируемого
объекта, критерии настройки алгоритма и управление ими также могут
быть не формализованы и меняться во времени. Это вполне
согласуется с приведенными ранее основными положениями предлагаемой
теории: система ЭВ должна быть принципиально открытой и процесс
ее обучения никогда не завершается созданием окончательной
формализованной модели.
При таком подходе система ЭВ получает свою собственную
«информационную машину», действующую в непрерывном режиме усвоения
и реструктуризации информации. Это открытая система с несчетным
множеством потоков, каждый из которых может состоять из
разнообразных структур.
Универсальность и достоверность предлагаемой теории
определяется тем, что она основана на расширении понятия модели ЭВ, позволяет
реализовывать различные алгоритмы ЭВ. При этом сама модель ЭВ
и ее сложность не фиксированы, как и число реализуемых
алгоритмов ЭВ.
Другое немаловажное достоинство предлагаемой теории и ее
отличительная особенность — программы, реализующие систему ЭВ,
44 Гл. 2. Общая теория эволюционных вычислений
предлагается создавать так же, как производится автоматизация
проектирования объектов и технологических процессов. Это означает, что
вначале на основе анализа задачи структурного синтеза или
оптимизации выделяются исходные спецификации и множество
взаимодействующих алгоритмов ЭВ. Затем строится модель ЭВ, которая формирует
значения еще одной разновидности входных воздействий. Эти
воздействия по обратным связям передаются на алгоритмы ЭВ, а также
на систему инициализации параметров и настройки алгоритмов ЭВ
в соответствии с общей структурой системы ЭВ, изображенной на
рисунке 2. Более того, в структуре системы ЭВ можно отказаться от
традиционной в теории управления обратной связи, если удастся
адекватно представить ее работу с помощью экспертных знаний и правил
работы с ними.
Еще одна отличительная черта общей теории ЭВ состоит в
следующем. В рамках традиционных методов оптимизации и структурного
синтеза предполагается, что генерация программы начинается после
проектирования алгоритма. Логика работы традиционных алгоритмов
не упорядочена и сложна, поэтому программы требуют значительного
времени на отладку. Ясность логики общей теории ЭВ, а также
разделение алгоритма ЭВ и модели оптимизируемого или синтезируемого
объекта приведет к тому, что проектирование программы,
описывающей ЭВ, а также формальный переход от алгоритма к реализующей его
программе потребует минимальной отладки. Увеличение времени на
создание модели компенсируется сокращением времени на ее отладку.
Кроме того, алгоритм и программа ЭВ строятся формально в
виде, понятном пользователю, в то время как понимание логики
совместной работы модели и алгоритма часто представляет большую
проблему для пользователя. Наконец, еще одним важным
преимуществом предлагаемой общей теории ЭВ являются широкие
возможности, которые она предоставляет для организации параллельных ЭВ.
2.5. Общие правила представления решений в моделях
эволюционных вычислений
Выше отмечалось, что важными элементами феноменологической
модели эволюционных вычислений являются представление
(кодирование) решений, а также правила, по которым модель
эволюционирует. В частности, согласно общей теории ЭВ, вначале фиксируется
популяция решений (множество объектов X), обладающих некоторыми
фенотипическими свойствами и связанных друг с другом посредством
определенной структуры. На основе свойств объектов формируется
критерий F (не обязательно аналитическое выражение), согласно
которому среди объектов выбираются наилучшие,
Xopt = axgmaxF[(p l(s)], s e 5,
2.5. Общие правила представления решений
45
где в качестве множества S строится так называемое генотипическое
кодовое пространство — множество представлений объектов х в виде
кодов (хромосом). Эволюция множества X задается эволюцией
представления 5. Таким образом, представление генотипа S и отображение
генотип —► фенотип (p~l: S —* X имеет важное значение для
организации эволюционных вычислений.
Возникает вопрос: каковы общие правила их проектирования?
Гольдберг в своей книге [30] определил два общих шаблона для
проектирования генотипа в генетическом алгоритме:
• представление решений в пространстве поиска должно быть как
можно более коротким, а различные совместимые по фенотипу
представления не должны взаимно влиять друг на друга;
• алфавит и кодирование длин различных генов должны быть,
по возможности, минимальными.
В течение последних десяти лет были разработаны различные
способы кодирования для обеспечения эффективного выполнения
генетических алгоритмов [7, 31]. Эти способы могут быть разделены на
следующие классы:
• бинарное кодирование;
• кодирование действительными числами;
• целочисленное кодирование;
• кодирование общей структуры данных.
Недостатки бинарного кодирования заключаются в существовании
хеммингова сдвига для пары закодированных значений, имеющих
большое хеммингово расстояние, в то время как эти величины принадлежат
к точкам с минимальным расстоянием в фенотипическом пространстве.
Например, пара хромосом 01111111 и 10000000 принадлежит
соседним точкам в фенотипическом пространстве (точки с минимальным
евклидовым расстоянием), но имеют максимальное хеммингово
расстояние в генотипическом пространстве. Для преодоления хеммингова
сдвига все биты должны изменяться одновременно, но вероятность
такого события очень мала. Поэтому для многих задач, встречающихся
в современных проблемах, затруднительно представить их решение
с помощью только бинарного кодирования.
С этой точки зрения кодирование действительными числами
является более эффективным при решении задач оптимизации функций.
Причина состоит в том, что топологическая структура пространства
генотипов для этого вида кодирования идентична структуре в
пространстве фенотипов. Поэтому появляется возможность сформировать
эффективные генетические операторы заимствованием полезных
приемов у традиционных методов.
Практика применения различных разновидностей эволюционных
алгоритмов показывает, что целочисленное кодирование лучше всего
подходит для комбинаторных оптимизационных задач [8].
В соответствии с кодированием общей структуры данных
различают одномерный и многомерные способы кодирования. В большинстве
46
Гл. 2. Общая теория эволюционных вычислений
случаев используется одномерное кодирование, однако, многие
проблемы требуют решений в многомерном пространстве, с использованием
многомерного кодирования.
В этой связи общая теория ЭВ позволяет дополнить представленные
выше два общих шаблона для проектирования генотипа в
эволюционных алгоритмах следующими правилами:
• представление генотипа должно быть сюръективным по
отношению ко всем фенотипам, т.е. каждый элемент множества S является
образом хотя бы одного элемента множества X:
VxeX =>3seS:x = (p-\s);
• для любой пары фенотипов мощность их генотипов должна быть
примерно одинакова,
Ужь х2 £ X =► \{8 G S: хх = ip~l{s)}\ « \{s eS:x2 = <p~l(s)}\.
• небольшие изменения в генотипе должны приводить к небольшим
изменениям в фенотипе:
V#i, X2 G X, s e S: Х\ = (f~l(s) & Х2 = <£_1(5) => х\ ~ #2-
Действительно, эволюционные алгоритмы выполняются на двух
типах пространств: кодирования и решения, другими словами,
пространствах генотипа и фенотипа. Согласно общей теории ЭВ, операторы
эволюции работают в пространстве генотипов, а оценка и отбор
происходят в фенотипическом пространстве, при этом в процессе отбора
осуществляется прямая взаимосвязь между хромосомами и поведением
декодированных решений.
Таким образом, отображение из генотипического пространства
в фенотипическое (<р~{: S —► X) оказывает значительное влияние на
поведение эволюционных алгоритмов. Одна из главных проблем здесь
заключается в том, что некоторые хромосомы могут соответствовать
или недопустимым, или незаконным решениям задачи. Эта проблема
представлена на рисунке 4 (см. вклейку) в виде отображения
пространств генотип-фенотип.
Уточним эти термины, поскольку в некоторых литературных
источниках они используются не вполне корректно.
Недопустимость относится к ситуации, когда решение,
декодированное из хромосом, лежит вне области допустимых решений данной
задачи. Незаконность относится к ситуации, когда в процессе работы
операторов алгоритма ЭВ получаются хромосомы, которые не
описывают решение конкретной задачи.
Таким образом, недопустимость хромосом следует из существа
многих оптимизационных задач с ограничениями. Независимо от
того, какой метод решения оптимизационной задачи используется —
традиционный или ЭА — он должен иметь дело с
ограничениями. Для многих оптимизационных задач допустимая область обычно
Незаконное
решение
Область допустимых
решений
Рис. 4. Отображение из генотипа в фенотип
Рис. 5. Типы отображений пространств генотип/фенотип
2.5. Общие правила представления решений
47
представляется в виде системы уравнений или неравенств, причем
оптимальное решение зачастую находится на границе между
допустимыми и недопустимыми областями. В таких случаях при работе
с недопустимыми хромосомами целесообразно применять процедуры по
аналогии с методом штрафных функций [12], что позволяет еще более
эффективно организовать процесс эволюционного поиска с целью
приближения к оптимуму с двух сторон (допустимой и недопустимой).
Что касается незаконности хромосом, то она вытекает из природы
их кодирования. В процессе решения многих задач комбинаторной
оптимизации методы кодирования обычно дают незаконное потомство
посредством простой одноточечной операции кроссинговера [7].
Однако поскольку незаконная хромосома не может быть декодирована
в решение, то штрафные методы в такой ситуации являются
неприменимыми.
Как следствие при использовании известных способов кодирования
или при разработке нового способа необходимо рассмотреть, можно ли
в базовом цикле алгоритма ЭВ провести эффективный поиск решений
этим способом или нет. Иными словами, необходимо дать
предварительную оценку способу кодирования. Одна из таких оценок
известна — легальность кодирования [32]. Свойство легальности
кодирования означает, что любая перестановка в хромосоме из-за применения
большинства операторов эволюции должна соответствовать законному
решению. Предлагаемая общая теория ЭВ позволяет построить
обобщение свойств кодирования:
• недостаточность;
• полнота;
• причинность.
Свойство недостаточности вытекает из дополнительных правил,
представленных выше для проектирования генотипа в эволюционных
алгоритмах, и означает, что отображение между кодированием
(генотипом) и решением (фенотипом) должно иметь вид 1-k-l. В общем
случае такое отображение может относиться к одному из следующих
типов:
• 1-k-l («один к одному»);
• n-k-1 («многие к одному»);
• 1-k-n («один ко многим»),
представленных на рисунке 5 (см. вклейку).
Самый лучший способ — это отображение «один к одному». Если
имеет место отображение «многие к одному», то для ЭА
неизбежны дополнительные затраты времени на поиск. Ситуация еще более
ухудшится при отображении «один к многим», так как необходимы
дополнительные процедуры на фенотипическом пространстве для
определения единственного из п возможных решений.
Свойство полноты означает, что любое решение имеет
соответствующее кодирование и любая точка в пространстве решений доступна
для эволюционного поиска.
48 Гл. 2. Общая теория эволюционных вычислений
Наконец, свойство причинности связывает малые вариации в
хромосомах пространства генотипов, которые появляются вследствие
мутации, с малыми вариациями в фенотипическом пространстве. Это
свойство было предложено, в первую очередь, для эволюционных стратегий
[33]. Оно определяет сохранение родственных (соседних) структур.
Таким образом, для успешного введения новой информации
посредством мутации ее оператор должен сохранять структуру соседства
в соответствующем фенотипическом пространстве.
2.6. Когнитивные возможности универсальной
феноменологической модели эволюционных
вычислений
В общей теории эволюционных вычислений важную роль играют
когнитивные возможности операторных конструкций алгоритмов ЭВ.
Расширение когнитивных возможностей операторов эволюционных
алгоритмов является важной стороной теории. Когнитивные возможности
эволюционных операторов тесно связаны с такими понятиями, как
самоадаптация и самоорганизация эволюционирующих природных
систем. Эти понятия определяются через процессы морфогенеза
(ненаследственных изменений, вызываемые факторами внешней среды),
через формирование ламарковских свойств индивидов, проходящих через
фазу обучения или адаптации, через неслучайное видообразование.
Интерпретация этих процессов в алгоритмах ЭВ требует разработки
механизмов самоадаптации, например для управления параметрами
эволюции [34].
Ниже с позиций общей теории эволюционных вычислений
рассматриваются пути и способы расширения когнитивных возможностей
операторных конструкций различных алгоритмов ЭВ.
Укажем пути и способы расширения когнитивные возможностей
операторных конструкций для различных, ранее рассмотренных
формализованных моделей ЭВ.
Для класса генетических моделей ЭВ расширение их когнитивных
возможностей связано, прежде всего, с представлением пространства
поиска решений и целевой функцией, а также с применением
разнообразных генетических операторов и механизмов селективного отбора.
Традиционной для ГА формой представления пространства поиска
решений является двоичное кодирование с применением кода Грэя [6].
Причина состоит в следующей особенности кода Грэя: расстояние по
Хеммингу между соседними целыми числами для кода Грэя всегда
равно 1, поэтому инвертирование отдельного бита в стринге не
приводит к существенному изменению кодируемого значения переменной, от
которой зависит решение. К тому же код Грэя преобразуется в
стандартный код и наоборот [6].
2.6. Когнитивные возможности модели эволюционных вычислений 49
Для некоторых практических приложений успешно применяется
проблемно-ориентированное кодирование в форме векторов, матриц
или древовидных структур данных. Длина кодируемого стринга при
этом не обязательно является постоянной. Это дает некоторые
преимущества, например, при решении таких задач, как проектирование
и оптимизация архитектуры искусственных нейросетей [35].
Еще одной возможной формой представления решений являются
диплоиды, предложенные Голдбергом [30] и содержащие два
гомологичных набора хромосом. Ответ на вопрос о том, какая аллель будет
выбрана при декодировании и оценке решения, зависит от ее
доминантности или рецессивности. Такой подход к представлению решений дает
определенные преимущества, если целевая функция является не
стационарной.
Рассмотрим теперь возможности расширения когнитивных свойств
основных операторных конструкций ГА.
Традиционно считалось, что вероятность мутации в ГА
невысокая, а сам оператор имеет вспомогательное значение. Однако в
работе [36] доказано, что оптимальное значение вероятности
мутации зависит от длины стринга L и приближенно равно рт « 1/L.
При проблемно-ориентированном кодировании оператор мутации
отличается от мутации при двоичном кодировании.
Предлагается альтернативная форма мутации, согласно которой
компонента вектора Uj после мутации определяется случайным
образом по следующей формуле:
u'j = Uj + (Pi, - 0,5) • 2Т, если foj ^ рсо.
В противном случае, если Д^ > рсо, то Uj = Uj. Здесь /3\j, fyj —
независимые величины, случайно распределенные на интервале [0, 1],
Т, Рсо — параметры, устанавливаемые пользователем.
Оператор инверсии был предложен Холландом [5] для изменения
последовательности генов, когда в хромосоме между двумя случайно
выбранными точками происходит инвертирование аллелей, а
значение целевой функции при этом не изменяется. Инверсия приводит
к увеличению пространства поиска решений, за счет этого появляется
возможность для подбора подходящей позиции и значения гена.
Несмотря на то, что существуют разные мнения относительно того,
насколько конструктивным является влияние оператора кроссинговера,
особенно вблизи точки оптимума, тем не менее, кроссинговер — это
основной оператор репродукции и получения новых решений в ГА.
Оператор кроссинговера характеризуется вероятностью его применения р*,
а также величинами позиционного и дистрибутивного смещения.
Существует множество разновидностей этого оператора: ЛГ-точечный,
универсальный, смешанный кроссинговер и т. д.
В частности, при выполнении ЛГ-точечного кроссинговера
происходит обмен родительских стрингов, как это показано в таблице 1 для
4-точечного кроссинговера. Чем больше ЛГ, тем меньше позиционное
4 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
50
Гл. 2. Общая теория эволюционных вычислений
и тем больше дистрибутивное смещение. Число обмениваемых битов
с ростом N приближается к биномиальному распределению с
математическим ожиданием L/2 [6].
Таблица 1
4-точечный кроссинговер
№ стринга
Родитель 1
Родитель 2
Потомок 1
Потомок 2
1 | 2 |з| 4 |б|
о|о|о|о|о|о|о|о|о|
Универсальный кроссинговер применяется чаще всего в
параметрической форме. При этом для каждой позиции бита в стринге с заданной
вероятностью 0,5 ^ puk ^ 0,8 происходит обмен родительских генов
по следующей схеме. Обозначим через Rz (z = 1, 2, ..., L)
равномерно распределенную на интервале [0, 1] случайную переменную. Если
Rz ^ Рик, то производится обмен родительскими генами в позиции z,
иначе обмен не производится. В таблице 2 приводится пример
универсального кроссинговера.
Табл ица 2
Универсальный кроссинговер
Родитель 1
Родитель 2
Обмен?
Потомок 1
Потомок 2
0
да
0
нет
0
нет
0
да
0
нет
0
да
0
да
0
нет
0
нет
Особенностью универсального кроссинговера является отсутствие
позиционного смещения. Это означает, что гены родительских стрин-
гов могут обмениваться с одинаковой вероятностью. Дистрибутивное
смещение универсального кроссинговера, напротив, является очень
высоким, т.е. число обмениваемых бит соответствует биномиальному
распределению с математическим ожиданием puk • L.
Другим вариантом оператора, расширяющим его когнитивные
возможности, является смешанный кроссинговер, который можно
использовать в сочетании с одноточечным или iV-точечным кроссинговером.
2.6. Когнитивные возможности модели эволюционных вычислений 51
Условием его применения является нумерация генов в стринге, как это
показано в таблице 3.
Таблица 3
Смешанный одноточечный
кроссинговер
Родитель 1
Номер гена
Родитель 2
Смеши
Номер гена
Одното
Номер гена
Возврат к v
Потомок 1
Номер гена
Потомок 2
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
1
9
1
вание номеров генов
8
1
3
0
1
0
чечный к
8
1
3
0
1
0
сходной
9
1
5
0
7
0
4
0
6
0
2
0
россинговер
1
9
0
5
0
7
0
4
0
6
0
2
нумерации генов
1|2|з|4|5|б|7|8|9
Из таблицы 3 видно, что вначале производится случайное
смешивание позиций генов, вследствие чего позиционное смещение крос-
синговера будет равно нулю. Затем выполняется одноточечный (или
TV-точечный) кроссинговер, после чего происходит возврат к исходной
нумерации генов. Дистрибутивное смещение смешанного кроссингове-
ра соответствует одноточечному (или TV-точечному) кроссинговеру.
Существуют и другие варианты кроссинговера, расширяющие
когнитивные возможности алгоритма ЭВ [37]. Однако вопрос о том,
какой вариант кроссинговера является более предпочтительным,
удовлетворительного ответа в настоящее время не имеет. Стандартными
считаются Af-точечный и универсальный кроссинговеры. В работе [37]
показывается, что при небольших популяциях (/л < 50)
предпочтительнее универсальный кроссинговер. В других исследованиях [6] не
рекомендуется применение одноточечного кроссинговера, в основном, из-за
высокого позиционного смещения, а также использование N как
переменной величины.
4*
52
Гл. 2. Общая теория эволюционных вычислений
Отметим также, что рассмотренные варианты, расширяющие
когнитивные возможности оператора кроссинговера, применяются для пары
родительских хромосом (парная рекомбинация). Однако это не
обязательно. Иногда полезно применять диагональный кроссинговер,
который является обобщением ЛГ-точечного кроссинговера, если число
рекомбинируемых родительских хромосом больше двух. В таблице 4
в качестве примера приводится диагональный 2-точечный кроссинговер
для трех родительских хромосом.
Таблица 4
Диагональный 2-точечный
кроссинговер
Родитель 1
Родитель 2
Родитель 3
Потомок 1
Потомок 2
Потомок 3
1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Как и при стандартном кроссинговере, выбор точек происходит
случайно на интервале от [1, L - 1]. Экспериментальные исследования
[6, 7] на множестве тестовых функций показали некоторое
преимущество мультирекомбинации перед ЛГ-точечным и универсальным крос-
синговером по скорости и качеству решения оптимизационных задач
при числе родителей, выбираемых для рекомбинации от 11 до 15.
Другим источником для расширения когнитивных возможностей
и вариабельности оператора кроссинговера является форма
представления хромосом в виде вектора вещественных чисел.
Выше отмечалось, что наряду с двоичным кодированием в
алгоритмах ЭВ можно использовать кодирование перестановок, например,
при решении задачи о коммивояжере, задачи о расписании и т.п. [8].
Рассмотренные ранее варианты рекомбинации не совсем подходят для
представления решений в форме перестановок. Поэтому рекомендуется
использовать операторы упорядочения, выбирая для выполнения
оператора от одной до М родительских хромосом. Существует несколько
разновидностей оператора: универсальный оператор упорядочения,
реберная рекомбинация, циклический кроссинговер, частично
отображаемый кроссинговер, упорядоченный кроссинговер и др. [6].
В этой связи для расширения когнитивных возможностей
алгоритмов ЭВ предлагается использовать универсальный оператор
упорядочения в сочетании с реберной рекомбинацией. Эта новая операторная
2.6. Когнитивные возможности модели эволюционных вычислений 53
конструкция является обобщением ранее рассмотренного
универсального кроссинговера. Здесь вместо использования разрезающих точек
случайным образом определяется двоичная маска, длина которой равна
длине L хромосомы, которая представляет собой перестановку из
целых чисел от 1 до L.
Пусть, например, случайно выбирается пара родительских
хромосом, определяется двоичная маска, затем в соответствии с маской
формируются два потомка. Первый потомок включает только те
элементы первого родителя, которым в маске соответствует значение 1,
а второй потомок включает только те элементы второго родителя,
которым в маске соответствует значение 0. Оставшиеся незаполненными
элементы первого потомка сортируются в соответствии с тем порядком,
в котором они стоят во втором потомке, а оставшиеся незаполненными
элементы второго потомка сортируются в соответствии с тем порядком,
в котором они стоят в первом потомке. В таблице 5 представлен пример
универсального оператора упорядочения (L = 9).
Таблица 5
Универсальный оператор упорядочения
Родитель 1
Родитель 2
Маска
Потомок 1
Потомок 2
1
4
1
2
3
0
3
5
0
4
2
1
5
1
0
6
8
1
7
7
0
8
9
0
9
6
1
Оператор реберной рекомбинации, в отличие от универсального
оператора упорядочения, передает информацию об отношении
смежности между элементами перестановки. Если перестановку представить
в виде графа, то каждое ребро графа связывает пару смежных вершин.
Например, если случайно выбрать пару родительских хромосом, то для
каждого целочисленного значения от 1 до L можно построить список
смежных вершин, причем общие ребра, встречающиеся у обеих
родителей, отмечаются знаком минус.
Результатом реберной рекомбинации является один потомок,
который образуется по следующей схеме: вначале случайно выбирается
любое целое число из пары родительских хромосом и устанавливается на
первую позицию потомка. Затем выбранное число удаляется из списка
смежных вершин и из списка смежных с уже выбранной вершиной
выбирается следующее число, которое устанавливается во вторую
позицию и т.д. Приоритетом при выборе очередного числа является
54
Гл. 2. Общая теория эволюционных вычислений
знак минус и кратчайшая длина списка смежности (при равенстве
приоритетов — произвольный выбор).
В таблице 6 представлен пример реберной рекомбинации (L = 5,
случайно выбранной является первая вершина).
Таблица 6
Реберная рекомбинация
Родитель 1
Родитель 2
1
2
3
4
5
Потомок
1
4
2
3
3
5
4
2
5
1
Список смежности
-2, 5, 4
-1,3,5
2, -4, 5
-3, 5, 1
4, 1, 3, 2
1
2
5
3
4
Для многочисленных разновидностей оператора упорядочения, как
и для оператора кроссинговера, также отсутствуют теоретически
обоснованные рекомендации по их практическому применению.
На практике при кодировании перестановок зачастую применяется
оператор упорядочения, когда из одного родителя образуется один
потомок, например, путем обмена случайно выбранных чисел, сдвига
нескольких соседних чисел на произвольное число позиций, скрем-
блирования, инверсии и т. п. Результаты сравнения качества решения
при использовании для упорядочения одного родителя и М родителей,
полученные на очень ограниченном подмножестве задач,
свидетельствуют о некотором преимуществе оператора упорядочения с одним
родителем.
Перспективным направлением расширения когнитивных
возможностей операторных конструкций модели ГА является использование
фрактальных множеств, алгоритмов одномерного дихотомического
поиска, Фибоначчи, золотого сечения и других поисковых процедур [7].
Геометрия многих объектов в природе имеет фрактальную
структуру. Фрактальные объекты, как известно, самоподобны.
Преобразования, создающие такие структуры, — это итерационные процессы с
обратной связью, когда одна и та же операция выполняется снова и снова,
аналогично эволюционным процессам. Здесь результат одной
итерации является начальным условием для другой, а между результатом
и реальным значением существует нелинейная зависимость.
Известными примерами фрактальных множеств являются множество Кантора,
2.6. Когнитивные возможности модели эволюционных вычислений 55
«снежинки» (кривая Коха), ковер Серпинского и другие множества,
обладающие свойством геометрической инвариантности.
Фракталы характеризуются понятием фрактальной размерности.
Например, для множества Кантора, которое состоит из N = 2п
разделенных интервалов длиной е = (1/3)п, фрактальная размерность равна
фрр = П^ ~ о,63.
п1пЗ
Фрактальные множества можно использовать в качестве
«строительных» блоков в эволюционных операторах кроссинговера, мутации
и др., тем самым расширяя их когнитивные возможности.
Используемые в базовом цикле алгоритма ЭВ эволюционные
операторы можно строить с применением процедуры дихотомического
поиска. Например, используя дихотомию, можно построить оператор
кроссинговера по приведенной ниже схеме.
• Пусть заданы две родительские хромосомы длиной L.
• Делим хромосому (отрезок L) пополам (при нечетном размере
хромосомы в любую часть берется большее ближайшее число
генов).
• Точка дихотомии определяет точку разрыва в операторе
кроссинговера.
• По правилам построения одноточечного кроссинговера получаем
две новых хромосомы-потомка.
• Каждую половину хромосомы-потомка снова делим на две части
и процесс продолжаем аналогичным образом до тех пор, пока
не будет получено заданное количество хромосом-потомков или
метод дихотомии завершится. При получении нереальных
решений (хромосом с повторяющимися генами) производится
восстановление реальных решений. При этом повторяющиеся гены
меняются на отсутствующие гены из хромосом-родителей.
• Конец работы алгоритма.
Используя числа Фибоначчи, можно построить оператор мутации
по следующей схеме.
• В выбранной хромосоме определяем точку разрыва. Она
соответствует третьему числу ряда Фибоначчи.
• Производим реализацию стандартного оператора мутации и
получаем новую хромосому-потомок.
• Вычисляем значение ЦФ хромосомы-потомка. Если получен
глобальный оптимум, то работа алгоритма завершена.
• Далее в качестве точки ОМ Фибоначчи выбираем 4, 5, ...
числа ряда Фибоначчи и переходим к вычислению значение ЦФ
хромосомы-потомка.
• Алгоритм заканчивает работу по достижению заданного критерия
или когда номер числа ряда Фибоначчи ^ L.
56
Гл. 2. Общая теория эволюционных вычислений
Оператор инверсии также может использовать как метод
Фибоначчи, так и принцип «золотого сечения». По методу Фибоначчи
построение оператора инверсии подчиняется следующей схеме.
• Пусть задана родительская хромосома длины L.
• Точка разрыва оператора инверсии соответствует третьему числу
ряда Фибоначчи.
• По правилам построения оператора инверсии, инвертируя правую
часть от точки оператора инверсии, получаем новую хромосому
потомка.
• Далее в качестве точки разрыва выбираем 4, 5, ... числа ряда
Фибоначчи и повторяем предыдущий шаг для получения новой
хромосомы потомка. Алгоритм оканчивает работу по достижению
заданного критерия или когда номер числа ряда Фибоначчи ^ L.
• Конец работы алгоритма.
Процедура построения оператора инверсии на основе метода
«золотого сечения» аналогична построению оператора инверсии по
Фибоначчи. Разница в том, что первая точка разрыва в операторе
инверсии определяется на расстоянии целой части 0,618L от любого
края хромосомы. Затем часть хромосомы, расположенная между точкой
разрыва и правым концом хромосомы, инвертируется. Вторая точка
разрыва в новой хромосоме определяется как ближайшее целое из
выражения (L - 0,618L) • 0,618. Далее процесс продолжается аналогично
до окончания возможности разбиения хромосомы или по достижению
заданного критерия.
Оператор селекции является чрезвычайно важным в базовом цикле
алгоритма ЭВ, поскольку благодаря ему хромосомы с более высоким
значением целевой функции получают большую возможность для
репродукции, нежели слабые хромосомы. Тогда имеет смысл обсудить
вопрос о расширении когнитивных возможностей этого процесса в
базовом цикле алгоритма ЭВ, разделив его на два этапа: собственно
селекцию и принятие решения о селективном выборе.
На первом этапе используется селекция на основе рулетки, когда
каждой хромосоме в популяции соответствует на колесе рулетки зона,
ширина которой пропорциональна величине целевой функции.
Проблема состоит в том, что число копий хромосом в списке родителей,
предназначенном для производства потомства, должно принимать
целочисленное значение; вероятность селекции p8(cLi) является
вещественным числом. Для решения этой проблемы в ГА обычно применяется
универсальная процедура случайной дискретизации [7].
Например, если ширина зоны на колесе рулетки для
родительских хромосом А, В, С и Д соответственно, равна 0,625; 0,025; 0,1
и 0,25, то число копий этих хромосом будет равно двум, нулю, одному
и одному соответственно. С целью практической реализации выбора
на основе рулетки предлагается следующая программа:
2.6. Когнитивные возможности модели эволюционных вычислений 57
sum := О
с помощью датчика случайных чисел на интервале [О, 1] выбрать
значение переменной U
for г — 1 to /i
begin
sum := sum + p8[fli)
до тех пор, пока sum > U
begin
копируем Ui в список хромосом для производства
потомков
U:=U+l
end
| end I
Другими не дискриминационными алгоритмами селекции являются
селекция на основе заданной шкалы, селекция путем ранжирования
и турнирная селекция. Д. Голдберг в своих работах [30] ввел понятие
«селекционного давления», которое измеряется числом t генераций
эволюционного процесса, после которого в популяции получается (//— 1)
лучших хромосом. Он исследовал алгоритмы селекции на примерах
функций
F(x) = хс и F(x) = ехр(с • х)
и отметил, что селекционное давление на основе заданной шкалы
имеет порядок 0(// • ln(/i)); селекционное давление на основе
ранжирования — порядок 0(1п(//)), а при селекции на основе турнирной
тактики давление в значительной мере зависит от размера популяции
и турнирных правил.
Проведенные нами эксперименты показали, что при использовании
обычной пропорциональной селекции качество популяции быстро
возрастает до тех пор, пока количество лучших хромосом не достигнет
примерно 50% от общего их числа. Это объясняется тем, что в начале
процесса эволюции сохраняется гетерогенность популяции, затем по
мере возрастания однородности хромосом, входящих в популяцию,
оператор кроссинговера становится менее эффективным и растет
значение оператора мутации. Иными словами, эффективность алгоритма
ЭВ сильно зависит от баланса между применяемой схемой
селекции и используемыми в базовом цикле эволюционными операторами.
Эта проблема может быть снята или, по крайней мере, значительно
ослаблена за счет линейного динамического или а-масштабирования
целевых функций алгоритма ЭВ [6].
Предлагается следующий способ, расширяющий когнитивные
возможности шага селекции в базовом цикле алгоритма ЭВ.
58
Гл. 2. Общая теория эволюционных вычислений
Линейное динамическое масштабирование для задачи поиска
максимума целевой функции определяется как
Ф(а>) = 71 • F(r(Si)) - тш{^(Г(а,-))},
где Щ е P(t), 7i — некоторая, определяемая пользователем
константа, P(t) — текущая популяция, операция min{-} позволяет удалять
«слабые» хромосомы. Если Uj G P(t — z), z = 0, 1, ..., W, то
динамически удаляются «слабые» хромосомы из W предыдущих генераций
популяции.
Масштабирование позволяет учитывать среднеквадратичное
отклонение значений целевой функции и определяется как
где 1 < 72 < 3, Е и о~е — математическое ожидание и
среднеквадратичное отклонение значений целевых функций хромосом, входящих
в популяцию.
Эксперименты показывают, что при использовании
масштабирования селекционное давление несколько возрастает, однако полностью
преодолеть недостатки пропорциональной селекции не удается.
При селективном ранжировании масштабирование не применяется,
потому что в этом случае вероятность селективного отбора каждой
хромосомы зависит от ее позиции в упорядоченной
последовательности отсортированных в порядке убывания значений целевых функций
множества хромосом популяции. Если обозначить через Етах
математическое ожидание функции качества лучшей хромосомы в популяции,
а через Ет\п — математическое ожидание функции качества худшей
хромосомы в популяции, то вероятность селекции (по алгоритму
селективного ранжирования) определяется как
pa(ai) = 1//X • [Етах - (£max - £min) ' (r{Oi) - l)/(/i - 1)],
где rifli) — ранг хромосомы, причем сумма p8(ai) равна 1.
Преимуществом алгоритма селективного ранжирования является то, что его
без изменения можно использовать для задач с отрицательным
значением целевой функции, а также для случая не только максимизации,
но и минимизации целевой функции (требуется лишь сортировка не по
убыванию, а по возрастанию). Недостаток алгоритма селективного
ранжирования проявляется лишь при необходимости быстрой замены
хромосом в популяции.
При турнирной селекции масштабирование не применяется и, в
отличие от селективного ранжирования, нет необходимости сортировки
2.6. Когнитивные возможности модели эволюционных вычислений 59
хромосом в популяции. Согласно размеру «турнира» случайно, с
вероятностью 1//х из популяции выбирается некоторое число £ хромосом
(2 < £ < /х), которые копируются в список родительских хромосом для
производства потомства. Этот процесс повторяется /i раз. С помощью
величины £ можно управлять селекционным давлением. Если £ = 2,
то говорят о бинарной турнирной селекции. С ростом £ влияние
размера популяции \х на величину селекционного давления возрастает.
Наоборот, если значение £ является постоянной величиной, а
величина [х возрастает, то селекционное давление уменьшается. Недостаток
турнирной селекции — теоретически может оказаться, что в списке
хромосом для воспроизводства потомков существует /х копий одной
и той же хромосомы. Сходная проблема также возникает в ходе
селекции на основе рулетки.
Отметим также, что для решения многих прикладных задач,
независимо от применяемой схемы селекции, для следующей генерации
выбираются лучшие (элитные) элементы популяции на основе сравнения
целевых функций. Элитная селекция впервые предложена К. де Йон-
гом [37]. Она гарантирует, что лучшие из найденных решений будут
долгое время присутствовать в последующих поколениях, независимо
от деструктивного влияния кроссинговера. При этом возрастает
опасность стагнации популяции вокруг значения локального оптимума.
Таким образом, когнитивные возможности селекции и операторов
репродукции далеко не исчерпываются известными подходами в ГА.
Еще одной важной особенностью предлагаемой универсальной
концепции ЭВ, инспирированных природными системами, является то, что
она позволяет учесть следующее обстоятельство.
Качество решения не всегда определяется значением целевой
функцией и может варьироваться в процессе моделирования и практических
экспериментов. Например, робастность представленного ранее базового
цикла алгоритма ЭВ может возрасти путем применения
детерминированного универсального или ЛГ-точечного кроссинговера, однако, это
приводит к снижению гетерогенности популяции, которая в
значительной мере определяется операторами кроссинговера. Аналогом этого
является существование ниш в природных экосистемах, в которых
родители замещаются на схожие по генотипу (или фенотипу) потомки.
Схожесть по генотипу оценивается хэмминговым расстоянием.
Схожесть по фенотипу оценивается евклидовым расстоянием между парой
индивидуумов, из которых выбирается индивид с лучшим значением
функции качества.
Была проведена экспериментальная проверка указанных способов
расширения когнитивных возможностей операторных конструкций
базового цикла алгоритма ЭВ. Проверка проводилась на трудных задачах
60
Гл. 2. Общая теория эволюционных вычислений
многокритериальной оптимизации, а также задач с мультимодальными
целевыми функциями. Эксперименты показали следующее.
В задачах многокритериальной оптимизации при не пустом
пространстве поиска для любого решения йв, не принадлежащего
множеству Парето-оптимальных решений, всегда найдется хотя бы одно
Парето-оптимальное решение йд, которое доминирует над ним, а
любые два Парето-оптимальных решения являются недоминирующими
по отношению друг к другу. Если целевая функция представляется
в аддитивной форме вида
F(u) = fci • Fx(u) + ... + кё • Fg(H)9
то задачу оптимизации можно решать отдельно для каждого целевого
критерия без специальной модификации алгоритма ЭВ с
минимальными шансами получить множество Парето-оптимальных решений.
Для решения трудных задач многокритериальной оптимизации
предлагается использовать некоторое подмножество хромосом популяции,
с которыми сравнивается случайно выбранная пара хромосом. Если
одна из выбранных хромосом оказывается недоминируемой, то она
оставляется для последующей репродукции. Если обе хромосомы
оказываются недоминируемыми, то их разделяют с целью будущей
репродукции. Недоминируемой хромосоме присваивается ранг 1. Из
оставшейся части популяции вновь выбирается недоминируемая хромосома,
которой присваивается ранг 2, и т. д.
Задачи практической оптимизации, как правило, включают
ограничения на переменные и граничные условия в виде равенств или
неравенств. Как учесть эти условия и ограничения в ходе
эволюционного поиска? Простейший способ — удаление всех потомков, для
которых исходные условия или ограничения не выполняются, —
является не очень практичным и затратным с точки зрения
вычислительных ресурсов. Существуют различные технические приемы для
учета ограничений в оптимизационных задачах [8, 12]. Часть из этих
приемов направлена на то, чтобы уменьшить возможность появления
решений задачи, не являющихся допустимыми. Другие приемы состоят
в том, чтобы недопустимые решения вообще не генерировались в ходе
выполнения алгоритма ЭВ.
Наиболее универсальным приемом из первой группы, не зависящим
от вида целевой функции и ограничений, считается введение штрафных
функций. Идея их построения состоит в замене целевой функции
данной задачи некоторой обобщенной функцией, значения которой
совпадают со значениями исходной функции внутри допустимой области,
но при приближении к границе области, а тем более при выходе
2.6. Когнитивные возможности модели эволюционных вычислений 61
из нее, резко возрастают (или убывают) за счет второго
слагаемого обобщенной функции — штрафной функции. Штрафные функции
строятся таким образом, что обеспечивают либо быстрое возвращение
в допустимую область, либо невозможность выхода из нее. Отметим
также, что параметризация штрафных функций сама по себе является
нетривиальной оптимизационной проблемой.
Однако проблему недопустимых решений можно решать,
используя когнитивное декодирование целевой функции, основанное на
различных эвристических приемах в зависимости от прикладной
задачи. Эта гипотеза была экспериментально проверена на примере
классической задачи поиска оптимального маршрута при
транспортировке грузов.
Задача состоит в следующем. Пусть имеется п потребителей грузов
и к транспортных средств ограниченной грузоподъемности,
отправляющихся из центрального депо. Необходимо минимизировать стоимость
перевозки грузов при ограничениях на время поставки товаров для
отдельных потребителей. Решения задачи кодируются в виде
перестановок п потребителей. Тогда при декодировании упорядочиваются
первые к потребителей и тем самым инициализируются к маршрутов
перевозки грузов. Для остальных (п — к) потребителей эвристически
определяются наилучшие маршруты при минимальных общих затратах
и выполнении всех ограничений задачи. При этом в ходе
эволюционного моделирования не исключается применение специальных
эволюционных операторов, гарантирующих получение допустимых решений
задачи.
Таким образом, используя общую теорию ЭВ, инспирированных
природными системами, можно значительно расширить круг
практических задач оптимизации и структурного синтеза, а за счет расширения
когнитивных возможностей операторных конструкций — адаптировать
алгоритм ЭВ к реальному эволюционному процессу путем создания
эффективных разновидности эволюционных операторов.
Рассмотрим теперь способы, связанные с расширением когнитивных
возможностей моделей генетического программирования.
В качестве исходной гипотезы для повышения эффективности
алгоритма ГП примем гипотезу о модульном построении программ,
состоящих из главной программы и специальных модулей-функций,
генерируемых в ходе моделирования эволюции. Были проведены эксперименты
для проверки гипотезы на примере классической задачи о
параллелепипедах [32]. Постановка задачи состоит в следующем. Два
параллелепипеда задаются тремя парами переменных: длина, ширина и высота
параллелепипеда. Целевой функцией является минимизация разницы
между объемами параллелепипедов. В исходной, случайно
сгенерированной популяции имеются несколько различных вариантов
исходных значений для переменных в задаче. Были установлены стартовые
62
Гл. 2. Общая теория эволюционных вычислений
условия в задаче: множество terminal set T = {L\y B\, H\y L<i, B2, #2};
множество function set F = {+, —,*,%} и функция качества,
указывающая на абсолютную ошибку, определяемую разностью между
желательным значением целевой функции и тем значением, которое
получается программно. В результате моделирования на 11-м шаге
эволюции было получено правильное алгебраическое выражение.
Если использовать предлагаемый способ модульного построения
программ, включив в нее главную программу и две подпрограммы-
функции от трех аргументов, то в результате моделирования на 13-м
шаге эволюции было получено правильное алгебраическое выражение.
Для задачи двух параллелепипедов (с точки зрения
вычислительной трудоемкости и структурной сложности) преимущество было за
классической моделью ГП. Однако был найден целый ряд примеров,
свидетельствующих об обратном [12].
В частности, проводились эксперименты, связанные с решением
задачи синтеза булевых функций, зависящих от нескольких
переменных и принимающих значение true, если четное число аргументов
(включая нуль) принимают значение true. В противном случае булева
функция принимает значение NIL (константа, обозначающая список,
в котором нет ни одного элемента). Для оценки функции качества
использовались комбинации булевых переменных. Результаты
моделирования однозначно свидетельствуют о преимуществе ГП с модульным
построением программ как по структурной сложности решений, так
и по вычислительной трудоемкости.
Общая теория ЭВ дает также определенные преимущества в
расширении когнитивных возможностей алгоритмов эволюционных
стратегий. В рассмотренной ранее в разделе 1.4 базовой модели ЭС мутация
отдельных переменных проводится независимо. Опираясь на общую
теорию ЭВ, предполагается ускорить процесс продвижения к
оптимуму с учетом ландшафта целевой функции, используя коррелируемый
оператор мутации [38].
Идея коррелируемой мутации реализуется с помощью
дополнительного параметра ЭС. Назовем этот параметр углом ротации. Каждое
решение Si (i = 1, 2, ..., /z) в популяции будет теперь состоять из трех
элементов,
Si = (xi, di, di),
где di G [-7Г, 7г] — угол ротации, который является внутренним
параметром ЭС и от которого зависит скорость сходимости алгоритма
оптимизации и адаптивные возможности ЭВ. Предварительная
проверка этой гипотезы путем экспериментального моделирования
показывает, что использование di как дополнительного параметра ЭС требует
модификации ранее рассмотренной базовой схемы ЭС на следующих
этапах:
2.6. Когнитивные возможности модели эволюционных вычислений 63
— инициализация: случайный выбор угла ротации на интервале
[-7Г, 7г] по закону равномерного распределения;
— рекомбинация: угол ротации является рекомбинируемым
параметром;
— мутация потомков: в рассмотренной ранее схеме мутации с
учетом di производятся следующие изменения:
a'k = <rkexp(iiN(0, l) + z2iVfc(0, I)),
а$ = а,+ /3-^(0,1),
Xj = Xj + Nj{0, В, а),
где Nj(0, a, 3) — случайный вектор, образованный из ковариационной
матрицы n-мерного нормального распределения с вектором
математического ожидания 0.
Эксперименты показывают, что указанное изменение ЭС за счет
коррелируемой мутации не требует каких-то значительных затрат,
положительно влияя на сходимость ЭС.
Когнитивные возможности ЭС могут быть расширены за счет
использования различных форм операторов репродукции. В частности,
схема рекомбинации двух родителей вида
xnj = uj ' xp\j + 0 ~~ из)' xP2j
может быть представлена следующим образом:
Родитель 1:
Родитель 2:
Uf
1 — и j:
Потомок:
4,0
8,0
6,2
3,6
1.8
0,8
0,2
0,7
0,9 0,5 0,2 0,6
0,1 0,5 0,8 0,4
4,4
4,9
1,0
0,4
У исследователей ЭС нет общего мнения о том, какая из форм
рекомбинации имеет преимущество. Для унимодальных целевых
функций наиболее подходящей является форма рекомбинации, при которой
фенотип потомка складывается из фенотипов нескольких родителей.
Для мультимодальных функций более подходящей является
рекомбинация в традиционной дискретной форме. Для параметров ЭС
рекомендуется применять рекомбинацию, предусматривающую одновременное
участие многих родителей.
Оператор селекции также расширяет возможности адаптации ЭС.
При (// + А)-селекции новая популяция образуется из объединенного
множества родителей и потомков и включает в себя элитные
индивиды, имеющие лучшие значения функции качества. Эксперименты
64
Гл. 2. Общая теория эволюционных вычислений
свидетельствуют в пользу (//, А)-селекции, которая имеет очевидные
преимущества перед (// + А)-селекцией прежде всего при решении
проблемы «локальных ям» и с точки зрения адаптивных свойств ЭС.
В самом деле, при (/i + А)-селекции индивид с лучшим
значением функции может неоправданно долгое время переходить из одной
популяции в другую, обладая при этом неудачно установленным
параметром ЭС. В [39] исследовалась (1 + 1)-селекция и было высказано
предположение о том, что доля успешных мутаций по сравнению
с их общим количеством должна составлять примерно 1/5, а сама
(1 + 1)-селекция может рассматриваться как один из видов случайной
градиентной стратегии. При (//, А)-селекции продолжительность жизни
отдельного индивида является ограниченной. Отметим также
эффективность соревновательных (турнирных) форм селекции в случае их
реализации на параллельных вычислителях. С этой целью из
объединенного множества родителей и потомков случайно, по закону
равномерного распределения выбираются £ индивидов (2 ^ £ < /х + А), часть
из которых копируется в следующую популяцию Р*+ь
Отметим также, что в традиционных подходах к ЭС их применяют
для задач оптимизации с непрерывными переменными. В предлагаемой
теории ЭВ, инспирированных природными системами, нет
принципиальных затруднений для использования ЭС в дискретной оптимизации.
С этой целью при выполнении оператора мутации можно применять
другие виды законов распределения, например, биномиальную
мутацию [6]. Можно также использовать представленную выше базовую
схемы ЭС, округляя значения переменных и функций. Аналогично
можно действовать при решении задач целочисленной оптимизации,
а также в случае, если задача оптимизации имеет комбинированный
характер. Другой путь предлагается в [10], однако, при этом
непрерывные переменные используются лишь во внутреннем цикле базовой
схемы ЭС при генерации потомков с дальнейшей их модификацией
в дискретные переменные во внешнем цикле. Отметим, что проблемы
смешанной оптимизации вообще являются характерными для многих
прикладных задач.
Для расширения когнитивных возможностей, теоретического
и практического развития идей эволюционного программирования
в теории ЭВ необходимо решить следующие проблемы:
• если глобальный оптимум функции качества в модели ЭП
отличается от 0, то это негативно влияет на устойчивость алгоритма ЭП;
• если значения функции качества являются очень большими,
то поиск становится квазислучайным;
• если пользователь не обладает информацией о глобальном
оптимуме, то согласование и подбор функции скаляризации,
используемой в модели ЭП, становится затруднительным;
2.7. Базовый цикл эволюционных вычислений
65
• необходимость установки 2 • п значений параметров эволюции
kj и Zj выдвигает перед пользователем дополнительные
оптимизационные трудности, даже если он использует стандартную
установку (kj = 1, Zj = 0).
Преодоление этих проблем требует модификации модели ЭП с
целью повышения ее адаптивных свойств. Укажем на возможный способ
модификации ЭП, расширяющий когнитивные возможности этой
разновидности моделей ЭВ.
Пусть популяция составляется не из векторов А* (г = 1, 2, ..., /i),
а из векторов Е* = (А*, Иг), где И* — вектор среднеквадратичного
отклонения, элементы которого Uj G Rn+ (J = 1,2, ..., п). Тогда речь
может идти о следующих отличиях модифицированной ЭП от
рассмотренных ранее этапов базовой модели ЭП. Предварительные
эксперименты с моделью ЭП Д2, 40] показывают, что на этапе инициализации
для каждого вектора А* дополнительно образуется вектор П* на основе
равномерного распределения в интервале [0, /?], где /3 > 0 является
параметром эволюции, который требует адаптации к каждому
конкретному классу задач. На этапе генерации потомков отличие состоит
в операторе мутации. В частности, потомок
% = &•%).
где ufj = Uj + UjaNj(0, 1), a'j = uj + u'jNj(0> l). Отметим, что если
коэффициент а выбрать слишком большим, то величина u'j может
стать отрицательной и тогда она заменяется на некоторое малое е > 0.
Если а выбрать слишком малым, то проявляется тенденция замедления
эволюции. Рекомендуемое значение а = 1/6.
Заслуживает внимания и другая идея. Речь идет о
программируемой мутации путем использования ковариационной матрицы,
составленной из коэффициентов корреляции.
Перспективным направлением диверсификации и адаптации ЭП
является также изменение процедур генерации потомков и селекции.
Например, на этапе генерации потомков из популяции с помощью
закона равномерного распределения в интервале [1, /х] случайно выбирается
родитель, из которого путем применения того или иного варианта
оператора мутации получают потомка. Далее потомок оценивается,
добавляется в популяцию, размер которой становится равным (/х+ 1),
после чего производится детерминированная селекция путем
исключения из популяции слабой особи.
2.7. Базовый цикл эволюционных вычислений
Следствием общей теории ЭВ является наличие базового цикла
в алгоритме ЭВ [24], графическое изображение которого приводится
на рисунке 6.
5 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
66 Гл. 2. Общая теория эволюционных вычислений
Из рисунка 6 видно, что базовый цикл включает следующую
последовательность шагов: вычисление целевой функции, оценку качества
решений, селективный отбор решений для репродукции и
репродукцию, т. е. создание новых решений. Базовый цикл соответствует
основным положениям предлагаемой общей теории ЭВ, инспирированных
природными системами, и является неотъемлемым элементом
структуры системы ЭВ.
Алгоритм организации вычислений в базовом цикле имеет
следующий вид:
Input: Функция для оценки качества решений cmpF
Input: ps — размер популяции решений
Data: t — текущий номер поколения
Data: P(t = 0) — исходная популяция решений
Data: параметры алгоритма, включая целевую функцию
Output: X* — найденное оптимизированное решение
begin
Pop := init Pop(ps) /*функция init выполняет
первоначальную случайную инициализацию популяции и будет
представлена ниже */
while (критерий останова) do
v := F (Pop, cmpp)
P(t) := selection (Pop, v)
t:=t+l
Pop := P(i) Лрепродукция потомков из отобранных
родительских решений с использованием композиции
операторов эволюции A: P(t + 1) = A(P{t))*/
return /*восстановление фенотипа Pop*/
I end I
Базовый цикл ЭВ не исключает существование различных
стратегий организации популяции в эволюционном алгоритме. Например,
стратегия вымирания предполагает, что популяция на следующем шаге
эволюции состоит только из потомков предыдущей популяции (в
области генетических алгоритмов стратегия вымирания соответствует
так называемым поколенческим алгоритмам [41], в которых очередная
популяция не содержит родительских хромосом, а включает лишь
хромосомы сгенерированных потомков).
Другой стратегией является способ, когда популяция на
следующем шаге эволюции P(t + 1) формируется как комбинация текущей
популяции P(t) и образованных на ее основе потомков. В этом
случае продолжительность жизни отдельных особей в популяции может
превышать одно поколение, следовательно, родители и их потомки
2.7. Базовый цикл эволюционных вычислений
67
Инициация
популяции
\>#—• [Фенотип X
Целевая функция
. i i i i г-1 Г Генотип G
Популяция
Вычисление L^T^Xl
целевой функции г/ \)г
Оценка
качества
решений
Популяция
*
Генотип G
♦
Операторы
алгоритма ЭВ
/
/
Репродукция
решений)
(создание новых JOL/vl (выбор для
Селекция
репродукции)
Рис. 6. Базовый цикл алгоритма эволюционных вычислений
конкурируют друг с другом за выживание. Например, в такой
разновидности эволюционных алгоритмов, как эволюционные стратегии для
описания перехода от одного поколения к другому используются
следующие обозначения: Л — число потомков, /х — число родителей. Тогда
запись вида (//, А) при А ^ /х в поколенческом алгоритме означает, что
из созданных А потомков от /х родителей (А — /х) худших потомков
будут исключены из следующего поколения. Стратегия (А + /х) при
А > /х будет обозначать, что в следующее поколение будут отобраны
по определенной стратегии /х особей из родителей и их потомков.
Еще одной стратегией организации популяции в эволюционном
алгоритме является элитизм: в следующем поколении обеспечивается
сохранение, по крайней мере, одного лучшего решения из текущего
поколения. Следствием этой стратегии является то, что если найден
глобальный оптимум, то эволюционный алгоритм гарантирует сходимость
процесса ЭВ, хотя возрастает риск попадания в «локальную яму».
