/




















































































































































































































































































































































































































































































































































































































































































































































































































































Автор: Люгер Дж. Ф.
Теги: компьютерные технологии информатика искусственный интеллект
ISBN: 5-8459-0437-4
Год: 2003




Текст
Искусственный
интеллект
Artificial
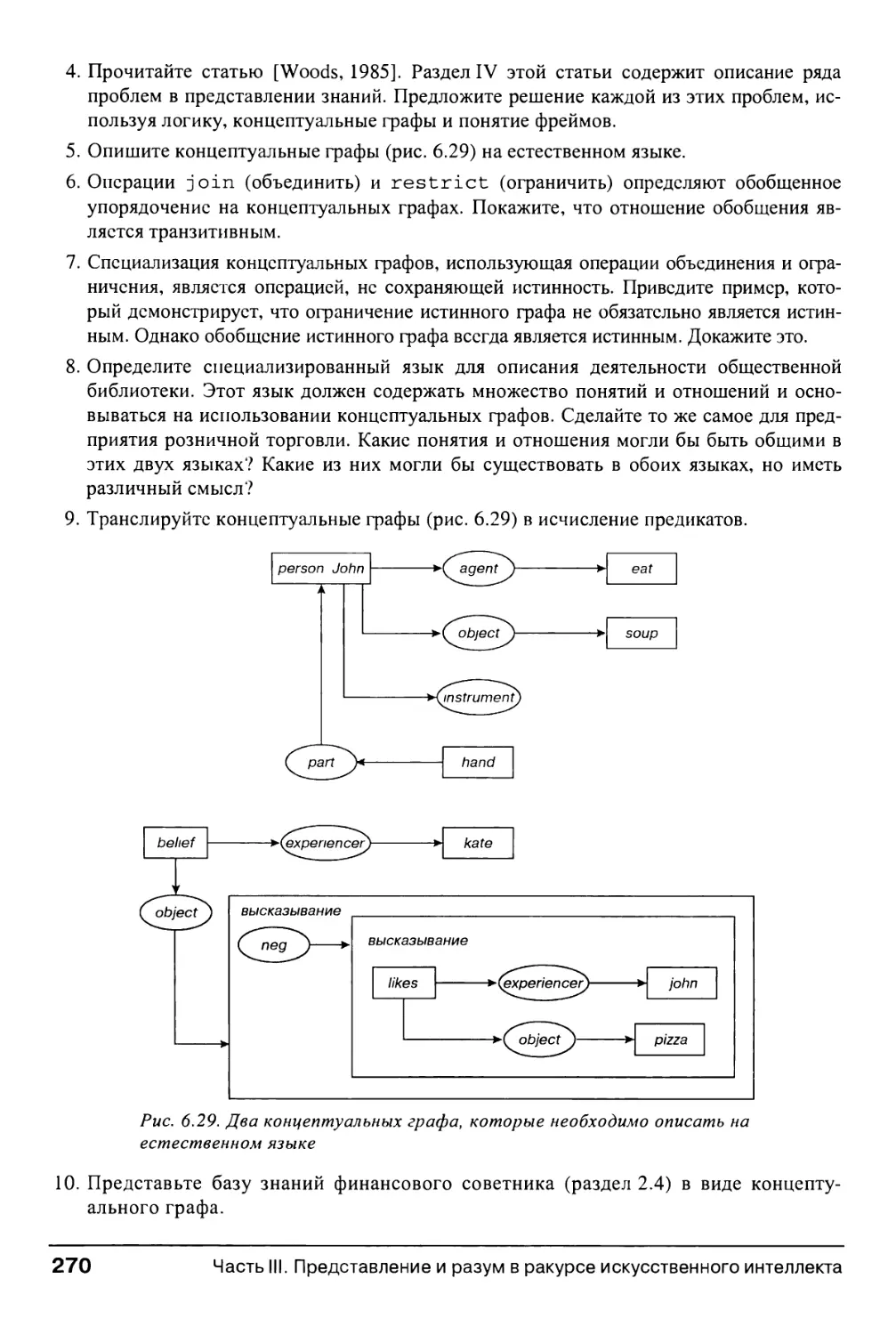
Intelligence
Structures and Strategies
for Complex Problem Solving
Fourth Edition
George F. Luger
▲
TT
ADDISON
WESLEY
AN IMPRINT OF PEARSON EDUCATION
Boston • Harlow, England • London • New York • Reading, Massachusetts • San Francisco
Toronto • Don Mills, Ontario • Sydney • Tokyo • Singapore • Hong Kong • Seoul • Taipei
Cape Town • Madrid • Mexico City • Amsterdam • Munich • Paris • Milan
Искусственный
интеллект
Стратегии и методы решения
сложных проблем
Четвертое издание
Джордж Ф. Люгер
Москва • Санкт-Петербург • Киев
2003
ББК 32.973.26-018.2.75
Л83
УДК 681.3.07
Издательский дом "Вильяме"
Зав. редакцией СИ. Тригуб
Перевод с английского Н.И. Галагана , К.Д. Протасовой,
докт. техн. наук Н.Н. Куссуль
Под редакцией докт. техн. наук Н.Н. Куссуль
По общим вопросам обращайтесь в Издательский дом "Вильяме" по адресу:
info@williamspublishing.com, http://www.williamspublishing.com
Люгер, Джордж, Ф.
Л83 Искусственный интеллект: стратегии и методы решения сложных проблем, 4-е издание. :
Пер. с англ. — М.: Издательский дом "Вильяме", 2003. — 864 с.: ил. — Парал. тит. англ.
ISBN 5-8459-0437-4 (рус.)
Данная книга посвящена одной из наиболее перспективных и привлекательных
областей развития научного знания — методологии искусственного интеллекта. В ней детально
описываются как теоретические основы искусственного интеллекта, так и примеры
построения конкретных прикладных систем. Книга дает полное представление о
современном состоянии развития этой области науки.
Книга будет полезна как опытным специалистам в области искусственного
интеллекта, так и студентам и начинающим ученым.
ББК 32.973.26-018.2.75
Все названия программных продуктов являются зарегистрированными торговыми марками соответствующих фирм.
Никакая часть настоящего издания ни в каких целях не может быть воспроизведена в какой бы то ни было
форме и какими бы то ни было средствами, будь то электронные или механические, включая фотокопирование и
запись на магнитный носитель, если на это нет письменного разрешения издательства Addison-Wesley UK
Authorized translation from the English language edition published by Addison-Wesley Publishing Company, lnc ,
Copyright © 2002
All rights reserved No part of this book may be reproduced, stored in retrieval system or transmitted in any form or by any
means, electronic, mechanical, photocopying, recording, or otherwise without either the prior written permission о the Publisher
Russian language edition published by Williams Publishing House according to the Agreement with R&I Enterprises
International, Copyright © 2002
ISBN 5-8459-0437-4 (рус.) © Издательский дом "Вильяме", 2003
ISBN 0-201-64866-0 (англ ) © Pearson Education Limited, 2002
Оглавление
Предисловие 19
Часть I. Искусственный интеллект: его истоки и проблемы 27
Глава 1. Искусственный интеллект: история развития и области приложения 29
Часть П. Искусственный интеллект как представление и поиск 57
Глава 2. Исчисление предикатов 73
Глава 3. Структуры и стратегии поиска в пространстве состояний 107
Глава 4. Эвристический поиск 149
Глава 5. Управление поиском и его реализация в пространстве состояний 185
Часть III. Представление и разум в ракурсе искусственного
интеллекта 219
Глава 6. Представление знаний 225
Глава 7. Сильные методы решения задач 273
Глава 8. Рассуждения в условиях неопределенности 325
Часть IV. Машинное обучение 369
Глава 9. Машинное обучение, основанное на символьном представлении
информации 371
Глава 10. Машинное обучение на основе связей 435
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 483
Часть V. Дополнительные вопросы решения задач
искусственного интеллекта 519
Глава 12. Автоматические рассуждения 521
Глава 13. Понимание естественного языка 561
Часть VI. Языки и технологии программирования для
искусственного интеллекта 603
Глава 14. Введение в PROLOG 609
Глава 15. Введение в LISP 685
Часть VII. Эпилог 777
Глава 16. Искусственный интеллект как эмпирическая проблема 779
Библиография 809
Алфавитный указатель авторов 841
Предметный указатель 848
6
Оглавление
Содержание
Предисловие 19
Добро пожаловать в четвертое издание! 19
Что нового в этом издании 21
Содержание книги 22
Использование книги 24
Дополнительный материал, доступный через Internet 25
Благодарности 25
Часть I. Искусственный интеллект: его истоки и проблемы 27
Попытка дать определение искусственному интеллекту 27
Глава 1. Искусственный интеллект: история развития и области приложения 29
1.1. Отношение к интеллекту, знанию и человеческому мастерству 29
1.1.1. Историческая подоплека 30
1.1.2. Развитие логики 32
1.1.3. Тест Тьюринга 35
1.1.4. Биологические и социальные модели интеллекта: агенты 38
1.2. Обзор прикладных областей искусственного интеллекта 42
1.2.1. Ведение игр 43
1.2.2. Автоматические рассуждения и доказательство теорем 43
1.2.3. Экспертные системы 44
1.2.4. Понимание естественных языков и семантическое моделирование 46
1.2.5. Моделирование работы человеческого интеллекта 47
1.2.6. Планирование и робототехника 48
1.2.7. Языки и среды ИИ 49
1.2.8. Машинное обучение 50
1.2.9. Альтернативные представления: нейронные сети и генетические алгоритмы 51
1.2.10. Искусственный интеллект и философия 52
1.3. Искусственный интеллект — заключительные замечания 53
1.4. Резюме и дополнительная литература 54
1.5. Упражнения 55
Часть II. Искусственный интеллект как представление и поиск 57
Введение в представление знаний 58
Обработка знаний, выраженных в качественной форме 61
Логическое получение новых знаний из набора фактов и правил 62
Отображение общих принципов наряду с конкретными ситуациями 63
Передача сложных семантических значений 63
Рассуждения на метауровне 65
Решение задачи методом поиска 66
Альтернативные схемы представления 70
Глава 2. Исчисление предикатов 73
2.0. Введение 73
2.1. Исчисление высказываний 73
2.1.1. Символы и предложения 73
2.1.2. Семантика исчисления высказываний 75
2.2. Основы исчисления предикатов 77
2.2.1. Синтаксис предикатов и предложений 78
2.2.2. Семантика исчисления предикатов 83
2.2.3. Значение семантики на примере "мира блоков" 87
2.3. Правила вывода в исчислении предикатов 89
2.3.1. Правила вывода 89
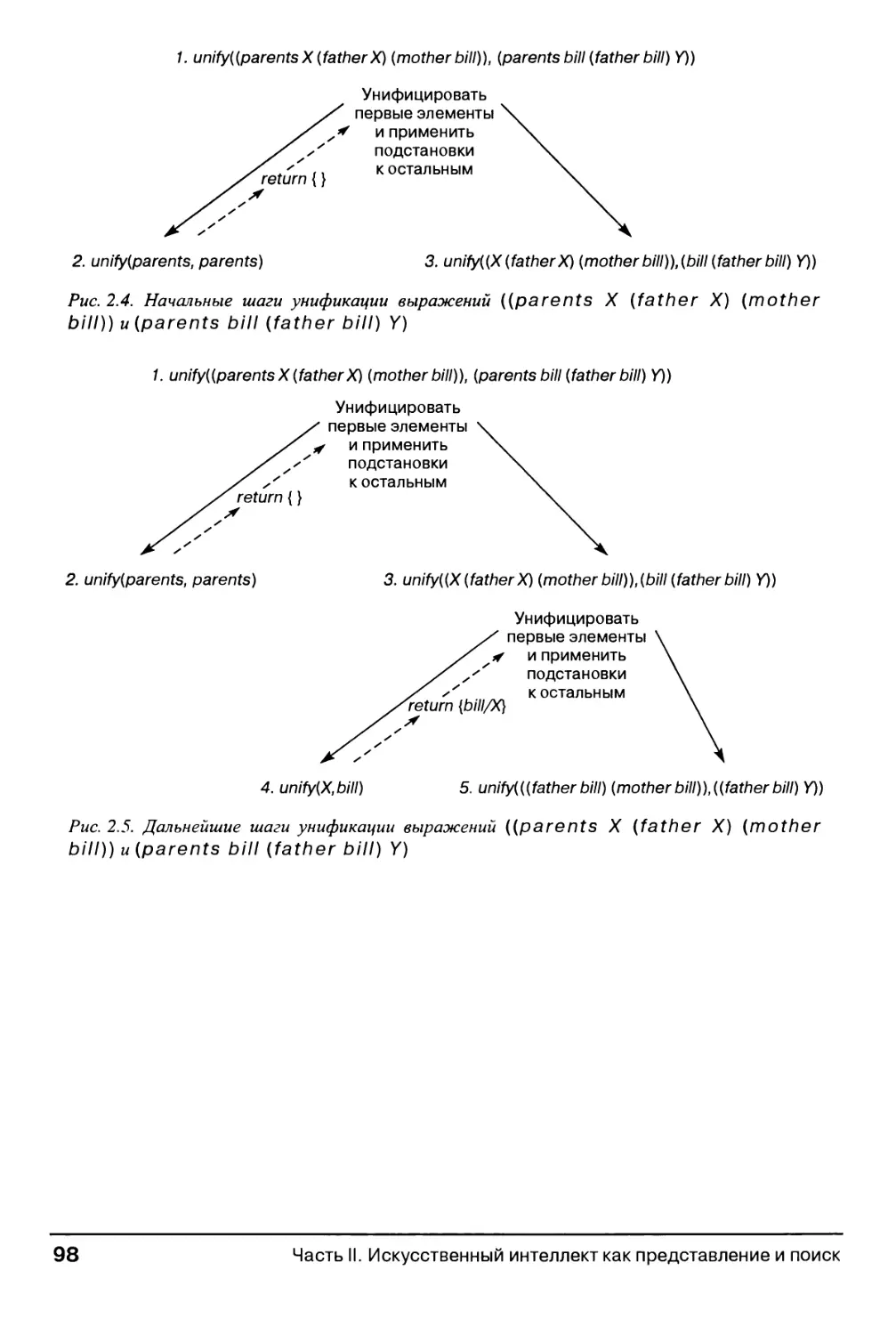
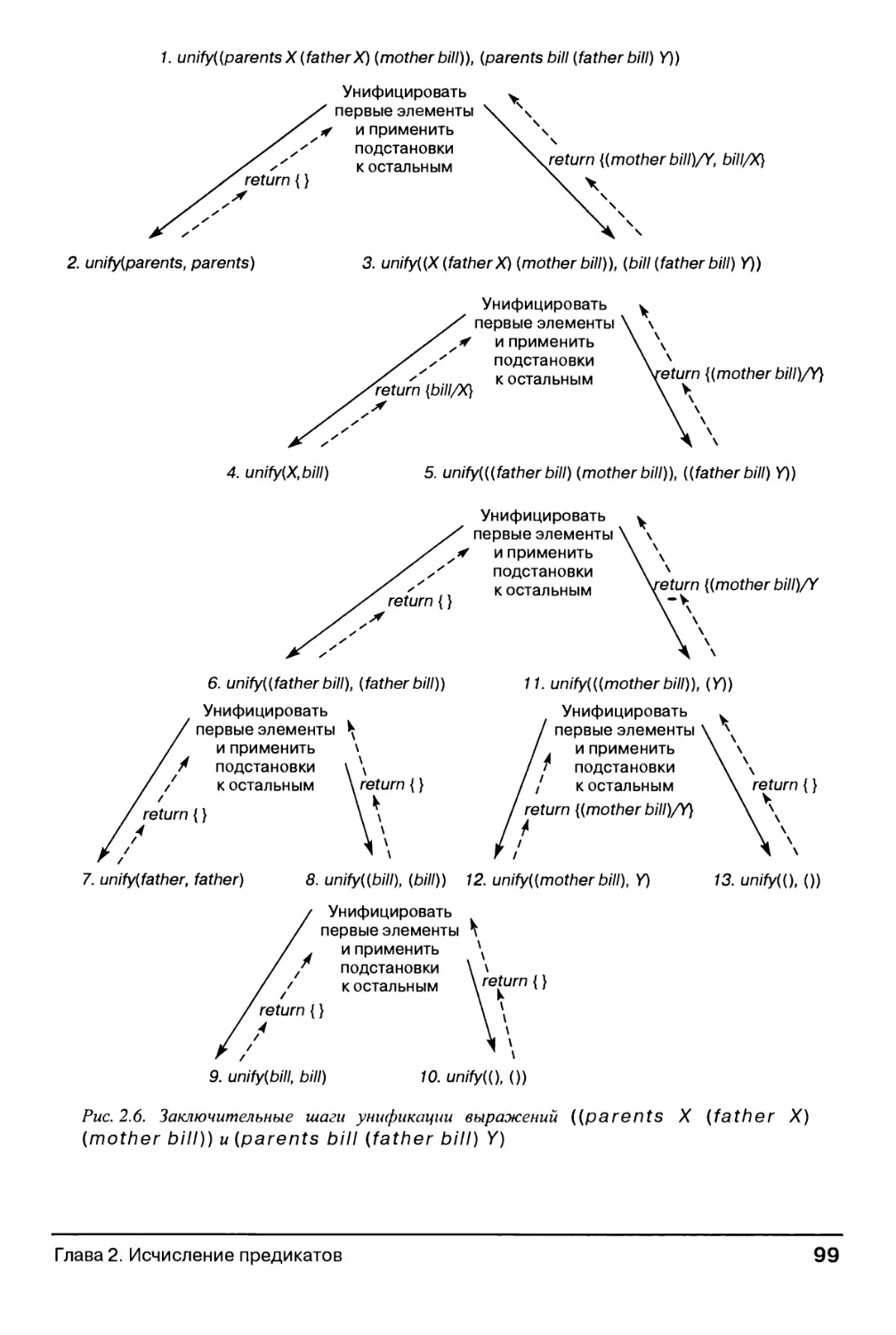
2.3.2. Унификация 92
2.3.3. Пример унификации 96
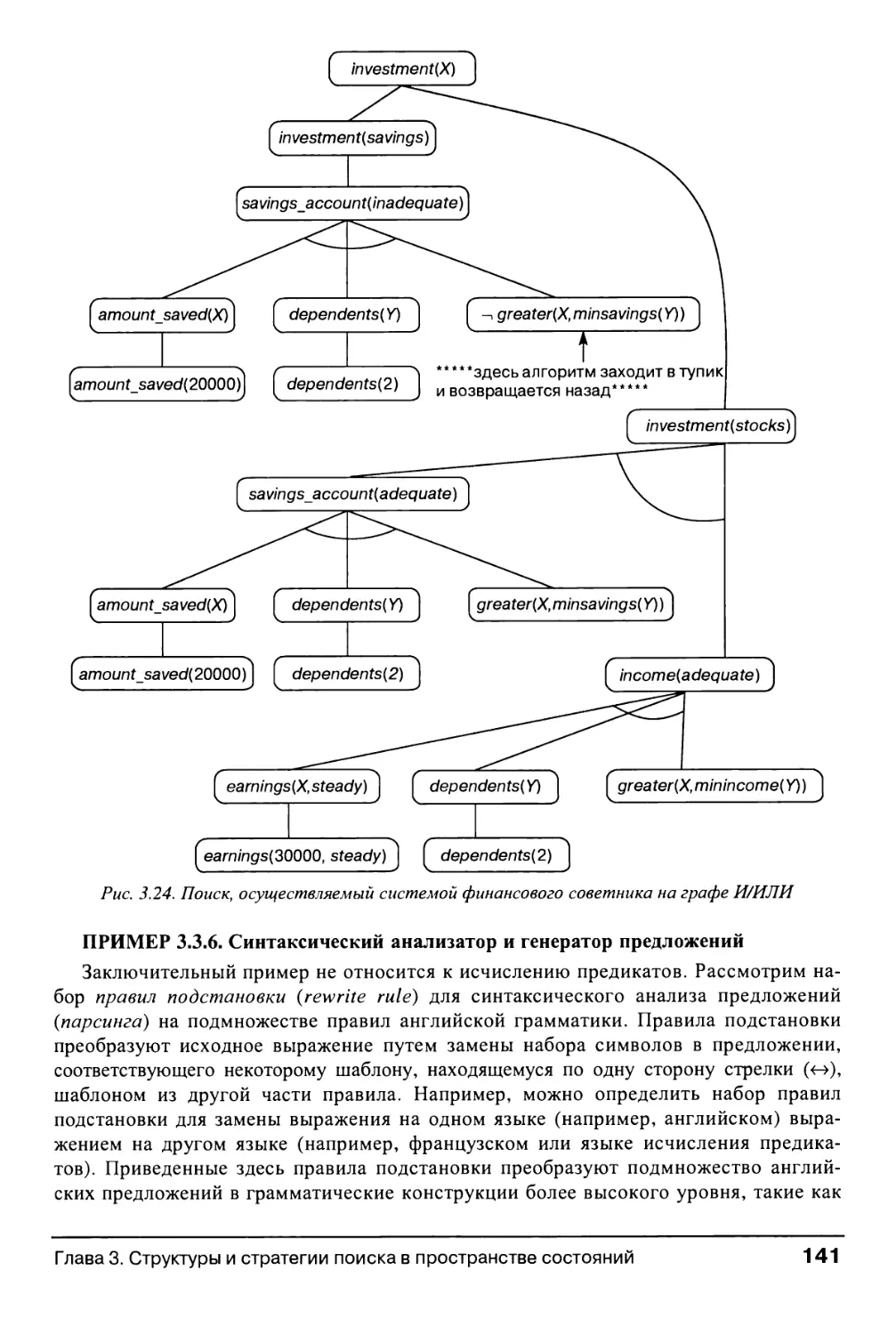
2.4. Приложение: финансовый советник на основе логики 100
2.5. Резюме и дополнительная литература 103
2.6. Упражнения 104
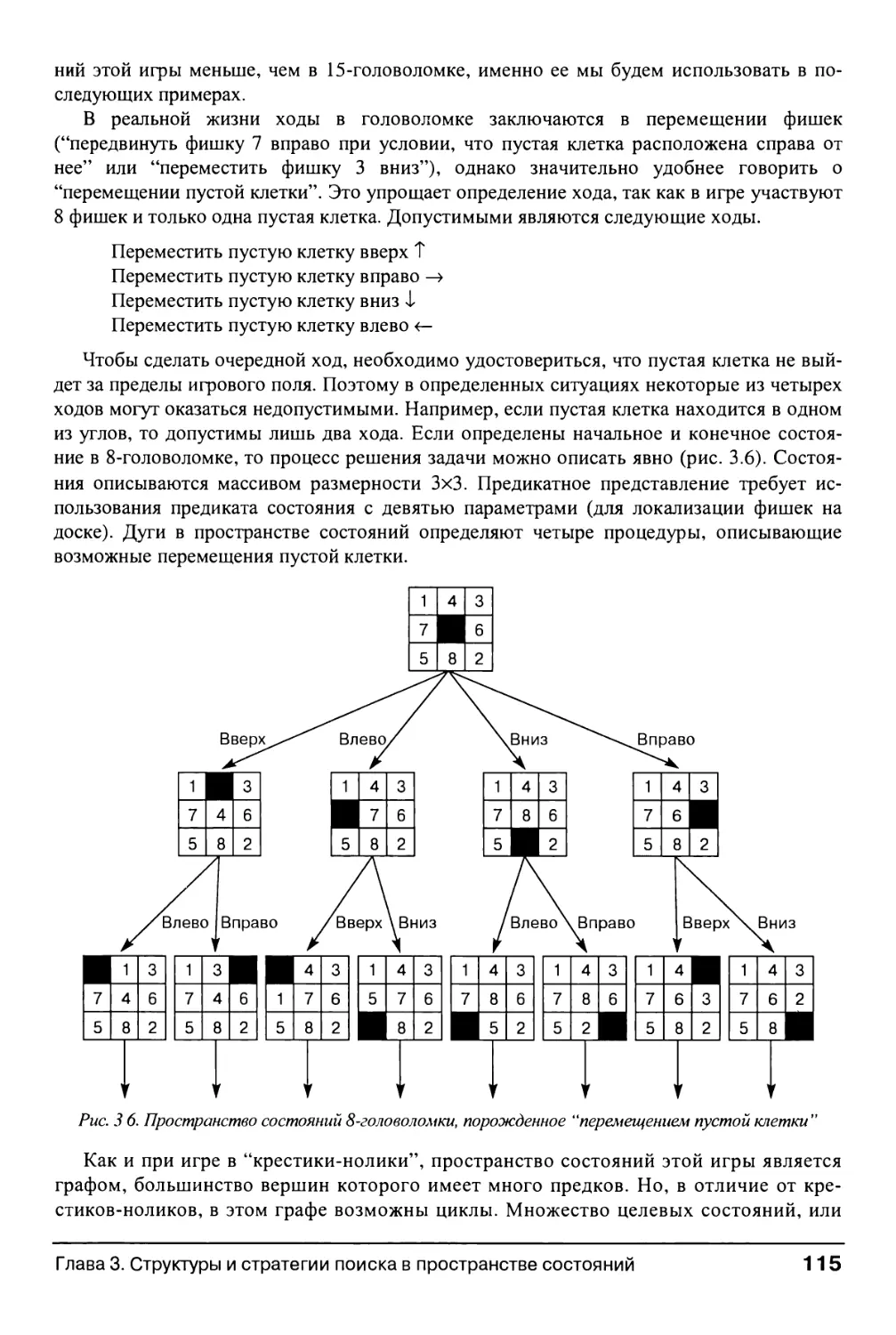
Глава 3. Структуры и стратегии поиска в пространстве состояний 107
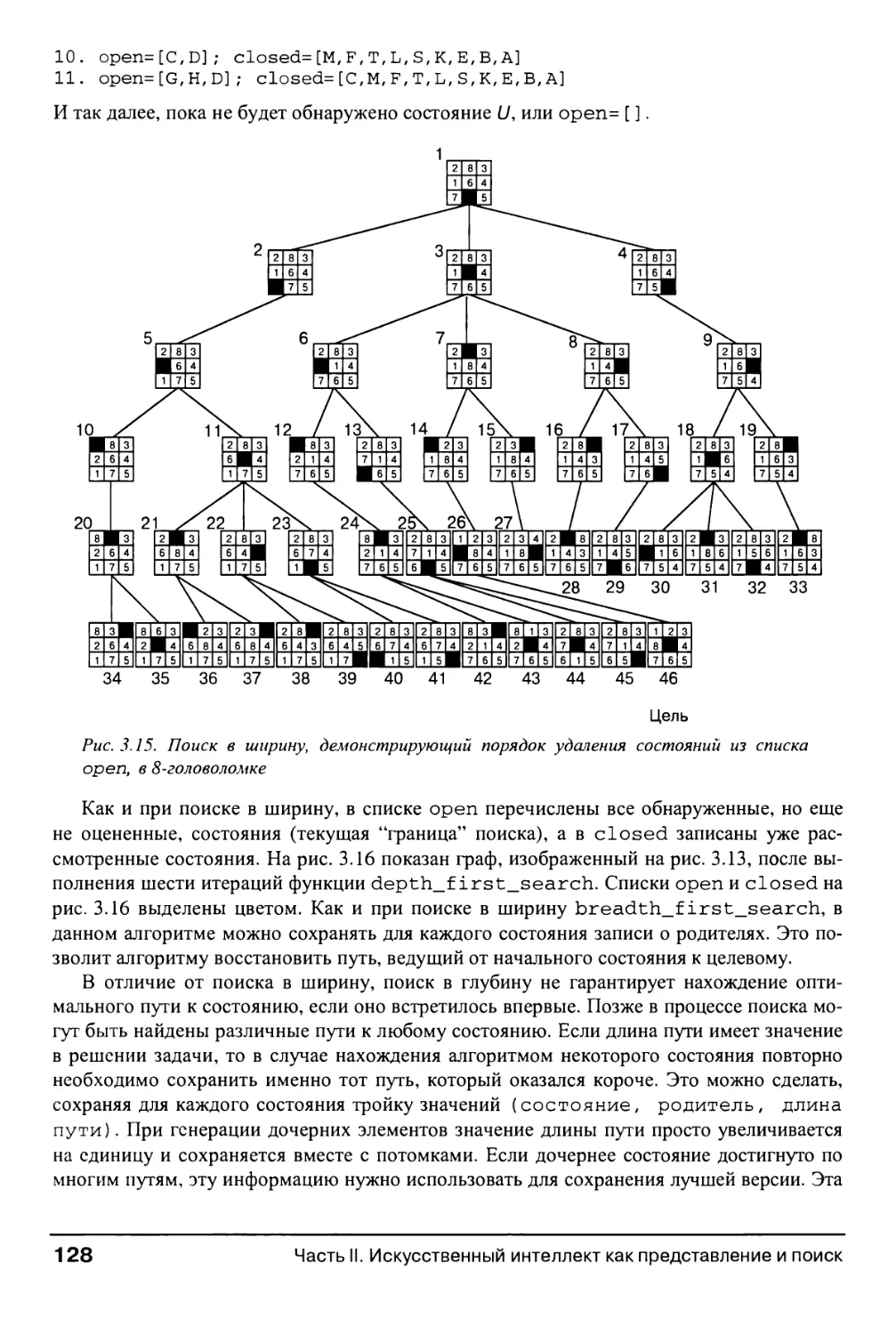
3.0. Введение 107
3.1. Теория графов 110
3.1.1. Структуры данных для поиска в пространстве состояний 110
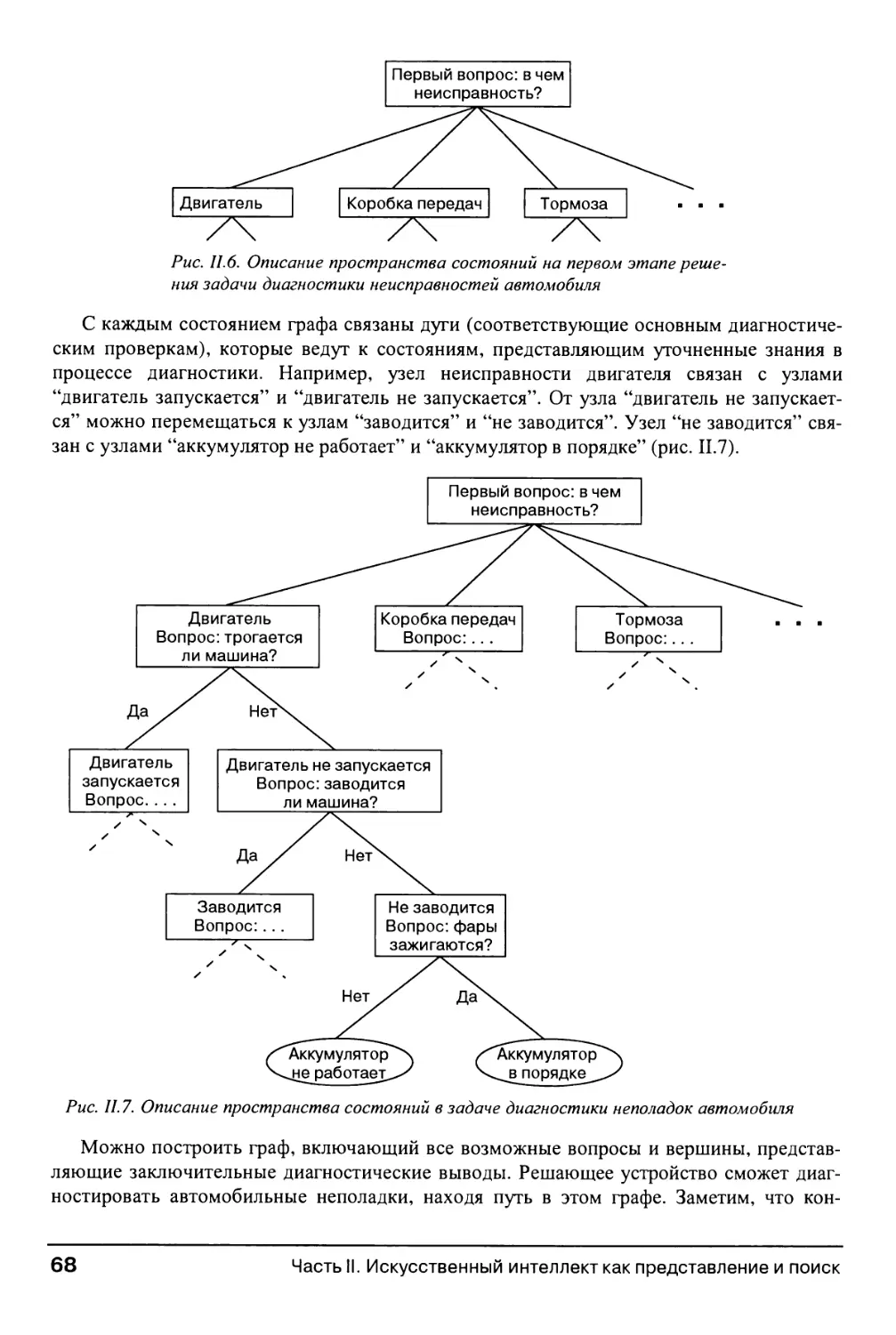
3.1.2. Представление задачи в пространстве состояний 112
3.2. Стратегии поиска в пространстве состояний 118
3.2.1. Поиск на основе данных и от цели 118
3.2.2. Реализация поиска на графах 121
3.2.3. Поиск в глубину и в ширину 124
3.2.4. Поиск в глубину с итерационным заглублением 131
3.3. Представление рассуждений в пространстве состояний на основе
исчисления предикатов 132
3.3.1. Описание пространства состояний логической системы 132
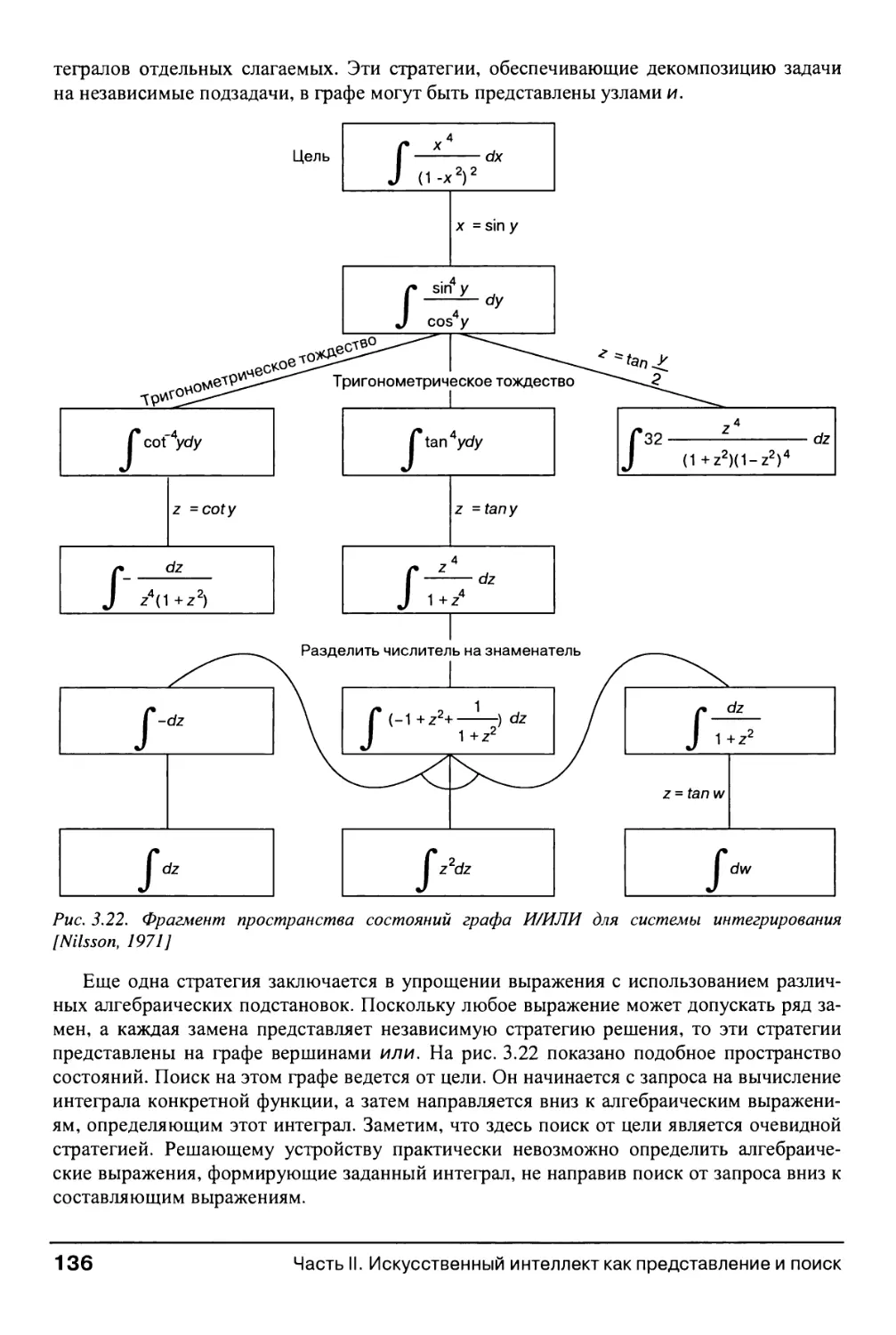
3.3.2. Графы И/ИЛИ 133
3.3.3. Примеры и приложения 135
3.4. Резюме и дополнительная литература 145
3.5. Упражнения 146
Глава 4. Эвристический поиск 149
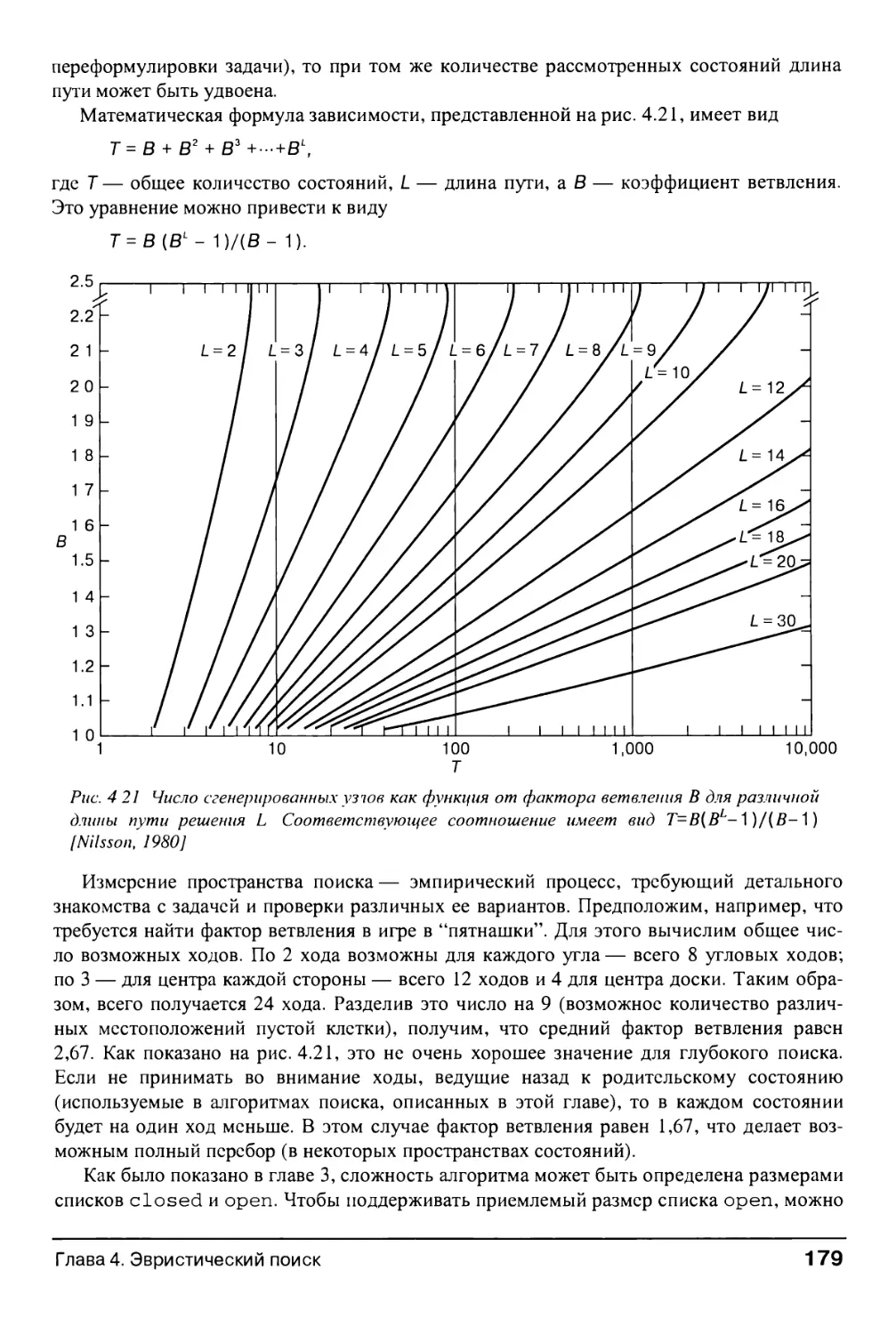
4.0. Введение 149
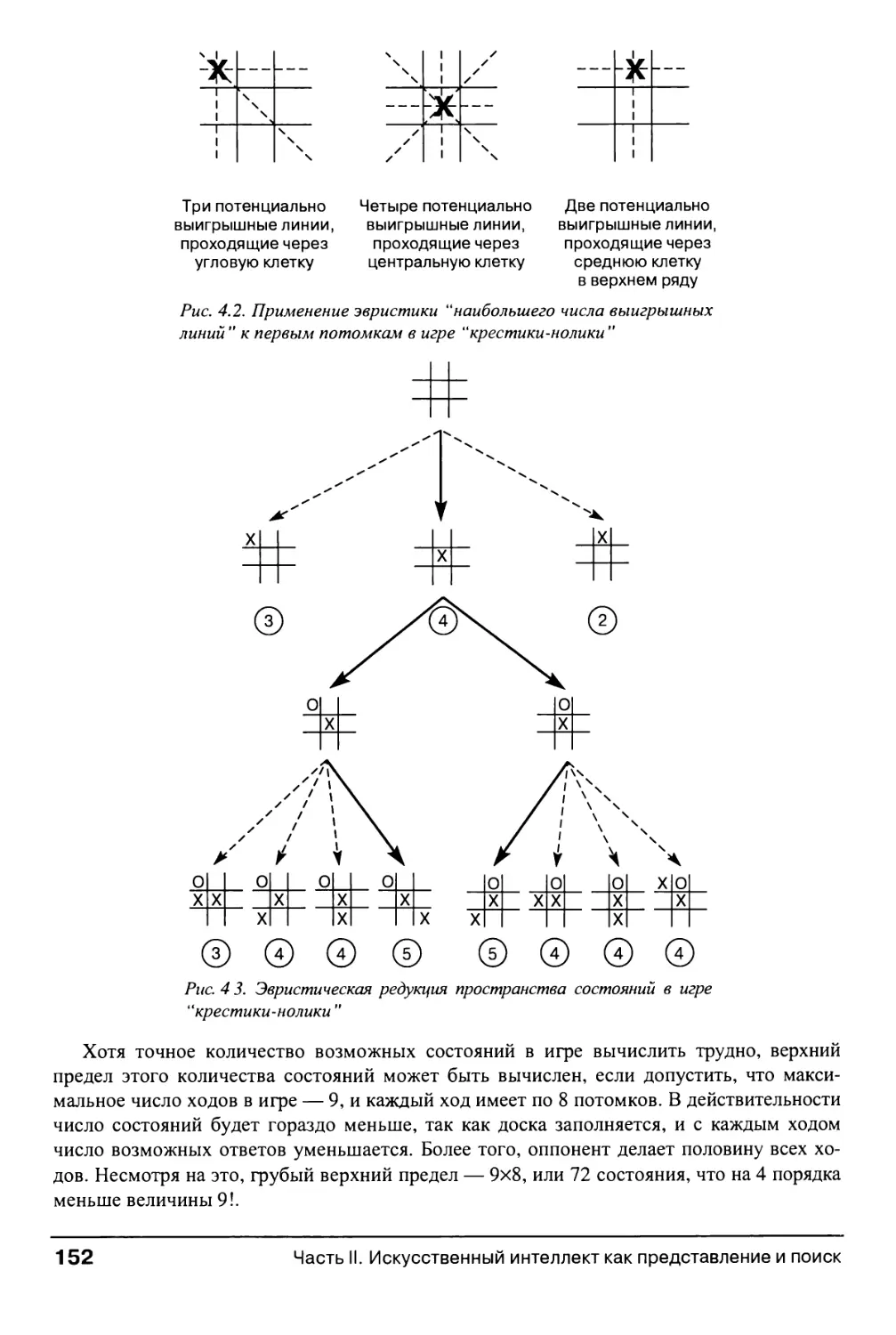
4.1. Алгоритм эвристического поиска 153
4.1.1. "Жадный" алгоритм поиска 153
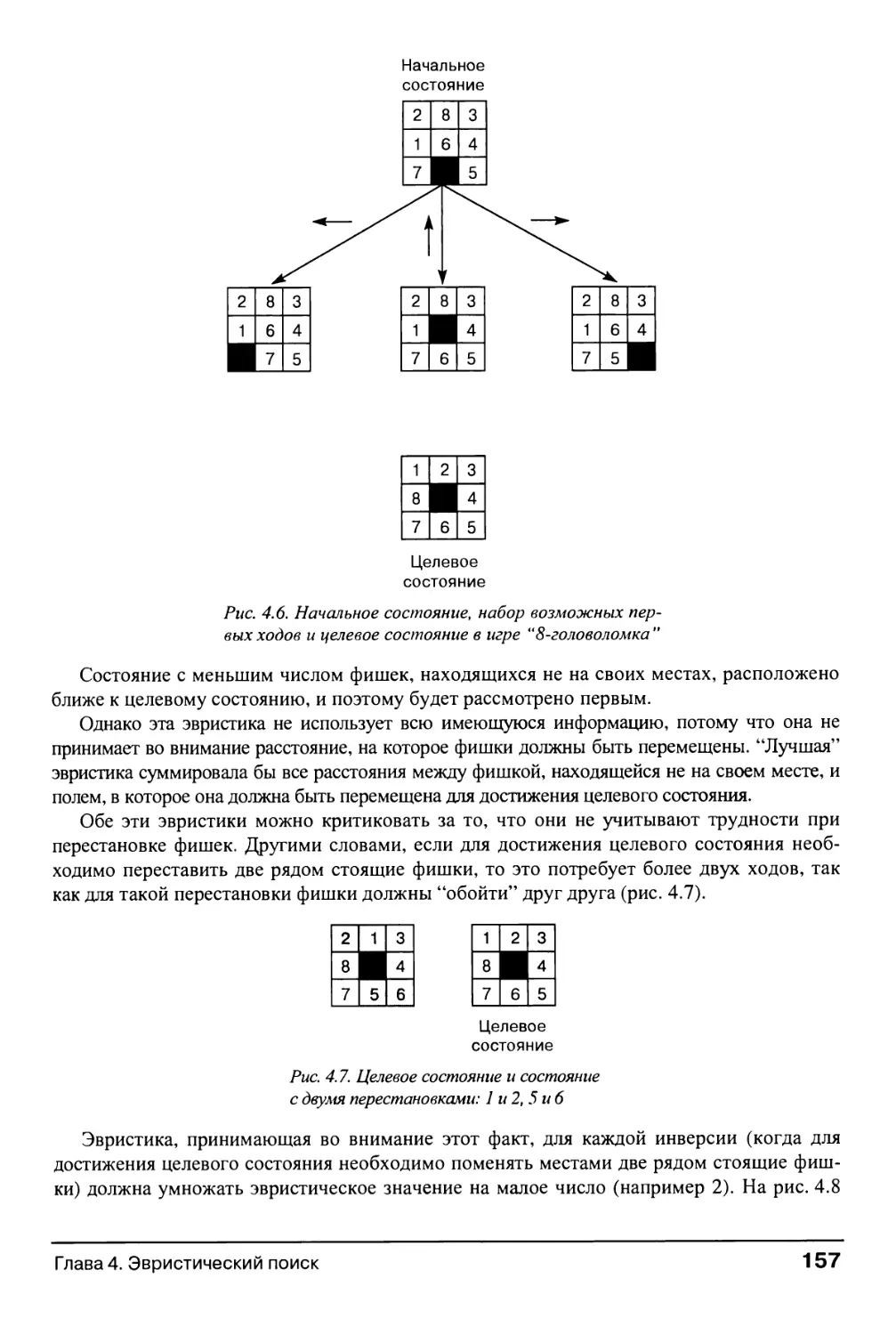
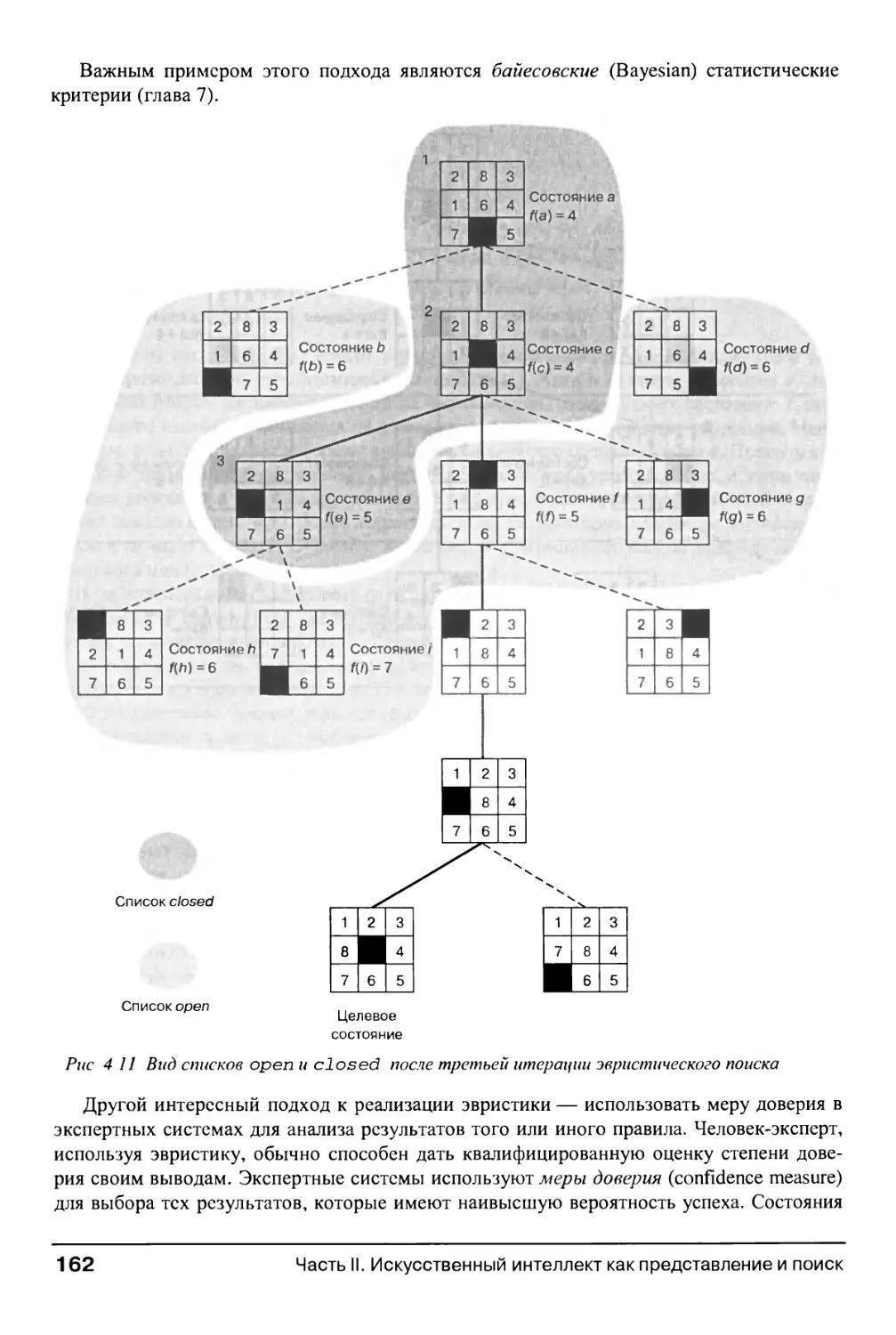
4.1.2. Функции эвристической оценки состояний 156
4.1.3. Эвристический поиск и экспертные системы 163
4.2. Допустимость, монотонность и информированность 164
8
Содержание
4.2.1. Мера допустимости 165
4.2.2. Монотонность 166
4.2.3. Информированные эвристики 167
4.3. Использование эвристик в играх 169
4.3.1. Процедура минимакса на графах, допускающих полный перебор 169
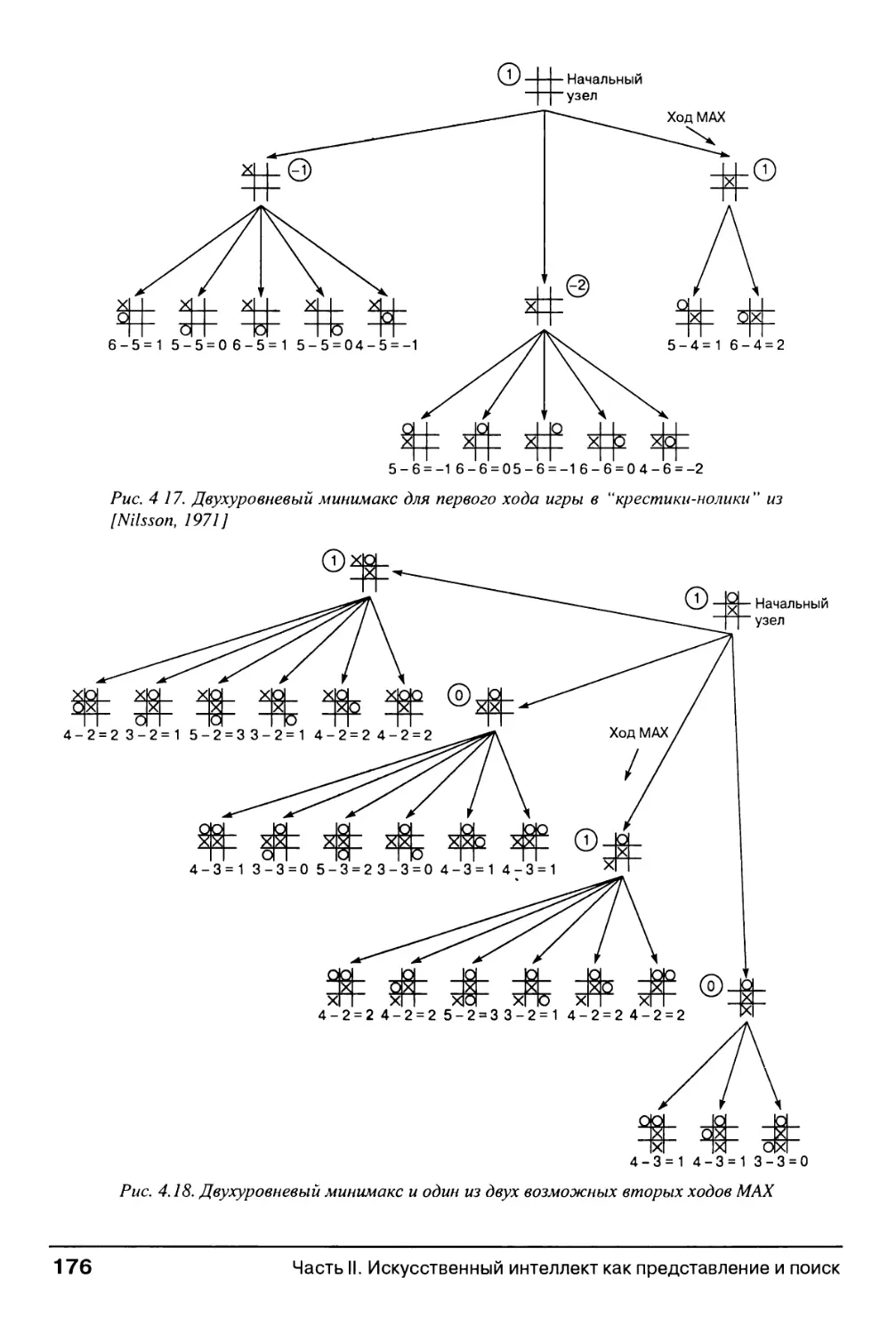
4.3.2. Минимакс при фиксированной глубине поиска 171
4.3.3. Процедура альфа-бета-усечения 175
4.4. Проблемы сложности 178
4.5. Резюме и дополнительная литература 181
4.6. Упражнения 181
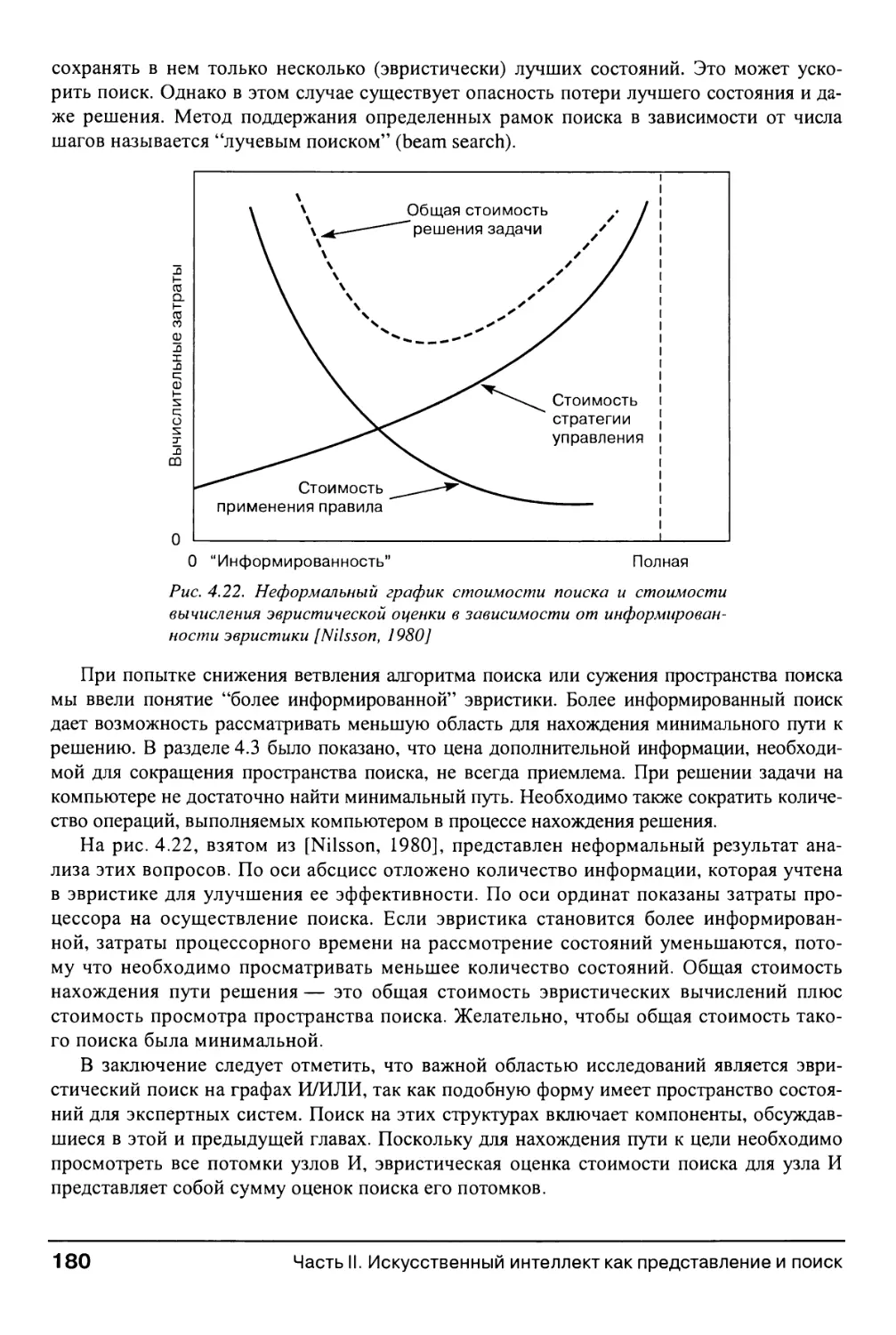
Глава 5. Управление поиском и его реализация в пространстве состояний 185
5.0. Введение 185
5.1. Рекурсивный поиск 186
5.1.1. Рекурсия 186
5.1.2. Рекурсивный поиск 187
5.2. Поиск по образцу 190
5.2.1. Пример рекурсивного поиска: вариант задачи хода конем 191
5.2.2. Усовершенствование алгоритма поиска по образцу 194
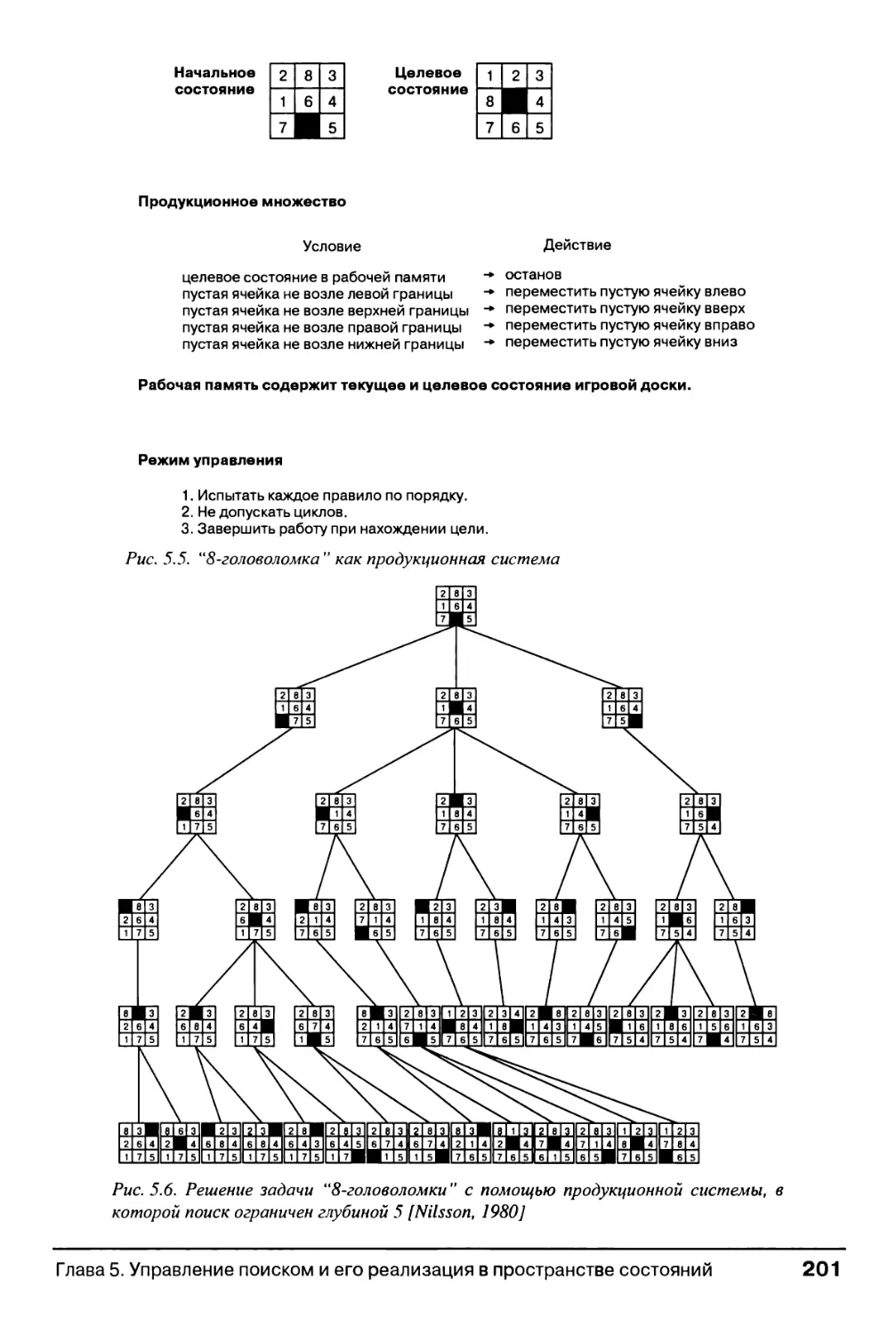
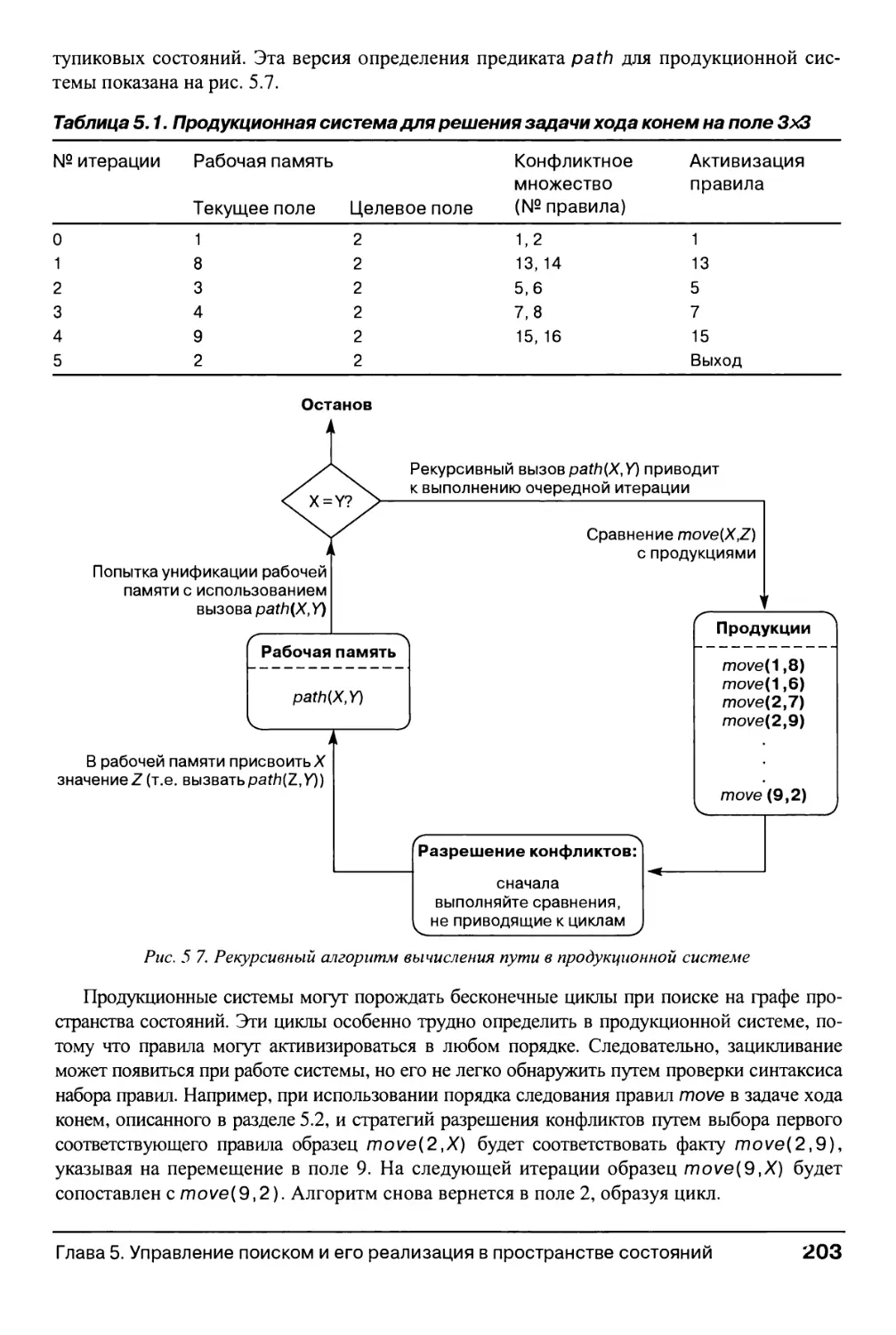
5.3. Продукционные системы 196
5.3.1. Определение и история развития 196
5.3.2. Примеры продукционных систем 200
5.3.3. Управление поиском в продукционных системах 205
5.3.4. Преимущества продукционных систем для ИИ 211
5.4. Архитектура "классной доски" 212
5.5. Резюме и дополнительная литература 215
5.6. Упражнения 216
Часть III. Представление и разум в ракурсе искусственного
интеллекта 219
Представление и интеллект 219
Глава 6. Представление знаний 225
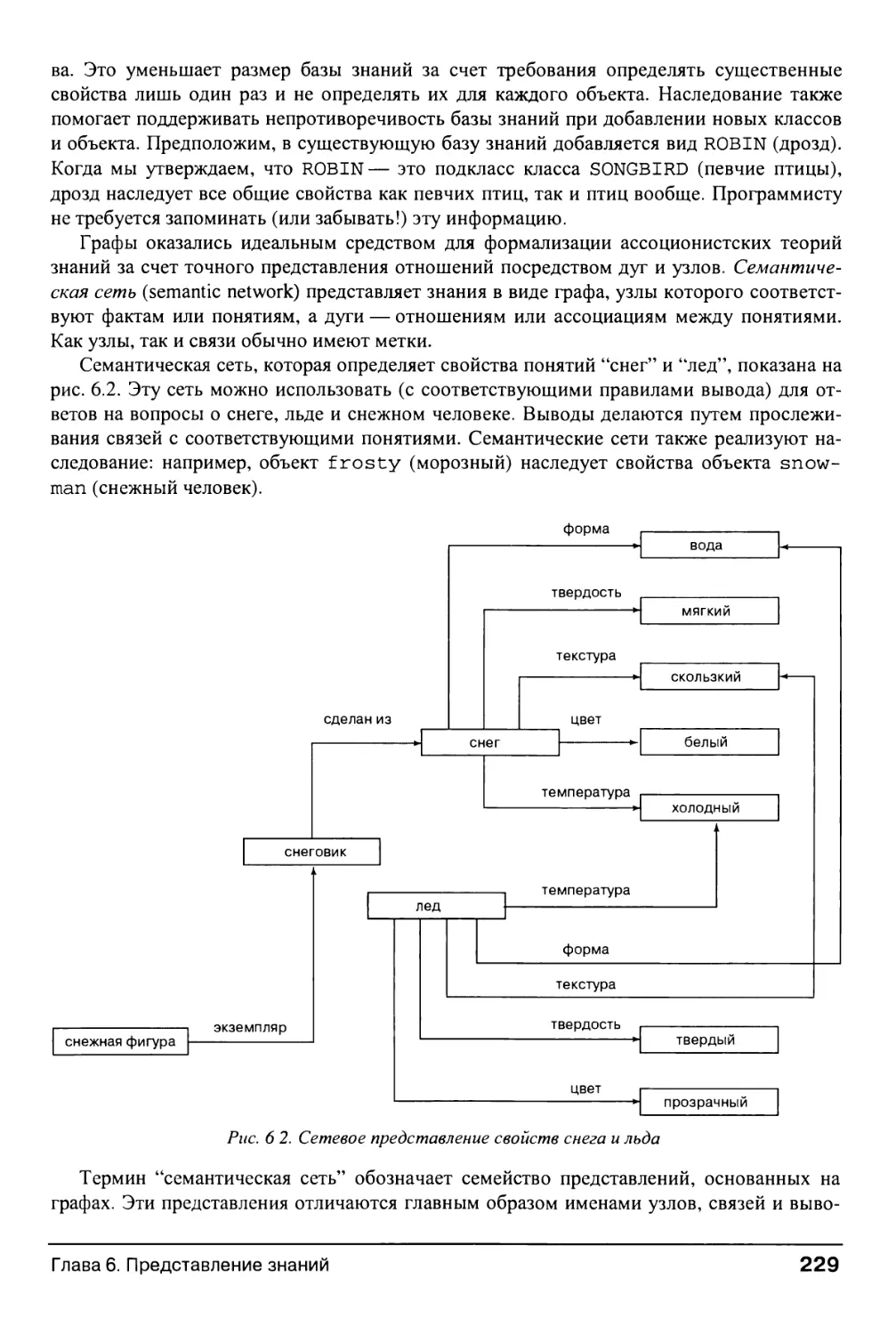
6.0. Вопросы представления знаний 225
6.1. Краткая история схем представления ИИ 226
6.1.1. Ассоционистские теории смысла 226
6.1.2. Ранние работы в области семантических сетей 230
6.1.3. Стандартизация сетевых отношений 232
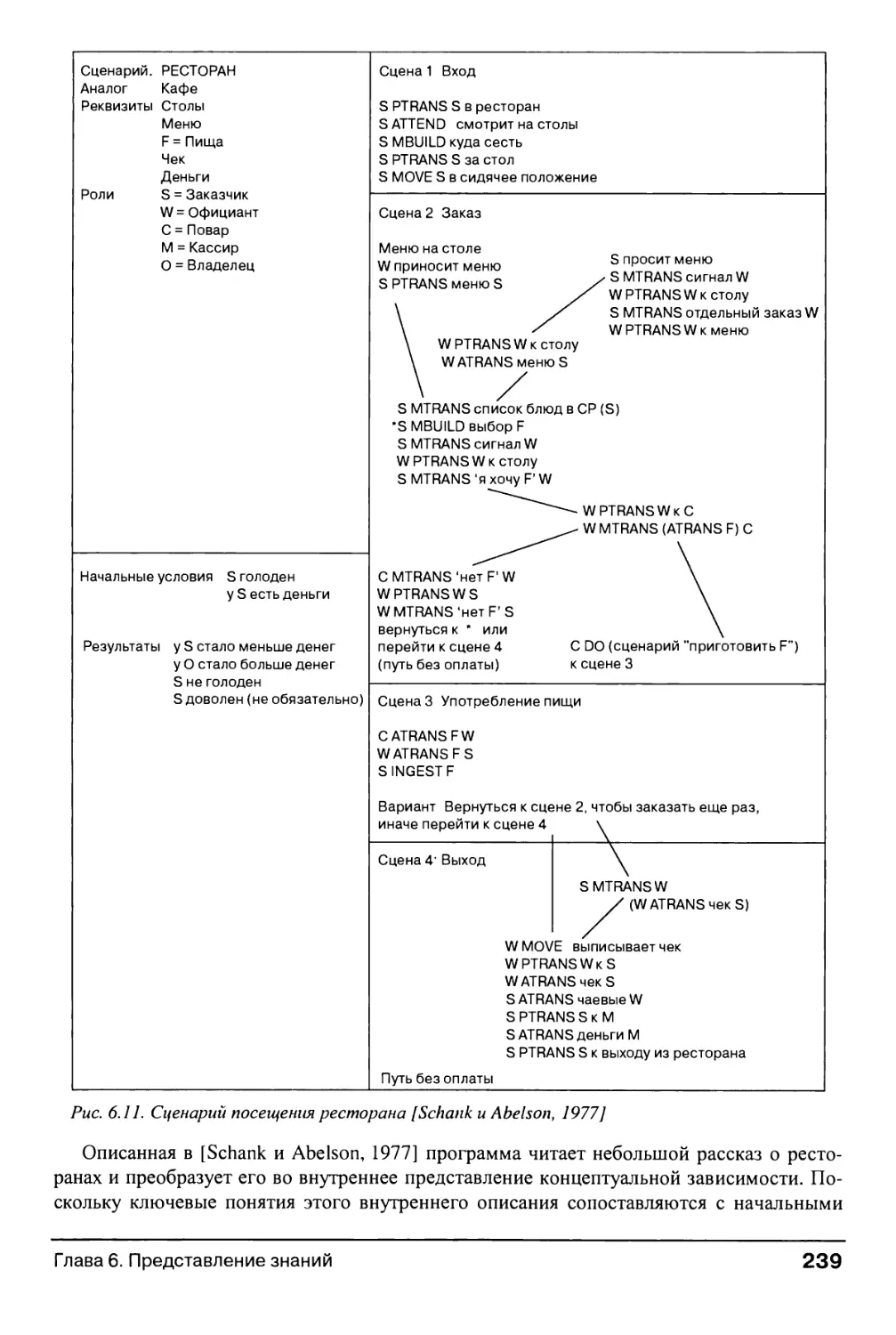
6.1.4. Сценарии 237
6.1.5. Фреймы 241
6.2. Концептуальные графы: сетевой язык 245
6.2.1. Введение в теорию концептуальных графов 245
6.2.2. Типы, экземпляры и имена 246
6.2.3. Иерархия типов 249
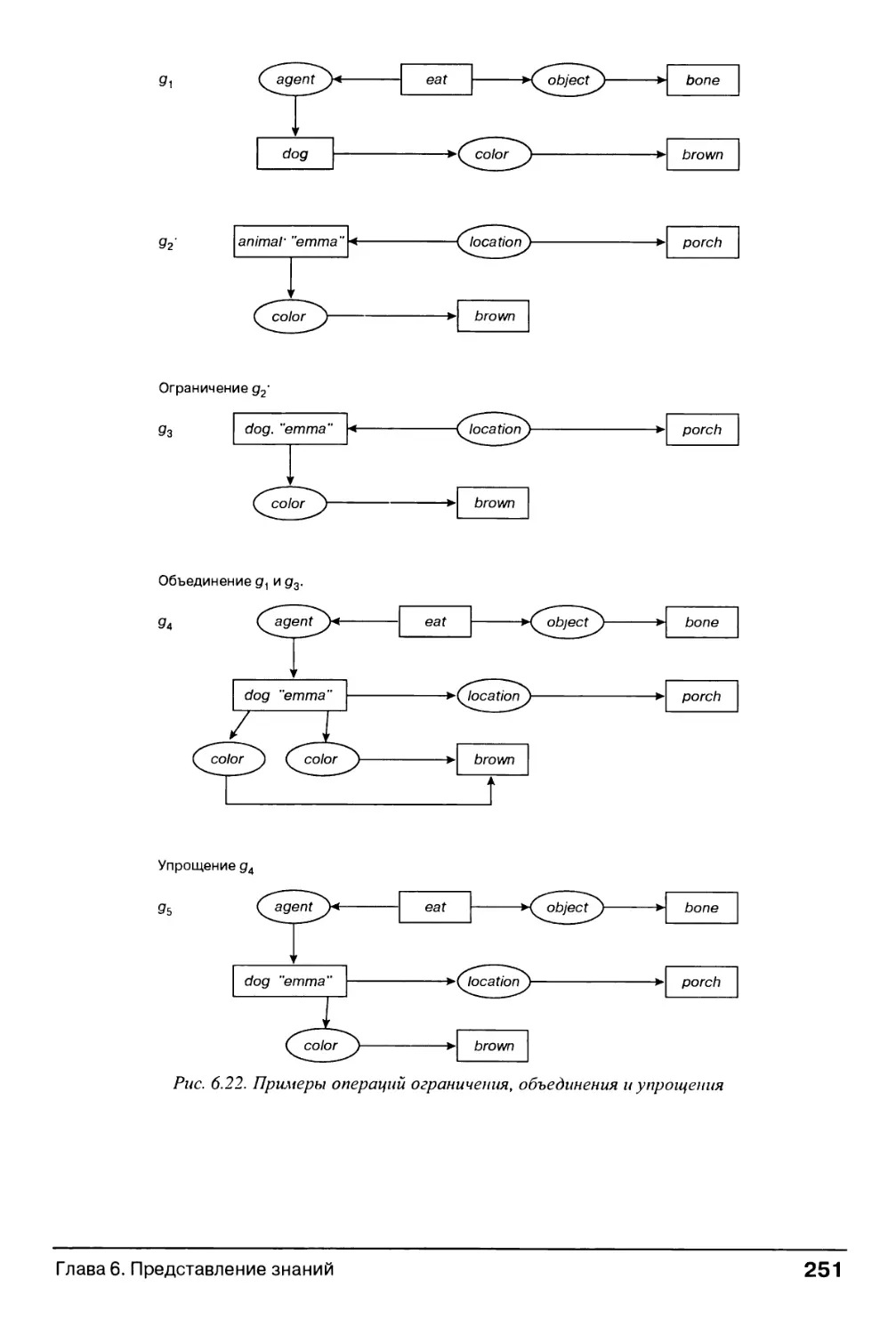
6.2.4. Обобщение и специализация 250
6.2.5. Пропозициональные узлы 253
6.2.6. Концептуальные графы и логика 253
6.3. Альтернативы явному представлению 255
Содержание
9
6.3.1. Гипотезы Брукса и категориальная архитектура 256
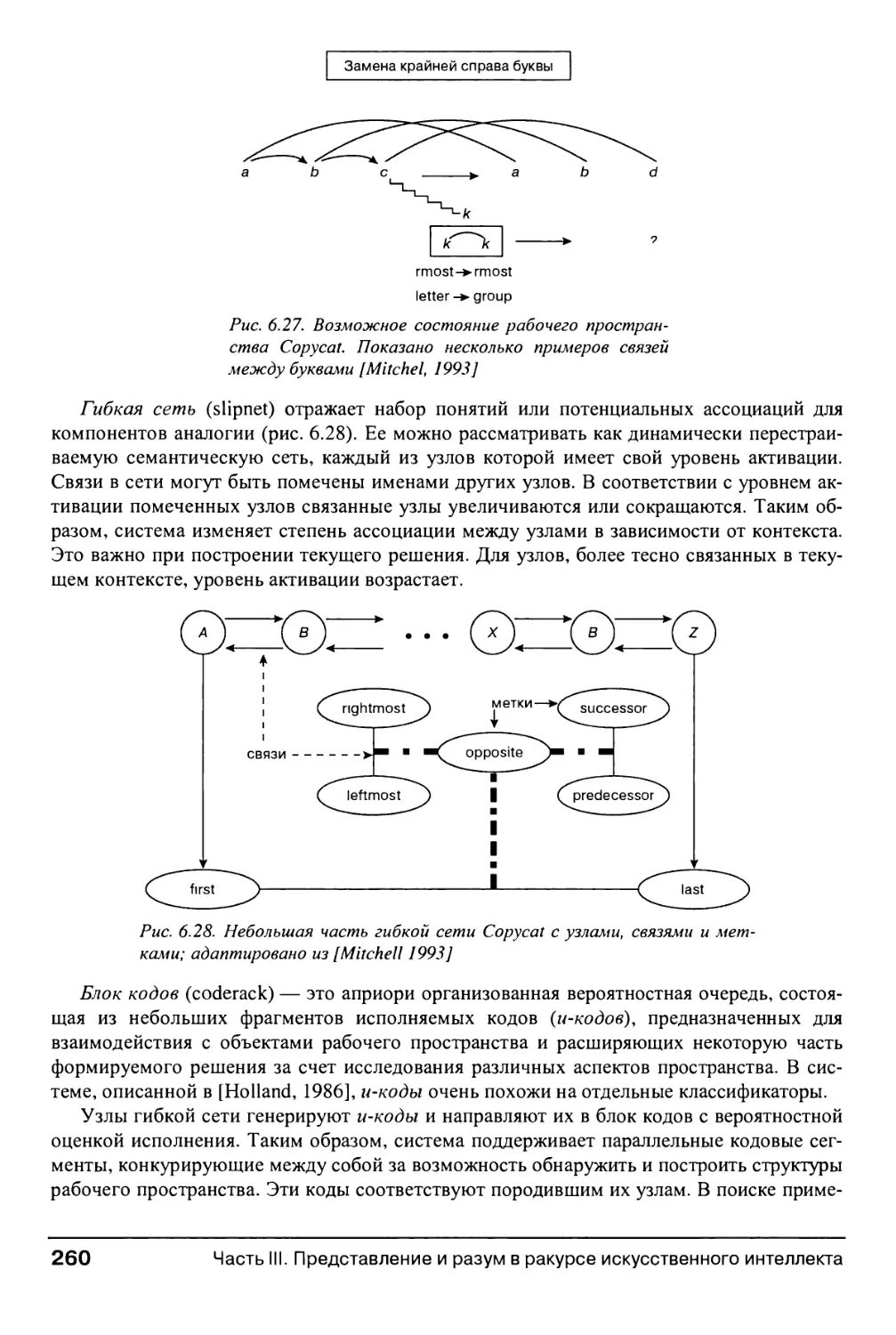
6.3.2. Архитектура Copycat 259
6.4. Агентно-ориентированное и распределенное решение проблем 261
6.4.1. Агентно-ориентированное решение задач: определение 262
6.4.2. Примеры и проблемы агентно-ориентированной парадигмы 264
6.5. Резюме и дополнительная литература 266
6.6. Упражнения 269
Глава 7. Сильные методы решения задач 273
7.0. Введение 273
7.1. Обзор технологии экспертных систем 275
7.1.1. Разработка экспертных систем, основанных на правилах 275
7.1.2. Выбор задачи и процесс инженерии знаний 276
7.1.3. Концептуальные модели и их роль в приобретении знаний 279
7.2. Экспертные системы, основанные на правилах 282
7.2.1. Продукционная система и решение задач на основе цели 282
7.2.2. Объяснения и прозрачность при рассуждениях на основе цели 286
7.2.3. Использование продукционной системы для рассуждений
на основе данных 287
7.2.4. Эвристики и управление в экспертных системах 290
7.3. Рассуждения на основе моделей, на базе опыта и гибридные системы 292
7.3.1. Введение в рассуждения на основе модели 292
7.3.2. Рассуждения на основе моделей: пример NASA 296
7.3.3. Введение в рассуждения на основе опыта 299
7.3.4. Гибридные системы: достоинства и недостатки систем
с сильными методами 303
7.4. Планирование 307
7.4.1. Введение 307
7.4.2. Использование макросов планирования: STRIPS 311
7.4.3. Адаптивное планирование 316
7.4.4. Планирование: пример NASA 318
7.5. Резюме и дополнительная литература 321
7.6. Упражнения 322
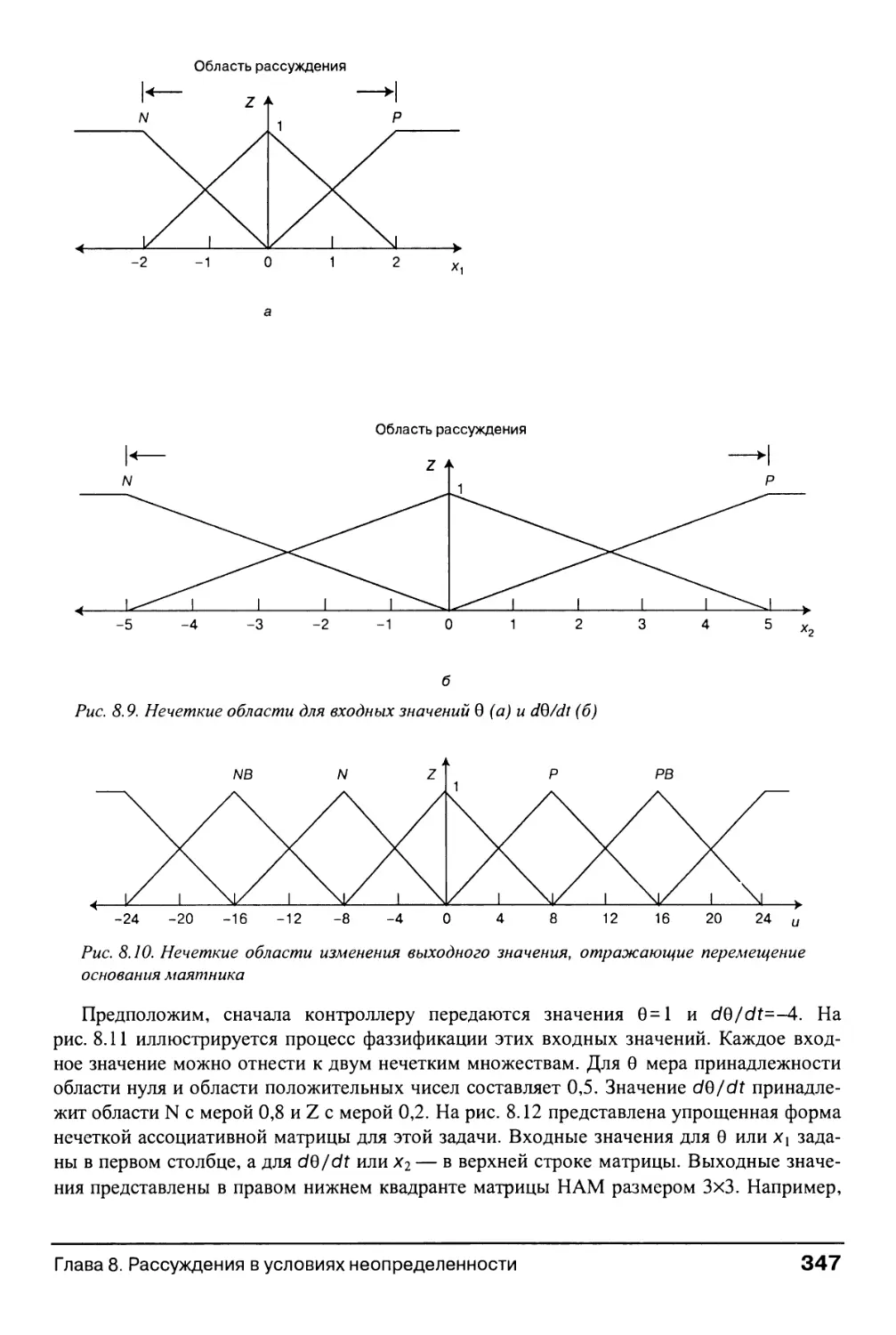
Глава 8. Рассуждения в условиях неопределенности 325
8.0. Введение 325
8.1. Абдуктивный вывод, основанный на логике 327
8.1.1. Логика немонотонных рассуждений 327
8.1.2. Системы поддержки истинности 331
8.1.3. Логики, основанные на минимальных моделях 336
8.1.4. Множественное покрытие и логическая абдукция 338
8.2. Абдукция: альтернативы логическому подходу 341
8.2.1. Неточный вывод на основе фактора уверенности 342
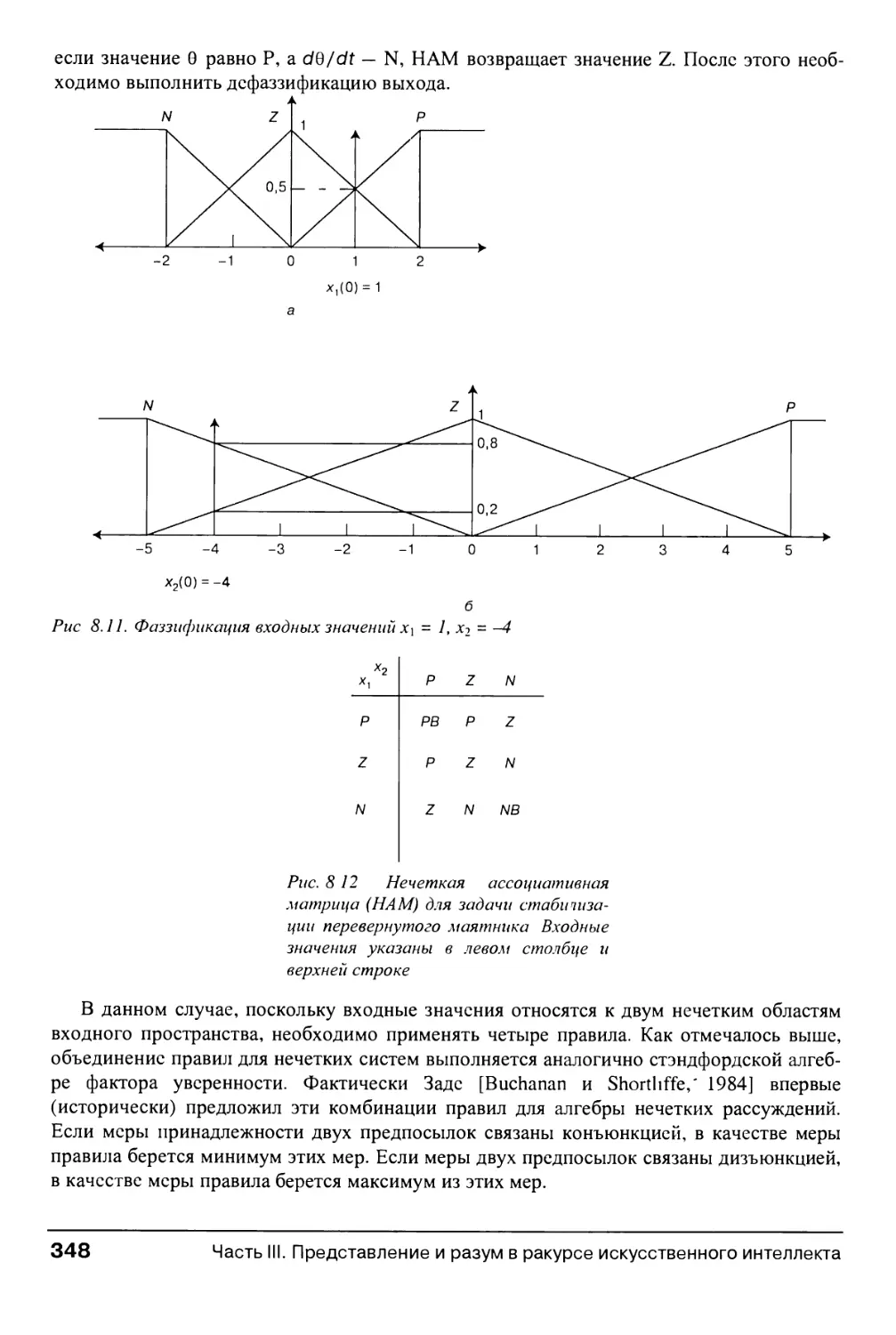
8.2.2. Рассуждения с нечеткими множествами 344
8.2.3. Теория доказательства Демпстера-Шафера 350
8.3. Стохастический подход к описанию неопределенности 354
8.3.1. Байесовские рассуждения 355
8.3.2. Байесовские сети доверия 359
10
Содержание
8.4. Резюме и дополнительная литература
8.5. Упражнения
365
367
Часть IV. Машинное обучение 369
Символьное, нейросетевое и эмерджентное обучение 369
Глава 9. Машинное обучение, основанное на символьном представлении
информации 371
9.0. Введение 371
9.1. Символьное обучение 374
9.2. Поиск в пространстве версий 380
9.2.1. Операция обобщения и пространство понятий 380
9.2.2. Алгоритм исключения кандидата 381
9.2.3. Программа LEX: индуктивное изучение эвристик поиска 388
9.2.4. Обсуждение алгоритма исключения кандидата 391
9.3. Индуктивный алгоритм построения дерева решений ID3 392
9.3.1. Построение дерева решений сверху вниз 394
9.3.2. Выбор свойств на основе теории информации 396
9.3.3. Анализ алгоритма ID3 398
9.3.4. Вопросы обработки данных для построения дерева решений 399
9.4. Индуктивный порог и возможности обучения 400
9.4.1. Индуктивный порог 400
9.4.2. Теория изучаемости 403
9.5. Знания и обучение 405
9.5.1. Алгоритм Meta-DENDRAL 406
9.5.2. Обучение на основе объяснения 407
9.5.3. Алгоритм EBL и обучение на уровне знаний 411
9.5.4. Обоснование по аналогии 412
9.6. Обучение без учителя 415
9.6.1. Научная деятельность и обучение без учителя 415
9.6.2. Концептуальная кластеризация 417
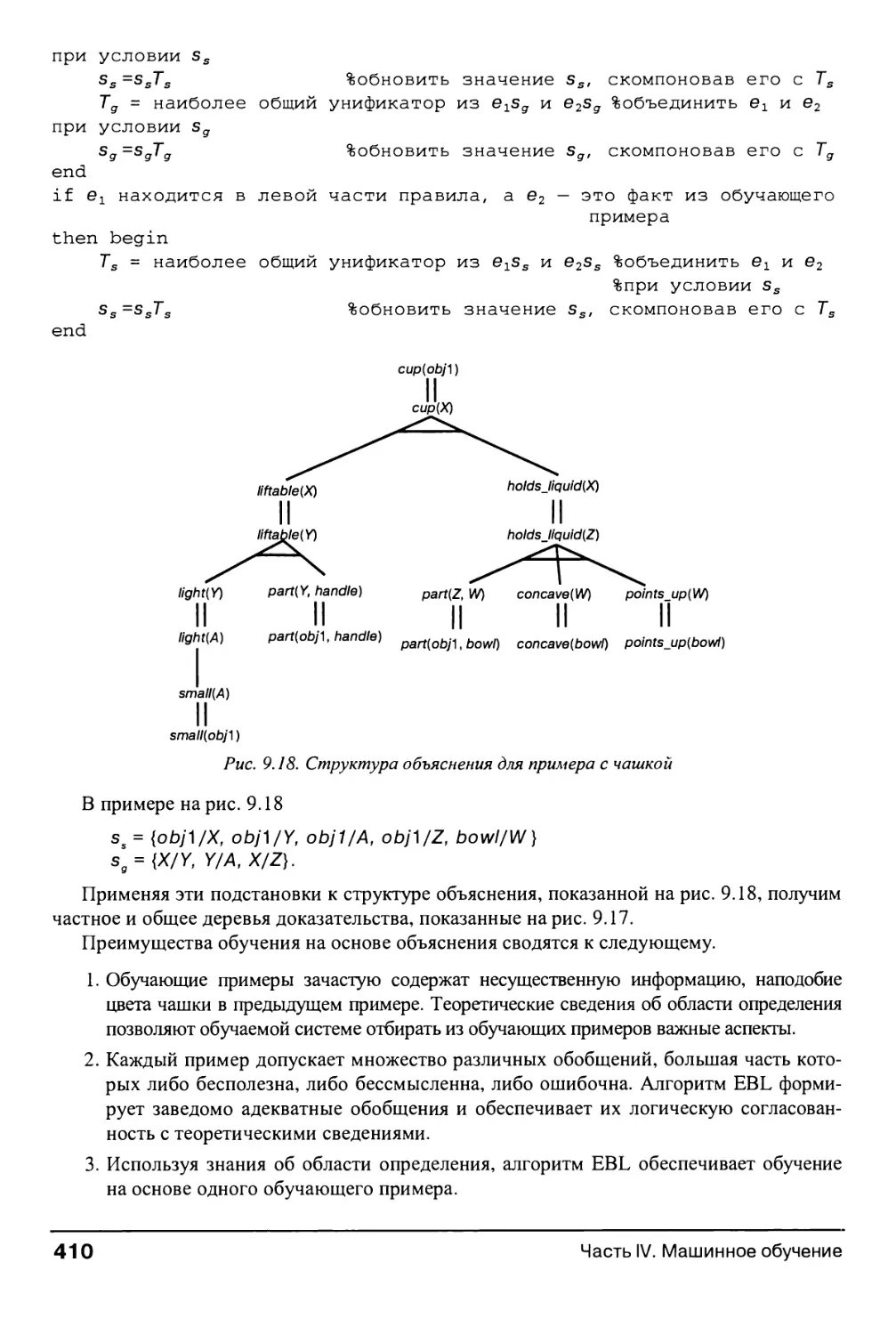
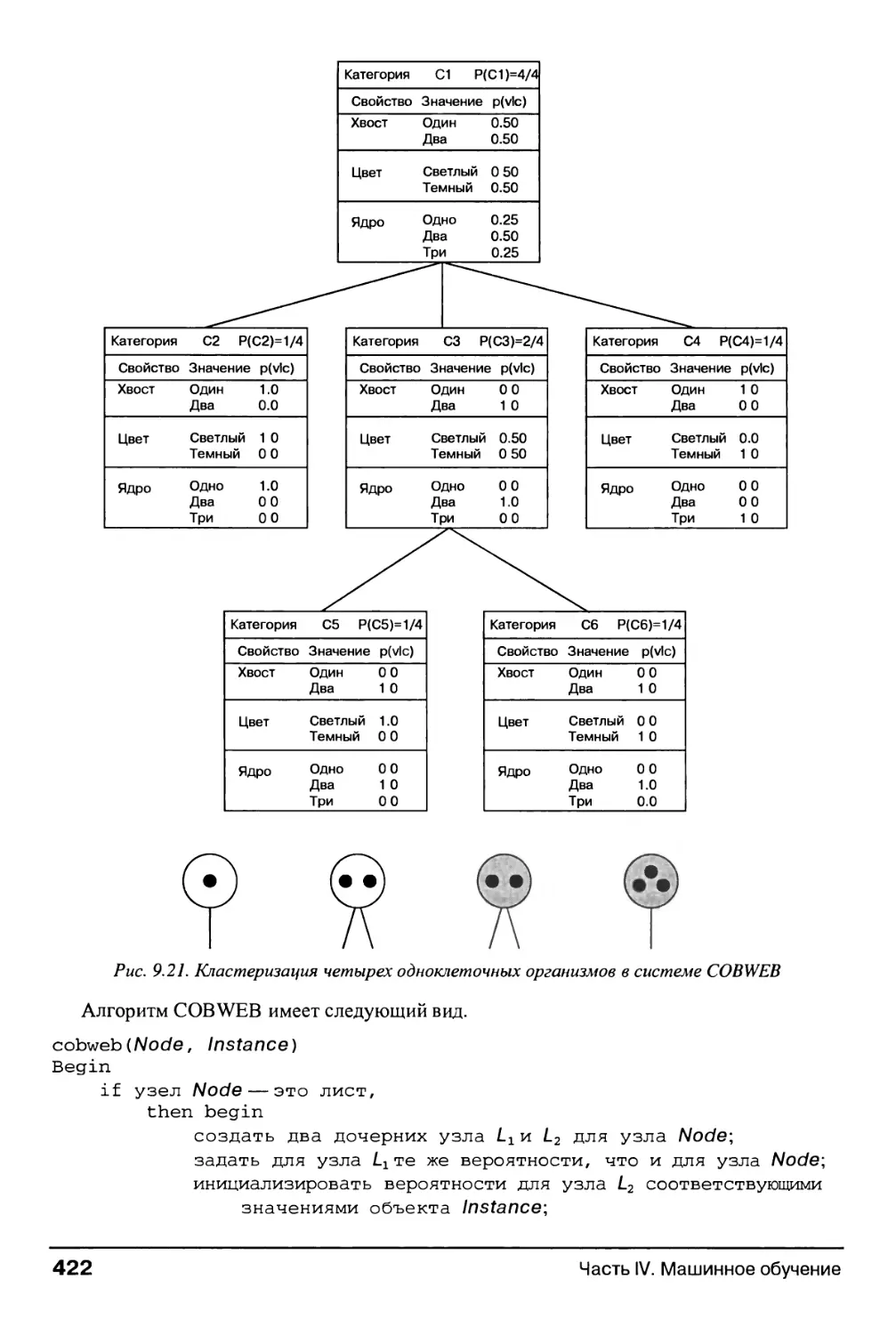
9.6.3. Программа СОВ-WEB и структурные таксономические знания 419
9.7. Обучение с подкреплением 424
9.7.1. Компоненты обучения с подкреплением 425
9.7.2. Пример: снова "крестики-нолики" 427
9.7.3. Алгоритмы вывода и их применение к обучению с подкреплением 429
9.8. Резюме и ссылки 431
9.9. Упражнения 432
Глава 10. Машинное обучение на основе связей 435
10.0. Введение 435
10.1. Основы теории сетей связей 437
10.1.1. Ранняя история 437
10.2. Обучение персептрона 439
10.2.1. Алгоритм обучения персептрона 439
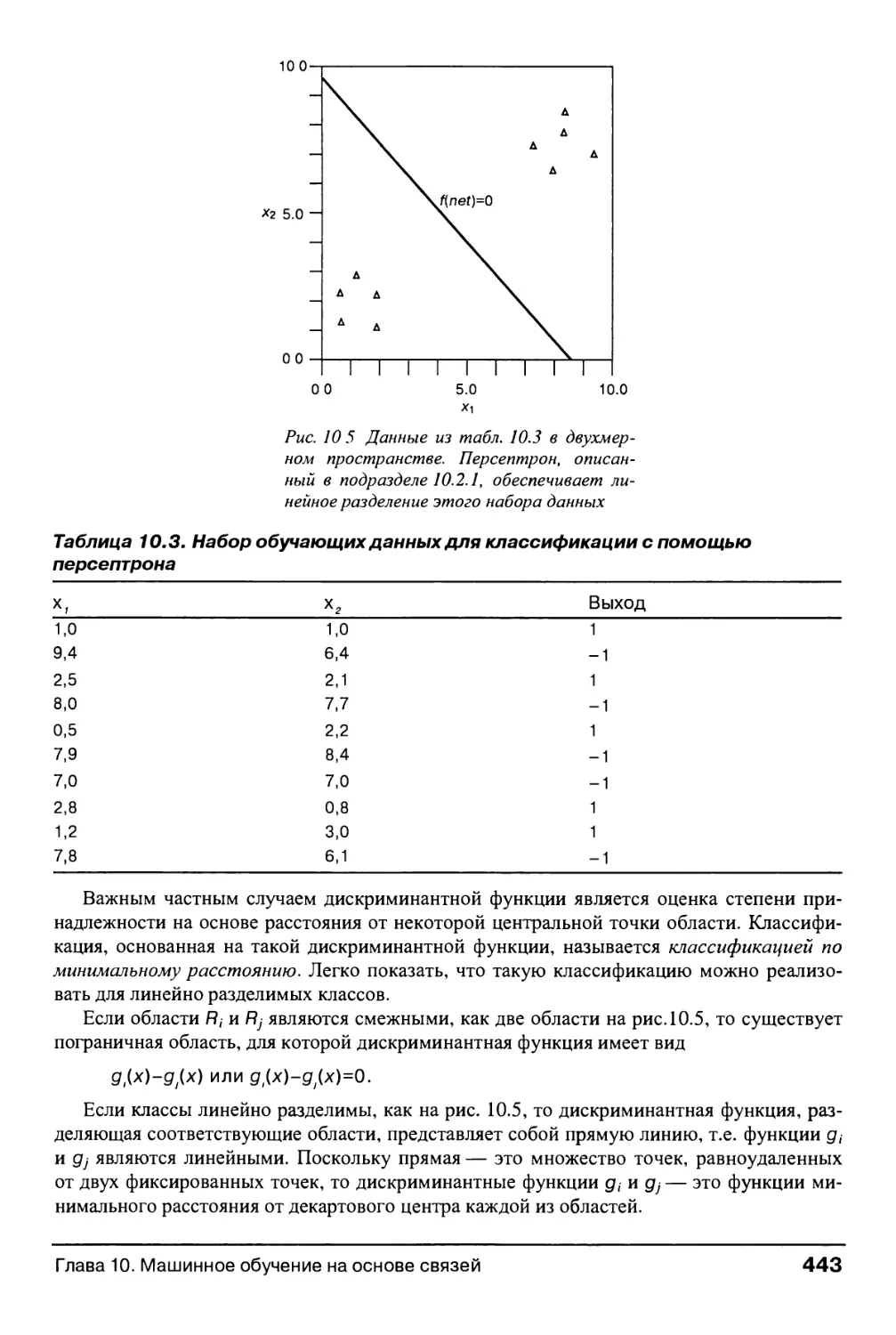
10.2.2. Пример: использование персептронной сети для классификации образов 442
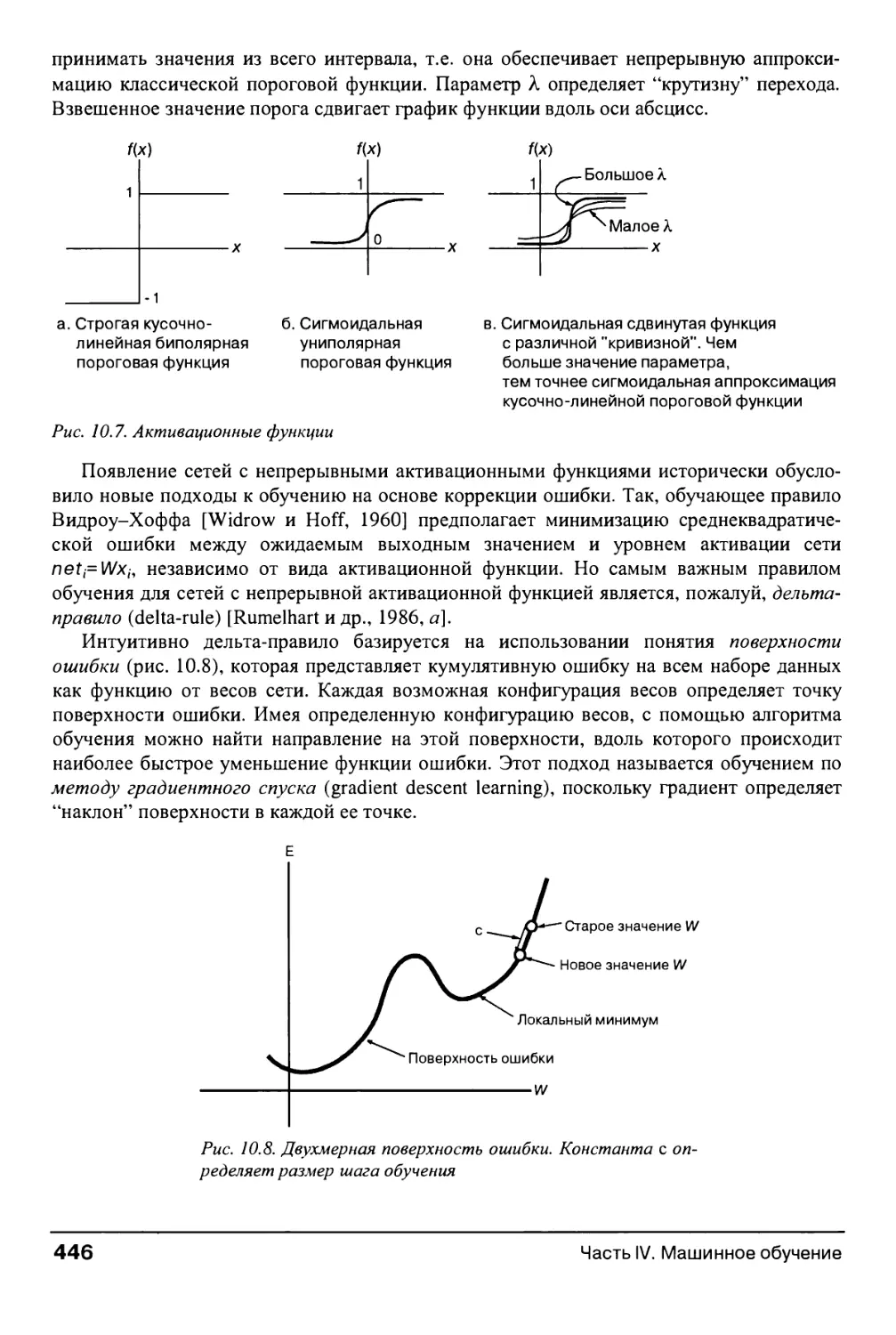
10.2.3. Обобщенное дельта-правило 445
10.3. Обучение по методу обратного распространения 448
Содержание
11
10.3.1. Вывод алгоритма обратного распространения 448
10.3.2. Пример применения метода обратного распространения ошибки:
система NETtalk 452
10.3.3. Применение метода обратного распространения для решения задачи
"исключающего ИЛИ" 454
10.4. Конкурентное обучение 455
10.4.1. Алгоритм обучения "победитель забирает все" для задачи классификации 455
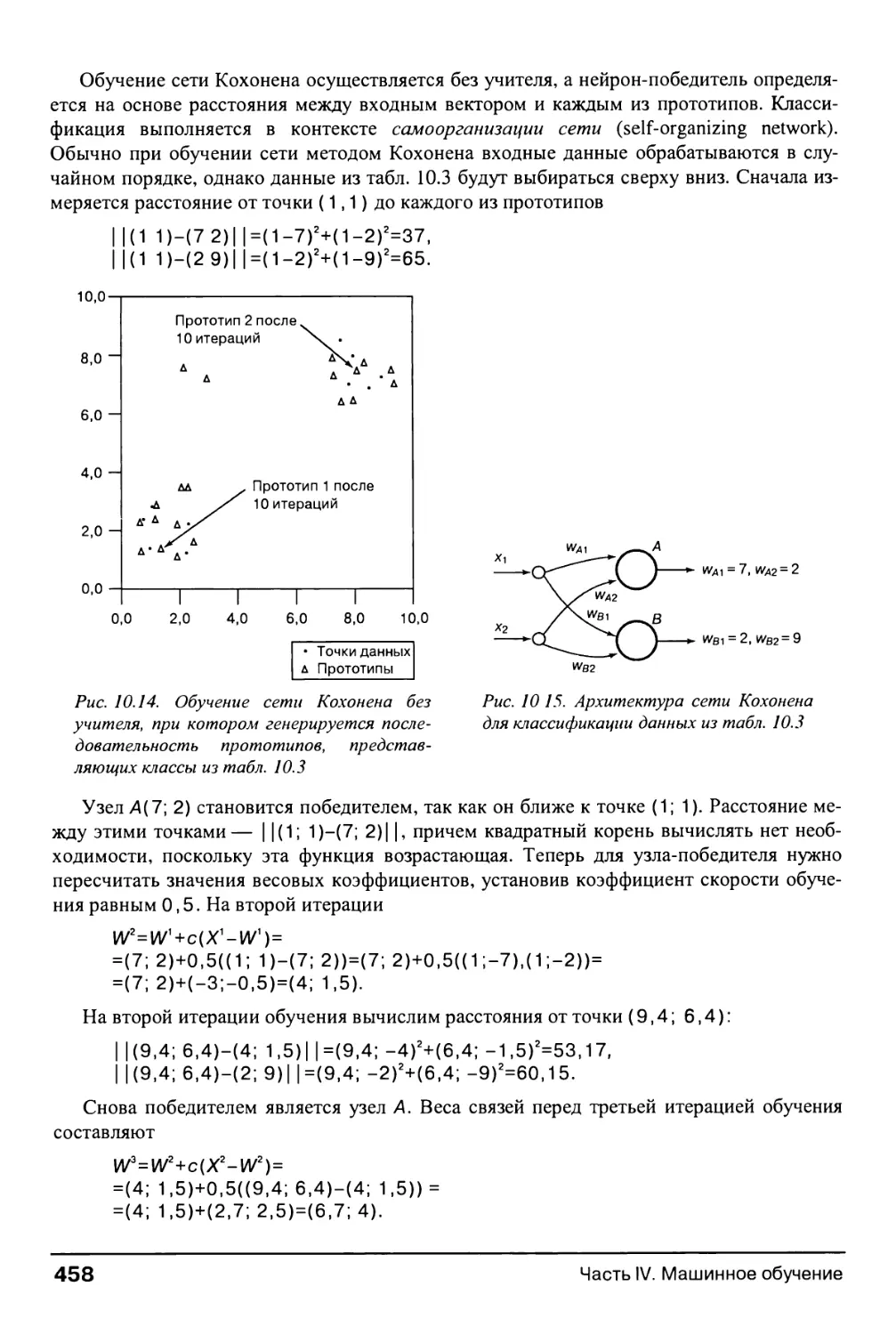
10.4.2. Сеть Кохонена для изучения прототипов 457
10.4.3. Нейроны Гроссберга и сети встречного распространения 459
10.5. Синхронное обучение Хебба 462
10.5.1. Введение 462
10.5.2. Пример алгоритма обучения Хебба без учителя 463
10.5.3. Обучение Хебба с учителем 466
10.5.4. Ассоциативная память и линейный ассоциатор 467
10.6. Аттракторные сети (сети "ассоциативной памяти") 471
10.6.1. Введение 471
10.6.2. Двунаправленная ассоциативная память 472
10.6.3. Примеры обработки данных в сети ДАП 475
10.6.4. Автоассоциативная память и сети Хопфилда 477
10.7. Резюме и дополнительная литература 481
10.8. Упражнения 482
Глава 11. Машинное обучение на основе социальных и эмерджентных
принципов 483
11.0. Социальные и эмерджентные модели обучения 483
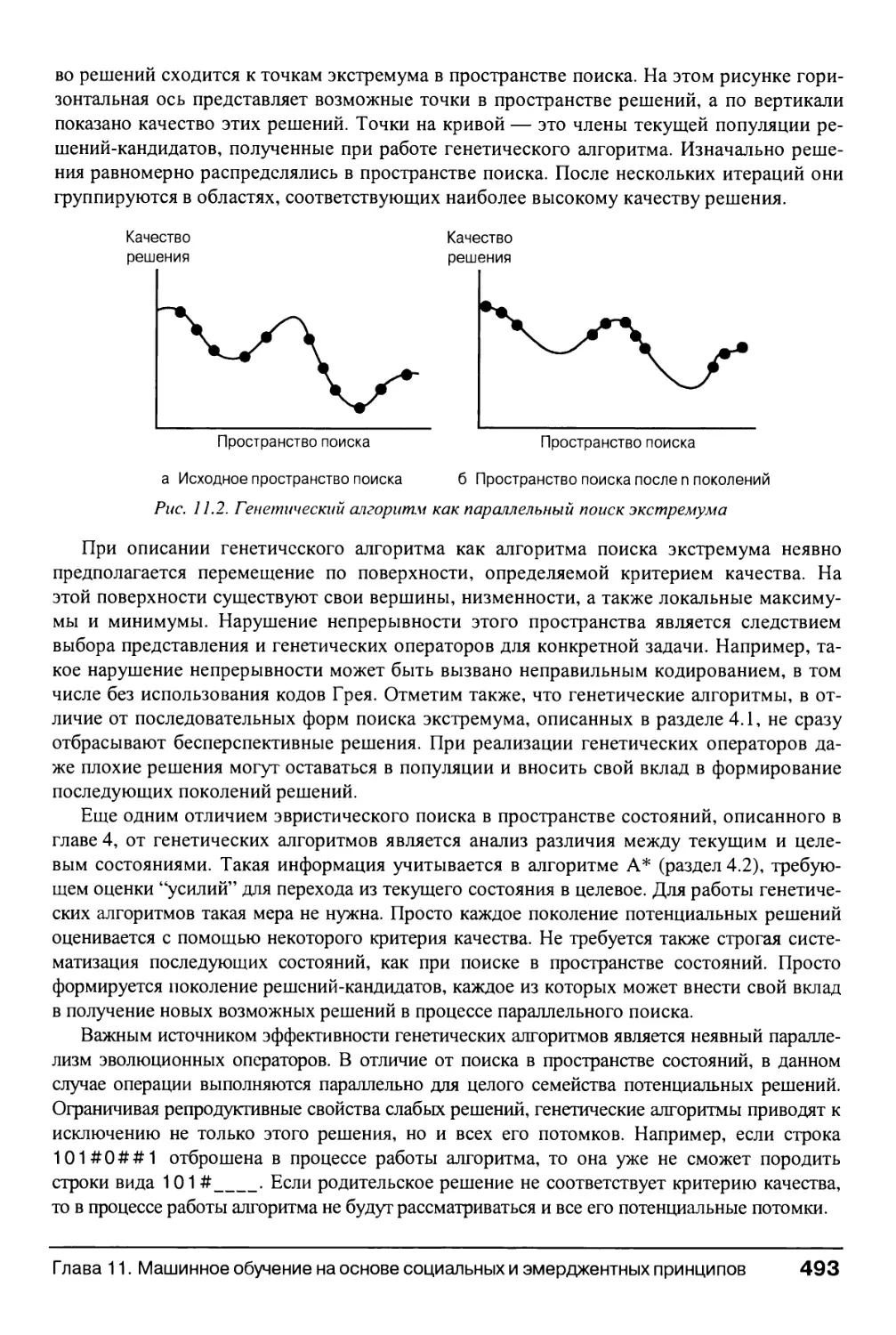
11.1. Генетические алгоритмы 485
11.1.3. Два примера: описание задачи в конъюнктивной нормальной
форме и задача коммивояжера 488
11.1.4. Обсуждение генетического алгоритма 491
11.2. Системы классификации и генетическое программирование 495
11.2.1. Системы классификации 495
11.2.2. Программирование с использованием генетических операторов 500
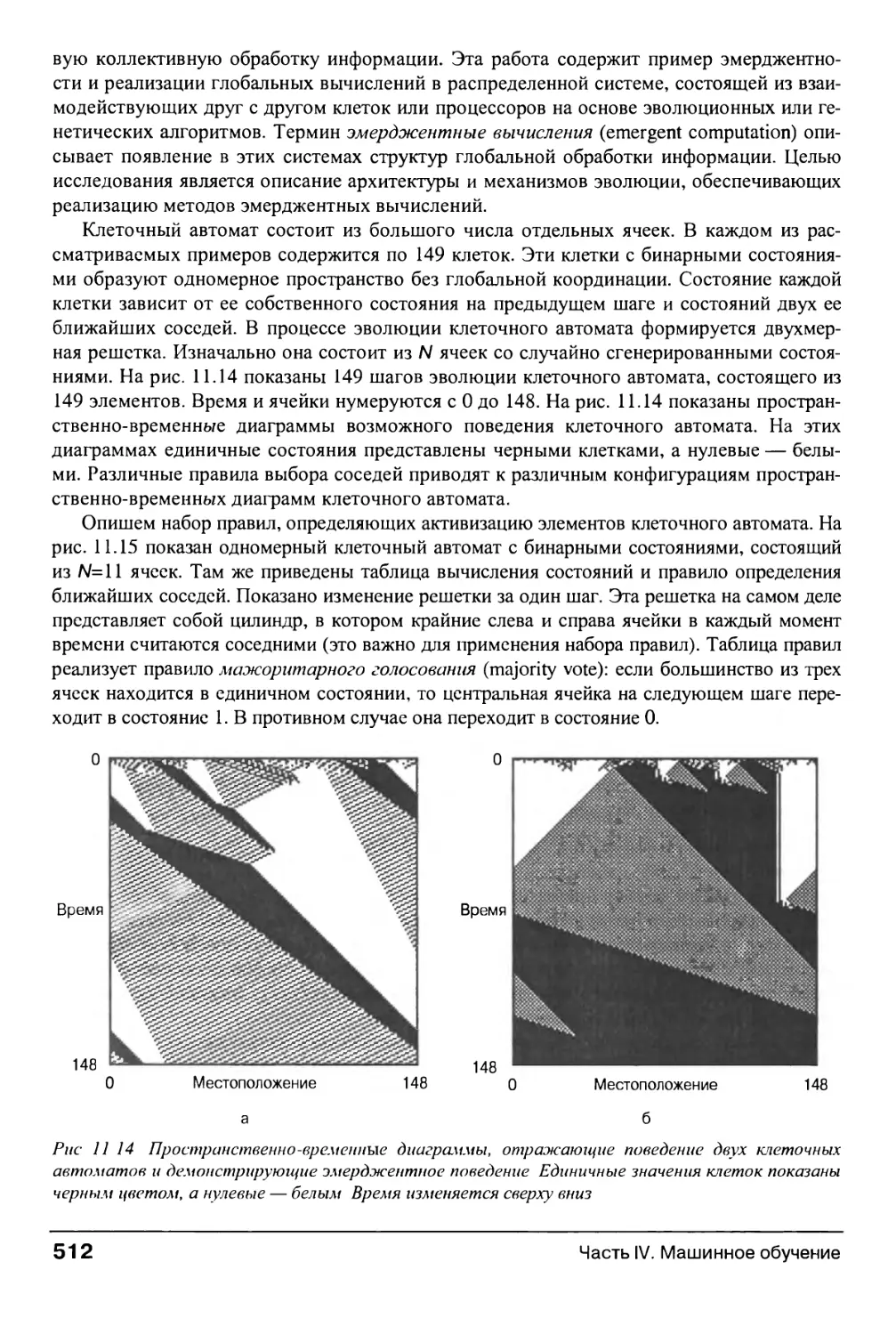
11.3. Искусственная жизнь и эмерджентное обучение 505
11.3.1. Игра "Жизнь" 506
11.3.2. Эволюционное программирование 509
11.3.3. Пример эмерджентности 511
11.4. Резюме и дополнительная литература 515
11.5. Упражнения 516
Часть V. Дополнительные вопросы решения задач
искусственного интеллекта 519
Автоматические рассуждения и естественный язык 519
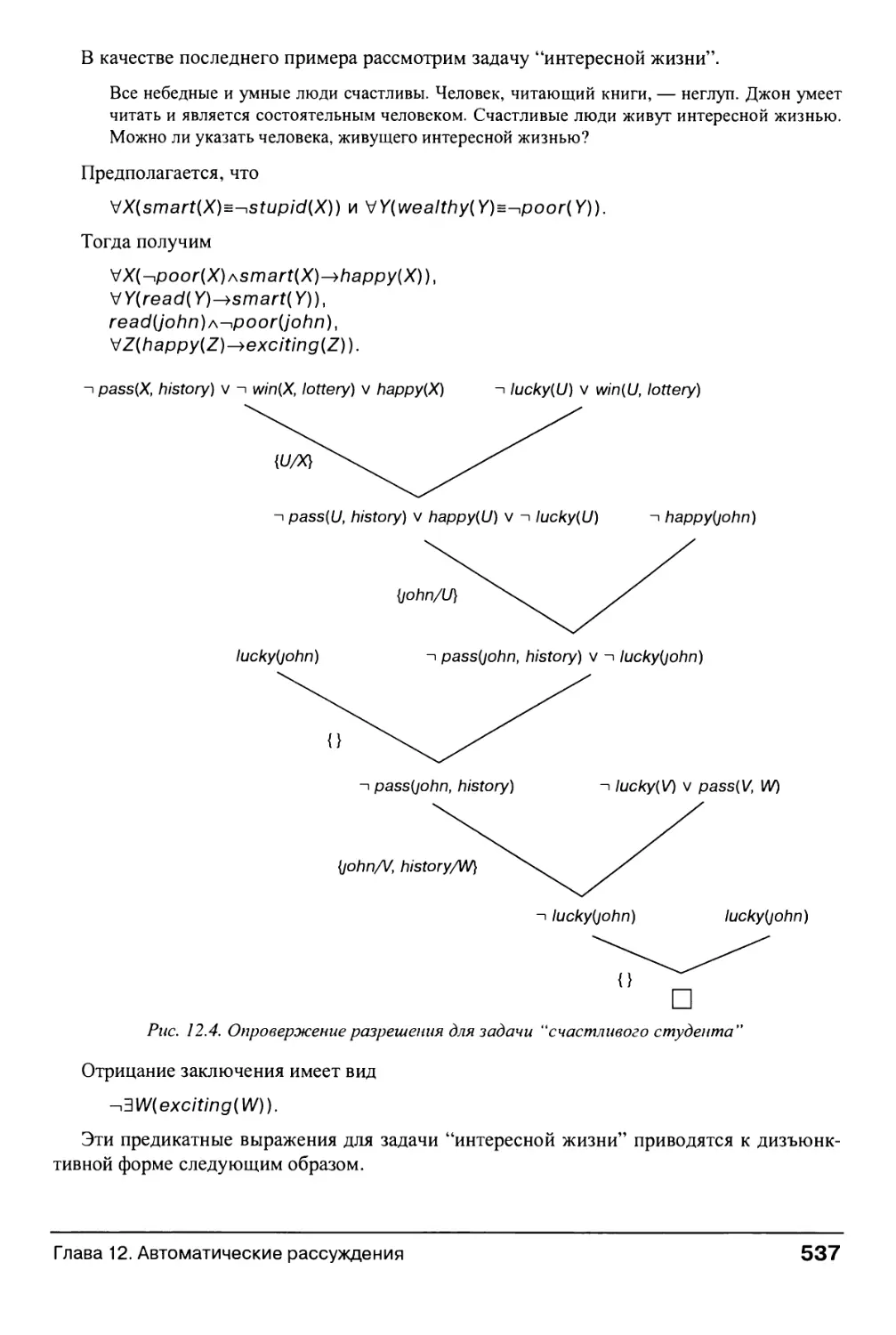
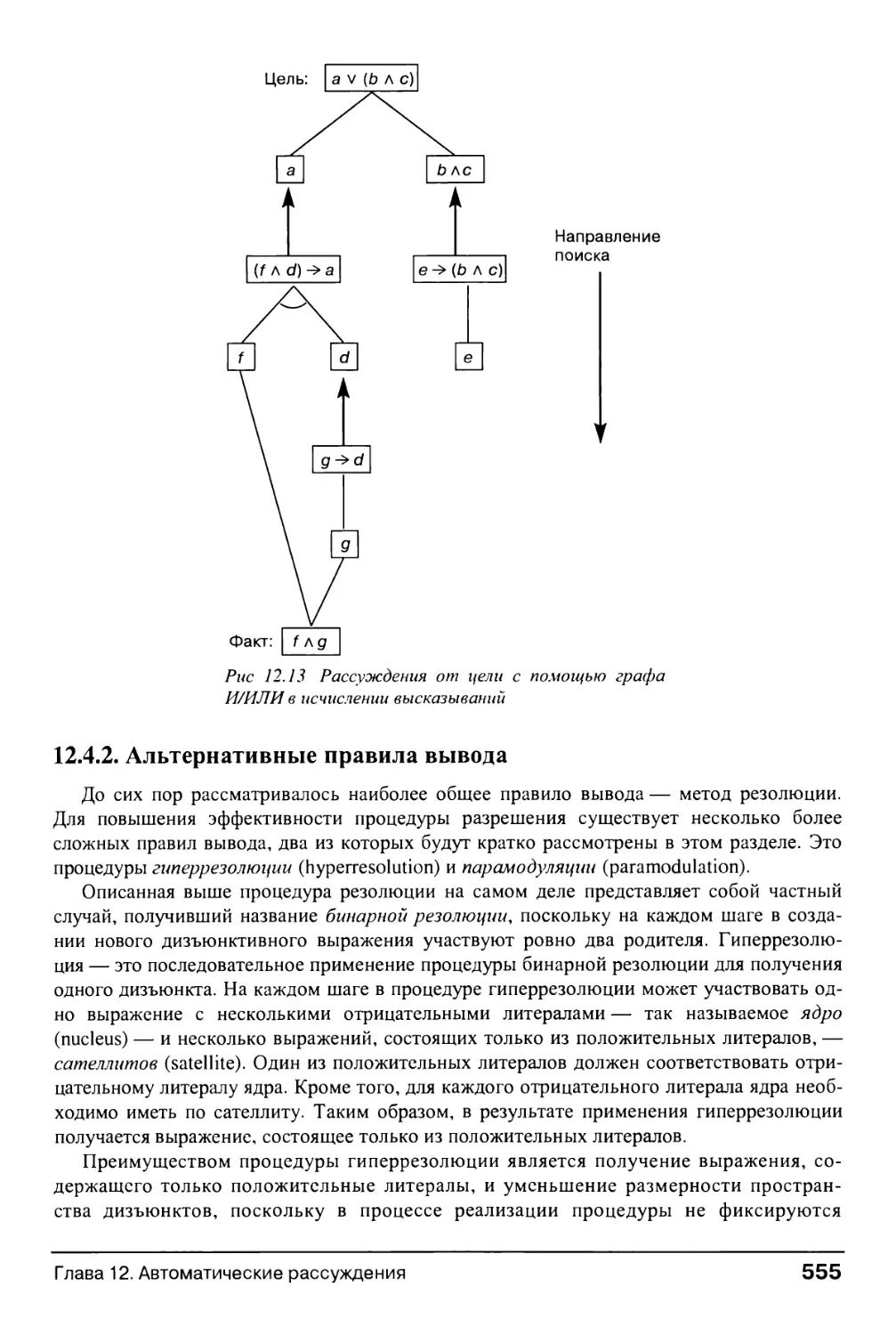
Глава 12. Автоматические рассуждения 521
12.0. Введение в слабые методы доказательства теорем 521
12.1. Система решения общих задач и таблицы отличий 522
12.2. Доказательство теорем методом резолюции 528
12.2.1. Введение 528
12
Содержание
12.2.2. Построение дизъюнктивной формы для опровержения разрешения 530
12.2.3. Процедура доказательства на основе бинарной резолюции 533
12.2.4. Стратегии и методы упрощения резолюции 538
12.2.5. Извлечение ответов в процессе опровержения 543
12.3. Язык PROLOG и автоматические рассуждения 546
12.3.1. Введение 546
12.3.2. Логическое программирование и язык PROLOG 547
12.4. Дополнительные вопросы автоматических рассуждений 552
12.4.1. Единое представление для реализации слабых методов решения 552
12.4 2. Альтернативные правила вывода 555
12.4.3. Стратегии поиска и их использование 557
12.5. Резюме и дополнительная литература 558
12.6. Упражнения 559
Глава 13. Понимание естественного языка 561
13.0. Проблема понимания естественного языка 561
13.1. Разбор языка: символьный анализ 564
13.1.1. Введение 564
13.1.2. Стадии анализа языка 565
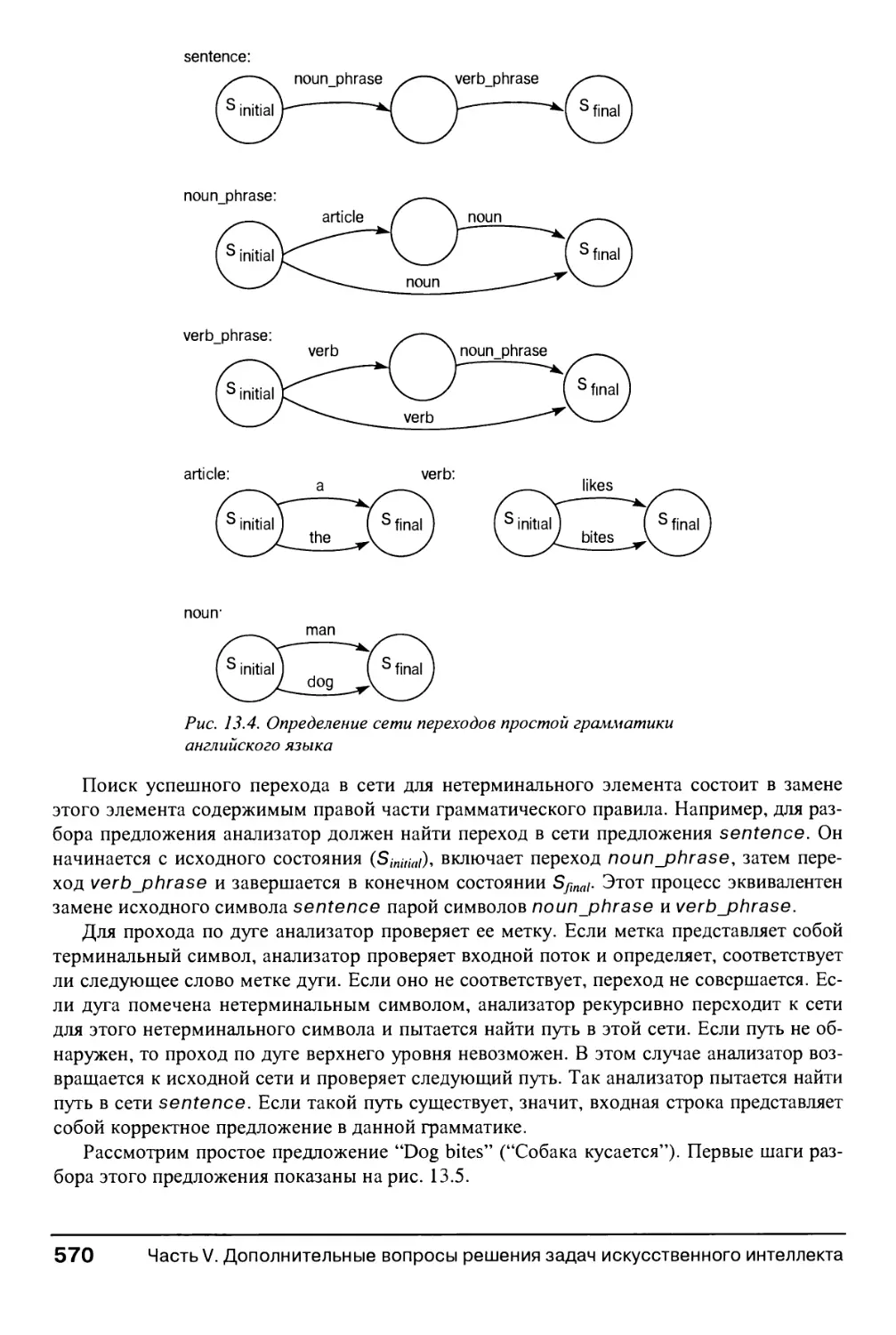
13.2. Синтаксический анализ 567
13.2.1. Спецификация и синтаксический анализ с использованием
контекстно-свободных грамматик 567
13.2.2. Анализаторы на основе сети переходов 569
13.2.3. Иерархия Хомского и контекстно-зависимые грамматики 573
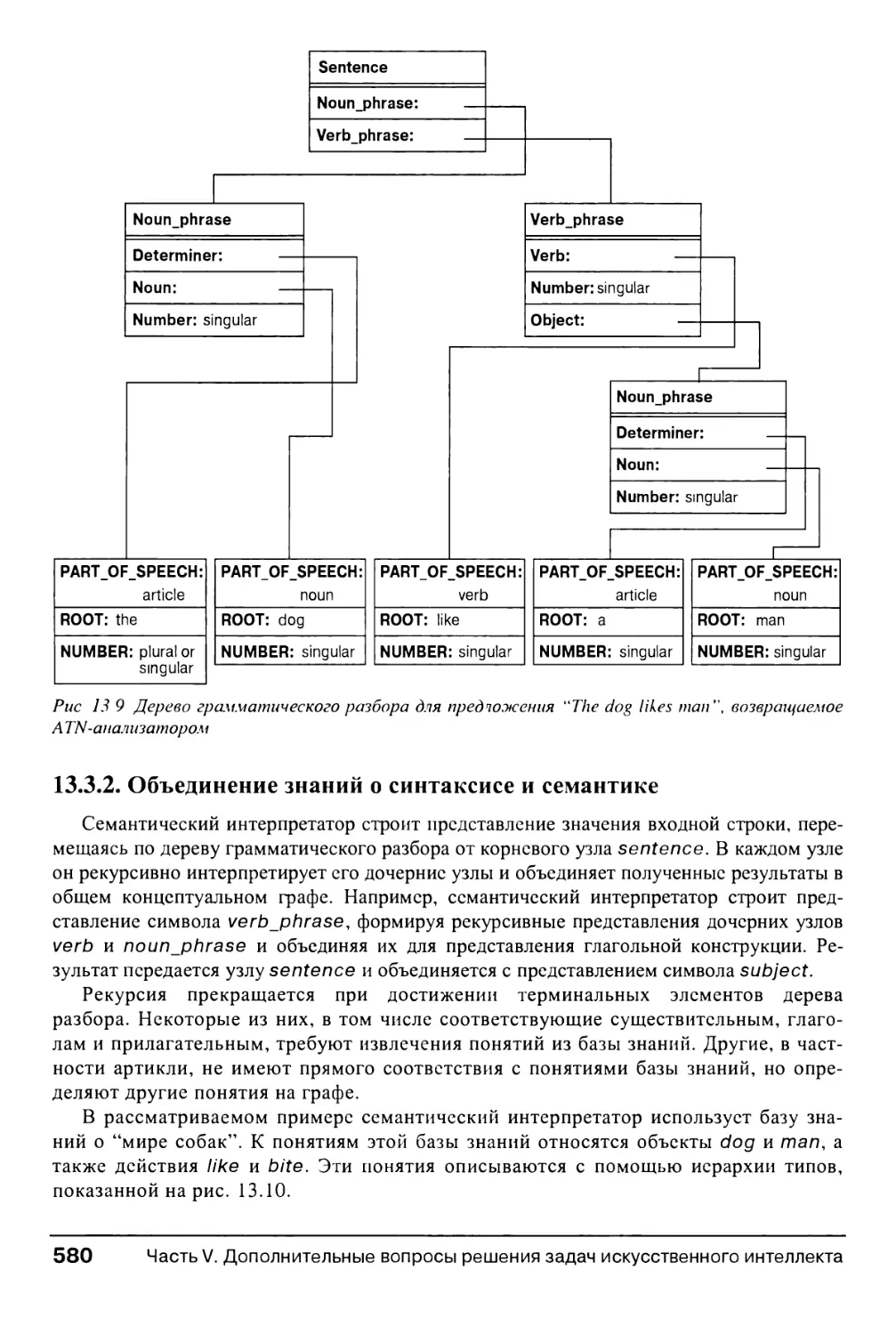
13.3. Синтаксис и знания в ATN-анализаторах 576
13.3.1. Анализаторы на основе расширенных сетей переходов 576
13.3.2. Объединение знаний о синтаксисе и семантике 580
13.4. Стохастический подход к анализу языка 585
13.4.1. Введение 585
13.4.2. Подход на основе марковских моделей 586
13.4.3. Подход на основе дерева решений 588
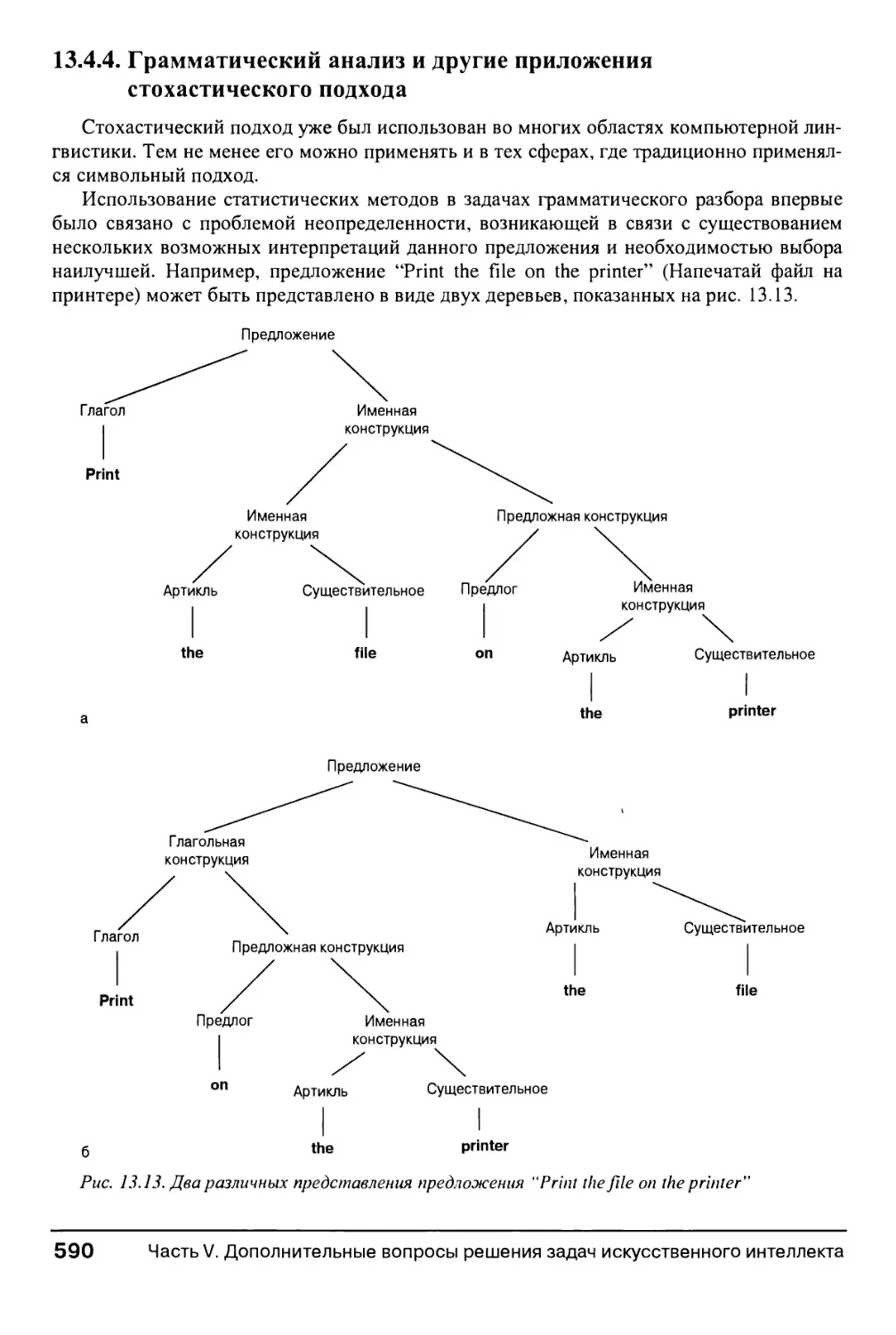
13.4.4. Грамматический анализ и другие приложения стохастического подхода 590
13.5. Приложения задачи анализа естественного языка 592
13.5.1. Обучение и ответы на вопросы 592
13.5.2. Интерфейс для базы данных 592
13.5.3. Извлечение информации и системы автоматического
резюмирования для Web 596
13.5.4. Использование алгоритмов обучения для обобщения извлеченной
информации 598
13.6. Резюме и дополнительная литература 598
13.7. Упражнения 600
Часть VI. Языки и технологии программирования
для искусственного интеллекта 603
Обзор языков PROLOG и LISP 606
PROLOG 606
LISP 607
Выбор языка реализации 608
Содержание
13
Глава 14. Введение в PROLOG 609
14.0. Введение 609
14.1. Синтаксис для программирования логики предикатов 610
14.1.1. Представление фактов и правил 610
14.1.2. Создание, изменение и мониторинг среды PROLOG 614
14.1.3. Списки и рекурсия в языке PROLOG 615
14.1.4. Рекурсивный поиск в языке PROLOG 618
14.1.5. Использование оператора отсечения для управления поиском
в языке PROLOG 620
14.2. Абстрактные типы данных в PROLOG 622
14.2.1. Стек 622
14.2.2. Очередь 624
14.2.3. Приоритетная очередь 624
14.2.4. Множество 625
14.3. Пример продукционной системы на языке PROLOG 626
14.4. Разработка альтернативных стратегий поиска 631
14.4.1. Поиск в глубину с использованием списка closed 631
14.4.2. Поиск в ширину в языке PROLOG 633
14.4.3. Реализация "жадного" алгоритма поиска на языке PROLOG 634
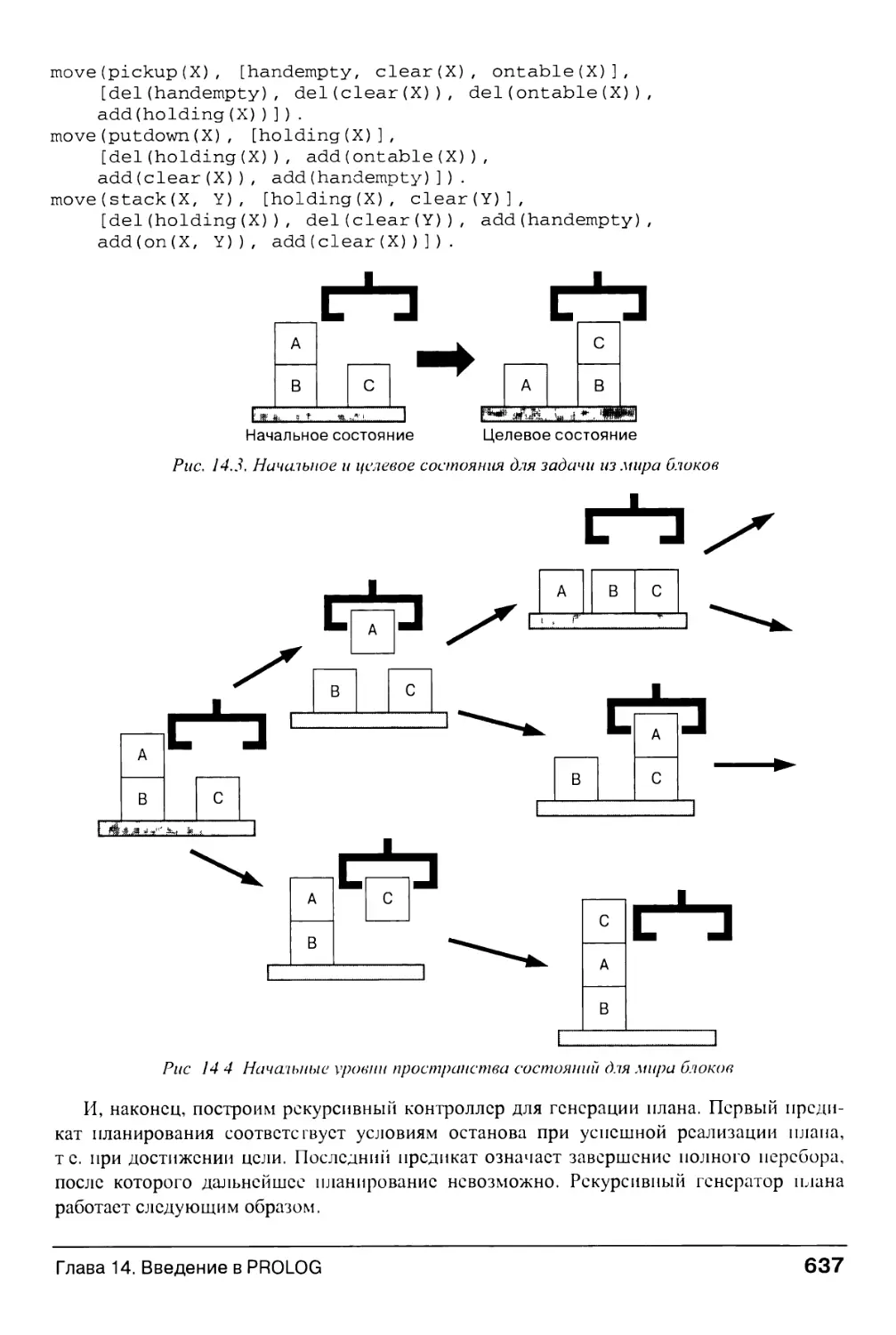
14.5. Реализация планировщика на языке PROLOG 636
14.6. Метапредикаты, типы и подстановки унификации в языке PROLOG 639
14.6.1. Металогические предикаты 639
14.6.2. Типы данных в языке PROLOG 640
14.6.3. Унификация, механизм проверки соответствия предикатов и оценка 643
14.7. Метаинтерпретаторы в языке PROLOG 646
14.7.1. Введение в метаинтерпретаторы: PROLOG в языке PROLOG 646
14.7.2. Оболочка для экспертной системы на основе правил 649
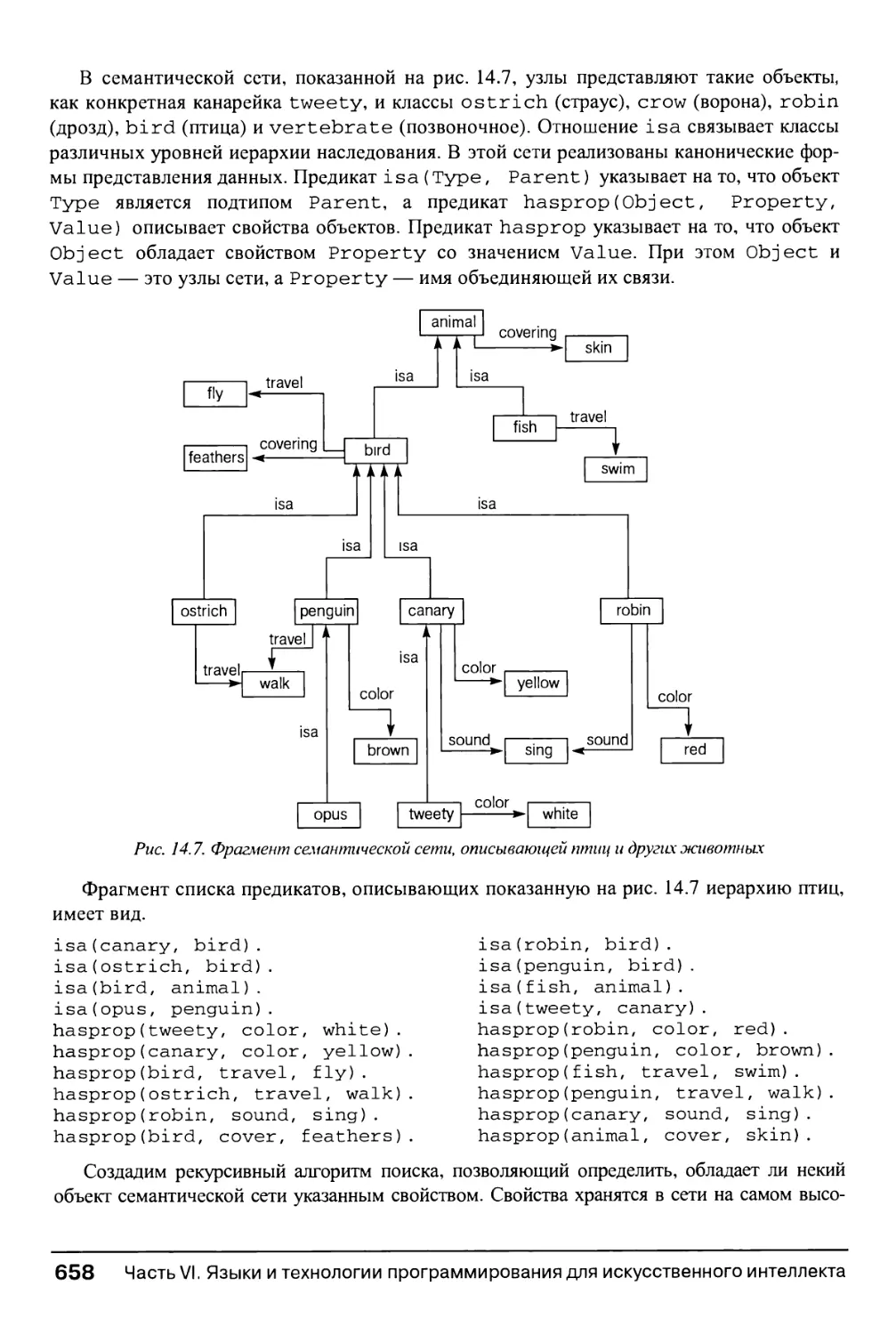
14.7.3. Семантические сети в языке PROLOG 657
14.7.4. Фреймы и схемы в языке PROLOG 659
14.8. Алгоритмы обучения в PROLOG 661
14.8.1. Поиск в пространстве версий языка PROLOG 661
14.8.2. Алгоритм исключения кандидата 666
14.8.3. Реализация обучения на основе пояснения на языке PROLOG 668
14.9. Обработка естественного языка на PROLOG 671
14.9.1. Семантические представления для обработки естественного языка 671
14.9.2. Рекурсивный анализатор на языке PROLOG 672
14.9.3. Рекурсивный анализатор на основе семантических сетей 675
14.10. Резюме и дополнительная литература 678
14.11. Упражнения 680
Глава 15. Введение в LISP 685
15.0. Введение 685
15.1. LISP: краткий обзор 686
15.1.1. Символьные выражения как синтаксическая основа LISP 686
15.1.2. Управление оцениванием в LISP: функции quote и eval 689
15.1.3. Программирование на LISP: создание новых функций 690
15.1.4. Управление программой в LISP: условия и предикаты 692
14
Содержание
15.1.5. Функции, списки и символьные вычисления 694
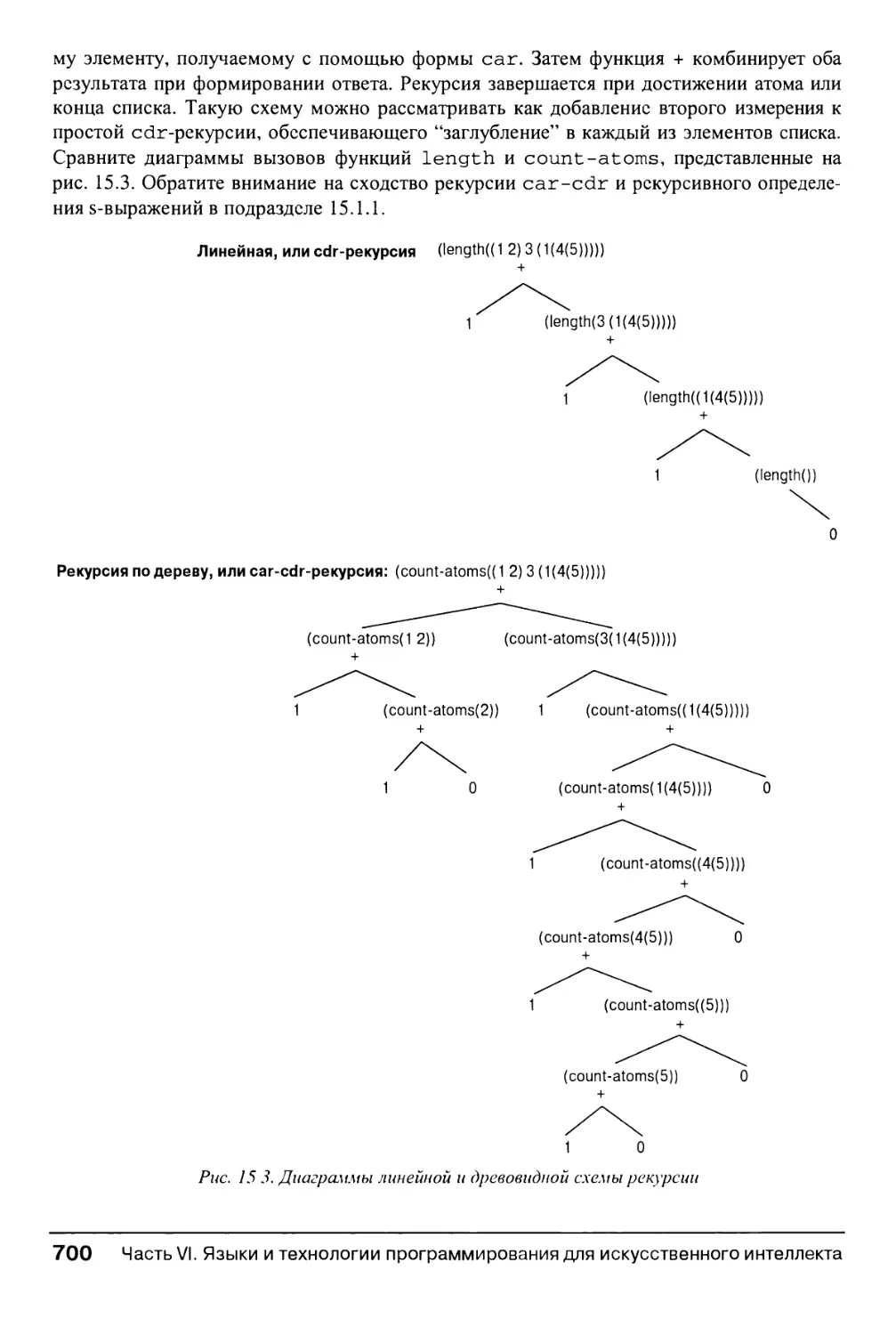
15.1.6. Списки как рекурсивные структуры 696
15.1.7. Вложенные списки, структуры и рекурсия car-cdr 698
15.1.8. Связывание переменных с помощью функции set 701
15.1.9. Определение локальных переменных с помощью функции let 703
15.1.10. Типы данных в Common LISP 705
15.2. Поиск в LISP: функциональный подход к решению задачи переправы
человека, волка, козы и капусты 706
15.3. Функции и абстракции высшего порядка 711
15.3.1. Отображения и фильтры 711
15.3.2. Функциональные аргументы и лямбда-выражения 713
15.4. Стратегии поиска в LISP 714
15.4.1. Поиск в ширину и в глубину 714
15.4.2. "Жадный" алгоритм поиска 717
15.5. Проверка соответствия шаблонам LISP 718
15.6. Рекурсивная функция унификации 720
15.7. Интерпретаторы и внедренные языки 724
15.8. Логическое программирование на языке LISP 727
15.8.1. Простой язык логического программирования 727
15.8.2. Потоки и их обработка 729
15.8.3. Интерпретатор для задач логического программирования
на основе потоков 731
15.9. Потоки и оценивание с задержкой 736
15.10. Оболочка экспертной системы на LISP 739
15.10.1. Реализация факторов достоверности 740
15.10.2. Архитектура оболочки lisp-shell 741
15.10.3. Классификация с использованием оболочки lisp-she 11 744
15.11. Семантические сети и наследование в LISP 746
15.12. Объектно-ориентированное программирование с использованием CLOS 749
15.12.1. Определение классов и экземпляров в CLOS 751
15.12.2. Определение родовых функций и методов 753
15.12.3. Наследование в CLOS 755
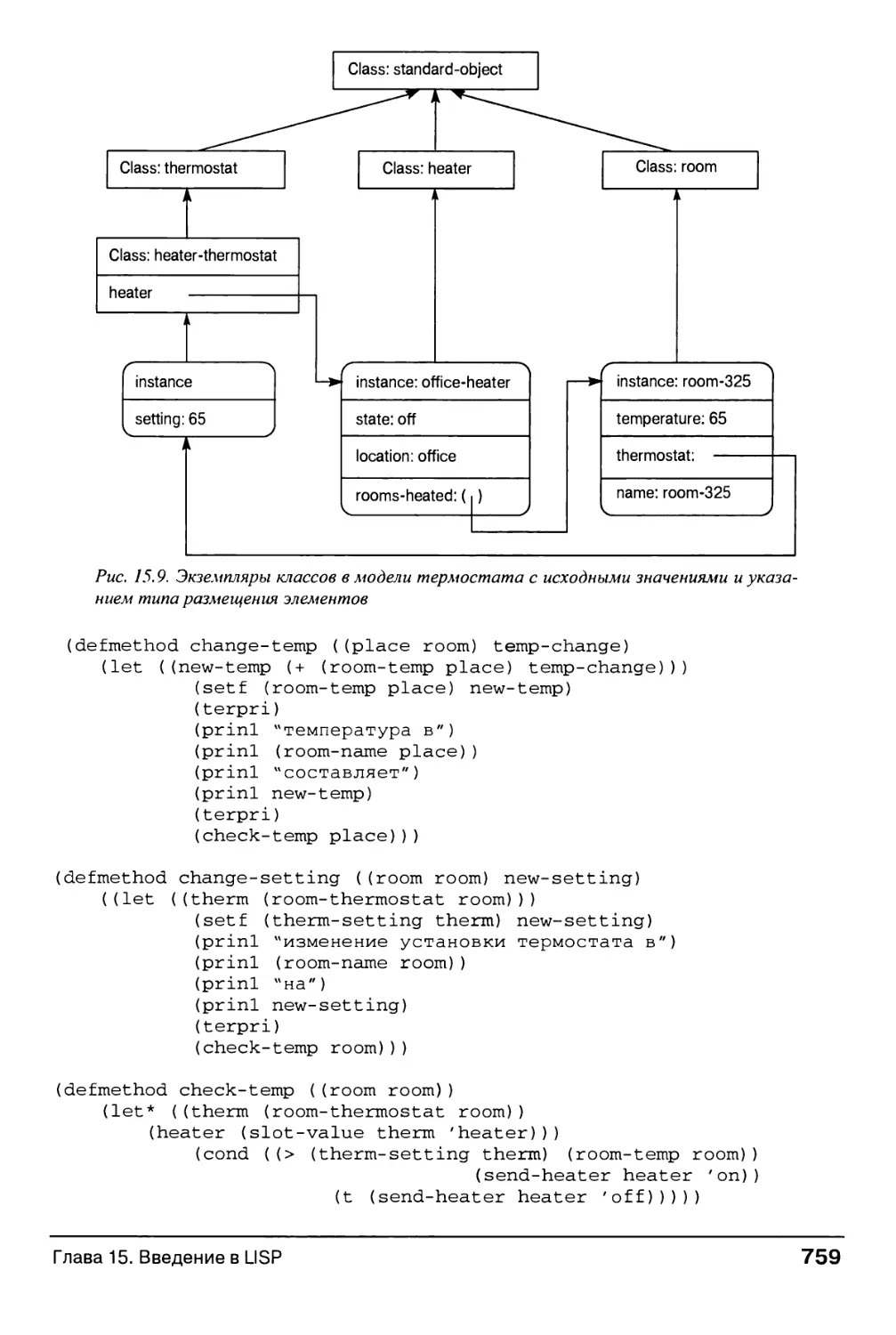
15.12.4. Пример: моделирование термостата 756
15.13. Обучение в LISP: алгоритм ID3 761
15.13.1. Определение структур с помощью функции de f s t rue t 761
15.13.2. Алгоритм ГОЗ 767
15.14. Резюме и дополнительная литература 772
15.15. Упражнения 773
Часть VII. Эпилог 777
Рассуждения о природе интеллекта 777
Глава 16. Искусственный интеллект как эмпирическая проблема 779
16.0. Введение 779
16.1. Искусственный интеллект: пересмотренное определение 781
16.1.1. Интеллект и гипотеза о физической символьной системе 781
16.1.2. Коннекционистские, или нейросетевые, вычислительные системы 786
Содержание
15
16.1.3. Агенты, интеллект и эволюция 789
16.2. Теория интеллектуальных систем 792
16.2.1. Ограничения психологии 793
16.2.2. Вопросы эпистемологии 795
16.2.3. Внедренный исполнитель и экзистенциальный разум 801
16.3. Искусственный интеллект: текущие задачи и будущие направления 803
16.4. Резюме и дополнительная литература 807
Библиография 809
Алфавитный указатель авторов 841
Предметный указатель 848
16
Содержание
Моей жене, Кэтлин, и нашим детям — Саре, Дэвиду и Питеру.
Si quid est in me ingenii, judices...
Цицерон (Cicero)
— Джордж Люгер (George Luger)
Предисловие
Чтобы научиться что-то делать,
надо делать это
— Аристотель (Aristotle), Этика
Добро пожаловать в четвертое издание!
Предложение о выпуске четвертого издания книги по искусственному интеллекту я
принял с удовольствием. Я расценил его как комплимент предыдущим изданиям, первое
из которых вышло более десяти лет назад. Это предложение означает, что наш подход к
искусственному интеллекту был широко поддержан. В новом издании представлены
самые современные наработки в этой области. Спасибо читателям, коллегам и студентам
за высокую оценку книги и неослабевающий интерес к ее теме.
Многие разделы прежних изданий замечательно выдержали проверку временем. Это
главы, посвященные логике, алгоритмам поиска, представлению знаний, продукционным
системам, машинному обучению и технологиям программирования на языках LISP и
PROLOG. Эти вопросы остаются центральными в области искусственного интеллекта,
поэтому существенной доработки соответствующих глав не потребовалось. Однако
некоторые главы, в том числе связанные с вопросами понимания естественного языка,
обучения с подкреплением и неточными рассуждениями, были подвергнуты значительной
переработке. Часть вопросов, которые в первых изданиях были лишь слегка затронуты,
но впоследствии доказали свою актуальность, описаны более детально. К ним относятся
эволюционирующие вычисления, рассуждения на основе логических доказательств и
решение задач на базе моделей. Эти изменения отражают современные тенденции и
состояние области искусственного интеллекта.
В ходе проекта мы получили поддержку от наших издателей, редакторов, друзей,
коллег, а главное — читателей, которым наша работа обязана своей долгой и
продуктивной жизнью. Мы были очень рады представившейся возможности — ученым очень
редко удается вырваться за рамки своей узкой специализации. Благодаря издателям и
читателям у нас это получилось.
Несмотря на то что искусственный интеллект, как и большинство инженерных
дисциплин, должен подтвердить свою значимость в коммерческом мире путем решения
важных практических задач, мы рассматриваем его с тех же позиций, что и многие наши
коллеги и студенты. Мы хотим понять и исследовать механизмы работы мозга,
обеспечивающие возможности интеллектуального мышления и осмысленной деятельности.
Отвергая несколько наивное утверждение о том, что интеллект — это исключительная пре-
рогатива человека, мы допускаем возможность эффективного исследования области
интеллекта, а также разработки интеллектуальных артефактов. В предыдущих изданиях
были отмечены три отличительные черты предлагаемого подхода к изучению
искусственного интеллекта. Поэтому имеет смысл в предисловии к четвертому изданию
вернуться к этой теме и оценить, насколько наши взгляды выдержали проверку временем в
процессе активного развития этой области знаний.
Основной целью мы считали "объединение разрозненных областей искусственного
интеллекта с помощью детального описания его теоретических основ,\ В процессе ее
реализации оказалось, что главная проблема — примирить исследователей, уделяющих
основное внимание изучению и анализу различных теорий интеллекта (чистых
теоретиков), с их коллегами, рассматривающими интеллект как средство решения конкретных
прикладных задач (практиками). Эта простая дихотомия оказалась на деле далеко не
такой простой. На современном этапе развития искусственного интеллекта жаркие споры
между теоретиками и практиками ведутся по множеству вопросов из самых разных
областей. Приверженцы символьного подхода спорят с почитателями нейронных сетей,
ученые-логики дискутируют с разработчиками форм искусственной жизни,
эволюционирующей вопреки логическим принципам, архитекторы экспертных систем противостоят
разработчикам программ на основе логических доказательств. И, наконец, самые
непримиримые дебаты ведутся между теми, кто считает задачу создания искусственного
интеллекта уже решенной, и пессимистами, вообще не верящими в возможность ее
решения. Наше исходное видение искусственного интеллекта как пограничной области науки,
призванной укротить бунтовщиков, прорицателей, старателей и других безудержных
мечтателей с помощью формализма и эмпиризма, трансформировалось в другую
метафору. Искусственный интеллект — это большой, хаотичный, но в целом мирный город,
который законопослушные горожане разделили на отдельные деловые и богемные
районы в соответствии со своими жизненными принципами. За годы работы над разными
изданиями книги у авторов начинает появляться общее видение архитектуры
искусственного интеллекта, отражающее структуру, культуру и жизненный уклад этого города.
Интеллект — это очень сложная область знаний, которую невозможно описать с
помощью какой-то одной теории. Ученые строят целую иерархию теорий,
характеризующих его на разных уровнях абстракции. На самом нижнем уровне этой иерархии
находятся нейронные сети, генетические алгоритмы и другие формы эволюционирующих
вычислений, позволяющие понять процессы адаптации, восприятия, воплощения и
взаимодействия с физическим миром, лежащим в основе любой формы интеллектуальной
деятельности. С помощью некоторого частично понятного процесса разрешения эта
хаотическая популяция "слепых" и примитивных действующих лиц превращается в более
строгие шаблоны логического вывода. Работая на этом уровне, последователи
Аристотеля изучают схемы дедукции, абдукции, индукции, поддержки истинности и другие
бесчисленные модели и принципы рассуждений. На более высоком уровне абстракции
разработчики экспертных систем, интеллектуальных агентов, систем понимания
естественного языка пытаются определить роль социальных процессов в создании, передаче и
подкреплении знаний. В четвертом издании книги мы рассмотрим все эти уровни
иерархии искусственного интеллекта.
Второй тезис, высказанный в предыдущих изданиях, касался центральной роли
"расширенных формализмов представления и стратегий поиска" в методологии
искусственного интеллекта. Это, пожалуй, наиболее спорный аспект наших предыдущих
рассуждений и раннего этапа развития искусственного интеллекта вообще. Многие исследова-
20
Предисловие
тели, работающие в области эволюционирующих вычислений ставят под сомнение роль
символьных рассуждений и семантики ссылок с процессе мышления. Несмотря на то что
идея представления как процедуры присвоения имен некоторым объектам во многом
утратила свою уникальность с появлением неявных представлений, обеспечиваемых ней-
росетевыми моделями или системами искусственной жизни, по мнению автора,
понимание вопросов представления и алгоритмов поиска остается очень важным моментом для
специалистов-практиков в области искусственного интеллекта. Более того, автор
считает, что навыки и знания, приобретенные при изучении способов представления и
механизмов поиска, являются неоценимым средством анализа таких аспектов несимвольных
областей искусственного интеллекта, как нейронные сети или генетические алгоритмы.
Сравнение, противопоставление и критические замечания в адрес различных подходов
современного искусственного интеллекта приводятся в главе 16.
Третье утверждение, сформулированное в начале жизненного цикла этой книги, —
"рассматривать искусственный интеллект в контексте эмпирической науки" осталось
неизменным. Здесь уместно привести цитату из предисловия к третьему изданию. Автор
продолжает верить, что искусственный интеллект — это не
". некое странное ответвление от научной традиции, а... часть общего пути к знанию и
пониманию самого интеллекта Более того, наши программные средства искусственного
интеллекта наряду с исследованием методологии программирования... идеально подходят для
изучения окружающего мира. Эти средства создают почву и для понимания и для
появления вопросов. Мы приходим к оценке и знанию феномена конструктивно, т.е. путем
последовательной аппроксимации.
Каждую разработку и программу можно рассматривать как эксперимент с природой- мы
предлагаем представление, генерируем алгоритм поиска, а затем ставим вопрос об адекватности нашей
характеристики некоторой части феномена интеллекта. И реальный мир дает ответ на этот
вопрос Наш эксперимент можно проанализировать, модифицировать, расширить и возобновить.
Нашу модель можно подкорректировать, а понимание — расширить".
Что нового в этом издании
Я, Джордж Люгер (George Luger), — единственный автор четвертого издания. Несмотря
на то что интересы Билла Стабблефилда (Bill Stubblefield) сместились в сторону новых
областей компьютерных наук, его след останется и в настоящем, и в последующих изданиях
книги. На самом деле эта книга является результатом моей работы в качестве профессора
компьютерных наук в университете Нью-Мексико и труда моих коллег, аспирантов и
друзей — членов сообщества специалистов в области искусственного интеллекта, а также
многих читателей, направивших по электронной почте свои комментарии, пожелания и
уточнения. Данная книга продолжает традиции предыдущих изданий, поэтому, чтобы отразить
коллективный вклад в ее написание, при изложении материала я буду по-прежнему
употреблять местоимение "мы". Отдельные слова благодарности за участие в подготовке
четвертого издания приводятся в соответствующем разделе этого предисловия.
Мы переделали многие разделы этой книги, чтобы отразить возрастающую роль
агентного подхода к решению задач как новой технологии искусственного интеллекта
(ИИ). При обсуждении основ ИИ мы определяем интеллект как физически воплощенный
и расположенный в природном и социальном мире контекст. В соответствии с этим
определением в главе 6 описывается эволюция схем представления ИИ, начиная от ассо-
Предисловие
21
циативного и раннего логического представлений через слабые и сильные методы
решения, включая коннекционистские и эмерджентные модели, и заканчивая ситуативными и
социальными подходами к решению задач ИИ. В главе 16 содержатся критические
замечания по каждой из парадигм.
При работе над четвертым изданием мы проанализировали все вопросы,
представленные ранее, и изложили их в более современной интерпретации. В частности, в главу 9
добавлен раздел, посвященный обучению с подкреплением. Описаны алгоритмы такого
обучения (метод временных разностей и Q-обучения), получающие сигналы из внешней
среды и формирующие на их основе политику изменения состояний.
Помимо содержащегося в предыдущих изданиях анализа систем вывода от данных и
от цели, в главе 7 представлены рассуждения на основе модели и опыта, в том числе
примеры из космической программы NASA. В эту главу добавлен раздел, посвященный
обсуждению преимуществ и недостатков каждого из этих подходов для решения задач,
интенсивно использующих знания.
В главе 8 описан подход к реализации рассуждений при неточной или неполной
информации. Представлено множество важных подходов к решению этой задачи, включая
байесовский подход к рассуждениям, сети доверия (belief network), модель Демпстера-
Шафера и неточный вывод с использованием фактора уверенности. Описаны также
приемы поддержания истинности в немонотонных ситуациях, а также рассуждения на
основе минимальных моделей и логической абдукции. В заключении главы глубоко
проанализированы байесовские сети доверия и алгоритм дерева клик для распространения
меры правдоподобия по сети доверия в контексте новой информации.
В главе 13 обсуждаются вопросы понимания естественного языка, включая раздел по
стохастическим моделям для постижения языка. Здесь описаны марковские модели,
CART-деревья, метод взаимной кластеризации информации и статистического
грамматического разбора. В заключении главы приводится несколько примеров, в том числе
приложения по восполнению текста и методы реферирования текстов для WWW.
И, наконец, в обновленной главе 16 мы снова возвращаемся к вопросам природы
интеллекта и возможности создания интеллектуальных машин. Последние достижения ИИ
рассматриваются с точки зрения психологии, философии и нейрофизиологии.
Содержание книги
В главе 1 дается введение в теорию искусственного интеллекта, предваренное
краткой историей попыток понять принципы работы мозга и сущность интеллекта с позиций
философии, психологии и других наук. Важно понимать, что ИИ — это старая наука,
уходящая корнями как минимум к трудам Аристотеля. Осмысление этого опыта играет
важную роль в понимании результатов современных исследований. В этой главе также
приводится обзор некоторых важных приложений ИИ. Цель главы 1 — обеспечить
основу и мотивацию для излагаемой далее теории и ее приложений.
В главах 2, 3, 4 и 5 (часть II) описаны средства решения задач ИИ. К ним относятся язык
теории предикатов, предназначенный для описания основных свойств предметной области
(глава 2), методы поиска, применяемые для рассуждения об этих описаниях (глава 3), а также
алгоритмы и структуры данных, используемые для реализации этого поиска. В главах 4 и 5
обсуждается важная роль эвристик в фокусировке и ограничении пространства поиска.
Представлено множество архитектур, предназначенных для построения алгоритмов поиска,
включая методологию "классной доски" и продукционные системы.
22
Предисловие
Главы 6, 7 и 8 составляют третью часть книги. В них описаны представления для
задач искусственного интеллекта и методы решения задач, интенсивно использующих
знания. В главе 6 рассматривается эволюция схем представлений для ИИ. Сначала
обсуждаются семантические сети и расширение этой модели на теорию концептуальной
зависимости, фреймы и сценарии. Затем глубоко анализируется конкретный формализм —
концептуальные графы. Основное внимание уделяется вопросам образования понятий в
процессе представления знаний и решению этих вопросов в современном языке
представления. В главе 13 показано, как концептуальные графы можно использовать для
реализации интерфейса с базой данных, работающего на основе естественного языка. В
заключении главы 6 рассмотрены более современные подходы к представлению, включая
агентно-ориентированные архитектуры и систему Copycat.
В главе 7 рассмотрена основанная на правилах экспертная система, а также системы
рассуждений на основе моделей и опыта, включая примеры из космической программы
NASA. Эти подходы к решению задачи представлены как естественное продолжение
материала, изложенного в первых пяти главах книги: продукционная система на основе
выражений из теории предикатов гармонично сочетается с алгоритмами поиска на графах.
В заключении главы анализируются преимущества и недостатки каждого из этих
подходов к решению задач, интенсивно использующих знания.
В главе 8 приводятся модели рассуждений в условиях неопределенности и методы
использования ненадежной информации. Здесь обсуждаются байесовские модели, сети
доверия (belief network), модель Демпстера-Шафера и неточный вывод с учетом фактора
уверенности, применяемые для рассуждения в условиях неопределенности. Описаны
приемы поддержания истинности, рассуждения на основе минимальных моделей и
логической абдукции, а также алгоритм дерева клик для байесовских сетей доверия.
В части IV (главы 9-11) подробно изложены вопросы машинного обучения. В главе 9
детально изучаются алгоритмы символьного обучения — обширной области
исследований, связанной с решением множества различных задач. Эти алгоритмы различаются по
своему назначению, используемым обучающим данным, стратегиям обучения и
представлениям знаний. К символьным алгоритмам обучения относятся индукция,
концептуальное обучение, поиск в пространстве версий и ID3. Подчеркивается роль индуктивного
порога, обобщения на основе реальных данных и эффективного использования знаний
при обучении на единственном примере на основе объяснения. Изучение категорий и
кластеризация понятий представлены в ракурсе обучения без учителя. Главу завершает
раздел, посвященный обучению с подкреплением, — способности интегрировать
обратную связь от внешней среды и политику принятия новых решений.
В главе 10 описаны нейронные сети, которые зачастую называют суб-символьными,
или коннекционистскими, моделями обучения. В нейронной сети информация
структурирована неявно. Она распространяется между набором взаимосвязанных процессоров с
учетом весовых коэффициентов, а обучение сводится к пересортировке и модификации
весов узлов сети. Рассмотрено множество нейроподобных архитектур, включая обучение
персептрона, метод обратного распространения ошибки и встречного распространения.
Изучены модели Кохонена, Гроссберга и Хебба. Описана аттракторная модель и
ассоциативное обучение, в том числе сети Хопфилда.
Генетические алгоритмы и эмерджентный подход к обучению представлены в
главе 11. С этой точки зрения обучение — это процесс адаптации и эволюции. После
нескольких примеров решения задач на основе генетических алгоритмов рассматривается
возможность применения этой методологии для решения более общих проблем. К ним
Предисловие
23
относятся системы классификации и генетическое программирование. Затем
описывается "социальное" обучение с примерами из области "искусственной жизни". В
заключение приводится пример эмерджентных вычислений, реализованных в институте Санта-
Фе. В главе 16 сравниваются и противопоставляются три подхода к машинному
обучению (символьный, коннекционистский и эмерджентный).
В части V (главы 12 и 13) продолжается представление важных областей применения
технологий ИИ. Одной из старейших областей является автоматическое доказательство
теорем, которое зачастую называют автоматическими рассуждениями. В главе 12
описываются первые программы, реализующие этот подход, включая Logic Theorist и
General Problem Solver. В этой главе основное внимание уделяется разрешающим
процедурам доказательства теорем, а особенно резолюции на основе опровержения.
Рассмотрены также более сложные методы вывода на основе гиперрезолюции и парамодуляции. В
заключении интерпретатор PROLOG описан как система вывода на основе хорновских
выражений и резолюции, а вычисления на PROLOG — как пример парадигмы
логического программирования.
Глава 13 посвящена проблеме понимания естественного языка. Традиционный
подход к пониманию языка, проиллюстрированный с использованием многих описанных в
главе 6 семантических структур, в этом издании дополнен описанием стохастического
подхода. Здесь рассмотрены марковские модели, CART-деревья, метод взаимной
кластеризации информации и статистического грамматического разбора. В заключении главы
приводится несколько примеров, включая приложения по восполнению текста и методы
реферирования текстов для использования в WWW.
В части VI описаны языки LISP и PROLOG. В главе 14 рассматривается PROLOG, а в
главе 15 — LISP. Эти языки представлены как средства решения задач искусственного
интеллекта на основе изложенных в предыдущих главах методов поиска, включая
алгоритмы поиска в ширину, глубину и "жадный" алгоритм. Реализация этих методов поиска
проблемно-независима, поэтому ее можно применять для создания оболочек поиска в
экспертных системах на основе правил построения семантических сетей, систем
понимания естественного языка и обучения.
И, наконец, глава 16 служит эпилогом этой книги. В ней рассмотрены возможности
науки об интеллектуальных системах, а также альтернативные современные подходы.
Обсуждаются современные рамки искусственного интеллекта и перспективы его развития.
Использование книги
Искусственный интеллект — это обширная область, поэтому объем этой книги
достаточно велик. Хотя для детального изучения всего материала потребуется не один
семестр, мы скомпоновали книгу таким образом, чтобы ее можно было читать по частям.
Выбирая отдельные части материала, можно сформировать семестровый и годичный
(двухсеместровый) курс изучения предмета.
Предполагается, что студенты уже прослушали курсы дискретной математики,
включая теорию предикатов и теорию графов. Если это не так, то при изучении начальных
разделов B.1 и 3.1) необходимо уделить этим теориям больше внимания. Надеемся
также, что студенты изучили курс по структурам данных, в том числе деревьям, графам,
методам рекурсивного поиска с помощью стеков, очередей и приоритетных очередей. Если
это не так, то обратите особое внимание на начальные разделы глав 3, 4 и 5.
24
Предисловие
В семестровом курсе мы кратко останавливаемся на первых двух частях книги. После
такой подготовки студенты готовы к восприятию материала части III. Затем мы изучаем
PROLOG и LISP (часть VI) и требуем от студентов построения различных представлений и
реализации стратегий поиска, описанных в первых главах. Один из языков, к примеру
PROLOG, можно ввести в первой части курса, а затем использовать его при изучении
структур данных и алгоритмов поиска. По нашему мнению, полезным средством
построения систем решения задач на основе правил и знаний являются метаинтерпретаторы,
представленные в главе, посвященной обработке естественного языка. PROLOG, в свою
очередь, — отличное средство для построения систем понимания естественного языка.
В двухсеместровом курсе имеется возможность рассмотреть области применения ИИ,
описанные в частях IV и V. Особенно это касается машинного обучения. Кроме того,
студенты реализуют гораздо более серьезные программные проекты. На наш взгляд, во
втором семестре очень важно, чтобы студенты познакомились с основными
первоисточниками знаний по искусственному интеллекту. Студенты должны понимать, где мы
находимся в данный момент, как мы к этому пришли, и представлять себе перспективы
развития ИИ. Для этой цели мы используем обзор [Luger, 1995].
Упомянутые в книге алгоритмы написаны на паскалеподобном псевдокоде. При этом
используются управляющие структуры языка Паскаль (Pascal) и описания проверок и
операций на родном языке. К числу управляющих структур Паскаля мы добавили две
новые полезные конструкции. Первая из них— модифицированный оператор case,
который не просто сравнивает значение переменной с постоянной меткой, как в обычном
Паскале, но и позволяет связывать с каждым элементом произвольную логическую
проверку. Оператор case по порядку выполняет эти проверки до тех пор, пока результат
одной из них не примет значение "истина". Тогда выполняется соответствующее
действие. Все остальные действия игнорируются. Читатели, знакомые с языком LISP, сразу же
заметят, что этот оператор обладает той же семантикой, что и оператор cond из LISP.
Вторым нововведением является оператор return, зависящий от одного аргумента.
Он может встречаться в любом месте процедуры или функции. При достижении этого
оператора программа немедленно завершает выполнение функции и возвращает
результат. Остальной стиль псевдокода соответствует синтаксису языка Pascal.
Дополнительный материал, доступный через Internet
Представленный в книге код на языках PROLOG и LISP читатели могут получить через
Internet. Там же можно найти подробные методические рекомендации по использованию этой
книги для преподавателей. Эти файлы находятся по адресу www.booksites .net/luger
или на личной странице автора www. cs . unm. edu/ -luger /.
Дополнительные материалы и программные средства, в том числе публикуемые
издательствами Addison-Wesley и Pearson Education, находятся по адресу www. aw. com/cs/
и www.pearsoneduc . com/computing. Автор с удовольствием ожидает электронных
писем читателей по адресу luger@cs . unm. edu.
Благодарности
Во-первых, мы хотим поблагодарить Билла Стабблефилда — соавтора первых трех
изданий за более чем десятилетний труд над этой книгой. Спасибо также многим рецензен-
Предисловие
25
там, которые помогли подготовить эти четыре издания. В их числе Дэннис Бахлер (Dennis
Bahler), Скона Бриттэн (Skona Brittain), Филипп Чен (Philip Chan), Питер Колингвуд (Peter
Collingwood), Джон Дональд (John Donald), Сара Дуглас (Sarah Douglas), Кристоф Жиред-
Карьер (Christophe Giraud-Carrier), Эндрю Косорезов (Andrew Kosoresov), Крис Малкольм
(Chris Malcolm), Рэй Муни (Ray Mooney), Брюс Портер (Bruce Porter), Джуд Шавлик (Jude
Shavlik), Карл Стерн (Carl Stern), Марко Валторта (Marco Valtorta) и Боб Верофф (Bob Ver-
off). Мы также благодарны за многочисленные предложения и комментарии, направляемые
непосредственно авторам книги ее читателями по электронной почте.
За помощь в реорганизации материала автор признателен своим аспирантам. Благодаря им
была переработана часть III, в которой впервые описана эволюция схем представлений для
задач искусственного интеллекта, создан отдельный раздел по машинному обучению, а
вопросы понимания естественных языков перенесены в конец книги. Мы благодарны Дану
Плессу (Dan Pless) за его вклад в подготовку материала по абдуктивному выводу для главы 8,
Карлу Стерну (Carl Stern) за помощь в написании главы 10, посвященной коннекционистско-
му обучению, Яреду Сайа (Jared Saia) за помощь в описании стохастических моделей для
главы 13. "Внешними" рецензентами четвертого издания стали Леон ван дер Торре (Leon van der
Torre) и Меди Дастани (Mehdi Dastard) из Нидерландов, а также Леонардо Боттачи (Leonardo
Bottaci) и Джулиан Ричардсон (Julian Richardson) из Великобритании. Среди американских
рецензентов следует отметить Марека Перковски (Marek Perkowski) из портлендского
университета и Джона Шеппарда (John Sheppard) из университета имени Джона Хопкинса. Барак
Пермуттер (Barak Pearmutter) рецензировал главы по машинному обучению. И, наконец,
Джозеф Льюис (Joseph Lewis), Крис Малколм (Chris Malcolm), Брэнден Мак-Гоннигл (Brendan
McGonnigle) и Акаша Танг (Akasha Tang) приняли участие в обсуждении главы 16.
Автор благодарен издательству Academic Press за разрешение на перепечатку
большей части материала из главы 10, которая была ранее опубликована в [Luger, 1994]. И,
наконец, большое спасибо студентам университета Нью-Мексико, которые более десяти
лет изучали эту книгу и описанные в ней программные средства. Они существенно
расширили наш горизонт, а также позволили избавиться от опечаток и неточностей.
Спасибо моим друзьям из издательства Addison-Wesley за поддержку при написании
книги, особенно Алану Апту (Alan Apt) за помощь в подготовке первого издания, Лизе
Моллер (Lisa Moller) и Мэри Тюдор (Mary Tudor) за участие в подготовке второго,
Виктории Хендерсон (Victoria Henderson), Луизе Вилсон (Louise Wilson) и Карен Мосман
(Karen Mosman) за содействие в работе над третьим, а также Кэйт Мансфилд (Keith
Mansfield), Карен Сюзерланд (Karen Sutherland) и Аните Аткинсон (Amte Atkinson) за
поддержку этого четвертого издания. Особая благодарность Линде Цицарелле (Linda Ci-
carella) из университета Нью-Мексико за помощь в подготовке рисунков.
Спасибо большое Томасу Бэрроу (Thomas Barrow) — всемирно признанному
художнику и профессору искусств университета Нью-Мексико, который сделал семь
фотографий для этой книги.
Во многих местах мы использовали рисунки и цитаты из работ других авторов. Мы
благодарны авторам и издателям за разрешение на использование этого материала.
Искусственный интеллект — это увлекательная и благодарная дисциплина. Осознав
его силу и глубину, вы получите удовольствие от изучения этой книги.
Джордж Люгер
1 июля 2001 года
26
Предисловие
Часть I
Искусственный
интеллект: его
истоки и проблемы
Всему есть начало, как говорил Санно Панса, и это начало должно
опираться на нечто, ему предшествующее. Индусы придумали слона,
который удерживал мир, но им пришлось поставить его на черепаху. Нужно
отметить, что изобретение состоит в сотворении не из пустоты, но из
хаоса: в первую очередь следует позаботиться о материале...
— Мэри Шелли (Mary Shelley), Франкенштейн
Попытка дать определение искусственному интеллекту
Искусственный интеллект (ИИ) можно определить как область компьютерной
науки, занимающуюся автоматизацией разумного поведения. Это определение наиболее
точно соответствует содержанию данной книги, поскольку в ней ИИ рассматривается как
часть компьютерной науки, которая опирается на ее теоретические и прикладные
принципы. Эти принципы сводятся к структурам данных, используемым для представления
знаний, алгоритмам применения этих знаний, а также языкам и методикам
программирования, используемым при их реализации.
Тем не менее это определение имеет существенный недостаток, поскольку само
понятие интеллекта не очень понятно и четко сформулировано. Большинство из нас
уверены, что смогут отличить "разумное поведение", когда с ним столкнутся. Однако вряд ли
кто-нибудь сможет дать интеллекту определение, достаточно конкретное для оценки
предположительно разумной компьютерной программы и одновременно отражающее
жизнеспособность и сложность человеческого разума.
Итак, проблема определения искусственного интеллекта сводится к проблеме
определения интеллекта вообще: является ли он чем-то единым, или же этот термин
объединяет набор разрозненных способностей? В какой мере интеллект можно создать, а в ка-
кой он существует априори? Что именно происходит при таком создании? Что такое
творчество? Что такое интуиция? Можно ли судить о наличии интеллекта только по
наблюдаемому поведению, или же требуется свидетельство наличия некоего скрытого
механизма? Как представляются знания в нервных тканях живых существ, и как можно
применить это в проектировании интеллектуальных устройств? Что такое самоанализ и
как он связан с разумностью? И, более того, необходимо ли создавать интеллектуальную
компьютерную программу по образу и подобию человеческого разума, или же
достаточно строго "инженерного" подхода? Возможно ли вообще достичь разумности
посредством компьютерной техники, или же сущность интеллекта требует богатства чувств и
опыта, присущего лишь биологическим существам?
На эти вопросы ответа пока не найдено, но все они помогли сформировать задачи и
методологию, составляющие основу современного ИИ. Отчасти привлекательность
искусственного интеллекта в том и состоит, что он является оригинальным и мощным
орудием для исследования именно этих проблем. ИИ предоставляет средство и
испытательную модель для теорий интеллекта: такие теории могут быть переформулированы на
языке компьютерных программ, а затем испытаны при их выполнении.
По этим причинам наше первоначальное определение, очевидно, не дает однозначной
характеристики для этой области науки. Оно лишь ставит новые вопросы и открывает
парадоксы в области, одной из главных задач которой является поиск самоопределения.
Однако проблема поиска точного определения ИИ вполне объяснима. Изучение
искусственного интеллекта — еще молодая дисциплина, и ее структура, круг вопросов и
методики не так четко определены, как в более зрелых науках, например, физике.
Искусственный интеллект призван расширить возможности компьютерных наук, а не
определить их границы. Одной из важных задач, стоящих перед исследователями,
является поддержание этих усилий ясными теоретическими принципами.
Из-за специфики проблем и целей искусственный интеллект не поддается простому
определению. Поэтому на первых порах просто опишем его как спектр проблем и
методологий, изучаемых разработчиками систем искусственного интеллекта. Это
определение может показаться глупым и бессмысленным, но оно отражает важный факт:
искусственный интеллект, как и любая наука, является сферой интересов человека, и лучше
всего рассматривать его в этом контексте.
Любая наука, включая ИИ, рассматривает некоторый круг проблем и разрабатывает
подходы к их решению. Краткое изложение истории искусственного интеллекта, рассказ
о личностях и их гипотезах, положенных в основу этой науки, поясняет, почему
некоторые проблемы стали доминировать в этой области и почему для их решения были взяты
на вооружение методы, описываемые в этой книге.
28
Часть I. Искусственный интеллект' его истоки и проблемы
Искусственный
интеллект: история
развития и области
приложения
Слушайте далее и вы еще более изумитесь ремеслам и богатствам природы,
открытым мною Величайшим было такое в старину, если человек заболевал, у него
не было защиты против болезни, ни исцеляющей еды, ни питья, ни мази, люди
вымирали от отсутствия лекарств, но я показал им, как смешивать мягкие
ингредиенты, чтобы изгонять всяческие хвори.
Это я сделал видимыми для человеческих очей пылающие знаки в небесах, что до
тех пор были в тумане Недра земли, скрытое благословение человечества, медь,
железо, серебро и золото — осмелится ли кто-нибудь заявить, что он открыл их
ранее меня7 Я уверен, никто, если он не лжец Говоря кратко- все ремесла, что
есть у смертных, идут от Прометея.
— Эсхил (Aeschylus), Прикованный Прометей
1.1. Отношение к интеллекту, знанию и человеческому
мастерству
Прометей говорит о результатах своего неповиновения богам Олимпа: его целью было
не только украсть огонь для людей, но и просветить их посредством дара ума, nous, или же
"сообразительности". Интеллект является основой всех разработанных человеком
технологий и цивилизации вообще. Работа классического греческого драматурга иллюстрирует
глубокую и давнюю уверенность в необычайной силе знания. Искусственный интеллект
применяется во всех сферах наследия Прометея: медицине, психологии, биологии,
астрономии, геологии и многих областях науки, которые Эсхил не в силах был себе представить.
Хотя поступок Прометея освободил людей от невежества, он навлек на него гнев
Зевса. За кражу знаний, прежде принадлежавших лишь богам Олимпа Зевс приказал
приковать Прометея к голой скале, чтобы стихии причиняли ему вечные страдания. Мысль о
том, что человеческое стремление к знаниям является проступком перед богами или
природой, прочно укоренилась в западной философии. На ней основана история Эдема,
она пронизывает сочинения Данте и Мильтона. И Шекспир, и древнегреческие трагики
считали амбиции разума причинами всех бедствий. Упорная вера в то, что жажда знаний
в конечном счете приведет к катастрофе, пережила и эпоху Возрождения, и век
Просвещения и даже научные и философские открытия XIX и XX веков. Поэтому не стоит
удивляться тому, что в научных и общественных кругах не утихает бурная полемика по
поводу искусственного интеллекта.
И вправду, современная технология не развеяла древний страх губительных
последствий интеллектуального честолюбия, она, скорее, сделала их более вероятными, а
может, и неотвратимыми. Легенды о Прометее, Еве, Фаусте пересказываются на языке
технологического общества. В своем предисловии к работе "Франкенштейн" (которая,
кстати, носит подзаголовок "Современный Прометей") Мэри Шелли пишет:
"Я была верным молчаливым слушателем долгих бесед между лордом Байроном и
Шелли В одной из них обсуждались различные философские доктрины, в частности,
сущность первопричин жизни, возможность их постижения и изучения Они говорили об
экспериментах доктора Дарвина (я имею в виду не то, что действительно делал доктор, а то,
что ему приписывали), который хранил вермишель в стеклянной емкости, пока она не
начала сама двигаться каким-то непостижимым образом. Это не значит, что таким образом
можно дать жизнь Но, должно быть, возможно оживить труп. Об этом свидетельствует
гальванизм, может быть, и можно изготовить составные части создания, соединить их
вместе и наполнить живительным теплом". [Buttler, 1998]
Шелли демонстрирует нам, в какой мере научные достижения, такие как работы
Дарвина и открытие электричества, убедили даже далеких от науки людей в том, что
творения природы не являются божественной тайной — их можно "разбирать" и
систематически изучать. Чудовище Франкенштейна — не продукт шаманских заклинаний или сделок
с преисподней; его собрали из отдельно "изготовленных" компонентов и наполнили
живительной силой электричества. Хотя наука девятнадцатого века не способна была
понять цель изучения принципов и создания в полной мере разумного агента, она
признавала мысль, что тайны жизни и разума можно приоткрыть с помощью научного анализа.
1.1.1. Историческая подоплека
К тому времени как Мэри Шелли окончательно и, вероятно, бесповоротно соединила
современную науку с мифом о Прометее, философские корни современных работ в
сфере искусственного интеллекта развивались уже несколько тысячелетий. Хотя моральные
и культурные проблемы, поднятые искусственным интеллектом, интересны и важны,
данное введение в большей степени касается интеллектуального наследия ИИ.
Логической отправной точкой этой истории можно считать гений Аристотеля, или, как его
называл Данте, "мастера тех, кто знает". Аристотель объединил интуитивное понимание,
тайны и предчувствия ранней греческой традиции с тщательным анализом и строгим
мышлением, которому суждено было стать стандартом для современной науки.
Для Аристотеля наиболее пленительным аспектом природы была ее изменчивость. В
работе "Физика" он определил свою "философию природы" как "изучение
изменяющихся вещей". Он делал различие между материей и формой', например, скульптура сделана
из материи бронзы и имеет форму человека. Изменение происходит в тот момент, когда
бронзе придают другую форму. Разделение материи и формы представляет философский
базис для современных научных концепций, таких как символьное исчисление или
абстракция данных. В любом исчислении (даже в работе с числами!) мы манипулируем об-
30
Часть I. Искусственный интеллект: его истоки и проблемы
разами, которые являются формой электромагнитной материи, а изменения формы этой
материи передают аспекты процесса решения. Абстрагирование формы от средства ее
представления не только позволяет производить вычисления над этой формой, но и
служит основой теории структур данных — ядра современных компьютерных наук.
В своей работе "Метафизика" Аристотель разработал теории неизменных вещей —
космологию и теологию. Но ближе всего к искусственному интеллекту подходит
аристотелевская эпистемология, или наука познания, обсуждаемая в его "Логике". Аристотель
считал эту книгу важным инструментом познания, поскольку чувствовал, что основой знания
является изучение самой мысли. В "Логике" рассматриваются вопросы истинности
суждений на основе их взаимосвязи с другими истинными утверждениями. Например, если
известно, что "все люди смертны" и "Сократ— человек", то можно заключить, что
"Сократ — смертен". В этом примере силлогизма используется дедуктивное правило modus
ponens. Хотя формальная аксиоматизация логических рассуждений в полном объеме
представлена лишь в работах Готлоба Фреге, Бертрана Рассела, Курта Геделя, Алана Тьюринга,
Альфреда Тарского и других, корни этих работ можно проследить вплоть до Аристотеля.
Идеи Ренессанса, основанные на греческой традиции, дали толчок развитию иного,
мощного представления о человечестве и его роли в природе. На смену мистицизму как
средству объяснения вселенной пришел эмпиризм. Часы (а следовательно, и расписание
работы фабрик) заменили собой ритм природы для тысяч городских жителей. Большинство
современных социальных и физических теорий уходят корнями к идее о возможности
математического анализа и постижимости природных или искусственных процессов. В
частности, ученые и философы поняли, что мышление само по себе как образ представления
знаний является трудным, но принципиальным предметом для научного изучения.
Должно быть, главным событием в развитии современных представлений стала
революция, произведенная Коперником, — замена древней геоцентрической модели
вселенной, где Земля и другие планеты на самом деле вращаются вокруг Солнца. После
столетий господства "очевидности", в которой научное объяснение природы и космоса
согласовывалось с религиозным учением и здравым смыслом, была предложена радикально
иная (и вовсе не очевидная) модель, объясняющая движение небесных тел. Возможно в
первый раз наши представления о мире рассматривались как фундаментально
отличные от их видимости. Этот разрыв между человеческим разумом и окружающей его
реальностью, между понятиями о вещах и самими вещами принципиален для современной
теории интеллекта и его организации. Эта брешь была расширена работами Галилея, чьи
научные наблюдения еще более расходились с "очевидными" истинами о мире, и чье
развитие математики как инструмента для описания мира усилило разрыв между миром
и нашими идеями о нем. Именно из этой "бреши" развивалось современное
представление о формировании разума: самоанализ стал важным мотивом в литературе, философы
начали изучать эпистемологию и математику, и систематизированное применение
научного метода стало соперничать с чувствами как орудиями познания мира.
Хотя в XVII и XVIII столетиях было получено немало результатов в эпистемологии и
смежных областях, ограничимся рассмотрением работ Рене Декарта. Декарт является
центральной фигурой в развитии современных концепций мышления и разума. В своих
знаменитых "Размышлениях" Декарт сделал попытку найти основу реальности исключительно
методами когнитивной интроспекции. Отвергая информацию, поступающую от органов
чувств, как неблагонадежную, Декарт был вынужден подвергнуть сомнению даже
существование физического мира и остался наедине с реальностью мысли. Ему пришлось
доказывать существование самого себя: "Cogito ergo sum" ("Я мыслю, следовательно, сущест-
Глава 1. Искусственный интеллект: история развития и области приложения , 31
вую"). После того как он достоверно установил свое собственное существование как
мыслящей сущности, Декарт вывел существование Бога как творца и, в конечном счете,
подтвердил реальность физической вселенной как необходимого творения Господа.
Здесь можно сделать два интересных наблюдения. Во-первых, раскол между
физическим миром и его интеллектуальным осмыслением стал таким значительным, что
появилась возможность рассматривать процесс мышления отдельно от чувственного
восприятия или предмета осмысления. Во-вторых, связь между разумом и физическим миром
стала столь тонкой, что понадобилось вмешательство всемилостивого Бога, чтобы дать
достоверное знание о физическом мире! Это понимание дуализма разума и физического
мира пронизывает всю картезианскую мысль, включая открытие аналитической
геометрии. Как иначе Декарт мог объединить столь "практичную" область математики, как
геометрия, с таким абстрактным математическим основанием, как алгебра?
Почему эта философская дискуссия включена в книгу по искусственному интеллекту?
Для ИИ особое значение имеют два важных следствия этих работ.
1. Разделив разум и физический мир, Декарт и его последователи установили, что
строение идей о мире не обязательно соответствует изучаемому предмету. На этом
основывается методология ИИ, а также эпистемологии, психологии, большей части
высшей математики и современной литературы: ментальные процессы существуют
сами по себе, подчиняются своим законам и могут изучаться посредством себя же.
2. Поскольку разум и тело оказались разделенными, философы сочли нужным найти
способ воссоединить их, ведь взаимодействие между умственным, res cogitans, и
физическим, res extensa, необходимо для человеческого существования.
По поводу проблемы "ума и тела" были написаны миллионы трудов и было
предложено множество решений, однако ни одно из них не смогло успешно объяснить
очевидные взаимодействия между умственными состояниями и физическими действиями.
Наиболее приемлемый ответ на этот вопрос, дающий необходимое основание для изучения
ИИ, состоит в том, что ум и тело вовсе не принципиально разные сущности. Согласно
этой точке зрения ментальные процессы происходят в таких физических системах, как
мозг (или компьютер). Умственные процессы, как и физические, можно, в конечном
счете, охарактеризовать с помощью формальной математики. Или, как сказал философ
XVII века Гоббс A651), "мышление есть лишь расчет".
1.1.2. Развитие логики
Поскольку мышление стало рассматриваться как форма вычислений, последующими
шагами в его изучении стали формализация и окончательная механизация. В XVIII в.
Готфрид Вильгельм фон Лейбниц в работе "Calculus Philosophicus" представил первую
систему формальной логики, а также соорудил машину для автоматизации ее
вычислений [Leibniz, 1887]. Эйлер в начале восемнадцатого века в своем анализе задачи о ке-
нигсбергских мостах (см. введение в главу 3) создал учение о представлениях, которые
абстрактно отражают структуру взаимосвязей реального мира [Euler, 1735].
Формализация теории графов также сделала возможным поиск в пространстве
состояний (state space search) — основной концептуальный инструмент искусственного
интеллекта. Графы можно использовать для моделирования скрытой структуры задачи.
Узлы графа состояний (state space graph) представляют собой возможные стадии
решения задачи; ребра графа отражают умозаключения, ходы в игре или другие шаги в реше-
32
Часть I. Искусственный интеллект: его истоки и проблемы
нии. Решение задачи — это процесс поиска пути к решению на графе состояний
(см. раздел 1.3 и главу 3). Описывая все пространство решений задачи, графы состояний
предоставляют мощный инструмент для измерения структурированности и сложности
проблем, анализа эффективности, корректности и общности стратегий решения.
Как один из основоположников науки исследования операций, а также разработчик
первых программируемых механических вычислительных устройств, математик XIX в.
Чарльз Бэббидж может также считаться одним из первых практиков искусственного
интеллекта [Morrison и Morrison, 1961]. "Разностная машина" Бэббиджа являлась
специализированным устройством для вычисления значений некоторых полиномиальных
функций и была предшественницей его "аналитической машины". Аналитическая машина,
спроектированная, но не построенная при жизни Бэббиджа, была универсальным
программируемым вычислительным устройством, которое предвосхитило многие
архитектурные положения современных компьютеров.
Описывая аналитическую машину, Ада Лавлейс [Lovelace, 1961], друг Бэббиджа, его
помощница и единомышленница, отмечала:
"Можно сказать, что аналитическая машина плетет алгебраические узоры подобно тому, как
станок Жаккарда ткет узоры из цветов и листьев. В этом, как нам кажется, заключается куда
больше оригинальности, чем в том, на что могла бы претендовать разностная машина".
Бэббиджа вдохновляло желание применить технологию его времени для
освобождения людей от рутины арифметических вычислений. В этом отношении, как и в
представлении о вычислительных машинах как механических устройствах, Бэббидж рассуждал
всецело с позиций XIX века. Тем не менее его аналитическая машина также
основывалась на многих идеях современности, таких как разделение памяти и процессора ("склад"
и "мельница", в терминах Бэббиджа), концепция цифровой, а не аналоговой машины и
программируемость, основанная на выполнении серий операций, закодированных на
картонных перфокартах. Отличительная черта описания Ады Лавлейс и работы
Бэббиджа в целом — это отношение к "узорам" алгебраических взаимосвязей как сущностям,
которые могут быть изучены, охарактеризованы, наконец, реализованы и подвергнуты
механическим манипуляциям без заботы о конкретных значениях, которые проходят
через "мельницу" вычислительной машины. Это и есть реализация принципа "абстракции и
манипуляции формой", впервые описанного Аристотелем.
Целью создания формального языка для описания мышления задавался также
Джордж Буль, математик XIX столетия, чью работу необходимо упомянуть при
рассмотрении истоков искусственного интеллекта [Boole, 1847, 1854]. Хотя Буль внес вклад во
множество областей математики, его наиболее известным открытием стала
математическая формализация законов логики— свершение, сформировавшее самую сердцевину
современных компьютерных наук. Роль булевой алгебры в проектировании логический
цепей хорошо всем известна, однако цели самого Буля в разработке его системы по духу
ближе к современному ИИ. В первой главе книги "Исследование законов мышления, на
которых основываются математические теории логики и вероятностей" Буль описывает
свои цели следующим образом.
Исследовать фундаментальные законы таких операций разума, какими совершается
рассуждение: дать им выражение в символическом языке исчисления и на этом основании
воздвигнуть науку логики и обучать логическому методу, ...наконец, из различных элементов
истины, усмотренной в этих изысканиях, составить некоторые вероятные догадки
касательно природы и склада человеческого ума.
Глава 1. Искусственный интеллект: история развития и области приложения 33
Значимость работы Буля состоит в необычайной силе и простоте предложенной им
системы. Три операции: "И" (обозначаемая * или л), "ИЛИ" (обозначаемая + или v) и
"НЕ" (обозначаемая символом -i) составляют ядро его логического исчисления. Эти
операции стали базой для последующего развития формальной логики, включая
разработку современных компьютеров. Сохраняя значения этих символов практически
идентичными соответствующим логическим операциям, Буль отмечал, что "символы логики
относятся к специальному закону, к которому символы количества как таковые не имеют
отношения". Этот "закон" утверждает, что для каждого элемента X алгебры Х*Х=Х
(поскольку мы знаем истинность чего-либо, повторение не может изменить это знание).
Это привело к ограничению булевых значений всего до двух чисел, которые
удовлетворяют этому уравнению, — 1 и 0. Стандартные определения операций булевого
умножения (И) и сложения (ИЛИ) следуют из этих соображений.
Булева система не только легла в основу двоичной арифметики, но и показала, что
необычайно простая формальная система может передать полную мощь логики. Это
предположение и система, разработанная Булем для демонстрации этого факта, стали
фундаментом для всех попыток современности формализовать логику, от работы
[Whitehead и Russell, 1950], последующих работ Тьюринга и Геделя до современных
систем автоматических рассуждений.
Готлоб Фреге (Frege) в своих "Основах арифметики" [Frege, 1884] создал ясный и
точный язык спецификации для описания основ арифметики. С помощью этого языка Фреге
формализовал многие вопросы, затронутые ранее в аристотелевской "Логике". Язык Фреге,
сейчас именуемый исчислением предикатов первого порядка, служит инструментом для
записи теорем и задания значений истинности, которые образуют элементы
математических умозаключений и описывают аксиоматический базис "смысла" этих выражений.
Предполагалось, что формальная система исчисления предикатов, которая включает
символы предикатов, теорию функций и квантированных переменных, станет языком для
описания математики и ее философских основ. Она также сыграла принципиальную роль в
создании теории представления для искусственного интеллекта (см. главу 2). Исчисление
предикатов первого порядка обеспечивает средства автоматизации рассуждений: язык для
построения выражений, теорию, позволяющую судить об их смысле, и логически
безупречное исчисление для вывода новых истинных выражений.
Работа Рассела и Уайтхеда особенно важна для фундаментальных принципов ИИ,
поскольку заявленной ими целью было вывести из набора аксиом путем формальных
операций всю математику. Хотя многие математические системы строились на основе
аксиом, интересно отношение Рассела и Уайтхеда к математике как к чисто формальной
системе. Это означает, что аксиомы и теоремы должны рассматриваться исключительно как
наборы символов: доказательства должны выводиться лишь посредством применения
строго определенных правил для манипулирования такими строками. При этом
исключается использование интуиции или "смысла" теорем в качестве основы доказательств.
Каждый шаг доказательства следует из строгого применения формальных
(синтаксических) правил к аксиомам или уже выведенным теоремам, даже если в
традиционных доказательствах этот шаг назывался "очевидным". Смысл, содержащийся в
теоремах и аксиомах системы, имеет отношение только к внешнему миру и совершенно
не зависит от логического вывода. Такой полностью формальный (реализуемый
техническими средствами) подход к математическим умозаключениям предоставил
существенную основу для его автоматизации в реальных вычислительных машинах.
Логический синтаксис и формальные правила вывода, разработанные Расселом и Уайтхедом,
34
Часть I. Искусственный интеллект: его истоки и проблемы
лежат в основе систем автоматического доказательства теорем, рассматриваемых в
главе 12, а также составляют теоретические основы искусственного интеллекта.
Альфред Тарский (Tarski) — еще один математик, чьи работы сыграли
принципиальную роль в процессе формирования искусственного интеллекта. Тарский
[Tarski, 1944, 1956] создал теорию ссылок (theory of reference), согласно которой
правильно построенные формулы (well-formed formulae) Фреге или Рассела-Уайтхеда
определенным образом ссылаются на объекты реального мира (см. главу 2). Эта концепция
лежит в основе большинства теорий формальной семантики. В работе "Семантическая
концепция истинности и основание семантики" Тарский описывает свою теорию ссылок
и взаимосвязей между значениями истинности. Современные исследователи
компьютерных наук связали эту теорию с языками программирования и другими компьютерными
реалиями [Burstall и Darlington, 1977].
Хотя в XVIII-XIX вв. и начале XX в. формализация науки и математики создала
интеллектуальные предпосылки для изучения искусственного интеллекта, он не стал
жизнеспособной научной дисциплиной до появления цифровых вычислительных машин. К
концу 1940-х гг. электронные цифровые компьютеры продемонстрировали свои
возможности в предоставлении памяти и процессорной мощности, требуемой для
интеллектуальных программ. Стало возможным реализовать формальные системы рассуждений в
машине и эмпирически испытать их достаточность для проявления разумности.
Существенной составляющей теории искусственного интеллекта является взгляд на цифровые
компьютеры как на средство создания и проверки теорий интеллекта.
Но цифровые компьютеры — не только рабочая лошадка для испытания теорий
интеллекта. Их архитектура наталкивает на специфичное представление таких теорий:
интеллект— это способ обработки информации. Например, концепция поиска как методики
решения задач обязана своим появлением в большей степени последовательному характеру
компьютерных операций, нежели какой-либо биологической модели интеллекта.
Большинство программ ИИ представляют знания на некотором формальном языке, а затем
обрабатывают их в соответствии с алгоритмами, следуя заложенному еще фон Нейманом
принципу разделения данных и программы. Формальная логика возникла как важный инструмент
представления для исследований ИИ, равно как теория графов играет неоценимую роль в
анализе пространства, а также предоставляет основу для семантических сетей и схожих
моделей. Эти методы и формализмы детально обсуждаются в последующих главах книги.
Здесь они упоминаются для подчеркивания симбиотических отношений между цифровыми
компьютерами и теоретическими основами искусственного интеллекта.
Мы часто забываем, что инструменты, которые мы создаем для своих целей, влияют
своим устройством и ограничениями на формирование наших представлений о мире.
Такое казалось бы стесняющее наш кругозор взаимодействие является важным аспектом
развития человеческого знания: инструмент (а научные теории, в конечном счете, тоже
инструменты) создается для решения конкретной проблемы. По мере применения и
совершенствования инструмент подсказывает другие способы его использования, которые
приводят к новым вопросам и, в конце концов, разработке новых инструментов.
1.1.3. Тест Тьюринга
Одна из первых работ, посвященных вопросу о машинном разуме в отношении
современных цифровых компьютеров, "Вычислительные машины и интеллект" была
написана в 1950 г. британским математиком Аланом Тьюрингом и опубликована в журнале
Глава 1. Искусственный интеллект: история развития и области приложения 35
"Mind" [Turing, 1950]. Она не теряет актуальности, как по части аргументов против
возможности создания разумной вычислительной машины, так и по части ответов на них.
Тьюринг, известный в основном благодаря своим трудам по теории вычислимости,
рассмотрел вопрос о том, можно ли заставить машину действительно думать. Отмечая, что
фундаментальная неопределенность в самом вопросе (что такое "думать"? что такое
"машина"?) исключает возможность рационального ответа, он предложил заменить
вопрос об интеллекте более четко определенным эмпирическим тестом.
Рис. 1.1. Тест Тьюринга
Тест Тьюринга сравнивает способности предположительно разумной машины со
способностями человека— лучшим и единственным стандартом разумного поведения. В
тесте, который Тьюринг назвал "имитационной игрой", машину и ее человеческого
соперника (следователя) помещают в разные комнаты, отделенные от комнаты, в которой
находится "имитатор" (рис. 1.1). Следователь не должен видеть их или говорить с ними
напрямую — он сообщается с ними исключительно с помощью текстового устройства,
например, компьютерного терминала. Следователь должен отличить компьютер от
человека исключительно на основе их ответов на вопросы, задаваемые через это устройство.
Если же следователь не может отличить машину от человека, тогда, утверждает
Тьюринг, машину можно считать разумной.
Изолируя следователя от машины и другого человека, тест исключает предвзятое
отношение — на решение следователя не будет влиять вид машины или ее электронный
голос. Следователь волен задавать любые вопросы, не важно, насколько окольные или
косвенные, пытаясь раскрыть "личность" компьютера. Например, следователь может
попросить обоих подопытных осуществить довольно сложный арифметический подсчет,
предполагая, что компьютер скорее даст верный ответ, чем человек. Чтобы обмануть эту
стратегию, компьютер должен знать, когда ему следует выдать ошибочное число, чтобы
показаться человеком. Чтобы обнаружить человеческое поведение на основе
эмоциональной природы, следователь может попросить обоих субъектов высказаться по поводу
стихотворения или картины. Компьютер в таком случае должен знать об эмоциональном
складе человеческих существ.
Этот тест имеет следующие важные особенности.
1. Дает объективное понятие об интеллекте, т.е. реакции заведомо разумного
существа на определенный набор вопросов. Таким образом, вводится стандарт для
определения интеллекта, который предотвращает неминуемые дебаты об "истинности"
его природы.
36
Часть I. Искусственный интеллект: его истоки и проблемы
2. Препятствует заведению нас в тупик сбивающими с толку и пока безответными
вопросами, такими как: должен ли компьютер использовать какие-то конкретные внутренние
процессы, или же должна ли машина по-настоящему осознавать свои действия.
3. Исключает предвзятость в пользу живых существ, заставляя опрашивающего
сфокусироваться исключительно на содержании ответов на вопросы.
Благодаря этим преимуществам, тест Тьюринга представляет собой хорошую основу
для многих схем, которые используются на практике для испытания современных
интеллектуальных программ. Программа, потенциально достигшая разумности в какой-либо
предметной области, может быть испытана сравнением ее способностей по решению
данного множества проблем со способностями человеческого эксперта. Этот метод
испытания всего лишь вариация на тему теста Тьюринга: группу людей просят сравнить
"вслепую" ответы компьютера и человека. Как видим, эта методика стала неотъемлемым
инструментом как при разработке, так и при проверке современных экспертных систем.
Тест Тьюринга, несмотря на свою интуитивную притягательность, уязвим для многих
оправданных нападок. Одно из наиболее слабых мест — пристрастие в пользу чисто
символьных задач. Тест не затрагивает способностей, требующих навыков перцепции или ловкости
рук, хотя подобные аспекты являются важными составляющими человеческого интеллекта.
Иногда же, напротив, тест Тьюринга обвиняют в попытках втиснуть машинный интеллект в
форму интеллекта человеческого. Быть может, машинный интеллект просто настолько
отличается от человеческого, что проверять его человеческими критериями — фундаментальная
ошибка? Нужна ли нам, в самом деле, машина, которая бы решала математические задачи так
же медленно и неточно, как человек? Не должна ли разумная машина извлекать выгоду из
своих преимуществ, таких как большая, быстрая, надежная память, и не пытаться
сымитировать человеческое познание? На самом деле, многие современные практики ИИ (например
[Ford и Hayes, 1995]) говорят, что разработка систем, которые бы выдерживали всесторонний
тест Тьюринга, — это ошибка, отвлекающая нас от более важных, насущных задач:
разработки универсальных теорий, объясняющих механизмы интеллекта людей и машин и
применение этих теорий к проектированию инструментов для решения конкретных практических
проблем. Все же тест Тьюринга представляется нам важной составляющей в тестировании и
"аттестации" современных интеллектуальных программ.
Тьюринг также затронул проблему осуществимости построения интеллектуальной
программы на базе цифрового компьютера. Размышляя в терминах конкретной
вычислительной модели (электронной цифровой машины с дискретными состояниями), он
сделал несколько хорошо обоснованных предположений касательно ее объема памяти,
сложности программы и основных принципов проектирования такой системы. Наконец,
он рассмотрел множество моральных, философских и научных возражений возможности
создания такой программы средствами современной технологии. Отсылаем читателя к
статье Тьюринга за познавательным и все еще актуальным изложением сути споров о
возможностях интеллектуальных машин.
Два возражения, приведенных Тьюрингом, стоит рассмотреть детально. "Возражение
леди Лавлейс", впервые сформулированное Адой Лавлейс, сводится к тому, что
компьютеры могут делать лишь то, что им укажут, и, следовательно, не могут выполнять
оригинальные (читай: разумные) действия. Однако экспертные системы (см. подраздел 1.2.3 и
главу 7), особенно в области диагностики, могут формулировать выводы, которые не
были заложены в них разработчиками. Многие исследователи считают, что творческие
способности можно реализовать программно.
Глава 1. Искусственный интеллект: история развития и области приложения 37
Другое возражение, "аргумент естественности поведения", связано с невозможностью
создания набора правил, которые бы говорили индивидууму, что в точности нужно
делать при каждом возможном стечении обстоятельств. Действительно, гибкость,
позволяющая биологическому разуму реагировать практически на бесконечное количество
различных ситуаций приемлемым, если даже и не оптимальным образом —
отличительная черта разумного поведения. Справедливо замечание, что управляющая логика,
используемая в большинстве традиционных компьютерных программ, не проявляет
великой гибкости или силы воображения, но неверно, что все программы должны писаться
подобным образом. Большая часть работ в сфере ИИ за последние 25 лет была
направлена на разработку таких языков программирования и моделей, призванных устранить
упомянутый недостаток, как продукционные системы, объектные системы, сетевые
представления и другие модели, обсуждаемые в этой книге.
Современные программы ИИ обычно состоят из набора модульных компонентов, или
правил поведения, которые не выполняются в жестко заданном порядке, а активизируются
по мере надобности в зависимости от структуры конкретной задачи. Системы обнаружения
совпадений позволяют применять общие правила к целому диапазону задач. Эти системы
необычайно гибки, что позволяет относительно маленьким программам проявлять
разнообразное поведение в широких пределах, реагируя на различные задачи и ситуации.
Можно ли довести гибкость таких программ до уровня живых организмов, все еще
предмет жарких споров. Нобелевский лауреат Герберт Саймон сказал, что большей частью
своеобразие и изменчивость поведения, присущие живым существам, возникли скорее
благодаря сложности их окружающей среды, чем благодаря сложности их внутренних
"программ". В [Simon, 1981] Саймон описывает муравья, петляющего по неровной,
пересеченной поверхности. Хотя путь муравья кажется довольно сложным, Саймон утверждает,
что цель муравья очень проста: вернуться как можно скорее в колонию. Изгибы и повороты
его пути вызваны встречаемыми препятствиями. Саймон заключает, что:
"Муравей, рассматриваемый в качестве проявляющей разумное поведение системы, на
самом деле очень прост Кажущаяся сложность его поведения в большей степени отражает
сложность среды, в которой он существует"
Эта идея, если удастся доказать применимость ее к организмам с более сложным
интеллектом, составит сильный аргумент в пользу простоты, а следовательно, постижимо-
сти интеллектуальных систем. Любопытно, что, применив эту идею к человеку, мы
придем к выводу об огромной значимости культуры в формировании интеллекта. Интеллект,
похоже, не взращивается во тьме, как грибы. Для его развития необходимо
взаимодействие с достаточно богатой окружающей средой. Культура так же необходима для
создания человеческих существ, как и человеческие существа для создания культуры. Эта
мысль не умаляет могущества наших интеллектов, но подчеркивает удивительное
богатство и связь различных культур, сформировавших жизни отдельных людей. Фактически
на идее о том, что интеллект возникает из взаимодействий индивидуальных элементов
общества, основывается подход к ИИ, представленный в следующем разделе.
1.1.4. Биологические и социальные модели интеллекта: агенты
Итак, мы рассмотрели математический подход к задаче построения интеллектуальных
устройств, подразумевающий, что основой самого интеллекта являются логические
умозаключения, а также основанный на "объективности" самих логических рассуждений. Этот
взгляд на знание, язык и мышление отражает традицию рационализма западной философии,
38
Часть I. Искусственный интеллект: его истоки и проблемы
развитую в работах Платона, Галилея, Декарта, Лейбница и многих других философов,
упомянутых ранее в этой главе. Также он отражает неявные предположения теста Тьюринга,
особенно его взгляд на символьные рассуждения как критерий интеллекта, и веру, что "лобовое"
сравнение с человеческим поведением пригодно для подтверждения интеллекта машины.
Опора на логику как способ представления языка и логические выводы как основной
механизм разумных рассуждений настолько доминирует в западной философии, что их
"истинность" часто кажется очевидной и неоспоримой. Поэтому не удивительно, что
подходы, основанные на этих предположениях, главенствуют в науке искусственного
интеллекта от ее зарождения до сегодняшнего дня.
Во второй половине XX века устои рационализма пошатнулись. Философский
релятивизм в разных своих формах задавался вопросом об объективном базисе языка, науки,
общества и самой мысли. Философия поздних работ Виттгенштейна [Wittgenstein, 1953]
вынудила пересмотреть понятие смысла в естественных и формальных языках. Труды
Геделя и Тьюринга подвергли сомнению основания самой математики.
Постмодернистские идеи изменили наши взгляды на значимость и ценность в художественном и
социальном контекстах. Искусственный интеллект также стал жертвой подобной критики.
Действительно, трудности, которые встали на пути ИИ к его целям, часто
рассматриваются как свидетельства ошибочности рационалистического взгляда [Winograd и
Flores, 1986], [Lakoff и Johnson, 1999].
Две философские традиции — Виттгенштейна с Хассерлом [Husserl, 1970, 1972] и
Хайдеггера [Heidegger, 1962] являются основополагающими в этом пересмотре западной
философии. В своей работе Виттгенштейн затронул многие допущения рационалистской
традиции, включая основания языка, науки и знания. Естественный язык был главным
предметом анализа Виттгенштейна. Этот философ опровергает мнение, что смысл
человеческого языка можно вывести из каких-либо объективных основ.
В трудах Виттгенштейна, как и в теории речи (speech act theory), развитой Остином
[Austin, 1962] и его последователями [Grice, 1975], [Searle, 1969], значение любого
высказывания зависит от человеческого, культурного контекста. Значение слова "сиденье",
к примеру, зависит от наличия физического объекта, который можно применить для
сидения на нем, а также культурных соглашений об использовании сидений. Когда,
например, большой плоский камень можно назвать сиденьем? Почему нелепо так называть
королевский трон? Какая разница между человеческим пониманием "сиденья" и
пониманием кота или собаки, которые в человеческом смысле сидеть не могут? Атакуя основы
смысла, Виттгенштейн утверждал, что мы должны рассматривать использование языка
посредством выбора и действий в изменчивом культурном контексте. Виттгенштейн
даже распространил свою критику на науку и математику, утверждая, что они в такой же
мере общественные конструкции, как и языки.
Хассерл, отец феноменологии, рассматривал абстракции как объекты, укоренившиеся
в конкретном "жизненном мире": рационалистская модель отодвигает конкретный
поддерживающий ее мир на второй план. Для Хассерла, как и для его ученика Хайдеггера и
их сторонника Мерло-Понти [Merleau-Ponty, 1962], интеллект заключался не в знании
истины, а в знании, как вести себя в постоянно меняющемся и развивающемся мире.
Таким образом, в экзистенциалистско-феноменологической традиции интеллект
рассматривается скорее с точки зрения выживания в мире, чем как набор логических
утверждений о мире (в сочетании со схемой вывода).
