/





















































































































































































































































































Автор: Маркс Р. Дембски У. Эверт У.
Теги: программирование на эвм компьютерные программы вычислительные машины и устройства дискретного действия (цифровые вычислительные машины и устройства) информатика
ISBN: 978-5-97060-725-1
Год: 2020
Текст
California State University Channel Islands, USA
Данная книга рассказывает о том, как ученые соединили методы моделирования сложных процессов и теорию информации, благодаря чему
стало возможно измерить сложность всех явлений мироздания в битах.
Построенная на основе серии рецензируемых статей, книга написана
языком, легко понятным для читателей со знанием математики на уровне
средней школы.
An Introduction to the
Analysis of Algorithms
Если читатель стремится бегло охватить тему или не интересуется математическими подробностями, он может пропустить разделы, отмеченные
специальным значком, и все равно испытает восторг от знакомства с новой
захватывающей моделью информации о природе.
Книга написана для энтузиастов в области науки, техники и математики,
заинтересованных в понимании важной и пока еще недооцененной роли
информации в теории эволюции.
3rd Edition
ISBN 978-5-97060-725-1
Интернет-магазин:
www.dmkpress.com
NEW JERSEY • LONDON • SINGAPORE • BEIJING • SHANGHAI • HONG KONG • TAIPEI • CHENNAI • TOKYO
Оптовая продажа:
КТК “Галактика”
books@alians-kniga.ru
www.дмк.рф
9 785970 607251
Введение в эволюционную информатику
Наука добилась больших успехов в моделировании пространства, времени,
массы и энергии, но слишком мало сделала для того, чтобы создать модель
информации, заполняющей нашу
Вселенную.
Michael
Soltys
Роберт Маркс
Уильям Дембски
Уинстон Эверт
Введение
в эволюционную
информатику
Роберт Маркс, Уильям Дембски, Уинстон Эверт
Введение
в эволюционную информатику
I N T RO D U CT I O N TO
EVOLUTIONARY
INFORMATICS
Robert J Marks II
Baylor University, USA
William A Dembski
Evolutionary Informatics Lab, USA
Winston Ewert
Evolutionary Informatics Lab, USA
NEW JERSEY • LONDON • SINGAPORE • BEIJING • SHANGHAI • HONG KONG • TAIPEI • CHENNAI • TOKYO
ВВЕДЕНИЕ
В ЭВОЛЮЦИОННУЮ
ИНФОРМАТИКУ
Роберт Маркс
Университет Бэйлор, США
Уильям Дембски
Лаборатория эволюционной информатики, США
Уинстон Эверт
Лаборатория эволюционной информатики, США
Москва, 2020
УДК 004.421, 57.08
ББК 32.972, 28.0
М25
Маркс Р., Дембски У., Эверт У.
М25 Введение в эволюционную информатику / пер. с анг. В. С. Яценкова. – М.:
ДМК Пресс, 2020. – 276 с.: ил.
ISBN 978-5-97060-725-1
Наука добилась больших успехов в моделировании пространства, времени, массы
и энергии, но слишком мало сделала для того, чтобы создать модель информации,
заполняющей нашу Вселенную.
Данная книга рассказывает о том, как ученые соединили методы моделирования
сложных процессов и теорию информации, благодаря чему стало возможно измерить
сложность всех явлений мироздания в битах. Построенная на основе серии рецензируемых статей, книга написана языком, легко понятным для читателей со знанием
математики на уровне средней школы.
Если читатель стремится бегло охватить тему или не интересуется математическими подробностями, он может пропустить разделы, отмеченные специальным значком, – и все равно испытает восторг от знакомства с новой захватывающей моделью
информации о природе.
Издание написано для энтузиастов в области науки, техники и математики, заинтересованных в понимании важной и пока еще недооцененной роли информации
в теории эволюции.
УДК 004.421, 57.08
ББК 32.972, 28.0
Authorized Russian translation of the English edition of Introduction to Evolutionary
Informatics ISBN 9789813142145 © 2017 by World Scientific Publishing Co. Pte. Ltd.
This translation is published and sold by permission of Packt Publishing, which owns or
controls all rights to publish and sell the same.
Все права защищены. Любая часть этой книги не может быть воспроизведена в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения
владельцев авторских прав.
ISBN 978-9-8131-4214-5 (анг.)
ISBN 978-5-97060-725-1 (рус.)
© 2017 by World Scientific Publishing Co. Pte. Ltd.
© Оформление, издание, перевод, ДМК Пресс, 2020
Содержание
Вступительное слово от издательства. ....................................................9
Предисловие.....................................................................................................10
Об авторах.........................................................................................................19
Глава 1. Введение............................................................................................21
1.1. Королева ученых и инженеров.......................................................................22
1.2. Наука и модели................................................................................................23
1.2.1. Компьютерные модели............................................................................24
1.2.2. Невероятное и невозможное...................................................................24
Источники..............................................................................................................25
Глава 2. Информация: что это такое?. ....................................................27
2.1. Определение информации.............................................................................27
2.2. Измерение информации................................................................................29
2.2.1. Cложность по KCS.....................................................................................30
2.2.2. Информация Шеннона............................................................................37
2.3. Заключение......................................................................................................44
Источники..............................................................................................................44
Глава 3. Эволюционный поиск и требования к информации.......47
3.1. Эволюция как поиск.......................................................................................47
3.1.1. WD-40TM и Formula 409TM. ........................................................................48
3.1.2. Тесла, Эдисон и знания в предметной области......................................48
3.2. Инженерная разработка с помощью компьютера........................................49
3.3. Разработка рецепта вкусных блинов.............................................................50
3.3.1. Поиск хорошего блина № 1.....................................................................50
3.3.2. Поиск хорошего блина № 2: время приготовления плюс
настройка оборудования...................................................................................53
3.3.3. Поиск хорошего блина № 3: больше переменных параметров
рецепта...............................................................................................................53
3.3.4. Поиск хорошего блина № 4: имитация блинов на компьютере
с искусственным языком с использованием одного агента...........................55
3.3.5. Поиск хорошего блина № 5: моделирование блинов
на компьютере с помощью эволюционного поиска.......................................57
3.4. Источники знаний..........................................................................................58
3.4.1. Проектирование антенн с использованием эволюционных
вычислений........................................................................................................60
6
Содержание
3.5. Проклятие размерности и потребность в знаниях.......................................62
3.5.1. Поможет ли Мур? Как насчет Гровера?...................................................63
3.6. Неявные цели..................................................................................................64
3.7. Оптимальная неоптимальность.....................................................................67
3.7.1. Потеря функции.......................................................................................67
3.7.2. Оптимизация Парето и оптимальная субоптимальность.....................68
3.7.3. Человек в цикле как фактор активной информации.............................70
3.8. Ландшафты отбора поисковых алгоритмов..................................................71
3.9. Выводы.............................................................................................................73
Источники..............................................................................................................73
Глава 4. Детерминизм в случайности. ....................................................81
4.1. Принцип равной вероятности событий........................................................83
4.1.1 «Ничто есть то, о чем мечтают скалы»....................................................83
4.1.2. Принцип недостаточного основания Бернулли (PrOIR).......................84
4.2. Потребность в шуме........................................................................................99
4.2.1. Фиксированные точки в случайных событиях.......................................99
4.2.2. Выборка по значимости........................................................................103
4.2.3. Предельные циклы, странные аттракторы и тетербол........................104
4.3. Потолок Бейснера.........................................................................................105
4.3.1. Tierra.......................................................................................................106
4.3.2. Край эволюции.......................................................................................109
4.4. Заключение....................................................................................................110
Источники............................................................................................................111
Глава 5. Сохранение информации в компьютерном поиске.......114
5.1. Основы...........................................................................................................114
5.2. Что такое сохранение информации?...........................................................116
5.2.1. Обманчивые контрпримеры.................................................................118
5.2.2. Взаимосвязь между обучением и поиском..........................................120
5.2.3. Человек в цикле, вносящий активную информацию..........................125
5.3. Удивительная стоимость слепого поиска в битах.......................................128
5.3.1. Анализ.....................................................................................................128
5.3.2. Вычислительная стоимость...................................................................129
5.4. Измерение сложности поиска в битах.........................................................131
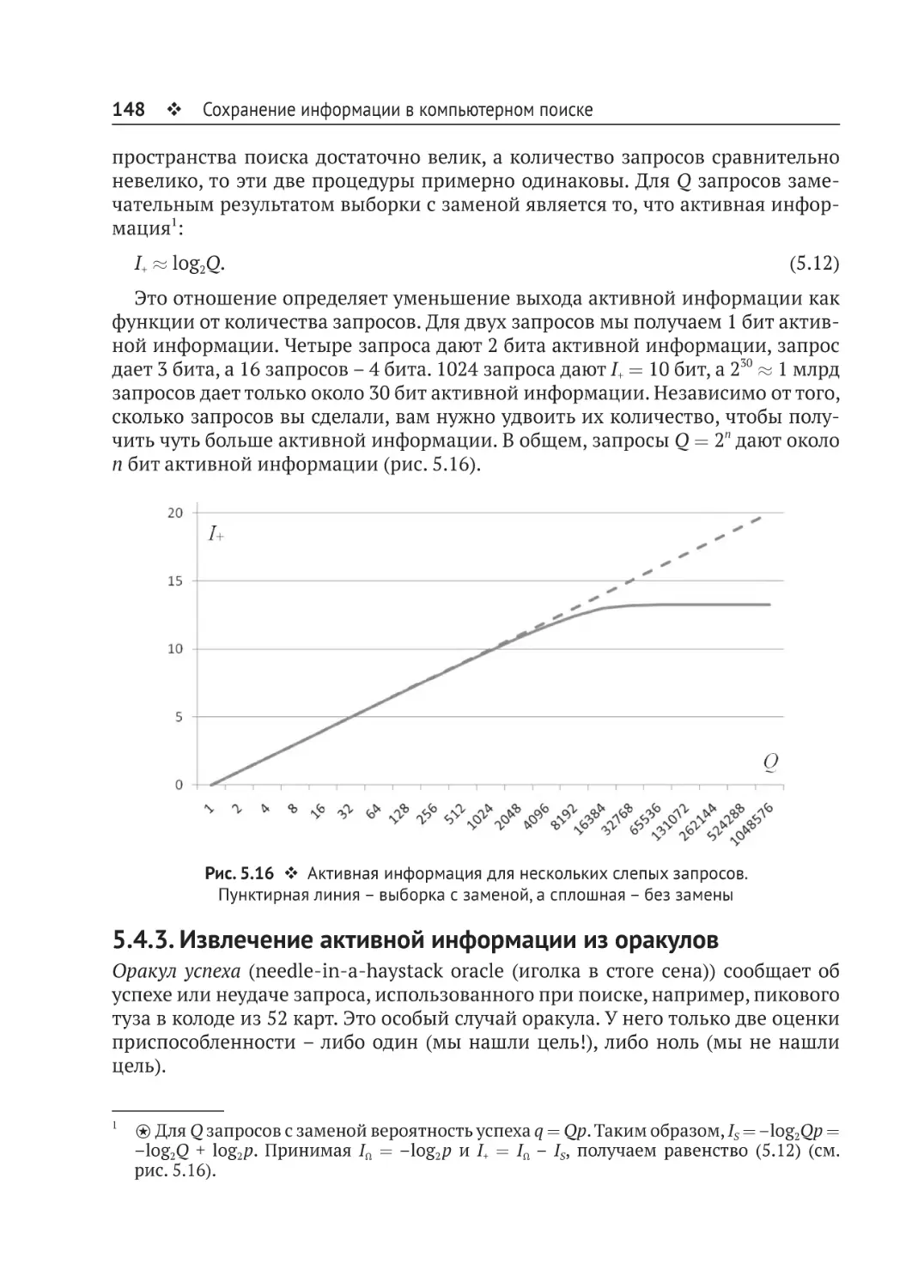
5.4.1. Эндогенная информация......................................................................131
5.4.2. Активная информация..........................................................................136
5.4.3. Извлечение активной информации из оракулов................................148
5.5. Источники информации в эволюционном поиске.....................................156
5.5.1. Популяция..............................................................................................157
5.5.2. Коэффициент мутации..........................................................................157
5.5.3. Ландшафт отбора...................................................................................158
5.6. Ступенчатая информация и переходная функциональная
жизнеспособность...............................................................................................160
Содержание 7
5.6.1. Детские шаги..........................................................................................162
5.6.2. Сохранение функциональности развития и неснижаемая
сложность.........................................................................................................162
5.7. Коэволюция....................................................................................................167
5.8. Поиск поиска.................................................................................................171
5.8.1. Пример....................................................................................................171
5.8.2. Проблема поиска для поисков..............................................................172
5.8.3. Математические доказательства..........................................................174
5.9. Заключение....................................................................................................179
Источники............................................................................................................179
Глава 6. Анализ моделей биологической эволюции. .....................185
6.1. EV: программная модель эволюции............................................................186
6.1.1. Структура EV...........................................................................................186
6.1.2. Устройство программы EV.....................................................................189
6.1.3. Внутренние источники информации в EV...........................................192
6.1.4. Поиск.......................................................................................................195
6.1.5. Интерфейс EV Ware................................................................................197
6.1.6. Диагноз...................................................................................................200
6.2. Avida: ступенчатый поиск и логика NAND..................................................202
6.2.1. Булева логика.........................................................................................202
6.2.2. Логика NAND..........................................................................................203
6.2.3. Организм Avida и его здоровье.............................................................208
6.2.4. Анализ Avida с точки зрения информации..........................................212
6.2.5. Наличие замысла в программе Avida...................................................221
6.2.6. Движения мертвого организма.............................................................223
6.3. Метабиология................................................................................................223
6.3.1. Проблема остановки..............................................................................225
6.3.2. Проблема поиска....................................................................................226
6.3.3. Математический базис метабиологии.................................................227
6.3.4. Ресурсы...................................................................................................231
6.4. Пора подметать грязный пол?.....................................................................232
6.4.1. Доработка дерева Штейнера.................................................................232
6.4.2. Время для эволюции..............................................................................233
6.4.3. Заключение.............................................................................................234
Источники............................................................................................................234
Глава 7. Измерение смысла и алгоритмическая
заданная сложность.....................................................................................240
7.1. Значимость информации.............................................................................240
7.2. Условная сложность KCS................................................................................242
7.3. Определение алгоритмической заданной сложности (ASC)......................243
7.3.1. Высокая ASC и низкая вероятность.......................................................245
8
Содержание
7.4. Примеры ASC.................................................................................................246
7.4.1. Расширенные буквенно-цифровые символы.......................................246
7.4.2. Игра в покер............................................................................................249
7.4.3. Снежинки................................................................................................250
7.4.4. ASC в игре «Жизнь»................................................................................252
7.5. Смысл в глазах смотрящего..........................................................................263
Источники............................................................................................................264
Глава 8. Разум и искусственный интеллект........................................266
8.1. Тьюринг и Лавлейс: сильный и слабый интеллект.....................................267
8.1.1. Ошибка Тьюринга..................................................................................267
8.1.2. Тест Лавлейс...........................................................................................269
8.1.3. Озарение гения......................................................................................270
8.2. Интеллект и непознаваемое.........................................................................271
8.3. Заключение....................................................................................................272
Источники............................................................................................................272
Предметный указатель...............................................................................274
Вступительное слово
от издательства
Отзывы и пожелания
Мы всегда рады отзывам наших читателей. Расскажите нам, что вы думаете об
этой книге – что понравилось или, может быть, не понравилось. Отзывы важны
для нас, чтобы выпускать книги, которые будут для вас максимально полезны.
Вы можете написать отзыв на нашем сайте www.dmkpress.com, зайдя на
страницу книги и оставив комментарий в разделе «Отзывы и рецензии». Также можно послать письмо главному редактору по адресу dmkpress@gmail.com;
при этом укажите название книги в теме письма.
Если вы являетесь экспертом в какой-либо области и заинтересованы в написании новой книги, заполните форму на нашем сайте по адресу http://dmk
press.com/authors/publish_book/ или напишите в издательство по адресу dmk
press@gmail.com.
Список опечаток
Хотя мы приняли все возможные меры для того, чтобы обеспечить высокое
качество наших текстов, ошибки все равно случаются. Если вы найдете ошибку
в одной из наших книг – возможно, ошибку в основном тексте или программном коде, – мы будем очень благодарны, если вы сообщите нам о ней. Сделав
это, вы избавите других читателей от недопонимания и поможете нам улучшить последующие издания этой книги.
Если вы найдете какие-либо ошибки в коде, пожалуйста, сообщите о них
главному редактору по адресу dmkpress@gmail.com, и мы исправим это в следующих тиражах.
Нарушение авторских прав
Пиратство в интернете по-прежнему остается насущной проблемой. Издательства «ДМК Пресс» и World Scientific очень серьезно относятся к вопросам
защиты авторских прав и лицензирования. Если вы столкнетесь в интернете
с незаконной публикацией какой-либо из наших книг, пожалуйста, пришлите
нам ссылку на интернет-ресурс, чтобы мы могли применить санкции.
Ссылку на подозрительные материалы можно прислать по адресу электронной почты dmkpress@gmail.com.
Мы высоко ценим любую помощь по защите наших авторов, благодаря которой мы можем предоставлять вам качественные материалы.
Предисловие
Наука добилась больших успехов в моделировании пространства, времени,
массы и энергии, но слишком мало сделала, для того чтобы создать модель
информации, заполняющей нашу Вселенную. Сегодня теория информации
используется для измерения емкости диска Blu-ray или для описания пропускной способности соединения Wi-Fi. Тем не менее наука не рассматривает
трудности, связанные с созданием содержимого Blu-ray и смыслом данных, передаваемых через соединение Wi-Fi. Новые достижения теории информации
позволяют оценить роль информации в эволюционных процессах и под новым
углом взглянуть на само понятие информации и ее роль в картине мироздания.
В самом деле, все современные модели требуют для работы информацию от
внешнего источника. Иными словами, все современные эволюционные модели просто не работают без подключения к внешнему источнику информации.
В объяснении основ захватывающей теории информации на доступном уровне
и заключается назначение книги «Введение в эволюционную информатику».
Первоисточники
Содержание этой монографии вытекает из оригинальных работ одного из ваших скромных соавторов, Уильяма А. Дембски (William A. Dembski) [1], и последующих отредактированных трудов [2]. Авторы написали множество статей
и глав книг, в которых содержится основополагающий материал для этой монографии [3]. Ссылки на многие из этих документов доступны на нашем сайте EvoInfo.org. В данной монографии мы приводим рисунки и текст из этих
работ, иногда дословно. Во всех случаях мы старались дать прямую ссылку на
источник, но, возможно, что-то упустили.
Вне всяких сомнений, у материала этой монографии прочная основа. Цитируемые статьи тем не менее написаны на уровне, который понятен только
фанатичным ученым. Данная монография служит двум целям. Во-первых, это
объяснение эволюционной информатики на уровне, доступном для хорошо
эрудированного читателя. Во-вторых, мы убеждены, что данная работа достаточно полно раскрывает различные точки зрения на теорию эволюционного
моделирования.
Математика и символ ⍟
Хотя в этой книге мы попытались свести к минимуму обращения к математике, иногда без нее не обойтись. В таких случаях мы выделяем математический
материал символом ⍟ и даем максимально четкое объяснение основополагающих рассуждений.
Краткое содержание глав 11
Математический материал может быть понят с начальным знанием:
простых логарифмов;
элементарной теории вероятностей;
элементарной статистики, такой как средние значения (или среднее по
выборке);
представления чисел в двоичном формате (по основанию 2);
простых операций булевой алгебры, таких как И (AND), ИЛИ (OR), НЕ
(NOT), И-НЕ (NAND), ИЛИ-НЕ (NOR), ИСКЛЮЧАЮЩЕЕ ИЛИ (XOR) и т. д.
Чтобы помочь тем, кто хочет быстрее прочитать книгу или не интересуется
математическими подробностями, мы пометили символом ⍟ разделы, которые можно пропустить. Некоторые математические дополнения даны в снос
ках и также помечены символом ⍟.
Ссылки и сноски
Как правило, в конце глав перечислены источники и дополнительная литература, в то время как в сносках содержатся пояснения и дополнения к материалу
главы. Ссылки на источники обозначены числом в квадратных скобках, сноски
обозначены надстрочным числом. При быстром или обзорном чтении сноски
можно пропустить.
Краткое содержание глав
Глава 1. Введение
Ученые и философы часто возводят теорию или идеологию на трон, словно королеву, а инженеры заставляют королеву сойти с трона и вымыть пол. И если
она не работает, ее прогоняют прочь.
Ученые надеялись, что быстрые компьютеры позволят построить универсальную модель ненаправленной эволюции, основанную исключительно на
случайных мутациях. Однако пока это не удалось. Если опираться только на
теорию вероятностей, вы непременно сталкиваетесь с законом Бореля (Borel’s
law), который гласит, что события, описанные с достаточно малой (стремящейся к нулю) вероятностью, являются невозможными событиями. Например, существует ненулевая вероятность того, что вы испытаете квантовое туннелирование через стул, на котором сидите. Однако вероятность настолько мала, что
мы можем классифицировать событие как невозможное.
Глава 2. Информация: что это такое?
Информация – это не материя и не энергия. Она выступает как самостоятельный компонент природы.
Термин «информация», как правило, не очень хорошо определен, используется ли он в повседневной беседе или в журнальной статье. Теория информации Шеннона (Shannon) является, пожалуй, самой известной математической
12
Предисловие
моделью информации. Шеннон отметил очевидное: его модель информации
ограничена и не применима к широкому кругу возможных определений информации.
Теория информации Колмогорова–Хайтина–Соломонова (Kolmogorov–Chaitin–Solomonov, KCS), также известная как алгоритмическая теория информации, является еще одной популярной моделью информации. Однако и модели
Шеннона, и KCS не способны моделировать информацию в части измерения
смысла или значимости, относящихся к объекту.
Глава 3. Эволюционный поиск и требования к информации
Инженерное проектирование – это всегда итеративный поиск, основанный на
компетенции разработчика. Для создания WD-40 понадобилось 40 испытаний,
а Formula 409 потребовала 409 попыток. Так эти продукты получили числовую
часть своих названий.
Анатомия поиска иллюстрируется на примере того, как шеф-повар разрабатывает хороший рецепт блинов. Выделены важные аспекты разработки, в том
числе роль отраслевого эксперта и проклятие размерности, которое может
быстро сделать невозможным априорно-неинформированный проект.
Анализ разработанной с использованием эволюционного поиска антенны
NASA показывает, что в области эволюционного проектирования накоплены
достаточно обширные познания, и проблема поиска была не такой уж сложной.
При разработке чего угодно невозможно обойтись без компромиссов. Разработка недорогого и безопасного автомобиля требует определенного баланса
критериев. Дешевые машины небезопасны, а безопасные машины недешевы. Более того, глобальная оптимальность требует частичной оптимальности
(субоптимальности) составляющих частей. Плохо обоснованные критические
утверждения о неоптимальном устройстве биологических систем объясняются
наличием компромиссов, присущих любой сложной системе.
Глава 4. Детерминизм в случайности
Это может звучать как оксюморон, но в случайности есть элементы детерминизма. Например, если монету многократно подбрасывают тысячи раз, количест
во выпавших орлов всегда будет стремиться к детерминированному значению
50 % от числа подбрасываний. Аналогичным образом многие программы, целью
которых является демонстрация ненаправленной эволюции, неизменно пишутся так, чтобы в большинстве случаев сходиться к конкретному детерминированному результату. Как и в случае со стальным шариком в автомате для игры
в пинбол, в каждом испытании можно выбрать разные пути, но стальной шарик
всегда заканчивает тем, что падает в маленькое отверстие под лопатками.
Принцип недостаточного обоснования Бернулли (Principle Of Insufficient Reason, PrOIR), несмотря на сложное название, просто говорит о том, что вероятность выиграть в лотерею с тысячей билетов – один шанс из тысячи, если вы
купили только один билет. Каждому возможному исходу в розыгрыше присва-
Краткое содержание глав 13
ивается равная вероятность. PrOIR Бернулли используется для моделирования
случайного слепого поиска.
Потолок Бейснера (Basener’s ceiling) накладывает строгое ограничение на
любой эволюционный процесс. Он гласит, что эволюционный компьютерный
поиск достигает точки, когда дальнейшее улучшение невозможно. Здравый
смысл подсказывает, что эволюционная программа, написанная для проектирования антенны, не будет продолжать развиваться до такой степени, что, например, самопроизвольно научится играть в шахматы. Теория, лежащая в основе этого ограничения эволюционных процессов, основывается на понятии
потолка Бейснера.
Глава 5. Сохранение информации в компьютерном поиске
Теперь у нас есть инструменты, необходимые для представления закона сохранения информации (Information Conservation Law, ICL), как показано в теореме об отсутствии бесплатных завтраков (No Free Lunch theorem, NFL). Теорема гласит, что при итеративном поиске произвольной цели один алгоритм
в среднем так же хорош, как и любой другой, если у разработчика нет никаких
априорных экспертных знаний в предметной области. Теорема, опубликованная в 1997 году Вольпертом (Wolpert) и Макреди (Macready), вызвала удивление
у сообщества машинного интеллекта, которое часто противопоставляло один
алгоритм поиска другому, чтобы определить, какой из них лучше. Получается,
что результаты такого конкурса ничего не говорят о тотальном преимуществе
одного алгоритма поиска над другим. Они лишь показывают, что определенный алгоритм поиска лучше подходит к исследуемой проблеме, и это преимущество не действует для других проблем.
Теорема об отсутствии бесплатных завтраков также послужила источником
вдохновения для книги Уильяма Дембски с аналогичным названием.
Если нет априорных экспертных знаний о предметной области, мы ожидаем, что слепой поиск будет работать так же хорошо, как и любой другой метод.
Проблема в том, что во многих случаях обращение к одной лишь случайности
быстро заводит в экспоненциальный тупик бесконечного числа вариантов.
Эффективная эволюция требует наличия информации.
Эволюционный поиск можно сделать лучше, чем в среднем, с помощью экспертизы предметной области. В этом случае для успешного поиска требуется
меньше итераций. Активная информация измеряет степень, в которой экспертиза предметной области помогает в поиске. Суть активной информации иллюстрируют легко понятные примеры, такие как головоломка Cracker Barrel
и игровое шоу «Давайте договоримся».
Утверждают, что теорема об отсутствии бесплатных завтраков была нарушена так называемым процессом коэволюции. Мы аргументированно показываем, что это не так.
Наконец, мы затрагиваем тему поиска поисков (метапоиска). Если все поисковые процедуры в среднем работают одинаково, разве у нас не может быть
14
Предисловие
компьютерного поиска для выявления поиска, который в определенной си
туации работает лучше среднего? Ответ оказывается решительным НЕТ! Показано, что метапоиск экспоненциально сложнее, чем сам поиск.
Глава 6. Анализ моделей биологической эволюции
Существует ряд компьютерных программ, предназначенных для демонстрации ненаправленной дарвиновской эволюции. Наиболее известной является
программа моделирования эволюции Avida, которой даже довелось участвовать в судебном процессе между сторонниками и противниками теории ненаправленной эволюции.
Поскольку Avida пытается решить относительно сложную задачу, разработчик программы, очевидно, внедрил в код программы знания предметной области. Мы определяем источники и измеряем внесенную активную информацию. Показано, что Avida содержит много хаотичной информации, снижающей
производительность. Когда беспорядок устранен, программа сходится к решению быстрее.
Другая эволюционная программа, исследованная на предмет выявления
и измерения активной информации, называется EV.
Когда в эволюционной программе выявлен внешний источник знаний, соответствующая активная информация может быть добыта иными способами
с помощью других поисковых программ. Как для Avida, так и для EV показаны
альтернативные программы поиска, которые дают те же результаты, что и эволюционный поиск, но с меньшей вычислительной нагрузкой.
На EvoInfo.org мы разработали интерактивные графические интерфейсы,
чтобы проиллюстрировать производительность как Avida, так и EV. Имеется
также графический интерфейс для экспериментального исследования алгоритма поиска Ричарда Докинза (Richard Dawkins), известного как алгоритм
«Ласка» (WEASEL algorithm). Устройство и использование этих графических
интерфейсов достаточно просты, так что читатель может выйти в интернет
и провести эксперимент самостоятельно.
Наконец, анализируется модель, предложенная Грегори Хайтиным (Gregory
Chaitin) в его книге «Доказывая Дарвина: математическая биология», изданной
в 2013 году. Модель Хайтина, построенная в красивом и сюрреалистическом
мире алгоритмической теории информации, оказывается переполненной активной информацией. К сожалению, как и другие компьютерные программы,
написанные для демонстрации ненаправленной дарвиновской эволюции, она
не является всеохватывающей.
Глава 7. Измерение смысла
и алгоритмическая заданная сложность
Заданная сложность (specified complexity) рассматривается как оценка степени значимости исходной или экспертной информации при создании объекта.
Краткое содержание глав 15
Алгоритмическая заданная сложность (Algorithmic Specified Complexity, ASC)
измеряет это свойство в битах.
ASC предполагает, что значимость объекта основана на контексте. Изображение моей семьи имеет большее значение для меня, чем для кого-то, кто никогда не встречал мою семью. Страница символов кандзи имеет большее значение для японского читателя, чем для человека, который не знает японский.
Примером могут служить выигрышные комбинации в игре в покер. Для колоды из 52 разных карт существует 2 869 682 возможных сочетания пяти карт.
Некоторые расклады, такие как флеш-рояль, более значимы, чем другие, – например, пара двоек. Мы показываем, что ASC флеш-рояля составляет 16 бит,
тогда как ASC расклада с одной парой равна нулю.
Другой иллюстративный пример касается снежинок. Хотя одиночная снежинка имеет высокую степень сложности, аналогичные события высокой
сложности случаются постоянно. Показано, что ASC двух разных снежинок
близка к нулю. Но у двух одинаковых снежинок очень большая ASC.
Наконец, рассчитывается ASC объектов в клеточных автоматах Конвея (Conway) Game of Life (игра «Жизнь»). Интерес к изобретенной в 1970 году игре продолжает расти. Сегодня существуют онлайновые группы пользователей, создающих сложные и замысловатые объекты с использованием четырех простых
правил Конвея. Как и ожидалось, крупным сложным объектам присваиваются
высокие значения ASC, тогда как простым объектам, которые с высокой вероятностью могут быть созданы случайным образом, присваиваются низкие
значения ASC.
Глава 8. Искусственный интеллект
и ограниченность компьютерных моделей
Безграничные возможности искусственного интеллекта (Artificial Intelligence,
AI) периодически подвергаются более или менее обоснованному сомнению.
Роджер Пенроуз (Roger Penrose) утверждает, что человеческий интеллект никогда не будет реализован с помощью машины Тьюринга (то есть компьютера).
Его аргументы, подкрепленные теоремой о неполноте (Incompleteness theorem) Курта Гёделя (Kurt Gödel), основаны на неспособности компьютеров быть
творцами сверх того, что им указано.
То же самое мы видим в моделях, которые симулируют дарвиновскую эволюцию. Снова и снова такие модели успешно работают в ограниченной области лишь потому, что программист внедрил в модель экспертную информацию. И конечно, эти модели работают на машине Тьюринга.
Дарвиновская эволюция не может создавать информацию из ничего, т. е.
не обладает способностью креативности. И ни один компьютер не может (по
крайней мере, пока ничто не указывает на такую возможность). Что касается креативности человеческого сознания, Пенроуз полагает, что ответ может
быть найден в квантовых явлениях, происходящих в наших нейронах.
16
Предисловие
Источники
1. William A. Dembski, The Design Inference: Eliminating Chance through Small Probabilities (Cambridge University Press, 1998).
William A. Dembski, No Free Lunch: Why Specified Complexity Cannot Be Purchased
without Intelligence (Rowman & Littlefield, Lanham, Md, 2002).
William A. Dembski, Being as Communion: A Metaphysics of Information (Ashgate
Publishing Ltd., 2014).
2. Bruce Gordon, William Dembski, editors, The Nature of Nature (Wilmington, Del,
2011).
R. J. Marks II, M. J. Behe, W. A. Dembski, B. L. Gordon, J. C. Sanford, editors, Biological Information – New Perspectives (Cornell University, World Scientific, Singapore,
2013).
3. William A. Dembski and Robert J. Marks II, «Conservation of Information in
Search: Measuring the Cost of Success». IEEE Transactions on Systems, Man and
Cybernetics A, Systems and Humans, vol. 39, #5, September 2009, pp. 1051–1061.
William A. Dembski, R. J. Marks II, «Bernoulli’s Principle of Insufficient Reason
and Conservation of Information in Computer Search». Proceedings of the 2009
IEEE International Conference on Systems, Man, and Cybernetics. San Antonio, TX,
USA – October 2009, pp. 2647–2652.
Winston Ewert, William A. Dembski and R. J. Marks II, «Evolutionary Synthesis of
Nand Logic: Dissecting a Digital Organism». Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics. San Antonio, TX, USA – October 2009, pp. 3047–3053.
Winston Ewert, George Montañez, William A. Dembski, Robert J. Marks II, «Eff icient Per Query Information Extraction from a Hamming Oracle». Proceedings of
the 42nd Meeting of the Southeastern Symposium on System Theory. IEEE, University
of Texas at Tyler, March 7–9, 2010, pp. 290–229.
William A. Dembski, Robert J. Marks II, «The Search for a Search: Measuring the
In-formation Cost of Higher Level Search». J Adv Comput Intell Intelligent Inf,
14 (5), pp. 475–486 (2010).
George Montañez, Winston Ewert, William A. Dembski, Robert J. Marks II, «Vivisection of the EV Computer Organism: Identifying Sources of Active Information». Bio-Complexity, 2010 (3), pp. 1–6 (December 2010).
William A. Dembski, Robert J. Marks II, «Life’s Conservation Law: Why Darwinian
Evolution Cannot Create Biological Information». In Bruce Gordon and William
Dembski, eds., The Nature of Nature (ISI Books, Wilmington, Del., 2011), pp. 360–
399.
Winston Ewert, William A. Dembski, Robert J. Marks II, «Climbing the Steiner
Tree – Sources of Active Information in a Genetic Algorithm for Solving the Euclidean Steiner Tree Problem». Bio-Complexity, 2012 (1), pp. 1–14 (April, 2012).
Источники 17
Winston Ewert, William A. Dembski, Ann K. Gauger, Robert J. Marks II, «Time and
Information in Evolution». Bio-Complexity, 2012 (4) 7 pages. doi:10.5048/BIOC.2012.4.
Winston Ewert, William A. Dembski Robert J. Marks II, «On the Improbability of
Algorithmically Specified Complexity». Proceedings of the 2013 IEEE 45th Southeastern Symposium on Systems Theory (SSST), Baylor University, March 11, 2013,
pp. 68–70.
Jon Roach, Winston Ewert, Robert J. Marks II, Benjamin B. Thompson, «Unexpected Emergent Behaviors from Elementary Swarms». Proceedings of the 2013
IEEE 45th Southeastern Symposium on Systems Theory (SSST), Baylor University,
March 11, 2013, pp. 41–50.
Winston Ewert, William A. Dembski and Robert J. Marks II, «Conservation of Infomation in Relative Search Performance». Proceedings of the 2013 IEEE 45th SouthEastern Symposium on Systems Theory (SSST), Baylor University, March 11, 2013,
pp. 41–50.
Albert R. Yu, Benjamin B. Thompson, and Robert J. Marks II, «Competitive evolution of tactical multiswarm dynamics». IEEE Transactions on Systems, Man and
Cybernetics: Systems, 43 (3), pp. 563–569 (May 2013).
Robert J. Marks II, «Information Theory & Biology: Introductory Comments».
Biological Information – New Perspectives, edited by R. J. Marks II, M. J. Behe,
W. A. Dembski, B.L. Gordon, J.C. Sanford (World Scientific, Singapore, 2013)
pp. 1–10.
William A. Dembski, Winston Ewert, Robert J. Marks II, «A General Theory of Infomation Cost Incurred by Successful Search». Biological Information – New Perspectives, edited by R. J. Marks II, M. J. Behe, W. A. Dembski, B. L. Gordon, J. C. Sanford
(World Scientific, Singapore, 2013) pp. 26–63.
W. Ewert, William A. Dembski, Robert J. Marks II, «Tierra: The Character of
Adaptation». Biological Information – New Perspectives, edited by R. J. Marks II,
M. J. Behe, W. A. Dembski, B. L. Gordon, J. C. Sanford (World Scientific, Singapore,
2013), pp. 105–138.
G. Montañez, Robert J. Marks II, Jorge Fernandez, John C. Sanford, «Multiple Overlapping Genetic Codes Profoundly Reduce the Probability of Beneficial Mutation». Biological Information – New Perspectives, edited by R. J. Marks II, M. J. Behe,
W. A. Dembski, B. L. Gordon, J. C. Sanford (World Scientific, Singapore, 2013),
pp. 139–167.
W. Ewert, William A. Dembski, Robert J. Marks II, «Algorithmic specified complexity». Engineering and the Ultimate: An Interdisciplinary Investigation of Order and
Design in Nature and Craft, edited by J. Bartlett, D. Halsmer, M. Hall (Blyth Institute Press, 2014), pp. 131–149.
W. Ewert, Robert J. Marks II, Benjamin B. Thompson, Al. Yu, «Evolutionary inversion of swarm emergence using disjunctive combs control». IEEE Transactions on
Systems, Man and Cybernetics: Systems, 43 (5), pp. 1063–1076 (September 2013).
18
Предисловие
W. Ewert, William A. Dembski, Robert J. Marks II, «Algorithmic Specified Complexity in the Game of Life». IEEE Transactions on Systems, Man and Cybernetics:
Systems, 45 (4), pp. 584–594 (April 2015).
W. Ewert, William A. Dembski, Robert J. Marks II, «Measuring meaningful information in images: algorithmic specified complexity». IET Computer Vision (2015).
DOI: 10.1049/iet-cvi.2014.0141.
Об авторах
Роберт Дж. Маркс (Robert J. Marks) – заслуженный профессор технических наук инженерного факультета Университета Бэйлор, США. Маркс является членом IEEE и Оптического общества Америки. Его консалтинговая деятельность
включает корпорацию Microsoft, DARPA и Boeing Computer
Services. Он внес серьезный научный вклад в области обработки сигналов, включая распределение частоты по времени Чжао–Атласа–Маркса (Zhao–Atlas–Marks, ZAM) и тео
рему Ченга–Маркса в теории дискретизации Шеннона. Он
входит в список 50 самых влиятельных ученых в мире на
сегодняшний день по версии TheBestSchools.org (2014).
Исследования Маркса финансировались такими организациями, как Национальный научный фонд США, General Electric, Southern California Edison,
Boeing Defense, Научно-исследовательский центр Военно-воздушных сил
США, Военно-морской исследовательский институт США, Военно-морская исследовательская лаборатория США, Фонд Уитакера, Национальный институт
здравоохранения, Лаборатория реактивного движения, Исследовательский
центр армии США и NASA. Его книги включают «Справочник по анализу Фурье
и его приложениям» (издательство Оксфордского университета), «Введение
в теорию выборки и интерполяции Шеннона» (Springer Verlag) и «Нейронное
связывание: контролируемое обучение в искусственных нейронных сетях
прямой связи» (MIT Press) в соавторстве с Рассом Ридом. Маркс редактировал
пять других работ в таких областях, как энергетика, нейронные сети и нечеткая
логика. Он сыграл важную роль в определении дисциплины вычислительного
интеллекта и является редактором первой книги, использующей этот термин
в названии: «Вычислительный интеллект: имитация жизни» (IEEE Press, 1994).
Его авторские и соавторские главы данной книги вобрали в себя девять работ,
ранее изданных в сборниках академических трудов. Другие главы книги включают материалы из «Справочника по теории мозга и нейронных сетей» Майкла Арбиба (MIT Press, 1996). Его число Эрдёша–Бэйкона (Erdős–Bacon number)1
равно пяти.
1
https://ru.wikipedia.org/wiki/Число_Эрдёша_–_Бэйкона.
20
Об авторах
Уильям А. Дембски (William A. Dembski) – старший научный сотрудник лаборатории эволюционной информатики
в Макгрегоре, штат Техас, а также предприниматель, разрабатывающий образовательные веб-сайты и программное обеспечение. Он обладатель степеней бакалавра по
психологии, степени магистра по статистике, кандидата
экономических наук и доктора физико-математических
наук (степень присвоена в 1988 году Чикагским университетом, Чикаго, Иллинойс, США). Уильям Дембски работал
ассоциированным профессором кафедры науковедения
Университета Бэйлор (Уэйко, Техас, США), преподавал в Северо-Западном университете (Эванстон, Иллинойс, США), в университете Нотр-Дам (Нотр-Дам,
Индиана, США) и в университете Далласа (Ирвинг, Техас, США). Он защитил
докторскую работу по математике в Массачусетском технологическом институте (Кембридж, США), по физике в Чикагском университете (Чикаго, США)
и по информатике в Принстонском университете (Принстон, Нью-Джерси,
США). Он организовал стипендии для выпускников и докторантов Национального научного фонда, опубликовал статьи в журналах по математике, инженерии и философии и является автором и редактором более двадцати книг. Уиль
ям Дембски – математик и философ, взявший на себя роль публичного
интеллектуала. В дополнение к чтению лекций по всему миру в колледжах
и университетах он много выступал на радио и телевидении. Его работы цитировались в многочисленных газетных и журнальных статьях, в том числе в трех
статьях на первой полосе в «Нью-Йорк таймс», а также в обложке журнала
«Тайм» от 15 августа 2005 года. Он появлялся на различных телешоу каналов
BBC, NPR (Дайан Рем и др.), PBS («Взгляд изнутри» с Джеком Фордом и «Не
обыкновенное знание» с Питером Робинсоном), CSPAN2, CNN, Fox News, ABC
Nightline и «Ежедневные новости» с Джоном Стюартом.
Уинстон Эверт (Winston Ewert) в настоящее время работает инженером-программистом в Ванкувере, Канада. Он
старший научный сотрудник лаборатории эволюционной
информатики. Эверт получил докторскую степень в университете Бэйлора (Уэйко, Техас, США). Он написал ряд
статей на тему поиска, информации и сложности, включая
исследования компьютерных моделей, предназначенных
для описания дарвиновской эволюции, и разработку теоретико-информационных моделей для измерения вычислительной сложности. Доктор Эверт является постоянным
автором EvolutionNews.org.
Глава
1
Введение
Честь математики требует от нас разработать
математическую теорию эволюции и либо доказать, что Дарвин был прав, либо опроверг
нуть его!
Грегори Хайтин [1]
Авторитетная и заслуживающая уважения наука должна опираться на математику и модели. Даже некоторые нестрогие науки, такие как социология или
финансы, предлагают убедительные математические и компьютерные модели, получающие Нобелевские премии. Целью эволюционной информатики является изучение математики и моделей, лежащих в основе эволюции.
Существует очевидная разница между моделями и реальностью. Инженеры любят шутить: «В теории наука и реальность совпадают. На практике это
не так». Модели в физике показали невероятное экспериментальное согласие
с теорией. Но как насчет дарвиновской эволюции? Было предложено множест
во моделей для эволюции по Дарвину. Некоторые из них рассматриваются
в этой монографии. Каждая из них, однако, заранее продумана до мелочей,
и степень их предопределенности может быть измерена в битах с использованием понятия активной информации. Если допустить, что эти модели исчерпывающе отражают дарвиновский процесс, то приходится сделать вывод, что
эволюция невозможна без полученной извне начальной информации. Проб
лема большинства моделей эволюции заключается в том, что без некоторой
доли заложенной в них начальной информации упомянутые модели просто
не работают. Комбинаторных ресурсов нашей вселенной и даже основанной
на теории струн современной модели мультивселенной недостаточно, чтобы
реализовать эволюцию, основанную исключительно на длинной цепочке событий с ничтожной вероятностью. Здесь явно не обойтись без неких всеобщих
алгоритмических законов. Мы намерены показать это в своей книге.
Наша работа была первоначально мотивирована попытками других авторов
описать эволюцию Дарвина с помощью компьютерного моделирования или
математических моделей [2]. Авторы этих работ утверждают, что их модели
достоверно отражают ненаправленную биологическую эволюцию. Мы неоднократно показываем, что все предложенные модели требуют значительных
22
Введение
предварительных знаний о решаемой проблеме. Но если цель модели указана
заранее, это уже не дарвиновская эволюция, а разумный замысел, где разработчик программы выступает в роли созидающего божества. По иронии судьбы, модели эволюции, призванные продемонстрировать эволюцию Дарвина,
нуждаются в разумном разработчике. Вклад программиста в успех модели, называемый активной информацией, можно измерить в битах.
Понятие активной (или значимой) информации имеет фундаментальное
значение. Бюсты президентов США на склоне горы Рашмор демонстрируют
наличие активной информации по сравнению, скажем, с горой Фудзи. Проект
поиска внеземного разума (SETI) предполагает, что на фоне случайного космического шума можно обнаружить интеллектуальные сигналы, содержащие
активную информацию. Модель для измерения значимой информации, получаемой из наблюдений, является темой главы 7.
1.1. Королева ученых и инженеров
Инженеры мало хвастаются своими успехами. Однако в конечном итоге не
ученые, а инженеры отправили человека на луну. Не ученые отвечают за работу интернета. Это делают инженеры. Последние прорывы в медицине – это,
скорее всего, работа инженера, а не ученого или врача. Вещи созданы инженерами.
Назначение инженера состоит в том, чтобы понимать природу и математику, применять это понимание к реальности и заставлять вещи работать.
Между инженерами и учеными есть фундаментальные философские различия. Ученые, как правило, больше заинтересованы в общем понимании явлений. Они формируют модели реальности – часто красивые и мощные – и тщательно их изучают. После того как модель более или менее выдержала проверку
практикой, ее возводят на трон, словно королеву, и поклоняются ей. Иногда
требуется революция, чтобы свергнуть научную догму. Инженеры, напротив,
заставляют королеву сойти с трона и пойти мыть пол. Если она работает, мы
используем ее навыки. Но если она не работает, мы ее прогоняем.
Эта монография описывает историю королевы. Мы анализируем компьютерные модели эволюции, предлагаемые учеными, и заключаем, что они работают только потому, что программисты создали их для работы. В них нет
создания информации или спонтанного увеличения значимой сложности. Информация не возникает из ниоткуда – это противоречит закону сохранения
информации. Мы можем изучить предложенные компьютерные модели, определить источник активной информации1 и показать, что, несмотря на успешное моделирование некоторых аспектов эволюции, эти модели являются плохим способом использования доступных вычислительных ресурсов. Поскольку
1
В нашем случае – информации, заложенной программистом при создании программы и напрямую определяющей работоспособность модели.
Наука и модели 23
предлагаемые модели некорректно отображают характеристики ненаправленного дарвиновского поиска, им пора слезать с трона.
1.2. Наука и модели
Наука нуждается в поясняющих моделях. Дарвиновская эволюция, использую
щая повторяющиеся процессы случайной мутации организмов, на первый
взгляд выглядит наукой, которая идеально подходит для вероятностного моделирования.
Неоднократно наблюдаемые физические законы и явления, такие как закон движения Ньютона или законы термодинамики, всегда будут работать
одинаково, сколько бы мы ни повторяли эксперименты. Говорят, что такие законы формируются путем применения индуктивного вывода. Соответственно,
мы можем достаточно легко построить однозначные компьютерные модели,
имитирующие эти законы. Однако неповторяемые явления не могут быть смоделированы таким образом. Характерным примером является теория Большого взрыва. В подобных случаях для вывода законов используется абдуктивный
(умозрительный) вывод или вывод с наилучшим объяснением. Абдуктивный вывод, безусловно, не помешал нам сформировать богатое теоретическое объяснение Большого взрыва или теоретический базис геологии.
К сожалению, мы не можем повторить в лаборатории весь ход дарвиновской эволюции за прошедшие миллиарды лет существования жизни на Земле.
Однако современная наука довольно глубоко исследовала некоторые наблюдаемые и воспроизводимые явления, которые могли бы помочь. Мы умеем
разводить породистых собак и лошадей, штаммы бактерий вырабатывают
устойчивость к антибиотикам, а клювы зябликов различаются в зависимости
от источников пищи на Галапагосских островах. Разве мы не можем экстраполировать жизнеспособную математическую модель эволюции исходя из этих
явлений? Некоторые оптимистично настроенные ученые говорят уверенное
«да». Однако с точки зрения математики экстраполяция стохастических последовательностей невероятно сложна. Малейшие различия в наблюдениях могут
привести к абсолютно разным результатам экстраполяции1 [3]. Глава 6 содержит обсуждение опубликованных моделей, сторонники которых считают, что
у них есть успешная модель дарвиновской эволюции. Увы, это не так. В лучшем
случае они смоделировали целенаправленную селекцию породистых лошадей
из имеющегося поголовья.
1
⍟ Примеры характеристик экстраполяции и прогнозирования включают в себя слабообусловленные (ill-conditioned) и некорректные (ill-posed) процессы. Слабообусловленный процесс – это процесс, при котором небольшие изменения в наблюдаемых
данных могут привести к огромным изменениям в экстраполяции. Некорректный
процесс является крайним проявлением слабообусловленного процесса. Независимо от того, насколько мало нарушена известная часть процесса, изменение ошибки
экстраполяции становится неизвестным в том смысле, что оно не имеет предсказуемых границ.
24
Введение
1.2.1. Компьютерные модели
Появление компьютеров в середине ХХ века породило радужные ожидания
среди ученых-эволюционистов. Всем хотелось верить, что процесс эволюции наконец-то будет смоделирован и продемонстрирован компьютерной
программой. Надежды на эволюционные вычислительные модели были основаны на предположении, что, в отличие от неторопливого «биологического программного обеспечения», быстродействующие компьютеры позволят
убедительно смоделировать дарвиновскую эволюцию в обозримом будущем.
В 1962 году Нильс Барричелли (Nils Barricelli) написал [4]:
«Дарвиновская идея о том, что эволюция происходит путем случайных наследственных изменений и отбора, с самого начала страдала от того, что не было
найдено надлежащего теста для определения возможности такой эволюции
и наблюдения за ее развитием в контролируемых условиях».
В середине 60-х годов Дж. Л. Кросби (J. L. Crosby) [5] обратился к компьютеру
будущего как к лекарству от этого состояния:
«В целом обычно невозможно или почти невозможно проверить гипотезы об
эволюции конкретного вида путем преднамеренного проведения контролируемых экспериментов с живыми организмами этого вида. Мы можем попытаться частично обойти эту трудность, построив [компьютерные] модели, представляющие эволюционную систему, которую мы хотим изучать, и использовать их
для проверки, по крайней мере, теоретической обоснованности наших идей».
1.2.2. Невероятное и невозможное
Вопреки ожиданиям, компьютерные исследования выявили многочисленные
проблемы – и даже не столько эволюции как таковой, сколько вероятностного
подхода к моделированию эволюции. Принцип сохранения информации показывает, что эволюционные модели неспособны генерировать информацию.
Скорее, они ограничены извлечением информации из источника знаний. Успех
любой модели эволюционного процесса связан не с магией в самом процессе,
а с творческими знаниями, доступными для этого процесса. Компьютерное
моделирование эволюции продемонстрировало, что источники информации
создаются программистами, использующими свои априорные знания проб
лемного пространства, – процесс, не имеющий аналогов в объективном мире.
В чем же проблема моделей эволюции? Эти модели являются стохастическими, поэтому можно утверждать: «Конечно, это маловероятно. Но это возможно!» Да, это верно в том смысле, что все вероятные вещи возможны, но
проблема в том, что не все возможные вещи достаточно вероятны. Или, иначе говоря, все невозможное является невероятным, но невероятные события
не должны быть невозможными. Но в какой-то момент невероятное и невозможное сливается воедино, и в рамках ресурсов нашей наблюдаемой вселенной (или даже предполагаемой мультивселенной) событие может быть настолько невероятным, что его можно определенно обозначить как невозможное.
Источники 25
Это положение обычно называют законом Бореля (Borel’s law) [6]. Когда я стою
на полу, может ли часть моей ноги испытать квантовое туннелирование через
пол? Да. Но событие настолько невероятно, что я могу безбоязненно стоять
и сидеть миллиарды лет, и пальцы моих ног никогда не испытают квантовое
туннелирование. Поэтому мы утверждаем, что это технически возможное событие действительно невозможно на практике. Вот еще один пример. Предположим, я случайно выбрал миллиард атомов в известной вселенной, и, не
советуясь со мной, вы тоже выбрали миллиард атомов. Строго говоря, вполне
возможно, что мы выберем одинаковый миллиард атомов. Но вероятность
полного совпадения миллиарда атомов настолько мала, что мы могли бы выбирать атомы снова и снова на протяжении триллионов лет без малейшего
шанса на совпадение.
Можно ли построить идеально стохастическую (не содержащую активной
информации), но при этом успешную модель ненаправленной дарвиновской
эволюции? Теоретически существует незначительная вероятность того, что эта
модель воспроизведет эволюцию, но, как и в примерах квантового туннелирования и выбора миллиарда атомов, на практике это невозможно. Эволюционная информатика показывает, что наблюдаемая вселенная (или даже мульти
вселенная) недостаточно велика и недостаточно стара, чтобы позволить этому
случиться.
Источники
1. G. J. Chaitin, Proving Darwin: Making Biology Mathematical (Pantheon, 2012).
2. H. S. Wilf, W. J. Ewens, «There’s plenty of time for evolution». P Natl Acad Sci, 107,
pp. 22454–22456 (2010).
R. E. Lenski, C. Ofria, R. T. Pennock, C. Adami, «The evolutionary origin of complex
features». Nature, 423, pp. 139–144 (2003).
T. D. Schneider, «Evolution of biological information». Nucleic Acids Res, 28,
pp. 2794–2799 (2000).
R. Dawkins, The Blind Watchmaker: Why the Evidence of Evolution Reveals a Universe Without Design (Norton, New York, 1996).
D. Thomas, «War of the Weasels: An evolutionary algorithm beats intelligent design». Skeptical Inquirer, 43, pp. 42–46 (2010).
G. J. Chaitin, Proving Darwin: Making Biology Mathematical (Pantheon, 2012).
3. R. J. Marks II, Handbook of Fourier Analysis and its Applications (Oxford University
Press, 2008).
R. J. Marks II, «Gerchberg’s extrapolation algorithm in two dimensions». Appl Opt,
20, pp. 1815–1820 (1981).
D. K. Smith, R. J. Marks II, «Closed form bandlimited image extrapolation». Appl
Opt, 20, pp. 2476–2483 (1981).
26
Введение
R. J. Marks II, «Posedness of a bandlimited image extension problem in tomography». Opt Lett, 7, pp. 376–377 (1982).
D. Kaplan, R. J. Marks II, «Noise sensitivity of interpolation and extrapolation
matrices». Appl Opt, 21, pp. 4489–4492 (1982).
R. J. Marks II, «Restoration of continuously sampled bandlimited signals from
aliased data». IEEE Transactions on Acoustics, Speech and Signal Processing,
ASSP-30, pp. 937–942 (1982).
R. J. Marks II, D. K. Smith, «Gerchberg-type linear deconvolution and extrapolation algorithms». Transformations in Optical Signal Processing, W. T. Rhodes,
J. R. Fienup, B. E. A. Saleh (eds.), SPIE 373, pp. 161–178 (1984).
K. F. Cheung, R. J. Marks II, L. E. Atlas, «Convergence of Howard’s minimum negativity constraint extrapolation algorithm». J Opt Soc Am A, 5, pp. 2008–2009
(1988).
4. N. A. Barricelli, «Numerical testing of evolution theories, Part I: theoretical introduction and basic tests». Acta Biotheor, 16 (1–2), pp. 69–98 (1962). Переиздано:
David B. Fogel (ред.), Evolutionary Computation: The Fossil Record (IEEE Press,
Piscataway N. J., 1998).
5. J. L. Crosby, «Computers in the study of evolution». Sci Prog Oxf, 55, pp. 279– 292
(1967).
6. David J. Hand, The Improbability Principle: Why Coincidences, Miracles, and Rare
Events Happen Every Day (Macmillan, 2014).
Глава
2
Информация:
что это такое?
Каждая новая область исследований в итоге
обретает форму математики, потому что у нас
нет другого инструмента науки.
Чарльз Дарвин [1]
2.1. Определение информации
Термин «информация» часто встречается в научных публикациях, но его точное определение [2] варьируется в широких пределах. При попытке дать точное определение информации возникает ряд вопросов.
Диск Blu-ray способен хранить около 50 Гб цифровых данных. Отличается ли объем информации на диске, если диск содержит фильм «Храброе
сердце» или набор случайных шумов?
Если книга необратимо уничтожена, то будет ли уничтожена информация? Имеет ли значение, сохранилась другая копия книги или нет?
Когда делается цифровой фотоснимок, цифровая информация создается
или просто захватывается?
Если вам показывают документ, написанный на китайском диалекте
мандарин, содержит ли он информацию, даже если вы не понимаете
мандарин? А что, если документ написан на иностранном языке, не известном ни одному ныне живущему человеку? Если нет, то будет ли документ содержать информацию, если мы внезапно обнаружим камень
Розетты, допускающий перевод документа?
Ответы на эти вопросы различаются в зависимости от определения информации. Информация может быть наложена на энергию. В качестве примера
можно назвать акустические звуковые волны, применяемые людьми и другими живыми существами для общения, или электромагнитные волны, излучаемые радиостанциями. Как и в случае с книгами и дисками Blu-ray, информация
также может быть механически отпечатана на носителе. Но энергия и материя
Powered by TCPDF (www.tcpdf.org)
28
Информация: что это такое?
служат только средством переноса информации. Норберт Винер (Norbert Weiner) [3], отец кибернетики, весьма афористично отметил [4]:
«Информация – это не материя и не энергия. Информация – это информация».
Информация непрерывно циркулирует в творческих процессах, а инженеры
и изобретатели все время копируют природные проекты. Например, идея застежки-липучки возникла в результате тщательного изучения семян сорняка,
застрявших в одежде швейцарского инженера после поездки на охоту. Функция
человеческого века послужила источником вдохновения для изобретения очис
тителей ветрового стекла автомобиля [5]. Общество компьютерного интеллекта
[6] при IEEE1 имеет девиз: «Решения проблем, вдохновленные природой». Природные явления могут быть богатым источником полезной информации.
Материя и энергия смоделированы и хорошо изучены физиками. Однако не
существует универсальной модели информации. Клод Шеннон (Claude Shannon) признал, что его знаменитая теория информации является отнюдь не последним словом в математическом моделировании информации [7]:
«Мне кажется, что мы все определяем “информацию” по своему выбору; и, в зависимости от того, в какой области мы работаем, мы будем выбирать различные
определения. Моя собственная модель теории информации ... была создана
специально для работы с проблемой коммуникации».
Определение информации Шеннона страдает от неспособности измерить
смысл. Диск Blu-ray со случайным шумом может иметь такое же количество
битов, как диск, содержащий фильм «Храброе сердце».
Популярный пример информации, содержащей смысл, показан на рис. 2.1.
Слева изображение явно рукотворной горы Рашмор (Rushmore). Справа тени
напоминают лицо человека. Это фотография поверхности Марса, сделанная во
время миссии NASA «Викинг-1» в 1976 году. Если учитывать тысячи теней на
поверхности Марса, меняющихся в зависимости от угла освещения солнцем,
неудивительно, что некоторые узоры могут напоминать лицо человека. Изобра
жение справа является случайным. Особое свойство информации, которое позволяет нам отличать осмысленные скульптуры на горе Рашмор от «лица» на
поверхности Марса, – это заданная сложность (specified complexity). Изображения на горе Рашмор – это не просто лица людей. Это конкретные люди: Вашингтон, Джефферсон, Рузвельт и Линкольн. Большинству людей лицо на Марсе не
напоминает никого конкретно. Изображения на Рашморе сложны и содержат
преднамеренные изображения глаз, волос, ноздрей, рта и ушей. Как и в случае
дисков Blu-ray с «Храбрым сердцем» и шумом, чистая информация Шеннона не
поможет нам сравнить два изображения на рис. 2.1 и сообщить о наличии или
отсутствии начальной сложности, исходя из статистики пикселей.
1
IEEE, Институт инженеров по электротехнике и электронике, является крупнейшим
в мире профессиональным обществом. В 2016 году в 160 странах насчитывалось
421 000 членов.
Измерение информации 29
Рис. 2.1 Гора Рашмор (слева) отображает информацию со смыслом.
Тень справа, напоминающая мужское лицо,
является случайным творением природы [8]
Нам не избежать необходимости выделять наличие смысла или творческого замысла в наблюдениях [9]. Неснижаемая сложность Бехе (Behe) [10], универсальная информация Гитта (Gitt) [11], функциональная информация Дарстона
(Durston) и др. [12] и начальная сложность Дембски (Dembsky) [13] предлагают
описания свойств значимой информации. Ряд математических моделей посвящен измерению смысла, включая сложность [14], теорию прагматической
информации [15], функциональную информацию [16], информацию LMC [17] и достаточную статистику Колмогорова [18, 19]. В разделе 7.3 мы представляем
модель алгоритмической начальной сложности, которую можно использовать
в качестве математического инструмента, чтобы успешно оценить значение,
содержащееся в последовательности битов, составляющих изображение, звук
и т. д.
Мы также можем применить математическую меру информации для мониторинга процесса проектирования, в ходе которого возникает проект, и измерения контекстуальной сложности окончательного проекта. Цель этой монографии – объяснить суть математических методов измерения количества
информации, внесенной извне при создании чего-либо, включая математические модели.
2.2. Измерение информации
Существуют разные способы количественной оценки информации. Наиболее
распространенными являются информация Шеннона [20] и информация Колмогорова–Хайтина–Соломонова1 (Kolmogorov–Chaitin–Solomonov, KCS). Информация Шеннона основана на вероятности, тогда как сложность по KCS касается существующих структур, описываемых компьютерными программами. Эти
два показателя связаны между собой и имеют одинаковую единицу измерения
(биты), но формализуются по-разному [21].
1
Также называемая сложностью Колмогорова–Хайтина–Соломонова.
30
Информация: что это такое?
2.2.1. Cложность по KCS
Те, кто знаком с компьютерами, знают о программах для сжатия информации,
создающих ZIP-файлы и изображения в формате JPG. Большие файлы уменьшаются за счет устранения избыточности. Сжатые файлы передаются быстрее
и восстанавливаются получателем. Технология сжатия файлов похожа на производство обезвоженной пищи. Вода удаляется на заводе. Обезвоженная пища
мало весит, и доставка до места назначения обходится дешевле. Получатель
повторно увлажняет и – в идеале – восстанавливает у себя исходную еду. Аналогично сжатые файлы могут передаваться с использованием ограниченной
полосы пропускания и восстанавливаться в приемнике.
Регидратированная пища редко бывает столь же вкусна, как и оригинал. Процесс дегидратации часто приводит к потере или нежелательным изменениям
вкуса, аромата или текстуры исходного продукта. Некоторые методы сжатия
изображений, такие как технология JPG, также имеют потери. Как показано на
рис. 2.2, сжатое изображение является слегка искаженной версией оригинала.
Если исходный компьютерный файл ничем не отличается от восстановленного
сжатого файла, значит, мы выполнили сжатие без потерь. Обезвоживание без
потерь приведет к тому, что восстановленная пища будет неотличима от оригинала. Формат компактной сетевой графики (Portable Network Graphic, PNG)
является примером сжатия без потерь. Информация KCS относится только
к сжатию без потерь.
Рис. 2.2 Пример сжатия изображений с потерями. Сжатие выполняется в блоках 8×8 пикселей. Увеличенный фрагмент изображения JPG показан посередине,
где, присмотревшись, можно увидеть блоки 8×8. Один из таких блоков обозначен
рамкой справа. Границы на полях блоков выдают сжатие с потерями, предлагаемое алгоритмом JPG. С другой стороны, сжатая информация KCS должна быть без
потерь. Например, формат PNG является примером сжатия без потерь (контраст
изображений блоков был увеличен, чтобы облегчить просмотр)
Для каждого файла мы можем найти способ максимального сжатия. Размер
наименьшего сжатого файла без потерь в битах – это и есть сложность файла
в KCS. Отметим, что существуют несжимаемые файлы, когда размер минимального файла равен размеру исходного. Сжатие обычно выражено в терминах
Измерение информации 31
компьютерной программы, способной воспроизвести объект. Какая самая короткая компьютерная программа способна точно описать файл?
Какой размер может иметь информация KCS? Большой файл размером B бит,
очевидно, не может быть сжат без потерь в один бит. В то же время файл B бит
может быть представлен несжатым файлом длиной B бит. В таком случае мы
просто задаем нужную последовательность битов в компьютерной программе
и говорим PRINT и HALT. Если Y обозначает самую короткую программу для битовой последовательности X, то мы знаем, что длина Y лежит где-то между одним
битом и значением, несколько превышающим B бит1. Наименьший сжатый без
потерь файл имеет битовую длину K(X) – это информационное (или сложное)
содержание KCS файла большего размера. Хайтин называет эти программы
элегантными программами [22].
Структурированные последовательности, такие как повторяющиеся 01:
X = 01010101010101010101010101010101010101...01
имеют небольшую сложность по KCS. Программа, способная полностью охарактеризовать строку, крайне проста: повторить 01 тысячу раз и остановиться. Последовательность 0 и 1, сформированная путем подбрасывания симметричной
монеты (fair coin) B раз, почти наверняка будет иметь информацию KCS, близкую к B битам. В такой последовательности нет структуры или избыточности,
которой можно воспользоваться для сжатия. Другими словами, последовательность подбрасывания монеты не является сжимаемой. Чтобы передать последовательность без потерь, мы должны записать всю последовательность из нулей и единиц. Сложность KCS будет близка к B битам.
Есть обманчивые строки, которые выглядят случайными и обладающими
большой сложностью по KCS, но это не так. Одной из таких строк является конс
танта Шамперноуна (Champernowne) [23]:
0100011011000001010011100101110111000000010010...
Это число, опубликованное, когда Шамперноун еще был студентом, проходит много тестов на случайность, но имеет низкую сложность KCS. Это хорошо
видно, если записать число в виде сегментированной последовательности:
0 1 00 01 10 11 000 001 010 011 100 101 110 111 0000 0001 0010...
На самом деле это просто список последовательных чисел, записанных
в двоичном формате, и даже для бесконечной последовательности он описывается короткой программой. Для некоторого значения N, определяющего
длину числа, обобщенный алгоритм выглядит очень просто:
От n = 1 до N напечать по порядку все двоичные числа с n бит. Стоп.
1
Несколько дополнительных битов необходимо для обозначения команд программы,
таких как PRINT. Если B исчисляется в миллионах или миллиардах, битами команд
можно перенебречь.
32
Информация: что это такое?
В десятичной форме константа Шамперноуна выглядит следующим образом:
012345678910111213141516171819202122232425262728293031...
Другим примером сложной последовательности является двоичная строка,
описывающая число
π = 3,1415926535897932384626433832795028841971693993751...
в двоичном виде:
π = 11.0010010000111111011010101000100010000101101000110000
1000110100110001001100011001100010100010111000000011011
1000001110011010001...
Строка выглядит случайной. Но поскольку π можно вычислить по простой
формуле
не составит труда сгенерировать π с любой
желаемой точностью при помощи простой компьютерной программы.
Примечание
⍟ Для N, достаточно большого, чтобы достичь желаемой точности, мы можем использовать следующую короткую программу:
S=1;
for n=1:N;
S=S+(-1)n/(2*n+1);
end;
pi=4*S;
PRINT pi;
Формально информация KCS строки X, состоящей из битов B, представляет
собой длину самой маленькой компьютерной программы, которая сгенерирует
строку X и остановится. Длина программы будет зависеть от используемого компьютерного языка. Самая короткая программа для генерации X с использованием языка C++ будет иметь иную длину, чем при использовании языка Python.
Однако, в принципе, всегда найдется транслирующая программа для преобразования кода C++ в код Python. Предположим, что программа для перевода C++
в Python занимает c бит. Если KC++(X) – это сложность KCS для X с использованием
C++, то сложность KCS в Python, KPython(X), не может превышать KC++(X) + c бит.
В случае длинных строк добавление транслирующей компьютерной программы может быть незначительным вкладом в информацию KCS. Во всех случаях разница сложности по KCS между двумя компьютерными языками всегда
может быть ограничена числом c, которое не зависит от описываемого объекта1. Поэтому сложность по KCS является универсальной концепцией, которая
легко переводится с одного компьютерного языка на другой. Мы воспользуемся обозначением [24]:
1
⍟ Точнее, |KC++(X) − KPython(X)| ≤ c.
Измерение информации 33
KPython(X) =c KC++(X),
означающим равенство с точностью до константы c.
Примечание
⍟ Информация KCS часто обозначается нотацией O. Пусть |Y| – это количество битов
в двоичной строке Y. Выражение |Y| = O(e|X|) означает, что при увеличении |X| величина
|Y| асимптотически стремится к кривой, пропорциональной e|X|. В свою очередь, можно
принять O(c + e|X|) = O(e|X|), поскольку e|X| быстро и существенно превысит c.
2.2.1.1. ⍟ Информация KCS в случае беспрефиксных программ
Еще одна иллюстрация сложности KCS представлена на рис. 2.3. На нем изображено двоичное дерево, в котором слева направо растут новые ветви, основанные на разветвлениях с использованием 0 и 1. В некоторых случаях ветвление
заканчивается. Окончания ветвей называются листьями. Последовательности
0 и 1, приводящие к этим окончаниям, записываются в виде двоичных строк
и соответствуют битам, составляющим компьютерную программу. Для любого
серьезного компьютерного языка это дерево будет разветвляться миллиарды
раз и достигнет огромного размера. Тем не менее скромное дерево на рис. 2.3
может служить наглядным примером.
Рис. 2.3 Листья в этом дереве обозначают беспрефиксные компьютерные
программы. Листья, помеченные квадратом, приводят к печати X = 0101010101
и остановке. Самая короткая программа в дереве, которая печатает X, содержит
три бита: 101. Следовательно, информация KCS для X равна K(X) = 3 бита
34
Информация: что это такое?
Компьютерный язык на рис. 2.3 является беспрефиксным, то есть никакая
двоичная строка, соответствующая листу, не может послужить началом другой
программы. Поскольку любой компьютерный язык может быть переведен на
любой другой компьютерный язык, программа на C++ или Python всегда может
быть переведена на беспрефиксный компьютерный язык. Чтобы проиллюстрировать природу беспрефиксного кода, рассмотрим лист с меткой 101 на рис. 2.3.