68
Гл. 2. Общая теория эволюционных вычислений
Алгоритм организации элитизма в процессе эволюционных
вычислений, представленный на псевдокоде, имеет следующий вид:
Input: Функция для оценки качества решений стр?,
представляющая собой компаратор, сравнивающий качество решений
Input: ps — размер популяции решений
Input: as — размер архива элитных решений
Data: t — текущий номер поколения
Data: P(t = 0) — исходная популяция решений
Data: Arc — архив элитных решений
Data: параметры алгоритма, включая целевую функцию
Output: X* — найденное оптимизированное решение
begin
t:=0
Arc := 0
Pop := init Pop(ps)
while (критерий останова) do
Arc := updateOptimalSetN(Arc, Pop) /*обновленное
оптимальное множество*/
Arc := pruneOptimalSet(Arcf as) (сокращение
оптимального множества решений до размера ps)
v := функция качества (Pop, Arc, cmpp)
P(t) := selection (Pop, Arc, v, ps)
t:=t+l
Pop := репродукцияР(£)
return /*восстановление фенотипа оптимального множества
решений (Pop U Arc)*/
end
Уточним различия в представленных выше на псевдокоде
алгоритмах, реализующих базовый цикл ЭВ и стратегию элитизма.
Во-первых, создается архив Arc элитных решений, который
первоначально является пустым множеством, а затем обновляется
функцией «updateOptimalSetN», которая сохраняет и обновляет полученные
элитные решения (алгоритмы реализации этой функции будут
подробно рассматриваться в последующих разделах). Во-вторых, если
множество элитных решений становится слишком большим, то функция
«pruneOptimalSet» сокращает его до величины ps. В принципе, в
алгоритмах, построенных по принципам, отличным от элитизма, такой
архив можно сделать пустым множеством (Arc := 0).
Еще одним следствием общей теории ЭВ является вывод о том, что
популяция большого размера необязательно будет приводить к
лучшему по качеству решению [42, 43].
2.8. Инструментальные средства для эволюционных вычислений 69
2.8. Инструментальные средства для поддержки
эволюционных вычислений
Для поддержки разработанной общей теории эволюционных
вычислений и когнитивных принципов построения эволюционных операторов
необходимы не только адекватные модели и эффективные алгоритмы.
Нужны инструментальные средства и соответствующая среда,
обеспечивающая возможность рационального выбора конкретных моделей
и алгоритмов эволюции, их подбора под решаемую задачу,
позволяющего осуществлять быстрое построение и динамическую
настройку параметров алгоритмов ЭВ [44]. В настоящее время предложено
большое количество различных реализаций моделей и алгоритмов ЭВ;
некоторые из них опробованы на тестовых задачах, однако их
применение в решении практических задач оптимизации, структурного синтеза
и принятия решений затруднено ввиду отсутствия или недостаточной
гибкости соответствующих программных систем. Существующие на
текущий момент программные средства, реализующие генетический
поиск, обладают рядом существенных недостатков:
• разработанное программное обеспечение жестко привязано к
решаемой задаче на этапах кодирования и декодирования ее
решений;
• программирование алгоритма ЭВ начинается практически с нуля;
• программное обеспечение закрыто для доработки или для
интеграции с другими программами;
• результатов поиска и промежуточных состояния популяции
решений не сохраняются, их невозможно анализировать в
дальнейшем;
• когнитивные возможности эволюционных операторов являются
ограниченными.
В этой связи в дальнейшем предстоит разработать архитектуру
среды поддержки ЭВ. Она должна включать общесистемную
среду и среду поддержки действий пользователя. Общесистемная среда
должна обеспечивать общее управление процессами ЭВ, содержать
базу данных и знаний моделей, алгоритмов и эволюционных операторов,
а также инструменты для сборки рабочих программ ЭВ. Среда
поддержки действий пользователя должна включать интерфейсную часть,
поддерживать действия пользователя по выбору вариантов алгоритма
и модели ЭВ, по настройке параметров алгоритма ЭВ с помощью
соответствующих диалоговых окон. Среда должна помогать подготавливать
определенные форматы исходных данных для решения конкретных
задач, а также обеспечивать визуализацию результатов ЭВ.
С теоретической точки зрения подобного рода структура позволит
устранить практически все описанные выше недостатки, но
сложность ее практической реализации, возможно, окажется значительной,
так как потребуется поддержка различных моделей и алгоритмов ЭВ.
70
Гл. 2. Общая теория эволюционных вычислений
Более перспективной представляется инструментальная среда
поддержки предлагаемой теории ЭВ, реализованная в САПР электронных
устройств. Вот список технических требований:
• возможность встраивания инструментальной среды в различные
существующие САПР как блока проектирования и/или
оптимизации;
• простота настройки эволюционного поиска, доступная не только
для специалиста в области эволюционного моделирования и
программирования;
• наличие блока подбора и адаптации операторов и параметров
алгоритмов ЭВ под решаемую задачу;
• возможность использования внешних функций, реализующих
когнитивные свойства эволюционных операторов, способы
кодирования и вычисления целевых функций;
• наличие встроенных библиотек алгоритмов и операторов ЭВ,
типов кодирования и тестовых функций, а также с возможностью
гибкой настройки базового цикла алгоритма ЭВ и
использованием внешних функций;
• возможность запуска алгоритма с созданной внешними
средствами или ранее сохраненной начальной популяцией;
• наличие блока анализа исходных данных, сохранения,
обработки и анализа результатов с расчетом основных статистических
данных;
• простота разработка инструментальных средств.
Эти требования хорошо согласуются с приведенными ранее
основными положениями теории. Система ЭВ должна быть принципиально
открытой, и процесс ее обучения никогда не завершается созданием
окончательной формализованной модели. В этом случае
инструментальные средства выполняют роль «информационной машины» для
системы ЭВ, которая способна действовать в непрерывном режиме
усвоения и реструктуризации информации. Роль обратной связи в
такой системе смогут выполнять экспертные знания и правила работы
с ними.
При разработке инструментальных средств и среды поддержки ЭВ
необходимо следовать следующим рекомендациям.
Требуется создать программы, реализующие эволюционный поиск
и позволяющие настраивать и управлять всеми его параметрами. Речь
идет о параметрах, устанавливаемых для популяций и не изменяемых
во время работы алгоритма ЭВ (количество запусков алгоритма,
функция качества), а также о параметрах, устанавливаемых для популяций
и которые могут изменяться.
Для исключения появления запрещенных комбинаций в хромосомах
и в связи со сложностью описания правил проверки на их отсутствие
в инструментальной среде должна иметься возможность подключать
внешний механизм проверки и коррекции хромосом после выполнения
композиции эволюционных операторов из внутренней библиотеки.
2.8. Инструментальные средства для эволюционных вычислений 71
База знаний инструментальной среды поддержки ЭВ должна
включать базу фактов и базу правил, предназначенную для подбора
параметров алгоритма ЭВ и их коррекции в ходе ЭВ. Это могут быть
продукционные правила с нечетким заданием переменных или
фреймовые структуры.
Логичным выглядит также требование возможности вычисления
целевых функций и функции качества в инструментальной среде путем
выбора из библиотеки тестовых функций или путем задания их
пользователем или с помощью внешней процедуры.
Немаловажным представляется наличие в инструментальной среде
средств для сохранения результатов моделирования, сбора статистики,
графического представления и анализа результатов.
С целью получения достоверной информации о качестве работы
исследуемого алгоритма ЭВ инструментальная среда должна позволять
производить несколько запусков с одинаковыми исходными
параметрами, использовать методы математической статистики.
Подобного рода структура инструментальной среды позволит
применять ее как при разработке и исследовании новых моделей и
алгоритмов ЭВ, так и в интересах совершенствования и практического
применения уже существующих разработок, использовать для решения
задач оптимизации, структурного синтеза, принятия решений в
области автоматизации проектирования, системного анализа и многих
ДРУГИХ.
Только подумайте: впервые в
истории вычислительной техники
массовые компьютеры не будут строиться
на основе фон-неймановской
архитектуры — они станут параллельными.
Приложения смогут одновременно
выполняться на нескольких ядрах. Такой
переход сулит огромные возможности,
но и потребует много усилий.
Большинство программистов, создающих
приложения для массовых вычислительных
систем, не использовали эту
технологию повседневно. Только сейчас
начинается процесс переноса принципов
многопоточности и параллелизма в
область массового программирования.
Dr. Dobb's Journal, август 2006 года
Глава 3
ОРГАНИЗАЦИЯ ПАРАЛЛЕЛЬНЫХ
ЭВОЛЮЦИОННЫХ ВЫЧИСЛЕНИЙ
3.1. Модель глобального параллелизма
Организация параллельной работы эволюционных алгоритмов в
гетерогенных компьютерных сетях или на параллельных
высокопроизводительных кластерных вычислителях может обеспечить
значительные выгоды с точки зрения производительности и масштабируемости.
Эволюционные алгоритмы в процессе своей работы требуют
немалых вычислительных ресурсов, поэтому актуальной является проблема
переноса эволюционных вычислений в распределенную
вычислительную среду.
Для этого имеются следующие веские основания. Все
эволюционные алгоритмы обладают свойством параллелизма и
предоставляют полноценные возможности для нахождения оптимальных решений.
Такие свойства у них появляются вследствие наличия механизмов
поддержания разнообразия в популяции на протяжении всего поиска
в распределенном пространстве решений. Практическая реализация
параллелизма эволюционных алгоритмов позволит всесторонне
исследовать пространство решений, что, в частности, является ключевым
3.1. Модель глобального параллелизма
73
моментом для решения трудных проблем многоэкстремальной
оптимизации, свойственной множеству практических задач из различных
прикладных областей.
Параллелизм эволюционных алгоритмов является следствием
общей теории эволюционных вычислений. Ранее был установлен факт
наличия базового цикла в алгоритмах эволюционных вычислений.
Напомним, что базовый цикл включает следующую последовательность
шагов: вычисление целевой функции, ее оценку, селективный отбор
решений и репродукцию новых решений. Цикл обладает свойством
массового параллелизма при обработке информации как на уровне
организации работы алгоритма, так и на уровне его компьютерной
реализации, что предполагает эффективную параллельную реализацию
процесса эволюционных вычислений [24].
Параллелизм на уровне компьютерной реализации означает
вычисление на параллельных системах или процессорах значений целевой
функции для разных решений, параллельное выполнение операторов
эволюционных вычислений, что пропорционально повышает скорость
работы алгоритма.
Параллелизм на уровне организации работы алгоритма
эволюционных вычислений достигается структурированием популяции решений.
Организация распараллеливания эволюционных вычислений на
базе распределенной вычислительной системы позволяет существенно
сократить время, затрачиваемое на решение задачи, как за счет
параллельного выполнения вычислений, так и за счет применения более
эффективных, чем в последовательном случае, способов реализации
алгоритмов.
Оба подхода эффективно реализуются на параллельных
вычислителях. Однако требуется особая организация эволюционных
вычислений путем логического разбиения алгоритма на ортогональные по
отношению к обрабатываемым данным гранулы (зерна) параллелизма
с минимизацией числа и объемов обменов между процессорами,
чего практически никогда не требуется при классической общей шине
вследствие ее огромной производительности и малой инерционности.
Гранула параллелизма — это последовательности инструкций
процессора, не требующих выполнения обменов данными с соседними
процессорами. Выделение гранул параллелизма позволяет избежать
чрезмерных потерь на простой процессоров во время обмена данными
и, как следствие, катастрофического снижения вычислительной
мощности. Иными словами, гранула параллелизма — это участок
алгоритма, выполняющийся на отдельном процессоре и не требующий при
своем исполнении данных от других процессоров. Выявление в
алгоритме гранул, которые могут выполняться независимо и параллельно,
является одной из главных задач при разработке параллельных
эволюционных алгоритмов.
Модели и способы организации параллелизма могут быть
различными: глобальный параллелизм, миграционная модель, диффузионная
74 Гл. 3. Организация параллельных эволюционных вычислений
модель [45]. Ответ на вопрос о том, какой из этих способов
организации распределенных эволюционных вычислений является более
эффективным, зависит от архитектуры вычислительной системы,
используемой для реализации эволюционных вычислений. Решающим
обстоятельством для оценки эффективности является то, насколько
успешно решается та или иная проектная задача с точки зрения
качества решения и вычислительной сложности.
Рассмотрим модель глобального параллелизма эволюционных
вычислений, представленную на рисунке 7.
« Мастер »-процессор
(Процессор 1) (Процессор 2
Рис. 7. Модель глобального параллелизма
В этой модели основной гранулой параллелизма или участком
эволюционного алгоритма, выполняющимся на отдельном процессоре
и не требующим при своем исполнении данных от других процессоров,
являются такие операции базового цикла эволюционных вычислений,
как расчет целевой функции и параллельное выполнение операторов
репродукции новых решений. Целевая функция отдельного
индивидуума в популяции, как правило, не зависит от других индивидуумов.
Поэтому вычисление целевых функций допускает распараллеливание.
При этом популяция хранится в общей памяти, отдельный процессор
считывает код решения (например хромосому в генетическом
алгоритме) из памяти и возвращает результат после вычисления
целевой функции. Процедура синхронизации здесь проводится лишь при
формировании новой популяции. В случае, если вычислительная
система имеет распределенную память, популяция и значения функции
качества отдельных индивидуумов хранятся в «мастер»-процессоре,
а расчеты производятся на вспомогательных процессорах.
При использовании модели глобального параллелизма трудность
для распараллеливания при реализации базового цикла
эволюционных вычислений представляет процедура селективного отбора
решений. Здесь преимущество (в смысле распараллеливания) получают
те формы селекции, которые не используют глобальную статистику
о популяции, например, «соревновательные» способы селекции [8].
Напротив, легко распараллеливаемыми являются такие наиболее
широко применяемые операторы эволюции, как мутация и кроссинговер,
(Процессор ЛП
3.2. Миграционная модель
75
так как они выполняются независимо друг от друга и, в основном,
случайным образом.
3.2. Миграционная модель
Если между отдельными подпопуляциями установить правила
миграции для индивидуумов, то получится миграционная модель,
показанная на рисунке 8.
-$> Хромосома
Q Подпопуляция
\ Путь миграции
Рис. 8. Миграционная модель параллелизма
В этой модели основной гранулой параллелизма являются все
операции базового цикла эволюционных вычислений, выполняемые
внутри подпопуляции. Для построения миграционной модели требуется
задать количество и размеры подпопуляции, топологию связей между
ними, частоту и интервал миграции, а также стратегию эмиграции
и иммиграции. Размеры и число подпопуляции определяются числом
и быстродействием используемых процессоров или транспьютеров. Что
касается топологии связей в миграционной модели, то можно
применять различные варианты: «островную» модель, предусматривающую
миграцию между любыми подпопуляциями; модель,
предусматривающую обмен решениями между соседними подпопуляциями и др.
Применение того или иного варианта миграционной модели зависит от
архитектуры параллельного вычислителя (сетевая, кольцевая или др.).
Частота миграции определяется размерами подпопуляции. При высокой
частоте подпопуляция может быстро потерять гетерогенность.
Наоборот, при слабой интенсивности миграции и большом числе
подпопуляции возрастает вероятность получения нескольких хороших решений,
однако сходимость алгоритма замедляется.
В работе [7] для обеспечения выбора особей для миграции
предлагается использовать общий буфер хромосом. Буфер заполняется
хромосомами нескольких популяций. При наступлении определенной
ситуации отдельная популяция обращается к буферу и считывает
оттуда часть или все хромосомы, добавляя в буфер часть своих
хромосом. В ходе ЭВ необходимо лишь определить механизм
регулирования размера буфера. Работа параллельного эволюционного
76 Гл. 3. Организация параллельных эволюционных вычислений
алгоритма при этом происходит следующим образом. Каждая
популяция эволюционирует отдельно от других. На каждой итерации
проверяется условие необходимости миграции (через заданный интервал,
вырождение популяции и т.п.). Если условие наступило, происходит
миграция хромосом через общий буфер. Затем проверяется размер
буфера. Если размер больше заданного значения, то выполняется
процедура отбора.
Отметим, что условия миграции могут быть разными для разных
популяций. Также различными могут быть композиции генетических
операторов для разных популяций.
i
| Миграция |
j
1
п *
ЩФ1
| Блок
i
f
J Популяция /
Т
Сортировка |
1
(
ОР /
t
Генетические 1
операторы |
1
\
!
J Эво.
1
| \
ЩФ[
f Бл
>
| Миграция
J
( ]
f
Популяция 2
Т
| Сортировка |
\
(
1 ОР2
▼
1 Генетические
| операторы
эк~2 *1
i
ЩФ]
' Бл
1
' г
'
Популяция 3\
Т
Сортировка |
1
г
ОР 3 1
▼
Генетические 1
операторы ]
ок! **
I
♦
пюционная адаптация
Блок 4
1
Рис. 9. Схема эволюционного поиска на основе миграции
Миграционная модель наиболее эффективно реализуется в
вычислительных системах с MIMD-архитектурой путем разделения общей
^ 1
1
г
1
Л
"" 1 А J
ГА
►
ГА
be х
А
ГА
-^
ГА
f~r —S
г
А
(\
А
(\
Рис. 10. Схема поиска на основе Рис. 11. Схема поиска на основе
тетраэдра гексаэдра (куба)
3.2. Миграционная модель
77
ЧГА
Рис. 12. Схема поиска на основе октаэдра
Рис. 13. Схема поиска на основе икосаэдра
популяции на отдельные подпопуляции, эволюционное моделирование
которых осуществляется на отдельных процессорах.
Опишем в качестве примера представленную на рисунке 9 новую
схему эволюционного поиска с использованием миграционной модели
параллелизма на примере генетических алгоритмов (ГА).
Эволюционный поиск осуществляется путем объединения хромосом
из различных популяций. Блоки 1-3 в схеме на рисунке 9
представляют собой разновидности генетического алгоритма. В каждом блоке
78 Гл. 3. Организация параллельных эволюционных вычислений
Рис. 14. Схема поиска на основе додекаэдра
Рис. 15. Поиск на основе полного графа на 5 вершин
выполняются различные операторы репродукции: в первом блоке
оператор репродукции ОР / на основе рулетки, во втором блоке используется
ОР 2 на основе заданной шкалы, в третьем блоке — ОР 3 на основе
элитной селекции. В блок миграции каждый раз отправляется лучший
представитель из популяции. Связь между блоками 1-3
осуществляется на основе следующих путей: (1-2, 2-3), (1-3). В блоке 4
осуществляется установление баланса на размер популяции на основе
эволюционной адаптации и управления всем процессом эволюционного
поиска.
Топология связей в миграционной модели может быть различной.
Рассмотрим возможные варианты топологии, представляя их с
помощью графов (граф — математический объект, состоящий из множества
вершин и множества ребер, находящихся в заданном отношении).
3.3. Диффузионная модель
79
Если в наличии имеется вычислительные ресурсы из N
процессоров, то для реализации представленной на рисунке 8 схемы
эволюционного поиска на основе миграции (N — 1)-ый процессор может
параллельно осуществлять эволюционную адаптацию и через блоки
миграции обмениваться лучшими представителями решений, а
последний блок будет осуществлять сборку лучших решений. Для
реализации миграционной модели используем Платоновы графы (правильные
многоугольники, которые, как считалось в древних учениях, обладают
внутренней природной красотой и гармонией) [8].
На рисунках 10-14 приведены предлагаемые схемы вариантов
топологии межпроцессорных связей, представленные в виде Платоновых
графов: схема на основе тетраэдра представлена на рисунке 10, схема
на основе гексаэдра представлена на рисунке 11, схема на основе
октаэдра представлена на рисунке 12, схема на основе икосаэдра
представлена на рисунке 13, схема на основе додекаэдра представлена
на рисунке 14. Межпроцессорные связи, представленные на рисунках
10-14, реализуют отношение «один ко многим», однако можно строить
конфигурации на основе иных типов вход-выходных отношений: «один
к одному», «многие к одному», «многие ко многим».
На рисунке 15 представлен еще один вариант топологии связей
в миграционной модели — полный граф, в котором все вершины
связаны.
3.3. Диффузионная модель
Если большую популяцию разделить на множество
немногочисленных подпопуляций, а композицию эволюционных операторов
применять лишь в ограниченной области, определяемой отношением
соседства, то получится диффузионная модель эволюционных вычислений,
представленная на рисунке 16.
Хромосома
Локальное
соседство
центральных
хромосом
Рис. 16. Диффузионная модель параллелизма
В этой модели основной гранулой параллелизма являются все
операции базового цикла эволюционных вычислений, выполняемые
внутри небольших по размеру подпопуляций. Это приводит к тому,
80 Гл. 3. Организация параллельных эволюционных вычислений
что хорошие решения медленно распространяются в популяции
(диффузия) и проблема попадания в «локальную яму» становится менее
острой.
Популяция в природе, как правило, состоит из отдельных, более или
менее изолированных локальных подпопуляций, допускающих
диффузию отдельных индивидуумов. Большинством существующих
эволюционных алгоритмов это обстоятельство игнорируется, алгоритмы
работают с одной большой неструктурированной популяцией. Другое
преимущество диффузионной модели состоит в том, что она также
допускают эффективную реализацию эволюционных вычислений на
массиве параллельных вычислителей с различной коммутационной
структурой. Однако наиболее эффективно диффузионная модель реализуется
в вычислительных системах с SIMD-архитектурой.
Топология связей в диффузионной модели также может быть
различной. Рассмотрим возможные схемные варианты топологии,
представляя их с помощью графов.
На рисунке 17 представлена кольцевая схема диффузии, на
рисунке 18 — схема кольцевой диффузии с циклами, использование которых
позволяет расширять область поиска лучших решений.
ГА
-Н ГА
ГА
Рис. 17.
ГА
ГА
ГА
ГА Н^
ГА
т
Схема кольцевой
диффузии
Рис. 18. Схема кольцевой
диффузии с циклами
Описанные схемы эволюционного поиска могут включать
гетерогенную смесь из нескольких эволюционных алгоритмов, выполняемых
параллельно, позволяют во многих случаях выходить из локальных
оптимумов.
Кроме того, после некоторого числа шагов работы эволюционных
алгоритмов (шаг — переход к новой популяции) можно случайным
образом «перемешивать» элементы в популяции, а затем
формировать новые текущие популяции с дальнейшей реализацией композиции
различных эволюционных операторов. При параллельном выполнении
эволюционных вычислений подобного рода процедура позволяет
сократить неперспективные популяции и расширить популяции, в которых
находятся «лучшие» решения.
3.4. Показатели эффективности работы параллельных алгоритмов 81
3.4. Показатели эффективности работы параллельных
алгоритмов
Повышение вычислительной мощности не только отдельного
процессора, но и путем параллелизации вычислений на многих
процессорах или вычислительных узлах, одновременно выполняющих
программу, считается одним из наиболее перспективных направлений [46].
Однако процесс разработки параллельных программ существенно
более труден, чем обычных последовательных, как и количественная
оценка их эффективности с точки зрения соответствия созданного
программного обеспечения архитектурным особенностям
многопроцессорной вычислительной системы [47]. Количественные ограничения на
производительность вычислительной сети требуют особой организации
вычислений — логического разбиения алгоритма на ортогональные по
отношению к обрабатываемым данным блоки (гранулы, зерна
параллелизма) с минимизацией числа и объемов обменов между процессорами,
чего практически никогда не требуется при классической общей шине
вследствие ее огромной производительности и малой инерционности.
Сейчас большой популярностью пользуются многоядерные и
кластерные архитектуры вследствие их значительной масштабируемости
и конкретной реализации в виде вычислительных кластеров [47].
В архитектуре этих вычислителей узлы близко связаны (по диаметру
сети и ее быстродействию). Напротив, в системах метакомпьютинга
допускается расположение узлов на значительных расстояниях, причем
узлы обычно гетерогенны. Соответственно приемы параллельного
программирования для указанных систем количественно разнятся.
Относительно большое время обмена данных в системах метакомпьютинга
требует реализации значительно большего размера гранулы
параллелизма, чтобы избежать чрезмерных потерь, связанных с простоем
процессоров во время обмена данными, а также катастрофического
снижения вычислительной мощности.
В общем случае производительность многопроцессорной структуры
зависит от производительности отдельных процессоров, от параметров
коммуникационной среды, от класса решаемых задач, а также от
конкретных технологий грануляции алгоритмов. Часто говорят о
мелкозернистом и крупнозернистом параллелизме. Представленная выше
миграционная модель параллелизма относится к крупнозернистому,
а диффузионная модель — к мелкозернистому параллелизму.
Принадлежность к тому или иному виду параллелизма, в основном, зависит
от параметров коммуникационной сети, обеспечивающей обмен
сообщениями между процессорами.
В большинстве случаев не удается полностью совместить обмен
данными с вычислениями внутри гранулы. Поэтому с целью
определения показателей эффективности работы параллельных
алгоритмов разделим общее время обработки данных в ходе эволюционных
6 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
82 Гл. 3. Организация параллельных эволюционных вычислений
вычислений на время обмена данными Обмена и время выполнения
гранулы параллелизма Гранула- Их отношение будет определять показатель
гранулярности параллельной программы. Сокращение времени Обмена
представляет собой, в основном, аппаратную задачу, а вот повышение
времени Гранула является алгоритмической задачей и достигается
именно на этапе распараллеливания разработанных эволюционных
алгоритмов.
Таким образом, отношение ГранулаДобмена указывает на
эффективность разработанного алгоритма и применяемой для решения задачи
вычислительной структуры. Это отношение также позволяет
определить круг задач, эффективно решаемых на данной вычислительной
структуре, принять решение о ее модернизации или модернизации
параллельной программы эволюционных вычислений. Если отношение
^гранулаДобмена < 1, то это мелкозернистый параллелизм, если
отношение £ГрДоб > 1, то это крупнозернистый параллелизм.
Как уже отмечалось, выявление в алгоритме гранул, выполняемых
независимо и параллельно, является одной из основных задач при
разработке эффективных распределенных алгоритмов эволюционных
вычислений.
В рамках данной книги прорабатываются два пути решения
поставленной задачи:
• создание на основе общей теории эволюционных вычислений
принципиально новых гранулированных эволюционных алгоритмов,
позволяющих эффективно использовать вычислительную мощность
современных вычислительных систем;
• модификация существующих эволюционных алгоритмов для
параллельных/многоядерных систем.
Однако загрузка ядер вычислительной работой не является
самоцелью. Она является только средством улучшения таких показателей
и характеристик эволюционных алгоритмов, как время работы,
качество поиска и т. д.
В качестве основного показателя эффективности работы
гранулированного эволюционного алгоритма примем следующее отношение:
ту- 1- поел
^эфф = ™—1
J- гран
где Тпосл и Ггран обозначают время выполнения последовательного
и гранулированного алгоритма соответственно. Все вычисления в
процессе выполнения алгоритма можно разделить на последовательные
(s), гранулированные (7) вычисления и накладные расходы по
организации параллелизма (Р). Тогда для задачи размерности iV, решаемой
на параллельном вычислителе с М процессорами, имеем следующую
зависимость:
Km(Ny M) — . (2)
s(N) + Ш1 + P(N, M)
3.4. Показатели эффективности работы параллельных алгоритмов 83
Эта оценка указывает на верхнюю границу для максимального
ускорения, которое может быть достигнуто на параллельном компьютере
с М процессорами, если объем вычислений равномерно распределен
между процессорами.
Согласно закону Амдала [46] ускорение выполнения программы
за счет распараллеливания ее инструкций на множестве вычислителей
ограничено временем, необходимым для выполнения ее
последовательных инструкций. Предположим, что необходимо решить некоторую
вычислительную задачу. Алгоритм решения этой задачи таков, что
некоторая доля а от общего объема вычислений может быть получена
только последовательными расчетами, а, соответственно, доля (1 -а)
может быть распараллелена идеально (то есть время вычисления
будет обратно пропорционально числу задействованных узлов М). Тогда
ускорение, которое может быть получено на вычислительной системе
из М процессоров, по сравнению с однопроцессорным решением не
будет превышать величины
Кэфф(М)
а(М- 1) + Г
Таким образом, согласно закону Амдала, только алгоритм, совсем
не содержащий последовательных вычислений (а = 0), позволяет
получить линейный прирост производительности с ростом количества
вычислителей в системе. При доле последовательных вычислений а
общий прирост производительности не может превысить величины
1/а. Если половина программного кода алгоритма — последовательная,
то общий прирост никогда не превысит двух. Закон Амдала
показывает, что прирост эффективности вычислений зависит от алгоритма
задачи и ограничен сверху для любой задачи с величиной а ф 0.
Иными словами, не для всякой задачи имеет смысл наращивание числа
процессоров в вычислительной системе.
Более того, если учесть время, необходимое для передачи данных
между узлами вычислительной системы, то график зависимости
времени вычислений от числа узлов будет иметь максимум. Это накладывает
ограничение на масштабируемость вычислительной системы, то есть
означает, что с определенного момента добавление новых узлов в
систему будет увеличивать время расчета задачи.
С учетом этого соотношение (2) примет вид следующей
зависимости:
k„(n. м) = —т±ш— ^
s(N) + ^ + P(N, M)
<К (N M\- >(N)+lW
ч -ftmax эфф!^. м) — —-
a(N) + 7( '
м
6*
84 Гл. 3. Организация параллельных эволюционных вычислений
Полученная оценка является теоретической границей
максимального ускорения, которого может достигнуть параллельный эволюционный
алгоритм.
3.5. Распараллеливание операций базового цикла
эволюционных вычислений
При модификации существующих алгоритмов или создании
принципиально новых гранулированных эволюционных алгоритмов
необходимо учитывать полученные теоретические оценки, модели
параллелизма, а также следующие рекомендации по распараллеливанию
операций, входящих в базовый цикл эволюционных вычислений:
• две составляющие базового цикла алгоритма эволюционных
вычислений потенциально могут значительно повлиять на параллелизм —
это оценка качества решения и репродукция новых решений;
• процесс вычисления целевой функции для каждого решения
может осуществляться параллельно и независимо от остальных решений;
• оценка качества решений может потребовать сложных расчетов
или моделирования и являться одним из наиболее трудоемких
этапов эволюционных вычислений; в процессе оценки качества требуется
сравнить значения функции качества каждого решения с остальными
и обновить структуры данных, что затрудняет процесс
распараллеливания;
• выполнение фазы селекции в базовом цикле алгоритма
эволюционных вычислений может потребовать доступа к определенным
подмножествам решений в популяции или обновления данных, поэтому
возможности ее распараллеливания зависят от выбора схемы селекции;
• выполнение фазы репродукции в базовом цикле алгоритма
эволюционных вычислений можно распараллелить; репродукция, являясь
независимой задачей, может включать либо копирование решения,
либо выполнение унарных, бинарных или n-арных эволюционных
операторов.
На рисунке 19 в общих чертах представлены потенциальные
возможности распараллеливания базового цикла алгоритма ЭВ [47].
Базовый цикл алгоритма ЭВ можно выполнять как на
однопроцессорной машине, так и на двуядернои машине, как это показано
на рисунке 20.
Поскольку объем популяции решений может быть значительно
больше, чем число имеющихся процессоров, то один общий поток
заданий будет распределяться по процессорам, что неизбежно приведет
к образованию очереди заданий и необходимости организации
процессов их обслуживания. Такой подход по эффективности может даже
уступать обработке заданий на однопроцессорной машине.
Распределенный алгоритм ЭВ будет эффективным только в том
случае, если задержки, вызванные передачей и обменом необходимыми
3.5. Распараллеливание операций базового цикла 85
Инициализация
популяции
11X1
/ I \
Рис. 19. Потенциальные возможности распараллеливания базового цикла
алгоритма ЭВ
Ядро /
Инициализация
Вычисление ЦФ
Репродукция
Ядро 2
Инициализация
Вычисление ЦФ
Г
Репродукция
Рис. 20. Параллельное выполнение алгоритма ЭВ на двуядерной машине
данными, будут незначительными. Например, если математическая
функция у/х вычисляется на одном процессоре, а подкоренное
выражение х — на другом, то это займет гораздо больше времени, чем
локальное вычисление х и у/х.
Уточним возможные варианты организации распределенных
вычислений. Наиболее простым подходом к организации распределенных
вычислений представляется глобальный параллелизм и клиент-серверная
схема его реализации. Роль клиента выполняет «мастер»-процессор,
реализующий выполнение основного шага, как это показано на
рисунке 20. Серверы выполняют вычисление целевой функции и
репродукцию, которые могут включать несколько ядер.
Однако для решения задач оптимизации и структурного синтеза
большой размерности клиент-серверная архитектура может оказаться
не оптимальной. Это произойдет в следующих случаях:
86 Гл. 3. Организация параллельных эволюционных вычислений
• в процессе решения задачи время, необходимое для передачи и
обмена данными между клиентом и серверами, значительно превышает
время, необходимое серверу для выполнения своих задач;
• представление решений и объем популяции требует значительной
памяти, поэтому организация распределенного алгоритма ЭВ строится
на основе миграционной или диффузионной модели параллелизма.
Используя теорию ЭВ, инспирированных природными системами,
мы можем легко смоделировать эволюцию в «островных подпопуля-
циях» на различных узлах в сети компьютеров, каждый из которых
представляет один «остров» (крупнозернистый параллелизм). Это
позволит преодолеть отмеченные выше недостатки клиент-серверной
архитектуры. Связь между узлами понадобится лишь для миграции между
«островами». Эта связь может осуществляться асинхронно через сеть
самостоятельно работающих алгоритмов ЭВ. Правила миграции могут
быть выбраны таким образом, чтобы оптимизировать сетевой трафик.
Память, требуемая для организации ЭВ на одной машине,
уменьшается, каждый узел работает независимо, как это показано на рисунке 21.
Узел 2
Оценка качества
Рис. 21. Параллельное выполнение алгоритмов ЭВ на узлах сети
В частности, на примере решения транспортных задач с помощью
генетических алгоритмов было показано, что параллельное их
использование на узлах многоядерной сети позволяет уменьшить время
работы алгоритма [48]. Экспериментальная проверка проводилась на
известных тестовых транспортных задачах с ограничением по времени.
Узел /
Инициализация
Вычисление ЦФ
Оценка качества
Репродукция
Селекция
СЕТЬ
Репродукция
Селекция
Инициализация
Вычисление ЦФ
3.5. Распараллеливание операций базового цикла 87
Фаза процесса репродукции новых решений в популяции
производилась параллельно, программа запускала столько потоков репродукции,
сколько имелось процессорных ядер. Схема работы соответствующей
экспериментальной многопоточной программы показана на рисунке 22.
( Вход )
Инициализация алгоритма
Создание z-ro решения
в популяции
Ожидание завершения
дочерних потоков
Оператор инициализации
Создание /-го решения
потомка
Ожидание завершения
дочерних потоков
Главный цикл ГА операторы кроссинговера, мутации и пр.
С Выход J
Рис. 22. Схема работы экспериментальной многопоточной программы
Инициализация генетического алгоритма ЭВ и запуск
дополнительных потоков происходил из главного потока, который создавался при
запуске программы.
На рисунке 22 блоки команд, выполняемые главным потоком,
изображены белыми, не закрашенными прямоугольниками. Серыми
прямоугольниками изображены блоки команд, выполняемые
дополнительными потоками, которые запускаются главным потоком.
Количество запускаемых потоков равно количеству ядер
процессора; во столько же раз уменьшалось время работы алгоритма.
Программа была построена так, что автоматически запрашивала у системы
ЭВ количество имеющихся процессорных ядер и запускала, если это
возможно, дополнительные потоки.
Отметим, что в многопоточной программе организация потоков
будет тем эффективнее, чем с меньшим количеством общих данных
работают потоки. Это связано с тем, что если потоки изменяют какие-то
общие данные, то необходимо применять специальные дополнительные
88 Гл. 3. Организация параллельных эволюционных вычислений
механизмы межпоточной синхронизации (критические секции,
семафоры, события и др.).
Действия по синхронизации потоков минимальны и запускаемые
потоки практически не мешают друг другу, т. е. время ожидания одного
потока, пока другие освободят общий используемый ресурс,
минимально.
Для проверки эффективности одного из предлагаемых способов
распараллеливания базового цикла алгоритма ЭВ было произведено
тестирование для решения тестовых задач Соломона [7] на двуядерном
процессоре сначала в однопоточном, затем в двупоточном режиме.
При решении всех тестовых задач Соломона время работы алгоритма
уменьшилось как минимум в два раза по сравнению с однопоточным
вариантом. Эксперименты показали эффективность даже такого
простейшего распараллеливания алгоритма ЭВ, так как при малых
трудозатратах программиста достигался выигрыш по времени во столько раз,
сколько имеется в системе процессорных ядер. Данный факт неуместно
игнорировать при разработке новых алгоритмов на базе общей теории
ЭВ, в связи с чем для предварительной проверки исходных гипотез
была разработана многопоточная архитектура на примере генетического
алгоритма.
Из предлагаемой теории вытекают и другие способы организации
параллельных ЭВ. В частности, в зависимости от задачи периодически
можно производить миграцию решений между узлами. Причем в этом
случае на различных узлах могут вычисляться различные целевые
функции, что, в свою очередь, открывает возможности для решения
трудных задач многокритериальной оптимизации. Более того, на
различных узлах сети могут быть установлены различные алгоритмы
ЭВ, инспирированных природными системами, модели которых были
представлены выше.
Таким образом, преимущества общей теории ЭВ, инспирированных
природными системами, заключаются в простоте реализации, скорости
и робастности поиска, в широких возможностях распараллеливания
алгоритмов ЭВ. Скорость поиска определяется временем работы
алгоритма ЭВ и временем достижения решением заданного качества,
а робастность выражается в устойчивости поиска к попаданию в точки
локальных экстремумов и способности постоянно, от поколения к
поколению увеличивать качество популяции решений.
Робастность зависит от когнитивных возможностей используемых
эволюционных операторов, а наибольшее влияние на скорость ЭВ
оказывают размеры популяций и хромосом [24], а также такие
особенности целевых функций качества решений, как многоэкстремальность
(множество ложных аттракторов), «обманчивость», изолированность,
дополнительный «шум».
На различных узлах сети могут быть распределены различные
алгоритмы эволюционных вычислений. Гетерогенная смесь этих
алгоритмов, имеющих общий базовый цикл выполнения композиции
3.5. Распараллеливание операций базового цикла 89
эволюционных операторов, будет более эффективной, нежели
гомогенный поиск.
Однако простота идеи программирования параллельных
эволюционных вычислений на практике требует выполнения некоторых условий.
В частности, в многопроцессорной системе разбиение на слишком
крупные гранулы не позволяет равномерно загрузить процессоры и
добиться минимального времени вычислений, а излишне мелкая
«нарезка» означает рост непроизводительных расходов на связь и
синхронизацию. Параллелизму присуща зависимость структуры эволюционного
алгоритма от топологии вычислительной платформы. Процесс создания
максимально эффективного алгоритма практически не
автоматизируется и связан с большими трудозатратами на поиск специфической
структуры алгоритма, оптимальной для конкретной топологии используемой
многопроцессорной системы. Найденная структура обеспечит
минимальное время получения результата, но, скорее всего, будет
неэффективна для другой конфигурации. Более суровое следствие зависимости
структуры эволюционного алгоритма от вычислительной платформы —
тотальная непереносимость не только исполняемых кодов, но и самого
исходного текста.
Раньше, чем разрывать
навозную кучу, надо оценить,
сколько на это уйдет времени и
какова вероятность того, что там
есть жемчужина.
А.Б. Мигдал
Глава 4
АЛГОРИТМЫ МИКРО-, МАКРО-
И МЕТАЭВОЛЮЦИОННЫХ ВЫЧИСЛЕНИЙ
4.1. Теоретические положения микро-, макро-
и метауровней эволюционных вычислений
При построении моделей и алгоритмов эволюционных вычислений
мы будем использовать три типа эволюции: микро-, макро- и метаэво-
люцию [8]. Представим основные теоретические положения, лежащие
в основе микро-, макро- и метаэволюционных алгоритмов.
Разработка эволюционных алгоритмов, представляемых ниже,
опирается на представленную в рамках данного проекта общую теорию
эволюционных вычислений как математических преобразований,
позволяющих трансформировать входной поток информации в выходной
по правилам, основанным на имитации механизмов эволюционного
синтеза, а также на статистическом подходе к исследованию ситуаций,
итерационном приближении к искомому решению и поисковой
оптимизации.
Понятие «поисковой оптимизации» как последовательности
действий, реализующих априорно неизвестную траекторию движения
к экстремуму оптимизируемой функции, с позиций информатики
является обобщением понятия «гомеостатика», поскольку позволяет
достигать не только устойчивости в системе, но и ее изменчивости.
Реализация эволюционных алгоритмов поиска оптимальных решений,
обладающих «памятью», позволяет надеяться на получение при
моделировании эволюционных механизмов принципиально новых
результатов.
Подчеркнем еще раз, что общая теория эволюционных
вычислений (как направление исследований) развивается усилиями
специалистов в области технических наук. Теория нацелена на создание
новых эвристических (программных и математических) алгоритмов
4.1. Теоретические положения уровней эволюционных вычислений 91
и не претендует на адекватность структур полученных
алгоритмических решений «истинным» структурам их биологических прототипов.
Разрабатываемые параллельные и распределенные эволюционные
алгоритмы поисковой оптимизации должны обязательно включать,
по крайней мере, четыре основных элемента:
• композицию эволюционных операторов, «генерирующих»
постоянную активность поисковых переменных в процессе эволюции;
• селективный отбор результатов и вычисление целевой функции
оптимизации;
• наличие «памяти», реализующей свойство адаптивности
поискового алгоритма;
• наличие гранул параллелизма.
Из четырех основных составляющих поискового оптимизационного
механизма эволюционных вычислений Ч. Дарвин [3] гениально угадал
первые два: ввел фундаментальное понятие «изменчивости» (поисковая
активность алгоритма через эволюционные операторы), «естественного
отбора» (селекция) и «полезности», «выгодности»,
«приспособленности» (прообраз целевой функции).
Из предлагаемой общей теории эволюционных вычислений следует,
что в качестве элементарных эволюционирующих единиц, лежащих
в основе разнообразных эволюционных алгоритмов (от генетических
алгоритмов до алгоритмов меметики), могут рассматриваться системы
всех уровней интеграции: от атомов (квантовые алгоритмы),
органических молекул и макромолекул — до биогеоценозов, биомов, природных
зон и даже ноосферы. Другое дело, что процесс видообразования
как одно из проявлений поискового оптимизационного процесса
действительно имеет в качестве одного из главных источников активное
поисковое поведение популяций.
Термин микроэволюция обозначает процесс адаптивных
преобразований популяций под действием естественного отбора. Он приводит
к дифференциации популяций внутри вида и возникновению новых
видов. Термин макроэволюция обозначают эволюцию надвидовых
таксонов, закономерности которой не всегда сводятся к закономерностям
микроэволюции. Термин метаэволюция обозначает процесс эволюции
целых популяций. Наконец, понятие надуровень предполагает
взаимодействие целых популяций, видов и частей видов, согласно В.
Вернадскому. На рисунке 23 приведена общая схема взаимодействия этих
уровней эволюции.
Применительно к разрабатываемым эволюционным алгоритмам
микроэволюция будет включать механизмы так называемого
искусственного отбора, естественного отбора и видообразования. Например,
в генетических алгоритмах искусственный отбор ведется по единичным
аллелям и количественным признакам, зависит от внешней среды.
Макроэволюционный уровень алгоритмов эволюционных вычислений
означает перестройку архитектуры и параметров алгоритмов на уровне
популяции в зависимости от внешней среды. Метаэволюционный
92 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Надуровень
Матаэволюция
Макроэволюция
уровень алгоритмов обозначает процесс эволюции на межпопуляцион-
ном уровне.
4.2. Генетические алгоритмы
Развитие генетических алгоритмов как наиболее широко
распространенной разновидности ЭВ идет по пути применения различных
способов кодирования хромосом, композиции и расширения
когнитивных возможностей различных генетических операторов, усложнения
поведения алгоритма, когда главным становится смысловое содержание
параметров управления эволюцией. В общей теории ЭВ генетические
алгоритмы представляют собой процедуру поиска, которая исследует
пространство строк определенной длины (генотип) для нахождения
хромосом с относительно высокой величиной пригодности.
Поиск является один из универсальных способов решения задач
оптимизации, управления, планирования, прогнозирования, принятия
решений. Процедура поиска лежит в основе генетических алгоритмов
как разновидности ЭВ. Особенность этой процедуры в том, что нельзя
заранее определить последовательность шагов, приводящих к
искомому результату. В генетических алгоритмах используется сочетание
двух видов поиска одновременно: случайный и локально
направленный поиск. Случайный поиск исследует решение целиком и
позволяет избежать попадания в локальный оптимум. Локальный поиск,
Внешняя среда
Вход
Микроэволюция
Выход
Рис. 23. Общая схема взаимодействия микро-, макро- и метаэволюций
4.2. Генетические алгоритмы
93
используя лучшие решения, позволяет приблизиться или даже найти
локальный, а возможно, и глобальный оптимум. От того, насколько
идеально алгоритм сочетает оба типа поиска, зависит конечный
результат. Классическими методами такой идеальный поиск осуществить
практически невозможно. Именно комбинирование элементов
направленного и стохастического типов поиска в генетических алгоритмах
приводит к неплохому балансу между исследованием и использованием
поискового пространства (генотипа).
Генотипы в генетических алгоритмах представляют собой строки
данных определенного типа (чаще всего это двоичная и
вещественная последовательность). Из-за линейной структуры этих генотипов
их часто называют хромосомами. Хромосомы могут иметь как
фиксированную, так и переменную длину. Для множества 5 хромосом
фиксированной длины справедливо следующее утверждение:
S = {V(s[l],s[2], ...,s[n])eSi, Vie 1,2, ...,n},
т.е. локусы генов Si являются постоянными, а их кортежи могут
содержать элементы различных типов. Для множества S хромосом
переменной длины справедливо следующее утверждение:
S = {Vlist s: s[i\ G Sit VO ^ i < len(s)},
т. е. позиции генов могут сдвигаться в ходе выполнения эволюционных
операторов.
Процесс выполнения и свойства эволюционных операторов
репродукции на основе фиксированной длины хромосом достаточно хорошо
исследованы [8]. В частности, при выполнении 0-арных операторов
репродукции этот процесс описывается формулой вида
reproduction() = (s[l], ..., s[n\): s[i] = 5i[Lrndu() x len(Si)J],
Уге 1,2, ...,n.
При выполнении унарных операций репродукции, в частности
мутации, в хромосоме фиксированной длины производится случайное
изменение гена; в процессе выполнения оператора пермутации
(перестановки) происходит обмен генов в хромосоме.
При выполнении бинарных операций репродукции, например, крос-
синговера, выполняется обмен генов между двумя хромосомами в
случайно выбранной одной или нескольких точках.
Менее изучен процесс и свойства эволюционных операторов
репродукции с переменной длиной хромосом. При выполнении 0-арных
операторов репродукции хромосома имеет случайную длину L > 0.
При выполнении унарных операций репродукции, в частности,
мутации в хромосоме с переменной длиной производится либо добавление,
либо удаление случайно выбранных генов в любую позицию
хромосомы. При выполнении бинарных операций репродукции, например
кроссинговера, выполняется обмен генов между двумя хромосомами
94 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
переменной длины в случайно выбранной одной или нескольких
точках; при этом хромосомы родителей и потомков могут иметь различную
длину.
При подготовке использования генетического алгоритма для
решения частной проблемы первый шаг состоит в определении
представления решений задачи в виде хромосом, т. е. на уровне генотипа, следуя
правилам проектирования и отображения генотипического
пространства в фенотипическое. Желательна предварительная оценка способа
представления (кодирования) решений с учетом свойств легальности,
недостаточности, полноты и причинности.
Проблемными вопросами генетических алгоритмов являются
фундаментальная теорема Холланда, сходимость и целесообразность их
применения для некоторых оптимизационных задач. Несмотря на
определенные успехи, связанные с решением многих практических задач,
основные положения генетических алгоритмов не выглядят вполне
завершенными. Рассмотрим эти вопросы с позиций общей теории ЭВ.
Исследование поискового пространства в генетических алгоритмах
происходит путем применения композиции операторов кроссинговера,
мутации, селекции и др. В генетических алгоритмах оператор
кроссинговера применяется как основной, и поведение генетической системы
в значительной степени зависит от него. Оператор мутации, который
осуществляет спонтанные случайные изменения в различных
хромосомах, чаще всего выполняет вспомогательную роль, хотя эмпирические
исследования для некоторых классов задач показывают более важную
роль оператора мутации [12]. Тем не менее, генетические операторы
кроссинговера, мутации и некоторые другие проводят случайный
поиск, синтезируют новые решения, однако они не могут гарантировать
появление оптимальных решений.
Известны две гипотезы [5] для объяснения того, как генетические
операторы используют информацию, распределенную в популяции, для
формирования субоптимальных решений:
• гипотеза строительных блоков;
• гипотеза сходимости популяции.
Согласно гипотезе строительных блоков кроссинговер комбинирует
признаки от двух родителей для производства потомства. Качество
потомков зависит от сложного взаимодействия простых признаков.
Поэтому важно, чтобы оператор кроссинговера в процессе скрещивания
был в состоянии передать потомству те наборы признаков, которые
вносят существенный вклад в оценку качества родительских хромосом.
Вторая гипотеза предполагает использование свойства сходимости
популяции для ограничения пространства поиска. Это достигается
использованием случайной выборки по функции распределения хромосом
в текущей популяции, в отличие от гипотезы строительных блоков,
которая усиливает комбинацию существенных признаков из
родительской популяции.
4.2. Генетические алгоритмы
95
Каким образом композиция генетических операторов поддерживает
эти гипотезы? Кроссинговер реально усиливает генетические
алгоритмы, расширяя пространство поиска в различных направлениях за счет
получения потомков с новой генетической информацией, возможно,
более привлекательных, нежели родители, а также обеспечивая
непрерывность и наследственную преемственность качественных признаков
родителей. С позиций общей теории ЭВ воспроизводство себе подобных
хромосом с помощью оператора кроссинговера можно
интерпретировать как построение нового допустимого решения по заданным
допустимым решениям. Свойства непрерывности и наследственной
преемственности интерпретируются как возможность использования
комбинаций существенных признаков, содержащихся в генотипах родителей,
для формирования генотипа потомка. Это обеспечивает передачу
наследственных признаков особей от поколения к поколению на уровне
обмена генами.
Механизмы размножения могут быть разными: ген из отцовской
хромосомы переходит в материнскую хромосому; ген из материнской
хромосомы переходит в отцовскую хромосому; взаимный обмен
генами между материнской и отцовской хромосомами; отцовская и
материнская хромосомы остаются без изменения [28]. Однако процесс
размножения особей должен удовлетворять первому и второму
законам наследственности Менделя, которые формулируются следующим
образом:
• два гена, определяющие тот или иной признак, не сливаются
и не растворяются один в другом, но остаются независимыми
друг от друга, расщепляясь при формировании гамет;
• родительские гены, определяющие различные признаки,
наследуются независимо друг от друга.
Это означает, что согласно первому закону гены (или
соответствующие им признаки родителей), имеющие одинаковые аллели, сохраняют
свои значения в потомстве, т.е. передаются с вероятностью, равной 1,
потомку по наследству. Гены родителей, имеющие разные аллели,
передаются потомку по наследству с вероятностью, равной 0,5, т. е.
половина гамет оказывается носителем аллели отца, а другая половина —
аллели матери.
В соответствии со вторым законом рекомбинация (обмен) генов
может происходить либо в каком-то одном гене, либо в нескольких
генах одновременно, т. е. передача родительских признаков потомству
может происходить в генах независимо друг от друга. При этом может
оказаться, что гаметы потомков либо совпадают с родительскими
гаметами, либо отличаются от них в одном или нескольких позициях.
Таким образом, кроссинговер может быть описан следующей
последовательностью шагов:
• из популяции случайно выбираются два потенциальных родителя;
• выполняется компьютерная жеребьевка для определения —
проводить или не проводить скрещивание;
96 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
• при положительном варианте ответа на предыдущем шаге
случайно выбирается одна или несколько точек расщепления;
• каждая исходная родительская строка перерезается в точках
расщепления;
• производится обмен генетическим материалом слева и справа от
точек расщепления и соединение полученных строк для
формирования потомства.
В то же время необходимо отметить некоторую деструктивность
кроссинговера, поскольку отдельные удачные решения могут быть
хаотично искажены.
Оператор мутации в генетических алгоритмах является источником
генетической изменчивости, под которой понимается изменение
качественных признаков особей в результате появления новых аллельных
форм в отдельных генах или целиком в хромосоме. Тем самым в
каждом поколении мутации поставляют в хромосомный набор популяции
множество различных генетических вариаций-мутантов. Самое главное
заключается в том, что этот фактор эволюции популяции является
источником новой генетической информации, не содержащейся ранее
в генах родителей и их потомков.
Мутации происходят независимо от того, приносят ли они особи
вред или пользу. Они не направлены на повышение или понижение
степени приспособленности особи, а только производят структурные
изменения в аллельных формах генов, что приводит к изменению
количественных признаков особи. Однако нельзя отрицать, что в принципе,
комбинация мутаций может привести к возникновению новых форм
в генотипе, которые обеспечивают увеличение его степени
приспособленности к внешней среде.
Механизмы выполнения мутаций могут быть разными: от простой
одноточечной мутации, связанной с изменением родительского гена
в одном из битов генной информации, до инверсной мутации, при
которой происходит изменение всех компонентов хромосомы. С точки
зрения общей теории ЭВ оператор мутации вводит элемент
вариабельности в популяцию, так как резко изменяет некоторое решение.
Основным параметром мутации является ее вероятность. Обычно в
генетических алгоритмах ее величина достаточно мала (порядка 0,01),
чтобы, с одной стороны, расширить область поиска, а с другой —
не привести к таким изменениям потомков, которые будут далеки
от приемлемых решений [7].