Многие авторы, например Дрейфусы [Dreyfus и Dreyfus, 1985], а также Виноград и
Флорес [Winograd и Flores, 1986], опирались на работы Виттгенштейна, Хассерла и Хай-
Глава 1. Искусственный интеллект: история развития и области приложения 39
деггера в своей критике ИИ. Хотя многие практики ИИ продолжают разработку
рационально-логической программной системы (также известной как GOFAI, или Good Old
Fashioned AI — старый-добрый ИИ), все возрастающее число исследователей этой
области, приняв во внимание эту критику, строят новые занимательные модели интеллекта.
Придерживаясь идей Виттгенштейна об антропологических и культурных корнях знания,
они обратились к социальным моделям интеллектуального поведения, иногда
называемым ситуативными.
Пример альтернативы логическому подходу — исследования в области коннекциони-
стского обучения (см. подраздел 1.2.9 и главу 10), в которых логике и работе
рационального разума уделяется мало внимания, но сделана попытка достичь разумности
посредством моделирования архитектуры реального мозга. В нейронных моделях интеллекта
упор делается на способность мозга адаптироваться к миру, в котором он существует, с
помощью изменений связей между отдельными нейронами. Знание в таких системах не
выражается явными логическими конструкциями, а представляется в неявной форме, как
свойство конфигураций таких взаимосвязей.
Иная модель интеллекта, заимствованная из биологии, навеяна процессами адаптации
видов к окружающей среде. В разработках искусственной жизни и генетических
алгоритмов (см. главу 11) принципы биологической эволюции применяются для решения сложных
проблем. Такие программы не решают задачи посредством логических рассуждений. Они
порождают популяции соревнующихся между собой решений-кандидатов и заставляют их
совершенствоваться с помощью процессов, имитирующих биологическую эволюцию:
неудачные кандидаты на решения отмирают, в то время как подающие надежды выживают и
воспроизводятся путем создания новых решений из частей "успешных" родителей.
Социальные системы дают еще одно модельное представление интеллекта с помощью
глобального поведения, которое позволяет им решать проблемы, которые бы не удалось
решить отдельным их членам. Например, хотя ни один индивидуум не в состоянии точно
предсказать количество буханок хлеба, которое потребит в заданный день Нью-Йорк,
система всех нью-йоркских пекарен отлично справляется со снабжением города хлебом и
делает это с минимальными затратами. Рынок акций отлично устанавливает относительную
ценность сотен компаний, хотя каждый отдельный инвестор имеет лишь ограниченное
знание о нескольких компаниях. Можно привести также пример из современной науки.
Отдельные исследователи из университетской, производственной или правительственной
среды сосредоточиваются на решении общих проблем. С помощью конференций и журналов,
служащих основным средством сообщения, важные для общества в целом проблемы
рассматриваются и решаются отдельными агентами, работающими отчасти независимо, хотя
прогресс во многих случаях также направляется субсидиями.
Эти примеры имеют два общих аспекта. Во-первых, корни интеллекта связаны с
культурой и обществом, а следовательно, разум является эмерджентным (emergent). Во-
вторых, разумное поведение формируется совместными действиями большого числа
очень простых взаимодействующих полуавтономных индивидуумов, или агентов.
Являются агенты нервными клетками, индивидуальными особями биологического вида или
же отдельными личностями в обществе, их взаимодействие создает интеллект.
Рассмотрим основные аспекты агентских и эмерджентных взглядов на интеллект.
1. Агенты автономны или полуавтономны. Следовательно, у каждого агента есть
определенный круг подзадач, причем он располагает малым знанием (или вовсе
не располагает знанием) о том, что делают другие агенты или как они это
делают. Каждый агент выполняет свою независимую часть решения проблемы и либо
40
Часть I. Искусственный интеллект: его истоки и проблемы
выдает собственно результат (что-то совершает) либо сообщает результат
другим агентам.
2. Агенты являются "внедренными". Каждый агент чувствителен к своей
окружающей среде и (обычно) не знает о состоянии полной области существования агентов.
Таким образом, знание агента ограничено его текущими задачами: "файл, который
я обрабатываю" или "стенка рядом со мной", агент не владеет информацией обо
всех файлах одновременно или физических границах предметной области.
3. Агенты взаимодействуют. Они формируют коллектив индивидуумов, которые
сотрудничают над решением задачи. В этом смысле их можно рассматривать как
"сообщество". Как и в человеческом обществе, знания, умения и обязанности
распределяются среди отдельных индивидуумов.
4. Сообщество агентов структурировано. В большинстве агентно-ориентированных
методов решения проблем каждый индивидуум, работая со своим собственным
окружением и навыками, координирует общий ход решения с другими агентами.
Таким образом, окончательное решение можно назвать не только коллективным, но и
кооперативным.
5. Наконец, явление интеллекта в этой среде является "эмерджентным". Хотя
индивидуальные агенты обладают некоторыми совокупностями навыков и
обязанностей, общий, совместный, результат сообщества агентов следует рассматривать как
нечто большее, чем сумма отдельных вкладов. Интеллект рассматривается как
явление, возникающее в сообществе, а не как свойство отдельного агента.
Основываясь на этих наблюдениях, определим агента как элемент сообщества,
который может воспринимать (часто ограниченно) аспекты своего окружения и
взаимодействовать с этой окружающей средой либо непосредственно, либо путем сотрудничества с
другими агентами. Большинство интеллектуальных методов решений требуют наличия
разнообразных агентов. Это могут быть простые агенты-механизмы, задача которых —
собирать и передавать информацию; агенты-координаторы, которые обеспечивают
взаимодействие между другими агентами; агенты поиска, которые перебирают пакеты
информации и возвращают какие-то избранные частицы; обучающие агенты, которые на
основе полученной информации формируют обобщающие концепции; и агенты,
принимающие решения, которые раздают задания и делают выводы на основе ограниченной
информации и обработки. Возвращаясь к старому определению интеллекта, агенты
можно рассматривать как механизмы, обеспечивающие выработку решения в условиях
ограниченных ресурсов и процессорных мощностей.
Для разработки и построения таких сообществ необходимы следующие компоненты.
1. Структуры для представления информации.
2. Стратегии поиска в пространстве альтернативных решений.
3. Архитектура, обеспечивающая взаимодействие агентов.
В последующих главах, в частности в разделе 6.4, приводятся рекомендации для
создания средств поддержки таких агентских сообществ.
Это предварительное рассмотрение возможностей теории автоматизированного
интеллекта ни в коей мере не ставит себе целью преувеличить достижения, полученные до
настоящего времени или преуменьшить работу, которую еще предстоит проделать. В
этой книге постоянно подчеркивается, как важно четко представлять себе границы на-
Глава 1. Искусственный интеллект: история развития и области приложения 41
ших текущих возможностей и сегодняшних свершений. Например, очень ограниченные
успехи сделаны в построении программ, которые могут "учиться" в интересном для
человека смысле. Также очень скромны достижения в моделировании семантической
сложности естественных языков, к примеру, английского. Даже в фундаментальных
вопросах, таких как организация знаний или управление сложностью и корректностью
большой компьютерной программы (например, большой базы знаний), требуются
значительные дальнейшие исследования. Основанные на знаниях системы, хотя и достигли
коммерческого успеха, имеют все еще много ограничений в качестве и общности своих
выводов. В частности, они не способны рассуждать на основе "здравого смысла"
(commonsense reasoning) или же проявлять знания о простейших свойствах реального
мира, например, о том, как изменяются со временем разные вещи.
Но следует сохранять трезвый взгляд на вещи. Обозреть достижения искусственного
интеллекта легче, честно представляя предстоящую работу. В следующем разделе мы
рассмотрим некоторые сферы исследований и разработок ИИ.
1.2. Обзор прикладных областей искусственного
интеллекта
Аналитическая машина не претендует на создание чего-либо нового. Ее способности
не превосходят наших знаний о том, как приказать ей что-либо исполнить ..
— Ада Байрон (Ada Byron), графиня Лавлейс
Прости, Дейв, я не могу позволить тебе это сделать .
— HAL 9000, компьютер из фильма 2001: Космическая одиссея
Вернемся к заявленной цели дать определение искусственному интеллекту путем
обозрения стремлений и достижений исследователей этой области. Две наиболее
фундаментальные проблемы, занимающие разработчиков ИИ, — это представление
знаний (knowledge representation) и поиск (search). Первая относится к проблеме
получения новых знаний с помощью формального языка, подходящего для
компьютерных манипуляций, всего спектра знаний, требуемых для формирования
разумного поведения. В главе 2 рассматривается исчисление предикатов как язык описания
свойств и отношений между объектами предметной области. Здесь для решения
нужны скорее рассуждения качественного характера, чем арифметические расчеты.
В главах 6-8 обсуждаются языки, разработанные для отражения неопределенностей
и структурной сложности таких областей, как рассуждения на основе "здравого
смысла" и понимание естественных языков. В главах 14 и 15 демонстрируется
использование языков LISP и PROLOG для реализаций этих представлений.
Поиск — это метод решения проблемы, в котором систематически просматривается
пространство состояний задачи (problem states), т.е. альтернативных стадий ее решения.
Примеры состояний задачи: различные размещения фигур на доске в игре или же
промежуточные шаги логического обоснования. Затем в этом пространстве альтернативных
решений производится перебор в поисках окончательного ответа. Ньюэлл и Саймон
[Newell и Simon, 1976] утверждают, что эта техника лежит в основе человеческого
способа решения различных задач. Действительно, когда игрок в шахматы анализирует
последствия различных ходов или врач обдумывает различные альтернативные диагнозы,
42
Часть I. Искусственный интеллект: его истоки и проблемы
они производят перебор среди альтернатив. Результаты применения этой модели и
средства ее реализации обсуждаются в главах 3, 4, 5 и 16.
Как и большая часть наук, ИИ разбивается на множество поддисциплин, которые,
разделяя основной подход к решению проблем, нашли себе различные применения.
Очертим в этом разделе некоторые из основных сфер применения этих отраслей и их
вклад в искусственный интеллект вообще.
1.2.1. Ведение игр
Многие ранние исследования в области поиска в пространстве состояний
совершались на основе таких распространенных настольных игр, как шашки, шахматы и
пятнашки. Вдобавок к свойственному им "интеллектуальному" характеру такие игры имеют
некоторые свойства, делающие их идеальным объектом для экспериментов. Большинство
игр ведутся с использованием четко определенного набора правил: это позволяет легко
строить пространство поиска и избавляет исследователя от неясности и путаницы,
присущих менее структурированным проблемам. Позиции фигур легко представимы в
компьютерной программе, они не требуют создания сложных формализмов, необходимых
для передачи семантических тонкостей более сложных предметных областей.
Тестирование игровых программ не порождает никаких финансовых или этических проблем.
Поиск в пространстве состояний — принцип, лежащий в основе большинства
исследований в области ведения игр, — представлен в главах 3 и 4.
Игры могут порождать необычайно большие пространства состояний. Для поиска в
них требуются мощные методики, определяющие, какие альтернативы следует
рассматривать. Такие методики называются эвристикалш и составляют значительную область
исследований ИИ. Эвристика — стратегия полезная, но потенциально способная
упустить правильное решение. Примером эвристики может быть рекомендация проверять,
включен ли прибор в розетку, прежде чем делать предположения о его поломке, или
выполнять рокировку в шахматной игре, чтобы попытаться уберечь короля от шаха.
Большая часть того, что мы называем разумностью, по-видимому, опирается на эвристики,
которые люди используют в решении задач.
Поскольку у большинства из нас есть опыт в этих простых играх, можно попробовать
разработать свои эвристики и испытать их эффективность. Для этого нам не нужны
консультации экспертов в каких-то темных для непосвященных областях, вроде медицины
или математики. Поэтому игры являются хорошей основой для изучения эвристического
поиска. Глава 4 рассказывает об эвристиках на примере этих простых игр; в главе 7 их
использование распространяется на построение экспертных систем. Программы ведения
игр, несмотря на их простоту, ставят перед исследователями новые вопросы, включая
вариант, при котором ходы противника невозможно детерминировано предугадать
(см. главу 8). Наличие противника усложняет структуру программы, добавляя в нее
элемент непредсказуемости и потребность уделять внимание психологическим и
тактическим факторам игровой стратегии.
1.2.2. Автоматические рассуждения и доказательство теорем
Можно сказать, что автоматическое доказательство теорем — одна из старейших
частей искусственного интеллекта, корни которой уходят к системам Logic Theorist
(логический теоретик) Ньюэлла и Саймона [Newell и Simon, 1963л] и General Problem
Глава 1. Искусственный интеллект: история развития и области приложения 43
Solver (универсальный решатель задач) [Newell и Simon, 19636] и далее, к попыткам
Рассела и Уайтхеда построить всю математику на основе формальных выводов теорем из
начальных аксиом. В любом случае эта ветвь принесла наиболее богатые плоды.
Благодаря исследованиям в области доказательства теорем были формализованы алгоритмы
поиска и разработаны языки формальных представлений, такие как исчисление
предикатов (см. главу 2) и логический язык программирования PROLOG (глава 14).
Привлекательность автоматического доказательства теорем основана на строгости и
общности логики. В формальной системе логика располагает к автоматизации. Разнообразные
проблемы можно попытаться решить, представив описание задачи и существенную
относящуюся к ней информацию в виде логических аксиом и рассматривая различные случаи задачи
как теоремы, которые нужно доказать. Этот принцип лежит в основе автоматического
доказательства теорем и систем математических обоснований (см. главу 12).
К сожалению, в ранних пробах написать программу для автоматического доказательства
не удалось разработать систему, которая бы единообразно решала сложные задачи. Это было
обусловлено способностью любой относительно сложной логической системы сгенерировать
бесконечное количество доказуемых теорем: без мощных методик (эвристик), которые бы
направляли поиск, программы доказывали большие количества не относящихся к делу теорем,
пока не натыкались на нужную. Из-за этой неэффективности многие утверждают, что чисто
формальные синтаксические методы управления поиском в принципе не способны
справиться с такими большими пространствами, и единственная альтернатива этому — положиться на
неформальные, специально подобранные к случаю (лат. "ad hoc") стратегии, как это, похоже,
делают люди. Это один из подходов, лежащих в основе экспертных систем (см. главу 7), и он
оказался достаточно плодотворным.
Все же привлекательность рассуждений, основанных на формальной логике, слишком
сильна, чтобы ее игнорировать. Многие важные проблемы, такие как проектирование и
проверка логических цепей, проверка корректности компьютерных программ и управление
сложными системами, по-видимому, поддаются такому подходу. Вдобавок исследователям
автоматического доказательства удалось разработать мощные эвристики, основанные на
оценке синтаксической формы логического выражения, которые в результате понижают
сложность пространства поиска, не прибегая к используемым людьми методам "ad hoc1'.
Еще одной причиной неувядающего интереса к автоматическому доказательству теорем
является понимание, что системе не обязательно решать особо сложные проблемы без
человеческого вмешательства. Многие современные программы доказательств работают как
умные помощники, предоставляя людям разбивать задачи на подзадачи и продумывать
эвристики для перебора в пространстве возможных обоснований. Программа для автоматического
доказательства затем решает более простые задачи доказательства лемм, проверки менее
существенных предположений и дополняет формальные аспекты доказательства, очерченного
человеком [Воуег и Moore, 1979], [Bundy, 1988], [Veroff, 1997].
1.2.3. Экспертные системы
Одним из главных достижений ранних исследований по ИИ стало осознание важности
специфичного для предметной области (domain-specific) знания. Врач, к примеру, хорошо
диагностирует болезни не потому, что он располагает некими врожденными общими
способностями к решению задач, а потому, что многое знает о медицине. Точно так же геолог
эффективно находит залежей ископаемых, потому что он способен применить богатые
теоретические и практические знания о геологии к текущей проблеме. Экспертное знание— это
44
Часть I. Искусственный интеллект: его истоки и проблемы
сочетание теоретического понимания проблемы и набора эвристических правил для ее
решения, которые, как показывает опыт, эффективны в данной предметной области. Экспертные
системы создаются с помощью заимствования знаний у человеческого эксперта и
кодирования их в форму, которую компьютер может применить к аналогичным проблемам.
Стратегии экспертных систем основаны на знаниях человека-эксперта. Хотя многие
программы пишутся самими носителями знаний о предметной области, большинство экспертных
систем являются плодом сотрудничества между таким экспертом, как врач, химик, геолог или
инженер, и независимым специалистом по ИИ. Эксперт предоставляет необходимые знания о
предметной области, описывая свои методы принятия решений и демонстрируя эти навыки на
тщательно отобранных примерах. Специалист по ИИ, или инженер по знаниям (knowledge
engineer), как часто называют разработчиков экспертных систем, отвечает за реализацию
этого знания в программе, которая должна работать эффективно и внешне разумно. Экспертные
способности программы проверяют, давая ей решать пробные задачи. Эксперт подвергает
критике поведение программы, и в ее базу знаний вносятся необходимые изменения. Процесс
повторяется, пока программа не достигнет требуемого уровня работоспособности.
Одной из первых систем, использовавших специфичные для предметной области знания,
была система DENDRAL, разработанная в Стэнфорде в конце 1960-х [Lindsay и др., 1980].
DENDRAL была задумана для определения строения органических молекул из химических
формул и спектрографических данных о химических связях в молекулах. Поскольку
органические молекулы обычно очень велики, число возможных структур этих молекул также
весьма внушительно. DENDRAL решает проблему большого пространства перебора, применяя
эвристические знания экспертов-химиков к решению задачи определения структуры. Методы
DENDRAL оказались весьма работоспособными. Она методично находит правильное
строение из миллионов возможных всего за несколько попыток. Данный подход оказался столь
эффективным, что "потомки" этой системы до сих пор используются в химических и
фармацевтических лабораториях по всему миру.
Программа DENDRAL одной из первых использовала специфичное знание для
достижения уровня эксперта в решении задач, однако методика современных экспертных
систем связана с другой программой— MYCIN [Buchanan и Shortliffe, 1984]. В ней
использовались знания экспертов медицины для диагностики и лечения спинального
менингита и бактериальных инфекций крови.
Программа MYCIN, разработанная в Стэнфорде в середине 1970-х, одной из первых
обратилась к проблеме принятия решений на основе ненадежной или недостаточной информации.
Она выводит ясные и логичные пояснения своих рассуждений, используя структуру
управляющей логики, соответствующую специфике предметной области, и критерии для надежной
оценки своей работы. Многие методики разработки экспертных систем, использующиеся
сегодня, были впервые разработаны в рамках проекта MYCIN (см. главу 7).
К числу других классических экспертных систем относится программа
PROSPECTOR, определяющая предполагаемые рудные месторождения и их типы,
основываясь на геологических данных о местности [Duda и др., 1979а, 19796]; программа
INTERNIST, применяемая для диагностики в сфере медицины внутренних органов;
программа Dipmeter Advisor, интерпретирующая протоколы бурения нефтяных скважин
[Smith и Baker, 1983]; и XCON, используемая для настройки компьютеров VAX.
Программа XCON была разработана в 1981 г., и одно время все машины VAX,
распространяемые компанией Digital Equipment, настраивались этой программой. Многочисленные
экспертные системы решают в настоящее время задачи в таких областях, как медицина,
образование, бизнес, дизайн и научные исследования [Waterman, 1986], [Durkin, 1994].
Глава 1. Искусственный интеллект: история развития и области приложения 45
Интересно отметить, что большинство экспертных систем были написаны для
специализированных предметных областей. Эти области довольно хорошо изучены и
располагают четко определенными стратегиями принятия решений. Проблемы, определенные
на нечеткой основе "здравого смысла", подобными средствами решить сложнее.
Несмотря на воодушевляющие перспективы экспертных систем, было бы ошибкой
переоценивать возможности этой технологии. Основные проблемы перечислены ниже.
1. Трудности в передаче "глубоких" знаний предметной области. Системе MYCIN, к
примеру, не достает действительного знания человеческой физиологии. Она не
знает, какова функция кровеносной системы или спинного мозга. Ходит предание,
что однажды, подбирая лекарство для лечения менингита, MYCIN спросила,
беремен ли пациент, хотя ей указали, что пациент мужского пола. Было это на самом
деле или нет, неизвестно, но это хорошая иллюстрация потенциальной
ограниченности знаний экспертной системы.
2. Недостаток здравомыслия и гибкости. Если людей поставить перед задачей,
которую они не в состоянии решить немедленно, то они обычно исследуют сперва
основные принципы и вырабатывают какую-то стратегию для подхода к проблеме.
Экспертным системам этой способности не хватает.
3. Неспособность предоставлять осмысленные объяснения. Поскольку экспертные
системы не владеют глубоким знанием своей предметной области, их пояснения обычно
ограничиваются описанием шагов, которые система предприняла в поиске решения. Но
они зачастую не могут пояснить, "почему" был выбран конкретный подход.
4. Трудности в тестировании. Хотя обоснование корректности любой большой
компьютерной системы достаточно трудоемко, экспертные системы проверять
особенно тяжело. Это серьезная проблема, поскольку технологии экспертных систем
применяются для таких критичных задач, как управление воздушным движением,
ядерными реакторами и системами оружия.
5. Ограниченные возможности обучения на опыте. Сегодняшние экспертные системы
делаются "вручную"; производительность разработанной системы не будет
возрастать до следующего вмешательства программистов. Это заставляет серьезно
усомниться в разумности таких систем.
Несмотря на эти ограничения, экспертные системы доказали свою ценность во
многих важных приложениях. Будем надеяться, что недоработки сподвигнут студентов
заняться этой важной отраслью компьютерных наук. Экспертные системы — одна из
основных тем этой книги. Они подробно обсуждаются в главах 6 и 7.
1.2.4. Понимание естественных языков и семантическое моделирование
Одной из долгосрочных целей искусственного интеллекта является создание
программ, способных понимать человеческий язык и строить фразы на нем. Способность
применять и понимать естественный язык является фундаментальным аспектом
человеческого интеллекта, а его успешная автоматизация привела бы к неизмеримой
эффективности самих компьютеров. Многие усилия были затрачены на написание программ,
понимающих естественный язык. Хотя такие программы и достигли успеха в ограниченных
контекстах, системы, использующие натуральные языки с гибкостью и общностью,
характерной для человеческой речи, лежат за пределами сегодняшних методологий.
46
Часть I. Искусственный интеллект: его истоки и проблемы
Понимание естественного языка включает куда больше, чем разбор предложений на
индивидуальные части речи и поиск значений слов в словаре. Оно базируется на
обширном фоновом знании о предмете беседы и идиомах, используемых в этой области, так
же, как и на способности применять общее контекстуальное знание для понимания
недомолвок и неясностей, присущих естественной человеческой речи.
Представьте себе, к примеру, трудности в разговоре о футболе с человеком, который
ничего не знает об игре, правилах, ее истории и игроках. Способен ли такой человек понять
смысл фразы: "в центре Иванов перехватил верхнюю передачу— мяч полетел к штрафной
соперника, там за него на "втором этаже" поборолись Петров и Сидоров, после чего был
сделан пас на Васина в штрафную, который из-под защитника подъемом пробил точно в дальний
угол"? Хотя каждое отдельное слово в этом предложении можно понять, фраза звучит
совершенной тарабарщиной для любого нефаната, будь он хоть семи пядей во лбу.
Задача сбора и организации этого фонового знания, чтобы его можно было
применить к осмыслению языка, составляет значительную проблему в автоматизации
понимания естественного языка. Для ее решения исследователи разработали множество методов
структурирования семантических значений, используемых повсеместно в искусственном
интеллекте (см. главы 6, 7 и 13).
Из-за огромных объемов знаний, требуемых для понимания естественного языка, большая
часть работы ведется в хорошо понимаемых, специализированных проблемных областях.
Одной из первых программ, использовавших такую методику "микромира", была программа
Винограда SHRDLU — система понимания естественного языка, которая могла "беседовать"
о простом взаимном расположении блоков разных форм и цветов [Winograd, 1973].
Программа SHRDLU могла отвечать на вопросы типа: "какого цвета блок на синем кубике?", а также
планировать действия вроде "передвинь красную пирамидку на зеленый брусок". Задачи
этого рода, включая управление размещением блоков и их описание, на удивление часто
всплывали в исследованиях ИИ и получили название проблем "мира блоков".
Несмотря на успехи программы SHRDLU в разговорах о расположении блоков, она
была не способна абстрагироваться от мира блоков. Методики представления,
использованные в программе, были слишком просты, чтобы передать семантическую организацию
более богатых и сложных предметных областей. Основная часть текущих работ в области
понимания естественных языков направлена на поиск формализмов представления, которые
должны быть достаточно общими, чтобы применяться в широком круге приложений и
уметь адаптироваться к специфичной структуре заданной области. Множество
разнообразных методик (большинство из которых являются развитием или модификацией
семантических сетей) исследуются с этой целью и используются при разработке программ,
способных понимать естественный язык в ограниченных, но достаточно интересных предметных
областях. Наконец, в текущих исследованиях [Marcus, 1980], [Manning и Schutze, 1999],
[Jurafsky и Martin, 2000] стохастические модели, описывающие совместное использование
слов в языке, применяются для характеристики как синтаксиса, так и семантики. Полное
понимание языка на вычислительной основе все же остается далеко за пределами
современных возможностей.
1.2.5. Моделирование работы человеческого интеллекта
В большей части рассмотренного выше материала человеческий интеллект
служит отправной точкой в создании искусственного, однако это не означает, что
программы должны формироваться по образу и подобию человеческого разума. Дейст-
Глава 1. Искусственный интеллект: история развития и области приложения 47
вительно, многие программы ИИ создаются для решения каких-то насущных задач
без учета человеческой ментальной архитектуры. Даже экспертные системы,
заимствуя большую часть своего знания у экспертов-людей, не пытаются моделировать
внутренние процессы человеческого ума. Если производительность системы — это
единственный критерий ее качества, нет особых оснований имитировать
человеческие методы принятия решений. Программы, которые используют несвойственные
людям подходы, зачастую более успешны, чем их человеческие соперники. Тем не
менее конструирование систем, которые бы детально моделировали какой-либо
аспект работы интеллекта человека, стало плодотворной областью исследований как в
искусственном интеллекте, так и в психологии.
Моделирование работы человеческого разума помимо обеспечения ИИ его основной
методологией оказалось мощным средством для формулирования и испытания теорий
человеческого познания. Методологии принятия решений, разработанные теоретиками
компьютерных наук, дали психологам новую отправную точку для исследования
человеческого разума. Вместо того чтобы гадать о теориях познания на неясном языке ранних
исследований или вообще оставить попытки описания внутренних механизмов
человеческого интеллекта (как предлагают специалисты по изучению поведения), многие
психологи приспособили язык и теорию компьютерной науки для разработки моделей
человеческого разума. Такие методы не только дают новую терминологию для характеристики
человеческого интеллекта. Компьютерная реализация этих теорий предоставляет
психологам возможность эмпирически тестировать, критиковать и уточнять их идеи
[Luger, 1994]. Обсуждение отношений между ИИ и попытками понять человеческий
разум приводится ниже и резюмируется в главе 16.
1.2.6. Планирование и робототехника
Исследования в области планирования начались с попытки сконструировать роботов,
которые бы выполняли свои задачи с некоторой степенью гибкости и способностью
реагировать на окружающий мир. Планирование предполагает, что робот должен уметь
выполнять некоторые элементарные действия. Он пытается найти последовательность
таких действий, с помощью которой можно выполнить более сложную задачу, например,
двигаться по комнате, заполненной препятствиями.
Планирование по ряду причин является сложной проблемой, не малую роль в
этом играет размер пространства возможных последовательностей шагов. Даже
очень простой робот способен породить огромное число различных комбинаций
элементарных движений. Представьте себе, к примеру, робота, который может
передвигаться вперед, назад, влево и вправо, и вообразите, сколькими различными
путями он может двигаться по комнате. Представьте также, что в комнате есть
препятствия, и что робот должен выбирать путь вокруг них некоторым оптимальным
образом. Для написания программы, которая могла бы разумно определить лучший путь
из всех вариантов, и не была бы при этом перегружена огромным их числом,
потребуются сложные методы для представления пространственного знания и управления
перебором в пространстве альтернатив.
Одним из методов, применяемых человеческими существами при планировании,
является иерархическая декомпозиция задачи (hierarchical problem decomposition).
Планируя путешествие в Лондон, вы, скорее всего, займетесь отдельно проблемами
организации перелета, поездки до аэропорта, самого полета и поиска подходящего вида транс-
48
Часть I. Искусственный интеллект: его истоки и проблемы
порта в Лондоне, хотя все они являются частью большого общего плана. Каждая из этих
задач может сама быть разбита на такие подзадачи, как, например, покупка карты
города, преодоление лабиринта линий метро и поиск подходящей пивной. Такой подход не
только эффективно ограничивает размер пространства поиска, но и позволяет сохранять
часто используемые маршруты для дальнейшего применения.
В то время как люди разрабатывают планы безо всяких усилий, создание
компьютерной программы, которая бы занималась тем же — сложная проблема. Казалось бы, такая
простая вещь, как разбиение задачи на независимые подзадачи, на самом деле требует
изощренных эвристик и обширного знания об области планирования. Не менее сложная
проблема — определить, какие планы следует сохранить, и как их обобщить для
использования в будущем.
Робот, слепо выполняющий последовательности действий, не реагируя на изменения
в своем окружении, или неспособный обнаруживать и исправлять ошибки в своем
собственном плане, едва ли может считаться разумным. Зачастую от робота требуют
сформировать план, основанный на недостаточной информации, и откорректировать свое
поведение по мере его выполнения. Робот может не располагать адекватными сенсорами для
того, чтобы обнаружить все препятствия на проектируемом пути. Такой робот должен
начать двигаться по комнате, основываясь на "воспринимаемых" им данных, и
корректировать свой путь по мере того, как выявляются другие препятствия. Организация
планов, позволяющая реагировать на изменение условий окружающей среды, — основная
проблема планирования [Lewis и Luger, 2000].
Наконец, робототехника была одной из областей исследований ИИ, породившей
множество концепций, лежащих в основе агентно-ориентированного принятия решений
(см. подраздел 1.1.4). Исследователи, потерпевшие неудачу при решении проблем,
связанных с большими пространствами представлений и разработкой алгоритмов поиска для
традиционного планирования, переформулировали задачу в терминах взаимодействия
полуавтономных агентов [Agre и Chapman, 1987], [Brooks, 199la]. Каждый агент отвечает за свою
часть задания, и общее решение возникает в результате их скоординированных действий.
Элементы алгоритмов планирования будут представлены в главах 6, 7 и 14.
Исследования в области планирования сегодня вышли за пределы робототехники,
теперь они включают также координацию любых сложных систем задач и целей.
Современные планировщики применяются в агентских средах [Nilsson, 1994], а также для
управления ускорителями частиц [Klein и др., 1999, 2000].
1.2.7. Языки и среды ИИ
Одним из наиболее важных побочных продуктов исследований ИИ стали достижения
в сфере языков программирования и средах разработки программного обеспечения. По
множеству причин, включая размеры многих прикладных программ ИИ, важность
методологии "создания прототипов", тенденцию алгоритмов поиска порождать чересчур
большие пространства и трудности в предсказании поведения эвристических программ,
программистам искусственного интеллекта пришлось разработать мощную систему
методологий программирования.
Средства программирования включают такие методы структурирования знаний, как
объектно-ориентированное программирование и каркасы экспертных систем (они
обсуждаются в части III). Высокоуровневые языки, такие как LISP и PROLOG (см. часть IV),
которые обеспечивают модульную разработку, помогают управиться с размерами и
Глава 1. Искусственный интеллект: история развития и области приложения 49
сложностью программ. Пакеты средств трассировки позволяют программистам
реконструировать выполнение сложного алгоритма и разобраться в сложных структурах
эвристического перебора. Без подобных инструментов и методик вряд ли удалось бы
построить многие известные системы ИИ.
Многие из этих методик сегодня являются стандартными методами разработки
программного обеспечения и мало соотносятся с основами теории ИИ. Другие же, такие как
объектно-ориентированное программирование, имеют значительный теоретический и
практический интерес. Наконец, многие алгоритмы ИИ сейчас реализуются на таких
традиционных для вычислительной техники языках, как C++ и Java.
Языки, разработанные для программирования ИИ, тесно связаны с теоретической
структурой этой области. В данной книге рассматривается и LISP, и PROLOG, и мы
старались удержаться от религиозных прений об их относительных достоинствах,
склоняясь, скорее, к той точке зрения, что "хороший работник должен знать все инструменты".
Главы, посвященные языкам программирования A4 и 15), рассматривают преимущества
применения различных языков для решения конкретных задач.
1.2.8. Машинное обучение
Обучение остается "крепким орешком" искусственного интеллекта. Важность
обучения, тем не менее, несомненна, поскольку эта способность является одной из главных
составляющих разумного поведения. Экспертная система может выполнять долгие и
трудоемкие вычисления для решения проблем. Но, в отличие от человеческих существ,
если дать ей такую же или подобную проблему второй раз, она не "вспомнит" решение.
Она каждый раз вновь будет выполнять те же вычисления — едва ли это похоже на
разумное поведение.
Большинство экспертных систем ограничены негибкостью их стратегий принятия
решений и трудностью модификации больших объемов кода. Очевидное решение этих
проблем — заставить программы учиться самим на опыте, аналогиях или примерах.
Хотя обучение является трудной областью, существуют некоторые программы,
которые опровергают опасения о ее неприступности. Одной из таких программ является
AM — Автоматизированный Математик, разработанный для открытия математических
законов [Lenat, 1977, 1982]. Отталкиваясь от заложенных в него понятий и аксиом
теории множеств, Математику удалось вывести из них такие важные математические
концепции, как мощность множества, целочисленная арифметика и многие результаты
теории чисел. AM строил теоремы, модифицируя свою базу знаний, и использовал
эвристические методы для поиска наилучших из множества возможных альтернативных теорем.
Из недавних результатов можно отметить программу Коттона [Cotton и др., 2000],
которая изобретает "интересные" целочисленные последовательности.
К ранним трудам, оказавшим существенное влияние на эту область, относятся
исследования Уинстона по выводу таких структурных понятий, как построение "арок" из
наборов "мира блоков" [Winston, 1975я]. Алгоритм ID3 проявил способности в выделении
общих принципов из разных примеров [Quinlan, 1986я]. Система Meta-DENDRAL
выводит правила интерпретации спектрографических данных в органической химии на
примерах информации о веществах с известной структурой. Система Teiresias —
интеллектуальный "интерфейс" для экспертных систем — преобразует сообщения на
высокоуровневом языке в новые правила своей базы знаний [Davis, 1982]. Программа Hacker
строит планы для манипуляций в "мире блоков" посредством итеративного процесса вы-
50
Часть I. Искусственный интеллект: его истоки и проблемы
работки плана, его испытания и коррекции выявленных недостатков [Sussman, 1975].
Работа в сфере обучения, основанного на "пояснениях", продемонстрировала
эффективность для обучения априорному знанию [Mitchell и др., 1986], [DeJong и Моопеу, 1986].
Сегодня известно также много важных биологических и социологических моделей
обучения. Они будут рассмотрены в главах, посвященных коннекционистскому и эмерд-
жентному обучению.
Успешность программ машинного обучения наводит на мысль о существовании
универсальных принципов, открытие которых позволило бы конструировать программы,
способные обучаться в реальных проблемных областях. Некоторые подходы к обучению
будут представлены в главах 9-11.
1.2.9. Альтернативные представления: нейронные сети
и генетические алгоритмы
В большей части методик, представленных в этой книге, для реализации интеллекта
используются явные представления знаний и тщательно спроектированные алгоритмы
перебора. Совершенно отличный подход состоит в построении интеллектуальных
программ с использованием моделей, имитирующих структуры нейронов в человеческом
мозге или эволюцию разных альтернативных конфигураций, как это делается в
генетических алгоритмах и искусственной жизни.
Рис. 1 2. Упрощенная схема нейрона
Схематическое представление нейрона (рис. 1.2) состоит из клетки, которая имеет
множество разветвленных отростков, называемых дендритами, и одну ветвь — аксон.
Дендриты принимают сигналы от других нейронов. Когда сумма этих импульсов
превышает некоторую границу, нейрон сам возбуждается, и импульс, или "сигнал", проходит
по аксону. Разветвления на конце аксона образуют синапсы с дендритами других
нейронов. Синапс — это точка контакта между нейронами. Синапсы могут быть
возбуждающими (excitatory) или тормозящими (inhibitory), в зависимости от того, увеличивают ли
они результирующий сигнал.
Такое описание нейрона необычайно просто, но оно передает основные черты,
существенные в нейронных вычислительных моделях. В частности, каждый вычислительный
элемент подсчитывает значение некоторой функции своих входов и передает результат к
присоединенным к нему элементам сети. Конечные результаты являются следствием
параллельной и распределенной обработки в сети, образованной нейронными
соединениями и пороговыми значениями.
Нейронные архитектуры привлекательны как средства реализации интеллекта по
многим причинам. Традиционные программы ИИ могут быть слишком неустойчивы и
чувствительны к шуму. Человеческий интеллект куда более гибок при обработке такой
Глава 1. Искусственный интеллект: история развития и области приложения 51
зашумленной информации, как лицо в затемненной комнате или разговор на шумной
вечеринке. Нейронные архитектуры, похоже, более пригодны для сопоставления зашум-
ленных и недостаточных данных, поскольку они хранят знания в виде большого числа
мелких элементов, распределенных по сети.
С помощью генетических алгоритмов и методик искусственной жизни мы вырабатываем
новые решения проблем из компонентов предыдущих решений. Генетические операторы,
такие как скрещивание или мутация, подобно своим эквивалентам в реальном мире,
вырабатывают с каждым поколением все лучшие решения. В искусственной жизни новые поколения
создаются на основе функции "качества" соседних элементов в прежних поколениях.
И нейронные архитектуры, и генетические алгоритмы дают естественные модели
параллельной обработки данных, поскольку каждый нейрон или сегмент решения
представляет собой независимый элемент. Гиллис [Hillis, 1985] отметил, что люди быстрее
справляются с задачами, когда получают больше информации, в то время как
компьютеры, наоборот, замедляют работу. Это замедление происходит за счет увеличения
времени последовательного поиска в базе знаний. Архитектура с массовым параллелизмом,
например человеческий мозг, не страдает таким недостатком. Наконец, есть нечто очень
привлекательное в подходе к проблемам интеллекта с позиций нервной системы или
генетики. В конце концов, мозг есть результат эволюции, он проявляет разумное
поведение и делает это посредством нейронной архитектуры. Нейронные сети, генетические
алгоритмы и искусственная жизнь рассматриваются в главах 10 и 11.
1.2.10. Искусственный интеллект и философия
В разделе 1.1 мы представили философские, математические и социологические
истоки искусственного интеллекта. Важно осознавать, что современный ИИ не только
наследует эту богатую интеллектуальную традицию, но и делает свой вклад в нее.
Например, поставленный Тьюрингом вопрос о разумности программ отражает наше
понимание самой концепции разумности. Что такое разумность, как ее описать? Какова
природа знания? Можно ли его представить в устройствах? Что такое навыки? Может ли
знание в прикладной области соотносится с навыком принятия решений в этой среде?
Как знание о том, что есть истина (аристотелевская "теория"), соотносится со знанием,
как это сделать ("практика")?
Ответы на эти вопросы составляют важную часть работы исследователей и
разработчиков ИИ. В научном смысле программы ИИ можно рассматривать как эксперименты.
Проект имеет конкретную реализацию в виде программы, и программа выполняется как
эксперимент. Разработчики программы изучают результаты, а затем перестраивают
программы и вновь ставят эксперимент. Таким образом возможно определить, являются ли
наши представления и алгоритмы достаточно хорошими моделями разумного поведения.
Ньюэлл и Саймон [Newell и Simon, 1976] предложили этот подход к научному познанию
в своей тьюринговской лекции 1976 г.
Ньюэлл и Саймон также предложили более сильную модель интеллекта в своей гипотезе о
физической символьной системе: физическая система проявляет разумное поведение тогда и
только тогда, когда она является физической символьной системой. В главе 16 подробно
рассматривается практический смысл этой теории, а также критические замечания в ее адрес.
Многие применения ИИ подняли глубокие философские вопросы. В каком смысле можно
заявить, что компьютер * 'понимает" фразы естественного языка? Продуцирование и
понимание языка требует толкования символов. Недостаточно правильно сформировать строку сим-
52
Часть I. Искусственный интеллект: его истоки и проблемы
волов. Механизм понимания должен уметь приписывать им смысл или интерпретировать
символы в зависимости от контекста. Что такое смысл? Что такое интерпретация?
Подобные философские вопросы встают во многих областях применения ИИ, будь то
построение экспертных систем или разработка алгоритмов машинного обучения. Эти
вопросы будут рассмотрены в данной книге по мере их появления. Философские аспекты
ИИ обсуждаются также в главе 16.
1.3. Искусственный интеллект — заключительные
замечания
Мы попытались дать определение искусственному интеллекту путем рассмотрения
основных областей его исследования и применения. Этот обзор обнаружил молодую и
многообещающую область науки, основная цель которой — найти эффективный способ понимания и
применения интеллектуального решения проблем, планирования и навыков общения к
широкому кругу практических задач. Несмотря на разнообразие проблем, затрагиваемых
исследованиями ИИ, во всех отраслях этой сферы наблюдаются некоторые общие черты.
1. Использование компьютеров для доказательства теорем, распознавания образов,
обучения и других форм рассуждений.
2. Внимание к проблемам, не поддающимся алгоритмическим решениям. Отсюда —
эвристический поиск как основа методики решения задач в ИИ.
3. Принятие решений на основе неточной, недостаточной или плохо определенной
информации и применение формализмов представлений, помогающих
программисту справляться с этими недостатками.
4. Выделение значительных качественных характеристик ситуации.
5. Попытка решить вопросы семантического смысла, равно как и синтаксической формы.
6. Ответы, которые нельзя отнести к точным или оптимальным, но которые в каком-
то смысле "достаточно хороши". Это результат применения эвристических
методов в ситуациях, когда получение оптимальных или точных oibctob слишком
трудоемко или невозможно вовсе.
7. Использование большого количества специфичных знаний в принятии решений
Это основа экспертных систем.
8. Использование знаний метауровня для более совершенного управления
стратегиями принятия решений. Хотя это очень сложная проблема, затронутая лишь
несколькими современными системами, она постепенно становится важной областью
исследований.
Надеемся, что это введение даст некоторое понятие об общей структуре и значимости
искусственного интеллекта. Предполагаем, что краткое обсуждение таких технических
вопросов, как перебор и представления, не были излишне поверхностными и неясными,
детальнее они будут рассмотрены впоследствии. Здесь они приведены для демонстрации
их значимости в общей организации этой области.
Как мы отмечали при обсуждении агентского решения проблем, объекты
приобретают смысл при взаимоотношении с другими объектами. Это не менее справедливо в
отношении фактов, теорий и методов, образующих любую научную область. Мы по-
Глава 1. Искусственный интеллект: история развития и области приложения 53
пытались дать понятие таких взаимосвязей, так что, когда будут представлены
отдельные технические аспекты искусственного интеллекта, они займут свое место в
постепенном понимании общей сущности и направлений этой сферы. Мы руководствуемся
наблюдением, принадлежащим психологу и системному теоретику Грегори Бэйтсону
[Bateson, 1979]:
"Разрушьте структуру, объединяющую предметы изучения, и вы неизбежно разрушите все
его качество".
1.4. Резюме и дополнительная литература
Перспективная область ИИ отражает некоторые из древнейших вопросов,
занимавших западную мысль, в свете современного вычислительного моделирования. Понятия
рациональности, представления и мышления сейчас находятся, вероятно, под более
пристальным рассмотрением, чем во все былые времена, поскольку компьютерная наука
требует их алгоритмического понимания! В то же время политические, экономические и
этические рамки мира людей заставляют нас помнить об ответственности за последствия
наших творений. Надеемся, последующие главы помогут вам лучше понять современные
методики ИИ и извечность проблем этой области.
Отличными источниками по вопросам, поднятым в этой главе, являются труды
[Haugeland, 1997, 1985], [Dennett, 1978, 1984, 1991, 1995]. Использованы такие
первоисточники, как "Физика", "Метафизика" и "Логика" Аристотеля; работы Фреге; труды Бэб-
биджа, Буля, Рассела и Уайтхеда. Весьма интересны работы Тьюринга, особенно его
представления о природе интеллекта и возможности разработки интеллектуальных
программ [Turing, 1950]. Биография Тьюринга [Hodges, 1983] представляет собой отличное
чтение. Критика теста Тьюринга может быть найдена в [Ford и Hayes, 1995].
Работы [Weizenbaum, 1976] и [Winograd и Flores, 1986] дают трезвую оценку
ограничениям и этическим аспектам ИИ. Саймон [Simon, 1981] положительно высказывается
об осуществимости искусственного интеллекта и его роли в обществе.
Упомянутые в разделе 1.2 применения ИИ призваны показать широту интересов
исследователей ИИ и сформулировать многие изучаемые ныне вопросы. Учебник [Вагг и
Feigenbaum, 1989] содержит введение в эти области. Кроме того, рекомендуем книги
[Nilsson, 1998] и [Pearl, 1984]. В них подробно рассмотрены вопросы ведения игр,
которые затронуты в главах 2-5. В главах 2, 3 и 12 обсуждается проблема автоматических
рассуждений. Некоторая избранная литература по этой теме включает труды [Wos и др.,
1984], [Bledsoe, 1977], [Boyer и Moore, 1979], [Veroff, 1977].
Прочитав главы 6 и 7, читатель может получить хорошее представление об
экспертных системах из книг [Harmon и King, 1985], [Hayes-Roth и др., 1984], [Waterman, 1986] и
[Durkin, 1994].
Понимание естественных языков — область непрекращающегося изучения,
некоторые важные взгляды на нее выражены в [Allen, 1995], [Winograd, 1983], [Schank и
Colby, 1973], [Wilks, 1972], [Lakoff и Johnson, 1999], [Jurafsky и Martin, 2000]; введение в
эту область представлено в главах 6 и 13 этой книги.
Использование компьютеров для моделирования работы человеческого разума, кратко
описанное в главе 16, более подробно обсуждается в [Newell и Simon, 1972], [Pylyshyn, 1984],
[Anderson, 1978] и [Luger, 1994]. Планирование и робототехника (см. главы 7 и 14)
представлены в т. 3 книги [Вагг и Feigenbaum, 1981], [Brooks, 1991a] и [Lewis и Luger, 2000].
54
Часть I. Искусственный интеллект: его истоки и проблемы
ИИ-ориентированные языки и среды разработки рассматриваются в главах 14 и 15 этой
книги, а также в [Forbus и deKleer, 1993]. Машинное обучение обсуждается в главах 9-11;
многотомном издании [Michalski и др., 1983, 1986], [Kondratoff и Michalski, 1990]; журналы
Journal of Artificial Intelligence и Journal of Machine Learning также являются важными
источниками информации по этой теме.
Главы 10 и 11 представляют взгляд на интеллект с упором на модульность структуры
и адаптацию в социальном и природном контексте. Работа [Minsky, 1985] — одна из
наиболее ранних и побуждающих к размышлению работ, отстаивающих эту точку зрения
(см. также [Ford и др., 1995] и [Langton, 1995]).
Книга [Shapiro, 1992] дает ясное и всестороннее описание области искусственного
интеллекта. Эта энциклопедия также проводит детальный анализ многих разных
подходов и противоречий, образующих текущее состояние этой дисциплины.
1.5. Упражнения
1. Предложите и аргументируйте собственное определение искусственного интеллекта.
2. Приведите несколько дополнительных примеров аристотелевского различия между
"материей" и "формой". Можете ли вы показать, как ваши примеры вписываются в
теорию абстракции?
3. Западная философская традиция во многом выросла из проблемы взаимоотношения
разума и тела. По вашему мнению.
а) разум и тело — сущности разной природы, каким-то образом взаимодействующие;
б) разум — всего лишь результат "физических процессов";
в) тело — лишь иллюзия мысли?
Обсудите ваши мысли по поводу проблемы разума и тела и ее важность для теории
искусственного интеллекта.
4. Приведите критические замечания по поводу тьюринговского критерия
"разумности" компьютерной программы.
5. Сформулируйте ваш собственный критерий "разумности" компьютерной программы.
6. Хотя вычислительная техника — относительно молодая дисциплина, философы и
математики размышляли о вопросах, существенных для автоматического решения
задач, на протяжении тысяч лет. Каково ваше мнение о существенности этих
философских вопросов по отношению к проектированию устройств интеллектуального
решения проблем? Аргументируйте свой ответ.
7. Рассмотрев различия между архитектурами современных компьютеров и
человеческого мозга, поясните, какое значение имеет исследование физиологической
структуры и функции биологических систем для разработки программ ИИ?
Аргументируйте свой ответ.
8. Выберите проблемную область, в которой, как вы считаете, затраты на разработку
экспертной системы были бы оправданы. Разъясните в общих чертах суть проблемы.
На основании своей интуиции скажите: какие аспекты принятия решений будет
наиболее сложно автоматизировать?
Глава 1. Искусственный интеллект: история развития и области приложения 55
9 Найдите еще два преимущества экспертных систем, кроме уже перечисленных в
тексте. Обсудите их с точки зрения интеллектуальных, социальных или экономических
результатов.
10. Поясните, почему вы считаете такой сложной проблему машинного обучения.
11 Считаете ли вы возможным для компьютера понимать и использовать естественный
(человеческий) язык?
12. Выявите и поясните два потенциально негативных последствия развития
искусственного интеллекта для общества.
56
Часть I. Искусственный интеллект: его истоки и проблемы
Часть II
Искусственный
интеллект как
представление
и поиск
Все науки описывают основные характеристики систем, изучаемых ими Эти
характеристики неизменно являются качественными по своей природе, поскольку
они задают термины, оперируя которыми, можно развить данную область науки
более детально..
Изучение логики и компьютеров показало, что интеллект присущ физическим
символьным системам В качественной структуре заключается основной принцип
теории вычислительных систем Символьные системы — это наборы комбинаций
символов (шаблонов) и способов их обработки (процессов), которые в то же время
описывают способы создания, разрушения и изменения символов Наиболее важное
свойство наборов символов заключается в том, что с их помощью можно
определять объекты, процессы или другие наборы символов Процессы при этом могут
быть интерпретированы ..
Второй принцип качественной структуры искусственного интеллекта заключается в
том, что символьные системы решают задачи путем генерации возможных решений, а
затем проверяют их в процессе поиска (или перебора вариантов) Для решения задачи
обычно создаются символьные выражения, а затем они последовательно
модифицируются до тех пор, пока не будут достигнуты условия решения.
— Ньюэлл (Newell) и Саймон (Simon), лекция по случаю вручения премии
Тьюринга в Ассоциации специалистов по компьютерной технике, 1976
Введение в представление знаний
В вышеупомянутой лекции Ньюэлл и Саймон доказывают, что интеллектуальная
деятельность как человека, так и машины, осуществляется с использованием следующих средств.
1. Символьные шаблоны (комбинации символов), предназначенные для описания
важнейших аспектов области определения задачи.
2. Операции с этими шаблонами, позволяющие генерировать потенциальные
решения проблем.
3. Поиск с целью выбора решения из числа всех возможных.
Описанные предположения формируют базис гипотезы о физической символьной
системе {physical symbol system hypothesis) (раздел 16.1). Эта гипотеза лежит в основе наших
попыток создания умных машин и делает очевидными основные предположения в
исследовании искусственного интеллекта. Гипотеза о физической символьной системе неявно
различает понятия шаблонов {patterns), сформированных путем упорядочения символов, и
среды {medium), в которой они реализованы. Если уровень интеллекта определяется
исключительно структурой системы символов, то любая среда, которая успешно реализует
правильные шаблоны и процессы, достигнет этого уровня интеллекта, независимо от того,
составлена она из нейронов, логических цепей, или это просто механическая игрушка.
Возможность построения машины, которая бы прошла тест Тьюринга, зависит от
вышеупомянутого разграничения. Согласно тезису Черча о вычислимости по Тьюрингу [Machtey
и Young, 1979] компьютеры способны осуществить любой эффективно описанный процесс
обработки символьной информации. Разве из этого не следует, что должным образом
запрограммированный цифровой компьютер обладает интеллектом?
Гипотеза о физической символьной системе также вкратце описывает главные вопросы
исследования в области искусственного интеллекта и разработки его приложений. К ним
относится определение структур символов и операций, необходимых для
интеллектуального решения задачи, а также разработка стратегий для эффективного и правильного поиска
потенциальных решений, сгенерированных этими структурами и операциями. Эти
взаимосвязанные проблемы представления знания и поиска (knowledge representation and search)
лежат в основе современных исследований в области искусственного интеллекта.
Гипотеза физической символьной системы оспаривается критиками, которые
утверждают, что интеллект является наследственно биологическим и экзистенциальным и не
может быть зафиксирован с помощью символов [Searle, 1980], [Winograd и Flores, 1986].
Эти суждения относятся к господствующему направлению исследований в области
искусственного интеллекта. Они определяют такие направления исследований, как
развитие теории нейронных сетей, генетических алгоритмов и агентно-ориентированных
методов (подход "агент-действие"). Несмотря на вышеуказанные возражения,
предположения гипотезы физической символьной системы лежат в основе почти всех практических
и теоретических работ в экспертных системах, в планировании и понимании
естественного языка. Эти проблемы будут рассмотрены в главе 16.
Задача любой схемы представления заключается в том, чтобы зафиксировать
специфику области определения задачи и сделать эту информацию доступной для механизма
решения проблемы. Очевидно, что язык представления должен позволять программисту
выражать знания, необходимые для решения задачи. Абстракция (abstraction), т.е.
представление только той информации, которая необходима для достижения заданной цели, является
58
Часть II. Искусственный интеллект как представление и поиск
необходимым средством управления сложными процессами. Кроме того, конечные
программы должны быть рациональными в вычислительном отношении. Выразительность и
эффективность являются взаимосвязанными характеристиками оценки языков
представления знаний. Многие достаточно выразительные средства представления в одних задачах
совсем неэффективны в других классах задач. Иногда выразительностью можно
пожертвовать в пользу эффективности. В то же время нельзя ограничивать возможности такого
отображения, позволяющего фиксировать существенные знания, что приводит к
эффективному решению конкретной задачи. Разумный компромисс между эффективностью и
выразительностью — нетривиальная задача для разработчиков интеллектуальных систем.
Языки представления знаний являются средством, позволяющим решать задачи. По
существу, способ представления знания должен обеспечить естественную структуру
выражения знания, позволяющую решить проблему. Способ представления должен сделать
это знание доступным компьютеру и помочь программисту описать его структуру.
Эти взаимные компромиссы в выборе способа представления знания можно показать на
примере представления чисел с плавающей точкой в компьютере (рис. II. 1). Вообще, для
полного описания вещественного числа требуется бесконечный ряд цифр, что не может
быть выполнено на конечном устройстве, т.е. на машине с конечным числом состояний.
Единственное решение этой дилеммы — представление числа в виде двух частей: его
значащих цифр и положения десятичной точки в пределах этих цифр. Несмотря на то что
вещественное число без искажения нельзя хранить в компьютере, можно создать его
представление, адекватно функционирующее в большинстве практических приложений.
Вещественное число: я
Десятичный эквивалент: 3,1415927 . . .
Представление с плавающей точкой 31416 1
t ^-Экспонента
' Мантисса
Представление в памяти компьютера: 11100010
Рис II. 1. Различные представления вещественного числа я
Представление числа с плавающей точкой уступает в выразительности, но
выигрывает в эффективности. Такое представление позволяет выполнять многократные
арифметические операции, обеспечивает эффективность их выполнения, не ограниченную
точностью вычислений с предельной ошибкой округления при любой предварительно
заданной погрешности. Представление числа с плавающей точкой также позволяет
анализировать ошибки округления. Подобно всем представлениям, это лишь абстракция,
символьный шаблон, определяющий желаемый логический объект, но не сам объект
непосредственно.
Массив — еще одно представление, принятое в теории вычислительных систем. Для
многих задач оно более естественно и эффективно, чем архитектура памяти,
реализованная в аппаратных средствах. Это представление во многих задачах оказывается
естественным и эффективным, уступая при этом в выразительности, что наглядно показано на
следующем примере обработки изображений. На рис. И.2 дано оцифрованное
изображение хромосом человека на стадии метафазы. В процессе обработки изображения
определяются номер и структура хромосомы, обнаруживаются разрывы, отсутствующие
фрагменты и другие аномалии.
Введение в представление знаний
59
Рис II 2. Оцифрованное изображение хромосом в метафазе
Визуальная сцена состоит из точек изображения. Каждая точка, или пиксель,
характеризуется расположением и числовым значением, представляющим уровень
серого цвета. Поэтому всю сцену вполне естественно представить в виде двухмерного
массива, где номер строки и столбца элемента массива определяет место
расположения пикселя (координаты X и У), а сам элемент массива — уровень серого цвета в
этой точке. Для обработки подобного изображения необходимо реализовать такие
операции, как поиск изолированных точек для удаления шума из образа, нахождение
пороговых уровней для распознаваемых объектов и их границ, суммирование
непрерывных элементов для определения размеров и плотности образов. Затем
полученные данные, описывающие изображения, могут быть преобразованы. Этот алгоритм
удобно программировать на языке FORTRAN, в котором непосредственно
реализованы операции с массивами. Однако программа была бы слишком громоздкой, если
бы в ней использовались такие средства, как исчисление предикатов, записи или
ассемблерный код, потому что они не обеспечивают естественного представления
данного материала.
Представляя изображение в виде массива пикселей, мы жертвуем разрешением
(сравните фотографию в газете с исходным изображением). Кроме того, массивы
пикселей не могут достаточно точно отображать семантическую организацию образа.
Например, массив пикселей не может представить организацию хромосом в отдельном ядре
клетки, их генетическую функцию или роль метафазы в делении клетки. Эти знания
легче фиксировать, используя такие понятия, как исчисление предикатов (глава 2) или
семантические сети (глава 6).
Схема представления знания должна удовлетворять следующим условиям.
60
Часть II. Искусственный интеллект как представление и поиск
1. Адекватно выражать всю необходимую информацию.
2. Поддерживать эффективное выполнение конечного кода.
3. Обеспечивать естественный способ выражения необходимых знаний.
Мак-Дермотт (McDermott) и его последователи утверждают, что секрет
написания хорошей программы, основанной на знаниях, заключается в выборе подходящих
средств представления. Программисты, специализирующиеся на языках низкого
уровня (Basic, FORTRAN, С и т.д.), порой строят неудачные экспертные системы
только потому, что эти языки не обладают достаточной выразительностью и не
обеспечивают модульность, необходимую для программирования на основе знаний
[McDermott, 1981].
Вообще говоря, задачи ИИ не решают путем их упрощения и "подгонки" к уже
имеющимся понятиям, предлагаемым традиционными формальными системами,
например массивам. Эти задачи связаны скорее с качественными, а не
количественными проблемами, с аргументацией, а не вычислениями, с организацией больших
объемов знаний, а не реализацией отдельного четкого алгоритма. Чтобы
удовлетворять этим требованиям, язык представлений искусственного интеллекта должен
обладать следующими свойствами.
1. Обрабатывать знания, выраженные в качественной форме.
2. Получать новые знания из набора фактов и правил.
3. Отображать общие принципы и конкретные ситуации.
4. Передавать сложные семантические значения.
5. Обеспечивать рассуждения на метауровне.
Рассмотрим этот перечень более подробно.
Обработка знаний, выраженных в качественной форме
Программирование искусственного интеллекта требует средств фиксации
(выражения) и рассуждений о качественных аспектах задачи. Рассмотрим простой
пример — размещение блоков на столе (рис. II.3).
a b
Рис. II.3. Мир блоков
Для представления расположения блоков можно использовать декартову систему
координат, где значения X и У задают координаты каждой вершины блока. Хотя этот
подход описывает мир блоков и является, несомненно, правильным представлением
для многих задач, в данном случае он неудачен, поскольку не позволяет
непосредственно зафиксировать свойства и отношения, необходимые для качественных
выводов. Это выводы о том, какие из блоков уложены друг на друга и какие имеют от-
Введение в представление знаний
61
крытый верх, чтобы их можно было взять и поднять. Исчисление предикатов
(predicate calculus) непосредственно фиксирует эту наглядную информацию. В
исчислении предикатов мир блоков может быть описан логическими утверждениями:
clear(c)
clear(a)
ontable{a)
ontable(b)
on(c, b)
cube(b)
cube(a)
pyramid(c)
Первое слово каждого выражения (опч clear и т.д.) — предикат (predicate),
обозначающий некоторое свойство или соотношение его параметров, приведенных в круглых
скобках. Параметры — это символы, обозначающие объекты (блоки) в предметной
области. Совокупность логических предложений описывает важные свойства и соотношения
мира блоков. Исчисление предикатов предоставляет программистам задач искусственного
интеллекта четкий язык описания и способ рассуждений относительно качественных аспектов
системы. Исчисление предикатов не единственный способ представления, но этот подход,
вероятно, наиболее понятен для многих задач. Кроме того, он является достаточно общим,
чтобы служить основой для других формальных моделей представления знания.
Исчисление предикатов подробно рассматривается в главе 2.
Вышеупомянутый пример иллюстрирует точное представление блоков на рис. II.3.
Это явное представление, поскольку очевидна связь между его элементами и нашим
собственным пониманием "мира" блоков. Знание можно также представлять неявно.
Например, с помощью нейронной сети (глава 10) можно представить эту конфигурацию
блоков в виде шаблонов взаимодействия между искусственными нейронами.
Соотношения между этими шаблонами и элементами мира блоков не очевидны. В большинстве
случаев единственный способ понять, какие знания содержатся в сети, — это
рассмотреть ее работу на примерах. Тем не менее возникает вопрос о соответствии неявных
представлений их явным эквивалентам: способна ли данная модель нейронной сети
передать все знания, которые необходимы в задаче? Сможет ли компьютер получать
доступ и эффективно управлять этими знаниями? Можно ли гарантировать правильность
логических выводов, сделанных нейронной сетью?
Логическое получение новых знаний из набора фактов и правил
Любой интеллектуальный объект должен обладать способностью логически получать
дополнительные знания из имеющегося описания реального мира. Люди, например, не
запоминают точное описание каждой пережитой ситуации (да это и невозможно).
Скорее, мы способны рассуждать об абстрактных описаниях классов объектов и состояний.
И язык представления знаний должен обеспечить эту возможность.
В примере из мира блоков можно определить тест, устанавливающий, является ли
блок открытым, т.е. не располагается ли на его верхней грани другой объект. Это
важный вопрос для робототехнической системы, в которой рука робота должна поднимать
блоки или укладывать их друг на друга. Это свойство не обязательно явно приписывать
каждому блоку. Можно определить общее правило, которое позволяет системе делать
62 Часть II. Искусственный интеллект как представление и поиск
логические выводы из имеющихся фактов. В исчислении предикатов это правило может
выглядеть так.
VX^3/ on(Y,X)=>clear(X).
Оно означает следующее: для любого элемента X элемент X является открытым, если не
существует такого У, что У находится на X. Это правило может применяться в различных
ситуациях при замене значений X и У. Позволяя программисту формулировать обобщенные
правила вывода, исчисление предикатов предоставляет большие удобства в выражении
знания. Кроме того, исчисление предикатов дает возможность проектировать гибкие и
достаточно общие системы, умеющие действовать разумно в различных ситуациях.
Нейронные сети тоже выводят новые знания из имеющихся фактов, хотя правила,
используемые ими, скрыты. Классификация — это общепринятая форма логического
вывода, выполняемого такими системами. Например, нейронную сеть можно обучить
узнавать все конфигурации блоков, в которых пирамида располагается поверх блока,
имеющего форму куба.
Отображение общих принципов наряду с конкретными ситуациями
В предыдущем разделе было продемонстрировано применение логических правил для
вывода дополнительных знаний из основных фактов. Кроме того, на примере с блоками
было показано, как использовать переменные в исчислении предикатов. Поскольку
интеллектуальная система должна быть максимально общей, любой хороший язык
представления нуждается в переменных. Необходимость качественных рассуждений делает
использование и реализацию переменных чрезвычайно сложной и тонкой задачей по сравнению с
их трактовкой в традиционных языках программирования. Значения, типы и правила
обработки данных в языках программирования, ориентированных на вычисления, чрезвычайно
ограничены и не годятся для реализации интеллектуальных систем. Для обработки
связанных переменных и объектов существуют специальные языки представления знаний
(главы 2, 14, и 15). Высокая способность обобщения — это ключевое свойство нейронных
сетей, систем обучения и других адаптивных систем. Эффективное обучение системы-
агента заключается в том, чтобы научиться обобщать данные, полученные в процессе
такого обучения, а затем правильно применить полученные знания в новых ситуациях.
Передача сложных семантических значений
Во многих областях искусственного интеллекта решение задачи требует использования
высокоструктурированных взаимосвязанных знаний. Например, чтобы описать автомобиль,
недостаточно перечислить его составные части. Адекватное описание должно учитывать
также способ соединения и взаимодействия этих частей. Структурное представление необходимо
во многих задачах, начиная с таких таксономических систем, как система классификации
растений по видам и родам, и заканчивая средствами описания таких сложных объектов, как
дизельный двигатель или человеческое тело в терминах составляющих их частей. В примере
блоков основой полного описания расположения были взаимодействия предикатов.
Семантические отношения также необходимы для описания причинных связей между
событиями. Они позволяют понять простые рассказы, например, детские сказки, или
представить план действий робота как последовательность элементарных действий,
которые должны быть выполнены в определенном порядке.
Введение в представление знаний
63
Хотя все эти ситуации могут быть представлены в виде совокупности предикатов или
адекватных им формализмов, для программиста, имеющего дело со сложными
понятиями и стремящегося дать устойчивое описание процессов в программе, необходимо
некоторое высокоуровневое представление структуры процесса.
Например, канарейку можно описать так. Канарейка— это маленькая желтенькая
птичка, а птичка — это крылатое летающее позвоночное животное. Эта формулировка
может быть представлена в виде набора логических предикатов:
hassize(canary, small)
hascovering(bird, feathers)
hascolor(canary, yellow)
hasproperty(bird, flies)
isa{canary, bird)
isa(bird, vertebrate)
Предикатное описание можно представить графически, используя для отображения
предикатов, определяющих отношения, дуги (arc) или связи (link) графа (рис. П.4). Такое
описание, называемое семантической сетью (semantic network), является фундаментальной
методикой представления семантического значения. Поскольку отношения явно выражены
связями графа, алгоритм рассуждений о предметной области может строить
соответствующие ассоциации, просто следуя по связям. В примере с канарейкой системе нужно
проследовать только по двум дугам, чтобы решить, что канарейка — это позвоночное
животное. Это значительно эффективнее, чем утомительный исчерпывающий поиск в базе
данных, содержащей описания на языке исчисления предикатов вида isa(X, V).
feathers
small
hascovering
hassize
^
vertebrate
t
i
isa
bird
i
[
isa
blue
UIIU
hasproperty
hascolor
flies
blue
Рис II4 Описание семантической сети для канарейки
Кроме того, знания могут быть организованы так, чтобы отражать естественную
структуру экземпляра класса из данной предметной области. Некоторые связи,
например, связи isa на рис. П.4, указывают на принадлежность к классу и задают свойства,
характерные для описания данного класса, которые наследуют все члены класса. Этот
механизм наследования встроен в язык непосредственно и позволяет сохранять знания на
самом высоком уровне абстракции. Наследование — инструмент представления
таксономической (классифицированной) структурированной информации, который
гарантирует, что все члены класса обладают общими свойствами.
Теория графов эффективно и естественно выражает сложные семантические знания.
Кроме того, она позволяет описывать структурную организацию базы знаний.
Семантические сети — это достойная альтернатива исчислению предикатов.
64 Часть II Искусственный интеллект как представление и поиск
Возможно, наиболее важное свойство семантических сетей — это способность
описывать семантические значения для систем понимания естественного языка. Например,
если необходимо понять детскую сказку, журнальную статью или содержание Web-
страницы, то в соответствующей прикладной программе следует закодировать
семантическую информацию и отношения, отражающие знания. Семантические сети —
подходящий для этого механизм. Они обсуждаются в главе 6, а их применение для описания
задач понимания естественного языка — в главе 13.
Рассуждения на метауровне
Интеллектуальная система должна не только знать предмет, но также знать о том, что
она знает этот предмет. Она должна быть способна решать задачи и объяснять эти
решения. Система должна описывать свои знания как в конкретных, так и в обобщенных
терминах, узнавать их ограничения и учиться в процессе взаимодействия с миром. Эта
"осведомленность о своих знаниях" составляет более высокий уровень знаний,
называемых метазнаниями, необходимых для проектирования и адекватного описания
интеллектуальных систем.
Проблему формализации метазнаний впервые исследовал Бертран Рассел (Russell) в
своей теории логических типов. Кратко ее можно описать так: если множества могут быть
членами других множеств (ситуация, аналогичная обладанию знанием о знании), то могут
существовать множества, которые являются членами самих себя. Согласно теории Рассела
это ведет к неразрешимым парадоксам. Рассел отверг эти парадоксы, классифицируя
множества как относящиеся к различным типам, в зависимости от того, содержат они
отдельные элементы или множества элементов и т.д. Множества не могут быть членами
множеств, относящихся к типу меньшего или равного значения. Это соответствует различиям
между знаниями и метазнаниями. Но при попытке формально описать эти рассуждения
Рассел столкнулся с многочисленными трудностями [Whitehead и Russell, 1950].
Способность обучаться на примерах, опыте или понимать инструкции высокого
уровня (в отличие от жесткого программирования) зависит от применения метазнаний.
Методы представления знаний, разработанные для программирования задач
искусственного интеллекта, обеспечивают возможность адаптации и модификации, так
необходимую для обучающихся систем, и формируют основу для дальнейших
исследований (главы 9-11).
Чтобы удовлетворять требованиям символьных вычислений, искусственный
интеллект должен обладать такими средствами, как языки представления, например,
исчисление предикатов, семантические сети, фреймы и объекты (главы 2 и 6). LISP и
PROLOG — языки для реализации этих и других представлений. Все эти
инструментальные средства подробно рассматриваются в книге.
Как следует из приведенных выше рассуждений о необходимых свойствах языка
представления знаний, решение задачи искусственного интеллекта можно свести к
выбору представления среди возможных альтернатив. Выбор подходящего представления
весьма важен для разработчиков компьютерных программ, обеспечивающих решение
задач искусственного интеллекта. Несмотря на большое разнообразие языков
представления, используемых в искусственном интеллекте, все они должны удовлетворять общим
требованиям выразительности, эффективности и правильности дедуктивных выводов.
Выбор и оценка языков представлений — весьма важная задача как для исследователей,
так и для программистов.
Введение в представление знаний
65
Решение задачи методом поиска
Вторым аспектом гипотезы о символьной системе Ньюэлла и Саймона является
поиск решения задачи среди альтернативных вариантов. С точки зрения простого
здравого смысла это выглядит разумно, поскольку именно так задачи решает
человек. Рассматривая ряд альтернативных вариантов, мы пытаемся решить проблему.
Шахматист обычно изучает возможные ходы и выбирает оптимальные согласно
таким критериям, как вероятные ответы противника или некоторая глобальная
стратегия, поддерживаемая на каждом этапе игры. Игрок также рассматривает
преимущества в краткосрочных стратегиях (например, взятие ферзя противника),
возможности пожертвовать фигуру за позиционное преимущество или строит предположения
относительно психологического состояния противника, его опыта и умения.
Математик при доказательстве трудной теоремы выбирает свою линию среди большого
набора сложных стратегий. Врач может систематично рассматривать ряд возможных
диагнозов и т.д. Такое интеллектуальное поведение лежит в основе методики поиска
решения в пространстве состояний.
В качестве простого примера рассмотрим игру "крестики-нолики". Для любой
заданной ситуации всегда существует только конечное число допустимых ходов
игрока. Первый игрок может разместить крестик в любой из девяти клеточек пустой
игровой доски. Каждый из таких шагов порождает различные варианты заполнения
игровой доски, которые позволяют противнику сделать восемь возможных ответных
ходов и т.д. Эту совокупность (в зависимости от возможной конфигурации игровой
доски) можно представить в виде вершин графа. Дуги графа представляют
разрешенные ходы, приводящие от одной конфигурации игровой доски к другой. Узлы
этого графа соответствуют различным состояниям игрового поля. Результирующая
структура называется графом пространства состояний.
Можно построить граф пространства состояний для игры "крестики-нолики"
(рис. II.5). Корневая вершина этого графа будет соответствовать пустой игровой
доске, указывающей на начало игры. Каждый следующий узел графа будет
представлять состояние игровой доски, возникающее в процессе игры в результате
допустимых ходов, а дуги между ними — связи между вершинами. Значение этого
графа состоит в том, что он дает возможность проследить последовательность шагов
в любой игре. Проход начинается с вершины, представляющей пустую игровую
доску, а перемещения по дугам приводят к вершинам-состояниям, представляющим или
очередной ход, или победу. Представление в пространстве состояний, таким
образом, позволяет рассматривать все возможные варианты игры "крестики-нолики" как
различные пути на графе пространства состояний.
Описав игру таким образом, можно с помощью поиска на графе найти
эффективную игровую стратегию. Иными словами, определить все пути, ведущие к
наибольшему числу побед и наименьшему числу поражений, и выбрать такую игру, которая
всегда будет вынуждать противника идти по одному из оптимальных для нас путей.
Возможность выбора эффективной стратегии — это не единственное преимущество
графа. Регулярность и точность представления пространства состояний позволяют
непосредственно реализовать игру на компьютере.
66
Часть II. Искусственный интеллект как представление и поиск
Рис. II5 Фрагмент пространства состояний для игры "крестики-нолики "
В качестве примера использования поиска для решения более сложной проблемы
рассмотрим задачу диагностирования механических неполадок в автомобиле. Хотя эта
проблема на первый взгляд и не кажется такой же легкой задачей поиска в
пространстве состояний, как игра "крестики-нолики" или шахматы, на самом деле она очень
хорошо подходит для этой стратегии. Вместо того, чтобы каждой вершине графа
пространства состояний ставить в соответствие "состояние игровой доски", будем
приписывать вершинам графа состояния частичного знания о механических неполадках
автомобиля. Процесс исследования признаков неполадок и устранения их причины
может быть представлен как поиск по всем состояниям, расширяющий наши знания о
них. Начальная вершина графа пуста, она указывает на то, что о причинах неполадок
ничего не известно. Первый вопрос, который механик мог бы задать клиенту, сводится
к следующему: какие основные части системы (двигатель, коробка передач, рулевое
управление, тормоза и т.д.), возможно, неисправны. Этот фрагмент диалога
представлен в виде совокупности дуг, ведущих от начального состояния к состояниям,
соответствующим отдельным подсистемам автомобиля (рис. II.6).
Решение задачи методом поиска
67
Первый вопрос: в чем
неисправность?
Двигатель
~7V
Коробка передач
7"\"
Тормоза
Рис. II. 6. Описание пространства состояний на первом этапе
решения задачи диагностики неисправностей автомобиля
С каждым состоянием графа связаны дуги (соответствующие основным
диагностическим проверкам), которые ведут к состояниям, представляющим уточненные знания в
процессе диагностики. Например, узел неисправности двигателя связан с узлами
"двигатель запускается" и "двигатель не запускается". От узла "двигатель не
запускается" можно перемещаться к узлам "заводится" и "не заводится". Узел "не заводится"
связан с узлами "аккумулятор не работает" и "аккумулятор в порядке" (рис. II.7).
Первый вопрос: в чем
неисправность?
Двигатель
Вопрос: трогается
ли машина?
Коробка передач
Вопрос:...
Тормоза
Вопрос:...
Двигатель
запускается
Вопрос. ...
Двигатель не запускается
Вопрос:заводится
ли машина?
Заводится
Вопрос:...
Не заводится
Вопрос: фары
зажигаются?
/^ккумуляторЧ
\^£по^ядке^^Х
Рис. II. 7. Описание пространства состояний в задаче диагностики неполадок автомобиля
Можно построить граф, включающий все возможные вопросы и вершины,
представляющие заключительные диагностические выводы. Решающее устройство сможет
диагностировать автомобильные неполадки, находя путь в этом графе. Заметим, что кон-
68
Часть II. Искусственный интеллект как представление и поиск
кретные вопросы, задаваемые в данном примере, определяют путь на графе. При этом
каждый следующий ответ удаляет из рассмотрения ненужные вопросы. Хотя эта задача
очень отличается от алгоритма нахождения оптимального пути в игре "крестики-
нолики", она тоже решается путем поиска в пространстве состояний.
Нейронные сети и другие адаптивные системы также выполняют поиск, особенно во
время обучения и адаптации. Всевозможные обобщения данных, которые
самообучающаяся программа может сформировать в процессе обучения, можно представить себе как
элементы пространства. Задача алгоритма обучения состоит в использовании обучающих
данных для поиска в этом пространстве. В нейронной сети, например, пространством поиска
является множество всех наборов возможных весов связей сети. В процессе поиска набора
связей, которые максимально соответствуют обучающим данным, эти веса изменяются.
Несмотря на эту очевидную универсальность, поиска в пространстве состояний не
достаточно для автоматизации интеллектуального поведения, обеспечивающего
(автоматическое) решение проблем. Но это важный инструмент для проектирования
интеллектуальных программ. Если бы поиска в пространстве состояний было достаточно,
то было бы довольно просто написать программу, играющую в шахматы. Для
определения последовательности ходов, ведущих к победе, на каждом этапе игры нужно было бы
осуществлять полный поиск по всему пространству состояний. Этот метод решения
задач известен как исчерпывающий поиск (exhaustive search), или поиск методом полного
перебора. Хотя полный перебор может применяться в любом пространстве состояний,
огромный размер пространства для интересных задач делает этот подход практически
неприемлемым. Игре в шахматы, например, соответствует приблизительно 10120
различных состояний игровой доски. Это на порядок больше, чем число молекул во Вселенной
или число наносекунд, которые минули с "большого взрыва" (момента создания
Вселенной). Поиск в таком пространстве состояний выходит за рамки возможностей любого
вычислительного устройства, размеры которого должны быть ограничены до известной
области мироздания, а реализация должна быть закончена прежде, чем эта область
подвергнется разрушительному действию энтропии.
В этой книге будет показано, как поиск в пространстве состояний можно
использовать для практического подхода к любой проблеме. Поиск обеспечивает структуру для
автоматизации решения задач, но эта структура лишена интеллекта. Такой подход не
дает возможности формально описать задачу. Кроме того, простой полный перебор
большого пространства вообще практически неосуществим и непригоден для описания
сущности разумной деятельности.
Однако в реальной жизни люди используют поиск: шахматист рассматривает ряд
возможных ходов, доктор исследует несколько возможных диагнозов, ученый-
программист принимает во внимание различные варианты проекта перед тем, как
приступить к написанию кода. Однако люди не используют полный перебор: шахматист
исследует только те ходы, которые, как свидетельствует опыт, должны быть
эффективными, доктор не требует проведения всех возможных анализов, которые не связаны каким-
либо образом с имеющимися симптомами болезни. Проектируя программные средства,
математик руководствуется опытом и теоретическими знаниями. Итак, решение задачи
человеком основано на субъективных правилах, направляющих поиск к тем частям
пространства состояний, которые по каким-то причинам кажутся "обещающими".
Эти правила известны под названием эвристик (heuristics). Они составляют одну из
центральных тем исследований в области искусственного интеллекта. Эвристика (термин
возник от греческого слова "находить") — это стратегия для выборочного поиска в про-
Решение задачи методом поиска
69
странстве состояний. Она направляет поиск вдоль линий, имеющих высокую
вероятность успеха, уводя при этом исследователя от потраченных впустую или очевидно
глупых усилий. Люди используют большое количество эвристик в решении задач. Если
спросить механика, почему автомобиль перегревается, он может сказать что-то типа:
"Обычно это означает, что не работает термостат". Если спросить доктора, что могло
вызвать тошноту и боль в животе, он скажет, что это "вероятно, кишечный грипп или
пищевое отравление".
Эвристика не абсолютно надежна. Даже лучшая игровая стратегия может быть
побеждена противником, диагностические средства, разработанные опытными врачами,
иногда терпят неудачу, опытные математики порой не в состоянии доказать трудную
теорему. Нет гарантий, что хороший эвристический подход может и должен приблизить нас к
верному оптимальному решению проблемы. Наиболее важно то, что эвристика
использует знание о природе задачи для эффективного поиска решения.
Поиск в пространстве состояний обеспечивает средства формализации процесса решения
проблемы, а эвристики позволяют привносить интеллект в этот формализм. Эти методы
подробно обсуждаются в начальных главах этой книги и по-прежнему лежат в основе самых
последних разработок в области искусственного интеллекта. В заключение заметим, что поиск в
пространстве состояний — это формализм, независимый от каких-либо особых стратегий
поиска, и используемый как отправная точка во многих подходах к решению задач.
В этой книге будут исследованы теоретические аспекты представления знаний и
поиска, а также рассмотрены вопросы применения этой теории для создания эффективных
программ. Описание способов представления знаний начинается с исчисления
предикатов (глава 2). Хотя исчисление предикатов — только одна из схем, используемых в
представлении знаний, оно обладает преимуществом четкой семантики и доказуемости
правильности высказываний, полученных с помощью правил вывода (inference rule). На
примере логики предикатов читатель познакомится с проблемами представления знаний
и их отношением к поиску. Затем будут продемонстрированы ограничения исчисления
предикатов и введены альтернативные схемы представления (главы 6-8).
Глава 3 знакомит с поиском в контексте простых игр. На примере игр можно изучать
вопросы, относящиеся к поиску в пространстве состояний, при этом не рассматривать
пока проблемы, связанные с представлением знаний в более сложных системах. Эта
методика затем применяется к пространствам состояний, определенным логическими
решающими устройствами и экспертными системами (главы 4, 5, 7 и 12).
В главе 4 обсуждаются вопросы применения алгоритмов поиска. При этом мы обратим
особое внимание на использование эвристик для управления поиском. В главе 5
рассматриваются продукционные системы (основанные на представлении знаний в виде
продукционных правил), представляющие собой обобщенную и мощную модель решения задач на
основе поиска. Глава 5 представляет другие способы решения задач, включая описание
методологии "классной доски" (стратегия решения сложных системных задач с привлечением
разнородных источников знаний, взаимодействующих через общее информационное поле).
Альтернативные схемы представления
Мы сознательно составили введение в искусственный интеллект так, чтобы показать
историческую перспективу. На начальных стадиях работа в области искусственного
интеллекта была, главным образом, мотивирована и обоснована философской перспекти-
70
Часть II. Искусственный интеллект как представление и поиск
вой гипотезы о физической символьной системе Ньюэлла и Саймона [Newell и
Simon, 1976]. В свете этой теории при разработке интеллектуальных искусственных
объектов преимущественное значение имели формальная логика и поиск. На протяжении
всей книги, главным образом во второй ее части, будет представлено немало успешных
результатов применения этих методик и инструментальных средств, основанных на
символьном представлении.
Однако существует много других подходов к представлению. В части 3 (глава 6)
рассказывается о том, как первые простые системы усложнялись по мере решения более
трудных задач. Появились нейросетевой, эволюционный, агентно-ориентированный и
другие подходы к задаче представления.
Обучающиеся машины отражают требования, выдвигаемые к более сложным
представлениям. В главе 9 будут рассмотрены традиционные подходы к обучению, основанные на
символьном представлении информации. Глава 10 посвящена нейросетевому обучению,
иногда называемому коннекционистским (connectionist). Глава 11 знакомит читателя с
социальными и эмерджентными моделями обучения, которые нашли свое отражение в
генетических алгоритмах, генетическом программировании и искусственной жизни.
Наконец, в настоящее время активно развивается стохастическое направление
исследований. Эти методы, основанные на теории Байеса, часто используются в таких
областях, как абдуктивные суждения (abductive inference), обучение с подкреплением
(reinforcement learning) и понимание естественного языка. Абдуктивные суждения важны
в "обосновании наилучшей трактовки". В областях неточных знаний стохастические
модели и связанные с ними алгоритмы вывода обеспечивают механизм логических
рассуждений и механизм, учитывающий новую информацию для достижения максимально
вероятного заключения. Например, в главе 8 представлены сети доверия (belief networks)
Байеса, используемые для диагностики.
Понимание естественного языка — это еще один пример задачи, решаемой на основе
шаблонов. Они могут быть представлены в виде множества фонем, последовательностей
слов или образцов рассуждений. Таким образом, вероятностный анализ шаблонов важен
как для понимания, так и для порождения естественного языка. В последнее время
исследователи привнесли стохастические методы и в эту научную область. Задача
понимания естественного языка рассматривается в главе 13.
В части II начинается рассмотрение схем представления.
Альтернативные схемы представления
71
Исчисление
п реди катов НИШ
Наконец мы в полной мере освоили возможности графического
изображения логического вывода — последней из наших способностей.
Это не столько естественный дар, сколько долгий и напряженный труд.
— Пирс (Pierce)
Существенное качество доказательства состоит в том,
чтобы заставить поверить.
— Ферма (Fermat)
2.0. Введение
В этой главе мы рассматриваем исчисление предикатов как язык представления
искусственного интеллекта. Достоинства исчисления предикатов описывались во введении в часть П.
Их преимущества заключаются в четко сформулированной формальной семантике,
обоснованности и полноте правил вывода. Эта глава начинается с краткого обзора исчисления
высказываний (раздел 2.1). В разделе 2.2 определяется синтаксис и семантика исчисления
предикатов. В разделе 2.3 мы обсуждаем правила вывода исчисления предикатов и их
применение в решении задач. В заключении этой главы демонстрируется использование исчисления
предикатов для реализации базы знаний финансового инвестиционного совета.
2.1. Исчисление высказываний
2.1.1. Символы и предложения
Исчисление высказываний и исчисление предикатов, рассматриваемое в следующем
подразделе, являются, прежде всего, языками. Используя их слова, фразы и
предложения, мы можем представлять свойства и отношения в окружающем мире и рассуждать о
них. Первый шаг в описании языка — это знакомство с его составляющими, т.е. набором
символов языка.
ОПРЕДЕЛЕНИЕ
СИМВОЛЫ ИСЧИСЛЕНИЯ ВЫСКАЗЫВАНИЙ
Символы исчисления высказываний — это символы высказываний
Р, Q. Я, S, ...,
значения истинности
true (истина), false (ложь)
и логические связки
Л, V, —I, —>, =
Символы высказываний (пропозициональные символы) составляют высказывания
(proposition) или утверждения относительно некоторого мира. Они могут быть как
истинны, так и ложны, например, "автомобиль красный" или "вода мокрая". Высказывания
обозначаются прописными буквами и начинаются буквой, расположенной в конце
английского алфавита. В исчислении высказываний предложения формируются из
элементарных символов согласно следующим правилам.
ОПРЕДЕЛЕНИЕ
ПРЕДЛОЖЕНИЯ ИСЧИСЛЕНИЯ ВЫСКАЗЫВАНИЙ
Каждый логический символ и символ истинности являются предложением.
Например: true, P, О и Я — предложения.
Отрицание предложения есть предложение.
Например: -. Р и -. false есть предложения.
Конъюнкция (логическое умножение), или операция И, двух предложений есть
предложение.
Например: Рл-iP является предложением.
Дизъюнкция (логическое сложение), или операция ИЛИ, двух предложений есть
предложение.
Например: Pv-iP является предложением.
Импликация (включение) одного предложения в другое есть предложение.
Например: P^>Q является предложением.
Эквивалентность двух предложений есть предложение.
Например: PvQ =R является предложением.
Легитимные предложения также называются правильно построенными формулами
(well-formed formulas — WFF), или ППФ.
В выражениях вида PaQ элементы Р и О называются конъюнктами (членами
конъюнктивных выражений). В выражениях вида PvQ элементы Р и О называются
дизъюнктами. В импликации P^>Q, P — предпосылка (premise), или антецедент (antecedent), a
О — заключение, или логическое следствие.
В предложениях исчисления высказываний знаки ( ) и [ ] используются для
группировки символов в подвыражения и, таким образом, дают возможность управлять
порядком их оценки и присваивания значений. Например, (PvQ)=R весьма отличается от
74
Часть II. Искусственный интеллект как представление и поиск
Pv(Q=R)t что можно продемонстрировать с помощью таблиц истинности (см.
подраздел 2.1.2).
Выражение является предложением или правильно построенной формулой (ППФ)
исчисления высказываний тогда и только тогда, когда оно может быть сформулировано в
виде некоторой последовательности допустимых символов согласно установленным
правилам. Например,
((PaQ)->P)=^Pv^QvP
является правильно построенным предложением в исчислении высказываний, поскольку:
Р, О, и R — высказывания и поэтому предложения;
PaQ — конъюнкция двух предложений, поэтому является предложением;
(PaQ)^>R — импликация одного предложения в другое, т.е. предложение;
-iP и -iQ — отрицания предложений, являющиеся предложениями;
-iPv-iO — дизъюнкция двух предложений, поэтому является предложением;
-iPv-.OvR — дизъюнкция двух предложений, т.е. предложение;
((РлО)—>P)=-iPv-iOvP— эквивалентность двух предложений, являющаяся
предложением.
Мы получили первоначальное предложение, которое было создано путем применения
ряда законных правил и поэтому является "правильно построенной формулой".
2.1.2. Семантика исчисления высказываний
В подразделе 2.1.1 мы познакомились с синтаксисом исчисления высказываний и
определили набор правил для создания допустимых предложений. В этом разделе мы
формально определим семантику ("значение") этих предложений. Поскольку программы
искусственного интеллекта должны быть согласованы с представляющими их
структурами, весьма важно продемонстрировать, что правдивость их заключений зависит только
от правдивости начального знания, т.е. что процедуры вывода не содержат логических
ошибок. Для этого весьма необходима точная интерпретация семантики.
Символ предложения соответствует утверждению относительно мироздания.
Например, Р может обозначать высказывание "идет дождь", а О — высказывание "Я живу в
коричневом доме". Предложение, давая некоторое описание мира, может быть как
истинным, так и ложным. Присвоение значения истинности логическим предложениям
называется интерпретацией. Следовательно, интерпретация (interpretation) — это
утверждение относительно правдивости предложения в некотором возможном мире.
Формально интерпретация— это отображение логических символов на множество
{Т, F) (true — истина, false — ложь). Как упомянуто в предыдущем разделе, символы true и
false являются также частями ряда ППФ исчисления высказываний; т.е. значения ППФ
отличны от значения истинности, присвоенного предложению. Чтобы подчеркнуть это
различие, для присвоения значения истинности используются символы Т и F.
Каждое возможное отображение значения истинности высказывания соответствует
возможной интерпретации мира. Например, если Р обозначает высказывание "идет
дождь", а О— "я на работе", то набор высказываний {P,Q} имеет четыре различных
функциональных отображения в таблице истинности {T,F}. Эти отображения
соответствуют четырем различным интерпретациям. Семантика исчисления высказываний,
подобно его синтаксису, определена индуктивно.
Глава 2. Исчисление предикатов
75
ОПРЕДЕЛЕНИЕ
СЕМАНТИКА ИСЧИСЛЕНИЯ ВЫСКАЗЫВАНИЙ
Интерпретация набора высказываний — это присвоение значения истинности, Т или
F, каждому пропозициональному символу.
Символу true (истина) всегда присваивается Г, а символу false (ложь) — значение F.
Интерпретации, или значения истинности, предложений (ППФ) определены
следующим образом.
Определение истинности отрицания -iP, где Р— это любой препозиционный
символ, осуществляется так. Высказывание -iP есть F, если Р имеет значение Г; и
высказывание -iP есть Г, если Р имеет значение F.
Определение истинности конъюнкции л осуществляется так: высказывание имеет
значение Т, только если оба конъюнкта имеют значение Г; иначе выражение имеет
значение F.
Определение истинности дизъюнкции v осуществляется так: высказывание имеет
значение F, только если оба дизъюнкта имеют значение F; иначе выражение имеет
значение Т.
Определение истинности импликации —> осуществляется так: высказывание имеет
значение F только тогда, когда предпосылка (символ перед импликацией) есть 7", и
значение истинности следствия (символа после импликации) есть F; иначе выражение
имеет значение Т.
Истинность эквивалентности = определяется так: высказывание эквивалентности
имеет значение Т только тогда, когда оба выражения имеют одинаковое значение
истинности для всех возможных интерпретаций; иначе выражение эквивалентности
имеет значение F.
Значения истинности сложных выражений часто описываются таблицами
истинности. Таблица истинности содержит все возможные варианты значения истинности для
элементарных суждений (атомарных формул), составляющих большие выражения, и
задает значение истинности выражениям для каждой возможной интерпретации. Таким
образом, в таблице истинности перечисляются все возможные варианты интерпретации
данного выражения. Например, таблица истинности для PaQ (рис. 2.1) дает значения
истинности выражения для каждого возможного значения операнда. Выражение PaQ
истинно только тогда, когда и Р, и О имеют значение Т. Операции "или" (v), "не" (-i),
"импликация" (—>) и "эквивалентность" (=) определены аналогичным образом.
Построение их таблиц истинности предлагается выполнить в качестве упражнений.
Два выражения в исчислении высказываний эквивалентны, если они имеют одни и те
же значения при всех возможных значениях элементов, составляющих выражение. Эта
эквивалентность может быть продемонстрирована с помощью таблиц истинности.
Например, доказательство эквивалентности P^Q и -iPvO определяется таблицей
истинности, показанной на рис. 2.2.
Демонстрируя идентичность таблиц истинности для двух различных предложений в
исчислении высказываний, мы можем доказывать эквивалентность следующих
выражений. Для логических выражений Р, О и Я
-.(-.P)sP
(PvQ)=(-nP->Q)
76
Часть II. Искусственный интеллект как представление и поиск
Закон контрапозиции импликации: P^Q = (-iQ—>—iP).
Закон Моргана: -.(PvO) = (-,Pa-.0) и -.(PaQ) = (-.Pv-.Q).
Законы коммутативности: (PaQ) = (QaP) и (PvQ)=(QvP).
Ассоциативный закон: ((PaQ)aR) = (Pa(QaR)).
Ассоциативный закон: ((PvQ)vR) = (Pv(QvR)).
Дистрибутивный закон: Pv(QaR) = (PvQ)a(PvR).
Дистрибутивный закон: Pa(QvR) = (PaQ)v(PaR).
Эти тождества могут быть использованы для приведения выражения исчисления
высказываний к синтаксически различным, но логически эквивалентным формам. Используя эти
тождества вместо таблиц истинности данных выражений, докажите эквивалентность
выражений, преобразуя одно выражение в другое через последовательность эквивалентных
выражений. Первая программа искусственного интеллекта Logic Theorist (Логический
теоретик) [Newell и Simon, 1956], разработанная Ньюэллом, Саймоном и Шоу, использовала
преобразования эквивалентных форм выражений для доказательства многих теорем из
[Whitehead и Russell, 1950]. Правила вывода дают возможность заменять логическое
выражение другими формами с эквивалентными значениями истинности, что очень важно. Для
использования правил modus ponens (раздел 2.3) и резолюции (resolution) (глава 12)
необходимо, чтобы выражения были заданы в определенной форме.
О PaQ
Т Т Т
Т F F
F T F
F F F
Q -,P -,PvQ P^>Q {-,PvQ)=(P^>Q)
Т | Т | F | Т | Т | T
T F F F F T
F T T T T T
F F T T IT T
Рис. 2.1. Таблица
истинности для
оператора а
Рис. 2 2. Таблица истинности,
демонстрирующая тождественность выражений
P->Q и -.PvQ
2.2. Основы исчисления предикатов
В исчислении высказываний каждый атомарный (элементарный) символ (Р, О и т.д.)
обозначает высказывание некоторой сложности. При этом не существует способа
получить доступ к компонентам отдельного суждения. Исчисление предикатов предоставляет
эту возможность. Например, вместо того, чтобы разрешить единственный символ
высказывания Р, обозначив все предложение "во вторник шел дождь", мы можем создать
предикат погода или weather, который описывает отношения между датой и погодой:
погода(вторник, дождь) или weather(tuesday, rain). Посредством правил ^вывода
можно изменять выражения исчислений предикатов, непосредственно обращаясь к их
компонентам и выводя новые предложения.
Кроме того, исчисление предикатов позволяет включать в выражения переменные.
Переменные помогают создавать обобщенные утверждения относительно классов
логических объектов. Например, можно заявить, что для всех значений X, где X— день
недели, утверждение погода(Х, дождь) или weather(X, rain) есть истина; т.е. каждый день
идет дождь. Как и при исчислении высказываний, сначала определим синтаксис языка
предикатов, а затем обсудим его семантику.
Глава 2. Исчисление предикатов
77
2.2.1. Синтаксис предикатов и предложений
Перед тем как определить синтаксис правильных выражений в исчислении
предикатов, определим алфавит и грамматику для создания символов языка. Это соответствует
лексическому аспекту определения языка программирования. Символы исчисления
предикатов, подобно лексемам в языке программирования, являются неприводимыми
(минимальными) синтаксическими элементами: они не могут быть разбиты операциями
языка на составляющие.
В этой книге мы представляем символы исчисления предикатов как строки букв и
цифр, начинающиеся с буквы. Пробелы и неалфавитно-цифровые символы использовать
нельзя, хотя символ подчеркивания (_) может использоваться для удобства чтения.
ОПРЕДЕЛЕНИЕ
СИМВОЛЫ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Алфавит исчисления предикатов состоит из следующих элементов.
1. Набор букв английского алфавита как верхнего, так и нижнего регистра.
2. Набор цифр —0, 1,..., 9.
3. Символ подчеркивания _.
Символы в исчислении предикатов начинаются с буквы, за которой следует
последовательность перечисленных выше знаков.
Приведем пример допустимых знаков в алфавите исчисления предикатов.
a R 6 9 р _z
Вот пример недопустимых знаков в алфавите исчисления предикатов.
# %@/&" "
К допустимым символам исчисления предикатов относятся следующие.
George fire3 torn_andJerry bill XXXX friends_of
Приведем примеры строк, содержащих неразрешенные знаки.
3jack "no blanks allowed" ab%cd ***71 duck\\\
Символы (или идентификаторы), как будет показано в подразделе 2.2.2,
используются для обозначения объектов, свойств или отношений в области рассуждения. Как и в
большинстве языков программирования, использование "слов", которые имеют
зарезервированное значение, помогает понимать программный код. Например, выражения
л(д,к) и любит(Джордж,Кейт) формально эквивалентны (т.е. имеют одинаковую
структуру). Однако второй вариант может быть удобнее для понимания (людьми-
читателями) смысла отношений, описанных этим выражением. Следует подчеркнуть, что
такие подробные имена предназначены исключительно для улучшения удобочитаемости
выражений. Единственное значение, которое может иметь выражение исчисления
предикатов, — это значение, определяемое их формальной семантикой.
Круглые скобки, запятые (,) и точки (.) используются исключительно для правильного
построения выражений и не обозначают объекты или отношения из области
рассуждения. Они называются несобственными символами (improper symbol).
78
Часть II. Искусственный интеллект как представление и поиск
Символы исчисления предикатов могут представлять переменные, константы,
функции или предикаты. Константами называют определенные объекты или свойства из
области рассуждения. Символьные константы должны начинаться со строчной буквы
(буквы нижнего регистра). Таким образом, george, tree, tall и blue — примеры
правильных символьных констант. Константы true (истина) и false (ложь) зарезервированы
как символы истинности.
Идентификаторы переменных используются для обозначения общих классов
объектов или свойств из области рассуждения. Переменные представляются
идентификаторами, начинающимися с прописной буквы. Так, George, BILL и Kate — допустимые
переменные, в то время как geORGE и bill — нет.
Исчисление предикатов также допускает существование функций для объектов из
некоторой области рассмотрения. Идентификаторы функций (подобно константам)
начинаются с символа нижнего регистра (строчной буквы). Функции обозначают
отображение одного или нескольких элементов множества (называемого областью
определения функции) в однозначно определяемый элемент другого множества
(множества значений функции). Элементы определения и множества значений —
это объекты из области рассмотрения. Помимо обычных арифметических функций,
таких как сложение и умножение, функции могут определять отображения между
нечисловыми областями.
Заметим, что наше определение символов исчисления предикатов не содержит чисел
или арифметических операторов. Система счисления не включена в примитивы
исчисления предикатов. Мы лишь аксиоматически определили "базовое" исчисление предикатов
[Manna и Waldinger, 1985]. Его производные представляют теоретический интерес, но
они менее важны в применении исчисления предикатов в качестве модели представления
искусственного интеллекта. Для удобства включим арифметику в язык описания.
Каждый функциональный символ связан с арностью (arity), указывающей на
количество параметров этой функциональной зависимости. Так, например, символ father мог бы
обозначать функцию арности 1, которая позволяет определить отца, a plus мог бы быть
функцией арности 2, которая отображает два числа в их арифметическую сумму.
Функциональное выражение — это идентификатор функции, за которым следуют его
аргументы (или параметры). Аргументы — это элементы области определения функции.
Число аргументов равно арности функции. Аргументы заключаются в круглые скобки и
разделяются запятыми. Например,
f(X,Y)
father(david)
price(bananas)
Все эти выражения являются правильно определенными функциональными
выражениями.
Каждое функциональное выражение обозначает отображение аргументов в
единственный объект множества значений, называемый значением функции. Например, если
father— это унарная функция, то father(david) является функциональным
выражением, значением которого (по желанию автора) есть george. Если plus — это функция
арности 2, определенная на множестве целых чисел, то p/tvsB,3) является
функциональным выражением, значением которого является целое число 5. Замена функции ее
значением называется ее оцениванием (evaluation).
Понятие символа исчисления предикатов, или терма, формализовано следующим
определением.
Глава 2. Исчисление предикатов
79
ОПРЕДЕЛЕНИЕ
СИМВОЛЫ И ТЕРМЫ
К символам исчисления предикатов относятся следующие.
1. Символы истинности true и false. Это зарезервированные символы.
2. Символы констант — это символьные выражения, начинающиеся с символа
нижнего регистра (строчный символ).
3. Символы переменных — это символьные выражения, начинающиеся с символа
верхнего регистра (прописной символ).
4. Функциональные символы — это символьные выражения, начинающиеся с
символа нижнего регистра (строчный символ). С функциями связывается арность,
указывающая на число их аргументов.
Функциональное выражение (function expression) состоит из функциональной
константы арности п, за которой следуют п термов fb f2, ..., tn, заключенных в
круглые скобки и отделенных друг от друга запятыми.
Терм исчисления предикатов может быть константой, переменной или
функциональным выражением.
Таким образом, термом исчисления предикатов обозначают объекты и свойства из
области определения данной задачи. Примеры термов:
cat
timesB,3)
X
blue
motherljane)
kate
Символы в исчислении предикатов могут также представлять предикаты.
Предикатные символы, подобно константам и именам функций, начинаются с буквы нижнего
регистра. Предикат указывает на отношения между несколькими объектами (в том числе
нулевым числом объектов) в мире. Количество объектов, связанных таким образом,
определяет арность предиката. Примеры предикатов:
like equals on near part_of
Атомарное высказывание (атомарная формула) (atomic sentence), самая
примитивная единица языка исчислений предикатов, является предикатом арности п, за которым
следует п термов, заключенных в круглые скобки и разделенных запятыми. Вот примеры
атомарных высказываний.
likes(george,kate) likes(X,george)
likes(george,susie) likes(X,X)
Hkes(george,sarah,tuesday) friends(bill,richard)
friends(bill,george) friendsffather_of(david),father_of(andrew))
helps(bill, george) helps(richard, bill)
Символами предикатов в этих выражениях являются likes, friends и helps. Символ
предиката может быть использован с различным числом аргументов. В этот пример
включены два различных предиката likes, один из которых зависит от двух, а другой —
80 Часть II. Искусственный интеллект как представление и поиск
от трех аргументов. Если символ предиката используется в предложениях с различной
арностью, то считается, что он представляет два различных отношения. Таким образом,
отношение предиката определяется его именем и арностью. Два отличных предиката
likes могли бы составлять часть одного и того же описания мира; однако этого избегают,
так как могут возникнуть недоразумения.
В приведенных выше примерах предикатов bill, george и kate являются
постоянными символами и представляют объекты из области определения задачи. Аргументы
предиката являются термами и могут также содержать переменные или функциональные
выражения. Например,
friends(father_of(david),father of(andrew))
является предикатом, описывающим отношения между двумя объектами из области
рассуждения. Аргументы здесь представлены как функциональные выражения, значения
которых (будем считать, что father of(david) есть george и father_of(andrew) есть
alien) являются параметрами предиката. После оценки функциональных выражений
представленное выше выражение примет вид.
friends(george, alien)
Эти идеи формализованы в следующем определении.
ОПРЕДЕЛЕНИЕ
ПРЕДИКАТЫ И АТОМАРНЫЕ ПРЕДЛОЖЕНИЯ
Символы предиката — это символы, начинающиеся с символа нижнего регистра.
Предикаты связаны с положительным целым числом, определяющим арность, или
''число аргументов", предиката. Предикаты с одинаковым именем, но различной
арностью считаются различными.
Атомарное предложение— это предикатная константа арности п, за которой
следуют п термов fb f2,..., f„, заключенных в круглые скобки и отделенных запятыми.
Значения истинности true и false тоже являются атомарными предложениями.
Атомарные предложения также называются атомарными выражениями, атомами
или предложениями.
Мы можем комбинировать атомарные предложения и формировать предложения в
исчислении предикатов, используя логические операторы. Это те же самые логические
связки, которые используются в исчислении высказываний
Л, V, -|, —> И =.
Переменная, встречающаяся в предложении в качестве параметра (аргумента),
относится к неопределенным объектам в области определения. Исчисление предикатов
первого порядка (подраздел 2.2.2) включает два символа: кванторы переменных (variable
quantifier) V и 3. Они ограничивают значение предложения, содержащего переменную.
За квантором следует переменная и предложение, как показано ниже.
3Yfriends(Y, peter)
VX likes(X,ice_cream)
Квантор всеобщности V означает, что предложение истинно для всех значений
переменной. В примере VX likes(X,ice cream) выражение истинно для всех значений X в
области определения X. Квантор существования 3 указывает, что предложение истинно
Глава 2. Исчисление предикатов
81
по крайней мере для одного значения в области определения. Выражение ЗУ
friends(Y,peter) истинно, если имеется по крайней мере один объект Y, который
является другом Питера. Более подробно кванторы рассматриваются в подразделе 2.2.2.
Предложения в исчислении предикатов определены индуктивно.
ОПРЕДЕЛЕНИЕ
ПРЕДЛОЖЕНИЯ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Каждое атомарное предложение есть предложение.
1. Если s — предложение, то его отрицание -«s тоже является предложением.
2. Если Si и s2 — предложения, то их конъюнкция SiASjToyKQ является предложением.
3. Если S\ и s2 — предложения, то их дизъюнкция s{vs2тоже является предложением.
4. Если Si и s2 — предложения, то их импликация s^Sj тоже является предложением.
5. Если Si hs2— предложения, то их эквивалентность Si=s2ToyKe является
предложением.
6. Если X — переменная и s предложение, то VX s есть предложение.
7. Если X — переменная и s предложение, то ЗХ s есть предложение.
Далее следуют примеры правильно построенных предложений.
Пусть times (умножить) и plus (сложить) — символы функций арности 2 и пусть
equal (равно) и foo являются предикатными символами арности 2 и 3 соответственно.
plus( two, three) (сложить два и три) — это функция, т.е. не атомарное предложение.
equal (plus(two,three), five) — это атомарное предложение.
equal(plusB,3), seven) — это атомарное предложение. Заметим, что это
предложение при стандартной интерпретации операций сложения и уравнивания является
ложным. Формальная правильность и истинность значения — независимые понятия.
ЗХ foo(X,two,plus(two,three))Aequal(plus(two,three)Jive)— предложение,
потому что оба конъюнкта являются предложениями.
(foo(two,two,plus(two,three)))^>equal(plus(two,three),five)=true) — это
предложение, потому что все его компоненты — предложения, связанные логическими
операторами.
Определение предложений исчисления предикатов и приведенные примеры приводят
к мысли о необходимости проверки: является ли выражение предложением. Метод такой
проверки можно записать в виде рекурсивной функции verify_sentence, которая
получает в качестве параметра рассматриваемое выражение и возвращает значение
success (успех), если выражение является предложением.
function verify_sentence(expression);
begin
case
выражение является атомарным предложением: return SUCCESS;
выражение имеет вид Q X s, где Q — либо V либо 3,а X — переменная,
если verify_sentence(s) возвращает SUCCESS
then return SUCCESS
else return FAI1;
выражение имеет вид —is:
if verify_sentence(s) возвращает SUCCESS
82
Часть II. Искусственный интеллект как представление и поиск
then return SUCCESS
else return FA11;
выражение имеет вид s± op s2/ где op — бинарный логический
оператор:
if verify_sentence (s^ возвращает SUCCESS и
verify_sentence(s2) возвращает SUCCESS
then return SUCCESS
else return FAIL;
в остальных случаях: return FAIL
end
end.
В заключение этого раздела приведем пример использования исчисления предикатов.
Рассмотрим модель простого мира. Рассматриваемая область определения — набор
семейных отношений в библейской генеалогии.
mother(eve,abel)
mother(eve,cain)
father(adam,abel)
father(adam,cain)
VXVYfather(X, Y)vmother(X, Y)^>parent(X, Y)
VXVYVZparent(X,Y)Aparent(X,Z)^>sibling(Y,Z)
В этом примере для определения набора отношений родителей и детей использованы
предикаты mother (мать) и father (отец). В терминах этих предикатов импликация дает
общее определение других отношений, в том числе родительских и братских. Интуиция
подсказывает, что импликацию можно использовать для описания братских отношений,
например sibling(cain, abel). Для реализации этого процесса на компьютере
необходимо его формализовать, т.е. определить алгоритмы вывода. При задании этих алгоритмов
нужно соблюдать осторожность, поскольку они действительно должны выводить
правильные заключения из данного набора утверждений исчисления предикатов. Для того
чтобы это было именно так, вначале определим семантику исчисления предикатов
(подраздел 2.2.2), а затем перейдем к правилам вывода (раздел 2.3).
2.2.2. Семантика исчисления предикатов
Определив правильно построенные выражения в исчислении предикатов, важно
задать их значения в терминах объектов, свойств и отношений в некотором мире.
Семантика исчисления предикатов обеспечивает формальную основу для определения
значений истинности корректно построенных выражений.
Истинность выражений зависит от соответствия констант, переменных, предикатов и
функций объектам и отношениям в области определения. Из истинности отношений в
области определения следует истинность соответствующих выражений.
Например, информация относительно некоторого человека Джорджа и его друзей
Кейт и Сьюзи может быть выражена так.
friends(george,susie)
friends(george,kate)
И если Джордж действительно друг Сьюзи и Keiii, ю каждое из лих выражений
будет иметь значение истинности Т. Если же Джордж --- друг Сьюзи, но не Кейт, то первое
выражение будет иметь значение истинности Г, а второе — значение истинности F.
Глава 2. Исчисление предикатов
83
Чтобы использовать исчисление предикатов для решения задач, объекты и отношения
в интерпретируемой области определения описываются с помощью набора корректных
выражений. Термы и предикаты этих выражений обозначают объекты и отношения в
области определения. Так формируется база данных выражений исчисления предикатов,
каждое из которых, имея значение истинности Г, описывает "состояние мира". Описание
Джорджа и его друзей — это простой пример такой базы данных. Другой пример — мир
блоков, описанный во введении в часть II.
Основываясь на интуиции, определим семантику исчисления предикатов формально.
Сначала определим интерпретацию в области определения D. Затем, используя эту
интерпретацию, определим присвоение значений истинности предложениям языка.
ОПРЕДЕЛЕНИЕ
ИНТЕРПРЕТАЦИЯ
Пусть область определения D — некоторое непустое множество.
Интерпретация на D — это связывание логических объектов из D с каждой
константой, переменной, предикатом и функциональным символом в выражении исчисления
предикатов на основе следующих правил.
1. Каждой константе ставится в соответствие элемент из D.
2. Каждой переменной ставится в соответствие непустое подмножество из D; оно
является областью допустимых значений для этой переменной.
3. Каждая функция f арности (числа операндов) т определяется для т параметров
из D и задает отображение из Dm в D.
4. Каждый предикат р арности п определяется для п параметров из D и задает
отображение из D" в {Г, F}.
При таком определении интерпретации, чтобы получить значение выражения,
следует присвоить выражению значение истинности на этой интерпретации.
ОПРЕДЕЛЕНИЕ
ЗНАЧЕНИЯ ИСТИННОСТИ ВЫРАЖЕНИЙ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Пусть существует выражение Е и интерпретация / для Е на непустой области
определения D. Значение истинности для Е определяется так.
1. Значение константы— это элемент из D, которому соответствует данная
константа в интерпретации /.
2. Значение переменной — это множество элементов из D, которые соответствуют
данной переменной в интерпретации /.
3. Значение функционального выражения — это такой элемент из D, который
получается в результате оценивания функции для значений параметров,
соответствующих интерпретации.
4. Значение символа истинности true — это Г, a false — F.
5. Значение атомарного предложения равно либо Г, либо F, и определяется
интерпретацией /.
6. Значение отрицания предложения равно Г, если значение предложения равно F; и
значение отрицания предложения равно F, если значение предложения равно Т.
84 Часть II. Искусственный интеллект как представление и поиск
7. Значение конъюнкции двух предложений равно Г, если оба предложения
принимают значение Г, иначе оно равно F.
8 -10. Значение истинности выражений, использующих операции v, —> и = ,
определяется значениями их операндов, как описано в подразделе 2.1.2.
Наконец, для переменной X и предложения S, содержащего X, выполняются
следующие соотношения.
11. Значение выражения VXS равно Г, если S равно Г для всех значений X из /, иначе
оно равно F.
12. Значение 3XS равно Г, если в интерпретации существует значение X, для
которого S равно Г; иначе оно равно F.
Квалификация переменных — это важная часть семантики исчисления предикатов. Если
переменная используется в предложении, например, X в предложении likes(george,X), то
она выполняет роль заполнителя и обозначает знакоместо. На это место в выражении
может быть подставлена любая константа, допускаемая интерпретацией. Заменяя
переменную X в предложении likes(george,X) значением kate или susie, получим
утверждения likes(george,kate) и likes(george,susie). Переменная X может быть замещена
любыми допустимыми константами. Данное имя переменной можно заменить любым
другим именем переменной, например Y или PEOPLE, при этом значение выражения не
изменится. Таким образом, переменная является шаблоном для подстановки. В
исчислении предикатов переменные должны быть связаны одним из двух кванторов:
универсальности или существования. Переменная считается свободной, если она не связана
квантором универсальности или существования. Выражение считается замкнутым
(closed), если все его переменные связаны кванторами. Основное выражение (ground
expression) вообще не имеет никаких переменных. В исчислении предикатов все
переменные должны быть связаны кванторами.
Для обозначения квантора всеобщности применяется символ V. Для указания
области действия квантора, т.е. выделения имен переменных, на которые
распространяется действие квантора, часто используются круглые скобки. Так, например,
VX(p(X)vq(Y)^r(X))
указывает, что переменная X связана квантором всеобщности в р(Х) и в г(Х).
Квантор всеобщности усложняет вычисление значения истинности предложения,
потому что для определения истинности выражения необходимо проверить все возможные
значения переменной. Например, чтобы определить значение истинности VX
likes(george,X), где переменная X задана на множестве всех людей, необходимо
проверить все возможные значения X.
Если область определения интерпретации бесконечна, исчерпывающая проверка всех
подстановок переменной, связанной квантором всеобщности, в вычислительном
отношении совершенно невозможна, так как алгоритм никогда не остановится. Из-за этой
проблемы исчисление предикатов считают неразрешимым.
Поскольку исчисление высказываний не использует переменные, предложения имеют
только конечное число возможных значений истинности, и их можно проверить полным
перебором. Для этого используются таблицы истинности.
Переменные также могут быть связаны квантором существования. В этом случае
выражение с переменной считается истинным, если оно истинно по крайней мере для
Глава 2. Исчисление предикатов
85
одного значения из области определения переменной. Квантор существования
обозначается 3. Область действия квантора существования также задается круглыми скобками,
в которых все вхождения переменной считаются связанными этим квантором.
Анализ истинности выражения, содержащего переменную, связанную квантором
существования, может оказаться не проще, чем оценивание выражений, содержащих
переменные под квантором всеобщности. Предположим, необходимо определить истинность
выражения. Для этого можно подставлять в него различные значения каждой
переменной, пока не будет найдено такое, которое делает выражение истинным. Если область
определения переменной бесконечна, и выражение ложно при всех подстановках
значений, алгоритм никогда не завершится.
Приведем несколько примеров взаимосвязи между операцией отрицания и
кванторами всеобщности и существования. Эти соотношения используются в системах
опровержения резолюций, описанных в главе 12. В приведенных соотношениях имя переменной
используется в качестве формального символа, который заменяет набор констант. Для
предикатов р и q и переменных X и У выполняются следующие соотношения.
-^ЗХр(Х)=\/Х^р(Х)
->\/Хр(Х)=ЗХ^р(Х)
3Xp(X)=3Yp(Y)
VXq(X)=VYq(Y)
\/X(p(X)Aq(X))=\/Xp(X)A\/Yq(Y)
3X(p(X)vq(X))=3Xp(X)v3Yq(Y)
На определенном нами языке переменные, связанные квантором всеобщности и
квантором существования, могут ссылаться только на объекты (или константы) из
рассматриваемой области определения. Имена предикатов и имена функций не могут быть
заменены именами переменных, стоящих под знаком квантора. Этот язык называется
исчислением предикатов первого порядка (first-order predicate calculus).
ОПРЕДЕЛЕНИЕ
ИСЧИСЛЕНИЕ ПРЕДИКАТОВ ПЕРВОГО ПОРЯДКА
Исчисление предикатов первого порядка позволяет связывать знаком квантора
переменные, соответствующие объектам из предметной области, но не предикаты или функции.
Например,
V(Likes)Likes(george,kate)
не является правильно построенным выражением в исчислении предикатов первого
порядка. Существуют исчисления предикатов высших порядков, в которых такие выражения
поддаются интерпретации. Некоторые исследователи [McCarthy, 1968], [Appelt, 1985]
использовали языки высших порядков, чтобы представить знания в программах понимания
естественного языка.
Многие грамматически правильные английские предложения могут быть
представлены в исчислении предикатов первого порядка с помощью символов, связок и
символьных переменных, определенных в этом разделе. Важно заметить, что не
существует уникального отображения предложений в выражения исчисления
предикатов. Английское предложение может иметь любое число различных представлений в
области исчисления предикатов. Основная трудность для программистов систем
искусственного интеллекта заключается в том, чтобы найти схему использования
предикатов, оптимальную с точки зрения выразительности и эффективности оконча-
86 Часть II. Искусственный интеллект как представление и поиск
тельного представления. Приведем примеры английских и русских предложений,
представленных средствами исчисления предикатов.
If it doesn't rain on Monday, Tom will go to the mountains. (Если в понедельник не будет
дождя, Том пойдет в горы )
-tweather(rain,monday)^>go(tom, mountains)
Emma is a Doberman pinscher and a good dog. (Эмма — это доберман-пинчер и хорошая собака.)
gooddog(emma)Aisa{emma,doberman)
All basketball players are tall. (Все баскетболисты — высокие )
\/X(basketball_player(X)->tall(X))
Some people like anchovies. (Некоторые люди любят анчоусы)
3X(person(X)Alikes(X,anchovies))
If wishes were horses, beggars would ride. (Если бы желания были лошадьми, то нищие бы
ездили верхом.)
equal(wishes,horses)->ride(beggars)
Nobody likes taxes. (Никто не любит налоги.)
-.ЗХ likes(X, taxes)
2.2.3. Значение семантики на примере "мира блоков"
В заключение этого раздела рассмотрим вопросы присвоения значений истинности
некоторым выражениям исчисления предикатов на примере из "мира блоков".
Предположим, мы хотим промоделировать мир блоков, изображенный на рис. 2.3, и
сконструировать алгоритм управления для руки робота. Для представления качественных
отношений в этом мире можно использовать предложения исчисления предикатов. С помощью
этих предложений нужно описать, свободна ли верхняя грань данного блока, можно ли
взять блок а, и т.д. Предположим, что компьютер обладает знаниями о расположении
каждого блока и руки, а также способен отслеживать перемещение блоков на столе
(используя трехмерную систему координат).
В этом примере из "мира блоков" нужно очень точно определить свои действия.
Сначала необходимо создать набор выражений исчисления предикатов, который должен
фиксировать текущее состояние мира блоков в рассматриваемой предметной области. В
разделе 2.3 будет представлена интерпретация и возможная модель мира блоков,
описанная набором выражений исчисления предикатов.
Исчисление предикатов декларативно, т.е. не существует никакой принятой
синхронизации или порядка рассмотрения каждого выражения. Тем не менее в разделе 7.4 мы
дополнительно рассмотрим процедурную семантику (procedural semantics) или ясно
определенную методологию для оценки этих выражений во времени. Конкретный пример
процедурной семантики для выражений исчисления предикатов — это язык PROLOG
(глава 14). Создаваемое нами ситуационное исчисление связано с рядом вопросов,
включающих проблему фреймов и немонотонности логических интерпретаций. Эти вопросы
будут представлены на рассмотрение позже. Для этого примера достаточно сказать, что
выражения исчисления предикатов будут оцениваться слева направо.
Глава 2. Исчисление предикатов
87
1
L J
^ШШШ^^^^Ш
С
a
b
d
шъ
on{c,a)
on{b,d)
ontable{a)
ontable{d)
cleat(b)
clear'(c)
hand_empty
Рис 2.З. Мир блоков и его описание
в исчислении предикатов
Здесь оп(с,а) означает, что блок с находится на блоке a; ontable(a) — блок а лежит
на столе; clear(c) — на блоке с нет других блоков; handempty — рука пуста.
Чтобы можно было поднять один блок и поставить его на другой, оба блока должны
быть свободными (открытыми для руки). На рис. 2.3 блок а не свободен. Поскольку рука
может перемещать блоки, она может изменять состояние мира и освобождать их.
Предположим, она снимает блок с с блока а и обновляет базу знаний, удалив из нее
утверждение оп(с,а). Программа при этом должна сделать логический вывод, что блок а
теперь свободен.
Следующее правило описывает действие "блок стал свободным".
VX(-n3V on(Y,X)->clear(X))
Следовательно, для любого X X свободен, если не существует У такого, что У
находится на X.
Это правило определяет не только значение "блок свободен", но и действие
"освободить блоки". Например, блок d не свободен, потому что, если переменная X
принимает значение d, а У— Ь, то предложение является ложным. Чтобы сделать это
определение истинным, блок Ь следует удалить с блока d. Это легко сделать, потому что в
компьютере записано местоположение всех блоков.
Помимо использования вышеописанного правила для определения условия
освобождения блока, можно добавить другие правила, описывающие операции укладки одного
блока на другой. Например: чтобы положить X на У, сначала нужно освободить руку,
затем освободить X, У и уж потом взять X (pick_up(X)) и поставить (put_down) его на У.
\fXyy((hand_emptyAclear(X)Aclear(Y)Apick_up(X)Aput_down(X,Y))-^
stack(X,Y))
Заметим, что в вышеупомянутом описании необходимо связать с каждым предикатом
действие руки робота, например pickup(X) (взять X). Как отмечалось ранее, для этого
необходимо дополнить семантику исчисления предикатов требованием, чтобы действия
выполнялись в том порядке, в котором они предписываются правилами. Однако эту
проблему лучше рассмотреть отдельно.
88
Часть II. Искусственный интеллект как представление и поиск
На рис. 2.3 представлена семантическая интерпретация этих выражений
исчисления предикатов. Она отображает константы и предикаты в набор выражений из
области определения D (в данном случае это блоки и отношения между ними).
Интерпретация сопоставляет значение истинности Г с каждым выражением в описании.
Для других наборов блоков, находящихся в другом расположении, или же,
например, для группы из четырех акробатов, могла бы быть предложена другая
интерпретация. Вопрос заключается не в уникальности интерпретаций. Главное,
интерпретация должна обеспечивать значение истинности для всех выражений в наборе, а сами
выражения должны достаточно детально описывать мир, предоставляя все
необходимые выводы. В следующем разделе эти идеи используются для формальной
основы правил вывода исчисления предикатов.
2.3. Правила вывода в исчислении предикатов
2.3.1. Правила вывода
Семантика исчисления предикатов обеспечивает основу для формализации теории
логического вывода (logical inference). Возможность логически выводить новые
правильные выражения из набора истинных утверждений — это важное свойство исчисления
предикатов. Логически выведенные выражения корректны, потому что они совместимы
со всеми предыдущими интерпретациями первоначального набора выражений. Вначале
обсудим вышесказанное неформально, а затем введем ряд определений для
формализации этих утверждений.
Говорят, что интерпретация, которая делает предложение истинным,
удовлетворяет этому предложению. Если интерпретация удовлетворяет каждому элементу
набора выражений, то говорят, что она удовлетворяет набору. Выражение X логически
следует из набора выражений S исчисления предикатов, если каждая интерпретация,
которая удовлетворяет S, удовлетворяет и X. Это утверждение дает основание для
проверки правильности правил вывода: функция логического вывода должна
производить новые предложения, которые логически следуют из данного набора
предложений исчисления предикатов.
Важно верно понимать значение слов логически следует: логическое следование
выражения X из S означает, что оно должно быть истинным для каждой интерпретации,
которая удовлетворяет первоначальному набору выражений S. Это означает, например, что
любое новое выражение исчисления предикатов, добавленное к миру блоков на рис. 2.3,
должно быть истинным в этом мире. Оно должно быть истинным и при любой другой
интерпретации, которую мог бы иметь этот набор выражений.
Термин логически следует вовсе не означает, что X выведено из S, или что его можно
вывести из S. Это просто означает, что X истинно для каждой интерпретации
(потенциально до бесконечности), которая удовлетворяет S. Однако системы предикатов
могут иметь бесконечное число возможных интерпретаций, поэтому практическая
необходимость проверять все интерпретации возникает весьма редко. В вычислительном
отношении правила вывода (inference rule) позволяют определять, когда выражение как
компонент интерпретации логически следует из этой интерпретации.
Понятие логически следует обеспечивает формальное основание для доказательства
разумности и правильности правил вывода.
Глава 2. Исчисление предикатов
89
Правило вывода обеспечивает создание новых предложений исчисления предикатов
на основе данных предложений. Следовательно, правила вывода производят новые
предложения, основанные на синтаксической форме данных логических утверждений. Если
каждое предложение X, полученное с помощью некоторого правила вывода на
множестве S логических выражений, также логически следует из S, то говорят, что это правило
вывода обосновано (sound).
Если система правил вывода способна произвести каждое выражение, которое может
логически следовать из S, то говорят, что эта система правил вывода является полной.
Приведенное ниже правило modus ponens и принцип резолюции (resolution),
представленный в главе 12, являются примерами обоснованных правил вывода, которые при
использовании соответствующих стратегий полны. Логические системы вывода обычно
используют обоснованные правила вывода, однако далее (в главах 5, 9, 10 и 14) мы
рассмотрим эвристические рассуждения и рассуждения на основе здравого смысла, которые
опускают это требование.
Формализуем эти мысли с помощью следующих определений.
ОПРЕДЕЛЕНИЕ
УДОВЛЕТВОРЯТЬ, МОДЕЛЬ, АДЕКВАТНОСТЬ
Для выражения X исчисления предикатов и интерпретации / имеют место следующие
определения.
Если X имеет значение Г на / при конкретных значениях переменных, то говорят, что
/ удовлетворяет X.
Если / удовлетворяет X при всех значениях переменных, то / является моделью X.
X выполнимо (satisfiable) тогда и только тогда, когда существуют такая интерпретация
и значение переменной, которые ему удовлетворяют; в противном случае X
невыполнимо (unsatisfiable).
Набор выражений выполним тогда и только тогда, когда существуют интерпретация и
значения переменных, которые удовлетворяют каждому элементу.
Если набор выражений невыполним, то говорят, что он противоречив (inconsistent).
Если X имеет значение Г для всех возможных интерпретаций, то говорят, что X имеет
силу, или адекватно (valid).
В примере на рис. 2.3 мир блоков является моделью для логического описания. При
этой интерпретации все предложения в примере были истинными. Если база знаний
реализована как набор истинных утверждений для предметной области задачи, то
предметная область служит моделью для базы знаний.
Выражение ЗХ (р(Х) л -ip(X)) противоречиво, потому что оно не может быть
удовлетворено ни при какой интерпретации или значениях переменных. С другой стороны,
выражение VX (p(X) v -ip(X)) адекватно.
Для проверки адекватности выражений, не содержащих переменных, можно
использовать метод таблиц истинности. Поскольку не всегда можно определить, адекватно ли
выражение, содержащее переменные (как говорилось выше, процесс может не
закончиться), говорят, что полное исчисление предикатов "неразрешимо". Однако существуют
методы доказательства, которые позволяют генерировать любое выражение, логически
следующее из данного набора выражений. Они называются процедурами полного
доказательства (complete proof procedures).
90
Часть II Искусственный интеллект как представление и поиск
ОПРЕДЕЛЕНИЕ
ПРОЦЕДУРА ДОКАЗАТЕЛЬСТВА
Процедура доказательства (proof procedure) — это комбинация правил вывода и
алгоритма применения этих правил к набору логических выражений для создания
новых предложений.
В главе 11 представлены процедуры доказательства для правил резолюции (resolution
inference rule).
Используя эти определения, можно формально определить термин "логически следует".
ОПРЕДЕЛЕНИЕ
ЛОГИЧЕСКИ СЛЕДУЕТ, ОБОСНОВАННЫЙ И ПОЛНЫЙ
Выражение исчисления предикатов X логически следует из набора S выражений
исчисления предикатов, если каждая интерпретация и значения переменных, которые
удовлетворяет S, удовлетворяют и X.
Правило вывода обосновано (sound), если каждое выражение исчисления предикатов,
полученное в соответствии с правилом из множества S выражений исчисления
предикатов, также логически следует из S.
Правило вывода полно (complete), если на данном множестве S выражений исчисления
предикатов правило позволяет вывести любое выражение, которое логически следует из S.
Правило modus ponens (правило отделения, или модус поненс) — это обоснованное
правило вывода. Если дано выражение вида P-^Q и другое выражение вида Р, и оба
выражения истинны на интерпретации /, то modus ponens позволяет нам сделать вывод,
что О тоже истинно на этой интерпретации. Действительно, поскольку modus ponens
является обоснованным правилом, О истинно для всех интерпретаций, для которых Р и
P-^Q являются истинными.
Определения правила modus ponens и ряда других полезных правил вывода даны ниже.
ОПРЕДЕЛЕНИЕ
МОДУС ПОНЕНС, МОДУС ТОЛЛЕНС, ИСКЛЮЧЕНИЕ "И", ВВЕДЕНИЕ "И",
УНИВЕРСАЛЬНОЕ ИНСТАНЦИРОВАНИЕ
Если известно, что предложения Р и P-^Q истинны, то модус поненс позволяет
вывести О.
Согласно правилу вывода модус толленс (modus tollens), если известно, что P-^>Q
является истинным и О ложно, можно вывести -iP.
Исключение "Я" — правило, позволяющее вывести истинность обоих конъюнктов на
основе истинности конъюнктивного предложения. Например, если PaQ истинно,
можно сделать вывод, что Р и О истинны.
Введение "И" позволяет вывести истинность конъюнкции из истинности ее
конъюнктов. Например, если Р и О истинны, то конъюнкция PaQ истинна.
Универсальное инстанцирование сводится к следующему: если любую переменную,
стоящую под квантором всеобщности в истинном предложении, заменить любым
соответствующим термом из области определения, то результирующее выражение —
истинно. Таким образом, если а принадлежит той же области определения, что и X и
VX р (X), то можно вывести р(а).
Глава 2. Исчисление предикатов
91
В качестве простого примера применения правила модус поненс в исчислении
высказываний рассмотрим следующие предложения: "если идет дождь, то земля будет
влажной" и "идет дождь". Если Р обозначает "идет дождь" и О есть "земля, влажная", то
первое выражение можно записать в виде P^Q. Поскольку действительно сейчас идет
дождь (Р истинно), получаем систему аксиом.
P->Q
Р
Применив правило модус поненс к набору истинных выражений, можно добавить тот
факт, что земля является влажной О.
Правило модус поненс также может быть применено к выражениям, содержащим
переменные. Рассмотрите в качестве примера обычный силлогизм "все люди
смертны, и Сократ — человек, поэтому Сократ — смертен". Высказывание "Все люди
смертны" может быть представлено в исчислении предикатов (по-русски и по-
английски) так.
VX (человек(Х)->смертный(Х)).
\/X(man(X)->mortal(X)).
"Сократ — человек"
человек(сократ).
man(socrates).
Поскольку X в выражении стоит под знаком квантора всеобщности, его можно
заменить любым значением из области определения X, и при этом утверждение будет
сохранять истинное значение согласно правилу универсального инстанцирования. Заменив в
выражении X на сократ, получим следующее утверждение.
человек(сократ)^смертный (сократ).
man(socrates)->mortal{socrates).
Применив правило модус поненс, приходим к выводу mortal(socrates). Он может
быть добавлено к набору выражений, которые логически следуют из
первоначальных утверждений. Можно использовать так называемый алгоритм унификации для
определения автоматическим решающим устройством правомочности замены X на
socrates и возможности применения правила модус поненс. Унификация
обсуждается в подразделе 2.3.2.
В главе 12 обсуждается более строгое правило вывода, называемое правилом
резолюции (resolution), которое является основой многих интеллектуальных
автоматических систем.
2.3.2. Унификация
Чтобы применять правила вывода типа модус поненс, система вывода должна
уметь определять, когда два выражения являются эквивалентными, или
равносильными. В исчислении высказываний это тривиально: два выражения равносильны
тогда и только тогда, когда они синтаксически идентичны. В исчислении предикатов
определение равносильности двух предложений усложняется наличием переменных.
Правило универсального инстанцирования позволяет заменять переменные под
знаком квантора всеобщности термами из области определения. Необходимо опреде-
92
Часть II. Искусственный интеллект как представление и поиск
лить процесс замены переменных, при котором несколько выражений могут стать
идентичными (обычно для того, чтобы можно было применять правила вывода).
Унификация — это алгоритм определения необходимых подстановок с целью
приведения в соответствие двух выражений исчисления предикатов. Пример такого процесса
приведен в предыдущем подразделе, где терм socrates из выражения man(socrates)
был использован в качестве подстановки для X в выражении VX(man(X)=>mortal(X)).
Эта подстановка позволила применить правило модус поненс и получить вывод
mortal(socrates). Еще один пример унификации был рассмотрен выше, когда
обсуждались фиктивные переменные (dummy). Поскольку р(Х) и р( У) эквивалентны, для
приведения предложений в соответствие (match) друг другу У можно заменить на X.
Унификация и такие правила вывода, как модус поненс, позволяют делать выводы на
множестве логических утверждений. Для этого логическая база данных должна быть
выражена в соответствующей форме.
Весьма важный аспект этой формы заключается в требовании, чтобы все переменные
стояли под знаком квантора всеобщности. Это обеспечивает полную свободу в
выполнении подстановок. Переменные, стоящие под квантором существования, можно устранить
из предложений в базе данных, заменив их константами, обеспечивающими истинность
предложения. Например, ЗХ parent(X,tom) может быть заменено выражением
parent(bob,tom) или parent(mary,tom), принимая во внимание, что Боб (bob) и Мэри
(тагу) являются родителями Тома (torn) в этой интерпретации.
Процесс удаления переменных, связанных квантором существования, усложнен тем
фактом, что значение этих подстановок может зависеть от значения других переменных
в выражении. Например, в высказывании VX ЗУ mother(X,Y) значение переменной У
под квантором существования зависит от значения X. Сколемизсщия (skolemization) —
это замена каждой переменной, связанной квантором существования, функцией
нескольких или всех имеющихся в предложении переменных, которая возвращает
соответствующую константу. В вышеупомянутом примере, поскольку значение У зависит от X, У
можно заменить сколемовской функцией (skolem function) f от X. Это порождает предикат
VX mother(X,f(X)). Сколемизация— это процесс, который также позволяет связывать
переменные, стоящие под квантором всеобщности, с константами. Этот аспект подробно
обсуждается в главе 12.
После удаления из логической базы данных переменных, связанных квантором
существования, можно применить унификацию и привести предложения в форму,
необходимую для применения таких правил вывода, как модус поненс.
Процесс унификации осложняется тем фактом, что переменная может быть заменена
любым термом, включая другие переменные и функциональные выражения
произвольной сложности. Эти выражения могут тоже содержать переменные. Например,
father(jack) можно использовать в качестве подстановки для X в выражении тап(Х)
для получения вывода, что отец Джека смертен.
Приведем несколько реализаций выражения
foo(X,a,goo(y)).
Их можно получить путем следующих подстановок.
1. foo(fred,a,goo(Z))
2. foo(W,a, goo(jack))
3. foo(Z,a,goo(moo(Z)))
Глава 2. Исчисление предикатов
93
В этом примере экземпляры подстановки, или унификации, которые делают
начальное выражение идентичным каждому из трех, можно записать в виде
{fred/X,Z/Y}
{W/Xjack/Y}
{Z/X,moo(Z)/Y}
Запись X/Y, ... означает, что X является подстановкой для переменной Y в
первоначальном выражении. Подстановка также называется связыванием. Говорят, что
переменная связана со значением, используемым в качестве подстановки.
При создании алгоритма унификации, который вычисляет подстановки, необходимые
для соответствия двух выражений, возникают некоторые проблемы.
Хотя константу можно систематически использовать в качестве подстановки для
переменной, любая константа рассматривается как "базовый экземпляр" и не может быть
заменена. Нельзя также два различных "базовых экземпляра" использовать в качестве
подстановки для одной и той же переменной.
Переменная не может быть унифицирована с термом, содержащим ее. Поэтому
переменная X не может быть заменена на р(Х), поскольку это порождает бесконечное
выражение: р(р(р(р(...Х)...). Тест для этой ситуации называется проверкой вхождения
(occurs check).
Вообще, процесс решения задачи требует ряда выводов и, следовательно, ряда
последовательных унификаций. Логические решающие устройства задач должны поддерживать
согласованность подстановок для переменных. Важно, чтобы любая унифицирующая подстановка
была сделана согласованно по всем вхождениям этой переменной во все выражения. А
выражения должны быть приведены в соответствие друг другу. Эта ситуация уже встречалась,
когда терм сократ использовался не только в качестве подстановки для переменной X в
предложении человек(Х), но и для переменной X в выражении смертен(Х).
Если переменная связана, все последующие унификации и процедуры вывода
должны учитывать это. Если переменная связана с константой, ее уже нельзя
связывать с другим термом при последующих унификациях. Если переменная Xj
использовалась в качестве подстановки для другой переменной Х2, а затем была заменена
константой, то вХ2тоже необходимо отразить это связывание. Множество замен,
используемых в последовательности выводов, играет важную роль, потому что оно
может содержать ответ на первоначальный вопрос (подраздел 12.2.5). Например,
если р(а,Х) унифицировать с предпосылкой правила p(Y,Z)=>q(Y,Z) при помощи
подстановки {a/Y,X/Z}, модус поненс позволяет вывести q(a,X) при той же
подстановке. Если мы сопоставим этот результат с предпосылкой правила q(W,b)=>r(W,b), то
выведем r(a,b) с учетом множества подстановок {а/И/Ь/Х}.
Другое важное понятие — это композиция подстановок унификации. Если S и S'
являются двумя множествами подстановок, то композиция S и S' (пишется SS') получается
после применения S' к элементам S и добавления результата к S. Рассмотрим пример
композиции последовательности подстановок
{X/Y,W/Z}, {V/X), {a/V, f(b)/W).
Они эквивалентны единственной подстановке
{a/Y, f(b)/Z).
Последняя подстановка была выведена путем компоновки {X/Y, W/Z} с {V/X} для
получения {V/Y, W/Z} и компоновки результата с {а/У, f(b)/W) для получения {a/Y, f{b)/Z}.
94 Часть II. Искусственный интеллект как представление и поиск
Композиция подстановок — это метод, с помощью которого объединяются
подстановки унификации. Его можно реализовать, используя рекурсивную функцию unify,
которая представлена ниже. Можно показать, что композиция является ассоциативной, но
не коммутативной. В упражнениях эти вопросы рассмотрены более подробно.
Последнее требование алгоритма унификации— унификатор (unifier) должен быть
максимально общим, т.е. для любых двух выражений должен быть найден наиболее
общий унификатор. Это очень важно, поскольку при потере общности в процессе решения
уменьшается вероятность достижения окончательного решения или такая возможность
исчезает полностью.
Например, предложения р(Х) и р( Y) можно унифицировать любым константным
выражением вида {fred/X, fred/Y}. Однако fred не является наиболее общим
унификатором. Используя в качестве унификатора любую переменную, можно получить более
общее выражение: {Z/X, Z/Y}. Решения, полученные при использовании первой
подстановки, всегда будут ограничены содержащейся в них константой fred, лимитирующей
логические выводы. Следовательно, fred можно использовать в качестве унификатора,
но это снижает универсальность результата.
ОПРЕДЕЛЕНИЕ
НАИБОЛЕЕ ОБЩИЙ УНИФИКАТОР
Если s — произвольный унификатор выражения Е, а д — наиболее общий
унификатор (most general unifier — mgu) этого набора выражений, то в случае применения s к
Е будет существовать еще один унификатор s' такой, что Es=Egs\ где Es и Egs' —
композиции унификаций, примененные к выражению Е.
Наиболее общий унификатор для набора выражений определяется с точностью до
обозначения. В конечном счете, не имеет никакого значения, как называется
переменная — X или V, поскольку это не снижает общности для результирующей унификации.
Унификация важна для любой системы решения задач искусственного интеллекта,
использующей в качестве средства представления исчисление предикатов.
Унификация определяет условия, при которых два (или больше) выражения исчисления
предикатов могут быть эквивалентными. Это позволяет использовать для логического
представления такие правила вывода, как резолюция (resolution), хотя этот процесс часто
требует поиска с возвратом (backtracking) для нахождения всех возможных
интерпретаций (см. главу 14).
Ниже будет представлен псевдокод для функции unify (унифицировать), которая
вычисляет подстановки унификации (если это возможно) для двух выражений исчисления
предикатов. Функция unify получает в качестве параметров два выражения исчисления
предикатов и возвращает либо наиболее общую подстановку унификации, либо
константу FAIL (отказ), если унификация невозможна. Эта функция определена рекурсивно:
вначале она пытается рекурсивно унифицировать исходные компоненты выражений. Если
это удается, все подстановки, возвращаемые в результате этой унификации,
применяются к остальным выражениям. Затем выполняется второй рекурсивный вызов функции
unify, в котором завершается унификация. Рекурсия прекращается, когда параметром
становится символ (предикат, имя функции, константа или переменная), или когда все
элементы выражения приводятся в соответствие.
Чтобы упростить работу с выражениями, в алгоритме применяется слегка
измененный синтаксис. Поскольку функция unify просто проверяет синтаксическое соот-
Глава 2. Исчисление предикатов
95
ветствие шаблону, она игнорирует различия между предикатами, функциями и
параметрами, свойственные исчислению предикатов. Представляя выражение в виде
списка (list) — упорядоченной последовательности элементов, первым из которых
является предикат, за которым следуют его параметры, мы упрощаем работу с
выражениями. Выражения, в которых сами параметры являются предикатами или
функциональными выражениями, представлены как списки в списках. Таким
образом сохраняется структура выражения. Списки заключены в круглые скобки (), а
элементы списка отделены друг от друга пробелами. Примеры выражений как в
исчислении предикатов, так и в синтаксисе списков представлены ниже.
Синтаксис исчисления предикатов Синтаксис списка
p(a,b) (р а Ь)
p(f(a),g(X,Y)) (р (f a) (g х Y))
equal(eve,mother(Cain)) (equal eve (mother cain) )
Представим функцию unify.
function unify(El,E2);
begin
case
El и Е2 — константы или пустые списки: %рекурсия завершается
if E1=E2 then return {}
else return FAIL;
El — переменная:
if El входит в Е2 then return FAIL
else return {E2/E1};
E2 — переменная:
if E2 входит в El then return FAIL
else return {E1/E2}
El или Е2 — пуст then return FAIL %списки различных размеров
otherwise: %E1 и Е2 списки
begin
НЕ1:=первый элемент El;
НЕ2:= первый элемент Е2 ;
SUBSl:=unify(HE1,HE2);
if SUBS1:=FAIL then return FAIL;
TE1:=apply(SUBSl,хвост El);
TE2:=apply(SUBSl,хвост E2) ;
SUBS2:=uni fу(TEl,TE2) ;
if SUBS2=FAIL then return FAIL;
else return composition(SUBS1,SUBS2)
end
end
%конец case
end
2.3.3. Пример унификации
Поведение вышеописанного алгоритма можно понять, проследив обработку запроса
unify((parents X (father X) (mother bill)), (parents bill (father bill) Y))
96
Часть II. Искусственный интеллект как представление и поиск
Поскольку ни один параметр не является атомарным символом, при первом вызове
функции unify она будет пытаться рекурсивно унифицировать первые элементы каждого
выражения с помощью вызова
unify(parents, parents).
Эта унификация успешно выполнится и возвратит пустую подстановку {}.
Применение ее к остальным выражениям не вызовет никаких изменений; затем вызывается
unify((X(fatherX) (mother bill)), (bill (father bill) Y)).
Древовидное описание выполнения алгоритма на этой стадии представлено на рис. 2.4.
Во втором вызове unify ни одно выражение не является атомарным, поэтому
алгоритм разделяет каждое выражение на его первый компонент и остальную часть. Затем
следует вызов
unify(X, bill).
Этот вызов завершается успешно, поскольку оба выражения атомарные, и одно из них —
переменная. В результате вызова возвращается подстановка {bill/X). Она применяется к
"хвосту" каждого выражения, а функция unify — к результатам подстановки (рис. 2.5).
unify(((fatherbill) (mother bill)), ((father bill)Y)).
В результате этого вызова должна быть получена унификация (father bill) с (father
bill). Это порождает вызовы
unify(father, father)
unify(bill, bill)
unify(( ), ( ))
Все они успешно завершаются, возвращая пустое множество подстановок, как
показано на рис. 2.6.
Затем функция unify вызывается для оставшихся выражений
unify(((motherbill)), (Y)).
Это, в свою очередь, приводит к вызовам
unify((motherbill), Y)
unify(( ),( )).
В первом из них (mother bill) унифицируется с Y. Заметим, что в процессе
унификации вместо переменной Y подставляется целая структура (mother bill). Таким образом,
унификация завершается успешно и возвращает подстановку {(mother bill)/Y}. Вызов
unify(()t())
возвращает {}. В результате комбинации с полученной ранее подстановкой {bill/X)
приходим к ответу {bill/X (mother bill)/Y}. Весь процесс подстановок иллюстрируется на
рис. 2.6. Вызовы пронумерованы, чтобы указать порядок их выполнения. Подстановки,
возвращенные каждым запросом, помечены на дугах дерева.
Глава 2. Исчисление предикатов
97
7. unify((parents X (fatherX) (mother bill)), (parents bill (father bill) Y))
Унифицировать
первые элементы
,* и применить
подстановки
" - ,, костальным
return {}
2. unify(parents, parents)
3. unify((X (fatherX) (motherbill)),(bill (fatherbill) Y))
Рис. 2.4. Начальные шаги унификации выражений ((parents X (father X) (mother
bill)) и (parents bill (father bill) Y)
1. unify((parents X (fatherX) (mother bill)), (parents bill (father bill) Y))
Унифицировать
первые элементы
* и применить
подстановки
к остальным
return {}
2. unify(parents, parents)
3. unify((X (fatherX) (mother bill)),(bill (fatherbill) Y))
Унифицировать
первые элементы
tf и применить
подстановки
к остальным
'return {bill/X\
4. unify(X,bill)
5. unify(((father bill) (motherbill)),((fatherbill) Y))
Рис. 2.5. Дальнейшие шаги унификации выражений ((parents X (father X) (mother
bill)) и (parents bill (father bill) Y)
98
Часть II. Искусственный интеллект как представление и поиск
7. unify((parents X (fatherX) (mother bill)), (parents bill (father bill) Y))
return {}
Унифицировать у
первые элементы
* и применить
подстановки
к остальным
2. unify(parents, parents)
^return {(mother bill)/Y, bill/X)
3. unify((X(fatherX) (mother bill)), (bill (father bill) Y))
'return {bill/X}
Унифицировать у
первые элементы \ \
* и применить
подстановки
костальным
eturn {(mother bill)/Y)
4. unify(X,bill)
5. unify(((father bill) (motherbill)), ((father bill) Y))
return {}
6. unify((fatherbill), (father bill))
Унифицировать
первые элементы
и применить
/ подстановки
к остальным
Унифицировать
первые элементы
* и применить
подстановки
костальным
eturn {(mother bill)/Y
return {}
7. unify(father, father)
11.unify(((motherbill)),(Y))
Унифицировать
первые элементы
и применить
подстановки
костальным
return {(mother bill)/Y)
return {}
8. unify((bill), (bill)) 12. unify((mother bill), Y)
Унифицировать
первые элементы
и применить
подстановки
костальным
13. unify((), ())
9. unify(bill, bill)
10. unify((), ())
Рис. 2.6. Заключительные шаги унификации выражений ((parents X (father X)
(mother bill)) u (parents bill (father bill) Y)
Глава 2. Исчисление предикатов
99
2.4. Приложение: финансовый советник на основе логики
В качестве последнего примера использования исчисления предикатов для
представления предметной области и рассуждения о ней разработаем простую систему, которую
можно применять в качестве "финансового советника". Хотя пример и прост, он
иллюстрирует много проблем, связанных с реальными приложениями.
Задача "советника" — помочь пользователю решить, положить деньги на
сберегательный счет или вложить их в акции. Некоторые инвесторы, возможно, захотят
распределить свой капитал между двумя вариантами. Рекомендации отдельным инвесторам
должны зависеть от их дохода и текущей накопленной суммы, т. е. удовлетворять
следующим требованиям.
1. Лица с недостаточными накоплениями должны в первую очередь увеличивать
сумму на счету, независимо от их дохода.
2. Лица с достаточными накоплениями и стабильным доходом должны
рассматривать более рискованные, но потенциально более выгодные инвестиции.
3. Лица с недостаточно высоким доходом, но уже имеющие значительные
накопления, могут захотеть рассмотреть возможность распределения их дохода между
накоплениями и акциями, чтобы, с одной стороны, оградить себя от потерь при
попытке увеличить доход за счет акций, а с другой, рискнуть и значительно
увеличить прибыль.
Соответствие между накоплением и доходом определяется числом иждивенцев,
которых данное лицо должно содержать. На каждого иждивенца необходимо иметь в банке
по крайней мере $5000. Достаточным считается стабильный доход, составляющий по
крайней мере $15000 в год плюс $4000 на каждого иждивенца.
Чтобы автоматизировать эти рекомендации, запишем их на языке исчисления
предикатов. Вначале необходимо выделить главное требование, которые следует принять во
внимание. Поэтому первое требование — это достаточность сбережений и дохода. Их
можно представить с помощью предикатов savings_account (сберегательный счет) и
income (доход) соответственно. Это унарные предикаты, параметром которых может
быть значение adequate (достаточен) или inadequate (недостаточен). Таким образом,
возможны следующие комбинации.
savings _account(adequate).
savings _account(inadequate).
income(adequate).
income(inadequate).
Заключения представим унарным предикатом investment (инвестиции), параметр
которого может принимать значения: stocks (акции), savings (сбережения) или
combination (сочетание — т.е. разбиение инвестиций).
Используя эти предикаты и импликацию, можно представить различные
инвестиционные стратегии. Приоритетное правило, которому должны следовать лица с
недостаточными средствами, — это увеличение сбережений на счету. Его можно записать так.
savingsaccount(inadequate) -> investment(savings).
Аналогично сохранение двух инвестиционных альтернатив можно представить
следующим образом.
100
Часть II. Искусственный интеллект как представление и поиск
savings_account(adequate) л income(adequate) -> investment(stocks).
savings_account(adequate) л income(inadequate)
-> investment(combination).
Затем, советник должен определить, достаточны ли сбережения и доходы. Это также
можно записать с помощью импликации. Потребность в арифметических вычислениях
приводит к использованию функций. Для определения минимума достаточных
сбережений создадим функцию minsavings. Функция minsavings зависит от одного
параметра, соответствующего числу иждивенцев, и возвращает результат умножения этого
параметра на 5000.
Используя функцию minsavings, достаточность сбережений можно определить
правилами
VXamount_saved(X) л 3Y(dependents(Y) л greater(X, minsavings(Y)))
-> savings_account(adequate).
VXamount_saved(X) л 3Y(dependents(Y) л ^greater(X,minsavings(Y)))
-> savings_account(inadequate),
где
minsavings(X) =5000 * X.
При этих определениях amount_saved(X) и dependents(Y) означают текущую
сумму сбережений и число иждивенцев (dependents) инвестора. Здесь greater(X,Y) —
стандартная арифметическая проверка, определяющая, что больше: X или Y. В этом
примере данная функция формально не определена.
Аналогично функцию minincome можно определить так.
minincome(X) =15000 +D000 * X).
Функция minincome используется для вычисления минимального приемлемого
дохода в зависимости от числа иждивенцев. Текущий доход инвестора представлен
предикатом earnings (доходы). Поскольку достаточный доход должен быть стабилен
и превышать минимально допустимое значение, earnings имеет два параметра.
Первый параметр — заработанная сумма, а второй может принимать значение steady
(стабильный) или unsteady (нестабильный). Приведем правила работы советника,
описывающего эту ситуацию.
VXearnings(X, steady) л 3Y(dependents(Y) л greater(X, minincome(Y)))
-> income(adequate).
VXearnings(X, steady) л 3Y(dependents(Y) л -. greater(X, inincome(Y)))
-> income(inadequate).
VXearnings(X, unsteady) -> income(inadequate).
Чтобы давать консультации, необходимо добавить к этому набору предложений
исчисления предикатов описание конкретного инвестора. Это— предикаты amountsaved (сумма
на счету), earnings (доходы) и dependents (иждивенцы). Например, человека с тремя
иждивенцами, имеющего $22000 в сбережениях, и с устойчивым доходом в $25000
можно описать так.
amount_saved B2000).
earn/ngsB5000, steady)
dependentsC).
Глава 2. Исчисление предикатов
101
Таким образом, мы построили логическую систему, состоящую из следующих
предложений.
1. savings_account(inadequate) -> investment(savlngs).
2. savings_account(adequate) л income(adequate) -> investment(stocks).
3. savings_account(adequate) л income(inadequate)
-> investment(combination).
4. V amount_saved(X) л 3 Y (dependents(Y) л greater(X, minsavings(Y)))
-> savings_account(adequate).
5. V Xamount_saved(X) л 3 Y (dependents(Y) л -. greater(X, minsavings(Y)))
-> savings_account(inadequate).
6. V X earnings(X, steady) лЗ Y (dependents (Y) л greater(X, minincome(Y)))
-> income(adequate).
7. V Xearnings(X, steady) л 3 Y (dependents(Y) л-. greater(Xf minincome(Y)))
-> income(inadequate).
8. \/Xearnings(X, unsteady) -> income(inadequate).
9. a/77ounf_savedB2000).
10. earn/ngsB5000, steady).
11. dependents^).
Здесь
minsavings(X) = 5000 * X
и
minincome(X) = 15000 + D000 * X).
Этот набор логических предложений описывает предметную область задачи.
Утверждения пронумерованы, поэтому на них можно ссылаться, описывая ход рассуждений.
Используя унификацию и правило л*одус поненс, можно вывести правильную
инвестиционную стратегию для этого лица как логическое следствие данных выше описаний.
На первом шаге нужно унифицировать конъюнкцию высказываний 10 и 11 с первыми
двумя компонентами предпосылки из 7. Иными словами,
earn/ngsB5000,steady) л dependentsC)
нужно объединить с
earnings(X,steady) л dependents(Y)
с учетом подстановки {2500 0/Х, 3/У}. Эта подстановка порождает новую импликацию.
earningsB5000, steady) л dependents^) л -.
greaferB5000, minincomeC)) -> income(inadequate).
Оценивая функцию minincome, приходим к выражению
earn/ngsB5000, steady) л dependentsC) л -, greaferB5000, 27000) ->
income(inadequate).
Поскольку в этом частном случае все три компонента предпосылки истинны согласно
предложениям 10, 11 и математическому определению функции greater (больше), их
конъюнкция тоже истинна. Из этого следует, что истинна и вся предпосылка. Поэтому
102 Часть II. Искусственный интеллект как представление и поиск
можно применить правило модус поненс и получить заключение income(inadequate),
означающее, что доход недостаточен. Добавим этот вывод к набору предложений,
присвоив ему номер 12.
12. income(inadequate).
Аналогично, унифицируя
amount_savedB2000) л dependents^)
с первыми двумя элементами предпосылки утверждения 4 с учетом подстановки
{22000/Х, 3/У], получим импликацию
amount_savedB2000) л dependents^) л greaterB2000, minsavingsC))
-> savings_account(adequate).
Оценивая функциюminsavingsC), приходим к выражению
amount_savedB2000) л dependentsC) л дгeater'B2000, 15000)
—> savings_account(adequate).
Опять же, поскольку все компоненты предпосылки этой импликации истинны, то вся
предпосылка истинна, поэтому можно снова применить модус поненс и получить
заключение savings_account(adequate). Представим его как предложение 13.
13. savings_account(adequate).
Анализируя выражения 3, 12 и 13, делаем вывод, что предпосылка в выражении 3
также истинна. Применив модус поненс в третий раз, получаем результат
investment(combination). Это предложение и есть рекомендация по инвестициям для
данного лица.
На этом примере мы показали использование исчисления предикатов для описания
реальной проблемы. Кроме того, мы сделали логические выводы на основе применения
правил вывода к исходному описанию задачи. Мы все же не обсуждали, как обеспечить
корректность вывода и реализовать этот алгоритм на компьютере. Эти вопросы будут
рассмотрены в главах 3, 4 и 5.
2.5. Резюме и дополнительная литература
В этой главе было рассмотрено исчисление предикатов как язык представления для
решения задач искусственного интеллекта. Были описаны и определены символы, термы,
выражения и семантика языка. Основываясь на семантике исчисления предикатов, мы
определили правила вывода, позволяющие получать предложения, логически следующие
из данного набора выражений. Мы описали алгоритм унификации, определяющий
подстановки переменных, которые приводят в соответствие два выражения, что весьма
важно для применения правил вывода. И в заключение главы мы привели пример системы,
выполняющей роль финансового советника. В ней знания о предметной области
представлены на языке исчисления предикатов, а в качестве методики решения задач
используется логический вывод.
Исчисление предикатов подробно обсуждается в ряде книг по теории вычислительных
машин и систем, в том числе в [Manna и Waldinger, 1985], [Gallier, 1986], [Chang и Lee, 1973],
[Andews, 1986]. Современные методы доказательства будут представлены в главе 12.
Глава 2. Исчисление предикатов
103
Применение исчисления предикатов как языка представления для задач
искусственного интеллекта описано в [Genesereth и Nilsson, 1987], [Nilsson, 1998], [Wos, 1995],
[Bundy, 1983, 1988] и [Brachman и Levesque, 1985]. Интересные современные
приложения автоматизированного вывода описаны в [Veroff, 1997].
2.6. Упражнения
1. Используя таблицы истинности, докажите тождества из подраздела 2.1.2.
2. Новый оператор © (читается "исключающее ИЛИ") можно определить следующей
таблицей истинности.
Р О P®Q
т т F
т F т
F Т Т
F F F
Создайте выражение исчисления высказываний, эквивалентное Р © О, используя
только операции л, v и —i.
Докажите их эквивалентность с помощью таблиц истинности.
3. Логический оператор <-> означает "тогда и только тогда". Выражение Р <-> О
эквивалентно (Р —> О)л (О —> Р). Базируясь на этом определении, докажите, что Р <-> О
логически эквивалентно (Pv О) —> (Ра О).
3.1. Используйте при этом таблицы истинности.
3.2. Воспользуйтесь последовательностью подстановок с учетом тождеств,
приведенных в подразделе 2.1.2.
4. Докажите, что в исчислении высказываний импликация транзитивна, т.е. что ((Р —>
Q) л (Q^> Я)) -> (Р-> R).
5. а. Докажите, что правило модус поненс для исчисления высказываний обоснованно.
Подсказка: используйте таблицы истинности и рассмотрите все возможные
интерпретации.
б. Абдукция (abduction) — это правило, которое позволяет вывести Р из Р —> О и О.
Покажите, что абдукция необоснована (см. главу 7).
в. Покажите, что правило модус толленс (modus tollens) ((P -> О) л-. О) -> -. Р
логично.
6. Попытайтесь унифицировать следующие пары выражений. Найдите их наиболее
общие унификаторы или же объясните, почему они не могут быть унифицированы:
а)р(Х,У) np(a,Z);
б)р(Х, X) ир(а,Ь);
в) ancestor(X,Y) и ancestor(bill,father(bill));
г) ancestor(X,father(X)) и ancestor(david,george);
д)д(Х) и-.д(а).
7. а. Скомпонуйте множества подстановок {а/Х, Y/Z} и {X/W, b/Y}.
104 Часть II. Искусственный интеллект как представление и поиск
б. Докажите, что композиция множеств подстановок ассоциативна.
в. Постройте пример, демонстрирующий, что композиция не коммутативна.
8. Реализуйте алгоритм unify (подраздел 2.3.2) на выбранном вами языке
программирования.
9. Приведите две альтернативные интерпретации для описания мира блоков (рис. 2.3).
10. Джейн Доу содержит четырех иждивенцев, имеет стабильный доход $30000 и $15000
на сберегательном счету. Составьте соответствующие предикаты, описывающие эту
ситуацию для системы финансового советника, рассмотренной в разделе 2.4,
выполните унификацию и получите выводы, необходимые для выдачи рекомендаций по
инвестициям.
11. Запишите набор логических предикатов, выполняющих простую диагностику
неисправностей автомобиля (если двигатель не заводится и фары не горят, значит,
неисправен аккумулятор). Не старайтесь слишком усложнять ситуацию, но рассмотрите
варианты поломки аккумулятора, отсутствия бензина, неисправности свечей
зажигания и стартера.
12. Следующий пример взят из книги [Wirth, 1976].
Я женился на вдове (давайте назовем ее И/), которая имеет взрослую дочь (назовем
ее D). Мой отец (F), который весьма часто навещал нас, влюбился в мою падчерицу и
женился на ней. Поэтому мой отец стал моим зятем, а моя падчерица стала моей
мачехой. Спустя несколько месяцев моя жена родила сына (Si), который стал шурином
(зятем) моему отцу, а потому моим дядей. Жена моего отца, т.е. моя падчерица, тоже
родила сына (S2).
Используя исчисление предикатов, создайте набор выражений, описывающих
данную ситуацию. Добавьте выражения, определяющие основные отношения в семье, в
том числе определение тестя (или свекра), и, используя правило модус поненс,
докажите заключение "Я сам себе дедушка".
Глава 2. Исчисление предикатов
105
Структуры
и стратегии поиска
в пространстве
состояний
Для того чтобы выжить, организм должен либо защитить себя броней (подобно
дереву или моллюску) и "надеяться на лучшее", либо развивать способность избегать
опасных путей и стремиться к безопасному соседству. Если он предпочел второе, ему
придется постоянно задавать себе основополагающий вопрос: "Что я сейчас делаю?1'.
— Даниэл С. Деннет (Daniel С. Dennett), Объяснение подсознания
Две дороги расходятся в желтом лесу,
Жаль, не могу я пройти по каждой из них.
Был одиноким я странником в этом лесу,
Долго стоял и смотрел на одну из них,
На ту, уходящую в даль, туда, где она исчезает вдали;
Затем я пошел по дороге другой...
— Роберт Фрост (Robert Frost), Невыбранная дорога
3.0. Введение
В главе 2 описано исчисление предикатов — пример языка представления в
искусственном интеллекте. Правильно составленные выражения исчисления предикатов позволяют
описывать объекты и отношения в области определения, а правила вывода (например, правило
отделения modus ponens) — логически получать новые знания из имеющихся описаний. Эти
правила вывода определяют пространство, в котором ведется поиск решения задачи. Глава 3
является введением в теорию поиска в пространстве состояний.
Чтобы разрабатывать и внедрять алгоритмы поиска, разработчик должен уметь
анализировать и прогнозировать их поведение. При этом перед ним стоят такие вопросы.
Гарантировано ли нахождение решения в процессе поиска?
Является поиск конечным, или в нем возможны зацикливания?
Если решение найдено, является ли оно оптимальным?
Как процесс поиска зависит от времени выполнения и используемой памяти?
Как интерпретатор может наиболее эффективно упростить поиск?
Как разработать интерпретатор для наиболее эффективного использования языка
представления?
Теория поиска в пространстве состояний (state space search) дает ответы на эти
вопросы. Представив задачу в виде графа пространства состояний, можно использовать
теорию графов для анализа структуры и сложности как самой задачи, так и процедуры
поиска ее решения.
Граф состоит из множества вершин и дуг, соединяющих пары вершин. В модели
пространства состояний решаемой задачи вершины графа представляют дискретные
состояния процесса решения, например, результаты логического вывода или различные
конфигурации игровой доски. Дуги графа описывают переходы между состояниями. Эти
переходы соответствуют логическим заключениям или допустимым ходам в игре. Так, в
экспертных системах состояния описывают знания о задаче на определенном этапе
исследования. Экспертные заключения в форме правил "если ..., то" позволяют получить
новую информацию. При этом каждый случай применения правила представляется как
дуга между состояниями.
Теория графов является наилучшим инструментом исследования структуры объектов и
их отношений. Именно это и привело к созданию теории графов в начале восемнадцатого
века. Швейцарский математик Леонард Эйлер изобрел теорию графов, чтобы решить
"задачу о кенигсбергских мостах". Город Кенигсберг расположен на двух берегах реки и
двух островах. Острова и берега реки соединены семью мостами, как показано на рис. 3.1.
Берег реки 1
Берег реки 2
Рис. 3.1. Город Кенигсберг
Задача о кенигсбергских мостах формулируется следующим образом. Существует ли
маршрут обхода города, при котором каждый мост пересекается ровно один раз? Хотя
местные жители после безуспешных попыток найти такой маршрут усомнились в его
существовании, никто не мог доказать его отсутствие. Создав модель графа, Эйлер
реализовал альтернативное представление карты города (рис. 3.2). Берега реки (гЬ"\ и гЬ2) и
острова (/1 и /2) описываются вершинами графа; мосты представлены помеченными
дугами между вершинами (Ы , Ь2, ..., Ь7). Представление в виде графа сохраняет
существенную информацию (структуру системы мостов), а несущественные данные (расстояние
и направление) игнорируются.
108
Часть II. Искусственный интеллект как представление и поиск
rb\
rb2
Рис. 3 2 Граф системы мостов города Кенигсберга
Кроме того, систему кенигсбергских мостов можно представить в терминах
исчисления предикатов. Предикат connect (соединить) соответствует дуге графа и утверждает,
что берега реки или острова связаны некоторым мостом. Для каждого моста необходимо
задать два предиката connect — по одному для каждого направления движения по мосту.
connect(i*\,/2,Ы )
connect(rb^ ,/1,Ь2)
connect(rb1 ,/1 ,ЬЗ)
connect(rb\ ,/2,Ь4)
connect(rb2,i\ ,Ь5)
connect(rb2,i\ ,Ь6)
connect(rb2,i2,b7)
соппесГ(/2,/1,Ы )
соллесГ(/1,гМ,Ь2)
connect(i\ ,гЫ,ЬЗ)
connect(i2,rb\ ,Ь4)
connect(i\ ,гЬ2,Ь5)
connect(i*\ ,гЬ2,Ь6)
connect(i2,rb2,b7)
Выражение connect(X,Y,Z) = connect(Y,X,Z), указывающее на то, что каждый мост
может быть пройден в любом направлении, позволяет исключить половину предикатов.
Представление с помощью предикатов эквивалентно представлению в виде графа в
смысле сохранения связности. Однако никакой алгоритм не может преобразовать одно
представление знаний в другое без потери информации. Структура задачи более
естественно отражается в представлении на основе графа. Доказательство Эйлера
иллюстрирует эти различия.
Чтобы доказать невозможность существования нужного маршрута, Эйлер вводит
понятие степени вершины графа, замечая, что каждая вершина может иметь четную либо
нечетную степень. Вершина четной степени имеет четное число дуг, соединяющих ее с
соседними вершинами. Вершина нечетной степени имеет нечетное число таких дуг.
Вершины нечетной степени могут использоваться только как начало либо как конец
маршрута. Все остальные вершины должны иметь четную степень, поскольку искомый
маршрут должен входить в каждую такую вершину и выходить из нее. Иначе такие
вершины будут пройдены определенное число раз, а затем окажутся тупиковыми.
Путешественник не сможет покинуть вершину, не используя еще раз уже пройденную дугу.
Эйлер заметил, что если число вершин нечетной степени не равно нулю либо двум,
то маршрут невозможен. Если существуют ровно две вершины нечетной степени, то
можно начать путь в одной из них и закончить в другой. Если же вершин нечетной
степени не существует, то маршрут может начаться и закончиться в одной и той же
Глава 3. Структуры и стратегии поиска в пространстве состояний
109
вершине. Итак, маршрут невозможен, если число вершин нечетной степени графа
отлично от 0 или 2, как в задаче о кенигсбергских мостах. Эта задача называется задачей
поиска пути Эйлера на графе.
Хотя предикатное представление описывает отношения между мостами,
берегами и островами, оно не учитывает понятие степени вершины. Представление в виде
графа обеспечивает однозначную связь каждой вершины с дугами, в отличие от
аргументов предикатов. Именно поэтому представление с помощью графа приводит к
понятию степени вершины и играет ключевую роль в доказательстве Эйлера. В этом
заключается преимущество теории графов с точки зрения анализа структуры
объектов, свойств и отношений.
В этой главе сначала приводится краткий обзор основ теории графов, а затем —
описание пространства состояний задачи и поиска на графах. Поиск в глубину и поиск
в ширину — это две стратегии поиска в пространстве состояний. Мы сравним их,
отмечая различия между поиском от цели и поиском на основе данных. В разделе 3.3
описание в пространстве состояний используется для вывода логических заключений.
На протяжении всей главы теория графов будет использована для анализа структуры и
сложности различных задач.
3.1. Теория графов
3.1.1. Структуры данных для поиска в пространстве состояний
Граф — это множество вершин и дуг между ними. В размеченном графе для каждой
вершины задается один или несколько дескрипторов (меток), которые позволяют
отличить одну вершину графа от другой. На графе пространства состояний эти дескрипторы
идентифицируют состояния в процессе решения задачи. Если дескрипторы двух вершин
не различаются, то эти вершины считаются одинаковыми. Дуга между двумя вершинами
определяется метками этих вершин.
Дуги графа также могут быть размеченными. Метка дуги используется для задания
именованного отношения (как в семантических сетях) либо веса дуги (как в задаче о
коммивояжере). Дуги между двумя вершинами тоже можно различать с помощью
меток (см. рис. 3.2).
Граф называется ориентированным, если каждой дуге приписано определенное
направление. Дуги в ориентированном графе обычно содержат стрелки, определяющие
ориентацию дуги. Дуги, которые можно проходить в любом из двух направлений, могут
содержать две стрелки-указателя, но чаще вовсе не имеют стрелок. На рис. 3.3
изображен размеченный ориентированный граф. По дуге (a,b) можно двигаться лишь от
вершины а к вершине Ь, по дуге (Ь,с) можно двигаться в любом из двух направлений.
Путь (path) на графе — это последовательность дуг, соединяющих соседние
вершины. Путь представляется списком дуг, систематизированным в порядке их следования.
На рис. 3.3 список [a,b,c,d] представляет путь, проходящий через вершины a,btc,d в
указанном порядке.
Корневой граф содержит единственную вершину, от которой существует путь к
любой вершине графа. Эта вершина называется корнем (root). При изображении корневого
графа корень обычно помещают в верхней части рисунка над всеми остальными
вершинами. Граф пространства состояний любой игры обычно является корневым графом,
110
Часть II. Искусственный интеллект как представление и поиск
причем в качестве корня выступает начальное состояние игры. Начальные ходы в
"крестики-нолики" представлены в корневом графе на рис. П.5. Это ориентированный
граф, в котором все дуги являются однонаправленными. Заметим, что этот граф не имеет
циклов; игроки не могут (как бы они этого не хотели) аннулировать ходы.
Дерево (tree) — это граф, на котором для любых двух вершин существует не более
одного пути между ними. Деревья обычно имеют корни, которые изображаются в
верхней части рисунка, как и для корневых графов. Поскольку для каждой вершины дерева
существует не более одного пути в эту вершину из любой другой вершины, то не
существует путей, содержащих петли или циклы.
Для корневых деревьев или графов отношения между вершинами описываются
понятиями родителя, потомка и вершин-братьев {siblings) — вершин дерева, имеющих
общую вершину-родителя. Они используются в обычном смысле наследования: при
проходе вдоль направленной дуги родитель предшествует потомку. Концы всех направленных
дуг, исходящих из одной вершины, называются вершинами-братьями. Аналогично на
пути ориентированного графа предок предшествует потомку. На рис. 3.4 вершина Ь
является родителем вершин е и f (которые являются потомками b и вершинами-
братьями). Вершины а и с являются предками вершин д, /7, /, а вершины д, /7, / являются
потомками а не.
с
Ь ~"
Узлы = {a,b,c,d,e}
flym = {(a,b),(a,d),(b,c),(c,b),(c,d),(of,a),(of,e),(e,c),(e,d)}
Рис. 3.3. Размеченный ориентированный граф
А Л\\
е f g h i
Рис. 3.4. Корневое дерево как пример семейных отношений
Прежде чем ввести определение пространства состояний задачи, приведем
формальные определения рассмотренных выше понятий.
ОПРЕДЕЛЕНИЕ
ГРАФ
Граф состоит из множества вершин NbN2, ..., А/„, которое не обязано быть конечным,
и множества дуг, соединяющих некоторые пары вершин.
Глава 3. Структуры и стратегии поиска в пространстве состояний
111
Дуги являются упорядоченными парами вершин; т.е. дуга (Л/з, Л/4) соединяет вершину
Л/з с вершиной Л/4, но не вершину Л/4 с Л/з, если (Л/4, Л/3) не является дугой. В
противном случае дуга, соединяющая Л/3 с Л/4, является ненаправленной.
Если направленная дуга соединяет вершины Л/; и Nk, то Л/; называется родителем Nk, а
Л/* — потомком Nj. Если граф содержит также дугу (Л/;, Л/,), то Nk и Л/, называются
вершинами-братьями.
Корневой граф имеет единственную вершину Л/5, в которую не входит ни одна дуга.
Таким образом, корень графа не имеет родителей.
Концевая вершина — это вершина, которая не имеет потомков.
Упорядоченная последовательность вершин [Л/ь Л/2, Л/з, ..., Л/„], где каждая пара
(Л/, f Л/,+1) является дугой, называется путем длины п-1 на графе.
В корневом графе вершина называется предком всех вершин, расположенных после
нее (правее нее), и в то же время потомком всех вершин, расположенных на пути к
ней (левее нее).
Если путь включает некоторую вершину более одного раза (т.е. в приведенном выше
определении пути некоторая вершина Л/; повторяется), то говорят, что путь содержит
петлю, или цикл.
Дерево — это граф, в котором существует единственный путь между любыми двумя
вершинами. (Следовательно, пути в дереве не содержат циклов.)
Ребра в корневом дереве ориентированы от корня. Каждая вершина в корневом
дереве имеет единственного родителя.
Две вершины называются связными, если существует путь, содержащий эти вершины.
3.1.2. Представление задачи в пространстве состояний
В пространстве состояний задачи вершины графа соответствуют состояниям
решения частных задач, а дуги — этапам решения задачи. Одно или несколько начальных
состояний, соответствующих исходной информации поставленной задачи, образуют
корень дерева. Граф также включает одно или несколько целевых условий, которые
соответствуют решениям исходной задачи. Поиск в пространстве состояний характеризует
решение задачи как процесс нахождения пути решения (цепочки, ведущей к решению
задачи) от исходного состояния к целевому.
Определим представление задачи в пространстве состояний более формально.
ОПРЕДЕЛЕНИЕ
ПОИСК В ПРОСТРАНСТВЕ СОСТОЯНИЙ
Пространство состояний представляется четверкой [N,A,S,GD] со следующими
обозначениями.
N — множество вершин графа или состояний в процессе решения задачи.
А — множество дуг между вершинами, соответствующих шагам в процессе решения
задачи.
S — это непустое множество начальных состояний задачи.
GD — непустое подмножество Л/, состоящее из целевых состояний. Эти состояния
описываются одним из следующих способов.
112
Часть II. Искусственный интеллект как представление и поиск
1. Измеряемыми свойствами состояний, встречающихся в процессе поиска.
2. Свойствами путей, возникающих в процессе поиска, например, стоимостью
перемещения по дугам пути.
Допустимый путь — это путь из вершины множества S в вершину из множества GD.
Цель может описывать состояние, например выигрышную конфигурацию в игре
"крестики-нолики" (рис. П.5) или "пятнашки" (рис. 3.5). С другой стороны, цель может
описывать некоторые свойства допустимых путей. В задаче о коммивояжере (рис. 3.7 и
3.8) поиск заканчивается при нахождении кратчайшего пути через все вершины графа. В
задаче грамматического анализа (раздел 3.3) поиск завершается нахождением пути
успешного анализа предложения.
Дуги в пространстве состояний соответствуют шагам процесса решения, а пути
представляют решения на различной стадии завершения. Путь является целью поиска. Он
начинается из исходного состояния и продолжается до тех пор, пока не будет достигнуто
условие цели. Порождение новых состояний вдоль пути обеспечивается такими
операторами, как "допустимые ходы" в игре или правила вывода в логической задаче или
экспертной системе.
Задача алгоритма поиска состоит в нахождении допустимого пути в пространстве
состояний. Алгоритмы поиска должны направлять пути от начальной вершины к целевой,
поскольку именно они содержат цепочку операций, ведущую к решению задачи.
Одна из общих особенностей графа и одна из проблем, возникающих при создании
алгоритма поиска на графе, состоит в том, что состояния иногда могут быть достигнуты
разными путями. Например, на рис. 3.3 путь от вершины а к вершине d может проходить
через вершины Ь и с либо непосредственно от а к d. Поэтому важно выбрать
оптимальный путь решения данной задачи. Кроме того, множественные пути к состоянию могут
привести к петлям или циклам. Тогда алгоритм никогда не достигнет цели. Если в
качестве целевой вершины на рис. 3.3 выбрать вершину е, а в качестве начальной —
вершину а, то образуется циклический путь abcdabcdabcd...
Если пространство поиска описывается деревом, как на рис. 3.4, проблема
зацикливания не возникает. Именно поэтому важно отличать задачи поиска на деревьях от задач
поиска на графах с петлями. Алгоритмы поиска на произвольных графах должны
обнаруживать и устранять петли в допустимых путях. При этом алгоритмы поиска на
деревьях выигрывают в эффективности за счет отсутствия этих тестов и затрат на них.
Игры в "крестики-нолики" и "пятнашки" можно использовать для иллюстрации поиска
в пространстве состояний. Оба эти примера объясняют смысл условия 1 в предыдущем
определении. В задаче о коммивояжере (пример 3.1.3) цель описывается условием вида 2.
ПРИМЕР 3.1.1. "Крестики-нолики"
Пространство состояний игры "крестики-нолики" изображено на рис. II.5. Исходным
состоянием является пустая игровая доска, а конечным или целевым состоянием —
доска, на которой в одной строке, столбце или по диагонали располагается три крестика
X (предполагается, что целью является победа игрока X). Путь из исходного состояния в
конечное содержит последовательность ходов, ведущих к победе игрока X.
Состояниями в пространстве являются все возможные конфигурации из крестиков и
ноликов, которые могут возникнуть в процессе игры. Конечно, большинство из
возможных З9 вариантов расположения символов {пусто, X, О} в девяти клетках никогда не
возникает в реальной игре. Дуги определяются допустимыми ходами игры, которые со-
Глава 3. Структуры и стратегии поиска в пространстве состояний
113
стоят в поочередном записывании X или О в пустую клетку. Граф пространства
состояний не является деревом, поскольку некоторые состояния третьего и более глубоких
уровней могут быть достигнуты различными путями. Однако в пространстве состояний
нет циклов, так как ориентированные дуги графа не позволяют возвращаться в уже
пройденное состояние. Если состояние достигнуто, вернуться вверх по графу
невозможно. Следовательно, нет необходимости проверки на цикл. Граф с этим свойством
называется ациклическим ориентированным графом {directed acyclic graph), сокращенно
DAG, и часто встречается при поиске в пространстве состояний.
1
12
z
10
2
13
■
9
3
14
«
8
4
5
6
7
1
•
7
2
■
6
3
*
5
15-головоломка 8-головоломка
Рис. 3.5. 15-головоломка и 8-головоломка
Вид пространства состояний дает возможность определить сложность задачи. В игре
"крестики-нолики" возможны девять первых ходов и восемь ответов противника на каждый
из них, затем следуют семь возможных вариантов поставить крестик и т.д. Следовательно,
имеется 9х8х7х...xl=9! всевозможных путей. Такое количество путей C62880) компьютер
способен обработать непосредственно полным перебором. Однако существует немало
важных задач, имеющих очень высокую факториальную или экспоненциальную сложность,
которая на много порядков выше, чем в этом случае. Например, в шахматах имеется 10120
возможных игровых путей; в шашках — 1040, причем некоторые из них никогда не возникают в
реальных играх. Такие пространства чрезвычайно сложны, и их невозможно исследовать
простым перебором вариантов. Стратегии поиска в пространствах больших размеров используют
эвристики, позволяющие уменьшить сложность поиска (глава 4).
ПРИМЕР 3.1.2. 8-головоломка
В игре в "пятнашки" с пятнадцатью фишками, или 15-головоломке, на рис. 3.5
пятнадцать пронумерованных фишек размещены на поле из 16 клеток. Одна клетка остается
пустой, так что фишки можно двигать и получать их различные конфигурации. Цель
игры— найти такую последовательность перемещений фишек в пустую клетку, которая
привела бы к заранее заданной целевой конфигурации. Это популярная игра, которой
большинство из нас забавлялось в детстве. (Я помню трехдюймовый квадрат с красными
и белыми фишками, окаймленными черным цветом).
Некоторые аспекты этой игры оказались весьма интересными для исследований в
области искусственного интеллекта. С одной стороны, пространство состояний этой игры
является достаточно большим, чтобы представлять интерес, а с другой— вполне
доступным для анализа (число возможных состояний составляет 16!, если различать
симметричные состояния). Состояния игры легко представимы. Игра достаточно богата для
апробации интересных эвристик (см. главу 4).
8-головоломка — это версия 15-головоломки размерности 3x3. В этой головоломке 8
фишек можно передвигать в пространстве из 9 клеток. Поскольку пространство состоя-
114
Часть II. Искусственный интеллект как представление и поиск
ний этой игры меньше, чем в 15-головоломке, именно ее мы будем использовать в
последующих примерах.
В реальной жизни ходы в головоломке заключаются в перемещении фишек
("передвинуть фишку 7 вправо при условии, что пустая клетка расположена справа от
нее" или "переместить фишку 3 вниз"), однако значительно удобнее говорить о
"перемещении пустой клетки". Это упрощает определение хода, так как в игре участвуют
8 фишек и только одна пустая клетка. Допустимыми являются следующие ходы.
Переместить пустую клетку вверх Т
Переместить пустую клетку вправо —>
Переместить пустую клетку вниз I
Переместить пустую клетку влево <-
Чтобы сделать очередной ход, необходимо удостовериться, что пустая клетка не
выйдет за пределы игрового поля. Поэтому в определенных ситуациях некоторые из четырех
ходов могут оказаться недопустимыми. Например, если пустая клетка находится в одном
из углов, то допустимы лишь два хода. Если определены начальное и конечное
состояние в 8-головоломке, то процесс решения задачи можно описать явно (рис. 3.6).
Состояния описываются массивом размерности 3x3. Предикатное представление требует
использования предиката состояния с девятью параметрами (для локализации фишек на
доске). Дуги в пространстве состояний определяют четыре процедуры, описывающие
возможные перемещения пустой клетки.
1
I
5
4
■
8
3
I
2
Вправо
1
7
5
4
8
3
6
2
Влево Вправо
■
7
5
1
4
8
]
'
3 I
6
2 |
| 1
7
I 5
з
4
8
'
Г
■ ■
6 I
2 |
1
I 5
<
7
8
}
'
3 I
6
2 |
I 1
5
■
4
7
8
'
f
3 I
6
2 |
I 1
7
■
4
8
5
1
r
3 ]
6
2 1
[ 1
7
I 5
4
8
2
'
f
3 I
6
■
I 1
7
I 5
4
6
8
1
r
■
3
2 |
1 1
7
I 5
4
6
8
]
f
3
2
■
Рис. 3 6. Пространство состояний 8-головоломки, порожденное "перемещением пустой клетки"
Как и при игре в "крестики-нолики", пространство состояний этой игры является
графом, большинство вершин которого имеет много предков. Но, в отличие от
крестиков-ноликов, в этом графе возможны циклы. Множество целевых состояний, или
Глава 3. Структуры и стратегии поиска в пространстве состояний
115
GD, — это особое множество конфигураций. Если одно из них встречается на пути,
поиск прекращается. Путь из начальной вершины в целевую — искомая
последовательность ходов.
Следует отметить, что полное пространство состояний 8-головоломки или 15-
головоломки состоит из двух несвязных подграфов (одинакового размера). Отсюда
следует, что ровно половина состояний являются недостижимыми из любой заданной
начальной вершины. Если поменять местами (вопреки правилам!) две соседние фишки, все
состояния из другой части пространства состояний окажутся достижимыми.
ПРИМЕР 3.1.3. Задача коммивояжера
Предположим, коммивояжер должен посетить пять городов и возвратиться
домой. Задача состоит в том, чтобы найти кратчайший путь. На рис. 3.7 дан пример
этой задачи. Вершины графа представляют города, а метка на каждой дуге
указывает стоимость путешествия по ней. Эта стоимость может означать длину отрезка пути
в милях, если коммивояжер пользуется автомобилем, или цену авиабилета при
использовании самолета. Для удобства предположим, что коммивояжер проживает в
городе А и должен вернуться в город А. Это предположение попросту сводит задачу с
л-городами к проблеме с л-1 городом.
Рис. 3.7. Пример пути в задаче коммивояжера
Рассмотрим один из возможных путей [A,D,C,B,E,A] длиной (стоимостью
путешествия) в 450 миль. Целью является нахождение пути кратчайшей длины, т.е. построение
цепочки с минимальной стоимостью. Заметим, что цель — это глобальное свойство
графа, а не свойство отдельного состояния. Это пример целевого состояния вида 2 из
определения поиска в пространстве состояний.
На рис. 3.8 указан способ представления возможных путей решения задачи и
приведены результаты их сравнения. Начиная от вершины А, к пути добавляются
возможные следующие состояния до тех пор, пока не исчерпается список городов и
путь возвратится в исходную точку. Целью является нахождение пути кратчайшей
длины (минимальной стоимости).
Как показано на рис. 3.8, исчерпывающий поиск в задаче коммивояжера состоит в
переборе (Л/-1)! вариантов, где N — число вершин графа (или число городов). Для 9
городов можно непосредственно проверить все вершины. Но в реальных ситуациях, на-
116
Часть II. Искусственный интеллект как представление и поиск
пример для 50 городов, непосредственный перебор невозможен. На самом деле
сложность вычислений /V! растет столь быстро, что очень скоро прямой перебор всех
вариантов станет неосуществимым.
250у
300
£<
375
A i
325
► D
425
> А
Путь:
ABCDEA
Путь:
ABCEDA
Стоимость: Стоимость*
375 425
Путь:
ABDCEA '
Стоимость:
475
Рис. 3.8. Поиск в задаче коммивояжера Метка каждой дуги соответствует
суммарному весу всего пути от начальной вершины А до конечной точки дуги
Разработано множество методов, сокращающих сложность поиска. Один из них —
это метод ветвей и границ [Horowitz и Sahni, 1978]. В этом методе на каждом шаге
порождается один из возможных вариантов пути, при этом учитывается наилучший из
ранее построенных путей. Этот путь используется в качестве границы для будущих
кандидатов. Поскольку на каждом шаге к пути добавляется один город, алгоритм анализирует
все возможные продолжения. Если обнаруживается, что все возможные продолжения
некоторого пути (ветвь) дороже, чем заданная граница, алгоритм уничтожает эту ветвь и
все возможные ее продолжения. В результате сложность поиска существенно
сокращается, но все же остается экспоненциальной A,26^вместо N\).
Еще одна стратегия состоит в конструировании пути по правилу "идти в
ближайший не посещенный город". Путь к "ближайшему соседу" на рис. 3.7 — это
[А, Е, D, В, С, А], его стоимость 375 миль. Этот метод высоко эффективен, так как
на каждом шаге выбирается лишь один вариант! К сожалению, эвристика поиска
ближайшего соседа не всегда приводит к получению пути кратчайшей длины, как
показано на рис. 3.9. Однако она является возможным компромиссом в случае, если
полный перебор неосуществим практически.
В разделе 3.2 исследуются стратегии поиска в пространстве состояний.
Глава 3. Структуры и стратегии поиска в пространстве состояний
117
Рис. 3.9. Пример пути в задаче коммивояжера,
полученный на основе поиска ближайшего соседа.
Заметим, что этот путь (A,E,D,B,C,A) имеет
стоимость 550 и не является кратчайшим.
Сравнительно высокая стоимость дуги (С,А) не
учитывается эвристикой
3.2. Стратегии поиска в пространстве состояний
3.2.1. Поиск на основе данных и от цели
Поиск в пространстве состояний можно вести в двух направлениях: от исходных
данных задачи к цели и в обратном направлении от цели к исходным данным.
При поиске на основе данных (data-driven search — поиск, управляемый данными),
который иногда называют прямой цепочкой (forward chaining), исследователь начинает
процесс решения задачи, анализируя ее условие, а затем применяет допустимые ходы или
правила изменения состояния. В процессе поиска правила применяются к известным фактам
для получения новых фактов, которые, в свою очередь, используются для генерации новых
фактов. Этот процесс продолжается до тех пор, пока мы, если повезет, не достигнем цели.
Возможен и альтернативный подход. Рассмотрим цель, которую мы хотим достичь.
Проанализируем правила или допустимые ходы, ведущие к цели, и определим условия
их применения. Эти условия становятся новыми целями, или подцелями, поиска. Поиск
продолжается в обратном направлении от достигнутых подцелей до тех пор, пока (если
повезет) мы не достигнем исходных данных задачи. Таким образом определяется путь от
данных к цели, который на самом деле строится в обратном направлении. Этот подход
называется поиском от цели, или обратной цепочкой. Он напоминает простой детский
трюк, заключающийся в поиске выхода из лабиринта из конечного искомого состояния к
заданному начальному.
Подведем итоги: поиск на основе данных начинается с условий задачи и выполняется
путем применения правил или допустимых ходов для получения новых фактов, ведущих
к цели. Поиск от цели начинается с обращения к цели и продолжается путем
определения правил, которые могут привести к цели, и построения цепочки подцелей, ведущей к
исходным данным задачи.
118 Часть II. Искусственный интеллект как представление и поиск
Наконец заметим, что в обоих случаях (и при поиске на основе данных и при поиске
от цели) исследователь работает с одним и тем же графом пространства состояний,
однако порядок и число состояний в процессе поиска могут различаться. Какую стратегию
поиска предпочесть, зависит от самой задачи. При этом следует учитывать сложность
правил, "форму" пространства состояний, природу и доступность данных задачи. Все это
может изменяться от задачи к задаче.
Как пример зависимости сложности поиска от выбора стратегии рассмотрим задачу, в
которой нужно подтвердить или опровергнуть утверждение "Я — потомок Томаса
Джефферсона". Положительным решением является путь по генеалогическому дереву от
"Я" до 'Томас Джефферсон". Поиск на этом графе можно вести в двух направлениях:
начиная от вершины "Я" строить цепочку предков к вершине "Томас Джефферсон",
или начиная с вершины "Томас Джефферсон" анализировать цепочку его потомков.
Простая оценка позволяет сравнить сложность поиска в обоих направлениях. Томас
Джефферсон родился примерно 250 лет назад. Если считать, что новое поколение
рождается каждые 25 лет, то длина искомого пути составляет примерно 10. Поскольку
каждый потомок имеет двух родителей, то путь от "Я" требует анализа 210 предков. С другой
стороны, поиск от вершины "Томас Джефферсон" требует анализа большего числа
состояний, поскольку родители обычно имеют более двух детей (особенно это касается
восемнадцатого и девятнадцатого столетий). Если допустить, что каждая семья имеет в
среднем троих детей, то в процессе поиска нужно проанализировать З10 вершин
генеалогического дерева. Таким образом, этот путь сложнее. Заметим, однако, что оба способа
поиска имеют экспоненциальную сложность.
Модуль решения задачи может использовать как стратегию поиска на основе данных,
так и на основе цели. Выбор зависит от структуры решаемой задачи. Процесс поиска от
цели рекомендован в следующих случаях.
1. Цель поиска (или гипотеза) явно присутствует в постановке задачи или может быть
легко сформулирована. Например, если задача состоит в доказательстве
математической теоремы, то целью является сама теорема. Многие диагностические
системы рассматривают возможные диагнозы, систематически подтверждая или
отвергая некоторые из них способом поиска от цели.
2. Имеется большое число правил, которые на основе полученных фактов позволяют
продуцировать возрастающее число заключений или целей. Своевременный отбор
целей позволяет отсеять множество возможных ветвей, что делает процесс поиска
в пространстве состояний более эффективным (рис. 3.10). Например, в процессе
доказательства математических теорем число используемых правил вывода
теоремы обычно значительно меньше количества, формируемого на основе полной
системы аксиом.
3. Исходные данные не приводятся в задаче, но подразумевается, что они должны
быть известны решателю. В этом случае поиск от цели может служить
руководством для правильной постановки задачи. В программе медицинской
диагностики, например, имеются всевозможные диагностические тесты. Доктор выбирает из
них только те, которые позволяют подтвердить или опровергнуть конкретную
гипотезу о состоянии пациента.
Таким образом, при поиске от цели подходящие правила применяются для
исключения неперспективных ветвей поиска.
Глава 3. Структуры и стратегии поиска в пространстве состояний
119
Направление Цель
поиска
Данные
Рис. 3 10. Пространство состояний, в котором при
поиске от цели ветви ненужных направлений поиска
эффективно отсекаются
Цель
Данные поиска
Рис. 3 11 Пространство состояний, в котором поиск на
основе данных отсекает ненужные данные и их логические
следствия и позволяет определить одну из нескольких
возможных целей
Поиск на основе данных применим к решению задачи в следующих случаях.
1. Все или большинство исходных данных заданы в постановке задачи. Задача
интерпретации состоит в выборе этих данных и их представлении в виде, подходящем
для использования в интерпретирующих системах более высокого уровня. На
стратегии поиска от данных основаны системы анализа данных определенного типа.
Это такие системы, как PROSPECTOR или Dipmeter, анализаторы геологических
данных, определяющие, какие минералы с наибольшей вероятностью могут быть
найдены в некотором месте.
2. Существует большое число потенциальных целей, но всего лишь несколько
способов применения фактов и представления информации о конкретном примере
задачи (рис. 3.11). Примером этого типа систем является программа DENDRAL —
экспертная система исследования молекулярных структур органических сосдине-
120
Часть II. Искусственный интеллект как представление и поиск
ний на основе формул, данных масс-спектрографа и знаний из химии. Для любого
органического соединения существует чрезвычайно большое число возможных
структур. Однако данные масс-спектрографа позволяют программе DENDRAL
оставить лишь небольшое число таких комбинаций.
3. Сформировать цель или гипотезы очень трудно. Например, при использовании
системы DENDRAL изначально может быть очень мало информации о возможной
структуре соединения.
При поиске на основе данных знания и ограничения, заложенные в исходной
постановке задачи, используются для нахождения пути к решению.
Подводя итог, заметим, что ничто не заменит тщательного анализа каждой
конкретной задачи. Необходимо учитывать такие особенности, как фактор ветвления при
использовании правил, доступность данных и простота определения потенциальных целей.
В главе 4 рассказывается о том, сколько новых состояний возникает в результате
применения правил поиска в обоих направлениях.
3.2.2. Реализация поиска на графах
При решении задач путем поиска на основе данных либо от цели требуется найти
путь от начального состояния к целевому на графе пространства состояний.
Последовательность дуг этого пути соответствует упорядоченной последовательности этапов
решения задачи. Если решатель задач имеет в своем распоряжении оракула или иное
непогрешимое средство предсказания для построения пути решения, то и поиска не
требуется. Модуль решения задачи должен безошибочно двигаться прямо к цели, запоминая
путь движения. Поскольку для интересных задач оракулов не существует, решатель
должен рассматривать различные пути до тех пор, пока не достигнет цели. Поиск с
возвратами {backtracking) — это метод систематической проверки различных путей в
пространстве состояний.
Начнем рассмотрение алгоритмов с поиска с возвратами, поскольку это один из
первых алгоритмов поиска в информатике, который допускает естественную реализацию в
рекурсивной среде, ориентированной на использование стеков (раздел 5.1). Упрощенная
версия поиска с возвратами на примере поиска в глубину (раздел 5.1) будет реализована в
части VI на языках LISP и PROLOG.
Алгоритм поиска с возвратами запускается из начального состояния и следует по
некоторому пути до тех пор, пока не достигнет цели либо не упрется в тупик. Если цель достигнута,
поиск завершается, и в качестве решения задачи возвращается путь к цели. Если же поиск
привел в тупиковую вершину, то алгоритм возвращается в ближайшую из пройденных
вершин и исследует все ее вершины-братья, а затем спускается по одной из ветвей, ведущих от
вершины-брата. Этот процесс описывается следующим рекурсивным правилом.
Если исходное состояние S не удовлетворяет требованиям цели, то из списка его потомков
выбираем первый S,/„/ji, и к этой вершине рекурсивно применяем процедуру поиска с
возвратами Если в результате поиска с возвратами в подграфе с корнем S(hud\ Цель нс
обнаружена, то повторяем процедуру для вершины-брата Sr/,/W2 Эта процедура продолжается
до тех пор, пока один из потомков рассматриваемой вершины-брата не окажется целевым
узлом, либо не выяснится, что рассмотрены уже все возможные потомки (все вершины-
братья). Если же ни одна из вершин-братьев вершины S не привела к цели, возвращаемся к
предку вершины S и повторяем процедуру с вершиной-братом S и т д.
Глава 3. Структуры и стратегии поиска в пространстве состояний
121
Алгоритм работает до тех пор, пока не достигнет цели либо не исследует все
пространство состояний. На рис. 3.12 изображен процесс поиска с возвратами в
гипотетическом пространстве состояний. Пунктирные стрелки в дереве указывают направление
процесса поиска в пространстве состояний (вниз или вверх). Числа возле каждой
вершины указывают порядок их посещения. Ниже приведем алгоритм поиска с возвратами.
В нем используются три списка, позволяющих запоминать путь от узла к узлу в
пространстве состояний.
SL (State List) — список исследованных состояний рассматриваемого пути. Если цель
уже найдена, то SL содержит список состояний пути решения.
NSL (New State List) — список новых состояний, он содержит вершины, подлежащие
рассмотрению, т.е. список вершин, потомки которых еще не были порождены и
рассмотрены.
DE (Dead Ends) — список тупиков, т.е. список вершин, потомки которых уже были
исследованы, но не привели к цели. Если состояние из этого списка снова встречается в
процессе поиска, то оно обнаруживается в списке DE и исключается из рассмотрения.
При описании алгоритма поиска с возвратами на графах общего вида (не только для
деревьев) необходимо учитывать возможность повторного появления состояний, чтобы
избежать их повторного рассмотрения, а также петель, ведущих к зацикливанию
алгоритма поиска пути. Это обеспечивается проверкой каждой вновь порожденной вершины
на ее вхождение в один из трех вышеуказанных списков. Если новое состояние
обнаружится хотя бы в одном из двух списков SL или DE, значит, оно уже рассматривалось, и
его следует проигнорировать.
function backtrack;
begin
SL:=[Start];NSL:=[Start];DE:=[];CS:=Start;
^инициализация:
while NSL*[] do %пока существуют неисследованные состояния
begin
if CS=goal(nnn удовлетворяет описанию цели)
then return SL; %при нахождении цели вернуть список
%состояний пути,
if CS не имеет потомков (исключая узлы, входящие в DE, SL, and NSL)
then begin
while SL не пуст и С5=первый элемент списка SL do
begin
добавить CS в DE; %внести состояние в список
%тупиков
удалить первый элемент из SL; %возврат
удалить первый элемент из NSL;
CS:= первый элемент NSL;
end
добавить CS в SL;
end
else begin
поместить потомок CS(кроме узлов, уже содержащихся в DE,
SL или NSL) в NSL;
CS:= первый элемент NSL;
добавить CS в SL
122 Часть II. Искусственный интеллект как представление и поиск
end
end;
return FAIL;
end.
Обозначим текущее состояние при поиске с возвратами через CS (current state).
Состояние CS всегда равно последнему из состояний, занесенных в список SL, и
представляет "фронтальную" вершину на построенном в данный момент пути. Правила вывода,
ходы в игре или иные соответствующие операторы решения задачи упорядочиваются и
применяются к CS. В результате возникает упорядоченное множество новых состояний,
потомков CS. Первый из этих потомков объявляется новым текущим состоянием, а
остальные заносятся в список новых состояний NSL для дальнейшего изучения. Новое
текущее состояние заносится в список состояний SL, и поиск продолжается. Если текущее
состояние CS не имеет потомков, то оно удаляется из списка состояний SL (именно в
этот момент алгоритм "возвращается назад"), и исследуется какой-либо из оставшихся
потомков его предка в списке состояний SL.
Алгоритм поиска с возвратами на графе из рис. 3.12 работает следующим образом.
Инициализируем списки.
SL=[A]; NSL=[A]; DE=[]; CS=A;
После Текущее Список Новые состояния Тупики
итерации
0
1
2
3
4
5
6
7
8
состояние
CS
А
В
Е
Н
1
F
J
С
G
состоянии
SL
[А]
[ВА]
[ЕВА]
[НЕВА]
[1 ЕВА]
[FBA]
[J FBA]
[СА]
[GCA]
NSL
[А]
[BCD А]
[EFBCDA]
[HIEFBCDA]
[1 EFBCDA]
[FBCDA]
[JFBCDA]
[CDA]
[GCDA]
DE
[]
[]
[]
[]
[Н]
[EIH]
[EIH]
[BFJEIH]
[BFJEIH]
Поиск с возвратами в данном случае является поиском на основе данных, при
котором корень дерева связывается с начальным состоянием, а потомки узлов анализируются
для построения пути к цели. Этот же алгоритм можно интерпретировать и как поиск от
цели. Для этого целевую вершину следует взять в качестве корня дерева и анализировать
совокупность предков для нахождения пути к начальному состоянию. При
использовании цели вида 2 (см. подраздел 3.1.2) этот алгоритм должен определить целевое
состояние, исследуя путь для SL.
Поиск с возвратами (backtrack) — это алгоритм поиска на графе пространства состояний.
Алгоритмы поиска на графах, которые будут рассматриваться далее, включая поиск в глубину
(depth-first), поиск в ширину (breadth-first) и поиск по первому наилучшему совпадению (best-
first search), используют идеи поиска с возвратами, в том числе следующие.
1. Формируется список неисследованных состояний (NSL), для того чтобы иметь
возможность возвратиться к любому из них.
2. Поддерживается список "неудачных" состояний (DE), чтобы оградить алгоритм от
проверки бесполезных путей.
Глава 3. Структуры и стратегии поиска в пространстве состояний
123
Рис. 3 12. Поиск с возвратами в
гипотетическом пространстве состояний
3. Поддерживается список узлов (SL) текущего пути, который возвращается по
достижении цели.
4. Каждое новое состояние проверяется на вхождение в эти списки, чтобы
предотвратить зацикливание.
В следующем разделе рассматриваются алгоритмы с использованием списков,
подобные алгоритму поиска с возвратами. Эти алгоритмы, среди которых поиск в глубину,
поиск в ширину и поиск по первому наилучшему совпадению (глава 4), отличаются от
поиска с возвратами более гибкими средствами и стратегиями поиска.
3.2.3. Поиск в глубину и в ширину
Определив направление поиска (от данных или от цели), алгоритм поиска должен
определить порядок исследования состояний дерева или графа. В этом разделе
рассматриваются два возможных варианта последовательности обхода узлов графа: поиск в глубину
(depth-fist) и поиск в ширину (breadth-first).
Рассмотрим граф, представленный на рис. 3.13. Состояния в нем обозначены буквами
(А, В, С, ...), чтобы на них можно было сослаться в следующих рассуждениях. При поиске в
глубину после исследования состояния сначала необходимо оценить все его потомки и их
потомки, а затем исследовать любую из вершин-братьев. Поиск в глубину по возможности
углубляется в область поиска. Если дальнейшие потомки состояния не найдены,
рассматриваются вершины-братья. Поиск в глубину исследует состояния графа на рис. 3.13 в таком
порядке: А, В, Е, К, S, L, T, F, М, С, G, N, Н, О, Р, U, D, I, Q, J, Я. Алгоритм поиска с
возвратами, рассмотренный в подразделе 3.2.2, осуществляет поиск в глубину.
Поиск в ширину, напротив, исследует пространство состояний по уровням, один за
другим. И только если состояний на данном уровне больше нет, алгоритм переходит к
следующему уровню. При поиске в ширину на графе из рис. 3.13 состояния
рассматриваются в таком порядке: А, В, С, D, E, F, G, hi, /, J, К, L, M, N, О, Р, О, Я, S, T, U.
Поиск в ширину осуществляется с использованием списков open и closed,
позволяющих отслеживать продвижение в пространстве состояний. Список open, подобно
NSL в алгоритме поиска с возвратами, содержит сгенерированные состояния, потомки
которых еще не были исследованы. Порядок удаления состояний из списка open
определяет порядок поиска. В список closed заносятся уже исследованные состояния.
Список closed объединяет списки DE и SL, используемые в алгоритме поиска с возвратами.
124
Часть II. Искусственный интеллект как представление и поиск
Km Lm Mm N% От Pm Q% fl«
t
f
1
Urn
Рис. 3.13. Граф, демонстрирующий работу
алгоритмов поиска в глубину и в ширину
%инициализация
%есть состояния
function breadth_first_search;
begin
open:=[Start];
closed := [ ];
while open * [ ] do
begin
удалить крайнее слева состояние из open, скажем X;
if X - цель then return SUCCESS %цель найдена
else begin
сгенерировать потомок X;
поместить X в список closed;
исключить потомок X, если он уже в списке
open или closed; %проверка на цикл
поместить остальные потомки в
правый конец списка open %очередь
end
end
return FAIL ^состояний не осталось
end.
Дочерние состояния генерируются правилами вывода, допустимыми ходами
игры, или другими операциями перехода состояний. На каждой итерации
генерируются все дочерние вершины состояния X и записываются в open. Заметим, что список
open действует как очередь и обрабатывает данные в порядке поступления (или
"первым поступил — первым обслужен"). Это структура данных FIFO first-in-first-
out. Состояния добавляются в список справа, а удаляются слева. Таким образом в
поиске участвуют состояния, которые находятся в списке open дольше всего,
обеспечивая поиск в ширину. Дочерние состояния, которые были уже записаны в списки
open или closed, отбрасываются. Если алгоритм завершается из-за невыполнения
условия цикла while (open= [ ]), то можно заключить, что весь граф исследован, а
желаемая цель не достигнута. Следовательно, поиск потерпел неудачу.
Глава 3. Структуры и стратегии поиска в пространстве состояний
125
Проследим путь алгоритма поиска в ширину breadth_f irst_search на графе,
изображенном на рис. 3.13. Числа 2, 3, 4, ... означают номер итерации цикла while. При
этом U — это желаемое целевое состояние.
1. open=[A]; closed=[]
2. open=[B/C/D]; closed=[A]
3. open=[C,D,E,F]; closed=[B/A]
4. open=[D/E/F/G/H]; closed=[С,В, A]
5. open=[E/F/G/H/I/J]; closed=[D,С,B,A]
6. open=[F/G/H/I,J,K,L]; closed= [E, D, С, В, A]
7. open= [G, H, I, J, K, L,M] (так как L уже в open); closed=[F,E,D,C,B,A]
8. open=[H#I#J#K,L#M#N]; closed=[G#F,E,D,С,В,A]
9. И так далее, пока или U найдено, или ореп=[]
На рис. 3.14 показан граф, изображенный на рис. 3.13, после шести итераций поиска в
ширину. Состояния из списков open и closed на рис. 3.14 выделены цветом. Не выделенные
состояния не были исследованы алгоритмом. Заметим, что "пограничные" состояния поиска
на любой стадии записываются в open, а уже рассмотренные — в closed.
Поскольку при поиске в ширину узлы графа рассматриваются по уровням, сначала
исследуются те состояния, пути к которым короче. Поиск в ширину, таким образом,
гарантирует нахождение кратчайшего пути от начального состояния к цели. Более того,
поскольку вначале исследуются состояния, найденные по кратчайшему пути, при
повторном проходе это состояние отбрасывается.
Иногда помимо имен состояний в open и closed необходимо хранить дополнительную
информацию. Например, заметим, что алгоритм поиска в ширину не поддерживает список
состояний на текущем пути к цели, как это делалось при поиске с возвратами (backtrack) в
списке SL. Все посещенные состояния хранятся в closed. Если путь является
решением, то он возвращается алгоритмом. Это может быть сделано путем накопления
информации о предках для каждого состояния. Состояние хранится вместе с записью
родительского состояния, т.е. в виде пары (состояние, родитель). Для графа на рис. 3.13
содержание списков open и closed на четвертой итерации было бы следующим.
open=[(D,A),(Е,В),(F,B),(G,C),(Н,С)]; closed-[(С#А)# (В,А),(A,nil)]
Я •
Рис. 3.14 Граф из рис. 3 13 на 6 итерации выполнения
алгоритма поиска в ширину. Состояния, содержащиеся в
списках open и closed, выделены цветом
В списке closed
В списке open
126
Часть II. Искусственный интеллект как представление и поиск
Используя эту информацию, можно легко построить путь (А, В, F), ведущий от А к F.
Когда цель найдена, алгоритм может восстановить путь решения, прослеживая его в
обратном направлении от цели к начальному состоянию по родительским состояниям.
Заметим, что состояние А имеет родителя nil (нуль), т.е. является начальным состоянием.
Это служит сигналом прекращения восстановления пути. Поскольку поиск в ширину
находит каждое состояние по кратчайшему пути и сохраняет первую версию каждого
состояния, этот путь от начала до цели является самым коротким.
На рис. 3.15 показаны состояния, удаленные из open и исследованные алгоритмом поиска
в ширину для 8-головоломки. Как и прежде, дуги соответствуют перемещению пустой клетки
вправо, вниз и влево. Номер рядом с каждым состоянием указывает порядок удаления из
open. В графе не показаны состояния, оставшиеся в open по завершении алгоритма.
Опишем алгоритм поиска в глубину — упрощенный алгоритм поиска с возвратами, уже
представленный в подразделе 3.2.3. В этом алгоритме состояния-потомки добавляются и
удаляются с левого конца списка open, т.е. список open реализован как стек магазинного типа
или структура LIFO — "last-in-first-out" ("последним пришел — первым обслужен"). При
организации списка open в виде стека предпочтение отдается самым "молодым" (недавно
сгенерированным состояниям), т.е. осуществляется принцип поиска в глубину.
function depth_first_search;
begin
open: = [Start] ;
%инициализация
closed:=[];
while open * [ ] do %есть состояния
begin
удалить крайнее слева состояние из open, скажем X;
if X — цель then return SUCCESS %цель достигнута
else begin
сгенерировать потомок X;
поместить X в список closed;
исключить потомок X, если он уже в open или closed;
%проверка цикла
поместить остальные потомки в левый конец списка open
%стек
end
end;
return FAIL %состояний не осталось
end.
Ниже показан процесс реализации алгоритма depth_f irst_search для графа из
рис. 3.13. Каждая успешная итерация цикла while описана одной строкой B, 3, 4, ...).
Начальные состояния списков open и closed указаны в строке 1. Пусть U — целевое состояние.
1. ореп=[А]; closed=[]
2. open=[B/C/D]; closed=[A]
3. open=[E/F/C/D]; closed=[B,A]
4. open=[K/L/F/C/D]; closed=[E,B,A]
5. open=[S/L/F/C/D]; closed=[К,Е,В,A]
6. open=[L/F/C/D]; closed=[S,К,Е,В,A]
7. open=[T/F/C/D]; closed= [L, S, К, Е, В, A]
8. open=[F/C/D]; closed=[T, L,S,К,E,B,A]
9. open=[M/C/D] , as L is already on closed; closed=[F, T, L,S,К,E,B,A]
Глава З. Структуры и стратегии поиска в пространстве состояний
127
10. open=[C/D]; closed=[M/F/T/L/S/K/E/B/A]
11. open=[G/H/D] ; closed= [C#M# F#T#L# S#K#E#B# A]
И так далее, пока не будет обнаружено состояние L/, или ореп= [ ].
34 35 36 37 38 39 40 41 42 43 44 45 46
Цель
Рис. 3.15. Поиск в ширину, демонстрирующий порядок удаления состояний из списка
open, в 8-головоломке
Как и при поиске в ширину, в списке open перечислены все обнаруженные, но еще
не оцененные, состояния (текущая "граница" поиска), а в closed записаны уже
рассмотренные состояния. На рис. 3.16 показан граф, изображенный на рис. 3.13, после
выполнения шести итераций функции depth_f irst_search. Списки open и closed на
рис. 3.16 выделены цветом. Как и при поиске в ширину breadth_f irst_search, в
данном алгоритме можно сохранять для каждого состояния записи о родителях. Это
позволит алгоритму восстановить путь, ведущий от начального состояния к целевому.
В отличие от поиска в ширину, поиск в глубину не гарантирует нахождение
оптимального пути к состоянию, если оно встретилось впервые. Позже в процессе поиска
могут быть найдены различные пути к любому состоянию. Если длина пути имеет значение
в решении задачи, то в случае нахождения алгоритмом некоторого состояния повторно
необходимо сохранить именно тот путь, который оказался короче. Это можно сделать,
сохраняя для каждого состояния тройку значений (состояние, родитель, длина
пути). При генерации дочерних элементов значение длины пути просто увеличивается
на единицу и сохраняется вместе с потомками. Если дочернее состояние достигнуто по
многим путям, эту информацию нужно использовать для сохранения лучшей версии. Эта
128
Часть II. Искусственный интеллект как представление и поиск
идея развивается при рассмотрении алгоритма Л {algorithm А) в главе 4. Заметим, что
сохранение лучшей версии состояния при простом поиске в глубину вовсе не
гарантирует, что цель будет достигнута именно по кратчайшему пути.
Km Lm Mm N т От Р* От Rm
к t
S • Т т
U
В списке closed
В списке open
Рис. 3.16. Граф, изображенный на рис. 3.13, после
выполнения шести итераций depth_first_search.
Состояния, содержащиеся в списках open и closed,
выделены цветом
На рис. 3.17 рассмотрен поиск в глубину на примере головоломки с 8 фишками. Как
отмечалось ранее, пустая клетка передвигается согласно одному из четырех возможных
правил (вверх, вниз, влево и вправо). Числа рядом с состояниями указывают порядок, в
котором они были рассмотрены и удалены из списка open. He показаны состояния,
находящиеся в open, когда цель уже найдена. Глубина поиска в данном случае была
ограничена пятью уровнями, чтобы не "затеряться в глубинах" пространства состояний.
После выбора стратегии поиска (на основе данных или от цели), оценки графа и
выбора метода поиска (в глубину или в ширину) дальнейший ход решения будет зависеть
от конкретной задачи. Влиять на выбор стратегии поиска может необходимость
обнаружения именно кротчайшего пути к цели, коэффициент ветвления пространства,
доступное время вычислений и возможности пространства, средняя длина пути к целевой
вершине графа, а также необходимость получения всех решений или только первого. При
выборе метода поиска несложно убедиться, что у любого подхода всегда имеются
определенные преимущества и недостатки.
Поиск в ширину. Поскольку при таком подходе до перехода к уровню п+1 всегда
исследуются все узлы на уровне л, поиск в ширину всегда находит самый короткий путь
к целевой вершине. Если в задаче существует простое решение, это решение будет
найдено. К сожалению, при большом коэффициенте ветвления, если состояния имеют
высокое среднее число потомков, комбинаторный взрыв может помешать алгоритму найти
решения. Это происходит потому, что все перспективные и неперспективные вершины
Глава 3. Структуры и стратегии поиска в пространстве состояний
129
для каждого уровня поиска находятся в списке open. Для глубокого поиска (когда цель
расположена глубоко) или для пространства состояний с высоким коэффициентом
ветвления этот поиск может быть весьма громоздким.
6 7 10 11 13 14 16 17 22 23 26 27 31
Цель
Рис. 3.17. Поиск в глубину для игры в "пятнашки " с 8 фишками, ограниченный 5 уровнями
Степень использования пространства при поиске в ширину измеряется в терминах
числа состояний в списке open и является экспоненциальной функцией длины пути в
любой момент времени. Если каждое состояние порождает в среднем В дочерних
состояний, то общее число состояний на данном уровне определяется умножением В на
число состояний предыдущего уровня. Значит, на уровне п число состояний составляет
Вп. При исследовании уровня п методом поиска в ширину все состояния помещаются в
open, что может быть нежелательно, если путь к решению достаточно длинный.
Поиск в глубину быстро проникает в глубины пространства. Если известно, что путь
решения будет длинным, то поиск в глубину не будет тратить время на поиск большого
количества "поверхностных" состояний на графе. С другой стороны, поиск в глубину
может "затеряться в глубинах" графа, пропуская более короткие пути к цели, или даже
"застрять" на не ведущем к цели бесконечно длинном пути.
Поиск в глубину эффективен для областей поиска с высокой степенью связности,
потому что ему не нужно помнить все узлы данного уровня в списке open. Степень
использования пространства состояний в случае поиска в глубину — это линейная функция
длины пути. На каждом уровне в open сохраняются только дочерние вершины
единственного состояния. Если у каждой вершины графа имеется в среднем В дочерних вер-
130
Часть II. Искусственный интеллект как представление и поиск
шин, и если поиск продвигается на п уровней вглубь пространства, то уровень
использования пространства составляет Вхп.
Так что же лучше: поиск в глубину или поиск в ширину? На этот вопрос можно
ответить так. Необходимо исследовать пространство состояний и проконсультироваться с
экспертами в данной области. В шахматах, например, поиск в ширину просто
невозможен. В более простых играх поиск в ширину не только возможен, но даже может
оказаться единственным способом избежать проигрышей или потерь в игре.
3.2.4. Поиск в глубину с итерационным заглублением
Хорошим решением проблем поиска в глубину является использование предельного
значения глубины поиска. Предельная глубина позволяет ограничить поиск только
заданным числом уровней. Это обеспечивает некоторое подобие "развертки" области
поиска в ширину при поиске в глубину.
Ограниченный поиск в глубину наиболее полезен, если известно, что решение
находится в пределах некоторой глубины, имеются ограничения во времени или пространство
состояний чрезвычайно велико (как в шахматах). В таких задачах число рассматриваемых
состояний ограничивают предельной глубиной поиска. На рис. 3.17 показан поиск в глубину
для 8-головоломки, для которого предельная глубина ограничена пятью уровнями.
Поэтому именно на этой глубине возникает поперечная развертка пространства.
Такая модификация позволяет исправить немало недостатков как поиска в глубину,
так и поиска в ширину. Итерационным заглублением [Korf, 1987] называется поиск в
глубину, первая итерация которого ограничена 1 уровнем. Если цель не найдена,
выполняется еще один шаг с предельной глубиной 2. В процессе поиска предельная глубина
увеличивается на 1 на каждой итерации. На каждой итерации алгоритм выполняет поиск
в глубину с учетом текущего предельного числа уровней. При этом при переходе от
одной итерации к другой информация о пространстве состояний не сохраняется.
Поскольку алгоритм исследует пространство "по уровням", он может гарантировать
нахождение кратчайшего пути к цели. Поскольку на каждой итерации осуществляется
только поиск в глубину, степень использования пространства на каждом уровне п
составляет Вхп, где В — среднее число дочерних состояний вершины.
На первый взгляд кажется, что итерационное продвижение в глубину менее
эффективно по времени, чем поиск глубину или в ширину. Однако временная сложность
алгоритма (время выполнения алгоритма в зависимости от размерности задачи) в
действительности имеет тот же самый порядок величины, что и каждый из этих алгоритмов —
0(Вп). Объяснение этого кажущегося парадокса приведено в [Korf, 1987].
Поскольку число вершин на данном уровне дерева растет экспоненциально с увеличением
глубины, почти все время вычислений тратится на самом глубоком уровне.
К сожалению, можно показать, что в наихудшем случае все рассмотренные в этой
главе стратегии поиска (поиск в глубину, в ширину и итерационное заглубление)
обладают экспоненциальной сложностью. Это характерно для всех неинформированных
алгоритмов поиска. Для снижения временной сложности алгоритмов поиска
используют направляющие эвристики. Поиск по первому наилучшему совпадению — это
алгоритм поиска, подобный представленным выше алгоритмам поиска в глубину и в
ширину. Однако в процессе поиска по первому наилучшему совпадению состояния в
списке open, определяющие текущую границу поиска, упорядочиваются согласно
Глава 3. Структуры и стратегии поиска в пространстве состояний
131
некоторому эвристическому показателю качества. На каждой итерации поиск
рассматривает не самые глубокие, а самые "лучшие" состояния. Поиск по первому
наилучшему совпадению — центральная тема главы 4.
3.3. Представление рассуждений в пространстве
состояний на основе исчисления предикатов
3.3.1. Описание пространства состояний логической системы
В разделе 3.1 при определении графа пространства состояний было отмечено, что его
вершины должны отличаться друг от друга, поскольку каждый узел представляет некоторое
состояние процесса решения. В качестве формального языка для описания этих различий и
отображения узлов графа в пространство состояний можно использовать исчисление
предикатов. Более того, для создания дуг и описания связей между состояниями можно
использовать правила вывода. Тогда методами поиска могут быть решены некоторые проблемы
исчисления предикатов. Например, таким образом можно определить, является ли некоторое
конкретное выражение логическим следствием данного набора утверждений.
Корректность и полнота правил вывода исчисления предикатов обеспечивает
корректность подобных заключений. Возможность получить формальное доказательство
целостности решения задачи с помощью алгоритма решения самой задачи является
уникальным преимуществом многих методов искусственного интеллекта.
Хотя состояния многих задач (например, "крестики-нолики") более естественно
описываются другими структурами данных (например, массивами), общая логика и
специфика решения многих задач ИИ приводят к использованию исчисления предикатов и
других моделей представления знаний, в том числе правил вывода (глава 7),
семантических сетей и фреймов (глава 6). Для всех этих моделей представления знаний можно
использовать стратегии поиска, аналогичные представленным выше.
Пример 3.3.1. Исчисление высказываний
В качестве первого примера рассмотрим задачу построения графа на основе набора
логических отношений из исчисления высказываний. Пусть р, д, г, ... — высказывания.
Рассмотрим следующие утверждения.
д->р
г->Р
\л->д
s^r
f->r
s^>u
s
t
Из этого набора утверждений на основе правила модус поненс могут быть выведены
определенные высказывания, в том числе р, г и и. Другие высказывания, в частности, v и
д, не могут быть выведены таким способом. Действительно, они логически не следуют
из этих утверждений. Отношения между начальными утверждениями и выведенными из
них описаны на рис. 3.18 с помощью ориентированного графа.
132
Часть II. Искусственный интеллект как представление и поиск
р
л
q r и •
ш ы
Pwc. .?./& /рд$ пространства Рис. 3.19. Граф И/ИЛИ для
состояний набора импликаций в выражения длГ—>р
исчислении высказываний
Дуги на рис. 3.18 соответствуют логическим импликациям (—>). Утверждения,
которые считаются истинными (s и f), соответствуют исходным данным задачи. Логические
следствия из данного набора утверждений соответствуют достижимым узлам. Путь на
графе отражает последовательность применения правила модус поненс. Например, путь
[s, r, р] соответствует такому ряду логических выводов.
Из s и s —> г следует г.
Из г и г —> р следует р.
Такой способ логического вывода информации сводится к нахождению пути от
вершины, помеченной квадратиком (начального узла), к целевому высказыванию. Таким
образом, задача логического вывода сводится к проблеме поиска на графе. При этом
используется поиск на основе данных — строится путь от известных (истинных)
высказываний к целевым утверждениям. К этому же пространству состояний можно применить и
стратегию поиска от цели. Поиск от целевого высказывания позволяет прийти к
обоснованию этой цели в классе истинных высказываний. Полученное пространство логических
следствий можно исследовать методом поиска как в глубину, так и в ширину.
3.3.2. Графы И/ИЛИ
В предыдущем примере все утверждения представляли собой импликации вида р—>д.
Способ представления логических операторов И и ИЛИ в таком графе не обсуждался.
Представление логических связей, определенных этими операторами, требует
расширения понятия модели графа. Граф, отражающий подобные взаимосвязи, называется
графом И/ИЛИ. Графы И/ИЛИ являются важным инструментом для описания областей
поиска, порожденных многими проблемами искусственного интеллекта, в том числе
задачами автоматического доказательства логических теорем и экспертными системами.
В выражениях вида длг—>р для обеспечения истинности р должны быть истинны как
Q, так и г. В выражениях вида gvr—>р истинность q или г достаточна для доказательства
того, что р— истина. Поскольку импликации (—>), содержащие дизъюнктивные (v)
предпосылки, могут быть записаны как пары отдельных импликаций, это выражение
часто записывается в виде д—>р, г^>р. Чтобы представить различные отношения
графически, на графах И/ИЛИ различают узлы и (and) и или (or). Если предпосылки
импликаций связаны оператором л, они называются и-узлами графа, а дуги, ведущие от этих узлов,
соединяются кривой. На рис. 3.19 в виде графа И/ИЛИ представлено выражение длг—>р.
Кривая, соединяющая дуги на рис. 3.19, означает, что для доказательства р должны
быть истинными обе предпосылки: q иг. Если предпосылки соединены оператором
ИЛИ, на графе они представляются узлами или. Дуги, ведущие от узлов или к следую-
А
Глава 3. Структуры и стратегии поиска в пространстве состояний
133
щей вершине, не соединяются кривой (рис. 3.20). Это указывает на то, что истина любой
из предпосылок является достаточным условием для истинности заключения.
Граф И/ИЛИ является частным случаем гиперграфа, в котором узлы соединены не
отдельными дугами, а множеством дуг. Приведем определение гиперграфа.
ОПРЕДЕЛЕНИЕ
ГИПЕРГРАФ
Гиперграф состоит из следующих элементов.
N — множество вершин.
Н — множество гипердуг. Гипердуга задается упорядоченной парой, в которой первый
элемент является отдельной вершиной из Л/, а второй —подмножеством множества N.
Обычный граф — это частный случай гиперграфа, в котором все множества
порожденных вершин (узлов-потомков) имеют мощность 1.
Гипердуги также называют к-коннекторами, где к — мощность множества
порожденных вершин. Если к= 1, то можно считать, что потомок является вершиной ИЛИ.
Если к> 1, то элементы множества потомков являются вершинами и. В этом случае
коннекторы изображаются в виде отдельных ребер, ведущих от родителя к каждой из
порожденных вершин и соединенных изогнутой линией (см. рис. 3.19).
Р
Рис. 3.20. Граф И/ИЛИ
выражения gvr—»р
Рис. 3.21. Граф И/ИЛИ для
набора выражений из исчисления
высказываний
ПРИМЕР 3.3.2. Поиск на графе И/ИЛИ
Второй пример тоже относится к исчислению высказываний. Сгенерируем граф,
содержащий оба вида потомков: и и или. Предположим, в некотором мире истинны
следующие предложения.
А
Ь
с
алЬ^с!
алс^е
bAd^f
але—>h
134
Часть II. Искусственный интеллект как представление и поиск
Этот набор утверждений определяет граф И/ИЛИ, показанный на рис. 3.21.
С помощью поиска на этом графе можно получить (вывести) ответы на
следующие вопросы.
1. Истинно ли/??
2. Является ли h истиной, если Ь больше не истина?
3. Каков кратчайший путь, доказывающий, что некоторое высказывание X истинно?
4. Показать, что высказывание р (не используемое в наборе исходных высказываний)
есть ложь. Что это значит? Что необходимо знать для получения этого заключения?
Поиск на графе И/ИЛИ требует хранения большего объема информации, чем поиск
на регулярных (однородных) графах. В качестве примера рассмотрим описанный выше
алгоритм поиска с возвратами. Потомки или проверяются в точном соответствии с этим
алгоритмом. А именно, если найден путь, проходящий через вершины или и
соединяющий цель с начальной вершиной, — задача решена. Если же некоторый путь не ведет к
целевой вершине, алгоритм возвращается и исследует другую ветвь. Однако при
исследовании вопроса об истинности родительской вершины узлов и необходимо доказать
истинность всех и-потомков.
В примере, показанном на рис. 3.21, для определения истинности h с помощью
стратегии поиска от цели {goal-directed strategy) сначала доказывается истинность
а и е. Истинность а очевидна, а выражение е истинно, если истинны и с и а, что
дано по условию задачи. Решающее устройство прослеживает все дуги, ведущие к
истинным предложениям. Затем истинные значения передаются и-узлу для
доказательства истинности h.
Стратегия определения истинности h на основе данных предполагает обработку
исходных данных (с, а и Ь) и добавление новых высказываний к набору известных фактов
в соответствии со связями графа И/ИЛИ. Сначала к набору фактов добавляется
высказывание е или d. Это дает возможность вывести новые факты. Процесс продолжается до
тех пор, пока не будет проверена желаемая цель h.