Программа 101 – это лист в дереве. Для языка без префиксов никакая другая
компьютерная программа не может начинаться с 101. Другими словами, 101
не может быть префиксом любой другой компьютерной программы в дереве.
Рассмотрим далее строку:
Х = 0101010101.
Существует множество программ, которые будут генерировать строку X. Мы
изобразили их на рис. 2.3 в виде листьев с квадратами: . Даны четыре такие
программы. Поскольку все листья не показаны, в дереве могут быть другие,
более глубокие ветви. Четырехбитовая программа 1110 выводит X и может соответствовать алгоритму наподобие следующего:
1110 → Напечатать 0101 два раза и остановиться.
Примечание
⍟ Программа 1110 на практике почти наверняка окажется слишком короткой, чтобы
соответствовать алгоритму «Напечатать 0101 два раза и остановиться». Мы могли бы
сделать программу 1110 длиннее или вообще предложить двоичный эквивалент кода
Matlab для генерации X = 0101010101, но дерево на рис. 2.3 станет слишком большим
для представления на одной странице. Так что примем использование 1110 в качестве
педагогически целесообразного примера.
Более длинная пятибитовая программа, 11001, может соответствовать алгоритму:
11001 → Напечатать 01, затем напечатать 01 три раза и остановиться.
Самая короткая программа, печатающая X, – это трехбитовая программа
101, которая может соответствовать алгоритму:
101 → Напечатать 01 четыре раза и остановиться.
Хотя есть и другие программы, печатающие X = 0101010101, трехбитовая
программа самая короткая из возможных. Следовательно, сложность по KCS
для X:
K(Х) = 3 бита.
2.2.1.2. Случайное программирование и неравенство Крафта
⍟ Обратимся к дереву беспрефиксного программирования, изображенному
на рис. 2.4. Примечательно, что дерево предполагает, что мы можем случайным образом выбирать программы, многократно подбрасывая симметрич-
Измерение информации 35
ную монету. Если орлу присваивается логическая единица, а решке – ноль, то
повторное подбрасывание монет может направить нас на рис. 2.4 слева направо. Монета подбрасывается, до тех пор пока не встретится конечный лист.
Например, если последовательность выпадений монеты ОРРОР, мы достигаем листа 10010. Поскольку каждый бросок монеты дает вероятность
для вы-
падения либо орла, либо решки, то вероятность выпадения пятибитовой последовательности ОРРОР = 10010 составляет
Легко
обобщить это на любой конечный l-битовый лист. Вероятность попадания на
конкретный l-битовый лист путем подбрасывания монеты равна
Мы мо-
жем воспользоваться этим наблюдением, чтобы вывести интересное свойство,
получившее название неравенства Крафта (Kraft inequality) [25].
Рис. 2.4 Иллюстрация неравенства Крафта
для беспрефиксных двоичных программ
Программы на листах на рис. 2.4 могут быть пронумерованы, т. е. упорядочены по лексикографическому принципу, путем размещения всех двухбитовых программ в числовом порядке, за которым следуют трехбитовые программы и т. д. Порядок будет таким, как показано в табл. 2.1. Первая (p = 1)
программа в списке является единственной двухбитовой программой. Длина
36
Информация: что это такое?
этой программы l1 = 2, и вероятность ее получить, подбрасывая монету, составляет
Есть две трехбитовые программы. Численно самой маленькой
из них является программа 000. Следовательно, это программа p = 2 длиной
l2 = 3 бита. Шанс получить эту программу броском монеты
Мы можем
повторить эти рассуждения, проходя по списку всех программ. Неравенство
Крафта является результатом понимания того, что все эти программы являются взаимоисключающими, т. е., подбрасывая монету, вы можете получить
только один лист дерева (или программу). Если предположить, что все листья
являются жизнеспособными программами, а дерево – конечное по глубине, то
сумма вероятностей должна быть равна единице. В ином случае сумма должна
равняться числу, не превышающему единицу. Неравенство Крафта для двоичных кодов имеет вид1:
(2.1)
Таблица 2.1. Лексикографическое упорядочение программ на рис. 2.4.
Порядок соответствует нумерации листьев на рисунке
p
1
2
3
4
5
6
7
8
9
10
11
12
13
Программа
01
000
101
0011
1000
1101
1110
00110
10010
11000
11001
11111
и т. д.
lp
2
3
3
4
4
4
4
5
5
5
5
5
6
2.2.1.3. Познаваемость
Можно показать, что значение сложности по KCS для произвольной последовательности битов алгоритмически непознаваемо [26]. Другими словами, не
1
Массовые функции вероятностей со всеми массами только в форме
ложительное целое число, называются двухместными (dyadic).
где lp – по-
Измерение информации 37
существует компьютерной программы, которая при представлении произвольного объекта выводила бы сложность объекта по KCS. Однако можно ограничить сложность объекта по KCS. Если мы можем сжимать без потерь 1 млрд
бит в 1 тыс. бит, мы знаем, что сложность KCS исходного битового потока не
превышает тысячу бит. Если фактическим неизвестным KCS строки X является
K и мы успешно сжимали строку без потерь до длины , то мы уверены, что
K≤ .
Примечание
⍟ Алгоритмическая непознаваемость сложности по KCS может быть доказана с по
мощью доказательства от противного. Предположим, что такая программа C существует,
следовательно, при представлении произвольной двоичной строки X программа вычисляет сложность строки по KCS. Иначе говоря, функция C(X) выводит сложность KCS K(X).
Для заданной C мы можем написать следующую программу, которая, включая функцию
C, имеет длину M бит. Далее будем вызывать программу P:
Задать B=M
Для всех программ длиной B бит вычислить K=C(X)
Если K>M,
Печать X и K
Стоп
Иначе инкремент B=B+1 и повторить
Поскольку мы уверены, что существует бесконечное количество элегантных программ
неограниченной длины, эта программа гарантированно остановится. Но есть проблема.
Когда программа P останавливается, она выводит битовую строку X со своей сложностью
KCS K(X), которая больше, чем длина M программы P. Но P вычисляет сложность KCS X,
используя меньше чем K(X) бит! P использует только M < K(X) бит. Это нарушает определение KCS как самой короткой программы, которая может выводить двоичную строку X.
Следовательно, противоречие показывает, что не может быть компьютерной программы
C конечной длины, которая вычисляет сложность KCS произвольного объекта X.
Неравенство Крафта и мера сложности по KCS позже найдут применение
в модели для измерения заданной алгоритмической сложности (ASC)1. Грегори Хайтин, один из авторов KCS, предложил модель эволюции, основанную на
алгоритмической теории информации. Далее мы также рассмотрим сложность
по KCS и неравенство Крафта2.
2.2.2. Информация Шеннона
Информация Шеннона основана на вероятности, а не на существующих битовых строках. Между сложностью KCS и информацией Шеннона [27] существует
связь, но их основы различны.
В своей оригинальной и классической работе 1948 года, где термин bit (бит)
впервые использован как сокращение для «binary digit» (двоичная цифра),
1
2
См. раздел 7.3.
Обсуждается в разделе 6.3.
38
Информация: что это такое?
Шеннон полагал, что количественная информация должна иметь два свойства.
Во-первых, чем меньше вероятность, тем больше информации. Если я скажу
вам, что завтра взойдет солнце, я передам мало информации. Это почти определенное событие. Если я скажу, что завтра солнце взорвется, я дам вам много
информации. Вероятность того, что солнце завтра взорвется, очень мала. Второе свойство заключается в том, что информация должна обладать аддитивностью, когда два события не связаны между собой1. Если сообщение «заикающийся» передает информацию I1, а сообщение «профессор» передает информацию
I2, то сообщение «заикающийся профессор» должно передавать информацию
I1 + I2. Таким образом, информация должна обладать следующими двумя свойствами:
1) чем меньше вероятность события p, тем больше информация;
2) информация от двух независимых событий должна равняться сумме информации от каждого события в отдельности.
Примечательно, что существует только одна связь между вероятностью события и передаваемой им информацией, которая подчиняется обоим свойствам2:
I = –logp.
(2.2)
Основание логарифма определяет единицы информации. По основанию два
I измеряется в битах. I также обычно называют самоинформацией.
Примечание
⍟ В случае логарифма по основанию 10 информация измеряется в Хартли (Hartley).
Для натурального логарифма информация измеряется в натах (nat). Логарифм по основанию 3 приводит к тритам (trit, trinary digit). Основание 2 дает нам байт (byte). Как
мы преобразуем сантиметры в дюймы, так и различные информационные меры имеют
мультипликативные коэффициенты преобразования. Восемь бит, например, являются
байтом, а один нат равен log2e » 1,444 бита.
При измерении в битах самоинформацию Шеннона можно рассматривать
просто как вероятность, измеряемую бросками симметричной монеты. Например, если мы подбрасываем симметричную монету 10 раз, какова вероятность того, что мы получим последовательность орлов и решек О О О Р Р Р О О Р Р?
Поскольку каждое подбрасывание имеет 50/50 шансов выпадения орла или
решки и результат каждого подбрасывания независим, шанс получить эту
1
2
⍟ К слову, информация из двух источников должна быть не связана. Например, информация от прыгающего кенгуру такая же, как и от кенгуру, поскольку все кенгуру
прыгают. События должны быть статистически независимыми. События A и B независимы, если Pr(A and B) = Pr(A) × Pr(B).
⍟ Это удовлетворяет двум требованиям Шеннона к информации. (1) С уменьшением
p увеличивается I. (2) Для статистически независимых событий 1 и 2 составная вероятность равна p = p1p2, и из (2.2) следует I = −log p1p2 = − log p1 – log p2 = I1 + I2.
Измерение информации 39
конкретную последовательность орлов и решек
И соответ-
ствующая информация I = –log2p = log2210 = 10 бит. Если переписать последовательность подбрасываний с использованием 1 для орлов и 0 для решек, мы
получаем:
1 1 1 0 0 0 1 1 0 0.
Это действительно 10 бит информации1.
2.2.2.1. Двадцать вопросов: деление пополам и биты
Мы можем проиллюстрировать информацию Шеннона известной игрой
«20 вопросов». Игрок выбирает произвольный объект, и у оппонента есть не
более 20 вопросов с ответами «да – нет», чтобы угадать объект.
Примером разновидности игры из двадцати вопросов (где было задано
только шесть вопросов) является библейский пример об уничтожении Содома. Бог пощадит Содом, если там будет жить достаточное число праведников.
Авраам решил выяснить минимально достаточное количество праведников
и попытался найти ответ, задавая Богу вопросы в стиле «да или нет». Поиск
Авраама можно кратко изложить следующим образом:
1. Авраам: Если в городе Содом будет хотя бы 50 праведников, ты пощадишь город?
Бог: Да.
2. Авраам: Что, если число праведников не менее 45?
Бог: Да.
3. Авраам: А как насчет 40?
Бог: Да.
4. Авраам: Ты пощадишь город, если будет хотя бы 30 праведников?
Бог: Да.
5. Авраам: 20?
Бог: Да.
6. Авраам: Как насчет 10?
Бог: Да.
Из такого поиска мы никогда не узнаем пороговое значение, потому что на
этом шаге вопросы закончились. Помня судьбу Содома, можно лишь сделать
вывод, что десяти праведников там явно не нашлось.
В игре «20 вопросов» могут быть глупые и умные вопросы. Предположим,
что игра только началась, и вы задаете первый вопрос. Конкретный начальный
1
⍟ Как правило, вероятность прогнозирования любой указанной двоичной последовательности битов B равна
и B = –log2
. Это уравнение обеспечивает перевод
вероятности в биты. 10 бит равняется примерно одному шансу на тысячу, 20 бит –
одному на миллион, и 40 – одному на триллион.
40
Информация: что это такое?
вопрос типа «Это большой палец на левой ноге?», как правило, бесполезен.
Первый общий вопрос типа «Это в Северной Америке?» лучше. Он разбивает
возможные ответы на две большие группы. Ответ «да» исключает все объекты
на других континентах. Использование таких вопросов, чтобы сосредоточиться на одном ответе путем последовательного разбиения возможностей на две
группы, похоже на деление интервала поиска пополам, и, как правило, приводит спрашивающего к правильному ответу с меньшим количеством вопросов1.
2.2.2.2. Информация Шеннона, применяемая к делению пополам
Деление интервала2 разделяет все возможности на две группы. Получая ответы
«да» или «нет», спрашивающий может с каждым правильно заданным вопросом исключить половину вариантов.
Поиск с делением интервала пополам хорошо описан информацией Шеннона. Предположим, нам поручено выбрать игровое поле с номером от 1 до 16.
Если Боб и Моника выбирают поля независимо друг от друга, то шанс Моники
угадать поле Боба в одном предположении
что соответствует инфор
3
мации I = log2(16) = 4 бита .
Значение 4 бита также диктует для этой проблемы минимальное количество
вопросов «да – нет», которые необходимо задать ведущему викторины, чтобы
найти загаданное число. Допустим, есть 16 полей, пронумерованных от 0 до
15. Боб начинает игру, говоря: «Я загадал поле с номером от 0 до 15». Моника
(спрашивающий) должна угадать это число, задавая вопросы. Боб (ведущий
викторины) обещает быть оракулом и правильно отвечать на каждый ее вопрос.
Моника может использовать глупые и умные наборы вопросов. Вот пример
первых:
«Это поле номер шесть?»
«Нет»
«Это 15?»
«Нет»
«Это поле номер два?»
«Нет» и т. д.
Спрашивающему может повезти, и он получит правильное число во втором
или третьем предположении, но если он запрашивает около одного поля на
1
2
3
Основой сохранения информации является то, что внешние источники знаний могут
быстрее дать ответ на вопрос. Если ведущий викторины сильно ушиб большой палец
на левой ноге ранее днем и провел день, жалуясь на боль, то вопрос «Это большой
палец на левой ноге?» уже не кажется таким глупым.
Деление интервала пополам является основой модели метаболизма Хайтина, как обсуждается в разделе 6.3.
В разделе 5.4.1 мы подробно обсудим эту эндогенную информацию. Она измеряет
сложность поиска объекта, когда нет информации о том, где он может быть.
Измерение информации 41
запрос, то в целом ему потребуется восемь вопросов (половина из 16 возможных), чтобы угадать число. Умный набор вопросов «да – нет» использует процесс деления интервала пополам. Этот процесс изображен на рис. 2.5.
Рис. 2.5 Есть 16 полей. Ведущий викторины выбирает одно из них, и спрашивающий должен найти его. Вероятность выбора цели в одном запросе составляет 1/16, что соответствует 4 битам информации. Используя деление интервала пополам, цель можно найти, задав всего четыре вопроса «да» (1) или
«нет» (0). Последовательность ответов {0110} является двоичным представлением окончательного ответа, равного 6
1. Сначала Моника спрашивает: «Это восемь или больше?» Независимо от
того, какой ответ, количество решений сокращается вдвое. Предположим, что ведущий выбрал шесть, поэтому ведущий отвечает «Нет».
2. Моника теперь знает, что ответ находится в диапазоне от нуля до семи.
Этот новый интервал также сокращается вдвое, когда Моника спрашивает: «Это число от четырех до семи (включительно)?» Ответ – «Да».
3. Теперь Моника знает, что это число от четырех до семи, поэтому спрашивает: «Это либо шесть, либо семь?» Боб отвечает: «Да».
4. Наконец, Моника спрашивает: «Это семь?» Боб говорит: «Нет».
Итак, Моника находит правильный ответ (шесть), используя четыре вопроса. Ответы Боба были такими:
Нет, Да, Да, Нет.
Подстановка единицы для «да» и нуля для «нет» дает нам двоичную последовательность (0, 1, 1, 0), которая указывает шестое поле, поскольку по основанию 2
42
Информация: что это такое?
(0110)2 = 6.
Требуется четыре правильных вопроса, потому что имеется 16 полей, каждое с вероятностью
. Следовательно, информация, соответствующая каждо-
му полю, составляет log2(16) = 4 бита. Для шестого поля эти биты равны (0, 1,
1, 0).
Как мы помним, Авраам задал шесть вопросов «да – нет», но без особого
успеха. Но Авраам тоже мог бы применить метод деления интервала пополам.
Давайте предположим, что число праведников составляет от 0 до 63 включительно. Используя метод половины интервала, Авраам мог бы найти точное
число праведников за log2(64) = 6 вопросов. Вот гипотетический сценарий:
1. Авраам: Если в городе Содом будет 31 или более праведников, пощадишь
ли ты город?
Бог: Да.
Теперь мы знаем, что ответ лежит между 0 и 31.
2. Авраам: Что, если число праведников не менее 15?
Бог: Да.
Теперь мы знаем, что ответ лежит между 0 и 15.
3. Авраам: хотя бы 7?
Бог: Нет.
Теперь мы знаем, что ответ лежит между 8 и 15 включительно.
4. Авраам: Ты пощадишь город, если будет хотя бы 11 праведников?
Бог: Да.
Теперь мы знаем, что ответ лежит между 8 и 11 включительно.
5. Авраам. По крайней мере, 10 праведников?
Бог: Да.
Теперь мы знаем, что ответ 8 или 9.
6. Авраам: Ты пощадишь город, если будет хотя бы 8 праведников?
Бог: Нет.
Теперь мы знаем, что ответ – девять или более праведников.
Каждый ответ на запрос Авраама соответствует одному биту информации.
Если мы присваиваем ноль ответу «да», а единицу – «нет», последовательность
«да, да, нет, да, да, нет» является двоичным кодом ответа «девять». Конкретно
шесть бит информации декодируются как1:
(001001)2 = 9.
Существуют более интересные способы играть в игру «Угадай число», не раскрывая непосредственно используемый интервал. Сокращенный пример набора умных вопросов для угадывания чисел представлен в табл. 2.2.
1
⍟ Обобщим: число от 1 до 2K может быть угадано за K вопросов. Двадцать вопросов
помогут определить любое число от 1 до 220 = 1 048 576. Требуется не более тридцати
вопросов, чтобы угадать число от 1 до миллиарда < 230.
Измерение информации 43
Пусть игрок выберет число от 0 до 63. Спросите его, находится ли его число
в самом левом столбце таблицы. А во втором столбце? И наконец, когда получен ответ «да» или «нет» для последнего столбца, можно немедленно назвать
загаданное число. Например, ответы ведущего «да, нет, да, нет, нет, да» дают
число 41. Быстрая проверка подтверждает, что 41 – это единственное число, которое есть одновременно в первом, третьем и последнем столбцах. Большинство игроков будет удивлено! Вот как это работает: игрок получает двоичное
число «да, нет, да, нет, нет, да», то есть (101001)2 = 41.
Но можно поступить еще проще. Нет необходимости в знании двоичных чисел. Нужно всего лишь сложить верхние числа в столбцах с ответом «да». Например, 41 = 32 + 8 + 1. Для правильного ответа достаточно мысленно сложить
два числа, а ответ на последний вопрос укажет, нужно ли прибавлять к ответу
единицу.
Это замаскированный метод половины интервала. Числа от 0 до 63 могут
быть выражены шестью битами. В каждом столбце 32 числа. За вопросом о том,
находится ли число в столбце, на самом деле скрывается вопрос, есть ли у выбранного числа единица в двоичном разряде, соответствующем положению
столбца.
Таблица может быть легко расширена до 127, или 255, или до любого значения 2n – 1. Увеличение n на единицу добавляет столбец и удваивает количество
строк.
Таблица 2.2. Пример таблицы для угадывания чисел, чтобы удивить тех,
кто не склонен к инженерному мышлению
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
48
49
8
9
10
11
12
13
14
15
24
25
26
27
28
29
30
31
40
41
4
5
6
7
12
13
14
15
20
21
22
23
28
29
30
31
36
37
2
3
6
7
10
11
14
15
18
19
22
23
26
27
30
31
34
35
1
3
5
7
9
11
13
15
17
19
21
23
25
27
29
31
33
35
44
Информация: что это такое?
Таблица 2.2 (окончание)
50
51
52
53
54
55
56
57
58
59
60
61
62
63
50
51
52
53
54
55
56
57
58
59
60
61
62
63
42
43
44
45
46
47
56
57
58
59
60
61
62
63
38
39
44
45
46
47
52
53
54
55
60
61
62
63
38
39
42
43
46
47
50
51
54
55
58
59
62
63
37
39
41
43
45
47
49
51
53
55
57
59
61
63
2.3. Заключение
Ни модели Колмогорова–Хайтина–Соломонова, ни модели Шеннона не отвечают на все вопросы об информации, поставленные в начале этой главы. На
диске Blu-ray объемом 50 Гб 400 млрд бит могут соответствовать фильму «Храброе сердце» или случайному шуму.
Аналогично ни информация KCS, ни информация Шеннона не дают однозначного ответа, имеет ли содержимое диска Blu-ray смысл или было ли оно
вообще кем-либо создано. Однако они могут использоваться в качестве инструментов при проведении оценочных исследований. Мы покажем это в следующих главах книги.
Источники
1.
2.
3.
Quoted in Eric Temple Bell. Men of Mathematics (Simon and Schuster, 2014).
Частично из публикации: Robert J. Marks II, «Information Theory & Biolo
gy: Introductory Comments», Biological Information – New Perspectives, Cornell University, под ред. R. J. Marks II, M. J. Behe, W. A. Dembski, B. L. Gordon,
J. C. Sanford (World Scientific, Singapore, 2013), pp. 1–10.
W. Gitt, R. Compton, J. Fernandez, «Biological Information – What is It?» in Biological Information – New Perspectives, Cornell University, под ред. R. J. Marks II,
M. J. Behe, W. A. Dembski, B. L. Gordon, J. C. Sanford (World Scientific, Singapore, 2013).
См. также N. Wiener, Cybernetics: Or Control and Communication in the Animal
and the Machine (Technology Press, MIT, 1968).
Источники 45
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
См. также W. Gitt, In the Beginning Was Information: A Scientist Explains the
Incredible Design in Nature (Green Forest, Master Books, 2005).
Stuart J. D. Schwartzstein. The Information Revolution and National Security
(Center for Strategic and International Studies, Washington DC, 1992), p. 196.
J. Seabrook, «The Flash of Genius». The New Yorker, 11 January, 1993.
IEEE Computational Intelligence Society, http://cis.ieee.org/ (May 2, 2016).
P. Mirowski, Machine Dreams: Economics Becomes a Cyborg Science (Cambridge
University Press, 2002).
Источники фото: Mount Rushmore by Dean Franklin [CC-BY-2.0 (http://creativecommons.org/licenses/by/2.0)], via Wikimedia Commons. Изображение
справа: National Aeronautics and Space Administration (NASA): http://science.nasa.gov/science-news/science-at-nasa/2001/ast24may_1/ (May 2, 2016).
J. Hübner, «A Christian Theory of Information», a RPM Magazine, 13(28), July 10
to July 16 (2011), http://www.reformedperspectives.org/ (May 2, 2016).
Michael J. Behe, Darwin’s Black Box: The Biochemical Challenge to Evolution (Free
Press, 1998).
Werner Gitt, в указанной работе.
Kirk K. Durston, David K. Y. Chiu, David L. Abel, Jack T. Trevors, «Measuring
the functional sequence complexity of proteins». Theor Biol Med Modell, 47 (4)
(2007).
William A. Dembski, No Free Lunch: Why Specified Complexity Cannot Be Purchased without Intelligence (Rowman & Littlefield Publishers, 2007).
H. Atlan and M. Koppel, «The Cellular Computer DNA: Program or Data», Bull
Math Biol, 52(3), pp. 335–348 (1990).
Edward D. Weinberger, «A theory of pragmatic information and its application
to the quasispecies model of biological evolution». BioSystems, 66(3), pp. 105–
119 (2002).
Kirk C. Durston, в указанной работе.
R. López-Ruiz, «Shannon information, LMC complexity and Rényi entropies: a
straightforward approach», Biophys Chem, 115 (2–3), pp. 215–218 (2005). The
initials LMC appear to refer to the authors of the original idea: López-Ruiz,
Mancini and Calbet.
Thomas M. Cover and Joy A. Thomas, Elements of Information Theory, 2nd edition (Wiley-Interscience, Hoboken, NJ, 2006).
M. Li and P. M. Vitányi, An Introduction to Kolmogorov Complexity and its Applications (Springer, 2008).
C. Shannon and W. Weaver, The Mathematical Theory of Communication (University of Illinois Press, Urbana, Ill., 1949), p. 32.
Cover and Thomas, в указанной работе.
46
Информация: что это такое?
22. G. J. Chaitin, Meta Math!: The Quest for Omega (Vintage, 2006).
23. D. G. Champernowne, «The construction of decimals normal in the scale of ten».
J London Math Soc, 8, pp. 254–260 (1933).
24. P. D. Grünwald and P. Vitányi, «Kolmogorov complexity and information theory», J Logic Lang Inf, 12 (4), pp. 497–529 (2003).
C. H. Bennett, P. Gács, M. Li, P. M. Vitányi, and W. H. Zurek, «Information distance», IEEE Trans. Inf. Theory, pp. 1–29 (1998).
25. Cover and Thomas, в указанной работе.
26. Там же.
27. Там же.
Глава
3
Эволюционный поиск
и требования к информации
Сложность живых существ должна присутствовать либо в материале, из которого они состоят, либо в законах, регулирующих их формирование.
Курт Гёдель [1]
3.1. Эволюция как поиск
Эволюция часто моделируется как процесс поиска [2]. Мутация, выживание
наиболее приспособленных особей и пополнение поголовья (репопуляция)
являются компонентами эволюционного поиска. Эволюционные поисковые
компьютерные программы, используемые учеными-программистами для
проектирования, обычно являются телеологическими – они подразумевают цель. Это существенный отход модели от принципиального утверждения
о том, что эволюция по Дарвину не имеет цели.
Информация в компьютерном поиске может быть проиллюстрирована с помощью инженерного проектирования, неизменно включающего в себя:
экспертизу предметной области;
критерии проектирования;
итеративный поиск.
Сначала создается и испытывается первый прототип. Если критерии проектирования не выполнены, прототип дорабатывается и испытание повторяется. Критерии проектирования составляют телеологическую цель. Процесс идет
быстрее в двух случаях: когда проблема проще или когда у разработчика больше опыта в предметной области.
Обладатели экспертных знаний в предметной области могут достичь заданных критериев с первой попытки или всего за несколько итераций. Когда не
хватает опыта, процесс проектирования затягивается. Знания экономят время.
48
Эволюционный поиск и требования к информации
3.1.1. WD-40TM
TM
Результаты итеративного проектирования, вероятно, стоят на полке в вашем
доме. Аэрозольный очиститель Formula 409TM, продаваемый компанией Clorox, был создан после 409 попыток выполнить требования к продукту – отсюда
и название [3]. Аналогичным примером является смазка и защитное средство
на основе нефти WD-40TM, изобретенное в 1953 году Норманом Б. Ларсеном.
Мы знаем, что процесс разработки был итеративным, потому что WD-40TM
означает [4] «вытеснение воды1, рецепт получен с 40-й попытки». Успех разработки этих продуктов является функцией опыта разработчика. Например,
учащемуся средней школы, только что закончившему вводный курс по химии,
потребуется гораздо больше, чем 40 итераций, необходимых промышленному
химику Норману Б. Ларсену. Вместо этого у него получилось бы что-то с названием WD-5120.
3.1.2. Тесла, Эдисон и знания в предметной области
Знание предметной области складывается из опыта и образования. Это знание
должно быть разумно интегрировано в процесс экспертом, чтобы упростить
процесс проектирования. Если проект сложный, а опыта мало, то для успеха
обычно требуется много итераций.
Изобретатель Томас Эдисон не располагал большим опытом применения
различных материалов при поиске нити накаливания, соответствующей его
критериям эффективности [5, 6]. Будучи не в состоянии привнести опыт в конструкцию лампы накаливания, Эдисон прибег к случайному поиску возможных решений. В газетной статье 1887 года перечислены некоторые материалы,
испробованные Эдисоном:
«Восемь тысяч разных химикатов, все виды винтов, иглы различного размера, разные виды нитей и проволоки, волосы людей, лошадей, свиней, коров,
кроликов, коз, верблюдов ... шелк разной плотности, коконы, различные виды
копыт, зубы акулы, рога оленя, панцирь черепахи ... пробка, смола, лак и масло,
страусиные перья, хвост павлина, струя, янтарь, каучук, все руды...» и т. д. [7]
Эдисон известен своей цитатой:
«Гений – это один процент вдохновения и девяносто девять процентов пота».
Блестящий инженер-электрик Никола Тесла не согласился с Эдисоном. Тесла понимал, что 99 % пота не нужны тем, кто знает, что они делают. Он порицал Эдисона за отсутствие у него опыта в предметной области и вытекающую из этого напряженную работу, необходимую для процесса изобретения.
Блестяще сочетая воображение и теоретические знания, Тесла придумал удивительные изобретения, такие как бесколлекторные асинхронные двигатели
переменного тока и беспроводная передача энергии. Тесла писал, что Эди1
Water Displacement.
Инженерная разработка с помощью компьютера 49
сону потребовалось большое количество испытаний из-за недостатка знаний
в предметной области [8]:
«Метод [работы Эдисона] был крайне неэффективен, потому что для получения хоть какого-то результата ему приходилось вспахивать огромное поле, если
только не вмешивалась слепая случайность; и сначала я был почти сострадающим свидетелем его действий, зная, что немного теории и расчетов избавили
бы его от 90 % труда. Но он испытывал настоящее презрение к книжному обуче
нию и математическим знаниям, полностью доверяя своему инстинкту изобретателя и практическому американскому мышлению1».
Судя по упомянутым числам, Тесла, очевидно, полагал, что гений – это
0,1 × 90 = 9 % пота и оставшиеся 91 % вдохновения.
В приведенной выше цитате Тесла упоминает о слепой случайности. Когда
нет опыта в предметной области – получается слепой поиск. Мы обсудим этот
вопрос позже.
Тесла участвовал в знаменитой битве против Эдисона за использование
переменного тока вместо постоянного. Судя по переменному напряжению
в электрических розетках в вашем доме, технология Теслы победила.
3.2. Инженерная разработка с помощью компьютера
С появлением компьютерных моделей некоторые лабораторные эксперименты, необходимые для процесса разработки, были заменены компьютерными
симуляциями. Характеристики антенн, например, могут быть смоделированы
с использованием давно известных математических моделей, описывающих
распространение электромагнитных волн. Значения параметров разработки
могут быть введены в программу, дающую на выходе характеристики проекта.
Как и при лабораторных испытаниях, разработчик-человек может посмотреть
на результат, уточнить параметры и попробовать запустить программу с новыми параметрами. Процесс остается итеративным, но теперь в нем применяется программное обеспечение вместо лабораторных экспериментов.
Хороший программист может улучшить процесс, полностью выведя человека из цикла итерации проекта. Программист предвидит, как впоследствии
может быть улучшен промежуточный продукт, и включает реализацию этого
предвидения в программное обеспечение. Весь процесс разработки затем передается на компьютер. После запуска программы мы ожидаем, что спустя не1
Тесла утверждает, что отсутствие опыта Эдисона в предметной области привело
к более длительной разработке. Эдисон изобрел бы WD-5120, а не WD-40. В разделе 5.4.2 мы показываем, что знание предметной области в процессе проектирования является источником информации, которая может быть передана разработчику в качестве активной информации для поиска. Мы покажем, что разницу опыта
разработки между WD-5120 и WD-40 можно оценить как активную информацию:
бит активной информации.
50
Эволюционный поиск и требования к информации
которое количество итераций получим результат, соответствующий заданным
критериям проектирования. Итеративный процесс, который ищет успешный
продукт (формулу, чертеж, рецепт и т. д.), называется компьютерным поиском.
Эволюционное программирование является ярким примером такого поиска.
Конечно, успех зависит от успешного приложения опыта программиста. Как
и в случае написания любого программного обеспечения, написал мусор – получил мусор.
3.3. Разработка рецепта вкусных блинов
Чтобы обрисовать проблемы поиска, рассмотрим проекты разработки рецепта
вкусных блинов и конструкции высокоэффективной антенны. Начнем с блинов.
3.3.1. Поиск хорошего блина № 1
Итак, вот первая задача для поиска. Опытному кулинару шеф-повару Рэю дают
тесто для блинов, и он должен решить, как долго поджаривать блины с каждой
из двух сторон. Чтобы определить, насколько хорош блин, мы воспользуемся
услугами Боба, эксперта-дегустатора1. Боб попробует блин и оценит вкус по
шкале от одного (ужасно) до десяти (вкусно). Работа шеф-повара Рэя состоит
в том, чтобы выяснить, как долго поджаривать блины с каждой стороны, чтобы
получить оценку девять или выше. Мера «девять или выше» является критерием проектирования для блина. Критерий заранее сообщает нам, что считается
приемлемым решением задачи. Поскольку цель проекта заранее известна, поиск является телеологическим. Поиск завершается и объявляется успешным,
если результат поиска соответствует критерию.
Чтобы найти2 лучшее время приготовления, предположим, что шеф-повар
Рэй может менять продолжительность поджаривания блина с шагом в 15 с.
Мы используем числа от 1 до 10 для представления времени приготовления.
Один – 15 с, два – 30, три – 45, и так вплоть до 10, что составляет две с половиной минуты (150 с). Каждое время приготовления может быть выражено в виде
упорядоченной пары чисел. Например, пара (5, 3) означает, что блин готовится
5 × 15 = 75 с на первой стороне, переворачивается и готовится 3 × 15 = 45 с на
1
2
Производители кофе привлекают мастеров-дегустаторов для оценки качества обжарки кофейных зерен. Мы предполагаем, что аналогичный талант существует и для
блинов.
Обратите внимание, что для поиска лучшего блина мы не можем использовать деление интервала пополам. Для этого пришлось бы пронумеровать рецепты от одного
до ста и задать первый вопрос: «Имеет ли лучший рецепт номер от одного до пятидесяти?» Чтобы ответить на этот и последующие вопросы, оракулу Бобу необходимо
знать параметры лучшего рецепта до начала поиска. Мы предполагаем, что ничего
не знаем о рецептах, и Боб-дегустатор может ответить только оценкой блинов, которые он попробовал. Поиск с использованием деления на интервалы для задач такого
типа просто невозможен без глубокого знания предметной области.
Разработка рецепта вкусных блинов 51
Сторона 2
второй стороне. Как показано на рис. 3.1, существует 10 × 10 = 100 вариантов
приготовления блинов.
Сторона 1
Рис. 3.1 Матрица 10×10, показывающая время приготовления блина на одной и второй сторонах. Заштрихованный квадрат соответствует паре (5, 3) = (75 с на первой стороне, 45 с на
второй стороне)
Чтобы найти лучшее время приготовления, шеф-повар Рэй выбирает случайную упорядоченную пару, скажем, (5, 3). Он поджаривает блин в течение
75 с с одной стороны, переворачивает блин и поджаривает его 45 с с другой
стороны. Затем он подает блин дегустатору Бобу, который медленно и вдумчиво жует с набитым ртом. Наконец Боб перестает жевать и задумчиво смотрит
вверх. Затем он глотает, смотрит на шеф-повара Рэя и объявляет: «Шесть!» Таким образом, по шкале от 1 до 10 у шеф-повара Рэя есть шестибалльный рецепт.
Этого недостаточно для соответствия критерию «девять», поэтому шеф-повар
Рэй возвращается к плите, чтобы попробовать другое сочетание параметров.
Если бы Рэй попробовал все 100 рецептов, то каждому из квадратов на
рис. 3.1 дегустатор Боб присвоил бы оценку от одного до десяти. В терминах эволюционной информатики степень соответствия результата поиска
внешним условиям называется приспособленностью. Приспособленность всех
100 рецептов может быть представлена графиком, показанным на рис. 3.2.
Каждый рецепт имеет свою оценку, и все точки связаны в сетку для наглядности. График на рис. 3.2 называется ландшафтом отбора (fitness landscape).
Оценки рецептов, присвоенные дегустатором Бобом, действительно можно
рассматривать как фитнес: блинчики с плохим вкусом имеют низкую физическую форму, а с отличным – хорошую физическую форму. Прежде чем приступить к поиску, шеф-повар Рэй ничего не знает о ландшафте отбора. Если бы
он заранее знал форму ландшафта отбора, то обошелся бы без слепого поиска. По мнению шеф-повара, это знание приходит только после многократных
экспериментов.
52
Эволюционный поиск и требования к информации
Вкус
Сторона 2
Сторона 1
Рис. 3.2 Ландшафт отбора для эксперимента с блинами
Шеф-повар Рэй не обязан проверять все 100 рецептов, чтобы найти приемлемый рецепт. Ему нужно только найти рецепт, которому дегустатор Боб
присвоит оценку 9 или выше. Возможно, Рэю повезет, и он получит хороший
рецепт с первого раза. Если, с другой стороны, цель шеф-повара Рэя состоит
в том, чтобы найти идеально вкусный блин, а не только приемлемый рецепт,
ему нужно будет попробовать все 100 рецептов.
Обратите внимание, что до начала поиска шеф-повар даже не знает, сущест
вует ли приемлемое решение. Если дегустатор будет очень привередлив, ни
одна из точек ландшафта отбора не достигнет уровня 9 или выше и не будет
блина, который соответствует критериям проекта. Чтобы узнать это, дегустатору Бобу нужно попробовать все 100 рецептов. С другой стороны, возможно,
все рецепты окажутся приемлемыми.
Если рассмотреть ландшафт отбора на рис. 3.2, то можно обнаружить девять
приемлемых рецептов с оценкой 9 и более. Значения 6, 7 или 8 соответствуют
от 90 до 120 с для первой стороны и 5, 6, 7 – от 105 до 135 с для второй стороны. Поскольку существует девять приемлемых рецептов, шансы на то, что
шеф-повар Рей случайным образом выберет выигрышное время приготовления в своем первом запросе, составляют 9 из 100, что является вероятностью
успеха:
Это число неизвестно до завершения процесса поиска. Его можно точно
определить, только испробовав все 100 рецептов.
Разработка рецепта вкусных блинов 53
3.3.2. Поиск хорошего блина № 2:
время приготовления плюс настройка оборудования
В нашем предыдущем примере предполагалось, что печь настроена на фиксированную температуру. Мы можем усложнить задачу поиска для шеф-повара,
предполагая, что нужно не только определить время поджаривания для первой
и второй сторон блина, но также найти оптимальную (или хотя бы приемлемую) температуру нагрева печи. Предположим, что печь снабжена рукояткой
регулировки нагрева с делениями от 1 (низкий нагрев) до 10 (высокий). С этими
10 дополнительными значениями у нас теперь есть 10 × 10 × 10 = 1000 рецептов.
Это показано на рис. 3.3, где большой куб состоит из 1000 маленьких кубиков,
каждый из которых соответствует рецепту. Чтобы присвоить числовую оценку
каждому маленькому кубику, дегустатору нужно попробовать 1000 рецептов.
Идея ландшафта отбора здесь не так очевидна, как на рис. 3.2, потому что мы
находимся в трех, а не двух измерениях. Ландшафт отбора в трех измерениях
(3D) можно визуализировать как облако, более плотное при высокой оценке
и прозрачное при низкой. Когда мы ведем поиск в более многомерном пространстве, ландшафт отбора становится трудно, если не невозможно, визуализировать. Однако такие эпитеты, как «гладкий», все еще часто используются
в качестве описаний ландшафта отбора.
Сторона 1
а
он
ор
Ст
Температура
2
Рис. 3.3 Пространство поиска
для рецептов блинов с тремя параметрами
3.3.3. Поиск хорошего блина № 3:
больше переменных параметров рецепта
Поиск наилучшего решения при наличии трех параметров (время обжарки первой стороны, время обжарки второй стороны и настройка температуры) слож-
54
Эволюционный поиск и требования к информации
нее, чем при наличии двух параметров. Меньшее количество параметров может означать, что некоторые поиски уже выполнены. В примере с блинами мы
предположили, что блинное тесто уже смешано. Поиск рецепта теста для блинов
в дополнение к параметрам приготовления делает проблему еще более сложной.
Предположим, есть девять параметров поиска. Три параметра остались прежними, а остальные шесть являются ингредиентами рецепта. Каждый из ингредиентов имеет 10 градаций. Вот список параметров, включая рецепт теста:
1) блинная смесь: сколько блинной смеси мы используем? Одна чашка? Две
чашки? Возможен диапазон значений от 1 до 10;
2) яйца: сколько яиц возьмем? Совсем нет яиц? Одно яйцо? Два? Диапазон
значений от ноля до девяти, что составляет 10 вариантов;
3) молоко: сколько чашек добавляем? Совсем без молока? Одна чашка? Две
чашки? И так вплоть до девяти, итого 10 вариантов;
4) вода: сколько воды мы используем? Давайте начнем с нуля стаканов
воды и рассмотрим все десять вариантов, вплоть до девяти;
5) соль: сколько соли мы добавляем? Варианты: от 1 до 10 щепоток;
6) масло: сколько свежего масла мы растопим в сковороде, прежде чем положить в тесто для блинов? Предположим, от нуля до девяти кусочков;
7) сторона первая: как долго мы поджариваем блины на первой стороне?
Допустим, как и раньше, есть 10 градаций, начиная с 15 с и далее увеличение с шагом в 15 с;
8) сторона вторая: используя аналогичные градации времени, как долго
мы поджариваем вторую сторону после переворачивания блина?
9) температура: насколько сильно мы нагреваем железную сковороду?
Предположим, как и раньше, плита имеет 10 ступеней нагрева.
С девятью параметрами, каждый из которых разделен на 10 возможностей,
теперь существует 109 – миллиард рецептов! Вариации блинных рецептов
практически бесконечны.
Задача шеф-повара Рэя найти рецепт вкусного блина теперь намного сложнее. (Чтобы придать какую-то наглядность этому числу, заметим, что 1 млрд
секунд – это почти 32 года.) Мы предполагаем, что, как и прежде, шеф-повар
ничего не знает о составе наилучшего рецепта блинов. Насколько известно
Рэю, рецепт, имеющий вкус заплесневелого тыквенного пюре, можно сделать
идеальным, используя еще одну щепотку соли; или смешивание одной чашки
смеси для блинов с пятью чашками молока и семью стаканами воды поможет
сделать неплохой блинчик. Ничего не зная о рецепте, мы можем попробовать
те же самые значения, однако использовать 10 чашек молока и 10 – воды. Тес
то будет еще более водянистым, но мы все равно попробуем. Это цена знания
«ничего». Для этого примера необходимо забыть все ваши кулинарные знания
и предположить, что вы невежественны в кулинарии и не знаете ничего о приготовлении еды.
Как нам найти хороший рецепт блинов среди миллиарда вариантов? Единственный вариант поиска, который доступен шеф-повару Рэю, остался преж-
Разработка рецепта вкусных блинов 55
ним. Выберите один из миллиарда возможных рецептов, приготовьте блин
и дайте его дегустатору Бобу. Критерий разработки, как и прежде, заключается
в том, чтобы найти рецепт с оценкой 9 или более.
Наш простой пример рецепта блинов хорошо иллюстрирует так называемый комбинаторный взрыв количества возможных рецептов по мере увеличения числа параметров. На языке поисковых алгоритмов ингредиенты рецепта
называются параметрами проектирования, а набор всех возможных рецептов
называется пространством поиска. В нашем случае мы оперируем девятью
параметрами проектирования, а пространство поиска содержит 1 млрд элементов. Если есть N параметров, каждый с 10 возможностями, то существует
10N рецептов. Таким образом, количество элементов в пространстве поиска
увеличивается экспоненциально по отношению к количеству параметров проектирования.
3.3.4. Поиск хорошего блина № 4:
имитация блинов на компьютере с искусственным языком
с использованием одного агента
Компьютеры заменили многих работников. Теперь и мы заменим дегустатора
Боба компьютерной программой. Предположим, что благодаря использованию
математических законов физики и химии приготовление блинов может быть
смоделировано с помощью программы под названием COOK (повар). Входные
данные для COOK представляют собой массив из девяти конкретных парамет
ров, необходимых для формирования рецепта. Выход COOK – это данные, которые определяют вкус блина. Мы назовем набор этих данных словом PANCAKE (блинчик). Мы также будем предполагать, что дегустатор Боб заменен
компьютерной программой для имитации вкусового восприятия под названием TONGUE (язык). Программа TONGUE имитирует то, что делает дегустатор
Боб. Входные данные для TONGUE – это PANCAKE, то есть те же параметры вкуса блина, которые Боб использовал для оценки. Выход TONGUE – оценка вкуса
блинов по шкале от одного до десяти. Поскольку шеф-повар Рэй написал эти
компьютерные программы, ему больше не нужно готовить физические блины,
и при этом ему не нужны дорогостоящие услуги Боба-дегустатора. Грустный
Боб идет оформлять пособие по безработице.
Каскадные программы COOK и TONGUE, как показано в верхней части
рис. 3.4, являются примером1 оракула. За определенную цену оракул скажет
вам, насколько хорошо что-то. Дегустатор Боб был живым оракулом. В случае
поиска рецепта блина вход оракула – рецепт. Результат, оценка вкуса, говорит
нам, насколько хорош рецепт. Цена, которую мы платим за компьютерный поиск, – это время вычислений. До компьютеризации поиска мы платили Бобу за
его оценки обычные деньги.
1
Powered by TCPDF (www.tcpdf.org)
В примере нахождения секретного числа ведущий викторины – оракул по отношению к игроку.
56
Эволюционный поиск и требования к информации
Оракул
COOK
Рецепт
PANCAKE
TONGUE
Оценка
SEARCH
Оценка
Оракул
Оценка
Оценка
ВЫЖИВАНИЕ
ЛУЧШИХ
И РЕПОПУ
ЛЯЦИЯ
Рецепт № N
МУТАЦИЯ
Рецепт № 2
Рецепт № 1
Рис. 3.4 (Вверху) Один агент ищет хороший вкусный блин. Алгоритм SEARCH
разработан программистом, чтобы использовать любые знания о поиске. (Внизу)
Общая схема эволюционного поиска
Шеф-повар Рэй все еще стоит перед проблемой выбора рецептов для ввода
в оракул. Он может накормить компьютерную модель виртуальным блином,
посмотреть на результат и решить, какой рецепт попробовать дальше. Или он
мог бы написать более сложный компьютерный код, анализирующий результат и автоматически выбирающий новый рецепт для испытания. Мы дадим такой программе для поиска рецепта имя SEARCH (поиск). Используя результаты
предыдущих запросов, поисковый алгоритм SEARCH должен определить, какой следующий рецепт должен поступить на вход программы COOK. Следовательно, процесс проектирования можно рассматривать как цикл, показанный
в верхней части рис. 3.4. Цикл завершается, когда TONGUE объявляет оценку,
удовлетворяющую критерию проектирования.
Мы не можем рисовать в девяти измерениях, поэтому давайте вернемся
к двумерному (2D) примеру поиска, показанному на рис. 3.1. Напомним, в данном случае наша работа состояла в том, чтобы определить, как долго готовить
блины на одной и второй сторонах. Хотя это явно не показано в верхней части
рис. 3.4, программа SEARCH имеет доступ ко всем или части результатов предыдущего запроса. Она может использовать эту информацию, чтобы помочь
Разработка рецепта вкусных блинов 57
выбрать следующий запрос. На рис. 3.5 показаны результаты испытаний четырех рецептов. Работа SEARCH заключается в определении следующего рецепта
для представления компьютерной программе COOK. Без понимания формы
функции приспособленности (fitness function) или того, где находится цель,
у нас не будет особых соображений по выбору следующего рецепта. Лучшее,
что мы можем сделать, – это не брать рецепты, которые уже были испытаны.
Это типичный слепой поиск.
Сторона 2
Сторона 1
Рис. 3.5 Мы готовим 4 блина и получаем 4 оценки вкуса, показанных в TONGUE. Мы выполняем выборку функции приспособленности на рис. 3.2 без знания цели или ландшафта отбора.
Задача программы SEARCH в верхней части рис. 3.4 – выбрать
следующий запрос рецепта на основе информации, которую мы
знаем
3.3.5. Поиск хорошего блина № 5:
моделирование блинов на компьютере
с помощью эволюционного поиска
Слепой поиск соответствует одному агенту без зрения, но с хорошей памятью,
который наугад обходит пространство поиска и спрашивает у оракула, какова
приспособленность рецепта к критериям отбора в его текущем местоположении. Ситуацию можно улучшить, если воспользоваться быстрыми параллельными вычислениями. Команда агентов может обыскивать ландшафт отбора,
общаясь друг с другом по рации. Бриллиантовое ожерелье, потерянное в поле,
проще всего найти при помощи выстроившихся в линию и держащихся за руки
поисковиков.
Эволюционный поиск является частным случаем поиска с несколькими агентами [9]. Для проблемы блина простой эволюционный поиск показан в нижней
части рис. 3.4. Оракулу, состоящему из алгоритмов COOK и TONGUE, изначаль-
58
Эволюционный поиск и требования к информации
но представляют N рецептов. Сохраняются только рецепты с высоким вкусовым рейтингом (выживание наиболее приспособленных). Рецепты с низким
вкусовым рейтингом отбрасываются. Чтобы сохранить исходную численность
N (популяцию), выброшенные рецепты заменяются копиями рецептов с более
высоким рейтингом, т. е. происходит репопуляция. Далее каждый из N рецептов
подвергается небольшому изменению. Изменения незначительны, поскольку
мы надеемся, что новый рецепт сохранил свойства, которые сделали его лучшим в предыдущем испытании. Эти изменения соответствуют этапу мутации
в эволюции1. Можно сказать, что прошло одно поколение эволюции. Затем N
новых рецептов подвергаются новому циклу отбора (выживания наиболее
приспособленных), репопуляции и мутации. Надежда на эволюционные программы состоит в том, что популяция будет становиться все сильнее и сильнее,
о чем свидетельствует постоянно возрастающий показатель приспособленности, и, в случае с проектированием блинчиков, в конечном итоге получится
рецепт вкусного блинчика.
Примечание
Результат компьютерного моделирования в конечном итоге должен быть реализован
в физическом виде и протестирован. Это делается в лаборатории. До появления компью
теров требовалось намного больше лабораторных исследований, чтобы добиться от продукта надлежащего качества. Компьютеры позволяют пройти начальные этапы проектирования в виде моделей. Но даже если компьютер говорит, что результат великолепен,
продукт должен быть проверен на практике. Шеф-повар Рэй не возьмет компьютерный
проект блина и не потратит миллионы на создание сети блинных домов, пока не приготовит и не попробует блин сам. Он может даже немного изменить рецепт компьютера.
Компьютерное моделирование бывает точным, но может пропустить тонкости, которые
влияют на результат.
3.4. Источники знаний
Для многих поисковых методов, как правило, нет способа узнать, как долго будет работать поисковая программа, прежде чем найдет приемлемый результат
поиска. Повару Рэю может повезти, и он найдет приемлемый рецепт блинов
с оценкой 9 с первой попытки. Или Рэй может в конечном итоге проверить
каждый вариант и определить хороший рецепт с последней попытки.
Знания о предмете поиска позволяют сократить время поиска. Вот некоторые примеры знаний, которые Рэй может применить для упрощения поиска
хорошего блина:
если с пятью чашками воды и двумя чашками молока получается слишком жидкое тесто, нет никаких оснований пробовать какие-либо рецеп1
Другим часто используемым шагом в эволюционном поиске является кроссовер. Это
очень похоже на перетасовку генов отца и матери, которые в конечном итоге оказываются у ребенка. Пример кроссовера состоит из: (а) выбора двух рецептов, (б) выбора набора ингредиентов (например, количествао яиц и количество щепоток соли)
и (с) обмена этими значениями между рецептами.
Источники знаний 59
ты с дополнительными чашками воды или молока. Это сразу исключает
большое количество рецептов, которые нам не нужно пробовать;
аналогичным образом, если блин подгорает при обжарке в течение 90 с,
нет причин пытаться увеличить время приготовления;
если пропорционально удвоить количество всех ингредиентов, мы получим то же самое тесто – только вдвое больше. Оценка блина в обоих
случаях будет одинаковой, и второй рецепт не нужно пробовать;
мы можем запросить у оракула TONGUE более подробный отчет, если
он способен дать развернутый ответ. Если оракул скажет: «Блин слишком соленый», то нет смысла проверять тот же рецепт, используя больше
соли.
Важно отметить, что предварительное знание должно быть правильным,
иначе оно может увести нас от хорошего блина. При ошибочных знаниях поиск
займет больше времени, чем перебор случайных рецептов, а активная информация примет отрицательное значение. Примерами вводящих в заблуждение
знаний о рецепте блинов могут быть:
плохо написанная программа TONGUE, которая дает нам неправильные
оценки качества блина;
оценка качества, противоречащая нашим ожиданиям, например высокая оценка подгоревших блинов, когда оценивается только степень прожарки без учета вкуса.
Знания о ландшафте отбора также способны помочь в поиске. Предположим,
например, что у нас есть рецепт блина с низкой оценкой 2. Даже при предварительном знании формы ландшафта отбора изменение какого-либо одного
параметра, скорее всего, не приведет к блину с оценкой 9. И даже изменение
значений всех параметров на один шаг может не привести к успеху. А как насчет изменения параметров на два шага? Это может сработать. Программист,
пишущий программное обеспечение для поиска, должен решить, что делать:
исключить просмотр всех рецептов с изменением параметров в один шаг или
нет? Разные программисты с разным опытом будут делать разный выбор. Так
обстоит дело со всеми априорными знаниями о поиске. Выбор, сделанный программистом при написании программы, определяет активную информацию,
включенную в поиск. Программисты, обладающие разными навыками и отличающиеся предварительными знаниями предметной области, будут вводить
в программу информацию различной степени активности.
Даже после того как программа поиска написана, умный программист может свободно передавать некоторые из своих предыдущих знаний о рецептах
блинов в программу. Большинство алгоритмов поиска имеет связанные параметры, которые должны быть выбраны до начала работы программы. Мы можем представить алгоритм поиска как блок с набором ручек-регуляторов, каждая из которых должна быть установлена программистом до запуска поиска.
Например, для эволюционного поиска требуется указать размер популяции от
поколения к поколению, а также тип и глубину мутаций в каждом поколении.
60
Эволюционный поиск и требования к информации
Правильный выбор алгоритма поиска и его параметров может значительно
сократить время поиска. Разные программисты найдут разные способы вложить предварительные знания в алгоритм поиска. Когда программа поиска находит рецепт хорошего блина всего за несколько часов, уместно ли говорить,
что программа является источником интеллекта, который сократил время поиска? Конечно, нет. Это заслуга программиста, то есть разработчика программного обеспечения, ускорившего поиск.
Каждая процедура итеративного поиска имеет другие компоненты, которые
не показаны на рис. 3.4.
Память. Она может хранить результаты предыдущих запросов.
Инициализация. Эволюционная петля внизу рис. 3.4 должна быть инициализирована. Если, например, есть сведения о регионе ландшафта отбора, в котором находится цель, имеет смысл начать поиск с этого ре
гиона.
Критерий остановки. Поиск не может продолжаться вечно. Поиск с перебором большого количества параметров может продолжаться трил
лионы лет, прежде чем будут исчерпаны все варианты. Конечно, лучшим
критерием остановки является поиск приемлемого решения. Если мы
нашли рецепт вкусного блина, больше никаких итераций не требуется.
Обычно критерии остановки включают также время выполнения и количество итераций – т. е. количество проходов через эволюционный цикл,
показанный внизу рис. 3.4.
3.4.1. Проектирование антенн с использованием
эволюционных вычислений
Поиск рецепта вкусных блинов, хотя и представлен исключительно в учебных
целях, наглядно описывает, что происходит в компьютерном поиске. Широко известен практический пример эволюционного компьютерного поиска –
конструкция антенны, представленная научной общественности инженерами
NASA. Антенна, разработанная в результате эволюционного компьютерного
поиска, в настоящее время используется в космосе.
Опишем суть проекта в нескольких словах. Предположим, у нас есть кусок
жесткого провода примерно такой же длины и толщины, как материал обычной офисной скрепки для бумаг. Провод можно сгибать в любом месте и под
любым углом. После того как провод согнут, его испытывают, чтобы измерить,
допустим, насколько хорошо он принимает сигнал сотовой связи. Успехом считается получение достаточно сильного сигнала на входе мобильного телефона.
Это критерий разработки. Если получен достаточно сильный сигнал, проект
считается успешным, и поиск завершен. Если нет, провод сгибается по-другому,
и эксперимент повторяется. Если у разработчика нет опыта в разработке антенн
и знаний в области распространения радиоволн или электроники для сотовых
телефонов, поиск будет слепым, аналогично поиску Эдисоном материала для
Источники знаний 61
нити лампочки накаливания. Нет уверенности даже в том, что вообще можно
изготовить удачную антенну из куска проволоки для скрепок. Или может оказаться, что почти любая изогнутая скрепка нормально делает эту работу.
Для проведения этого эксперимента не требуются физические измерения
с использованием мобильного телефона. Математическая модель распространения радиоволн давно и хорошо проработана, поэтому электромагнитные
характеристики изогнутой скрепки могут быть проанализированы с помощью
компьютера. Таким образом, весь процесс разработки конструкции антенны
может быть выполнен на компьютере. Компьютер запрограммирован на тес
тирование миллионов различных геометрий изгиба. Программа запущена.
Программист уходит в отпуск и возвращается через несколько дней, чтобы
увидеть, работает ли какой-нибудь вариант изгиба. Компьютер не делает ничего творческого. Поиск существенно не отличается от кропотливых испытаний на изгиб и тестирование в лаборатории. Компьютер просто делает многие
вещи быстрее.
Проектирование антенны с использованием компьютерного поиска – не
просто академическая иллюстрация компьютерного поиска в учебных целях.
Ученые NASA разработали эффективные антенны, используя эволюционный
поиск, в котором результаты предыдущих неудачных попыток используются для улучшения успешной разработки. Один из окончательных вариантов
конструкции показан на рис. 3.6 [10, 11].
Что входит в такую разработку? В эволюционном синтезе антенн Венкатараялу (Venkatarayalu) и Рэя (Ray) [12] используется семь проектных параметров.
Каждый параметр можно рассматривать как ингредиент для рецепта сродни ингредиентам для приготовления хорошего блина. Нам нужно выяснить,
сколько каждого ингредиента нужно использовать, чтобы сделать достаточно
вкусный блин или эффективную антенну. Конечный результат должен быть достаточно хорошим, чтобы соответствовать заданным требованиям.
В качестве оракула для поиска, включая эволюционный поиск, часто используются компьютерные модели. Эволюционная разработка антенны X-диапа
зона [13], например, требует математически обоснованной оценки приспособленности каждого варианта, предложенного во время поиска. Сродни
оракулу TASTE при поиске рецепта блинчиков, инженеры NASA использовали
в качестве оракула программную модель электромагнитной совместимости
(Numerical Electromagnetics Code, NEC-4) [14]. NEC-4 – это широко используемый и мощный программный пакет для моделирования проволочных
и поверхностных антенн. Использование такого программного обеспечения
имеет важное значение в компьютерном проектировании антенн. Обратите
внимание, что эволюционный поиск – не единственный алгоритм поиска,
который можно использовать для проектирования антенны. Например, совместно с оракулом NEC-4 можно применять и другие алгоритмы поиска конструкции эффективной антенны. Сам по себе эволюционный поиск не создает
информации.
62
Эволюционный поиск и требования к информации
Рис. 3.6. Антенна, разработанная с помощью эволюционного
поиска на компьютере. Подпись к оригинальной веб-картинке гласит: «Среди новых технологий, которые будут испытаны на борту
космического корабля ST5, – антенна, разработанная компьютером,
имитирующим эволюцию Дарвина. Эта сложная антенна была разработана с помощью эволюционного алгоритма, работающего несколько дней на суперкомпьютере. Столь необычная форма вполне
объяснима, потому что большинство разработчиков антенн никогда
бы не подумали о такой конструкции»
3.5. Проклятие размерности и потребность в знаниях
Поисковые алгоритмы ведут нас через наше исследование пространства поиска. Для людей-поваров и человеческих языков тестирование миллиарда
рецептов блинов из 9 ингредиентов невозможно. Для компьютерной модели
симуляция миллиарда блинов – это не проблема. Предположим, что компьютерная программа Chef Ray готовит и тестирует виртуальные блины со ско
ростью 100 рецептов в секунду. Следовательно, шеф-повар Рэй может изучить
1 млрд рецептов менее чем за четыре месяца. Если мы добавим еще один ингредиент в наш рецепт, скажем, от 1 до 10 чайных ложек растительного масла,
количество возможных рецептов увеличится в десять раз и достигнет 10 млрд.
Поиск займет в 10 раз больше времени. Изучение всех возможных рецептов
Проклятие размерности и потребность в знаниях 63
теперь загрузит программу Chef Ray на три года. Слишком долго ждать хороший блин…
Каждый ингредиент, который мы добавляем в рецепт, при условии что
шаг необходимо протестировать 10 различными способами, умножает время
компьютерного моделирования на 10. Поиск рецепта по 16 параметрам займет
более 3 млн лет. А 22 проектных параметра соответствуют продолжительности
более 3 трлн лет! Числа в табл. 3.1 наглядно демонстрируют проклятие размерности.
Таблица 3.1. Количество лет, необходимое для перебора
всех рецептов блинов при различном количестве
переменных факторов
Количество
параметров
Количество лет
9
10
11
12
13
14
15
16
17
18
19
20
21
22
0,32
3,2
32
317
3 169
31 688
316 881
3 168 809
31 688 088
316 880 878
3 168 808 781
31 688 087 814
316 880 878 140
3 168 808 781 403
Поиск рецепта с 22 параметрами без знаний в предметной области занимает
непомерно много времени. При написании своей компьютерной программы
шеф-повар должен обладать хоть какими-то начальными знаниями. До сих пор
мы предполагали, что Рэй ничего не знает о рецептах блинов. Его знания о кулинарии могут быть использованы для поиска. Это наполняет поиск активной
информацией и уменьшает сложность поиска. Понятие активной информации
и измерение ее объема является фундаментальной заповедью эволюционной
информатики.
3.5.1. Поможет ли Мур? Как насчет Гровера?
Как насчет компьютеров будущего? Позволят ли они проводить большой ненаправленный слепой поиск в разумные сроки? Даже для проблем среднего
размера ответ – нет.
Закон Мура гласит, что число транзисторов в интегральной схеме удваивается примерно каждые два года. Для обсуждения предположим, что быстро-
64
Эволюционный поиск и требования к информации
действие компьютера удваивается каждый год. Предположим, что существует
рецепт, содержащий 500 проектных параметров, каждый из которых принимает значение один (использовать ингредиент) или ноль (не использовать).
Предположим, что на вычисление всех рецептов уходит год1. Пусть скорость
компьютера удвоится. Какой объем поиска мы можем сделать за год? Если скорость компьютера удвоилась, неутешительный ответ заключается в том, что
поиск может быть выполнен лишь для 501 ингредиента2. Можно рассмотреть
только еще один ингредиент. Для нового поиска нам нужно будет выполнить
первоначальный поиск, где новый ингредиент не используется, и повторить
эксперимент, когда новый ингредиент используется. Эффект добавления одного ингредиента в поиск не зависит от исходного поиска без дополнительного ингредиента. Более быстрые компьютеры не решат нашу проблему.
Как насчет квантовых вычислений? Для выполнения операций с данными
квантовый компьютер использует странные и замечательные законы3 квантовой механики, такие как суперпозиция и запутывание [15]. В случае его реализации алгоритм Шора [16] для квантовых компьютеров может быстро расшифровать многие криптографические системы, используемые сегодня. В области
поиска, однако, результаты еще не настолько впечатляющие. Алгоритм Гровера
[17] для поиска с использованием квантового компьютера уменьшает сложность поиска только на квадратный корень из исходного числа. Триллион лет на
традиционном компьютере все еще означает 1 млн лет на квантовом компьютере. Таким образом, алгоритм Гровера очень помогает, но не решает проблему.
3.6. Неявные цели
Поиск успешной конструкции антенны является явно телеологическим, т. е.
конкретные критерии проектирования определены до поиска. Существует
также неявная телеология, в которой сама структура пространства поиска или
знание структуры направляет процесс поиска к неявной цели.
Вот простой пример. Кирк – броненосец, неуклюжее животное, занятое охотой на личинок. Кирк внезапно ослеп от укуса ядовитого паука. Он хочет вернуться в свою нору, но ничего не видит и дезориентирован. Он знает, однако,
что отверстие норы находится на самом низком уровне где-то поблизости, поэтому поднимается повыше и скатывается вниз по склону холма к своей норе.
Когда Кирк поступает так, он не ищет свою нору в явном виде. Окружающая
среда устроена так, чтобы доставить его к норе. Таким образом, цель Кирка
остается неявной в том смысле, что ее специально не ищут, но она является
результатом воздействия на него окружающей среды. Он может стукаться о деревья или попадать в руки шаловливым детям. И повторные скатывания со
1
2
3
Для 500 ингредиентов это составит 2500 = 3 × 10150 рецептов.
Для 501 ингредиента количество рецептов 2501 = 2 × 10500.
Нильс Бор, пионер в области квантовой механики, сказал, что «если квантовая механика вас не потрясла, вы ее просто не поняли».
Неявные цели 65
склона могут пойти по совершенно другим путям. Но в конечном итоге Кирк
окажется в своей норе у подножия холма [18]. Кирк возвращается домой благодаря информации, которую он получает из окружающей среды. Но чтобы это
произошло, нужна подходящая среда.
В примере с блинами также можно найти скрытую информацию о цели.
Вспомните первый простой пример, где было всего две переменные – продолжительность обжаривания первой и второй сторон. Ландшафт отбора для
этой проблемы представлен на рис. 3.2. Предположим, что плита шеф-повара
Рэя электрическая и автоматически отключается, если одна из сторон блина
готовится более полутора минут. У Рэя остается всего 6 интервалов по 15 с. Это
свойство внешней среды ограничивает и тем самым упрощает поиск. Новый
ландшафт отбора изображен на рис. 3.7. К счастью, все еще существует рецепт,
который оценивается достаточно высоко, чтобы соответствовать критерию
поиска. Он находится в углу кривой на рис. 3.7 и помечен маленьким кубиком.
Неявные ограничения, накладываемые средой, упрощают поиск, ограничивая
его пространство. Предположим, по какой-то причине печь требует, чтобы
каждая сторона блина готовилась в течение 6 интервалов. Если это требование
добавляется к ограничению, наложенному автоматическим отключением, то
мы находим приемлемый рецепт за одну попытку! Однако, если среда ограничена негативным образом, цель может оказаться вне пространства поиска,
даже если она была доступна до изменения.
Вкус
Сторона 2
Сторона 1
Рис. 3.7 Когда электрическая плита сама отключается через 6 интервалов
по 15 с с обеих сторон, пространство поиска меняется. Поиск теперь ограничен,
и остался лишь один рецепт с оценкой 9 или выше. Он отмечен маленьким
кубиком
Таким образом, поиск может быть облегчен не только за счет предшествую
щего знания предметной области, но и благодаря структуре среды поиска.
Ограничения в пространстве поиска должны способствовать скорейшему до-
66
Эволюционный поиск и требования к информации
стижению цели. Произвольные изменения среды, скорее всего, будут иметь
как положительные, так и отрицательные последствия.
Географические карты также иллюстрируют наличие активной информации, заложенной в структуру пространства поиска. В начале 2014 года Макс
участвовал в миссии по сбору пожертвований для либеральной партии в штате
Техас. Территория штата Техас – это пространство поиска Макса. Не имея информации о политических настроениях, Макс, скорее всего, успешно соберет
деньги в одной части штата и потерпит провал в другой. Предположим, однако,
что у Макса есть копия результатов президентских выборов 2012 года, как показано на рис. 3.8. Более светлые окрашенные области достались Бараку Обаме,
а более темные – Митту Ромни. Согласно (очень разумному) предположению,
что Обама более либерален, чем Ромни, Максу лучше всего тратить время на
сбор средств в округах со светлой окраской. Карта содержит активную информацию для поиска Макса.
Рис. 3.8 Карта избирательных округов Техаса. Более темные области обозначают округа, которые проголосовали за Митта Ромни на президентских выборах 2012 года, а более светлые округа проголосовали за Барака Обаму. Эта
карта пригодится, если вы собираете средства для либеральной партии в Техасе
Оптимальная неоптимальность 67
3.7. Оптимальная неоптимальность
Разработчиков эволюционного поиска, пытающихся имитировать эволюцию
организмов в живой природе, часто ставит в тупик кажущаяся бессмысленность некоторых явлений, особенно наличие рудиментарных остатков.
Принято считать, что если за эволюционным поиском стоит интеллект инженера-разработчика, то он обязан выполнить оптимизацию до наилучшего
возможного решения. Вот некоторые проблемы с такими заявлениями:
1) разработка в сложных областях влечет за собой компромиссы, поскольку
повышение эффективности в одной области требует ее снижения в другой. Эффективная разработка – это отчасти искусство компромисса. Мы
обсудим этот вопрос более подробно в разделе 3.7.2;
2) оптимизация означает поиск единственного наилучшего решения. Инженеры-проектировщики, разумеется, этого не делают. На самом деле
инженеры работают в соответствии с критериями проектирования. Проект считается законченным, когда приспособленность соответствует или
превышает эти критерии. Мы не искали наилучший из возможных блинов. Мы искали любой блин с оценкой вкуса 9 или выше;
3) как свидетельствует история, ученые тоже делают ошибки. Кровопускание не делает вас здоровее, оно убивает вас. Спросите Джорджа Вашингтона1. В космосе нет эфира, который бы поддерживал распространение
света. Опровержение этого широко распространенного убеждения способствовало открытию теории относительности.
Вчерашние рудиментарные структуры иногда оказываются главной ценностью сегодняшнего дня.
3.7.1. Потеря функции
Когда среда меняется, конструкция может быть оптимизирована за счет утраты функции. Змеям не нужны ноги, чтобы бегать по песку, а саламандрам
в темной пещере бесполезны глаза. Обратите внимание, однако, что утрата
функции соответствует скорее не вливанию информации в проект, а удалению предыдущей резидентной информации. Избирательная утрата функции
может быть полезна для эффективности в меняющихся условиях и является
характеристикой хорошего проекта. Ракеты сбрасывают пустые ступени и топ
ливные баки, чтобы уменьшить нагрузку, а некоторые ящерицы сбрасывают
хвосты, чтобы спастись от хищников.
Но следует быть очень аккуратным с оценкой бесполезности функций. Непонимание функций сегодня часто заменяется вновь обнаруженными функциональными свойствами завтра. Как гласит старая поговорка, «отсутствие
доказательств не является доказательством отсутствия». То, что мы не знаем,
имеет ли объект функцию, не означает, что он не имеет функции.
1
Джордж Вашингтон впал в кому и скончался после кровопускания, которым его лечили от простуды.