Оператор селекции обеспечивает движущую силу дарвиновского
естественного отбора в генетических алгоритмах. Чем больше эта сила,
тем быстрее может завершиться генетический поиск; при меньшей
величине этой силы эволюционный процесс будет протекать
медленнее. Селекция направляет генетический поиск в перспективные
«районы» поискового пространства, используя для этого процедуру
перехода от одной популяции к следующей. Существует много возможных
4.2. Генетические алгоритмы
97
вариаций селекции — от вычислительно трудоемких подходов до
сравнительно простых схем.
Пожалуй, самым известным способом отбора в генетических
алгоритмах является метод рулетки: определяется вероятность отбора
(выживания) для каждой хромосомы пропорционально величине ее
качества (пригодности, приспособленности) путем вращения колеса
рулетки столько раз, каков размер популяции, выбирая каждый раз
одну хромосому для новой популяции. Иными словами, колесо рулетки,
являясь стохастической процедурой выбора, служит методом отбора.
Некоторые недостатки процедуры отбора по методу рулетки состоят
в том, что уже на ранних этапах эволюции проявляется тенденция
доминирования «очень хороших» особей в процессе отбора; а на более
поздних этапах конкуренция среди таких хромосом становится менее
сильной и в большей степени доминирует случайный поиск.
Другим методом отбора является турнирная селекция, которая
одновременно сочетает случайный и детерминированный подход к
отбору. Турниры похожи на маленькие «бои» между членами популяции,
чтобы увидеть, кто примет участие в следующем поколении. Здесь
случайно определяется множество хромосом, из которого отбираются
лучшие особи для репродукции. Число хромосом в этом множестве
называется размером турнира, который чаще всего принимается
равным 2 (бинарный турнир). После получения пары хромосомы с более
высокой оценкой пригодности отбираются в новую популяцию. Процесс
продолжается до тех пор, пока не будет сформирована вся популяция.
Ранжированная селекция начинается с упорядочивания популяции
по величине функции качества. Далее каждой хромосоме
присваивается ранг, и хромосомы с более высоким рангом имеют большую
вероятность включения в следующую популяцию. Функция
присваивания может быть линейной или нелинейной. Эта процедура отбора
акцентирует внимание в ходе селекции на хромосомах, обладающих
лучшими характеристиками.
Наконец, кроме указанных способов селекции существуют так
называемые элитные виды селекции, которые гарантируют, что в
процессе селекции будут сохраняться лучшие (в смысле пригодности)
хромосомы популяции. Элитные методы рекомендуется применять в
сочетании с любой из указанных выше схем селекции.
Учитывая указанные выше особенности генетических операторов
и положения общей теории ЭВ, обратимся к фундаментальной теореме
Холланда [5]. Холланд исходил из биологического понимания
адаптации как любого процесса в искусственных системах, посредством
которого структура системы прогрессивно эволюционирует, приводя
к большей эффективности системы в среде, в которой она
функционирует. Формализация процесса адаптации приводит к понятию шаблона
(schema), которое включает в себя подмножество подобных между
собой стрингов в популяции, совпадающих в определенных позициях
хромосомы длиной L. Шаблон создается за счет введения символа
7 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
98 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
безразличия, обозначаемого (х), в алфавит генов и представляет все
строки, которые соответствуют ему на позициях, отличных от х.
Первоначально теоретические результаты, полученные Холландом,
относилась к простейшему генетическому алгоритму. Этот алгоритм
предусматривал бинарное кодирование, рулеточную селекцию, оператор
мутации и одноточечный кроссинговер. В более поздних исследованиях
эти результаты стали обобщаться на другие формы и модификации
генетических алгоритмов [6, 7].
При использовании генотипов S с фиксированной длиной
хромосом L и двоичным алфавитом (0, 1) позиция гена в хромосоме (ло-
кус) определяет свойства генотипа. Шаблон характеризует множество
хромосом, имеющих локусы, совпадающие в определенных позициях.
Шаблон фиксированной длины L при двоичном кодировании может
включать 2L хромосом.
Рассмотрим пример. Шаблон Н\ = 1хх длиной 3 описывает
множество экземпляров хромосом {100, 101, 110, 111}, алфавит которых
состоит из символов 1, 0 и неопределенного значения (х), которое
может быть или 0 или 1. Отдельные хромосомы одновременно могут
принадлежать разным шаблонам. Например, хромосома 101
одновременно принадлежит шаблонам Яг = 10х или Щ = 1x1. Шаблон Н\ по
сравнению с #2 и Щ содержит меньшее число заранее фиксированных
двоичных значений. Это число называется порядком шаблона Н и
обозначается через о(#), т.е. о(Н\) = 1, o(#2) = о(Щ) = 2. Расстояние
между первой и последней фиксированными позициями называется
длиной шаблона и обозначается через d(H). Например, d(H\) = 0,
d(#2) = 1» ^(#з) = 2. На рисунке 24 представлены отдельные шаблоны
и хромосомы для рассмотренного примера.
Рис. 24. Пример шаблонов хромосом с фиксированной длиной, равной 3
Если популяция содержит /х хромосом, то в зависимости от ее
гетерогенности число экземпляров шаблонов колеблется от 2L до
/x-2L. Таким образом, хотя в процессе работы генетического
алгоритма при фиксированном размере популяции ps текущая популяция
включает /х хромосом, однако, неявно алгоритм обрабатывает
существенно большее, нежели /х, число шаблонов (неявный параллелизм).
4.2. Генетические алгоритмы
99
При двоичном кодировании параллелизм генетического алгоритма
является наивысшим.
Таким образом, при выводе своей теоремы Холланд опирался на
два важных свойства шаблона. Первое свойство определяет порядок
шаблона o(S) — число позиций 0 и 1, т.е. фиксированных позиций
(а не х), представленных в шаблоне. Проще говоря, порядок
шаблона — это его длина минус число символов безразличия. Определение
порядка необходимо при вычислении вероятности выживания шаблона
для оператора мутации.
Второе свойство характеризует длину d(S) шаблона, которая
представляет собой расстояние между первой и последней фиксированными
позициями в хромосомной строке битов. Это свойство дает оценку
компактности информации, содержащейся в шаблоне. Определение длины
важно при вычислении вероятности выживания шаблона при
скрещивании хромосом, выполняемом с помощью оператора кроссинговера.
Из базового цикла ЭВ, представленного на рисунке 6, следует,
что компьютерное моделирование эволюционного процесса включает
следующую последовательность из четырех повторяемых шагов:
• вычисление целевой функции;
• оценка качества решений;
• селекция хромосом для репродукции;
• репродукция (создание новых решений с использованием
операторов кроссинговера и мутации).
Начнем обсуждение теоремы Холланда с позиций общей теории ЭВ
с шага селекции. Селекционный отбор направлен на то, чтобы
хромосомы с лучшим значением функции качества получили преимущество
в ходе репродукции перед «слабыми» хромосомами, в то время как
применение генетических операторов рекомбинации расширяет
пространство поиска решений. Задача состоит в том, чтобы найти некий
оптимальный баланс между уже имеющимися решениями и вновь
получаемыми новыми решениями, что имеет важное значение для
адаптации системы.
Обозначим через £(#, t) число строк в популяции,
соответствующих шаблону Н в момент времени t. Определим среднюю пригодность
хромосом в популяции P(t), отвечающих шаблону Н. Допустим, что
популяция включает га хромосомных строк {а\у a<i, ..., am},
соответствующих шаблону Н в момент времени t. Тогда средняя пригодность
хромосом в популяции P(t), отвечающих шаблону Я;, равна
771
Суммирование в данной формуле ведется по всем хромосомам,
которые одновременно принадлежат шаблону Hi и популяции P(t).
7*
100 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Теперь можно вычислить среднюю пригодность для всей популяции
P(t) размером N как математическое ожидание вида
N
m[f(p(*))] = ^.£f№,*)
TV
i=\
В соответствии с процедурой селекции создаются промежуточные
популяции, состоящие из хромосом, отобранных на этой стадии
эволюции. При этом каждая хромосомная строка копируется нуль, один
или больше раз в зависимости от ее пригодности. Хромосома dj будет
отобрана в следующую популяцию P(t+ 1) с вероятностью, равной
F(aj)
Р> M[F(P(t))\'
После шага селекции в момент времени t -f 1 ожидаемое число
хромосом, соответствующих шаблону Я, будет равно £(Я, t + 1). Далее
необходимо учесть следующее:
• для некоторой «средней» хромосомы, определяемой шаблоном Я,
вероятность ее отбора равна
M[F(H, t)]
F(P(t)) '
• число хромосом, удовлетворяющих шаблону Я, равно £(Я, t)\
• число отбираемых хромосом определяется размером
популяции N.
Тогда при указанных условиях в момент времени t + 1 ожидаемое
число хромосом, соответствующих эталону Я, будет определяться
следующим выражением:
р,н,) = !»<).»Мв1.
Учитывая, что средняя пригодность популяции хромосом P(t) будет
равна M[P(t)] = F(P(i))/N, полученную формулу можно
преобразовать к следующему виду:
№t + i) = t{H,t).M£W$l (3)
Отсюда следует, что если пренебречь влиянием операторов мутации
и кроссинговера и рассматривать только селекцию с помощью
пропорциональной рулетки, то в следующей генерации популяции P(t+ 1)
предполагается получить число экземпляров шаблона Я,
пропорциональное отношению пригодности шаблона к средней пригодности
популяции. Это означает, что шаблон с пригодностью выше средней
пригодности дает в следующую популяцию P(t) большее число хромосом,
а шаблон с пригодностью ниже средней — меньшее число хромосом.
Таким образом, число экземпляров шаблона Я в следующей популяции
прямо пропорционально среднему значению пригодности этого шаблона
4.2. Генетические алгоритмы
101
и обратно пропорционально среднему значению пригодности
предыдущей популяции. Соотношение (3) в теории генетических алгоритмов
называется уравнением репродуктивного роста шаблона. Оценим
долговременный эффект соотношения (3).
Допустим, что шаблон Я имеет пригодности выше среднего
значения на е%:
М[Н, t] = M[P(t)} + eM[P(t)].
Тогда
£(#,*) = £(#,0).(1+е)<. (4)
Формула (4) представляет собой геометрическую прогрессию: при
переходе от одной популяции к следующей шаблон Я получает число
хромосом, увеличивающееся по экспоненциальному закону.
Однако селекция не создает новых точек (потенциальных решений)
для поиска в пространстве решений. Селекция лишь копирует
некоторые строки для создания промежуточных популяций. Вследствие этого
необходим ввод в популяцию новых индивидуумов, что
осуществляется посредством рекомбинации с помощью генетических операторов
кроссинговера и мутации. Рассмотрим влияние этих операторов на
ожидаемое число хромосомных строк, удовлетворяющих шаблону Я,
в популяции.
Используя указанные выше свойства шаблона, длину d(H) и
порядок шаблона о(Н), попробуем определить вероятность «выживания»
шаблона Я при выполнении одноточечного кроссинговера и мутации.
Пусть число позиций в хромосомах равно L. Точка скрещивания
для кроссинговера выбирается случайно из L — 1 позиций. Некоторый
шаблон Я будет «уничтожен» одноточечным кроссинговером, если
точка скрещивания кроссинговера окажется между первой и последней
позициями, а второй родитель не является экземпляром шаблона Я.
Вследствие этого вероятность гибели (разрушения) этого шаблона Я
будет равна
pd(H) = d(H)/(L-l).
Соответственно вероятность выживания некоторого шаблона Я
определяется как
р,{Н) = 1 -pd(H) = \-d{H)/{L-\).
Однако скрещиванию подвергаются не все, а только некоторые
хромосомы. Их количество определяется вероятностью кроссинговера рс.
Это означает, что фактически вероятность выживания шаблона Я
будет оцениваться величиной
p,{S) = l-pc[d(H)/{L-l)].
(5)
102 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Если учесть, что точка скрещивания может оказаться между
фиксированными позициями шаблона, то сохраняются шансы его
выживания. Вследствие этого необходимо изменить формулу (5) выживания
шаблона следующим образом:
ps(S)^l-pc[d(H)/(L-l)}. (6)
Комбинируя эффекты выполнения операторов селекции и кроссин-
говера (формулы (3) и (6)), получим следующее соотношение,
описывающее репродуктивный рост хромосом-представителей шаблона Н
в последующих генерациях:
№(+1))№0 M[f(я't)] d(H). ■ (7)
Полученное неравенство (7) показывает, что ожидаемое число
хромосом, удовлетворяющих шаблону Н в следующей генерации, является
функцией фактического количества хромосом, отвечающих шаблону,
относительной пригодности шаблона и его длины d(H).
При оценке влияния оператора мутации на репродуктивный рост
хромосом, порождаемых некоторым шаблоном Н, следует иметь в
виду, что этот оператор изменяет единственную позицию в пределах
хромосомы с вероятностью рш. Очевидно, что все остальные
фиксированные позиции шаблона должны оставаться неизменными, если
шаблон подвергся мутации. Таким образом, вероятность изменения
(инвертирования) отдельного бита в хромосоме равна рт, а
вероятность выживания шаблона Н составляет величину 1 — рт. Поскольку
одноточечная мутация не зависит от других мутаций, то вероятность
выживания шаблона Н из исходной популяции Р(0) с учетом порядка
шаблона о(Н) равна
р,(Я) = (1-Рт)°(Я).
Поскольку рш <С 1, то последняя формула преобразуется к виду
р8(Н) « 1 - о(Н)Рт. (8)
Объединяя эффекты выполнения операторов селекции, кроссинго-
вера и мутации (формулы (7), (8)), получим следующее соотношение,
описывающее рост хромосом в популяции, отвечающих эталону Н:
№ t+i)> № t) M[F{*^ -. (9)
М[Р(0]-[1-Рс-|^|-о(Я).Рт]
Как и в предыдущих, более простых формулах (3) и (7),
последнее выражение определяет ожидаемое число сходных с шаблоном Н
хромосомных строк в последующих генерациях как функцию числа
таких строк в текущей популяции, относительной пригодности эталона,
а также его длины и порядка.
4.2. Генетические алгоритмы
103
Выражение (9) определяет теорему Холланда для генетических
алгоритмов, иногда называемую теоремой шаблонов, которую можно
теперь переформулировать следующим образом: шаблоны, обладающие
малой определяющей длиной, низким порядком и пригодностью, выше
средней в популяции, будут увеличивать число строк, сходных с
шаблоном, в последующих генерациях по экспоненциальному закону.
Понятным, но спорным объяснением практической эффективности
ГА и важности кроссинговера выглядит гипотеза Д. Голдберга [30],
согласно которой в ходе генетического поиска, особенно в области
близкой к оптимуму, желательно формировать хромосомы из шаблонов
меньшего порядка с короткой определенной длиной, отбирая из них
лучшие решения вместо селекции только элитных хромосом.
С позиций общей теории ЭВ постепенное, с помощью
кроссинговера, формирование квазиоптимальных решений, на наш взгляд,
является все же сильным упрощением генетических алгоритмов.
Представляется, что для практики применения генетических алгоритмов в ЭВ
нетипичным выглядит подход, заключающийся в декомпозиции общей
задачи на множество независимых подзадач. Такой подход
используется скорее в традиционных методах оптимизации.
Теорема Холланда весьма упрощенно описывает поведение
генетических алгоритмов, а ее доказательство, построенное на
элементах теории вероятности, не учитывает достаточно большой разброс
значений функций пригодности шаблонов в некоторых практических
задачах. Была установлена вычислительная ошибка, которая приводит
к неверным результатам для задачи об игровых автоматах. К тому
же, поскольку популяция в генетических алгоритмах имеет конечную
величину, то возникает неизбежная ошибка при определении
значения функции пригодности шаблона. Эта ошибка в оценке ставит под
сомнение значение теоремы в плане ее практического применения, за
исключением очень простых приложений, для которых теорема
становится почти тавтологией, описывающей пропорциональный
селективный отбор. Эффект ошибки при определении значения пригодности
шаблона состоит в том, что в популяции реального размера
действительное значение функции пригодности может существенно отличаться
от среднестатистического значения даже для начальной популяции.
Другое критическое замечания относительно теоремы Холланда,
с позиций общей теории ЭВ, касается предположения о
независимости экземпляров, выбираемых из различных шаблонов популяции.
Нельзя считать независимыми экземпляры хромосом, если популяции
на основе двух пересекающихся шаблонов имеют различную скорость
сходимости. Этот факт имеет место даже для бесконечно больших
популяций. Он состоит в том, что значение функции пригодности
шаблона в популяции быстро начинает отклоняться от теоретического
среднего значения, что никак нельзя объяснить на основании теоремы
Холланда.
104 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Для любого метода оптимизации особый теоретический интерес
представляет вопрос о сходимости к глобальному оптимуму и об
условиях сходимости. Из теоремы Холланда не следует сходимость ГА
к глобальному оптимуму. Исследования в области сходимости ГА
сконцентрированы, в основном, на простейших ГА, а сходимость
многочисленных модификаций ГА для решения практических оптимизационных
задач является малоисследованной проблемой. Было доказано [49],
что простейший ГА не сходится к глобальному оптимуму за конечное
время. Доказательство основано на фундаментальной теории цепей
Маркова и сводится к следующему.
Цепь Маркова является специальной формой для описания
случайных процессов. Она характеризуется тем, что процесс состоит из
дискретных состояний и протекает дискретно во времени. Вероятность
того, что процесс будет в момент времени (t + 1) находиться в
некотором состоянии v, если он к моменту t находился в состоянии w,
зависит только от этих состояний и не зависит от течения
процесса в предшествующих состояниях цепи. Эта вероятность называется
вероятностью перехода из состояния v в состояние w и обозначается
через pvw > 0. Если вероятность pvw не зависит от £, то цепь Маркова
считается однородной. Обычно вероятности переходов представляются
в форме квадратной матрицы Р, в которой число строк и столбцов
соответствует числу к возможных состояний цепи, причем сумма
элементов любой строки равна 1.
Пусть для данного начального вектора распределения возможных
состояний р(0) получается к моменту t вектор с распределением
вероятностей p(t) = p(0) • Рг. Если для некоторой степени t справедливо
Рг • Р = Рь, то стохастический процесс к моменту времени t находится
в равновесии, а Р1 является равновесной матрицей, содержащей
одинаковые строки. Пусть необходимо найти максимум некоторой функции
Р(а), где а £ {0, 1}L, при условии 0 < F(a) < сю и F(a) ф const.
Простейший ГА с вероятностями мутации и кроссинговера рт, рсе
е (0, 1) и пропорциональной рулеточной селекцией описывается
однородной марковской цепью. Состояниями цепи являются состояния
популяции, пространство которых Y = {0, 1}LN. Изменение состояния
популяции описывается матрицей Р, которая образуется в результате
выполнения операторов кроссинговера, мутации и селекции.
Известно [49], что матрица Рг сходится к локальному оптимуму только в том
случае, если матрица переходов Р является примитивной (существует
некоторое £, при котором матрица Р1 состоит только из положительных
вероятностей, т. е. pvw > 0 для всех v, w) и сумма элементов любой
строки равна 1. Следовательно, простейший ГА соответствует цепи
Маркова с эргодической матрицей переходов, т. е. не зависит от
исходной популяции. Однако условие сходимости простейшего ГА к
глобальному оптимуму может не выполняться, т.е. не существует гарантий
того, что за неограниченное время алгоритм найдет абсолютно лучшее
решение.
4.2. Генетические алгоритмы
105
Проиллюстрируем на примере этот результат с позиций общей
теории ЭВ. Пусть популяция состоит из хромосом, каждая из которых
кодируется 2-битовой строкой. Тогда возможными вариантами эволюции
популяции при размере популяции N = 2 будут элементы следующего
множества:
S = {(00, 00), (00, 01), (00, 10),(00, 11), (01, 00), (01, 01), (01, 10),
(01, 11), (10,00), (10,01), (10, 10), (10, 11), (11,00),
(11,01), (11,10), (11,11)}.
Если размер популяции N будет равным 3, то возможными
вариантами эволюции популяции будут элементы следующего множества:
5 = {(00,00,00), (00,00,01), (00,00,10), (00,00,11),
(00,01,00),(00,01,01),(00,01,10),(00,01,И),
(И, 11,00), (И, 11,01), (11, И, 10), (11,11,11)}.
Число элементов множества S при N = 3 равно 64. В общем случае,
если хромосомы имеют длину L битов, то мощность множества S
равна 2LN.
При N = 2 и L = 2 размеры марковской матрицы вероятностей
переходов Р равны 16 х 16, а каждый элемент матрицы р^ означает
вероятность перехода от г-го в j-oe состояние, причем
L-N
Обозначим через 7Г* векторную строку, fc-й элемент которой равен
вероятности возникновения k-ro состояния на шаге t генетического
алгоритма. Тогда справедлива следующая оценка:
7Г*+1 = 7Tt • Р.
Таким образом, начиная с заданной начальной 7Го вектор-строки,
можно оценить вероятность состояния вектора после п-го шага
эволюции:
я*п = ^о • Рп>
где Рп вычисляется путем умножения матрицы Р саму на себя
(п — 1) раз.
Поведение генетического алгоритма (без учета мутации) можно
описать следующими тремя вариантами:
• алгоритм может сходиться к одному или более поглощающему
состоянию (состояние, из которого он не имеет переходы в другие
состояния);
106 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
• алгоритм допускает переход к другим состояниям, из которых,
в свою очередь, возможен переход к одному из поглощающих
состояний;
• алгоритм никогда не достигнет поглощающего состояния.
Принимая во внимание вышесказанное и обозначив через Ь
число поглощающих состояний, через и число состояний, из которых
возможен переход в другие состояния, можно построить матрицу Р,
разделив ее на следующие подматрицы:
где I — это единичная матрица размером (b x Ь), О — нулевая
матрица размером (6 х w), R — матрица размером (и х 6), содержащая
вероятности перехода из непоглощающих состояний в поглощающие
состояния, Q — матрица размером (и х и), содержащая вероятности
переходов между не поглощающими состояниями.
Из свойств марковских цепей вытекает следующее соотношение:
Vk„r or )'
где матрица переходов Кп на шаге п определяется как
Kn = I + Q + Q2 + Q3 +... + Qnl.
Матрица Кп позволяет вычислить, как часто марковский процесс
находится в непоглощающих состояниях, прежде чем он достигнет
поглощающего состояния. Тогда при п —> со имеем
lim K„ = (I-Q)-'.
п—юо
Следовательно,
„1™oP"=((I-QI)-'.R £)'
причем известно, что обратная матрица (I-Q)-1 всегда существует.
Таким образом, из приведенных выше соотношений следует, что
для заданной начальной 7Го вектор-строки при п —> оо марковская цепь
с вероятностью 1 перейдет в поглощающее состояние. Это означает, что
существует ненулевая вероятность того, что поглощающее состояние
является глобальным оптимумом в поставленной задаче. Тем не менее,
следует признать, что методология управления сходимостью даже для
простейшего ГА до сих пор не выработана.
Однако Холланд, предлагая свой простейший ГА, не утверждал, что
этот алгоритм предназначен в первую очередь для решения
оптимизационных задач. На решение различных практических задач
оптимизации с учетом разнообразных ограничений направлены многочисленные
4.2. Генетические алгоритмы
107
поздние публикации модификаций простейшего ГА, сделанные
другими исследователями. Заметим также, что для практики проблемный
вопрос о глобальной сходимости метода оптимизации все же является
второстепенным. Гораздо более важным для практики является другой
вопрос: находит или нет применяемый алгоритм близкое к
оптимальному решение за возможно более короткое время? Ответ на этот
вопрос для ГА также не выглядит однозначным, поскольку в теории ГА
пока не получено исчерпывающих объяснений успешных эмпирических
результатов, связанных с практическим решением многих
оптимизационных задач.
Каковы критерии того, насколько подходящим является ГА для
решения тех или иных задач? Проводились исследования [30] так
называемых обманчивых проблем (deceptive problems), при решении которых
интуитивно можно предположить, что ГА должен найти глобальный
оптимум. В генетике [28] было установлено влияние эпистазии (эпи-
стаз означает, что при взаимодействии между генами из разных
аллелей один ген подавляется другим геном) на результативность решения
той или иной задачи с помощью ГА. Иначе говоря, если оценивать
степень влияния друг на друга переменных задачи (эта оценка сама по
себе является довольно сложной задачей) в процентах, то при низкой
степени эпистазии предпочтительнее использовать не ГА, а
градиентные методы. При высокой степени эпистазии преимущество перед
ГА получают методы слепого случайного поиска. Существует [50, 51]
классификация задач, для решения которых наиболее или наименее
подходят те или иные алгоритмы эволюционных вычислений.
Рассмотрим с позиций общей теории ЭВ и статистического
корреляционного анализа вопрос о том, трудной или легкой для ГА является
прикладная проблема, основываясь на ландшафтном представлении
функций пригодности (ландшафт — это гиперповерхность, образуемая
функцией).
Очевидно влияние генетических операторов на результаты работы
генетического алгоритма. Обозначим эту взаимосвязь применяемого
генетического оператора через коэффициент корреляции гго. Этот
коэффициент устанавливает взаимосвязь между значениями функций
пригодности родительских хромосом и хромосом-потомков, т. е. он
отражает влияние на ландшафт применяемого генетического оператора.
Чтобы определить гго, вначале необходимо случайно задать
исходную популяцию из N родительских хромосом. Затем к данному
множеству применяются генетические операторы мутации или разновидности
кроссинговера для репродукции N потомков. Если обозначить через
ф(род) и ф(пот) значения функций пригодности хромосом родителей
и потомков, то коэффициент корреляции определяется выражением
следующего вида:
гго = соу(Фрод,Ф(пот))/(^(Ф(р°д) • ^(Фпот)),
108 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
где соу(Ф(род),Ф(пот)) - ковариация от Ф(род) и Ф(пот). Ковариация
определяется следующим образом:
1 N
с™(Ф(род),Ф(пот)) = ± ]Г(ф<род) - м[Ф(род)]). (ф!пот) - [ф(пот)]),
2=1
где величины М[Ф(род)], М[Ф(пот)] являются математическим
ожиданиями функций пригодности родителей и потомков, а величины <т(Ф(род)),
а(Ф(пот)) — их среднеквадратичными отклонениями в случайной
выборке из N хромосом.
Например, для задачи поиска оптимального маршрута при
транспортировке грузов [12] приводятся следующие данные относительно
коэффициента корреляции гго: чем выше гго, тем более плавным
является ландшафт функции пригодности для исследуемого генетического
оператора. Высокое значение гго говорит о том, что многие элементы
родительских хромосом находят свое отражение в потомках.
Однако знание коэффициента корреляции гго само по себе не
достаточно для решения вопроса о том, является или нет данная
задача легко ГА-разрешимой. Известны тестовые функции (бенчмарки),
имеющие сложные мультимодальные ландшафты, которые ГА легко
оптимизирует, и наоборот, трудные для ГА унимодальные задачи [52].
Поэтому более универсальным представляется подход, когда для
оценки ГА-разрешимости задачи применяются не коэффициент
корреляции гго, а методы корреляционного анализа. Они основаны на
эвристических оценках расстояния между актуальными значениями функции
пригодности и глобальным оптимумом (в случае, если он является
известным). При использовании в ГА двоичного кодирования в
качестве расстояния обычно выбирается расстояние по Хеммингу (D).
Если обозначить через гфо указанный коэффициент корреляции между
актуальным значением функции пригодности (Ф) в заданном
пространстве поиска и значением функции в точке глобального оптимума (О),
то коэффициент корреляции определяется как
Гфо = СОУ(Ф, 0)/(<7(Ф) • (7(0)), (10)
ГДе
соу(Ф, 0) = ± £(Ф, - М[Ф]) • (Dz - [D]),
2=1
причем величины М[Ф] и M[D] являются математическим ожиданиями
функций пригодности и расстояния, а величины <т(Ф), cr(D) — их
среднеквадратичными отклонениями в случайной выборке из N хромосом.
Величину (10) можно рассматривать как меру ГА-разрешимости
задачи, причем ее идеальным значением в случае максимизации было
бы значение гфо = —1,0, а в случае минимизации — гфо = +1,0.
4.3. Алгоритмы генетического программирования 109
Существуют примеры [6] тестовых задач с известным
значением глобального максимума, для которых определялись значения гфо,
после чего исследуемые задачи классифицировались на следующие
группы:
• легко ГА-разрешимые (гфо ^ —0,15);
• трудно ГА-разрешимые (—0,15 < гфо < 0,15);
• обманчивые (гфо ^ 0,15).
Если значение глобального оптимума заранее неизвестно, то можно
использовать вместо него лучшее из известных решений.
Таким образом, достоверность и обоснованность общей теории
эволюционных вычислений и ее следствий подтверждается
непротиворечивостью известным результатами для генетических алгоритмов,
высокой степенью сходимости теоретически полученных результатов
с экспериментальными данными. Анализ существующих публикаций
в отечественной и зарубежной научной литературе также позволяет
сделать вывод о непротиворечивости полученных в рамках общей
теории ЭВ научных результатов с известными ранее генетическими
алгоритмами.
4.3. Алгоритмы генетического программирования
Алгоритмы генетического программирования и генетические
алгоритмы — два разных вида эволюционных алгоритмов. С позиций
общей теории ЭВ основной особенностью алгоритмов генетического
программирования, которые направлены на решение задач
автоматического синтеза программ на основе входных обучающих данных путем
индуктивного вывода, являются не только древовидные структуры
данных, используемые для представления генотипа [9, 12, 32, 40, 43, 53].
В традиционных моделях вычислений (ввод-обработка-вывод)
исходная информация на входе обрабатывается заданной программой
вычислений для получения заранее неизвестного результата. Иначе обстоит
дело в генетическом программировании: здесь целью является поиск
неизвестной программы по известным входным данным и выходным
образцам. Рисунок 25 иллюстрирует эту особенность генетического
программирования.
Действительно, для многих практических задач сложно
зафиксировать свойства функциональной зависимости выходных параметров
от входных величин, еще сложнее привести аналитическое описание
такой зависимости.
Одним из способов решения данной проблемы является применение
алгоритмов генетического программирования путем решения задачи
символьной регрессии [43]. Регрессия дает математическое
выражение в символьной форме, которое можно подвергнуть
содержательному анализу, упростить и далее использовать для моделирования или
оптимизации. Эффективность применения алгоритмов генетического
110 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
( Известны образцы ,
i h \__
Входы Выходы
V
Необходимо найти
Рис. 25. Генетическое программирование в контексте общей теории ЭВ
программирования определяется тщательной настройкой их
параметров. Это препятствует их более широкому распространению, поскольку
требует от пользователей высокой квалификации и большого опыта
в применении эволюционного моделирования. Поэтому необходимо
разрабатывать адаптивные алгоритмы генетического
программирования с расширенными когнитивными возможностями. Кроме того, при
решении задачи символьной регрессии с помощью метода
генетического программирования возникает проблема подбора численных
коэффициентов модели, что приводит к необходимости минимизации функции
ошибки аппроксимации, которая является, чаще всего,
многоэкстремальной. В рамках общей теории ЭВ это приводит к необходимости
разрабатывать и применять комбинации алгоритмов генетического
программирования (для построения моделей) и генетических алгоритмов
(для уточнения параметров модели).
В канонических работах Коза [9] древовидные структуры данных
алгоритма генетического программирования предназначались для
представления математических функций. Однако с точки зрения общей
теории ЭВ алгоритмы генетического программирования предоставляют
совершенно новые возможности для машинного обучения, нежели
генетические алгоритмы. С одной стороны, они требуют гораздо меньше
предположений о структуре возможных решений, а с другой стороны,
нацелены на эволюционный синтез новых решений в явном виде, в
отличие от нейросетей. Не случайно растет интерес к алгоритмам
генетического программирования как средству автоматизации разработки
программного обеспечения, а полученные в последнее десятилетие
результаты (квантовый алгоритм для задачи Гровера [18], сортирующие
сети и др.) превосходят аналогичные, созданные «вручную» и
свидетельствуют об их большом потенциале.
Древовидные структуры являются наиболее распространенным
вариантом представления генотипического пространства S в
генетическом программировании, поэтому для их представления обычно
применяются языки функционального программирования (Лисп и др.),
>
4.3. Алгоритмы генетического программирования 111
в которых программы естественным образом интерпретируются в виде
последовательности вычислений. При этом существенно упрощается
техника выделения наиболее пригодных поддеревьев решений.
Рассмотрим операторы, применяемые для репродукции и синтеза деревьев.
Для работы генетического алгоритма, согласно базовому циклу ЭВ,
представленному на рисунке 6, необходимо вначале создать множество
случайных хромосом в виде строк векторов определенного типа
фиксированной или переменной длины. Аналогично, для работы алгоритма
генетического программирования также необходима случайная
инициализация популяции программ, например, в виде древовидных структур
(унарная репродукция). Внутренними узлами дерева являются
элементы множества нетерминальных (function set) символов (стандартные
арифметические операции, математические, логические функции или
другие процедуры, использующие аргументы). Листьями дерева
являются терминальные символы (terminal set): переменные, константы,
действия, функции без аргументов. Причем, множество terminal set
должно быть замкнуто относительно множества function set.
Для того, чтобы предотвратить чрезмерное разрастание дерева,
вводят ограничение на максимальное количество функциональных
элементов в дереве или максимальную глубину (d) дерева. Если в ходе
выполнения генетических операторов получится дерево,
превосходящее заданное ограничение, то вместо конфликтного дерева копируется
родительское дерево.
Также следует отметить возможность появления интронов — ничего
не делающих участков кода, примером которых при записи в
префиксной символьной форме являются: (NOT (NOT X)), (IF (2=1)...X),
(-Х 0), (*Х 1).
Для управления популяциями программ в алгоритмах
генетического программирования необходимо определить критерий качества.
Выбор критерия качества зависит от конкретной задачи и обычно сводится
к определению набора задач, которые должна решать
эволюционирующая программа. Сам критерий качества — это функция, вычисляющая
эффективность решения задач данной программой. При линейном
критерии качества учитывается различие между результатом выполнения
программы и требуемым решением реальной задачи. Следовательно,
линейный критерий качества можно рассматривать как сумму ошибок
при наборе задач. Возможны также другие меры качества, например,
с нормализованным в диапазоне от 0 до 1 критерием качества,
подразумевающим деление общего критерия качества на количество всех
возможных ошибок. Отметим, преимущество нормализации
проявляется при работе с большими популяциями программ. Кроме того, мера
качества может учитывать размер программы и поощрять создание
компактных программ небольшого размера.
Генетические операторы в пространстве программ содержат как
преобразование самого дерева (например, мутация, пермутация),
так и обмен фрагментами между различными деревьями (например,
112 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
кроссинговер). При мутации в структуру программы вносятся
случайные изменения, например, представленные на рисунке 26, мутация
вставкой и мутация удалением.
Мутация вставкой Мутация удалением
Рис. 26. Мутации в структуре программы
Пермутация аналогична оператору инвертирования строк в
генетических алгоритмах и состоит в перемене мест конечных символов или
поддеревьев, например, как это показано на рисунке 27.
Рис. 27. Пермутация перестановкой поддерева
Кроссинговер подразумевает обмен поддеревьев двух программ,
например, как это показано на рисунке 28.
Рис. 28. Кроссинговер путем обмена поддеревьями
Этот оператор также можно использовать для преобразования
одного родительского дерева путем перемены мест в двух его поддеревьях.
При случайном выборе точки скрещивания два идентичных
родительских дерева могут дать различное потомство. Точкой скрещивания
может служить также корневой узел программы.
В алгоритмах генетического программирования унарным
оператором репродукции является также редактирование деревьев с
целью упрощения математических формул. Например, выражение вида
4.3. Алгоритмы генетического программирования 113
у = х - х + (1 • х) 4- (5 — 3) можно упростить путем замены (1-х)
на х, (5 - 3) на 2, что иллюстрируется на рисунке 29. Эта замена
путем редактирования упрощает программный код и уменьшает время
выполнения программы.
Рис. 29. Редактирование путем замены
В результате замены создается новое дерево, хотя, с точки зрения
функционального аспекта, созданный потомок эквивалентен
родительской хромосоме.
Другими, потенциально полезными унарными операторами
репродукции для алгоритмов генетического программирования являются
инкапсуляция, упаковка и лифтинг. Идея оператора инкапсуляции,
представленного на рисунке 30, состоит в выявлении полезных
поддеревьев, не подлежащих уничтожению другими операторами репродукции
в процессе эволюции.
А
Рис. 30. Унарный оператор инкапсуляции
Инкапсуляция, как вспомогательная операция, особенно полезна
в специальных приложениях, таких как эволюция искусственной
нейронной сети [35].
Для проведения операции упаковки сначала на дереве выбирается
поддерево с корневым нетерминальным узлом, из которого выходят
несколько новых листьев, среди которых, по крайней мере, один
является незанятым. Затем из исходного дерева вырезается выбранное
поддерево, которое добавляется к одному из вновь созданных новых
листьев.
8 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
114 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Пример унарного оператора упаковки представлен на рисунке 31.
Оператор лифтинга является обратным оператору упаковки.
Рисунок 32 иллюстрирует выполнение унарного оператора лифтинга.
Рис. 31. Унарный оператор упаковки
Ал л
Рис. 32. Унарный оператор лифтинга
Концепция автоматически определяемых функций (ADF) [9]
обеспечивает модульность алгоритмов генетического программирования.
Идея использования ADF заключается в стремлении повысить
эффективность алгоритмов ГП за счет модульного построения программ,
состоящих из главной программы и ADF-модулей, генерируемых в ходе
моделирования эволюции. В качестве ADF, как правило, используются
корневые и нетерминальные вершины дерева.
Структура программы с ADF, число ADF-модулей и параметры
каждой ADF определяются до начала эволюции. Все вершины данной
структуры имеют свой номер, а список аргументов включает
отдельные локальные переменные, которые определяются при вызове ADF.
Завершает установку общей программы задание функции главной
программы.
Настройка ADF (их число, аргументы и т. п.) зависит от
решаемой задачи, имеющихся вычислительных ресурсов и предварительного
опыта. Отметим также необходимость типизации вершин дерева, иначе
при выполнении оператора кроссинговера могут быть синтезированы
синтаксически некорректные решения [54].
Предположим, что целью является аппроксимация некоторой
функции у(х), зависящей от переменной х. В геноме используются две
ADF функции f\{a) и /2(a, b). Функция f\ зависит от параметра а,
функция /г — от параметров а и 6. На рисунке 33 представлен пример
генотипа в виде древовидной структуры с ADFi и ADE2.
4.3. Алгоритмы генетического программирования 115
Рис. 33. Пример кодирования генотипа с ADF
Представленная в качестве примера структура кодирует следующее
математическое выражение:
w(x) = /2(4,/i(x))*(/1(x) + 3),
где
fl(a) = a + 7, /2(а,Ь) = (-а)*Ь.
Следовательно, у(х) = ((-4) * (х + 7)) * ((х + 7) + 3).
Дж. Коза впервые применил ADF-функции для поиска символьной
регрессии. В более поздних работах были приведены примеры их
применения для целого ряда других важных задач, таких эволюция
поведения агента, проектирование электрических схем, эволюция
поведения роботов и др. Сравнительный анализ алгоритмов генетического
программирования с ADF и без ADF показывает [32], что для
некоторых задач, с точки зрения вычислительной трудоемкости и
структурной сложности программ, преимущество за алгоритмами генетического
программирования без ADF. Однако имеется целый ряд примеров,
свидетельствующих об обратном: о преимуществе алгоритмов
генетического программирования с ADF как по структурной сложности
решений, так и по их вычислительной трудоемкости.
С позиций общей теории ЭВ идея использования ADF-функций
может быть дополнена автоматически определяемыми макросами (ADM)
для определения программного кода.
Авторы [55], исследуя решения различной длины, получаемые с
помощью алгоритмов генетического программирования, обратили
внимание на так называемый эффект «компрессионного давления», которым
обладают решения с малой структурной сложностью. Это означает, что
программы, генерируемые алгоритмом ГП, зачастую содержат
«лишние» блоки, не влияющие на функциональные возможности программы
и на значение ее функции пригодности. В генетике это
соответствует уже упоминавшемуся понятию интрона, который является
нечувствительным к кроссинговеру. С учетом этого вводится [55] понятие
116 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
эффективной сложности, величина которой равна величине
структурной (абсолютной) сложности программы за вычетом величины
нитронов, содержащихся в программе. Принято считать, что применение
кроссинговера носит деструктивный характер, если функция
пригодности потомков ухудшается. Следовательно, для программы с
относительно большим значением структурной сложности, но содержащей
много интронов, опасность деструктивного воздействия кроссинговера
уменьшается.
Проанализируем эту ситуацию с учетом приведенных ранее
критических замечаний относительно теоремы Холланда. Обозначим через
Се(йг) эффективную сложность программы a,i (i = 1,2, ...,//), через
Ca(ai) абсолютную сложность программы а*, через Рс — вероятность
применения кроссинговера, а через Pd — вероятность того, что
применение кроссинговера приведет к деструктивному эффекту, причем
Pd = 0, если кроссинговер проводится с интроном. _
Пусть Ф(аг) — значение функции пригодности программы а^, Ф(£) —
среднее значение функций пригодности всех программ в популяции
P(t). Если применяется пропорциональная селекция, то нижняя оценка
Ai(t+ 1) «доли» программы а* в популяции P(t + 1) примерно равна
М* + О = Mt)' *(*)/*(*) • О " Рс' Се{ог)/{Са(аг) -Pd)=
= (ФЫ - Рс • Ф(щ) - Се((ц)/Са(аг) • Р*)М1)/Щ.
Выражение в скобках представляет собой определение эффективной
функции пригодности
ФеЫ = Ф(<ц) - Рс • Ф(<ц) • Се(аг)/Са{аг) • Pd%
которая соответствует вкладу программы а* в следующую
популяцию P(t+1). Отсюда следует, что репродуктивные шансы некоторой
программы di тем выше, чем меньше отношение между эффективной
и абсолютной сложностью программы. Достигнуть этого можно двумя
путями. Первый заключается в увеличении абсолютной сложности
путем добавления интронов, второй — в поиске простых решений.
Имеющиеся эмпирические данные подтверждают приведенные выше
соображения. Эти данные свидетельствуют о следующем:
• на начальных этапах работы алгоритма генетического
программирования среднее значение функции пригодности от
популяции к популяции изменяется очень сильно, в то время как Фе
изменяется относительно медленно; между тем репродуктивные
свойства некоторой программы зависят прежде всего от значения
ее функции пригодности;
• несколько позднее темп изменения среднего значения функции
пригодности популяции уменьшается, однако, начинает расти
соотношение между эффективной и абсолютной сложностью,
иными словами, возрастает «компрессионное давление» и Фе
уменьшается;
4.3. Алгоритмы генетического программирования П_7
• на заключительных этапах работы алгоритма генетического
программирования экспоненциально растет абсолютная сложность
программы за счет интронов, в то время как Фе остается на
относительно низком уровне; среднее значение функции
пригодности популяции продолжает улучшаться, а деструктивное влияние
кроссинговера слабеет.
Теоретически обоснованное и эмпирически наблюдаемое явление
«компрессии» таит в себе опасность преждевременной сходимости
алгоритма генетического программирования к субоптимальным
решениям. Если ввести внешнее управление этим процессом с помощью
некоторого коэффициента D, пропорционального абсолютной сложности
программы, то с учетом этого выражение для Фе принимает
следующий вид:
Фе(сц) = Ф(йг) - D • Ca(Oi) - Рс ' Ф(а<) • С'e(Oi)/'С'а(сц) • Pd.
Однако эксперименты показывают, что подобного рода внешнее
управление не решает обозначенной проблемы.
Кроме того, при выполнении большинства указанных операторов
для репродукции необходимо выбирать узел дерева. Этот вопрос
также является проблемой алгоритмов генетического программирования.
Возможно, этот вопрос не имеет большого теоретического значения,
однако, он играет важную роль с точки зрения практики. В
литературных источниках чаще всего предлагается случайный выбор узла
(для мутации, кроссинговера и др.), но не описывается, как именно
это должно быть сделано.
Древовидные структуры — не единственный вариант отображения.
Другими подходами к генетическому программированию являются:
линейное генетическое программирование, эволюционные
грамматические правила, основанные на графах параллельные распределенные
алгоритмы генетического программирования, алгоритмы сетевого
генетического программирования, алгоритмы булевского
программирования [54]. Несмотря на различие этих подходов с точки зрения общей
теории ЭВ, эти алгоритмы генетического программирования должны
оцениваться с единых позиций:
• корректность алгоритмов;
• возможности алгоритмов генетического программирования для
решения NP-трудных задач;
• функциональность алгоритмов.
Сформулируем рекомендации по решению указанных проблем.
При использовании генетических операторов возможна ситуация,
при которой созданная программа будет соответствовать
некорректному выражению. В этом случае рекомендуется следующее:
• повторять кроссинговер, пока не будет получено корректное
дерево;
• добавить полученную программу в популяцию с нулевой
пригодностью;
118 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
• выполнять генетические операторы с экспрессией генов, которая
заключается в том, чтобы с определенного места на дереве
встречались только терминальные символы (впрочем, некорректность
все же может возникнуть, если используются разные типы
данных).
С позиций общей теории ЭВ вопрос о корректности или
некорректности синтезируемых программ должен обсуждаться на более
фундаментальном уровне. В частности, в генетическом программировании
нетрудно вычислить такую характеристику, как размер синтезируемой
программы, в отличие от определения алгоритмической
разрешимости программы. Эта проблема была поставлена еще Д. Гильбертом,
а А. Чёрч и А. Тьюринг показали невозможность существования
формальной процедуры, которая позволяла бы решать, выводимо ли
данное высказывание из некоторого набора математических аксиом.
Не существует общего алгоритма для остановки работы алгоритмов
генетического программирования, а также формальной процедуры
тестирования для определения правильности работы синтезированной
программы.
Между тем функциональное тестирование программного
обеспечения — это важнейшая проблема в области программной
инженерии. Предположим, что в процессе работы алгоритма генетического
программирования была синтезирована программа, которая в
качестве входных данных получает два целых чисел (32 бита) и
обрабатывает их на выходе. Для полного тестирования этой программы
по всем возможным входам потребуется провести 232 * 23^ = 264 =
= 18446744073709551616 испытаний. Если частота на тест будет
равна 1 мс, то для полного тестирования потребуется примерно
584 542 года. Понятно, что для большинства практических приложений
входное пространство имеет гораздо большую размерность. Поэтому
существует возможность выбора лишь очень малой части из
возможных сценариев тестирования. Следовательно, нет никаких гарантий
правильной работы программы во всех возможных ситуациях.
Сформулируем с позиций общей теории ЭВ предложения о
возможностях применения алгоритмов генетического программирования для
решения некоторых практических задач: задачи символьного
регрессионного анализа, вейвлет-анализа, распределения ресурсов и работ,
оценки кредитного риска и др.
Задачей символьного регрессионного анализа является подбор
математического выражения, наилучшим образом описывающего
вычислительную модель для принятия решений. В качестве исходных
данных в задаче выступает совокупность имеющихся
экспериментальных данных или экспертных знаний об объекте, отражающих
неизвестную зависимость определенного свойства объекта Y от другого
свойства или параметра X со случайной погрешностью, распределенной,
как правило, по нормальному закону. По совокупности этих данных
4.3. Алгоритмы генетического программирования И9
требуется подобрать такую функцию (регрессию), которая отображает
зависимость Y от X с минимальной погрешностью.
Иными словами, задача символьной регрессии на практике связана
с необходимостью по модели «черного ящика», в которой
зафиксированы отдельные входные и выходные связи объекта со средой, но
отсутствует информация о внутренней структуре объекта, установить
аппроксимирующую функцию объекта в аналитическом виде и
определить численные значения ее коэффициентов. Иногда этот процесс
называют идентификацией объекта.
Как применить ГП для решения задачи символьной регрессии?
Пусть, например, регрессионный квадратный полином имеет вид
Y = X2 - X + 2, где X принимает значения в диапазоне [-1, 1].
Проблема состоит в том, чтобы автоматически создать компьютерную
программу, реализующую данную регрессию.
Для программного вычисления регрессии будем использовать
математические операции сложения (+), вычитания (-), умножения (*)
и деления (%), множество переменных X, а также множество числовых
констант из некоторого диапазона, например, от —2 до +2. Оценку
программ различной величины и сложности, автоматически
генерируемых с помощью генетических операторов, будем осуществлять в
зависимости от того, насколько близки к целевому значению указанного
полинома полученные программой результаты. Например, чем меньше
среднеквадратичная ошибка, тем лучше программа. В качестве
иллюстрации возьмем три случайных хромосомы, представленных на
рисунке 34 в виде древовидных структур.
Yi=2 Y2 = 2-X Уз = Х2 + 2
Рис. 34. Древовидные структуры программ
Например, структура, представленная на рисунке 34 в виде дерева
слева, была образована путем случайного выбора операции
вычитания в качестве корневой вершины дерева. Затем случайно в качестве
аргументов были выбраны операция деления «%» и константа «—1».
Для операции деления случайно была выбрана одна переменная X.
Программа реализует функцию Yi = 2. Аналогично были построены
120 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
два других дерева, реализующих функции Уг = 2 - X и Уз = X2 + 2
соответственно.
На рисунке 35 представлены ошибки регрессии для каждой из трех
случайно выбранных хромосом начальной популяции (область между
кривыми на интервале [—1, 1]).
<
-1
н
1
к
-1
1
ч
-1
А
1
Рис. 35. Ошибка регрессии для трех программ
В частности, для программы, реализующей функцию Y\t область
на интервале [-1, 1] между параболической кривой Y = X2 - X + 2
и прямой Y\ графически иллюстрирует величину ошибки (величина
интеграла абсолютной ошибки равна 1,0). Интеграл абсолютной ошибки
для прямой Уг равен 1,33, а для параболы Уз — 1,0.
В качестве критерия завершения ГП выберем достижение
ошибки не более 0,1. После того, как установлено значение целевой
функции пригодности каждой хромосомы, необходимо синтезировать
программы-потомки. Произведем мутацию для Y\ и кроссинговер
между Уг и Уз. Получаем деревья, представленные на рисунке 36. Оператор
мутации случайно заменяет в дереве, соответствующем Y\,
вершину «%» на вершину «*», а правую вершину «X» на вершину «—1».
Перед выполнением одноточечного оператора кроссинговера
случайным образом определяются точки кроссинговера в хромосомах,
соответствующих Уг и Уз- Пусть для родительской хромосомы Уг это будет
вершина «—», а для Уз — правая вершина «X» на дереве,
представленном на рисунке 34. Оператор кроссинговера образует два потомка
(-Х) и (X2 — X + 2) путем обмена списками между двумя
программами при сохранении синтаксической корректности вновь получаемых
программ, которые представлены на рисунке 36. Видно, что один
из них эквивалентен исходной регрессии, т. е. является алгебраически
правильным решением задачи автоматического синтеза компьютерной
программы, реализующей вычисление функции квадратного полинома
вида X2 - X + 2 в диапазоне значений X от -1 до +1.
Регрессионный анализ является одним из широко используемых
видов аппроксимации. Другим подходом для приближенного решения
различных задач аппроксимации являются вейвлеты. Точного
определения, что такое «вейвлет», какие функции можно назвать вейвлета-
ми, насколько нам известно, пока не существует. Если есть сигнал
(а сигналом может быть все, что угодно, начиная от записи показаний
4.3. Алгоритмы генетического программирования \2\_
Рис. 36. Хромосомы после мутации и кроссинговера
датчика и кончая оцифрованной речью или изображением), то идея
применения вейвлетов для многомасштабного анализа сигнала
заключается в следующем.
Разложение сигнала производится по базисным функциям
(собственно, это и есть вейвлеты), которые конструируются на основе
производных функций Гаусса, колеблются вокруг оси абсцисс и быстро
сходятся к нулю по мере увеличения абсолютного значения аргумента.
Свертка сигнала с одним из вейвлетов позволяет выделить
особенности сигнала в области локализации вейвлета, причем, чем больший
масштаб он имеет, тем более широкая область сигнала будет оказывать
влияние на результат свертки.
Согласно принципу неопределенности чем менее функция растянута
во времени, тем большую частотную область она имеет. При
перемасштабировании функции произведение временного и
частотного диапазонов остается постоянным и представляет собой площадь
в частотно-временной (фазовой) плоскости. Одно из преимуществ
вейвлет-преобразования как раз состоит в том, что оно покрывает
фазовую плоскость ячейками одинаковой площади, но разной формы.
Это позволяет хорошо локализовать низкие гармоники сигнала в
частотной области, а высокие скачки и пики — во временной области,
более того, позволяет исследовать поведение фрактальных функций,
не имеющих производных ни в одной своей точке.
Использование базисных вейвлет-функций в ГП расширяет сферу
их применения в таких областях, как фильтрация и предварительная
обработка данных, анализ состояния и прогнозирование ситуаций на
фондовых рынках, распознавание образов, синтез, сжатие и обработка
речевых сигналов и медицинских изображений, обучение нейросетей
и во многих других случаях [43].
При решении задачи распределения ресурсов необходимо задать
источники и адресаты ресурсов, минимизируя расходы на их
перераспределение или отыскав наилучший способ распределения. В задаче
распределения работ по машинам обычно требуется выполнить все
задания за минимальное время.
Аналогии с природными явлениями подсказывают различные пути
для решения этих задач, например модель, метафорой которой является
122 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
поведение муравья [15]. На основе этой модели решаются и
другие задачи, аналогичные распределению ресурсов и работ (прокладка
автомобильных маршрутов, маршрутизация в вычислительных сетях,
раскраска графов и т.п.).
Модель включает создание искусственного муравья, наиболее
эффективно проходящего сетку на торе. По этой сетке пролегает
извилистая дорожка, на которой находится пища. Модель простого муравья
включает два его состояния: текущую позицию муравья на торе и
направление, в котором он смотрит (влево, вправо, вверх или вниз).