Поиск на графе И/ИЛИ можно рассматривать следующим образом. Операторы л (и-
узлы графа) означают декомпозицию задачи. Иными словами, задача разбивается на
подзадачи, которые должны быть решены для решения исходной проблемы. Оператор v
(или) в представлении на основе исчисления предикатов определяет точку выбора между
альтернативными путями решения задачи, или стратегиями. Нахождение пути к цели
вдоль любой из ветвей является достаточным условием для решения общей задачи.
3.3.3. Примеры и приложения
ПРИМЕР 3.3.3. Система MACSYMA
Приведем еще один пример графа И/ИЛИ. Им является программа символьного
интегрирования математических функций. MACSYMA — это известная программа,
которая широко используется математиками. Логические рассуждения в системе MACSYMA
могут быть представлены в виде графа И/ИЛИ. Процесс интегрирования затрагивает
один важный класс задач, в которых выражение разбивается на подвыражения. Эти
подвыражения могут быть проинтегрированы независимо друг от друга, затем результат
алгебраически объединяется в конечное выражение. К примерам этой стратегии относится
правило интегрирования по частям и правило разложения интеграла суммы на сумму ин-
Глава 3. Структуры и стратегии поиска в пространстве состояний
135
тегралов отдельных слагаемых. Эти стратегии, обеспечивающие декомпозицию задачи
на независимые подзадачи, в графе могут быть представлены узлами и.
z2L
z =coty
z -tany
/dz
z4A +
z2)
f-
■dz
Разделить числитель на знаменатель
Рис. 3.22. Фрагмент пространства состояний графа И/ИЛИ для системы интегрирования
[Nilsson, 1971]
Еще одна стратегия заключается в упрощении выражения с использованием
различных алгебраических подстановок. Поскольку любое выражение может допускать ряд
замен, а каждая замена представляет независимую стратегию решения, то эти стратегии
представлены на графе вершинами или. На рис. 3.22 показано подобное пространство
состояний. Поиск на этом графе ведется от цели. Он начинается с запроса на вычисление
интеграла конкретной функции, а затем направляется вниз к алгебраическим
выражениям, определяющим этот интеграл. Заметим, что здесь поиск от цели является очевидной
стратегией. Решающему устройству практически невозможно определить
алгебраические выражения, формирующие заданный интеграл, не направив поиск от запроса вниз к
составляющим выражениям.
136
Часть II. Искусственный интеллект как представление и поиск
ПРИМЕР 3.3.4. Поиск от цели на графе И/ИЛИ
Этот пример взят из исчисления предикатов и представляет поиск от цели на графе.
Цель, истинность которой должна быть доказана, в этом случае представляет собой
выражение исчисления предикатов, содержащее переменные. В этой задаче аксиомы — это
логические описания отношений между собакой Фредом и его хозяином Сэмом. При
этом мы предполагаем, что холодный день — это не теплый день. Кроме того, в этом
примере не рассматривается проблема, вызванная эквивалентными выражениями
предикатов. Она будет обсуждаться далее в главах 6 и 12. Факты и правила в этом
представлении даны в виде предложений на английском (и русском) языке, за которыми следуют их
представления на языке исчисления предикатов.
1. Fred is a collie. (Фред — это колли.)
collie(fred).
колли(Фред).
2. Sam is Fred's master. (Сэм — хозяин Фреда.)
master(fred,sam).
day(saturday).
3. The day is Saturday. (Сегодня суббота).
day(saturday).
4. It is cold on Saturday. (Холодно в субботу.)
^(warm(saturday)).
5. Fred is trained. (Фред дрессированный.)
trained(fred).
6. Spaniels are good dogs and so are trained collies. (Спаниели — хорошие собачки, а
колли такие же обученные.)
VX[spaniel(X)v(collie(X)Atrained(X))^>gooddog(X)]
7. If a dog is a good dog and has a master then he will be with his master. (Если собака
хорошая и имеет хозяина, тогда она находится рядом с хозяином.)
V(X,V,Z) [gooddog(X)Amaster(X,Y)Alocation(YtZ)^location(X,Z)]
8. If it is Saturday and warm, then Sam is at the park. (Если в субботу тепло, то Сэм
находится в парке.)
(day(saturday)Awarm(saturday))^location(samtpark).
9. If it is Saturday and not warm, then Sam is at the museum. (Если в субботу не тепло, то
Сэм находится в музее.)
(day(saturday)A-i(warm(saturday)))^>location(samtmuseum).
Цель— это выражение ЗХ location(fredtX) или ЗХ место(Фред,Х), означающее
"Where is Fred?" (Где же Фред?). Алгоритм с возвратами исследует альтернативные
значения этой порожденной цели: "if fred is a good dog and fred has a master and fred's master
is at a location then fred is at that location also." (Если Фред хороший пес, и Фред имеет
хозяина, и хозяин Фреда находится в некотором месте, то Фред находится в том же месте.)
Исследуются предпосылки этого правила: что значит "good dog" (хороший пес) и т.д.
Таким образом создается граф И/ИЛИ, показанный на рис. 3.23.
Рассмотрим этот поиск детально. Это пример поиска от цели с использованием
исчисления предикатов. Он иллюстрирует роль унификации (объединения) при порожде-
Глава 3. Структуры и стратегии поиска в пространстве состояний
137
нии области поиска. Необходимо решить задачу: "Где же Фред?". Эту задачу можно
сформулировать так: найти подстановку для переменной X, если она существует, при
которой location(fred,X) или место(Фред,Х) является логическим следствием
начальных утверждений.
Раз уж необходимо определить расположение Фреда, то первыми будут исследованы
те предложения, в заключении которых содержится выражение MecTo(location). Итак,
первым будет рассмотрено высказывание 7. Заключение этого высказывания
location(X,Z) (или Mecro(X,Z)) затем объединяется с выражением location(fred,X) с
помощью подстановок {fred/X,X/Z}). Предпосылки этого правила при том же наборе
подстановок составляют w-потомки основной цели.
gooddog(fred)Amaster(fred,Y)Alocation(Y,X).
хорошаясобака(Фред)лхозяин(Фред,У)лместо(У,Х).
location (X,Z)
gooddog{X)
Направление
поиска
( master(X.Y) I
location(Y.Z)
V
( . ^ ( ^ ( ^ ( ^ С л
collie{X) trained{X) \master{fred,sam)\ day(saturday) \-л (warm(saturday))
[ collie(fred) J [ trained(fred) J
Подстановки = {fred/X, sam/Y, museum/Z}
Рис. 3.23. Подграф решения, показывающий, что Фред в музее
Это выражение можно интерпретировать так: один из путей нахождения Фреда
состоит в следующем. Нужно убедиться, является ли Фред хорошей собакой, затем
выяснить, кто хозяин Фреда, а уж затем определить местонахождение хозяина. Начальная
цель, таким образом, заменяется тремя подцелями. Они являются w-вершинами, поэтому
все должны быть разрешены.
Чтобы разрешить эти подцели, решатель сначала определяет, является ли Фред хорошей
собакой. Это соответствует заключению высказывания 6, затем используется подстановка
{fred/X}. Предпосылка высказывания 6 — это логическая сумма (или) двух выражений:
spaniel(fred)v(collie(fred)Atrained(fred)).
Первая из этих итш-вершин— spaniel(fred). База данных не содержит этого
утверждения, поэтому решающее устройство должно предположить, что это ложь. Другая или-
вершина— это (collie(fred)Atrained(fred)), т.е. Фред— это колли и Фред
дрессирован. Обе эти предпосылки должны быть истинны. Так и есть в соответствии с
высказываниями 1 и 5.
138
Часть II. Искусственный интеллект как представление и поиск
Итак, доказано, что выражение gooddog(fred) истинно. Затем решающее устройство
исследует вторую предпосылку высказывания 7: master(X,Y). Применяя подстановку
{fred/X} к выражению master(X,Y), получим master(fred,Y), а затем объединим это
выражение с фактом master(fred,sam) (высказывание 2). Это порождает
унифицированную (обобщающую) замену {sam/Y}, которая также обеспечивает значение sam
третьей подцели высказывания 7, создавая новую цель location(sam,X).
Разрешая эту цель, предположим, что решающее устройство проверяет правила по
порядку. Цель location(sam,X) вначале будет унифицирована с заключением
высказывания 7. Заметим, что каждый раз исследуется одно и то же правило с различными
значениями связывания для X. Напомним, если X является фиктивной переменной (глава 2),
то она может иметь любое значение (любой ряд, начинающийся с прописной буквы).
Поскольку диапазон действия конкретного значения какой-либо переменной
ограничивается пределами предложения, в котором содержится эта переменная, то исчисление
предикатов не имеет никаких глобальных переменных. Иначе эту мысль можно выразить
так: значения переменных передаются другим предложениям как параметры, не
имеющие фиксированной области действия (памяти). Таким образом, многократные
повторения X в различных правилах в этом примере указывают на различные формальные
параметры (раздел 12.3).
Разрешая предпосылки правила 7 с вновь выведенными значениями связывания,
решатель отвергнет их, потому что Сэм не является хорошей собакой. Здесь алгоритм
поиска вернется назад к цели location(sam,X) и проверит заключение правила 8. Но и эта
попытка потерпит неудачу, вызывая еще один возврат назад. Затем последует
объединение (унификация) с заключением высказывания 9 location(sam.museum).
Поскольку предпосылки предложения 9 подтверждаются другими высказываниями
(предложения 3 и 4), то заключение 9 истинно. Результаты унификации передаются
вверх по дереву и приводят к заключительному ответу ЗХ location(fred,X), откуда
получим location(fredt museum).
Важно тщательно исследовать природу поиска на графе от цели и сравнить его с
поиском на основе данных из примера 3.3.2. Дальнейшее обсуждение этой
проблемы, включая более строгое сравнение этих методов поиска на графах, рассмотрим
на следующем примере. Но детальное описание приводится только при обсуждении
продукционной системы (основанной на представлении знаний в виде
продукционных правил) в главе 5 и в приложении, описанном в части IV. Еще одна мысль,
неявно использованная в этом примере, заключается в том, что порядок высказываний
влияет на порядок поиска. В рассмотренном выше примере были по порядку
исследованы все имеющиеся предложения, указывающие на расположение объекта. При
этом использовался поиск с возвратами и отвергались утверждения, истинность
которых была опровергнута.
ПРИМЕР 3.3.5. Финансовый советник (повторно)
В последнем примере из главы 2 исчисление предикатов использовалось для
представления набора правил, описывающих действия системы — финансового
советника. В том примере использовалось правило модус поненс для формирования
совета конкретному человеку о наилучшем способе инвестиций. Мы не обсуждали
путь решения, проделанный программой к соответствующим выводам. Это задача
поиска. Данный пример иллюстрирует лишь один подход к осуществлению
логически обоснованного поиска в системе финансового советника. Здесь используется
Глава 3. Структуры и стратегии поиска в пространстве состояний
139
поиск от цели в глубину и с возвратами. В рассуждениях будем использовать
предикаты, составленные в разделе 2.4. Эти предикаты здесь не дублируются.
Предположим, что клиент имеет двух иждивенцев, вклад в размере $20000 и
устойчивый доход $30000 в год. В главе 2 было сказано, что к набору уже существующих
выражений исчисления предикатов можно добавлять новые. И, наоборот, программа может
начать поиск без этой конкретной информации, запрашивая у пользователя необходимые
дополнительные сведения. Преимущество этого метода состоит в том, что можно не
хранить ненужные данные, которые не будут полезными для решения. Этот подход часто
используют в экспертных системах.
Цель консультаций состоит в том, чтобы определить наилучший способ инвестиций.
Это представлено выражением исчисления предикатов ЗХ investment(X), где X —
целевая переменная, которую мы стремимся связать. Были приведены три правила A, 2 и 3)
которые дают заключения об инвестициях, поэтому запрос будет унифицирован
(объединен) с заключениями этих правил. Если для первоначального исследования
выбрать правило 1, то его предпосылка savings_account(inadequate) становится
подцелью, т.е. дочерней вершиной, которую необходимо достичь.
Для получения дочерних узлов подцели savings_account(inadequate) применяется
единственно возможное правило 5, которое порождает и-вершину.
amount_saved(X)Adependents(Y)A-lgreater(Ximinsavings(Y))
Если доказывать составляющие этого выражения слева направо, то компонент
amount_saved(X) будет рассмотрен первым. Поскольку приведенные ранее правила не
содержат этой подцели, система запрашивает пользователя о дополнительных данных.
После чего к имеющемуся списку добавляется предикат amount_savedB0000) с
унифицирующей заменой 20000 вместо X, и первая подцель становится истинной.
Поскольку мы исследуем вершину м, в случае неудачи с первым компонентом нам не
понадобилось бы исследовать остальные две подцели.
Аналогично подцель dependents(Y) ведет к запросу пользователя, затем ответ
dependentsB) (иждивенцев 2) добавляется к логическому описанию. Подцель ставится
в соответствие выражению путем подстановки {2/У]. Затем алгоритм поиска оценивает
истинность выражения -igreafer(X,minsavings( Y)).
Оценка этого выражения приводит к значению "ложь" и невыполнению подцели,
определяемой всей вершиной и. Затем алгоритм поиска возвращается к
родительской вершине savings account(inadequate) и пытается найти альтернативный
вариант доказательства истинности этой вершины. Эта попытка приводит к
генерированию следующей дочерней вершины и продолжению поиска. Поскольку нет
правила, содержащего эту подцель, поиск завершается неудачей и возвращается к цели
верхнего уровня investment(X). С этой целью унифицируются заключения правила 2,
приводя к новым подцелям
savings _account(adequate)Ai'ncome(adequate).
Продолжая поиск, доказываем, что savings account(adequate) истинно как
заключение правила 4, a income(adequate) следует из правила 6. Дальнейшие детали поиска
оставлены на рассмотрение читателю, а исследуемый граф И/ИЛИ в его окончательном
виде приведен на рис. 3.24.
140
Часть II. Искусственный интеллект как представление и поиск
investment^)
\ amount_saved{X)\ dependents{Y) -,greater(X,minsavings{Y))
[amount_savedB0000)\ f dependentsB) J и воз
здесь алгоритм заходит в тупик
возвращается назад*****
[ investment(stocks)}
[ amount_saved{X)\ \ dependents(Y) ] greater(X,minsavings(Y))\
\ . ) \ . ) \ J
Г amount_saved( 20000I f dependentsB) J
f income(adequate) J
f earnings(X,steady) J [ dependents(Y) j f greater(X,minincome(Y)) J
earnings{30000, sfeady) dependentsB)
Рис. 3.24. Поиск, осуществляемый системой финансового советника на графе И/ИЛИ
ПРИМЕР 3.3.6. Синтаксический анализатор и генератор предложений
Заключительный пример не относится к исчислению предикатов. Рассмотрим
набор правил подстановки (rewrite rule) для синтаксического анализа предложений
(парсинга) на подмножестве правил английской грамматики. Правила подстановки
преобразуют исходное выражение путем замены набора символов в предложении,
соответствующего некоторому шаблону, находящемуся по одну сторону стрелки (<->),
шаблоном из другой части правила. Например, можно определить набор правил
подстановки для замены выражения на одном языке (например, английском)
выражением на другом языке (например, французском или языке исчисления
предикатов). Приведенные здесь правила подстановки преобразуют подмножество
английских предложений в грамматические конструкции более высокого уровня, такие как
Глава 3. Структуры и стратегии поиска в пространстве состояний
141
именная или глагольная конструкция и предложение. Эти правила используются для
синтаксического анализа последовательности слов в предложении, т.е. для
определения правильности построения предложений и их грамматической корректности, а
также для моделирования лингвистической структуры предложений.
Рассмотрим пять упрощенных правил английской грамматики.
1. Предложение— это именная конструкция пр (noun phrase), за которой следует
глагольная конструкция vp (verb phrase).
sentence <-> np vp
2. Именная конструкция — это существительное (п).
пр<г+п
3. Именная конструкция пр — это артикль art, за которым следует существительное п.
np^art n
4. Глагольная конструкция vp (verb phrase) — это глагол.
vp<->v
5. Глагольная конструкция — это глагол, за которым следует именная конструкция.
vp<->v пр
Кроме этих правил грамматики, синтаксический анализатор использует словарь
данного языка. Эти слова называются терминалами (terminals). В правилах подстановки они
определены как части речи. В нашем небольшом "словаре" имеются такие слова: a, the
(артикли), man (человек), dog (пес), likes (любит) и bites (кусает). Они являются
терминалами простой грамматики.
6. а — артикль.
arf<->a
7. the — артикль.
art^the
8. Человек — существительное.
n<r+man
9. Собака — существительное.
n<^>dog
10. Любить — глагол (verb).
v<->//7ces
11. Кусать — глагол.
v<r+bites
Приведенные выше правила подстановки определяют граф И/ИЛИ (рис. 3.25).
Sentence (предложение) — корень графа. Элементам, стоящим в левой части правил
подстановки, соответствуют и-вершины этого графа. Несколько правил с одинаковым
заключением формируют вершины или. Заметим, что листья, или узлы-терминалы,
графа — это грамматически правильные слова английского языка.
Выражение считается правильно построенным, если оно состоит только из терминальных
символов. При этом для выражения существует ряд подстановок, которые путем применения
правил вывода преобразуют его в символ sentence (предложение). И, наоборот, анализ
142 Часть II. Искусственный интеллект как представление и поиск
можно рассматривать как построение дерева синтаксического анализа, у которого
листьями являются слова рассматриваемого выражения, а символ sentence — его корнем.
man dog a the man dog
Рис. 3.25. Граф И/ИЛИ для простой грамматики из примера 3.3.6. Для
упрощения графа некоторые вершины (пр, art и т.д.) дублируются
Синтаксический анализ предложения 'The dog bites the man" с помощью дерева
грамматического разбора приведен на рис. 3.26. Это дерево является поддеревом графа PI/ИЛИ,
показанного на рис. 3.25, и построено в процессе поиска. Алгоритм синтаксического анализа на
основе данных осуществляет поиск путем сопоставления правых частей правил подстановки с
элементами предложения и пробует найти одинаковые пары. Как только соответствие
найдено, часть выражения, соответствующая правой части правила, заменяется образцом из его
левой части. Это продолжается до тех пор, пока предложение не будет сведено к символу
sentence (указывающему на успешное завершение синтаксического анализа), или пока не
будут исчерпаны правила, которые можно применить к предложению (что указывает на
неудачу). Проследим путь синтаксического анализа предложения 7ze dog bites the man\
1. Правило 7 — это первое правило, которое можно применить, записывая the как art
(артикль). Получаем предложение: art dog bites the man.
2. Правило 7 применяется на следующей итерации и получается art dog bites art man.
3. Применение правила 8 порождает предложение art dog bites art п.
4. Правило 3 выводит предложение art dog bites пр.
5. Правило 9 порождает art n bites пр.
6. В результате применения правила 3 получим пр bites пр.
7. Правило 11 порождает пр v пр.
8. Правило 5 порождает пр vp.
9. Правило 1 приводит это предложение к заключению sentence, подтверждая
корректность первоначального предложения.
Глава 3. Структуры и стратегии поиска в пространстве состояний
143
the dog bites the man
Рис. 3.26. Представление предложения "The
dog bites the man " в виде дерева
грамматического разбора. Заметим, что оно определяет
поддерево графа, показанного на рис. 3.25
Рассмотренный пример осуществляет синтаксический анализ в глубину на основе данных,
поскольку он всегда применяет к выражению правило наивысшего уровня. Например,
выражение art n приводится к пр до того, как bites приводится к v. Синтаксический анализ также
можно выполнить путем поиска от цели. Тогда точкой отсчета является sentence, а в
процессе поиска находится ряд подстановок, которые соответствуют левым частям правил. Ряд
подстановок (если такой существует) приведет в конце концов к нужному предложению.
Синтаксический анализ, или парсинг, важен не только для задач понимания
естественного языка (глава 13), но также для построения трансляторов и интерпретаторов для
машинных языков [Aho и Ullman, 1977]. В литературе можно найти много алгоритмов
синтаксического анализа для всех классов языков. Например, существуют алгоритмы
синтаксического анализа от цели, которые умеют заглядывать вперед, чтобы определить,
какое правило из входного потока нужно применить следующим.
В приведенном выше примере мы рассмотрели очень простой алгоритм поиска на
графе ШИЛИ — неинформированный метод. Однако для этого примера можно
реализовать очень интересную стратегию поиска. Метод хранения текущего выражения и
упорядоченное нахождение подходящих правил — примеры использования продукционной
системы для осуществления поиска и основная тема главы 5.
Правила подстановки также используются для генерирования допустимых
предложений согласно правилам грамматики. Предложения могут быть сгенерированы путем
поиска от цели верхнего уровня sentence. Этот поиск заканчивается, если больше нет
правил, которое можно было бы применить. Поиск приводит к цепочке терминальных
символов, которая является допустимым предложением в данной грамматике. Например,
sentence — это пр, за которым следует vp (правило 1).
Заменяя пр на п (правило 2), получаем п vp.
Подстановка man — первого значения из множества п (правило 8) — приводит к
man vp.
144
Часть II. Искусственный интеллект как представление и поиск
Теперь для пр поиск успешен, и рассматривается vp. Правило 3 заменяет vp на V,
получаем man v.
Правило 10 заменяет v на likes.
man likes найдено как первое допустимое предложение.
Если необходимо получить все допустимые предложения, этот поиск можно
систематично повторять, пока не будут испытаны все варианты, т.е. пока не будет исследовано
все пространство состояний. Затем можно генерировать предложения "a man //Tees",
"the man likes" и т.д. Всего при исчерпывающем поиске (полном переборе) можно
построить 84 корректных предложения. Они включают такие семантические аномалии, как
"the man bites the dog" (человек кусает собаку).
Синтаксический анализ и генерирование предложений могут использоваться при
решении различных задач. Например, если нужно найти все предложения, завершающие
фразу "the man", решателю можно представить незаконченный ряд "the man...". Поиск
на основе данных можно направить вверх и вывести завершающее предложение
sentence (правило 1). Затем пр заменяется the man, и поиск от цели определяет все
возможные vp, которые завершают предложение. Этот алгоритм поиска позволяет
построить предложения типа "the man likes", "the man bites the man" (человек кусает
человека) и т.д. В этих примерах мы имеем дело только с синтаксической
корректностью. Проблема семантики — это иная задача. В главе 2 исследована проблема
построения семантики выражений формальной логики и выражений естественного языка. Эта
проблема значительно сложнее, она будет обсуждаться в главе 13.
Последний пример иллюстрирует чрезвычайную гибкость исследования пространства
состояний. В следующей главе мы обсудим использование эвристик для фокусировки
поиска на минимальной области пространства состояний. В главе 5 рассмотрим
продукционные системы и другие формализмы управления методами поиска, а также иные
приемы поиска и языки представления.
3.4. Резюме и дополнительная литература
Глава 3 познакомила читателя с теоретическими основами поиска в пространстве
состояний. При этом для анализа структуры и сложности стратегий поиска при решении
задач использовалась теория графов. Рассматривая основы теории графов, мы показали
пути ее применения для решения задач на основе поиска на графе пространства
состояний. Кроме того, в этой главе приводится сравнение поиска на основе данных и от цели,
поиска в глубину и в ширину.
Графы И/ИЛИ позволяют осуществлять поиск в пространстве состояний, реализуя
логические рассуждения. Стратегии поиска, описанные в главе 3, были
проиллюстрированы рядом примеров, в том числе на примере системы финансового советника,
представленного в главе 2.
Основные принципы поиска на графах обсуждаются в учебниках по теории алгоритмов, в
том числе в [Cormen, Leiserson, Rivest, 1990], [Helman и Veroff, 1986], [Sedgewick, 1983],
[Horowitz и Sahni, 1978]. Алгоритмы поиска на графах И/ИЛИ представлены также в главе 12,
и реализованы в главах, посвященных языкам PROLOG и LISP.
Преимущества поиска на графах для моделирования решения интеллектуальных задач
рассмотрены в [Newell и Simon, 1972]. Стратегии поиска обсуждаются в [Nilsson, 1998],
Глава 3. Структуры и стратегии поиска в пространстве состояний
145
[Winston, 1992] и [Charniak и McDermott, 1985]. В [Pearl, 1984] представлены алгоритмы
поиска и заложены основы материала, приведенного в главе 4. Развитие новых приемов
поиска на графах — это традиционная и широко обсуждаемая тема на ежегодных
конференциях по ИИ.
3.5. Упражнения
1. Гамильтонов путь— это путь, проходящий через каждую вершину графа только
один раз. Какие условия необходимы для существования такого пути? Существует ли
такой путь на карте Кенигсберга?
2. Представьте в виде графа задачу переправы человека, волка, козы и капусты из
раздела 14.3 (см. рис. 14.1 и 14.2). Пусть узлы представляют расположение объектов
в пространстве. Например, человек и коза находятся на западном берегу реки, а волк
и капуста — на восточном. Приведите преимущества стратегий поиска в ширину и в
глубину для этого пространства.
3. Приведите пример задачи о коммивояжере, в которой стратегия ближайшего соседа
при нахождении оптимального пути приводит к неудаче. Предложите другую
эвристику для этой задачи.
4. Пройдите "вручную" алгоритм с возвратами для графа, показанного на рис. 3.27. Начните
с состояния Л. Проследите значения списков NSL, SL, CS по пути к решению.
5. Реализуйте алгоритм поиска с возвратами на языке программирования по вашему
выбору.
6. Определите, какой алгоритм поиска (от цели или на основе данных)
предпочтительнее для решения каждой из следующих задач. Обоснуйте ваш ответ.
6.1. Диагностика неисправностей автомобиля.
6.2. Вы встретили даму, которая утверждает, что она ваша дальняя родственница и у
вас есть общий предок по имени адмирал Ушаков. Вы хотели бы проверить ее
заявление.
6.3. Один человек утверждает, что он приходится вам дальним родственником. Он не
знает имени вашего общего предка, но знает, что это было не более восьми
поколений назад. Вы хотели бы найти этого предка или доказать, что его не существовало.
6.4. Программа автоматического доказательства теорем для планиметрии.
6.5. Программа интерпретации звуковых сигналов, отличающая звуки большой
подводной лодки от маленькой субмарины, кита от стаи рыб.
6.6. Экспертная система, которая поможет человеку классифицировать растения по
виду, роду и т.д.
7. Обоснуйте выбор поиска в ширину или в глубину для примеров из упражнения 6.
8. Запишите алгоритм с возвратами для графа И/ИЛИ.
9. Решите задачу о хорошей собаке из примера 3.3.4 с помощью стратегии поиска на
основе данных.
10. Приведите еще один пример задачи поиска на графе И/ИЛИ и сформируйте
фрагмент пространства поиска.
146
Часть II. Искусственный интеллект как представление и поиск
11. Проследите траекторию выполнения алгоритма на основе данных для системы
"финансового советника", описанной в примере 3.3.5, для клиента с четырьмя
иждивенцами, имеющего $18000 на счету в банке и устойчивый доход $25000 в год.
Основываясь на сравнении этой задачи с примером в тексте главы, предложите
наилучшую стратегию для решения задачи в общем виде.
12. Добавьте к правилам английской грамматики, описанным в примере 3.3.6, правила
для прилагательных и наречий.
13. Добавьте к описанию английской грамматики из примера 3.3.6 правила для фраз с
предлогами.
14. Добавьте правила составления сложноподчиненных предложений вида
sentence <-> sentence и sentence.
J К L M N OP R
Рис. 3.27. Поиск на графе
Глава 3. Структуры и стратегии поиска в пространстве состояний
147
Эвристический
поиск
Проблема, с которой сталкивается символьная система при решении
поставленной задачи, заключается в том, чтобы, используя ограниченные ресурсы обработки,
найти решение, удовлетворяющее определенному условию. Если бы символьная
система могла управлять порядком генерации потенциальных решений, то следовало бы
добиться того, чтобы нужные решения появлялись как молено раньше. Символьной
системе необходимо проявлять интеллект для успешного решения этой проблемы
Интеллект для системы с ограниченными ресурсами обработки — это поиск
разумной последовательности действий ..
— Ньюэлл и Саймон, лекция по случаю вручения премии Тьюринга, 1976
Я аккуратный..
Аккуратный .. О, да,
Аккуратный во всех отношениях ..
— Либер и Столлер (Lieber и Stoller)
4.0. Введение
В [Polya, 1945] эвристика определяется как "изучение методов и правил открытий и
изобретений". Это слово имеет греческий корень, глагол eurisco означает "исследовать".
Когда Архимед выскочил из ванны, держа золотой венец, он закричал "Эврика!", что
значит "Я нашел!". В пространстве состояний поиска эвристика определяется как набор
правил для выбора тех ветвей из пространства состояний, которые с наибольшей
вероятностью приведут к приемлемому решению проблемы.
Специалисты по искусственному интеллекту используют эвристику в двух ситуациях.
1. Проблема может не иметь точного решения из-за неопределенности в
постановке задачи и/или в исходных данных. Медицинская диагностика — пример
такой проблемы. Определенный набор признаков может иметь несколько
причин; поэтому врачи используют эвристику, чтобы поставить наиболее точный
диагноз и подобрать соответствующие методы лечения. Система технического
зрения — другой пример задачи с неопределенностью. Визуальные сцены
часто неоднозначны, вызывают различные (часто не связанные друг с другом)
предположения относительно протяженности и ориентации объектов.
Оптический обман — хорошая иллюстрация таких двусмысленностей. Системы тех-
нического зрения часто используют эвристику для выбора наиболее вероятной
интерпретации из нескольких возможных.
2. Проблема может иметь точное решение, но стоимость его поиска может быть
слишком высокой. Во многих задачах (например, игра в шахматы) рост
пространства возможных состояний носит экспоненциальный характер, другими словами,
число возможных состояний растет экспоненциально с увеличением глубины
поиска. В этих случаях методы поиска решения "в лоб" типа поиска в глубину или в
ширину могут занять слишком много времени. Эвристика позволяет избежать этой
сложности и вести поиск по наиболее "перспективному" пути, исключая из
рассмотрения неперспективные состояния и их потомки. Эвристические алгоритмы
могут (как правило, на это надеются проектировщики) остановить этот
комбинаторный рост и найти приемлемое решение.
К сожалению, подобно всем правилам открытия и изобретения, эвристика может
ошибаться. Эвристика — это только предложение следующего шага, который будет
сделан на пути решения проблемы. Такие предположения часто основываются на опыте или
интуиции. Поскольку эвристика использует такую ограниченную информацию, как
описание текущих состояний в списке open, то она редко способна предсказать дальнейшее
поведение пространства состояний. Эвристика может привести алгоритм поиска к
субоптимальному решению или не найти решение вообще. Это ограничение присуще
эвристическому поиску и не может быть устранено "лучшей" эвристикой или более
эффективным алгоритмом поиска [Garey и Johnson, 1979].
Эвристика и разработка алгоритмов для эвристического поиска в течение
достаточно долгого времени остаются основным объектом исследования в проблемах
искусственного интеллекта. Игра и доказательство теорем — два самых старых
приложения в области искусственного интеллекта; оба они нуждаются в эвристике для
сокращения числа состояний в пространстве поиска. Невозможно рассмотреть
каждый вывод, который может быть сделан в той или иной области математики, или
каждый возможный ход на шахматной доске. Эвристический поиск — часто
единственный практический метод решения таких проблем.
Исследование в области экспертных систем подтвердило важность эвристики как
основного компонента при решении задач. Эксперт-человек, решая проблему, анализирует
доступную информацию и делает вывод. Интуитивные правила ("rules of thumb"),
которые использует эксперт, чтобы эффективно решить ту или иную проблему, в
значительной степени эвристичны по природе. Такие эвристики были созданы и формализованы
разработчиками экспертных систем.
Эвристические алгоритмы состоят из двух частей: эвристической меры и
алгоритма, который использует ее для поиска в пространстве состояний. В подразделе 4.1.1
мы рассмотрим один из эвристических алгоритмов поиска — так называемый
"жадный" алгоритм (best first). Разработка эвристик и оценка их эффективности
описаны в конце этой главы.
Рассмотрим игру в "крестики-нолики" (рис. П.5). Исчерпывающий поиск (полный
перебор вариантов) в этой игре затруднителен, но возможен. На каждый из девяти первых
ходов существует восемь возможных ответов. На которые, в свою очередь, можно
ответить семью различными вариантами и т.д. Простой анализ позволяет найти общее число
возможных состояний, которые следует рассмотреть в исчерпывающем поиске, —
9х8х7х..., или 9!.
150
Часть II. Искусственный интеллект как представление и поиск
Рис 4.1. Первые три уровня пространства состояний в игре "крестики-нолики",
редуцированные с учетом симметрии
Учитывая симметрию задачи, можно уменьшить пространство поиска. Проблема
множества возможных конфигураций в действительности сводится к поиску возможных
симметричных конфигураций игровой доски. Таким образом, существует не девять, а
только три возможных первых хода — в угол, на верхнюю центральную клетку и в центр
решетки. Редукции на втором уровне и далее сокращают размерность пространства до
12x7!, как показано на рис. 4.1. Симметрия игрового пространства, подобная
рассмотренной выше, может быть описана как математический инвариант, и если она
существует в задаче, то может быть успешно использована для значительного уменьшения
пространства состояний. Простая эвристика может свести на нет необходимость поиска: мы
можем делать такие ходы на доске, в которых крестики имеют наибольшее количество
выигрышных линий. (Первые три состояния игры "крестики-нолики" просчитаны
именно таким образом, рис. 4.2.) Если число потенциальных побед равно, берется первое из
таких состояний. Затем алгоритм выбирает состояние с наивысшим эвристическим
значением. Для хода X берем центральную клетку. Заметим, что при этом отбрасываются не
только остальные возможные ходы, но и их потомки. Отсюда следует, что после первого
хода размерность пространства состояний уменьшается на 2/3 (рис. 4.3).
Оппонент после первого хода может выбрать один из двух возможных ответных
ходов (как показано на рис. 4.3). Что бы ни выбрал оппонент, к результирующему
состоянию игры может быть применена эвристика. Эвристика использования "наибольшего
числа выигрышных линий" выбирает среди возможных ходов наилучший. При
продолжении поиска каждый новый ход устраняет необходимость обработки потомков
отброшенных узлов, таким образом, полный перебор не требуется. На рис. 4.3
продемонстрирован редукционный поиск на первых трех шагах игры. Каждое состояние игры
помечено соответствующим ему эвристическим значением.
Глава 4. Эвристический поиск
151
ж
\
ч
ч
ч
—
/
/
/
/
1
1
1
Ж
1
1
1
/
/
/
/
ч
ч
ч
ч
*
Три потенциально
выигрышные линии,
проходящие через
угловую клетку
Две потенциально
выигрышные линии,
проходящие через
среднюю клетку
в верхнем ряду
Рис. 4.2. Применение эвристики "наибольшего числа выигрышных
линий " к первым потомкам в игре "крестики-нолики "
Четыре потенциально
выигрышные линии,
проходящие через
центральную клетку
© © © ©
Х| | || |Х
© © © ©
Рис. 4 3. Эвристическая редукция пространства состояний в игре
"крестики-нолики "
Хотя точное количество возможных состояний в игре вычислить трудно, верхний
предел этого количества состояний может быть вычислен, если допустить, что
максимальное число ходов в игре — 9, и каждый ход имеет по 8 потомков. В действительности
число состояний будет гораздо меньше, так как доска заполняется, и с каждым ходом
число возможных ответов уменьшается. Более того, оппонент делает половину всех
ходов. Несмотря на это, грубый верхний предел — 9x8, или 72 состояния, что на 4 порядка
меньше величины 9!.
152
Часть II. Искусственный интеллект как представление и поиск
В следующем разделе (разделе 4.1) представлен алгоритм эвристического поиска и
продемонстрированы его характеристики с использованием различных эвристик для
игры в "пятнашки" над 8 числами (назовем ее 8-головоломка). В разделе 4.2 мы обсудим
такие теоретические понятия, относящиеся к эвристическому поиску, как допустимость
и монотонность. В разделе 4.3 рассматривается использование минимаксного подхода и
альфа-бета-усечения для эвристик в играх со многими участниками. В заключительном
разделе проверяется общность эвристического поиска и еще раз обосновывается его
существенная роль в решении задач искусственного интеллекта.
4.1. Алгоритм эвристического поиска
4.1.1. "Жадный" алгоритм поиска
Наиболее простой путь эвристического поиска— это применение процедуры поиска
экстремума (hill climbing). Стратегии, основанные на поиске экстремума, оценивают не
только текущее состояние поиска, но и его потомков. Для дальнейшего поиска выбирается
наилучший потомок; при этом о его братьях и родителях просто забывают. Поиск
прекращается, когда достигается состояние, которое лучше чем любой из его наследников. Поиск
экстремума — название стратегии, которая может быть использована энергичным, но
слепым альпинистом, поднимающимся вдоль наиболее крутого склона до тех пор, пока он не
сможет идти дальше. Так как в этой стратегии данные о предыдущих состояниях не
сохраняются, то алгоритм не может быть восстановлен из точки, которая привела к "неудаче".
Основная проблема стратегий поиска экстремума — это их тенденция
останавливаться в локальном максимуме. Другими словами, как только они достигают состояния,
имеющего лучшую оценку, чем его потомки, алгоритм завершается. Если это состояние
является не решением задачи, а только локальным максимумом, то такой алгоритм
неприемлем для данной задачи. Это значит, что решение может быть оптимальным на
ограниченном множестве, но из-за формы всего пространства, возможно, никогда не будет
выбрано наилучшее решение. Пример такого локального экстремума появляется в игре в
"пятнашки". Часто для того, чтобы передвинуть фишку в нужную позицию, необходимо
сдвинуть фишку, находящуюся в наилучшей позиции. Без этого невозможно решить
головоломку, но в то же время на данном этапе это ухудшает состояние системы. Дело в
том, что "лучший" не означает "идеальный". Методы поиска без механизмов возврата
или других приемов восстановления не могут отличить локальный максимум от
глобального. Существуют методы приближенного решения этой проблемы, например, случайное
возмущение оценки. Однако гарантированно решать задачи с использованием техники
поиска экстремума нельзя. Вариант алгоритма поиска экстремума предлагается в
тестовой программе, описанной в подразделе 4.3.2.
Несмотря на эти ограничения, алгоритм поиска экстремума может быть достаточно
эффективным, если оценивающая функция позволяет избежать локального максимума и
зацикливания алгоритма. В общем, однако, эвристический поиск требует более гибкого
метода, предусмотренного в "жадном" алгоритме поиска, где при использовании
приоритетной очереди возможно восстановление алгоритма из точки локального максимума.
Подобно алгоритмам поиска в глубину и алгоритмам поиска в ширину, описанным в
главе 3, "жадный" алгоритм поиска использует списки сохраненных состояний: список
open отслеживает текущее состояние поиска, а в closed записываются уже проверен-
Глава4. Эвристический поиск
153
ные состояния. На каждом шаге алгоритм записывает в список open состояние с учетом
некоторой эвристической оценки его "близости к цели". Таким образом, на каждой
итерации рассматриваются наиболее перспективные состояния из списка open. Псевдокод
для функции, реализующей "жадный" алгоритм поиска приведен ниже.
function best_first_search;
begin
open := [Start];
%инициализация
closed := [ ] ;
while open Ф [ ] do доставшиеся состояния
begin
удалить первое состояние X из списка open;
if X=goal, return путь от Start к X
else begin
сгенерировать потомок X;
for каждого потомка X do
case
потомок не содержится в списке open или closed:
begin
присвоить потомку эвристическое значение;
добавить потомок в список open
end;
потомок уже содержится в списке open:
if потомок был достигнут по кратчайшему пути
then записать это состояние в список open
потомок уже содержится в списке closed:
if потомок был достигнут по кратчайшему пути then
begin
удалить состояние из списка closed;
добавить потомок в список open
end;
end; %case
поместить X в список closed;
переупорядочить состояния в списке open в соответствии
с эвристикой (лучшие слева)
end;
return FAIL %список OPEN пуст
end.
На каждой итерации функция best_f irst_search удаляет первый элемент из
списка open. Достигнув цели, алгоритм возвращает путь, который ведет к решению.
Заметим, что каждое состояние сохраняет информацию о предшествующем состоянии,
чтобы впоследствии восстановить его и позволить алгоритму найти кратчайший путь к
решению (см. подраздел 3.2.3.).
Если первый элемент в списке open не является решением, то алгоритм использует
продукционные правила проверки соответствия и операции, чтобы сгенерировать все возможные
потомки данного элемента. Если потомок уже находится в списке open или closed, то
алгоритм выбирает кратчайший из двух возможных путей достижения этого состояния.
Затем функция best_f irst_search вычисляет эвристическую оценку состояний в
списке open и сортирует список в соответствии с этими эвристическим значениям. При
этом "лучшие" состояния ставятся в начало списка. Заметим, что из-за эвристической
154
Часть II. Искусственный интеллект как представление и поиск
природы оценивания следующее состояние должно проверяться на любом уровне
пространства состояний. Отсортированный список open часто называют приоритетной
очередью (priority queue).
А-5
Б-4 С-4 D-6
Е-5 F-5 G-4 Н-3 / J
А Л
у w v 1 /\/\ ч
к' V ч1 т t \t Ч Ч
К L М N 0-2 Р-З Q R
i i
i i
i i
Y Г
S Т
Рис 4.4. Эвристический поиск в гипотетическом
пространстве состояний
На рис. 4.4 показано гипотетическое пространство с эвристическими оценками
некоторых из его состояний. Состояния, рядом с которыми стоит их эвристическая оценка, были
сгенерированы функцией best_f irst_search. Состояния, по которым велся
эвристический поиск, отмечены полужирном шрифтом; заметьте, что поиск не ведется по всему
пространству. Другими словами, цель "жадного" алгоритма поиска состоит в том, чтобы
прийти к целевому состоянию кратчайшим путем. Чем более обоснованной является
эвристика (см. подраздел 4.2.3), тем меньше состояний нужно проверить при поиске цели.
Путь, по которому функция best_f irst_search находит целевое состояние,
показан на рисунке жирными стрелками. Предположим, что Р — целевое состояние (см.
рис. 4.4). Поскольку Р — цель, состояния на пути к Р имеют низкие эвристические
значения. Эвристика подвержена ошибкам: состояние О имеет более низкое эвристическое
значение, чем целевое, и поэтому было исследовано ранее. В отличие от поиска
экстремума, который не сохраняет приоритетную очередь для отбора "следующих" состояний,
данный алгоритм восстанавливается после ошибки и находит целевое состояние.
1. open = [А-Б]\ closed = [].
2. Вычисляем Л-5;орел = [8-4, С-4, D-6];c/osed = [А-5].
3. Вычисляем Б-4; ореп = [С-4'Е-5, F-5, D-6]; closed = [в-4, А-5].
4. Вычисляем С-4; open = [Н-3, G-4, Е-5, F-5, D]; closed= [С-4, Б-4, А-5].
5. Вычисляем Н-3; open = [0-2, Р-З, G-4, Е-5, F-5, D-6];
closed = [Н-3, С-4, Б-4, А-5].
6. Вычисляем 0-2; open = [Р-З, G-4, Е-5, F-5, D-6];
closed = [0-2, Н-3, С-4, Б-4, А-5].
7. Вычисляем Р-З; решение найдено]
Глава 4. Эвристический поиск
155
Д-5 Щ
S-4 C-4 D-6
И А К
Е-5 F-5 G-4 Н-3 / J
ЛЛ I Т\/\\
К L М N 0-2 Р-3 О Я
I I
S Г
Состояния из списка open Состояния из списка closed
Рис 4 5 Эвристический поиск в гипотетическом
пространстве состояний. Состояния из списков open и
cl osed выделены
На рис. 4.5 показано пространство после пятой итерации цикла while. Здесь
показаны состояния, содержащиеся в списках open и closed. В open сохраняется текущая
граница поиска, а в closed — уже рассмотренные состояния. Заметьте, что граница
поиска очень искривлена, отражая тем самым приспособленческую природу "жадного"
алгоритма поиска.
"Жадный" алгоритм поиска всегда выбирает наиболее перспективное состояние в
open для продолжения. Однако, поскольку при выборе состояния используется
эвристика, которая может оказаться ошибочной, алгоритм не отказывается от остальных
состояний, и сохраняет их в списке open. В данном случае эвристика обеспечивает
поиск вниз; этот путь оказывается ошибочным, но алгоритм в итоге возвращается к
некоторому ранее сгенерированному "лучшему" состоянию в open и затем
продолжает поиск в другой части пространства. В примере на рис. 4.4 после нахождения
потомков состояния В казалось, что они имеют плохие эвристические оценки, и поэтому
поиск сместился к состоянию С. При этом потомки состояния В были сохранены в open
на случай, если алгоритму необходимо будет вернуться к ним позже. В функции
best_f irst_search, как и в алгоритмах из главы 3, список open позволяет
возвращаться назад по ошибочному пути.
4.1.2. Функции эвристической оценки состояний
Рассмотрим эффективность нескольких различных эвристик для решения
8-головоломки. На рис. 4.6 показано начальное и целевое состояние для 8-головоломки
вместе с первыми тремя возможными состояниями, сгенерированными в процессе поиска.
Самая простая эвристика подсчитывает количество фишек, находящихся не на своих
местах, в каждом состоянии, сравнивая его с целевым состоянием.
156
Часть II. Искусственный интеллект как представление и поиск
Начальное
состояние
2
1
7
8
6
3
4
J5_
t
t
2
i
7
8
■
6
3
z
5
2
1
7
8
6
A
3
4
■
1
i
7
2
■
6
3
z
5
Целевое
состояние
Рис. 4.6. Начальное состояние, набор возможных
первых ходов и целевое состояние в игре "8-головоломка "
Состояние с меньшим числом фишек, находящихся не на своих местах, расположено
ближе к целевому состоянию, и поэтому будет рассмотрено первым.
Однако эта эвристика не использует всю имеющуюся информацию, потому что она не
принимает во внимание расстояние, на которое фишки должны быть перемещены. "Лучшая"
эвристика суммировала бы все расстояния между фишкой, находящейся не на своем месте, и
полем, в которое она должна быть перемещена для достижения целевого состояния.
Обе эти эвристики можно критиковать за то, что они не учитывают трудности при
перестановке фишек. Другими словами, если для достижения целевого состояния
необходимо переставить две рядом стоящие фишки, то это потребует более двух ходов, так
как для такой перестановки фишки должны "обойти" друг друга (рис. 4.7).
1
I
7
2
■
6
3
Z
5
Целевое
состояние
2
I
7
1
■
5
3
±
6
Рис. 4.7. Целевое состояние и состояние
с двумя перестановками: 1 и 2, 5 и 6
Эвристика, принимающая во внимание этот факт, для каждой инверсии (когда для
достижения целевого состояния необходимо поменять местами две рядом стоящие
фишки) должна умножать эвристическое значение на малое число (например 2). На рис. 4.8
2
1
■
8
6
'
3
4
5
Глава 4. Эвристический поиск
157
показан результат применения каждой из этих трех эвристик к трем потомкам,
изображенным на рис. 4.6.
На рис. 4.8 показан результат применения оценивающих функций. Эвристика "суммы
расстояний", кажется, действительно дает более точную оценку затрат, чем простой подсчет
числа фишек, находящихся не на своих местах. Эвристика перестановки фишек не может найти
различий между этими состояниями, давая каждому из них оценку, равную нулю. Эвристика
"суммы состояний" не приводит к решению, так как ни одно из этих состояний не содержит
ни одной прямой инверсии. Четвертый вариант эвристики, преодолевающий ограничения,
накладываемые на эвристику "перестановки фишек", — сложить расстояния между фишками,
удвоив расстояния между элементами, которые должны быть взаимно переставлены.
Этот пример иллюстрирует, насколько трудно найти хорошую эвристику. Наша цель
состоит в том, чтобы, используя ограниченную информацию, содержащуюся в описании
отдельного состояния, все же сделать правильный выбор. Каждая из эвристик,
предложенных выше, игнорирует некоторые критические элементы информации, и поэтому
может быть улучшена. Разработка хорошей эвристики — это эмпирическая проблема, в
решении которой помогают рассуждения и интуиция. Но все же решающий критерий
оценки эвристики — это ее эффективность при решении практических задач.
Поскольку эвристика может быть ошибочной, существует вероятность, что алгоритм
поиска может пойти по ложному пути. Эта проблема возникала при поиске в глубину, где
подсчет глубины использовался для того, чтобы определить ложные пути. Эта идея может
быть также применена в эвристическом поиске. Если два состояния имеют одинаковые или
почти одинаковые эвристические значения, то предпочтительнее исследовать состояние,
которое расположено ближе к корневому состоянию графа. Это состояние с большей
вероятностью расположено на пути к цели. Расстояние от начального состояния к его потомкам
может быть измерено путем вычисления уровня глубины для каждого состояния.
2
1
■
8
6
7
3
4
5
2
±
7
8
■
6
3
z
5
2
1
7
8
6
*
3
4
■
Фишки,
находящиеся
не на своих
местах
Сумма
расстояний
до целевого
состояния
для фишек,
находящихся
не на своих местах
Удвоенное
число
прямых
перестановок
фишек
1
I
7
2
■
6
3
i
5
Целевое
состояние
Рис. 4.8. Три возможных варианта эвристики в 8-головоломке
158
Часть II. Искусственный интеллект как представление и поиск
Для начального состояния это значение равно 0 и увеличивается на 1 для каждого
уровня поиска. Это позволяет записать фактическое число шагов, необходимых для
достижения в процессе поиска из стартового состояния любого из его потомков. Это
значение может быть добавлено к эвристической оценке каждого состояния для того, чтобы
сместить поиск к наиболее подходящим состояниям.
Таким образом, оценивающая функция f состоит из двух компонентов:
f(n) = g(n) + h(n),
где д(п) — фактическая длина пути от произвольного состояния п к начальному, а
h (п) — эвристическая оценка расстояния от состояния п к цели.
Например, в 8-головоломке значением h(n) можно считать число фишек,
находящихся не на своих местах. Если рассмотреть состояния, изображенные на рис. 4.6, то
значения f для каждого из них будут равны 6, 4 и 6 соответственно (рис. 4.9).
На рис. 4.10 показано значение f для каждого состояния графа "жадного"
алгоритма поиска для 8-головоломки. Рядом с каждым состоянием указан его
эвристический вес Цп) = g(n) + h(n). Номер в верхней части состояния указывает порядок, в
котором это состояние было взято из списка open. Некоторые состояния
(/7, д, Ь, d, л, к и /) не пронумерованы, так как они оставались в списке open на
момент завершения алгоритма.
д(п) = 0
9(n) = ^
2
1
■
8
6
^
3
4
5
Начальное
состояние
2
1
7
8
6
3
4
5
2
I
7
8
■
6
3
Z
5
2
1
7
8
6
*
3
4
■
Значение f{n) для каждого состояния, 6
mef[n) = g{n)+h{n),
д{п) = реальное расстояние от л до начального состояния,
h{n) = число фишек, находящихся не на своих местах
Целевое
состояние
Рис. 4.9. Эвристика f для состояний в игре "^-головоломка'
1
I
7
2
■
6
3
±
5
Глава 4. Эвристический поиск
159
Содержание списков open и closed, которые генерируют этот граф, приведено ниже.
1. open = [a4]; closed = [].
2. open = [с4, be, de]; closed = [a4].
3. open = [e5, f5, be, de, g6]; closed = [aA, c4].
4. open = [f5, he, b6, de, g6, 77]; closed = [a4, c4, e5].
5. open = [y'5, /76, be, de, g6, /c7, 77]; closed = [a4, c4, e5, f5].
6. open = [/5, /76, Ь6, d6, g6, /c7, 77]; c/osed = [a4, c4, e5, f5J5].
7. open = [m5, he, be, de, g6, nl, kl, 77]; closed = [a4, c4, e5, f5,/5, /5].
8. Найдено решение т = цель\.
На 3 шаге состояния е и 1 имеют эвристическое значение, равное 5. Состояние е
было проверено первым, его потомками являются h и /. Хотя h является потомком е, для
него число фишек, расположенных не на своих местах, соответствует состоянию f; при
этом данное состояние находится на один уровень ниже в пространстве состояний. Мера
глубины, д(п), заставляет алгоритм выбирать 1 в качестве оценки на шаге 4. Поэтому
алгоритм возвращается к состоянию f, находящемуся на один уровень выше, и затем
продолжает двигаться к цели по другой ветке. Граф пространства состояний на этой стадии
поиска показан на рис. 4.11. Здесь закрашены области, в которых находятся состояния из
списков open и closed. Обратите внимание на приспособленческую природу поиска
до первого наилучшего совпадения.
В действительности компонент д(п) функции оценки придает нашему поиску
свойства поиска в ширину. Он предотвращает возможность заблуждения из-за ошибочной
оценки: если эвристика непрерывно возвращает "хорошие" оценки для состояний на
пути, не ведущем к цели, то значение g будет расти и доминировать над h, возвращая
процедуру поиска к кратчайшему пути. Это избавляет алгоритм от зацикливания. В
разделе 4.2 рассмотрены условия, при которых "жадный" алгоритм поиска с использованием
функции оценки гарантирует выбор кратчайшего пути к цели.
Подведем итог.
1. Операции над состояниями позволяют генерировать потомков текущего состояния.
2. Каждое новое состояние проверяется на предмет того, встречалось ли оно раньше
(т.е. находится ли оно в списках open или closed). Таким образом
предотвращаются циклы.
3. Каждому состоянию п соответствует значение f, равное сумме его глубины в
пространстве поиска д(п) и некоторой эвристической оценки расстояния от него до
цели h(n). Другими словами, h ведет алгоритм поиска к эвристически наиболее
перспективным состояниям, в то время как значение g удерживает алгоритм от
упорного следования по неверному пути.
4. Состояния в списке open сортируются в соответствии со значениями f. Сохраняя все
состояния в списке open, алгоритм сможет уберечь себя от неудачного завершения.
5. Эффективность алгоритма может быть увеличена за счет представления списков
open и closed в виде кучи (heap) или левостороннего дерева (leftist trees).
"Жадный" алгоритм поиска — это общий алгоритм для эвристического поиска на
любом графе пространства состояний (как и алгоритмы поиска в ширину или в глубину,
рассмотренные ранее).
160 Часть II. Искусственный интеллект как представление и поиск
Уровень поиска
9(п) =
2
1
7
8
6
3
4
5
Состояние а
f(a) = 4
д(п) = О
■
2
7
в
1
6
3
4
5
д(п) = л
1
I
7
2
■
6
3
I
5
Состояние m
f(m) = 5
1
7
■
2
8
А
3
4
5
Состояние п
f(n) = 7
д(л) = 5
Целевое
состояние
Рис. 4.10. Пространство состояний, сгенерированное при эвристическом поиске на графе игры
в "пятнашки"
Этот алгоритм, в одинаковой степени применимый к поиску данных и поиску решения
задачи, поддерживает различные функции оценки. Далее мы продолжим рассматривать
поведение эвристического алгоритма поиска на других примерах (раздел 4.2). Благодаря своей
универсальности "жадный" алгоритм поиска может использоваться с различными эвристиками,
начиная от субъективных оценок "хороших" состояний и заканчивая сложными критериями
оценки состояний, ведущих к цели, на основе вероятностного подхода.
Глава 4. Эвристический поиск
161
Важным примером этого подхода являются байесовские (Bayesian) статистические
критерии (глава 7).
1 2
1
7
8
6
з]
4 I
5
Состояние а
Ца) = 4
I 2
1
■
8
6
2.
~з1
4
5 1
Состояние Ь
ЦЬ) = 6
Т^нг
■
2
j 7
71
1
6
~3~|
4
5 |
Состояние h
2
7
■
8
1
JL
3 |
4
5 I
Состояние/
ПО
""" I ^"""^
I 2 I 8 I 3 I
I 7 I 6J 5 I
l 2 1 1 3
1 1 8 1 4 1
1 7 j 6J 5 j
1 2 1 3 1
1 1 | g | 4 |
I 7 | 16 I 5 I
| 1 | 2 | 3 |
| 7 | 6 | 5 |
Состояние с
Цс) = 4
-*^^
Состояние f Г
ЦП-о г
""^-^
Г2
1
| 7
I 8
6
5
2 I
1
7 |
8
4
6
з
4
1
J
■
И
2
1
7 ]
1
8
6 ]
4
5 |
Состояние d
/(d) = 6
Состояние g
Цд) = б
Список closed
Список орел
1
8
7
2
■
6
3
3
5
Целевое
состояние
1
7
■
2
8
«
3
4
5
Р//с 4 77 5г/Э списков open и closed после третьей итерации эвристического поиска
Другой интересный подход к реализации эвристики — использовать меру доверия в
экспертных системах для анализа результатов того или иного правила. Человек-эксперт,
используя эвристику, обычно способен дать квалифицированную оценку степени
доверия своим выводам. Экспертные системы используют меры доверия (confidence measure)
для выбора тех результатов, которые имеют наивысшую вероятность успеха. Состояния
162
Часть II. Искусственный интеллект как представление и поиск
с наиболее низкой мерой доверия могут быть полностью исключены из рассмотрения.
Этот подход к эвристическому поиску будет рассмотрен в следующем разделе.
4.1.3. Эвристический поиск и экспертные системы
Простые игры типа "пятнашек4' по ряду причин являются идеальными примерами для
исследования поведения алгоритмов эвристического поиска.
1. Области поиска достаточно обширны, чтобы использовать эвристические упрощения.
2. Большинство игр достаточно сложны и допускают большое разнообразие
эвристических оценок для сравнения и анализа.
3. Игры, как правило, описываются достаточно просто. Описание пространства
состояний игровой доски может быть сделано явно. Это позволяет исследователям
сосредоточиться на поведении эвристики, а не на проблеме описания задачи.
4. Поскольку каждый элемент пространства состояний имеет одно представление
(описание доски), одна эвристика может применяться во всей области поиска. Это
отличает алгоритмы эвристического поиска от систем типа финансового
советника, где каждый элемент представляет собой подцель с собственным явным
представлением.
Более реалистические проблемы затрудняют выполнение и анализ эвристического
поиска, требуя сложной эвристики, которая имеет дело с различными ситуациями в
пространстве состояний. Однако результаты, полученные в простых играх, могут быть
использованы при решении проблем, возникающих в экспертных системах, планировании,
интеллектуальном управлении и машинном обучении. В отличие от игры в "пятнашки", в
этих системах к каждому состоянию не может быть применена одна и та же эвристика.
Эвристики, решающие специфические задачи, "зашиваются" в синтаксис и семантику
соответствующих операторов решения данной задачи. На каждом шаге решения
определяется, какую эвристику следует использовать. Операция (эвристика), которая должна
быть применена к тому или иному состоянию в пространстве, определяется в процессе
проверки соответствия шаблону.
Пример 4.1.1. Модификация системы финансового советника
Эвристические критерии поиска традиционно используются при решении задач ИИ.
Вернемся к задаче разработки финансового советника, рассмотренной в главах 2 и 3, где
база знаний представляет собой набор логических заключений, принимающих значения
"истина" или "ложь". В действительности эти правила эвристичны по своей природе.
Например, одно из правил гласит, что человеку с достаточными сбережениями и
доходом следует вложить свой капитал в акции:
savings account(adequate) л income(adequate) => investment (stocks).
На самом деле такой человек предпочтет более безопасную комбинированную
стратегию или вообще не будет трогать свои сбережения. Таким образом, данное правило
эвристично, и при решении проблемы необходимо попытаться учесть эту
неопределенность. Можно принимать во внимание дополнительные факторы, такие как возраст
инвестора, его карьеру и другие вопросы. Однако все это существенно не влияет на
эвристическую природу финансового совета.
Глава 4. Эвристический поиск
163
Один из путей решения данной проблемы в экспертных системах состоит в том,
чтобы с каждым правилом вывода связать весовой коэффициент (называемый мерой
доверия (confidence measure) или фактором уверенности (certainty factor)). Это дает
возможность измерить степень доверия к каждому такому выводу.
Каждое заключение связывают с мерой доверия, представляющей собой вещественное
число из интервала [-1; 1]. При этом 1 (истина) соответствует полному доверию, а -1
(ложь) — недоверию. Значения из этого отрезка соответствуют степени доверия выводу.
Например, приведенному выше правилу можно дать оценку 0,8, отражая, таким образом, малую
вероятность того, что оно не верно. Остальным заключениям можно присвоить другие веса.
savings_account(adequate) л income(adequate)
=> investment(stocks) with confidence = 0,8.
savings_account(adequate) л income(adequate)
=> investment(combination) with confidence = 0,5.
savings_account(adequate) л income(adequate)
=> investment(savings) with confidence = 0,1.
Эти правила отражают следующую общую стратегию. Человеку с достаточными
сбережениями и доходом настоятельно советуют вложить капитал в акции, но существует
некоторая возможность (и комбинированная стратегия должна учитывать ее) того, что он
может по-прежнему оставлять средства в банке. Эвристические алгоритмы поиска могут
использовать эти факторы уверенности по-разному. Например, можно вычислять
результаты применения всех правил с учетом степени доверия к ним. Такой полный перебор
всех возможностей может быть полезен, например, в медицине. Или программа может
возвращать только результат с наибольшим фактором уверенности, если остальные
решения не представляют интереса. Это позволит ей игнорировать другие правила,
радикально сужая область поиска. Можно также игнорировать правила с низкой мерой
доверия, например, не выше 0,2. Это позволит медленнее сужать пространство поиска.
При использовании меры доверия возникает ряд важных вопросов. Что понимается под
"числовой мерой доверия"? Например, как рассчитать степень доверия, если один вывод
используется как предпосылка для других? Как объединять меры доверия, если к одному и тому
же выводу можно прийти несколькими путями? Как назначать меру доверия
основополагающим правилам? Эти проблемы более подробно будут обсуждаться в главе 7.
4.2. Допустимость, монотонность и информированность
Поведение эвристики можно оценивать по ряду параметров. Например, наряду с
решением задачи может понадобиться алгоритм нахождения кратчайшего пути к нему. Это
важно, когда каждый дополнительный шаг к цели имеет очень высокую стоимость,
например, при планировании пути для автономного робота в опасной среде. Эвристика,
которая находит самый короткий путь к цели, называется допустимой (admissible). В
других приложениях кратчайший путь к решению может быть не так важен, как общая
эффективность решения задачи.
Можно задать вопрос: существуют ли лучшие эвристики? И в каком смысле одна
эвристика "лучше" другой? В этом состоит информированность (informedness) эвристики.
Можно ли гарантировать, что обнаруженное в процессе эвристического поиска
состояние нельзя было найти по короткому пути от начального состояния? Это свойство
называется монотонностью (monotonicity). Ответы на эти и другие вопросы, связанные с
эффективностью эвристик, составляют содержание этого раздела.
164 Часть II. Искусственный интеллект как представление и поиск
4.2.1. Мера допустимости
Алгоритм поиска называется допустимым, или приемлемым (admissible), если
гарантирует нахождение кратчайшего пути к решению. Поиск в ширину является допустимой
стратегией поиска. Поскольку сначала рассматриваются все состояния графа на уровне п
и лишь затем состояния на уровне п+1, то целевые состояния будут найдены по
кратчайшему из возможных путей. К сожалению, поиск в ширину часто слишком
неэффективен при практическом использовании.
Используя функцию оценки f(n)=g(n) + h(n), введенную в предыдущем разделе, можно
охарактеризовать класс допустимых эвристических стратегий поиска. Если п — узел графа
пространства состояний, то д(п) представляет глубину, на которой это состояние было
найдено, a h(n) — эвристическую оценку расстояния от узла п до цели. В этом смысле
f(n) оценивает общую стоимость пути от начального состояния к целевому через узел п.
При определении свойств допустимой эвристики определим функцию оценки f* так:
r(n)=g*(n)+h*(n),
где д*(п) — стоимость кратчайшего пути от начального узла к узлу п, a h* —
фактическая стоимость кратчайшего пути от узла п до цели. Отсюда следует, что f* (п) —
фактическая стоимость оптимального пути от начального узла до целевого через узел п.
В дальнейшем мы увидим, что при использовании функции best_f irst_search с
функцией оценки f* результирующая стратегия поиска будет допустимой. Поскольку
такие "оракулы" как f* для большинства реальных проблем не существуют, будем
использовать функцию оценки f как наиболее близкую к f*. В алгоритме А д(п) — стоимость
текущего пути к состоянию п является разумной заменой оценки д*, но они не равны:
д(п)>д*(п). Они равны только в том случае, если на графе найден оптимальный путь к п.
Аналогично заменим h*(n) на h(n) — эвристическую оценку минимальной
стоимости достижения целевого состояния из узла п. Как правило, вычислить h* невозможно,
но достаточно часто можно определить, действительно ли эвристическая оценка h(n)
ограничена сверху, т.е. действительно ли h(n) h*(n) не превосходит фактической
стоимости кратчайшего пути h*(n). Если алгоритм использует функцию оценки f, в которой
h(n) < h*(n), то он называется алгоритмом А*.
ОПРЕДЕЛЕНИЕ
АЛГОРИТМ А, ДОПУСТИМОСТЬ, АЛГОРИТМ А*
Рассмотрим функцию оценки f (п) = д (п) + h (n), где
п — любое состояние, достижимое в процессе поиска,
д (п) — стоимость пути из начального состояния к узлу п,
h (п) — эвристическая оценка стоимости пути от п к цели.
Если эта функция оценки используется в алгоритме best_f irst_search
(раздел 4.1), результирующий алгоритм называется алгоритмом А.
Поисковый алгоритм является допустимым, если для любого графа он всегда
выбирает оптимальный путь к решению.
Если в алгоритме А используется функция оценки, в которой значение h(n) меньше
или равно стоимости минимального пути от п до цели, такой алгоритм поиска
называется алгоритмом А * (произносится "А со звездочкой").
Теперь можно сформулировать свойство алгоритмов А*.
Все алгоритмы А* допустимы.
Глава 4. Эвристический поиск
165
Допустимость алгоритмов А* является теоремой, которую читателю предлагается
доказать в рамках упражнений в конце главы (см. также [Nilsson, 1980], с. 76-78). Теорема
гласит, что любой алгоритм А* (т.е. алгоритм, использующий такую эвристику /i(n), при
которой h(n)<h*(n) для всех п) гарантирует нахождение минимального пути от п до
цели, если такой путь вообще существует.
Заметим, что поиск в ширину может быть охарактеризован как алгоритм А*, в
котором f(n) = g(n)+0. Решение о рассмотрении каждого состояния принимается
исключительно с учетом его расстояния от начального состояния. В подразделе 4.2.3 будет
показано, что множество узлов, рассматриваемых алгоритмом А*, — это подмножество
состояний, рассматриваемых при поиске в ширину.
Примерами алгоритмов А* являются некоторые эвристики, применяемые для игры в
"пятнашки". Для этой задачи невозможно вычислить значение h*(n), но можно показать,
что эвристика ограничена сверху фактической стоимостью кратчайшего пути к цели.
Например, число фишек, расположенных не на месте, меньше или равно числу шагов,
требуемых для их перемещения в целевую позицию. Таким образом, такая эвристика
допустима и гарантирует нахождение оптимального (или кратчайшего) пути решения.
Сумма прямых расстояний фишек, находящихся не на своих местах, до их целевой
позиции также меньше или равна минимальному фактическому пути их перемещения в
целевое состояние. Использование малых множителей для прямых перестановок фишек
является допустимой эвристикой.
Такой подход к доказательству допустимости эвристик может применяться в
любых задачах эвристического поиска. Даже если не всегда можно вычислить
фактическую стоимость кратчайшего пути к цели, довольно часто удается доказать, что
эвристика ограничена сверху этим самым значением. Если этот факт будет доказан, то
результирующий поиск будет ограничен сверху кратчайшим путем к цели в случае
существования такого пути.
4.2.2. Монотонность
Напомним, что определение алгоритмов А* не требует, чтобы д(п) было равно д*(п).
Это означает, что допустимая эвристика может первоначально достигать "нецелевых"
состояний, следуя по субоптимальному пути, но в конечном счете алгоритм найдет
оптимальный путь ко всем состояниям, лежащим на пути к цели. Естественно спросить,
существует ли эвристика, которая является "локально допустимой", т.е. позволяет
последовательно находить кратчайший путь к каждому состоянию, которое встречается в
процессе поиска. Это свойство называется монотонностью (monotonicity).
ОПРЕДЕЛЕНИЕ
МОНОТОННОСТЬ
Эвристическая функция h монотонна, если
1. Для всех состояний п, и пр где п; — потомок п„
/7(п() - h(nt) < cost(njf nt)
Здесь cost(nif rij) — фактическая стоимость (количество шагов) перемещения от
состояния п, к rij.
2. Эвристическая оценка целевого состояния равна нулю, или h(Goal) = 0.
166
Часть II. Искусственный интеллект как представление и поиск
Один из способов описания свойства монотонности состоит в том, чтобы считать
область поиска всюду локально совместимой с используемой эвристикой. Разность
между эвристическими значениями некоторого состояния и любого из его потомков
связана с фактической стоимостью перемещения между ними. Это говорит о том,
что эвристика всюду допустима и достигает каждого состояния по кратчайшему
пути от его предка.
Если "жадный" алгоритм поиска на графе использует монотонную эвристику, то
некоторыми важными шагами можно пренебречь. Поскольку такая эвристика
находит кратчайший путь к любому состоянию при первом проходе через него, то
исчезает необходимость вычисления пути к этому же состоянию при последующих
проходах, поскольку новый путь заведомо не будет короче. Это позволяет отбрасывать
любое состояние, через которое алгоритм проходит во второй раз, без модификации
информации в списке open или closed.
При использовании монотонной эвристики в процессе поиска в пространстве
состояний эвристическое значение для каждого состояния п заменяется фактической
стоимостью пути к п. Поскольку реальная стоимость в каждой точке пространства не меньше
эвристической оценки, f не уменьшается. Таким образом, функция f является монотонно
неубывающей (в соответствии с названием).
Докажем, что любая монотонная эвристика допустима. Представим любой путь в
пространстве в виде последовательности состояний Si, S2..., Ss, где S\ — начальное
состояние, a S,,— целевое. Рассмотрим последовательность шагов по произвольно
выбранному пути.
От Si к S2 h(Si)-h(S2) < cost(Si, S2) по свойству монотонности
От S2 к S3 h(S2)-h(STl) < cost(S2, SO no свойству монотонности
От S3 к S4 fr(S3)-fr(S4) < cost(Si, S4) по свойству монотонности
по свойству монотонности
по свойству монотонности
От S^_i к S^ A?(S^,_i)—A7(S^) < cosf(Sj,_i, SA.) по свойству монотонности
Суммируя каждый столбец и используя свойство монотонности A?(Sg)=0, получим
От Si к Sg h(Si)-h(SK) < cost(Su S„)
Это означает, что монотонная эвристика h является эвристикой А* и она допустима.
Оставим в качестве упражнения проверку утверждения, что допустимость эвристики
означает ее монотонность.
4.2.3. Информированные эвристики
Заключительный вопрос этого раздела— сравнительный анализ способности двух
эвристик найти кратчайший путь. Рассмотрим эвристику А*.
ОПРЕДЕЛЕНИЕ
ИНФОРМИРОВАННОСТЬ
Если для двух А*-эвристик h\ и /ъ для всех состояний п в пространстве поиска
выполняется неравенство h\(n) < h2(n), то эвристика h2 называется более
информированной, чем h\.
Глава 4. Эвристический поиск
167
Это определение можно использовать при сравнении эвристик для игры в
"пятнашки". Как было сказано выше, поиск в ширину эквивалентен алгоритму А* с
эвристикой h\, при которой h\(x) = 0 для всех состояний х. Очевидно, что это значение
меньше, чем h*. Мы также показали, что число фишек h2, находящихся не на своих
местах, является нижней границей для h*. Следовательно, h\<h2<h*. Таким образом,
эвристика, основанная на числе фишек, находящихся не на своих местах, является более
информированной, чем поиск в ширину. На рис. 4.12 показаны пространства поиска этих
двух эвристик. Обе эвристики hx и h2 находят оптимальный путь к решению, но h2 в
процессе поиска оценивает намного меньше состояний.
Точно так же можно доказать, что вычисление суммы расстояний между фишками,
находящимися не на своих местах, является более информированной эвристикой, чем
определение числа фишек, находящихся не на своих местах. Для этого можно изобразить
последовательность областей поиска (каждая последующая меньше предыдущей),
сходящуюся к прямому оптимальному пути решения.
Если эвристика h2 более информирована, чем Ьь то множество состояний,
проверяемых эвристикой h2, является подмножеством состояний, проверяемых hx Это можно
доказать методом "от обратного". Предположим, что существует по крайней мере одно
состояние, проверяемое Ь2, а не h\. Поскольку h2— более информированная эвристика,
чем h\, то для любого п h2(n)<hx(n). Кроме того, обе эти эвристики ограничены
вышеупомянутым значением h*. Следовательно, наше предположение неверно.
Вообще, чем более информирован алгоритм А*, тем меньше состояний требуется
проверить, чтобы получить оптимальное решение.
Однако следует быть осторожным, так как при использовании более
информированной эвристики уменьшение числа состояний в пространстве поиска может потребовать
неоправданно больших объемов вычислений.
Интересным примером подобной ситуации являются компьютерные программы
игры в шахматы. Один из возможных подходов к такой программе — использование
простых эвристик и поиск в глубину в расчете на быстродействие компьютера. Для
оценки состояния и увеличения глубины поиска такие программы часто используют
специализированные аппаратные средства. Другой подход состоит в применении
более сложной эвристики и уменьшении числа просматриваемых состояний. Эта
эвристика вычисляет тактическое преимущество, рассматривает позиции фигур,
возможность атак, учитывает проходные пешки и так далее. Сложность вычислений
при такой эвристике может расти экспоненциально (эта проблема будет обсуждаться
в разделе 4.4). Поскольку общее время для первых 40 шагов игры ограничено, важно
оптимизировать принятие компромиссных решений между поиском и эвристической
оценкой. Оптимальное сочетание поиска и эвристик — открытый эмпирический
вопрос в компьютерных шахматах.
168
Часть II. Искусственный интеллект как представление и поиск
Целевое
состояние
Рис. 4 12 Сравнение пространств состояний, просматриваемых при использовании
эвристического поиска и поиска в ширину Часть графа, просматриваемая при использовании
эвристического поиска, затемнена Оптимачьное решение выделено жирной линией
Эвристика представляет собой функцию f[n)=i>{n)+h(n), где 1г(п) — число фишек,
находящихся не на своих местах
4.3. Использование эвристик в играх
В то время две противоположные концепции вызвали многочисленные споры. Лучшие
игроки различат два принципиальных типа Игры — формальный и психологический
— Герман Гессе (Hermann Hesse), Магистр Луди (Игра в бисер)
4.3.1. Процедура минимакса на графах, допускающих полный перебор
Игры всегда были важной прикладной областью для эвристических алгоритмов. Игры
для двух человек более сложны, чем простые головоломки из-за существования
"враждебного" и, по существу, непредсказуемого противника. Такие игры не только
Глава 4. Эвристический поиск
169
обеспечивают некоторые интересные возможности для развития эвристик, но и создают
большие трудности в разработке алгоритмов поиска.
Сначала рассмотрим игры с небольшим пространством состояний, обеспечивающим
возможность исчерпывающего поиска. В таких играх проблема решается
систематическим перебором всех возможных ходов и контрмер противника. Затем рассмотрим игры,
в которых полный перебор либо невозможен, либо нежелателен. Поскольку в таких
играх можно просмотреть только ограниченную часть пространства состояний, игрок
вынужден использовать эвристику, чтобы прийти к победе.
Игра "ним" (nim) — это одна из игр, пространство состояний которой допускает
исчерпывающий поиск. В этой игре на стол между двумя противниками выкладывается
некоторое число фишек. При каждом ходе игрок должен разделить "кучку" фишек на два
непустых набора разных размеров. Например, 6 фишек можно разделить на группы 5 и 1
или 4 и 2, но не 3 и 3. Первый игрок, который не сможет больше сделать ход,
проигрывает. Для разумного числа фишек в пространстве состояний этой игры можно
реализовать полный перебор. На рис. 4.13 показано пространство состояний для 7 фишек.
В играх, не допускающих исчерпывающего описания пространства состояний,
основная трудность заключается в предсказании действий противника. Простой способ учесть
такие действия — предположить, что ваш противник использует тс же самые знания о
пространстве состояний, что и вы, и применяет эти знания для своей победы. Хотя это
предположение имеет свои ограничения (которые будут обсуждаться в подразделе 4.3.2),
оно дает разумную основу для предсказания поведения противника. Метод минимакса
реализует поиск в игровом пространстве с учетом этого предположения.
/
2-
ч.
1
-1
-1
-1
■"ч
-1
J
Рис 4 13 Пространство состояний дчя одного из
вариантов игры "ним" В каждом состоянии семь фишек
делятся на несколько кучек
170
Часть II. Искусственный интеллект как представление и поиск
Назовем противников в игре MIN и МАХ. Эти имена выбраны по следующим
причинам: МАХ представляет игрока, пытающегося выиграть, или максимизировать свое
преимущество, a MIN — противника, который пытается минимизировать счет своего
оппонента. Предполагается, что MIN использует ту же самую информацию и всегда
пытается достичь наихудшего для МАХ состояния.
При реализации стратегии минимакса пометим каждый уровень в области поиска
именем игрока, выполняющего очередной ход: MIN или МАХ. В примере на рис. 4.14
первый ход делает MIN. Каждому листовому узлу присвоим значение 1 или 0, в
зависимости от победителя: МАХ или MIN. В процессе реализации процедуры минимакса эти
значения передаются вверх по графу согласно следующему правилу.
• Если родительское состояние является узлом МАХ, то ему присваивают
максимальное значение.
• Если родительское состояние — узел MIN, то ему присваивают минимальное
значение.
Значение, связываемое таким образом с каждым состоянием, отражает наилучшее
состояние, которого этот игрок может достичь (принимая во внимание действия
противника в соответствии с алгоритмом минимакса). Таким образом, полученные значения
используются для того, чтобы выбрать наилучший среди возможных шагов. Результат
применения алгоритма минимакса к графу пространства состояний для игры "ним"
показан на рис. 4.14.
Значения вершинам присваиваются снизу вверх на основе принципа минимакса.
Поскольку любой из возможных первых шагов MIN ведет к вершинам со значением 1, второй
игрок, МАХ, всегда может победить, независимо от первого хода MIN. MIN может
победить только в том случае, если МАХ допустит ошибку. На рис. 4.14 видно, что MIN может
выбрать любой из возможных вариантов первого хода — все они открывают возможные
пути победы МАХ, отмеченные на рисунке полужирными линиями со стрелками.
Хотя существуют игры, где возможен полный перебор, все же наиболее интересными
являются случаи, в которых он неприменим. В следующем разделе будет рассмотрено
эвристическое приложение минимакса.
4.3.2. Минимакс при фиксированной глубине поиска
При использовании минимакса в более сложных играх редко удастся построить
полный граф пространства состояний. Обычно поиск выполняют вглубь на определенное
число уровней, которое определяется располагаемыми ресурсами времени и памяти
компьютера. Эта стратегия называется прогнозированием п-го слоя (n-ply look-ahead), где
п — число исследуемых уровней. Такой подграф не отражает всех состояний игры, и
поэтому его узлам невозможно присвоить значения, отражающие победу или поражение.
Поэтому с каждой вершиной связывают значение, определяемое некоторой
эвристической функцией оценки. Значение, которое присваивается каждой из п вершин на пути от
корневой вершины, — не показатель возможности достичь победы (как в предыдущем
примере). Это просто эвристическое значение оптимального состояния, которое может
быть достигнуто за п шагов от этой корневой вершины. Прогнозирование увеличивает
силу эвристики, позволяя применить се на большей области пространства состояний.
Стратегия минимакса интегрирует эти отдельные оценки в значение, которое
присваивается родительскому состоянию.
Глава 4. Эвристический поиск
171
MAX
4-1-1-1
г-
3-2-1-1
2-2-2-1
MIN
г
3-
v
Ч
1-1
■1
0
\
-1
j
2-2-1-1-1
MAX
2-1-1-1-1-1
Рис. 4.14. Принцип минимакса для игры "ним ". Жирные линии показывают
пути к победе МАХ. Каждому узлу присвоено значение 0 или 1 в
соответствии с процедурой минимакса
В конфликтной игре каждый игрок пытается переиграть другого, и многие игровые
эвристики прямо измеряют преимущество одного игрока над другим. В шахматах очень
важно иметь преимущество в какой-либо части игровой доски, так что простая эвристика
может учитывать разность количества частей, где имеют преимущество либо МАХ, либо
MIN, и максимизировать ее. Можно применить и более сложную стратегию —
присваивать различные значения частям доски, в зависимости от позиции фигур на доске
(например, ферзь против пешки или король против пешки). Большинство игр дают
безграничные возможности для создания всевозможных эвристик.
Графы игр рассматриваются по уровням. Как показано на рис. 4.14, МАХ и MIN
делают шаги поочередно. Каждой ход игрока определяет новый уровень графа. Типичная
игровая программа предсказывает ходы до определенной фиксированной глубины,
которая определяется пространственными или временными ограничениями компьютера.
Состояния до этой глубины оцениваются эвристикой и на основе минимакса
распространяются обратно к начальному состоянию. Алгоритм поиска затем использует эти
производные значения, чтобы выбрать наилучший среди возможных ходов.
Присвоив оценку каждому состоянию выбранного слоя, программа передает это
значение каждому родительскому состоянию. Если родительское состояние относится к
уровню MIN, ему передается минимальное из состояний всех его потомков. Если
родительское состояние — узел уровня МАХ, минимакс назначает ему максимальное
значение из всех его потомков.
Максимизируя значения для родительских узлов МАХ и одновременно минимизируя
их для MIN, алгоритм осуществляет проход по графу, присваивая значения потомкам те-
172
Часть II. Искусственный интеллект как представление и поиск
кущего состояния. Затем эти значения используются алгоритмом для выбора наилучшего
потомка текущего состояния. На рис. 4.15 алгоритм минимакса проиллюстрирован на
гипотетическом пространстве состояний с четырьмя уровнями.
Самые ранние работы по ИИ в этой области — это программа игры в шашки,
созданная Самюэлем (Samuel) в 1959 году. Эта программа была исключением для того
времени, особенно учитывая существующие ограничения для компьютеров 50-х годов. Мало
того, что эта программа игры в шашки применяла эвристический поиск, в ней также
присутствовал простой алгоритм обучения. Эта программа была во многом пионерской,
и ее все еще используют при создании игровых и обучающихся программ.
Программа Сэмюэля оценивала состояние доски, используя взвешенную сумму
нескольких различных эвристических значений
Za<x< •
В этой сумме X/ представляет такие особенности состояния игровой доски, как
тактические преимущества, расположение фигур, ситуация в центре доски, возможность
жертвовать фигурами за тактическое преимущество и даже тенденцию перемещения
фигур одного из игроков у края доски. Коэффициенты при xi специально настраиваются
таким образом, чтобы отражать вклад каждого фактора в общую оценку ситуации. Таким
образом, если преимущество в какой-либо части доски важнее, чем, скажем, в центре, то
это отражает соответствующий коэффициент.
Программа Самюэля позволяет рассматривать необходимое число уровней (обычно
ограниченное возможностями компьютера) и оценивает все состояния на данном уровне,
используя полиномиальную оценку. Затем с помощью различных вариаций алгоритма
минимакса эти значения распространяются по графу в обратном направлении. После
этого игрок может делать ход в наилучшее состояние с учетом хода противника. Затем
весь процесс повторяется.
Если в процессе полиномиального оценивания некоторые ходы теряются, то программа
настраивает коэффициенты, чтобы повысить эффективность. Другими словами, большие
весовые коэффициенты уменьшаются (поскольку они вносят максимальный вклад в
неправильную оценку), а меньшие веса оценок увеличиваются, чтобы усилить их влияние. Если
программа побеждает, то противник, соответственно, проигрывает. Программа обучается,
играя против человека или против другой версии такой же программы.
Таким образом, программа Сэмюэля использовала алгоритм поиска экстремума для
обучения, пытаясь улучшить эффективность и сделать локальные уточнения в
полиномиальной оценке. Самюэль ограничил алгоритм поиска экстремума, введя проверку
эффективности индивидуальных взвешенных эвристических оценок и удаляя наименее
эффективные. Программа имеет некоторые интересные особенности. Например, из-за
ограниченности глобальной стратегии она чувствительна к функциям оценки, приводящим
к ловушкам. Модуль самообучения программы уязвим в случае противоречивой игры
оппонента. Например, если противник широко использовал различные стратегии или
просто играл "по-дурацки", то веса в полиномиальной оценке начинали принимать
"случайные" значения, что приводило к полному снижению эффективности.
Сделаем несколько заключительных замечаний о процедуре минимакса. Прежде
всего следует заметить, что оценки любого (предварительно выбранного) уровня
могут быть неверными. При использовании эвристики с ограниченным
прогнозированием сохраняется вероятность, что путь, приводящий в дальнейшем к плохой си-
Глава 4. Эвристический поиск
173
туации, не будет обнаружен вовремя. Если ваш противник по шахматам предлагает
ладью в качестве приманки, чтобы забрать вашего ферзя, а оценка не идет дальше
того уровня, где предлагается ладья, то у такого состояния будет наилучшая оценка.
К сожалению, подобный выбор состояния может привести к тому, что игра будет
проиграна! Это обычно называется эффектом горизонта. Для противостояния
такой ситуации обычно просматривают граф состояний на несколько уровней глубже
состояния с хорошей оценкой. Это селективное углубление поиска в важных
областях, однако, не позволяет полностью исключить эффект горизонта, так как поиск все
равно должен остановиться в какой-нибудь точке и, следовательно, останется слеп к
состояниям, лежащим за ее пределами.
MIN
2 359 0 742 156
Рис 4 15 Минимакс в гипотетическом пространстве состояний
В алгоритме минимакса существует и другой эффект, связанный с эвристическими
оценками. Оценки, которые находятся очень глубоко в пространстве, могут не
приниматься во внимание из-за их большой глубины [Pearl, 1984]. Подобно тому, как среднее
произведений отличается от произведения средних, оценка минимакса (которую мы
хотим получить) отличается от минимаксной оценки (которую мы получаем). В этом
смысле обычно (хотя и не всегда) лучше использовать более глубокий поиск с оценкой
состояний и алгоритмом минимакса. Детальное обсуждение этой проблемы и средств ее
решения можно найти в [Pearl, 1984].
В завершение обсуждения алгоритма минимакса представим его приложение к
игре в "крестики-нолики" (раздел 4.1), описанное в [Nilsson, 1980]. Здесь
используется чуть более сложная эвристика, позволяющая измерить конфликт в игре. Эта
эвристика состоит в следующем. Выбирается состояние, которое необходимо оценить,
находятся все победные строки для МАХ, а затем из их числа вычитается общее
количество победных строк для MIN. Алгоритм поиска пытается максимизировать эту
разность. Если данное состояние приводит к победе МАХ, то оно оценивается как
+°о; а если оно приводит к победе MIN — как -оо. На рис. 4.16 показано применение
этой эвристики к нескольким состояниям.
На рис. 4.17, 4.18 и 4.19 показано применение эвристики, представленной на
рис. 4.16, в алгоритме двухуровневого минимакса. На этих рисунках
продемонстрирована эвристическая оценка, возврат на основе минимакса, ход МАХ, а также
некоторые ограничения на ходы с равными эвристическими значениями [Nilsson, 1971].
174
Часть II. Искусственный интеллект как представление и поиск
E(n)-
Для X существует 6
возможных вариантов
победы
Для О существует 5
возможных вариантов
победы
6-5=1
ъ\~
X
--
-/
[
1•
•о-
А'
■-!-
-:-
о
Для Xсуществует 4 возможных варианта победы
Для О имеется 6 возможных вариантов победы
Е(п) = 4-6 = -2
О
Для X имеется 5 возможных вариантов победы
Для О существует 4 возможных варианта победы
Е(л) = 5-4=1
Эвристика - Е{п)=М{п)-0{п)
где М(л) — общее число возможных вариантов моей победы,
О(п) — общее число возможных вариантов победы оппонента,
Е(п) — общая оценка состояния п
Рис 4 16 Эвристика, учитывающая конфликт в игре
"крестики-нолики "
4.3.3. Процедура альфа-бета-усечения
Прямой алгоритм минимакса требует двух проходов по области поиска. Первый
позволяет пройти вглубь области поиска и там применить эвристику, а второй —
присвоить эвристические значения состояниям, следуя вверх по дереву. Минимакс
рассматривает все ветви в пространстве поиска, включая те из них, которые могли
быть исключены более интеллектуальным алгоритмом. Разработчики игровых
стратегий в конце 1950-х годов создали алгоритм [Newell и Simon, 1976], который
получил название альфа-бета-усечения и позволил повысить эффективность поиска в
играх с двумя участниками [Pearl, 1984].
Идея альфа-бета-поиска проста: вместо того, чтобы рассматривать все состояния
некоторого уровня графа, алгоритм выполняет поиск в глубину. В процессе поиска
участвуют два значения, называемые альфа (alpha) и бета (beta). Значение альфа,
связанное с узлами МАХ, никогда не уменьшается, а значение бета, связанное с
узлами MIN, никогда не увеличивается. Предположим, что для некоторого узла МАХ
значение альфа равно 6. Тогда МАХ может не рассматривать состояния, которые
связаны с нижележащими узлами MIN и имеют значения меньше или равные 6.
Альфа — самое плохое значение, которое может принимать МАХ, если MIN будет
придерживаться "наилучшей" стратегии. Точно так же, если значение бета для узла
MIN равно 6, то не следует рассматривать нижележащие вершины МАХ, с которыми
связаны значения 6 или более.
Глава 4. Эвристический поиск
175
\}J —И— Начальный
I I узел
Ход MAX
5-6 =-1 6-6 = 05 -6 = -16-6 = 04-6 = -2
Рис. 4 17. Двухуровневый минимакс для первого хода игры в "крестики-нолики" из
[Nilsson, 1971]
Щ: ^z e|i e^ sjg^ ^§p ®Ч§Ь
4-3 = 1 3-3 = 0 5-3 = 23-3 = 0 4-3 = 1 4-3 = 1 ХП
у] лм х]0| XI Ю XI
4-2 = 2 4-2 = 2 5-2 = 3 3-2 = 1 4-2 = 24-2 = 2
®
4-3 = 1 4-3 = 1 3-3 = 0
Рис. 4.18. Двухуровневый минимакс и один из двух возможных вторых ходов МАХ
176
Часть II. Искусственный интеллект как представление и поиск
Начиная альфа-бета-процедуру, мы опускаемся на полную глубину графа, используя
поиск в глубину, и вычисляем эвристические оценки для всех состояний этого уровня.
Предположим, что все они — узлы MIN. Максимальное из этих значений MIN
возвращается родительскому состоянию (узлу МАХ, как и в алгоритме минимакса). Затем это
значение передается прародителям узлов MIN как потенциальное граничное значение бета.
Затем алгоритм опускается к другим потомкам потомков и не рассматривает их
родительские состояния, если их значения больше или равны данному значению бета.
Аналогичные процедуры можно описать для альфа-отсечения по потомкам второго поколения
вершины МАХ.
Существуют два условия останова алгоритма поиска на основе значений альфа и бета.
1. Поиск может быть остановлен ниже любого узла MIN, значение бета которого
меньше или равно значению альфа любого из его предков МАХ.
2. Поиск может быть остановлен ниже любого узла МАХ, значение альфа которого
больше или равно значению бета любого из его предков MIN.
Ход МАХ ©-Ш Начальный
Рис. 4.19. Двухуровневый минимакс применительно к ходу X в конце игры [Nilsson, 1971]
Таким образом, альфа-бета-усечение выражает отношение между узлами уровней п и
п+2. При этом из рассмотрения могут быть исключены целые поддеревья с корнями на
уровне п+1. Например, на рис. 4.20 изображено пространство поиска из рис. 4.15, к
которому применен алгоритм альфа-бета-усечения. Заметим, что результирующее
возвращаемое значение идентично полученному в алгоритме минимакса, но при этом
процедура альфа-бета-усечения значительно экономичнее минимакса.
При удачном порядке состояний в области поиска процедура альфа-бета-усечения может
эффективно удваивать глубину поиска в рассматриваемом пространстве при фиксированных
пространственно-временных характеристиках компьютера [Nilsson, 1980]. Если же узлы
расположены неудачно, процедура альфа-бета-усечения осуществляет поиск в таком же
пространстве, как и обычный минимакс. Однако поиск проводится только за один проход.
Глава 4. Эвристический поиск
177
4.4. Проблемы сложности
Наиболее сложным аспектом комбинаторных задач является экспоненциальный рост
пространства поиска, который зачастую не учитывают разработчики программ. Поскольку
основные виды человеческой деятельности (вычислительной и другой) происходят в
линейном времени, нам трудно представить себе экспоненциальный рост. Мы часто слышим
жалобу: "Если бы я имел более мощный (или быстрый или высоко производительный)
компьютер, моя проблема была бы решена". Такие жалобы, часто вызываемые проблемой
"взрывного" роста числа состояний, обычно беспочвенны. Просто проблема была понята
не достаточно глубоко и не были предприняты действия по ее решению.
Комбинаторный рост ошеломляет. Было показано, что количество состояний, просматри
ваемых при полном переборе в пространстве возможных шахматных ходов, составляет 10
Это не просто "очень большое количество" — это число сопоставимо с числом молекул во
вселенной или с числом наносекунд, прошедших после "большого взрыва".
120
МАХ
Для А значение р=3 (А будет не больше, чем 3)
В является C-усеченным, так как 5>3
Для С значение а=3 (С будет не меньше, чем 3)
D является а-усеченным, так как 0<3
Еявляется а-усеченным, так как 2<3
С принимает значение 3
Рис. 4 20 Альфа-бета-усечение применительно к пространству
состояний из рис. 4 15 Состояния без числовых меток не оценивались
Были предложены несколько метрик для вычисления сложности. Одна из них —
фактор ветвления пространства. Фактор ветвления определяется как среднее
количество ветвей (потомков), выходящих из любого состояния в пространстве поиска. Число
состояний на глубине п поиска равно фактору ветвления, возведенному в п-ю степень.
После вычисления фактора ветвления можно оценить стоимость поиска пути любой длины.
На рис. 4.21 показана зависимость между фактором ветвления В, длиной пути L и общим
количеством состояний Т в процессе поиска для малых значений. Графики представлены
в логарифмическом масштабе, поэтому L — не прямая линия.
Несколько примеров из этого рисунка показывают, как плохи дела на самом деле.
Если фактор ветвления равен 2 (например, в бинарном дереве), то для исследования всех
путей на шесть уровней вглубь области поиска требуется рассмотреть приблизительно
100 состояний. А для углубления на 12 уровней требуется рассмотреть около 10000
состояний. Если фактор ветвления может быть уменьшен до 1,5 (с помощью эвристики или
178
Часть II. Искусственный интеллект как представление и поиск
переформулировки задачи), то при том же количестве рассмотренных состояний длина
пути может быть удвоена.
Математическая формула зависимости, представленной на рис. 4.21, имеет вид
Т= В + В2 + В3 + -+8\
где Т— общее количество состояний, L — длина пути, а Б — коэффициент ветвления.
Это уравнение можно привести к виду
Т= В (BL - \)/(В- 1).
10,000
Рис. 4 21 Число сгенерированных узчов как функция от фактора ветвления В для различной
длины пути решения L Соответствующее соотношение имеет вид T=B{BL-\)/{B-\)
[Nilsson, 1980]
Измерение пространства поиска — эмпирический процесс, требующий детального
знакомства с задачей и проверки различных ее вариантов. Предположим, например, что
требуется найти фактор ветвления в игре в "пятнашки". Для этого вычислим общее
число возможных ходов. По 2 хода возможны для каждого угла — всего 8 угловых ходов;
по 3 — для центра каждой стороны — всего 12 ходов и 4 для центра доски. Таким
образом, всего получается 24 хода. Разделив это число на 9 (возможное количество
различных местоположений пустой клетки), получим, что средний фактор ветвления равен
2,67. Как показано на рис. 4.21, это не очень хорошее значение для глубокого поиска.
Если не принимать во внимание ходы, ведущие назад к родительскому состоянию
(используемые в алгоритмах поиска, описанных в этой главе), то в каждом состоянии
будет на один ход меньше. В этом случае фактор ветвления равен 1,67, что делает
возможным полный перебор (в некоторых пространствах состояний).
Как было показано в главе 3, сложность алгоритма может быть определена размерами
списков closed и open. Чтобы поддерживать приемлемый размер списка open, можно
Глава 4. Эвристический поиск
179
сохранять в нем только несколько (эвристически) лучших состояний. Это может
ускорить поиск. Однако в этом случае существует опасность потери лучшего состояния и
даже решения. Метод поддержания определенных рамок поиска в зависимости от числа
шагов называется "лучевым поиском" (beam search).
О "Информированность" Полная
Рис. 4.22. Неформальный график стоимости поиска и стоимости
вычисления эвристической оценки в зависимости от
информированности эвристики [Nilsson, 1980]
При попытке снижения ветвления алгоритма поиска или сужения пространства поиска
мы ввели понятие "более информированной" эвристики. Более информированный поиск
дает возможность рассматривать меньшую область для нахождения минимального пути к
решению. В разделе 4.3 было показано, что цена дополнительной информации,
необходимой для сокращения пространства поиска, не всегда приемлема. При решении задачи на
компьютере не достаточно найти минимальный путь. Необходимо также сократить
количество операций, выполняемых компьютером в процессе нахождения решения.
На рис. 4.22, взятом из [Nilsson, 1980], представлен неформальный результат
анализа этих вопросов. По оси абсцисс отложено количество информации, которая учтена
в эвристике для улучшения ее эффективности. По оси ординат показаны затраты
процессора на осуществление поиска. Если эвристика становится более
информированной, затраты процессорного времени на рассмотрение состояний уменьшаются,
потому что необходимо просматривать меньшее количество состояний. Общая стоимость
нахождения пути решения — это общая стоимость эвристических вычислений плюс
стоимость просмотра пространства поиска. Желательно, чтобы общая стоимость
такого поиска была минимальной.
В заключение следует отметить, что важной областью исследований является
эвристический поиск на графах ШИЛИ, так как подобную форму имеет пространство
состояний для экспертных систем. Поиск на этих структурах включает компоненты,
обсуждавшиеся в этой и предыдущей главах. Поскольку для нахождения пути к цеди необходимо
просмотреть все потомки узлов И, эвристическая оценка стоимости поиска для узла И
представляет собой сумму оценок поиска его потомков.
180
Часть II. Искусственный интеллект как представление и поиск
4.5. Резюме и дополнительная литература
Пространства поиска интересных задач обычно увеличиваются экспоненциально.
Эвристический поиск — это основной инструмент для управления таким ''комбинаторным
взрывом". В данной главе представлен "жадный" алгоритм поиска, а затем
проанализировано поведение эвристических алгоритмов. Мы рассмотрели такие их свойства, как
допустимость, монотонность и информированность. Эвристический поиск был
рассмотрен на простых примерах типа игры в "пятнашки", а затем распространен на более
сложные пространства состояний, возникающие при проектировании экспертной системы
(глава 6). В данной главе также была рассмотрена эвристика, применяемая в играх с
двумя участниками. Она использует процедуру минимакса и альфа-бета-усечения для
предсказания ходов противника. Теория сложности играет важную роль почти в каждой
области информатики, особенно при анализе роста пространства состояний и
эвристическом усечении. Теория сложности исследует сложность задач (в противоположность
алгоритмам). Ключевая посылка теории сложности состоит в наличии класса существенно
сложных задач. Этот класс, получивший название класса NP-сложных задач
(Nondeterministically Polynomial), включает проблемы, которые не могут быть решены в
разумное время без использования эвристики. Этому классу принадлежат почти все
задачи поиска. По этой проблеме мы особенно рекомендуем книги [Garey и Johnson, 1979]
и [Moret и Shapiro, 1991].
В [Pearl, 1984] детально описаны такие вопросы, как разработка и анализ эвристик. В
[Korf, 1987, 1998, 1999] продолжено исследование алгоритмов поиска, в том числе
описан алгоритм IDA*. Программы игры в шахматы вызывают постоянный интерес на
протяжении всей истории развития искусственного интеллекта. Новые результаты в этой
области часто представляются и обсуждаются на ежегодных конференциях.
Автор благодарит Нильса Нильсона [Nilsson, 1980] за его подход и примеры, которые
были использованы в этой главе.
4.6. Упражнения
1. Придумайте эвристику, которую можно было бы использовать в программе
размещения блоков для решения задачи "поставить блок X на блок Y". Будет ли такая
эвристика допустимой? Монотонной?
2. Головоломка скользящих фишек включает три черные и три белые фишки, а также
пустую клетку, как показано на рис. 4.23.
В этой головоломке допустимы два хода с соответствующей стоимостью.
Фишку можно передвинуть в соседнюю пустую позицию Этот ход стоит 1. Фишка
может перепрыгивать на пустое место через одну или две другие фишки Стоимость этого
хода равна количеству перепрыгнутых фишек.
Цель игры состоит в том, чтобы все белые фишки расположить слева, а черные —
справа. Местоположение пустой клетки не важно.
2.1. Проанализируйте сложность пространства состояний и наличие циклов.
2.2. Предложите эвристику для решения этой проблемы и проанализируйте ее на
допустимость, монотонность и информированность.
Глава 4. Эвристический поиск
181
в
в
в
W
W
W
Рис. 4.23. Головоломка скользящих блоков
3. Сравните три эвристики для игры в "пятнашки" (см. рис. 4.8) с эвристикой сложения
суммы расстояний для фишек, находящихся не на своих местах, с удвоенным числом
прямых перестановок. Сравните их по следующим критериям:
а) точность оценки расстояния к цели. Для этого требуется найти кратчайший путь к
решению, а затем использовать его как эталон;
б) информированность. Какая из упомянутых эвристик наиболее эффективно
сокращает пространство состояний?
в) монотонность для игры в "пятнашки";
г) допустимость. Какая из этих эвристик ограничена сверху фактической стоимостью
пути к цели? Обоснуйте свои предположения для общего случая или приведите
контрпример.
4. а. Как было сказано выше, "жадный" алгоритм поиска для предотвращения
зацикливания использует список closed. А что если отказаться от этого теста и определять
зацикливания на основе д{пI Сравните эффективность этих двух подходов.
б. Функция best_f irst_search не проверяет, является ли состояние целевым,
пока оно не удалено из списка open. Эту проверку можно выполнять при
рассмотрении новых состояний. Как это отразится на эффективности алгоритма? На
допустимости?
5. Докажите, что алгоритм А* допустим. Подсказка: при доказательстве следует
показать, что:
а) для алгоритма А* поиск закончится;
б) в списке open всегда существует узел, который находится на оптимальном пути
к цели;
в) если путь к цели существует, то алгоритм А* закончится нахождением
оптимального пути к цели.
6. Подразумевает ли допустимость выполнение свойства монотонности эвристики?
Если нет, опишите, когда допустимость подразумевает монотонность.
7. Докажите, что набор состояний, рассмотренных в алгоритме А*, является
подмножеством состояний поиска в ширину.
8. Докажите, что более информированная эвристика просматривает более узкую
область поиска. Подсказка: формализуйте доказательство, представленное в
подразделе 4.2.3.
9. Шифр Цезаря — это простая схема кодирования, основанная на циклических
перестановках алфавита, в которой /-й символ алфавита заменяется (/+п)-м символом.
Например, при использовании шифра Цезаря со сдвигом 4 слово "Caesar" запишется
как "Geiwev".
9.1. Приведите три эвристики, которые можно использовать для расшифровки
шифра Цезаря.
182
Часть II. Искусственный интеллект как представление и поиск
9.2. В простом шифре подстановки каждый символ заменяется другим на основе
некоторого произвольного взаимно однозначного отображения. Какая из эвристик,
предложенных для шифра Цезаря, может использоваться для расшифровки такого
шифра? Объясните. (Спасибо Дону Моррисону (Don Morrison) за этот вопрос.)
10. Реализуйте стратегию минимакса на дереве, показанном на рис. 4.24.
11. Выполните альфа-бета-усечение слева направо для дерева из упражнения 10. Выполните
на этом же дереве усечение справа налево. Объясните, почему результаты отличаются.
12. Рассмотрите трехмерную игру в "крестики-нолики". Проанализируйте сложность
пространства состояний. Предложите эвристику для этой игры.
13. Выполните альфа-бста-усечение для игры в "крестики-нолики" (см. рис. 4.17, 4.18 и 4.19).
Сколько вершин можно устранить в каждом случае?
14. а. Создайте алгоритм для эвристического поиска на графе И/ИЛИ. Обратите
внимание на то, что для определения значения родительского узла необходимо
просмотреть значения всех его потомков. Таким образом, при вычислении эвристических
оценок стоимости пути к цели оценка стоимости узла AND состоит (как минимум) из
суммы оценок стоимости различных ветвей.
б. Используйте этот алгоритм для поиска на графе (рис. 4.25).
Рис 4 24 Дерево дчя применения
принципа минимакса
h(A) = 1
/7(8) = 2
/7(C) = 5
/7(D) = 3
h(E) = 2
Рис 4 25. Пример графа для поиска
Глава 4. Эвристический поиск
183
Управление поиском
и его реализация
в пространстве
состояний
Если мы аккуратно отделим влияние среды, в которой выполняется задача, от
влияния аппаратных компонентов и организации, то получим истинную простоту
адаптивной системы. Как мы видели, для описания способа решения человеком таких задач, как
шахматы, логика и криптоарифметика (cryptarithmetic), необходимо постулировать
только очень простую систему обработки информации. Очевидно сложное поведение
системы обработки информации в данной среде обусловлено взаимодействием
требований среды с несколькими основными параметрами системы, в частности,
характеристиками ее блоков памяти
— А. Ньюэлл и Н. А. Саймон, Решение проблем человеком, 1972
То, что мы называем началом, часто будет концом,
Приходя к концу, мы приходим к началу
Конец — это наше начало
— Т. С. Элиот (Т. S. Eliot), Четыре квартета
5.0. Введение
В главах 3 и 4 представлены задачи, решаемые методом поиска в пространстве
состояний. Этот подход "пространства состояний" к решению задачи позволяет
использовать теорию графов для создания и анализа компьютерных программ. В главе 3
определен общий алгоритм поиска с возвратами , а также алгоритмы поиска в глубину и в
ширину. Эвристический поиск был представлен в главе 4. Следующие понятия
характеризуют данные и управляющие структуры, используемые для реализации поиска
в пространстве состояний.
1. Представление решения задачи в виде пути от начального состояния к целевому.
2. Алгоритм поиска, систематически проверяющий наличие альтернативных путей к цели.
3. Поиск с возвратами или другой механизм, позволяющий выходить из тупиковых
состояний и находить путь к цели.
4. Списки, содержащие точную информацию о рассматриваемых в данный момент
состояниях, в том числе:
а) список open, позволяющий алгоритму в случае необходимости исследовать
ранее не рассмотренные состояния;
б) список closed, содержащий рассмотренные состояния. Он позволяет алгоритму
избегать зацикливаний и учитывать тупиковые пути.
5. Список open можно рассматривать, как стек для поиска в глубину, очередь для
поиска в ширину или приоритетную очередь для "жадного" алгоритма поиска.
В данной главе вводятся высокоуровневые методы для построения алгоритмов поиска.
Первый из них — рекурсивный поиск, определяющий поиск в глубину с возвратами более
кратким и естественным способом, чем в главе 3. Этот механизм составляет основу многих
алгоритмов в разделе 5.1. Применение унификации в процессе поиска в пространстве
состояний расширяет возможности рекурсивного поиска. Этот алгоритм поиска по образцу
(раздел 5.2) положен в основу языка PROLOG, описанного в главе 14, и многих экспертных
систем, рассмотренных в главе 7. Раздел 5.3 посвящен так называемым продукционный
системам. Это общая архитектура для решения образно-ориентированных проблем, которая
широко используется как для моделирования человеческого образа мышления при решении
многих задач, так и для построения экспертных систем и других приложений ИИ. Наконец, в
разделе 5.4 рассматривается еще одно представление для решения задач искусственного
интеллекта — так называемая модель классной доски (blackboard).
5.1. Рекурсивный поиск
5.1.1. Рекурсия
В математике рекурсивное определение объекта — это его описание в терминах
частей этого же определения. В информатике рекурсия используется для определения и
анализа структур данных и процедур. Рекурсивная процедура состоит из следующих этапов.
1. Рекурсивный шаг: вызов процедуры из этой же процедуры для повторения
последовательности действий.
2. Условие, которое обеспечивает выход из процедуры и таким образом
предотвращает зацикливание (рекурсивная версия бесконечного цикла).
Оба этих компонента необходимы и появляются во всех рекурсивных определениях и
алгоритмах. Рекурсия — естественный инструмент управления массивами данных,
которые имеют правильную структуру и неопределенный размер, например, списками,
деревьями и графами. Рекурсия особенно удобна для поиска в пространстве состояний.
Простой пример — алгоритм определения принадлежности данного элемента списку.
Списком (list) называют упорядоченную последовательность элементов и
фундаментальных строительных блоков структур данных. Списки использовались как альтернативная
форма записи выражений исчисления предикатов (глава 2) и для представления списков
open и closed в алгоритмах поиска из главы 3. Процедура проверки принадлежности
элемента списку определяется так.
186
Часть II. Искусственный интеллект как представление и поиск
function member(item, list);
begin
if список пуст
then return FAIL %останов
else
if item = первому элементу списка
then return SUCCESS %останов
else
begin
tail := список после удаления первого элемента;
member(item, tail) %рекурсия
end
end.
Эта процедура сначала проверяет, пуст ли список, и, если да, алгоритм возвращает
ошибку. В противном случае он сравнивает выбранный элемент с первым элементом
списка. Если они равны, происходит успешное завершение процедуры. Таким образом, это
условия завершения процедуры. Если ни одно из приведенных выше условий завершения не
выполнено, процедура удаляет первый элемент из списка и снова вызывает сама себя для
сокращенного списка. Это позволяет исследовать каждый элемент списка по очереди.
Обратите внимание на то, что список конечен, и каждый шаг рекурсии уменьшает его размер
на один элемент. Это означает, что данный алгоритм не приведет к зацикливанию.
В приведенном выше алгоритме используются две фундаментальные операции со
списком: первая из них (head) возвращает первый элемент списка, вторая операция (fa/7)
возвращает список, полученный после удаления первого элемента. Эти операции наряду
с рекурсией составляют основу высокоуровневых операций со списком типа member.
Данные операции поддерживаются языками обработки списков LISP и PROLOG и
подробно описаны в главах, посвященных каждому из этих языков.
Рекурсия, поддерживаемая каким-либо языком программирования, расширяет
возможности более традиционных управляющих конструкций, например, циклов и
условных операций. Другими словами, любая итерационная процедура может быть также
реализована рекурсивно. Удобство рекурсивных формулировок — ясность и компактность
выражения. Математические понятия логики или функций не поддерживают таких
механизмов, как упорядочение, ветвление и итерация. Для индикации повторения можно
использовать рекурсию. Поскольку рекурсию проще описать математически, чем явные
итерации, то легче формально проанализировать правильность и сложность рекурсивных
алгоритмов. Рекурсия часто используется в системах автоматической генерации или
верификации программ, необходимых при создании компиляторов и интерпретаторов.
Однако более важным является тот факт, что рекурсия — это естественный способ
реализации таких стратегий искусственного интеллекта, как поиск на графе.
5.1.2. Рекурсивный поиск
Прямое преобразование описанного в главе 3 алгоритма поиска в глубину в
рекурсивную форму иллюстрирует эквивалентность рекурсии и итерационного подхода.
Этот алгоритм для поддержки списка состояний использует глобальные переменные
open и closed.
function depthsearch; %переменные open и closed глобальные
begin
Глава 5. Управление поиском и его реализация в пространстве состояний 187
if список open пуст
then return FAIL;
current_state := первый элемент списка open;
if current_state равно целевому состоянию
then return SUCCESS
else
begin
open := хвост списка open;
closed := closed с добавлением current_state;
для каждого потомка current_state
if не в списке closed или open
%построение стека
then добавить потомок в начало списка open
end;
depthsearch %рекурсивный вызов
end.
Поиск в ширину можно описать фактически тем же самым алгоритмом. При этом
необходимо сохранять список closed как глобальную структуру данных и рассматривать
список open как очередь, а не как стек.
Из представленного алгоритма ясно, что поиск в глубину не использует все
возможности рекурсии. Процедуру можно упростить, используя рекурсию непосредственно (а
не через список open) для рассмотрения состояний и нахождения путей в их
пространстве. В новой версии алгоритма глобальная переменная closed используется для
обнаружения повторяющихся состояний и предотвращения циклов. Список open неявно
используется в записях активации рекурсивной среды.
function depthsearch (current_state);
%closed — глобальная переменная
begin
if current_state равно целевому состоянию
then return SUCCESS;
добавить current_state в список closed;
while current_state имеет непроверенные потомки
begin
child := следующий непроверенный потомок;
if потомок не член списка closed
then if depthsearch(child) = SUCCESS
then return SUCCESS
end;
return FAIL %поиск исчерпан
end
Вместо того чтобы находить все потомки данного состояния, а затем помещать их в
список open, этот алгоритм рассматривает потомки по одному. Для каждого из них
рекурсивно находятся все потомки, а затем рассматривается очередной потомок исходного
состояния. Следует заметить, что алгоритм предполагает определенный порядок
операторов генерации состояний. Если при рекурсивном поиске некоторый потомок является
целевым состоянием, то процедура поиска успешно завершается, и, естественно,
алгоритм игнорирует братьев данного потомка. Если рекурсивный вызов для одного из
потомков приведет в тупик, то будет рассмотрен брат этого потомка, а также все его
потомки. Таким образом, алгоритм обходит весь граф аналогично алгоритму поиска в
глубину (см. подраздел 3.2.3). Читателю рекомендуется проверить это утверждение.
188
Часть II. Искусственный интеллект как представление и поиск
Рекурсия позволяет обойтись без списка open. Механизм, посредством которого
можно реализовать рекурсию на каком-либо языке программирования, должен включать
отдельную запись активации (activation record) [Aho и Ullman, 1977] для каждого
рекурсивного вызова. Каждая такая запись активации должна содержать локальные переменные и
состояние выполнения для каждого вызова процедуры. При каждом рекурсивном вызове
процедуры с новым состоянием новая запись активации сохраняет параметры процедуры
(состояние), все локальные переменные и текущее состояние выполнения. В рекурсивном
алгоритме поиска состояния, находящиеся на рассматриваемом пути, сохраняются в
последовательности записей активации рекурсивных вызовов. Запись каждого вызова содержит
также последнюю операцию, которая была сделана при генерации соответствующего
потомка. Это позволяет генерировать при необходимости брата данного потомка.
Возврат производится, если ни один из потомков данного состояния не привел к
цели, что послужило причиной неудачного завершения процедуры. В этом случае в
процедуру генерации потомков возвращается значение FAIL. Затем эта процедура
применяется к брату данного состояния. В рассматриваемом случае внутренние
механизмы рекурсии заменяют список open, который был использован в итерационной
версии алгоритма. Рекурсивная реализация позволяет программисту ограничить
рассмотрение единственным состоянием и его потомками, а не иметь дело со всем
списком open. Возможность рекурсии выражать глобальные понятия в простой форме —
главный источник ее удобства.
Поиск в пространстве состояний — процесс рекурсивный по природе. Чтобы найти
путь от текущего состояния к цели, необходимо двигаться в дочернее состояние, затем из
него перейти к потомку и так далее. Если соответствующее дочернее состояние не ведет
к цели, то необходимо рассмотреть состояние того же уровня, на котором находится
родительское состояние. Рекурсия разбивает большую и трудную проблему (поиск во всем
пространстве состояний) на более простые части (генерирование потомков отдельного
состояния), а затем применяет (рекурсивно) эту стратегию к каждому потомку. Этот
процесс продолжается до тех пор, пока не будет найдено целевое состояние или
исчерпано все пространство состояний.
Задача символьного интегрирования, рассмотренная в подразделе 3.3.3, является
превосходным примером мощности рекурсивного подхода в задачах поиска. При
интегрировании выражения обычно выполняется замена переменных или декомпозиция
интеграла, сведение его к совокупности более простых интегралов (подзадач). Эти
подзадачи также могут быть решены рекурсивно с последующим объединением
результатов в решении исходной задачи. Например, после применения правила суммы
интегралов (интеграл суммы равняется сумме интегралов) можно попытаться
рекурсивно проинтегрировать каждое из слагаемых. В дальнейшем можно снова применять
декомпозицию и замену, пока не будет проинтегрирован каждый из членов. Затем
результаты интеграции объединяются (посредством суммирования) в конечный
результат. Таким образом, рекурсия — это естественный инструмент для систематической
декомпозиции задачи с последующим объединением результатов решения частных
задач для решения исходной проблемы.
В следующем разделе этот рекурсивный подход будет расширен до некоторого
контроллера логического решателя задач, который использует унификацию и вывод для
генерации пространства логических отношений и поиска в нем. Алгоритм поддерживает
операцию логического умножения нескольких целей and, а также построение обратных
цепочек от цели к предпосылкам.
Глава 5. Управление поиском и его реализация в пространстве состояний 189
5.2. Поиск по образцу
В разделе 5.2 рекурсивный поиск будет применен к пространству логического
вывода. В результате получим общую процедуру поиска для исчисления предикатов.
Допустим, необходимо построить алгоритм, который определяет, является ли
выражение исчисления предикатов логическим следствием некоторого набора утверждений.
Это предполагает поиск от цели с применением правил модус поненс, определяющих
переходы между состояниями. Имея цель (типа р(а)), алгоритм использует унификацию
для выбора импликаций, заключения которых соответствуют цели (например, q(X) —>
р(Х)). Поскольку алгоритм обрабатывает импликации как потенциальные правила для
разрешения запроса, их часто называют просто правилами. После унификации цели с
заключением импликации (или правила) и применения результирующих подстановок ко
всему правилу предпосылка этого правила становится новой целью (q(a)). Ее называют
подцелью. Затем алгоритм повторяется для подцелей. Если подцель соответствует факту
в базе знаний, поиск прекращается. Последовательность выводов, ведущая от исходной
цели к данным фактам, доказывает истинность первоначальной цели.
function pattern_search (current_goal);
begin
if current_goal содержится в списке closed
%проверка на зацикливание
then return FAIL
else добавить current_goal в список closed;
while в базе данных остаются правила или факты для унификации do
begin
case
current_goal унифицируется с фактом:
return SUCCESS;
current_goal — это конъюнкция(р л ...):
begin
for каждого конъюнкта do
вызвать pattern_search для конъюнкта;
if pattern_search успешно завершается для всех
конъюнктов
then return SUCCESS
else return FAIL
end;
current_goal унифицируется с заключением правила
(р в q -^ p) :
begin
применить подстановку унификации цели
к предпосылке (q) ;
вызвать pattern_search для предпосылки;
if pattern_search завершен успешно
then return SUCCESS
else return FAIL
end;
end; %конец оператора case
end;
return FAIL
end.
190 Часть II. Искусственный интеллект как представление и поиск
В функции pattern_search поиск выполняется с помощью модифицированной
версии рекурсивного алгоритма, который, чтобы установить соответствие двух
выражений, использует унификацию (подраздел 2.3.2), а для создания потомков состояний —
правило модус поненс. Текущее состояние поиска представлено переменной cur-
rent_goal. Если current_goal соответствует факту, алгоритм возвращает
SUCCESS. В противном случае алгоритм пытается сопоставить current_goal с
заключением некоторого правила, рекурсивно просматривая все предпосылки. Если cur-
rent_goal не согласуется ни с одним из утверждений, алгоритм возвращает FAIL.
Этот алгоритм также обрабатывает конъюнктивные цели, которые часто встречаются в
предпосылках правила.
Для простоты этот алгоритм не решает проблему согласования подстановок
переменных при унификации. Это важно при разрешении конъюнктивных запросов с общими
переменными (например р(Х)лц(Х)). Оба конъюнкта должны быть согласованы не
только между собой, но и с унифицированными значениями переменной X
(подраздел 2.3.2). Эту проблему мы рассмотрим в конце раздела.
Главное преимущество использования таких общих методов, как унификация и
правило модус поненс, для генерации состояний заключается в том, что
результирующий алгоритм может просматривать любое пространство логических выводов.
Специфические проблемы описываются утверждениями исчисления предикатов. Таким
образом, знания о задаче отделяются от реализации ее решения на компьютере. Функция
pattern_search обеспечивает первую реализацию такого отделения знаний от
управления.
5.2.1. Пример рекурсивного поиска: вариант задачи хода конем
Использование исчисления предикатов с общим контроллером для решения задач
поиска можно проиллюстрировать на примере упрощенной версии задачи хода конем
(knight's tour problem). В шахматах конь может перемещаться на два поля по горизонтали
или вертикали и на одно поле в перпендикулярном направлении. При этом он не должен
выйти за пределы шахматной доски. Таким образом, в самом общем случае существует
не более восьми возможных ходов (рис. 5.1).
Традиционная формулировка задачи заключается в том, чтобы найти такую
последовательность ходов конем, при которой он становится на каждую клетку только один раз.
Эта задача дала толчок к развитию и представлению алгоритмов поиска. Пример,
который мы используем в этом разделе, — упрощенная версия задачи хода конем. Здесь
необходимо найти такую последовательность ходов, при которой конь побывал бы в
каждом поле уменьшенной шахматной доски Cx3) только один раз. (Полная задача хода
конем рассмотрена в подразделе 5.3.2.)
На рис. 5.2 показана шахматная доска, размером 3x3, где каждая клетка помечена
целым числом от 1 до 9. Для простоты эта схема маркировки будет использоваться вместо
более общей схемы, в которой каждая клетка маркируется двумя цифрами, номером
строки и номером столбца. Поскольку размер шахматной доски уменьшен, мы просто
перечислим возможные ходы, а не будем разрабатывать общий оператор перемещения.
В этом случае допустимые ходы на доске можно описать с помощью предиката move,
параметрами которого являются номера начальной и конечной клетки допустимого хода.
Например, move( 1,8) перемещает коня из верхнего левого угла в середину нижнего
ряда. Предикаты на рис. 5.2 описывают все возможные ходы для шахматной доски 3x3.
Глава 5. Управление поиском и его реализация в пространстве состояний 191
Рис. 5.1. Допустимые ходы конем на шахматной доске
movef^lfi)
move( 1,6)
moveB,9)
move{2J)
move{2>A)
move{3,Q)
move{4,9)
moveD,3)
moyeF,1)
move{6,7)
move{7,2)
moveG,6)
move{Qf3)
move(8,1)
move{9f2)
move(9f4)
1
4
7
2
5
8
3
6
9
Рис 5 2. Шахматная доска 3x3 с допустимыми ходами
для упрощенной задачи хода конем
Эти предикаты составляют базу знаний для задачи хода конем. В качестве примера
использования унификации для обращения к этой базе знаний проверим существование
различных ходов на шахматной доске. Для определения возможности перемещения коня
из клетки 1 в клетку 8 будем вызывать процедуру pattern_search (move (l, 8) ).
Поскольку данная цель унифицируется с фактом move{ 1,8) в базе знаний, функция
возвращает значение SUCCESS без каких-либо подстановок переменных.
Другой запрос позволяет определить, куда конь может переместиться из некоторого
местоположения, например, из клетки 2. В этом случае цель move{2, X) унифицируется
с двумя различными предикатами в базе знаний с подстановками {7/Х} и {9/Х}. Для
цели moveB,3) результатом будет FAIL, так как в базе знаний не существует элемента
moveB,3). Ответом на запрос move{5,Y) тоже будет FAIL, потому что не существует
утверждений, задающих перемещение из клетки 5.
Следующая задача состоит в построении алгоритма поиска для определения пути
последовательных шагов по доске. Это можно сделать с помощью импликаций исчисления
192
Часть II. Искусственный интеллект как представление и поиск
предикатов. Они добавляются к базе знаний как правила для создания путей
последовательных шагов. Чтобы подчеркнуть, что эти правила обеспечивают поиск от цели, мы
изменили направление стрелки импликации. Следовательно, правила будем писать как
Заключение <- Предпосылка.
Например, путь с двумя ходами можно записать так.
V X, У [path2(Xt У) <- 3 Z [move{X, Z)Amove(Z, У)]].
Это правило утверждает, что для всех клеток X и У существует путь с двумя ходами,
если существует такая клетка Z, что конь может переместиться из X в Z, а затем — из Z в У.
Общее правило path2 можно применять различными способами. Например, оно
подходит для проверки существования двухходового пути из одной клетки в другую. Если
функция pattern_search вызывается для цели pafh2A,3), то проверяется
соответствие этой цели последовательности правил path2{X, У). При этом выполняются
подстановки для предпосылок правила. Результатом является конкретное правило, которое
определяет условия, необходимые для такого пути.
pafAi2A,3) <-3Z[moveA, Z) л move(Z, 3)].
Затем функция pattern_search вызывает сама себя с этим параметром.
Поскольку это конъюнкция двух выражений, pattern_search пытается разрешить каждую
подцель отдельно. Это требует не только согласованности обеих подцелей, но и
непротиворечивости связывания всех переменных. Подстановка 8 вместо Z дает возможность
согласовать обе подцели.
Другой запрос может состоять в том, чтобы найти все клетки, которые могут быть
достигнуты из клетки 2 за два хода. Это достигается вызовом pattern_search для
цели path2B, У). Используя подобный процесс, можно найти все возможные
подстановки, включая {6/У) и {2/У) (с промежуточным значением Z, равным 7), а также {2/У)
и {4/У} (с промежуточным значением 9). Дальнейшие запросы могут состоять в том,
чтобы найти путь за два хода из клетки с некоторым номером в ту же самую клетку, из любой
клетки в клетку 5 и так далее. Обратите внимание на одно из преимуществ поиска по
образцу: в качестве начальной цели могут быть взяты самые разнообразные запросы.
Аналогично путь с тремя ходами проходит через две промежуточные клетки, которые
являются частью пути от начального состояния к цели. Такой путь может быть
определен следующим образом.
VX, Y[path3(X, V)<-3Z, W[move(XtZ)Amove(Zt W) л move(WtY)]].
Используя это определение, можно рассматривать такие задачи, как path2>C\ ,2),
pafh3A ,Х) или даже path3{X, У). Эти задачи мы оставляем читателю в качестве
упражнений.
Очевидно, что аналогичным способом можно решать задачи нахождения пути
произвольной длины. Просто необходимо указать соответствующее количество
промежуточных мест "приземления". Также очевидно, что путь большей длины может быть
определен в терминах пути меньшей длины.
V X, У [path3(Xt У) <- 3Z [move(Xt Z) л path2(Z, У)]].
Это дает возможность получить общее рекурсивное правило.
V X, У [path(X, У) <r- 3Z [move(X, Z) л path(Z, У)]].
Последнее правило можно использовать для проверки существования пути
произвольной длины. Такая задача может быть сформулирована следующим образом: "Найти
Глава 5. Управление поиском и его реализация в пространстве состояний 193
путь из одной клетки в другую, делая при этом ход из начальной клетки в
промежуточную, а затем из промежуточной в конечную".
Это рекурсивное правило "пути" неполно в том смысле, что в нем не определено
условие выхода из рекурсии. Поэтому любая попытка определить путь к цели, используя
предикат path, будет безуспешной, потому что каждая попытка найти промежуточный
путь, снова будет приводить к рекурсивному вызову path(Z, Y). Это объясняется тем, что
не определено условие достижения конечного состояния. Этот недостаток может быть
исправлен, если к базе знаний добавить условие path{X, X). Поскольку path(X, X)
унифицируется только с предикатами типа path{3,3) или path{5,5), то оно определяет
необходимое условие завершения рекурсии. Тогда общее рекурсивное определение пути
задается двумя формулами исчисления предикатов.
VXpaf/7(X,X)
VX, Y[path{Xt Y) <- 3 Z [move(X, Z) л path(Z, /)]].
Еще раз обратите внимание на элегантность и простоту рекурсивной формулировки.
Если объединить приведенные выше условия с рекурсивной процедурой pat-
tern_search, то эти правила позволяют найти всевозможные пути в задаче хода
конем. Объединяя их с правилами перемещения коня, получим полное описание задачи
(или базы знаний).
moveA,8) moveC\, 6) moveB, 9) moveBf 7)
move{3, 4) moveC, 8) move{4, 9) moveD, 3)
moveF, 1) moveF, 7) moveG, 2) moveG, 6)
move(Q, 3) move(Q, 1) move(9, 2) move{9f 4)
VXpafh(X, X)
VX, Y[path(Xt Y) <- 3 Z [move(X, Z) л path(Z, Y)]].
Следует заметить, что при решении задачи использовались логические описания,
определяющие пространство состояний, и процедура pattern_search поиска в этом
пространстве. Хотя правило path достаточно удовлетворительно определяет путь, оно не
указывает, как найти этот путь. Действительно, на шахматной доске существует много других
путей, которые не ведут к цели, но, тем не менее, удовлетворяют этому определению.
Например, если не принимать во внимание механизм предотвращения зацикливания, то поиск
цели path( 1,3) может привести к зацикливанию между клетками 1 и 8, вместо
нахождения правильного пути 1—>8—>3. Таким образом, логическими следствиями базы знаний
являются и цикл, и правильный (допустимый) путь. Аналогично, если рекурсивное
правило будет проверяться перед условием выхода из рекурсии, то условие выхода из
рекурсии path( 3,3) будет проигнорировано, и поиск продолжится безо всякого смысла.
5.2.2. Усовершенствование алгоритма поиска по образцу
Хотя начальная версия функции pattern_search определяет правильное поведение
алгоритма поиска для выражений исчисления предикатов, все же стоит обратить внимание
на некоторые тонкости. Они включают порядок рассмотрения альтернативных вариантов и
корректную обработку полного набора логических операторов (л, v и —i). Логика по своей
сути декларативна, и без предписаний стратегии поиска она определяет пространство
возможных выводов, но не указывает решателю, как выделить из него полезные.
Для реализации рассуждений средствами исчисления предикатов необходим такой
режим управления, который осуществляет систематический поиск в пространстве, и при
194
Часть II. Искусственный интеллект как представление и поиск
этом позволяет избежать тупиковых путей и зацикливания. Алгоритм управления типа
pattern_search должен пытаться найти альтернативные пути в некоторой
последовательности. Знание этой последовательности позволяет разработчику программы
управлять поиском, должным образом систематизируя правила в базе знаний. Самый
простой способ определения такой последовательности — потребовать, чтобы алгоритм
проверял правила и факты в том порядке, в котором они встречаются в базе знаний.
В задаче хода конем это гарантирует, что условие выхода из рекурсии path(X, X) будет
рассматриваться перед следующим рекурсивным шагом.
Другая проблема заключается в наличии логических связок в предпосылках правил,
например, в импликациях вида: р<-длг или p<^qA(rws). Оператор л означает, что
результат будет истиной, если выражения q и г тоже истинны. Кроме того, конъюнкты в
выражениях должны разрешаться с помощью согласованных значений переменных. Так,
чтобы найти значение выражения р(Х)лд(Х), не достаточно разрешить р(Х) и д(Х),
используя подстановку {а/Х} и {Ь/Х}. Оба конъюнкта должны быть разрешены с помощью
одного и того же соответствующего значения переменной X. С другой стороны, оператор
v (или) обеспечивает истинность для всего выражения, если хотя бы одна из его частей
является истиной. Алгоритм поиска должен принимать это во внимание.
Последнее дополнение к рассмотренному алгоритму — это его способность находить
цель, используя логическое отрицание —i. Функция pattern_search обрабатывает
инвертированные цели, разрешая вначале операнд отрицания —i. Если эта подцель
достижима, то процедура pattern_search возвращает FAIL. Если же эта цель
недостижима, то pattern_search возвращает пустое множество подстановок, указывающих на
успех. Обратите внимание на то, что даже если подцель содержит переменные, то
результат разрешения ее отрицания не может содержать никаких подстановок. Это связано
с тем, что отрицание —i принимает значение "истина", только если его операнд не
удовлетворяется. Следовательно, операция отрицания не может возвращать никаких
значений связывания для этого операнда.
Наконец, алгоритм должен возвращать не значение SUCCESS, а те значения связывания,
которые использовались при решении. Например, для нахождения пути move(\, X)
существенной частью решения являются подстановки {6/Х} и {8/Х}.
Окончательная версия функции pattern_search, возвращающая множество
унификаций, удовлетворяющих каждой подцели, имеет следующий вид.
function pattern_search(current_goal);
begin
if current_goal содержится в closed %проверка на зацикливание
then return FAIL
else добавить current_goal в список closed;
while остаются унифицирующие факты или правила do
begin
case
current_goal унифицируется с фактом:
return унифицирующие подстановки;
current_goal инвертирована (—i p) :
begin
вызвать pattern_search для р;
if pattern_search возвращает FAIL
Глава 5. Управление поиском и его реализация в пространстве состояний 195
then return {}; %отрицание истинно
else return FAIL;
end;
current_goal — это конъюнкция (р л . . . ) :
begin
for каждого конъюнкта do
begin
вызвать pattern_search для конъюнкта;
if pattern_search возвращает FAIL
then return FAIL;
else применить подстановки к другим конъюнктам;
end;
if pattern_search возвращает SUCCESS для всех конъюнктов
then return композицию всех унификаций;
else return FAIL;
end;
current_goal — это дизъюнкция (p v ...):
begin
repeat for каждого дизъюнкта
вызвать pattern_search для дизъюнкта
until больше нет дизъюнктов или SUCCESS;
if pattern_search возвращает SUCCESS
then return подстановки
else return FAIL;
end;
current_goal унифицируется с заключением (p in p<—q):
begin
применить подстановки унификации цели к предпосылке (q);
вызвать pattern_search для предпосылки;
if pattern_search возвращает SUCCESS
then return объединение подстановок р и q
else return FAIL;
end;
end; %окончание оператора case
end %окончание цикла while
return FAIL
end.
Этот алгоритм поиска в пространстве правил исчисления предикатов и фактов
положен в основу языка PROLOG (в котором используется хорновская форма предикатов,
см. подраздел 12.3) и многих оболочек экспертных систем, работающих от цели
(см. часть VI). Альтернативный принцип управления поиском по образцу обеспечивают
продукционные системы, которые будут рассмотрены в следующем разделе.
5.3. Продукционные системы
5.3.1. Определение и история развития
Продукционная система (production system) — это модель вычислений, играющая
особо важную роль в задачах искусственного интеллекта как для создания алгоритмов
196
Часть II. Искусственный интеллект как представление и поиск
поиска, так и для моделирования решения задач человеком. Продукционная система
обеспечивает управление процессом решения задачи по образцу и состоит из набора
продукционных правил (production rule), рабочей памяти (working memory) и цикла
управления "распознавание-действие".
ОПРЕДЕЛЕНИЕ
ПРОДУКЦИОННАЯ СИСТЕМА
Продукционную систему можно определить на основе следующих категорий.
1. Набор продукционных правил. Их часто просто называют продукциями
(productions). Продукция — это пара "условие-действие", которая определяет одну
порцию знаний, необходимых для решения задачи. Условная часть правила — это
образец (шаблон), который определяет, когда это правило может быть применено
для решения какого-либо этапа задачи. Часть действия определяет
соответствующий шаг в решении задачи.
2. Рабочая память (working memory) содержит описание текущего состояния
мира в процессе рассуждений. Это описание является образцом, который
сопоставляется с условной частью продукции с целью выбора соответствующих действий
при решении задачи. Если условие некоторого правила соответствует
содержимому рабочей памяти, то может выполняться действие, связанное с этим
условием. Действия продукционных правил предназначены для изменения содержания
рабочей памяти.
3. Цикл "распознавание-действие". Управляющая структура продукционной
системы проста: рабочая память инициализируется начальным описанием задачи.
Текущее состояние решения задачи представляется набором образцов в рабочей
памяти. Эти образцы сопоставляются с условиями продукционных правил; что
порождает подмножество правил вывода, называемое конфликтным
множеством (conflict set). Условия этих правил согласованы с образцами в рабочей
памяти. Продукции, содержащиеся в конфликтном множестве, называют
допустимыми. Выбирается и активизируется одна из продукций конфликтного
множества (разрешение конфликта). Активизация правила означает выполнение его
действия. При этом изменяется содержание рабочей памяти. После того как
выбранное правило сработало, цикл управления повторяется для
модифицированной рабочей памяти. Процесс заканчивается, если содержимое рабочей памяти
не соответствует никаким условиям.
В процессе разрешения конфликтов (conflict resolution) выбирается для выполнения
правило из конфликтного множества. Стратегии разрешения конфликтов могут быть
достаточно простыми, например, выбор первого правила, условие которого
соответствует состоянию мира. Можно для такого выбора использовать сложную эвристику.
Следует подчеркнуть, что продукционная система допускает использование
дополнительных эвристик для управления алгоритмом поиска.
Чистая продукционная модель не имеет никакого механизма выхода из тупиковых
состояний в процессе поиска; она просто продолжает работать до тех пор, пока не
будут исчерпаны все допустимые продукции. Многие практические реализации
продукционных систем содержат механизмы возврата в предыдущее состояние
рабочей памяти.
Глава 5. Управление поиском и его реализация в пространстве состояний 197
Схема продукционной системы представлена на рис. 5.3.
Простой пример работы продукционной системы представлен на рис. 5.4. Данная
продукционная система сортирует строку, состоящую из символов а, Ь и с. В этом
примере продукция является допустимой, если ее условие соответствует части строки в
рабочей памяти. При выполнении правила подстрока, которая соответствовала его
условию, заменяется строкой из правой части правила. Продукционная система — это общая
модель вычислений, которая может быть запрограммирована для выполнения какой-
либо задачи на компьютере. Однако настоящее ее предназначение — это реализация
интеллектуальных систем.
Впервые идея разработки программ компьютерных вычислений, основанных на
"продукционных правилах", появилась в [Post, 1943]. В этой работе модель
продукционных правил предложена в качестве формальной теории вычислений. Основа этой
теории — набор правил вывода для строк, во многом аналогичный правилам
синтаксического анализа из примера 3.3.6. Эта теория также тесно связана с алгоритмами Маркова
[Markov, 1954] и подобно им эквивалентна машине Тьюринга.
Интересное приложение продукционных правил к моделированию человеческого
мышления описано в работах Нюэлла и Саймона из технологического института
Carnegie Institute of Technology (теперь — Carnegie Mellon University) в 1960-1970-х
годах. Программы, которые они разработали, включая Универсальный решатель задач
(General Problem Solver), послужили важным приложением продукционных систем в
искусственном интеллекте. Авторы исследовали человеческое мышление в процессе
решения различных задач, таких как задачи по логике предикатов или игре в шахматы.
Были составлены и разобраны на элементарные компоненты протоколы (образцы
поведения, включая словесные описания процесса решения задачи, движения глаз и т.д.)
решения различных задач. Эти компоненты рассматривались как основные биты
знания о методах решения задач человеком, для которых был реализован поиск на графе
(так называемом графе поведения задачи). Для осуществления поиска в этом графе
использовалась продукционная система.
Продукционные правила представляли множество навыков человека при решении
задач. Текущий фокус внимания был описан как текущее состояние мира. При работе
продукционной системы "внимание" (или "текущий фокус") решателя задачи
сопоставляется с продукционным правилом, которое изменяет состояние "внимания" и
приводит его к соответствию с другим продукционным правилом (представляющим
некоторый навык), и так далее.
Следует заметить, что в работе Ньюэлла и Саймона продукционная система
использовалась не только для реализации поиска на графе, но и для представления модели
человеческого поведения при решении задачи. Продукции соответствуют навыкам
решения задач в долгосрочной памяти человека. Подобно навыкам в долгосрочной памяти
эти продукции не изменяются при работе системы. Они вызываются по "образцу" для
данной специфической проблемы, а новые навыки могут быть добавлены к
существующей базе знаний без соответствующей команды записи. Рабочая память продукционной
системы соответствует краткосрочной памяти, или текущей области внимания
человека, и описывает текущую стадию решения задачи. Содержание рабочей памяти после
решения задачи не сохраняется.
Эти результаты описаны в книгах [Newell и Simon, 1972] и [Luger, 1978],
[Luger, 1994].
198
Часть II. Искусственный интеллект как представление и поиск
Шаблон
рабочей
памяти
i
[
\
Г
С1^А1
С2-А2
СЗ^АЗ
Шаблон-» Действие
Сл->Ал
Рис. 5.3. Продукционная система. Цикл
выполняется до тех пор, пока образец рабочей памяти не
будет более соответствовать ни одному из
условий продукционных правил
Набор продукций-
1. ba -> ab
2. ca -» ac
3 cb -> be
Конфликтное Применение
Итерация # Рабочая память множество правила
0
1
2
3
4
5
6
cbaca
cabca
acbca
acbac
acabc
aacbc
aabec
1,2,3
2
2,3
1,3
2
3
0
1
2
2
1
2
3
Останов
Рис. 5.4. Работа простой продукционной системы
Ньюэлл, Саймон и другие исследователи использовали продукционные правила для
моделирования различия между новичками и экспертами ([Larkin и др., 1980], [Simon и
Simon, 1978]) в таких областях, как решение алгебраических и физических задач.
Продукционные системы также составляют основу для изучения человеческого и
компьютерного обучения [Klahr и др., 1987]. На этой традиции построены системы ACT*
[Anderson, 19836] и SOAR [Newell, 1990].
Продукционные системы обеспечивают модель представления человеческого
опыта в форме правил и позволяют разрабатывать алгоритмы поиска по образцу —
центральный элемент основанных на правилах экспертных систем. В экспертных
системах продукционные модели не обязательно являются точной реализацией
человеческого подхода к решению задачи. Однако существуют такие аспекты
продукционных систем, которые делают их полезными в качестве потенциальной модели
Глава 5. Управление поиском и его реализация в пространстве состояний 199
решения задачи человеком (модульность правил, разделение знания и управления,
разделение рабочей памяти и навыков в решении задач). Это служит идеальным
инструментом для разработки экспертных систем.
В результате исследования продукционных систем в Университете Карнеги Мел-
лон (Carnegie Mellon University) появилось важное семейство языков для систем
искусственного интеллекта. Это так называемые OPS-языки официальных
продукционных систем (Official Production System). Хотя сначала они предназначались для
моделирования человеческого подхода к решению задач, эти языки оказались очень
эффективными для программирования экспертных систем и других приложений
искусственного интеллекта. OPS5 — язык реализации для VAX-конфигуратора XCON
и других экспертных систем, разработанных в Корпорации цифрового оборудования
(Digital Equipment Corporation) [McDermott, 1981, 1982], [Soloway и др., 1987],
[Barker и O'Connor, 1989]. Широко распространены OPS-интерпретаторы для
персональных компьютеров и рабочих станций. Активно используется созданная в НА-
СА объектно-ориентированная версия продукционной системы CLIPS,
реализованная на языке программирования С.
В следующем разделе мы рассмотрим примеры использования продукционных
систем для решения разнообразных задач поиска.
5.3.2. Примеры продукционных систем
ПРИМЕР 5.3.1. И снова "8-головоломка"
Пространство поиска для задачи "8-головоломка", описанной в главе 3, является
достаточно сложным и интересным. В то же время оно настолько мало, что не вызывает
особых трудностей в рассмотрении. "8-головоломка" часто используется для изучения
различных стратегий поиска, например, поиска в глубину и в ширину, а также
эвристических стратегий (см. главу 4). Здесь мы рассмотрим продукционную систему.
Не уменьшая общности, будем говорить о "перемещении пустой клетки" вместо
перемещения пронумерованной фишки. Допустимые ходы определены продукциями,
показанными на рис. 5.5. Естественно, если пустая клетка находится в центре, допустимы все
четыре хода. Если пустая клетка находится в одном из углов, возможны только два хода.
Если начальное и целевое состояние для "8-головоломки" определены, то можно создать
продукционную систему, просматривающую пространство поиска задачи.
В реализации решения этой задачи каждую конфигурацию на игровой доске
можно представить с помощью предиката состояния с девятью параметрами (для
девяти возможных положений восьми фишек и пустой клетки). Правила можно
представить как импликации, предпосылки которых обеспечивают проверку
необходимых условий. С другой стороны, для описания состояния игровой доски можно
использовать массивы или списки.
Пример решения этой задачи на основе поиска в пространстве состояний, описанный
в [Nilsson, 1980], проиллюстрирован на рис. 5.5 и 5.6. Поскольку путь к решению может
находиться очень глубоко, если его не направлять, поиск был ограничен предельной
глубиной. Простой прием для реализации предельной глубины поиска — следить за длиной
текущего пути, и в случае превышения предельной длины отслеживать путь в обратном
направлении, т.е. запускать механизм поиска с возвратом. На рис. 5.6 предельная
глубина поиска равна 5. Заметим, что число возможных состояний рабочей памяти растет
экспоненциально с увеличением глубины поиска.
200 Часть II. Искусственный интеллект как представление и поиск
Начальное
состояние
2
1
7
8
6
3
4
_5_
Целевое
состояние
1 | 2| 3 |
7 | б| 5 |
Продукционное множество
Условие
Действие
целевое состояние в рабочей памяти ■* останов
пустая ячейка не возле левой границы ■* переместить пустую ячейку влево
пустая ячейка не возле верхней границы ■* переместить пустую ячейку вверх
пустая ячейка не возле правой границы ■* переместить пустую ячейку вправо
пустая ячейка не возле нижней границы ■* переместить пустую ячейку вниз
Рабочая память содержит текущее и целевое состояние игровой доски.
Режим управления
1. Испытать каждое правило по порядку.
2. Не допускать циклов.
3. Завершить работу при нахождении цели.
Рис. 5.5. "8-головоломка" как продукционная система
Рис. 5.6. Решение задачи "8-головоломки" с помощью продукционной системы, в
которой поиск ограничен глубиной 5 [Nilsson, 1980]
Глава 5. Управление поиском и его реализация в пространстве состояний 201
ПРИМЕР 5.3.2. Задача хода конем
Задача хода конем на доске размером 3X3, представленная в разделе 5.2, может быть
решена с помощью продукционных систем. В этом случае каждый ход можно
представить как правило, предпосылки которого описывают расположение коня в конкретной
клетке, а действие перемещает коня в другую клетку. Все возможные ходы коня
описываются с помощью шестнадцати продукционных правил.
Рабочая память содержит и текущее, и целевое состояние доски. В режиме
управления правила применяются до тех пор, пока текущее состояние не уравняется с целевым.
Тогда процесс останавливается. По простой схеме разрешения конфликтов запускается
первое же правило, которое не вызывало зацикливания поиска. Поиск может привести к
тупиковым состояниям, из которых каждое возможное перемещение приводит в уже
посещенное состояние и, следовательно, вызывает зацикливание. Поэтому режим
управления должен обеспечить возврат. Действия этой продукционной системы при
определении существования пути из поля 1 в поле 2 представлены в табл. 5.1.
эавила
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Условие
Конь в поле 1 —>
Конь в поле 1 —>
Конь в поле 2 —>
Конь в поле 2 —>
Конь в поле 3 —>
Конь в поле 3 —>
Конь в поле 4 —>
Конь в поле 4 —>
Конь в поле 6 —>
Конь в поле 6 —>
Конь в поле 7 —>
Конь в поле 7 —>
Конь в поле 8 —>
Конь в поле 8 —>
Конь в поле 9 —>
Конь в поле 9 —>
Действие
Ход конем в поле 8
Ход конем в поле 6
Ход конем в поле 9
Ход конем в поле 7
Ход конем в поле 4
Ход конем в поле 8
Ход конем в поле 9
Ход конем в поле 3
Ход конем в поле 1
Ход конем в поле 7
Ход конем в поле 2
Ход конем в поле 6
Ход конем в поле 3
Ход конем в поле 1
Ход конем в поле 2
Ход конем в поле 4
Интересно заметить, что реализация предиката пути path в задаче хода конем из
раздела 5.2 фактически обеспечивает построение продукционной системы! С этой точки
зрения pattern_search— это просто интерпретатор, а реальный поиск фактически
осуществляется с помощью предиката path. Продукционные правила— это факты
перемещений move, первый параметр которых определяет условие (на доске должно быть
достаточно места, чтобы сделать ход), а второй — действие (поле, в которое конь может
перейти). Цикл "распознавание-действие" (recognize-act) реализуется с помощью
рекурсивного предиката пути path. Рабочая память содержит текущее и желаемое целевое
состояние. Ее можно представить параметрами предиката пути path. На данной итерации
конфликтное множество — это все выражения перемещений, которые унифицируются с
целью move(X,Z). Эта программа использует простую стратегию разрешения
конфликтов, состоящую в выборе и активизации первого предиката перемещения в базе знаний,
который не ведет к повторному состоянию. Контроллер также осуществляет возвраты из
202
Часть II. Искусственный интеллект как представление и поиск
тупиковых состояний. Эта версия определения предиката pa th для продукционной
системы показана на рис. 5.7.
Таблица 5.1. Продукционная система для решения задачи хода конем на поле 3x3
№ итерации Рабочая память
Текущее поле Целевое поле
Конфликтное
множество
(№ правила)
1,2
13,14
5,6
7,8
15,16
Активизация
правила
1
13
5
7
15
Выход
Рекурсивный вызов paf/7(X,V) приводит
к выполнению очередной итерации
Попытка унификации рабочей
памяти с использованием
вызова path(X,Y)
Сравнение move{X,Z)
с продукциями
Рабочая память
path(X,Y)
В рабочей памяти присвоить X
значение Z (т.е. вызватьpath{Z,Y))
Продукции
move{i ,8)
move{i ,6)
moveB,7)
moveB,9)
move (9,2)
Г Л
Разрешение конфликтов:
сначала
выполняйте сравнения,
не приводящие к циклам
Рис. 5 7. Рекурсивный алгоритм вычисления пути в продукционной системе
Продукционные системы могут порождать бесконечные циклы при поиске на графе
пространства состояний. Эти циклы особенно трудно определить в продукционной системе,
потому что правила могут активизироваться в любом порядке. Следовательно, зацикливание
может появиться при работе системы, но его не легко обнаружить путем проверки синтаксиса
набора правил. Например, при использовании порядка следования правил move в задаче хода
конем, описанного в разделе 5.2, и стратегий разрешения конфликтов путем выбора первого
соответствующего правила образец moveBtX) будет соответствовать факту moveB,9),
указывая на перемещение в поле 9. На следующей итерации образец move(9tX) будет
сопоставлен с move(9t2). Алгоритм снова вернется в поле 2, образуя цикл.
Глава 5. Управление поиском и его реализация в пространстве состояний 203
Чтобы предотвратить зацикливание, функция pattern_search проверяла
глобальный список посещенных состояний closed. Стратегия разрешения конфликтов
сводилась к следующему: выбиралось первое соответствующее перемещение, которое ведет в
еще не посещенное состояние.
В продукционной системе список уже обследованных состояний closed не является
глобальной переменной, а хранится непосредственно в рабочей памяти. Предикат пути
path можно модифицировать таким образом, чтобы использовать рабочую память для
обнаружения циклов.
Предположим, что функция pattern_search не поддерживает глобальный список
closed и не выполняет проверку на наличие циклов. Предположим также, что язык
исчисления предикатов расширен специальной конструкцией assert(X) (добавить
утверждение в базу знаний), которая заносит в рабочую память свой параметр X. Конструкция
assert — не обычный предикат, а выполняемое действие, следовательно, assert всегда
завершается успешно.
Предикат assert используется для помещения в рабочую память "маркера",
указывающего на проверенное состояние. Этот маркер представляется унарным предикатом
Ьееп(Х), параметром которого является поле игровой доски. Маркер Ьееп(Х)
добавляется к рабочей памяти после посещения нового состояния X. Для разрешения
конфликтов можно потребовать, чтобы при реализации правила move{X,Z) в рабочей памяти
отсутствовал маркер been(Z). Для конкретного значения Z это можно проверить,
сопоставив образец с содержимым рабочей памяти.
Модифицированное рекурсивное определение пути выглядит так.
VX pa th(X,X)
VX.Vpath(XtY) <r-3Z move{Xt Z) л^ (been{Z)) л assert(been(Z)) л path(Z,Y).
В этом определении move(X,Z) успешно выполнится при первом совпадении с
предикатом move. При этом переменная Z станет связанной. Если предикат been(Z)
соответствует элементу рабочей памяти, то -i (been(Z)) принимает значение
"ложь". Тогда функция patern_search возвращается и ищет другое соответствие
для move(XyZ). Если клетка Z является новым состоянием, то поиск продолжается,
a been(Z) добавляется в рабочую память для предотвращения дальнейших
зацикливаний. Реальная активизация продукционного правила происходит на следующем
шаге рекурсии. Таким образом, наличие предикатов been в рабочей памяти
обеспечивает обнаружение зацикливаний в продукционной системе.
Заметим, что исчисление предикатов используется как язык описания продукционных
правил и элементов рабочей памяти. Процедурная сущность продукционных систем
требует, чтобы цели в определении предиката path были исследованы слева направо. Этот
порядок интерпретации обеспечивается функцией patern_search.
ПРИМЕР 5.3.3. Полная задача хода конем
Решение задачи хода конем можно обобщить для полной шахматной доски
размером 8x8. Поскольку не имеет смысла нумеровать ходы в такой сложной задаче,
заменим 16 ходов набором из 8 правил, генерирующих допустимые ходы конем. Эти
ходы (продукции) соответствуют 8 возможным вариантам перемещения коня
(см. рис. 5.1).
Если пронумеровать строки и столбцы шахматной доски, то можно сформулировать
продукционное правило для хода конем: вниз на две клетки и вправо на одну.
204
Часть II. Искусственный интеллект как представление и поиск
УСЛОВИЕ: current row<6 л current column<7
ДЕЙСТВИЕ: new row = current row + 2 л new column = current column*]
Если для представления продукций использовать исчисление предикатов, то игровую
доску можно определить предикатом square(RtC) (или Keadpam(R,C)), где R — строка,
С — столбец шахматной доски. Приведенное выше правило может быть записано в
исчислении предикатов следующим образом.
move(square(Rowt Column), square(Newrow, Newcolumn)) <-
less_than_or_equals(Rowi 6) л
equals(Newrowt plus(Row, 2)) л
less_than_or_equals(Columnt 7) л
equals(Newcolumnt plus(Columnt 1))
Здесь plus (плюс) — функция сложения, less_than_or_equals (меньше или равно) и
equals (равно) тоже имеют очевидную арифметическую интерпретацию. Это правило
можно дополнить, написав еще семь правил для определения оставшихся допустимых
ходов. Эти правила заменяют факты move в версии задачи 3x3.
Функция path (путь) в примере 3x3 определяет цикл управления в этой задаче. Как
мы уже видели, при процедурной интерпретации описаний в исчислении предикатов,
например с помощью алгоритма pattern_search, семантика исчисления предикатов слегка
изменяется. Одно из таких изменений — это последовательность разрешения целей. При
этом к выражениям исчисления предикатов добавляется процедурная семантика (или
упорядочение). Еще один пример изменений — введение таких металогических
предикатов, как assert (утверждать), которые указывают на действия вне интерпретации
значений истинности для выражений исчисления предикатов. Эти проблемы более детально
обсуждаются при рассмотрении языка PROLOG в главе 14, а также при описании
реализации механизма логического программирования в LISP в главе 15.
ПРИМЕР 5.3.4. Финансовый советник как продукционная система
Во второй и третьей главе мы разработали модель небольшой системы "финансового
советника". Для представления знаний о финансовом состоянии вкладчика было
использовано исчисление предикатов, а для определения наилучшего способа вложения денег
применялся поиск на графе. Продукционная система является естественным средством
для реализации такой модели. Импликации логических описаний составляют
продукционные правила. Вся конкретная информация, в том числе зарплата клиента, число
иждивенцев и т.п., помещается в рабочую (оперативную) память. Правила начинают
функционировать, как только удовлетворяются их предпосылки. Из противоречивой
совокупности правил выбирается некоторое правило. Оно выполняется, а его заключение
добавляется в рабочую память. Это продолжается до тех пор, пока в рабочую память не
будут добавлены все возможные заключения верхнего уровня. Действительно, многие
оболочки экспертных систем являются продукционными системами с поддержкой
дополнительных возможностей. Среди них: интерфейс пользователя, поддержка
рассуждений с неопределенностью, редактирование базы знаний и контроль выполнения поиска.
5.3.3. Управление поиском в продукционных системах
Модели продукционных систем предоставляют дополнительные возможности по
добавлению эвристического управления к алгоритму поиска. Эти дополнительные удобства
Глава 5. Управление поиском и его реализация в пространстве состояний 205
включают выбор стратегии (на основе данных или от цели), выбор самой структуры
правил и стратегий для разрешения конфликтов.
Управление посредством выбора стратегии поиска: на основе данных или от цели
Поиск на основе данных начинается с описания задачи (например, в виде набора
логических аксиом, признаков болезни или массива данных, который необходимо
интерпретировать), затем из имеющихся данных выводятся новые знания. Это осуществляется
путем применения правил вывода, например, допустимых ходов в игре или других
операций, генерирующих новые состояния в текущем описании мира, и добавления
результатов к описанию рассматриваемой задачи. Этот процесс продолжается до тех пор, пока
не будет достигнуто целевое состояние.
Такое представление рассуждений на основе данных подчеркивает их соответствие
модели продукционной системы. "Текущее состояние мира" (это исходные данные, которые
приняты как истина или выведены как истина с помощью правил вывода) помещается в
рабочую память. Затем в цикле "распознавание-действие" текущее состояние сравнивается с
(упорядоченным) набором продукций. Если эти данные соответствуют условиям одного из
правил вывода (унифицируются с ними), применение этого правила добавляет новую
порцию информации к текущему состоянию мира (изменяя рабочую память).
Все продукционные правила имеют форму CONDITION —> ACTION (условие—>
действие). Если условие CONDITION соответствует некоторым элементам рабочей
памяти, выполняется действие ACTION. Если продукционные правила
сформулированы как логические импликации и действие ACTION добавляет утверждения в
рабочую память, то активизация правила соответствует применению модус поненс. При
этом на графе создается новое состояние.
На рис. 5.8 представлен простой пример поиска на основе данных для набора
продукционных правил, записанных в виде импликаций исчисления высказываний.
Стратегия разрешения конфликтов — это простая стратегия выбора допустимого
правила, которое сработало раньше всего (или совсем не активизировалось). Поиск
прекращается, когда цель достигнута. Кроме того, на рисунке также представлены
порядок активизации правил и состояния рабочей памяти в процессе выполнения, а
также граф пространства поиска.
До сих пор мы рассматривали функционирование продукционных систем на основе
данных. Однако существуют продукционные системы, осуществляющие поиск от цели.
В главе 3 говорилось о том, что поиск от цели начинается с цели и возвращается назад к
фактам, соответствующим данной цели. Чтобы реализовать это в продукционной
системе, цель помещается в рабочую память, а затем проверяется ее соответствие действиям
ACTION правил вывода. Проверка соответствия действиям выполняется точно так же,
как при поиске на основе данных проверяется выполнение условий CONDITION
(например, с помощью унификации). Все продукционные правила, заключения
(ACTION) которым соответствуют цели, формируют конфликтное множество.
После проверки соответствия действий ACTION их условия CONDITION добавляются
в рабочую память, формируя новые подцели (или состояния) поиска.
Затем проверяется соответствие новых состояний заключениям ACTION остальных
продукционных правил. Этот процесс продолжается до тех пор, пока не будет найден
факт, содержащийся в начальном описании задачи, или, как часто бывает в экспертных
системах, факт, непосредственно полученный путем запроса у пользователя
необходимой информации. Поиск прекращается, когда условия всех продукционных правил, ис-
206
Часть II. Искусственный интеллект как представление и поиск
пользованных (активизированных) в процессе поиска, окажутся истинными. Эти условия
и цепочка правил, ведущих к исходной цели, составляют доказательство ее истинности.
Продукционное множество:
1 рлд->цель
2. rAs^p
3. wAr-^q
4. tAu^q
5 v->s
6. начало->улглд
Последовательность выполнения:
Номер
итерации
0
1
2
3
4
Рабочая память
начало
начало, v, r, q
начало, v, г, g, s
начало, v, г, д, s, р
начало, v, г, д, s, p, цель
Множество
конфликтов
6
6,5
6,5,2
6,5,2, 1
6,5,2,1
Примененное
правило
6
5
2
1
останов
Просмотренная часть пространства:
начало
направление
поиска
V
цель
Рис. 5 8 Поиск на основе данных в продукционной системе
На рис. 5.9 дан пример рассуждений от цели на том же наборе продукционных правил,
который показан на рис. 5.8. Заметим, что в процессе поиска от цели активизируется
совсем другая последовательность продукционных правил и исследуется не то
пространство, что в версии поиска на основе данных.
Как следует из вышеописанных примеров, продукционная система обеспечивает
естественную реализацию поиска от цели и на основе данных. Продукционные
правила — это закодированный набор правил вывода (знаний в экспертной системе,
основанной на правилах) для изменения состояния внутри графа. Если текущее
состояние мира (набор истинных утверждений, описывающих мир) соответствует
условиям CONDITION продукционного правила, то действие ACTION этого правила
определяет новое (истинное) описание существующего мира. Этот процесс
рассматривается как поиск от данных.
С другой стороны, если проверяется соответствие цели части ACTION набора
продукционных правил, а затем в качестве подцелей выбираются условия
CONDITION, истинность которых должна быть доказана (путем сопоставления
заключений ACTION в следующем цикле работы продукционной системы), то задача
решается путем поиска от цели.
Поскольку набор правил может активизироваться или на основе данных или от
цели, можно сравнить эффективность этих подходов. Сложность поиска для обеих
стратегий измеряется таким понятием, как коэффициент ветвления (branching fac-
Глава 5. Управление поиском и его реализация в пространстве состояний 207
tor) (раздел 4.4). Этот критерий сложности поиска позволяет оценить стоимость
обеих версий решения задачи (поиск на основе данных или от цели) и выбрать
наиболее эффективную стратегию.
Можно также использовать комбинацию стратегий. Например, вначале вести
поиск в прямом направлении от данных до тех пор, пока число состояний не станет
достаточно большим. Затем изменить направление поиска, направив его от цели, и
использовать возможные подцели для выбора среди состояний. Опасность такого
подхода состоит в том, что при использовании эвристического, или "жадного",
алгоритма поиска (глава 4) просмотренные части графа могут не совпасть друг с
другом. Тогда потребуется более длительный поиск, чем при простом подходе
(рис. 5.10). Однако если коэффициент ветвления пространства не изменяется и
используется исчерпывающий поиск, комбинированная стратегия поиска может
значительно сузить исследуемое пространство, как показано на рис. 5.11.
П родукцион ное
множество:
1. рлд-щель
2. rAs->p
3. wAr-+q
4 fA(J->Q
5. v-»s
6. начало-wArAq
Последовательность выполнения:
Номер
итерации
0
1
2
3
4
5
6
Рабочая память
цель
цель, р, q
цель, р, q, г, s
цель, р, q, г, s, w
цель, р, q, г, s, w, f, и
цель, р, q, г, s, w, t, и, v
цель, р, q, г, s, w, t, и, v, начало
Множество
конфликтов
1
1,2,3,4
1,2,3,4,5
1,2,3,4,5
1,2,3,4,5
1,2,3,4,5,6
1,2,3,4,5,6
Примененное
правило
1
2
3 _J
4
5
6
останов
Просмотренная часть пространства:
цель
направление
поиска
V
Рис. 5.9. Поиск от цели в продукционной системе
208
Часть II. Искусственный интеллект как представление и поиск
Начало
Цель
Рис 5 10 Двунаправленный расширенный поиск
Состояния, проверенные
в процессе прямого поиска
Состояния, проверенные
в процессе обратного поиска
Начало
Цель
Состояния, проверенные лишь
в процессе прямого поиска
Состояния, проверенные как
в процессе прямого поиска,
так и при поиске в обратном
направлении
Рис. 5 11. Двунаправленный поиск, отсекающий большую часть пространства,
исследуемую при однонаправленном поиске
Глава 5. Управление поиском и его реализация в пространстве состояний 209
Управление поиском с помощью структуры правил
Структура правил в продукционной системе, включая различия между условием и
действием, а также порядок проверки условий, определяет метод исследования
пространства. Описывая исчисление предикатов как язык представления, мы
подчеркивали декларативный характер его семантики. Таким образом, выражения исчисления
предикатов всего лишь определяют истинные отношения в области формулировки
задачи и не делают никаких утверждений относительно порядка интерпретации их
компонентов. Следовательно, некоторое частное правило может иметь вид VX (foo(X) л
доо(Х) —* тоо(Х)). Согласно правилам исчисления предикатов альтернативная форма
того же правила может быть такой VX (foo(X) —> тоо(Х) v —igoo(X)).
Эквивалентность этих двух выражений может быть продемонстрирована с помощью таблицы
истинности (раздел 2.1).
Хотя эти формулировки логически эквивалентны, они не ведут к одинаковым
результатам, если интерпретируются как продукции (продукционные правила), потому что
реализация продукционной системы обеспечивает определенный порядок проверки
соответствия и активизации правил. По этой причине форма представления правил
определяется удобством (или возможностями) проверки соответствия правилам в конкретной
задаче. Это является результатом выбора способа интерпретации правил продукционной
системой. Продукционная система налагает на декларативный язык описания правил
процедурную семантику.
Поскольку продукционная система проверяет правила в определенном порядке,
программист может управлять поиском через структуру и порядок следования правил в
продукционном наборе.
Несмотря на то что выражения VX(foo(X) л доо(Х) -> тоо(Х)) и VX (foo(X) ->
тоо(Х) v -.goo(X)) логически эквивалентны, при реализации поиска они
обрабатываются не одинаково.
Квалифицированные специалисты кодируют наиболее значащие (ключевые)
эвристики, руководствуясь своими профессиональными знаниями. В очередности
предпосылок содержится важная процедурная информация, необходимая для
успешного решения проблемы. Очень важно, чтобы эта формулировка (форма
выражения) сохранялась при написании программы. Например, когда механик говорит:
"Если двигатель не вращается, и фары не горят, проверьте аккумулятор", водителю
предлагается определенная последовательность действий. В логически
эквивалентном предложении "Двигатель вращается или фары горят, или проверьте
аккумулятор" эта информация теряется. Такая формулировка правил не выдерживает
критики, так как при управлении поиском необходимо, чтобы система вела себя логично,
а последовательность активизации правил была понятной.
Управление поиском через разрешение конфликтов
Продукционные системы (как и все системы, основанные на знаниях) позволяют
представлять эвристики непосредственно в правилах, описывающих знания. Кроме
того, они предлагают другой метод эвристического управления — через разрешение
конфликтов. Простейшая подобная стратегия сводится к тому, чтобы выбирать
первое соответствующее правило из рабочей памяти. Однако для разрешения
конфликтов (conflict resolution) потенциально может быть применена любая стратегия.
Например, в OPS5 поддерживаются следующие стратегии разрешения конфликтов
[Brownston и др., 1985].
210
Часть II. Искусственный интеллект как представление и поиск
1. Рефракция {refraction). Рефракция означает, что после активизации правила оно не
может быть запущено снова, пока не изменятся элементы рабочей памяти,
соответствующие его условиям. Рефракция препятствует зацикливанию.
2. Новизна {recency). Стратегия новизны отдает предпочтение правилам, условия
которых соответствуют образцам, добавленным в рабочую память последними. Это
позволяет сосредоточить поиск на одной линии рассуждения.
3. Специфичность {specifity). Согласно этой стратегии целесообразнее использовать
более конкретное, а не более общее правило. Одно правило более специфично
(конкретно) чем другое, если оно содержит больше условий, а значит,
соответствует меньшему количеству образцов в рабочей памяти.
5.3.4. Преимущества продукционных систем для ИИ
Как видно из предыдущих примеров, продукционная система обеспечивает общую
структуру осуществления поиска. Благодаря ее простоте, модифицируемости и гибкости в
применении знаний для решения задач продукционная система, как оказалось, может быть важным
механизмом для конструирования экспертных систем и других приложений ИИ. Главные
преимущества продукционных систем искусственного интеллекта описаны ниже.
Разделение знания и управления. Продукционная система — изящная модель
разделения знания и управления в компьютерной программе. Управление обеспечивается
циклом "распознание-действие" продукционной системы. При этом знания о методах
решения задач сосредоточены непосредственно в правилах. Преимущество такого
разделения заключается в простоте изменения базы знаний, при котором не требуется
изменять код программы управления. И, наоборот, это позволяет изменять код управляющей
части программы, не трогая набор правил вывода.
Естественное соответствие поиску в пространстве состояний. Компоненты
продукционной системы естественно отображаются в логическую структуру поиска в пространстве
состояний. Последовательные состояния рабочей памяти составляют вершины графа
пространства состояний. Правила вывода — набор возможных переходов между состояниями.
Разрешение конфликтов обеспечивает выбор перехода (ветви) в пространстве состояний. Эти
правила упрощают выполнение, отладку и документирование алгоритмов поиска.
Модульность продукционных правил. Важный аспект в моделировании
продукционных систем — это отсутствие синтаксического взаимодействия между
продукционными правилами. Правила могут только влиять на активизацию других правил, изменяя
образец в рабочей памяти. Правила не могут "вызывать" другие правила непосредственно,
как подпрограммы. При этом они не могут устанавливать значения переменных в других
продукционных правилах. Область действия переменных этих правил ограничена
отдельным правилом. Эта синтаксическая независимость способствует инкрементальной
разработке экспертных систем путем последовательного добавления, удаления или
изменения знаний (правил) системы.
Управление на основе образцов (pattern-directed control). Задачи, решаемые с
помощью программ ИИ, требуют особой гибкости при выполнении программы. Это
вызвано еще и тем фактом, что правила в продукционной системе могут запускаться в любой
последовательности. Описание задачи, представляющее текущее состояние мира,
определяет конфликтное множество и, следовательно, конкретный путь поиска и решения.
Возможности эвристического управления поиском. Несколько методов
эвристического управления были описаны в предыдущем разделе.
Глава 5. Управление поиском и его реализация в пространстве состояний 211
Трассировка и трактовка. Модульность правил и итерационный характер их
выполнения облегчают контроль за работой продукционной системы. На каждой стадии
цикла "распознание-действие" рассматривается некоторое правило. Поскольку каждое
правило соответствует отдельной "порции" (chunk) знаний о методах решения задач,
содержание правила должно давать ясную интерпретацию текущего состояния системы и
действия. Более того, цепочка правил, используемых в процессе решения, отражает как
путь на графе, так и "цепочку рассуждений", приводящую к решению задачи человека-
эксперта. В главе 7 это будет описано детально. Напротив, единая линия управления или
процедура, написанная на традиционном языке программирования, например, Pascal или
FORTRAN, фактически бессмысленна.
Независимость от выбора языка. Модель управления продукционной системой не
зависит от представления правил и рабочей памяти, если это представление
поддерживает сравнение с образцами. Мы описали продукционные правила как импликации
исчисления предикатов вида А => В, где истинность А и правило вывода модус поненс
позволяют сделать заключение В. Существует немало преимуществ применения логического
представления знаний и обоснования правил вывода, однако модель продукционной
системы может работать и с другими представлениями.
Исчисление предикатов обеспечивает преимущество логически обоснованного
вывода, однако немало задач требует рассуждений, которые не обоснованы в логическом
смысле. Для них необходимы вероятностные рассуждения, правила умолчания и
недостоверные свидетельства. В главах 6, 7 и 8 мы обсудим альтернативные правила вывода,
предоставляющие такие возможности. Независимо от типа используемых правил вывода,
продукционная система обеспечивает средства поиска в пространстве состояний.
Правдоподобная модель решения задачи человеком. Среди первых моделей,
использующих продукционные системы, были модели нахождения решения задач человеком
[Newell и Simon, 1972]. Эти системы, главным образом, использовались в качестве модели
человеческой деятельности в различных областях научных исследований (глава 16).
Поиск на основе образцов (pattern-directed search) позволяет исследовать
пространство логического вывода в исчислении предикатов. На этой методике основано немало
задач. В них исчисление предикатов используется для моделирования таких
специфических аспектов мира, как время и изменения. В следующем разделе представлена
методология "классной доски" как разновидность продукционной системы. В методологии
"классной доски" группы однотипных продукционных правил объединены в источники
знаний, которые участвуют в решении задачи путем общения через глобальную рабочую
память "классной доски".
5.4. Архитектура "классной доски"
Методология "классной доски" (blackboard) — заключительный механизм (алгоритм)
управления, представленный в этой главе. Если необходимо исследовать состояния в
пространстве логического вывода некоторым детерминированным способом, применение
продукционных систем обеспечивает значительную гибкость, позволяя одновременно
представить в рабочей памяти множество частных решений и выбрать следующее состояние путем
разрешения конфликтов. Методология "классной доски" расширяет возможности
продукционных систем, позволяя организовать рабочую память в виде отдельных модулей,
каждый из которых соответствует подмножеству продукционных правил. "Классная доска" ин-
212
Часть II. Искусственный интеллект как представление и поиск
тегрирует отдельные наборы продукционных правил и координирует действия
многочисленных решателей задач в пределах единой глобальной структуры.
Решение многих задач требует координации ряда различных типов знания.
Например, программа понимания (распознавания) речи должна сначала обработать
фрагменты речи, представленные в виде оцифрованной волны. Далее в процессе
распознавания необходимо выделить в этом речевом фрагменте отдельные слова,
сформировать их в предложения и, наконец, синтезировать семантическое
представление полученного значения.
При взаимодействии множества процессов в ходе решения одной большой задачи
может возникнуть немало сопутствующих проблем. Примером этого служит задача
слияния (объединения) показаний датчиков [Lesser и Corkill, 1983]. Предположим,
имеется сеть датчиков, соответствующих различным процессам. Предположим
также, что процессы могут сообщаться. Поэтому соответствующая интерпретация
данных каждого отдельного датчика зависит от данных, полученных другими
датчиками этой единой сети. Эта проблема возникает и в задаче управления траекторией
движения самолета, находящегося в поле обзора многочисленных радарных
установок с последующим объединением показаний всех датчиков в процессе обработки
информации.
Архитектура "классной доски" (стратегия решения сложных системных задач с
привлечением разнородных источников знаний, взаимодействующих через общее
информационное поле) — модель управления, которая успешно применяется для решения этой и
других задач, требующих координации различных процессов или источников знания.
"Классная доска" — центральная глобальная база данных, предназначенная для связи
независимых асинхронных источников знаний. На рис. 5.12 дано схематичное
представление архитектуры "классной доски".
На рис. 5.12 каждый источник знаний KSi (knowledge source) получает свои данные
от "классной доски", обрабатывает их и возвращает результаты "классной доске" для их
дальнейшего использования другими источниками знаний. Это изолированные
процессы, действующие согласно своим собственным спецификациям (описанию). Поэтому при
параллельной обработке информации или мультипроцессорной системы эти системы
участвуют в решении единой задачи независимо друг от друга. Это асинхронная система,
поскольку каждый источник знаний KSt начинает свою работу, когда находит
соответствующие входные данные на "классной доске". Закончив обработку данных, он
возвращает свои результаты и ожидает новых входных данных.
Подход "классной доски" к организации большой программы изначально был
реализован в системе HEARSAY-II [Erman и др., 1980], [Reddy, 1976]. HEARSAY-II —
это программа понимания речи. Первоначально она была разработана как внешний
интерфейс для базы данных публикаций по теории вычислительных систем.
Предполагалось, что абонент библиотеки может обратиться к компьютеру на английском
языке с запросом типа: "Есть ли у вас какие-нибудь работы авторов Фейгенбаума
(Feigenbaum) и Фельдмана (Feldman)?". Компьютер должен ответить на этот вопрос,
предоставив информацию из базы данных библиотеки. Понимание речи требует
интеграции ряда различных процессов, которым необходимы различные знания и
алгоритмы. Сложность этих алгоритмов и знаний может расти экспоненциально.
Обработка сигналов, распознавание фонем, слогов и слов, синтаксический анализ и
семантический анализ — все эти процессы связаны друг с другом в процессе
интерпретации речи.
Глава 5. Управление поиском и его реализация в пространстве состояний 213
Глобальная
классная доска"
Рис. 5.12. Архитектура "классной доски"
Архитектура "классной доски" позволила скоординировать в системе HEARSAY-II
несколько различных источников знания, необходимых для этой сложной задачи.
"Классная доска" обычно организована в двух измерениях. В HEARSAY-II этими
измерениями были время, в течение которого звучала речь, и уровень анализа фрагмента
активной речи. Каждый уровень анализа реализовывался различными классами источников
знания. Эти уровни анализа таковы.
KS\ Форма волны (временная диаграмма) акустического сигнала.
KS2 Фонемы или возможные звуковые сегменты акустического сигнала.
KSi Слоги, которые могут быть составлены из фонем.
KS4 Возможные слова, результат анализа первого /<S/.
KSs Возможные слова, результат анализа второго KS (обычно рассматриваются
слова из различных частей данных).
KS6 Генерация возможных последовательностей слов.
KS7 Связывание последовательности слов в фразы.
Эти процессы можно визуализировать в виде компонентов (см. рис. 5.12). При
обработке устной речи форма волны произнесенного сигнала рассматривается на самом
нижнем уровне. Обработку этих данных выполняют определенные источники знаний.
Результаты их анализа переносятся на доску и используются другими процессами. Из-за
неоднозначности разговорного языка на каждом уровне доски могут присутствовать
многочисленные конкурирующие гипотезы. Источники знаний более высоких уровней
пытаются устранить неоднозначности конкурирующих гипотез.
Процесс анализа в HEARSAY-II не следует рассматривать просто как
последовательность этапов анализа на низком уровне и создания данных, которые затем могут быть
проанализированы на более высоком уровне. Система HEARSAY-II значительно
сложнее. Если KS на одном уровне не может обработать (осмыслить) переданные ему данные,
то он делает запрос к соответствующему источнику о новых данных. Затем, получив
новые данные, делает еще одну попытку их обработки или принимает другую гипотезу
относительно первоначально полученных данных. Кроме того, различные /<S, могут
одновременно работать над разными фрагментами речи. Все процессы, как было уже сказано,
являются асинхронными и управляемыми на основе данных. Они запускаются с
появлением входных данных и продолжают работу, пока не закончат задание, затем
возвращают свои результаты и ждут следующего задания.
Один из KSh называемый планировщиком, обрабатывает сообщения о результатах
обработки информации, передаваемые между другими KSi. Планировщик ранжирует ре-
214
Часть II. Искусственный интеллект как представление и поиск
зультаты деятельности каждого KSj и с помощью приоритетной очереди обеспечивает
некоторое направление решения задачи. Если ни один из источников знаний не активен,
планировщик решает, что задача завершена, и прекращает свою работу.
Когда программа HEARSAY содержала базу данных около 1000 слов, она работала
достаточно хорошо, хотя немного медленно. Когда же база данных была расширена, данные
оказались слишком сложными для источников знания, и /CS, не могли их обработать.
Система HEARSAY-Ш [Balzer и другие, 1980], [Erman и др., 1981]— это обобщение подхода,
принятого в HEARSAY-П. Временное измерение в HEARSAY-Ш не используется, но
различные уровни анализа сохранены. "Классная доска" в HEARSAY-II1 предназначена для
взаимодействия с реляционной базой данных общего назначения. На самом деле, HEARSAY-Ш —
это оболочка для проектирования экспертных систем (см. подраздел 7.1.1).
Важным нововведением в HEARSAY-Ш стало отделение планировщика и превращение
его в контроллер ("классную доску") для первичной классной доски предметной области.
Появление второй "классной доски" позволило разделить процесс планирования и реализовать
его с помощью многочисленных источников знаний подобно тому, как сама задача
разделяется на различные уровни анализа. За разные аспекты процедуры решения (например, когда и
как применять знания о предметной области) стали отвечать различные К5,-. Таким образом,
вторая "классная доска" позволяет сравнить и сбалансировать разные решения отдельных
задач [Nii и Aiello, 1979], [Nii, 1986a], [Nii, 19866]. Существует и альтернативная модель
"классной доски", согласно которой важные части базы знаний остаются на "классной доске",
а не распределяются по источникам знаний [Skinner и Luger, 1991].
5.5. Резюме и дополнительная литература
В главе 5 обсуждалась реализация стратегий поиска, описанных в главах 3 и 4. Таким
образом, ссылки, перечисленные в заключительной части глав 3 и 4, относятся также и к
этой главе. В главе 5 представлена рекурсия как важный инструмент программирования
поиска на графе, а затем в рекурсивной форме реализован алгоритм поиска с возвратами
(backtrack algorithm) из главы 3. Поиск по образцу (pattern-directed search) с
использованием унификации и правил вывода упрощает реализацию поиска в пространстве
логического вывода.
Было показано, что продукционная система является естественной структурой для
моделирования решения задач и реализации алгоритмов поиска. Эта глава завершается
примерами реализации продукционных систем, осуществляющих поиск на основе
данных и от цели. Действительно продукционные системы всегда были важной парадигмой
для программирования задач ИИ, начиная с работ Ньюэлла и Саймона и их коллег из
Carnegie Mellon University [Newell и Simon, 1976], [Klahr и др., 1987]. Продукционная
система также является важной структурой, поддерживающей исследования в области
когнитивистики (науки о мышлении) [Newell и Simon, 1972], [Luger, 1994].
Конкретные реализации продукционных систем описаны в [Brownston и др., 1985] и
[Waterman и Hayes-Roth, 1978].
Ранние исследования по модели "классной доски" описаны в работах, посвященных
системе HEARSAY-П,— [Reddy, 1976], [Erman и др., 1980]. Дальнейшее развитие
методологии "классной доски" описано в работах [Lesser и Corkill, 1983], [Nii, 1986a],
[Nii, 19866], посвященных системе HEARSAY-Ш, и [Engelmore и Morgan, 1988].
Глава 5. Управление поиском и его реализация в пространстве состояний 215
Исследования по продукционным системам, планированию и структурам "классной
доски" остаются областью активных исследований в искусственном интеллекте.
Интересующемуся читателю рекомендуем обратиться к последним трудам конференций
American Association for Artificial Intelligence Conference и International Joint Conference on
Artificial Intelligence. Морган Кауфманн (Morgan Kaufmann) издал труды конференций, а
также сборник докладов по вопросам ИИ.
5.6. Упражнения
1. Алгоритм проверки вхождения из подраздела 5.1.1 рекурсивно определяет, является
ли данный элемент членом списка.
1.1. Составьте алгоритм, вычисляющий число элементов в списке.
1.2. Составьте алгоритм, вычисляющий число атомов в списке.
Различие между атомами и элементами состоит в том, что элемент сам может быть
списком. (Дополнительная информация содержится в разделе 15.1.)
2. Напишите рекурсивный алгоритм поиска в ширину (с использованием списков open
и closed). Можно ли с учетом рекурсии обойтись при поиске в ширину без списка
open! Объясните.
3. Проследите выполнение рекурсивного алгоритма поиска в глубину (без
использования списка open) в пространстве состояний, показанном на рис. 3.10.
4. В древнеиндийской чайной церемонии принимают участие три человека: взрослый, слуга
и ребенок. Они выполняют четыре задачи: поддерживают огонь, подают пирожки,
наливают чай и читают стихи. Эти задачи перечислены в порядке убывания важности. В
начале церемонии все четыре задачи выполняет ребенок. Затем они по одной переходят к
слуге и взрослому. В конце церемонии все четыре задачи выполняет взрослый. Никто не
может браться за менее важную задачу, чем те, которые он уже выполняет. Сгенерируйте
последовательность шагов передачи задач от ребенка к взрослому. Запишите
рекурсивный алгоритм выполнения последовательности этих шагов.
5. Используя определения перемещения и пути для задачи хода конем из раздела 5.2,
проследите выполнение алгоритма pattern_search для следующих целей:
a)paf/7A,9);
б)раГ/7A,5);
в)раГ/7G,6).
Если предикаты move выполняются по порядку, то в алгоритме поиска часто
бывают зацикливания. Как обнаружить цикл и реализовать возврат в этом случае?
6. Запишите на языке псевдокода версию алгоритма pattern search с поиском в
ширину (раздел 5.2). Оцените временную и пространственную эффективность этого
алгоритма.
7. Используя в качестве модели правило из примера 5.3.3, запишите восемь правил
перемещения для полной версии игры хода конем 8x8.
8. Используя целевое и начальное состояния, показанные на рис. 5.5, промоделируйте
ход решения "8-головоломки" продукционной системой с использованием
следующих стратегий:
216
Часть II. Искусственный интеллект как представление и поиск
а) поиск от цели;
б) поиск на основе данных.
9. Рассмотрите задачу финансового советника, описанную в главах 2, 3 и 4. Используя
исчисление предикатов в качестве языка представления, решите следующие задачи.
9.1. Опишите задачу явно в виде продукционной системы.
9.2. Сгенерируйте пространство состояний и содержимое рабочей памяти при
решении задачи, описанной в примере из главы 3, на основе данных.
9.3. Решите эту же задачу, используя стратегию поиска от цели.
10. В подразделе 5.3.3 представлены общие стратегии разрешения конфликтов на основе
рефракции (refraction), новизны (recency) и специфичности (specificity). Предложите
и обоснуйте еще две такие стратегии.
11. Предложите две прикладные задачи, для решения которых можно использовать
структуру "классной доски". Кратко охарактеризуйте организацию "классной доски"
и источников знания для каждой задачи.
Глава 5. Управление поиском и его реализация в пространстве состояний 217
Часть III
Представление
и разум в ракурсе
искусственного
интеллекта
Наш век беспокойства в значительной мере является результатом попыток
выполнять сегодняшнюю работу вчерашними средствами...
— Маршалл Мак-Люган (Marshall McLugan)
Может быть, стоит рассматривать мозг как набор контроллеров для
осуществляемой деятельности? Этот небольшой сдвиг в перспективе окажет большое влияние на то,
как мы конструируем науку о мышлении. На самом деле это требует больших изменений
в нашем ходе мыслей об интеллектуальном поведении. Необходимо отказаться от:
мыслей (привычных со времен Декарта) о разуме как сфере, отличной от сферы тела;
разделения восприятия, познания и действия; идеи исполнительного центра, где мозг
выполняет высокоуровневые рассуждения; и, более того, отказаться от исследовательских
методов, которые искусственно отделяют мысль от осуществляемого действия.
— Энди Кларк (Andy Clark), Being There
Представление и интеллект
Вопрос представления (representation) как наилучшего способа фиксации
критических аспектов интеллектуального поведения для использования в компьютере или
взаимодействия с людьми был постоянной темой в течение всей пятидесятилетней истории
ИИ. Часть III начнем с обзора трех господствующих подходов к представлению,
принятых в настоящее время исследователями ИИ. Первый подход, сформулированный в
1950-х и 1960-х годах Ньюэллом и Саймоном в их работе, связанной с программой Logic
Theorist (Логический теоретик) [Newell и Simon, 1956, 1963а], состоит в использовании
слабых методов решения проблем (weak problem-solving method). Второй подход,
получивший распространение в 1970-х и 1980-х годах и поддерживаемый разработчиками
первых экспертных систем, сводится к применению сильных методов решения проблем
(см. цитату Фейгенбаума в начале главы 7). В более современных исследованиях,
особенно в областях робототехники и агентных методов [Brooks, 1987, 1989], [Clark, 1997],
делается акцент нераспределенных и внедренных представлениях интеллекта
Познакомимся с каждой из этих методологий представления интеллекта. Три главы,
из которых состоит часть III, включают более детальные описания этих подходов.
В конце 1950-х и начале 1960-х Алан Ньюэлл (Alan Newell) и Герберт Саймон
(Herbert Simon) написали несколько компьютерных программ для проверки гипотезы о
том, что интеллектуальное поведение является результатом эвристического поиска.
Программа Logic Theorist, разработанная совместно с Дж. Шоу (J. С. Show) [Newell и Simon,
1963а], доказывала теоремы из области элементарной логики с помощью системы
обозначений и аксиом, описанных в [Whitehead и Russell, 1950]. Авторы характеризуют свое
исследование как ориентированное на понимание
" ..сложных процессов (эвристик), которые эффективны при решении проблем.
Следовательно, мы не заинтересованы в методах, которые гарантируют решение, но требуют большого
количества вычислений. Скорее, мы желаем понять, как математик должен доказывать
теорему, даже когда в начале или в процессе доказательства он не знает, как достичь цели "
В более поздней программе GPS (General Problem Solver) Ньюэлл и Саймон [Newell и
Simon, 1963e], [Newell и Simon, 1972] продолжили поиск общих принципов
интеллектуального решения проблем. Система GPS решала задачи, сформулированные как проблемы поиска в
пространстве состояний. При этом в процессе решения задачи выполнялось множество
операций для изменения представления состояний. Система GPS искала последовательность
операций, которая могла бы преобразовать исходное состояние в целевое, осуществляя поиск
таким же образом, как и алгоритмы, рассмотренные в предыдущих главах.
Для управления поиском в пространстве состояний система GPS использовала анализ
целей и средств (means-aids analysis) — общую эвристику для выбора среди
альтернативных операций преобразования состояния. В процессе анализа целей и средств
проверяются синтаксические различия между текущим и целевым состояниями и выбирается
оператор, который может уменьшить эти различия. Предположим, например, что
система GPS пытается доказать эквивалентность двух логических выражений. Если текущее
состояние содержит оператор л, а у цели нет этого оператора, то в процессе анализа
целей и средств удаления этого оператора из выражений можно выбрать соответствующее
преобразование, например закон де Моргана (см. раздел 12.1).
Ожидалось, что система GPS сможет стать общей архитектурой для
интеллектуального решения проблем, независимо от области, поскольку в ней используется эвристика,
которая проверяет лишь синтаксическую форму состояний. Программы, подобные GPS,
ограниченные стратегиями, основанными на синтаксисе, и ориентированные на широкое
разнообразие применений, называются решателями задач на основе слабых методов
(weak method problem solver).
К сожалению, не существует единой эвристики, которая может успешно применяться
ко всем предметным областям. В общем случае методы, с помощью которых мы решаем
проблемы, используют большое количество знаний о ситуации. Врачи способны
диагностировать болезни, так как дополнительно к общим возможностям решения задач имеют
обширные медицинские знания. Архитекторы проектируют дома потому, что обладают
знаниями в области архитектуры. Безусловно, эвристики, используемые в медицинском
диагнозе, могут быть бесполезными при проектировании офисного здания.
220 Часть III. Представление и рг -п/м в ракурсе искусственного интеллекта
Слабые методы значительно отличаются от сильных методов {strong method),
которые используют точные знания частной проблемной области. Рассмотрим правило для
системы диагностики автомобилей.
если
двигатель не заводится и
фары не горят,
то
проблема в аккумуляторе или в проводах @.8)
Эта эвристика, перефразированная как правило "если..., то...", фокусирует поиск на
подсистеме аккумулятора автомобиля, исключая другие компоненты и уменьшая
пространство поиска. Отметим, что эта частная эвристика, в отличие от анализа целей и
средств, использует знание о функционировании автомобиля, а также знание о
взаимосвязях между аккумулятором, фарами и стартером. Она бесполезна в любой проблемной
области, за исключением авторемонта.
Решатели задач на основе сильных методов не только используют специфические
знания о предметной области, но и требуют большого количества таких знаний.
Например, эвристика "неисправен аккумулятор" не слишком полезна при диагностике
поломки карбюратора и может быть вообще бесполезной в любой области, выходящей
за рамки диагностики автомобилей. Таким образом, главной проблемой при
разработке программы, основанной на знаниях, есть проблема извлечения и организации
больших объемов специфических знаний о предметной области. Правила могут также
содержать меру @,8 в приведенном выше правиле), чтобы отразить достоверность
этой части знаний о предметной области.
При использовании подхода на основе сильных методов разработчик программы
делает определенные предположения о природе интеллектуальной системы. Эти
предположения формализованы Брайаном Смитом (Brian Smith) [Smith, 1985] в виде гипотезы
о представлении знаний (knowledge representation hypothesis). Согласно этой гипотезе
" ..любой механически материализованный интеллектуальный процесс будет состоять из
компонентов, которые а) мы, как внешние наблюдатели, естественно выбираем для
представления пропозиционального учета знания всего этого процесса, и б) независимо от
внешнего семантического свойства играют формальную роль в реализации поведения,
соответствующего этому знанию "
Важным аспектом этой гипотезы является предположение, что знание будет
представлено пропозиционалъно, т.е. в форме, которая точно представляет знание вопроса и
которая может рассматриваться внешним наблюдателем как "естественное" описание
этого знания. Второе важное предположение состоит в том, что поведение системы
должно определяться предложениями базы знаний, и что это поведение должно
соответствовать воспринятому смыслу этих предложений.
В последнее время при описании вопросов представления в ИИ часто используются
такие термины, как агентное, внедренное (воплощенное,), или эмерджентное решение
задач. Некоторые исследователи, работающие в прикладных областях, таких как роботи-
ка, разработка игр и Internet, включая [Brooks, 1987, 1989], [Agre и Chapman, 1987],
[Jennings, 1995] и [Wooldridge, 2000], подвергли сомнению требование наличия какой-
либо централизованной базы знаний или общецелевой схемы вывода. Решатели задач
разрабатываются как распределенные агенты: ситуативные, автономные и гибкие.
С этой точки зрения решение задач рассматривается как распределенный процесс
взаимодействия агентов, решающих задачи в различных подконтекстах своих областей,
Представление и интеллект
221
например, Internet-броузера или агента безопасности. Процесс решения разбивается на
несколько компонентов с небольшой или вовсе отсутствующей координацией
задач.Ситуативный агент может осуществлять сенсорное восприятие своего окружения, а
также реагировать в этом контексте без ожидания инструкций от некоторого общего
контроллера. Например, в интерактивной игре агент может решать локальную задачу
типа защиты от конкретной атаки или подачи сигнала без общего обзора всей ситуации.
Агенты автономны, т.е. они часто должны действовать без прямого вмешательства
людей или общего управляющего процесса. Таким образом, автономные агенты
управляют своими собственными действиями и внутренним состоянием. Кроме того, гибкие
агенты должны чувствовать ситуацию их локального окружения, а также быть
предусмотрительными — должны уметь предвидеть ситуации. И, наконец, они должны гибко
отвечать другим агентам проблемной области, переговариваясь о задачах, целях и
соответствующих процессах.
Некоторые исследователи в области роботики создали свои агентные системы. Родни
Брукс (Rodney Brooks) из лаборатории MIT Robotics Laboratory разработал так
называемую категориальную архитектуру (subsamption architecture) — многослойную
последовательность конечных автоматов, каждый из которых действует в своем собственном
контексте, поддерживая также функциональность на более высоких уровнях. Мануэла
Велосо (Manuela Veloso) из лаборатории роботики Карнэги Меллон создала команду
футбольных роботов-агентов, которые взаимодействуют в рамках футбольных турниров.
И, наконец, этот ситуативный и внедренный подход к представлению
описывается некоторыми философами, включая [Dennett, 1991, 1995] и [Clark, 1997], как
соответствующая характеристика человеческого интеллекта. Ниже в этой книге будут
приведены дополнительные схемы представлений, включая коннекционистский
(глава 10) и генетический (глава 11) подходы. Общие вопросы представления снова
обсуждаются в главе 16.
В главе 6 в деталях исследуются основные подходы к представлению, принятые в
ИИ. Мы начинаем с ранних представлений, включающих семантические сети,
сценарии, фреймы и объекты. Эти схемы рассматриваются с эволюционной точки зрения,
показывая путь развития от самых ранних исследований ИИ до современных средств.
Далее описываются концептуальные графы Джона Сова (John Sowa) — представление,
используемое для понимания естественного языка. Наконец приводятся агентный и
ситуативный подходы к представлению. В частности, рассматривается категориальная
архитектура Родни Брукса, которая ставит под вопрос необходимость центральной базы
точных знаний, используемой с общецслевым контроллером.
В главе 7 обсуждаются системы, усиленные знаниями, и рассматриваются проблемы
приобретения, формализации и отладки баз знаний. Мы представляем различные схемы
вывода для систем правил, включая рассуждения, от цели и от данных. Кроме систем,
основанных на правилах, будут представлены рассуждения, основанные на моделях и
примерах. Первые пытаются точно представить теоретические основы и
функциональность области, например, электронных цепей, в то время как вторые строят точную базу
данных, описывающую существующие успешные и неудачные примеры из проблемной
области, чтобы помочь в будущем при решении проблем. Глава 7 завершается обзором
планирования {planning), при котором точные знания должны быть организованы так,
чтобы управлять решением проблем в таких сложных областях, как роботика.
Глава 8 описывает ряд приемов, которые направлены на представление решения
задач в условиях неопределенности и неуверенности. В этих ситуациях мы пытаемся
222
Часть III. Представление и разум в ракурсе искусственного интеллекта
как можно лучше объяснить часто неоднозначную информацию. Этот тип
рассуждений часто называют абдуктивными (abductive reasoning). Сначала будет
представлена немонотонная логика и логика поддержки истинности, расширяющая логику
предикатов за счет включения ситуаций с неопределенностью. Однако решение
многих интересных и важных проблем не всегда можно свести к дедуктивной логике.
Для рассуждений в этих условиях вводится ряд других эффективных средств,
включая байесовский подход, подход Демстера-Шафера и неточный вывод на основе
фактора уверенности. Глава содержит также раздел по нечетким рассуждениям и
завершается кратким описанием стохастических агентов.
В части VI многие из этих представлений реализованы на языках LISP и PROLOG.
Представление и интеллект
223
Представление
знаний
Эта грандиозная книга, универсум, написана на языке математики, и ее символами
служат треугольники, круги и другие геометрические фигуры, без которых невозможно
понять ее слово — без них бродишь в темноте лабиринта...
— Галилео Галилей (Galileo Galilei), 1638
Поскольку нет организма, который может покрыть бесконечное разнообразие, одной
из основных функций всех организмов есть разбиение окружения на классы, при котором
неидентичные стимулы могут трактоваться как эквивалентные...
— Элеанор Рош (Eleanor Rosch), Принципы категоризации, 1978
Мы всегда имеем два универсума рассуждений — назовем их "физический " и
"феноменальный " (или, как вы желаете) — один связан с вопросами количества и
формальной структуры, другой — с теми качествами, которые соответствуют слову
"мир". Каждый из нас имеет собственные ментальные миры, собственные внутренние
маршруты и ландшафты, и они не требуют ясной нейрологической "корреляции ".
— Оливер Сакс (Oliver Sacks),
Человек, который ошибочно принял свою жену за шляпу, 1987
6.0. Вопросы представления знаний
Представление информации для решения интеллектуальных проблем — важная и трудная
задача, лежащая в основе ИИ. Раздел 6.1 содержит краткую историческую ретроспективу
ранних исследований по представлениям: в нее включены семантические сети (semantic
networks), концептуальные зависимости (conceptual dependency), сценарии (script) и фреймы
(frame). Раздел 6.2 посвящен более современным представлениям — концептуальным графам
(conceptual graph), предназначенным для решения задач понимания естественного языка. В
разделе 6.3 обсуждается требование создания централизованных и явных схем представления.
Альтернативой является категориальная архитектура (subsumption architecture) Брукса для
роботов. В разделе 6.4 представлены агенты— другая альтернатива централизованному
управлению. В последующих главах приведено расширенное обсуждение представлений,
включая стохастическое (раздел 8.3), коннекционистское (глава 10) и генетическое
(эмерджентное) (глава 11).
Начинаем наше обсуждение с исторической ретроспективы, в которой база знаний
описывается как отображение объектов и отношений предметной области в
вычислительные объекты и программные отношения [Bobrow, 1975]. Результаты вывода в базе
знаний должны соответствовать результатам действий или наблюдений в мире.
Вычислительные объекты, отношения и выводы, привычные программисту, выражаются
языком представления знаний.
Существуют общие принципы организации знаний, которые применяются в различных
областях и могут прямо поддерживаться языком представления. Например, иерархии классов
можно найти как в научных, так и в общесмысловых классификационных системах. Но как
обеспечить общий механизм для их представления? Как представить определения?
Исключения? Как научить интеллектуальную систему по умолчанию делать предположения о
недостающей информации и проверять истинность подобных предположений? Как наилучшим
образом представить время? Причинность? Неопределенность? Прогресс в создании
интеллектуальных систем зависит от открытия принципов организации знаний и от поддержки их
высокоуровневыми средствами представления.
Полезно делать различие между схемой представления и средой ее выполнения. Это
подобно различию между структурами данных и языками программирования. Языки
программирования являются средой выполнения; структурой данных служит схема.
Обычно языки представления знаний являются более ограниченными, чем исчисление
предикатов или языки программирования. Эти ограничения принимают форму точных
структур для представления категорий знания. Средой, в которой они выполняются,
могут быть PROLOG, LISP либо такие языки, как C++ или Java.
Обсуждение данных вопросов иллюстрирует традиционный обзор схем
представления ИИ, приведенный в разделах 6.1 и 6.2. Этот обзор, как правило, включает
глобальную базу знаний из языковых структур, отражающих статику и "предопределенные
центры реального мира". Более поздние исследования в области роботики [Brooks, 199la],
[Lewis и Luger, 2000], ситуативного познания [Agre и Chapman, 1987], [Lakoff и
Johnson, 1999], агентного решения проблем [Jennings и др., 1998], [Wooldridge, 2000] и
философии [Clark, 1997] бросили вызов традиционному подходу. Эти проблемные
области требуют распределенного знания; мира, который сам может быть использован как
частная структура знания; возможности рассуждать при неполной информации и даже на
основе представлений, которые изменяются в процессе экспериментов в проблемной
области. Эти подходы приводятся разделах 6.3 и 6.4.
6.1. Краткая история схем представления ИИ
6.1.1. Ассоционистские теории смысла
Усилиями философов и математиков уровень логических представлений возрос и
позволяет характеризовать принципы правильного рассуждения. Основная задача
логики — разработка формальных языков представления знаний с совершенными и
полными правилами вывода. Поэтому в семантиках исчисления предикатов
основное внимание уделяется сохранению истинности операций на корректно
построенных выражениях. В результате усилий психологов и лингвистов по оценке природы
человеческого понимания возникла альтернативная линия исследований. Она
меньше связана со становлением науки корректных рассуждений, а больше тяготеет к
226
Часть III. Представление и разум в ракурсе искусственного интеллекта
описанию способов приобретения и использования знаний о мире. Этот подход
доказал, в частности, полезность применения ИИ в области понимания естественных
языков и рассуждений на основе здравого смысла.
Существует много проблем, которые возникают при отображении рассуждений на
основе здравого смысла в формальную логику. Например, обычно принято думать, что
операторы v и —> соответствуют конструкциям русского языка "или" и "если.., то...".
Однако эти операторы в логике связаны только со значениями истинности и игнорируют
специфическую взаимосвязь между посылками и заключением конструкции "если..,
то..." (скорее корреляционную, чем причинную). Например, предложение "Если
птица— кардинал, то ее цвет— красный" (ассоциация птицы с красным цветом) может
быть описано в исчислении предикатов следующим образом.
VX ((кардинал(Х) -> красный(Х)).
Это предложение может быть заменено логически эквивалентным выражением
посредством ряда сохраняющих истинность операций из главы 2:
VX {—[краеный(Х) -> -пКардинал(Х)).
Второе выражение истинно тогда и только тогда, когда истинно первое. Однако
эквивалентность значений истинности в данном случае не сохраняется. Если
рассматривать физическую основу истинности этих выражений, то факт, что лист
бумаги не красный и не является птицей-кардиналом, служит основой для истинности
второго выражения. Из эквивалентности двух выражений следует, что второе
является также основой для истинности первого. Это приводит к заключению, что белый
цвет листа бумаги служит причиной того, что кардиналы красные. Эта линия
рассуждений представляется лишенной смысла и довольно глупой. Причина такой
бессвязности в том, что логическая импликация лишь выражает связь между
значениями истинности своих операндов, в то время как выражение в русском языке
предполагает положительную корреляцию между членством в классе и обладанием
свойствами этого класса. Действительно, определенный цвет птицы связан с ее
генетическим строением. Эта связь теряется во второй версии выражения. Хотя факт,
что бумага не красная, обеспечивает истинность обоих выражений, но не отражает
причинную природу цвета птиц.
Ассоционистские (associationist theory) теории определяют значение объекта в
терминах сети ассоциаций с другими объектами. С точки зрения такой теории восприятие
объекта происходит через понятия. Понятия являются частью всего нашего знания о мире и
связываются соответствующими ассоциациями с другими понятиями. Эти связи
представляют свойства и поведение объекта. Например, на основании опыта мы ассоциируем
понятие "снег" с другими, такими как "холод", "белый", "снежный человек", "скользкий"
и "лед". Наше знание о снеге и истинность утверждений типа "снег белый" возникают из
этой сети ассоциаций.
Из психологии известно, что люди ассоциируют понятия, а также иерархически
организуют свои знания с помощью информации самых верхних уровней классификационной
иерархии. Коллинс (Collins) и Квиллиан (Quillian) [Collins и Quillian, 1969] моделировали хранение
информации человеком и управление ею, используя семантическую сеть (рис. 6.1). Структура
этой иерархии была получена в лаборатории в результате тестирования групп людей.
Субъектам задавались вопросы о различных свойствах птиц, такие как "Канарейка — это
птица?" или "Канарейка может петь?" или "Канарейка может летать?".
Глава 6. Представление знаний
227
Breathe
Предполагаемая иерархия,
объясняющая время реакции
Канарейка имеет кожу
Канарейка — это животное
Sing
Yellow Fly
"Сложность" предложения
Рис. 6.1. Семантическая сеть, разработанная Коллинсом и Квиллианом в их исследовании по
хранению информации и времени отклика человека [Harmon и King, 1985]
Хотя ответы на эти вопросы, возможно, просты, изучение времени реакции показало,
что при ответе на вопрос "Может ли канарейка летать?" оно больше, чем на вопрос
"Может ли канарейка петь?". Коллинс и Квиллиан объясняют эту разницу во времени
ответа тем, что люди запоминают информацию на самом абстрактном уровне. Вместо
того, чтобы запоминать конкретные свойства для каждой птицы (канарейки летают,
дрозды летают, ласточки летают), люди запоминают, что канарейки — птицы, а птицы
(обычно) имеют свойство летать. Даже более общие свойства, такие как питание,
дыхание и движение запоминаются на уровне "животное". Таким образом, попытка
вспомнить, может ли канарейка дышать, занимает больше времени, чем воспоминание, может
ли канарейка летать. Это, конечно, происходит из-за того, что для получения ответа
человек должен дольше путешествовать по иерархии структур памяти.
Быстрее всего вспоминаются самые конкретные свойства птицы, скажем, может ли
она петь или является ли она желтой. Оказалось, что отрицательная трактовка также
делалась на наиболее детальном уровне. Когда субъекта спрашивают, может ли страус
летать, он отвечает быстрее, чем когда его спрашивают, может ли страус дышать. Таким
образом, иерархия страус —>птица —> животное не прослеживалась, чтобы получить
отрицательную информацию, — она запоминалась наряду с понятием "страус". Эта
организация знаний была формализована в системах наследования.
Системы наследования позволяют нам запоминать информацию на самом высоком
уровне абстракции, что уменьшает размер баз знаний и помогает избежать
противоречий. Например, если мы строим базу знаний о птицах, то можем определить свойства,
общие для всех птиц, например способность летать или иметь родителей, для широкого
класса птиц BIRD и разрешаем частным представителям птиц наследовать такие свойст-
228
Часть III. Представление и разум в ракурсе искусственного интеллекта
ва. Это уменьшает размер базы знаний за счет требования определять существенные
свойства лишь один раз и не определять их для каждого объекта. Наследование также
помогает поддерживать непротиворечивость базы знаний при добавлении новых классов
и объекта. Предположим, в существующую базу знаний добавляется вид ROBIN (дрозд).
Когда мы утверждаем, что ROBIN— это подкласс класса SONGBIRD (певчие птицы),
дрозд наследует все общие свойства как певчих птиц, так и птиц вообще. Программисту
не требуется запоминать (или забывать!) эту информацию.
Графы оказались идеальным средством для формализации ассоционистских теорий
знаний за счет точного представления отношений посредством дуг и узлов.
Семантическая сеть (semantic network) представляет знания в виде графа, узлы которого
соответствуют фактам или понятиям, а дуги — отношениям или ассоциациям между понятиями.
Как узлы, так и связи обычно имеют метки.
Семантическая сеть, которая определяет свойства понятий "снег" и "лед", показана на
рис. 6.2. Эту сеть можно использовать (с соответствующими правилами вывода) для
ответов на вопросы о снеге, льде и снежном человеке. Выводы делаются путем
прослеживания связей с соответствующими понятиями. Семантические сети также реализуют
наследование: например, объект frosty (морозный) наследует свойства объекта
snowman (снежный человек).
сделан из
*
снеговик
снежная фигура
лед
форма
твеодость
текстура
снег
цвет
температура
форма
текстура
твердость
цвет
вода
мягкий
скользкий
белый
холодный
,
,
твердый
„
прозра1
нмьт
Рис. 6 2. Сетевое представление свойств снега и льда
Термин "семантическая сеть" обозначает семейство представлений, основанных на
графах. Эти представления отличаются главным образом именами узлов, связей и выво-
Глава 6. Представление знаний
229
дами, которые можно делать в этих структурах. Однако общее множество
предположений и отношений содержится во всех языках представления сетей. Это иллюстрирует
история сетевых представлений. В разделе 6.2 будут рассмотрены концептуальные графы
[Sowa, 1984] — более современный язык сетевого представления, который интегрирует
многие из этих идей.
6.1.2. Ранние работы в области семантических сетей
Сетевые представления имеют почти такую же длинную историю, как и логика. Фре-
ге (Frege), например, разработал три системы обозначений для логических выражений.
Возможно, наиболее ранней работой, имеющей прямое влияние на современные
семантические сети, была система экзистенциальных графов, разработанная Чарльзом Пирсом
(Charles Peirce) в девятнадцатом столетии [Roberts, 1973]. Теория Пирса использовала
всю выразительную силу исчисления предикатов первого порядка с аксиоматической
основой и формальными правилами вывода.
Графы давно используются в психологии для представления структур понятий и
ассоциаций. Пионером в этой области был Сэлз [Selz, 1913, 1922], который использовал
графы для представления иерархии понятий и наследования свойств. Он также
разработал теорию схематического упреждения, которая повлияла на работы по фреймам и
схемам в ИИ. Андерсон (Anderson), Норман (Norman), Румельхарт (Rumelhart) и другие
использовали сети, чтобы моделировать человеческую память и интеллектуальные
проявления [Anderson и Bower, 1973], [Norman и др., 1975].
Много исследований на основе сетевых представлений было сделано в области
понимания естественных языков. В общем случае для понимания естественных языков
требуется намного больше знаний, чем для работы специализированных экспертных систем.
Оно включает понимание общего смысла, принципов действия физических объектов,
взаимодействий, происходящих между людьми, и принципов организации коллективов
людей. Программа должна понимать намерения, убеждения, гипотетические
рассуждения, планы и цели. Из-за требований большого количества необходимых знаний
проблема понимания естественных языков всегда являлась движущей силой исследований в
области представления знаний.
Первые компьютерные реализации семантических сетей были созданы в начале 1960-
х для использования в системах автоматического (машинного) перевода. В работе
[Masterman, 1961] Мастерман определил множество из 100 примитивных типов понятий
и использовал их в словаре из 15000 понятий. В [Wilks, 1972] продолжено построение
систем понимания естественных языков на основе работы Мастермана (Masterman) в
области семантических сетей. В числе других ранних работ по исследованию ИИ,
использующих сетевые представления, можно назвать [Ceccato, 1961], [Raphael, 1968],
[Reitman, 1965], [Simmons, 1966].
В конце 1960-х была написана известная программа, которая иллюстрирует многие
особенности ранних семантических сетей [Quillian, 1967]. Эта программа
характеризовала английские слова примерно таким же образом, как это делает словарь: слово
определяется в терминах других слов, и так же формулируются составляющие этих
определений. В отличие от формального определения слов в терминах базовых аксиом каждая
формулировка просто ведет к другим определениям, неструктурированными и,
возможно, окольными путями. При просмотре слова мы прослеживаем эту цепочку до тех пор,
пока не убедимся, что понимаем первоначальное слово.
230
Часть III. Представление и разум в ракурсе искусственного интеллекта
Каждый узел в сети Куиллиана соответствует словесному понятию, имеющему
ассоциативные связи с другими понятиями, из которых формируется его определение. База
знаний организована в плоскости, каждая из которых является графом,
характеризующим одно слово. На рис. 6.3, взятом из статьи [Quillan, 1967], показаны три плоскости,
задающие три различных определения слова "plant": plant 1 (растение), plant 2
(место, где работают люди) и plant 3 (процесс помещения семени в землю).
Plant 1 Живая структура, которая не является животным,
часто с листьями, получающая пищу из воздуха, воды и земли.
2 Оборудование, используемое для некоторого
производственного процесса
3 Помещать (семя, растение и т п ) в землю
для выращивания
or or
Рис 6 3 Три плоскости, представляющие три определения слова "plant" [Quillian, 1967]
Программа использовала эту базу знаний для поиска отношений между парами
английских слов. Получив два слова, она осуществляла на графах поиск в ширину для
нахождения общего понятия, или узла пересечения. Пути к общему узлу представляли
отношение между словесными понятиями. Например, на рис. 6.4, взятом из той же статьи,
показана точка пересечения путей, ведущих от понятий cry (плач) и comfort (покой).
Используя пересечение этих путей, программа смогла заключить следующее.
Плач (cry 2), помимо всего прочего, связан с производством печальных звуков. Покой
(comfort 3) может уменьшить печаль [Quillan, 1967].
Числа в ответах указывают, какие именно значения слов выбрала программа.
Куиллиан предполагал, что этот подход к семантике обеспечит следующие
возможности систем понимания естественных языков.
1. Определять смысл английского текста путем построения совокупности узлов
пересечения.
2. Выбирать смысл слов, находя самые короткие пути к точкам пересечения с путями для
других слов предложения. Например, в английском предложении 'Tom went home to
Глава 6. Представление знаний
231
water his new plant" ("Том пришел домой полить свое новое растение") система сможет
выбрать значение слова "plant", основываясь на пересечении понятий <4water" и "plant".
3. Гибко отвечать на вопросы, основываясь на ассоциациях между понятиями в
вопросах и в системе.
1
( sad )
Рис. 6.4. Пересечение путей, ведущих от понятий cry (плач) и comfort (покой) [Quillan, 1967]
Хотя эта и другие ранние работы показали силу графов для моделирования
ассоциативного смысла, они были ограничены чрезмерной общностью формализма. Знание
обычно структурировалось в терминах специфических отношений, таких как объект-
свойство, класс-подкласс и агент-глагол-объект. Исследования в области сетевых
представлений часто фокусировались на спецификации этих отношений.
6.1.3. Стандартизация сетевых отношений
Само по себе представление отношений в виде графов имеет мало преимуществ
перед исчислением предикатов — это только другая запись отношений между объектами.
Сила сетевых представлений состоит в определении связей и специфических правил
вывода, определяемых механизмом наследования.
Хотя ранняя работа Куиллиана установила такие наиболее значительные особенности
формализма семантических сетей, как помеченные дуги и связи, иерархическое
наследование и вывод на основе ассоциативных связей, она не позволяла преодолеть сложность
многих проблемных областей. Одной из главных причин этого была ограниченность
связей, которые не охватывали более глубоких семантических аспектов знаний. Большая
часть связей представляла общие ассоциации между узлами и не обеспечивала реальной
основы для структурирования семантических отношений. Та же проблема возникала при
попытке использовать исчисление предикатов для охвата семантики смысла. Хотя этот
формализм является очень выразительным и позволяет представлять почти любой вид
знаний, он слишком общий и переносит бремя конструирования соответствующего
множества фактов и правил на программиста.
Большинство работ по сетевым представлениям, развивающих работы Куиллиана,
сводились к определению обширного множества меток связей (отношений) для более
232
Часть III. Представление и разум в ракурсе искусственного интеллекта
полного моделирования семантики естественного языка. За счет реализации базовых
семантических отношений естественного языка как части формализма, а не как части
знаний о предметной области, базы знаний позволяют автоматизировать работу и
обеспечивают большую общность и непротиворечивость.
В [Brachman, 1979] отмечено следующее.
Ключевым вопросом здесь является выделение примитивов для языков семантических
сетей. Примитивами сетевого языка являются те понятия, для понимания которых
интерпретатор программируется заранее, и которые (обычно) не представлены в самом
сетевом языке.
В [Simmons, 1973] подчеркнута необходимость стандартизации отношений с
учетом грамматики английского языка. В этом подходе, основанном на работе
[Fillmore, 1968], связи определяются ролью существительных и групп
существительных в действии, описываемом предложением. К числу возможных ролей
(падежных отношений) относятся агент, объект, инструмент, место и время.
Предложение представляется как набор узлов, один из которых соответствует
глаголу, а остальные связанные с ним узлы представляют других участников действия.
Эта структура называется падежным фреймом {case frame). При разборе
предложения программа находит глагол и ищет в базе знаний соответствующий ему
падежный фрейм. Затем она связывает значения агента, объекта и тому подобного с
соответствующими узлами падежного фрейма. Используя этот подход, предложение
"Sarah fixed the chair with glue" ("Сара укрепила стул клеем") можно представить
сетью, показанной на рис. 6.5.
Сара
агент
время
укрепить
объект
*
инструмент
прошедшее
стул
клей
Рис. 6 5. Падежный фрейм, представляющий
предложение "Сараукрепила стул клеем"
Таким образом, сам язык представления включает многие глубинные связи
естественного языка, такие как отношение между глаголом и его субъектом (агентное
отношение) или глаголом и его объектом. Знание падежной структуры английского
языка является частью самого сетевого формализма. При разборе отдельного
предложения становится ясно, что Сара — это человек, производящий укрепление, а
клей используется для соединения частей стула. Отметим, что эти лингвистические
отношения запоминаются отдельно (независимо) от реального предложения и
даже от языка, на котором сформулировано предложение. Подобный подход принят
в сетевых языках, предложенных в [Norman, 1972], [Rumelhart и др., 1972] и
[RumelhartH др., 1973].
Ряд исследователей уделяли большое внимание дальнейшей стандартизации имен
связей [Masterman, 1961], [Wilks, 1972], [Schank и Colby, 1973], [Schank и Nash-
Webber, 1975]. Каждое исследование было направлено на установление полного множе-
Глава 6. Представление знаний
233
ства примитивов для единообразного представления семантической структуры
выражений естественного языка. Эти множества призваны помочь в реализации рассуждений с
использованием элементов языка. Они должны быть независимы от индивидуальных
особенностей отдельных языков или фраз.
Возможно, наиболее амбициозной попыткой формального моделирования глубинных
семантических структур естественного языка является теория концептуальной
зависимости (conceptual dependency) Ригера (Rieger) и Шенка (Schank) [Schank и Rieger, 1974]. В
рамках теории концептуальной зависимости рассматриваются четыре типа примитивов,
на основе которых определяется смысл выражений. К ним относятся:
• ACT — действия (actions);
• РР — объекты (picture producers);
• АА — модификаторы действий (action aiders);
• PA — модификаторы объектов (picture aiders).
Предполагается, что каждое из действий должно приводить к созданию одного или
нескольких примитивов ACT. Перечисленные ниже примитивы выбраны в качестве
основных компонентов действия.
• ATRANS — передавать отношение (давать).
• PTRANS — передавать физическое расположение объекта (идти).
• PROPEL — применять физическую силу к объекту (толкать).
• MOVE — перемещать часть тела (владельцем).
• GRASP — захватывать объект (исполнителем).
• INGEST — поглощать объект (есть).
• EXPEL — издавать звуки (кричать).
• MTRANS — передавать ментальную информацию (сказать).
• MBUILD — создавать новую ментальную информацию (решать).
• CONC — осмысливать идею (думать).
• SPEAK — производить звук (говорить).
• ATTEND — слушать.
Эти примитивы используются для определения отношений концептуальной
зависимости, которые описывают смысловые структуры, такие как падежные отношения
или связи объектов и значений. Отношения концептуальной зависимости — это
концептуальные синтаксические правила, которые выражают семантические связи в
соответствии с грамматикой языка. Эти отношения могут быть использованы для
конструирования внутреннего представления английского предложения. На рис. 6.6
представлен список основных концептуальных зависимостей [Schank и
Rieger, 1974]. Эти зависимости охватывают базовые семантические структуры
естественного языка. Например, первая концептуальная зависимость на рис. 6.6
описывает отношение между подлежащим и сказуемым, а третья — отношение глагол-
объект. Они могут сочетаться и представлять простые транзитивные предложения,
такие как "John throws the ball" ("Джон бросает мяч") (рис. 6.7).
234
Часть III. Представление и разум в ракурсе искусственного интеллекта
РР о ACT указывает, что исполнитель действует
РР ~ РА указывает, что объект имеет определенный признак
О
АСТЧ- РР означает объект действия
^Rp-pp
►РР
ACT <- обозначает реципиента и донора для объекта действия
I—^Р"
Dp-pp
►РР
ACT <-\ указывает направление объекта действия
i—^р"
ACT <^- 0 означает инструментальную концептуализацию действия
X
| указывает, что X вызывается Y
Y
™ I—*РА2
РР *» указывает изменение состояния объекта
1—*РА1
РР1 <- РР2 указывает, что РР2 является либо частью, либо владельцем РР1
Рис. 6.6. Концептуальные зависимости [Schank и Rieger, 1974]
John< > *PROPELw < Ball
\<j >* PROPEL* ^—
Puc. 6 7. Представление концептуальных зависимостей в
предложении "John throws the ball"
1
2
3
4
5
6
7
8
9
PPOACT
PP<*PA
PP<*PP
PP
t
PA
PP
4
PP
ACT4-PP
ACT^PP
1 cPP
дст^о
ACT^PP
1 <PP
P
Джон о PTRANS
John «* height (>average)
John «* doctor
boy
t
nice
dog
If POSS-BY
John
John о PROPEL^ cart
JohnOATRANS <?T-*John
«fo 1——с Mary
book
■ John
John о INGEST <- ft
tn do
ice cream fo
spoon
Pr~Afield
John о PTRANS <r\
/к '—<bag
Джон бежал.
Джон высокий
Джон — доктор
Милый мальчик
Собака Джона
Джон двигал тележку
Джон взял книгу у Мэри
Джон съел мороженое.
Джон удобрил поле
fertilizer
10 РР J~~>PA2 plants J *size>x Растения выросли
1—<.РА\ I—<size=x
11 (а) о (Ь) о Bill о PROPEL^ bullet ^Г* В°Ь Билл застрелил Боба.
х Jt: Bobtheai,hHo) un
4 0 Т yesterday
о John о PTRANS Вчера Джон бежал
р
Рис. 6.8. Некоторые базовые концептуальные зависимости, взятые
из работы [Schank и Colby, 1973], и их использование для
представления более сложных английских предложений
Глава 6. Представление знаний
235
И, наконец, ко множеству концепций может быть добавлена временная и модальная
информация. Шенк приводит следующий список модификаторов отношений.
р — прошедшее время
f — будущее время
t — передача
к — продолжительность
ts — начало передачи
? — вопрос
t/— окончание передачи
с — условие
/ — отрицание
nil — настоящее время
delta? — независимость от времени
В рамках теории эти отношения считаются конструкциями первого уровня —
простейшими семантическими отношениями, на основе которых могут быть построены более сложные
структуры. Примеры того, как эти базовые концептуальные зависимости могут сочетаться для
представления смысла простых английских предложений, показаны на рис. 6.8.
На рис. 6.9 показано, как на основе этих примитивов представляется выражение "John
ate the egg" ("Джон съел яйцо"). Символы здесь имеют следующий смысл:
• < указывает направление зависимости;
• <=> — обозначает отношение агент-глагол;
• р — указывает на прошедшее время;
• INGEST — определяет примитивное действие теории;
• О — обозначает объектное отношение;
• D — указывает направление объекта при выполнении действия.
Другим примером структур, которые могут быть построены на основе
концептуальных зависимостей, является графическое представление предложения "John prevented
Магу from giving a book to bill" ("Джон предостерег Мэри, чтобы она не давала книгу
Биллу") (рис. 6.10). Этот частный пример интересен тем, что он демонстрирует
представление причинности.
р
John о *DO*
t
Р О с/ О
John о 4NGEST* < Egg John о 'ATRANS* < Book
t Dr—►^INSIDE* < John p t Rp* Bill
L<*MOUTH*< John L< Mary
Рис. 6.9. Концептуальная зависимость, пред- Рис. 6.10. Представление концептуальной
заставляющая выражение "John ate the egg" висимости для предложения "John prevented
[Schank и Rieger, 1974] Mary from giving a book to bill" [Schank и
Rieger, 1974]
236
Часть III. Представление и разум в ракурсе искусственного интеллекта
Теория концептуальной зависимости имеет ряд важных преимуществ. Во-первых,
за счет построения формальной теории семантик естественного языка уменьшаются
проблемы, связанные с двусмысленностью. Во-вторых, само представление в
процессе построения канонической формы смысла выражений охватывает много
естественно-языковых семантик. Это означает, что все выражения, которые имеют один
и тот же смысл, будут внутренне представлены синтаксически идентичными, а не
только семантически эквивалентными графами. Это каноническое представление —
попытка упростить выводы, требуемые для понимания. Например, мы можем
продемонстрировать, что два выражения означают одну и ту же сущность, с помощью
простого сопоставления графов концептуальной зависимости. Представление,
которое не обеспечивает канонической формы, может потребовать большого количества
операций на графах различной структуры.
К сожалению, процесс преобразования выражений в каноническую форму вряд ли
можно полностью алгоритмизировать. Как отмечено в [Woods, 1985] и других работах,
преобразование в каноническую форму нельзя реализовать даже для моноидов —
алгебраических групп, которые значительно проще, чем естественный язык. Более того, нет
уверенности, что люди запоминают свои знания в какой-нибудь канонической форме.
Критические замечания высказывались также по поводу вычислительной
сложности преобразования предложения в набор примитивов низкого уровня. Кроме
того, сами примитивы не позволяют охватить многие более тонкие понятия, играющие
важную роль в использовании естественного языка. Например, представление слова
"tall" ("высокий") во втором выражении на рис. 6.8 не учитывает неопределенность
этого термина, как это делается в системах нечеткой логики [Zadeh, 1983],
описанных в разделе 7.3.
Однако нельзя сказать, что модель концептуальной зависимости интенсивно не
изучалась и не была хорошо понята. Уточнение и расширение этой модели
продолжалось более десяти лет. Важными для развития теории концептуальных
зависимостей являются работы, посвященные сценариям и пакетам организации памяти.
Работы по сценариям связаны с изучением организации знаний в памяти и ее роли в
рассуждениях (см. подраздел 6.1.4). Пакеты организации памяти стали одной из
вспомогательных исследовательских областей для разработки механизмов
рассуждений, основанных на опыте (раздел 7.3). Теория концептуальной зависимости
является полностью разработанной моделью семантики естественного языка. Она
широко применяется и дает непротиворечивые результаты.
6.1.4. Сценарии
Программа, понимающая естественный язык, должна использовать большое
количество исходных знаний, чтобы понять даже простейший разговор (раздел 13.0).
Согласно экспериментальным данным люди организуют это знание в структуры,
соответствующие типовым ситуациям [Bartlett, 1932]. Читая статью о ресторанах,
бейсболе или политике, мы устраняем любые двусмысленности в тексте с учетом
тематики статьи. Если сюжет статьи неожиданно меняется, человек делает краткую
паузу в процессе чтения, необходимую для модификации структуры знания.
Возможно, слабо структурированный текст тяжело понять именно потому, что мы не
можем с легкостью связать его с какой-нибудь из структур знания. В этом случае
ошибки понимания возникают из-за того, что мы не можем решить, какой контекст
Глава 6. Представление знаний
237
использовать для разрешения неопределенных местоимений и других
двусмысленностей разговора.
Сценарий (script) — это структурированное представление, описывающее
стереотипную последовательность событий в частном контексте. Сценарии первоначально были
предложены в [Schank и Abelson, 1977] как средство для организации структур
концептуальной зависимости в описаниях типовых ситуаций. Сценарии используются в
системах понимания естественного языка для организации базы знаний в терминах ситуаций,
которые система должна понимать.
Большинство людей в ресторане полностью спокойны (т.е. они знают, чего ожидать и
как действовать). Их либо встречают на входе, либо знак указывает, куда они должны
пройти, чтобы сесть. Меню либо лежит на столе, либо предоставляется официантом,
либо посетитель его просит. Мы понимаем процедуры для заказа еды, принятия пищи,
оплаты счета и ухода.
В действительности ресторанный сценарий совершенно отличается от других
сценариев принятия пищи, например, в ресторанах "быстрого обслуживания" или в рамках
"официального семейного обеда". В сети ресторанов "быстрого обслуживания" заказчик
входит, становится в очередь, оплачивает заказ (до принятия пищи), ожидает подноса с
едой, берет поднос, пытается найти свободный стол и т.д. Это — две различные
последовательности событий, и каждая имеет отдельный сценарий. Сценарий включает
следующие компоненты.
• Начальные условия, которые должны быть истинными при вызове сценария. В
этом сценарии они включают открытый ресторан и голодного посетителя,
имеющего некоторую сумму денег.
• Результаты или факты, которые являются истинными, когда сценарий
завершается; например, клиент сыт и его деньги потрачены, владелец ресторана имеет
больше денег.
• Предположения, которые поддерживают контекст сценария. Они могут включать
столы, официантов и меню. Множество предположений описывают принятые по
умолчанию условия реализации сценария. Например, предполагается, что
ресторан должен иметь столы и стулья, если не указано противоположное.
• Роли являются действиями, которые совершают отдельные участники.
Официант принимает заказы, доставляет пищу и выставляет счет. Клиент делает
заказ, ест и платит.
• Сцены. Шенк (Schank) разбивает сценарий на последовательность сцен, каждая из
которых представляет временные аспекты сценария. Сценарий похода в ресторан
включает следующие сцены: вход, заказ, принятие пищи и т.д.
Элементы сценария — основные "части" семантического значения —
представляются отношениями концептуальной зависимости. Собранные вместе во фреймоподобной
структуре они представляют последовательность значений или событий. Описанный
выше сценарий посещения ресторана представлен на рис. 6.11.