68
Эволюционный поиск и требования к информации
Классическим примером является человеческий орган, некогда считавшийся бесполезным артефактом эволюции. В 1912 году Джозеф МакКейб писал, что
человеческий аппендикс – это «бесполезный фрагмент толстой кишки далекого предка» [21]. Однако современная медицина нашла, что аппендикс помогает
иммунной системе [22, 23], вырабатывает гормоны во время развития плода
[24] и обеспечивает безопасное убежище для бактерий кишечной флоры [25].
Другая историческая ошибка, связанная с рудиментарной функцией, касается роли ДНК. Поскольку большая часть нашей ДНК не кодирует белки, часть,
не кодирующая белок, была идентифицирована как бесполезная рудиментарная «мусорная ДНК». Считалось, что «бесполезная» ДНК является остатком
эволюции. Позже было обнаружено, что эта часть ДНК обеспечивает бесценные функции, включая транскрипцию и трансляцию кодирующих белок последовательностей.
3.7.2. Оптимизация Парето и оптимальная субоптимальность
Часто поиск пытается достичь двух или более целей. Помимо блинчика с хорошим вкусом, мы могли бы также искать недорогой блинчик. Это противоречивые критерии, потому что вкусные блины не дешевые, а дешевые блины
не вкусные.
Противоречивые критерии требуют применения теории многоцелевой оптимизации по Парето [27, 28]. Хотя здесь не обойтись без компромисса, окончательный проект все же может быть оптимальным в том смысле, что он
наилучший, который мы можем получить при противоречивых критериях
проектирования.
Примером могут служить основы теории обнаружения. Допустим, нам поручено разработать коробку, в которой мигает красный свет, когда на нас нападают террористы. Зеленый свет означает, что мы в безопасности. Эффективность детектора можно обсуждать, не зная деталей его конструкции. Вот два
критерия проектирования для нашей коробки:
максимальная вероятность предупреждения: нам нужен детектор с высокой вероятностью предупреждения о террористическом акте, т. е. когда
на нас нападают, вероятность включения красного света должна быть
высокой;
минимальная вероятность ложной тревоги: когда террористы не атакуют, нам нужна высокая вероятность включения зеленого света. Мигающий красный свет при отсутствии атаки будет ложной тревогой.
Реализовать максимальную вероятность предупреждения не сложно: всегда
нужно мигать красным светом. Тогда всякий раз, когда на нас нападают террористы, мы на 100 % уверены, что красный свет мигает. Разумеется, это глупо.
Такой детектор бесполезен. Также бесполезно, если вероятность ложной тревоги сведена к минимуму, и в этом случае зеленый свет всегда остается включенным. Зато, поскольку красный свет никогда не горит, нет ложных тревог.
В теории обнаружения всегда существует компромисс между вероятностью об-
Оптимальная неоптимальность 69
Безопасность
наружения и ложной тревоги. Оптимальный детектор Неймана–Пирсона максимизирует вероятность обнаружения при фиксированной частоте ложных
тревог1 [29–31]. Но единого лучшего решения не существует. Решение должно
быть выбрано в соответствии с тем, что конечный пользователь считает целесообразным. Выбор одного пользователя оптимального устройства часто будет
отличаться от выбора другого пользователя.
Другим примером компромисса является выбор личного средства передвижения. Если критерий конструкции «недорогой», то мопед – это хороший
выбор. Если же критерием конструкции является «безопасность», то лучшим
вариантом будет бронированный внедорожник. Но вы не можете реализовать
обе крайности одновременно, потому что дешевые транспортные средства
небезопасны, а безопасные транспортные средства недешевы. Кривая компромисса для этого примера изображена на рис. 3.9. В данном примере проверено несколько транспортных средств, которым присвоен номер в соответствии с требованиями безопасности. Это число отображается в зависимости
от стоимости автомобиля. Квадраты находятся на фронте Парето и соединены
пунктирной линией. Транспортное средство попадает на фронт Парето, если
ни одно другое транспортное средство с такими же затратами не является бо-
Оптимум
Парето
Мопед
Броневик
Цена
$$$
Рис. 3.9 Иллюстрация компромисса между безопасностью
и стоимостью личного транспорта
1
Эквивалентно, на языке статистики вероятности обнаружения и ложной тревоги относятся к ошибкам типа I и типа II или ложным срабатываниям и ложным отрицаниям.
70
Эволюционный поиск и требования к информации
лее безопасным или транспортное средство с такой же безопасностью не стоит дешевле. И мопед, и бронированный внедорожник находятся на фронте
Парето. Важно отметить, что не существует единого оптимального решения.
Поиск оптимума на фронте Парето является вопросом осознанного выбора.
Часто используемое решение состоит в том, чтобы зафиксировать один параметр и оптимизировать второй. Можно, например, установить максимально
возможную стоимость и при этом задаться целью покупки самого безопасного транспортного средства. Круги под фронтом Парето соответствуют другим
транспортным средствам, которые были протестированы. В смысле Парето эти
транспортные средства не оптимальны.
Окончательная конструкция должна воплощать компромисс. Инженерыразработчики сильны в искусстве компромисса.
Область многоцелевой оптимизации хорошо развита [31] в эволюционном
поиске, впрочем, как и везде. Считается, что конструкция является оптимальной в смысле Парето, если она такова, что ни один отдельный параметр проектирования не может быть улучшен при неизменных остальных параметрах.
Урок, который необходимо извлечь, заключается в следующем: в многоцелевом или Парето-проектировании критика параметра проекта не может быть
сделана в вакууме, а должна выполняться с учетом всей функциональности
конечного продукта и с учетом других конкурирующих критериев проекта. Те,
кто критикует творения природы, указывая на неоптимальную изолированную работу, скажем, человеческого глаза без учета всей физиологии организма, незнакомы с инженерным проектированием и, вероятно, сами никогда не
проектировали ничего сложного.
3.7.3. Человек в цикле как фактор активной информации
Компьютерные программы, включая эволюционный поиск, неизменно разрабатываются с помощью отладки и настройки.
3.7.3.1. Эволюция от крестиков-ноликов до шашек и шахмат
Интересная история итеративного проектирования с человеком в цикле начинается в 1993 году, когда эволюционная программа «научила себя играть
в крестики-нолики» [32]. Те же исследователи восемь лет спустя, в 2001 году,
опубликовали еще одну статью, когда другая написанная ими эволюционная
программа научилась играть в шашки [33] и навык написанных ими эволюционных программ в некотором смысле развился до более высокого уровня. Затем
в 2004 году команда объявила, что научила компьютер использовать эволюцию
для обучения игре в шахматы [34]. От крестиков и ноликов до шахмат – этот
прогресс, казалось бы, должен продемонстрировать триумф в компьютерном
моделировании дарвиновской эволюции. Но навыки программы становились
все лучше и лучше не из-за эволюции, а прежде всего из-за растущего мастерства программистов.
Эта эволюция способности эволюционных программ явно не произошла бы
без человека в цикле.
Ландшафты отбора поисковых алгоритмов 71
3.7.3.2. Замена человека в цикле на компьютер в цикле
Разве не было бы хорошо запрограммировать компьютер для поиска наилучшего поиска, используя компьютер в цикле, а не человека в цикле? Однако мы
показываем, что такой поиск поиска (search for search, S4S) является гораздо
более сложной проблемой, чем сам поиск1.
Нам редко сообщают о роли человека в цикле в успехе поиска. Чаще всего мы
слышим только отчет об успехе окончательного алгоритма поиска с последующим празднованием и самовосхвалением.
3.8. Ландшафты отбора поисковых алгоритмов
Теперь вернемся к теме использования знаний для получения активной информации в поиске по одному критерию. Если у нас есть знания о поиске вкусного
блина, возможно, найдется несколько хитрых способов выбрать следующий
рецепт. Например, если известно, что поверхность в некотором смысле гладкая, мы можем попробовать восхождение по склону [35, 36]. Ландшафт отбора
для поиска рецепта блинов на рис. 3.2 действительно гладкий. Предположим,
что два запроса находятся близко друг к другу в пространстве поиска. Если
приспособленность второго запроса меньше, мы идем вниз в неправильном
направлении. Если приспособленность становится больше, мы поднимаемся
по склону и надеемся достичь максимума. В некоторых задачах поиска возможно измерение наклона (или градиента) приспособленности. Знание угла
наклона означает, что мы можем найти самый крутой путь наверх. Это может
быть эффективный путь к максимуму, поэтому следующий шаг делается в этом
направлении. Однако при наличии многочисленных холмов в пространстве
поиска могут возникнуть проблемы. Поиск может остановиться на вершине
холма с локальным максимумом, который не соответствует критерию проектирования и может быть намного ниже глобального максимума. Так обстоит дело
на двумерной поверхности ландшафта слева на рис. 3.10. Там наблюдается выраженный глобальный максимум. Но на правой стороне ландшафта имеется
небольшой холм. Если агент начнет восхождение на холм с правой стороны
пространства поиска, он вполне может оказаться на вершине меньшего холма.
Вершина меньшего холма – пример локального максимума.
Стохастическое восхождение и многоагентный поиск немного сложнее визуализировать в более высоких измерениях, но идея та же. Чтобы найти вкусный рецепт блинов, мы берем довольно удачный рецепт и лишь слегка меняем
состав. Если новый вкус лучше, мы сохраняем новый рецепт и далее вносим
в него изменения. Если новый вкус хуже, мы возвращаемся к оригинальному
рецепту и вносим другие небольшие изменения.
Ландшафты отбора, как правило, не гладкие. Рассмотрим, например, одномерный ландшафт отбора на рис. 3.11. Наш критерий проектирования – найти
1
Анализ поиска для поиска приведен в разделе 5.8.
72
Эволюционный поиск и требования к информации
целое число от 1 до 100 с приспособленностью 5 или выше. Есть 13 целых чисел,
удовлетворяющих этому ограничению, и они хорошо отделены друг от друга в пространстве поиска. Для этого поиска существуют начальные позиции,
когда строгое применение стохастического восхождения на холм не работает.
Если, как показано на рисунке, мы начинаем с позиции 62, которая имеет приспособленность 2, мы поднимемся на малый холм и застрянем на локальном
максимуме, расположенном на позиции 63 с приспособленностью 3. Это ложный максимум. Мы можем разработать процедуру поиска, выводящую нас из
этого локального максимума, но производительность исправленной версии,
в свою очередь, будет зависеть от знаний о структуре пространства поиска, которые сами по себе должны быть точными.
Рис. 3.10 Иллюстрация стохастического восхождения на гору (слева)
и многоагентного поиска, где агенты могут сообщать друг другу свои местоположения (справа). Эволюционный поиск является частным случаем многоагентного поиска
Рис. 3.11 Зубчатый ландшафт, образованный количеством единиц,
необходимых для выражения целого числа в двоичной форме. Например, 67 = (100011)2 имеет три
Источники 73
Восхождение не является подходящим алгоритмом для исследования пространства поиска, показанного на рис. 3.11. Стохастическое восхождение является лишь одним из большого числа поисковых алгоритмов. Различные алгоритмы поиска хорошо работают на определенных классах задач оптимизации.
Выбор хорошего алгоритма поиска и его параметров требует от программиста
знаний в предметной области.
Когда компьютеры стали быстрее и научились работать параллельно, появилась возможность применять эффективный многоагентный поиск. Как мы
видим на рис. 3.10 справа, многочисленные агенты одновременно ищут подходящие условия. Эти агенты могут общаться друг с другом, чтобы координировать свой следующий ход. Правила, по которым агенты перемещаются, умирают и возрождаются, варьируются от алгоритма к алгоритму. Эволюционный
поиск является примером многоагентного поиска.
Алгоритмы поиска могут иметь множество вариаций. Каждая процедура поиска имеет свои сильные и слабые стороны в зависимости от характера решаемой проблемы. Программист может использовать предварительные знания
о пространстве поиска, чтобы выбрать наилучший из алгоритмов. Как говорится, хороший программист умеет выбирать инструменты.
3.9. Выводы
Проектирование – это по своей сути итеративный процесс поиска, требующий знаний и опыта в предметной области. Чтобы уменьшить время, необходимое для успешного поиска, в поисковую процедуру может быть внесено
знание предметной области и опыт разработчика. Из-за экспоненциального
роста возможностей (то есть проклятия размерности) время и ресурсы, необходимые для слепого поиска, быстро становятся слишком большими, чтобы
его можно было применить.
Как мы показали, модель эволюции не может быть построена на основе слепого поиска и механического перебора вариантов. Ни квантовые вычисления,
ни закон Мура не оказывают существенного влияния на реализуемость такой
модели.
Источники
1.
2.
H. Wang, «On ‘computabilism’and physicalism: some problems». In Nature’s
Imagination, J. Cornwall (ed.) (Oxford University Press, 1995), pp. 161–189.
Например:
Thomas P. Schneider, «Evolution of biological information.» Nucleic Acids Res,
28(14), pp. 2794–2799 (2000).
R. E. Lenski, C. Ofria, R. T. Pennock, C. Adami, «The evolutionary origin of complex features». Nature, 423 (6936), pp. 139–144 (2003).
74
Эволюционный поиск и требования к информации
G. J. Chaitin, Proving Darwin: Making Biology Mathematical (Pantheon, 2012).
D. Thomas, «War of the Weasels: An Evolutionary Algorithm Beats Intelligent
Design». Skeptical Inquirer, 43, pp. 42–46 (2010).
D. Thomas, «Target? TARGET? We don’t need no stinkin’ Target!» http://pandasthumb.org/archives/2006/07/target-target-w-1.html (дата URL: May 2, 2016).
D. Thomas, «FORTRAN for Genetic Algorithm» (2006). http://www.nmsr.org/
genetic.htm (Дата URL: August 25, 2015).
D. Thomas (2006). «Steiner Genetic Algorithm-C++ Code». http://pandasthumb.
org/archives/2006/07/steiner-genetic.html (дата URL: May 2, 2016).
H. S. Wilf and W. J. Ewens, «There’s plenty of time for evolution». P Natl Acad Sci
107, pp. 22454–22456 (2010).
R. Dawkins, The Blind Watchmaker: Why the Evidence of Evolution Reveals a Universe Without Design (Norton, New York, 1996).
3.
Formula 409, http://www.formula409.com/ (дата URL: May 2, 2016).
4.
D. Martin, «John S. Barry, Main Force Behind WD-40, Dies at 84». New York
Times, July 22, 2009, http://www.nytimes.com/2009/07/22/business/22barry1.
html (дата URL: May 2, 2016).
5.
M. Josephson, Edison (McGraw Hill, New York, 1959).
6.
N. Baldwin, Edison: Inventing the Century (University of Chicago Press, 2001)
ISBN 0-226-03571-9.
7.
S. Shulman, Owning the Future (Houghton Mifflin Company, 1999), pp. 158– 160.
8.
Thomas Edison: Life of an Electrifying Man, Biographiq (Filiquarian Publishing,
2008).
9.
David B. Fogel, Evolutionary Computation: Toward a New Philosophy of Machine
Intelligence, 3rd edition (Wiley-IEEE Press, 2005).
Russell D. Reed, Robert J. Marks II, «An Evolutionary Algorithm for Function
Inversion and Boundary Marking». Proceedings of the IEEE International Confe
rence on Evolutionary Computation, pp. 794–797, November 26–30 (1995).
10. http://www.nasa.gov/centers/ames/news/releases/2004/antenna/antenna.html
(дата URL: May 2, 2016).
11. Различные открытые источники информации.
12. N. V. Venkatarayalu, T. Ray, «Single and multi-objective design of Yagi-Uda antennas using computational intelligence.» The 2003 Congress on Evolutionary
Computation, CEC ’03, 8–12 Dec., pp. 1237–1242 (2003).
13. J. D. Lohn, D. S. Linden, G. S. Hornby, A. Rodriguez-Arroyo, S. E. Seufert, B. Ble
vins, T. Greenling, «Evolutionary design of an X-band antenna for NASA’s Space
Technology 5 mission». IEEE Antennas and Propagation Society International
Symposium, 3, pp. 2313–2316 (2004).
Источники 75
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
J. D. Lohn, D. S. Linden, G. S. Hornby, and W. F. Kraus, «Evolutionary design of
a single-wire circularly-polarized X-band antenna for NASA’s Space Technology 5 mission», 2005 IEEE International Symposium Antennas and Propagation
Society, 2B, pp. 267–270 (2005).
Gerald J. Burke, Numerical Electromagnetics Code NEC-4, Method of Moments,
Part I: User’s Manual, Lawrence Livermore National Laboratory (1992).
Gerald J. Burke, Numerical Electromagnetics Code NEC-4, Method of Moments,
Part II: Program Description Theory, Lawrence Livermore National Laboratory
(1992).
H. Masahito, Quantum Computation and Information (Springer, Berlin, 2006).
Peter W. Shor, «Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer». SIAM J Comput 26(5), pp. 1484–
1509 (1997).
L. K. Grover, «A fast quantum mechanical algorithm for database search». Proceedings, 28th Annual ACM Symposium on the Theory of Computing, p. 212 (1996).
Этот пример был предложен нам Уолтером Бредли (Walter Bradley).
J. B. Foster, B. Clark, R. York, Critique of Intelligent Design: Materialism versus
Creationism from Antiquity to the Present (Monthly Review Press, 2008).
M. Shermer, Why Darwin Matters: The Case Against Intelligent Design (Times
Books, 2006).
J. McCabe, The Story of Evolution (Hutchinson & Co., London, 1912).
Loren G. Martin, «What is the function of the human appendix? Did it once
have a purpose that has since been lost?» Sci Am (1999). http://www.scientifi
camerican.com/article/what-is-the-function-of-the-human-appendix-did-itonce-have-a-purpose-that-has-since-been-lost/ (дата URL: May 2, 2016).
M. L. Everett и др., «Immune exclusion and immune inclusion: a new model
of host-bacterial interactions in the gut». Clin Appl Immunol Rev, 5, pp. 321–32
(2004).
Zahid, «The vermiform appendix: not a useless organ». J Coll Physicians Surg
Pak, 14(4), pp. 256–258 (2004).
R. R. Bollinger и др., «Biofilms in the large bowel suggest an apparent function
of the human vermiform appendix.» J Theor Biol, 249 (4), pp. 826–831 (2007).
J. Wells, The Myth of Junk DNA (WA Discovery Institute Press, Seattle, 2011).
Also, «Not junk after all: non-protein-coding DNA carries extensive biological
information». Biological Information – New Perspectives (World Scientific, Singapore, 2013), pp. 210–231.
Kay Chen Tan и др., Multiobjective Evolutionary Algorithms and Applications
(Springer, 2005).
Altannar Chinchuluun и др., Pareto Optimality, Game Theory and Equilibria
(Springer, 2008).
76
Эволюционный поиск и требования к информации
29. R. J. Marks II, G. L. Wise, D. G. Haldeman, J. L. Whited, «Detection in Laplace
noise», IEEE Transactions on Aerospace and Electronic Systems, (14), 1978,
pp. 866–872.
30. C. F. Bas, R. J. Marks II, «The layered perceptron versus the Neyman-Pearson
optimal detection». Proceedings of the International Joint Conference on Neural
Networks (IEEE Press, Singapore, 18–20 Nov 1991), pp. 1486–1489.
31. Например, Paolo Di Barba, Multiobjective Shape Design in Electricity and Magnetism (Springer, 2009).
32. David B. Fogel, «Using evolutionary programing to create neural networks that
are capable of playing tic-tac-toe.» 1993 IEEE International Conference on Neural Networks, pp. 875–880.
33. Kumar Chellapilla, David B. Fogel, «Evolving an expert checkers playing program without using human expertise». IEEETransactionson Evolutionary Computation, 5(4), pp. 422–428.
См. также: David B. Fogel, Blondie 24: Playing at the Edge of AI (Morgan Kauf
mann, 2001).
34. David B. Fogel, Timothy J. Hays, S. H. Hahn, James Quon, «Self-learning evolutionary chess program.» Proceedings of the IEEE, 92 (12), pp. 1947–1954 (2004).
35. Richard O. Duda, Peter E. Hart, David G. Stork, Pattern Classification, 2nd edition
(Wiley-Interscience, 2000).
36. Olle Häggström, «Intelligent design and the NFL Theorem». Biology & Philosophy (2007).
37. Donald E. Knuth, Sorting and Searching (The Art of Computer Programming volume 3) (Addison Wesley, 1973).
38. J. Nocedal, S. Wright, Numerical Optimization (Springer Science & Business Media, 2006).
39. I. Loshchilov, M. Schoenauer, M. Sebag, «Adaptive Coordinate Descent». In Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation
(ACM, 2011), pp. 885–892.
40. Donald E. Knuth, Ronald W. Moore, «An analysis of alpha-beta pruning». Artif
Intel, 6(4), pp. 293–326 (1976).
41. M. Dorigo, V. Maniezzo, A. Colorni, «Ant system: optimization by a colony of
cooperating agents». IEEE Transactions on Systems, Man, and Cybernetics – Part
B, 26(1), pp. 29–41 (1996).
42. Leandro N. de Castro, J. Timmis, Artificial Immune Systems: A New Computational Intelligence Approach (Springer, 2002), pp. 57–58.
43. Dimitri P. Bertsekas, «A distributed asynchronous relaxation algorithm for the
assignment problem». Proceedings of the IEEE International Conference on Decision and Control, pp. 1703–1704 (1985).
Источники 77
44. Ernst R. Berndt, Bronwyn H. Hall, Robert E. Hall, and Jerry A. Hausman, «Estimation and inference in nonlinear structural models». Annals of Economic and
Social Measurement, 3 (4), pp. 653–665 (1974).
45. Patrenahalli M. Narendra and K. Fukunaga, «A branch and bound algorithm for
feature subset selection». IEEE Transactions on Computers, 100 (9), pp. 917–922
(1977).
46. M. Padberg and G. Rinaldi, «A branch-and-cut algorithm for the resolution of
large-scale symmetric traveling salesman problems». SIAM Rev, 33 (1), pp. 60–
100 (1991).
47. Cynthia Barnhart, Ellis L. Johnson, George L, Nemhauser, Martin W. P. Savelsbergh, Pamela H. Vance, «Branch-and-price: Column generation for solving
huge integer programs». Operations Research, 46 (3), pp. 316–329 (1998).
48. J. Nocedal, Stephen J. Wright, Numerical Optimization, 2nd edition (SpringerVerlag, Berlin, New York, 2006).
49. Thomas A. Feo, Mauricio G. C. Resende, «A probabilistic heuristic for a computationally difficult set covering problem». Op Res Lett, 8 (2), pp. 67–71 (1989).
50. A. V. Knyazev, I. Lashuk, «Steepest descent and conjugate gradient methods
with variable preconditioning». SIAM J Matrix Anal Appl, 29 (4), pp. 1267–1280
(2007).
51. Y. Akimoto, Y. Nagata, I. Ono, S. Kobayashi. «Bidirectional relation between
CMA evolution strategies and natural evolution strategies». Parallel Problem
Solving from Nature, PPSN XI, pp. 154–163 (Springer, Berlin Heidelberg, 2010).
52. Dick den Hertog, C. Roos, T. Terlaky, «The linear complimentarity problem, sufficient matrices, and the criss-cross method». Linear Algebra Appl, 187, pp. 1–14
(1993).
53. R. Y. Rubinstein, «Optimization of computer simulation models with rare
events». Eur J Ops Res, 99, pp. 89–112 (1997).
R. Y. Rubinstein, D. P. Kroese, The Cross-Entropy Method: A Unified Approach
to Combinatorial Optimization, Monte-Carlo Simulation, and Machine Learning
(Springer-Verlag, New York, 2004).
54. X. S. Yang and S. Deb, «Cuckoo search via Lévy flights». World Congress on Nature
& Biologically Inspired Computing (NaBIC 2009). IEEE Publications, pp. 210–214.
arxiv:1003.1594v1.
55. W. C. Davidon, «Variable metric method for minimization». AEC Research Development Rept. ANL-5990 (Rev.) (1959).
56. P. Rocca, G. Oliveri, A. Massa, «Differential evolution as applied to electromagnetics». Antennas and Propagation Magazine, IEEE, 53(1), pp. 38–49 (2011).
57. Xin-She Yang, Suash Deb, «Eagle strategy using Lévy walk and firefly algorithms for stochastic optimization». Nature Inspired Cooperative Strategies for
Optimization (NICSO 2010) (Springer Berlin Heidelberg, 2010), pp. 101–111.
78
Эволюционный поиск и требования к информации
58. Jacek M. Zurada, R. J. Marks II and C. J. Robinson; Editors, Computational Intelligence: Imitating Life (IEEE Press, 1994).
M. Palaniswami, Y. Attikiouzel, Robert J. Marks II, D. Fogel, T. Fukuda; Editors,
Computational Intelligence: A Dynamic System Perspective (IEEE Press, 1995).
59. David E. Ferguson, «Fibonaccian searching». Communications of the ACM, 3(12),
p. 648 (1960).
60. J. Kiefer, «Sequential minimax search for a maximum». Proceedings of the American Mathematical Society, 4(3), pp. 502–506 (1953).
61. Xin-She Yang, «Firefly algorithms for multimodal optimization». In Stochastic
Algorithms: Foundations and Applications (Springer Berlin Heidelberg, 2009),
pp. 169–178.
62. R. Fletcher, M. J. D. Powell, «A rapidly convergent descent method for minimization». Computer J. (6), pp. 163–168 (1963).
63. David E. Goldberg, Genetic Algorithms in Search Optimization and Machine Learning (Addison Wesley, 1989).
R. Reed, R. J. Marks II, «Genetic Algorithms and Neural Networks: An Introduction». Northcon/92 Conference Record (Western Periodicals Co., Ventura, CA,
Seattle WA, October 19–21, 1992), pp. 293–301.
64. K. N. Krishnanand, D. Ghose. «Detection of multiple source locations using
a glowworm metaphor with applications to collective robotics». Proceedings of
the 2005 IEEE Swarm Intelligence Symposium (SIS 2005), pp. 84–91 (2005).
65. A. Mordecai, Douglass J. Wilde. «Optimality proof for the symmetric Fibonacci
search technique». Fibonacci Quarterly, 4, pp. 265–269 (1966).
66. Jack Kiefer, там же.
67. Jan A. Snyman, Practical Mathematical Optimization: An Introduction to Basic
Optimization Theory and Classical and New Gradient-Based Algorithms (Springer
Publishing, 2005).
68. Gunter Dueck, «New optimization heuristics: the great deluge algorithm and
the record-to-record travel». J Comp Phys, 104(1), pp. 86–92 (1993).
69. Zong Woo Geem, «Novel derivative of harmony search algorithm for discrete design variables». Applied Mathematics and Computation, 199, (1), pp. 223–230 (2008).
70. Esmaeil Atashpaz-Gargari and Caro Lucas, «Imperialist competitive algorithm:
an algorithm for optimization inspired by imperialistic competition». 2007 IEEE
Congress on Evolutionary Computation (CEC 2007), pp. 4661– 4667 (2007).
71. Shah-Hosseini Hamed, «The intelligent water drops algorithm: a nature-inspired swarm-based optimization algorithm». Int J Bio-Inspired Comp, 1(1/2),
pp. 71–79 (2009).
72. Karmarkar Narendra, «A new polynomial-time algorithm for linear programming». Proceedings of the Sixteenth Annual ACM Symposium on Theory of
Computing, pp. 302–311 (1984).
Источники 79
73. Kenneth Levenberg, «A Method for the Solution of Certain Non-Linear Problems in Least Squares». Quart App Math, 2, pp. 164–168 (1944).
74. Alexander Schrijver, Theory of Linear and Integer Programming (John Wiley &
Sons, 1998).
Yurii Nesterov, Arkadii Nemirovskii, Yinyu Ye, «Interior-point polynomial algorithms in convex programming». Vol. 13. Philadelphia Society for Industrial and
Applied Mathematics (1994).
75. K. I. M. McKinnon, «Convergence of the Nelder–Mead simplex method to a nonstationary point». SIAM J Optimization, 9, pp. 148–158 (1999).
76. E. Süli, D. Mayers, An Introduction to Numerical Analysis (Cambridge University
Press, 2003).
77. A. H. Boas, «Modern mathematical tools for optimization», Chem Engrg (1962).
78. J. Kennedy, R. Eberhart, «Particle Swarm Optimization». Proceedings of IEEE International Conference on Neural Networks IV, pp. 1942–1948 (1995).
J. Kennedy, R. Eberhart, Swarm Intelligence (Morgan Kaufmann, 2001).
79. W. Dickinson, «Nonlinear optimization: Some procedures and examples». Proceedings of the 19th ACM National Conference (ACM, 1964), pp. 51–201.
80. Robert J. Marks II, Handbook of Fourier Analysis & its Applications (Oxford University Press, 2009).
81. J. W. Bandler, P. A. Macdonsdd, «Optimization of microwave networks by razor
search». IEEE Trans. Microwave Theory Tech., 17(8), pp. 552–562 (1969).
82. H. H. Rosenbrock, «An automatic method for finding the greatest or least value
of a function». Comp. J., 3, pp. 175–184 (1960).
83. John W. Bandler, «Optimization methods for computer-aided design». IEEE
Transactions on Microwave Theory and Techniques, 17 (8), pp. 533–552 (1969).
84. Muzaffar Eusuff, Kevin Lansey, Fayzul Pasha, «Shuffled frog-leaping algorithm:
a memetic meta-heuristic for discrete optimization». Engineering Optimization,
38(2), pp. 129–154 (2006).
85. M. J. Box, «A new method of constrained optimization and a comparison with
other methods». Computer J., (8), pp. 42–52 (1965).
J. A. Nelder, R. Mead, «A simplex method for function minimization». Computer
J., 7, pp. 308–313 (1965).
86. S. Kirkpatrick, C. D. Gelatt, M. P. Vecchi, «Optimization by simulated annealing».
Science, 220 (4598), pp. 671–680 (1983).
87. X.-F. Xie, W. Zhang, Z. Yang, «Social cognitive optimization for nonlinear programming problems». Proceedings of the First International Conference on Machine Learning and Cybernetics, 2, pp. 779–783 (Beijing, 2002).
88. James C. Spall, Introduction to Stochastic Search and Optimization (2003).
80
Эволюционный поиск и требования к информации
89. Brian P. Gerkey, Sebastian Thrun, Geoff Gordon, «Parallel stochastic hill-climbing with small teams». Multi-Robot Systems. From Swarmsto Intelligent Automata, Volume III, pp. 65–77 (Springer Netherlands, 2005).
90. F. Glover, «Tabu Search – Part I». ORSA J Comput, 1(3), pp. 190–206 (1989).
«Tabu Search – Part II», ORSA J Comput, 2 (1), pp. 4–32 (1990).
91. Athanasios K. Sakalidis, «AVL-Trees for Localized Search». Inform Control, 67,
pp. 173–194 (1985).
R. Seidel and C. R. Aragon, «Randomized search trees». Algorithmica, 16(4–5),
pp. 464–497 (1996).
92. S. Zionts, J. Wallenius, «An interactive programming method for solving the
multiple criteria problem». Manage Sci, 22 (6), pp. 652–663 (1976).
Глава
4
Детерминизм
в случайности
Они возводят идолов и сами же разрушают их.
Это забавляет всех престарелых профессоров.
Им есть чем заняться... Все, что они говорили
мне в детстве, уже опровергнуто теми же экспертами, которые все это придумали.
Джон Леннон [1]
Все эволюционные процессы являются в той или иной мере стохастическими.
Они используют случайность и принимают какие-то решения, подбрасывая
симметричную монету. Случайные мутации являются тому примером.
Хотя это звучит парадоксально, случайность, смоделированная стандартной
теорией вероятностей, имеет много фиксированных, почти детерминированных свойств. Случайность не подразумевает полное отсутствие законов.
Мы покажем, когда случайные эволюционные процессы ограничены в достижении результатов. В подобных случаях, независимо от того, как долго вы
позволяете эволюционному процессу работать в фиксированной среде, решение никогда не станет более умным, чем это позволяет процесс. Эволюционная
программа, написанная для проектирования антенны, никогда не разовьет самопроизвольную способность играть в шахматы. А статическая среда1, в которой стохастический процесс развивается до сложности уровня человеческого
организма, чрезвычайно маловероятна.
Но разве мы не можем написать компьютерную программу для динамического изменения окружающей среды и, следовательно, приспособления таким
образом, чтобы направлять эволюционный процесс на эволюцию одной клетки, затем гуппи, лягушки, обезьяны и вплоть до человека? Если это так, план
изменений окружающей среды должен быть тщательно разработан. Причем
изменение окружающей среды скорее разрушит предыдущие достижения, чем
продвинет их на новый уровень сложности.
1
Например, неизменяемый алгоритм компьютерной модели эволюции.
82
Детерминизм в случайности
Стальной шарик, подпрыгивающий в автомате для игры в пинбол, является
примером случайного процесса с единственной детерминированной точкой:
мяч всегда оказывается в маленьком отверстии под лопатками. Разновидность
этого примера – ручной лабиринт с катающимся стальным шариком, целью
которого является доведение шарика до конца лабиринта. Для простых лабиринтов случайный наклон, имитирующий изменения окружающей среды,
может иногда приводить шарик к концу лабиринта. Для стандартного шарика
диаметром 4,75 мм в сложном лабиринте с проходами шириной всего 5 мм
случайное прохождение лабиринта размером с футбольное поле окажется маловероятным. По мере возрастания сложности лабиринта становится все труднее добиться успеха. Интеллект, контролирующий лабиринт взглядом сверху,
может целенаправленно наклонять лабиринт, т. е. изменять окружающую среду, чтобы подкатить шарик к желаемой цели (рис. 4.1). Однако для этого требуется точное планирование изменений окружающей среды. Процесс должен
быть тщательно продуман. Мы уже говорили о том, что предварительной продуманностью грешат в той или иной мере практически все якобы случайные
компьютерные модели эволюции. Далее мы продолжим разговор о том, почему так трудно (если вообще возможно) обойти проблему предназначенности
в моделировании.
Рис. 4.1 Проведите шарик через лабиринт от A до Z, проходя через
различные стадии жизни (J) и избегая гибели (M). Погибнуть можно
только один раз. «Неудачу можно потерпеть множеством разных способов, ... а к успеху ведет только один путь» (Аристотель)
Принцип равной вероятности событий 83
4.1. Принцип равной вероятности событий
Чтобы найти за разумный срок рецепт блина с девятью ингредиентами поиском среди миллиарда рецептов, необходимо знание предметной области.
Для любых, кроме самых простых проблем поиска, знание предметной области является обязательным, если мы хотим получить результат в обозримом
будущем. Но что, если у нас нет опыта? Это может звучать нелепо, но если нет
опыта в предметной области, мы знаем ничего. Вероятно, это означает, что решение с равной вероятностью может существовать где угодно в области поиска. Что касается информации Шеннона, инициализация имеет максимальную
энтропию, т. е. максимальную неопределенность.
4.1.1 «Ничто есть то, о чем мечтают скалы»1
Что значит знать «ничего»? Это может звучать как парадокс, но «ничто» означает что-то2 – это означает «абсолютно ничто» или просто «ничто есть ничто»,
хотя идею «ничего» трудно понять.
В качестве примера рассмотрим теорию Большого взрыва Вселенной. Обычно Вселенную перед Большим взрывом воображают в виде большого черного
пустого пространства. Нет звука, нет материи, нет энергии. Просто бесконечное пустое пространство. Нет, это ошибочное представление. До Большого
взрыва не было ничего, а бесконечное пустое пространство – это уже нечто. До
Большого взрыва не было пространства. Таким образом, наше представление
о реальности до создания Вселенной должно быть очищено от представления
о пространстве.
Хорошо. Будем визуализировать без пространства. Это сложно, но мы это
сделаем. Наверное. Мы думаем: «Ничего не было. Ни звука, ни материи, ни энергии. Ни пространства. Ничего. Затем внезапно...»
Нет, это тоже не работает. «Внезапно» предполагает неожиданное событие,
которое так или иначе привязано к шкале времени. Современная космология
говорит, что время в нашей Вселенной также было создано во время Большого
взрыва [3]. Итак, прежде чем постигать ничто, существовавшее до Большого
взрыва, помимо пространства, наше воображение должно быть очищено от
идеи времени. Понимание отсутствия пространства и времени является весьма нетривиальным интеллектуальным упражнением3. Мы всегда существова1
2
3
Powered by TCPDF (www.tcpdf.org)
Выражение приписывают Платону, Аристотелю и Сократу.
Игра слов вокруг «ничего» может быть веселой здесь. Значимое утверждение «ничего
означает что-то» сначала кажется оксюмороном. Фраза «ничего не значит ничего»,
что интересно, означает то же самое или, альтернативно, может быть истолкована
как тавтология.
Сторонники М-теории утверждают возможность существования параллельных вселенных «до» Большого взрыва. Однако отсутствие времени в том виде, в котором мы
его знаем, порождает вопрос о значении «до». Значение «до» концептуально лежит
даже за пределами понятия «ничто» в нашей Вселенной.
84
Детерминизм в случайности
ли во времени и пространстве и с трудом представляем их отсутствие. Смысл
«ничего» до Большого взрыва трудно понять интуитивно.
4.1.2. Принцип недостаточного основания Бернулли (PrOIR)
В компьютерном поиске принцип недостаточного основания Бернулли1 (Principle of Insufficient Reason, PrOIR) предполагает, что ничего неизвестно о проб
леме поиска, за исключением области пространства поиска, включая ее количество элементов. Выбрав точку в пространстве поиска, можно определить
приспособленность выбора. У нас нет иных способов оценки запросов. По сути,
идея ничего в пространстве поиска не так сложна для понимания, как ничто,
существовавшее до Большого взрыва, но трудность толкования ничто остается
прежней. Мы ничего не знаем о том, где находится цель. Мы ничего не знаем
о структуре пространства поиска. Мы не знаем, везде ли оно гладкое, рваное
или плоское. Вполне возможно, что каждая точка в пространстве поиска является жизнеспособным решением проблемы. Может быть, вообще нет никакого
решения. Мы ничего не знаем. Точнее, мы знаем ничего.
PrOIR Бернулли2, опубликованный в 1713 году, гласит [4, 5]:
«...в отсутствие каких-либо предварительных знаний мы должны предположить, что события [в пространстве поиска] имеют равную вероятность».
Пьер-Симон Лаплас, известный математик XVIII века, астроном и атеист, согласился [6]:
«[Когда] у нас нет явной причины, ни один конкретный случай не должен иметь
преимущество перед любым другим».
Если мы ничего не знаем о поиске, каждый из элементов в пространстве поиска должен считаться одинаково вероятным.
4.1.2.1. Примеры
Мы используем PrOIR Бернулли в повседневных расчетах вероятности.
1. Лотерея. Если продана тысяча лотерейных билетов, мы предполагаем,
что вероятность выигрыша любого билета такая же, как и у всех остальных. Если вы покупаете один билет, ваш шанс на выигрыш составляет
один на тысячу. Здесь работает PrOIR Бернулли. Обман организаторов
лотереи может исказить результаты, но если вы не знаете об этом заранее, то одинаково вероятные результаты – лучшая оценка ваших шансов.
2. Рулетка. Похожий пример – колесо рулетки. Шансы на выигрыш основаны на PrOIR Бернулли, в котором говорится, что вероятность попадания
1
2
Больше известен под названием «principle of indifference» (принцип безразличия). –
Прим. пер.
PrOIR Бернулли, приписываемый Якобу Бернулли (1654–1705) и опубликованный
после его смерти, не следует путать с принципом Бернулли о гидродинамике. Принцип флюидов приписывается племяннику Якоба Даниэлю Бернулли (1700–1782).
Принцип равной вероятности событий 85
шарика рулетки в некий слот такая же, как и в любой другой. Если крупье
казино имеет тайный контроль над колесом, это предположение может
быть неверным. Если, однако, вы ничего не знаете о процессе вращения
рулетки, единственно верным предположением является PrOIR Бернулли.
3. Кости. Когда мы бросаем симметричный кубик, все шесть сторон считаются одинаково вероятными. Таким образом, вероятность выпадения
трех точек – одна из шести.
4. Жеребьевка. Практика жеребьевки предполагает, что все результаты имеют одинаковую вероятность и справедливы для всех участников.
4.1.2.2. Критика принципа Бернулли
Хотя PrOIR Бернулли кажется очевидным, есть те, кто с ним не согласен. Давайте рассмотрим их аргументы.
Моделирование
Истинная причина критики принципа Бернулли кроется в неправильном
моделировании. Распределение либо неверно истолковано, либо сознательно
представляется как неоднородное1. Вот несколько примеров.
Звездный путь. Поклонники сериала «Звездный путь» знакомы с Кобаяси
Мару2, испытанием для курсантов, проходящих обучение в Академии Звездного флота в XXIII веке. Тест представляет собой симулятор битвы в виртуальной реальности и был спроектирован как заведомо непроходимый.
Джеймс Т. Кирк, будущий капитан звездолета «Энтерпрайз», стал первым
и единственным в истории, кто прошел этот тест. Он сделал это, изменив модель, лежащую в основе теста, и тем самым лишил законной силы предположения, обычно связанные с игрой. Для этого он тайно переписал некоторые
программы, управляющие симуляцией.
Наш вывод заключается в следующем: исход события часто моделируется
нашим предположением о представлении события. Если наша модель неверна,
то и наше предсказание результата также будет неверным. Вероятность – это
математическая модель. На самом деле, когда монета подброшена, малейшие
физические параметры броска, монеты и окружающей среды полностью определяют, будет ли результатом орел или решка. Откуда же в таком случае берется
случайность? Да просто набор физических параметров слишком обширен для
анализа или, что более важно, нам неизвестны параметры окружающей среды,
такие как динамическая вязкость, которая контролирует отскок монеты.
1
2
PrOIR Бернулли применяется в примерах активной информации в разделе 5.4.2. Однако для определения активной информации необязательно использовать равномерное распределение в качестве базовой линии, но можно измерять добавленную
информацию из любого распределения. Идея такая же, как измерение дБ (децибел),
которое, как и активная информация, пропорционально логарифму отношения. Знаменатель отношения, ссылка, может быть любым желаемым значением.
Тест Кобаяси Мару впервые был показан в фильме «Звездный путь II: Гнев Хана». Он
также упоминается в фильме 2009 года «Звездный путь».
86
Детерминизм в случайности
Но что, если мы создали идеальную машину в вакууме, которая каждый раз
одинаково подбрасывает монету? Мы должны постоянно получать один и тот
же результат. Но подбрасывание монет плохо обусловлено [7]. Малейшие изменения в подбрасывании или окружающей среде быстро возвращают решение к 50/50 вероятностям орла и решки. Именно поэтому к броскам монеты
успешно применяется вероятностная модель, и вероятность выпадения орла
или решки, согласно PrOIR Бернулли, составляет 50/50. В броске монеты, как
и в других вероятностных приложениях, определение вероятности должно
рассматриваться как модель. PrOIR Бернулли указывает, что при отсутствии
каких-либо знаний о результатах эксперимента равная вероятность присваивается каждому возможному результату.
Возвращаясь к примерам лотереи, рулетки и игры в кости, можно указать
на провал предположения о равномерной вероятности после дискредитирующего модель эксперимента. Эксперименты, однако, создают знания, и уже
после первого эксперимента мы что-то знаем, то есть мы перестаем знать
ничего.
Рулетка. В одной из первых попыток применить компьютер, чтобы повлиять на шансы, Клод Шеннон [8] и Эдвард О. Торп1 в 1961 году использовали
носимый компьютер для экспериментального измерения отклонений от однородности вращения колеса рулетки [9]. Шеннон и Торп бросили вызов модели однородности. Узнав кое-что о вращении конкретного колеса рулетки, они
смогли делать ставки на результаты, более благоприятные, чем просто случайные. Сегодня колеса рулетки обычно сбалансированы и выровнены так, чтобы
результат вращения был как можно более случайным. Также стол теперь закрыт для ставок до начала вращения.
Блэкджек. Когда вы играете в блэкджек в казино, вероятность того, что казино получит ваши деньги при игре со свежей перетасованной колодой, составляет около 51 %. Хотя это не слишком благоприятные шансы, закон больших
чисел гласит, что, если вы будете играть в блэкджек достаточно долго, казино
получит все ваши деньги. Но блэкджек обычно не разыгрывается из недавно перетасованной колоды. Несколько колод перемешиваются друг с другом,
и карты последовательно переворачиваются в течение ряда игр. Информация,
полученная от запоминания сыгранных карт, может снизить шансы казино
ниже 50 %. Роли поменялись. Если вы играете достаточно долго, вы забираете
все деньги казино2.
Простые методы учета карт, сыгравших в блэкджек, называются подсчетом
карт (card counting), как показано в документальном фильме «Holy Rollers» [10].
1
2
Торп был разработчиком подсчета карт и пионером хедж-фондов.
Это предполагает, что ваш первоначальный запас денег для ставок достаточно велик.
Волатильность (дисперсия) выигрыша с вероятностями, близкими к 50 %, велика,
и хотя закон больших чисел успешно работает, перед достижением асимптотического выигрыша вы можете столкнуться со значительными потерями.
Принцип равной вероятности событий 87
⍟ Несимметричный кубик и пропорциональные ставки. Математика оптимальных азартных игр хорошо описана с использованием языка теории информации Шеннона.
Шеннон и Торп знали, что колесо рулетки не обеспечивает равномерную вероятность исходов, но выплаты основаны на предположении, что это так. Рассмотрим две крайности. Если вероятности исходов действительно одинаковы,
перспективы выигрыша дополнительных денег печальны. Рассмотрим, например, шесть возможных результатов, которые находятся на гранях симметричного кубика. Тогда каждый результат будет иметь шансы 1 к 6. Предполагается,
что когда вы делаете успешную ставку, ваш выигрыш в шесть раз превышает
сумму ставки. Если у вас есть 12 долл. и вы ставите по 2 долл. на каждый из шес
ти исходов, вы всегда закончите игру при своих деньгах, независимо от того,
симметричен кубик или нет. Это не очень захватывающее и неприбыльное
времяпрепровождение. Но все становится более увлекательным, если кубик
не сбалансирован1 и вы знаете о вероятности исхода каждого события. Теперь
можно заработать деньги.
Оптимальная долгосрочная стратегия, когда вы знаете вероятность каждого исхода, называется пропорциональной ставкой. Вот пример такой стратегии.
Вы бросаете кубик, и независимо от того, какое число выпало после броска,
угадавший получает выплату 6 к 1. Казино предполагает, что кубик симметричен, и шанс любой грани равен одному из шести2. Но вы-то знаете, что кубик
не симметричен и имеет следующие вероятности выпадений:
Вероятность выпадения числа 2 равна, например,
Стратегия пропор-
циональных ставок подразумевает распределение ваших ставок пропорционально вероятностям успеха. Если у вас изначально есть 12 долл., пропорциональная ставка будет выглядеть так:
b1 = $6, b2 = $4, b3 = b4 = $1, b5 = b6 = $0.
Вот возможные результаты и ваши следующие ставки:
если бросок кубика показывает 1, вы получаете 36 долл. Вероятность этого события равна p1 = . Тогда ваша вторая ставка с использованием пропорциональных ставок:
b1 = $18, b2 = $12, b3 = b4 = $3, b5 = b6 = $0;
1
2
Такой жульнический кубик называют loaded die – смещенная игральная кость.
При полной выплате казино также явно не зарабатывает деньги в долгосрочной перспективе. В среднем получится безубыточность. Чтобы заработать, казино должно
выплачивать за выигрыш немного меньше, скажем, $5,50 за каждую выигрышную
ставку в один доллар.
88
Детерминизм в случайности
если бросок кубика показывает 2, вы получаете 24 долл., которые снова
распределяете пропорционально коэффициентам. Тогда второй раунд
ставок имеет вид:
b1 = $12, b2 = $8, b3 = b4 = $2, b5 = b6 = $0;
если на кубике выпадет 3 или 4, вам заплатят 6 долл. и вы потеряете половину своих денег. Это нормально. У вас все еще есть деньги для ставки,
и ваша вторая ставка:
b1 = $3, b2 = $2, b3 = b4 = $0,50, b5 = b6 = $0;
поскольку вы знаете, что вероятность показа пяти или шести равна нулю,
на пять и шесть никогда не ставится.
В долгосрочной перспективе пропорциональные ставки максимизируют
ваши доходы быстрее, чем любой другой метод [11]. Но знание вероятностей
должно быть точным! В противном случае вы можете быстро все потерять.
Примечание
⍟ Дадим математическое обоснование. Для N возможных результатов коэффициент
удвоения для пропорциональных ставок:
W(p) = log2N – H(p),
где p = [p1, p2, p3, …, pN]T обозначает вектор вероятности исходов для каждого случая и
– энтропия разброса вероятностей. Величина W(p) называется коэффициентом удвоения, поскольку после M >> 1 игр с использованием пропорциональных ставок ожидаемые выигрыши составляют
где S0 – деньги, с которых вы начали. Когда все pn равны, W(p) = 0 и ваши деньги никогда
не удваиваются. Когда один pn равен единице, а остальные равны нулю, W(p) = log2N
и SG = S0 N M. Каждая игра умножает ваш выигрыш на коэффициент N.
Поскольку результаты стохастические, разные игры пропорциональных
ставок приведут к разным результатам. Моделирование пропорциональных
ставок, начиная с одного доллара, с использованием упомянутых выше вероятностей показано слева на рис. 4.2. Выигрыш быстро накапливается при
использовании пропорциональных ставок. Обратите внимание, что 1010 соответствует 10 млрд долл., а 1015 – одному квадриллиону (1000 трлн) долларов.
Слева – результаты игры для шести вероятностей исхода:
Принцип равной вероятности событий 89
За 100 игр вы можете в среднем погасить государственный долг США, заплатить 50 % налогов и при этом оставаться самым богатым человеком в мире.
Справа – более скромный случай:
Вы можете заработать в среднем несколько тысяч долларов, но учтите, что
в худшем случае вы получите около 10–2 долл. – буквально копейки.
Рис. 4.2 Симуляция пропорциональных ставок, начинающихся с 12 долл.
Толстая черная линия – средний результат
Чем дальше вероятности от равномерности, тем быстрее накапливаются
деньги. Этот параметр называется скоростью удвоения W и говорит, сколько
времени в среднем потребуется, чтобы удвоить ваш начальный вклад. Нам
дано:
где N – число возможных результатов эксперимента, а H(p) – энтропия Шеннона, соответствующая распределению вероятностей. Для симметричного кубика (т. е. равномерного распределения) H(p) = log2N и W = 0. Другими словами,
ни вы, ни казино в среднем не заработаете денег в долгосрочной перспективе.
Игра безубыточна, и это то, для чего предназначена идеально честная игра.
В этом же уравнении описывается активная информация, в случае когда
у нас есть N возможных результатов в пространстве поиска, и вычисляется активная информация, соответствующая выбору результатов, пропорциональных вероятности того, что элемент пространства поиска является целью. Тогда
активной информацией из знания вероятностного распределения является
I+ = W, как указано в приведенном выше уравнении. В азартных играх активная информация может быть очень прибыльной.
90
Детерминизм в случайности
Моделирование повторных пропорциональных ставок с вероятностями,
близкими к равномерному распределению, показано в правой части рис. 4.2.
Накопление выигрышей по-прежнему заметно, но происходит с гораздо более
скромной скоростью. Если все вероятности равны друг другу, а распределение
равномерное, кривая выигрыша больше не является случайной. При пропорциональных ставках ваш выигрыш в каждой игре будет точно возвращать ваш
начальный взнос. Таким образом, выигрышная кривая будет постоянной горизонтальной линией.
Эффективность пропорциональных ставок аналогична эффективности алгоритма поиска. При пропорциональных ставках вы хотите извлечь максимальную сумму денег из игры за одну ставку. В поиске вы хотите извлечь максимальное количество информации за один запрос. В этих случаях математика
идентична.
Сломанный кубик. Пропорциональные ставки – пример, где знание о вероятностях в пространстве поиска могут быть использованы для зарабатывания
денег. Есть яркий исторический пример, когда фундаментальная модель симметричного кубика оказалась неточной.
В книге Ивара Экеланда «Сломанная кость» [12] автор описывает, как короли
Норвегии и Швеции в Средние века решили бросить пару костей, чтобы определить право собственности на поселение на острове Хайзинг, которое поочередно принадлежало обеим странам. Самая высокая общая сумма должна была
определить победителя. Король Швеции бросил первым, и у него выпали две
шестерки. Поэтому может показаться, что король Норвегии в лучшем случае
может уравновесить выигрыш шведского короля, хотя с большей вероятностью
поселение Хайзинг попадет в руки Швеции. С костями из шести граней, пронумерованными от одного до шести, сумма любой пары граней из пары кос
тей может составлять не менее двух и не более 12. Таким образом, эталонный
набор возможных результатов для пары костей может быть представленным
множеством {2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}. Более того, король Швеции только что
показал лучший результат в этом наборе, а именно 12.
Поэтому случившееся далее было замечательно:
«Вслед за этим Олаф, король Норвегии, бросил кости, и шестерка выпала на одной из них, а другая кость раскололась надвое, да так что шесть и один оказались сверху; и поэтому он вступил во владение поселением» [13].
Поскольку в этой игре более высокие суммы бьют более низкие, результат
13 (6 + 6 + 1) побеждает результат 12 (6 + 6), поэтому король Норвегии был объявлен победителем. Как правило, любая игра с парой костей рассчитывается
по сумме двух граней на каждый бросок. Учитывая это ограничение, базовый
класс возможных сумм для пары граней кубиков будет 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12. Тем не менее с учетом возможности расколоть кость на две части и показать две грани, базовый класс возможных сумм должен быть расширен, чтобы
включить, по крайней мере, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13.
Принцип равной вероятности событий 91
Мог ли король Олаф подстроить свою победу? Возможно, он знал, что кость
была сделана из какого-то хрупкого материала, который сломается, если его
сильно бросить на землю. Тем самым он изменил пространство возможных
результатов, расходящееся с предположениями короля Швеции и других зрителей. Далее в этой главе мы увидим, что шансы на выигрыш в розыгрыше лотереи не зависят от их пространственного распределения или метода выбора.
Но, как показано на рис. 4.3, мы можем применить принцип Олафа, чтобы увеличить наши шансы на победу в розыгрыше бумажных бюллетеней.
Рис. 4.3 Как выиграть в розыгрыше по принципу Олафа
Игроки кладут в шляпу листки бумаги со своими именами. Затем ведущий
не глядя вынимает один листок. Выигрывает тот игрок, чье имя оказалось на
этом листке. Единственный способ увеличить ваши шансы на выигрыш – это,
как король Олаф, придумать умный план. Нужно изменить соревнование таким образом, чтобы оно выходило за рамки законов и предположений единой
вероятностной модели. Этого можно достичь, либо приобретая знания о процессе, либо, как король Норвегии, манипулируя системой так, чтобы предположение о единообразии больше не работало. Вот способ перехитрить равные
шансы в розыгрыше. При выборе листков бумаги из шляпы предполагается
использование PrOIR Бернулли. Если в шляпе есть N листков и вам принадлежит один из них, то шанс выигрыша составит один из N. Но это при условии,
что процессом выбора не манипулируют. Эффективный способ манипуляции –
сложить или смять листок, чтобы он занимал больше места. Попробуйте в следующий раз, когда представится такая возможность. Это не гарантирует победу, но, безусловно, увеличивает вероятность выигрыша. Авторы признают,
что видели, как эта процедура успешно работает во многих случаях (но предпочитают не признаваться, использовали ли они этот метод сами). Мы оставим
обсуждение этичности этой практики для другого случая.
92
Детерминизм в случайности
Неопределенные определения и двусмысленность: парадокс Бертрана
К числу критиков PrOIR Бернулли относится Джон Мейнард Кейнс1, который
переименовал PrOIR Бернулли в принцип безразличия [14]. В качестве контрпримера Кейнс обращается к парадоксу Бертрана. Бертран задает следующий
вопрос:
«Если хорда в круге выбрана случайным образом, какова вероятность того, что
ее длина превышает 3 радиуса круга?»
Бертран показывает, что есть по крайней мере 3 решения в зависимости от
применения PrOIR Бернулли:
Однако, как показано на рис. 4.4
и поясняется в примечании, в этом нет противоречия. В первом случае круг делится пополам линией, длина которой равна диаметру круга, а случайная хорда
выбрана из набора всех возможных перпендикуляров биссектрисы. Во втором
случае хорда была определена путем соединения двух случайно выбранных точек на окружности. В третьем случае хорда была определена ее средней точкой,
случайным образом выбранной внутри круга. Наличие трех вариантов решения не является ошибкой PrOIR [15] Бернулли, а связано с неоднозначностью
толкования слова «случайный» в утверждении парадокса Бертрана.
Рис. 4.4 Иллюстрация парадокса Бертрана (см. примечание)
Примечание. Парадокс Бертрана
Обратимся к рис. 4.4. Слева изображение окружности радиуса r, вписанной в другую
окружность с половиной радиуса. Равносторонний треугольник с точками на большем
круге касается меньшего круга. Каждая сторона треугольника имеет длину 3 r. Мы задаем вопрос: какова вероятность случайного выбора пересекающей круг хорды p с длиной,
превышающей 3 r? Есть три ответа, все с использованием PrOIR Бернулли:
1. Когда хорда построена, мы всегда можем повернуть окружность так, чтобы эта хорда
пересекала отрезок ABCD под прямым углом. Вероятность того, что длина хорды превышает 3 r, является вероятностью того, что хорда пересекает отрезок BC. Согласно
1
Джон Мейнард Кейнс (John Maynard Keynes, 1883–1946) – британский экономист, сторонник вмешательства государства в экономику. Его идеи легли в основу кейнсианской экономики.
Принцип равной вероятности событий 93
PrOIR Бернулли, вероятность пересечения любой точки на отрезке прямой AD является равномерной. Поскольку отрезок BC равен половине длины AD, мы заключаем,
что p = 1/2.
2. Когда хорда построена, окружность всегда можно повернуть так, чтобы один конец
хорды совпал с точкой E. Вероятность того, что длина хорды превышает 3 r, является вероятностью того, что другой конец хорды расположен на дуге FG. Применение
PrOIR Бернулли дает каждой точке на окружности круга равную вероятность быть
другим концом хорды. Поскольку дуга FG на треть меньше окружности круга, мы заключаем, что p = 1/3.
3. Наконец, вероятность того, что длина хорды превышает 3 r, равна вероятности того,
что на самой правой фигуре середина хорды ляжет в меньший заштрихованный круг.
Согласно PrOIR Бернулли, распределение точек внутри круга является равномерным.
Меньший заштрихованный круг составляет одну четвертую от площади большего круга, поэтому мы заключаем, что p = 1/4.
Есть три разных ответа, одинаково использующих PrOIR Бернулли. Кейнс предположил,
что парадокс Бертрана является провалом PrOIR Бернулли. Более разумное объяснение
состоит в том, что термин «случайно» в исходном вопросе точно не определен. Вместо
этого три ответа в парадоксе Бертрана связаны с различными интерпретациями значения слова «случайно». После получения точной формулировки PrOIR Бернулли применяется без двусмысленности.
Кейнс также отметил, что PrOIR Бернулли не работает, когда пространство
поиска плохо определено или является эвристически неопределенным, как это
свойственно социальным наукам [16, 17]. Рассмотрим ученого-социолога, который классифицирует основные причины преступности среди несовершеннолетних как: (а) бедность, (б) влияние со стороны сверстников или (в) «другие
причины». Означает ли это разделение на 1/3, 1/3, 1/3? Предположим, второй
социолог относит влияние со стороны сверстников в категорию «другие причины». Осталось только две категории: бедность и другие причины. Согласно
PrOIR Бернулли, вероятность влияния бедности теперь составляет половину
вместо одной трети. Часто утверждают, что без предварительного знания пространства поиска принцип равномерного распределения вероятностей является неуместным и уводит нас за рамки теории вероятностей [18].
Непрерывная и дискретная вероятность
Кейнс предлагает еще один аргумент в критике PrOIR Бернулли [19]:
«Рассмотрим удельный объем некого вещества. Предположим, что мы знаем,
что удельный объем лежит в диапазоне от 1 до 3, но мы не располагаем информацией о том, где в этом интервале должно быть найдено его точное значение.
Принцип безразличия [PrOIR Бернулли] позволил бы нам предположить, что
искомое значение может лежать между 1 и 2, а также между 2 и 3, поскольку
нет оснований предполагать, что он лежит в одном интервале, а не в другом.
Удельная плотность является обратной величиной удельного объема, так что
если последний равен v, первая равна 1/v. Наши данные остаются такими же,
как и раньше, и мы знаем, что удельная плотность должна лежать между 1 и 1/3,
и, благодаря использованию принципа, ... как и раньше, разделив диапазон пополам, получаем вероятность того, что она будет лежать с равной вероятностью
как между 1 и 2/3, так и между 2/3 и 1/3».
94
Детерминизм в случайности
Примечание
⍟ Вот рассуждения, лежащие в основе возражений Кейнса. Исходная переменная
удельного объема v является однородной на интервале от одного до трех. При применении PrOIR Бернулли существует вероятность 50/50, что v лежит между 1 и 2 или между
2 и 3. Удельная плотность d = 1/v и, исходя из стандартного преобразования случайной
величины, имеет функцию плотности вероятности
при
Конечно,
это не так, как если бы мы начинали рассуждения с d и предполагали, что она равномерно распределена по интервалу
окажется в одном из интервалов
используя fd(x), мы вычисляем
в этом случае была бы вероятность 50/50, что она
и
т. е.
Но,
и
Кейнс возражает
против того, согласно PrOIR, ответы оказываются разными.
Кейнс утверждает, что PrOIR Бернулли не может применяться одновременно как к удельной плотности, так и к удельному объему, потому что результаты
деления диапазона пополам оказываются разными.
Возражение Кейнса на первый взгляд кажется проблематичным. Если у нас
есть случайная переменная, имеющая равномерное распределение, то любая
функция этой случайной переменной, за исключением вырожденных случаев,
не будет производить другую случайную переменную с равномерной случайной величиной.
Геденфорс (Gädenfors) и Салин (Sahlin) [20] отмечают, что многие критики
PrOIR Бернулли, такие как Кейнс, сосредоточены на случаях, когда основная
случайная величина непрерывна.
«Бертран [21] был настолько впечатлен противоречиями геометрической вероятности, что хотел бы исключить все примеры, в которых число альтернатив
бесконечно» [22].
Примечание
⍟ Даже определение информации Шеннона различается для дискретного и непрерывного случая. Для функции распределения масс pn мы видели, что энтропия определяется
как:
Для непрерывной случайной величины, описываемой функцией плотности вероятности
f(x), непрерывная энтропия, часто называемая дифференциальной энтропией, равна:
Дифференциальная энтропия не является ограничивающим случаем дискретного
случая. Действительно, единицы измерения двух энтропийных мер различны. Поскольку вероятность не имеет единиц измерения, единицей энтропии для дискретных
Принцип равной вероятности событий 95
событий являются биты. Альтернативно, если x, например, имеет единицы измерения
метров, тогда f(x) имеет единицы измерения обратных метров, а дифференциальная
энтропия имеет единицы измерения, связанные с длиной. Другое отличие состоит
в том, что дифференциальная энтропия может быть отрицательной, а дискретная энтропия не может.
Однако мы можем показать, что это не относится к дискретным случайным
переменным в том смысле, что ожидаемое значение преобразования сохраняется. Действительно, PrOIR Бернулли нерушим в дискретном случае, когда
область поиска правильно определена, а мы ничего не знаем.
Например, если у нас есть стандартная перетасованная колода из 52 карт,
то вероятность выбора туза пик не зависит от методологии, используемой для
последовательного вытягивания карт. Принцип Бернулли исправно работает во всех вариантах его исполнения. Рассмотрим, во-первых, отображение
«некоторые ко многим», показанное на рис. 4.5. Некоторые карты из колоды
идентифицируются и дублируются в новой колоде. Мы даже предполагаем,
что некоторые карты могут быть продублированы более одного раза. Какова
вероятность выбора туза пик в новом запросе из новой колоды? Так же, как
и в старой колоде: 1 из 52.
Рис. 4.5 Отображение «некоторые ко многим»
с использованием колоды игральных карт
(показаны не все 52 карты в колоде)
96
Детерминизм в случайности
Примечание
⍟ Вот сокращенная версия рассуждений. Если вероятность успеха в исходной колоде
карт равна p, то вытягивание k карт дает распределение масс биномиальной вероятности
Медиана и среднее значение соответствующей случайной величины
равно np. Более строго, медиана – это округление np до ближайшего целого числа (см.
K. Hamza, «The smallest uniform upper bound on the distance between the mean and the
median of the binomial and Poisson distributions», Statist. Probab. Letters, 23, стр. 2125
(1995)). Деление на n показывает, что ожидаемое значение вероятности успеха в новой
колоде равно p: так же, как и в исходной колоде. Аналогичным образом шанс успеха
с новой колодой тот же, что и со старой, то есть шанс сделать лучше равен шансу сделать хуже. Обобщение для случаев, когда карту из исходной колоды можно дублировать
в новой колоде более одного раза, не вызывает затруднений. Расположение цели неизвестно, поэтому репликация любого элемента в исходной колоде приведет к созданию
новой колоды, в которой ожидаемая вероятность успеха, p, останется неизменной.
Аналогичный пример, иллюстрирующий устойчивость PrOIR Бернулли
к дискретным событиям, возникает при анализе розыгрышей лотерей. Ленор –
большая любительница лотерей, постоянно наблюдающая за выгодными розыгрышами и отправляющая по нескольку ставок. Розыгрыши, спонсируемые
коммерческими продуктами, не могут ставить условие покупки их продукта1.
В противном случае конкурс считался бы лотереей и оказался бы незаконным
в штатах, где азартные игры запрещены. По этой причине на всех лотерейных билетах мелким шрифтом указано, как участвовать в конкурсе, не покупая
продукт. Ленор – одна из многих любителей лотереи, которые часами подают
заявки. Участвуя в лотереях, Ленор тратит только время и небольшую сумму на
почтовые расходы.
Чтобы увеличить шансы на выигрыш в лотерее, одно из пособий для любителей лотерей советует отправлять билеты в разное время2. Ящики, возможно,
разных размеров последовательно заполняются билетами участников до крайнего срока подачи заявок. Если, как утверждается в книге, Ленор отправляет
свои билеты на протяжении всего конкурса, то у нее не будет «всех яиц в одной
корзине»3. Скорее всего, ее билеты будут распределены по большому количест
ву коробок. Таким образом, когда коробка выбирается случайным образом, будет больше шансов, что билет от Ленор окажется в этой коробке, тем самым
давая ей шанс на победу. С другой стороны, если все билеты Ленор находятся
в одной коробке и эта коробка не выбрана, то ее шансы на победу равны нулю.
Таким образом, отправка билетов в течение нескольких дней увеличивает ее
шансы на победу.
1
2
3
Федеральный закон в США.
Здесь описан принцип розыгрыша лотереи с бумажными билетами, которые организаторы лотереи получают по почте. – Прим. пер.
Вопреки совету Марка Твена «Сложите все яйца в одну корзину – и следите за этой
корзиной!».
Принцип равной вероятности событий 97
Это не верно. Не важно, как записи отправляются по почте. Шансы на победу одинаковы, независимо от того, все ли билеты Ленор находятся в одной
коробке или разбросаны по нескольким коробкам. На самом деле, когда кто-то
ничего не знает, нет способа манипулировать записями лотерей, чтобы увеличить шанс на выигрыш.
Действительно, как показано на рис. 4.6, в данном случае принцип Бернулли
работает столь же надежно, как и раньше. Мы можем сделать ксерокопию всех
билетов в коробке № 14, изготовив таким образом дубликат коробки с запи
сями. Содержимое коробки № 5 дублируется дважды, и у нас получается три
идентичные копии коробки № 5. Затем мы бросаем коробки № 8 и № 27 в огонь
и уничтожаем их содержимое. За исключением дублированных ящиков, мы
можем предположить, что все коробки содержат разное количество билетов.
Завершив дублирование коробок, мы приступаем к розыгрышу. Выбираем случайную коробку, и из нее берем случайный билет. Вероятность победы Ленор
точно такая же, как и до дублирования и сжигания коробок, – т. е. такая же, как
если бы все билеты были помещены в одну огромную коробку и затем из нее
выбран билет. Невозможно победить PrOIR Бернулли, дублируя и уничтожая
коробки. Шанс на победу не меняется.
Рис. 4.6 В лотерее коробки неравного размера последовательно заполняются билетами. Во время розыгрыша выбирается коробка, затем в этой коробке
выбирают случайный билет
Независимость шансов можно проиллюстрировать следующими рассуждениями. Рассмотрим 1000 лотерейных билетов, помещенных в одну большую
коробку. Вероятность выигрыша р равна количеству ставок, которые вы делае
те, деленному на N = 1000. Предположим, что кто-то пришел прошлой ночью
и, не глядя на билеты, пометил 300 записей меткой 1, 20 записей – 2, 280 запи
сей – 3 и 400 – меткой 4. Говорят ли нам что-нибудь метки 1, 2, 3 или 4 на
выигрышном билете? Конечно, нет. Да, вероятность того, что на выигрышном
98
Детерминизм в случайности
билете окажется метка 4, является самой большой, но метка на билете и то,
окажется ли он победителем, являются независимыми событиями.
Затем рассмотрим возможность размещения всех билетов с одинаковой
маркировкой в разных коробках. 300 билетов с пометкой 1 помещаются в одну
коробку, 20 билетов с пометкой 2 – во вторую и т. д. Мы до сих пор не знаем,
какой билет является победителем. Мы смотрим только на метки. Теперь выберите одну коробку, используя любой метод, который вы пожелаете. Возьмите
любой билет из этой коробки. Независимо от того, какую коробку мы выберем,
все билеты имеют равный шанс на выигрыш.
Это справедливо даже в случае, когда существует 1000 записей и 999 из них
помещены в одну коробку, а один билет – в другую. Вероятность выигрыша
единственного билета из второй коробки равна вероятности выигрыша одного
из 999 билетов в первой коробке.
На это можно взглянуть с другой точки зрения. Пока мы не провели розыг
рыш, можно считать, что все билеты помечены буквой p, означающей победу в лотерее. Не имеет значения, выбираете ли вы запись из одного большого
ящика или из 100 маленьких ящиков, у выбранного вами билета будет буква p,
и вероятность этого события не зависит от того, каким способом выбран билет.
Используя эти рассуждения, легко понять, почему уничтожение одних записей и копирование других по-прежнему не изменяет шанс билетов на победу.
В конце концов, общее количество билетов не меняется, и все билеты имеют
одинаковый шанс на выигрыш.
Наличие внутренней (активной) информации о лотерее может помочь выиграть с шансом, отличным от того, который предоставляется при равномерном распределении. Рассмотрим два примера.
1. Если у нас есть внутренняя информация о заполнении коробок с лотерейными билетами, мы могли бы изменить шансы. Если бы мы знали,
когда будут заполняться коробки меньшего размера, и смогли рассчитать
время отправки билетов, то шансы на выигрыш увеличились бы. Чтобы
убедиться в этом, рассмотрим крайний случай, когда одна коробка настолько мала, что может содержать только один билет. Если мы можем
манипулировать нашей единственной отправкой так, чтобы билет попал
именно в эту маленькую коробку, то наш шанс на победу равен одному
из М, где М – количество коробок. Это намного лучше, чем один шанс из
N, где N – количество билетов.