Возможными действиями муравья являются повороты направо или налево
и движение прямо. Средством восприятия окружающей среды является
функция, сообщающая, есть ли пища в квадрате, на который смотрит
муравей.
Используя ГП, необходимо обучить муравья находить наибольшее
количество пищи за минимальное число ходов. Вначале генерируется
популяция из нескольких сотен искусственных муравьев,
перемещающихся по тору, следуя по следам пищи ограниченное число шагов.
Степень приспособленности муравья определяется количеством пищи,
найденной за наименьшее число шагов. Поведение муравья
определяется логическими выражениями, состоящими из элементарных действий
(влево, вправо, прямо) и функций (продукционные правила с
условиями и действиями, «родословная» муравья и т.п.). Каждому
выражению соответствует древовидная структура. После инициализации
производится селективный отбор лучших муравьев для копирования
в следующем поколении. У более приспособленных родителей больше
шансов произвести потомство. Затем, согласно базовому циклу ЭВ,
применяются разновидности генетических операторов кроссинговера
и мутации, формируется новая популяция.
Модели оценки кредитного риска широко используются в
финансовой сфере для решения вопроса о выдаче кредита. Решения задачи
оценки кредитного риска достаточно детально исследовались
методами математической статистики, машинного обучения и искусственных
нейросетей [43]. Основная проблема здесь заключается в
необходимости сокращения стоимости анализа кредитного риска, в возможности
быстрого принятия решения по кредитованию, страховке и
уменьшению возможного риска.
В настоящее время задача оценки кредитного риска решается
с помощью таких функционально-ориентированных методов, как дис-
криминантный анализ, логистические регрессионные функции,
искусственные нейросети, деревья решений. Нейросети считаются
наиболее популярным подходом, превосходящим по точности традиционные
статистические методы, особенно для нелинейного случая, а к их
недостаткам относят трудности решения задачи в случае
неоднородных признаков и небольшом объеме исходных данных в обучающей
выборке. Для индуктивных алгоритмов характерным является
универсальность подхода к принятию решения независимо от стратегий
4.3. Алгоритмы генетического программирования 123
маркетинга, использование ассоциативных правил для
прогнозирования ситуации. К недостаткам индуктивных алгоритмов относят
трудности, связанные с классификацией объектов, описание которых
отличается от объектов, входящих в обучающую выборку.
Указанные недостатки можно преодолеть, если использовать
комбинированный подход, когда с помощью ГП строятся продукционные
правила ЕСЛИ-ТО, а затем по небольшой выборке исходных
данных по схеме ГП строится дискриминантная функция, необходимая
для прогнозирования возможного решения о выдаче кредита.
В частности, с помощью ГП можно построить простые и
понятные правила принятия решения, ограничивая максимальную глубину
иерархического дерева, а также используя не только отношения типа
^, =, ^, но и булевские операции AND, OR, NOT. Например, для
кредитоспособного клиента правило вида
IF(Xi > 0,3 OR X2 < 0,4) THEN (клиент=кредитоспособный)
может быть представлено в виде дерева ГП, как это показано на
рисунке 37.
Рис. 37. Правило ЕСЛИ-ТО в виде дерева
Обращает на себя внимание тот факт, что лицо, принимающее
решение, может получить другое правило при тех же данных, но без
необходимости переобучения, как в нейросетях. Затем с помощью ГП
строится дискриминантная прогнозная функция для данных, которые
не удовлетворяют ни одному из имеющихся правил или, наоборот,
удовлетворяют более, чем одному правилу, после чего определяется
целевая функция в ГП как сумма абсолютных величин разницы между
наблюдаемыми данными и ожидаемым результатом.
Что приведет к лучшим результатам: долгая эволюция одной
популяции в течение N поколений или эволюция М популяций в течение
N/M поколений? Этот вопрос позволяет по-новому взглянуть на
теорию и практику не только эволюционных алгоритмов, но и других
стохастических методов, направленных на рациональное
использование вычислительных ресурсов в ходе поиска оптимального решения.
Сегодня этот вопрос не снят с повестки дня, несмотря на
существенное увеличение производительности компьютерных вычислений
124 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
и возможности параллельной обработки ЭА. По существу, он является
не только теоретической проблемой, но важен с практической точки
зрения из-за существующей опасности преждевременной сходимости
алгоритма, так как, обнаружив эту опасность в ходе эволюции, можно
сэкономить ресурсы.
Этот вопрос обсуждался в [30]. Например, одним из признаков
сходимости называлась относительная однородность популяции или
отсутствие существенной разницы в популяции в течение нескольких
поколений. Однако подобного рода признаки не работают для ГП!
Утверждалось [9], что если плотность вероятности функции
сходимости во времени t известна, то можно вычислить оптимальное время
для рестарта эволюции. Однако ни в одной из работ не дается ответ
на вопрос: что результативнее, быстрая смена нескольких популяций
или долгая эволюция одной популяции?
Особенностью предлагаемого нами подхода при решении
указанных выше задач, в отличие от известных работ, является
стремление определить, обнаружен оптимум или нет, какова вероятность его
обнаружения, как быстро сходится процесс к глобальному оптимуму
или же это преждевременная сходимость. Целью является получение
численного ответа на вопрос о сравнительной результативности ГП
при быстрой смене нескольких популяций и при относительно долгой
эволюции одной популяции.
В частности, генетическое программирование применялось для трех
рассмотренных выше задач. Эксперименты показали, что для двух
из них планирование выбора максимального числа поколений в
качестве одного из основных параметров алгоритма ГП является по
существу иррациональным: лучшие результаты получаются, если
гибко управлять многократной сменой нескольких популяций в течение
относительно небольшого числа поколений.
Вывод был получен для случая, когда сравнивались результаты ГП
для mi популяций за время t\ и шг популяций за время t<i, при
условии, что т\ * t\ = шг * h- Оптимальность ГП оценивалась по среднему
ожидаемому выигрышу в момент времени t (трудность состояла в том,
что оценки не являлись статистически независимыми), а также по
разнообразию популяции (трудность состояла в необходимости большого
числа оценок).
Результаты решения задач символьной регрессии, о распределении
ресурсов и оценке кредитного риска имели различную динамику, хотя
использовались популяции большого размера при относительно
небольшом времени эволюции.
Отличительной особенностью регрессионной задачи являлась
непрерывность целевой функции. Что касается ожидаемого качества
эволюции «большой» популяции, то уже при числе поколений большем,
чем 32, оно оказывалось хуже, чем при меньшем в 2 раза числе
поколений. Наоборот, смена популяций при числе поколений менее 8
4.3. Алгоритмы генетического программирования 125
давала худшие результаты, нежели результаты для одной большой
популяции.
Для задачи распределения ресурсов и работ при турнирной
стратегии селекции целевая функция монотонно улучшалась от поколения
к поколению, а выявленные особенности качества популяции, в
основном, соответствовали результатам, полученным для задачи
регрессионного анализа.
Для задачи оценки кредитного риска использовались реальные
наборы данных по кредитным историям, взятым из открытого репози-
тория UCI. Данные характеризовались свыше 10 различными
признаками-атрибутами клиента, а обучающая выборка включала несколько
сотен отчетов с положительной и отрицательной оценкой
кредитоспособности. Выявить аналогичные предыдущим закономерности в
динамике качества популяции для этой задачи не удалось. Однако
результаты свидетельствуют о преимуществах алгоритма ГП в сравнении
с другими методами, во всяком случае, алгоритм позволяет быстро
и автоматически определить адекватную дискриминантную функцию
(линейную или нелинейную), не прибегая к помощи ЛПР, а также
обрабатывать небольшие наборы данных по понятным ЛПР
продукционным правилам.
Несомненно, что алгоритмы генетического программирования
дают неплохие решения для различных задач, однако их результаты
еще требуется проанализировать и интерпретировать. Это означает,
что решения должны быть представлены в удобной для восприятия
пользователя форме, а это, в свою очередь, не всегда удается сделать
в алгоритмах генетического программирования.
Что касается вопроса, связанного с завершением работы алгоритмов
генетического программирования, то в линейном генетическом
программировании это делается через определение верхней границы для
шагов эволюции. При использовании древовидных структур и
распределенных алгоритмов генетического программирования условия
завершения работы алгоритма будут несколько сложнее [43].
Наши рекомендации по оценке возможностей алгоритмов
генетического программирования для решения NP-трудных задач с позиций
общей теории ЭВ состоят в следующем:
• использование различных функций пригодности;
• использование модели эволюции Ламарка или эффекта
Болдуина [56].
Рекомендация, касающаяся функциональности алгоритмов
генетического программирования, состоит в следующем. Необходимо
ограничивать размер программного кода и повышать его эффективность за
счет сокращения числа интронов. Размер программного кода (число
элементарных команд) всегда является конечным, однако, он может
расти в процессе эволюции, например, за счет увеличения числа
интронов в программе, что приводит к целому ряду побочных эффектов,
таких как:
126 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
• неоправданный рост программ;
• генерируемые потомки функционально являются такими же, как
их родители, что делает выполняемые генетические операторы
бесполезными;
• увеличивается объем памяти, необходимой для работы алгоритма
генетического программирования.
В заключение отметим еще одну причину, по которой алгоритмы
генетического программирования являются важной и перспективной
составляющей ЭВ, — генетическое программирование сходно с
естественным процессом эволюции, поскольку эволюционный синтез и
трансформацию программ можно выполнять непрерывно.
4.4. Алгоритмы эволюционных стратегий
С позиций общей теории ЭВ эволюционные стратегии являются
эвристическим алгоритмом оптимизации, основанным на идеях
адаптации и эволюции, и имеют следующие особенности:
• процесс эволюции рассматривается на уровне фенотипа, в
отличие от генетических алгоритмов, которые акцентируют внимание
на генетическом механизме наследственности на уровне
хромосом;
• эволюционные стратегии анализируют эволюцию на уровне целой
популяции;
• в эволюционных стратегиях оператор мутации применяется с
частотой, соответствующей нормальному закону распределения, что
является оправданным для выбранного уровня моделирования,
в отличие от мутации на генном уровне, где она проявляется как
редкое событие и практически не влияет на фенотип;
• эволюционные стратегии наиболее подходят для задач,
описываемых непрерывными функциями.
Действительно, в генетических алгоритмах зачастую
затруднительно учесть множество особенностей и технических деталей реальных
задач. Генетические алгоритмы обрабатывают астрономическое число
возможных популяций, большинство из которых имеют
несущественные отличия. Выявить подобные отличия они не могут, поскольку
не учитывают семантические и прагматические различия между
популяциями и теми изменениями, которые могут существенно повлиять
на ход эволюции. По этой причине разработка алгоритмов
эволюционных стратегий для организации ЭВ является перспективным подходом,
состоящим в выработке фенотипических решений из параметров
генотипов.
Ранее в разделе 1.4 уже была представлена модель
эволюционных стратегий. Уточним теперь эту модель с позиций общей
теории ЭВ. Пусть, как и ранее, задача состоит в минимизации
целевой функции F(x\,X2, ...,жп), где Х{ — вещественные переменные
(г = 1,2, ...,п), причем каждому индивиду эволюционной стратегии
4.4. Алгоритмы эволюционных стратегий
127
соответствует вектор в n-мерном пространстве, который представляет
собой некоторое решение поставленной задачи. Напомним, что
каждый индивид в ЭС характеризуется некоторым среднеквадратичным
отклонением Oj (j — 1, 2, ..., га; 1 ^ га ^ п), которое для оператора
мутации означает среднюю величину наследственной изменчивости.
Величина о, является параметром, характеризующим адаптивные
свойства эволюционных стратегий. Будем считать, что если 1 < т < п,
то ai,a2, ...,(7m_i жестко связаны с переменными xi,X2, ...,xm_i,
а величина cfj для остальных переменных xm,xm+i, ...,xn
является свободной (для большинства практических приложений га — 1
или га = п).
Уточним дальше этапы алгоритма эволюционных стратегий в
соответствии с базовым циклом ЭВ.
а) Инициализация алгоритма путем генерации начальной
популяции P(t = 0) из /i индивидов вида Sk = (#ь 5k), где к = 1,2, ..., /х.
Если отсутствуют предположения о местоположении глобального
оптимума, то индивиды из начальной популяции желательно распределить
равномерно по всему пространству поиска решения. Рекомендуется
случайная генерация начальной популяции по равномерному закону
распределения, а при га = п — установка одинакового для всех <т?
значения, равного 3,0.
б) Оценка решения. Для каждого индивида Sk устанавливается
функция качества Ф(а&), которая идентифицируется с целевой
функцией F(xfc), т.е. считаем, что Ф(а&) = F(xk). Этот этап эволюционных
стратегий является обязательным лишь для ЭС с (/л + А)-селекцией,
в отличие от (/i, А)-селекции.
в) Генерация потомков. Задача состоит в получении А потомков
из /х родителей. Для этого необходимо выбрать родителей, провести
их рекомбинацию и репликацию (копирование и передача фенотипа
родителей потомкам), а затем мутацию потомков. При этом
рекомендуется соотношение /х/А « 1/7, причем /х « 15, А « 100. Данный этап
алгоритма выполняется обычно А раз и включает в себя следующую
последовательность действий:
• случайный выбор родителей, причем два случайно выбираемых
родителя производят одного потомка, а вероятность выбора
некоторого родителя для всех родителей одинакова и равна 1//х;
• рекомбинация (включая репликацию): в результате случайного
обмена отдельными родительскими фенотипическими
компонентами возникает потомок, причем фенотипические признаки
выбираются из одного или двух родителей; этот оператор дискретной
рекомбинации аналогичен одноточечному оператору кроссинго-
вера в генетическом алгоритме, в отличие от оператора
мутации, который, является промежуточной рекомбинацией;
неверным представляется утверждение о том, что оператор
рекомбинации не является важным для эволюционных стратегий, поскольку
128 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
он ускоряет процесс оптимизации и играет значительную роль
в ходе адаптивной установки параметров эволюционных
стратегий;
• мутация потомков: сначала производится пошаговое изменение
фенотипа потомков путем их мультипликации по нормальному
логарифмическому закону распределения, после этого
производится мутация выражения каждой логарифмической переменной,
в котором к ее значению прибавляется нормально распределенная
величина с математическим ожиданием, равным 0, и среднеквад-
ратическим отклонением Gj\ таким образом, имеем
а£ = а*ехр(м#(0, 1) + ^(0, 1)),
х'. = Xj + а^(0, 1), Vi ^ га: а] = afmJ
где iV(0, 1) обозначает единичную реализацию нормально
распределенной переменной потомка; Л^(0, 1) — вновь определяемое
для j-й переменной значение iV(0, 1); l\ — постоянный
коэффициент; i2 — коэффициент, варьируемый при каждой мутации.
Рекомендуются следующие значения: ь\ « у/2п — 1, ^ ~ \/2у/п — 1.
На практике обычно используются значения констант ti и ^ на
интервале от 0,1 до 0,2. В случае если га = 1, мутация упрощается
и формально имеет следующий вид:
a1 = aexp{i0N(0, 1)),
х1. =Xj+afNj(01 1).
В целом применение закона нормального распределения при
мутации вполне соответствует фенотипическому закону о том, что дети
похожи на своих родителей, а небольшие изменения в
наследовании признаков, наоборот, воспринимаются как значимые. Напротив,
при мультипликативной мутации среднеквадратичных отклонений
нормальный логарифмический закон распределения имеет следующие
преимущества: среднеквадратичное отклонение автоматически остается
постоянным; малые изменения происходят чаще, чем большие; медиана
мультипликативного изменения близка к единице, поэтому ошибки
в селекции приводят лишь к небольшому дрейфу в решении.
Предположим, что среднеквадратичное отклонение при
мультипликативной мутации лежит вблизи 0 на расстоянии е. Это означает, что
в ходе оптимизации пространство поиска практически не сокращается
и не возникает проблема «локальной ямы». Таким образом,
эволюционные стратегии позволяют адаптивно найти подходящее значение
среднеквадратичного отклонения и можно вести речь о двухуровневом
процессе оптимизации, т.е. на одном уровне происходит поиск
оптимального значения переменных, а на другом — настройка и установка
параметров ЭС. Причем самоадаптивная установка параметров
эволюции позволяет максимально гибко учитывать разнообразие ландшафта
4.4. Алгоритмы эволюционных стратегий
129
целевой функции, конечно, при достаточно большом размере
популяции /х.
г) Оценка потомков. Производится оценка каждого потомка а' =
= (£', <т'); Ф(а') = F(x') и ограничивается размер промежуточной
популяции.
д) Детерминированная селекция. На данном этапе алгоритма
эволюционных стратегий необходимо образовать новую популяцию
с учетом вновь появившихся А потомков. Это так называемая (/х, А)-
селекция или эволюционная (/х, А)-стратегия, которая не дает шансов
индивидам с «плохим» значением функции качества. Хотя в ходе
естественного отбора побеждает сильнейший, однако, материал для
эволюции зачастую дают побежденные. Поэтому на данном этапе селекции
рекомендуется отдельные из отбрасываемых решений запоминать в
отдельный список для последующего периодического их использования
в ходе эволюции.
Пропорция /х/А указывает на степень «суровости» селекции.
Управляя этой пропорцией, скажем, в сторону уменьшения дроби, мы тем
самым ужесточаем селективный отбор. Анализ показывает [33], что для
мультимодальных целевых функций желательна «мягкая» селекция,
в отличие от унимодальных функций (снижается опасность попадания
в «локальную яму»).
е) Критериями остановки алгоритма эволюционных стратегий
являются максимальное число шагов эволюции tmax, отсутствие
прогресса в смысле заметного улучшения значений целевой функции, малая
разница между лучшим и худшим значением функции для текущей
популяции и т. п.
У исследователей эволюционных стратегий нет общего мнения
о том, какая из форм рекомбинации имеет преимущество. В литературе
приводятся результаты [57] эмпирического сравнительного анализа,
из которых следует, что для унимодальных целевых функций наиболее
подходящей является форма рекомбинации, при которой фенотип
потомка складывается из фенотипов нескольких родителей. Для
мультимодальных функций более подходящей является рекомбинация в
традиционной дискретной форме. Для переменных х рекомендуется
применять дискретную рекомбинацию, а для параметров эволюционных
стратегий — мультирекомбинацию.
ж) Селекция. При (/х + А)-селекции новая популяция образуется
из объединенного множества родителей и потомков и включает в себя
элитные индивиды, имеющие лучшие значения функции
пригодности. Эксперименты свидетельствуют в пользу (/х, А)-селекции,
которая имеет очевидные преимущества перед (/х + А)-селекцией (прежде
всего при решении проблемы «локальных ям» и с точки зрения
адаптивных свойств ЭС). В самом деле, при (/х + А)-селекции индивид
с лучшим значением функции может неоправданно долгое время
переходить из одной популяции в другую, обладая при этом неудачно
установленным параметром ЭС. В то время как при (/х, А)-селекции
9 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
130 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
продолжительность жизни отдельного индивида является
ограниченной. Отметим также эффективность соревновательных (турнирных)
форм селекции в случае их реализации на параллельных
вычислителях. С этой целью из объединенного множества родителей и потомков
случайно, по закону равномерного распределения выбираются £
индивидов (2 ^ £ < /х + А), часть из которых копируется в следующую
популяцию P(t+ 1). Рехенберг [39], исследуя (1 + 1)-селекцию,
высказал предположение о том, что доля успешных мутаций по сравнению
с их общим количеством должна составлять примерно 1/5, а сама
(1 + 1)-селекция может рассматриваться как один из видов случайной
градиентной стратегии.
Мы исследовали с позиций общей теории ЭВ задачи
многокритериальной оптимизация, состоящие в получении эффективных или
Парето-оптимальных решений, из которых затем с учетом
субъективных или иных предпочтений принимается к реализации единственное
решение в предположении, что заданы g целей. Одна из возможных
эволюционных стратегий состоит в том, что селекция новой
популяции разделяется на g отдельных этапов для каждой целевой
функции. Если выбирать fi/g индивидов, характеризующих отдельную цель
в предположении одинаковой важности целей, то это соответствует
(/х, А)-селекции. Однако при многокритериальной оптимизации
важность отдельных целей может быть различной. Оказывается, что
механизм эволюционных стратегий вполне применим при
многокритериальной оптимизации с различным «весом» целевых функций. Для этого
достаточно изменить долю селектируемых индивидов в популяции в
соответствии с «весом» той или иной цели.
Другая рекомендация, являющаяся следствием из общей теории
ЭВ, сводится к тому, что размер популяции /х может быть
переменным, поскольку популяция охватывает все найденные в данный
момент недоминируемые решения (Парето-множество). Число
потомков А, напротив, можно установить постоянным, что соответствует
(/х + А)-селекции, в которой родители и потомки конкурируют между
собой, а все недоминируемые решения являются «бессмертными».
Для популяций большого размера предлагается использовать
состязательную Парето-селекцию, идея которой заключается в следующем.
Из объединенного множества родителей и потомков выбираются £
индивидов (2 ^ £ < /х 4- А) с одинаковой вероятностью селективного
выбора. Из £ решений определяются недоминируемые, которые копируются
в следующую популяцию P(t +1), причем все £ индивидов
одновременно присутствуют в популяции P(t). Этот процесс повторяется до тех
пор, пока размер популяции Р(£+ 1) не станет равным /х.
Эволюционные стратегии традиционно применяются для задач
оптимизации с непрерывными переменными. Нет принципиальных
затруднений для использования эволюционных стратегий в
дискретной оптимизации. С этой целью при выполнении оператора
мутации можно применять другие виды законов распределения, например,
4.4. Алгоритмы эволюционных стратегий
131
биномиальную мутацию. Можно также использовать представленную
выше базовую схемы эволюционных стратегий, округляя значения
переменных, значения функции пригодности и конечные результаты
процесса оптимизации. Можно действовать аналогично при решении
задач целочисленной оптимизации, а также в случае, если задача
оптимизации имеет комбинированный характер. Предлагается и другой
путь [39], однако при этом непрерывные переменные используются
лишь во внутреннем цикле базового цикла эволюционных стратегий
при выполнении генерации потомков с дальнейшей их модификацией
в дискретные переменные во внешнем цикле. Отметим, что проблемы
смешанной оптимизации вообще являются характерными для многих
прикладных проблем. Рассмотрим в качестве примера
оптимизационную задачу упорядочения.
Сформулируем постановку задачи следующим образом. Пусть
имеется п машин и га мест для их размещения. Необходимо найти такое
размещение машин, чтобы суммарные затраты на их первоначальную
установку и транспортные затраты на перемещение продукции были
минимальными.
Формально эта задача сводится к поиску оптимальной перестановки
при заданных значениях затрат dj на установку г-ой машины на
j-oe место, затратах а^ на транспортировку материалов от места г
к месту /с, а также bjm — объем продукции, передаваемой от j-ой
машины к ш-ой машине (г, j, fc, m = 1,2, ..., га). Тогда для некоторой
перестановки ф необходимо минимизировать целевую функцию вида
п к п
Z = J2 С^(г) + J2 ^2 aik ' Ьф({)ф(к)>
г=\ i=\k=\
Пространство решений составляет п\. Каждое отдельное решение
(перестановка) кодируется, например, в виде вектора (2,6,1,3,5,4), где
внутри перестановки указан номер машины, а место ее установки
определяется порядковым номером внутри вектора. Пусть применяется
(1, 100)-селекция, т.е. из каждого родителя образуется путем мутации
100 потомков без всякой рекомбинации. Мутация заключается в
случайной взаимной перестановке двух машин. Потомок с минимальным
значением целевой функции образует новую родительскую популяцию,
а родитель участия в отборе больше не принимает.
С помощью программного счетчика нетрудно установить, как
часто вновь образованный потомок имеет худшее значение функции
пригодности, нежели родитель. После того, как счетчик достигнет
некоторого граничного значения (мы эмпирически установили, что
граница составляет величину около (га/10+ 2)), необходимо начать
процедуру дестабилизации. Она заключается в проведении от трех
до восьми парных мутаций и завершается в момент обнуления
счетчика. После завершения дестабилизации процесс оптимизации
продолжается по прежней схеме. Моделирование эволюции прекращается
9*
132 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
по достижении £тах — максимального числа шагов эволюции. В
качестве решения выбирается лучшее из найденных в ходе эволюции
решений. Начальная перестановка выбирается случайно.
К этому необходимо добавить, что реальные задачи оптимизации,
как правило, содержат ограничения в форме равенств или неравенств.
Если пространство ограничений является многомерным, то на этапе
инициализации затраты времени на генерацию допустимых решений
могут оказаться значительными. В этом случае рекомендуется
использовать метод, основанный на идеях штрафных функций, что позволяет
сводить задачи поиска условного экстремума к задачам на безусловный
экстремум.
В ходе проведения исследований было установлено, что
максимальное быстродействие алгоритма эволюционных стратегий достигается
при соотношении /х/Л из интервала [1/5, 1/7]. В частности,
быстродействие (1/Л)-селекции возрастает лишь как логарифм от Л.
Что касается вопроса о вычислительной сложности (/х//х, А)-се-
лекции с точки зрения числа шагов эволюции, которые необходимы
алгоритму эволюционных стратегий, чтобы достигнуть заданного
улучшения целевой функции, то оценки для (////i, А)- и (/х/А)-селекций
соответственно имеют следующий вид:
См/м.А = 0(п/А),
GMfA = 0(n/lnA).
Пока эти оценки были получены для вполне определенной целевой
функции. Вопрос об их обобщении на другие модели остается
неясным, поскольку все зависит от того, насколько удачно данная модель
аппроксимирует оптимизируемую целевую функцию. Кроме того,
имеются и другие теоретические аспекты эволюционных стратегий, такие
как их сходимость, частота мутации в конкретной задаче,
самоадаптивность, влияние кореллируемой мутации на целевую функцию, которые
требуют дальнейших усилий в области развития эволюционных
стратегий с позиций общей теории ЭВ.
4.5. Алгоритмы эволюционного программирования
История эволюционного программирования начиналась с
момента появления первых компьютеров. В 1949 году в цикле лекций
Дж. фон Нейман исследовал вопрос об уровне организационной
сложности, необходимой для самовоссоздания естественной системы не на
уровне генетики и биохимии [58], а представив основные требования,
необходимые для самовоссоздания. Он разработал (но не реализовал)
самовоспроизводящуюся автоматическую конструкцию,
представляющую собой двухмерную решетку с большим числом отдельных
автоматов с 29 состояниями. Каждое следующее состояние отдельного
автомата конструкции являлось функцией его текущего состояния
4.5. Алгоритмы эволюционного программирования 133
и состояний четырех ближайших соседей. Интересно, что для
обеспечения функциональности универсальной машины Тьюринга фон
Нейману потребовалось спроектировать самовоспроизводящийся автомат,
содержащий около 40000 клеток.
Игра «Жизнь», предложенная математиком Дж. Конвеем, получила
широкую популярность благодаря ее описанию в журнале Scientific
American в 1970-1971 годах. Эта игра — интуитивный описательный
пример модели вычислений, получившей название клеточных
автоматов (cellular automata — семейство простых конечных автоматов,
демонстрирующее эмерджентное поведение при взаимодействии
элементов популяции) [59]. Область ЭВ, получившая название
эволюционного программирования (evolutionary programming), основывается на
формальном анализе самовоспроизводящихся машин и уходит корнями
вглубь теории вычислений. Эмпирические результаты и программы,
разработанные в этом направлении, демонстрируют различные формы
искусственной жизни, а успех работы этих программ определяется
не некоторым заранее заданным критерием качества, а простым
фактом выживания и самовоспроизводства особей. Признаком пригодности
является само выживание. Интеллект этой системы — это артефакт
простой организации и взаимодействия с окружающей средой [60].
Идеи эволюционного программирования при компьютерном синтезе
интеллектуальных автоматов, способных инновационным образом
реагировать на стимулы, поступающие из внешней среды, стали одним
из направлений искусственного интеллекта. Эти идеи выглядят сегодня
актуальными в теории многоагентных систем, искусственной жизни
и коллективного поведения. Существует, правда, и другая сторона
медали. Всем известны компьютерные вирусы и черви, способные
выживать в чуждой среде, воспроизводить себя (обычно разрушая в
памяти любую информацию, необходимую для этого воспроизводства)
и инфицировать другие узлы.
Напомним особенности алгоритмов эволюционного
программирования:
• популяция в алгоритмах эволюционного программирования
рассматривается как центральный объект эволюции;
• биологическая эволюция является, в первую очередь, процессом
приспособления на поведенческом уровне, а не на уровне таких
генетических структур как хромосомы;
• популяция особей в эволюционном программировании отражает
характер поведения, вид общения и пр.: этот уровень абстракции
в природе не предусматривает рекомбинации;
• в алгоритмах эволюционного программирования отсутствует
оператор кроссинговера, также как и некоторые другие операторы,
используемые в генетическом программировании;
• мутация в эволюционном программировании является
единственным оператором поиска альтернативных решений на уровне
фенотипа, а не на уровне генотипа, как в генетических алгоритмах.
134 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Ранее в разделе 1.5 была представлена формализованная модель
ЭП. Уточним ее с позиций общей теории ЭВ. Пусть решается задача
минимизации функции F(a\, . ..,ап), зависящей от_тг непрерывных
переменных, которые представляются в виде вектора А = (а\, ...,ап),
что в ЭП соответствует отдельному артефакту.
С позиций общей теории ЭВ представим уточненный алгоритм
эволюционного программирования.
а) Инициализация. На этапе инициализации случайным
образом генерируется популяция Р(0), состоящая из /х артефактов А*
(г = 1,2, ..., //). Рекомендуемое значение размера популяции // ^ 200.
Значение элемента aj для каждого артефакта А*
устанавливается случайно с помощью равномерного распределения на интервале
[lj, rj] e i?, lj < Tj. Границы интервала lj, rj имеют значение лишь
на этапе инициализации. В ходе дальнейшей эволюции пространство
поиска в принципе является неограниченным. Стандартная форма ЭП
предполагает решение оптимизационной задачи, в которой
оптимальное значение равно функции равно нулю, lj = —50, rj = 50.
_б) Оценка решения. Каждая особь А^ определяет фитнесс-функцию
Ф(А^), которая зачастую равна значению целевой функции (Ф = F,
хотя в общем случае они могут и не совпадать). В случае
несовпадения функции качества и целевой функции значение Ф преобразуется
с помощью некоторой случайной величины &. Например, если
результирующее значение функции качества получилось отрицательным,
то оно преобразуется путем скаляризации в положительное число.
Таким образом, в общем случае считаем, что Ф(А^) = fi(F(Ai), &).
Совокупность из /х артефактов образует множество родителей,
необходимых для следующего этапа ЭП.
в) Генерация потомков. Этот этап выполняется /i раз (г = 1, 2, ...
..., ц) и включает в себя следующие действия:
• репликация путем копирования г-ro родителя А^ = (аь ..., ап);
• мутация скопированного родителя путем сложения нормально
распределенной случайной величины с нулевым математическим
ожиданием и динамически изменяемым среднеквадратичным
отклонением.
Из родителя Ai возникает потомок А^. Стандартное отклонение
(«ширина мутации») полученной случайной величины зависит от
родительского значения функции соответствия Ф. При этом глобальный
оптимум равен 0 (если это не так, то проводится соответствующее
преобразование). Идея состоит в том, чтобы повысить эффективность
процесса оптимизации путем сокращения «ширины мутации» при
приближении к оптимуму. Значение переменной потомка определяется
по формуле
a'j = aj + sqrt(kj • Ф(А*) + Zj) • Nj(0% 1),
4.5. Алгоритмы эволюционного программирования 135
где kj — константа скаляризации, Ф(А*) — значение функции качества
родителя, Zj — дисперсия, ЛГДО, 1) — стандартная нормально
распределенная величина, определяемая для каждого j = 1, 2, ..., п. Значения
kj, Zj являются параметрами эволюционного программирования и
устанавливаются пользователем. В общем случае число этих параметров
равно 2п. Однако на практике обычно устанавливают к3; = 1, Zj = О
(J = 1, 2, ..., п). Тогда квадратный корень (sqrt) в формуле для
вычисления a'j упрощается, и она принимает следующий вид:
a'j = aj + sqrt^(A~)) • ЛГДО, 1).
г) Оценка потомка происходит путем определения значения его
функции качества Ф(А^) = 0(^(А^, &), после чего потомок
добавляется в популяцию, причем А{ > AM+i. При окончании этапа размер
популяции становится равным 2/х.
д) Селекция выполняется по соревновательному принципу, согласно
которому каждый родитель или потомок попарно сравнивается с h
противниками, причем величина h (h ^ 1) является параметром
эволюционного программирования, устанавливается пользователем и обычно
принимает значения от h = 0,05// до h = 0,1 /i. Противники выбираются
случайно, с помощью закона равномерного распределения. Победитель
определяется путем попарного сравнения функций качества. Артефакт
побеждает в соревновании, если его функция качества, по меньшей
мере, не хуже, чем у противника. Для представленной выше задачи
минимизации общее число побед Wi г-ого артефакта (г = 1,2, ..., 2/х)
определяется путем суммирования отдельных побед, когда Ф(А^) ^ Ф(А^).
Суммирование ведется для d = 1, 2, ..., h, d Ф i, причем d является
целочисленным значением случайной величины, равномерно
распределенной в интервале [1, 2/х], которое для каждого d определяется заново.
После этого все артефакты сортируются по убыванию числа побед
(а не по значению функций качества). Лучшие артефакты образуют
новую родительскую популяцию размером /i. При одинаковом числе
побед преимущество получает артефакт с лучшим значением функции
качества. Очевидно, что при таком механизме селекции «слабые»
артефакты имеют некоторую отличную от нуля вероятность репродукции.
С ростом значения параметра h селекция начинает принимать
дискриминационный элитный характер;
е) В качестве критерия останова могут быть следующие заданные
пользователем события: достижение в ходе эволюции заданного числа
поколений tmax; достижение заданного уровня качества, когда значение
функций качества всех артефактов в популяции превысило некоторое
пороговое значение; достижение заданного уровня сходимости, когда
артефакты в популяции настолько подобны, что дальнейшее их
улучшение происходит чрезвычайно медленно.
136 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Параметры алгоритма эволюционного программирования
выбираются таким образом, чтобы обеспечить скорость работы алгоритма
и поиск лучшего решения.
Одним из наиболее объективных средств тестирования
эволюционных алгоритмов является классическая задача теории игр, называемая
«дилеммой узников» [61].
Эта задача служит моделью конфликтной ситуации, в которой
интересы игроков (агентов) хотя и различны, но не являются
антагонистическими. Игроками считаются два узника, находящиеся в
предварительном заключении по подозрению в совершении преступления.
При отсутствии прямых улик возможность их осуждения в
значительной степени зависит от того, заговорят они или будут молчать. Потери
игроков описываются матрицей следующего вида:
м
г
м
(1,1)
(0,5)
Г
(5,0)
(3,3)
Ясно, что наиболее выгодным для них является молчание (М).
Однако простое рассуждение показывает, что, не имея никаких
контактов между собой и к тому же не очень доверяя друг другу, каждый
из узников, поразмышляв, придет к выводу, что нужно сознаваться (Г).
Задачей эволюционного программирования является поиск такой
игровой стратегии, которая позволит минимизировать средние потери
при многократном повторении игровой ситуации. Можно представить
каждую совместную игровую стратегию одним из состояний конечного
автомата.
Множество возможных входных сигналов автомата при символьном
представлении равно {(м/м), (м/г), (г/м), (г/г)}. Множеством выходов
автомата являются символы {м, г}.
В качестве исходных для эксперимента выбирались следующие
параметры: размер популяции /х = 50, число ходов в игре — не менее
150, число состояний, переходы состояний, первый ход, а также выход
автомата устанавливались случайно. Каждый автомат копировался,
над ним производилась мутация на базе равномерного распределения.
В дальнейшем каждый автомат попарно сравнивался с 99 другими,
причем в качестве функции приспособленности выбирались ожидаемые
средние потери. Хотя в игре возможна стохастическая селекция,
предпочтительнее применять детерминированный отбор, согласно которому
из 100 автоматов выбирались 50 лучших. Критерием останова в данной
задаче являлось значение tmax = 200. Ниже в матрице в качестве
иллюстрации приводится список возможных автоматных состояний
и переходов между состояниями, полученный в ходе работы алгоритма:
4.5. Алгоритмы эволюционного программирования 137
Состояние
Переходы
состояний
So
г, г/
г, SO
м, г/
г. Si
м, м/
м, S3
г, м/
г, S6
Si
м, г/
м, Si
г, м/
г, S3
г, г/
м, S3
м, м/
Г, S4
s2
м, м/
г, S,
м, г/
г, Si
г, г/
м, S3
м, м/
М, S4
S3
м, г/
Г, S2
м, м/
м, S2
г, г/
г, S5
г, м/
м, S6
s4
м, г/
г, Si
г, г/
м, Si
м, м/
М, S2
г, м/
М, S7
s5
м, м/
Г, S2
г, м/
м, S3
м, г/
r,S5
г, г/
г, S5
s6
г, г/
г, S5
м, м/
г, S6
г, м/
М, S7
s7
м, м/
г, S,
г, м/
м, S3
г, г/
м, S6
м, г/
м, S8
Здесь So — это стартовое состояние, входом которого являлось
решение узника говорить («г»), а, например, запись в столбце S4
(г,г/м, S2) означает, что узник на очередном ходе принял решение
говорить, на предыдущем ходе использовалась стратегия г/м, автомат
из состояния S4 переходит в состояние S2.
Эксперименты с автоматами показали, что примерно в течение
первых 20 ходов преобладает стратегия молчания, хотя уже после
5-10 ходов начинает встречаться стратегия кооперативного поведения,
которая в дальнейшем однозначно становится доминирующей.
Эволюционное программирование удачно дополняет арсенал
эвристических методов поиска субоптимальных решений, обладая
свойствами адаптивности, способности к обучению, параллелизма. ЭП
позволяет проявить преимущества эволюционных вычислений в областях,
отличных от оптимизации функций, например при формировании
стратегий поведения и взаимодействия программных агентов в многоагент-
ных средах, принятия решений в классификационных задачах и т. п.
Параметры эволюционного программирования выбираются таким
образом, чтобы обеспечить скорость работы и асимптотическую
сходимость алгоритма. Процесс эволюционного программирования также
можно представить в виде однородной цепи Маркова, которая
характеризуется тем, что вероятность перехода между состояниями цепи
не зависит от времени t и представляется квадратной матрицей
переходов. Число строк и столбцов матрицы соответствует числу возможных
состояний марковской цепи, причем сумма вероятностей в каждой
строке матрицы всегда равна 1. Обозначим матрицу переходов через Р
и назовем состояния, из которых переход невозможен, поглощающими.
Ранее отмечалось, что для t —► 00 справедливо соотношение
НтР* =
I О
(I-Q)-^ О
где I — это единичная матрица, О — нулевая матрица, R —
матрица, содержащая вероятности перехода из непоглощающих состояний
в поглощающие состояния, Q — матрица, содержащая вероятности
138 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
переходов между не поглощающими состояниями, причем обратная
матрица (I — Q)"1 существует всегда.
Отсюда следует, что при t —► оо марковская цепь с вероятностью 1
перейдет в поглощающее состояние. Этот фундаментальный результат
для марковских цепей вполне применим к алгоритму эволюционного
программирования. Действительно, примем в качестве состояний
марковской цепи все векторы А* популяции P(t). Множество всех
возможных популяций соответствует множеству состояний цепи. Исключение
составляют популяции, которые включают глобальный оптимум. Они
могут быть объединены в отдельный класс эквивалентных
поглощающих состояний. Из справедливости предыдущего предела вытекает при
t —► оо следующее:
lim(I-Q)-1R=[l],
где [1] — единичный вектор. Это означает, что вероятность найти
глобальный оптимум при любой исходной популяции равна 1, если
число шагов эволюции tmax —► оо.
Представленный алгоритм эволюционного программирования
тестировался на различных задачах. В частности, тестовым примером была
функция Клауса-Хотца для комбинаторной задачи определения
перестановок. Требовалось максимизировать функцию следующего вида:
I Фг ~ Фз
п—\ п
^) = ЕРЗ=2-ЕЕ^ и-!.* »•
\Фз ~^1
г — J
3-г
где ф — некоторая перестановка на множестве натуральных чисел
1, 2, ..., п. В результате тестирования были получены, например,
следующие значения: Fmax(^) = 164 для п = 10, FmaLK(ip) = 6693 для
п = 50, Fmax(^) = 31 301 для п = 100.
Интерес представляют также другие тестовые функции:
• непрерывная функция Растригина от двух переменных,
2
F(xu x2) = £(10cos27nri - х\) - 20,
г=\
которая имеет один глобальный и 102 локальных максимумов,
представленных на рисунке 38 (см. вклейку);
• непрерывная функция Растригина от десяти переменных,
ю
F(xu ...,x10) = 5Z(10cos27nr*~x?)" 100'
г=\
которая имеет один глобальный и 1010 локальных максимумов;
Рис. 38. График двухпараметрической функции Растригина
4.6. Обучающие классификаторы
139
• функция де Йонга от пяти переменных с непрерывным
множеством глобальных максимумов,
5
F(x\, ..., х5) = ^lnt(zi),
г=\
где Int(xi) — целая часть числа Х{\
• стохастическая непрерывная нелинейная гауссова функция от
десяти переменных, имеющая один глобальный и 210 локальных
максимумов,
ю
F(x\, ...,х10) = J2(xi ~gauss(0, 1)),
i=\
где gauss(0, 1) — функция, возвращающая случайную величину
с нормальным распределением, математическим ожиданием,
равным 0, и дисперсией, равной 1;
• непрерывная функция Гриванка от десяти переменных, имеющая
один глобальный и множество локальных максимумов,
ю ю
П*ь...,*10) = Пс08:|-£шо-1;
г=1 г=1
• функции Розенбрука и Шеффера,
Fr(xu х2) = 100(х? - х\)2 + (1 - xi)2, xi, х2 Е [-2,048; 2,047],
Fs(xu х2) = (х? + х2)0'25 • [sin2(50 • (х2 + х22)ол) + 1,0],
Х1,х2 € [-100; 100];
• непрерывная, динамическая функция от двух переменных с
периодом 5 секунд, имеющая один глобальный и множество
локальных максимумов,
F(X, Y) = VX2 + У2 + 100(cos0,5ttX + со80,5тгУ) - X2 - У2,
где X = X - 20 - 20cos0,4tt£, Y = Г - 20 - 20sin0,47rt, * -
время (сек).
4.6. Обучающие классификаторы
Обучающие классификаторы, являясь одной из разновидностей ЭВ,
таксономия которых представлена на рисунке 1, построены на
сочетании эволюционных моделей и моделей компьютерного обучения
решению задач классификации [12]. Термин «компьютерная модель
классификации» (КМК) впервые предложил Дж. Холланд [62], где речь
шла о разработке когнитивной модели процесса обучения. В настоящее
время данный термин используется в областях искусственного
интеллекта, связанных с методами машинного обучения. Точное определение
140 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
термина «обучение» дать довольно трудно, однако, большинство
авторов считают обучаемость качеством адаптивной системы, которая
способна совершенствовать свое поведение, накапливая, например, опыт
решения такого важного класса интеллектуальных задач, каковыми
являются задачи классификации. Наиболее общей формой решения
подобного рода задач является индуктивная программа, способная
обучаться на основе обобщения правил классификации и извлечения
из предъявляемых примеров (прецедентов) полезных закономерностей.
Представим правила классификации в виде продукций:
(i); S; Р; ЕСЛИ (условия) ТО (действия); N,
где (i) — имя продукции, S — ситуации в предметной области, Р —
условие применимости продукции (предикат), ЕСЛИ (условия) ТО
(действия) — ядро продукции, которое указывает на условия
выполнения действия; N — постусловие продукции. В этом случае вполне
уместной выглядит аналогия между КМК и моделью искусственной
нейросети, в которой роль нейронов играют продукции. Однако на наш
взгляд, КМК имеют перед нейросетью очевидные преимущества:
представление знаний в виде наглядно интерпретируемых продукционных
правил; транспарентность и простота интеграции знаний в КМК.
Ядром КМК является база знаний в форме множества случайно
инициализируемых продукционных правил классификации. Для
кодирования условий продукции используем алфавит {0, 1,#}, где
символ # указывает на возможность 0 или 1. Для кодирования действия
продукции применим бинарный алфавит {0, 1}. Оказалось, что
подобного рода кодирование является удобным для обработки продукций
с помощью эволюционного алгоритма. Приведем пример
классификатора.
Пусть КМК решает задачу поиска в некотором пространстве
ситуаций, принимая информацию от датчиков слева, в центре, справа.
При положительной реакции посылается сигнал 1, в противном
случае — 0. Тогда запись вида
ЕСЛИ (0, 1, #) ТО (1) или < 0 1 # : 1>
означает, что если левый датчик «молчит», в отличие от правого, то все
равно, что происходит справа, и необходимо двигаться прямо. Такая
формализация учитывает, что обучение — это одновременно
способность и действие; при этом, однако, появляется возможность
сравнивать похожие ситуации и обобщать свойства предъявляемых
прецедентов. Вообще, способность к обобщению является очень важной, иначе
размерность множества правил классификации резко возрастает.
Пусть имеется два классификатора, содержащих по два условия
и по одному действию:
<0 0##, ### 1 : 1 1> и
<0 0 0#, 000 1 :0 1>.
4.6. Обучающие классификаторы
141
Будем считать второй классификатор более специфичным, нежели
первый, поскольку он содержит меньшее число символов #. Например,
при получении информации об условиях вида (0000) и (0001) оба
классификатора выполнимы, в отличие от ситуации (ООН) и (0101),
в которой действует только первое правило. Вместе оба
классификатора образуют элементарную иерархию правил, что является менее
затратным способом представления знаний, нежели формирование
правил для каждой отдельной ситуации, а также существенно облегчает
адаптацию КМК к новым ситуациям, позволяет вести речь о
накоплении опыта и самообучении.
Реакцию КМК на некоторую ситуацию можно разделить на две
фазы: исполнение (получение информации) и подкрепление. На первой
фазе сенсоры (детекторы) принимают информацию из окружающей
среды и кодируют ее в виде стринга битов. Затем проверяются
условия выполнения классификационных правил, и классификаторы, для
которых эти условия выполняются, копируются в отдельный список.
По частоте применения классификатора можно судить о его
полезности. Выбранное к исполнению действие посылается на эффекторы и
активизирует выполнение задачи системой. Фаза подкрепления
соответствует этапу закрепления знаний в процессе обучения или поощрению
КМК за правильные действия. Если обозначить через A(t) полезность
классификатора из списка исполнимых в момент времени £, через
^2 A(i) — суммарное значение полезности, то механизм динамического
изменения ^ A(t) можно представить в виде рекурсии,
J2Mt)^ZA(t)-a^A(t) + aB + al3J2Mt+l)>
где а (0 < а ^ 1) — коэффициент наказания, /3 (0 < /3 ^ 1) —
коэффициент поощрения, В — вознаграждение за правильные действия,
A(t+ 1) — прогнозируемая полезность.
В рамках общей теории ЭВ предлагается дополнить
представленный выше классический механизм поощрений-штрафов правилами
эволюции с целью придания процессу обучения более динамичных
свойств путем исключения «плохих» классификаторов и заменой их
на потенциально лучшие. Иными словами, после завершения фазы
подкрепления КМК либо переводится в фазу исполнения, либо
вызывается (периодически или случайно) эволюционный алгоритм, например
генетический, в котором полезность классификатора в ходе селекции
выступает в качестве целевой функции.
Понятно, что представленная модель процесса обучения является
упрощенной и не позволяет моделировать мыслительный акт на базе
запоминаемой информации для действительно сложных задач
адаптации. Поэтому предлагается расширить архитектуру КМК путем
введения в модель памяти в виде некоторого списка сообщений
ограниченной длины, в котором действуют, например аукционные правила, т.е.
преимущество получает более специфичный классификатор с самым
высоким значением полезности.
142 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Другой рекомендацией, направленной на расширение возможностей
КМК, является идея Грефенстетта [63] о декомпозиции процесса
обучения на эпизоды, в конце которых по цепи обратной связи с внешней
средой определяется наиболее активный и полезный классификатор.
Данный классификатор может быть использован с целью построения
стабильной цепи правил классификации, что представляется очень
важным, скажем, при поддержке процессов диагностирования и
контроля за технологическими процессами на транспорте.
Экспериментальное моделирование подтвердило нетривиальность
процесса обучения. Причины здесь следующие:
• для оптимизации процесса классификации генетический алгоритм
должен получать объективную информацию о полезности
классификатора, что требует определенного времени для стабилизации процесса;
• отрицательное влияние на обучение оказывает генерация в ходе
эволюции копий уже существующих или эквивалентных продукций;
• длинные цепи продукций строятся довольно долго и не всегда
стабильны, а КМК требует установки параметров, поиск подходящих
значений которых также является нетривиальной оптимизационной
задачей;
• полученные путем мутации и кроссинговера продукции с высоким
значением полезности могут «вытеснять» подходящие, но редко
активизируемые классификаторы.
В этой связи интерес представляет гибридизация КМК с
различными эволюционными методами, а также с нечеткими множествами, что
обеспечит более широкое применение КМК в сферах, где традиционно
используются модели нейросетей: распознавание образов, таксономия,
прогнозирование и т. п.
4.7. Алгоритмы роевого интеллекта
Ранее в разделе 1.6 отмечалось, что рой можно рассматривать
как многоагентную систему, в которой каждый агент функционирует
автономно по довольно примитивным правилам, однако, поведение всей
системы получается вполне разумным. Используя модель роевого
интеллекта, удалось получить неплохие результаты для решения задачи
коммивояжера, задачи оптимизации транспортных маршрутов, задачи
раскраски графа, задачи о назначениях, задача оптимизации сетевых
графиков, задача календарного планирования и многих других [8].
Особенно эффективны роевые модели при динамической оптимизации
процессов в распределенных нестационарных системах, например
трафиков в телекоммуникационных сетях. Основу поведения роя
составляет самоорганизация, обеспечивающая достижения общих целей роя
на основе низкоуровневого взаимодействия. Рой не имеет
централизованного управления, и его особенностями являются прямой и непрямой
обмен локальной информацией только между отдельными особями.
4.7. Алгоритмы роевого интеллекта
143
В общем случае в роевых моделях многомерное пространство
поиска населяется роем частиц. Формальная модель роевого алгоритма
была представлена в разделе 1.6. В соответствии с базовым циклом ЭВ
она включает последовательность шагов, связанных с созданием
исходной популяции, расчетом целевой функции для каждого индивидуума,
лучший из которых объявляется «центром притяжения», к которому
устремляются все остальные с ускорением, зависящим от расстояния
до «центра». Далее процесс итерационно повторяется заданное
число раз.
Последний «центр тяжести» соответствует найденному локальному
оптимуму х*. Рой не знает, где именно находится цель, но на каждой
итерации рой знает, как далеко она находится. Эффективной
стратегией будет следование за индивидуумом, который на данный момент
находится к цели ближе всего.
Рассмотрим подробнее разновидности алгоритмов роя на примерах
поведения стаи птиц, муравьиной колонии, роя пчел.
Моделируя поведение стаи птиц, обозначим через ft текущее
значение целевой функции — время завершения выполнения всех действий,
включенных в модель на итерации t, через /best — лучшее значение
целевой функции, Ft — лучшее значение целевой функции среди всех
индивидуумов. Тогда скорость индивидуума на следующем шаге (£+ 1)
вычисляется как
vt+i =vt + k{* rnd(0, 1) * (/best - ft) + fa * rnd(0, 1) * (Ft - ft),
а значение целевой функции как
Л+i = ft +vt+i,
где vt — скорость индивидуума на итерации t, rnd(0, 1) — случайное
число на интервале (0, 1), k\, k<i — некоторые коэффициенты.
Таким образом, согласно модели роя после случайной
инициализации популяции индивидуумов, для каждого из них вычисляется
значение целевой функции ft. Если оно окажется лучше, чем /best»
то /best обновляется. Далее среди /best выбирается лучшее значение Ft
и затем вычисляются, согласно приведенным выше формулам, новые
значения скоростей индивидуумов и текущие значение их целевых
функций. Итерационный процесс повторяется.
В чем состоит модификация предлагаемого алгоритма в сравнении
с каноническим алгоритмом роя? В более тесной аналогии с
естественным поведением роя в природе. Во-первых, при определении
центра притяжения всех индивидуумов роя его координаты не задаются
однозначно. Это достигается тем, что при вычислении параметров
движения каждой частицы к центру тяжести на них накладывается
случайная составляющая. Во-вторых, на ускорение, с которым каждая
частица движется к центру тяжести, также накладывается случайная
составляющая. В-третьих, решение об использовании (или не
использовании) случайных составляющих принимается по правилам лотереи
144 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
(«орел»/«решка»). Наконец, в -четвертых, для улучшения сходимости
алгоритма, расширения пространства поиска и приближения
математической модели к естественному поведению роя в природе вводятся
«сумасшедшие» индивидуумы, законы движения которых случайны
и не связаны с роем.
Отметим также высокую степень распараллеливания операторов
предлагаемого модифицированного алгоритма.
При тестировании модели выяснилось, что объем популяции
в 10 индивидуумов достаточен, чтобы получить хорошие результаты.
Рекомендуемый размер популяции равен 20-40 индивидуумов, хотя
для некоторых специальных задач размер популяции достигал
от 100 до 200 частиц. Число итераций выбирается следующим
образом. Если, например, целочисленная переменная изменяется на
интервале [—10, 10], то число итераций около 20. Коэффициенты fci
и &2 в экспериментах выбирались равными 2 либо варьировались
на интервале [0, 4].