238
Часть III. Представление и разум в ракурсе искусственного интеллекта
Сценарий. РЕСТОРАН
Аналог Кафе
Реквизиты Столы
Меню
Р = Пища
Чек
Деньги
Роли S = Заказчик
W = Официант
С = Повар
М = Кассир
О = Владелец
Начальные условия S голоден
у S есть деньги
Результаты у S стало меньше денег
у О стало больше денег
S не голоден
S доволен (не обязательно)
Сцена 1 Вход
S PTRANS S в ресторан
S ATTEND смотрит на столы
S MBUILD куда сесть
S PTRANS S за стол
S MOVE S в сидячее положение
Сцена 2 Заказ
Меню на столе
W приносит меню | ^Т.о ^ ш
S PTRANS меню S / S MTRANS сигнал W
/ W PTRANS W к столу
\ у/ S MTRANS отдельный заказ
\ ^ W PTRANS W к меню
\ W PTRANS W к столу
\ W ATRANS меню S
\ /
S MTRANS список блюд в СР (S)
*S MBUILD выбор F
S MTRANS сигнал W
W PTRANS W к столу
S MTRANS 'я хочу F'W
^"^•^ W PTRANS W к С
^^ W MTRANS (ATRANS F) С
С MTRANS'нет F'W \
W PTRANS WS \
W MTRANS'нет F'S \
вернуться к * или \
перейти к сцене 4 С DO (сценарий "приготовить F")
(путь без оплаты) к сцене 3
Сцена 3 Употребление пищи
С ATRANS FW
WATRANSFS
S INGEST F
Вариант Вернуться к сцене 2, чтобы заказать еще раз,
иначе перейти к сцене 4 \
Сцена 4" Выход
\
SMTRANSW
/ (W ATRANS чек S)
WMOVE выписывает чек
W PTRANS WkS
W ATRANS чек S
S ATRANS чаевые W
S PTRANS S к М
S ATRANS деньги М
S PTRANS S к выходу из ресторана
Путь без оплаты
W
Рис. 6.1 L Сценарий посещения ресторана [Schank и Abelson, 1977]
Описанная в [Schank и Abelson, 1977] программа читает небольшой рассказ о
ресторанах и преобразует его во внутреннее представление концептуальной зависимости.
Поскольку ключевые понятия этого внутреннего описания сопоставляются с начальными
Глава 6. Представление знаний
239
условиями сценария, программа связывает объекты, представленные в рассказе, с
ролями и предположениями, упомянутыми в сценарии. Результатом является расширенное
представление контекста рассказа, использующее сценарий для заполнения
отсутствующей информации и предположений по умолчанию. Затем программа отвечает на
вопросы о рассказе, ссылаясь на сценарий. Сценарий допускает рациональные предположения
по умолчанию, которые являются существенными в понимании естественного языка.
Рассмотрим несколько примеров.
Пример 6.1.1
John went to a restaurant last night. He ordered steak. When he paid he noticed he was
running out of money. He hurried home since it had started to rain. (Джон зашел в ресторан
прошлым вечером. Он заказал бифштекс. Рассчитываясь, он заметил, что остался без
денег. Он поспешил домой, пока не начался дождь.)
Используя сценарий, система может правильно ответить на вопросы о том, обедал ли
Джон прошлым вечером (рассказ лишь подразумевает это), что использовал Джон:
наличные или кредитную карточку, как Джон получил меню, что он купил.
Пример 6.1.2
Sue went out to lunch. She sat at a table and called a waitress, who brought her a menu.
She ordered a sandwich. (Сью пошла на ланч. Она села за стол и позвала официантку,
которая принесла ей меню. Она заказала сэндвич.)
По поводу этого текста логично задавать следующие вопросы. Почему
официантка принесла меню Сью? Была ли Сью в ресторане? Кто платил? Кто заказал
сэндвич? Последний вопрос достаточно сложен. Ответ "официантка" (упомянутая
последней женщина) является неправильным. Роли сценария помогают разрешить
ссылки на местоимения и другие двусмысленности. Сценарии также могут быть
использованы для интерпретации неожиданных результатов или прерывания
деятельности по написанному сценарию.
Пример 6.1.3
Kate went to a restaurant. She was shown to a table and ordered steak from a waitress. She
sat there and waited for a long time. Finally, she got mad and left. (Кейт вошла в ресторан.
Ей указали стол, и она заказала бифштекс у официантки. Она села и долгое время
ждала. Наконец она разозлилась и ушла.)
На основе этого рассказа можно сформулировать следующие вопросы. Кто сидел
и ждал? Почему она ждала? Кто разозлился и ушел? Почему она разозлилась?
Отметим, что существуют и другие вопросы, на которые нельзя ответить с помощью
сценария. К ним относится следующий. Почему люди злятся, когда официант долго не
приходит? Подобно любой системе, основанной на знаниях, сценарии требуют
наличия всей необходимой базовой информации. Подобно фреймам и другим
структурированным представлениям использование сценариев сопряжено с определенными
проблемами, включая проблему соответствия сценариев и чтения между строк.
Рассмотрим пример 6.1.4, связанный со сценарием посещения ресторана или
концерта. Контекст здесь играет важную роль, так как слово "bill" может означать как
счет в ресторане, так и программу концерта.
240
Часть III. Представление и разум в ракурсе искусственного интеллекта
Пример 6.1.4
John visited his favorite restaurant on the way to the concert. He was pleased by the bill
because he liked Mozart. (По пути на концерт Джон посетил свой любимый ресторан.
Он был доволен программой, так как любил Моцарта.)
Поскольку выбор сценария обычно основан на соответствии "ключевых" слов, часто
трудно определить, какой из двух или более сценариев следует использовать. Проблема
соответствия сценария является "глубинной", т.е. не существует алгоритма,
гарантирующего правильный выбор. Она требует эвристических знаний об организации мира, а
сценарии помогают лишь в организации этого знания. Проблема чтения между строк
тоже очень сложна: нельзя наперед указать возможные случаи, которые могут нарушить
сценарий. Например, рассмотрим следующую ситуацию.
Пример 6.1.5
Melissa was eating dinner at her favorite restaurant when a large piece of plaster fell from
the ceiling and landed on her date. (Мелисса обедала в своем любимом ресторане, когда
большой кусок штукатурки отвалился с потолка и упал на ее финики.)
Здесь уместны следующие вопросы. Ела ли Мелисса финиковый салат? Что она
делала дальше? Были ли финики Мелиссы запачканы? Как показывает этот пример,
структурированные представления могут быть негибкими. Рассуждения могут быть
локализованы в одном сценарии, даже если он не соответствует ситуации.
Пакеты организации памяти решают проблему негибкости сценария, представляя
знания с помощью более мелких компонентов вместе с правилами для их динамического
связывания в схемы, соответствующие текущей ситуации [Schank, 1982]. Организация
памяти знаний особенно важна для реализации рассуждений, основанных на опыте, в
которых решатель должен эффективно находить в памяти подходящее решение прежней
проблемы [Kolodner, 1988a] (раздел 7.3).
Проблемы организации и поиска знаний очень трудны и характерны для
моделирования семантического значения. Евгений Черняк [Charniak, 1972] показал, какое
количество знаний требуется для понимания даже простых детских рассказов. Рассмотрим
фрагмент текста, описывающий вечеринку в честь дня рождения: "Mary was given two kites for
her birthday so she took one back to the store" ("В день рождения Мэри подарили два
воздушных змея, поэтому она вернула один из них в магазин"). Мы должны знать о
традиции дарить подарки в день рождения; знать, что такое воздушный змей и почему Мэри
могла не захотеть иметь двух змеев. Мы должны знать о магазинах и их политике
обмена. Несмотря на эти проблемы, программы, использующие сценарии и другие
семантические представления, могут понимать естественный язык в ограниченных предметных
областях. Примером может служить программа, которая интерпретирует сообщения,
поступающие по каналам новостей. Благодаря использованию сценариев природных
катастроф, успешных сделок и других стереотипных историй программа достигла заметных
успехов в этой ограниченной, но реальной области [Schank и Riesbeck, 1981].
6.1.5. Фреймы
Фреймы (frame) — это другая схема представления, во многом подобная сценариям и
ориентированная на включение в строго организованные структуры данных неявных
(подразумеваемых) информационных связей, существующих в предметной области. Это
Глава 6. Представление знаний
241
представление поддерживает организацию знаний в более сложные единицы, которые
отображают структуру объектов этой области.
В статье [Minsky, 1975] фреймы описываются следующим образом.
Вот суть теории фреймов. Когда некто встречается с новой ситуацией (или существенно
меняет свою точку зрения на проблему), он выбирает из памяти структуру, называемую
"фреймом". Этот сохраненный каркас при необходимости должен быть адаптирован и
приведен в соответствие с реальным изменением деталей [Minsky, 1975]
В соответствии с [Minsky, 1975] фрейм может рассматриваться как статическая
структура данных, используемая для представления хорошо понятных стереотипных ситуаций.
Возможно, наше собственное знание о мире тоже организовано во фреймоподобные
структуры. Мы приспосабливаемся к каждой новой ситуации, вызывая информацию,
основанную на опыте. Затем мы адаптируем эти знания в соответствии с новой ситуацией.
Например, достаточно один раз остановиться в гостинице, чтобы составить
представление о всех гостиничных номерах. Там почти всегда есть кровать, ванная, место для
чемодана, телефон, аварийно-эвакуационная информация на внутренней стороне двери и
т.д. Детали каждого номера при необходимости могут изменяться. Может варьироваться
цвет портьер, расположение и тип выключателей и т.п. С фреймом гостиничного номера
связана также информация, принимаемая по умолчанию. Если нет простыней, нужно
вызвать горничную, если нужен лед, необходимо посмотреть в холле и т.д. Нам не надо
подстраивать сознание для каждого нового гостиничного номера. Все элементы
обобщенного номера организуются в концептуальную структуру, к которой мы обращаемся,
когда останавливаемся в гостинице.
Эти высокоуровневые структуры можно представить в семантической сети, организуя
ее как совокупность отдельных сетей, каждая из которых представляет некоторую
стереотипную ситуацию. Фреймы так же, как объектно-ориентированные системы,
обеспечивают механизм подобной организации, представляя сущности как
структурированные объекты с поименованными ячейками и связанными с ними значениями. Таким
образом, фрейм или схема рассматривается как единая сложная сущность.
Например, гостиничный номер и его компоненты могут быть описаны рядом
отдельных фреймов. Помимо кровати во фрейме должен быть представлен стул: ожидаемая
высота — от 20 до 40 см, число ножек — 4, значение по умолчанию — предназначен для
сидения. Далее фрейм представляет гостиничный телефон: это вариант обычного
телефона, но расчет за переговоры связывается с оплатой гостиничного номера. По
умолчанию существует специальный гостиничный коммутатор, и человек может использовать
этот телефон для заказа еды в номер, внешних звонков и получения других услуг. На
рис. 6.12 изображен фрейм, представляющий гостиничный номер.
Каждый отдельный фрейм можно рассматривать как структуру данных, во многом
подобную обычной "записи", с информацией, соответствующей стереотипным
сущностям. Ячейки фрейма содержат такую информацию.
{.Данные для идентификации фрейма.
2. Взаимосвязь этого фрейма с другими фреймами. "Гостиничный телефон" может
служить специальным экземпляром "телефона", который, в свою очередь, может
служить примером "механизма связи".
3. Дескрипторы требований для фрейма. Стул, например, имеет высоту сидения от
20 до 40 см, его задняя часть выше 60 см, и т.д. Эти требования могут быть
использованы для определения соответствия новых объектов стереотипу фрейма.
242
Часть III. Представление и разум в ракурсе искусственного интеллекта
w
специализация* номер
положение гостиница
содержит гостиничный стул
гос
тиничныи телефон-
тиничная кровать -
т
гостиничная кровать
суперкласс кровать
назначение спать
размер королевский
часть фрейм
'
гостиничный стул
специализация стул
высота 20-40 см
ножки 4
назначение для сидения
гостиничный телефон
специализация, телефон
назначение, заказы в номер
расчет, вместе с оплатой номера
матрац
суперкласс подушка
изготовитель фирма
Рис. 6.12. Часть фрейма, описывающего гостиничный номер. "Специализированный"
класс содержит указатель на суперкласс
4. Процедурная информация об использовании описанной структуры. Важной
особенностью фреймов является возможность присоединить к ячейке процедурный код.
5. Информация по умолчанию. Это значения ячейки, которые должны быть
истинными, если не найдены противоположные. Например, стулья имеют 4 ножки, на
телефонах есть кнопки, гостиничные кровати заправляются персоналом.
6. Информация для нового экземпляра. Многие ячейки фрейма могут оставаться
незаполненными, пока не указано значение для отдельного экземпляра или пока они
не понадобятся для некоторого аспекта решения задачи. Например, цвет кровати
может оставаться неопределенным.
Фреймы расширяют возможности семантических сетей рядом важных
особенностей. Хотя фреймовое описание гостиничных кроватей на рис. 6.12 может быть
эквивалентно сетевому описанию, фреймовая версия намного яснее той, в которой кровать
описывается с помощью ее различных атрибутов. В сетевой версии существует просто
совокупность узлов. Такое представление в значительной степени зависит от
интерпретации структуры. Возможность организации знаний в такие структуры является
важным свойством баз знаний.
Фреймы позволяют организовать иерархию знаний. В сети каждое понятие
представляется узлами и связями на одном и том же уровне детализации. Однако очень часто для
одних целей объект необходимо рассматривать как единую сущность, а для других —
учитывать детали его внутренней структуры. Например, обычно нас не интересует
механическое устройство автомобиля, пока что-то не сломается. При обнаружении поломки
мы достаем схему автомобильного двигателя и пытаемся устранить проблему.
Процедурные вложения являются важным свойством фреймов, так как они
позволяют связать фрагменты программного кода с соответствующими сущностями
Глава 6. Представление знаний
243
фреймового представления. Например, в базу знаний можно включить возможность
генерировать графические образы. Для этого больше подходит графический язык,
чем сетевой. С помощью процедурных вложений можно создавать демоны (demon).
Демон — это процедура, которая является побочным эффектом некоторого другого
действия в базе знаний. Например, при каждом изменении определенной ячейки в
системе можно запускать процедуру контроля соответствия типов или тест
непротиворечивости.
Системы фреймов поддерживают наследование классов. Значения ячеек и
используемые по умолчанию значения класса наследуются через иерархию класс/подкласс и
класс/член. Например, гостиничный телефон можно реализовать как подкласс обычного
телефона, обладающий следующими особенностями: внешние звонки проходят через
коммутатор гостиницы (для расчета), и гостиничные услуги можно заказывать по
прямому номеру. Некоторым ячейкам можно присвоить значения но умолчанию. Они
используются, если нет другой информации. Например, в гостиничных номерах стоят
кровати, поэтому туда необходимо идти, если вы хотите спать. Если вы не знаете, как
позвонить портье, попытайтесь набрать "нуль".
Когда создается экземпляр фрейма класса, система будет пытаться заполнить его
ячейки либо заданными пользователем значениями, либо значениями по умолчанию,
взятыми из фрейма класса, либо выполнит некоторую процедуру или демон для
получения значения экземпляра. Как и в семантических сетях, ячейки и значения по умолчанию
наследуются через иерархию класс/подкласс. Конечно, используемая по умолчанию
информация может привести к немонотонности описания данных, поскольку корректность
такой информации не всегда можно доказать (см. раздел 8.1).
В работе [Minsky, 1975] приводится пример использования фреймов в рассуждениях
по умолчанию. Рассматривается задача выявления ситуации, в которой различные
проекции объекта на самом деле представляют один и тот же объект. Например, три
проекции куба на рис. 6.13 действительно выглядят различными. В [Minsky, 1975] предложена
система фреймов, которая распознает их как проекции одного и того же объекта, по
умолчанию учитывая наличие невидимых сторон.
Система фреймов на рис. 6.13 представляет четыре плоскости куба. Штриховые
линии показывают плоскости, невидимые в этой проекции. Связи между фреймами
отражают отношения между видами, которые представлены фреймами. Конечно, если
бы учитывалась дополнительная информация о цветах или узорах граней, узлы были
бы более сложными. В действиетльности каждая ячейка фрейма может содержать
указатель на другой фрейм. Это позволит избежать избыточности информации, поскольку
одни и те же данные можно использовать в нескольких различных ячейках (плоскость
Ена рис. 6.13).
Фреймы расширяют возможности семантических сетей, позволяя представлять
сложные объекты не в виде большой семантической структуры, а в виде единой сущности
(фрейма). Это также позволяет естественным образом представить стереотипные
сущности, классы, наследование и значения по умолчанию. Хотя фреймы, подобно логическим
и сетевым представлениям, являются мощным средством, многие проблемы организации
сложных баз знаний все же должны решаться на основе опыта и интуиции программиста.
Исследования, проведенные в 1970-х годах в Массачусетском технологическом
институте и исследовательском центре Xerox Palo Alto Research Center, привели к разработке
философии объектно-ориентированного программирования и созданию важных языков
реализации, включая Smalltalk, Java, C++ и, наконец, CLOS (раздел 15.12).
244
Часть III. Представление и разум в ракурсе искусственного интеллекта
к
А
\
»\
В
Вправо
П
В
Вправо
А"
В
71
С
/
Пространственный фрейм
Аксонометрические фреймы
Влево
Рис 6 13 Пространственный фрейм для представления куба [Minsky, 1975a]
Маркеры отношений в
общетерминальной структуре могут
представлять больше инвариантных
(в том числе пространственных) свойств
6.2. Концептуальные графы: сетевой язык
Вслед за первыми работами по созданию схем представления в ИИ (раздел 6.1) был
предложен ряд сетевых языков для моделирования семантики естественного языка и
других областей. В этом разделе мы детально рассмотрим конкретный формализм,
чтобы показать, как этими средствами решаются задачи представления смысла. Примером
сетевого языка представления являются концептуальные графы [Sowa, 1984]. Мы
определим правила формирования концептуальных графов и манипулирования ими, а также
опишем соглашения для представления классов, экземпляров и отношений. В
подразделе 13.3.2 показывается, как этот формализм может быть использован для представления
смысла в задачах понимания естественного языка.
6.2.1. Введение в теорию концептуальных графов
Концептуальный граф (conceptual graph) — это конечный, связанный, двудольный
граф. Узлы графа представляют понятия, или концептуальные отношения. В
концептуальных графах метки дуг не используются. Отношения между понятиями
представляются узлами концептуальных отношений. На рис. 6.14 узлы dog (собака) и brown
(коричневый) представляют понятия, a color (цвет)— концептуальное отношение.
Чтобы различать эти типы узлов, узлы понятий будем представлять прямоугольниками, а
концептуальные отношения — эллипсами.
В концептуальных графах узлы понятий представляют либо конкретные, либо
абстрактные объекты в мире рассуждений. Конкретные понятия, такие как кошка, телефон
или ресторан, характеризуются нашей способностью сформировать их образ. Отметим,
что к конкретным относятся обобщенные понятия, например, cat (кошка) или
restaurant (ресторан), а также понятия конкретных кошек и ресторанов. Мы можем также
сформировать образ обобщенной кошки. Абстрактные понятия включают такие
абстракции как любовь, красота, верность, для которых не существует образов в нашем вообра-
Глава 6. Представление знаний
245
жении. Узлы концептуальных отношений описывают отношения, включающие одно или
несколько понятий. Одним из преимуществ концептуальных графов без использования
помеченных дуг является простота представления отношений любой арности. Л/-арное
отношение представляется узлом концептуального отношения, имеющего N дуг, как
показано на рис. 6.14.
Каждый концептуальный граф представляет одно высказывание. Типовая база знаний
будет состоять из ряда таких графов. Графы могут быть произвольной сложности, но они
должны быть конечными. Например, граф на рис. 6.14 представляет высказывание "А
dog has a color of brown" ("Собака коричневого цвета"). На рис. 6.15 изображен более
сложный граф, представляющий высказывание "Mary gave John the book" ("Мэри дала
Джону книгу"). В этом графе концептуальные отношения используются для
представления форм глагола "give" ("давать"). Из этого примера ясно, как концептуальные графы
используются для моделирования семантики естественного языка.
bird
-К flies
flies (летает) — унарное отношение
dog
-К color
w brown
color (цвет) — бинарное отношение
parents (родители) — тернарное отношение
Рис. 6.14. Концептуальные отношения разной арности
>С object
person Mary
agent >*-
give
person' John К
rectpientj*-
book
Рис. 6.15. Граф предложения "Магу gave John the book'
6.2.2. Типы, экземпляры и имена
Разработчики первых семантических сетей в основном не заботились об определении
отношений класс-элемент и класс-подкласс, в результате чего возникала семантическая
неоднозначность. Например, отношение между экземпляром и его классом отличается от
отношения между классом (собака) и его суперклассом (плотоядные). Подобным
образом одни свойства принадлежат экземплярам, а другие — самим классам. В связи с этим
представление должно обеспечить механизм для такого различия. Свойства "иметь мех"
и "любить кости" относятся к отдельным собакам, а сам класс "собака" не обладает
свойствами "иметь мех" или "есть что угодно". Свойства, соответствующие классу,
включают имена и место в зоологической классификации.
246
Часть III. Представление и разум в ракурсе искусственного интеллекта
В концептуальных графах каждое понятие является уникальным экземпляром
конкретного типа. Каждый прямоугольник понятия снабжается меткой типа, определяющей
класс или тип экземпляра, представленного этим узлом. Таким образом, узел,
снабженный меткой dog (собака), представляет некоторый объект этого типа. Типы имеют
иерархическую структуру. Тип dog (собака) является подтипом типа carnivore
(плотоядные), который, в свою очередь, является подтипом mammal (млекопитающие) и
т.д. Прямоугольники с одной и той же меткой типа отражают понятия одного и того же
типа. Однако эти прямоугольники могут либо представлять, либо не представлять одно и
то же индивидуальное понятие.
Каждый прямоугольник понятия помечается именами типа и экземпляра. Метки типа
и экземпляра отделяются двоеточием. Граф на рис. 6.16 показывает, что собака Emma —
коричневая. Граф на рис. 6.17 означает, что некая неспецифицированная сущность типа
dog имеет коричневый цвет. Если экземпляр не указан, понятие представляет неспеци-
фицированный индивидуум этого типа.
Концептуальные графы позволяют также описывать конкретные, но неименованные
экземпляры. Для обозначения каждого экземпляра в мире рассуждений используется
уникальный дескриптор, называемый маркером (marker). Он представляет собой число,
перед которым расположен символ "#". Маркеры отличаются от имен тем, что они
являются уникальными: экземпляр может иметь одно имя, несколько имен или вовсе быть
безымянным, но он имеет ровно один маркер. Подобным образом различные экземпляры
могут быть тезками, но не могут иметь один и тот же маркер. Это различие дает
возможность преодолевать семантические неоднозначности, возникающие при именовании
объектов. Граф на рис. 6.17 означает, что конкретная собака #1352 — коричневая.
dog' етта
brown
Рис. 6.16. Концептуальный граф, показывающий,
что собака Етта — коричневого цвета
dog#1352
-+(. color
*\ brown
Рис. 6.17. Концептуальный граф, показывающий,
что отдельная (но безымянная) собака —
коричневого цвета
Маркеры позволяют отделить экземпляры от их имен. Если собака #1352 имеет имя
Эмма, для его описания можно использовать концептуальное отношение name (имя).
Результатом является граф на рис. 6.18. Имя, заключенное в двойные кавычки, указывает,
что это строка. Там, где не возникает опасность неоднозначности, мы можем упростить
граф и ссылаться на экземпляр прямо по имени. При таком соглашении граф на рис. 6.18
эквивалентен графу на рис. 6.16.
dog #1352
brown
Рис. 6 18. Концептуальный граф, показывающий,
что собака с именем Етта — коричневого цвета
Глава 6. Представление знаний
247
Хотя как в разговорной речи, так и в формальном представлении мы часто игнорируем
различие между экземпляром и его именем, оно является важным и должно быть
поддержано языком представления. Например, если мы говорим, что "John" — обычное мужское
имя, мы утверждаем, что это свойство самого имени, а не какого-нибудь экземпляра с
именем John. Это позволяет представлять такие английские выражения, как "Chimpanzee' is the
name of species of primates" ("Шимпанзе является именем вида приматов"). Подобным
образом можно представить факт наличия у объекта нескольких имен. Граф на рис. 6.19
представляет ситуацию, описанную в лирической песне Леннона и Маккартни A968 года) о
девушке с именем McGill, которая называла себя Lil, но все ее знали как Nancy.
С пате \
'
'
1 "McGill"
person #941765
т
w/
*v
С пате у
пате у
т
"Nancy"
"Lil"
Рис. 6.19. Концептуальный граф для
представления человека с тремя именами
Вместо обращения к объекту по маркеру или по имени можно использовать
обобщенный маркер * для определения неспецифицированных экземпляров. Эта информация
часто опускается в метках понятий: узел, заданный только меткой типа dog,
эквивалентен узлу dog: *. Дополнительно к обобщенному маркеру концептуальные графы
позволяют использовать именованные переменные. Они представляются звездочкой, за
которой следует имя переменной (например, *Х или *f oo). Это полезно, если два
отдельных узла должны обозначать один и тот же, но не указанный экземпляр. Граф на
рис. 6.20 представляет утверждение "The dog scratches its ear with its paw" ("Собака чешет
ухо лапой"). Хотя мы не знаем, какая собака чешет свое ухо, переменная *Х указывает,
что лапа и ухо принадлежат одной и той же собаке, которая чешется.
Итак, каждый узел понятия означает экземпляр определенного типа. Это объект,
относящийся к данному понятию, или объект ссылки (referent). Ссылка задается либо
индивидуально, либо для всех экземпляров в целом. Если для объекта ссылки используется
маркер экземпляра, понятие является конкретным, а если общий маркер — понятие
считается родовым.
(object \-
(^агГу~
dog *X
Рис. 6.20. Концептуальный граф для предложения "The dog scratches its ear
with its paw "
248
Часть III. Представление и разум в ракурсе искусственного интеллекта
6.2.3. Иерархия типов
Как показано на рис. 6.21, иерархия типов— это частичное упорядочение на
множестве типов, которое можно обозначить символом <. Если s и t — есть типы и
t < s, то говорят, что t — это подтип s, a s — cynepmun t. Поскольку эта
систематизация частична, тип может иметь один или несколько супертипов, а также один
или несколько подтипов. Если s, t и и — типы, причем t<s и t<u, то говорят, что
t — это общий подтип для s и и. Подобным же образом, если s<v и u<v, то v —
общий cynepmun для s и и.
Рис 6.21. Иерархия типов, иллюстрирующая
подтипы, супертипы, универсальный и
абсурдный тип. Дуги представляют отношения
Иерархия типов концептуальных графов представляет собой решетку, описывающую
общий вид системы множественного наследования. В этой решетке типы могут иметь
множество родителей и детей. Однако каждая пара типов должна иметь минимальный
общий cynepmun и максимальный общий подтип. Тип v является минимальным общим
супертипом для типов s и и, если s<v и u<v и для любого общего супертипа w типов s и
u v<w. Максимальный общий подтип имеет аналогичное определение. Минимальный
общий супертип совокупности типов служит для определения свойств, присущих только
этим типам. Поскольку многие типы, такие как emotion (эмоция) и rock (рок), не
имеют общих супертипов или подтипов, необходимо добавлять типы, которые
выполняют эти роли. Чтобы иерархия типов действительно стала решеткой, в концептуальные
графы включают два специальных типа. Универсальный тип (universal type)
обозначается символом | и является супертипом всех типов. Абсурдный тип (absurd type)
обозначается символом 1 и является подтипом всех типов.
Глава 6. Представление знаний
249
6.2.4. Обобщение и специализация
Теория концептуальных графов включает ряд операций для создания новых графов
на основе существующих. Они позволяют генерировать новый граф путем либо
специализации, либо обобщения существующего графа, и очень важны для представления
семантики естественного языка. На рис. 6.22 показаны четыре операции, а именно:
копирование, ограничение, объединение и упрощение. Предположим, что дх и д2 —
концептуальные графы.
Правило копирования позволяет сформировать новый граф д, который является
точной копией д\.
Ограничение позволяет заменить узлы понятий графа узлами, представляющим их
специализацию. Возможны две ситуации.
1. Если понятие помечено общим маркером, то общий маркер может быть заменен
индивидуальным.
2. Метка типа может быть заменена одной из меток его подтипов, если это
соответствует объекту ссылки понятия. На рис. 6.22 мы можем изменить animal
(животное) на dog (собака).
Правило объединения позволяет интегрировать два графа в один. Если узел
понятия сх графа S\ идентичен узлу понятия с2 графа s2, то можно сформировать новый
граф, вычеркивая с2 и связывая все его отношения с сх. Объединение— это правило
специализации, так как результирующий граф является менее общим, чем любой из его
компонентов.
Если граф содержит два одинаковых отношения, то одно из них может быть
вычеркнуто вместе со всеми его дугами. В этом заключается правило упрощения.
Дублирующиеся отношения часто возникают в результате операции объединения, как на
графе д4 на рис. 6.22.
250
Часть III. Представление и разум в ракурсе искусственного интеллекта
agent )<-
dog
>( object J H bone
->•( color
>\ brown
g2' lanimal' "emma"[+
> brown
> porch
Ограничение g2'
g3 dog. "emma" |<-
*• brown
*-\ porch
Объединение д] и g3.
g4 ^ agent )<-
dog "emma"
7
С color у ( color
>C object j-
->( location
brown
bone
porch
Упрощение д4
g5 { agent
dog "emma"
color
->( object
->( location
brown
bone
> porch
Рис. 6.22. Примеры операций ограничения, объединения и упрощения
Глава 6. Представление знаний
251
Для использования правил ограничения необходимо так сопоставить два понятия,
чтобы их можно было объединить. Это позволит реализовать наследование. Например,
замена обобщенного маркера индивидуальным реализует наследование экземпляром
свойств типа. Замена метки типа меткой подтипа определяет наследование между
классом и суперклассом. Путем объединения одного графа с другим и ограничения
определенных узлов понятий можно реализовать наследование различных свойств. На рис. 6.23
показано, как шимпанзе наследует свойство "иметь руку" от класса primates
(приматы) при замене метки типа меткой подтипа. Кроме того, на рисунке показано, как
экземпляр Bonzo наследует это свойство с помощью инстанцирования общего понятия.
primate
K^arfJ)"
hand
Концептуальный граф
chimpanzee
^^рапу~
hand
Наследование свойства подклассом
chimpanzee bonzo\
*^^рагГу~
hand
Наследование свойства экземпляром
Рис. 6.23. Наследование в концептуальных графах
Таким же образом объединение и ограничение можно применять для реализации
правдоподобных высказываний, обычно используемых для понимания языка. Если мы
говорим "Mary and Tom went out for pizza together" ("Мэри и Том пошли вместе в
пиццерию"), то автоматически делаем ряд предположений: они ели круглый итальянский хлеб,
покрытый сыром и томатным соусом. Они ели его в ресторане и каким-то образом
рассчитались за него. Это рассуждение может быть сделано на основе объединения и
ограничения. Мы формируем концептуальный граф выражения и объединяем его с
концептуальными графами (из базы знаний) для пиццы и ресторанов. Результирующий граф
позволяет предположить, что они ели томатный соус и оплатили счет.
Объединение и ограничение являются правилами специализации. Они определяют
частичное упорядочение на множестве полученных графов. Если граф дх является
специализацией дъ то мы можем говорить, что д2— обобщение д{. Иерархия обобщения
играет важную роль в представлении знаний. Иерархия обобщения используется в
качестве основы для наследования и других общесмысловых схем рассуждения, а также во
многих методах обучения, позволяя нам, например, конструировать обобщенное
утверждение на основе частного обучающего примера.
Эти правила не являются правилами вывода. Они не гарантируют, что из истинных
графов будут выводиться истинные графы. Например, при ограничении графа на рис. 6.22
результат может не быть истинным — Emma может быть кошкой. Подобным же образом
пример объединения на рис. 6.22 тоже не сохраняет истинность: собака на крыльце и
собака, которая ест кости, могут быть различными животными. Эти операции являются
каноническими правилами формирования (canonical formation rule), и, даже не сохраняя
истинность, они обладают незаменимым свойством — сохраняют "осмысленность". Это важно
252
Часть III. Представление и разум в ракурсе искусственного интеллекта
при использовании концептуальных графов в задачах понимания естественного языка.
Рассмотрим три выражения.
Albert Einstein formulated the theory of relativity. (Альберт Эйнштейн сформулировал теорию
относительности)
Albert Einstein plays center for the Los Angeles Lakers. (Альберт Эйнштейн — центровой в
команде Los Angeles Lakers )
Conceptual graphs are yellow flying popsicles. (Концептуальные графы являются желтыми
летающими мюмзиками.)
Первое выражение является истинным, а второе — ложным. Третья фаза вообще
бессодержательна: грамматически правильная, оно не имеет смысла. Второе предложение, хоть и
ложное, является осмысленным. Я могу представить Альберта Эйнштейна на баскетбольной
площадке. Канонические правила формирования накладывают ограничения на семантику
смысла, т.е. не позволяют формировать бессмысленные графы на основе осмысленных. Не
являясь смысловыми правилами вывода, они формируют основу для многих правдоподобных
рассуждений в системах понимания естественного языка и для общесмысловых рассуждений.
6.2.5. Пропозициональные узлы
Графы можно использовать для определения отношений между объектами мира, а
также между высказываниями. Рассмотрим, например, утверждение "Tom believes that
Jane likes pizza" ("Том верит, что Джейн любит пиццу"). Здесь believes — это
отношение, аргументом которого является высказывание. Концептуальные графы включают
тип понятий proposition (высказывание), объектом ссылки которого является
множество концептуальных графов. Это позволяет определить отношения, включающие
высказывания. Понятия высказываний, или пропозициональные понятия, изображаются
прямоугольником, содержащим другой концептуальный граф. Эти понятия с
соответствующими отношениями могут использоваться для представления знаний о
высказываниях. На рис. 6.24 показан концептуальный граф для приведенного выше утверждения.
Отношение experiencer (чувствующий) аналогично отношению agent (агент) — оно
тоже связывает субъект с глаголом. Связь experiencer используется для состояний
доверия, которые основываются скорее на интуиции, чем на действиях.
На рис. 6.24 показано, как концептуальные графы с пропозициональными узлами
могут использоваться для выражения модальных понятий знания и доверия. Модальные
логики (modal logic) связаны с различными типами высказываний. Они позволяют выразить
то, во что верится, возможное, вероятное или обязательно истинное, подразумеваемое
как результат действия или противоречащее фактам [Turner, 1984].
6.2.6. Концептуальные графы и логика
Используя концептуальные графы, можно легко представить такие конъюнктивные
понятия, как 'The dog is big and hungry" ("Собака большая и голодная"), но это
представление не позволяет описать отрицание или дизъюнкцию. Не решен также вопрос кван-
тификации переменных.
Мы можем реализовать отрицание, используя пропозициональные понятия и унарную
операцию пед. Ее аргументом является пропозициональное понятие, которое в
результате применения операции пед становится ложным. В концептуальном графе на
Глава 6. Представление знаний
253
рис. 6.25 операция neg используется для представления утверждения "There are no pink
dogs" ("Розовых собак не бывает").
высказывание
person Jane
agent J
pizza
T
likes
1
object J
Рис. 6.24 Концептуальный граф утверждения "Тот
believes that Jane likes pizza", иллюстрирующий
использование понятий высказываний
Используя отрицание и конъюнкцию, можно формировать графы для представления
дизъюнктивных утверждений в соответствии с правилами логики. Чтобы упростить эту
процедуру, можно определить отношение or, включающее два высказывания и
представляющее их дизъюнкцию.
Предполагается, что в концептуальных графах родовые понятия связаны квантором
существования. Например, родовое понятие "dog" ("собака") на графе, представленном
на рис. 6.14, действительно представляет переменную, связанную квантором
существования. Этот граф соответствует логическому выражению
3X3 Y(dog(X)AColor(X,Y)Abrown( Y)).
Используя отрицание и квантор существования (подраздел 2.2.2), можно также
представить квантор всеобщности. Например, граф на рис. 6.25 можно рассматривать как
представление логического утверждения
VX^Y(-^(dog(X)AColor(X)Y)Apink(Y))).
Рис. 6.25. Концептуальный граф утверждения "There
are no pink dogs"
Концептуальные графы по своей выразительной силе эквивалентны исчислению
предикатов. Как видно из этих примеров, существует прямое соответствие представления
концептуальных графов системе обозначений исчисления предикатов. В [Sowa, 1984]
254
Часть III. Представление и разум в ракурсе искусственного интеллекта
предложен следующий алгоритм преобразования концептуального графа д в выражение
исчисления предикатов.
1. Каждое из п родовых понятий графа д связать с отдельной переменной хь х2,..., хп.
2. Каждое конкретное понятие в д связать с отдельной константой. Эта константа
может быть просто именем или маркером, используемым для указания объекта
ссылки для данного понятия.
3. Представить каждый узел понятия унарным предикатом, имя которого
соответствует типу этого узла, и аргументом которого является переменная или константа
данного узла.
4. Представить каждое п-арное концептуальное отношение на графе д п-арным
предикатом с тем же именем. Каждый аргумент предиката является переменной или
константой, соответствующей узлу понятия, связанного с этим отношением.
5. Сформировать тело выражения исчисления предикатов в виде конъюнкции всех
атомарных выражений, построенных в пп. 3 и 4. Все переменные в выражении
считаются связанными квантором существования. Например, граф на рис. 6.16
представляется выражением исчисления предикатов вида
ЗХ,(с1од(Етта)лсо1ог(Етта1Х,)лЬго\А/п(Х,)).
Хотя концептуальные графы можно описать в синтаксисе исчисления предикатов,
они поддерживают ряд специальных механизмов вывода, таких как объединение и
ограничение, не являющихся частью исчисления предикатов.
Мы представили синтаксис концептуальных графов и определили операцию
ограничения как средство реализации наследования. Однако это не весь спектр операций и
правил вывода, которые можно реализовать на таких графах. Кроме того, до сих пор не
рассматривалась проблема определения необходимых понятий и отношений для такой
предметной области, как естественный язык. Мы вернемся к этим вопросам в
подразделе 13.3.2 и используем концептуальные графы для реализации базы знаний простой
программы понимания естественного языка.
6,3, Альтернативы явному представлению
В последние годы исследователи ИИ продолжали изучать роль представления в
реализации интеллекта. Кроме коннекционистского и эмерджентного подходов,
рассматриваемых в главах 10 и 11, наиболее достойной альтернативой явному представлению
является методология, описанная в работах Брукса из Массачусетского технологического
института [Brooks, 1991а]. Брукс ставит под сомнение необходимость какой-либо
централизованной схемы представления и с помощью своей категориальной архитектуры
(subsumption architecture) показывает, как интеллектуальные сущности могут развиваться
из более низких вспомогательных форм интеллекта.
Другой взгляд на проблему явного и статического представления содержится в
работах Мелани Митчелл (Melanie Mitchell) и Дугласа Хофстадтера (Douglas Hofstadter) из
университета штата Индиана. Архитектура Copycat (подражательная архитектура) — это
развивающаяся сеть, которая адаптируется к смыслу отношений, открываемых в
процессе экспериментирования с внешним миром.
Важным прикладным аспектом исследования Брукса и Митчелл является то, что их
идеи были разработаны на искусственных объектах, а затем проверялись с некоторыми
Глава 6. Представление знаний
255
ограничениями в реальной ситуации. Как отмечается во введении к главе 16, это ставит
работы Брукса и Митчелл в разряд эмпирических наук: их эксперименты разработаны и
проведены, в результате чего догадки были подтверждены или отвергнуты, и как
следствие — реализовано следующее поколение экспериментов.
6.3.1. Гипотезы Брукса и категориальная архитектура
Брукс выдвинул гипотезу о том, что интеллект и рациональное поведение не
возникает в нематериальных (невоплощенных) системах, подобных системам доказательства
теорем, или даже в традиционных экспертных системах (раздел 7.2). Эту гипотезу автор
подтвердил на примерах созданных им роботов. Брукс считает, что интеллект является
продуктом взаимодействия определенной многослойной системы со своим окружением.
Более того, Брукс придерживается точки зрения, что интеллектуальное поведение
возникает при взаимодействии архитектур, организованных из более простых сущностей. В
этом состоит основная идея его категориальной архитектуры (subsumption architecture).
Категориальная архитектура реализована Бруксом в системе управления роботом. Эта
архитектура представляет собой совокупность объектов-обработчиков, предназначенных
для решения отдельных задач. Каждый такой объект является конечным автоматом,
который непрерывно преобразует воспринимаемую входную информацию в выходное
управляющее воздействие и зачастую реализуется с помощью простого множества
продукционных правил типа условие-^действие (раздел 5.3). С помощью этих правил
можно определить (случайным образом, т.е. без знания глобального состояния), какие
действия соответствуют текущему состоянию подсистемы. Брукс допускает некую
обратную связь от более низких уровней системы.
Перед тем как представить пример архитектуры Брукса на рис. 6.26,
познакомимся с его философией. Брукс полагает, что "при построении больших
интеллектуальных систем представление является неправильной единицей абстракции".
Следовательно "явные представления и модели мира можно строить лишь на низших
уровнях интеллекта. Оказывается, в качестве модели мира лучше использовать сам
мир" [Brooks, 1991 я]. Таким образом, Брукс рассчитывает строить
интеллектуальные системы инкрементально. На каждом этапе архитектуры он предлагает создать
завершенную систему и обеспечить надежность функционирования ее составных
частей и их интерфейсов. На каждом шаге проектирования он строит завершенные
интеллектуальные системы, которые тестируются в мире, требующем
действительного восприятия и действия [Brooks, 199la].
На рис. 6.26, взятом из работы [Brooks, 199la], показана трехуровневая
категориальная архитектура. Каждый уровень представляет собой сеть фиксированной топологии,
состоящую из простых конечных автоматов, имеющих несколько состояний, один или
два внутренних регистра, один или два таймера и доступ к простым вычислительным
устройствам, позволяющим, например, вычислить сумму векторов. Эти конечные
автоматы работают асинхронно, посылая и получая сообщения фиксированной длины. В
системе нет централизованного управления. Наоборот, каждый конечный автомат
управляется данными, получаемыми им через сообщения. При получении сообщения или
завершении временного периода ожидания состояние автомата изменяется. В системе нет
глобальных данных или каких-либо динамически создаваемых коммуникационных
связей. Таким образом, в ней невозможно реализовать общее управление. Все конечные
автоматы равноправны и являются пленниками своей связности.
256
Часть III. Представление и разум в ракурсе искусственного интеллекта
EXPLORE.
look
.
Generate
Heading
turn
forward
-4-
WANDER
wander
heading
ft
sonar data
map
1—►
—►
feelforce
collide
avoid
runaway w
halt
AVOID-
Рис. 6.26. Функции трехуровневой категориальной
архитектуры из работы [Brooks 1991a]. Уровни реализуют
функции AVOID (избегать), WANDER (перемещаться),
EXPLORE (исследовать)
На рис. 6.26 представлено подмножество функций трехслойной архитектуры,
реализованной в одном из первых роботов [Brooks, 1991я]. Робот был оснащен кольцом из
двенадцати сонарных датчиков. Каждую секунду эти датчики давали двенадцать радиальных
измерений расстояния до препятствия. На самом низком уровне категориальной архитектуры
реализуется функция AVOID (избежать), которая предотвращает столкновение робота с
объектами, вне зависимости от того, являются они статическими или движущимися.
Автомат с меткой, помеченный sonar data (сонарные данные), выдает мгновенную
информацию тар, которая передается на автоматы collide (столкновение) и feedforce
(ощущение препятствия), первый из которых способен генерировать сообщение halt
(остановиться) для автомата, отвечающего за перемещение робота вперед. При
активизации автомата feedforce он способен генерировать инструкции runaway (уйти прочь)
или avoid (обойти), чтобы избежать опасности.
Эта сеть конечных автоматов самого низкого уровня генерирует инструкции halt
(остановиться) и avoid (обойти) для всей системы. Следующий слой WANDER
(перемещение) определяет способ перемещения системы, генерируя для робота
случайное направление heading каждые 10 секунд. Автомат AVOID (нижний уровень)
получает направление heading от автомата WANDER и связывает его с результатами работы
уровня AVOID. Автомат WANDER использует этот результат для подавления поведения
более низкого уровня, заставляя робота двигаться в направлении, близком к заданному, и
в то же время избегать столкновения со всеми препятствиями. И, наконец,
активизируясь, автоматы turn (повернуть) и forward (прямо) (на верхнем уровне архитектуры)
будут подавлять любые новые импульсы, присланные от автомата WANDER.
Верхний уровень EXPLORE (исследовать) позволяет изучить окружение робота. При
этом он осматривает (look) отдаленные места и достигает их, планируя путь plan. Этот
уровень способен подавлять инструкции автомата WANDER и наблюдать за тем, как
усилиями нижнего уровня робот огибает препятствия. Он корректирует отклонения и
фокусирует робота на достижении цели, сдерживая блуждающее поведение, но разрешает
автомату самого низкого уровня уклоняться от препятствий на пути. При реализации
отклонений, сгенерированных на более низком уровне, уровень EXPLORE вызывает
автомат plan, чтобы вновь сориентировать систему на достижение цели. Основой кате-
Глава 6. Представление знаний
257
гориальной архитектуры Брукса является то, что система не требует централизованных
символьных рассуждений и генерирует все свои действия без поиска среди возможных
следующих состояний. Хотя такой конечный автомат генерирует инструкции для
действий исходя из своего текущего состояния, глобально система действует на основе
взаимодействия нижних системных уровней.
Представленная трехслойная архитектура взята из раннего проекта Брукса по
разработке робота, передвигающегося к цели. В последние годы его исследовательская группа
разработала сложные системы с большим количеством уровней [Brooks, 1993], [Brooks и
Stein, 1994]. Одна система способна путешествовать по лаборатории роботики Массачу-
сетского технологического института в поисках пустых алюминиевых банок на рабочих
столах. В этой системе реализованы уровни для открытия дверей офисов, поиска
рабочих столов и распознавания банок. Другие уровни отвечают за управление рукой робота
для сбора этих банок в мусорную корзину.
Брукс утверждает, что поведение верхнего уровня возникает в результате разработки и
тестирования отдельных слоев более низкого уровня архитектуры. Четкое окончательное
поведение, требующее как внутри-, так и межуровневых связей, формируется в процессе
эксперимента. Таким образом, категориальная архитектура успешно реализована в нескольких
простых прикладных робототехнических системах [Brooks, 1989], [Brooks, 1991a].
С категориальной архитектурой и другими подходами к проектированию систем
управления связано несколько важных проблем (см. также раздел 16.2).
1. Существует проблема достаточности локальной информации на каждом уровне
системы. Поскольку на каждом уровне чисто реактивные конечные автоматы
принимают решения по локальной информации, т.е. по данным текущего уровня, в
процессе принятия решений не учитывается информация с других локальных
уровней. По определению такое решение будет недальновидным.
2. Если не существует абсолютного "знания" или "модели" сложного окружения, как
можно на основе локальной входной информации об ограниченной ситуации
сгенерировать инструкции для выполнения глобально приемлемых действий? Как
может верхний уровень согласовывать возможные результаты?
3. Как чисто реактивный компонент с очень ограниченным набором состояний может
обучаться в своей среде? Если агент должен быть интеллектуальным, на некотором
уровне системы нужна достаточная информация для реализации механизмов обучения.
4. Существует проблема масштабирования. Хотя Брукс и его помощники объявили о
реализации категориальных архитектур из шести и даже десяти уровней, необходимо
сформулировать принципы дальнейшего масштабирования интересного поведения.
Может ли этот подход быть обобщен на очень большие и сложные системы?
Наконец, мы должны задать вопрос: что такое "эмерджентность"? Не мистика ли это?
На настоящем этапе развития науки эмерджентность относится к явлениям, с которыми
мы можем только считаться. Нам поставили задачу разработать систему, обладающую
интеллектом, и испытать ее. К сожалению, без дальнейшей разработки этой инструкции
эмерджентность остается только словом, описывающим то, что мы еще не можем
понять. В результате очень трудно определить, как можно использовать эту технологию
для дальнейшего построения более сложных систем. В следующем разделе мы опишем
гибридную архитектуру Copycat, позволяющую открывать инварианты в проблемной
области исследовательским путем.
258
Часть III. Представление и разум в ракурсе искусственного интеллекта
6.3.2. Архитектура Copycat
Часто приходится слышать критические замечания в адрес традиционных схем
представления ИИ, связанные с их статичностью и неспособностью отражать динамическую
природу мыслительных процессов и интеллекта. Например, попадая в новую ситуацию,
человек часто бывает поражен ее сходством с уже известными ситуациями. Часто
отмечается, что человек получает информацию как снизу вверх, т.е. стимулируется новыми
образами окружения, так и сверху вниз, т.е. связывается с ожидаемым результатом.
Copycat — это архитектура решения задач, разработанная в диссертации Мелани
Митчелл [Mitchell, 1993] под руководством Дугласа Хофстадтера [Hofstadter, 1995] в Индиан-
ском университете. Архитектура Copycat основывается на многих предшествующих ей
техниках представления, включая модели классной доски (раздел 5.4), семантические сети
(раздел 6.2), сети связей (глава 10) и системы классификации [Holland, 1986]. Она также
использует подход Брукса к решению задач, состоящий в активном взаимодействии с
предметной областью. Однако в отличие от моделей Брукса и сетей связей в Copycat в
состав решателя задач входит глобальное "состояние". Более того, представление является
его динамической характеристикой. Copycat поддерживает механизм, подобный
семантической сети, который растет и изменяется в процессе непрерывного взаимодействия со
своим окружением. Таким образом, представление является менее хрупким и более
обтекаемым — оно включает ту информацию, которую счел важной сам агент, а не ту, которую
считал важной разработчик программы. И, наконец, компоненты Copycat позволяют
изучать ситуацию сверху вниз и снизу вверх, а также устанавливают аналогии.
Изначально задачей Copycat являлось восприятие и определение простых аналогий. В
этом смысле архитектура базируется на ранних работах [Evans, 1968] и [Reitman, 1965].
Примером такой задачи является комплектация групп взаимосвязанных понятий: hot
(горячий) и cold (холодный), tall (высокий) и wall (стена), short (короткий), wet
(мокрый), hold (крепость) или построение групп понятий на основе иерархической
организации мира, в частности, bear (медведь) и pig (свинья), либо chair (стул) и foot
(ножка), table (стол), coffee (кофе), strawberry (земляника). Архитектура Copycat
применялась для завершения упорядоченных в алфавитном порядке строк, таких как: a be и
abd или ijk и ?, либо abc и abd или iijjkk и ?.
Copycat включает три основных компонента: рабочее пространство (workspace),
гибкую сеть (slipnet), блок кодов (coderack). Эти составляющие взаимодействуют через
подсистему измерения температуры. Температурный механизм включает степень
восприятия в системе, а также управляет степенью случайности при принятии решения.
Высокая температура свидетельствует, что информации для принятия решения мало, низкая
температура означает противоположное. Таким образом, при высоких температурах
решения более случайны, а при понижении температуры система достигает консенсуса. И,
наконец, низкая температура говорит о "созревании" решения, а также отражает его
"достоверность".
Рабочее пространство — это глобальная структура, подобная классной доске,
описанной в разделе 5.5, предназначенная для создания объектов, инспектируемых другими
компонентами системы. В этом смысле оно во многом подобно области сообщений в
классификационной системе Холланда [Holland, 1986]. В рабочем пространстве организуется
иерархия воспринимаемых структур (три строки алфавитных символов). На рис. 6.27
представлено возможное состояние рабочего пространства со связями (стрелками) между
соответствующими компонентами строк. Обратите внимание на то, что на ранних стадиях
построения аналогии образуется связь между элементом с и парой /с/с.
Глава 6. Представление знаний
259
Замена крайней справа буквы
rmost-^rmost
letter -► group
Рис. 6.27. Возможное состояние рабочего
пространства Copycat. Показано несколько примеров связей
между буквами [Mitchel, J 993]
Гибкая сеть (slipnet) отражает набор понятий или потенциальных ассоциаций для
компонентов аналогии (рис. 6.28). Ее можно рассматривать как динамически
перестраиваемую семантическую сеть, каждый из узлов которой имеет свой уровень активации.
Связи в сети могут быть помечены именами других узлов. В соответствии с уровнем
активации помеченных узлов связанные узлы увеличиваются или сокращаются. Таким
образом, система изменяет степень ассоциации между узлами в зависимости от контекста.
Это важно при построении текущего решения. Для узлов, более тесно связанных в
текущем контексте, уровень активации возрастает.
0^:0—• • • 0z=0zr0
Рис. 6.28. Небольшая часть гибкой сети Copycat с узлами, связями и
метками; адаптировано из [Mitchell J 993]
Блок кодов (coderack) — это априори организованная вероятностная очередь,
состоящая из небольших фрагментов исполняемых кодов (и-кодов), предназначенных для
взаимодействия с объектами рабочего пространства и расширяющих некоторую часть
формируемого решения за счет исследования различных аспектов пространства. В
системе, описанной в [Holland, 1986], и-коды очень похожи на отдельные классификаторы.
Узлы гибкой сети генерируют и-коды и направляют их в блок кодов с вероятностной
оценкой исполнения. Таким образом, система поддерживает параллельные кодовые
сегменты, конкурирующие между собой за возможность обнаружить и построить структуры
рабочего пространства. Эти коды соответствуют породившим их узлам. В поиске приме-
260
Часть III. Представление и разум в ракурсе искусственного интеллекта
ров уже сгенерированных сущностей состоит работа сверху вниз. Пытаясь
идентифицировать и наладить отношения, уже существующие между объектами рабочего
пространства, u-коды могут также работать снизу вверх.
По мере создания структур в рабочем пространстве повышается степень активации
узлов, которые генерируют исполнительные коды. Это позволяет в контексте текущего
состояния решения проблемы влиять на будущее поведение системы. Важным элементом
архитектуры Copycat является использование случайности. Большинство решений
принимается случайно, а вероятность выбора действия или структуры определяется соответствием
этой сущности текущему состоянию решения задачи. Фактор случайности также
предохраняет программу от попадания в "тупиковые ситуации". Более того, выбранный наугад
"ошибочный" элемент (очевидно, не относящийся к текущему пути) открывает
возможность перехода к другим потенциальным путям решения. Это помогает решать проблему
"эффекта горизонта" (раздел 4.3), когда неудачность текущего пути изначально невидима.
Случайность, таким образом, привносит неоднородность в пространство поиска, что
является одним из преимуществ генетических алгоритмов (глава 11).
И, наконец, температура служит механизмом обратной связи, определяющим степень
"зацепления" структур, построенных в рабочем пространстве. При низкой степени
зацепления вероятностный характер выбора, сделанного системой, не столь важен, поскольку
оба варианта одинаково приемлемы. При высокой степени зацепления с внутренне
непротиворечивым решением влияние вероятностного выбора возрастает, поскольку
варианты теснее связаны с формируемым решением.
Copycat представляет собой гибкую архитектуру, структуры которой развиваются как
на основе данных, так и с учетом ожидаемого результата, поэтому отражают инварианты
своего окружения. Однако эта архитектура имеет ряд недостатков. Во-первых, несмотря
на то, что рассуждения по аналогии являются общей и важной особенностью интеллекта,
алфавитная предметная область Copycat настолько семантически слаба, что результаты
рассуждений по аналогии мало понятны. Это превращает данную архитектуру в
игрушечную систему. Во-вторых, Copycat не дообучается. С каждым новым образом она
пытается сформировать строки шаблонов. Для рассуждений по аналогии требуется, чтобы
система интегрировала новые знания в уже существующую в ней систему понятий,
развивая силу аналогии при каждом столкновении с окружающим миром.
Известно несколько новых проектов, развивающих Copycat и предназначенных для
проверки архитектуры в более сложной среде. В [Marshall, 1999] продолжено
моделирование связей по аналогии. В [Lewis и Luger, 2000] архитектура Copycat расширена для
использования в системе управления мобильным роботом. Таким образом, система
Copycat значительно развита за счет взаимодействия с конкретным окружением с целью
обучения. Результатом этого взаимодействия является карта пространства, исследуемого
роботом. Объекты обнаруживаются и наносятся на карту, а заодно планируются и
перепланируются маршруты движения между объектами. В следующем разделе будут
рассмотрены агентно-ориентированный и компонентный подходы к решению задач.
6.4. Агентно-ориентированное и распределенное
решение проблем
В 1980-е годы исследователями ИИ было сделано два открытия, которые имели
важное значение для последующего анализа роли представления в интеллектуальном реше-
Глава 6. Представление знаний
261
нии проблем. Первым было появление традиций распределенного искусственного
интеллекта (РИИ). Первый рабочий семинар по РИИ состоялся в Массачусетсском
технологическом институте в 1980 году и был посвящен вопросам, связанным с интеллектуальным
решением задач системами, состоящими из множества решателей. Исследователями
РИИ было решено, что их не интересуют такие вопросы параллелизма низкого уровня,
как распределенная обработка на нескольких машинах или распараллеливание сложных
алгоритмов. Они хотели понять, как распределенные решатели можно эффективно
скоординировать для интеллектуального решения проблем. Фактически это было началом
эры распределенной обработки в искусственном интеллекте с использованием и
координацией исполнителей (actor) и демонов (daemon) и разработкой систем классной доски,
рассмотренных в разделе 5.4.
Вторым открытием исследователей ИИ, уже представленным в разделе 6.3, стали
работы Брукса и его группы. Работа Брукса оказала большое влияние на традиционный
взгляд исследователей ИИ на представления и рассуждения (раздел 6.3.1). Во-первых,
понимание того, что интеллектуальное решение проблем не требует централизованного
запоминания знаний, обрабатываемых некоторой общецелевой схемой вывода, привело к
понятию распределенных и взаимодействующих моделей интеллекта, где каждый
элемент распределенного представления отвечает за собственный компонент процесса
решения проблемы. Во-вторых, факт, что интеллект является ситуативным и активным, в
контексте отдельных задач позволяет решателю перевести часть процесса решения в
окружающую среду. Это дает возможность каждому решателю решать поступающую
задачу, ничего не зная о процессе решения в остальной части системы. Таким образом, один
Web-агент может проверять список товаров, в то время как другой проверяет
кредитоспособность заказчика. При этом оба агента не осведомлены о принятии решения на
более высоком уровне, например: разрешить или не разрешить покупку.
Оба эти направления 1980-х годов повлияли на текущее состояние разработок и
использование интеллектуальных агентов.
6.4.1. Агентно-ориентированное решение задач: определение
Прежде чем двигаться дальше, определим, что мы подразумеваем под словами
"агент", "агентно-ориентированная система" и "мультиагентная система". Однако это
несколько проблематично, так как мнения различных групп исследователей по этому
вопросу расходятся. Наше определение и обсуждение базируется на работах [Jennings,
Sycara и Wooldridge, 1998], [Wooldridge, 2000], [Lewis и Luger, 2000].
Будем считать, что мультиагентная система — это вычислительная программа, блоки
решения задач (решатели) которой расположены в некоторой среде, и каждый из них
способен к гибким, автономным и социально организованным действиям, направленным
(либо нет) на предопределенные реалии или цели. Таким образом, четырьмя свойствами
интеллектуальной агентной системы, включающей программные решатели задач,
являются: ситуативность, автономность, гибкость и социальность.
Ситуативность (situatedness) интеллектуального агента означает, что он воспринимает
окружение, в котором действует, и может изменять это окружение. Примеры окружения
для ситуативных агентов — это Internet, среда ведения игры или "обитания" робота.
Конкретным примером агента может служить игрок в виртуальный футбол в соревнованиях
роботов ROBOCUP [Veloco и др., 2000], который должен взаимодействовать с мячом и
противником, не зная размещения, намерений и успехов других игроков. Это понятие си-
262
Часть III. Представление и разум в ракурсе искусственного интеллекта
туативности отличается от принятого в более традиционных решателях задач, таких как
планировщик STRIPS (раздел 7.4) или экспертная система MYCIN (раздел 7.3), которые
поддерживали централизованные и исчерпывающие знания о своих прикладных областях.
Автономная система (autonomous system) может взаимодействовать со своим
окружением без прямого вмешательства других агентов. Для этого она должна
контролировать свои действия и внутренние состояния. Некоторые автономные агенты могут также
обучаться на своем опыте, чтобы улучшить свое поведение в дальнейшем (см. часть IV).
В Internet автономный агент мог бы распознавать кредитную карточку вне зависимости
от решения других вопросов электронной коммерции. В системе ROBOCUP агент
должен передать мяч партнеру или забить гол (в зависимости от конкретной ситуации).
Гибкий агент (flexible agent) должен демонстрировать качества отзывчивости или
предусмотрительности (в зависимости от ситуации). Отзывчивый агент получает стимулы от
своего окружения и вовремя отвечает на них соответствующим образом.
Предусмотрительный агент не просто реагирует на ситуацию в своем окружении, но и адаптируется,
целенаправленно действует и выбирает альтернативы в различных ситуациях. Агент по
поиску кредитора, например, должен уметь предоставить пользователю несколько вариантов
или найти другое кредитное агентство, если недостаточно одной альтернативы.
Футбольный агент должен изменить свою тактику игры в зависимости от замысла противника.
И, наконец, агент является социальным (social agent), если он может
соответствующим образом взаимодействовать с другими программными или человеческими агентами.
После всего сказанного становится ясно, что агент является лишь частью сложного
процесса решения проблем. Взаимодействия социального агента ориентированы на
достижение целей более крупной мультиагентной системы. Эта социальная направленность
агентной системы должна решать много проблем, в том числе такие. Как различные
агенты выделяют подзадачи при решении проблем? Как агенты могут взаимодействовать
друг с другом, чтобы облегчить решение системной задачи более высокого уровня (в
системе ROBOCUP, например, вести счет)? Как один агент может поддерживать цели
другого агента (например, управлять вопросами безопасности в Internet)? Все эти
вопросы социальной направленности являются предметом современных исследований.
Мы описали основы создания мультиагентных систем. Мультиагентные системы
идеально подходят для решения проблем, включающих большое количество методов
решения, точек зрения и сущностей. В этих областях мультиагентные системы имеют
преимущества распределенного и конкурентного решения проблем, в том числе за счет
реализации сложных схем взаимодействия. Примеры взаимодействия показывают
совместные действия по достижению общей цели. В этом и состоит гибкость
социальных взаимодействий, которая отличает мультиагентные системы от традиционного
программного обеспечения и обусловливает интерес к агентной парадигме.
В последние годы термин мультиагентная система относят ко всем типам
программных систем, составленных из множества полуавтономных компонентов.
Распределенная агентная система рассматривает пути решения частных задач с помощью ряда
модулей (агентов), которые взаимодействуют на основе совместного использования
знаний о задаче в процессе решения. Исследования в области мультиагентных систем
сосредоточены на синтезе поведения множества иногда уже существующих автономных
агентов, ориентированных на решение данной проблемы. Мультиагентная система
может рассматриваться как сильно связанная сеть решателей, совместно работающих над
проблемами, которые могут выходить за рамки возможностей индивидуальных агентов
[Durfee и Lesser, 1989].
Глава 6. Представление знаний
263
Решатели мультиагентной системы, являясь автономными, могут в то же время быть
неоднородными. На основе [Jennings, Sycara и Wooldridge, 1998] можно выделить четыре
важные характеристики мультиагентного решения проблем. Во-первых, каждый агент имеет
неполную информацию и недостаточные возможности для решения всей задачи, вследствие
чего страдает от ограниченности знаний. Во-вторых, не существует глобального системного
контроллера для решения всей проблемы. В-третьих, знания и входные данные задачи тоже
децентрализованы, и, в-четвертых, процесс рассуждения часто является асинхронным.
Наконец, разработчики традиционных объектно-ориентированных систем не видят ничего
нового в агентно-ориентированной системе. Их можно понять, если рассматривать свойства
отдельных агентов и объектов. Объекты определяются как вычислительные системы с
инкапсулированным состоянием, они обладают методами, связанными с этим состоянием, и
совершают действия в окружающей среде, а также взаимодействуют, передавая сообщения.
Различие между объектами и агентами состоит в том, что объекты редко контролируют
свое поведение. Агенты следует рассматривать не как сущности, вызывающие конкретные
методы друг друга, а как субъекты, которые запрашивают выполнение необходимых
действий. Далее, агенты являются гибкими, т.е. чутко реагирующими на изменение внешней среды,
предусмотрительными и социально настроенными. И, наконец, при взаимодействии агентов
зачастую можно выделить свои собственные потоки управления. Все эти различия не
означают, однако, что такой объектно-ориентированный язык, как CLOS, рассматриваемый в
разделе 15.12, не является подходящей средой для построения агентной системы. Наоборот, сила и
гибкость CLOS делает его идеальным для решения этой задачи.
6.4.2. Примеры и проблемы агентно-ориентированной парадигмы
Чтобы конкретизировать идеи предыдущего раздела, опишем ряд прикладных
областей, в которых целесообразно использовать агентно-ориентированное решение задач.
Заодно приведем ссылки на исследования в этих проблемных областях.
• Производство. Производственная область может моделироваться как иерархия
рабочих областей. Можно рассматривать рабочие области для мукомольного
производства, штукатурных, малярных работ, сборки и т.д. Эти рабочие области
затем можно сгруппировать в производственные подсистемы. Каждая из подсистем
функционирует внутри некоторого производственного процесса. Впоследствии
эти подсистемы можно объединить в фабрику. Еще более крупная сущность —
компания — может контролировать деятельность каждой из этих фабрик,
например, управлять заказами, учетом товаров, ростом производства, прибылью и т.п.
Литературные ссылки на агентно-ориентированное производство включают
работы по формированию последовательности производственных процессов [Chung и
Wu, 1997], производственных операций [Oliveira и др., 1997] и совместному
созданию продукции [Cutosky и др., 1993], [Darr и Birmingham, 1996].
• Автоматическое управление. Поскольку контроллеры процессов обычно
являются автономными, реактивными и зачастую распределенными системами, не
удивительно, что агентные модели приобретают в этой области важное значение.
Существуют исследования по управлению транспортными системами [Согега и
др., 1996], управлению космическими аппаратами [Schwuttke и Quan, 1993],
электронно-лучевыми ускорителями [Perriolat и др., 1996], [Klein и др., 2000],
управлению воздушным транспортом [Ljunberg и Lucas, 1992] и другие.
264
Часть III. Представление и разум в ракурсе искусственного интеллекта
• Телекоммуникации. Телекоммуникационные системы являются большими
распределенными сетями, состоящими из взаимодействующих компонентов, которые
требуют мониторинга и управления в реальном времени. Агентно-ориентированные
системы использовались для сетевого управления и менеджмента [Schoonderwoerd и
др., 1997], [Adler и др., 1989], передачи информации, переключения [Nishibe и
др., 1993] и обслуживания [Busuoic и Griffiths, 1994]. Более полный обзор
приложений в этой области содержится в [Veloco и др., 1994].
• Транспортные системы. Системы грузоперевозок едва ли не по определению
являются распределенными, ситуативными и автономными. Приложения в этой
области включают управление пассажиропотоками и транспортом для транспортных
баз [Burmeister и др., 1997] и кооперативное составление транспортных
расписаний [Fischer и др., 1996].
• Информационный менеджмент. Изобилие, разнообразие и сложность
информации в современном обществе почти безграничны. Агентные системы могут
обеспечить интеллектуальный информационный менеджмент, особенно в Internet. Как
человеческий фактор, так и информационная организация как будто сговорились
против комфортного доступа к информации. Двумя критическими агентными
задачами являются фильтрация данных — получение из всей доступной
информации лишь той небольшой порции, которая нас действительно интересует, и сбор
информации — задача накопления и определения приоритетов среди отобранных
порций информации. Среди приложений можно отметить WEBMATE [Chen и
Sycara, 1998], систему фильтрации электронной почты [Maes, 1994], поиск в Web
[Lieberman, 1995] и агент поиска эксперта [Kautz и др., 1997].
• Электронная коммерция. Современная коммерческая деятельность
осуществляется под управлением человека: мы решаем, когда купить или продать, какое
количество и по каким ценам, и даже, какая информация необходима нам к
определенному времени. Несомненно, коммерция является областью, подходящей для
агентных моделей. Хотя полная разработка электронных коммерческих агентов
может быть осуществлена только в будущем, несколько систем уже реализовано.
Например, современные программы могут принимать решения по многим
покупкам и продажам на основании большого количества разнородной и
распределенной информации. Было разработано несколько агентных систем для управления
портфелем ценных бумаг [Sycara и др., 1996], системы— помощники покупателя
[Doorenbos и др., 1997], [Krulwich, 1996] и интерактивные каталоги [Schrooten и
van de Velde, 1997], [Takahashi и др., 1997].
• Интерактивные игры и театр. Участники игр и театральные герои
функционируют в богатой интерактивной среде. Игровые агенты могут втягивать нас в
военные игры, в сценарии управления финансами и даже в спортивные состязания.
Театральные агенты играют роль человеческих прототипов и могут создавать
иллюзию жизни в эмоциональных ситуациях, при моделировании критических
ситуаций в медицине или при обучении разнородным задачам. Исследования в
этой области включают компьютерные игры [Wavish и Graham, 1996] и
интерактивные модели личностей [Hayes-Roth, 1995], [Trappl и Petta, 1997].
Разумеется, существует много других областей, для которых подходит агентно-
ориентированная парадигма реализации. Несмотря на то что агентная технология имеет
много потенциальных преимуществ, для интеллектуального решения проблем еще необ-
Глава 6. Представление знаний
265
ходимо преодолеть ряд трудностей. Приведенный ниже список вопросов сформулирован
на основе идей, изложенных в работах [Jennings и др., 1998], [Bond и Gasser, 1988].
• Как систематизировать, формализовать, распределить задачи агентов? Более того,
как соответствующим образом синтезировать результаты их решения?
• Как обеспечить передачу сообщений и взаимодействие агентов? Какие
существуют языки и протоколы передачи сообщений? Что и когда можно назвать
подходящей информацией?
• Как обеспечить согласованное поведение агентов при выборе действий и
принятии решений? Как справляться с нелокализованными воздействиями и избегать
вредных взаимодействий с агентами?
• Как отдельные агенты могут представлять и обрабатывать информацию о
действиях, планах и знаниях других агентов для их координации? Как агенты могут
судить о состоянии координируемых ими процессов?
• Как распознать и скоординировать различные точки зрения и конфликтные
намерения агентов?
• Как распознать опасное поведение всей системы, например, хаотичное или
вибрирующее, и избежать его?
• Как распределять и контролировать ограниченные ресурсы как отдельного агента,
так и системы в целом?
• И, наконец, какие технические средства и программные технологии существуют
для разработки и поддержки агентных систем?
Методы разработки интеллектуального программного обеспечения, необходимые для
поддержки агентных технологий решения проблем, можно встретить на протяжении всей
книги. Во-первых, требования к представлению процесса интеллектуального решения
проблем стали постоянной темой нашего изложения. Во-вторых, вопросы поиска,
особенно эвристического, можно найти в части II. В-третьих, область планирования,
представленная в разделе 7.4, обеспечивает технологию упорядочения и координацию
подцелей при организации решения проблем. В-четвертых, мы представляем идею
стохастических агентных рассуждений в условиях неопределенности в разделе 8.3. И, наконец,
вопросы обучения в областях автоматизированных рассуждений и понимания
естественного языка рассматриваются в частях V и IV. Эти подобласти традиционного
искусственного интеллекта важны для создания агентных архитектур.
Существует ряд других вопросов разработки агентных моделей, которые находятся вне
сферы этой книги, например, языки коммуникаций, схемы взаимодействия и методы
распределенного управления. Они рассматриваются в [Jennings, Sycara и Wooldridge, 1998] и в
трудах соответствующих конференций (AAAI, IJCAI и DAI).
6.5. Резюме и дополнительная литература
В этой главе рассмотрены многие из основных альтернатив для представления
знаний, включая использование логики, правил, семантических сетей и фреймов. Кроме
того, описаны системы без централизованной базы знаний или общецелевой схемы
рассуждений. Наконец, мы рассмотрели распределенное решение проблем с агентами. Резуль-
266
Часть III. Представление и разум в ракурсе искусственного интеллекта
таты тщательного изучения показывают новый уровень понимания преимуществ и
ограничений каждого из этих подходов к представлению. Тем не менее дебаты по вопросам
естественности, эффективности и соответствия каждого из подходов продолжаются. Мы
заканчиваем эту главу кратким обсуждением нескольких важных подходов в области
представления знаний.
Первый из них — это выбор и степень детализации атомарных символов для
представления знаний. Объекты мира составляют область определения отображения;
вычислительные объекты в базе знаний являются его областью значений. Природа атомарных
элементов языка в значительной степени определяет форму описания мира, например,
если "автомобиль" — это наименьший атом представления, то система не может
рассуждать о двигателях, колесах и какой-либо другой части автомобиля. Однако, если этим
частям соответствуют атомы, то для представления "автомобиля" как единого понятия
может потребоваться более крупная структура со своими способами управления.
Другой пример компромиссного решения при выборе символов может быть найден в
работах, посвященных пониманию естественного языка. Сложные понятия, значение
которых не описывается одним словом, нельзя представить с помощью программ,
использующих отдельные слова в качестве элементов смысла. Существуют также определенные
трудности в выделении разного смысла одного и того же слова или разных слов с одним
и тем же смыслом. Один из подходов к этой проблеме заключается в использовании
семантических примитивов — независимых от языка концептуальных единиц,
используемых в качестве основы для представления естественного языка. Хотя эта точка зрения
устраняет проблему использования отдельных слов как единиц смысла, возникают
другие проблемы: многие слова требуют сложных структур для их определения; кроме того,
при небольшом множестве примитивов сложно уловить тонкие различия, такие как
"push" и "shove" (толкать) или "yell" и "scream" (пронзительный крик).
Полнота — свойство базы знаний, которое обеспечивается подходящим
представлением. Отображение является полным по отношению к свойству или классу объектов, если все
вхождения точно соответствуют элементу представления. Предполагается, что
географические карты должны быть полными на некотором уровне детализации. Карту, на которой
упущен город или река, нельзя рассматривать как навигационную. Хотя большинство баз
знаний не полны, полнота относительно определенных свойств или объектов является
обязательной. Например, предположение полноты представления позволяет планировщику
игнорировать возможные эффекты проблемы границ (frame problem).
При описании задачи как последовательности состояний мира, вызываемых
некоторыми действиями или событиями, нужно учитывать, что эти действия или события
изменяют лишь небольшую часть компонентов описания. Программа должна иметь
возможность выявить побочные эффекты и подразумеваемые изменения в описании мира.
Проблема описания побочных явлений действий называется проблемой границ. Например,
робот, складывающий тяжелые ящики на грузовик, должен учитывать понижение уровня
дна автомобиля с каждым новым ящиком. Если представление является полным, то
неопределенных побочных эффектов не будет, и проблема границ исчезает. Трудность
проблемы границ является следствием того, что для большинства областей невозможно
построить полную базу знаний. Язык представления должен помогать программисту в
решении вопросов, какие знания можно опустить без потери информации.
С проблемой полноты связан вопрос пластичности или модифицируемости
представления: при отсутствии полноты необходимо восполнить отсутствующие знания.
Поскольку большинство баз знаний являются неполными, желательно, чтобы процесс мо-
Глава 6. Представление знаний
267
дификации или адаптации был простым. Кроме синтаксической простоты процесса
восполнения знаний представление должно гарантировать непротиворечивость базы знаний
при добавлении и удалении информации. Наследование является примером того, как
схема представления может обеспечить непротиворечивость.
Несколько систем, включая Copycat [Mitchell, 1993], решали вопрос пластичности за
счет разработки сетевых структур, которые изменяются и развиваются, встречаясь с
ограничениями естественного мира. В этих системах представление является результатом
приобретения новых данных (построения снизу вверх) с учетом ожидаемого результата.
Примером систем этого типа является рассуждение по аналогии.
Другим полезным свойством представления, связанным с отображением мира в базу
знаний, является гомоморфизм. В данном случае гомоморфизм означает однозначное
соответствие между объектами и действиями мира и вычислительными объектами и
операциями языка. При гомоморфном отображении база знаний отражает воспринятую
структуру области и может быть организована более естественным образом.
Кроме естественности, однозначности и легкости использования схемы
представления могут быть оценены по их вычислительной эффективности. В [Levesque и
Brachman, 1985] обсуждается компромисс между выразительностью и эффективностью.
Когда в качестве схемы представления используется логика, система является высоко
выразительной вследствие полноты. Однако системы, основанные на неограниченной
логике, как правило, не очень эффективны (см. главу 12).
Большинство вопросов представления относятся к любой информации, накапливаемой и
используемой компьютером. Существует еще ряд вопросов, которые должны решаться
разработчиками распределенных и агентных систем. Многие из этих вопросов относятся к
принятию решений на основе частной (локальной) информации, распределенной относительно
выполняемых задач. Эти вопросы решаются с помощью агентных языков передачи
сообщений и разработки алгоритмов для кооперации и совместного использования информации
агентами. Большинство этих вопросов представлено в разделе 6.4. И, наконец, совершенно
новые языки и представления могут потребоваться при реализации философских аспектов
распределенного, основанного на окружении интеллекта, предложенных в [Clark, 1997],
[Haugeland, 1997] и [Dennett, 1991, 1995], где так называемые '"неплотные" системы
используют окружение и других агентов в качестве критической среды для запоминания и
использования знаний. Необходимы также средства представления и поддержки, которые в
соответствии с [Brooks, 1991a] "используют мир в качестве модели".
В заключение расширим ссылки на материалы, представленные в главе 6. Ассоцианист-
ские теории как модели компьютерной и человеческой памяти и рассуждений изучались в
[Selz, 1913,1922], [Anderson и Bower, 1973], [Sowa, 1984], [Collins и Quillian, 1069].
Важным результатом в области разработки языков структурированного
представления знаний являются языки представления KRL [Bobrow и Winograd, 1977] и KL-ONE
[Brachman, 1979], которые играют особую роль как семантические основы
структурированных представлений.
Наш обзор концептуальных графов в значительной степени основан на книге [Sowa, 1984].
Отсылаем читателя к этому изданию для более детального знакомства. Согласно этой работе
концептуальные графы сочетают выразительную силу исчисления предикатов, модальной
логики и логик более высоких порядков с богатством множества встроенных понятий и
отношений, полученных из эпистемологии, психологии и лингвистики.
Существует ряд других интересных подходов к представлению. Например, Брахман,
Файкс и Ливиски предложили представление, которое подчеркивает функциональную
268
Часть III. Представление и разум в ракурсе искусственного интеллекта
специфику, т.е. тип информации, запрашиваемой или хранимой в базе знаний [Brachman
и др., 1985], [Levesque, 1984].
В более детальном изучении этих вопросов может помочь ряд книг. Издание
[Brachman и Levesque, 1985] является компиляцией важных статей на эту тему. Многие
из статей, на которые ссылается данная глава, могут быть найдены там, хотя ссылки на
них даются как на первоисточники. Полезными могут стать [Bobrow и Collins, 1975],
[Devis, 1990], [Weld и deKleer, 1990] и труды любой из конференций по ИИ вообще, или
по представлению знаний в частности, например [Brachman и др., 1990].
В настоящее время существует значительное количество статей, развивающих
направления, предложенные Бруксом по категориальной архитектуре. Особое внимание
стоит уделить работам [Brooks, 1991a], [Brooks и Stein, 1994], [Maes, 1994], [Veloco и
др., 2000]. Дальнейшие исследования поддерживают философскую точку зрения о
распределенной и материализованной природе знаний и интеллекта. Особый интерес
представляет работа [Clark, 1997].
Агентно-ориентированные исследования являются достаточно популярными в
современном ИИ [Jennings и др., 1998]. На ежегодных конференциях по ИИ (IAAI, IJCAI)
агентным исследованиям посвящены целые секции. Для ознакомления с новейшими
достижениями в этой области мы бы порекомендовали изучить последние труды этих
конференций. Кроме того, следует ознакомиться с трудами конференции в области
распределенного искусственного интеллекта (РИИ). Обзор и ссылки на важные прикладные
области агентно-ориентированных исследований были представлены в разделе 6.4.
Вопросы представления знаний находятся на стыке искусственного интеллекта и ког-
нитологии [Luger, 1994] и [Clark, 1997]. Книга [Luger, 1995] объединяет классические
статьи, которые освещают разработку многих схем представления знаний.
6.6. Упражнения
1. В общесмысловых рассуждениях такие понятия, как причинность, аналогия,
эквивалентность используют не так, как в формальных языках. Например, если мы говорим
"Инфляция заставила Джейн просить о повышении", то предполагаем более сложные
причинные зависимости, чем в простых физических законах. Если мы говорим
"Используйте нож или стамеску для подрезки дерева", то предполагаем важное
понятие эквивалентности. Приведите примеры трансляции этих и других понятий в
формальный язык.
2. В подразделе 6.2.1 приведены некоторые аргументы против использования логики
для представления общесмысловых знаний. Приведите аргумент в пользу
использования логики для представления этих знаний.
3. Запишите каждое из этих выражений в терминах исчисления предикатов,
концептуальных зависимостей и концептуальных графов.
"Jane gave Tom an ice cream cone" ("Джейн дала Тому порцию мороженого").
"Basketball players are tall" ("Баскетболисты высокие").
"Paul cut down the tree with an axe" ("Пол срубил дерево топором").
"Place all the ingredients in a bowl and mix thoroughly" ("Поместите все ингредиенты в миску
и тщательно перемешайте").
Глава 6. Представление знаний
269
4. Прочитайте статью [Woods, 1985]. Раздел IV этой статьи содержит описание ряда
проблем в представлении знаний. Предложите решение каждой из этих проблем,
используя логику, концептуальные графы и понятие фреймов.
5. Опишите концептуальные графы (рис. 6.29) на естественном языке.
6. Операции join (объединить) и restrict (ограничить) определяют обобщенное
упорядочение на концептуальных графах. Покажите, что отношение обобщения
является транзитивным.
7. Специализация концептуальных графов, использующая операции объединения и
ограничения, является операцией, не сохраняющей истинность. Приведите пример,
который демонстрирует, что ограничение истинного графа не обязательно является
истинным. Однако обобщение истинного графа всегда является истинным. Докажите это.
8. Определите специализированный язык для описания деятельности общественной
библиотеки. Этот язык должен содержать множество понятий и отношений и
основываться на использовании концептуальных графов. Сделайте то же самое для
предприятия розничной торговли. Какие понятия и отношения могли бы быть общими в
этих двух языках? Какие из них могли бы существовать в обоих языках, но иметь
различный смысл?
9. Транслируйте концептуальные графы (рис. 6.29) в исчисление предикатов.
Рис. 6.29. Два концептуальных графа, которые необходимо описать на
естественном языке
10. Представьте базу знаний финансового советника (раздел 2.4) в виде
концептуального графа.
270 Часть III. Представление и разум в ракурсе искусственного интеллекта
11. Приведите пример из вашего опыта, который говорит об организации человеческой
памяти по типу сценариев или фреймов.
12. Используя концептуальные зависимости, определите сценарий для:
а) ресторана быстрого приготовления пищи;
б) общения с продавцом бывших в употреблении автомобилей;
в) похода в оперный театр.
13. Постройте иерархию подтипов для понятия транспортное средство-, например,
его подтипами могли бы быть наземное транспортное средство или морское
транспортное средство. Они, в свою очередь, могли бы иметь свои подтипы.
Сделайте то же самое для понятий перемещаться и сердитый.
14. Постройте иерархию типов, в которой некоторые типы не имеют общего супертипа.
Дополните множество типов таким образом, чтобы иерархия превратилась в
решетку. Может ли эта иерархия быть выражена с помощью дерева наследования? Какие
проблемы могут возникнуть при этом?
15. Каждая из следующих последовательностей символов генерируется в соответствии с
некоторым правилом. Опишите представление правил или отношений, необходимых
для продолжения каждой последовательности:
а) 2, 4, 6, 8,...
б) 1,2,4,8,16,...
в) 1,1,2,3,5,8,...
гI,а,2.с, 3,f,4, ...
д) о, t, t, f, f, s, s, ...
16. В разделе 6.3 было представлено два примера рассуждений по аналогии. Опишите
соответствующее представление и стратегию поиска, позволяющие сделать
оптимальный выбор. Приведите несколько примеров аналогий, которые можно
реализовать на основе предложенного вами представления.
а) hot (горячий) и cold (холодный); tall (высокий) и wall (стена), short (короткий),
wet (мокрый), hold (крепость)
б) bear (медведь) и pig (свинья); chair (стул) и foot (ножка), table (стол), coffee
(кофе), strawberry (земляника)
17. Опишите представление, которое могло бы использоваться в программе решения по
аналогии проблем, подобных показанным на рис. 6.30. Этот класс задач изучался в
работе [Evans, 1968]. Представление должно учитывать такие существенные
признаки, как размер, форма и относительное местоположение.
18. В статье [Brooks, 1991a] содержится обсуждение роли представления в
традиционном ИИ. Прочтите эту статью и прокомментируйте ограничения явной и
общецелевой схем представления.
19. В конце подраздела 6.3.1 содержится пять вопросов, которые должны быть решены для
успешного решения задач на основе категориальной архитектуры [Brooks, 199Id].
Прокомментируйте хотя бы один из этих вопросов.
20. Определите пять свойств, которые должен иметь язык для реализации агентно-
ориентированной службы Internet. Прокомментируйте роль языка Java как общеце-
Глава 6. Представление знаний
271
левого агентного языка для разработки служб Internet. Согласны ли вы, что
подобную роль выполняет и язык CLOS? Почему? Изобилие информации по этому
вопросу находится в самой Internet.
is to
Выберите один
А
и
Рис. 6.30. Пример задачи, решаемой по аналогии
21. Ряд важных вопросов, относящихся к агентно-ориентированному решению задач,
был представлен почти в самом конце раздела 6.4. Обсудите один из них.
22. Предположим, вы разработали агентную систему для представления командной игры
в американский футбол. Для взаимодействия агентов в защите или нападении они
должны иметь представление о планах других агентов и возможных ответах на
создавшуюся ситуацию. Как бы вы построили модель целей и планов других
взаимодействующих агентов?
23. Выберите одну из прикладных областей для агентных архитектур, описанных в
главе 6.4. Выберите статью исследовательского или прикладного характера из этой
области. Разработайте структуру агентов, которые могли бы решать задачу. Разбейте
проблему так, чтобы определить ответственность каждого агента. Составьте список
соответствующих процедур взаимодействия.
272
Часть III. Представление и разум в ракурсе искусственного интеллекта
Сильные методы
решения задач
Основным принципом инженерии знаний является то, что возможности решателя
задач интеллектуального агента в первую очередь определяются его информационной
базой и лишь во вторую — используемым методом вывода. Экспертные системы должны
быть сильны знаниями, даже если они слабы методами. Это важный вывод, который
лишь недавно по достоинству оценили исследователи ИИ Долгое время они занимались
почти исключительно разработкой различных методов вывода. Но можно использовать
почти любой метод. Сила заключается в знаниях.
— Эдвард Фейгенбаум (Edward Feigenbaum), Стэндфордский университет
Nam et ipsa scientia potestas est {Знание — сила).
— Фрэнсис Бэкон (Francis Bacon)
7.0. Введение
Продолжая изучать вопросы представления и интеллекта, рассмотрим важный
компонент ИИ — сильные методы решения задач, или методы, основанные на знаниях.
Человек-эксперт способен действовать на высоком уровне, так как много знает об
области своей деятельности. Это простое наблюдение является главным обоснованием для
разработки сильных методов, или решателей проблем, основанных на знаниях (см.
введение к части III). Экспертные системы используют знания специфичной предметной
области. Обычно разработчики экспертной системы приобретают эти знания с помощью
экспертов, методологию и деятельность которых затем эмулирует система. Так же, как опытные
люди, экспертные системы являются "специалистами" по узкому кругу проблем. Подобно
людям, они обладают как теоретическими, так и практическими знаниями: человек-
эксперт, обеспечивающий систему знаниями, обычно привносит собственное
теоретическое понимание предметной области, а также снабжает систему "хитростями",
кратчайшими путями решения и эвристиками, полученными из опыта решения проблем.
Экспертные системы обычно предоставляют следующие возможности.
1. Отслеживают свои процессы рассуждения, выводя промежуточные результаты и
отвечая на вопросы о процессе решения.
2. Позволяют несколько модифицировать базу знаний (добавлять и удалять информацию).
3. Рассуждают эвристически, используя для получения полезных решений во многом
несовершенные знания.
Процесс рассуждения экспертной системы должен быть открыт для проверки,
обеспечивая информацию о состоянии решения проблемы и объясняя выборы и решения,
которые делает программа. Объяснения важны для человека-эксперта, например врача или
инженера, если он должен принять рекомендацию компьютера. В самом деле, мало кто
из экспертов будет принимать советы других людей, не говоря уже о том, чтобы
следовать совету машины, не учитывая ее аргументацию. Как и любые программные средства,
экспертные системы должны обеспечивать простоту прототипирования, тестирования и
изменения. Для поддержки итеративной методологии разработки используются языки и
средства программирования задач ИИ. В чисто продукционной системе, например,
модификация одного правила не имеет глобальных синтаксических побочных эффектов.
Правила могут добавляться или удаляться без необходимости дальнейших изменений
всей программы. Разработчики экспертной системы часто объясняют, что легкость
модификации базы знаний является главным фактором производства успешных программ.
Следующей особенностью экспертных систем является использование эвристических
методов решения проблем. Разработчики экспертных систем установили, что
неформальные "трюки" и "интуитивные правила" являются существенным дополнением к
стандартной теории, предоставляемой учебниками и курсами. Иногда эти правила
усиливают теоретические знания с учетом здравого смысла, а зачастую они просто дают
кратчайший путь к решению.
Экспертные системы строятся для решения широкого круга проблем в таких
областях, как медицина, математика, машиностроение, химия, геология, вычислительная
техника, бизнес, законодательство, оборона и образование. Эти программы решают
разнообразные проблемы. Следующий список из работы [Waterman, 1986] является полезным
конспектом общих задач экспертных систем.
• Интерпретация — формирование высокоуровневых выводов из наборов строк
данных.
• Прогнозирование — проектирование возможных последствий данной ситуации.
• Диагностика — определение причин неисправностей в сложных ситуациях на
основе наблюдаемых симптомов.
• Проектирование— нахождение конфигурации компонентов системы, которая
удовлетворяет целевым условиям и множеству проектных ограничений.
• Планирование — разработка последовательности действий для достижения
множества целей при данных начальных условиях и временных ограничениях.
• Мониторинг — сравнение наблюдаемого поведения системы с ее ожидаемым
поведением.
• Инструктирование — помощь в образовательном процессе по изучению
технической области.
• Управление — управление поведением сложной среды.
В этой главе мы сначала рассмотрим технологию, которая дает возможность решать
проблемы на основе знаний. Успешная инженерия знаний должна обеспечивать решение
широкого круга проблем: от выбора соответствующей прикладной области до извлечения и
формализации знаний по решению задач. В разделе 7.2 будут рассмотрены системы, основанные
на правилах. При этом продукционная система будет представлена как программная
архитектура для реализации процессов решения и анализа. В разделе 7.3 рассматриваются приемы
274
Часть III. Представление и разум в ракурсе искусственного интеллекта
рассуждений на основе моделей и опыта. Раздел 7.4 посвящен планированию — процессу
организации частей знаний в непротиворечивую последовательность действий по достижению
цели. Приемы рассуждения в неопределенных ситуациях, описанные в главе 8, также важны
для разработки решателей задач на основе сильных методов.
7.1. Обзор технологии экспертных систем
7.1.1. Разработка экспертных систем, основанных на правилах
На рис. 7.1 показаны модули, которые составляют типичную экспертную систему.
Пользователь взаимодействует с системой через пользовательский интерфейс, который
скрывает многие сложности, в том числе внутреннюю структуру базы правил. При
разработке интерфейса экспертной системы используют разнообразие стилей, включая
"вопрос-ответ", меню управления или графический интерфейс. Тип интерфейса
определяется потребностями пользователя и требованиями базы знаний и системы вывода.
Ядром экспертной системы является база знаний, которая содержит знание из частной
прикладной области. В экспертной системе, основанной на правилах, это знание
представляется в форме правил если..., то..., как в примерах из раздела 7.2. База знаний
содержит как общие знания, так и информацию о частных случаях.
Механизм вывода применяет знания при решении реальных задач. По существу, он
является интерпретатором базы знаний. В продукционной системе механизм вывода
совершает цикл распознавание-действие. Процедуры, которые выполняют этот
управляющий цикл, отделены от самих продукционных правил. Такое разделение механизма
вывода и базы знаний важно поддерживать по нескольким причинам.
1. Оно дает возможность представить знания более естественным образом.
Например, правила если..., то... точнее описывают навыки человека по решению задач,
чем компьютерный код более низкого уровня.
2. В связи с тем, что база знаний отделяется от программных управляющих структур
более низкого уровня, разработчики экспертной системы могут сосредоточиться на
накоплении и организации знаний, а не на деталях их компьютерной реализации.
3. В идеале разделение знаний и управления позволяет вносить изменения в одну
часть базы знаний без создания побочных эффектов в других.
4. Разделение знаний и управляющих элементов программы позволяет использовать
в различных системах одни и те же модули управления и интерфейса пользователя.
Оболочка экспертной системы включает все компоненты, показанные на рис. 7.1,
а база знаний и данные о частных случаях могут пополняться для новых
приложений. Штриховые линии на рис. 7.1 ограничивают модули оболочки.
Экспертная система должна сохранять информацию о частных случаях, в том числе
факты и выводы. Сюда включаются данные, полученные в отдельном случае решения
задачи, частные заключения, степени доверия к заключениям и тупики в процессе
поиска. Эта информация отделяется от общей базы знаний.
Подсистема объяснений позволяет программе пояснить свое рассуждение
пользователю. Она обеспечивает обоснования заключений системы в ответ на вопросы "как?"
(раздел 7.2), объяснение необходимости конкретных данных, а также ответы на вопросы
"почему?" (раздел 7.2).
Глава 7. Сильные методы решения задач
275
Пользователь
i
В пользовательском
интерфейсе можно
использовать.
вопросы и ответы,
меню,
естественный
язык или
графические
обозначения
Редактор
базы знаний
Машина
вывода
Подсистема
объяснений
'
г
Общая
база знаний
Данные
частных случаев
,
i
Рис. 7.1. Архитектура типовой экспертной системы для конкретной
предметной области
Многие системы включают также редактор базы знаний. Редакторы баз знаний
помогают программистам локализовать и откорректировать сбои в действиях программы,
используя информацию, обеспечиваемую подсистемой объяснений. Кроме того, они
могут помочь в пополнении новых знаний, поддержке корректности синтаксиса правил и в
проверке на непротиворечивость при изменениях в базе знаний.
Важной причиной сокращения времени разработки и настройки современных
экспертных систем является наличие оболочек. В Internet можно найти оболочки CLIPS,
J ASS, а в части VI предлагаются оболочки для LISP и PROLOG. К сожалению,
программные оболочки не решают всех проблем, возникающих при разработке экспертных
систем. Хотя разделение знаний и уровня управления, модульность архитектуры
продукционной системы и использование соответствующего языка представления знаний
помогают при построении экспертной системы, извлечение и формализация знаний для
конкретной области остаются пока очень трудными задачами.
7.1.2. Выбор задачи и процесс инженерии знаний
Экспертные системы привлекают значительные денежные инвестиции и человеческие
усилия. Попытки решить слишком сложную, малопонятную или, другими словами, не
соответствующую имеющейся технологии проблему могут привести к дорогостоящим и
постыдным неудачам. Поэтому были выработаны критерии оправданности решения
данной задачи с помощью экспертной системы.
1. Необходимость решения оправдывает стоимость и усилия по разработке
экспертной системы. Многие экспертные системы были построены в таких областях,
как разведка минералов, бизнес, оборона и медицина, где существует большой
потенциал для экономии денег, времени и защиты человеческой жизни.
2. Отсутствие человеческого опыта в ситуациях, где он необходим. В геологии,
например, существует необходимость удаленной экспертизы минирования и
бурения. Геологи и инженеры часто сами проходят большие расстояния, что связано с
большими затратами и потерями времени. При использовании экспертной системы
многие проблемы удаленных районов могут быть решены без их посещения.
3. Проблема может быть решена с использованием символьных
рассуждений. Решение проблемы не требует физической ловкости или конкретных на-
276
Часть III. Представление и разум в ракурсе искусственного интеллекта
выков. Современным роботам и системам зрения не хватает ума и гибкости,
присущих человеку.
4. Проблемная область является хорошо структурированной и не требует
рассуждений на основе здравого смысла. Высокотехнологичные области очень
удобны для изучения и формализации: для них четко определена терминология и
построены ясные и конкретные концептуальные модели. Рассуждения на основе
здравого смысла трудно автоматизировать.
5. Проблема не может быть решена традиционными вычислительными
методами. Технология экспертных систем не должна использоваться там, где это не
является необходимостью. Если проблема может быть удовлетворительно решена
более традиционными методами, она не должна рассматриваться как кандидат для
решения экспертными системами.
6. Известны эксперты, способные взаимодействовать между собой и четко
выражать свои мысли. Знания, используемые экспертными системами,
формируются из опыта и суждений людей, работающих в данной области. Важно, чтобы эти
эксперты не только хотели, но и были способны поделиться знаниями.
7. Проблема имеет приемлемые размеры и границы. Например, программа,
пытающаяся воплотить весь опыт врача, нереальна. Программа, подсказывающая
медицинские решения по использованию конкретного медицинского оборудования
или конкретного множества диагнозов, более практична.
К разработке экспертной системы необходимо привлекать инженеров по знаниям,
экспертов в данной предметной области и конечных пользователей. Инженер по
знаниям является экспертом по языку ИИ и представлению. Его главная задача — выбрать
программный и аппаратный инструментарий для проекта, помочь эксперту в данной
области членораздельно сформулировать необходимую информацию, а также реализовать
ее в корректной и эффективной базе знаний. Часто инженер по знаниям изначально не
знаком с прикладной областью.
Знания о предметной области обеспечивает эксперт. Экспертом предметной
области обычно является тот человек, который работал в этой области и понимает
принципы решения ее задач, знает приемы решения, может обеспечить управление
неточными данными, оценку частичных решений и имеет другие навыки, делающие
его экспертом. Эксперт в предметной области отвечает за передачу этих навыков
инженеру по знаниям.
В большинстве приложений основные проектные ограничения определяет конечный
пользователь. Обычно разработка продолжается до тех пор, пока пользователь не будет
удовлетворен. Навыки и потребности пользователя учитываются в течение всего цикла
разработки. Постоянно отслеживаются следующие вопросы. Делает ли программа
работу пользователя более легкой, быстрой, удобной? Какой уровень объяснения необходим
пользователю? Может ли пользователь предоставить системе корректную информацию?
Является ли адекватным интерфейс? Соответствует ли рабочая среда пользователя
ограничениям на использование программ? Например, интерфейс, требующий ввода данных
с клавиатуры, не подходит для использования в кабине истребителя.
Так же, как и большинство разработок ИИ, экспертные системы требуют
нетрадиционного жизненного цикла разработки, основанного на раннем прототипировании и
постепенной модификации кода. Обычно работа с системой начинается с попытки
инженера по знаниям описать процессы, происходящие в данной предметной области. Этому
Глава 7. Сильные методы решения задач
277
помогает взаимодействие с экспертом в данной области. Адекватность описания
достигается с помощью предварительных интервью с экспертами и наблюдения за ними в
процессе работы. Далее инженер по знаниям и эксперт начинают процесс извлечения
знаний по решению проблем. Для этого эксперту задается ряд простых задач, которые он
пытается решить, объясняя используемые при этом приемы. Зачастую этот процесс
записывают на видео- и аудиокассеты.
Иногда полезно, чтобы инженер по знаниям был новичком в предметной области.
Общеизвестно, что человек-эксперт не всегда может точно объяснить ход решения
сложной проблемы. Часто он забывает упомянуть шаги, которые за годы работы в
этой области стали для него вполне очевидными или даже автоматическими. В силу
своего относительно слабого знакомства с предметной областью инженеры по знаниям
могут заметить эти концептуальные разрывы и попросить о помощи. Когда инженер
по знаниям получит общее представление о предметной области и проведет несколько
сеансов решения задач с экспертом, он сможет приступить к разработке системы:
выбрать способ представления знаний (например, правила или фреймы), определить
стратегию поиска (прямой, обратный, в глубину, в ширину и т.п.), разработать
пользовательский интерфейс. После выполнения этих обязательных этапов инженер по
знаниям строит прототип.
Этот прототип должен быть способен решить проблемы из данной предметной
области и обеспечить испытательный стенд для проверки предварительных проектных
решений. Когда прототип готов, инженер по знаниям и эксперт в предметной области
испытывают и уточняют знания путем решения конкретных задач и устранения дефектов.
Если предположения, сделанные при проектировании прототипа, оказываются
корректными, прототип можно поступательно расширять до тех пор, пока он не превратится в
окончательную систему.
Экспертные системы строятся методом последовательных приближений.
Выявляемые ошибки приводят к коррекции и наращиванию базы знаний. В этом смысле база
знаний скорее "растет", чем конструируется. На рис. 7.2 представлена блок-схема,
описывающая исследовательский цикл разработки программы. Этот подход к
программированию был изучен Сеймуром Папертом (Seymour Papert) с помощью его
языка LOGO [Papert, 1980], а также Аланом Кэем (Alan Key). Согласно философии LOGO
отслеживание откликов компьютера на некорректное представление идей в
программном коде приводит к коррекции кода (отладке) и преобразованию в более точный код.
Этот процесс проб и корректировки проектов-кандидатов является общепринятым в
разработке экспертных систем и кардинально отличается от таких проработанных
иерархических процессов, как проектирование сверху вниз.
Если прототип стал слишком громоздким, или проектировщики решили изменить
подход к проблеме, прототип можно просто выбросить. Прототип позволяет
разработчикам исследовать проблему и ее важные взаимосвязи посредством реального
конструирования программы для ее решения. После завершения постепенной
модификации зачастую создается более прозрачная версия, обычно с меньшим
количеством правил.
Другой важной особенностью экспертных систем является то, что программа никогда
не должна рассматриваться как законченная. Эвристическая база знаний всегда будет
иметь ограниченные возможности. Модульность модели продукционной системы
позволяет естественным образом добавить новые правила или в любое время
подкорректировать существующую базу правил.
278
Часть III. Представление и разум в ракурсе искусственного интеллекта
Определение
задач и целей
Разработка
и создание прототипа
Тестирование/использование
системы
Анализ и исправление
недостатков
Л\
неудачно
успешно
Рис. 7.2. Исследовательский цикл разработки
7.1.3. Концептуальные модели и их роль в приобретении знаний
На рис. 7.3 представлена упрощенная модель процесса извлечения знаний, которая
могла бы служить первой аппроксимацией для понимания задач приобретения и
формализации человеческого опыта. Человек-эксперт, работая в прикладной области,
оперирует знанием, мастерством и практическими навыками. Это знание часто является
неопределенным и неточным. Инженер по знаниям должен транслировать этот неформальный
опыт в формальный язык вычислительной системы. В процессе формализации
практической деятельности человека возникает ряд важных вопросов.
1. Человеческое мастерство часто недоступно для осознания разумом. Как отмечает
Аристотель в своей "Этике": "Все, чему мы должны научиться, мы изучаем на
собственном опыте". Навыки врача формируются за годы обучения в интернатуре и в
процессе работы с пациентами. После многолетней работы эти навыки становятся
интегрированными и существуют в основном на уровне подсознания. Эксперты
могут затрудняться точно описать то, что они делают при решении проблем.
Глава 7. Сильные методы решения задач
279
Извлечение знаний
if p(x) Л q(X,Y)
then r{Y)
ifu(X) л v(Y)
thens(X,V)
If r(VO as{X,Y)
thenf(X.y)
Опыт
Реализованная система
Рис. 7.3. Стандартный взгляд на построение экспертной системы
2. Человеческий опыт часто принимает форму знания о том, как справиться с
ситуацией, а не о том, каковы рациональные характеристики этой ситуации. Мы
вырабатываем сложные механизмы действия, а не формируем фундаментальное
понимание этих механизмов. Наглядным примером этого является уникальная
последовательность действий при верховой езде: опытный наездник для поддержания
равновесия не решает в реальном времени многочисленные системы
дифференциальных уравнений, а использует интуитивное ощущение гравитации, момента и
инерции для формирования адекватной управляющей процедуры.
3. Приобретение знаний часто рассматривается как получение фактических
знаний об объективной реальности так называемого "реального мира". Как
показано в теории и на практике, человеческий опыт представляет модели мира,
формируемые отдельным человеком или группой людей. Такие модели
создаются под воздействием социальных процессов, скрытых закономерностей и
эмпирических методологий.
4. Опыт накапливается. Люди не только получают новые знания, но и
перерабатывают существующие, что сопровождается продолжительными дебатами в науке.
Следовательно, инженерия знаний является сложной задачей, связанной с жизненным
циклом любой экспертной системы. Чтобы упростить эту задачу, полезно создать
концептуальную модель — прослойку между человеческим опытом и реализованной
программой (рис. 7.4). Под концептуальной моделью понимается концепция знаний о
данной области, построенная инженером по знаниям. Несомненно, отличаясь от модели
эксперта в данной области, концептуальная модель действительно определяет структуру
формальной базы знаний.
Из-за сложности большинства интересных областей этот промежуточный результат
нельзя рассматривать как окончательный. Инженеры по знаниям должны
задокументировать и передать свое представление о предметной области с помощью общих методов
проектирования программ. При разработке экспертной системы необходимо описать
требования к системе. Однако из-за специфики жизненного цикла разработки требования
к экспертной системе должны развиваться вместе с прототипом. Словари терминов,
графические представления пространства состояний и комментарии в коде сами являются
частью этой модели. Публикуя эти проектные решения, мы уменьшаем количество
ошибок как при реализации, так и при сопровождении программы.
280
Часть III. Представление и разум в ракурсе искусственного интеллекта
Концептуальная модель
Извлечение знаний
Программирование системы
ifp(x)AQ(X,rO
thenr(V)
if u(X) av{Y)
thens(X,V)
rtr(Y) л s(X,Y)
thenf(X,Vl
JL_
ffl
\
ACME
Машина вывода
т
т
Опыт Реализованная система
Рис 7 4 Роль ментальных или концептуальных моделей в решении проблем
Инженеры по знаниям должны сохранять записи своих интервью с экспертами по
предметной области. Часто по мере улучшения понимания проблемной области инженеры
по знаниям формируют новые интерпретации или открывают новую информацию. Записи
наряду с документированием данных и интерпретаций играют важную роль при
рассмотрении проектных решений и тестировании прототипов. Наконец, эта модель играет
промежуточную роль при формализации знаний. Выбор языка представления оказывает
значительное влияние на модель предметной области, создаваемую инженером по знаниям.
Концептуальная модель не является формальной или исполняемой на компьютере.
Это промежуточное проектное решение, шаблон для начала процесса кодирования
человеческого опыта. Если инженер по знаниям использует модель исчисления предикатов,
она может быть представлена в виде набора простых сетей, определяющих состояния
рассуждений посредством типичных способов решения проблем. Лишь после
дальнейших уточнений эта сеть превратится в набор правил "если..., то...".
При создании концептуальной модели рассматриваются следующие вопросы.
Является ли решение проблемы детерминированным или оно основано на поиске? Как
выполняется рассуждение: на основе данных (возможно, с генерацией и
тестированием) или на основе цели (с учетом некоторого множества вероятных гипотез)?
Существуют ли стадии рассуждения? Хорошо ли изучена область и может ли она
обеспечить глубокие прогнозирующие модели, или все знание существенно эвристично?
Можно ли для решения новых проблем использовать примеры прежних задач и их
решений, или сначала необходимо преобразовать эти примеры в общее правило?
Является ли знание точным, или оно "размытое" и приближенное, и для него
используются численные оценки определенности (глава 8)? Позволяют стратегии
рассуждений делать стабильные выводы или внутренняя неопределенность системы
требует немонотонного рассуждения, возможности формулировать утверждения,
которые впоследствии могут модифицироваться или отменяться (раздел 8.1)? И,
наконец, требует ли структура знаний о данной области отказаться от вывода на основе
Глава 7. Сильные методы решения задач
281
правил в пользу таких альтернативных схем, как нейронные сети или генетические
алгоритмы (часть IV)?
В контексте концептуальной модели должны также учитываться потребности
конечных пользователей. Чего они ожидают от конечной программы? Каков уровень их
опыта: новичок, средний пользователь или эксперт? Какие уровни объяснений им
требуются? Какой интерфейс наилучшим образом удовлетворяет их нужды?
Получив ответы на эти и другие вопросы, а также знания о предметной области,
можно приступать к разработке концептуальной модели, а затем и самой экспертной
системы. Поскольку продукционные системы, впервые представленные в главе 5,
предлагают собственные мощные средства для организации и применения знаний, они часто
используются в качестве платформы для представления знаний в экспертных системах.
7.2. Экспертные системы, основанные на правилах
В экспертных системах, основанных на правилах, знания о решении задач
представляют в виде правил "если..., то...". Этот подход, являясь одним из старейших методов
представления знаний о предметной области в экспертной системе, применяется в
системах, архитектура которых показана на рис. 7.1. Как один из наиболее естественных он
широко используется в коммерческих и экспериментальных экспертных системах.
7.2.1. Продукционная система и решение задач на основе цели
Архитектура экспертной системы, основанной на правилах, может быть рассмотрена в
терминах модели продукционной системы решения задач, представленной в части П. Между
ними есть большое сходство: продукционная система считается интеллектуальным
предшественником архитектуры современных экспертных систем, в которой продукционные правила
позволяют лучше понять конкретную ситуацию. Когда Ньюэлл и Саймон разрабатывали
продукционную систему, их целью было моделирование деятельности человека при решении
задач. Если экспертную систему на рис. 7.1 рассматривать как продукционную, то базу знаний о
предметной области можно считать набором продукционных правил. В системе, основанной
на правилах, пары "условие~Деиствие" представляются правилами "если..., то... ", в которых
посылка (часть если) соответствует условию, а заключение (часть то) — действию. Если
условие удовлетворяется, экспертная система осуществляет действие, означающее истинность
заключения. Данные частных случаев можно хранить в рабочей памяти. Механизм вывода
осуществляет цикл продукционной системы "распознавание-действие". При этом управление
может осуществляться либо на основе данных, либо на основе цели.
Многие предметные области больше соответствуют прямому поиску. Например, в
проблеме интерпретации большая часть информации представляет собой исходные
данные, при этом часто трудно сформулировать гипотезы или цель. Это приводит к прямому
процессу рассуждения, при котором факты помещаются в рабочую память, и система
ищет для них интерпретацию (см. раздел 3.2).
В экспертной системе на основе цели в рабочую память помещается целевое
выражение. Система сопоставляет заключения правил с целевым выражением и помещает
их предпосылки в рабочую память. Это соответствует декомпозиции проблемы на
более простые подцели. На следующей итерации работы продукционной системы
процесс продолжается, эти предпосылки становятся новыми подцелями, которые сопос-
282
Часть III. Представление и разум в ракурсе искусственного интеллекта
тавляются с заключениями правил. Система работает до тех пор, пока все подцели в
рабочей памяти не станут истинными, подтверждая гипотезу. Таким образом,
обратный поиск в экспертной системе приближенно соответствует процессу проверки
гипотез при решении проблем человеком.
В экспертной системе, чтобы достичь подцели, следует запросить информацию у
пользователя. В некоторых экспертных системах разработчики определяют, какие подцели
могут достигаться путем запроса к пользователю. Другие системы обращаются к
пользователю, если не могут вывести истинность подцели на основе правил из базы знаний.
В качестве примера решения задач на основе цели с запросами к пользователю
рассмотрим небольшую экспертную систему диагностики автомобиля. Это не полная
система диагностики, так как она содержит всего четыре очень простых правила. Она
приводится как пример, демонстрирующий образование цепочек правил, интеграцию новых
данных и использование возможностей объяснения.
Правило 1: если
топливо поступает в двигатель и
двигатель вращается,
то
проблема в свечах зажигания.
Правило 2: если
двигатель не вращается и
фары не горят,
то
проблема в аккумуляторе или проводке.
Правило 3: если
двигатель не вращается и
фары горят,
то
проблема в стартере.
Правило 4: если
в баке есть топливо и
топливо поступает в карбюратор,
то
топливо поступает в двигатель.
Для работы с этой базой знаний цель верхнего уровня проблема в X помещается в
рабочую память, как показано на рис. 7.5. Здесь X— переменная, которая может
сопоставляться с любой фразой, например, проблема в аккумуляторе или проводке.
В процессе решения задачи она будет связана с некоторым значением. С выражением в
рабочей памяти сопоставляются три правила: правило 1, правило 2 и правило 3. Если мы
разрешаем конфликты, предпочитая правила с наименьшим номером, будет
активизироваться правило 1. При этом X связывается со значением свечи зажигания, и
предпосылки правила 1 помещаются в рабочую память (рис. 7.6). Таким образом, система
выбирает для исследования гипотезу о неисправности свечей зажигания. Это можно
рассматривать как выбор системой ветви ИЛИ на графе И/ИЛИ (глава 3).
Отметим, что для истинности заключения правила 1 должны быть удовлетворены две
предпосылки. Они являются ветвями И графа поиска, представляющего декомпозицию
задачи (действительно ли проблема в свечах зажигания) на две подзадачи (топливо
поступает в двигатель и двигатель вращается). Затем можно активизировать
правило 4, заключение которого сопоставляется с целевым утверждением топливо
поступает в двигатель, и его предпосылки помещаются в рабочую память (рис. 7.7).
Глава 7. Сильные методы решения задач
283
Рабочая память
проблемах
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
Рис. 7.5. Начало работы продукционной
системы диагностики неисправностей
автомобиля
Рабочая память
топливо поступает
в двигатель
двигатель
вращается
проблема
в свечах зажигания
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
t_
Рис 7.6. Продукционная система после
активизации правила 1
Рабочая память
в баке есть топливо
топливо поступает
в карбюратор
топливо поступает
в двигатель
двигатель
вращается
проблема
в свечах зажигания
t_
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
Рис 7.7. Система после активизации правша 4.
Обратите внимание на использование стека в
процессе приведения цели
284
Часть III. Представление и разум в ракурсе искусственного интеллекта
топливо \
поступает )
в двигатель У
двигатель
вращается
/ двигатель Л ( А (двигатель V фа
\ не вращается /\ /\не вращается J \
Правило 4
топливо поступает
. в двигатель
в баке
есть топливо
/топливо
| ( поступает
\в карбюратор
Рис. 7.8. Граф И/ИЛИ при сравнении заключения правила 4 с первой предпосылкой правила 1 в
примере диагностики автомобиля
Теперь в рабочей памяти существуют три элемента, которые не соответствуют ни
одному из заключений в наборе правил. В подобной ситуации экспертная система будет
запрашивать пользователя. Если пользователь подтвердит истинность всех трех подцелей,
экспертная система успешно определит, что автомобиль не заводится из-за
неисправности свечей зажигания. При поиске этого решения система исследовала крайнюю слева
ветвь графа И/ИЛИ, показанного на рис. 7.8.
Конечно, это очень простой пример. И не только потому, что база знаний об
автомобиле ограничена, а также потому, что в этом примере не учитывается ряд важных
аспектов реализации. Правила описаны на русском, а не на формальном языке. При
обнаружении решения реальная экспертная система сообщит пользователю свой диагноз (наша
модель просто останавливается). Необходимо также поддерживать достаточно длинную
историю рассуждений, чтобы в случае необходимости возвратиться назад. Если вывод о
неисправности свечей зажигания окажется неудачным, нужно иметь возможность
возвратиться на второй уровень и проверить правило 2. Заметим, что информация по
упорядочению подцелей в рабочей памяти на рис. 7.7 и на графе, представленном на рис. 7.8,
явно не выражена. Однако, несмотря на простоту, этот пример подчеркивает важность
поиска на основе продукционной системы и его представления графом И/ИЛИ в
экспертных системах, основанных на правилах.
Ранее мы подчеркивали, что экспертная система должна быть открытой для
инспектирования, легко модифицируемой и эвристической по природе. Архитектура
продукционной системы является важным фактором для каждого из этих требований. Легкость
Глава 7. Сильные методы решения задач
285
модификации, например, определяется синтаксической независимостью продукционных
правил: каждое правило является "глыбой" знаний, которая может модифицироваться
независимо. Однако существуют семантические ограничения, поскольку
индивидуальные правила связаны по смыслу. Значит, они должны быть согласованы в любом
процессе редактирования или модификации. Ниже мы обсудим генерацию объяснений и
управление выводом.
7.2.2. Объяснения и прозрачность при рассуждениях на основе цели
Продукционная система осуществляет поиск на графе. Программы подсистемы
объяснений на рис. 7.1 отслеживают процесс поиска на графе и используют эту
информацию, чтобы отвечать на вопросы пользователя. С помощью продукционных правил
каждый шаг процесса рассуждений документируется автоматически.
Обычно экспертные системы, основанные на правилах, отвечают на два вопроса —
"почему?" и "как?". Вопрос "почему?" возникает, когда программа запрашивает
информацию у пользователя, и его ответ означает "почему вы запрашиваете эту
информацию?". Ответом является текущее правило, которое система пытается
активизировать. Ответом на вопрос "как вы получили этот результат?" является
последовательность правил, использованных для достижения цели.
Предположим, автомобильная экспертная система имеет средства объяснения, и
в процессе работы достигла стадии, представленной конфигурацией рабочей памяти
на рис. 7.7. Приведенный ниже диалог начинается с вопроса компьютера к
пользователю о целях, представленных в рабочей памяти. Ответы пользователя выделены
жирным шрифтом.
в баке есть топливо?
да
топливо поступает в карбюратор?
да
двигатель вращается?
почему
Здесь пользователь задает вопрос: "Почему вы хотите знать, вращается ли
двигатель?". Система отвечает с помощью символьного представления правила, к которому
относится вопрос.
Было установлено, что:
1. топливо поступает в двигатель,
поэтому если
2. двигатель вращается,
то проблема в свечах зажигания.
Поскольку пользователь на первые два вопроса ответил "да", это дало возможность
активизировать правило 1 и проверить его первую предпосылку. Отметим, что
объяснением поведения системы является только вывод правила, которое находится в
рассмотрении на данный момент. Однако это обеспечивает адекватное объяснение причин,
почему программа хочет знать, вращается ли двигатель. В ответ на вопрос "почему"
система отмечает, что, по ее данным, топливо поступает в двигатель. Предположим,
пользователь далее спрашивает:
как топливо поступает в двигатель?
286
Часть III. Представление и разум в ракурсе искусственного интеллекта
Ответом является последовательность рассуждений, приведшая к этому заключению.
Она восстанавливается обратным проходом от цели вдоль соответствующих правил до
информации, введенной пользователем.
Из правила 4 следует:
если
в баке есть топливо и
топливо поступает в карбюратор,
то
топливо поступает в двигатель.
в баке есть топливо — указано пользователем
топливо поступает в карбюратор — указано пользователем
Таким образом, архитектура продукционной системы обеспечивает основу для этих
объяснений. В каждом цикле управления выбирается и активизируется новое правило.
После каждого цикла программа может быть остановлена и проинспектирована.
Поскольку каждое правило представляет "глыбу" знаний по решению проблемы, текущее
правило обеспечивает контекст для объяснения. Этим продукционный подход
отличается от более традиционных архитектур: если программу на С или C++ остановить во
время исполнения, то вряд ли текущее выражение будет иметь много смысла.
Итак, система, основанная на знаниях, отвечает на вопросы "почему?", отображая
текущее правило, которое она пытается активизировать. В ответ на вопросы "как?" она
предоставляет последовательность рассуждений, которая привела к цели. Хотя эти
механизмы являются концептуально простыми, они обладают хорошими возможностями
объяснений, если база знаний организована логически грамотно. Главы по языкам LISP и
PROLOG в части IV демонстрируют использование стеков правил и деревьев
доказательств для объяснений. Если объяснения должны быть логичными, важно не только,
чтобы база знаний выдавала корректный ответ, но и чтобы каждое правило
соответствовало одному шагу процесса решения проблемы. Если в одном правиле базы знаний
заключено несколько шагов или правила сформулированы произвольным образом,
получить правильные ответы на вопросы "как?" и "почему?" будет сложнее. Это не только
подрывает доверие пользователя к системе, но и делает программу более трудной для
понимания и модификации разработчиками.
7.2.3. Использование продукционной системы для рассуждений
на основе данных
Пример диагностики автомобиля в подразделе 7.2.1 иллюстрирует использование
продукционной системы для реализации поиска на основе цели. В этом примере использовался
поиск в глубину, так как перед переходом к соседним целям для каждой обнаруженной в
базе правил подцели производился исчерпывающий поиск. Однако, как мы видели в
разделе 5.3, продукционная система является также идеальной архитектурой и для рассуждений
на основе данных. В примере 5.3.1 этот процесс был продемонстрирован для игры в
"пятнашки", а в примерах 5.3.2 и 5.3.3 — для задачи о ходе конем. В каждом из этих
примеров конфликт разрешался посредством извлечения и применения первого
обнаруженного в базе знаний правила. При этом выполнялся поиск в глубину, хотя в этих примерах не
было механизма возврата для выхода из "тупиковых состояний" в пространстве поиска.
В рассуждениях на основе данных чаще применяется поиск в ширину. Алгоритм
очень прост: содержимое рабочей памяти сравнивается с предпосылками каждого пра-
Глава 7. Сильные методы решения задач
287
вила в упорядоченной базе правил. Если данные в рабочей памяти приводят к
активизации правила, результат помещается в рабочую память, и управление передается
следующему правилу. После рассмотрения всех правил поиск повторяется сначала.
Рассмотрим, например, задачу автомобильной диагностики на основе правил из
подраздела 7.2.1. Если предпосылка правила не выводится из других правил, то
недостающая информация запрашивается при необходимости. Например, предпосылка правила 1
топливо поступает в двигатель не является запрашиваемой, так как этот факт
является заключением другого правила, а именно — правила 4.
Поиск в ширину на основе данных начинается из состояния, показанного на рис. 7.9.
Оно очень напоминает состояние, изображенное на рис. 7.5. Отличие состоит лишь в
отсутствии информации в рабочей памяти. Предпосылки четырех правил проверяются на
предмет "запрашиваемой" информации. Предпосылка топливо поступает в
двигатель не является запрашиваемой, поэтому правило 1 применить нельзя, и
управление переходит к правилу 2. Информация двигатель не вращается является
запрашиваемой. Предположим, ответом на этот вопрос будет ложь, тогда в рабочую
память заносится фраза двигатель вращается, как показано на рис. 7.10.
Рабочая память
Продукционные
правила
Рабочая память
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
Двигатель
вращается
Правило 1
> Правило 2
Правило 3
Правило 4
Рис. 7.9. Продукционная система в
начале процесса рассуждения на
основе данных
Рабочая память
Рис. 7.10. Продукционная система
после оценки первой предпосылки
правила 2, которая оказалась ложной
Продукционные
правила
Топливо поступает
в двигатель
Топливо поступает
в карбюратор
В баке есть топливо
Двигатель
вращается
• Правило 1
Правило 2
Правило 3
Правило 4
Рис. 7.11. Основанная на данных
продукционная система после рассмотрения правила
4 начинает второй проход по правилам
Но правило 2 применить нельзя, поскольку первая из двух конъюнктивных
предпосылок является ложной. Управление переходит к правилу 3, в котором первая посылка снова
принимает значение "ложь". В правиле 4 обе предпосылки являются запрашиваемыми.
Предположим, ответом на оба вопроса будет "истина", тогда предложения в баке есть
топливо и топливо поступает в карбюратор помещаются в рабочую память.
Туда же заносится и заключение правила — топливо поступает в двигатель.
288
Часть III. Представление и разум в ракурсе искусственного интеллекта
Итак, по первому разу все правила рассмотрены, и начинается повторное
рассмотрение правил с учетом нового содержания рабочей памяти. Как показано на рис. 7.11, при
сопоставлении правила 1 с данными в рабочей памяти его заключение — проблема в
свечах зажигания — помещается в рабочую память. Больше никаких правил
применить нельзя, и сеанс решения задачи завершается. На рис. 7.12 показан граф поиска, узлы
которого содержат информацию, находящуюся в рабочей памяти (РП).
Первый проход
по правилам
РП:
как на
рис 7.9
Правило 1
РП-
как на
рис. 7 9
Правило 4
Правило
неприменимо
РП'
как на
рис. 7.10
РП.
как на
рис. 7.10
Правило
неприменимо
Правило
неприменимо
РП-
как на
рис. 7.11
Правило
активизируется
Второй проход
по правилам
РП.
как на
рис. 7.11
Правило 1
РП.
как на
рис. 7.11, плюс
проблема в свечах
зажигания
Правило 4
Останов в связи с отсутствием
подходящих правил
Правило
активизируется
Рис. 7.12. Граф поиска в ширину на основе данных, узлами которого
является информация из рабочей памяти (РП)
Важной модификацией используемой в предыдущем примере стратегии поиска в
ширину является так называемый оппортунистический поиск. Это простая стратегия поиска:
всякий раз при активизации правила для вывода новой информации управление переходит
к правилу, содержащему эту новую информацию в качестве предпосылки. Следовательно,
любая вновь выведенная информация (состояние графа поиска в результате обработки
"запрашиваемых" предпосылок не изменяется) является движущей силой для определения
активизируемых в дальнейшем правил. Из-за случайного порядка следования правил
представленный пример, сам по себе очень простой, также оказался оппортунистическим.
В завершение раздела, посвященного рассуждениям на основе данных, затронем
вопросы объяснений и прозрачности в системах прямого поиска. Во-первых, по сравнению
Глава 7. Сильные методы решения задач
289
с системами, основанными на цели (подразделы 7.2.1, 7.2.2), рассуждения на основе
данных выполняются менее целенаправленно. Причина этого очевидна — в системе,
основанной на цели, рассуждение направлено на решение конкретной задачи, которая
разбивается на более мелкие, и эти подзадачи, в свою очередь, могут дробиться дальше. В
результате поиск всегда направлен по иерархии, ведущей от этой цели к ее составляющим.
В системах на основе данных ориентация на цель отсутствует. Поиск выполняется по
дереву, зависящему лишь от порядка следования правил и появления новой информации. В
итоге процесс поиска часто кажется "расплывчатым" и несфокусированным.
Во-вторых, и это является прямым результатом только что сказанного, пояснения,
выдаваемые пользователю в процессе поиска, весьма ограничены. В системах на основе
правил в ответ на вопрос "почему?" пользователю представляется рассматриваемое
правило (см. подраздел 7.2.2). Однако, если последовательность правил точно не
отслеживается (например, с помощью оппортунистического поиска), это объяснение нельзя
развить. "Расплывчатость" поиска на основе данных затрудняет подобные объяснения. И,
наконец, при достижении цели системе трудно дать исчерпывающее объяснение в ответ
на вопрос "как?". В качестве частичного или полного объяснения можно лишь
использовать содержимое рабочей памяти или список активизированных правил. Но опять-таки
эти пояснения не дают полного согласованного обоснования, которое мы наблюдали в
рассуждениях на основе цели.
7.2.4. Эвристики и управление в экспертных системах
Вследствие разделения базы знаний и механизма вывода, а также особенностей
работы механизма вывода важным методом программного управления поиском является
структурирование и упорядочение правил в базе знаний. Такое микроуправление на
множестве правил открывает новые возможности, особенно с учетом зависимости
стратегий управления от специфики предметной области и объема знаний. Хотя правило вида
if p, q, and r then s (если р, q и г, то s) напоминает логическое выражение, оно
может быть интерпретировано как последовательность процедур или шагов решения
задачи: "чтобы получить s, сначала нужно выполнить р, затем д, затем г". Важность
упорядочения правил и их предпосылок была неявно продемонстрирована в только что
рассмотренных примерах из раздела 7.2.
Этот процедурный метод интерпретации правил является существенным
компонентом практического использования знаний и часто отражает стратегию решения задачи
человеком-экспертом. Например, предпосылки правила можно упорядочить таким
образом, что наиболее вероятные отрицательные ответы или простые подтверждения истины
будут проверяться первыми. Это дает возможность отбросить правило (и, следовательно,
отсечь часть пространства поиска) как можно раньше. Правило 1 в примере с
автомобилем предполагает ответы на вопросы в такой последовательности: сначала требуется
определить, поступает ли топливо в двигатель, а затем — вращается ли двигатель. Это
неэффективно, так как при попытке выяснить, поступает ли топливо в двигатель,
вызывается другое правило, и, в конечном счете, пользователь должен ответить еще на два
вопроса. При изменении порядка предпосылок отрицательный ответ на вопрос
"вращается ли двигатель" исключает это правило из рассмотрения до проверки более
конкретного условия. Тем самым эффективность системы повышается.
Есть еще одна причина для такого упорядочения. Если двигатель не вращается, то не
имеет значения, поступает ли в него топливо. В правиле 4 пользователя сначала просят
290
Часть III. Представление и разум в ракурсе искусственного интеллекта
проверить наличие топлива в баке, а затем его поступление в карбюратор. В этой
ситуации первая проверка легче второй. Таким образом, для повышения общей
эффективности системы должны быть рассмотрены все аспекты: порядок следования правил и
предпосылок, стоимость каждой проверки, размер отсекаемого пространства поиска,
наиболее типичные случаи и т.д.
Планирование порядка правил, организация предпосылок в правилах и определение
стоимости различных проверок — действия, эвристичные по своей природе. В
большинстве экспертных систем, основанных на правилах, эти эвристики отражают подходы
человека-эксперта и, несомненно, могут давать ошибочные результаты. В нашем примере,
если топливо поступает в двигатель и двигатель вращается, проблема может заключаться
в распределителе, а не свечах зажигания.
Рассуждения на основе данных создают дополнительные проблемы и обеспечивают
новые возможности управления. К ним относятся эвристики высокого уровня, такие как
рефракция, оппортунистический поиск и учет особенностей предметной области,
представленные в подразделе 5.3.3. При более специфичном подходе множества правил
группируются в соответствии со стадиями процесса решения. Например, в задаче
диагностики автомобиля можно выделить четыре различные стадии: формирование
ситуации, сбор данных, анализ (возможность возникновения нескольких проблем
одновременно), заключение и рекомендации по ремонту.
Для такого поэтапного решения задачи следует создать описание для каждой стадии
решения и использовать их в качестве первой предпосылки всех правил, относящихся к
этой стадии. Например, сначала в рабочую память можно поместить утверждение
стадия — формирование ситуации. Если в рабочей памяти нет описания других
стадий, то будут активизироваться лишь правила, содержащие в качестве предпосылки
факт стадия — формирование ситуации. Разумеется, в каждом правиле эта
предпосылка должна располагаться первой. Для перехода к следующей стадии при
активизации последнего правила факт стадия — формирование ситуации нужно
вычеркнуть и заменить его фактом, определяющим стадию сбора данных. Первой
предпосылкой всех правил, относящихся к стадии сбора информации, должна быть следующая:
если стадия — сбор данных и .... По окончании стадии сбора данных
последнее правило должно вычеркивать этот факт и дописывать в рабочую память факт
перехода к стадии анализа данных. На этой стадии будут обрабатываться лишь те правила,
первой предпосылкой которых является факт если стадия — анализ данных....
До сих пор в своем обсуждении мы описывали поведение продукционной системы в
терминах исчерпывающего рассмотрения базы правил. Хотя такое поведение является
достаточно дорогостоящим, оно включает внутреннюю семантику продукционной
системы. Однако существует ряд алгоритмов, таких как RETE [Forgy, 1982], которые могут
быть использованы для оптимизации поиска потенциально полезных правил. По
существу, алгоритм RETE интегрирует правила в сетевую структуру, позволяющую системе
сопоставлять правила с данными, прямо указывающими на правило. Этот алгоритм
значительно ускоряет выполнение, особенно для больших множеств правил, в то же время
сохраняя семантику поведения, описанную в данном разделе.
И в заключение, правила были и остаются важным средством построения решателей
задач, основанных на знаниях. Правила экспертной системы содержат знания людей-
экспертов в том виде, в котором они используются на практике. Поэтому они часто
являются смесью теоретических знаний, полученных из опыта эвристик и специальных
правил управления нерегулярными случаями и другими исключениями. Во многих си-
Глава 7. Сильные методы решения задач
291
туациях этот подход доказал свою эффективность. Тем не менее эвристические системы
могут давать сбои в том случае, если задача не соответствует ни одному из имеющихся
правил, или эвристическое правило ошибочно применяется к неподходящей ситуации.
Человек-эксперт не испытывает подобных проблем, потому что обладает более глубоким
теоретическим пониманием предметной области, позволяющим осмысленно применять
эвристические правила или прибегать в новых ситуациях к рассуждениям на основе
базовых принципов. Описываемые далее в подразделе 7.3.1 подходы, основанные на
моделях, обеспечивают подобные возможности для экспертных систем.
Возможность обучаться на примерах является другой человеческой способностью,
которую эмулируют системы решения задач, основанные на знаниях. Рассуждения на
основе опыта (подраздел 7.3.3) поддерживают базу знаний примеров решения задач.
При столкновении с новой проблемой механизм рассуждений выбирает из сохраненного
множества случай, напоминающий решаемую задачу, и затем пытается применить его
стратегию решения к новой проблеме. В юриспруденции примером рассуждений на
основе опыта является доказательство по прецеденту.
7.3. Рассуждения на основе моделей, на базе опыта
и гибридные системы
7.3.1. Введение в рассуждения на основе модели
Человеческий опыт — это чрезвычайно сложная смесь теоретических знаний,
эвристик решения задач, примеров прошлых проблем и их решений, навыков восприятия и
интерпретации, а также других аспектов, которые можно описать лишь как интуитивные.
С годами человек-эксперт вырабатывает очень точные правила поведения в обычных
ситуациях. Часто эти правила принимают форму прямых ассоциаций между
наблюдаемыми симптомами и окончательными диагнозами, скрывая их более глубокие причинно-
следственные связи.
Например, экспертная система MYCIN может предложить диагноз, исходя из таких
симптомов, как "головная боль", "тошнота" или "жар". Хотя эти параметры могут быть
индикаторами болезни, правила, напрямую связывающие их с диагнозами, не отражают
более глубокого причинного понимания человеческой физиологии. Правила системы
MYCIN позволяют определить название болезни, но не объясняют ее причины. Подход,
основанный на более глубоких объяснениях, должен учитывать присутствие
инфекционных агентов, результирующее воспаление содержимого клетки, наличие
внутричерепного давления и причинную связь с наблюдаемыми симптомами головной боли,
повышенной температуры и тошноты.
Например, в экспертной системе, предназначенной для анализа причин
неисправности полупроводника на основе правил, описательный подход позволит строить
диагностику неисправности цепи на таких симптомах, как обесцвечивание компонентов
(возможно, указывающее на брак), история неисправностей в подобных приборах или
внутренние наблюдения компонента с помощью электронного микроскопа. Однако
подходы, которые используют правила для связи наблюдений с диагнозами, являются
бесполезными для более глубокого анализа структуры и функций прибора. Более точное
объяснение могло бы начинаться с построения детализированной модели физической
структуры цепи и уравнений, описывающих ожидаемое поведение каждого компонента
292
Часть III. Представление и разум в ракурсе искусственного интеллекта
цепи и их взаимодействия. Диагнозы могли бы основываться на сигналах, полученных из
различных точек, и модели цепи для определения точных мест неисправности.
Поскольку экспертные системы первого поколения основывались на эвристических
правилах, полученных из описаний методов решения задач человеком-экспертом, они
обладали рядом ограничений [Clancy, 1985]. Если ситуация не соответствовала
заложенным в систему эвристикам, она просто терпела неудачу, хотя более строгий
теоретический анализ мог бы привести к успешному решению. Часто экспертные системы
применяли эвристики в несоответствующих ситуациях, в которых более глубокое понимание
проблемы могло бы указать другой курс. Эти ограничения позволяют преодолеть
подходы, основанные на моделях. Механизм рассуждения, который базируется на
спецификации и функциональности физической системы, называется системой на основе модели.
Система рассуждений на основе модели осуществляет программное моделирование тех
функций, которые необходимо понять или зафиксировать. (Существуют, конечно, и
другие типы систем, основанных на моделях, в частности, логические и стохастические. Они
будут рассмотрены в главе 8.)
Первые системы рассуждений на основе моделей появились в середине 1970-х и
продолжали развиваться в 1980-х годах [Davis и Hamscher, 1992]. Интересно отметить, что
некоторые из наиболее ранних работ были направлены на создание программных
моделей различных физических приборов, таких как электронные цепи, с целью их изучения
[deKleer, 1976], [Brown и др., 1982]. В этих работах прибор или цепи описывались в виде
набора правил, например, законов Кирхгофа и Ома. Обучающая система могла
проверить знания студента в данной области, а также передать ему недостающие данные.
Правила, с одной стороны, обеспечивали представление функциональности, а с другой —
представляли собой среду для передачи знания студенту. Развитием этих ранних
обучающих систем, задача которых сводилась к моделированию и обучению
функциональности системы, стали системы рассуждения на основе моделей, предназначенные для
устранения неисправностей. При выявлении неисправности в физической системе
модель предлагает множество прогнозируемых вариантов поведения. Неисправность
отражается в различии между ожидаемым и наблюдаемым поведением. Система, основанная
на модели, сообщает пользователю, чего ожидать, а различия между наблюдаемым и
ожидаемым поведением приводят к идентификации неисправностей.
Качественные рассуждения на основе моделей включают следующие аспекты.
1. Описание каждого компонента прибора, позволяющее моделировать их поведение.
2. Описание внутренней структуры прибора. Оно обычно содержит представление
компонентов и их взаимосвязей наряду с возможностью моделировать их
взаимодействие. Требуемая степень знаний внутренней структуры зависит от
применяемого уровня абстракции и ожидаемого диагноза.
3. Диагностика частной проблемы. Это требует наблюдений реального поведения
прибора, обычно — измерения его входов и выходов. Входные и выходные
измерения получить легче всего.
Задача заключается в определении неисправных компонентов с учетом наблюдаемого
поведения. Это требует дополнительных правил, описывающих известные формы
неисправностей для различных компонентов и их комбинаций. Система рассуждений должна обнаружить
наиболее вероятные неисправности, объясняющие наблюдаемое поведение системы.
Для представления причинно-следственной и структурной информации в моделях
можно использовать различные структуры данных. Для отражения причинности и функ-
Глава 7. Сильные методы решения задач
293
циональности прибора в программе рассуждений на основе моделей зачастую
используют правила. Правила могут также использоваться для фиксации отношений между
компонентами. Объектно-ориентированные системы (см. раздел 15.12) также являются
прекрасным средством описания устройства и внутренней структуры компонентов модели.
При этом переменные — члены объекта представляют устройство или состояние
компонентов, а методы определяют функциональность устройства.
Чтобы конкретизировать процесс разработки и описания модели, рассмотрим
несколько примеров анализа устройств и цепей, взятых из работы [Davis и Hamscher, 1992].
Поведение устройства описывается множеством выражений, определяющих отношения
между значениями на клеммах прибора. Для сумматора, показанного на рис. 7.13, эти
выражения имеют такой вид.
Если известны значения в точках А и В, то значение в точке С
вычисляется как А+В (сплошная линия).
Если известны С и А, значение в точке В вычисляется как С-А
(крупный пунктир).
Если известны значения С и В, значение в точке А вычисляется
как С-В (пунктир).
С-В;'
• /
V
С-А\
Рис. 7 13 Описание поведения сумматора из [Shrobe (ред ), 1988]
Для представления этих отношений нет необходимости использовать алгебраическую
форму записи. С таким же успехом могут быть использованы кортежи отношений, а
ограничения могут быть представлены с помощью функций LISP. Целью рассуждений на
основе модели является представление знаний, определяющих функциональность сумматора.
В качестве второго примера рассмотрим схему из трех мультиплексоров и двух
сумматоров (рис. 7.14). В этом примере входные значения задаются в точках А-Е, а
выходные вычисляются в точках F и G. Ожидаемые выходные значения задаются в круглых
скобках, а действительные выходы — в квадратных. Задача заключается в определении
неисправности, объясняющей различие между этими значениями. В точке F наблюдается
конфликт: ожидаемым выходным значением является 12, а реально полученным— 10.
Проверяя зависимости в этой точке, определяем, что значение в точке F вычисляется как
функция от ADD-1. Это значение, в свою очередь, зависит от выходов MULT-1 и MULT-
2. Одно из этих устройств содержит неисправность, следовательно, необходимо
рассмотреть три гипотезы: либо поведение сумматора неадекватно, либо некорректным
является один из двух его входов. Тогда проблему надо искать дальше в цепи.
Если исходя из результата F (значения 10) предположить, что поведение ADD-1 и
значение 6 его первого входа X корректны, то значение на втором входе ADD-1
(обозначим его Y) должно быть равно 4. Но это противоречит ожидаемому значению 6,
являющемуся результатом правильного поведения MULT-2 и входов В и D. Мы
наблюдали за этими входами и знаем, что на них поступали правильные значения. Следова-
294 Часть III Представление и разум в ракурсе искусственного интеллекта
тельно, неисправен модуль MULT-2. Вариантом второй гипотезы может быть
предположение, что модуль ADD-1 исправен, а неисправен компонент MULT-1.
Продолжая рассуждения, приходим к выводу, что если на первый вход X модуля
ADD-1 поступает корректное значение и сам ADD-1 работает корректно, то значение
второго входа Y должно быть равно 4. Если это так, то G должно принимать значение
10, а не 12, так что выход MULT-2 должен равняться 6 и быть корректным. Здесь мы
отбрасываем гипотезу, что неисправность содержится в MULT-1 или в ADD-1. Эти
модули можно рассмотреть при дальнейшем тестировании.
В рассуждениях о ситуации, показанной на рис. 7.14, рассматривались три задачи.
1. Создание гипотезы о том, какие компоненты устройства могли вызвать
расхождение ожидаемого и реального значений.
2. Проверка гипотезы, в процессе которой при заданной совокупности потенциально
неисправных компонентов определяется, какой из них может объяснить
наблюдаемое поведение.
3. Выделение гипотез, когда в результате тестирования остается несколько версий
(как на рис. 7.14) и необходимо определить, какая дополнительная информация
может помочь выявить неисправность.
(F=12)
[F=10]
В-3
С=2
П-п
Ь-о
*
MULT-1
—►■
—►
MULT-2
MULT-3
*"
*
ADD-1
ADD-2
(G=12)
[G=12]
Рис 7.14 Направленные информационные потоки,
из работы [Shrobc (ред ), 1988]
И, наконец, мы должны отметить, что в примере на рис. 7.14 предполагается, что
неисправен единственный модуль. Мир не всегда так прост, хотя предположение о
единственной неисправности является полезной и часто корректной эвристикой.
Поскольку методы, основанные на качественных моделях, требуют понимания
принципов функционирования рассматриваемых устройств, они устраняют многие из
ограничений эвристических подходов. Подходы, основанные на моделях, позволяют
представить устройства и схемы на причинном и функциональном уровне, а не рассуждать о
причинах неисправностей на основе наблюдаемых явлений. Программный код отражает
как функции модулей, так и внутренние зависимости системы. Такие модели часто более
надежны, чем эвристические подходы. Однако обратной стороной такого точного
моделирования является то, что стадия извлечения знаний требует большой скрупулезности, а
Глава 7. Сильные методы решения задач
295
результирующая программа может оказаться громоздкой и медлительной. Поскольку
эвристические подходы "компилируют" распространенные случаи в общее правило, они
зачастую более эффективны.
Однако с подходом на основе модели связаны более глубокие проблемы. Как и
рассуждения на основе правил, модель системы — это всего лишь модель. Она является
необходимой абстракцией системы и на некотором уровне детализации становится
некорректной. Например, рассмотрим входные клеммы на рис. 7.14. Мы считали эти значения
заданными и корректными, не проверяя состояние самих шин и контактов с
мультиплексорами. А если повреждены провода или неисправны контакты? Если пользователь не
учел эту информацию, модель не будет соответствовать действительному устройству.
Любая модель описывает идеальную ситуацию, т.е. предполагаемые действия
системы, а не реальные. Неисправным соединением считается контактная точка в системе, в
которой небрежно соединены два провода или устройства (например, когда два провода
соединены плохим припоем). Большинство рассуждений, основанных на моделях, не
обеспечивают диагностику неисправности соединения из-за априорных предположений
базовой модели и заложенных в них методов поиска для определения аномалий.
Дефекты соединений можно просто считать новыми проводами, которые не являются частью
первоначального проекта. В этом состоит неявное "предположение о замкнутости мира"
(раздел 8.1), согласно которому структура описания модели предполагается полной, и
все, что не описано в модели, просто не существует.
Но, несмотря на эти недостатки, рассуждения на основе моделей являются важным
дополнением к инструментальным средствам инженера по знаниям. Исследователи
продолжают углублять наше понимание диагностики за счет исследования принципов
эффективного решения этой задачи человеком-экспертом, а также улучшения машинной
реализации алгоритмов [Stern и Luger, 1997].
7.3.2. Рассуждения на основе моделей: пример NASA
В настоящее время NASA разрабатывает флотилию интеллектуальных космических
зондов, предназначенных для автономного исследования солнечной системы [Williams и
Nayak, 1996], [Bernard и др., 1998]. Этот проект начался с разработки программного
обеспечения для первого зонда в 1997 и запуска аппарата Deep Space 1 в 1998 году. Для
успешной работы в суровых условиях космического путешествия космический корабль в ответ на
неудачи должен уметь радикально перестраивать свой режим управления и учитывать эти
неудачи при планировании оставшейся части полета. Для обеспечения приемлемой
стоимости и скорости реконфигурации необходимо быстро подключать стандартные модули,
которые составляют программное обеспечение полета. Кроме того, NASA считает, что
множество неудачных сценариев и возможных ответов будет слишком большим, чтобы
использовать простой перечень всех возможных случаев. Космический корабль должен
реактивно размышлять при реконфигурации своей системы управления.
В системе Livingstone [Williams и Nayak, 1996] реализованы ключевые функции
реактивных самоорганизующихся автономных систем, основанных на моделях. Языком
представления рассуждений на основе моделей в Livingstone является пропозициональное
исчисление. Обратите внимание на отход от исчисления предикатов первого порядка
(глава 2) — традиционного языка представления в задачах диагностики на основе моделей.
Основываясь на своих предыдущих исследованиях по разработке быстрой
пропозициональной логики для конфликтных алгоритмов диагностики, Вильяме (Williams) и Наяк
296
Часть III. Представление и разум в ракурсе искусственного интеллекта
(Nayak) решили, что пришло время для построения быстрой реактивной системы,
реализующей дедукцию в цикле восприятие-реакция. Дальновидные рассуждения модели
должны поддерживать единую централизованную модель для решения различных инженерных
задач. В автономных системах это означает использование единой модели для поддержки
выполнения различных задач. Такие задачи включают поддержку истории
разрабатываемых планов (раздел 7.4), поддержку аппаратных режимов, аппаратуру для реконфигурации,
определение аномалий, диагностику, устранение неисправностей. В системе Livingstone все
эти задачи автоматизированы с помощью единой модели и общего корневого алгоритма.
Это значительно расширяет возможности решателей задач, основанных на моделях.
На рис. 7.15 показана упрощенная схема подсистемы главного двигателя космического
корабля Cassini — наиболее сложного из построенных к настоящему времени. Он состоит
из гелиевого, топливного, кислородного баков, пары главных двигателей, регуляторов,
клапанов, пироклапанов и трубопроводов. Гелиевый бак поддерживает давление в двух
топливных баках с помощью регуляторов, понижающих высокое давление гелия до рабочего
уровня. Когда топливные пути к главному двигателю открываются (изображение клапана
не заштриховано), в главный двигатель подаются топливо и кислород. Там они
смешиваются, смесь воспламеняется, и этот процесс сопровождается толчком. Пироклапаны могут
активизироваться (т.е. изменить состояние) только один раз, переходя из открытого к
закрытому состоянию или наоборот. Их функцией является временная изоляция частей
подсистемы главного двигателя или постоянная изоляция отказавших компонентов. Клапанами
управляют специальные драйверы (на рис. 7.15 не показаны) и акселерометр, который
измеряет ускорение, сгенерированное двигателями.
Асе
I—J Регуляторы
—гЗ^-1
н< м
Гелиевый
бак
Условные обозначения
X Клапан (закрыт)
J Пироклапан (закрыт)
Рис. 7.15. Упрощенная схема системы двигателей Livingstone
из работы [Williams и Nayak, 1996]
Высокоуровневой целью системы является выполнение толчка из начального
положения, показанного на рис. 7.15. Эта цель может быть достигнута различными
способами: толчок обеспечивается или главными двигателями, или открытием топливных путей
к главному двигателю. Например, для толчка можно открыть клапаны, ведущие к левому
двигателю, или активизировать пару пироклапанов и открыть клапаны, ведущие к
правому двигателю. Другие конфигурации соответствуют различным комбинациям
активизации пироклапанов. Эти конфигурации имеют различные характеристики, поскольку
активизация пироклапанов является необратимым действием и требует значительно
больше энергии, чем открытие или закрытие клапанов.
Глава 7. Сильные методы решения задач
297
Предположим, подсистема главного двигателя была сконфигурирована так, чтобы
обеспечить толчок от левого главного двигателя путем открытия ведущих к нему
клапанов. Допустим, что этот двигатель неисправен, например перегрет, и не может
обеспечить требуемый толчок. Для того чтобы обеспечить необходимый толчок даже в этой
ситуации, космический корабль следует перевести в новое состояние, в котором толчок
делается главным двигателем, расположенным с правой стороны. В идеале это достигается
активизацией двух пироклапанов, ведущих к правой части системы, и открытием
оставшихся клапанов без активизации дополнительных пироклапанов.
Диспетчер конфигурации постоянно пытается перевести космический корабль в
состояние наименьшей стоимости, при котором достигается множество динамически
изменяющихся целей высокого уровня. Когда корабль отклоняется от выбранного пути из-за
повреждений, диспетчер анализирует сенсорные данные, чтобы определить текущую
конфигурацию корабля, а затем переводит его в новое состояние, чтобы достичь цели.
Диспетчер конфигурации является дискретной системой управления, которая обеспечивает
конфигурацию, необходимую для достижения множества целей. Алгоритм планирования,
поддерживающий работу диспетчера конфигурации, представлен в подразделе 7.4.4.
Рассуждения о конфигурациях и автономных реконфигурациях в системе требуют
использования понятий рабочего и аварийного режимов, устранения неисправностей и
изменения конфигурации. В системе NASA эти понятия описываются с помощью
диаграммы состояний: устраняемые неисправности — это переходы от неисправного
состояния к рабочему. К рабочему состоянию применимы изменения конфигурации.
Неисправности — это переходы от нормального к аварийному состоянию.
В работе [Williams и Nayak, 1996] управление автономной системой осуществляется с
помощью реактивного диспетчера конфигурации и планировщика высокого уровня.
Планировщик (раздел 7.4) генерирует последовательность целей по реконфигурации
системы. Диспетчер конфигурации отслеживает переходы системы (в нашем случае —
системы двигателей космического корабля) вдоль желаемой траектории. Таким образом,
управление конфигурацией осуществляется посредством наблюдения и управления
переходами между состояниями системы.
Чтобы определить необходимую последовательность управляющих воздействий,
диспетчер конфигурации на основе моделей использует спецификацию переходов
системы. В примере на рис. 7.15 каждый элемент схемы моделируется системой переходов.
Взаимодействие компонентов, показанное на рисунке помощью связей, моделируется с
помощью переменных, используемых в соответствующих компонентах системы.
Диспетчер конфигурации интенсивно использует модель для определения текущего
состояния системы и выбора оптимальных управляющих воздействий для достижения
своих целей. Это существенно в ситуациях, в которых при использовании простых
методов проб и ошибок каждая неточность может привести к катастрофе. Диспетчер
конфигурации использует модель для построения желаемой последовательности управлений с
помощью двух модулей: оценки и реконфигурации (РО и РР на рис. 7.16). Модуль РО
поэтапно генерирует множество всех системных траекторий, совместимых с моделью
переходов, последовательностью управлений и измеренных значений. Модуль РР
использует модель переходов объекта управления и фрагменты траекторий,
сгенерированные РО в текущем состоянии, для определения множества таких управляющих значений,
при которых конфигурационная цель достигается в следующем состоянии. Модули РО и
РР являются реактивными. Подсистема РО определяет текущее состояние на основе
предыдущего и текущих наблюдений. Модуль РР рассматривает лишь действия, которые
достигают конфигурационной цели в следующем состоянии.
298
Часть III. Представление и разум в ракурсе искусственного интеллекта
Цели высокого .
уровня
Планировщик
Подтверждение
Диспетчер
конфигурации
Наблюдаемые
значения
РО
Цели
конфигурации
РР
Система
Управляющие
воздействия
Рис. 7.16. Конфигурационная система управления на
основе модели [Williams и Nayak, 1996]
В следующем разделе будут рассмотрены рассуждения на основе опыта — прием,
позволяющий использовать прошлый опыт работы в данной предметной области в новых
ситуациях. В разделе 7.4 представлены вопросы планирования и снова рассмотрен
пример системы, разработанной NASA.
7.3.3. Введение в рассуждения на основе опыта
Эвристические правила и теоретические модели — вот два типа информации,
которые человек-эксперт использует для решения проблем. Еще одной мощной стратегией,
используемой экспертами, является рассуждение на основе опыта решения задач. В
рассуждениях на основе опыта для решения новых проблем используется детальная база
данных, содержащая известные решения задач. Эти решения могут быть собраны
экспертами в области знаний или могут отображать результаты предыдущих успешных и
неудачных попыток поиска решения. Например, медицинская диагностика основывается
не только на теоретических моделях болезней, анатомии и физиологии, но и на изучении
истории болезни и врачебного опыта, приобретенного при лечении других пациентов.
Системы CASEY [Koton, 1988a, 19886] и PROTOS [Bareiss и др., 1988] являются
примерами рассуждений на основе опыта в медицине.
Юристы тоже подыскивают прецеденты и пытаются убедить суд, что нужно
действовать по аналогии с известной ситуацией. Хотя общие законы вырабатываются в
рамках демократических процессов, их интерпретация обычно основана на
прецедентах. Интерпретация закона в некоторой предыдущей ситуации определяет его текущую
интерпретацию. Таким образом, важным компонентом правовых рассуждений
является идентификация прецедента для принятия решения в конкретном случае. В работах
[Rissland, 1983] и [Rissland и Ashly, 1987] предложены механизмы рассуждений на
основе опыта, предназначенные для поддержки правовых споров.
Программисты часто повторно используют старые программы для адаптации
существующих структур к похожей новой ситуации. Архитекторы используют свои знания об
эстетической привлекательности и полезности существующих сооружений для разработки
новых зданий, которые будут восприняты современниками как красивые и удобные.
Историки используют исторические факты, чтобы помочь государственным деятелям,
чиновникам и гражданам понять прошлые события и планировать будущее. Возможность
рассуждать на основе опыта является краеугольным камнем человеческого интеллекта.
Другие области рассуждения на основе опыта включают проектирование, где
успешно выполненный проект может использоваться в новой ситуации, и диагностику, где час-
Глава 7. Сильные методы решения задач
299
то приходят на ум неудачи прошлого. Хорошим примером этого является также
диагностика аппаратных средств. Эксперт в этой области для решения текущей проблемы
помимо использования богатых теоретических знаний по электронике и механическим
системам учитывает успехи и неудачи прошлого. Рассуждения на основе опыта составляют
важный компонент многих диагностических систем, включая системы диагностики
спутникового оборудования [Skinner и Luger, 1992] и анализа неисправностей
полупроводниковых компонентов [Stern и Luger, 1997].
Рассуждения на основе опыта обеспечивают ряд преимуществ для разработки
экспертных систем. Процесс извлечения знаний может быть упрощен, если механизм
рассуждения будет использовать записанные решения экспертов по ряду проблем. Это
могло бы освободить инженера по знаниям от необходимости разрабатывать общие правила
на основе примеров, полученных от экспертов. Механизм рассуждения сможет обобщать
правила автоматически, применяя их к новым ситуациям.
Подходы к таким рассуждениям позволяют экспертной системе учиться на своем
опыте. После решения задачи путем поиска система может сохранить это решение,
чтобы воспользоваться им при возникновении подобной ситуации (без привлечения поиска).
Важно запоминать информацию как об успешных, так и о неудачных попытках решения.
Таким образом, рассуждения на основе опыта являются мощным средством для
обучения. Одним из первых примеров таких систем является программа для игры в шашки
[Samuel, 1959] (см. подраздел 4.3.2), где важные позиции на доске, найденные
посредством поиска или эксперимента, запоминались для последующего использования.
Механизм рассуждения на основе опыта функционирует следующим образом.
1. Находит подходящие случаи в памяти. Случай является подходящим, если
решение может быть успешно применено в новой ситуации. Поскольку механизмы
рассуждения не могут знать этого наперед, для выбора случаев обычно
используются эвристики. Как люди, так и искусственные механизмы рассуждения,
определяют подобие на основе общих признаков: например, если у двух пациентов
наблюдается ряд общих признаков, связанных с симптомами и историей болезни, то
велика вероятность, что у них одно и то же заболевание, и им подходит один и тот
же курс лечения. Для эффективного поиска случаев память должна быть
организована соответствующим образом. Обычно ситуации индексируются по их
существенным признакам, что обеспечивает эффективный поиск аналогичных случаев.
Идентификация существенных признаков зависит от ситуации.
2. Приспосабливает найденную ситуацию к текущей. Обычно случай — это
последовательность операций, преобразующих начальное состояние в целевое. Механизм
рассуждения должен модифицировать некоторые операции в сохраненном решении с
учетом специфики текущей проблемы. Здесь могут быть полезны такие
аналитические методы, как подбор зависимости параметров, общих для сохраненных случаев и
новой проблемы. Если аналитические связи между ситуациями отсутствуют, могут
использоваться более эвристические методы — например, справочники.
3. Применяет преобразованное решение. Модификация известного случая не
обязательно гарантирует удовлетворительное решение проблемы. Может
потребоваться еще одна итерация выполнения первых трех шагов.
4. Сохраняет успешное или неудачное решение для дальнейшего использования.
Сохранение новых случаев требует адаптации индексной структуры. Существуют
специальные методы поддержки индексов. К ним относятся алгоритмы
кластеризации [Fisher, 1987] и другие приемы машинного обучения [Stubblefield и Luger, 1996].
300
Часть III. Представление и разум в ракурсе искусственного интеллекта
Для реализации рассуждения на основе случая могут потребоваться специальные
структуры данных. В простейшей ситуации случаи запоминаются как кортежи отношений, где
одни аргументы описывают сопоставляемые признаки, а другие — этапы решения. Случаи
могут представляться и более сложными структурами, такими как деревья вывода. Обычно
случай запоминается как множество правил типа ситуация-действие. Факты, описывающие
ситуацию, являются существенными признаками этого случая, а операторы,
представляющие действия, описывают преобразования, используемые в новой ситуации. При
использовании такого представления для организации и оптимизации поиска подходящих случаев
могут применяться такие алгоритмы, как RETE [Forgy, 1982].
Наиболее трудным вопросом в решении проблем на основе опыта является выбор
существенных признаков для индексирования и поиска ситуаций. В [Kolodner и
др., 1993] при решении задач на основе случаев считается, что они должны быть
организованы в соответствии с целями и потребностями решателя проблем. Это означает, что
необходимо выполнить тщательный анализ дескрипторов ситуации в контексте того, как
эти случаи должны быть использованы в процессе решения.
Например, рассмотрим проблему слабого коммуникационного сигнала на спутнике в
момент времени 10:24:35 GMT. На основе анализа определяется, что, кроме всего прочего,
система имеет низкую мощность. Низкая мощность может быть следствием того, что
солнечные батареи неправильно ориентированы по отношению к Солнцу. Наземные
контроллеры регулируют ориентацию спутника, мощность увеличивается, и коммуникационный
сигнал снова становится сильным. Для записи этого случая можно использовать ряд
существенных признаков. Наиболее важным из них является слабый коммуникационный сигнал
или низкий ресурс мощности. Другой существенный признак — время возникновения
проблемы A0:24:35). В соответствии с целями и потребностями решателя задач
существенными признаками являются слабый коммуникационный сигнал и низкий ресурс мощности.
Время события может не иметь никакого значения, за исключением случая, если поломка
произошла именно после того, как Солнце скрылось за горизонтом [Skinner и Luger, 1995].
Другой существенной проблемой является представление таких понятий, как слабый
сигнал или низкая мощность. Поскольку эта ситуация вряд ли повторится в точности, то
значение сигнала целесообразно представлять интервалами действительных чисел,
определяющими хороший, граничный, слабый и опасный уровни.
В работе [Kolodner, 1993] предлагается множество возможных эвристик для
организации, хранения и поиска ситуаций. К ним относятся следующие.
1. Упорядочение на основе целей. Случаи систематизируются, по крайней мере
частично, на основе описания цели. Выполняется поиск случаев, цель которых
соответствует текущей ситуации.
2. Упорядочение по существенным признакам. Выбираются случаи, для которых
наиболее важные признаки (или большинство важных признаков) совпадают.
3. Предпочтение точных совпадений. Сначала рассматриваются все случаи точного
совпадения признаков, а затем более общие соответствия.
4. Частотное предпочтение. Сначала проверяются наиболее типичные случаи.
5. Предпочтение новизны. Предпочтение отдается случаям, которые использовались
последними.
6. Предпочтение легкости адаптации. Используются первые, наиболее легко
адаптируемые к текущей ситуации, случаи.
Глава 7. Сильные методы решения задач
301
Рассуждения на основе опыта имеют ряд преимуществ при разработке экспертных
систем. Как только инженеры по знаниям остановились на некотором представлении
случая, дальнейшее извлечение знаний не представляет труда. Оно сводится к сбору и
сохранению накопленных ситуаций. Описания случаев могут быть найдены в
исторических записях или при наблюдении современных явлений.
Рассуждения на основе опыта поднимают ряд важных теоретических вопросов,
относящихся к человеческому обучению и рассуждениям. Одним из наиболее острых и
критических вопросов является определение степени подобия. Хотя меру подобия двух
случаев можно описывать как функцию, зависящую от числа общих признаков, такое
представление содержит ряд тонкостей. Например, большинство объектов и ситуаций имеют
бесконечное число свойств. Однако механизм рассуждений на основе опыта, как
правило, выбирает случаи из очень небольшого архива поиска, составляемого инженером по
знаниям. Несмотря на некоторые исследования возможности решателя определять
соответствующие признаки из своего собственного опыта [Stubblefield, 1995], определение
информативности признаков остается сложной проблемой.
Другой важной проблемой, с которой сталкиваются специалисты при реализации
рассуждений на основе опыта, является проблема компромисса между запоминанием и
вычислением. По мере запоминания новых случаев механизм рассуждений становится все более
интеллектуальным, способным лучше решать различные проблемы. Действительно по мере
добавления в память новых случаев результаты рассуждений до некоторого момента будут
улучшаться. Но по мере роста базы данных время, необходимое для поиска и обработки
информации о прецедентах, тоже растет. Снижение эффективности для больших баз
данных также может объясняться пересечением понятий и другими помехами. Одним из
решений этой проблемы является хранение лишь "наилучших" или "прототипных" случаев и
вычеркивание тех, которые являются избыточными или редко используемыми.
Следовательно, система рассуждений должна забывать случаи, которые не доказали свою
полезность. Примером ранних работ в этой области может служить алгоритм запоминания
позиций на шашечной доске [Samuel, 1959]. Однако в общем случае не ясно, как можно
автоматизировать такие решения. Это остается областью активного поиска [Kolodner, 1993].
Автоматизированные объяснения рекомендаций — еще один тип рассуждения на
основе опыта. В ответ на вопрос, почему в данной ситуации рекомендуется принимать
именно это лекарство, единственным объяснением системы является то, что именно это
назначение было сделано в предыдущий период времени. Иногда используются
объяснения, основанные на сходстве описаний текущей и предыдущей ситуаций. В примере
задачи спутниковой коммуникации подходящий случай был выбран на основе слабого
коммуникационного сигнала. Этот способ рассуждения тоже не обеспечивает более
глубокого объяснения, чем то, которое было выработано ранее в подобной ситуации. Но
зачастую этого может быть достаточно.
Однако многие исследователи убеждены, что простое повторение целей высокого
уровня и используемых случаев является недостаточным объяснением [Leake, 1992],
[Stern и Luger, 1992]. Вернемся к ситуации со спутником. Предположим, что
переориентация солнечной батареи помогает улучшить качество сигнала, но через три часа сигнал
снова становится слабым. Используя частотную эвристику и эвристику новизны, мы
снова переориентируем солнечную батарею. Через три часа слабый сигнал повторяется.
Каждые три часа мы используем одно и то же назначение. Этот пример основан на
реальной ситуации, в которой была обнаружена более сложная причина, а именно: перегрелся
гироскоп и давал искаженные данные об ориентации спутника. Окончательно решить
302
Часть III. Представление и разум в ракурсе искусственного интеллекта
проблему и определить причину слабого коммуникационного сигнала удалось лишь с
помощью рассуждений на основе модели поведения спутника [Skinner и Luger, 1995].
Рассуждения на основе опыта обеспечивают обучение по аналогии. Для повторного
использования прошлого опыта необходимо выделить существенные признаки прошлой
ситуации и построить отображение, позволяющее применить этот опыт в текущей ситуации.
Примером подхода к решению задач на основе опыта является трансформационная
аналогия [Carbonell, 1983]. Новая задача решается путем модификации существующих решений
до тех пор, пока их нельзя будет применить к данной ситуации. Операторы, которые
модифицируют решение задачи, определяют абстракцию более высокого уровня, или Т-
пространство, в котором состояниями служат решения задачи, подлежащие
преобразованию (рис. 7.17). Целью является преобразование исходного решения в возможное решение
поставленной проблемы. Для модификации решения можно его исключить,
переупорядочить шаги в решении, соединить новые решения или изменить параметры в текущем
решении. Трансформационная аналогия — типичный пример решения задач на основе опыта.
Более поздние работы уточняют этот подход. В них рассматриваются такие вопросы, как
представление случаев, стратегии организации памяти случаев, поиск подходящих
ситуаций и использование их для решения новых задач. Более полная информация о
рассуждениях на основе опыта содержится в [Hammond, 1989], [Kolodner, 1988a] и
[Kolodner, 19885]. Исследования по аналогии рассматриваются далее в контексте
машинного обучения на основе символов (см. подраздел 9.5.4).
Т-пространство
Рис. 7.17. Трансформационная аналогия из [Carbonell, 1983]
7.3.4. Гибридные системы: достоинства и недостатки систем
с сильными методами
Успехи построения экспертных систем для решения сложных практических проблем
продемонстрировали работоспособность основной идеи построения систем на основе
знаний. Эффективность механизма рассуждения определяется его знаниями в данной области,
а не методами рассуждения. Это наблюдение, впрочем, поднимает один из главных
вопросов искусственного интеллекта — вопрос представления знаний. На практическом уровне
Глава 7. Сильные методы решения задач
303
каждый инженер по знаниям должен выбрать наиболее эффективный способ их
представления. Представление знаний связано также с рядом таких теоретически важных и
интеллектуально сложных вопросов, как управление недостающей и неопределенной
информацией, определение выразительности представления, отношение между языком
представления и обучением, приобретеним знаний и эффективностью механизма рассуждения.
В этой главе мы рассмотрели ряд основных подходов к представлению знаний:
экспертные системы, основанные на правилах, механизмы рассуждений на основе моделей
и опыта. Подытожим достоинства и недостатки каждого из перечисленных подходов к
решению проблем.
Рассуждения на основе правил
Преимущества этого подхода сводятся к следующему.
1. Возможность использовать знания экспертов в очень простой форме. Это важно в
областях, зависящих от эвристик управления сложной и/или отсутствующей
информацией.
2. Правила отображаются в пространство состояний поиска. Возможности
объяснения облегчают отладку программ.
3. Отделение знаний от управления упрощает разработку экспертной системы,
обеспечивая итеративный процесс разработки, в котором инженер накапливает,
реализует и тестирует отдельные правила.
4. В ограниченных предметных областях возможны хорошие результаты. Поскольку
для интеллектуального решения задачи требуется большой объем знаний,
экспертные системы ограничиваются узкими областями. Однако существует много
областей, в которых разработка подобных систем оказалась чрезвычайно полезной.
5. Хорошие возможности объяснения. Хотя системы на основе правил поддерживают
гибкие, проблемно-зависимые объяснения, необходимо отметить, что максимальное
качество этих объяснений зависит от структуры и содержания правил. Возможности
объяснения в системах, основанных на данных и на целях, сильно различаются.
Недостатки рассуждений, основанных на правилах.
1. Правила, полученные от экспертов, часто являются эвристическими по природе и
не охватывают функциональных знаний или знаний, основанных на моделях.
2. Эвристические правила обычно не являются робастными и не позволяют управлять
отсутствующей информацией или неожиданными значениями данных.
3. Другой особенностью правил является их неприменимость на границе области
определения. В отличие от людей, системы на основе правил при столкновении с
новыми проблемами обычно не способны возвратиться назад к первоначальным
принципам рассуждения.
4. Объяснения применимы лишь на описательном уровне. Теоретические
обоснования отсутствуют. Это связано с тем, что эвристические правила напрямую
связывают симптомы с решениями и не обеспечивают более глубоких рассуждений.
5. Знания являются проблемно-зависимыми. Формализованные знания о некоторой
предметной области, как правило, очень специфичны и применимы только к
данной области. Современные языки представления знаний не обеспечивают
гибкости, присущей человеку.
304
Часть III. Представление и разум в ракурсе искусственного интеллекта
Рассуждения на основе опыта
Преимущества рассуждений на основе опыта сводятся к следующему.
1. Возможность напрямую использовать исторический опыт. Во многих областях
необходимую информацию можно получить из существующих исторических
материалов, записей или других источников. При этом устраняется необходимость
интенсивного приобретения знаний с помощью человека-эксперта.
2. Возможность сокращения рассуждений. Если известен аналогичный случай, новые
задачи решаются гораздо быстрее, чем при использовании правил или моделей.
3. Рассуждения на основе опыта позволяют избежать прошлых ошибок и использовать
прошлые успехи. Они обеспечивают модель обучения, как интересную с теоретической
точки зрения, так и достаточно практичную для применения в сложных ситуациях.
4. Не требуется всестороннего анализа знаний о данной области. В отличие от систем,
основанных на правилах, где инженер по знаниям должен описать взаимодействие
правил, рассуждения на основе опыта обеспечивают простую аддитивную модель
приобретения знаний. Для использования этого подхода необходимо обеспечить
соответствующее представление случаев, индексирование данных и стратегию адаптации.
5. Соответствующие стратегии индексирования повышают эффективность решения
задач. Мощность механизма рассуждений на основе опыта определяется
возможностью выявлять отличительные особенности целевой проблемы и выбирать
соответствующий случай из базы данных. Алгоритмы индексации часто обеспечивают
эту функциональность автоматически.
Рассмотрим недостатки рассуждений на основе опыта.
1. Описания случаев обычно не учитывают более глубокие знания о предметной области.
Это снижает качество объяснения и во многих ситуациях приводит к ошибочному
применению опыта, а значит, к неправильным или низкокачественным советам.
2. Большая база данных может привести к снижению производительности системы.
3. Трудно определить хороший критерий для индексирования и сравнения случаев.
Словари поиска и алгоритмы определения подобия необходимо тщательно
отлаживать вручную. Это может нейтрализовать многие из преимуществ, присущих
рассуждениям на основе опыта.
Рассуждения на основе моделей
Преимущества рассуждений на основе моделей сводятся к следующему.
1. Возможность использовать при решении задач функциональные и структурные
знания о предметной области. Это увеличивает эффективность механизма
рассуждений при решении различных задач, включая те, которые не были предусмотрены
при разработке системы.
2. Механизмы рассуждений на основе моделей обычно очень эффективны. Они
являются мощными и гибкими средствами решения задач, поскольку, как и люди,
часто возвращаются к исходным данным при столкновении с новой проблемой.
3. Некоторые знания можно использовать в разных задачах. Системы рассуждений на
основе моделей зачастую базируются на теоретических научных знаниях.
Поскольку наука обычно оперирует общими теориями, такое обобщение часто
расширяет возможности механизма рассуждений на основе моделей.
Глава 7. Сильные методы решения задач
305
4. Обычно системы рассуждений, основанные на моделях, обеспечивают причинные
объяснения. Таким образом пользователям можно передать более глубокое
понимание причин неисправности, которое может сыграть важную образовательную
роль (см. также раздел 16.2).
Недостатки рассуждений на основе моделей таковы.
1. Отсутствие экспериментального (описательного) знания предметной области.
Эвристические методы, используемые при рассуждениях на основе правил, отражают
важный класс экспертных оценок.
2. Необходимость точной модели предметной области. Знания из многих областей
имеют строгую научную основу, которую можно использовать в рассуждениях на
основе моделей. Однако во многих сферах, например, в некоторых медицинских
направлениях, большинстве проблем проектирования или финансовых
приложениях, хорошо определенная научная теория отсутствует. В таких случаях подходы,
основанные на моделях, не могут быть использованы.
3. Высокая сложность. Рассуждения, основанные на моделях, обычно ведутся на
детализированном уровне, что приводит к значительным усложнениям. Именно по
этой причине эксперты в первую очередь разрабатывают эвристики.
4. Исключительные ситуации. Необычные обстоятельства, например, замыкание или
взаимодействие множества неисправностей электронных компонентов, могут
изменить функциональность системы таким образом, что ее трудно будет предсказать.
Гибридные системы
Важной областью исследований является комбинация различных моделей
рассуждений. В гибридной архитектуре, объединяющей несколько парадигм, эффективность
одного подхода может компенсировать слабости другого. Комбинируя различные подходы,
можно обойти недостатки, присущие каждому из них в отдельности.
Например, сочетание рассуждений на основе правил и опыта может обеспечить
следующие преимущества.
1. Просмотр известных случаев до начала рассуждений на основе правил позволяет
снизить затраты на поиск.
2. Примеры и исключения можно сохранять в базе данных ситуаций.
3. Результаты поиска можно сохранить для будущего использования. При этом
механизм рассуждений позволит избежать затрат на повторный поиск.
Комбинация рассуждений на основе правил и моделей открывает следующие
возможности.
1. Объяснения дополняются функциональными знаниями. Это может быть полезно в
обучающих системах.
2. Повышается устойчивость системы при отказах. При отсутствии эвристических
правил, используемых в данном случае, механизм рассуждений может прибегнуть
к рассуждениям от исходных принципов.
3. Поиск на основе модели дополняется эвристическим поиском. Это может
помочь в сложных рассуждениях, основанных на модели, и обеспечивает
возможность выбора.
306
Часть III. Представление и разум в ракурсе искусственного интеллекта
Комбинация рассуждений на основе моделей и опыта дает следующие преимущества.
1. Более разумное объяснение ситуаций.
2. Проверка аналогичных случаев до начала более экстенсивного поиска посредством
рассуждений на основе моделей.
3. Обеспечение записи примеров и исключений в базу данных случаев, которые
могут быть использованы для управления выводом на основе модели.
4. Запись результатов вывода на основе моделей для будущего использования.
Гибридные методы заслуживают внимания как исследователей, так и разработчиков
приложений. Однако построение таких систем требует решения целого ряда проблем.
Необходимо определить метод рассуждения для данной ситуации, момент изменения метода
рассуждения, выяснить различия между методами рассуждения, разработать представления,
обеспечивающие совместное использование знаний. Далее будут рассмотрены вопросы планирования
или организации частей знаний для решения более сложных проблем.
7.4. Планирование
7.4.1. Введение
Задача планировщика— определить последовательность действий модуля решения,
например системы управления. Традиционное планирование основано на знаниях,
поскольку создание плана требует организации частей знаний и частичных планов в
процедуру решения. Планирование используется в экспертных системах при рассуждении о
событиях, происходящих во времени. Планирование находит приложения как в
производстве, так и в управлении. Оно также важно в задачах понимания естественного языка,
поскольку люди часто обсуждают планы, цели и намерения.
В этом разделе будут использованы примеры из традиционной робототехники.
(Современная робототехника, как указано в разделе 6.3, во многом основывается на
реактивном управлении, а не на планировании.) Пункты плана определяют атомарные
действия робота. Однако при описании плана нет необходимости опускаться до
аппаратного уровня (или микроуровня) и говорить о таких деталях, как "поворот шестого
шагового двигателя на один оборот". Планировщики описывают действия на более
высоком уровне в терминах их воздействий на мир. Например, планировщик для робота из
мира блоков может оперировать такими действиями, как "взять объект а" или "перейти в
местоположение х". На таких планах высокого уровня строится управление действиями
настоящего робота.
Например, для реализации пункта плана "принести блок а из комнаты б" требуется
следующая последовательность действий.
1. Положить все, что есть в руке.
2. Пройти в комнату б.
3. Подойти к блоку а.
4. Взять блока.
5. Выйти из комнаты б.
6. Вернуться в первоначальное местоположение.
Глава 7. Сильные методы решения задач
307
Планы создаются путем поиска в пространстве возможных действий до тех пор, пока
не будет найдена последовательность, необходимая для решения задачи. Это
пространство представляет состояния мира, которые изменяются при выполнении каждого
действия. Поиск заканчивается, когда достигается целевое состояние (описание мира). Таким
образом, многие принципы эвристического поиска, включая алгоритмы решения А*,
подходят и для планирования.
Задача планирования не зависит от существования реального робота. Изначально
(в 1960-е годы) при решении задач компьютерного планирования полные планы
формировались заранее, перед тем, как робот совершал свое первое действие. Таким образом,
планы разрабатывались без наличия робота вообще! В последнее время благодаря
реализации сложных механизмов восприятия и реагирования исследователи сфокусировались
на более интегрированной последовательности план-действие.
Планирование зависит от методов поиска и поднимает ряд уникальных вопросов.
Например, описание состояний мира может быть значительно сложнее, чем в предыдущих
примерах поиска. Рассмотрим ряд предикатов, необходимых для описания комнат,
коридоров и объектов в окружении робота. При этом необходимо представить не только мир
робота, но и воздействие его атомарных действий на этот мир. Полное описание каждого
состояния задачи может быть очень громоздким.
Другой отличительной особенностью планирования является необходимость
характеризовать сложные неатомарные состояния и действия. Захват объекта означает
изменение его местоположения и состояния руки робота (теперь она сжимает объект). При этом
не изменяется местоположение дверей, комнат или других объектов. Описание того, что
истинно в одном состоянии мира и изменяется при выполнении некоторого действия,
называется проблемой границ [McCarthy, 1980], [McCarthy и Hayes, 1969]. По мере
усложнения пространства состояний задачи вопрос поддержки истории изменений, связанных
с каждым действием, и инвариантных признаков описания состояния становится все
более важным. В этой главе будут представлены два подхода к проблеме границ, но, как
показано ниже, ни один из них не является полностью удовлетворительным.
Другие важные вопросы включают генерацию планов, хранение и обобщение хороших
планов, восстановление системы после неожиданных сбоев (часть мира могла оказаться не
такой, как ожидалось, возможно вследствие случайного сдвига относительно прежнего
местоположения) и поддержку соответствия между миром и его программной моделью.
ов
b
а
с
Q. CD
Рис. 7.18. Мир блоков
308
Часть III. Представление и разум в ракурсе искусственного интеллекта
В примерах этого раздела мы ограничим мир робота множеством блоков на
поверхности стола и действиями руки робота, которая может поставить блоки один на другой,
взять верхний блок и переместить блок в пределах стола. На рис. 7.18 показаны пять
блоков а, Ь, с, с/, е, установленных на верхней поверхности стола. Все блоки являются
кубами одинакового размера. Некоторые блоки располагаются непосредственно друг на
друге, образуя стеки. Рука робота имеет захват, который может схватить любой
свободный блок (тот, который не имеет блоков на своей верхней грани) и переместить его в
любое место на поверхности стола или на верхнюю грань любого другого свободного блока.
Рука робота может выполнять следующие задания (U, V,W,X,YuZ — переменные).
gofo(X,V,Z) Перейти в местоположение, описанное координатами X, У и Z. Это
местоположение может быть неявно задано в команде pickup(W), где
блок W имеет координаты X, У, Z.
pickup{W) Взять блок W из его текущего местоположения и держать его.
Предполагается, что блок является свободным, захват в это время пуст и
компьютер знает текущее местоположение блока ИЛ
putdown(W) Опустить блок W в некоторой точке на столе. Записать новое
местоположение для ИЛ При выполнении данной задачи предполагается,
что в данный момент блок W удерживается захватом.
stack(U,V) Поместить блок U на верхнюю грань блока V. При этом захват должен
держать блок U, и верхняя грань V должна быть свободна.
unstack(U,V) Убрать блок U с верхней грани V. Перед выполнением этой команды
блок U должен быть свободен, располагаться на верхней поверхности
блока V, и рука должна быть пустой.
Состояние мира описывается множеством предикатов и отношений между ними.
location(WJ(,YZ) Блок W имеет координаты X, V, Z.
оп(Х,У) Блок X находится непосредственно на верхней поверхности блока У.
clear(X) Верхняя грань блока X пуста.
gripping(X) Захват робота удерживает блок X.
grippingQ Захват робота пуст.
ontable(W) Блок W находится на столе.
Запись ontable(W) является короткой формой предиката /осаГ/олСИЛХ,/^), где Z —
уровень стола. Предикат оп(Х,У) указывает, что нижняя часть блока X находится на
верхней грани блока У. Если местоположение каждого блока и информация об их
перемещении в новое место записаны в компьютере, то описание мира можно значительно
упростить. При этом устраняется необходимость в команде, поскольку такие команды,
как pickupiX) или sfac/c(X), неявно содержат местоположение X.
Тогда мир блоков, показанный на рис. 7.18, может быть представлен множеством
предикатов Состояние 1. Поскольку предикаты, описывающие состояние мира на
рис. 7.18, являются истинными одновременно, полное описание состояния является
конъюнкцией (л) всех этих предикатов.
Состояние 1
ontable(a). on(b,a). clear(b).
Ontable(c). on(e,d). clear(c).
Ontable(d). grippingQ. clear(e).
Глава 7. Сильные методы решения задач
309
Теперь для clear(b), ontable(a) и grippingQ опишем ряд истинных отношений (в
декларативном смысле) или правил выполнения (в процедурном смысле).
1. (VX) (clear(X) <- -. (BY) (on(V,X))).
2. (VV) (VX) -. (on(YX) <r- (ontable(Y)).
3. (VV) grippingQ <-> -, (gripping(Y)).
Согласно первому утверждению, если блок X свободен, то не существует блока V,
расположенного на верхней грани X. Процедурно его можно интерпретировать так: "Для
освобождения блока X нужно убрать любой блок Y, который может находиться на
верхней грани X".
Теперь разработаем правила, воздействующие на состояния и приводящие к новым
состояниям. С этой целью снова введем процедурную семантику для логического
представления предикатов. Операторы (pickup, putdown, stack, unstack) определяются
следующим образом.
4. (VX) (pickup(X) —> (gripping(X) <— (gripping()Aclear(X)A ontable(X)))).
5. (VX) (putdown(X) —> ((grippingQ л ontable(X) л clear(X)) <— gripping(X))).
6. (VX) (VV) (stack(X,Y) -> ((on(X,V) л grippingQ л clear(X)) <- (clear(Y) л
gripping(X)))).
7. (VX) (VV) (unstack(X,Y) -> ((clear(Y) л gripping(X)) <- (on(X,V)Ac/ear(X) л
grippingQ)).
Рассмотрим четвертое правило: для всех блоков X pickup(X) означает gripping(X),
если рука пуста и блок X свободен. Отметим форму этого правила: Д—>(В<—С). Это
означает, что из А следует новый предикат S, если условие С истинно. Это правило можно
использовать для генерации новых состояний в пространстве. Если предикат С является
истинным, то в наследуемом состоянии В тоже является истинным. Другими словами,
оператор А может быть использован для создания нового состояния, описываемого
предикатом S, если предикат С является истинным. Для создания этих операторов можно
использовать и альтернативные подходы, описанные в подразделе 7.4.2, [Nilsson, 1980] и
[Rich и Knight, 1991].
Прежде чем использовать эти правила взаимосвязи для генерации новых состояний
мира блоков, надо обратиться к проблеме границ. При описании нового состояния мира
используются аксиомы границ — правила, определяющие инвариантные предикаты.
Например, если применить оператор pickup к блоку В на рис. 7.18, то все предикаты,
относящиеся к остальным блокам, в следующем состоянии останутся истинными. Для мира
блоков можно описать несколько правил границ.
8. (VX) (VV) (VZ) (unstack(YZ) -» (ontable(X) <- ontable(X))).
9. (VX) (VV) (VZ) (stack(YZ) -» (ontable(X) <- ontable(X))).
Эти правила означают, что предикат ontable инвариантен по отношению к
операторам stack и unstack. Это истинно даже при идентичности X и Z; если же V=Z, то одно из
этих выражений не будет истинным.
Другие аксиомы границ сводятся к тому, что операторы stack и unstack изменяют
значения предикатов on и clear лишь для некоторых параметров. Так, в нашем примере
оператор unstack(c,d) не затрагивает значение on(b,a). Аналогично оператор
310 Часть III. Представление и разум в ракурсе искусственного интеллекта
gripping(Y) не затрагивает отношение clear(X), даже если X=Y или истинно выражение
grippingQ. Кроме того, оператор gripping затрагивает не отношение on(X,Y), a
ontabie(X), гдеХ—удерживаемый блок. Таким образом, для нашего примера
необходимо описать ряд аксиом границ.
Операторы и аксиомы границ определяют пространство состояний. Рассмотрим
состояние, определяемое оператором unstack. Для выполнения оператора unstack(X,Y)
должны выполняться три условия одновременно, а именно: on(X,Y), grippingO и
clear(X). Когда эти условия выполняются, применение оператора unstack приводит к
новым предикатам gripping(X) и clear(Y). Остальные предикаты, описывающие
состояние 1, останутся истинными и в состоянии 2. Переход к состоянию 2 осуществляется
посредством применения оператора unstack и аксиом границ к предикатам состояния 1.
Состояние 2
ontable(a). on(b,a). clear(b).
ontable(c). clear(c). clear(d).
ontable(d). gripping(e).clear(e).
Подведем итоги.
1. Планирование можно рассматривать как поиск в пространстве состояний.
2. Новые состояния определяются такими общими операторами, как stack и
unstack, и правилами границ.
3. Для нахождения пути из начального состояния к целевому могут применяться
методы поиска на графах. Операции переходов для этого пути составляют план.
На рис. 7.19 показан пример пространства состояний, в котором поиск выполняется с
применением описанных выше операторов. Если к этому процессу решения задачи
добавить описание цели, то план можно рассматривать как множество операторов,
описывающих путь от текущего состояния этого графа к целевому (см. подраздел 3.1.2.).
Такое описание задачи планирования позволяет определить ее теоретические
корни. Это — поиск в пространстве состояний и исчисление предикатов. Однако
такой способ решения может быть очень сложным. В частности, использование
правил границ для вычисления инвариантов может экспоненциально усложнить поиск,
что видно на примере очень простой задачи из мира блоков. Действительно, если
ввести новый предикат для описания цвета, формы или размера, необходимо
определить новые правила границ, которые должны быть связаны со всеми
соответствующими действиями!
Предполагается также, что подзадачи общей задачи являются независимыми и могут
быть решены в произвольном порядке. В интересных и сложных предметных областях
это условие выполняется редко. Обычно предусловия и действия, необходимые для
достижения одной подцели, противоречат предусловиям и действиям, необходимым для
достижения другой. Проиллюстрируем эти проблемы и опишем подход к планированию,
который в значительно мере помогает их преодолеть.
7.4.2. Использование макросов планирования: STRIPS
Система STRIPS (современное название — SRI International) — это система
планирования, разработанная в Стандфордском исследовательском институте (Stanford
Research Institute Planning System) [Fikes и Nilsson, 1971], [Fikes и др., 1972]. В нача-
Глава 7. Сильные методы решения задач
311
ле 1970-х годов этот контроллер использовался для управления роботом SHAKEY.
Система STRIPS решала проблему эффективного представления знаний и
выполнения операций планировщика с учетом противоречивости подцелей и обеспечивала
начальную модель обучения: успешные планы сохранялись и обобщались как
макрооператоры, которые затем могли быть использованы в подобных ситуациях. В
оставшейся части этого раздела описывается использованный в STRIPS подход к
планированию и треугольные таблицы — структуры данных, используемые для
организации и запоминания макроопераций.
^
а
b
с
е
d
&]
b
а
с
d
е
d
5
1 b
а
с
^
Ч
а
с
е
d
b
е
d
а с
е
d
ГьП
Рис. 7.19. Фрагмент пространства состояний для мира блоков
В рассматриваемом примере с блоками четыре оператора pickup, putdown, stack и
unstack описываются тройками элементов. Первым элементом тройки является
множество предусловий (П), которым должен удовлетворять мир для применения оператора.
Второй элемент тройки — список дополнений (Д) к описанию состояния, которые
являются результатом применения оператора. И, наконец, список вычеркиваний (В) состоит
из атомов, которые удаляются из описания состояния после применения оператора. Эти
списки исключают необходимость использования отдельных аксиом границ.
Рассматриваемые операторы можно представить следующим образом.
312
Часть III. Представление и разум в ракурсе искусственного интеллекта
П: gripping( ) лс1еаг(Х) Aontable(X)
Д: gripping(X)
В: ontable(X) Agripping( )
П: gripping(X)
Д: ontable(X) Agripping( ) л clear(X)
В: gripping(X)
П: clear(Y) Agripping(X)
Д: on(X,Y) Agripping( ) Aclear(X)
B: clear(Y) л gripping(X)
П: clear(X) Agripping( ) аоп(Х,У)
unstack(X, Y) д; gripping(X) л c/ear( V)
B: gripping( ) л оп(Х, V)
Важной особенностью списков добавления и вычеркивания является то, что они
описывают аксиомы границ. Подходу, основанному на списках добавления и вычеркивания,
присуща некоторая избыточность. Например, в операторе unstack добавление
gripping(X) может подразумевать вычеркивание grippingQ. Однако эта избыточность
имеет свои преимущества. Каждый дескриптор состояния, который не упоминается в
списке добавления или вычеркивания, остается истинным в описании нового состояния.
К недостаткам подхода, основанного на списках добавления и вычеркивания, можно
отнести следующее. Здесь для формирования нового состояния не используется процесс
доказательства теорем. Однако это не является серьезной проблемой, так как
доказательство эквивалентности двух подходов может гарантировать корректность метода списков
добавления и вычеркивания.
Подход, основанный на списках добавления и вычеркивания, в нашем примере дает
те же результаты, что и правила вывода с аксиомами границ. Поиск в пространстве
состояний (см. рис. 7.19) для обоих подходов реализуется одинаково.
Некоторые проблемы планирования не решает ни один из этих двух подходов. При
решении задачи ее зачастую делят на подзадачи, например unstack(e,d) и unstack(b,a).
Попытка независимого достижения этих подцелей может вызвать проблемы, если
действия, необходимые для достижения одной цели, направлены на разрушение другой.
Несовместимость подцелей может быть результатом неправильного предположения о
линейности (независимости) подцелей. Нелинейность пространства план-действие может сделать
поиск решений чрезмерно трудным или даже невозможным. Приведем простой пример
несовместимых подцелей. Используем исходное состояние 1, показанное на рис. 7.18.
Предположим, что целью планирования является состояние G, показанное на рис. 7.20, в
котором on(b, a)Aon(a, с), а блоки d и е остаются в том же положении, что и в состоянии 1.
Можно отметить, что одна из частей конъюнктивной цели on(b,a)Aon(a,c) — оп(Ь,а) —
в состоянии 1 истинна. Для достижения второй подцели оп(а, с) это условие должно
быть нарушено.
Представление данных в виде треугольной таблицы [Fikes и Nilsson, 1971],
[Nilsson, 1980] позволяет смягчить некоторые последствия этих аномалий. Треугольная
таблица является структурой данных для организации последовательности действий,
включая потенциально несовместимые подцели. Она решает проблему противоречиво-
pickup(X)
putdown(X)
stack(X, Y)
Глава 7. Сильные методы решения задач
313
сти подцелей внутри макроопераций посредством представления глобального
взаимодействия последовательностей операций. В треугольной таблице предусловия одного
действия сопоставляются с постусловиями списков добавления и вычеркивания
предшествующего действия.
Рис. 7.20. Целевое состояние для мира блоков
Треугольные таблицы служат для определения применимости макрооператора при
построении плана. Повторное использование этих макрооператоров увеличивает
эффективность поиска при планировании в STRIPS. Действительно макрооператор можно
обобщить, заменяя названия блоков в частном примере именами переменных. Затем для
сокращения поиска можно вызвать новый обобщенный макрооператор. В главе 9 методы
обобщения макроопераций обсуждаются при описании обучения на основе символов.
Повторное использование макрооператоров помогает также решить проблему
противоречивости подцелей. Если планировщик разработал план достижения целей вида
stack(X, Y)AStack(Y, Z), то этот план можно запомнить и использовать повторно. Это
исключает необходимость разбивать цель на подцели и позволяет избежать
возможных усложнений.
На рис. 7.21 представлена треугольная таблица для макрооператора stack(X,
Y)AStack(Y, Z). Этот макрооператор можно применять в состояниях, для которых
истинно выражение оп(Х, Y)AClear(X)AClear(Z). Эта треугольная таблица соответствует
начальному состоянию 1 при X=d, Y=a и Z=c.
Атомарные действия плана записываются вдоль диагонали. Эти четыре действия
(pickup, putdown, stack и unstack) рассмотрены ранее в данном разделе. Множество
предусловий каждого из этих действий описывается в строке, соответствующей этому
действию, а постусловия — в соответствующем столбце. Например, в строке 5
содержатся предусловия, а в столбце 6 — постусловия (списки добавления и вычеркивания)
для оператора pickup(X). Постусловия одних действий являются предусловиями
других (дальнейших). Цель треугольной таблицы — соответствующим образом
упорядочить предусловия и постусловия каждого действия при достижении более крупной
цели. Таким образом треугольные таблицы решают вопросы нелинейности
планирования на уровне макрооператора. Эти же вопросы можно решить и на основе других
подходов, в том числе при использовании частично упорядоченных планировщиков
[Russell и Norvig, 1995].
314
Часть III. Представление и разум в ракурсе искусственного интеллекта
grippingi)
cleariX)
oniX,Y)
ontableiY)
cleariZ)
unstackiXX
grippingiX)
cleariY)
)
putdowniX)
grippingi)
cleariX)
ontableiX)
pickup iY)
grippingiY)
stackiY,Z)
grippingi)
cleariY)
oniY,Z)
pickupiX)
grippingiX)
stackiX,Y)
oniX,Y)
cleariX)
grippingi)
12 3 4 5 6 7
Рис. 7.21. Треугольная таблица
Одним из преимуществ треугольных таблиц является возможность преодоления
неожиданных или аварийных ситуаций, таких как сдвиг блока. Часто в случае аварии для
продолжения реализации плана требуется вернуться на несколько шагов назад. При необходимости
планировщик может возвратиться назад к нужным строкам и столбцам таблицы, чтобы
проверить, какие подцели еще истинны. После такой проверки планировщик знает, каким должен
быть следующий шаг решения. Это формализуется с помощью понятия ядра.
Ядро п-го порядка, или п-е ядро, — это пересечение всех строк, начиная с п-й, с п
столбцами, начиная с крайнего слева. На рис. 7.21 мы очертили третье ядро жирной
линией. При выполнении плана, представленного треугольной таблицей, /-я операция (т.е.
операция в /-й строке) может быть выполнена, если все предикаты, содержащиеся в /-м
ядре, истинны. Это позволяет проверить, какой шаг может быть выполнен, и
восстановить выполнение плана при его нарушении. Для этого в треугольной таблице нужно
найти и выполнить действие, соответствующее ядру максимального порядка. Это дает
возможность не только возвратиться к предыдущим шагам плана, но и скачкообразно
перейти вперед после неожиданного события.
Условия в крайнем слева столбце — это предусловия для макродействия в целом.
Условия в самой нижней строке добавляются в мир при выполнении макрооператора.
Треугольная таблица может быть сохранена как макрооператор со своим собственным
множеством предусловий и списками добавления и вычеркивания.
Разумеется, подход на основе треугольной таблицы несколько скрывает семантику
предыдущих моделей планирования. Например, в таблице описываются лишь те
постусловия, которые одновременно являются предусловиями последующих действий. Таким
образом, для получения корректного результата необходима дальнейшая верификация
треугольных таблиц, возможно, с учетом дополнительной информации, позволяющей
сформировать последовательности треугольных таблиц.
Глава 7. Сильные методы решения задач
315
При использовании макрооператоров возникают и другие проблемы. С увеличением
числа макрооператоров планировщик использует более сложные операции, а размер
исследуемого пространства состояний уменьшается. К сожалению, предусловия всех
операторов необходимо проверять на каждом шаге поиска. Необходимое для определения
применимости оператора сопоставление с образцом может значительно усложнить
процесс поиска и свести на нет преимущества макроопераций. Проблемы необходимости
сохранения макроопераций и определения следующего оператора остаются предметом
многих исследований. В следующем разделе будет описан алгоритм адаптивного
планирования, при котором одновременно могут удовлетворяться несколько подцелей.
7.4.3. Адаптивное планирование
С момента появления ранних работ по планированию, описанных в предыдущем
разделе [Fikes и Nilsson, 1971], в этой области был получен ряд значительных
результатов. Многие из них не связаны с конкретной предметной областью. Но в последнее
время особое значение приобретает планирование в специфических областях, где
используется распределенный механизм "восприятие-реакция". В следующих разделах
будет описана не зависящая от предметной области система адаптивного
планирования, а также более специфический планировщик Бартона (Burton) из NASA. В качестве
дополнительной литературы по исследованиям в области планирования рекомендуем
книгу [Allen и др., 1990].
Адаптивное, или телео-реактивное, планирование (АП) впервые было предложено в
[Nilsson, 1994] и [Benson, 1995]. Принцип АП может применяться во многих областях,
требующих скоординированного управления сложными подсистемами для достижения
целей более высокого уровня. Здесь иерархическая архитектура управления (сверху
вниз) соединяется с агентным подходом (раздел 6.4) или управлением снизу вверх.
Результатом является система, которая может решать сложные проблемы посредством
координации простых проблемно-ориентированных агентов. Такой подход можно
обосновать следующим образом. Простые агенты хорошо работают в ограниченных
пространствах. С другой стороны, контроллер более высокого уровня может делать более общие
заключения, относящиеся ко всей системе. Например, он позволяет оценить, как текущее
локальное решение воздействует на процесс решения общей задачи.
Адаптивное управление объединяет аспекты управления по обратной связи и
планирование конкретных действий. Адаптивная программа — это
последовательность действий, обеспечивающих выполнение целенаправленного плана. В отличие
от более традиционных сред интеллектуального планирования [Weld, 1994] здесь не
делается предположений о дискретности и непрерывности действий, а также о
полной предсказуемости их результатов. Наоборот, целенаправленные действия могут
поддерживаться в течение длительного периода времени, т.е. действие выполняется
до тех пор, пока удовлетворяются предусловия и не достигнута соответствующая
цель. В [Nilsson, 1994] такие действия называются продолжительными (durative). Они
могут быть прерваны при активизации некоторого другого действия, более близкого к
цели верхнего уровня. При изменении среды управляющие действия быстро
изменяются, отражая новое состояние решения проблемы.
Последовательности продолжительных действий представляются специальными
структурами данных — TR-деревьями (рис. 7.22). TR-дерево описывается множеством
пар условие—>действие или продукционными правилами (раздел 5.3). Например,
316
Часть III. Представление и разум в ракурсе искусственного интеллекта
Сг->Аг,
СЯ-*АЯ,
где С, — условия, а Д — соответствующие им действия. С0 — это ссылка на цель
верхнего уровня дерева, а А0 — нулевое действие, показывающее, что при достижении цели
верхнего уровня никаких действий не требуется. На каждом цикле работы такой системы
условия С; оцениваются сверху вниз (Со, Сь ..., С„) до тех пор, пока не находится первое
истинное условие, и действие, связанное с этим условием, выполняется. Затем цикл
повторяется. Частота повторения определяется скоростью реакции контура управления.
со
/ \а2
Й
а3/\*4
С2
сз '
С4
va5
Рис 7 22 Простое TR-дерево,
содержащее правила условие-^ действие для
достижения цели верхнего уровня
[Klein и др , 2000]
Продукции С,—>Д организуются таким образом, что каждое действие Д, если оно
непрерывно выполняется при нормальных условиях, обеспечивает истинность некоторого
условия более высокого уровня в TR-дереве. Проход по TR-дереву можно рассматривать
как адаптивный. Если некоторое непредвиденное событие в среде управления
изменяет результат предыдущих действий, алгоритм возвращается назад к условию правила
более низкого уровня, и работа по достижению всех целей высокого уровня
возобновляется. Аналогично, если в среде выполнения задачи случается нечто непредвиденное,
то управление автоматически перейдет к действию, связанному с истинным условием.
TR-деревья могут создаваться с помощью алгоритмов планирования, которые
используют общепринятые в искусственном интеллекте методы редукции целей. Начиная от цели
верхнего уровня, планировщик находит действия, результат которых приводит к
достижению этой цели. Предусловия этих действий образуют новое множество подцелей, и
эта процедура исполняется рекурсивно. Процесс завершается, когда предусловия
конечных узлов выполняются в текущей среде. Таким образом алгоритм планирования
выполняет редукцию цели верхнего уровня к текущему состоянию. Конечно, действия часто
имеют побочные эффекты, и планировщик должен тщательно следить за тем, чтобы
каждое действие не изменяло предусловия действий более высокого уровня TR-дерева.
Таким образом, редукция целей связана с удовлетворением ограничений за счет
использования различных стратегий переупорядочения действий.
Итак, алгоритмы TR-планирования используются для построения планов, листья
которых соответствуют текущему состоянию среды. Обычно они не позволяют строить
Глава 7. Сильные методы решения задач
317
планы, которые можно реализовывать из любого состояния мира, так как подобные
планы слишком велики для запоминания и эффективного выполнения. Это очень важно,
поскольку иногда непредвиденные события могут привести мир в состояние, не
удовлетворяющее предусловиям TR-дерева. В этом случае потребуется перепланирование. Как
правило, это делается при повторном запуске планировщика.
В [Benson, 1994] и [Nilsson, 1995] описывается использование адаптивного
планирования для ряда прикладных областей, включая управление распределенными агентами-
роботами и построение тренажера для пилотов. В [Klein и др., 1999], [Klein и др., 2000]
адаптивный планировщик используется для построения и испытания портативной
управляющей системы для ускорителя пучков заряженных частиц. В этих работах область
применения адаптивного планирования обосновывается следующим образом.
1. Ускоритель пучков — это динамическая и зашумленная система.
2. На процесс настройки ускорителя часто влияют стохастические процессы,
радиопомехи или осцилляция источника пучков.
3. Многие действия в процессе настройки являются продолжительными. Это
особенно касается процедур тонкой настройки и оптимизации, которые продолжаются до
тех пор, пока не будут достигнуты некоторые критерии.
4. TR-деревья обеспечивают естественный способ описания планов настройки,
предлагаемых физиками. В самом деле, при небольшом содействии физики сами могут
разработать собственные TR-деревья.
Более подробное описание этих приложений можно найти в литературе, указанной в
заключительной части главы. В следующем разделе мы вернемся к примеру
рассуждений на основе модели из раздела 7.3 и опишем алгоритмы управления-планирования для
двигательной установки космического аппарата.
7.4.4. Планирование: пример NASA
В этом разделе будет описан планировщик для механизма рассуждений на основе
моделей. Вернемся к примеру из [Williams и Nayak, 1996], описанному в подразделе 7.3.2.
Система Livingstone — это реактивный диспетчер конфигурации, использующий
компонентную модель двигательной установки космического корабля для определения
действий по ее реконфигурации (рис. 7.23).
Цели высокого .
уровня
Планировщик
Исполнитель
Подтверждение
Наблюдаемые
значения
РО
Цели
конфигурации
Диспетчер
конфигурации
РР
Космический
корабль
Команды
Рис. 7 23 Реактивное управление конфигурацией на основе модели из [Williams
и Nayak, 1996a]
318
Часть III. Представление и разум в ракурсе искусственного интеллекта
Каждый компонент системы двигателей можно представить в виде
последовательности переходов, описывающей поведение этого элемента в рабочем, аварийном
режимах и переходы между этими режимами, а также стоимость и вероятность
переходов (рис. 7.24). На рис. 7.24 элементы open и closed представляют нормальные
рабочие режимы, a stuck open и stuck closed — аварийные. Команда open имеет
единичную стоимость и вызывает переход от режима closed к open, а команда close —
наоборот. Аварийные переходы переводят клапан из нормального рабочего режима в
один из аварийных режимов с вероятностью 0,01.
open 0,01 stuck open
Нормальный переход
со стоимостью .
Аварийный переход
с вероятностью
closed 0,01 stuck closed
Рис. 7.24. Модель системы переходов клапана из
[Williams и Nayak, 1996a]
Поведение элемента в каждом из режимов описывается формулами
пропозициональной логики, а переходы между режимами — формулами пропозициональной логики при
ограниченном времени. Это описание можно использовать для моделирования цифровых
и аналоговых устройств [deKleer и Williams, 1991], [Weld и deKleer, 1990], а также
программного обеспечения реального времени на основе модели параллельных реактивных
систем [Manna и Penueh, 1992]. Модель системы переходов космического корабля — это
композиция систем переходов его компонентов. При этом множество состояний
конфигурации космического корабля определяется как прямое произведение состояний его
компонентов. Предполагается, что системы переходов всех компонентов действуют
синхронно, т.е. каждый переход состояний космического корабля связан с переходом
состояний его компонентов. Диспетчер конфигурации, основанный на модели, использует
модель переходов системы как для идентификации текущей конфигурации космического
корабля в режиме оценивания (РО), так и для перевода корабля в новое состояние в
режиме реконфигурации (РР). В РО поэтапно генерируются все переходы космического
корабля в состояние, совместимое с текущими наблюдениями. Например, на рис. 7.25
показана ситуация, при которой в предыдущем состоянии левый двигатель запускается
нормально, а в текущем состоянии отсутствует тяга. Задача РО — идентифицировать
состояние, в которое может перейти корабль с учетом этого наблюдения. На рисунке
показаны два возможных перехода, соответствующих неисправности одного из клапанов
главного двигателя. Неисправные клапаны обведены кружочками. При этом можно
также учитывать многие другие переходы, включая маловероятные двойные отказы.
В РР определяются команды, переводящие корабль в состояние для достижения цели
(рис. 7.26). Этот рисунок соответствует ситуации, в которой в режиме идентификации
обнаружена неисправность клапана, ведущего к левому двигателю. В РР предполагается,
что для восстановления нормальной тяги в следующем состоянии необходимо открыть
соответствующий набор клапанов, ведущих к правому двигателю. На рисунке показаны
две из множества конфигураций, позволяющих достичь желаемой цели при изменении
состояния клапанов, обведенных кружками. Переход к верхней конфигурации дешевле,
так как для него необходимо лишь активизировать пироклапаны (см. подраздел 7.3.2).
Глава 7. Сильные методы решения задач
319
Тогда клапаны, ведущие к левому двигателю, перекрываются, и система продолжает
работу с одним двигателем. Использование модели космического корабля как в РО, так и в
РР обеспечивает корректное достижение целей конфигурации.
Возможные текущие
конфигурации при
наблюдении "нет тяги"
Рис. 7 25 Режим оценивания из [Williams и Nayak, J 996а]
Текущая конфигурация
_L_
^ ^?
Возможны следующие
конфигурации,
обеспечивающие
"нормальную тягу"
^ чр
^? ^
Рис. 7.26. Режим реконфигурации из [Williams и Nayak, 1996a]
Оба режима (РО и РР) являются реактивными (см. раздел 6.4). В РО текущая
конфигурация определяется на основе предыдущей конфигурации и текущих наблюдений.
В РР рассматриваются лишь те команды, которые обеспечивают достижение цели в
следующем состоянии. При этом ключевую роль играет предположение о синхронности
переходов. Альтернативой является последовательное моделирование множества
переходов для отдельных компонентов. Однако в этом случае текущая и целевая
конфигурация могут оказаться далеко друг от друга, и возможность ограничить
вывод небольшим фиксированным числом состояний будет сведена на нет. Поэтому в
модели переходы считаются синхронными. Если переходы в программно-
аппаратном обеспечении не синхронны, система Livingstone исходит из
предположения, что все поочередные переходы корректны и поддерживают достижение же-
320
Часть III. Представление и разум в ракурсе искусственного интеллекта
лаемой конфигурации. В системе Burton, развивающей основные возможности
Livingstone, это предположение отсутствует. В системе Burton планировщик определяет
последовательность управляющих воздействий, производящих все желаемые переходы
[Williams и Nayak, 1997]. NASA использует архитектуру Burton в проекте Tech Sat 21.
В системе Livingstone не нужно генерировать все переходы и, соответственно,
управляющие команды. Требуются только наиболее вероятные переходы и оптимальная команда
управления. Для их эффективного вычисления задачи РО и РР необходимо
переформулировать как задачи комбинаторной оптимизации. В такой постановке в РО поэтапно
генерируются наиболее вероятные траектории корабля. Затем в РР определяется команда
наименьшей стоимости, которая переводит корабль из наиболее вероятной текущей
конфигурации к конфигурации, соответствующей желаемой цели. Задачи комбинаторной
оптимизации решаются с помощью алгоритма поиска до первого наилучшего соответствия
(best-first). Более формальное описание РО и РР, а также детальное описание алгоритмов
поиска и планирования содержится в [Williams и Nayak, 1996, 1996а].
7.5. Резюме и дополнительная литература
Экспертные системы, основанные на правилах, строятся в виде продукционных
систем. Вне зависимости от того, основан конечный продукт на данных или на цели,
моделью программы является продукционная система, генерирующая граф поиска (глава 5).
В главах 14 и 15 будут представлены оболочки экспертных продукционных систем,
написанные на языках PROLOG и LISP соответственно. Эти оболочки позволяют
реализовать поиск на основе цели. Правила могут включать степень надежности, что
обеспечивает возможность эвристического поиска.
Представленный в этой главе материал можно дополнить рядом работ. Особенно
рекомендуем подборку оригинальных публикаций по системе MYCIN [Buchanan и Shor-
tliffe, 1984]. Для робастной реализации поиска на основе данных можно использовать
программное обеспечение CLIPS, распространяемое NASA [Giarratano и Riley, 1989].
К важным книгам по общей инженерии знаний относятся [Hayes-Roth и др., 1984],
[Waterman, 1986], [Alty и Coombs, 1984], [Johnson и Keravnou, 1985], [Harmon и др., 1988]
и [Negoita, 1985]. Советуем также прочитать [Ignizio, 1991], [Mockler и Dologite, 1992] и
[Durkin, 1994].
Поскольку экспертные системы должны обладать обширными знаниями в конкретной
предметной области, важным источником знаний для них являются описания примеров
из этой области. Книги из этой категории включают [Klahr и Waterman, 1986], [Keravnou
и Johnson, 1986], [Smart и Langeland-Knudsen, 1986], [Coombs, 1984], [Prerau, 1990].
Особенно рекомендуем книгу [Durkin, 1994] из-за ее многочисленных практических
предложений по созданию экспертных систем.
Разработан ряд методов для извлечения знаний. Подробная информация по
отдельным методологиям представлена в [McGraw и Harbison-Briggs, 1989] и [Chorafas, 1990],
а также в [Mockler и Dologite, 1992].
Рассуждения на основе примеров являются ответвлением более ранних исследований
группы Шенка (Schank) из Йельского университета по сценариям (см. подразделы 6.1.3
и 6.1.4). Книга [Kolodner, 1993] является всеобъемлющим введением в эту область знаний, а
также предлагает ценные взгляды на разработку и проектирование подобных систем. В
работах [Leake, 1992,1996] содержатся важные комментарии по реализации объяснений в систе-
Глава 7. Сильные методы решения задач
321
мах, основанных на примерах. В настоящее время существует ряд коммерческих
программных продуктов, поддерживающих технологию систем, основанных на примерах.
Рассуждения на основе моделей берут начало в явном представлении логических
цепочек и областях математики, изучающих процессы обучения [Brown и Burton, 1978],
[Brown и VanLehn, 1980], [Brown и др., 1982]. Более современные исследования
представлены в [Hamscher и др., 1992] и [Davis и др. 1982]. В [Skinner и Luger, 1995] и других
работах по агентным архитектурам [Russell и Norvig, 1995] описываются гибридные
экспертные системы, в которых взаимодействие множества подходов к решению проблем
может создать синергетический эффект.
В разделе, посвященном планированию, описаны некоторые из структур данных и
методы поиска, предназначенные для создания планировщиков общего назначения. По
этой тематике можно также порекомендовать описание ABSTRIPS или ABstract для
генератора отношений STRIPS [Sacerdotti, 1974] и системы NOAH для нелинейного или
иерархического планирования [Sacerdotti, 1975], [Sacerdotti, 1977]. Более современные
планировщики описаны в разделе 15.3 и работе [Benson и Nilsson, 1995].
Метапланирование — это метод рассуждения не только о плане, но и о процессе
планирования. Это играет важную роль в разработке экспертных систем. В качестве первоисточников
можно посоветовать литературу по системам Meta-DENDRAL [Lindsay и др., 1980] и Teiresias
[Devis, 1982]. Непрерывно взаимодействующие с окружающей средой планировщики, т.е.
системы, моделирующие изменяющееся окружение, описаны в [McDermott, 1978].
Дальнейшие исследования включают оппортунистическое планирование, использующее
метод классной доски, и планирование, основанное на объектно-ориентированном описании
[Smoliar, 1985]. Несколько обзоров по области планирования содержатся в словарях [Вагг и
Feigenbaum, 1989] [Cohen и Feigenbaum, 1982] и энциклопедии по искусственному интеллекту
[Shapiro, 1987]. Вопросы нелинейного и частично упорядоченного планирования
представлены в [Russel и Norvig, 1985]. К этой области относится и работа [Allen и др., 1990].
Наше описание и анализ рассуждений на основе моделей, а также алгоритмы
планирования взяты из [Williams и Nayak, 1996, 1996а]. Мы благодарны авторам, а также издательству
AAAI Press за разрешение описать эти исследования в своей книге.
7.6. Упражнения
1. В разделе 7.2 мы ввели набор правил для диагностики автомобиля. Определите
возможных инженеров по знаниям, экспертов в данной предметной области и
потенциальных конечных пользователей для такого приложения. Опишите ожидания,
возможности и потребности каждой из этих групп.
2. Вернемся к упражнению 1. Создайте на русском языке или псевдокоде 15 правил "если...,
то..." (отличных от описанных в разделе 7.2) для представления отношений в этой
предметной области. Постройте граф, представляющий взаимосвязи этих 15 правил.
3. Рассмотрите граф из упражнения 2. Какой поиск вы рекомендуете использовать: на
основе данных или на основе цели? Поиск в ширину или в глубину? Каким образом
здесь могут помочь эвристики поиска? Обоснуйте ответы на эти вопросы.
4. Выберите другую область для разработки экспертной системы. Ответьте на вопросы
1-3 для этого приложения.
5. Реализуйте экспертную систему, используя коммерческую оболочку. Особенно
рекомендуем оболочку CLIPS [Giarratano и Riley, 1989].
322
Часть III. Представление и разум в ракурсе искусственного интеллекта
6. Оцените оболочку, которую вы использовали при выполнении упражнения 5. Каковы
ее сильные и слабые стороны? Что в ней можно улучшить? Подходит ли она для
решения вашей задачи? Для каких задач предназначен этот инструментарий?
7. Создайте систему рассуждений на основе модели для простого электронного прибора.
Скомбинируйте несколько небольших приборов для создания большой системы. Для
описания функциональности системы можно использовать правила "если..., то...".
8. Прочтите и прокомментируйте статью [Devis и др., 1982].
9. Прочтите одну из ранних статей о рассуждениях на основе моделей, посвященную
обучению детей арифметике [Brown и Burton, 1978] или электронике [Brown и
VanLehn, 1980]. Прокомментируйте этот подход.
10. Постройте механизм рассуждений на примерах для произвольно выбранного
приложения, например, задачи выбора курсов по вычислительной технике и компьютерным
наукам при изучении базовых университетских дисциплин или получении степени магистра.
11. Используйте коммерческое программное обеспечение (найдите в Internet) для построения
системы рассуждений на примерах из упражнения 10. Если нет готового программного
обеспечения, постройте такую систему на языках PROLOG, LISP или Java.
12. Прочтите и прокомментируйте статью [Kolodner, 1991 я].
13. Опишите остальные аксиомы границ, необходимые для четырех операторов
pickup, putdown, stack и unstack, упомянутых в правилах 4-7 из раздела 7.4.
14. Используйте операторы и аксиомы границ из предыдущего упражнения для
генерации пространства поиска, показанного на рис. 7.19.
15. Покажите, как можно использовать списки add и delete для замены аксиом
границ при генерации состояния 2 на основе состояния 1 в разделе 7.4.
16. Используйте списки добавления и вычеркивания для генерации пространства поиска
из рис. 7.19.
17. Спроектируйте автоматический контроллер, который мог бы использовать списки
добавления и вычеркивания для генерации графа поиска, подобного
представленному на рис. 7.19.
18. Укажите не менее двух несовместимых (по предусловиям) подцелей в операторах из
мира блоков (рис. 7.19).
19. Прочтите исследование ABSTRIPS [Sacerdotti, 1974] и объясните, как управлять
линейными (или несовместимыми) подцелями при планировании задач.
20. В подразделе 7.4.3 был представлен планировщик, созданный Нильсоном и его
учениками в Стэндфордском университете [Benson и Nillson, 1985]. Адаптивное
планирование позволяет описывать продолжительные действия, т.е. такие, которые
остаются истинными в течение определенных временных периодов. Почему системы
адаптивного планирования предпочтительнее планировщиков типа STRIPS?
Постройте адаптивный планировщик на языках PROLOG, LISP или Java.
21. Прочтите статьи [Williams и Nayak, 1996], [Williams и Nayak, 1996a] и обсудите
системы планирования на основе моделей.
22. Расширьте схему представления в пропозициональном исчислении, введенную в
[Williams и Nayak, 1996a, С. 973] для описания переходов состояний двигательной
установки.
Глава 7. Сильные методы решения задач
323
Рассуждения
в условиях
неопределенности
Любая традиционная логика обычно предполагает использование точных
символов Поэтому она применима не к земной жизни, а лишь к
воображаемому небесному существованию.
— Бертран Рассел (Bertrand Russel)
Свойством разума является удовлетворенность той степенью точности,
которую допускает природа субъекта, а не ожидание точности там, где
возможно лишь приближение к истине.
— Аристотель (Aristotle)
Если законы математики опираются на реальность, они являются
неопределенными. А коль скоро они точны, они не отражают реальность.
— Альберт Эйнштейн (Albert Einstein)
8.0. Введение
Процедуры вывода, описанные в частях I и И, а также большинство процедур из
части III основаны на модели рассуждения, используемой в исчислении предикатов: из
корректных предпосылок с помощью обоснованных правил вывода можно получить новые
гарантированно корректные заключения. Однако, как было показано в главе 7,
существует много ситуаций, для которых такой подход не годится. Зачастую полезные
заключения должны быть получены из неудачно сформулированных и неопределенных данных с
использованием несовершенных правил вывода.
Извлечение полезных заключений из неполных и неточных данных с помощью
несовершенного вывода является неразрешимой задачей, однако человек в повседневной
жизни справляется с этим достаточно успешно. Мы ставим корректные медицинские
диагнозы и рекомендуем лечение на основании неоднозначных симптомов; анализируем
автомобильные проблемы; понимаем языковые выражения, часто являющиеся
неполными или двусмысленными; узнаем друзей по голосу или по походке и т.д.
Для демонстрации проблемы рассуждения в условиях неопределенности рассмотрим
правило 2 экспертной системы диагностики автомобиля, представленной в разделе 7.2:
если
двигатель не вращается и
фары не горят,
то
проблема в аккумуляторе или проводке.
На первый взгляд, это правило напоминает обычное предикатное выражение,
используемое в правиле вывода модус поненс. Однако это не так — оно эвристично по природе.
Возможно, хотя и маловероятно, что аккумулятор и проводка исправны, просто у
автомобиля поврежден стартер и перегорели фары. Невозможность завести двигатель и
отсутствие света не обязательно означают неисправность аккумулятора или проводки.
Интересно, что обратное утверждение правила истинно.
если
проблема в аккумуляторе или проводке,
то двигатель не вращается и фары не горят.
Если чудо не произойдет, при неисправном аккумуляторе ни освещение, ни двигатель
работать не будут!
Эта экспертная система обеспечивает пример абдуктивного рассуждения. Формально
абдукция означает, что из P-+Q и О можно вывести Р. Абдукция является
необоснованным (unsound) правилом вывода, означающим, что заключение не обязательно истинно
для каждой интерпретации, при которой истинны предпосылки (раздел 2.2).
Хотя абдукция и является необоснованной, она часто используется при решении
проблем. "Логически корректная" версия правила об аккумуляторе не очень важна при
диагностике автомобильных неисправностей, поскольку предпосылка ''проблема в
аккумуляторе" в реальной задаче является целью, а заключение — наблюдаемыми симптомами,
с которыми необходимо работать. Тем не менее правило может быть использовано аб-
дуктивно, подобно правилам во многих экспертных системах. Неисправности или
болезни вызывают (имплицируют) симптомы, а не наоборот; но диагноз должен ставиться от
симптомов к причинам, их вызвавшим.
В системах, основанных на знаниях, с правилом часто связывается фактор
уверенности для измерения степени доверия его заключению. Например, правило P-+Q (.9)
выражает следующее: "Если вы верите, что Р истинно, то О будет выполняться в 90%
случаев". Таким образом, эвристические правила могут выражать политику доверия.
Следующая проблема рассуждений в экспертных системах — как извлечь полезные
сведения из данных с неполной или некорректной информацией. Для отражения
достоверности данных можно использовать меру неопределенности, например, утверждение
"освещение работает на полную мощность (.2)" указывает, что фары горят, но очень
слабо. Меру достоверности и несовершенства данных можно учесть в правилах.
В этой главе обсуждается несколько способов управления абдуктивным выводом и
неопределенностью, главным образом при решении задач, основанных на знаниях.
В разделе 8.1 показывается, как логические формализмы можно развить для решения
абдуктивных задач. В разделе 8.2 рассматривается несколько альтернатив логическому
подходу, в том числе неточный вывод на основе фактора уверенности, "нечеткие"
рассуждения и теория Демпстера-Шафера. Эти простые приемы разработаны для
разрешения некоторых проблем байесовского подхода, всплывающих при построении
экспертных систем.
326
Часть III. Представление и разум в ракурсе искусственного интеллекта
В разделе 8.3 вводятся стохастические подходы к неточному выводу. Эти приемы
основаны на теореме Байеса, относящейся к рассуждениям о частоте событий на основе
априорной информации о них. В заключение приводятся стохастические модели,
представленные с помощью байесовских сетей доверия (belief network).
8.1. Абдуктивный вывод, основанный на логике
До сих пор в основном рассматривались логические подходы к решению задач, при
которых часть знаний явно используется в рассуждениях, и, как явствует из главы 7,
может обеспечить объяснения для выведенных заключений. Но традиционная логика имеет
и свои ограничения, особенно в условиях неполной или неопределенной информации.
В этих ситуациях традиционные процедуры вывода не могут быть использованы. В
разделе 8.1 приводится несколько расширений традиционной логики, позволяющих
поддерживать абдуктивный вывод.
В подразделе 8.1.1 логический подход расширяется для описания мира изменяющейся
информации и степени доверия ей. Традиционная математическая логика является
монотонной. Она основана на множестве аксиом, принимаемых за истинные, из которых выводятся
следствия. Добавление в эту систему новой информации может вызвать только увеличение
множества истинных утверждений. Добавление знаний никогда не приводит к уменьшению
множества истинных утверждений. Это свойство монотонности приводит к проблемам при
моделировании рассуждений, основанных на доверии (belief) и предположениях. При
рассуждении в условиях неопределенности человек делает выводы на основе текущей информации и
степени уверенности в ней. Однако, в отличие от математических аксиом, мера доверия и
выводы могут изменяться по мере накопления информации.
Проблему изменяющейся степени доверия решают немонотонные рассуждения.
Система немонотонных рассуждений управляет степенью неопределенности, делая
наиболее обоснованные предположения в условиях неопределенной информации. Затем
выполняется вывод на основе этих предположений, принимаемых за истинные. Позже мера
доверия может измениться и потребовать перепроверки всех заключений, выведенных с
ее использованием. Затем для сохранения непротиворечивости базы знаний могут быть
использованы алгоритмы поддержки истинности (подраздел 8.1.2). Другие расширения
логического подхода включают "минимальные модели" (подраздел 8.1.3) и метод,
основанный на множественном покрытии (подраздел 8.1.4).
8.1.1. Логика немонотонных рассуждений
Немонотонность является важной особенностью общесмысловых рассуждений и
решения задач человеком. В большинстве случаев при планировании мы делаем
многочисленные предположения. Например, выезжая на автомобиле, следует учитывать состояние
дорог и транспорта. При нарушении одного из предположений, например, из-за аварии
на обычном маршруте, планы изменяются и выбирается альтернативный маршрут.
Традиционные рассуждения, использующие логику предикатов, основываются на
трех важных предположениях. Во-первых, выражения теории предикатов должны
адекватно описывать соответствующую предметную область. Следовательно, в виде
предикатов должна быть представлена вся информация, необходимая для решения задачи. Во-
вторых, информационная база должна быть непротиворечивой, т.е. части знаний не
должны противоречить друг другу. И, наконец, с использованием правил вывода количе-
Глава 8. Рассуждения в условиях неопределенности
327
ство известной информации увеличивается монотонно. При невыполнении хотя бы
одного из этих правил основанный на логике традиционный подход работать не будет.
Немонотонные системы решают все три вопроса. Во-первых, системы рассуждений
часто сталкиваются с отсутствием знаний о предметной области. В данном случае эти
знания важны. Предположим, у нас нет знаний о предикате р. Отсутствие знания
означает, что мы не уверены в истинности р или мы уверены, что р не является истинным! На
этот вопрос можно ответить несколькими способами. Система PROLOG (см. главу 14)
использует предположение о замкнутости мира и считает ложью все те утверждения,
истинность которых не может доказать. Человек часто выбирает альтернативный подход,
допуская истинность утверждения, пока не будет доказано обратное.
Другой подход к проблеме отсутствия знания заключается в точном определении
истины. В человеческих отношениях применяется принцип презумпции невиновности.
Результат этих ограничивающих предположений позволяет эффективно восполнить
упущенные детали нашего знания, продолжить рассуждения и получить новые заключения,
основанные на этих предположениях. Предположение о замкнутости мира и его
альтернативы обсуждаются в подразделе 8.1.3.
Основа человеческих рассуждений — знание о традиционном ходе вещей в мире.
Большинство птиц летает. Родители, как правило, любят и поддерживают своих детей. Выводы
делаются на основе непротиворечивости рассуждения с предположениями о мире. В этом
разделе обсуждаются модальные операторы, такие как is consistent with (согласуется с) и
unless (если не) для реализации рассуждений, основанных на предположениях.
Второе предположение, используемое в системах, основанных на традиционной логике,
заключается в том, что знание, на котором строятся рассуждения, непротиворечиво. Для
человеческих рассуждений это очень ограничительное предположение. В задачах диагностики
часто принимается во внимание множество возможных объяснений ситуации,
предполагается, что некоторые из них истинны, пока не подтверждаются альтернативные предположения.
При анализе авиакатастроф эксперт рассматривает ряд альтернативных причин, исключая
некоторые из них по мере появления новой информации. При рассмотрении альтернативных
сценариев люди используют знание о том, каков этот мир обычно. Желательно, чтобы
логические системы тоже могли принимать во внимание альтернативные гипотезы.
И, наконец, для использования логики необходимо решить проблему адаптации базы
знаний. При этом возникают два вопроса. Первый — как добавлять в базу знания,
которые основываются только на предположениях, и второй — что необходимо делать, если
одно из предположений окажется некорректным. Для решения первого вопроса можно
обеспечить добавление нового знания на основе предположений. Это новое знание
априори может считаться корректным и, в свою очередь, использоваться для вывода
нового знания. Цена этого подхода — необходимость отслеживать весь ход рассуждений и
доказательств, основанных на предположениях. Мы должны быть готовы к пересмотру
любого знания, основанного на этих предположениях.
Поскольку заключения иногда пересматриваются, немонотонные рассуждения
называются аннулируемыми, т.е. новая информация может свести на нет предыдущие
результаты. Структуры представления и процедуры поиска, отслеживающие рассуждения
логической системы, называются системами поддержки истинности, или СПИ. При
аннулируемом рассуждении СПИ сохраняют непротиворечивость базы знаний, отслеживая
заключения, которые позднее могут быть оспорены. В подразделе 8.1.2 рассматривается
несколько подходов к поддержке истинности. Рассмотрим операторы, обеспечивающие
аннулируемость рассуждений в системах, основанных на традиционной логике.
328
Часть III. Представление и разум в ракурсе искусственного интеллекта
При реализации немонотонного рассуждения можно расширить логику с помощью
оператора unless. Этот оператор поддерживает вывод на основе предположения о ложности
аргумента. Допустим, имеется следующее множество выражений из логики предикатов.
р(Х) unless q(X) ->r(X),
P(Z).
r(l/l/)->s(LV).
Первое правило означает, что г(Х) можно вывести, если истинно р(Х), и мы не
верим, что истинно q(X). Если эти условия выполняются, мы выводим г(Х), а используя
г(Х), можем вывести s(X). Впоследствии, если обнаружится, что q(X) истинно, г(Х) и
s(X) должны быть отменены. Заметим, что оператор unless связан скорее с понятием
веры, чем истинности. Впоследствии изменение значения аргумента с "вероятно, ложь
либо неизвестно" на "точно либо вероятно истина" может вызвать отмену всех выводов,
зависящих от этих предположений. Расширяя логику за счет рассуждений на основе
предположений, которые позже могут быть отменены, мы вводим в механизм
рассуждений элемент немонотонности.
Описанная выше схема рассуждений может быть использована также для описания
правил умолчания [Reiter, 1980]. Замена р(Х) unless q(X) -> г(Х) на р(Х) unless ab
р(Х) -> г(Х), где ab p(X) — это abnormal p(X), означает, что при отсутствии аномалии,
такой как птица с перебитым крылом, можно сделать вывод, что если X — птица, то X
может летать.