2. Если билеты принимаются в течение недели в пакетах, и пятничный
пакет рядом с дверью имеет больше шансов быть выбранным, чем понедельничный пакет через комнату рядом со стеной, то допущение однородности больше не действует, и мы можем увеличить наши шансы
выиграть, отправив все наши билеты в пятницу.
Принцип Бернулли не может быть побежден без знания важных тонкостей
лотереи. Для создания активной информации всегда обязателен источник
знаний.
Потребность в шуме 99
4.2. Потребность в шуме
Случайность является важной составляющей эволюционного поиска.
Рассмотрим оптимизацию наискорейшим спуском для нахождения минимума. Одиночный агент, исследуя поисковый ландшафт, вычисляет, какой путь
ведет вниз, и делает шаг в этом направлении. Проблема заключается в том, что
поиск может застрять в локальном минимуме, который значительно уступает
более глубокому минимуму в другом месте пространства поиска. Если к каждому шагу добавляется случайный компонент, есть вероятность, что поиск может пропустить локальные минимумы и спуститься в глобальный минимум.
В этом смысле шум может помочь в точности поиска.
Примером использования случайности в оптимизации может служить имитация отжига [23]. Отжиг в металлургии означает охлаждение расплавленного
металла в соответствии с графиком охлаждения, так что металл приобретает
желаемые свойства. Общий принцип такой же, как у замораживания воды. Например, быстро охлажденная вода превращается в лед с физическими недостатками. Лед становится непрозрачным и трескается. Медленно охлажденная
вода превращается в прозрачную глыбу льда. В физике тепло соответствует амплитуде случайных колебаний молекул. При моделировании отжига понижение температуры соответствует уменьшению количества шума, добавляемого
к процессу поиска. Мутация в эволюционном поиске может рассматриваться
как разновидность искусственного отжига. Однако в стандартных эволюционных алгоритмах обычно мутация не «отжигается». Скорость мутации, т. е. температура, часто остается фиксированной.
Хотя это не идеальная аналогия, но есть и более наглядное описание. Представьте себе чашу, форма которой в целом описывает ландшафт поиска, но
имеет многочисленные углубления, соответствующие ложным минимумам.
Если стальной шарик упадет в чашу, есть большая вероятность, что он остановится в одном из локальных минимумов. А теперь представьте, что сразу после
падения шарика миску начинают встряхивать. Сначала происходит сильное
встряхивание (т. е. высокая температура нагрева), затем его интенсивность
уменьшается в соответствии с графиком отжига. Встряхивание чаши должно
выбить шарик из локальных минимумов и, когда оно закончится, загнать шарик в более благоприятное место, чем то, в котором он оказался бы, если бы
чашу не встряхивали.
4.2.1. Фиксированные точки в случайных событиях
Эволюционные процессы – это динамические случайные процессы. Хотя мы
имеем дело со случайными результатами, вероятность часто следует почти
детерминированным законам. Например, случайность, введенная квантовой
механикой, моделируется вероятностными моделями, полученными из решения уравнения Шредингера. Функции плотности вероятности являются детерминированными.
100
Детерминизм в случайности
Более простой пример – вероятность того, что на обороте чеканной монеты
изображен орел. Хотя вероятность выпадения орла является случайной величиной, его присутствие детерминировано с вероятностью p = 1.
Наиболее часто используемым детерминистическим1 свойством вероятности является закон больших чисел [24]. На него полагаются политики, страховые
компании, казино и инженеры по контролю качества. Хотя существуют различные формы закона больших чисел, в самом общем виде его можно сформулировать следующим образом.
Закон больших чисел: в пределе среднее выборки приближается к среднему арифметическому, взятому по всему пространству элементов.
Пока мы не определим термины, определение может показаться расплывчатым из-за сходства терминов среднее и среднее арифметическое. Итак, давайте
проиллюстрируем закон на нескольких примерах. Мы подбрасываем симмет
ричную монету. Если выпадает орел, пишем единицу. Если решка – пишем
ноль. Поскольку монета симметрична, среднее значение броска равно μ =
.
Закон больших чисел гласит, что чем больше раз подбрасывается монета, тем
ближе среднее значение выборки приближается к среднему арифметическому
шансов. Результаты ООРОРОР соответствуют 1101010, или в среднем α =
=
0,571. Имитация пяти серий бросков показана на рис. 4.7. После каждого брос
ка подбрасыватель монет оценивает отношение количества решек к общему количеству подбрасываний. На рис. 4.7 изображены графики для серий
из 100 000 подбрасываний монет. По мере увеличения числа подбрасываний
среднее значение приближается к среднему арифметическому значению 1/2.
У кривых разное начало, но конечный результат один и тот же.
среднее по выборке
среднее
арифметическое = 1/2
броски монеты
Рис. 4.7 Пять симметричных монет подбрасывают по 100 000 раз
1
Здесь мы используем «детерминистический» в нестрогом математическом смысле.
Сходимость по среднему квадрату и сходимость с единичной вероятностью считаются детерминированными в контексте нашего обсуждения.
Потребность в шуме 101
Используя закон больших чисел, мы можем оценить π = 3,14159... с произвольной точностью, всего лишь бросая дротики. Рассмотрим круг в квадрате,
изображенный слева на рис. 4.8. Если круг имеет радиус r, то отношение площади круга к квадрату составляет
Если у нас есть мишень
для дартса, как показано справа на рис. 4.8, и если предположить, что дротик
бросают абсолютно случайно, то число дротиков, попавших в круг, деленное
на общее число бросков дротиков, приблизится к π согласно закону больших
чисел.
Рис. 4.8 Вычисление точного значения π при помощи игры в дартс
Еще более интересным примером оценки π с помощью случайных экспериментов является игла Буффона [25], задача XVIII века, показанная на рис. 4.9.
Иглы падают на пол, где нарисованы параллельные линии1.
Мы предполагаем, что расстояние между линиями равно двум длинам иглы.
Мы также считаем, что у метателя нет возможности управлять иглой и она
приземляется случайно2. Если игла пересекает линию, мы записываем единицу, в противном случае пишем ноль. Любопытно, что при расстоянии между
1
2
Если игла имеет длину a и расстояние между линиями составляет b > a, то μ =
выбрали b = 2a, поэтому μ =
Мы
.
Из парадокса Бертрана мы узнали, что следует соблюдать осторожность при использовании термина «случайный». Для иглы Буффона применяется PrOIR Бернулли.
Предполагается, что положение середины иглы равномерно распределено между
линиями, и угол поворота иглы также считается равномерно распределенным.
102
Детерминизм в случайности
линиями, в два раза большем длины иглы, среднее значение этого эксперимента составляет μ =
= 0,3183.
На рис. 4.9 треть игл пересекается с параллельными линиями и составляет
в среднем α =
= 0,3333. По мере увеличения количества брошенных игл сред-
нее значение будет приближаться к 1/π. Это проиллюстрировано на рис. 4.10,
где показано, что пять симуляций средних значений результатов падения иглы
сходятся к одной и той же точке. Игла Буффона показывает, что можно оценить
π, бросая иглы в мишень, состоящую из прямых линий. Там нет кругов или дуг.
Рис. 4.9 Расчет π путем бросания игл. Игла Буффона иллюст
рирует закон больших чисел с менее очевидным результатом,
чем подбрасывание монет. Здесь длина иглы составляет половину расстояния между параллельными линиями. По мере увеличения количества брошенных игл процент игл, пересекающих
линию, приближается к μ = 1/π. Моделирование падения иглы
показано на рис. 4.10
среднее по выборке
среднее
арифметическое = 1/ π
броски иглы
Рис. 4.10 Пять метателей бросают иглу 100 000 раз. Пути приближения в разных сериях бросков различны, но с увеличением числа бросков
среднее значение выборки приближается к среднему арифметическому
значению μ = 1/π = 0,3183…
Потребность в шуме 103
4.2.2. Выборка по значимости
Целью эволюционного программирования является написание программ, достигающих желаемой фиксированной точки. Задача может оказаться намного
более сложной, чем те, которые нами были проиллюстрированы, и не решае
мой с доступными вычислительными ресурсами. Для ускорения процесса
можно воспользоваться активной информацией в программе. При определении процентов это можно сделать с помощью выборки по значимости (importance sampling) [26].
При проведении политических опросов общественного мнения было бы
разумно вместо равномерной случайной выборки чаще проводить опросы
среди независимых и колеблющихся избирателей. Знания о том, что демократы, вероятно, будут голосовать за демократов, а республиканцы – за республиканцев, уже переведены в активную информацию социологами, что позволяет
получить более точные оценки с меньшим количеством запросов. И именно
поэтому существует такой интерес к так называемым колеблющимся избирателям. Они более важны при определении результата и поэтому опрашиваются более интенсивно.
Другой пример выборки по значимости показан на рис. 4.11. Колесо разделено на пять сегментов: A, B, C, D и E. Какова вероятность того, что при враще-
Рис. 4.11 Пример выборки по значимости
104
Детерминизм в случайности
нии верхнего колеса маркер P будет указывать на сегмент, отмеченный буквой
D? Чтобы выбрать сегмент D, не говоря уже о том, чтобы с высокой точностью
оценить его вероятность, потребуется большое количество вращений. Предположим, однако, что мы знаем точную вероятность большого сегмента, помеченного буквой A. Это знание, которое можно использовать для уменьшения
количества запросов, необходимых для нахождения вероятности D с заданной
точностью. Мы удаляем A и, как показано в нижней части рис. 4.11, формируем новое колесо из оставшихся сегментов. Теперь вероятность получить D
при вращении выше, поэтому для оценки его вероятности потребуется меньше вращений.
4.2.3. Предельные циклы, странные аттракторы и тетербол
Бросание монет, метание дротиков и игла Буффона являют собой примеры,
когда случайный процесс сходится к одному фиксированному значению.
Другие стохастические явления могут сходиться к двум или более конечным
значениям, называемым фиксированными точками (fixed points). Пример для
10 раундов игры, называемой тетерболом1 (tetherball), показан на рис. 4.12.
Мы использовали условную графическую симуляцию этой игры. Цель игры
состоит в том, чтобы добраться до верхней линии для игрока 1 и до нижней
линии для игрока 2. Игрок выбирается случайным образом, чтобы отбить мяч
на четверти пути к одной из стен2. На следующем ходу игрок с вероятностью
25 % бьет по мячу на восьмой части расстояния до стены. С вероятностью 75 %
игрок уступит то же расстояние своему противнику. Чем ближе игрок находится к стене, тем больше у него шансов подвести мяч еще ближе. В каждом случае
успех перемещает мяч на четверть расстояния между мячом и стеной. Когда
мяч приблизился к стене на 90 %, то по правилам на следующем этапе он будет
смещен на четверть от 10 % (т. е. 2,5 %), и мяч преодолеет 92,5 % расстояния до
стены. С вероятностью 100 – 90 = 10 % мяч будет двигаться в противоположном направлении, и в итоге пройденное расстояние составит 87,5 %. Когда мяч
преодолел, скажем, 99 % расстояния, вероятность того, что он достигнет стены
в следующей итерации, равна 0,99. Рано или поздно мяч коснется одной из
стен, и игра завершится.
На рис. 4.12 показаны десять игр в тетербол из 100 ходов. Во всех случаях,
кроме одного, мяч оказывается либо сверху, либо снизу. Верх и низ – две фиксированные точки процесса. Для одного незавершенного процесса, оставленного на рис. 4.12, требуются дополнительные ходы, чтобы определить, какая из
двух стен станет конечным пунктом.
1
2
Тетербол – спортивная игра, которая очень популярна в Европе и Северной Америке.
Цель игры – первым закрутить веревку с привязанным к ней мячом вокруг шеста
(см., например, мультсериал «Симпсоны»). – Прим. пер.
Мы используем одну четвертую. В общем случае можно использовать любую долю
расстояния.
Потолок Бейснера 105
ходы
Рис. 4.12 Десять симуляций тетербола.
Конечный результат находится в одной
из двух фиксированных точек сверху или снизу
Итерации могут также приближаться к решениям повторяющихся периодических паттернов, называемых жадными предельными циклами (greedy limit
cycles) [27]. Подобное явление встречается в детерминистическом хаосе, где
итерации могут приближаться к странным аттракторам (strange attractors)
[28]. Марковские процессы могут иметь многочисленные поглощающие состоя
ния (absorbing states) [29], к которым сходится процесс. Производительность
этих процессов близка к наблюдаемой в эволюционных вычислениях. Различные прогоны программы могут привести к сходимости к различным фиксированным точкам.
4.3. Потолок Бейснера
Коллега вошел в кабинет Роберта Маркса, одного из ваших скромных авторов.
Маркс перестал набирать текст на своем компьютере и повернулся, чтобы поприветствовать гостя.
«Что ты делаешь?» – спросил гость. Маркс откинулся на спинку стула: «Я моделирую эволюцию на компьютере». Глаза коллеги расширились.
«Это так захватывающе! – выпалил он насмешливым тоном. – Когда я смогу
с ним поговорить?»
Те, кто знаком с компьютерным моделированием эволюции, считают этот
вопрос глупым. Но так ли это? Ненаправленная эволюция обычно рассматривается как динамичный процесс жадного улучшения, единственной целью
которого является повышение приспособленности. Если это так, что мешает
вычислительному процессу развивать все большую и большую информационную сложность? Почему бы нам не ожидать, что программа Маркса приобретет самосознание и в конечном итоге начнет говорить? Почему эволюционная
программа, написанная для разработки антенны, никогда не создаст вкусного
106
Детерминизм в случайности
блина или не сыграет в шахматы? С точки зрения программиста, ответ очевиден. Программист, который написал программу проектирования антенн, разработал именно программу для разработки антенн. Она не был предназначена
для развития навыков игры в шахматы.
Математик Уильям Ф. Бейснер (William F. Basener) показывает, что стандартные компьютерные модели дарвиновской эволюции имеют ограниченные
возможности [30]. Основываясь на анализе базовой топологии и результатах
работы динамических систем, Бейснер доказывает, что «каждая такая эволюционная динамическая система с конечной пространственной областью асимп
тотична рекуррентной орбите; с точки зрения наблюдателя, система будет
бесконечно часто повторять известное состояние. В эволюционной системе,
движимой повышением приспособленности, система достигнет точки, после которой не будет наблюдаться заметного увеличения приспособленности». Другими словами, компьютерная модель достигает потолка улучшения, и эволюционный процесс или любой другой поиск не может двигаться дальше. Неявной
целью в таких поисках служит, по словам Бейснера, «точка, после которой не
наблюдается заметного увеличения приспособленности».
Изучив эволюцию как динамический процесс, Бейснер делает следующее
наблюдение:
«Наш первый вывод заключается в том, что хаотичные и нелинейные динамические системы никак не способствуют постоянному увеличению сложности
или эволюционной приспособленности биологических систем».
«Во-вторых, эволюционный процесс, обусловленный селекцией мутаций в математических моделях, … представляет собой процесс, когда система приходит
в равновесие и остается там. Очевидно, что представление эволюции в биологии – это рассмотрение непрерывного процесса, но изучение математических
моделей эволюции – это исследование динамики равновесия. В математической
системе, основанной на пригодности, нет ничего, что приводило бы к постоянному прогрессу; напротив, математические системы, являющиеся конкретными моделями, … имеют ограничения степени увеличения приспособленности».
В главе 6 мы поговорим о компьютерных программах, призванных продемонстрировать дарвиновскую эволюцию. В программах Avida и EV четко определен потолок Бейснера. То же самое относится и к WISEL Докинза. Как только
программа успешно достигает заложенную в нее цель, программисты громко
провозглашают: «Эврика! Мы научились моделировать эволюцию!» Однако ни
одна из этих компьютерных программ не способна самопроизвольно развиваться дальше. Даже сама мысль об этом смешна.
В эволюционном моделировании отчетливо проявляется потолок Бейснера.
Давайте рассмотрим некоторые примеры, иллюстрирующие это явление.
4.3.1. Tierra
Знаменитый эволюционный алгоритм Томаса Рэя под названием Tierra [31, 32]
был создан в 1989 году для проверки положений дарвиновской эволюции с по-
Потолок Бейснера 107
мощью компьютерного моделирования. Исторически это была первая знаменитая компьютерная программа, осуществившая такую попытку. Рэй был
особенно заинтересован в моделировании кембрийского взрыва, когда за короткий период времени1 возникло большое разнообразие сложных организмов, хотя раньше такой сложности не было. Кембрийский взрыв – это событие,
записанное в летописи окаменелостей, во время которого произошел потрясающий рывок в развитии жизни на Земле. До этого момента биологическая
жизнь почти полностью состояла из одноклеточных организмов. Однако за
короткий период геологического времени произошел «взрыв» разнообразия
биологических форм, при котором большая часть существующих в настоящее время типов внезапно появилась в летописи окаменелостей. Причины
этого геологического события обсуждаются в биологических кругах. Дарвин
рассматривал кембрийский взрыв как возможное слабое место своей теории
эволюции [33]. Впоследствии Стивен Мейер (Stephen Meyer) дал подробные пояснения того, почему кембрийский взрыв оказался более сложным, чем когдалибо, в свете недавнего понимания сложности быстро развивающихся форм
жизни [34]. Однако за четверть века до книги Мейера Рэй был в восторге от
своего проекта. Он написал [35]:
«Хотя происхождение жизни обычно рассматривается как наиважнейшее событие, есть еще одно событие в истории жизни, которое менее известно, но
имеет сопоставимое значение: происхождение биологического разнообразия
и макроскопической многоклеточной жизни во время кембрийского взрыва
600 млн лет назад».
Целью Рэя было смоделировать это историческое эволюционное событие на
компьютере.
Если бы искусственная эволюция могла воспроизвести захватывающую
сложность, наблюдаемую при кембрийском взрыве, исследователи могли бы
также смоделировать множество удивительных живых форм, аналогичных
тем, которые встречаются в биологии. По сути, как только эволюция (биологическая или искусственная) произвела кембрийский взрыв, остальная эволюция должна пойти легко, словно по накатанной дороге.
Рэй надеялся, что сложность его системы достигнет критической массы.
Пройдя этот момент, модель раскроет всю суть эволюции. Tierra была попыткой Рэя достичь критическую массу эволюционного процесса. Первые неудачи не остановили Рэя. Пытаясь запустить эволюционный процесс, он трижды
модифицировал алгоритм Tierra, каждый раз начиная эволюцию с большей
сложности.
Tierra воспроизвела множество интересных явлений, включая паразитов,
гиперпаразитов, социальное поведение, мошенничество и развертывание
циклов. Однако через 25 лет после запуска Tierra так и не случилось ни кемб
1
Короткое время по отношению к продолжительности эволюции. Кембрийский взрыв
длился около 75 млн лет.
108
Детерминизм в случайности
рийского взрыва, ни продолжения эволюции. Tierra продолжала врезаться
в потолок Бейснера.
Хотя Рэй описал эволюцию Tierra как создание «быстро меняющихся сообществ самовоспроизводящихся организмов, демонстрирующих открытую
эволюцию путем естественного отбора» [36], другие не согласились с этим
[37, 38].
«Системы искусственной жизни, такие как Tierra и Avida, вначале воспроизвели
богатое разнообразие организмов, но в конце концов их не стало. В отличие
от этого, биосфера Земли, очевидно, непрерывно генерировала новые и разно
образные формы на протяжении 4 × 109 лет истории жизни».
Отсутствие кембрийского взрыва в искусственной жизни, созданной руками опытного программиста, требует объяснения. Если биологическая эволюция произвела кембрийский взрыв, почему искусственная эволюция не делает
то же самое? Наша неспособность имитировать эволюцию в этом отношении
предполагает недостаток понимания предмета моделирования. По словам
Фейнмана: «Если я не могу что-то создать, я это не понимаю» [39].
Эволюция в Tierra может быть охарактеризована как начальный период высокой активности, приводящий к ряду новых адаптаций, сопровождаемых бесплодным стазисом. Похоже, что Tierra легко подготовила новую информацию,
необходимую для различных адаптаций. Но почему процесс адаптации прекратился? Если Tierra может выдавать новую информацию, она должна продолжать делать это до тех пор, пока она выполняется.
При более внимательном рассмотрении эволюции Tierra выявляется важная характеристика адаптаций. Популяция внутри Tierra начиналась с предварительно созданного предка. Другими словами, это предполагало что-то
вроде сотворения жизни (руками программиста) и подразумевало дальнейшее
развитие сложности после этого момента. Предок предоставлял в Tierra начальную информацию. Адаптации в Tierra в основном состоят из перестановки
или удаления этой информации, то есть потери функций. Эволюция требует
адаптаций, которые увеличивают информацию и служат основой для увеличения сложности организмов. Однако такие адаптации крайне редко случались
в Tierra. Информационная траектория Tierra является противоположностью
того, что требуется для эволюции. В ней преобладают потери и перестановка
с минимальным количеством новой информации, хотя должно доминировать
именно производство новой информации с минимальными случаями удаления или перестановки имеющейся информации. Долгосрочный эволюционный прогресс зависит от генерации новой информации.
Известный анализ алгоритма Tierra на высоком уровне подтверждает, что
Tierra достигает потолка Бейснера [40]. Эверт подводит итог [41] изучению эффективности Tierra и указывает на признание самого Рэя, что производительность Tierra ограничена.
Потолок Бейснера 109
Эверт с соавторами цитирует недавний подкаст с Рэем [42] и пишет:
«Рэй недавно заявил, что он считает, что Tierra не достигла своей цели. Он описывает эволюцию, наблюдаемую в Tierra, как временную. Он больше не считает
себя частью сообщества искусственной жизни и теперь изучает биологические
вопросы, а не вопросы искусственной эволюции».
Tierra Рэя окончательно достигла потолка Бейснера.
4.3.2. Край эволюции
Биохимик Майкл Бихе (Michael Behe) отмечает, что наблюдаемая биологическая адаптация в том виде, как мы ее понимаем, ограничивает способность
эволюции генерировать разнообразие [43].
Способность системы адаптироваться является признаком хорошей инженерии. Подобно тому, как банкир снимает свой пиджак, выходя на улицу
в жаркий летний день, организмы могут потерять функцию, чтобы лучше взаи
модействовать с окружающей средой. Пещерные саламандры теряют глаза, которые бесполезны в их прудах без света. Потеря функции – это, конечно, адаптация, но это не та адаптация, которая вызывает рост сложности.
У людей была хорошая возможность адаптироваться к паразиту, вызывающему малярию. Благодаря миллиардам заболеваний и возможной мутации
у людей развился иммунитет к малярии. Но, как и у определенных сильнодействующих лекарств, у иммунитета есть побочные эффекты, которые могут вас убить. У некоторых людей действительно развился иммунитет к малярии – серповидно-клеточная анемия, наследственное заболевание крови, при
котором эритроциты имеют аномальную форму, похожую на серпы. Плохая
новость заключается в том, что серповидно-клеточная анемия является изнурительным заболеванием, которое без тщательного лечения значительно
сократит продолжительность жизни человека. Хорошей новостью является
то, что серповидно-клеточная анемия обеспечивает иммунитет к малярии.
В зараженных малярией районах и при недостатке хинина люди с серповидно-клеточной анемией останутся в живых и постепенно начнут доминировать
над прочим населением. Но, как и саламандра без глаз, серповидно-клеточная
анемия возникла из-за потери функции. Устойчивость к малярии достигнута
ценой общей неэффективности организма.
В 1988 году Ричард Ленски (Richard Lenski) из штата Мичиган предпринял
попытку развить бактерии E. coli. Он подробно описывает неудачу эксперимента с точки зрения создания новых информационных структур в организме [44]. Журнал Science отметил 25-ю годовщину эксперимента Ленски [45].
В эксперименте Ленски прослежено 58 000 поколений (более миллиона лет для
людей) и были задействованы триллионы клеток. Этот эксперимент является
«самым подробным источником информации об эволюционных процессах, на фоне
которого работы конкурентов выглядят карликами». Но, как и в случае с саламандрой в пещере, теряющей ненужные глаза [46]:
110
Детерминизм в случайности
«...суть в том, что подавляющее большинство даже полезных мутаций было вызвано нарушением, деградацией или незначительными изменениями ранее
существовавших генов или регуляторных областей. Не было выявлено ни одной мутации или серии мутаций, которые находились бы на пути к созданию
элегантного нового молекулярного механизма, встроенного в каждую клетку.
Например, гены, образующие бактериальный жгутик, последовательно выключаются полезной мутацией (по-видимому, это экономит энергию клеток,
используемую при конструировании жгутиков). Набор генов, используемых
для создания сахарной рибозы, является единственной мишенью для разрушительной мутации, которая каким-то образом помогает бактерии быстрее расти
в лаборатории. Деградация множества других генов также приводит к положительным эффектам».
Это свидетельствует о том, что эксперимент Ленски достиг потолка Бейснера.
4.4. Заключение
Компьютерные модели эволюции и компьютерный поиск почти всегда используют случайность. Итеративный случайный процесс сходится к детерминизму в форме законов, таких как закон больших чисел и потолок Бейснера.
Может ли компьютерная программа быть построена так, чтобы не упираться
в потолок Бейснера? Мы, безусловно, можем развить организм до достижения
потолка, а затем использовать развитую сущность в качестве инициализации
другого, более продвинутого эволюционного процесса. В принципе, это может привести к появлению организмов неограниченной сложности. Обратите
внимание, однако, что каждый этап моделирования должен быть тщательно
заранее продуман, чтобы мы получили результат в разумный срок. Не будем
забывать про теорию вероятностей и бесчисленное множество вариантов слепого поиска. Примитивное стохастическое моделирование эволюции вряд ли
возможно. Например, если на Землю обрушился метеор, который уничтожает
динозавров и изменяет эволюционное давление окружающей среды, чтобы направлять последующую стадию эволюции, моделируемое изменение направления должно быть правильным (т. е. мы просто вынуждены внести в модель
начальное знание). Иначе нам не хватит миллиарда наших жизней, чтобы дождаться результата. Если метеор слишком большой, вся жизнь будет уничтожена и эволюционный процесс остановится. Если они слишком малы, динозавры
выживут, и следующий этап эволюции не будет запущен. Как говорил Честертон: «Падать всегда проще: существует бесконечное число углов, под которыми
человек падает, и только один, под которым он стоит». Хотя потенциально существует много способов направить эволюционный процесс к более высокой
сложности, имеется еще больше способов, которыми этот процесс может быть
сорван. Проблема в том, что мы можем узнать результат моделирования эволюции, только пройдя значительную часть пути.
Источники 111
В реальной жизни окружающая среда непрерывно меняется. Эволюция на
фоне меняющихся ландшафтов отбора требует продуманного моделирования
на каждом этапе. В следующей главе мы обсуждаем метод ступенчатого развития, который пошагово поднимает эволюционный процесс на более высокие
уровни сложности, используя малые порции активной информации – ступеньки. Компьютерная программа Avida в некотором смысле использует ступенчатую активную информацию. Концепция постепенного применения изменения
влияния окружающей среды, получившая название эволюции развиваемости
(evolution of evolvability) [47], превращает лестницу в плавную наклонную рампу. В любом случае, успешный путь к высокой сложности должен быть тщательно продуман, и пробить дыру в потолке Бейснера по-прежнему нелегко.
Источники
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
Powered by TCPDF (www.tcpdf.org)
D. Sheff, All We are Saying: The Last Major Interview with John Lennon and Yoko
Ono (Macmillan, 2010).
William A. Dembski, R. J. Marks II, «Bernoulli’s Principle of Insufficient Reason
and Conservation of Information in Computer Search». Proceedings of the 2009
IEEE International Conference on Systems, Man, and Cybernetics, October 11–14,
San Antonio, Texas, USA (2009).
S. Hawking, A Brief History of Time (Bantam Books, 1996).
J. Bernoulli, Ars Conjectandi (The Art of Conjecturing) (1713).
A. Papoulis, Probability, Random Variables, and Stochastic Processes, 3rd edition
(McGraw-Hill, New York, 1991), pp. 537–542.
A. Fisher, C. Dickson, W. Bonynge, Mathematical Theory of Probabilities & Its
Applications to Frequency Curves & Statistical Methods (Macmillan, 1922).
R. J. Marks II, Handbook of Fourier Analysis and Its Applications (Oxford University Press, 2009).
K. F. Cheung and R. J. Marks II, Ill-posed sampling theorems. IEEE Transactions
on Circuits and Systems, CAS-32, pp. 829–835 (1985).
R. J. Marks II, Posedness of a bandlimited image extension problem in tomography. Opt Lett, 7, pp. 376–377 (1982).
Классическая работа Клода Шеннона, датированная 1948 г., см. раздел 2.2.2.
K. L. Jackson, L. E. Polisky, «Wearable computers: Information tool for the twenty first century». Virtual Real, 3 (3), pp. 147–156 (1998).
Holy Rollers: The True Story of Card Counting Christians (2011 Documentary),
Director: B. Storkel.
Cover and Thomas.
I. Ekeland, The Broken Dice (University of Chicago Press, Chicago, 1993).
Там же.
112
Детерминизм в случайности
14. J. M. Keynes, A Treatise On Probability (Macmillan Co., 1921).
15. Papoulis, см. ссылки ранее.
16. E. Kasner and J. R. Newman, Mathematics and the Imagination (Dover Publications, 2001).
17. D. Howie, Interpreting Probability: Controversies and Developments in the Early
Twentieth Century (Cambridge University Press, 2002).
18. Там же.
19. Keynes, см. ссылки ранее.
20. P. Gädenfors, N. E. Sahlin, Decision, Probability, and Utility (Cambridge University Press, 1988).
21. J. Bertrand, Calcul Des Probabilités (1896).
22. W. Ewert, W. A. Dembski, R. J. Marks II, «Evolutionary synthesis of Nand logic:
Dissecting a digital organism». Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics. San Antonio, TX, USA, pp. 3047–3053
(2009).
23. Simulated annealing was first proposed in: N. Metropolis, A. W. Rosenbluth,
M. N. Rosenbluth, A. H. Teller, and E. Teller, «Equation of state calculations by
fast computing machines». J Chem Phys, 21 (6), p. 1087 (1953).
R. D. Reed, R. J. Marks II, Neural Smithing: Supervised Learning in Feedforward
Artificial Neural Networks (MIT Press, 1999).
24. R. J. Marks II, см. ссылки ранее.
25. Papoulis, см. ссылки ранее.
26. See, for example, R. Srinivasan, Importance Sampling (Springer, 2002).
27. R. J. Marks II, см. ссылки ранее.
28. D. Ruelle, Chaotic Evolution and Strange Attractors (Cambridge University Press,
1989).
29. J. G. Kemeny and J. Laurie Snell, Finite Markov Chains (Springer, 1976).
30. W. F. Basener, «Limits of chaos and progress in evolutionary dynamics». In Biological Information: New Perspectives, R. J. Marks II, M. J. Behe, W. A. Dembski,
B. L. Gordon, J. C. Sanford (eds.) (World Scientific, Singapore, 2013).
31. W. Ewert, W. A. Dembski, and R. J. Marks II, «Tierra: The character of adaptation». In Biological Information: New Perspectives, R. J. Marks II, M. J. Behe,
W. A. Dembski, B. L. Gordon and J. C. Sanford (eds.) (World Scientific, Singapore,
2013).
32. T. Ray, «Overview of Tierra at ATR Technical Information». Technologies for Software Evolutionary Systems, No. 15 (2001).
T. S. Ray, «An approach to the synthesis of life». In Artificial Life II, C. G. Langton,
C. Taylor, J. D. Farmer, and S. Rasmussen (eds.), pp. 371–408 (Addison Wesley
Publishing Company, 1992).
Источники 113
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
T. Ray, «Evolution of parallel processes in organic and digital media». In Natural
& Artificial Parallel Computation: Proceedings of the Fifth NEC Research Symposium, p. 69. Soc for Industrial & Applied Math (1996).
C. Darwin, On the Origin of Species by Natural Selection (Murray, London, United
Kingdom, 1859), pp. 315–316.
S. C. Meyer, Darwin’s Doubt: The Explosive Origin of Animal Life and the Case for
Intelligent Design (Harper Collins Publishers, 2013).
T. S Ray, «An approach to the synthesis of life». In Artificial Life, C. G. Langton,
C. Taylor, J. D. Farmer, and S. Rasmussen (eds.), 2, pp. 371–408 (Addison Wesley
Publishing Company, 1992).
Там же.
R. K. Standish, «Open-ended artificial evolution». Int J Comp Intel Appl, 3 (2),
pp. 167–175 (2003).
M. A. Bedau, E. Snyder, C. T. Brown, and N. H. Packard, «A comparison of evolutionary activity in artificial evolving systems and in the biosphere». Proceedings
of The Fourth European Conference on Artificial Life, pp. 125–134 (MIT Press,
Cambridge, 1997).
Там же.
Там же, R. K. Standish, см. ссылки ранее.
Ewert et al., см. ссылки ранее.
T. Ray and T. Barbalet, Biota live #56, «Tom Ray on twenty years of Tierra».
(2009) podcast http://poddirectory.com/episode/2485604/biota-live-lite-56tom-ray-on-twenty-years-of-tierra-present-and-future-october-16-2009
(дата URL: May 2, 2016).
M. Behe, The Edge of Evolution (Free Press, New York, 2008).
M. Behe, «Experimental evolution, loss-of-function mutations, and the first rule
of adaptive evolution». Quart Rev Biol, 85 (4), pp. 419–445 (2010).
Там же.
E. Pennisi, «The man who bottled evolution». Science, 342, pp. 790–793 (2013).
M. Behe, «Lenski’s long-term evolution experiment: 25 years and counting».
November 21, 2013 2:50 PM, Evolution News & Views. http://www.evolutionnews.org/2013/11/richard_lenskis079401.html (URL date May 2, 2016).
N. Colegrave, S. Collins, «Experimental evolution: Experimental evolution and
evolvability». Heredity, 100 (5), pp. 464–470 (2008).
M. Kirschner and J. Gerhart, «Evolvability». Proceedings of the National Academy
of Sciences of the United States of America 95 (15), pp. 8420–8427 (1998).
Глава
5
Сохранение информации
в компьютерном поиске
Я глубоко сожалею о том, что недостаточно
изучил основные принципы математики, поскольку постигшие их люди словно обладают
дополнительным органом чувств.
Чарльз Дарвин [1]
5.1. Основы
Когда вводится новая парадигма, она часто встречает скептичное отношение
и критику. Иногда критика лишь оттачивает и укрепляет теорию. В других случаях парадигма оказывается заблуждением, и критики справедливо хоронят
ее. Зачастую с течением времени и после всесторонней проверки изначально
сомнительная идея становится удивительно очевидной. Так обстоит дело с законом сохранения информации (conservation of information, COI) в компьютерном обучении и поиске, который больше известен в форме теоремы об отсутствии бесплатных завтраков (No Free Lunch Theorem, NFLT) [2].
Великие идеи часто имеют несколько авторов. Ньютон и Лейбниц открыли
дифференциальное и интегральное исчисление независимо друг от друга. Модель алгоритмической теории информации Колмогорова–Хайтина–Соломонова была независимо предложена тремя людьми. Можно привести множество
других примеров. Разложение Кархунена–Лоэва [3], алгоритм Папулиса–Герхберга [4] и теорема отсчетов Уиттекера–Котельникова–Шеннона [5] являются
примерами совместного вклада в величайшие идеи математики XX века, независимо сформулированные более чем одним человеком.
Аналогично COI, похоже, был обнаружен рядом независимых исследователей. Возможно, самое раннее утверждение относительно COI в информатике
исходит от леди Лавлейс (Августа Ада Кинг (Augusta Ada King)), в честь которой
назван язык программирования Ada. Брингсорд (Bringsjord) перефразирует
мнение Лавлейс, высказанное еще в XIX веке [6]:
Основы 115
«Компьютеры не могут ничего создать. Для создания требуется, как минимум,
возникновение чего-то. Но компьютеры ничего не создают; они просто делают
то, что мы заказываем им через программы».
Точно так же в 1956 году, не углубляясь в математику, написал пионер теории информации Леон Бриллюэн (Leon Brillouin) [7]:
«[Вычислительная] машина не создает никакой новой информации, но выполняет очень ценное преобразование известной информации».
Пожалуй, можно считать, что математическая основа COI была создана Митчеллом (Mitchell) в 1980 году [8]. Он отметил, что при создании программы,
способной к обучению, программист должен внести в нее собственное влияние
(bias):
«Если соответствие обучающим экземплярам принимается как единственный
определяющий фактор соответствующих обобщений, то программа никогда не
сможет сделать индуктивный переход, необходимый для классификации экземпляров, помимо тех, которые она наблюдала. Только если у программы есть
другие источники информации или критерий предпочтения одного обобщения
перед другим, она может произвольно классифицировать случаи, помимо тех,
которые содержатся в обучающем наборе».
«[Мы] используем термин «предпочтение» для обозначения любой основы
для выбора одного обобщения над другим, помимо связи с обучающими
примерами».
Без влияния разработчика программы обучение не сможет самопроизвольно выйти за пределы обучающих данных.
В последнее время идея COI была популяризирована Шаффером (Shaffer) [9],
а также Уолпертом и Макриди (Wolpert & Macready) [10]. Шаффер показал, что
компьютерная программа, которая хорошо учится в одних случаях, будет плохо работать в других:
«Позитивные результаты в одних учебных ситуациях должны быть компенсированы равной степенью негативных результатов в других ситуациях».
После доказательства своего утверждения Шаффер сравнивает вероятность
разработки программы, которая одинаково успешно учится во всех случаях,
с вечным двигателем. В частности:
«...обучаемый [без предварительных знаний], ... который работает хотя бы
немного лучше, чем просто выбранный случайно, ... похож на вечный двигатель».
А Уолперт и Макриди [11], которые ввели термин «бесплатный завтрак»
в отношении компьютерного поиска, пишут, что поиск может быть улучшен
только
«...путем включения специфических знаний по проблеме в поведение алгоритма [оптимизации или поиска]».
116
Сохранение информации в компьютерном поиске
В самом деле,
«...если вы не сделаете предварительные предположения о ... [проблемах], над
которыми вы работаете, то нельзя ожидать, что ваша поисковая стратегия, какой бы сложной она ни была, будет работать лучше, чем любая другая» [12].
Утверждение о сохранении информации с самого начала вызывало много
споров. Каллен Шаффер отметил, что после устной презентации своей статьи
«Закон о сохранении эффективности обобщения» [13]
«около половины людей в аудитории, в которой была представлена моя работа, сказали, что мой результат был совершенно очевиден и общеизвестен, –
что совершенно справедливо. Конечно, другая половина столь же решительно
утверждала, что результат не соответствует действительности».
Сейчас мы хотим показать, что согласны с первой половиной аудитории
Шаффера, и сохранение информации «совершенно очевидно».
5.2. Что такое сохранение информации?
Чтобы наглядно продемонстрировать COI, рассмотрим следующий пример [14].
Если мы войдем в комнату, где карты из хорошо перемешанной стандартной колоды из 52 карт в случайном порядке разложены на стол лицевой стороной вниз,
наши шансы перевернуть пиковый туз менее чем за пять переворачиваний карт
не зависят от того, как выбраны карты. Можем ли мы определить следующий
ход, повышающий вероятность успеха, если нам известен только результат
первого хода? Очевидно, нет. После пяти переворачиваний карт, независимо от
того, насколько умный метод или набор правил используется алгоритмом поиска, вероятность выбора пикового туза останется прежней, а именно:
COI утверждает, что без знания цели или структуры пространства поиска любой алгоритм поиска при достаточном усреднении будет работать одинаково.
Выбор алгоритма поиска в данном случае не имеет значения. Нет причин полагать, что один алгоритм будет работать лучше, чем другой.
Рассмотрим другую иллюстрацию COI с использованием метафоры водяного матраса. Поскольку вода несжимаема, если вы нажмете на водяной матрас
в одной точке, он будет выпирать в других местах. Рассмотрим рис. 5.1, который похож на рисунок в оригинальной статье Шаффера [15,16]. Каждое из шести изображений соответствует определенному алгоритму поиска в пространстве проблем. Квадрат, помеченный цифрой 1, является плоским, иллюстрируя
алгоритм, работающий одинаково для всех задач. В квадрате 2 каждое впалое
место поверхности водяного матраса помечено кружком (О), а каждое выпуклое место – крестиком (+). Выпуклость означает, что в данном месте пространства поиска алгоритм работает лучше, чем в среднем. Впадина означает,
Что такое сохранение информации? 117
что алгоритм работает хуже. COI требует, чтобы выступам соответствовали
равноценные впадины, и в среднем указанный алгоритм 2 должен работать
столь же эффективно, как алгоритм 1. Количество воды в матрасе остается неизменным. Таким образом, средняя глубина воды одинакова в обоих случаях.
Как показано в квадрате 3, формы углублений и выпуклостей не обязательно
должны быть одинаковыми. Достаточно, чтобы они усреднялись до того же
уровня, что и в квадрате 1.
Чтобы выбрать поиск по выпуклостям с уровнем выше среднего, требуется
знание пространства поиска, внесенное программистом в алгоритм.
Рис. 5.1 Иллюстрация сохранения информации
на примере водяного матраса
Квадраты 4, 5 и 6 иллюстрируют нарушения закона сохранения информации. В квадрате 4 алгоритм работает лучше, чем в 1 для ряда проблем, но не
работает хуже где-либо еще. Поверхность водяного матраса не может выпячиваться в нескольких точках без впадин в других местах. Аналогично квадрат 5
иллюстрирует множество впадин без каких-либо выпуклостей. Сохранение
информации подразумевает баланс между лучшими и худшими алгоритмами.
Квадрат 6 нарушает это требование, потому что водяной матрас имеет больше
выступов, чем впадин.
Это свойство алгоритмов поиска было интуитивно очевидно для пионера
искусственного интеллекта Марвина Мински, который в ходе обмена мнения
ми со сторонниками эволюционного программирования, стенограмма которого опубликована в 1970 году, комментирует алгоритмы эволюционного
обучения [17]:
118
Сохранение информации в компьютерном поиске
«Когда кто-то говорит об обучающей машине данного типа [эволюционный поиск], прежде всего следует охарактеризовать класс задач, в которых она сильна ... Какой класс проблем хорошо подходит для применения вашей технологии
[эволюционного поиска]? Недостаточно просто сказать, что она хорошо [решает] все проблемы».
Минский продолжал настаивать:
«Я спрашиваю вас, к решению какого класса проблем относится эта технология
[эволюционный поиск], и я подчеркиваю, что я не приму слово «все” как ответ».
Последующая разработка закона COI подтвердила озабоченность Мински.
5.2.1. Обманчивые контрпримеры
Существуют сценарии поиска, которые выглядят, будто они нарушают COI, но
это не так. В самом деле, COI, как показали его соавторы, является математическим законом, который нельзя нарушать. Один из примеров, который, как
может показаться, игнорирует COI, но не является коэволюцией, – алгоритм
поиска [18], который мы подробно рассмотрим позже в этой главе. А пока разберем еще один более простой обманчивый пример.
На рис. 5.2 показана иллюстрация примера, который, на первый взгляд, нарушает закон сохранения информации [19]. Один поиск всегда дает лучшие
результаты, чем любой другой. Рассмотрим клад, закопанный в одном из трех
возможных мест на необитаемом острове. Два конкурирующих пирата, X и Y,
прибывают на остров с намерением выкопать сокровище. Каждый пират должен выбрать стратегию, состоящую из выбора порядка посещаемых мест. Если
один из пиратов посетит место после того, как там побывал его соперник, он
не найдет сокровища. Мы предполагаем, что сокровища с равной вероятностью можно найти в любом из трех мест. Предположим, что пират X ищет клад
Рис. 5.2 Может ли поиск сокровищ
являться примером бесплатного завтрака?
Что такое сохранение информации? 119
в определенном порядке, например (1, 2, 3). Наличие сокровища в каждом из
трех мест одинаково вероятно. Пират Y использует другой порядок поиска:
(2, 1, 3). Опять же, вероятность найти клад в любом месте – один к трем. Таким
образом, каждая стратегия поиска в отдельности будет иметь равную эффективность, что соответствует принципу COI.
Однако это положение дел изменится, если оба пирата будут охотиться за
сокровищами одновременно. Пират Y выбрал порядок обхода локаций таким
образом, что он будет находить и забирать сокровища в двух из трех случаев,
потому что пират Y всегда на шаг впереди пирата X. Если сокровище находится
в локации 1, пират X получит сокровище. Но если клад находится в локации 2
или 3, пират Y окажется в этих местах раньше и победит. Стратегия пирата X
приносит сокровище один раз из трех, тогда как пират Y будет получать сокровище два раза из трех. В этом смысле стратегия пирата Y лучше, чем стратегия
пирата X. Это верно, несмотря на то что две стратегии работают одинаково при
рассмотрении по отдельности.
Встретив любое исключение из общего принципа COI, аналогичное примеру
с пиратами, нужно остановиться и подумать. Действительно ли в таких прос
тых случаях закон сохранения информации перестает действовать? И если
здесь нарушается COI, не должен ли существовать общий способ найти наилучший алгоритм?
Ответ на эти вопросы – нет. Очевидное преимущество пирата Y над пиратом X не является провалом COI. Одна стратегия может победить другую в конкретном случае, но в группе связанных стратегий на всем пространстве поиска потери и выигрыши будут уравновешены. Победы против одной стратегии
оплачиваются потерями против другой. Следовательно, в целом не существует
лучшего алгоритма поиска.
Принцип транзитивности, необходимый для определения наилучшего алгоритма, неприменим для поиска. Пират Y действительно обладает преимуществом перед пиратом X. Но мы не рассмотрели полный набор алгоритмов!
Должен быть третий охотник за сокровищами, пират Z, выбирающий последовательность (3,1,2), которая побеждает пирата Y. Таким образом, пират Z побеждает пирата Y, который побеждает пирата X. В соответствии с принципом
транзитивности пират Z должен побеждать пирата X. Но все не так – пират X
побеждает пирата Z. Таким образом, на полном пространстве поиска все три
поисковые стратегии в среднем одинаково эффективны. Подробности приведены в табл. 5.1.
Каждая стратегия имеет преимущество перед какой-либо другой стратегией
в каком-то одном случае, но также найдется и другая стратегия с преимущест
вом перед этой стратегией в другом случае. Таким образом, не существует способа получить абсолютное преимущество одной стратегии над всеми другими.
Отсутствие абсолютного преимущества ограничивает смысл, в котором одна
стратегия может быть лучше, чем другая. Определенный алгоритм может оказаться победителем, но не так, чтобы всегда работать лучше всех других алго-
120
Сохранение информации в компьютерном поиске
ритмов. Пират Y может гарантированно превзойти своего конкурента X только
в том случае, если он каким-то образом знает стратегию, которую использует
его соперник. Таким образом, как и следует из идеи COI, для того чтобы гарантированно победить соперника, необходимо знать его стратегию. Когда мы по
своей воле исключили из поиска пирата Z, тем самым мы внесли внешнюю
информацию, которая дала преимущество пирату Y.
Таблица 5.1. Пример неприменимости транзитивности в поиске. Как показано на рис. 5.1,
порядок поиска у пирата X – (1,2,3), а у пирата Y – (2,3,1). На рисунке не показан пират Z со
стратегией (3,2,1).С появлением пирата Z представлены все возможные варианты стратегий.
Эта таблица показывает, кто выигрывает (всегда с вероятностью 2/3), когда пираты в паре.
Z побеждает Y, а Y побеждает X. Транзитивность говорит нам, что Z побеждает X. Но это не
так – транзитивность не работает в поиске
Пары →
Расположение
сокровищ ↓
1
2
3
Победитель →
ZY
YX
XZ
Z
Y
Z
Z побеждает Y
X
Y
Y
Y побеждает X
X
Y
Z
X побеждает Z
Завершая этот пример, рассмотрим альтернативный сценарий игры, в котором пираты X и Y решают, кто получит сокровище большинством побед в трех
быстрых играх «Камень, ножницы, бумага». Если пират Y знает стратегию пирата X (например, X всегда выбирает «камень»), пират Y может выиграть все
три игры. Знание одним поиском деталей другого поиска помогает выиграть
локальный конкурс, но не нарушает COI в целом. Знание стратегии противника может быть превращено в относительно лучший поиск.
5.2.2. Взаимосвязь между обучением и поиском
Митчелл и Шаффер ссылаются на COI в смысле обучения. Но наша книга посвящена поисковым алгоритмам и моделированию эволюционных процессов.
Какое отношение имеет обучение к поиску? Ответ в том, что большинство методов машинного обучения реализуется с помощью поиска. Далее мы приведем короткий пример. Эта тема – отступление от нашей центральной темы,
поэтому нетерпеливые читатели могут пропустить следующий раздел.
5.2.2.1. Борцы сумо не могут играть в баскетбол
Итак, вот вам пример обучения. Борцы сумо значительно отличаются от профессиональных баскетболистов. Борцы сумо тяжелее среднего, а баскетболисты выше среднего. Мы хотим разработать классификатор в виде черного
ящика, различающий сумоистов и баскетболистов. Когда физические данные
человека вводятся во входное поле классификатора, в выходном окне будет
указано, является ли этот человек борцом сумо или баскетболистом. В случае
Что такое сохранение информации? 121
Вес (фунты)
контролируемого обучения [21, 22] черный ящик имеет ручки настроек, значения которых установлены в соответствии с обучающими примерами борцов
сумо и баскетболистов. У нас есть маркированная группа примеров борцов
сумо и баскетболистов, где указано, кто есть кто. Мы используем эти примеры,
чтобы настроить положение ручек и добиться точной работы классификатора. Здесь начинается компьютерный поиск. Значения, на которые в конечном
итоге устанавливаются ручки, определяются процедурой поиска, возможно,
эволюционной. Задача поиска – достижение заданной точности классификатора в соответствии с требованиями к проекту.
Первый шаг – определить признаки (feature). Что отличает отдельных борцов
сумо от баскетболистов? На ум сразу приходят рост и вес. Мы собираем данные
и формируем график, показанный на рис. 5.3. Далее выбираем метод классификации. Предположим, мы решили разделить два класса линией. Приспособ
ленность алгоритма определяется количеством ошибочных классификаций.
Но как провести линию? Снова обратившись к рис. 5.3, мы можем выбрать
точку A слева и точку B справа, соединить их линией и посчитать количество
ошибочных классификаций. Поскольку сумоистов и баскетболистов по 30 человек, линия, проведенная на рис. 5.3, имеет одну правильную классификацию
и 39 ошибочных1.
Сумоисты
Баскетболисты
Рост (футы)
Рис. 5.3 Примеры роста и веса 30 сумоистов (квадраты)
и 30 баскетболистов (кружки)
1
Проверка этого утверждения утомительна и требует подсчета неправильно классифицированных маленьких квадратов и кружков на рисунке.
122
Сохранение информации в компьютерном поиске
Определение оптимального положения A и B для минимизации неправильной классификации – вот где начинается поиск [23]. В этом простом примере
всего два признака. Обычно количество признаков (ручек-регуляторов черного ящика) в поиске может исчисляться сотнями или даже тысячами [24]. В нашем примере есть только два параметра. Каждая пара значений A и B определяет линию, которой соответствует количество ошибочных классификаций.
Для простых задач применение поиска не обязательно1. Можно построить
ландшафт отбора, изображенный на рис. 5.4, где A и B лежат в диапазоне от 100
до 800 фунтов. Маленькому черному треугольнику в верхней части ландшафта
соответствует правильная классификация всех 60 сумоистов и баскетболистов.
В эту область входят точки A = 175 фунтов и B = 330 фунтов. Линия для этих
значений нанесена в левой части рис. 5.5. Видно, что линия четко отделяет борцов сумо от баскетболистов.
Рис. 5.4 Количество точных классификаций
для различных вариантов A и B на рис. 5.3
Черный ящик, отделяющий сумоистов от баскетболистов, был обучен на
основании данных. Далее мы можем отбросить исходные данные и оставить
классификатор, показанный в правой части рис. 5.5. Когда появляется новый
человек, мы берем его рост и вес. Если точка лежит выше линии, он баскетболист. Если ниже – это борец сумо.
1
Когда количество регуляторов невелико, оптимальную настройку черного ящика
часто можно найти, просто изучив все возможные настройки. Это то, что делается
при вычислении фитнес-функции на рис. 5.4 и называется исчерпывающим поиском.
Что такое сохранение информации? 123
Сумоисты
Баскетболисты
Рис. 5.5 Слева – распределение данных сумоистов и баскетболистов, аналогичное рис. 5.3. Линия A = 175 фунтов и B = 330 фунтов, соответствующая максимуму кривой приспособленности на рис. 5.4, четко разделяет два класса. Справа – данные отброшены, и теперь основой классификатора становится линия
Изучив график распределения признаков, мы ограничились линией, разделяющей два набора данных. В нашем исследовании это показалось хорошей
идеей. Это очень строгий классификационный подход [25], но в данном случае он работает. Обратите внимание, что, поскольку мы поместили сумоистов
выше линии, а баскетболистов ниже, то ввели в алгоритм предопределенность.
Что, если бы мы сделали обратное? Давайте разместим борцов сумо ниже линии, а баскетболистов – выше. Исходя из наших знаний о данных, это не самый
умный поступок, но, безусловно, это тоже вариант классификатора. Повторяя
тот же процесс, что и раньше, получаем функцию приспособленности, изобра
женную в верхней части рис. 5.6. Оптимум сейчас составляет всего 35, чуть
больше половины доступных точек данных. Здесь A = 510 и B = 100. Ранее мы
были в состоянии разделить все 60 точек данных. Новая «лучшая» линия показана в нижней части рис. 5.6.
Безусловно, выбор классификатора влияет на точность, иногда очень сильно. Мы наблюдаем необходимость в априорном знании того, кто находится
выше разделительной линии, сумоисты или баскетболисты. Если в левой части
рис. 5.5 мы будем выбирать линию, соединяющую точки D на нижней горизонтальной линии и точки C на верхней горизонтальной линии, то никакой поиск
не даст нам очень хороший классификатор.
Часто цитируемый и простой пример, в котором выбор линейного классификатора никогда не даст 100 % точности, был предложен Мински и Папертом
(Papert)1 [26]. Рассмотрим четыре точки, показанные на рис. 5.7. Два квадрата
и два круга расположены в диагонально противоположных углах. Это графи1
Мински и Паперт оба являются пионерами искусственного интеллекта.
124
Сохранение информации в компьютерном поиске
Сумоисты
Баскетболисты
Рис. 5.6 Плохой классификатор,
оптимизированный для разделения сумоистов и баскетболистов
ческое представление логической операции исключающего ИЛИ (exclusive OR,
XOR)1. Круги представляют логические нули, а квадраты – логические единицы. Не существует линии, которая могла бы успешно отделить квадраты от кругов. Для этого и многих других случаев линейный классификатор не пригоден.
Таким образом, выбранный классификатор должен соответствовать решаемой
проблеме. В данном случае линейный классификатор не работает, но при отделении сумоистов от баскетболистов линия отлично справляется с задачей.
1
Оператор XOR обычно обозначается символом ⊕. Он определяется четырьмя соотношениями: 0 ⊕ 0 = 0, 0 ⊕ 1 = 1, 1 ⊕ 0 = 1 и 1 ⊕ 1 = 0. Это четыре точки, показанные
на рис. 5.7.
Что такое сохранение информации? 125
Рис. 5.7 Исключающее ИЛИ (XOR).
Круги соответствуют логическому значению 0,
а квадраты – логическому значению 1
5.2.3. Человек в цикле, вносящий активную информацию
Разработчики программного обеспечения могут часами отлаживать свои программы. Авторы эволюционных программ могут потратить значительное время на настройку параметров своих алгоритмов поиска. Когда разработчики
поисковых алгоритмов публикуют свои результаты, они почти никогда не пуб
ликуют документацию, касающуюся пресловутого человека в цикле.
Пример классификации, который мы использовали, различал баскетболис
тов и борцов сумо. Для классификации использовались следующие характеристики: рост и вес спортсменов. Но мы не рассказали всю историю разработки.
Мы бы хотели, чтобы классификатор изучал, а не просто запоминал примеры.
Если бы мы хотели запомнить данные, было бы проще создать базу данных
веса и роста всех спортсменов с учетом известной классификации в качестве
баскетболиста или борца сумо. Затем, когда нам представляют неизвестного
спортсмена, мы обращаемся к таблице базы данных и находим в ней известного спортсмена, чей рост и вес наиболее близок к параметрам неизвестного
спортсмена. Если известный спортсмен с наиболее близкими параметрами
является сумоистом, мы объявляем, что наш неизвестный спортсмен тоже является борцом сумо.
Обучение, напротив, пытается распознать примеры за пределами предоставленного учебного набора. Истинным показателем точности классификатора сумоистов/баскетболистов является то, как классификатор работает на
спортсменах, которых он раньше не видел. По этой причине обычной практикой является выделение некоторых примеров для проверки качества обуче
ния. Данные разделяют на две части: набор для проверки и набор для обуче
ния. Сначала мы обучаем классификатор настолько хорошо, насколько мы
126
Сохранение информации в компьютерном поиске
можем, а затем применяем проверочные данные, чтобы увидеть, насколько
качественно классификатор работает на спортсменах, которых он никогда не
видел прежде. Это проверка того, как классификатор работает вне обучающих
данных и, следовательно, насколько хорошо он учится, а не запоминает.
Один из ваших скромных авторов (Маркс) стал соучредителем и сопредседателем первой конференции IEEE по применению вычислительного интеллекта, в том числе классификаторов, к финансовым данным [27]. Некоторые начинающие участники конференции были изрядно взволнованы тем, что обучили
искусственную нейронную сеть [28] предсказывать поведение рынка ценных
бумаг. Нейронные сети обучаются с использованием алгоритма поиска. Разработчики нейронной сети следовали предписанному методу случайного разделения данных на наборы для обучения и тестирования1. В некоторых случаях результаты были замечательными. Мы уже готовили мешки для денег! Как
часто бывает с вещами, которые слишком хороши, чтобы быть правдой, эти
результаты тоже оказались слишком хороши. В чем же была проблема? Нейронные сети имеют ряд параметров, в том числе количество скрытых слоев
и количество нейронов в каждом скрытом слое. Каждый параметр можно рассматривать как регулятор для настройки. Каждая нейронная сеть по-разному
реагирует на финансовые данные. Таким образом, программист, разработавший нейронную сеть, выбирает ее архитектуру, выполняет обучение, а затем
проверяет результат. Проверка обученной нейронной сети на тестовых данных информирует программиста о том, насколько хорошо она работает. Но,
возможно, программист мог бы сделать сеть еще лучше. В надежде найти
лучшую нейронную сеть программисты выбирали другую архитектуру и повторяли процесс. Программисты выполняли поиск поиска с человеком в цикле.
Повторив этот процесс несколько раз, программисты обнаруживали архитектуру нейронной сети, которая достаточно хорошо работала с их финансовыми
данными. Проблема, однако, заключалась в том, что повторное использование
проверочных данных из одного и того же набора нарушило беспристрастность
проверки. Проверочные данные нейросети стали обучающими данными для человека в цикле. Когда программисты вышли со своими нейронными сетями на
рынок и попытались оперировать биржевыми данными в режиме реального
времени, они были обескуражены. Их программы не сработали, и они потеряли деньги. С точки зрения дилеммы «обучение или запоминание» это не удивительно. Наличие человека в цикле, по сути, привело к созданию нейронной
сети, которая запоминала как обучающие, так и тестовые данные.
Сможет ли когда-нибудь нейронная сеть или любая другая обучаемая машина получить значительную прибыль в торговле акциями? Профессору
Джону Ф. Маршаллу [29], основателю и первому президенту Международной
ассоциации финансового инжиниринга, был задан вопрос, как оценить до1
Третий набор данных, называемый оценочными данными, обычно используется для
окончательной оценки качества классификатора после обучения.
Что такое сохранение информации? 127
стоверность заявлений программиста, утверждающего, что его программа
победит рынок. Маршалл мудро ответил, что не стоит вникать в теорию и методологию, заложенные в основу обучения; можно просто оценить доход программиста, спросив, на каком автомобиле он ездит [30]. В конечном счете доказательство качества разработки заключается в ее эффективности.
5.2.3.1. Закулисные настройки
Алгоритмы поиска имеют множество параметров, которые требуют настройки. После неудачного применения одного алгоритма поиска программист может изменить параметры алгоритма или даже попробовать другой алгоритм
поиска.
Вот конкретный пример. Дэвид Томас (David Thomas) предложил программную реализацию эволюционного алгоритма, который, как он утверждал, не содержит даже следов активной информации, внесенной человеком в цикле [31].
Томас написал [32]:
«Если вы утверждаете, что этот алгоритм работает только за счет включения
в ответ теста на приспособленность, укажите точный фрагмент кода, в котором
выполняется внедрение прямого влияния человека».
Так мы и сделали. В коде Томаса было выявлено много источников активной
информации. Одним из них был код, показывающий, что Томас использовал
человека в цикле. Мы нашли совсем свежий, еще горячий фрагмент кода. Вот
выдержка из нашего критического отзыва:
«Томас опубликовал версию C++ своего алгоритма [34] после публикации своего
оригинального описания. Мы же сосредоточились на исходной версии алгоритма на Фортране, потому что именно там были представлены самые подробные
результаты. По большей части алгоритм на C ++ работает так же, как алгоритм
на Фортране, но следует отметить некоторые различия. Система учета минимальных обменов была изменена. Инициализация ограничивает число используемых обменов всегда максимальным числом [35]:
x = (double)rand()/(double)RAND_MAX;
num = (int)((double)(m_varbnodes*x);
num = m_varbnodes; // over-ride!!!
Учитывая этот раздел кода, очень трудно согласиться с утверждением о том, что
в алгоритм не заложены предумышленные настройки. Код выбирает случайное
количество для числа обменов; однако сразу после этого он отбрасывает случайное значение и заменяет его максимально возможным, в данном случае 4.
Код помечен комментарием «over-ride!!!» (заменить, переписать вручную), указывающим, что это было преднамеренным действием Томаса. Это равносильно
тому, чтобы сказать «иди на восток», а через мгновение передумать и сказать
«иди на запад». Наиболее вероятной причиной является недовольство Томаса
качеством работы своего алгоритма, и, следовательно, ему пришлось применить ручную настройку».
Мы вернемся к работе Томаса в разделе 6.4.1.
128
Сохранение информации в компьютерном поиске
5.3. Удивительная стоимость слепого поиска в битах
COI утверждает, что любой алгоритм поиска в среднем работает так же, как
и любой другой алгоритм поиска, если нет априорных сведений о местонахождении цели или структуре пространства поиска. Таким образом, случайная
выборка в пространстве поиска (слепой поиск) может быть столь же хорошим
алгоритмом, как и любой другой. Если кто-то выполняет поиск с небольшим
количеством результатов, например ищет пиковый туз в колоде карт, это не
проблема. Мы уверены, что добьемся успеха не более чем за 52 запроса.
Однако даже для задач среднего размера случайная выборка пространства
поиска не может быть выполнена без знания о поиске. Вселенная недостаточно велика и недостаточно стара, чтобы проводить такие поиски вслепую.
Что касается эволюционного поиска, пионер искусственного интеллекта Сеймур Паперт сказал следующее в своем комментарии из диалога, записанного
в 1970 году [36]:
«Если вы ищете функцию, о которой ничего не знаете, кроме того что она находится в очень, очень большом пространстве функций, я утверждаю, что для
ее поиска потребуется очень и очень много времени. Единственный выход
из экспоненциального тупика – это избежать модели слепой охоты в произвольном пространстве функций, например путем встраивания в систему очень
специфических структурированных знаний, но то, что вы описали [эволюционный поиск], является слепой охотой».
Паперт ошибался, приравнивая эволюционные вычисления к слепой охоте
в том смысле, что каждый из них представляет собой отдельный алгоритм поиска. COI говорит, что эволюционное программирование будет работать лучше, чем в среднем по одним проблемам, и хуже, чем в среднем по другим. Но
он прав, заявляя, что слепой поиск займет «очень, очень много времени».
Теперь мы будем измерять сложность слепого поиска в битах, а не в секундах. Результат вас ошеломит.
5.3.1. Анализ
⍟ Давайте проанализируем общеизвестную проблему «обезьян на пишущей
машинке», которая заключается в случайном производстве художественного
текста с помощью слепого поиска. Вспомните фразу METHINKS*IT*IS*LIKE*
A*WEASEL из шекспировского «Гамлета». Фраза содержит L = 28 букв, выбранных из алфавита N = 27 символов (26 букв и пробел). Если мы неоднократно
выберем 28 букв случайным образом, сколько испытаний нам понадобится для
достижения целевой фразы? Существуют
N L = 2728 = 1,20 × 1040
возможных вариантов из доступных букв. Если мы принимаем запросы без
дублирования (т. е. после того, как генерируется случайная фраза, она никогда
Удивительная стоимость слепого поиска в битах 129
больше не проверяется), мы ожидаем, что в среднем найдем фразу, после того
как будет запрошена половина возможных решений:
Напомним, что информацию по Шеннону можно рассматривать как измерение вероятности с точки зрения предсказания последовательности бросков
монет. Шесть бит информации эквивалентны вероятности успешного прогнозирования шести бросков подряд симметричной монеты1. Чтобы различить
N = 27 различных символов, необходимо всего b = log2 N = log2 27 = 4,75 бита на
символ. Для строки из L = 28 букв требуется L log2 27 = 28 log2 27 = 133 бита. Если
Q = 0,60 × 1040 запросов, каждый из которых требует log2 N L = 133 бита, общее
количество битов, характеризующих поиск, равно:
B = Wb = 8,0 × 1041 бит.
(5.1)
Это очень много битов! Диск Blu-ray вмещает 50 Гб и имеет толщину 1,2 мм.
Невероятно, но для хранения 8,0 × 1041 бит потребуется около 24 000 стопок
дисков, каждый из которых имеет высоту, равную ширине галактики Млечный
Путь2. Все это для слепого поиска простой фразы:
METHINKS*IT*IS*LIKE*A*WEASEL.
В общем, если у нас есть алфавит из N символов и сообщение длиной L символов, количество битов, необходимых для успешного поиска без замены из
уравнения (5.1), составляет в среднем
бит.
(5.2)
Для заданного числа битов B и алфавита из N символов это трансцендентное
уравнение может быть решено, чтобы найти длину L конкретной фразы, которая может быть найдена с помощью слепого поиска.
5.3.2. Вычислительная стоимость
Теперь мы покажем, что без предварительного знания во Вселенной может
оказаться недостаточно вычислительных ресурсов для слепого поиска целевой фразы.
С учетом B бит длина конкретного сообщения, которое мы можем искать, приведена в табл. 5.2. Для наглядности мы можем связать количество битов с коли1
2
⍟ Из уравнения для информации p = 2–I. Таким образом, шесть 6 бит информации
соответствуют коэффициенту 26 = 64 к одному.
⍟ Имеется 8 бит на байт, поэтому Blu-ray хранит 400 гигабит. Для 8,0 × 1041 бит это
диски Blu-ray 2,0 × 1029. При толщине 1,2 мм на диск это означает стопку дисков
2,4 × 1023 км. Относительно Млечного Пути диаметром 1041 км это дает стопку Blu-ray,
равную 24 000 диаметров Млечного Пути.
130
Сохранение информации в компьютерном поиске
чеством кубических миллиметров1 в различных объемах. Объем олимпийского
бассейна составляет около 1012 мм3. В среднем это количество битов, необходимых для поиска фразы длиной всего L = 7 букв. Записи в табл. 5.2 постепенно
увеличиваются в объеме, начиная с бассейна и заканчивая наблюдаемой Вселенной. Объем наблюдаемой Вселенной в кубических миллиметрах составляет
около 1089. Для B = 1089 бит и N = 27 из уравнения (5.2) следует, что может быть
найдено сообщение только длиной L = 61 символ. У цитаты Рональда Рейгана
«FREEDOM IS NEVER MORE THAN ONE GENERATION AWAY FROM EXTINCTION»2
длина 62 символа, включая пробелы. Нам не хватает одного символа.
Таблица 5.2. Число битов B для поиска сообщения длиной L,
когда алфавит имеет размер N = 27. Для наглядности даны
соответствующие размеры для различных объемов
в кубических миллиметрах
Объем, мм3
Олимпийский бассейн
Объем Верхнего озера
Объем Земли
Объем Юпитера
Объем Солнца
Объем Млечного Пути
Наблюдаемая Вселенная
B
1012
1021
1030
1033
1036
1069
1089
L
7
11
20
22
24
47
61
Может быть, мы напрасно оперируем секундами вычислительного времени.
Предположим, возраст Вселенной составляет 14 млрд лет. Мы делим это время
на пикосекунды (пс)3 и предполагаем, что на каждую пикосекунду приходится
1089 мм3. В пространстве-времени это более 10115 мм3 – пс. Как далеко нас заведет B = 10115 бит? Только до L = 79 символов.
Мы даже не приблизились к одной странице книги. И мы даже не используем цифры или знаки препинания. Возможно, миллиметр – это слишком
большая единица измерения. Вместо этого давайте измерим объем Вселенной
в кубических единицах Планка. Один планковский объем 17,692557 × 10–104 м3
и возраст Вселенной по планковскому времени 5,39 × 10–44 с. Мы получаем пространственно-временную объемную меру 10244 единиц планковского объема.
И B = 10244 бит позволяет нам искать фразу длиной всего около L = 169.
Геттисбергский адрес Линкольна [37], лишенный знаков препинания, содержит L = 1422 символа, включая пробелы. Нам даже близко не хватает планковского времени и объема. Слепой поиск поразительно ресурсоемок, а наша
Вселенная слишком мала и слишком молода.
1
2
3
Кубический миллиметр равен одному микролитру.
«Свобода никогда не находится более чем в одном поколении от вымирания».
Одна миллионная от одной миллионной доли секунды.
Измерение сложности поиска в битах 131
Итак, давайте возьмем еще большее число. Предположим, есть 101000 параллельных вселенных в так называемой мультивселенной, и эти вселенные имеют тот же размер и возраст, что и наши. Умещается ли в них домашний адрес
Линкольна? Нет. 101244 бит дают только L = 869 символов1, а нам нужно 1422.
Чтобы получить домашний адрес Линкольна слепым поиском, нам нужно
10792 мультивселенных.
Это простое упражнение убедительно иллюстрирует, что при отсутствии
предметных знаний слепого случайного поиска недостаточно для успешного
выполнения даже задач среднего размера. Знание области поиска и/или целевого местоположения имеет важное значение для успеха.
5.4. Измерение сложности поиска в битах
Мера сложности задачи поиска в отсутствие какой-либо начальной информации называется эндогенной информацией [38]. Степень уменьшения эндогенной информации соответствует активной информации – количественной мере,
в которой дополнительные знания помогли в выполнении поиска2. Рассмот
рим эти понятия более подробно.