Муравьиные алгоритмы являются еще одной разновидностью
роевых моделей. В ходе наблюдения за муравьиными колониями было
обнаружено, что почти слепым муравьям удается находить кратчайшие
маршруты до источников пищи [15, 64]. Муравей по мере продвижения
откладывает на почве феромоновые метки, запах которых распознается
другими муравьями. Муравьи, не сталкивающийся с прежде
проложенным следом, двигаются произвольно, однако, если они наталкиваются
на след, то с высокой вероятностью перемещаются по нему, усиливая
его своими собственными метками. Вероятность выбора направления
движения пропорциональна величине феромона в найденном следе,
т.е. чем больше муравьев пройдет по одному и тому же пути, тем он
становится более привлекательным. На рисунке 39 представлен пример
подобного рода коллективного поведения муравьиной колонии.
Если считать муравейником пункт А, то задача муравьиной колонии
состоит в поиске кратчайшего пути до источника пищи в пункте D
(рисунок 39, а). Если на уже проложенном пути появляется
препятствие или будет обнаружен более короткий путь к цели, то муравью
в пункте F следует выбрать направление к пункту С или к пункту Е
(рисунок 39, б). Выбор зависит от количества феромона, оставленного
предыдущими муравьями.
Будем считать, что феромоновый след на направлениях FCD
и FED первоначально одинаков, однако, путь FED короче, нежели
путь FCD. Вначале муравьи, достигающие пункта F, будут с
одинаковой вероятностью выбрать путь FCD или FED. Однако поскольку
путь FED короче, чем FCD, то по нему за единицу времени пройдет
большее количество муравьев до пункта D, соответственно, на пути
FED будет большее количество феромона и он в дальнейшем будет
использоваться с большей вероятностью (рисунок 39, в).
Однажды выбрав путь, при условии неизменности окружающей
среды, муравьи предпочтут тот же самый маршрут до тех пор, пока,
4.7. Алгоритмы роевого интеллекта
145
Рис. 39. Пример моделирования поведения реальных муравьев
например, между пунктами F и Е не возникнет препятствие
(рисунок 39, г).
С позиций общей теории эволюционных вычислений нас
интересует не моделирование жизни колонии муравьев, а имитация
поведения колонии в качестве средства повышения эффективности работы
эволюционных алгоритмов. При этом вычислительная модель может
несколько отличается от природной модели. Например, муравьи могут
иметь память, быть не полностью слепыми, находиться в пространстве
с дискретным временем и др. Проиллюстрируем возможные
модификации муравьиных алгоритмов на примере задачи о коммивояжере.
Коммивояжеру необходимо посетить W городов, не заезжая в один
и тот же город дважды, и вернуться в исходный пункт по маршруту
с минимальной стоимостью. Пусть задана модель задачи в виде графа
G = (X, [/), где \Х\ = п — множество вершин (города), \U\ = т —
множество ребер (возможные пути между городами). Дана матрица
чисел D(z, j), где г, j € 1, 2, ..., п, представляющих собой стоимость
переезда из вершины Х{ в Xj. Тогда требуется найти перестановку <р
из элементов множества X такую, что значение целевой функции равно
Fitness(<p) = D(p(l), <p{n)) + £{D(p(t), Ф + 1))} -♦ min.
г
10 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
146 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Если граф не полносвязный, то в матрице D, в ячейках,
соответствующих отсутствующим ребрам в графе, ставится бесконечность,
в результате чего проход по данному ребру будет исключен.
Определим свойства муравья.
1. Каждый муравей обладает собственной «памятью», хранящий
список городов J{tk (табу-лист), которые необходимо посетить
муравью к, который находится в городе г.
2. Муравьи обладают «зрением», обратно пропорциональным длине
ребра:
щ = l/Dij.
«Зрение» определяет «жадность» выбора муравья. Чем ближе
находится вершина графа, тем он лучше «виден» и тем больше он стремится
попасть в нее.
3. Каждый муравей способен улавливать след феромона, которое
будет определять желание муравья пройти по данному ребру. Уровень
феромона в момент времени t на ребре Dij будет соответствовать т^(£).
4. Вероятность перехода муравья из вершины г в вершину j будет
определяться следующим соотношением:
Рам*) =
Tij(t)]a-[THi(t)]f
£ [т«(*)]° • МО]'
{ Pijik(t)=0,
г. jeJi.k,
j i A
(ID
где a, /3 — это параметры, задающие «вес» следа феромона. При a = О
муравей стремиться выбирать кратчайшее ребро, при /3 = 0 — ребро
с наибольшим количеством феромона.
На рисунке 40 представлен пример, иллюстрирующий поведение
муравья для задачи о коммивояжере.
Т4. з = 2,5
Т4.7=1,7
#4,3=2
Хз, XI-
Рис. 40. Пример моделирования поведения муравья при решении задачи
коммивояжера
4.7. Алгоритмы роевого интеллекта
147
Здесь муравей прошел путь по вершинам 1-6-5-4, и, находясь
в вершине 4, выбирает направление между вершинами 7 и 3.
С течением времени вероятность выбора кратчайшего пути
увеличивается, поскольку количество откладываемого феромона обратно
пропорционально длине маршрута и задается в следующем виде:
ATijtk(t) = { Lk(t) (12)
1 0, (t,j)*Tfc(t),
где Q — параметр, имеющий значение порядка длины оптимального
пути, Lk{t) — длина маршрута Tk(t).
Испарение феромона определяется следующим выражением:
т
тф +1) = (1 - р) • Tijit) + £ Д^-.fcW. О3)
к=\
где m — количество муравьев, р — коэффициент испарения (0 ^ р ^ 1).
Пусть начальным расположением колонии муравьев будет
следующее: количество муравьев равно числу вершин в графе, а каждому
из них соответствует вершина, с которой он начинает свое
путешествие.
Простые муравьиные алгоритмы для задачи коммивояжера
известны [15, 65, 66]. Его оценка временной сложности зависит от времени
жизни колонии, количества вершин графа и числа муравьев и равна
0(t * га * п2), где t — количество итераций (время жизни колонии),
га — число муравьев, п — число вершин. Попробуем теперь с позиций
общей теории эволюционных вычислений провести и экспериментально
оценить возможные модификации простого муравьиного алгоритма.
Укажем следующие направления модификации:
• появление «элитных» муравьев;
• изменение начального расположения муравьиной колонии;
• применение шаблонов в муравьиных алгоритмах.
Элитными считаются муравьи, чьи маршруты лучше остальных.
Тогда формула (12) для элитных муравьев принимает следующий вид:
*т-® = Ае-Т7®- (14)
где А€ — коэффициент, регулирующий влияние элитных муравьев.
Укажем несколько вариантов различных значений Ае. Если Ае = О,
то влияние муравья игнорируется, а его маршрут не отмечается феро-
моновым следом. Если Ае € (0, 1), то уровень феромонов на маршруте
отмечается слабо (или наоборот — феромон быстро испаряется). Если
Ае = 1, то влияние муравья равнозначно другим (простой муравьиный
алгоритм). Если Ае £ (1, ос), то влияние элитного муравья
усиливается.
10*
148 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Выбор значения Ае влияет на эффективность (вычислительную
мощность) алгоритма, которая определяется качеством получаемых
решений в сочетании с трудоемкостью их получения и скоростью
сходимости.
Для инициализации базового цикла, представленного ранее на
рисунке 6, для алгоритмов эволюционных вычислений необходимо
сформировать начальную популяцию решений. Поэтому начальное
расположение муравьиной колонии также оказывает влияние на
качество решения и сходимость муравьиного алгоритма. Здесь возможны
несколько стратегий формирования начальной популяции:
• в каждой вершине находится по одному муравью (трудоемкость
алгоритма оценивается как 0(t * п3), поскольку п = га);
• муравьи случайно распределены в вершинах графа;
• вся колония находится в одной вершине;
• в каждый момент времени, т. е. на каждой итерации, вся колония
перемещается в случайно выбранную вершину, из которой
каждый муравей начинает свой маршрут.
Еще одним направлением повышения эффективности работы
муравьиного алгоритма является использование двух гипотез: гипотезы
строительных блоков и гипотезы сходимости популяции. Ранее уже
отмечалось, что, синтезируя новые решения в результате выполнения
композиции эволюционных операторов, важно сохранить те части
решений (шаблоны строительных блоков), которые вносят существенный
вклад в общую оценку функции качества. Гипотеза сходимости
предполагает ограничение пространства поиска решений.
Рассмотрим в качестве примера такую схему формирования
строительных блоков, которая позволяет существенно снизить временные
затраты, связанные с вычислением вероятностей перехода из одной
вершины в другие по формуле (11).
Пусть муравей к находится в вершине г. Тогда, чтобы найти
следующую вершину в текущем маршруте, необходимо вычислить
вероятности перехода в другие вершины, используя выражение (11). Временная
сложность алгоритма нахождения следующей вершины является
линейной и равна 0(п * log(a)), где п — число вершин, а а —
некоторый заданный коэффициент. Это объясняется использованием функции
возведения в степень при расчете вероятности перехода в некоторую
вершину по формуле (11). Действуя по определенной схеме, найти
переход в следующую вершину можно с временной сложностью, равной
0(1), причем объем вычислений на первом шаге не зависит от уровня
феромонов на ребрах. Время, затрачиваемое на вычисление
вероятностей, является одинаковым и не зависит от значения t даже в случае,
если выбор очередного ребра, инцидентного вершине г, очевиден
(вероятность выбора очень высокая, например 0,999).
4.7. Алгоритмы роевого интеллекта
149
Что собой представляет шаблон строительного блока? Это вектор
размерностью п (число вершин в графе), содержащий номера вершин,
в которые желательно перейти из вершины г. Иначе говоря,
строительные блоки представляют собой непрерывные части решений (подмарш-
руты гамильтонова цикла). Пространство поиска решения при этом
существенно сокращается, а сформированные блоки рассматриваются
как укрупненные вершины.
Как формируется шаблон строительного блока? Стратегии
формирования шаблона также могут быть различными. Например, перед
началом работы муравьиного алгоритма на основе имеющейся
информации о длинах ребер выделятся ребра, имеющие высокую вероятность
попадания в гамильтонов маршрут коммивояжера. Однако формировать
шаблоны можно также динамически, в процессе работы муравьиного
алгоритма. Например, задав некоторое пороговое значение вероятности
перехода из вершины г в вершину j, можно приступать к
формированию шаблона, если порог будет превышен в процессе работы алгоритма.
В целом отметим, что временная сложность муравьиных
алгоритмов (ВСА), применяемых для эволюционных вычислений, зависит
не только от таких начальных параметров, как число вершин п, размер
колонии га и число итераций Т. Согласно (10) ВСА также зависит
от параметров а и /?, т. е. от настройки алгоритма.
Наиболее трудоемкой и повторяющейся операцией в муравьином
алгоритме является вычисление вероятности выбора муравьем
очередного ребра по формуле (11). Расчет этой вероятности включает
в себя операции суммирования, умножения и возведения в степень.
Предположим, что для возведения в степень используется алгоритм
быстрого возведения в степень, ВСА которого равна 0(log2+1). Тогда
ВСА муравьиного алгоритма выражается зависимостью 0(Т -т-п2 х
х (log2a + log2/?)).
Быстродействие алгоритма повышается в среднем в 2-4 раза, если
при возведении в степень используются только целочисленные
операнды, а также, если в алгоритме исключить многократное повторение
одинаковых операций с одними и теми же операндами. Речь идет об
операции возведения в степень 0 «зрения» муравья щ. Действительно,
оба числа являются константами, поэтому нет смысла при расчете
вероятности перехода fc-ro муравья из вершины г в j на каждой итерации
вычислять значение rjfjy которое является константой на протяжении
всей «жизни» муравьиной колонии. Поэтому под «зрением» муравья
будем понимать следующее выражение:
щ = {l/Daf.
150 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Соответственно выражение (10) будет иметь следующий вид:
Pijk(t)= М*)]°-**'(*) , jejik,
Pij,k{t)=0, J$Ji.k'
ВСА алгоритма также изменяется и становится равной
0(T-ra-n2-log2a).
Время работы алгоритма зависит прямо пропорционально от
значения коэффициента а. Если считать параметры муравьиного алгоритм
Т, га, а константами, то ВСА зависит только от размерности задачи —
0(п2).
Эксперименты со стандартными бенчмарками позволили выявить
следующие зависимости качества получаемых решений и скорости
сходимости от параметров муравьиного алгоритма:
• с ростом размеров колонии муравьев га улучшается качество
решения и снижается скорость сходимости алгоритма;
• при малых значениях параметров а и /3 (1, 2, 3) качество выше,
с ростом значений этих параметров повышается сходимость
алгоритма;
• наилучшее качество достигается при значениях коэффициента
испарения феромона р Е [0,5; 0,9], алгоритм быстрее сходится при
р€[0;0,3];
• качество решений выше, если при начальном размещении
муравьи случайно распределены в вершинах графа, причем
необязательно, чтобы численности колонии и вершин совпадали;
• алгоритм быстрее сходится, если при начальном размещении
в каждой вершине находится по одному муравью;
• алгоритм тем быстрее сходится, чем выше коэффициент Ае,
регулирующий влияние элитных муравьев;
• качество решений выше, если длина шаблона строительных
блоков варьируется в интервале 0-30% от общего числа вершин;
• алгоритм тем быстрее сходится, чем больше длина шаблона
строительных блоков.
Полученные экспериментальные результаты позволяют с большей
определенностью подходить к выбору параметров алгоритма при
решении задачи коммивояжера с различными начальными данными.
Еще одной разновидностью алгоритмов роевого интеллекта
является поведение пчелиного роя [68]. Канонический алгоритм
известен [66]. Он состоит в следующем.
4.7. Алгоритмы роевого интеллекта
151
После инициализации популяции из N пчел-разведчиков по
случайным позициям все пчелы сортируются в соответствии со значениями
целевых функций (ЦФ) тех участков, на которых они находятся. Среди
общего количества участков га определяется е элитных участков, на
которые направляются и пчел-разведчиков. Эти пчелы образуют новые
участки в окрестностях элитных. После чего в окрестности остальных
участков (га - е), в зависимости от значения их ЦФ, отправляются
рабочие пчелы (I = N -п).
Таким образом, работа канонического пчелиного алгоритма зависит
от следующих основных параметров: общее число пчел-разведчиков
(iV); общее число участков (га); число элитных участков (е); число
пчел-разведчиков на элитных участках (п); число пчел (/) на
остальных (ш — е) участках; начальный размер участков, т. е. размер
участков вместе с их окрестностями (5); максимальное число итераций
алгоритма (/).
Идея пчелиного алгоритма заключается в том, что все пчелы на
каждом шаге будут выбирать как элитные участки для исследования,
так и участки в окрестности элитных, что позволит, во-первых,
разнообразить популяцию решений на последующих итерациях, во-вторых,
увеличить вероятность обнаружения близких к оптимальным решений.
Канонический пчелиный алгоритма включает следующие шаги:
1° создание популяции пчел;
2° оценка ЦФ пчел в популяции;
3° выбор участков для поиска в их окрестности;
4° отправка пчел-разведчиков;
5° выбор пчел с лучшими значениями ЦФ с каждого участка;
6° отправка рабочих пчел, осуществляющих случайный поиск
и оценка их ЦФ;
7° формирование новой популяции пчел;
8° проверка условий окончания алгоритма; если они выполняются,
переход к п. 9, иначе — п. 2;
9° конец работы алгоритма.
Данный алгоритм может быть улучшен за счет того, что на каждой
итерации начальный размер участков S уменьшается путем их деления
на адаптивный параметр Д, величина которого варьируется в
зависимости от качества получаемого на каждой итерации решения, то есть:
чем хуже получается решение, тем ближе параметр R к 1.
В [66] была предложена еще одна разновидность пчелиного
алгоритма. Ее идея основана на четком распределении обязанностей
между отдельными его индивидами пчелиного роя: рабочие пчелы;
пчелы-исследователи; пчелы-разведчики.
Рабочие пчелы занимаются поиском источников нектара и
снабжают информацией о качестве исследованных участков
пчел-исследователей, которые все это время находятся в улье и получают информацию
152 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
об объекте исследования только от рабочих пчел. Пчелы-разведчики,
в свою очередь, осуществляют случайный поиск новых источников
нектара.
Таким образом, пчелиный алгоритм несколько меняется и его
основные шаги включают:
1° определение месторасположения источников нектара;
2° поиск каждой рабочей пчелой новых источников нектара на
заданном ей участке и исследование лучшего из них;
3° выбор источника нектара пчелой-исследователем с определенной
вероятностью, в зависимости от его качества;
4° если решение на исследуемом участке не улучшается с течением
нескольких итераций переход к п. 5;
5° запоминание лучшего источника нектара;
6° случайное заполнение оставшейся части популяции;
7° повторение пп. 2-6 пока не будет достигнут критерий останова.
Были проведены экспериментальные исследования канонического
пчелиного алгоритма (ВА), улучшенного пчелиного алгоритма (IBA),
а также алгоритма колонии пчел (ABC). Эксперименты проводились
на примере задач минимизации нелинейной несепарабельной функции
Розенбрука вида
Fr(x\, х2) = Ю0(х2{ - х\)2 + (1 - xi)2, хих2е [-2,048; 2,047],
а также многоэкстремальной функции Растригина вида
F(X) = 10п + jr(x\ - 10cos(27rx0).
г=1
В ходе экспериментов для канонического алгоритма ВА были взяты
значения N = 50, е = 5, га = 15, п = 25, I = 25, S = (0,5; 3), для
алгоритма IBA — значения N = 60, е = 1, т = 3, п = 50, Z = 10;
первоначальный размер участков S = 6 и R = 1,05, для ЛВС-алгоритма
число участков для поиска 5 = 20. Для всех трех алгоритмов было
взято фиксированное значение предельного числа итераций /, равное
100. Результаты экспериментов в виде зависимости значения ЦФ от
числа итераций / для функции Розенбрука представлены на
рисунке 41, а для функции Растригина — на рисунке 42.
Из рисунков 41 и 42 видно, что алгоритм ABC превосходит
алгоритмы ВА и IBA как по качеству получаемых решений, так и по времени
работы. Кроме того, он оперирует меньшим числом параметров, и,
соответственно, не требует больших вычислительных затрат.
4.7. Алгоритмы роевого интеллекта
153
О 10 20 30 40 50 60 70 80 90 I
Рис. 41. Зависимости значений ЦФ от числа итераций / в алгоритмах ВА, IBA
и ABC для функции Розенбрука
Рис. 42. Зависимости значений ЦФ от числа итераций I в алгоритмах ВА, IBA
и ABC для функции Растригина
154 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
В заключение отметим, что представленные разновидности
эволюционных роевых алгоритмов благодаря своей простоте и скорости
определенно могут считаться одними из самых перспективных для
построения распределенных алгоритмов, инспирированных природными
системами.
4.8. Алгоритмы моделирования отжига, пороговые,
потоковые и алгоритмы рекордов
Моделирование отжига, пороговые, потоковые и алгоритмы
рекордов с позиций общей теории ЭВ являются разновидностями
эволюционных алгоритмов, конкурирующими с генетическими алгоритмами,
алгоритмами генетического и эволюционного программирования,
эволюционными стратегиями и роевыми алгоритмами [21].
В разделе 1.8 была представлена формализованная модель отжига.
Проведенные с позиций общей теории ЭВ эксперименты позволяют
сделать следующие выводы. Значительное влияние на результаты,
получаемые с использованием модели отжига, оказывает «план охлаждения»,
который устанавливает динамику изменения параметра Tt и количество
проводимых итераций It. Один из вариантов плана состоит в установке
высокого начального значения То для того, чтобы вначале
практически каждое решение запоминалось и выбиралось с определенной
вероятностью. Благодаря этому на начальном этапе процесса
оптимизации удается избежать преждевременного сокращения пространства
поиска. На последующих этапах можно применять пропорциональное
уменьшение параметра Т: Tt+\ = а • Ти где а — некоторая константа
(0,8 ^ а ^ 0,99). Таким образом, обеспечивается асимптотическое
приближение к значению Tmin = 0.
Отметим, что модифицированный алгоритм отжига
продемонстрировал толерантность к неоптимальным решениям: вероятность
«выживания» решения тем выше, чем выше значение Т и чем меньше разница
между сравниваемыми решениями. Это помогает избежать попадания
в локальный экстремум целевой функции. Напротив, на завершающей
фазе оптимизационного процесса чем меньше значение Т, тем меньше
пространство поиска, а при Г = 0 «выживали» только лучшие решения.
Медленное «охлаждение», в отличие от быстрого, приводит к лучшим
результатам, т.е. выбирать необходимо между скоростью сходимости
алгоритма и его результативностью.
Процесс, моделируемый по алгоритму отжига, является
марковским и при определенных допущениях относительно применяемого
«плана охлаждения» можно доказать его сходимость к глобальному
оптимуму с экспоненциальным ростом времени его поиска. Поэтому
при ограничении на время оптимизации алгоритм отжига является
эвристическим.
4.8. Алгоритмы отжига, пороговые, потоковые и рекордов 155
Другой важной особенностью при реализации алгоритма отжига
является установление отношения соседства и механизма, с
помощью которого осуществляется переход от одного решения к
другому. Определение отношения соседства зависит от решаемой задачи.
Выбор новой точки среди соседних рекомендуется делать случайно.
Для сокращения времени поиска оптимизированного расписания
рекомендуется комбинировать алгоритм отжига с другими эволюционными
алгоритмами.
Проведенные эксперименты по сравнению потокового и порогового
алгоритмов показали, что, немного уступая в качестве найденных
решений, потоковый алгоритм позволяет быстрее находить решение [21].
На наш взгляд это объясняется двумя обстоятельствами. Во-первых,
многие оптимизационные задачи являются мультиэкстремальными, т. е.
зачастую имеют много различных хороших решений. Во-вторых, с
ростом размерности пространства поиска имеется больше возможностей
выйти из локальной «ямы».
Эксперименты также показывают, что алгоритм рекордных оценок
и потоковый алгоритм можно модифицировать с помощью
стохастического или детерминированного определения соседних точек. Эту роль
в потоковом алгоритме играет параметр V, а в модели рекордных
оценок — параметр AW. Если параметр V выбран очень малым, а
параметр AW — очень большим, то можно рассчитывать на близкое
к оптимальному решение, правда, за относительно долгое время
вычислений, в противном случае — наоборот.
Проведенный сопоставительный анализ рассмотренных
разновидностей алгоритмов эволюционных вычислений, а также гипотез,
лежащих в их основе, позволяет сформулировать следующие рекомендации
по их применению в эволюционных вычислениях:
• построение начальной модели, правил, по которым она
эволюционирует, а также подходов к представлению (кодированию) решений
является ключевым условием их успешного применения для
организации эволюционных вычислений;
• алгоритмы отжига, пороговый, потоковый и рекордных оценок
имеют наибольшую степень сходства с алгоритмами эволюционных
стратегий и эволюционного программирования, однако имеются и
отличия: размер популяции решений в этих алгоритмах равен единице
или двум; поиск решений ведется локально от точки к точке; мутация
является единственным оператором поиска, а селекция проводится
по специальным правилам;
• для эффективного управления скоростью сходимости процесса
поиска можно использовать различные механизмы, инспирированные
природными системами, например: «план охлаждения» в алгоритме
отжига, аналогичные механизмы в пороговом, потоковом и
алгоритме рекордных оценок; однако эти процедуры не обладают свойством
156 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
параллелизма, который, наоборот, является отличительной чертой
генетических и роевых алгоритмов.
4.9. Алгоритмы табуированного поиска
Идеи, связанные с табуированным поиском (tabu search), появились
в середине 80-х годов. Алгоритмы табуированного поиска также
являются разновидностями эволюционных алгоритмов согласно
таксономии, представленной на рисунке 1. Они имеют определенное сходство
с известным методом градиентного спуска с памятью [68].
В процессе поиска ведется список табуированных (запрещенных
для уничтожения) решений из числа уже оцененных. Критические
параметры алгоритмов табуированного поиска — глубина списка
запретов, определение текущего состояния, размер области вокруг текущего
состояния. В процессе поиска осуществляются операции аспирации
(включение в запрещенный список решений в окрестности
табуированного) и диверсификации, которая добавляет фактор случайности
в процесс поиска.
Ниже, исходя из базового цикла ЭВ, на примере задачи
минимизации функции приводится описание предлагаемого алгоритма
табуированного поиска х* <— tabuSearch(f, п).
Input: / — целевая минимизируемая функция
Input: п — максимальная длина списка запретов (п > 0)
Data: pnew — новое решение
Data: р* — лучшее (текущее) решение
Data: tabu — список запретов
Output: X* — лучшее из найденных решений
begin
р* := init Pop(n)
tabu := createList(l,p*)
while (критерий останова) do
Pnew := мутация(р*)
if noucK(pneWl tabu) < 0 then
if f(Pnew) < f(p*) then p* := pnew
if ллина^аЬи) ^ n then tabu := deleteListItem(tabu, 0)
tabu := addListItem(tabu, pnew)
return p*
1 end |
Теория ЭВ позволяет сформулировать обобщение
представленного алгоритма табуированного поиска для однокритериальной
задачи на случай решения задачи многокритериальной оптимизации
х* <— tabuSearchMO(cmpF, n, а):
4.10. Алгоритмы гармонического поиска
157
Input: стрг — функция для оценки качества решений,
представляющая собой компаратор, сравнивающий качество решений
Input: п — максимальная длина списка запретов (п > 0)
Input: as — максимальный размер архива решений
Data: tabu — список запретов
Data: pnew — новое решение
Data: Arc — архив лучших новых решений
Output: X* — лучшее из найденных решений
begin
Arc := 0
Pnew ~ createQ
tabu := 0
while критерий останова() do
if searchltemu(pnewy tabu U Arc) < 0 then
Arc := updateOptimalSet(Arc, Pnew)
Arc := pruneOptimalSet(Arcy as)
v := функция качества (Arc, cmpp)
if длина(£а£ш) ^ n then tabu := deleteListItem(tabu, 0)
tabu := addListItem{tabu, pnew)
Pnew := select(Arc, v, 1)
Pnew '= mutate(pnew)
return /* восстановление фенотипа множества (Arc) */
| end |
Здесь использованы ранее применявшиеся обозначения функций.
4.10. Алгоритмы гармонического поиска
С позиций общей теории эволюционных вычислений
перспективным направлением расширения когнитивных возможностей операторов
эволюционных алгоритмов является использование алгоритмов
гармоничного поиска (дихотомия, Фибоначчи, золотое сечение) и
фрактальных множеств [7, 8]. Например, геометрия многих объектов в природе
имеет фрактальную структуру. Фрактальные объекты, как известно,
самоподобны. Преобразования, создающие такие структуры, — это
итерационные процессы с обратной связью, когда одна и та же
операция выполняется снова и снова, аналогично эволюционным процессам.
Здесь результат одной итерации является начальным условием для
другой, а между результатом и реальным значением существует
нелинейная зависимость. Известными примерами фрактальных множеств
являются множество Кантора, «снежинки» (кривая Коха), ковер Сер-
пинского и другие множества, обладающие свойством геометрической
инвариантности.
Фракталы характеризуются понятием фрактальной размерности.
Их множества можно использовать в качестве «строительных» блоков
158 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
в эволюционных операторах кроссинговера, мутации и др., тем самым
расширяя их когнитивные возможности.
Используемые в базовом цикле алгоритма ЭВ эволюционные
операторы можно строить, применяя процедуру дихотомического поиска.
Например, для построения оператора кроссинговера на основе
дихотомии необходимо выполнить следующую последовательность действий:
1° пусть заданы две родительские хромосомы длины L;
2° делим хромосому (отрезок L) пополам (при нечетном размере
хромосомы в любую часть берется большее ближайшее число
генов);
3° точка дихотомии определяет точку разрыва в операторе
кроссинговера;
4° по правилам построения одноточечного кроссинговера получаем
две новых хромосомы-потомка;
5° каждую половину хромосомы-потомка снова делим на две части
и процесс продолжаем аналогично до тех пор, пока не будет
получено заданное количество хромосом-потомков или метод
дихотомии завершится; при получении нереальных решений (хромосом
с повторяющимися генами) производится восстановление
реальных решений, при этом повторяющиеся гены меняются на
отсутствующие гены из хромосом-родителей;
6° конец работы алгоритма.
Для построения оператора мутации с использованием чисел
Фибоначчи необходимо выполнить следующую последовательность
действий:
1° в выбранной хромосоме определяем точку разрыва (она
соответствует третьему числу ряда Фибоначчи);
2° производим реализацию стандартного оператора мутации и
получаем новую хромосому-потомок;
3° вычисляем значение ЦФ хромосомы-потомка; если получен
глобальный оптимум, то — конец работы алгоритма;
4° далее в качестве точки ОМ Фибоначчи выбираем 4, 5, ... числа
ряда Фибоначчи и переходим к пункту 3;
5° алгоритм заканчивает работу по достижению заданного критерия
или когда номер числа ряда Фибоначчи ^ L.
Оператор инверсии также может быть с использованием как
метода Фибоначчи, так и принципа «золотого сечения». Для построения
оператора инверсии на базе метода Фибоначчи разработан следующий
алгоритм:
1° пусть задана родительская хромосома длины L;
2° точка разрыва оператора инверсии соответствует третьему числу
ряда Фибоначчи;
3° по правилам построения оператора инверсии, инвертируя правую
часть от точки оператора инверсии, получаем новую хромосому
потомка;
4.11. Алгоритмы меметики
159
4° далее в качестве точки разрыва выбираем 4, 5, ... числа ряда
Фибоначчи и переходим к п. 3;
5° алгоритм оканчивает работу по достижению заданного критерия
или когда номер числа ряда Фибоначчи становится больше либо
равен L.
Алгоритм построения оператора инверсии на основе метода
«золотого сечения» аналогичен построению оператора инверсии по
Фибоначчи. Разница в том, что первая точка разрыва в операторе
инверсии определяется на расстоянии целой части 0,618L от любого
края хромосомы. Затем часть хромосомы, расположенная между точкой
разрыва и правым концом хромосомы, инвертируется. Вторая точка
разрыва в новой хромосоме определяется как ближайшее целое из
выражения (L — 0,618L) • 0,618. Далее процесс продолжается аналогично
до окончания возможности разбиения хромосомы или по достижению
заданного критерия.
4.11. Алгоритмы меметики
Мем — это устойчивая структура информации, способная к
репликации [69]. С позиций общей теории ЭВ алгоритмы меметики
представляют собой разновидность эволюционных алгоритмов, в которых
мемы рассматриваются как единицы информации, распространяемые
между людьми посредством имитации, обучения и др. Мемы, подобно
генам, можно рассматривать в качестве репликаторов, то есть как
информацию, копируемую вариационно и селективно.
В меметике концепции из эволюционной теории (в частности, по-
пуляционной генетики) переносятся на человеческую культуру. Меме-
тика также использует математические модели в попытке объяснить
такие социальные явления, как религия и политические системы.
Критики меметики говорят, что меметика игнорирует достижения таких
наук как социология, психология и др.
Проблемными в меметике являются следующие ниже вопросы.
• Каким образом можно измерить мем как единицу культурной
эволюции?
• Насколько отличаются биологическая и культурная эволюции?
• Выполняются ли в меметике классические требования к валид-
ности исследований (фальсифицируемость, когерентизм, бритва
Оккама)?
Принцип действия генетических алгоритмов для решения
оптимизационных задач заключается в имитации природной эволюции
(в генах кодируются характеристики фенотипа). Принцип действия
алгоритмов меметики для решения тех же оптимизационных задач
заключается в имитации социальной эволюции (поведенческие модели
передаются в виде мемов). П. Москато [70] использовал в качестве
примера китайское боевое искусство кунг-фу, поколения мастеров
которого разработали методику обучения своих студентов определенным
160 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
последовательностям движений, состоящих из ряда элементарных
агрессивных и оборонительных структур-мемов. Новые мемы
появлялись редко, далеко не случайным образом и почти всегда приводили
к улучшению.
Отметим также идейную близость меметики с моделями эволюции
Ж. Ламарка, де Фриза, К. Поппера, М. Кимуры, И. Шмальгаузена
и эффектом Болдуина [56, 71, 72], которые примерно с тех же позиций
пытаются объяснить фенотипические изменения в природных системах,
их влияние на приспособленность и адаптацию вида.
Известно, что модель Ламарка, представленная на рисунке 43, дает
несколько иную модель эволюции, нежели принятая в генетике.
Внешняя
среда
Наследствен nu^ i d
1
Приспособляемость
1
Отбор
1
'
Эволюционная
смена
форм
1 ЮПуллцпл
1
{
Выход
Рис. 43. Модель эволюции Ж. Ламарка
Модель эволюции Ламарка включает два основных принципа:
• человек может приобрести новые, полезные свойства в течение
жизни и потерять те свойства, которые оказались
неиспользованными;
• приобретенные свойства могут наследоваться в потомках.
В эпоху Ламарка о существовании генов и ДНК еще не было
известно. Вейсманн был первым, кто утверждал, что наследственная
информация высших организмов отделена от соматических клеток и,
следовательно, не может зависеть от них. Эксперименты показади [8],
что модель эволюции по Ламарку наряду с пороговым и потоковым
алгоритмами, а также алгоритмами отжига или табуированного поиска
можно использовать для выполнения локального поиска в некоторой
окрестности, случайно изменяя генотип или выбирая лучшие из
полученных решений.
4.11. Алгоритмы меметики
161
В основе модели эволюции де Фриза, представленной на
рисунке 44, лежит представление о социальных и географических
катастрофах, приводящих к резкому изменению видов и популяций.
Вход
Выход
Мутационная
изменчивость
'
!
Популяция
1
(
Изоляция части
популяции
1
1
Эволюционная
смена
форм
Внешняя
среда
Отбор
А
Дифференциация
видов
Рис. 44. Модель эволюции де Фриза
В модели эволюции К. Поппера, представленной на рисунке 45,
мутация интерпретируется как эволюционный процесс случайных проб
и ошибок, а отбор — как один из способов управления с помощью
устранения ошибок при взаимодействии с внешней средой.
Эволюционная последовательность событий, согласно Попперу,
представляется в виде схемы: исходная проблема-пробные решения-
устранение ошибок-новая проблема.
Эволюционная модель М. Кимуры, представленная на рисунке 46,
основана на нейтральном отборе.
Согласно Кимуре эволюция заключается в реализации
последовательностей поколений, а в результате эволюции выбирается только
один вид.
Эффект Болдуина был впервые обнаружен в 1896 году. Он
представляет собой возможные сценарии взаимодействия между эволюцией
и обучением, с учетом «стоимости» обучения одного индивидуума.
Суть эффекта Болдуина состоит в следующем.
11 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
162 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
Вход
Выход
t
Популяция
♦
Метод проб
и ошибок
♦
Мутационная
изменчивость
1
Эволюционная
смена форм
Внешняя
среда
Отбор
Дифференциация
видов
Рис. 45. Модель эволюции К. Поп пера
Дублирование
Популяция
Вход
1 ZH
Случайная
редукция
♦
Эволюционная
смена форм
Нейтральный отбор
i
i
f Выход
Рис. 46. Эволюционная модель М. Кимуры
(Вход
Выход
J
Рис. 47. Эволюционная модель И. Шмальгвузена
4.11. Алгоритмы меметики
163
Управляющий блок
(внешняя среда)
Вход
Популяция
Первая перекодировка
I
Борьба за
существование
Адаптация
I
Естественный отбор
Нет
Размножение
(вторая перекодировка)
Адаптация
Преобразование по
заданной
(унаследованной
программ)
Нет
Выход
Рис. 48. Структурная схема эволюционного алгоритма, построенного на основе
модели И. Шмальгаузена
Во-первых, срок обучения дает людям возможность приспособиться
к окружающей среде или даже изменить фенотип. Эта фенотипиче-
ская пластичность может помочь индивидууму увеличить свою
приспособленность и, следовательно, вероятность воспроизводства
потомства. Однако приобретенные свойства не влияют на генотип и сразу
не наследуются. Во-вторых, в дальнейшем в ходе последующих шагов
и*
164 Гл. 4. Алгоритмы микро-, макро- и метаэволюционных вычислений
эволюции приобретенные свойства могут закрепиться на генетическом
уровне (процесс генетической ассимиляции). В-третьих, эффект
Болдуина может вначале приводить к замедлению скорости эволюции,
но в последующем происходит значительное улучшение результатов.
Как и эволюция по Ламарку, де Фризу, Попперу, Кимуре эффект
Болдуина может быть добавлен к классу алгоритмов ЭВ для
выполнения локального поиска вблизи оптимума.
И. Шмальгаузен [71] попытался представить эволюцию Дарвина
в терминах теории управления и кибернетики. Он выделил объект
управления (биогеоценоз), в который по каналам прямой и обратной
связи передаются управляющие сигналы от материнской популяции
к дочерней и от популяции к биогеоценозу. Следуя Шмальгаузену,
эволюция представляет собой авторегулируемый процесс, основанный
на обратной связи, как это показано на рисунке 47.
Управляющим блоком является внешняя среда, а регулируемым
блоком — популяция. Популяция приспосабливается и адаптируется
к условиям внешней среды. Как и ранее рассмотренные модели,
эволюция по И. Шмальгаузену может быть добавлена к гетерогенному
множеству различных моделей классу, а алгоритмы, построенные на
ее основе, могут быть успешно применены для выполнения локального
поиска вблизи оптимума.
Приведем алгоритм, основанный на модели эволюции по И.
Шмальгаузену [73]. Пусть популяция меняется от поколения t к поколению
t + 1 (t G T\ t = О, 1, 2, ..., п, где п — число поколений). Это
происходит на основе механизмов генетической изменчивости. В
эволюционном цикле авторегулирования вначале происходит
преобразование генотип/фенотип, затем размножение организмов, прошедших
естественный отбор. Такой отбор является процессом регулирования.
На рисунке 48 приводится схема эволюционного алгоритма,
построенного на основе модели И. Шмальгаузена.
Здесь блок «соответствие 1?» проверяет, насколько исследуемая
популяция соответствует условиям регулятора. В блоке проверки
логического условия «соответствие 2?» анализируется правильность
преобразования по заданной программе.
Отродясь такого не было,
и вот — опять.
Виктор Черномырдин
Глава 5
ЭВОЛЮЦИОННЫЕ ВЫЧИСЛЕНИЯ
И ЭКСТРЕМАЛЬНЫЕ ЗАДАЧИ НА ГРАФАХ
5.1. Разбиение графов
Сформулируем постановку задачи разбиения взвешенного графа
на заданное или произвольное число частей. Пусть задан граф
G = (X, Е, W), где X представляет множество вершин графа, Е —
множество ребер, a W — общий суммарный вес вершин. Вес вершины
соответствует интегральной оценке, в которую могут входить
различные ограничения на исследуемую модель. Причем значения Wi £ W
не превышают некоторой пороговой величины.
Пусть В = {Si, B2, • •» Bs} — множество разбиений графа G на
части В\,В2, ...,Ва, причем В{ П В2 П ... П Bs = 0, и В\ U B2 U
U...UBe = В. Пусть каждое разбиение Bi состоит из элементов
Bi = {61,62» -,6П}, п = \Х\. Тогда задача разбиения графа G на
части заключается в получении разбиения Bi e В, удовлетворяющего
следующим условиям и ограничениям:
(Vft <Е В){Вг ф 0),
(VBit Bj e B){[Bi Ф Bj -> х* п х^- = 0] л
Л [(£г П Ej = Ei:j) V (Ei П Ej = 0)]),
UBl = B, {jEi = E, \JXi = X, \Е^\ = К^.
i=\ t=l i=l
Целевая функция для разбиения графа G запишется так:
*=iEE*m. (is)
i=i j=i
где г ф j, ATi,j — число связей между частями Bi и Bj при разбиении
графа G на части; / — количество частей в разбиении; К — суммарное
количество ребер при разбиении графа на части.
166 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Построим гранулированную схему разбиения графа на части на
основе эволюционных вычислений. Такая схема представлена на
рисунке 49. Здесь в первом блоке строится текущая (начальная)
популяция решений, т. е. определяется заданное подмножество В\, B<i, ..., Bk
(к ^ s). На построение популяции оказывает влияние внешняя среда
в виде ЛПР или ЭС. Целевой функцией является выражение (2).
Текущая (начальная)
популяция разбиений
(решений)
В\, £?2, •••, Bk
Внешняя
среда
Вычисление
КиК2 Кк
определение
КСГ>
Сортировка популяции
на основе целевой
функции К
СГПУ
4
Селекция популяции
(получение «родительских» пар)
Реализация генетических
операторов
ОК
ОМ
ои
от
Модифицированные операторы
Построение новой
популяции
решений
Адаптация
Выход
Рис. 49. Гранулированная схема разбиения графа
5.1. Разбиение графов
167
Предлагается следующий метод разбиения графов на части. Метод
разбиения основан на трех принципах разбиения графов на части:
• построение кластеров (массивов, определенным образом
связанных между собой вершин графа);
• агрегация, направленная на присоединение вершин графа к
кластерам;
• агрегация, протекающая в условиях случайного присоединения
вершин графа к кластерам;
• объединенная эволюция Дарвина, Ламарка и Фриза.
Опишем каждый принцип подробнее. Процесс создания кластеров
основан на механизме построения минимальных массивов в графе
или гиперграфе [8]. Введем понятие кластера в графе G = (X, U).
Кластер — это часть графа ФСС причем Ф = (Х\, U\), X\ С X,
U\ С U. Вершины кластера соединены внутренними ребрами с
остальными вершинами Х\Х\ графа G. Мощность подмножества внешних
ребер кластера обозначим /. Кластер Фг будем называть минимальным,
если для любого другого кластера Ф7, Ф^ С Фг выполняется
условие fi ^ fj. Другими словами, удаление произвольных вершин из Фг
(Фг\Хт) приводит к новому кластеру с большим числом внешних
ребер. По определению будем считать, что
(УФ, С G) (Фг ф 0),
(\/xi E X) (xi — минимальный кластер).
Это означает, что минимальный кластер не может быть пустым.
Кроме того, в тривиальном частном случае каждая вершина графа
образует минимальный кластер. Справедливы следующие утверждения:
• если Ф, и Ф^ являются минимальными кластерами, Фг (£. Ф^
И Ф^ <[. Фг, ТО Фг П Ф, = 0;
• пусть Фг, Ф^ — минимальные кластеры; если Ф5 = Фг U Ф^ и fs <
< fi Л fs < /j, то Ф3 — минимальный кластер;
• пусть Фь Фг, ...,Фь — минимальные кластеры, причем любое
объединение части из них не является минимальный кластер; если
Фг = Ф1 иФ2и...иФь и /i < /i ЛЛ < /2, ..., Л/i < Д, то Фг -
минимальный кластер.
На их основе опишем предлагаемый метод построения
минимальных кластеров в графе как совокупность определенных приемов и
операций.
а) Упорядочим все локальные степени вершин графа как
тривиальные минимальные кластеры.
б) Начиная с вершин с большей локальной степенью, попарно
проанализируем все вершины графа G. Если определяется пара вершин
(xi, Xj), для которой справедливо
f = p(xi) + p(xj)-2ritj,
168 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
то Ф = (Х\, U\), X\ = {хь Xj} и Ф является минимальным кластером.
Здесь р(х{), p{xj) — локальные степени вершин Х{, Xj\ rij — число
ребер, соединяющих вершины х^, Xj между собой; / — число ребер,
соединяющих минимальный кластер с остальными вершинами
графа G, причем / < p(xi)y f < p(xj). Минимальный кластер Ф заносим
в специальный список, а вершины Xj, Xj исключаем из рассмотрения.
Повторяем п. б). Если новых минимальных кластеров не образовалось,
то переход к п. в).
в) Вершины Xi, Xj в минимальном кластере заменяем одной Xij.
При этом ребра, соединяющие Xi и Xj, удаляются, а ребра из вершины
Xi, Xj к другим вершинам приписываются общей вершине Xij.
Получается граф G'.
г) В графе G' анализируются все вершины. Если определится
тройка вершин ха, #в, £с> для которой справедливо соотношение
/ = р{хг) + р{хв) + р(хс) - 2га,в - 2гВ)С - 2га,с,
причем, если / < р(ха), / < р(хв), f < р(хс), то вершина ха, хв, хс
образует минимальный кластер. Переход к п. б). Минимальный
кластер заносится в список. Если минимальных кластеров больше нет,
то перейти к п. д).
д) Увеличим параметр мощности минимального кластера на
единицу и переходим к п. в). Если мощность минимального кластера
равна заданному числу или равна числу вершин графа, то завершение
работы.
Метод может быть применен для построения заданного
количества минимальных кластеров определенной мощности, а также для
построения квазиминимальных кластеров, когда fc — fj ^ е. Здесь
е — наименьшее относительное отклонение от минимального кластера
(е = 0, 1,2, ...).
После построения набора минимальных кластеров, если в графе G
остались свободные вершины, необходимо провести процедуру
агрегации. Она заключается в пробном помещении вершин в минимальный
кластер с анализом ЦФ. Вершина помещается в минимальный
кластер, если нарушение минимального кластера происходит на величину,
не превышающую е.
Рассмотрим основную идею предлагаемого метода для задачи
разбиения гиперграфа Я = (X, Е) на части с минимизацией числа связей К.
Для каждого ребра е^ G Е можно определить разрезающую функцию
как число точек, попадающих в различные блоки. Если хотя бы
одна вершина ребра гиперграфа лежит не в той части, что остальные
вершины этого ребра, то обязательно будет существовать, по крайней
мере, одно разрезающее ребро. Просуммировав все разрезающие ребра,
получим общее число К межблочных связей, которое необходимо
минимизировать.
Предлагаемый двухуровневый метод разбиения гиперграфа
включает следующую совокупность приемов и операций. На первом уровне
5.1. Разбиение графов
169
строятся популяции решений. Далее определяется ЦФ. В качестве
ЦФ выбирается К. Затем полученная популяция сортируется и
упорядочивается согласно ЦФ. После этого, используя селекцию,
выбираются родительские пары для выполнения генетических операторов
(ГО). Перед выполнением ГО в каждой хромосоме (текущий вариант
разбиения) определяется стоимость каждого строительного блока (СБ).
Работа ГО начинается с модифицированного оператора кроссинговера
(МОК). При этом точка или точки ОК определяются не случайно,
а направленно, выделяя лучшие СБ в каждой хромосоме.
Определим трудоемкость метода. Пусть Np — размер популяции,
Nn — количество полученных потомков, Nq — количество генераций
ГА. Тогда общая трудоемкость метода определяется как
Т « [(Nptp + Nntn + (Np + Nn)tc]NG,
где tp — трудоемкость построения одной хромосомы в популяции; tn —
трудоемкость генерации одного потомка; tc — совокупная трудоемкость
селекции и отбора. Трудоемкость генерации одного потомка зависит
от сложности применяемого ГО и изменяется от 0(п) до O(nlogn).
Трудоемкость селекции и отбора может меняться от 0(п) до 0(п2).
Введем коэффициент, определяющий относительную величину
удовлетворительных решений при одной генерации метода,
/Л ^Чпок
где ЛГлок — количество удовлетворительных решений (локальных опти-
мумов); п — размер хромосомы; ЛГобщ — общее количество решений.
Причем Л^общ может быть равно п\. Данную величину можно повысить,
увеличив число генераций с 1 до Nq- Тогда
r(i) = ^.NG.
•«'общ
Тогда трудоемкость описанного метода составляет 0(\п2) для одной
генерации, здесь А — коэффициент, определяемый количеством ГО.
Допустимое решение экстремальной задачи разбиения графа на
части является n-мерным вектором. В том случае, когда эта задача
принадлежит классу задач переборного типа, имеется конечное
множество допустимых решений, в которых каждая компонента вектора
может быть закодирована с помощью целого неотрицательного числа
А Е [0, Vi], г = 1, п, где (V^ + 1) — число возможных дискретных
значений г — управляемой переменной в области поиска D. Это
позволяет поставить во взаимно однозначное соответствие каждому вектору
Рг G D вектор (3 с целочисленными компонентами. Символьная модель
экстремальной задачи разбиения графа на части может быть
представлена в виде множества бинарных строк, которые описывают
конечное множество допустимых решений, принадлежащих области
поиска D. Необходимо отметить, что выбор символьной модели исходной
170 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
экстремальной задачи разбиения графа на части во многом определяет
эффективность и качество применяемых эволюционных вычислений.
Представим, например, разбиение графа G = (X, U) на две части
в виде бинарной строки Е(Х\, Х^), состоящей из п бит, расположенных
в порядке возрастания их номеров. Каждому номеру бита поставим
во взаимно однозначное соответствие номер вершины графа (1-й бит
соответствует вершине х\, 2-й бит — вершине #2, ..., n-й бит —
вершине хп). Потребуем, чтобы бинарное значение сц 1-го бита указывало,
какому подмножеству вершин (Х\ или Х^) принадлежит вершина xf.
• оц = 1, если 1-я вершина х\ е X входит в состав подмножества
вершин Х\\
• а\ = 0, если 1-я вершина X|Gl входит в состав подмножества
вершин Х%.
Число битов, содержащих 1 в бинарной строке Е(Х\, -Хг), должно
равняться мощности подмножества вершин подграфа G\ = (X\,U\),
равной порядку этого подграфа п\. Так, для произвольного графа G на
6 вершин получим следующую кодировку разбиения в виде бинарных
строк:
Е{ХиХ2):
1
1
Х\
1
2
Х2
0
3
хг
0
4
Х\
0
5
Х5
1
6
хе
— номер бита
— номер вершины
В задаче оптимального разбиения графа на части в качестве
хромосомы выступает конкретное разбиение, удовлетворяющее заданным
условиям, что позволяет интерпретировать решения задачи разбиения
как эволюционный процесс, связанный с перераспределением вершин
Xi e X графа G по частям разбиения.
Для описания популяций введено два типа вариабельных
признаков, отражающих качественные и количественные различия между
хромосомами [8]. Качественные признаки — это признаки, которые
позволяют однозначно разделять совокупность хромосом на четко
различимые группы. Количественные признаки — это признаки,
проявляющие непрерывную изменчивость и задаваемые числами.
При взаимодействии хромосомы с внешней средой ее генотип
порождает совокупность внешне наблюдаемых количественных
признаков, включающих степень приспособленности fi(Pk) хромосомы Pk
к внешней среде и ее фенотип. Если задан критерий оптимальности К,
то степенью приспособленности /i(Pfc) каждой хромосомы является
численное значение функции К, определенное для допустимого
решения PfcGD. В общем случае степень приспособленности /i(Pfc) ^ 0
можно задать с помощью следующего выражения:
• /x(Pfc) = Q2(x), если решается задача максимизации
функции Q{x)\
5.1. Разбиение графов
171
• /i(Pfc) = \/(Q2(x) + 1), если решается задача минимизации
функции Q(x).
Отсюда следует, что чем больше численное значение степени
приспособленности /x(Pfc), тем лучше хромосома приспособлена к внешней
среде. Следовательно, цель эволюции хромосом заключается в
повышении их степени приспособленности. Степень приспособленности /х(Р&)
в задаче разбиения просто совпадает с критерием оптимальности К —
общей суммой числа внешних ребер между частями разбиения.
Очевидно, что в популяции Р* может иметь место наличие
нескольких различающихся форм того или иного вариабельного признака
(так называемый полиморфизм). Это позволяет проводить разделение
популяции на ряд локальных подпопуляций Р* С Р*, г = 1, ..., V,
включающих в свой состав те хромосомы, которые имеют одинаковые
или «достаточно близкие» формы тех или иных качественных и/или
количественных признаков.
Так, в задаче оптимального разбиения графа на части для
дифференциации хромосом Pfc G Р* по количественному признаку может
быть выбрано, например, условие, что в локальную популяцию Р* С Р*
включаются только те хромосомы, у которых значение К не
превосходит некоторой заданной величины. Тогда другую локальную
популяцию Р£ С Р* составят все те хромосомы Рь которые не попали в Р\.
При решении проблем разбиения графов на части часто возникают
задачи группировки элементов, обладающих одинаковыми свойствами.
Для решения таких задач будем использовать идеи построения
квазиминимальных кластеров на основе агрегации фракталов [8].
Необходимо сгруппировать элементы, обладающие наибольшим
числом одинаковых свойств. Данная задача относится к классу задач
разбиения и может быть решена одним из методов, описанных выше.
Рассмотрим эту задачу подробнее. Предварительно выполняется
анализ матричной модели. В результате анализа предлагается
устранить из рассмотрения строки матрицы, содержащие все единицы, все
нули, а также строки, содержащие около 1% нулей или единиц. Такие
свойства не будут влиять на создание требуемых групп, так как все
или почти все элементы будут входить, или не входить в формируемые
группы. Затем производится разбиение матрицы R на две части: Pi
«перспективных» хромосом и Рг «неперспективных» хромосом.
Как отмечалось выше, размер популяции можно варьировать в
зависимости от качества получаемых решений. В принципе, можно
выполнить некоторое множество генераций данной операции. Произведем
теперь склеивание (объединение) групп по критерию максимума общих
свойств.
Оценка трудоемкости метода для одной генерации меняется от
0(ап) до 0(an logn). Метод может выполняться параллельно.
Вычислительная трудоемкость метода определяется как
Т » (Nptp + NptoK + NptCKJl)NGl
172 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
где £<эк — трудоемкость ОК, а tCKJl — трудоемкость операции
склеивания.
Компьютерная реализация методов разбиения графов и гиперграфов
показала их преимущество по сравнению с известными методами
парного обмена и методом проб и ошибок. Управление процессом поиска
при разбиении позволяет находить оптимальные параметры.