Другой модальный оператор для расширения логических систем рассматривается в
[McDermott и Doyle, 1980]. Авторы усиливают логику предикатов первого порядка
модальным оператором М, который помещается перед предикатом и читается как "не
противоречит". Введем следующие предикаты: good_student — быть хорошим студентом,
studyJhard — прилежно учиться, graduates — окончить ВУЗ. Тогда предложение
VX good_student(X) л М study_hard(X) -> graduates(X)
может быть прочитано следующим образом: для любого X, где X — хороший студент,
если факт, что X прилежно учится, не противоречит остальной информации, то X закончит
ВУЗ. Конечно, основной проблемой здесь является точное определение значения "не
противоречит остальной информации".
Сначала заметим, что утверждение "не противоречит остальной информации" может
оказаться неразрешимым. Причина в том, что модальный оператор формирует
супермножество для уже неразрешимой системы (см. подраздел 2.2.2), и таким образом сам
будет неразрешимым. Существуют два способа преодоления неразрешимости.
Первый — использование метода доказательства от противного. В нашем примере можно
попробовать доказать выражение not(study_hard(X)). Если не удастся доказать, что X
не учится, то можно предположить, что X учится. Этот подход часто используется в
PROLOG-подобной реализации логики предикатов. К сожалению, метод доказательства
от противного может слишком ограничить область интерпретации.
Второй подход к проблеме непротиворечивости заключается в выполнении
эвристического и ограниченного (по времени или по памяти) поиска истинности предиката
(в нашем примере — study_hard(X)). Если поиск не приводит к доказательству
ложности предиката, можно предположить, что он истинен. При этом следует понимать,
что утверждение graduates и все основанные на нем заключения в дальнейшем
могут быть отменены.
Глава 8. Рассуждения в условиях неопределенности
329
Используя оператор "не противоречит", можно получить противоречивые
результаты. Предположим, Петр является хорошим студентом, но любит вечеринки. Тогда для
описания ситуации можно использовать следующее множество предикатов.
VX good_student(X) л М study_hard(X) -> graduates(X)
VXparty_person (X) л М not(study_hard(X)) -> not(graduates{X))
good_student(peter)
party_person(peter),
где party_person — любитель вечеринок. Из этого множества выражений можно вывести
как заключение, что он окончит ВУЗ, так и заключение, что он его не окончит (если нет
более точной информации о привычках Петра и не известно, прилежен ли он в учебе)!
Одним из методов рассуждения, позволяющих избежать таких противоречивых
результатов, является отслеживание связывания переменных, используемых в модальном
операторе "не противоречит". Таким образом, единожды связав значение peter с
предикатом studyJnard или not(study_hard), система должна предотвратить связывание
этого значения с противоположным по смыслу предикатом. Другие системы немонотонной
логики [Mcdermott и Doyle, 1980] являются еще более консервативными и
предотвращают любые заключения из таких потенциально противоречивых множеств выражений.
Возможна и другая аномалия.
VYvery_smart(Y) л М not(study_hard{Y)) -> not{study_hard(Y))
VX not(very_smart(X)) л М not(study_hard(X)) -> not(study_hard(X)),
где very_smart — очень умный.
Из этих выражений можно вывести новое выражение.
VZ M not(study_hard{Z)) -> not(study_hard(Z)).
Последующие исследования семантики оператора "не противоречит" направлены
на решение проблем с такими аномальными рассуждениями. Одним из дальнейших
расширений является логика, обеспечивающая автоматическое образование понятий
(autoepistemic logic) [Moore, 1985].
Другой немонотонной логической системой является логика умолчания (default logic),
созданная Рейтером [Reiter, 1980]. Логика умолчания использует новое множество
правил вывода вида
A(Z)a: B(Z)-*C(Z)t
которое читается так: если A(Z) доказуемо и если оно не противоречит знаниям,
позволяющим предположить B(Z), можно вывести C(Z).
На первый взгляд, логика умолчания во многом подобна описанной выше
немонотонной логике Мак-Дермотта и Дойла. Важным различием между ними является метод, с
помощью которого совершается рассуждение. В логике умолчания используются
специальные правила вывода правдоподобного расширения исходного множества
аксиом/теорем. Каждое расширение создается путем использования одного из правил вывода
логики умолчания для знаний, представленных исходным множеством аксиом/теорем.
Таким образом, естественно получается ряд правдоподобных расширений исходной базы
знаний. Это можно продемонстрировать на следующем примере.
VX good_student(X) л: study_hard(X) -> graduates(X)
VYparty(Y) л: not{study_hard(Y)) -> not( graduates(Y)).
Каждое выражение можно использовать для создания уникального правдоподобного
расширения, основанного на исходном множестве знаний.
330
Часть III. Представление и разум в ракурсе искусственного интеллекта
Логика умолчания позволяет использовать в качестве аксиомы для дальнейших
рассуждений любую теорему, выведенную в рамках правдоподобного расширения. Но,
чтобы установить, какое расширение должно использоваться при дальнейшем решении
задачи, необходимо обеспечить управление процессом принятия решений. Логика
умолчания ничего не говорит о выборе возможных правдоподобных расширений из базы
знаний. Подробнее эти темы рассмотрены в работах [Reiter и Criscuolo, 1981] и
[Touretzky, 1986].
Наконец, существует способ немонотонных рассуждений на основе множественного
наследования. Упомянутый выше Петр (хороший студент и любитель вечеринок) мог
наследовать лишь одно из множества свойств. Поскольку он — хороший студент, то,
вероятно, он окончит ВУЗ. Но он может наследовать и другое свойство (в данном случае
частично противоречащее первому) — быть любителем вечеринок. Следовательно, он
может и не окончить ВУЗ.
Важной проблемой, с которой сталкиваются системы немонотонного рассуждения,
является эффективная проверка множества заключений в свете изменяющихся
предположений. Например, если для вывода s используется предикат г, то отмена г исключает
также s, а равно и любое другое заключение, использующее s. Если отсутствует
независимый вывод s, s должно быть исключено из списка корректных утверждений.
Реализация этого процесса в худшем случае требует пересчета всех заключений при каждом
изменении предположений. Представляемые ниже системы поддержки истинности
обеспечивают механизм для поддержки непротиворечивости базы знаний.
8.1.2. Системы поддержки истинности
Система поддержки истинности (СПИ) может использоваться для защиты
логической целостности заключений системы вывода. Как отмечалось в предыдущем разделе,
всякий раз, когда изменяются предположения в базе знаний, необходимо заново
проверить все заключения. Системы поддержки рассуждений решают эту проблему,
пересматривая заключения в свете новых предположений.
Один из способов решения этой проблемы обеспечивает алгоритм возврата, впервые
предложенный в подразделе 3.2.2. Возврат к предыдущему состоянию является
систематическим методом для исследования всех альтернатив в точках ветвления при решении задач
на основе поиска. Однако существенным недостатком такого алгоритма поиска является
способ систематического выхода из тупиков пространства состояний и просмотра
последних вариантов переходов. Этот подход иногда называется хронологическим возвратом к
предыдущему состоянию. Алгоритм хронологических возвратов систематически проверяет
все альтернативы в пространстве, однако способ реализации этого механизма является
затратным по времени, неэффективным, а при очень большом пространстве — бесполезным.
В процессе поиска желательно отступить назад прямо в точку пространства, где
возникла проблема, и откорректировать решение в этом состоянии. Этот подход называется
возвратом с учетом зависимостей. Рассмотрим пример немонотонного рассуждения.
Нам необходимо прийти к заключению р, которое мы не можем вывести прямо. Однако
существует правдоподобное предположение д, которое, будучи истинным, приводит к р.
Таким образом, предполагая q истинным, мы выводим р. Продолжаем рассуждение и на
основе истинности р выводим г и s. Двигаясь еще дальше, уже без учета р, г или s
выводим истинность t и и. И, наконец, доказываем, что прежнее предположение q является
ложным. Что делать в данной ситуации?
Глава 8. Рассуждения в условиях неопределенности
331
Алгоритм поиска с хронологическими возвратами должен пройти все шаги
рассуждения в обратном порядке. Возврат с учетом зависимостей обеспечивает переход
непосредственно к источнику противоречивой информации, а именно — к первому
предположению об истинности q. Далее надо двигаться вперед, отменяя истинность р, г и s. В
это же время можно проверить, могут ли г и s быть выведены независимо от р и q. To,
что они были выведены из неправильного предположения, не означает, что они не могут
быть доказаны иным образом. И, наконец, так как t и и были выведены без р, г или s,
пересматривать их не надо.
Для использования в системе рассуждения алгоритма возврата с учетом зависимостей
необходимо выполнить следующие действия.
1. Связать с каждым выполняемым заключением его обоснование. Это обоснование
описывает процесс вывода данного заключения. Обоснование должно содержать
все факты, правила и предположения, используемые для получения заключения.
2. Обеспечить механизм нахождения множества ложных предположений в рамках
обоснования, которое привело к противоречию.
3. Отменить ложные предположения.
4. Создать механизм, отслеживающий отмененные предположения и отменяющий
все заключения, которые используют в своих обоснованиях отмененные ложные
предположения.
Конечно, отмененные заключения не обязательно являются ложными, так что
необходимо перепроверить, могут ли они быть выведены независимо от отмененных
предпосылок. Ниже приводится два метода построения систем возврата с учетом зависимостей.
В [Doyle, 1979] описана одна из первых систем поддержки истинности, названная
системой поддержки истинности с учетом обоснования (justification based truth maintenance
system), или СПИО. Джон Дойл (Jon Doyle) был первым исследователем, который явно
отделил систему поддержки истинности, сеть предположений и их обоснования от системы
рассуждений, действующей в некоторой предметной области. Результатом этого
разделения является то, что СПИО взаимодействует с решателем задач (возможно, системой
автоматического доказательства теорем), получая информацию о новых предположениях и
обоснованиях и, в свою очередь, поставляя решателю задач информацию о
предположениях, которые должны быть достоверными с учетом существующих обоснований.
СПИО выполняет три основные операции. Первая — проверка сети обоснований. Эту
проверку может инициировать решатель задач с помощью запросов вида: "Должен ли я
доверять предположению р? Почему я должен доверять предположению р? Какие
предположения лежат в основе р?".
Второй операцией СПИО является модификация сети зависимостей на основе
информации, поставляемой решателем задач. Модификация подразумевает введение новых
предположений, дополнение или устранение предпосылок, дополнение противоречий и
обоснование предположений. Последней операцией СПИО является адаптация сети. Эта
операция выполняется всякий раз, когда происходит изменение сети зависимостей.
Операция адаптации пересматривает все предположения в соответствии с существующими
обоснованиями.
Для демонстрации СПИО сконструируем простую сеть зависимостей. Рассмотрим
модальный оператор М, представленный в подразделе 8.1.1, который помещается перед
предикатом и читается как "не противоречит". Например,
332
Часть III. Представление и разум в ракурсе искусственного интеллекта
VXgood_student(X) л M study_hard{X) -> study_hard(X)
VYpartyjDerson(Y) -> not( study_hard(Y))
good_student(david)
Поместим это множество предположений в сеть обоснований.
В СПИО каждый предикат, представляющий предположение, связывается с двумя
другими множествами предположений. Первое множество, помеченное на рис. 8.1
меткой /Л/, является множеством предположений, которые должны быть достоверными для
рассматриваемого предположения. Второе множество OUT является множеством
предположений, которые не должны быть истинными для рассматриваемого предположения.
На рис. 8.1 представлено обоснование предиката study_hard{david), выведенного из
предоставленных выше предикатов. Обозначения на рис. 8.1 адаптированы из работы
[Goodwin, 1982] и объясняются на рис. 8.2. Предпосылки обоснований помечаются в
соответствии с рис. 8.2, я, а комбинации предположений, приводящих к заключению,
обозначаются в соответствии с рис. 8.2, б.
J ►Г goodstudent(david)
OUT
J >( party_person(Y) J-
Рис. 8.1. Сеть обоснований утверждения о том, что Давид учится
прилежно
D—*0 >=0-^CD
(not{b))
Рис 8.2. Обоснование предпосылки и конъюнкция двух
предположений а и not(b), доказывающих с [Goodwin, J 982]
Из информации, приведенной на рис. 8.1, решатель задач может заключить, что
study_hard(david) истинно, так как предпосылка good_student{david) считается
истинной и совместимой с фактом, что хорошие студенты прилежно учатся. К тому же в
этом примере нет информации о том, что Давид не учится прилежно.
Добавим предпосылку party_person(david). Это дополнение позволяет вывести
not(study_hard(david)), и предпосылка study_hard(david) больше не поддерживается.
Обоснования для этой новой ситуации отражены на рис. 8.3. Обратите внимание на
метки IN и OUT.
Как свидетельствуют рис. 8.1 и 8.3, в СПИО предикатные отношения явно не
выражаются через начальное множество предположений. СПИО — это просто сеть,
позволяющая рассматривать лишь отношения между атомарными предположениями и их
отрицаниями и использующая эти данные для подтверждения предположений. Полное
множество предикатных связей и схем вывода (VX, л, v, —» и т.д.) используется в самом
решателе задач. В системах, описанных в [McAllester, 1978] и [Martins и Shapiro, 1988],
СПИО и решатель задач объединены в рамках общего представления.
Глава 8. Рассуждения в условиях неопределенности
333
j ►Г good_student{david)
( not{study_hard{david))
OUT
J ►Г party_person{david) J w V
Рис. 8.3. Новая разметка информации,
приведенной на рис. 8.1, связанная с новой предпосылкой
ра rty_person (da vid)
СПИО описывает лишь зависимости между предположениями, но не содержимое
этих предположений. Поэтому предположения заменяются идентификаторами, часто
имеющими вид пь п2, ..., которые ассоциируются с объектами (узлами) сети. Тогда
алгебра множеств IN и OUT позволяет СПИО рассуждать о поддержке предположений.
Итак, СПИО работает со множествами узлов и обоснований. Узлы означают
предположения, а обоснования поддерживают их. С узлами ассоциированы метки IN
и OUT, указывающие статус предположения для данного узла. Мы можем
рассуждать о поддержке любого узла посредством отнесения его ко множествам IN и OUT
других узлов, составляющих их обоснования. Первичными операциями алгебры
СПИО являются операторы проверки, модификации и адаптации, указанные выше.
И, наконец, поскольку проверка обоснования производится путем обратного
просмотра связей самой сети обоснований — это пример возврата с учетом
зависимостей. Для получения более полной информации об этом подходе в СПИО читайте
[Doyle, 1983] или [Reinfrank, 1989].
Другим типом системы поддержки истинности является система поддержки
истинности на основе предположений (СПИП). Термин "на основе предположений" впервые
был введен в работе [deKleer, 1984], хотя подобные идеи можно отыскать и в [Martins и
Shapiro, 1983]. В этих системах для узлов сети не используются метки IN и OUT. Узлы
скорее являются множествами предпосылок (предположений), лежащих в основе их
вывода. В [deKleer, 1984] также учитывается различие между узлами-предпосылками,
являющимися истинными везде, и узлами, которые могут описывать предположения
решателя задач, которые позже могут быть отменены.
Преимущество СПИП по отношению к СПИО состоит в дополнительной гибкости,
которую обеспечивает СПИП, работая со множеством возможных состояний предположений.
Пометив предположения с помощью множеств предпосылок, при которых они истинны,
получаем не единое состояние предположения (в СПИО все узлы /Л/), а скорее ряд
возможных состояний— набор всех подмножеств, поддерживающих предпосылки. Создание
различных множеств предположений или возможных миров позволяет сравнивать
результаты, получаемые при выборе разных предпосылок, обнаруживать противоречия и
избавляться от них, а также обеспечивает существование различных решений задачи.
К недостаткам СПИП относятся невозможность представления множества предпосылок,
которые сами являются немонотонными, и управления ими с помощью решателя задач.
Взаимодействие между СПИП и решателем задач реализовано аналогично
системе СПИО. Оно основано на операторах проверки, модификации и адаптации.
Единственное различие состоит в том, что в СПИП нет единого состояния
предположения, а есть подмножества потенциальных предпосылок. Цель СПИП — найти
минимальные множества предпосылок, достаточные для поддержки каждого узла. Эти
334
Часть III. Представление и разум в ракурсе искусственного интеллекта
вычисления производятся путем распространения и комбинирования меток, начиная
с меток предпосылок.
Ниже детально описывается пример из [Martins, 1992]. Предположим, что существует
сеть ПСПИ, представленная на рис. 8.4. В этой сети nh n2, п4 и п5 являются
предпосылками, которые по предположению являются истинными. Сеть зависимостей отражает тот
факт, что с помощью посылок пх и п2 выводится п3, с помощью п3 и п4 выводится п7, с
помощью п4 и п5 выводится п6, и, наконец, с помощью п6 выводится п7.
Рис. 8.4. Разметка узлов в сети зависимостей ПСПИ
На рис. 8.5 представлена решетка зависимостей предпосылок (подмножество/
супермножество), показанных на рис. 8.4. Эта решетка подмножеств обеспечивает
хороший способ визуализации пространства комбинаций предпосылок. Если
некоторые предпосылки вызывают подозрение, СПИП сможет определить, как они
соотносятся с другими предпосылками подмножеств. Например, узел л3 на рис. 8.4
поддерживается всеми множествами предпосылок, которые находятся выше {пь п2) в
решетке на рис. 8.5.
Механизм рассуждения СПИП избавляется от противоречий путем удаления из узлов
тех множеств предпосылок, которые являются несовместимыми. Предположим,
например, что необходимо проверить рассуждения, представленные на рис. 8.4, в связи с
противоречивостью узла л3. Поскольку меткой л3 является множество {ль л2}, это
множество предпосылок определяется как противоречивое. Когда эта противоречие
обнаруживается, все множества предпосылок, относящиеся к супермножеству {ль л2},
помечаются как противоречивые и удаляются из сети зависимостей. В этой ситуации
должна быть удалена одна из возможных меток, ведущих к л7. Полное описание
алгоритма устранения противоречий можно найти в [deKleer, 1986].
Существует несколько других важных подходов к рассуждениям с помощью СПИ.
Логические системы поддержки истинности (ЛСПИ) строятся на результатах работы
[McAllester, 1978]. В ЛСПИ отношения между предположениями представляются с
помощью выражений (дизъюнктов), которые можно использовать для вывода значений
истинности соответствующих предложений. Другой подход — механизм рассуждений на
основе множественной достоверности (МДР) — подобен механизму рассуждений
СПИП за исключением того, что решатель задач и система поддержки истинности
объединены в одну систему. МДР основывается на логическом языке SWM*, описывающем
состояния знаний. Каждое состояние знаний описывается парой дескрипторов: первый
отражает базу знаний, а второй — набор множеств в этой базе знаний, предпосылки
которых являются несовместимыми. Алгоритмы проверки на несовместимость в процессе
рассуждений можно найти в [Martins, 1992].
Глава 8. Рассуждения в условиях неопределенности
335
( (п1,п2,л4)) ( (п1,п2,п5) ) (п1,п4,п5) (п2, л4, п5)
(л1,л2) J (п1,л4) (л1,л5) (п2,л4) (л2, л5) (л4, л5)
(л1) (л2) (л4) (л5)
О
Рис. 5 5. Решетка предпосылок сети, показанной на рис. 8.4. Множества в
рамках со скругленными углами определяют иерархию несовместимости
[Martins, 1992]
8.1.3. Логики, основанные на минимальных моделях
В предыдущих разделах мы расширили логику с помощью нескольких модальных
операторов, которые были специально разработаны для рассуждений об обычных
состояниях мира. Это позволяет ослабить требования к полноте наших знаний о мире.
Модальные операторы появились вследствие необходимости создания более гибкого и
изменчивого описания мира. В этом разделе представляются логики, специально
разработанные для рассуждения в двух ситуациях: когда множество утверждений описывает
лишь истинные положения, и когда из-за природы решаемой задачи множества
предположений являются истинными в большинстве случаев. В первой ситуации используется
предположение о замкнутости мира, во второй — ограничения. Эти подходы часто
называют рассуждениями на минимальных моделях (reasoning over minimum models).
Как указывалось в разделе 2.3, моделью называется интерпретация, которая
удовлетворяет множеству предикатных выражений S для всех значений переменных.
Существует несколько определений минимальной модели. Автор определяет минимальную
модель как модель, для которой не существует подмоделей, удовлетворяющих множеству
выражений S при всех значениях переменных.
Важность минимальных моделей для реализации рассуждений определяется тем,
что для описания ситуаций в мире существует (потенциально) бесконечное число
предикатов. Например, для описания ситуаций в задаче о миссионерах и каннибалах
336 Часть III. Представление и разум в ракурсе искусственного интеллекта
(раздел 14.10, упражнение 7) можно использовать неограниченное число предикатов, в
том числе следующие: берега реки находятся достаточно близко друг от друга, ветер и
течение являются несущественными факторами и т.д. При определении задачи мы
довольно экономны в своих описаниях. Мы используем лишь информативные и
необходимые для решения задачи предикаты.
Предположение о замкнутости мира основывается на минимальной модели мира.
Используются только предикаты, необходимые для решения. Предположение
замкнутости влияет на семантику отрицания в рассуждении. Например, если мы хотим
определить, является ли студент членом группы, то можем просмотреть список (базу данных)
этой группы. Коль скоро студент явно не помещен в эту базу данных (минимальная
модель), он не является членом класса. Аналогично, если необходимо узнать, существует
ли авиасообщение между двумя городами, необходимо просмотреть список всех рейсов.
Если прямой рейс туда не помещен, то он не существует.
Предположение о замкнутости мира сводится к следующему. Если вычислительная
система не может сделать заключения об истинности р(Х), то истинно not(p(X)). Как
будет показано в разделе 12.4, на предположении о замкнутости мира строится вывод в
системе PROLOG. В разделе 12.4 при использовании минимальных моделей неявно
учитываются три предположения (аксиомы). Этими аксиомами являются уникальность имен,
замкнутость мира и замкнутость предметной области. Уникальность имен означает, что все
атомы с различными именами являются различными. Замкнутость мира приводит к тому, что
экземплярами отношений являются лишь те, которые выведены из имеющихся выражений
(дизъюнктов). Замкнутость предметной области означает, что атомарными предложениями
в предметной области являются только те, которые принадлежат модели. Если эти три
предположения подтверждаются, минимальная модель является полной логической
спецификацией. В противном случае требуется алгоритм поддержки истинности.
Если для использования предположения о замкнутости мира требуется, чтобы были
определены все предикаты, составляющие модель, то для алгебры ограничений
[McCarthy, 1980], [Lifschitz, 1984], [McCarthy, 1986] необходимо, чтобы были
определены только предикаты, существенные для решения задачи. В алгебре ограничений в
систему добавляются аксиомы, определяющие минимальную интерпретацию на предикатах
из базы знаний. Эти "метапредикаты" (предикаты над предикатами утверждений задачи)
описывают способ интерпретации конкретных предикатов. Таким образом, они
определяют границы (или ограничивают) возможные интерпретации предикатов.
В работе [McCarthy, 1980] идея ограничения используется в задаче о миссионерах и
каннибалах. Для решения этой задачи необходимо разработать последовательность
ходов (по переправе лодки через реку) для шести символов при множестве ограничений. В
[McCarthy, 1980] приводится большое число абсурдных ситуаций, которые вполне могли
быть использованы при формулировке задачи. Некоторые из них, такие как фактор
ветра, уже были упомянуты в этом разделе. Несмотря на то что человек рассматривает эти
ситуации как абсурдные, соответствующие рассуждения не столь очевидны. Аксиомы
ограничений, которые Мак-Карти (McCarthy) предлагает добавить в описание задачи,
позволяют точно ограничить множество предикатов.
В качестве другого примера ограничений рассмотрим предикатное выражение из
объектно-ориентированной спецификации рассуждений на основе здравого смысла (раздел 8.5).
VXbird(X) л not (abnormal(X)) -> flies(X),
где bird — птица.
Глава 8. Рассуждения в условиях неопределенности
337
Это выражение может встретиться в рассуждениях, в которых одним из свойств
птицы является flies (летает). Но что означает предикат abnormal (аномальный)? То, что
птица— пингвин, у нее перебито крыло или она мертва? Спецификация предиката
abnormal принципиально невозможна.
В алгебре ограничений система аксиом, или множество метаправил, в рамках
исчисления предикатов первого порядка используется для генерации предикатов для
некоторой предметной области. Система правил обеспечивает наименьшее расширение для
определенной формулы. Например, если В является системой предположений,
включающей знание о мире К и знание из предметной области А(р) о предикате р, то р можно
считать минимизированным в том смысле, что минимально возможное количество
атомов ау, удовлетворяющее p(aj), является также совместимым с А(р) и К. Знание мира К
вместе с А(р) и схемой ограничения используются для вывода заключений в
стандартном исчислении предикатов первого порядка. Эти заключения затем добавляются в
систему предположений В.
Допустим, для мира блоков из раздела 5.4 имеется выражение
isblock(A) л isblock(B) л isblock(C),
утверждающее, что А, В и С являются блоками. Ограничение предиката isblock
приводит к утверждению
VX(isblock(X) <- ((Х=А) v (X=B)v (X=C))).
Это выражение означает, что блоками являются только Л, В и С, т.е. только те объекты,
которые считаются блоками согласно предикату isblock. Подобным образом предикат
isblock(A) v isblock(B)
может быть ограничен утверждением
\/X(isblock(X) *- ((X=A)v (X=B))).
Более подробная информация об использовании схемы аксиом для вывода результатов
содержится в [McCarthy, 1980] (раздел 4).
Использование ограничений для таких операторов, как abnormal, аналогично
предположению о замкнутости мира, так как допустимы только те связывания переменных,
которые может поддерживать abnormal. Алгебра ограничений, однако, позволяет
расширить процесс рассуждений посредством предикатного представления. Если имеется
предикат р(Х) vg(X), то можно ограничить либо предикат р, либо д, либо оба сразу.
Таким образом, в отличие от предположения замкнутости мира, алгебра ограничений
позволяет описать возможные связывания переменных через набор предикатов.
Более поздние результаты в области логики ограничений можно найти в [Genesereth и
Nilsson, 1987]. Важный результат получен в работе [Lifschitz, 1986]. Там вводится
понятие точечной ограниченности, когда минимальная модель описывает отдельные
предикаты и их возможные реализации, а не всю предметную область. Другой важный
результат приведен в работе [Pedis, 1988], согласно которой возможны рассуждения об
отсутствии знаний у отдельного агента.
8.1.4. Множественное покрытие и логическая абдукция
Как отмечалось во введении к этой главе, при абдуктивных рассуждениях
рассматриваются правила типа р=><7, в которых q является обоснованным предположением. Тре-
338
Часть III. Представление и разум в ракурсе искусственного интеллекта
буется найти пример истинности предиката р. Абдуктивные рассуждения не являются
традиционными, их часто называют обоснованием наилучшего объяснения данных q. В
этом разделе детально рассматривается процесс генерации объяснений в области абдук-
тивного вывода.
В дополнение к уже представленным методам абдуктивных рассуждений исследователи
ИИ используют также множественное покрытие и логический анализ. Подход к абдукции
на основе множественного покрытия объясняет принятие некоторого предположения в
рамках некоторой поясняющей гипотезы тем, что это единственный способ обоснования
необъяснимого множества фактов. Основанный на логике подход к абдукции описывает
правила вывода для абдукции вместе с определением допустимых форм их использования.
В рамках множественного покрытия абдуктивное объяснение определяется как покрытие
предикатов, описывающих наблюдения, с помощью предикатов, описывающих гипотезы. В
работе [Reggia и др., 1983] описывается покрытие, основанное на бинарном причинном
отношении Я, где Я является подмножеством множества {ГипотезыхНаблюдения}.
Таким образом, абдуктивным объяснением множества наблюдений S2 является множество
гипотез S1, достаточное для объяснения S2. Оптимальным является минимальное
покрытие множества S2. Слабость этого подхода заключается в том, что он сводит
объяснение к простому списку гипотез S1. В ситуациях, где существуют взаимосвязанные или
взаимодействующие причины, или где требуется понимание структуры или
последовательности причинных взаимодействий, модель множественного покрытия является неадекватной.
Логические подходы к абдукции основаны на более сложной модели объяснения. В
работе [Levesque, 1989] абдуктивным объяснением некоторого ранее необъясненного
множества наблюдений О считается минимальное множество гипотез Н, совместимых с
исходными знаниями агента К. Из гипотез Н и исходных знаний К должны следовать
наблюдения О. Более формально
abduce{K,0) = Н тогда и только тогда, когда
а) из К не следует О,
б) из Ни К следует О,
в) Ни К не противоречиво,
г) не существует подмножества Н, обладающего свойствами 1, 2 и 3.
Отметим, что в общем случае для данного множества наблюдений О может
существовать несколько множеств гипотез или потенциальных объяснений.
Логическое определение абдуктивного объяснения обеспечивает соответствующий
механизм получения объяснения в контексте системы баз знаний. Если из поясняющих
гипотез должны следовать наблюдения О, то для построения полного объяснения нужно
рассуждать в обратном направлении от О. Как было показано в разделах 3.3 и 6.2, можно начать
с конъюнктивных компонентов О и проводить рассуждения от заключений к антецедентам.
Этот подход, основанный на построении обратной цепочки вывода, также кажется
естественным, так как условия, поддерживающие этот обратный процесс, вероятно, можно
рассматривать как причинные законы, играющие основную роль, каковую играют причинные
знания в конструировании объяснений. Модель является удобной, поскольку она напоминает
хорошо знакомые исследователям ИИ обратный вывод и вычислительные модели дедукции.
Существуют также интеллектуальные способы нахождения полного множества
абдуктивных объяснений. Системы поддержки истинности, основанные на
предположениях (СПИП) ([deKleer, 1986], подраздел 7.2.3), реализуют алгоритм вычисления мини-
Глава 8. Рассуждения в условиях неопределенности
339
мальных множеств поддержки — множества высказываний (не аксиом), из которых
логически следует данное предложение. Все возможные индуктивные объяснения
множества наблюдений представляют собой декартово произведение множеств поддержки.
Несмотря на простоту, точность и удобство логической абдукции, ей присущи два
взаимосвязанных недостатка: высокая вычислительная сложность и семантическая
слабость. В работе [Selman и Levesque, 1990] установлено, что сложность задач абдукции
аналогична сложности вычисления множеств поддержки СПИП. Стандартное
доказательство того факта, что задача СПИП является NP-сложной, основывается на
существовании примеров задач с экспоненциальным числом решений. Авторы не рассматривают
вопрос о потенциальной сложности ряда задач, сводя эту проблему к нахождению
меньшего множества NP-сложных решений. Для заданной базы знаний хорновских
выражений (см. раздел 12.2) авторы приводят алгоритм нахождения единственного объяснения
порядка 0(/с*п), где к — число пропозициональных переменных, ал- число вхождений
литералов. Однако, если ввести ограничение на типы искомых объяснений, задача снова
становится NP-сложной даже для хорновских дизъюнктов.
Одним из интересных результатов работы [Selman и Levesque, 1990] является тот
факт, что добавление определенных типов целей или ограничений в задачу абдукции
действительно значительно усложняет вычисление. С точки зрения решения задач
человеком эта дополнительная сложность удивляет — для человека добавление
дополнительных ограничений на поиск объяснений упрощает задачу. Причина усложнения задачи в
логической модели абдукции заключается в том, что добавление ограничений приводит к
появлению дополнительных дизъюнктов задачи, а не к модификации структуры задачи,
упрощающей вывод решения.
Поиск объяснения в логической модели можно описать как задачу нахождения
множества гипотез с определенными логическими свойствами. Эти свойства, включая
совместимость с исходными знаниями и выводимость того, что должно быть объяснено,
предназначены для накопления необходимых условий объяснений, т.е. минимальных
условий, которым должны удовлетворять объясняющие гипотезы, претендующие на роль
абдуктивных объяснений.
Одной из простых стратегий получения качественных объяснений является
определение абдуктивного множества фактов, т.е. множества дизъюнктов, из которого должны
выбираться гипотезы-кандидаты. Это множество дизъюнктов позволяет заранее
ограничить поиск теми факторами, которые потенциально могут играть существенную роль в
выбранной области. Другой стратегией является добавление критерия отбора для оценки
и выбора объяснений. Были предложены различные стратегии отбора, включая
минимальность множества. Согласно этой стратегии из двух согласованных множеств
предпочтение отдается минимальному, т.е. тому, которое содержится в другом. Критерий
простоты приводит к выбору экономных множеств гипотез, т.е. таких, которые содержат
меньше непроверенных предположений [Levesque, 1989].
Критерии минимальности и простоты можно рассматривать как реализацию
принципа бритвы Оккама. К сожалению, критерий минимальности множества практически не
приводит к усечению пространства поиска. Его применение лишь исключает финальные
объяснения, являющиеся супермножествами других существующих объяснений. Сам по
себе критерий простоты тоже дает сомнительные преимущества при поиске. Несложно
сконструировать примеры, в которых объяснение, требующее большего множества
гипотез, является более предпочтительным по сравнению с некоторым простым множеством.
Действительно сложные причинные механизмы, как правило, требуют большего количе-
340
Часть III. Представление и разум в ракурсе искусственного интеллекта
ства гипотез, однако абдукция таких механизмов может быть хорошо обоснованной,
особенно если присутствуют определенные ключевые элементы этого механизма, уже
проверенные с помощью наблюдения.
Интересными являются и два следующих механизма выбора объяснения,
принимающие во внимание как свойства множества гипотез, так и свойства процедуры
доказательства. Первый — абдукция на основе стоимости — сводится к оценке стоимости
потенциальных гипотез и правил. Общая стоимость объяснения вычисляется как сумма общей
стоимости и правил, используемых для абдукции. Затем конкурирующие множества
гипотез сравниваются по стоимости. Одной из естественных семантик, которые могут быть
добавлены к этой схеме, является вероятностная семантика [Charniak и Shimony, 1990]
(раздел 13.4). Чем выше стоимость гипотезы, тем ниже вероятность событий; чем выше
стоимость правил, тем менее вероятны причинные механизмы. Метрики, основанные на
стоимости, можно использовать в сочетании с алгоритмами поиска наименьшей
стоимости, такими как поиск до первого наилучшего совпадения (см. главу 4), значительно
уменьшающими вычислительную сложность задачи.
Второй механизм — выбор на основе когерентности — применяют в том случае, когда
необходимо объяснить не простое высказывание, а множество высказываний. В работе [Ng и
Моопеу, 19901 доказано, что метрика когерентности лучше метрики простоты для выбора
объяснений при анализе естественно-языковых текстов. Авторы определяют когерентность
как свойство графа доказательства. Более когерентными считаются объяснения с большим
количеством связей между парами наблюдений и меньшим числом непересекающихся
разбиений. Критерий когерентности основан на эвристическом предположении о том, является
ли предмет объяснения единственным событием или действием с различными аспектами.
Обоснование метрики когерентности в задачах понимания естественного языка строится на
"принципе красноречия", который говорит о том, что речь оратора должна быть связной и
предметной [Gnce, 1975]. Не трудно распространить этот подход на другие ситуации.
Например, в задаче диагностики все наблюдения рассматриваются в комплексе, поскольку
предполагается, что они являются проявлениями одной и той же неисправности.
В разделе 8.1 мы рассмотрели расширения традиционной логики, поддерживающие
рассуждения с неопределенными или недостающими данными. Ниже будут описаны
нелогические подходы к рассуждениям в ситуациях неопределенности, в том числе Стэнд-
фордская алгебра фактора уверенности, рассуждения с использованием нечетких
множеств и теории обоснования Демпстера-Шафера.
8.2. Абдукция: альтернативы логическому подходу
Логические подходы, описанные в разделе 8.1, являются громоздкими и вычислительно
сложными, особенно при их использовании в экспертных системах. В качестве альтернативы
в некоторых ранних экспертных системах (например PROSPECTOR) была сделана попытка
применить для абдуктивного вывода байесовские методы (раздел 8.3). Однако применимость
этого подхода ограничивается предположениями о независимости, непрерывности
обновления статистических данных и сложностью вычислений для поддержки стохастического
вывода. Альтернативное решение было использовано в Стэндфорде для разработки ранних
экспертных систем, в том числе MYCIN [Buchanan и Shortliffe, 1984].
При рассуждениях на основе эвристических знаний человек-эксперт может дать
адекватные и полезные оценки достоверности заключения. Люди оценивают заключение с
Глава 8. Рассуждения в условиях неопределенности
341
помощью таких терминов, как "весьма вероятно", "маловероятно", "почти наверняка"
или "возможно". Эти "весовые коэффициенты" не основаны на тщательном
вероятностном анализе. Они сами являются эвристиками, выведенными из опыта рассуждений о
предметной области. В разделе 8.2 вводятся три методологии абдуктивного вывода:
Стэндфордский метод неточного вывода на основе фактора уверенности, нечеткие
рассуждения и теория Демпстера-Шафера. В разделе 8.3 представлены стохастические
подходы к описанию неопределенностей.
8.2.1. Неточный вывод на основе фактора уверенности
Стэндфордская теория фактора уверенности основывается на ряде наблюдений.
Во-первых, в традиционной теории вероятностей сумма вероятностей отношения и его
отрицания должна равняться единице. Однако нередки ситуации, при которых человек-
эксперт, оценив вероятность (достоверность) некоторого отношения значением 0.7,
полагает, что отношение истинно, и вовсе не учитывает, что оно может быть ложным. Еще
одно предположение, подкрепляющее теорию фактора уверенности, состоит в том, что
знание самих правил намного важнее, чем знание алгебры для вычисления их
достоверности. Мера уверенности (или доверия) — это неформальная оценка, которую человек-
эксперт добавляет к заключению, например: "вероятно, это так", "почти наверняка, это
так" или "это совершенно невероятно".
Стэндфордская теория фактора уверенности вводит некоторые простые
предположения о мере доверия и предлагает правила для объединения свидетельств при выводе
заключений. Первым допущением является разделение меры доверия и недоверия ("за" и
"против") для каждого отношения.
Пусть МВ(Н\ Е) — мера уверенности в гипотезе Н при заданном свидетельстве Е.
Обозначим через MD( Н \ Е) меру недостоверности гипотезы Н при заданном
свидетельстве Е.
Тогда:
1 > МВ(Н\Е) > 0, еслиМО(Н|Е) = 0,
или
1 > MD(H\ Е) > 0, если МВ(Н\ Е) = 0.
Эти две меры накладывают ограничения друг на друга, так как заданной считается часть
свидетельства в пользу данной гипотезы, либо против нее. В этом состоит важное различие
между алгеброй уверенности и теорией вероятности. Если связь между мерами доверия и
недостоверности установлена, их можно снова объединить следующим образом.
CF(H\E) = МВ(Н\Е) - MD(H\E).
С приближением фактора уверенности CF (certainty factor) к 1 усиливается доверие к
гипотезе, а с приближением CF к -1 — ее отрицание. Близость значения CF к 0 означает,
что доказательств в пользу гипотезы и против нее слишком мало, либо эти свидетельства
сбалансированы.
Когда эксперты формируют базу правил, они сопоставляют с каждым правилом
определенное значение CF. Фактор CF отражает их уверенность в надежности правила.
Меры уверенности позволяют регулировать производительность системы, хотя слабые
вариации меры доверия обычно мало влияют на общую результативность. Эта вторая
роль меры доверия подтверждает тезис о том, что "знание — сила". Другими словами,
наилучшей гарантией корректности диагностики является целостность самих знаний.
342
Часть III. Представление и разум в ракурсе искусственного интеллекта
Предпосылка каждого правила состоит из ряда фактов, связанных операциями
конъюнкции и дизъюнкции. При использовании продукционного правила учитываются
факторы доверия, связанные с каждым условием предпосылки. Их сочетание определяет
меру доверия всей предпосылке следующим образом.
Для предпосылок Р1 и Р2
CF(P1 and P2) = M//V(CF(P1), CF(P2))
и
CF(P1 orP2) = MAX(CF(P^), CF(P2)).
Для получения фактора уверенности в заключении правила объединенный фактор
уверенности в предпосылках CF, полученный с помощью приведенных выше правил,
умножается на CF самого правила.
Рассмотрим, например, следующее правило базы знаний
(Р1 and P2) огРЗ-> Я1@,7) and R2 @,3),
где Р1, Р2 и РЗ — предпосылки, а Я1 и Я2 — заключения правила с фактором доверия
CF, равным 0,7 и 0,3 соответственно. Эти числа добавляются к правилу при его
разработке и представляют уверенность эксперта в выводе, если все предпосылки известны с
полной определенностью. Если в процессе выполнения программы для PI, P2 и РЗ
получены значения CF, равные 0,6, 0,4 и 0,2 соответственно, то в данном случае Я1 и Я2
следует учитывать с факторами доверия CF, равными 0,28 и 0,12 соответственно. Ниже
приводятся вычисления для этого примера.
CF(P1@,6) and P2@,4)) = М/Л/@,6; 0,4) = 0,4
CF(@,4) огРЗ@,2)) = ШХ@,4; 0,2) = 0,4
Значение CF для Я1 в описании правила равно 0,7, так что Я1 добавляется ко
множеству конкретных знаний о данной ситуации со значением CF= @,7)* @,4) = 0,28.
Значение CF для Я2 в общем правиле равно 0,3, так что Я2 добавляется ко множеству
знаний о данной ситуации со значением CF @,3) * @,4) = 0,12.
Требуется определить еще одну метрику. Как объединить несколько значений CF,
если два или более правил приводят к одному и тому же результату Я? Правило для этого
случая отражает аналогию алгебры достоверности с теорией вероятности. Меры доверия
при объединении независимых свидетельств перемножаются. Многократно используя
это правило, можно объединять результаты любого количества правил, используемых
для определения результата Я. Если СГ(Я1) представляет фактор доверия результату Я, а
ранее не использованное правило приводит к результату Я (снова) со значением СГ(Я2),
то новое значение CF результата Я вычисляется следующим образом:
СГ(Я1) + СГ(Я2) - (СГ(Я1) * СГ(Я2)),
если СГ(Я1) и СГ(Я2) положительны,
СГ(Я1) + СГ(Я2) + (СГ(Я1) * СГ(Я2)),
если СГ(Я1) и СГ(Я2) отрицательны и
CF(fl1) + CF(fl2)
1-М/Л/(|СР(Я1)|,|СР(Я2)|)
во всех остальных случаях, где | Х| — абсолютное значение X.
Глава 8. Рассуждения в условиях неопределенности
343
Кроме легкости вычислений эти комбинационные уравнения имеют другие
полезные свойства. Во-первых, значение фактора CF, вычисленное согласно этому
правилу, всегда будет лежать между 1 и -1. Во-вторых, в результате объединения
противоположные значения CF сокращаются, что тоже является положительным
моментом. И, наконец, комбинированная мера CF является монотонно
возрастающей (убывающей) функцией, что в какой-то мере и следовало ожидать для
обобщенного свидетельства.
Итак, мера уверенности стэндфордской алгебры описывает человеческую
(субъективную) оценку причинной вероятностной меры. Как указывалось в
подразделе 7.1.2, в традиционном байесовском подходе, если А, В и С влияют на D, то при
рассуждении о D необходимо выделить и скомбинировать все априорные и апостериорные
вероятности, включая P(D), P(D\A), P(D|8), P(D|C), P(A\D). Подход, основанный на
стэндфордском факторе уверенности, позволяет специалисту по знаниям описать все эти
взаимосвязи одним фактором CF доверия правилу, т.е. if A and В and С then D(CF). Эта
простая алгебра лучше отражает способ мышления человека-эксперта.
Теория фактора уверенности может быть подвергнута критике как
необоснованная. Несмотря на то что она определяется в рамках формальной алгебры, значение
меры доверия не так строго обосновано, как в теории вероятностей. Однако теория
фактора уверенности не пытается строить алгебру для "корректного" рассуждения.
Она обеспечивает компромисс, позволяющий экспертной системе объединять
свидетельства по мере решения задачи. Эти меры являются эвристическими в том
смысле, что уверенность эксперта в результатах является неполной, эвристической и
неформальной. В системе MYCIN факторы CF используются при эвристическом
поиске для установки приоритетов целей и определения точки отсечения, после которой
цель не должна более рассматриваться. Но, несмотря на использование факторов CF
для поддержки выполнения программы и сбора информации, производительность
программы определяется качеством правил.
8.2.2. Рассуждения с нечеткими множествами
Традиционная формальная логика основывается на двух предположениях. Первое
связано с установлением принадлежности — для любого элемента и множества,
принадлежащего некоторому универсуму, элемент является либо членом множества,
либо членом дополнения множества. Второе предположение основано на законе
исключения третьего (the law of excluded middle), утверждающем, что элемент не
может одновременно принадлежать множеству и его дополнению. Оба этих
предположения нарушаются в теории нечетких множеств (fuzzy set theory) Лофти Заде. С
точки зрения нечетких множеств множества и законы рассуждений в рамках
традиционной логики называют четкими.
Главное утверждение Заде [Zadeh, 1983] заключается в том, что теория
вероятностей является хорошим инструментом для измерения случайности информации, но
не подходит для измерения смысла информации В самом деле, путаница,
возникающая при использования слов и фраз естественного языка, связана скорее с
отсутствием ясности (неопределенность), чем со случайностью. Это является критической
точкой для анализа языковых структур и играет важную роль для определения меры
достоверности продукционных правил. Для измерения неопределенности Заде пред-
344
Часть III. Представление и разум в ракурсе искусственного интеллекта
лагает теорию возможностей, в то время как теория вероятностей позволяет
определить меру случайности.
Теория Заде дает количественное выражение неточности. Для этого вводится
функция принадлежности множеству, которая может принимать реальные значения в
интервале между 0 и 1. Понятие нечеткого множества (fuzzy set) может быть описано
следующим образом: пусть S — множество, as — элемент этого множества. Нечеткое
подмножество F множества S определяется функцией принадлежности mF(s), задающей
"степень" принадлежности s к F.
На рис. 8.6 представлен стандартный пример нечеткого множества, где S —
множество положительных чисел, a F— нечеткое подмножество S, называемое множеством
малых чисел. Приведенные ниже различные числовые значения могут иметь
распределение "возможности", определяющее их "нечеткую принадлежность" множеству малых
чисел: mF(l) = 1,0, mFB) = 1,0, mFC) = 0,9, mFD)= 0,8, ..., mFE0) = 0,001 и т.д.
Для описания принадлежности положительного числа X множеству малых чисел
создается распределение mF возможности для всего множества положительных чисел S.
Теория нечетких множеств связана не с созданием этих распределений, а скорее с
правилами вычисления комбинированных возможностей на выражениях, содержащих
нечеткие переменные. Таким образом, она включает правила сочетания мер
возможности для выражений, содержащих нечеткие переменные. Законы изменения меры
возможности для операций or, and и not над этими выражениями напоминают
соответствующие соотношения из стэндфордской алгебры фактора уверенности (см.
подраздел 8.2.1).
Для нечеткого множества, представленного множеством малых чисел на рис. 8.6,
каждое число принадлежит этому множеству с соответствующей мерой достоверности. В
традиционной логике "четких" множеств достоверность того, что элемент принадлежит
множеству, равна либо 1, либо 0. На рис. 8.7 представлена функция принадлежности
множествам понятий "низкие, средние и высокие мужчины". Отметим, что любой
элемент может принадлежать более чем одному множеству. Например, мужчина ростом
5' 10" принадлежит как множеству средних, так и множеству высоких мужчин.
низкий средний высокий
; n^^
4' 4'6" 5' 5'6" 6' 6'6" |
Рис. 8.6. Нечеткое множество, представ- Рис. 8.7. Нечеткие множества,
представляющее "малые целые числа'' ляющие низких, средних и высоких мужчин
Далее приводятся правила для сочетания и передачи нечетких мер для задачи,
ставшей уже классической в литературе по нечетким множествам, — задачи управления
перевернутым маятником. На рис. 8.8 представлен перевернутый маятник, который
необходимо удерживать в вертикальном положении. Положение маятника регулируется
посредством перемещения основания системы в направлении отклонения маятника и
действием силы тяжести. Детерминированный способ решения задачи стабилизации
маятника в состоянии равновесия может быть описан с помощью набора
дифференциальных уравнений [Ross, 1995]. Преимущество нечеткого подхода к управлению
маятниковой системой состоит в том, что можно описать алгоритм эффективного управления
системой в реальном времени. Этот алгоритм управления приводится ниже.
Глава 8. Рассуждения в условиях неопределенности
345
Упростим задачу стабилизации маятника, рассматривая ее в двухмерном
пространстве. Как показано на рис. 8.8, в качестве входных значений контроллера используются две
измеряемые величины: первая — угол отклонения маятника от вертикали 6, а вторая —
скорость d6/df, с которой движется маятник. Обе эти величины положительны в правом
квадранте и отрицательны в левом. Оба эти значения подаются на вход нечеткого
контроллера на каждой итерации работы системы. Выходом котроллера являются величина
и направление перемещения основания системы. Команды по перемещению с указанием
его направления обеспечивают сохранение равновесия маятника.
шшшшпшшшш
Рис. 8.8. Перевернутый
маятник и входные значения 6 и dO/dt
Для объяснения работы нечеткого контроллера опишем процесс решения задачи на
основе нечетких множеств. Данные, описывающие состояние маятника F и d6/df),
интерпретируются как нечеткие меры (рис. 8.9), которые используются во множестве
нечетких правил. Этот шаг может быть очень эффективно реализован за счет
использования нечеткой ассоциативной матрицы (НАМ) (fuzzy associative matrix), показанной на
рис. 8.12. В НАМ отношения вход-выход кодируются напрямую. Правила не
объединяются, как при традиционном решении задач на основе правил. Все применимые правила
активизируются, а затем их результаты объединяются. Общий результат обычно задается
областью пространства нечетких выходных параметров (рис. 8.10), который затем
подвергается дефаззификации для получения "четкого" управляющего воздействия.
Заметим, что и входные, и выходные значения контроллера являются "четкими" значениями.
Они представляют точные показания некоторого монитора на входах и точные команды
управления на выходе.
Опишем нечеткие области входных значений, 6 и dQ/dt. В этом примере для ряда
нечетких областей входных значений ситуация упрощена, но показан полный цикл
применения правил и получения результата контроллера. Диапазон входных значений 6 (от -2
до +2 радиан) разделяется на три области: область отрицательных чисел N (Negative),
окрестность нуля Z (Zero) и область положительных чисел Р (Positive) (рис. 8.9, а). На
рис. 8.9, б представлены три области, на которые разбивается диапазон изменения (от -5
до +5 градусов в секунду) второго входного значения dQ/dt: N, Р и Z.
На рис. 8.10 представлены подмножества выходных значений: большое
отрицательное NB (Negative Big), отрицательное N (Negative), нулевое Z (Zero), положительное Р
(Positive) и большое положительное РВ (Positive Big). Величина и направление
перемещения изменяются в диапазоне от -24 до +24.
346
Часть III. Представление и разум в ракурсе искусственного интеллекта
Область рассуждения
Z А
Область рассуждения
Z А
Рмс. 5.9. Нечеткие области для входных значений 6 (aj w dQ/dt (б)
Рис. 8. JO. Нечеткие области изменения выходного значения, отражающие перемещение
основания маятника
Предположим, сначала контроллеру передаются значения 6=1 и dQ/dt=-4. На
рис. 8.11 иллюстрируется процесс фаззификации этих входных значений. Каждое
входное значение можно отнести к двум нечетким множествам. Для 6 мера принадлежности
области нуля и области положительных чисел составляет 0,5. Значение dQ/dt
принадлежит области N с мерой 0,8 и Z с мерой 0,2. На рис. 8.12 представлена упрощенная форма
нечеткой ассоциативной матрицы для этой задачи. Входные значения для 6 или х{
заданы в первом столбце, а для dQ/dt или х2 — в верхней строке матрицы. Выходные
значения представлены в правом нижнем квадранте матрицы НАМ размером 3x3. Например,
Глава 8. Рассуждения в условиях неопределенности
347
если значение G равно Р, a dd/dt — N, НАМ возвращает значение Z. После этого
необходимо выполнить дефаззификацию выхода.
<—
А
Л
у/ Z
у\ °5
Z_ 1 X
1
Ч 4
- - 7
р
< /
—►
О 1 2
х,@) = 1
Рис 8.11. Фаззификация входных значений Х\ - l,Xi- —4
х2
р
Z
N
Р
РВ
Р
Z
Z
р
Z
N
N
Z
N
NB
Рис. 8 12 Нечеткая ассоциативная
матрица (НАМ) для задачи стабичиза-
ции перевернутого маятника Входные
значения указаны в левом столбце и
верхней строке
В данном случае, поскольку входные значения относятся к двум нечетким областям
входного пространства, необходимо применять четыре правила. Как отмечалось выше,
объединение правил для нечетких систем выполняется аналогично стэндфордской
алгебре фактора уверенности. Фактически Заде [Buchanan и Shortliffe,' 1984] впервые
(исторически) предложил эти комбинации правил для алгебры нечетких рассуждений.
Если меры принадлежности двух предпосылок связаны конъюнкцией, в качестве меры
правила берется минимум этих мер. Если меры двух предпосылок связаны дизъюнкцией,
в качестве меры правила берется максимум из этих мер.
348
Часть III. Представление и разум в ракурсе искусственного интеллекта
В нашем примере все пары связаны конъюнкцией, так что в качестве меры правила
берется минимум их мер:
IF х, = Р and x2 = Z THEN u = P
т/л@,5; 0,2) = 0,2 Р
IFx,= Pandx2= Л/THEN u = Z
m/n@,5; 0,8)=0,5Z
IF x, = Z and x2 = Z THEN u = Z
m/n@,5; 0,2)=0,2Z
IF x, = Z and x2= N THEN и = N
m/n@,5; 0,8)=0,5 A/
Затем полученные результаты объединяются (выполняется дефаззификация). В нашем
примере объединяются две области, показанные на рис. 8.10, полученные в результате
активизации этого множества правил. Существует ряд методов дефаззификации [Ross, 1995].
Выберем один из наиболее известных — метод центра тяжести. При использовании этого
метода окончательным выходным значением контроллера, применяемым к маятнику, является
значение центра тяжести объединения областей выходных значений. На рис. 8.13
представлены и само объединение и центр тяжести объединения областей. Этот выход или результат
применяется к системе, снова измеряются значения q и dq/dt, и цикл управления повторяется.
Ми
N Z\ P
И,0
/ \/0,5 \/ \
/ / \0,2
,/ , ,/ ■ \l/ , \, ■ \,
-16
-12
12
16
Ми
/
-16
N
Z
0,5
I
к.
1,0
0
р
\\_02__
"Л,
16
и@) = -2
Рис 8.13 Нечеткие коисеквенты (а) и их объединения (б).
Центр тяжести объединения (-2) является четким выходом
При описании систем нечетких рассуждений мы не рассматривали ряд вопросов,
включая колебания в процессе сходимости и выбор оптимальных коэффициентов.
Нечеткие системы предоставляют инженерам мощный инструментарий для борьбы с
неточностью измерений, особенно в области управления.
Глава 8. Рассуждения в условиях неопределенности
349
8.2.3. Теория доказательства Демпстера-Шафера
До сих пор мы описывали методы, которые рассматривают отдельные высказывания
и числовые оценки степени достоверности. Одним из ограничений вероятностных
подходов к неопределенности является то, что они используют единственную
количественную меру, вычисление которой может оказаться очень сложной задачей. Это связано с
неопределенностью результата объединения при отсутствии должного обоснования
предпосылок, наследованием ограничений эвристических правил и ограниченностью
наших собственных знаний.
Альтернативный подход, называемый теорией обоснования Демпстера-Шафера,
рассматривает множества предположений и ставит в соответствие каждому из них
вероятностный интервал доверия (правдоподобия), которому должна принадлежать степень
уверенности в каждом предположении. Мера доверия обозначается be/ и изменяется от
нуля, что указывает на отсутствие свидетельств в пользу множества предположений, до
единицы, означающей определенность. Мера правдоподобия предположения р - pl(p)
определяется следующим образом:
pl(p) = 1 -bel(not(p)).
Таким образом, правдоподобие также изменяется от нуля до единицы и вычисляется
на основе меры доверия предположению not(p). Если not(p) вполне обоснованно, то
bel(not(p))= 1, a pl(p) равно 0. Единственно возможным значением для bel(p) также
является нуль.
Предположим, что существуют две конкурирующие гипотезы h\ и h2- При отсутствии
информации, поддерживающей эти гипотезы, мера доверия и правдоподобия каждой из
них принадлежат отрезку [0; 1 ]. По мере накопления информации эти интервалы будут
уменьшаться, а доверие гипотезам — увеличиваться. Согласно байесовскому подходу
(при отсутствии свидетельств) априорные вероятности распределяются поровну между
двумя гипотезами: Р(/?,) = 0,5. Подход Демпстера-Шафера также подразумевает это. С
другой стороны, байесовский подход может привести к такой же вероятностной мере независимо
от количества имеющихся данных. Таким образом, подход Демпстера-Шафера может быть
очень полезен, когда необходимо принимать решение на основе накопленных данных.
Итак, подход Демпстера-Шафера решает проблему измерения достоверности, делая
коренное различие между отсутствием уверенности и незнанием. В теории вероятностей
мы вынуждены выражать степень нашего знания о гипотезе h единственным числом
P(h). Проблема такого подхода, по мнению Демпстера-Шафера, заключается в том, что
мы просто не всегда можем знать значения вероятностей, и поэтому не любой выбор
P(h) может быть обоснован.
Функция доверия Демпстера-Шафера удовлетворяет аксиомам, которые слабее
аксиом теории вероятности, и сводится к теории вероятности, если все вероятности известны.
Функции доверия позволяют использовать имеющиеся знания для ограничения
вероятностей событий при отсутствии точных значений вероятностей.
Теория Демпстера-Шафера основана на двух идеях. Первая — получение степени
доверия для данной задачи из субъективных свидетельств о связанных с ней проблемах,
и вторая — использование правила объединения свидетельств, если они основаны на
независимых атомах. Это правило объединения первоначально было предложено Демпсте-
ром [Dempster, 1968]. Далее представляется неформальный пример рассуждения
Демпстера-Шафера, затем описывается правило Демпстера объединения свидетельств и,
наконец, применение этого правила к более жизненной ситуации.
350
Часть III. Представление и разум в ракурсе искусственного интеллекта
Рассмотрим субъективные вероятности правдивости свидетельств моей подруги
Мелиссы. Вероятность того, что ей можно верить, составляет 0,9, а того, что верить
нельзя, — 0,1. Предположим, Мелисса говорит, что мой компьютер сломался. Это
утверждение истинно, если Мелиссе можно верить, но оно не обязательно ложно, если ей верить
нельзя. Таким образом, утверждение Мелиссы, что мой компьютер сломался,
обосновывается с достоверностью 0,9, а то, что он исправен — с достоверностью 0,0.
Достоверность 0,0 не означает уверенности в том, что компьютер не сломался, как это означала
бы вероятность 0,0. Это просто означает, что утверждение Мелиссы не дает причин
верить, что мой компьютер не сломался. Мера правдоподобия р/ в этой ситуации равна
р1(компьютер_сломался) =1 - Ье\(поХ(компьютер _сломался))=\ - 0,0,
или 1,0, и моя мера доверия Мелиссе есть [0,9; 1,0]. Заметим, что еще нет основания
считать, что мой компьютер не сломался.
Далее рассмотрим правило Демпстера для объединения свидетельств. Допустим, мой
друг Билл также говорит, что мой компьютер сломался. Предположим, вероятность того,
что Биллу можно верить, составляет 0,8, а что верить нельзя— 0,2. Я также должен
предположить, что утверждения Билла и Мелиссы о моем компьютере независимы друг
от друга, т.е. они вызваны разными причинами. Событие "Билл заслуживает доверия"
также должно быть независимо от события, определяющего степень доверия Мелиссе.
Вероятность правдивости и Билла и Мелиссы равна произведению их вероятностей —
0,72; вероятность неправдивости обоих — 0,02. Вероятность того, что верить можно по
крайней мере одному из них — 1-0,02 = 0,98. Поскольку оба они говорят, что мой
компьютер сломался, и вероятность того, что по крайней мере один из них заслуживает
доверия, равна 0,98, можно установить степень достоверности события поломки
компьютера [0,98; 1,0].
Предположим, Билл и Мелисса расходятся в том, что мой компьютер сломался:
Мелисса утверждает, что он сломался, а Билл говорит, что нет. В этом случае они оба
одновременно не могут говорить правду и не могут оба вызывать доверие. Либо обоим им
нельзя верить, либо нельзя верить одному из них. Априорная вероятность того, что
можно верить лишь Мелиссе, составляет 0,9*A - 0,8) = 0,18, а того, что верить можно только
Биллу, — 0,8*A - 0,9) = 0,08, а того, что ни одному из них верить нельзя, — 0,2*0,1 =
0,02. Имея вероятность того, что по крайней мере одному из друзей верить нельзя, @,18
+ 0,08 + 0,02) = 0,28, можно вычислить апостериорную вероятность того, что верить
можно лишь Мелиссе, и мой компьютер сломан — 0,18/0,28 = 0,643; или апостериорную
вероятность того, что прав лишь Билл, и мой компьютер исправен — 0,08/0,28 = 0,286.
При этом было использовано правило Демпстера для объединения свидетельств. После
заявления Мелиссы и Билла о том, что компьютер сломан, мы рассмотрели три
гипотетические ситуации, связанные с поломкой: Биллу и Мелиссе можно верить; Биллу можно
верить, а Мелиссе нет; Мелиссе можно верить, а Биллу нет. Доверие результату анализа
возможных гипотетических сценариев составила 0,98. При втором использовании правила
Демпстера свидетельства расходились. Снова были проанализированы все возможные
сценарии. Исключалась единственная ситуация, связанная с тем, что верить можно обоим.
Таким образом, либо Мелиссе можно верить, а Биллу нет; либо можно верить Биллу, а не
Мелиссе; либо нельзя верить никому из них. Суммарная достоверность поломки составила
0,64. Достоверность того, что компьютер не сломан (согласно мнению Билла), — 0,286.
Поскольку правдоподобие поломки составляет 1 -bel(not(поломка)) — 0,714, мера
доверия принадлежит интервалу [0,28; 0,714].
Глава 8. Рассуждения в условиях неопределенности
351
Используя правило Демпстера, можно получить меру доверия для одной задачи
(Был ли компьютер сломан?) из вероятности для другой (Является ли свидетельство
надежным?). Для применения правила необходимо предположить, что задачи, для
которых известны вероятности, независимы, но эта независимость лишь априорная.
Она исчезает, когда возникает конфликт между различными атомами обоснования.
Использование подхода Демпстера-Шафера в каждой ситуации приводит к
решению двух связанных проблем. Во-первых, мы разделяем неопределенность
ситуации на априорно независимые части. Во-вторых, применяем правило Демпстера.
Эти две задачи взаимосвязаны: предположим опять-таки, что Билл и Мелисса
независимо друг от друга сказали, что они были уверены в том, что мой компьютер
сломан. Предположим также, что я вызвал мастера для проверки компьютера, и что оба
(и Билл, и Мелисса) были свидетелями этого. Из-за этого общего события мы не
можем больше сравнивать степени доверия. Однако, явно учитывая возможность
приглашения мастера, можно получить три независимых атомарных обоснования:
правдивость Мелиссы, правдивость Билла и основание для присутствия мастера,
которые можно затем объединить с помощью правила Демпстера.
Предположим, существует исчерпывающее множество взаимоисключающих гипотез.
Обозначим его через О. Наша цель — приписать некоторую меру доверия т различным
подмножествам Z множества О; т иногда называют вероятностной функцией
чувствительности (probability density function) подмножества О. Реально свидетельства
поддерживают не все элементы Q. В основном поддерживаются различные
подмножества Z множества О. Более того, поскольку элементы О предполагаются
взаимоисключающими, доказательство в пользу одного из них может оказывать влияние на
доверие другим элементам. В чисто байесовской системе (раздел 8.3) обе эти
ситуации разрешаются за счет рассмотрения всех комбинаций условных вероятностей. В
системе Демпстера-Шафера эти взаимодействия учитываются напрямую путем
непосредственного манипулирования множествами гипотез. Величина mn(Z) означает
степень доверия, связанную с подмножеством гипотез Z, а п представляет число
источников свидетельств. Правило Демпстера имеет вид
т (Z)_ Sxn^z^n^W^n-iOO
1-2м=д.2(ХК,(У)'
Например, мерой доверия mn(Z) гипотезе Z для л=3 источников свидетельств
считается сумма произведений гипотетических мер доверия т\(Х) и m2(Y), совместное
вхождение которых поддерживаетZ, т.е. XnY=Z. Как видно из примера, знаменатель правила
Демпстера допускает пустое пересечение X и Y, а сумма мер доверия должна быть
нормализована.
Применим празило Демпстера к задаче медицинской диагностики. Предположим, что
рассматривается область О, содержащая четыре гипотезы: пациент был без сознания (С),
у него был грипп (F), мигрень (Н) или менингит (М). Наша задача — связать меры
доверия со множествами гипотез в рамках О. Как отмечалось выше, это именно множество
гипотез, поскольку они ничем не обоснованы. Например, лихорадка свидетельствует в
пользу {C,F,M}. Поскольку элементы О трактуются как взаимоисключающие гипотезы,
подтверждение одной из них может влиять на достоверность других. Как уже
говорилось, подход Демпстера-Шафера разрешает взаимодействие посредством прямой
обработки множества гипотез.
352
Часть III. Представление и разум в ракурсе искусственного интеллекта
Для вероятностной функции чувствительности т и всех подмножеств Z множества О
значение m(g,) представляет меру доверия, которая назначается каждому д, из О.
Причем сумма всех т(д,) равна 1. Если О содержит п элементов, то существует 2я
подмножеств О — это очень много. Проблема упрощается за счет того, что многие из
подмножеств недопустимы. Таким образом, существует некоторое упрощение, и невозможные
значения могут быть проигнорированы. И, наконец, правдоподобие О есть р/@) = 1-
Im(g,), где д, — множество гипотез, имеющих некоторую вероятность поддержки. При
отсутствии информации о некоторых гипотезах, что чаще всего бывает в начале
процесса диагностики, р/( О) = 1,0.
Предположим, первая часть свидетельства — у пациента лихорадка. Она
поддерживает {C,F,M} с вероятностью 0,6. Назовем это первой мерой доверия тх. Если это всего
лишь гипотеза, то т\{С,F,M} =0,6, где Ш!(О) = 0,4 для оставшегося распределения мер
доверия. Важно отметить, что m!(Q)=0,4 представляет оставшуюся часть распределения
достоверности, т.е. все другие возможные меры доверия О, а не достоверность
дополнения {С, FtM).
Предположим теперь, что мы получили некоторые новые данные для постановки
диагноза. К примеру, у пациента сильная рвота, которая свидетельствует о {C,F,H} со
степенью доверия 0,7. Назовем меру доверия этому свидетельству т2. Для нее мы имеем
m2{C,F,H}=0,l и m2{Q}=0,3. Используем правило Демпстера для объединения этих двух
свидетельств тх и т2. Пусть X— набор подмножеств О, на котором т\ принимает
ненулевые значения, и Y — набор подмножеств О, на котором т2 принимает ненулевые
значения. Затем по правилу Демпстера определим объединенную меру доверия т3 на
подмножествах Z множества Q.
При его применении к диагнозам прежде всего отметим, что не существует пустых
множеств XnY, так что знаменатель равен 1. Распределение вероятностей т3 приведено в
табл. 8.1.
Таблица 8.1. Использование правила Демпстера объединения свидетельств
тх
m{{C,F,M}=Qfi
mi{Q}=0,4
mi{C,F,M}=0,6
mi{Q}=0,4
т2
m2{C,F,H }=0,7
m2{C,F,H }=0,7
m2{Q}=0,3
m2{Q}=0,3
m3
m3{C,F}=0,42
m3{C,F,H}=0,28
m3{C,F,M}=0,18
m3{O}=0,12
Четыре множества Z, представляющие все возможные способы пересечения X и
/согласно правилу Демпстера, составляют крайний справа столбец табл. 8.1. Степень
доверия вычисляется перемножением мер достоверности элементов X и У, для которых
заданы тх и /772. Отметим, что в этом примере каждое множество в Z уникально, что не
является частым случаем.
Расширим пример, чтобы показать, как в процессе анализа факторизуются пустые
множества достоверности. Предположим, получен новый факт, отражающий результаты
лабораторного анализа, который связан с менингитом. Теперь т4{М}= 0,8 и ш4{0}= 0,2.
Чтобы объединить результаты предыдущего анализа т3 с т4 для получения ш5, можно
использовать формулу Демпстера (табл. 8.2).
Глава 8. Рассуждения в условиях неопределенности
353
Таблица 8.2. Использование правила Демпстера для объединения т3с т4с
целью получения т5
ГПт,
m3{C,F}=0,42
т3{О}=0,12
m3{C,F}=0,42
т3{О}=0,12
m3{C,F,H }=0,28
m3{C,F,/W}=0,18
m3{C,F,H }=0,28
m3{C,F,M}=0,18
т4
m4{/W}=0,8
m4{/W}=0,8
т4{О}=0,2
т4{О}=0,2
m4{M}=0,8
m4{M}=0,8
m4{Q}=0,2
т4{О}=0,2
m5
m5{ } =0,336
m5{/W}=0,096
m5{C,F}=0,084
m5{Q}=0,024
m5{} =0,224
m5{/W}=0,144
m5{C,F,H}=0,056
m5{C,F,/W}=0,036
Сразу отметим, что m5{/W} получается в результате пересечения двух различных пар
множеств, поэтому общая вероятность т5{М] = 0,240. Кроме того, в результате
пересечения нескольких пар множеств получается пустое множество {}. Таким образом,
знаменатель уравнения Демпстера равен 1 - @,336 + 0,224) = 1 - 0,56 = 0,44. Окончательные
значения функции доверия т5 будут иметь вид
т5{М} = 0,545 m5{C,F} =0,191 m5{}=0,56
m5{C,F,H} =0,127 m5{C,F,M} =0,082 m5{Q} =0,055
Во-первых, высокая достоверность пустого множества т5 { } = 0,56 означает
существование конфликта свидетельств на множестве мер доверия ту. Данный пример
позволяет показать несколько особенностей рассуждения Демпстера-Шафера, поэтому в нем
автор пожертвовал медицинской согласованностью. Во-вторых, при существовании
больших множеств гипотез, а также сложного множества свидетельств вычисление мер
доверия может оказаться громоздким, хотя, как уже отмечалось, количество
рассуждений все же значительно меньше, чем при использовании байесовского подхода. И
последнее, подход Демпстера-Шафера является очень полезным инструментом, когда
более строгие байесовские рассуждения себя не оправдывают.
Подход Демпстера-Шафера является примером алгебры, поддерживающей в
рассуждении субъективные вероятности, в противоположность объективным вероятностям Бай-
еса. В субъективной теории вероятностей мы строим алгебру рассуждений, часто
ослабляя некоторые ограничения Байеса. Иногда субъективные вероятности лучше отражают
рассуждения эксперта-человека. В последнем разделе главы 8 будут рассмотрены
байесовские рассуждения, включая использование сетей доверия.
8.3. Стохастический подход к описанию
неопределенности
В рамках теории вероятностей можно определить (зачастую априори) шансы
наступления событий. Можно также описать, как комбинации событий влияют друг на друга.
Хотя последние достижения в области теории вероятностей были получены
математиками начала двадцатого столетия, включая Фишера, Неймана и Пирсона, попытка создать
комбинаторную алгебру уходит корнями через средние века к грекам, включая Лулла,
Порфирия и Платона [Glymour и др., 1995а]. Теория вероятностей строится на предпо-
354
Часть III. Представление и разум в ракурсе искусственного интеллекта
ложении о том, что, зная частоту наступления событий, можно рассуждать о частоте
последующих комбинаций событий. Например, можно вычислить шансы на выигрыш в
лотерее или в игре в покер.
Существует ряд ситуаций, при которых вероятностный анализ является подходящим
средством. Во-первых, эта теория применима, если мир является действительно
случайным, как при игре хорошо перетасованными картами или при беспристрастном
поведении крупье. В картах, например, следующая карта является функцией от типа колоды и
уже вытянутых карт. Во-вторых, этот подход применим при описании "нормального"
мира. Хотя события в мире могут не быть совершенно случайными, для предсказания
события часто неизвестны причины и их взаимосвязь. Статистические корреляции
являются полезной заменой для причинно-следственного анализа, хотя в работах [Glymour и
Cooper, 1999], [Pearl, 2000] делается попытка связать понятия вероятности и
причинности. Дальнейшее использование вероятностей позволяет выявить возможные
исключения в общих взаимосвязях. Статистический подход группирует все исключения, а затем
использует эту меру для описания исключения общего вида. Другая важная роль
статистики — это основа для индукции и обучения (например, алгоритм ID3 из раздела 9.3).
При решении задач, основанных на знаниях (глава 7), часто приходится проводить
рассуждения с ограниченными знаниями и неполной информацией. Многие
исследовательские группы направляли свои усилия на изучение различных форм вероятностных
рассуждений. В этом разделе сначала описывается полный байесовский анализ, а затем
ограниченная форма байесовского вывода, называемая сетями доверия.
8.3.1. Байесовские рассуждения
Байесовские рассуждения основаны на формальной теории вероятностей и
интенсивно используются в некоторых современных областях исследований, включая
распознавание образов и классификацию. Теория Байеса обеспечивает вычисление сложных
вероятностей на основе случайной выборки событий. Например, в рамках простых
вероятностных вычислений можно определить, как карты могут распределяться среди игроков.
Предположим, я — один из четырех игроков в карточной игре, в которой все карты
распределены равномерно. Если у меня нет пиковой дамы, я могу заключить, что
вероятность ее нахождения у каждого из остальных игроков равна 1/3. Аналогично можно
заключить, что вероятность нахождения у каждого из игроков червового туза также
составляет 1/3, и что любой игрок имеет обе карты с вероятностью 1/3*1/3 или 1/9,
предположив, что события получения двух карт являются независимыми.
В математической теории вероятностей отдельные вероятности вычисляются либо
аналитически комбинаторными методами, либо эмпирически. Если известно, что А и В
независимы, вероятность их комбинации вычисляется по следующему правилу:
вероятность(А&В) = вероятность(А) * вероятность(В)
ОПРЕДЕЛЕНИЕ
АПРИОРНАЯ ВЕРОЯТНОСТЬ
Априорная вероятность (prior probability), часто называемая безусловной
вероятностью (unconditional probability) события, — это вероятность, присвоенная событию
при отсутствии знания, поддерживающего его наступление. Следовательно, это
вероятность события, предшествующего какой-либо основе. Априорная вероятность
события обозначается Р(событие).
Глава 8. Рассуждения в условиях неопределенности
355
АПОСТЕРИОРНАЯ ВЕРОЯТНОСТЬ
Апостериорная вероятность (posterior probability), часто называемая условной
вероятностью (conditional probability) события, — это вероятность события при некотором
заданном основании. Апостериорная вероятность обозначается Р(событие \ основание).
Априорная вероятность выпадения двойки или тройки при бросании игральной
кости — это сумма двух возможностей, деленная на общее число возможных альтернатив,
т.е. 2/6. Априорная вероятность болезни отдельного человека равна числу людей с этим
заболеванием, деленному на число людей, находящихся под наблюдением.
Апостериорная вероятность заболевания d у человека с симптомом s равна:
P(d\s) = | dns | / | s |,
где прямые скобки обозначают число элементов множества. В правой части этого
уравнения указано число людей, имеющих как заболевание d, так и симптом s, деленное на
количество людей с симптомом s. Расширим это уравнение
P(d\s) = P(d ns) I P(s)
и получим эквивалентное соотношение для P(s \ d) и Р( d n s):
P(s\d) = P(d ns) / P(d),
P(dns) = P(s\d) * P(d).
Подстановка этого результата в соотношение P(d\s) дает теорему Байеса (для одной
болезни и одного симптома):
P(d\s) = (P(s\d)*P(d))/P(s).
Важной особенностью теоремы Байеса является то, что числа в правой части уравнения
получить легче, чем значение в его левой части. Например, вследствие меньшей популяции
намного легче определить число больных менингитом, имеющих головные боли, чем процент
больных менингитом из общего числа страдающих головной болью. Более важной
особенностью теоремы Байеса является то, что для простого случая одной болезни и одного симптома
в вычислениях участвует не очень много чисел. Трудности начинаются, когда мы
рассматриваем комплексные заболевания dm из области заболеваний D и комплексные симптомы sn
из множества возможных симптомов S. При рассмотрении каждой болезни из D и каждого
симптома из S отдельно необходимо собрать и интегрировать тхп измерений. (В
действительности тхп апостериорных вероятностей плюс (т+п) априорных вероятностей.)
К сожалению, анализ при этом становится намного сложнее. До сих пор мы
рассматривали симптомы отдельно. В действительности отдельные симптомы встречаются редко.
Например, когда врач осматривает пациента, он должен учитывать много различных комбинаций
симптомов. Эту ситуацию описывает форма правила Байеса с комплексными симптомами.
P(cf|st& s2 &...& sn) = (P(d)*P(s:& s2&...& sn\d)) I P(s^& s2&...& sn).
Для обработки одного заболевания с одним симптомом необходимо лишь тхп
измерений. Для каждой пары симптомов s, и sy и болезни d необходимо знать как P(st & s,- |
d), так и P(Si & Sj). Если S содержит п симптомов, число таких пар будет п*(п-1), или
приблизительно п2. Если мы захотим воспользоваться правилом Байеса, то придется
вычислить около (тхп2 условных вероятностей) + (п2 вероятностей симптомов) + (т
вероятностей болезней) или собрать тхп2+п2+т единиц информации. В реальной
медицинской системе с 200 заболеваниями и 2000 симптомами это значение превышает 800000000!
356
Часть III. Представление и разум в ракурсе искусственного интеллекта
Однако есть некоторая надежда, что многие из этих пар будут независимы,
т.е. P(Si | Sj)= P(Si). Независимость означает, что вероятность s, не зависит от s;. В
медицине большинство симптомов не связаны, например, облысение с кашлем. Но даже
если десять процентов симптомов зависимы, необходимо рассматривать около
80000000 отношений.
Во многих задачах диагностики приходится иметь дело с отрицательной
информацией, когда симптом у пациента отсутствует (например, низкое давление крови). В обоих
случаях необходимо, чтобы
P(nots) = 1 - P(s) и P(notd\s)= 1 - P(d\s).
Наконец, следует отметить, что P(s\d) и P(d\s) — это не одно и то же, и в любой
ситуации эти величины будут иметь различные значения. Эти отношения и попытка
избежать циклических рассуждений являются важными при разработке байесовских сетей
доверия (подраздел 8.3.2).
Далее будет представлен один из наиболее важных результатов теории
вероятностей — теорема Байеса в общей форме. Она обеспечивает способ вычисления
вероятности гипотезы /-/,, следующей из отдельного основания, если даны лишь вероятности
основания, следующего из реальных причин (гипотез).
Г[Н,\Е)- P(£I".>*P(H)
ХР(Е\Нк)*Р(Нк)'
где
Р(Н/| Е) — вероятность истинности /-/,- при заданном основании Е;
P(Hi) — вероятность истинности Н/вообще;
Р(Е\ HJ — вероятность наблюдения основания, если истинно /-/,;
п — число возможных гипотез.
Предположим, необходимо определить вероятность обнаружения меди на основе
пробы грунта. Для этого нужно знать наперед вероятность обнаружения каждого из
множества минералов и вероятность определенного грунта при обнаружении каждого
отдельного минерала. Тогда можно использовать теорему Байеса для определения
вероятности присутствия меди на основе пробы грунта. Этот подход используется в системе
PROSPECTOR, созданной в Стэндфордском университете и применяемой для
геологоразведки (меди, молибдена и др.). Система PROSPECTOR позволила обнаружить
коммерчески значимые залежи минералов в нескольких местах [Duda и др., 1979а].
Для использования теоремы Байеса существует два главных требования. Первое
заключается в том, что должны быть известны вероятности взаимосвязи основания с различными
гипотезами, а также вероятности взаимосвязи различных частей основания. Второе, и иногда
более трудное в определении, требование заключается в том, что должны быть вычислены все
взаимосвязи между основанием и гипотезами или Р( Е | НК). Вообще и особенно в таких
областях, как медицина, предположение независимости не может быть априори обоснованным.
Последняя проблема, затрудняющая использование сложных байесовских систем,
заключается в переопределении таблицы вероятностей при выявлении новых взаимосвязей
между гипотезами и обоснованиями. В таких активных исследовательских областях, как
медицина, новые открытия осуществляются непрерывно. Для корректности заключений
байесовских рассуждений требуется (постоянное) вычисление полных вероятностей,
включая объединенные вероятности. Во многих областях такой обширный сбор данных и
Глава 8. Рассуждения в условиях неопределенности
357
верификация не возможны, а если и возможны, то стоят очень дорого. Там, где эти
предположения выполняются, байесовский подход обеспечивает математически хорошо
обоснованное управление неопределенностью. Большинство областей экспертных систем не
удовлетворяют этим требованиям и должны опираться на эвристический подход. Более
того, из-за сложности задач даже очень мощные компьютеры не могут использовать
байесовские методы для успешного решения задач реального времени. В завершение этого раздела
приведем небольшой пример, позволяющий показать, как полный байесовский подход
можно использовать для организации взаимосвязей гипотеза-основание.
Предположим, вы ведете автомобиль по скоростной трассе и осознаете, что
существенно снижаете скорость из-за большого скопления транспорта. Вы пытаетесь найти
возможное объяснение снижения скорости. Может, это связано с ремонтом дороги?
Была авария? Возможно, существуют и другие объяснения. Через несколько минут вы
проезжаете мимо группы дорожных рабочих в оранжевых комбинезонах, расположившихся
посреди дороги. В этот момент вы решаете, что наилучшим объяснением является
ремонт дороги. И альтернативная гипотеза аварии отбрасывается. Аналогично, если бы
вы увидели впереди "мигалку" автомобиля автоинспекции или скорой помощи,
наилучшим объяснением этой ситуации стала бы транспортная авария, позволяющая отбросить
версию о ремонте дороги. Отказ от гипотезы вовсе не означает, что она вообще
невозможна. Скорее, в контексте нового основания она имеет намного меньшую вероятность.
На рис. 8.14 представлена байесовская интерпретация этой ситуации. Ремонт дороги
связывается с оранжевыми комбинезонами и замедленным движением. Аналогично
авария связывается с мигалкой и замедленным движением. Далее согласно рис. 8.14
строится объединенное вероятностное распределение для отношения ремонт дороги и
замедленное движение. Упрощенно предположим, что эти переменные могут принимать
значения true 0) ши false (/). Вероятностные распределения для этого случая показаны на
рис. 8.15. Отметим, что, если ремонт имеет значение f, замедленное движение
невозможно, а при значении t — возможно. Отметим также, что вероятность того, что дорога
сконструирована как скоростная С = true, равна 0,5, а вероятность замедленного
передвижения Г = true равна 0,4 (это относится к штату Нью-Мексико).
Ремонт
Авария
©Оранжевые (j\
комбинезоны \__у
Замедленное
движение
Мигалка
Рис. 8.14. Байесовское представление
транспортной проблемы с возможными объяснениями
С
истина=0,5
f
1
Т
t
f
t
f
P
0,3-
0,2
0,1 -I
0,4
T — истина = 0,4
Рис 8.15. Распределение объединенной вероятности
для переменных из рис. 8.14
358
Часть III. Представление и разум в ракурсе искусственного интеллекта
Далее рассматривается вероятность ремонта дороги при условии замедленного
движения — Р(С\ Т) or P(C=t\ T=t). Используя упрощенное правило Байеса, получим
Р(С\Т) = P(C=t,T=t)/(P(C=t,T=t) + P(C=f,T=t)) =0,3/@,3+0,1 )=0,75.
Так что теперь вероятность ремонта дороги при замедленном движении возрастает с
0,5 до 0,75. Аналогично эта вероятность возрастет еще больше при наличии
комбинезонов, позволяющих напрочь отбросить гипотезу аварии.
Кроме необходимости знать значение любого из параметров в каждом состоянии,
следует учитывать вопросы сложности. Рассмотрим вычисление объединенной
вероятности для всех параметров, показанных на рис. 8.14 (используя топологическую
сортировку переменных).
Р(С,А,В>Т>Ц=Р(СГР(А\СГР(В\С>АГР(Т\С>А,ВУР(ЦС,А,В>Т).
Это, конечно, общая декомпозиция вероятностных мер, которая всегда истинна.
Стоимость генерации таблицы объединенной вероятности экспоненциально возрастает с
ростом числа параметров. В данном случае требуется таблица размером 2", или 32. Мы
рассматриваем игрушечную проблему лишь с пятью параметрами. Для более интересной
ситуации, скажем, с тридцатью или более параметрами потребуется таблица
объединенной вероятности с биллионом элементов. Байесовские сети доверия позволяют решить
вопросы представления и сложности вычислений.
8.3.2. Байесовские сети доверия
Несмотря на то, что байесовская теория вероятностей обеспечивает математическую
основу для рассуждений в условиях неопределенности, сложность, возникающая при ее
применении к реальным предметным областям, может оказаться недопустимой. К
счастью, мы можем уменьшить эту сложность, сфокусировав поиск на меньшем множестве
наиболее адекватных событий и свидетельств. Подход, называемый байесовскими
сетями доверия (Bayesian belief network) [Pearl, 1988], предлагает вычислительную модель
рассуждения с наилучшим объяснением множества данных в контексте ожидаемых
причинных связей в предметной области.
Байесовские сети доверия ослабляют многие ограничения полной байесовской
модели и показывают, как данные из предметной области (или даже отсутствующие данные!)
позволяют разделять и фокусировать рассуждения. Наблюдения показывают, что
модульность предметной области часто позволяет ослабить многие ограничения
зависимости/независимости, требуемые для правила Байеса. В большинстве ситуаций не надо
строить большую таблицу объединенной вероятности, содержащую вероятности всех
возможных комбинаций событий и свидетельств. Человек-эксперт выбирает локальные
явления, которые заведомо связаны друг с другом, и получает вероятности или меры
влияния, которые отражают лишь эти кластеры событий. Эксперты предполагают, что
остальные события или условно независимы, или их корреляции настолько малы, что
ими можно пренебречь.
Рассмотрим снова пример транспортной задачи, показанный на рис. 8.14. Если
предположить, что параметры зависят только от вероятностей их родителей, т.е. допустить,
что при наличии знания о родителях узлы являются независимыми от других
предшественников, то вычисление P(C,A,BtTtL) выполняется следующим образом:
P(C,A,BJ,L) = P(C)*P(A)*P(B\C)*P(T\CA)*P(L\A).
Глава 8. Рассуждения в условиях неопределенности
359
Чтобы лучше проиллюстрировать сделанное нами упрощение, рассмотрим
вероятность Р(В | С, А) из предыдущего уравнения. В последнем уравнении мы ослабили ее до
Р(В\ С). Это основывается на предположении, что авария не влияет на ремонт дороги.
Аналогично на "оранжевые комбинезоны" не влияет замедленное движение, но ремонт и
авария учитываются в Р(Т\ С, А), а не в Р(Т\ С, А,В). Наконец, P(L\ CtAtBtT)
ослабляется до P(L\A)\ Вероятностное распределение для P(C,A,B,T,L) теперь имеет всего 20
параметров (а не 32). При переходе к более жизненной проблеме, скажем, с 30
переменными, где каждое состояние имеет максимум двух родителей, в распределении будет не
более 240 элементов. Если каждое состояние имеет трех родителей, в распределении
будет максимум 480 элементов — значительно меньше, чем биллион, требуемый для
полного байесовского подхода!
Необходимо обосновать зависимость узла сети доверия от родительских узлов. Связи
между узлами сети доверия представляют условные вероятности причинного влияния. В
рассуждении эксперта, использующего причинно-следственный вывод, неявно
предполагается, что эти влияния являются направленными, т.е. реализация некоторого события
вызывает другие события в сети. Кроме того, рассуждение причинного влияния не
является цикличным, а раз так, воздействие не может вернуться назад, чтобы вызвать себя.
По этим причинам байесовские сети доверия могут быть естественным образом
представлены в виде ациклического направленного графа (АНГ) (подраздел 3.1.1), где
логически последовательные рассуждения отображаются как пути, проходящие через дуги
причина-симптом.
В транспортном примере мы имеем даже более устойчивую ситуацию — здесь нет
ненаправленных циклов. Это позволяет очень просто вычислять вероятностное
распределение в каждом узле. Распределение узлов, не имеющих родителей, находится
непосредственно. Значения узлов-наследников вычисляются на основе вероятностного
распределения каждого из родителей путем соответствующих вычислений по таблицам
условных вероятностей. Это возможно потому, что мы не заботимся о корреляциях между
родителями любого узла (поскольку сеть задается как ациклический направленный
граф). Это обеспечивает естественное абдуктивное отделение, при котором авария
совсем не коррелирует с наличием "оранжевых комбинезонов" (см. рис. 8.14).
Далее рассмотрим предположение, неявно используемое в рассуждениях многих
экспертов: присутствие или отсутствие данных об области может разделять и фокусировать
поиск объяснений. Этот факт имеет важные комплексные последствия для пространства
поиска. Приведем несколько примеров и концепцию d-отделения (d-separation),
поддерживающую эти интуитивные рассуждения.
Сначала рассмотрим задачу диагностики наличия масла в автомобиле: предположим,
старые поршневые кольца вызывают чрезмерное потребление масла, что, в свою
очередь, приводит к низкому уровню масла. Эта ситуация отображается на рис. 8.16, а, где
А — старые поршневые кольца, V — чрезмерное потребление масла и Б — низкий
уровень масла. Ничего не зная о чрезмерном потреблении масла, мы получаем причинное
отношение между старыми поршневыми кольцами и низким уровнем масла. Однако,
если проверка показывает, что переменная У, характеризующая чрезмерное потребление
масла, имеет значение true или false, то переменные, описывающие старые поршневые
кольца и низкий уровень масла, не зависят друг от друга.
Во втором примере старые поршневые кольца могут вызвать как синий выхлоп, так и
низкий уровень масла. Эта ситуация показана на рис. 8.16, б, где V— старые поршневые
кольца, А — синий выхлоп и В — низкий уровень масла. Не зная, какое значение имеет
360
Часть III. Представление и разум в ракурсе искусственного интеллекта
переменная В — true или false, — мы не знаем, являются ли переменные А (синий
выхлоп) и В (низкий уровень масла) коррелированными; наличие информации о
переменной V (старые поршневые кольца) означает, что эти переменные не коррелированы.
Рис 8 16 Последовательная связь узлов (а), в
которых влияние распространяется от А к В до тех пор,
пока существует V, расходящаяся связь (б), где
информация распространяется к наследникам V до тех
пор, пока определено значение V; сходящаяся связь (в):
если ничего не известно о V, то его родители
независимы, в противном случае между родителями
существует корреляция
И, наконец, если низкий уровень масла вызван либо чрезмерным его потреблением,
либо утечкой, то при наличии данных о низком уровне масла эти две возможные
причины являются коррелированными. Более того, если переменная V (низкий уровень масла)
истинна (рис. 8.16, в), то утечка масла объясняет его чрезмерное потребление. Если же
состояние переменной V (низкий уровень масла) неизвестно, то эти две возможные
причины являются независимыми. В любом случае информация о низком уровне масла
является ключевым элементом в процессе рассуждения. Эта ситуация изображена на
рис. 8.15, в, где переменная А означает чрезмерное потребление масла, В — утечку и V —
низкий уровень масла.
Уточним эти интуитивные представления, определив ^-отделение узлов в сети
доверия [Perl, 1988].
ОПРЕДЕЛЕНИЕ
^-ОТДЕЛЕНИЕ
Два узла А и В в ациклическом направленном графе являются d-omdПленными, если
все пути между ними блокированы. Путь — это любая непрерывная
последовательность связей на графе (связывающая узлы в любом направлении, например, на
рис. 8.17, б— путь от Л к В). Путь является блокированным, если существует
промежуточный узел У, обладающий одним из следующих свойств:
связь является последовательной или расходящейся, и состояние V известно;
связь является сходящейся, и ни У, ни любой из наследников V не имеют
обоснования.
Глава 8. Рассуждения в условиях неопределенности
361
Дополнительные примеры последовательных, расходящихся и сходящихся
отношений между узлами приводятся на рис. 8.17. Из этого рисунка видно, как ^-отделение
влияет на построение путей.
Перед тем как закончить рассмотрение графов на рис. 8.16, покажем, как
предположения байесовской сети доверия упрощают вычисления условных вероятностей. По
закону Байеса любое объединенное распределение вероятностей может рассматриваться
как произведение условных вероятностей. На рис. 8.16, а условная вероятность для пути
от А до V и от V до В вычисляется следующим образом
Р{АХВ) = Р(А) * P(V\A) * P(B\A,V).
Используем предположение байесовской сети доверия, что условная вероятность
переменной при заданных значениях вероятностей всех ее предшественников равна
условной вероятности при заданных значениях лишь для родителей. В результате в
приведенном выше уравнении Р( В \ А, V) заменяется на Р( В \ V), поскольку V является прямым
родителем S, а А — нет. Объединенные вероятностные распределения для трех сетей,
показанных на рис. 8.16, вычисляются следующим образом.
3)P{AtVtB) = Р(А) * P(V\A) * P{B\V),
6)P(V,A,B) = P(V) * P(A\V) * P(B\V),
b)P(A,B,V) = P(A) * P(B) * P(V\AtB).
Как показывает транспортный пример (см. рис. 8.14), в более масштабных
байесовских сетях доверия многие переменные условных вероятностей могут быть исключены.
Это делает сети доверия значительно более простыми в реализации, чем полный
байесовский анализ.
В следующем примере [Pearl, 1988] рассматривается более сложная байесовская сеть.
Как показано на рис. 8.17, переменная season (сезон) определяет вероятность rain (идет
дождь), а также вероятность water (вода поступает из поливной системы). Переменная Wet
sidewalk (мокрый тротуар) будет коррелировать с дождем или водой из поливной системы.
Наконец, тротуар будет slick (блестящим) в зависимости от того, мокрый он или нет. На
рисунке показаны вероятностные отношения для этой ситуации. Отметим также, что в отличие
от транспортного примера в данном графе имеется ненаправленный цикл.
Теперь зададим вопрос, как может быть описана вероятность мокрого тротуара
P(WS). Это не может быть сделано так, как было описано выше, т.е. P(W) = P(W\ S) *
P(S) или P(R) = P(R\S) * P(S). Обе причины WS являются взаимно независимыми,
например: если время года — это лето, то можно использовать как Р(И/), так и P(R).
Таким образом, должны быть вычислены полные корреляции двух переменных, а также их
корреляция с S. В данной ситуации это возможно, но сложность таких вычислений
экспоненциально зависит от числа возможных причин WS. Результаты вычислений
представлены на рис. 8.18. Здесь вычисляется один элемент* при истинных значениях R и W;
для простоты предполагается, что переменная S (время года) может принимать значения
либо hot (теплое), либо cold (холодное).
х = P(R = t, W= t) для всех условий S, season
= P(S = hot) * P(R = t \ S = hot) * P(W = t | S = hot) +
P(S = cold) * P(R = t \ S = clod) * P(W= t\S = cold)
Аналогичным образом можно вычислить остальные значения таблицы, показанной на
рис. 8.18. При этом получим объединенную вероятность дождя и воды из поливной
системы. Такой "макроэлемент" представляет Р(WS) = P(WS \ R,W) * P(R,W). Эта задача
362
Часть III. Представление и разум в ракурсе искусственного интеллекта
решена в рамках приемлемых объемов вычислений, но проблема состоит в том, что
объем вычислений экспоненциально увеличивается с ростом числа родителей состояния.
Время года
W|S) ( Я ) Дождь P{W\S) [ W) дивная система)
Мокрый тротуар
P(SL\WS) (SL) Блестящий тротуар
Рис. 8.17. Пример байесовской сети доверия, где
вероятностные зависимости указаны рядом с
каждым узлом. Этот пример взят из [Pearl 1988J
R
t
t
f
f
W
t
f
t
f
P
>\
Ts=,
hot
cold
Рис. 8.18. Распределение вероятностей
для P(WS) как функция от P(W) и P(R)
при заданном влиянии S. Вычисляется
влияние х при R=t и W= t
Назовем этот макроэлемент объединенной переменной для вычисления P(WS).
Теперь введем понятие клики, чтобы заменить ограничения АНГ из рис. 8.17
ациклическим деревом клик, которое показано на рис. 8.19. Прямоугольники означают
переменные, выше и ниже которых находятся клики. Размер таблицы, описывающей
передачу параметров через следующую клику, экспоненциально зависит от числа этих
параметров. Необходимо отметить, что в клике должна быть представлена связанная
переменная вместе с ее родителями. Таким образом, при построении сети доверия
(процесс инженерии знаний) необходимо задумываться о количестве родителей
каждого состояния. Как показано на рис. 8.19, б, клики могут пересекаться и передавать
информацию через полное дерево клик, называемое объединенным деревом.
Представим алгоритм создания объединенного дерева на основе сети доверия. Этот алгоритм
разработан в [Lauritzen и Spiegelhalter, 1988].
1. Для всех узлов сети доверия сделать все направленные связи ненаправленными.
2. Для каждого узла начертить связи между всеми его родителями (штриховая линия
между узлами R и W на рис. 8.19, б).
3. Просмотреть каждый цикл в результирующем графе длины >3 и добавить
дополнительные связи, ослабляющие этот цикл до дерева. Этот процесс называется
триангуляцией и не является необходимым для примера, показанного на рис. 8.19, б.
4. Сформировать объединенное дерево из результирующих триангулярных структур.
Это делается с помощью выявления максимальных клик (клик, являющихся
полными подграфами, а не подграфами больших клик). Переменные в этих кликах
объединяются, и создается результирующее объединенное дерево. В нем
соединяются любые два объединения, содержащих по крайней мере одну общую
переменную, как показано на рис. 8.19, а.
Процесс триангуляции, описанный в п. 3, является критическим, так как при
распространении информации результирующее объединенное дерево должно иметь
минимальную вычислительную стоимость. К сожалению, это решение является NP-сложным. Но,
к счастью, для получения результата часто достаточно применить несложный ограни-
Глава 8. Рассуждения в условиях неопределенности
363
ценный алгоритм. Отметим, что размеры таблиц, необходимых для обработки
объединенного дерева, показанного на рис. 8.19, составляют 2*2*2, 2*2*2 и 2*2 соответственно.
Рис 8.19. Объединенное дерево (а) для
байесовской вероятностной сети (б) Отметим, что мы
начали конструировать таблицу переходов для
прямоугольника, содержащего Я, И/
И, наконец, рассмотрим пример сети на рис. 8.17 и вернемся к вопросу d-отделсния.
Напомним, что при наличии некоторой информации d-отделенис позволяет
проигнорировать при вычислении вероятностных распределений часть сети доверия.
1. SL d-отделимо от Я, S, И/, если известно И/S.
2. d-отделение является симметричным, т.е. S также d-отделимо (и не является
объяснением SL) при знании И/S.
3. Я и И/ являются зависимыми вследствие S, но значения S, Я и И/ являются d-
отд елейными.
4. Если известно значение И/S, то Я и И/ не являются d-отделимыми, если же
значение WS не известно — являются.
5. При заданной цепочке Я->И/5—>SL, если известно И/S, то Я и SL являются d-
отделимыми.
Мы должны быть осторожны, если известна информация о наследниках некоторого
состояния. Например, если известно SL, то Я и И/ не являются d-отдслимыми, поскольку
SL коррелирует с И/S, а И/S, Я и И/ не являются d-отдслимыми.
Заключительный комментарий: байесовские сети доверия отражают рассуждения
человека о сложных областях, где некоторые факторы известны и априори связаны с другими.
Поскольку рассуждение реализуется при постепенной конкретизации информации,
последующий поиск ограничивается, и в результате оказывается более эффективным. Эта
эффективность поиска сильно контрастирует с представлением (поддерживаемым
применением точного закона Байеса) о том, что добавление информации вызывает
экспоненциальный рост статистических отношений и расширение результирующей области поиска.
Существует ряд алгоритмов для построения сетей доверия и распространения
информации при получении нового основания. Автор особенно рекомендует подход,
основанный на передаче сообщений, изложенный в [Pearl, 1988], а также метод триангуляции
дерева клик, предложенный в работе [Laurintzen и Spiegelhalter, 1988]. В работе [Druzdel
364
Часть III. Представление и разум в ракурсе искусственного интеллекта
и Henrion, 1993] также представлены алгоритмы, позволяющие вычислить
распространение влияния в сети. В работе [Dechter, 1996] в основу унифицированной системы
вероятностного вывода положен алгоритм сегментного исключения.
Однако при использовании сетей доверия остается много ограничений как с точки
зрения инженерии знаний, так и с точки зрения вычислительной сложности [Xiang и др., 1993],
[Laskey и Mahoney, 1997]. Эти ограничения мотивированы разнообразием исследований в
иерархических и компонуемых байесовских моделях [Koller и Pfeffer, 1997, 1998], [Pfeffer и
др., 1999], [Xiang и др., 2000]. Эти новые формализмы моделирования поддерживают
декомпозицию модели подобно объектно-ориентированному проектированию программного
обеспечения. Дальнейшие расширения до полных стохастических моделей Тьюринга
можно найти в [Koller и Pfeffer, 1997], [Pless и др., 2000]. В работе [Pearl, 2000] используются
стохастические методы поддержания философской идеи причинности.
Стохастические методы играют важную роль в области искусственного интеллекта,
например, в решении задач с вероятностными агентами [Kosoresow, 1993]. Со
стохастическими методами мы снова встретимся при рассмотрении проблем обучения
(раздел 9.7) и задач понимания естественного языка (глава 13).
8.4. Резюме и дополнительная литература
С самого начала исследований в области искусственного интеллекта существовал
круг ученых, хорошо чувствовавших логику и предлагавших ее расширения,
достаточные для представления интеллекта. Для описания рассуждений в условиях
неопределенности были предложены важные альтернативы исчислению предикатов первого порядка.
1. Многозначные логики расширили логику путем добавления к стандартным
значениям true и false таких новых значений истинности, как unknown. Это может
обеспечить механизм для отделения ложных утверждений от утверждений,
истинность которых просто неизвестна.
2. Модальные логики добавляют операторы, которые позволяют решать проблемы,
связанные со знаниями, их достоверностью, необходимостью и возможностью.
В данной главе обсуждались модальные операторы unless и consistent with.
3. Временные логики дают возможность квантифицировать выражения
относительно логики, указывая, например, что выражение всегда истинно или будет истинно
в определенное время в будущем.
4. Логики более высокого порядка. Многие категории знаний включают понятия
более высокого порядка, в которых под знаком квантора могут находиться не
только переменные, но и предикаты. Действительно для работы с этими знаниями
нужны логики более высокого порядка или достаточно логики первого порядка?
Если они нужны, как их описать наилучшим образом?
5. Логические формулировки определений, прототипов и исключений.
Исключения часто рассматриваются как необходимая особенность системы определений.
Однако неосторожное использование исключений подрывает семантику
представления. Другим вопросом является различие между определением и прототипом или
описанием типичных представителей. Какова разница между свойствами класса и
типичного представителя? Как должны быть представлены прототипы? Когда
прототип является более адекватным представлением, чем определение?
Глава 8. Рассуждения в условиях неопределенности
365
Представления, основанные на логике, продолжают оставаться важной областью
исследований [McCarthy, 1968], [Hayes, 1979], [Weyhrauch, 1980], [Moore, 1982], [Turner, 1984].
Существуют и другие важные достижения в области систем рассуждений с
поддержкой истинности (СПИ). Основанные на логике СПИ (ЛСПИ) изложены в работе
[McAllester, 1978]. В ЛСПИ отношения между предположениями представляются
дизъюнктами, которые могут быть использованы для вывода значений истинности любых
предположений. Другим подходом является механизм рассуждений на основе
множественной достоверности (МДР), подобный механизму рассуждений СПИП [deKleer, 1984].
Аналогичные идеи могут быть найдены в [Martins и Shapiro, 1983]. МДР основывается на
логическом языке SWM*, описывающем состояния знаний. Алгоритмы для проверки
непротиворечивости базы знаний в процессе рассуждения приводятся в [Martins, 1991].
Более полная информация по алгебре узлов содержится в [Doyle, 1983] или
[Reinfrank, 1989]. Логика умолчания позволяет рассматривать любую теорему,
выведенную в расширении системы, в качестве аксиомы для дальнейших рассуждений. Эти
вопросы рассматриваются в [Reiter и Criscuolo, 1981] и [Touretzky, 1986].
В области немонотонных рассуждений, логики достоверности и поддержки
истинности, кроме оригинальных статей, существует обширная литература [Doyle, 1979],
[Reiter, 1985], [deKleer, 1986], [McCarthy, 1980]. Стохастические модели описаны в
[Pearl, 1988], [Shafer и Pearl 1990], [Davis, 1990] и многочисленных докладах последних
конференций AAAI и IJCAI. Автор рекомендует также энциклопедию искусственного
интеллекта [Shapiro, 1992]. Обширный материал собран в книгах [Josephson и Josephson,
1994] и [Hobbs и Moore, 1985]. Работа [Pearl 2000] вносит свой вклад в понимание
причинно-следственных отношений в мире.
Дальнейшие исследования по ограничениям и минимизации логической модели
можно найти в [Genesereth и Nilsson, 1987], [Lifschitz, 1986] и [McCarthy, 1986]. Важный
вклад в развитие ограниченного вывода вносит работа [Pedis, 1988], учитывающая
отсутствие знаний у отдельного агента. Важная коллекция статей по немонотонным
системам собрана в книге [Ginsburg, 1987].
В качестве литературы по нечетким системам мы бы рекомендовали оригинальную
статью [Zadeh, 1983]. Более современные реализации этого подхода можно найти в
работах [Yager и Zadeh, 1994] и [Ross, 1995]. Задача перевернутого маятника, представленная
в подразделе 8.2.2, взята из [Ross, 1995].
Алгоритмы реализации байесовских сетей доверия на основе передачи сообщений
изложены в [Pearl, 1988], а метод триангуляции клик (раздел 8.3) изложен в [Lauritzen и
Spiegelhalter, 1988]. Этот алгоритм обсуждается в [Shapiro, 1992]. Введение в
байесовские сети доверия содержится в [van der Gaag, 1996], а обсуждение качественных
вероятностных сетей приводится в [Druzdel, 1996].
Стохастические представления и алгоритмы продолжают оставаться очень
актуальной областью исследований [Xiang и др., 1993], [Laskey и Mahoney, 1997]. Ограничения
байесовского представления обусловили исследования по иерархическим и
компонуемым байесовским моделям [Koller и Pfeffer, 1997, 1998], [Pfeffer и др., 1999], [Xiang и
др., 2000]. Дальнейшее расширение этих результатов до полных моделей Тьюринга
можно найти в [Pless и др., 2000].
366
Часть III. Представление и разум в ракурсе искусственного интеллекта
8.5. Упражнения
1. Укажите три прикладные области, в которых необходимы рассуждения в условиях
неопределенности. Выберите одну из этих областей и разработайте шесть правил
вывода, отражающих рассуждения в ней.
2. Даны следующие правила, применяемые в экспертной системе, работающей на
основе "обратной цепочки".
А л not(B) => С@,9)С v D => Е@,75)
Г=>Л@,6)
G => D@,8)
Система может вывести следующие факты (с заданной достоверностью).
F@,9)
Б(-0,8)
6@,7)
Используйте стэндфордскую алгебру фактора уверенности для определения Е и его
достоверности.
3. Рассмотрите простое MYCIN-подобное правило: if А л (В v С) => D@,9) л Е@,75).
Обсудите вопросы, возникающие при работе с такими неопределенностями в
контексте байесовского подхода. Как это правило можно использовать в рассуждениях
Демпстера-Шафера?
4. Приведите новый пример диагностических рассуждений и используйте уравнение
Демпстера-Шафера из подраздела 8.2.3 для объединения свидетельств, аналогичного
приведенному в табл. 8.1 и 8.2.
5. Используйте схему аксиом, представленную в работе [McCarthy, 1980, раздел 4], для
воссоздания результатов, приведенных в разделе 8.1.3.
6. Создайте сеть рассуждений, подобную представленной на рис. 8.4, и постройте
решетку зависимостей для ее посылок, как это сделано на рис. 8.5.
7. Рассуждения на минимальных моделях являются важными в повседневной жизни
человека. Приведите не менее двух примеров, предполагающих использование
минимальных моделей.
8. Вернитесь к примеру перевернутого маятника из пода 8.2.2. Воспроизведите не
менее двух итераций работы нечеткого контроллера.
9. Напишите программу, реализующую нечеткий контроллер из подраздела 8.2.2.
10. С использованием литературных источников (например [Ross, 1995]) опишите две
области, в которых применимо нечеткое управление. Разработайте множество
нечетких правил для этих областей.
11. Добавьте некоторую новую связь на рис. 8.26, скажем, соединяющую сезон с
тротуаром, и создайте дерево клик для представления этой ситуации. Сопоставьте
сложность этой задачи с той, которая представлена деревом клик на рис. 8.17.
12. Добавьте оценки, необходимые для завершения табл. 8.4.
13. Создайте алгоритм реализации байесовских сетей доверия и примените его к задаче
скользкого тротуара из подраздела 8.3.2. Можно использовать подход передачи со-
Глава 8. Рассуждения в условиях неопределенности
367
общений, изложенный в [Pearl, 1988], или метод триангуляции клик, предложенный
в [Launtzen и Spiegelhalter, 1988].
14. Создайте граф байесовской сети доверия для новой области применения (например,
медицинской диагностики, геологоразведки или анализа автомобильных
неисправностей). Обратитесь к примерам d-отделения и создайте дерево клик для этой сети.
15. Создайте дерево клик и объединенное дерево для ситуации, показанной на рис. 8.20.
Ограбление, вандализм и землетрясение — все это может вызвать тревогу в доме.
Существует также мера потенциальной опасности района, где расположен дом.
16. Рассмотрите диагностические рассуждения, приведенные в подразделе 8.2.3, и
представьте их в виде байесовской сети доверия. Сопоставьте эти два подхода к задаче
диагностики.
( N j Качество района
/ Вандализм
Ограбление ( Я ) ( ^ ) ( ^ ) Землетрясение
( A ) Тревога
Рис 8 20. Сеть доверия, иллюстрирующая
возможность тревоги доме в зависимости
от различных опасностей
368
Часть III. Представление и разум в ракурсе искусственного интеллекта
Часть IV
Машинное обучение
Точность — это не истина...
— Генри Матисс (Henri Matisse)
Настоящее и будущее являются настоящим с точки зрения будущего и будущим с
точки зрения прошедшего...
— Т. С. Элиот (Т. S.Eliot)
Каждый крупный результат является конечным продуктом длинной
последовательности маленьких действий.
— Кристофер Александер (Christopher Alexander)
Символьное, нейросетевое и эмерджентное обучение
В ответ на вопрос о том, какие проявления интеллекта, свойственные человеку,
труднее всего компьютеризировать, помимо творческих способностей, принятия этических
решений и социальной ответственности, чаще всего называют понимание естественного
языка и способность к обучению. В течение многих лет эти две области были целью и
камнем преткновения для развития искусственного интеллекта. Одной из причин
сложности и важности исследования языка и процесса обучения является то, что эти области
связаны со многими другими проявлениями человеческого интеллекта. Система,
обладающая искусственным интеллектом, должна решать вопросы на человеческом языке на
основе машинного обучения и автоматического доказательства теорем. В части IV
описано несколько подходов к машинному обучению. В части V рассмотрены вопросы
автоматического доказательства теорем и понимания естественного языка.
В главе 9 описываются методы обучения, основанные на символах. Сначала
рассматривается набор символов, представляющих сущности и взаимосвязи между ними в области их
определения. Символьные алгоритмы обучения обеспечивают возможность корректного и
полезного обобщения, которое тоже можно выразить в терминах этих символов.
Подходы к обучению на основе связей, изложенные в главе 10, предполагают
описание знаний в виде примеров деятельности в сетях, состоящих из отдельных небольших
обрабатывающих элементов. По примеру мозга живых существ такие сети обучаются за
счет модификации собственной структуры и весовых коэффициентов связей при
получении обучающей информации. В отличие от поиска и обобщения, выполняемых методами
символьного представления языка, модели на основе связей позволяют выявить
инвариантные фрагменты данных и представить их в структуре сети.
Если сети связей построены по принципам нервной системы биологических
организмов, то аналогами эмерджентных моделей, рассмотренных в главе 11, являются
генетические и эволюционные процессы. Генетические алгоритмы начинают свою работу с
целой популяции кандидатов на решение проблемы. Решения оцениваются по некоторому
критерию, позволяющему отобрать наилучшие. Комбинация таких претендентов
составляет новое поколение возможных решений. Таким образом по принципу Дарвина
строится последовательность все более точных решений. Этот подход предполагает поиск
источника интеллекта в самом процессе развития, который (хотя некоторые это и
оспаривают) стал источником самой жизни.
Машинное обучение связано со множеством важных философских проблем и
проблем образования понятий. К ним относятся проблема обобщения — как машина может
идентифицировать инвариантные фрагменты данных и в дальнейшем использовать их
для решения интеллектуальных проблем, например, для работы с новыми, не
известными ранее данными. Вторая проблема машинного обучения — природа индуктивного
порога. Этот порог напоминает использование разработчиками программ собственной
интуиции и эвристик в моделировании, представлении и алгоритмизации процесса
обучения. Примерами таких проявлений являются выделение "важных" понятий в области
определения, использование конкретного алгоритма поиска или выбор архитектуры
нейронной сети для обучения. Индуктивный порог с одной стороны обеспечивает процесс
обучения, а с другой — ограничивает информационную емкость системы. И последний
философский вопрос, получивший название эмпирической дилеммы, открывает вторую
сторону медали: если в обучающейся системе нет заданных наперед индуктивных
порогом, как можно научиться чему-то полезному, или даже вредному? Как вообще можно
у шать, что система чему-то научилась? Этот вопрос зачастую возникает в эмерджентных
моделях и моделях обучения без учителя. Эти три вопроса более подробно обсуждаются
в разделе 16.2.
370
Часть IV. Машинное обучение
Машинное обучение,
основанное
на символьном
представлении
информации
Разум, как я и утверждал, в процессе наполнения большим количеством простых
идей, переданных через органы чувств из внешнего мира или сформированных как
отражение собственных операций, получает также информацию о том, что
некоторые из этих простых идей тесно связаны друг с другом..., что впоследствии по
невнимательности мы склонны трактовать как одну простую идею.
— Джон Лок (John Locke)
Простое созерцание мира ничего не значит. Созерцание переходит в наблюдение,
наблюдение — в осмысление, осмысление — в установление связей, поэтому можно
сказать, что каждый внимательный взгляд в мир является актом теоретизации.
Однако это надо делать сознательно, с долей самокритики, свободой мышления, не
боясь смелых высказываний и иронии.
— Гете (Goethe)
9.0. Введение
Способность к обучению присуща любой системе, обладающей интеллектом. В
нашем мире символов и их интерпретации термин "неизменный интеллект" кажется
противоестественным. Интеллектуальные агенты должны иметь возможность изменяться при
взаимодействии с окружающим миром, а также в процессе приобретения опыта на
основе своих внутренних состояний и действий. Три следующие главы будут посвящены
проблеме машинного обучения. Они отражают три подхода к этой проблеме: первый —
на основе символьного представления информации, второй — на основе связей, и третий
основан на принципах генетики или эволюционной теории.
Обучение играет важную роль в практических применениях искусственного
интеллекта. Фейгенбаум (Feigenbaum) и Мак-Кордак (McCorduck) в 1983 году назвали
проблему машинного обучения основным препятствием к широкому распространению ин-
Шшш
■
теллектуальных систем. Эта проблема возникает при создании экспертных систем на
основе традиционного представления знаний, описанного в разделе 7.1. Одним из решений
этой проблемы является возможность обучения на примерах с учителем или на основе
внутренних представлений об области определения.
Герберт Симон (Herbert Simon) определил обучение следующим образом.
"Обучение — это любое изменение в системе, приводящее к улучшению решения задачи
при ее повторном предъявлении или к решению другой задачи на основе тех же данных".
[Simon, 1983]
Это краткое определение затрагивает множество вопросов, связанных с разработкой
обучаемых программ. Обучение подразумевает обобщение на основе опыта.
Производительность системы должна повышаться не только при повторном решении одной и той же
задачи, но и при решении аналогичных задач из той же предметной области. Поскольку
область определения обучающих данных обычно достаточно широка, то обучаемая система
зачастую может обработать не все возможные примеры, и этот ограниченный опыт она
должна корректно распространить на недостающие примеры. Такая задача индукции
(induction) является центральной для обучения. Для большинства задач имеющихся в
наличии данных недостаточно, чтобы гарантировать оптимальное обобщение независимо от
типа используемого алгоритма. Обучаемые системы должны обобщать информацию
эвристически, т.е. отбирать те аспекты, которые вероятнее всего окажутся полезными в
будущем. Такой критерий отбора называется индуктивным порогом (inductive bias).
Определение Симона описывает обучение как свойство системы улучшить повторное
решение задачи. Как следует из вышесказанного, формирование возможных изменений,
приводящих к такому улучшению, — это сложная задача. При исследовании природы
обучения может оказаться, что подобные изменения на самом деле снижают
производительность системы. Поэтому предотвращение и выявление таких проблем — это еще
одна задача алгоритма обучения.
Обучение приводит к изменениям в обучаемой системе. Это несомненно. Однако
точная природа этих изменений и наилучший способ их представления далеко не так
очевидны. Один из подходов к обучению сводится к явному представлению в системе
знаний об области определения задачи. На основе своего опыта обучаемая система
строит или модифицирует выражение на формальном языке и сохраняет эти знания для
последующего использования. Символьные подходы, описанные в разделах 9.2-9.6,
строятся на предположении, что основное влияние на поведение системы оказывают знания
об области определения в их явном представлении.
Нейронные сети (neural network), или сети связей (connectionist network), обучаются не
на основе символьного языка. Подобно мозгу живых организмов, состоящему из
огромного количества нервных клеток, нейронные сети — это системы взаимосвязанных
искусственных нейронов. Знания программы неявно представлены в общей организации и
взаимодействии этих нейронов. Такие системы не строят явную модель мира, они сами
принимают его форму. Нейронные сети обучаются не за счет добавления новой информации в свою
базу знаний, а за счет модификации своей общей структуры в ответ на получаемую извне
информацию. Нейросетевой подход к обучению будет рассмотрен в главе 10.
В главе 11 описывается генетическое (genetic learning), или эволюционное, обучение
(evolutionary learning). Естественно, наиболее впечатляющим примером обучаемой
системы является организм человека или животного, который эволюционировал вместе с
окружающим миром. Этот эмерджентный подход к обучению, основанный на адаптации,
отражен в генетических алгоритмах, генетическом программировании и исследовании
искусственной жизни.
372
Часть IV. Машинное обучение
Машинное обучение — это обширная область исследований, предлагающая большое
количество проблем и алгоритмов их решения. Эти алгоритмы различаются своими задачами,
исходными данными, стратегиями обучения и способами представления знаний. Однако все
они сводятся к поиску полезной информации в пространстве возможных понятий и ее
корректному обобщению. В разделе 9.1 будет рассмотрен контур символьного машинного
обучения, в рамках которого будут введены общие предположения для этой области знаний.
В разделе 9.1 рассматриваются различные задачи обучения, но посвящена эта глава в
основном индуктивному обучению. Индукция (способность обобщения на основе
множества примеров) — одна из наиболее фундаментальных задач обучения. Типичной
задачей индуктивного обучения является изучение понятий (concept learning), при котором
на основе примеров некоторого понятия выводится его определение, позволяющее в
будущем корректно распознавать экземпляры такого понятия, как "кот", "детские заболе-
вaния,, или "удачное вложение акций". В разделах 9.2 и 9.3 рассмотрены два алгоритма
концептуальной индукции: поиск в пространстве версий (version space search) и ЮЗ.
В разделе 9.4 рассматривается роль индуктивного порога в процессе обучения.
Пространство поиска в задачах обучения обычно чрезвычайно велико. Эта проблема
сложности усугубляется проблемой выбора наилучшего варианта обобщения на основе
обучающих данных. Индуктивный порог используется во всех методах для ограничения
пространства возможных обобщений. Алгоритмы из разделов 9.2 и 9.3 основаны на данных. Они не
используют априорных знаний об изучаемой предметной области, а определяют главные
свойства общего понятия на основе большого количества примеров. Алгоритмы,
выполняющие обобщение на базе обучающих данных, называются алгоритмами обучения на
основе подобия (similarity-based learning). В отличие от таких методов, человек в процессе
обучения может использовать априорные знания о предметной области. Например, для
эффективного обучения человеку не требуется большого количества примеров. Зачастую
одного примера, аналогии или пространного намека вполне достаточно для формирования
общего понятия. Эффективное использование таких знаний повышает результативность
обучения и снижает вероятность ошибок. В разделе 9.5 рассматривается обучение на основе
объяснения (explanation-based learning), обучение по аналогии и другие приемы,
использующие априорные знания для обучения с помощью ограниченного числа примеров.
Алгоритмы, представленные в разделах 9.2-9.5, отличаются друг от друга
стратегиями поиска, языками представления и объемом используемых априорных знаний. Однако
все они предполагают, что обучающие данные классифицированы. Обучаемой системе
сообщается, к какому классу относится данный пример. Такой подход, предполагающий
наличие информации о классификации обучающих данных, называется обучением с
учителем (supervised learning).
В разделе 9.6 продолжается изучение индуктивных методов обучения. Здесь
рассматривается обучение без учителя (unsupervised learning), предполагающее извлечение
полезной информации интеллектуальным агентом при отсутствии корректно
классифицированных обучающих данных. Основной проблемой обучения без учителя является
формирование категорий (category formation), или концептуалышя кластеризация
(conceptual clustering). Как интеллектуальный агент должен разделить объекты на
полезные категории? Как вообще определить, полезна ли эта категория? В этом разделе будут
рассмотрены два алгоритма формирования категорий— CLUSTER/2 и СОВ-WEB. И,
наконец, в разделе 9.7 представлено обучение с подкреплением (reinforcement learning),
при котором агент помещается в среду и получает от нее отклик. Процесс обучения
предполагает активную деятельность агента и интерпретацию обратной связи,
полученной в ответ на его действия. Обучение с подкреплением отличается от обучения с учите-
Глава 9. Машинное обучение, основанное на символьном представлении... 373
лем тем, что в нем не участвует учитель, напрямую оценивающий каждое действие.
Агент сам должен выработать политику интерпретации обратной связи.
Все представленные в этой главе подходы к обучению обладают общим свойством.
Их можно рассматривать как вариации поиска в пространстве состояний. Даже в
процессе обучения с подкреплением строится функция значимости в пространстве состояний.
Далее проблема машинного обучения будет рассматриваться в общем контексте поиска.
9.1. Символьное обучение
Алгоритмы обучения можно охарактеризовать с нескольких точек зрения (рис. 9.1).
1. Данные и цели задачи обучения. Одной из основных характеристик обучения
является его цель и имеющиеся данные. Например, алгоритмы изучения понятий,
описанные в разделах 9.2 и 9.3, начинают свою работу с набора положительных (и
зачастую отрицательных) примеров целевого класса. Обучение должно
сформировать общее определение, позволяющее в дальнейшем распознавать экземпляры
этого класса. В отличие от обучения, основанного на данных, обучение на основе
объяснения (раздел 9.5) предполагает извлечение общего знания из каждого
обучающего примера и наличие исходной базы знаний о конкретной области
определения. Алгоритмы концептуальной кластеризации, описанные в разделе 9.6,
иллюстрируют еще один вариант проблемы индукции. Они начинают свою работу с
набора неклассифицированных экземпляров. Их задачей является категоризация этих
данных, имеющая определенный смысл для обучаемой системы.
Язык представления
Пространство понятий
Операции
Эвристический
поиск
►
Приобретенные знания
Данные и цели
задачи обучения
Рис. 9.1. Общая модель процесса обучения
374
Часть IV. Машинное обучение
Примеры — не единственный источник данных для обучения. Человек,
например, зачастую обучается на основе высокоуровневых рекомендаций. При
изучении программирования преподаватель сообщает своим студентам, что в
цикле всегда должно достигаться условие завершения. Этот безусловно
корректный совет напрямую неприменим. Его необходимо реализовать в виде
конкретных правил управления счетчиками циклов или логических условий на
языке программирования. Еще одним типом обучающих данных является
аналогия (подраздел 9.5.4), которую необходимо корректно интерпретировать до
начала использования. Если преподаватель сообщает студентам, что
электричество напоминает воду, студенты должны корректно интерпретировать эту
аналогию — электричество распространяется по проводам, как жидкость в
водопроводе. Как и для потока жидкости можно измерить количество
электричества (силу тока) и его давление в потоке (напряжение). Однако, в отличие от
воды, электричество не увлажняет вещи и не помогает мыть руки.
Интерпретируя аналогию, следует выявить осмысленное сходство и исключить ложные
или несущественные детали.
Характеристикой алгоритма обучения также является его цель (target). Цель
многих алгоритмов — понятие (concept), или общее описание класса объектов.
Алгоритмы обучения также могут использовать планы, эвристики решения проблемы
или другие формы процедурного знания.
Свойства и качество обучающих данных — это еще одно направление для
классификации задач обучения. Данные могут поступать от учителя из окружающей
среды или генерироваться самой программой. Они могут быть достоверными или
непроверенными, структурированными или неорганизованными. Данные могут
включать как положительные, так и отрицательные примеры, или состоять только
из положительных примеров. Данные могут быть подготовлены либо требовать
дополнительных экспериментов по их извлечению.
2. Представление полученных знаний. Программы машинного обучения могут
использовать любые языки представления, описанные в этой книге. Например, в
программах, обучаемых классификации объектов, понятия могут быть представлены
выражениями из теории предикатов или с помощью фреймов и объектов. Планы
могут описываться как последовательности операций или треугольные таблицы.
Эвристики представляются в виде правил вывода.
Для того чтобы сформулировать проблему изучения понятий следует представить
экземпляры понятий в виде конъюнктивных выражений с параметрами. Например,
два экземпляра понятия "мяч" (которых недостаточно для изучения самого
понятия) можно представить в следующем виде.
s/ze(ob/1, small) л color(obj^, red) л shape(ob'^, round)
slze(obj2, large) л color(obj2, red) л shape(obj2, round)
Общее понятие "мяч" можно описать так.
size(X, Y) л color(Xf Z) л shape(X, round)
Тогда любое выражение, удовлетворяющее этому общему определению,
представляет мяч.
Глава 9. Машинное обучение, основанное на символьном представлении... 375
3. Набор операций. Имея набор экземпляров для обучения, система должна
построить обобщение, эвристическое правило или план, удовлетворяющие ее целям. Для
решения этой задачи необходимо уметь оперировать представлениями. К
типичным операциям относятся обобщение или специализация символьных выражений,
настройка весов нейронной сети или другая модификация представления данных в
программе. В рассмотренном выше примере изучения понятий обучаемая система
может вывести определение, заменив конкретное значение переменными.
Рассмотрим первое выражение.
s/ze(ob/1, small) л color(obj^f red) л shape(oby'1, round)
Если заменить одну константу переменной, получим следующее обобщение.
sizeiobj], X) a color(obj^f red) л shape(ob/1, round)
s/ze(ob/1, small) л color(obj], X) л shape(ob/1, round)
s/ze(oby'1, small) л color(obj], red) л sbape(oby'1, X)
size(X, small) л color(X, red) л shape(Xf round)
Пространство понятий. Язык представления наряду с описанными выше
операциями определяет пространство потенциальных определений понятий.
Обучаемая система, чтобы найти нужное понятие, должна выделить это
пространство. Сложность такого пространства понятий — основная мера сложности
задачи обучения.
Эвристический поиск. Обучаемые программы должны учитывать направление и
порядок поиска, а также для повышения эффективности поиска использовать
имеющиеся в наличии обучающие данные и эвристики. В рассмотренном выше
примере изучения понятия "мяч" алгоритм может выбрать первое выражение в
качестве кандидата и включить его в последующие примеры. Например, имея
единственный обучающий пример
s/ze(oby'1, small) л color(obj^, red) л shape(oby'1, round),
обучаемая система выберет его в качестве кандидата на определение понятия. Этот
пример корректно описывает лишь один экземпляр.
Если алгоритму предъявить второй экземпляр этого понятия
size(obj2, large) л color(obj2, red) л shape(obj2, round),
обучаемая система может обобщить понятие-кандидат, заменив конкретные
значения переменными, и сформировать понятие, удовлетворяющее описаниям обоих
экземпляров. В результате получится более общее понятие-кандидат, точнее
соответствующее целевому понятию "мяч".
size(X, Y) л color(X, red) л shape(X, round)
Этот подход изучения понятий на положительных и отрицательных примерах
описан в работе Патрика Винстона [Winston, 1975a]. Его программа строит общие
определения таких структурных понятий, как арка, описывая их составные части.
Обучающие данные — это последовательность положительных и отрицательных
примеров понятия. Это примеры структур, удовлетворяющих определенным
условиям или почти удовлетворяющих им. "Почти удовлетворительными" считаются
экземпляры, для принадлежности к категории которым не хватает одного свойства или
отношения. "Почти удовлетворительные" экземпляры позволяют программе выде-
376 Часть IV. Машинное обучение
лить свойства, которые можно использовать для исключения отрицательных
примеров из целевого понятия. На рис. 9.2 показаны положительные примеры и "почти
удовлетворительные" экземпляры понятия "арка".
Арка
Арка
Почти удовлетворительный
пример
Почти удовлетворительный
пример
Рис 9 2 Хорошие и "почти удовлетворительные"
примеры понятия "арка"
Программа представляет понятия в виде семантической сети (рис. 9.3). Она
обучается, уточняя описание кандидата на роль целевого понятия на основе обучающих данных.
Программа Винстона уточняет описание кандидата с помощью обобщения и
специализации. Обобщение приводит к такому изменению графа, которое обеспечивает
соответствие графу новых экземпляров понятия. На рис. 9.3, а показана арка из трех блоков и
представляющий ее граф. В следующем обучающем примере (рис. 9.3, б) перекладиной
арки служит пирамида, а не блок. Этот пример не соответствует описанию понятия-
кандидата. Программа сопоставляет эти графы, пытаясь определить степень их
изоморфизма, с помощью имен узлов. После сопоставления графов программа может выявить
различия между ними. На рис. 9.3 графы соответствуют друг другу по всем компонентам
за исключением верхнего элемента: в первом графе этому элементу соответствует узел
brick (блок), а во втором — узел pyramid (пирамида). На рис. 9.3, в показана иерархия
обобщения этих понятий. Программа строит обобщенный граф, заменяя
соответствующий узел ближайшим общим супертипом для объектов brick и pyramid. В данном
примере это polygon (многогранник). В результате получается понятие, представленное
графом на рис. 9.3, г.
Глава 9. Машинное обучение, основанное на символьном представлении... 377
а. Пример арки и ее сетевого описания
б. Пример другой арки с сетевым описанием
в. Базовые знания о том, что блок и пирамида являются частным случаем
многогранника
isa,
brick
polygon
Jsa
pyramid
г. Обобщение, включающее оба примера
Рис. 9.3. Обобщение описания, позволяющее исключить множественное представление
"Почти удовлетворительные" примеры отличаются от целевого понятия одним
свойством. Для их исключения программа выполняет специализацию описания кандидатов.
На рис. 9.4, а представлено описание понятия-кандидата. Оно отличается от "почти
удовлетворительного" примера на рис. 9.4, б отношением touch (касается) в последнем
описании. Программа строит специализацию графа, добавляя связь must-not-touch (не
должно касаться) (рис. 9.4, в). Заметим, что этот алгоритм существенно зависит от
близости отрицательных примеров целевому понятию. Определяя единственное
отличительное свойство, алгоритм уточняет понятие-кандидат.
378
Часть IV. Машинное обучение
а. Вариант описания арки
б. "Почти удовлетворительный" пример и его описание
в. Специализированное описание арки, исключающее "почти удовлетворительный"
пример
Рис 9.4. Специализация описания с целью исключить "почти удовлетворительные"
примеры. На рис. 9.4, в к графу, представленному на рис. 9 4, а, добавлены ограничения,
исключающие его соответствие графу на рис. 9.4, б
Эти операции — специализация сети за счет добавления связей и обобщение путем
замены имени узла или связи более общим понятием — задают пространство возможных
определений понятия. Программа Винстона выполняет поиск экстремума в пространстве
понятий на основе обучающих данных. Поскольку программа не отслеживает маршрут
поиска, ее производительность существенно зависит от порядка предъявления
обучающих примеров. Неудачный порядок может завести программу в тупик пространства
поиска. Обучающие примеры необходимо предъявлять программе в порядке,
способствующем изучению данного понятия, подобно тому как преподаватель организует свои
занятия со студентами. Качество и порядок следования обучающих примеров важны
также для алгоритма сопоставления графов: для эффективного сопоставления графы не
должны сильно различаться.
Глава 9. Машинное обучение, основанное на символьном представлении... 379
Являясь одной из первых реализаций принципа индуктивного обучения, программа
Винстона иллюстрирует свойства и проблемы большинства подходов к машинному
обучению. Они используют операции обобщения и специализации, чтобы определить
пространство возможных понятий. Поиск в этом пространстве осуществляется на основе
данных, и все эти алгоритмы обучения зависят от качества обучающих данных. В
следующих разделах рассматриваются эти проблемы и приемы их решения в системах
машинного обучения.
9.2. Поиск в пространстве версий
Поиск в пространстве версий (version space search) [Mitchell 1978, 1982]
иллюстрирует индуктивное обучение как реализацию поиска в пространстве понятий. Поиск в
пространстве версий основан на том, что операция обобщения упорядочивает понятия в
пространстве поиска. Затем этот порядок используется для выбора направления поиска.
9.2.1. Операция обобщения и пространство понятий
Обобщение и специализация — самые типичные операции при определении
пространства понятий. К основным операциям обобщения, применяемым в машинном
обучении, относятся следующие.
1. Замена конкретных значений переменными. Например,
color{ball, red)
приводится к виду
color{X, red).
2. Исключение условий из конъюнктивных выражений. Так,
shape(X, round) л size{X, small) л color(X, red)
сводится к выражению
shape(X, round) л color(x, red).
3. Добавление в выражение операции дизъюнкции. Например,
shape(X, round) л size(X, small) л color(X, red)
приводится к
shape(X, round) л size(X, small) л (color(X, red) v color(X, blue)).
4. Замена свойства родительским объектом согласно иерархии классов. Если объект
primary_color (основной цвет) является суперклассом для свойства red (красный), то
color(X, red)
заменяется на
color(X, primary_color).
Операцию обобщения можно описать в терминах теории множеств. Пусть Р и О —
множества предложений, удовлетворяющих выражениям р и q из теории предикатов
соответственно. Выражение р является более общим, чем д, если P^Q. В приведенных
выше примерах множество предложений, удовлетворяющих выражению color(X, red),
включает набор элементов, удовлетворяющих выражению color(ball, red). Аналогично
380
Часть IV. Машинное обучение
в примере 2 множество круглых и красных объектов является более общим, чем
множество маленьких красных и круглых объектов. Заметим, что отношение "более общий"
позволяет упорядочить логические предложения в соответствующем пространстве. Это
отношение можно обозначить символом ">", т.е. p>q означает, что выражение р
является более общим, чем q. Такая систематизация существенно сужает направление поиска,
выполняемого алгоритмом обучения.
Это отношение можно описать в терминах покрытия (covering). Если понятие р
является более общим, чем понятие д, то говорят, что р покрывает д. Отношение покрытия
определяется следующим образом. Пусть р(х) и д(х) — описания, представляющие
собой положительные примеры понятия. Другими словами, для объекта х
р(х)—>pos/f/Ve(x) и q(x)->pos/f/Ve(x). Говорят, что р покрывает д, если
д(х)—>pos/f/Ve(x) является логическим следствием р(х)—>pos/f/Ve(x).
Например, color(X, Y) покрывает color(ball, Z), которое, в свою очередь, покрывает
color(ball, red). В качестве простого примера рассмотрим множество объектов со
следующими свойствами.
Sizes = {large, small}
Colors = {red, white, blue}
Shapes = {ball, brick, cube}
Эти объекты можно представить с помощью предиката obj{Sizes, Colors, Shapes).
Операция обобщения, осуществляемая путем замены конкретных значений
переменными, определяет пространство, представленное на рис. 9.5. Индуктивное обучение можно
рассматривать как поиск в этом пространстве понятия, удовлетворяющего всем
обучающим примерам.
9.2.2. Алгоритм исключения кандидата
В этом разделе представлены три алгоритма [Mitchell, 1982] поиска в пространстве
понятий. Эти алгоритмы основываются на понятии пространства версий (version space),
представляющем собой множество всех описаний понятия, согласующихся с обучающими
примерами. Эти алгоритмы работают за счет сужения пространства версий с появлением новых
примеров. Первые два алгоритма обеспечивают сужение пространства версий в направлении
от частного к общему и от общего к частному соответственно. Третий алгоритм, называемый
алгоритмом исключения кандидата (candidate elimination), объединяет оба подхода и
реализует двунаправленный поиск.
Эти алгоритмы основаны на данных. Обобщение выполняется на основе
обнаруженных в обучающих данных закономерностей. Кроме того, поскольку в этих алгоритмах
используются классифицированные обучающие данные, их можно считать
разновидностью обучения с учителем (supervised learning).
Как и программа Винстона, реализующая обучение на основе структурных описаний,
алгоритмы поиска в пространстве версий используют и положительные, и
отрицательные примеры целевого понятия. Хотя операцию обобщения можно реализовать только
на положительных примерах, отрицательные примеры позволяют предотвратить
излишнее обобщение. Изученное понятие должно быть не только общим, чтобы
соответствовать всем положительным примерам, но и частным, чтобы исключить все
отрицательные. В пространстве, представленном на рис. 9.5, все множество положительных
экземпляров покрывается понятием obj(X, Y, Z).
Глава 9. Машинное обучение, основанное на символьном представлении... 381
obj(X, Y, Z)
obj(X, Y, ball) obj(X, red, Y) obj(small, X, Y)
Л. ^х^\ ^ I • • •
obj{X, red, ball) obj{small, X, ball) obj{small, red, X)
obj{small, red, ball) obj{large, red, ball) obj{small, white, ball)
• • •
Рис. 9.5. Пространство понятий
Однако это понятие является слишком общим, поскольку включает все существующие
экземпляры. Чтобы избежать излишнего обобщения, необходимо систематизировать
обучающие данные в минимально возможной степени, чтобы покрыть лишь
положительные примеры, либо использовать отрицательные примеры для исключения лишних
объектов. Как показано на рис. 9.6, отрицательные примеры предотвращают избыточное
обобщение за счет специализации понятий и исключения отрицательных примеров.
Представленные в этом разделе алгоритмы используют оба приема. Поиск от частного к
общему на множестве гипотез S выполняется следующим образом.
Begin
Инициализировать S первым положительным обучающим примером;
N - множество всех отрицательных примеров.
Для каждого положительного примера р
Begin
Для каждого se S, не удовлетворяющего примеру р, заменить
s минимальным более общим понятием,
удовлетворяющим примеру р;
Удалить из S все гипотезы, более общие, чем некоторые
другие гипотезы из S;
Удалить из S все гипотезы, удовлетворяющие рассмотренному
ранее отрицательному примеру из N;
End;
Для каждого отрицательного примера п
Begin
Удалить все экземпляры S, удовлетворяющие П;
Добавить П в множество N для проверки последующих
гипотез на предмет излишнего обобщения;
End;
End
382
Часть IV. Машинное обучение
Понятие, составленное только Понятие, построенное на базе положительных
из положительных примеров и отрицательных примеров
Рис. 9 6 Роль отрицательных примеров в предотвращении излишнего обобщения
В алгоритме поиска от частного к общему используется множество гипотез S,
элементами которого являются кандидаты на определение понятия. Чтобы избежать
излишнего обобщения, эти определения-кандидаты формируются как максимально
конкретные обобщения (maximally specific generalization) исходных обучающих данных. Понятие
с является максимально конкретным, если оно покрывает все положительные примеры,
не удовлетворяет ни одному отрицательному, и для любого другого понятия с'
покрывающего все положительные примеры, с'> с. На рис. 9.7 представлен пример
применения этого алгоритма к пространству версий из рис. 9.5. В подразделе 14.8.1 алгоритм
поиска в пространстве версий от частного к общему реализован на языке PROLOG.
S: {} Положительный: obj(small, red, ball)
S: {obj(small, red, ball)} Положительный: obj(small, white, ball)
S: {obj(small, X, ball)} Положительный: obj(large, blue, ball)
f
S:{obj{Y,X, ball)}
Рис. 9.7. Поиск от частного к общему в пространстве версий при
изучении понятия "ball"
Можно выполнять поиск и от общего к частному. Рассмотрим алгоритм,
использующий множество G максимально общих понятий, покрывающее все положительные и ни
одного отрицательного примера. Понятие с является максимально общим, если оно не
покрывает отрицательных примеров, и для любого другого понятия с' не покрывающего
отрицательных примеров, с>с'. В этом алгоритме отрицательные примеры
обеспечивают специализацию понятий-кандидатов, а положительные позволяют избежать
чрезмерной конкретизации понятий.
Глава 9. Машинное обучение, основанное на символьном представлении... 383
Begin
Инициализировать G наиболее общим понятием в пространстве;
Р содержит все положительные примеры
Для каждого отрицательного примера П
Begin
Для каждого geG, удовлетворяющего примеру п, заменить
д его наиболее общей специализацией,
не удовлетворяющей примеру П;
Удалить из G все гипотезы, более частные, чем некоторые
другие гипотезы из G;
Удалить из G все гипотезы, не удовлетворяющие
некоторым примерам из Р;
End;
Для каждого положительного примера р
Begin
Удалить из G все гипотезы, не удовлетворяющие р,-
Добавить р в множество Р;
End;
End
G: {obj(X,Y,Z)}
Отрицательный: obj(small, red, brick)
G: {obj(large, Y, Z), obj(X, white, Z),
obj{X, blue, Z), obj(X, Y, ball), obj{X, Y, cube)}
G: {obj(large, Y, Z),
obj(X, white, Z), obj(X, Y, ball)}
G: {obj{large, white, Z),
obj(X, white, Z), obj(X, Y, ball)}
Положительный: obj(large, white, ball)
Отрицательный: obj{large, blue, cube)
Положительный: obj(small, blue, ball)
G: {obj(X, Y, ball)}
Рис. 9 8. Поиск от общего к частному в пространстве версий при изучении понятия "ball"
На рис. 9.8 показан пример применения этого алгоритма к пространству версий
из рис. 9.5. В этом примере алгоритм использует базовые знания о том, что свойство
size (размер) может принимать значения {large, small}, свойство color (цвет) —
значения {red, white, blue}, а свойство shape (форма)— {ball, brick, cube}. Эти знания
играют важную роль при формировании понятий путем замены конкретных
значений переменными.
384
Часть IV. Машинное обучение
Алгоритм исключения кандидата объединяет оба подхода и обеспечивает
двунаправленный поиск, который дает множество преимуществ для обучаемой системы.
Алгоритм поддерживает два множества понятий-кандидатов: G — множество
максимально общих понятий-кандидатов, a S — множество максимально конкретных. В
процессе работы алгоритма специализация множества G и обобщение множества S
выполняется до тех пор, пока они не сойдутся к целевому понятию. Алгоритм имеет
следующий вид.
Begin
Инициализировать G наиболее общим понятием в пространстве;
Инициализировать S первым положительным обучающим примером;
Для каждого положительного примера р
Begin
Удалить все элементы G, не удовлетворяющие примеру р;
Для каждого seS, не удовлетворяющего примеру р, заменить
s наиболее частным обобщением,
удовлетворяющим примеру р;
Удалить из S все гипотезы, более общие, чем некоторые
другие гипотезы из S;
Удалить из S все гипотезы, более общие, чем некоторые
гипотезы из G;
End;
Для каждого нового отрицательного примера П
Begin
Удалить все элементы S, удовлетворяющие П;
Для каждого geG, удовлетворяющего примеру п, заменить
g его наиболее общей специализацией,
не удовлетворяющей примеру П;
Удалить из G все гипотезы, более частные, чем некоторые
другие гипотезы из G;
Удалить из G все гипотезы, более частные, чем
некоторые гипотезы из S;
End;
Если G=S и оба множества содержат по одному элементу,
значит, найдено единственное понятие, удовлетворяющее
всем данным;
Если G и S пусты, значит, не существует понятия, покрывающего
все положительные примеры и не удовлетворяющего
отрицательным;
End
На рис. 9.9 проиллюстрирована работа алгоритма исключения кандидата в
пространстве версий из рис. 9.5. Заметим, что здесь не показаны понятия, которые были получены
в процессе обобщения или специализации, но исключены из множества допустимых
гипотез как слишком общие или частные. Исследование этой части алгоритма предлагается
выполнить самостоятельно в качестве упражнения. Программная реализация этого
алгоритма на языке PROLOG описана в подразделе 14.8.2.
Глава 9. Машинное обучение, основанное на символьном представлении... 385
G: {obj(X, Y, Z)}
S:{)
Положительный: obj{small, red, ball)
G: {obj(X, Y, Z)}
S: {obj{small, red, ball)}
Отрицательный: obj{small, blue, ball)
G: {obj{X, red, Z)}
S: {obj{small, red, ball)}
Положительный: obj{large, red, ball)
G: {obj{X, red, Z)}
S: {obj(X, red, ball)}
Отрицательный: obj(large, red, cube)
G: {obj(X, red, ball)}
S: {obj(X, red, ball)}
Рис. 9.9. Изучение понятия "red ball" с помощью алгоритма исключения кандидата
Объединение двух направлений поиска в одном алгоритме обеспечивает несколько
преимуществ. Множества G и S содержат обобщенную информацию об отрицательных и
положительных примерах соответственно, что устраняет необходимость хранения этих
примеров. Например, после обобщения множества S с целью покрытия очередного
положительного примера множество G используется для исключения из S понятий,
покрывающих отрицательные примеры. Поскольку G — это множество максимально общих
понятий, не удовлетворяющих ни одному из отрицательных примеров, то элемент
множества S, более общий, чем любой элемент из G, должен удовлетворять некоторым
отрицательным примерам. Аналогично, поскольку S — это множество максимально
конкретных обобщений, покрывающих все положительные примеры, то любой новый
элемент G, более частный, чем элемент S, не покрывает некоторые положительные
экземпляры, и его необходимо исключить.
На рис. 9.10 показано абстрактное представление алгоритма исключения кандидата.
Символом "+" обозначены положительные обучающие примеры, а символом "-" —
отрицательные. Во внутреннем круге заключены все известные положительные примеры,
покрываемые понятиями S. Внешний круг соответствует множеству G; любые примеры
за его пределами являются отрицательными. Затененная часть изображения содержит
целевое понятие, а также другие его определения, которые могут оказаться либо
слишком общими либо слишком частными (отмечены символом "?"). В процессе работы
алгоритма внешняя окружность "сжимается", чтобы исключить отрицательные экземпля-
386
Часть IV. Машинное обучение
ры, а внутренняя — "расширяется" для включения новых положительных примеров. В
итоге оба процесса сходятся к единому целевому понятию. Алгоритм исключения
кандидата позволяет определить, когда найдено единственно возможное описание целевого
понятия. Если множества S и G содержат одно и то же понятие, значит, алгоритм
завершился успешно. Если G и S пусты, значит, не существует понятия, удовлетворяющего
всем положительным примерам и ни одному отрицательному. Это может произойти в
случае противоречивости данных или при условии неудачного выбора языка
представления (подраздел 9.2.4).
— /
/ 9
Граница G
• ? /+""+* ?
«' ? '.+ + ! ?
?
V
■ Целевые понятия
ГраницаS
Рис 9.10 Изменение множеств G и S в процессе работы
алгоритма исключения кандидата
Интересным свойством алгоритма исключения кандидата является его инкременталь-
ность. Инкрементальные алгоритмы обучения предполагают поочередную обработку
обучающих примеров и формирование удовлетворительного, хотя, возможно, и неполного,
обобщения после предъявления каждого из экземпляров. В отличие от них алгоритмы
пакетной обработки (например, ID3 из раздела 9.3) требуют наличия всех обучающих
примеров до начала обучения. Множества G и S в процессе работы алгоритма исключения
кандидата сужают множество потенциальных понятий: если с — целевое понятие, то для
всех geG и seS g>c>s. Любое понятие, более общее, чем некоторое понятие из G,
будет покрывать отрицательные примеры; любое понятие, более частное, чем
некоторое понятие из S, не покрывает некоторые положительные примеры. Это означает,
что множества G и S охватывают набор приемлемых понятий.
В следующем разделе эти рассуждения будут проиллюстрированы на примере
программы, использующей метод исключения кандидата для изучения эвристик поиска.
Программа LEX [Mitchell и др, 1983] обучается эвристикам для решения задач
символьного интегрирования. Эта программа не только демонстрирует использование множеств
G и S для определения частных понятий, но и иллюстрирует такие вопросы, как
сложность задач многошагового обучения и взаимоотношения между компонентами
обучения и решения проблемы в сложной системе.
Глава 9. Машинное обучение, основанное на символьном представлении... 387
9.2.3. Программа LEX: индуктивное изучение эвристик поиска
Программа LEX изучает эвристики для решения задач символьного интегрирования.
Она интегрирует алгебраические выражения методом эвристического поиска. На основе
выражения, которое необходимо проинтегрировать, система выполняет поиск цели —
выражения, не содержащего знака интеграла. Компонент обучения использует данные
компонента решения задачи для индуктивного обучения эвристикам, что повышает
производительность модуля решения.
Программа LEX выполняет поиск в пространстве, определенном операциями над
алгебраическими выражениями. Эти операции представляют собой типичные
преобразования, выполняемые при интегрировании. К ним относятся следующие.
ОР1: J rf{x) dx -> г J f{x) dx
OP2: \u dv -> uv - \v du
OP3: 1*f(x)^>f(x)
OPA: \(f,(x)+f2(x)) dx -> Jft(x) dx + \f2(x) dx
Операции — это правила, в левой части которых указаны условия их использования.
Однако в этих выражениях определены лишь условия, при которых можно применять
эти операции, но они не включают эвристик, определяющих, когда это нужно делать.
Программа LEX изучает эти эвристики на собственном опыте. Эвристиками называются
выражения вида:
Если состояние текущей задачи удовлетворяет условию Р,
значит, нужно применить операцию О с ограничением В.
Например, типичной эвристикой для программы LEX является следующая.
Если состояние текущей задачи удовлетворяет условию
\х transcedental(x) dx,
значит, нужно применить операцию ОР2 с обозначениями
U = X;
dv= transcedental(x) dx
Здесь эвристика предполагает интегрирование по частям для вычисления интеграла от
произведения х и некоторой трансцендентной (т.е. тригонометрической) функции отх.
Язык представления понятий в программе LEX состоит из символов, изображенных на
рис. 9.11. Заметим, что эти символы представлены в виде иерархии обобщения, где каждый
символ соответствует всем своим потомкам в этой иерархии. Обобщение выражений
выполняется путем замены символа его предшественником в иерархии обобщения.
j3xcos(x) dx.
Программа LEX может изменить обозначение cos на trig. Тогда выражение
примет вид
J3xtrig(x) dx.
Например, рассмотрим выражение
Кроме того, можно заменить число 3 символом /с, представляющим любое целое число
\кх cos(x) dx.
На рис. 9.12 представлено пространство версий для ОР2, определенное этими
обобщениями.
388
Часть IV. Машинное обучение
expr
(combf f)
sin cos tan In exp
Рис. 9.П. Фрагмент иерархии символов программы LEX
G: Jf1(x)f2B)dx—► apply OP2
/ poly(x) f2(x) dx
—*- apply OP2
/transc(x)f2(x)dx
—+ apply OP2
/ kx cos(x) dx
—*• apply OP2
/ 3x trig(x) dx
—•• apply OP2
Puc. 9.12. Пространство версий для операции ОР2
Глава 9. Машинное обучение, основанное на символьном представлении... 389
Программа LEX состоит из 4 компонентов.
1. Компонент обобщения, использующий для поиска эвристик метод исключения
кандидата.
2. Компонент решения задачи, вычисляющий решение.
3. Компонент критики, извлекающий положительные и отрицательные примеры в
процессе решения задачи.
4. Генератор задач, формирующий новые задачи-кандидаты.
Программа LEX поддерживает несколько пространств версий. Каждое из них связано
с определенной операцией и представляет частично изученную эвристику для такой
операции. Компонент обобщения обрабатывает эти версии с использованием
положительных и отрицательных примеров применения операции, сгенерированных модулем
критики. Получив положительный пример, программа LEX определяет, включен ли этот
экземпляр в пространство версий для соответствующей операции. Положительный пример
включается в пространство версий, если он покрывается некоторым понятием из G.
Затем программа использует этот положительный пример для обновления эвристики. Если
ни одна из существующих эвристик не удовлетворяет этому примеру, создается новое
пространство версий, для которого в качестве первого положительного примера
используется данный экземпляр. Это может привести к созданию нескольких пространств
версий для одной операции с разными эвристиками.
Модуль решения задачи строит дерево поиска при решении задачи интегрирования.
В программе процессорное время, отводимое на решение задачи, ограничено. При
этом для решения задачи используется алгоритм поиска по первому наилучшему
совпадению со специально разработанными эвристиками. Интересно, что в качестве
частных определений эвристики в программе LEX используются множества G и S. Если
для данного состояния можно применить несколько операций, выбирается та, которая
больше всего соответствует этому состоянию. Степень соответствия определяется как
процентное соотношение всех понятий, расположенных в пределах G и S,
удовлетворяющих текущему состоянию. Поскольку вычислительные затраты на проверку всех
понятий-кандидатов могут оказаться значительными, степень соответствия в
программе определяется через процентное соотношение элементов G и S, удовлетворяющих
данному состоянию. Заметим, что с уточнением эвристик производительность
системы LEX значительно повышается.
Положительные и отрицательные примеры применения операций извлекаются в
процессе решения задач в модуле решения. При отсутствии учителя программа должна сама
разделить примеры на положительные и отрицательные. Это пример решения проблемы
выделения кредита (credit assignment). Если обучение рассматривается в контексте
решения многошаговой задачи, то зачастую неясно, какое из действий в
последовательности отвечает за полученный результат. Если модуль решения проблемы получает
неверный ответ, то как узнать, какой из нескольких шагов стал причиной ошибки? В модуле
критики программы LEX эта проблема решается с помощью предположения о том, что
путь решения — это кратчайший путь к цели. Программа классифицирует применение
операций по этому (предположительно) кратчайшему пути как положительные примеры,
а операции, удаленные от него, рассматривает как отрицательные.
Однако при изучении кратчайшего пути к решению в модуле критики необходимо
учитывать тот факт, что модифицируемые эвристики необязательно являются допус-
390
Часть IV. Машинное обучение
тимыми (глава 4). Путь, найденный в модуле решения, необязательно на самом деле
является кратчайшим. Чтобы удостовериться в отсутствии операций, ошибочно
классифицированных как отрицательные примеры, в программе LEX сначала
рассматриваются пути, начинающиеся с этих операций, и проверяется, не ведут ли они к
лучшему решению. Обычно в процессе решения одной задачи формируются от двух до
двадцати обучающих примеров. Эти положительные и отрицательные примеры
передаются в модуль обобщения, где они используются для обновления пространства
версий соответствующих операций.
Модуль генератора задач — наименее развитая часть программы. Хотя для
автоматизации выбора задач использованы различные стратегии, большинство примеров вводится
вручную. Один из подходов к генерации примеров состоит в покрытии частных эвристик
для двух операций с целью научить программу различать эти операции.
Эмпирические тесты показывают, что программа LEX эффективно обучается
полезным эвристикам. В рамках одного исследования программе LEX было предъявлено пять
тестовых и двенадцать обучающих задач. Перед началом обучения она решала тестовые
задачи в среднем за двести шагов без использования эвристик в процессе поиска. После
формирования эвристики на основе двенадцати обучающих задач программа смогла
решить те же тестовые задачи в среднем за двадцать шагов.
В программе LEX затронуты многие аспекты обучения, в том числе такие проблемы,
как выделение кредитов, выбор обучающих примеров, взаимоотношения компонентов
решения задачи и обобщения. На примере этой программы видна роль
соответствующего представления понятий. Эффективность программы во многом обеспечивается
иерархической организацией понятий. Эта иерархия достаточно невелика, чтобы ограничить
пространство возможных эвристик и обеспечить эффективный поиск, и в то же время
достаточно богата для создания эффективных эвристик.
9.2.4. Обсуждение алгоритма исключения кандидата
Алгоритм исключения кандидата демонстрирует способ применения метода поиска в
пространстве состояний и представления знаний к решению задачи машинного обучения.
Однако, как и большинство важных научных результатов, этот алгоритм нельзя оценивать
в отрыве от других задач. Он связан со множеством задач машинного обучения.
Обучение на основе поиска, подобно другим задачам поиска, связано с операциями в
некоторых пространствах. Поскольку алгоритм исключения кандидата реализует поиск в
ширину, он может оказаться неэффективным. Если специфика задачи такова, что
множества G и S интенсивно увеличиваются, возможно, следует выработать эвристики для
исключения состояний из этих множеств на основе лучевого поиска (beam search) (см. главу 4).
Еще один подход к решению этой проблемы, описанный в разделе 9.4, предполагает
использование индуктивного порога для дальнейшего уменьшения размера пространства
понятий. Такие пороги вносят ограничения в язык представления понятий. В программе
LEX порог создан с помощью иерархии обобщения понятий. Язык представления понятий
в этой программе достаточно строг, чтобы обеспечить формирование множества
эффективных эвристик и уменьшить пространство понятий до "обозримых размеров".
Применение порогов позволяет упростить пространство понятий, но может привести к
неспособности системы адекватно представить изучаемые понятия. Следовательно, метод исключения
кандидата не сойдется к целевому понятию, а множества G и S окажутся пустыми. В этом
состоит противоречие между выразительностью и эффективностью обучения.
Глава 9. Машинное обучение, основанное на символьном представлении... 391
Неудачное завершение алгоритма может также быть вызвано шумом или
противоречивостью обучающих данных. Задача обучения на зашумленных данных очень важна для
реальных приложений, в которых данные могут быть неполными или противоречивыми.
Алгоритм исключения кандидата нельзя назвать устойчивым к шуму. Даже один неверно
классифицированный обучающий пример может сделать алгоритм расходящимся.
Одним из решений этой проблемы является использование нескольких множеств G и S.
Помимо пространства версий, полученного для всех обучающих примеров, создаются
дополнительные пространства на основе всех примеров за исключением одного, двух
экземпляров и т.д. Если алгоритм не сходится для исходных множеств G и S, его
проверяют на "усеченных" множествах, в надежде, что они окажутся согласованными. К
сожалению, такой подход слишком неэффективен для практического использования.
Отметим важную роль исходных знаний в процессе обучения. Иерархия понятий
программы LEX основана на знаниях алгебры, и это принципиально важно для
эффективности алгоритма. Может ли изучение области определения сделать обучение более
эффективным? Ответ на этот вопрос содержится в разделе 9.5.
Важное значение программы LEX состоит в выявлении взаимосвязей между
представлением знаний, реализацией обобщения и поиском в процессе индуктивного
обучения. Хотя исключение кандидата— это лишь один из многих алгоритмов обучения, в
нем проявляются общие проблемы обучения: сложность, обеспечение выразительности и
использование знаний и данных в процессе обобщения. Эти проблемы являются
центральными для всех алгоритмов машинного обучения. Поэтому они еще не раз будут
упоминаться в этой главе.
9.3. Индуктивный алгоритм построения дерева
решений ЮЗ
Алгоритм ID3 [Quinlan, 1986a] подобно методу исключения кандидата обеспечивает
изучение понятий на примерах. Особый интерес представляют способ хранения
полученных знаний, подход к управлению сложностью, эвристика для выбора понятий-
кандидатов и возможности обработки зашумленных данных. В алгоритме ЮЗ понятия
представляются в виде дерева решений (decision tree). Такое представление позволяет
классифицировать объект путем проверки значения определенных свойств.
Например, рассмотрим задачу оценки кредитного риска на основе кредитной истории,
текущего долга, наличия поручительства и дохода. В табл. 9.1 представлены примеры с
известным кредитным риском. Дерево решений на рис. 9.13 содержит приведенные в
табл. 9.1 данные и позволяет корректно классифицировать все объекты в таблице. Каждый
внутренний узел дерева решений представляет некоторое свойство, например, кредитную
историю или доход. Каждому возможному значению этого свойства соответствует ветвь
дерева. Узлы-листья отражают результаты классификации, в частности, низкий или
средний риск. С помощью этого дерева можно классифицировать клиента, тип которого
неизвестен: для каждого внутреннего узла проверяется значение соответствующего свойства
для данного клиента и осуществляется переход по соответствующей ветви. Процесс
завершается при достижении конечного узла, определяющего класс объекта.
Заметим, что при классификации каждого конкретного экземпляра с помощью этого
дерева учитываются не все свойства, представленные в табл. 9.1. Например, если человек
имеет хорошую кредитную историю и низкий долг, то согласно дереву без учета дохода
392
Часть IV. Машинное обучение
и поручительства с ним связывается низкий риск. Это дерево позволяет корректно
классифицировать все примеры.
Таблица 9.1. Данные о кредитной истории
№п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Риск
Высокий
Высокий
Средний
Высокий
Низкий
Низкий
Высокий
Средний
Низкий
Низкий
Высокий
Средний
Низкий
Высокий
Кредитная история
Плохая
Неизвестна
Неизвестна
Неизвестна
Неизвестна
Неизвестна
Плохая
Плохая
Хорошая
Хорошая
Хорошая
Хорошая
Хорошая
Плохая
Долг
Высокий
Высокий
Низкий
Низкий
Низкий
Высокий
Низкий
Низкий
Низкий
Высокий
Высокий
Высокий
Высокий
Высокий
Поручительство
Нет
Нет
Нет
Нет
Нет
Адекватное
Нет
Адекватное
Нет
Адекватное
Нет
Нет
Нет
Нет
Доход
от0до$15
от 15 до $35
от 15 до $35
от0до$15
свыше $35
свыше $35
от0до$15
свыше $35
свыше $35
свыше $35
от0до$15
от 15 до $35
свыше $35
от 15 до $35
Кредитная история
Неизвестна Плохая
Хорошая
Долг
Поручительство
Высокий Низкий
/ \
Нет Адекватное
/ \
Долг
/\
Высокий Низкий
/ \
Высокий риск Поручительство Высокий риск
/\
Средний риск
Поручительство Низкий риск
Нет Адекватное
/ \
Доход
А
Нет Адекватное
/ \
Доход
от 0 до $15 от 15 до $35 свыше $35
/ I \
Низкий риск
от 0 до $15 от 15 до $35 свыше $35
/ I \
Высокий риск
Средний риск
Низкий риск
Высокий риск!
Средний риск I Низкий риск
Рис. 9.13. Дерево решений для оценки кредитного риска
В целом, размер дерева, необходимого для классификации конкретного набора
примеров, варьируется в зависимости от проверяемых свойств. На рис. 9.14 показано
дерево, которое гораздо проще предыдущего, но позволяет корректно классифицировать
примеры из табл. 9.1.
Глава 9. Машинное обучение, основанное на символьном представлении... 393
Доход
Кредитная история
Неизвестна Плохая Хорошая Неизвестна Плохая Хорошая
/ i \ ,, / i \
Д°лг I Высокий риск! IСредний риск I I Низкий риск! IСредний риск! I Низкий риск
Высокий Низкий
Высокий риск
Средний риск
Рис. 9.14. Упрощенное дерево решений для оценки кредитного риска
Имея набор обучающих примеров и несколько деревьев решений, позволяющих
корректно классифицировать эти примеры, следует выбрать дерево, которое с наибольшей
вероятностью позволит корректно классифицировать неизвестные экземпляры. По алгоритму
ЮЗ таким деревом считается простейшее дерево решений, покрывающее все обучающие
примеры. В основу такого предположения положена проверенная временем эвристика,
согласно которой предпочтение отдается простоте без дополнительных ограничений. Этот
принцип впервые был сформулирован в 1324 году философом-схоластом Вильямом из Ок-
кама (William of Occam) и получил название "бритвы Оккама" (Occam's Razor).
"Глупо прилагать больше усилий, чем нужно для достижения цели .. Не стоит
приумножать сущности сверх необходимого."
Более современная версия этого принципа сводится к выбору простейшего ответа,
соответствующего исходным данным. В данном случае это наименьшее дерево решений,
которое позволяет корректно классифицировать все имеющиеся примеры.
Хотя принцип "бритвы Оккама" хорошо зарекомендовал себя в качестве общей
эвристики для всех видов интеллектуальной деятельности, его использование в данном
алгоритме имеет более точное обоснование. Если предположить, что существующих
примеров достаточно для построения корректного обобщения, то проблема сводится к
выделению необходимых свойств из дополнительных примеров. Простейшее дерево решений,
покрывающее все примеры, вероятнее всего, не будет содержать излишних ограничений.
И хотя эта идея основывается на интуитивных рассуждениях, ее можно проверить на
практике. Некоторые из таких эмпирических результатов представлены в
подразделе 9.3.3. Однако, прежде чем переходить к их изучению, рассмотрим алгоритм ЮЗ,
позволяющий строить деревья решений на основе примеров.
9.3.1. Построение дерева решений сверху вниз
Согласно алгоритму ID3 дерево решений строится сверху вниз. Заметим, что каждое
свойство позволяет разбить набор обучающих примеров на непересекающиеся
подмножества, к каждому из которых относятся все примеры с одинаковым значением этого
свойства. По алгоритму ID3 каждый узел дерева представляет некоторое свойство, на
394
Часть IV. Машинное обучение
основании которого выполняется разделение набора примеров. Таким образом, алгоритм
рекурсивно строит поддерево для каждого раздела. Эта процедура длится до тех пор,
пока все элементы раздела не будут отнесены к одному и тому же классу. Этот класс
становится конечным узлом дерева. Поскольку для построения простого дерева решений
важную роль играет порядок тестирования, в алгоритме ID3 реализован специальный
критерий выбора теста для корневого узла каждого поддерева. Чтобы упростить описание, в
этом разделе рассматривается алгоритм построения деревьев решений в предположении,
что существует соответствующая функция выбора. Сама эвристика выбора для
алгоритма ID3 рассматривается в подразделе 9.3.2.
Например, рассмотрим процесс построения дерева, представленного на рис. 9.14, на
основе данных из табл. 9.1. Имея полную таблицу примеров, алгоритм ID3 выбирает в
качестве корневого свойства значение дохода на основе функции выбора, описанной в
подразделе 9.3.2. При этом множество примеров делится на три части, как показано на рис. 9.15.
Элементы каждой части представлены порядковыми номерами примеров в таблице.
Доход
от 0 до $15 от 15 до $35
свыше $35
Примеры {1,4,7, 11} Примеры {2, 3, 12, 14} Примеры {5, 6, 8, 9, 10, 13}
Рис. 9.15. Фрагмент дерева решений
Доход
от 0 до $15 от 15 до $35 свыше $35
Высокий риск
Кредитная история
Примеры {5, 6, 8, 9, 10, 13}
Неизвестна Плохая Хорошая
эхая Хороша?
i Ч
Примеры {2, 3} Примеры {14} Примеры {12}
Рис. 9.16. Еще один фрагмент дерева решений
Алгоритм индукции начинает свою работу с отбора корректно классифицированных
элементов целевых категорий. Алгоритм ЮЗ строит дерево решений следующим образом.
function induce_tree {example_set, Properties)
Begin
если все элементы набора примеров exampleset принадлежат к
одному и тому же классу,
то вернуть конечный узел, отнеся его к этому классу,
иначе, если множество Properties пусто,
то вернуть конечный узел, именем которого является
Глава 9. Машинное обучение, основанное на символьном представлении... 395
объединение всех имен классов в example_set
иначе Begin
выбрать свойство Р и назначить его корнем
текущего дерева;
удалить свойство Р из множества Properties
для каждого значения V свойства Р
Begin
создать ветвь дерева с меткой V;
к разделу partitionv отнести
элементы множества example set, для
которых свойство Р принимает значение V;
вызвать функцию induce_tree (partitionv,
Properties) , добавить результаты к ветви V
End
End
End
Согласно алгоритму ID3 функция induee_tгее рекурсивно вызывается для
каждого раздела. Например, пусть к разделу {1, 4, 7, 11} относятся клиенты с высоким
риском; алгоритм ID3 создаст соответствующий конечный узел. Затем в качестве корневого
узла поддерева раздела {2, 3, 12, 14} выбирается свойство "кредитная история". На
рис. 9.14 элементы этого раздела в свою очередь разбиваются на три группы: {2, 3},
{14} и {12}. Таким образом, строится дерево, представленное на рис. 9.14. Оставшуюся
часть дерева читателям предлагается построить самостоятельно. Реализация этого
алгоритма на языке LISP описана в разделе 15.13.
Прежде чем переходить к рассмотрению эвристики выбора, проанализируем
взаимосвязь алгоритма построения дерева и поиска в пространстве понятий. Набор всех
возможных деревьев решений можно рассматривать как пространство версий. Операции
перемещения в этом пространстве соответствуют добавлению частей дерева. Алгоритм
ID3 реализует вариант поиска по первому наилучшему совпадению в пространстве всех
возможных деревьев. Он добавляет дерево к текущему поддереву и продолжает поиск,
не возвращаясь к исходной точке. Это обеспечивает высокую эффективность алгоритма,
а также зависимость от критерия выбора свойств.
9.3.2. Выбор свойств на основе теории информации
Каждое свойство можно рассматривать с точки зрения его вклада в процесс
классификации. Например, если необходимо определить виды животных, то одним из
признаков классификации является откладывание яиц. Алгоритм ID3 при выборе корня
текущего поддерева оценивает удельный вес информации, добавляемой каждым свойством.
Затем он выбирает свойство, имеющее наибольшую информативность.
Теория информации [Shannon, 1948] обеспечивает математическую основу для
измерения информативности сообщения. Каждое сообщение можно рассматривать как
экземпляр в пространстве возможных сообщений. Передача сообщения соответствует
выбору одного из возможных сообщений. С этой точки зрения целесообразно определить
информационную емкость сообщения в зависимости от размера пространства и частоты
использования каждого возможного сообщения.
Важную роль количества возможных сообщений можно оценить на примере
азартных игр, сравнив ценность сообщения с правильным прогнозом результата вращения ру-
396
Часть IV. Машинное обучение
летки и подбрасывания монеты. Поскольку количество возможных состояний для
рулетки значительно превышает количество результатов подбрасывания монеты, то
правильный прогноз для игры в рулетку гораздо информативнее, тем более, что и ставки в этой
игре значительно выше. Следовательно, такое сообщение несет больше информации.
Роль вероятности передачи каждого сообщения видна из следующего примера.
Предположим, что существует монета, при подбрасывании которой в трех из четырех случаев
выпадает решка. Если знать, что вероятность выпадания решки составляет 3/4, то в 3/4
случаев можно правильно угадать результат игры.
Шеннон формализовал эти наблюдения, определив количество информации в
сообщении как функцию от вероятности р передачи каждого возможного сообщения, а
именно -log2p. Имея пространство сообщений M={mh mi, ..., тп) и зная вероятности р(т;)
для каждого сообщения, информативность этих сообщений можно вычислить
следующим образом.
/[M] = fX-PH)log2(p(m^)l = E[-log2p(rn/)].
Количество информации в сообщении измеряется в битах. Например,
информативность сообщения в результате подбрасывания обычной монеты составляет
l[Coin]=-p(head)\og2(p(head)) - p(tail)\og2(p(tail))
=-1/2 log2A/2) - 1/2 log2A/2)
= 1 бит.
Если же монета такова, что вероятность выпадения решки составляет 75%, то
информативность сообщения равна
/[Со/п]=-3/4 log2C/4) - 1/4 1од2A/4)
=-3/4*(-0,415)-1/4*(-2)
=0,811 бит.
Это определение позволяет формализовать интуитивные рассуждения об
информативности сообщений. Теория информации широко используется в компьютерных науках
и телекоммуникациях, в том числе для определения информационной емкости
телекоммуникационных каналов, при разработке алгоритмов сжатия данных и устойчивых к
шуму коммуникационных стратегий. В алгоритме ID3 теория информации используется для
выбора наиболее информативного свойства при классификации обучающих примеров.
Дерево решений можно рассматривать с точки зрения информации о примерах.
Информативность дерева вычисляется на основе вероятностей различных типов
классификации. Например, если предположить, что все примеры в табл. 9.1 появляются с
одинаковой вероятностью, то
р(высокий риск)=6/и, р(средний рисж)=714 и р(низкий риск)=5/,А.
Следовательно, информативность распределения D9i, описанного в табл. 9.1, а
значит, и любого дерева, покрывающего эти примеры, составляет
/ [D9 J=-6/14 log2F/14)-3/14 log2C/14)-5/14 log2E/14)
=-6/14*(-1,222)-3/14*(-2,222)-5/14*(-1,485)
= 1,531 бит.
Количество информации, обеспечиваемое при выборе данного свойства в качестве
корня текущего дерева, равно разности общего количества информации в дереве и коли-
Глава 9. Машинное обучение, основанное на символьном представлении... 397
чества информации, необходимого для завершения классификации. Количество
информации, необходимое для завершения дерева, определяется как взвешенное среднее
информации во всех его поддеревьях. Взвешенное среднее вычисляется как сумма
произведений информативности каждого поддерева и процентного соотношения примеров в
этом поддереве.
Предположим, что существует набор обучающих примеров С. Если корнем текущего
дерева является свойство Р, которое может принимать п значений, то множество С будет
разделено на подмножества {Ch Съ ■■■, С„}. Информация, необходимая для завершения
построения дерева при выборе свойства Р, составляет
Выигрыш от использования свойства Р вычисляется как разность общей
информативности дерева и объема информации, необходимого для завершения построения дерева.
gain(P)=l[C]-E[P]
Возвращаясь к примеру из табл. 9.1, при выборе в качестве корня дерева свойства
"доход" примеры будут разделены натри группы: Ci={1, 4, 7, 11}, Сг={2, 3, 12, 14}
и Сз={5, 6, 8, 9, 10, 13}. Информация, необходимая для завершения построения
дерева, составляет
Е[доход] = 4/14*/[CJ + 4/14*/[С2] + 6/14*/[С3]
=4/14*0,0 +4/14*1,0 + 6/14*0,650
=0,564 бит.
Информационный выигрыш от такого разбиения данных табл. 9.1. составляет
да'ш(доход) = /[D91] - Е[доход]
= 1,531 -0,564
= 0,967 бит.
Аналогично можно показать, что
да1п(кредитная история) = 0,266
gain(debt)b = 0,581
gain(collateral) = 0,576.
Поскольку доход обеспечивает наибольший информационный выигрыш, именно это
свойство выбирается в качестве корня дерева решений алгоритма ID3. Такой анализ
рекурсивно выполняется для каждого поддерева до полного построения всего дерева.
9.3.3. Анализ алгоритма ID3
Несмотря на то что алгоритм ID3 строит простое дерево решений, совсем не
очевидно, что с помощью этих деревьев можно эффективно классифицировать неизвестные
примеры. Поэтому алгоритм ID3 был протестирован на контрольных примерах и
реальных приложениях. Тесты подтвердили его хорошую работоспособность.
Например, в работе [Quinlan, 1983) исследована производительность алгоритма ID3
на примере задачи классификации эндшпилей при игре в шахматы. В примерах
эндшпилей участвовали белые король и ладья и черные король и конь. Задачей алгоритма
было научиться распознавать позиции, приводящие к поражению черных за три хода.
398
Часть IV. Машинное обучение
В качестве свойств использовались различные высокоуровневые признаки, такие как
"невозможность безопасного перемещения короля". При этом учитывались 23
подобных признака.
С учетом симметрии область определения задачи включает 1,4 миллиона различных
позиций, среди которых 474 тысячи приводят к поражению черных за три хода.
Алгоритм ID3 строил дерево на случайно выбранном обучающем множестве и тестировался
на 10000 различных комбинаций, которые тоже выбирались случайным образом.
Результаты тестирования приведены в табл. 9.2. Более подробный анализ результатов
тестирования приводится в работе [Quinlan, 1983].
Эти результаты подтверждаются и другими тестами и конкретными приложениями.
Существуют варианты алгоритма ЮЗ, позволяющие решать задачи в условиях зашум-
ленных данных и очень больших обучающих множеств. Более подробная информация
приводится в работе [Quinlan, 1986a, б].
Таблица 9.2. Результаты тестирования алгоритма ЮЗ
Размер обучающего Процентное отно- Количество ошибок Прогнозируемый
множества шение к размеру на 10000 примеров максимум ошибок
всего пространства
200 0^01 199 728
1000 0,07 33 146
5000 0,36 8 29
25000 1,79 6 7
125000 8,93 2 1
9.3.4. Вопросы обработки данных для построения дерева решений
В работе [Quinlan, 1983] впервые предлагается использовать теорию информации для
построения поддеревьев дерева решений. Именно эта работа положена в основу
приведенного выше обоснования алгоритма. Рассмотренные примеры были достаточно
понятны и просты. Однако в них не затрагивалось множество проблем, которые зачастую
возникают при работе с большими массивами данных.
1. Первая проблема — плохие данные. Это означает, что несколько наборов данных с
идентичными свойствами приводят к различному результату. Что делать при
отсутствии априорной информации о достоверности данных?
2. Данные для некоторых наборов признаков отсутствуют, возможно, из-за очень
высокой стоимости их получения. Нужно ли проводить экстраполяцию или лучше
ввести новое значение "неизвестен"? Как обойти эту проблему?
3. Некоторые признаки могут принимать значения из непрерывного интервала. Такие
данные подлежат дискретизации и последующей группировке. Можно ли
придумать более эффективный подход?
4. Набор данных может быть слишком большим для алгоритма обучения. Что делать
в этой ситуации?
Решение этих проблем привело к созданию нового поколения алгоритмов обучения,
основанных на построении дерева решений. Наиболее известным из них является
алгоритм С4.5 [Quinlan, 1996]. Для решения этих проблем также используются такие приемы,
Глава 9. Машинное обучение, основанное на символьном представлении... 399
как добавление повторяющихся элементов (bagging) и усиление (boosting). Поскольку
данные для обучения представляют собой векторы признаков или наборы примеров, их
можно подвергнуть некоторым преобразованиям, чтобы удостовериться в идентичности
результатов классификации.
Метод добавления повторяющихся элементов предполагает дублирование
обучающих множеств с заменой некоторых обучающих примеров. При использовании усиления
в формировании каждого обучающего множества участвуют все примеры, но с учетом
весового коэффициента каждого экземпляра в обучающем множестве. Этот вес должен
отражать степень важности соответствующего вектора. После настройки весов
получаются различные классификаторы, поскольку за счет весовых коэффициентов система
концентрирует внимание на разных примерах. Набор полученных классификаторов
объединяется в один общий классификатор. При использовании метода добавления
повторяющихся элементов вклад всех компонентных классификаторов одинаков, а в методе
усиления классификаторы имеют различный вес, определяемый их точностью.
При работе с очень большими наборами данных их зачастую делят на подмножества, на
одном из которых строят дерево решений. Это дерево проверяют на других подмножествах. В
настоящее время литература по методам обучения на основе деревьев решений очень
обширна. Много информации содержится в Internet. Опубликовано большое количество результатов
использования алгоритмов построения деревьев поиска на этих данных.
И, наконец, достаточно просто конвертировать дерево решений в соответствующий набор
правил. Для этого каждый путь в дереве решений нужно описать в виде отдельного правила.
Левая часть этого правила (глава 5) состоит из решений, приводящих к конечному узлу.
Действие в правой части выражения — это узел-лист или результат поиска по дереву. Затем этот
набор правил можно настроить таким образом, чтобы он описывал поддеревья дерева
решений. Впоследствии его можно применять для классификации новых данных.
9.4. Индуктивный порог и возможности обучения
В предыдущих разделах основное внимание уделялось обобщению по эмпирическим
данным. Однако важную роль в успешном индуктивном обучении играют также
априорные знания и предположения о природе изучаемых понятий. Индуктивный порог
(inductive bias) — это любой критерий, используемый обучаемой системой для
ограничения пространства понятий или для выбора понятий в рамках этого пространства. В
следующем разделе будет рассмотрена необходимость использования и типы порогов,
обычно применяемых в процессе обучения. В подразделе 9.4.2 приводятся теоретические
результаты исследования эффективности индуктивных порогов.
9.4.1. Индуктивный порог
Пространство обучающих примеров обычно достаточно велико. Поэтому без
некоторого его разделения обучение на основе поиска практически невозможно. Например,
рассмотрим задачу классификации битовых строк (состоящих из 0 и 1) на основе
положительных и отрицательных примеров. Поскольку такая классификация — это просто
разделение множества всех строк на подмножества, общее количество вариантов
классификации соответствует мощности этого множества. Для т примеров существует 2т
вариантов классификации. Однако для строки, состоящей из п битов, количество воз-
400
Часть IV. Машинное обучение
можных комбинаций составляет 2п. Поэтому число вариантов классификации всех
битовых строк длины п составляет 2 в степени 2п. Для л=50 это число превышает
количество молекул во вселенной. Поэтому без некоторых эвристических ограничений
невозможно организовать эффективный поиск в таких пространствах.
Еще одним обоснованием необходимости порога служит сама природа индуктивного
обобщения. Обобщение не сохраняет истинности высказываний. Например, встретив
честного политика, нельзя утверждать, что все политики честны. Сколько честных
политиков нужно встретить, чтобы прийти к такому заключению? Несколько сотен лет назад
эта проблема была описана как задача индукции следующим образом.
"Вы говорите, что одно предложение вытекает из другого. Однако необходимо признать,
что это умозаключение не интуитивно и не демонстративно. Тогда какова же его природа?
Можно сказать, что оно проверяется экспериментально, но это слабое утешение. Все
умозаключения, основанные на опыте, предполагают, что будущее аналогично прошедшему, и
что сходные причины приведут к подобным результатам". [Hume, 1748].
В XVIII столетии эта работа считалась опасной, особенно на фоне попыток религиозного
сообщества математически доказать существование бога. Однако вернемся к индукции.
В индуктивном обучении обучающие данные — это лишь подмножество всех
экземпляров области определения. Следовательно, для любой обучающей выборки возможны
различные обобщения. Вернемся к примеру с классификацией битовых строк.
Предположим, что в качестве положительных примеров некоторого класса строк системе были
предъявлены строки {1100, 1010}. Для этого примера допустимо много различных
обобщений: все строки, начинающиеся с " и заканчивающиеся "; множество строк,
начинающихся с "; множество четных строк или любое другое подмножество,
включающее рассмотренный пример {1100, 1010}. На основе чего система может сделать
обобщение? Одних данных для этого недостаточно, поскольку все приведенные примеры
обобщений согласуются с этими данными. Обучаемая система должна сделать
дополнительные предположения о "вероятных понятиях".
В задачах обучения такие предположения зачастую принимают форму эвристик
выбора ветвей в пространстве поиска. Примером такой эвристики является функция выбора
на основе теории информации, используемая в алгоритме ID3 (подраздел 9.3.2).
Алгоритм ЮЗ выполняет поиск экстремума в пространстве возможных деревьев решений. На
каждом этапе он проверяет все свойства, которые можно использовать для расширения
дерева, и выбирает из них наиболее информативное. Это "жадная" эвристика, поскольку
предпочтение отдается тем ветвям в пространстве поиска, которые дают наилучший
результат в продвижении к цели.
Такая эвристика позволяет алгоритму ID3 выполнять эффективный поиск в
пространстве деревьев решений и решить проблему выбора приемлемого обобщения на основе
ограниченного объема данных. В алгоритме ID3 предполагается, что минимальное
дерево, корректно классифицирующее все обучающие примеры, вероятнее всего, будет
корректно классифицировать и последующие обучающие примеры. Это предположение
основано на том, что маленькие деревья, скорее всего, будут соответствовать имеющимся
данным. Если же обучающее множество достаточно велико, то такие деревья должны
включать все существенные признаки для определения принадлежности классу. Как
описано в подразделе 9.3.3, это предположение обосновывается решением практических
задач. Подобное предпочтение простых определений понятий используется в таких
алгоритмах обучения, как CLUSTER/2 из подраздела 9.6.2.
Глава 9. Машинное обучение, основанное на символьном представлении... 401
Еще один тип индуктивного порога представляет собой синтаксическое ограничение
на представление изучаемых понятий. Такие пороги не являются эвристиками для
выбора ветвей в пространстве понятий. Они ограничивают размер самого пространства за
счет представления изучаемых понятий ограниченными средствами языка. Например,
деревья решений — это гораздо более ограничительный язык представления, чем теория
предикатов. Существенное уменьшение размера пространства понятий обеспечивает
высокую эффективность алгоритма ID3.
Примером синтаксического порога, который может оказаться эффективным при
классификации битовых строк, является ограничение описания примеров шаблонами,
состоящими из символов {0, 1, #}. Каждый шаблон определяет класс всех
соответствующих ему строк, при этом соответствие задается следующими правилами.
Если в некоторой позиции шаблона строки содержится "О", значит,
и целевая строка должна содержать "О" в этой позиции.
Если в некоторой позиции шаблона строки содержится ", значит,
и целевая строка должна содержать " в этой позиции.
Символ "#" в некоторой позиции соответствует либо w1" либо "О".
Например, шаблон ##0" определяет набор строк {111 0, 1100, 1010, 1000}.
Использование классов, соответствующих таким шаблонам, значительно уменьшает
размер пространства понятий. Для строк длины п можно определить 3" различных
шаблонов. Это значительно меньше, чем 2 в степени 2" возможных понятий в
неограниченном пространстве. Порог также позволяет упростить реализацию поиска в пространстве
версий, поскольку в этом случае обобщение означает замену символов " или " в
шаблоне символом "#". Однако наличие этого порога приводит к невозможности
представления (а следовательно, и изучения) некоторых понятий. Например, с помощью
такого шаблона нельзя представить все строки, содержащие четное число нулей и единиц.
Противоречие между выразительностью и эффективностью — типичная
проблема обучения. Например, в программе LEX четные и нечетные целые не различаются.
Следовательно, она не может обучиться эвристике, основанной на этом различии. И
хотя в некоторых программах порог изменяется в соответствии с данными
[Utgoff, 1986], большинство обучаемых программ основываются на фиксированном
пороге срабатывания.
В задачах машинного обучения используются различные типы порогов.
Конъюнктивные пороги (conjunctive bias) ограничивают возможности обучения
конъюнкцией литералов. Это достаточно типичный подход, поскольку использование
дизъюнкции в определениях понятий вызывает проблемы при обобщении. Например,
предположим, что в представлении понятий в рамках алгоритма исключения кандидата
можно свободно использовать операцию дизъюнкции. Поскольку максимально
конкретным обобщением набора положительных примеров является простая дизъюнкция этих
примеров, то обучаемая система вообще не сможет выполнить обобщение. Такая
система будет просто добавлять новые операнды [Mitchell, 1980].
Ограничения на количество дизъюнктов (limitation on the number of disjuncts). Чисто
конъюнктивные пороги являются слишком жесткими для многих приложений. Повысить
выразительность представления можно, разрешив использовать небольшое ограниченное
число дизъюнктов.
402
Часть IV. Машинное обучение
Векторы признаков (feature vector) — это представления, описывающие объекты
через наборы свойств, значения которых различны для разных объектов. В табл. 9.1
объекты представлены именно наборами признаков.
Деревья решений (decision tree) — это представления понятий, эффективность
которых подтверждается алгоритмом ID3.
Хорновские выражения (Horn clauses) налагают ограничения на форму вывода,
используемую при автоматическом доказательстве. Хорновские выражения детально
описаны в разделе 12.2.
Помимо синтаксических порогов, рассмотренных в этом разделе, во многих
программах при описании области определения используются конкретные знания о ней. Они
обеспечивают чрезвычайно эффективные ограничения, или пороги. В разделе 9.5
освещаются подходы к выбору порогов на основе знаний. Однако, прежде чем рассматривать
роль знаний в обучении, кратко рассмотрим теоретические результаты, обосновывающие
эффективность индуктивных порогов (см. также раздел 16.2).
9.4.2. Теория изучаемое™
Задачей индуктивных порогов является такое ограничение множества целевых
понятий, при котором возможны эффективный поиск и формирование удачных определений
понятий. Проблема количественной оценки эффективности индуктивных порогов была
исследована теоретически.
Качество определения понятия можно выразить в терминах корректной
классификации с его помощью объектов, не включенных в обучающее множество. Несложно
написать алгоритм обучения, формирующий понятия, с помощью которых можно корректно
классифицировать все примеры из обучающей выборки. Однако, поскольку в области
определения обычно содержится большое количество экземпляров, часть из которых
может быть недоступна для обучения, алгоритм должен строить обобщения на основе
некоторой выборки из всех возможных примеров. Поэтому чрезвычайно важную роль
играет эффективность работы алгоритма на новых данных. При тестировании алгоритма
обучения множество всех примеров обычно делится на два непересекающихся
подмножества: обучающее и тестовое. После обучения программы на обучающем множестве ее
проверяют на тестовом.
Эффективность и корректность алгоритма можно рассматривать как свойство языка
представления понятий, т.е. индуктивного порога, а не конкретного алгоритма обучения.
Алгоритмы обучения выполняют поиск в пространстве понятий. Если это пространство
хорошо структурировано и содержит удачные определения понятий, то любой
обоснованный алгоритм обучения будет эффективно работать на этих определениях. Если же
пространство является очень сложным, то алгоритм не даст хороших результатов. Это
можно пояснить на следующем примере.
Понятие "мяч" является изучаемым. Для его изучения можно ввести удобный язык
описания свойств объекта. Увидев относительно небольшое количество мячей, человек
может прийти к выводу, что мячи круглые. Рассмотрим понятие, которое невозможно
изучить. Допустим, группа людей прошла по всей планете, собрала набор из нескольких
миллионов произвольных объектов и назвала этот класс "выбранными объектами".
Понятие "выбранный объект" не просто требует чрезвычайно сложного представления.
Скорее всего, с его помощью будет невозможно классифицировать незнакомые объекты,
принадлежащие ко множеству выбранных. Эти рассуждения приводят к выводу о том,
Глава 9. Машинное обучение, основанное на символьном представлении... 403
что алгоритмы обучения находят понятие в пространстве, согласованном с данными.
Понятие "мяч" является изучаемым, поскольку его можно определить в терминах
нескольких свойств, т.е. выразить средствами языка с порогами. При попытке описать
понятие "выбранный объект" потребуется перечислить длинный список всех свойств всех
объектов этого класса. Поэтому "изучаемость" нужно определять в терминах не
конкретного алгоритма, а языка представления понятий. В целом можно сказать, что
"изучаемость" формулируется не в терминах конкретной области определения, а в
терминах синтаксических свойств языка описания понятий.
При определении изучаемости необходимо принимать во внимание не только
эффективность, но и ограниченность набора данных. В целом, нельзя рассчитывать на
построение точного и корректного понятия на основе случайного набора примеров.
Скорее, подобно вычислению математического ожидания в статистике, мы находим
понятие, которое с высокой вероятностью является корректным. Следовательно,
корректность понятия — это вероятность корректной классификации экземпляра во всем
пространстве примеров.
Помимо корректности изученных понятий необходимо также учитывать вероятность
нахождения таких понятий. Существует небольшая вероятность того, что нетипичность
выбранных примеров приведет к невозможности обучения. Следовательно, конкретное
распределение положительных примеров или конкретное обучающее множество,
выбранное из этих примеров, могут оказаться недостаточными для формирования
корректного понятия. При этом нужно учитывать две возможности: вероятность нетипичности
примеров и вероятность нахождения удачного понятия (обычную ошибку оценивания). В
приведенном ниже определении РАС-изучаемости эти возможности ограничены
значениями 8 и £ соответственно.
Итак, изучаемость — это свойство пространства понятий, определяемое языком их
представления. При исследовании этого пространства необходимо учитывать
вероятность нетипичности данных и вероятность, с которой результирующее понятие позволит
корректно классифицировать неизвестные экземпляры.
В 1984 году эти рассуждения были формализованы в теории приближенно
корректного с высокой вероятностью РАС-обучения (probably approximately correct learning)
[Valiant, 1984].
Класс понятий является РАС-изучаемым, если существует эффективный алгоритм,
который с высокой вероятностью находит приближенно корректное понятие. Под
"приближенно корректным" понимается понятие, которое позволяет корректно
классифицировать высокий процент новых примеров. Таким образом, алгоритм должен с
высокой вероятностью находить понятие, которое является почти корректным, при
этом сам алгоритм должен быть эффективным. Интересным свойством этого
определения является то, что оно необязательно зависит от распределения положительных
примеров в пространстве данных. Оно зависит от природы языка понятий, т.е. от
порога и желаемой степени корректности. И, наконец, сделав предположение о
распределении примеров, зачастую можно повысить производительность, т.е. обойтись
меньшим количеством примеров.
Формально понятие РАС-изучаемости определяется следующим образом. Пусть С —
это множество понятий с, а X — множество экземпляров. В качестве понятий могут
выступать алгоритмы, шаблоны или другие средства деления множества X на
положительные и отрицательные примеры. Множество С является РАС-изучаемым, если существует
алгоритм, обладающий следующими свойствами.
404
Часть IV. Машинное обучение
1. Если для ошибки понятия е и вероятности ненахождения понятия 8 существует
алгоритм, который за полиномиальное время 1 /е и 1/5 в случайной выборке
примеров размера п = \Х\ находит такое понятие с, являющееся элементом множества
С, при котором вероятность ошибки обобщения, превышающая е, меньше, чем 5.
Следовательно, для элемента у, подчиняющегося тому же распределению, что и
элементы множества X, выполняется соотношение
Р[Р[у неверно классифицируется с помощью понятия с]>е]<5.
2. Время работы алгоритма для п примеров является полиномиальным и составляет
1/БИ1/5.
Это определение РАС-изучаемости позволило доказать эффективность нескольких
индуктивных порогов. Например, в работе [Valiant, 1984] показано, что класс выражений
k-CNF является изучаемым. Выражения k-CNF— это предложения в конъюнктивной
нормальной форме с ограничением на количество дизъюнктов. Выражения формируются
из операторов конъюнкции схас2а...спч где с, — дизъюнктивное выражение, состоящее
не более чем из к литералов. Этот теоретический результат обосновывает общепринятое
описание понятий в конъюнктивной форме, используемое во многих алгоритмах
обучения. Мы не будем приводить доказательство этого утверждения, а отошлем читателя к
исходной статье, где обосновывается этот результат, а также свойство изучаемости при
использовании других порогов. Результаты исследования изучаемости понятий и
индуктивных порогов приводятся в работах [Haussler, 1988] и [Martin, 1997].
9.5. Знания и обучение
Алгоритмы ID3 и исключения кандидата выполняют обобщение за счет поиска
закономерностей в обучающих данных. Такие алгоритмы называют основанными на подобии
(similarity based learning), поскольку обобщение для них является функцией подобия
обучающих примеров. Пороги, реализованные в этих алгоритмах, представляют собой
синтаксические ограничения на форму представления изученных знаний. Они не предполагают
строгих ограничений для семантики области определения. В этом разделе рассматриваются
алгоритмы обучения, основанные на объяснении (explanation-based learning), которые при
обобщении руководствуются знаниями об области определения. На первый взгляд идея
использования априорных знаний в процессе обучения кажется противоречивой. Однако и в
машинном обучении и в исследованиях ученых-когнитологов известен тот факт, что
дополнительные априорные знания об области определения повышают эффективность
обучения. Одним из подтверждений важности знаний в процессе обучения является то, что
алгоритмы обучения, основанные на подобии, опираются на относительно большой объем
обучающих данных. В отличие от них человек может сформировать корректные
обобщения на основе нескольких обучающих примеров. Поэтому во многих практических
приложениях такие же требования выдвигаются и к обучаемым программам.
Еще одним аргументом в пользу априорных знаний является тот факт, что на любом
множестве обучающих примеров можно построить неограниченное количество
обобщений, большинство из которых окажутся либо бессмысленными либо неадекватными.
Одним из средств решения этой проблемы является включение индуктивных порогов. В
этом разделе рассматриваются алгоритмы, выходящие за пределы простого
использования синтаксических порогов и подтверждающие роль строгих знаний об области
определения в процессе обучения.
Глава 9. Машинное обучение, основанное на символьном представлении... 405
9.5.1. Алгоритм Meta-DENDRAL
Алгоритм Meta-DENDRAL [Buchanan, Mitchell, 1978] — это один из первых и лучших
примеров применения знаний в индуктивном обучении. Алгоритм Meta-DENDRAL
формирует правила, используемые программой DENDRAL для масс-спектрографического анализа
данных. Эта программа восстанавливает структуру органических молекул на основе
химических формул и данных масс-спектрографических экспериментов.
В масс-спектрографе молекулы подвергаются бомбардировке электронами, что
приводит к разрыву некоторых химических связей. Специалисты-химики измеряют вес
оставшихся фрагментов молекулы и интерпретируют эти результаты, чтобы восстановить
исходную структуру соединения. В программе DENDRAL знания используются в форме
правил интерпретации масс-спектрографических данных. Исходным предположением
для правила служит граф, соответствующий определенной молекулярной структуре.
Выводом правила является граф с указанием мест расщепления молекулы.
Алгоритм Meta-DENDRAL формирует эти правила на основе результатов масс-
спектрографического исследования молекул известной структуры. Входными данными
алгоритма Meta-DENDRAL являются структура известных соединений, а также масса и
относительная плотность фрагментов, полученных в результате спектрографической
обработки. На основе интерпретации этих данных восстанавливается исходная структура
молекулы. Обобщение данных о нарушении структуры конкретных молекул становится
основой формирования единых правил.
При обучении в программе DENDRAL используется "теория полупорядка" из
органической химии. Хотя эта теория не позволяет напрямую строить правила вывода, она
поддерживает интерпретацию нарушений структуры известных молекул. Теория
полупорядка состоит из правил, ограничений и эвристик следующего вида.
Двойные и тройные связи не разрываются.
В экспериментальных данных можно наблюдать лишь фрагменты, размер
которых превышает 2 атома углерода.
На основе теории полупорядка в программе DENDRAL формируются пояснения
структурных нарушений, указывающие наиболее вероятные места расщепления, а также
направления возможного перемещения атомов вдоль линий разрывов.
Эти пояснения составляют набор положительных примеров для программы
формирования правил. Ограничения в левой части правил строятся на основе поиска от общего к
частному. Работа алгоритма начинается с рассмотрения наиболее общего описания
расщепления X! *Х2. Этот шаблон означает, что расщепление, обозначенное символом "*",
может произойти между любыми двумя атомами. Этот шаблон уточняется таким образом:
добавление атомов: X, *Х2 -» Xz-X: *X2,
где оператор "-" означает химическую связь, или
инстанцирование атомов и атрибутов атомов: Х/Х2 -» С*Х2.
Алгоритм Meta-DENDRAL обучается только на положительных примерах путем
поиска экстремума в пространстве понятий. Излишнее обобщение предотвращается за счет
такого ограничения правил-кандидатов, при котором они покрывают лишь половину
обучающих примеров. В последующих модулях программы эти правила оцениваются и
уточняются путем модификации слишком общих или частных правил.
Преимущество алгоритма Meta-DENDRAL состоит в использовании знаний об
области определения для преобразования одномерных данных в более удобную форму. Это
406
Часть IV. Машинное обучение
обеспечивает устойчивость программы к шумам за счет исключения потенциально
ошибочных данных на основе теории, а также способность к обучению на сравнительно небольшом
числе примеров. Интерпретация данных составляет основу обучения на основе объяснения.
9.5.2. Обучение на основе объяснения
В обучении на основе объяснения явное представление теоретических знаний об
области определения используется для построения пояснений к обучающим примерам
обычно с целью доказательства того, что данный пример следует из этой теории.
Фильтрация шума в обучении на основе объяснения выполняется за счет обобщения пояснений
к примерам, а не на основе самих примеров. При этом выбираются соответствующие
аспекты опыта, и обучающие данные систематизируются в строгую и логически
согласованную структуру.
Существует несколько различных реализаций этой идеи. Например, она оказала
значительное влияние на представление общих операторов планирования (см. раздел 5.4 и
9.5) в программе STRIPS [Fikes и др., 1972]. В алгоритме Meta-DENDRAL тоже
использованы преимущества теоретической интерпретации обучающих примеров. В последние
годы многие авторы предложили альтернативные формулировки этой идеи [DeJong и
Моопеу, 1986; Minton, 1988]. Типичным примером является алгоритм обобщения на
основе объяснения, разработанный Митчеллом и его коллегами в 1986 году. В этом разделе
будет рассмотрен вариант алгоритма обучения на основе объяснения EBL (explanation-
based learning), разработанный Дейонгом и Муни (DeJong и Моопеу] в 1986 году.
Исходными данными для алгоритма EBL являются следующие.
1. Целевое понятие. Задача обучаемой системы— выработать эффективное
определение этого понятия. В зависимости от типа приложения целевым понятием может
быть система классификации, доказанная теорема, план достижения цели или
эвристика для решения задачи.
2. Обучающий пример. Это пример цели.
3. Теоретические сведения об области определения. Набор правил или фактов,
используемых для объяснения того, почему обучающий пример является
экземпляром целевого понятия.
4. Критерий функциональности. Средства описания формы, которую может
принимать определение понятия.
Для иллюстрации алгоритма EBL рассмотрим пример изучения понятия "чашка". Эта
задача была описана Винстоном (Winston) в 1983 году и адаптирована к обучению на
основе объяснения Митчеллом и его коллегами в 1986 году. Целевым понятием в этой задаче
является правило, которое можно использовать для выяснения, является ли объект чашкой.
premise(X) -» сир(Х),
где premise — это конъюнктивное выражение, содержащее переменную X.
Допустим, теоретические сведения о чашках представлены в виде следующих правил.
liftable(X) л holdsJiquid(X) -> сир(Х)
part(Z, W) л concave(W) л points_up(W) -» holdsJiquid(Z)
light(Y) л part(Y, handle) -> liftable(Y)
small(A) -> light(A)
made_of(A, features) -» light(A)
Глава 9. Машинное обучение, основанное на символьном представлении... 407
Обучающий пример — это экземпляр целевого понятия, который в данном случае
имеет такой вид:
cup(obj^)
sma//(ob/1)
part(obj^, handle)
owns(bob, ob/1)
part(obj^, bottom)
part(obj^, bowl)
points_up(bowl)
concave(bowl)
color(obj^, red).
И, наконец, предположим, что согласно критерию функциональности целевые
понятия должны определяться в терминах таких наблюдаемых, структурных свойств
объектов, как part (часть) и concave (вогнутость). Можно сформулировать правила,
позволяющие обучаемой системе определить, является описание функциональным или это
просто набор предикатов.
С помощью этих теоретических сведений можно обосновать тот факт, что пример
действительно является экземпляром изучаемого понятия. Такое обоснование будет
иметь вид доказательства, что целевое понятие логически вытекает из примера, как для
первого дерева на рис. 9.17. Заметим, что в этом объяснении такие несущественные
примеры из обучающих данных, как красный цвет color(obj^ , red), не учитываются, а
внимание акцентируется на важных свойствах изучаемого понятия.
На следующем этапе обучения объяснение следует обобщить и получить определение
понятия, которое можно использовать для распознавания других чашек. В алгоритме
EBL эта процедура реализована за счет замены переменными тех конкретных значений в
дереве доказательства, которые связаны только с конкретным обучающим примером (см.
рис. 9.17). На основе обобщенного дерева алгоритм EBL определяет новое правило,
заключением которого является корневой узел дерева, а начальными условиями —
конъюнкция листьев
small(X) л part(X, handle) л part(X, W) л concave(W) л points_up(W) -> сир(Х).
При построении обобщенного дерева доказательства основная цель — заменить
переменными те константы, которые относятся к обучающему примеру, и оставить
конкретные значения и ограничения, которые являются частью теоретических сведений об
области определения. В этом примере значение handle (ручка) относится к
теоретическим данным об области определения, а не к обучающему экземпляру. Поэтому оно
оставлено как существенное ограничение в окончательном правиле.
Обобщенное дерево доказательства можно построить на основе обучающего
примера различными способами. В работе Митчелла сначала строится дерево
доказательства для конкретного примера, которое затем обобщается с помощью
процесса, получившего название регрессии цели (goal regression). В процессе регрессии
цели обобщенная цель (в нашем примере сир(Х)) приравнивается к корню дерева
доказательства, при этом конкретные значения заменяются переменными. Такие
подстановки выполняются рекурсивно по всему дереву до тех пор, пока не будут
заменены все соответствующие константы. Этот процесс более подробно описан в
работе [Mitchell и др., 1986].
408
Часть IV. Машинное обучение
Доказательство того, что объект оЬ/7 является чашкой
С17р@Ь/1)
Hght(obp) partfabfl, handle) part^obfi, bowl) concave(bowl) points_up(bowl)
sma//(ob/1)
Обобщенное доказательство того, что объект X— чашка
сир{Х)
Hght(X)
part{X, handle) part{X, W) concave(W) points_up{W)
small{X)
Рис. 9.17. Частное и обобщенное доказательство того факта, что объект Xявляется чашкой
В [DeJong и Моопеу, 1986] предложен альтернативный подход, позволяющий
строить обобщенные и частные деревья одновременно. Это достигается благодаря особому
варианту дерева доказательства, содержащему правила выявления отличий цели от
понятия, сформированного за счет подстановки переменных в реальное
доказательство. Это дерево называется структурой объяснения (explanation structure) (рис. 9.18) и
представляет абстрактную структуру доказательства. Обучаемая система
поддерживает два различных списка подстановок для структуры объяснения: список конкретных
подстановок, необходимый для объяснения обучающего примера, и список общих
подстановок для обоснования обобщенной цели. Эти списки подстановок строятся в
процессе создания структуры объяснения.
Списки общих и частных подстановок формируются следующим образом. Пусть ss
nsg — списки частных и общих подстановок соответственно. Для всех соответствующих
выражений et и е2 в структуре объяснения s5 и sg обновляются по следующему правилу.
if ex находится в левой части правила, а е2 — в его заключении,
then begin
Ts = наиболее общий унификатор из exss и e2ss %объединить ех и е2
Глава 9. Машинное обучение, основанное на символьном представлении... 409
при условии ss
Ss =SSTS
%обновить значение ss, скомпоновав его с Ts
наиболее общий унификатор из е^д и e2sg %объединить ех и е2
при условии sg
sg=sgTg %обновить значение sg, скомпоновав его с Тд
end
if e1 находится в левой части правила, а е2 — это факт из обучающего
примера
then begin
Ts = наиболее общий унификатор из eiSs и e2ss %объединить ех и е2
%при условии ss
ss =SSTS %обновить значение ss, скомпоновав его с Ts
end
holds_liquid(X)
II
holds liquid(Z)
^^
light(Y) part(Y, handle) part(Z, W) concave(W) points up(W)
II II II II II
llght(A) part(ob^, handle) part{obj^ bowt) concave{bowri points_up(bowi)
small(A)
II
sma//(ob/1)
Puc. 9.18. Структура объяснения для примера с чашкой
В примере на рис. 9.18
s = {оЬ/1/Х, ob/1/V, obj1/A, obj^/Z, bowl/W)
sg = {X/Y, Y/A.X/Z).
Применяя эти подстановки к структуре объяснения, показанной на рис. 9.18, получим
частное и общее деревья доказательства, показанные на рис. 9.17.
Преимущества обучения на основе объяснения сводятся к следующему.
1. Обучающие примеры зачастую содержат несущественную информацию, наподобие
цвета чашки в предыдущем примере. Теоретические сведения об области определения
позволяют обучаемой системе отбирать из обучающих примеров важные аспекты.
2. Каждый пример допускает множество различных обобщений, большая часть
которых либо бесполезна, либо бессмысленна, либо ошибочна. Алгоритм EBL
формирует заведомо адекватные обобщения и обеспечивает их логическую
согласованность с теоретическими сведениями.
3. Используя знания об области определения, алгоритм EBL обеспечивает обучение
на основе одного обучающего примера.
410
Часть IV. Машинное обучение
4. Построение объяснений позволяет обучаемой системе предполагать наличие
связей между ее целями и опытом, подобно тому как определение чашки создается на
основе ее структурных свойств.
Алгоритм EBL применялся для решения многочисленных задач обучения.
Например, в работе [Mitchell и др., 1983] обсуждается вопрос добавления EBL к
алгоритму LEX. Допустим, первый положительный пример использования операции ОР1
встретился при вычислении интеграла \7х2 dx. Согласно алгоритму LEX этот пример
станет элементом множества S, содержащего наиболее конкретные обобщения.
Однако человек сразу же определит, что используемый при решении этой задачи прием
не зависит от значений коэффициента и показателя степени и может применяться
для любых вещественных значений этих переменных (за исключением показателя
степени -1). Поэтому можно обобщить этот пример и сделать вывод о том, что
операцию ОР1 необходимо применять для вычисления любых интегралов вида JriX(r2*~
1} dx, где Г\ и г2 — любые вещественные числа. Для такого обобщения алгоритм LEX
был модифицирован на базе знаний алгебры и обучения на основе объяснения.
Реализация алгоритма обучения на основе объяснения на языке PROLOG приводится в
подразделе 14.8.3.
9.5.3. Алгоритм EBL и обучение на уровне знаний
Алгоритм EBL элегантно демонстрирует роль знаний в обучении, однако при его
изучении возникает много важных вопросов. Один из самых очевидных сводится к
следующему: чему на самом деле учится система на основе объяснения? Чистый
алгоритм EBL позволяет лишь выучить правила в рамках дедуктивного замыкания
(deductive closure) существующих теоретических сведений. Это означает, что
изученные правила можно сформулировать лишь на основе базы знаний без
использования обучающих примеров вообще. Основная роль обучающего примера сводится к
фокусированию внимания обучаемой системы на существенных аспектах области
определения задачи. Следовательно, алгоритм EBL зачастую рассматривают как
одну из форм ускорения обучения или реструктуризации базы знаний. Он ускоряет
процесс обучения, поскольку не требует построения дерева доказательства,
лежащего в основе нового правила. Однако он не позволяет изучить никакой новой
информации. Это отличительное свойство алгоритма было сформулировано Дитрихом
(Dietterich) при обсуждении обучения на уровне знаний в 1986 году.
Алгоритм EBL извлекает неявную информацию из набора правил и делает ее явной.
Например, рассмотрим игру в шахматы. Минимальные знания правил этой игры в
сочетании с неограниченными возможностями просчета наперед различных комбинаций
обеспечивают компьютеру чрезвычайно высокий уровень игры в шахматы. К
сожалению, шахматы слишком сложны для реализации изучаемого подхода. Любая обучаемая
на основе объяснения система, которая сможет освоить стратегию игры в шахматы, на
самом деле получит новые (с практической точки зрения) знания.
Алгоритм EBL также позволяет отказаться от требования наличия полной и
корректной теории описания области определения и сконцентрироваться на приемах
уточнения неполных теоретических сведений в контексте EBL. Обучаемая система
строит фрагмент дерева решений. Ветви доказательства, которые не могут быть
достроены, указывают на неполноту теории. В этой области возникает множество
интересных вопросов. К ним относятся: разработка эвристик для обоснования с помо-
Глава 9. Машинное обучение, основанное на символьном представлении... 411
щью неполной теории, формирование методологии выделения кредитов и выбор
одного из нескольких неуспешных доказательств, подлежащего исправлению.
Дальнейшее развитие обучения на основе объяснения предполагает его
интеграцию с подходом к обучению на основе подобия. В этой области тоже было
предложено множество базовых схем, в том числе предполагающих использование
алгоритма EBL для уточнения обучающих данных на основе теории с последующей
передачей этих частично обобщенных данных компоненту обучения на основе подобия
для дальнейшего обобщения. Кроме того, неудачные объяснения можно
использовать для выявления неполноты теории с последующим переходом к обучению на
основе подобия.
Были изучены вопросы обоснования на основе ошибочной теории, варианты
доказательства теорем, методы работы с зашумленными или неполными обучающими
данными и методы определения сгенерированных правил, подлежащих сохранению.
9.5.4. Обоснование по аналогии
Если "чистый" алгоритм EBL обеспечивает лишь дедуктивное обучение, то
обоснование по аналогии — это более гибкий метод использования имеющихся знаний.
Обоснование по аналогии строится на следующих предпосылках. Если две ситуации сходны в
некотором отношении, то весьма вероятно, что они окажутся сходными и в других
аспектах. Например, если два дома расположены в одной местности и похожи по
архитектуре, то они, скорее всего, имеют одинаковую стоимость. В отличие от доказательств,
используемых в алгоритме EBL, метод аналогии не является логически строгим. В этом
смысле он подобен индукции. Как замечено в [Russell, 1989] и других работах,
аналогия — это вид индукции на основе единственного примера. В примере с домами
свойства одного дома прогнозируются на основе информации о втором.
Как было указано при рассмотрении обоснования на основе опыта (раздел 7.3),
аналогия очень полезна для применения имеющихся знаний к новым ситуациям. Например,
предположим, студент изучает свойства электричества, а преподаватель сообщает ему,
что электричество напоминает воду, причем напряжение соответствует давлению, сила
тока — величине потока, а сопротивление — пропускной способности канала. С
помощью этой аналогии студент сможет легче понять закон Ома.
В стандартной математической модели аналогии используется источник аналогии,
который может представлять собой решение задачи, пример или относительно
понятную теорию, а также не совсем понятная цель. Аналогия — это отображение
соответствующих элементов источника и цели. Заключение по аналогии расширяет это
отображение на новые элементы области определения цели. Возвращаясь к аналогии
электричества и воды, на основе сведений о соответствии напряжения и давления, а
также силы тока и величины потока жидкости можно сделать вывод, что пропускная
способность канала соответствует сопротивлению. Это поможет лучше разобраться с
природой сопротивления.
При участии многочисленных авторов был разработан унифицированный подход к
реализации вычислительных моделей обоснования по аналогии [Hall, 1989]; [Kedar-
Cabelli, 1988]; [Wolstencroft, 1989]. Обычно этот процесс состоит из следующих этапов.
1. Поиск (retrieval). Зная целевую проблему, необходимо выбрать потенциальный
источник аналогии. При этом нужно выделить те свойства цели и источника,
которые подтверждают правдоподобие аналогии, а также проиндексировать
412
Часть IV. Машинное обучение
знания согласно этим свойствам. В целом, в процессе поиска определяются
исходные элементы отображения.
2. Развитие (уточнение). Обнаружив источник, зачастую следует выделить
дополнительные свойства и отношения источника. Например, иногда в качестве базиса для
аналогии необходимо разработать специфическое пояснение для решения
проблемы в области определения источника.
3. Отображение и логический вывод (mapping and inference). Этот этап предполагает
отображение атрибутов источника в область определения цели. Здесь
используются и известные соответствия и вывод по аналогии.
4. Подтверждение (justification). На этом этапе проверяется корректность
отображения. При необходимости его следует модифицировать.
5. Обучение (learning). Полученные знания сохраняются в такой форме, которая
может быть полезна в будущем.
Эти этапы реализованы в многочисленных вычислительных моделях обоснования
по аналогии. Например, теория структурного отображения (structure mapping theory)
[Falkenhainer, 1990], [Falkenhainer и др., 1989], [Gentner, 1983] не только позволяет
решить проблему поиска полезных аналогий, но и обеспечивает правдоподобную
модель понимания аналогий человеком. Основной вопрос при использовании аналогии
заключается в том, как отличить выразительные, глубокие аналогии от поверхностных
сравнений. В своей работе Гентнер (Gentner) утверждает, что истинные аналогии
должны акцентировать внимание на систематичных, структурных свойствах области
определения, а не на малосущественном сходстве. Например, аналогия "атом подобен
солнечной системе" глубже, чем "подсолнух напоминает солнце", поскольку первая
отражает целую систему взаимосвязей между элементами, движущимися по своим
орбитам, а вторая описывает лишь внешнее сходство, состоящее в том, что оба объекта
имеют круглую форму и желтый цвет. Это свойство отображения аналогии называется
систематичностью (systematicity).
Теория структурного отображения формализует эти рассуждения. Рассмотрим
пример аналогии атома и солнечной системы, описанный в [Gentner, 1983] и
проиллюстрированный на рис. 9.19. Область определения источника включает предикаты
yellow(sun)
blue(earth)
hotter-than(sun, earth)
causes(more-massive(sun, earth), attract(sun, earth))
causes(attract(sun, earth), revolves-around(earth, sun)).
Область определения цели содержит предикаты
more-massive(nucleus, electron)
revolves-around(electron, nucleus).
При структурном отображении задается соответствие структур источника и цели,
определяемое следующими правилами.
Глава 9. Машинное обучение, основанное на символьном представлении... 413
Отображение по аналогии
Рис. 9.19. Отображение для аналогии
1. Из описания источника исключаются лишние свойства. Поскольку аналогия
концентрирует внимание на системе отношений, сначала необходимо исключить
предикаты, описывающие несущественные свойства источника. В структурном
отображении эта процедура формализуется путем исключения из описания источника
предикатов с единственным аргументом (унарных предикатов). Это обосновано
тем, что предикаты с более высокой арностью, описывающие отношения между
несколькими сущностями, содержат систематичную информацию с более высокой
степенью вероятности, что и требуется для аналогии. В нашем примере
исключаются утверждения, определяющие цвет Солнца и Земли yellow(sun) и
blue(earth). Заметим, что в описании источника все еще могут содержаться
утверждения, не имеющие значения для аналогии, например, утверждение о том, что
Солнце теплее Земли hotter-than(sun, earth).
2. Отношения отображаются из описания источника в описание цели без изменений.
Могут отличаться лишь параметры этих отношений. В нашем примере для
источника и цели отношения revolves-around (вращается вокруг) и more-massive
(более массивный) одинаковы. Такой подход используется во многих теориях
построения аналогий. Он позволяет сократить число возможных отображений, а
также согласуется с эвристикой о предпочтениях в отображении.
3. При построении отображения в качестве его фокуса целесообразно выбирать
отношения более высокого порядка. В нашем примере отношением более высокого
порядка выступает causes, поскольку его аргументами являются другие
отношения. Это называется принципом систематичности (systematicity principle).
414
Часть IV. Машинное обучение
Такие правила приводят к отображению
sun -> nucleus
earth -> electron.
Расширяя это отображение, приходим к выражениям
causes(more-massive(nucleusf electron), attract(nucleusf electron))
causes(attract(nucleus, electron), revolves-around(electronf nucleus)).
Теория структурного отображения была реализована и протестирована в различных
областях определения. Однако она еще далека от полной теории аналогии, поскольку не
позволяет решить такую проблему, как поиск источника аналогии. Она подтверждается
вычислительным экспериментом и объясняет многие аспекты обоснования по аналогии,
свойственного человеку. И, наконец, в этом разделе уже упоминалось обоснование на
основе опыта (case-based reasoning), описанное в разделе 7.3. В этом контексте при
создании и применении базы полезного опыта важная роль отводится аналогии.
9.6. Обучение без учителя
Описанные выше алгоритмы построены на принципе обучения с учителем (supervised
learning). В них предполагается существование учителя, некоторой меры соответствия
или другого внешнего метода классификации обучающих данных. Обучение без учителя
(unsupervised learning) не предполагает наличия учителя и обеспечивает формирование
понятий в самой обучаемой системе. Пожалуй, лучшим примером обучения без учителя
в человеческом сообществе является наука. Ученые не получают знаний от учителя. Они
сами выдвигают гипотезы, объясняющие их наблюдения, оценивают эти гипотезы по
таким критериям, как простота, общность и элегантность, а затем тестируют их с помощью
разработанных ими экспериментов.
9.6.1. Научная деятельность и обучение без учителя
Одной из первых и наиболее успешных систем, позволяющих "открывать" новые
знания, является программа AM [Davis и Lenat, 1982]; [Lenat и Brown, 1984], которая
выводит интересные, а иногда и оригинальные, понятия в математике. Эта программа
основывается на теории множеств, операциях по созданию новых знаний путем модификации
и комбинирования существующих понятий и наборе эвристик для выявления
"интересных" понятий. За счет поиска в пространстве математических понятий
программа AM "открыла" натуральные числа и несколько важных понятий теории чисел,
например, существование простых чисел.
Так, программа AM "открыла" натуральные числа, модифицируя свое представление
о "множествах с повторяющимися элементами". К таким множествам относится,
например {а, а, Ь, с, с}. При специализации определения такого множества, в котором
содержатся только элементы одного типа, возникла аналогия с натуральными числами.
Например, множество с повторяющимися элементами {1, 1, 1, 1} соответствует числу 4.
Объединение таких множеств соответствует сложению чисел: {1, 1}и{1, 1} = {1, 1, 1,
1} или 2 + 2 = 4. В процессе дальнейшего изучения этого понятия было обнаружено,
что умножение — это последовательность операций сложения. С помощью эвристики
определения новых операций путем обращения существующих программа AM
Глава 9. Машинное обучение, основанное на символьном представлении... 415
"открыла" целочисленное деление. Затем было найдено понятие простого числа,
имеющего только два делителя (само число и 1).
При создании нового понятия программа AM оценивает его в соответствии с
несколькими эвристиками, позволяющими определить "интересность" понятия. Простые
числа оказались интересными. Это заключение основано на частоте их появления. При
оценке понятия по этой эвристике программа AM генерирует экземпляры базового
понятия и проверяет их соответствие новому определению. Если все экземпляры
удовлетворяют определению нового понятия, значит, это тавтология, и новое понятие получает
низкую оценку. Аналогично исключаются понятия, не соответствующие ни одному из
сгенерированных экземпляров. Если понятие описывает значительную часть примеров
(как при использовании простых чисел), программа AM классифицирует его как
интересное и отбирает для дальнейшей модификации.
Несмотря на то что программе AM удалось открыть простые числа и несколько
других интересных понятий, она не смогла продвинуться дальше элементарной теории
чисел. В [Lenat и Brown, 1984] были проанализированы преимущества программы и ее
ограничения. Изначально считалось, что основным преимуществом программы являются
се эвристики, однако впоследствии оказалось, что своим успехом программа обязана
языку представления математических понятий. Понятия в ней представлены
рекурсивными структурами на языке программирования LISP. Поскольку описание основано на
удачно спроектированном языке программирования, в определяемом пространстве
плотность интересных понятий очень высока. Особенно это проявляется на ранних этапах
поиска. При последующем исследовании понятий пространство расширяется по законам
комбинаторики, и "доля" интересных понятий в общем пространстве уменьшается. Это
наблюдение еще раз подчеркивает связь между представлением и поиском.
Еще одной причиной, обусловившей невозможность получения дальнейших
впечатляющих результатов на основе первых достижений программы AM, является ее
неспособность "учиться учиться". В процессе приобретения математических знаний она не
выводит новых эвристик. Следовательно, качество поиска снижается с увеличением
математической сложности задач. В этом смысле программа никогда не достигнет
глубокого понимания математики. Эта проблема впоследствии была решена в программе
EVRISKO, которая способна обучиться новым эвристикам [Lenat, 1983].
Проблема автоматического обучения исследовалась во многих программах. В
программе IL [Sims, 1987] для "открытия" новых математических понятий использованы
различные приемы обучения, в том числе методы автоматического доказательства
теорем и обучения на основе объяснения (раздел 9.5). Автоматический вывод
целочисленных последовательностей описан также в [Cotton и др., 2000].
В программе BACON [Langley и др., 1987] разработаны и реализованы математические
модели формирования количественных научных закономерностей. Например, на основе
данных об удаленности планет от Солнца и периоде их вращения по орбитам система
BACON повторно "открыла" законы Кеплера о движении планет. С помощью вычислительной
модели реализации открытий человека в различных предметных областях, BACON
обеспечила полезные средства и методологию исследования процессов научной деятельности
человека. В системе SCAVENGER [Stubblefield, 1995], [Stubblefield, 1996] применен вариант
алгоритма ЮЗ для повышения способности формирования полезных аналогий. В работе
[Shrager и Langley, 1990] описано множество других самообучающихся систем.
Несмотря на то что научная деятельность — важная область исследования, до сих пор
в ней были получены очень незначительные результаты. Более фундаментальной про-
416
Часть IV. Машинное обучение
блемой обучения без учителя, при решении которой был достигнут серьезный прогресс,
является изучение категорий. В [Lakoff, 1987] сделано предположение о том, что
категоризация — это основа человеческого познания: высокоуровневые теоретические знания
зависят от способности систематизировать конкретный опыт в логически согласованной
классификационной иерархии. Большая часть знаний человека относится к категориям
объектов, например к лошадям, а не к отдельно взятой конкретной лошади, например,
Росинанту или Боливару. В работе [Nordhausen и Langley, 1990] отмечено, что
формирование категорий — основа единой теории научных исследований. При исследовании
процессов химических реакций ученые основывались на известной классификации
соединений по таким категориям, как "кислота" и "щелочь".
В следующем разделе рассматривается концептуальная кластеризация (conceptual
clustering) — проблема формирования полезных категорий на основе
неклассифицированных данных.
9.6.2. Концептуальная кластеризация
Для решения задачи кластеризации (clustering problem) требуются набор
неклассифицированных объектов и средства измерения подобия объектов. Целью кластеризации
является организация объектов в классы, удовлетворяющие некоторому стандарту
качества, например на основе максимального сходства объектов каждого класса.
Числовая таксономия (numeric taxonomy) — один из первых подходов к решению
задач кластеризации. Числовые методы основываются на представлении объектов с
помощью набора свойств, каждое из которых может принимать некоторое числовое значение.
При наличии корректной метрики подобия каждый объект (вектор из п значений
признаков) можно рассматривать как точку в п-мерном пространстве. Мерой сходства двух
объектов можно считать расстояние между ними в этом пространстве.
Используя метрику подобия, типичные алгоритмы кластеризации строят классы по
принципу "снизу вверх". В рамках этого подхода, зачастую называемого стратегией
накопительной кластеризации (agglomerative clustering), категории формируются следующим образом.
1. Проверяются все пары объектов, выбирается пара с максимальной степенью
подобия, которая и становится кластером.
2. Определяются свойства кластера как некоторые функции свойств элементов
(например, среднее значение), и компоненты объектов заменяются этими
значениями признаков.
3. Этот процесс повторяется до тех пор, пока все объекты не будут отнесены к
одному кластеру.
4. Можно сказать, что многие алгоритмы обучения без учителя оценивают плотность
по методу максимального правдоподобия (maximum likelihood density estimation). Это
означает построение распределения, которому с наибольшей вероятностью
подчиняются исходные данные. Примером реализации такого подхода является
интерпретация набора фонем в приложении обработки естественного языка (глава 13).
Результатом работы такого алгоритма является бинарное дерево, листья которого
соответствуют экземплярам, а внутренние узлы — кластерам более общего вида.
Этот алгоритм можно распространить на объекты, представленные наборами
символьных, а не числовых, свойств. Единственной проблемой при этом является измерение
Глава 9. Машинное обучение, основанное на символьном представлении... 417
степени подобия объектов, определенных символьными, а не числовыми, значениями.
Логично связать степень сходства двух объектов с относительным числом совпадающих
значений признаков. Если даны объекты
objecf\={small, red, rubber, ball),
object2={small, blue, rubber, ball),
object3={large, black, wooden, ball),
то можно ввести метрику подобия
similarity(object1, object2) = 3/4,
similarity(objecM, object?,) = similarity(object2, objectZ) = 74-
Однако алгоритмы кластеризации на основе подобия неадекватно учитывают роль
семантических знаний при формировании кластеров. Например, созвездия на небесной
сфере описываются не только взаимным расположением звезд, но и существованием
обычных человеческих понятий, таких как "большой ковш".
При определении категорий не все свойства имеют одинаковый вес. В зависимости от
контекста каждое свойство может стать более важным, чем другие, а простая метрика
подобия не позволяет выделить главные признаки. Человеческие категории в гораздо
большей степени определяются целью категоризации и априорными знаниями о
предметной области, а не внешним сходством. В качестве примера рассмотрим китов,
которые относятся к категории млекопитающих, а не рыб. При этом внешнее сходство не
учитывается, основное внимание уделяется задачам классификации биологических
организмов на основе физиологических признаков и с учетом эволюции.
Традиционные алгоритмы кластеризации не только не учитывают цели и базовые
знания, но и не обеспечивают осмысленное семантическое обоснование
сформированных категорий. В этих алгоритмах кластер представляется перечислением всех его
элементов. Алгоритмы не позволяют получить содержательные определения или общие
правила описания семантики категории, которые можно было бы использовать для
классификации как известных, так и неизвестных представителей этой категории. Например,
множество людей, которые избирались на пост генерального секретаря ООН, можно
представить в виде обычного списка. Содержательное определение
{X | X, которые избирались на пост генерального секретаря ООН)
позволяет выделить семантические свойства класса и классифицировать будущих
представителей этой категории.
Концептуальная кластеризация (conceptual clustering) позволяет решить эти проблемы
за счет использования методов машинного обучения для создания общих определений
понятий и применения базовых знаний при формировании этих категорий. Хорошим
примером реализации этого подхода является система CLUSTER/2 [Michalski и Stepp, 1983].
В ней для представления категорий используются базовые знания в форме языковых порогов.
В системе CLUSTER/2 формируются к категорий на базе к опорных объектов, где
к — это параметр, настраиваемый пользователем. Программа оценивает полученные
кластеры, выбирает новые опорные объекты и повторяет этот процесс до тех пор, пока
не будет достигнут критерий качества. Этот алгоритм имеет следующий вид.
1. Выбрать к опорных объектов из множества существующих. Это можно сделать с
помощью генератора случайных чисел.
2. Для каждого опорного объекта, используя его в качестве положительного примера,
а все остальные — в качестве отрицательных, создать наиболее общее определе-
418
Часть IV. Машинное обучение
ние, покрывающее все положительные и ни одного отрицательного примера.
Заметим, что при этом может образоваться несколько классов, связанных с другими (не
относящимися к опорным) объектами.
3. Классифицировать все объекты в соответствии с этими описаниями. Заменить
каждое максимально общее определение максимально конкретным, покрывающим
все объекты этой категории. При этом снижается вероятность перекрытия классов
при классификации новых, неизвестных ранее объектов.