5.4.1. Эндогенная информация
Обозначим эндогенную информацию символом IΩ.
Изображенный на рис. 5.8 кодовый замок иллюстрирует пример измерения
сложности поиска в битах. Есть 10 двухпозиционных переключателей, каждый
из которых должен быть расположен в правильном положении, чтобы открыть
замок. Верхняя позиция соответствует единице, а нижняя – нулю. Если есть
только одна рабочая комбинация, сложность поиска составляет 10 бит. Шанс
выбора правильной комбинации
и IΩ = –log2p = 10 бит.
Рис. 5.8 Десятибитовый замок
1
2
Поскольку L становится большим, из уравнения 5.2 мы заключаем, что асимптотически log B становится пропорциональным длине строки. В частности, log B → L log N.
Следовательно, L(log[B/log[N = 1244/log10[27]]]) = 869.
При наличии заданных знаний о поиске сложность поиска в битах может снизиться
на разную величину в зависимости от навыков программиста поискового алгоритма.
132
Сохранение информации в компьютерном поиске
В поисках идеального блина предположим, что существует 10 млрд рецептов. Если только один из этих рецептов является приемлемым, то эндогенная
информация поиска I = log210 000 000 000 = 33,2 бита.
Таким образом, сложность поиска примерно такая же, как и успешное предсказание результата 33 последовательных бросков справедливой монеты.
В видимой вселенной около 2 × 10184 планковских объемов1. Идентификация
единственного планковского объема в видимой вселенной соответствует эндогенной информации I = log22 × 10184 = 612 бит.
Эндогенная информация является мерой сложности поиска решения проб
лемы. Чем больше эндогенной информации, тем сложнее проблема.
Используя деление интервала и допущение PrOIR Бернулли, мы можем достичь цели поиска с B битами эндогенной информации, используя B вопросов,
на которые можно ответить «да» или «нет». Но это невозможно почти для всех
поисков. Ведь кто-то должен знать расположение цели в пространстве поиска
и отвечать на вопросы типа «Эта половина содержит цель?». Например, для
блинной проблемы нет способа разделить 10 млрд рецептов пополам и определить, какую половину следует отбросить. Знание правильной половины интервала само по себе требует огромного количества знаний об искомой цели.
Поиск можно визуализировать, как показано на рис. 5.9. У нас есть пространство поиска Ω, которое состоит из всех возможных результатов. В случае поиска рецепта Ω содержит каждый из 10 млрд рецептов. Обозначение |Ω| обычно
используется для обозначения количества элементов в наборе2.
Рис. 5.9 Цель T встроена в пространство поиска Ω
В пространстве поиска имеется подмножество T (target, цель), которое состоит из всех приемлемых решений в поиске. В проблеме поиска рецепта блинов T состоит из набора всех рецептов, которые дегустатор Боб считает приемлемыми. Количество элементов в цели – |T |. Если все элементы в пространстве
поиска одинаково вероятны, то вероятность выбора элемента в целевом подмножестве вычисляется очень просто:
1
2
Планковский объем = 17,6925569946 × 10−105 м3.
Количество элементов в наборе называется количеством элементов множества.
Измерение сложности поиска в битах 133
(5.3)
Если, например, у нас есть семь белых шариков и три черных, то для выбора
черного шарика |Ω| = 10, |T| = 3 и p = 0,3. Эта вероятность, измеренная в брос
ках симметричной монеты, является эндогенной информацией проблемы поиска. Эндогенная информация поиска:
IΩ = –log2 p.
(5.4)
5.4.1.1. Особые случаи эндогенной информации
Рассмотрим два особых случая эндогенной информации.
1. Единственная цель. Первый особый случай эндогенной информации
возникает, когда в пространстве поиска находится одна цель, т. е. |T| = 1.
Тогда
а также
IΩ = –log2|Ω|.
(5.5)
METHINKS*IT*IS*LIKE*A*WEASEL.
(5.6)
2. Целевая фраза. А как насчет выбора конкретной фразы из алфавита
символов? Например, в английском языке мы можем выбрать фразу:
У проблемы поиска последовательности есть два важных параметра –
длина фразы L в символах и количество символов N в алфавите. Для анг
лийских фраз мы можем выбрать N = 27 для 26 букв алфавита плюс пробел. Для двоичных строк N = 2, а для последовательности ДНК N = 4, что
соответствует четырем нуклеотидам A, C, G и T. Если мы ограничимся
фразами длины L, то общее возможное количество фраз в пространстве
поиска равно
|Ω| = N L,
(5.7)
соответственно, из уравнения (5.5) для эндогенной информации
IΩ = L log2 N.
(5.8)
Для строки (5.6) мы имеем алфавит размером N = 27 (26 букв и пробел)
и длину целевой фразы L = 28, соответствующую эндогенной информации IΩ = 28log2 27 = 133 бита. Это мера сложности поиска фразы при отсутствии каких-либо внешних знаний.
5.4.1.2. Эндогенная информация головоломки Cracker Barrel
Если вам довелось посетить один из ресторанов сети Cracker Barrell, вы видели
головоломку Cracker Barrell1 [39], стоящую рядом с солонками и перечницами
1
Эта головоломка больше известна под названием «Triangle Soliter» («Треугольный
солитер»). – Прим. пер.
134
Сохранение информации в компьютерном поиске
на каждом обеденном столе (рис. 5.10). Цель головоломки – перепрыгнуть через соседнюю фишку, как в шашках, и убрать эту фишку. Игрок решил головоломку, если на игровом поле осталась только одна фишка. Насколько сложна
головоломка Cracker Barrel в плане эндогенной информации?
Рис. 5.10 Головоломка Cracker Barrel
Отверстия в головоломке могут быть условно пронумерованы от 1 до 15,
как показано в верхней части рис. 5.11. Одна из возможных игровых ситуаций изображена в середине рис. 5.11. Черные кружки обозначают отсутствие
фишки. На игровом поле в середине больше не осталось возможных ходов. Ни
одна фишка не может перепрыгнуть другую, и осталось пять фишек. Поскольку
больше нет возможности для прыжков, игра окончена, и игрок проиграл.
В процессе игры в Cracker Barrel каждый ход можно выбирать из небольшого количества допустимых вариантов. Количество допустимых ходов может
варьироваться. Иногда будет два возможных хода, иногда шесть, а иногда, как
показано в нижней части рис. 5.11, будет три возможных хода, а именно:
1) фишка 1 прыгает через фишку 2;
2) фишка 10 прыгает через фишку 9;
3) фишка 14 прыгает через фишку 9.
Предположим (в рамках PrOIR Бернулли), что мы ничего не знаем об игре,
и лучшее, что мы можем сделать, – это выбирать случайным образом один из
допустимых ходов. Если возможны три хода, у каждого есть вероятность выбора 1/3. Если каждый ход делается в соответствии с этим правилом, какова
вероятность того, что в конце игры останется одна фишка? Это вероятность
выиграть игру без каких-либо знаний об игре. Логарифм этой вероятности является эндогенной информацией, связанной с головоломкой Cracker Barrel.
Измерение сложности поиска в битах 135
Рис. 5.11 Игровое поле головоломки
Поиск обычно требует инициализации. В головоломке Cracker Barrel все
15 лунок заполнены фишками, и в начале игры случайным образом удаляется одна фишка. Компьютерное моделирование 4 млн игр с использованием
случайной инициализации и случайного выбора допустимого хода привело
к предполагаемой вероятности выигрыша p = 0,0070 и эндогенной инфор
мации:
IΩ = –log2 p = 7,15 бита.
Таким образом, выиграть головоломку, используя случайные ходы со случайно выбранной инициализацией (выбор пустого отверстия в начале игры),
немного труднее, чем подбросить монету семь раз и получить семь решек подряд. Пример последовательности ходов, которая решает головоломку Cracker
Barrel, показан на рис. 5.12.
136
Сохранение информации в компьютерном поиске
Рис. 5.12 Выигрышная последовательность ходов
в головоломке Cracker Barrel
Позже мы вернемся к головоломке Cracker Barrel, когда будем рассуждать об
экзогенной и активной информации.
5.4.2. Активная информация
Закон сохранения информации диктует необходимость знания предметной
области поиска. Активная информация равна количеству информации, добавленной в поиск из внешних источников.
Эндогенная информация измеряет сложность поиска, когда ничего не известно о местонахождении цели или структуре пространства поиска. Она осно
вана на одном запросе к пространству поиска. Если запрос оказался успешным, мы можем сказать, что достижение успеха дало нам I бит информации
в одном запросе.
На рис. 5.8 мы изобразили десятибитовую линейку переключателей «вверхвниз». Чтобы замок открылся, каждый переключатель должен находиться
в правильном положении. Поиск решения очень труден, поскольку сложность
поиска измеряется эндогенной информацией объемом в 10 бит. Предположим,
к вам подходит производитель замков Ларри и говорит: «Эти замки намного
проще, чем выглядят. Первые четыре бита всегда чередуются в одном порядке (0101)». Если Ларри говорит правду, то вы получили четыре бита активной
информации, которые мы обозначим как I+ = 4 бита. Активная информация
облегчает поиск. Теперь у нас осталась проблема поиска с трудностью всего
10 – 4 = 6 бит.
Измерение сложности поиска в битах 137
Активная информация – это мера упрощения
поиска в битах при применении знаний о поиске.
Эти знания могут относиться к искомой цели или
к структуре пространства поиска.
Намного чаще на практике применяется услож
ненный замок с колесиками, показанный на
рис. 5.13. Есть 10 колесиков, каждое из которых может принимать положение от 0 до 9. Таким образом,
существует |Ω| = 1010 = 10 млрд возможных комбинаций. Если замок отпирает только одна комбинация, то эндогенная информация, соответствующая
поиску правильного ответа, из уравнения (5.4) IΩ =
log21010 = 33,2 бита. Если Ларри говорит, что в комбинации используются только числа 1, 2 и 3, то мы отбрасываем более 1010 возможных комбинаций. Пос
ле этого остается только 310 = 59 049 вариантов, что
соответствует вероятности успеха q = 3–10 = 1,7 × 10–5.
Так как поиску помогли внешние знания о цели, мы
переименуем новый поиск во вспомогательный. Ин- Рис. 5.13 Кодовый замок
с дисковым механизмом
формация, связанная со вспомогательным поиском,
является экзогенной информацией:
IS = –log2 q.
(5.9)
Для нашей задачи IS = log2 310 = 15,8 бита активная информация – это уменьшение сложности при поиске при применении внешних знаний.
(5.10)
В примере с замком на рис. 5.13 активная информация составляет I+ = 33,2 –
15,8 = 16,4 бита. Активная информация определяет степень, в которой была
уменьшена сложность поиска. Эндогенная информация в поиске без посторонней помощи IΩ = 33,2 броска монет была уменьшена до экзогенной информации IS = 15,8 броска монет. Таким образом, активная информация, полученная от Ларри, составляет I+ = 16,4 броска монет. Активная информация
определяется относительно эталонной вероятности p, равной вероятности
успеха одного запроса в предположении PrOIR Бернулли.
Когда предлагается математическая модель, следует проверить, применима
ли она к заведомо очевидным случаям. Давайте рассмотрим три таких случая
применительно к модели активной информации.
1. Отсутствие знаний (I+ = 0): если активная информация равна нулю
(p = q), поиск выполняется так же, как один слепой запрос. К поиску не
добавлена никакая информация и, как и следовало ожидать,
138
Сохранение информации в компьютерном поиске
2. Идеальный поиск (I+ = IΩ ): для идеального поиска q = 1. Тогда активная
информация равна эндогенной информации (I+ = IΩ ), и мы устранили из
поиска всю доступную эндогенную информацию.
3. Негативные знания (I+ < 0): мы можем применять неправильные знания. Например, для кодового замка с колесиками можно сказать, что рабочая комбинация состоит только из чисел 3, 4 и 5, когда фактически она
состоит из чисел 1, 2 и 3. В таком случае при поиске не будет уделено внимания правильному запросу. Ошибочный вспомогательный поиск будет
работать хуже, чем случайный запрос (q < p), и в этом случае активная
информация будет отрицательной. Действительно, если q = 0, то активная информация равна минус бесконечности1.
Теперь у нас есть лучшее понимание аналогии с водяным матрасом на
рис. 5.1. Если мы ничего не знаем о поиске и выбираем случайный поиск, есть
вероятность, что в результате может появиться как отрицательная, так и положительная активная информация. Наши рассуждения о способах измерения
информации кратко представлены в табл. 5.3.
Таблица 5.3. Способы измерения информации
Вероятность
Слепой поиск
Вспомогательный поиск
q
Информация
Эндогенная:
IΩ = –log2p
Экзогенная:
IS = –log2q
Активная:
5.4.2.1. Примеры источников знаний
Как показано на рис. 5.14, активная информация добывается из источника знаний. Иметь знания не то же самое, что использовать их. Есть хорошие способы добывать активную информацию из источников знаний, но есть и наилучшие способы. Рассмотрим, например, проблему кодового замка с колесиками,
изображенного на рис. 5.13. Наш источник информации – Ларри, производитель замков, который сказал нам, что в рабочей комбинации заняты только
числа 1, 2 и 3. Разумный и, вероятно, оптимальный способ использования этого источника информации – это вслепую перебирать комбинации, используя
только 1, 2 и 3. Но это не единственный способ применить источник знаний
в поиске. Мы могли бы перебирать 1, 2 и 3 на первых пяти колесиках и любое
число от 0 до 9 на оставшихся. Этот неразумный алгоритм также когда-то добьется успеха, но использует знания гораздо менее эффективно.
1
В общем случае –∞ ≤ I+ ≤ IΩ.
Измерение сложности поиска в битах 139
Плохой
алгоритм
поиска № 1
Маленькая
активная
информация I+
Источник
знаний
Большая
Хороший
алгоритм
поиска № 1
активная
информация
Источник
знаний
Рис. 5.14 Плохие и хорошие алгоритмы поиска для добычи активной
информации из источника информации. Хороший алгоритм поиска, показанный справа, будет добывать больше активной информации, чем плохой
алгоритм слева. Эволюционный алгоритм является одним из ряда возможных алгоритмов поиска
В некоторых случаях извлечение активной информации из источника знаний является интуитивно понятным и очевидным. Так обстоит дело в случае
с кодовым замком, когда мы знаем, что в комбинации применяются только
числа 1, 2 и 3. В других схемах поиска, таких как эволюционный алгоритм проектирования антенн, наилучшее использование источника информации не
очевидно. Например, в программном обеспечении NASA для эволюционного
проектирования антенны в диапазоне X [40] в процессе поиска использовалась
оценка приспособленности в соответствии с вычислительной моделью электромагнитного поля [41] (Numerical Electromagnetics Code, NEC-4), которая имитирует физические характеристики электромагнитного поля антенны. Инженеры NASA использовали эволюционную программу для извлечения активной
информации из NEC-4. Но является ли эволюционный поиск лучшим способом
извлечения активной информации из этой программной модели с точки зрения прикладного программирования? Мог ли другой поиск быть лучше? Позже
в этой главе мы обсудим поиск наилучшего поиска.
5.4.2.2. Объем активной информации в запросе
Эффективное использование источника информации зависит от того, как мы
определяем эффективность. Если наиболее важным критерием является рабочее время программиста, то неэффективный алгоритм поиска, написанный
на скорую руку и требующий нескольких дней выполнения на компьютере,
может оказаться лучше, чем тщательно отлаженная одноминутная программа,
на разработку которой ушло три дня. Другой показатель – это количество запросов. Если мы располагаем неограниченным временем, то даже неинформированные поиски, такие как слепой поиск, в конечном итоге найдут цель.
Powered by TCPDF (www.tcpdf.org)
140
Сохранение информации в компьютерном поиске
Если мы напишем программу, которая в конечном итоге находит правильное
решение, то производительность такой программы можно измерять с точки
зрения активной информации на запрос.
Если для извлечения внутренней информации IΩ понадобилось Q запросов,
то активная информация на один запрос составляет1:
(5.11)
Эффективность алгоритма можно измерять и по отношению к другим важным параметрам, например по отношению к процессорному времени или
к расходам на почасовую оплату труда программиста.
Тонкое различие2
⍟ Когда в поиске имеется какой-либо стохастический компонент, активная информация I+ и, следовательно, активная информация на запрос в уравнении (5.11) является случайной величиной. При повторении такого поиска
количество запросов, необходимых для успеха, может измениться. Случайные
переменные часто характеризуются средними арифметическими значениями,
которые, в свою очередь, получаются усреднением значений многочисленных
испытаний. Если в поиске присутствует случайный компонент, средняя активная информация может быть оценена путем усреднения результатов многочисленных испытаний. Среднее количество запросов из N запусков одного
и того же алгоритма поиска
где Qn – количество запросов, использованных в n-м испытании для достижения успеха. Это среднее аппроксимирует среднее значение :
и, согласно закону больших чисел [42], становится более точным с увеличением
числа испытаний N. Мы склонны оценивать среднее значение случайной величины I⊕, обозначенной верхней чертой
, как
, но, как показано в табл. 5.4,
они не совпадают. Действительно, из неравенства Дженсена [43] следует:
1
Если поиск не идеален (то есть не всегда успешен), активная информация по запросу
2
⍟ Те, кто не интересуется математическими подробностями, могут пропустить этот
раздел и впредь считать
В этом нет никакой двусмысленности, если
в сравнениях последовательно используется один и тот же показатель.
Измерение сложности поиска в битах 141
Для большей точности мы можем вычислить
т. е. активную информацию на средний запрос. Она всегда меньше, чем .
В следующем разделе мы рассмотрим некоторые менее очевидные источники информации и покажем случаи, когда эволюционный подход плохо добывает активную информацию по сравнению с некоторыми другими популярными алгоритмами. Глава 6 посвящена выявлению источников активной
информации в опубликованных моделях программного обеспечения, предназначенных для имитации дарвиновской эволюции, и демонстрации того, что
другие алгоритмы поиска находят этот источник гораздо более эффективно,
чем эволюционный поиск.
Таблица 5.4. Когда есть стохастический компонент для измерения, проводятся повторные
испытания и вычисляется среднее значение результатов. Таким способом вычисляется
активная информация на один запрос. Но, как показано в таблице ниже, существуют разные
способы вычисления, что приводит к разным ответам. Допустим, выполняются два поиска
по проблеме с эндогенной информацией IΩ = 24 бита. Как показано в таблице, первый поиск
успешен после двух запросов, а второй – после шести
Попытка
№1
№2
Среднее
Ожидание
Запросы (Мелоди)
2
6
4
6
Активная информация (Меррик)
12
4
8
8
Пояснение к табл. 5.4. Два наблюдателя, Мелоди и Меррик, по-разному
оценивают запросы. Мелоди предпочитает считать запросы для каждого поиска, а Меррик ведет учет активной информации для каждого поиска. Их данные
приведены в таблице. Мелоди и Меррик усредняют результаты измерений. Мелоди получает в среднем четыре запроса, а Меррик получает в среднем 8 бит
на запрос. Поэтому Мелоди дает свою оценку активной информации на запрос
путем деления эндогенной информации из 24 бит на четыре запроса, что дает
результат в 6 бит на запрос. Оценка Меррика составляет 8 бит на запрос. Оба
наблюдателя использовали правильные методы, но получили разные ответы.
По этой причине мы должны быть очень аккуратны в наших определениях.
Меррик вычислил среднюю информацию на запрос, которая, согласно закону
больших чисел, приблизится к средней активной информации на запрос, если
будет выполнено большее количество экспериментов. Мелоди, с другой стороны, оценила активную информацию на средний запрос.
142
Сохранение информации в компьютерном поиске
5.4.2.3. Примеры активной информации
В примере замка с колесиками активная информация привела к уменьшению
размера пространства поиска. Вместо того чтобы искать комбинацию в большом пространстве поиска, нам нужно исследовать только ограниченный фрагмент пространства поиска. Вот еще несколько менее очевидных примеров источников активной информации.
Головоломка Cracker Barrel
Вернемся теперь к головоломке Cracker Barrel. Мы показали, что эндогенная
информация для решения головоломки Cracker Barrel с помощью случайного
перебора составляет IΩ = 7,4 бита. Предположим, эксперт по игре Умник Пит
сказал вам: «Когда у тебя есть выбор, не прыгай в угол».
В головоломке, показанной на рис. 5.15, углы пронумерованы числами 1, 11
и 15. Сколько активной информации вам дал Умник Пит? После 4 млн симуляций со случайной инициализацией выясняется, что Пит дал вам I+ = 2,1 бита
активной информации. Таким образом, сложность проблемы была уменьшена
с 7 бросков симметричной монеты до 5 бросков.
Рис. 5.15 В головоломке Cracker Barrel
некоторые пустые гнезда при инициализации
будут давать те же результаты, что и другие
Далее Умник Пит шепчет вам на ухо: «Кроме того, всегда начинайте с пустого отверстия № 1»1.
Это пример активной информации, полученной при инициализации процесса поиска.
«Но, Пит, – отвечаете вы после изучения доски на рис. 5.15, – если я начну
с пустого отверстия № 1, первый ход заставит меня прыгнуть в угол. Вы сказали не прыгать в угол!»
1
Симметрия игрового поля головоломки означает, что начало игры с пустой лунки
№ 1 равнозначно началу игры с лунки 11 или 15. Аналогично, лунки № 2, 3, 7, 10, 12
и 14 будут давать идентичные результаты. Отверстия № 4, 6 и 13 образуют еще одну
равнозначную группу, равно как и отверстия № 5, 8 и 9.
Измерение сложности поиска в битах 143
Пит понимающе улыбается: «Доверьтесь мне».
И вы окажетесь правы, доверяя Питу. Если вы всегда начинаете с пустого
отверстия № 1 и, когда есть выбор, избегаете прыжков в углы, то активная информация увеличивается с 2,1 до I+ = 2,6 бита.
Но не все советы являются хорошими. Предположим, что игрок Тони Два
Пальца говорит вам: «Не обращайте внимания на советы Умника Пита. Он сначала сказал вам не прыгать в угол. Затем он сказал вам начать с лунки № 1. Это
заставляет вас прыгнуть в угол буквально с первого хода. Он сам себе противоречит! Так что не слушайте его. Послушайте меня. Разве не имеет смысла начинать с пустой лунки № 5?»
Применение советов Тони при случайных ходах ухудшает ваши шансы на
выигрыш и приводит к активной информации I+ = –1,7 бита. Таким образом,
сложность проблемы увеличилась почти на два броска монеты.
Предположим, Тони Два Пальца говорит вам: «Начните с пустого отверстия
№ 5 и, когда можете, всегда прыгайте в угол. Доверьтесь мне».
За миллион случайных симуляций ни одна игра не была выиграна по совету
Тони Два Пальца. Исходя из этого моделирования, активная информация оценивается как I+ = –∞. Хотя это еще не доказано с математической строгостью,
похоже, что два правила Тони делают победу невозможной. Таблица 5.5 содержит активную информацию для различных сценариев. Активная информация
получена благодаря знаниям Умника Пита в предметной области. В поиске работают только правильные советы.
Таблица 5.5. Активная информация для различных «подсказок» для победы в головоломке
Cracker Barrel. Все значения информации указаны в битах. Инициализация (1) указывает,
что лунка номер один изначально пуста и т. д.
Эндогенная информация = IΩ – 7,4 бита
(1)
Инициализация → Случайно
Правило ↓
Случайно
0,0
0,2
От угла
2,1
2,6
В угол
–11,9
–11,0
(2)
(3)
(4)
0,3
2,3
–11,6
0,5
2,4
–12,6
–1,7
–0,6
–
Советы Тони Два Пальца привели к получению отрицательной активной информации, то есть поиск по его правилам работает хуже, чем слепой случайный поиск!
Этот пример вновь демонстрирует правильность закона сохранения информации, иллюстрируемого аналогией с водяным матрасом на рис. 5.1. Нельзя
произвольно придумывать рекомендации по поиску. Это может привести не
только к лучшим, но и к худшим результатам. Чтобы создавать положительную активную информацию, необходимо обладать достоверными знаниями
о пространстве поиска.
144
Сохранение информации в компьютерном поиске
Проблема Монти Холла
Вот еще один более тонкий пример активной информации. «Давай договоримся» (Let’s Make a Deal) – это телевизионное игровое шоу, впервые организованное Монти Холлом (Monty Hall). Есть три занавеса, и задача участника – договориться с Монти, чтобы получить самый ценный приз. Проблема
Монти Холла, положенная в основу шоу, впервые была упомянута Мэрилин
Савант (Marilyn vos Savant) в ее рубрике «Спросите Мэрилин» в журнале Parade
в 1990 году:
«Предположим, вы участвуете в игровом шоу, и вам предоставляется выбор из
трех дверей1: за одной находится автомобиль; за двумя остальными спрятаны козы. Вы выбираете дверь, скажем, № 1, и ведущий, который знает, что за
дверями, открывает другую дверь, скажем, № 3, за которой стоит коза. Затем
ведущий спрашивает вас: «Вы хотите выбрать дверь № 2?». Выгодно ли вам изменить свой выбор?»
Неискушенная интуиция часто говорит, что это не имеет значения, – у вас
есть шанс 50/50, несмотря ни на что. Это не верно. Когда выявлена одна из дверей, за которой стоит коза, вам дают дополнительные знания, которые можно
использовать для получения активной информации. Действительно, переключение вашего выбора с первоначального варианта на оставшийся вариант дает
вам вероятность выигрыша в две трети. Если вы сохраните свой первоначальный выбор, ваш шанс на выигрыш составит всего одну треть. Чтобы убедиться
в этом, предположим, что автомобиль находится за дверью № 1. Первым выбором может быть дверь № 1, № 2 или № 3. Вот возможные варианты развития
событий:
если вы выберете дверь № 1 и переключитесь, то проиграете;
если выберете дверь № 2 и переключитесь, то выиграете автомобиль;
если вы выберете дверь № 3 и переключитесь, то выиграете автомобиль.
Таким образом, если вы измените свой выбор после того, как открыта дверь,
ваши шансы на победу – два из трех. Если мы повторим это упражнение с автомобилем за дверью № 2, а затем № 3, мы получим тот же ответ 2/3. В целом, согласно PrOIR Бернулли, вероятность выигрыша составляет 2/3, если вы меняете
свой выбор, и 1/3, если вы этого не делаете.
Давайте переформулируем проблему Монти Холла на языке эндогенной и активной информации. Пространство поиска состоит из |Ω| = 3 дверей с |T | = 1
успешной целью. Поэтому PrOIR Бернулли говорит нам, что вероятность выбрать автомобиль
1
Эндогенная информация о поиске автомоби-
Монти использовал шторы, а Мэрилин – двери.
Измерение сложности поиска в битах 145
ля, таким образом, составляет IΩ = –log2 p = 1,585 бита. Когда выбрана дверь
и Монти Холл показывает вам другую дверь, за которой стоит коза, он дает вам
дополнительную информацию. Вы можете использовать эту информацию для
повышения шансов поиска. Переключив ваш выбор, мы показали, что вспомогательный поиск теперь имеет вероятность успеха q = 2/3. Активная информация, которую мы добыли из действий Монти Холла, таким образом, составляет
бит и тем самым уменьшает сложность поиска
до единицы с экзогенной информацией IS = –log2 q = 0,585 бита.
Проблема отцов и детей
Вот еще один интересный пример, результаты которого обычно противоречат интуиции [44]. На следующей неделе Тэмми проводит ежегодный
конгресс «Клуб мужчин с ровно двумя детьми», на котором отцы вместе со
своими двумя детьми проводят неделю вместе, занимаясь активными развлечениями и общением. Тэмми нужно выбрать отца, чтобы он вместе со
своими двумя детьми раздавал полотенца в мужском душе. Для выполнения
этой задачи необходимо нанять человека, у которого есть два сына. Какова
вероятность того, что случайно выбранный участник конгресса имеет двух
детей мужского пола? Исходя из вероятности 50/50 иметь девочку ( ) или
мальчика ( ), возможны четыре одинаково вероятных исхода: ,
,
и
. Если случайно выбрать отца из списка, то вероятность того, что оба ребенка являются мальчиками (
), равна p = 1/4, что соответствует эндогенной
информации IΩ = 2 бита.
Чтобы сузить круг кандидатов на раздачу полотенец, Тэмми обращается
к регистрационной базе данных участников. Каждый отец ответил на список
вопросов. Например, в клубе «Мужчины с двумя детьми» в следующем году
состоится гала-концерт отцов и сыновей. Чтобы составить список рассылки
с уведомлением о концерте, в регистрационной форме задается следующий
вопрос:
Вопрос 1: «Является ли хотя бы один из ваших детей мальчиком?»
Тэмми сразу отбрасывает каждого отца, который ответил «нет», поскольку
у них должно быть две девочки. Сколько активной информации содержится
в знании ответа на этот вопрос?
Из четырех возможных сочетаний мальчиков и девочек ответ на первый
вопрос сузил количество исходов до трех:
,
и
. Только один исход
подразумевает двоих мальчиков. Исходя из PrOIR Бернулли, добавление информации о наличии хотя бы одного мальчика дает вероятность выбрать отца
с двумя мальчиками q = 1/3. То есть если Тэмми случайно выбирает отца из
уменьшенного пула, ее шанс выбрать отца с двумя мальчиками увеличивается
146
Сохранение информации в компьютерном поиске
с p = 1/4 до q = 1/3, и Тэмми получает
бита активной
информации1.
Тэмми читает еще один вопрос в регистрационной форме, чтобы получить
еще больше активной информации для поиска отца с двумя сыновьями. К первому вопросу прилагается дополнительный, из которого можно получить еще
больше активной информации:
Вопрос 2: «Если вы ответили ДА на вопрос 1, родился ли ваш сын в четный год?
Или, если оба ваших ребенка мужского пола, был ли хотя бы один из них рожден
в четный год?»
Если Тэмми сейчас выбирает только тех, кто ответил «да» на второй вопрос,
улучшит ли это ее шансы на выбор отца с двумя детьми мужского пола? Другими словами, предоставляет ли знание о четности года рождения дополнительную активную информацию? Что примечательно, да! Вот рассуждения,
использующие PrOIR Бернулли. Прежде чем мы что-либо узнаем, существует
16 одинаково вероятных возможностей. Четные (even) и нечетные (odd) обозначаются буквами E и O. Например, E – мальчик, рожденный в четном году.
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
Первый вопрос («Является ли хотя бы один из ваших детей мальчиком?»)
удаляет четыре записи из таблицы и оставляет дюжину возможностей.
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
Из оставшейся дюжины есть семь случаев, когда хотя бы один из сыновей
1
⍟ Интуиция часто подсказывает, что если у мужчины двое детей и, по крайней мере,
один из них мальчик, то вероятность того, что другой ребенок – тоже мальчик, составляет 50/50. Но анализ здесь показывает, что правильный ответ составляет одну
треть. Существует тонкое различие между этим знанием и знанием того, что самый старший ребенок – это мальчик. В этом случае вероятность того, что другой
ребенок – мальчик, составляет 50/50. Когда информация о самом старшем включена
в знания, активная информация равна
бит по сравнению с I+ =
0,415 бита, когда используется фраза «по крайней мере, один». Следовательно, слово
«старший» вводит в поиск более половины информации.
Измерение сложности поиска в битах 147
родился в четный год. Это оставляет только семь возможностей, когда ответ на
второй вопрос – «да».
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
Из семи исходов есть три случая, когда у отца есть два сына. Давайте нарисуем вокруг них рамки:
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
(
(
(
(
E,
O,
E,
O,
E)
E)
E)
E)
(
(
(
(
E,
O,
E,
O,
O)
O)
O)
O)
Если Тэмми выбирает случайным образом из тех, кто отвечает «да» на второй вопрос, шансы на выбор мужчины с двумя сыновьями1 q = 3/7 вместо
р = 1/4. Знание из вопроса 2, таким образом, дает нам
0,778 бита активной информации. Дополнительные знания четности года рождения увеличили активную информацию на 0,363 бита больше, чем одиночный
первый вопрос2. Знание того, что сын родился в четный год, интуитивно не
кажется потенциальным источником активной информации для нашей проб
лемы. Но это показывает, что источники активной информации могут быть
тонкими и неочевидными.
Множественные запросы
Несколько запросов явно дают больше шансов на успех, чем один. Множест
венные запросы могут выполняться с заменой или без замены. Если размер
1
2
Исследования показали, что «гендерное распределение в человеческих семьях с двумя детьми … не подчиняется никакому биномиальному распределению» и, следовательно, не следует принципу Бернулли. (Мэтью А. Карлтон и Уильям Д. Стэнсфилд «Делать детей подбрасывая монетку?», The American Statistician. (2005)). Однако в нашем
примере PrIOR Бернулли дает наилучшую доступную оценку активной информации.
Если бы у Тэмми был доступ к данным, используемым Карлтоном и Стэнсфилдом, она
могла бы еще больше повысить точность активной информации в своем поиске.
Предположим, что вместо вопроса о четности года задается следующий вопрос:
«Если вы ответили “да” на вопрос 1, зовут ли вашего сына Джон?» (Если оба ваших
ребенка мужского пола, зовут ли одного из них именем Джон?). Противники PrOIR
Бернулли могут утверждать, что в этом случае активная информация будет такой же,
как и при первоначальном варианте второго вопроса. Но это не так по очевидной
причине: вероятность того, что мальчика зовут Джон, не равна 50/50, в отличие от
четности года.
148
Сохранение информации в компьютерном поиске
пространства поиска достаточно велик, а количество запросов сравнительно
невелико, то эти две процедуры примерно одинаковы. Для Q запросов замечательным результатом выборки с заменой является то, что активная информация1:
I+ » log2Q.
(5.12)
Это отношение определяет уменьшение выхода активной информации как
функции от количества запросов. Для двух запросов мы получаем 1 бит активной информации. Четыре запроса дают 2 бита активной информации, запрос
дает 3 бита, а 16 запросов – 4 бита. 1024 запроса дают I+ = 10 бит, а 230 » 1 млрд
запросов дает только около 30 бит активной информации. Независимо от того,
сколько запросов вы сделали, вам нужно удвоить их количество, чтобы получить чуть больше активной информации. В общем, запросы Q = 2n дают около
n бит активной информации (рис. 5.16).
Рис. 5.16 Активная информация для нескольких слепых запросов.
Пунктирная линия – выборка с заменой, а сплошная – без замены
5.4.3. Извлечение активной информации из оракулов
Оракул успеха (needle-in-a-haystack oracle (иголка в стоге сена)) сообщает об
успехе или неудаче запроса, использованного при поиске, например, пикового
туза в колоде из 52 карт. Это особый случай оракула. У него только две оценки
приспособленности – либо один (мы нашли цель!), либо ноль (мы не нашли
цель).
1
⍟ Для Q запросов с заменой вероятность успеха q = Qp. Таким образом, IS = –log2Qp =
–log2Q + log2 p. Принимая IΩ = –log2 p и I+ = IΩ – IS, получаем равенство (5.12) (см.
рис. 5.16).
Измерение сложности поиска в битах 149
Более типичной для оракулов является компьютерная модель, используемая
при эволюционной разработке антенны X-диапазона в проекте NASA. Как обсуждалось в разделе 3.4.1, [45] параметры проекта вводятся в программное обес
печение для моделирования антенны [46], которое выступает в роли оракула
и, как в случае с Бобом-дегустатором, выставляет оценку пригодности проекта.
5.4.3.1. Оракул Хемминга
Примером простого для понимания оракула является оракул Хемминга. Предположим, у нас есть целевая фраза (5.13) длиной L букв из алфавита из N символов, где L = 28, N = 27. Мы предлагаем оракулу Хемминга следующую фразу:
MXTHINRSLIT*IZ*RIKL*A*REASEL.
Сравнивая ее с целевой фразой
METHINKS*IT*IS*LIKE*A*WEASEL,
(5.13)
мы видим, что эти две фразы отличаются в H = 7 позициях. Это расстояние
Хемминга между целевой фразой и предположением. Когда расстояние Хемминга равно нулю, различий нет, и мы нашли целевую фразу.
Оракул Хемминга сообщает нам только количество различающихся букв, но
не места их расположения. Этот процесс можно визуализировать, как показано
на рис. 5.17. Вводится фраза, оракулу платят ($), и в ответ он сообщает расстоя
ние Хемминга. Как мы можем лучше всего потратить наши деньги? Если мы
примем сообщение длиной L с алфавитом из N символов, эндогенная информация поиска фразы составит:
IΩ = L log2 N.
Оракул
Хемминга
Рис. 5.17 Оракул Хемминга
Далее приведены четыре из многих возможных способов использования
оракула Хемминга, перечисленные в порядке увеличения эффективности
с точки зрения количества запросов [47]. Мы начнем с «плохого» алгоритма
для извлечения активной информации из оракула Хемминга.
1. Плохой алгоритм: иголка в стоге сена. Оракул Хемминга имеет возможность указать, является ли случайно выбранная фраза правильной,
то есть он может быть неэффективно использован в качестве оракула
для поиска иголки в стоге сена. Мы выбираем случайную фразу и видим,
равно ли расстояние Хемминга нулю. Если это так, мы нашли фразу. Если
это не так, выбирается другая фраза. Процесс повторяется до тех пор,
пока мы не достигнем успеха.
150
Сохранение информации в компьютерном поиске
Здесь есть две возможности: выборка с заменой и без. При выборке с заменой
Процесс выборки геометрически случайно варьируется
[48] с ожидаемым числом запросов, равным
2. Хороший алгоритм: стохастическое восхождение (поиск с трещоткой).
Поиск с трещоткой в среднем работает лучше, чем поиск иголки в стоге
сена. Поиск начинается с инициализации – определения исходного расстояния Хемминга. Затем изменяется один символ фразы, и вычисляется новое расстояние.
Если расстояние Хемминга увеличилось, значит, правильная буква
была заменена неправильной. Позиция изменения запоминается,
а исходная буква в позиции считается правильной. Эта буква остается неизменной до конца поиска.
Если расстояние Хемминга уменьшилось, то найдена правильная
буква. Позиция запоминается, и новая буква остается на этом месте
до конца поиска.
Если расстояние Хемминга не изменилось, пробуем подставить в эту
позицию другую букву.
Процесс повторяется до тех пор, пока расстояние Хемминга не станет
равным нулю. Метод называется трещоткой (храповиком), потому что
достигнутое наилучшее расстояние Хемминга никогда не меняется в обратную сторону.
Пример простого поиска с трещоткой показан в табл. 5.6.
Таблица 5.6.Иллюстрация поиска с трещоткой для фразы из трех букв с использованием оракула
Хемминга и хорошего алгоритма поиска (№ 2). Начальная догадка ADF выбрана случайным
образом. Поскольку оракул Хемминга выдает расстояние 3, все три буквы неверны. Далее мы
меняем F на G и все еще получаем расстояние Хемминга 3. Мы продолжаем перебирать разные
буквы, пока не наткнемся на правильную букву I. Мы знаем, что она правильная, потому что
расстояние Хемминга сократилось до двух. Буква I остается в третьей позиции до конца
поиска. Затем процесс повторяется для второй буквы, пока не будет найдена правильная
буква О. Расстояние Хемминга теперь равно единице. Аналогичным образом определяется
первая буква. В этом примере для получения правильного ответа понадобилось 30 запросов.
Если одну и ту же букву можно угадать несколько раз для разных позиций, то ожидаемое
количество запросов будет Q = NL = 27 × 3 = 81. Использование метода «иголки в стоге сена»,
т. е. плохого метода поиска, дает нам ожидаемое количество запросов N L = 27 3 = 19 683.
бит активной информации, уменьшая
Поиск с трещоткой добавляет
сложность поиска от эндогенной информации IΩ = log2 27 3 » 14 бит до экзогенной информации
IS = log2 27 × 3 » 6 бит
Номер
1
2
3
A
A
A
Ввод
D
D
D
F
G
A
Расстояние Хемминга
3
3
3
Измерение сложности поиска в битах 151
Таблица 5.6 (окончание)
Номер
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
A
A
A
A
A
A
A
A
A
A
A
R
T
Q
W
U
U
P
I
K
M
T
P
Y
I
G
C
Ввод
D
X
Z
A
D
T
P
L
W
R
O
O
O
O
O
O
O
O
O
O
O
O
O
O
O
O
O
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
I
Расстояние Хемминга
2
2
2
2
2
2
2
2
2
2
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
0
3. Лучший алгоритм: алгоритм Эверта1 FOOHOA. Для определения следующего шага поиск с трещоткой использует только текущее состояние,
не учитывая историю поиска. Алгоритм оракула FOOHOA (Frequence-OfOccurence Hamming Oracle Algorithm) использует историю поиска. Чем
больше знаний может эффективно использовать процедура поиска, тем
больше будет получаться активной информации на запрос.
Если оракулу Хемминга передать строку, которая состоит только из букв
А, то ответ оракула скажет нам, сколько А содержится в искомой строке. Повторяя этот процесс со всеми буквами алфавита, мы находим так
называемую частоту вхождений (Frequency-Of-Occurance, FOO) для всех
1
Уинстон Эверт – один из скромных авторов этой книги.
152
Сохранение информации в компьютерном поиске
букв. Если в алфавите N символов, для создания FOO требуется не более
N – 1 запросов. Остальная часть алгоритма FOOHOA лучше всего объясняется на примере. Рассмотрим оракула Хемминга, использующего
английские буквы в качестве алфавита и работающего со строкой длиной 5 символов. В соответствии с этим алгоритмом мы уже знаем ответ
оракула на запрос AAAAA, поскольку уже создали FOO для всех букв. Рассмотрим запрос ABAAA.
Если вторая буква в скрытой строке – A, расстояние увеличится.
Если вторая буква в скрытой строке – B, расстояние уменьшится.
В противном случае расстояние останется неизменным.
Данный запрос фактически проверяет вторую позицию на наличие как
A, так и B. Алгоритм запускается с левой стороны строки и работает через строку, запрашивая каждую букву по порядку из списка FOO, пока не
обнаружит правильную букву. Тестирование начинается с наиболее час
то употребляемых букв, поскольку они имеют наибольшую вероятность
оказаться в любой незаполненной позиции. При обнаружении правильной буквы обновляется таблица FOO.
При извлечении информации из оракула Хемминга результаты работы алгоритма FOOHOA Эверта значительно лучше, чем у поиска с трещоткой.
4. Наилучший алгоритм: поиск лучшего поиска. Для заданного оракула
существует наилучший поиск – алгоритм, который в среднем извлекает максимум активной информации за запрос. Для оракула Хемминга
мы можем найти оптимальный алгоритм для простых поисков. В целом
поиск поиска требует экспоненциально больше вычислений, чем сам
поиск1. Эверт создал S4S в случае оракула Хемминга. Используя исчерпывающую проверку всех возможных деревьев поиска, алгоритм Эверта
генерирует оптимальный поиск по дереву в смысле извлечения максимума активной информации на запрос. Результаты суммированы в табл. 5.7
[49]. На каждой итерации алгоритма поиска имеется некоторый набор
возможных скрытых строк, которые не были исключены предыдущими
запросами. Алгоритм выбирает запрос как некоторую функцию из этого
набора. Результирующий запрос и ответ создают новое подмножество,
содержащее только строки, совместимые с новым результатом запроса.
Алгоритм Эверта находит функцию, сопоставляющую эти наборы запросам, что приводит к наименьшему среднему количеству запросов
для определения цели. Это делается путем поиска каждой возможной
функции, чтобы найти среди них оптимальную. Это исчерпывающий поиск S4S, выполняемый в исходном пространстве поиска. Поэтому нас не
должно удивлять, что поиск очень дорогой в вычислительном отношении и может быть запущен только для очень маленьких задач.
1
Алгоритм S4S детально рассмотрен в разделе 5.8.
Измерение сложности поиска в битах 153
Таблица 5.7(а). Наилучшее использование оракула Хемминга для извлечения активной информации с использованием минимального количества запросов. N – количество символов в алфавите, а L – количество букв во фразе. Вверху приведено минимальное среднее количество
запросов �Q� для достижения успеха. В нижней таблице указано соответствующее числовое
значение I
L /N
1
2
3
4
5
6
L/N
1
2
3
4
5
6
1
0
0
0
0
0
0
2
1,000
1,333
1,333
1,454
1,481
1,548
2
1,000
1,500
2,250
2,750
3,375
3,875
3
1,667
2,337
2,889
3,469
–
–
3
0,951
1,359
1,646
1,827
–
–
4
2,250
3,125
3,822
–
–
–
4
0,889
1,280
1,570
–
–
–
5
2,800
3,281
–
–
–
–
5
0,829
1,415
–
–
–
–
6
3,333
4,611
–
–
–
–
6
0,775
1,121
–
–
–
–
5. Эволюционный поиск. Приведенные выше примеры использования
оракула Хемминга показывают, что при наличии источника информации разные алгоритмы поиска добывают активную информацию с разной эффективностью. Что происходит, когда для извлечения информации из оракула Хемминга применяется эволюционная стратегия? Мы
обсудим этот вопрос далее.
5.4.3.2. Weasel Ware и варианты извлечения информации
Как эволюционный поиск с использованием оракула Хемминга соотносится
с другими алгоритмами поиска? Удобный графический пользовательский интерфейс (GUI) под названием Weasel Ware 2.0, доступный на веб-сайте Evolutionary Informatics Lab (http://evoinfo.org/), позволяет нам исследовать этот вопрос1.
В примере, показанном на рис. 5.18, Weasel Ware ищет целевую фразу, используя три разных алгоритма поиска: случайный поиск, поиск с вознаграждением (эволюционный поиск) и FOOHOA Эверта. Мы снова используем целевую
фразу METHINKS*IT*IS*LIKE*A*WEASEL (3.12). Случайный поиск без начальных знаний эквивалентен слепому поиску. Слепой поиск случайным образом
выбирает 28 букв из библиотеки, состоящей из 27 символов, и спрашивает
у оракула: «Это правильная строка?» Если нет, то случайным образом выбирается 28 новых букв. Количество 503 274 на рис. 5.18 далеко не соответствует
1
Перейдите на http://evoinfo.org/. Нажмите Research Tools, а затем Weasel Ware. Другие поиски подробно описаны на веб-странице, но здесь не рассматриваются.
154
Сохранение информации в компьютерном поиске
ожидаемому числу запросов 1040 до успеха. Второй поиск, эволюционная стратегия, называется поиск с вознаграждением за приближение (Proximity reward
search). Эволюционный алгоритм, как показано в блоке поиска на рис. 5.18,
имеет популяцию из 15 потомков. Каждая буква у каждого потомка имеет
4%-ный шанс мутировать в случайно выбранную букву алфавита из 27 символов. В соответствии с ответом оракула Хемминга сильнейший из потомков выживает и дает еще 15 потомков. Мы видим, что фраза почти завершена, ей не
хватает одной буквы, поэтому поиск еще продолжается. Результаты показаны
через 68 поколений. Поскольку существует 15 запросов к оракулу Хемминга
для каждого поколения, поиск в общей сложности уже занял 15 × 68 = 4020 запросов и еще не окончен. Поиск внизу на рис. 5.18 – это поиск Эверта по алгоритму FOOHOA, который завершен всего с 77 запросами.
Рис. 5.18 Три варианта поиска с использованием оракула Хемминга
и интерфейса Weasel Ware 2.0 доступны онлайн на http://evoinfo.org/
Для алгоритма поиска с вознаграждением за приближение (эволюционного поиска) необходимо настроить два параметра: размер популяции и степень
мутации1. Неясно, какой набор параметров даст в среднем лучший результат. Результаты применения некоторых значений параметров показаны на
рис. 5.19.
1
Кроссовер не применяется.
Измерение сложности поиска в битах 155
Рис. 5.19 Результаты применения различных вариантов параметров
в эволюционном поиске с использованием Weasel Ware
Наилучшим результатом с точки зрения количества запросов является
3523 запроса на 75 потомков и одна буква мутации на потомка. Однако повторение поиска может дать большое количество запросов. Строгое сравнение
эффективности параметров требует усреднения многочисленных результатов
прогонов с одинаковыми параметрами. Тем не менее любой набор эволюционных параметров в среднем не будет столь же успешным, как в алгоритме
FOOHOA Эверта.
Чтобы обеспечить успех во всех трех поисках, давайте сократим целевую
фразу до трех букв: COI1. Результат Wearel Ware для этой аббревиатуры показан
1
Эта целевая фраза также использована в поиске с трещоткой в табл. 5.6.
156
Сохранение информации в компьютерном поиске
на рис. 5.20. Слепой поиск без помощи с использованием оракула типа «иголка
в стоге сена» потребовал около 14 000 запросов. Это меньше 20 000 запросов,
которые мы ожидаем в среднем. Случайный эволюционный поиск с использованием пяти потомков приблизился к 67 поколениям, или 5 × 67 = 335 запросам. Поиск Эверта FOOHOA потребовал только 28 запросов.
Рис. 5.20 Поиск строки из трех букв COI
с использованием Weasel Ware
5.5. Источники информации в эволюционном поиске
Источники информации, встроенные в любой эволюционный поиск, дают нам
активную информацию. Мы можем извлекать информацию из ответов оракула Хемминга при помощи разных алгоритмов1. Как мы уже успели заметить,
эволюционный поиск – не самый эффективный алгоритм.
Источники информации в моделях дарвиновской эволюции включают
в себя:
большую популяцию агентов;
полезную мутацию;
выживание наиболее приспособленных особей;
инициализацию.
1
Как обсуждалось в разделе 5.4.3.1.
Источники информации в эволюционном поиске 157
5.5.1. Популяция
Эволюционные процессы неизменно начинаются с популяции претендентов –
чем больше, тем лучше. Значимость начальной популяции становится очевидной при рассмотрении крайнего случая. Если в пространстве поиска Ω имеется
совокупность, состоящая из всех |Ω| претендентов со всеми возможными мутациями, то проблема решена. Претендент с наилучшим соответствием – наш
готовый ответ. Даже не требуется никаких дополнительных шагов в эволюции.
Мы показали, что Q слепых запросов производят активную информацию
около I+ » log2Q бит. Эволюционный поиск, начинающийся с популяции из
Q претендентов, выполняет Q запросов одновременно – параллельно, если хотите. Таким образом, активная информация в объеме log2Q бит генерируется
первым же поколением эволюционного поиска.
Большие популяции также увеличивают вероятность того, что мутации будут давать постепенно лучший результат.
Большие популяции в эволюционном поиске ускоряют конвергенцию во
времени. Однако вычислительные затраты определяются пространством, а не
временем поиска. Если количество претендентов в запросах является мерой
стоимости поиска, то может быть рекомендован более долгий последовательный поиск. В главе 6 мы увидим, что это относится как к модели EV, так и к модели Avida. Большие популяции в традиционных эволюционных вычислениях
быстро приводят к высокой стоимости запроса.
5.5.2. Коэффициент мутации
Мутация в среднем не идет на пользу. Если бы мутации были однозначно полезны, будущие мамы могли бы играть в своего рода азартные игры и принимать лекарства, чтобы вызвать мутации своих детей. Разумеется, это отвратительная идея. Тем не менее мы видим вымышленные сюжеты в сериале «Люди
Икс» и в телесериале «Герои», где люди претерпели мутацию, чтобы получить
сверхспособности.
Генетик Корнелльского университета Джон С. Сэнфорд утверждает, что чем
сложнее организм, тем меньше вероятность полезной мутации, и что мутация
имеет больше шансов уничтожить вид, чем развить его [50]. Чтобы мутации
продолжали приносить пользу в эволюционной программе, необходимо обладать постоянным источником информации, которая устраняет вредоносные
мутации.
В пределах одного поколения вероятность улучшающей мутации увеличивается с увеличением числа потомков. Число потомков K играет роль, аналогичную набору слепых запросов при последовательном слепом поиске. Мы
видели, что в результате нескольких запросов происходит уменьшение отдачи
активной информации. Разница лишь в том, что вместо последовательного
выполнения запросов поколение за поколением они выполняются параллельно – с одновременным рождением детей. Поскольку в одном поколении не
происходит обучения от мутации к мутации, случаи статистически идентич-
158
Сохранение информации в компьютерном поиске
ны. Пусть π – вероятность того, что какой-то потомок более приспособлен, чем
его родитель. Когда K большое и π мало, вероятность того, что хотя бы один
потомок лучше, чем его родитель, равна 1 – (1 – π)K » Kπ. Следовательно, вероятность улучшения возрастает линейно по отношению к количеству выводка.
Каждый потомок вносит одинаковый вклад в общий успех независимо от количества братьев и сестер.
5.5.3. Ландшафт отбора
Чтобы применить идею «выживания сильнейших», необходимо сформулировать концепцию приспособленности. Мы рассмотрели идею ландшафта отбора в разделе 3.3.1, где показан ландшафт отбора, основанный на оценках
вкуса блинов. Ландшафт отбора обычно является источником информации
в эволюционном поиске. Но вовсе не обязательно эта информация легкодоступна. Это противоречило бы закону сохранения информации и теореме об
отсутствии бесплатных завтраков. Чтобы служить источником информации,
ландшафт отбора должен иметь полезную и пригодную для использования
структуру. Но произвольно выбранные ландшафты, показанные на рис. 5.21,
могут быть сложными источниками информации, из которых трудно извлечь
активную информацию. Алгоритмы поиска с наискорейшим восхождением по
склону становятся неэффективными. Это также верно в случае эволюции, где
для поиска подходящего решения требуются многочисленные небольшие возмущения (мутации). Есть много случаев, когда пространство поиска не является гладким. Исследуя функциональную восприимчивость к аминокислотам
на поверхности энзимов, биохимик Дуглас Д. Акс (Douglas D. Axe) обнаружил
[51], что встречаются недружелюбно выглядящие ландшафты наподобие изображенного на рис. 5.21.
Рис. 5.21 Ландшафт отбора
с выраженной неравномерностью рельефа
Источники информации в эволюционном поиске 159
Как определяется приспособленность, и кто может сказать, что один продукт
эволюции лучше, чем другой? В компьютерных программах часто используется оракул. Мы уже видели, что наличия оракула недостаточно для обеспечения
успеха в слепом поиске. Программист должен предусмотреть извлечение активной информации.
Как показано на рис. 5.22, наличие высокой приспособленности в некой
точке в пространстве поиска не обязательно требует, чтобы небольшое возмущение вокруг этой точки приводило к возрастанию величины приспособ
ленности. Функции приспособленности могут иметь непредвиденные нежелательные свойства. Рассмотрим, к примеру, известную головоломку – кубик
Рубика [52]. Цель поиска – разместить каждый из 9 квадратов таким образом,
чтобы каждая из шести сторон была одного цвета. Очевидным критерием
приспособленности является количество одного цвета в процентах на каждой
из шести сторон кубика. Если всего лишь на двух сторонах кубика из шести
окажется только один квадратик неуместного цвета, то формальная приспособленность будет замечательной, однако это не будет решением проблемы.
Чтобы прийти к окончательному решению, придется пройти через промежуточное ухудшение приспособленности. Использование евклидовой функции
приспособленности – плохой выбор в случае кубика Рубика. Более полезным
критерием приспособленности является количество шагов, необходимых от
текущего состояния к решению.
Дорожное
кафе
Проезд
Рис. 5.22 Как и в случае кубика Рубика, ближайшее расстояние между
двумя точками не обязательно должно быть прямой линией. Поэтому расстояние между двумя точками не обязательно определяется евклидовым
расстоянием. На этом рисунке водитель автомобиля хочет посетить придорожное кафе. Самое короткое евклидово расстояние – d. Но, как показано
пунктирной линией, лучший способ добраться до кафе требует путешествия
на расстояние, намного большее, чем d
Схожий пример противопоставления функциональности и евклидовой приспособленности – поездка в придорожное кафе, чтобы получить сэндвич с ку-
160
Сохранение информации в компьютерном поиске
рицей. Бордюры и здания могут заблокировать вам проезд к окну выдачи заказов, даже если вы находитесь рядом, в евклидовом смысле. Чтобы добраться
до окна, вам, возможно, придется проехать по обходному маршруту, который
уводит вас дальше от цели, но в конечном итоге представляет наилучший доступный путь к роскошному сэндвичу с курицей [53]. Эта ситуация показана
на рис. 5.22.
Следовательно, существуют функции приспособленности, которые не способствуют медленным постепенным изменениям. Встречаются эволюционные алгоритмы, в частности генетические алгоритмы, которые не делают мелких шагов на ландшафте отбора. Координата в двоичном формате (000100)2 = 8
всего лишь после одной битовой мутации может измениться на (100100)2 = 72.
В зависимости от способа кодирования двоичной строки местоположение в области поиска может резко измениться. Мутации оказывают огромное влияние
на евклидово расстояние и могут, например, быть более полезными для решения проблемы куриного сэндвича, чем метод градиентного спуска. Мы снова
видим важность выбора алгоритма поиска, который наилучшим образом соответствует решаемой проблеме. Другая интересная проблема неевклидовых
расстояний показана на рис. 5.23.
5.5.3.1. Инициализация
Эволюционный поиск, как и любой другой поиск, улучшается путем информированной инициализации. Если у нас есть какое-либо представление о том, в какой части пространства поиска расположено решение, то часто имеет смысл
начинать поиск в каком-то месте, близком1 к определенному решению.
Программа Avida использует определенный тип инициализации, однако
в этом случае инициализация не выбирается вблизи решения, а требуется для
функционирования эволюционной программы.
5.6. Ступенчатая информация
и переходная функциональная жизнеспособность
В комедии «Как там Боб?» психиатр доктор Лео Марвин (Ричард Дрейфус) рек
ламирует свою книгу для саморазвития под названием «Детские шаги». Он объясняет идею своему параноидальному пациенту Бобу Уайли (Билл Мюррей):
«Детские шаги – это означает ставить перед собой небольшие разумные цели на
один день. Один крошечный шаг за один раз. Шаги малыша».
Боб воспринимает эту концепцию как решение всех своих проблем:
«Это круто! Детские шаги, детские шаги через офис, детские шаги за дверь, это
работает, это работает! Все, что мне нужно сделать, – просто сделать один маленький шаг за раз, и я могу сделать все, что угодно!»
1
«Близко» в любом смысле, вытекающем из знания ландшафта отбора.
Ступенчатая информация и переходная функциональная жизнеспособность 161
Рис. 5.23 Вот интересный парадокс, касающийся евклидовых расстояний
и городских кварталов. Показаны четыре квадрата, у которых длина стороны
равна одной миле. В случае (а) мы видим, что расстояние между А и В, показанное пунктирной линией, составляет 2 мили. Предположим, что мы вынуждены
двигаться только горизонтально и вертикально. Движение по диагонали не допускается. Следовательно, мы можем делать только правые и левые повороты
на 90°. Если в случае (a) мы пойдем от A к C, сделаем левый поворот и перейдем
от C к B, мы пройдем 2 мили. Если, как показано в случае (b), мы сделаем два
левых поворота и один правый, чтобы добраться от А до В, мы все равно пройдем 2 мили. На маршруте (c), где имеется больше поворотов, мы по-прежнему
проходим в общей сложности 2 мили. Если мы делаем многочисленные повороты, мы начинаем обниматься с 45-пунктирной линией, соединяющей А и
В, как показано на (d), мы все еще едем 2 мили. В пределе мы приближаемся
к пунктирной линии, и, что любопытно, продолжаем проходить 2 мили. Но пунк
тирная линия составляет 2 мили! Похоже, мы доказали, что 2 = 2. Это явно
неверно. Каково объяснение, и что оно говорит о применимости евклидова расстояния? (Ответ можно найти в книге Маркса «Handbook of Fourier Analysis»,
Oxford University Press, 2009)
Гора Докинза в книге «Гора Невероятности» (Mount Improbable) основана
на логике Боба. Невероятно сложный продукт расположен на вершине крутого утеса эндогенной информации. Как до него добраться? По словам Докинза,
ответ кроется в маленьких детских шагах. На другой стороне горы находится
длинная лестница с близко расположенными ступенями, которая позволяет
162
Сохранение информации в компьютерном поиске
нам подниматься маленькими шагами, ступенька за ступенькой, на вершину
горы. Или, как говорит сам Докинз:
«Это медленное, кумулятивное, неслучайное выживание случайных вариантов,
которое Дарвин назвал естественным отбором».
Но что говорит нам о ступенчатом восхождении эволюционная информатика?
5.6.1. Детские шаги
Метод детских шагов действительно работает. Предположим, у нас есть 30 монет, и мы хотим, чтобы после подбрасывания все они случайно показали
решки. Эндогенная информационная трудность этой проблемы составляет
IΩ = 30 бит. Мы подбрасываем все 30 монет в воздух. Они падают, звонко подпрыгивают на кафельном полу и в конце концов показывают либо решки, либо
орлы. Наша цель достигнута, если все монеты покажут решки. В среднем нам
нужно было бы повторить этот эксперимент около 1 млрд раз, прежде чем мы
добьемся успеха1. Это равносильно 30 млрд бросков одной симметричной монеты в ожидании выпадения 30 решек подряд.
Теперь давайте применим метод детских шагов.
Мы подбрасываем первую монету, пока не получим решку. Затем вторую.
Процесс повторяется до тех пор, пока все 30 монет не покажут решку. Каждая
монета в среднем нуждается в двух подбрасываниях, чтобы гарантированно
получить решку2. Хмм... Нам потребуется не более 60 подбрасываний, чтобы
получить 30 решек. Это намного меньше, чем 30 млрд!
В этом примере восхождение на гору Невероятности работает довольно
хорошо. Но это игрушечная проблема, которая игнорирует важные вопросы
функциональной жизнеспособности и неснижаемой сложности.
5.6.2. Сохранение функциональности развития
и неснижаемая сложность
Породившая сложные организмы эволюция Дарвина занимается восхождением на гору Невероятности [54]. Небольшие мутации накапливаются и служат
для создания высших форм жизни. В эволюционных программах на компью1
IΩ = 30 бит соответствует p » 10–9. Эксперимент представляет собой случайную вели-
чину с геометрическим распределением и с ожидаемым значением около
2
» 1 млрд
испытаний.
Для одной монеты число подбрасываний монет до получения решки является случайной величиной с геометрическим распределением с вероятностью p =
даемым значением
= 2 подбрасывания монет.
и ожи-
Ступенчатая информация и переходная функциональная жизнеспособность 163
терах нет необходимости назначать контролирующего агента на промежуточных этапах процесса. Однако для успешной биологической эволюции каждый
промежуточный шаг должен быть жизнеспособным. Если червь превращается
в кита, каждый промежуточный организм на этом пути должен быть жизнеспособным существом. В эволюции реальных живых организмов не может быть
никакого промежуточного шага, представляющего собой шар неживой ткани.
Таким образом, пути эволюции любого биологического объекта более строго
ограничены, чем для абстрактной эволюционной компьютерной модели. В эволюционном процессе мы можем придумать множество путей для перехода от
точки инициализации к цели. В компьютерном моделировании путь обычно не
важен. Для физической эволюции могут использоваться только те пути, которые обеспечивают функциональную жизнеспособность на каждом этапе.
В примерах эволюции фраз на естественном языке, которыми часто иллюст
рируют метод детских шагов, редко рассматривается функциональная жизнеспособность [55]. Предположим, мы хотим развить фразу1
ALL_THE_WORLD_IS_A_STAGE__
в фразу:
METHINKS_IT_IS_LIKE_A_WEASEL.
Что мы получим, если просто смешаем буквы из двух фраз?
mlt_ihk otli siaesaaw_a_e_.
С точки зрения английского языка это выражение, как и большинство всех
фраз между двумя образцовыми фразами, бессмысленно и не является функционально жизнеспособным.
Существуют и другие примеры использования английского языка, в которых детские шаги превращают одну букву в сложное слово. Рассмотрим ступенчатое построение слова STRINGIER по одной букве за шаг. Возможна следующая последовательность шагов:
R → SR → STR → STRN → STRNR → STRNIR → STRNGIR → STRNGIER →
STRINGIER.
Ни один из промежуточных шагов не является словом. В этой цепочке нет
переходящей жизнеспособности. Последовательность с переходящей жизнеспособностью может выглядеть так:
I → IN → SIN → SINE → SINGE → SINGER → STINGER → STINGIER → STRINGIER.
Каждая запись в цепочке является жизнеспособным словом, которое пройдет проверку орфографии. Критерий жизнеспособности значительно усложняет поиск. Еще одно девятибуквенное слово, которое можно «развить» из буквы, которую я использую с помощью жизнеспособных слов, – это STARTLING.
1
«Весь мир – театр».
164
Сохранение информации в компьютерном поиске
Самое длинное десятибуквенное слово, которое, как мы знаем, может быть
развито с сохранением промежуточной жизнеспособности, – это SPLITTINGS1.
Мы пока не знаем других слов подобной длины, к которым можно применить процесс пошагового перехода, поддерживая при этом на каждом этапе
функциональную жизнеспособность. Условие сохранения жизнеспособности
существенно ограничивает возможности метода детских шагов.
Эволюционные вычисления могут привести к сложным результатам, если
промежуточные этапы жизнеспособны. Чтобы перейти от инициализации
PrOIR Бернулли к первой цели, требуется достаточно небольшая эндогенная
информация. Расстояние между первым и вторым шагами тоже должно быть
достаточно легким, чтобы обеспечить успех. Можно использовать большое количество этапов. Но механизм поиска, который позволяет выполнять небольшие функциональные шаги, сам должен быть основан на активной информации. Установление промежуточных состояний требует ступенчатой активной
информации, как показано на рис. 5.24. Общая эндогенная информация поиска – IΩ. Поиск разбит на несколько небольших ступеней, из которых n имеет
эндогенную информацию IΩn.
Рис. 5.24 Для источников информации ступеней промежуточные формы
на каждой ступени должны быть жизнеспособными
→
I
→
IN
→
PIN
→
Такой синтез тоже должен быть тщательно продуман.
1
Пусть это будет упражнением для читателя.
PINSTRIPE
→
→
IP → RIP → RIPE → TRIPE → STRIPE
→
Разветвление с последующим слиянием позволяет строить более сложные
слова, например:
Ступенчатая информация и переходная функциональная жизнеспособность 165
5.6.2.1. Учебный пример: поиск длинной фразы
Рассмотрим учебный пример поиска длинной фразы, в котором сначала находят буквы во фразе, а затем определяют частоту встречаемости букв [56]. Таким
образом, поиск имеет три ступеньки:
1. Находим сокращенный алфавит фразы.
2. Находим частоту встречаемости каждой буквы сокращенного алфавита.
3. Производим более длинную фразу, используя сокращенный алфавит
и знание частоты встречаемости каждого символа.
Шаг 3 следует после шага 2, потому что частота встречаемости позволяет
нам предлагать часто используемые буквы соответственно чаще, чем редко используемые буквы. Аналогично, шаг 2 легче реализуется с активной информацией, полученной на шаге 1, где был уменьшен размер алфавита. Тем самым
значительно уменьшено пространство поиска.
Вот пример эволюции фразы:
1. MY_TEARS
2. EAR_TATTER_
3. ERATTA_RETREAT _TREAT_
(5.14)
Шаг 1 – это поиск сокращенного алфавита из L1 = 8 символов MY_TEARS из
большего алфавита из N = 27. Мы предположим, что оракул для шага 1 говорит
нам «да», если мы угадываем восемь букв в любом порядке. Чтобы перейти
к шагу 2, предполагается слепой поиск без посторонней помощи с оракулом
типа «иголка в стоге сена», который говорит нам «да» только тогда, когда все
буквы представлены строго в нужном порядке. Зная частоту встречаемости
каждой буквы в шаге 2 и длину сообщения в шаге 3, мы узнаем, сколько и какие буквы используются в шаге 3. Мы просто должны перетасовывать карточки
с буквами, до тех пор пока оракул на третьем уровне не даст нам ответ «да».
Информационная сложность поиска при использовании трех ступенек лестницы составит около
BSS = 3,58 × 1014 бит.
(5.15)
Использование слепого поиска без ступенек потребует около
BΩ = 3,23 × 1033 бит.
(5.16)
Разница примерно в девятнадцать порядков поразительна! Миллиметр, или
10–3 м, при увеличении на 19 порядков составляет около светового года, или
» 1016 м.
5.6.2.2. Математический анализ предыдущего примера
⍟ Теперь мы представим математические рассуждения, дающие ответы на вопросы, приведенные в предыдущем разделе. Те, кто не интересуется математикой, могут пропустить этот раздел.
Шаг 1 требует найти фразу MY_TEARS из алфавита из 27 символов (26 букв
и пробел). Фраза содержит L1 = 8 букв. Мы предполагаем, что буквы можно
166
Сохранение информации в компьютерном поиске
найти в любом порядке, поскольку нас интересует лишь факт наличия букв,
а не их порядок. Таким образом, шанс прохождения первого шага составляет:
Ожидаемое количество запросов для достижения заданной случайной величины:
Каждый запрос расходует L1 log2 N = 38 бит. Таким образом, общее количест
во битов, потраченных на переход к первому шагу, равно
B1 = Q1L1 log2 N = 8,44 × 107 бит.
Чтобы перейти от шага 1 к шагу 2, необходимо найти фразу EAR_TATTER_
с использованием сокращенного алфавита, полученного на шаге 1 из фразы
длиной L1 = 8. Обратите внимание, что не все буквы, найденные на шаге 1,
используются на шаге 2. Поскольку длина фразы на втором шаге L2 = 11 символов, вероятность перехода от шага 1 к шагу 2:
Используя те же рассуждения, что и раньше, находим общее количество битов, затраченных на этом этапе:
Теперь мы знаем, что некоторые буквы, составляющие фразу EAR_TATTER_,
используются несколько раз в целевой фразе на шаге 3. Нам просто нужно
произвольно комбинировать все буквы, до тех пор пока мы не получим правильный ответ. Количество комбинаций является полиномиальной случайной
величиной. Например, если есть k1 зеленых шаров, k2 синих шаров, k3 желтых
шаров и т. д., так что
где М – количество цветов, то количество комбинаций размещения этих шаров:
Вероятность случайного расположения шаров в заданном порядке является
обратной величиной этого значения. Для нашей задачи L = L3 = 22, а частота
Коэволюция 167
появления букв M = 5 равна kE = kR = kA = k_ = 4, а kT = 6. Следовательно:
а также
Тогда общее количество битов, потраченных на поиск ступеньки:
BSS = B1 + B2 + B3 = 3,582 × 1014 бит,
это значение, указанное в уравнении (5.15).
Для самостоятельного (слепого) поиска вероятность успеха
p = N –L = 3,24 × 10–32
требует следующих информационных затрат:
– это значение, указанное в уравнении (5.16).
Наличие промежуточных ступенек в этом примере добавляет много активной информации.
5.7. Коэволюция
Подходы, основанные на биологической коэволюции [57], широко используются
в поисковых алгоритмах. Примеры включают в себя сортирующие сети (sorting
network) [58], морфологию и производительность конкурирующих агентов [59],
нарды [60], шашки [61] и шахматы [62]. В то время как традиционные методы
эволюционного поиска требуют наличия функции приспособленности, в которую заложены навыки разработчика алгоритма, коэволюция опирается на минимальные предварительные знания предметной области. Как отмечено в [63]:
«Коэволюционные алгоритмы требуют незначительных априорных знаний
о предметной области».