Применение модифицированных ГО позволяет повысить качество разбиения.
Следует заметить, что с увеличением числа генераций время
решения повышается, но это повышение незначительное и
компенсируется получением множества локально-оптимальных решений. В то же
время скорость выполнения предлагаемых методов существенно выше,
нежели известного метода ветвей и границ. Разбиение графов с
применением гранулированного параллелизма позволяет всегда получать
локальные оптимумы, иметь возможность выхода из них и приближаться
к получению оптимальных и квазиоптимальных решений. Причем, что
особенно важно, оценка ВСА не уходит из области полиномиальной
сложности (ВСА « O(nlogn) — 0(ап3)).
Актуальной практической задачей при разбиении графом является
задача поиска компонент связности и точек сочленения.
Подграфы d = {Х{, Ui) графа G = (X, U), Х{ С X, Щ С С/,
называются компонентами связности, если они не имеют друг с другом
общих вершин и общих ребер. Тогда для компонент Gi = (Xi, Ui),
Gj = (Xj9 Uj), ..., Gk = (Xk, Uk) имеем
Xi П Xj П ... П Xk = 0, Ui П Uj П ... П Uk = 0.
Причем,
k k
U Xi = X, \JUi = U, i^j^UiDUjAXiPiXj = 0.
i=\ i=l
Граф можно разбить на компоненты, внутри которых вершины
не связаны между собой. Ребро щ G U графа G = (X, U), удаление
которого приводит к увеличению компонент связности, называется
мостом.
Харари доказана следующая теорема [74].
Пусть щ е U — ребро связного графа G. Тогда эквивалентными
являются следующие утверждения:
— щ — мост графа G;
— мост щ не принадлежит ни одному простому циклу графа G\
— в графе G существуют такие вершины Xk, #/, что ребро щ
принадлежит любой простой цепи, соединяющей Хк с xi\
— существует разбиение множества вершин X графа G на такие
подмножества Xqj Хр, что для любых вершин Хк G Хя и xs G Хр
ребро щ принадлежит любой простой цепи, соединяющей Хк и х8.
Точкой сочленения графа G = (X, £/), \Х\ = n, \U\ = m
называется вершина Xi G X, удаление которой увеличивает число несвязных
5.1. Разбиение графов
173
компонент графа. Следовательно, если Xi € X является точкой
сочленения графа, то граф G — Х{ не связен.
Граф, не имеющий точек сочленения, называется неразделенным.
Блоком графа называется его максимальный неразделенный подграф.
Приведем модифицированный алгоритм определения точек
сочленения и блоков.
а) Анализируем поочередно все вершины графа G = (X, U), \Х\ —
= n, Xi £ X, г = 1, 2, ..., п, удаляя одну за другой с инцидентными
ребрами.
б) Просматриваем поочередно полученные подграфы и проверяем
получение компонент связности. В результате получаем все точки
сочленения G.
в) Образуем систему строк. Каждая строка соответствует точке
сочленения, причем в эти строки добавлены индексы соответствующих
точек сочленения.
г) Выполним операцию пересечения строк первой со второй, третью
с результатом пересечения первой и второй строк и т. д. В результате
получим все блоки графа и точки сочленения.
д) Конец работы алгоритма.
Для практических задач важно нахождение частей графа, имеющих
точки касания между частями графа. На рисунке 50 показаны пять
точек касания г, j, fc, Z, га, которые соединяют шесть частей графа.
Алгоритм определения таких частей основан на эволюционных
вычислениях. Его эффективность возрастает, когда заранее заданы размеры
частей Gi и количество возможных точек соприкосновения.
Рис. 50. Граф из шести частей с точками касания г, j, к, I, m
На рисунке 51 приведен параллельный эволюционный алгоритм
с миграцией хромосом для определения блоков и точек сочленения
графов.
В первом блоке формируется популяция альтернативных решений
задачи. Во втором блоке происходит разбиение популяции на три
части. Они представляют собой элитные (лучшие решения), худшие
174 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
ГЕНЕРАЦИЯ ПОПУЛЯЦИИ
Разбиение популяций на
подпопуляции (ПП 1, ПП2, ППЗ)
Вычисление ЦФ
Ранжирование
популяции
t
Репродукция ПП 1
Блок ГО
Миграция ПП 1
Нет
Вычисление ЦФ
Линейная
селекция
I
Репродукция ПП2
Блок ГО
Миграция ПП2 Um-
Нет
Вычисление ЦФ
Специальная
селекция
I
Репродукция ППЗ
Блок ГО
Миграция ППЗ
Нет
Рис. 51. Схема параллельного эволюционного алгоритма с использованием
миграционной модели
и среднего качества. В третьем блоке — вычисление целевых
функций (ЦФ) задачи компоновки. В четвертом блоке выполняется анализ
и выбор альтернативных решений для дальнейшего поиска локально-
оптимальных результатов.
Далее в каждой части реализуется гибридный генетический
жадный алгоритм. В первой части, в блоке генетических операторов (ГО)
выполняется жадный алгоритм, во второй — генетический, а в
третьей — комбинированный. Блоки миграции осуществляют обмен
решениями для предотвращения преждевременной сходимости
алгоритмов. В блоках репродукции определяются перспективные решения для
дальнего анализа. В блоках ранжирования и селекции происходит
упорядочение анализируемых решений.
5.1. Разбиение графов
175
Генетические алгоритмы (ГА) обычно используют представление
фиксированной длины. Строки, обработанные обычными ГА,
сохраняют постоянное число бит, каждый из которых соответствует
конструкции фенотипа. Предлагается каждое альтернативное решение
(хромосому) представлять в виде переменной длины. Вместо того, чтобы
определять хромосому как последовательность битов, ее, подобно
естественной копии, будем определять как последовательность генов. Ген,
в свою очередь, определен как последовательность позиций хромосомы,
которые несут информацию о специфической особенности в фенотипе.
Эта модель имеет вид G = U(g^). Здесь gi — специфический ген,
г — 1, 2, ..., п\ Vi £ {0, 1}. Ген gi может быть представлен как
целочисленный или вещественный вектор; п — общее количество генов в
хромосоме; V — двоичный вектор, определяющий положение активации
каждого гена gf. если V = 1, то его связанный ген, gv, активизируется,
и наоборот. Тогда модель хромосомы — двойная строка,
составленная из совокупности генов и вспомогательной двоичной строки V.
Первая строка — главная строка, вторая строка — маска активации.
В этом случае алгоритм может представлять решения произвольных
размеров. Оператор кроссинговера (ОК) анализирует содержание двух
строк, чтобы произвести потомков. Оператор мутации (ОМ)
выполняется стандартно и действует только на главную строку хромосомы.
Описан [8] генетический оператор проекции (ОП). Этот оператор дает
возможность управлять способом, которым алгоритм охватывает
различные области поиска. ОП применяется только к маске активации.
Он подобен ОМ: каждый бит маски активации изменяется с низкой
вероятностью, активизируя или дезактивируя соответствующие гены.
Существует три стратегии применения этого оператора:
увеличивающейся длины генотипов, колеблющейся длины генотипов и равномерно
распределенной начальной популяции [7]. Вводится еще две стратегии:
стандартная и комбинированная. Когда не могут быть найдены лучшие
решения, при увеличении числа компонентов популяция будет
сводиться к меньшим решениям.
Рассмотренный алгоритм применим для задач, связанных с
введением дублирующих элементов. Дублируются элементы схемы,
соответствующие точкам сочленения графа. Это позволяет уменьшить число
внешних связей. Алгоритм позволяет также уменьшить число выводов
за счет увеличения числа логических элементов схемы. Это особенно
эффективно, когда схема может быть так распределена на кристалле,
чтобы элементы, соответствующие точкам сочленения графа,
принадлежали нескольким блокам.
176 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
5.2. Размещение вершин графов
Постановка задачи размещения вершин графа состоит в
следующем. Пусть задана модель плоскости для задачи размещения,
представленная на рисунке 52.
Прямоугольник R(e)
Xi
0 1 2 3 4 5
Рис. 52. Модель плоскости для размещения вершин графа
На исходную плоскость накладывается декартова система
координат с осями s и t. В каждую ячейку плоскости может быть размещена
вершина графа или гиперграфа. Основной целью размещения обычно
является минимизация общей суммарной длины ребер графа или
гиперграфа. Иногда используется другой критерий (или ограничение) —
минимизация общего числа пересечений ребер графов.
Расстояние между вершинами вычисляется на основе одной из
известных формул [8]:
&i4j — \Si Sj\ ~r \Т{ lj\y
di.j = \J\Si -Sj\2 + \ti-tj\2.
(16)
(17)
Здесь (sj, U), (sj, tj) — координаты xiy Xj элементов (вершин
графов), dij — расстояние между элементами Xi, Xj на заданной
плоскости. Причем выражение (16) позволяет определить манхеттеново
расстояние, т.е. расстояние между двумя вершинами, определенное
по вертикальным и горизонтальным направлениям. Шаг (расстояние)
5.2. Размещение вершин графов
177
между двумя рядом лежащими вершинами по горизонтали и
вертикали считается равным единице. Выражение (17) позволяет вычислить
евклидово расстояние между двумя вершинами. В случае ребра
гиперграфа его длина подсчитывается как полупериметр прямоугольника,
охватывающего его концевые точки. Тогда общая длина всех ребер
графа определяется по формуле
п п
г=1 j = \
Здесь L(G) — общая суммарная длина ребер графа, Cij —
количество ребер, соединяющих вершины Х{ и Xj. Число пересечений ребер
графа определяют по формуле
(G) = i £ Щии). (19)
Uijeu
Здесь 11(G) — общее число пересечений ребер графа, И(щ^) —
число пересечений ребра щ^, соединяющего вершины Х{, Xj.
Рассмотрим алгоритмы, минимизирующие L(G) и 11(G) (L(G) —>
—► min, 11(G) —► min). Отметим, что минимизация суммарной длины
ребер графа обычно приводит к минимизации числа пересечений.
Такая одновременная минимизация длины и пересечений происходит до
некоторого предела, начиная с которого уменьшение длины приводит
к увеличению числа пересечений.
Введем комплексный критерий для (18) и (19),
A(G) = aL{G) +011(G). (20)
Здесь а, (3 — коэффициенты, учитывающие степень важности того
или иного критерия (а + (3 = 1). Значения а и /3 могут определяться
на основе опыта или экспертных оценок в задаче размещения.
В задаче размещения входными данными являются множества
вершин графовой или гиперграфовой модели X = {хь Х2, ..., хп},
множество ребер графа U = {иь г^, ..., ит} или гиперграфа Е = {е\, ег, ...
...,ет} и множество позиций Q = {q\, q%, ...,q/}. Причем \Х\ ^ \Q\,
если производится размещение вершин на заданные позиции. Если
производится размещение ребер, то количество позиций должно быть
не меньше количества концевых точек размещаемых ребер.
Сформулируем задачу размещения как назначение каждой вершины
графа (гиперграфа) в единственную позицию таким образом, чтобы
оптимизировать ЦФ. В качестве ЦФ выбирается выражение (20).
Выходными данными будут позиции назначения для каждой вершины.
В качестве ограничений выбираются следующие условия. Для
каждого Xi G X назначается только одна позиция qi e Q. Соответственно,
каждой позиции ^ е Q соответствует, по крайней мере, один элемент
xi E X. Известно [3], что задача размещения относится к классу
12 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
178 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
iVP-полных проблем. Поэтому постоянно производится поиск
эвристических процедур для повышения качества и уменьшения
сложности алгоритмов. Алгоритм считается «хорошим», если его ВСА 0(п),
O(nlogn), 0(n2).
Рассмотрим размещение вершин графа на плоскости в решетке
заданной конфигурации. В настоящее время существует несколько
различных подходов, связанных с применением эволюционных алгоритмов
для размещения вершин графа на плоскости [7, 8].
Например, один из подходов заключается в следующем. Сначала
формируется популяция решений, обычно случайным образом. Далее
в каждом элементе популяции выполняется ОМ. Затем вычисляется
ЦФ, производится сортировка решений и назначение элементов в
заданные позиции. В случае необходимости производится возврат к
блоку мутации, и вся процедура продолжается аналогично до
преждевременной сходимости или пока не выполнится заданное число итераций.
Данный подход является простым в реализации и имеет ВСА
линейного типа, но получаемые локальные оптимумы далеки от глобального.
Это связано с большим упрощением ЭМ и неиспользованием всей
многогранности и широких возможностей эволюции.
Предлагаются два новых эволюционных алгоритма для размещения
вершин графа (гиперграфа) на плоскости и линейке с оптимизацией
выражения (20).
В первом алгоритме используется композиция дополнительных ГО,
гомеостатического управления и синергетических и иерархических
принципов, инспирированных природными системами. Структурная
схема этого алгоритма размещения показана на рисунке 53.
Во втором алгоритме размещения вершин графа на плоскости,
представленном на рисунке 54, для решения задачи используются модели
эволюции Дарвина, Ламарка и де Фриза.
Оба алгоритма включают следующие гранулы параллелизма.
Начальная популяция конструируется тремя способами А\, А%, А?>. В
способе А\ популяция решений (заданных размещений) формируется
случайным образом. В способе А<± популяция решений получается путем
неоднократного применения последовательного алгоритма размещения.
Формирование популяции способом А^ производится совместно
случайным и направленным образом. После формирования популяции
к каждому ее элементу применяется оператор мутации. Причем ОМ
может выполняться независимо для каждого элемента популяции.
В задачах размещения, с нашей точки зрения, интерес может
представлять использование ОМ, основанных на знаниях о
решаемой задачи. Такие ОМ называются «аргументированными знаниями»
(АЗОМ). В АЗОМ могут переставляться местами любые выбранные
гены в хромосоме. Как правило, в АЗОМ точка или точки мутации
определяются не случайно, а направленно [8].
5.2. Размещение вершин графов
179
Вход
I
Формирование
популяции Р
Л, | А2 |
СГПУ
11 Оператор инверсии
Формирование
новой
популяции Р'
Л2
W
Оператор мутации
ОМ, 1 ОМ2 |"ОМ7
OHi
ОИ2
Оператор сегрегации
OCi | ОС2 1 ОС7
Оператор
транслокации
ОТ,
ОТ2
Оператор
кроссинговера
ОК1|ОК2|ОКз| ОК4 |ОК51
Сортировка
х
Оценка
размещения
I
Выход Н*-1
Моделирование
Вычисление ЦФ
БЭА
<Н>
Внешняя
среда
Рис. 53. Структурная схема алгоритма размещения
Предварительно вычисляется верхняя оценка абсолютно
минимального размещения для заданной конфигурации плоскости. После
каждого ГО их результаты сравниваются с оценкой. При получении искомых
12*
180 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Внешняя
среда
Шкала эволюции
I
эд
т
эл
I
ЭФ
X
Вход
Формирование
популяции Р
СГПУ
Формирование
новой
популяции Р'
Оператор мутации
,-»»| OMi 1 ОМ2
ОМз
Оператор инверсии
ои,
ои2
Оператор
сегрегации
ОС, ОС2
ОС3
Оператор
транслокации
ОТ,
ОТ2
Оператор
кроссинговера
4OKJOK2IOK3IOK4I ОКГ
Сортировка
Оценка размещения
X
Выход Y+*
Моделирование
Вычисление ЦФ
ЭС
Адаптация
Нет
С Выход J
Рис. 54. Структурная схема алгоритма размещения на основе эволюционных
моделей Дарвина, Ламарка и де Фриза
5.2. Размещение вершин графов
181
результатов алгоритм заканчивает свою работу. После реализации ОК
для каждой хромосомы вычисляется ЦФ и на ее основе сортируются
варианты решений. Затем формируется новая популяция, и процесс
продолжается аналогично с учетом СГПУ. Возможен выход из каждого
оператора в отдельности при получении локального оптимума.
ВСА размещения на основе предлагаемых алгоритмов меняется от
0(ап) до 0(/Зп2), где а и /3 — коэффициенты, зависящие от
используемых процедур поиска и их специфики. Вероятность получения
оптимального результата равна
Рг(ОПТ) = Pi(Np + Nn)NG,
где pi — вероятность получения оптимального результата при
генерации одной хромосомы в популяции.
Второй подход к размещению вершин графа на плоскости основан
на использовании метаэволюционной оптимизации. Это позволяет
повысить качество решений при увеличении затрат времени.
Предлагается модифицированный алгоритм размещения вершин
графа в решетке на основе метаэволюционной оптимизации.
Структурная схема алгоритма имеет вид, представленный на рисунке 55. Здесь
популяция создается тремя способами: направленно (Pi), случайно-
направленно (Рг) и случайно (Рз). ЭД, ЭЛ и ЭФ — это модели
эволюции Дарвина, Ламарка и де Фриза, ЭС — экспертная система,
БЗ — база знаний.
Минимальный размер популяции составляет п/2, где п = \Х\.
Минимальное число генераций — Ng = Юп. Алгоритм включает два
строительных блока и построен таким образом, что в процессе его работы
устанавливается относительный баланс. Причем, на вход одного блока
подается набор случайно полученных хромосом, а на вход второго —
заданный набор хромосом.
Далее применяется композиция эволюционных операторов (ОК,
ОМ, ОС, ОТ, ОИ и др.), разработанные авторами данного проекта.
Затем определяя ЦФ, находим лучшее размещение с заданными
параметрами.
Размер популяции в алгоритме можно выбирать исходя из опыта
ЛПР и имеющихся вычислительных ресурсов. Рекомендуемый размер
популяции N « п/2, где п — число вершин графа. Число генераций
популяций обычно является задаваемым параметром. Хотя, глобальный
минимум может быть получен как на первой генерации, так и не
найден на последней генерации.
Важным вопросом в метагенетическом алгоритме размещения
является понятие шкал ГО [75]. Обозначим размер популяции Р через Np,
число генераций как No, число размещаемых вариантов для
копирования iV0ff. Тогда шкалы ОК и ОМ можно определить, согласно [76],
следующим образом:
182 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Вход
БЭА1
Вход
Конструирование
популяции
Pi
Р2 |
'
г
ГО
♦
Рз
Вычисление
ц
ф
Нет
Конструирование
популяции
Pi
Р2
Т
ГО
Рз
Вычисление
ЦФ
Локальный
поиск
ЭД, ЭЛ, ЭФ
Нет
Локальный
поиск
ЭД, ЭЛ, ЭФ
Выход
БЭА2
Выход
ЭС
БЗ
Рис. 55. Структурная схема метаэволюционного алгоритма
5.3. Поиск маршрута минимальной длины
183
Здесь ОК управляется посредством шкалы OK (i?0k). -Rok
определяется как отношение числа потомков, полученных в каждой генерации
алгоритма, к размеру популяции. Отметим, что Д0к косвенно оценивает
отношение числа точек разрыва (применение ОК) в районах с высокой
ЦФ к числу точек разрыва в других местах популяций. Высокая Д0к
позволяет анализировать большее пространство, и шанс нахождения
оптимума увеличивается. В то же время очень высокая Д0к требует
значительных вычислительных ресурсов. Количество генераций в 03
ПР определяется по следующей формуле:
Здесь Ncn — количество генераций алгоритма, задаваемых
пользователем.
Шкала мутации R0fA определяется как процент общего числа генов
в популяции, которые в ней меняются местами (мутируют). Так, при
размещении п вершин графа в решетке и при размере популяции Np
имеем „ м в
Дом = n'N^^. (21)
В (21) nNp — число генов в популяции Р. Величина R0M
символизирует парный обмен генов при мутации. Шкалы остальных ГО
определяются аналогично.
Для анализа ВСА разработанных алгоритмов размещения были
исследованы основные гранулы параллелизма. Сложность описанных
алгоритмов размещения является полиномиальной величиной. Для
одной генерации ВСА лежит в пределах 0(а.\п2)-0(а2пг), где ot\, a<i —
коэффициенты, определяемые количеством ГО и их спецификой.
С увеличением числа генераций в алгоритме время решения растет,
но это повышение незначительное и компенсируется получением
множества локально-оптимальных решений.
5.3. Поиск маршрута минимальной длины
Задача поиска маршрута минимальной длины, больше известная
как задаче о коммивояжере (ЗК, в английской интерпретации TSP),
является классической NP-полной задачей и состоит в нахождении
кратчайшего гамильтонова цикла в графе. ЗК нашла широкое
применение в различных областях. Без каких-либо изменений в постановке она
используется для проектирования разводки коммуникаций, разработки
архитектуры вычислительных сетей кольцевой топологии и пр.
Кроме того, ЗК имеет теоретическую ценность, являясь асимптотической
оценкой исследования различных эвристических алгоритмов, которые
могут быть затем применены для решения более сложных задач
комбинаторной оптимизации, например, квадратичной задачи о назначениях,
частным случаем которой является ЗК.
184 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Рассмотрим постановку задачи. В словесной форме ЗК трактуется
следующим образом: коммивояжеру необходимо посетить N городов,
не заезжая в один и тот же город дважды, и вернуться в
исходный пункт по маршруту с минимальной стоимостью. Пусть дан граф
G = (X, С/), где \Х\ = п — множество вершин (города), \U\ = га —
множество ребер (возможные пути между городами). Дана матрица
чисел R(i, j), где г, j G 1, 2, ..., п (стоимость транспортировки из
вершины Х{ в Xj). Требуется найти такую перестановку tp из элементов
множества X, что ЦФ имеет следующий вид:
Fitness(^) = R(<p(l), <p{n)) + £{R(<p(i), Ф + 1))} -► min. (22)
Если граф не является полным, то дополнительными условиями
для d, согласно (9), являются следующие ограничения:
<<р(г),¥>(г+1))€#, Vi G 1, 2, ..., п - 1 и (<р(1), ^(n)> G U.
Данные ограничения можно учесть, например, проставив большие
числа в матрицу R в ячейках, соответствующих отсутствующим
ребрам в графе. Поэтому в дальнейшем для решения ЗК будем
рассматривать полные графы с весами на ребрах.
Фиксация вершины старта коммивояжера может быть
использована для сужения пространства поиска, которое в этом случае равно
(п — 1)!. Поэтому в общем случае ЗК чувствительна к выбору
начальных условий. В этой связи для создания структуры алгоритма
эффективно используются синергетические и гомеостатические принципы
управления [8].
iVP-полнота ЗК подразумевает, что поиск ведется в пространстве,
растущем от п экспоненциально. Соответственно, время работы
алгоритмов, основанных на полном переборе или на построении дерева
решений (методы ветвей и границ, золотого сечения и др.), растет
экспоненциально в зависимости от числа вершин графа. Поэтому для
решения ЗК большой размерности можно использовать различные
эволюционные алгоритмы.
Их несомненным достоинством является способность находить
оптимальные или близкие к ним решения ЗК при п ^ 100 за
полиномиальное время вычислений. Недостатком является то, что
найденное наилучшее решение в общем случае не является оптимальным.
В практических задачах, для графов большой размерности (п ^ 1000)
упомянутый недостаток эволюционных алгоритмов не является
существенным, так как найденные решения отличаются от оптимальных
лишь на доли процента. Соответственно, двумя основными критериями
при решении ЗК, оценивающими эволюционный алгоритм, являются
скорость сходимости и близость получаемого решения к оптимальному
решению (если оно известно) или же к лучшим стандартным
решениям (бенчмаркам), полученным с помощью других алгоритмов (если
оптимум не известен).
5.3. Поиск маршрута минимальной длины
185
Кратко рассмотрим классификацию алгоритмов, применяемых для
решения ЗК [8]. Эвристические алгоритмы для ЗК могут быть
условно разбиты на два класса — класс алгоритмов, работающих только
с одним решением, и класс алгоритмов, работающих с множеством
(популяцией) решений. Первый класс алгоритмов обычно имеет более
высокую скорость сходимости, но в общем случае неспособен к
выходу из многих локальных оптимумов. Второй класс эвристических
алгоритмов осуществляет параллельный поиск в нескольких точках
пространства решений. Алгоритмы этого класса имеют значительно
больше шансов найти оптимальное решение, но параллельный поиск
обычно имеет ВСА большего порядка. Наиболее известными
представителями этого класса являются ГА с жадными стратегиями и ГА
с последовательным случайным или направленным преобразованием
специальных матриц [8].
На основе разработанной общей теории эволюционных вычислений
предлагаются новые эволюционные алгоритмы с гранулированным
параллелизмом.
Будем представлять ЗК в виде матрицы смежности. Это дает
возможность анализировать шаблоны, применяемые в эволюционном
алгоритме. Шаблоны соответствуют строительным блокам. Например,
шаблон (##### 7 #) есть множество всех изменений, в котором
элемент (6 - 7) имеет место. Элементы любой части шаблона
конкурируют с другими элементами этой части, элементы с лучшей
производительностью преимущественно расширяются через популяцию. Это
приводит к сокращению размерности пространства поиска и построению
больших блоков высокой производительности в процессе выполнения
оператора кроссинговера.
Приведем алгоритм выполнения оператора кроссинговера при
решении задачи коммивояжера:
а) для каждой пары хромосом случайным образом выберем точку
ЖОК и в качестве номера стартовой вершины графа возьмем номер
отмеченного гена в хромосоме;
б) сравним частичную стоимость путей, ведущих из текущих
вершин в хромосомах родителях, и выберем из них кратчайший;
в) если выбранная таким образом вершина графа уже была
включена в частичный путь, то следует взять случайную вершину из числа
еще не отмеченных вершин и присвоить полученной таким образом
вершине значение текущей;
г) при преждевременном образовании циклов выбирается другой
кратчайший путь;
д) повторяем пункты б) и в) до тех пор, пока не будет построен
гамильтонов цикл с минимальной суммарной стоимостью ребер;
е) конец работы алгоритма.
Решение-потомок в этом алгоритме формируется как
последовательность вершин графа в том порядке, в котором они становились
текущими.
186 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
В алгоритме используется предположение о предпочтительности
перехода в ближайшую соседнюю вершину. Однако это не всегда
приводит к оптимуму, поскольку иногда требуется пренебречь
локальным выигрышем ради достижения глобальной цели. Существуют пути,
позволяющие избежать этой ситуации. Один из этих путей реализует
следующий альтернативный алгоритм выполнения оператора кроссин-
говера при решении задачи коммивояжера:
а) случайным образом выбрать стартовую вершину в первом
родителе;
б) текущий родитель — первый родитель;
в) кроссинговер выполняется следующим образом: определяется,
какая из соседних вершин (соседними являются вершины,
расположенные в хромосоме справа и слева от рассматриваемой вершины)
в анализируемом родителе ближе к текущей вершине; ближайшая
из соседних вершин, не вошедшая в путь ЗК, становится новой
текущей вершиной; если только одна из двух соседних вершин не вошла
в путь ЗК, то она становится текущей; если обе соседние вершины
являются посещенными (тупиковая ситуация), то выбрать ближайшую
вершину из числа еще не посещенных, а в качестве текущего родителя
выбирается другой родитель;
г) повторять кроссинговер пока все вершины не будут посещены,
потомок формируется как последовательность посещаемых вершин;
д) конец работы алгоритма.
На рисунке 56 приведена структурная схема этого алгоритма.
Данная схема аналогична схеме для решения задачи размещения вершин
графа. Однако в отличие от нее, введен блок локального поиска,
который позволяет получать локальные экстремумы в ЗК, все ГО
ориентированы на использовании знаний о решаемой ЗК, изменен порядок
использования ГО. В ЗК решающую роль играют ОК и его
модификации, поэтому ОК в данной схеме примеряется первым. Использование
остальных ГО может варьироваться в зависимости от конкретной ЗК.
Блок редукции оставляет размер популяции постоянным на каждой
генерации.
В дополнение к моделям эволюции Дарвина, Ламарка и Фриза
введен новый блок моделирующий эволюцию Поппера [77]. Это
позволяет уменьшить «жадность» оператора кроссинговера, что
разнообразит популяцию, если есть добавление нового генетического материала
с высокими ЦФ, производимого случайными факторами или же
дополнительными эвристиками.
После достижения локального минимума в популяции наблюдается
большое число одинаковых маршрутов. В этой связи может
наступить преждевременная сходимость к локальному решению, связанная
с потерей разнообразия в популяции. Для предотвращения
преждевременной сходимости в алгоритме применяется совместная эволюция
по моделям Дарвина, Ламарка, Фриза и Поппера. Это дает
возможность активно реализовывать адаптацию к внешней среде, эффективно
5.3. Поиск маршрута минимальной длины
187
I Внешняя
среда
Поиск
эп М
Шкала эволюции
Т
эд
X
I
эл
X
I
ЭФ
X
Вход
Формирование
популяции Р
А, | Л2 1 "АГ
СГПУ
Редукция
Формирование
новой
популяции Р'
ок
r»»l)KOKl OKi | ОК2
Оператор
инверсии
ОИ1
ОИ2
Оператор
сегрегации
Od 1 ОС2 ГОСТ
JE
Оператор
транслокации
ОТ,
ОТ2
Оператор мутации
ом, | ом2 1 РМз
1 j_' i
Моделирование
Вычисление ЦФ
ЭС
Адаптация
Нет
Q Выход j
Рис. 56. Структурная схема алгоритма для решения ЗК
188 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
использовать параллелизм и специальные ГО. Таким образом, после
нахождения локального экстремума, активизируются специальные
алгоритмы и блоки, меняющие общую и частные стратегии поиска.
Например, в ЗК факт нахождения в локальном (глобальном)
экстремуме устанавливается в случае, если некоторое число хромосом
в популяции имеют одинаковую длину маршрута. При большом числе
вершин одинаковые длины маршрутов указывают на их одинаковую
конфигурацию. Существует ряд других признаков попадания в
локальный оптимум, например, не улучшение длины наилучшего маршрута
в течении t поколений. Для выхода из локального оптимума
предлагается выполнять следующие эвристики:
• из всех маршрутов, имеющих одинаковую длину, только один
остается неизменным, над всеми другими выполняются
модифицированные ГО;
• из всех маршрутов только наилучший остается неизменным, над
всеми другими выполняются модифицированные ГО.
Модифицированные ГО представляют собой полную или частичную
рандомизацию решения. Такие изменения в популяции могут
разрушать хромосомы с высокой ЦФ, однако, лучшее решение в популяции
остается неизменным. Эксперименты показали, что после 10 генераций
популяция вновь содержит решения с высокой ЦФ и либо выходит
из локального минимума, либо возвращается в него обратно и
требуется новое применение описанных выше или других эвристик на
следующем этапе поиска.
В результате применения описанного подхода растет частота
нахождения оптимального решения с сохранением хорошей сходимости.
Было установлено, что отличные показатели в решении ЗК являются
следствием использования как модифицированного оператора кроссингове-
ра, дающего возможность не столь хорошим решением гарантировано
оставлять часть своего лучшего хромосомного набора в популяции, так
и использования модели эволюции Поппера. Кроме того, применение
ГО, работающих со всей популяцией, обеспечивает влияние случайных
факторов, которые необходимы для выхода из локальных минимумов.
Введение ГО, работающих со всей популяцией, известно как метод
«социальных катастроф», поскольку они имеют своими аналогами такие
процессы в обществе, как война, революция, эпидемия [78]. Отметим,
что такие ГО и эвристики работают не все время, а только в ситуациях,
когда однообразие в популяции достигает высокого уровня. Совместная
эволюция регламентирует и управляет таким процессом эволюционных
вычислений.
Разработанный алгоритм был протестирован на известных тестовых
задачах о коммивояжере — Oliver's 30, Eilon's 50 и Eilon's 75. В ЗК с 30
городами алгоритм всегда находит оптимальное решение. Оптимальное
решение здесь находится в среднем за 500 итераций.
5.3. Поиск маршрута минимальной длины
189
Для увеличения быстродействия процесса определения гамильтоно-
вых цепей предлагается использовать следующую модификацию
алгоритма роевого интеллекта для определения гамильтоновых цепей.
Пусть требуется найти в полном неориентированном конечном
графе гамильтонову цепь минимального общего веса. Гамильтонова
цепь — это гамильтонов цикл без возвращения в стартовую
вершину. Пройдя по всем вершинам графа один раз и достигнув
конечной вершины, мы не будем возвращаться в исходную, а исключим
из рассмотрения последнюю итерацию алгоритма. Такая модификация
алгоритма позволит свести поиску критических связей к определению
гамильтоновых цепей в неориентированном конечном графе.
Приведем некоторые допущения в поставленной задаче. Пусть
число вершин графа равно п. Тогда решением модифицированной задачи
о коммивояжере будет нахождение конечных (не замкнутых)
маршрутов, а также минимального по длине пути, который проходится по всем
вершинам только однажды.
Расстояние от вершины г до вершины j (dij) определяется
следующим соотношением:
dij = [{х{ - Xj)2 + {yi - yj)2}.
К исходным данным относится также матрица размерностью
(N, Е), где N — описывает порядок размещения вершин, а Е —
расстояние между вершинами.
Пусть bi(t), где г = 1, ..., п — число агентов в вершине г в момент
времени t, при этом общее число агентов га равно
п
т = J2 МО-
Каждый агент должен соблюдать следующие правила:
• он должен выбирать вершину с вероятностью, зависящую от
расстояния и числа следов в указанном направлении;
• он не имеет право посещать уже пройденные вершины до
окончания всего маршрута, когда будет достигнута конечная вершина списка;
• после того, как весь путь пройден, будут активизированы метки.
Пусть Uj(t) — интенсивность меток на интервале (г, j) в момент
времени t. Каждый агент в момент времени t выбирает следующую
вершину, в которой он окажется в момент времени (£+ 1).
Следовательно, если мы проведем т итераций алгоритма Ant
Colony для т агентов в интервале (t,t+ 1), тогда каждая п-итерация
алгоритма приведет к тому, что каждый агент сможет закончить тур.
Интенсивность меток рассчитывается в соответствии с формулой
Tij(t + П) = р * Tij(t) + ATij,
190 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
где р — некоторый коэффициент, представляющий увеличение
интенсивности меток на интервале (£, t+ 1),
т
г=1
где AtJ*j — эффективность промежутка (г, j) на протяжении маршрута,
выбранного fc-м агентом:
Первое условие выполняется, если fc-й агент использует
направление (г, j) в момент времени (t,t+l). Второе условие вступает в силу
в противном случае.
Коэффициент р должен быть меньше 1, чтобы предотвратить
неограниченное накопление меток. Предполагается, что интенсивность
следов Tij(t) в момент времени t = 0 равна некоторой константе,
Tij(0) = c.
Для удовлетворения ограничений (каждый агент должен посетить
п различных вершин) с каждым агентом ассоциируется некоторая
структура данных, которая называется табуированным списком. В нем
сохраняются те вершины, которые уже посетили к моменту времени t,
таким образом агенту запрещается посещение одной и той же вершины
до окончания пути. Когда маршрут пройден, значения в табуированном
списке подсчитываются для каждого текущего агента. Табуированный
список затем обнуляется, и агент опять может продолжать движение,
начиная со стартовой вершины.
Определим tabuk как динамически увеличивающийся вектор,
который содержит tabu-список fc-ro агента, где tabuk(s) — s-й элемент
списка (т. е. s — вершина, которую посетил fc-й агент в текущем
маршруте), причем мощность списка \tabuk(s)\ = n, где п — число
вершин графа.
Пусть щ — величина, обратная расстоянию (щ = l/dij), тогда
вероятность pij перехода агента из вершины г в j вычисляется по
следующей формуле [15]:
Р&(*)=<
fcj(*)]tt*foj]
где j e allowedk
keIJTl3{tr*h3] и allowed, = {N-tabuk} (23)
0
где а, /3 — параметры контроля влияния видимости меток, allowedk —
список «разрешенных» (до этой итерации еще непосещенных) вершин.
Структурная схема модифицированного муравьиного алгоритма
имеет вид, представленный на рисунке 57.
5.3. Поиск маршрута минимальной длины
191
Начало
/ Формирование новой популяции
Задание ненаправленного конечного
графового представления КС-
матрицы вершин
3 Максимальное количество циклов NCm
Счетчик времени t = 0 и счетчик
циклов NC=0
Для каждого интервала (г, j) задать
начальное значение интенсивности
следов nj(t) = c, а также Ат^ =0.
Т
6 Разместить т агентов в п узлах
Т
Задать индекс tabu-списка s= 1
Определение стартующей вершины
(первой) для каждого агента
с последующим занесением в tabu-список
8
9
10
11
■^^"^ Список вершин полон ^
-^(пройдены все п вершин)?^^-
1 Нет
Наращивание счетчика вершин s = s+l
1
1
Перемещаем агента из вершины i в у с
выбранной вероятностью р£ (к)
*
Заносим вершину /
в tabu-список (tabufc(s))
Да
©
Рис. 57. Модифицированный роевой алгоритм для определения гамильтоновых
цепей (лист 1)
192 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
12
13
14
15
Ду
16
17
Перемещаем агента из вершины
(п— 1) вп
Т
Подсчитываем длину пройденного
каждым агентом пути Lk
1
Переопределяем лучший
результат
т
1 —
Ат^= I Kk , если i,j€tabufc
1 °
= Ат^+Атг)
1
'
Увеличиваем счетчик времени
t = t + n
1
'
Для каждой из вершин i и /
увеличиваем интенсивность следов
nj (t + n) = p- Tij (t) + Arij
18
19
Увеличиваем счетчик циклов
NC=NC+1
Для каждого интервала (i, j) задаем
Art?=0
20 < NC<NC max-
Да
21 '
Выводим кратчайший
путь, все маршруты
Конец
Рис. 57. Модифицированный роевой алгоритм для определения гамильтоновых
цепей (лист 2)
5.3. Поиск маршрута минимальной длины
193
Возможность перехода от одной вершины к другой обратно
пропорционально зависит от расстояния (т. е. близко расположенные вершины
будут выбраны с большей вероятностью, что отражает выполнение
«жадного конструктивно-эвристического подхода») и интенсивности
меток в момент времени t.
Опишем управляющие входные параметры модифицированного
алгоритма.
В момент времени t = О агенты случайно распределены между
различными вершинами, начальные величины интенсивности меток т^-(О)
равны некоторой константе с.
Первый элемент tabu-списка каждого агента эквивалентен номеру
вершины (строительного блока, фрагмента БИС), из которой
происходит старт цикла. Каждый агент перейдет из вершины г в вершину j,
выбрав следующую вершину с вероятностью, рассчитанной по формуле.
Интенсивность меток Tij(t) дает информацию о числе агентов,
которые в прошлом выбрали тот же путь — ребро (г, j). Параметр щ
использует эвристику выбора ближайшей вершины.
После п итераций, пройдя все вершины единожды и достигнув
последней, все агенты завершат свой маршрут и их tabu-списки будут
заполнены. В этой точке для каждого fc-того агента подсчитывается
значение Lk и рассчитывается тг* по формуле.
Этот процесс повторяется до тех пор, пока счетчик числа
маршрутов не достигнет максимума, установленного пользователем (NCmax)
или все агенты не пойдут по одному пути. На каждой итерации
сохраняются все маршруты (гамильтоновы цепи), пройденные
агентами, соответствующие критическим связям в рассматриваемой графовой
модели коммутационной схемы. При выполнении следующей итерации
модифицированного алгоритма АС список критических связей
корректируется — повторяющиеся цепи исключаются.
При рассмотрении работы блоков алгоритма отметим следующее:
— блоки 1-3 задают начальные параметры работы системы;
— блоки 4-6 инициализируют входные параметры:
• t = О, где t — счетчик времени;
• для каждого интервала (г, j) задается начальное значение
интенсивности следов Tij(t) = с, а также Дт^ = 0;
• т агентов размещаются в п узлах (га > п);
— блок 7 определяет стартующую вершину:
• s = 1, где s — индекс tabu-списка;
• если к е (1,га), то начальная вершина fc-ro агента заносится
в tabu-список tabiik(s);
— блоки 8-11 определяют цикл прохождения по всем вершинам
с одновременным занесением в tabu-список:
• продолжать до тех пор, пока tabu-список не станет пустым;
• s = 5+l;
13 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
194 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
• для k G (1,ш) выбрать вершину j для продолжения движения
с вероятностью Pij{t), вычисленной по формуле (23). (При этом в
момент времени t fc-й агент находится в вершине г = tabuk(s — 1));
• переместить fc-того агента в вершину j;
• вставить вершину j в tabuk(s);
— блоки 12-16 служат для обработки ситуации, когда завершился
проход по всем вершинам: для всех к Е (1, ш):
• переместить fc-того агента из списка tabuk(n - 1) в список
tabuk{n)\
• подсчитать длину Lk маршрута, пройденного fc-м агентом;
• для каждого интервала (г, j) и для всех к Е (1, га) выполнить
где первое условие выполняется, если интервал (г, j) принадлежит
маршруту из списка tabuk. Второе условие вступает в силу в
противном случае, а также если ATij := Дт^- + Ат-%;
• для каждого интервала (г, j) подсчитать т^(£ + п) по формуле
Tij(t + n) = p* nj(t) + Arij\
• t = t+l\
— блоки 18-19 служат для наращивания счетчика циклов и
обнуления интенсивности:
•NC=NC+U
• для каждого интервала (г, j) задать ATij = 0;
— блоки 20-22 служат для обработки условия NC < NCm&x:
• если NC < NCmax и не наблюдается стагнационное поведение,
тогда обнулить все tabu-списки и перейти на блок 2;
• иначе вывод кратчайшего пути и останов.
Время работы алгоритма зависит от размера анализируемой
матрицы: чем больше размер матрицы, тем больше может потребоваться
времени. Время работы предлагаемого алгоритма в лучшем случае
имеет порядок роста п, т.е. 0(п), где п — число вершин графа.
Среднее время работы алгоритма АС зависит от выбранного
распределения вероятностей, числа вершин графа.
Для решения задачи коммивояжера разработан новый муравьиный
алгоритм. Колония муравьев представляет собой систему с очень
простыми правилами автономного поведения особей. Однако несмотря на
примитивность поведения каждого отдельного муравья, поведение всей
колонии оказывается достаточно разумным. Основой поведения
муравьиной колонии служит низкоуровневое взаимодействие, благодаря
которому, в целом, колония представляет собой разумную многоагентную
систему. Взаимодействие определяется через химическое вещество —
феромон, откладываемого муравьями на пройденном пути. При
выборе направления движения муравей исходит не только из желания
5.3. Поиск маршрута минимальной длины
195
пройти кратчайший путь, но и из опыта других муравьев, информация
о котором передается через уровень феромонов на пройденном пути.
С течением времени происходит процесс испарения феромонов, которое
является отрицательной обратной связью.
Рассмотрим основные свойства, которыми обладают муравьи:
• каждый муравей обладает собственной «памятью» для хранения
списка городов J^, которые необходимо посетить муравью к, находясь
в городе г;
• муравьи обладают «зрением», уровень которого обратно
пропорционален длине ребра,
• каждый муравей способен улавливать след феромона (уровень
феромона в момент времени t на ребре Dij будет соответствовать т^(£));
• вероятность перехода муравья из вершины г в вершину j будет
определяться следующим соотношением:
Ptjk{t) = фш_^ш^ JeJik9
где а, /3 — эмпирические коэффициенты [15]. Нетрудно заметить,
что данное выражение производит эффект «колеса рулетки».
Количество феромона, откладываемого муравьем, определяется следующим
образом:
< Q (i,j)eTk(t),
Anj,k(t) = { МО' V'J/ *w' (25)
1 0, (i,j)tTk(t),
где Q — параметр, имеющий значение порядка длины оптимального
пути, Lk(t) — длина маршрута Tk{t). Испарение феромона
определяется следующим выражением:
771
тф + 1) = (1 -р) • Tij(t) + £ Arijtk(t), (26)
fc=i
где га — количество муравьев, р — коэффициент испарения (0 ^ р < 1).
Рассмотрим элитное поведение муравьев. Элитой называются
муравьи, чьи маршруты лучше остальных. Разработана следующая
модификация, основанная на знаниях об «элитных» муравьях. Данная
модификация не учитывает количество элитных муравьев. Выражение
для элиты принимает вид:
где Ае — «авторитет» элитных муравьев. Таким образом, мы можем
регулировать влияние «элитных» муравьев с помощью коэффициента Ае.
Оптимальное значение Ае, в основном, будет зависеть от размерности
13*
196 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
графа, численности колонии, времени жизни. Его значение во многом
определяет скорость сходимости. Это очень важно, поскольку в
реальных ситуациях чаще всего приходится балансировать между качеством
решения и временем работы.
В муравьиных алгоритмах (МА) обычно принято считать, что
в каждой вершине изначально находится по одному муравью [8].
Предлагается четыре правила начального расположения муравьев в
вершинах графа при решении задачи коммивояжера:
— «Одеяло» — реализация стандартного размещения муравьев,
в каждой вершине находиться по одному муравью; тогда сложность
данного алгоритма выражается следующей зависимостью — 0(t*n*),
поскольку п = т\
— «Дробовик» — случайное распределение муравьев на вершины
графа, причем необязательно, чтобы численности колонии и вершин
совпадали;
— «Фокусировка» — вся колония находится в одной вершине;
— «Блуждающая колония» — в каждый момент времени, т. е. на
каждой итерации, вся колония перемещается в случайно выбранную
вершину.
Сходимость МА и качество решения сильно зависят от начального
расположения колонии. Исследуем возможность применения шаблонов
в МА. В отличие от генетических алгоритмов рассмотрим лишь один
шаблон. Это объясняется большими временными затратами на
сложные вычисления при нахождении вероятностей перехода из одной
вершины в другие. Сложность алгоритма нахождения следующей
вершины — 0(к * п), где п — число вершин, а к — некоторый коэффициент,
больший 1. Имея шаблон, получаем следующую вершину за O(l).
Кодировка шаблона следующая. Пусть имеется вектор В
размерностью п, где п — число вершин в графе. Тогда Bi будет содержать номер
вершины, в которую необходимо перейти из вершины г. Таким образом,
исследуемый шаблон представляет собой набор «строительных» блоков.
Рассмотрим следующий пример:
г
Bi
1
7
2
6
3
*
4
*
5
*
6
3
7
*
На основе вектора В составляются следующие «строительные»
блоки: (1-7), (2-6-3). Таким образом, попадая в вершину 2, муравей без
лишних предварительный вычислений переходит в вершину 6, а затем
в 3. Из 7, соответственно, в 1.
5.3. Поиск маршрута минимальной длины
197
Предлагаются следующие две стратегии формирования шаблона
для муравьиного алгоритма: статический и динамический шаблон.
Статический шаблон формируется перед началом работы МА на
основе знаний о длинах ребер. Пусть заранее задано число
фиксированных ребер Е3 на отрезке [1, п]. Шаблон заполняется информацией
о Е31 ребрах минимальной длины.
Динамический шаблон формируется по ходу работы МА. Шаблон
заполняется информацией о ЕЗУ ребрах с наибольшим количеством
феромона. Для этого случайно выбирается часть решения, которая
является маршрутом заданной длины I. Например, пусть дана следующая
матрица:
Позиции
Вершины
1
9
2
8
3 | 4 | 5 | 6 | 7 | 8 | 9
3 6
10
1
11
9
Пусть I = 5, а выбранный маршрут представляется как часть
решения с 4 позиции по 8:
7
2
10
5
4
Далее, используя алгоритм перебора на основе метода «ветвей
и границ», получаем кратчайший маршрут на заданном множестве
вершин. Таким образом, возникает эффект «выпрямления» на участке
решения. Конечное решение представляет собой маршрут
Позиции
Вершины
1
9
2
8
3 | 4 j 5 J 6 | 7 | 8 | 9
3 6
10
1
11
9
В МА «выпрямление» выступает в качестве интеллектуального
блока (назовем его «выпрямитель») или черного ящика, на входе которого
подается подграф с исходным множеством вершин и отношениями
между ними (весами ребер), а на выходе получаем кратчайший обход
этих вершин. На рисунке 58 представлен рассмотренный выше пример.
Жирными линиями выделены ребра, входящие в подграф («область
выпрямления» выделена пунктиром).
Определим влияние «выпрямителей» на ВСА всего алгоритма.
Псевдокод МА имеет следующий вид:
198 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
ввод матрицы расстояний D;
инициализация параметров алгоритма — а, /3, Q, Аеу /;
инициализация ребер — присвоение видимости щ и начальной
концентрации феромона;
модифицированная стратегия начального размещения муравьев;
выбор начального кратчайшего маршрута Т* и определение L*;
цикл по времени жизни колонии t — 1, £max;
цикл по всем муравьям к = 1, га;
построить маршрут Т на основе (11) и рассчитать длину
U
промежуточное выпрямление Т и пересчет L;
if L < L\ then L* = L и Т* = T;
конец цикла по муравьям;
цикл по всем ребрам графа;
обновить следы феромона на ребре на основе (25)-(26);
конец цикла по ребрам графа;
формирование шаблона;
обновить следы феромона «элиты» на основе (27);
конец цикла по времени жизни колонии;
дополнительное выпрямление Т* и пересчет L*;
вывод кратчайшего маршрута Т* и его длины L*.
До выпрямления После выпрямления
Рис. 58. Пример использования выпрямления
Оценка ВСА известного алгоритма равна 0(t * (га * (п2 + /!))) или
0(t *ra*n2 + t*ra* /!). ВСА предлагаемого модифицированного МА
будет лучше в К раз:
js t • га • п + t • тп • /! , t • га • Z! , /!
А = 2 = 1 ' 9 = ' 2 *
t mn t - т • п п
Использование частичного перебора не требует больших временных
затрат, но значительно улучшает решения муравьев, получаемые на
начальной стадии адаптации.
5.4. Раскраска и изоморфизм графов
199
В предлагаемом алгоритме решения задачи ЗК промежуточная
популяция решений не создавалась, получаемый потомок замещал
наихудшую хромосому в популяции. Отличительной особенностью
разработанного алгоритма является его способность хорошо работать на
популяциях с малым числом хромосом, что уменьшает сложность
и ВСА. Это связано с высокой степенью использования миграции
между популяциями. Полученные результаты в решении ЗК позволяют
говорить об эффективности метода и целесообразности его применения
для решения других задач оптимизации.
5.4. Раскраска и изоморфизм графов
Рассмотрим задачу раскраски графа (РГ). Раскраской вершин графа
G = (X, U) называется разбиение множества вершин X на L
непересекающихся классов (подмножеств)
ХЬХ2, ...,XL; X=\JXi; Х<р|*; = 0; t.j€/ = {l,2, ...,L},
t=i
таких что внутри каждого подмножества Xi не должно содержаться
смежных вершин. Если каждому подмножеству Xi поставить в
соответствие определенный цвет, то вершины внутри этого подмножества
можно окрасить в один цвет, а вершины другого подмножества Xj —
в другой цвет и т.д. до раскраски всех подмножеств. В этом случае
граф называется L-раскрашиваемым [8].
Основной стратегией для РГ являются некоторые эвристики,
которые дают с первой попытки результаты с локальным оптимумом.
• Составляется упорядоченный в порядке убывания степеней
вершин список. Первая вершина удаляется из списка и окрашивается
в цвет 1. Просматривая список, в цвет 1 раскрашиваются и
удаляются из него все вершины, несмежные с первой выбранной и между
собой. Далее выбирается вторая вершина из списка, она окрашивается
в цвет 2 и удаляется. Процесс продолжается аналогично, пока не будут
окрашены все вершины.
• Вершины графа упорядочиваются по убыванию локальных
степеней. Затем по порядку каждая вершина после анализа связности
раскрашивается в наименьший возможный цвет.
• Выбирается вершина графа с наименьшей локальной степенью
и удаляется из графа вместе с инцидентными ребрами. В оставшемся
графе повторяется та же процедура. Вершины графа раскрашиваются
в минимально возможный для этой процедуры цвет в порядке,
обратном порядку удаления.
• Выбирается вершина графа максимальной степени и
раскрашивается в цвет 1. Затем все нераскрашенные вершины разбиваются на два
подмножества: Х\ -смежные с раскрашенными и Хг-несмежные с
раскрашенными. Выбор очередной вершины для раскраски в минимально
200 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
возможный цвет осуществляется по наибольшей степени в Х\. Далее
процесс продолжается аналогично до заполнения цвета 1. После этого
вершины, раскрашенные цветом 1, удаляются, и процедура
продолжается до полной РГ.
• Для вершины Х{ выбирается цвет fc, если и только если среди
вершин, смежных с Х{ вершиной, существуют уже раскрашенные вершины
цветов с = 1,2, ..., fc — 1, fc + 1, A; -f 2, ... и нет вершин, помеченных
цветом к.
• Предварительно для каждой вершины задан набор цветов, в
которые она может быть раскрашена. Упорядочение вершин производится
следующим образом. Определяются вершины с минимальным числом
N — p(xi) + ZijC, где р(х{) — локальная степень вершины Х{ е X
графа G = (X, С/), Zi — число запрещенных цветов для данной вершины,
С — общее число цветов. Вершина Х{ с miniV удаляется из графа
вместе с ребрами. Для оставшегося графа повторяется такая же
процедура и т.д. Затем вершины красятся в минимальный возможный цвет
в порядке, обратном порядку удаления.
Алгоритм раскраски на основе одной из рассмотренных эвристик
может быть следующий: упорядочить вершины по убыванию
локальных степеней; каждой вершине упорядоченного списка назначать
первый имеющийся цвет, если это возможно; продолжать процесс до
полной РГ.
Алгоритм на основе такой эвристики раскрашивает граф
последовательно вершину за вершиной, присваивая каждой вершине цвет, если
это возможно, не учитывая глобальных последствий такой раскраски.
Это быстрый алгоритм РГ, его ВСА равна 0(ап), т. к. он рассматривает
один из возможных вариантов раскраски каждой вершины.