4. Классы могут перекрываться даже для объектов обучающего множества. В
систему CLUSTER/2 включен алгоритм настройки перекрывающихся определений.
5. С помощью метрики расстояния выбрать элемент, ближайший к центру каждого
класса. Метрика расстояния может напоминать описанную выше метрику подобия.
6. Используя эти центральные элементы в качестве опорных, повторить пункты 1-5.
Алгоритм завершается после формирования приемлемых кластеров. Типичной
мерой качества является сложность общих описаний классов. Например, согласно
принципу "бритвы Оккама" следует отдавать предпочтение кластерам с
синтаксически простыми определениями, т.е. с малым числом конъюнктов.
7. Если кластеры неприемлемы, но в течение нескольких итераций не наблюдается
никаких улучшений, выберите новые опорные объекты, ближайшие к границе
кластеров, а не к его центру.
Этапы работы алгоритма CLUSTER/2 показаны на рис. 9.20.
ш
и
После выбора опорных объектов (п 1)
После создания общих описаний (п. 2, 3).
Заметим, что категории перекрываются
После конкретизации описания понятий (п. 4)
Пересекающиеся фрагменты все еще есть
Рис. 9.20. Этапы выполнения алгоритма CLUSTER/2
После устранения дублирования элементов (п. 5)
9.6.3. Программа СОВ-WEB и структурные таксономические знания
Многие алгоритмы кластеризации, как и многие алгоритмы обучения с учителем,
типа ID3, определяют категории в терминах необходимых и достаточных условий
принадлежности этим категориям. Эти условия представляют собой наборы
признаков, свойственных каждому элементу категории и отличных от признаков другой ка-
Глава 9. Машинное обучение, основанное на символьном представлении... 419
тегории. Таким образом можно описать многие категории, к примеру, множество
всех членов ООН, однако человеческие категории не всегда соответствуют этой
модели. На самом деле они характеризуются большей гибкостью и более
разветвленной структурой, чем в описанном выше примере.
Например, если бы человеческие категории на самом деле определялись
необходимыми и достаточными условиями принадлежности, мы не смогли бы отличить степень
этой принадлежности. Однако психологи отмечают важное значение прототипов в
человеческих категориях [Rosch, 1978]. Например, для человека малиновка— более
типичный пример птицы, чем курица, а дуб — более типичный пример дерева, чем пальма (как
минимум, в северных широтах).
Эти рассуждения подтверждаются теорией семейного сходства (family resemblance
theory), которая гласит, что категории определяются сложной системой сходства между
элементами, а не необходимыми и достаточными условиями принадлежности членов
[Wittgenstein, 1953]. При такой категоризации может не существовать свойств, общих
для всех элементов класса. В работе [Wittgenstein, 1953] приводится пример категории
"игра": не все игры предполагают наличие двух или нескольких игроков (например,
компьютерные игры), не для всех игр четко сформулированы правила (например, для
детских), и не все игры предполагают соревнование, подобно перетягиванию каната. Тем не
менее эта категория хорошо определена и недвусмысленна.
Человеческие категории также отличаются от большинства формальных
иерархий наследования (глава 8) тем, что не все уровни человеческой таксономии
одинаково важны. Психологам удалось продемонстрировать существование категорий
базового уровня (base-level category) [Rosch, 1978]. Базовая категория — это
классификация, которая чаще всего используется для описания объектов в терминах,
изученных с раннего детства, на уровне, в некотором смысле охватывающем наиболее
фундаментальные свойства объекта. Например, категория "стул" является более
базовой, чем любое ее обобщение, в частности, "мебель", или любая ее специализация,
например, "офисный стул". "Машина" — это более базовая категория, чем "седан"
или "транспортное средство".
Обычные средства представления классов или их иерархии, в том числе логическое
представление, иерархия наследования, векторы признаков или деревья решений, не
учитывают этого, хотя это очень важно не только для ученых-когнитологов, целью которых
является познание человеческого интеллекта. Это имеет большое значение и для
построения полезных приложений искусственного интеллекта. Пользователи оценивают
программу в терминах гибкости, робастности и соответствия ее поведения человеческим
стандартам. И хотя вовсе не требуется, чтобы все алгоритмы искусственного интеллекта
учитывали параллельность обработки информации мозгом человека, все алгоритмы
изучения категорий должны оправдывать ожидания пользователя относительно структуры и
поведения этих категорий.
Эти проблемы учтены в системе COB-WEB [Fisher, 1987]. Не претендуя на
звание модели человеческого познания, эта система учитывает категории базового
уровня и степень принадлежности элемента соответствующей категории. Кроме
того, в программе COBWEB реализован инкрементальный алгоритм обучения, не
требующий представления всех обучающих примеров до начала обучения. Во многих
приложениях обучаемая система получает данные со временем. В этом случае она
должна строить полезные определения понятий на основе исходных данных и
обновлять эти описания с появлением новой информации. В системе COBWEB также
420
Часть IV. Машинное обучение
решена проблема определения корректного числа кластеров. В программе
CLUSTER/2 формируется изначально заданное число категорий. Пользователь может
изменять это число, однако такой подход нельзя назвать гибким. В системе COBWEB
для определения количества кластеров, глубины иерархии и принадлежности
категории новых экземпляров используется глобальная метрика качества.
В отличие от рассмотренных ранее алгоритмов, в системе COBWEB реализовано
вероятностное представление категорий. Принадлежность категории определяется не
набором значений каждого свойства объекта, а вероятностью появления значения.
Например, p(fi=Vij\ck) — это условная вероятность, с которой свойство f, принимает значение
Vij, если объект относится к категории ск.
На рис. 9.21 показана система классификации программы COBWEB, приведенная
в работе [Gennari и др., 1989]. Это пример категоризации четырех одноклеточных
организмов, изображенных в нижней части рисунка. Каждый класс определяется
значениями следующих свойств: цвет, количество хвостов и ядер. Например, к
категории СЗ относятся объекты, имеющие по 2 хвоста и ядра с вероятностью 1,0, и
светлые с вероятностью 0,5.
Как видно из рис. 9.21, для каждой категории в иерархии определены вероятности
вхождения всех значений каждого свойства. Это важно как для категоризации новых
экземпляров, так и для изменения структуры категорий для более полного соответствия
свойствам их элементов. Поскольку в системе COBWEB реализован инкрементальный
алгоритм обучения, она не разделяет эти операции. При предъявлении нового
экземпляра система COBWEB оценивает качество отнесения этого примера к существующей
категории и модификации иерархии категорий в соответствии с новым представителем.
Критерием оценки качества классификации является полезность категории (category
utility) [Gluck и Corter, 1985]. Критерий полезности категории был определен при
исследовании человеческой категоризации. Он учитывает влияние категорий базового уровня
и другие аспекты структуры человеческих категорий.
Критерий полезности категории максимизирует вероятность того, что два
объекта, отнесенные к одной категории, имеют одинаковые значения свойств и значения
свойств для объектов из различных категорий отличаются. Полезность категории
определяется формулой
ХХХ^ = vMfi = v.j\cMck \fi =v>j)-
k i j
Значения суммируются по всем категориям ck, всем свойствам f, и всем значениям
свойств Vij. Значение p(fi=Vjj\ck) называется предсказуемостью (predictability). Это
вероятность того, что объект, для которого свойство f{ принимает значение Vy, относится к
категории ск. Чем выше это значение, тем вероятнее, что свойства двух объектов,
отнесенных к одной категории, имеют одинаковые значения. Величина p(ck\f(=vij) называется
предиктивностью (predictiveness). Это вероятность того, что для объектов из категории
ск свойство fj принимает значение v(j. Чем больше эта величина, тем менее вероятно, что
для объектов, не относящихся к данной категории, это свойство будет принимать
указанное значение. Значение p(fi=vtj) — это весовой коэффициент, усиливающий влияние
наиболее распространенных свойств. Благодаря совместному учету этих значений
высокая полезность категории означает высокую вероятность того, что объекты из одной
категории обладают одинаковыми свойствами, и низкую вероятность наличия этих свойств
у объектов из других категорий.
Глава 9. Машинное обучение, основанное на символьном представлении... 421
Категория
Свойство
Хвост
Цвет
Ядро
С2 Р(С2)=1/4
Значение p(vlc)
Один 1.0
Два 0.0
Светлый 1 0
Темный 0 0
Одно 1.0
Два 0 0
Три 0 0
Категория С1 Р(С1)=4/4
Свойство Значение p(vlc)
Хвост
Один
Два
0.50
0.50
Цвет
Светлый 0 50
Темный 0.50
Ядро
Одно 0.25
Два 0.50
Три 0.25
Категория
Р(СЗ)=2/4
Свойство Значение p(vlc)
Хвост
Один
Два
00
1 0
Цвет
Светлый 0.50
Темный 0 50
Категория
Свойство
Хвост
Цвет
Ядро
С4 Р(С4)=1/4
Значение p(vlc)
Один 1 0
Два 0 0
Светлый 0.0
Темный 1 0
Одно 0 0
Два 0 0
Три 1 0
Категория С5 Р(С5)=1/4
Свойство Значение p(vlc)
Хвост Один 0 0
Два 1 0
Цвет Светлый 1.0
Темный 0 0
Ядро Одно 0 0
Два 1 0
Три 0 0
Категория С6 Р(С6)=1/4
Свойство Значение p(vlc)
Хвост Один 0 0
Два 1 0
Цвет Светлый 0 0
Темный 1 0
Ядро Одно 0 0
Два 1.0
Три 0.0
i.V
Рис. 9.21. Кластеризация четырех одноклеточных организмов в системе COBWEB
Алгоритм COBWEB имеет следующий вид.
cobweb (Node, Instance)
Begin
if узел Node — это лист,
then begin
создать два дочерних узла Lx и L2 для узла Node;
задать для узла 1хте же вероятности, что и для узла Node;
инициализировать вероятности для узла L2 соответствующими
значениями объекта Instance;
422
Часть IV. Машинное обучение
добавить Instance к Node, обновив вероятности для узла
Node ;
end
else begin
добавить Instance к Node, обновив вероятности для узла
Node ;
для каждого дочернего узла С узла Node
вычислить полезность категории при отнесении
экземпляра Instance к категории С;
пусть Si — значение полезности для наилучшей
классификации С1;
пусть S2 — значение для второй наилучшей
классификации С2;
пусть S3 — значение полезности для отнесения
экземпляра к новой категории;
пусть S4 — значение для слияния С1 и С2 в одну категорию;
пусть S5 — значение для разделения С1 (замены
дочерними категориями);
end
if Si — наилучшее значение,
then cobweb(Ci, Instance) % отнести экземпляр к Ui
else, if S3 _ наилучшее значение,
then инициализировать вероятности для новой
категории значениями Instance
else, if S4 _ наилучшее значение,
then begin
пусть Ст — результат слияния С± и С2;
cobweb(Cm, Instance)
end
else, if S3 _ наилучший результат,
then Begin
разделить С1;
cobweb(Cm, Instance)
end;
end
В системе COBWEB реализован метод поиска экстремума в пространстве возможных
кластеров с использованием критерия полезности категорий для оценки и выбора
возможных способов категоризации. Сначала вводится единственная категория, свойства
которой совпадают со свойствами первого экземпляра. Для каждого последующего
экземпляра алгоритм начинает свою работу с корневой категории и движется далее по
дереву. На каждом уровне выполняется оценка эффективности категоризации на основе
полезности категории. При этом оцениваются результаты следующих операций.
1. Отнесение экземпляра к наилучшей из существующих категорий.
2. Добавление новой категории, содержащей единственный экземпляр.
3. Слияние двух существующих категорий в одну новую с добавлением в нее этого
экземпляра.
4. Разбиение существующей категории на две и отнесение экземпляра к лучшей из
вновь созданных категорий.
Глава 9. Машинное обучение, основанное на символьном представлении... 423
На рис. 9.22 показаны процессы слияния и разделения узлов. Для слияния двух узлов
создается новый узел, для которого существующие узлы становятся дочерними. На
основе значений вероятностей дочерних узлов вычисляются вероятности для нового узла.
При разбиении один узел заменяется двумя дочерними.
Этот алгоритм достаточно эффективен и выполняет кластеризацию на разумное
число классов. Поскольку в нем используется вероятностное представление
принадлежности, получаемые категории являются гибкими и робастными. Кроме того, в нем
проявляется эффект категорий базового уровня, поддерживается прототипирование и
учитывается степень принадлежности. Он основан не на классической логике, а, подобно методам
теории нечетких множеств, учитывает "неопределенность" категоризации как
необходимый компонент обучения и рассуждений в гибкой и интеллектуальной манере.
Разбиение
Дочерний узел1
Дочерний узел2
Слияние
Рис. 9.22. Слияние и разбиение узлов
В следующем разделе описывается обучение с подкреплением, при котором, подобно
системам классификации из раздела 11.2, для изучения оптимального набора отношений
условие-отклик учитываются обратные связи с внешней средой.
9.7. Обучение с подкреплением
Человек обычно обучается в процессе взаимодействия с окружающим миром. Однако
обратная связь, вызванная действиями человека, не всегда проявляется сразу и в явной
форме. Например, в человеческих взаимоотношениях результаты наших действий
сказываются лишь по прошествии некоторого времени. На примере взаимодействия с миром
всегда можно проследить причинно-следственные связи [Pearl, 2000], а также последова-
424
Часть IV. Машинное обучение
тельности действий, приводящие к реализации сложных целей. Как интеллектуальные
агенты люди вырабатывают политику своей деятельности в окружающем их мире. При
этом "мир" выступает в роли учителя, но его уроки зачастую слабы и трудно усваиваются.
9.7.1. Компоненты обучения с подкреплением
В процессе обучения с подкреплением вырабатывается вычислительный алгоритм
перехода от ситуации к действиям, которые максимизируют вознаграждение. Агенту не
сообщается напрямую, как поступить или какое действие предпринять. Он сам на основе
своего опыта узнает, какие действия приводят к наибольшему вознаграждению.
Действия агента определяются не только сиюминутным результатом, но и последующими
действиями и случайными вознаграждениями. Эти два свойства (метод "проб и ошибок" и
подкрепление с задержкой) являются основными характеристиками обучения с
подкреплением. Следовательно, такое обучение реализует более общую методологию, чем
алгоритмы обучения, описанные выше в этой главе.
Обучение с подкреплением не определяется конкретными методами обучения. Оно
характеризуется действиями объекта в среде и откликом этой среды. Любой метод,
реализующий подобное взаимодействие, относится к обучению с подкреплением. Такое
обучение отличается от обучения с учителем, при котором "учитель" с использованием
примеров напрямую инструктирует или тренирует обучаемую систему. При обучении с
подкреплением агент обучается сам с помощью проб, ошибок и обратной связи. Он
определяет оптимальную политику для достижения цели во внешней среде. (В этом смысле
данный метод напоминает обучение классификации, описанное в разделе И .3.)
При обучении с подкреплением необходимо также учитывать не только
существующие, но и будущие знания. Чтобы оптимизировать возможное вознаграждение, агент не
только должен опираться на свои знания, но и исследовать еще неизведанную им часть
окружающего мира. Такое исследование (возможно) позволит ему сделать лучший
выбор в будущем. Однако очевидно, что одно исследование или его полное отсутствие
дадут плохой результат. Агент должен изучить различные возможности и выбрать
наиболее перспективные. В задачах со стохастическими параметрами для получения
достоверных оценок попытки исследования должны повторяться многократно.
Многие проблемно-ориентированные алгоритмы, описанные ранее в этой книге,
включая алгоритмы планирования, методы принятия решений или алгоритмы поиска,
можно рассматривать в контексте обучения с подкреплением. Например, можно создать
план с помощью телео-реактивного контроллера (раздел 7.4), а затем оценить его на
основе алгоритма обучения с подкреплением. По существу, в алгоритме обучения с
подкреплением DYNA-Q [Sutton, 1990, 1991] модельное обучение объединено с
планированием и действием. Такое обучение с подкреплением обеспечивает метод оценки как
плана, так и модели, а также их полезности для решения задач в сложной среде.
Введем некоторые обозначения из области обучения с подкреплением.
t — дискретный момент времени в процессе решения задачи;
s, — состояние задачи в момент времени f, которое зависит от sM и ам;
а, — действие в момент времени t, зависящее от s,;
г, — вознаграждение в момент времени f, зависящее от sM и ам;
я — политика выполнения действий в зависимости от состояния, т.е. отображение из
пространства состояний в пространство действий;
я — оптимальная политика;
Глава 9. Машинное обучение, основанное на символьном представлении... 425
V— функция ценности, т.е. \Л(э) — это ценность состояния s при использовании
политики я.
В подразделе 9.7.2 при постоянной политике я описан метод временных разностей
(temporal difference learning) для изучения V на основе s.
В обучении с подкреплением участвуют 4 компонента: политика я, функция
вознаграждения г, отображение значений V и, зачастую, модель внешней среды. Политика
определяет выбор обучаемого агента и способ его действия в определенное время. Такая
политика может быть представлена правилами вывода или простой таблицей поиска. Как
уже упоминалось, в конкретной ситуации политика может выступать результатом
расширенного поиска, анализа модели или процесса планирования. Она может быть
стохастической. Политика — это критичный компонент агента обучения, поскольку ее одной
достаточно для определения поведения в заданный момент времени.
Функция вознаграждения (reward function) r, задает отношение состояние-цель для
данной задачи в момент времени г. Она определяет отображение каждого действия, или,
более точно, каждой пары "состояние-отклик", в меру вознаграждения, определяющую
степень эффективности этого действия для достижения цели. В процессе обучения с
подкреплением перед агентом ставится цель максимизации общего вознаграждения,
получаемого в результате решения задачи.
Функция стоимости, или ценности (value function), V— это свойство каждого
состояния среды, определяющее величину вознаграждения, на которое может
рассчитывать система, продолжая действовать из этого состояния. Если функция вознаграждения
определяет сиюминутную эффективность пары "состояние-отклик", то функция
ценности задает долговременную перспективность состояния среды. Значение состояния
определяется как на основе его внутреннего качества, так и на основе качества состояний,
вероятно, последующих за данным, т.е. вознаграждения, получаемого при переходе в эти
состояния. Например, пара "состояние-действие" может приводить к низкому
сиюминутному вознаграждению, но иметь высокую ценность, поскольку за ней обычно
следуют другие состояния с высоким вознаграждением. Низкая ценность соответствует
состояниям, не приводящим к успешному решению задачи.
Без функции вознаграждения нельзя определить значение ценности, которую
необходимо оценить для получения более высокого вознаграждения. Однако в процессе
принятия решений нас в первую очередь интересует ценность, поскольку она определяет
состояния и их комбинации, приводящие к максимальному вознаграждению.
Вознаграждение предоставляется непосредственно внешней средой, а стоимость может многократно
оцениваться со временем на основе успешного и ошибочного опыта. На самом деле,
наиболее критичным и сложным моментом обучения с подкреплением является создание
метода эффективного определения ценности. Один из таких методов — правило
обучения на основе временных разностей — будет продемонстрирован в подразделе 9.7.2.
Последним и необязательным элементом обучения с подкреплением является модель
внешней среды. Модель — это механизм реализации аспектов поведения внешней
среды. Как следует из раздела 7.3, модели можно использовать не только для выявления
сбоев, как в диагностике, но и при определении плана действий. Модели позволяют
оценить результаты возможных действий без их реального выполнения. Планирование на
основе моделей — это современное дополнение к парадигме обучения с подкреплением,
поскольку в ранних системах значения вознаграждения и ценности определялись только
пробными действиями и ошибками агента.
426
Часть IV. Машинное обучение
9.7.2. Пример: снова "крестики-нолики"
Проиллюстрируем алгоритм обучения с подкреплением на примере игры "крестики-
нолики". Этот пример уже рассматривался в главе 4. Он же использован в [Sutton и Barto,
1998] для иллюстрации обучения с подкреплением. Целесообразно сравнить обучение с
подкреплением с другими подходами, например минимаксным, и разграничить их.
Напомним, что "крестики-нолики" — это игра для двух человек, которые по очереди
расставляют свои метки X и О в сетке, размером 3x3 (см. рис. II.V). Побеждает игрок,
первым составивший ряд из трех меток либо по горизонтали, либо по вертикали, либо по
диагонали. Как известно читателю из раздела 4.3, при наличии полной информации о
планах оппонента эта игра всегда завершается вничью. Однако при использовании
обучения с подкреплением можно получить более интересный результат. В этом разделе
будет показано, как можно разгадать планы соперника и выработать политику,
позволяющую максимизировать свое преимущество. Эта политика эволюционирует при
изменении стиля игры соперника и строится на использовании модели.
Во-первых, необходимо создать таблицу, в которой каждому возможному состоянию
игры соответствует одно число. Эти числа, определяющие ценность состояния, отражают
текущую оценку вероятности победы, если игра начинается с этого состояния. Они будут
использованы для выработки стратегии чистой победы, при которой победа соперника или
ничья рассматриваются как поражение. Такой подход позволяет сконцентрироваться на
победе, и этим он отличается от рассмотренной в разделе 4.3 модели, предполагающей 3
возможных исхода: победа, поражение и ничья. Это действительно важное отличие. В
обучении с подкреплением учитывается поведение реального соперника, а не полная
информация о действиях некоего идеализированного оппонента. В таблице значения ценности
нужно проинициализировать следующим образом: 1 — для тех состояний, которые
приводят к победе, 0 — для приводящих к поражению или ничьей и 0,5 — для всех остальных
неизвестных позиций. Это соответствует 50% вероятности победы для этих состояний.
Теперь нужно многократно сыграть в игру с этим противником. Для простоты
предположим, что мы ставим крестики, а наш оппонент — нолики. На рис. 9.23 показана
последовательность ходов — возможных и реализованных. Прежде чем сделать ход,
оцените каждое из возможных состояний, в которое можно перейти из данного состояния.
По таблице определите текущее значение ценности для каждого состояния. Чаще всего
придется делать "жадные" ходы, т.е. выбирать состояния с максимальным значением
функции ценности. Иногда, возможно, потребуется сделать пробный ход и выбрать
следующее состояние случайным образом. Такие пробные ходы позволяют выявить
упущенные альтернативы и расширить пространство оптимизации.
В процессе игры значение функции ценности для каждого выбранного состояния
изменяется, чтобы лучше отразить вероятность принадлежности данного состояния к "победному"
пути. Эта величина ранее была названа функцией вознаграждения для состояния. Для этого
ценность выбранного состояния вычисляется как функция от ценности следующего
выбранного состояния. Как показывают направленные вверх стрелки на рис. 9.23, при таких
возвратах не учитывается ход соперника. Таким образом, ценность предыдущего состояния
уточняется с учетом ценности последующего (и, конечно, победы или поражения). Ценность
предыдущего состояния изменяется на величину разности между значениями ценности двух
последовательных состояний, умноженную на некоторый коэффициент с, получивший
название шагового множителя, или параметра шага (step-size parameter).
V(sn)=V(sn)+c(V(sn^)-V(sn)).
Глава 9. Машинное обучение, основанное на символьном представлении... 427
Мой ход /
Ход соперника
Ход соперника
(ПОБЕДА')
Рис. 9.23. Последовательность ходов при игре в
"крестики-нолики". Пунктирные линии со стрелкой
указывают возможные ходы, сплошные линии со
стрелкой вниз задают выбранные ходы, а линии со
стрелкой вверх определяют вознаграждение при
изменении значения ценности для состояния
В этом соотношении sn представляет состояние, выбранное в момент времени п, а
sn+i — состояние, выбранное в момент п+1. Это уравнение — пример правила обучения
на основе временных разностей (temporal difference learning rule), поскольку изменение
состояния вычисляется как функция от разности значений ценности V(sn+l)-V(sn) для
двух последовательных моментов времени п+1 и п. Такие правила обучения будут
обсуждаться ниже в этой главе.
Для игры в "крестики-нолики" правило временньгх разностей достаточно
эффективно. Со временем целесообразно уменьшить шаговый множитель с, поскольку для более
обученной системы значения ценности должны изменяться меньше. Тогда можно
гарантировать сходимость функции ценности для каждого состояния к значению вероятности
победы при игре с данным соперником. Интересно отметить, что неизменность шагового
множителя приведет к тому, что такая политика никогда не сойдется и будет постоянно
изменяться, отражая изменение (улучшение) стиля игры противника.
Этот пример иллюстрирует много важных свойств обучения с подкреплением. Во-
первых, такое обучение происходит в процессе взаимодействия с внешней средой, в дан-
428
Часть IV. Машинное обучение
ном случае — с соперником. Во-вторых, здесь имеется явная цель (отраженная в
целевых состояниях), и, чтобы ее достичь, необходимо планировать и прогнозировать с
целью обеспечить долгосрочное влияние конкретных ходов. Например, алгоритм обучения
с подкреплением, по существу, строит многоходовые комбинации, которые могут
обмануть неопытного соперника. Важное свойство обучения с подкреплением состоит в том,
что результата планирования и прогнозирования можно достичь, не моделируя явно
поведение соперника и не проводя расширенный поиск.
В рассмотренном примере для обучения не нужны никакие базовые знания, кроме
правил игры. (Просто все состояния, кроме конечных, инициализируются
значением 0,5.) Однако такая "уравниловка" вовсе не обязательна — при обучении с
подкреплением можно учесть и любую реальную информацию о начальных состояниях. Кроме
того, при наличии данных о ситуации для значений состояний можно использовать и
сведения из этой модели. Важно помнить, что обучение с подкреплением применимо в
любом случае, даже при отсутствии модели, однако при наличии модельной информации
ее тоже можно учесть.
В примере игры "крестики-нолики" вознаграждение амортизируется с каждым
следующим шагом. Здесь используется "близорукий" агент, максимизирующий только
сиюминутное вознаграждение. На самом деле, при более пристальном изучении обучения с
подкреплением необходимо учитывать "обесценивание" вознаграждения со временем. Пусть
коэффициент у представляет текущее значение будущего вознаграждения. При получении
вознаграждения на к шагов позже его стоимость снижается в у*-1 раз- Такая мера
"обесценивания" важна для реализации обучения с подкреплением на базе принципа
динамического программирования. Этот подход будет описан в следующем разделе.
"Крестики-нолики" — это пример игры с участием двух соперников. Обучение с
подкреплением можно также применять при отсутствии противника, учитывая только
обратную связь с окружающей средой. Рассмотренный пример характеризуется конечным
(к тому же очень маленьким) пространством состояний. Обучение с подкреплением
можно также применять для очень больших и бесконечных пространств. В последнем
случае ценность состояния определяется только при достижении этого состояния и его
участии в решении. Например, в работе [Tesauro, 1995] упомянутое выше правило
временных разностей встроено в нейронную сеть для обучения игре в нарды. Несмотря на
то что пространство состояний игры в нарды содержит 1020 значений, разработанная
программа играет на уровне лучших специалистов.
9.7.3. Алгоритмы вывода и их применение к обучению
с подкреплением
В работе [Sutton и Barto, 1998] выделены три семейства алгоритмов обучения с
подкреплением на основе вывода: обучение по правилу временных разностей, метод
динамического программирования и метод Монте-Карло. К этим типам сводятся все
современные подходы к обучению с подкреплением. Методы временных разностей основаны
на использовании известных траекторий и пересчете значений ценности состояния на
основе ценности последующего состояния. Пример правила обучения игре в "крестики-
нолики" на основе временных разностей рассмотрен в предыдущем разделе.
Метод динамического программирования предполагает вычисление функции
стоимости предыдущего состояния на основе значения функции стоимости последующего.
Состояния систематически обновляются с учетом модели распределения для последующего
состояния. Обучение с подкреплением методом динамического программирования осно-
Глава 9. Машинное обучение, основанное на символьном представлении... 429
вано на том, что для любой политики к и любого состояния s выполняется следующее
рекурсивное уравнение
Vя (s) = ]>>(a|s) * J>(s -> s'\a) * (Ra(s -> s') + y(V*(s'))),
a s'
где rc(a|s) — вероятность действия а для данного состояния s при использовании
стохастической политики к, 7t(s—>s'| a) — вероятность перехода из состояния s в б'под
действием а. Это выражение называется "уравнением Беллмана для I/71". Оно выражает
соотношение между стоимостью состояния и рекурсивно вычисляемыми значениями
стоимости его последующих состояний. На рис. 9.24, а показан первый этап вычислений,
где для состояния s рассматриваются три возможных последующих состояния. При
использовании политики к вероятность воздействия а составляет n(a\s). Для каждого из
этих трех состояний в результате воздействия окружающей среды может осуществиться
переход в одно из нескольких состояний, скажем, s' с вознаграждением г. В уравнении
Беллмана эти возможности усредняются с учетом вероятности реализации каждой из
них. Согласно этому уравнению стоимость начального состояния s пропорциональна
стоимости всех последующих состояний с коэффициентом у и вознаграждению,
полученному вдоль всего пути.
а) б)
Рис. 9.24. Диаграммы вычисления V*, а) и Q* б) методом
обратного прохода
Классический метод динамического программирования имеет ограниченное
применение, поскольку он предполагает наличие идеальной модели. Если количество
состояний и управляющих воздействий составляют пит соответственно, то метод
динамического программирования позволяет находить оптимальную политику за полиномиальное
время, несмотря на то, что общее число детерминистских политик равно пт. В этом
смысле скорость динамического программирования экспоненциально возрастает по
сравнению с прямыми методами поиска в пространстве политик, поскольку прямые методы для
обеспечения таких же гарантий требуют всесторонней оценки каждой политики.
Метод Монте-Карло не требует наличия полной модели. При использовании этого
метода испытывается каждая траектория изменения состояний, и по результатам таких
испытаний обновляется значение функции стоимости. Для работы метода Монте-Карло
нужен лишь опыт, т.е. последовательность состояний, управляющих воздействий и
вознаграждений, полученная в результате реального взаимодействия с внешней средой или
его моделирования. Реальный эксперимент интересен тем, что он не требует начальных
знаний об окружающей среде, но позволяет получить оптимальный результат. Обучение
на основе модельного эксперимента тоже дает хорошие результаты. При этом нужна мо-
430
Часть IV. Машинное обучение
дель, которая может быть не аналитической, а численной. Она должна просто
генерировать траектории и может не вычислять точные значения вероятностей. Таким образом,
она не должна обеспечивать полное распределение вероятностей всех возможных
переходов, которое требуется в динамическом программировании.
Итак, метод Монте-Карло решает задачу обучения с подкреплением за счет
усреднения результатов экспериментов. Для обеспечения хорошей обусловленности результатов
метод Монте-Карло работает только с полными экспериментами, т.е. все тесты должны в
итоге завершаться. Более того, оценки стоимости и политики изменяются только по
завершении каждого теста. Следовательно, метод Монте-Карло является инкрементальным
в смысле последовательности экспериментов, а не шагов. Термин Монте-Карло
зачастую употребляется в более широком значении для обозначения любого метода
оценивания, в котором важную роль играет случайный компонент. Здесь он используется для
методов, основанных на усреднении результатов экспериментов.
В обучении с подкреплением используются и другие методы, среди которых наиболее
известным является Q-обучение [Watkins, 1989], представляющее собой вариант подхода на
основе временных разностей. Название метода продиктовано следующими соображениям. О —
это функция, отображающая пары состояние-действие в изученные значения стоимости
О: (состояние хвоздействие) -> стоимость
Для одного шага Q-обучения выполняется соотношение
0(sflaf)<-A-c)*0(sflaf) + c*[rf+1+ ^*max 0(sf+1la)-0(sflaf)]f
а
где с<1 и у<1, а гг+| — вознаграждение для состояния s,+1. Метод Q-обучения
проиллюстрирован на рис. 9.24, б. Если на рис. 9.24, а начальный узел представляет состояние, для
которого показаны возможные управляющие воздействия, то в рамках Q-обучения обратный
проход выполняется для пар состояние-управление, поэтому на рис. 9.24, б корневым узлом
является управляющее воздействие вместе с породившим его состоянием.
В Q-обучении обратный проход осуществляется для узлов управления с учетом
вознаграждения и максимума функции О по всем возможным управлениям, вычисленным
для последующего состояния. При полном рекурсивно определенном Q-обучении
нижние узлы дерева являются конечными и достигаются в результате выполнения
последовательности действий с учетом вознаграждения, начиная с корневого узла.
Интерактивное Q-обучение предполагает прямой проход в пространстве возможных
действий и не требует построения полной модели мира. Его также можно выполнять в пакетном
режиме. Легко видеть, что Q-обучение— это разновидность метода временных разностей.
Более подробное описание этого метода приводится в [Watkins, 1989] и [Sutton и Barto, 1998].
С помощью обучения с подкреплением решено большое количество важных задач,
включая обучение игре в нарды [Tesauro, 1994,1995]. В [Sutton и Barto, 1998] с точки зрения
обучения с подкреплением проанализирована программа игры в шашки, описанная в разделе 4.3.
Там же рассмотрены вопросы обучения с подкреплением для управления лифтом,
динамического выделения каналов, составления расписаний и других проблем.
9.8. Резюме и ссылки
Машинное обучение — одна из наиболее привлекательных областей искусственного
интеллекта, призванная решить основную задачу моделирования интеллектуального по-
Глава 9. Машинное обучение, основанное на символьном представлении... 431
ведения. В этой научной области возникает множество вопросов, связанных с
представлением знаний, поиском и даже базовыми положениями самого искусственного
интеллекта. Можно выделить три обзора, посвященных вопросам машинного обучения. Это
работы [Langley, 1995]; [Mitchell, 1997]; [Martin, 1997].
Стоит отметить также более ранние обзоры [Kondratoff и Michalski, 1990]; [Michalski
и др., 1983], [Michalski и др., 1986], а также сборник статей [Shavlik и Dietterich, 1990],
включающий работы, опубликованные, начиная с 1958 года. Поместив все эти
результаты в одну книгу, редакторы сделали очень важное дело как для специалистов в области
искусственного интеллекта, так и для новичков, желающих познакомиться с этой
областью знаний. В [Klahr, 1987] тоже собраны статьи по машинному обучению, включая
работы, относящиеся к более когнитивному подходу.
Работа [Weiss и Kulikowski, 1991] — это вводный обзор по всей области, включая
стохастические, нейросетевые методы и алгоритмы машинного обучения. Читатели,
заинтересованные в получении более глубоких знаний в области рассуждений по аналогии, могут
обратиться к работам [Carbonell, 1983,1986]; [Holyoak, 1985]; [Kedar-Cabelli, 1988]; [Thagard, 1988].
Материал по вопросам создания новых знаний и формирования теорий содержится в [Langley
и др., 1987] и [Shrager и Langley, 1990]. В [Fisher и др., 1991] собраны статьи по
кластеризации, формированию понятий и другим формам обучения без учителя.
В рамках машинного обучения много работ посвящено алгоритму ID3 и его
модификациям. В [Feigenbaum и Feldman, 1963] описан алгоритм запоминания ЕРАМ, в котором
используется специальный вид дерева решений, получивший название дискриминаитной сети
(discrimination net) и позволяющий строить последовательности бессмысленных слогов.
Квинлану (Quinlan) впервые удалось использовать теорию информации для генерирования
дочерних узлов дерева решений. В [Quinlan, 1993] и других работах описаны модификации
алгоритма ЮЗ и решены вопросы обработки зашумленных данных и атрибутов,
принимающих значения из непрерывного интервала [Quinlan, 1996]; [Auer и др., 1995]. В [Stubblefield и
Luger, 1996] алгоритм ЮЗ применяется для улучшения процесса восстановления источника в
задаче рассуждения по аналогии.
Первые примеры обучения с подкреплением приводятся в [Michie, 1961]; [Samuel,
1959]. Большая часть материала этой главы почерпнута из [Sutton и Barto, 1998]. Метод
Q-обучения более подробно описан в диссертации [Watkins, 1989]. Вопросы обучения на
основе временных разностей освещены в [Sutton, 1998], а все алгоритмы обучения с
подкреплением описаны в [Bertsekas и Tsitsiklis, 1996].
Вопросам машинного обучения посвящен журнал "Machine learning". Новые
результаты в этой области ежегодно докладываются на конференциях "International
Conference on Machine Learning", "European Conference on Machine Learning",
"American Association of Artificial Intelligence Conference" и "International Joint
Conference on Artificial Intelligence".
Вопросы обучения на основе связей освещены в главе 10, а социальное обучение и
другие методы — в главе 11. Роль индуктивных порогов и обобщения в обучении
описывается в разделе 16.2.
9.9. Упражнения
1. Вспомните программу изучения понятий Винстона и рассмотрите задачу изучения
понятия "ступенька". Ступенька состоит из расположенных рядом маленького и
432
Часть IV. Машинное обучение
большого блоков (рис. 9.25). Создайте семантическую сеть для представления трех
или четырех положительных и "почти удовлетворительных" примеров и покажите
это понятие в развитии.
Рис. 9.25. Ступенька
2. На рис. 9.9, отражающем работу алгоритма исключения кандидата, не показаны
понятия, которые были сгенерированы, а потом отброшены из-за их чрезмерной
общности или конкретности, либо были "поглощены" другими понятиями. Повторите
процесс, отображая эти понятия и указывая причины их исключения.
3. Реализуйте алгоритм поиска в пространстве версий на языке PROLOG или на любом
другом языке программирования. Если вы выбрали PROLOG, воспользуйтесь
рекомендациями из подраздела 14.14.1.
4. Используя функцию выбора на основе теории информации из подраздела 9.4.3,
покажите, как алгоритм ID3 строит дерево, представленное на рис. 9.14 для данных из
табл. 9.1. Учитывайте приращение информативности для каждого теста.
5. С помощью формулы Шеннона докажите, что информативность сообщения о
результатах вращения рулетки выше, чем информативность сообщения о результате
подбрасывания монеты. Что можно сказать о сообщении "не 00"?
6. В некоторой предметной области составьте таблицу примеров, наподобие
классификации животных по видам, и продемонстрируйте процесс построения дерева
решений с помощью алгоритма ID3.
7. Реализуйте алгоритм ID3 на любом языке программирования и протестируйте эту
программу на данных по кредитной истории, приведенных в этой главе. При
реализации на языке LISP воспользуйтесь алгоритмами и структурами данных,
приведенными в разделе 15.13.
8. Подумайте, какие проблемы возникают при использовании атрибутов, принимающих
значения из непрерывного интервала, например, из множества вещественных чисел.
Предложите свои методы решения этих проблем.
9. Еще одной проблемой для алгоритма ЮЗ являются некачественные или неполные
данные. Данные считаются некачественными, если для одного и того же набора атрибутов
возможны несколько различных результатов. Данные называются неполными, если часть
значений атрибутов отсутствует, возможно, из-за слишком высокой стоимости их
получения. Как решить эти проблемы за счет модификации алгоритма ШЗ?
10. Познакомьтесь с алгоритмом построения дерева решений С4.5 из [Quinlan, 1993] и
протестируйте его на одном из наборов данных. В этой работе приводится полный
текст программы и тестовые наборы данных.
11. Подберите теоретические сведения для обучения на основе объяснения в некоторой
предметной области. Проследите за поведением системы в процессе обучения.
12. Разработайте алгоритм обучения на основе объяснения на любом языке
программирования. Если вы выбрали PROLOG, воспользуйтесь алгоритмом из подраздела 14.14.3.
Глава 9. Машинное обучение, основанное на символьном представлении... 433
13. Вспомните пример игры в "крестики-нолики" из подраздела 9.7.2. Реализуйте
алгоритм обучения на основе временных разностей на любом языке программирования.
Как изменится алгоритм, если принять во внимание симметричность задачи?
14. Что произойдет, если алгоритм на основе временных разностей из задачи 13 будут
использовать оба игрока?
15. Проанализируйте задачу игры в шашки с точки зрения обучения с подкреплением.
Воспользуйтесь при этом результатами анализа из [Sutton и Barto, 1998].
16. Можно ли решить проблему перевернутого маятника, рассмотренную в подразделе 8.2.2
(см. рис. 8.8), с помощью обучения с подкреплением? Разработайте простую функцию
вознаграждения и воспользуйтесь алгоритмом на основе временных разностей.
17. Еще одной тестовой задачей для обучения с подкреплением является так называемая
проблема решетки. На рис. 9.26 показана решетка размером 4x4. Две
заштрихованные ячейки по углам решетки — это целевые конечные состояния агента. Из любой
другой ячейки агент может двигаться вверх, вниз, влево или вправо. Он не может
выйти за пределы решетки: при такой попытке состояние не изменяется.
Вознаграждение для всех ходов, за исключением перехода в конечное состояние, составляет -1.
Постройте решение на основе алгоритма временных разностей, описанного в
подразделе 9.7.2.
г=-1
для любого хода
Рис. 9.26. Пример решетки 4x4 из работы [Sutton и
Barto, 1998]
Действия
434
Часть IV. Машинное обучение
Машинное обучение
на основе связей
Кошка, которая однажды села на горячую печь, никогда больше не
сядет ни на горячую, ни на холодную...
— Марк Твен (Mark Twain)
Все неизвестное остается неясным до тех пор, пока не пытаешься
его уточнить...
— Бертран Рассел (Bertrand Russell)
...как будто волшебный фонарик освещает изнутри образы на экране...
— Т. С. Элиот (T.S. Eliot), Песнь любви Альфреда Прафрока
10.0. Введение
В главе 9 основное внимание уделялось символьному подходу к обучению.
Центральной идеей такого подхода является использование символов для обозначения
объектов и отношений между ними в некоторой предметной области. В этой главе будут
рассмотрены нейроподобные, или биологические, подходы к обучению.
Нейроподобные модели, известные также как системы параллельной распределенной
обработки или системы связей, не предполагают явного использования символьного
представления в задаче обучения. Интеллектуальные свойства этих систем
обеспечиваются взаимодействием простых компонентов (биологических или искусственных
нейронов) и настройкой связей между ними в процессе обучения или адаптации. Нейроны
организованы в несколько слоев, поэтому такие системы являются распределенными.
Информация обрабатывается параллельно, т.е. все нейроны одного слоя одновременно и
независимо друг от друга получают и преобразуют входные данные.
Однако в нейросетевых моделях символьное представление играет важную роль при
формировании входных векторов и интерпретации выходных значений. Например, для
создания нейронной сети разработчик должен определить схему кодирования образов
для их передачи в нейронную сеть. Выбор схемы кодирования может сыграть ключевую
роль для способности (или неспособности) сети к обучению.
Сети связей выполняют параллельную и распределенную обработку информации,
однако при этом символы не рассматриваются как символы. Входная информация из пред-
метной области преобразуется в числовые векторы. Связи между элементами или
нейронами тоже представляются числовыми значениями. И, наконец, преобразование
образов — это результат числовых операций, как правило, векторно-матричного умножения.
Выбранная архитектура сети составляет индуктивный порог системы.
Алгоритмы и архитектуры, реализующие этот подход, не предполагают явного
программирования. Они просто выбираются для обучения сети. В этом и состоит основное
преимущество такого подхода: инвариантные свойства входной информации выявляются
за счет выбора соответствующей архитектуры и метода обучения. При этом могут
появляться "странные" аттракторы. Но явное программирование здесь не требуется. Именно
таким системам посвящена данная глава.
Сети связей лучше всего подходят для решения следующих задач.
• Классификация — определение категории или группы, к которой принадлежат
входные значения.
• Распознавание образов — идентификация структуры или шаблона данных.
• Реализация памяти, в том числе задача контекстной адресации памяти.
• Прогнозирование, например, диагностика болезни по ее симптомам, определение
следствий на основе известных причин.
• Оптимизация — поиск наилучшей структуры ограничений.
• Фильтрация — выделение полезного сигнала из фонового шума, отбрасывание
несущественных компонентов сигнала.
Описанные в этой главе методы лучше всего подходят для решения задач, которые
трудно описать символьными моделями. К ним обычно относятся задачи, предметная
область которых требует осознания либо плохо формализуется с помощью явно
определенного синтаксиса.
В разделе 10.1 рассматривается история развития нейроподобных моделей. Здесь
представлены основные компоненты, необходимые для обучения нейронной сети,
включая "механический" нейрон, а также описаны некоторые исторически значимые ранние
результаты в этой области, в том числе нейрон Мак-Каллока-Питтса (McCulloch-Pitts),
разработанный в 1943 году. Развитие этих нейросетевых парадигм в течение последних
40 лет во многом обусловило современное состояние проблемы машинного обучения.
В разделе 10.2 в историческом контексте представлено правило обучения персептро-
на (perceptron), или дельта-правило (delta rule). Рассматривается пример, в котором пер-
септрон выступает в роли классификатора. В разделе 10.3 вводятся сети со скрытыми
слоями и освещается алгоритм обучения на основе обратного распространения ошибки
(backpropagation). Такие архитектуры позволили преодолеть проблему линейной
разделимости, присущую ранним нейросетевым моделям. Алгоритм обратного
распространения состоит в компенсации ошибки на тех узлах многослойной сети с непрерывными
пороговыми функциями, которые дают некорректный результат.
В разделе 10.4 представлены модели Кохонена [Kohonen, 1984] и Хехта-Нильсена
[Hecht-Nielsen, 1987] и конкурентные методы (competitive learning) их обучения. В этих
моделях векторы весовых коэффициентов используются для представления самих
образов, а не мощности связей. Алгоритм обучения "победитель забирает все" (winner-takes-
all) выбирает узел, образ которого (вектор весовых коэффициентов) наиболее точно
соответствует входному вектору, и настраивает эти коэффициенты для обеспечения еще
более точного соответствия. Это алгоритм обучения без учителя, поскольку нейрон-
436
Часть IV. Машинное обучение
победитель— это просто нейрон, вектор весовых коэффициентов которого наиболее
близок входному вектору. Комбинация слоев нейронов Кохонена и Гроссберга приводит
к созданию сети, которая может служить интересной моделью для обучения по методу
встречного распространения.
В разделе 10.5 представлена модель обучения с подкреплением Хебба [Hebb, 1949].
Хебб высказал предположение о том, что при каждом возбуждении нейрона вследствие
передачи ему импульса от другого нейрона сила связи между этими нейронами
возрастает. Алгоритм обучения Хебба— это простой алгоритм настройки весов связей. Будут
представлены версии этого алгоритма для обучения с учителем и без учителя, а также
линейная ассоциативная память (linear associator), основанная на модели Хебба.
В разделе 10.6 вводится очень важный тип нейроподобных моделей, получивших
название аттракторных сетей (attractor network). В этих сетях для циклической передачи
сигналов используются обратные связи. Выходом сети является ее состояние в
положении равновесия. В процессе настройки весов связей формируется множество
аттракторов. При подаче на вход сети образов, относящихся к зоне притяжения аттрактора, сеть
сходится к состоянию равновесия, соответствующему данному аттрактору.
Следовательно, аттракторы можно использовать для хранения образов в памяти. Тогда, имея входной
образ, можно получить либо ближайший из сохраненных образов либо ассоциированный
с ним. Первый тип сети называется автоассоциативной (autoassociative memory), а
второй— гетероассоциативной памятью (heteroassociative memory). В 1982 году физик-
теоретик Джон Хопфилд (John Hopfield) разработал класс аттракторных сетей,
доказательство сходимости которых сводится к минимизации функции энергии. Сети Хопфил-
да можно использовать для решения задач оптимизации при наличии ограничений, в
частности задачи коммивояжера. При этом критерий оптимизации записывается как
функция энергии системы (подраздел 10.6.4).
В главе 11, заключительной главе части IV, представлены эволюционные модели
обучения, в том числе генетические алгоритмы и модели "искусственной жизни".
Вопросы представления информации и порогов в обучении, а также преимущества каждой из
парадигм рассматриваются в разделе 16.3.
10.1. Основы теории сетей связей
10.1.1. Ранняя история
Зачастую теорию нейронных сетей считают очень современной наукой, однако ее
истоки относятся к периоду ранних работ в области компьютерных наук, психологии и
философии. Например, еще Джон фон Нейман пришел в восторг от теории клеточных автоматов и
нейроподобного подхода к вычислениям. Первые работы в области нейросетевого
обучения выполнялись под влиянием психологической теории обучения животных [Hebb, 1949].
В этом разделе будут описаны основные компоненты нейронных сетей и методы их
обучения, а также представлены исторически важные ранние работы в этой области.
Основой нейронных сетей является искусственный нейрон, схема которого показана
на рис. 10.1. Искусственный нейрон имеет следующую структуру.
• Входные сигналы х,. Это данные, поступающие из окружающей среды или от
других активных нейронов. Диапазон входных значений для различных моделей
может отличаться. Обычно входные значения являются дискретными (бинарными)
Глава 10. Машинное обучение на основе связей
437
и определяются множествами {0,1} или {-1,1} либо принимают любые
вещественные значения.
Рис. 10 1. Искусственный нейрон, входной вектор X,
вес связей W, и пороговая функция f, определяющая
выходное значение нейрона Сравните эту схему с
изображением реального нейрона, приведенным на рис. 1.2
• Набор вещественных весовых коэффициентов w,. Весовые коэффициенты
определяют силу связи между нейронами.
• Уровень активации нейрона Zvv^,, который определяется взвешенной суммой
его входных сигналов.
• Пороговая функция f, предназначенная для вычисления выходного значения
нейрона путем сравнения уровня активации с некоторым порогом. Пороговая
функция определяет активное или неактивное состояние нейрона.
Помимо этих свойств отдельных нейронов, нейронная сеть также характеризуется
следующими глобальными свойствами.
• Топология сети (network topology) — это шаблон, определяющий наличие связей
между отдельными нейронами. Топология является главным источником
индуктивного порога.
• Используемый алгоритм обучения (learning algorithm). В этой главе
представлены различные алгоритмы обучения.
• Схема кодирования (encoding scheme), определяющая интерпретацию данных в
сети и результатов их обработки.
Первым примером нейросетевой модели является нейрон Мак-Каллока-Питтса
[McCulloch и Pitts, 1943]. На вход нейрона подаются биполярные сигналы (равные +1
или -1). Активационная функция — это пороговая зависимость, результат которой
вычисляется следующим образом. Если взвешенная сумма входов не меньше нуля, выход
нейрона принимается равным 1, в противном случае 1. В своей работе Мак-Каллок
и Питтс показали, как на основе таких нейронов можно построить любую логическую
функцию. Следовательно, система из таких нейронов обеспечивает полную
вычислительную модель.
На рис. 10.2 показан пример вычисления логических функций И и ИЛИ с помощью
нейронов Мак-Каллока-Питтса. Каждый из этих нейронов имеет три входа, первые два
из которых задают аргументы функции х и у, а третий, иногда называемый пороговым
(bias), всегда равен 1. Весовые коэффициенты связей для входных нейронов составляют
соответственно +1, +1 и -2. Тогда для любых входных значений х и у нейрон
вычисляет значение х+у-2. Если это значение меньше 0, выходным значением нейрона является
438
Часть IV. Машинное обучение
-1, в противном случае— 1. Из табл. 10.1 видно, что такой нейрон, по существу,
вычисляет значение функции хлу. Аналогично можно удостовериться в том, что второй
нейрон на рис. 10.2 вычисляет значение логической функции ИЛИ.
X +1
_У +1_
1 -2
Рис. 10.2. Вычисление логических функций И и ИЛИ с
помощью нейронов Мак-Каллока-Питтса
Таблица 10.1. Модель Мак-Каллока-Питтса для вычисления функции
логического И
X
1
1
0
0
У
1
0
1
0
х+у-
0
-1
-1
-2
-2
ВЫХОД
1
-1
-1
-1
Несмотря на то что Мак-Каллок и Питтс продемонстрировали возможности нейросетевых
вычислений, реальный интерес к этой области проявился только после разработки
применимых на практике алгоритмов обучения. Первые модели обучения во многом связаны с
работами специалиста по психологии Д. О. Хебба (D. О. Hebb), который в 1949 году предположил,
что обучение биологических существ связано с модификацией синапсов в мозгу. Он показал,
что многократное возбуждение синапса приводит к повышению его чувствительности и
вероятности его возбуждения в будущем. Если некоторый стимул многократно приводит к
активизации группы клеток, то между этими клетками возникает сильная ассоциативная связь.
Поэтому в будущем подобный стимул приведет к возбуждению тех же связей между
нейронами, что в свою очередь обеспечит распознавание стимула (более точно утверждение Хебба
приводится в подразделе 10.5.1). Модель обучения Хебба основана только на идее
подкрепления и не учитывает забывчивость, штрафы за ошибки или износ. Современные психологи
пытались реализовать модель Хебба, но не смогли получить достаточно общих результатов
без добавления механизма забывчивости [Rochester и др., 1988], [Quinlan, 1991]. Модель
обучения Хебба более подробно будет рассмотрена в разделе 10.5.
В следующем разделе модель нейрона Мак-Каллока-Хебба расширена за счет
формирования слоев взаимосвязанных нейронов и добавления алгоритмов их взаимодействия. Первая
версия такой нейроподобной структуры получила название nepcenmpona (perceptron).
10.2. Обучение персептрона
10.2.1. Алгоритм обучения персептрона
Фрэнк Розенблатт [Rosenblatt, 1958] предложил алгоритм обучения для одного типа
однослойной нейронной сети, получившей название персептрона (perseptron). По
способу распространения сигналов персептрон аналогичен нейрону Мак-Каллока-Хебба, при-
Глава 10. Машинное обучение на основе связей
439
мер которого будет описан в подразделе 10.2.2. Входные значения персептрона являются
биполярными (равны -1 или 1), а вес — вещественным числом. Уровень активации
персептрона вычисляется как взвешенная сумма его входов, Sx,w,-. Выходное значение
персептрона вычисляется с помощью строгой пороговой функции: если уровень активации
превышает или равен пороговому значению, выход персептрона принимается равным 1,
в противном случае 1. Таким образом, выходное значение персептрона вычисляется
на основе его входных значений х„ весовых коэффициентов w, и порога t следующим
образом.
1, если 1х(ил > t,
-1, если £x(w( < f.
Для настройки весов персептрона используется простой алгоритм обучения с
учителем. Персептрон пытается решить предлагаемую задачу, после чего ему
предъявляется корректный результат. Затем веса персептрона изменяются таким
образом, чтобы уменьшить ошибку на его выходе. При этом используется следующее
правило. Пусть с— постоянный коэффициент скорости обучения, ad— ожидаемое
значение выхода. Настройка весового коэффициента для /-го компонента входного
вектора выполняется по формуле
Avv=c(d-sign(Ix(w()) xr
Здесь sign(Sx,w,-) — выходное значение персептрона, равное +1 или -1. Разность
между желаемым и реальным выходными значениями может быть равна 0, 2 или - 2.
Следовательно, для каждого компонента входного вектора выполняются такие действия.
Если значения желаемого и реального выхода совпадают, ничего не происходит.
Если реальное выходное значение равно -1, а желаемое — 1, то весовой
коэффициент для /-го входа увеличивается на 2 сх,.
Если реальное выходное значение равно -1, а желаемое — 1, то весовой
коэффициент для /-го входа уменьшается на 2сх,.
При использовании такой процедуры получается вес, минимизирующий среднюю
ошибку на всем обучающем множестве. Если существует набор весовых
коэффициентов, обеспечивающий корректное выходное значение для каждого элемента
обучающего множества, то такая процедура обучения персептрона позволяет его получить
[Minsky и Papert, 1969].
Первоначально появление персептрона было встречено с большим энтузиазмом.
Однако в 1965 году Нильс Нильсон (Nils Nilsson) и другие исследователи выявили
ограниченность модели персептрона. Они показали, что персептрон не решает целого
класса достаточно сложных задач, в которых данные не являются линейно
разделимыми. И хотя впоследствии появились различные усовершенствования модели
персептрона, в том числе многослойные персептроны, Минский и Пейперт в своей книге
"Perceptions" доказали, что с помощью персептрона нельзя решить проблему
линейной разделимости [Minsky и Papert, 1969].
Классическим примером задачи классификации, данные которой не обладают
свойством линейной разделимости, является проблема "исключающего ИЛИ" (табл. 10.2).
Функцию "исключающего ИЛИ" можно представить с помощью следующей таблицы
истинности.
440
Часть IV. Машинное обучение
Таблица 10.2. Таблица истинности для функции "исключающее ИЛИ"
х, х2 Выход
1 1 О
1 0 1
О 1 1
о о о
Рассмотрим персептрон с двумя входами Xi и х2, двумя весовыми коэффициентами W\
и vv2 и пороговым значением t. Для реализации этой функции сеть должна настроить
весовые коэффициенты таким образом, чтобы выполнялись следующие неравенства
(рис. 10.3).
w/l+w^Kf (из первой строки таблицы истинности),
vv/1+O > t (из второй строки таблицы истинности),
0+w2*1 > г (из первой строки таблицы истинности),
0+0 < t (т.е. положительный порог, из последней строки
таблицы истинности).
Эта система неравенств для W\ и w2 и г не имеет решения. Тем самым
подтверждается, что персептрон не может решить проблему "исключающего ИЛИ". Несмотря на то
что существуют многослойные сети, способные решить эту проблему (см.
подраздел 10.3.3), алгоритм обучения персептрона предназначен только для обучения
однослойных сетей.
Невозможность решения задачи "исключающего ИЛИ" для персептрона объясняется тем,
что два класса, которые должна различать сеть, не являются линейно разделимыми (рис. 10.3).
В двухмерном пространстве невозможно провести прямую, разделяющую множества точек с
координатами {@,0), A,1)} и {A,0), @,1)}.
Можно считать, что входные данные сети определяют
пространство. Каждый компонент входного вектора определяет на- *11
правление, а каждое входное значение задает точку в этом про- 0(°-
странстве. В задаче "исключающего ИЛИ" четыре входных
вектора с координатами хх и х2 определяют точки, показанные на
рис. 10.3. Задача обучения классификации сводится к
разделению этих точек на две группы. В п-мерном пространстве
множество является линейно разделимым, если его можно разбить на рис jq j Задача
классы с помощью п-мерной гиперплоскости. (В двухмерном "исключающего ИЛИ".
пространстве п-мерной гиперплоскостью является прямая, в В двухмерном про-
трехмерном — плоскость и т.д.) странстве нельзя про-
В результате выявления проблемы линейной разделимости вести прямую, разде-
направление исследований сместилось в сторону архитектур, ос- ляюи4Ую пары точек
нованных на символьном представлении, а прогресс в области ^0,1), A,0)} и
нейросетевой методологии значительно замедлился. Однако " ' '' * ' "
дальнейшие исследования в 1970-х и 1980-х годах показали, что
эта проблема является разрешимой.
В разделе 10.3 будет описан метод обучения по правилу обратного распространения,
который является обобщением алгоритма обучения персептрона для многослойных
сетей. Однако прежде чем переходить к изучению этого метода, рассмотрим пример сети
персептронного типа, выполняющей классификацию образов. В завершение раздела 10.2
будет изложено обобщенное дельта-правило (generalized delta-rule) — обобщение алго-
@,0) A,0)
°-*2
Глава 10. Машинное обучение на основе связей
441
ритма обучения персептрона, используемое в многочисленных нейросетевых
архитектурах, в том числе основанных на методе обратного распространения.
10.2.2. Пример: использование персептронной сети
для классификации образов
На рис. 10.4 показана общая схема решения задачи классификации. Строки данных из
пространства возможных точек выбираются и преобразуются к новому виду в
пространстве данных и соответствующих им образов. В этом новом пространстве образов
выделяются признаки и определяются сущности, представляемые ими. Например,
рассмотрим задачу со звуковыми сигналами, записанными на цифровом устройстве. Эти
акустические сигналы трансформируются в амплитудно-частотное представление, а затем
система классификации по этим признакам может распознать, кому принадлежит данный
голос. Еще одним примером задачи классификации является медицинская диагностика,
предполагающая сбор информации с помощью медицинского диагностического
оборудования и классификацию симптомов по различным категориям болезней.
Для рассматриваемого примера в блоке преобразователя и извлечения признаков
на рис. 10.4 данные из предметной области задачи трансформируются в двухмерные
векторы декартова пространства. На рис. 10.5 показаны результаты анализа
информации, приведенной в табл. 10.3, с помощью персептрона с двумя входами. В
первых двух столбцах таблицы содержатся векторы данных, используемые для
обучения сети. В третьем столбце представлены ожидаемые результаты классификации,
+ 1 или -1, используемые для обучения сети. На рис. 10.5 показаны обучающие
данные и линия разделения классов данных, полученных после предъявления обученной
сети каждого входного образа.
Строки данных
Пространство
строк данных
Преобразователь
*2"
Данные
Пространство
образов
•
1 Модуль
извлечения
| признаков
Признаки
Пространство
признаков
Классификатор
•
*
faiacci
Класс,,
Класс
Признаки
Рис. 10.4. Полная система классификации
Сначала познакомимся с общей теорией классификации. Каждая группа данных,
выявленная классификатором, может быть представлена некоторой областью в
многомерном пространстве. Каждому классу Я, соответствует дискриминантная функция д„
определяющая степень принадлежности этой области. Среди всех дискриминантных функций
для области Ri максимальное значение имеет функция д,:
9iW>9jM для всех/, "\<]<п.
В простом примере из табл. 10.3 двухмерные входные векторы делятся на два класса,
первому из которых соответствует значение 1, а второму 1.
442
Часть IV. Машинное обучение
100
*2 5.0
10.0
Рис. 10 5 Данные из табл. 10.3 в
двухмерном пространстве. Персептрон,
описанный в подразделе 10.2.1, обеспечивает
линейное разделение этого набора данных
Таблица 10.3. Набор обучающих данных для классификации с помощью
персептрона
Выход
1,0
9,4
2,5
8,0
0,5
7,9
7,0
2,8
1,2
7,8
1,0
6,4
2,1
7,7
2,2
8,4
7,0
0,8
3,0
6,1
1
-1
1
-1
1
-1
-1
1
1
-1
Важным частным случаем дискриминантной функции является оценка степени
принадлежности на основе расстояния от некоторой центральной точки области.
Классификация, основанная на такой дискриминантной функции, называется классификацией по
минимальному расстоянию. Легко показать, что такую классификацию можно
реализовать для линейно разделимых классов.
Если области Я, и Я, являются смежными, как две области на рис. 10.5, то существует
пограничная область, для которой дискриминантная функция имеет вид
gr,(x)-gr;(x) или gr,(x)-gry(x)=0.
Если классы линейно разделимы, как на рис. 10.5, то дискриминантная функция,
разделяющая соответствующие области, представляет собой прямую линию, т.е. функции gr,
и gj являются линейными. Поскольку прямая — это множество точек, равноудаленных
от двух фиксированных точек, то дискриминантные функции gf, и д, — это функции
минимального расстояния от декартового центра каждой из областей.
Глава 10. Машинное обучение на основе связей
443
Линейную разделяющую функцию можно вычислить с помощью персептрона,
показанного на рис. 10.6 и содержащего два обычных входа и пороговый вход с постоянным
значением 1. Персептрон выполняет вычисление по следующей формуле
f(ne0=f(w1*x1+w2*x2+w3*1), где f(x)=sign(x).
Если f(x) = +1, то х принадлежит одному классу, если f(x) = -1 — другому. Такое
преобразование называется кусочно-линейной биполярной пороговой функцией (рис. 10.7, а).
Пороговый вход служит для смещения пороговой функции вдоль вертикальной оси. Величина
этого смещения определяется в процессе обучения с помощью настройки весового
коэффициента w3.
Используем данные из табл. 10.3 для обучения персептрона, показанного на рис. 10.6.
Инициализируем значения веса случайным образом, например [0,75, 0,5, -0,6], и
применим алгоритм обучения персептрона, описанный в подразделе 10.2.1. Верхний
индекс переменной, в частности 1 в выражении f (net) \ задает номер текущей итерации
алгоритма. Обработка данных начинается с первой строки таблицы
f(nefI=f@,75*1+0,5* 1-0,6* 1 )=f@,65)=1.
Поскольку значение f(nefI=l корректно, настройка весовых коэффициентов не
нужна. Следовательно, W2=Wl. Для второго обучающего примера
f(ne02=f@,75*9,4+0,5*6,4-0,6*1)=f(9,65)=1.
*i
порог
Рис. 10 6. Персептрон для классификации
данных из табл 10 3 с кусочно-линейной
биполярной пороговой функцией
Для данного обучающего примера на выходе персептрона ожидается значение -1,
значит, для настройки весов необходимо применить обучающее правило, описанное в
подразделе 10.2.1,
H/f=H/f-1+c*(df-sign((H/f)T*Xf1))Xf,
где с — постоянный коэффициент обучения, X и W — векторы входов и весовых
коэффициентов, t — номер итерации обучения, Т — символ транспонирования, dr_1 —
ожидаемый результат в момент времени t-1 (или, как в данном случае, в момент времени
t=2). Выход сети при t=2 равен 1, следовательно, разность между ожидаемым и
реальным выходом сети составляет d2-sign((W2)T)*X2) = -2. На самом деле для биполярного
персептрона инкремент обучения всегда составляет либо + 2сХ либо -2сХ, где X—
вектор из обучающего множества. Коэффициент скорости обучения — это небольшое
вещественное число, наподобие 0,2. Обновим вектор весовых коэффициентов:
" 0,75 "
0,50
-0,60
-0,4
[9,41
6,4
_1-°_
=
-3,01"
-2,06
-1,00
444
Часть IV. Машинное обучение
Теперь нужно вычислить выходное значение сети для третьего обучающего примера
с учетом настроенных весов
f(nefK=f(-3,01*2,5-2,06*2,1-1,0*1)=f(-12,84)=-1.
Это значение снова не совпадает с ожидаемым выходом. На следующей итерации
веса l/И обновляются таким образом
"-3,01"
-2,06
-1,00
+ 0,4
[2,51
2,1
.1°_
=
"-2,01"
-1,22
-0,60
После десяти итераций обучения сети персептрона формируется линейное
разделение, показанное на рис. 10.5. Примерно через 500 шагов обучения вектор весовых
коэффициентов будет равен [-1,3; -1,1; 10,9]. Нас интересует линейное разделение двух
классов. В терминах дискриминантных функций д, и gry разделяющая поверхность
представляет собой множество точек, для которых gf,(x)= gry(x) или gf,(x) - gry(x) = 0, т.е.
уровень активации равен 0. Уравнение функционирования сети можно записать в
терминах весов
net=w,x]+w2x2+w3.
Следовательно, линейная разделяющая поверхность между двумя классами
определяется линейным уравнением
-^tЗ*x,+(-^l^)*x2+^0t9=0.
10.2.3. Обобщенное дельта-правило
Для обобщения идеи сети персептрона нужно заменить его строгую пороговую
функцию активационной функцией другого типа. Например, непрерывные активационные
функции позволяют строить более тонкие алгоритмы обучения за счет более точного
вычисления ошибки измерения.
На рис. 10.7 показаны графики некоторых пороговых функций: кусочно-линейной
биполярной пороговой функции (рис. 10.7, я), используемой для персептрона, и
нескольких видов сигмоидальных функций (sigmoid). Сигмоидальные функции получили такое
название благодаря тому, что их график напоминает латинскую букву "S" (рис. 10.7, б).
Типичная сигмоидальная активационная функция, или логистическая функция (logistic
function), задается уравнением
f(nef)=1/A+e"x,"ef), где nef=Zx,w,.
Здесь, как и ранее, х, — /-и вход, wt — вес связи, X — параметр "кривизны",
используемый для настройки формы сигмоидальной кривой. При больших значениях А форма
сигмоиды приближается к обычной кусочно-линейной пороговой функции с диапазоном
значений {0,1}, а при значениях параметра "кривизны", близких к 1, она напоминает
прямую линию.
Аргументом пороговой функции является уровень активации нейрона, а ее
значением — выход нейрона. Сигмоидальная активационная функция непрерывна, что позволяет
точнее оценить ошибку на выходе сети. Подобно обычной пороговой функции,
сигмоидальная активационная функция отображает точки области определения в значения из
интервала @,1). Однако в отличие от обычной пороговой функции сигмоида может
Глава 10. Машинное обучение на основе связей
445
принимать значения из всего интервала, т.е. она обеспечивает непрерывную
аппроксимацию классической пороговой функции. Параметр А определяет "крутизну" перехода.
Взвешенное значение порога сдвигает график функции вдоль оси абсцисс.
flx)
flx)
1
f(x)
1
Большое л
Малое А
х
а. Строгая кусочно-
линейная биполярная
пороговая функция
б. Сигмоидальная
униполярная
пороговая функция
в. Сигмоидальная сдвинутая функция
с различной "кривизной". Чем
больше значение параметра,
тем точнее сигмоидальная аппроксимация
кусочно-линейной пороговой функции
Рис. 10.7. Активационные функции
Появление сетей с непрерывными активационными функциями исторически
обусловило новые подходы к обучению на основе коррекции ошибки. Так, обучающее правило
Видроу-Хоффа [Widrow и Hoff, 1960] предполагает минимизацию среднеквадратиче-
ской ошибки между ожидаемым выходным значением и уровнем активации сети
neti=WXi, независимо от вида активационной функции. Но самым важным правилом
обучения для сетей с непрерывной активационной функцией является, пожалуй, дельта-
правило (delta-rule) [Rumelhart и др., 1986, а].
Интуитивно дельта-правило базируется на использовании понятия поверхности
ошибки (рис. 10.8), которая представляет кумулятивную ошибку на всем наборе данных
как функцию от весов сети. Каждая возможная конфигурация весов определяет точку
поверхности ошибки. Имея определенную конфигурацию весов, с помощью алгоритма
обучения можно найти направление на этой поверхности, вдоль которого происходит
наиболее быстрое уменьшение функции ошибки. Этот подход называется обучением по
методу градиентного спуска (gradient descent learning), поскольку градиент определяет
"наклон" поверхности в каждой ее точке.
Старое значение W
Новое значение W
Локальный минимум
Поверхность ошибки
W
Рис. 10.8. Двухмерная поверхность ошибки. Константа с
определяет размер шага обучения
446
Часть IV. Машинное обучение
Дельта-правило предполагает использование непрерывной и дифференцируемой
активационной функции. Этими свойствами обладает рассмотренная выше
логистическая функция. Дельта-правило для настройки у'-го весового коэффициента /-го узла
сети имеет вид
с(с(,-0,)Г(леГ,)х,,
где с — постоянный коэффициент скорости обучения, d, и О, — ожидаемый и реальный
выходы /-го нейрона, f' — производная активационной функции /-го узла, а ху — у'-ое
входное значение /-го узла. Покажем, как выводится эта формула.
Среднеквадратическая ошибка на выходе сети пропорциональна сумме квадратов
ошибок для каждого узла
Еггог = A/2)Х(с(/-0/.J ,
где di — ожидаемое значение выхода нейрона, а О, — его реальное значение. При
суммировании ошибки возводятся в квадрат, чтобы отрицательные и положительные
ошибки не компенсировали друг друга.
Рассмотрим случай, когда сеть состоит из единственного (выходного) слоя
нейронов. Более общий случай наличия скрытых слоев будет описан в разделе 10.3. Сначала
необходимо определить скорость изменения ошибки на каждом из выходных нейронов
сети. Для этого нужно взять частную производную (partial derivative), определяющую
скорость изменения векторной функции по одной из переменных. Частная
производная общей ошибки для каждого /-го нейрона выходного слоя составляет
dError a(i/2rI(d,-o,f 3A/2r(d;_Q[f
Такое упрощение возможно, поскольку рассматриваемая сеть содержит лишь один
выходной слой нейронов, а значит, ошибка на выходе одного из узлов не влияет ни на
какие другие нейроны. Вычисляя производную, получим
Определим скорость изменения ошибки для каждого из весовых коэффициентов wk
для /-го узла. С этой целью вычислим частную производную функции ошибки для
каждого из узлов по весовым коэффициентам связей wk, ведущих к этому узлу,
dError _ dError „ ЭО,
dwk dOi dwk '
Учитывая предыдущее соотношение, получим
dWk dwk
Рассмотрим правую часть этого выражения, где вычисляется частная
производная реального выхода /-го нейрона по весовым коэффициентам связей, ведущих к
нему. Выходное значение нейрона выражается через весовые коэффициенты
следующим образом:
0=f(l/l/X,), где WX=netr
Глава 10. Машинное обучение на основе связей
447
Поскольку f — непрерывная функция, можно вычислить ее производную
^ = xk*f'(W,Xl) = f'(netl)*xk.
Подставляя это соотношение в предыдущее уравнение, получим
дЕггог
Эил,
- = -(di-OiVf\netiyxk.
Для минимизации ошибки необходимо изменить значение веса в направлении
антиградиента. Следовательно,
Awk=-c^^ = -c[-(di-Oi)*f\neti)*xk] = c(di-Oi)*f\netl)*xk.
dwk
Несложно заметить, что дельта-правило напоминает метод вычисления экстремума,
описанный в разделе 4.1. Там он применялся для минимизации локальной ошибки на
каждом этапе. Этот метод состоит в поиске наклона поверхности ошибки в окрестности
некоторой точки. Такое свойство приводит к неустойчивости дельта-правила, поскольку
с его помощью нельзя отличить локальный минимум от глобального.
Существенное влияние на эффективность дельта-правила оказывает коэффициент
скорости обучения с (см. рис. 10.8). Значение этого коэффициента определяет
величину изменения весов на каждом шаге обучения. Чем больше с, тем быстрее вес
приходит к оптимальному значению. Однако если коэффициент с слишком велик,
алгоритм может "проскочить" точку экстремума или осциллировать в окрестности
этой точки. Небольшие значения коэффициента скорости обучения позволяют
устранить эту проблему, но замедляют процесс обучения. Оптимальное значение этого
коэффициента иногда определяется с учетом фактора момента [Zurada, 1992] —
параметра, настраиваемого экспериментально для каждого конкретного приложения.
Хотя дельта-правило обеспечивает возможность обучения только однослойных
сетей, его обобщение приводит к методу обратного распространения ошибки —
алгоритму обучения многослойных сетей. Этот алгоритм рассматривается в
следующем разделе.
10.3. Обучение по методу обратного распространения
10.3.1. Вывод алгоритма обратного распространения
Из предыдущего раздела ясно, что однослойные сети персептронного типа обладают
ограниченными возможностями классификации. В разделах 10.3 и 10.4 будет показано,
что добавление нескольких слоев позволяет снять эти ограничения. В разделе 16.3
рассмотрены вычислительно полные многослойные нейронные сети, эквивалентные классу
машин Тьюринга. Однако для таких сетей долгое время не существовало эффективного
алгоритма обучения. В этом разделе описывается обобщенное дельта-правило,
обеспечивающее решение этой проблемы.
Нейроны в многослойной сети располагаются по слоям (рис. 10.9), причем элементы
слоя л связаны только с узлами слоя л+ 1. При многослойной обработке сигнала ошибка
на выходе сети может быть вызвана сложными процессами внутри нее. Поэтому источ-
448
Часть IV. Машинное обучение
ник ошибки в выходном слое сети необходимо анализировать в комплексе. Метод
обратного распространения ошибки обеспечивает способ настройки весов с учетом
многослойной структуры нейронной сети.
ш
Выходной слой
Прямое
распространение
информации в сети
J L
Скрытый слой
Обратное
распространение
ошибки
_J L_
(^ Входной слой J)
if tin
Рис. 10.9 Обратное распространение ошибки в нейронной
сети со скрытым слоем
В рамках этого подхода ошибка на выходе сети распространяется в обратном
направлении к скрытым слоям. Анализируя обучение по дельта-правилу, несложно
заметить, что вся информация, необходимая для модификации весов нейрона, относится
только к этому нейрону, за исключением самой величины ошибки. Для нейронов
выходного слоя величина ошибки вычисляется просто как разность между ожидаемым и
реальным выходным значением. Для узлов скрытых слоев ошибку определить значительно
сложнее. В качестве активационной функции при использовании метода обратного
распространения обычно выбирается логистическая функция
f(nef)=1/A+e~Xnef), где net=lxtwr
Применение этой функции обусловлено тремя причинами. Во-первых, она относится к
классу сигмоидных функций. Во-вторых, поскольку она непрерывна, то ее производная
существует в каждой точке. В-третьих, поскольку максимальное значение производной
соответствует сегменту наиболее быстрого изменения функции, то наибольшая ошибка соответствует
узлам, для которых уровень активации наименее определен. И, наконец, производная этой
функции легко вычисляется с помощью операций умножения и вычитания
f(nef)=A/A+eXnef))'=X(f(nef)*A-f(nef))).
Метод обратного распространения является обобщением дельта-правила. В нем тоже
используется метод градиентного спуска, описанный в разделе 10.2. Для узлов скрытого
слоя ошибка вычисляется на основе ошибки выходного слоя. Формулы вычисления
добавок к весовому коэффициенту связи wki между /с-м и /-м нейронами по методу
обратного распространения ошибки имеют вид
1. Awu=-\c*(drOi)*Oi( 1 -Oi)xk для узлов выходного слоя;
2. Awkl=-Ac*OjA-0,)^(-delta; *\л/у) xk для узлов скрытых слоев.
Глава 10. Машинное обучение на основе связей
449
Во втором соотношении у — индекс узла следующего слоя, до которого
распространяется сигнал от /-го нейрона, и
de/fay=-^p = (d/-0,)*0/A-0/).
Вычислим производную от этой функции. Сначала возьмем производную для первой
формулы по весовым коэффициентам связей с выходным слоем. Как и ранее, требуется
вычислить скорость изменения ошибки сети в зависимости от /с-го веса связи wk с /-м
нейроном. Этот случай рассматривался при выводе дельта-правила в подразделе 10.2.3,
где было показано, что
дЕггог
dwu
= -(dl-Oi)*f(neti)*xk.
Поскольку f — логистическая активационная функция, то
V(net)=V( 1 /A +eXne')) = M{net)*{ 1 - f(nef)).
Напомним, что f(nef/) = 0/. Подставляя это выражение в предыдущее уравнение,
получим
дЕггог
dwu
-^(d/-0/)*0/(d/-0/)*xfc
Поскольку для минимизации ошибки вес должен изменяться в направлении,
обратном градиенту, то при вычислении добавки к весовому коэффициенту для /-го нейрона
эту производную нужно умножить на -с:
Aivfc=-c*(cf-0,)*0,.A-0,)xfc,
Выведем формулу настройки весов для нейронов скрытого слоя. Для простоты
сначала предположим, что сеть содержит только один скрытый слой. Возьмем один /-й
нейрон скрытого слоя и проанализируем его вклад в общую ошибку на выходе сети. Для
этого рассмотрим вклад /-го нейрона в ошибку на выходе у-го нейрона выходного слоя, а
затем просуммируем этот вклад для всех элементов выходного слоя. И, наконец, учтем
вклад в общую ошибку /с-го весового коэффициента связи с /-м нейроном. Эта ситуация
изображена на рис. 10.10.
Выходной слой 01 О 2 О— О; О
Скрытый слой О 01 02
Входной слой О 1 О 2 О
Рис. 10.10. Общий вклад £ -deltaj * wSJ i-го
j
нейрона в ошибку на выходе сети,
принимаемый во внимание при настройке весового
коэффициента wki
450
Часть IV. Машинное обучение
Сначала рассмотрим частную производную ошибки сети по выходу /-го нейрона
скрытого слоя. Для этого можно воспользоваться цепным правилом
дЕггог _ дЕггог „ dnetj
дО., ~ dnetj дО}
Первый множитель в правой части этого соотношения, взятый с обратным знаком,
обозначим deltSj
delta={SError)/{Snet.).
Тогда предыдущее соотношение можно переписать в виде
дЕггог , и .dnet-,
-deltas-
дО,. ' dOi
Напомним, что уровень активации у'-го нейрона netj выходного слоя вычисляется как
сумма произведений весовых коэффициентов и выходных значений узлов скрытого слоя
netj=HwiPi'
Поскольку частные производные вычисляются только по одному компоненту
суммы — по связи между нейронами / и/, получим
dnet:
где Wij — вес связи между /*-м нейроном скрытого слоя и у'-м нейроном выходного слоя.
Подставляя этот результат в формулу производной ошибки, получим
дЕггог , .. *
— = -de/fa;*w,.
Теперь просуммируем это выражение по всем связям /-го нейрона с узлами
выходного слоя
— = > -delta, * ил,.
дО., у J ,J
Это соотношение определяет чувствительность ошибки на выходе сети к выходу /-го
нейрона скрытого слоя. Теперь определим значение delta} — чувствительность ошибки
сети к уровню активации /-го нейрона скрытого слоя. Это даст возможность получить
чувствительность ошибки сети к весовым коэффициентам входящих связей /-го узла.
Снова воспользуемся цепным правилом
. |х дЕггог дЕггог^ дО,
-delta, =-
dnetj дО/ dnetj
Поскольку используется логистическая активационная функция,
-^- = до,*A-0().
dnet.
Глава 10. Машинное обучение на основе связей
451
Подставляя это значение в уравнение для deltah приходим к соотношению
-delta, = ЛО, * A - О,-) * £ -deltal * wtj .
i
Теперь можно оценить чувствительность ошибки на выходе сети к весу входящих
связей /-го нейрона скрытого слоя. Рассмотрим /с-й весовой коэффициент связи wk с /-м
узлом. Согласно цепному правилу
ЭЕггог ЭЕггог^dnet, , |х + Эneti . |х .
= * '- = -delta, * '- = -delta, * хк,
dwk, dnet, dwk, dwk,
где xk — /с-й вход /-го нейрона.
Подставляя это соотношение в выражение для delta h получим
^I^ = 0,^-0,)YJ(-delta^w,j)xk.
°wki i
Поскольку для минимизации ошибки вес необходимо изменять в направлении
антиградиента, то его настройка выполняется по формуле
Awk, = -Лс дЕгГ0Г = Ac* Q A - О,- )£ (delta j * wtj) хк.
°Wki i
Для сетей с несколькими скрытыми слоями эта процедура рекурсивно применяется
для распространения ошибки от л-го скрытого слоя к слою п-1.
Несмотря на то что метод обратного распространения ошибки позволяет решить
проблему обучения многослойных сетей, он не лишен своих недостатков. Поскольку он
основан на методе поиска экстремума, то может сходиться к локальному минимуму, как на
рис. 10.8. И, наконец, этот метод вычислительно не прост, особенно для сетей со
сложной поверхностью ошибки.
10.3.2. Пример применения метода обратного распространения
ошибки: система NETtalk
Система NETtalk — интересный пример нейросетевого решения сложной проблемы
обучения [Sejnowski и Rosenberg, 1987]. Система NETtalk обучается произносить
английский текст. Это достаточно сложная задача для явного подхода, основанного на
символьном представлении информации, например для системы, основанной на правилах,
поскольку английское произношение очень нерегулярно.
Система NETtalk учится читать строку текста и возвращает фонему с
соответствующим ударением для каждой буквы строки. Фонема — это базовая единица звука в языке,
а ударение — относительная громкость этого звука. Поскольку произношение каждой
буквы зависит от контекста и окружающих ее букв, система NETtalk работает с окном,
содержащим семь символов. При перемещении текста в этом окне NETtalk для каждой
буквы возвращает пару фонема-ударение.
Архитектура системы NETtalk показана на рис. 10.11. Сеть состоит из 3 слоев
нейронов. Входные узлы соответствуют семи символам текстового окна. Каждая позиция в
окне представляется 29 входными нейронами, по одному для каждой буквы алфавита и 3
для знаков пунктуации и пробелов. Буква в каждой позиции активизирует соответст-
452
Часть IV. Машинное обучение
вующий нейрон. Узлы выходного слоя представляют фонемы с помощью 21 свойства
человеческой артикуляции. Остальные 5 нейронов кодируют ударение и границы слогов.
Сеть NETtalk содержит 80 скрытых нейронов, 26 выходных узлов и 18629 связей.
26 выходных нейронов ООООО
80 скрытых нейронов ООООООООООООООООООО О
7x29входов iQO Qi ЮС) Oi Pd Oi OP Oi OP* Oi OQ .Oi iQO Oi
a - с a t
Рис. 10.11. Топология сети системы NETtalk
При обучении системы NETtalk ей предъявляется окно размером 7 символов, и
система пытается "произнести" среднюю букву. После сравнения ее произношения с
корректным веса системы настраиваются по методу обратного распространения ошибки.
Этот пример иллюстрирует множество интересных свойств нейронных сетей, часть
из которых отражают природу человеческого обучения. Например, в начале, когда
процентное соотношение корректных ответов невелико, процесс обучения идет достаточно
быстро и замедляется с увеличением доли правильных ответов. Как и для человека, чем
больше слов сеть научится произносить, тем легче ей будет выговорить неизвестные
слова. Эксперименты, в которых некоторые весовые коэффициенты случайным образом
изменялись, показал, что сеть устойчива к повреждению структуры. Исследования также
показали высокую эффективность переобучения поврежденной сети.
Еще один интересный аспект многослойных сетей — роль скрытых слоев. Любой
алгоритм обучения должен выполнять обобщение на неизвестные сети точки предметной
области. Скрытые слои играют важную роль, позволяя сети реализовать это обобщение.
Подобно многим сетям, обучаемым по методу обратного распространения, в скрытом
слое системы NETtalk содержится меньше нейронов, чем во входном. Это означает, что
для кодирования информации, содержащейся в обучающих образах, в скрытом слое
используется меньше нейронов, т.е. этот слой реализует некоторую форму абстракции.
Такое сжимающее кодирование приводит к тому, что различные входные образы в скрытом
слое имеют идентичное представление. В этом и состоит обобщение.
Система NETtalk обучается достаточно эффективно, хотя для этого требуется большое
число обучающих примеров, а также многократное повторение итераций обучения на одних и
тех же обучающих данных. В работе [Shavlik и др., 1991] приводятся данные
экспериментального сравнения результатов решения этой задачи методом обратного распространения и с
помощью алгоритма ID3. Оказалось, что оба алгоритма дают одинаковые результаты, хотя
по-разному обучаются и используют данные. В этом исследовании общее множество
примеров разделялось на две части: обучающую и тестовую выборки. Обе системы (ГОЗ, описанная
в разделе 9.3, и NETtalk) смогли корректно произнести 60% тестовых данных после обучения
на 500 примерах. Однако для обучения системы ГОЗ понадобился один проход по
обучающему множеству, а для системы NETtalk итерации обучения многократно повторялись. В
проведенном исследовании обучение завершилось после 100 итераций.
Как показывает этот пример, взаимосвязь между подходами к обучению,
основанными на символьном и сетевом представлении информации, гораздо сложнее, чем может
Глава 10. Машинное обучение на основе связей
453
показаться на первый взгляд. В следующем примере метод обратного распространения
применяется для решения задачи "исключающего ИЛИ".
10.3.3. Применение метода обратного распространения для решения
задачи "исключающего ИЛИ"
В завершение этого раздела рассмотрим задачу "исключающего ИЛИ" и покажем,
как ее можно решить с помощью нейронной сети со скрытым слоем. На рис. 10.12
показана сеть с двумя входными нейронами, одним скрытым и одним выходным элементом.
Сеть также содержит два пороговых нейрона, первый из которых связан с единственным
нейроном скрытого слоя, а второй — с выходным нейроном. Уровни активации
скрытого и выходного нейронов вычисляются обычным образом как скалярное произведение
векторов весовых коэффициентов и входных значений. К этому значению добавляется
величина порога. Веса обучаются по методу обратного распространения при
использовании сигмоидальной активационной функции.
Пороговый нейрон
/1
h
Рис. 10.12. Решение задачи "исключающего ИЛИ"
методом обратного распространения. Здесь Wy —
весовые коэффициенты связей, Н — скрытый нейрон
Следует отметить, что входные нейроны напрямую соединены обучаемыми связями с
выходным нейроном. Такие дополнительные связи зачастую позволяют снизить размерность
скрытого слоя и обеспечивают более быструю сходимость. На самом деле сеть, показанная на
рис. 10.12, не является единственно возможной. Для решения задачи "исключающего ИЛИ"
можно подобрать множество различных архитектур нейронных сетей.
Сначала веса связей инициализируются случайным образом, а затем настраиваются с
использованием данных из таблицы истинности функции "исключающего ИЛИ"
@; 0)->0; A; 0)->1; @; 1)->1; A;1)->0.
После 1400 циклов обучения для этих четырех обучающих примеров получаются
весовые коэффициенты следующего вида (значения округлены до 1 знака после запятой)
и/ж=-7.о wHB=2,e и/О1=-7,0 и/он=-11 ,о
И/„2=-7,0 И/ое=7,0 И/О2=-4,0.
Для входного вектора @,0) на выходе скрытого нейрона будет получено значение
f@*(-7,0)+0*(-7l0) + 1*2l6)=fBl6)->1.
Для этого же входного образа выходное значение сети будет вычисляться по формуле
f@*(-5,0)+0*(-4l0)+1*(-11,0)+1*7l0)=f(-4,0)->0.
Для входного вектора A,0) выходом скрытого нейрона будет
fA*(-7l0)+0*(-7,0) + 1*2l6)=f(-4l4)->0,
Пороговый нейрон
wqb
454
Часть IV. Машинное обучение
а на выходе сети будет получено значение
fA*(-5l0)+0*(-4l0)+0*(-11,0)+1*7l0)=fBl0)->1.
Для входного вектора @; 1) будут получены аналогичные выходные значения. И,
наконец, рассмотрим входной вектор A; 1). Для него на выходе скрытого слоя получим
fA*(-7,0)+1*(-7l0)+1*2,6)=f(-11l4)->0l
а на выходе сети
fA*(-5,0)+1*(-4l0)+0*(-11l0) + 1*7l0)=f(-2l0)->0.
Понятно, что сеть прямого распространения, обученная по методу обратного
распространения ошибки, обеспечивает нелинейное разделение этих данных. Пороговая
функция f— это сигмоида, график которой показан на рис. 10.7, б, несколько смещенная в
положительном направлении за счет обучаемого порога.
В следующем разделе будут рассмотрены модели конкурентного обучения.
10.4. Конкурентное обучение
10.4.1. Алгоритм обучения "победитель забирает все" для задачи
классификации
В алгоритме "победитель забирает все" [Kohonen, 1984], [Hecht-Nielsen, 1987] при
предъявлении сети входного вектора возбуждается единственный нейрон, наиболее
точно соответствующий этому образу. Подобный алгоритм можно рассматривать как
реализацию механизма конкуренции между нейронами сети (рис. 10.13). На рис. 10.13 вектор
входных значений X=(xlf х2, ..., хт) передается слою нейронов сети Л, В, ..., Л/, причем
нейрон В оказывается победителем, а его выходной сигнал равен 1.
*1
*2
^Х ^^"^^^^^х^х Победитель
// ^ *"
Рис. 10.13. Слой нейронов при работе
алгоритма "победитель забирает все".
Нейрон-победитель определяется на основе
входных векторов
Глава 10. Машинное обучение на основе связей
455
Алгоритм "победитель забирает все" реализует принцип обучения без учителя,
поскольку нейрон-победитель выбирается по максимальному уровню активности. Вектор
весовых коэффициентов нейрона-победителя модифицируется для более точного
соответствия входному вектору. Если W — вес нейрона-победителя, а X — входной вектор,
то вектор W модифицируется следующим образом
ди/^х'-'-иЛ'),
где с — малый положительный параметр обучения, который обычно уменьшается в
процессе обучения. Вектор весовых коэффициентов нейрона-победителя настраивается
путем добавления к нему ЛИ/'.
Согласно этому соотношению каждый компонент вектора весовых коэффициентов
увеличивается или уменьшается на величину x—w,. Целью такой настройки является
максимальное приближение нейрона-победителя к входному вектору. Алгоритм
"победитель забирает все" не требует прямого вычисления уровней активации для
поиска нейрона с наиболее сильным откликом. Уровень активации нейрона напрямую
зависит от близости вектора весов входному вектору. Для /-го нейрона с нормализованным
вектором весовых коэффициентов И/, уровень активации W,X — это функция евклидово-
го расстояния между И/, и входным образом X. В этом можно убедиться, вычислив
евклидово расстояние для нормализованного вектора И/,
jX-W^yjiX-Wf =JX2-2XWi + Wl2 .
Из этого соотношения видно, что среди всех нормализованных векторов весовых
коэффициентов максимальный уровень активации WX соответствует векторам с
минимальным евклидовым расстоянием | |Х-И/| |. Во многих случаях более эффективно
определять победителя, вычисляя евклидово расстояние, а не уровни активации для
нормализованных векторов весов.
Правило обучения Кохонена "победитель забирает все" рассматривается здесь по
нескольким причинам. Во-первых, это метод классификации, который можно сравнить с
эффективностью персептрона. Во-вторых, его можно комбинировать с другими нейросе-
тевыми архитектурами и обеспечить тем самым более сложные модели обучения. В
последующих разделах будет рассмотрена комбинация метода обучения Кохонена с
алгоритмом обучения с учителем Гроссберга. Такая комбинированная архитектура, впервые
предложенная Робертом Хехт-Нильсеном (Robert Hecht-Nielsen) [Hecht-Nielsen, 1987,
1990], называется сетью встречного распространения (counterpropagation network). Эта
нейросетевая парадигма будет рассмотрена в подразделе 10.4.3.
Прежде чем завершить это введение, следует отметить несколько важных
модификаций алгоритма "победитель забирает все". Иногда в этот алгоритм добавляется
параметр "совести", который обновляется на каждой итерации и препятствует
слишком частым "победам" одних и тех же нейронов. Благодаря этому параметру
пространство входных образов равномерно представляется всеми нейронами сети.
В некоторых модификациях алгоритма определяется не нейрон-победитель, а
множество ближайших нейронов, и настраиваются весовые коэффициенты связей всех
нейронов этого множества. Еще один подход сводится к дифференцированной
настройке весовых коэффициентов всех нейронов из окрестности нейрона-победителя.
В рамках этого метода обучения веса обычно инициализируются случайными
значениями и нормализуются [Zurada, 1992]. В работе [Hecht-Nielsen, 1990] показано, что
алгоритм "победитель забирает все" можно рассматривать в качестве эквивалента
456
Часть IV. Машинное обучение
/с-значного анализа множества данных. В следующем разделе будет описан алгоритм
Кохонена обучения без учителя "победитель забирает все", предназначенный для
решения задач кластеризации.
10.4.2. Сеть Кохонена для изучения прототипов
Вопросы классификации данных и исследования роли прототипов в обучении
традиционно относились к компетенции психологов, лингвистов, специалистов по
компьютерным наукам и теории обучения [Wittgenstein, 1953], [Rosch, 1978], [Lakoff, 1987]. Роль
прототипов и классификации в интеллектуальной деятельности — это также основная
тема данной книги. В разделе 9.5 описаны методы классификации, основанные на
символьном представлении информации, и вероятностные алгоритмы кластеризации,
реализованные в системах COBWEB и CLUSTER/2. В разделе 10.2 представлен нейросетевой
алгоритм классификации с помощью персептрона, а в этом разделе рассмотрен алгоритм
кластеризации Кохонена "победитель забирает все" [Kohonen, 1984].
На рис. 10.4 снова показаны данные из табл. 10.3. На эти точки наложены наборы
прототипов, сформированных в процессе обучения сети. В результате итерационного
обучения персептрона формируется такая конфигурация весовых коэффициентов,
которая обеспечивает линейное разделение двух классов. Как было показано, линейная
поверхность, определяемая этими весами, получается путем неявного вычисления центра
каждого кластера в евклидовом пространстве. Этот центр кластера служит прототипом
класса при решении задачи классификации с помощью персептрона.
С другой стороны, алгоритм обучения Кохонена не требует участия учителя. При
таком обучении набор прототипов создается случайным образом и уточняется до тех пор,
пока прототипы не обеспечат явного представления кластеров данных. В процессе
работы алгоритма коэффициент скорости обучения постепенно уменьшается, чтобы каждый
новый входной вектор оказывал все меньшее влияние на прототип.
В системах, обучаемых по методу Кохонена, типа CLUSTER/2, используется строгий
индуктивный порог, т.е. желаемое количество прототипов явно задается в начале работы
алгоритма, а затем постоянно уточняется. Это позволяет разработчику определить
конкретное число прототипов, представляющих каждый кластер данных. Метод встречного
распространения (подраздел 10.4.3) обеспечивает дополнительное управление
выбранным числом прототипов.
На рис. 10.15 показана сеть Кохонена, предназначенная для классификации данных из
табл. 10.3. Эти данные представлены в двухмерном декартовом пространстве, поэтому
прототипы, представляющие кластеры данных, тоже являются упорядоченными парами.
Для представления кластеров данных выбрано два прототипа— по одному на каждый
кластер. Узлы А и В случайным образом инициализированы значениями G,2) и B,9).
Случайная инициализация подходит только для таких простых примеров, как этот.
Обычно в качестве начальных значений векторов весовых коэффициентов выбираются
представители каждого кластера.
Вектор весовых коэффициентов нейрона-победителя является ближайшим к
входному вектору. Этот вектор весов уточняется и становится еще ближе к входным
данным, в то время как весовые коэффициенты остальных нейронов остаются
неизменными. Благодаря явному вычислению евклидова расстояния от входного вектора до
каждого из прототипов нет необходимости нормализовать эти векторы, как описано в
подразделе 10.4.1.
Глава 10. Машинное обучение на основе связей
457
Обучение сети Кохонена осуществляется без учителя, а нейрон-победитель
определяется на основе расстояния между входным вектором и каждым из прототипов.
Классификация выполняется в контексте самоорганизации сети (self-organizing network).
Обычно при обучении сети методом Кохонена входные данные обрабатываются в
случайном порядке, однако данные из табл. 10.3 будут выбираться сверху вниз. Сначала
измеряется расстояние от точки A,1) до каждого из прототипов
||A 1)-G 2)||=A-7J+A-2J=37,
||A 1)-B 9)||=A-2J+A-9J=65.
IU.U
8,0 -
6.0 -
4.0 -
2,0 -
п п
А*
А
А
• А'
Прототип
2 после
10 итераций N^ .
А
А
АА
S А
А*
I I
АА
„ Прототип 1 после
10 итераций
i i
1 х-~хЛ
0,0
2,0
4.0
6.0
8.0
10,0
*2
• Точки данных
а Прототипы
WA2=2
». wsi = 2, wS2 = 9
Рис. 10.14. Обучение сети Кохонена без
учителя, при котором генерируется
последовательность прототипов,
представляющих классы из табл. 10.3
Рис. 10 15. Архитектура сети Кохонена
для классификации данных из табл. 10.3
Узел АG\ 2) становится победителем, так как он ближе к точке A; 1). Расстояние
между этими точками— 11A; 1)-G; 2)| |, причем квадратный корень вычислять нет
необходимости, поскольку эта функция возрастающая. Теперь для узла-победителя нужно
пересчитать значения весовых коэффициентов, установив коэффициент скорости
обучения равным 0,5. На второй итерации
И/2=И/1+с(Х1-И/1)=
=G; 2)+0,5(A; 1)-G; 2))=G; 2)+0,5(A;-7),A;-2))=
=G;2)+(-3;-0,5)=D; 1,5).
На второй итерации обучения вычислим расстояния от точки (9,4; 6,4):
| |(9,4; 6,4)-D; 1,5)| |=(9,4; -4J+F,4; -1,5J=53,17,
| |(9,4; 6,4)-B; 9)| |=(9,4; -2J+F,4; -9J=60,15.
Снова победителем является узел А. Веса связей перед третьей итерацией обучения
составляют
W3=W2+c(X2-W2)=
=D; 1,5)+0,5((9,4; 6,4)-D; 1,5)) =
=D; 1,5)+B,7;2,5)=F,7;4).
458
Часть IV. Машинное обучение
На третьей итерации для точки B,5; 2,1) имеем
| 1B,5; 2,1)-F,7; 4)| |=B,5-6|7J+B|1-4J=21,25,
| |B,5; 2,1)-B;9)||=B,5-2J+B,1-9J=47,86.
Узел А снова становится победителем, и для него вычисляется новый весовой вектор.
На рис. 10.14 показана эволюция прототипов в течение 10 итераций. Алгоритм
генерации данных, представленных на рис. 10.14, выбирает очередные входные данные из
табл. 10.3 случайным образом, поэтому эти точки отличаются от вычисленных выше. Как
показано на рис. 10.14, в процессе обучения прототипы постепенно смещаются к центрам
кластеров. Напомним, что обучение выполняется без учителя на основе алгоритма с
подкреплением "победитель получает все". В процессе такого обучения строится
последовательность явных прототипов, представляющих кластеры данных. Некоторые
исследователи, в том числе Зурада [Zurada, 1992] и Хехт-Нильсен [Hecht-Nielsen, 1990], показали, что
алгоритм обучения Кохонена по существу эквивалентен /с-значному анализу.
В следующем разделе будет рассмотрен модифицированный алгоритм выбора
прототипов, основанный на модели Гроссберга, являющейся расширением сети Кохонена.
10.4.3. Нейроны Гроссберга и сети встречного распространения
До сих пор рассматривалась задача кластеризации входных данных без участия
учителя. Для обучения нейронной сети при этом требуются некоторые начальные знания об
области определения задачи. В процессе определения характеристик данных, а также
истории обучения идентифицируются классы и выявляются границы между ними.
Поскольку данные классифицируются на основе подобия их векторного представления,
учитель может поспособствовать в калибровке полученных результатов или в
присвоении имен этим классам. Это можно сделать с помощью обучения с учителем, при
котором выходы слоя, обучаемого по методу "победитель забирает все", используются в
качестве входов второго слоя сети. Решения этого выходного слоя можно явно
скоординировать (подкрепить) с помощью учителя.
Такой подход позволяет, например, отобразить результаты слоя Кохонена в
выходные образы или классы. Это можно сделать с помощью алгоритма "исходящей звезды"
(outstar) Гроссберга [Grossberg, 1982], [Grossberg, 1988]. Комбинированная сеть,
включающая слой нейронов Кохонена и слой Гроссберга, впервые была предложена
Робертом Хехт-Нильсеном и получила название сети встречного распространения
(counterpropagation network) [Hecht-Nielsen, 1987, 1990].
Слой Кохонена достаточно подробно рассмотрен в подразделе 10.4.2, поэтому
здесь остановимся на слое Гроссберга. На рис. 10.16 показан слой нейронов А, В, ...,
А/, один из которых — J — является победителем. Алгоритм Гроссберга предполагает
наличие обратной связи от учителя, представленной вектором У, с целью подкрепления
весов связей от нейрона J к нейрону / выходного слоя, который должен
активизироваться. Согласно алгоритму обучения Гроссберга вес исходящей связи Wjj от нейрона J к
нейрону / увеличивается.
В сети встречного распространения сначала обучается слой Кохонена. После
определения победителя его выходное значение устанавливается равным 1, а выходные
значения всех остальных нейронов Кохонена принимаются равными 0. Нейрон-победитель и
все нейроны выходного слоя, с которыми он связан, формируют так называемую
"исходящую звезду" (рис. 10.16). Обучение слоя Гроссберга осуществляется для
компонентов этой "звезды".
Глава 10. Машинное обучение на основе связей
459
Входные
данные X
Слой нейронов,
обучаемых по
методу "победитель
забирает все"
^7\0
Выходной
слой
Ожидаемый
выход Y
Рис. 10 16. "Исходящая звезда" для нейрона J в сети,
обучаемой по методу "победитель забирает все". Вектор Y— это
ожидаемый выход слоя Гроссберга. Жирной линией выделены
связи нейрона, выход которого равен 1, выходные значения всех
остальных нейронов слоя Кохонена равны О
Если каждый кластер входных векторов представляется одним классом и всем членам
этого класса соответствует одно и то же значение выходного слоя, то в итеративном
обучении нет необходимости. Требуется лишь определить, с каким нейроном слоя Кохонена
связан каждый класс, а затем назначить веса связей между каждым нейроном-
победителем и выходным слоем на основе ассоциации между классами и ожидаемыми
выходными значениями. Например, если J-й нейрон Кохонена соответствует всем
элементам кластера, для которого ожидаемым выходом сети является /= 1, то для связи
между нейронами J и / нужно установить значение vv,,— 1, а для всех остальных весовых
коэффициентов исходящих связей нейрона J — Wjk=0.
Если одному кластеру могут соответствовать различные выходные нейроны, то для
настройки весовых коэффициентов "исходящей звезды" применяется итеративная
процедура обучения с учителем на основе ожидаемого вектора Y. Целью процедуры
обучения является усреднение ожидаемых выходных значений для элементов каждого
кластера. Веса связей нейрона-победителя с выходными нейронами настраиваются
согласно формуле
tV+1 = tV+c(V-tV)l
где с — малый положительный коэффициент обучения, И/' — вектор весовых
коэффициентов связей нейрона-победителя с выходным слоем, а У— ожидаемый выходной
вектор. Заметим, что этот алгоритм обучения приводит к усилению связей между узлом J
слоя Кохонена и узлом / выходного слоя только в том случае, если / — нейрон-
победитель, и его выход равен 1, а желаемый выход при этом тоже равен 1. Поэтому
данный алгоритм можно считать разновидностью метода обучения Хебба, согласно
которому связь между нейронами усиливается всякий раз при ее возбуждении. Идея
обучения Хебба более подробно описана в разделе 10.5.
Применим сеть встречного распространения для распознавания кластеров данных из
табл. 10.3. Покажем на этом примере, как реализуется алгоритм обучения такой сети.
460
Часть IV. Машинное обучение
Допустим, параметр хх в табл. 10.3 представляет скорость двигателя в силовой
установке, а х2 — его температуру. Оба параметра откалиброваны таким образом, что
принимают значения из диапазона [0; 10]. Предположим, система мониторинга через заданные
интервалы времени снимает данные с двигателей, и должна рассылать уведомление, если
скорость и температура чрезмерно возрастут. Переименуем выходные значения в
табл. 10.3 следующим образом: будем считать, что значение +1 соответствует
"безопасному" состоянию, а -1 — "опасному". Сеть встречного распространения при
этом будет выглядеть примерно так, как показано на рис. 10.17.
Слой
Входной "победитель Выходной
слой Xi забирает все" слой
Скорость
Температура
Рис. 10 17. Сеть встречного распространения для
распознавания классов из табл. 10.3. Обучению подлежат
весовые коэффициенты WAS и WAD связей узла А с
выходными нейронами
Поскольку точно известно, каким выходным значениям слоя Гроссберга должны
соответствовать нейроны-победители слоя Кохонена, можно напрямую задать эти
значения. Для демонстрации обучения слоя Гроссберга обучим сеть с помощью указанной
выше формулы. Если (произвольным образом) принять решение о том, что узел S
выходного слоя отвечает за безопасную ситуацию, а узел D — за опасную, то веса связей
нейрона А слоя Кохонена с выходным слоем должны быть равны [1; 0], а веса связей
нейрона В — [0; 1 ]. Благодаря симметрии этой ситуации можно ограничиться
рассмотрением процесса обучения только для "исходящей звезды" нейрона А.
Прежде чем приступать к обучению слоя Гроссберга, необходимо обучить слой
Кохонена. Сходимость процесса обучения для слоя Кохонена была рассмотрена на этом же
примере в подразделе 10.4.2. Входные векторы для обучения исходящих связей нейрона
А имеют вид [xi, Х2, 1, 0]. Здесь Х\ и Х2 — это значения из табл. 10.3, соответствующие
нейрону А слоя Кохонена, а два других компонента указывают на то, что узел А является
победителем, т.е. безопасное состояние двигателя соответствует значению "истина", а
опасное — значению "ложь" (см. рис. 10.15). Веса исходящих связей нейрона А
инициализируем значениями [0; 0] и коэффициент скорости обучения сделаем равным 0,2
И/1 = [0; 0]+0,2[[1; 0]-[0; 0]] = [0; 0]+[0,2; 0]=[0,2; 0],
И/2=[0,2; 0]+0,2[[1; 0]-[0,2; 0]] = [0,2; 0] + [0,16; 0] = [0,36; 0],
И/3=[0,36; 0]+0,2[[1; 0]-[ 0,36; 0]] = [ 0,36; 0] + [0,13; 0] = [0,49; 0],
ИГ=[0,49; 0]+0,2[[1; 0]-[ 0,49; 0]] = [ 0,49; 0] + [0,1; 0] = [0,59; 0],
И/5=[0,59; 0]+0,2[[1; 0]-[ 0,59; 0]] = [ 0,59; 0] + [0,08; 0] = [0,67; 0].
Глава 10. Машинное обучение на основе связей
461
Несложно удостовериться, что в процессе обучения значения весовых
коэффициентов сходятся к [1; 0]. Естественно, из-за однозначности соответствия нейрона-победителя
нейрону выходного слоя можно было бы просто назначить веса связей и не использовать
алгоритм обучения вообще.
Покажем, что такие значения весов обеспечивают адекватное функционирование сети
встречного распространения. Если на вход сети, показанной на рис. 10.17, подать первый
вектор из табл. 10.3, то уровень активности нейрона А составит [1; 1], а нейрона В —
[0; 0]. Взвешенная сумма этих значений для нейрона S выходного слоя составит 1. Если
веса исходящих связей нейрона В составляют [0; 1], то уровень активации нейрона D
будет равен 0, что и требуется для данной задачи. Выбирая второй вектор из табл. 10.3,
получим уровень активации для узла А [0; 0], а для узла В — [1; 1 ]. Взвешенная сумма этих
значений для нейрона S составляет 0, а для нейрона D — 1. Аналогично можно
проверить корректность функционирования сети для всех данных из табл. 10.3.
С точки зрения теории познания для сети встречного распространения можно предложить
ассоциативную интерпретацию. Вернемся к рис. 10.17. Обучение слоя Кохонена можно
рассматривать как знакомство с условным стимулом, поскольку сеть изучает образы по мере их
поступления. Обучение слоя Гроссберга — это связывание нейронов (безусловных стимулов)
с некоторым откликом. В рассмотренном случае сеть обучится рассылать уведомление об
опасности при соответствии данных некоторому шаблону. После обучения система будет
правильно реагировать на новые данные даже без участия учителя.
Другая когнитивная интерпретация сводится к подкреплению определенных связей в
памяти для данного шаблона. Этот процесс напоминает построение таблицы поиска для
откликов на шаблоны данных.
Сеть встречного распространения имеет, в некотором смысле, значительное
преимущество перед сетью обратного распространения. Подобно сети обратного
распространения, она обучается классификации на основе нелинейного разделения. Однако делается
это за счет препроцессинга, обеспечиваемого слоем Кохонена, с помощью которого
данные делятся на кластеры. Такая кластеризация обеспечивает существенное
преимущество по сравнению с сетью обратного распространения, поскольку устраняет
необходимость выполнения поиска, требуемого для обучения скрытых слоев такой сети.
10.5. Синхронное обучение Хебба
10.5.1. Введение
Теория обучения Хебба основывается на следующем наблюдении: если один нейрон
в биологической системе участвует в возбуждении другого нейрона, то связь между
ними усиливается. В [Hebb, 1949] указано следующее:
"Если аксон клетки А многократно участвует в возбуждении клетки В, то имеет место
некоторый процесс роста или метаболического изменения в одной или обеих клетках,
приводящий к усилению влияния клетки А на клетку В."
Такой подход к обучению выглядит достаточно привлекательно, поскольку он
основан на поведенческом принципе подкрепления, который наблюдается на нейронном
уровне. Нейрофизиологические исследования подтвердили идею Хебба о том, что при
совместном возбуждении нейронов синаптические связи между ними могут усиливаться.
Однако этот процесс оказался гораздо сложнее предположения Хебба об "усилении
462
Часть IV. Машинное обучение
влияния". Представленный в этом разделе закон обучения получил название метода
обучения Хебба, несмотря на то, что его идея оказалась несколько абстрактной. Такое обучение
относится к категории синхронного (coincidence), поскольку значения весов изменяются в
ответ на события, происходящие в нейронной сети. Законы обучения, относящиеся к этой
категории, описываются своими временными и пространственными свойствами.
Обучение Хебба используется в многочисленных нейросетевых архитектурах. Оно
реализуется как в интерактивном, так и в кумулятивном режимах. Эффект усиления
связей между нейронами при их взаимном возбуждении можно математически
промоделировать с помощью настройки весов связей между ними с учетом знака произведения их
выходных значений.
Остановимся на конкретной реализации этого подхода. Предположим, что выход
нейрона / связан со входом нейрона у. Добавкой к весовому коэффициенту связи между
этими нейронами А И/ можно определить коэффициент скорости обучения с, взятый со
знаком произведения (o*Oj). В табл. 10.4 приводятся данные о знаке произведения o*Oj
выходов нейронов / и у в зависимости от знака каждого из множителей. Из первой строки
таблицы видно, что если оба выхода нейронов положительны, то и весовая добавка A W
имеет знак "+". Следовательно, если нейрон / участвует в возбуждении нейрона у, то
связь между ними усиливается.
Таблица 10.4. Зависимость знака произведения от знаков выходных значений
нейронов
О, Oj 0*0]
+ + +
+ - _
+
+
Вторая и третья строки таблицы соответствуют ситуации, когда знаки выходных
значений нейронов различаются. Поскольку знаки отличаются, необходимо уменьшить
влияние нейрона / на выход нейрона у. Следовательно, инкремент к весовому
коэффициенту связи выбирается с отрицательным знаком. И, наконец, в четвертой строке знаки
выходов нейронов / и у снова совпадают, и сила этой связи увеличивается. Такой
механизм настройки весов способствует укреплению связей между нейронами, если их
выходные сигналы имеют одинаковый знак, и уменьшению этой связи в противном случае.
В следующих разделах рассматриваются два типа обучения Хебба — без учителя и с
учителем. Сначала рассмотрим алгоритм обучения без учителя.
10.5.2. Пример алгоритма обучения Хебба без учителя
Напомним, что при обучении без учителя для корректировки выходных значений не
используется внешнее воздействие. Веса модифицируются исключительно на основе
информации о входах и выходах нейрона. Обучение такой сети сводится к усилению
отклика сети на уже "виденные" образы. В следующем примере будет показано, как метод
Хебба используется для моделирования обучения на основе обусловленного отклика,
когда в роли условия для желаемого отклика выступает произвольно выбранный стимул.
При обучении Хебба без учителя веса нейрона / можно настраивать по формуле
AW=c*f(X,W)*X,
Глава 10. Машинное обучение на основе связей
463
где с — малый положительный коэффициент обучения, f(X, W) — выходное значение /-
го нейрона, а X — его вход.
Покажем, как обучение Хебба можно использовать для преобразования отклика сети из
вида основного или безусловного стимула к условному. Это позволит промоделировать метод
обучения, разработанный при экспериментах Павлова, когда у собаки вырабатывался
условный рефлекс на звонок. После того, как подача пищи собаке многократно сопровождалась
звонком, при звуке звонка у нее начиналось слюноотделение. Сеть, показанная на рис. 10.18,
содержит два слоя: входной слой с шестью нейронами и выходной слой с одним нейроном.
Выходной нейрон может принимать значение +1, соответствующее возбужденному
состоянию этого нейрона, и -1, соответствующее его невозбужденному состоянию.
Примем коэффициент скорости обучения равным 0,2. В этом примере сеть обучается на
образ [1;-1;1;-1;1;-1], представляющий собой конкатенацию двух образов: [1;-1;1] и
[-1; 1;-1 ] • Образ [ 1; -1; 1 ] соответствует безусловному стимулу, а образ [-1; 1;-1 ] — новому.
Зрительная
информация
Слуховая
информация
I Aw I
Рис. 10.18. Пример нейронной сети, для которой применяется
обучение Хебба без учителя
Предположим, сеть положительно реагирует на безусловный стимул, но не
воспринимает новый стимул. Положительный отклик сети на безусловный стимул можно
обеспечить с помощью весового вектора [ 1; -1; 1 ], в точности соответствующего входному
образу, а нейтральный отклик на новый стимул — с помощью вектора весов [ 0; 0; 0 ].
Конкатенация этих двух векторов весовых коэффициентов дает исходный вектор весов
сети [1 ;-1 ;1 ;0;0;0].
Теперь сеть нужно обучить реакции на входной образ таким образом, чтобы новая
конфигурация весов обеспечивала положительный отклик на новый стимул. На первом
шаге работы сети вычислим
ИЛХ=A*1)+((-1)*(-1))+A*1)+@*(-1))+@*1)+@*(-1))=
=A)+A)+A)=3,
fC)=signC)=1.
Теперь определим новый вектор весовых коэффициентов W2
И/2=[1;-1;1;0;0;0]+0,2*1*[1;-1;1;-1;1;-1] =
= [1;-1;1;0;0;0] + [0,2;-0,2;0|2;-0|2;0|2;-0|2] =
= [1|2;-1|2;1|2;-0|2;0,2;-0,2].
Вычислим отклик сети на тот же входной образ с учетом обновленного вектора весов
ИЛХ=A|2*1)+((-1|2)*(-1))+A|2*1)+((-0|2)*(-1))+@|2*1)+((-0|2)*(-1))=
=A|2)+A|2)+A|2)+@,2)+@12)+@,2)=4|2|
fD,2)=1.
*1
Л'2
*3
Х4
*Ь
*Ь
1
W2
W3
W4
W5
W&
Учитель
464
Часть IV. Машинное обучение
Определим новый вектор весовых коэффициентов И/3
И/а=[1|2;-1|2;1|2;-0|2;0,2;-0|2]+0|2*1*[1;-1;1;-1;1;-1] =
= [1|2;-1|2;1|2;-0,2;0|2;-0|2] + [0,2;-0|2;0|2;-0|2;0|2;-0|2] =
= [1,4;-1|4;1|4;-0,4;0|4;-014].
Несложно заметить, что произведение векторов ИЛХ продолжает возрастать, при
этом абсолютное значение каждого элемента вектора весовых коэффициентов в каждом
цикле обучения увеличивается на 0,2. После 13 итераций обучения вектор весовых
коэффициентов примет вид
И/'3=[3,4,-3,4;3,4,-2,4;2,4,-2,4].
Теперь этот обученный вектор весов можно использовать для тестирования отклика
сети на два отдельных образа. При этом ожидается, что сеть будет по-прежнему
положительно реагировать на безусловный стимул, и, что гораздо важнее, будет давать
положительный отклик на новый, обусловленный, стимул. Сначала проверим реакцию сети на
безусловный стимул [1;-1;1]. Три последних элемента входного вектора заполним
произвольно выбранными значениями 1 и -1. Например, определим реакцию сети на вектор
[1;-1;1;1;1;-1]
sign(l/irX)=sign(C,4*1)+((-3,4)*(-1))+C,4*1)+
+(-2,4*1)+B,4*1)+((-2,4)*(-1)))=
=signC,4+3,4+3,4-2,4+2,4+2,4)=
=signA2,6)=+1.
Таким образом, сеть по-прежнему положительно реагирует на исходный безусловный
стимул. Теперь проверим реакцию сети на тот же безусловный стимул и другой случайно
выбранный вектор в последних трех позициях [1;-1;1;1;-1;-1]
sign(tV*X)=sign(C,4*1 )+((-3,4)*(-1 ))+C,4*1)+
+ (-2,4*1 ) + B,4*(-1))+((-2,4)*(-1)))=
=signC,4+3,4+3,4-2,4-2,4+2,4)=
=signG,8)=+1.
Этот входной вектор тоже приводит к положительному отклику сети. На самом деле
эти два примера свидетельствуют о том, что сеть чувствительна к исходному стимулу,
связь с которым была усилена благодаря его многократному повторению.
Теперь определим отклик сети на новый стимул [-1;1;-1], закодированный в
последних трех позициях входного вектора. Первые три элемента заполним случайно
выбранными значениями из множества {-1;1} и проверим реакцию сети на входной вектор
[1;1;1;-1;1;-1]
sign(H/*X)=sign(C,4*1)+((-3,4)*1)+C,4*1)+
+(-2,4*(-1))+B,4*1)+((-2,4)*(-1)))=
=signC,4-3,4+3,4+2,4+2,4+2,4)=
=signA0,6)=+1.
Второй стимул тоже успешно распознан!
Проведем еще один эксперимент, слегка изменив входной вектор. Этот случай будет
соответствовать ситуации, когда используется новый вид еды и другой тип звонка.
Протестируем сеть на входном векторе [1;-1;-1;1;1;-1], где первые три элемента не
совпадают с исходным стимулом, а вторые три отличаются от обусловленного
sign(H/*X)=sign(C,4*1)+((-3,4)*(-1))+C,4*(-1))+
Глава 10. Машинное обучение на основе связей
465
+ (-2,4*1 )+B,4*1)+((-2,4)*(-1)))=
=signCl4+3,4-3l4-214+2l4+2l4)=
=signE,8)=+1.
Следовательно, распознан даже слегка отличный стимул.
Что же получилось в результате обучения Хебба? Благодаря многократному
совместному появлению старого и нового стимула была создана ассоциация между новым
стимулом и старым откликом. Сеть научилась обеспечивать прежний отклик на новый стимул
без участия учителя. Такая повышенная чувствительность также позволяет сети правильно
отвечать на слегка модифицированный стимул. Это достигается за счет синхронного
обучения Хебба, в процессе которого сила отклика на общий образ увеличивается, что
приводит к усилению отклика сети на каждый отдельный компонент этого образа.
10.5.3. Обучение Хебба с учителем
Правило обучения Хебба основано на принципе усиления связи между нейронами при их
взаимном возбуждении. Этот принцип можно адаптировать и к обучению с учителем, если
вес связи настраивать на ожидаемый, а не реальный выход нейрона. Например, если входной
потенциал нейрона В, поступающий от нейрона А, является положительным, и от нейрона В
ожидается положительный отклик, то связь между этими нейронами усиливается.
Проверим, как с помощью метода обучения Хебба с учителем можно научить сеть
распознавать набор ассоциаций между образами. Ассоциации задаются как набор
упорядоченных пар {<ХЬ Vi>, <X2l V2>,..., <Х„ У,>}, где X, и V, — вектор ассоциируемых между
собой образов. Предположим, размерность вектора X, равна л, а размерность V,— т.
Построим сеть, соответствующую этой ситуации. Она должна состоять из двух слоев,
первый из которых содержит л нейронов, а второй — т (рис. 10.19).
Для обучения этой сети воспользуемся формулой настройки весов из
предыдущего раздела
AtV=c*f(XftV)*X,
где f(X,l/l/) — реальный выход нейронной сети. При обучении с учителем заменим
реальный выход нейронов ожидаемым выходным вектором D. Получим
ALV=c*D*X.
У^ У2 Ут
x^ х2 хз хп
Рис. 10.19. Изучение ассоциаций с помощью метода
обучения Хебба с учителем
466
Часть IV. Машинное обучение
Возьмем пару векторов <XbVi> из набора ассоциаций и применим это правило
обучения к узлу к выходного слоя
Al/V/If=c*cffc*x,,
где ЛИ/,*— весовая добавка к связи нейрона / входного слоя с узлом к выходного слоя,
dk — ожидаемый выход /с-го нейрона, а х, — /-й элемент вектора X. Эта формула
применяется для настройки всех весов связей всех нейронов выходного слоя. Вектор <хи
х2,..., хп> — это входной вектор X, a <db d2,..., dn> — выходной вектор Y. Применяя
эту формулу для настройки отдельных весов связей с каждым нейроном выходного слоя,
приходим к формуле модификации весов для всего выходного слоя
AW=c*Y*X,
где Y*X — внешнее векторное произведение (outer vector product), определяемое как матрица
[Уг*1 Уг*2 ••' У^*п~\
YX = \^2 *1 ^2 *2 ^2 " *п
\_Ут *\ Ут'Х2 Ут ' Хп J
Чтобы обучить сеть всему набору ассоциированных пар, нужно организовать
итерационную процедуру настройки весов для каждой пары <Х,, /,-> по формуле
Wt" = Wt+c*Y;Xr
Для всего обучающего множества имеем
W' = W°+c*{YSX,+ У2*Х2+...+У,*Х,),
где И/0 — исходная конфигурация весов. Если исходные веса и/0 инициализировать
нулевым вектором <0;0;...;0>,а коэффициент обучения с выбрать равным 1, получим
следующую формулу вычисления весов
W=Y*X + У2*Х2+... + У,*Х,.
Сеть, отображающая вектор входов в вектор выходов и обученная по этой формуле
настройки весов, называется линейным ассоциатором (linear associator). Как станет ясно
впоследствии, такая модель позволяет хранить множество ассоциаций в матрице связей. Это
приводит к возможности взаимодействия между сохраненными шаблонами. Проблемы,
возникающие при таком взаимодействии, будут рассмотрены в следующих разделах.
10.5.4. Ассоциативная память и линейный ассоциатор
Нейронная сеть, представляющая собой линейный ассоциатор, впервые была предложена
Т. Кохоненом [Kohonen, 1972] и Дж. Андерсоном [Anderson и др., 1977]. В этом разделе будет
описана линейная ассоциативная сеть, предназначенная для хранения и восстановления
образов из памяти. Будут изучены различные формы памяти, в том числе гетероассоциативная,
автоассоциативная и интерполятивная модели. Будет проанализирована возможность
использования линейного ассоциатива для реализации интерполятивной памяти на базе метода
обучения Хебба. В завершение раздела будут рассмотрены проблемы интерференции или помех,
возникающих при хранении в памяти нескольких образов.
Сначала введем несколько определений, связанных с хранением информации в
памяти. Входные образы и хранимые в памяти значения являются векторами. Для устранения
Глава 10. Машинное обучение на основе связей
467
проблемы представления обычно вводится индуктивный порог, предполагающий
задание множества векторов признаков. Хранимые в памяти ассоциации представляются в
виде набора векторных пар {<Xi, Y\ >, <Х2, Y2 >,..., <Х,, Yt>}. Для каждой пары
векторов <Х„ Yt> образ X, — это ключ для восстановления образа Yt. Существует три типа
ассоциативной памяти.
1. Гетероассоциативная память (heteroassociative memory)— это такое
отображение, при котором вектору X, наиболее близкому к Х„ ставится в соответствие
возвращаемый вектор У/.
2. Автоассоциативная память (autoassociative memory) — это такое отображение,
при котором для всех пар ХрУ,-. Поскольку каждый вектор X, ассоциируется с
самим собой, эта форма памяти используется в основном для восстановления
полного вектора по его части.
3. Интерполятивная память (interpolative memory)— это такое отображение Ф:
X—>У, при котором отличному от эталона вектору Х=Х,+д/ ставится в соответствие
выходной вектор Ф(Х) = Ф(Х,+А ,) = /,+ £, где Е=Ф(А,). При интерполятивном
отображении каждый из ключей эталона связывается с соответствующим образом в
памяти. Если же входной вектор отличается от эталонного на вектор А, то
выходной вектор тоже отличается от эталонного на величину Е, где Е=Ф(А,).
Автоассоциативная и гетероассоциативная память используются для
восстановления одного из запомненных эталонов. Они моделируют память в ее исходном
значении, при котором извлекаемый образ является точной копией запомненного. Можно
также сконструировать память таким образом, чтобы выходной вектор отличался от
сохраненного в памяти в некотором семантическом смысле. В этом и состоит роль ин-
терполятивной памяти.
Линейный ассоциатор, представленный на рис. 10.20, реализует одну из форм интер-
полятивной памяти. Как следует из подраздела 10.5.3, его работа основана на модели
обучения Хебба. Веса связей инициализируются с помощью соотношения, приведенного
в подразделе 10.5.3
И/=У1*Х1+ У2*Х2+... + У,*Хг
При таких значениях весовых коэффициентов для каждого эталонного ключа сеть
будет восстанавливать точно соответствующий ему эталонный образ, в противном случае
она будет осуществлять интерполяционное отображение.
Теперь введем несколько понятий, которые помогут проанализировать поведение
этой сети. Сначала введем метрику, позволяющую определить точное расстояние между
векторами. Все векторы-эталоны в рассмотренном примере являются хемминговыми, т.е.
состоящими только из -1 и +1. Для описания расстояния между хемминговыми
векторами можно ввести хеммингово расстояние (Hamming distance). Определим хеммингово
пространство следующим образом:
Нп={Х=(х1,х2,...,хп)}, где каждый элемент х, принимает значения из
множества {+1 ;-1}.
Хеммингово расстояние определяется между двумя любыми векторами в хемминго-
вом пространстве как
| \X,Y\ |= количеству различных компонентов в векторах X и Y.
468
Часть IV. Машинное обучение
У2= V/21*2 + W22*2 + W2r>^2
Ут= W/T71X/T7 + Wm2*m + • -Wm„Xm
У1 У2 Ут
*1 X2 X3 Xn
Pwc. 70.20. Линейная ассоциативная сеть. На вход
сети подается вектор Х„ а на выходе получается
соответствующий ему вектор /,-, каждый компонент
которого у} является линейной комбинацией входов. В
процессе обучения каждый выходной нейрон
подкрепляется соответствующими ему корректными
выходными сигналами
Например, хеммингово расстояние в четырехмерном хемминговом пространстве
между векторами
A;-1;-1;1) иA;1;-1;1) равно 1,
(-1;-1;-1;1) и A;1;1-;1) равно 4,
A;-1;1;-1) и A;-1;1;-1) равноО.
Введем еще два определения. Дополнением хеммингового вектора называется вектор,
все компоненты которого противоположны компонентам исходного вектора. Например,
дополнением к A;-1;-1;-1) является вектор (-1;1;1;1).
Определим понятие ортонормальности векторов. Ортонормалъными называются
ортогональные или перпендикулярные векторы единичной длины. Покомпонентное
произведение ортонормальных векторов равно 0. Следовательно, скалярное произведение
любых двух векторов X, и X, из набора ортонормальных векторов равно 0, если эти
векторы различны:
Xft=blt, где Ъч =1, если /=/, и 5/у =0 в остальных случаях.
Покажем, что определенный выше линейный ассоциатор обладает следующими
двумя свойствами. Пусть Ф(Х) — выполняемое сетью отображение. Во-первых, для любого
входного вектора Х„ точно соответствующего одному из эталонов, выход сети Ф(Х,)
равен соответствующему выходному эталонному вектору /,-. Во-вторых, для любого
входного вектора Хь не соответствующего ни одному из эталонов, выход сети Ф(Х*) равен
вектору Yk, представляющему собой интерполяцию вектора Х^. Более точно, для Хк= X,
+Д/, где X, — эталонный вектор, сеть возвращает значение
Y=Yt+E, где Е=Ф(Д,).
Глава 10. Машинное обучение на основе связей 469
Сначала покажем, что при подаче на вход сети одного из эталонов она возвращает
соответствующий ему эталонный образ.
По определению активационной функции сети
Ф(Х) = И/Х,.
Поскольку
W=Y*X+ Y2*X2+...+Yn*Xnt
получим
Ф(Х,)=(У1*Х1+ У2*Х2+...+ Vn*Xn)X =
= Y,X,Xi+Y2X2X+...+ YnXnXi
по закону дистрибутивности. Поскольку из сказанного выше следует, что Х^=8у, то
Ф(Х,) = УА, + У2К +--+ Y&, +...+ Ynbni.
По условию ортонормальности 5у=1 при /=/ и 0 в остальных случаях. Тогда
Ф(Х,) = У1*0 + у2*0 +...+ У,*1 +...+ Yn*0= Yr
Можно также показать, что для входного вектора Xh не соответствующего ни одному
из эталонов, сеть выполняет интерполирующее отображение. Так, для Хк= X, +А„ где
X, — один из эталонных векторов
Ф(Х,)= Ф(Х,+Д,) = У+Е,
где У, — вектор, связанный с Х„ а
Е= Ф(Д,)= (Y,*X,+ Y2*X2+...+ Yn*Xn) A,.
Детали доказательства можно опустить.
Теперь приведем пример обработки данных с помощью линейного ассоциатора. На
рис. 10.21 показана простая линейная ассоциативная сеть, отображающая
четырехмерный вектор X в трехмерный вектор Y. Поскольку сеть работает в хемминговом
пространстве, в качестве активационной функции необходимо использовать описанную выше
функцию sign.
У\ У2 Уз
*1 X2 Хз Х4
Рис 10.21. Линейный ассоциатор, весовая
матрица которого вычисляется по
формуле из предыдущего раздела
Допустим, требуется запомнить две векторные ассоциации <ХЬ Vj>, <X2, У2>, где
Х^И;-!;-!;-!]**/^!-!;!;!],
Х2=[-1;-1;-1;1]*+У2=[1;-1;1].
470
Часть IV. Машинное обучение
1
1
1
1
-1
-1
1
-1
-1
1
-1
-1
+
-1
1
-1
-1
1
-1
-1
1
-1
1
-1
1
=
-2
2
0
0
0
-2
0
0
-2
CsJ
-2
0
Используя определенную в предыдущем разделе формулу инициализации весов для
линейного ассоциатора, получим
W=Y*X+ Y2*X2+ Y3*X3+...+Yn*Xn.
С помощью операции внешнего векторного произведения YlXl+Y2X2 вычислим
весовую матрицу сети
И/ =
Проверим работу линейного ассоциатора для одного из эталонов. Начнем с вектора
Х= [ 1;— 1;— 1;— 1 ] из первой эталонной пары и вычислим связанный с ним вектор Y.
yl=((-2)*1)+@*(-1))+@*(-D)+B*(-1))=-4l sign(-4)=-1,
y2=B*1)+@*(-1))+@*(-1))+((-2)*(-1))=4lsignD)=1l
y3=@*1)+((-2n-1))+((-2)*(-1))+@*(-1))=4lsignD)=1.
Следовательно, У!=[-1;1;1] — получена вторая половина пары.
Приведем пример линейной интерполяции эталона. Рассмотрим вектор Х=[1;-1;1;1].
yl=((-2)*1)+@*(-1))+@*1)+B*1)=0lsign@)=1l
y2=B*1)+@*(-1))+@*(-D)+((-2)*1)=0lsign@)=1l
y3=@*1)+((-2)*(-1))+((-2)*1)+@*1)=0lsign@)=1.
Заметим, что вектор У=[1;1;1] не соответствует ни одному из эталонов.
Подытожим несколько наблюдений относительно линейных ассоциаторов.
Ожидаемые свойства таких сетей основываются на предположении, что эталонные экземпляры
составляют множество ортонормальных векторов. Это ограничивает их практическую
применимость по двум причинам. Во-первых, может не существовать очевидного
отображения реальной жизненной ситуации в ортонормированный набор векторов. Во-
вторых, количество сохраняемых образов ограничено размерностью векторного
пространства. Если требование ортонормированности нарушается, образы смешиваются в
памяти, что приводит к помехам (crosstalk).
Обратите внимание на то, что линейный ассоциатор восстанавливает эталонный
образ только тогда, когда входной вектор в точности соответствует эталонному. При
отсутствии точного соответствия входного вектора сеть выполняет интерполяционное
отображение. Можно возразить, что интерполяция не является памятью в прямом смысле
этого слова. Зачастую требуется реализовать истинные свойства памяти, когда при
подаче на вход приближенного ключа сеть восстанавливает точный соответствующий ему
эталонный образ. Для этого нужно ввести в рассмотрение аттракторный радиус,
обеспечивающий притяжение векторов из некоторой окрестности.
В следующем разделе описывается аттракторная версия линейной ассоциативной сети.
10.6. Аттракторные сети (сети "ассоциативной памяти")
10.6.1. Введение
До сих пор рассматривались сети прямого распространения информации (feedforward
network). В таких сетях данные поступают на входные нейроны и сигнал распространяется к
последующим слоям до выхода из сети. Еще одним важным классом нейронных сетей явля-
Глава 10. Машинное обучение на основе связей
471
ются сети с обратными связями (feedback network). Архитектура таких сетей отличается тем,
что выходной сигнал передается прямо или косвенно назад, ко входам нейрона.
Отличия сетей с обратными связями от сетей прямого распространения состоят в
следующем.
1. Между нейронами существуют обратные связи.
2. Имеется некоторая временная задержка, т.е. сигнал распространяется не мгновенно.
3. Выходом сети является ее состояние по завершении процесса сходимости.
4. Полезность сети зависит от свойств сходимости.
Когда сеть с обратными связями приходит к неизменному состоянию, такое состояние
называется состоянием равновесия, которое и рассматривается в качестве выхода сети.
В сетях с обратными связями, которые будут рассмотрены в подразделе 10.6.2,
состояния сети инициализируются входным вектором. Сеть обрабатывает этот образ,
передавая его несколько раз от входа к выходу до тех пор, пока не достигнет состояния
равновесия. Состояние равновесия сети — это и есть образ, извлеченный из памяти. В
подразделе 10.6.3 будут рассмотрены сети, реализующие гетероассоциативную память, а в
подразделе 10.6.4 — модели автоассоциативной памяти.
Интересны и важны когнитивные аспекты этих сетей, реализующих модель
контекстно адресуемой памяти. Этот тип ассоциативных связей описывает извлечение из
долговременной памяти номера телефона, чувства досады или даже распознавания человека
по части его фотографии. Исследователи выделяют множество ассоциативных аспектов
этого типа памяти в структурах данных, основанных на символьном описании, включая
семантические сети, фреймы и объектные системы, рассмотренные в главе 6.
Аттрактор (attractor) — это состояние, к которому со временем сходятся другие
состояния из некоторой окрестности. Каждому аттрактору в сети соответствует область,
внутри которой сеть всегда эволюционирует к этому состоянию. Эта область
характеризуется аттракторным радиусом. Аттрактор может содержать одно состояние сети или
несколько состояний, по которым происходит циклическое перемещение.
Попытки понять и математически описать свойства аттракторов привели к
формированию понятия функции энергии сети [Hopfield, 1984]. Сети с обратными связями,
функция энергии которых обладает тем свойством, что любой переход состояний этой сети
приводит к уменьшению сетевой энергии, обязательно сходятся к точке равновесия. Эти
сети будут описаны в подразделе 10.6.3.
Аттракторные сети можно использовать для реализации контекстно адресуемой
памяти, запоминая нужные образы в качестве аттракторов сети. Их также можно
применять для решения задач оптимизации, в том числе для задачи коммивояжера, создавая
отображения функции стоимости в задаче оптимизации в энергию сети. Решение этой
задачи приводит к уменьшению общей энергии сети. Этот тип задач решается с
помощью так называемых сетей Хопфилда.
10.6.2. Двунаправленная ассоциативная память
Двунаправленная ассоциативная память (ДАП), впервые описанная в [Kosko, 1988],
состоит из двух полносвязных слоев обрабатывающих элементов. Может также
существовать обратная связь каждого нейрона с самим собой. Сеть ДАП, отображающая п-
мерный входной вектор Хп в m-мерный выходной вектор Ут, показана на рис. 10.22.
Поскольку связи между нейронами слоев X и У являются двунаправленными, то веса связей
необходимо определять для обоих направлений.
472
Часть IV. Машинное обучение
У\ Уг Ут
x^ х2 хп
Рис. 10.22. Сеть ДАП для примера из
подраздела J0.6.2. Каждый нейрон может
быть связан с самим совой
Подобно весам в линейном ассоциаторе, веса связей в сети ДАП можно вычислить
заранее. Для определения весов используется тот же метод, что и в линейной ассоциативной
модели. Векторы состояний в архитектуре ДАП рассматриваются в хемминговом пространстве.
Пусть даны Л/ пар векторов, составляющих набор эталонов, которые необходимо
сохранить в памяти. Подобно описанной в подразделе 10.5.4 процедуре, веса связей
вычислим следующим образом:
И/=У1*Х1+ У2*Х2+... + У,*Х,.
Это соотношение позволяет вычислить веса связей от слоя X к слою У (см. рис. 10.22).
Например, w32 — это вес связи, ведущий от третьего нейрона слоя X ко второму нейрону слоя У.
Предполагается, что между двумя нейронами существует лишь одна связь. Следовательно,
весовые коэффициенты связи между слоями X и У одинаковы в обоих направлениях, т.е.
матрица весов связей, ведущих от слоя У к слою X, является транспонированной матрицей W.
Сеть ДАП можно рассматривать как автоассоциативную модель, если набор
ассоциаций имеет вид <XlyX,i>,<X2yX'2>. ••• Поскольку в этом случае слои X и У идентичны, слой
У можно вообще исключить (рис. 10.23). Пример автоассоциативной сети будет
рассмотрен в подразделе 10.6.4.
Рис 10.23. Автоассоциативная сеть со входным
вектором I, Предполагается, что между каждыми двумя
нейронами существует одна связь, так что Wjj=Wjj и
матрица весовых коэффициентов симметрична
Сеть ДАП используется для извлечения из памяти образов при подаче входного
образа на вход слоя X. Если входной образ зашумлен или неполон, то сеть ДАП зачастую
может восполнить этот образ и извлечь из памяти связанный с ним вектор.
Глава 10. Машинное обучение на основе связей
473
Чтобы извлечь данные из памяти сети ДАП, нужно выполнить следующие действия.
1. В нейронную сеть передается исходная пара векторов (X, У), где X — это образ, для
которого нужно восстановить связанный с ним эталон, а У— случайно заданный
вектор.
2. Информация распространяется от слоя X к слою У, и вычисляются значения
нейронов слоя У.
3. Выходные значения нейронов слоя У передаются на вход слоя X, и вычисляются
значения нейронов этого слоя.
4. Два предыдущих действия продолжают выполняться до тех пор, пока состояние
сети не стабилизируется, т.е. значения векторов X и У перестанут изменяться.
Указанный алгоритм описывает распространение информации в сети ДАП в обоих
направлениях до достижения точки равновесия. Работу алгоритма можно начинать с
передачи в сеть значений слоя У, тогда после сходимости можно получить значение
вектора X. Эта сеть в полном смысле является двунаправленной: в качестве входа можно
использовать вектор X и вычислять ассоциированный с ним вектор У, а можно на
основании вектора У определять значение вектора X. Пример такой сети будет рассмотрен в
следующем разделе.
После сходимости процесса обработки состояние равновесия представляет собой
один из эталонов, использованных для построения исходной матрицы весов. На вход
сети подается вектор с известными свойствами: либо идентичный одному из векторов
эталонной пары, либо слегка отличный от него. Этот вектор используется для
восстановления второго вектора из эталонной пары. В качестве расстояния выбирается хеммингово
расстояние, измеряемое как количество различающихся элементов векторов. Благодаря
свойству ортонормированности сходимость сети ДАП к одному вектору означает также
сходимтость к его дополнению. Следовательно, вектор дополнения тоже становится
аттрактором сети. Пример этой ситуации будет рассмотрен в следующем разделе.
Сходимость сети ДАП определяется несколькими факторами. Если в матрице
весов сохранено слишком много эталонов, то они оказываются очень близки друг к
другу, что приводит к появлению псевдоустойчивых состояний в сети. Этот
феномен получил название помех, которые приводят к появлению локальных минимумов
в пространстве энергии сети.
Давайте кратко остановимся на обработке информации в сети ДАП. Умножая
входной вектор на матрицу связей, получим входные значения элементов второго слоя.
Простая пороговая функция приводит полученный результат к виду, необходимому для
хранения вектора в хемминговом пространстве.
net (У) = WXt или для каждого элемента у, net(yj = Iw/;*xr
Аналогичное соотношение справедливо для вычисления значения нейронов слоя X.
Пороговая функция в момент времени f+1 имеет вид
+1, если net>Ot
f(netM) = \f(nett), если net = Ot
-1, если net<0.
В следующем разделе будет рассмотрено несколько примеров работы
двунаправленной ассоциативной памяти.
474
Часть IV. Машинное обучение
10.6.3. Примеры обработки данных в сети ДАП
На рис. 10.24 показана небольшая сеть ДАП, которая является одним из простейших
вариантов линейного ассоциатора, представленного в подразделе 10.5.4. Эта сеть
выполняет отображение четырехмерного вектора X в трехмерный вектор У и наоборот.
Допустим, требуется запомнить в сети две пары эталонов
X=[^\-^\-^\-^]^Y=[^\^\^]1
Х2=[-1;-1;-1;1]оУ2=[1;-1;1].
Веса для
i вычисления
У на основе X
1
1
1
-1
-1
-1
-1 -1
-1 -1
-1 -1
+
-1
1
-1
-1
1
-1
-1
1
-1
1
-1
1
=
0
2
0
-2
0
-2
-2
0
-2
0
-2
0
Веса для
вычисления
Хна основе Y
Рис. 10.24. Сеть ДАП для примеров из подраздела 10.6.3
Построим матрицу весов согласно формуле, приведенной в предыдущем разделе
W = YtX\ + Y2Xt2 + YX+... + YNXtN,
W =
Матрица весовых коэффициентов связей слоя У со слоем X представляет собой
транспонированную матрицу для W и имеет вид
0 2 0'
-2 0 -2
-2 0 -2
0 -2 0
Выберем несколько векторов и протестируем работу сети ДАП. Сначала возьмем
одну из эталонных пар, подадим на вход сети вектор X и проверим, получится ли на выходе
сети вектор У. Пусть Х= [ 1; -1; -1; -1 ]. Тогда
yl=A*0)+((-1)*(-2))+((-1)*(-2)) + ((-1)*0)=4IfD) = 1I
y2=A*2)+((-1)*0)+((-1)*0)+((-1)*(-2))=4IfD) = 1I
y3=A*0)+((-1)*(-2))+((-1)*(-2)) + ((-1)*0)=4IfD) = 1.
Итак, получен второй вектор из эталонной пары. Читатель может взять этот вектор У
в качестве входного и убедиться, что на выход будет получен вектор Х= [1 ;-1 ;-1 ;-1 ].
В качестве следующего примера рассмотрим Х=[1; 1; 1;-1], а элементы вектора У
инициализируем произвольным образом. В этом случае сеть выдаст результат
y1 = A*0)+A*(-2))+A*(-2))+((-1)*0)=-4If(-4)=-1I
y2=A*2)+A*0)+A*0)+((-1)*(-2))=4IfD) = 1I
y3=A*0)+A*(-2))+A*(-2)) + ((-1)*0)=-4If(-4)=-1.
Глава 10. Машинное обучение на основе связей
475
Этот результат получен с учетом того, что для векторного аргумента [-4; 4; -4]
значение пороговой функции равно [-1; 1; -1]. Вычислим значение компонентов вектора X.
х1=((-1)*0LA*2)+((-1)*0)=21
x2=((-D*(-2))+A*0)+((-1)*(-2))=4I
х3=((-1)*(-2))+A*0)+((-1)*(-2))=41
х4=((-1)*0)+A*(-2))+((-1)*0)=-2.
После применения пороговой функции получим исходный вектор [1; 1; 1;-1].
Поскольку при обработке этого вектора получается устойчивый результат, может
показаться, что мы выявили еще одну пару эталонных векторов. Однако на самом деле
рассмотренный пример является дополнением ко второй паре эталонов <Х2, Y{>. Это еще раз
подтверждает, что в сети ДАП для каждой пары прототипов ее дополнение тоже
является эталоном. Следовательно, в сети ДАП записаны еще два прототипа
Хз=[-1;1;1;1]<->Уз=[-1;-1;-1],
Х4=[1;1;1;-1]<->У4=[-1;1;-1].
Выберем вектор из окрестности одного из эталонов, например Х=[1; -1; 1; -1].
Заметим, что хеммингово расстояние от этого вектора до ближайшего эталона составляет 1.
Инициализируем случайным образом вектор У=[-1;-1;-1]. Вычислим значения
нейронов второго слоя сети
уГ=A*0) + ((-1)*(-2)) + A*(-2)) + ((-1)*0) = 0,
уГ1=(Г2) + ((-1)*0) + (Г0) + ((-1)*(-2)) = 4,
уГ=0*0) + ((-1)*(-2)) + A*(-2)) + ((-1)*0) = 0.
Напомним, что по определению пороговой функции, приведенному в конце
подраздела 10.6.2, для у\ = 0 f(yl+l) = f(y'j). Поскольку первый и третий элементы вектора Y
были инициализированы случайным образом значением -1, то У=[-1; 1; -1]. Теперь
снова вычислим значение X.
х1=((-1)*0)+A*2)+((-1)*0)=21
х2=((-1)*(-2))+A*0)+((-1)*(-2))=41
х3=((-1)*(-2))+A*0)+((-1)*(-2))=41
x4=((-D*0)+A*(-2))+((-1)*0)=-2.
Применяя пороговую функцию, получим вектор Х=[1; 1; 1; -1]. Повторяя этот
процесс, снова вычислим вектор У
У1=A*0)+A*(-2))+A*(-2)) + ((-1)*0)=-41
У2=A*2) + A*0)+A*0)+((-1)*(-2))=41
Уз=A*0) + A*(-2))+A*(-2)) + ((-1)*0)=-4.
В результате применения пороговой функции получим У=[-1;1;-1]. Этот вектор
идентичен предыдущему, следовательно, сеть перешла в устойчивое состояние. Таким
образом, после двух проходов по сети ДАП ближайший к Х4 образ совпал с сохраненным
в сети эталоном. Точно так же можно восстановить изображение лица или любое другое
изображение при отсутствии или искажении части информации. Хеммингово расстояние
между исходным вектором Х=[1; -1; 1; -1] и прототипом Х4=[1; 1; 1; -1] равно 1.
Поэтому неудивительно, что сеть пришла к состоянию <Х4, Y4 >.
В рассмотренном примере обработка данных начиналась с вектора X. Естественно, можно
действовать и в обратном направлении, восстанавливая вектор X по исходному вектору У.
476
Часть IV. Машинное обучение
В работе [Hecht-Nielsen, 1990] приводятся интересные результаты анализа сети ДАП.
Там показано, что свойство ортонормальности, необходимое для линейной ассоциативной
сети, для сети ДАП является слишком ограничительным. Автор показывает, что для
построения сети требуется лишь линейная независимость векторов, чтобы ни один из
векторов в пространстве эталонов не представлял собой линейную комбинацию других.
10.6.4. Автоассоциативная память и сети Хопфилда
Нейросетевые архитектуры получили всеобщее признание во многом благодаря
исследованиям Джона Хопфилда, физика из Калифорнийского технологического
института. Он изучал свойства сходимости сетей на основе принципа минимизации энергии, а
также разработал на основе этого принципа семейство нейросетевых архитектур. Как
физик Хопфилд рассматривал вопросы устойчивости физических объектов с точки
зрения минимизации энергии физической системы. Примером такого подхода является
моделирование отжига и охлаждения металлов.
Рассмотрим сначала основные характеристики ассоциативных сетей с обратными
связями. Начальным состоянием таких сетей является подаваемый на вход вектор. Сеть
обрабатывает этот сигнал с использованием обратных связей до тех пор, пока не
достигнет устойчивого состояния. Для того чтобы такую архитектуру можно было
использовать в качестве модели ассоциативной памяти, необходимо обеспечить выполнение двух
свойств. Во-первых, необходимо гарантировать переход сети в некоторое устойчивое
состояние из любого начального состояния. Во-вторых, это устойчивое состояние должно
быть ближайшим ко входному вектору в некоторой метрике.
Сначала рассмотрим автоассоциативную сеть, построенную на тех же принципах, что
и сеть ДАП. В предыдущем разделе было отмечено, что сети ДАП можно
трансформировать в модели автоассоциативной памяти, если в качестве X и У выбирать идентичные
векторы. В результате такого выбора, как будет ясно из дальнейшего, квадратная
матрица весов становится симметричной. Пример такой ситуации показан на рис. 10.23 и
описан в подразделе 10.6.2.
Матрица весов для автоассоциативной сети, в которой хранится набор эталонных
векторов {Х\, Х2, ... ,Х„}, создается по правилу
и/=£х,х,г.
1
При создании автоассоциативной памяти на основе гетероассоциативной вес связи от
узла х, к узлу х; равен весу связи от х; к х„ т.е. матрица весовых коэффициентов является
симметричной. Для выполнения этого предположения требуется лишь, чтобы между
двумя элементами сети существовала единственная связь с фиксированным весом.
Возможен также особый случай, когда ни один из узлов сети не связан напрямую сам с
собой, т.е. связь между х, и х, отсутствует. При этом на главной диагонали матрицы
весовых коэффициентов будут располагаться нули.
Как и при работе с сетью ДАП, матрица весов строится на основе запоминаемых в
памяти образов. Продемонстрируем это на простом примере. Рассмотрим три
эталонных вектора
Х2=[-1;1;1;-1;-1],
Х3=[1;1;-1;1;1].
Глава 10. Машинное обучение на основе связей
477
Вычислим матрицу весов по формуле И/ = ^Х,Х,Г
W =
или
1
-1
1
-1
1
3
-1
-1
1
3
-1
1
-1
1
-1
-1
3
-1
1
-1
1
-1
1
-1
1
-1
-1
3
-3
-1
-1
-1
-1
1
1
-3
3
1
-1
-1
3
-1
-1
1
3
+ -1 1 1 -1 -1 + -1 -1 1-1-1
w =
Будем использовать пороговую функцию
[+1, если net>Ot
f(nefr+1) = |f(nefr), если net = Ot.
[-1, если net<0.
Сначала проверим результат работы сети для одного из эталонов Х3= [1;1;-1;1;1].
Получаем
Х3* W= [7; 3; -9; 9; 7],
а после применения пороговой функции приходим к состоянию [ 1; 1; -1; 1; 1 ]. Таким
образом, при подаче в сеть этого вектора она сразу же сходится к нему. Это значит, что
эталоны сами являются устойчивыми состояниями, или аттракторами.
Теперь проверим следующий вектор, хеммингово расстояние от которого до эталона
Х3 равно единице. Сеть должна сойтись к этому эталону. Это означает извлечение из
памяти образа по частично искаженным данным. Выберем Х= [ 1; 1; 1; 1; 1 ]:
X* W= [5; 1; -3; 3; 5].
После применения пороговой функции приходим к вектору Х3 = [ 1; 1; -1; 1; 1 ].
Рассмотрим третий пример, выбрав на этот раз вектор, расстояние от которого до
ближайшего прототипа равно 2, допустим, Х=[1; -1; -1; 1; -1]. Не сложно убедиться,
что этот вектор находится на расстоянии 2 от вектора Х3, на расстоянии 3 от вектора Xt и
4 от Х2. Вычислим произведение
Х*и/=[3;-1; -5;5;3],
а после применения пороговой функции получим [ 1; -1; -1; 1; 1 ]. Это состояние не
является устойчивым, поэтому вычислим
[1;-1;-1; 1; 1] * И/= [9;-3;-7; 7; 9],
а с учетом порога получим [ 1; -1; -1; 1; 1 ]. Теперь это состояние оказалось
устойчивым, но оно не совпадает ни с одним из исходных образов. Возможно, это еще один
минимум функции энергии? Однако при ближайшем рассмотрении видно, что этот вектор
478
Часть IV. Машинное обучение
является дополнением к исходному прототипу Х2=[-1; 1; 1; -1; -1 ]. Как и в гетероассо-
циативной сети ДАП, аттракторами автоассоциативной сети являются как исходные
прототипы, так и их дополнения, т.е. в данном случае сеть имеет шесть аттракторов.
До сих пор рассматривались автоассоциативные сети, основанные на линейной
ассоциативной модели памяти. Одной из целей Джона Хопфилда было создание общей
теории автоассоциативных сетей, применимой к любой однослойной сети с обратными
связями, которая удовлетворяет набору простых ограничений. Хопфилд доказал, что для
этого класса однослойных сетей с обратными связями всегда существует функция
энергии сети, обеспечивающая ее сходимость к устойчивому состоянию.
Еще одной целью Хопфилда было распространение дискретной модели на вариант
непрерывного времени, более точно соответствующий условиям функционирования
реальных нейронных сетей. Типичный способ моделирования непрерывного времени в
сетях Хопфилда сводится к последовательной, а не послойной обработке узлов. Это
делается с помощью процедуры случайного выбора обрабатываемого нейрона с
одновременным применением некоторого метода, позволяющего убедиться в равномерности
обработки всех нейронов сети.
Структура сети Хопфилда идентична рассмотренной выше архитектуре
автоассоциативной памяти. Она состоит из одного слоя связанных между собой нейронов (см.
рис. 10.23). Функция активации, или пороговая функция, тоже совпадает с
рассмотренной. Следовательно, для /-го узла
+1, если Y,wijxj'd>Ti
i
x°ldt если ^МцХ?*^.
j
-1, если YsWnxT<T>
i
При такой архитектуре для получения сети Хопфилда необходимо обеспечить лишь
одно дополнительное ограничение. Если w^ — это вес связи от узла / к узлу у, то весовые
коэффициенты в сети Хопфилда должны удовлетворять условию
\л/п=0 \//,ил= wn V/, у, \ф\.
Для обучения сети Хопфилда не существует никаких специальных методов. Подобно
сети ДАП, ее веса обычно вычисляются заранее.
На сегодняшний день поведение сетей Хопфилда, как и персептронов, изучено
гораздо лучше, чем свойства других классов сетей. Это связано с тем, что поведение сетей
Хопфилда описывается в терминах функции энергии
» i »
Покажем, что благодаря свойствам этой функции любое изменение состояний сети
приводит к уменьшению общей энергии сети. Учитывая факт существования минимума
функции И и уменьшения значения функции при каждом изменении состояния сети, не
сложно прийти к выводу, что сеть будет сходиться из любого начального состояния.
Сначала покажем, что для любого обрабатывающего элемента к изменение его состояния
приводит к уменьшению значения функции Н. Вычислим величину изменения энергии АН
AH=H(Xnew)-H(X0,d).
Глава 10. Машинное обучение на основе связей
479
Учитывая определение функции Н, получим
ан=-ХЕ^ХГ"ХГ"+2Е7лпе" +yLHwXdxJld -2YJix°
I I I J
^new _ „old
Поскольку для i=k x°ew = x, , то слагаемые, не содержащие хк, можно исключить.
Получим
АН = -2xnkewJ^w^x™ +2ТкхпГ + 2x°kldl£wkJx°ld W •
У У
Учитывая тот факт, что iv,,=0 и и^=1У,„ приходим к соотношению
ДЯ = 2(хкоИ-хГ')|
>**Г
Чтобы показать отрицательность АН, рассмотрим два случая. Сначала предположим,
что значение хк изменилось с -1 на +1. Тогда множитель в квадратных скобках должен
быть положительным. Поскольку xkd -xnkew =-2 , то АН отрицательно. Теперь
предположим, что значение х* изменилось с 1 на -1. Тогда по тем же причинам АН отрицательно.
Если жехк не изменялось, то xkd -xkew = 0 и АН= 0.
Отсюда следует, что сеть должна сходиться из любого начального состояния. Более
того, состояние сети после сходимости соответствует локальному минимуму энергии.
Если это состояние еще не достигнуто, значит, существует переход, приводящий к
дальнейшему уменьшению общей энергии сети, и согласно алгоритму обучения для
модификации выбирается именно этот узел.
Было показано, что сети Хопфилда обладают одним из двух свойств, которыми
должны обладать сети ассоциативной памяти. Однако можно показать, что сети
Хопфилда в целом не удовлетворяют второму свойству: они не всегда сходятся к
устойчивому состоянию, которое является ближайшим к исходному. Для решения этой проблемы
не существует общего метода.
Сети Хопфилда также можно применять для решения задач оптимизации, в том числе
задачи коммивояжера. Для этого разработчик должен определить отображение функции
стоимости этой задачи в функцию энергии Хопфилда. Тогда переход к минимум энергии
сети приведет также к минимизации стоимости в соответствии с состоянием данной
задачи. Хотя для многих интересных задач, в том числе для задачи коммивояжера, такое
отображение удалось построить, в целом построение отображения из пространства
данных задачи в функцию энергии — очень сложная проблема.
В этом разделе рассмотрены гетероассоциативные и автоассоциативные сети с
обратными связями. Проанализированы динамические свойства этих сетей и предложены
очень простые примеры, отражающие эволюцию состояний систем к своим аттракторам.
Было показано, как линейную ассоциативную сеть можно модифицировать в аттрактор-
ную есть ДАП. При обсуждении сетей Хопфилда, функционирующих в непрерывном
времени, было продемонстрировано, как поведение сети можно описать в терминах
функции энергии. Класс сетей Хопфилда обладает гарантированной сходимостью,
поскольку каждый переход в такой сети уменьшает общую энергию сети.
Однако основанный на энергии подход к изучению сетей связей все же не
позволяет решить некоторых проблем. Во-первых, достигнутое состояние энергии не
обязательно соответствует глобальному минимуму для данной системы. Во-вторых, сети
Хопфилда не обязательно сходятся к аттрактору, ближайшему к данному входному
480
Часть IV. Машинное обучение
вектору. С этим связано неудобство их использования для реализации контекстно
адресуемой памяти. В-третьих, при использовании сетей Хопфилда для решения задач
оптимизации не существует общего метода построения отображения ограничений в
функцию энергии Хопфилда. И, наконец, существует предельное значение общего
количества минимумов энергии, которые можно сохранить в сети и извлечь из нее, и это
число нельзя установить точно. Эмпирическое тестирование таких сетей показывает,
что количество аттракторов составляет лишь малую часть общего числа узлов в сети.
Этот и другие связанные с ним вопросы активно изучаются в работах [Hecht-Nielsen,
1990], [Zurada, 1992] и [Freeman, Skapura, 1991].
В рамках таких биологических подходов, как генетические алгоритмы и клеточные
автоматы, предпринимаются попытки построить модели обучения на принципах
эволюции форм жизни. Обработка данных в этих моделях тоже является параллельной и
распределенной. Например, в генетических алгоритмах кандидатом на роль решения задачи
является целая популяция образов. В процессе работы алгоритма эта популяция
эволюционирует с учетом принципов воспроизводства, мутации и естественного отбора. Эти
подходы рассматриваются в главе 11.
10.7. Резюме и дополнительная литература
В этой главе были рассмотрены вопросы обучения в сетях связей. В разделе 10.1 они
описаны с исторической точки зрения. Для более подробного ознакомления с этими
вопросами мы рекомендуем ознакомиться с работами [McCulloch, Pitts, 1943], [Selfridge, 1959],
[Shannon, 1948], [Rosenblatt, 1958]. Важно также изучить физиологические модели, особенно
предложенные Дональдом Хеббом [Hebb, 1949]. Наука о познании продолжает исследовать
взаимосвязи между обучением и структурой мозга. Эти вопросы описаны в [Ballard, 1997],
[Franklin, 1995], [Jeannerod, 1997] и [Elman и др., 1996].
За рамками рассмотрения остались многие важные математические и
вычислительные аспекты сетей связей, описанные в работах [Hecht-Nielsen, 1990], [Zurada, 1992] и
[Freeman, Skapura, 1991].
Специалисты по машинному обучению должны рассматривать и множество других
вопросов, связанных как с представлением, так и с реализацией вычислений. К числу
этих проблем относятся выбор архитектуры и структуры связей сети, определение
параметров обучения и множество других. Существуют так называемые нейро-символьные
гибридные системы, которые тоже могут отражать различные аспекты интеллекта.
Сеть прямого распространения — одна из наиболее распространенных нейросетевых
архитектур. Поэтому в этой главе достаточно много внимания уделялось ее истокам,
использованию и развитию. Введение в теорию нейронных сетей, а также информация о
вычислительных средствах обучения содержится в двухтомнике [Rumelhart и др., 19865].
Этому же вопросу посвящена работа [Grossberg, 1988].
При использовании сетей прямого распространения возникает множество других
вопросов, в том числе проблема выбора количества скрытых слоев и нейронов,
формирования обучающего множества, настройки коэффициентов обучения, использования
пороговых нейронов и т.д. Многие из этих вопросов входят в общее понятие индуктивного
порога, определяющего роль знаний, наблюдений и средств, используемых для решения
задачи. Многие их этих вопросов рассматриваются в главе 16.
Большинство разработчиков нейросетевых архитектур описали их в своих работах
[Anderson и др., 1977], [Grossberg, 1976, 1988], [Hinton и др., 1986], [Hecht-Nielsen, 1989,
1990], [Hopfield, 1982, 1984], [Kohonen, 1972, 1984], [Kosko, 1988] и [Mead, 1989]. Более
Глава 10. Машинное обучение на основе связей
481
современные подходы, в том числе графические модели, описаны в работах [Jordan, 1999],
[Frey, 1998]. Можно порекомендовать и хороший современный учебник [Bishop, 1995].
10.8. Упражнения
1. Постройте нейрон Мак-Калока-Питтса, вычисляющий функцию логического
следования =>.
2. Постройте персептронную сеть на языке LISP и реализуйте в ней пример задачи
классификации, описанный в подразделе 10.2.2.
2.1. Сгенерируйте свой набор данных, аналогичный представленному в табл. 10.3, и
используйте его для решения задачи классификации.
2.2. Воспользуйтесь результатами работы классификатора и весами связей для
определения специфики разделяющей линии.
3. Реализуйте сеть прямого распространения на языке LISP или C++ и используйте ее
для решения задачи "исключающего ИЛИ", описанной в подразделе 10.3.3. Решите
эту задачу с помощью нескольких сетей различной архитектуры, например, сети с
двумя скрытыми узлами без пороговых нейронов. Сравните скорость сходимости
разных сетевых архитектур.
4. Реализуйте сеть Кохонена на языке LISP или C++ и используйте ее для решения
задачи классификации данных из табл. 10.3. Сравните полученные результаты с
описанными в подразделах 10.2.2 и 10.4.2.
5. Реализуйте сеть встречного распространения и используйте ее для решения задачи
"исключающего ИЛИ". Сравните полученные результаты с данными для сети
прямого распространения, приведенными в подразделе 10.3.3. Используйте свою сеть
встречного распространения для разделения классов из табл. 10.3.
6. С помощью сети прямого распространения решите задачу распознавания десяти
рукописных цифр. Для этого можно размещать цифры в сетке размером 4x6. Если
фрагмент цифры попадает на данную клетку, присвойте ей значение 1, если нет —
значение 0. Этот вектор из двадцати четырех элементов можно использовать в
качестве входного вектора сети. Для построения обучающего множества можете
воспользоваться и другим подходом. Решите эту же задачу с помощью сети встречного
распространения. Сравните полученные результаты.
7. Выберите входной образ, отличный от использованного в подразделе 10.5.2, и
примените метод обучения Хебба без учителя для распознавания этого образа.
8. В подразделе 10.5.4 для создания ассоциаций между двумя парами векторов
использован линейный ассоциатор. Выберите три новые пары векторов и решите эту же
задачу. Проверьте, обладает ли ваш линейный ассоциатор свойством интерполятивно-
сти, т.е. может ли он находить близкие к эталону векторы? Постройте
автоассоциативный линейный ассоциатор.
9. Вспомните сеть ДАП, описанную в подразделе 10.6.3. Измените пары ассоциаций,
выбранные в этом разделе, и постройте для них матрицу весов. Выберите новые
векторы и протестируйте свою сеть ДАП.
10. Опишите различия между сетью ДАП и линейным ассоциатором. Что такое помехи и
как предотвратить их появление?
11. Постройте сеть Хопфилда для решения задачи коммивояжера для десяти городов.
482
Часть IV. Машинное обучение
Машинное обучение
на основе
социальных
и эмерджентных
принципов
Как можно ограничить эту энергию, действующую в течение долгих веков и
строго изучающую общую организацию, структуру и привычки каждого существа —
благословляющую на добро и отсекающую зло? Я не вижу границ этой энергии,
которая медленно, но верно адаптирует каждое создание
к самым сложным жизненным отношениям.
— Чарльз Дарвин (Charles Darwin), О происхождении видов
Первый закон пророчества:
"Когда признанный пожилой ученый утверждает, что нечто возможно, он почти всегда
прав. Если он утверждает, что нечто невозможно, он, вероятнее всего, ошибается."
Второй закон:
"Единственный способ постичь границы возможного —
отважиться на небольшой шаг за его пределы. "
Третий закон:
"Любая достаточно развитая технология неотличима от магии. "
— Артур Кларк (Arthur С. Clarke), Профили будущего
11.0. Социальные и эмерджентные модели обучения
На ранних этапах развитие сетей связей во многом было обусловлено целью создания
искусственной нервной системы. Однако это не единственный биологический прототип для
разработки алгоритмов машинного обучения. В этой главе рассматриваются алгоритмы
обучения, основанные на принципах биологической эволюции: выживании сильнейших
особей популяции в процессе ее развития. Роль отбора сильнейших представителей
популяции ярко проявляется на примере эволюции видов, а также в социальных процессах, при-
водящих к изменению и формированию культуры. Эти процессы были формализованы с
помощью теории клеточных автоматов, генетических алгоритмов, генетического
программирования, искусственной жизни и других форм эмерджентных вычислений.
Эмерджентные, или проявляющиеся, модели (emergent model) обучения имитируют
наиболее элегантную и мощную форму адаптации — эволюцию форм жизни
растительного и животного мира. Как отметил Чарльз Дарвин, нет "границ этой энергии, которая
медленно, но верно адаптирует каждое создание к самым сложным жизненным
отношениям". В процессе простого варьирования некоторых свойств наиболее жизнеспособных
поколений и выборочного отсева менее удачных экземпляров повышаются
адаптационные способности и проявляются отличия между особями популяции. Эволюция и
зарождение новых свойств происходят в популяциях материальных особей, которые
действуют друг на друга и подвергаются внешнему воздействию. Таким образом, необходимость
отбора исходит не только из внешней среды, но и от взаимодействия между членами
популяции. Экосистема включает множество членов, кумулятивное поведение которых
формирует оставшуюся часть популяции и формируется под ее воздействием.
Простота процессов, лежащих в основе эволюции, обеспечивает их достаточно общее
обоснование. Виды создаются в процессе биологической эволюции за счет отбора наиболее
благоприятных изменений генома. Аналогично в процессе культурной эволюции при
передаче социально обработанных и модифицированных единиц информации формируются знания.
Генетические алгоритмы и другие формальные эволюционные аналоги обусловливают более
точное решение задачи за счет операций над популяциями кандидатов на роль решения.
Генетический алгоритм решения задачи включает три стадии, первая из которых
предполагает представление отдельных потенциальных решений в специальном виде,
удобном для выполнения эволюционных операций изменения и отбора. Зачастую таким
представлением являются обычные битовые строки. На второй стадии реализуются
скрещивание и мутации, присущие биологическим формам жизни, в результате которых
появляется новое поколение особей с рекомбинированными свойствами своих
родителей. И наконец на основе некоторого критерия отбора (fitness function) выбираются
"лучшие" формы жизни, т.е. наиболее точно соответствующие решению данной
проблемы. Эти особи отбираются для выживания и воспроизведения, т.е. для формирования
нового поколения потенциальных решений. В конечном счете некоторое поколение особей
и станет решением исходной задачи.
В генетических алгоритмах применяются и более сложные представления, в том
числе правила вывода, эволюционирующие в процессе взаимодействия с внешней средой.
Например, в генетическом программировании за счет комбинирования и "мутации"
фрагментов программного кода программа эволюционирует и сходится к решению
задачи, например к выделению инвариантного множества.
Примеры обучения, представляющего собой социальное взаимодействие с целью
выживания, можно найти в таких играх, как "Жизнь". Эта игра изначально была
разработана математиком Джоном Хортоном Конвеем (John Horton Conway) и представлена
широкой общественности Мартином Гарднером в журнале "Scientific American" в 1970 и
1971 годах. В этой игре рождение, жизнь и смерть особей — это функция их
собственного состояния и состояния их ближайших соседей. Обычно для определения игры
достаточно небольшого количества правил — трех или четырех. Как показали эксперименты с
игрой "Жизнь", несмотря на эту простоту, в ее рамках могут эволюционировать
чрезвычайно сложные структуры, в том числе многоклеточные организмы, имеющие функцию
саморепликации [Poundstone, 1985].
484
Часть IV Машинное обучение
Один из важных подходов к искусственной жизни (artificial life) состоит в
моделировании условий биологической эволюции за счет взаимодействия конечных автоматов,
заданных наборами состояний и правил перехода. Эти автоматы могут принимать
информацию из внешней среды, в частности, от ближайших соседей. Правила переходов
содержат инструкции по рождению, продолжению жизни и смерти. Если популяция
таких автоматов свободно действует в своей предметной области, и ее особи могут
взаимодействовать как параллельные асинхронные агенты, то иногда можно наблюдать
эволюцию практически независимых "форм жизни".
Можно привести еще один пример. В работах [Brooks, 1986, 1987] описаны простые
роботы, действующие как автономные агенты, способные решать задачи в лабораторных
условиях. При этом центральный алгоритм управления отсутствует, а кооперация
отдельных особей становится артефактом распределенного и автономного поведения
каждого из них. Сообщество ученых, работающих в области искусственной жизни,
регулярно проводит конференции и выпускает журнал, на страницах которого обсуждаются
новейшие результаты в этой области [Langton, 1995].
В разделе 11.1 вводятся эволюционные модели и описываются генетические
алгоритмы (genetic algorithm) [Holland, 1975] — подход к обучению на основе параллелизма,
общего взаимодействия и, как правило, битового представления. В разделе 11.2
представлены системы классификации (classifier system) и генетического программирования
(genetic programming) — сравнительно новые области исследования, в которых
методология генетических алгоритмов применяется для решения более сложных задач, в
частности, для построения и уточнения наборов правил вывода [Holland и др., 1986], а также
для создания и настройки компьютерных программ [Koza, 1992]. В разделе 11.3
представлена методология искусственной жизни [Langton, 1995]. Этот раздел начинается со
знакомства с игрой "Жизнь". В завершение раздела приводится пример "эмерджентного
поведения", описанный в [Crutchfield и Mitchell, 1995].
11.1. Генетические алгоритмы
Подобно нейронным сетям, генетические алгоритмы основываются на свойствах
биологического прототипа. В рамках этого подхода обучение рассматривается как
конкуренция внутри популяции между эволюционирующими кандидатами на роль решения
задачи. Каждое решение оценивается согласно критерию отбора. По результатам оценки
определяется, будет ли этот экземпляр участвовать в следующем поколении решений.
Затем с помощью операций, аналогичных трансформации генотипа в процессе
биологического воспроизводства, создается новое поколение решений-кандидатов.
Пусть Р( X) — поколение решений-кандидатов х\ в момент времени t
Ра) = {х\,х<2,...х'п).
В общем виде генетический алгоритм можно представить следующим образом.
procedure genetic algorithm;
begin
установить f: = 0;
инициализировать популяцию P(t)\
while не достигнуто условие завершения
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 485
begin
вычислить значение критерия качества для каждого члена
популяции P(t);
на основе значений критерия качества выбрать из P(t) нужное
число членов;
создать следующее поколение с помощью генетических операций;
заменить с учетом значений критерия качества особей
популяции P(t) их потомками;
установить время f: = f+1
end
end.
Этот алгоритм отражает основные принципы генетического обучения. Его
конкретные реализации могут отличаться в зависимости от задачи. Какое процентное
соотношение особей выживает в следующем поколении? Сколько особей участвуют в
скрещивании? Как часто и к кому применяются генетические операторы? Процедуру "заменить
особей популяции P(f)" можно реализовать простейшим образом, заменив
фиксированное процентное соотношение слабейших кандидатов. Более сложный подход
состоит в упорядочении популяции согласно критерию качества и удалении особей с
учетом вероятности, обратно пропорциональной значению критерия качества. Такую
меру можно использовать для выбора исключаемых особей. И хотя для наилучших
особей популяции вероятность их исключения очень низка, все же существует шанс
удаления самых "сильных" особей популяции. Преимущество этой схемы состоит в
возможности сохранения некоторых "слабых" особей, которые в дальнейшем могут
внести свой вклад в получение более точного решения. Такой алгоритм замены
известен под многими именами, в том числе как метод Монте-Карло (Monte-Carlo),
правило рулетки (roulette wheel) или алгоритм отбора пропорционально критерию
качества (fitness proportionate selection).
Несмотря на то что в подразделе 11.1.3 вводится более сложный принцип
представления, при изучении генетических алгоритмов решение задачи будем описывать с
помощью обычных битовых строк. Предположим, что необходимо с помощью генетического
алгоритма научиться классифицировать строки, состоящие из единиц и нулей. В такой
задаче популяцию битовых строк можно описывать с помощью шаблона, состоящего из
1, 0 и символов #, которые могут соответствовать как 1, так и 0. Следовательно, шаблон
1##00##1 представляет все восьмибитовые строки, начинающиеся, заканчивающиеся 1 и
содержащие в середине строки два нуля подряд.
При работе генетического алгоритма популяция кандидатов Р( 0) некоторым образом
инициализируется. Обычно инициализация выполняется с помощью датчика случайных
чисел. Для оценки решений-кандидатов вводится критерий качества f{x]),
определяющий меру соответствия каждого кандидата в момент времени Г. При классификации
мерой соответствия кандидатов является процентное соотношение правильных ответов на
множестве обучающих примеров. При таком критерии качества каждому решению-
кандидату соответствует значение
f(x])/m (P, f),
где т(Р, t) — среднее значение критерия качества для всех членов популяции. Обычно
мера соответствия изменяется во времени, поэтому критерий качества может быть
функцией от стадии решения всей проблемы или f(x]).
486
Часть IV. Машинное обучение
После анализа каждого кандидата выбираются пары для рекомбинации. При этом
используются генетические операторы, в результате выполнения которых новые решения
получаются путем комбинации свойств родителей. Как и в естественном процессе
эволюции, степень участия в репродуктивном процессе для каждого кандидата определяется
значением критерия качества: кандидаты с более высоким значением критерия качества
участвуют в процессе воспроизводства с более высокой вероятностью. Как уже отмечалось,
выбор осуществляется на основе вероятностных законов, когда слабые члены популяции
имеют меньшую вероятность воспроизводства, однако такая возможность не исключается.
Выживание некоторых слабейших особей имеет важное значение для развития популяции,
поскольку они могут содержать некоторые важные компоненты решения, например,
фрагмент битовой строки, которые могут извлекаться при воспроизводстве.
Существует множество генетических операторов получения потомства,
обладающего свойствами своих родителей. Наиболее типичный из них называется
скрещиванием (crossover). При скрещивании два решения-кандидата
делятся на несколько частей и обмениваются этими частя- D Л
м Входные битовые строки:
ми, результатом становятся два новых кандидата. На
рис. 11.1 показана операция скрещивания шаблонов бито- 11 #0:101 # #110:#0#1
вых строк длины 8. Эти строки делятся на две равные час- \ \ \ /
, Результирующие битовые строки:
ти, после чего формируются два потомка, содержащих по J KJ K
одному сегменту каждого из родителей. Заметим, что раз- -| 1#о#0#1 #110101 #
биение родительских особей на две равные части — это
достаточно произвольный выбор. Решения-кандидаты мо- риа /7.7. Использование скре-
гут разбиваться в любой точке, которую можно выбирать щивания для двух битовых
и изменять случайным образом в ходе решения задачи. строк длины 8. Символ # озна-
Предположим, что целевой класс— это набор всех чает "произвольное значение"
строк, которые начинаются и заканчиваются единицей. Обе
родительские строки, показанные на рис. 11.1, достаточно хорошо подходят для решения
этой задачи. Однако первый их потомок гораздо точнее соответствует критерию качества,
чем любой из родителей: с помощью этого шаблона не будет пропущен ни один из целевых
примеров, а нераспознанными останутся гораздо меньше строк, чем в реальном классе
решения. Заметим также, что его "собрат" гораздо хуже, чем любой из родителей, поэтому
этот экземпляр, скорее всего, будет исключен в одном из ближайших поколений.
Мутация (mutation) — это еще один важный генетический оператор. Она состоит в
случайном выборе кандидата и случайном изменении некоторых его свойств. Например, мутация
может состоять в случайном выборе бита в шаблоне и изменении его значения с 1 на 0 или #.
Значение мутации состоит в возможном восполнении важных компонентов решения,
отсутствующих в исходной популяции. Если в рассмотренном выше примере ни один из членов
исходной популяции не содержит 1 в первой позиции, то в процессе скрещивания нельзя
получить потомка, обладающего этим свойством. Значение первого бита может измениться лишь
вследствие мутации. Этой цели можно также достичь с помощью другого генетического
оператора — инверсии (inversion), которая будет описана в подразделе 11.1.3.
Работа генетического алгоритма продолжается до тех пор, пока не будет достигнуто
условие его завершения, например, для одного или нескольких кандидатов значение
критерия качества не превысит некоторого порога. В следующем разделе приводятся
примеры кодирования информации в генетических алгоритмах, а также примеры
генетических операторов и критериев качества для двух задач: возможности описания проблемы
в конъюнктивной нормальной форме и задачи коммивояжера.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 487
11.1.3. Два примера: описание задачи в конъюнктивной нормальной
форме и задача коммивояжера
Выберем две задачи и обсудим для них вопросы представления и выбора критериев
качества. Следует отметить три момента. Во-первых, не все задачи естественно и легко
описать на уровне битового представления. Во-вторых, генетические операторы должны
предотвращать появление нежелательных взаимоотношений внутри популяции, например,
обязаны обеспечивать присутствие и уникальность всех городов в маршруте
коммивояжера. И, наконец, следует обсудить важные взаимосвязи между значением критерия качества
для различных состояний и методом кодирования, выбранным для данной задачи.
Описание проблемы в конъюнктивной нормальной форме
Описание в конъюнктивной нормальной форме (КНФ) — это представление
выражения в виде последовательности операторов, связанных отношением И (л). Каждый из
этих операторов должен представлять собой дизъюнктивное выражение, определяемое
отношением ИЛИ (v), или литерал. Например, для литералов а, Ь, с, с/, е и f выражение
(—iavc)A(—iavcv—ie)A(—ibvcvdv—ie)A(av—ibvc)A(—ievf)
является конъюнктивной нормальной формой. Это выражение представляет собой
конъюнкцию пяти операторов, каждый из которых является дизъюнкцией двух или
нескольких литералов. Понятия предложения и его представления были введены в главе 2.
Там же обсуждались вопросы представления в конъюнктивной нормальной форме и
предлагался метод сокращения числа операторов в КНФ. В разделе 12.2 будет приведено
доказательство теоремы о разрешении.
Представимость в конъюнктивной нормальной форме означает существование таких
логических значений A или 0 либо true и false) для каждого из шести литералов, при
которых КНФ-выражение принимает значение true. Несложно проверить, что для
доказательства представимости рассмотренного выше выражения в конъюнктивной
нормальной форме достаточно присвоить значение false литералам а, Ь и е. Еще одно
решение обеспечивается присвоением литералу е значения false, ас — true.
Естественным представлением данных для задачи КНФ-описания является
последовательность из шести битов, каждый из которых представляет значение одного из шести
литералов а, Ь, с, с/, е и f. Таким образом, выражение
10 10 10
означает, что литералы а, с и е принимают значение true, а Ь, d и f— false. Для такой
комбинации значений литералов приведенное выше выражение принимает значение
false. Читатель может самостоятельно подобрать такие значения литералов, при которых
общее выражение истинно.
В процессе выполнения генетических операторов требуется получить потомка, для
которого КНФ-выражение является истинным. Следовательно, в результате выполнения каждого
генетического оператора должна получаться битовая строка, которая может рассматриваться
как кандидат на роль решения задачи. Этим свойством обладают все рассмотренные до сих
пор генетические операторы. В частности, в результате скрещивания и мутации получаются
битовые строки, которые могут стать решением задачи. Менее типичные операторы, такие
как инвертирование (inversion) (изменение порядка следования битов в шестибитовой строке
на обратный) или обмен (exchange) (перемена мест двух произвольных битов), тоже
обеспечивают получение кандидата на роль решения КНФ-проблемы. С этой точки зрения трудно
обеспечить более удачное представление данных в задаче КНФ.
488
Часть IV. Машинное обучение
Выбор критерия качества для этой популяции битовых строк не столь однозначен. С
одной стороны, задача считается решенной, если найдена комбинация битов, при которой
выражение принимает значение true. Поэтому на первый взгляд сложно определить критерий, с
помощью которого можно оценить ''качество" битовых строк как потенциальных решений.
Однако существует множество вариантов. Следует отметить, что полное КНФ-выражение
представляет собой конъюнкцию пяти операторов. Поэтому можно определить рейтинг
решения по шкале от 0 до 5 в зависимости от количества операторов, принимающих значение
true. Тогда каждому из образов можно сопоставить соответствующий рейтинг:
1 1 0 0 1 0 — рейтинг 1,
О 1 0 0 1 0 — рейтинг 2,
0 1 0 0 1 1 — рейтинг 3,
1 0 1 0 1 1 — рейтинг 5,
следовательно, эта комбинация является решением. Такой генетический алгоритм
обеспечивает разумный подход к решению КНФ-проблемы. Одним из важнейших свойств этого
подхода является неявный параллелизм, обеспечиваемый за счет одновременной обработки
целой популяции решений. Этому представлению естественным образом соответствуют
генетические операторы. И, наконец, поиск решения выполняется по принципу "разделяй и
властвуй", поскольку решение задачи делится на несколько элементов. В упражнениях к этой
главе читателю будет предложено рассмотреть другие аспекты этой проблемы.
Задача коммивояжера
Задача коммивояжера — это классический пример тестовой задачи для методов
искусственного интеллекта и компьютерных наук вообще. Впервые она упоминалась в
разделе 3.1 при описании графов. Пространство состояний этой задачи для N городов
включает Л/! возможных состояний. Было показано, что эта задача является Л/Р-полной,
поэтому для ее решения предлагалось множество различных эвристических подходов.
Формулировка задачи достаточно проста.
Коммивояжеру требуется посетить N городов. Для каждой пары городов по маршруту
следования установлена стоимость (например расстояние). Требуется найти путь минимальной
стоимости, который начинается из некоторого города, обеспечивает посещение остальных
городов ровно по одному разу и возврат в точку отправления.
Задача коммивояжера используется на практике, в том числе обеспечивает решение
проблемы разводки электронных схем, задачи рентгеновской кристаллографии и
маршрутизации при производстве СБИС. Некоторые из этих задач в процессе прохождения
пути минимальной стоимости требуют посещения десятков тысяч точек (городов).
Большой интерес представляет анализ класса задач коммивояжера с точки зрения
эффективности их реализации. Вопрос заключается в том, стоит потратить несколько часов на
получение субоптимального решения на рабочей станции или дешевле разработать
простой компьютер, который за несколько минут обеспечит вполне приемлемый результат.
Задача коммивояжера — это интересная и сложная проблема, затрагивающая множество
аспектов реализации стратегии поиска.
Как можно решить эту задачу с помощью генетического алгоритма? Во-первых,
можно выбрать представление для маршрута посещения городов, а также подобрать
используемые генетические операторы. В то же время выбор критерия качества в данном
случае достаточно прост — требуется оценить лишь длину пути. После этого маршруты
можно упорядочить по длине — чем короче, тем лучше.
Рассмотрим несколько очевидных представлений, которые имеют достаточно сложные
последствия. Предположим, необходимо посетить девять городов 1, 2, ..., 9. Тогда путь
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 489
можно представить упорядоченным списком из девяти целых. Представим порядковый
номер каждого города строкой из четырех битов: 0001, 0010,..., 1001. Тогда выражение
0001 0010 0011 0100 0101 0110 0111 1000 1001
представляет последовательность посещения городов по возрастанию их порядковых
номеров. Пробелы в этом выражении поставлены только для простоты восприятия.
Какие генетические операторы можно использовать для решения этой задачи?
Скрещивание однозначно не подходит, поскольку получаемая в результате строка, скорее всего, не
будет представлять собой путь, при котором каждый город посещается только один раз.
Действительно, при скрещивании некоторые города выпадут из последовательности, а
другие встретятся в ней дважды. Что можно сказать о мутации? Предположим, что
крайний слева бит в обозначении шестого города ОНО изменится на 1. Тогда полученное
число 1110 будет соответствовать порядковому номеру 14, который не входит в
допустимый перечень городов. Инвертирование городов в выражении пути в данном случае
является допустимой операцией, однако достаточно ли ее для получения необходимого
решения? Одним из способов поиска минимального пути является генерирование и
оценка всех возможных перестановок из Л/ элементов в списке городов. Поэтому
генетические операторы должны обеспечить возможность получения этих перестановок.
Задачу коммивояжера можно решить и по-другому: проигнорировать битовое
представление и присвоить городам обычные порядковые номера 1, 2,..., 9. Путь между этими городами
будет представлять собой некоторую последовательность девяти цифр, а соответствующие
генетические операторы позволят формировать новые пути. В этом случае мутация как
случайный обмен двух городов в маршруте будет допустимой операцией, но скрещивание по-
прежнему окажется бесполезным. Обмен фрагментов маршрута на другие фрагменты того же
пути либо любой оператор, меняющий местами номера городов маршрута (без удаления,
добавления или дублирования городов), окажется достаточно эффективным. Однако при таких
подходах невозможно обеспечить сочетание лучших родительских свойств в потомке,
поскольку для этого требуется формировать его на основе двух родителей.
Многие исследователи [Davis, 1985], [Oliver и др., 1987] разработали операторы
скрещивания, устраняющие эти проблемы и позволяющие работать с упорядоченным списком
посещаемых городов. Например, в работе [Davis, 1985] определен оператор, получивший
название упорядоченного скрещивания (order crossover). Допустим, имеется девять городов
1, 2,..., 9, порядок следования которых представляет очередность их посещения.
В процессе упорядоченного скрещивания потомок строится путем выбора
подпоследовательности городов в пути одного из родителей. В нем также сохраняется
относительный порядок городов другого родителя. Сначала выбираются две точки
сечения, обозначенные символом |, которые случайным образом устанавливаются в одних и
тех же позициях каждого из родителей. Местоположение точек сечения выбирается
случайным образом, однако для каждого из родителей эти точки совпадают. Например, если
для двух родителей pi и р2 точки сечения располагаются после 3-го и 7-го городов
р1=A92|4657|83),
р2=D59| 1876J23),
то два потомка cl и с2 получаются следующим образом. Сначала для каждого из
потомков копируются фрагменты строк родителей, расположенные между точками сечения.
с1=(ххх|4657|хх),
с2=(ххх| 1876 |хх).
490
Часть IV. Машинное обучение
Затем после второй точки сечения одного из родителей помещаются города,
соответствующие другому родителю, с сохранением порядка их следования. При этом уже
имеющиеся города пропускаются. При достижении конца строки операция продолжается
сначала. Так, последовательность подстановки городов из р2 имеет вид
234591876.
Поскольку города 4, 6, 5 и 7 не учитываются (они уже входят в состав первого
потомка), получается укороченный ряд 2, 3, 9, 1, 8, который и подставляется в cl с
сохранением порядка следования этих городов в р2:
с1=B39|4657| 18).
Аналогично получим второй потомок
с2=C92|1876|45).
Итак, в упорядоченном скрещивании фрагменты пути передаются от одного родителя р 1
потомку cl, при этом порядок посещения городов наследуется и от другого родителя р2.
Этот подход основан на интуитивном предположении о том, что порядок обхода городов
играет важную роль в поиске кратчайшего пути. Поэтому информация о порядке
следования сохраняется для потомков.
Алгоритм упорядоченного скрещивания гарантирует однократное посещение всех
городов. К результату этой операции мутацию следует применять крайне осторожно. Как
указывалось выше, она должна сводиться к перемене мест двух городов в рамках одного
маршрута. Инвертирование (простое изменение порядка посещения городов) в данном
случае неприменимо, поскольку при этом не формируется нового пути. Однако если в
рамках одного маршрута выбрать некий фрагмент и инвертировать его, то это может
дать хороший результат. Например, путь
с1=B39|4657|18)
после инвертирования его средней части примет вид
с1=B39|7564|18).
Можно ввести еще один оператор мутации, который состоит в случайном выборе
города и перемещении его в случайно выбранное положение в рамках маршрута. Такой
оператор мутации можно применять и для фрагмента пути, например, выбрав фрагмент
трех городов и поместив его в новое случайно выбранное положение. В упражнениях к
этой главе приводятся и другие примеры генетических операторов.
11.1.4. Обсуждение генетического алгоритма
Рассмотренные примеры подчеркивают характерные для генетических алгоритмов
проблемы представления знаний, выбора операторов и определения критерия качества.
Выбранное представление должно поддерживать генетические операторы. Иногда, как в КНФ-задаче,
естественным является битовое представление. В этом случае для получения потенциальных
решений можно напрямую использовать такие традиционные генетические операторы, как
скрещивание и мутацию. В задаче коммивояжера ситуация совсем другая. Во-первых, для нее
не подходит битовое представление. Во-вторых, при определении операторов мутации и
скрещивания для каждого потомка необходимо отслеживать выполнение требуемых свойств
(присутствие в маршруте всех городов при однократном посещении каждого из них).
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 491
И, наконец, при реализации генетических операторов существенная информация
должна передаваться следующему поколению. Если эта информация, как в КНФ-задаче,
связана со значением истинности, то в результате выполнения генетических операторов
это свойство должно сохраняться в следующем поколении. В задаче коммивояжера
критичной является последовательность городов в маршруте, поэтому потомкам должны
передаваться фрагменты этой информации. Чтобы обеспечить такое наследование
свойств, необходимо соответствующим образом выбрать способ представления данных и
генетические операторы для каждой задачи в отдельности.
Завершая обсуждение способа представления данных, рассмотрим проблему
"естественности" такого представления. В качестве простого, но несколько искусственного,
примера рассмотрим задачу выделения чисел 6, 7, 8 и 9. Естественным представлением,
обеспечивающим сортировку данных, является обычное целочисленное описание, поскольку
среди десяти цифр каждая следующая на 1 больше предыдущей. При переходе к двоичному
описанию эта естественность исчезает. Рассмотрим битовое представление чисел 6,7, 8 и 9:
01100111 1000 1001.
Заметим, что числа 6 и 7, а также 8 и 9 отличаются друг от друга на один бит. Однако
числа 7 и 8 не имеют между собой ничего общего! Это свойство представления может
вызвать большие проблемы при решении задач, требующих систематизации этих образов. Для
решения проблемы неоднородного представления используется множество приемов,
получивших общее название кодирования Грея (gray coding). Например, код Грея для первых
шестнадцати двоичных чисел приводится в табл. 11.1. Заметим, что здесь каждое число
отличается от своих соседей ровно на один бит. Обычно при использовании кодирования
Грея вместо обычного двоичного представления переходы между состояниями при
реализации генетических операторов являются более естественными и гладкими.
Таблица 11.1. Коды Грея для двоичных чисел О, 1,..., 15
Двоичное число
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
Код Грея
0000
0001
0011
0010
0110
0111
0101
0100
1100
1101
1111
1110
1010
1011
1001
1000
Важным преимуществом генетических алгоритмов является параллельная природа
поиска. Они реализуют одну из мощных форм поиска экстремума, поддерживающую
несколько решений. На рис. 11.2, взятом из работы [Holland, 1986], показано, как множест-
492
Часть IV. Машинное обучение
во решений сходится к точкам экстремума в пространстве поиска. На этом рисунке
горизонтальная ось представляет возможные точки в пространстве решений, а по вертикали
показано качество этих решений. Точки на кривой — это члены текущей популяции
решений-кандидатов, полученные при работе генетического алгоритма. Изначально
решения равномерно распределялись в пространстве поиска. После нескольких итераций они
группируются в областях, соответствующих наиболее высокому качеству решения.
Качество Качество
решения решения
Пространство поиска Пространство поиска
а Исходное пространство поиска б Пространство поиска после п поколений
Рис. 11.2. Генетический алгоритм как параллельный поиск экстремума
При описании генетического алгоритма как алгоритма поиска экстремума неявно
предполагается перемещение по поверхности, определяемой критерием качества. На
этой поверхности существуют свои вершины, низменности, а также локальные
максимумы и минимумы. Нарушение непрерывности этого пространства является следствием
выбора представления и генетических операторов для конкретной задачи. Например,
такое нарушение непрерывности может быть вызвано неправильным кодированием, в том
числе без использования кодов Грея. Отметим также, что генетические алгоритмы, в
отличие от последовательных форм поиска экстремума, описанных в разделе 4.1, не сразу
отбрасывают бесперспективные решения. При реализации генетических операторов
даже плохие решения могут оставаться в популяции и вносить свой вклад в формирование
последующих поколений решений.
Еще одним отличием эвристического поиска в пространстве состояний, описанного в
главе 4, от генетических алгоритмов является анализ различия между текущим и
целевым состояниями. Такая информация учитывается в алгоритме А* (раздел 4.2),
требующем оценки "усилий" для перехода из текущего состояния в целевое. Для работы
генетических алгоритмов такая мера не нужна. Просто каждое поколение потенциальных решений
оценивается с помощью некоторого критерия качества. Не требуется также строгая
систематизация последующих состояний, как при поиске в пространстве состояний. Просто
формируется поколение решений-кандидатов, каждое из которых может внести свой вклад
в получение новых возможных решений в процессе параллельного поиска.
Важным источником эффективности генетических алгоритмов является неявный
параллелизм эволюционных операторов. В отличие от поиска в пространстве состояний, в данном
случае операции выполняются параллельно для целого семейства потенциальных решений.
Ограничивая репродуктивные свойства слабых решений, генетические алгоритмы приводят к
исключению не только этого решения, но и всех его потомков. Например, если строка
1 01 # 0 # # 1 отброшена в процессе работы алгоритма, то она уже не сможет породить
строки вида 1 01 # . Если родительское решение не соответствует критерию качества,
то в процессе работы алгоритма не будут рассматриваться и все его потенциальные потомки.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 493
Поскольку генетические алгоритмы все шире применяются для решения прикладных
задач и математического моделирования, в последнее время повышается интерес к
осмыслению их теоретических основ. Естественно, возникают следующие вопросы.
1. Можно ли охарактеризовать типы задач, для которых генетические алгоритмы
работают наиболее эффективно?
2. Для каких типов задач они работают плохо?
3. Что означает высокая и низкая эффективность генетического алгоритма для
решения некоторого типа задач?
4. Существуют ли законы, описывающие поведение генетических алгоритмов на
макроуровне? В частности, можно ли спрогнозировать изменения значений
критерия качества для элементов популяции?
5. Существует ли способ описать результаты таких различных генетических
операторов, как скрещивание, мутация, инвертирование и т.д.?
6. При каких условиях (для каких задач и генетических операторов) генетические
алгоритмы работают лучше, чем традиционные интеллектуальные методы поиска?
Многие из этих вопросов выходят за рамки тематики данной книги. В работе
[Mitchell, 1996] указано, что в теоретическом осмыслении генетических алгоритмов пока
еще больше открытых вопросов, чем приемлемых ответов. Тем не менее с момента
появления генетических алгоритмов исследователи пытаются понять принципы их работы
[Holland, 1975]. И хотя многие вопросы, как и приведенные выше, относятся к
макроуровню, их анализ начинается с микроуровня битового представления.
В [Holland, 1975] вводится понятие схемы (schema) как общего шаблона и
строительного блока решения. Схема— это шаблон битовых строк, описываемый символами 1, О
и #. Например, схема 10##01 представляет семейство шестибитовых строк,
начинающихся с фрагмента 10 и завершающихся символами 01. Поскольку центральный
фрагмент ## описывает четыре возможные комбинации битов, 00, 01, 10, 11, то вся схема
представляет четыре битовые строки, состоящие из 1 и 0. Традиционно считается, что
каждая схема описывает гиперплоскость [Goldberg, 1989]. В этом примере данная
гиперплоскость пересекает множество всех возможных шестибитовых представлений.
Центральным моментом традиционной теории генетических алгоритмов является
утверждение, что подобные схемы — это строительные блоки семейств решений. Генетические
операторы скрещивания и мутации оперируют такими схемами в процессе поиска
потенциальных решений. Эти операции описываются теоремой о схемах [Holland, 1975],
[Goldberg, 1989]. По Холланду, для повышения производительности в некоторой среде
адаптивная система должна идентифицировать, проверить и реализовать некоторые
структурные свойства, формализуемые с помощью схем.
Анализ схем Холланда предполагает, что алгоритм выбора по критерию качества
сводится к поиску подмножеств в пространстве поиска, наилучшим образом
удовлетворяющих данному критерию. Следовательно, эти подмножества описываются схемами,
для которых значение критерия качества выше среднего. При выполнении генетических
операторов скрещивания строительные блоки с высоким показателем качества
складываются вместе и формируют "улУчшенные" строки. Мутации позволяют гарантировать,
что генетические особенности не будут утеряны в процессе поиска, т.е. эти операторы
обеспечивают переход к новым областям поверхности поиска. Таким образом,
генетические алгоритмы можно рассматривать как некое обобщение процесса поиска с сохране-
494
Часть IV. Машинное обучение
нием важных генетических свойств. Холланд изначально анализировал генетические
алгоритмы на битовом уровне. Более современные работы распространяют результаты
этого анализа на другие схемы представления [Goldberg, 1989]. В следующем разделе
генетические алгоритмы будут применены к более сложным представлениям.
11.2. Системы классификации и генетическое
программирование
Первые генетические алгоритмы почти целиком базировались на низкоуровневом
представлении, в частности, битовых строках {0, 1, #}. Помимо того что битовые
строки являются естественным представлением для реализации генетических операторов,
они обеспечивают для генетических алгоритмов столь же высокую производительность,
как и другие несимвольные подходы, в том числе нейросетевые. Однако существуют
задачи, например, проблема коммивояжера, для которых естественным является
кодирование на более высоком уровне представления. При глубоком исследовании может
возникнуть вопрос о реализации генетических алгоритмов для таких высокоуровневых
представлений, как правила вывода или фрагменты программного кода. Важным аспектом
этих представлений является возможность комбинирования таких фрагментов
высокоуровневых знаний, как цепочки правил вывода или вызовы функций.
К сожалению, достаточно сложно определить генетические операторы,
поддерживающие синтаксическую и семантическую структуру логических взаимоотношений и в
то же время обеспечивающие эффективное применение скрещивания и мутации.
Одним из возможных путей совмещения преимуществ правил вывода и генетического
обучения является преобразование логических утверждений в битовые строки и
применение для них стандартного оператора скрещивания. Однако получаемые после
скрещивания и мутации битовые строки зачастую не обладают свойствами логических
выражений. В качестве альтернативы этому представлению можно определить новые
варианты скрещивания, применимые напрямую к высокоуровневым представлениям,
таким как правила вывода или фрагменты кода на высокоуровневом языке
программирования. В этом разделе описываются примеры каждого из подходов, расширяющие
возможности генетических алгоритмов.
11.2.1. Системы классификации
В [Holland, 1986] разработаны проблемно-ориентированные архитектуры,
получившие название систем классификации (classifier system), в которых генетическое
обучение применяется к правилам логического вывода. Система классификации включает
стандартные элементы системы вывода (рис. 11.3): правила вывода (называемые здесь
классификаторами), рабочую память, входные датчики (или декодеры) и выходные
элементы (эффекторы). Отличительной особенностью системы классификации является
конкурентный подход к разрешению конфликтов, применение генетических алгоритмов
для обучения и алгоритма "пожарной цепочки" (bucket brigade algorithm) для
распределения поощрений и наказаний в процессе обучения. Обратная связь со внешней средой
дает возможность оценить качество классификаторов-кандидатов, что необходимо для
реализации генетического обучения. Система классификации, показанная на рис. 11.3,
включает следующие основные компоненты.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 495
Внешняя J
среда /
(
Вход
Выход
J Обратная
' связь
Декодер
*
Список входящих сообщений
Эффекторе
"*
1
г
Внутренние сообщения 1
рабочей памяти
'
'
Список исходящих сообщений
Генетические
операторы
для изменения
правил
Декодер
i
1 L
Т
i
Правила классификации
продукционной памяти
Распределение креди
принципу "пожарной це
ГОВ ПО —
почки"—
А
i
k
Рис 11.3. Взаимодействие системы классификации с внешней средой
1. Детекторы входящих сообщений от внешней среды.
2. Детекторы обратных связей со внешней средой.
3. Эффекторы, передающие результаты применения правил во внешнюю среду.
4. Набор правил вывода, представляющий собой популяцию классификаторов.
Каждому классификатору соответствует свое значение критерия качества.
5. Рабочая память для правил классификации, в которой результаты правил выбора
интегрированы с входной информацией.
6. Набор генетических операторов для модификации правил вывода.
7. Система для предоставления кредита правилам, участвующим в выполнении
успешных действий.
При решении задачи классификатор работает как традиционная система
логического вывода. На детекторы системы классификации из внешней среды поступает
сообщение, например, информация о сделанном игроком ходе. Это событие
кодируется и помещается в качестве образа во внутренний список сообщений — рабочую
память системы вывода. Эти сообщения при обычной работе системы вывода на
основе данных соответствуют условиям правил классификации. Выбор "наиболее
активного классификатора" осуществляется по схеме аукциона, в которой
предлагаемая цена — это функция аккумулированного значения критерия качества для такого
классификатора и уровня соответствия между входным стимулом и его условием.
Эти сообщения добавляются в рабочую память классификаторов с наиболее
высоким уровнем соответствия. Из обновленного списка сообщения могут передаваться
через эффекторы во внешнюю среду либо активизировать новые правила
классификации в процессе работы системы вывода.
Системы классификации реализуют одну из форм обучения с подкреплением
(раздел 9.7). На основе информации, поступающей от учителя или определяемой
значением критерия качества, обучаемая система вычисляет значение критерия
качества для популяции правил-кандидатов и строит новую популяцию с помощью
одного из вариантов генетического обучения. Системы классификации обучаются дву-
496
Часть IV. Машинное обучение
мя способами. Первый способ состоит в использовании системы поощрений,
настраивающей меру качества правил классификации за счет усиления полезных
правил и ослабления действия ошибочных. Алгоритм распределения кредитов передает
часть вознаграждения или штрафа каждому правилу классификации, принимавшему
участие в формировании окончательного правила. Такое распределение различных
вознаграждений между взаимодействующими классификаторами зачастую
реализуется с помощью алгоритма "пожарной цепочки". Этот алгоритм решает проблему
распределения кредитов и штрафов для систем, выход которых является
результатом последовательного применения набора правил. Как распределить штрафы
между правилами этой цепочки в случае ошибки на выходе? Какое из правил цепочки
является источником ошибки: последнее или одно из предыдущих? Алгоритм
"пожарной цепочки" позволяет распределить кредиты и штрафы между правилами
этой последовательности в зависимости от вклада каждого правила в окончательное
решение. Аналогичное распределение поощрений и штрафов на основе ошибки на
выходе обеспечивает алгоритм обратного распространения, описанный в
разделе 10.3. Более подробная информация об этом содержится в [Holland, 1986].
Вторая форма обучения связана с модификацией самих правил на основе
генетических операторов типа мутации и скрещивания. При таком подходе выживают лучшие
правила, а в результате их комбинации формируются новые классификаторы.
Каждое правило классификации состоит из трех компонентов и работает, как
обычная система вывода: на основе некоторого условия проверяется соответствие
данных содержимому рабочей памяти. В процессе обучения генетические операторы
могут модифицировать как условия, так и действия правила вывода. Второй
компонент правила — действие — может изменять внутренний список сообщений
(продукционную память). И, наконец, каждому правилу соответствует мера качества.
Как уже отмечалось, этот параметр изменяется как при успешном, так и при
неуспешном применении правила. Эта мера изначально присваивается каждому правилу при
его создании генетическим оператором. Например, мерой качества может служить
среднее значение качества двух родителей.
Взаимодействие этих компонентов системы классификации можно
продемонстрировать на простом примере. Предположим, набор подлежащих классификации
объектов определяется шестью атрибутами (условиями с1, с2, ..., сб). Допустим также, что
каждый из этих атрибутов может принимать 5 различных значений. И хотя каждый
атрибут имеет свой физический смысл (например, параметр сЪ описывает цвет, а с5 —
погоду), без потери общности допустимые значения всех атрибутов можно описать целыми
числами {1, 2,..., 5}. Предположим, согласно правилам вывода объекты разбиваются на
4 класса: А1, Л2, ЛЗ, А4.
Таким образом, каждый классификатор можно описать в виде соотношения
(с1, с2, сЗ, с4, с5, сб) -> Ait где /=1, 2, 3, 4,
где каждое из условий с/ принимает значение из диапазона {1, 2, ..., 5}
соответствующего атрибута. Обычно условию может соответствовать и произвольное значение #
каждого атрибута. В правой части соотношения выражение Ai обозначает один из
классов А1, А2, АЪ или А4. В табл. 11.2 приводится набор классификаторов. Обратите
внимание на то, что несколько различных условных шаблонов могут соответствовать
одному классу, как в правилах 1 и 2, либо два одинаковых шаблона могут
соответствовать различным классам.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 497
Таблица 11.2. Наборы условий для различных классов
Условие (атрибуты) Действие (класс) Номер правила
B##3##) —> Л1 2
(##43##) ->уА2 3
A #####) ->Л2 4
(##43##) ->ЛЗ 5
Как показано выше, система классификации — это еще одна форма вездесущих систем,
основанных на правилах логического вывода. Единственным отличительным свойством
правил классификации, использованных в приведенном примере, является применение
строк цифр и символов # для представления шаблонов условий. Такое представление
условий обеспечивает применение генетических алгоритмов в правилах логического вывода.
Далее будет исследован вопрос генетического обучения в системах классификации.
Чтобы упростить изложение, будем рассматривать обучение системы только для класса
А\. Не принимая во внимание другие классы, присвоим шаблонам условий значение 1 или 0 в
зависимости от соответствия классу Л1. Заметим, что это упрощение не ограничивает
общности рассуждения, поскольку эти выкладки можно распространить на случай обучения для
нескольких классов. Для этого достаточно ввести вектор, соответствующий конкретному
условному шаблону. Например, классификатор из табл. 11.2 можно описать в виде
A###1#)_>A000),
B##3##)->A000),
A#####)_>@Ю0),
(##43##)->@110).
Последняя строка в этом примере соответствует правилам классификации для классов
А2 и A3, но не А\ или А4. Заменяя 0 или 1 подобными векторными представлениями
классов, можно оценить эффективность правила для классификации на несколько классов.
Для определения корректности классификации будем использовать правила из
табл. 11.2. А именно, будем рассматривать их в качестве учителя для оценки качества
правил в системе классификации. Как в большинстве генетических систем обучения,
выберем случайным образом исходную популяцию правил. Каждому шаблону условий
сопоставим параметр качества (fitness) или силы (strength) (вещественное число из
диапазона от 0,0 до 1,0). Этот параметр силы s будем вычислять на основе качества каждого
родительского правила с учетом предыстории.
В каждом цикле обучения с помощью правил будем пытаться классифицировать
входы и проверять качество классификации с помощью учителя ими меры качества.
Например, предположим, что на некотором шаге получена следующая популяция кандидатов
на роль правил классификации, для каждого элемента которой 1 означает корректный
результат классификации, а 0 — неверный:
(###21#)->1 s=0,6,
(##3##5)->0 s=0,5,
B1####)->1 s=0,4,
(#4###2)->0 s=0,23.
Допустим, из среды поступило новое входное сообщение A 4 3 2 1 5), и учитель (на
основе первого правила из табл. 11.2) классифицировал этот вектор как положительный
498
Часть IV. Машинное обучение
пример для класса А1. Посмотрим, что происходит при передаче этого образа в рабочую
память при попытке его классификации с помощью 4 правил-кандидатов. Этот образ
соответствует правилам 1 и 2. Разрешение конфликта между подходящими правилами
выполняется на основе конкуренции. В нашем примере степень соответствия каждого
правила вычисляется как сумма произведений степеней соответствия каждого из атрибутов и
меры качества данного правила. Неопределенному атрибуту # соответствует значение 0,5, а
при точном соответствии атрибута ему присваивается степень 1,0. Для нормировки
полученное значение делится на длину входного вектора. Поскольку первый классификатор для
данного входного вектора дает два точных соответствия и 4 неопределенных атрибута,
общая степень его соответствия входному вектору составляет (D*0,5+2* 1)*0,6)/6=0,4. Для
второго классификатора тоже имеется 2 точных соответствия и 4 неопределенных
атрибута, поэтому его степень соответствия составляет 0,33. В нашем примере по принципу
конкуренции побеждает классификатор с максимальной степенью соответствия, но в более
сложных задачах желательно учитывать некоторый порог.
Таким образом, победило первое правило, в соответствии с которым предъявленный
образ относится к классу Л1. Поскольку это действие корректно, мера качества первого
правила увеличивается и принимает новое значение, приближенное к 1. Если бы
результат выполнения этого правила оказался некорректным, его мера качества была бы
уменьшена. Если для получения результата в системе многократно выполняется
некоторый набор правил, то определенную долю подкрепления должны получить все правила,
участвующие в получении результата. Точная процедура пересчета меры качества
определяется в зависимости от системы и может оказаться очень сложной. Она может
строиться на основе алгоритма "пожарной цепочки" или другого метода распределения
кредитов. Более подробная информация по этому вопросу содержится в [Holland, 1986].
После вычисления меры качества правил-кандидатов в алгоритме обучения
применяются генетические операторы для создания следующего поколения правил. Сначала на
основе принципа отбора выбирается множество правил с наиболее высоким значением
критерия качества. Этот выбор базируется на значении меры качества, но может учитывать
и дополнительные случайные величины. Элемент случайности обеспечивает возможность
отбора правил с плохими показателями качества, которые, невзирая на общее
несоответствие, могут привнести полезные элементы в решение задачи. Допустим, в рассмотренном
примере для дальнейшей работы выбраны первые два правила классификации. После
случайного выбора точки скрещивания между четвертым и пятым элементами
(###2|1#)-*1 s=0,6,
(##3#|#5)-*0 s=0,5,
получим потомки
(##3#|1#)-*0 s=0,53,
(###2|#5)-*1 s=0,57.
Мера качества каждого потомка — это взвешенная функция показателей качества их
родителей. Весовые коэффициенты определяются местоположением точки скрещивания.
Первый потомок получил 1/3 информации от классификатора с мерой качества 0,6 и
2/3 — от классификатора с мерой качества 0,5. Поэтому его мера качества составляет
A/3*0,6)+B/3*0,5)=0,53. С помощью аналогичных рассуждений выясним, что мера
качества второго потомка равна 0,57. Результат выполнения правила (значение 0 или 1)
определяется соответствием большинства атрибутов. В типичных системах классификации
эти два новых правила, наряду с их родителями, входят в набор классификаторов, с
которыми работает система на следующем этапе.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 499
Можно определить и оператор мутации. Простая мутация заключается в случайной
замене любого значения атрибута произвольным значением из допустимого диапазона.
Например, 5 можно изменить на 1, 2, 3, 4 или #. Как указывалось при описании
генетических алгоритмов, операторы мутации призваны внести элемент случайности в поиск
классификатора, в то время как скрещивание позволяет сохранить удачные фрагменты
данных из родительских шаблонов в их потомках.
Рассмотренный пример достаточно прост и призван лишь проиллюстрировать работу
основных компонентов системы классификации. В реальных системах может
срабатывать несколько правил, и все они могут передавать свои результаты в рабочую память.
Зачастую для предотвращения явного доминирования одного из классификаторов в
процессе решения применяется схема налогообложения, при которой его мера качества на
каждом успешном шаге несколько снижается. Здесь также не описан алгоритм
"пожарной цепочки", позволяющий в различной степени "поощрять" правила,
участвующие в успешном решении задачи и передаче сообщения во внешнюю среду. Кроме
того, как правило, генетические операторы применяются для трансформации
классификаторов не на каждом шаге работы алгоритма. Обычно существует некий общий
параметр, определяемый с учетом специфики каждого приложения, в частности, на основе
анализа обратной связи со внешней средой, на основе которого принимается решение о
необходимости применения генетических операторов.
Описанный пример взят из работы [Holland, 1986], выполненной в университете
штата Мичиган. Такой подход можно рассматривать как численную модель познания, в
которой знания (классификаторы) обучаемой сущности формируются в процессе
взаимодействия с внешней средой и модифицируются со временем. При этом оценивается
общая работа всей системы, а не качество отдельного классификатора. В работе [Michalski
и др., 1983], выполненной в университете Питтсбурга (Pittsburg), предложен
альтернативный подход к построению систем классификации, в котором при создании нового
поколения классификаторов основное внимание уделяется отдельным правилам. Такой
подход реализует предложенную Михальски (Michalski) модель индуктивного обучения.
В следующем разделе рассматривается еще одно интересное приложение
генетических алгоритмов, обеспечивающее эволюцию компьютерных программ.
11.2.2. Программирование с использованием генетических операторов
В нескольких предыдущих разделах рассматривалось применение генетических
алгоритмов для все более сложных структур данных. А что произойдет, если применить
генетические преобразования битовых строк к правилам "если..., то..."! Возникает
естественный вопрос, можно ли применять генетические и эволюционные операторы для
создания более крупномасштабных вычислительных средств. Известны два основных
примера для этой области, связанные с генерацией компьютерных программ и
эволюцией систем, реализующих конечные автоматы.
В [Koza, 1992] высказано предположение, что удачная компьютерная программа
может эволюционировать за счет применения генетических операторов. При этом
структурами, к которым применяются принципы генетического программирования, являются
иерархически организованные фрагменты компьютерных программ. Алгоритм обучения
поддерживает популяцию программ-кандидатов. Качество программы определяется ее
способностью решать некоторый класс задач, а модификация программы выполняется за
счет применения скрещивания и мутации к поддеревьям программы. При генетическом
500
Часть IV. Машинное обучение
программировании поиск выполняется в пространстве компьютерных программ
различного размера и сложности. Фактически пространство поиска — это множество всех
возможных компьютерных программ, составленных из вызовов функций и
последовательностей символов, соответствующих предметной области задачи. Как и генетическое
обучение, такой поиск содержит элемент случайности, во многом выполняется "вслепую",
но, на удивление, оказывается достаточно эффективным.
При генетическом программировании сначала инициализируется популяция случайно
сгенерированных программ, составленных из соответствующих программных
фрагментов. Эти фрагменты в зависимости от предметной области задачи могут содержать
стандартные арифметические операции, математические и логические функции, а также
специфические функции для данной предметной области. В число программных
компонентов включаются данные стандартных типов: логические, целочисленные, с плавающей
точкой, векторные символьные или многозначные.
После инициализации генерируется популяция из тысяч компьютерных программ.
Каждая новая программа создается с применением генетических операторов.
Скрещивание, мутация и другие обеспечивающие воспроизводство операторы необходимо
адаптировать для создания компьютерных программ. (Ниже мы кратко остановимся на
нескольких примерах.) Качество каждой новой программы определяется ее способностью
решать задачи из конкретной предметной области. Сам критерий качества тоже
формируется с учетом предметной области. Программы с высоким значением критерия
качества выживают и участвуют в формировании следующего поколения программ.
Итак, генетическое программирование включает следующие шесть компонентов,
многие из которых напоминают составные части генетических алгоритмов.
1. Набор структур, подвергающихся трансформации с помощью генетических
операторов.
2. Набор исходных структур, соответствующих предметной области.
3. Мера качества для оценки этих структур, выбираемая с учетом предметной области.
4. Набор генетических операторов для трансформации структур.
5. Описания параметров и состояний элементов каждого поколения.
6. Набор условий останова.
В следующих разделах эти компоненты будут рассмотрены более подробно.
В генетическом программировании операции выполняются над иерархически
организованными программными модулями. Основным средством представления компонентов
программных языков был и остается язык LISP. В [Koza, 1992] программные фрагменты
представлены в виде символьных выражений на языке LISP, или s-выражений. Описание
s-выражений, их естественное представление в виде структур деревьев, а также
эффективность такого представления более подробно рассматриваются в разделе 15.1.
Генетические операторы оперируют s-выражениями. В частности, они отображают
древовидные структуры s-выражений (фрагменты программ на языке LISP) в новые
деревья (другие программы на LISP). Хотя эти s-выражения появились еще в работе [Koza,
1992], другие исследователи применяли этот подход к различным парадигмам
программирования и в более позднее время.
Генетическое программирование позволяет строить полезные программы на основе
исходных данных и предикатов, описывающих предметную область задачи. При задании
области определения для поколения программ, предназначенных для решения некоторо-
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 501
го множества задач, необходимо сначала проанализировать возможные конечные
значения составных элементов и самого решения, а также функции, необходимые для
получения этих конечных значений. В [Koza, 1992] отмечено, что "...при использовании
генетического программирования необходимо знать..., что некоторая композиция функций и
конечных значений приводит к решению проблемы".
Чтобы инициализировать структуры, модифицируемые с помощью генетических
операторов, необходимо создать два множества: множество функций F и множество
конечных значений Г, требуемых для данной предметной области. Множество F может
состоять из простых операций {+, -, *, /} или включать более сложные функции, такие как
sin(x), cos(x) и матричные операции. Множество Г может содержать целые или
вещественные числа, матрицы или более сложные выражения. Множество символов Г должно
быть замкнуто относительно функций из F.
Затем генерируется популяция исходных "программ" путем случайного выбора
элементов из множеств F и Т. Например, выбирая элемент из множества Г, мы получаем
вырожденное дерево, состоящее из одного корневого элемента. Более интересной
является ситуация, когда сначала выбирается элемент из F, скажем, +. В этом случае
получается корневой узел дерева с двумя потенциальными потомками. Допустим, после этого в
качестве первого потомка инициализатор выбирает из F операцию * (с двумя
потенциальными потомками), а в качестве второго — конечное значение 6 из множества Т.
Следующими случайно выбранными элементами могут стать конечное значение 8 и функция
+ из F. Допустим, процедура завершается выбором значений 5 и 7 из множества Т.
Случайно сгенерированная таким образом программа представлена на рис. 11.4. На
рис. 11.4, а показано дерево после первого выбора операции +, на рис. 11.4, б— после
выбора конечного значения 6, а на рис. 11.4, в — окончательная программа. Для
инициализации процесса генетического программирования формируется целое поколение
подобных программ. Для контроля размерности этой популяции можно применять ограничения,
например, на максимальную глубину программ. Описание подобных ограничений, а также
различных методов генерирования исходных популяций содержится в [Koza, 1992].
5 7
а б. в.
Рис. 114. Случайная генерация исходной
программы. Узлы, обозначенные символом
окружности, соответствуют функциям
До сих пор рассматривались вопросы представления (s-выражения) и древовидные
структуры, необходимые для инициализации процесса эволюции программ. Для управления
популяциями программ необходимо определить критерий качества. Выбор критерия качества
зависит от конкретной задачи и обычно сводится к определению набора задач, которые должна
решать эволюционирующая программа. Сам критерий качества — это функция,
вычисляющая эффективность решения задач данной программой. Линейный критерий качества (raw
502
Часть IV. Машинное обучение
fitness) учитывает различие между результатом выполнения программы и требуемым
решением реальной задачи. Следовательно, линейный критерий качества можно рассматривать как
сумму ошибок при наборе задач. Возможны также другие меры качества. Нормализованный
критерий качества подразумевает деление общего критерия качества на количество всех
возможных ошибок. Следовательно, нормализованный критерий качества может изменяться в
диапазоне от 0 до 1. Преимущество нормализации проявляется при работе с большими
популяциями программ. Мера качества учитывает размер программы, например, можно поощрять
создание компактных программ небольшого размера.
Генетические операторы в пространстве программ содержат как преобразование самого
дерева, так и обмен фрагментами между различными деревьями. В [Koza, 1992] описаны
основные преобразования, получившие название воспроизводства (reproduction) и скрещивания
(crossover). Воспроизводство — это выбор программ текущего поколения и копирование их
(без изменений) в популяцию следующего поколения. Скрещивание подразумевает обмен
поддеревьев двух существующих программ. Допустим, существуют две родительские
программы, представленные на рис. 11.5, в которых символом | показаны точки скрещивания.
Дочерние деревья, полученные в результате скрещивания, изображены на рис. 11.6.
Скрещивание также можно использовать для преобразования одного родительского дерева путем
перемены мест в двух его поддеревьях. При случайном выборе точки скрещивания два
идентичных родительских дерева могут дать различное потомство. Точкой скрещивания также
может служить корневой узел программы.
а б. а. б.
Рис. 115 Две программы, подлежащие скрещи- Рис. 11.6. Дочерние программы, полученные в
ванию в случайно выбранной точке \ результате скрещивания
Известно множество менее распространенных и менее полезных генетических
преобразований деревьев программ. К ним относятся мутация (mutation), при которой в
структуру программы просто вносятся случайные изменения (например, замена
конечного значения другим значением или поддеревом). Перестановка (permutation) аналогична
оператору инвертирования строк. Она тоже выполняется для отдельных программ и
состоит в перемене мест конечных символов или поддеревьев.
Текущее пополнение программ отражает состояние решения. Не существует
специальных методов, позволяющих учитывать рельеф поверхности, определяемой критерием
качества. С этой точки зрения генетическое программирование напоминает алгоритм
поиска экстремума, описанный в разделе 4.1. Генетическое программирование сходно с
естественным процессом эволюции, поскольку трансформации программ можно
выполнять непрерывно. Тем не менее ограниченность времени и вычислительных ресурсов
требуют задания условий останова. Такие условия обычно зависят от значения критерия
качества и потребляемых вычислительных ресурсов.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 503
Поскольку генетическое программирование — это метод генерирования
компьютерных программ, то его можно отнести к области автоматического программирования. Над
проблемой автоматического создания компьютерных программ на основе
фрагментарной информации исследователи работают с самого начала развития искусственного
интеллекта [Shapiro, 1992]. Генетическое программирование можно рассматривать как
одно из средств в этой важной области исследований. В конце этого раздела будет
приведен простой пример генетического программирования из [Mitchell, 1996].
Эволюция программы, моделирующей третий закон Кеплера о движении планет
В [Koza, 1992] описано много приложений метода генетического программирования,
позволяющих решать интересные задачи. Однако большинство этих примеров слишком
объемны и сложны. В то же время в [Mitchell, 1996] приводится простой пример,
иллюстрирующий многие важные понятия генетического программирования. Третий закон
Кеплера о движении планет описывает функциональные зависимости между периодом
орбиты Р и средним расстоянием от этой планеты до Солнца Л.
Формула третьего закона Кеплера имеет вид
Р2=сА\
где с — константа. Если считать, что единицей измерения величины Р является земной
год, а величина Л — это количество средних расстояний от Земли до Солнца, то с=1. Для
этого отношения s-выражение имеет вид
P=(sqrt(MH^))).
Целевая программа, реализующая это соотношение, представлена в виде древовидной
структуры на рис. 11.7.
В этом примере множество конечных символов выбирается очень просто: оно
включает только одно значение Л. Набор функций тоже задается несложно, в частности {+, -,
*, /, sq, sqrt}. Создадим случайным образом популяцию программ. Исходная популяция
может иметь вид
(*А(-(*А A)(sqrX А))) мера качества: 1
(/А(/(/А А)(/А А))) мера качества: 3
(+Л(*( sqrtAH)) мера качества: О
Значения меры качества будут обоснованы ниже. Как указывалось выше в этом
разделе, на исходную популяцию могут накладываться ограничения по размеру и глубине
программ, определяемые знаниями о предметной области. Эти три примера
описываются деревьями программ, показанными на рис. 11.8.
Определим набор тестов для программ этой популяции. Допустим, нам известна
некоторая информация о планетах, которая должна найти свое подтверждение при работе
программы. Предположим, известны данные, приведенные в табл. 11.3. Эти сведения
получены из работы [Urey, 1952].
Поскольку мера качества должна определять степень соответствия результатов
программы этим данным, ее можно определить как количество результатов работы
программы, отличающихся от эталонных данных не более чем на 20%. Это определение
использовано для получения меры качества трех программ, представленных на рис. 11.8.
Читателю предлагается создать еще несколько элементов исходной популяции,
сконструировать операторы скрещивания и мутации, позволяющие формировать новые
поколения программ, и определить условия останова.
504
Часть IV. Машинное обучение
(sort)
(sort)
(sort)
AAA AAAA A
Мера качества = 1 Мера качества = 3 Мера качества = О
Рис 11.7. Целевая про- Рис. 118 Исходная популяция программ для вычисления периодов орбиты
грамма, моделирующая
третий закон Кеплера
Таблица 11.3. Набор данных о движении планет из работы [Urey, 1952]. А — это
относительный размер главной полуоси орбиты, а Р — относительный период,
приведенный к данным для Земли
Планета
А (вход)
Р (выход)
Венера
Земля
Марс
Юпитер
Сатурн
Уран
0,72
1,0
1,52
5,2
9,53
19,1
0,61
1,0
1,87
11,9
29,4
83,5
11.3. Искусственная жизнь и эмерджентное обучение
Ранее в этой главе была описана упрощенная версия игры "Жизнь". Эта игра,
которую можно эффективно визуализировать на компьютере, имеет очень простое описание.
Впервые она была предложена математиком Джоном Хортоном Конвеем (John Horton
Conway) и получила широкую популярность благодаря ее описанию в журнале Scientific
American в 1970-1971 годах. Игра "Жизнь"— это простой пример модели вычислений,
получившей название клеточных автоматов (cellular automata). Клеточный автомат —
это семейство простых конечных автоматов, демонстрирующее интересное
эмерджентное поведение при взаимодействии элементов популяции.
ОПРЕДЕЛЕНИЕ
МАШИНА С КОНЕЧНЫМ ЧИСЛОМ СОСТОЯНИЙ, или КОНЕЧНЫЙ АВТОМАТ
Понятие конечного автомата включает следующие элементы.
1. Множество /, называемое входным алфавитом.
2. Множество S возможных состояний автомата.
3. Известное начальное состояние s0.
4. Функция N: Sxl-^S, определяющая следующее состояние для каждой
упорядоченной пары состояние-вход.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 505
Выход машины с конечным числом состояний — это функция текущего состояния и
состояний ближайших конечных автоматов. Так, состоянием конечного автомата в момент
t+l является функция от его собственного состояния и состояния его соседей в момент
времени t Благодаря взаимодействию каждого элемента клеточного автомата со своими
соседями достигается гораздо более разнообразное поведение, чем поведение отдельного элемента.
Такая взаимозависимость является одним из наиболее привлекательных свойств клеточных
автоматов. Поскольку выход каждого элемента зависит от состояния его соседей, эволюцию
состояний набора элементов можно описать как процесс социальной адаптации.
В примерах, описанных в этом разделе, явно не вычисляется значение критерия
качества для каждого элемента. Мера качества определяется как результат взаимодействия
элементов популяции, которое может привести к "отмиранию" отдельных автоматов. Неявно
качество выражается в выживании отдельных особей из поколения в поколение. Для
клеточных автоматов обычно применяется обучение без учителя. Как и при естественной
эволюции, адаптация выполняется на основе действий других особей этой популяции.
Важную роль такого обучения можно оценить с глобальной, социально
ориентированной точки зрения. Такой подход устраняет необходимость концентрировать внимание
на отдельных особях и позволяет выявить инвариантности и регулярные зависимости в
обществе в целом. Этот важный аспект будет проанализирован в подразделе 11.3.2.
И, наконец, в отличие от обучения с учителем, эволюция не должна быть "направленной".
Нельзя считать, что общество движется к некоторой заранее заданной точке "омега". При
явном использовании меры качества в предыдущих разделах этой главы на самом деле
ставилась задача сходимости процесса обучения. Однако, как отмечено в работах [Gould,
1977], [Gould, 1996], эволюцию нельзя рассматривать с точки зрения улучшения мира, а
лишь с точки зрения его выживания. Единственной мерой прогресса является
продолжение существования.
11.3.1. Игра "Жизнь"
Рассмотрим простую двухмерную решетку или игровую доску, показанную на рис. 11.9.