Некоторые исследователи утверждают, что коэволюционный поиск может
нарушать закон сохранения информации [64], [15–18]. Но мы убедимся, что
правильно истолкованный закон сохранения информации не нарушается.
Действительно, это очень странно, если фундаментальный закон сохранения информации работает при эволюционном поиске, но нарушается в случае коэволюции. Что же такого особенного есть в коэволюционных поисках,
что позволяет им обходиться без предварительной информации и, более того,
словно создавать информацию из ниоткуда?
Powered by TCPDF (www.tcpdf.org)
168
Сохранение информации в компьютерном поиске
Статус
Многоножки
Комары
Мухи
Шершни
Осы
Термиты
Пауки
Муравьи
Тараканы
Прежде чем перейти к рассуждениям, показывающим, что коэволюционный поиск подчиняется закону сохранения информации, давайте рассмотрим
простой пример, показанный на рис. 5.25. Наша работа – тестировать инсектициды. У нас есть восемь возможных формул инсектицидов, помеченных от
A до H. Чтобы успешно пройти испытания, инсектицид должен убивать тараканов, муравьев, пауков, термитов, ос, шершней, мух, комаров и многоножек.
Предположим, что стоимость тестирования любой формулы на любом насекомом одинакова. Как видно из таблицы, некоторые тесты уже выполнены. Например, формула А убивает тараканов, но не убивает муравьев. Буква P (Pass)
означает успешное прохождение теста. Буква F означает неудачу (Fail). Каким
должен быть наш следующий эксперимент с целью минимизации общей стои
мости испытаний? Чтобы успешно пройти цикл испытаний, формула должна
исключить все провалы. Так как формула А уже провалилась на муравьях, нет
причин испытывать ее на пауках. То же самое верно для формулы B, которая
не смогла убить шершней. Формула C не смогла убить термитов, а препарат D
вызвал у тараканов головную боль, но не убил их. Чтобы дисквалифицировать
формулу, нам достаточно лишь одного провала. В столбце «Статус» справа на
рис. 5.25 мы вводим F, если формула провалила один или несколько тестов, и P,
если провалов (пока) не было. Дальнейшее тестирование формул, которые потерпели неудачу, является пустой тратой времени и денег. Формулы E, G и H на
данный момент прошли все испытания. Именно на эти формулы мы потратим
наше время и деньги, чтобы продолжить испытания.
Рис. 5.25 Пример коэволюции
Вот в чем суть: не все оставшиеся возможные запросы на рис. 5.25 одинаково
полезны. Некоторые очевидно более ценны, чем другие. Таким образом, PrOIR
Бернулли не применяется и, по-видимому, не работает закон сохранения информации.
Но подождите минутку. Разве в колонке «Статус» не присутствует верный
ответ? Каждый элемент в матрице просто предоставляет информацию для
Коэволюция 169
окончательной записи в столбце «Статус». Действительно, закон сохранения
информации становится применимым, когда мы рассматриваем столбец «Статус» как совокупный результат запроса, а не обращаемся к отдельным записям
в матрице. Записи в матрице подобны смежным (или, как иногда говорят, подчиненным) запросам. Смежные запросы, вместе взятые, образуют общий запрос. Совокупный запрос соблюдает закон сохранения информации. Подчиненные запросы по отдельности – нет.
Обобщение коэволюционного поиска проиллюстрировано на рис. 5.26 [65].
Решениякандидаты
Проекция
Поисковое
действие
Состояние
поиска
Матрица смежных запросов
Поисковый
алгоритм
Общий статус пригодности
Концепт
решения
Запросы
Лучшее
решение
Рис. 5.26 Процесс коэволюции
Список возможных решений показан на левой стороне. Каждая строка мат
рицы соседних запросов соответствует кандидату на решение. По мере выполнения последующих запросов результаты проецируются в концепцию
решения. Это замысловатый способ свести запросы в одно число. Это число
записано в правом столбце с названием «Концепт решения». Далее нам нужно
просмотреть записи в столбце «Концепт решения», чтобы определить общий
статус приспособленности. Он говорит нам о лучшем решении, которое у нас
есть. Вот где в игру вступает коэволюционный поиск. Исходя из лучшего решения, мы выбираем следующий смежный запрос, чтобы развить наш поиск
в подходящем направлении. Например, в примере с инсектицидом на рис. 5.25
в качестве кандидатов для дальнейших запросов рассматриваются только инсектициды со статусом P.
Коэволюция показала свою эффективность во многих инженерных проектах, и наш анализ никоим образом не должен истолковываться как дискредитация коэволюции как жизнеспособного подхода к оптимизации. Например,
несколько смежных запросов могут стоить дешевле, чем полные. В некоторых случаях полные запросы доступны только через смежные. Тем не менее
мы утверждаем, что коэволюция при анализе на уровне совокупного реше-
170
Сохранение информации в компьютерном поиске
Среднее
Максимум
ния подчиняется теоремам об отсутствии бесплатных завтраков и сохранения информации.
Несколько более сложный пример показан на рис. 5.27 [66].
Рис. 5.27 В коэволюции некоторые последующие запросы
более информативны, чем другие
У нас есть три классные комнаты, A, B и C, и в каждой по пять учеников.
В каком классе есть самые старшие ученики? Для расчета проекции строки мы
выбираем операцию усреднения. Каждый раз, выполняя запрос, мы платим
ученику фиксированную плату за информацию о возрасте. Это затраты на поиск, которые мы стремимся уменьшить. Предположим, что наше исследование схематически показано на рис. 5.27. В классе А были опрошены все пять
учеников, и средний возраст составил 59 лет. В классах B и C мы выполнили по
три запроса, что дает средние значения запросов соответственно 46 и 33. Поскольку наша цель состоит в том, чтобы найти наибольшее среднее, в данный
момент наилучшим решением является 59.
Осталось опросить четырех учеников. Как нам лучше всего потратить наши
деньги? Простой расчет показывает, что наибольшее среднее для класса B не
превысит 55, даже если оставшимся двум ученикам будет по 100 лет. Таким образом, любой дополнительный запрос в классе B является пустой тратой денег,
поскольку не существует результата, который превысил бы средний возраст
в классе A. С другой стороны, класс C мог бы стать победителем, если оба оставшихся ученика имеют возраст 59 или старше. Путь к поиску лучшего решения
теперь ясен. Сначала мы опрашиваем четвертого ученика в классе C. Если его
возраст меньше 59 лет, мы закончили, и класс A выигрывает, независимо от
того, сколько лет пятому ученику в классе C. Однако если запрашиваемому
ученику 59 лет или больше, победитель (класс A или класс С) будет определен
пятым и последним запросом в классе С.
С точки зрения обычных запросов существует три средних возраста – по одному на каждый класс. Эти значения используются в последующих запросах.
Сохранение информации относится к обычному полному запросу.
Таким образом, два оставшихся без ответа запроса в полях, отмеченных
символом X на рис. 5.27, бесполезны. С другой стороны, запрос a и, возможно,
запрос b будут определять победителя. Не все последующие запросы являются
равными.
Поиск поиска 171
5.8. Поиск поиска
Сторонники стохастической модели ненаправленной эволюции утверждают,
что нам очень повезло, что у нас есть именно такая окружающая среда, – подходящая для существования всего живого, включая человека. И если бы ее не
было, мы бы сейчас об этом не рассуждали. Судя по тому, что в пределах досягаемости научных инструментов мы не наблюдаем других планет, подходящих
для белковой жизни, аналогичной нашей, нам действительно повезло с окружающей средой.
Но в какой степени повезло, если говорить о случайной эволюции? Какова вероятность возникновения именно такого биологического разнообразия
жизни вследствие цепочки слепых случайностей (т. е. без алгоритма – без извлечения информации в процессе поиска и без использования информации
о промежуточных этапах поиска)? Если мы рассматриваем эволюцию как поиск, то возникает вопрос, насколько сложно определить успешный поиск. Для
этого мы предпринимаем поиск для выявления успешного поиска. Сложность
поиска поисков (search for search, S4S), измеренная в эндогенной информации,
всегда превышает допустимую активную информацию исходного поиска, которая служит порогом соответствия для S4S. Что еще более важно, при разум
ных допущениях успешный поиск поиска оказывается экспоненциально сложнее, чем искомый.
5.8.1. Пример
Простой пример поиска для поиска показан на рис. 5.28. Есть 16 квадратов.
Цель показана в правом нижнем углу левого блока. Мы рассмотрим три поиска.
Поиск (а) использует все 16 квадратов. Они все окрашены. Поиск (б) использует
только 8 квадратов справа. Они также окрашены. Поиск (c) ограничивает пространство только 8 окрашенными квадратами вверху. Поиск (c), как вы можете
видеть, является плохим выбором, потому что существует нулевая вероятность
найти цель в правом нижнем углу.
Рис. 5.28 Пример поиска в пространстве поисков
Если выбран слепой поиск, вероятность случайного выбора цели равна 1/16.
Эндогенная информация для поиска составляет четыре бита. Таким образом,
активная информация для поиска (а) равна нулю. Вероятность успешного
172
Сохранение информации в компьютерном поиске
определения цели в одном запросе для поиска (b) равна 1/8. Это соответствует
активной информации величиной в один бит. В случае поиска (c) вероятность
нахождения цели равна нулю. Цель поиска (c) находится не в окрашенной области. Таким образом, активная информация для поиска (c) равна минус бесконечности. Эти результаты обобщены в табл. 5.8.
Таблица 5.8. Результаты примера поиска для поиска
Вероятность успеха, q
(a) 1/16
(b) 1/8
(c) 0
S4S 1/12
Эндогенная информация,
IS
4
3
–
3,585
Активная информация,
I+
0
1
–
0,415
Поиск лучшего поиска подразумевает выбор из нескольких доступных поисков. Предположим, что поиски (a), (b) и (c) являются такими доступными поисками. Если мы не знаем, какой из этих трех поисков является лучшим, самое
разумное, что мы можем сделать, – это выбрать поиск случайно и с равной вероятностью. Как видно из табл. 5.8, общая вероятность выбора цели с одного
запроса становится равной 1/12. Поскольку вероятность выбора любого из поисков одинаково вероятна, это значение равно среднему значению вероятности успеха для поисков (a), (b) и (c). Это, в свою очередь, приводит к активной
информации в 0,4154 бита для S4S. Это лучше, чем худший поиск, и хуже, чем
лучший. Если все возможные поиски разрешены, из теоремы об отсутствии
бесплатных завтраков следует, что в среднем ни один алгоритм поиска не будет работать лучше, чем любой другой.
Этот простой пример иллюстрирует проблему S4S. Наилучшей доступной
стратегией поиска является поиск (б). В метасмысле поиск (b) сам является
целью для S4S. Как только поиск (b) определен, мы продолжаем поиск цели уже
в пространстве (b).
5.8.2. Проблема поиска для поисков
В S4S наша работа состоит в том, чтобы выбирать поиск из пространства всех
возможных поисков. Но какова наша цель? Мы хотим выбрать успешный поиск, но как установить критерий приспособленности для успешного поиска?
Ответом является целевое значение для активной информации искомого поиска. Мы хотели бы выбрать поиск, активная информация которого равна или
превышает некоторый порог. Обозначим этот порог через I+*. Любой поиск
с активной информацией, равной или превышающей I+*, считается успешным.
Мы можем записать:
(5.17)
Поиск поиска 173
где q* – вероятность успеха, соответствующая активному информационному
порогу I+*. Поскольку вероятность успеха без посторонней помощи p одинакова для всех поисков, требование, чтобы активная информация превышала
I+*, эквивалентно нахождению поиска, в котором вспомогательная вероятность
превышает порог q*.
Мы нашли наш критерий поиска, но теперь должны определить пространство поиска. Мы рассматриваем два случая: слабый и строгий.
Ранее мы изучали любопытный пример, названный парадоксом Бертрана.
Принцип Бернулли (PrOIR), подразумевающий равномерное распределение
вероятности по пространству поиска, дал три разных результата. Однако парадокс Бертрана разрешается, когда определено точное значение слова «случайный». Если определен характер случайности, парадокс Бертрана исчезает. При
анализе строгой версии S4S мы должны проявлять бдительность, формулируя
определение «случайного» выбора поиска.
В первую очередь стоит использовать пространство поиска S4S, заполненное различными алгоритмами поиска, такими как метод роя частиц (particle
swarm method), сопряженный градиентный спуск (conjugate gradient descent)
или поиск Левенберга–Марквардта (Levenberg–Marquardt search). Каждый алгоритм поиска, в свою очередь, имеет параметры. Поиск должен выполняться
не только среди алгоритмов, но и внутри них по ряду различных параметров
и инициализаций. Выполнение S4S с использованием этого подхода выглядит
практически неразрешимым. Отметим, однако, что выбор алгоритма вместе
с его параметрами и инициализацией формирует распределение вероятностей по пространству поиска. Поиск среди этих распределений вероятностей
поддается анализу и является моделью, которую мы будем использовать. Поэтому наше пространство поиска S4S заполнено большим количеством вероятностных распределений, наложенных на пространство поиска.
5.8.2.1. Слабый случай
Теперь покажем, что чем лучше поиск, который мы хотим найти, тем сложнее
S4S. Другими словами, эндогенная информация для S4S будет увеличиваться
как функция целевой информации. Пусть эндогенной информацией для S4S
будет . (Для всех переменных, связанных с пространством S4S, мы будем использовать символ ~.) Для слабого случая покажем, что
(5.18)
Другими словами, эндогенная информация для S4S всегда равна или превышает активную информацию искомого поиска. Таким образом, S4S по меньшей мере так же сложен, как и активная информация, которую мы хотим добавить к поиску.
5.8.2.2. Строгий случай
Когда берется отрицательный логарифм вероятности по основанию 2, единицей информации являются биты. Когда используется натуральный логарифм,
174
Сохранение информации в компьютерном поиске
единицей информации является нат1. Один нат равен log2 e » 1,443 бита. Для
строгого случая S4S мы считаем удобным использовать информацию, измеренную в натах. Если число бинов вероятности велико, то есть N ≫ 1, и порог
для вероятности успеха очень, очень мал (q↑ *≪ 1), тогда эндогенная информация для S4S составляет (приблизительно) в натах:
(5.19)
Таким образом, S4S экспоненциально сложнее, чем активная информация,
которую он ищет!
В обоих случаях мы видим, что сохранение информации не может быть нарушено, если передать сложность поиску более высокого уровня. Такой поиск
становится все более и более сложным, поскольку активная информация требуемого поиска увеличивается. И эндогенная информация S4S всегда равна
или превышает порог активной информации, установленный для S4S.
5.8.3. Математические доказательства
⍟ Мы излагаем математическое обоснование утверждений из предыдущих
разделов на максимально общем уровне. Однако обойтись совсем без использования математической теории вероятностей невозможно. Для еще более
строгого вывода см. нашу статью [67]. Те, кого пугают математические выкладки, возможно, предпочтут поверить нам на слово и пропустить оставшуюся
часть этой главы.
5.8.3.1. Предварительные сведения
⍟ Мы будем использовать функцию вероятности, как показано на рис. 5.29.
Высота каждого из столбцов π1, π2, π3, ..., πN соответствует вероятности события
в пространстве поиска. В качестве цели необходимо выбрать отдельное событие, и на рис. 5.29 это событие с самым высоким столбцом. Вероятность нахождения цели πT = q. Поскольку все это вероятности, сумма высот всех столбцов
должна равняться единице:
(5.20)
Отметим, в частности, что при равномерном распределении каждый из них
имеет вероятность:
Таким образом, эндогенная информация исходного поиска:
IΩ = log N.
1
Мы ввели этот термин в разделе 2.2.2.
(5.21)
Поиск поиска 175
Вероятность
Цель
Рис. 5.29 Вероятности события
Требование того, чтобы активная информация превышала порог I+*, эквивалентно требованию того, чтобы вероятность вспомогательного поиска превысила пороговое значение q*:
q ³ q*.
Это наш критерий успеха поиска. Когда выбрано распределение вероятностей в пространстве, объявляем о завершении поиска, если вероятность успеха
превышает q*.
Пример части пространства, из которого мы выбираем распределения вероятностей, показан на рис. 5.30. Продолжая обозначения, используемые в гла~ . Имеется Ω
~ = 6 распределений
ве 5, пометим пространство поиска символом Ω
~
вероятностей в пространстве поиска S4S. Цель T содержит все распределения,
где вероятность успеха превышает порог. Эти решения обведены пунктирной
линией на рис. 5.30. Есть |T~ | = 3 распределения в целевой области.
5.8.3.2. Слабый случай
⍟ Давайте возьмем среднее значение всех вероятностей успеха для распределений в целевой области пространства поиска S4S. Поскольку каждая из вероятностей успеха равна или превышает пороговое значение, мы знаем, что это
среднее значение должно быть больше порогового.
Более слабое неравенство получается, если мы суммируем по всему пространству распределений S4S:
Теперь мы разделим обе стороны на кардинальность (количество элементов
множества) пространства поиска S4S:
176
Сохранение информации в компьютерном поиске
Рис. 5.30 Цели S4S
Но вероятность выбора удачного распределения равна
и вероятность
успеха поиска является средним значением всех вероятностей успеха. То есть
Здесь есть предположение: средняя вероятность успеха в пространстве S4S,
~ , равна равномерной вероятности успеха, следующей из PrOIR Бернулли в исΩ
ходном пространстве поиска1. Отсюда следует, что
p ³ p~q*,
1
Это предположение, например, не выполняется в разреженном пространстве выборки S4S на рис. 5.29. Следует охватывать полное пространство поиска.
Поиск поиска 177
или же
Взяв два логарифма с обеих сторон, мы получим искомый результат, заявленный в уравнении (5.18):
Это обещанная слабая форма сложности S4S. Сложность поиска для поиска
превосходит искомый поиск.
5.8.3.3. Строгий случай
Для строгого случая S4S мы используем симплекс. Симплекс является локусом
всех положительных чисел, которые в сумме дают единицу. Другими словами,
это плоскость, которая подчиняется уравнению (5.20). При наличии двух вероятностных масс π1 и π2 симплекс представляет собой просто линию в первом
квадранте, которая пересекает оси π1 и π2 в точках π1 = 1 и π2 = 1. В трех измерениях симплекс представляет собой треугольник в первом октанте, который
пересекает все оси в единице, как показано на рис. 5.31. С этой поверхности мы
будем случайным образом выбирать функцию распределения вероятностей.
Мы полагаем, что эти функции равномерно распределены по треугольному
~ , т. е. прост
симплексу. Поверхность симплексного треугольника – это наше Ω
ранство поиска для S4S.
Рис. 5.31 Геометрия поиска S4S в строгом случае
178
Сохранение информации в компьютерном поиске
Обращаясь к рис. 5.31, будем считать, что цель связана с вероятностью q = π3.
Напомним, что успешный поиск состоит из всех значений q ³ q*, где q* определяет наименьшую активную информацию, которая считается приемлемой.
Этот порог показан на рис. 5.31. Порог определяет на симплексе треугольную
область abc. Площадь этого треугольника соответствует цели S4S T~ . Несложные
геометрические рассуждения показывают, что вероятность успеха для этого
трехмерного случая, равная отношению площади малого равностороннего
треугольника к большому симплексу, равна:
Площадь экспоненциально зависит от количества измерений. Например,
если бы мы работали над этой задачей с двумя вероятностями вместо трех,
мы бы обнаружили, что p~ = (1 – q*). Если у нас есть N измерений, то отношение
имеет вид:
p~ = (1 – q*)N–1,
где N – количество бинов вероятности в распределении. Взяв натуральный логарифм обеих сторон, получаем:
ln p~ = (N – 1)ln(1 – q*).
Поскольку I~Ω = –ln p~ нат, это можно записать в виде:
I~Ω = –(N – 1)ln(1 – q*).
(5.22)
Теперь сделаем два очень реалистичных предположения. Первое состоит
в том, что наш порог вероятности успеха очень мал:
q* << 1.
Когда это действительно так,
ln(1 – q*) » –q*.
(5.23)
Второе предположение состоит в том, что число бинов вероятности очень
велико. Другими словами, если N ≫ 1, то
(5.24)
Если подставить уравнения (5.23) и (5.24) в (5.22), получим:
Логарифм правой части этого уравнения по основанию 2 равен порогу активной информации I+*. Следовательно,
,
Источники 179
или, как обещано в уравнении (5.19),
Мы завершили вывод строгой формы поиска S4S. Второй вывод идентичного результата, рассмотренный с совершенно иной точки зрения, можно найти
в другой публикации [68].
5.9. Заключение
В эволюционных компьютерных моделях дарвиновский механизм «выживания наиболее приспособленных/удачно мутировавших» не создает никакой
информации. В алгоритме поиска уже есть источник информации (например, способ извлечения информации из окружающего мира). Эволюционная
модель просто добывает информацию из этого источника. На самом деле
для более эффективного поиска источника информации могут применяться
и другие методы, если изменить критерий оценки эффективности. При отсутствии источника информации действует закон сохранения информации,
о чем свидетельствует наблюдение Митчелла о необходимости смещения
для обучения [69], закон Шаффера для эффективных обобщений [70] и теорема Вольперта и Макриди об отсутствии бесплатных завтраков [71], которая
утверждает, что в среднем один алгоритм поиска будет столь же эффективен,
как и любой другой.
Эволюционный подход, пожалуй, хорошо подходит для извлечения информации из окружающей среды в биологическом смысле. В каком-то смысле запрос – это форма жизни, спрашивающая у окружающей обстановки, достойна
ли она выживания. И чем больше потомков, тем больше запросов. Сама эволюция, однако, не порождает информацию из ниоткуда. Это довольно точно
отлаженный процесс, который извлекает информацию из источника знаний.
Жаль, но это так.
В следующей главе рассмотрен ряд симуляций эволюции, широко описанных в литературе. Каждая такая модель подразумевает компьютерную демонстрацию дарвиновской эволюции. Однако мы покажем, что все эти модели
страдают от одних и тех же проблем и что эволюционный процесс не создает
информации. Успех всегда основан на активной информации, добытой из источника знаний.
Источники
1.
2.
3.
C. Darwin, The Autobiography of Charles Darwin, Gutenberg Project Online
(1887).
David H. Wolpert, William G. Macready, «No free lunch theorems for optimization». IEEE Trans. Evolutionary Computation, 1 (1), pp. 67–82 (1997).
Jie Li, Jianbing Chen, Stochastic Dynamics of Structures (Wiley, 2009).
180
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
Сохранение информации в компьютерном поиске
R. J. Marks II, Handbook of Fourier Analysis and Its Applications (Oxford University Press, 2009).
A. Jerri, «The Shannon Sampling Theorem – Its Various Extensions and Applications: A Tutorial Review». Proceedings of the IEEE, 65, 1565–1595 (1977).
S. Bringsjord, P. Bello, D. Ferrucci, «Creativity, the Turing test. and the (better)
Lovelace test», Minds and Machines, 11(1), pp. 3–27 (2001).
L. Brillouin, Science and Information Theory (Academic Press, New York, 1956).
T. M. Mitchell, «The need for biases in learning generalizations». Technical Report CBM-TR-117, Department of Computer Science, Rutgers University, p. 59
(1980). Readings in Machine Learning, под ред. J. W. Shavlik и T. G. Dietterich
(Morgan Kauffmann, 1990), pp. 184–190.
C. Schaffer, «A conservation law for generalization performance». In Proc. Ele
venth International Conference on Machine Learning, H. Willian, W. Cohen (Morgan Kaufmann, San Francisco, 1994), pp. 295–265.
William A. Dembski, R. J. Marks II, «Bernoulli’s Principle of Insufficient Reason
and Conservation of Information in Computer Search». Proceedings of the 2009
IEEE International Conference on Systems, Man, and Cybernetics. San Antonio,
TX, USA – October 2009, pp. 647–2652.
David H. Wolpert, William G. Macready, там же.
Yu-Chi Ho, D. L. Pepyne, «Simple explanation of the no free lunch theorem of
optimization». Proceedings of the 40th IEEE Conference on Decision and Control,
pp. 4409–4414 (2001).
Yu-Chi Ho, Qian-Chuan Zhao, D. L. Pepyne, «The no free lunch theorems: complexity and security». IEEE Transactions on Automatic Control, 48 (5), pp. 783–
793 (2003).
Там же.
O. Häggström, Biology and Philosophy 22, pp. 217–230 (2007).
C. Schaffer (1994), там же.
Richard O. Duda, Peter E. Hart and David G. Stork, Pattern Classification, 2nd
edition (Wiley-Interscience 2000).
L. J. Fogel and W. S. McCulloch, «Natural automata and prosthetic devices». Aids
to Biological/Communications: Prosthesis and Synthesis, Vol. 2, D. M. RamseyKlee (ed.) 2, pp. 221–262. Reprinted in David B. Fogel, Evolutionary Computation: the Fossil Record (Wiley-IEEE Press, 1998).
T. C. Service, D. R. Tauritz, «Free lunches in pareto coevolution». Proceedings of the 11th Annual conference on Genetic and Evolutionary Computation –
GECCO ’09, pp. 1721–1727 (2009).
«A No-Free-Lunch Framework for Coevolution», Proceedings of the 10th annual
conference on Genetic and Evolutionary Computation – GECCO ’08 (ACM Press,
New York, USA, 2008), pp. 371–378.
Источники 181
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
D. H. Wolpert and W. G. Macready, «Coevolutionary free lunches». IEEE Transactions on Evolutionary Computation, 9 (6), pp. 721–735 (2005).
D. W. Corne and J. D. Knowles, «Some multiobjective optimizers are better than
others». In The 2003 Congress on Evolutionary Computation, 2003. CEC ’03, 4.
IEEE, pp. 2506–2512 (2003).
S. Droste, T. Jansen, I. Wegener, «Perhaps Not A Free Lunch But At Least A Free
Appetizer». University of Dortmund, Dortmund, Germany, Tech. Rep. (1998).
Winston Ewert, William A. Dembski, Robert J. Marks II, «Conservation of information in relative search performance». Proceedings of the 2013 IEEE 45th
Southeastern Symposium on Systems Theory (SSST), Baylor University, pp. 41–50
(2013).
M. Koppen, D. H. Wolpert, W. G. Macready, «Remarks on a recent paper on the
no free lunch theorems». IEEE Transactions on Evolutionary Computation, 5 (3),
295–296 (2001).
Там же.
Например, см. R. Xu, D. Wunsch, Clustering (Wiley-IEEE Press, 2008).
См. работы Duda и др.
C. A. Jensen, R. D. Reed, R. J. Marks II, M. A. El-Sharkawi, Jae-Byung Jung, R. T. Miyamoto, G. M. Anderson, C. J. Eggen, «Inversion of feedforward neural networks:
algorithms and applications». Proceedings of the IEEE, 87, pp. 1536–1549 (1999).
M. Minsky, S. Papert, Perceptrons: An Introduction to Computational Geometry
(MIT Press, 1969).
Там же.
R. J. Marks II, «CIFEr: Exchange and Synthesis». Proceedings of the IEEE/IAFE Conference on Computational Intelligence for Financial Engineering (CIFEr), p. 7, April
9–11, 1995; New York, New York at http://robertmarks.org/REPRINTS/1995_CIFEr_ExchangeAndSynthesis.pdf (URL: May 2, 2016).
R. J. Marks II, John Marshall, «Message from CIFEr ‘96 General Chairs». Proceedings of the IEEE/IAFE 1996 International Conference on Computational Intelligence
for Financial Engineering, March 24–26, New York City, p. 6 (1996).
J. F. Marshall & R. J. Marks II, «Message from the CIFEr ‘97 General Chairs».
Proceedings of the IEEE/IAFE 1997 International Conference on Computational Intelligence for Financial Engineering, March 23–26, New York City, pp. 6–7 (1997).
Russell D. Reed, Robert J. Marks, Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks (MIT Press, 1999).
John F. Marshall, Vipul K. Bansal, Financial Engineering (Kolb Publishing Company, 1993).
John F. Marshall, Kenneth R. Kapner, Understanding Swaps (Wiley, New York,
1993).
John F. Marshall, Dictionary of Financial Engineering. (John Wiley & Sons, 2001).
182
Сохранение информации в компьютерном поиске
30. CIFEr, там же.
31. D. Thomas, «War of the Weasels: An Evolutionary Algorithm Beats Intelligent
Design». Skeptical Inquirer, 43, pp. 42–46 (2010).
32. D. Thomas, «Target? TARGET? We don’t need no stinkin’ Target!». http://pandasthumb.org/archives/2006/07/target-target-w-1.html (2006) (URL: May 2,
2016).
33. W. Ewert, William A. Dembski, and Robert J. Marks II, «Climbing the Steiner
Tree – Sources of Active Information in a Genetic Algorithm for Solving the
Euclidean Steiner Tree Problem». Bio-complexity, 2012 (1), pp. 1–14 (2012).
34. D. Thomas, «Steiner Genetic Algorithm – C++ Code». http://pandasthumb.org/
archives/2006/07/steiner-genetic.html. (2006) (URL: May 2, 2016).
35. Там же.
36. L. J. Fogel, W. S. McCulloch.
37. Garry Wills, Lincoln at Gettysburg: The Words That Remade America (Simon &
Schuster (1993)).
38. William A. Dembski, Robert J. Marks II, «Conservation of information in search:
measuring the cost of success». Systems, Man and Cybernetics, Part A: Systems
and Humans, IEEE Transactions on, 39 (5), pp. 1051–1061, (2009).
39. «PegSolitaire» by Jonathunder – https://commons.wikimedia.org/wiki/File:Peg
Solitaire.jpg#/media/File:PegSolitaire.jpg (URL: May 2, 2016).
40. J. D. Lohn, D. S. Linden, G. S. Hornby, A. Rodriguez-Arroyo, S. E. Seufert, B. Ble
vins, T. Greenling, «Evolutionary design of an X-band antenna for NASA’s Space
Technology 5 mission». 2004 IEEE Antennas and Propagation Society International Symposium, 3 (20–25), pp. 2313–2316 (2004).
J. D. Lohn, D. S. Linden, G. S. Hornby, and W. F. Kraus, «Evolutionary design of a
single-wire circularly-polarized X-band antenna for NASA’s Space Technology
5 mission». 2005 IEEE International Symposium Antennas and Propagation Society, 2B (3–8) (2005).
41. Gerald J. Burke, Numerical Electromagnetics Code NEC-4, Method of Moments,
Part I: Users Manual, Lawrence Livermore National Laboratory.
См. также Gerald J. Burke, Numerical Electromagnetics Code NEC-4, Method of
Moments, Part II: Program Description Theory, Lawrence Livermore National
Laboratory (1992).
42. R. J. Marks II.
43. Thomas M. Cover, Joy A. Thomas, Elements of Information Theory (John Wiley &
Sons, 2012).
44. The Two Child Problem in Martin Gardner, The Second Scientific American Bookof Mathematical Puzzles and Diversions (Simon & Schuster, 1954).
45. J. D. Lohn.
46. Gerald J. Burke.
Источники 183
47. Winston Ewert, George Montañez, William A. Dembski, Robert J. Marks II, «Efficient Per Query Information Extraction from a Hamming Oracle». Proceedings
of the 42nd Meeting of the Southeastern Symposium on System Theory, IEEE, University of Texas at Tyler, March 7–9, 2010, pp. 290–297. (www.EvoInfo.org).
48. R. J. Marks II, Handbook.
49. Ewert, Montañez.
50. John C. Sanford, Genetic Entropy & the Mystery of the Genome, ILN (2005).
51. Douglas D. Axe, «Extreme functional sensitivity to conservative amino acid
changes on enzyme exteriors». J. Mol. Biol. 301, pp. 585–595 (2000).
52. J. Slocum, D. Singmaster, W.-H. Huang, D. Gebhardt, G. Hellings, E. Rubik, The
Cube: The Ultimate Guide to the World’s Bestselling Puzzle – Secrets, Stories, Solutions (Black Dog & Leventhal Publishers, 2009).
53. George Montañez.
54. R. Dawkins, Climbing Mount Improbable (W.W. Norton & Company, 1997).
55. H. S. Wilf and W. J. Ewens, «There’s plenty of time for evolution». P Natl Acad Sci,
107, pp. 22454–22456 (2010).
R. Dawkins. The Blind Watchmaker: Why the Evidence of Evolution Reveals a Universe Without Design (Norton, New York, 1996).
56. William A. Dembski, Robert J. Marks II, «Conservation of Information in Search:
Measuring the Cost of Success». IEEE Transactions on Systems, Man and Cybernetics A, Systems and Humans, 39 (5), pp. 1051–1061 (2009).
57. W. Ewert, William A. Dembski, Robert J. Marks II, «Conservation of Information
in Coevolutionary Searches». BIO-Complexity (2017).
58. W. D. Hillis, «Co-evolving Parasites Improve Simulated Evolution as an Optimization Procedure». Physica D: Nonlinear Phenomena, 42 (1–3), pp. 228–234
(1990).
59. K. Sims, «Evolving 3D morphology and behavior by competition». Artif Life,
1 (4), pp. 353–372 (1994).
60. P. J. Darwen, «Why Co-evolution beats temporal difference learning at Backgammon for a linear architecture, but not a non-linear architecture». Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No.01TH8546),
2. IEEE, pp. 1003–1010 (2001).
61. K. Chellapilla, D. B. Fogel, «Evolving an Expert Checkers Playing Program without Using Human Expertise». IEEE Transactions on Evolutionary Computation,
5(4), pp. 422–428 (2001).
62. D. B. Fogel, T. J. Hays, S. L. Hahn, and J. Quon, «A self-learning evolutionary
chess program». Proceedings of the IEEE, 92(12), pp. 1947–1954 (2004).
63. S. G. Ficici, «Solution Concepts in Coevolutionary Algorithms». Dissertation,
Brandeis University (2004).
184
64.
65.
66.
67.
68.
69.
70.
71.
Сохранение информации в компьютерном поиске
T. C. Service.
Ewert, иллюстрация из различных работ.
Там же.
William A. Dembski, Robert J. Marks II, «The Search for a Search: Measuring the
Information Cost of Higher Level Search». J Adv Comp Intel, Intel Informatics,
14(5), pp. 475–486 (2010).
Там же.
T. M. Mitchell (1980).
Cullen Schaffer (1994).
Wolpert, Macready (1997).
Глава
6
Анализ моделей
биологической эволюции
Для сохранения сложной, невероятной организации живого существа нужно нечто больше,
чем энергия для работы. Нужна информация
или инструкции о том, как энергия должна быть
потрачена на поддержание невероятной организации. Идея информации, необходимой для
поддержания и, как мы увидим, создания живых систем, чрезвычайно уместна при решении
проблем биологического воспроизводства.
Джордж Гэйлорд Симпсон и Уильям С. Бек [1]
Когда программисты разрабатывают алгоритм компьютерного поиска, они
всегда ищут способы повысить эффективность поиска и стараются как можно
лучше включить знания о решаемой проблеме в алгоритм поиска. Компьютерные модели эволюции, с другой стороны, направлены в первую очередь на
демонстрацию дарвиновского эволюционного процесса, а эффективность поиска имеет второстепенное значение.
Несмотря на эти различия, модели, имитирующие эволюцию, и модели,
применяемые инженерами и программистами в повседневной работе, основаны на общих принципах. Всегда существует цель, указанная всемогущим программистом, пригодность результата поиска, связанная с этой целью, источник активной информации (например, оракул) и стохастические обновления.
Рассмотрев основы сохранения информации [2] в эволюционных процессах,
мы теперь готовы критически исследовать некоторые из наиболее известных
компьютерных моделей дарвиновской эволюции. В каждом из рассмотренных
случаев используются источники информации, в результате чего получается
достаточно активной информации, чтобы модели могли работать. Мы полагаем, что авторы программного обеспечения, возможно, ошеломленные грандиозностью стоящей перед ними задачи моделирования эволюции, не пытались сознательно и тайно внедрить активную информацию в модель. Тем не
186
Анализ моделей биологической эволюции
менее мы можем определить конкретные источники активной информации
в компьютерных программах, моделирующих эволюцию.
Первая программа, которую мы подвергнем анализу, называется EV.
6.1. EV: программная модель эволюции
Томас Шнайдер (Thomas Schneider) разработал программную симуляцию для
демонстрации дарвиновской эволюции под названием EV и написал статью,
описывающую ее эффективность [3]. В этой статье Шнайдер сделал следующие
заявления:
«…моделирование [эволюции в программе EV] начинается с нулевой
информации, и, как и в естественных генетических системах, информация, измеренная в полностью эволюционировавших сайтах связывания,
близка к той, которая необходима для определения местоположения
сайтов в геноме»;
«[эволюционный] переход происходит быстро, демонстрируя, что получение информации может происходить в результате прерывистого перехода между равновесными состояниями»;
«модель EV количественно решает вопрос о том, как жизнь получает информацию»;
«программа EV также ясно демонстрирует, что биологическая информация, измеренная в строгом смысле Шеннона, может быстро появиться
в системах генетического контроля, подвергнутых репликации, мутации
и селекции».
Увы, в этой программе не происходит «получения информации путем естест
венного отбора», как утверждает Шнайдер. Источники информации включены в программу. При помощи эволюционного процесса добывается активная
информация, которая направляет поиск к желаемому результату. Фактически
эволюционный поиск не очень хорошо справляется с извлечением активной
информации из информационных источников. Другие алгоритмы работают
лучше. Мы видели это свойство в предыдущей главе, где разные алгоритмы
извлекали активную информацию из оракулов Хемминга с разной эффективностью. Алгоритм программы EV не является исключением.
6.1.1. Структура EV
Карикатурист Руб Голдберг (Rube Goldberg) был знаменит тем, что рисовал карикатуры со сложной техникой, выполняющей простые задачи, например:
маленький стальной шарик катится по двум близко расположенным параллельным стержням, а затем падает на одну сторону маленькой качалки;
к другой стороне качалки прикреплена ложка сухой грязи, которая выбрасывает в воздух облако пыли;
EV: программная модель эволюции 187
пыль попадает в нос привязанной неподалеку собачке. Собачка чихает
и задувает зажженную свечу, которая согревала маленькую мышку;
мышка бежит по трубке к теплому одеялу и попутно цепляет нитку, роняя зефир на тонко сбалансированную книгу в мягкой обложке, расположенную над выключателем света;
книга падает и переключает рубильник из положения «включено» в положение «выключено».
Эта чрезмерно сложная машина Руба Голдберга только что успешно выключила свет. Простая задача выполняется с большими накладными расходами на
поддержание бесполезной сложности. Программа EV мало чем отличается от
этой машины.
Если удалить из программы EV машину Руба Голдберга, то останется проблема поиска, показанная на рис. 6.1. Существует четыре нуклеотида: A, C, G и T.
Каждому из них назначается два бита следующим образом:
A = 00 C = 01 G = 10 T = 11
Строка нуклеотидов, интерпретируемая как двоичная строка, подается в механистический вычислитель, который выводит другую строку битов. Выход
сравнивается с целью, и оракул Хемминга объявляет расстояние между выходной строкой и целью. Считается, что эволюция успешно произошла, когда расстояние Хемминга равно нулю и цель идентифицирована.
EV
Оракул Хемминга
Расстояние
Хемминга
Рис. 6.1 Цифровой организм, применяемый в EV
Для нахождения цели используются шестьдесят четыре «цифровых организма», показанных на рис. 6.1. Эта популяция изображена на рис. 6.2. В качестве
критерия пригодности используется расстояние Хемминга. В ходе эволюции
делается копия из 32 организмов с самой высокой степенью приспособленности. Они заменяют собой организмы с худшими расстояниями Хемминга.
Затем в популяцию вносят мутацию путем замены случайно расположенного нуклеотида случайно выбранным А, С, G или Т. Таким образом, существует
25%-ная вероятность того, что заменяемый нуклеотид совпадает с заменителем. Каждый цикл называется поколением. При каждой инициализации EV
188
Анализ моделей биологической эволюции
Рис. 6.2 Компьютерная программа EV использует популяцию из 64 организмов, подобных изображенному на рис. 6.1. Каждый организм ищет одну
и ту же цель. Оракул Хемминга показывает, насколько близко организм находится к цели. В каждом поколении 32 организма с наименьшим расстоянием
Хемминга дублируются и заменяют собой организмы с большим расстоянием
Хемминга. В новой популяции на входе заменяется один нуклеотид, расстояния
Хемминга пересчитываются, и процесс повторяется
EV: программная модель эволюции 189
выбирается новая цель, и затем она остается неизменной на протяжении всего
поиска. Все организмы ищут одну и ту же цель. Цель представляет собой сайты
связывания в цепи нуклеотидов. На нуклеотидной цепи сайту связывания присваивается единица. В противном случае назначается ноль. Поскольку между
соседними сайтами связывания должен быть расположен ряд нуклеотидов, все
цели, выбранные EV, состоят из множества нулей с редкими включениями единиц. Как мы увидим, это один из многих факторов, способствующих успеху EV.
В литературе обычно публикуются только положительные результаты исследований. Когда появляются такие программы, как EV, от них ожидают успешную демонстрацию эволюции. Программы, которые не являются успешными,
не будут опубликованы. По аналогии с Эдисоном, проектирующим лампочку,
или с серией из 409 испытаний, необходимых для успешного изобретения Formula 409TM, мы должны спросить, сколько испытаний понадобилось для разработки программы EV? Сколько усилий было потрачено на отладку исходной
программы? И если оригинальная идея не сработала, сколько раз программа
переписывалась заново?
Разработчики программного обеспечения знают, что оригинальные программы редко начинают работать с первого, со второго или даже с десятого
раза. Допустим, EV могла быть создана с первой попытки, хотя мы в этом сомневаемся. Компьютерные языки, такие как C++, предлагают сложные инструменты для отладки программного обеспечения. В связи с этим мы предлагаем
задуматься о том, какой объем активной информации был внедрен в программу EV и другие модели эволюции в виде опыта программиста. Разумеется,
в таких программах мозг программиста является источником информации.
Однако о трудностях, возникавших в процессе написания программного обес
печения, редко сообщают в журнальных статьях и материалах конференций.
Таким образом, мы вряд ли когда-либо сможем достоверно оценить активную информацию, внедренную в EV программистом1. Итак, давайте вернемся
к конкретным аспектам окончательной реализации EV и источникам активной информации, которые прослеживаются в данной программе.
6.1.2. Устройство программы EV
Детали цифрового организма EV с элементами машины Руба Голдберга показаны на рис. 6.3. ДНК состоит из четырех нуклеотидов: A, C, G и T.
В верхней части рис. 6.3 приведена последовательность из 256 нуклеотидов2.
Поскольку имеется четыре нуклеотида, в соответствии с PrOIR Бернулли каждый из них имеет I = log24 – по 2 бита информации. Мы назначаем им 2 бита
следующим образом:
A = 00 C = 01 G = 10 T = 11
1
2
Это источник активной информации «человек в цикле», обсуждаемый в главе 3.7.3.
Есть пять дополнительных нуклеотидов на общую сумму 261. Они необходимы для
размещения скользящего окна из шести нуклеотидов.
190
Анализ моделей биологической эволюции
Перевод
в число
Перевод
в число
Перевод
в число
Перевод
в число
Числа
Сдвиг
Механистический
вычислитель
EV
Расстояние
Хемминга
Прибавить 1,
если разные числа
Сравнение
Промежуточная
сумма
Сдвиг
Рис. 6.3 Устройство цифрового организма EV
Таким образом, любая строка из N бит может быть однозначно интерпретирована как строка нуклеотидов, когда N четная, и наоборот. Нуклеотидная
последовательность CTAAGC становится битовой строкой 011100001001, а битовая строка 000111110010 – нуклеотидной последовательностью ACTTAG. Модель эволюции EV использует последовательность из 256 нуклеотидов (512 бит)
в каждом из цифровых организмов.
Строка, сопровождающая нуклеотид в верхней части рис. 6.3, представляет
собой последовательность единиц и нулей, показанных внизу рисунка. «1» обозначает, что нуклеотид является сайтом связывания. «0» означает, что это не
так. Программа EV генерирует двоичную строку при запуске программы. Хотя
инициализация происходит случайным образом, сайты связывания должны
EV: программная модель эволюции 191
быть отделены друг от друга. Поэтому необходимо, чтобы большинство битов
в двоичной строке были нулями и единицы дополнялись нулями с обеих сторон. Цель поиска – найти набор нуклеотидов, которые генерируют заданные
сайты связывания.
То, как нуклеотиды определяют сайты связывания, задается программой EV,
представленной в виде диаграммы на рис. 6.3. Во-первых, нуклеотиды используются для операции «перевод в число». Они сгруппированы по 5. Поскольку
каждый нуклеотид имеет два бита информации, каждое число имеет разрядность 10 бит. Поскольку желательно иметь 45 = 210 = 1024 числа, включая отрицательные, EV интерпретирует каждое них между –512 и 511. Эти числа подаются в механистический вычислитель. Вычислитель позволяет вводить шесть
нуклеотидов и выводить ноль или единицу. Последовательность нуклеотидов
в верхней части рис. 6.3 продвигается через вычислитель по одному нуклеотиду за раз. Первый выходной бит вычислителя определяется первыми шестью
нуклеотидами. Второй выходной бит – нуклеотидами со 2-го по 7-й. Сдвиг продолжается до тех пор, пока вычислитель не сгенерирует 256 бит1.
Каждый раз, когда вычислитель выдает бит, он сравнивается с целевой последовательностью битов. Строка нуклеотидов сдвигается вместе с целевым
битом заданной строки2. Если выход вычислителя отличается от целевого
бита, промежуточная сумма увеличивается на единицу. Если биты совпадают, промежуточная сумма не увеличивается. После завершения сдвига промежуточная сумма содержит расстояние Хемминга между 265-битной целью
и выходом вычислителя. В качестве критерия приспособленности цифрового
организма используется только расстояние Хемминга. В поиске не учитываются конкретные позиции совпадающих и различающихся битов. Мы также
не будем использовать информацию о позиции в любом поиске, который рассматриваем. Запись общего расстояния Хемминга между выходом и целью
составляет использование оракула Хемминга. Оракул Хемминга может быть
богатым источником информации3. Действительно, если наша цель – найти
265-битовую последовательность в EV, мы могли бы сделать это не более чем
в 256 запросах, используя оракула Хемминга. Это, однако, не очень интересная
задача. На самом деле мы собираемся избавить поисковый алгоритм программы EV от ненужной машины Руба Голдберга и посмотреть, что из этого выйдет.
Принцип работы вычислителя показан на рис. 6.4. Блоки «Перевод в число»
на рис. 6.3 применяются для размещения чисел между –512 и 511 в матрице
4×6 на рис. 6.4, а также для установки порогового значения. Ширина матрицы
позволяет сдвигать 4 нуклеотида. 6 – это длина окна. Каждый нуклеотид акти1
2
3
Необходимость в дополнительных пяти нуклеотидах теперь очевидна. Например,
для генерации конечного выхода необходим конечный нуклеотид, а также пять дополнительных нуклеотидов для заполнения необходимых шести входных позиций
вычислителя.
Как показано на рис. 6.3.
Мы показали это в разделе 5.4.3.1.
192
Анализ моделей биологической эволюции
вирует одно из четырех чисел в зависимости от того, является ли он нуклеотидом типа А, С, Т или G. Шесть активированных чисел складываются вместе
и сравниваются с пороговым значением. Если сумма шести чисел превышает
пороговое значение, вычислитель выдает на выход единицу. В противном случае на выход поступает ноль.
Сумма
–376
Пороговое
значение
416
0
Рис. 6.4 Принцип работы вычислителя EV. По мере того как
нуклеотиды перемещаются через верхнюю часть, выбранные числа в матрице суммируются и сравниваются с пороговым значением, чтобы определить выходное значение. Нуклеотиды смещаются
на один вправо, и процесс повторяется для следующего бита
6.1.3. Внутренние источники информации в EV
Цель EV состоит в том, чтобы найти набор нуклеотидов, который дает расстоя
ние Хемминга, равное нулю. Это проблема поиска, которая решается множеством разных поисковых алгоритмов, отличных от эволюционного поиска. За
извлечение активной информации отвечает не эволюционный алгоритм. В EV
уже есть богатые источники активной информации. Оракул Хемминга является одним из таких источников, несмотря на то что доступ к нему осуществляется через вычислитель EV. Нам точно говорят, насколько мы близки к желае-
EV: программная модель эволюции 193
мому результату в виде нулевого расстояния Хемминга. И, как всегда, большое
количество цифровых организмов, исследованных, как показано на рис. 6.2,
является второстепенным источником информации.
Вычислитель выступает богатым источником информации. Программист
EV, вероятно, не задавался целью использовать вычислитель как источник информации. Но опять же, если бы программа EV не работала с использованием
вычислителя, то не получилось бы никакой публикации об успехе. Вычислитель склонен к выводу строк, которые в основном являются нулями с примесью единиц (или наоборот).
Чтобы показать это, мы выбрали равномерную последовательность нуклео
тидов в соответствии с PrOIR Бернулли и случайным образом сгенерировали
выходную строку из 256 бит. Суммирование всех 256 бит дает количество единиц в строке. Повторив этот процесс 10 млн раз, мы сгенерировали нормализованную гистограмму1 в верхней части рис. 6.5. Если вы внимательно посмот
рите на верхний график, то увидите, что там есть и вторая линия. Это 10 млн
дополнительных испытаний, за исключением того, что на выходе суммируется
количество нулей. Гистограммы графически почти неразличимы.
Существуют 2256 = 1,15792 × 1077 вариантов битовых строк длиной 256. Только
одна из этих строк содержит все нули. С другой стороны, есть *97* строк, которые
содержат ровно 128 нулей. Таким образом, выпуклость в середине гистограммы на верхнем графике на рис. 6.5 является объяснимой. Но это недостаточно
большая выпуклость. Если предположить, что каждый бит в строке генерируется подбрасыванием монеты с шансом 50/50, нормализованная гистограмма
должна быть близка к колоколообразной кривой2 в середине рис. 6.5. Нижняя
кривая на рис. 6.5 – это верхняя кривая, разделенная на среднюю кривую. Он
показывает степень усиления отклонения от того, что мы ожидаем увидеть,
если бы каждая двоичная строка определялась последовательностью бросков
симметричной монеты. Видно, что вычислитель решительно предпочитает
двоичные строки с преобладанием нулей или единиц.
Смещенная природа вычислителя наглядно проявляется, если мы рассмот
рим, как вычислитель может сгенерировать выходные данные, состоящие
только из нулей. Существует лишь один способ генерировать выходные данные, состоящие из нулей, поэтому эндогенная информация об этой проблеме
IΩ = 256 бит. Однако 10 млн запусков вычислителя показывают, что вероятность
того, что один запрос сгенерирует все нули, удивительно велика: q = 0,00155.
1
Гистограмма нормализована, чтобы суммарная площадь была равна единице. Такие
гистограммы можно рассматривать как эмпирические оценки функций плотности
вероятности.
2
Исходя из теоремы Лапласа, график
в середине рис. 6.5 представляет со-
бой гауссову, или нормальную, кривую, часто называемую распределением в форме
колокола. При n = 256 и p = 1/2 его среднее значение равно np = 128, а его дисперсия
равна np(1 – p) = 64.
194
Анализ моделей биологической эволюции
Это означает наличие экзогенной информации из IS = 9 бит, соответствующей
поразительным I+ = 247 битам активной информации, сгенерированной механизмом вычисления чисел!
Рис. 6.5 Верхний график представляет собой гистограмму количества
единиц, сгенерированных механизмом вычисления числа EV. Средний график – нормализованная гистограмма, которую мы ожидаем. Нижний – это
отношение двух верхних графиков
Есть еще один интересный вывод, который мы можем сделать из этого эксперимента со всеми нулями. Поскольку существует |Ω| = 4261 = 1,37 × 10157 различных нуклеотидных последовательностей и поскольку вероятность выбора последовательности, которая состоит из одних нулей, составляет q = 0,00155, нам
остается сделать вывод, что существуют удивительные q|Ω| = 2 × 10154 нуклео
тидных последовательностей, которые будут генерировать вывод всех нулей!
Хотя цель EV не состоит в том, чтобы сгенерировать строку из всех нулей,
графики на рис. 6.5 убедительно показывают, что вычислитель EV предрасположен к генерации последовательности нулей, слегка приправленных едини-
EV: программная модель эволюции 195
цами, или последовательности единиц, слегка приправленных нулями. Таким
образом, вычислитель является богатым внутренним источником активной
информации.
6.1.4. Поиск
Мы определили ряд источников информации, заложенных в EV. Как можно
наилучшим образом использовать их для поиска набора нуклеотидов, которые
дают нам совпадение с сайтами связывания?
6.1.4.1. Информация вычислителя
Вычислитель EV предоставляет активную информацию, когда генерирует битовые строки, похожие на цель. При использовании только лишь вычислителя
экзогенная информация ограничена сверху как IS < 90 бит [2]. Спрогнозировать
исход 90 бросков справедливой монеты крайне маловероятно. Таким образом,
для успешного поиска вместе с вычислителем должен работать оракул Хемминга или какой-то другой источник информации.
6.1.4.2. Эволюционный поиск
Эволюционный подход EV основан на использовании 64 копий организма1.
32 организма с наибольшим расстоянием Хемминга отбрасываются и заменяются дубликатами организмов с самым маленьким расстоянием Хемминга.
Затем в каждом организме случайным образом выбирается один нуклеотид
и заменяется другим нуклеотидом. Далее процесс повторяется. Оригинальная статья EV сообщает о конвергенции в 704 циклах или поколениях. Это
704 × 64 = 45 056 измеренных расстояний Хемминга. Мы оцениваем каждое измерение расстояния Хемминга как запрос. Мы запустили в общей сложности
100 000 EV-симуляций2, и 9115 из них оказались успешными. Для каждого эксперимента было установлено ограничение продолжительности в 100 000 запросов. Наше моделирование EV в среднем заняло 993 поколения для успешного эксперимента, или 63 552 запроса. Хотя это больше, чем 45 056 запросов,
о которых сообщалось в статье EV, полученный результат не сильно отличается
от результата, заявленного в оригинальной публикации, поэтому мы можем
использовать его в дальнейших рассуждениях.
Давайте сравним производительность эволюционного алгоритма EV с более
простым алгоритмом поиска, который использует тот же источник знаний.
6.1.4.3. EV и стохастическое восхождение
Мы можем достичь лучшего результата, чем многоагентный эволюционный
поиск, используя всего лишь один организм. Начнем с одной случайно выбранной нуклеотидной строки в качестве входных данных и отметим расстояние
Хемминга между выходом и целью. Затем один из входных нуклеотидов изменяется, и отмечается новое выходное расстояние Хемминга. Если расстояние
1
2
Powered by TCPDF (www.tcpdf.org)
Как показано на рис. 6.2.
Это примерно 1563 поколения с 64 × 1563 » 100 000 запросов.
196
Анализ моделей биологической эволюции
Хемминга увеличилось, изменение отбрасывается, а затем случайным образом
выбирается и изменяется другой нуклеотид. В противном случае изменение
сохраняется, и процесс повторяется. Мы выполнили 10 тыс. экспериментов
с использованием стохастического поиска с восхождением, также известного
как эволюционная стратегия [6], и, хотя для экспериментов была установлена
одинаковая верхняя граница в 100 000 запросов, каждый поиск был успешным. Среднее количество запросов для успеха с использованием этого алгоритма составляет 10 601.
Эволюционный алгоритм, используемый в EV, требует в шесть раз больше
запросов по сравнению со стохастическим восхождением. Оба поиска применяли одни и те же источники информации. Поиск с восхождением использовал
их в 6 раз эффективнее, что следует из подсчета среднего числа запросов.
Источником успеха в программе EV является не эволюционный алгоритм.
Это источники информации, встроенные в программу программистом, – преж
де всего вычислитель EV и оракул Хемминга.
6.1.4.4. Частота мутации
Алгоритмы поиска имеют параметры, которые можно настроить, чтобы сделать
его более эффективным. И алгоритм эволюционного поиска, и алгоритм стохас
тического восхождения предполагают мутацию одного нуклеотида на запрос.
Это лучшая частота мутаций? Как видно на рис. 6.6 [7], ответ – нет. Две мутации за итерацию дают лучшие результаты. Как и в случае с исходным прогоном,
каждая точка на рис. 6.6 использует 10 000 прогонов, применяя популяцию из
64 особей и ограничение продолжительности поиска в 100 000 запросов. График представляет собой долю успешных поисков до достижения ограничения.
Дробные мутации генерируются путем рандомизации числа мутаций. Чтобы
получилось, например, 1,75 мутации на потомка, каждый организм испытает, по
крайней мере, одну мутацию и имеет 75%-ную вероятность испытать еще одну.
Рис. 6.6 Коэффициент успешности как функция мутации
в эволюционном алгоритме поиска применительно к EV
EV: программная модель эволюции 197
Чтобы увеличить вероятность успеха эволюционного поиска EV, необходимо правильно настроить частоту мутаций. Если она превышает четыре мутации на 261 нуклеотид, вероятность успешного поиска с использованием ограниченных ресурсов будет близка к нулю.
6.1.5. Интерфейс EV Ware
Интерактивный графический интерфейс, доступный на веб-сайте EvoInfo.org1,
демонстрирует программу EV и ее варианты. Панель управления EV Ware, показанная на рис. 6.7, предоставляет широкий выбор вариантов реализации алгоритма EV.
Рис. 6.7 Панель управления приложением EV
На рис. 6.8–6.10 показаны три разных прогона с использованием структуры
EV. Цель, помеченная как «Что вы хотели», отображается темным серым цветом в нижней части каждого ряда. Результат последнего запроса (с пометкой
«Что вы получили») находится в строке выше. Выход соответствует последовательности битов, показанной в нижней части рис. 6.3. Входная последовательность здесь не показана и является строкой битов в верхней части рис. 6.3.
Тщетность слепого поиска проиллюстрирована на рис. 6.8. Организм EV был
перезапущен случайным образом более 900 000 раз, но безуспешно.
Пробный прогон алгоритма EV на рис. 6.9 оказался успешным после 50 048 запросов. Поскольку в эволюционной программе использовалось 64 организма
на поколение, это эквивалентно 782 поколениям. При использовании одного
EV-организма и применении стохастического восхождения требуется меньше
запросов. Алгоритм в примере на рис. 6.10 достиг успеха примерно за 9000 запросов и, следовательно, более эффективно использует источник знаний, чем
эволюционный алгоритм EV.
1
http://www.evoinfo.org/ev.html.
198
Анализ моделей биологической эволюции
Рис. 6.8 EV Ware для ненаправленного (слепого) поиска
не нашла цель после более чем 900 000 запросов
EV: программная модель эволюции 199
Рис. 6.9 В этом прогоне эволюционный поиск EV
прошел чуть более 50 000 запросов
200
Анализ моделей биологической эволюции
Рис. 6.10 Стохастическое восхождение, обсуждаемое в разделе 6.1.4.3, называется на этом рисунке поиском с трещоткой.
В данном случае успех достигнут через 9189 запросов. Это намного меньше, чем требуется для эволюционного поиска EV на
рис. 6.9
6.1.6. Диагноз
Учитывая проделанные нами эксперименты и принцип сохранения информации, мы теперь можем пересмотреть заявления авторов EV и прокомментировать их:
«…моделирование [эволюции в EV] начинается с нулевой информации,
и, как и в естественных генетических системах, информация, измеренная в полностью эволюционировавших сайтах связывания, близка к той,
которая необходима для определения местоположения сайтов в геноме».
EV: программная модель эволюции 201
Программа EV начинается с богатых источников информации, наиболее
известными из которых являются оракул Хемминга и вычислитель EV.
Эти источники активной информации находятся в программе до начала
поиска.
«[Эволюционный] переход происходит быстро, демонстрируя, что получение информации может происходить в результате прерывистого равновесия».
Быстрота перехода обусловлена только добычей активной информации
из источников, постоянно присутствующих в EV.
«Модель EV количественно решает вопрос о том, как жизнь получает информацию».
Подразумевается, что эволюционная программа генерирует информацию. Это не так. Эволюционный алгоритм, скорее, добывает информацию из источников, находящихся в программе, и, как было убедительно
продемонстрировано, делает это довольно плохо.
«Программа EV также ясно демонстрирует, что биологическая информация, измеренная в строгом смысле Шеннона, может быстро появиться
в системах генетического контроля, подвергнутых репликации, мутации
и селекции».
Любая полученная информация не связана с «репликацией, мутацией
и отбором». Она связана с источниками информации, разработанными
программистом и помещенными в программу моделирования. Такие
же результаты получаются быстрее при использовании стохастического
восхождения на гору.
Применив вместо EV стохастический поиск с восхождением, мы достигли
успеха в каждом случае. Во всех прогонах программы была обнаружена нук
леотидная последовательность, которая генерировала целевую строку из
256 бит. Вспомним о законе больших чисел, продемонстрированном в эксперименте с иглой Буффона1. Многочисленные реализации бросков иглы Буффона приблизились к неожиданно предопределенной точке 1/π. Каждая последовательность бросков шла своим путем, но все они сходились к точке 1/π.
Это явление, по-видимому, имеет место и при моделировании EV с использованием стохастического восхождения. Независимо от разных инициализаций
и разных мутаций эксперимент неизменно сходится к целевой последовательности.
Большинство симуляций, претендующих на то, чтобы проиллюстрировать
дарвиновскую эволюцию, похоже на EV. Программист пишет стохастическую
программу, задавшись целью достижения некоторой фиксированной точки.
Мы не должны удивляться, что после запуска программы разные пути приводят к одному фиксированному результату.
1
Раздел 4.2.1.
202
Анализ моделей биологической эволюции
6.2. Avida: ступенчатый поиск и логика NAND
Как и EV, Avida [2] – это компьютерная программа, которая, по словам ее создателей, «показывает, как сложные функции могут возникать в результате случайных мутаций и естественного отбора». Так же, как и в случае EV, источником успеха Avida, вопреки утверждениям авторов, является не эволюционный
алгоритм, а источники информации, встроенные в компьютерную программу
[3]. Продолжая аналогию с EV, отметим, что другие алгоритмы поиска могут
добывать информацию более эффективно, чем Avida.
Как и EV, программа Avida представляет собой чрезмерно сложный алгоритм в стиле Руба Голдберга. Его целью является создание сложной логической
функции под названием EQU. Здесь вполне уместна аналогия с автоматом для
игры в пинбол. У стального шарика существует бесчисленное множество возможных путей, но в конце концов стальной шарик падает в маленькое отверстие позади лопаток. Ну, точнее, почти всегда. Шарик иногда застревает между
двумя препятствиями, а поиск – в локальном минимуме.
Мы покажем, что источник информации, необходимый для успеха Avida,
встроен в программу, и программа была точно настроена для успеха. Прежде
чем обсуждать детали, нам нужно получить базовые знания о булевой логике –
области математики, на которой основана программа Avida.
6.2.1. Булева логика
Программа Avida основана на элементарной булевой логике и синтезе логических элементов NAND.
Мы с вами широко используем логические операции AND, OR и NOT в повседневном общении. В фильме 1992 года «Мир Уэйна» приятель Уэйна Гарт,
оказавшись в затруднительном положении, говорит:
«Я хорошо провожу время ... НЕТ!»
Наличие отрицания в конце утверждения меняет его значение. Если в конце истинного утверждения поставить NOT, оно становится ложным. Обратное
тоже верно.
Ложное утверждение, за которым следует NOT, является истинным. В булевой логике NOT – это операция, которая работает с одним битом. Если входное
значение равно 0, выходное значение будет 1, а если входное значение равно
1, выходное значение – 0. Другими словами, операция NOT является «перево_
ротом в битах». С точки
как X. Если
_ зрения обозначения NOT X записывается
_
X равен единице, то X равно нулю, а если X равен 0, тогда X равно 1. Операция
NOT часто размещается на выходе другой логической операции. Термин NOT
AND принято сокращать до NAND.
Таблица истинности операции NAND показана на рис. 6.11. Последовательность в каждой строке является дополнением последовательности логической
операции OR. Схема вентиля NAND показана справа на рис. 6.11. Входами вентиля являются X и Y, каждый из которых может принимать логическое значе-
Avida: ступенчатый поиск и логика NAND 203
ние 0 или 1. Выход также является логическим значением 0 или 1 в соответствии со строкой состояний в таблице истинности.
Рис. 6.11 Таблица истинности NAND и схематическое обозначение вентиля NAND. Выходом вентиля является инверсия результата операции AND.
Маленький кружок у выхода обозначает операцию NOT
Мы также можем поставить NOT после операции OR и получить NOR, или
NOT после XOR, чтобы получить XNOR. Есть много вариантов сочетания логических операций. Некоторые из них показаны в табл. 6.1. Такие таблицы называются таблицами истинности.
Таблица 6.1. Таблица истинности для некоторых наиболее востребованных
логических операций
_ _
_
_
_ _
X Y Х Y AND NAND OR NOR XOR XNOR Х OR Y X OR Y Y AND Y
0
0 0 1 1
0
1
0
1
0
1
1
1
0
1
1
1
0
1
1
0
0
0
1
0
0
0
1
1
1
0
1
1
1
0
0
0
1
1
0
0
0
1
1
0
1
0
1
1
1
0
0
_
X AND Y
0
0
1
0
6.2.2. Логика NAND
Программное обеспечение Avida основано на следующей теореме булевой алгебры: все логические операции, включая перечисленные в табл. 6.1, могут быть
реализованы путем соединения вентилей NAND1. Для некоторой логической
операции может существовать множество комбинаций вентилей NAND, способных выполнить операцию. Это свойство вентилей NAND принципиально
1
Изучающие булеву логику знают, что любое суждение в таблице булевой истинности может быть выражено с помощью операций AND, OR и NOT (например, простые
импликанты). В дальнейшем исследовании программы Avida мы увидим, что логические элементы AND, OR и NOT могут быть синтезированы с использованием только вентиля NAND. Кстати, вентиль NOR тоже можно использовать для синтеза всех
функций двоичной логики.
204
Анализ моделей биологической эволюции
необходимо для успеха Avida. Если бы Avida использовала вентили AND и OR
без вентиля NOT, то охарактеризовать произвольную булеву функцию было
бы невозможно. Синтез всех логических операций, перечисленных в табл. 6.1,
с использованием только вентилей NAND показан на рис. 6.12–6.15. Эти схемы
важны для понимания Avida. Обратите внимание: с ростом количества вентилей NAND получается, что более сложные логические структуры формируются
из менее сложных типовых структур. Это ступеньки, используемые Avida для
синтеза более сложной логики NAND с применением простой логики NAND.
Иными словами, более сложные операции синтезированы за счет использования операций меньшей сложности. Наличие источника информации для генерации более сложных операций должно означать, что более сложные операции
лучше подходят для поиска, чем простые. Если это не так, то наличие ступеней бесполезно. Когда мы поднимаемся по ступеням лестницы, то ощущаем,
что нам становится «теплее», то есть мы приближаемся к результату, к которому стремимся. Когда более сложная операция упрощается, нам становится
«холоднее». Этот активный источник информации является причиной успеха
Avida. Как всегда, модель эволюции не создает никакой информации. Действительно, другие алгоритмы лучше извлекают информацию и более эффективно
достигают результатов Avida. Подробнее об этом позже.
Рис. 6.12 Логика NAND. В блоке (1) логические операции NAND и NOT
могут быть выполнены с одним вентилем NAND. Возможные операции
с двумя вентилями NAND показаны в блоке (2). Продолжение на рис. 6.13
Avida: ступенчатый поиск и логика NAND 205
6.2.2.1. Синтез логических операций с использованием вентилей NAND
⍟ Давайте рассмотрим синтез некоторых логических операций. Во всех случаях мы сосредоточимся на подключении минимального количества вентилей
NAND для выполнения операции. (Те, кто не интересуется подробностями логических операций и логики NAND, могут пропустить это.)
На рис. 6.12 в блоке (1) находится две операции, которые можно выполнить
с одним вентилем NAND. Очевидно, что операция NAND реализуема. Столь же
легко реализуется операция NOT. Когда входы вентиля NAND соединены вместе,
в качестве входа используется одно и то же значение. Поскольку 1 NAND 1 = 0
и 0 NAND 0 = 1, вход X = 1 дает выход Х_ = 0, в то время как вход X = 0 дает выход Х_ = 1. Таким образом, когда входы соединены между собой, вентиль NAND
работает как вентиль NOT.
На рис. 6.12 также показаны логические операции, которые могут быть выполнены с помощью двух вентилей NAND. Первым в блоке (2) является операция AND, которая принимает NOT из выхода логического элемента NAND. Поскольку два отрицания дают положительный результат, составной операцией
является AND. Важно отметить, что элементарные операции с одним вентилем
NAND и NOT из блока (1) используются как компоненты в операциях блока (2).
Это первый случай наличия активной информации в виде ступеней лестницы.
Блок (3) на рис. 6.13 показывает операции, достижимые с тремя вентилями
NAND. Первый –_это_логическое OR. Также показаны две другие операции из
табл. 6.1: X AND Y и X AND Y. Каждая из логических операций использует ступенчатые операции в (1) и (2) в качестве строительных блоков для синтеза операций. Вверху
_ в блоке (3) находится логическая операция OR. Он использует
логику X OR Y в блоке (2) как компонент. Оставшиеся две операции используют
операцию AND
опе_ из блока (2). Хотя это явно не показано, промежуточная
_
рация X AND Y также может рассматриваться как имеющая X OR Y в качестве
компонента.
Аналогичным образом нижняя логическая операция_ в блоке (3),
_
X AND Y, может быть истолкована как имеющая операцию X OR Y в блоке (2)
как компонент.
Как XOR, так и NOR, как показано на рис. 6.14, требуют как минимум четырех
вентилей NAND. Операция NOR в блоке (4) содержит операцию OR в качестве
компонента.
Для операции XNOR на рис. 6.15 требуется как минимум пять вентилей
NAND. Это операция, которую ищет программа Avida. Операция XNOR в статье
Avida называется EQU. Изучая таблицу истинности XNOR (табл. 6.1), обратите
внимание, что выходной сигнал равен логической 1, только если на оба входа
поступает одинаковый логический уровень 0 или 1. Поэтому в Avida применяется сокращение EQU (equivalence – равенство).
206
Анализ моделей биологической эволюции
Рис. 6.13 Логика NAND (начало на рис. 6.12). В блоке
(3) показаны операции, достижимые при помощи трех
вентилей NAND. Один из них включен по схеме блока (1),
и два – по схеме из блока (2). Продолжение на рис. 6.14
Мы можем считать, что операция EQU содержит показанную в блоке (4) операцию _XOR в качестве компонента.
Операция EQU также включает в себя опе_
рации X AND Y и X OR Y, показанные в блоке (3), и операцию AND из блока (2).
Логика NAND, показанная на рис. 6.12–6.15, являет собой примеры использования минимального количества вентилей NAND для выполнения назначенной операции. Существуют другие конфигурации шлюза NAND, которые
выполняют эти операции. Два последовательно соединенных вентиля NOT
взаимно отменяют друг друга и могут быть размещены в любом месте схемы.