Рассмотрим граф, изображенный на рисунке 59. Это колесо Wj
содержит 7 вершин. Первые шесть вершин расположены в виде кольца,
а седьмая вершина расположена в центре кольца и соединена со
всеми остальными вершинами. Пусть задан следующий порядок вершин
графа: <765432 1>. Алгоритм раскрасит вершины следующим
образом: Х\ = {7}; X<i = {6, 4, 2} и I3 = {5, 3, 1}. Получим колесо
Wj, представленное на рисунке 60, которое раскрашено 3 цветами.
Если в графе имеется одна вершина, смежная всем остальным, то она
раскрашивается одним цветом и удаляется из упорядоченного списка.
Предлагается совместить указанные эвристики РГ с новым
эволюционным алгоритмом раскраски графов. Стратегия совмещения
предполагает использование специального кодирования решений в алгоритме.
Кодировка основана на упорядочивании вершин графа по уменьшению
значений локальных степеней вершин. Эта последовательность затем
декодируется, каждой вершине назначается некоторый цвет.
Первое, что необходимо в ЭА, связано с заменой бинарной ЦФ
на ЦФ раскраски вершин. Согласно ЦФ выбираем первый ген
(вершину) в хромосоме и присваиваем ей первый реальный цвет, если
5.4. Раскраска и изоморфизм графов
201
Рис. 59. Граф G
Рис. 60. Колесо Wj
это возможно. Каждая альтернатива учитывает предыдущие
использованные цвета. Перестановка списка элементов получается в результате
упорядочивания элементов в списке (тривиальная перестановка просто
оставляет предыдущий порядок). Список вершин сортируется.
Следующим шагом в ЭА является замена инициализации на
случайную или основанную на знаниях о решаемой задачи перестановку.
Алгоритм генерирует случайным или заданным образом
отсортированный список вершин. Жадная эвристика генерирует только одну
хромосому, но эта хромосома имеет шанс оказаться лучше, чем средняя.
Такая процедура гарантирует, что с помощью алгоритма как минимум
не ухудшается результат эвристики. В результате изменений порядка
элементов в упорядоченном списке получим новый список вершин
графа. Применяя к полученным хромосомам композицию ГО,
определяем ЦФ.
Проблема ОК для упорядоченных хромосом была исследована [8]
и был представлен упорядоченный ОК. Предлагается следующая
модификация данного оператора. Оператор сохраняет основную часть
первого родителя, а также добавляет информацию о втором родителе.
202 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Информация, которая здесь закодирована, не имеет фиксированного
значения, связанного с его позицией в хромосоме. Оператор
позволяет второму родителю «сказать» первому родителю, какие элементы
следует упорядочить по-другому. Сетевой эффект оператора состоит
в совмещении относительного порядка вершин двух родителей с
хромосомами двух потомков.
Формальная запись модифицированного алгоритма упорядоченного
ОК имеет следующий вид. Для выбранного родителя 1 и родителя 2
потомок 1 получается следующим образом:
а) генерируется бинарная строка-шаблон, количество элементов
в которой совпадает с длиной родителей;
б) гены из родителя «1», соответствующие единицам в строке
шаблона, копируются на следующий шаг;
в) создается список генов из родителя «1», соответствующих «0»
в бинарной строке;
г) последовательно просматривая элементы родителя «2», помещают
в пустые позиции хромосомы еще не вошедшие гены;
д) объединяя эти элементы без повторений, получается
потомок «1»;
е) конец работы алгоритма.
Построение потомка «2» производится аналогичным образом.
Рассмотрим пример для графа, представленного на рисунке 59.
Пусть альтернативные решения закодированы следующим образом:
Pi: 123456789
Р2: 975318642
БС: 0 1 0 0 0 1 0 0 0.
Результат после второго шага:
Рц -2 - - -6- - -
Р2: 9 - 5 3 1 - 6 4 2.
Окончательный результат:
Р3: 925316748
Р4: 9 8 5 3 1 7 6 4 2.
Здесь бинарная строка (БС) указывает на смежность
соответствующих вершин в Pi и Р2. То есть 1 в БС показывает, что вершины 5 и 9
связаны между собой. Если смежных вершин в заданных родителях
нет, тогда БС заполняется 0 и 1 случайным образом. Выполнив жадное
декодирование, получим, что хромосома Рз соответствует следующей
РГ: Хх = {9, 2, 4}, Х2 = {5, 3, 7}, Хъ = {1, 6} и Х4 = {8}. Для Р4
получим РГ: Хх = {9, 3, 4}, Х2 = {8, 5, 1}Д3 = {7, 6} и ХА = {2}.
Как видно, часть структуры каждого родителя зафиксирована
одним родителем (как указано в битовой строке). Остальные
переупорядочены так, что элементы остаются в том же порядке, в котором
они были в другом родителе. Заметим, что основную вычислительную
сложность при выполнении модифицированного оператора ОК
имеет операция декодирования. Оценка ВС А для этой операция равна
0(ап2)у где п — размер хромосомы, а — коэффициент, указывающий
5.4. Раскраска и изоморфизм графов
203
наклон параболы. В данном алгоритме эффективно используются все
разработанные ГО.
В литературе описан оператор частичной мутации. Он выбирает
часть родительской хромосомы и, произведя перестановки внутри нее,
переносит эту часть в потомка, а остальную оставляет без изменений.
Такой тип мутации не имеет параметров, хотя для длинных хромосом
полезно ограничивать длину секции. Все ГО такого вида имеют
сложное декодирование. Предлагается новая стратегия с одновременным
декодированием хромосом.
Например, пусть для графа G, представленного на рисунке 59,
задана популяция Р = {Р\, Р2, Рз, Р4}, где
Рь 1 2 3456 7 89,
Р2: 98 7 6 5432 1,
Р3: 1 3 5 7 9 2 4 6 8,
Р4: 9 7 5 3 1 8 6 4 2.
В хромосоме Р\ выбирается ген, соответствующий вершине с
максимальной степенью. Если таких вершин несколько, то они
анализируются последовательно в произвольном порядке.
В первой хромосоме выбираем элемент 9. Следующей вершиной
будет выбрана вершина 1, согласно оператору кроссинговера.
Дальнейшие шаги на всей популяции приводят к тупиковым ситуациям.
Следовательно, определен первый цвет Х\ = {9, 1}. Элементы 9, 1
исключаются из всех хромосом популяции Р. Далее в Pi выбирается
элемент 7. Согласно оператору кроссинговера получим второй цвет
Хч = {7, 6, 4}. Продолжая аналогично, найдем РГ, состоящую из
четырех цветов Хз = {8, 2, 5} и Х± = {3}. Данная методика позволяет
сокращать размер хромосом (альтернативных решений) на каждом
шаге и время РГ соответственно.
Кроме ГО необходимо также определить тип селекции. Для задачи
РГ наиболее применима модифицированная элитная селекция, которую
предлагается реализовать по следующей схеме.
Все хромосомы t-ro поколения упорядочиваются в порядке
убывания значений степеней вершин (приспособленности к внешней среде).
Выживают только первые щ из упорядоченных хромосом, т. е. те, для
которых ранг r(Pl) равный fc-й позиции в упорядоченной
последовательности хромосом меньше или равен rii, r(Pl) ^ щ.
Структура гибридного алгоритма, используемого для решения
задачи РГ, представлена на рисунке 61.
В данной структуре используются идеи совместной эволюции,
установление баланса, адаптации к внешней среде, активное
взаимодействие с внешней средой, иерархическое управление эволюционными
вычислениями. ВСА такого класса лежит в пределах 0(an2)-0(f3n3),
где а, /3 — коэффициенты, определяющие наклон кривых в
зависимости от сложности ГО, п — длина хромосомы (альтернативного
решения).
204 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
| Внешняя!
среда
ЭП
ir
I
эд
Шкала эволюции
I
эл
X
I
Поиск
Нет
ЭФ
X
[
СГПУ
Редукция
Формирование
новой
популяции Р'
Вход
]
Сортировка вершин
РГ согласно ЖЭ
I
Формирование
популяции Р
*
ок
ок,
ок2
ОК3
!
ОМ
1
'
мго
\>~\
рЛИТ!
14Н
сел
екцим
■—^
Вычисление ЦФ
-I Лучшее решение I
I
Выход
ЭС
Адаптация
Да
Нет
Q Выход J
Рис. 61. Структура гибридного ЭА
5.4. Раскраска и изоморфизм графов
205
Задача РГ тесно связана с построением независимых или внутренне
устойчивых подмножеств (НП, ВУП), а также определением клик
графа. Если две любые вершины подмножества X' графа G = (X, С/),
X' С X, не смежные, то оно называется внутренне устойчивым.
Подмножество Ф/CI графа G — (X,U) называется максимальным
внутренне устойчивым подмножеством или независимым, если добавление
к нему любой вершины Х{ С X делает его внутренне устойчивым.
Подмножество Ф* будет независимым, если
VXi e Ф^Гх^ПФ; = 0).
НП различаются по числу входящих в них элементов. В
произвольном графе G можно выделить семейство всех НП вида Фг =
= {Фь Фг, ...,Фв} или его части [8]. ЖС, используемые для РГ,
также эффективно используются для построения семейства НП.
Например, построим семейство НП для графа G на рисунке 58. Здесь
предварительно производим упорядочивание вершин по возрастанию,
начиная с наименьшей локальной степени. Работу модифицированного
оператора кроссинговера покажем на примере.
Пусть для графа G на рисунке 62 задана популяция
Р = {РьР2,Рз, Ра.Ръ), где
Рь 1 23456 789,
Р2: 98 7654 3 2 1,
Р3: 6 1 5 4 7 9 3 8 2,
Р4: 4 9 3 7 8 1 7 6 2,
i%: 56789234 1.
Работа алгоритма начинается с выбора в упорядоченной
хромосоме Р$ первого элемента — 5. Далее выбираем вершину 6, т.к. она
соседняя вершине 5 в хромосоме Р$ и не смежная ей. Аналогично
выбираем вершину 7 в этой хромосоме. После этого, анализируя
популяцию Р, в хромосоме Рз выбираем вершину 9.
Рис. 62. Граф G для определения НП
206 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Дальнейший анализ популяции Р показывает, что построено первое
НП Ф1 = {5, 6, 7, 9}. Существует большое число стратегий построения
НП. Одна из них — построение независимых СБ на две, три, четыре
и т.д. вершины с дальнейшим объединением этих СБ в НП. Другая
стратегия (в ширину) предусматривает нахождение всех НП, куда
входит первая рассматриваемая вершина (в нашем случае вершина 5),
с дальнейшим анализом других вершин на предмет создания новых
НП. Третья стратегия (в глубину) предусматривает последовательный
анализ всех вершин в упорядоченном списке (хромосома Р5) До
получения семейства НП. Четвертая стратегия является комбинацией
первых трех. Применяя четвертую стратегию для графа G на
рисунке 62, получим набор НП Ф2 = {6, 7, 8}, Ф3 = {7, 8, 2}, Ф4 = {8, 1, 3},
Ф5 = {9, 2, 4, 5}, Ф6 = {1, 2, 5}, Ф7 = {2, 5, 7, 9}, Ф8 = {3, 5, 7, 9},
Фд = {4, 5, 6, 9}. Очевидно, что данный набор не полный. Для
получения полного семейства НП необходимо продолжить реализацию
отмеченных стратегий. Описанная методика эффективно используется
для РГ. Например, пусть Ф5 задает первый цвет Х\ = {9, 2, 4, 5},
Фг задает второй цвет Хч = {6, 7, 8}, а Ф4\Ф8 задает третий цвет
Хз = {1,3}. Следовательно, граф G на рисунке 62 раскрашивается
тремя красками. Оценка ВСА для алгоритма построения семейства НП
лежит в пределах 0(ап2)-0(/Зп4).
Подмножество из максимального числа смежных между собой
вершин в графе называется кликой. Заметим, что обратной для построения
НП является задача построения клик графа [7, 8]. В графе можно
выделить некоторое семейство клик: К — {К\, Я^ •••> Kz}-
Предложенные стратегии и ЭА, описанный выше, могут быть применены для
семейства клик.
Большое число комбинаторно-логических задач и 03 на графах
требует установления изоморфизма или изоморфного вложения между
заданными структурами [8]. Данная проблема, как и все остальные
рассмотренные выше проблемы, является TVP-полной. Поэтому
разрабатываются различные эвристики для получения приемлемых
практических результатов.
Задача распознавания изоморфизма графов (РИГ) состоит в
следующем. Для заданных графов G\ = (X\, U\) и С?2 = (-Хг, С/г) тРе_
буется определить, существует ли взаимно однозначное отображение
<р: Х\ —> X<i такое, что U = (я, у) Е U\ тогда и только тогда, когда
(¥>(х), tp(y)) E С/2.
В настоящее время известны полиномиальные алгоритмы для
следующих классов графов: графы ограниченной степени; графы с
ограниченной кратностью собственных значений; fc-разделимые графы;
fc-стягиваемые графы и т.д. [7, 8].
Особого внимания заслуживают сильнорегулярные графы (СГ).
Граф G = (X, р, njp п°п), \х\ = п называется n-вершинным регулярным
графом степени р, если в нем любая пара смежных вершин имеет гг.}j
общих соседей, а любая пара несмежных вершин — п^ общих соседей.
5.4. Раскраска и изоморфизм графов
207
Сильнорегулярные графы образуют класс наиболее трудных задач для
РИГ. Для СГ известен алгоритм с ВСА 0(a\og2n) [8].
Существует ряд задач, которые полиномиально сводятся друг к
другу и к задаче РИГ G\ и G<i'.
• РИГ и построение порождающего множества для группы
автоморфизмов графа, где G = G\ U G2;
• РИГ и существование изоморфной подстановки (ВСА « 0(п2))\
• РИГ и число симметрии графа (ВСА « 0{п2))\
• РИГ и автоморфное разбиение множества вершин графа (ВСА «
* 0(п2));
• РИГ и число изоморфизмов графов (ВСА « 0(п2));
• РИГ и определение существования автоморфизма для пары
фиксированных вершин графа G (ВСА « 0(п2)).
Известно, что задача изоморфного вложения графа также является
iVP-полной задачей [8]. Она имеет много сходства и в то же время
существенно (по сложности) отличается от РИГ. Например, для
решения задачи изоморфизма подграфа G\ с использованием известных
алгоритмов РИГ необходимо разработать процедуру выделения в
графе G подмножества Х\ С X равномощного с множеством вершин Х^
графа G2.
Данная процедура включает fci действий, где к\ = I J, n = \Х\,
щ = \Х21. Следовательно, к\ раз надо применять и алгоритм РИГ.
Поэтому при выделении каждого подграфа G\ в графе G необходимо
выполнять &2 действий, где к2 = ( ) (mi — количество ребер
\т2 J
в подграфе G\, m<i — в графе G2, т\ > тг).
Задача изоморфного вложения за полиномиальное время может
быть решена за полиномиальное время, если G\ — лес, a G2 — дерево.
Наибольшую трудоемкость представляет установление
изоморфизма однородных графов, имеющих автоморфные подграфы [8]. Для
решения таких задач используются методы разбиения исследуемых
графов на различные уровни. При этом ВСА алгоритма снижается с 0(п\)
до 0(к\), где п — число элементов в графе, а к — число
элементов в наибольшем автоморфном подграфе, т.е. в таком подграфе, где
не имеет значения выбор вершин для установления соответствия.
Основная идея таких алгоритмов заключается в следующем. В
графах, исследуемых на изоморфизм, выбираются две предполагаемо
изоморфные вершины. Относительно них производится разбиение всех
оставшихся вершин на два класса. В первый класс включаются
вершины, смежные предполагаемым изоморфным вершинам.
Например, на рисунке 63, а, б показаны два графа G, G'. Пусть
G = (X, [/), G = {Х\ U'), \Х\ = \Х'\ = 6, \U\ = \U'\ = 9, локальные
степени всех вершин графа равны трем.
208 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
а б
Рис. 63. а) граф G, б) граф G'
Необходимо установить изоморфизм графов G и G'. Другими
словами, необходимо определить, существует ли отношение
эквивалентности:
X <=> Х\ U «=>[/' такое, что если ребро (х^ xj) & ребру (х[, х^),
ТО Х{ <& х[, Xj <F> Xj, Xi, XJ £ X, x\, Xj £ X'.
Покажем на примере реализацию эвристики разбиения для
установления изоморфизма однородных графов. Выберем одну вершину
в графе G и одну в графе G'. Относительно них выполним разбиение:
{1} {2,4,6}1+ {3,},_ (G),
{1'} {4',5',6>+ {2',3>_ (С).
В данном разбиении вершины Х2, Х4, Хб смежные вершине xj,
а вершины хз, xs не смежные вершине х\ графа G. Аналогичное
разбиение выполнено для графа G'. Предположим, что вершины х\ и х\
П-изоморфны. Далее выбираются подмножества меньшей мощности
и внутри них проверяется смежность вершин. В примере вершины хз,
xs и х'2, Хз не смежные. Поэтому процесс разбиения продолжается:
{1} {3},_ {{2,4,6}з+}1+ {{5}з-},-.
{1'} {2>_ {{4',5',6'Ь+}И+ {{3'Ь_}Г_.
Продолжая процесс аналогично, получим, что граф G изоморфен
графу G'. Подстановка вершин запишется в виде
(1 246351
*" \ 1' 4' 5' 6' 2' 3' /"
В рассматриваемом примере подмножества вершин {хг, Х4, Хб}
и {х'А, х'ъ, Xg} являются автоморфными, т.е. каждая вершина в одном
подграфе может быть изоморфна любой вершине второго подграфа.
5.4. Раскраска и изоморфизм графов
209
В примере ВСА РИГ 0(6!) была сведена к ВСА РИГ 0(3!). В
алгоритмах такого типа необходим перебор между элементами автоморфных
подграфов. Причем, как следует из рассмотрения примера, такой
перебор здесь выполняется последовательно для всех вершин в подграфе,
кроме последней вершины. В этой связи применение архитектур
эволюционного поиска с адаптацией и совместными моделями Дарвина,
Ламарка, Фриза и Поппера позволяет повысить скорость установления
изоморфизма графов.
В рассматриваемой задаче РИГ после получения подмножеств
разбиения в подмножествах наибольшей мощности предлагается
выполнять композицию ГО. Это позволяет параллельно анализировать все
подмножества автоморфных вершин.
Например, на рисунках 64, 65 показаны нетривиальные,
неоднородные графы G и G'. В этих графах |Х| = \Х'\ = 7, \U\ = \U'\ = 8, р{ = 1,
Р2 = 3, рз = 3, ра = 3, р5 = 3, рб = 2, pi = 1; ра = 1, рь = 3, рс = 3,
Pd = 3, ре = 3, р/ = 2, pg = 1. Вершина 1 может быть П-изоморфна
вершине а или g.
Рис. 64. Нетривиальный граф G
Рис. 65. Нетривиальный граф G'
В первом случае нас ждет тупик, а во втором — успех. Мы
предположили, что вершина 1 П-изоморфна вершине g. Тогда из связности
графа и эвристики разбиения следует, что вершина 7 П-изоморфна
вершине а. Отсюда вытекает, что вершина 6 П-изоморфна вершине /.
Далее необходимо установить существует ли соответствие между
подмножествами автоморфных вершин {2, 3, 4, 5} и {6, с, d, e}. В этом
случае, как отмечалось выше, в общем, необходимо выполнить полный
перебор между этими подмножествами вершин. Для этих
подмножеств это — 4!. Выполняя такие преобразования, получим, что
вершина 2 П-изоморфна вершине 6, вершина 3 П-изоморфна вершине d,
14 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
210 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
4 — с и 5 — е. Отсюда следует, что графы G и С, представленные
на рисунке 63, изоморфны, а подстановка изоморфизма, переводящая
один граф в другой, имеет следующий вид:
Г 1 23456 71
\abdcefgj'
Наличие вершин с различными локальными степенями упрощает
процесс РИГ. Это позволяет выбирать начальные условия для
эвристики разбиения. В примере, соответствующем рисунку 63, всего два
способа для выбора разбиения, в то время как на графах, в
соответствии с рисунками 64, 65, возможны шесть способов разбиения. В
однородных графах все степени вершин одинаковы, поэтому начальные
условия выбираются произвольно, случайным образом. В этой связи
при установлении изоморфизма в однородных графах оценка ВСА в
самом лучшем случае будет составлять О(ап), в самом худшем случае —
0((3п\). Если графы неизоморфны, то за одну итерацию установить
результат невозможно. Необходимо провести сравнение на изоморфизм
одной случайно выбранной вершины из одного графа со всеми
остальными вершинами другого графа.
Пусть заданы два графа G и С, представленные на рисунке 66.
При этом G = (X, £/), G' = (X', £/'), |Х| = \Х'\ = 6, \U\ = \U'\ = 9.
Локальные степени всех вершин графа равны 3. Пусть вершина 1
графа G П-изоморфна вершине а графа G'. Тогда
{1} {2,4,6}1+ {3,5},_(G).
{a} {b,d,f}l>+ {e,c},<_(G").
Для дальнейшего анализа выбираем соответствующие
подмножества наименьшей мощности {3, 5} и {е, с}. Вершины (3, 5) в графе G
5.4. Раскраска и изоморфизм графов
211
смежные, а вершины (с, е) в графе G' — не смежные. Следовательно,
вершина 1 не может быть изоморфна вершине а. В этой связи
необходимо провести аналогичные операции для проверки изоморфизма
вершины 1 с остальными вершинами графа G'. Далее получим следующее:
{1} {2,4,6}1+ {3,5},_ (G),
{6} {a,c,e}v+ {d,/},/_ (С).
Вершины (3, 5) в графе G смежные, а вершины (d, /) в графе G' —
не смежные. Следовательно, вершина 1 не может быть изоморфна
вершине Ь. Продолжая аналогичные построения, имеем, что вершина 1
не может быть изоморфна вершинам с, d, е. Наконец, предположим, что
вершина 1 графа G П-изоморфна вершине / графа G'. Тогда получим
следующее:
{1} {2,4,6}1+ {3,5},_ (G).
{/} {a,c,e}v+ {b,d}v. (С).
Вершины (3, 5) в графе G смежные, а вершины (6, d) в графе G1 —
не смежные. Следовательно, вершина 1 не может быть изоморфна
вершине Ь. Проанализированы все вершины графа G' на предмет
изоморфизма с вершиной 1 графа G. Во всех случаях ответ отрицательный.
Поэтому граф G неизоморфен графу G'.
Рассмотрим пример распознавания изоморфизма графов G и С,
представленных на рисунках 67, 68.
Рис. 67. Граф G
В соответствии с рисунками 67, 68, G = (X, [/), G1 = [Х\ U'),
\Х\ = \Х'\ = 10, \U\ = \U'\ = 15, локальные степени всех вершин графа
равны трем. Предположим, что вершина 1 графа G П-изоморфна
вершине а графа G'. Тогда получим
{1} {2, 5,6}1+ {3,4, 7, 8, 910}i_ (G),
[а] {6,е,/}г+ {c,d,/i,£,fc,i}F_ (С).
14*
212 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Рис. 68. Граф С
Для дальнейшего анализа выбираем соответствующие
подмножества наименьшей мощности {2, 5, 6} и {6, е, /}. Предположим, что
вершина 2 П-изоморфна вершине Ь. В этом случае получим
{1} {2}1+ [{5,6},+],_ [{7,3},+,{.4,8,910}i_],_ (G),
{a} {b}v+ [{e,/},4]i'- [{g,c}y+,{d,h,k,i}v-]v- (С).
Как видно, П-изоморфизм сохраняется. Продолжая далее, получим
{1} {2}1+ [{5,6}1+],_
[[{7},+, {3}1+]1+, [{9, 10},_, {4, 8},_],_],_ (G),
{a} {b}v+ [{е,/},,+],,_
ЕКвГ>1'+. {c}i'+]i'+. [{i, k}v-, {h, d, }v-}v-}v- (C).
Так как вершины (Л, d) в графе G' смежные, а вершины (4, 8)
в графе G не смежные, то вершина 1 не может быть изоморфна
вершине а, вершина 2 — 6, вершина 7 — g и вершина 3-е. Продолжая
аналогично, получим, что граф G не изоморфен графу G1.
При поиске подстановки изоморфизма графов для организации
гранул параллелизма предлагается применять триединый подход на основе
микро-, макро- и метаэволюции. На этапе микроэволюции эвристика
разбиения позволяет получить строительный блок. Перераспределение
генетического материала на основе ГО и их модификаций выполняется
внутри каждого строительного блока. За счет этого уменьшается
размер хромосом в популяции и сокращается время реализации основного
алгоритма.
На уровне макроэволюции эффективно использовать фрактальные
множества [8]. Каждый строительный блок представляется как
объединенная вершина нового графа. В этом случае размер хромосом
5.4. Раскраска и изоморфизм графов
213
ЭД и ЭЛ
ЭФ
ЭП
Генерация нового
множества
оптимизационных
параметров
Использование
истории предыдущих
решений для
генерации лучших
множеств параметров
Адаптация
Компенсатор
1
Внешняя
среда
Генерация
популяции
т
Селекция
~г~
ЦФ
т
ои
I
ок
л
ом
I
мго
HZ
Оценка
СГПУ
Редуктор
Определение
новой популяции
Фильтр
хромосом
Рис. 69. Структурная схема управления процессом эволюционных вычислений
уменьшается и появляется возможность увеличить число генераций
ЭА для получения оптимального результата. Это особенно актуально
при анализе однородных неизоморфных графов с одинаковым числом
вершин и ребер.
214 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
На этапе метаэволюции происходит миграция хромосом из одной
популяции в другую и различные модифицированные ГО над
популяциями.
Схема для управления ЭВ в процессе решения переборных
комбинаторно логических задач на графах, представленная на рисунке 69,
строится на основе обратных информационных связей и объединения
концепции эволюции с синергетическими и гомеостатическими
принципами управления (СГПУ).
В соответствие с этой схемой после реализации ЭА
компенсатор при взаимодействии с внешней средой реализует синергетические
принципы, а фильтр хромосом поддерживает гомеостаз. При этом
лучшие хромосомы отправляются для смешивания популяций и выхода
из локальных оптимумов.
Редуктор уменьшает размер популяции, устраняя хромосомы со
значением ЦФ ниже средней. Блоки: сумматор, редуктор и фильтр
хромосом, позволяют повысить эффективность реализации эволюции
и скорость РИГ. Следует отметить, что в графах большой размерности
с нетривиальными автоморфизмами (К > 100) процесс установления
изоморфизма резко усложняется, но использование предлагаемого
алгоритма управления ЭВ на порядок снижает оценку ВСА, позволяет
повысить качество решения и уменьшить время поиска.
5.5. Построение клик, независимых и доминирующих
множеств
Для решения задачи выделения экстремальных (независимых,
доминирующих) подмножеств в графе разработано два новых
генетических алгоритма (ПГА1 и ПГА2), отличающиеся методикой кодирования
и нахождения значений целевой функции, а также применяемыми
генетическими операторами. Общим у этих алгоритмов является то,
что оба имеют одинаковую структуру базового цикла эволюционных
вычислений.
Для ПГА1 разработана методика кодирования, когда каждое
решение представляет собой бинарную хромосому длиной N, где N —
число вершин исследуемого графа G. Каждому гену соответствует
определенная вершина графа. Вершины упорядочиваются, например,
в порядке возрастания их номеров. То есть первому гену соответствует
первая вершина графа, второму гену — вторая вершина и т.д. Если
значение гена равно 1, то данная вершина включается в экстремальное
подмножество, если значение гена равно 0, то вершина не включается
в экстремальное подмножество.
5.5. Построение клик, независимых и доминирующих множеств 215
Рассмотрим пример кодирования решения для задачи выделения
доминирующих подмножеств в некотором графе G. Пусть задана
хромосома следующего вида:
1
0
1
0
1
1
0
Это означает, что данной хромосоме соответствует доминирующее
подмножество X' = {х\, хз, £5, хб}» так как гены 1, 3, 5, 6
рассматриваемой хромосомы — являются ненулевыми. Длина хромосомы
свидетельствует о том, что исследуемый граф G имеет 7 вершин (N = 7).
Для ПГА2 предлагается следующая методика кодирования
альтернативных решений. Длина хромосомы равна числу вершин
исследуемого графа. Числовые значения разрядов хромосомы соответствуют
номерам вершин графа. Начальная популяция формируется случайным
образом, причем различные хромосомы отличаются друг от друга
порядком следования вершин.
Для оценки качества полученных решений применяется следующая
процедура. В хромосоме (строке) выбирается первая позиция, затем
данная числовая последовательность просматривается слева направо.
На каждом шаге проверяется выполнение заданного условия. Так, при
построении независимых подмножеств таким условием является
отсутствие общих ребер между рассматриваемыми вершинами. В результате
выполнения данной процедуры будет сформировано одно
экстремальное подмножество некоторой длины.
Качество полученных решений определяется длиной
соответствующих им подмножеств. При формировании на некотором шаге
подмножества, аналогичного уже существующему подмножеству, оно
исключается из популяции.
Методика кодирования решений для алгоритма ПГА1, обеспечивает
гомологичность хромосом. Следовательно, к ним можно применять
стандартные генетические операторы кроссинговера и мутации. Другое
дело, что не все полученные решения будут являться доминирующими
подмножествами, но для этого предусмотрена специальная процедура
проверки условия доминирования.
В данном алгоритме использованы следующие генетические
операторы.
Стандартный одноточечный оператор кроссинговера, в котором
при скрещивании случайно выбирается точка разрыва внутри
хромосомы. Затем происходит обмен участками родительских хромосом,
расположенных слева и справа от точки разрыва хромосом; часть первого
родителя, расположенная левее точки скрещивания, и часть второго
родителя, расположенная правее точки скрещивания, копируются от
первого потомка. Второй потомок формируется из правой части первого
родителя и левой части второго родителя.
216 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Универсальный оператор кроссинговера, в котором случайно или
целенаправленно генерируется маска, по которой производится
скрещивание. В маске для каждого гена задается число 0 или 1. Нуль
подразумевает, что первому потомку достанется ген 1-го родителя,
а второму — ген 2-го родителя. Для значения 1 в маске применяется
обратный порядок обмена, показанный ниже.
0
0
1
1
1
1
1
0
0
0
0
0
0
0
1
0
0
1
1
0
1
1
0
0
1
Родитель 1
Родитель 2
Маска
Потомок 1
Потомок 2
Оператор простой мутации, в котором случайным образом в
хромосоме выбирается ген и его значение меняются на обратные величины.
0
О
Родитель
0
0
Ш
0
0
Потомок
Здесь
X
0
1
0
1
0
0
0
1
1
0
— ген, выбранный для мутации.
Оператор мутации обменом, в котором случайным образом в
хромосоме выбираются два гена, после чего эти гены меняются местами.
Родитель
Потомок
Оператор инверсии, в котором случайным образом в хромосоме
выбираются две точки разрыва, после чего гены, расположенные между
выбранными точками, инвертируются.
Родитель
Потомок
В алгоритме ПГА2 использовался упорядочивающий оператор
кроссинговера. Например, выполнение упорядочивающего оператора
кроссинговера имеет вид, представленный ниже.
0
1
0
1
0
0
0
1
0
1
5.5. Построение клик, независимых и доминирующих множеств 217
1 | 2 I 3 | 4 I 5 I Родитель 1
Родитель 2
Потомок 1
5
4
3
2
1
1
2
5
4
3
5 4 12 3 Потомок 2
В процессе выполнения данного оператора кроссинговера
случайным образом выбирается точка разрыва. Левые от точки разрыва части
копируются в новые хромосомы без изменений, а правые
переупорядочиваются таким образом, чтобы новые хромосомы не содержали
повторяющихся вершин.
В алгоритме ПГА2 также использован оператор мутации обменом.
При этом из популяции случайным методом выбирается хромосома,
к которой будет применен оператор мутации. После этого в хромосоме
случайным образом выбираются две позиции и производится их
перестановка между собой.
2 [Щ 4 5 [Щ
2 Г[Г] 4 5 [з]
Родитель
Потомок
Здесь X — обмениваемые гены.
В данном алгоритме для выбора хромосом используется случайная
селекция. Может также применяться модификация данного алгоритма.
В этом случае после создания начальной популяции решений и
выделения в них экстремальных подмножеств производится
переупорядочение всех строковых последовательностей (хромосом) следующим
образом. Вначале записывается последовательность чисел,
соответствующая сформированному на базе данной хромосомы подмножеству,
а затем оставшиеся вершины.
Тогда точка кроссинговера выбирается случайно среди первых Lp
позиций, причем величина Lp соответствует мощности
сформированного экстремального подмножества.
Например, пусть для графа G\ = (X, £/), представленного на
рисунке 70, получено следующее решение.
6
3
2
4
5
1
218 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Просматривая данную последовательность, получим независимое
подмножество X' — {х^, #2, х\}- Переупорядочивая эту числовую
последовательность, получим
6
2
1
3
4
5
Таким образом, результат применения оператора кроссинговера
будет иметь нижеследующий вид.
6
3
5
1
4
2
6
6
2
3
5
1
4
Родитель 1
Родитель 2
Потомок 1
356214 Потомок 2
Формальная запись алгоритма ПГА1 включает выполнение
нижеследующих шагов.
а) Вводим параметры алгоритма.
б) Генерируем начальную популяцию, используя стратегию
дробовика, которая заключается в заполнении популяции случайно
сгенерированными хромосомами.
в) Производим итерацию.
г) При помощи случайной селекции (операции отбора хромосом
для кроссинговера) выбираем хромосом-родителей. Производим
кроссинговер с заданной вероятностью. Если производим кроссинговер,
то выбираем случайно один из используемых кроссинговеров.
д) Производим мутацию для каждой хромосомы с заданной
вероятностью. Если производим мутацию, то выбираем случайно один
из используемых операторов мутации.
е) Производим операцию отбора, при этом оставляем лучшие
решения.
Покажем работу алгоритма на примере графа Сг, представленного
на рисунке 71.
5.5. Построение клик, независимых и доминирующих множеств 219
Рис. 71. Граф G2
Пусть создана следующая начальная популяция:
1: 1,0 ДО ,0, 1,0
2: 0,0,0,1,1,1,0
3: 0,1,1,0,0,1,1 — (доминирующее подмножество)
4: 1,0,0,0,0,1,0
5: 0,1,1,0,0,0,0.
После первой итерации алгоритма популяция будет иметь вид
1: 1,0,1,0,0,1,0
2: 0,1,0,1,1,1,0 — (доминирующее подмножество)
3: 0,1,1,0,1,0,1 — (доминирующее подмножество)
4: 1,0,0,1,0,1,0
5: 0,1,1,0,0,1,0.
После второй итерации популяция будет иметь вид
1: 1,0,1,0,0,1,1
2: 0,1,0,1,1,1,1 — (доминирующее подмножество)
3: 0,1,1,0,1,1,1 — (доминирующее подмножество)
4: 1,1,0,1,0,1,0 — (доминирующее подмножество)
5: 0,1,1,0,0,1,0.
После третьей итерации популяция будет иметь вид
1: 1,0,0,0,0,1,1
2: 1,1,0,1,1,1,1 — (доминирующее подмножество)
3: 0,1,1,0,1,1,1 — (доминирующее подмножество)
4: 0,1,0,1,0,1,0 — (доминирующее подмножество)
5: 1,1,1,0,0,1,0.
Таким образом, лучшее найденное доминирующее подмножество
имеет мощность 3 и включает вершины 2, 4, 6.
Формальная запись алгоритма ПГА2 включает выполнение
следующих шагов:
а) формируется начальная популяции и производится оценка
входящих в нее хромосом (подсчитываются значения их целевых функций);
220 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
б) в популяции случайным образом выбираются хромосомы для
применения генетических операторов;
в) с помощью операторов кроссинговера и мутации создаются новые
решения;
г) производится оценка вновь образованных решений;
д) из популяции удаляются повторяющиеся хромосомы;
е) если прошло заданное число итераций, то — конец работы
алгоритма, иначе переход к п. б).
Структурная схема алгоритма ПГА2 для выделения экстремальных
подмножеств представлена на рисунке 72.
(^ Начало ^)
Создание начальной
популяции
Селекция
Операторы
кроссинговера
и мутации
Оценка популяции
и отбор
Нет
Выбор наилучшего
решения
^ Конец ^)
Рис. 72. ПГА выделения экстремальных подмножеств
5.5. Построение клик, независимых и доминирующих множеств 221
Приведем описание разработанного модифицированного
эволюционного алгоритма выделения независимых подмножеств в графе.
Вначале опишем структуру кодирования и декодирования хромосом.
Они оказывают наибольшее влияние на эффективность эволюционного
поиска, поскольку необходимо учитывать специфику рассматриваемой
задачи. Подходы к кодированию хромосом определяют тип и
трудоемкость применяемых к ним эволюционных операторов, а также
трудоемкость операций кодирования и декодирования.
Рассмотрим структуру хромосомы, используемую в
рассматриваемом здесь алгоритме.
Пусть задан граф G = (X, U). Необходимо найти
максимальное независимое подмножество гртаХ1 число внутренней
устойчивости 77(G) = l^maxl и наибольшее семейство независимых
подмножеств wmax-
Выполним теоретическую оценку нижней /mm и верхней /тах
границы числа внутренней устойчивости. Тогда хромосома будет иметь вид
/
1
7
2
9
4
0
0
0
_oJ
N
Число генов в хромосоме N равно верхней оценке числа внутренней
устойчивости /тах- Значением гена является номер вершины в графе G.
Заполненная часть хромосомы / представляет собой внутренне
устойчивое или независимое подмножество, / G [/min, /max]- Так как / может
быть меньше N, то оставшаяся часть хромосомы заполняется нулями.
Параметр / определяет длину внутренне устойчивого или
независимого подмножества, поэтому его целесообразно использовать для
оценки качества хромосомы. Тогда целевой функцией хромосомы, а также
критерием оптимизации будет являться /, а целью оптимизации —
максимизация функции вида
F(H) = lH, F(#)-max.
Рассмотрим теперь стратегию формирования начальной популяции.
Она представляет собой множество внутренне устойчивых
подмножеств, некоторые из которых могут быть независимыми. Создание
популяции можно описать следующим образом.
Сначала случайным образом формируется множество вершин,
мощность которого выбирается случайно в пределах [Zmin, /max].
Проверяется, является ли это множество внутренне устойчивым; если да,
то хромосома записывается в начальную популяцию, если нет, то
формируется новое множество вершин. Процесс продолжается до тех пор,
пока не будет сформировано заданное число хромосом.
222 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Например, начальная популяция может быть представлена
следующим набором хромосом (Zmin = 3, /max = 9):
Я,:
Я?:
Hv.
Я4:
Я5:
Не:
Я7:
Я8:
Я9:
Як>:
12
3
1
2
2
1
3
1
3
7
10
8
7
11
5
7
6
5
8
10
7
6
10
5
7
12
8
9
11
3
1
4
12
0
1
9
1
0
14
8
0
7
9
0
12
10
2
0
6
2
0
0
0
0
8
15
0
0
8
9
0
0
0
0
14
0
0
0
9
6
0
0
0
0
3
0
0
0
13
0
0
0
0
0
0
0
0
0
15
0
Рассмотрим вопрос о выборе композиции эволюционных
операторов. Они, с одной стороны, должны обеспечивать разнообразие
популяции и препятствовать преждевременной сходимости, а с другой,
не должны давать нелегальных решений.
Предлагается использовать следующие операторы:
• модифицированный упорядочивающий одноточечный оператор
кроссинговера;
• модифицированный оператор мутации;
• элитный и равновероятный операторы отбора.
Рассмотрим их подробнее.
Поскольку используются негомологичные хромосомы, то
применение стандартных операторов кроссинговера (одноточечный,
двухточечный и т.д.) невозможно в силу того, что они дают большое число
нелегальных решений. Поэтому используем модификацию
упорядочивающего одноточечного кроссинговера для негомологичных числовых
хромосом. Приведем схему работы этого оператора кроссинговера.
Из двух родительских хромосом выбирается такая хромосома,
которая имеет меньшую длину заполненной части (1\). Случайным образом
выбирается точка скрещивания в пределах [l,/i]. Далее в хромосому
первого потомка копируется хромосома первого родителя до точки
кроссинговера, а гены потомка, расположенные правее точки
скрещивания, записываются в последовательности, соответствующей второму
родителю. При этом второй родитель просматривается от начала до
конца, слева направо, а элементы, которых не хватает в потомке,
добавляются, начиная по порядку от точки кроссинговера. Для
создания второго потомка применяется обратный порядок указанных выше
действий.
5.5. Построение клик, независимых и доминирующих множеств 223
Ниже представлен пример работы такого оператора кроссинговера.
Родитель 1:
Родитель 2:
Потомок 1:
Потомок 2:
12
10
6
3
0
0
0
0
0
1
7
10
13
9
4
0
0
0
12
10
1
7
13
9
4
0
0
1
7
12
10
6
3
0
0
0
Рассмотрим теперь схему работы модифицированного оператора
мутации, используемого в разработанном алгоритме.
Пусть заполненная часть хромосомы-родителя равна 1\, а нулевая /о-
Случайным образом сформируем множество вершин А, не
принадлежащих родительской хромосоме, |Л| Е [1,/о]- Допишем эти вершины
в хромосому. Зададим случайное число п, где п Е [0,1\], и удалим
п генов от начала хромосомы. Полученное множество вершин
записывается в хромосому потомка (пример — ниже).
Родитель:
После добавления генов:
Потомок:
12
10
6
3
0
0
0
0
0
12
10
6
3
7
9
11
0
0
6
3
7
9
11
0
0
0
0
Оператор селективного отбора формирует новую популяцию из
общего множества индивидов как родителей, так и потомков текущей
популяции, что способствует выживанию наиболее приспособленных
к внешней среде индивидов и исключению нереализуемых решений.
В разработанном алгоритме предлагается использовать совместно
два оператора отбора:
• элитный отбор — в новую популяцию отбираются только лучшие
решения из текущей популяции;
• равновероятный отбор — является полной
противоположностью элитного, здесь вероятность выживания хромосомы не зависит
от ее ЦФ.
В процессе отбора пользователь задает вероятность элитного
отбора Рэ. При равновероятном отборе Рр = 1 - Рэ. Генерируется случайное
число р, р е [0, 1]. Если р попадает в интервал [0, Рэ], то выполняется
элитный отбор, иначе — выполняется равновероятный отбор.
Такой подход к организации отбора позволяет управлять
разнообразием популяции и добиться лучших результатов, чем при
использовании какого-либо одного вида отбора.
224 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Структурная схема разработанного алгоритма представлена на
рисунке 73. Поясним работу алгоритма.
Начало
Ввод исходных данных
и задания параметров ГА
Оценка верхней и нижней границы
числа внутренней устойчивости
I
Формирование начальной
популяции
Кроссинговер
I
Мутация
I
Вычисление целевой функции
I
Выбор независимых
подмножеств из популяции
Вывод максимального
НП и семейства НП
i ~
Конец
Рис. 73. Структурная схема алгоритма
5.5. Построение клик, независимых и доминирующих множеств 225
На первом шаге алгоритма вводятся начальные данные:
• исходный граф G = (X, U)\
• параметры алгоритма (вероятности кроссинговера, мутации,
элитного и равновероятного отбора; размер популяции хромосом;
количество генераций ЭА).
Далее рассчитывается верхняя и нижняя оценка числа внутренней
устойчивости и формируется начальная популяция.
После этого начинается итеративный процесс применения
композиции эволюционных операторов к исходной популяции. На каждой
итерации с заданной вероятностью к хромосомам текущей популяции
применяются операторы кроссинговера и мутации. Далее
рассчитываются целевые функции хромосом и производится их проверка на
независимость. Независимые подмножества заносятся в отдельный список.
После этого, в соответствии с заданной вероятностью, производится
элитный или равновероятный отбор хромосом в новую популяцию.
Процесс продолжается до тех пор, пока не будет выполнено условие
останова — заданное число генераций.
Представим теперь новый эволюционный алгоритм выделения
доминирующих подмножеств в нечетких гиперграфах.
В качестве входной информации используем матрицу
инцидентности нечеткого неориентированного гиперграфа 1-го рода.
Гиперграф Н = (X, D), в котором X = {xj, г G I = {1, 2, ...
..., п} — множество вершин; D = {dj}, j G J = {1, 2, ..., га} —
множество нечетких ориентированных ребер, причем каждое ребро dj =
= ... = fidm есть расплывчатый кортеж в X. Здесь xi{, xi2, ..., Xis G X,
a fjidj — функция принадлежности, определяющая степень
инцидентности ребра dj и вершины Xi для всех Xi G Х\ при этом элементы
(/J>dj {xa)/xa), xa G X, для которых /х^ (ха) = 0, в кортеж dj не
включаются. Отметим, что данное ограничение не является критическим:
разработанный алгоритм будет легко работать с ребрами разной степенью
инцидентности — параметры и операторы ЭА останутся неизменными,
необходимо лишь изменить функцию перерасчета ЦФ.
Помимо этого задается степень внешней устойчивости
доминирующего подмножества. Пусть К — степень внешней устойчивости ДП,
тогда строим суграф начального графа такой, что ребро, у которого
функция принадлежности больше величины (1 —К), не включается
в данный суграф. Затем решаем задачу нахождения ДП в данном су-
графе. Полученные ДП будут иметь степень внешней устойчивости К.
Для графа G = (X, Г) доминирующее множество вершин
(называемое также внешне устойчивым множеством) есть множество вершин
S С X, выбранное так, что для каждой вершины Xj, не входящей
в 5, существует ребро, идущее из некоторой вершины множества 5
в вершину Xj. ДП называется минимальным, если нет другого ДП,
содержащегося в нем.
15 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
226 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Решением задачи является доминирующее подмножество с
указанной степенью внешней устойчивости, целевой функцией — мощность
полученного ДП. Чем меньше мощность ДП, тем ЦФ выше:
/?[G] = mjn|S|
MIN,
где Р — семейство всех минимальных ДП графа.
На рисунке 74 приводится пример гиперграфа.
Рис. 74. Гиперграф и его матрица инцидентности
Соответствующая данному гиперграфу матрица инцидентности
имеет следующий вид:
~Г\
2
3
4
5
6
7
8
| 1
Г05~
0,5
0,5
0
0
0
0
0
2
0
0
0,35
0
0
0
0
0,35
3
0
0
0
0
0
0,4
0,4
0,4
4
0
0
0
0
1
1
0
0
5
0
0
0
0,3
0,3
0
0
0
Приведенный на рисунке 74 гиперграф в дальнейшем будем
использовать для иллюстрации примеров.
Опишем основные этапы разработки эволюционного алгоритма
выделения доминирующих подмножеств в нечетких гиперграфах:
кодирование хромосом, структуры алгоритма и применяемую композицию
эволюционных операторов. В процессе описания используется
специальная терминология.
«Семья» — популяция хромосом (обычно небольшого размера).
В семье есть глава — хромосома с лучшей ЦФ. Каждая семья имеет
5.5. Построение клик, независимых и доминирующих множеств 227
свой герб, рейтинг и коэффициент вырождения. Семья формируется
при помощи определенной стратегии на основе хромосомы-основателя.
«Герб семьи» — бинарная хромосома. Герб семьи имеет следующий
смысл: если ген герба равен 1, то значение данного гена у всех
членов семьи одинаковое и не изменяется в результате применения
композиции эволюционных операторов. Ген, имеющий значение 1,
будем считать фиксированным. Процентное соотношение фиксированных
генов к длине герба назовем коэффициентом вырождения.
«Рейтинг семьи» — число, которое характеризует динамику
развития семьи. Рейтинг — это целое знаковое число, изначально равное 0.
Рейтинг изменяется по следующим правилам:
— если значение ЦФ главы семьи не улучшилось в течение
итерации, то рейтинг уменьшается на 1;
— если значение ЦФ главы семьи улучшилось в течение итерации,
то рейтинг увеличивается на 1;
— если рейтинг достиг определенного значения, то обнуляем его,
а один ген в гербе семьи фиксируем;
— если рейтинг достиг определенного значения, то обнуляем его,
а один ген в гербе семьи расфиксируем.
В разработанном ЭА используются две популяция: популяция семей
и популяция ДП. Все новые ДП, полученные в популяции семей,
копируются в популяцию ДП. Алгоритм включает последовательность
приведенных ниже шагов.
— Ввод данных ГА.
— Генерация начальной популяции семей. Хромосомы-основатели
генерируются случайно.
— Проводим итерацию.
— Внутри каждой семьи с заданной вероятностью применяется ОК.
Критерий отбора следующий: если для данной хромосомы выполняем
ОК, то парой для нее является глава семьи. После выбора и
произведения ОК получаем двух потомков и оцениваем их. Затем решаем вопрос:
оставлять их или нет в семье. Для этого подсчитаем их ЦФ. Выбираем
лучшего из потомков и сравниваем его по ЦФ с каждой хромосомой
в семье. Если находим хромосому хуже, то заменяем ее на данного
потомка.
— Внутри каждой семьи производим ОМ с заданной вероятностью.
— Для каждой семьи с заданной вероятностью решаем, будем ли
проводить ОК. Если да, то выбираем случайно семью и производим
ОК между главами выбранных семей. Если ЦФ детей больше ЦФ
родителя и потомок не удовлетворяет гербу, то формируем новую семью
с потомком в качестве основателя; если потомок удовлетворяет гербу,
то просто делаем его главой семьи.
— Вычисляем рейтинг каждой семьи.
— Изменяем коэффициент вырождаемости.
— Если коэффициент вырождаемости вышел за определенные
пределы, то уничтожаем данную семью, а на ее месте формируем новую.
15*
228 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
— Отбираем новые ДП и помещаем их в популяцию ДП.
— Обрабатываем популяцию с ДП: применяем композицию
ОК, ОМ.
— Производим селективный отбор, если он необходим.
— Выполняем следующую итерацию, если эта не последняя.
Для работы алгоритма предлагается использовать следующую
структуру хромосом. Хромосома представляет собой бинарный вектор,
является гомологичной, имеет длину К. Каждая аллель хромосомы —
это номер вершины (первый ген — первая вершина, второй — вторая,
и т.д.). Для каждой хромосомы известно, является ли она ДП или нет.
Любая хромосома образует некоторый подграф.
Декодирование хромосомы проводится следующим образом:
просматриваем хромосому и те вершины, чей ген равен 1, включаем ее
в текущий ПГ. Полученный таким образом ПГ анализируем, является
ли он ДП или нет.
Используется следующая оценка ЦФ. Значение ЦФ — это пара
чисел <Л, В>. Значение А находится в пределах от 0 до К и обозначает,
сколько вершин не смежные данному ПГ. Значение В определяется
в том случае, если ПГ является ДП и равно мощности данного ПГ.
Сравнение ЦФ в алгоритме предлагается проводить следующим
способом:
— пусть ЦФ1 = <А\, В\>, ЦФ2 = <Л2, В2>\
— если А\ = К (ПГ является ДП) и А2 = К, то лучше та ЦФ,
у которой меньше значение В\
— если А\ < К и A<i < К, то лучше та, у которой меньше
значение А;
— если у одной из ЦФ А = К, а у другой — нет, то первая функция
считается лучше.
Например, пусть С\ := (1 0 1 0 0 0 1 0), ПГ содержит 1, 3, 7
вершины и не является ДП, ЦФ := (А = 6, В = X); С2 := (0 1 10 10 10),
ПГ содержит 2, 3, 5, 7 вершины, является ДП, ЦФ := (А = 8, В = 4).
Стратегия формирования семьи заключается в том, что вначале
выбираем хромосому-основателя (ХО), затем фиксируем случайное
количество ген в гербе и генерируем членов семьи путем мутации ХО.
Например, герб := 1 0 1 0 1 0 1; ХО := 1 1 0 0 1 1 0; HXpl := 1 1 0 1 1 1 0,
НХр2 := 1 0 0 1 1 0 0.
Введем понятие логического ГО. Пусть заданы 2 бинарных гена
и надо получить из них новый ген. Данную задачу можно решить,
используя 4 логические операции: «И», «ИЛИ», импликация и
эквивалентность:
«И» «ИЛИ» импликация (—►) эквивалентность (=)
00-+0 00-^0 00-+ 1 00-+ 1
0 1 ->0 0 1 -> 1 0 1 — 1 01-0
10 — 0 10-1 10-0 10-0
11-111-1 11-1 11-1
5.5. Построение клик, независимых и доминирующих множеств 229
Тогда, для выполнения логического кроссинговера выбираем двух
родителей, производим над ними выбранную логическую операцию,
в результате которой получаем потомка 1. Для этих же родителей
выполняем другую логическую операцию и получаем потомка 2.
Например,
Р1: 1 0 1 0 1 1
Р2: 0 1 0 0 1 О
П1: 0 0 0 0 1 0(«И>)
П2: 1110 0 1 («ИЛИ»)-
Логический оператор кроссинговера можно выполнить внутри
семьи, например, для герба 10 0 1 10 имеем
Р1: 1 0 1 0 1 1
Р2: 1 1 0 0 1 О
П1: 10 0 0 1 О («И»)
П2: 1 1 1 0 1 1 («ИЛИ»).
Итого получаем 8 различных вариантов оператора кроссинговера, 4
из которых применяются внутри семей, а 4 — между семьями.
Далее можно производить кроссинговер через обмен: каждую пару
генов дважды меняем с некоторой вероятностью. Например,
Р1: 1 0 1 0 1 1
Р2: 1 1 0 0 1 О
П1: 1 000 1 О
П2: 1110 11
Герб: 10 0 110
Р1: 1 0 1 0 1 1
Р2: 1 1 0 0 1 О
П1: 1 0 1 0 1 О
П2: 1 1 00 1 1.