На этом рисунке одна из клеток закрашена черным (занята), а восемь соседних —
заштрихованы. Со временем внешний вид доски изменяется, при
этом состояние каждой клетки в момент времени f+1 — это
функция ее состояния и состояний ее ближайших соседей в
момент времени t. Игра подчиняется трем простым
правилам. Во-первых, если для некоторой клетки (занятой или
свободной) ровно три ближайшие соседние клетки заняты, то
она будет занята в следующий момент времени. Во-вторых,
если для некоторой занятой клетки заняты также ровно две
соседние клетки, то она тоже будет занята в следующий
момент времени. И, наконец, во всех остальных ситуациях в
следующий момент времени клетка остается свободной.
Одна из интерпретаций этих правил сводится к
следующему. Для каждого поколения или момента времени жизнь
каждой популяции (черный цвет клетки или состояние,
равное 1) является результатом ее собственной жизни, а также жизни ее соседей в
предыдущем поколении. А именно, слишком плотная населенность (более трех занятых соседних
клеток) или разреженность соседних популяций (менее двух) в каждый момент времени
приводят к невозможности жизни в следующем поколении.
1
ш
1
ш
Ж
yiy,
ш
Рис. 11.9. Заштрихованная
область определяет группу
соседей в игре "Жизнь "
506
Часть IV. Машинное обучение
Например, рассмотрим состояние, показанное на рис. 11.10, а. Здесь ровно две клетки
(обозначенные символом X) имеют ровно по три занятые соседние клетки. Следующее
поколение показано на рис. 11.10, б. Здесь также существуют две клетки (обозначенные
символом Y), у которых есть три занятых соседа. Несложно убедиться, что состояние
жизни будет циклически переходить между рис. 11.10, а и 11.10, б. Читателю
предлагается определить следующее состояние для рис. 11.11, а и 11.11, б, а также исследовать
другие возможные конфигурации "мира". В работе [Poundstone, 1985] описано большое
разнообразие и богатство структур, получаемых в результате игры "Жизнь", в том числе
планеры (glider) — шаблоны ячеек, которые перемещаются по игровой доске в
повторяющихся циклах изменения формы.
Благодаря своей способности обеспечивать разнообразное коллективное поведение в
процессе взаимодействия простых клеток клеточные автоматы стали мощным средством
изучения математических принципов эмерджентности жизни на основе простых,
неодушевленных компонентов. По определению искусственная жизнь — это жизнь,
созданная ценой усилий человека, а не природы. Как видно из предыдущего примера,
искусственная жизнь имеет ярко выраженную тенденцию к развитию, т.е. система жизни
строится на основе взаимодействия ее атомов. Регулярности этой формы жизни объясняются
правилами работы конечных автоматов.
Но как в данном случае можно воздействовать на процесс развития жизни?
Например, в биологии множество созданных природой живых сущностей во всей своей
сложности и многообразии подчиняется воле случая и исторической неопределенности. Мы
верим в существование логических закономерностей в работе над созданием этого
множества, однако их может и не быть. Вряд ли мы сможем исследовать общие
закономерности, ограничившись рассмотрением лишь созданных природой биологических
сущностей. Важно изучить полный набор возможных биологических закономерностей, часть из
которых может нарушаться вмешательством случая. Остается только гадать, как бы
выглядел современный мир, если бы по воле случая не вымерли динозавры. Чтобы
построить теорию существования, необходимо понять границы возможного.
X
X
LIZlZ^BZJIJIJ
а б
Рис 11 10. Множество соседей, создающих эффект
переключения света
Помимо известных попыток специалистов по антропологии и других ученых
заполнить бреши в изучении реальной эволюции, не прекращаются дискуссии о циклическом
характере самой эволюции. Что бы произошло, если бы эволюция началась из других
начальных условий? Что бы изменилось при включении других переходных процессов в
нашей физической и биологической среде? Как пошел бы процесс развития? Что
осталось бы нетронутым? Путь развития, который реально был пройден на Земле, — это
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 507
лишь одна из многих возможных траекторий. Ответы на некоторые из этих вопросов
можно получить, сгенерировав хотя бы некоторые из множества возможных ситуаций.
Рис. 11.11. Что произойдет с этими образами в
следующем жизненном цикле?
Технология искусственной жизни — это не просто артефакт из предметной области
биологии или компьютерных наук. Исследователи из других областей, в том числе
специалисты по химии и фармакологии, построили синтетические артефакты, тесно
связанные со знанием реальных форм жизни в нашем мире. Например, в области химии
изучение строения вещества и многих созданных природой компонентов привело к
необходимости анализа этих компонентов, их составных частей и границ. Этот анализ и попытки
рекомбинации позволили создать многочисленные соединения, не существующие в
природе. Знание о строительных блоках природных соединений привело к разработке их
синтетических аналогов и созданию новых, не известных ранее веществ. Благодаря
внимательному изучению естественных химических соединений люди пришли к некоторому
пониманию множества возможных соединений вообще.
Одним из средств понимания мира является моделирование и анализ общества на
основе взаимодействия и движения. Примером такой модели является игра "Жизнь".
Последовательность жизненных циклов, показанная на рис. 11.12, иллюстрирует
упомянутую ранее структуру "планер". Планер перемещается по жизненному пространству,
циклически изменяя свою форму. За четыре такта он перемещается в новое положение со
сдвигом на одну клетку вправо и вниз.
■
гам
шш
■
Шаг 0 Шаг1 Шаг 2
Рис II 12 Перемещение''планера" по экрану
ШагЗ
Шаг 4
Интересным аспектом игры "Жизнь" является исследование взаимодействия различных
структур (членов общества). Сложно понять и спрогнозировать, что произойдет при
взаимодействии планера с другими структурами. Например, на рис. 11.13 показан пример
совместного существования двух планеров. Через четыре такта планер, передвигающийся вниз и
влево, поглощается другой сущностью. Интересно отметить, что наши онтологические описания,
в том числе такие термины, как "сущность", "планер", "переключение света", "поглощается",
508
Часть IV. Машинное обучение
отражают наши антропоцентрические представления о формах жизни, в том числе и
искусственной, и их взаимодействии. Человеку свойственно оперировать терминами и
закономерностями, присущими социальным структурам.
Шаг 0 Шаг1 Шаг 2 ШагЗ Шаг 4
Рис. 11.13 "Поглощение" "планера" другой сущностью
11.3.2. Эволюционное программирование
Игра "Жизнь" — это интуитивный описательный пример клеточного автомата.
Описание клеточных автоматов можно обобщить, охарактеризовав их как машину с конечным
числом состояний. В этом разделе будут рассмотрены сообщества связанных друг с другом
машин с конечным числом состояний и проанализировано их взаимодействие. Эта область
знаний получила название эволюционного программирования (evolutionary programming).
История эволюционного программирования возникла в момент зарождения самих
компьютеров. В 1949 году в цикле лекций Джона фон Неймана исследован вопрос о том,
какой уровень организационной сложности необходим для самовоссоздания. В [Burks,
1970] цель фон Неймана определена так: "...это не попытка моделировать
самовоспроизводство естественной системы на уровне генетики и биохимии. Автор хотел
абстрагироваться от естественной проблемы самовоспроизводства".
Не вдаваясь в химические, биологические и механические тонкости, фон Нейман
постарался представить основные требования, необходимые для самовоспроизводства. Он
разработал (но не реализовал) самовоспроизводящуюся автоматическую конструкцию,
представляющую собой двухмерную решетку с большим числом отдельных автоматов с 29
состояниями. Каждое следующее состояние отдельного автомата конструкции являлось функцией
его текущего состояния и состояний четырех ближайших соседей [Burks, 1970, 1987].
Интересно, что для обеспечения функциональности универсальной машины
Тьюринга фон Нейману потребовалось спроектировать самовоспроизводящийся автомат,
содержащий около 40 000 клеток. Это универсальное вычислительное устройство было также
конструктивно универсальным в смысле его способности чтения входных данных с
магнитной ленты, их интерпретации и использования специальной руки для создания
описанной на ленте конфигурации в незанятой части клеточного пространства. Поместив на
магнитной ленте описание самого автомата, фон Нейман создал самовоспроизводящийся
автомат [Arbib, 1966].
Позднее, в 1968 году, Кодд (Codd) уменьшил число состояний
самовоспроизводящегося автомата, необходимых для обеспечения вычислительной универсальности, с 29 до
8. Однако для этого ему потребовалось примерно 100 000 000 клеток. После этого Девор
(Devore) упростил машину Кодда и разработал автомат, содержащий примерно 87 500
клеток. В последние десятилетия был разработан самовоспроизводящийся автомат,
состоящий из 100 клеток по 8 состояний каждая, не обладающий вычислительной
универсальностью [Langton, 1986], [Hightower, 1992], [Codd, 1992]. Подробные описания этих
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 509
научных результатов содержатся в материалах конференций, посвященных проблемам
искусственной жизни [Langton, 1989], [Langton и др., 1992].
Таким образом, формальный анализ самовоспроизводящихся машин уходит корнями
вглубь теории вычислений. Интересные результаты демонстрируют также эмпирические
исследования форм искусственной жизни. Успех работы этих программ определяется не
некоторым заранее заданным критерием качества, а простым фактом выживания и
самовоспроизводства особей. Признаком успеха является само выживание. Но существует и
другая сторона медали. Всем известны компьютерные вирусы и черви, способные
выживать в чуждой среде, воспроизводить себя (обычно разрушая в памяти любую
информацию, необходимую для этого воспроизводства) и инфицировать другие узлы.
В заключение этого раздела остановимся на двух исследовательских проектах,
упомянутых ранее в этой книге: проекте Родни Брукса (Rodney Brooks) из Массачусетского
технологического института и Нильса Нильсона (Nils Nilsson) и его студентов из Стэн-
форда. Работа Брукса упоминалась в разделе 6.3, а проект Нильсона — при описании
вопросов планирования в подразделе 7.4.3. В контексте данной главы эти два описания
будут рассмотрены с точки зрения искусственной жизни и феномена эмерджентности.
Родни Брукс [Brooks, 1991a, 19916] из Массачусетского технологического института
построил исследовательскую программу, основываясь на исследовании искусственной
жизни, а именно — на интеллектуальном поведении, проявляющемся при
взаимодействии простых автономных агентов. Подход Брукса, зачастую называемый "интеллектом
без представления", предусматривает различные способы создания искусственного
интеллекта. Брукс утверждает следующее.
"Необходимо постепенно наращивать возможности интеллектуальной системы,
отталкиваясь на каждом шаге от полной системы, в которой автоматически обеспечивается
корректность фрагментов и их интерфейсов.
На каждом шаге необходимо строить полные интеллектуальные системы, которые можно
"выпускать" в реальный мир с реальными ощущениями и действиями В противном случае
мы будем обманывать сами себя.
Мы следовали такому подходу и построили группы автономных мобильных роботов. При
этом мы пришли к неожиданному заключению
При исследовании очень простых уровней интеллекта мы обнаружили необходимость
явного представления и моделей мира. Гораздо лучше использовать реальный мир в качестве
его собственной модели."
Брукс построил серию роботов, способных обнаруживать препятствия и
перемещаться вокруг офисов и зданий Массачусетского технологического института. Они могут
передвигаться, исследовать и обходить другие объекты. Каждая из этих сущностей
основывается на идее Брукса об архитектуре категоризации (subsumption architecture),
которая "воплощает фундаментальные идеи декомпозиции поведения на уровни и
постепенную структуризацию путем апробации в реальном мире". Интеллект этой
системы — это артефакт простой организации и взаимодействия с окружающей средой.
Брукс утверждает: "мы конфигурируем конечные автоматы, располагая их по уровням
управления. Каждый уровень строится на базе существующих. Нижние уровни никогда
не основываются на существовании высоких". Более подробная информация содержится
в работах [Brooks, 1987, 1991], [Lewis и Luger, 2000].
Нильс Нильсон со своими студентами из Стэнфорда, в частности Скоттом Бенсоном (Scott
Benson), разработал систему телео-реактивного управления агентами. По сравнению с рабо-
510
Часть IV. Машинное обучение
той Брукса, Нильсон предложил более глобальную агентную архитектуру, состоящую из
подсистем, интеграция которых обеспечивает функции, необходимые для робастного и гибкого
существования в динамической среде. Такая система обеспечивает соответствующую
реакцию на различные ситуации в окружающей среде исходя из целей агента: переключение
внимания между несколькими конкурирующими целями, планирование новых действий при
выходе ситуации за определенные разработчиком пределы, а также изучение результатов своих
действий для последующего построения более надежных планов.
Нильсон и его ученики разработали телео-реактивную программу управления
агентом, направляющую агента к цели с учетом постоянно изменяющихся внешних
обстоятельств [Nilsson, 1994], [Benson, 1995], [Benson и Nilsson, 1995].
Эта программа в значительной мере напоминает продукционную систему (глава 5),
но при этом поддерживает длительные действия (durative action), т.е. действия,
происходящие в течение произвольных периодов времени, такие как "двигаться вперед,
пока...". Поэтому, в отличие от обычной системы логического вывода, в данном случае
необходимо постоянно отслеживать условия и выполнять действия, в наибольшей
степени соответствующие им. Сказанное выше можно подытожить следующим образом.
1. Данный подход поддерживает принцип планирования, требующий стереотипной
программы отклика. Эта архитектура также поддерживает планирование,
позволяющее агентам соответствующим образом быстро реагировать на типичные
ситуации (отсюда термин "реактивный"). Действия агентов также являются
динамическими и подчиняются определенным целям (поэтому "телео").
2. Агенты должны иметь возможность поддерживать несколько изменяемых во
времени целей и предпринимать действия, соответствующие организации этих целей.
3. Поскольку невозможно запомнить все стереотипные ситуации, необходимо
обеспечить агенту возможность динамического планирования (а при необходимости и
перепланирования) последовательности действий и изменения положения вещей
во внешней среде.
4. Наряду с постоянным перепланированием в соответствии со внешними
обстоятельствами важно обеспечить возможность обучения системы. В этой работе
реализованы методы обучения и адаптации, позволяющие агенту автоматически
изменять заложенную в нем программу.
Более подробная информация содержится в работах [Nilsson, 1994], [Benson, 1995],
[Benson и Nilsson, 1995], [Klein и др., 2000].
Эти две работы служат примерами огромного множества исследовательских
проектов, основанных на использовании агентов. По своей сути они являются
экспериментальными и поднимают вопросы, с которыми сталкивается естественный мир. Во
взаимодействии с внешним миром формируются и "выживают" успешные алгоритмы, а
неспособные к адаптации системы "отмирают". Этот аспект искусственного интеллекта
более подробно будет описан в завершение главы 16.
И наконец рассмотрим научные результаты, полученные в институте Санта-Фе (Santa
Fe Institute).
11.3.3. Пример эмерджентности
В [Crutchfield и Mitchell, 1994] исследована возможность эволюции и взаимодействия
простых систем с целью формирования взаимосвязей, обеспечивающих высокоуровне-
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 511
вую коллективную обработку информации. Эта работа содержит пример эмерджентно-
сти и реализации глобальных вычислений в распределенной системе, состоящей из
взаимодействующих друг с другом клеток или процессоров на основе эволюционных или
генетических алгоритмов. Термин эмерджентные вычисления (emergent computation)
описывает появление в этих системах структур глобальной обработки информации. Целью
исследования является описание архитектуры и механизмов эволюции, обеспечивающих
реализацию методов эмерджентных вычислений.
Клеточный автомат состоит из большого числа отдельных ячеек. В каждом из
рассматриваемых примеров содержится по 149 клеток. Эти клетки с бинарными
состояниями образуют одномерное пространство без глобальной координации. Состояние каждой
клетки зависит от ее собственного состояния на предыдущем шаге и состояний двух ее
ближайших соседей. В процессе эволюции клеточного автомата формируется
двухмерная решетка. Изначально она состоит из N ячеек со случайно сгенерированными
состояниями. На рис. 11.14 показаны 149 шагов эволюции клеточного автомата, состоящего из
149 элементов. Время и ячейки нумеруются с 0 до 148. На рис. 11.14 показаны
пространственно-временные диаграммы возможного поведения клеточного автомата. На этих
диаграммах единичные состояния представлены черными клетками, а нулевые —
белыми. Различные правила выбора соседей приводят к различным конфигурациям
пространственно-временных диаграмм клеточного автомата.
Опишем набор правил, определяющих активизацию элементов клеточного автомата. На
рис. 11.15 показан одномерный клеточный автомат с бинарными состояниями, состоящий
из Л/=11 ячеек. Там же приведены таблица вычисления состояний и правило определения
ближайших соседей. Показано изменение решетки за один шаг. Эта решетка на самом деле
представляет собой цилиндр, в котором крайние слева и справа ячейки в каждый момент
времени считаются соседними (это важно для применения набора правил). Таблица правил
реализует правило мажоритарного голосования (majority vote): если большинство из трех
ячеек находится в единичном состоянии, то центральная ячейка на следующем шаге
переходит в состояние 1. В противном случае она переходит в состояние 0.
0 Местоположение 148 0 Местоположение 148
а б
Рис 11 14 Пространственно-временные диаграммы, отражающие поведение двух клеточных
автоматов и демонстрирующие эмерджентное поведение Единичные значения клеток показаны
черным цветом, а нулевые — белым Время изменяется сверху вниз
512
Часть IV. Машинное обучение
Таблица правил
окрестность: 000 001010 011 100 101 110 111
результирующее значение: 0 0 0 1 0 1 1 1
Решетка
Окрестность' N\
i
/
1
0
1
0
0
1
1
1
0
1
0
0
1
0
0
0
1
1
1
1
0
1
Рис. 11.15. Пример одномерного бинарного клеточного
автомата, состоящего из N= 11 элементов. Здесь
показаны решетка и таблица правил для ее обновления.
Этот клеточный автомат является циклическим, т.е.
два крайних значения считаются соседями
В работе [Crutchfield и Mitchell, 1994] предпринята попытка построения клеточного
автомата, выполняющего следующие коллективные вычисления, получившие название
победы большинства (majority wins): если исходная решетка содержит большинство
единиц, то на следующем шаге все элементы автомата переходят в состояние 1, в
противном случае — в состояние 0. При этом были использованы клеточные автоматы, в
которых окрестность состояла из семи ячеек (по три соседа с каждой стороны от центра).
Интересным аспектом оказалось сложность построения правила, реализующего такие
вычисления. На самом деле в работе [Mitchell и др., 1996] показано, что простое правило
мажоритарного голосования для семи соседей не реализует правило победы
большинства. Для поиска требуемого правила был использован генетический алгоритм.
Описанный в разделе 11.1 генетический алгоритм применялся для создания таблицы
правил в экспериментах с клеточным автоматом. А именно, он использовался для
настройки правил преобразования одномерной бинарной популяции элементов клеточного
автомата. Критерий качества формировался с целью подкрепить правила,
обеспечивающие победу большинства для клеточного автомата.
Таким образом, со временем на основе генетического алгоритма был сформирован
набор правил, обеспечивающий победу большинства. Отобранные на основе критерия
качества элементы популяции случайным образом комбинировались с помощью
скрещивания, а затем каждый потомок с малой вероятностью подвергался мутации. Этот
процесс продолжался для ста поколений, при этом для каждого поколения вычислялся
критерий качества [Crutchfield и Mitchell, 1994].
Как определить наилучший клеточный автомат, реализующий эмерджентные
вычисления? Подобно многим пространственным естественным процессам,
конфигурация ячеек со временем зачастую образует динамически гомогенные области в
пространстве. В идеале следует автоматизировать процесс анализа и определения этих
закономерностей. В работе [Hanson и Crutchfield, 1992] разработан язык минимальных
детерминистских конечных автоматов, с помощью которого описаны области
притяжения аттракторов для каждого конечного автомата. Этот язык можно использовать и
для описания нашего примера.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 513
Иногда (как на рис. 11.14, а) эти области заметны невооруженным глазом и
представляют собой инвариантные поверхности. Обозначим эти области символом Л, а затем
выделим инвариантные элементы, чтобы лучше описать взаимодействия, определяемые
пересечением этих областей. В табл. 11.4 описаны три Л-области: Л°, состоящая из нулей,
Л1, состоящая из единиц, и Л2, содержащая повторяющиеся фрагменты 10001. На
рис. 11.14, а имеются и другие Л-области, но пока они нас не интересуют.
Выделяя инвариантные элементы Л-областей, можно отследить их взаимодействие. В
табл. 11.4 описано взаимодействие шести Л-областей, в том числе по границе областей
Л1 и Л°. Эта граница между единичной и нулевой областями называется внедренной
частицей a (embedded particle а). В работе [Crutchfield и Mitchell, 1994] утверждается, что
внедренные частицы — это основной механизм передачи информации (или сигналов) в
больших пространственно-временных областях. При столкновении этих частиц
реализуются соответствующие логические операции. Поэтому поведение клеточных автоматов
обусловлено информационно-обрабатывающими элементами, представляющими собой
наборы областей, их границ, частиц и взаимодействия.
Таблица 11.4. Каталог регулярных областей, частиц (границ областей),
их скоростей (в скобках) и взаимодействий, описывающих пространственно-
временное поведение клеточного автомата на рис. 11.14, а. Запись р~Л"Лу
означает, чтор —это частица, формирующая границу между регулярными
областями Л* и Лу
Регулярные области
Л°=0* Л1=1* Л2=A0001)*
Частицы (скорости)
а~Л1Л°A) Р~Л°Л1@)
у~Л2Л°(-2) 5~Л°Л2A/2)
П~Л2Л1D/3) и~Л1Л2C)
Взаимодействия
Распад а—>у+И
Реакция а+5->ц, ti+cx->y. Д+у->а
Аннигиляция ri+ц-Ю,, у+&->@0
На рис. 11.16 показана эмерджентная логика, представленная на рис. 11.14, а. Здесь
выделены Л-области с инвариантным содержимым, а также пограничные частицы.
Увеличенные фрагменты на рис. 11.16 демонстрируют логику взаимодействия двух
внедренных частиц. В правом верхнем углу показано взаимодействие а+5—>ц, реализующее
логику отображения соответствующей конфигурации сигналов а и 5 в сигнал jli. Ниже
показано взаимодействие частиц jLi-hy—>cx. Более полное описание взаимодействия частиц
содержится в табл. 11.4.
Итак, важным результатом работы [Crutchfield и Mitchell, 1994] является
исследование методов описания эмерджентных вычислений в пространственно распределенных
системах, состоящих из локально взаимодействующих клеточных процессоров.
Локальное взаимодействие элементов определяет и глобальное. Роль генетических алгоритмов
сводится к изучению локальных правил взаимодействия, которые в результате приводят
к обработке информации на больших пространственно-временных интервалах. В работе
[Crutchfield и Mitchell, 1994] для характеристики пространственно-временных
отношений использованы идеи теории формальных языков.
514
Часть IV. Машинное обучение
Рис. 11.16. Анализ эмерджентной логики для классификации плотности областей на рис. 11.14, а.
Этот клеточный автомат характеризуется тремя Л-областями, шестью частицами и шестью
видами их взаимодействия, описанными в табл. 11.4. Области выделены с помощью нелинейного
преобразования с 18 состояниями, описанного в [Mitchell и др., 1996]
Результат эволюции клеточного автомата отражает качественно новый уровень
поведения, который отличается от низкоуровневого взаимодействия распределенных элементов.
Глобальное взаимодействие частиц иллюстрирует сложную координацию, возникающую в
результате набора простых действий. Применение генетического алгоритма для правил
изменения состояния отдельных частиц отражает процесс эволюции, реализующий новый
уровень поведения, необходимый для эффективных эмерджентных вычислений.
Значение работы [Crutchfield и Mitchell, 1994] состоит в том, что в ней с помощью
генетических алгоритмов продемонстрировано эмерджентное высокоуровневое поведение
клеточного автомата. Более того, авторы предложили вычислительные средства
описания инвариантности, построенные на основе теории формальных языков. Продолжение
исследований даст возможность изучить природу сложности: определить характеристики
жизни и понять принципы формирования родов, видов и экосистем.
11.4. Резюме и дополнительная литература
Основоположником развития генетических алгоритмов и биологического обучения стал
Джон Холланд (John Holland) [Holland, 1975, 1986]. В последней работе вводится понятие
системы классификации. Анализ генетических систем содержится в [Forrest, 1990],
[Mitchell, 1996], [Forrest и Mitchell, 1993я, 19936]. Формальный анализ генетических
алгоритмов и обучения проводится также в [Goldberg, 1989], [Mitchell, 1996], [Koza, 1992, 1994].
Как отмечено выше, в работе [Holland, 1986] впервые вводится понятие системы
классификации. Классификаторы позволяют определить общий подход к обучению. Аналогичные
идеи развиваются в [Rosenbloom и Newell, 1987] и [Rosenbloom и др., 1993].
Джон Коза (John Koza) — это основной исследователь в области генетического
программирования [Koza, 1992,1994]. Описанный в подразделе 11.2.2 пример использования
генетических алгоритмов для изучения третьего закона Кеплера предложен в [Mitchell, 1996].
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 515
Игра "Жизнь" изначально была создана математиком Джоном Хортоном Конвеем (John
Horton Conway), однако приобрела широкую популярность после ее обсуждения в журнале
Scientific American. Исследование вычислительной мощности конечных автоматов уходит
корнями к первым цифровым компьютерам. Большой вклад в эти исследования внес Джон
фон Нейман, который фактически впервые показал, что вычислительная мощность
конечного автомата соответствует универсальной машине Тьюринга. Большинство его ранних
результатов представлены в работах [Burks, 1966, 1970 и 1987]. Другие исследователи
[Hightower, 1992], [Koza, 1992] описали, как на основе этих ранних работ по конечным
автоматам строится модель искусственной жизни. Вопросы искусственной жизни
исследованы также в работах [Langton, 1986], [Ackley и др., 1992]. Труды конференций,
посвященных проблемам искусственной жизни, собраны в [Langton, 1989, 1990].
В [Dennett, 1995] и других работах отмечена важность эволюционной теории в
развитии философского мышления. Этой же теме посвящена работа [Gould, 1996].
Кратко описанная в разделе 11.3 концепция агентного обучения изложена в работах
[Brooks, 1986, 1987, 1991я, 19915], [Nilsson, 1994], [Benson и др., 1995]. В работах
[Maes, 1989], [Maes, 1990] предложена модель распределенной обработки информации в
сетях, которая получила свое дальнейшее развитие в работе [Hayes-Roth и др., 1993].
Результаты, описанные в подразделе 11.3.3, базируются на работе [Crutchfield и
Mitchell, 1994].
11.5. Упражнения
1. Генетический алгоритм должен поддерживать поиск в пространстве вероятных
комбинаций и обеспечивать выживание на основе генетических шаблонов. Опишите, как
эти задачи решаются с помощью различных генетических операторов.
2. Вспомните проблему разработки представления для генетических операторов при
решении задач из различных предметных областей. В чем здесь состоит роль
индуктивного порога?
3. Вернемся к задаче построения конъюнктивной нормальной формы, описанной в
подразделе 11.1.3. В чем состоит роль количества дизъюнктов, определяющих
построение конъюнктивной нормальной формы в пространстве решений? Укажите
другие возможные представления и генетические операторы для этой задачи. Можно
ли выбрать другую меру качества?
4. Постройте генетический алгоритм для решения задачи представимости в
конъюнктивной нормальной форме.
5. Подумайте над проблемой выбора соответствующего представления для задачи
коммивояжера, описанной в подразделе 11.1.3. Определите другие возможные
генетические операторы и меры качества для этой задачи.
6. Постройте генетический алгоритм поиска решения задачи коммивояжера.
7. Определите роль представления, в том числе кодирования Грея, для описания
пространства поиска в генетических алгоритмах. Приведите примеры двух предметных
областей, в которых этот вопрос играет важную роль.
8. Познакомьтесь с теоремой схем Холланда [Mitchell, 1996], [Koza, 1992]. Как теория
схем описывает эволюцию пространства решений при использовании генетических
516
Часть IV. Машинное обучение
алгоритмов? Что утверждает эта теория относительно задач, не подлежащих
кодированию битовыми строками?
9. Как алгоритм "пожарной цепочки" [Holland, 1986] связан с методом обратного
распространения ошибки?
10. Напишите программу, решающую задачу моделирования третьего закона Кеплера,
описанную в подразделе 11.2.2.
11. Сформулируйте ограничения (упомянутые в подразделе 11.2.2) по использованию
методов генетического программирования для решения задач. Например, какие
компоненты решения не могут эволюционировать в рамках парадигмы генетического
программирования ?
12. Познакомьтесь с первыми описаниями игры "Жизнь" в журнале Scientific American.
Назовите другие структуры искусственной жизни, подобные описанному в
подразделе 11.3.1 планеру.
13. Напишите программу моделирования искусственной жизни, реализующую
функциональность, показанную на рис. 11.10-11.13.
14. В разделе 11.3 упоминаются исследования, ориентированные на агентов.
Ознакомьтесь с публикациями по этим вопросам.
15. Определите роль индуктивного порога в выборе представления стратегий поиска и
операторов, используемых в моделях обучения из главы 11. Является ли
генетическая модель обучения изолированной или ее можно распространить на более
широкие области?
16. Изучите глубже вопросы эволюции и эмерджентности. Прочтите и обсудите работы
[Dennett, 1995], [Gould, 1996].
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов 517
Часть V
Дополнительные
вопросы решения
задач
искусственного
интеллекта
Точность — это не истина...
— Генри Матисс (Henri Matisse)
Время настоящее и время прошедшее — это лишь настоящее для времени
будущего, а время будущее содержится в прошедшем...
— Т. С. Элиот (Т. S. Eliot), Бернт Нортон
... любой крупный результат является следствием длинной
последовательности мельчайших действий.
— Кристофер Александер (Christopher Alexander)
Автоматические рассуждения и естественный язык
В части V рассматриваются два важных приложения искусственного интеллекта:
понимание естественного языка и автоматические рассуждения. Приступая к созданию
искусственного интеллекта, необходимо решить проблемы языка, рассуждений и обучения.
Предлагаемые решения этих проблем основываются на средствах и методах,
упомянутых в предыдущих разделах этой книги. В свою очередь эти проблемы оказали
существенное влияние на развитие самого искусственного интеллекта и его методов. Во введе-
нии к части III обсуждались преимущества и недостатки слабых методов решения задач
(weak method). Проблема использования таких методов обусловлена сложностью
пространства поиска и трудностью описания конкретных знаний о мире с помощью общего
представления. Несмотря на успешное развитие экспертных систем и сильных методов
решения задач, во многих случаях требуются более общие подходы. На самом деле
стратегии управления в самих экспертных системах основаны на использовании слабых
методов. Многообещающие результаты по созданию могут быть получены в области
автоматических рассуждений и доказательства теорем (automated reasoning). Эти
приемы нашли свое применение во многих важных областях, включая разработку
интегрированных сетей, верификацию и доказательство корректности программ, а также,
косвенно, при создании языка программирования PROLOG. В главе 12 рассматриваются
вопросы, связанные с автоматическими рассуждениями.
Сложность понимания естественных языков при решении задач искусственного
интеллекта объясняется многими причинами. В частности, для использования языка необходимы
большой объем знаний, способностей и опыта. Успешное понимание языка требует
осмысления естественного мира, знания человеческой психологии и социальных аспектов. Для
этого нужна реализация логических рассуждений и интерпретация метафор. Из-за
сложности и многогранности человеческого языка на первое место выходит проблема
исследования представления знаний. Попытки таких исследований увенчались успехом лишь
частично. На основе знаний были успешно разработаны программы, понимающие естественный
язык в отдельных предметных областях. Возможность создания систем, решающих
проблему понимания естественного языка, до сих пор является предметом споров.
Методы представления, описанные в главе 6, в том числе семантические сети, сценарии
и фреймы, играют важную роль в решении задачи понимания естественного языка. В
последнее время для решения этой задачи привлекаются методы корреляционного анализа
языковых шаблонов. Языковые конструкции — это не случайный набор звуков или слов.
Их можно моделировать на основе байесовского подхода. В главе 13 будут рассмотрены
синтаксические, семантические и стохастические методы понимания естественного языка.
С широким распространением технологий World Wide Web и интенсивным
использованием механизмов поиска вопрос понимания естественного языка стал еще важнее.
Общий поиск полезной информации в неструктурированном тексте, возможность
резюмирования информации, или "понимания" текста, — это важнейшие новые технологии.
Теоретические основы программных средств, базирующихся на символьном
представлении и стохастическом распознавании образов, представлены в главе 13.
И, наконец, в части VI будут рассмотрены многие структуры данных, используемые
при решении задач понимания естественного языка. В разделах 14.7 и 15.11 описаны
семантические сети и фреймовые системы, а в разделе 14.9 — рекурсивный семантический
сетевой анализатор. В главе 16 обсуждаются некоторые существующие проблемы в
понимании языка, обучении и решении сложных задач.
520 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Автоматические
рассуждения
Как это получается, — спросил этот проницательный человек, — когда мне
приходит идея, я могу выйти за ее рамки и связать с другими, не
содержащимися в ней, как будто эти идеи неразрывно связаны с первоначальной ?
— Иммануил Кант (Immanuel Kant),
Prolegomena to a Future Metaphysics
Любое рациональное решение молено рассматривать как вывод, полученный
на основе некоторых начальных условий .. Следовательно, поведение
рационального человека можно контролировать, если задать ему фактические
предположения, на базе которых он строит свое заключение.
— Симон (Simon),
Decision-Making and Administrative Organization, 1944
Доказательство — это искусство, а не наука...
— Вое (Wos), Automated Reasoning, 1984
12.0. Введение в слабые методы доказательства теорем
В [Wos и др., 1984] сказано, что система автоматического доказательства "применяет
однозначные описания для представления информации, точные правила вывода для
формирования заключений и внимательно сформулированные стратегии для управления этими
правилами". Авторы добавляют, что применение стратегий к правилам вывода для
получения новой информации — это искусство. "Хороший выбор представления подразумевает
использование обозначений, повышающих вероятность решения проблемы, и включение
полезной, хотя и не самой необходимой, информации. Хорошие правила вывода— это
правила, удачно использующие выбранное представление. Хорошие стратегии— это
принципы управления правилами вывода, повышающие эффективность программы
автоматических рассуждений."
Отсюда следует, что для построения систем автоматических рассуждений
используются слабые методы решения проблем. Они строятся на таком однородном
представлении, как теория предикатов первого порядка (глава 2), теория хорновских выражений
(раздел 12.3) или операторов разрешения (раздел 12.2). Правила вывода должны быть
согласованными и по возможности полными. В качестве общих стратегий применяются
поиск в ширину, в глубину, "жадные" алгоритмы поиска и, как будет видно из этой
главы, такие эвристики, как множество поддержки (set of support) и единичное
предпочтение (unit preference). Они обеспечивают возможность исчерпывающего поиска.
Разработка стратегий поиска, а особенно эвристик для этих стратегий, — во многом
искусство. Нельзя гарантировать, что приемлемое решение задачи будет найдено в рамках
допустимого времени и ограниченного объема памяти.
Слабые методы решения проблем — это важное средство, а также основа для
сильных методов. Системы вывода и экспертные системы на основе правил — это примеры
реализации слабых методов решения задач. Даже если правила в системе вывода или
экспертной системе описывают сильные проблемно-ориентированные эвристики, их
применение регулируется общими стратегиями вывода (слабыми методами).
Приемы реализации слабых методов были в центре внимания ученых в области
искусственного интеллекта с момента зарождения этой науки. Эти приемы зачастую
относят к области доказательства теорем (theorem proving), хотя автор предпочитает более
общее название — автоматические рассуждения (automated reasoning). В начале этой
главы (раздел 12.1) будут рассмотрены один из первых примеров автоматических
рассуждений — система для решения задач общего вида General Problem Solver, а также
использование анализа целей и средств (means-ends analysis) и таблиц отличий (difference
tables) для управления поиском.
В разделе 12.2 представлен важный результат в области автоматических
рассуждений — система доказательства теорем на основе резолюции (resolution theorem prover).
Будет описан язык представления, правило вывода, стратегии поиска и средства
извлечения ответов при доказательстве теорем разрешения. В качестве примера рассуждений
на основе хорновских выражений в разделе 12.3 описан механизм вывода для языка
PROLOG и показано, как этот язык реализует философию декларативного
программирования с помощью интерпретатора, основанного на доказательстве теорем разрешения. В
заключение этой главы (раздел 12.4) приводятся краткая информация о естественной
дедукции, решении уравнений и более сложных правилах вывода.
12.1. Система решения общих задач и таблицы отличий
Система решения общих задач GPS (General Problem Solver) [Newell и Simon, 19636],
[Ernst и Newell, 1969] стала результатом исследований Алана Ньюэлла (Allen Newell) и
Герберта Саймона (Herbert Simon) из института технологий имени Карнеги.
Предшественницей этой системы можно считать более раннюю компьютерную программу LT
(Logic Theorist) [Newell и Simon, 1963я]. С помощью программы LT были доказаны
многие теоремы, приведенные в [Whitehead и Russell, 1950].
Подобно остальным системам решения задач на основе слабых методов, в программе
LT использовано унифицированное представление и семантические правила вывода, а
также разработано несколько стратегий или эвристических методов управления
процессом поиска решения. В программе LT в качестве средства представления (representation
medium) использовано исчисление высказываний (раздел 2.1), а в роли правил вывода
выступают подстановка (substitution), замена (replacement) и открепление (detachment).
Подстановка позволяет заменить любое вхождение символа в предположении,
представляющем собой аксиому или теорему, заведомо истинным выражением. Например, в
522 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
выражение (BvB)—>B вместо В можно подставить —А и получить выражение
(-Av-A)^-A.
Замена позволяет использовать вместо выражения его определение или
эквивалентную форму. Например, при логической эквивалентности выражений —AvB и ,4—>В
выражение -iAv—А можно заменить А —>—id.
Открепление — это правило вывода, которое в главе 2 было названо правилом
модус поненс.
В программе LT эти правила вывода были использованы для поиска в ширину при
доказательстве теорем. Программа пытается найти последовательности операций,
приводящих к заведомо истинным аксиомам или теоремам. В исполняемом модуле LT
реализованы четыре метода.
1. Метод подстановки напрямую применяется для текущей задачи, чтобы привести ее
к известным аксиомам и теоремам.
2. Если этот метод не приводит к успешному доказательству, используются все
возможные открепления и замены, и для каждого из результатов снова применяется
метод подстановки. Если получить доказательство теоремы не удается, то все эти
результаты добавляются в список подзадач (subproblem list).
3. Затем для поиска новой подзадачи, решение которой обеспечивает доказательство
исходного утверждения, используется метод цепочки, учитывающий
транзитивность импликации. Таким образом, если для задачи а^>с получено Ь^>с, то в
качестве новой подзадачи выбирается а^>Ь.
4. Если первые три метода не приводят к ожидаемому результату, то система
выбирает следующую подзадачу из списка.
Эти четыре метода применяются до тех пор, пока не будет найдено решение, не
исчерпается список подзадач, память или время, выделенные для решения задачи. Таким
образом, система LT выполняет поиск в ширину в пространстве задач.
В исполняемой программе подстановка, замена и открепление выполняются в рамках
процесса проверки соответствия (matching process). Допустим, необходимо доказать
утверждение р—>(д—>р). В процессе проверки соответствия сначала выявляется одна из
аксиом р—>(gvp) как наиболее соответствующая в терминах различия для данной
области определения (в данном случае в обоих выражениях совпадает основной логический
оператор —»). Затем при проверке соответствия устанавливается идентичность левых
операндов основного логического оператора обоих выражений. И, наконец, определяется
различие правых операндов. На основе различия между операторами 4hv можно
предложить очевидную замену для доказательства теоремы. Процесс проверки соответствия
помогает управлять поиском при реализации всех подстановок, замен и откреплений.
Он гораздо более эффективен, чем простой метод проб и ошибок, что обеспечивает
успешное решение задач с помощью программы LT.
Рассмотрим эффективность проверки соответствия на примере доказательства
теоремы 2.02 из книги [Whitehead и Russell, 1950]: р—>(д—>р). В процессе проверки
соответствия в качестве замены находится аксиома р—>(gvp). Подстановка —\q вместо q приводит
к доказательству теоремы. Проверка соответствия, управление подстановкой и правила
замещения приводят к прямому доказательству теоремы без привлечения поиска в
пространстве других аксиом или теорем.
Глава 12. Автоматические рассуждения
523
Для второго примера постараемся с помощью программы LT доказать утверждение
1. (AvA)-^A — в процессе проверки соответствия выявляется наилучшая аксиома из
пяти возможных.
2. (-iAv-iA)-^-iA — подстановка -iA вместо А.
3. (A->-iA)->-iA — замена v или -i на —>.
4. (р—>-ip)—>-ip — подстановка р вместо А.
Что и требовалось доказать.
Программа LT доказывает эту теорему на основе пяти аксиом примерно за десять
секунд. Реальное доказательство выполняется за два этапа и не требует поиска. На первом
этапе в процессе проверки соответствия выбирается самая подходящая аксиома, поскольку
ее форма наиболее близка к утверждению, которое требуется доказать: выраже-
ние—>предложение. Затем вместо А подставляется —А. Этим определяется второй (и
последний) этап, который приводит к замене v на —>. Программа LT не только является
первым примером системы автоматических рассуждений, но и демонстрирует роль стратегий
поиска и эвристик в средствах автоматического доказательства теорем. Во многих случаях
LT за несколько шагов приходит к таким решениям, которые с большим трудом можно
найти только путем полного перебора. Некоторые теоремы не решаются с помощью
программы LT, поэтому авторы программы внесли некоторые предложения по ее улучшению.
Примерно в это же время исследователи из технологического института Карнеги
(Carnegie Institute of Technology), а также специалисты из Йельского университета
[Moore и Anderson, 1954] начали высказывать свои идеи о способах решения логических
задач. И хотя их основной целью было изучить процессы человеческого мышления,
решающие этот класс задач, они сравнили принципы решения задач человеком с
подходами, реализованными в компьютерных программах наподобие LT. Это положило начало
новой научной области, получившей современное название психологии обработки
информации (information processing psychology). Данная наука пытается объяснить
наблюдаемое поведение организмов с помощью примитивной программы обработки
информации, моделирующей такое поведение [Newell и др., 1958]. Это исследование также стало
одной из первых работ в области науки о мышлении — когнитологии (cognitive science),
о которой речь пойдет в разделе 16.2 [Luger, 1994].
Пристальное изучение этих первых программ показало существенные отличия
человеческих подходов к мышлению от компьютерных реализаций наподобие LT. В
человеческом поведении прослеживается существенная роль анализа целей и средств, в
котором методы уменьшения различий (средства) тесно связаны с конкретными отличиями
(целями). По ним можно проиндексировать операторы уменьшения различий.
Рассмотрим простейший пример. Если начальное утверждение имеет вид р—>д, а
целью является -npvg, то различие состоит в том, что в исходном выражении участвует
символ —>, а в целевом — v (а также в исходном утверждении есть выражение р, а в
целевом ip). Таблица отличий должна содержать различные способы замены —> на v,
а также удаления отрицания. Такие преобразования необходимо поочередно применять
до полного устранения отличий и доказательства теорем.
В наиболее интересных задачах различия в исходных и целевых утверждениях нельзя
устранить напрямую. В этом случае из таблицы выбирается оператор, частично
устраняющий эти отличия. Такая процедура применяется рекурсивно до полного устранения
отличий. При этом может потребоваться применение различных методов поиска.
524 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
В среднем столбце табл. 12.1 [Newell и Simon, 19636] представлены двенадцать
правил преобразования для решения логических задач. В правом столбце приводятся
рекомендации по их применению.
Таблица 12.1. Правила преобразования для логических задач
№ п/п Правило преобразования Рекомендации по применению
Применяется, если А и В — два основных выражения
Применяется, если А и В — два основных выражения
Применяется только к основному выражению
Применяется, если А и ЛэБ — два основных выражения
Применяется, если Az>B и БэС — два основных выражения
Применяется только к основному выражению
Применяется только к основному выражению
Применяется, если А и В — два основных выражения
1
2
3
4
5
6
7
8
9
10
А-В->В-А
AvB->BvA
Az)B-*~Bz)~A
А-А++А
AvA<r*vA
A-(B-C)<r>(A-B)-C
Av(BvC)<^(AvB)vC
AvB<^>~{~A~B)
Az)B<^>~AvB
A-(BvC)<r>(A-B)v(A-C)
Av{B-C)<r>(AvB)-(AvC)
AB^A
A B^B
A^AvX
А] я „
-^AB
11
12
Az)B
Az)B
Bz)C
->в
->Л=>С
Применяется, если Л и ЛэБ —два основных выражения
Применяется, если Л D В и БэС — два основных выражения
В табл. 12.2 представлено доказательство, сгенерированное человеком [Newell и
Simon, 19636]. При этом человеку, не имеющему опыта в решении задач формальной
логики, были предоставлены правила преобразования из табл. 12.1. Требовалось
преобразовать выражение (Pz>—P)«(—iPz>Q) к виду —1(—iQ*P). В обозначениях из главы 2 символ
~ обозначает —i, • обозначает л, a z> >. В табл. 12.1 символ —> или <-> обозначает
корректную замену. В правом столбце табл. 12.2 указаны правила из табл. 12.1,
применяемые на каждом этапе доказательства.
Таблица 12.2. Доказательство теоремы на основе исчисления высказываний
Применение правил
~(~QP)
Правило 6 применяется к левой и правой части 1
Правило 6 применяется к левой части 1
Правило 8 применяется к 1
Правило 6 применяется к 4
№п/п
1
2
3
4
5
Последовательность
преобразований
(Яэ~Р)-(~ЯэО)
(~Rv~P) (RvQ)
(~Rv~P)(~Rz)Q)
Rz>~P
~Rv~P
Глава 12. Автоматические рассуждения
525
Окончание табл. 12.2
№ п/п Последовательность Применение правил
6
7
8
9
10
11
12
13
14
преобразований
~toO
flvQ
(~Pv~P).(flvQ)
P^R
~OdR
PdO
~PvQ
~(P~Q)
~(~QP)
Правило 8 применяется к 1
Правило 6 применяется к 6
Правило 10 применяется к 5 и 7
Правило 2 применяется к 4
Правило 2 применяется к 6
Правило 12 применяется к 6 и 9
Правило 6 применяется к 11
Правило 5 применяется к 12
Правило 1 применяется к 13. Что и требовалось доказать
В работе [Newell и Simon, 19636] стратегии решения задач человеком названы процессом
уменьшения различий, а общий процесс использования преобразований для уменьшения
различий в конкретной задаче — анализом целей и средств. Алгоритм выполнения этого анализа
получил название системы решения общих задач GPS (General Problem Solver).
На рис. 12.1 показаны схема функционирования и таблица связей для GPS. Требуется
преобразовать выражение А в выражение В. Для этого сначала необходимо найти
различие D между А и В. Во втором блоке первой строки решается подзадача— уменьшение
D. Третий блок указывает на то, что процедура уменьшения различия является
рекурсивной. Уменьшение различий выполняется во второй строке, где для D выбирается
оператор О. На самом деле список операторов формируется на основе таблицы связей.
Операторы из этого списка последовательно проходят тест применимости (feasibility test). В
третьей строке на рис. 12.1 используется нужный оператор и уменьшается D.
Используемая в GPS модель решения задач основана на двух компонентах.
Первый — описанная выше общая процедура сравнения двух состояний и уменьшения их
различий. Второй — таблица связей (table of connections), описывающая взаимосвязи
между существующими различиями и конкретными преобразованиями, применяемыми
для их уменьшения. Таблица связей для 12 преобразований, описанных в табл. 12.1,
показана на рис. 12.1. Для уменьшения различий в алгебраической форме при решении
задач наподобие ханойских башен или моделировании более сложных игр, таких как
шахматы, могут применяться другие таблицы связей. Многочисленные применения системы
GPS описаны в [Ernst и Newell, 1969].
Структурирование процесса уменьшения различий для конкретной предметной области
помогает организовать поиск в пространстве состояний. Эвристический или приоритетный
порядок уменьшения различий неявно определяется порядком преобразований на основе
таблицы отличий. Согласно этому порядку обычно сначала выполняются более общие
преобразования, а затем — специализированные. Зачастую при определении порядка преобразований
учитывается мнение экспертов по данной предметной области.
Система GPS послужила толчком для развития исследований во многих направлениях.
Одним из них стало использование методов искусственного интеллекта для анализа
человеческого поведения в процессе решения задач. В частности, используемые в GPS методы анализа
целей и средств были заменены системой логического вывода, представляющей собой более
точную модель обработки информации человеком (глава 16). В современных экспертных
системах правила вывода используются вместо отдельных элементов таблицы отличий GPS.
526 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Цель: преобразовать объект Л в объект В
Сравнить Л и В
для поиска
отличий D
попе
т
D
Подзадача:
привести D
fail
т
Л'
Подзадача:
преобразовать
Л'вБ
fail
т
success
3
Успешное завершение
Неудачное завершение Неудачное завершение
Успешное
завершение
Цель: уменьшить различия D между объектами Л и В
Найти оператор (
Э,
позволяющий
уменьшить D
1
попе
i
о.
Проверить
применимость
(предварительно)
<—
по
Да^
Подзадача:
применить О к Л
для получения Л'
<—
fail
Л'
3
Неудачное завершение
Цель: применить оператор О к объекту Л
D
Проверить
соответствие условий О для
объекта Л для поиска
отличий D
Подзадача:
уменьшить D
попе
Получить результат
fail
д.. Неудачное завершение
► Успешное завершение
Л'
Подзадача:
применить О к Л'
fail
Неудачное завершение
♦-Успешное
завершение
А"
► Успешное
завершение
Тест на применимость (предварительный) для описанной логической задачи:
Совпадает ли основной логический оператор (т.е. Л «В -> В хуже, чем PvQ)?
Не слишком ли велико выражение (те {АуВ)*{АуС) -> Л v(B»C) хуже, чем Р»0)9
Не является ли оператор слишком простым (т.е. Д -> Д »Д применимо к любому выражению)?
Удовлетворяются ли второстепенные условия (например, правило 8 применимо только для
основного выражения)?
Таблица связей
Добавить термы
Удалить термы
Изменить логический оператор
Изменить знак
Изменить знак операнда
Изменить группировку
Изменить положение
R1 R2 R3 R4 R5 R6 R7 R8 R9 R10 R11R12
X X X X X X
X XX "XT*
XXX |"
I I I I X I I I I I I I
X XX ~|
X X
5ГПП————ГП————Г"
Символ "X" означает применимость некоторого варианта правила.
Система GPS выбирает соответствующий вариант
Рис. 12.1. Схема функционирования и таблица связей для системы GPS
Методы GPS получили свое развитие и в других интересных направлениях. Так, вместо
таблицы отличий в системах STRIPS и ABSTRIPS стали использовать таблицы операций
(operator table) для планирования (planning). Планирование — это важный аспект
управления роботами. Чтобы решить задачу, например, перейти в другую комнату и принести
некоторый предмет, компьютер должен разработать план, определяющий действия робота.
Сначала необходимо положить предмет, который робот держит "в руках", затем подойти к
двери, выйти из комнаты, найти нужную комнату, войти в нее, подойти к объекту и т.д. При
Глава 12. Автоматические рассуждения
527
формировании планов для системы STRIPS (Stanford Research Institute Problem Solver)
используется таблица операций, выступающая аналогом таблицы отличий GPS [Fikes и
Nilsson, 1971, 1972], [Sacerdotti, 1974]. Каждой операции (примитивному действию робота)
в этой таблице соответствует набор предусловий, аналогичных тесту применимости из
рис. 12.1. Таблица операций также содержит списки добавления и удаления, с помощью
которых модифицируется модель "мира" после выполнения операций. Система
планирования, подобная STRIPS, была описана в разделе 7.4, а ее реализация на языке PROLOG
будет рассмотрена в разделе 14.5.
Итак, первыми моделями автоматических рассуждений в области искусственного
интеллекта являются системы Logic Theorist (LT) и General Problem Solver (GPS). В этих
программах реализованы слабые методы решения задач, использовано унифицированное
представление, набор правил вывода и методы или стратегии применения этих правил. Эти же
компоненты применяются в разрешающих процедурах доказательства теорем (resolution proof
procedure) — более современном и мощном аппарате автоматических рассуждений.
12.2. Доказательство теорем методом резолюции
12.2.1. Введение
Резолюция — это один из приемов доказательства теорем в области исчисления
высказываний или предикатов, относящийся к сфере искусственного интеллекта с середины 60-х
годов прошлого столетия [Bledsoe, 1977], [Robinson, 1965], [Kowalski, 19796]. Резолюция — это
правило вывода, используемое для построения опровержений (refutation) (подраздел 12.2.3).
Важным практическим применением метода резолюции, в частности при создании систем
опровержения, является современное поколение интерпретаторов языка PROLOG (рис. 12.2).
Принцип резолюции (или разрешения), введенный в работе [Robinson, 1965],
описывает способ обнаружения противоречий в базе данных дизъюнктивных выражений при
минимальном использовании подстановок. Опровержение разрешения — это способ
доказательства теоремы, основанный на формулировке обратного утверждения и
добавлении отрицательного высказывания к множеству известных аксиом, которые по
предположению считаются истинными. Затем правило резолюции используется для
доказательства того, что такое предположение ведет к противоречию (доказательство от
обратного). Поскольку в процессе доказательства теоремы показывается, что обратное
утверждение несовместимо с существующим набором аксиом, исходное утверждение
должно быть истинным. В этом и состоит доказательство теорем.
Процесс доказательства от обратного состоит из следующих этапов.
1. Предположения или аксиомы приводятся к дизъюнктивной форме (clause form)
(подраздел 12.2.2).
2. К набору аксиом добавляется отрицание доказываемого утверждения в
дизъюнктивной форме.
3. Выполняется совместное разрешение этих дизъюнктов, в результате чего
получаются новые основанные на них дизъюнктивные выражения (подраздел 12.2.3).
4. Генерируется пустое выражение, означающее противоречие.
5. Подстановки, использованные для получения пустого выражения, свидетельствуют
о том, что отрицание отрицания — истинно (подраздел 12.2.4).
528 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Резолюция — это согласованное правило вывода (см. главу 2). Однако оно не
является полным. Резолюция является полной в смысле опровержения, т.е. если в наборе
высказываний имеется противоречие, то на основе этого набора всегда можно
сгенерировать пустое или нулевое выражение. Этот вопрос более подробно обсуждается при
описании существующих стратегий построения опровержений в подразделе 12.2.4. Для
доказательства от обратного требуется, чтобы аксиомы и отрицание исходного
утверждения были приведены к нормальной дизъюнктивной форме (clause form). В
дизъюнктивной форме логическая база данных представляется в виде набора дизъюнкций, или
литералов (literal). Литерал — это простейшее выражение или его отрицание.
Наиболее типичная форма резолюции, получившая название бинарной резолюции
(binary resolution), применяется к двум выражениям, одно из которых является
литералом, а другое — его отрицанием. Если литералы содержат переменные, то их
необходимо унифицировать и привести к эквивалентному виду. Затем генерируется новое
выражение, состоящее из дизъюнктов всех предикатов этих двух выражений, за исключением
этого литерала и его отрицания, которые считаются "вычеркнутыми".
Прежде чем перейти к более строгому описанию этой методики в следующем
разделе, рассмотрим простейший пример. На основе принципа резолюции докажем
утверждение, аналогичное полученному с помощью правила модус поненс. При этом ставится
задача не показать эквивалентность правил вывода (принцип резолюции на самом деле
является более общим, чем правило отделения модус поненс (композиционное правило)),
а лишь познакомить читателя с этим процессом.
Докажем, что утверждение "Фидо смертен" следует из утверждений "Фидо —
собака", "Собаки — это животные" и "Все животные смертны". Преобразовывая эти
предположения в предикатную форму и применяя правило отделения, получим следующее.
1. Собаки — это животные: V(X)(dog(X)—>ап/та/(Х)).
2. Фидо — собака: dog(fido).
3. На основе правила отделения и подстановки {fido/X} получим: animal(fido).
4. Все животные смертны: \/(Y)(animal(Y)^>die(Y)).
5. На основе правила отделения и подстановки {fido/Y} получим: die(fido).
По принципу резолюции эти предикаты необходимо преобразовать в
дизъюнктивную форму.
Предикатная форма Дизъюнктивная форма
V(X)(dog(X)^an/ma/(X)) -^dog(X)vanimal(X)
dog(fido) dog(fido)
M{Y){animal{Y)^die{Y)) -^animal(Y)vdie(Y)
Запишем отрицание целевого утверждения "Фидо смертен".
-idie(fido) -idie(fido)
Выполняя резолюцию с использованием обратных литералов, получим новые
дизъюнктивные выражения, представленные на рис. 12.2. Этот процесс зачастую называют
созданием конфликта (clashing).
Символ 1 на рис. 12.2 означает пустой дизъюнкт или противоречие. Он
символизирует конфликт предиката и его отрицания, т.е. наличие двух противоречивых
высказываний в пространстве дизъюнктов. Последовательность подстановок (операций унифика-
Глава 12. Автоматические рассуждения
529
ции), применяемая для приведения предикатов к эквивалентной форме, позволяет
определить значения переменных, при которых целевое высказывание истинно. Например,
определяя, смертно ли некоторое существо, следует построить отрицание в виде
-iC(Z)d/e(Z), а не -die(fido). Подстановка {fido/Z} на рис. 12.2 означает, что Фидо —
представитель животного мира, который смертен. Более подробно этот пример будет
рассмотрен в последующих разделах.
12.2.2. Построение дизъюнктивной формы для опровержения
разрешения
Метод резолюции требует преобразования всех операторов базы данных, описывающих
ситуацию, к стандартной дизъюнктивной форме. Это связано с тем, что резолюция — это
операция над парой дизъюнктов, приводящая к созданию новых дизъюнктов. Такая форма
представления базы данных называется конъюнкцией дизъюнктов (conjunction of disjuncts).
Это конъюнкция, поскольку по предположению все выражения в базе данных
одновременно являются истинными. В то же время — это дизъюнкция, поскольку каждое выражение
описывается с помощью оператора дизъюнкции. Таким образом, всю базу данных,
представленную на рис. 12.2, можно описать в следующей форме.
(^dog(X)vanimal(X))A(^animal(Y)vdie(Y))A(dog(fido)).
К этому выражению следует добавить (с помощью конъюнкции) отрицание целевого
выражения, в данном случае —\die(fido). Таким образом, база данных описывается как
набор дизъюнктов, а операторы конъюнкции можно опустить.
-1 dog{X) v animal{X) -i animal(Y) v die(Y)
dog{fido) -i dog(Y) v die{Y)
{fido/Y) \ /
die(fido) -i die{fido)
□
Рис. 12 2. Доказательство разрешения для задачи "смертной собаки"
530 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Рассмотрим алгоритм, представляющий собой последовательность преобразований
по приведению набора предикатов к дизъюнктивной форме. В [Chang и Lee, 1973]
показано, что такие преобразования можно использовать для приведения любого множества
выражений в области теории предикатов к набору дизъюнктов, противоречивому в том и
только в том случае, если исходное множество выражений является противоречивым.
Такая дизъюнктивная форма не является строго эквивалентной исходному множеству
предикатов, поскольку в ней могут быть утрачены некоторые аспекты интерпретации.
Это связано с тем, что сколемизация ограничивает возможные подстановки для
переменных, связанных квантором существования [Chang и Lee, 1973]. Однако при этом
сохраняется значение истинности выражений. Следовательно, если в исходном множестве
предикатов есть противоречие, то оно остается и в дизъюнктивной форме. Такие
преобразования не нарушают полноты доказательства опровержения.
Проиллюстрируем процесс приведения к конъюнктивной нормальной форме на
конкретном примере и дадим краткое пояснение каждому из шагов. Эти пояснения не претендуют на
роль доказательства эквивалентности преобразований для теории предикатов в целом.
В следующих выражениях согласно принятым в главе 2 соглашениям прописными
буквами обозначены переменные A/V, X, У и Z), строчными буквами из середины
алфавита (/, тип) — константы и граничные значения, а начальными строчными буквами
(а, Ь, с, d и е) — имена предикатов. Для улучшения читабельности выражений
используется два типа скобок: круглые и квадратные. В качестве примера рассмотрим
выражение, где X, Y и Z — переменные, а / — константа.
(УХ)([а(Х)лЬ(Х)]->[с(Х, I)aCY)(CZ)[c(Y, Z)]->cf(X, V))])v(VX)(e(X)). (i)
1. Сначала исключим оператор —> с использованием эквивалентной формы,
приведенной в главе 2: a—>b=-tavb. После этого преобразования выражение (i) примет вид
(VX)(-,[a(X)Ab(X)]v[c(X, I)aCY)(CZ)[^c(Y, Z)]vd(X, V))])v(VX)(e(X)). (ii)
2. Теперь выполним преобразование операторов отрицания. Для этого можно
воспользоваться формулами, описанными в главе 2, например такими.
—,(—,а)=а
-.CX)a(X)=(VX)-.a(X)
-.(VX)b(X)sCX)-.b(X)
—i(aAb)=—iav—ib
-i(avb)=-iaA-ib
Используя эти тождества, формулу (ii) можно привести к виду
(VX)([-,a(X)v-,b(X)]v[c(XI I)aCY)(CZ)[^c(Y, Z)]vd(X, /))])v(VX)(e(X)). (iii)
3. Теперь переименуем все переменные таким образом, чтобы переменные, ограниченные
различными кванторами, имели различные имена. (Эта операция называется
стандартизацией переменных.) Как было указано в главе 2, имя переменной — это лишь
обозначение "знакоместа". Оно не влияет ни на истинность выражения, ни на общность
высказывания. Воспользуемся на этом шаге следующим преобразованием
((\/X)a(X)v(\/X)b(X))=((\/X)a(X)v(\/Y)b(Y)).
Поскольку в (iii) содержится два вхождения переменной X, переименуем ее
следующим образом
(VX)([-,a(X)v-,b(X)]v[c(XI I)aCY)(CZ)[^c(Y, Z)]vd(X, Y))])v(VW)(e(W)). (iv)
Глава 12. Автоматические рассуждения
531
4. Переместим все кванторы влево, не изменяя порядок их следования. Это можно
сделать, поскольку в п. 3 была исключена возможность любого конфликта между
именами переменных. Формула (iv) примет вид
(VX)Cy)CZ)(VI/H)([-,a(X)v-,b(X)]v[c(X, /)л(-,с(У, Z)vd(X, Y))]ve(W)). (v)
На этом шаге получено выражение в предваренной, или пренексной нормальной форме
(prenex normal form), поскольку все кванторы вынесены в начало предложения.
5. Теперь исключим все кванторы существования с помощью процесса сколемизации
(skolemization). В выражении (v) используется квантор существования для
переменной Y. Если выражение содержит переменную, связанную квантором
существования, например CZ)(foo(..., Z, ...)), значит, существует значение переменной Z,
при котором выражение foo истинно. Сколемизация позволяет определить такое
значение. При этом сколемизация необязательно показывает, как получить это
значение. Она лишь является методом присвоения имени значению, которое
должно существовать. Если искомым значением является /с, то указанное
выражение можно записать в виде foo(..., /с, ...). Итак, CX)(dog(X)) можно заменить
выражением dog(fido), где имя fido взято из области определения X для обозначения
отдельного экземпляра X При этом fido называется сколемовской константой
(skolem constant). Если предикат имеет несколько аргументов, и переменная,
связанная квантором существования, следует за переменными, связанными квантором
всеобщности, то она должна быть функцией этих переменных. Это отражено в
процессе сколемизации. Рассмотрим выражение
(VX)CY)(mother(X, Y)).
Оно означает, что у каждого человека есть мать. Каждый человек — это
переменная X, а существование матери — функция от конкретно взятого человека X В
результате сколемизации получим
(\/X)mother(X,m(X)).
Это означает, что у каждого X есть мать (значение т для этого X). Вот другой
пример. Выражение
(VX)(Vy)CZ)(VH/)(foo(X, У, Z, И/))
в результате сколемизации можно привести к виду
(VX)(VV)(VI/LO(foo(X, Y, f(X, Y), И/)).
Связанные квантором существования переменные Y и Z находятся под квантором
всеобщности переменной X (справа от нее), но не под квантором всеобщности
переменной И/. Поэтому каждую из этих переменных можно заменить сколемовской
функцией от X Заменяя переменную Y сколемовской функцией f(X), a Z — g(X),
формулу (v) преобразуем к виду
(VX)(VH/)(ba(X)v^b(X)]v[c(X, /)A(-,c(f(X), g(X))vd(X, f(X)))]ve(H/)). (vi)
После сколемизации можно перейти к п. 6, в котором просто удаляется префикс.
6. Исключим все кванторы всеобщности. К этому моменту (после п. 5) остались лишь
переменные, связанные кванторами всеобщности, и все конфликты переменных
устранены (в п. 3). Следовательно, все кванторы можно опустить, поскольку любая
процедура доказательства предполагает выполнение утверждения для всех
переменных. Формула (vi) примет вид
532 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
[-.a(X)v-,b(X)]v[c(X, /)A(-.c(f(X), g(X))vd(X, f(X)))]ve(LV). (vii)
7. Теперь представим это выражение в виде конъюнкции дизъюнктов. Для этого
воспользуемся свойствами ассоциативности и дистрибутивности операций л и v.
Напомним (глава 2), что
av(bvc)=(avb)vc,
ал(Ьлс)=(алЬ)лс.
Это означает, что операции л и v можно группировать произвольным образом.
При необходимости можно воспользоваться свойством дистрибутивности из
главы 2. Поскольку выражение
aA(bvc)
уже представляет собой дизъюнктивную форму, его не нужно преобразовывать. Однако
для операции дизъюнкции следует воспользоваться дистрибутивным законом
av(bAc)=(avb)A(avc).
Окончательно выражение (vii) примет вид
[-.a(X)v-ib(X)vc(X, /)ve(l/l/)]A[-.a(X)v-,b(X)v-,c(f(X), g(X))vd(X, f(X))ve(LV)]. (viii)
8. Теперь выделим каждый конъюнкт в отдельное выражение. Предложение (viii)
будет представлено в виде двух выражений
^a(X)v^b(X)vc(X, /)ve(lV), (ixa)
-.a(X)v-,b(X)v-.c(f(X), g(X))vcf(X, f(X))ve(LV). (ixb)
9. И, наконец, снова разделим переменные, т.е. присвоим переменным в каждом
выражении, сгенерированном в п. 8, различные имена. Это делается на основе
приведенного в главе 2 тождества
(УХ)(а(Х)лЬ(Х))=(УХ)а(Х)л(УУ)Ь(Х),
которое в свою очередь следует из того, что имена переменных — это лишь
обозначения знакомест. Теперь, вводя новые имена переменных U и V, преобразуем
формулы (ixa) и (ixb) к виду
-na(X)v^b(X)vc(X, /)ve(lV), (xa)
-.a(L/)v-,b(L/)v-,c(f(L/), g(U))vd(Ut f(l/))ve(V). (xb)
Значение такой стандартизации станет понятно только после описания процедуры
унификации в процессе резолюции. Она сводится к поиску наиболее общей унифицированной
формы, обеспечивающей эквивалентность предикатов в двух выражениях, а затем ее
подстановке вместо всех переменных с одинаковыми именами в рамках одного выражения.
Так, если имена некоторых переменных совпадают, то в процессе унификации они могут
быть переименованы с последующей (возможной) потерей общности решений.
Описанный процесс используется для приведения любого набора выражений из
теории предикатов к дизъюнктивной форме. При этом свойство полноты опровержения
сохраняется. Проиллюстрируем процедуру резолюции, используемую для генерации
доказательств на основе этих выражений.
12.2.3. Процедура доказательства на основе бинарной резолюции
Процедура опровержения разрешения (resolution refutation) дает ответ на запрос или
генерирует новый результат путем сведения набора выражений к противоречию, пред-
Глава 12. Автоматические рассуждения
533
ставленному нулевым выражением (□). Противоречие возникает при попарной
резолюции выражений из базы данных. Если резолюция не приводит к противоречию
напрямую, то полученное в результате выражение — резольвента (resolvent) — добавляется в
базу данных выражений, и процесс продолжается.
Прежде чем показать, как происходит процесс резолюции в исчислении предикатов,
рассмотрим пример из области исчисления высказываний (без переменных). Рассмотрим
два родительских выражения pi и р2 из области исчисления высказываний
р1: asva2v...v ап,
р2: b1vb2v...v bm,
содержащих два литерала а, и Ь;, при которых —.а,= Ь;, где 1</<п и \<j<m. В результате
бинарной резолюции получим выражение
a1va2v...vaMva.+1v...vanvb1vb2v...vb; ^vb^v.^v bm.
Таким образом, резольвента состоит из дизъюнкции всех литералов двух
родительских выражений за исключением литералов а, и Ь;.
Простое рассуждение позволит выйти за рамки принципа резолюции. Допустим, что
av—ib и bvc — два истинных выражения. Заметим, что одно из значений b или -ib
обязательно истинно, а второе — ложно (bv-ib — это тавтология). Следовательно, значение
одного из литералов в выражении
avc
должно быть истинно. Выражение avc — это резольвента двух родительских выражений
av-ib и bvc.
Рассмотрим теперь пример из области исчисления высказываний. Требуется
получить значение а на основе следующих аксиом (естественно, /<—m=m—>/ для всех
предложений / ит):
а<^Ьлс,
Ь,
с<— сУле,
evf,
C(A-.f.
Приведем первую аксиому к дизъюнктивной форме.
а<^Ьлс,
av-i(bAC), поскольку /-)m=-i/vm,
av-ibv-ic, по закону де Моргана.
Остальные аксиомы приводить не нужно, поэтому получаем набор следующих
выражений.
av-ibv-iC,
b,
cv-idv-ie,
evf,
d,
-.f.
Доказательство по методу резолюции показано на рис. 12.3. Сначала к набору
выражений добавлено отрицание целевого выражения а. Символ J означает, что база данных
выражений содержит противоречие.
534 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
a v -i b v -ic
ib v ^c
-«с cv^dv-ie
evf ^dv-ie
fv ^d
П
Pz/c. J2.3. Доказательство теоремы методом
резолюции для примера из области исчисления
высказываний
Для того чтобы использовать бинарную резолюцию в исчислении предикатов, при
котором каждый литерал может содержать переменные, необходимо обеспечить
эквивалентность двух литералов с различными именами переменных или одинаковым постоянным
значением. В подразделе 2.3.2 был определен процесс унификации, реализующий
согласованную и более общую подстановку для обеспечения эквивалентности предикатов.
Алгоритм резолюции в исчислении предикатов во многом аналогичен этому же
процессу для исчисления высказываний за исключением следующих моментов.
1. Литерал и его отрицание в родительских выражениях дают резольвенту только в том
случае, если они унифицированы для некоторой подстановки а. Затем а применяется
к этой резольвенте до ее добавления к набору дизъюнктов. При этом требуется,
чтобы а была наиболее общим унификатором для родительских выражений.
2. Унифицирующие подстановки, используемые для поиска противоречий, обеспечивают
связывание переменных, при котором исходный запрос является истинным. Этот
процесс, получивший название извлечения ответа (answer extraction), будет описан ниже.
Иногда для нескольких литералов в одном выражении существует объединяющая
подстановка. При этом может не существовать опровержения для наборов дизъюнктов,
содержащих это выражение, даже если этот набор является противоречивым. Например,
рассмотрим выражения
p(X)vp(f(Y))t
^p(W)v^p(f(Z)).
Не сложно заметить, что при простой резолюции эти выражения можно свести лишь
к эквивалентной форме или тавтологии, а не к противоречию. То есть никакая
подстановка не сделает их противоречивыми.
Глава 12. Автоматические рассуждения
535
В подобной ситуации можно применить факторизацию выражений (factoring). Если
подмножество литералов в некотором выражении имеет наиболее общий унификатор
(подраздел 2.3.2), то это выражение можно заменить новым выражением, получившим
название фактора (factor). Фактор — это исходное выражение, к которому применена
подстановка наиболее общего унификатора, а затем удалены оставшиеся литералы.
Например, два литерала в выражении p(X)vp(f( Y)) можно унифицировать с помощью
подстановки {f(Y)/X}. Выполним подстановку в обоих литералах и получим выражение
р(f(У))vp(f(Y)), а затем заменим это выражение его фактором p(f(Y)). Любая система
опровержения разрешения, включающая факторизацию, является полной в смысле
опровержения. Стандартизацию переменных (выполняемую в п. 3 подраздела 12.2.2) можно
интерпретировать как простое применение факторизации. Факторизацию также можно
рассматривать как часть процесса вывода в процедуре гиперрезолюции (hyperresolution),
описанной в подразделе 12.4.2.
Приведем пример опровержения разрешения из области исчисления предикатов.
Рассмотрим следующую историю "счастливого студента".
Любой студент, который сдает экзамен по истории и выигрывает в лотерею, — счастлив.
Известно, что любой удачливый или старательный студент может сдать все экзамены.
Джон не относится к числу старательных студентов, но достаточно удачлив. Любой
удачливый студент выигрывает в лотерею. Счастлив ли Джон?
Сначала запишем эти предложения в предикатной форме.
Любой студент, который сдает экзамен по истории и выигрывает в лотерею, — счастлив.
VX(pass(X, history)Awin(X, lottery)^happy(X)).
Известно, что любой удачливый или старательный студент может сдать все экзамены:
\/X\/Y(study(X)vlucky(X)^>pass(X, Y)).
Джон не относится к числу старательных студентов, но достаточно удачлив:
-iStudy(john)Alucky(john).
Любой удачливый студент выигрывает в лотерею-
\/X(lucky(X)^>win(X, lottery)).
Приведем эти четыре высказывания предикатов к дизъюнктивной форме
(подраздел 12.2.2).
1. -ipass(X, history)v-iWin(X, lottery)whappy(X).
2. ^study(Y)vpass(Y,Z).
3. ^lucky(W)vpass(W, V).
4. -iStudy(john).
5. lucky(john).
6. -ilucky(U)vwin(U, lottery).
Добавим к этим выражениям отрицание заключения в дизъюнктивной форме.
7. -ihappy(john).
Граф опровержения разрешения, показанный на рис. 12.4, отражает процесс
получения противоречия и, следовательно, доказывает, что Джон счастлив.
536 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
В качестве последнего примера рассмотрим задачу "интересной жизни".
Все небедные и умные люди счастливы. Человек, читающий книги, — неглуп. Джон умеет
читать и является состоятельным человеком. Счастливые люди живут интересной жизнью.
Можно ли указать человека, живущего интересной жизнью?
Предполагается, что
\/X(smart(X)=^stupid(X)) и \/Y(wealthy(Y)=^poor(Y)).
Тогда получим
\/X(^poor(X)Asmart(X)^happy(X))}
\/Y(read(Y)^smart(Y))}
read(john)A~ipoor(john)}
\/Z(happy(Z)^exciting(Z)).
i pass(X, history) v -i win(X, lottery) v happy(X) -i lucky(U) v win(U, lottery)
i pass{U, history) v happy(U) v -i lucky{U)
i happyfjohn)
{john/U}
luckyfjohn)
-i passfjohn, history) v -i luckyfjohn)
i pass(john, history)
i lucky(V) v pass(V, W)
{john/V, history/W)
i luckyfjohn)
luckyfjohn)
Рис. J2.4. Опровержение разрешения для задачи "счастливого студента"
Отрицание заключения имеет вид
SW(exciting{W)).
Эти предикатные выражения для задачи "интересной жизни" приводятся к
дизъюнктивной форме следующим образом.
Глава 12. Автоматические рассуждения
537
poor(X)A^smart(X)vhappy(X),
^read(Y)vsmart(Y),
read(john),
-npoor(john),
^happy(Z)vexciting(Z),
-iexciting(W).
Граф опровержения для этого примера показан на рис. 12.5.
-1 exciting{W) -> happy{Z) v exciting(Z)
-i happy(Z) poor(X) v -i smart(X) v happy(X)
poor(X) v -i smart(X) -> read( Y) v smart( V)
-i poor(john) poor(Y) v -i read{Y)
{john/Y} \w ^^
-i read{john) read{john)
{} N. /^
П
Рг/с. 72 5 Доказательство разрешения для задачи "интересной жизни"
12.2.4. Стратегии и методы упрощения резолюции
На рис. 12.6 показано отличное от представленного на рис. 12.5 дерево
доказательства для того же пространства поиска. Эти доказательства чем-то схожи, например, для
резолюции они оба требуют выполнения пяти действий. Кроме того, в обоих
доказательствах с помощью подстановки унификации получено, что Джон относится к числу людей,
живущих "интересной жизнью".
Однако такое сходство не обязательно. При определении системы резолюции
(подраздел 12.2.3) порядок комбинации дизъюнктивных выражений не устанавливался.
Это очень важный момент: если в пространстве дизъюнктов существует Л/ выражений, то
имеется Л/2 способов их комбинации даже на первом уровне. Результирующий набор
выражений тоже достаточно велик. Даже если 20% комбинаций приводят к формированию
новых выражений, то на следующем этапе число возможных комбинаций станет еще
больше. Для больших задач такой экспоненциальный рост достаточно быстро приводит к
чрезмерной громоздкости вычислений.
538 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Поэтому в процедурах резолюции, которые относятся к слабым методам решений
задач, очень большое значение имеют эвристики поиска. Подобно эвристикам,
рассмотренным в главе 4, для каждой конкретной проблемы не существует строгого
обоснования наилучшей стратегии. Тем не менее существуют общие стратегии, позволяющие
бороться с экспоненциальным ростом числа возможных комбинаций.
-1 happy{Z) v exciting{Z) poor{X) v -> smart{X) v happy{X)
-i read(Y) v smart(Y) exciting(Z) v poor{Z) v -> smart(Z)
-i read(Y) v exciting(Y) v poor(Y) -> poor{john)
{john/Y)^^^ ^^^
read(john) -i read(john) v excitingfjohn)
exciting{john) -> exciting{ W)
{john/Щ \. ^^
□
Pwc. 72.6. £и/е одно опровержение разрешения для задачи ''интересной жизни"
Прежде чем приступить к описанию этих стратегий, необходимо сделать несколько
пояснений. Во-первых, основываясь на определении невыполнимости выражения из
главы 2, назовем набор дизъюнктивных выражений невыполнимым (a set of clauses is unsat-
isfiable), если не существует интерпретации, доказывающей выполнимость этого набора.
Во-вторых, правило вывода будем считать полным в смысле опровержения (refutation
complete), если невыполнимость набора дизъюнктивных выражений может быть
доказана с помощью одного этого правила. Этим свойством обладает процедура резолюции с
факторизацией [Chang и Lee, 1973]. И, наконец, стратегия является полной, если на ее
основе с помощью полного в смысле опровержения правила вывода можно
гарантированно найти опровержение для невыполнимого набора дизъюнктивных выражений.
Примером полной стратегии является поиск в ширину (breadth-first).
Стратегия поиска в ширину
Приведенный выше анализ сложности полного перебора дизъюнктивных выражений
основывается на поиске в ширину. На первом этапе выполняется бинарная резолюция
всех дизъюнктов в пространстве выражений. На следующем этапе в пространство поиска
к исходным выражениям добавляются дизъюнктивные выражения, сгенерированные при
резолюции дизъюнктов. На п-м этапе обрабатываются все выражения, полученные
ранее, а также исходное множество дизъюнктов.
Глава 12. Автоматические рассуждения
539
Такая стратегия приводит к очень быстрому разрастанию пространства поиска, поэтому
не пригодна для решения больших задач. Однако она обладает интересным свойством.
Подобно поиску в ширину, эта стратегия гарантирует нахождение кратчайшего пути к
решению, поскольку на каждом этапе работает только с одним уровнем и не предполагает
никакого углубления. Кроме того, данная стратегия является полной, поскольку, если ее
использовать достаточно долго, она гарантированно обнаружит опровержение, если таковое
существует. Следовательно, стратегия поиска в ширину является достаточно адекватной
для небольших задач, подобных рассмотренным выше. На рис. 12.7 приводится
иллюстрация стратегии поиска в ширину для задачи "интересной жизни".
pooriX)v-'smart(X) -> read(Y) ~< poorijohn) ^happy{Z) read(john) -> exciting(W)
^read(john)v poor(X) ~<read(john) -> smartijohn) pootiZ) happyijohn) poorijohn) poor(X) -i smart(john) poorijohn)
happyijohn) v^read(X) v happyijohn) v exciting(john) v^read(Z) v happyijohn) v^smartiX) v excitingijohn)
v exciting(X)
Рис. 12 7. Полное пространство состояний для задачи "интересной жизни", полученное при
использовании стратеги поиска в ширину (для двух уровней)
Стратегия "множества поддержки"
Стратегия "множества поддержки" — это отличная стратегия поиска в больших
пространствах дизъюнктивных выражений [Wos и Robinson, 1968]. Для некоторого набора
исходных дизъюнктивных выражений S можно указать подмножество 7", называемое
множеством поддержки. Для реализации этой стратегии необходимо, чтобы одна из
резольвент в каждом опровержении имела предка из множества поддержки. Можно
доказать, что если S— невыполнимый набор дизъюнктов, a S-T— выполнимый, то
стратегия множества поддержки является полной в смысле опровержения [Wos и др., 1984].
Если исходный набор дизъюнктов является согласованным, то этим требованиям
удовлетворяет любое множество поддержки, включающее отрицание исходного запроса.
Эта стратегия основывается на том, что добавление отрицания доказываемого
выражения приводит к противоречивости пространства возможных дизъюнктов. Множество
поддержки ускоряет процесс резолюции для пар выражений, в которых одно
представляет собой отрицание цели или полученное на его основе дизъюнктивное выражение.
На рис. 12.5 приведен пример применения стратегии "множества поддержки" для
решения задачи "интересной жизни". Поскольку множество поддержки опровержения
существует при наличии самого опровержения, оно может составлять основу полной
стратегии. Одним из способов реализации такой стратегии является выполнение поиска в
ширину для всех возможных множеств поддержки опровержения. Естественно, это
гораздо более эффективный путь, чем поиск в ширину в пространстве всех дизъюнктивных
540 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
выражений. Необходимо лишь удостовериться в том, что проверены все резольвенты
отрицания целевого выражения, а также все их потомки.
Стратегия предпочтения единичного выражения
Заметим, что в приведенных выше примерах резолюции противоречие возникает при
появлении выражения, не содержащего литералов. Следовательно, каждый раз при
получении результирующего выражения с меньшим числом литералов мы приближаемся к
генерации выражения, не содержащего литералов вообще. В частности, получение
выражения, состоящего из одного литерала или так называемого единичного выражения
(unit clause), гарантирует, что резольвента будет меньше, чем наибольшее родительское
выражение. Стратегия предпочтения единичного выражения предполагает максимальное
использование единичных выражений в процессе резолюции. На рис. 12.8 эта стратегия
проиллюстрирована для задачи "интересной жизни". Совместное применение стратегии
предпочтения единичного выражения и стратегии "множества поддержки" позволяет
получить более эффективную полную стратегию.
1 exciting{W)
1 happy(Z) v exciting{Z)
poor{X) v -i smart(X) v happy{X)
i poorfjohn)
{john/X}
read{Y) v smart{Y)
{john/Y}
readfjohn) -i read(john)
Рис 12.8. Использование стратегии предпочтения единичного
выражения для решения задачи "интересной жизни "
Стратегия единичного разрешения — это близкая стратегия, требующая, чтобы одна
из резольвент всегда представляла собой единичное выражение. Это более строгое
требование, чем требования, выдвигаемые стратегией предпочтения единичного выражения.
Можно показать, что стратегия единичного разрешения не является полной. Для этого
можно использовать тот же пример, что и для демонстрации неполноты стратегии
линейной входной формы.
Глава 12. Автоматические рассуждения
541
Стратегия линейной входной формы
Стратегия линейной входной формы предполагает прямое использование отрицания
цели и исходных аксиом. Она сводится к получению нового дизъюнктивного выражения
за счет резолюции отрицания цели с одной из аксиом. Полученный результат
разрешается с одной из аксиом для создания нового выражения, которое в свою очередь
разрешается с одной из аксиом. Этот процесс продолжается до получения пустого дизъюнкта.
На каждом этапе резолюция выполняется для вновь полученного выражения и аксиомы,
сформулированной для исходного утверждения задачи. Ранее полученные выражения
никогда не используются для резолюции, как и не используются две аксиомы вместе.
Стратегия линейной входной формы не является полной, в чем несложно убедиться на примере
следующего набора из четырех дизъюнктивных выражений (который, очевидно, является
невыполнимым). Независимо от того, какое из дизъюнктивных выражений выбрано в
качестве отрицания цели, стратегия линейного входа не приводит к противоречию.
—iav—ib,
av—ib,
—iavb,
avb.
Другие стратегии и методы упрощения
Автор не ставил перед собой задачу исчерпывающего анализа всех стратегий или
большинства сложных приемов доказательства теорем на основе логического вывода и принципа
резолюции. Они описаны в других источниках, в частности в работах [Wos, 1984] и [Wos,
1988]. Наша задача— познакомить читателя с основными средствами, разработанными для
этой области исследований, и показать, как их можно использовать для решения задач.
Процедура резолюции — это один из приемов, применяемых в слабых методах решения задач.
В этом смысле резолюцию можно рассматривать как механизм вывода для
исчисления предикатов, требующий дополнительного анализа и осторожного применения
различных стратегий. В представляющих интерес больших задачах случайный выбор
выражений для резолюции столь же бесперспективен, как и попытки написать хорошую
статью путем нажатия случайных комбинаций клавиш на компьютере. Количество таких
комбинаций слишком велико!
Используемые в этой главе примеры тривиально малы и содержат все необходимые для
решения задачи дизъюнкты (и не только необходимые). Такая ситуация в реальных задачах
встречается довольно редко. Выше было рассмотрено несколько простых стратегий борьбы с
этой комбинаторной сложностью. В завершение этого подраздела приведем несколько
важных соображений, относящихся к разработке систем решения задач на основе резолюции.
В разделе 12.3 будет показано, как с помощью системы опровержения разрешения при
комбинировании стратегий поиска можно обеспечить "семантику" для логического
программирования (logic programming), в частности, для разработки интерпретаторов для языка PROLOG.
При управлении поиском очень полезно комбинировать стратегии, например,
стратегию "множества поддержки" со стратегией предпочтения единичного выражения.
Эвристики поиска можно также встраивать в правила вывода (сортируя литералы слева
направо). Такое упорядочение наиболее эффективно для усечения пространства поиска.
Подобное неявное использование стратегий играет важную роль в программировании на
языке PROLOG (раздел 12.3).
Критерием при разработке стратегии решения может служить общность заключений.
С одной стороны, необходимо обеспечить максимально возможную общность промежу-
542 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
точных решений, поскольку это дает большую свободу их использования при
резолюции. Так, резолюцию дизъюнктивных выражений, требующую специализации за счет
связывания переменных, например {jo h п/Х}, необходимо отложить на максимально
позднее время. С другой стороны, если решение требует связывания конкретных
переменных, как при выяснении, инфицирован ли Джон стафилококком, подстановки
{john/Person} и {staph/lnfection} позволяют ограничить пространство поиска и
повысить вероятность и скорость нахождения решения.
При выборе стратегии большое значение имеет вопрос полноты. В некоторых
приложениях очень важно знать, что решение обязательно будет найдено (если оно
существует). Это можно гарантировать, используя полные стратегии.
Повышения эффективности можно добиться за счет ускорения проверки
соответствия. Можно исключить избыточные (и ресурсоемкие) операции унификации выражений,
которые не приводят к получению новых резольвент, индексируя каждое дизъюнктивное
выражение по содержащимся в нем литералам и их положительным и отрицательным
значениям. Это позволяет напрямую находить потенциальные резольвенты для любого
выражения. Кроме того, некоторые выражения необходимо исключить сразу же после их
получения. Не следует рассматривать тавтологии, поскольку они никогда не могут
принимать ложное значение, и не дают новой информации для получения решения.
Еще одним типом выражений, не несущих новой информации, являются так
называемые категоризированные (subsumed) выражения — частный случай уже
существующего более общего выражения. Например, выражение pijohri) не информативно в
пространстве, где уже существует выражение VX(p(X)). В этом случае pQ'ohn) можно
опустить без потери общности. Это даже полезно, поскольку количество выражений в
пространстве уменьшается. Аналогично выражение р(Х) относится к категории
p(X)vq(X). Частная информация ничего не добавляет к уже существующей общей.
И, наконец, включение процедур (procedural attachment) позволяет без дальнейшего
поиска оценить или обработать любое выражение, которое может дать новую
информацию. Оно основано на принципах арифметики и состоит в сравнении атомов или
выражений либо "запуске" любой другой детерминистской процедуры, добавляющей в
процессе решения задачи конкретную информацию или ограничения. Например, можно
использовать процедуру для вычисления связывания переменной при наличии для этого
достаточной информации. Такое связывание переменной ограничивает возможные
варианты резолюции и приводит к усечению пространства поиска.
Теперь рассмотрим, как в процессе опровержения можно извлекать ответы.
12.2.5. Извлечение ответов в процессе опровержения
Примеры, для которых гипотеза истинна, представляют собой подстановки для
поиска опровержения. Следовательно, сохраняя информацию о подстановках унификации,
сделанных при опровержении разрешения, можно получить данные для корректного
ответа. В этом подразделе будут рассмотрены три таких примера и метод "учета" для
извлечения ответов из опровержения разрешения.
Метод записи ответов очень прост. Берется исходное подлежащее доказательству
заключение и к нему добавляется каждая подстановка унификации, сделанная в процессе
резолюции. Таким образом, исходное заключение становится "учетчиком" всех
сделанных в процессе резолюции подстановок унификации. При компьютерной реализации это
может потребовать увеличения числа указателей, если при поиске опровержения
существует несколько вариантов выбора. Для получения альтернативного пути решения пона-
Глава 12. Автоматические рассуждения
543
добится механизм управления, например возврата. Однако при аккуратной реализации
эту дополнительную информацию можно сохранить.
Рассмотрим несколько примеров. На рис. 12.5, иллюстрирующем доказательство
существования человека, живущего интересной жизнью, использованы подстановки
унификации, представленные на рис. 12.9. Если сохранить исходную цель и применить к
этому выражению все подстановки опровержения, мы получим ответ на вопрос, кто этот
человек, живущий интересной жизнью.
На рис. 12.9 показано, что с помощью опровержения
разрешения можно не только доказать, что утверждение "никто не живет
интересной жизнью" ложно, но и определить, что "счастливым"
человеком является Джон. Это общий результат, в котором
подстановки унификации, приводящие к опровержению, совпадают с
выражениями, позволяющими получить значения, при которых
исходное требование является истинным.
Рассмотрим еще один пример, связанный с простой историей.
Собака Фидо идет туда, куда идет ее хозяин Джон. Джон — в
библиотеке. Где Фидо?
exciting{W)
{Z/Щ
exciting{Z)
{X/Z}
exciting{X)
{Y/X)
exciting{Y)
{john/Y}
excitingijohn)
{}
Сначала представим эту историю в виде выражений
исчисления предикатов и сведем их к дизъюнктивной форме. Предикаты
имеют вид
at{john,X)^>at{fido,X),
at(John, library).
Дизъюнктивные выражения
^at{john, Y)vat{fido, Y),
at(john} library).
Отрицание заключения имеет вид
^at{fido, Z).
Это означает, что Фидо — нигде.
На рис. 12.10 показан процесс извлечения ответа. Литерал,
отслеживающий подстановки унификации, — это исходный запрос
"Где Фидо?"
at(fido,Z).
Еще раз подчеркнем, что подстановка унификации, приводящая к противоречию,
содержит информацию об условиях выполнения исходного запроса: "Фидо в библиотеке".
Последний пример демонстрирует, как в процессе сколемизации можно получить
значение, из которого извлекается ответ. Рассмотрим следующую ситуацию.
У каждого человека есть родитель. Родитель родителя — это дедушка. Требуется доказать,
что у конкретного человека Джона есть родитель.
Следующие предложения описывают факты и взаимоотношения этой ситуации. Во-
первых, "У каждого человека есть родитель":
(VX)Cy)p(X, Y).
"Родитель родителя — это дедушка":
(VX)(vy)(VZ)p(X, Y)aP(Y, Z)^gp(X, Z).
excitingijohn)
Рис 12 9.
Подстановки унификации,
примененные к исходному
запросу, резолюция
которого
представлена на рис. 12.5
544 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Требуется найти значение И/, при котором gp(john, W) или 3(W)(gp(john, И/)).
Отрицанием цели является предложение —B(W)(gp(john, W)) или
^gp(john} И/).
at{fido, Z) -1 at(fido, Z) -i atijohn, X) v at{fido, X)
at{fido, X) -i atfjohn, X) atQohn, library)
{library/X} N. /
at{fido, library) Q
Pwc. 12.10. Процесс извлечения ответа для задачи поиска Фидо
В процессе приведения указанных выше предикатов к дизъюнктивной форме для
опровержения разрешения квантор существования в первом предикате "У каждого
человека есть родитель" требует построения сколемовской функции. В данном случае она
строится достаточно просто: нужно взять конкретное значение X и найти для него
родителя. Функцию нахождения предка для X назовем ра(Х). Для Джона это будет его отец
или мать. Для данной задачи дизъюнктивная форма предикатов будет иметь вид:
р(Х,ра(Х)),
^р(И/, Y)v^P(Y,Z)vgp(W,Z),
^gp{john, V).
Процессы опровержения разрешения и извлечения ответов для этой задачи
представлены на рис. 12.11. Отметим, что подстановки унификации при извлечении
ответа имеют вид
gp(john}pa(pa(john))).
Ответ на вопрос о том, есть ли у Джона дедушка, состоит в нахождении "ближайшего
предка ближайшего предка Джона". Сколемизированная функция позволяет вычислить
этот результат.
Описанный выше общий процесс извлечения ответа может использоваться в любых
процедурах опровержения, где применяются подстановки унификации, показанные на
рис. 12.9 и 12.10, или сколемовские функции, показанные на рис. 12.11. Этот процесс
позволяет находить ответы. Метод действительно очень прост: экземпляры (подстановки
унификации), приводящие к противоречию, в то же время обеспечивают истинность
отрицания заключения (исходного запроса). Хотя в этом подразделе не доказывается
применимость метода для любой задачи, работоспособность этого процесса
проиллюстрирована на нескольких примерах. Более подробное описание процесса извлечения ответов
можно найти в [Nilsson, 1980] и [Wos и др., 1984].
Глава 12. Автоматические рассуждения
545
gp (John, V) -п gp {John, V) -i p{W,Y) v -i p{Y,Z) v gp{W,Z)
{john/W, V/Z}
У
gp {john, V) -. p{]ohn, Y) v -. p(V,V) p(X,pa(X))
{/оЛлА ра(Х)/У}
У
gp (уолл, V) -i p{pa{john), V) p(X, pa(X))
{ра(/оЛл)/Х,ра(Х)/\/}
У
gp (john, pa{pa(john))) □
Pwc. 72 77 Сколемизация как часть процесса извлечения ответа
12.3. Язык PROLOG и автоматические рассуждения
12.3.1. Введение
Только понимание реализации языка программирования обеспечивает его корректное
использование, надежность полученных результатов и возможность устранения
побочных эффектов. В этом разделе будет описана семантика языка PROLOG и его связь с
вопросами автоматических рассуждений, рассмотренными в предыдущем разделе.
Серьезным ограничением процедуры резолюции, описанной в разделе 12.2, является
требование полной однородности базы данных задачи. В процессе приведения
предикатной формы описания или преобразования дизъюнктивной формы может быть утеряна
важная информация о решении проблемы. Утраченная информация не является
подтверждением или опровержением некоторой части проблемы, а скорее может служить
процедурным описанием способа использования этой информации. Например, отрицание
целевого выражения может иметь вид
av—ibvcv—\d,
где а, Ь, с и d — литералы. В процессе резолюции можно использовать стратегию
поиска для получения пустого дизъюнкта. Стратегию можно применять ко всем литералам, и
выбор конкретного литерала зависит от выбора самой стратегии. Используемые для
резолюции стратегии являются слабыми эвристиками. Они не подразумевают глубоких
знаний о конкретной предметной области задачи.
Например, отрицание целевого выражения в приведенном выше примере можно
преобразовать к предикатной форме
а<— Ьл—|Слс/.
Это выражение можно интерпретировать так: ''Проверить, истинно ли выражение а, а
также Ь и с/, и ложно ли выражение с". Это правило служит для решения а и предостав-
546 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
ляет соответствующую эвристическую информацию. На самом деле проще всего
обеспечить ложное значение общего предиката с помощью подцели Ь, поскольку наименее
ресурсоемким по времени является следующий порядок выполнения операций: "Проверить
значение Ь, посмотреть, ложно ли с, а затем проверить сГ. Существует неявная эвристика:
сначала нужно проверить простейший способ получения ложного значения, а если он не
сработает, перейти к остальной (возможно, более сложной) части решения. Эксперты могут
разработать процедуры и взаимоотношения, которые не только сами являются истинными,
но и содержат информацию о том, как воспользоваться этой истиной. При решении
большинства интересных задач эти эвристики не стоит игнорировать [Kowalski, 19795].
В следующем разделе вводятся хорновские выражения, а их процедурная
интерпретация используется в качестве точной стратегии, позволяющей сохранить эту
эвристическую информацию.
12.3.2. Логическое программирование и язык PROLOG
Чтобы понять математические основы языка PROLOG, введем определение
логического программирования (logic programming). Затем добавим к нему точную стратегию
поиска для получения аппроксимации этой стратегии поиска, которую иногда называют
процедурной семантикой (procedural semantics) языка PROLOG. Для полноты описания
языка PROLOG будет рассмотрено использование оператора not и предположения о
замкнутости мира (closed world assumption).
Рассмотрим базу данных дизъюнктивных выражений, подготовленную для
опровержения разрешения (раздел 12.2). Если ограничить это множество выражениями,
содержащими не более одного положительного литерала (а также 0 или более отрицательных
литералов), получим пространство дизъюнктов с некоторыми интересными свойствами.
Во-первых, задачи, описываемые с помощью этого набора дизъюнктов, сохраняют
свойство невыполнимости (unsatisfiability) для опровержения разрешений, т.е. являются
полными в смысле опровержения (раздел 12.2). Во-вторых, важным преимуществом
ограничения нашего представления этим подклассом всех дизъюнктов является наличие
очень эффективной стратегии поиска опровержения, основанной на использовании
линейной входной формы, предпочтении единичного выражения и сведении целевого
выражения слева направо с помощью поиска в глубину. При эффективной реализации
рекурсии (конечных рекурсивных вызовов) эта стратегия гарантирует нахождение
опровержения, если пространство дизъюнктов обладает свойством невыполнимости [van
Emden и Kowalski, 1976]. Хорновское выражение содержит не более одного
положительного литерала, т.е. может быть записано в форме
а V—ib 1V—ib2 v... V—|Ьл,
где аиЬ, — положительные литералы. Чтобы подчеркнуть ключевую роль
единственного положительного литерала в разрешении, хорновские выражения обычно записывают в
виде импликации с положительным литералом в качестве заключения
а<^Ь,лЬ2л...лЬп.
Прежде чем обсудить стратегию поиска, дадим формальное определение
подмножеству хорновских выражений (Horn clause). Это подмножество вместе со стратегией
недетерминистского приведения целевого выражения называется логической программой
(logic program).
Глава 12. Автоматические рассуждения
547
ОПРЕДЕЛЕНИЕ
ЛОГИЧЕСКАЯ ПРОГРАММА
Логическая программа — это множество выражений, связанных квантором
всеобщности, записанных в форме исчисления предикатов первого порядка вида
а<— Ь^аЬ2аЬ2а. . .лЬл.
Здесь аиЬ, — положительные литералы, которые иногда называют атомарными
целями. При этом а — это заголовок выражения, а конъюнкция Ь, — его тело.
Такие предложения называются хорновскшш выражениями (Horn clause) теории
предикатов первого порядка. Они могут быть записаны в трех формах: когда исходное
дизъюнктивное выражение не содержит положительных литералов, когда оно не содержит
отрицательных литералов и когда оно содержит один положительный и один или несколько
отрицательных литералов. Эти варианты обозначены цифрами 1, 2 и 3 соответственно.
1. <— biAb2Ab?)A.. .лЬп — это так называемое беззагочовочное выражение или
проверяемые цели.
2.а,<-
а2<-
называются фактами (fact)
3. а<-Ь1л...лЬА7 называется отношением правила.
Теория хорновских выражений допускает только такие формы Слева от символа
импликации <— может располагаться только один литерал, и он должен быть
положительным. Все литералы справа от символа <— тоже положительны. Приведение выражений,
содержащих не более одного положительного литерала, к хорновской форме,
выполняется в три этапа. Сначала выбирается положительный литерал в выражении, если он
существует, и перемещается в его левую часть (на основе коммутативного свойства
дизъюнкции). Этот единственный положительный литерал становится заголовком хорновско-
го выражения. Затем все выражение приводится к хорновской форме по правилу
av^b 1 v^b2v.. .v^bn=a<—1( —i/d 1 v^b2v... v^bn).
И, наконец, на основе закона дс Моргана зга запись приводится к виду
э<^-Ь]аЬ2а...аЬп}
где для систематизации промежуточных целей Ь, используется коммутативное свойство
конъюнкции.
Следует отмстить, что порой невозможно преобразовать дизъюнктивные выражения
из произвольного пространства к хорновской форме. Некоторые выражения не могут
быть записаны в такой форме, например pvg. Для создания хорновскою выражения в
исходном предложении должно содержаться не более одного положительного литерала.
Если этот критерий не выполняется, то может понадобиться пересмотреть исходную
предикатную форму описания проблемы. Как будет видно из дальнейшего,
преимуществом хорновской формы представления является возможность реализации эффективной
стратегии опровержений.
548 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Алгоритм вычисления в логической программе реализует детерминированное
приведение целевого выражения. Если целевое выражение имеет вид
<—а1ла2л...лал,
то на каждом шаге вычислений алгоритм произвольным образом выбирает некоторое
значение а, 1</<п. Затем на основе недетерминированного выбора строится выражение
а1<—Ь1лЬ2л...лЬл,
которое используется для приведения целевого выражения путем унификации а1 и а,
с помощью подстановки £. Новое целевое выражение принимает вид
<—(а1л...ла/ 1лЬ1лЬ2л...лЬпла/+1л...лап)£.
Такой процесс недетерминированного приведения целевого выражения продолжается до
тех пор, пока целевое множество не окажется пустым.
Если отказаться от недетерминированности за счет упорядочения подзадач в процессе
приведения, то результат вычислений не изменится. Ко всем результатам, получаемым с
помощью недетерминированного поиска, можно также прийти путем полного
упорядоченного перебора. Однако, снижая уровень недетерминированности, можно определить
стратегии, позволяющие исключить ненужные ветви из пространства поиска. Так, основная
задача практических языков логического программирования— обеспечить программиста
средствами контроля, а по возможности и уменьшить уровень недетерминированности.
С помощью этих средств программист может обеспечить порядок приведения и выбрать
набор дизъюнктивных выражений, используемых для приведения каждого целевого
выражения. (Как и в алгоритмах поиска на графах, для предотвращения бесконечных циклов в
доказательствах необходимо предпринимать дополнительные меры предосторожности.)
Согласно абстрактной спецификации логическая программа должна обладать ясной
семантикой, свойственной системам опровержения разрешения. В работе [van Emden и
Kowalski, 1976] показано, что минимальной интерпретацией, при которой логическая
программа истинна, является сама интерпретация этой программы. Поэтому в
практических языках программирования, таких как PROLOG, в процессе работы программы
можно вычислить только подмножество связанных с ней интерпретаций [Shapiro, 1987].
Последовательный язык PROLOG— это аппроксимация интерпретатора для модели
логического программирования, спроектированная для эффективного выполнения на
машине фон Неймана. Этот интерпретатор применялся до сих пор в данной книге.
Последовательный PROLOG для управления поиском в процессе доказательства использует как
порядок целей в выражении, так и порядок выражений в программе. Если известно некоторое
число целей, PROLOG всегда обрабатывает их слева направо. В процессе поиска
унифицируемого выражения имеющиеся дизъюнкты всегда проверяются в том порядке, в котором
они подаются программистом. После обработки каждого выбранного выражения к записи
унификации добавляется указатель возврата, позволяющий в случае неудачного исходного
выбора использовать другие выражения (опять же в заданном программистом порядке).
Если процесс не увенчается успехом для всех возможных выражений в пространстве
дизъюнктов, то вычисления завершаются неудачно. При использовании оператора cut для
эффективного поиска в глубину (подраздел 14.1.5) интерпретатор на самом деле может
обработать не все комбинации выражений в пространстве поиска.
Опишем работу интерпретатора более формально. Пусть имеется цель
<—а1ла2ла3л...лал
Глава 12. Автоматические рассуждения
549
и программа Р. Интерпретатор PROLOG последовательно выбирает первое
дизъюнктивное выражение из Р, заголовок которого унифицирует а\. Затем это выражение
используется для приведения целей. Если
а}<^Ь,лЬ2л...лЬп —
приводящее выражение для унификации!;, то целевое выражение принимает вид
<— (Ь,лЬ2л.. .лЬпла2ла3л.. .лал)£.
Затем интерпретатор PROLOG пытается выполнить приведение крайней слева цели Ьь
используя первое выражение программы Р, унифицирующее Ь\. Предположим,
Ь^<^с,ас^а...ас
1 2 р
при подстановке унификации ф. Тогда целевое выражение приводится к виду
<—(с1лс2л...лсрлЬ2л...лЬлла2ла3л...лал)£ф.
Заметим, что список целей обрабатывается как стек, поэтому целесообразно выполнять
поиск в глубину. Если интерпретатор языка PROLOG не находит подстановку унификации,
приводящую к решению, то он возвращается к ближайшей точке выбора унификации,
восстанавливает все установленные после этого связи и выбирает следующее выражение для
унификации (в соответствии с порядком в программе Р). Таким образом, PROLOG
реализует поиск в глубину слева направо в пространстве дизъюнктивных выражений.
Если целевое выражение приводится к нулевому предложению ( J), то приводящая к
этому композиция подстановок унификации
обеспечивает интерпретацию, при которой исходное целевое выражение истинно. Помимо
возврата в соответствии с порядком следования выражений в программе, последовательный
язык PROLOG допускает использование выражения cut или !. Как описано в
подразделе 14.1.5, выражение cut можно поместить в дизъюнктивное выражение в качестве самой
цели. Тогда интерпретатор, достигнув этого выражения, фиксирует текущий путь выполнения
программы и подмножество подстановок унификации, сделанных после выбора выражения,
содержащего cut. При этом само выбранное дизъюнктивное выражение становится
единственным средством приведения целевого выражения. Если процесс приведения завершится
неудачно после выражения cut, то все дизъюнктивное выражение считается ложным.
На практике для реализации механизма cut необходимо хранить возвратные
указатели для участвующего в приведении выражения и всех его компонентов,
расположенных до выражения cut. Наличие выражения cut может означать, что вычисляются
только некоторые из возможных интерпретаций модели.
Подводя итог описанию последовательного языка PROLOG, следует сравнить его с
моделью опровержения разрешения из раздела 12.2.
1. В логическом программировании пространство дизъюнктивных выражений,
используемых для резолюции, содержит подмножество хорновских выражений. Для
возможности представления в хорновской форме каждое выражение должно
включать не более одного положительного литерала.
2. Следующие структуры позволяют представить задачу в хорновской форме.
2.1. Целевые выражения
<—Ь1лЬ2л...лЬп —
550 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
это список утверждений, которые необходимо проверить в процессе
опровержения разрешения. Для каждого а, строится отрицание, выполняются
подстановки унификации и приведение до получения пустого выражения (если
таковое существует).
2.2. Факты
ал<--
это отдельные выражения, используемые для резолюции.
2.3. Хорновские правила или аксиомы
а<^Ь]лЬ2л...лЬп
позволяют выполнять приведение для соответствующих подцелей.
3. При использовании стратегии предпочтения единичных выражений, линейной
входной формы (методики предпочтения фактов и использования отрицания цели и
ее дочерних резольвент, описанной в подразделе 12.2.4) и применении принципа
поиска выражений для резолюции в глубину (с возвратом) и слева направо система
доказательства теорем на основе резолюции работает как интерпретатор языка
PROLOG. Поскольку эта стратегия является полной в смысле опровержения, она
гарантирует нахождение решения (т.е. исключает отсечение интерпретаций за счет
использования выражения cut).
4. И, наконец, композиция подстановок унификации в процессе доказательства
обеспечивает интерпретацию (ответ), для которой целевое выражение является истинным. Это
точно соответствует процессу извлечения ответа, описанному в подразделе 12.2.5.
Важным свойством современных интерпретаторов языка PROLOG является неявное
использование в его реализации предположения о замкнутости пространства (closed world
assumption). В теории предикатов доказательство -ip(X) эквивалентно доказательству того, что
р(Х) логически ложно, т.е. выражение р(Х) ложно для каждой интерпретации, для которой
набор аксиом является истинным. Интерпретатор языка PROLOG на основе алгоритма
унификации из главы 2 дает более частный результат, чем общий принцип опровержения
разрешения, описанный в разделе 12.2. Вместо проверки всех интерпретаций он тестирует только
те выражения, которые содержатся в базе данных в явной форме. Сформулируем эти
ограничения, чтобы четко увидеть неявную ограниченность языка PROLOG.
Предположим, что для каждого предиката р и каждой переменной X из р множество
аь а2, ..., а„ составляет область определения X. Работа интерпретатора PROLOG в
процессе унификации основывается на следующих принципах.
1. Аксиома об уникальности имен. Для всех элементов области определения а1Фа^ если
эти значения не идентичны. Следовательно разноименные элементы различаются.
2. Аксиома замкнутости мира (closed world).
p(X)^p(a^)vp(a2)v...vp(an).
Это означает, что возможными реализациями отношения являются только те
выражения, которые содержатся в описании задачи.
Глава 12. Автоматические рассуждения
551
3. Аксиома о замыкании области определения (domain closure).
(X=a1)v(X=a2)v...v(X=an).
Эта аксиома гарантирует, что элементы, содержащиеся в описании задачи,
представляют собой полный список единственно возможных элементов.
Эти три аксиомы неявно реализованы в интерпретаторе языка PROLOG, что
подтверждается ограниченностью множества возможных интерпретаций PROLOG.
Неформально это означает, что в языке PROLOG все целевые выражения, для
которых нельзя доказать истинность, считаются ложными. Это может привести к аномалии:
если значение, обеспечивающее истинность целевого выражения, не содержится в
текущей базе данных, то PROLOG считает данное выражение ложным.
В языке PROLOG неявно присутствуют и другие ограничения, присущие всем языкам
программирования. Наиболее важными из них, помимо проблемы отрицания, являются
нарушения семантической модели для логического программирования. В частности,
следует отметить отсутствие проверки вхождений, что приводит к возможности унификации
выражения с его подмножеством (раздел 2.3), а также использование выражения cut.
Современное поколение интерпретаторов PROLOG следует рассматривать с
практической точки зрения. Некоторые проблемы вызваны тем, что на сегодняшний день не
существует эффективного пути их решения (проверка вхождения). Другие связаны с
попытками оптимизировать использование поиска в глубину с возвратом (выражение cut).
Многие аномалии языка PROLOG являются результатом попытки реализовать
недетерминированную семантику чистого логического программирования на последовательном
компьютере. К ним относятся проблемы, связанные с выражением cut.
В заключительном разделе главы 12 рассматриваются альтернативные схемы
логического вывода, применяемые для автоматических рассуждений.
12.4. Дополнительные вопросы автоматических
рассуждений
Мы рассмотрели слабые методы решения задач, основанные на синтаксических
свойствах представления и применении стратегий для выбора комбинаций в процессе
полного перебора. В завершение этой главы приведем некоторые комментарии по основным
аспектам слабых методов решения
12.4.1. Единое представление для реализации слабых методов решения
Процедура доказательства разрешения требует приведения всех аксиом к дизъюнктивной
форме. Такое единое представление позволяет разрешать выражения и упрощает разработку
эвристик для решения задачи. Основным недостатком этого подхода является возможность
потери важной эвристической информации в процессе се сдинообразно1 о кодирования.
Формат представления правила "если..., то... " зачастую более информативен для
использования правила отделения или реализации поиска в продукционной системе, чем один из
подобных синтаксических вариантов. Кроме того, такой формат позволяет эффективно
использовать это правило. Допустим, требуется представить абдуктивный вывод (abductive inference)
(раздел 8.0) утверждения ''если двигатель не заводится и фары не включаются, то, возможно,
сел аккумулятор". С помощью этого правила можно проверить аккумуляюр.
552 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
При записи этого правила в дизъюнктивной форме теряется эвристическая
информация о способе его применения. Если записать это правило в предикатной форме
-ifи rn_overA-^lights-^battery, то его дизъюнктивная форма будет иметь вид
turnovervlightsvbattery. Это выражение можно записывать по-разному, причем
каждая форма записи может представлять отдельную импликацию.
{^turn_overA^lights)^battery,
{^turn_over^(batteryvlights),
{^batteryA^lights)^turn over,
(^battery^(turn_overvlights)
и т.д.
Чтобы сохранить эвристическую информацию в процессе автоматических рассуждений,
некоторые исследователи разработали методы рассуждений, предполагающие кодирование
эвристик путем формирования правил по аналогии с разработкой отношений человеком-
экспертом [Nilsson, 1980], [Bundy, 1988]. Этот подход уже был рассмотрен в разделе 3.3,
а его реализация на языке PROLOG описана в разделе 12.3. Экспертные системы на основе
правил также позволяют программисту контролировать поиск с помощью структуры
правил. Эта идея будет развита в следующих двух примерах, в которых сохраняется форма
импликации, и эта информация используется для управления поиском на графе.
Рассмотрим задачу рассуждения на основе данных с использованием следующих
фактов, правил (аксиом) и цели.
Факт:
(av(bAc))
Правила (аксиомы).
(а-^(сУле)),
(Ь->0,
(c->(gv/7))
Цель:
<^evf.
Доказательство утверждения evf показано на рис. 12.12. Обратите внимание на
использование связки И для отношения v и связки ИЛИ для отношения л в пространстве
поиска на основе данных. Если известно, что а или Ьлс — истинно, то необходимо
проводить рассуждения с помощью обоих дизъюнктов, чтобы гарантировать сохранение
истинности. Поэтому эти два пути соединяются. С другой стороны, если Ь и с — истинны,
то можно продолжать исследовать любой из этих конъюнктов. В процессе проверки
соответствия любое промежуточное состояние, например с, заменяется заключением
правила, в частности, gv/7, предпосылка которого соответствует этому состоянию.
Исследование обоих состояний е и f на рис. 12.12 приводит к достижению цели evf.
Аналогичным образом можно использовать проверку соответствия правил на графе
И/ИЛИ при рассуждениях на основе цели. Если в описании цели содержится символ v,
как в примере на рис 12.13, то каждую альтернативу можно исследовать независимо.
Если целевое выражение представляет собой конъюнкцию, то необходимо обрабатывать
оба конъюнкта.
Цель
(av(bAC)).
Глава 12. Автоматические рассуждения
553
Правила (аксиомы):
(fAd)->a,
(е->(Ьлс)),
Факт:
/лд.
Цель: evf
Направление
поиска
Факт:
a v (b л с)
Рис. 12.12. Рассуждения на основе данных на графе И/ИЛИ в исчислении
высказываний
Хотя эти примеры взяты из исчисления высказываний, в теории предикатов поиск
выполняется аналогично. После подстановок унификации для литералов можно
применять правила вывода и осуществлять поиск по различным ветвям пространства.
Естественно, подстановки унификации должны быть согласованными но различным ветвям И
пространства поиска.
В этом подразделе предложены методы решения, позволяющие сохранить
эвристическую информацию в представлении данных для слабых методов решения задач. Таким
образом, в экспертных системах программист может задавать в рамках правила
эвристическую информацию. Экспертные системы основаны на описаниях в форме правил, т.е.
учитывают для управления поиском порядок правил или порядок следования
предпосылок в рамках одного правила. При таком подходе отсутствует возможность применения
однородных процедур поиска на полном наборе правил, таких как метод резолюции.
Однако правило отделения все же можно использовать, что подтверждается графами,
приведенными на рис. 12.12 и 12.13. Продукционные системы, основанные на поиске в
глубину, в ширину или "жадном" алгоритме поиска, представляют собой пример
архитектуры для реализации систем правил (см. примеры в главах 4, 5, 7, 14 и 15).
554 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Направление
поиска
Факт;
Рис 12.13 Рассуждения от цели с помощью графа
И/ИЛИ в исчислении высказываний
12.4.2. Альтернативные правила вывода
До сих пор рассматривалось наиболее общее правило вывода — метод резолюции.
Для повышения эффективности процедуры разрешения существует несколько более
сложных правил вывода, два из которых будут кратко рассмотрены в этом разделе. Это
процедуры гиперрезолюции (hyperresolution) и парамодуляции (paramodulation).
Описанная выше процедура резолюции на самом деле представляет собой частный
случай, получивший название бинарной резолюции, поскольку на каждом шаге в
создании нового дизъюнктивного выражения участвуют ровно два родителя.
Гиперрезолюция — это последовательное применение процедуры бинарной резолюции для получения
одного дизъюнкта. На каждом шаге в процедуре гиперрезолюции может участвовать
одно выражение с несколькими отрицательными литералами — так называемое ядро
(nucleus) — и несколько выражений, состоящих только из положительных литералов, —
сателлитов (satellite). Один из положительных литералов должен соответствовать
отрицательному литералу ядра. Кроме того, для каждого отрицательного литерала ядра
необходимо иметь по сателлиту. Таким образом, в результате применения гиперрезолюции
получается выражение, состоящее только из положительных литералов.
Преимуществом процедуры гиперрезолюции является получение выражения,
содержащего только положительные литералы, и уменьшение размерности
пространства дизъюнктов, поскольку в процессе реализации процедуры не фиксируются
Глава 12. Автоматические рассуждения
555
промежуточные результаты. Подстановки унификации во всех выражениях должны
быть согласованы.
Продемонстрируем применение процедуры гиперрезолюции на примере следующего
набора дизъюнктивных выражений.
-птагг/есУ(Х, Y)v-^mother(X, Z)vfather(Y, Z),
married(kate, george)vlikes(george, kate),
mother(kate, sarah).
С помощью гиперрезолюции заключение можно получить за один шаг.
father(george, sarah)vlikes(george, kate).
Ядром в этом примере является первое выражение. Два другие — сателлиты.
Сателлиты состоят лишь из положительных дизъюнктов, причем на каждый отрицательный
литерал ядра приходится по одному сателлиту. Заметим, что в данном случае ядро
представляет собой дизъюнктивную форму импликации
married(X, Y)Amother(X, Z)->father(Y, Z).
Заключение этого правила — часть окончательного результата. Заметим, что в
процессе отсутствуют промежуточные результаты типа
-^mother(kate, Z)vfather(george, Z)vlikes(george, kate),
которые обычно получаются при использовании бинарной резолюции в том же
пространстве дизъюнктивных выражений.
Гиперрезолюция — это согласованная и полная процедура. В сочетании с другими
стратегиями, такими как стратегия "множества поддержки", свойство полноты может нарушаться
[Wos и др., 1984]. Для создания ядра и сателлитных выражений могут потребоваться
специальные стратегии поиска, хотя в большинстве случаев эти выражения легко проиндексировать
по имени и свойству положительности или отрицательности каждого литерала. Это позволяет
подготовить ядро и сателлитные выражения к процедуре гиперрезолюции.
Важным и сложным вопросом в разработке механизмов доказательства теорем является
контроль равенства. Особенно сложные задачи возникают в областях, где большинство
фактов и взаимосвязей имеют несколько представлений, например, могут быть получены путем
применения свойств ассоциативности и коммутативности выражений. Такой областью
является математика. Вот простой пример. Арифметическое выражение 3+D+5) может быть
представлено во многих различных формах, в том числе 3+(D+0)+5). Такие выражения
сложны для использования подстановок, унификации и проверки равенства с другими
выражениями в рамках автоматического решения математических задач.
Демодуляция (demodulation) — это процесс перефразирования или преобразования
выражений для их автоматической записи в выбранной канонической форме. Единичные
дизъюнкты, используемые для преобразования к этой форме, называются демодуляторами
(demodulator). Они задают равенство различных выражений и позволяют заменять
выражение его канонической формой. При правильном использовании демодуляторов вся вновь
сгенерированная информация приводится к указанной форме еще до ее поступления в
пространство дизъюнктивных выражений. Например, пусть имеется демодулятор
equal(father(father(X)), grandfather(X))
и новое выражение
age(father(father(sarah)), 86).
556 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Прежде чем добавить это выражение в пространство дизъюнктов, применяется
демодулятор, и выражение добавляется в виде
age(grandfather(sarah), 86).
В данном случае проблема равенства связана с именами понятий. Как
предпочтительнее классифицировать человека: как отца отца father(father(X)) или дедушку
grandfather(X)l Подобным образом можно указать канонические имена для всех членов
семьи, в частности определить, что брат отца brother(father(Y)) — это дядя uncle(Y).
Указав канонические имена, под которыми должна храниться информация, можно
разработать демодуляторы, в частности equal, приводящие всю новую информацию к
выбранной форме. Заметим, что демодуляторы — это всегда единичные выражения.
Парамодуляция — это обобщение подстановки равенства на уровне термов.
Например, пусть дано выражение
older(mother(Y), Y)
и отношение равенства
equal(mother(sarah), kate)
Тогда можно выполнить парамодуляцию и получить
older{kate, sarah).
Заметим, чго проверка соответствия и замены {sarah/Y} и {mother(sarah)/kate}
выполняется на уровне термов. Основное различие между процедурами демодуляции и парамо-
дуляции состоит в том чю последняя допускает нетривиальную замену переменных в обоих
аргументах равенства предикатов При демодуляции замена выполняется с помощью
демодулятора. Для получения окончательного вида выражения можно использовать несколько
демодуляторов. Парамодуляция выполняется лишь один раз для любой ситуации.
Итак, рассмотрены простые примеры мощных механизмов вывода. Эти механизмы можно
рассматривать как более общие приемы резолюции в пространстве дизъюнктивных
выражений. Как и другие описанные выше правила вывода, они тесно связаны с выбором
представления, и для их реализации требуется применение соответствующих стратегий.
12.4.3. Стратегии поиска и их использование
Иногда предметная область приложения диктует специальные требования к правилам
вывода и эвристикам по их использованию. Выше уже рассматривался вопрос
использования демодуляторов для реализации равнозначных подстановок. В естественной
дедуктивной системе (natural deduction system), описанной в работе [Bledsoe, 1971],
использованы две важные стратегии доказательства теорем на основе резолюции,
получившие название стратегий расщепления (split) и приведения (reduce).
Эти стратегии разрабатывались для использования в математике, в частности, для
применения в теории множеств. Идея этих стратегий состоит в разбиении теоремы на
части с целью ее упрощения и возможности использования таких традиционных
методов, как метод резолюции. Стратегия расщепления состоит в разделении различных
математических форм на соответствующие части. Доказательство соотношения АлВ
эквивалентно доказательству А и доказательству В. Аналогично доказательство Л<->В — это
доказательство А—>В иА<г-В.
Стратегия приведения тоже сводится к делению больших доказательств на
составляющие. Например, доказательство того, что seAnB можно свести к доказательству
Глава 12. Автоматические рассуждения
557
двух соотношений se А и se Б. Или доказательство истинности некоторого свойства
выражения —\(AkjB) аналогично доказательству этого свойства для —А и для -нВ. Разделяя
доказательства больших теорем на фрагменты меньшего объема, можно ограничить
пространство поиска. В работе [Bledsoe, 1971] используются также подстановки равенства.
Как неоднократно отмечалось в предыдущих главах, корректное использование
стратегий — это, скорее, искусство, требующее хорошего знания области приложения, а
также соответствующего представления и правил вывода. В заключение этой главы
приведем несколько общих правил, которые при осмысленном использовании могут
оказаться очень эффективными, но, как и всякое правило, имеют свои исключения. Эти
рекомендации обобщают опыт многих исследователей, работающих в этой области
[Bledsoe, 1971], [Nilsson, 1980], [Wos и др., 1984], [Wos, 1988], а также собственные
представления автора книги о слабых методах решения задач. Приведем эти
рекомендации без дополнительных комментариев.
• По возможности используйте дизъюнктивные выражения с меньшим числом
литералов.
• Прежде чем применять общие правила вывода, разбивайте задачу на подзадачи.
• По возможности используйте предикаты равенства.
• Применяйте демодуляторы для создания канонических форм.
• Пользуйтесь парамодуляцией при работе с правилами вывода для предикатов
равенства.
• Реализуйте стратегии, сохраняющие "полноту1'.
• Используйте стратегию "множества поддержки" в задачах, содержащих
потенциальные противоречия.
• В процесс резолюции старайтесь использовать единичные выражения.
• Выполняйте категоризацию новых выражений.
• Используйте средства упорядочения выражений и литералов в рамках более
крупных выражений, отражающие ваши интуитивные представления и опыт решения
задач из данной области.
12.5. Резюме и дополнительная литература
Системы автоматических рассуждений и другие слабые методы решения задач
составляют важную область искусственного интеллекта. Они используются для выработки
общих стратегий поиска в игровых задачах, при доказательстве теорем и для поддержки
рассуждений в системах на основе баз знаний. Эти методы применяются для разработки
оболочек экспертных систем и механизмов вывода.
Слабые методы требуют выбора представления, правил вывода и стратегий поиска.
Эти три составляющие неразрывно связаны между собой и не могут рассматриваться
независимо друг от друга. Выбор этих элементов также во многом определяется
спецификой приложения. Рекомендации по выбору основных составляющих слабых методов
решения задач приведены в конце предыдущего раздела.
Резолюция — это процесс построения возможных интерпретаций в пространстве
дизъюнктивных выражений, к которому добавлено отрицание целевого выражения, до
558 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
возникновения противоречия. В этой книге не рассматриваются вопросы полноты
процедуры опровержения разрешения. Они освещаются в работе [Chang и Lee, 1973].
Любознательному читателю можно порекомендовать ознакомиться с соответствующей
литературой. В частности, работа [Chang и Lee, 1973] — это очень доступная книга,
рассчитанная на неподготовленного читателя. Формальные основы описанного подхода
изложены в [Loveland, 1978]. Множество ранних классических работ в этой области собраны в
[Siekmann и Wrightson, 1983я, 19836]. Важные результаты в области автоматических
рассуждений изложены в работах [Nilsson, 1980], [Genesereth и Nilsson, 1987], [Kowalski,
19795], [Lloyd, 1984], [Wos и др., 1984, 1988], [Robinson, 1965], [Bledsoe, 1977]. Важный
вклад в методику доказательства теорем внесла работа [Воуег и Moore, 1979]. К ранним
работам в этой области относятся [Feigenbaum и Feldman, 1963] и [Newell и Simon, 1972].
В течение последних двадцати пяти лет все новые результаты в области
автоматических рассуждений докладывались на конференции CADE (Conference on Automated
Deduction). В настоящее время много работ посвящены проверке соответствия моделей,
разработке систем верификации и представления иерархических знаний [McAllester,
1999], [Ganzinger и др., 1999]. Продолжают свои исследования Ларри Вое (Larry Wos) и
его коллеги из Аргонской национальной лаборатории. В частности, работа [Veroff, 1997]
по теории автоматических рассуждений посвящена Восу. Стоит отметить также работы
[Bundy, 1983, 1988], выполненные в Эдинбургском университете, а также [Kaufmann и
др., 2000], выполненную в университете штата Техас.
12.6. Упражнения
1. Приведите предикаты, описанные в разделе 2.4, к дизъюнктивной форме и
используйте процедуру опровержения разрешения для ответа на запрос о том, должен ли
конкретный инвестор выполнять investment^combination)!
2. С помощью процедуры резолюции докажите утверждение из упражнения 12 к главе 2.
3. Используйте процедуру резолюции для ответа на запрос из примера 3.3.4.
4. В главе 5 представлена упрощенная форма игры "хода конем". Приведите правило
path3 к дизъюнктивной форме и с помощью процедуры резолюции получите ответ
на запрос paf/?3C, 6). Затем воспользуйтесь рекурсивным вызовом процедур в
дизъюнктивной форме.
5. Как можно использовать процедуру резолюции для реализации поиска в
продукционной системе?
6. Как с помощью резолюции реализовать рассуждения от данных? Используйте этот
метод для определения пространства поиска в упражнении 1. Какие проблемы могут
возникнуть в задачах, где пространство поиска достаточно велико?
7. Воспользуйтесь процедурой резолюции для решения задачи переправы человека,
волка, козы и капусты из раздела 14.3.
8. Воспользуйтесь методом резолюции для решения задачи из [Wos и др., 1984].
Условия задачи следующие. Четыре человека — Роберта, Тельма, Стив и Пит —
работают на восьми различных работах. Каждый из них работает ровно на двух работах.
Они занимают следующие должности: руководитель, охранник, санитар, телефонист,
полицейский, учитель, актер и боксер. Санитар — это мужчина. Муж
руководителя — телефонист. Роберта — не боксер. Пит не имеет высшего образования. Робер-
Глава 12. Автоматические рассуждения
559
та, руководитель и полицейский любят вместе играть в гольф. Кто на какой работе
работает? Покажите, как изменится задача с учетом пола каждого из сотрудников.
9. Приведите два примера гиперрезолюции, где ядро состоит не менее чем из четырех
литералов.
10. Напишите демодулятор для выражения sum, приводящий дизъюнктивные
выражения вида equal(ans, sumE, sumF, minusF)))) к виду equal(ans, sumE, 0)).
Разработайте демодулятор для приведения этого результата к виду equal(ans, 5).
11. Постройте "каноническое множество" из шести типов семейных отношений.
Напишите демодуляторы для приведения различных форм отношений к канонической
форме. Например, "брат матери" — это "дядя".
12. Примените три стратегии опровержения из подраздела 12.2.4 для решения задачи
"счастливого студента", проиллюстрированной на рис. 12.4.
13. Приведите следующее выражение из предикатной формы к дизъюнктивной
V(X)(p(X)->{V(V)[p(y)->p(f(Xf Y))]A-,\f(Y)[q(X, Y)->p(Y)])).
14. Создайте граф И/ИЛИ для решения следующей задачи на основе данных.
Факт: -id(F)v[b@Ac@].
Правила: -id(X)->-ia(X) и Ь(У)->е(У) и g(H/)<-c(lV).
Доказать: -ia(Z)ve(Z).
15. Докажите, что стратегия линейной входной формы не является полной в смысле
опровержения.
16. Создайте граф И/ИЛИ для решения следующей задачи и объясните, почему
невозможно получить целевое выражение.
r(Z)vs(Z)?
Факт: p(X)vq(X).
Правила: р{а)-^г{а) и q{b)-^s{b).
17. Используйте процедуры факторизации и резолюции для опровержения следующих
выражений p(X)vp(f(Y)) и -ip(l/V)v-1p(/:(Z)). Постарайтесь построить опровержение
без факторизации.
18. Альтернативной семантической моделью для логического программирования
является Flat Concurrent PROLOG [Shapiro, 1987]. Сравните эту модель с семантикой
языка PROLOG, описанной в разделе 12.3.
560 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Понимание
естественного ШШШШ
языка
Чем объяснить потребность в словах?
— Тсрснс (Terence)
До меня доходит
Какой-то ураган в твоих словах,
Но не слова
— Вильям Шекспир (William Shakespeare), Отелло
13.0. Проблема понимания естественного языка
Проблема понимания естественного языка, будь то текст или речь, в значительной
мере зависит от знания предметной области. Понимание языка — это не просто передача
слов. Оно требует знаний о целях говорящего, контексте, в также о данной предметной
области. Программы, реализующие понимание естественного языка, требуют
представления этих знаний и предположений. При их создании необходимо учитывать такие
аспекты, как немонотонность, изменение убеждений, иносказательность, возможность
обучения, планирования и практическая сложность человеческих взаимоотношений.
Следует отметить, что все эти проблемы являются краеугольными для самого
искусственного интеллекта в целом.
Например, рассмотрим следующие строки из восемнадцатого сонета Шекспира.
"Сравню ли с летним днем твои черты?
Но ты милей, умеренней и краше
Ломает буря майские цветы,
И так недолговечно лето наше!"
В рамках упрощенной, буквальной трактовки каждого слова смысл этих стихов
понять невозможно. Для его понимания нужно ответить на следующие вопросы.
1. Чем объясняется необычайная притягательность произведений Шекспира? Чтобы
понять эти строки, необходимо знать, что такое человеческая любовь и каковы ее
социальные традиции. Шекспир не просто пытался отработать причитающийся ему гонорар.
2. Почему Шекспир сравнивает свою возлюбленную с летним днем? Означает ли это,
что она длится 24 часа и при общении с ней кожа покрывается летним загаром, или
она ассоциируется у автора с ощущением тепла и летней красоты?
3. Какие выводы можно сделать из этого фрагмента? Смысл сказанного явно не
отражен в тексте. Он постигается с помощью метафор, аналогий и базовых знаний.
Например, буря и скоротечность лета ассоциируются с перипетиями человеческой
жизни и любви.
4. Как человек понимает метафоры? Слова не просто описывают совокупность
объектов, как ячейки в таблице. Смысл этих стихов состоит в сопоставлении
характеристик летнего дня и возлюбленной автора. Какие из этих свойств могут быть
приписаны обоим объектам, а какие нет, и главное, почему некоторые свойства
подчеркиваются, а другие даже не упоминаются?
5. И, наконец, должна ли компьютерная система понимания языка знать, что такое
"ямб"? Как компьютер ответит на вопрос, о чем эти стихи?
Если напрямую объединить словарные значения слов этого сонета, то это не добавит
ясности. Чтобы уловить смысл стихов, нужно задействовать сложный механизм
понимания слов, синтаксического разбора предложения, построения представления
семантических значений и их интерпретации в свете знаний предметной области.
Рассмотрим второй пример, взятый из объявления о вакансиях на факультете
компьютерных наук.
"Факультет компьютерных наук университета Нью-Мексико . проводит конкурс на
замещение двух должностей профессора. Требуются специалисты в следующих областях:
программное обеспечение, в том числе анализ, проектирование и средства разработки...;
системы, включая архитектуру, компиляторы, сети...
Кандидаты должны иметь степень доктора наук по специальности...
На факультете выполняются международные проекты в области адаптивных вычислений,
искусственного интеллекта, поддерживаются тесные связи с институтом Санта-Фе и
несколькими национальными лабораториями ."
В связи с этим объявлением возникает несколько вопросов.
1. Как читатель узнает, что это объявление касается вакантных должностей именно
этого факультета?
2. Какие языки и средства программирования необходимо знать для работы в
университете (они явно не указаны в объявлении)? Человек, хорошо знакомый с
процессом преподавания в университете, сможет понять, что речь идет о языках Cobol,
PROLOG и UML.
3. Какое отношение к этому объявлению имеют сведения о международных проектах
и связях с другими лабораториями?
4. Как компьютер поймет, о чем это объявление? Что ему необходимо знать, чтобы
направить объявление по Internet кандидату наук, который занимается поиском
работы в Web?
562 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Понимание естественных языков связано (как минимум) с тремя вопросами. Во-
первых, предполагается большой объем человеческих знаний. Язык описывает
взаимосвязи в сложном реальном мире, с которыми должна быть знакома любая система,
претендующая на понимание языка. Во-вторых, язык имеет некоторую структуру: слова
состоят из фонем, и, в свою очередь, составляют предложения и фразы. Порядок
следования фонем, слов и предложений не является случайным. Без корректного использования
этих компонентов общение невозможно. И, наконец, языковые конструкции — это
продукт некоторого агента — человека или компьютера. Агенты внедрены в сложную среду
и развиваются в направлениях, определяемых их индивидуальностью и социумом.
Языковые действия являются целенаправленными.
В этой главе предлагается введение в проблему понимания естественного языка и
кратко рассматриваются вычислительные средства ее решения. Хотя основное внимание
будет уделено вопросам понимания текста, разработка систем понимания и генерации
речи тоже сопряжена с решением этих проблем, а также с дополнительными
сложностями, связанными с распознаванием и выделением слов из контекста.
В первых системах искусственного интеллекта разработчики старались ограничить
предметную область системы (поскольку для успешной работы системы требуется
знание предметной области) и создавали приложения, работающие в минимальной
предметной области. К числу таких систем относится SHRDLU [Winograd, 1972], которая
могла работать с блоками различной формы и цвета и с помощью "руки" перемещать
указанный блок (рис. 13.1).
Система SHRDLU могла отвечать на заданные на английском языке вопросы типа
"Что находится на красном блоке?" или выполнять запросы вида "Поместите зеленую
пирамиду на красный брусок". Она понимала местоимения, например, могла обработать
запрос: "Есть ли здесь красный блок? Подними его". Она даже понимала эллипсис, в
частности "Какого цвета блок находится на синем бруске? Какой формы?". Поскольку мир
блоков очень прост, то система была снабжена полной базой знаний о нем.
Взаимодействие с этим "миром" не требует знания таких общих понятий, как время, возможности,
убеждения и разработки приемов представления этих знаний. Благодаря ограниченности
предметной области в системе SHRDLU достигнута интеграция синтаксиса и семантики.
Ее пример доказывает, что при достаточных знаниях о предметной области
компьютерная система может эффективно работать с естественным языком.
Рис. 13.1. "Мир" блоков
Глава 13. Понимание естественного языка
563
Помимо хорошего знания предметной области система понимания языка должна
моделировать шаблоны и предположения самого языка. Мощным средством для такого
моделирования являются марковские цепи (Markov Chain). Например, в языковых конструкциях
предлоги и прилагательные обычно стоят перед существительными, а не наоборот.
Марковские модели также могут отражать взаимодействия между принципами построения
языковых конструкций и реальным миром, для описания которого они предназначены.
В разделе 13.1 представлен символьный подход к пониманию языка. Раздел 13.2
посвящен синтаксическому анализу, в разделе 13.3 рассматриваются вопросы
моделирования синтаксиса и семантики. В разделе 13.4 представлен стохастический подход к
выявлению закономерностей в языковых выражениях. И наконец в разделе 13.5
рассматриваются несколько приложений для систем понимания естественного языка: ответы на
вопросы, получение информации из базы данных, выполнение Web-запросов и анализ
текстовой информации.
13.1. Разбор языка: символьный анализ
13.1.1. Введение
Язык — это сложный феномен, понимание которого включает такие разнообразные
процессы, как распознавание звуков и печатных букв, синтаксический разбор, вывод се-
мантик высокого уровня и даже учет эмоционального контекста, передаваемого с
помощью ритма и интонации. Для управления этой сложностью лингвисты определили
различные уровни анализа естественного языка.
1. Просодия (prosody), к которой относятся анализ ритма и интонации языка. Этот
уровень анализа достаточно сложно формализуем, поэтому им зачастую
пренебрегают. Однако его значение очевидно. Сила ритма и интонации наиболее ярко
проявляется в поэзии и религиозных песнопениях. Ритмика языка играет важную роль
также в детских играх и колыбельных.
2. Фонология (phonology) — наука о звуках и их комбинациях в языковых структурах.
Эта область лингвистики играет важную роль в компьютерном распознавании и
генерации речи.
3. Морфология (morphology) — анализ компонентов (морфем), из которых состоят
слова. К этой области относятся вопросы правил формирования слов, в том числе
использования префиксов (в английском языке ип-, поп-, anti- и др.) и суффиксов (-
ing, -ly и др.) для модификации значения корня слова. Морфологический анализ
играет важную роль в определении значения слова в предложении, в том числе
времени глагола, числа и части речи.
4. Синтаксический анализ (syntax) связан с изучением правил сочетания слов в
отдельных фразах и предложениях, а также использованием этих правил для разбора
и генерации предложений. Эта область наиболее формализована, и поэтому
успешно применяется для автоматизации лингвистического анализа.
5. Семантика (semantics) изучает значение слов, фраз и предложений, а также
способы его передачи в выражениях естественного языка.
6. Прагматика (pragmatics) — наука о способах использования языка и его
воздействии на слушателя. Например, с помощью прагматики можно объяснить, почему
564 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
слово "Да" является неудовлетворительным ответом на вопрос "Знаете ли вы,
который час?".
7. Знания об окружающем мире (world knowledge) — это сведения о реальном
физическом мире, в котором мы живем, мире человеческих социальных
взаимоотношений, а также значении целей и стараний в общении людей. Эти общие базовые
знания играют важную роль для полного понимания значения текста или беседы.
Эти уровни анализа кажутся достаточно естественными и подтверждаются с точки
зрения психологии, однако не дают полного представления о языке. Они все тесно
связаны между собой, и даже низкоуровневые изменения интонации и ритма могут полностью
изменить значение слова. Примером этому является сарказм. Для синтаксиса и
семантики такая взаимосвязь очевидна, и хотя между этими понятиями проводится четкая линия,
на самом деле эту границу сложно охарактеризовать. Например, предложение "Они едят
яблоки" можно интерпретировать по-разному в зависимости от контекста. Синтаксис
тоже оказывает сильное влияние на семантику, что подтверждается важным значением
структуры словосочетаний при интерпретации предложений.
Несмотря на то что природа различий синтаксиса и семантики является предметом
ожесточенных споров, эти различия сохраняются и играют важную роль в понимании
естественного языка. Эти глубинные вопросы будут также рассмотрены в главе 16.
13.1.2. Стадии анализа языка
Конкретная структура программ понимания естественного языка варьируется в
зависимости от используемой идеологии и целей приложения. Проблема понимания языка может
возникать при реализации интерфейса с базой данных, системы автоматического перевода,
программы интерактивного обучения и др. Во всех этих системах исходное предложение
необходимо привести к внутреннему представлению, отражающему его значение.
Основные стадии решения задачи понимания естественного языка показаны на рис. 13.2
Первая стадия — это синтаксический разбор (parsing), т.е. анализ синтаксической
структуры. В процессе синтаксического разбора проверяется, корректно ли сформировано
предложение, и определяется его лингвистическая структура. За счет идентификации таких
основных лингвистических отношений, как подлежащее-сказуемое, сказуемое-дополнение, в
процессе синтаксического разбора строится базис для семантической интерпретации. Результаты
анализа зачастую представляются в виде дерева разбора (parse tree). В синтаксическом
анализаторе используются знания синтаксиса языка, морфологии и, частично, семантики.
Вторая стадия — это семантическая интерпретация (semantic interpretation), в
результате которой формируется представление содержания текста. На рис. 13.2 этот
процесс показан в виде концептуального графа. К другим наиболее часто используемым
представлениям относятся концептуальные зависимости, фреймы и логические
представления. В процессе семантической интерпретации используются знания о значении
слов и лингвистической структуре, в том числе синонимы существительных или
глаголов. На рис. 13.2 показано, что в программе используется знание значения слова /ess
(целовать) для добавления в качестве используемого по умолчанию инструмента
значения lips (губы). На этой стадии также выполняется проверка семантической
согласованности. Например, определение глагола kiss может включать ограничения, связанные с
тем, что человек может целовать только человека, т.е. Тарзан целует Джейн и (обычно)
не целует обезьяну Читу.
Глава 13. Понимание естественного языка
565
Входные данные: Tarzan kissed Jane
Синтаксический разбор
Дерево грам- sentence
матического ^
разбора:
noun phrase
noun
Tarzan
verb
kissed
noun phrase
I
noun
Jane
Семантическая интерпретация
Внутреннее представление:
person: tarzan
person: jane
Интерпретация знаний об
окружающем мире
Расширенное представление:
possess
pet: cheetah
Передать в блок генерации
ответов, обработчику
запросов к базе данных,
транслятору и т.д.
Рис. 13.2. Стадии создания внутреннего представления предложения
На третьей стадии структуры из базы знаний добавляются к внутреннему
представлению предложения для формирования расширенного представления значения
предложения. Для полного понимания предложения требуются знания о реальном мире, в том
числе знание того факта, что Тарзан любит Джейн, Джейн и Тарзан живут в джунглях и
обезьяна Чита — это друг Тарзана. Эта окончательная структура представляет значение
текста и используется системой для дальнейшей его обработки.
Например, в интерфейсе с базой данных эта расширенная структура используется для
формирования представления запроса с учетом организации базы данных. Затем этот
запрос может быть преобразован в соответствующий запрос на языке управления базами
данных (подраздел 13.5.2). В обучающих программах эта расширенная структура может
представлять содержимое материала и использоваться для ответов на вопрос по
заданной теме (см. обсуждение сценариев в главе 6 и подраздел 13.5.3).
Эти стадии присутствуют во всех системах, хотя могут быть по-разному реализованы
в виде программных модулей. Например, во многих программах дерево разбора не
строится в явном виде. Вместо этого напрямую генерируется внутреннее семантическое
представление. Тем не менее оно неявно участвует в разборе предложения.
Инкрементальный синтаксический разбор (incremental parsing) [Allen, 1987] — это типичный при-
566 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
ем, в рамках которого фрагмент внутреннего представления формируется при разборе
каждой существенной части предложения. Объединение таких фрагментов составляет
полную структуру предложения, которая зачастую используется для устранения
двусмысленностей и общего руководства действиями синтаксического анализатора.
13.2. Синтаксический анализ
13.2.1. Спецификация и синтаксический анализ с использованием
контекстно-свободных грамматик
В главах 3 и 14 вводится понятие правил вывода (rewrite rule), используемых для
определения грамматики. Перечисленные ниже правила определяют грамматику для
простых транзитивных предложений типа "Человек любит собаку". Для удобства эти
правила перенумерованы.
1. sentence<r^noun_phrase verbjphrase
2. noun_phrase<r^noun
3. noun_phrase<r^article noun
4. verb_phrase<r^verb
5. verb_phrase<r^verb noun_phrase
6. arf/c/e<->a
7. arf/c/e<->the
8. noL/n<->man
9. noL/n<->dog
10. verb<->likes
11. verb<->bites
В правой части правил 6-11 содержатся английские слова. Эти правила формируют
словарь доступных слов, которые могут появляться в предложении. Эти слова являются
терминалами (terminal) грамматики и определяют лексикон (lexicon). Термины,
определяющие лингвистические понятия более высокого уровня (sentence, noun_phrase),
называются нетерминальными и выделяются стилем формул. Заметим, что терминалы не
встречаются в левой части правил.
Корректное предложение — эта любая строка терминалов, которую можно разделить
на части с помощью этих правил. Трансформация начинается с нетерминального
символа sentence и в результате серии последовательных подстановок, определенных
правилами грамматики, приводит к формированию строки терминалов. Корректная
подстановка — это замена символа, соответствующего левой части правила, символом из
правой части этого правила. На промежуточных стадиях вывода строки могут включать как
терминалы, так и нетерминальные выражения. Такое представление называется
сентенциальной формой (sentential form). Трансформация предложения "The man bites the dog"
выглядит следующим образом (табл. 13.1).
Глава 13. Понимание естественного языка
567
Таблица 13.1. Трансформация предложения
Строка Применяемое правило
Sentence 1
nounjDhrase verb_phrase 3
article noun verbjphrase 7
The noun verbjphrase 8
The man verbjDhrase 5
The man verb nounjDhrase 11
The man bites nounjDhrase 3
The man bites article noun 7
The man bites the noun 9
The man bites the dog
Это пример трансформации сверху вниз (top-down derivation). Она начинается с
символа sentence и завершается строкой терминалов. Трансформация снизу вверх
начинается со строки терминалов, включает замену элементов правой части правила
соответствующими элементами из левой части и завершается символом sentence.
Трансформацию можно представить в виде дерева, получившего название дерева
грамматического разбора (parse tree), в котором каждый узел — это символ из набора
правил грамматики. Внутренние узлы дерева — нетерминальные. Каждый узел и его
потомки — это левая и правая части некоторого правила грамматики соответственно.
Листовые узлы — это терминалы, а символ sentence — корень дерева. Дерево разбора для
предложения 4The man bites the dog" показано на рис. 13.3.
Существование трансформации или дерева разбора не только доказывает
корректность предложения с точки зрения грамматики, но и определяет его структуру.
Фразовая структура грамматики (phrase structure) определяет глубинную лингвистическую
организацию языка. Например, разделение предложения на глагольную и именную
конструкции (фразы) определяет отношение между действием и его агентом. Такая
фразовая структура играет ключевую роль в семантической интерпретации, поскольку
определяет промежуточные стадии трансформации, на которых может выполняться
семантическая обработка.
Разбор предложений — это задача построения трансформации или дерева
грамматического разбора для входной строки на основе формального определения грамматики.
Алгоритмы грамматического разбора делятся на два класса: анализаторы сверху вниз
(top-down parser), которые начинают свою работу с высокоуровневого символа sentence
и строят дерево, листья которого составляют целевое предложение, и анализаторы снизу
вверх (down-top parser), работа которых начинается со слов предложения (терминалов), и
в результате последовательных операций формируется символ sentence.
Основная трудность решения задачи грамматического разбора состоит в выборе из
существующего набора правила, которое следует использовать на каждом шаге
трансформации. При неправильном выборе анализатор может не распознать корректно
предложение. Например, при разборе предложения 'The dog bites" методом снизу вверх в
результате применения правил 7, 9 и 11 будет получена строка article noun verb. После
этого ошибочное применение правила 2 генерирует строку article nounjjrhase verb,
которую нельзя привести к символу sentence. На самом деле анализатор должен
использовать правило 3. Аналогичные проблемы возникают и при разборе сверху вниз.
568 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
sentence
nounphrase verb_phrase
article noun verb noun_phrase
article noun
The man bites the dog
Рис 13 3 Дерево грамматического разбора
для предложения "The man bites the dog "
Проблема выбора корректного правила на каждой стадии грамматического разбора
решается за счет установки возвратных указателей и обратного перехода к исходной ситуации при
некорректном выборе правила (подобно тому, как это происходит в рекурсивных
анализаторах спуска, описанных в разделе 14 9) или предварительной проверки исходной строки на
предмет наличия свойств, позволяющих определить выбор применяемых правил.
Обратная задача — это задача генерации (generation), или формирования, корректных
предложений на основе внутреннего семантического представления. Генерация
начинается с представления некоторого осмысленного содержимого (в частности,
семантической сети или графа концептуальных зависимостей) и состоит в построении
грамматически корректного предложения, отражающего этот смысл. Однако генерация — это не
просто задача, обратная пониманию. При ее решении возникают отдельные сложности,
для устранения которых требуются специальные методологии.
Поскольку грамматический разбор играет особо важную роль в обработке не только
естественных, но и программных языков, ученые разработали многочисленные
алгоритмы такого анализа. Они включают стратегии обработки информации снизу вверх и
сверху вниз. Полный обзор алгоритмов грамматического анализа выходит за рамки этой
главы, однако мы остановимся на принципах работы анализаторов на основе сети
переходов (transition network). Сети переходов не обладают достаточной мощностью для
анализа естественных языков, но они были положены в основу расширенных сетей
переходов (augmented transition network), которые зарекомендовали себя как полезные и
мощные средства работы с естественным языком.
13.2.2. Анализаторы на основе сети переходов
Анализатор на основе сети переходов представляет грамматику в виде набора конечных
автоматов или сетей переходов. Каждая сеть соответствует одному нетерминальному
элементу грамматики. Дуги в таких сетях помечены терминальными или нетерминальными
символами. Все пути в такой сети, ведущие от начального состояния к конечному,
соответствуют некоторому правилу для нетерминальных элементов. Последовательность меток дуг
такого пути — это последовательность символов в правой части правила. Грамматика,
рассмотренная в подразделе 13.2.1, может быть описана с помощью сетей переходов,
показанных на рис. 13.4. Если грамматика содержит несколько правил для нетерминальных
элементов, то в соответствующей сети содержится несколько путей от начала к цели.
Например, правила noun_phrase^>noun и noun_phrase^>article noun изображаются в виде
различных путей в сети noun_phrase на рис. 13.4.
Глава 13. Понимание естественного языка
569
Рис. 13.4. Определение сети переходов простой грамматики
английского языка
Поиск успешного перехода в сети для нетерминального элемента состоит в замене
этого элемента содержимым правой части грамматического правила. Например, для
разбора предложения анализатор должен найти переход в сети предложения sentence. Он
начинается с исходного состояния (S;„;,;rt/), включает переход noun_phrase, затем
переход verbphrase и завершается в конечном состоянии Sfmai. Этот процесс эквивалентен
замене исходного символа sentence парой символов noun_phrase и verb_phrase.
Для прохода по дуге анализатор проверяет ее метку. Если метка представляет собой
терминальный символ, анализатор проверяет входной поток и определяет, соответствует
ли следующее слово метке дуги. Если оно не соответствует, переход не совершается.
Если дуга помечена нетерминальным символом, анализатор рекурсивно переходит к сети
для этого нетерминального символа и пытается найти путь в этой сети. Если путь не
обнаружен, то проход по дуге верхнего уровня невозможен. В этом случае анализатор
возвращается к исходной сети и проверяет следующий путь. Так анализатор пытается найти
путь в сети sentence. Если такой путь существует, значит, входная строка представляет
собой корректное предложение в данной грамматике.
Рассмотрим простое предложение "Dog bites" ("Собака кусается"). Первые шаги
разбора этого предложения показаны на рис. 13.5.
570 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
verb_phrase
final
8 Вызвать
1Ть 7. Вернуть \ \ verb_phrase
Phrase success \
2 Вызвать
article /
ss 4. Вызвать 6. Вернуть
3 Путь 4\noun success
не найден Vx
5 Считать "dog" из
входного потока
Рис. 13 5 Анализ предложения "Dog bites" с помощью сети переходов
1. Анализатор начинает свою работу с сети sentence и пытается совершить переход
по дуге с меткой nounjDhrase. Для этого он переходит к сети nounjDhrase.
2. В сети nounphrase анализатор сначала пытается совершить переход по дуге
article. Для этого он переходит к сети article.
3. В сети article нельзя найти путь к конечному узлу, поскольку ни одна из дуг не
помечена первым словом предложения <kdog". В результате безуспешной попытки
поиска пути анализатор возвращается к сети nounjDhrase.
4. Анализатор пытается пройти по дуге noun в сети nounjDhrase и переходит к
сети noun.
5. Проход по дуге с меткой "dog" завершается успешно, а именно она соответствует
первому слову входного потока.
6. Результат поиска в сети noun положителен. Это значит, что дуга с меткой noun в
сети nounjDhrase ведет к конечному состоянию.
7. Сеть noun_phrase возвращает успешный результат сети самого верхнего уровня,
разрешая переход по дуге nounjDhrase.
8. Аналогичная последовательность шагов приводит к разбору части предложения
verb phrase.
Ниже приведен псевдокод работы анализатора на основе сети переходов. Этот анализатор
определен с помощью двух взаимно рекурсивных функций parse и transition.
Аргументом функции parse является символ грамматики. Если это терминальный символ, то
функция parse сверяет его со следующим словом входного потока. Если он нетерминальный,
Глава 13. Понимание естественного языка
571
функция parse следует к сети переходов, связанной с этим символом, и вызывает функцию
transition для поиска пути в этой сети. Функция transition в качестве параметра
использует состояние сети переходов и пытается найти путь в этой сети с помощью метода
поиска в глубину. Для разбора предложения вызывается функция parse (sentence).
function parse(символ_грамматики);
begin
сохранить указатель на текущую позицию во входном потоке;
case
символ_грамматики является терминальным:
if символ_грамматики соответствует следующему слову во
входном потоке
then return(success)
else begin
переустановить входной поток;
return(failure)
end;
символ_грамматики является нетерминальным:
begin
перейти к сети переходов, соответствующей символу
грамматики;
состояние:^начальное состояние сети;
if transition(состояние) возвращает success
then return(success)
else begin
переустановить входной поток;
return(failure)
end
end;
end
end.
function transition(текущее_состояние) ;
begin
case
текущее_состояние - это конечное состояние:
return(success)
текущее_состояние - это не конечное состояние:
while существуют непроверенные переходы из текущего
состояния
do begin
символ_грамматики: = метка следующего непроверенного
перехода;
if parse(символ_грамматики) возвращает success
then begin
следующее_состояние:^состояние в конце
перехода;
if transition(следующее_состояние)
возвращает success
then return(success)
end
end
572 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
return(failure)
end
end.
Поскольку анализатор может совершить ошибку и должен возвратиться к исходному
состоянию, функция parse сохраняет указатель на текущую позицию во входном
потоке, позволяя переустановить входной поток в эту позицию в случае возврата анализатора.
Такой анализатор на основе сети переходов может определить корректность
предложения, но не может построить дерево грамматического разбора. Для решения этой задачи
необходимо построить функцию, возвращающую поддерево дерева разбора, а не просто
символ success. Для этого процедуру анализа нужно модифицировать следующим образом.
1. При каждом вызове функции parse, параметром которой является терминальный
символ, соответствующий следующему символу входного потока, она должна
возвращать дерево, состоящее из одного листового узла, помеченного этим символом.
2. Если функция parse вызывается для нетерминального значения параметра
символ_грамматики, она вызывает функцию transition. При успешном
завершении функции transition она возвращает упорядоченный набор поддеревьев
(который будет описан ниже). Функция parse строит на их основе дерево, корнем
которого является символ_грамматики, а дочерними элементами— поддеревья,
возвращаемые функцией transition.
3. При поиске пути в сети функция transition вызывает функцию parse для
метки каждой дуги. При успешном завершении функция parse возвращает
дерево, являющееся результатом разбора соответствующего символа. Функция
transition сохраняет эти поддеревья в виде упорядоченного набора и при
нахождении пути в сети возвращает упорядоченный набор деревьев разбора,
соответствующий последовательности меток дуг этого пути.
13.2.3. Иерархия Хомского и контекстно-зависимые грамматики
В подразделе 13 2.1 была определена малая часть правил английского языка на
основе контекстно-независимой грамматики (context-free grammar). В такой грамматике в
левой части правил может содержаться только по одному нетерминальному символу.
Следовательно, правило можно применять к любому вхождению этого символа,
независимо от контекста. Хотя контекстно-независимые грамматики зарекомендовали себя как
мощное средство определения языков программирования и других формализмов в
компьютерных науках, есть основания считать, что сами по себе они недостаточно
эффективны для представления правил построения естественного языка. Например,
рассмотрим, что произойдет, если добавить к описанной в подразделе 13.2.1 грамматике
существительные и глаголы не только в единственном, но и во множественном числе:
поип<г^теп,
noun<->dogs,
i/erb<->bite,
\/erb<-> I ike.
С помощью полученной грамматики можно осуществлять грамматический разбор
предложений вида 'The dogs like the men" и "A men likes a dogs", в которых артикли и
множественное число употребляются некорректно Анализатор допускает такие предло-
Глава 13. Понимание естественного языка
573
жения, поскольку существующие правила не используют контекст для координации
применимости единственного и множественного числа. Например, правило,
определяющее предложение sentence как именную конструкцию noun_phrase, за которой
следует глагольная verb_phrase4 не требует согласованности числа существительного и
глагола. Та же проблема согласованности возникает при использовании артиклей.
Языки, определяемые контекстно-независимыми грамматиками, составляют лишь один из
классов иерархии формальных языков. Такая иерархия называется иерархией Хомского
(Chomsky hierarchy) [Hopcroft и Ullman, 1979], [Chomsky, 1965]. На нижнем уровне этой
иерархии находится класс регулярных языков (regular language). Регулярным называется язык,
грамматика которого может быть определена с использованием конечных автоматов. Хотя
регулярные языки активно используются в компьютерных науках, они недостаточно
эффективны для представления синтаксиса большинства языков программирования.
Контекстно-независимые языки (context-free language) в иерархии Хомского
расположены на уровень выше регулярных языков. Они определяются с помощью правил
вывода (подраздел 13.2.1). В левой части контекстно-независимых правил может
располагаться только один нетерминальный символ. Класс контекстно-независимых языков
можно анализировать с помощью сетей переходов. Интересно отметить, что если в
анализаторе на основе сетей переходов не допускать рекурсии (т.е. дуги помечать только
терминальными символами, не приводящими к "вызову" другой сети), то класс таких
языков будет соответствовать множеству регулярных выражений. Таким образом,
регулярные языки — это строгое подмножество контекстно-независимых языков.
Контекстно-зависимые языки (context-sensitive language) составляют строгое
супермножество контекстно-независимых языков. Они определяются с помощью контекстно-
зависимых грамматик, которые допускают использование нескольких символов в левой
части правила для определения контекста применения этого правила. Таким образом,
гарантируются глобальные ограничения, в частности, согласованность единственного и
множественного числа. Единственным ограничением для правил контекстно-зависимой грамматики
является непревышение правой части правила размера его левой части [Hopcroft и Ullman, 1979].
Четвертым классом, составляющим супермножество контекстно-зависимых языков,
является класс рекурсивно-перечислимых языков (recursively enumerable language). Такие
языки определяются с помощью неограниченных продукционных правил. Поскольку эти
правила не такие жесткие, как контекстно-зависимые, класс рекурсивно-перечислимых
языков является строгим супермножеством контекстно-зависимых языков. Этот класс не
представляет интереса для определения синтаксиса естественного языка, хотя тоже
играет важную роль в теории компьютерных наук. Остальная часть этой главы будет
посвящена анализу английского языка, как относящегося к классу контекстно-зависимых.
Простая контекстно-независимая грамматика для предложений вида article noun verb
(артикль существительное глагол), в которых согласовано единственное и
множественное число артиклей и существительных, а также существительных и глаголов, имеет вид
sentence<r+noun_phrase verb_phrase,
noun_phrase<r+article number noun,
noun_phrase<r+number noun,
number<r^singular,
numbers plural,
article singular<r+a singular,
article singular<r^tbe singular,
article p/ura/<->some plural,
article p/ura/<->the plural,
574 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
singular noun<->man singular,
singular noun<->dog singular,
plural noun<->men plural,
plural noun<r^6ogs plural,
singular verb_phrase<^singular verb,
plural verb _phrase<^>plural verb,
singular verb^likes,
singular verb^bites,
plural verb^like,
plural verb^bite.
В этой грамматике нетерминальные символы singular и plural обеспечивают
ограничения при определении правил применения различных артиклей, существительных и
глагольных конструкций с целью согласования форм единственного и множественного
числа. Трансформация предложения "The dogs bite" с использованием этой грамматики
выполняется следующим образом.
sentence.
nounjphrase verb_phrase.
article plural noun verb phrase.
The plural noun verb_phrase.
The dogs plural verbjphrase.
The dogs plural verb.
The dogs bite.
Аналогично контекстно-зависимую грамматику можно использовать для проверки
выполнения синтаксических соглашений. Например, добавив к данной грамматике нетерминальный
символ actofjbiting, можно запретить использование предложений вида "Man bites dog"
(человек кусает собаку). Этот нетерминальный символ можно использовать для
предотвращения построения предложений, в которых действие bites выполняет существительное man.
Контекстно-зависимые грамматики позволяют определять языковые структуры, не
охваченные контекстно-независимыми грамматиками, но их практическое применение при
создании анализаторов сопряжено с некоторыми сложностями следующего характера.
1. При использовании контекстно-зависимых грамматик резко возрастает количество
правил и нетерминальных символов. Представьте себе сложность контекстно-
зависимой грамматики, необходимой для описания форм числа (единственного и
множественного) и лица (первого, второго и третьего), а также всех остальных
форм соглашений, принятых в английском языке.
2. В контекстно-зависимых грамматиках размывается структура фраз языка, столь
ясно представимая с помощью контекстно-независимых правил.
3. При попытке описать более сложные соглашения и обеспечить семантическую
согласованность самой грамматики теряются многие преимущества разделения
синтаксического и семантического компонентов языка.
4. Контекстно-зависимые грамматики не решают проблемы построения
семантического представления значения текста. Анализатор, который просто принимает или
отвергает предложение, никому не нужен. Он должен возвращать эффективное
представление семантического значения предложений.
В следующем разделе будут рассмотрены расширенные сети переходов ATN
(augmented transition network), с помощью которых можно определять контекстно-
Глава 13. Понимание естественного языка
575
зависимые языки. Такой способ представления обладает некоторыми преимуществами
по сравнению с контекстно-зависимыми грамматиками при разработке анализаторов.
13.3. Синтаксис и знания в ATN-анализаторах
Альтернативой для контекстно-зависимых грамматик является сохранение простой
структуры правил контекстно-независимой грамматики и расширение этих правил за счет
добавления процедур, выполняющих необходимые контекстуальные проверки. Такие процедуры
выполняются при использовании правила в процессе анализа. Вместо использования
грамматики для представления таких понятий, как формы единственного и множественного числа,
времена глаголов, одушевленные и неодушевленные предметы, их можно представлять с
помощью средств (feature), связанных с терминальными и нетерминальными символами
грамматики. Связанные с правилами грамматики процедуры обращаются к этим средствам для
присвоения значений и выполнения необходимых проверок. К грамматикам, использующим
расширения контекстно-независимых грамматик для реализации контекстной зависимости,
относятся расширенные грамматики фразовой структуры (augmented phrase structure)
[Heidorn, 1975], [Sowa, 1974], расширения логичеекга грамматик (augmentation of logic
grammar) [Allen, 1987] и расширенные сети переходов ATN (augmented transition network).
Этот раздел посвящен ATN-анализу и вопросам разработки простых ATN-анализаторов
для предложений из "мира собак", о которых шла речь в подразделе 13.2.1. Будут
выполнены первые два шага процедуры, проиллюстрированной на рис. 13.2: создание дерева
разбора и его использование для построения представления смысла предложения. В этом
примере будут использованы концептуальные графы, хотя ATN-анализаторы можно также
строить на основе сценариев, фреймов и логических представлений.
13.3.1. Анализаторы на основе расширенных сетей переходов
Расширенные сети переходов усиливают возможности обычных сетей за счет
добавления процедур, связанных с дугами сети. Эти процедуры выполняются ATN-анализатором
при проходе соответствующих дуг. Процедуры могут присваивать значения и выполнять
проверки, приводящие к запрещению перехода при несоблюдении заданных условий
(например, соглашений об использовании форм единственного и множественного числа).
С помощью этих процедур также можно строить дерево разбора, применяемое для
генерации внутреннего семантического представления смысла предложения.
Процедуры могут связываться как с терминальными, так и нетерминальными
символами (в том числе verb, noun_phrase). Например, слово можно описывать с
использованием его морфологического корня, а с помощью процедуры задавать часть речи,
единственное или множественное число, лицо и т.д. Нетерминальные символы грамматики
описываются аналогично. Именная конструкция описывается артиклем,
существительным, его числом и лицом. Как терминальные, так и нетерминальные символы можно
представить с помощью фреймоподобной структуры с именами ячеек и их значениями.
Значения этих ячеек могут задавать процедуры или указатели на другие структуры. На-
г/шмер, первая ячейка фрейма предложения может содержать указатель на определение
именной конструкции. На рис. 13.6 показаны фреймы для нетерминальных символов
sentence, nounphrase и verbphrase в описанной выше простой грамматике.
Отдельные слова представляются с помощью аналогичных структур. Каждое слово в
словаре определяется фреймом, в котором указано, к какой части речи оно относится,
576 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
морфологический корень и существенные грамматические свойства. В нашем примере
необходимо проверять только соответствие форм единственного и множественного
числа. В более сложных грамматиках могут учитываться также лицо и другие свойства.
В этих записях словаря может содержаться определение концептуального графа
значения слова, используемое при семантической интерпретации. Полный словарь
рассматриваемой грамматики показан на рис. 13.7.
Предложение
Noun phrase:
Verb phrase:
Именная конструкция
Determiner:
Noun:
Number:
Глагольная конструкция
Verb:
Number-
Object"
Рис 13.6. Структуры для представления нетерминальных символов
предложения, а также именной и глагольной конструкций
Слово
а
bite
bites
dog
dogs
Определение
PART OF SPEECH, article
ROOT: a
NUMBER: singular
PART_OF_SPEECH:verb
ROOT: bite
NUMBER-plural
PART_OF_SPEECH:verb
ROOT bite
NUMBER: singular
PART_OF_SPEECH:noun
ROOT: dog
NUMBER: singular
PART_OF_SPEECH:noun
ROOT: dog
NUMBER- plural
Слово
like
likes
man
men
the
Определение
PART_OF_SPEECH-verb
ROOT: like
NUMBER: plural
PART_OF_SPEECH-verb
ROOT: like
NUMBER, singular
PART_OF_SPEECH:noun
ROOT man
NUMBER: singular
PART_OF_SPEECH- noun
ROOT: man
NUMBER: plural
PART_OF_SPEECH: article
ROOT: the
NUMBER: plural or singular
Рис. 13.7. Записи словаря для простой ATN-cemu
Глава 13. Понимание естественного языка
577
На рис. 13.8 показана сеть ATN для данной грамматики. С помощью псевдокода описаны
процедуры, выполняемые для каждой дуги. Метками дуг являются как нетерминальные
символы грамматики (как и на рис. 13.4), так и числа, используемые для указания функций,
связанных с каждой дугой. Для прохода дуги эти функции должны быть успешно выполнены.
При обращении к сети нетерминального символа анализатор создает новый фрейм.
Например, при входе в сеть nounphrase создается фрейм noun_phrase. Ячейки
фрейма заполняются функциями для этой сети. Этим ячейкам могут быть присвоены значения
грамматических свойств или указатели на компоненты синтаксической структуры (т.е.
символ verbjDhrase может состоять из символов verb и noun_phrase). При
достижении конечного состояния сеть возвращает полученную структуру.
function sentence-1;
begin
NOUNPHRASE := структура, возвращаемая
сетью noun_phrase,
SENTENCE SUBJECT ■= NOUN_PHRASE;
end
function sentences-
begin
VERB_PHRASE := структура, возвращаемая
сетью verbphrase network;
if NOUN_PHRASE NUMBER =
VERB_PHRASE NUMBER
then begin
SENTENCE VERB_PHRASE := VERB_PHRASE,
return SENTENCE
end
else fail
end.
noun_phrase: function noun_phrase-1,
begin
ARTICLE = фрейм определения для следующего входного слова;
if ARTICLE PART_OF_SPEECH=article
then NOUN_PHRASE DETERMINER := ARTICLE
else fail
end
3
function noun_phrase-2;
begin
NOUN .= фрейм определения для следующего входного слова;
if NOUN PART_OF_SPEECH=cyщecтвитeльнoe и
NOUN NUMBER согласуется с
NOUN_PHRASE DETERMINER NUMBER
then begin
NOUN_PHRASE NOUN .= NOUN,
NOUN_PHRASE.NUMBER .= NOUN.NUMBER
return NOUN_PHRASE
end
else fail
end.
Рис 13.8. ATN-грамматика для проверки соответствия числа и построения дерева разбора
sentence:
noun_phrase^~ verbphrase
578 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
function noun_phrase-3
begin
NOUN := фрейм определения для следующего входного слова;
if NOUN PART_OF_SPEECH= существительное
then begin
NOUN_PHRASE.DETERMINER := unspecified;
NOUN_PHRASE.NOUN := NOUN
NOUN_PHRASE.NUMBER := NOUN.NUMBER
end
else fail
end
function verb_phrase-1
begin
VERB := фрейм определения для следующего входного слова;
if VERB.PART_OF_SPEECH=verb
then begin
VERB_PHRASE.VERB := VERB;
VERB_PHRASE.NUMBER:=VERB.NUMBER;
end;
end.
function verb_phrase-2
begin
NOUN_PHRASE := структура, возвращаемая сетью
noun_phrase;
VERB_PHRASE.OBJECT .= NOUN_PHRASE;
return VERB_PHRASE
end.
function verb_phrase-3
begin
VERB := фрейм определения для следующего входного слова;
if VERB PART_OF_SPEECH=verb
then begin
VERB_PHRASE.VERB := VERB;
VERB_PHRASE.NUMBER:=VERB.NUMBER;
VERB_PHRASE.OBJECT := unspecified;
return VERB_PH RASE;
end,
end.
При проходе дуг с метками noun, article и verb считывается следующее слово из
входного потока и извлекается его определение из словаря. Если это слово относится к
несоответствующей части речи, переход по дуге не совершается. В противном случае
возвращается фрейм определения.
На рис. 13.8 фреймы и ячейки обозначены идентификатором ФРЕЙМ.ЯЧЕЙКА, в
частности ячейка числа фрейма глагола обозначена VERB.NUMBER. В процессе разбора
каждая функция строит и возвращает фрейм, описывающий соответствующую
синтаксическую структуру. В этой структуре содержатся указатели на структуры, возвращаемые
сетями более низкого уровня. Функция самого высокого уровня (уровня предложения)
возвращает структуру sentence, представляющую дерево разбора входного потока. Эта
структура передается семантическому интерпретатору. На рис. 13.9 показано дерево
грамматического разбора, возвращаемое для предложения "The dog likes man".
На следующей стадии обработки естественного языка на основе полученного дерева
разбора (наподобие представленного на рис. 13.9) строится семантическое
представление знаний о предметной области и смысла предложения.
Рис 13.8. (Окончание)
Глава 13. Понимание естественного языка
579
Sentence
Noun_phrase:
Verb_phrase:
Noun_phrase
Determiner:
Noun:
Number: singular
PART_OF_SPEECH:
article
ROOT: the
NUMBER: plural or
singular
Verb_phrase
Verb:
Number: singular
Object:
PART_OF_SPEECH:
noun
ROOT: dog
NUMBER: singular
Noun_phrase
Determiner:
Noun:
Number: singular
PART_OF_SPEECH:
verb
ROOT: like
NUMBER: singular
PART_OF_SPEECH:
article
ROOT: a
NUMBER: singular
PART_OF_SPEECH:
noun
ROOT: man
NUMBER: singular
Рис 13 9 Дерево грамматического разбора для предчожсния "The dog likes man", возвращаемое
А ТЫ -анализатором
13.3.2. Объединение знаний о синтаксисе и семантике
Семантический интерпретатор строит представление значения входной строки,
перемещаясь по дереву грамматического разбора от корневого узла sentence. В каждом узле
он рекурсивно интерпретирует его дочерние узлы и объединяет полученные результаты в
общем концептуальном графе. Например, семантический интерпретатор строит
представление символа verb_phrase, формируя рекурсивные представления дочерних узлов
verb и noun_phrase и объединяя их для представления глагольной конструкции.
Результат передается узлу sentence и объединяется с представлением символа subject.
Рекурсия прекращается при достижении терминальных элементов дерева
разбора. Некоторые из них, в том числе соответствующие существительным,
глаголам и прилагательным, требуют извлечения понятий из базы знаний. Другие, в
частности артикли, не имеют прямого соответствия с понятиями базы знаний, но
определяют другие понятия на графе.
В рассматриваемом примере семантический интерпретатор использует базу
знаний о "мире собак". К понятиям этой базы знаний относятся объекты dog и man, a
также действия like и bite. Эти понятия описываются с помощью иерархии типов,
показанной на рис. 13.10.
580 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
state
A
I animate physobj |
act ^4\^^^
| animal
bite dog person teeth like
Рис. 13.10 Иерархия типов для
примера из "мира собак "
Помимо понятий необходимо определить отношения, которые будут использованы в
концептуальных графах. В нашем примере участвуют следующие понятия.
• Символ agent (агент) связывает понятие act (действие) с понятием типа animate
(одушевленный). Агент определяет отношение между действием и одушевленным
объектом, инициирующим это действие.
• Символ experiencer (носитель состояния) связывает понятие state (состояние) с
понятием типа animate (одушевленный). Он определяет отношение между
психическим состоянием и его носителем.
• Символ instrument (инструмент) связывает понятие act (действие) с понятием entity
(сущность) и определяет инструмент, используемый для выполнения действия.
• Символ object (объект) связывает понятие event (событие) или state (состояние)
с понятием entity (сущность) и представляет отношение "действие-объект".
• Символ part (часть) связывает понятия типа physobj (физический объект) и
определяет отношение между целым и его частью.
При построении интерпретации особо важная роль отводится глаголам, поскольку
они определяют отношения между подлежащим, дополнением и другими компонентами
предложения. Каждый глагол можно представить с помощью падежного фрейма (case
frame), определяющего следующие данные.
1. Лингвистические отношения (агент, объект, инструмент и т.д.), соответствующие
данному глаголу. Например, транзитивные глаголы связаны с объектом, а
нетранзитивные — нет.
2. Ограничения на значения, которые могут присваиваться любому компоненту
падежного фрейма. Например, в падежном фрейме для глагола "bites" утверждается,
что агент должен относиться к типу dog. Тогда предложение "Man bites dog" будет
отклонено как семантически некорректное.
3. Используемые по умолчанию значения компонентов падежного фрейма. Во
фрейме глагола "bites" для понятия, связанного с отношением instrument, по
умолчанию используется значение teeth.
Глава 13. Понимание естественного языка
581
Падежные фреймы для глаголов like и bite показаны на рис. 13.11.
Рис. 13 11 Падежные фреймы для глаголов "like" и "bite"
Определим действия, позволяющие строить семантическое представление правил
или процедур для каждого потенциального узла дерева грамматического разбора. В
нашем примере правила описываются в виде процедур на языке псевдокода. В
каждой процедуре при неуспешном завершении конкретного теста или объединения
данная интерпретация отклоняется как семантически некорректная.
procedure sentence;
begin
вызвать процедуру noun phrase для получения представления
подлежащего;
вызвать процедуру verb_phrase для получения представления
сказуемого с зависимыми словами;
с помощью объединения и ограничения связать понятие
существительного,
возвращаемое для подлежащего, с агентом графа
для глагольной
конструкции
end
procedure noun_phrase;
begin
вызвать процедуру noun для получения представления
существительного;
case
неопределенный артикль и единственное число: понятие,
определяемое существительным, является общим;
определенный артикль и единственное число: связать маркер с
понятием, определяемым существительным;
множественное число: указать, что существительное
во множественном числе
582 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
end case
end.
procedure verb_phrase;
begin
вызвать процедуру verb для получения представления глагола;
if с глаголом связано дополнение
then begin
вызвать процедуру noun_phrase для получения представления
дополнения;
с помощью объединения и ограничения связать понятие,
определяемое дополнением, с дополнением,
соответствующим сказуемому
end
end.
procedure verb;
begin
получить падежный фрейм для глагола
end.
procedure noun;
begin
получить понятие для существительного
end.
Артикли не соответствуют понятиям в базе знаний, но позволяют определить,
каким является понятие, связанное с данным существительным: общим или
конкретным. Представление понятий во множественном числе в книге не рассматривается.
Их обработка с помощью концептуальных графов описывается в [Sowa, 1984].
С помощью этих процедур для иерархии понятий, показанной на рис. 13.10, и
падежных фреймов, представленных на рис. 13.11, можно описать действия
семантического интерпретатора, предпринимаемые для построения семантического
представления предложения "The dogs like a man" на основе дерева грамматического
разбора, изображенного на рис. 13.9. Последовательность этих действий
проиллюстрирована на рис. 13.12.
Числа в скобках в следующем списке соответствуют порядковым номерам на
рис. 13.12.
1. Сначала для узла, соответствующего предложению, вызывается процедура
sentence.
2. Процедура sentence вызывает процедуру noun_phrase.
3. Процедура noun_phrase вызывает процедуру noun.
4. Процедура noun возвращает понятие, связанное с существительным dog A на
рис. 13.12).
5. Поскольку артикль является определенным, процедура noun_phrase связывает
маркер #1 с этим понятием B) и возвращает данное понятие процедуре sentence.
6. Процедура sentence вызывает процедуру verb_phrase.
Глава 13. Понимание естественного языка
583
Рис 13 12. Построение семантического представчения на
основе дерева грамматического разбора
7. Процедура verb_phrase вызывает процедуру verb, позволяющую получить
падежный фрейм для глагола like C).
8. Процедура verb_phrase вызывает процедуру noun_phrase, которая в свою
очередь вызывает процедуру noun для получения понятия, связанного с
существительным man D).
9. Поскольку артикль является неопределенным, процедура noun_phrase
определяет это понятие как общее E).
10. Процедура verb_phrase ограничивает понятие entity в падежной рамке и
объединяет его с понятием, соответствующим существительному man F). Эта
структура возвращается процедуре sentence.
11. Процедура sentence объединяет понятие dog: #1 с узлом experiencer
падежной рамки G).
Полученный концептуальный граф представляет значение предложения.
Генерация языковых конструкций — это связанная задача, решаемая с помощью
программ понимания естественного языка. Генерация английских выражений требует
построения семантически корректного выхода на основе внутреннего представления
значения. Например, отношение agent означает связь подлежащее-сказуемое между двумя
понятиями. С помощью простых подходов соответствующие слова присоединяются к
готовым шаблонам (template) предложений. Эти шаблоны можно рассматривать в качестве
образцов предложений или их фрагментов, в частности, глагольной и именной конструк-
584 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
ций. Выходной результат строится путем прохода по концептуальному графу и
комбинирования этих фрагментов. Более сложные подходы к генерированию языковых
конструкций связаны с использованием грамматик преобразования для отображения значения
в диапазон возможных предложений [Winograd, 1972], [Allen, 1987].
В разделе 13.5 будет описан способ программного построения внутреннего
представления текста на естественном языке. Это представление может быть использовано в
самых различных приложениях, два из которых будут представлены в разделе 13.5. Однако
сначала в разделе 13.4 будут описаны стохастические подходы выявления шаблонов и
общих закономерностей языка.
13.4. Стохастический подход к анализу языка
13.4.1. Введение
В разделе 13.1 был описан принцип понимания языка на основе шаблонов. В
разделах 13.2 и 13.3 отмечалось, что семантические аспекты языка и связанные с ними знания
могут быть представлены фонематическими структурами и описаниями на уровне
предложения. В этом разделе вводятся стохастические модели, поддерживающие на этих же
уровнях анализ структур на основе шаблонов, обеспечивающий понимание языка.
Статистические языковые методы — это приемы, используемые при рассмотрении
естественного языка как случайного процесса. В обыденном смысле случайность
подразумевает отсутствие структуры, определения или понимания. Однако рассмотрение
естественного языка как случайного процесса позволяет обобщить детерминистскую точку
зрения. С помощью статистических (или стохастических) приемов можно с достаточной
степенью точности моделировать как хорошо определенные части языка, так и аспекты,
обладающие некоторой степенью случайности.
Рассмотрение языка как случайного процесса позволяет переопределить многие
основные задачи, связанные с пониманием естественного языка, в более строгом
математическом смысле. Например, в качестве интересного упражнения можно выбрать
несколько предложений из предыдущего абзаца (включая запятые и скобки) и вывести эти
же слова в порядке, заданном генератором случайных чисел. Полученный в результате
текст вряд ли будет осмысленным. Интересно отмстить [Jurafsky и Martin, 2000], что
подобные структурные ограничения действуют на многих уровнях лингвистического
анализа, включая структуры звуков, комбинации фонем, грамматические структуры и т.д.
В качестве примера использования стохастического подхода рассмотрим задачу
определения частей речи.
Большинство людей знакомы с этой задачей со времен изучения грамматики в школе.
Для каждого слова в предложении необходимо определить, к какой части речи оно
относится. Если слово является глаголом, то можно указать его наклонение, а также
переходность. Для существительных нужно определить число. Сложности возникают при
обработке слов типа swing. В выражении "output potential swing" (перепад выходного напряжения)
это слово выступает в роли существительного, а в выражении "swing at the ball" (ударить по
мячу) — в роли глагола. Приведем фразу Пикассо и выделим в ней части речи.
Art is a lie that lets us see the truth.
Сущ. Глагол Артикль Сущ. Мсстоим. Глагол Местоим. Глагол Артикль Сущ.
Глава 13. Понимание естественного языка
585
Для решения задачи опишем ее формально. Пусть имеется множество слов языка
S^{w\, ..., wn], например {a, aardwark, ..., zygote], и множество частей речи или
дескрипторов Sr={fi, ..., tm]. Предложение, состоящее из п слов, — это последовательность
из п случайных величин И/ь И/2, ..., Wn. Эти переменные являются случайными
величинами, поскольку могут принимать любое из значений множества Sw с некоторой
вероятностью. Дескрипторы 7"ь Г2, ..., Тп тоже составляют последовательность случайных
величин. Значение случайной величины Г,- обозначим через th а значение И/, — через wt.
Требуется найти наиболее вероятную последовательность дескрипторов для слов
данного предложения. То есть нужно найти последовательность t\, t2, ...,t„,
максимизирующую значение
PG"i=fi T=tn\W=w, W=wn).
Напомним (раздел 8.3), что запись Р(Х|У) означает вероятность X при условии Y.
Зачастую имена случайных переменных опускают и пишут просто
P(f t„\w IV,). A)
Заметим, что если точно известно распределение вероятности, то за достаточно
длительное время можно максимизировать значение вероятности по всем возможным
наборам дескрипторов и получить оптимальный результат для данной последовательности
слов. Более того, если для каждого предложения существует лишь одна корректная
последовательность дескрипторов, то с помощью данного вероятностного метода ее всегда
можно найти. Вероятность этой последовательности будет составлять 1, а вероятность
всех остальных последовательностей — 0. В этом смысле статистический подход
является обобщением детерминистского.
В реальной жизни из-за ограниченности объема памяти, данных и времени этим
точным методом воспользоваться нельзя и приходится довольствоваться аппроксимациями.
Далее в этом разделе будет рассмотрено несколько способов аппроксимации A) (в
порядке улучшения).
Для начала отметим, что A) можно записать по-другому
P(t, tn\w, wn)=P(tv .... tn% wv .... wn)/P(wv .... wn).
Поскольку максимум этого выражения находится за счет выбора t\, t2,..., tn, его
можно упростить и записать в виде
P(fp .... fn, wv .... wn) =
P(f1)P(iv1|f1)P(f2|riliv1) ...P(tn\w, wnt t, tn ,)= B)
flP(t,\tv ...tt,_vWv ....l/l^FK^, ...,fMl Wv ...,WM)
Заметим, что соотношение B) эквивалентно A).
13.4.2. Подход на основе марковских моделей
На практике (как было указано в разделе 8.3) обычно достаточно сложно
максимизировать вероятностные соотношения, зависящие от многих случайных величин. Именно к
таким соотношениям относится B). Это связано с тремя причинами. Во-первых,
достаточно сложно хранить вероятность случайной величины, обусловленную многими
другими случайными величинами, поскольку число возможных вероятностей
экспоненциально возрастает с ростом количества определяющих факторов. Во-вторых, даже если
586 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
удастся сохранить все значения вероятностей, их достаточно трудно оценить. Оценка
обычно делается эмпирически путем подсчета количества вхождений события в
размеченном вручную обучающем множестве. Если это событие встречается лишь несколько раз, то
оценка его вероятности будет неточной. Таким образом, легче оценить вероятность
P(caf|f/7e), чем P(cat\the dog chased the), поскольку последняя фраза встречается в
обучающем множестве гораздо реже. И, наконец, нахождение цепочки дескрипторов,
максимизирующей структуру вида B), займет очень много времени (это будет показано ниже).
Поэтому сначала найдем некоторую удовлетворительную аппроксимацию B). Введем
два основных предположения:
PUjf, ti,, wy ил.,) соответствует P(f,.|fM)
и
P(w |f1t .... f., 1f wv .... w,,) соответствует P(w | tf].
Эти предположения называются марковскими (Markov assumption), поскольку они
предполагают, что текущее состояние зависит от предыдущих. Подставляя эти
приближения в B), получим
flPit^nw.lt,). C)
Соотношение C) гораздо удобнее с практической точки зрения, поскольку входящие
в него вероятности можно легко оценить и хранить. Напомним, что C) — это лишь
аппроксимация выражения Р(гь .... tn\wu .... wn), которую необходимо максимизировать
путем выбора дескрипторов гь .... tn. К счастью, это можно сделать с помощью
алгоритма динамического программирования, известного под названием алгоритма Витерби
(Viterbi algorithm) [Viterbi, 1967], [Forney, 1973]. Алгоритм Витерби вычисляет
вероятность последовательности дескрипторов г2 для каждого слова в предложении, где г —
число возможных дескрипторов. На данном шаге рассматриваемая последовательность
дескрипторов может быть записана в следующем виде.
article article {best tail]
article verb {best tail)
article noun {best tail)
noun article {best tail]
noun noun {best tail),
где [best tail] — наиболее вероятная последовательность дескрипторов, найденная
динамически для оставшихся п-2 слов и данного дескриптора п-1.
Для каждого возможного значения дескриптора под номером п-1 и дескриптора под
номером п существует своя запись в этой таблице (получается г последовательностей
дескрипторов). На каждом шаге алгоритм находит максимальные вероятности и
добавляет по одному дескриптору к каждой последовательности {best tail}. Этот алгоритм
гарантирует нахождение последовательности дескрипторов, максимизирующей
соотношение C) за время 0(f s), где г — число дескрипторов, s — количество слов в
предложении. Если вероятность Р(г,) обусловлена последними п дескрипторами, а не
последними двумя, то работа алгоритма Витерби завершится за время 0(f'7s). Отсюда видно,
почему зависимость от слишком большого числа предыдущих значений увеличивает время
нахождения максимума.
Глава 13. Понимание естественного языка
587
К счастью, аппроксимация C) является удовлетворительной. Для 200 возможных
дескрипторов и большого обучающего множества, предназначенного для оценки вероятностей, с
помощью этого метода можно расставить дескрипторы с точностью 97%, что сопоставимо с
точностью работы человека. Удивительная точность марковской аппроксимации наряду с ее
простотой делают эту модель пригодной для использования во многих приложениях.
Например, в большинстве систем распознавания речи используются так называемые модели
триграмм (trigram), обеспечивающие некоторые 'грамматические знания" для прогнозирования
слов с учетом уже сказанного. Модель триграмм — это простая марковская модель, в которой
вероятность текущего слова обусловлена двумя предыдущими словами. При работе с такими
моделями используется алгоритм Витерби и другие описанные выше приемы. Более
подробная информация по этому вопросу содержится в [Jurafsky и Martin, 2000].
13.4.3. Подход на основе дерева решений
Очевидной проблемой, возникающей при использовании марковского подхода,
является учет только локального контекста. Если вместо задачи определения частей речи для
слов в предложении требуется определить действующее лицо, объект действия или залог
глаголов, следует учитывать более широкий контекст. Эту проблему можно
проиллюстрировать на примере следующего предложения.
The policy announced in December by the President guarantees lower taxes.
{Политика, провозглашенная в декабре президентом, гарантирует снижение налогов.)
На самом деле действующим лицом в данном случае является President, однако
программа на основе марковской модели, вероятнее всего, назовет действующим лицом
policy, a announced— глаголом в действительном залоге. Естественно, если бы
программа могла задавать вопросы типа "Описывает ли данное существительное
неодушевленный предмет?" или "Встречается ли слово by на несколько слов раньше
рассматриваемого существительного?", то она определила бы действующее лицо гораздо точнее.
Напомним, что задача расстановки дескрипторов эквивалентна максимизации
выражения B), т.е.
ПР^Г,, ...tt,_vwv ...,^м)Р(иф ...,fM. iv, ivM)
Теоретически увеличение контекста позволяет находить более точные оценки
вероятности. При этом для уточнения вероятностей желательно иметь возможность
использовать ответы на приведенные выше грамматические вопросы.
Эту проблему можно решить несколькими путями. Во-первых, марковский подход
можно комбинировать с методами грамматического разбора, описанными в предыдущих
разделах этой главы. Во-вторых, можно находить вероятности, обусловленные ответами
"Да" и "Нет", с помощью алгоритма ЮЗ (который подробно описан в разделе 9.3, а его
реализация на языке LISP — в разделе 15.13) или подобного ему алгоритма. В алгоритме
ID3 среди большого множества вопросов выбираются только те, которые обеспечивают
хорошую оценку вероятности. В более сложных задачах обработки естественного языка,
в том числе в задаче грамматического разбора, деревья решений, на которых
основывается работа алгоритма ID3, оказываются более предпочтительными, чем марковские
модели. Далее будет показано, как использовать алгоритм ID3 для построения дерева
решений в задаче грамматического разбора.
588 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Выше уже упоминался вопрос "Описывает ли данное существительное
неодушевленный предмет?". Подобные вопросы можно задавать только в том случае, если известно,
какие существительные описывают одушевленные или неодушевленные предметы.
На самом деле существует способ автоматического разделения множества слов на эти
классы. Этот прием получил название кластеризации взаимной информации (mutual
information clustering). Взаимная информация, распределенная между двумя случайными
величинами X и V, определяется следующим образом:
Кластеризация взаимной информации для словаря слов начинается с помещения
каждого слова словаря в отдельное множество. На каждом шаге с помощью
диграммы (bigram), т.е. модели следующего слова, вычисляется средняя взаимная
информация между множествами и выбирается разбиение множеств, состоящих из двух
слов, минимизирующее потери средней взаимной информации для всех классов.
Например, пусть изначально существуют слова cat, kitten, run и green. На первом
шаге алгоритма строятся множества
{cat}, {kitten}, {run}, {green}.
Скорее всего, вероятность появления некоторого слова после слова cat примерно
равна вероятности появления этого слова после слова kitten. Другими словами,
P{eats | cat)~P{eats \ kitten),
P{meows| cat) ^P(meows|kitten).
Таким образом, для случайных величин XI, Х2, /1, V2, при которых
X^={{cat}, {kitten}, {run}, {green}},
V1 =слово, следующее за Х1,
X2={{cat, kitten}, {run}, {green}},
У2=слово, следующее за Х2.
Общей информации в Х2 и V2 не намного меньше, чем в XI и VI. Следовательно,
слова cat и kitten с большой вероятностью можно сгруппировать. Если продолжить эту
процедуру до получения комбинаций всех возможных классов, то получится бинарное
дерево. Тогда словам, расположенным в листовых узлах этого дерева, можно присвоить
двоичные коды (bit code), описывающие путь перемещения по дереву до достижения
этого слова. Такие коды отражают семантическое значение слов. Например,
caf=01100011,
kitten=01100010.
Более того, может оказаться, что коды всех слов, "напоминающих существительные",
в качестве крайнего слева бита содержат 1, а третий бит всех неодушевленных
предметов тоже равен 1.
Такая новая кодировка слов словаря позволяет анализатору более эффективно
задавать вопросы. Заметим, что при кластеризации контекст не принимается во внимание,
поэтому слово book (книга) может быть классифицировано как "напоминающее
существительное", хотя в предложении "book a flight" (заказать билет на самолет) его
необходимо рассматривать как глагол.
Глава 13. Понимание естественного языка
589
13.4.4. Грамматический анализ и другие приложения
стохастического подхода
Стохастический подход уже был использован во многих областях компьютерной
лингвистики. Тем не менее его можно применять и в тех сферах, где традиционно
применялся символьный подход.
Использование статистических методов в задачах грамматического разбора впервые
было связано с проблемой неопределенности, возникающей в связи с существованием
нескольких возможных интерпретаций данного предложения и необходимостью выбора
наилучшей. Например, предложение "Print the file on the printer" (Напечатай файл на
принтере) может быть представлено в виде двух деревьев, показанных на рис. 13.13.
Предложение
Глагол
Именная
конструкция
Print
Именная
конструкция
Предложная конструкция
Артикль
Существительное Предлог
Именная
конструкция
the
file
Артикль
Существительное
the
printer
Предложение
Глагольная
конструкция
Глагол
Предложная конструкция
Именная
конструкция
Артикль
Существительное
Print
Предлог
Именная
конструкция
the
file
Артикль
Существительное
б the printer
Рис. 13.13. Два различных представления предложения "Print the file on the printer"
590 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
В подобной ситуации одних правил грамматики для выбора корректного представления
недостаточно. Необходимо учитывать некоторую контекстную и семантическую
информацию. Такую неопределенность можно разрешить с помощью стохастических методов. Для
данного примера можно использовать то же средство, что и для определения частей
речи, — алгоритм ID3. Он позволяет предсказать вероятность корректности разбора на
основе семантических вопросов о данном предложении. Если в предложении существует
некоторая синтаксическая неопределенность, то можно выбрать представление, вероятность
корректности которого максимальна. Обычно для использования этого подхода требуется
иметь обучающее множество предложений с их корректными представлениями.
В последнее время специалисты по статистическому моделированию естественных
языков активизировали свою деятельность и стали применять статистические методы
грамматического разбора без использования грамматики. Хотя принципы работы
анализаторов, не учитывающих грамматику, выходят за рамки данной книги, следует
отметить, что они более близки к системам распознавания образов, чем к традиционным
принципам грамматического разбора, описанным выше в этой главе.
Разбор без учета грамматики дает достаточно хорошие результаты. В экспериментах по
сравнению его эффективности с результатами работы грамматических анализаторов на
одинаковом множестве предложений разбор без учета грамматики обеспечивает 78%
эффективности, а с учетом — 69% [Magerman, 1994]. Эти результаты достаточно хороши, но
их нельзя считать выдающимися. Гораздо важнее другое. Описание грамматики для
традиционного анализатора требует примерно десяти лет педантичной работы грамотного
лингвиста, в то время как анализатор без учета грамматики, не использующий жестко
закодированной лингвистической информации и основанный лишь на сложных математических
моделях, может сам извлекать необходимую информацию из обучающих данных. Более
подробная информация по этому вопросу содержится в [Manning и Schutze, 1999].
Понимание речи, преобразование речи в текстовую информацию и распознавание
рукописного текста — это еще три области, имеющие богатую историю использования
стохастических методов для моделирования языка. В этих областях для прогнозирования
следующего слова чаще всего используется статистический метод на основе модели триграмм.
Эффективность этой модели объясняется ее простотой. С ее помощью можно предсказать
следующее слово по двум предыдущим. В настоящее время специалисты в области
статистической обработки языка стараются сохранить простоту и легкость использования этой
модели при добавлении грамматических ограничений и более долгосрочных зависимостей.
Этот новый подход получил название метода грамматических триграмм (grammatical tri-
gram). Грамматические триграммы содержат информацию об основных связях между
парами слов (такими как подлежащее-сказуемое, артикль-существительное или сказуемое-
дополнение). Совокупность этих ассоциаций образует грамматику связей (link grammar).
Такую грамматику построить гораздо легче, чем традиционную. При этом для нее
достаточно эффективными оказываются вероятностные методы.
В работе [Berger и др., 1994] описана статистическая программа Candide,
осуществляющая перевод французского текста на английский язык. В ней для разработки
вероятностной модели процесса перевода использованы как статистические методы, так и
теория информации. Для ее обучения требуется только большое множество пар
предложений на французском и английском языке. При этом результаты работы программы
сопоставимы (а в некоторых случаях и превосходят их) с результатами коммерческой
программы Systran [Berger и др., 1994]. Интересно отметить, что в процессе перевода
система Candide не выполняет традиционного грамматического разбора. В ней
используются только грамматические триграммы и грамматика связей.
Глава 13. Понимание естественного языка
591
Можно указать несколько областей, в которых стохастические методы
моделирования языка еще не применялись, но могут дать хорошие результаты. К таким областям
относятся задачи извлечения информации или получения определенного количества
конкретной информации из рукописного текста, а также поиск в Web. Статистический
подход к обработке естественных языков более подробно описан в работах [Jurafsky и
Martin, 2000] и [Manning и Schutze, 1999].
13.5. Приложения задачи анализа естественного языка
13.5.1. Обучение и ответы на вопросы
Интересным применением технологии понимания естественного языка является
написание программы, которая может читать рассказ или другой фрагмент текста на естественном
языке и отвечать на вопросы о нем. В главе 6 обсуждались некоторые вопросы представления
знаний, связанные с пониманием текстов, включая важность сочетания базовых знаний с
контекстом выбранного фрагмента. Как видно из рис. 13.2, программа может объединять
семантическое представление входных данных со структурами концептуальных графов в базе
данных. Более сложные представления, в том числе сценарии (подраздел 6.1.4), позволяют
моделировать более сложные ситуации, в том числе зависящие от времени.
После построения расширенного представления текста программа может интеллектуально
отвечать на вопросы о его содержании. Вопрос приводится к внутреннему представлению и
проверяется его соответствие расширенному представлению текста. Рассмотрим пример,
показанный на рис. 13.2. Эта программа может прочесть предложение 'Tarzan kissed Jane"
(Тарзан поцеловал Джейн) и построить его расширенное представление.
Допустим, программе задан вопрос "Who loves Jane?" (Кто любит Джейн?).
Вопросительное слово определяет сущность вопроса. При ответе на вопрос со словом who (кто)
требуется указать агента действия. Вопросы what (что) требуют найти объект действия.
Вопросы how (как) подразумевают определение средств выполнения действия и т.д.
Граф для вопроса "Who loves Jane?" показан на рис. 13.14. Узел агента на этом графе
помечен вопросительным знаком, указывающим на то, что целью вопроса является
определение агента. Затем эта структура объединяется с расширенным представлением
исходного текста. Понятие, связанное с понятием person: ? на графе запроса, дает ответ на
этот вопрос: "Tarzan loves Jane" (Тарзан любит Джейн). В качестве примера реализации
этого подхода можно рассматривать анализатор на основе рекурсивной семантической
сети спуска, реализованный на языке PROLOG и описанный в разделе 14.9.
ч
/ ^
V
'
person: ?
Рис. 13.14. Концептуальный граф для вопроса "Who loves Jane?"
13.5.2. Интерфейс для базы данных
Основным узким местом при разработке программ понимания естественного языка
является получение достаточных знаний о предметной области. Современные техноло-
592 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
гии применяются только для узких предметных областей с хорошо определенной
семантикой. Этому критерию удовлетворяют предложения, связанные с разработкой
интерфейсов для баз данных, понимающих естественный язык. Несмотря на то что в базах
данных обычно хранятся гигантские объемы информации, эта информация имеет
достаточно регулярную структуру и связана с узкой предметной областью. Более того,
семантика баз данных очень хорошо определена. Эти свойства наряду с возможностью
передачи в базу данных запроса на естественном языке делают интерфейс для такой базы
данных важным приложением технологии понимания естественного языка.
Задача такого интерфейса — перевести вопрос с естественного языка в формат
стандартного запроса на языке базы данных. Например, с помощью такого интерфейса
вопрос "Who hired John Smith?" (Кто нанял на работу Джона Смита?) можно перевести в
запрос на языке SQL [Ullman, 1982] следующего вида.
SELECT MANAGER
FROM MANAGER_OF_HIRE
WHERE EMPLOYEE='John Smith'
При выполнении такого преобразования программа должна не просто выполнить
исходный запрос. Ей также необходимо решить, где выполнять поиск в базе данных
(отношение MANAGER_OF_HIRE), выбрать имя поля (MANAGER) и ограничения для
данного запроса (EMPLOYEE^ Л John Smith'). Эта информация не содержится в исходном
вопросе. Ее требуется найти в базе данных на основе сведений об организации этой базы
и понимания содержания вопроса.
В реляционной базе данных (relational database) данные связаны отношениями между
сущностями различных доменов. Предположим, что необходимо построить базу данных
сотрудников, в которой нужно будет находить зарплату каждого сотрудника и
определять, кто принял его на работу. Эта база данных должна состоять из трех доменов
(domain) или наборов сущностей: менеджеров, сотрудников и зарплат. Эти данные
можно связать двумя отношениями: employee_salary, связывающим сотрудника с его
зарплатой, и manager_of_hire, связывающим сотрудника с его менеджером. В
реляционной базе данных отношения обычно представляются в виде таблиц, в которых
перечислены экземпляры реализации отношения. Столбцам таблицы при этом присваиваются
имена, которые называются атрибутами (attribute) отношения. На рис. 13.15 показаны
таблицы для отношений employee_salary и manager_of_hire. Отношение man-
ager_of_hire имеет два атрибута— employee и manager. Значения отношения —
это пары сотрудник-менеджер.
manager_of_hire: employee_salary:
employee
John Smith
Alex Barrero
Don Morrison
Jan Claus
Anne Cable
manager
Jane Martinez
Ed Angel
Jane Martinez
Ed Angel
BobVeroff
employee
John Smith
Alex Barrero
Don Morrison
Jan Claus
Anne Cable
salary
$35,000.00
$42,000.00
$50,000.00
$40,000.00
$45,000.00
Рис. 13.15. Два отношения из базы данных сотрудников
Если предположить, что каждому сотруднику соответствует уникальное имя,
менеджер и зарплата, то имя сотрудника можно использовать в качестве ключа (key)
Глава 13. Понимание естественного языка
593
для атрибутов salary и manager. Один атрибут может выступать ключом для
другого атрибута, если он уникальным образом определяет значения элементов
этого второго атрибута. В корректном запросе указывается целевой атрибут и задается
значение или множество ограничений. База данных возвращает указанное значение
целевого атрибута. Взаимосвязь между ключами и другими атрибутами можно
изобразить графически разными способами, включая диаграммы "сущность-связь"
(entity-relationship diagram) [Ullrnan, 1982] и диаграммы потоков данных (data flow
diagram) [Sowa, 1984]. Оба эти подхода позволяют представить связь ключей с
атрибутами в виде направленного графа.
Концептуальные графы можно расширить за счет включения диаграмм этих
взаимосвязей [Sowa, 1984]. Отношение в базе данных, определяющее эту связь, обозначается с
помощью ромба с меткой имени отношения. Атрибуты отношения — это понятия в
концептуальном графе, а стрелки направлены от ключей к другим атрибутам. Графы
"сущность-отношение" для отношений employee_salary и manager_of_hire
показаны на рис. 13.16.
В процессе преобразования вопроса на английском языке к виду формального
запроса необходимо определить запись, содержащую ответ на этот вопрос, поле, значение
которого должно возвращаться, и значения ключей, определяющих это поле. Вместо
прямого перевода вопроса на английском языке на язык базы данных его сначала
необходимо перевести на более выразительный язык, в частности, язык концептуальных графов.
Это необходимо, поскольку многие вопросы на естественном языке могут трактоваться
неоднозначно или требовать дополнительной интерпретации для получения хорошо
структурированного запроса к базе данных. Именно этому и способствуют более
выразительные языки представления.
Интерфейс взаимодействия с базой данных должен разобрать и интерпретировать
запрос, представив его в виде концептуального графа, как было описано выше в этой
главе. Затем этот граф объединяется с информацией из базы знаний с помощью
операций объединения и ограничения. В нашем примере необходимо обрабатывать запросы
вида: "Who hired John Smith?" (Кто нанял на работу Джона Смита) или "How much
does John Smith earn?" (Сколько зарабатывает Джон Смит). Для каждого
потенциального запроса нужно хранить граф, определяющий его сказуемое, и все связанные с
этим вопросом диаграммы "сущность-связь". Запись базы знаний для глагола hire
показана на рис. 13.17.
manager
employee
salary
Рис.1316. Диаграммы "сущность-связь"
для отношений employee_salary и
manager_of_hire
hire
employee \
manager
Рис 13 17 Запись базы знаний для
запросов о "нанимателе"
594 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
Семантический интерпретатор строит граф для запроса пользователя и объединяет
его с соответствующей записью из базы знаний. Если существует граф "сущность-
отношение", отражающий связь ключей с целью вопроса, то этот граф можно
использовать для формирования запроса к базе данных. На рис. 13.18 показан граф запроса для
вопроса "Who hired John Smith?" ("Кто нанял на работу Джона Смита?") и результат его
объединения с элементом базы знаний, показанным на рис. 13.17. На рис. 13.18 также
показан запрос SQL, сформированный на основе этого графа. Заметим, что имя
соответствующей записи, целевое поле и ключ для запроса в вопросе на естественном языке не
указаны. Эти сведения извлекаются из базы знаний.
Семантическая интерпретация
запроса на естественном языке:
hire
person: ?
person: "John smith"
Расширенный граф запроса,
Запрос на языке SQL-
SELECT MANAGER
FROM MANAGER_OF_HIRE
WHERE EMPLOYEE = "John smith"
Рис. 13.18 Получение запроса к базе данных с помощью графа,
представляющего вопрос на естественном языке
Как видно из рис. 13.18, в исходном вопросе об агенте и объекте не содержится
никакой информации, за исключением того, что они оба относятся к типу person. Чтобы
объединить этот граф с элементом базы знаний, соответствующим глаголу hire, эти
символы сначала необходимо привести к типу manager и employee соответственно. Для
выполнения проверки типов в исходном запросе можно использовать иерархию типов.
Если John smith не относится к типу employee, то вопрос должен быть отнесен к
разряду некорректных, и программа должна это автоматически определить.
После построения расширенного графа запроса программа проверяет целевое
понятие, помеченное символом ?, и определяет, что отношение manager_of_hire
связывает ключ с этим понятием. Поскольку ключу соответствует значение John smith, то
вопрос является корректным, и программа может сформировать соответствующий запрос к
базе данных. Преобразование графа "сущность-связь" в запрос SQL или запрос на любом
другом языке выполняется достаточно просто.
Глава 13. Понимание естественного языка
595
Хотя этот пример очень прост, он иллюстрирует использование подхода на основе
знаний для построения интерфейса взаимодействия с базой данных. В нашем примере
для представления информации использовались концептуальные графы, но это далеко не
единственный способ. Здесь могут применяться другие представления, в том числе
фреймы или логические языки предикатов.
13.5.3. Извлечение информации и системы автоматического
резюмирования для Web
С технологией World Wide Web связано много интересных задач и возможностей
применения искусственного интеллекта и программ понимания естественного языка.
Одной из основных задач интеллектуального программного обеспечения является
резюмирование интересных материалов из Web.
При нахождении информации, например, по ключевым словам или с помощью других
более сложных механизмов поиска, система извлечения информации (information extraction
system) должна получить на вход этот текст и прореферировать его с учетом заданной наперед
сферы интересов или предметной области. Она должна найти полезную информацию,
связанную с этой предметной областью, и закодировать ее в виде, удобном для представления
конечному пользователю или сохранения в структурированной базе данных.
В отличие от систем глубокого понимания естественного языка, система извлечения
информации "просматривает" текст в поиске соответствующих разделов и
концентрирует свое внимание только на обработке этих разделов. Например, система извлечения
информации может резюмировать информацию из предложений о работе в области
компьютерных наук. Вернемся к примеру, приведенному в разделе 13.0.
Пример объявления о вакансиях в области компьютерных наук
"Факультет компьютерных наук университета Нью-Мексико... проводит конкурс на
замещение двух должностей профессора. Требуются специалисты в следующих областях:
программное обеспечение, в том числе анализ, проектирование и средства разработки...;
системы, включая архитектуру, компиляторы, сети...
Кандидаты должны иметь степень доктора наук по специальности...
На факультете выполняются международные проекты в области адаптивных вычислений,
искусственного интеллекта, поддерживаются тесные связи с институтом Санта-Фе и
несколькими национальными лабораториями..."
Система извлечения информации может получать важные сведения с помощью
подобных предложений и заполнять шаблон определенной структуры.
Пример частично заполненного шаблона
Организация: факультет компьютерных наук университета Нью-Мексико
Город: Albuquerque
Штат: NM 87131
Описание вакансии: должность профессора
Необходимая квалификация: степень доктора наук по специальности...
Требуемые навыки: умение использовать программное обеспечение и средства
разработки, в том числе для анализа и проектирования...
Опыт практической деятельности: ...
Сведения об организации: (текст прилагается)
596 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
В первых системах обработки данных на естественном языке для извлечения
информации использовались самые разные подходы, от традиционных средств, выполняющих
подробный семантический анализ и снабженных полным синтаксическим описанием каждого
предложения, до систем, использующих методы сравнения ключевых слов, не обладающих
уровнем лингвистического анализа и базой знаний. Однако в процессе разработки таких
систем выявились очевидные недостатки этих крайних подходов. Более современный
процесс извлечения информации описан в [Cardie, 1997] следующим образом.
1. Текст: факультет компьютерных наук университета Нью-Мексико... проводит
конкурс на замещение двух должностей профессора. Требуются специалисты в
следующих областях...
2. Разметка и тэгирование: факультет/noun компьютерных/adj наук/noun...
3. Анализ предложения: факультет/subj проводит/verb конкурс/obj...
4. Извлечение: Организация: факультет компьютерных наук...
Описание вакансии: должность профессора
5. Объединение: HbK>-MeKcm<o=NM...
6. Генерация шаблона: результат приведен выше.
Хотя детали архитектурной реализации системы извлечения информации могут
различаться в зависимости от приложения, последовательность выполнения основных
функций при этом не изменяется.
Сначала каждое предложение, найденное на Web-узле, подлежит разметке и тэгиро-
ванию. Для решения этой задачи можно использовать стохастический подход,
описанный в разделе 13.4. Затем следует стадия анализа предложений, на которой выполняется
грамматический разбор и выделяются глагольные группы, существительные и другие
грамматические конструкции. После этого на этапе извлечения информации
выполняется поиск семантических сущностей, соответствующих данной области. В
рассматриваемом примере на этом этапе определяется название организации, вакансии, требования к
кандидату и т.д.
Стадия извлечения информации — это первый этап процесса, полностью
определяемый спецификой предметной области. На этой стадии система выявляет специфические
отношения между соответствующими компонентами текста. В нашем примере в роли
организации выступает факультет компьютерных наук, а его местоположением
считается университет Нью-Мексико. На стадии объединения строится список синонимов и
выполняется разрешение анафор. В частности, символы Нью-Мексико и NM определяются
как синонимы, а в процессе резолюции анафор факультет компьютерных наук из первого
предложения связывается со словом "факультет" в последующем тексте.
На этапе объединения применяется вывод на уровне рассуждений, который в свою
очередь вносит вклад в генерацию шаблона. В процессе такого вывода определяется
количество различных отношений в тексте, фрагменты информации связываются с нолями
шаблона, а затем строится и сам шаблон.
Несмотря на значительный прогресс в области развития искусственного интеллекта,
современные системы извлечения информации тоже не лишены проблем. Во-первых,
можно значительно улучшить точность и робастность этих систем. Ошибки в процессе
извлечения информации скорее всего связаны с недостаточным пониманием исходного
текста. Во-вторых, построение систем извлечения информации для новой предметной
области может оказаться достаточно сложным и ресурсоемким процессом [Cardie, 1997].
Глава 13. Понимание естественного языка
597
Обе эти проблемы связаны с ориентированной на предметную область природой задач
извлечения информации. Процесс извлечения информации можно улучшить за счет
настройки лингвистических источников знаний на конкретную область, однако
модификация лингвистических знаний вручную — это сложный и трудоемкий процесс.
Тем не менее в настоящее время существует множество интересных приложений
описанной технологии. В работе [Glasgow и др., 1997] представлена система поддержки
страхования жизни. В [Soderland и др., 1995] описана система анализа медицинских
карточек пациентов, применяемая в системе страхования. Известна программы анализа
газетных публикаций и их резюмирования [MUC-5, 1994], системы автоматической
классификации юридических документов [Holowczak и Adam, 1997] и программы извлечения
информации из компьютерных списков вакансий [Nahm и Моопеу, 2000].
13.5.4. Использование алгоритмов обучения для обобщения
извлеченной информации
Рассмотрим приложение, в котором многие описанные в этой главе идеи объединены с
алгоритмами машинного обучения, изложенными в разделах 9.3 и 15.13. В работах [Cardie и
Моопеу, 1999] и [Nahm и Моопеу, 2000] высказана идея о том, что процесс извлечения
информации из текста можно обобщить за счет применения алгоритмов машинного обучения.
Суть подхода достаточно проста. Полностью или частично заполненные шаблоны
собираются с соответствующих Web-узлов. Эта информация сохраняется в реляционной
базе данных, на основе которой с использованием алгоритмов обучения наподобие ID3
или С4.5 строятся деревья решений. Как известно из раздела 9.3, подобные деревья
решений могут отражать неявные связи в наборе данных. (Этот прием называют
"добычей" данных — data mining.) Предполагается, что эти вновь выявленные
зависимости можно использовать для уточнения исходных шаблонов и базы знаний,
принимающей участие в процессе извлечения информации. Приведем пример информации,
которая может быть извлечена в процессе анализа вакансий в области компьютерных наук.
Если требуется специалист на факультет компьютерных наук, значит, опыт работы с
конкретной платформой не обязателен. Или, если имеется вакансия профессора в
университете, значит, кандидат должен иметь опыт исследовательской работы. Более
подробно эти вопросы освещены в [Nahm и Моопеу, 2000].
13А Резюме и дополнительная литература
Как следует из этой главы, существует множество подходов к определению грамматик и
разбору предложений на естественном языке. В качестве типичных примеров таких
подходов были рассмотрены марковские модели и ATN-анализаторы. Грамотные студенты
должны быть знакомы и с другими возможностями. К ним относятся грамматики
преобразований (transformational grammar), семантические грамматики (semantic grammar),
падежные грамматики (case grammar) и функциональные грамматики (function grammar)
[Winograd, 1983], [Allen, 1995]. В грамматиках преобразований для представления
глубинной структуры или смысла предложения используются контекстно-независимые правила.
Такую глубинную структуру можно представить в виде дерева грамматического разбора,
состоящего не только из терминальных и нетерминальных элементов, но и включающего
наборы символов, именуемых грамматическими маркерами (grammatical marker). С помо-
598 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
щью грамматических маркеров можно представить такие свойства, как число, время и
другие контекстно-зависимые аспекты лингвистической структуры. Затем с помощью набора
правил более высокого уровня (так называемых правил преобразования) эта глубинная
структура трансформируется в поверхностную структуру (surface structure), более близкую
к естественной форме предложения. Например, предложения "Tom likes Jane" (Том любит
Джейн) и "Jane is liked by Tom" (Джейн любима Томом) имеют одинаковую глубинную, но
различную поверхностную структуру.
Правила трансформации применяются к самим деревьям разбора. С их помощью
выполняются проверки, требующие глобального контекста, и строится удобная
поверхностная структура. Например, с помощью правила преобразования можно проверить, что число
для узла, представляющего подлежащее, соответствует числу сказуемого. С помощью
правил трансформации простую глубинную структуру можно отобразить в различные
поверхностные структуры, заменяя действительный залог страдательным или утверждение
вопросом. Хотя грамматики преобразований подробно не описаны в этой книге, они являются
важной альтернативой для грамматик описания структуры неоднозначных фраз.
Исчерпывающее описание грамматик и методов разбора естественного языка
приводится в [Winograd, 1983]. В этой книге особое внимание уделено грамматикам
преобразования. В [Allen, 1997] содержится обзор проектных решений программ понимания
естественного языка. Еще одним источником по вопросам обработки естественного языка,
затронутым в этой главе, является книга [Harris, 1985]. Рекомендуем также ознакомиться
с [Gazdar и Melhsh, 1989]. В [Charniak, 1993] представлены материалы по применению
статистических методов для анализа структуры языка.
Семантический анализ естественного языка связан с решением многих сложных
вопросов, относящихся к представлению знаний (глава 6). Эти вопросы затрагиваются в
[Charniak и Wilks, 1976]. Из-за сложности моделирования знаний и необходимости учета
социального контекста в процессе анализа естественного языка многие авторы
поднимают вопрос о возможности применения этой технологии за пределами ограниченных
предметных областей [Searle, 1980], [Winograd и Flores, 1986], [Smith, 1996].
В работе [Schank и Riesbeck, 1981] задачи понимания естественного языка решаются
на основе технологии концептуальной зависимости. В [Schank и Abelson, 1977]
обсуждается роль структур организации знаний более высокого уровня в программах обработки
естественного языка.
Значение контекстуальных знаний в моделировании рассуждений отмечается в [Searle,
1969]. В [Fass и Wilks, 1983] предложена теория семантического предпочтения (semantic
preference theory), которая может стать основой моделирования семантики естественного
языка. Семантическое предпочтение — это обобщение падежной грамматики, допускающее
преобразования падежных фреймов. Это обеспечивает большую гибкость семантики
представления, а также возможность представления таких понятий, как метафора и аналогия.
Полное описание иерархии Хомского читатель найдет в [Hopcroft и Ullman, 1979].
Концептуальные графы и их применение при моделировании семантики баз данных
описаны в [Sowa, 1984].
Современное состояние технологии обработки языка описано в работах [Jurafsky и
Martin, 2000], [Manning и Schutze, 1999], [Cole, 1997] и в зимнем номере журнала А/
Magazine за 1997 год.
Новейшие исследования и тенденции в области понимания естественного языка как с
традиционной, так и со стохастической точек зрения представлены в трудах ежегодных
конференций по искусственному интеллекту и журнале Journal of the Association for
Computational Linguistics.
Глава 13. Понимание естественного языка
599
13.7. Упражнения
1. Классифицируйте каждое из следующих предложений как синтаксически
некорректное; синтаксически корректное, но бессмысленное; осмысленное, но неверное или
верное. Когда в процессе понимания предложения выявляется каждая из этих проблем?
Colorless green ideas sleep furiously.
Fruit flies like a banana.
Dogs the bite man a.
George Washington was the fifth president of the USA
This exercise is easy
A want to be under the sea in an octopus's garden in the shade.
2. Опишите структуры представления и знания, необходимые для понимания
следующих предложений.
The brown dog ate the bone.
Attach the large wheel to the axle with the hex nut.
Mary watered the plants.
The spirit is willing but the flesh is weak
My kingdom for a horse
3. Выполните разбор следующих предложений с использованием грамматики из "мира
собак", описанной в подразделе 13.2.1. Какие из этих предложений недопустимы? Почему?
The dog bites the dog
The big dog bites the man.
Emma likes the boy.
The man likes
Bite the man
4. Дополните грамматику из "мира собак" таким образом, чтобы она включала
описание недопустимых предложений из упражнения 3.
5. Выполните разбор каждого из предложений с использованием контекстно-зависимой
грамматики из подраздела 13.2.3.
The men like the dog
The dog bites the man
6. Постройте дерево грамматического разбора для каждого из следующих
предложений. При этом вам придется дополнить простые грамматики более сложными
лингвистическими конструкциями, такими как прилагательные, наречия и вводные
конструкции. Если предложение допускает несколько вариантов разбора, постройте
диаграмму для каждого из них и объясните, какая семантическая информация нужна для
выбора правильного варианта.
Time flies like an arrow but fruit flies like a banana.
Tom gave the big, red book to Mary on Tuesday
Reasoning is an art and not a science.
To err is human, to forgive divine
7. Дополните грамматику из "мира собак", включив в нее прилагательные и именные
конструкции. Учтите, что прилагательные в английском языке не имеют числа.
Совет: используйте рекурсивное правило adjective list, возвращающее либо пустой
результат, либо прилагательное, за которым следует список прилагательных.
Представьте эту грамматику в виде сети переходов.
600 Часть V. Дополнительные вопросы решения задач искусственного интеллекта
8. Добавьте следующие контекстно-независимые правила к грамматике из "мира собак"
из подраздела 13.2.1. Представьте результирующую грамматику в виде сетей перехода.
sentence<r+noun_phrase verb phrase prepositionaljphrase,
prepositional_phrase<r^preposition noun_phrase,
preposition<r+with,
preposition<r^tot
preposition<r^on.
9. Разработайте ATN-анализатор для грамматики из "мира собак" с прилагательными
(упражнение 7) и вводными фразами (упражнение 8).
10. Определите понятия и отношения в концептуальных графах, необходимых для
представления грамматики из упражнения 9. Определите процедуры построения
семантического представления на основе дерева грамматического разбора.
11. Дополните контекстно-зависимую грамматику из подраздела 13.2.3 для обеспечения
проверки семантического соответствия между подлежащим и сказуемым. А
именно — люди не должны кусать собак, хотя собаки могут либо любить, либо кусать
людей. Выполните соответствующую модификацию ATN-грамматики.
12. Дополните ATN-грамматику из подраздела 13.2.4, включив в нее вопросы who и what.
13. Объясните, как марковские модели из раздела 13.4 можно комбинировать с
символьными подходами к пониманию языка, описанными в разделах 13.1-13.3.
14. Дополните пример интерфейса взаимодействия с базой данных из подраздела 13.6.2,
чтобы иметь возможность отвечать на вопросы вида "How much does Don Morrison earn?".
При этом потребуется дополнить грамматику, язык представления и базу знаний.
15. Для предыдущей задачи разместите слова, в том числе и знаки препинания, в
случайном порядке.
16. Допустим, что наряду с другими сотрудниками в отношении employee_salary
(подраздел 13.6.2) перечислены менеджеры. Дополните этот пример таким образом,
чтобы получить возможность обрабатывать запросы вида "Find any employee that
earns more than his or her manager" ("Найдите сотрудников, которые зарабатывают
больше, чем их работодатели").
17. Как стохастический подход из раздела 13.4 можно объединить с методами анализа
базы данных из раздела 13.5?
18. Использование стохастического подхода для изучения образов, содержащихся в
реляционных базах данных, — важное современное направление исследований,
которое иногда называют "добычей данных" (data mining) (см. раздел 13.3). Как можно
использовать этот подход для ответов на запросы к реляционным базам данных,
подобные приведенным в разделе 13.5?
19. На основе материала из раздела 13.5 разработайте систему извлечения информации
для некоторой области знаний, которую можно использовать в WWW.
Глава 13. Понимание естественного языка
601
Часть VI
Языки и технологии
программирования
для искусственного
интеллекта
Карта — это не территория; имя — это не сам объект.
— Альфред Коржибски (Alfred Korzybski)
Чему я научился, кроме корректного использования нескольких средств?
— Гари Снайдер (Gary Snyder), Языки, их понимание и уровни абстракции
В части VI мы сначала обсудим вопросы, связанные с выбором языка
программирования для задач искусственного интеллекта. Затем в главах, посвященных языкам LISP и
PROLOG, будут рассмотрены многочисленные приемы программирования, которые
можно использовать для построения интеллектуальных систем. Основная задача
программирования искусственного интеллекта— сформировать представление и
управляющие структуры, необходимые для решения интеллектуальной задачи. Требования к
этим структурам во многом определяют необходимые свойства языка реализации. Во
введении к этой части сначала перечисляются требования, выдвигаемые к языкам
программирования задач искусственного интеллекта, а затем вводятся языки
программирования LISP и PROLOG. Эти два языка чаще всего применяются для решения задач
искусственного интеллекта. Их синтаксис и семантика дают богатую почву для
рассуждения о задачах и их решении. Эти языки оказали ощутимое влияние на историю развития
искусственного интеллекта. Во многом это определяется их мощностью, а также
возможностью их рассмотрения как ''средства мышления".
Возможность формирования абстракций высокого уровня на основе опыта — это
одна из главных и мощнейших особенностей человеческого мозга. Абстракции позволяют
объединить детали описания сложной предметной области в общую характеристику
организации и поведения. Они позволяют понять весь спектр частностей, выявляемых в
этой предметной области. Например, входя в незнакомый дом, человек может
сориентироваться в нем: найти гостиную, спальню, кухню и ванную. Абстракция позволяет
осмыслить вариации, встреченные в разных домах. Для описания полной картины могут
понадобиться тысячи слов, но абстракция дает возможность сжато представить важные
свойства целого класса объектов.
Создавая теории для описания классов явлений, человек на основе свойств отдельных
объектов выделяет существенные качественные и количественные характеристики класса.
Отсутствие деталей при этом компенсируется точностью описания и силой
прогнозирования корректной теории. Абстракция — важнейшее средство понимания сложности
окружающего нас и внутреннего мира, а также управления этой сложностью. Процесс
абстрагирования происходит непрерывно и рекурсивно: знания организуются в различные уровни
абстракции, начиная с механизмов выделения структуры из хаоса и заканчивая
построением тонких научных теорий. Большинство наших идей связаны с другими идеями.
Иерархическая абстракция (hierarchical abstraction) — организация опыта в
структуру абстрактных классов и описаний все более высокого уровня — это важное средство
понимания поведения и структуры сложных систем, включая компьютерные программы.
Подобно тому, как поведение животных можно изучать без учета физиологии их нервной
системы, алгоритм можно рассматривать как отдельную характеристику, не зависящую
от реализующей его программы.
Например, рассмотрим две различные реализации бинарного поиска, написанные на
языке FORTRAN с использованием массивов и C++ с использованием указателей.
По существу, эти программы эквивалентны, несмотря на различие их реализаций. Такое
отделение алгоритма от кода — лишь один из примеров иерархической абстракции в
компьютерных науках.
В [Newell, 1982] выделены два уровня описания интеллектуальных систем: знаний
(knowledge level) и символов (symbol level). Уровень символов связан с конкретными
формализмами, применяемыми для представления знаний в процессе решения задач.
Примером рассмотрения задачи на таком уровне является описание в главе 2 логики
предикатов как языка представления. Выше расположен уровень знаний, связанный с
содержанием информации и способами ее использования.
Такое разграничение отражается на архитектуре систем на основе знаний и стиле их
разработки. Поскольку пользователи общаются с программой в терминах своих знаний и
возможностей, программы реализации искусственного интеллекта должны иметь четко
выделенный уровень знаний. Отделение базы знаний от используемой структуры
управления отражает эту точку зрения и упрощает разработку гармоничного поведения
системы на уровне знаний. Аналогично на уровне символов определяется язык представления
для базы знаний, в частности, логические или продукционные правила. Его отделение от
уровня знаний позволяет программисту решать проблемы выразительности,
эффективности и простоты программирования, не относящиеся к более высоким уровням
поведения системы. Ниже уровня символов располагается уровень организации программы и
решения вопросов разработки (рис. VI. 1).
Ценность многоуровневого подхода к разработке систем сложно переоценить. Он
позволяет программисту отвлечься от сложности, относящейся к нижним уровням, и скон-
604 Часть VI. Языки и технологии программирования для искусственного интеллекта
центрировать свои усилия на вопросах, соответствующих данному уровню абстракции.
Такой подход позволяет выделить теоретические основы искусственного интеллекта и
абстрагироваться от деталей конкретной реализации или языка программирования. Он
позволяет модифицировать реализацию, повышая ее эффективность, или выполнить портирование
на другую платформу, не затрагивая поведение системы на более высоких уровнях.
Уровень знаний
Символьный уровень
Уровень алгоритмов и структур данных
Уровень языков программирования
Уровень компоновки
Микрокод
Машинные инструкции
Уровни аппаратных средств
Рис VI1 Уровни системы, основанной на знаниях из [Newell, 1982]
Уровень знаний определяет возможности интеллектуальной системы. Сами знания не
зависят от формализмов, используемых для их представления, а также выразительности
выбранного языка программирования. На уровне знаний решаются следующие вопросы.
Какие запросы допустимы в системе? Какие объекты и отношения играют важную роль в
данной предметной области? Как добавить в систему новые знания? Будут ли факты
изменяться со временем? Как в системе будут реализованы рассуждения о знаниях?
Обладает ли данная предметная область хорошо понятной систематикой? Имеется ли в ней
непонятная или неполная информация? Важным шагом в разработке архитектуры
программы является внимательный анализ вопросов этого уровня и выбор конкретного
способа представления, используемого на символьном уровне.
На символьном уровне принимаются решения о структуре представления и
организации знаний. Важнейшим вопросом является выбор языка программирования. Как
известно из глав 6-8, логика — это лишь один из многих формализмов представления
знаний. Язык представления должен не только давать возможность выражать
необходимые знания, но и быть согласованным, модифицируемым и вычислительно
эффективным. Он должен помогать программисту познакомиться с организацией базы
знаний. Эти критерии зачастую противоречивы, что требует внимательного подхода к
разработке языков представления.