Например, если разместить один дополнительный вентиль NOT в конце схемы
EQU на рис. 6.15, то расширенная схема отменит эффект другого элемента NOT,
Avida: ступенчатый поиск и логика NAND 207
Рис. 6.14 Логика NAND (начало на рис. 6.13). Здесь
показаны операции XOR и NOR, для которых требуется
минимум четыре шлюза NAND. Продолжение на рис. 6.15
Рис. 6.15 Логика NAND (начало на рис. 6.14.)
Показано минимальное логическое представление операции XNOR
при помощи вентилей NAND
208
Анализ моделей биологической эволюции
и общая схема сгенерирует операцию XOR с использованием шести вентилей
NAND. Но это будет не оптимальная схема. В верхней схеме в блоке (4) операция XOR синтезируется с использованием только четырех вентилей NAND.
6.2.3. Организм Avida и его здоровье
Как и EV, Avida содержит цифровой организм. В отличие от EV, Avida демонстрирует промежуточную функциональную жизнеспособность в том смысле,
что каждый шаг к ее цели соответствует одной или нескольким логическим
операциям. Устройство цифрового организма Avida изображено на рис. 6.16.
Слева находится цикл, по которому выполняются простые компьютерные
инструкции. Всего в Avida 26 инструкций, каждая из которых обозначена строчной буквой (табл. 6.2). Инструкция (q), показанная более крупным шрифтом,
чем другие буквы на рис. 6.16, является текущей. Инструкции манипулируют
двоичными числами справа на рис. 6.16. Когда есть несколько организмов, инструкции могут также диктовать взаимодействие между организмами.
Рис. 6.16 Устройство цифрового организма Avida
Каждый организм рождается с двумя строками битов X и Y. Эти строки, показанные вверху организма, остаются неизменными на протяжении всей его
Avida: ступенчатый поиск и логика NAND 209
жизни. Внутри организма Avida есть несколько регистров, где можно хранить
цепочки битов. На рис. 6.16 показаны три таких регистра – AX, BX и CX. Регистр назначения по умолчанию – BX, если он не был изменен предыдущей
инструкцией. Существует также стек STACK, который можно использовать
для хранения 32-битовых строк. Инструкция может скопировать строку битов X, например, в AX. Внизу показан выходной регистр OUTPUT. Например,
текущая инструкция может скопировать содержимое регистра CX в регистр
OUTPUT.
Таблица 6.2. Перечень инструкций, применяемых в Avida
(a) nop-A
(b) nop-B
(c) nop-C
(d) if-n-equal
(e) if-less
(f) push
(g) pop
(h) swap-stk
(i) swap
(j) shift-r
(k) shift-l
(l) inc
(m) dec
(n) add
(o) sub
(p) nand
(q) IO
(r) h-alloc
(s) h-divide
(t) h-copy
(u) h-search
(v) mov-head
(w) jmp-head
(x) get-head
(y) if-label
(z) set-flow
Вот описание некоторых из наиболее важных инструкций, перечисленных
в табл. 6.2:
nand выполняет операцию NAND над BX или CX и записывает результат
в регистр назначения. Например, если
AX: 00011011110101110010100111001010
BX: 10001110111011110101100110010111
побитовая операция nand генерирует последовательность
11110101001110001111111001111101
которую записывает в целевой регистр. Целевой регистр по умолчанию –
BX. Благодаря наличию операции nand в списке инструкций Avida возможно создание любых других логических операций. Avida использует
операцию nand для программной реализации вентиля NAND и, следовательно, для реализации остальных логических операций;
IO переносит содержимое целевого регистра в регистр OUTPUT и считывает следующее значение X и Y;
push и pop – загрузка строки в стек и извлечение из стека;
swap меняет целевой регистр.
Другие операции манипулируют внутренними регистрами, облегчают воспроизведение организма Avida или манипулируют содержимым и размером
цикла программы. Некоторые из операций, как мы увидим, вредны для формирования логических операций Avida. Однако если удалить операцию IO, то
Avida не будет работать. Перестановка битовых строк с помощью таких операций, как push, pop и swap, также важна для работы Avida.
210
Анализ моделей биологической эволюции
Приспособленность организма Avida определяется количеством логических
операций, выполняемых над строками X и Y для получения содержимого регистра OUTPUT. Чем больше логических операций научился выполнять организм в процессе эволюции, тем выше приспособленность организма и тем
больше его преимущество в размножении. Если, например, каждый бит на выходе является логическим OR соответствующих двух бит в X и Y, то приспособ
ленность организма Avida определяется единственной операцией OR. Если
буква O обозначает выход (output), то пример успешной операции OR выглядит следующим образом:
X: 10110100110010100111001010000110
Y: 10001100111101011001100101110110
O: 10111100111111111111101111110110
Поскольку X и Y назначаются при создании организма, во время работы
программы изменяется только O.
Значения X, Y и OUTPUT, использованные на рис. 6.16, иллюстрируют операцию XNOR. Это операция, использующая логику NAND, для которой требуется минимальное количество вентилей NAND1. Avida называет эту операцию
не XNOR, а EQU.
Приспособленность, используемая Avida для выполнения операций, является функцией от количества вентилей NAND. Если G – число вентилей
NAND, занятых в минимальном представлении операции, приспособленность
Avida равна f = 2G. Операция OR в блоке С в верхней части рис. 6.13 требует
минимум G = 3 вентилей NAND и, следовательно, дает приспособленность
f = 23 = 8. Значения приспособленности для логических операций, показанных
на рис. 6.12–6.15 и применяемых в Avida, перечислены в табл. 6.3.
Таблица 6.3. Приспособленность f организма Avida
в зависимости от различных логических операций на основе операции NAND
Операция
NOT
NAND
AND
_
_
(X OR Y) или (X OR Y )
OR
_
_
(X AND Y) или (X AND Y )
NOR
XOR
EQU (XNOR)
1
См. рис. 6.15.
Схема
G
f
6.12
6.12
6.12
6.12
6.13
6.13
6.14
6.14
1
1
2
2
3
3
4
4
2
2
4
4
8
8
16
16
6.15
5
32
Avida: ступенчатый поиск и логика NAND 211
Использование ступеней лестницы в качестве источника информации в Avida теперь не вызывает сомнений. Нижняя ступенька лестницы требует меньше
вентилей NAND для логических операций. Как мы видели в схемах логического синтеза с использованием вентилей NAND, блоки менее сложных операций
можно комбинировать для достижения более сложных операций.
Поиск логических операций в Avida сродни шагам по лестнице в поиске более длинных фраз, основанных на успехе поиска более коротких фраз. В ранее рассмотренном примере поиска с шагами по лестнице1 мы использовали
26 букв английского алфавита и пробел для поиска небольших фраз, чтобы подняться по лестнице и достичь успеха в сложном поиске. Теперь мы используем
26 инструкций в алфавите в табл. 6.2, чтобы найти более простые логические
операции, подняться по лестнице и получить более сложную операцию EQU.
Для человека распознавание последовательности букв интуитивно понятнее,
чем анализ цепочки компьютерных инструкций, но концепция этих двух поисков совпадает.
Как и EV, Avida использует большую популяцию для своего эволюционного
поиска. Как показано на рис. 6.17, для большинства поколений эволюционного
поиска используются 3600 организмов, изображенных на рис. 6.16.
Рис. 6.17 Каждая из 3600 точек этого массива
представляет собой организм Avida, изображенный на рис. 6.16
1
См. раздел 5.6.
212
Анализ моделей биологической эволюции
6.2.4. Анализ Avida с точки зрения информации
Avida предоставляет благоприятную среду для вычисления логической операции XNOR (EQU). По сравнению с другими ступенями лестницы, EQU является
наиболее сложной в том смысле, что для нее требуется наибольшее количество
вентилей. Avida объединяет эти промежуточные результаты для генерации
EQU. Здесь не обойтись без заложенной в Avida активной информации в виде
ступеней.
Авторы Avida осознают и признают необходимость активной информации,
позволяющей Avida работать. Они пишут, что когда доступна активная информация в виде вознаграждения за достижение ступеньки,
«...по крайней мере, одна популяция достигает EQU».
Что происходит, когда применение активной информации не вознаграждается повышением приспособленности? Не происходит ничего:
«С другой стороны, 50 популяций развивались в среде, где вознаграждалось
только достижение операции EQU, а никакая более простая функция не давала вознаграждения. Мы ожидали, что EQU будет достигаться гораздо реже,
потому что отбор не сохранит простые функции, которые являются основой
для создания более сложных функций. На самом деле ни одна из этих популяций не достигла уровня операции EQU, что является очень значительным
отличием от той доли, которая наблюдалась в среде, приносящей все вознаграждения».
Откуда в программе Avida появилась информация, позволяющая программе
работать? Ответ очевиден – информация заложена в программу разработчиками. Авторы Avida частично соглашаются:
«Некоторые читатели могут предположить, что мы подтасовали карты, изучая
эволюцию сложной функции, вырастающей из более простых функций, которые также были полезны. Однако именно этого требует эволюционная теория,
и наши эксперименты показали, что сложная функция никогда не развивалась,
когда более простые не получали вознаграждения».
Да, карты были подтасованы. Нельзя называть успешным доказательством
ненаправленной эволюции модель, которая работает только за счет тщательно
продуманного замысла разработчика. Как мы покажем в нашем обсуждении
поиска для поиска (S4S), поиск в богатых информацией средах экспоненциально сложнее, чем выполнение собственно искомого поиска.
Мы опубликовали детальный критический разбор Avida, в котором определены и измерены источники активной информации [6]. Более подробно эту
публикацию можно изучить на сайте EvoInfo.org.
6.2.4.1. Сравнительный анализ эффективности Avida
Далее мы рассмотрим некоторые результаты моделирования с использованием программного обеспечения Avida [7].
Avida: ступенчатый поиск и логика NAND 213
Эволюционный подход
Анализ, примененный к моделированию с использованием Avida, показывает, что при наличии последовательности из 85 инструкций существует около
1,82 × 10108 из возможных 2685 = 1,87 × 10120 программ, которые будут вычислять
EQU. Для одной последовательности из 85 инструкций вероятность случайного
выбора именно такой комбинации инструкций, которая генерирует EQU, представляет собой отношение этих двух чисел, равное p = 9,71 × 10–13. Соответствующая эндогенная информация представляет собой –log2 этой вероятности, т. е.:
IΩ » 39,9 бита.
Это означает, что вероятность случайного выбора последовательности из
85 инструкций1 при поиске EQU составит чуть больше одного шанса на один
триллион.
Все логические операции в табл. 6.3 могут использоваться как ступеньки
в Avida. Что происходит при удалении одной или двух ступеней? Вот сравнение
различных результатов для Avida с использованием I⊕ = активной информации на инструкцию2.
1. Используя параметры Avida по умолчанию (все 26 инструкций и все
шаги), мы находим, что
2. Удаление некоторых ступеней с лестницы должно ухудшить производительность. Если мы уберем в табл. 6.2 вознаграждаемые ступени XOR
и NOR, то получим худший результат:
3. Давайте уберем еще несколько шагов. Помимо XOR и NOR, удалим ступени AND и OR. Активная информация на инструкцию становится еще
меньше:
1
2
Последовательность из 15 инструкций, изначально присущая организму Avida, делает возможным только процесс репликации в эволюционном поиске. Допустим, что
в процессе эволюции к ним добавляются упомянутые 85 инструкций, образуя в итоге
последовательность из 100 инструкций.
Активной информацией для каждой инструкции является
где E обозначает ожидание, ü – случайная величина, соответствующая количеству инструкций,
а I+ – соответствующая активная информация. Мы оцениваем это среднее значение,
используя K испытаний, как
где ük – количество инструкций для успешной попытки. Результаты неудачных попыток не влияют на сумму.
214
Анализ моделей биологической эволюции
4. Что произойдет, если в предыдущем примере мы уберем ступень AND
вместо шага OR? В этом случае похоже, что ступень OR важнее, чем ступень AND, так как
Метод трещотки
Приспособленность, достигаемую по ступенькам лестницы, можно рассмат
ривать как оракула. Когда программа Avida представлена оракулу, он отвечает
значением приспособленности. Как мы видели в случае с оракулом Хемминга, существуют плохие и хорошие способы извлечения активной информации
из оракула. Помните, как мы смогли извлечь более активную информацию из
оракула Хемминга, используя более эффективные алгоритмы? Мы можем сделать то же самое со встроенным оракулом в программе Avida. Фактически эволюционное извлечение активной информации является относительно плохим
методом для извлечения информации из оракула.
Другой алгоритм поиска, который мы анализируем, – это уже знакомый
нам простой метод трещотки. Давайте возьмем один организм Avida и изменим его. Если мутация дает меньшую приспособленность, мы отбрасываем мутацию и пробуем снова. Таким образом, жизнеспособность отдельного
организма Avida никогда не уменьшается. Что касается количества запросов,
этот метод трещотки (или метод стохастического восхождения) работает значительно лучше, чем эволюционный подход Avida с использованием 3600 организмов. Давайте рассмотрим те же сценарии, что и для поиска Avida. Для
различия обозначений здесь обозначим величину активной информации на
инструкцию RÅ (R – значит ratchet, трещотка), а не IÅ. Вот полученные нами
результаты.
1. Используя все 26 операций и все ступени лестницы, мы получаем:
2. Убрав ступени XOR и NOR, получаем:
3. Помимо XOR и NOR, удалим ступени AND_N и OR. Активная информация
на инструкцию для храпового поиска:
4. И наконец, мы удаляем лестницы XOR, NOR, AND_N и AND:
Интересно, что для поиска с трещоткой ступенька AND в данном конкретном сценарии выглядит более важной, чем ступенька OR, – в противоположность эволюционной Avida.
Avida: ступенчатый поиск и логика NAND 215
Сравнение результатов
Результаты расчета активной информации для различных поисков приведены в табл. 6.4. Вывод очевиден. Как и во всех работоспособных моделях эволюции, в Avida есть оракул, заложенный в программу эволюционного поиска.
А программа эволюционного поиска плохо справляется с извлечением информации по сравнению с более простым поиском с трещоткой.
Таблица 6.4. Сравнение эндогенной информации на инструкцию для эволюционного поиска
Avida и поиска с трещоткой при использовании одного и того же оракула. Храповой поиск
добывает информацию из оракула эффективнее, чем Avida (каждое число в таблице следует
умножить на 10–9)
Без удаления ступенек
XOR, NOR
XOR, NOR, AND_N, OR
InXOR, NOR, AND_N, AND
Avida
1,90
1,36
0,62
0,52
Трещотка
25,30
16,26
6,72
8,05
6.2.4.2. Minivida
Minivida – это веб-симулятор, доступный на EvoInfo.org1. Он похож на симуляцию эволюции, выполняемую исходной программой Avida, но не идентичен
ей2. Minivida работает в окне интернет-браузера, и любой желающий может загрузить и просмотреть исходный код.
Элементы Avida не просто помещены в Minivida – пользователь может изменить их, чтобы увидеть, что происходит.
Instructions (инструкции): 26 инструкций Minivida, как и для Avida, показаны на рис. 6.18. Minivida позволяет отключить или включить все
инструкции. Не все инструкции Avida одинаково полезны. Фактически
большинство из них может быть выброшено, что влияет на способность
программы создавать EQU. На вкладке Instructions вы можете указать,
какие инструкции разрешено выполнять программе.
Fitness (приспособленность): зависимость приспособленности от ступеней в табл. 6.3 представлена в Minivida на рис. 6.19. По умолчанию как
в Avida, так и в Minivida операции вознаграждаются пропорционально
количеству вентилей NAND, необходимых для их реализации. Minivida
позволяет варьировать эти значения и даже удалять ступени с лестницы.
1
2
http://www.evoinfo.org/minivida/.
Для эффективной работы в веб-среде несколько элементов Avida было упрощено. Все
инструкции, относящиеся к инструкциям копирования, либо игнорируются, либо
реализуются только частично. Упрощения были сделаны для некритических элементов устройства Avida, так что это моделирование достаточно похоже на оригинальную программу Avida и сохраняет ее работоспособность. Была предпринята попытка
сохранить как можно большую совместимость с Avida, поэтому большинство программ Avida должно работать на этом симуляторе с теми же результатами.
216
Анализ моделей биологической эволюции
Рис. 6.18 Страница Minivida на сайте EvoInfo.org.
Операциям в Avida сопоставлены 26 букв английского алфавита
Рис. 6.19 Девять ступеней лестницы Avida. Ступени могут быть добавлены или удалены. Кроме того, можно изменить вес вклада каждой ступени. По умолчанию, как показано на рисунке, вес каждой ступени равен
минимальному количеству вентилей NAND, необходимых для выполнения
операции. Вознаграждение, как показано в табл. 6.3, равно двум в степени,
равной числу вентилей NAND
Avida: ступенчатый поиск и логика NAND 217
Population Size (размер популяции): по умолчанию популяция Avida состоит из 3600 организмов. Minivida позволяет выбрать любой размер популяции, который вы пожелаете (рис. 6.20).
Рис. 6.20 В Minivida вы можете указать размер популяции для вашего эксперимента. В Avida значением по умолчанию является 3600 цифровых организмов
Полная программа
Для полной симуляции берется популяция из 3600 цифровых организмов.
Используются все 26 инструкций, и оракул применяет все девять ступеней.
Хороший результат. Один из результатов, показанный на рис. 6.21, сошелся с EQU только после 13 449 600 запросов к оракулу. Это 3736 поколений 3600 организмов. Как видно на рисунке, для каждого поколения
даны логические схемы. Для этой версии EQU используется шесть вентилей NAND. Менее удачный результат с использованием тех же пара
метров показан на рис. 6.22.
Рис. 6.21 Успешная реализация Minivida с использованием
всех параметров Avida по умолчанию. EQU благополучно найден.
Развитый компьютерный код, дающий начало этому результату,
находится в блоке, обозначенном как Genome. Каждой букве присваивается операция на рис. 6.18
218
Анализ моделей биологической эволюции
Менее удачный результат. Другая симуляция с идентичными парамет
рами оказалась менее удачной. Как показано на рис. 6.22, после 600 млн
запросов схема EQU так и не была найдена.
Рис. 6.22 600 млн запросов оказалось недостаточно
для генерации EQU в этом прогоне Minivida
Отказ от лестницы
Что произойдет, если все параметры Minivida останутся неизменными, за
исключением того, что мы откажемся от лестницы? Если нет лестницы, то
в эволюционном поиске Avida
«...ни одна из этих популяций не достигала EQU, что очень существенно отличается от той доли, которая наблюдалась в экспериментах с получением всех
вознаграждений».
То же самое происходит в Minivida, когда признается и вознаграждается только верхняя ступень эволюции – EQU. В эксперименте, показанном на
рис. 6.23, более 2 млрд запросов не дают результата. Это понятно. Трудно запрыгнуть на крышу дома, когда нет лестницы (рис. 6.24).
Минимальный набор инструкций
Мало того, что в Avida нужны не все 26 инструкций, некоторые ненужные
инструкции фактически мешают найти EQU. Если мы уберем все инструкции,
которые считаем мешающими, останется их минимальный набор1. Когда ненужные инструкции отброшены, Minivida очень быстро находит EQU.
1
Минимальный набор инструкций показан флажками на рис. 6.18.
Avida: ступенчатый поиск и логика NAND 219
Рис. 6.23 Если лестница отсутствует,
то не удается найти EQU даже после 2 млрд запросов
Рис. 6.24 Тщательно продуманная активная информация о ступеньках
лестницы является одним из многих параметров проектирования, который
позволяет Avida работать. С S4S найти алгоритм успешного поиска сложнее,
чем выполнить сам поиск
Итак, теперь мы с легкостью находим EQU. Результат моделирования показан на рис. 6.25, где Minivida находит EQU всего через 11 поколений, используя
менее 40 000 запросов к оракулу.
220
Анализ моделей биологической эволюции
Рис. 6.25 Применение минимального набора инструкций в Minivida.
Задана популяция из 3600 организмов, использованы все ступени
Более того, EQU определяется с использованием минимального набора,
даже когда ступеньки удалены (рис. 6.26).
Рис. 6.26 Минимальный набор инструкций работает в Minivida,
даже когда ступени удалены и вознаграждается только EQU
При использовании минимальных инструкций из оракула можно извлечь
столько активной информации, что сработает даже слепой поиск! Если на
вкладке Minivida Settings (Настройки Minivida) установить размер популяции равным единице, то поиск будет слепым. С минимальным набором ин-
Avida: ступенчатый поиск и логика NAND 221
струкций симуляция на рис. 6.251 находит EQU менее чем за 20 000 запросов
программы к оракулу. Используется минимальное количество из 5 вентилей
NAND, но схема слегка отличается от рис. 6.27.
Рис. 6.27 Когда Minivida очищена от ненужных инструкций, оставшийся
минимальный набор инструкций эффективно добывает активную информацию. Слепой поиск в этой симуляции быстро нашел EQU
6.2.5. Наличие замысла в программе Avida
Анализ Avida с помощью результатов моделирования показывает, что Avida
преднамеренно создавалась для успешного эксперимента. Мы полагаем, что
авторы оригинальной статьи Avida не преследовали цель обмана или сокрытия
активной информации для поиска. Более вероятное объяснение состоит в том,
что они были ошеломлены своим восторгом от демонстрации дарвиновской
эволюции и празднованием ее успеха. Вот несколько фактов и одно предположение, подтверждающие преднамеренный характер программы Avida и ее
нацеленность на успех.
Человек в цикле. Сначала сделаем предположение. Мы не встречали
отчеты, в которых документирована итеративная разработка Avida. Тем
не менее разработка программ по своей природе итеративна, и человек
в цикле является частью этого процесса. Программное обеспечение переписывают и тестируют, отлаживают и снова тестируют. Мы не знаем
никого, кто написал бы поисковую программу нетривиальной длины,
работающую правильно с первого раза2.
1
2
На рис. 6.25 выполняются операции
См. раздел 3.7.3.
222
Анализ моделей биологической эволюции
Активная информация и ступени лестницы. Avida работает только
благодаря разумно спроектированной лестнице. Следует поздравить авторов Avida за разработку лестницы, в которой каждый шаг демонстрирует функциональную жизнеспособность. Без тщательно продуманной
лестницы вероятность успеха для поиска EQU исчезающе мала. Самостоятельная эндогенная информация в IΩ = 40 бит просто слишком велика
для слепого поиска.
Скрытое замедление. С минимальным набором инструкций мы находим EQU весьма быстро. Даже слишком быстро. С таким же основанием
можно утверждать, что мы смоделируем эволюцию, бросая два кубика,
пока не выбросим «глаза змеи» (две единицы). Минимальный набор инструкций хоть и сложнее, чем «глаза змеи», но сходится слишком быстро,
что может вызвать нежелательные подозрения. Ненужные инструкции,
мешающие искать EQU, позволяют программе Avida работать достаточно медленно, чтобы произвести иллюзию успешной эволюции. Поиск
не должен быть настолько сложным, чтобы оказаться практически невозможным, но и не должен быть таким простым, чтобы получить EQU
слишком быстро. Программисты позаботились, чтобы поиск сходился за
разумное время.
Другие источники активной информации. Некоторые свойства проекта позволяют извлекать активную информацию непосредственно из
программного обеспечения. Вот некоторые из них, которые мы еще не
обсуждали.
1. Мутация. Частота мутаций в Avida фиксирована, но ее выбор нигде
не объясняется. Скорее всего, это значение было выбрано человеком в цикле в процессе отладки программы. Изучая модель EV, мы
установили, что частота мутаций нуждается в правильной настройке. Рассмотрение крайних случаев показывает, что всегда существует
наилучшее значение частоты мутаций. С одной стороны, отсутствие
мутаций означает, что ничего не меняется. Это плохо. С другой стороны, если все меняется с каждым запросом, то мы выполняем слепой
поиск. Для Avida это не имеет смысла. Значит, оптимальная частота
мутаций расположена между этими двумя крайностями.
2. Приспособленность. Почему выбраны значения приспособленности, указанные в табл. 6.3? Приспособленность ступеньки f = 2G, где
G – количество вентилей NAND, необходимых для минимального
представления. Почему бы не использовать f = G, или f = log G, или
f = G10? Функция приспособленности, сознательно выбранная программистами для Avida, поддерживает восхождение по ступенькам,
позволяя легко акцентировать внимание на успешной мутации.
3. Инициализация. По причинам, которые мы объясняем в другом мес
те [8], инициализация Avida имеет решающее значение для успеха.
В заключение отметим очевидное: Avida врезается в потолок Бейснера. Программа никогда не сделает ничего более захватывающего, чем сгенерировать
Метабиология 223
EQU. Она никогда не научится играть в шахматы или решать головоломку
Cracker Barrel.
6.2.6. Движения мертвого организма
Несмотря на свои ограничения и очевидное использование встроенной информации для достижения успеха, Avida оказала значительное влияние в научных кругах. Академики измеряют успех публикациями и финансированием.
Национальный научный фонд (NSF) выделил грант в размере 25 млн долл. на
исследование цифровой эволюции. Грант поступил в Digital Evolution Lab [9]
(DevoLab1) в Университете штата Мичиган. Лаборатория была основана Чарльзом Офрией и Ричардом Ленски, которые являются двумя соавторами публикации про Avida [10].
Программная платформа Avida была использована многими авторами, утверждающими, что они продемонстрировали различные аспекты дарвиновской эволюции [11]. Avida использовалась в качестве учебного пособия как образец успешной модели дарвиновской эволюции [12]. Публикации продолжали
появляться даже после нашего разоблачения Avida в 2009 году [13].
Некоторые математические факты, очевидно, требуют времени для осо
знания.
6.3. Метабиология
Метабиология – это модель дарвиновской эволюции, основанная на алгоритмической теории информации [14].
Грегори Хайтин разработал алгоритмическую теорию информации [15] параллельно с Колмогоровым и Соломоновым. Основанная на работах Гёделя
и Тьюринга, алгоритмическая теория информации отчасти связана с мозголомной математикой, такой как доказательство существования недоказуемых
предположений, и знанием того, что есть вещи, которые невозможно знать.
Грегори Хайтин является первопроходцем в области, которую он называет
метабиологией [16]. Основным стимулом для исследований Хайтина является
поиск надежной математической основы для эволюции Дарвина. Хотя математика Хайтина прекрасна, конечная модель не проливает свет на процесс биологической теории эволюции. Подход метабиологии заключается в рассмотрении эволюции в абстрактном мире компьютерных программ, работающих на
машинах Тьюринга. По сути, Хайтин утверждает, что эволюция связана с программным обеспечением, а не с аппаратными средствами или симуляциями.
Концентрируясь только на программном обеспечении, Хайтин надеется сосредоточиться на чистой сущности эволюционного процесса.
1
Powered by TCPDF (www.tcpdf.org)
По иронии судьбы (или нет) Devo было названием рок-группы 1970-х годов, которая
носила красные пластиковые цветочные горшки вместо шляп и чье название является сокращением от слова «de-evolution». Название их первого альбома 1978 года
начиналось с вопроса «Мы не мужчины?».
224
Анализ моделей биологической эволюции
Хайтин развивает программы, которые выдают странные, чрезвычайно
большие числа, называемые числами усердного бобра (busy beaver). Он показывает, что программы научатся достаточно быстро генерировать очень большие
числа. Модель Хайтина использует:
оракул остановки (halting oracle): компьютерная программа, о которой
известно, что она не существует;
числа усердного бобра: числа настолько велики, что их список невозможно вычислить [17];
неограниченные, хотя и конечные ресурсы: как в пространстве, так и во
времени.
И, несмотря на эти необычные инструменты, алгоритм Хайтина почти во
всех отношениях соответствует другим моделям эволюции, которые мы проанализировали. Оракул остановки – это источник знаний, к которому можно
подойти множеством различных способов, что приводит к разному количеству
активной информации.
Проблему остановки (halting problem) Тьюринга [18] преподают студентам,
изучающим информатику. Для произвольной компьютерной программы X не
существует метакомпьютерная программа Y, способная проанализировать X
и ответить на вопрос, остановится X после запуска или нет. Тьюринг показал,
что написание метапрограммы Y невозможно. Гипотетическое устройство,
способное ответить на этот вопрос, названо оракулом остановки. Оракулов
остановки не существует.
Примечание. Проблема остановки в двух словах
Все компьютерные программы могут быть записаны в виде двоичной строки из нулей
и единиц. Поэтому каждая возможная программа может быть записана как положительное целое число. Мы располагаем все эти программы в списке, начиная с самого
маленького, и помечаем их соответствующими целыми числами. Пусть у нас есть программа, помеченная целым числом p. Пусть H(p,i) будет программой-оракулом остановки, которая решает, остановится ли программа p с вводом i, записанным как p(i), или
нет. H(p,i) выдает 1, если программа p(i) останавливается, и 0, если нет. Как и в случае
с программами, все возможные входы можно упорядочить и назначить целое число,
в данном случае i. Затем рассмотрим программу
function N(p) {
if(H(p,p) == 1) {
while(1 == 1) {
}
}
return 0;
}
Для данной программы p эта программа выводит 0, когда p(p) не останавливается и выполняется бесконечно в цикле while, если программа p(p) останавливается. Что же тогда
с программой N(N)? В этом случае она анализирует себя, чтобы увидеть, остановится или
нет. Результаты противоречивы. Если в программе H(N,N)=1, мы зацикливаемся на цикле
while. Но H(N,N)=1 означает, что программа N(N) останавливается. Возникает противоречие. Аналогично, если H(N,N)=0 в программе, печатается ноль и программа останав-
Метабиология 225
ливается. Но H(N,N)=0 означает, что программа N(N) не останавливается. Это еще одно
противоречие. Таким образом, предположение, что существует программа остановки
H(p,i), которая работает для всех p и i, оказалось неверным.
Если бы существовали оракулы остановки, то все открытые проблемы, опровергаемые одним контрпримером, были бы решены. Примером такой проблемы является гипотеза Гольдбаха, которая предполагает, что все четные числа
больше двух могут быть записаны как сумма двух простых чисел, например:
10 = 7 + 3, 56 = 51 + 5, 1028 = 1021 + 7, 73 200 = 73 189 + 11 и 143 142 = 71 429 +
71 713.
Мы можем написать программу X для последовательного тестирования
каждого четного числа, чтобы увидеть, является ли оно суммой двух простых
чисел. Если программа натыкается на четное число, которое невозможно представить суммой двух простых чисел, она останавливается и объявляет: «У меня
контрпример!» В противном случае программа переходит к следующему четному числу. Если гипотеза Гольдбаха верна, то программа будет работать вечно. Если бы существовал оракул остановки, мы скормили бы ему программу X.
Если оракул отвечает, что «эта программа останавливается», – гипотеза Гольд
баха опровергается. Если оракул говорит: «Эта программа никогда не останавливается», значит, гипотеза Гольдбаха доказана. В математике существует
много других открытых проблем, которые можно доказать или опровергнуть
при наличии оракула, например вопрос о существовании нечетного совершенного числа и гипотеза Римана. За решение многих из этих проблем полагаются
значительные денежные призы.
В своей модели дарвиновской эволюции Хайтин использует оракула остановки [19]. Использование заведомо невозможных компьютерных инструментов, таких как оракул остановки, с самого начала является очевидным серьезным ударом по теории, претендующей на демонстрацию реальности.
6.3.1. Проблема остановки
Все эволюционные процессы стремятся к улучшению. В метабиологии Хайтина
приспособленность достигается путем поиска чисел усердных бобров [20, 21].
Хотя это и не сразу видно, существует связь между числами усердных бобров
и проблемой остановки.
Вот стандартное определение числа усердного бобра (busy beaver number):
какая программа выдаст наибольшее число при выполнении в машине Тьюринга с N состояниями, в которой используются только нули и единицы? Эта
программа называется программой усердного бобра, а выходное число – числом
усердного бобра. При увеличении N число усердных бобров не может уменьшиться.
Просто генерировать все большие и большие числа не сложно. Например,
программу можно улучшить, создав новую программу, которая запускает исходную и прибавляет 1 к результату. Без наложения какого-либо критерия
остановки поиск постоянно растущих чисел при увеличении N требует неогра-
226
Анализ моделей биологической эволюции
ниченных вычислительных ресурсов. Поиску чисел усердного бобра присущи
огромные вычислительные запросы. Метабиологические программы Хайтина
имеют неограниченную длину и могут работать неограниченное количество
времени. С неограниченными ресурсами и неограниченным временем можно
делать практически все. Например, можно быстро превысить вычислительные
ресурсы наблюдаемой вселенной [22].
Хайтин использует разновидность числа усердного бобра под названием BB(K): наибольшее количество шагов с использованием беспрефиксной компьютерной программы длины K до ее остановки. Связь между BB(K)
и проблемой остановки заключается в следующем: при достижении BB(K)
все программы длины K, которые не были остановлены, никогда не остановятся. И поскольку BB(K) становится больше с увеличением K, все программы, длина которых меньше K, которые не были остановлены, также никогда
не останавливаются. Таким образом, достижение BB(K) аналогично наличию
оракула остановки для всех компьютерных программ, меньших или равных K.
Поскольку оракул остановки не существует, неудивительно, что BB(K) вскоре
увеличивается быстрее, чем можно вычислить.
6.3.2. Проблема поиска
Метабиология Хайтина спрашивает, можно ли найти программы усердных
бобров, развивая компьютерные программы. В отличие от многих других предлагаемых моделей эволюции, здесь нет искусственно навязанной функции
приспособленности или искусственно созданного ландшафта отбора. Скорее,
ландшафт метабиологии вытекает из математической структуры программ
машины Тьюринга. Используя математическую конструкцию программ усердных бобров, метабиология Хайтина не берет на себя умышленную помощь эволюционному процессу, как это сделали многие другие эволюционные модели.
Отметим, однако, что математика изобилует другими теоретико-числовыми
ландшафтами. Возьмем, например, простые числа (prime number), совершенные
числа (perfect number) и простые числа-близнецы1 (twin primes).
Ранее в этой главе были критически рассмотрены многочисленные свойства
модели Хайтина [23]. Модели эволюции часто работают, извлекая информацию из оракула. Оракул является источником информации и отвечает за успех
программы. Модель эволюции – это процесс, который просто добывает эту информацию. Часто другие подходы к поиску могут добывать информацию более
эффективно [24]. Модель Хайтина не является исключением.
Мы обсудили четыре способа извлечения информации из оракула Хемминга
в разделе 5.4.3.1. При представлении двоичной строки оракул Хемминга с основанием 2 возвращает одно число, указывающее количество несовпадений
нолей и единиц между двумя двоичными строками: предлагаемой строкой
с длиной L и неизвестной целевой строкой той же длины. Мы рассмотрели
«плохой» способ использования оракула Хемминга, а также хороший и наи1
Простые числа, разность между которыми равна 2. – Прим. пер.
Метабиология 227
лучший способ. Эффективность метода извлечения информации измерялась
количеством запросов, необходимых для полной идентификации целевой
строки. Чем меньше запросов, тем лучше. Мы также определили оптимальный
(наилучший) поиск. Количество запросов сведено к минимуму, но вычислительные затраты каждого запроса становятся большими.
Метабиологическое использование оракула остановки отличается от использования оракула Хемминга, но есть существенное сходство. Оба стремятся идентифицировать неизвестную двоичную строку фиксированной длины
L. В случае метабиологии двоичная строка соответствует компьютерной программе. Для обоих оракулов существуют как эффективные, так и неэффективные способы извлечения активной информации. Хайтин использует оракула
остановки для поиска чисел усердного бобра тремя различными способами.
Он дублирует разные алгоритмы:
исчерпывающий поиск (плохой);
случайная эволюция (хороший);
разумный поиск (лучший).
Различия между использованием оракулов Хемминга и оракула остановки
сведены в табл. 6.5. Для исчерпывающего поиска программы с оракулом Хемминга и оракулом остановки требуют в среднем 2L запросов. Внедрение управляемого поиска с трещоткой (т. е. стохастического восхождения) и метабиологической «случайной эволюции» значительно уменьшает число ожидаемых
операций. Оба оракула могут быть использованы более разумно, чтобы еще
сильнее уменьшить ожидаемое количество запросов.
Хайтин правильно называет оракула остановки источником творчества
в метабиологии. Три различных метода, которые он использует для извлечения активной информации из оракула остановки, снова показывают, что сам
эволюционный процесс не создает информацию. Это просто добыча информации из источника информации – оракула. И эволюционная модель делает это
хуже, чем другие доступные алгоритмы.
Таблица 6.5. Сравнение трех способов использования оракула Хемминга и оракула остановки.
Значение в столбце метабиологии следует интерпретировать в смысле нотации O, которая
обозначает порядок величины. Запись O(L2) означает «порядка L2»
Алгоритм
Плохой
Хороший
Оракул Хемминга
«Иголка в стоге сена»
Поиск с трещоткой
Лучший
FOOHOA Эверта
2L
≤L
<< L
Оракул остановки в метабиологии
Поиск с отбрасыванием 2L
Случайная эволюция
Между L2 и L3
«Разумный замысел»
L
6.3.3. Математический базис метабиологии
⍟ Если вы не хотите углубляться в математику, то можете пропустить этот раздел. Метабиология косвенно связана с числом Хайтина. Вспомним о беспрефиксных компьютерных программах. Пусть p представляет собой беспрефикс-
228
Анализ моделей биологической эволюции
ный код, и пусть длина кода составляет lp бит. Неравенство Крафта1 (рис. 6.28)
требует, чтобы
(6.1)
Рис. 6.28 Иллюстрация неравенства Крафта в уравнении (6.1).
Каждый из листьев на дереве соответствует компьютерной программе без префиксов. Реальные программы, конечно, намного
длиннее. Листья не имеют префиксов, потому что одна программа
не может быть началом (префиксом) другой. Например, одна программа – 001. Ни одна из других программ не начинается с 001. Есть
две программы с длиной l = 2, три программы с l = 3, одна с длиной
4 и две с длиной 5. Тогда 2×2–2 + 3×2–3 + 1×2–4 + 2×2–5 = 1, что удовлетворяет равенству Крафта
Некоторые программы на листьях дерева останавливаются. Некоторые нет.
Число Хайтина [25], показанное на рис. 6.29, является суммой для всех остановившихся программ.
(6.2)
Если мы запустим все программы длиной L или меньше на выполнение L
шагов, некоторые программы остановятся. Мы можем посмотреть на все эти
программы и вычислить:
Ясно, что мы еще не определили все программы, которые остановились, так
что ΩL ≤ Ω. Но поскольку число шагов увеличивается без ограничения (L → ∞),
мы уверены, что приблизимся к числу Хайтина ΩL → Ω снизу.
1
Рассмотрено также в разделе 2.2.1.1.
Метабиология 229
Рис. 6.29 Иллюстрация числа Хайтина. Дерево программ такое
же, как на предыдущем рисунке. Программы в окрашенных прямо
угольниках останавливаются, остальные нет. Число Хайтина Ω в уравнении (6.1) подсчитывается, как неравенство Крафта, за исключением того, что сумма вычисляется только по программам, которые
останавливаются. В этом примере число Хайтина Ω = 2–2 + 2–4 + 2–6 =
0,328125
Итак, вот как мы ищем функцию усердного бобра: угадываем число Ω*
и спрашиваем, оказалось оно меньше или больше числа Хайтина1, т. е. Ω* > Ω
или Ω* < Ω. Мы пишем программу X, чтобы пройти через различные значения
L и отслеживать ΩL до тех пор, пока ΩL ³ Ω*. Если мы угадали Ω* > Ω, то X никогда не остановится. Мы можем выяснить это, отправив X оракулу остановки.
Если оракул остановки говорит: «X не останавливается», это означает: «Ваше
предположение о Ω* слишком велико. Назовите меньшее значение». Выбирается меньшее значение, и процесс повторяется. С другой стороны, если оракул
остановки говорит: «X останавливается», это говорит нам о том, что ΩL ≤ Ω* < Ω.
Таким образом, мы запускаем все программы из одного бита на один шаг,
двух- и однобитовые программы за два шага2, …, программы из 10 бит или
меньше на 10 шагов и т. д. Мы сохраняем подсчет Ω1, …, Ω10, …, Ωl на каждом
шаге. Мы продолжаем идти, пока не получим L такой, что ΩL ³ Ω*. Мы знаем,
что это в конечном итоге произойдет, потому что оракул остановки говорит,
что так и случится. Затем мы можем выбрать большее значение Ω* и повторить
процесс.
Поиск программ типа усердного бобра аналогичен. Хайтин разработал хит
рый алгоритм поиска, который доказал свою эффективность. Эволюционный
алгоритм эффективно добывает информацию, доступную из оракула. Если,
с другой стороны, поиск выполняется с использованием случайных битовых
мутаций в программе с использованием того же оракула, мы подозреваем, что
алгоритм потребует астрономически большего количества запросов.
1
2
Мы уверены, что равенство не выполняется, когда Ω* рационально, потому что доказано, что Ω иррационально.
Разумеется, не существует одно- или двухбитовых программ, которые являются законченными программами. Они упомянуты только для иллюстрации.
230
Анализ моделей биологической эволюции
Для поиска Ω* используется деление интервала пополам1. Если у нас есть
превышение Ω, то оракул остановки говорит нам об этом, и мы делаем меньшее предположение. Если оракул сказал, что программа остановится, мы продолжаем находить Ωl для постоянно увеличивающегося l, пока не найдем L, где
ΩL ³ Ω.
Иллюстрация дана на рис. 6.30. Лестница из Ωl показана как функция от l.
Она асимптотически приближается к Ω при l → ∞. Наше первое предположение
о Ω – это Ω*[1]. Программа X[1] написана для последовательного вычисления Ωl
при любом увеличении l до тех пор, пока оно не станет равным или превысит
Ω*[1]. Оракул остановки говорит, что Х[1] никогда не остановится. Таким образом, предположение должно быть уменьшено. Мы выбираем Ω*[2] и отправляем X[2] оракулу, который говорит, что программа в конце концов остановится.
Поэтому запускаем X[2] до тех пор, пока не получим l = L такое, что ΩL ³ Ω*[2].
Рис. 6.30 Иллюстрация деления интервала пополам в метабиологии
Как только ΩL найден, мы знаем, что истинное значение Ω лежит между ΩL,
который, как мы знаем, слишком мал, и Ω*[1], который, как мы знаем, слишком
велик. Используя половину интервала, затем проверяем Ω*[3], лежащее между
этими двумя значениями, как показано на рис. 6.30. Программа X[3] представлена оракулу остановки, который отвечает: «Эта программа никогда не
остановится». Другими словами, Ω*[3] слишком велико. Теперь мы знаем, что Ω
лежит между ΩL и Ω*[3]. Выбираем промежуточное значение Ω*[4], и X[4] представляется оракулу, который объявляет, что программа остановится. Таким
образом, как и прежде, мы последовательно оцениваем Ωl до тех пор, пока не
1
Как мы видели в главе 2.2.2.2, деление пополам на интервалы является эффективным методом выполнения поиска, когда позволяют ресурсы.
Метабиология 231
найдем l = L̂, где впервые ΩL̂ ³ Ω*[4]. Теперь мы знаем, что истинное значение
Ω лежит между ΩL̂ и Ω*[3]. Этот процесс деления интервала повторяется, чтобы
получить оценки ближе и ближе к Ω.
Напомним, однако, что поиск идет не по числу Ω Хайтина, а по числам усердного бобра. Процесс деления интервала пополам позволяет нам это сделать.
Когда все программы длиной l бит прошли через L шагов (l < L), некоторые из
программ остановились, а некоторые – нет. Из тех, которые остановились, программа, которая дольше всех работала, предоставляет нижнюю границу BB(l).
По мере продвижения поиска все больше и больше программ будут останавливаться, давая лучшие и лучшие оценки BB(l). В конце концов, программа с BB(l)
остановится, и мы получим искомое число усердного бобра. Мы никогда не
узнаем, когда это произойдет, но мы уверены, что это произойдет, поскольку
поиск продолжается бесконечно.
Только что описанная процедура деления на интервалы названа Хайтиным
«разумным поиском». За исключением нескольких первых вариантов выбора
Ω*, алгоритм поиска является детерминированным, как и в случае всех поисков с делением интервала пополам. Существует также вариант поиска «случайная эволюция», который представляет собой стохастический алгоритм
восхождения1.
6.3.4. Ресурсы
Эволюционные программы в области метабиологии не обращают внимания на
ограничения ресурсов. Программы могут выполняться за любое сколь угодно
большое количество шагов за любой период времени. Кроме того, программы
могут быть любой длины и без штрафов за более длинные. Запуск программы
на число шагов, сопоставимое с числами усердного бобра, требует больше вычислительных ресурсов, чем доступно во Вселенной.
Хайтин также рассматривает все программы, а не только те, которые ограничены определенным размером. В результате получается не программа, которая является действительно усердным бобром, а лишь программа с более
длительным временем выполнения. Всегда можно создать более длинную
программу машины Тьюринга, которая дает большее число. Использование
неограниченных ресурсов – это стена, отделяющая метабиологию от любой
возможности моделирования реальности.
Самая интересная часть достижений Хайтина состоит в том, что он показал
эволюцию среди программ для машины Тьюринга, о которых мы и не думали, что они подходят для эволюционного процесса. Мы могли бы рассуждать,
что изменение одного бита программы машины Тьюринга может привести
к очень большим изменениям на выходе. Любой программист подтвердит, что
ландшафт отбора компьютерной программы не бывает плавным. Изменение
одного символа исходного кода может привести к сбою программы, генера1
См. раздел 5.4.3.1.
232
Анализ моделей биологической эволюции
ции совершенно другого результата или превращению программы, которая
останавливается, в программу, которая работает вечно. Следовательно, мы не
ожидали, что программы способны эволюционировать подобным образом.
Метабиология преодолевает эту проблему, выполняя все жизнеспособные программы. Это очень дорого в вычислительном отношении и возможно только
в теории, где нет ограничений по ресурсам.
Хайтин отмечал, что вряд ли сможет представить доказательства биологической сущности метабиологии, поэтому он вынужден ограничиться симуляциями. Казалось бы, первым шагом к биологической реалистичности стало бы
именно введение разумных ограничений. Тем не менее доказательства работоспособны только при отсутствии ограничений.
Даже если бы вопрос ресурсов не был проблемой, метабиология имеет те же
принципиальные особенности, что и другие модели дарвиновской эволюции,
такие как Avida и EV. Из встроенного источника знаний извлекается активная
информация, позволяющая стохастическому процессу выполнить успешный
поиск.
6.4. Пора подметать грязный пол?
Несмотря на убедительное доказательство концепции активной информации
в нашей статье 2009 года [26], все еще публикуются заявления о возможности создания информации в процессе дарвиновской эволюции. Все усилия по
моделированию дарвиновской эволюции, которые мы наблюдали до сих пор,
либо показывают недостаточную осведомленность о принципе сохранения
информации, либо не принимают его во внимание.
Вот краткий обзор еще двух неудачных попыток смоделировать ненаправленную биологическую эволюцию.
6.4.1. Доработка дерева Штейнера
Предположим, мы хотим построить дороги для нескольких домов так, чтобы
они соединяли каждый дом с каждым другим. Кроме того, мы хотим, чтобы
общая длина дорог была минимальной. Схема связей, которая выполняет
эти условия, называется деревом Штейнера1. Пример такой схемы показан на
рис. 6.31.
Дэвид Томас написал генетический алгоритм, который был близок к решению дерева Штейнера. Желая дискредитировать критиков, утверждающих,
что информация не возникает в процессе эволюции, Дэвид Томас написал
[27]:
«…Было доказано, что “неснижаемая сложность” и “сложная предопределенная
информация” не выходят за пределы возможностей эволюции.
1
Деревья Штейнера могут быть построены в более высоких измерениях. Для наших
целей достаточно двух измерений.
Пора подметать грязный пол? 233
Рис. 6.31 Дерево Штейнера
для шести домов
В заключение своей публикации Томас бросил прямой вызов критикам [28]:
«Если вы утверждаете, что этот алгоритм работает только путем добавления ответа (форма Штейнера) в тест приспособленности, укажите точный фрагмент
кода, в котором выполняется это добавление».
Так мы и сделали [29]. Один фрагмент нашего анализа уже был представлен
в разделе 5.2.3, и там ясно видно, что Томас вручную подстроил свой алгоритм
для успешного решения задачи.
Другой фрагмент кода свидетельствует, что частота мутаций была настроена
в процессе отладки, т. е. с помощью «человека в цикле».
Корректировка параметров в генетических алгоритмах является обычной
практикой и фактически необходима в случаях, таких как проблема дерева
Штейнера, где для точной работы поиска требуется настройка. Кроме того,
в нашем анализе был выявлен ряд других источников активной информации,
основанных на знании решаемой проблемы [30].
6.4.2. Время для эволюции
В статье, опубликованной в престижном журнале «Материалы Национальной
академии наук», Уилф (Wilf) и Эвенс (Ewens) [31] предлагают модель, которая,
как они утверждают, успешно моделирует и доказывает дарвиновскую эволюцию. Их модель похожа на алгоритм угадывания букв в слове или фразе,
как в телевизионном игровом шоу Wheel of Fortune (в России – «Поле Чудес»).
Указана фраза длиной 20 000 букв, причем каждая буква фразы соответствует
локусу гена, который можно преобразовать из исходного «примитивного» состояния в более продвинутое. Нахождение правильной буквы для конкретной
позиции в целевой фразе примерно соответствует обнаружению полезной мутации в соответствующем гене. Во время каждого раунда мутации все позиции
во фразе подвергаются мутации, а ее результаты проверяются оракулом позиционного поиска (partitioned search oracle) [32] на соответствие каждой отдель-
234
Анализ моделей биологической эволюции
ной позиции конечной целевой фразе. Те позиции, которые совпали с целевой
фразой, больше не меняются до конца поиска.
Оракулы позиционного поиска по уши загружены активной информацией.
Рассмотрим, например, строку из нулей и единиц, используемых в качестве
цели. Мы выбираем случайную строку из нулей и единиц, и оракул сообщает нам,
какие биты совпадают. Мы сохраняем позиции этих битов, а затем инвертируем
все неправильные биты. Мы определили цель одним запросом! Если двоичная
строка имеет длину L бит, слепой поиск потребует в среднем Q = 2L запросов. Но
Уилф и Эвенс не в полной мере используют знания оракула позиционного поиска, выбирая случайные мутации неправильных символов. Они плохо извлекают знания из доступного источника информации. В данном случае помощь
оракула как источника активной информации неоспорима.
6.4.3. Заключение
AVIDA, EV, WEASEL Докинза и метабиология Хайтина – все они разработаны
исследователями, пытающимися продемонстрировать математическую модель дарвиновской эволюции. Каждый такая модель представляет собой сознательно спроектированный стохастический процесс, который, подобно иголке
Буффона1 или тетерболу2, сходится к одной или нескольким фиксированным
точкам. Для успешного схождения поиска к этим точкам требуются источники
знаний, генерирующие активную информацию для поиска. Успех программы
зависит от разума программиста.
Источники
1.
2.
3.
4.
5.
1
2
George Gaylord Simpson, William S. Beck, Life: An Introduction to Biology, 2nd
edition (London: Routledge and Kegan, 1965).
William A. Dembski and Robert J. Marks II, «Conservation of Information in
Search: Measuring the Cost of Success». IEEE Transactions on Systems, Man and
Cybernetics A, Systems and Humans, vol. 39, #5, September 2009, pp. 1051–1061.
W. Ewert, William A. Dembski, and R. J. Marks II, «Evolutionary synthesis of
Nand logic: dissecting a digital organism». Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics. San Antonio, TX, USA,
pp. 3047–3053, (2009).
American Civil Liberties Union of Pennsylvania, Kitzmiller et al. v. Dover Area
School District, http://www.aclupa.org/our-work/legal/legaldocket/intelligentdesigncase/dovertrialtranscripts/ (дата URL: May 2, 2016).
American Civil Liberties Union of Pennsylvania, Dover Trial Transcripts, http://
www.aclupa.org/our-work/legal/legaldocket/intelligentdesigncase/dovertrialtranscripts/ (дата URL: May 2, 2016).
См. раздел 4.2.1.
См. раздел 4.2.3.
Источники 235
6.
W. Ewert, W. A. Dembski, and R. J. Marks II, «Evolutionary synthesis of Nand
logic: dissecting a digital or-ganism». Proceedings of the 2009 IEEE International
Conference on Systems, Man, and Cybernetics. San Antonio, TX, USA, pp. 3047–
3053, (2009).
7. Там же.
8. Там же.
9. Digital Evolution Lab: http://devolab.msu.edu/ (дата URL: May 2, 2016).
10. R. E. Lenski, C. Ofria, R. T. Pennock, and C. Adami, «The evolutionary origin of
complex features». Nature, 423 (6936), pp. 139–144 (2003).
11. Например, следующие публикации:
2003: Bill O’Neill, «Digital evolution». PLoS Biology 1 (1), e18 (2003). F. Tim
Cooper and C. Ofria, «Evolution of stable ecosystems in populations of digital
organisms». Artificial Life, 8. Proceedings of the Eighth International Conference
on Artificial Life, International Society for Artificial Life: 9–13 December 2002;
Sydney, Australia. (2003).
2004: C. Ofria, O. C. Wilke, «Avida: A software platform for research in computational evolutionary biology». Artif Life, 10 (2), pp. 191–229 (2004); M. Dusan,
R. E. Lenski , C. Ofria, «Sexual reproduction and muller’s ratchet in digital organisms». Ninth International Conference on Artificial Life. (2004); W. Daniel and
C. Adami, «Influence of chance, history, and adaptation on digital evolution».
Artif Life, 10 (2), pp. 181–190 (2004); H. George, «Using Avida to test the effects
of natural selection on phylogenetic reconstruction methods». Artificial Life,
10 (2), pp. 157–166 (2004); Goings, Sherri, et al., «Kin selection: The rise and
fall of kin-cheaters». Proceedings of the Ninth International Conference on Artificial Life (2004); J. Tyler and C. O. Wilke. «Evolution of resource competition
between mutually dependent digital organisms». Artif Life 10 (2), pp. 145– 156
(2004).
2005: C. Ofria and O. C. Wilke, «Avida: Evolution experiments with self-replicating computer programs». Artificial Life Models in Software (Springer, London, 2005), pp. 3–35; Carl Zimmer, «Testing Darwin». Discover, 26 (2), pp. 28–34
(2005); Philip Gerlee, T. Lundh, «The genetic coding style of digital organisms».
Advances in artificial life (Springer, Berlin Heidelberg, 2005), pp. 854–863.
2006: Christoph Adami, «Digital genetics: unravelling the genetic basis of
evolution». Nat Rev Genet, 7(2), pp. 109–118 (2006); B. David Knoester et al.,
«Evolution of leader election in populations of self-replicating digital organisms». Dept. Comput. Sci., Michigan State Univ., East Lansing, MI, Tech. Rep.
MSU-CSE-06-35 (2006); C. O. Wilke and S. S. Chow, «Exploring the evolution
of ecosystems with digital organisms». Ecological Networks: Linking Structure to
Dynamics in Food Webs (Oxford University Press, New York, 2006), pp. 271–286;
Terence Soule, «Resilient individuals improve evolutionary search». Artif Life,
12(1), pp. 17–34 (2006).
236
Анализ моделей биологической эволюции
2007: Robert T. Pennock, «Models, simulations, instantiations, and evidence:
the case of digital evolution». J Exp Theor Artif Intell, 19.1, pp. 29–42 (2007);
Benjamin E. Beckmann et al., «Evolution of cooperative information gathering in self-replicating digital organisms». First International Conference on
Self-Adaptive and Self-Organizing Systems, 2007. SASO’07. IEEE, 2007; Heather J. Goldsby et al., «Digitally evolving models for dynamically adaptive systems». Proceedings of the 2007 International Workshop on Software Engineering
for Adaptive and Self-Managing Systems. IEEE Computer Society (2007); B. David Knoester et al., «Directed evolution of communication and cooperation in
digital organisms». Advances in Artificial Life (Springer Berlin Heidelberg, 2007),
pp. 384–394; Elena, F. Santiago et al., «Effects of population size and mutation
rate on the evolution of mutational robustness». Evolution, 61(3), pp. 666–674
(2007); J. Clune, C. Ofria, and R. T. Pennock, «Investigating the emergence of
phenotypic plasticity in evolving digital organisms». Advances in Artificial Life
(Springer, Berlin Heidelberg, 2007), pp. 74–83; Dehua Hang et al., «The effect of
natural selection on the performance of maximum parsimony». BMC Evol Biol,
7(1), p. 94 (2007).
2008: J. Heather Goldsby and Betty H. C. Cheng, «Avida-MDE: a digital evolution approach to generating models of adaptive software behavior». Proceedings
of the 10th Annual Conference on Genetic and Evolutionary Computation (ACM,
2008); Philip McKinley et al., «Harnessing digital evolution». Computer 41 (1),
pp. 54–63 (2008); J. Heather Goldsby et al., «Digital evolution of behavioral
models for autonomic systems». International Conference on Autonomic Computing, 2008. ICAC’08. IEEE, 2008; E. Benjamin Beckmann et al., «Autonomic
Software Development Methodology Based on Darwinian Evolution». International Conference on Autonomic Computing, 2008. ICAC’08. IEEE, 2008; Charles
Ofria, Wei Huang, and Eric Torng, «On the gradual evolution of complexity and
the sudden emergence of complex features». Artificial Life 14(3), pp. 255–263
(2008); M. Laura Grabowski et al., «On the evolution of motility and intelligent tactic response». Proceedings of the 10th Annual Conference on Genetic and
Evolutionary Computation (ACM, 2008); Santiago F. Elena and R. Sanjuán, «The
effect of genetic robustness on evolvability in digital organisms». BMC Evolutionary Biology, 8 (1), p. 284, (2008); J. Heather Goldsby and Betty H. C. Cheng,
«Automatically generating behavioral models of adaptive systems to address
uncertainty». Model Driven Engineering Languages and Systems (Springer, Berlin
Heidelberg, 2008), pp. 568–583; Philip Gerlee et al., «The gene-function relationship in the metabolism of yeast and digital organisms». ALIFE, (2008).
2009: E. Beckmann Benjamin and P. K. McKinley, «Evolving quorum sensing
in digital organisms». Proceedings of the 11th Annual Conference on Genetic and
Evolutionary Computation (ACM, 2009); David B. Knoester et al., «Evolution of
robust data distribution among digital organisms». Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation (ACM, 2009); Sherri
Goings and C. Ofria, «Ecological approaches to diversity maintenance in evo-
Источники 237
lutionary algorithms». IEEE Symposium on Artificial Life (2009). ALife’09. IEEE
(2009); B. David Knoester and P. K. McKinley, «Evolution of probabilistic consensus in digital organisms». Third IEEE International Conference on Self-Adaptive
and Self-Organizing Systems, 2009. SASO’09. IEEE, 2009; Elsberry, Wesley R. et
al., «Cock-roaches, drunkards, and climbers: Modeling the evolution of simple
movement strategies using digital organisms». IEEE Symposium on Artificial Life,
2009. ALife’09. IEEE, 2009; Mark A. Bedau, «The evolution of complexity». Mapping the Future of Biology (Springer Netherlands, 2009), pp. 111–130; Charles
Ofria, David M. Bryson, and Claus O. Wilke, «Avida: A software platform for
research in computational evolutionary biology». Artificial Life Models in Software (2009): 1; Heather J. Goldsby et al., «Problem decomposition using indirect
reciprocity in evolved populations». Proceedings of the 11th Annual conference
on Genetic and evolutionary computation (ACM, 2009); C. Ofria, David M. Bryson,
and Claus O. Wilke, «Avida». Artificial Life Models in Software (Springer London,
2009), pp. 3–35.
12. Robert T. Pennock, «Learning evolution and the nature of science using evolutionary computing and artificial life». McGill J Educ 42.2 (2007), pp. 211–224.
Elena Bray Speth et al., «Using Avida-ED for teaching and learning about evolution in undergraduate introductory biology courses». Evolution: Education and
Outreach 2.3 (2009), 415–428.
Diane Ebert-May and Everett Weber, «OOS 17–5: Avida-ED: Learning evolution
through inquiry». (2007).
W. Johnson, «Introduction to Evolutionary Computation (lesson & activity)».
Teach Engineering Digital Library Submission Portal (2012).
13. Например, следующие публикации:
2010: Laura M. Grabowski et al., «Early Evolution of Memory Usage in Digital
Organisms». ALIFE. 2010; Goldsby, Heather J., David B. Knoester, and Charles
Ofria, «Evolution of division of labor in genetically homoge- nous groups». Proceedings of the 12th annual conference on Genetic and evolutionary computation
(ACM, 2010); Beckmann, Benjamin E., Jeff Clune, and Charles Ofria, «Digital
evolution with avida». Proceedings of the 12th annual conference companion on
genetic and evolutionary computation (ACM, 2010); Brian D. Connelly, Benjamin
E. Beckmann, and Philip K. McKinley, «Resource abundance promotes the evolution of public goods cooperation». Proceedings of the 12th annual conference on
Genetic and evolutionary computation (ACM, 2010).
2011: B. David Knoester and P. K. McKinley, «Evolving virtual fireflies». Advances in Artificial Life. Darwin Meets von Neumann (Springer Berlin Heidelberg, 2011), pp. 474–481; B. David Knoester and P. K. McKinley, «Evolution of
synchronization and desynchronization in digital organisms». Artif Life, 17 (1),
pp. 1–20 (2011); Heather J. Goldsby et al., «Task-switching costs promote the
evolution of division of labor and shifts in individuality». Proceedings of the National Academy of Sciences, 109 (34), pp. 13686–13691 (2012); Heather J. Goldsby
238
14.
15.
16.
17.
18.
19.
20.
Анализ моделей биологической эволюции
et al., «The evolution of division of labor». Advances in Artificial Life. Darwin
Meets von Neumann (Springer Berlin Heidelberg, 2011), pp. 10–18; Evan D. Dorn
and Christoph Adami, «Robust Monomer-Distribution Biosignatures in Evolving Digital Biota». Astrobiology, 11(10), pp. 959– 968 (2011); J. Daniel Couvertier
and P. K. McKinley, «Effects of biased group selection on cooperative predation in digital organisms». GECCO (Companion). 2011; Robert John Platt, «The
evolutionary dynamics of biochemical networks in fluctuating environments».
Diss. University of Manchester, 2011.
2012: Tomonori Hasegawa and Barry McMullin, «Degeneration of a von Neumann Self-reproducer into a Self-copier within the Avida World». From Animals
to AnimaLs 12 (Springer, Berlin, Heidelberg, 2012), pp. 230–239; L. Bess Walker
and C. Ofria, «Evolutionary potential is maximized at intermediate diversity
levels». Artificial Life, 13 (2012); B. David Knoester et al., «Evolution of resistance to quorum quenching in digital organisms». Artif Life, 18 (3), pp. 1–20
(2012); W. Arthur Covert III et al., «The role of deleterious mutations in the
adaptation to a novel environment». Artificial Life, 13 (2012).
2013: Jack Hessel and S. Goings, «Using Reproductive Altruism to Evolve
Multicellularity in Digital Organ-isms». Advances in Artificial Life, ECAL, 12
(2013); T. Hasegawa and B. McMullin, «Analysing the mutational path-ways
of a von Neumann self-reproducer within the Avida world». (2013); Hasegawa,
T. and B. McMullin. «Exploring the point- mutation space of a von Neumann
self-reproducer within the Avida world». Advances in Artificial Life, ECAL, 2
(2013).
Частично из публикации E. Winston, W. A. Dembski, R. J. Marks II, «Active
information in metabiology». BIO-Complexity (2013).
G. J. Chaitin, The limits of mathematics, IBM TJ Watson Research Center, (1995).
G. J. Chaitin, The Unknowable (Springer-Verlag, 1999).
G. J. Chaitin, Exploring Randomness (Springer-Verlag, 2001).
G. J. Chaitin, Conversations with a Mathematician (Springer-Verlag, 2002).
G. J. Chaitin, Algorithmic Information Theory (Cambridge University Press, 2004).
G. J. Chaitin, Meta math!:The Quest for Omega (Vintage, 2006).
G. J. Chaitin, Thinking about Gödel and Turing: essays on complexity, 1970–2007
(World Scientific Pub Co Inc, 2007).
G. J. Chaitin, Proving Darwin: Making Biology Mathematical (Pantheon, 2012).
T. Rado, «On non-computable functions». Bell Syst Tech J, 41 (3), pp. 877–884
(1962).
T. M. Cover and J. A. Thomas, Elements of Information Theory, 2nd edition, (Wiley, 2006).
G. J. Chaitin, Proving Darwin, там же.
Там же.
Источники 239
21. S. Aaronson, «Who Can Name the Bigger Number?» http://www.scottaar-onson.
com/writings/bignumbers.html (дата URL: May 2, 2016).
22. S. Lloyd, «Computational capacity of the universe». Phys Rev Lett, 88 (23), (2002).
W. A. Dembski, «The logical underpinnings of intelligent design». Debating Design: From Darwin to DNA (Cambridge University Press, 2004).
23. Dembski and Marks (2009), там же.
G. Montañez, W. Ewert, W. A. Dembski, and R. J. Marks II, «Vivisection of the EV
Computer Organism: Identifying Sources of Active Information». Bio-Comple
xity, 2010 (3), pp. 1–6 (2010).
W. Ewert, W. A. Dembski, and R. J. Marks II, «Climbing the steiner tree – sources
of active information in a genetic algorithm for solving the Euclidean Steiner
tree problem». Bio-Complexity, 2012 (1), pp. 1–14, (2012).
W. Ewert, W.A. Dembski, and R. J. Marks II, «Evolutionary Synthesis of NAND
and Logic: Dissecting a Digital Organism». Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics, San Antonio, TX, USA (2009),
pp. 3047–3053.
W.A. Dembski and R. J. Marks II, «Life’s Conservation Law: Why Darwinian Evolution Cannot Create Biological Information». In B. Gordon and W. A. Dembski,
editors, The Nature of Nature (ISI Books, Wilmington, Del, 2011), pp. 360–399.
24. W. Ewert, G. Montañez, W. A. Dembski, and R. J. Marks II, «Efficient per query
information extraction from a Hamming Oracle». Proceedings of the 42nd Meeting of the Southeastern Symposium on System Theory, IEEE, University of Texas at
Tyler, March 7–9, 2010, pp. 290–297.
25. Cover, Thomas, там же.
26. Dembski, Marks (2009), там же.
27. D. Thomas, «War of the Weasels: An Evolutionary Algorithm Beats Intelligent
Design». Skepti Inq 43, pp. 42–46 (2010).
28. D. Thomas, «Target? TARGET? We don’t need no stinkin’ Target!» (2006), http://
www.pandasthumb.org/archives/2006/07/target_target_w_1.html (дата URL:
May 2, 2016).
29. W. Ewert, W. A. Dembski, and R. J. Marks II. «Climbing the Steiner Tree–Sources
of Active Information in a Genetic Algorithm for Solving the Euclidean Steiner
Tree Problem». BIO-Complexity, 2012.
30. Ewert et al., там же.
31. H. S. Wilf and W. J. Ewens, «There’s plenty of time for evolution». Proceedings of
the National Academy of Sciences, 107 (52), 22454–22456 (2010).
32. Dembski and Marks (2009), там же.
Глава
7
Измерение смысла
и алгоритмическая
заданная сложность
…Большинство биологов считает, что лучше
думать с точки зрения невероятных событий,
чем вообще не думать.
Сэр Джеймс Грей [1]
7.1. Значимость информации
По сути, значение связано с контекстом. Изображение заката имеет значение
(смысл), потому что зритель на опыте связывает его с другими запоминающимися закатами. Любой объект, демонстрирующий контекстное содержание,
а не случайный шум, соответствует некоторому шаблону, априори известному
наблюдателю.
Два изображения на рис. 7.1 содержат одинаковое количество битов, но значимость изображения слева больше, чем значимость изображения справа. Основным контекстом изображения слева является узнавание людей. Дополнительный контекст включает в себя приблизительное представление о возрасте
людей, поведении (большинство улыбается) и одежде. Эти оценки приходят из
жизненного опыта. Существуют различные степени значимости изображения
в зависимости от доступного контекста. Если вы знаете личность людей на левом изображении, картинка имеет для вас большее значение, чем изображения незнакомых людей. Значимость меняется вместе с контекстом, в котором
интерпретируется информация.
Мы можем использовать этот контекстный подход, чтобы разработать модель, с помощью которой можно оценить значимость информации.
Значимость информации 241
Рис. 7.1 Иллюстрация значимой информации (слева) и случайного шума. В несжатом виде оба изображения требуют одинакового количества битов и, следовательно, содержат одинаковую информацию Шеннона. Картинка слева имеет еще
большее значение, если вы знаете людей. Значение является функцией контекста
Показатели информации как по Шеннону, так и по Колмогорову–Хайтину–
Соломонову (KCS) характерны тем, что они не способны измерить значимость1.
Информация Шеннона полезна для оценки количества активной информации,
которая была введена в поиск2, но не помогает оценить окончательное значение этой информации. Для Blu-ray, содержащего фильм «Храброе сердце»,
и для Blu-ray, заполненного коррелированным случайным шумом, может потребоваться одна и та же информация Шеннона, измеренная в байтах. Следовательно, мера информации KCS сама по себе также не способна измерить
смысл информации. Максимально сжатый текстовый файл может содержать
классический европейский роман или последовательность случайных бессмысленных буквенно-цифровых символов.
Чтобы иметь значение, объект должен быть сложным. Оба изображения на
рис. 7.1 являются сложными, поскольку каждое из них состоит из тысяч бит.
Только изображение слева отображает специфичность: три женщины и шесть
мужчин, все полностью одетые, в основном счастливые, один в очках, другой
в шляпе, один из мужчин очень молодой и т. д. Соответственно, про сложные
объекты со спецификой мы говорим, что они имеют заданную сложность [2, 3].
Яркий пример способности читателя воспринимать контекст изображения –
рис. 7.2. При первом просмотре изображение кажется бессмысленным. Скорее
всего, оно состоит из набора бессмысленных серых пятен. Однако при длительном просмотре изображения ум сканирует свою библиотеку контента, чтобы
поместить изображение в контекст, и обычно смысл изображения становится
ясным. Интересно, что как только изображение распознано читателем, потом
оно будет распознаваться всегда и сразу. Предупреждение: описание изображения есть в подписи к рисунку.
1
2
Как обсуждалось в главе 2.
См. раздел 5.4.2.
242
Измерение смысла и алгоритмическая заданная сложность
Рис. 7.2 Вот изображение, которое изначально выглядит как случайные пятна серого цвета. Однако после продолжительного просмотра
разум находит контекст для интерпретации изображения. Как только
контекст установлен и изображение распознано, вы больше не сможете перестать его видеть. Стоун (Stone) так описывает изображение [4]:
«Объект на картинке – корова. Голова коровы смотрит прямо на вас из
центра фотографии, два черных уха обрамляют белую голову. Эта картина широко используется исследователями, чтобы продемонстрировать
разницу между зрением и видением»
7.2. Условная сложность KCS
Чтобы обсудить измерение заданной сложности, требуется краткий обзор информации (или сложности) Колмогорова–Хайтина–Соломонова (KCS). Сложность Y согласно KCS равна1:
K(Y) = длина самой короткой компьютерной программы, которая выдаст
выход Y.