Еще один вариант кроссинговера возможен через организацию
циклического не семейного обмена. Для этого гены первого родителя,
расположенные по четным локусам, помещаем в первый потомок по
тем же локусам, а соответствующие гены второго родителя помещаем
во второй потомок. Затем гены первого родителя, расположенные по
нечетным локусам, помещаем в первого потомка по тем же локусам,
а соответствующие гены второго родителя помещаем во второй
потомок. Например,
Р1: 1 0 1 0 1 1
Р2: 1 1 0 0 1 0
П1: 1 1 1 0 1 0
П2: 1 000 1 1.
Помимо описанных операторов можно применять стандартные
и специальные операторы мутации:
• берем хромосому, начинаем работу со случайного гена;
• меняем значение гена на противоположное;
• если изменение привело к улучшению ЦФ, то изменение
закрепляем и переходим к следующему гену;
230 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
• если изменение не привело к улучшению, то изменение
восстанавливаем и повторяем процесс заданное число шагов.
Представим теперь алгоритм выделения независимых подмножеств
в гиперграфе.
Как и в предыдущем алгоритме, используется ряд ограничений:
рассматриваются только нечеткие гиперграфы первого рода, т.е. те,
у которых вершины лишены нечеткости и степень принадлежности
вершины xi ребру ej одинакова для всех вершин инцидентных данному
ребру ej.
Алгоритм работает с ребрами разной степени инцидентности,
параметры и операторы алгоритма неизменны, необходимо лишь изменить
структуру представления данных и расчета ЦФ.
Введем следующие обозначения: К — мощность графа; ПГ —
подграф.
Для примера работы алгоритма воспользуемся гиперграфом,
заданным на рисунке 74.
В качестве начальных исходных данных алгоритм использует
популяцию Р = {Р\, P<i, ..., Pfc}. Длина хромосомы определяется
количеством вершин в нечетком гиперграфе. В течение одной итерации,
которая называется генерацией (поколением), оцениваются структуры
текущей популяции и с учетом этих оценок формируется новая
популяция вариантов решений исходной задачи. Начальная популяция
может выбираться случайно, эвристически, с помощью точного метода
или различных комбинированных способов.
Каждая новая структура популяции P(t + 1) выбирается из Р{г) на
основе процедур селекции и отбора. Анализ и преобразование
выполняются на основе рекомбинации генетических признаков. Она состоит
из композиции эволюционных операторов, осуществляющих изменение
внутреннего представления рассматриваемых структур. К ним
относятся кроссинговер, мутация, селекция, отбор и другие.
Так как в данной задаче используются гомологичные хромосомы,
то ограничений на формирование начальной популяции не
накладываются, что способствует применению любого алгоритма формирования
популяции, например
12 3 4 5
0
1
0
1
1
Каждый номер гена характеризует конкретную вершину, т.е., если
возьмем 5-й ген, то он соответствует 5-ой вершине.
Декодирование хромосомы проводится следующим образом.
Просматриваем хромосому и те вершины, чей ген равен 1, включаются
в текущее решение. Полученное таким образом решение анализируем:
является ли оно НП или нет. Если да, то добавляем его в список
решений и обозначаем хромосому как пустое подмножество.
5.5. Построение клик, независимых и доминирующих множеств 231
Начало
i
Создание
начальной популяции
1
Задание
параметров ГА
i
/
j=0;j<KoI;j + +
/,
1
ОС
1
ок
1
ом
1
ло
1
он
1
Расчет ЦФ
1
Отбор
1
\
'
Выбор
лучшего решения
♦
/
Конец
Рис. 75. Структурная схема алгоритма
Целевая функция рассчитывается следующим образом. Пусть
имеется хромосома (0 1 10 0 10 1), причем она является НП. Тогда
вершины (2 3 6 8) образуют подграф Р, у которого ЦФ = \Р\ = 4. Чем
больше ЦФ, тем больше и размер НП, тем и решение лучше.
Алгоритм решения задачи основан на эволюционной стратегии
поиска. При решении задачи использовалась композиция следующих
эволюционных операторов [13]:
• операторы мутации (простая, точечная, обмена, инверсия,
«золотого сечения»);
232 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Схема ЛО
Генерация N
VR-вероятность ЛО
Выбираем оператор
«И» «ИЛИ» «НЕ»
Рис. 76. Структурная схема логических операторов
• операторы кроссинговера (стандартный одно- и двухточечный,
универсальный, упорядочивающий, частично-соответствующий,
«золотого сечения»);
• селекция (случайная, элитная, на основе рулетки).
Кроме того, при решении данной задачи были использованы
логические операторы:
«И»
00-0
0 1-0
10-0
11 — 1
«ИЛИ»
00-0
0 1-1
10-1
11-1
инверсия (->)
0- 1
1 -0
эквивалентность (=)
00- 1
0 1-0
10-0
11-1
Опишем словесно алгоритм нахождения НП.
На первом этапе вводятся все необходимые данные (число
итераций, размер популяции, длина хромосомы). На втором этапе
генерируем начальную популяцию и подсчитываем ЦФ.
Дальнейшую работу алгоритма опишем пошагово.
Шаг 1: Проверяем условия выполнения ГО. Если номер итерации
меньше количества итераций, то увеличиваем счетчик итераций и
переходим на шаг 2, иначе — на шаг 9.
Шаг 2: Производим селекцию (например, по правилу рулетки).
Шаг 3: Выполняются операторы кроссинговера. С помощью правила
рулетки выбирается, какой кроссинговер будет проводиться для
конкретных хромосом.
Шаг 4: Выполняются операторы мутации. С помощью правила
рулетки выбирается, какая разновидность оператора мутации будет
проводиться для конкретной хромосомы.
5.6. Построение дерева Штейнера
233
Шаг 5: Выполняются логические операции. Для этого выбирается
одна из рассмотренных логических операций.
Шаг 6: Если хромосома является НП, то случайно добавляется еще
одна вершина.
Шаг 7: Расчет целевой функции хромосом, сортировка по
убыванию.
Шаг 8: Используя элитный отбор, отбираем лучшие хромосомы
и помещаем их в новую популяцию. Переходим на шаг 1.
Шаг 9: Вывод лучшего решения и останов программы.
Укрупненная структурная схема разработанного алгоритма имеет
вид, представленный на рисунке 75, а схема выполнения логических
операторов представлена на рисунке 76.
5.6. Построение дерева Штейнера
Задача построения дерева Штейнера формулируется следующим
образом. Для заданных точек плоскости хь Х2, ..., хп построить
кратчайшее покрывающее дерево с п' ^ п вершинами. Обычно решение
задачи Штейнера (ЗШ) рассматривают в областях прямоугольной
конфигурации. Для п ^ 5 решение ЗШ известно. В общем случае известны
условия, которым должны удовлетворять деревья Штейнера.
Дополнительные точки, вводимые при построении кратчайшего покрывающего
дерева, называются точками Штейнера.
Предлагается новый эволюционный алгоритм построения дерева
Штейнера. Структурная схема алгоритма представлена на рисунке 77.
Новый алгоритм отличается от существующих эволюционных
алгоритмов тем, что кодируются области параметров, а не сами параметры
(координаты точек Штейнера), осуществляется поиск среди популяций
точек, используются специальные правила кодирования решений.
При кодировании битовые строки (стринги) включают в себя
информацию о координатах точек Штейнера. В процессе кодирования граф
необходимо разбить на области, включающие три или четыре вершины.
Каждый стринг содержит информацию о координатах точек Штейнера
(их количество колеблется от 0 до 2 в каждой области) своей области.
Одноточечный кроссинговер в данном случае является
малоэффективным, поэтому рекомендуется использовать двухточечный оператор
кроссинговера. Примеры ОК представлены на рисунках 78 и 79.
Модификация оператора мутации для алгоритма построения дерева
Штейнера состоит в том, что случайным образом выбирается точка
мутации (ген, стринг), которая удаляется, а вместо удаленной точки
генерируется новая.
Пример ОМ представлен на рисунке 80.
Основной сложностью применения эволюционных алгоритмов для
построения деревьев Штейнера является оптимальное кодирование
234 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
С
Начало
3
Создание структуры базы
данных хромосом
Разбиение множеств точек
на области
Генерация начальной
популяции По
Выполнение модифицированных
генетических операторов
Добавление потомков в базу
данных хромосом
Вычисление значения целевой
функции для каждой хромосомы
Сортировка хромосом по
возрастанию целевой функции
Удаление точек Штейнера
со степенью /
С
Конец
")
Реализация методики
кодирования
Рекомендуется
использовать метод
Прима- Крускала
Рекомендуется
использовать метод
сортировки вставками
Удаляются точки
Штейнера с
инцидентными им
ребрами
Рис. 77. Структурная схема эволюционного алгоритма построения дерева
Штейнера
5.6. Построение дерева Штейнера
235
1
(XuYi)(Xt,Y2)
Родители
{XuYi)(Xa.Yi)
(X,,Yi)(Xt.Y2)
1 |
(ХиЪ)
1 Потомки j—
(XltYi)(X2,Yt)
(X,,yi)(X2,F2)
(jfi.yi)(x2.y2)
(ХьУ,)
Рис. 78. Пример двухточечного OK
хромосом в популяции. Существует ряд методов и способов
кодирования минимальных покрывающих деревьев и деревьев Штейнера.
Опишем некоторые из них.
Метод кодирования с помощью таблицы маршрутов основан на
кодировании хромосом с помощью генов, описывающих маршруты
в графе. Доказано, что в графе G = (V, Е) существует |V| x (|V - 1|)
возможных пар типа «источник-цель». Пара «источник-цель» может
быть соединена с помощью набора ребер графа (маршрута).
Обычно существует множество маршрутов между источником и
целью в каждой паре. Например, в графе, представленном на
рисунке 81, а, возможные маршруты между ^о и V4 следующие: vq-v*,
vo-vs-vt, .... Метод кодирования представлен таблицей маршрутов,
включающей в себя R возможных маршрутов, построенных для
каждой пары «источник-цель». На рисунке 81, б представлена таблица
маршрутов для пары (г>о, v*).
Размер таблицы маршрутов R является параметром данного метода.
Маршруты в таблице сортируются по их длине, что важно для решения
задач построения минимальных покрывающих деревьев.
Таким образом, для вершины-источника vo и набора вершин-целей
D = {и\, г/2, ..., Uk] хромосома может быть представлена строкой
целых чисел (стрингом) длиной к. Ген gi (1 ^ г ^ к) хромосомы в массиве
{О, 1, ..., R — 1} представляет возможный маршрут между vo и щ,
где щ £ D. Связь между хромосомой, геном и таблицей маршрутов
представлена на рисунке 82.
Хромосома является представлением решения задачи построения
минимальных покрывающих деревьев, так как она содержит
информацию о маршруте между вершиной-источником и любой из вершин-
целей. Однако хромосома не обязательно может представлять дерево,
236 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
©
J—Ф
L-Чз)
Ф
<5>
<6>Н<8>
Ф
ФН<5>—1
S
Ф
ь
1
1
-и
1
—1—
1
1
1
Л i i/^N ^
>
—0
D-H
! V
• JV
к-4-ч
ш
J
>
V:
i
1
—1—
i
—i-
i
1
i
V !
©
я
о
н
о
3S
х
Рис. 79. Пример двухточечного ОК
что не является серьезной проблемой; хромосома с циклами и
неудовлетворительным значением целевой функции будет удалена в
последующих поколениях (популяциях).
Другой метод кодирования заключается в представлении хромосом
в виде дерева. Достоинством этого метода является то, что хромосомы
в виде древовидного графа легко декодируются. Метод заключается
5.6. Построение дерева Штейнера
237
s
s
О
О—гО
<г>
+-©
■&
-f Точка мутации |—|
ь
>,
2
О
Рис. 80. Пример модифицированного оператора мутации
/ \
а б
Рис. 81. Пример маршрута в графе (а) и таблица маршрутов (б)
Таблица маршрутов для Vo — Va \
маршрута
0
1
1
1
1
Я-1
Маршрут
Vo-V4
V0-V5-V4
1
1
1
Vo-V5-Vl-V2-Vs-V4\
238 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
9\
92
9к
Таблица маршрутов для Vq — щ
№
маршрута
Маршрут
О
Д-1
V0-Ui
Vq-...-Щ
Vo-
Рис. 82. Пример представления хромосом
в том, что через все точки (вершины) исходного множества проводятся
горизонтальные и вертикальные линии, образующие решетку Хана-
на [8]. Точки пересечения решетки какой-либо области будут являться
возможными вариантами точек Штейнера. Таким образом, хромосома
будет состоять из битов, соответствующих возможным точкам
Штейнера. Разрядность каждого бита является двоичной: 1 — присутствие
данной точки Штейнера; 0 — отсутствие точки Штейнера.
Еще один способ кодирования, представленный в различных
модификациях, состоит в следующем. Битовые строки (стринги) включают
в себя информацию о координатах точек Штейнера. При этом каждый
стринг (ген) содержит информацию о некоторых флагах,
используемых для генерации точек Штейнера, и координатах точек Штейнера
в одной из областей (частей), на которые разбит граф (множество
точек на координатной плоскости). Достоинство этого метода состоит
в исключении получения циклов в графе (недостаток первого метода)
и в отсутствии каких-либо проблем при декодировании хромосомы.
Это связано с тем, что хромосома не содержит информацию о ребрах,
соединениях и вершинах графа, что исключает изменение положения
точек графа при применении генетических операторов, таких как крос-
синговер, мутация и т. д.
Идея кодирования по данному способу состоит в следующем.
Генотип представляет собой набор точек Штейнера. Избранные точки
5.6. Построение дерева Штейнера
239
Штейнера описываются стрингами, в которых каждый бит
соответствует своей вершине. Например, генотип описан следующим образом:
{(7г(0), £тг(0))> •••» (п(з — 1)» *тг(в-1))}» гДе s — количество возможных
точек Штейнера, tk G {0, 1}, к = О, 1, ..., s - 1. Точки 5 G V\VT
определяются генотипом: 5 = {vk € V | tk — 1}. Они являются точками
Штейнера и входят в состав дерева, если tk = 1. Дерево Штейнера
в графе G вычисляем, используя набор 5 U W U {s} вершин, которые
необходимо соединить.
Предлагаемый метод кодирования хромосом для поиска дерева
Штейнера является модификацией рассмотренных методов. В процессе
кодирования граф необходимо разбить на области, включающие 3, 4
или 5 вершин. Каждый стринг содержит информацию о координатах
точек Штейнера. Пример кодирования представлен на рисунках 83
и 84. Алгоритм создания начальной популяции с помощью этого
способа будет описан ниже.
Блок 1
Блок 2
—1
Блок 4
!>—
—<
!>—
Блок 5
Блок 3
6
—с
\>—
Блок 6
Рис. 83. Условное исходное коммутационное поле блоков ЭВА
На рисунке 83 представлен пример исходного коммутационного
поля блоков ЭВА, а на рисунке 84 представлена графовая модель
исходного коммутационного поля, а результат кодирования в виде
хромосомы.
Если через каждую точку из исходного множества точек провести
горизонтальные и вертикальные линии, то решение задачи Штейнера
для ортогональной метрики можно получить, рассматривая в качестве
возможных дополнительных точек только точки пересечения
полученной сетки линий. На рисунке 85 представлен пример решетки Ханана
для 5 точек.
Для поиска таких точек временная сложность алгоритма в худшем
случае составит 0(п2).
На рисунке 85 для пяти входных вершин создано 12 точек
Штейнера. В 2000 году был разработан так называемый алгоритм «вертексной
редукции». С помощью такого алгоритма уменьшается количество
вариантов возможных точек Штейнера, что уменьшает временную
сложность алгоритма до 0(п) без ухудшения общей длины соединений
дерева Штейнера. На рисунке 86 показано, как из графа,
представленного на рисунке 85, исключается 5 из 12 точек Ханана.
240 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
у.'
Y2\Y?
Область 1
Область 2
0=^0-^^
0 [- I ®=4=0
Л\ Ao
X?
(Х,.У,)(Х2.У2)
(ХьУ.)
Рис. 84. Модифицированный метод кодирования
с^,—,-
о
<>
о
о
Рис. 85. Построение точек Ханана
Как показано на рисунке 86, только две из пяти точек Ханана
оказались действительно точками Штейнера для исходного графа.
Другими словами, остались точки со степенью, превышающей значение 2.
Таким образом, все точки Ханана в результате построения дерева
Штейнера, имеющие степень более 2, являются точками Штейнера.
5.6. Построение дерева Штейнера
241
а
о
Рис. 86. Исключение точек Ханана методом вертексной редукции
Предлагается использовать решетки Ханана для создания
начальной популяции хромосом и последующей композиции ГО.
Суть предлагаемого алгоритма с использованием решетки Ханана
для создания начальной популяции состоит в следующем.
а) Множество вершин разбивается произвольным образом на
области. При этом в каждой области количество точек п находится в
интервале 3 ^ п ^ К. Параметр К является входным параметром алгоритма
и подлежит дальнейшему экспериментальному исследованию.
б) В каждой из областей через каждую вершину проводятся
горизонтальные и вертикальные линии, образующие решетку Ханаана для
конкретной области. Точки пересечения решетки какой-либо области
будут являться возможными вариантами точек Штейнера.
в) В каждую из областей случайным образом вводятся
дополнительные точки, которые при построении дерева могут оказаться
точками Штейнера. Случайный выбор координат этих точек производится
среди пересечений решетки Ханана. Число таких точек изменяется
от 0 до 2.
г) Проводится соединение вершин и точек из п. «в» любым
эвристическим методом таким образом, чтобы в результате соединения
получилось ортогональное минимальное покрывающее дерево
(например методом Прима-Крускала).
д) Проводится кодирование полученного дерева Штейнера
модифицированным методом, представленным выше. Каждый стринг содержит
информацию о координатах точек Штейнера (их количество колеблется
от 0 до 2 в каждой области) в своей области.
Пример работы комбинированного алгоритма создания начальной
популяции представлен на рисунке 87.
16 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
242 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Область 2 Область 1
Область 2 Область 1 Область 2 Область 1
Рис. 87. Пример работы комбинированного алгоритма создания начальной
популяции
5.7. Построение максимальных паросочетаний
Одной из важнейших комбинаторных задач на графах является
определение максимального паросочетания. Данная задача относится
к классу ЛГР-полных проблем. Поэтому разработка эволюционных
алгоритмов определения максимального паросочетания является
актуальной и важной задачей. В проекте предлагается новый алгоритм
определения максимального паросочетания в двудольных графах.
Данный метод в отличие от известных позволяет получать набор
квазиоптимальных решений за приемлемое время.
Пусть G = (X, U) — неориентированный граф. Два ребра графа
называются независимыми, если они не имеют общей вершины. Паро-
сочетанием (ПС) называется подмножество ребер М С [/, не имеющих
общих концов. Причем каждое ребро щ е U смежно одному ребру
из М. Паросочетание — это множество независимых ребер.
Максимальное паросочетание (МПС) — это паросочетание М, содержащее
максимально возможное число ребер. Известно, что число ребер в ПС
графа G = (X, U) \Х\ = п не превышает [п/2], где [п/2] ближайшее
большее п целое.
Пусть задан двудольный граф G = (X = A U В; U). Произведем
разбиение подмножества А на две части. В первую включаются вершины,
в которые не входят ребра паросочетания. Во вторую часть
включаются вершины, в которые входят ребра паросочетания. Если первая
часть пуста, то исходное паросочетание являются максимальным.
Далее среди вершин второй части выбирается вершина с наименьшей
5.7. Построение максимальных паросочетаний 243
локальной степенью. Если таких вершин несколько, то выбирается
любая. Из выбранной вершины Х{ Е В имеем ребро (х;, Xj), которое
не является ребром паросочетания. Затем продолжаем строить цепь
назад по ребру паросочетания. Получаем цепь (xiy Xj)(xj, Xk). Далее
продолжаем аналогично. Работа заканчивается, когда нет возврата по
ребру паросочетания. Далее из исходного паросочетания удаляются
ребра, имеющиеся в цепи, и добавляются ребра цепи, которые в нем
отсутствуют.
Например, имеем граф G = (A U B\ U), представленный в
двудольном виде на рисунке 88. Задано исходное паросочетание ПС =
= {(1, 7), (2, 6)}. Разобьем подмножество А = {1, 2, 3, 4} на две
части: {1, 2} и {3, 4}. Во второй части вершины имеют одинаковую
локальную степень равную 2. Выбираем вершину 5 и строим цепь:
5—>7<— 1—>8—>5. После анализа в паросочетание добавляем ребро
(5, 8). Переходим к вершине 4. Строим цепь 4 —► 6 <— 2 —► 10. В этой
цепи нет ребер, которые можно добавить в паросочетание. Строим
новую цепь 3 —* 10.
После анализа получаем, что ребро (3, 10) можно добавить к ПС.
В результате построено МПС = {(1, 7), (2, 6), (5, 8), (3, 10)},
показанное жирными линиями на рисунке 88.
Рис. 88. Паросочетание в графе
Рассмотрим эвристику построения МПС на основе анализа
специальной матрицы смежности и построения в ней «параллельных
диагоналей». Применим идеи квантового поиска. Например, пусть задан
граф G = (А, В; [/), представленный на рисунке 89.
Рис. 89. Исходный граф примера
16*
244 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Специальная матрица смежности этого графа имеет вид:
10 11
Я = 0
Й
R
\
1
(
1
ч
Ч1ч
^
\
Й
{
ч\'
^
\
\
ч1:
\
^
ТО
ГМ
ч1
1
В матрице можно выделить семь «параллельных» диагоналей:
ПС, ={(1,7)},
ПС2 = {(1,9)},
ПС3 = {(1,11)},
ПС4 = {(2, 7), (3, 8), (5, 10)}.
ПС5 = {(2, 9), (3, 10)},
ПС6 = {(2, 11)},
ПС7 = {(4, 8), (6, 10)},
Каждая из таких диагоналей является паросочетанием
исследуемого графа. При наличии всех единиц на главной диагонали матрицы
получается максимальное паросочетание. Полученные диагонали
можно представить в виде амплитуды, как это показано на рисунке 90.
т т т
1
^Сл <л£л фръ фСл .лСь ^р° <лО*
Рис. 90. Амплитуда паросочетаний
Для дальнейших исследований выберем амплитуду ПС4 и на основе
суперпозиции с другими диагоналями (FIQ) построим максимальное
паросочетание. Операция суперпозиции для объединения частичных
решений графовых задач подробно описывается в [8].
5.7. Построение максимальных паросочетаний
245
Для получения большего числа диагоналей с максимальным числом
элементов произведем расширение матрицы:
11
2
3
4
5
6
7
гс
\
8
i
i
V
N1N
У
9
\Г
^
\
\
10
\
^
\
^
чК
111
1 7
N
1 |ч1
\
8
\
>
9
1
1
\
ч*
10
1
\
1
111
1
1
Как видно из рисунка, получено новое паросочетание
ПС8 = {(1, 11), (2, 7), (3, 8), (5, 10)}, ПС8 = ПС7 U ПС3,
которое является максимальным.
Отметим, что матрицу можно расширить справа, слева, сверху
и снизу. Например, пусть граф G задан следующей матрицей:
R =
5
^
^
\
1
6
^
ч'
, 1 N
\
\
7
\
<
чЛ
V
^
8
1
\
Ч1\
vi
^
Построим расширенные матрицы сверху и снизу. Это дает
возможность получить две новых диагонали с максимальным числом
элементов.
Такое расширение соответствует следующим операциям
суперпозиции:
ПС1 = {(2, 5), (3, 6), (4, 7)} U {(1, 8)}, |IICi| = 4,
ПС2 = {(1, 6), (2, 7), (3, 8)} U {(4, 5)}, |ПС2| = 4.
246 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Это позволяет получить два новых максимальных паросочетания
ПС1 и ПС2.
Композиция полученных паросочетаний имеет следующий вид:
R =
5
кл^
6
7
8
Г\
К*
Ч1
,1ч
к
ч
>
>
N
V
^
^
п
Формальная запись предлагаемого алгоритма имеет
следующий вид:
— строится специальная матрица смежности;
— определяются диагонали матрицы, соответствующие паросочета-
ниям графа;
— строится квантовая амплитуда, из нее выбирается амплитуда
с максимальным значением;
— производится суперпозиция максимальной диагонали с другими
путем расширения специальной матрицы слева, справа, сверху
и снизу;
— определяются максимальные паросочетания;
— конец работы алгоритма.
5.7. Построение максимальных паросочетаний 247
Время работы алгоритма зависит от размера анализируемой
матрицы: чем больше размер матрицы, тем больше может потребоваться
времени. На графах размерность задачи определяется числом вершин п
и число ребер т графа. Оценим для задачи определения паросочетания
в двудольном графе время работы алгоритма в худшем случае, среднее
время работы алгоритма и время работы алгоритма в лучшем случае.
Время работы предлагаемого алгоритма в лучшем случае имеет
порядок 0(п). Знание времени работы алгоритма в худшем случае
позволяет гарантировать, что алгоритм обязательно завершит работу
за некоторое время при данном размере входа. Время работы алгоритма
в худшем случае имеет порядок роста ran2, т. е. 0(тп2). Среднее время
работы зависит от выбранного распределения вероятностей, изменения
числа ребер и при фиксированном числе вершин графа.
Возможны и другие подходы для определения паросочетаний в
двудольных графах G = (Х\ U Х2, U), Х\ U Х2, Х\ П Х2 = 0.
Рассмотрим их.
Пусть задан двудольный граф, показанный на рисунке 91.
В нем можно определить паросочетание М\ = {(1,6), (3,8)}.
В графе на рисунке 92 максимальным паросочетанием будет
Л^2 = {(5, 8), (3, 7), (2, 6)} (выделено жирными линиями). В этом
графе также существует еще одно МПС: М'2 = {(4, 8), (3, 7), (2, 6)}.
Рис.91. Двудоль- Рис.92. Макси-
ный граф G мальное ПС
248 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Для нахождения МПС в двудольном графе будем использовать
специальную матрицу смежности R:
1
2
R= 3
4
5
Строки матрицы соответствуют вершинам Х\, а столбцы —
вершинам X<l. На пересечении строк и столбцов ставится значение 1 или О
в зависимости от наличия или отсутствия соответствующего ребра.
Такая модель требует в 4 раза меньше ячеек памяти для
представления матрицы в ЭВМ. Это особенно существенно при анализе графов
на сотни тысяч вершин.
Предлагается еще один новый алгоритм для определения
максимального паросочетания. Данный алгоритм применим не только для
двудольных графов, но также для произвольных графов, в которых
необходимо выделить максимальную двудольную часть. Идея
алгоритма состоит в следующем. В матрице R ищется диагональ с наибольшим
числом элементов. Если таких диагоналей несколько, то выбирается
любая. Например, в матрице R диагональ с наибольшим числом
элементов имеет вид Д = {(2, 6), (3, 7), (4, 8)}. Следовательно,
определено МПС М'2 для графа на рисунке 93.
Сформулируем следующую гипотезу. Главная диагональ матрицы Д,
полностью заполненная элементами, соответствует МПС. Суммарное
число единиц соответствует суммарному числу ребер МПС. Каждая
единица главной диагонали определяет ребро МПС.
Доказательство следует из способа построения специальной
матрицы по заданному двудольному графу, т. к. каждой вершине из Х\
главной диагонали ставится в соответствие одна и только одна вершина
из Хч. Отметим, что предварительно необходимо упорядочить вершины
двудольного графа по возрастанию элементов.
Формальная запись предлагаемого алгоритма определения
максимального паросочетания имеет следующий вид:
а) определить вершины подмножеств Х\ и Х^ двудольного графа G;
б) упорядочим вершины Х\ и X<i,
в) построить матрицу R и определить в ней главную диагональ;
6 7 8 9
1
^
\
ч
<
\
1
\
ч4^
1
1
5.7. Построение максимальных паросочетаний
249
Рис. 93. Двудольный граф G
г) если главная диагональ заполнена элементами полностью, то
построено МПС и переход к п. «ж», иначе переходим к п. «д»;
д) в матрице R определить все диагонали и выбрать диагональ
с наибольшим числом элементов;
е) выполняется процедура агрегации и преобразования на основе
генетических операторов, в результате чего строится МПС;
ж) конец работы алгоритма.
Пусть например, дан двудольный граф, представленный на
рисунке 94.
Рис. 94. Двудольный граф G
250 Гл. 5. Эволюционные вычисления и экстремальные задачи на графах
Построим специальную матрицу R этого графа. Она имеет
следующий вид:
6 7 8 9 10
Согласно алгоритму определяем главную диагональ Д =
= {(1, 6), (2, 7)}. Она не заполнена элементами полностью.
Определяем другие диагонали:
Д, = {(1, 8), (2, 9), (3, 10)}; Д2 = {(2, 10)};
Дз = {(2, 8), (4, 10)}; Д4 = {(5, 6)}.
В качестве базовой диагонали для определения МПС выбираем
Дь так как она содержит наибольшее число элементов. Выполняем
агрегацию:
Д!ПД2^0, Д!ПД3^0, Д!ПД^0, Д!ПД4 = 0.
Следовательно, элемент (5,6) из Д4 добавляется к Дь На этом
построение МПС завершено: М\ = {(1, 8), (2, 9), (3, 10), (5, 5)}
и |Mi|=4.
Таким образом, рассмотренный алгоритм применим как для
произвольных графов, в которых необходимо выделить максимальную
двудольную часть, так и для двудольных графов. Для этого вначале
определяется максимальное паросочетание, а затем на основе
агрегации и применения ГО строится максимальное паросочетание.
Например, пусть задан граф G в соответствии с рисунком 93.
Для его двудольной части МПС равно М = {(2, 6), (3, 7), (4, 8)}.
Применяя процедуру агрегации, получим МПС для графа, представленного
на рисунке 94: М = {(2, 6), (3, 7), (4, 8), (5, 9)}.
Временная сложность алгоритма в лучшем случае равна 0(пт)у
в худшем случае — 0(п\), в среднем — в пределах от 0(п2) до 0(п3).
Заключение
Основные результаты монографии заключаются в следующем.
Представлена таксономия моделей эволюционных вычислений.
На основе гипотез и закономерностей эволюционных вычислений
сформулированы и обоснованы основные положения теории эволюционных
вычислений, приведена их феноменологическая модель, рассмотрены
ее когнитивные возможности и общие правила представления решений.
Как одно из следствий теории установлено существование базового
цикла эволюционных вычислений. Рассмотрены вопросы
организации параллельных эволюционных вычислений, различные модели
параллелизма и показатели эффективности работы параллельных
эволюционных алгоритмов. Описаны теоретические положения микро-,
макро- и метауровней эволюционных вычислений, разработаны
новые разновидности алгоритмов эволюционных вычислений, которые
проиллюстрированы на примерах экстремальных задач на графах.
Авторы отдают себе отчет, что за рамками книги остались многие
прикладные вопросы эволюционных вычислений, которые ждут своих
исследователей. Общая теория эволюционных вычислений,
представленная в работе, является попыткой обобщить существующие
разнообразные модели и эвристические алгоритмы, опираясь на гипотезы и
закономерности, присущие природным системам, на практике доказавшие
свою непримитивность. Читатели вольны отнестись к этой попытке
с известной долей скептицизма. Мы считаем, что различия в
существующих моделях эволюционных вычислений не носят методологический
характер и не затрагивают фундаментальные принципы, присущие
эволюции независимо от формы и уровня абстракции модели.
Эволюционные вычисления изначально являются
недетерминированными, что подчеркивает их принадлежность к разработкам в
области вычислительного интеллекта. По мнению авторов, они могут
составить основу для построения эффективных интеллектуальных
информационных систем, позволяющих учитывать когнитивные
аспекты и оперировать с большими объемами неточной или неполной
информации.
С учетом широких возможностей для распараллеливания
эволюционных вычислений они способны выдать фантастический скачок
производительности по сравнению со случайным поиском и
«перемолоть» трудные практические задачи в самых разных областях,
когда даже неизвестно, как искать правильное решение. Кроме того,
эволюционные вычисления (как разновидность математических
преобразований) предоставляют удобные средства для алгоритмического
252
Заключение
решения различных задач проектирования, оптимизационного синтеза,
прогнозирования и управления, а процедуры эволюционного поиска,
несмотря на кажущуюся хаотичность и непредсказуемость, являются
очень устойчивыми.
Основная цель работы и один из замыслов авторов состояли в том,
чтобы сделать достоянием читателей основные положения общей
теории эволюционных вычислений, а также следствия из этой теории.
По сути, теория предлагает переход от традиционного
программирования различных разновидностей эволюционных алгоритмов к новой
концепции, которая может описывать сколь угодно сложную систему
зависимостей и структур, основанных на природных аналогиях, при
сохранении основного требования к вычислительной модели — адекватности
исследуемому объекту. Причем модель не обязательно должна быть
формальной (например в виде логических, алгебраических,
дифференциальных и т. п. уравнений), она может эволюционировать во времени;
цели моделируемого объекта и критерии настройки и управления ими
также могут быть не формализованы и меняться во времени. В этом
смысле система, реализующая эволюционные вычисления, является
принципиально открытой, может действовать в непрерывном режиме
усвоения и реструктуризации информации; ее сложность не
фиксирована, как и число параллельно реализуемых алгоритмов эволюционных
вычислений.
В настоящее время ведется работа по созданию среды и
инструментальных средств поддержки эволюционных вычислений, включающих
библиотеку тестовых функций (бенчмарки), как для создания новых
алгоритмов, так и в интересах совершенствования и практического
применения уже существующих разработок. По мнению авторов, это
позволит получить эффективные решения многих трудных задач
оптимизации, структурного синтеза, принятия решений в самых различных
областях.
Возможные замечания, рекомендации, пожелания и исправления
будут с благодарностью рассмотрены авторами.
Список литературы
1. Godel К. Uber formal unentscheidbare Satze der Principia Mathematica und
verwandter Systems // Monatshefte fur Mathematik und Physik. — 1931. —
N38.
2. Вернадский В.И. Биосфера ноосфера. — M.: Рольф, 2006.
3. Дарвин Ч. Происхождение видов путем естественного отбора. —
М.: Тайдекс Ко, 2003.
4. Редько ВТ. Эволюция, нейронные сети, интеллект: модели и концепции
эволюционной кибернетики. — М.: Комкнига, 2005.
5. Holland J.H. Adaptation in natural and artificial systems. — An Arbor: the
Uni of Michigan press, 1975.
6. Родзин СИ. Интеллектуальные системы. Генетические алгоритмы:
базовая концепция, когнитивные возможности и проблемные вопросы
теории. - М.: ФИЗМАТЛИТ, 2007.
7. Гладков Л.А., Курейчик В.В., Курейчик В.М. Генетические
алгоритмы. - М.: ФИЗМАТЛИТ, 2010.
8. Гладков Л .А., Курейчик В.В., Курейчик В.М., Сорокалетов П.В. Био-
инспирированные методы в оптимизации. — М.: ФИЗМАТЛИТ, 2009.
9. Koza J.R. Genetic Programming. — Cambridge: MA:MIT Press, 1992.
10. Rechenberg I. Evolutionsstrategie — Optimierung technischer systeme nach
prinzipien der biologischen evolution. — Stuttgart: Frommann-Holzboog
Verlag, 1973. - 195 s.
11. Schwefel H.-P. Evolutionsstrategie und numerische optimierung:
Dissertation Ph. D. — Technical University of Berlin, 1975.
12. Родзин СИ., Ковалев СМ. Информационные технологии:
интеллектуализация обучения, моделирование эволюции, распознавание речи. —
Ростов-на-Дону: Изд-во СКНЦ ВШ, 2002.
13. Курейчик В.М., Родзин СИ. Компьютерный синтез программных
агентов и артефактов// Программные продукты и системы. — 2004. — № 1. —
С. 23-27.
14. Fogel L.J., Owens A.J., Walsh MJ. Artificial Intelligence through simulated
evolution. — New York: J. Wiley&Sons, 1966.
15. Dorigo M., Maniezzo V., Colorni A. The Ant System: Optimization by
a colony of cooperating objects// IEEE Trans, on Systems, Man, and
Cybernetics. - 1996. - Part B. - N 26(1) - pp. 29-41.
16. Манин Ю.И. Вычислимое и невычислимое. — М.: Советское радио, 1980.
17. Feynman R.P. Simulating physics with computers // International Journal
of Theoretical Physics. - 1982. - V. 21. - N 6. - pp. 467-488.
18. Grover L.K. Synthesis of Quantum Superpositions by Quantum
Computation// Physical Rev. Letters. - 2000. - V. 85. - N 6. - pp. 1334-1337.
19. Валиев К.А., Конан А.А. Квантовые компьютеры: надежда и
реальность. — Ижевск: НИЦ «Регулярная и хаотическая динамика», 2001.
254
Список литературы
20. Курейчик В.В., Сороколетов П.В. Новая технология эволюционно-
квантового поиска// Известия высших учебных заведений.
Электромеханика. - 2007. - № 3. - С. 48-52.
21. Родзин СИ. Интеллектуальные системы. О некоторых алгоритмах,
инспирированных природными системами. — М.: ФИЗМАТЛИТ, 2009.
22. Romeo F. A theoretical framework for simulated annealing // Science. —
1983. - N 220. - pp. 671-680.
23. Курейчик В.В., Курейчик В.М. Родзин СИ. Концепция
эволюционных вычислений, инспирированных природными системами// Известия
ЮФУ. Технические науки. — Таганрог: Изд-во ТТИ ЮФУ. — 2009. —
№ 4 (93). - С. 16-27.
24. Родзин СИ. Эволюционные вычисления: единая теория и организация
параллелизма// Нечеткие системы и мягкие вычисления: сб. ст. 3-й
Всероссийской научной конф.: В 2-х т. Т. I. — Волгоград: Изд-во ВолгГТУ,
2009. - С. 30-40.
25. Каира Ф. Паутина жизни. Новое научное понимание живых систем. —
М.: ИД «Гелиус», 2002.
26. Голицын Г.А., Петров В.М. Информация и биологические принципы
оптимальности: Гармония и алгебра живого. — М.: Комкнига, 2005.
27. Дубинин И.П. Избранные труды. Проблемы гена и эволюции. Т. 1. —
М.: Наука, 2000.
28. Клав У., Каммингс М. Основы генетики. — М.: Техносфера, 2007.
29. Wolpert D.H., Macready W.G. The no free lunch theorems for
optimization// IEEE Trans. Evol. Сотр. - 1997. - V. 1. - N 1. - pp. 67-82.
30. Goldberg D.E. Genetic algorithms in search, optimization, and machine
learning. — USA: Addison-Wesley publishing company, inc., 1989.
31. Родзин СИ. Интеллектуальные системы. Проблемы и перспективы
создания единой концепции гибридных эволюционных вычислений. —
М.: ФИЗМАТЛИТ, 2005.
32. Курейчик В.М., Родзин СИ. Эволюционные алгоритмы: генетическое
программирование (обзор)// Известия РАН. Теория и системы
управления. - 2002. - № 1. - С. 127-137.
33. Rodzin S.I. Schemes of Evolution Strategies // Proc. of 2002 IEEE Int.
Conf. on Al-Systems (ICAIS, sept. 2002). — IEEE Сотр. Society: Los
Alamos, California. — pp. 375-380.
34. Курейчик В.В., Курейчик В.М., Сороколетов П.В. Анализ и обзор
моделей эволюции// Известия РАН. Теория и системы управления. — 2007. —
№5. -С. 114-126.
35. Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети,
генетические алгоритмы и нечеткие системы. — М.: Горячая линия —
Телеком, 2004.
36. Back Т. Evolutionary algorithms in theory and practice. — NY: Oxford Uni
press, 1996.
37. De Jong K., Spears W.M. An analysis of the interacting roles of population
size and crossover in genetic algorithms. — Berlin: Springer, 1991.
38. Родзин СИ. Эволюционные стратегии: концепция и результаты //
Перспективные информационные технологии и интеллектуальные
системы. — 2002. — № 2. — С. 4 — 12 [Электронный ресурс] — Режим
доступа: http://pitis.tsure.ru/fileslO/rlsl.pdf свободный. — Загл. с экрана.
Список литературы
255
39. Rechenberg I. Evolutionsstrategie. — Stuttgart: Frommann-Holzboog,
1994.
40. Курейчик В.М., Родзин СИ. Эволюционные вычисления: генетическое
и эволюционное программирование// Новости искусственного
интеллекта. - 2003. - № 5(59). - С. 13-19.
41. Растригин Л А. Адаптация сложных систем. — Рига: Зинатне, 1981.
42. Букатова И.Л. Эволюционное моделирование и его приложения. —
М.: Наука, 1979.
43. Родзин СИ. О некоторых прикладных задачах генетического
программирования // Труды межд. конф. «Интеллектуальные системы» (AIS'07)
и «Интеллектуальные САПР» (CAD-2007). Научное издание в 4-х
томах. - М.: ФИЗМАТЛИТ, 2007. - Т.1. - С. 79-88.
44. Курейчик В.В.У Сороколетов П.В., Хабарова И.В. Эволюционные
модели с динамическими параметрами. — Таганрог: Изд-во ТТИ ЮФУ, 2007.
45. Родзин СИ. Мягкие параллельные вычисления // Новости
искусственного интеллекта. — 2005. — № 4. — С. 53-58.
46. Гергелъ В.П. Теория и практика параллельных вычислений. — М:
Интернет-Университет Информационных технологий; БИНОМ, Лаборатория
знаний, 2007.
47. Родзин СИ. Организация параллельных эволюционных вычислений при
поиске и оптимизации проектных решений// Известия ЮФУ.
Технические науки. - Таганрог: Изд-во ТТИ ЮФУ. - 2009. - № 4 (93). -
С. 39-46.
48. Курейчик В.М., Емельянова Т.С Решение транспортных задач с
использованием комбинированного генетического алгоритма // Труды 11-й
национальной конференции по искусственному интеллекту КИИ-2008. —
2008. - Т. 1 - С. 158-164.
49. Rudolph G. Convergence analysis of canonical genetic algorithms // IEEE
trans, on neural networks. — 1994. — V. 5. — b.l.
50. Goncalves G., Allaoui #., Kurejchik V. Hybrid parallel genetic approach for
one-dimensional bin packing problem // 23rd European conf. of Operational
Research, Bonn, July 5-8, 2009. — pp. 202-208.
51. Родзин СИ. О проблемных вопросах теории генетических алгоритмов //
Известия ТРТУ. Интеллектуальные САПР. — Таганрог: Изд-во ТРТУ,
2006, № 8(63). - С. 51-56.
52. Родзин СИ. К вопросу о тестировании генетических алгоритмов //
Известия ТРТУ. Интеллектуальные САПР. — Таганрог: Изд-во ТРТУ,
2003, № 2(31). - С. 303-304.
53. Родзин СИ., Курейчик В.М., Гулякина НА. Эволюционные
вычисления: генетическое программирование // Перспективные
информационные технологии и интеллектуальные системы. — 2009. —
№ 2 (38). — С. 3 — 17. [Электронный ресурс] — Режим доступа:
http://pitis.tsure.ru/files38/01.pdf свободный. — Загл. с экрана.
54. Weise T. Global Optimization Algorithms: Theory and Application. —
[Электронный ресурс]. — Publish Date: 2008. Режим доступа:
http://www.it-weise.de/ свободный. — Загл. с экрана.
55. Nordin P., Banzhaf W. Evolving turing-complete programs for a register
machine with self-modifying code// Proc. of the sixth int. conf. on genetic
Programming. — San Francisko: Morgan Kaufmann, 1995.
256
Список литературы
56. Whitley L.D., Gordon V.S., Mathias K.E. Lamarckian evolution, the place-
baldwin effect and function optimization // In PPSN III: Proc. of the int.
conf. on Evolutionary Computation. 1994. — pp. 6-15. — online available
at http://citeseerx.ist.psu.edu/viewdoc/.
57. Kursawe F. Breeding ES — first results // Seminar «Evolutionary
algorithms and their applications», 1996. — pp. 47-59.
58. Нейман Дж. Теория самовоспроизводящихся автоматов. — М.: Мир,
1971.
59. Berlekamp E.R., Conway J.-H., Guy R.K. Winning Ways for your
Mathematical Plays, II: Games in Particular. — Academic Press, 1982.
60. Рапопорт Г.Н., Герц AT. Искусственный и биологические интеллекты.
Общность структуры, эволюция и процессы познания. — М.: Комкнига,
2005.
61. Родзин СИ. Теория принятия решений. — Таганрог: Изд-во ТТИ ЮФУ,
2010.
62. Holland J.H. Induction: processes of inference, learning and discovery. —
Cambridge: MA; MIT Press, 1986.
63. Grefenstette J.J. Strategy acquisition with genetic algorithms. // Handbook
of genetic algorithms. — NY: Van Nostrand Reinhold, 1991.
64. Редько ВТ. От моделей поведения к искусственному интеллекту. —
М.: Комкнига, 2006.
65. Kennedy J. Particle swarm optimization// Proc. IEEE int. conf. on Neural
Networks. - NJ: IEEE Service Center, 1995. - pp. 1942-1948.
66. Abraham Л., Grosbn G., Ramos V. Swarm Intelligence in Data Mining. —
Berlin-Heidelberg: Springer Verlag, 2006.
67. Курейчик В.В., Полупанова Е.Е. Эволюционная оптимизация на основе
алгоритма колонии пчел // Известия ЮФУ. Технические науки. —
Таганрог: Изд-во ТТИ ЮФУ. - 2009. - № 12 (101). - С. 47-54.
68. Glover F. Tabu Search. - Cambridge: MA; MIT Press, 1997.
69. Blackmore S. The Meme Machine. — Oxford: University Press, 1999.
70. Moscato P. Memetic algorithms. Handbook of Applied Optimization. —
Oxford: University Press, 2002, chapter 3.6.4. - pp. 157-167.
71. Шмалъгаузен И.И. Факторы эволюции. Теория стабилизирующего
отбора. - М.: Наука, 1968.
72. Колчинский Э.И. Эрнст Майр и современный эволюционный синтез. —
М.: Товарищество научных изданий КМК, 2006.
73. Курейчик В.М. Об одной модели эволюции Шмальгаузена // Известия
ЮФУ. Технические науки. — Таганрог: Изд-во ТТИ ЮФУ. — 2009. —
№ 4 (93). - С. 7-16.
74. Харари Ф. Теория графов. — М.: Мир, 1977.
75. Kureichik V.M., Kureichik V.V. Genetic Algorithms. — Konstaz: Hartung-
Gorre Verlag, 2004.
76. Kureichik V.M., Malioukov S.P., Kureichik V.V., Malioukov A.S.
Algorithms for Applied CAD Problems. — Berlin Heidelberg: Springer-Verlag,
2009.
77. Эволюционная эпистемология и логика социальных наук: Карл Поппер
и его критики/ Составление Д.Г. Лахути, В.Н. Садовского, В.К.
Финна. - М.: Эдиториал УРСС, 2000.
78. Емельянов В.В., Курейчик В.В., Курейчик В.М. Теория и практика
эволюционного моделирования. — М.: ФИЗМАТЛИТ, 2003.
Список используемых определений и сокращений
В монографии применяются следующие термины и определения.
Адаптация — способность живого организма или технической
системы изменять свое состояние и поведение (параметры, структуру,
алгоритм функционирования) в зависимости от изменения условий
внешней путем накапливания и использования информации о ней.
Алгоритм — точное предписание, процесс, ведущий от
варьируемых данных к искомому результату.
Анализ — метод исследования путем разбора целого на части.
Аппроксимация функции — определение по экспериментальным
данным функции, наилучшим образом приближающейся к неизвестной
зависимости и удовлетворяющей определлнным критериям
База знаний — основной компонент интеллектуальной системы,
содержащий экспертные знания об определенной предметной области.
Собрание правил, эвристик и процедур, организованных различными
моделями представления знаний.
Ген — часть решения (несколько бит).
Генотип — закодированное решение.
Гипотеза — предположение о закономерной связи явлений.
Закономерность, зависимость — отношение между функцией
и ее аргументами.
Квантовые вычисления — вычисления, выполняемые на
гипотетическом вычислительном устройстве (квантовом компьютере) с
помощью следующего квантового алгоритма: берется система кубитов, на
которой записывается начальное состояние, затем состояние системы
или ее подсистем изменяется посредством базовых квантовых
операций; в конце измеряется значение, которое является результатом.
Когнитология — междисциплинарная теория, с помощью
которой изучаются процессы восприятия, познания, понимания, мышления,
обучения и моделируется работа естественных и искусственных
интеллектуальных систем.
Концепция — система взглядов, то или иное понимание явления,
основная точка зрения, руководящая идея, замысел.
Локус — местоположение, позиция гена в хромосоме.
Метод (способ) — путь исследования, систематизированная
совокупность шагов, приемов, действий и операций, которые необходимо
предпринять, чтобы решить определенную задачу и достичь цели
познавательной или практической деятельности.
17 В.В. Курейчик, В.М. Курейчик, СИ. Родзин
258 Список используемых определений и сокращений
Методология — система базисных принципов, методов, методик,
способов и средств их реализации в научно-практической
деятельности.
Модель — материальный или виртуальный объект, отличный от
исходного, но способный заменить его в рамках решаемых задач;
система зависимостей, имитирующая структуру и функционирование
исследуемого объекта. Основное требование к модели — адекватность
объекту.
Обобщение — вид абстракции в моделях данных, при котором
множество подобных объектов рассматривается как один обобщенный
объект.
Оператор (в математике, программировании) — функция, тип
программной функции.
Параллелизм (многопоточность) — свойство вычислительных
платформ и компьютерных программ, позволяющее исполнять разные
операции программ одновременно на разных устройствах. Параллелизм
в эволюционной теории — независимое появление сходных черт
строения у разных групп организмов на основании особенностей,
унаследованных от общих предков.
Поиск — движение в структурированном пространстве от одних
узлов этого пространства к другим. Если поиск является
целенаправленным, то задается множество начальных узлов, с которых поиск может
начинаться, и множество конечных узлов, при достижении которых
поиск прекращается. Движение по структуре поискового пространства
определяется стратегией поиска. Эвристический поиск осуществляется
на основе правил, упрощающих или ограничивающих пространство
поиска решения. Эвристики могут быть как количественными, так и
качественными.
Принцип — исходное положение теории, основная особенность
устройства, механизма или прибора.
Программа — упорядоченная последовательность команд,
подлежащая обработке.
Распределенные вычисления — способ решения трудоемких
вычислительных задач с использованием двух и более компьютеров,
объединенных в сеть. Являются частным случаем параллельных
вычислений, то есть одновременного решения различных частей
одной вычислительной задачи несколькими процессорами одного или
нескольких компьютеров. Поэтому необходимо, чтобы решаемая задача
была сегментирована, то есть разделена на подзадачи, которые могут
вычисляться параллельно. При этом для распределенных вычислений
приходится также учитывать возможное различие в вычислительных
ресурсах, которые будут доступны для расчета различных подзадач.
Более того, не всякую задачу можно разделить на подзадачи, которые
можно решать параллельно.
Теория (теоретические основы, положения) — система основных
идей в той или иной отрасли знания.
Список используемых определений и сокращений 259
Фенотип — раскодированное решение.
Хромосома — решение (код).
Эволюционные алгоритмы — группа методов эвристического
поиска решений, моделирующих процессы природной эволюции.
Эволюционные вычисления — математические преобразования,
позволяющие трансформировать входной поток информации в
выходной по правилам, основанным на имитации механизмов эволюционного
синтеза, а также на статистическом подходе к исследованию ситуаций
и итерационном приближении к искомому решению.
В книге используются следующие сокращения:
БЗ — база знаний;
ВСА — временная сложность алгоритма;
ГА — генетический алгоритм;
ГО — генетические операторы;
ГП — генетическое программирование;
ДП — доминирующее подмножество;
ЖОК — «жадный» оператор кроссинговера;
ЗК — задача о коммивояжере;
КМК — компьютерная модель классификации;
ЛПР — лицо, принимающее решение;
НП — независимое подмножество;
ОИ — оператор инверсии;
ОК — оператор кроссинговера;
ОМ — оператор мутации;
ОР — операторы репродукции;
ОС — оператор сегрегации;
ОТ — оператор транслокации;
ОУ — оператор удаления;
ПГА — простой генетический алгоритм;
РГ — раскраска графа;
РИГ — распознавание изоморфизма графов;
САПР — система автоматизированного проектирования;
СБ — строительный блок;
СБИС — сверхбольшие интегральные схемы;
СБСУ — синергетический блок самоорганизации и упорядочивания;
СГПУ — синергетические и гомеостатические принципы
управления;
СГ — сильнорегулярные графы;
СППР — система поддержки принятия решения;
17*
260 Список используемых определений и сокращений
ФМ — фрактальное множество;
ФП — функция пригодности;
ЦФ — целевая функция;
ЧФ — числа Фибоначчи;
ЭА — эволюционные алгоритмы;
ЭВ— эволюционные вычисления;
ЭД — эволюция Дарвина;
ЭЛ — эволюция Ламарка;
ЭП — эволюционное программирование;
ЭС — эволюционные стратегии;
ЭФ — эволюция де Фриза.
Что собой представляют
гипотезы, закономерности и модели
эволюционных вычислений, их
алгоритмы? Как осуществляются
математические преобразования
в процессе эволюционных вычислений? Как
организовать их параллельное выполнение? Как
решаются с помощью эволюционных вычислений
экстремальные задачи на графах?
Эти и другие вопросы обсуждаются в книге, которая
будет интересна всем, кто изучает
теорию и практику создания
интеллектуальных
информационных систем и технологий,
а также специалистам по
системному анализу, теоретической
информатике, автоматизации
проектирования и управления,
компьютерному моделированию
и вычислительной математике.