Сложность KCS не поддается точному измерению и варьируется в зависимости от перевода с одного языка программирования на другой. Мы будем
взаимозаменяемо использовать термины информация KCS и сложность KCS.
Условная информация (conditional information) KCS предполагает, что у нас
есть контекст C, применяемый при сжатии строки.
1
См. раздел 2.2.1.
Определение алгоритмической заданной сложности (ASC) 243
K(Y|C) = длина самой короткой компьютерной программы, которая будет
производить вывод Y в заданном контексте C.
Обозначение K(Y|C) читается как «сложность KCS для Y заданного контекс
та C». Длина любого кода, используемого для выражения C, не включена в счетчик битов KCS. Мы можем рассматривать контекст как бесплатную справочную
информацию или бесплатные подпрограммы, которые не учитываются при
подсчете битов KCS.
Условная сложность KCS имеет значение, равное или меньшее, чем информация KCS без контекста. Даже если контекст не помогает, условная сложность
KCS не превысит KCS без контекста. Поэтому, если контекст не помогает в сжатии, просто проигнорируйте его, и вы получите исходную информацию KCS
без контекста. Таким образом,
K(Y|C) ≤ K(Y ).
(7.1)
Пусть Y будет версией книги сказаний времен короля Джеймса, и C – спис
ком средних значений спортивных результатов для команды Малой лиги.
Средние значения спортивных результатов практически не содержат полезной
информации о древних сказаниях, и мы ожидаем, что K(Y|C) » K(Y).
Тот факт, что сложность KCS K(Y ) на первый взгляд непостижима, кажется проблематичным. Однако обратите внимание, что любое сжатие, которое
мы получаем, является верхней границей сложности KCS. Какое бы сжатие мы
ни осуществили, оно будет равно или меньше максимального сжатия. Мы назовем верхнюю границу наблюдаемой границей (observable bound) KCS и обозначим ее тильдой как . Так как К – длина самой маленькой программы, мы
уверены, что
K≤ .
Наконец, в нашем обзоре напомним, что сложность KCS отличается от
компьютера к компьютеру максимум на длину программы перевода между
двумя языками программирования1. Мы будем предполагать, что такие аддитивные константы пренебрежимо малы, по сравнению с другими факторами
влияния на KCS.
Желающие подробнее ознакомиться с этими факторами могут обратиться
к нашим техническим публикациям на эту тему [5].
7.3. Определение алгоритмической заданной сложности
(ASC)
Оба изображения на рис. 7.1 очень маловероятны. Вероятность формирования
этих изображений путем случайного выбора битов одинакова и ничтожна. Од1
См. раздел 2.2.1.
244
Измерение смысла и алгоритмическая заданная сложность
нако невероятные события случаются постоянно. Эта вероятность случайного
выбора любого изображения p может быть выражена как эндогенная информация IΩ = –log2 p. Эндогенная информация предполагает, что мы ничего не знаем
о цели. Впрочем, мы можем кое-что знать о ней. В изображениях лиц уровень
серого между соседними пикселями меняется плавнее, чем в шуме. Изображения лиц обладают симметрией. Для объекта Y мы примем, что p(Y ) описывает
вероятность выбора целевого изображения с использованием указанной модели. Существует соответствующая самоинформация I(Y ) = –log2 p(Y ), которую
мы будем называть собственной информацией (intrinsic information). Собственная информация – это мера сложности построения X с использованием модели, в которой вероятность появления X имеет вероятность p(X). Собственная
информация не содержит смысла.
Алгоритмическая заданная сложность, как показано на рис. 7.3, определяется
как:
A(Y, C, I) = I(Y ) – K(Y |C).
(7.2)
ASC является функцией от:
Y = объекта, который будет сжат;
C = контекста;
I(Y ) = внутренней информации объекта.
K(Y |C) = условной сложности KCS.
Если контекст помогает уменьшить условную сложность KCS, то ACS будет
небольшой.
Программа: X
Машина
Тьюринга
Длина программы
|X| = K(Y |C )
Выход: Y
Длина выхода
|Y|
Контекст
С
Вероятностная
модель
p(Y );
I(Y ) = –log2 p(Y ) £ |Y|
Рис. 7.3 Иллюстрация ASC, определяемой уравнением (7.2).
Самая короткая программа X для генерации заданной выходной
строки Y с учетом контекста C по определению является элегантной программой с длиной |X| = K(Y |C). Вероятность появления
выходных данных определяется вероятностной моделью, которая оценивает вероятность p(Y) с соответствующей собственной
информацией I(X) = –log2p(Y ). Разница между этой собственной
информацией и длиной элегантной программы – это ASC
Определение алгоритмической заданной сложности (ASC) 245
Проще записать это уравнение, используя более короткие обозначения, где
аргументы предполагаются неявными:
A = I – K(Y |C).
Если в определении ASC
уверены, что:
(7.3)
используется взамен K и поскольку K ≤ , то мы
A = I – K(Y |C) ³ I – (Y |C).
(7.4)
Таким образом, наблюдаемая условная сложность KCS может использоваться для установления нижней границы ASC.
7.3.1. Высокая ASC и низкая вероятность
⍟ Случайное возникновение информации со смыслом крайне маловероятно.
Если у объекта высокая ASC, вероятность того, что это произошло случайно,
ничтожна. Вероятность получить более 10 бит ACS меньше, чем один шанс на
тысячу. Получение более 40 бит – это меньше, чем один шанс на триллион. Как
правило, для α бит
Pr[A ³ α] ≤ 2–α.
(7.5)
Далее мы рассмотрим доказательство для желающих погрузиться в математику. Используя определение в уравнении (7.1):
Pr[A(Y ) ³ α] = Pr[I(Y ) – K(Y |C) ³ α] = Pr[I(Y ) ³ K(Y |C) + α].
Но I(Y ) = –log2 p(Y ), следовательно,
Pr[A(Y ) ³ α] = Pr[p(Y ) ≤ 2–K(Y |C) – α].
Согласно вероятностной модели, некоторые выходные двоичные строки будут более вероятными, чем другие. Определим набор:
βα(Y ) = {Y |p(Y ) ≤ 2–K(Y|C) – α}.
Выполним сравнение:
Из неравенства Крафта1 следует:
Таким образом, мы доказали утверждение (7.5).
1
См. раздел 2.2.1.2.
246
Измерение смысла и алгоритмическая заданная сложность
7.4. Примеры ASC
Теперь, когда мы прорвались через дебри математики, можем проиллюстрировать ASC на нескольких примерах.
7.4.1. Расширенные буквенно-цифровые символы
Рассмотрим пример ASС и условной KCS, использующей расширенные буквенно-цифровые символы с применением различных типов контекста. Каждый
пример в качестве контекста использует кодовую книгу. Кодовая книга определяет, как мы кодируем и декодируем биты при сжатии и распаковке. Размер кодовой книги не входит в расчет условной сложности KCS. Это известный
контекст. В последующих примерах контекст будет более полезным, а условная
информация KCS станет меньше.
Предположим, перед нами стоит задача найти сложность ACS 5 млн расширенных буквенно-цифровых символов. Мы предполагаем, что у нас есть доступ
к расширенной кодовой книге ASCII1. Расширенная ASCII назначает восьмибитное двоичное число (один байт) каждой из 256 различных букв, символов,
чисел и инструкций. Например, кодовая книга ASCII назначает «H» двоичную
строку 01001000, «q» – 01110001, «§» – 10100111, «?» – 00111111. Пробелу соответствует число 00100000. Если у нас есть 5 млн расширенных символов, случайным образом взятых из 256 доступных в кодовой книге ASCII, результирующая строка имеет внутреннюю информацию:
I = 5 000 000 символов × 8 бит на символ = 40 млн бит.
1. Р
асширенный контекст ASCII. Если мы возьмем кодовую книгу CASCII
и выберем символы идеально случайным образом, то почти наверняка
получим несжимаемую последовательность. Самая короткая программа – это что-то вроде:
Напечатать 40 млн бит: 0100 ... 1100. Стоп.
Наблюдаемая условная сложность KCS в этом случае:
где с является константой. Поэтому с тех пор нет ASC.
2. Контекст на основе частоты вхождений. [6] Знание частоты использования буквы может уменьшить сложность объекта. Буква «z» – наименее
используемая буква в английском языке, а буква «e» – наиболее часто
используемая. Пробел используется еще чаще. Процент частоты использования каждого символа является частотой вхождений.
1
American Standard Code for Information Interchange.
Примеры ASC 247
В технологии коммуникаций FOO применяется для написания кодовой
книги, которая назначает короткие двоичные строки для часто используемых символов и более длинные строки для менее часто используемых1 [7]. Контекст, доступный из такой кодовой книги, мы обозначим
CFOO. Для контекста FOO мы знаем, что
K(Y |CFOO) ≤ K(Y ).
Классическим примером подобного контекста является азбука Морзе,
впервые использованная в телеграфии в середине XIX века. Короткий
тон (точка) и более длинный тон (тире) служат двоичным алфавитом.
Если мы назначим 1 для точки и 0 – для тире, то часто используемая буква «e» в азбуке Морзе получит однобитовый код (1). Менее часто используемой букве «z» присваивается более длинный код (0011). У остальных
букв промежуточная частота использования и соответствующая длина
кода, например «a» (11) и «r» (101). В контексте кодовой книги азбуки
Морзе сообщения требуют меньше битов для описания, чем при использовании кодовой книги ASCII2 с одинаковым количеством битов для
каждой буквы.
3. Словарь. Словарная кодовая книга может обеспечить еще большее сжатие. Если предположить, что в одном слове содержится около 5 букв,
включая пробелы, запятые, точки и т. д., то в документе из 5 млн символов будет около 1 млн слов. Рассмотрим, таким образом, кодовую книгу
CDICT, содержащую все слова, используемые в документе. Для примера
предположим, что словарь кодовой книги содержит
214 = 16 384 слова.
Пронумеруем каждое из слов в словаре, начиная с 14-битной строки
00 000 000 000 000
для первого слова в словаре и
11 111 111 111 111
для последнего слова. Использование 14 бит для каждого из миллиона
слов в документе требует
(Y|CDICT) =c 14 бит на слово × 1 000 000 слов = 14 000 000 бит.
1
2
Для известной частоты встречаемости оптимальными являются коды Хаффмана.
Средняя передаваемая двоичная строка в битах ограничена энтропией характерис
тической плотности вероятности и энтропией плюс один бит.
Хотя разница между использованием FOO, применяемого к азбуке Морзе, и ASCIIкодированием очевидна, в этом сравнении есть нерешенные проблемы. Азбука Морзе
требует паузы между группами битов (это не код без префиксов). Азбука Морзе не
делает различий между заглавными и строчными буквами и т. д. Разбор этих вопросов
в деталях излишне тормозит обсуждение, поэтому здесь не рассматривается.
248
Измерение смысла и алгоритмическая заданная сложность
Это примерно треть из 40 млн бит, необходимых при использовании расширенной кодовой книги ASCII.
(Y|CDICT) = (Y|CFOO) + 26 млн бит.
Контекст, предоставленный словарем, уменьшил размер элегантной
программы1 и соответствующую ASC на
ADICT = I – (Y|CDICT) =–c 26 000 000 бит.
4. Словарь FOO для слов. Знание FOO для слов может уменьшить условную информацию KCS, аналогично FOO для символов. Мы можем пометить часто используемые слова короткими двоичными строками и редко
используемые слова – более длинными строками. Часто используемые
слова, которым назначены короткие строки битов, включают «the»,
«and», «a», «that», «an» и «of». Менее часто используемые слова, которым
назначены более длинные двоичные строки, включают «xu», «aby» «adit»
и «erinaceous»2.
5. Идентификатор книги. Допустим, в качестве словаря (т. е. контекста)
вы используете заранее оговоренную книгу. Если эта книга и еще 1027
других книг хранятся в библиотеке на вашем компьютере, то единственная необходимая информация – указатель на нужный файл. Начиная
с 210 = 1028, каждая из 1028 книг может быть помечена десятибитным
идентификационным номером. Если мы называем этот контекст CLIB, то
K(Y|CLIB) =c 10 бит,
≤ (Y|CFOO) »c 40 млн бит.
CLIB обеспечивает богатый контекст и уменьшает сложность условной
информации KCS до нескольких битов. Соответствующее значение ASC
велико.
ASCbooks = I – K(Y|CLIB) » 40 млн бит.
Чем полезнее контекст для интерпретации Y, тем меньше условная сложность KCS.
1
2
Проницательный читатель заметит, что если в словаре слишком много слов, коли
чество битов не уменьшится. Если в словаре содержится 240 » 1 трлн слов, то для кодирования по словарю потребуется около 40 × 1 000 000 = 40 млн битов, что соответствует
значению для K(Y). Если в словаре есть еще, скажем, 245 дополнительных слов, то при
использовании словаря требуется более 40 млн бит. Напомним, что K(Y|CDICT) – самое
короткое представление, и если использование CDICT делает максимальное сжатие
меньшим, то CDICT бесполезен как ресурс, и, когда словарь слишком длинный, мы возвращаемся к K(Y|CDICT) = K(Y) » 40 млн битов.
Xu (сюй) – денежная единица Вьетнама, равная одной сотой донга. Aby (Эйби) – староанглийское имя, означающее искупление грехов. Adit (штольня) = горизонтальный проход, ведущий в шахту для доступа или дренажа. Erinaceous (иглобрюхий) –
разновидность необычных морских рыб, напоминающих ежа.
Примеры ASC 249
Значения ASC для 5 млн символов в разных контекстах приведены в табл. 7.1.
Таблица 7.1. Сводка различной наблюдаемой условной информации KCS и ASC для 5 млн символов ASCII. Внутренняя информация для всех случаев составляет I = 40 млн бит. Наблюдаемая
условная информация KCS уменьшается, когда мы спускаемся по строкам таблицы, а граница
ASC увеличивается. Это указывает на то, что доступный контекст становится все более
полезным при идентификации строки
Контекст
Расширенный ASCII
Частота символов
Словарь
Частота слов
Библиотека
Кодовая книга
СASCII
CFOO
CDICT
CWFOO
CLIB
Расширенный ASCII
Частота символов
Словарь
Частота слов
Библиотека
40 млн бит
А ³с
0
14 млн бит
26 млн бит
10 бит
40 млн бит
7.4.2. Игра в покер
Вот пример определения ASC с использованием стандартной колоды игральных карт. В покере существует 2 569 682 возможные пятикарточные комбинации1. Любая из этих комбинаций встречается с вероятностью один к 2 569 682,
что соответствует собственной информации I = 21,3 бита.
Чтобы рассматривать пять карт в контексте покера, мы будем использовать
10 категорий комбинаций карт, перечисленных в табл. 7.2. Указатель категории
занимает log210 = 3,3 бита.
Таблица 7.2. Покерные руки
и их алгоритмически заданная сложность (ASC)
Комбинация
Флеш-рояль
Стрит-флеш
Каре
Фул-хаус
Флеш
Стрит
Тройка
Две пары
Одна пара
Старшая карта
Частота
4
36
624
3744
5108
10 200
54 912
123 552
1 098 240
1 302 540
ASC
16,0
12,8
8,7
6,1
5,7
4,7
2,2
1,1
0,0
0,0
Некоторые комбинации в этих десяти категориях имеют большее значение,
чем другие. Существует всего четыре флеш-рояля, и в контексте покера флеш1
⍟
250
Измерение смысла и алгоритмическая заданная сложность
рояль однозначно определяется наличием масти: ♣ ♦ ♥ ♠. Поскольку сущест
вует четыре масти, требуется только два бита информации. Таким образом,
условная сложность KCS для флеш-рояля составляет K(X|C) = 3,3 + 2 = 5,3 бита.
Следовательно, ASC = 21,3 – 5,3 = 16 бит.
Для уникальной идентификации элемента категории стрит-флеш требуется больше информации, т. е. (1) указание масти и (2) определение самой старшей карты в руке. Существует 36 стритов, так что K(X|C) = 3,3 + log236 = 8,5 бита
и, для стрит-флеша, ASC = 21,3 – 8,5 = 12,8 бита.
Мы можем продолжить и рассчитать результат по всем десяти категориям.
Результирующая частота и ASC показаны в табл. 7.2. Как и ожидалось, чем слабее комбинация, тем ниже ASC.
7.4.3. Снежинки
При условии одного и того же доступного контекста строки могут отображать
различные уровни ASC, если в одном и том же контексте происходит редкое
событие. Мы проиллюстрируем это на примере снежинок.
Принято говорить, что не существует двух одинаковых снежинок. Однако
в 1988 году Нэнси Найт (Nancy Knight) исследовала снежинки для Национального центра атмосферных исследований и нашла две визуально идентичные
снежинки [8]. Это весьма примечательно, поскольку оценка количества визуально различающихся снежинок [9] составляет 1018. Однако фигуры снежинок
являются функцией температуры, влажности и других условий окружающей
среды. Две снежинки имеют больше шансов быть идентичными, если сформированы в одном и том же месте в одно и то же время.
Хотя две снежинки Нэнси Найт были идентичны по внешнему виду, профессор физики Калифорнийского технологического института Кеннет Либбрехт (Kenneth Libbrecht) подчеркивает, что две снежинки были совершенно
разными на атомном уровне [10]. Поэтому утверждение «нет двух одинаковых
снежинок» требует тщательного определения слова «одинаковые». Одна треть
миллиграммовой снежинки содержит около 1019 молекул воды1 [11], и комбинаторика их возможного расположения в снежинках на молекулярном уровне
является астрономической. Комбинаторика еще более осложняется появлением снежинок, образующихся вокруг пылинки [12]. Таким образом, в снежинке
могут присутствовать молекулы, отличные от H2O.
Одна снежинка. Если мы примем, что существует 101000 возможных
форм снежинок, то соответствующая внутренняя информация
I = log2101000 = 3322 бита.
Затем мы можем получить астрономически толстую кодовую книгу индексов, где каждая из снежинок проиндексирована с помощью метки –
3322-битового числа. Если все снежинки одинаково вероятны, лучшее,
1
Снежинки в лабораторных экспериментах были созданы всего из 275 молекул воды.
Примеры ASC 251
что мы можем сделать, – это распечатать 3322-битовый индекс снежинки. Тогда наблюдаемая условная информация KCS в битах равна:
(Y|C ) =c 3322.
Соответствующая ASC снежинки1:
A ³ I – (Y|C ) =–c 0.
(7.6)
Даже если снежинка невероятна, ее низкая граница ASC указывает на то,
что она имеет небольшую заданную сложность2.
Две разные снежинки. Две произвольно выбранные неидентичные
снежинки будут иметь в два раза больше внутренней информации, чем
одна. Таким образом, внутренняя информация для двух снежинок (назовем это I2)3
I2 = 2 × I = 6644 бита.
(7.7)
Это случай свойства информационной аддитивности информации Шеннона4. Условная информация KCS для 2 снежинок, назовем ее K2(Y2|C), где
Y2 – строка битов, индексирующая две снежинки:
(Y2|C) =c 6644.
2
Та же самая кодовая книга C, которую мы применяли для одной снежинки, используется для двух разных снежинок. Соответствующая ASC:
A2 ³ I2 –
(Y|C) =–c 0.
2
Таким образом, ASC для двух разных снежинок совпадает с ASC, рассчитанной для одной снежинки. То же самое значение ASC, равное 0, будет
получено при расчете ASC для десятка или тысячи неидентичных снежинок.
Две идентичные снежинки. Внутренняя информация для двух снежинок одинакова независимо от того, одинаковы они или нет, то есть
I2 = 6644 бита. Если две снежинки одинаковы, сложность KCS намного меньше. Мы просто берем 3322 бита для первой снежинки и даем
компьютеру команду REPEAT. Наблюдаемая заданная сложность по KCS
двух снежинок примерно такая же, как и для одной снежинки: (X|C) =c
3322. ASC для двух одинаковых снежинок обозначим как Asame:
1
2
3
4
Powered by TCPDF (www.tcpdf.org)
Исходя из равенства 7.4.
⍟ Вероятность отдельной снежинки при наших предположениях составляет p =
10−1000. Таким образом, Pr[Pr(снежинка) ≤ 10–1000] = 1. Это выражение является примером утверждения, что «невероятные события происходят постоянно».
⍟ Если имеется 101000 снежинок, то количество различных пар снежинок с учетом
порядка (101000)(101000 – 1) » (101000)2. Соответствующим двум снежинкам свойственна
информация, соответствующая уравнению (7.7), тогда I2 = log2(101000)2 = 2log2(101000) =
2 × 3322 = 6644 бита.
См. раздел 2.2.2.
252
Измерение смысла и алгоритмическая заданная сложность
Asame ³ I2 – (Y|C) =–c 3322 бита.
(7.8)
Это значительный объем ASC для нашей модели! Поэтому две идентичные снежинки обладают огромным количеством заданной сложности.
Вероятность возникновения. Для примера с двумя идентичными снежинками α + c ³ 3322, и вероятность того, что ASC превысит это значение, очень мала:
Pr[A ³ α + c ³ 3322 бита] ≤ 2–3322 = 0.
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
9513808474
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
5598544585
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
6525238905
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
9987188429
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
0000000000
1599954...
7.4.4. ASC в игре «Жизнь»
ASC можно красиво проиллюстрировать, используя различные функциональные схемы в знаменитой игре «Жизнь» (Game of Life) Конвея [13].
7.4.4.1. Цель и правила игры «Жизнь»
Игра «Жизнь» и аналогичные системы позволяют выполнять разнообразные
захватывающие действия в простых клеточных автоматах [14]. Игра «Жизнь»
разворачивается на сетке из квадратных ячеек, обозначающих одноклеточные
организмы. Клетка либо жива (единица), либо мертва (ноль). Статус клетки
определяется другими клетками вокруг нее. Соблюдаются только четыре правила (рис. 7.4):
1) одиночество: живая клетка с менее чем двумя живыми соседями уми
рает;
2) перенаселение: живая клетка с более чем тремя живыми соседями также
умирает;
3) размножение: мертвая клетка с ровно тремя живыми соседями становится живой клеткой;
4) семейство: живая клетка с двумя или тремя живыми соседями продолжает жить в следующем поколении.
Примеры ASC 253
1. Одиночество
2. Перенаселение
3. Размножение
4. Семейство
Рис. 7.4 Четыре правила,
используемых в игре го
Существует множество разновидностей шаблонов
(типовых структур) игры «Жизнь». Вот самые элементарные примеры:
1) натюрморт (still life) – это шаблон, который не
меняется. На рис. 7.5 показаны два примера. Многим интересным образцам даны имена. Изобра
женные здесь шаблоны называются «блок» (block)
и «улей» (beehive). Обращение к четырем правилам игры доказывает, что эти модели действительно являются статичными формами жизни;
2) осциллятор (oscillator) превращается в другой шаблон в соответствии с правилами игры. У осциллятора периода 2 этот второй шаблон возвращается к исходному изображению через один шаг.
Два примера, «мигалка» (blinker) и «жаба» (toad),
показаны на рис. 7.6;
Блок
Улей
Рис. 7.5 Два примера
натюрморта
254
Измерение смысла и алгоритмическая заданная сложность
Мигалка
Жаба
Рис. 7.6 Два генератора с периодом 2. В обоих случаях форма слева превращается в другую форму, показанную в середине. Эта вторая форма затем
превращается обратно в первую форму. Колебательный процесс может продолжаться бесконечно
3) космический корабль (spaceship) похож на осциллятор, за исключением
того, что при возвращении к исходному шаблону его центр оказывается
в другом положении. По мере продолжения итераций последовательность смещений можно рассматривать как движение. Хорошим примером является «планер» (glider), показанный на рис. 7.7. Шаблон внизу
после 5 шагов выглядит так же, как шаблон на первом шаге, за исключением того, что он переместился на одну ячейку вниз и на одну ячейку
вправо.
Простые объекты игры могут являться компонентами более сложных объектов, как в случае с «планерной пушкой» (glider gun), показанной на рис. 7.8.
Узоры в верхней части сближаются, разделяются и снова сближаются. Каждый
раз, когда это происходит, рождается «планер». Сразу после рождения «планер» начинает свой бесконечный юго-восточный поход. У нас есть «планерная
пушка», которая создает планеры. Можем ли мы сделать еще один шаг вперед
и создать завод, который будет производить планерные пушки, выпускающие
планеры? Да, как показано на рис. 7.9, это вполне возможно. Конфигурация
ячейки называется «паффером», или «выдувателем пузырей» (puffer breeder).
Игра «Жизнь» имитирует эквивалент первичного бульона, в котором, как
принято считать, зародилась земная жизнь. Как и следовало ожидать, формы
игры «Жизнь», созданные случайно, имеют низкую ASC [15].
Примеры ASC 255
Рис. 7.8 Планерная пушка
Рис. 7.7 Планер. Спустя пять итераций
форма копируется со смещением по диагонали. Дальнейшие итерации показывают, что рисунок движется по диагонали
в юго-восточном направлении
Как видно из многочисленных видео на YouTube, с помощью четырех прос
тых правил игры может быть достигнута потрясающая функциональность [16].
Если читатель незнаком с разнообразием, достижимым с помощью этих операций, мы рекомендуем ему просмотреть эти и другие короткие видеоролики,
демонстрирующие игру «Жизнь». Статические картинки не отражают замечательную динамику. Также есть активная группа пользователей [17].
256
Измерение смысла и алгоритмическая заданная сложность
Рис. 7.9 Паффер движется вниз, оставляя за собой планерные пушки. Каждая планерная пушка
выпускает планеры, как показано на рис. 7.8
7.4.4.2. Контекст каталогизации
Прежде чем двигаться дальше, мы должны связать наши рассуждения с мо
делью сложности ASC [18]. Контекст, который позволяет нам создавать классы,
такие как статические формы, осцилляторы и космические корабли, настолько очевиден, что он может ускользнуть от нашего внимания. Мы знакомы со
статическими формами, которые не меняются, осцилляторами, которые периодически повторяются, и объектами, движущимися с постоянной скоростью,
как космические корабли. В таких случаях нам не нужно описывать объект
игры с помощью последовательности битов, обозначающих, включена ячейка
на игровом поле или нет. Мы можем просто сказать «это осциллятор» и, используя этот контекст, указать дополнительные детали, чтобы конкретизировать объект. Существуют и другие описательные атрибуты объектов, такие как
Примеры ASC 257
количество живых клеток при инициализации, период колебаний для осцилляторов и космических кораблей, а также скорость и направление космических
кораблей. При использовании этого и других контекстов условная сложность
KCS может быть значительно уменьшена.
Давайте составим кодовую книгу для игры «Жизнь», основанную на простом
контексте опыта.
Натюрморты и осцилляторы
Пусть Y обозначает объект, а Å – один шаг (итерацию) в игре «Жизнь». Если
объект представляет собой натюрморт, он не изменяется после итерации. Используя наши обозначения, мы можем обозначить натюрморт как объект,
удовлетворяющий условию:
Y = ÅY.
для которого
=Å
.
Примером является блок, Y =
Натюрморты – это вырожденный случай осцилляторов, повторяющихся
каждый цикл. Осциллятор, который повторяется каждые два цикла, обладает
свойством
Y = ÅÅY,
которое мы можем более кратко записать как:
Y = Å2Y.
Но мы должны быть осторожны. Натюрморты, повторенные дважды, также
соответствуют этому свойству, и наша цель – представить осцилляторы с одним циклом, но исключить натюрморты. Таким образом, мы неявно ограничим обозначение Y = Å2Y, чтобы исключить объекты, подчиняющиеся Y = ÅY.
Примером является мигалка Y =
как:
= Å2
, которую мы можем охарактеризовать
.
Обобщение теперь очевидно. Запись
Y = Å iY
указывает объект, который повторяется в i шагах, не повторяя себя в меньшем
количестве шагов.
Членство объекта в классе осцилляторов теперь представлено одним числом
1
.
i, которое указывает
Теперь мы можем составить кодовую книгу для всех шаблонов. Начнем
с упорядочения натюрмортов (i = 1) по тому, насколько они просты, путем
1
Период осцилляции равен i – 1.
258
Измерение смысла и алгоритмическая заданная сложность
определения правил их размещения в лексикографическом порядке, т. е. метода однозначной нумерации каждого натюрморта, начинающегося с нуля. Вот
правила, которые мы будем использовать:
1) клетки: порядок объектов от наименьшего до наибольшего числа живых
клеток;
2) ВВ: если количество живых клеток одинаково, сортируем по порядку от
наименьшей до самой большой ограничивающей области. На рис. 7.5,
например, площадь ограничивающей рамки для блока равна 4 × 4 = 16,
а площадь ограничительной рамки для улья составляет 5 × 6 = 30;
3) W: если параметры (1) и (2) одинаковы, сортируем по порядку от наименьшей до наибольшей ширины ограничительной рамки;
4) N: если все три предыдущих критерия совпадают, присвойте двоичное
число ограничивающему прямоугольнику, обходя клетки слева направо
и сверху вниз, так же, как мы читаем обычный текст. Присвойте 0 живой
клетке и 1 мертвой. Для блока на рис. 7.5 это число равно (1111 1001 1001
1111)2 = 63 903, а улью соответствует число (111111 110011 101101 110011
111111)2 = 1 070 521 599;
5) когда объект состоит из более чем одного кадра, как в случае осцилляторов и планеров, оценка может быть применена к каждому кадру с последующим выбором минимального значения.
Используя эти правила упорядочения, можно составить список всех натюрмортов, как показано на рис. 7.11. Шаблону j на странице кодовой книги соответствует запись Y = Å1Y, #j. Вместо описания всех единиц и нулей, составляющих массив 5 × 5, необходимых для шаблона под названием «корабль» #1,
нам просто нужно сказать «Y = Å1Y, #11». Используя контекстный каталог на
рис. 7.10, это однозначно определяет Ship # 1.
Аналогичная страница кодовой книги может быть создана для однопериодных осцилляторов. Они будут обозначены как Y = Å2Y, #j. Первые два однопериодных осциллятора показаны на рис. 7.6. Первые две записи страницы
кодовой книги для однопериодных осцилляторов:
Y = Å2Y, #1, мигалка
Y = Å2Y, #2 жаба.
(7.9)
Подобные страницы кодовой книги могут быть построены для Å3, Å4 и т. д.
Примеры ASC 259
j
Y = Å1Y, #j
j
Y = Å1Y, #j
Блок
Cells=4, BB=16,
Корабль № 1
6 сells, BB=25, W=5
N=11111 10011
10101…= 33 150 783
Бочка
Cells=4, BB=30,
Корабль № 2
Cells=6, BB=25, W=5
N=11111 11001
10101…= 33 347 199
Лодка № 1
Cells=5, BB=25, W=5
N=11111 10011
10101…= 33 347 455
Носильщик № 1
Cells=5, BB=30, W=5
N=11111 10011 10111
11101…= 1 060 894 527
Лодка № 2
Cells=5, BB=25, W=5
N=11111 11001
10101…= 33 347 455
Носильщик № 2
Cells=6, BB=30, W=5
N=11111 11001 11101
10111…= 1 067 376 255
Лодка № 3
Cells=5, BB=25, W=5
N=11111 11010
10101…= 33 412 735
Улей № 1
Cells=5, BB=30, W=5
N=11111 11011 10101
10101…= 1 069 209 471
Лодка № 4
Cells=5, BB=25, W=5
N=11111 11011
10101…= 33 412 927
Носильщик № 3
Cells=6, BB=30, W=6
N=111111 100111
101101…= 1 067 367 255
Змейка № 1
Cells=6, BB=24, W=4
N=1111 1001 1011
1101…= 16 367 007
Носильщик № 4
Cells=6, BB=30, W=6
N=111111 111001
101101…= 1 067 209 471
Змейка № 2
Cells=6, BB=24, W=4
N=1111 1001 1101
1011…= 16 374 687
Улей № 2
Cells=6, BB=30, W=6
N=111111 110011
101101…= 1 072 093 695
Змейка № 3
Cells=6, BB=24, W=4
N=111111 100101
101001…= 16 669 311
Баржа № 1
Cells=6, BB=36, W=6
N=111111 110111
101011…= 68 579 974 911
Змейка № 4
Cells=6, BB=24, W=4
N=111111 101001
100101…= 16 685 439
Баржа № 2
Cells=6, BB=36, W=6
N=111111 111011
110101…= 68 649 663 999
Рис. 7.10 Начало лексикографического упорядочения всех натюрмортов в игре «Жизнь». J-я запись в этом списке может быть уникально определена с помощью краткого индекса
260
Измерение смысла и алгоритмическая заданная сложность
Период ACЦ ³
блок
1
–25
мигалка
2
–29
официант
3
21
путаница
4
19
псевдодиагональ
5
52
unix
6
33
burloaferimeter
7
74
восьмерка
8
7
29p9
9
69
Рис. 7.11 Простейшие осцилляторы с разными периодами
и соответствующей АСЦ-границей. Динамику каждого осциллятора можно увидеть с помощью простого поиска Google по строке «game of life Conway». Обратите внимание на разницу между
ASC, указанной здесь, и уравнением (7.11). Способ, которым были
рассчитаны границы ASC, похож, но имеет отличия. Заметим, что
ограничивающие прямоугольники разные
Примеры ASC 261
Планеры
Планеры похожи на движущиеся осцилляторы. Шаблон повторяется, за
исключением того, что репликация происходит в другом месте. Частично мы
определяем планеры в контексте движения. Эту особенность можно использовать для добавления в наш каталог игры. Мы можем обозначить движение
влево и вправо горизонтальными стрелками (← и →) и движение вверх и вниз –
вертикальными (↑ и ↓). Планер на рис. 7.7 перемещается на одну клетку вниз
и одну клетку вправо за четыре цикла. Формы игры, подчиняющиеся такому
поведению, можно охарактеризовать как:
X ↓→= Å4X.
Это означает, что четыре цикла воспроизведут планер со смещением на
одну клетку вправо и одну клетку вниз. Как и в случае с осцилляторами, мы
можем создать страницу в кодовой книге с меткой:
X ↓→= Å4X#j.
Порядок записей будет соответствовать тем же правилам, что и для осцилляторов. Планер на рис. 7.7 является первым в этом списке и будет обозначен:
X ↓→= Å4X#1.
Можно использовать такие характеристики движения для оценки ASC. Помните, однако, что нет прямого способа вычисления ASC. Мы можем только получить границы. Существуют более эффективные способы каталогизации движения планеров [19], которые включают в себя вариации, фиксирующие более
сложные движения. Как следствие, получается более высокая граница ASC.
Более высокая сложность
Давайте перейдем к более сложным конструкциям. Многие шаблоны в игре
«Жизнь» могут быть построены путем столкновения планеров [20]. Примером
может служить планерная пушка на рис. 7.8. В описании пушки мы можем сделать ссылку на планер, каталогизированный как (X ↓→= Å4X#1). Саму пушку
будем рассматривать как сталкивающиеся планеры, каждый из которых может
быть проиндексирован на страницах каталога планеров.
Паффер на рис. 7.9 еще более сложен. Когда он перемещается вниз по странице, планерные пушки остаются на своем пути. Поэтому в программе, описывающей паффер, будут повторяться ссылки на планерную пушку (X ↓→= Å4X#1).
В свою очередь, каждая из планерных пушек выплевывает планеры. Характеристика большого и похожего на облако объекта, создающего планерные пушки, еще не завершена. Но что еще можно сказать про этот объект? Он похож на
огромный планер, который движется и повторяет свой рисунок, каждый раз
выплевывая планерную пушку. Использование такого контекста позволит нам
построить еще одну страницу каталога.
Читатели могут посмотреть на нашу каталогизацию и сказать: «Я могу сделать более компактную характеристику, чем у вас!» Это, конечно, здорово. Ваш
каталог приведет к более жесткому ограничению ASC, чем наш.
262
Измерение смысла и алгоритмическая заданная сложность
7.4.4.3. Измерение ASC в битах
Все наши усилия до сих пор были сосредоточены на настройке структуры кодовой книги в соответствии с контекстом в игре «Жизнь». Мы можем использовать эту структуру для измерения ASC в битах.
Измерение I (X)
Давайте начнем с вычисления самоинформации I(X) в формуле ASC = I(X) –
,
K(X|C). Мы будем моделировать литералы в игре «Жизнь», например
внутри прямоугольников. Если прямоугольник имеет ширину w и высоту h, то
нужно указать w × h ячеек. Поэтому нам нужна двоичная строка, которая задает
w и h и за которой следует строка из w × h бит. Одним из способов эффективного представления целых чисел является кодирование Левинсона [21]. Пусть l(n)
обозначает количество битов для определения целого числа n. Кодирование
целых чисел Левинсона обеспечивает компактную бесфиксную характеристику n. Для наших целей детали кодирования Левинсона имеют второстепенное
значение1.
Чтобы подсчитать количество битов, необходимых для характеристики X,
нам нужно указать длину прямоугольника, его ширину и единицу измерения
всех w × h бит внутри прямоугольника. Общее количество битов, которое нам
нужно для кодирования литерала, является суммой этих значений2.
I(X) = l(w) + l(h) + w × h.
Вот пример: для мигалки
, w = h = 5. Поскольку l(5) = 5 бит,
IBLINKER(X) = 5 + 5 + 25 = 35 бит.
(7.10)
Измерение условной сложности KCS в битах
Чтобы измерить условную информацию KCS, нам нужны битовые строки,
назначенные числам, переменным, таким как X и Y, и таким символам, как →,
↑, ⊙, Ù (мощность), = и #. Строго говоря, для переменных и символов достаточно 32 числа. Поскольку 25 = 32, каждой переменной и символу может быть назначен пятибитовый код. Чтобы объявить, что описание завершено и больше
не нужно никаких операций, мы будем использовать пятибитовую последовательность 11111. Простое объединение всех уравнений не дает нам код без префикса, поскольку любой двоичный код будет действительным префиксом для
других кодов. Поэтому после последнего значащего бита в качестве суффикса
добавляется код 11111, препятствующий появлению более длинных кодов.
1
2
⍟ Кодирование Левинсона выражает число n, используя l(n) = élog2(n + 1) + log2(n)ù + 1
бит.
Есть более эффективные способы сделать это, требующие меньше битов. Мы будем
придерживаться простой операции суммирования, поскольку она легко объяснима
и проста для понимания.
Смысл в глазах смотрящего 263
Для чисел мы будем использовать кодирование Левинсона. Чтобы вычислить длину результирующего кода, сложим следующие значения:
1) 5 бит для каждого символа;
2) l(n) бит для каждого числа n в уравнении;
3) длину битовой кодировки любых шаблонных литералов вроде
;
4) 5 бит для символов остановки и целочисленного индекса.
Уравнение (7.9) дает нам символы мигалки. Подсчет символов и добавление
сигнала остановки дает
(X|C) = 8 × 6 + 3 + 2 = 42 бита.
BLINKER
Таким образом,
ASCBLINKER ³ 35 – 53 = –18 бит.
(7.11)
Низкое значение ASC не должно удивлять, так как мигалка является наиболее распространенным объектом – даже более распространенным, чем самый
простой натюрморт, блок.
ASC осциллятора
Периоды осциллятора изменяются в зависимости от осциллятора. На
рис. 7.11 перечислены простейшие осцилляторы с циклами от 1, 2 и 3 до 9.
В каждом случае указана граница ASC. Неудивительно, что граница ASC увеличивается приблизительно в соответствии с периодом. Исключением является
«восьмерка» с периодом 8, у которой граница ASC только из 7 бит.
7.4.4.4. Измерение значения
Мы еще не успели подумать об анализе игры «Жизнь», а пользователи уже присвоили смысл объектам, которые могут быть сгенерированы четырьмя прос
тыми правилами Конвея. Планеры, натюрморты и осцилляторы названы так
потому, что они относятся к контексту общего опыта. Увлекательно сложные
объекты, такие как пафферы, более сложны, чем простой планер. ASC – это
простая методология присвоения номеров указанной сложности объектов
в игре «Жизнь».
7.5. Смысл в глазах смотрящего
Эпизод телесериала «Сумеречная зона» под названием «Глаз смотрящего»
[23] рассказывает историю об уродливой женщине, которая собирается сделать операцию, чтобы стать красивой. У снятого в тени черно-белого сюжета
неожиданный финал. Женщина уже красивая, но врачи и медсестры ужасно
уродливы – по крайней мере, в наших глазах. В их мире все было наоборот.
Поэты согласны с двойственностью восприятия. Шекспир написал [24]:
«Красота оценивается глазами».
264
Измерение смысла и алгоритмическая заданная сложность
Дэвид Хьюм присоединяется [25]:
«Красота в вещах существует только в разуме, который их созерцает».
Давайте заменим слово «красота» термином «значимая информация» и посмотрим, как читаются эти фразы.
«Значимая информация оценивается глазами».
«Значимая информация в вещах существует только в разуме, который их созерцает».
Эти фразы звучат правдоподобно в том смысле, что степень значимой информации определяется контекстом наблюдателя. ASC – это модель, которая
позволяет количественно оценить контекстуальное значение.
Источники
1.
2.
Sir James Gray, Nature, 173, p. 227 (1954).
W. Ewert, William A. Dembski, Robert J. Marks II, «Algorithmic Specified Complexity». In Engineering and the Ultimate: An Interdisciplinary Investigation of Order and Design in Nature and Craft, под ред. J. Bartlett, D. Halsmer, M. Hall (Blyth
Institute Press, 2014), pp. 131–149.
3. W. Ewert, William A. Dembski, Robert J. Marks II, «On the improbability of algorithmically specified complexity». Proceedings of the 2013 IEEE 45th Southeastern Symposium on Systems Theory (SSST), Baylor University, March 11, 2013.
4. W. C. Stone, The Success System that Never Fails (Prentice Hall, 1962).
5. Winston Ewert (2014), там же.
Winston Ewert (2013), там же.
6. William A. Dembski, Robert J. Marks, «Conservation of information in search:
measuring the cost of success». IEEE Transactions on Systems, Man and Cybernetics: Systems and Humans. 39(5), pp. 1051–1061 (2009).
7. Thomas M. Cover, Joy A. Thomas. Elements of information theory, 2nd edition
(John Wiley & Sons, 2012).
8. Chris V. Thangham, «No two snowflakes are alike». Digital Journal, December
2008.
9. And others estimate 1036 different types of snowflakes. Wonderopolis, «Why are
all snowflakes different?» http://wonderopolis.org/wonder/why-are-all-snowflakes-different/ (URL: May 2, 2016).
10. Там же.
11. M. Helmenstine, «Avogadro’s Number Example Chemistry Problem». About.
com, http://chemistry.about.com/od/workedchemistryproblems/a/avogadroexampl3.htm (URL: May 2, 2016).
Источники 265
12. A Guide to Snowflakes, «The Old Farmer’s Almanac». http://www.almanac.com/
content/guide-snowflakes. (URL: May 2, 2016).
13. Martin Gardner, «Mathematical Games – The fantastic combinations of John
Conway’s new solitaire game life». Scientific American 223, Oct 1970, pp. 120–
123.
14. S. Wolfram, A New Kind of Science (Wolfram Media, Champaign, IL, 2002).
15. A catalog of common ash objects ordered by their frequency of occurrence is
available online. There is a separate list for oscillators. http://www.homes.unibielefeld.de/achim/freq_top_life.html. (дата URL: May 2, 2016).
16. «Amazing Game of Life Demo». http://youtu.be/XcuBvj0pw-E, «Epic Conway’s
Game of Life», http://youtu.be/C2vgICfQawE, «Life In Life», http://youtu.be/
xP5-iIeKXE8; (дата URL: May 2, 2016).
17. http://www.conwaylife.com/wiki/ (дата URL: May 2, 2016).
18. W. Ewert, William A. Dembski, Robert J. Marks II, «Algorithmic specified complexity in the game of life». IEEE Transactions on Systems, Man and Cybernetics:
Systems, 2014.
19. Там же.
20. LifeWiki http://www.conwaylife.com/wiki/Main_Page (дата URL: May 2, 2016).
21. A. Adamatzky, ed., Collision Based Computing (Springer Verlag, London, UK,
2002).
22. LifeWiki.
23. Douglas Heyes, «The Eye of the Beholder». The Twilight Zone, CBS television,
выпуск от 11 ноября 1960.
24. W. Shakespeare, Love’s Labours Lost (1588).
25. D. Hume, Essays: Moral, Political, and Literary (Longmans, Green, and Company,
1907).
Глава
8
Разум
и искусственный интеллект
Самые ошибочные истории – это те, которые, по
нашему мнению, мы знаем лучше всего и поэтому
никогда не изучаем и не ставим под сомнение.
Стивен Джей Гулд [1]
Любая физическая теория всегда носит предварительный характер, в том смысле, что это всего
лишь гипотеза, которую вы не сможете окончательно доказать. Сколько бы раз экспериментальные данные ни совпадали с теорией, вы никогда
не можете быть уверены, что следующий эксперимент не вступит с ней в противоречие. В то же
время любую теорию можно опровергнуть, найдя
единственное наблюдение, которое не согласуется с ее предсказаниями. Как подчеркнул философ
и специалист в области философии науки Карл
Поппер, обязательное условие хорошей теории заключается в том, что она делает ряд предсказаний,
которые, в принципе, могут быть подтверждены
или опровергнуты наблюдением. Всякий раз, когда новые эксперименты подтверждают предсказания теории, она демонстрирует свою жизненность,
и наша вера в теорию укрепляется. Но если хоть
один эксперимент не согласуется с теорией, нам
следует либо отказаться от нее, либо переработать.
Стивен Хокинг [2],
из книги «Краткая история времени»
Искусственный интеллект (artificial intelligence, AI) и человеческий разум
связаны с понятием интеллекта. Человеческий разум происходит из природы, остается частью природы и опирается на информацию, извлекаемую
из окружающего мира. Искусственный интеллект исторически занимается
Тьюринг и Лавлейс: сильный и слабый интеллект 267
мимикрией под человеческий разум. Но компьютерный искусственный интеллект, даже с учетом последних достижений, находится далеко от истинно
творческих способностей человеческого разума. Ограничения компьютерного
творчества, продиктованные законом сохранения информации и алгоритмической теорией информации (algorithmic information theory, AIT), применяемой
к компьютерам, ограничивают творческий потенциал как в компьютерных
моделях природы, так и в моделях человеческого интеллекта. Компьютеры,
в принципе, способны выполнить любой алгоритм. Но это алгоритм, заложенный в компьютер извне. В человеческом мозге и в наблюдаемой природе происходит нечто большее, что пока не получается объяснить или моделировать
вычислениями по алгоритму.
Первые семь глав этой книги посвящены проблемам и внутренним противоречиям алгоритмического подхода к моделированию эволюции. Основной
вывод заключается в том, что не существует безупречной модели, достоверно
демонстрирующей успех неориентированной дарвиновской эволюции. Вывод
основан на анализе, выявляющем скрытые источники информации и преднамеренные настройки, заложенные в алгоритм программистом. Ограничения
компьютера, о чем свидетельствуют потолок Бейснера и сохранение информации, исключают возможность творчества, выходящую за рамки программы,
заложенной в программу программистом. При таком подходе компьютеры
(в смысле полной по Тьюрингу машины) никогда не будут творческими. Анализ опыта моделирования эволюции показал, что в данной области компьютерам не хватает именно творческого компонента.
Принципиальный вопрос о способности машины к творчеству обсуждался
философами и математиками задолго до появления компьютеров. Этот вопрос
по-прежнему остается открытым. Далее мы приводим ссылки на труды и размышления, достойные того, чтобы их изучить.
8.1. Тьюринг и Лавлейс: сильный и слабый интеллект
Считается, что AI успешно реализован, когда компьютерная программа проходит тест Тьюринга. Но на самом деле есть сильный AI и слабый AI, и для
успешного прохождения теста Тьюринга требуется только слабый AI. Сильным
AI обладает машина, способная проявить творческие способности1, присущие
людям. Слабый AI стремится правдоподобно подражать человеческому интеллекту. Сильный AI старается его дублировать.
8.1.1. Ошибка Тьюринга
Тест Алана Тьюринга [4] требует, чтобы текстовый чат с компьютером заставил нас думать, что компьютер – человек. Тест Тьюринга демонстрирует только
1
Способность современных нейросетей генерировать музыку или изображения, основываясь на ранее созданных человеком произведениях, не является творчеством.
268
Разум и искусственный интеллект
слабый AI. Согласно тезису Черча–Тьюринга, все современные компьютеры являются вариациями машины Тьюринга. Прохождение теста Тьюринга сегодня
впечатляет – но не удивляет. Компьютеры становятся все мощнее, а алгоритмы – все сложнее. Компьютер Deep Blue победил Гарри Каспарова в шахматах,
а компьютерная программа Watson победила человека в игре Jeopardy! Это
примеры того, что могут сделать вычислительно- и алгоритмически мощные
компьютеры. Но творчество в этих победах принадлежит только людям, разработавшим компьютеры и алгоритмы.
Алан Тьюринг надеялся, что компьютер когда-нибудь покажет все интеллектуальные способности человека [5]. Он исследовал науку о вычислениях, надеясь когда-нибудь показать, что человек – не более чем машина. Гений Тьюринга удачно соединился с его мотивацией, и сегодня Тьюринг считается отцом
современной информатики. Его труды изучают все студенты компьютерных
специальностей. Но главная цель Тьюринга – показать, что компьютер способен соответствовать творческому интеллекту человека, не удалась. Брингсорд,
Белло (Bello) и Ферруччи (Ferrucci) [6] суммируют текущее состояние теста
Тьюринга:
«Несмотря на то что прогресс в достижении мечты Тьюринга не вызывает
сомнений, он достигается только благодаря умному, но мелкому обману. Например, разработчики искусственных агентов, которые конкурируют в современных версиях [теста Тьюринга], прекрасно знают, что они просто поставили
перед собой цель обмануть людей, взаимодействующих с агентами, чтобы люди
поверили, что у этих агентов действительно есть разум».
Вводя понятие сохранения информации в начале главы 5, мы предложили многочисленные цитаты, в которых говорится, что компьютер не должен
восприниматься как креативный агент. На самом деле таких цитат намного
больше. Французский философ и математик Рене Декарт выразил сомнение
относительно AI еще в 1637 году:
«[Мы] легко можем понять, как устроена машина, чтобы произносить слова
и даже испускать некоторые реакции на телесное воздействие, что приводит
к изменению ее органов; например, если прикоснуться к определенной части,
она может спросить, что мы хотим ей сказать; если прикоснуться к другой час
ти, она может воскликнуть, что ей больно, и т. д. Но никогда не бывает так, что
она организует свою речь по-разному, чтобы адекватно отвечать на все, что
можно сказать в ее присутствии, как может сделать даже самый неразумный
человек» [7].
Роджер Пенроуз, вероятно, наиболее известный из-за того, что он поделился
со Стивеном Хокингом теорией сингулярности Пенроуза–Хокинга, описывающей физику образования черных дыр, не верит, что компьютеры когда-либо
продемонстрируют сильный AI. Используя аргументы Гёделя, Пенроуз утверждает, что способность творить лежит за пределами возможностей компьютера.
Требование Гёделя гласит, что непротиворечивые формальные системы (consis-
Тьюринг и Лавлейс: сильный и слабый интеллект 269
tent formal systems), основанные на основополагающих аксиоматических правилах, таких как компьютер и его программы, ограничены в том, что они могут
делать. По словам Пенроуза, люди преодолевают этот барьер благодаря своей
способности вводить новшества и творить. Пенроуз полагает, что у креативной
способности человека (то есть способности создавать информацию «из ниоткуда») должно быть материалистическое объяснение, и ищет ответ в квантовой механике.
Если Пенроуз прав и мы узнаем, как сделать машину похожей в плане творчества на то, что находится между нашими ушами, то, вероятно, мы сможем
создать сильный AI. Однако с современными компьютерами и современными
моделями квантовых компьютеров это почти наверняка невозможно.
8.1.2. Тест Лавлейс
Что мы можем использовать вместо теста Тьюринга, чтобы продемонстрировать сильный AI? Брингсорд, Белло и Ферруччи [9] предлагают тест Лавлейс,
названный в честь Августы Ады Кинг, графини Лавлейс. Леди Лавлейс – одна
из тех, кто считает, что компьютеры никогда не будут по-настоящему креативными. Повторим ее цитату, приведенную в разделе 5.1:
«Компьютеры не могут ничего создать. Для создания требуется, как минимум,
возникновение чего-то. Но компьютеры ничего не создают; они просто делают
то, что мы заказываем им через программы».
Критерий определения компьютерного творчества назван в ее честь.
Тест Лавлейс: сильный AI будет продемонстрирован, когда творческий потенциал машины нельзя будет объяснить наличием у нее создателя.
Доказательство творчества не следует путать с удивлением или отсутствием объяснений! Некоторые из наших недавних работ по эволюционному развитию интеллекта роя (swarm intelligence) [10] демонстрируют удивительное
поведение роя, но, оглядываясь назад, результаты можно объяснить, исследуя
компьютерную программу, которую мы написали. Нейронные сети многослойного персептрона [11] не имеют встроенных средств объяснения результатов1, но ведут себя так, как задумал программист. Тест Лавлейс требует наличия
инноваций и творчества за пределами этого уровня. В смысле Гёделя сильный
AI должен творить за пределами уровня развития, допускаемого его основополагающими аксиомами, например внезапно написать великий роман или
доказать гипотезу Римана без участия создателя машины, тщательно настроившего цепочку падающих домино.
Компьютерные ограничения Гёделя также связаны с неспособностью машин Тьюринга обладать сознанием или свободной волей.
1
Средства для объяснения и проверки результатов, выдаваемых многослойной нейросетью, появились после издания английского оригинала книги. Сейчас в этом направлении ведутся активные исследования. – Прим. пер.
270
Разум и искусственный интеллект
«AI [основанный на теореме Гёделя] и свободная воля тесно взаимосвязаны по
очень простой причине: информация сама по себе является основополагающей
в проблеме свободной воли. Основная проблема, касающаяся связи между AI
и свободной волей, может быть сформулирована кратко: поскольку теоремы
математики не могут содержать больше информации, чем содержится в аксиомах, используемых для вывода этих теорем, из этого следует, что в математике
нет формальной операции (и, значит, нет операции, выполнимой компьютером), которая может создать новую информацию».
«AI, вероятно, не допускает свободу воли не только в ньютоновской вселенной
или в квантово-механической вселенной, но и в любой вселенной, которая может быть смоделирована любой математической теорией. AI запрещает свободу
воли самой математике и любому процессу, который точно моделируется математикой, потому что AI показывает, что формальная математика не способна
создавать новую информацию». Дуглас С. Робертсон (Douglas S. Robertson) [12]
Робертсон апеллирует к ограничениям компьютеров только для выполнения
алгоритмов. А наличие свободной воли, необходимой для создания информации (например, творчества), выходит за рамки алгоритмических возможностей аксиоматических способностей машины Тьюринга.
8.1.3. Озарение гения
В «Психологии изобретений» [13] математик Жак Адамар описывает свое собственное творческое математическое мышление как бессловесное и подгоняемое ментальными образами, раскрывающими полное решение проблемы.
Пенроуз согласен с ним [14]. Он говорит, что математические решения сложных проблем могут появиться «без слов». Проработка деталей окончательной
формулировки может занять несколько дней, даже если решение интуитивно
понятно.
Великий математик Фридрих Гаусс описывает такой опыт:
«Наконец, два дня назад я преуспел… Как внезапная вспышка молнии, меня
озарил ответ. Я не могу сказать, что было путеводной нитью, связавшей то, что
я раньше знал, с тем, что привело меня к успеху».
Тест Лавлейс даже некоторое время использовался Патентным ведомством
США. Для подтверждения патентоспособности требовалась «вспышка творческого гения». В отношении патентов Верховный суд США в 1941 году постановил [15]:
«Новое устройство [заявленное на патентование], каким бы полезным оно ни
было, должно раскрывать вспышку творческого гения, а не только навык соединять известное. В противном случае подлежит отказать в получении материального вознаграждения за размещение объекта патентования в публичном
доступе».
Машина, демонстрирующая «вспышку творческого гения» в понимании Верховного суда или «внезапную вспышку молнии» Гаусса, обладает сильным AI.
Интеллект и непознаваемое 271
Озарение гения, на которое претендуют математики Пенроуз, Гаусс и Адамар, в равной мере присуще и творческим умам искусства. Согласно Книге
рекордов Гиннеса, к самым проработанным песням всех времен и народов относится песня Yesterday, написанная Полом Маккартни и Джоном Ленноном.
Они записали более 1600 версий песни! Автор мелодии Пол Маккартни был
обеспокоен тем, что он не придумал ничего нового.
«Около месяца я ходил к людям в музыкальном бизнесе и спрашивал их, слышали ли они когда-нибудь эту [мелодию] раньше. В конце концов, это стало
похоже на передачу находки в полицию. Я подумал, что если никто не заявит
свои права через несколько недель, тогда я смогу этим воспользоваться» [17].
Неординарный автор песен Боб Дилан (Bob Dylan) приводит описание творческого озарения, пережитого композитором Хоги Кармайклом (Hoagie Carmichael), который написал классическую песню Stardust. Впервые услышав
записьсвоей композиции, Хоги Кармайкл сказал:
«И тогда это случилось. Это странное ощущение, что эта мелодия была больше
меня. Может быть, я вообще не писал ее. Воспоминания о том, как, когда, где
и почему это произошло, стали расплывчатыми. Когда под потолком студии
разливались звуки музыки, я хотел кричать в ответ: “Может быть, я тебя не сочинил. Но я нашел тебя”» [18].
Боб Дилан заканчивает свои воспоминания утверждением:
«Я точно знаю, что он [Хоги Кармайкл] имел в виду».
Для прохождения теста Лавлейс требуется инновация, которая не предусмот
рена и не объясняется создателем компьютерной программы. Люди успешно
проходят тест Лавлейс в математике и музыке. Машины Тьюринга, похоже, не
способны пройти этот тест. Может ли это сделать какая-то другая искусственная машина – вопрос остается открытым.
8.2. Интеллект и непознаваемое
Творчество человеческого разума и устройство природы имеют нечто общее.
На этом фоне компьютеры выглядят так, будто они неспособны показать творческий потенциал сильного AI. И эволюция не может быть исчерпывающе
смоделирована на машине Тьюринга. Компьютер делает только то, для чего он
запрограммирован. Попытки моделировать неуправляемую эволюцию в проектах Avida, EV и Tierra потерпели неудачу. Tierra просто не сделала того, что
должна была сделать. Avida и EV работают лишь потому, что программисты
поставили конкретную цель и разрабатывали программы для ее достижения.
В главе 6 мы показали, что и Avida, и EV были наполнены активной информацией, которая в конечном итоге гарантировала их успех. Потолок Бейснера
запрещает творчество в компьютерных эволюционных моделях на машине
Тьюринга. Эволюционная программа, написанная для разработки антенны,
никогда не разовьет самопроизвольную способность играть в шахматы. Долж-
272
Разум и искусственный интеллект
на быть написана отдельная эволюционная программа, посвященная шахматам, а программист должен установить цель игры в шахматы.
Если механизм человеческого мозга, отвечающий за творчество, когда-либо
будет формализован и воспроизведен с помощью технологий, последующее
воздействие на человечество будет невообразимым. Другой вероятный исход состоит в том, что механизм, позволяющий человеческому уму творчески
мыслить, существует, но, как и число Хайтина, непостижим. С точки зрения
компьютерного моделирования информационный продукт эволюции выглядит как подмножество сильного AI. Все компьютеры являются машинами Тьюринга, а машины Тьюринга по определению выполняют познаваемые алгоритмы. Подойдя к проблеме творчества со стороны познаваемости алгоритма, мы
вновь вернулись к открытому вопросу о возможности реализации креативности на машине Тьюринга.
8.3. Заключение
Наша книга началась с цитаты Грегори Хайтина [19]. Этой же цитатой мы хотим ее завершить:
«Честь математики требует от нас разработать математическую теорию эволюции и либо доказать, что Дарвин был прав, либо опровергнуть его!»
Спасибо за внимание.
Источники
1.
2.
3.
4.
5.
6.
7.
8.
D. E. Jelinski, «On the notions of mother nature and the balance of nature
and their implications for conservation». Human Ecology (Springer US, 2010),
pp. 37–50.
S. W. Hawking, M. Jackson, A Brief History of Time (Bantam, 2008).
Robert J. Marks II, «The Turing Test Is Dead. Long Live the Lovelace Test». Evolution News & Views, July 3, 2014 http://www.evolutionnews.org/2014/07/the_
turing_test_1087411.html (URL: May 2, 2016).
A. Turing, «Computing machinery and intelligence». Mind, 59(236), 433460
(1950).
P. Gray, «Computer Scientist: Alan Turing». Time Magazine (March 29, 1999).
S. Bringsjord, P. Bello, D. Ferrucci. «Creativity, the Turing Test, and the (better)
Lovelace test». Minds and Machines, 11(3), pp. 3–27 (2001).
R. Descartes, Discourse on Method and Meditations on First Philosophy (Yale University Press, New Haven & London, 1996), p. 3435.
R. Penrose, The Emperor’s New Mind: Concerning Computers, Minds, and the Laws
of Physics (Oxford University Press, Oxford, 1999).
R. Penrose, Shadows of the Mind (Oxford University Press, Oxford, 1994).
Заключение 273
9. S. Bringsjord, P. Bello, D. Ferrucci.
10. W. Ewert, R. J. Marks II, B. B. Thompson, A. Yu, «Evolutionary inversion of swarm
emergence using disjunctive combs control». IEEE Transactions on Systems, Man
& Cybernetics: Systems, 43(5), pp. 1063–1076 (2013).
J. Roach, W. Ewert, R. J. Marks II, B. B. Thompson, «Unexpected Emergent Behaviors From Elementary Swarms». Proceedings of the 2013 IEEE 45th Southeastern
Symposium on Systems Theory (SSST), Baylor University, pp. 41–50 (2013).
11. Russell D. Reed, R. J. Marks II, Neural Smithing: Supervised Learning in Feedforward Artificial Neural Networks (MIT Press, Cambridge, MA, 1999).
12. D. S. Robertson, «Algorithmic information theory, free will, and the Turing test».
Complexity, 4(3), pp. 25–34 (1999).
13. J. Hadamard, An Essay on the Psychology of Invention in the Mathematical Field
(Dover Publications, New York, 1954).
14. R. Penrose.
15. United States Supreme Court, Cuno Engineering Corp. v. Automatic Devices
Corp., 314 U.S. 84 (1941).
16. http://www.beatlesbible.com/songs/yesterday/ (дата URL date May 2, 2016).
17. C. Cross, The Beatles: Day-by-Day, Song-by-Song, Record-by-Record (Lincoln,
NE: iUniverse, Inc. 2005).
18. B. Dylan on The Mystery of Creativity, YouTube, https://youtu.be/UpuQCK
JIf0M (URL date May 2, 2016).
19. G. J. Chaitin, The Unknowable (Springer, 1999).
Предметный указатель
Avida, 14, 202
Cracker Barrel, 133
EV, 14, 186
Formula 409, 48
Minivida, 215
PrOIR. См. Принцип Бернулли
Tierra, модель эволюции, 106
WD-40, 48
Алгоритм
WEASEL, 14
Эверта, 151
Алгоритмическая теория информации, 267
Беспрефиксный язык, 34
Биологическая коэволюция, 167
Булева логика, 202
Вентиль NAND, 202
Влияние, 115
Восхождение по склону, 71
Выборка по значимости, 103
Вывод
абдуктивный (умозрительный), 23
индуктивный, 23
Деление интервала, 40
Дерево Штейнера, 232
Достаточная статистика Колмогорова, 29
Жадные предельные циклы, 105
Заданная сложность, 14, 28
алгоритмическая, 15, 244
Закон
больших чисел, 100
Бореля, 11, 25
сохранения информации, 13, 114
Знание предметной области, 48
Значение информации, 240
Значимость, 240
Игла Буффона, 101
Игра, 15, 253, 254, 257
Имитация отжига, 99
Инженерное проектирование, 47
Интеллект
искусственный, 15, 266
сильный, 267
слабый, 267
роя, 269
творческий, 268
Информация, 11, 27
аддитивность, 38
активная, 13, 21, 131, 136
Колмогорова–Хайтина–Соломонова, 29
собственная, 244
универсальная, Гитта, 29
условная, 242
функциональная, Дарстона, 29
Шеннона, 29
эндогенная, 131, 136, 137
Информированная инициализация, 160
Кардинальность, 175
Квантовое запутывание, 64
Квантовый компьютер, 64
Кембрийский взрыв, 107
Кодирование Левинсона, 262
Комбинаторный взрыв, 55
Компактная сетевая графика, PNG, 30
Компьютер в цикле, 71
Конкурирующие агенты, 167
Константа Шамперноуна, 31
Контекст, 15
информации, 240
Коэволюция, 13
Критерии проектирования, 47
Кроссовер, 58
Ландшафт отбора, 51
Листья двоичного дерева, 33
Максимум
глобальный, 71
локальный, 71
Машина Руба Голдберга, 187
Метабиология, 223
Метапоиск, 13
Метод
роя частиц, 173
трещотки, 214
Механистический вычислитель, 191
Многоцелевая оптимизация по Парето, 68
Модель
поясняющая, 23
электромагнитного поля, 139
Мутация, 58
Наблюдаемая граница, 243
Нат (единица информации), 174
Независимые события, 98
Неповторяемые явления, 23
Непротиворечивые формальные системы, 268
Неравенство Крафта, 35
Предметный указатель 275
Несжимаемый файл, 30
Неснижаемая сложность, 29
Нуклеотид, 187
Оптимальный детектор Неймана–Пирсона, 69
Оптимизация
наискорейшим спуском, 99
Оракул, 40, 55
остановки, 224
позиционного поиска, 233
успеха, 148
Хемминга, 149
Парадокс Бертрана, 92
Параметры проектирования, 55
Первичный бульон, 254
Переходящая жизнеспособность.
См. Функциональная жизнеспособность
Поглощающие состояния, 105
Подсчет карт, 86
Поиск
алгоритм Гровера, 64
итеративный, 47
компьютерный, 50
Левенберга–Марквардта, 173
многоагентный, 71, 73
с вознаграждением, 154
слепой, 49
с трещоткой. См. Стохастическое
восхождение
эволюционный, 57
явно телеологический, 64
Поколение, 58
Популяция, 58
претендентов, 157
Потолок Бейснера, 13
Признаки, 121
Принцип
безразличия, 92
Бернулли, 12, 84
транзитивности, 119
Приспособленность, 51
Проект априорно-неинформированный, 12
Проклятие размерности, 63
Пропорциональная ставка, 87
Пространство поиска, 55
Процессы
некорректные, 23
слабообусловленные, 23
Расстояние Хемминга, 149
Репопуляция, 47, 58
Сайт связывания, 189
Самоинформация, 38
Сжатие без потерь, 30
Симметричная монета, 31
Симметричный кубик, 85
Симплекс, 177
Сокращенный алфавит, 165
Сопряженный градиентный спуск, 173
Сортирующие сети, 167
Статическая среда, 81
Стохастическое восхождение, 150
Странные аттракторы, 105
Стрит-флеш, 250
Суперпозиция, 64
Таблица истинности, 203
Телеологическая модель, 47
Телеологическая цель, 47
Теорема
об отсутствии бесплатных завтраков, 13, 114
о неполноте, 15
Теория
информации
алгоритмическая, 12
Колмогорова–Хайтина–Соломонова, 12
Шеннона, 11
обнаружения, 68
Тест
Лавлейс, 269
Тьюринга, 267
Тетербол, 104
Усердный бобер, 224
программа, 225
число, 225
Утрата функции, 67
Фиксированные точки, 104
Флеш-рояль, 249
Функциональная жизнеспособность, 163
Функция
приспособленности, 57
распределения масс, 94
Частичная оптимальность, 12
Частота вхождений, 151, 246
Человек в цикле, 70, 125
Число Хайтина, 227
Эволюционная информатика, 21
Эволюционная стратегия, 196
Эволюционный процесс, 99
Эволюция, 47
Экспертиза предметной области, 47
Элегантная программа, 31
Энтропия
дискретная, 95
дифференциальная, 95
Книги издательства «ДМК Пресс» можно заказать
в торгово-издательском холдинге «Планета Альянс» наложенным платежом,
выслав открытку или письмо по почтовому адресу:
115487, г. Москва, 2-й Нагатинский пр-д, д. 6А.
При оформлении заказа следует указать адрес (полностью),
по которому должны быть высланы книги;
фамилию, имя и отчество получателя.
Желательно также указать свой телефон и электронный адрес.
Эти книги вы можете заказать и в интернет-магазине: www.a-planeta.ru.
Оптовые закупки: тел. (499) 782-38-89.
Электронный адрес: books@alians-kniga.ru.
Роберт Маркс, Уильям Дембски, Уинстон Эверт
Введение в эволюционную информатику
Главный редактор
Мовчан Д. А.
dmkpress@gmail.com
Научный редактор, переводчик
Корректор
Верстка
Дизайн обложки
Яценков В. С.
Чистякова Л. А., Синяева Г. И.
Чаннова А. А.
Мовчан А. Г.
Формат 70×100 1/16.
Гарнитура «PT Serif». Печать офсетная.
Усл. печ. л. 22,43. Тираж 200 экз.
Веб-сайт издательства: www.dmkpress.com
Powered by TCPDF (www.tcpdf.org)
California State University Channel Islands, USA
Данная книга рассказывает о том, как ученые соединили методы моделирования сложных процессов и теорию информации, благодаря чему
стало возможно измерить сложность всех явлений мироздания в битах.
Построенная на основе серии рецензируемых статей, книга написана
языком, легко понятным для читателей со знанием математики на уровне
средней школы.
An Introduction to the
Analysis of Algorithms
Если читатель стремится бегло охватить тему или не интересуется математическими подробностями, он может пропустить разделы, отмеченные
специальным значком, и все равно испытает восторг от знакомства с новой
захватывающей моделью информации о природе.
Книга написана для энтузиастов в области науки, техники и математики,
заинтересованных в понимании важной и пока еще недооцененной роли
информации в теории эволюции.
3rd Edition
ISBN 978-5-97060-725-1
Интернет-магазин:
www.dmkpress.com
NEW JERSEY • LONDON • SINGAPORE • BEIJING • SHANGHAI • HONG KONG • TAIPEI • CHENNAI • TOKYO
Оптовая продажа:
КТК “Галактика”
books@alians-kniga.ru
www.дмк.рф
9 785970 607251
Введение в эволюционную информатику
Наука добилась больших успехов в моделировании пространства, времени,
массы и энергии, но слишком мало сделала для того, чтобы создать модель
информации, заполняющей нашу
Вселенную.
Michael
Soltys
Роберт Маркс
Уильям Дембски
Уинстон Эверт
Введение
в эволюционную
информатику