Подобно разделению уровней знаний и символов, в программе можно разграничить
символьный уровень, алгоритмы и структуры данных, используемые для его реализации.
Например, поведение логической системы решения задач, основанной на хэш-таблицах,
будет отличаться от ее реализации на базе бинарных деревьев только быстродействием.
Это вопрос реализации, который должен оставаться прозрачным на символьном уровне.
Многие алгоритмы и структуры данных, используемые в задачах обработки естественного
языка, сводятся к работе с деревьями и таблицами. Но есть и специфические для
искусственного интеллекта представления. Они приводятся в виде псевдокода во всех частях
книги, а их реализация на языках LISP и PROLOG описана в соответствующих главах.
Обзор языков PROLOG и LISP
605
Ниже уровня алгоритмов и структур данных располагается уровень языка. На этом
уровне важную роль играет стиль программирования. Хотя хороший стиль
программирования предполагает разделение конкретных свойств языка программирования и
вышестоящих уровней, специфика задач искусственного интеллекта требует их глубокой
взаимосвязи. Кроме того, структура языка должна удовлетворять ограничениям,
обусловленным еще более низкими уровнями компьютерной архитектуры, включая
операционную систему, архитектуру аппаратных средств, объем памяти и быстродействие
процессора. Языки LISP и PROLOG обеспечивают реализацию требований символьного
уровня и учитывают архитектуру более низкого уровня. Этим объясняется их
популярность при решении задач искусственного интеллекта.
Рассмотрим основные свойства языков LISP и PROLOG.
Обзор языков PROLOG и LISP
PROLOG
PROLOG— это наиболее известный пример языка логического программирования
(logic programming language). Логическая программа— это набор спецификаций в рамках
формальной логики. PROLOG основан на теории предикатов первого порядка. Само имя
этого языка программирования расшифровывается как Programming in Logic
(Программирование в логике). При выполнении программы интерпретатор постоянно
реализует вывод на основе логических спецификаций. Идея использования возможностей
представления теории предикатов первого порядка — это одно из основных преимуществ
применения языка PROLOG для компьютерных наук вообще и искусственного интеллекта
в частности. Применение теории предикатов первого порядка в языке программирования
обеспечивает прозрачный, элегантный синтаксис и хорошо определенную семантику.
Развитие языка PROLOG уходит корнями в исследования, связанные с доказательством
теорем, а точнее, с разработкой алгоритмов опровержения резолюции [Robinson, 1965].
В этой работе разработана процедура доказательства, получившая название резолюции
(resolution), которая и стала основным методом вычислений на языке PROLOG. В главе 12,
посвященной вопросам автоматического доказательства теорем, описаны системы
резолюции на основе опровержения (resolution refutation system) (см. разделы 12.2 и 12.3).
Благодаря этим свойствам PROLOG зарекомендовал себя в качестве полезного средства
исследования таких экспериментальных вопросов программирования, как автоматическая
генерация кода, верификация программ и разработка высокоуровневых языков
программирования. PROLOG, как и другие основанные на логике языки, поддерживает
декларативный стиль программирования — т.е. конструирование программы в терминах
высокоуровневого описания ограничений предметной области задачи. В отличие от него, процедурный
стиль программирования предполагает написание программы в виде последовательности
инструкций по выполнению алгоритма. В логическом программировании компьютеру
сообщается, "что есть истина", а не "как это сделать". Это позволяет программистам
сосредоточиться на решении задачи и создании спецификаций для предметной области, а не на
деталях написания низкоуровневых алгоритмических инструкций вида "что делать далее".
Первая PROLOG-программа была написана в начале 1970-х годов во Франции в
рамках проекта по пониманию естественного языка [Colmerauer и др., 1973], [Roussel, 1975],
[Kowalski, 1979a]. Теоретические основы этого языка описаны в работах [Kowalski,
606 Часть VI. Языки и технологии программирования для искусственного интеллекта
1979а, 19796], [Hayes, 1977], [Lloyd, 1984]. Основной этап развития языка PROLOG
приходится на 1975-1979 годы, когда на кафедре искусственного интеллекта университета
Эдинбурга Дэвид Уоррен (David H.D. Warren) и Фернандо Перейра (Fernando Pereira)
отвечали за реализацию этого языка. Они создали первый интерпретатор PROLOG,
достаточно робастный для предъявления его всей компьютерной общественности. Этот
продукт базировался на системе DEC 10 и мог работать как в режиме интерпретатора, так и
в режиме компилятора. Описание этого кода и результаты сравнения PROLOG с языком
LISP приводятся в [Warren и др., 1977]. Эта версия стала первым стандартом языка
PROLOG и была описана в книге [Clocksin и Mellish, 1984]. В нашей книге используется
именно этот стандарт, который известен под названием эдинбургского синтаксиса.
Преимущества этого языка были продемонстрированы при разработке исследовательских
проектов, призванных оценить и повысить выразительность логического программирования.
Многие приложения, реализованные на этом языке, описаны в трудах Международной
конференции по искусственному интеллекту и Симпозиума по логическому программированию.
Ссылки на дополнительную литературу приводятся к конце главы 14.
LISP
Язык LISP был впервые предложен Джоном Маккарти (John McCarty) в конце 50-х
годов. Вначале этот язык рассматривался как альтернативная модель вычислений на
основе теории рекурсивных функций. В своей первой работе [McCarthy, 1960] автор языка
сформулировал поставленную перед ним цель следующим образом. Требуется создать
язык для символьных, а не числовых вычислений, реализующий модель вычислений на
основе теории рекурсивных функций [Church, 1941]. При этом нужно обеспечить четкое
определение синтаксиса и семантики этого языка и продемонстрировать формальную
полноту этой вычислительной модели. Хотя LISP — это один из старейших
компьютерных языков, все еще находящихся в использовании (наряду с языками FORTRAN и
COBOL), при внимательном рассмотрении его истории развития становится ясно, что он
постоянно идет в авангарде языков программирования. Эта модель программирования
зарекомендовала себя столь хорошо, что на принципах функционального
программирования были основаны многие другие языки, в том числе SCHEME, ML и FP.
Основным структурным блоком программ и данных в LISP является список. (Отсюда
и аббревиатура LISP— Lisp Processing, или обработка списков.) LISP поддерживает
большое число встроенных функций работы со списками как со связными структурами
указателей. LISP обеспечивает для программиста всю мощь и общность связанных
структур данных, освобождая их от необходимости явно управлять указателями и реали-
зовывать операции с ними.
Изначально LISP был компактным языком, состоящим из функций построения и
обработки списков, позволяющим определять новые функции, проверять равенство и
оценивать выражения. Единственными средствами управления были рекурсия и условные
операторы. В терминах этих примитивов при необходимости определялись более
сложные функции. Однако со временем лучшие из новых функций стали частью самого
языка. Этот процесс расширения языка за счет добавления к нему новых функций привел к
созданию многочисленных диалектов LISP, зачастую включающих сотни
специализированных функций для структурирования данных, управления программой, реализации
вещественных и целочисленных вычислений, ввода-вывода, редактирования функций
LISP и трассировки выполнения программ. Эти диалекты способствовали превращению
Обзор языков PROLOG и LISP
607
LISP из простой и элегантной теоретической модели вычислений в богатую, мощную
среду для построения больших программных систем. Из-за быстрого разрастания ранних
диалектов LISP агентство защиты новейших исследовательских проектов Defense
Advanced Research Projects Agency в 1983 году предложило стандартный диалект,
получивший название Common LISP.
Хотя Common LISP появился как квинтэссенция диалектов LISP, широкое
распространение получили другие многочисленные диалекты. Один из них — SCHEME —
элегантное переосмысление LISP, используемое как для решения задач искусственного
интеллекта, так и для изучения общих фундаментальных принципов программирования.
В данной книге будет использован именно Common LISP.
Выбор языка реализации
Искусственный интеллект сформировался как отдельная область знаний и
продемонстрировал свою применимость для решения многих практических задач на основе
языков LISP и PROLOG. Однако в последнее время удельный вес этих языков при решении
задач искусственного интеллекта несколько снизился. Это объясняется требованиями к
разработке программных систем. Системы искусственного интеллекта зачастую служат
модулями других больших приложений, поэтому стандарты разработки приводят к
необходимости использования единого языка программирования всего приложения.
Современные системы искусственного интеллекта реализуют на многих языках, включая
Smalltalk, С, C++ и Java. Тем не менее LISP и PROLOG продолжают играть свою роль в
разработке прототипов программ и новых методов решения задач.
Кроме того, эти языки служат для обоснования многих средств, которые впоследствии
включаются в современные языки программирования. Наиболее ярким примером является
язык Java, в котором используются динамическое связывание, автоматическое управление
памятью и другие средства, впервые реализованные в языках программирования задач
искусственного интеллекта. Создается впечатление, что весь остальной мир
программирования до сих пор пытается перенять стандарты от языков реализации искусственного
интеллекта. С этой точки зрения ценность LISP, PROLOG или Smalltalk со временем будет
неуклонно повышаться. Автор уверен, что эти языки пригодятся читателю, даже если
впоследствии он найдет свое место в C++, Java или любом другом конкурирующем языке.
608 Часть VI. Языки и технологии программирования для искусственного интеллекта
Введение в PROLOG
Все объекты человеческих размышлений и исследований естественным образом
можно разделить на два вида: "связи идей" и "сущность фактов".
— Дэвид Хьюм (David Hume), К вопросу о человеческом разуме
Единственный способ улучшить наши рассуждения — это сделать их столь же
осязаемыми, как математические формулы, чтобы уметь найти ошибку с одного
взгляда и иметь возможность в споре с оппонентами просто сказать: "Давайте
посчитаем... и посмотрим, кто из нас прав".
— Лейбниц (Leibniz), Искусство открытая
14.0. Введение
Как реализация принципов логического программирования язык PROLOG вносит
интересный и существенный вклад в решение задач искусственного интеллекта. Наиболее
важное значение имеет декларативная семантика (declarative semantics) — средство
прямого выражения взаимосвязей в задачах искусственного интеллекта, а также
встроенные средства унификации и некоторые приемы проверки соответствия и поиска.
В этой главе будут затронуты многие важные вопросы логического программирования и
организации языка PROLOG.
В разделе 14.1 представлены базовый синтаксис языка PROLOG и несколько простых
программ, демонстрирующих использование исчисления предикатов в качестве языка
представления. Будет показано, как отслеживать состояние среды PROLOG и использовать
оператор отсечения (cut operator) для реализации поиска в глубину на языке PROLOG.
В разделе 14.2 рассматривается вопрос создания абстрактных типов данных (АТД)
(abstract data types — ADT) на языке PROLOG. К ним относятся стеки (stack), очереди
(queue) и приоритетные очереди (priority queue), используемые для построения
продукционной системы в разделе 14.3 и разработки в разделе 14.3 управляющих структур для
алгоритмов поиска, описанных в главах 3, 4, 6. В разделе 14.5 по материалам раздела 7.4
разрабатывается планировщик (planner). В разделе 14.6 вводится понятие метапредика-
тов (meta-predicate) — предикатов, область интерпретации которых составляют сами
выражения языка PROLOG. Например, выражение atom(X) является истинным, если
X — это атом, т.е. константа. Метапредикаты можно использовать для наложения
ограничения типов при интерпретации программы на языке PROLOG. В разделе 14.7
метапредикаты используются для построения метаинтерпретаторов (meta-interpreter) на
языке PROLOG, которые, в свою очередь, применяются для создания интерпретаторов
языка PROLOG, а также для построения интерпретаторов цепочек правил.
В разделе 14.8 иллюстрируется применение языка PROLOG для машинного
обучения. В качестве примеров рассматривается поиск в пространстве версий и обучение на
основе объяснения из главы 9. В разделе 14.9 строится рекурсивный анализатор на
основе семантических сетей, принципы работы которого изложены в главе 13. В завершение
обсуждаются общие вопросы процедурного и логического программирования, а также
отличия этих подходов от декларативных методов решения задач.
14.1. Синтаксис для программирования логики
предикатов
14.1.1. Представление фактов и правил
Несмотря на существование многочисленных диалектов языка PROLOG, в этой книге
используется исходная версия языка C-PROLOG, разработанная Уорреном (Warren) и
Перейрой (Pereira) [Clocksin и Mellish, 1984]. Чтобы упростить представление данных на
языке PROLOG, при описании логики предикатов в главе 2 используются многие
соглашения, принятые в этом языке. Однако существуют многочисленные отличия синтаксиса
логики предикатов от языка PROLOG. Например, в C-PROLOG символ : - соответствует
символу <— логики предикатов первого порядка. Приведем еще несколько отличий
синтаксиса PROLOG от обозначений, используемых в главе 2.
Название операции Обозначение в логике предикатов Обозначение в языке PROLOG
или v
только если <_
не ->_
Как и в главе 2, имена предикатов и связанных переменных представляют собой
последовательности буквенно-цифровых символов, которые начинаются с буквы.
Переменные представляются в виде строк буквенно-цифровых символов, которые
начинаются (хотя бы) с прописной буквы. Так, выражение
likes(X, susie).
или, еще лучше,
likes(Everyone, susie).
может представлять тот факт, что "каждый любит Сьюзи". Или
likes(george, Y), likes(susie, Y).
представляет множество людей, которых любят Джордж и Сьюзи.
Допустим, на языке PROLOG необходимо представить следующее отношение:
"Джордж любит Кейт и Джордж любит Сьюзи". Его можно записать в виде
likes(george, kate), likes(george, susie).
Таким образом, "Джордж любит Кейт или Джордж любит Сьюзи" можно представить так:
likes(george, kate); likes(george, susie).
610 Часть VI. Языки и технологии программирования для искусственного интеллекта
not
И, наконец, "Джордж любит Сьюзи, если Джордж не любит Кейт" описывается так
likes(george, susie) :- not(likes(george, kate)).
Из этих примеров видно, как связки л, v, —, и <— из логики предикатов
представляются на языке PROLOG. Имена предикатов (наподобие likes), количество и порядок
следования параметров и даже постоянное или переменное число параметров определяются
требованиями (неявной "семантикой") конкретной задачи. В этом языке программирования
не существует никаких ограничений, кроме требования правильного построения формул.
Программа на языке PROLOG — это набор спецификаций из логики предикатов первого
порядка, описывающих объекты и отношения между ними в предметной области задачи.
Набор спецификаций называется базой данных (database) конкретной задачи. Интерпретатор
PROLOG отвечает на вопросы, касающиеся этого набора спецификаций. Запросы к базе
данных — это шаблоны, представленные в том же логическом синтаксисе, что и записи базы
данных. Интерпретатор PROLOG использует поиск на основе шаблонов для определения
того, являются ли эти запросы логическим следствием содержимого базы данных.
Интерпретатор обрабатывает запросы, выполняя поиск в базе данных в глубину слева
направо и определяя, является ли данный запрос логическим следствием спецификаций из базы
данных. PROLOG— это в основном интерпретируемый язык. Некоторые версии языка
PROLOG работают только в режиме интерпретации, другие допускают компиляцию части
или всего набора спецификаций для ускорения выполнения программы. PROLOG — это
интерактивный язык: пользователь вводит запросы в ответ на приглашение ?-.
Допустим, требуется описать "мир симпатий и антипатий" Джорджа, Кейт и Сьюзи.
База данных для эгой задачи может содержать следующий набор предикатов.
likes(george, kate).
likes(george, susie).
likes(george, wine),
likes(susie, wine).
likes(kate, gin),
likes(kate, susie).
Этот набор спецификаций имеет очевидную интерпретацию или отображение на
"мир" Джорджа и его друзей. Этот мир является моделью для базы данных (раздел 2.3).
Затем интерпретатору можно задавать вопросы
?- likes(george, kate).
Yes
?- likes(kate, susie).
Yes
?- likes(george, X).
X = kate
X = susie
X = wine
?- likes(george, beer),
no
Отметим несколько моментов в этих примерах. Во-первых, при обработке запроса
likes (george, X) пользователь последовательно вводит приглашение ;, поэтому
интерпретатор возвращает все термы из спецификации базы данных, которые можно
Глава 14. Введение в PROLOG
611
подставить вместо X. Они возвращаются в том порядке, в котором были найдены в базе
данных: сначала kate, затем susie и наконец wine. Хотя это противоречит
философии непроцедурных спецификаций, детерминированный порядок — это свойство
большинства интерпретаторов, реализованных на последовательных машинах. Программист
на языке PROLOG должен знать порядок поиска элементов в базе данных.
Заметим также, что последующие ответы на запрос выдаются после
пользовательского приглашения ; (или). При этом происходит возврат к последнему найденному
результату. Последовательные приглашения приводят к нахождению всех возможных ответов
на запрос. Если решений больше не существует, интерпретатор выдаст ответ по.
Приведенные выше примеры также иллюстрируют допущение замкнутости мира (closed
world assumption) или отрицание как ложь (negation as failure). В языке PROLOG
предполагается, что любое выражение является ложным, если нельзя доказать истинность его отрицания.
При обработке запроса likes (george, beer) интерпретатор ищет предикат
likes (george, beer) или некоторое правило для получения likes (деогде, beer).
Поскольку поиск не завершается успехом, запрос считается ложным. Таким образом, в языке
PROLOG предполагается, что все знания о мире представлены в базе данных.
Допущение замкнутости мира приводит к многочисленным практическим и
философским сложностям в языке. Например, невозможность включить некоторый факт в базу
данных зачастую означает, что его истинность неизвестна. Однако в силу допущения
замкнутости мира этот факт трактуется как ложный. Если некоторый предикат был
упущен или при его вводе была допущена опечатка наподобие likes (george, beeer),
то ответом на данный запрос будет по. Аспект трактовки отрицания как лжи — очень
важный вопрос в области искусственного интеллекта. Хотя это предположение
обеспечивает простой способ решения проблемы нсзаданных знаний, более сложные подходы,
в том числе многозначные логики (истина, ложь, неизвестно) и немонотонные
рассуждения (см. главу 9) обеспечивают гораздо более богатый контекст для интерпретации.
Выражения PROLOG, использованные в приведенной выше базе данных, являются
примерами спецификации фактов (fact). PROLOG также позволяет определять правила
(rule), описывающие взаимосвязи между фактами с использованием логической
импликации : -. При создании правила на языке PROLOG слева от символа : - может
располагаться только один предикат. Этот предикат должен быть положительным литералом
(positive literal), т.е. не должен представлять собой символ с отрицанием (раздел 12.3).
Все выражения логики предикатов, содержащие отношения импликации или
эквивалентности (<—, —> и <->), должны быть приведены к этой форме, которая получила
название хорновской (Horn clause). В хорновской дизъюнктивной форме в левой части
импликации (заключении) должен содержаться единственный положительный литерал. Логика
хорновских дизъюнктов (Horn clause calculus) эквивалентна полной теории предикатов
первого порядка, применяемой для доказательств на основе опровержения (см. главу 12)
Допустим, к спецификациям приведенной выше базы данных требуется добавить
правило, определяющее двух друзей Его можно описать следующим образом
friends(X, Y) :- likes(X, Z), likes(Y/ Z).
Это выражение можно интерпретировать так. "X и У — друзья, если существует такое
Z, что X любит Z и У любит Z". Здесь важно отмстить два момента Во-первых,
поскольку ни в логике предикатов, ни в самом языке PROLOG не определены глобальные
переменные, то шкала (область определения) переменных X, У и Z ограничена правилом
friends. Во-вторых, переменные, унифицируемые или связываемые с X, У и Z, согла-
612 Часть VI. Языки и технологии программирования для искусственного интеллекта
сованы по всему выражению. Обработку правила friends интерпретатором языка
PROLOG можно проиллюстрировать на следующем примере.
Если к набору спецификаций из предыдущего примера добавлено правило friends,
то интерпретатору можно передать запрос.
?- friends(george, susie).
yes
Для ответа на этот запрос PROLOG осуществляет поиск в базе данных с помощью
алгоритма с возвратом, представленного в главах 3 и 5. Запрос f riends (george,
susie) унифицируется (проверяется на соответствие) с заключением правила
friends (X, Y) :- likes (X, Z) , likes (Y, Z). При этом переменной X
соответствует значение george, a Y — susie. Интерпретатор ищет значение переменной Z,
для которого выражение likes (george, Z) истинно. Это выполняется с помощью
первого факта в базе данных, в котором Z соответствует kate.
Затем интерпретатор пытается определить, истинно ли выражение likes (susie,
kate). Если оно окажется ложным, то на основе допущения замкнутости мира данное
значение для Z (kate) отклоняется. Тогда интерпретатор возвращается для поиска
второго значения Z в выражении likes (george, Z).
Затем проверяется соответствие выражения likes (george, Z) второму
дизъюнкту в базе данных, при этом переменная Z связывается со значением susie. После этого
интерпретатор пытается найти соответствие для выражения likes (susie, susie).
Если эта попытка тоже завершается неудачей, то интерпретатор снова переходит к базе
данных (возвращается) в поисках следующего значения для Z. На этот раз в третьем
предикате будет найдено значение wine, и интерпретатор постарается показать, что
likes (susie, wine) истинно. В данном случае значение wine является связкой для
значений george и susie. Интерпретатор PROLOG проверяет соответствие целей
шаблонам в том порядке, в котором эти шаблоны были введены в базу данных.
Важно отметить взаимосвязь между кванторами всеобщности и существования в
логике предикатов и обработкой переменных в программе PROLOG. Если переменная
содержится в спецификации базы данных PROLOG, то предполагается, что она связана
квантором всеобщности. Например, выражение likes (susie, Y) согласно семантике
предыдущих примеров означает "Сьюзи любит каждого". В процессе интерпретации
некоторого запроса любой терм, список или предикат может быть связан с Y. Аналогично в
правиле friends (X, Y) :- likes (X, Z) , likes (Y, Z) допускаются любые
связанные переменные X, Y и Z, удовлетворяющие спецификации этого выражения.
Для представления на языке PROLOG переменной, связанной квантором
существования, можно использовать два подхода. Во-первых, если известно конкретное значение
переменной, то его можно ввести в базу данных напрямую. Так, likes (george,
wine) — это экземпляр выражения likes (george, Z), и его можно ввести в базу
данных, как это было сделано в предыдущих примерах.
Во-вторых, для поиска экземпляра переменной, доставляющего выражению значение
"истина", можно обратиться с запросом к интерпретатору. Например, чтобы определить,
существует ли такое значение Z, при котором выражение likes (george, Z) истинно,
этот запрос можно передать интерпретатору. Он проверит, существует ли такое значение
переменной Z. Некоторые интерпретаторы PROLOG находят все значения, связанные
квантором существования. Для получения всех значений с помощью интерпретатора
C-PROLOG требуется повторять пользовательское приглашение ;.
Глава 14. Введение в PROLOG
613
14.1.2. Создание, изменение и мониторинг среды PROLOG
При написании программы на языке PROLOG сначала создается база данных
спецификации. Для добавления новых предикатов к спецификации в интерактивной среде
применяется предикат assert. Так, с помощью команды
?- assert(likes(david, sarah))
к спецификации добавляется предикат likes (david, sarah). Теперь в ответ на запрос
?- likes(david, X).
будет возвращен результат
X = sarah.
С помощью предиката assert можно контролировать добавление новых
спецификаций в базу данных. Предикат asserta (Р) добавляет предикат Р в начало списка
предикатов с именем Р, a assertz (Р) — в конец списка предикатов Р. Это важно для
построения иерархии и выбора приоритетов поиска. Для удаления предиката Р из базы
данных используется предикат retract (P). Следует отметить, что во многих
реализациях языка PROLOG предикат assert ведет себя более непредсказуемо, т.е. точное
время добавления нового предиката в среду может зависеть от многих других факторов,
влияющих как на порядок следования предикатов, так и на реализацию возвратов.
Создание спецификации путем последовательного использования предикатов
assert и retract — очень утомительный процесс. Вместо этого можно создать файл,
содержащий все спецификации для языка PROLOG, с помощью обычного редактора.
После создания файла (назовем его myf ile) нужно вызвать PROLOG и поместить весь
файл в базу данных с помощью команды consult. Так, запрос
?- consult(myfile).
yes
добавляет предикаты, содержащиеся в файле myf ile, в базу данных. Существует и
краткая форма предиката consult, которую целесообразно использовать для
добавления в базу данных нескольких файлов. При этом используется следующее обозначение
?- [myfile].
yes
Предикаты read и write используются для взаимодействия с пользователем.
Команда read(X) считывает следующий терм из текущего входного потока и добавляет
его к X. Входные выражения разделяются точкой. Команда write (X) помещает X в
выходной поток. Если X — не связанная переменная, то выводится целое число, перед
которым располагается символ подчеркивания. Это целое число представляет внутренний
регистрационный номер переменной, необходимый для работы среды доказательства
теорем (принцип разделения переменных описан в подразделе 12.2.2).
Предикаты see и tell используются для считывания информации из файла и записи
в файл. Команда see(X) открывает файл X и определяет текущий входной поток, как
порожденный в X. Если переменная X не связана с существующим файлом, то команда
see (X) завершается неудачей. Аналогично команда tell (X) открывает файл для
выходного потока. Если файла X не существует, то команда tell (X) создает файл, имя
которого совпадает со связанным значением X. Команды seen(X) и told(X)
закрывают соответствующие файлы.
614 Часть VI. Языки и технологии программирования для искусственного интеллекта
Некоторые предикаты языка PROLOG помогают отслеживать состояние базы
данных, а также связанных с ней вычислений. Среди них наиболее важными являются
listing, trace и spy. При использовании команды listing (имя_предиката), где
параметром является имя предиката, в частности member (подраздел 14.1.3),
интерпретатором возвращаются все дизъюнкты из базы данных с соответствующим именем
предиката. Заметим, что в данном случае число аргументов предиката не указано, поэтому
возвращаются все варианты данного предиката, независимо от числа аргументов.
Команда trace позволяет пользователю отслеживать состояние интерпретатора
PROLOG. В процессе мониторинга в выходной файл выводятся все целевые утверждения,
обрабатываемые интерпретатором PROLOG. Зачастую этой информации для пользователя
слишком много. Возможности трассировки во многих средах PROLOG слишком сложны
для понимания и требуют дополнительного изучения и опыта. Обычно при трассировке
работающей программы PROLOG можно получить следующую информацию.
1. Уровень глубины рекурсивных вызовов (помечается в строке слева направо).
2. Когда предпринимается первая попытка обработки целевого утверждения (иногда
используется команда call).
3. Когда цель успешно достигнута (с помощью команды exit).
4. Возможность других соответствий целевому утверждению (команда retry).
5. Невозможность достижения цели, поскольку все попытки завершились неудачно
(зачастую используется команда fail).
6. Полная трассировка прерывается командой not race.
Если требуется более избирательный мониторинг, то применяется команда spy. Имя
отслеживаемого предиката обычно задается в качестве аргумента, но иногда оно определяется с
помощью префиксного оператора (указывается после этого оператора). Так, с помощью
команды spy member выводится информация обо всех случаях использования предиката
member. Аргументом предиката spy может быть также список предикатов с указанием их
арности. Так, команда spy [member/ 2 , append/3] определяет мониторинг всех случаев
использования целевого утверждения member с двумя аргументами и утверждения append с
тремя аргументами. Команда no spy удаляет все контрольные точки.
14.1.3. Списки и рекурсия в языке PROLOG
В предыдущих подразделах на нескольких простых примерах представлен синтаксис
языка PROLOG. В этих примерах PROLOG предстает как механизм вычисления на базе
выражений логики предикатов (в хорновской дизъюнктивной форме). Это согласуется со
всеми принципами вывода в рамках логики предикатов, представленными в главе 2. Для
проверки соответствия шаблонам в языке PROLOG используется унификация и
возвращаются значения переменных (связанные переменные), обеспечивающие истинность
выражения. Эти значения унифицированы с переменными в конкретном выражении, но
не связаны в общей среде.
Ниже будет показано, что основным механизмом управления при программировании
на языке PROLOG является рекурсия. Однако сначала рассмотрим несколько несложных
примеров обработки списков. Список (list) — это структура данных, представляющая
собой упорядоченный набор элементов (или даже самих списков). Рекурсия — это
естественный способ обработки списочных структур. Для обработки списков в языке PROLOG
Глава 14. Введение в PROLOG
615
используют процедуры унификации и рекурсии. Сами элементы списков заключаются в
квадратные скобки ([ ]) и отделяются друг от друга запятыми. Приведем несколько
примеров списка на языке PROLOG.
[1, 2, 3, 4]
[[george, kate], [alien, amy], [don, pat]]
[torn, dick, harry, fred]
[ ]
Первый элемент списка может отделяться от его хвоста оператором |. Хвост списка —
это список после удаления первого элемента. Например, для списка [torn, dick, harry,
fred] первым элементом является torn, а хвостом— список [dick, harry, fred]. С
помощью оператора | и процедуры унификации можно разделить список на компоненты.
• Если список [torn, dick, harry, fred] соответствует шаблону [x|Y],to
X = torn и Y = [dick, harry, fred].
• Если список [torn, dick, harry, fred] соответствует шаблону [X, y|z],to
X = tom,Y = dick и Z = [harry, fred].
• Если список [torn, dick, harry, fred] соответствует шаблону [X, Y,
Z|W],toX = tom,Y = dick, Z = harry,W = [fred].
• Если список [torn, dick, harry, fred] соответствует шаблону [W, X, Y,
Z|V],toW = tom,X = dick, Y = harry, Z = fred,V =[].
Помимо разбиения списка на отдельные элементы унификацию можно использовать
для построения списочной структуры. Например, если X = torn, Y = [dick] и L
унифицируется с [X | Y], то переменная L будет связана со списком [ torn, dick]. Термы,
отделенные друг от друга запятыми и расположенные до вертикальной черты, являются
элементами списка, а находящаяся после вертикальной черты структура всегда является
списком, а точнее, его хвостом.
Рассмотрим простой пример рекурсивной обработки списка: проверку
принадлежности элемента списку с помощью предиката member. Определим предикат, позволяющий
выявить наличие элемента в списке. Предикат member должен зависеть от двух
аргументов: элемента и списка. Он принимает значение "истина", если данный элемент
содержится в списке. Например,
?- member(a, [a, b, с, d, e]).
Yes
?- member(a, [l, 2, 3, 4]).
No
?- member(X, [a, b, c]).
X = a
X = b
X = с
no
Чтобы определить предикат member рекурсивно, сначала проверим, является ли X
первым элементом списка
member(X, [х|т]).
616 Часть VI. Языки и технологии программирования для искусственного интеллекта
Этот предикат проверяет, идентично ли значение X первому элементу списка. Если
нет, то естественно проверить, содержится ли X в оставшейся части (Т) списка. Это
определяется следующим образом.
member(X, [У|Т]):- member(X, Т).
Таким образом, проверка наличия элемента в списке на языке PROLOG выполняется
с помощью двух строк.
member(X, [Х|Т]).
member(X, [Y|T]):- member(X, Т).
Этот пример иллюстрирует значение встроенного в PROLOG порядка поиска, при
котором условие останова помещается перед рекурсивным вызовом, а значит, проверяется
перед следующим шагом работы алгоритма. При обратном порядке следования
предикатов условие останова может никогда не проверяться. Выполним трассировку предиката
member (с, [а, Ь, с]) с нумерацией.
1: member(X, [Х|Т]).
2: member(X, [У|Т]):- member(X, Т).
?- member(с, [a, b, с]).
call l. fail, since c^a
call 2. X = c, Y = a, T = [b, c] , member(c, [b, c] ) ?
call 1. fail, since c^b
call 2. X = c, Y = b, T = [c], member(с, [с])?
call 1. success, с = с
yes (to second call 2.)
yes (to first call 2.)
yes
Хороший стиль программирования на языке PROLOG предполагает использование
анонимных переменных (anonymous variable). Они служат для указания профаммисту и
интерпретатору того, что определенные переменные используются исключительно для проверки
соответствия шаблону, т.е. само связывание переменных не является частью процесса
вычислений Так, чтобы проверить, совпадает ли элемент X с первым элементом списка, обычно
используют запись member (X, [X | _] ). Символ _ означает, что, несмотря на важное
значение хвоста списка в процессе унификации запроса, содержимое хвоста не играет роли.
Анонимные переменные необходимо также использовать в рекурсивном утверждении при
проверке наличия элемента в списке, если значение головы списка не играет роли.
member(X, [х|_]).
member(X, [_|Т]) :- member(X, Т).
Хорошим упражнением для углубления понимания природы списков и рекурсивного
управления является запись элементов списка по одному в строке. Допустим, требуется
таким образом записать элементы списка [а, Ь, с, d]. Для этого можно определить
рекурсивную команду.
writelist([ ]).
writelist([Н|Т]) :- write(H), nl, writelist(T).
Этот предикат записывает элементы списка по одному в строке, поскольку nl
означает переход на новую строку в выходном потоке. Если требуется записать элементы
списка в обратном порядке, то рекурсивный предикат должен следовать перед командой
Глава 14. Введение в PROLOG
617
write. Тогда можно гарантировать, что список будет пройден до конца еще до записи
его элементов. Затем будет записан последний элемент списка и выполнен рекурсивный
вызов процедуры для всех предшествующих элементов списка. Запись списка в
обратном порядке определяется следующим образом.
reverse_writelist([ ] ) .
reverse_writelist([Н|Т]) :- reverse_writelist(T) , write(H), nl.
Читателю предлагается пронаблюдать поведение этих предикатов, запустив их в
режиме трассировки.
14.1.4. Рекурсивный поиск в языке PROLOG
В разделе 5.2 рассматривалась задача "хода конем" размерности 3x3 в рамках теории
предикатов. Для перемещения коня использовалась квадратная доска следующего вида.
1
4
7
2
5
8
3
6
9
Допустимые ходы можно представить на языке PROLOG с помощью предиката
move. Предикат path определяет алгоритм нахождения пути между его аргументами за
О или более ходов. Заметим, что предикат path определен рекурсивно.
moveA, б). moveC, 4).move(б, 7).move(8, 3).
moved, 8) . moveC/ 8) .move (б, 1) .move (8, 1) .
moveB , 7). moveD, 3).moveG, б).move(9, 4).
moveB, 9). moveD, 9).moveG, 2).move(9, 2).
path(Z, Z).
path(X, Y) :- move(X/ W), not(been(W)), assert(been(W)), path(W, Y).
Это определение предиката path представляет собой реализацию на языке PROLOG
алгоритма, описанного в главе 5. Как было указано выше, assert— это встроенный
предикат PROLOG, который всегда имеет значение "истина" и попутно помещает свои
аргументы в базу данных спецификаций. Предикат been используется для записи
посещенных ранее состояний и предотвращения циклов
Такое использование предиката been противоречит цели разработчика программы,
состоящей в создании спецификации логики предикатов без использования глобальных
переменных. В частности, been C ) после добавления в базу данных представляет собой факт,
доступный любой другой процедуре в этой базе данных, а значит, имеющий глобальный
контекст. Более того, создание глобальных структур для управления программой нарушает
базовый принцип моделирования продукционных систем, в которых логика (спецификации
задачи) хранится отдельно от средств управления программой. В данном случае структуры
been были созданы как глобальные спецификации, предназначенные для модификации
исполнения самой программы.
Как было предложено в главе 3, для отслеживания посещенных состояний и
предотвращения циклов при вызове предиката path можно использовать список. Для выявления
дублированных состояний (циклов) можно воспользоваться предикатом member. Такой
подход позволяет обойти проблему использования глобального утверждения been(W).
618 Часть VI. Языки и технологии программирования для искусственного интеллекта
Поиск в глубину с помощью алгоритма с возвратами, описанного в главах 3 и 5, на языке
PROLOG может быть реализован следующим образом.
path(Z, Z, L).
path(X, Y, L):-move(X/ Z), not(member(Z, L)), path(Z, Y#[Z|L]).
Здесь member — определенный выше предикат.
Третий параметр предиката path— это локальная переменная, представляющая
список уже посещенных состояний. При генерации нового состояния (с использованием
предиката move) оно помещается в начало списка состояний [ Z | L ] для следующего
вызова path, если оно до сих пор не содержалось в списке посещенных состояний
not(member(Z, L)).
Следует отметить, что все параметры предиката path являются локальными, а их
текущее значение зависит от места вызова на графе поиска. При каждом рекурсивном
вызове к этому списку добавляется новое состояние. Если все продолжения из данного
состояния завершаются неудачей, неудачей завершается и соответствующий вызов path.
Если интерпретатор возвращается к родительскому вызову, то третий параметр,
представляющий список посещенных состояний, принимает свое предыдущее значение.
Таким образом, в процессе поиска с возвратом на графе состояния добавляются и
удаляются из этого списка.
При успешном завершении вызова path первые два параметра принимают
одинаковые значения. Третий параметр — это список посещенных состояний в пути решения, в
котором эти состояния перечислены в обратном порядке. Таким образом, можно вывести
на печать все этапы решения. Спецификацию PROLOG для задачи "хода конем" с
использованием списков и поиска в глубину с возвратами можно получить с помощью
этого определения path и приведенных выше спецификаций предикатов move и member.
Вызов интерпретатора PROLOG для команды path(X, Y, [X] ), где X и Y— это
числа из диапазона от 1 до 9, позволяет найти путь из состояния X в состояние Y, если
этот путь существует. Третий параметр инициализирует список посещенных состояний
начальным состоянием X. Заметим, что в языке PROLOG регистр символов не
учитывается. Первые два параметра должны определять любое представление состояний в
области определения задачи, а третий — список состояний. С помощью унификации
выполняется обобщенная проверка соответствия шаблонам для всех возможных типов
данных. Таким образом, path — это общий алгоритм поиска в глубину, который можно
использовать для любого графа. В разделе 14.3 он будет применен для реализации
продукционной системы решения задачи "о перевозке человека, волка, козы и капусты" с
соответствующими спецификациями состояний.
Вернемся к решению задачи "хода конем" на поле 3x3. Полную задачу "хода конем"
на поле 8x8 на языке PROLOG читателю предлагается решить самостоятельно (см.
упражнения к главам 14 и 15). Для этого пронумеруем обе части алгоритма path.
1. is path(Z, Z, L).
2. is path(X, Y, L) :- move(X/ Z) , not (member (Z, L) ) , path(Z, Y/[Z|L]).
?- path(l, 3, [1]).
Выполним трассировку этой задачи.
path(l, 3, [1]) attempts to match 1. fail 1*3.
path(l, 3, [1]) matches 2. X is 1, Y is 3, L is [1]
moveA, Z) matches Z as 6, not(memberF, [1])) is true,
call pathF, 3, [6,1])
Глава 14. Введение в PROLOG
619
pathF, 3, [6,1]) attempts to match 1. fail 6*3.
pathF, 3, [6,1]) matches 2. X is 6, Y is 3, L is [6,1].
moveF,Z) matches Z as 7, not(memberG,[6,1])) is true,
pathG/3/[7,6,1])
pathG#3,[7,6,1]) attempts to match 1. fail 7*3.
pathG#3# [7#6#1]) matches 2. X is 7, Y is 3, L is [7,6,1].
moveG,Z) is Z = 6, not(memberF, [7,6,1])) fails, backtrack!
moveG,Z) is Z = 2, not(memberB, [7,6,1])) true,
pathB,3,[2,7,6,1])
path call attempts 1, fail, 2*3.
path matches 2, X is 2, Y is 3, L is [2,7,6,1]
move matches Z as 7, not(member (...)) fails, backtrack!
move matches Z as 9, not(member(...)) true,
path(9,3,[9,2,7,6,1])
path fails 1, 9*3.
path matches 2, X is 9, Y is 3, L is [9,2,7,6,1]
move is Z = 4, not(member (...)) true,
pathD, 3,[4,9,2,7,6,1])
path fails 1, 4*3.
path matches 2, X is 4, Y is 3, L is [4,9,2,7,6,1]
move Z = 3, not(member (...)) true,
pathC, 3, [3,4,9,2,7,6,1])
path attempts 1, true, 3=3, yes
yes
yes
yes
yes
yes
yes
В заключение отмстим, что рекурсивный вызов path — это оболочка (shell), или
общая управляющая структура для поиска на графе. В path(X, Y, L) X — текущее
состояние, Y — целевое. Если X и Y совпадают, рекурсия прекращается. L — список
состояний в текущем пути к состоянию Y. При обнаружении каждого нового состояния Z с
помощью вызова move(X, Z) это состояние помещается в список [Z|L]. Проверка
наличия состояния в списке выполняется с помощью вызова not (member (Z, L) ).
Эта проверка гарантирует отсутствие циклов в найденном пути.
Отличие между списком состояний L в рассмотренном алгоритме поиска пути и
замкнутым множеством closed из главы 3 состоит в том, что это множество содержит
все посещенные состояния, а в списке L хранится только текущий путь. Желательно
расширить запись, создаваемую при вызове path, и хранить все посещенные состояния.
Это будет сделано в разделе 14.4.
14.1.5. Использование оператора отсечения для управления поиском
в языке PROLOG
Оператор отсечения (cut) представляется символом ! и указывается в качестве
целевого утверждения без аргументов. При этом его применение имеет несколько побочных
эффектов. Во-первых, этот оператор всегда выполняется при его первом достижении, а
во-вторых, если при возврате оказывается невозможным вернуться к предыдущему со-
620 Часть VI Языки и технологии программирования для искусственного интеллекта
стоянию, то вес целевое утверждение, в котором содержится этот оператор, считается
ложным. В качестве простого примера использования оператора отсечения рассмотрим
реализацию вызова предиката path для поиска двухшагового пути в задаче "хода
конем". Можно создать следующий предикат path2.
path2(X, Y) :-move(X,Z), move(Z,Y).
Между точками X и Y существует двухшаговый путь, если между ними существует
"промежуточная остановка" Z. Предположим, для данного примера существует
следующая база данных ходов конем.
moveA
moveA
moveF
move(б
move(8
move(8
6) .
8) .
7) .
1) •
3) .
1) •
В ответ на запрос о поиске двухшаговых путей из состояния 1 интерпретатор выдаст
четыре значения.
7- path2A,W).
W = 7
W = 1
W = 3
W = 1
no
Если в предикате path2 используется оператор отсечения, то ответов будет только два.
path2(X, Y) :-move(X,Z), !, move(Z,Y).
?- path2A,W).
W = 7
W = 1
Это происходит потому, что переменная Z принимает только одно значение (первое
связанное с ней) — 6. Если первая подцель реализуется успешно, то переменная Z связывается со
значением 6, и достигается оператор отсечения. Поэтому в дальнейшем возврат к первой
подцели не выполняется, и переменная Z не связывается с другими значениями.
Оператор отсечения в программировании используется для нескольких целей. Во-
первых, как видно из данного примера, он позволяет программисту явно управлять
формой дерева поиска. Если дальнейший поиск (полный перебор) не требуется, то в этой
точке можно выполнить явное усечение дерева. При этом код на языке PROLOG
напоминает вызов функций: если предикат PROLOG (или набор предикатов) "возвращает"
одно множество значений (связей) и достигается оператор отсечения, то интерпретатор
не выполняет поиск для других подстановок унификации. Если это множество значений
не приводит к решению, то поиск решения не продолжается.
Глава 14. Введение в PROLOG
621
Во-вторых, оператор отсечения позволяет управлять рекурсией. Например, при
вызове предиката path
path(Z, Z, L).
path(X, Z, L) :- move(X, Y) , not(member(Y, L) ) , path(Y, Z,^!!,]), !.
добавление оператора отсечения означает, что в результате поиска на графе будет найдено
только одно решение. Уникальность решения обеспечивается тем, что последующие
решения будут найдены после выполнения дизъюнктивного выражения path (Z, Z, L). Если
пользователь запрашивает остальные решения, то предикат path(Z, Z, L) принимает
значение "ложь" и тем самым инициирует вызов второго предиката path для продолжения
поиска (полного перебора) на графе. Если оператор отсечения размещается после
рекурсивного вызова path, то этот вызов не может быть повторен (в результате возврата) для
продолжения поиска.
Важным побочным эффектом использования оператора отсечения является
ускорение работы программы и экономия памяти. Если этот оператор использован внутри
предиката, то указатели в памяти, необходимые для возврата к предикатам, расположенным
слева от оператора отсечения, не создаются. Дело в том, что они никогда не понадобятся.
Таким образом, применение оператора отсечения приводит к нахождению желаемого
решения только при более эффективном использовании памяти.
Оператор отсечения также можно использовать при реализации рекурсии для повторной
инициализации вызова path и продолжения поиска на графе. Эта возможность будет
продемонстрирована в разделе 14.3 при описании общего алгоритма поиска. Для реализации этого
алгоритма нам также понадобится разработать несколько абстрактных типов данных.
14.2. Абстрактные типы данных в PROLOG
Эффективность программирования в любой среде можно повысить за счет сокрытия
информации и введения процедурных абстракций. Поскольку в алгоритмах поиска на
графе, описанных в главах 3-5, используются такие структуры данных, как множество
(set), стек (stack), очередь (queue) и приоритетная очередь (priority queue), логично
ввести их в языке PROLOG, что и будет сделано в этом разделе.
Как уже отмечалось ранее, основными средствами построения структур для поиска на
графе являются рекурсия, списки и проверка соответствия шаблонам. С помощью этих
строительных блоков создаются абстрактные типы данных (АТД). Все процедуры обработки
списков и рекурсивные вызовы, определяющие АТД, "сокрыты" внутри этой абстракции, которая
в значительной мере отличается от обычных статических структур данных.
14.2.1. Стек
Стек (stack) — это линейная структура, доступ к которой осуществляется только с
одного конца. Следовательно, все элементы добавляются и удаляются из структуры с
одного и того же конца. Иногда стек называют структурой данных LIFO (Last-In-First-
Out) — "последним вошел, первым вышел". Примером работы этой структуры может
служить алгоритм поиска в глубину из подраздела 3.2.3. Для функционирования стека
необходимо определить следующие операции.
1. Проверка наличия элементов в стеке (проверка пустоты стека).
2. Добавление элемента в стек.
622 Часть VI. Языки и технологии программирования для искусственного интеллекта
3. Выталкивание (или удаление) последнего элемента (верхушки) из стека.
4. Просмотр последнего элемента (верхушки) без его удаления.
5. Проверка наличия данного элемента в стеке.
6. Добавление списка элементов в стек.
Операции 5 и 6 можно определить на основании первых четырех операций.
Теперь опишем эти операции на языке PROLOG, используя в качестве строительных
блоков списки.
1. empty_stack( [ ] ). Этот предикат можно использовать либо для проверки
пустоты стека, либо для создания нового пустого стека.
2 - 4. stack(Top/ Stack, [Top | Stack] ). Этот предикат выполняет операции
выталкивания, добавления и считывания последнего элемента стека в зависимости
от связанных переменных, передаваемых ему в качестве параметров. Например,
если первые два аргумента представляют собой связанные переменные, то в
третьем аргументе формируется новый стек. Аналогично, если третий элемент связан со
стеком, можно получить значение верхушки стека. Тогда второй аргумент будет
связан с новым стеком, из которого удален последний элемент. И, наконец, если
передать стек в качестве третьего аргумента, то через первый элемент можно
получить значение его верхушки.
5. member_stack(Element, Stack) :- member(Element, Stack). Это
выражение позволяет определить, содержится ли данный элемент в стеке.
Естественно, этот же результат можно получить с помощью рекурсивного вызова,
просматривая следующий элемент стека, а затем, если этот элемент не соответствует
значению аргумента Element, выталкивая его из стека. Эту процедуру
необходимо выполнять до тех пор, пока предикат проверки пустоты стека не примет
значение "истина".
6. add_list_to_stack(List/ Stack, Result) :- append(List/
Stack, Result). Значение первого аргумента List добавляется к значению
второго аргумента Stack для получения нового стека Result. Эту же операцию
можно выполнить, выталкивая элементы из стека List и добавляя каждый
следующий элемент во временный стек до тех пор, пока стек List не окажется
пустым. Затем нужно выталкивать по очереди элементы из временного стека и
добавлять их в стек Stack до опорожнения временного стека. Предикат append
подробно описан в разделе 14.8.
Осталось определить предикат reverse_print_stack, выводящий стек в
обратном порядке. Это очень полезно, если в стеке в обратном порядке хранится текущий путь
от начального состояния к текущему состоянию графа поиска. Несколько примеров
использования этого предиката будут приведены в следующих подразделах.
reverse_print_stack(S) :- empty_stack(S).
reverse_print_stack(S) :-
stack(E, Rest, S) ,
reverse_print_stack(Rest),
write(E), nl.
Глава 14. Введение в PROLOG
623
14.2.2. Очередь
Очередь (queue) — это структура данных FIFO (First-In-First-Out) — "первым вошел,
первым вышел". Ее зачастую рассматривают как список, в котором элементы удаляются
из одного конца, а добавляются в другой. Очередь использовалась для определения
поиска в ширину в главах 3 и 4. Для реализации очереди требуются следующие операции.
1. empty_queue ( [ ] ). Этот предикат либо выполняет проверку очереди на
пустоту, либо инициализирует новую пустую очередь.
2. enqueue (Е, [ ] , [Е] ).
enqueue (E, [Н|Т], [H|Tnew]) :- enqueue(E, Т, Tnew). Этот
рекурсивный предикат добавляет в очередь, определяемую вторым аргументом, элемент Е.
Третий элемент представляет новую очередь.
3. dequeue (Е, [Е|Т], Т). Этот предикат создает новую очередь (третий
аргумент), которая является результатом удаления очередного элемента (первого
аргумента) из исходной очереди, определяемой вторым аргументом.
4. dequeue (Е, [Е | Т] , _). Этот предикат позволяет прочитать следующий
элемент Е данной очереди.
5. member_queue(Element, Queue) :- member(Element, Queue). Это
выражение проверяет, содержится ли элемент Element в очереди Queue.
6. add_list_to_queue(List, Queue, Newqueue) :- append(Queue,
List, New-queue). Очистка всех элементов очереди.
Очевидно, что операции 5 и 6 можно реализовать на основе первых четырех
операций. Предикат append описан в разделе 14.10.
14.2.3. Приоритетная очередь
В приоритетной очереди (priority queue) элементы обычной очереди упорядочены, и
каждый новый элемент добавляется в соответствующее место. Оператор удаления
элемента из очереди извлекает из нее лучший отсортированный элемент. Приоритетная
очередь была использована при разработке "жадного" алгоритма поиска в главе 4.
Поскольку приоритетная очередь — это, по существу, отсортированная обычная
очередь, многие из ее операций совпадают с операциями для обычной очереди. К таким
операциям относятся empty_queue, member_queue и dequeue (следующим
элементом для операции dequeue является "лучший" отсортированный элемент). Операции
enqueue в приоритетной очереди соответствует операция insert_pq, поскольку
каждый новый элемент должен помещаться в отведенное для него место.
insert_pq(State, [ ], [State]):- !.
insert_pq(State, [H|Tail], [State, H|Tail]):-
precedes(State, H).
insert_pq(State, [H|T], [H|Tnew]):-
insert_pq(State, T, Tnew).
precedes(X, Y) :- X < Y. %оператор сравнения зависит от типов
%элементов
Первый аргумент такого предиката — это вновь добавляемый элемент. Вторым
аргументом является существующая приоритетная очередь, а третьим — расширенная
очередь. Предикат precedes отвечает за соблюдение порядка элементов в очереди.
624 Часть VI. Языки и технологии программирования для искусственного интеллекта
Следующим оператором для приоритетной очереди является insert_list_pq.
Этот предикат используется для добавления несортированного списка или множества
элементов в приоритетную очередь. Это необходимо при добавлении дочернего
состояния в приоритетную очередь при реализации "жадного" алгоритма поиска (глава 4 и
подраздел 14.4.3). Оператор insert_list_pq использует оператор insert_pq для
добавления в приоритетную очередь каждого нового элемента.
insert_list_pq([ ], L, L).
insert_list_pq([State/Tail], L, New_L) :-
insert_pq(State, L, L2),
insert_list_pq(Tail, L2, New_L).
14.2.4. Множество
И, наконец, опишем абстрактный тип данных множество (set). Множество — это набор
неповторяющихся элементов. Его можно использовать для объединения всех дочерних
состояний или поддержания списка closed в алгоритме поиска, представленном в главах 3 и
4. Множество элементов, например {а, Ь}, представляется в виде списка [а, Ь], в
котором порядок элементов не играет роли. Для множества необходимо определить операции
empty_set, member_set, delete_if_in_set и add_if_not_in_set.
Потребуются также операции для объединения и сравнения множеств, включая union,
intersection, set_difference,subset и equal_set.
empty_set([ ]).
member_set(E, S) :-
member(E, S).
delete_if_in_set(E, [ ], [ ]).
delete_if_in_set(E, [E|T], T) :- !.
delete_if_in_set(E, [Н|Т], [H|T_new]) :-
delete_if_in_set(E, T, T_new), !.
add_if_not_in_set(X, S, S) :-
member(X, S), !.
add_if_not_in_set(X, S, [X|S]).
union([ ], S, S).
union([H|T], S, S_new):-
union(T, S, S2) ,
add_if_not_in_set(H, S2, S_new), !.
subset([ ], _).
subset([H|T], S) :-
member_set(H, S),
subset(T, S).
intersection([ ], _, [ ]).
intersection![H|T], S, [H|S_new]) :-
member_set(H, S),
intersection(T, S, S_new), !.
intersection([_|T], S, S_new) :-
intersection(T, S, S_new), !.
set_difference([ ], _, [ ]) .
set_difference([H|T], S, T_new) :-
member_set(H, S),
set_difference(T, S, T_new), !.
set_difference([H|T], S, [H|T_new]) :-
set_difference(T, S, T_new), !.
Глава 14. Введение в PROLOG
625
equal_set(SI, S2) :-
subset(SI, S2),
subset(S2# SI).
14.3. Пример продукционной системы на языке PROLOG
В этом разделе будет рассмотрена продукционная система для решения задачи
перевозки человека, волка, козы и капусты. Эта задача формулируется следующим образом.
Человеку требуется переправиться через реку и перевезти с собой волка, козу и капусту. На
берегу реки находится лодка, которой должен управлять человек Лодка одновременно может
перевозить не более двух пассажиров (включая лодочника). Если волк останется на берегу с
козой, то он ее съест. Если коза останется на берегу с капустой, то она уничтожит капусту.
Требуется выработать последовательность переправки через реку таким образом, чтобы все
четыре пассажира были доставлены в целости и сохранности на другой берег реки.
Рассмотрим продукционную систему, обеспечивающую решение этой проблемы. Во-
первых, очевидно, что эту задачу можно представить как задачу поиска на графе. Для
этого нужно учесть все возможные ходы, доступные в каждый момент решения задачи.
Некоторые из этих ходов могут оказаться неудовлетворительными, поскольку приводят к
получению неустойчивых состояний (кто-то кого-то съест).
Для начала предположим, что все состояния устойчивы, и просто рассмотрим граф
возможных состояний. В лодке можно перевозить четыре комбинации пассажиров:
человека и волка, человека и козу, человека и капусту, а также одного человека.
"Состоянием мира" является некоторая комбинация символов на двух берегах. На
рис. 14.1 показаны несколько состояний процесса поиска. "Состояние мира" можно
представить с помощью предиката state(F, W, G, С),в котором первый параметр
определяет местоположение человека, второй параметр — местоположение волка,
третий — козы, а четвертый — капусты. Предполагается, что река течет с севера на юг,
поэтому берега обозначим символами е (восточный) и w (западный). Таким образом,
state(w, w, w, w) означает, что все объекты расположены на западном берегу. Эта
ситуация соответствует началу решения задачи.
Следует отметить, что все описанные соглашения были произвольно выбраны
автором. На самом деле, как отмечают специалисты в области искусственного интеллекта,
выбор соответствующего представления — зачастую наиболее критичный аспект
решения задачи. Выбранные соглашения обеспечивают удобное представление логики
предикатов на языке PROLOG. Различные состояния мира создаются в результате переправы
через реку и представляются изменениями значений параметров предиката state
(рис. 14.1). Возможны также и другие представления.
Теперь опишем общий граф для данной проблемы переправы. Пока не будем
учитывать тот факт, что некоторые состояния являются неустойчивыми. На рис. 14.2 показано
начало графа возможных переправ через реку. Поскольку человек всегда управляет
лодкой, то нет необходимости вводить отдельное представление для местоположения лодки.
На рис. 14.2 показана часть графа, на котором необходимо выполнять поиск пути.
Описанный выше рекурсивный вызов предиката path обеспечивает механизм
управления поиском в продукционной системе. Продукционные правила — это правила
изменения состояния в процессе поиска. Определим их на языке PROLOG как правила move.
Поскольку язык PROLOG оперирует хорновскими дизъюнктами, то продукционные
правила на языке PROLOG должны либо напрямую описываться в хорновской дизъюнк-
626 Часть VI. Языки и технологии программирования для искусственного интеллекта
тивной форме, либо преобразовываться к этому формату. Выберем первый вариант
(процесс приведения правил "если..., то..." к хорновской дизъюнктивной форме описан
в разделе 12.2). В хорновской дизъюнктивной форме шаблоны текущего и последующего
состояний должны располагаться в голове дизъюнктивного выражения, т.е. слева от
оператора : -. Они являются аргументами предиката move. Условия, которым должно
удовлетворять продукционное правило для возвращения следующего состояния,
размещаются справа от оператора : -. Как будет показано в следующем примере, эти условия также
могут быть представлены в виде ограничений унификации.
N
state(w, w, w, w)
state(e, w, e, w)
state(w, w, e, w)
state(e, w, e, e)
state(w, w, w, e)
state(e, e, w, e)
state(w, e, w, e)
FWGC
WC
FWC
W
FWG
FG
W-
FCG
FWC
WC
Рис 14 1 Пример последовательности перевозок для задачи переправы
человека, волка, козы и капусты
Сначала определим правила для перевозки через реку волка. Это правило должно
учитывать перевозку как с левого берега на правый, так и наоборот, а также должно быть
применимо, если человек и волк находятся на противоположных берегах реки. Таким образом,
оно должно преобразовывать состояние state(e, е, G, С) в состояние state (w,
w, G, С), а состояние state (w, w, G, C) —Bstate(e/ e, G, С). Для состоя -
Hnftstate(c/ w, G, С) и state(w, e, G, С) оно должно принимать значение
"ложь". Переменные G и С представляют тот факт, что третий и четвертый параметры
могут быть связаны с любым из значений е или w. Независимо от значений этих параметров
они не изменяются после переправы человека и волка. Некоторые из полученных
состояний могут оказаться "неустойчивыми".
Следующее правило move применимо только в том случае, если человек и волк
находятся на одном и том же берегу и переправляются на противоположный берег реки.
Заметим, что местоположение козы и капусты не изменяется.
move(state(X#X#G#C)# state(Y,Y,G,С)) :- орр(Х, Y).
opp(е, w) .
орр(w, е).
Глава 14. Введение в PROLOG
627
state(w, w, w, w)
state(e, e, w, w)
state(e, w, e, w) state(e, w, w, e) state(e, w, w, w)
state(w, e, w, w) state(w, w, e, w) state(w, w, w, e)
state(e, e, e, w)
state(e, e, w, e) state(e, w, e, e,]
Рис 14 2 Часть графа состояний дчя задачи переправы чеювека,
волка, козы и капусты с учетом неустойчивых состояний
Это правило срабатывает в том случае, если в качестве первого параметра предикату
move передается состояние (текущее положение на графе), соответствующее
одинаковому местоположению человека и волка При активизации этого правила генерируется
новое состояние (второй параметр предиката move), в котором значение Y
противоположно значению X. Для получения этого нового состояния должны быть выполнены два
условия. Во-первых, должны совпадать значения первых двух параметров, а во-вторых,
оба новых местоположения должны быть противоположны старым.
Первое условие проверяется неявно в процессе унификации. Следовательно, если
первые два параметра не совпадают, то предикат move даже не вызывается. Эту
проверку можно явно выполнить с помощью следующего правила.
move(state(F, W, G, С), state(Z, Z, G, О) :- F=W# opp(F, Z) .
В этом эквивалентном правиле move сначала проверяется равенство значений F и W, и
только при его выполнении (расположении обоих объектов на одном берегу реки) параметру
Z присваивается значение, противоположное F. Заметим, что в языке PROLOG присваивание
можно реализовать с помощью связывания значений переменных в процессе унификации.
Связанные значения распространяются на все вхождения переменной в дизъюнктивном
выражении, и область действия переменной ограничивается содержащим ее дизъюнктом.
В процессе усечения поиска важную роль играет такое мощное средство
программирования систем искусственного интеллекта, как проверка соответствия шаблонам.
Состояния, не удовлетворяющие шаблонам, автоматически отсекаются для данного
правила. В этом смысле первая версия правила move обеспечивает более эффективное
представление, поскольку, если первые два параметра не совпадают, то в процессе
унификации это состояние даже на рассматривается.
Теперь создадим предикат, позволяющий проверить безопасность каждого нового
состояния, чтобы в процессе переправы через реку ни один из объектов не был съеден. Не-
628 Часть VI. Языки и технологии программирования для искусственного интеллекта
безопасным является любое состояние, в котором второй и третий параметры совпадают
и противоположны первому параметру. В этом случае волк съест козу. Кроме того,
небезопасным является и такое состояние, при котором одинаковы третий и четвертый
параметры, и при этом они противоположны первому. Тогда коза съест капусту. Эти
небезопасные ситуации можно представить в виде следующих правил unsafe.
unsafe(state(X, Y, Y, С)) :- opp(X, Y).
unsafe(state(X, W, Y, Y)) :- opp(X, Y).
Здесь необходимо отметить несколько моментов. Во-первых, если состояние "не
является небезопасным" not unsafe (т.е. безопасно), то согласно определению
встроенной процедуры not в языке PROLOG для этого состояния не может быть истинным ни
один из предикатов unsafe. Следовательно, ни один из этих предикатов не может быть
унифицирован с текущим состоянием, или при унификации их условия не должны
выполняться. Во-вторых, встроенная процедура not не эквивалентна операции логического
отрицания -1 в теории предикатов первого порядка. Процедура not — это, скорее,
отрицание за счет невыполнения противоположного утверждения. Чтобы проверить, как
поведет себя предикат unsafe, необходимо протестировать множество состояний.
Добавим к предыдущему продукционному правилу проверку not unsafe.
move(state(X/ X, G, С), state(Y, Y, G, C)) :-
opp(X, Y), not(unsafe(state(Y, Y, G, C))).
Процедура not unsafe проверяет приемлемость нового состояния в процессе поиска с
помощью вызова предиката unsafe. Если все критерии удовлетворяются, включая проверку
(в алгоритме path) отсутствия этого состояния в списке уже пройденных состояний, для
данного состояния вызывается (рекурсивно) алгоритм path для перехода глубже по графу. При
вызове предиката path новое состояние добавляется к списку уже пройденных.
Аналогично можно разработать три других продукционных правила,
представляющих переправу через реку человека с козой, капустой и без "пассажиров". Для вывода
результатов трассировки добавим к каждому правилу команду writelist.
Команда reverse_print_stack используется в условии останова алгоритма
path для вывода пути окончательного решения. И, наконец, добавим пятое
"псевдоправило", которое не содержит никаких условий и поэтому всегда срабатывает
при невыполнении всех предыдущих правил. Оно означает возврат вызова алгоритма
path из текущего состояния. Это псевдоправило позволяет пользователю отслеживать
поведение продукционной системы в процессе ее работы.
Теперь рассмотрим полную программу на языке PROLOG, реализующую
продукционную систему решения задачи переправы человека, волка, козы и капусты. Она должна
включать предикаты unsafe и writelist, а также предикаты, описывающие
абстрактный тип данных стек (подраздел 14.2.1).
move(state(X/ X, G, С) , state(Y, Y, G, С)) :-
орр(Х, Y) not(unsafe(state(Y, Y, G, C))),
writelist([*попытка переправить человека и волка'; Y, Y, G, С] ) .
move(state(X/ W, X, С) , state(Y, W, Y, С) ) :-
орр(Х, Y), not(unsafe(state(Y, W, Y, С))),
writelist(['попытка переправить человека и козу', Y, W, Y, С] ) .
move (state (X, W, G, X), state(Y, W, G, Y) ) :-
opp(X, Y), not(unsafe(state(Y, W, G, Y) ) ) ,
writelist(['попытка переправить человека и капусту', Y, W, G, Y]) .
Глава 14. Введение в PROLOG
629
move(state(X/ W, G, C), state(Y, W, G, C)) :-
opp(X, Y) , not(unsafe(state(Y, W, G, C) )),
writelist(['попытка переправить одного человека', Y, W, G, С] ) .
move(state(F/ W, G, C), state(F# W, G, C)) :-
writelist([x ВОЗВРАТ из', F, W, G, C] ) , fail,
path(Goal, Goal, Been_stack):-
write(хПуть решения: '), nl,
reverse_print_stack(Been_stack).
path(State, Goal, Been_stack):-
move(State/ Next_state),
not(member_stack(Next_state, Been_stack)),
stack(Next_state, Been_stack, New_been_stack) ,
path(Next_state, Goal, New_been_stack),!.
opp(e, w) .
opp (w, e) .
Этот код вызывается в запросе go, инициализирующем рекурсивный вызов
алгоритма path. Чтобы упростить работу программы, можно создать предикат test,
облегчающий ввод начальных данных.
go(Start, Goal) :-
empty_stack(Empty_been_stack),
stack(Start, Empty_been_stack/ Been_stack),
path(Start, Goal, Been_stack).
test :- go(state(w, w, w, w), state(e, e, e, e)).
Этот алгоритм возвращается из состояний, не обеспечивающих дальнейшего
продвижения. Для мониторинга связывания различных переменных в процессе каждого вызова
алгоритма path можно использовать команду trace. Следует отметить, что эта
система является общей программой перемещения четырех объектов из любого (допустимого)
местоположения на берегах реки в любое другое (допустимое) местоположение, включая
поиск обратного пути к начальному состоянию. Другие интересные свойства этой
продукционной системы, в том числе зависимость результатов поиска на графе от порядка
следования правил, можно проиллюстрировать в следующих упражнениях. Приведем
некоторые результаты трассировки выполнения программы, отображая лишь правила,
действительно используемые для генерации новых состояний.
?- test.
попытка переправить человека и козу е w e w
попытка переправить одного человека w w e w
попытка переправить человека и волка е е е w
попытка переправить человека и козу w e w w
попытка переправить человека и капусту е е w e
попытка переправить человека и волка w w w e
попытка переправить человека и козу е w e e
ВОЗВРАТ из е, w, e, e
ВОЗВРАТ из w, w, w, e
попытка переправить одного человека w e w e
попытка переправить человека и козу е е е е
Путь решения:
state (w, w, w, w)
state(e, w, e, w)
state(w, w, e, w)
630 Часть VI. Языки и технологии программирования для искусственного интеллекта
statei
state
state
state
state
(e,
(w,
(e,
(w,
(e,
e,
e,
e,
e,
e,
e,
w,
w,
w,
e,
w)
w)
e)
e)
e)
Итак, эта программа на языке PROLOG реализует продукционную систему решения
задачи переправы человека, волка, козы и капусты. Правила move составляют продукционную
память. Рабочая память представлена аргументами вызова алгоритма path. Механизм
управления продукционной системой реализуется с помощью рекурсивного вызова path. И,
наконец, порядок следования правил для генерации дочерних состояний (разрешения конфликта)
определяется порядком расположения этих правил в продукционной памяти.
14.4. Разработка альтернативных стратегий поиска
Как видно из предыдущего раздела, в самом языке PROLOG реализован поиск в
глубину с возвратом. Этот момент более детально будет описан в разделе 14.7. Теперь
рассмотрим, как реализовать на языке PROLOG альтернативные стратегии поиска,
описанные в главах 3-5. Для записи состояний в процессе поиска в глубину, в ширину и при
реализации алгоритма поиска будут использованы списки open и closed. В случае
неудачного завершения поиска в некоторой точке мы не будем возвращаться к
предыдущим значениям этих списков. Они будут обновляться при вызове алгоритма path, и
поиск будет продолжаться с новыми значениями. Для предотвращения хранения старых
версий списков open и closed будет использован оператор отсечения.
14.4.1. Поиск в глубину с использованием списка closed
Поскольку при возвратах в рекурсивных вызовах значения переменных
восстанавливаются, алгоритм поиска в глубину из раздела 14.3 пополняет список пройденных
состояний только состояниями, относящимися к текущему пути к цели. И хотя проверка
наличия в списке каждого нового состояния позволяет избежать циклов, она требует
повторного тестирования тех областей пространства, которые уже были достигнуты ранее
при построении других путей, но отклонены на данный момент из-за их
бесперспективности. Это более полное множество состояний составляет список, получивший название
closed в главе 3 и Closed_set в следующем алгоритме.
В множестве Closed_set хранятся все состояния текущего пути и состояния,
отвергнутые при возврате алгоритма. Следовательно, теперь оно не представляет путь от
исходного к текущему состоянию. Для хранения информации о пути определим
упорядоченную пару [ State, Parent ], представляющую каждое состояние и его родителя.
Начальное состояние Start будет представлено парой [Start, nil]. Эти пары
будут использованы для воссоздания пути решения из множества Closed_set.
Опишем на языке PROLOG структуру программы для поиска в глубину, отслеживая
значения списков open и closed и проверяя каждое новое состояние на его наличие в
списке пройденных. Алгоритм path зависит от трех параметров: стека Open_stack,
Closed_set (обрабатываемого как множество) и целевого состояния Goal. Текущее
состояние State является следующим состоянием для Open_stack. Операторы
stack и set описаны в разделе 14.2.
Глава 14. Введение в PROLOG
631
Поиск начинается с предиката до, инициализирующего вызов алгоритма path.
Заметим, что при выполнении команды до в стек Open_stack помещается пара,
описывающая начальное состояние с нулевым родителем [Start, nil]. Множество
Closed_set пока пусто.
go(Start, Goal) :- ,
empty_stack(Empty_open),
stack([Start, nil], Empty_open, Open_stack),
empty_set(Closed_set),
path(Open_stack, Closed_set, Goal).
Вызов алгоритма path, зависящего от трех аргументов, имеет вид.
path(Open_stack, _, _) :-
empty_stack(Open_stack),
write('Эти правила не привели к решению').
path(Open_stack, Closed_set, Goal)
stack([State, Parent], _, Open_stack), State = Goal,
write('Решение найдено!')/ nl,
printsolution([State, Parent], Closed_set).
path(Open_stack, Closed_set, Goal) :-
stack([State, Parent], Rest_open_stack, Open_stack),
get_children(State, Rest_open_stack, Closed_set, Children),
add_list_to_stack(Children, Rest_open_stack, New_open_stack) ,
union([[State, Parent]], Closed_set, New_closed_set),
path(New_open_stack, New_closed_set, Goal), !.
get_children(State, Rest_open_stack, Closed_set, Children) :-
bagof(Child, moves(State, Rest_open_stack,
Closed_set, Child), Children),
moves(State, Rest_open_stack, Closed_set, [Next, State]) :-
move(State, Next),
not(unsafe(Next)), % проверка зависит от задачи
not(member_stack( [Next, _] , Rest_open_stack)) ,
not(member_set([Next, _], Closed_set)).
Предполагается, что правила move и (при необходимости) предикат unsafe
некоторым образом определены
move(Present_state, Next_state) :- ... % первое правило
move(Present_state, Next_state) :- ... % второе правило
При вызове первой команды path поиск прекращается, если стек Open_stack пуст.
Это означает, что в списке open больше не содержатся состояния для продолжения
поиска. Обычно это свидетельствует о том, что для данного графа выполнен поиск полным
перебором. Второй вызов path завершается при нахождении решения, которое и выводится
на печать. Поскольку состояния графа поиска представлены парами [State, Parent],
команда printsolution перейдет ко множеству Closed_set и рекурсивно перестроит
путь решения. Заметим, что путь решения будет выведен r прямом порядке.
printsolution([State, nil], _) :-
write(State), nl.
printsolution([State, Parent], Closed_set) :-
member_set([Parent, Grandparent], Closed_set),
printsolution([Parent, Grandparent], Closed_set),
write(State), nl.
632 Часть VI Языки и технологии программирования для искусственного интеллекта
В третьем вызове path используется стандартный для многих интерпретаторов
языка PROLOG предикат bagof. Он позволяет хранить все подстановки унификации для
данного шаблона в едином списке. Второй параметр предиката bagof — это шаблон, с
которым производится сравнение в базе данных. Первый параметр определяет
подлежащие хранению в списке компоненты второго параметра. Например, нас могут
интересовать связанные значения для одной переменной предиката. Все связанные переменные
первого параметра накапливаются в списке и связываются с третьим параметром.
В этой программе предикат bagof накапливает состояния, достигнутые при
срабатывании всех существующих продукционных правил. Естественно, необходимо хранить все
потомки конкретного состояния, поэтому их можно добавить в соответствующем порядке в
список open. Вторым аргументом предиката bagof является новый предикат moves,
вызывающий предикаты move для генерации всех состояний, которые могут бьпь достигнуты с
помощью данного продукционного правила. Аргументами предиката moves являются
текущее состояние, списки open и closed и переменная, представляющая состояние, достшас-
мос при "хорошем" ходе. Прежде чем возвратить это состояние, предикат moves проверяет,
что это новое состояние Next не содержится в множествах rest_open_stack, open
(поскольку текущее состояние удалено) и closed_set. Предикат bagof вызывает moves и
накапливает все состояния, удовлетворяющие этим условиям. Третий api-умснт предиката
bagof представляет новые состояния, помещенные в стек Open_stack.
В некоторых реализациях предикат bagof принимает значение "ложь", если для
второго аргумента не найдено никаких соответствий, а значит, третий аргумент пуст. Это
можно исправить с помощью подстановки (bagof (X, moves (S, Т, С, X) ,
List) ; List= [ ] ) для текущих вызовов предиката bagof в данном коде.
Поскольку состояния поиска представлены парами "состояние-родшель". предикаты
проверки вхождения элемента во множество member_set необходимо модифицировать таким
образом, чтобы они отражали структуру проверки соответствия шаблону Необходимо
проверить, совпадает ли пара "состояние-родитель" с первым элементом списка таких пар, и, если
нет — выполнить рекурсивное сравнение со всеми остальными элементами списка
member_set([State, Parent], [[State, Parent]| _]).
member_set(X, [_|T]) :- member_set(X, T).
14.4.2. Поиск в ширину в языке PROLOG
Теперь рассмотрим оболочку (shell) алгоритма поиска в ширину, явно использующую
списки open и closed. Эту оболочку совместно с правилами move и предикатами
unsafe можно применять для решения любой задачи поиска. Алгоритм вызывается
следующим образом.
go(Start, Goal) :-
empty_queue(Empty_open_queue),
enqueue([Start, nil], Empty_open_queue, Open_queue),
empty_set(Closed_set),
path(Open_queue, Closed_set, Goal).
Значения параметров Start и Goal очевидны. Они представляют начальное и
целевое состояния. В этом алгоритме, как и при поиске в глубину, снова создаются
упорядоченные пары [State, Parent] для хранения информации о каждом состоянии и его
родителе. Начальное состояние Start представляется парой [Start, nil] . Эта ип-
Глава 14. Введение в PROLOG
633
формация используется командой print solution для воссоздания пути решения на
основе множества Closed_set. Первым параметром предиката path является
открытая очередь Open_queue, вторым— множество Closed_set, а третьим— целевое
состояние Goal. Переменные, значения которых не учитываются в дизъюнктивном
выражении, обозначаются символом _.
path(Open_queue/ _, _) :-
empty_queue(Open_queue),
write('Поиск завершен, решение не найдено').
path(Open_queue/ Closed_set/ Goal) :-
dequeue([State, Parent], Open_queue, _), State = Goal,
write('Путь решения:'), nl,
printsolution([State, Parent], Closed_set).
path(Open_queue, Closed_set, Goal) :-
dequeue([State, Parent], Open_queue, Rest_open_queue) ,
get_children(State, Rest_open_queue, Closed_set, Children),
add_list_to_queue(Children, Rest_open_queue, New_open_queue) ,
union([[State, Parent]], Closed_set, New_closed_set) ,
path(New_open_queue, New_closed_set, Goal), !.
get_children(State, Rest_open_queue, Closed_set, Children) :-
bagof(Child, moves(State, Rest_open_queue,
Closed_set, Child), Children).
moves(State, Rest_open_queue, Closed_set, [Next, State]) :-
move(State, Next),
not(unsafe(Next)), ^проверка зависит от задачи
not(member_queue([Next, _], Rest_open_queue)),
not(member_set([Next, _], Closed_set)).
Этот фрагмент кода назван оболочкой, поскольку здесь не описаны правила move. Их
необходимо добавить с учетом конкретной предметной области задачи. Операторы
queue и set описаны в разделе 14.2.
Первое условие останова алгоритма path определяется для случая, когда предикат
path вызывается с пустым первым аргументом Open_queue. Эта ситуация возникает,
только если для графа больше не осталось непроверенных состояний, а решение не было
найдено. Решение находится при вызове второго предиката path, когда голова очереди
Open_queue совпадает с целевым состоянием Goal.
В процессе поиска пути предикаты bagof и moves накапливают все дочерние
состояния для текущих состояний и поддерживают очередь. Работа этих предикатов
описана в предыдущем разделе. Чтобы воссоздать путь решения, каждое состояние
сохраняется в виде пары [State, Parent]. Родителем начального состояния является
указатель nil. Как упоминалось в подразделе 14.4.1, попарное представление состояний
требует некоторого усложнения проверки соответствия шаблонам в предикатах member,
moves и printsolution.
14.4.3. Реализация "жадного" алгоритма поиска на языке PROLOG
Оболочка для реализации "жадного" алгоритма поиска — это модификация
программы поиска в ширину, в которой открытая очередь для каждого нового вызова path
заменяется приоритетной очередью, упорядоченной по эвристическому критерию. В
предлагаемом алгоритме эвристическая мера неразрывно связана с каждым новым
состоянием открытой очереди и применяется для систематизации ее элементов. Мы будем также
634 Часть VI. Языки и технологии программирования для искусственного интеллекта
хранить информацию о родителе каждого состояния. Как и при реализации поиска в
ширину, она используется для построения пути решения командой printsolution.
Чтобы отслеживать всю необходимую для поиска информацию, каждое состояние
представим в виде списка из пяти элементов: описание состояния, родительское состояние,
целое число, определяющее глубину поиска на графе, целое число, определяющее
эвристическую меру качества состояния, и целочисленная сумма третьего и четвертого элемента.
Первый и второй элементы списка находятся обычным образом, третий определяется
путем добавления единицы к предыдущей глубине, четвертый — это эвристическая мера для
конкретной задачи. Пятый элемент списка используется для упорядочения состояний в
открытой очереди Open_pq и вычисляется по формуле f (n)=g(n)+h(n) (см. главу 4).
Как и ранее, правила move не приводятся. Они определяются с учетом специфики
задачи. Операторы работы с очередью и приоритетной очередью описаны в разделе 14.2.
Мера качества состояния heuristic тоже определяется с учетом специфики задачи и
отражает эвристический характер четвертого параметра в списке описаний.
Этот алгоритм имеет два условия останова и вызывается следующим образом.
до(Start, Goal) :-
empty_set(Closed_set),
empty_pq(Open),
heuristic(Start, Goal, H),
insert_pq([Start, nil, 0, H, H], Open, Open_pq),
path(Open_pq, Closed_set, Goal).
Здесь nil — это родительское состояние для состояния Start, a H— его
эвристическая мера качества. Приведем код программы, реализующей "жадный" алгоритм поиска.
path(Open_pq, _, _) :-
empty_pq(Open_pq),
write('Поиск завершен, решение не найдено.'),
path(Open_pq, Closed_set, Goal) :-
dequeue_pq([State, Parent, _, _, _], Open_pq, _),
State = Goal,
write('Путь решения:'), nl,
printsolution([State, Parent, _, _, _], Closed_set).
path(Open_pq, Closed_set, Goal) :-
dequeue_pq([State, Parent, D, H, S], Open_pq, Rest_open_pq),
get_children([State, Parent, D, H, S], Rest_open_pq,
Closed_set, Children, Goal),
insert_list_pq(Children, Rest_open_pq, New_open_pq),
union([[State, Parent, D, H, S]], Closed_set, New_closed_set),
path(New_open_pq, New_closed_set, Goal), !.
Предикат get_children генерирует все дочерние состояния для состояния State.
Как и в предыдущих алгоритмах поиска, в нем используются предикаты bagof и
moves. Работа этих предикатов более подробно описана в подразделе 14.4.1. Правила
переходов, проверки безопасности допустимых переходов и эвристическая мера качества
определяются с учетом конкретной задачи. Проверка принадлежности элемента
множеству должна быть специально реализована для списков из пяти элементов.
get_children([State,_, D, _, _], Rest_open_pq, Closed_set,
Children, Goal) :-
bagof(Child, moves([State, _, D, _, _], Rest_open_pq,
Closed_set, Child, Goal), Children).
Глава 14. Введение в PROLOG
635
moves([State, _, Depth, _, _], Rest_open_pq/ Closed_set/
[Next, State, New_D, H, S], Goal) :-
move(State, Next),
not(unsafe(Next)), ^определяется с учетом задачи
not(member_pq([Next, _, _, _, _], Rest_open_pq)),
not(member_set([Next, _, _, _, _], Closed_set)),
New_D is Depth + 1,
heuristic(Next, Goal, H), ^определяется с учетом задачи
S is New_D + H.
И, наконец, команда printsolution выводит путь решения. Она рекурсивно
находит пары [State, Parent] путем проверки соответствия первых двух элементов в
описании состояния первым двум элементам пятиэлементных списков, составляющих
множество Closed_set. Родителем начального состояния является указатель nil.
printsolution([State, nil, _, _, _], _) :-
write(State), nl.
printsolution([State, Parent, _, _, _], Closed_set) :-
member_set([Parent, Grandparent, _, _, _], Closed_set),
printsolution([Parent, Grandparent, _, _, _], Closed_set),
write(State), nl.
14.5. Реализация планировщика на языке PROLOG
В разделе 5.4 был описан алгоритм планирования на основе теории предикатов.
В нем логика предикатов использовалась как для представления состояний мира
планирования, так и для описания правил изменения таких состояний. В этом разделе будет
разработана реализация этого алгоритма на языке PROLOG.
Состояния мира, включая начальное и целевое, представим в виде списков предикатов.
В рассматриваемом примере начальное и целевое состояния можно описать таким образом.
start = [handempty, ontable(b), ontable(c), on(a, b), clear(c),
clear(a)]
goal = [handempty, ontable(a), ontable(b), on(c, b), clear(a),
clear(c)]
Эти состояния наряду с фрагментом пространства поиска показаны на рис. 14.3 и 14.4.
Переходы в этом "мире блоков" описываются с помощью списков добавления и
удаления, как в разделе 7.4. Предикаты move зависят от трех аргументов. Первый — имя
предиката move с его параметрами. Второй аргумент — это список предусловий, т.е. перечень
предикатов, которые должны быть истинны в описании состояния мира, чтобы данное
правило перехода было применимо к этому состоянию. Третий аргумент — это список
добавления и удаления или перечень предикатов, которые добавляются к состоянию мира или
удаляются из него для создания нового состояния в результате применения правила
перехода. Заметим, что в данном случае полезно использовать абстрактные типы данных и
операции над множествами, в том числе объединение, пересечение, разность и т.д. Их удобно
применять для управления предусловиями, а также добавления и удаления списков.
Четыре перехода в этом мире можно описать следующим образом.
move(pickup(X) , [handempty, clear(X), on(X, Y) ] ,
[del(handempty), del(clear(X)), del(on(X,Y)),
add(clear(Y)), add(holding(X))]).
636 Часть VI. Языки и технологии программирования для искусственного интеллекта
move(pickup(X), [handempty, clear(X), ontable(X)],
[del(handempty), del(clear(X)), del(ontable(X)),
add(holding(X))]).
move(putdown(X), [holding(X)],
[del(holding(X)), add(ontable(X)),
add(clear(X)), add(handempty)]).
move(stack(X/ Y), [holding(X), clear(Y)],
[del(holding(X)), del(clear(Y)), add(handempty),
add(on(X, Y)), add(clear(X))]).
ЕЕ
в
н, .и
в
^ЗЖ^Н2в
Начальное состояние Целевое состояние
Рис. 14.3. Начальное и целевое состояния для задачи из мира блоков
Рис 14 4 Начальные уровни пространства состояний для мира блоков
И, наконец, построим рекурсивный контроллер для генерации плана. Первый
предикат планирования соответствует условиям останова при успешной реализации плана,
т е. при достижении цели. Последний предикат означает завершение полного перебора,
после которого дальнейшее планирование невозможно. Рекурсивный генератор плана
работает следующим образом.
Глава 14. Введение в PROLOG
637
1. Находим отношение для предиката move.
2. С помощью операции получения подмножества проверяем, выполняются ли
предусловия Preconditions для данного состояния.
3. Предикат change_state генерирует новое состояние Child_state с
использованием списка добавления и удаления.
4. С помощью предиката member_stack проверяем, не содержится ли новое
состояние в списке уже пройденных.
5. Оператор stack добавляет новое состояние Child_state в стек
New_move_s tack.
6. Оператор stack добавляет исходное состояние name в стек New_been_stack.
7. С помощью рекурсивного вызова предиката plan на основе дочернего состояния
Child_state и обновленных стеков New_move_stack и Been_stack
находится новое состояние.
Для реализации алгоритма требуются дополнительные утилиты, описанные при
рассмотрении абстрактных типов данных (стека и множества) в подразделах 14.2.1 и 14.2.4.
Естественно, поиск реализуется на основе стеков с помощью алгоритма поиска в глубину
с возвратами и завершается после нахождения первого пути к цели. Алгоритмы
планирования на основе поиска в ширину и "жадного" алгоритма поиска читателю предлагается
реализовать самостоятельно в качестве упражнений.
plan(State, Goal, _, Move_stack) :-
equal_set(State, Goal),
write(xпереходы'), nl,
reverse_print_stack(Move_stack).
plan(State, Goal, Been_stack, Move_stack) :-
move(Name, Preconditions, Actions),
conditions_met(Preconditions, State),
change_state(State, Actions, Child_state),
not(member_stack(Child_state, Been_stack)),
stack(Name, Been_stack, New_been_stack),
stack(Child_state, Move_stack, New_move_stack),
plan(Child_state, Goal, New_been_stack, New_move_stack) , !.
plan(_, _, _) :- write(xПри таких переходах план невозможен!').
conditions_met(P, S)
subset(P, S),
change_state(S, [ ], S).
change_state(S, [add(P)|T], S_new) :-
change_state(S, T, S2),
add_if_not_in_set(P, S2, S_new), !.
change_state(S, [del(P)|T], S_new) :-
change_state(S, T, S2),
delete_if_in_set(P, S2, S_new), !.
reverse_print_stack(S) :-
empty_stack(S).
reverse_print_stack(S) :-
stack(E, Rest, S),
reverse_print_stack(Rest),
write(E), nl.
638 Часть VI. Языки и технологии программирования для искусственного интеллекта
И, наконец, выпишем предикат до для инициализации аргументов предиката plan, а
также предикат test для демонстрации простого метода запуска системы планирования.
go(Start, Goal) :-
empty_stack(Move_stack),
empty_stack(Been_stack),
stack(Start/ Been_stack/ New_been_stack),
plan(Start/ Goal, New_been_stack/ Move_stack).
test :-
go([handempty, ontable(b)/ ontable(c)/ on(a, b), clear(c),
clear(a)],
[handempty, ontable(a), ontable(b), 011@, b) , clear(a),
clear(c)]).
14.6. Метапредикаты, типы и подстановки унификации
в языке PROLOG
14.6.1. Металогические предикаты
Металогические конструкции позволяют повысить выразительность
программирования в любой среде. Такие конструкции будем называть метапредикатами (meta-
predicate), поскольку они предназначены для проверки соответствия, формирования
запросов и управления другими предикатами, составляющими спецификацию предметной
области задачи. Их можно использовать для рассуждения о предикатах в PROLOG, а не
для обозначения термов или объектов, что свойственно обычным предикатам. Метапре-
дикаты в языке PROLOG служат для реализации (как минимум) пяти целей.
1. Определение "типа" выражения.
2. Добавление ограничений "типа" в логические приложения.
3. Построение, разделение и оценка структур PROLOG.
4. Сравнение значений выражений.
5. Преобразование предикатов, передаваемых в виде данных, в исполняемый код.
Выше было описано, как в программу на языке PROLOG можно ввести глобальные
структуры, т.е. данные, доступные во всем множестве дизъюнктов. К текущему набору
дизъюнкт С можно добавить с помощью команды assert (С).
Использование команд assert и retract связано с некоторой опасностью.
Поскольку эти команды создают и удаляют глобальные структуры, они приводят к
побочным эффектам, которые могут вызвать другие проблемы, присущие плохо
структурированным программам. Однако глобальные структуры иногда необходимо
использовать. Это требуется при создании в среде PROLOG семантических сетей (semantic
net) и фреймов (frame). Глобальные структуры также можно использовать для
описания новых результатов, получаемых с помощью основанной на правилах оболочки.
Эта информация должна быть глобальной, чтобы к ней могли получить доступ другие
предикаты или правила.
К числу других метапредикатов, применяемых для управления представлениями,
относятся следующие.
Глава 14. Введение в PROLOG
639
• var (X) принимает значение "истина" только в том случае, если X — несвязанная
переменная.
• nonvar (X) принимает значение "истина" только в том случае, если переменная
X связана с постоянным термом.
• = . . создает список из терма предиката.
Например, foo (а, Ь, с) = . . Y унифицирует Y со списком [foo, a, b, с].
Голова списка Y— это имя функции, а хвост содержит аргументы этой функции.
Метапредикат = . . можно также использовать для выполнения обратного действия.
Так, если выражение Х=. . [foo, a7 Ь, с] истинно, то значением X является
foo(a, b, с).
• functor (А, В, С) принимает значение "истина", если аргумент А — это терм,
главный функтор которого имеет имя В и арность С.
Например, выражение functor (foo (a, b) , X, Y) истинно для значений
переменных Х= f оо и Y=2. Если один из аргументов метапредиката f unctor (А, В, С)
является связанной переменной, то можно получить значения других переменных, в
частности, все термы с заданным именем и/или арностью.
• clause(А, В) унифицирует В с телом дизъюнкта, голова которого
унифицирована с аргументом А.
Если в базе данных существует предикат р (X) : - q(X), то clause (p (a) , Y)
истинно для Y=q (а). Этот метапредикат полезно использовать для связывания
управляющих правил в интерпретаторе.
• any_predicate ( . . . , X, ...) :-Х выполняет предикат X, являющийся
аргументом произвольного предиката.
Так, некоторый предикат X можно передавать в качестве параметра и выполнять в
любое удобное время. Предикат call (X), где X — дизъюнкт, тоже завершается
успешно при выполнении предиката X. Этот краткий список металогических предикатов очень
полезен при построении и интерпретации структур данных искусственного интеллекта,
описанных в предыдущих главах. Поскольку PROLOG позволяет легко управлять
собственными структурами, то несложно реализовать интерпретаторы, модифицирующие
семантику языка PROLOG. Это и будет сделано ниже.
14.6.2. Типы данных в языке PROLOG
Во многих приложениях неограниченное использование подстановок унификации
может привести к возникновению ошибок. PROLOG— это нетипизированный язык.
В процессе унификации просто проверяется соответствие шаблонам без всякой их
привязки к типам данных. Например, значение выражения append (nil, 6, 6)
выводится из определения предиката append. На примере строго типизированных языков
наподобие Pascal можно удостовериться в том, что проверка соответствия типов помогает
программистам избежать многих проблем. Многие исследователи предлагают ввести
понятие типов данных (type) и в язык PROLOG [Neves и др., 1986], [Mycroft и O'Keefe, 1984].
Типизированные данные особенно полезны для использования в реляционных базах
данных [Neves и др., 1986], [Malpas, 1987]. Логические правила можно применять в
качестве ограничений для этих правил и типизировать их, чтобы обеспечить согласованность и
640 Часть VI. Языки и технологии программирования для искусственного интеллекта
осмысленную интерпретацию запросов. Допустим, в базе данных универмага содержатся
отношения inventory (каталог), suppliers (поставщики), supplier_inventory
(товар-поставщик) и т.п. Определим базу данных как множество отношений с
именованными полями, которые можно рассматривать как наборы кортежей. Например, отношение
inventory может состоять из четырехэлементных кортежей, где
<Pname, Pnumber, Supplier, Weight> G inventory
только в том случае, если Supplier— это имя поставщика товара с номером
Pnumber, именем Pname и весом Weight. Допустим также, что
<Supplier, Snumber, Status, Location> G suppliers
только в том случае, если Supplier— это имя поставщика с порядковым номером
Snumber, статусом Status из города Location, a
<Supplier, Pnumber, Cost, Department> G supplier_inventory
только в том случае, если Supplier— это имя поставщика партии с номером
Pnumber, стоимостью Cost в отдел Department.
В языке PROLOG можно определить правила, реализующие различные запросы и
выполняющие проверку соответствия типов для этих отношений. Например, запрос
"располагаются ли поставщики партии товаров № 1 в Лондоне" на языке PROLOG
можно представить так.
?- getsuppliers(Supplier, l, london).
Правило
getsuppliers(Supplier, Pnumber, City) :-
cktype(City, suppliers, city),
suppliers(Supplier, _, _,City),
сktype(Pnumber, inventory, number),
supplier_inventory(Supplier, Pnumber, _, _),
cktype(Supplier, inventory, name).
реализует этот запрос и накладывает ограничение на кортежи базы данных. Первые
переменные Pnumber и City связываются, если запрос унифицируется с головой
правила. Предикат cktype выполняет проверку принадлежности элемента Supplier
множеству suppliers, проверку легитимности 1 как инвентарного номера и проверку того,
что london — это возможное местоположение поставщика.
Пусть предикат cktype зависит от трех аргументов: значения, имени отношения и
имени поля. Допустим, он проверяет соответствие каждого значения типу отношения.
Например, можно определить списки допустимых значений для переменных Supplier,
Pnumber и City и реализовать типизацию данных с помощью запросов проверки
принадлежности предлагаемых значений этим спискам. Кроме того, можно определить
логические ограничения на возможные значения в рамках одного типа. Например, можно
потребовать, чтобы инвентарные номера не превышали 1000.
Необходимо понимать различия в реализации проверки соответствия типов между
стандартными языками наподобие Pascal и языком PROLOG. Для отношения
suppliers в языке Pascal можно определить следующий тип данных.
type supplier = record
sname: string;
Глава 14. Введение в PROLOG
641
snumber: integer;
status: boolean;
location: string
end
Программист на языке Pascal определяет новые типы (в данном случае supplier) в
терминах уже существующих, таких как boolean и integer. Если программист
использует переменные этого типа, то компилятор автоматически выполняет проверку
соответствия типов.
В PROLOG отношение supplier можно представить в виде
supplier(sname(Supplier),
snumber(Snumber),
status(Status),
location(Location)).
Проверка соответствия типов осуществляется с помощью таких правил, как get
suppliers и cktype. Различие проверки соответствия типов между языками Pascal и
PROLOG очевидно. При объявлении типа в языке Pascal компилятору передается тип
данных как всей структуры (record), так и ее отдельных компонентов (boolean,
integer, string). При объявлении переменной указывается ее тип (record), а затем
создаются процедуры для доступа к этим типизированным структурам.
procedure changestatus (X: supplier);
begin
if X.status then. . . .
Поскольку PROLOG — это не процедурный язык, в нем объявление не отделяется от
использования типов данных, а проверка соответствия типов осуществляется в процессе
выполнения программы. Рассмотрим правило
supplier_name(supplier(sname(Supplier), snumber(Snumber),
status(true), location (london)))
integer(Snumber), write(Supplier).
Предикат supplier_name получает в качестве аргументов экземпляр предиката
Supplier и записывает имя данного поставщика. Однако это правило успешно реализуется
только в том случае, если номер поставщика — это целое число, переменная статуса
принимает значение true, и поставщик располагается в Лондоне. Важной особенностью проверки
соответствия типов является ее реализация с помощью алгоритма унификации (true,
london) и встроенного системного предиката integer. Можно ввести ограничение на выбор
значений из определенного списка. Например, можно потребовать, чтобы значение
переменной Snumber выбиралось из списка номеров поставщиков. Ограничения на запросы к базе
данных определяются с помощью правил типа cktype и supplier_name и реализуют
проверку соответствия типов в процессе выполнения программы.
Таким образом, мы рассмотрели три способа типизации данных в языке PROLOG.
Первый и наиболее мощный состоит в использовании унификации для ограничения
возможных значений переменных. Второй способ — применение встроенных предикатов
PROLOG для ограниченной проверки соответствия типов. Примерами его реализации
являются метапредикаты var(X), clause (X, Y) и integer (X). Третий способ —
ограниченное использование типизации в рассмотренном примере, где проверка
соответствия типов выполняется с помощью правил, определяющих принадлежность
значений Supplier, Pnumber и City к заданным спискам.
642 Часть VI. Языки и технологии программирования для искусственного интеллекта
Четвертый, более радикальный, подход — это полная проверка соответствия типов
данных и предикатов, предложенная в [Mycroft и O'Keefe, 1984]. В этой работе все имена
предикатов связываются с определенным типом и фиксированной арностью. Более того,
типизируются и сами имена переменных. Преимущество этого подхода состоит в том, что
ограничения на вложенные предикаты и переменные в программе на языке PROLOG
определяются самой программой. Несмотря на то что выполнение программы при этом
замедляется, такой подход обеспечивает очень высокий уровень безопасности типов.
Таким образом, вместо встроенной проверки соответствия типов в языке PROLOG
допускается проверка соответствия в процессе выполнения под полным контролем
программиста. Этот подход имеет множество преимуществ для разработчиков систем
искусственного интеллекта, включая следующие.
1. Программист не должен постоянно заботиться о строгой типизации. Он может
писать программы, работающие для любых типов объектов. Например, предикат
проверки принадлежности элемента списку выполняет общую проверку,
независимо от типа элементов списка.
2. Гибкость типизации помогает разрабатывать программы в новых областях знаний.
Программисты могут абстрагироваться от проверки соответствия типов на ранних
стадиях разработки программы и ввести ее для выявления ошибок при более
глубоком понимании задачи.
3. Представления данных в области искусственного интеллекта плохо согласуются со
встроенными типами данных таких языков, как Pascal, C++ или Java. PROLOG
позволяет определять типы с использованием всей мощи логики предикатов. Эта
гибкость хорошо видна на примере с базой данных.
4. Поскольку проверка соответствия типов осуществляется в процессе выполнения
программы, а не во время компиляции, то программист сам определяет, когда ее
следует начинать Это позволяет отложить проверку соответствия типов до
момента связывания определенных переменных или до другого момента.
5. Контроль проверки соответствия типов во время исполнения позволяет писать
программы, в которых новые типы создаются в процессе выполнения. Это можно
использовать, например, в программах обучения.
14.6.3. Унификация, механизм проверки соответствия предикатов
и оценка
Важная особенность программирования на языке PROLOG состоит в том, что
интерпретатор ведет себя как система доказательства теорем на основе резолюции (см.
раздел 12.3). Как система доказательства теорем PROLOG выполняет последовательность
разрешающих процедур над элементами базы данных, а не оценивает операторы и
выражения подобно компиляторам традиционных языков. Это приводит к важному
результату: переменные связываются (инстанцируются, принимают значения) с помощью
подстановки унификации, а не за счет оценки, если, конечно, оно не требуется явно. Такая
парадигма программирования приводит к своеобразным последствиям.
Первым, и наиболее важным, результатом является ослабление требований к
определению переменных как входных или выходных параметров. Преимущество этого
подхода мы уже наблюдали на примере предиката append, с помощью которого можно либо
объединять списки, либо проверять корректность их объединения, либо делить список на
Глава 14. Введение в PROLOG
643
части. В разделе 14.9 подстановка унификации также будет рассмотрена как механизм
проверки соответствия и обработки ограничений при грамматическом разборе и
генерации предложений.
Унификация — это мощное средство экспертных систем, основанных на правилах и
фреймах. Разновидность такой проверки соответствия должна присутствовать во всех
продукционных системах. Поэтому при написании таких систем на универсальных
языках программирования алгоритм унификации зачастую приходится реализовывать
вручную (реализация алгоритма унификации на языке LISP приводится в разделе 15.6).
Важное различие между вычислениями на основе унификации и применением более
традиционных языков состоит в том, что процедуры унификации выполняют
синтаксическую проверку соответствия структур данных (с соответствующими параметрами
подстановки). Они не оценивают выражения. Например, предположим, что требуется
создать предикат successor, успешно выполняющийся, если его второй аргумент на
единицу больше первого. Не понимая сущности унификации, такой предикат можно
определить следующим образом.
successor(X, Y):- Y = X + 1.
Он не будет работать, поскольку оператор = не оценивает свои аргументы, а лишь
пытается унифицировать выражения в левой и правой части. Этот предикат будет
успешно выполнен, если Y можно унифицировать со структурой Х+1. Поскольку 4 не
унифицируется с 3 + 1, то вызов successor C , 4) завершится неудачно. С другой
стороны, с помощью оператора = можно проверять эквивалентность (определяемую путем
унификации) любых двух выражений.
Чтобы корректно определить предикат successor и другие арифметические
предикаты, необходимо оценивать значения арифметических выражений. В языке PROLOG
для этого существует оператор is. Он оценивает выражение в правой части и пытается
унифицировать результат с объектом из левой части. Так, в выражении
X is Y + Z
осуществляется унификация объекта X со значением суммы Y и Z. Поскольку при этом
выполняются арифметические вычисления, это приводит к таким последствиям.
1. Если переменные Y и Z не имеют значений (не связаны во время выполнения), то
реализация оператора is приводит к ошибке времени выполнения.
2. Аналогично, если X и Z — связанные переменные, то с помощью выражения X is Y
+ Z нельзя получить значение Y (как в декларативных языках программирования).
3. Оператор is необходимо использовать для оценки значений выражений,
содержащих арифметические операции +,-,*,/ и mod.
И, наконец, как и в логике предикатов, переменные в языке PROLOG могут иметь одно и
только одно связывание. Если в процессе локального присваивания или унификации
переменная получила некоторое значение, то она не сможет принять новое значение за
исключением случаев возврата в пространстве поиска. Следовательно, is — это не функция,
подобная традиционному оператору присваивания. Выражение X is X + 1 всегда ложно.
С помощью оператора is можно корректно определить предикат successor (X, Y).
А именно,
successor (X, Y) :-Y is X + 1.
644 Часть VI. Языки и технологии программирования для искусственного интеллекта
Он будет корректно выполняться, если переменная X связана с числовым значением.
Его можно использовать либо для вычисления значения Y на основе X, либо для
проверки значений X и Y.
?- successor C, X).
X = 4
yes
?- successor C, 4).
yes
?- successor D, 2).
no
?- successor (Y, 4).
failure, error in arithmetic expression
Как следует из этого обсуждения, интерпретатор PROLOG не оценивает выражения
подобно тому, как это делается при использовании традиционных языков программирования.
Программист должен явно реализовать оценивание с помощью оператора is. Явное
управление оценкой, как и в LISP, упрощает обработку выражений (в том числе данных,
передаваемых в качестве параметров), а также их создание и модификацию в рамках программы.
Это свойство наряду с возможностью оперировать выражениями логики предикатов
как данными и выполнять эти выражения с помощью предиката call существенно
упрощает разработку различных интерпретаторов, таких как оболочка экспертной системы
из следующего раздела.
В завершение обсуждения преимуществ вычислений на основе унификации приведем
пример, в котором объединение строк выполняется с помощью разностных списков
(difference list). В качестве альтернативы традиционному обозначению списка в PROLOG
его можно представить в виде разности двух списков. Например, список [а, Ь]
эквивалентен списку [а, b | []]-[] или [a, b, с] - [с]. Такое представление имеет
несколько преимуществ по сравнению с традиционным синтаксисом списков. Если
список [а, Ь] представлен в виде разности [a, b | Y] - Y, то он на самом деле
описывает потенциально бесконечный класс всех списков, первыми двумя элементами которых
являются а и Ь. Такое представление обладает интересным свойством сложения.
X-Z=X-Y+Y-Z
Это свойство можно использовать для определения следующей однострочной
логической программы, в которой X-Y — первый список, Y-Z — второй, a X-Z — результат
их конкатенации.
catenate(X - Y, Y-Z, X - Z).
Эта операция объединяет два списка произвольной длины за постоянное время за
счет унификации списочных структур, а не за счет повторного присваивания,
основанного на длине списков (как при использовании предиката append). Вызов предиката
catenate дает следующие результаты.
?- catenate ([a, b|Y]-Y, [1, 2, 3] - [ ], W).
Y = [1, 2, 3]
W = [а, Ь, 1, 2, 3] - [ ]
Как показано на рис. 14.5, значение (поддерево) Y во втором параметре
унифицируется с обоими вхождениями Y в первом параметре конкатенации. В этом проявляется сила
унификации, которая не сводится к простой подстановке значений переменных. В про-
Глава 14. Введение в PROLOG
645
цессе унификации выполняется проверка соответствия общих структур: все вхождения Y
должны принимать значение целого поддерева. Этот пример также иллюстрирует
преимущество корректного представления. Таким образом, разностные списки
представляют целый класс списков, включая возможные результаты конкатенации.
В этом разделе рассмотрены отличительные особенности и преимущества
реализованного в языке PROLOG подхода к вычислениям, основанного на унификации.
Унификация — это ядро декларативной семантики PROLOG.
Добавление разностных списков: После связывания Yco списком [1,2, 3], Z —
со списком [] и сложения:
X-Y+Y-Z
ь v 2Л
3 []
з []
Рис. J4.5. Древовидные диаграммы конкатенации на основе разностных списков
14.7. Метаинтерпретаторы в языке PROLOG
14.7.1. Введение в метаинтерпретаторы: PROLOG в языке PROLOG
Как на Lisp, так и на PROLOG, можно писать программы для работы с выражениями,
написанными в рамках синтаксических соглашений языка. Такие программы будем
называть метаинтерпретаторами (meta-interpreter). Например, оболочка экспертной
системы интерпретирует набор правил и фактов, описывающих конкретную задачу. И хотя
правила для задачи описываются с помощью синтаксиса применяемого языка,
метаинтерпретатор может переопределять их семантику.
В качестве примера метаинтерпретатора определим семантику чистого языка
PROLOG в самом языке PROLOG. Предикат solve получает в качестве параметра
целевое утверждение и обрабатывает его согласно семантике PROLOG.
solve(true) :-!.
solve(not A) :- not(solve(A)).
solve((A, B)) :-!, solve(A), solve(B).
solve(A) :- clause(A, B), solve(B).
Допустим, существует следующий простой набор суждений.
р(Х, Y) :- q(X), r(Y).
q(X) :- s(X).
Г(Х) :- t(X).
s(a) .
646 Часть VI. Языки и технологии программирования для искусственного интеллекта
t(b) .
t(c) .
Тогда предикат solve будет вести себя как интерпретатор PROLOG.
?- solve(p(a, b)).
yes
?- solve(p(X, Y)).
X = a, Y = b;
X = a, Y = c;
no
?- solve(p(f, g)).
no
Предикат solve реализует тот же поиск в глубину слева направо на основе цели, что
и интерпретатор PROLOG.
Возможность написания метаинтерпретаторов для языка имеет несколько
теоретических преимуществ. Например, в [McCarthy, 1960] описан простой метаинтерпретатор для
LISP, представляющий собой часть доказательства того факта, что этот язык является
полным (по Тьюрингу). С более практической точки зрения метаинтерпретаторы можно
использовать для расширения или модификации семантики базового языка для обеспечения
его более полного соответствия специфике приложения. Такая методология
программирования получила название металингвистической абстракции (meta-linguistic abstraction),
подразумевающей создание высокоуровневого языка для решения конкретных задач.
Например, семантику стандартного языка PROLOG можно модифицировать таким
образом, чтобы спрашивать пользователя о значении любого целевого утверждения, истинность
которого нельзя определить с помощью базы данных. Это можно обеспечить путем
добавления следующих выражений в конец предыдущего определения предиката solve.
solve(A) :- askuser(A).
askuser(A) :- write(A),
writeC? Введите значение true, если целевое утверждение
истинно, и false в противном случае'), nl,
read(true).
Поскольку это определение добавляется в конец списка других правил solve, оно
вызывается только в том случае, если остальные правила не срабатывают. Предикат
solve запускает предикат askuser для передачи пользователю запроса о значении
целевого утверждения А. Команда askuser выводит целевое утверждение и инструкции
пользователю. Предикат read (true) пытается унифицировать введенное
пользователем значение с термом true. Если пользователь ввел значение false (или значение,
которое нельзя унифицировать со значением true), то эта попытка завершится
неудачей. Таким образом, мы расширили семантику предиката solve и изменили поведение
языка PROLOG. Приведем пример использования определенной выше простой базы
знаний, иллюстрирующий поведение дополненного предиката solve.
?- solve(p(f, g)).
s(f)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
true.
t(g)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
true.
yes
Глава 14. Введение в PROLOG
647
Следующее расширение метаинтерпретатора позволяет ему отвечать на вопросы
"Почему?". Если интерпретатор задает пользователю вопрос, то пользователь может
ответить ему встречным вопросом why (почему). Ответом на этот запрос должно служить
текущее правило, которое пытается разрешить программа. Это реализуется за счет хранения
стека правил в текущей строке рассуждений в качестве второго параметра предиката
solve. При каждом вызове команды clause для обратной связи с целевым
утверждением предикат solve помещает выбранное правило в стек. Тогда в стеке будет записана вся
цепочка правил, начиная от цели наивысшего уровня и заканчивая текущей подцелью.
Поскольку пользователь теперь может вводить два корректных ответа на запрос,
предикат askuser вызывает предикат respond, который либо завершается успешно при
вводе пользователем значения true (как было описано выше), либо записывает
последнее правило в стек, если пользователь вводит ответ why. Предикаты respond и
askuser являются взаимно рекурсивными, поскольку после вывода ответа на запрос
why предикат respond вызывает askuser для вывода следующего запроса
пользователю о значении целевого утверждения. Заметим, однако, что на этот раз при вызове
askuser его параметром является хвост стека правил. Таким образом,
последовательность запросов why просто приводит к последовательному извлечению правил из стека
до его опорожнения. Это позволяет пользователю отследить всю цепочку рассуждений.
solve(true, _) :-!.
solve(not(A), Rules) :- not(solve(A, Rules)).
solve((A, B), Rules) :- !, solve(A, Rules), solve(B, Rules).
solve(A/ Rules) :- clause(A/ B), solve(B/ [(A :- B)|Rules]).
solve(A/ Rules) :- askuser(A, Rules).
askuser(A, Rules) :- write(A),
write("? Введите значение true, если целевое утверждение
истинно, и false в противном случае'), nl,
read(Answer), respond(Answer, A, Rules),
respond(true, _, _).
respond(why, A, [Rule|Rules]) :- write(Rule), nl,
askuser(A, Rules).
respond(why, A, [ ]) :- askuser(A, [ ]).
Например, команду solve можно выполнить для простой базы данных, введенной
ранее в этом разделе. Обратите внимание, насколько успешно запросы why позволяют
отследить цепочку рассуждений.
?- solve(p(f, g) , [ ] ) .
s(f)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
why.
q(f) :- s(f)
s(f)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
why.
p(f, g) :- (q(f), r(g))
s(f)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
true.
t(g)? Введите значение true, если целевое утверждение истинно,
и false в противном случае
true.
yes
648 Часть VI. Языки и технологии программирования для искусственного интеллекта
Важным расширением предиката solve является построение дерева доказательства
для любой успешно реализованной цели. Построение деревьев доказательств
обеспечивает оболочкам экспертных систем возможность ответа на запросы "как". Это свойство
важно для любого алгоритма, в котором используются рассуждения о результатах
решения задачи, в частности, алгоритма обучения на основе пояснений (раздел 9.5).
Обычный интерпретатор PROLOG можно модифицировать за счет рекурсивного
построения дерева доказательства для целевого утверждения в случае успешного
разрешения цели. В следующем определении дерево доказательства возвращается в качестве
второго параметра предиката solve. Доказательством атомарного утверждения true
является само это утверждение. Такое свойство приводит к построению рекурсии. При
разрешении цели А с помощью правила А : -В можно построить доказательство В и
возвратить структуру (А : - Proof В). При разрешении конъюнкции целей А и В
можно просто объединить деревья доказательств для обеих целей: (Proof A, Proof В).
Определение метаинтерпретатора, обеспечивающего построение деревьев
доказательств, имеет следующий вид.
solve(true, true) :-!.
solve(not(A), not ProofA) :- not(solve(A, ProofA)).
solve((A, B),(ProofA, ProofB)) :- solve(A, ProofA), solve(B,
ProofB).
solve(A, (A :- ProofB)) :- clause(A, B) , solve(B, ProofB).
solve(A, (A :- given)) :- askuser(A) .
askuser(A/ Proof) :- write(A),
write('Введите значение true, если целевое утверждение истинно,
и false в противном случае'), read(true).
Запуск этого предиката для рассмотренной выше простой базы данных дает
следующий результат.
?- solve(p(a/ b), Proof).
Proof = p(a, b) :-
((q(a) :-
s(a) :-
true)),
(r(b) :-
(t(b) :-
true)))
В следующем разделе эти приемы используются для реализации оболочки экспертной
системы exshell. В ней база знаний используется в форме правил решения задачи.
Система запрашивает у пользователя необходимую информацию, записывает
специфические данные, отвечает на запросы how и why и реализует механизм неточных
рассуждений на основе фактора уверенности из главы 8. И хотя система exshell гораздо
сложнее описанных выше метаинтерпретаторов PROLOG, она является лишь
расширением этой методологии. Ее ядром служит предикат solve, реализующий обратный
поиск цепочек правил и фактов.
14.7.2. Оболочка для экспертной системы на основе правил
В этом разделе будут описаны основные предикаты, используемые при построении
интерпретатора для основанной на правилах экспертной системы под управлением цели.
В завершение раздела будет продемонстрирована эффективность применения оболочки
Глава 14. Введение в PROLOG
649
exshell для базы знаний автомобильной диагностики. Если читатель желает
познакомиться с этими результатами до изучения основных предикатов оболочки exshell,
рекомендуем ему "заглянуть" в конец раздела.
База знаний оболочки exshell состоит из правил и спецификаций запросов к
пользователю. Правила представляются с помощью предиката rule вида rule(R, CF).
Первый параметр — это утверждение для базы знаний, записанное с помощью
стандартного синтаксиса PROLOG. Утверждения могут представлять собой правила PROLOG
вида (G : - Р), где G — это голова правила, а Р — конъюнктивный шаблон, при
котором правило G истинно. Первый параметр предиката rule может также являться фактом
PROLOG. Параметр CF характеризует степень доверия разработчика заключению
правила. Система exshell реализует механизм неточных рассуждений на основе фактора
уверенности, предложенный для системы MYCIN, описанной в главе 8. Параметр CF
может изменяться в диапазоне от 100 (если факт заведомо истинный) до -100 (для
заведомо ложных фактов). Если значение параметра CF близко к нулю, значит, степень
уверенности для данного факта неизвестна. Приведем типичное правило из базы знаний для
диагностики неисправностей автомобилей.
rule((bad_component(starter) :- (bad_system(starter_system) ,
lights(come_on))), 50).
rule(fix(starter, 'замените стартер'), 100).
Первое правило утверждает следующее. Если "неисправной" оказалась система
стартера, и фары включаются, значит, плохим компонентом является стартер с фактором
уверенности 50. Второе утверждение означает, что починить неисправный стартер
можно путем его замены (с уверенностью 100). В оболочке exshell предикат rule
используется для извлечения правил, дающих заключение для указанной цели, подобно
тому, как в более простой версии предиката solve используется встроенный предикат
clause для извлечения правил из глобальной базы данных PROLOG.
Система exshell поддерживает запросы к пользователям о неизвестных данных.
Однако, поскольку интерпретатор не должен задавать вопросы для каждой
неразрешенной цели, программист может явно указать, какую информацию следует получить. Это
можно сделать с помощью предиката askable.
askable(car_starts).
Этот предикат означает, что интерпретатор может запрашивать у пользователя
значение истинности цели car_starts, если необходимая информация отсутствует и не
может быть выведена с помощью базы данных.
Помимо определенной программистом базы знаний правил и допустимых запросов,
система exshell поддерживает свои собственные данные, относящиеся к конкретным
ситуациям. Поскольку оболочка запрашивает у пользователя информацию, ответы необходимо
сохранять. Это позволяет программе избегать повторных запросов в процессе консультации.
Ядром метаинтерпретатора exshell является предикат solve, зависящий от
четырех аргументов. Первый аргумент — это целевое утверждение, которое требуется
разрешить. При успешном разрешении цели оболочка exshell связывает второй аргумент со
степенью уверенности, вычисляемой на основе базы знаний. Третий аргумент — это стек
правил, применяемый для ответов на запросы why, а четвертый — порог отсечения для
метода неточных рассуждений на основе фактора уверенности. Такой подход позволяет
ограничивать пространство поиска, если значение фактора уверенности (степень
достоверности) опускается ниже заданного порога.
650 Часть VI. Языки и технологии программирования для искусственного интеллекта
При разрешении цели G предикат solve сначала пытается выявить соответствие
цели G любому факту, уже полученному от пользователя. Известные факты
представляются с помощью предиката known(A, CF). Например, known (car_starts, 85)
означает, что пользователь уже сообщил о том, что автомобиль запускается со степенью
достоверности 85. Если значение целевого утверждения неизвестно, предикат solve
пытается разрешить его с помощью базы знаний. Он обрабатывает отрицание цели,
разрешая ее и умножая достоверность этой цели на -1. При этом разрешение
конъюнктивных целей производится слева направо. Если G — это положительный литерал, то
предикат solve проверяет все правила, голова которых соответствует G. В случае неудачного
завершения этой операции solve передает запрос пользователю. При получении от
пользователя значения достоверности цели предикат solve добавляет эту информацию
в базу данных с помощью предиката known.
% Ситуация 1: истинное значение целевого утверждения уже известно
solve(Goal, CF, _, Threshold) :-
known(Goal, CF), !,
above_threshold(CF/ Threshold). %Проверка порога достоверности
% Ситуация 2: отрицание цели
solve(not(Goal), CF, Rules, Threshold) :-!,
invert_threshold(Threshold, New_threshold),
solve(Goal, CF_goal, Rules, New_threshold),
negate_cf(CF_goal, CF).
% Ситуация З: конъюнктивные цели
solve((Goal_l, Goal_2), CF, Rules, Threshold) :- !,
solve(Goal_l, CF_1, Rules, Threshold),
above_threshold(CF_l, Threshold),
solve(Goal_2, CF_2, Rules, Threshold),
above_threshold(CF_2, Threshold),
and_cf(CF_l, CF_2, CF) . ^Вычисление CF для конъюнкции целей
% Ситуация 4: обратная связь с правилом в базе знаний
solve(Goal, CF, Rules, Threshold) :-
rule((Goal :- (Premise)), CF_rule),
solve(Premise, CF_premise, [rule((Goal :- Premise),
CF_rule)|Rules], Threshold),
rule_cf(CF_rule, CF_premise, CF),
above_threshold(CF, Threshold).
% Ситуация 5: добавлени факта в базу знаний
solve(Goal, CF, _, Threshold) :-
rule(Goal, CF),
above_threshold(CF, Threshold).
% Ситуация 6: запрос к пользователю
solve(Goal, CF, Rules, Threshold) :-
askable(Goal),
askuser(Goal, CF, Rules), !,
assert(known(Goal, CF)),
above_threshold(CF, Threshold).
Консультации с пользователем начинаются с помощью версии предиката solve с
двумя параметрами. Первый аргумент — это цель верхнего уровня в базе знаний, а
второй — переменная, которая будет связана с фактором уверенности в цели после анализа
базы знаний. Этот предикат выводит набор инструкций пользователю, вызывает команду
retractall (known (_, _) ) для очистки любой остаточной информации от преды-
Глава 14. Введение в PROLOG
651
1,
1,
1,
1,
1,
write(x
write(x
write(x
write(x
write(x
дущих запусков оболочки exshell, а затем вызывает предикат solve с
соответствующими значениями четырех параметров.
solve(Goal, CF) :-
print_instructions,
retractall(known(_, _)),
solve(Goal/ CF, [ ], 20),
%Порог 20
Команда print_instructions сообщает пользователю список допустимых
ответов на запрос exshell.
print_instructions :-
'Возможные ответы: '),
'Фактор уверенности в истинности запроса. '),
Число от -100 до 100. '),
why. ' ) ,
how(X), где X - это целевое утверждение')/ nl.
Следующий набор предикатов позволяет вычислить коэффициенты достоверности.
(В оболочке exshell используется разновидность метода неточных рассуждений на
основе фактора уверенности, представленного в подразделе 8.2.1.) Фактор уверенности
для конъюнкции двух целей — это минимум среди факторов уверенности каждой из
целей. Фактор уверенности для отрицания факта вычисляется путем умножения фактора
уверенности этого факта на -1. Степень уверенности в гипотезе, полученной с помощью
правила, равна произведению факторов уверенности предпосылок и самого этого
правила. Предикат above_threshold определяет, превышает ли значение фактора
уверенности заданный порог. В системе exshell пороговое значение используется для
отсечения цели, если уверенность в ней слишком низка. Заметим, что предикат
above_threshold отдельно определяется для отрицательных и положительных
значений порога. При положительном значении порога отсечение выполняется в том случае,
если фактор уверенности не превышает этого порога. Отрицательное значение порога
означает, что мы пытаемся доказать ложность цели. Поэтому для отрицательных целей
поиск прерывается, если значение фактора уверенности цели превышает заданный порог.
Команда invert_threshold вызывается для умножения значения порога на -1.
and_cf(A, В, А) :-
А = < В.
and_cf(A, В, В) :-
В < А.
negate_cf(CF, Negated_CF) :-
Negated_CF is - 1 * CF.
rule_cf(CF_rule/ CF_premise/ CF) :-
CF is (CF_rule * CF_premise/100).
above_threshold(CF/ T) :-
T >= 0, CF >= T.
above_threshold(CF/ T) :-
T < 0, CF =< T.
invert_threshold(Threshold, New_threshold) :-
New_threshold is -1 * Threshold.
Предикат askuser выводит запрос и считывает ответ пользователя. Предикаты
respond выполняют действия, соответствующие введенной пользователем информации.
652 Часть VI. Языки и технологии программирования для искусственного интеллекта
askuser(Goal, CF, Rules) :- ^Запрашивает ответ пользователя
в отношении цели
nl, write('Запрос к пользователю: '),
write(Goal), nl, write(x?'),
read(Answer),
respond(Answer, Goal, CF, Rules).
%Обрабатывает ответ
В качестве ответа на запрос пользователь может ввести значение параметра CF из
диапазона от -100 до 100, отражающее степень его доверия истинности цели, запрос why
или how(X).
Отвеюм на запрос why является правило, расположенное в данный момент в верхушке
стека. Как и в предыдущей реализации, успешная обработка запросов why приводит к
последовательному извлечению правил из стека. Это позволяет восстановить всю цепочку
рассуждений. Если ответ пользователя соответствует шаблону how(X), то предикат
respond вызывает команду build_proof для построения дерева доказательства для X и
команду write_proof для вывода этого доказательства в удобной для восприятия форме.
Все неизвестные входные значения "отлавливаются" предикатом respond.
% Ситуация 1: пользователь вводит корректный фактор уверенности
respond(CF, _, CF, _) :-
number(CF),
CF =< 100, CF >= -100.
% Ситуация 2: пользователь вводит запрос why
respond(why, Goal, CF, [Rule|Rules]) :-
write_rule(Rule),
askuser(Goal, CF, Rules).
respond(why, Goal, CF, [ ]) :-
write('Перейти к вершине стека правил. '),
askuser(Goal, CF, [ ]).
% Ситуация 3: Пользователь вводит запрос how.
% Строится и выводится доказательство
respond(how(X), Goal, CF, Rules) :-
build_proof(X, CF_X, Proof), !,
write(X), write(xзаключение получено с уверенностью ')/
write(CF_X),nl, nl,
write('Доказательство '), nl, nl,
write_proof(Proof, 0), nl, nl,
askuser(Goal, CF, Rules).
% пользователь вводит запрос how, доказательство построить нельзя
respond(how(X), Goal, CF, Rules) :-
write('Истинность ')/ write(X), nl,
write(хеще неизвестна. '), nl,
askuser(Goal, CF, Rules).
% Ситуация 4: неизвестный ввод
respond(_, Goal, CF, Rules) :-
write('Неизвестный отклик.'), nl,
askuser(Goal, CF, Rules).
Определение предиката build_proof почти полностью соответствует определению
предиката solve с четырьмя параметрами. Однако build_jproof не спрашивает
пользователя о неизвестных фактах, поскольку они уже сохранены среди данных, соответствующих
определенным ситуациям. Предикат build_jproof строит дерево доказательства цели.
Глава 14. Введение в PROLOG
653
build_proof(Goal, CF, (Goal, CF :- given)) :-
known(Goal, CF), !.
build_proof(not Goal, CF, not Proof) :-
!, build_proof(Goal, CF_goal, Proof), negate_cf(CF_goal, CF) .
build_proof((Goal_l, Goal_2), CF, (Proof_1, Proof_2)) :-
!, build_proof(Goal_l, CF_1, Proof_l),
build_proof(Goal_2, CF_2, Proof_2), and_cf(CF_l, CF_2, CF).
build_proof(Goal, CF, (Goal, CF :- Proof)) :-
rule((Goal :- Premise), CF_rule),
build_proof(Premise, CF_premise, Proof),
rule_cf(CF_rule, CF_premise, CF),
build_proof(Goal, CF, (Goal, CF :- fact)) :-
rule(Goal, CF).
И, наконец, создадим предикаты, определяющие простой интерфейс пользователя.
Как правило, для его написания требуются огромные объемы кода. Сначала определим
предикат вывода правила в удобном для восприятия формате.
write_rule(rule((Goal :- (Premise)), CF)) :-
write(Goal), write(x:-'), nl,
write premise(Premise), nl,
write(XCF = '), write(CF), nl.
write_rule(rule(Goal, CF)) :-
write(Goal), nl,
write(XCF = ')/ write(CF), nl.
Тогда предикат write_premise записывает конъюнкты из предусловий правила.
write_premise((Premise_l, Premise_2)) :-
!, write_premise(Premise_l),
write_premise(Premise_2).
write premise(not Premise) :-
!, write(x ')/ write(not), write(x ')/ write(Premise), nl.
write_premise(Premise) :-
write(x ')/ write(Premise), nl.
Команда write_proof выводит доказательство с отображением структуры дерева.
write_proof((Goal, CF :- given), Level) :- %Выводит дерево
%доказательства
indent(Level), write(Goal), %c указанием уровней
write(x CF= '), write(CF),
write(x получено от пользователя'), nl, !.
write_proof((Goal, CF :- fact), Level) :-
indent(Level), write(Goal), write(x CF = '), write(CF),
write(x факт из базы знаний'), nl, !.
write_proof((Goal, CF :- Proof), Level) :-
indent(Level), write(Goal), write(x CF = '), write(CF),
write(x :- ') ,
nl, New_level is Level + 1, write_proof(Proof, New_level), !.
write_proof(not Proof, Level) :-
indent(Level), write((not)), nl,
New_level is Level + 1, write_proof(Proof, New_level), !.
write_proof((Proof_1, Proof_2), Level) :-
write_proof(Proof_1, Level), write_proof(Proof_2, Level), !.
indent@).
654 Часть VI. Языки и технологии программирования для искусственного интеллекта
90)
80)
indentA) :-
write(' '), l_new is 1-1, indent(l_new).
Для иллюстрации работы оболочки exshell рассмотрим следующую простую
базу знаний для диагностики неисправностей автомобилей. Целью верхнего уровня
является утверждение fix, зависящее от одного параметра. С помощью базы знаний
решение задачи разбивается на поиск неисправной системы, поиск неисправного
компонента в рамках этой системы и построение совета по решению проблемы на
основе поставленного диагноза. Заметим, что база знаний является неполной, т.е.
существует множество симптомов, которые невозможно диагностировать. В этом
случае программа exshell попросту не работает. Расширение базы знаний на
некоторые из этих случаев и добавление правил, срабатывающих при неприменимости
остальных правил, — это интересная задача, которую читатель может решить в
качестве упражнения.
rule((fix(Advice) :- %Запрос верхнего уровня
(bad_component(X), fix(X,Advice))), 100).
rule((bad_component(starter) :-
(bad_system(starter_system), lights(come_on))), 50).
rule((bad_component(battery) :-
(bad_system(starter_system),
rule((bad_component(timing) :-
(bad_system(ignition_system)
rule((bad_component(plugs) :-
(bad_system(ignition_system)
rule((bad_component(ignition_wires) :-
(bad_system(ignition_system), not plugs(dirty),
tuned_recently)), 80).
rule((bad_system(starter_system) :-
(not car_starts/ not turns_over)), 90).
rule((bad_system(ignition_system) :-
(not car_starts/ turns_over/ gas_in_carb)), 80).
rule((bad_system(ignition_system) :-
(runs(rough), gas_in_carb)), 80).
rule((bad_system(ignition_system) :-
(car_starts/ runs(dies), gas_in_carb)), 60).
rule(fix(starter, 'заменить стартер'), 100).
%Совет по устранению проблемы
rule(fix(battery, 'заменить или зарядить аккумулятор'), 100).
rule(fix(timing, 'настроить временные параметры'), 100).
rule(fix(plugs, 'заменить свечи зажигания'), 100).
rule(fix(ignition_wires, 'проверить провода в системе зажигания'),
100) .
askable(car_starts). %Можно спросить пользователя о цели
askable(turns_over).
askable(lights(_)).
askable(runs(_)).
askable(gas_in_carb).
askable(tuned_recently).
askable(plugs(_)).
not lights(come_on))
, not tuned_recently)
, plugs(dirty))), 90)
Глава 14. Введение в PROLOG
655
Теперь воспользуемся этой базой знаний в работе системы exshell. На рис. 14.6
показано пространство поиска. Сплошной линией обозначены пройденные участки,
пунктирной — непройденные, а жирной — решения.
solve(fix(X))
badcomponent
(starter)
bad_system
(starter_system)
bad_component
(battery)
badsystem
(starter_system)
bad_component(X)
bad_component
(timing)
badsystem
(ignition_system)
not starts not not starts not not starts turns
turns over turns over over
nottuned_recently
Успешное
завершение
gasjn
carb
fix(X.Advice)
fix(timing,
'настроить временные
параметры')
Успешное
завершение
Успешное Неудачное Успешное Неудачное Успешное Успешное Успешное
завершение завершение завершение завершение завершение завершение завершение
Рис 14 б Граф поиска для системы диагностики неисправностей автомобилей. Пунктирные
линии обозначают непройденные ветви, а жирные — окончательное решение
?- solve(fix(X), CF).
Возможные ответы:
Фактор уверенности в истинности запроса.
Число от -100 до 100.
why.
how(X), где X - это целевое утверждение
Запрос к пользователю:car_starts
? -100.
Запрос к пользователю:turns_over
? 85.
Запрос к пользователю:gas_in_carb
? 75.
Запрос к пользователю:tuned_recently
? -90.
X = 'настроить временные параметры' CF = 48.0
Теперь рассмотрим ситуацию, при которой в этой же задаче используются запросы
how и why. Сравните ответы с соответствующими поддеревьями и путями, показанными
на рис. 14.6.
?- solve(fix(X), CF).
Возможные ответы:
Фактор уверенности в истинности запроса.
Число от -100 до 100.
why.
656 Часть VI. Языки и технологии программирования для искусственного интеллекта
how(X), где X - это целевое утверждение
Запрос к пользователю:car_starts
? -100.
Запрос к пользователю:turns_over
? why.
bad_system(starter_system):-
not car_starts
not turns_over
CF = 90
Запрос к пользователю:turns_over
? why.
bad_component(starter):-
bad_system(starter_system)
lights(come_on)
CF = 50
Запрос к пользователю:turns_over
? why.
fix(_0) :-
bad_component(starter)
fix(starter, _0)
CF = 100
Запрос к пользователю:turns_over
? why.
Возврат к верхушке стека правил.
Запрос к пользователю:turns_over
? 85.
Запрос к пользователю:gas_in_carb
? 75.
Запрос к пользователю:tuned_recently
? why.
bad_component(timing):-
bad_system(ignition_system)
not tuned_recently
CF = 80
Запрос к пользователю:tuned_recently
? how(bad_system(ignition_system)).
bad_system(ignition_system) заключение получено с
достоверностью 60.0
Доказательство
bad_system(ignition_system) CF= 60.0 :-
not car_starts CF = -100 получено от пользователя
turns_over CF = 85 получено от пользователя
gas_in_carb CF = 75 получено от пользователя
Запрос к пользователю:tuned_recently
? -90.
X = 'настроить временные параметры' CF = 48.0
14.7.3. Семантические сети в языке PROLOG
В этом разделе рассмотрим реализацию наследования для простого языка
семантических сетей (глава 6). Этот язык не обладает всей мощью и общностью таких средств, как
концептуальные графы. В частности, мы не будем учитывать важное различие между
классами и их экземплярами. Однако такая ограниченность упрощает реализацию языка.
Глава 14. Введение в PROLOG
657
В семантической сети, показанной на рис. 14.7, узлы представляют такие объекты,
как конкретная канарейка tweety, и классы ostrich (страус), crow (ворона), robin
(дрозд), bird (птица) и vertebrate (позвоночное). Отношение isa связывает классы
различных уровней иерархии наследования. В этой сети реализованы канонические
формы представления данных. Предикат isa (Туре, Parent) указывает на то, что объект
Туре является подтипом Parent, а предикат hasprop (Object, Property,
Value) описывает свойства объектов. Предикат hasprop указывает на то, что объект
Object обладает свойством Property со значением Value. При этом Object и
Value — это узлы сети, a Property — имя объединяющей их связи.
animal
А А
fly
travel
feathers
covering L-fbird
covering
skin
A AAA
ostrich
fish
travel
penguin
travel
travel
►
walk
canary
color
brown
opus
robin
color
yellow
sound
sing
sound
color
red
tweety
color
white
Рис. 14.7. Фрагмент семантической сети, описывающей птиц и других животных
Фрагмент списка предикатов, описывающих показанную на рис. 14.7 иерархию птиц,
имеет вид.
isa(canary, bird).
isa(ostrich, bird).
isa(bird, animal).
isa(opus, penguin).
hasprop(tweety, color, white).
hasprop(canary, color, yellow)
hasprop(bird, travel, fly).
hasprop(ostrich, travel, walk)
hasprop(robin, sound, sing).
hasprop(bird, cover, feathers)
isa(robin, bird),
isa(penguin, bird).
isa(fish, animal),
isa(tweety, canary),
hasprop(robin, color, red),
hasprop(penguin, color, brown)
hasprop(fish, travel, swim),
hasprop(penguin, travel, walk)
hasprop(canary, sound, sing),
hasprop(animal, cover, skin).
Создадим рекурсивный алгоритм поиска, позволяющий определить, обладает ли некий
объект семантической сети указанным свойством. Свойства хранятся в сети на самом высо-
658 Часть VI. Языки и технологии программирования для искусственного интеллекта
ком уровне, на котором они истинны. С помощью наследования объект или подкласс
приобретает свойства своего суперкласса. Так, свойство fly относится к объекту bird и всем его
подклассам. Исключения размещаются на отдельном уровне исключений. Так, страус
ostrich и пингвин penguin ходят (walk), но не летают (fly). Предикат hasproperty
начинает поиск с конкретного объекта. Если информация напрямую не связана с этим объектом,
он переходит по связи isa к суперклассам. Если суперкласса больше не существует, и
предикат hasproperty не нашел нужного свойства, поиск завершается неудачей.
hasproperty(Object, Property, Value):-
hasprop(Object, Property, Value),
hasproperty(Object, Property, Value) :-
isa(Object, Parent),
hasproperty(Parent, Property, Value).
Предикат hasproperty выполняет поиск в глубину в иерархии наследования.
В следующем разделе будет показано, как применять наследование для представления на
основе фреймов и реализовывать отношения деревьев и множественного наследования.
14.7.4. Фреймы и схемы в языке PROLOG
Семантические сети можно разбивать на части, добавляя к описаниям узлов
дополнительную информацию и обеспечивая тем самым фреймовую структуру. Переопределим
рассмотренный в предыдущем подразделе пример с использованием фреймов. Каждый
фрейм будет представлять набор отношений семантической сети, а ячейка isa —
определять иерархию фреймов (рис. 14.8).
В первой ячейке каждого фрейма содержится имя узла, например, name(tweety)
или name (vertebrate). Во второй ячейке определяется отношение наследования
между данным узлом и его родителями. Поскольку в нашем примере сеть имеет
древовидную структуру, каждый узел содержит лишь одну связь — предикат isa зависит от
одного аргумента. В третьей ячейке содержится список свойств, описывающих этот узел.
В этом списке можно использовать любые предикаты PROLOG, в том числе flies,
feathers или color (brown). В последней ячейке фрейма находится список
исключений и принимаемых по умолчанию значений для данного узла. Его элементы тоже
могут представлять собой либо отдельные слова, либо предикаты, описывающие свойства.
name- bird
isa animal
properties flies
feathers
default'
name, animal
isa animate
properties: eats
skin
default.
name, canary
isa: bird
properties, color(yellow)
sound(sing)
default, size(small)
name tweety
isa: canary
properties:
default: color(white)
Рис. 14.8. Фреймы для базы знаний о птицах
Глава 14. Введение в PROLOG
659
На нашем языке фреймов каждый предикат frame связывает имена ячеек, списки
свойств и принимаемые по умолчанию значения. Это позволяет различать типы знаний и
приписывать им разное поведение в иерархии наследования. Хотя при такой реализации
подклассы могут наследовать свойства обоих списков, для конкретных приложений
могут оказаться полезными и другие представления. Например, можно наследовать только
используемые по умолчанию значения или строить третий список, содержащий свойства
самого класса, а не его экземпляров. Такие значения иногда называются значениями
класса (class value). Например, можно сделать так, чтобы класс canary определял вид
певчей птицы. Это свойство не должно наследоваться подклассами или экземплярами:
tweety — не есть вид певчих птиц. Дальнейшее расширение этого примера
предлагается выполнить в качестве упражнения в конце этой главы.
Теперь опишем отношения, показанные на рис. 14.8, на языке PROLOG с помощью
предиката факта frame с четырьмя аргументами. Для проверки соответствия типов
предиката frame, в частности, для проверки того, что в третьей ячейке фрейма содержится
список, элементы которого принимают значение из заданного диапазона свойств, можно
использовать методы, предложенные в подразделе 14.6.2.
frame(name(bird),
isa(animal),
[travel(flies), feathers],
[ ]) .
frame (name (penguin) ,
isa(bird),
[color(brown)],
[travel(walks)]).
frame(name(canary),
isa(bird),
[color(yellow), call(sing)],
[size(small)]).
frame(name(tweety),
isa(canary),
[ ],
[color(white)]).
Определив для фрейма (рис. 14.8) полное множество описаний и отношений
наследования, разработаем процедуры для извлечения свойств из этого представления.
get(Prop, Object) :-
frame(name(Object), _, List_of_properties, _),
member(Prop, List_of_properties).
get(Prop, Object) :-
frame(name(Object), _, _, List_of_defaults),
member(Prop, List_of_defaults).
get(Prop, Object) :-
frame(name(Object), isa(Parent), _, _),
get(Prop, Parent).
Если структура фреймов допускает множественное наследование свойств (см. также
раздел 15.12), то в наше представление и стратегию поиска необходимо внести соответствующие
изменения. Во-первых, в представлении фрейма аргумент, связанный с предикатом isa,
должен содержать список суперклассов данного объекта. Каждый суперкласс этого списка — это
родительский класс объекта, указанного в первом аргументе предиката frame. Если opus
относится к классу пингвинов penguin и представляет собой персонаж мультфильма
(cartoon_char), то это можно представить следующим образом.
660 Часть VI. Языки и технологии программирования для искусственного интеллекта
frame(name(opus),
isa([penguin, cartoon_char]),
[color(black)],
[ ]) .
Теперь проверим свойства объекта opus с помощью возврата по иерархии isa к
обоим суперклассам penguin и cartoon_char. Между третьим и четвертым
предикатами get в предыдущем примере нужно добавить дополнительное определение.
get(Prop, Object) :-
frame(name(Object), isa(List), _, _),
get_multiple(Prop, List).
Предикат get_multiple можно определить следующим образом.
get_multiple(Prop, [Parent|_]) :-
get(Prop, Parent).
get_multiple(Prop, [_|Rest]) :-
get_multiple(Prop, Rest).
В этой иерархии свойства класса penguin и его суперклассов будут проверены до
начала проверки свойств класса cartoon_char.
И, наконец, с каждой ячейкой фрейма можно связать любую процедуру на языке
PROLOG. Имея фреймовое представление для данного примера, в качестве параметра
предиката frame можно добавить правило PROLOG или список таких правил. Для этого
все правило нужно заключить в скобки, как это делалось при реализации оболочки ех-
shell, и включить эту структуру в список аргументов предиката frame. Например,
можно разработать список правил отклика для объекта opus, обеспечив для этого
персонажа возможность давать различные ответы на разные вопросы.
Этот список правил (где каждое правило заключено в скобки) должен стать параметром
предиката frame, определяющим соответствующий ответ в зависимости от значения X,
передаваемого фрейму opus. Более сложными примерами могут служить правила управления
термостатом или создания графического изображения на основе множества значений. Такие
примеры представлены в разделе 15.12, где важную роль в объектно-ориентированном
представлении играют связанные с объектами процедуры, зачастую называемые методами.
14.8. Алгоритмы обучения в PROLOG
14.8.1. Поиск в пространстве версий языка PROLOG
В главе 9 описано несколько алгоритмов символьного машинного обучения. В этом и
следующем разделах будут реализованы два из них: алгоритмы поиска в пространстве
версий (version space search) и обучения на основе пояснения (explanation-based learning).
Сами эти алгоритмы описаны в главе 9, а здесь приводится лишь их реализация на языке
PROLOG. Такой выбор языка для реализации алгоритмов машинного обучения
обусловлен тем, что он очень иллюстративен, поддерживает встроенные механизмы проверки
соответствия шаблонам, а его возможности рассуждений на метауровне упрощают
построение и работу с новыми представлениями.
Сначала реализуем поиск от частного к общему, а затем — полный двунаправленный
алгоритм исключения кандидата. Читателю будут предложены советы по построению
Глава 14. Введение в PROLOG
661
системы поиска в пространстве версий от общего к частному. Эти алгоритмы поиска
независимы от используемого представления понятий, если это представление
поддерживает соответствующие операции обобщения и специализации. Мы будем использовать
представление объектов в виде списков свойств. Например, маленький красный мяч
можно описать с помощью следующего списка.
[small, red, ball].
Понятие маленького красного объекта можно описать с помощью списка с переменной.
[small, red, X].
Такое представление называется вектором признаков (feature vector). Оно менее
выразительно, чем полная логика, поскольку с его помощью нельзя представить класс "всех
красных и зеленых мячей". Однако оно упрощает обобщение и обеспечивает строгий
индуктивный порог (раздел 9.4). Вектор признаков можно обобщить, подставляя вместо
константы переменные. Например, наиболее конкретным обобщением для векторов [small,
red, ball] и [small, green, ball] является вектор [small, X, ball]. Этот вектор
покрывает каждую из специализаций и является наиболее конкретным из всех таких векторов.
Будем считать, что вектор признаков покрывает другой вектор признаков, если он
либо идентичен этому вектору, либо является более общим. Заметим, что в отличие от
процедуры унификации отношение покрытия covers асимметрично: существуют
значения, для которых X покрывает У, но У не покрывает X. Например, вектор [X, red, ball]
покрывает вектор [large, red, ball], но не наоборот. Определим предикат covers для
векторов признаков следующим образом.
covers([], []).
covers([HI|Tl], [H2|T2]) :- ^переменные покрывают друг друга
var(Hl), var(H2)/ covers(Tl, T2).
covers([HI|Tl], [H2|T2]) :- ^переменная покрывает константу
var(Hl), atom(H2)/ covers(Tl, T2).
covers([HI|Tl], [H2|T2]) :- ^проверка соответствия констант
atom(Hl), atom(H2)/ Hi = H2,
covers(Tl, T2).
Теперь необходимо определить, является ли один вектор признаков строго более
общим, чем другой (т.е. векторы не идентичны). Определим соответствующий предикат
more_general.
more_general(X, Y) :- not(covers(Y, X)), covers(X, Y).
Обобщение векторов признаков реализуется с помощью предиката generalize,
зависящего от трех аргументов. Первый аргумент— это вектор признаков, представляющий
гипотезу (он может содержать переменные). Второй аргумент— экземпляр, не
содержащий переменных. Третий аргумент предиката generalize связывается с наиболее
конкретным обобщением гипотезы, покрывающей данный экземпляр. Предикат generalize
рекурсивно сканирует векторы признаков, сравнивая соответствующие элементы. Если два
элемента совпадают, в результирующий вектор включается значение соответствующего
компонента вектора гипотезы. Если эти элементы не совпадают, то в соответствующую
позицию результирующего вектора помещается переменная. Обратите внимание на
использование выражения not (Feature\=Inst_prop) во втором определении предиката
обобщения. Это двойное отрицание позволяет проверить, можно ли унифицировать два
атома без реального выполнения процедуры унификации и формирования любого
нежелательного связывания переменных. Определим предикат generalize.
662 Часть VI. Языки и технологии программирования для искусственного интеллекта
generalize([], [], []) .
generalize([Feature|Rest], [Inst_prop|Rest_inst],
[Feature|Rest_gen]) :-
not(Feature \ = Inst_prop), generalize(Rest, Rest_inst/ Rest_gen).
generalize([Feature|Rest], [Inst_prop|Rest_inst], [_|Rest_gen]) :-
Feature \ = Inst_prop/ generalize(Rest, Rest_inst/ Rest_gen).
Эти предикаты задают основную операцию для представления векторов признаков.
Остальная часть реализации не будет зависеть от конкретного представления и может
применяться к различным представлениям и операциям обобщения.
Как было указано в разделе 9.2, поиск от частного к общему в пространстве понятий
можно проводить за счет поддержания списка Н гипотез-кандидатов. Гипотезы в Н — это
наиболее конкретные понятия, покрывающие все положительные примеры и ни одного
отрицательного. Ядром алгоритма является процедура process, зависящая от пяти
аргументов. Первый аргумент— это обучающий экземпляр positive (X) или negative (X),
указывающий на то, что X является положительным или отрицательным примером. Второй
и третий аргументы — это текущий список гипотез и список отрицательных экземпляров.
В процессе реализации предикат process связывает четвертый и пятый аргументы с
обновленными списками гипотез и отрицательных экземпляров соответственно.
Первое выражение в этом определении инициализирует пустое множество гипотез
первым положительным экземпляром. Второе обрабатывает положительные обучающие
примеры путем обобщения гипотез-кандидатов для обеспечения покрытия этих
примеров. Затем ликвидируется чрезмерное обобщение за счет удаления всех гипотез, которые
являются более общими, чем другие, а также гипотез, покрывающих некоторые
отрицательные примеры. Третье выражение в этом определении служит для обработки
отрицательных примеров за счет удаления любых гипотез, покрывающих эти экземпляры.
process(positive(Instance), [], N, [Instance], N) .
process (positive (Instance) , H, N, Updated_H, N) :-
generalize_set(H, Gen_H, Instance),
delete(X, Gen_H, (member(Y, Gen_H),
more_general(X, Y)), Pruned_H),
delete(X, Pruned_H, (member(Y, N),
covers(X, Y)), Updated_H).
process (negative (Instance) , H, N, Updated_H, [Instance |N] ) :-
delete(X, H, covers(X, Instance), Updated_H).
process(Input, H, N, H, N):- ^Отслеживание ошибок ввода
Input \= positive(_),
Input \= negative(_),
write('Введите либо положительный пример positive(Instance) либо
отрицательный negative(Instance) ')/ nl.
Интересным аспектом этой реализации является предикат delete, представляющий
собой обобщение обычного процесса удаления всех повторных вхождений элемента из
списка. Один из аргументов этого предиката используется для определения того, какие
элементы подлежат удалению из списка. С помощью предиката bagof предикат delete
проверяет соответствие своего первого аргумента (который обычно является переменной)
каждому элементу второго аргумента (который обязательно должен быть списком). Затем
для каждого такого связывания выполняется проверка, указанная с помощью третьего
аргумента. Эта проверка представляет собой любую последовательность вызовов целевых
утверждений языка PROLOG. Если список элементов таков, что данная проверка завершается
Глава 14. Введение в PROLOG
663
неудачно, то предикат delete исключает этот элемент из результирующего списка.
Результат возвращается через последний аргумент. Предикат delete— это прекрасный
пример метарассуждений в языке PROLOG. Имея возможность передавать спецификацию
элементов, которые требуется удалить из списка, программист тем самым получает общее
средство реализации целого спектра операций со списками. Так, предикат delete
позволяет определять различные фильтры, используемые в процедуре process, в очень
компактной форме. Зададим предикат delete следующим образом.
delete(X, L, Goal, New_L) :-
(bagof(X, (member(X, L), not(Goal)), New_L); New_L = [ ]).
Предикат generalize_set рекурсивно сканирует список гипотез и обобщает
каждую из них в соответствии с обучающим примером. При этом предполагается
возможность существования нескольких обобщений кандидатов одновременно. На самом деле
описанное в разделе 9.2 представление в виде признаков допускает лишь одно наиболее
конкретное обобщение. Однако в целом это неверно, поэтому необходимо определить
алгоритм для общего случая.
generalize_set([ ], []/_).
generalize_set ( [Hypothesis | Rest] , Updated_H, Instance) :-
not(covers(Hypothesis, Instance)),
(bagof(X, generalize(Hypothesis, Instance, X), Updated_head),
Updated_head = [ ]),
generalize_set(Rest, Updated_rest, Instance),
append(Updated_head, Updated_rest, Updated_H).
generalize_set([Hypothesis|Rest], [Hypothesis|Updated_rest] ,
Instance) :-
covers(Hypothesis, Instance),
generalize_set(Rest, Updated_rest, Instance).
Правило specif ic_to_general реализует цикл для считывания и обработки
обучающих примеров.
specific_to_general(H, N) :-
write(УН='),write(Н),nl,write(yN='),write(N), nl,
write('Введите пример:')/
read(Instance), process(Instance, H, N, Updated_H, Updated_N),
specific_to_general(Updated_H, Updated_N).
Следующий пример иллюстрирует выполнение алгоритма.
?- specific_to_general([] , []).
Н = []
N = []
Введите пример: positive([small, red, ball]).
H = [[small, red, ball]]
N = []
Введите пример: negative([large, green, cube]).
H = [[small, red, ball]]
N = [[large, green, cube]]
Введите пример: negative([small, blue, brick]).
H = [[small, red, ball]]
N = [[large, green, cube], [small, blue, brick]]
Введите пример: positive([small, green, ball]).
H = [[small, _66, ball]]
664 Часть VI. Языки и технологии программирования для искусственного интеллекта
N = [[large, green, cube], [small, blue, brick]]
Введите пример: positive([large, blue, ball]).
H = [[_116, _66, ball]]
N = [[small, blue, brick], [large, green, cube]]
Вторая версия алгоритма, описанного в подразделе 9.2.2, выполняет поиск в направлении
от общего к частному. В этой версии множество гипотез-кандидатов инициализируется
наиболее общим среди возможных понятий. Для представления с помощью вектора признаков —
это список переменных. Затем выполняется специализация понятий-кандидатов,
предотвращающая покрытие отрицательных примеров. В представлении на основе векторов признаков
эта операция сводится к замене переменных константами. При получении нового
положительного примера удаляются любые гипотезы-кандидаты, не покрывающие его.
Реализация этого алгоритма во многом аналогична описанной выше реализации
поиска от частного к общему, включая использование общего предиката delete для
определения различных фильтров для списка понятий-кандидатов.
В системе поиска от общего к частному процедура process будет зависеть от шести
параметров. Первые пять соответствуют версии поиска от частного к общему. Первый
параметр— это обучающий пример вида positive (Instance) или negative (Instance),
второй— список гипотез-кандидатов, включающий наиболее общие гипотезы, не
покрывающие отрицательных примеров. Третий параметр — список положительных примеров,
используемый для удаления любых слишком специализированных гипотез-кандидатов.
Четвертый и пятый параметры — это обновленные списки гипотез и положительных примеров
соответственно. Шестой параметр — это список допустимых подстановок переменных для
специализации понятий. Для специализации путем подстановки константы вместо
переменной следует знать допустимые значения каждого компонента вектора признаков. Эти
значения необходимо передавать с помощью шестого параметра предиката process.
В рассматриваемом примере векторов [Size, Color, Shape] список типов может иметь
вид [[small, medium, large], [red, blue, green], [ball, brick, cube]]. Заметим, что
позиция каждого подсписка соответствует компоненту вектора признаков, в котором
используются значения этого списка. Например, первый подсписок определяет допустимые
значения первого компонента вектора признаков.
Реализацию этого алгоритма предлагается осуществить в качестве упражнения. Для
ориентировки приведем результаты работы нашей реализации.
?- general_to_specific([[_,_,_]],[], [[small,medium,large],
[red,blue,green],
[ball, brick, cube]]).
H = [[_0, _1, _2]]
P = []
Введите пример: positive([small, red, ball]).
H = [[_0, _1, _2]]
P = [[small, red, ball]]
Введите пример: negative([large, green, cube]).
H = [[small, _89, _90], [_79, red, _80],[_69, _70, ball]]
P = [[small, red, ball]]
Введите пример: negative([small, blue, brick]).
H = [[_79, red, _80],[_69, _70, ball]]
P = [[small, red, ball]]
Введите пример: positive([small, green, ball]).
H = [[_69, _70, ball]]
P = [[small, green, ball], [small, red, ball]]
Глава 14. Введение в PROLOG
665
14.8.2. Алгоритм исключения кандидата
Полный алгоритм исключения кандидата, описанный в подразделе 9.2.2,
представляет собой комбинацию двух однонаправленных алгоритмов поиска. Его ядром тоже
является предикат process, зависящий от шести аргументов. Первый аргумент—
обучающий пример, второй и третий аргументы — G и S — это множества максимально общих
и максимально конкретных гипотез соответственно. Четвертый и пятый аргументы
соответствуют обновленным версиям этих множеств. Шестой аргумент предиката process
содержит список допустимых подстановок для специализации векторов признаков.
Для положительных примеров предикат process выполняет обобщение множества S
наиболее конкретных обобщений с целью покрытия этого примера. Затем из S
исключаются любые чрезмерно обобщенные элементы. Кроме того, из множества G тоже удаляются
все элементы, не обеспечивающие покрытия этого обучающего примера. Интересно
отметить, что элемент S является чрезмерно общим, если не существует покрывающих его
элементов G. Дело в том, что множество G содержит такие гипотезы-кандидаты, которые, с
одной стороны, являются максимально общими, а с другой — не покрывают
отрицательных примеров. Для удаления гипотез используется предикат delete.
При поступлении отрицательного примера предикат process выполняет
специализацию всех гипотез в G, чтобы исключить этот пример. При этом из S удаляются все
кандидаты, покрывающие этот отрицательный пример. Как указывалось выше,
специализация векторов признаков сводится к замене переменных константами. Для этого
требуется передать список допустимых подстановок в качестве шестого аргумента
предиката process. Определение предиката process имеет следующий вид.
process(negative(Instance), G, S, Updated_G/ Updated_S/ Types) :-
delete(X, S, covers(X, Instance), Updated_S),
specialize_set(G, Spec_G/ Instance, Types),
delete(X, Spec_G/ (member(Y, Spec_G), more_general(Y, X)),
Pruned_G),
delete(X, Pruned_G/ (member(Y, Updated_S) , not(covers(X, Y))) ,
Updated_G).
process(positive(Instance), G, [], Updated_G/ [Instance], _):-
^Инициализация S
delete(X, G, not(covers(X, Instance)), Updated_G).
process(positive(Instance), G, S, Updated_G/ Updated_S/ _) :-
delete(X, G, not(covers(X, Instance)), Updated_G),
generalize_set(S, Gen_S/ Instance),
delete(X/ Gen_S/ (member(Y/ Gen_S), more_general(X, Y)),
Pruned_S),
delete(X, Pruned_S/ not((member(Y, Updated_G), covers(Y, X))),
Updated_S).
process(Input, G, P, G, P, _):-
Input \= positive(_), Input \= negative(_),
write('Введите либо положительный positive(Instance) либо
отрицательный
пример negative(Instance):')/ nl.
Предикат generalize_set выполняет обобщение всех элементов множества
гипотез-кандидатов с целью покрытия обучающего примера. Его реализация в точности
идентична версии, определенной в программе поиска от частного к общему. В качестве пара-
666 Часть VI. Языки и технологии программирования для искусственного интеллекта
метра он получает множество гипотез-кандидатов и вычисляет все максимально общие
специализации этих гипотез, исключающие (не покрывающие) обучающий пример.
Обратите внимание на использование предиката bagof для получения всех специализаций.
specialize_set([], [], _, _).
specialize_set ( [Hypothesis | Rest] , Updated_H, Instance, Types):-
covers(Hypothesis, Instance),
(bagof(Hypothesis, specialize(Hypothesis, Instance, Types),
Updated_head),
Updated_head = []),
specialize_set(Rest, Updated_rest, Instance, Types) :-
append(Updated_head, Updated_rest, Updated_H).
specialize_set([Hypothesis|Rest],[Hypothesis|Updated_rest],
Instance,Types):-
not(covers(Hypothesis, Instance)),
specialize_set(Rest, Updated_rest, Instance, Types).
Предикат specialize находит среди элементов вектора признаков тот, который
является переменной. Он связывает эту переменную с константой, выбираемой им из
списка допустимых значений таким образом, чтобы она не соответствовала обучающему
примеру. Напомним, что предикат specialize_set вызывает предикат specialize
с помощью предиката bagof для получения всех специализаций. При однократном
вызове предиката specialize он лишь подставляет константу вместо первой
переменной. Использование предиката bagof обеспечивает получение всех специализаций.
specialize([Prop|_], [Inst_prop|_], [Instance_values|_]):-
var(Prop),
member(Prop, Instance_values), Prop \= Inst_prop.
specialize([_|Tail], [_|Inst_tail], [_|Types]):-
specialize(Tail, Inst_tail, Types).
Определения предикатов generalize, more_general, covers и delete
совпадают с соответствующими определениями этих предикатов в программе поиска от
частного к общему. Предикат candidate_elim реализует цикл верхнего уровня, выводит
текущие значения множеств G и S, а также вызывает предикат process.
candidate_elim([G], [S], _) :-
covers(G, S), covers(S, G),
write('целевое понятие: ')/ write(G),nl.
candidate_elim(G, S, Types) :-
write(yG='),write(G),nl,write(*S=' ),write(S), nl, write('Введите
пример: '),
read(Instance),
process(Instance, G, S, Updated_G, Updated_S, Types),
candidate_elim(Updated_G, Updated_S, Types).
В заключение этого раздела представим результаты трассировки алгоритма
исключения кандидата. Обратите внимание на инициализацию множеств G и S, а также список
допустимых подстановок.
?- candidate_elim([[_,_,_]], [], [[small, medium, large], [red,
blue, green],
[ball, brick, cube]]).
G= [[_0, _1, _2]]
S= []
Глава 14. Введение в PROLOG
667
Введите пример: positive([small, red, ball]).
G= [[_0, _1, _2]]
S= [[small, red, ball]]
Введите пример: negative([large, green, cube]).
G= [[small, _96, _97], [_86, red, _87], [_76, _77, ball]]
S= [[small, red, ball]]
Введите пример: negative([small, blue, brick]).
G= [[_86, red, _87], [_76, _77, ball]]
S= [[small, red, ball]]
Введите пример: positive([small, green, ball]).
G= [[_76, _77, ball]]
S= [[small, _351, ball]]
Введите пример: positive([large, red, ball]).
target concept is: [_76, _77, ball]
yes
14.8.3. Реализация обучения на основе пояснения на языке PROLOG
В этом разделе будет описана реализация на языке PROLOG алгоритма обучения на
основе пояснения, изложенного в подразделе 9.4.2. Наша реализация основывается на
алгоритме prolog_ebg, предложенном в работе [Kedar-Cabelli и McCarty, 1987], и
иллюстрирует возможности унификации в языке PROLOG. Несмотря на то что на многих
языках достаточно сложно реализовать алгоритм обучения на основе пояснения, его
версия на PROLOG очень проста.
Этот алгоритм не строит структуру пояснения и не поддерживает отдельные
множества для подстановок обобщения и специализации, как это описано в разделе 9.4. В нем
дерево доказательства для обучающих примеров и обобщенное дерево доказательства
строятся одновременно.
В этом примере будут использованы деревья доказательств, аналогичные применяемым
в оболочке exshell (подраздел 14.7.2). При выявлении факта в системе prolog_ebg
этот факт возвращается как лист дерева доказательства. Доказательство конъюнкции целей
представляет собой конъюнкцию доказательств каждой из них. Доказательство цели,
требующее построения цепочки правил, представляется в виде (Goal :- Proof), где
Proof связывается с деревом доказательства для предпосылок этих правил.
Ядром алгоритма является предикат prolog_ebg. Он зависит от четырех
аргументов. Первый из них — это целевое утверждение, доказываемое с помощью обучающего
примера. Второй — обобщение цели. Если теория описания области определения
допускает доказательство конкретной цели, то третий и четвертый аргументы связываются с
деревом доказательства для цели и его обобщения. В частности, при реализации примера
из подраздела 9.5.2 нужно вызвать предикат prolog_ebg со следующими аргументами.
prolog_ebg(cup(obj1), cup(X)/ Proof, Gen_proof).
Предполагается, что на языке PROLOG представлена теория описания области
определения и обучающий пример из подраздела 9.4.2. При успешном завершении
процедуры prolog_ebg параметры Proof и Gen_proof будут связаны с деревьями
доказательств, показанными на рис. 9.17.
Процедура prolog_ebg — это простая вариация метаинтерпретатора, описанного в
подразделе 14.7.2. Основное отличие состоит в том, что разрешение цели и ее
обобщения выполняется параллельно. Еще один интересный аспект алгоритма связан с исполь-
668 Часть VI. Языки и технологии программирования для искусственного интеллекта
зованисм предиката duplicate для создания двух версий каждого правила. Первая
версия — это правило из теории описания предметной области, а вторая связывает
переменные этого правила со значениями из обучающего примера. Определим предикат
prolog_ebg.
prolog_ebg(A/ GenA, A, GenA) :- clause(A, true).
prolog_ebg((A, B), (GenA,GenB), (AProof,BProof),
(GenAProof,GenBProof)) :- !,
prolog_ebg(A, GenA, AProof, GenAProof),
prolog_ebg(B, GenB, BProof, GenBProof).
prolog_ebg(A, GenA, (A :- Proof), (GenA :- GenProof)) :-
clause(GenA, GenB),
duplicate((GenA :- GenB), (A :- B)),
prolog_ebg(B, GenB, Proof, GenProof).
Предикат duplicate основывается на использовании предикатов assert и
retract для создания копии выражения PROLOG с новыми переменными.
duplicate(Old, New) :- assert(y$marker'(Old)),
retract ( *$marker'(New)).
Предикат extract_support возвращает последовательность операционных узлов
наивысшего уровня согласно определению предиката operational. Он реализует
рекурсивный проход по дереву. Рекурсия прекращается при обнаружении узла в дереве
доказательства, квалифицируемого как операционный.
extract_support(Proof, Proof) :- operational(Proof) .
extract_support((A :- _), A) :- operational(A).
extract_support((AProof, BProof), (A, B)) :-
extract_support(AProof, A),
extract_support(BProof, B).
extract_support((_ :- Proof), B) :- extract_support(Proof, B) .
Последним компонентом алгоритма является построение изученного правила на
основе предикатов prolog_ebg и extract_support.
ebg(Goal, Gen_goal, (Gen_goal :- Premise)) :-
prolog_ebg(Goal, Gen_goal, _, Gen_proof),
extract_support(Gen_proof, Premise).
Проиллюстрируем выполнение этих предикатов на примере изучения структурных
определений чашки из подраздела 9.5.2 [Mitchell и др., 1986]. Сначала опишем теорию
предметной области чашек и других физических объектов. Эта теория включает
следующие правила.
cup(X) :- liftable(X), holds_liquid(X).
holds_liquid(Z) :- part(Z, W), concave(W), points_up(W).
liftable(Y) :- light(Y), part(Y, handle).
light(A):- small(A).
light(A):- made_of(A, feathers).
Обучаемой системе также дается следующий пример, о котором известно, что
ob j 1 — чашка.
small(objl).
part(objl, handle),
owns(bob, objl).
Глава 14. Введение в PROLOG
669
part(obj1, bottom),
part(obj1, bowl).
points_up(bowl).
concave(bowl).
color(obj1, red).
С помощью критерия операционности определим предикаты, которые можно
использовать в правиле.
operational(small(_)).
operational(part(_, _)).
operational(owns(_, _))•
operational(points_up(_)).
operational(concave(_)).
Запуск алгоритма для этого примера иллюстрирует поведение этих предикатов.
?- prolog_ebg(cup(obj1), cup(X), Proof, Gen_proof).
X = _0,
Proof = cup(obj1) :-
((liftable(objl) :-
((light(obj1) :-
small(obj1)), part(obj1, handle))),
(holds_liquid(obj1) :-
(part(obj1, bowl),
concave(bowl), points_up(bowl))))
Gen_prooof = cup(_0) :-
((liftable(_0) :-
((light(_0) :-
small(_0)),
part(_0, handle))),
(holds_liquid(_0) :-
(part(_0, _106),
concave(_106),
points_up(_106))))
Если предикату extract_support передать обобщенное дерево доказательства,
полученное после выполнения предиката prolog_ebg, то он возвратит операционные
узлы дерева доказательства, упорядоченные слева направо.
?- extract_support((cup(_0) :-
((liftable(_0) :-
((light(_0) :-
small(_0)),
part(_0, handle))),
(holds_liquid(_0) :-
(part(_0/_10б), concave(_106) ,
points_up(_106))))), Premise),
_0 = _0, _106 = _1,
Premise = (small(_0),part(_0,handle)),part(_0,_1), concave(_1),
points_up(_1)
И, наконец, предикат ebg использует описанные выше процедуры для построения
нового правила на основе предъявленного примера.
?- ebg(cup(obj1), cup(X), Rule).
X = _0,
670 Часть VI. Языки и технологии программирования для искусственного интеллекта
Rule = cup(_0) :-
((small(_0), part(_0/handle)),part(_0/_110), concave(_110),
points_up(_110))
14.9. Обработка естественного языка на PROLOG
14.9.1. Семантические представления для обработки
естественного языка
Благодаря встроенным возможностям поиска и проверки соответствия шаблонам
язык PROLOG органично подходит для решения задач обработки естественного языка.
Грамматику естественного языка можно описать на PROLOG напрямую, как это будет
сделано при описании контекстно-независимой и контекстно-зависимой грамматик в
подразделе 14.9.2. На PROLOG легко создать и семантические представления, в чем мы
сможем убедиться при описании падежных фреймов в этом разделе. Семантические
представления также можно реализовать либо с помощью теории предикатов первого
порядка, либо на основе метаинтерпретатора для другого представления, как было
предложено в подразделе 14.7.4. И, наконец, семантический вывод, в том числе объединение,
ограничение и наследование в концептуальных графах можно напрямую описать на
языке PROLOG, в чем читатель сможет убедиться, прочитав подраздел 14.9.3.
Как известно из раздела 6.2, концептуальные графы можно преобразовать в
выражения теории предикатов, а значит, напрямую описать на языке PROLOG. Имена узлов
концептуальных отношений становятся при этом именами предикатов, а арность
отношения определяет количество аргументов. Каждый предикат PROLOG, как и каждый
концептуальный граф, представляет одно предложение.
Концептуальные графы, представленные на рис. 6.11, на языке PROLOG можно
описать следующим образом.
bird(X), flies(X).
dog(X), color (X, Y), brown(Y).
child(X), parents (X, Y, Z) , father(Y), mother (Z).
Здесь X, Y и Z — переменные, связанные с соответствующими объектами. Как было
указано в разделе 14.6, к параметрам можно добавить информацию о типах. С помощью
вариации предикатов isa можно также определить иерархию типов.
Падежные фреймы, введенные в подразделе 13.3.2, тоже очень легко построить на
языке PROLOG. С каждым глаголом связывается список семантических отношений.
Среди них могут быть агенты, инструменты и объекты. Ниже будут рассмотрены
примеры для глаголов give (давать) и bite (кусать). Например, глагол give может быть связан с
подлежащим, дополнением и непрямым дополнением. Очевидным примером реализации
этих структур является английское предложение "John gives Mary the book" (Джон дает
Мэри книгу). Применяемые по умолчанию значения можно определить в падежном
фрейме, связав их с соответствующими переменными. Например, для глагола bite
(кусать) можно определить используемый по умолчанию инструмент— teeth (зубы) —
и указать, что инструмент для кусания (teeth) принадлежит агенту. Падежные фреймы
для этих двух глаголов могут иметь следующий вид.
verb(give,
[human (Subject),
Глава 14. Введение в PROLOG
671
agent (Subject, give),
act_of_giving (give),
object (Object, give),
inanimate (Object),
recipient (Ind_obj/ give),
human (Ind_obj) ] ).
verb(bite,
[animate (Subject),
agent (Subject, Action),
act_of_biting (Action),
object (Object, Action),
animate (Object),
instrument (teeth, Action),
part_of (teeth, Subject) ] ).
Логическое программирование предоставляет широкие возможности для построения
грамматик и представления семантических значений. Далее на PROLOG будут построены
рекурсивные анализаторы, а затем к ним будут добавлены семантические ограничения.
14.9.2. Рекурсивный анализатор на языке PROLOG
Рассмотрим приведенное ниже подмножество правил грамматики английского языка.
Эти правила являются непроцедурными, поскольку просто определяют отношения
между частями речи. С помощью этого подмножества правил можно определить
корректность многих простых предложений.
Sentence<r^NounPhrase VerbPhrase,
NounPhrase<r+Noun,
NounPhrase<r+Article Noun,
VerbPhrase<r+Verb,
VerbPhrase<r^Verb NounPhrase.
Добавим к этим правилам грамматики небольшой словарь.
Article (а),
Article(the),
Noun(man),
Noun(dog),
Verb(likes),
Verb(bites).
На рис. 14.9 показано дерево грамматического разбора предложения "The man bites
the dog", в котором связь and соответствует конъюнкции в правилах грамматики. Эти
правила естественным образом описываются на PROLOG. Например, предложение
sentence — это именная конструкция nounphrase, за которой следует глагольная
конструкция verbphrase.
sentence(Start,End) :- nounphrase(Start, Rest), verbphrase(Rest, End).
Каждое правило на PROLOG зависит от двух параметров, первый из которых
представляет собой последовательность слов в форме списка. Правило проверяет, является ли
некоторая начальная часть списка допустимой частью речи. Оставшийся суффикс списка
должен соответствовать второму параметру, поскольку анализ предложений выполняет-
672 Часть VI. Языки и технологии программирования для искусственного интеллекта
ся слева направо. Если правило описания предложения срабатывает успешно, то второй
параметр предиката sentence представляет собой оставшуюся часть предложения,
полученную после разбора фраз nounphrase и verbphrase. Если список представляет
собой корректное предложение, то в остатке получается пустой список [ ]. Для
глагольной и именной конструкции определяются две альтернативные формы описания.
Article 1 [ Noun ] | Verb ]
| Article ] [ Noun
the man bites the dog
Рис 14 9 Дерево грамматического разбора
И/ИЛИ для предложения ''The man bites the dog"
Для простоты само предложение тоже описывается в виде списка [the, man,
bites, the, dog]. Список разделяется на составляющие и передается различным
грамматическим правилам для проверки синтаксической корректности. Обратите внимание
на то, как выполняется проверка соответствия шаблонам для списка в вопросительном
предложении. Сначала отбрасывается голова списка или голова со вторым элементом, а
предикату передается оставшаяся часть списка и т.д. Предикат utterance в качестве
параметра получаст подлежащий анализу список и вызывает правило sentence. При этом
второй параметр правила инициализируется пустым списком [ ]. Полная грамматика
определяется следующим образом.
utterance(X) :- sentence(X, [ ]).
sentence(Start, End) :- nounphrase(Start, Rest), verbphrase(Rest,
End) .
nounphrase([Noun|End], End) :- noun(Noun).
nounphrase([Article, Noun|End], End) :- article(Article),
noun(Noun).
verbphrase([Verb|End], End) :- verb(Verb).
verbphrase([Verb J Rest], End) :- verb(Verb), nounphrase(Rest, End).
article(a).
article(the).
noun(man).
noun(dog).
verb(likes).
verb(bites).
Теперь можно проверять корректность построения конкретных предложений.
?- utterance([the, man, bites, the, dog]).
Yes
Глава 14. Введение в PROLOG
673
?- utterance([the, man, bites, the]),
no
Интерпретатор может также предложить возможные варианты слов для неполных
предложениий.
?- utterance([the, man, likes, X]).
X = man
X = dog
no
И, наконец, этот же код можно использовать для построения множества всех
предложений, корректно сконструированных в рамках данных правил грамматики и
ограниченного словаря.
?- utterance(X).
[man, likes]
[man, bites]
[man, likes, man]
[man, likes, dog]
и т.д.
Если пользователь продолжает запрашивать решения, то в результате он получит все
возможные корректно сконструированные предложения, которые могут быть
сгенерированы на основе заданных правил грамматики и словаря. Заметим, что PROLOG
выполняет поиск в глубину слева направо.
Правила грамматики — это спецификация корректных конструкций выражений в данном
подмножестве легитимных предложений английского языка. Код на языке PROLOG
представляет этот набор логических спецификаций. Интерпретатору передаются запросы об этом
наборе. Таким образом, ответом является функция от спецификации и заданного вопроса.
В этом состоит основное преимущество вычислений на языке, который сам представляет
собой систему доказательства теорем на основе спецификаций. Более подробная информация о
PROLOG как системе доказательства теорем приводится в главе 12.
Предыдущий пример можно естественным образом расширить, добавив к нему
условия согласованности форм существительного и глагола. Тогда для каждого элемента
словаря необходимо указать форму этого слова в единственном и множественном числе,
а для предикатов nounphrase и verbphrase ввести дополнительный параметр,
отражающий числовую форму number данной фразы. В этом случае существительное в
единственном числе должно быть связано с глаголом в форме единственного числа.
Контекстная зависимость существенно повышает мощность грамматики.
Приведенная выше версия реализует контекстно-независимую грамматику. Теперь построим
контекстно-зависимую грамматику на языке PROLOG (раздел 13.2). В ней сохраняется
контекстная информация, необходимая для проверки соответствия формы числа. Такая
модификация достигается за счет расширения предыдущего кода.
utterance(X) :- sentence(X, [ ]).
sentence(Start, End) :- nounphrase(Start, Rest, Number),
verbphrase(Rest, End, Number).
674 Часть VI. Языки и технологии программирования для искусственного интеллекта
nounphrase([Noun|End], End, Number) :- noun(Noun, Number),
nounphrase([Article, Noun|End], End, Number) :- noun(Noun, Number),
article(Article, Number),
verbphrase([Verb|End], End, Number) :- verb(Verb, Number),
verbphrase([VerbJRest], End, Number) :- verb(Verb, Number),
nounphrase(Rest, End, _).
article(a, singular),
article(these, plural),
article(the, singular).
article(the, plural),
noun(man, singular),
noun(men, plural).
noun(dog, singular).
noun(dogs, plural).
verb(likes, singular),
verb(like, plural),
verb(bites, singular).
verb(bite, plural).
Теперь снова протестируем предложения.
?- utterance([the, men, like, the, dog]).
yes
?- utterance([the, men, likes, the, dog]).
no
На второй запрос получен отрицательный ответ, поскольку существительное men и
глагол likes не согласуются по числу. Если в качестве целевого утверждения ввести
?- utterance([the, men|X]).,
то этот предикат с помощью параметра X вернет все глагольные конструкции,
дополняющие фразу "the men...", в которых числовая форма существительных и глаголов будет
согласована.
В рассмотренном примере взятые из словаря параметры обеспечивают дополнительную
информацию о значениях слов в предложении. Обобщая этот подход, можно построить
мощный грамматический анализатор естественного языка. В словарь можно включать все новую и
новую информацию о членах предложения, создавая базу знаний о значениях слов
английского языка. Например, люди являются одушевленными и социальными объектами, а собаки —
одушевленными и несоциальными. Тогда можно добавить новые правила типа "Социальные
объекты не кусают одушевленных несоциальных существ". Это позволит исключить
предложения типа [the, man, bites, the, dog]. Если же несоциальный объект больше не
является одушевленным, то его, конечно же, могут съесть в ресторане.
14.9.3. Рекурсивный анализатор на основе семантических сетей
Теперь расширим множество контекстно-зависимых правил грамматики, включив в
него условия семантической согласованности. Это можно сделать, определив для
падежных фреймов глаголов соответствующие семантические описания подлежащих и
дополнений. Затем ограничим полученные подграфы семантических сетей, обеспечив их
взаимную согласованность. Это достигается с помощью таких операций над графами, как
объединение и ограничение. Они выполняются для каждой части графа, возвращаемой в
качестве дерева разбора.
Глава 14. Введение в PROLOG
675
Сначала представим правила грамматики. Заметим, что предикат самого верхнего уровня
utterance возвращает не просто предложение, а граф предложения Sentence_graph.
Предикаты компонентов отношений грамматики (nounphrase и verbphrase) вызывают
предикат j о in для слияния ограничений соответствующих графов.
utterance(X, Sentence_graph) :-
sentence(X, [ ], Sentence_graph).
sentence(Start, End, Sentence_graph) :-
nounphrase(Start, Rest, Subject_graph),
verbphrase(Rest, End, Predicate_graph),
join([agent(Subject_graph)], Predicate_graph, Sentence_graph) .
nounphrase([Noun | End], End, Noun_phrase_graph) :-
noun(Noun, Noun_phrase_graph).
nounphrase([Article, Noun | End], End, Noun_phrase_graph) :-
article(Article),
noun(Noun, Noun_phrase_graph).
verbphrase([Verb | End], End, Verb_phrase_graph) :-
verb(Verb, Verb_phrase_graph).
verbphrase([Verb | Rest], End, Verb_phrase_graph) :-
verb(Verb, Verb_graph),
nounphrase(Rest, End, Noun_phrase_graph),
join([object(Noun_phrase_graph)], Verb_graph,
Verb_phrase_graph).
Опишем предикаты для выполнения операций ограничения и объединения графов.
На самом деле они представляют собой метапредикаты, поскольку оперируют другими
структурами PROLOG. Их можно рассматривать как утилиты, реализующие ограничения
для объединяемых фрагментов семантических сетей.
join(X, X, X) .
join(A, В, С) :-
isframe(A), isframe(B), !,
join_frames(А, В, С, not_joined).
join(A, В, С) :-
isframe(A), is_slot((B), !,
join_slot_to_frame(В, А, С).
join(A, В, С) :-
isframe(B), is_slot(A), !,
join_slot_to_frame(А, В, С).
join(A, В, С) :-
is_slot(A), is_slot(B), !,
join_slots(А, В, С).
Предикат join_frames рекурсивно проверяет соответствие каждой ячейки
(свойства) первого фрейма ячейкам второго. Предикат join_slot_to_frame
получает в качестве параметров ячейку и фрейм и находит в этом фрейме ячейки,
соответствующие первому параметру. Предикат join_slots проверяет соответствие двух ячеек
с учетом иерархии типов.
join_frames([А | В], С, D, ОК) :-
join_slot_to_frame(А, С, Е) , !,
join_frames(В, Е, D, ok).
join_frames([ А | В], С, [А | D], ОК) :-
join_frames(В, С, D, ОК), !.
join_frames([], A, A, ok).
676 Часть VI. Языки и технологии программирования для искусственного интеллекта
join_slot_to_frame(A, [В | С], [D | С]) :-
join_slots(A, B, D).
join_slot_to_frame(A/ [B | C], [B | D]) :-
join_slot_to_frame(A, C, D).
join_slots(A, B, D) :-
functor(A, FA, _), functor(B, FB, _),
match_with_inheritance(FA, FB, FN),
arg(l, A, Value_a), arg(l, B, Value_b),
join(Value_a, Value_b, New_value),
D =. . [FN | [New_value]].
isframe([_ | _]).
isframe ([ ]) .
is_slot(A) :- functor(A, _, 1).
И, наконец, создадим словарь, представляющий собой иерархию иерархий, и опишем
падежные фреймы для глаголов. В рассматриваемом примере будем использовать простую
иерархию, в которой перечислены все корректные специализации. Третьим аргументом
предиката match_with_inheritance является общая специализация первых двух. Более
жизненная реализация должна содержать граф иерархий, на котором выполняется поиск общих
специализаций. Предлагаем читателю выполнить это в качестве упражнения.
match_with_inheritance(X, X, X).
match_with_inheritance(dog, animate, dog).
match_with_inheritance(animate, dog, dog).
match_with_inheritance(man, animate, man).
match_with_inheritance(animate, man, man).
article(a).
article(the).
noun(fido/ [dog(fido)]).
noun(man, [man(X)]).
noun(dog, [dog(X)]).
verbdikes, [action( [liking (X) ]) , agent ( [animate (X) ]) ,
object (animate(Y)])]).
verb(bites, [action([biting(Y)]), agent([dog(X)]),
object ( animate(Z)])]).
Теперь проанализируем несколько предложений и выведем граф Sentence_graph.
?- utterance([the, man, likes, the, dog], X).
X = [action([liking(_54)]), agent([man(_23)]), object([dog(_52)])].
?- utterance([fido, likes, the, man], X).
X = [action([liking(_62)]), agent([dog(fido)]),
object ( [man(_70)])].
?- utterance([the, man, bites, fido], Z) .
no
В первом предложении утверждается, что некоторый человек, имя которого
неизвестно, любит безымянную собаку. Последнее предложение, несмотря на свою
синтаксическую корректность, не удовлетворяет семантическим ограничениям, поскольку
агентом глагола bites должна быть собака. Во втором предложении конкретная собака Фидо
любит безымянного человека. В последнем примере проверим, может ли Фидо укусить
безымянного человека.
?- utterance([fido, bites, the, man], X).
X= [action([biting(_12)]), agent([dog(fido)]),
object ( [man (_17 )]) ] .
Глава 14. Введение в PROLOG
677
Этот анализатор можно расширять во многих интересных направлениях, в частности,
добавить к нему прилагательные, наречия и вводные фразы, либо позволить
использовать сложные предложения. Эти добавления нужно включить в граф предложения.
Каждый элемент словаря может иметь несколько значений, допустимых только при
соблюдении некоторых общих требований к предложению. Дополнительные примеры
приводятся в перечне упражнений.
14.10. Резюме и дополнительная литература
В таких традиционных языках программирования, как FORTRAN и С, логика
описания задачи и управление выполнением алгоритма решения неразрывно связаны друг с
другом. Программа на таком языке — это просто последовательность действий,
выполняемых для получения ответа. Такие языки называются процедурными (procedural).
В PROLOG логика описания задачи отделена от ее выполнения. Как следует из глав 5-7,
на это существует множество причин.
Не стоит и говорить, что PROLOG еще не достиг состояния полного совершенства.
Однако уже сейчас можно показать, что логическое программирование, реализуемое на
языке PROLOG, обладает некоторыми преимуществами непроцедурной семантики.
Рассмотрим пример декларативной природы PROLOG. Возьмем предикат append.
append([ ], L, L).
append([X|T], L, [X|NL]) :- append(T, L, NL).
Он является непроцедурным элементом, поскольку определяет отношения между
списками, а не набор операций по их объединению. Следовательно, различные запросы
могут приводить к вычислению различных аспектов этого отношения. Чтобы лучше
понять предикат append, можно провести трассировку процесса объединения двух
списков. Вот пример запроса и ответа.
?- append([a, b, с], [d, e], Y).
Y = [а, Ь, с, d, e]
Выполнение предиката append не рекурсивно по хвосту, поскольку конкретные
значения переменных достигаются после успешного завершения рекурсивного вызова.
Следовательно, после завершения рекурсивного вызова X располагается в голове списка
[ X | NL ]. Для этого каждый вызов необходимо записывать в стек PROLOG. Рассмотрим
следующий пример трассировки.
1. append([ ], L, L).
2. append([X|T], L, [X|NL]) :- append(T, L, NL).
?- append([a, b, c], [d, e], Y).
try match 1, fail [a, b, c]*[ ]
match 2, X is a, T is [b, c], L is [d, e], call append([b, c],
[d, e] , NL)
try match 1, fail [b, c]*[ ]
match 2, X is b, T is [c], L is [d, e], call append([c],
[d, e] , NL)
try match 1, fail [c]*[ ]
match 2, X is c, T is [ ], L is [d,e], call append([ ],
[d, e] , NL)
678 Часть VI. Языки и технологии программирования для искусственного интеллекта
match 1, L is [d, e] (for BOTH parameters), yes
yes, N is [d, e] , [X|NL] is [c, d, e]
yes, NL is [c, d, e] , [X|NL] is [b, c, d, e]
yes, NL is [b, c, d, e] , [X|NL] is [a, b, c, d, e]
Y = [a, b, c, d, e] , yes
В большинстве алгоритмов PROLOG параметры предикатов можно разделить на
"входные" и "выходные", поскольку в большинстве определений предполагается, что
при вызове предиката некоторые параметры должны быть связаны, а другие — нет.
Но это не обязательно так. На самом деле параметры в PROLOG вообще не делятся на
входные и выходные. Код на PROLOG — это просто набор спецификаций истинных
утверждений или описание логики ситуации. В частности, предикат append задает такое
отношение между тремя списками, при котором третий список является результатом
вставки первого в начало второго.
Чтобы проиллюстрировать это утверждение, рассмотрим разные варианты
использования предиката append.
?- append([a, b], [с], [a, b, с]).
yes
?- append([а], [ с ] , [а, b, с]).
по
?- append(X, [b, с] , [а, Ь, с]) .
X = [а]
?- append(X, Y, [а, Ь, с]).
X = [ ]
Y = [а, Ь, с]
X = [а]
Y = [Ь, с]
X = [а, Ь]
Y = [с]
X = [а, Ь, с]
Y = [ ]
по
В последнем запросе PROLOG возвращает все списки X и Y, которые в результате
конкатенации дают список [ а, b, с ] — всего четыре пары списков. Как было указано
выше, append — это описание логики отношения между тремя списками. Результат
работы интерпретатора зависит от запроса.
Решение задач на основе множества спецификаций корректных отношений в данной
предметной области в сочетании с работой системы доказательства теорем связано со
многими интересными и важными аспектами. Такое средство находит свое применение в столь
разнообразных областях знаний, как понимание естественного языка, обработка баз
данных, написание компиляторов и машинное обучение. Работу интерпретатора PROLOG
нельзя до конца осмыслить без осознания понятий из области доказательства теорем
резолюции, особенно процесса опровержения хорновских дизъюнктов, описанного в главе 12.
PROLOG — это язык программирования общего назначения. В связи с
ограниченностью объема книги в этой главе были опущены его многочисленные важные аспекты.
Любознательному читателю автор рекомендует познакомиться со многими замечатель-
Глава 14. Введение в PROLOG
679
ными книгами, в том числе [Clocksin и Mellish, 1984], [Maier и Warren, 1988], [Sterling и
Shapiro, 1986], [O'Keefe, 1990], [VanLe, 1993], [Lucas, 1996] или [Ross, 1989]. В работах
[King, 1991], [Gazdar и Mellish, 1989] описано применение языка PROLOG во многих
важных приложениях теории искусственного интеллекта.
Более полное описание типов PROLOG, а также предложения по созданию
алгоритмов проверки соответствия типов приводятся в [Mycroft и O'Keefe, 1984]. Применение
стеков правил и деревьев доказательств при разработке экспертных систем описано в
[Sterling и Shapiro, 1986].
Во многих книгах рассматриваются вопросы построения таких представлений
искусственного интеллекта, как семантические сети, фреймы и объекты [Walker и др., 1987],
[Malpas, 1987].
Средства представления языка PROLOG настолько органично подходят для решения
задач понимания естественного языка, что PROLOG часто используют для моделирования
таких языков. Первый интерпретатор PROLOG был разработан для анализа французского
языка на основе грамматики метаморфоз (metamorphosis grammar) [Colmerauer, 1975].
В [Pereira и Warren, 1980] создана грамматика определенных дизъюнктов (definite clause
grammar). Свой вклад в развитие этой области исследований внесли работы [Dahl, 1977],
[Dahl и McCord, 1983], [McCord, 1982], [McCord, 1986], [Sowa, 1984], [Walker и др., 1987].
Интеллектуальные корни языка PROLOG уходят к теоретическим принципам
использования логики для описания задач. В этой области автор особенно рекомендует книги
[Kowalski, 1979a, 19796].
Неослабевающий интерес вызывают и другие, отличные от PROLOG, среды
логического программирования. К ним относятся параллельные языки логического
программирования [Shapiro, 1987]. В [Nadathur и Tong, 1999] описан Lambda-PROLOG— язык
логического программирования более высокого уровня. В работе [Hill и Lloyd, 1994]
предложен язык Goedel, а в [Somogyi и др., 1995] — язык Mercury. Goedel и Mercury— две
относительно новые среды декларативного логического программирования.
14.11. Упражнения
1. Создайте на языке PROLOG реляционную базу данных. Представьте кортежи данных в
виде фактов, а ограничения — в виде правил. В качестве примеров можно рассмотреть
базу данных товаров в универмаге или записей о сотрудниках в отделе кадров.
2. Напишите на языке PROLOG программу, решающую задачу Вирта "I am my own
grandfather" (Я — мой собственный дедушка) (глава 2, упражнение 12).
3. Напишите на PROLOG программу проверки принадлежности элемента списку. Что
произойдет, если элемент не принадлежит списку? Дополните эту спецификацию
таким образом, чтобы она позволяла разбивать список на элементы.
4. Разработайте на PROLOG программу unique (Bag, Set), которой передается
параметр Bag (список, который может содержать повторяющиеся элементы), а она
возвращает параметр Set (множество без повторяющихся элементов).
5. Напишите на PROLOG программу вычисления количества элементов в списке
(список в списке считается одним элементом). Разработайте программу подсчета
атомов в списке (вычисления количества элементов во всех подсписках). Совет:
можно воспользоваться несколькими метапредикатами типа atom().
680 Часть VI. Языки и технологии программирования для искусственного интеллекта
6. Напишите на PROLOG код программы, решающей задачу перевозки человека, волка,
козы и капусты.
6.1. Выполните этот код и постройте граф поиска.
6.2. Измените порядок следования правил для получения альтернативных путей решения.
6.3. Используйте оболочку, описанную в этой главе, для реализации поиска в ширину.
6.4. Опишите полезные для данной задачи эвристики.
6.5. Постройте решение на основе эвристического поиска.
7. Выполните задания 6.1-6.5 из упражнения 6 для следующей задачи.
Три миссионера и три каннибала стоят на берегу реки и хотят переправиться через
нее. У берега находится лодка, в которую могут поместиться только два человека, и
ни одна из групп не умеет плавать. Если на одном из берегов реки миссионеров
окажется больше, чем каннибалов, то каннибалы превратятся в миссионеров. Требуется
найти последовательность перемещений всех людей через реку, не влекущую за
собой никаких превращений.
8. Воспользуйтесь своей программой для решения модифицированной задачи
миссионера и каннибала. Например, решите эту же задачу для 4 миссионеров и 4
каннибалов, если лодка может перевезти только двух человек. Решите эту же задачу для
случая, если в лодке помещается три человека. Постарайтесь обобщить решение на
целый класс задач миссионера и каннибала.
9. Напишите программу на PROLOG для решения полной задачи хода конем 8x8.
Используйте при этом архитектуру продукционной системы, предложенную в этой
главе и главе 5. Выполните задания 6.1-6.5 из упражнения 6.
10. Выполните задания 6.1-6.5 из упражнения 6 для задачи о кувшинах с водой.
Есть два кувшина, содержащие 3 и 5 литров воды соответственно. Их можно заполнять,
опорожнять и сливать воду из одного в другой до тех пор, пока один из них не окажется
полным или пустым. Выработайте последовательность действий, при которой в большем
кувшине окажется 4 литра воды. (Совет: используйте только целые числа.)
11. Воспользуйтесь алгоритмом path для решения задачи хода конем в этой главе.
Перепишите его вызов в рекурсивной форме вида
path(X, Y) :- path(X, W), move(W, Y).
Выполните трассировку и опишите результаты.
12. Напишите программу передачи значений на верхний уровень дерева или графа игры.
Используйте при этом:
а) минимаксный подход;
б) отсечение дерева альфа-бета;
в) оба подхода для игры в "крестики-нолики".
13. Напишите на PROLOG программу реализации процесса поиска для алгоритма
финансового консультанта, описанного в главах 2-5. Воспользуйтесь архитектурой
продукционной системы. Чтобы сделать программу интереснее, добавьте несколько правил.
14. Допишите код для системы планирования из раздела 14.5. Рассмотрите ситуацию,
требующую нового множества перемещений, добавив такие фигуры, как пирамида
или сфера.
Глава 14. Введение в PROLOG
681
15. Разработайте планировщик на основе поиска в ширину для примера из раздела 14.5.
Добавьте к этому алгоритму соответствующие эвристики. Можно ли определить
допустимость эвристики?
16. Создайте для системы планирования структуру, подобную треугольной таблице.
Используйте ее для сохранения и обобщения успешных последовательностей перемещений.
17. Создайте полный набор предикатов АТД для приоритетной очереди из раздела 14.2.
18. Реализуйте проверку соответствия типов, позволяющую предотвратить аномалию
вида append(nil, 6, 6).
19. Действительно ли процедура конкатенации разностных списков выполняется за
линейное время (раздел 14.6)? Поясните.
20. Создайте базу данных товаров из подраздела 14.6.2. Реализуйте проверку
соответствия типов для набора из шести запросов на множестве этих кортежей данных.
21. Дополните определение языка PROLOG в PROLOG (раздел 14.7), включив в него
оператор отсечения и операции логического И и ИЛИ.
22. Добавьте новые правила к оболочке exshell. Добавьте новые подсистемы для
выявления неисправностей коробки передач или тормозов.
23. Создайте базу знаний для новой предметной области оболочки exshell.
24. Работа оболочки exshell завершается неудачно, если предложенное целевое
утверждение нельзя доказать с помощью существующей базы правил. Дополните
оболочку exshell таким образом, чтобы при невозможности доказательства цели она
вызывала эту цель как запрос PROLOG. Добавление этой возможности потребует
изменения предикатов solve и build_proof.
25. Оболочка exshell позволяет пользователю отвечать на запросы, вводя степень
доверия или запросы why и how. Дополните эту оболочку таким образом, чтобы
пользователь мог вводить ответы у для истинных запросов и п — для ложных. Эти
ответы должны соответствовать степеням доверия 100 и -100.
26. Вспомните концептуальные графы, используемые для описания "мира собак" в
разделе 6.2. Опишите эти графы на PROLOG. Разработайте правила PROLOG для
операций restrict, join и simplify. Совет: создайте список предложений,
конъюнкция которых составляет граф. Тогда операции на графах будут соответствовать
операциям управления списками.
27. Реализуйте систему на основе фреймов с наследованием, поддерживающую определение
трех видов ячеек: свойств класса, наследуемых подклассами, свойств, наследуемых
экземплярами данного класса, но не его подклассами, и ненаследуемых свойств класса.
Опишите преимущества и проблемы, связанные с таким разграничением.
28. Реализуйте поиск от общего к частному в пространстве версий с использованием
векторов признаков (раздел 9.4.1). Специализация вектора признаков выполняется за
счет замены переменных константами. Поскольку для этого требуется указать
алгоритму список допустимых значений для каждого поля вектора признаков, ему
необходим дополнительный аргумент. Следующее определение цели верхнего уровня
иллюстрирует необходимость инициализации для рассмотренного примера. Объекты
могут быть маленькими, средними или большими, красными, синими или зелеными
и иметь форму шара, бруска или куба.
682 Часть VI. Языки и технологии программирования для искусственного интеллекта
run_general :-
general_to_specific([[_, _,_]], [],
[[small, medium, large], [red, blue, green], [ball, brick,
cube]]).
29. Реализуйте теорию описания предметной области для примера из главы 9. Запустите
этот пример с помощью команды prolog_ebg.
30. Дополните определение предиката ebg таким образом, чтобы после построения
нового правила оно добавлялось в логическую базу данных и могло использоваться в
последующих запросах. Проверьте производительность полученной системы с
помощью теории достаточно богатой предметной области. Такую теорию можно
построить самостоятельно либо дополнить теорию из примера с чашками, добавив
в нее описание различных типов чашек, например, чашек без ручки.
31. В главе 15 приводится реализация алгоритма ID3 из главы 12 на языке LISP.
Создайте с ее помощью реализацию этого алгоритма на языке PROLOG. He пытайтесь при
этом просто перевести код LISP на PROLOG. Эти языки различны и, подобно
естественным языкам, для описания одних и тех же объектов требуют различных идиом.
Придерживайтесь стиля PROLOG.
32. Постройте на PROLOG ATN-анализатор из подраздела 13.2.4. Добавьте вопросы
who и what.
33. Напишите на PROLOG код для подмножества правил грамматики английского языка
(раздел 14.9). Добавьте к рассмотренному примеру:
а) прилагательные и наречия для модификации глаголов и существительных;
б) вводные фразы (можно ли сделать это с помощью рекурсивного вызова?);
в) сложные предложения (два предложения, объединенные операцией конъюнкции).
34. Описанный в этой главе простой анализатор естественного языка допускает
грамматически корректные предложения, которые могут иметь недопустимое значение,
в частности "The man bites the dog" (Человек кусает собаку). Такие предложения
можно исключить из грамматики, добавив в нее данные о семантической
допустимости. Разработайте на PROLOG небольшую семантическую сеть, позволяющую
рассуждать о некоторых аспектах возможной интерпретации грамматических правил
английского языка.
35. Переработайте анализатор на основе семантических сетей из подраздела 13.3.2,
обеспечив более богатое представление класса иерархий. Перепишите определение
предиката match_with_inheritance, чтобы вместо перечисления общих
специализаций двух элементов он вычислял такие специализации с помощью поиска по
иерархии типов.
Глава 14. Введение в PROLOG
683
Введение в LISP
—...Заглавие этой песни называется "Пуговки для сюртуков"
— Вы хотите сказать — песня так называется? — спросила Алиса,
стараясь заинтересоваться песней.
— Нет, ты не понимаешь, — ответил нетерпеливо Рыцарь — Это заглавие так
называется. А песня называется "Древний старичок ".
— Мне надо было спросить: это у песни такое заглавие? — поправилась Алиса.
-Да нет, заглавие совсем другое. "С горем пополам "/ Но это она только так называется!
— А песня эта какая? — спросила Алиса в полной растерянности.
— Я как раз собирался тебе об этом сказать.
— Льюис Кэррол (Lewis Carroll), Алиса в Зазеркалье
Старайтесь в сложном видеть простоту.
— Лао Тзу (Lao Tzu)
15.0. Введение
За более чем сорокалетнюю историю своего существования LISP зарекомендовал себя в
качестве хорошего языка программирования задач искусственного интеллекта. Изначально
разработанный для символьных вычислений, за время своего развития LISP был расширен и
модифицирован в соответствии с новыми потребностями приложений искусственного
интеллекта. LISP — это императивный язык (imperative language). Его программы описывают, как
выполнить алгоритм. Этим он отличается от декларативных языков (declarative language),
программы которых представляют собой определения отношений и ограничений в
предметной области задачи. Однако, в отличие от таких традиционных императивных языков, как
FORTRAN или C++, LISP — еще и функциональный язык (functional language): его синтаксис
и семантика продиктованы математической теорией рекурсивных функций. Мощь
функционального программирования в сочетании с богатым набором таких высокоуровневых средств
построения символьных структур данных, как предикаты, фреймы, сети и объекты,
обеспечили популярность LISP в сообществе ИИ. LISP широко используется как язык реализации
средств и моделей искусственного интеллекта, особенно среди исследователей.
Высокоуровневая функциональность и богатая среда разработки сделали его идеальным языком для
построения и тестирования прототипов систем.
В этой главе кратко описаны синтаксис и семантика диалекта Common LISP. При
этом особое внимание уделено средствам языка, используемым для программирования
задач искусственного интеллекта; рассказано о применении списков для создания сим-
вольных структур данных, а также реализации интерпретаторов и алгоритмов поиска для
управления этими структурами. Приводятся примеры программ на языке LISP,
включающие реализацию механизмов поиска, систем проверки соответствия шаблонам;
системы доказательства теорем; оболочки экспертных систем, основанные на правилах;
алгоритмы для обучения и объектно-ориентированного моделирования. Мы, конечно, не
сможем дать исчерпывающее описание LISP. Этой тематике посвящено много
замечательных книг, ссылки на которые помещены в конце данной главы. В этой книге мы
сфокусируемся лишь на использовании LISP для реализации языков представления и
алгоритмов для программирования задач искусственного интеллекта.
15.1. LISP: краткий обзор
15.1.1. Символьные выражения как синтаксическая основа LISP
Синтаксическими элементами языка программирования LISP являются
символьные выражения (symbolic expression), которые также называют s-выражениями
(s-expression). В виде s-выражений представляются и программы, и данные, s-выражение
представляет собой либо атом (atom), либо список (list). Атомы LISP— это базовые
синтаксические единицы языка, включающие числа и символы. Символьные атомы
состоят из букв, цифр и следующих неалфавитно-цифровых символов.
*-+/@$%Л&_<>~
Приведем несколько примеров атомов LISP.
3.1416
100
х
hyphenated-name
*some-global*
nil
Список — это последовательность атомов или других списков, разделенных
пробелами и заключенных в скобки. Вот несколько примеров списков.
A2 3 4)
(torn тагу John Joyce)
(a (b с) (d (e f)))
( )
Заметим, что элементами списков могут быть другие списки. При этом глубина
вложенности может быть произвольной, что позволяет создавать символьные структуры
любой формы и сложности. Пустой список () играет особую роль при построении
структур данных и управлении ими. У него даже есть специальное имя— nil; nil —
это единственное s-выражение, которое одновременно является и атомом, и списком.
Список — чрезвычайно гибкое средство построения структур представления. Например,
его можно использовать для представления выражений из теории предикатов.
(on block-1 table)
(likes bill X)
(and (likes george kate) (likes bill merry))
686 Часть VI. Языки и технологии программирования для искусственного интеллекта
Этот синтаксис позволяет представить выражения теории предикатов в описанном в
этой главе алгоритме унификации. Следующие два примера демонстрируют способы
использования списков для реализации структур данных, необходимых в приложениях баз
данных. В подразделе 15.1.5 описана реализация простой системы извлечения данных на
основе этих представлений.
( B467 (lovelace ada) programmer) C592 (babbage charles)
computer-designer))
((key-1 value-1) (key-2 value-2) (key-3 value-3))
Важным свойством LISP является использование одинакового синтаксиса для
представления не только данных, но и программ. Например, списки
(* 7 9)
(- ( + 3 4) 7)
можно интерпретировать как арифметические выражения в префиксной форме записи.
LISP обрабатывает эти выражения именно так: ( *7 9) означает произведение 7 на 9.
Если на компьютере установлен LISP, то пользователь может вести интерактивный
диалог с его интерпретатором. Интерпретатор выводит приглашение (в качестве примера в
этой книге используется символ >), считывает введенные пользователем данные,
пытается оценить их и в случае успеха выводит результат. Например,
> (* 7 9)
63
>
Здесь пользователь ввел выражение (* 7 9), а интерпретатор выдал результат
63 — значение, связанное с этим выражением. После этого LISP выводит следующее
приглашение и ожидает ввода пользователя. Такой цикл называется циклом чтения-
оценки-печати (read-eval-print loop) и составляет основу интерпретатора LISP.
Получив список, интерпретатор LISP пытается проанализировать его первый элемент
как имя функции, а остальные элементы — как ее аргументы. Так, s-выражение (f x
у) эквивалентно более традиционной математической записи f(x, у). Выводимое LISP
значение является результатом применения этой функции к ее аргументам. Выражения
LISP, которые могут быть осмысленно оценены, называются формами (form). Если
пользователь вводит выражение, которое нельзя корректно оценить, то LISP выводит
сообщение об ошибке и позволяет пользователю выполнить трассировку и внести
исправления. Вот пример сеанса работы с интерпретатором LISP.
> (+ 14 5)
19
> (+ 1 2 3 4)
10
> (- (+ 3 4) 7)
0
> (* ( + 2 5) (- 7 (/ 21 7)))
28
> (= (+ 2 3) 5)
t
> (> (* 5 6) ( + 4 5))
t
> (a b с)
Error: invalid function: a
Глава 15. Введение в LISP
687
В нескольких из этих примеров аргументы сами являются списками, например (- (+
3 4) 7). Это выражение представляет композицию функций и в данном случае
читается так: "вычесть 7 из результата сложения 3 и 4". Слово "результат" выделено для того,
чтобы подчеркнуть, что функции - в качестве аргумента передается не s-выражение (+
3 4), а результат его оценивания.
Оценивая функцию, LISP сначала оценивает ее аргументы, а затем применяет функцию,
задаваемую первым элементом выражения, к оценке аргументов. Если аргументы сами
являются функциями, то LISP рекурсивно применяет это правило для их оценивания. Таким
образом, LISP допускает вложенность вызовов функций произвольной глубины. Важно
помнить, что по умолчанию LISP оценивает все объекты. При этом используется
соглашение, что числа соответствуют сами себе. Например, если интерпретатору передать значение
5, то LISP вернет результат 5. С символами, например х, могут быть связаны выражения.
При оценивании связанных символов возвращается результат связывания. Связанные
символы могут появляться в результате вызова функций (подраздел 15.1.2). Если символ не
связан, то при его оценке выдается сообщение об ошибке.
Например, оценивая выражение (+(*2 3)(*3 5)), LISP сначала оценивает
аргументы (*2 3) и (*3
(+(*2 3)(*3 5))
+
Рис. 15.1. Древовидная диа
грамма оценивания про
стой функции LISP
5). Для первого аргумента LISP оценивает его параметры 2 и 3,
возвращая соответствующие им арифметические значения. Эти
значения перемножаются и в результате дают число 6.
Аналогично результатом оценки выражения (*3 5) является 15.
Затем эти результаты передаются функции сложения более
высокого уровня, при оценивании которой возвращается 21.
Диаграмма выполнения этих операций показана на рис. 15.1.
Помимо арифметических операций LISP включает
множество функций работы со списками. К ним относятся функции
построения и комбинирования списков, доступа к элементам
списков и проверки различных свойств. Например, функция list
принимает любое количество аргументов и строит на их основе
список. Функция nth получает в качестве аргументов число и
список и возвращает указанный элемент этого списка.
Нумерация элементов списка начинается с нуля. Вот примеры
использования этих и других функций работы со списками.
> (list 1 2
A2 3 4 5)
> (nth О
а
> (nth 2
3
> (nth 2
(с 3)
> (length
4
> (member
nil
> (null (
t
3 4
' (a b с
(list 1
'((a 1)
5)
d))
2 3
(b 2)
(abed))
'A2345))
5))
(c 3)
(d 4)))
))
Функции работы со списками более подробно будут описаны в подразделе 15.1.5.
Основные идеи этого раздела можно изложить в виде следующего определения.
688 Часть VI. Языки и технологии программирования для искусственного интеллекта
ОПРЕДЕЛЕНИЕ
S-ВЫРАЖЕНИЕ
s-выражение можно рекурсивно определить следующим образом.
1. Атом — это s-выражение.
2. Если Si, s2, ..., sn — s-выражения, то s-выражением является и список (s{,s2, ..., s„).
Список — это неатомарное s-выражение.
Форма— это подлежащее оцениванию s-выражение. Если это список, то первый
элемент обрабатывается как имя функции, а последующие оцениваются для
получения ее аргументов.
Оценивание выражений выполняется следующим образом.
Если s-выражение — число, то возвращается значение этого числа.
Если s-выражение — атомарный символ, возвращается связанное с ним значение.
Если этот символ не связан, возвращается сообщение об ошибке.
Если s-выражение — это список, оцениваются все его аргументы, кроме первого, а к
полученному результату применяется функция, определяемая первым аргументом.
В LISP в виде s-выражений представляются и программы, и данные. Это не только
упрощает синтаксис языка, но и в сочетании с возможностью управления оценкой
s-выражений упрощает написание программ, обрабатывающих в качестве данных другие
программы. Это облегчает реализацию интерпретаторов на LISP.
15.1.2. Управление оцениванием в LISP: функции quote и eval
В нескольких примерах из предыдущего раздела перед списками аргументов
располагался символ одинарных кавычек '. Этот символ, который также может быть
представлен функцией quote, представляет собой специальную функцию, которая не оценивает
свои аргументы, а предотвращает их оценивание. Зачастую это делается для того, чтобы
аргументы обрабатывались как данные, а не как оцениваемая форма.
Оценивая s-выражения, LISP сначала старается оценить все аргументы. Если
интерпретатору передается выражение (nth 0 (a b с d) ), то он сначала пытается
оценить аргумент (a b с d). Эта попытка приведет к ошибке, поскольку а— первый
элемент этого s-выражения — не является функцией LISP. Чтобы предотвратить это,
следует воспользоваться встроенной функцией quote. Она зависит от одного аргумента
и возвращает этот аргумент без его оценки. Например,
> (quote (a b с))
(a b с)
> (quote (+13))
( + 1 3)
Поскольку функция quote используется довольно часто, то в LISP допускается ее
сокращенное обозначение в виде символа '. Поэтому предыдущие примеры можно
переписать в следующем виде.
> ' (a b с)
(a b с)
> '(+13)
(+ 1 3)
Глава 15. Введение в LISP
689
В целом, функция quote используется для предотвращения оценивания аргументов,
если они должны обрабатываться не как формы, а как данные. В рассмотренных ранее
примерах выполнения простых арифметических действий функция quote не нужна,
поскольку числа всегда оцениваются своими значениями. Рассмотрим результат
применения функции quote в следующих вызовах функции list.
> (list (+ 12) (+3 4))
C 7)
> (list '(+12) '(+34))
((+12) (+3 4))
В первом примере аргументы не квотированы, поэтому они оцениваются и
передаются в функцию list согласно используемой по умолчанию схеме. Во втором примере
функция quote предотвращает оценку, и в качестве аргументов функции list
передаются сами s-выражения. И хотя (+1 2) — это осмысленная форма LISP, функция
quote предотвращает ее оценивание. Возможность предотвратить оценивание
программ и обращаться с ними как с данными — важное свойство LISP.
В допопнение к функции quote LISP также предоставляет в распоряжение пользователя
функцию eval, позволяющую оценить s-выражение. Она зависит от одного аргумента,
представляющего собой s-выражение. Этот аргумент оценивается как обычный аргумент функции.
Однако результат снова оценивается, и в качестве значения выражения eval возвращается
окончательный результат. Вот примеры применения функций eval и quote.
> (quote (+2 3))
( + 2 3)
> (eval (quote (+ 2 3))) /функция eval отменяет результат выполнения
5
/функции quote
,р> (list '* 2 5) /строится оцениваемое s-выражение
(* 2 5)
> (eval (list '* 2 5)) /строится и оценивается выражение
10
Функция eval, по существу, обеспечивает обычное оценивание s-выражений. Благодаря
функциям quote и eval существенно упрощается разработка метаинтерпретаторов
(meta-interpreter)— вариаций стандартного интерпретатора LISP, определяющих
альтернативные или дополнительные возможности этого языка программирования. Эта важная
методология программирования иллюстрируется на примере "инфиксного интерпретатора" в
разделе 15.7 и разработки оболочки экспертной системы в разделе 15.10.
15.1.3. Программирование на LISP: создание новых функций
Диалект Common LISP включает большое количество встроенных функций, в том
числе следующие.
• Полный спектр арифметических функций поддержки целочисленной,
вещественной, комплексной арифметики и работы с рациональными числами.
• Разнообразные функции организации циклов и управления программой.
• Функции работы со списками и другими структурами данных.
• Функции ввода-вывода.
690 Ччоть VI. Языки и технологии программирования для искусственного интеллекта
• Формы для контроля оценивания функций.
• Функции управления средой и операционной системой.
Все функции LISP невозможно перечислить в одной главе. Более подробная
информация о них содержится в специальной литературе по LISP.
Программирование в LISP сводится к определению новых функций и построению
программ на основе богатого спектра встроенных и пользовательских функций. Новые
функции определяются с помощью функции defun, имя которой представляет собой
сокращение фразы "define function". После определения функции ее можно использовать
так же, как и любую другую встроенную функцию языка.
Предположим, что требуется определить функцию square, зависящую от одного
аргумента и возводящую его в квадрат. Эту функцию в LISP можно определить
следующим образом.
(defun square (x)
(* х х) )
Первым аргументом функции defun является имя определяемой функции,
вторым — список ее формальных параметров, которые должны быть символьными
атомами. Остальные аргументы — это нуль или s-выражения, составляющие тело новой
функции, т.е. код LISP, определяющий ее поведение. Как и все функции LISP, defun
возвращает значение, представляющее собой просто имя новой функции.
Важным результатом работы функции defun является побочный эффект, состоящий
в создании новой функции и добавлении ее в среду LISP. В рассмотренном примере
определяется функция square, зависящая от одного аргумента и возвращающая результат
умножения этого аргумента на себя. После определения функции ее необходимо
вызывать с тем же числом аргументов или фактических параметров. При вызове функции
фактические параметры связываются с формальными, и тело функции оценивается с
учетом этого связывания. Например, при вызове (square 5) значение 5 связывается
с формальным параметром х в теле определения. Оценивая тело ( * х х), LISP сначала
оценивает аргументы функции. Поскольку в этом вызове параметр х связан со значением
5, то оценивается выражение ( * 5 5).
Более строго синтаксис выражения defun имеет вид.
(defun <имя функции> (<формальные параметры>) <тело функции>)
В этом определении описания элементов формы заключены в угловые скобки о. Это
обозначение будет использовано и далее. Заметим, что формальные параметры функции
defun представляются в виде списка.
Вновь определенную функцию можно использовать так же, как и любую другую
встроенную функцию. Предположим, что необходимо вычислить длину гипотенузы
прямоугольного треугольника, зная длины двух его других сторон. Эту функцию можно
определить на основе теоремы Пифагора, используя определенную ранее функцию
square, а также встроенную функцию sqrt. Следующий пример кода снабжен
подробными комментариями. LISP поддерживает однострочные комментарии, т.е.
игнорирует весь текст, начиная с первого символа ;, и до конца строки.
(defun hypotenuse (x у) ;длина гипотенузы равна
(sqrt (+ (square x) ;корню квадратному из суммы
(square у)))) ;квадратов двух других сторон.
Глава 15. Введение в LISP
691
Этот пример довольно типичен, поскольку большинство программ LISP состоят из
относительно небольших функций, выполняющих отдельные хорошо определенные
задачи. После определения эти функции используются для реализации функций более
высокого уровня до тех пор, пока не будет описано поведение самого высокого уровня.
15.1.4. Управление программой в LISP: условия и предикаты
Реализация ветвления в LISP тоже основывается на оценивании функций.
Управляющие функции выполняют проверку и в зависимости от результатов выборочно
оценивают альтернативные формы. Например, рассмотрим следующее определение функции
вычисления модуля (заметим, что в LISP имеется встроенная функция abs,
вычисляющая абсолютное значение числа).
(defun absolute-value (x)
(cond ((< х 0) (- х)) ;если х меньше 0, вернуть -х
((>= х 0) х))) ;в противном случае возвращается х
В этом примере используется функция cond, реализующая ветвление. Аргументом
этой функции является множество пар условие-действие (condition/action pair).
(cond (<условие1> <действие1>)
{<условие2> <действие2>)
(<условиеп> <действиеп>) )
Условие и действие могут быть произвольными s-выражениями, при этом каждая
пара заключается в скобки. Подобно функции defun cond не оценивает все свои
аргументы. Она оценивает условия по порядку до тех пор, пока одно из них не возвратит
значение, отличное от nil. В этом случае оценивается соответствующее действие, и
полученный результат возвращается в качестве значения выражения cond. Ни одно из других
действий и ни одно из последующих условий не оцениваются. Если все условия
возвращают значение nil, то и функция cond возвращает nil.
Приведем альтернативное определение функции absolute-value.
(defun absolute-value (x)
(cond ((< х 0)(- х)) ;если х меньше 0, вернуть -х
(t х))) ;в противном случае возвращается х
В этой версии учитывается тот факт, что второе условие (>= х 0) — всегда
истинно, если первое условие ложно. Атом t в последнем условии оператора cond — этом
атом LISP, который соответствует значению "истина". Его оценка всегда совпадает с
самим атомом. Следовательно, последнее действие выполняется только в том случае, если
все предыдущие условия возвращают значение nil. Эта конструкция очень полезна,
поскольку позволяет задать действие, выполняемое оператором cond по умолчанию в том
случае, если все предыдущие условия не выполняются.
Несмотря на то что в качестве условий оператора cond можно использовать любые
оцениваемые s-выражения, в LISP существуют специальные функции, получившие
название предикатов (predicate). Предикат — это функция, возвращающая логическое
значение ("истина" или "ложь") в зависимости от того, удовлетворяют ли ее параметры
некоторому свойству. Наиболее очевидными примерами предикатов являются операторы
сравнения вида =, > и >=. Вот некоторые примеры арифметических предикатов в LISP.
692 Часть VI. Языки и технологии программирования для искусственного интеллекта
> (= 9 (+ 4 5))
t
> (>= 17 4)
t
> (< 8 (+ 4 2))
nil
> (oddp 3) ;проверка четности аргумента
t
> (minusp 6) /проверка неотрицательности аргумента
> (numberp 17) /проверка, является ли аргумент числом
t
> (numberp nil)
nil
> (zerop 0) /проверка равенства аргумента нулю
t
> (plusp 10) /проверка строгой положительности аргумента
t
> (plusp -2)
nil
Заметим, что в этих примерах предикаты возвращают значения t или nil, а не
"истина" и "ложь". Вообще, в LISP значение предиката nil соответствует логическому
значению "ложь", а любое отличное от него значение (не обязательно t) обозначает
"истина". Примером функции, использующей это свойство, является предикат member.
Он зависит от двух аргументов, причем второй аргумент обязательно должен быть
списком. Первый аргумент — это элемент списка, определяемого вторым аргументом.
Предикат member возвращает суффикс второго аргумента, начальным элементом которого
является первый аргумент. Если первый аргумент не является элементом списка,
предикат member возвращает результат nil. Например,
> (member 3 'A 2 3 4 5))
C 4 5)
Такое соглашение дает следующее преимущество. Предикат возвращает значение,
которое в случае истинности условия может использоваться для дальнейшей обработки.
Кроме того, при таком соглашении в качестве условия в форме cond можно выбирать
любую функцию LISP.
Форму if, зависящую от трех аргументов, можно использовать как альтернативу
функции cond. Первым параметром является само условие. Если результатом проверки
условия является ненулевое значение, то оценивается второй аргумент функции if и
возвращается результат этой оценки. В противном случае возвращается результат оценки
третьего аргумента. При бинарном ветвлении конструкция i f в целом обеспечивает
более прозрачный и изящный код, чем функция cond. Например, с помощью формы if
функцию absolute-value можно определить следующим образом.
(defun absolute-value (x)
(if (< х 0) (- х) х))
Помимо функций if и cond, в LISP содержится обширный набор управляющих
конструкций, в том числе итеративных, таких как циклы do и while. Хотя эти функции
очень полезны и обеспечивают программисту широкие возможности управления
программой, они здесь не будут обсуждаться. Эту информацию читатель сможет найти в
специализированной литературе по LISP.
Глава 15. Введение в LISP
693
Одно из наиболее интересных средств управления программой в LISP связано с
использованием логических операций and, or и not. Функция not зависит от одного
аргумента и возвращает значение t, если этот аргумент раве,н nil, и nil — в противном
случае. Функции and и or могут зависеть от любого числа параметров. Они ведут себя
точно так же, как и соответствующие логические операторы. Однако важно понимать,
что функции and и or основываются на условной оценке (conditional evaluation).
При обработке формы and LISP оценивает ее аргументы слева направо. Процесс
завершается, если один из аргументов принимает значение nil, или после оценки последнего
аргумента. По завершении работы форма and возвращает значение последнего оцененного
аргумента. Следовательно, ненулевое значение возвращается только в том случае, если все
аргументы функции отличны от нуля. Аналогично аргументы формы or оцениваются только
до появления ненулевого значения, которое и возвращается в качестве результата. Некоторые
из аргументов этих функций могут оставаться неоцененными, что иллюстрируется на примере
оператора print. Помимо вывода значения своего аргумента, в некоторых диалектах LISP
функция print по завершении работы возвращает значение nil.
> (and (oddp 2) (print "второй оператор был оценен"))
nil
> (and (oddp 3) (print "второй оператор был оценен"))
второй оператор был оценен
> (or (oddp 3) (print "второй оператор был оценен"))
t
> (or (oddp 2) (print "второй оператор был оценен"))
второй оператор был оценен
Поскольку в первом выражении результатом оценки (oddp 2 ) является nil,
функция and просто возвращает значение nil без оценивания формы print. Во втором
выражении результатом оценки (oddp 3 ) является t, и форма and оценивает выражение
print. Аналогично можно проанализировать работу функции or. Поведение этих
функций очень важно понимать. Дело в том, что их аргументами могут быть формы,
оценка которых связана с получением побочных эффектов, подобных функции print.
Условный анализ логических функций позволяет управлять процессом выполнения
программы LISP. Например, форму or можно использовать для получения альтернативных
решений и проверки их до тех пор, пока одно из них не даст отличный от нуля результат.
15.1.5. Функции, списки и символьные вычисления
В предыдущих разделах был рассмотрен синтаксис LISP и введено несколько полезных
функций. Все они применялись для решения простых арифметических задач, однако истинная
сила LISP проявляется в символьных вычислениях. Они основываются на использовании
списков для построения структур данных любой сложности, состоящих из символьных и
числовых атомов, а также создании форм для управления ими. Простоту обработки символьных
структур данных, а также естественность построения абстрактных типов данных в LISP
продемонстрируем на простом примере управления базой данных. В нашем приложении будут
выполняться операции над записями, содержащими информацию о сотрудниках. В полях
записи заданы имя, зарплата и табельный номер сотрудника.
Эти записи представляются в виде списков, первыми тремя элементами которых
являются имя, зарплата и табельный номер. С помощью функции nth можно определить
функции доступа к различным полям записи. Например, определим следующую
функцию получения поля имени.
694 Часть VI. Языки и технологии программирования для искусственного интеллекта
(defun name-field (record)
(nth 0 record))
Приведем пример ее использования.
> (name-field '((da Lovelace) 45000.00 338519))
(Ada Lovelace)
Аналогично можно определить функции получения доступа к полям зарплаты и
табельного номера salary-field и number-field соответственно. Поскольку имя— это тоже
список, состоящий из двух элементов (собственно имя и фамилия), целесообразно определить
функцию, которая на основе параметра name вычисляет либо имя, либо фамилию.
(defun first-name (name)
(nth 0 name))
Вот пример ее использования.
> (first-name (name-field '((Ada Lovelace) 45000.00 338519)))
Ada
Помимо доступа к отдельным полям записи необходимо реализовать функции
создания и модификации записей. Они определяются с помощью встроенной функции LISP
list. Функция list получает произвольное число аргументов, оценивает их и
возвращает список, содержащий значения параметров в качестве своих элементов. Например,
> (list 12 3 4)
A2 3 4)
> (list '(Ada Lovelace) 45000.00 338519)
((Ada Lovelace) 45000.00 338519)
Как видно из второго примера, функцию list можно использовать для определения
конструктора записей в базе данных.
(defun build-record (name salary emp-number)
(list name salary emp-number))
Вот пример ее использования.
> (build-record '(Alan Turing) 50000.00 135772)
((Alan Turing) 50000.00 135772)
Теперь с помощью функций доступа и build-record можно создать функцию,
возвращающую модифицированную копию записи. Например,
(defun replace-salary-field (record new-salary)
(build-record (name-field record)
new-salary
(number-field record)))
> (replace-salary-field '((Ada Lovelace) 45000.00 338519) 50000.00)
((Ada Lovelace) 50000.00 338519)
Заметим, что эта функция на самом деле не обновляет саму запись, а создает ее
модифицированную копию. Эту обновленную версию записи можно сохранить, связав ее с
глобальной переменной с помощью функции setf (подраздел 15.1.8). Хотя в LISP
существуют формы, позволяющие модифицировать конкретный элемент списка в
исходной структуре (без создания копии), хороший стиль программирования не предполагает
их использования, поэтому в этой книге они не упоминаются. Если в приложении ис-
Глава 15. Введение в LISP
695
пользуются не слишком большие структуры, их модификация выполняется с помощью
создания новой копии структуры.
В рассмотренных выше примерах был создан абстрактный тип данных для обработки
информации о сотрудниках. В этом разделе созданы различные функции доступа к
элементам структуры данных и их модификации. При этом программисту не приходится
заботиться о реальной структуре списков, используемых для реализации записей базы
данных. Это упрощает разработку высокоуровневого кода, а также делает этот код более
доступным для понимания и поддержки.
Приложения искусственного интеллекта требуют обработки больших объемов знаний
о предметной области. Используемые для описания этих знаний структуры данных, в
частности объекты и семантические сети, достаточно сложны. Поэтому человеку проще
обрабатывать эти знания в терминах их смыслового значения, а не конкретного
синтаксиса их внутреннего представления. Поэтому методология построения абстрактных
типов данных играет важную роль при разработке приложений искусственного интеллекта.
Поскольку LISP позволяет легко определять новые функции, он является идеальным
языком для построения абстрактных типов данных.
15.1.6. Списки как рекурсивные структуры
В предыдущем разделе для реализации доступа к полям записей простой базы данных
сотрудников использовались функции nth и list. Поскольку все записи о сотрудниках
имели фиксированную длину (состояли из трех элементов), то этих двух функций было
достаточно. Однако для выполнения операций над списками неизвестной длины, в
частности для реализации поиска на неуказанном числе записей этого мало. Для выполнения
такой операции необходимо иметь возможность сканировать список итеративно или
рекурсивно, завершая проход при выполнении некоторых условий (т.е. при нахождении
нужной записи) или после просмотра всего списка. В этом разделе вводятся операции со
списками, причем для определения функций обработки списков используется рекурсия.
Основными функциями доступа к компонентам списков являются саг и cdr. Первая из
них зависит от одного аргумента, который сам является списком, и возвращает его первый
элемент. Функция cdr тоже зависит от одного аргумента, который должен быть списком, и
возвращает этот же список после удаления его первого элемента. Например, так.
> (car '(a b с)) ;Заметим, что список квотирован
а
> (cdr '(a b с))
(Ь с)
> (саг '((а Ь) (с d))) /первый элемент списка может быть списком
(а Ь)
> (cdr '((а Ь) (с d)))
((с d))
> (car (cdr '(a b с d)))
b
Функции car и cdr основаны на рекурсивном подходе к выполнению операций со
списочными структурами. Операции над каждым элементом списка выполняются
следующим образом.
1. Если список пуст, операция завершается.
2. В противном случае обрабатывается этот элемент и осуществляется переход к
следующему элементу списка.
696 Часть VI. Языки и технологии программирования для искусственного интеллекта
По этой схеме можно определить множество полезных функций работы со списками.
Например, язык Common LISP включает предикат member, определяющий принадлежность
некоторого s-выражения списку, и length, позволяющий найти длину списка. Определим свои
собственные версии этих функций. Функция my-member будет зависеть от двух
аргументов — произвольного s-выражения и списка my-list. Она должна возвращать nil,
если s-выражение не является элементом списка my-list. В противном случае она будет
возвращать список, содержащий это s-выражение в качестве первого элемента.
(defun my-member (element my-list)
(cond ((null my-list) nil) /элемент не является членом списка
((equal element (car my-list)) my-list)
;элемент найден
(t (my-member element (cdr my-list)))))
;шаг рекурсии
Вот пример использования функции my-member.
> (my-member 4 'A23456))
D 5 6)
> (my-member 5 '(abed))
nil
Аналогично определим собственные версии функций length и nth.
(defun my-length (my-list)
(cond ((null my-list) 0)
(t ( + (my-length (cdr my-list)) 1))))
(defun my-nth (n my-list)
(cond ((zerop n) (car my-list)) ;функция zerop проверяет
;равенство нулю
(t (my-nth (-n 1) (cdr my-list)))))
/своего аргумента
Интересно отметить, что приведенные примеры использования функций саг и cdr в
то же время иллюстрируют историю развития LISP. Ранние версии языка содержали не
так много встроенных функций, как диалект Common LISP. Программистам приходилось
самим определять функции проверки принадлежности элемента списку, вычисления
длины списка и т.д. Со временем наиболее общие из этих функций вошли в стандарт
языка. Common LISP — легко расширяемый язык. Он позволяет легко создавать и
использовать собственные библиотеки повторно используемых функций.
Помимо саг и cdr LISP содержит множество функций построения списков. Одна из
них— list, зависящая от произвольного числа аргументов,"представляющих собой
s-выражения. Функция оценивает их и возвращает список результатов (подраздел 15.1.1).
Более примитивным конструктором списков можно считать функцию cons, параметрами
которой являются два s-выражения. Эти параметры оцениваются, и возвращается список, первым
элементом которого является значение первого аргумента, а хвостом — значение второго.
> (cons 1 'B34))
A2 3 4)
> (cons ' (a b) ' (с d e) )
( (a b) с d e)
Функцию cons можно считать обратным преобразованием для функций саг и cdr,
поскольку результатом применения функции саг к значению, возвращаемому функцией cons,
Глава 15. Введение в LISP
697
всегда является первый аргумент cons. Аналогично результатом применения функции cdr к
значению, возвращаемому формой cons, всегда является второй аргумент этой формы.
> (car (cons 1 'B 3 4)))
1
> (cdr (cons 1 'B 3 4)))
B 3 4)
Приведем пример использования функции cons. Для этого определим функцию
filter-negatives, параметром которой является числовой список. Эта функция
должна удалять из списка все отрицательные значения. Функция filter-negatives
рекурсивно проверяет элементы списка. Если первый элемент отрицателен, он
исключается, и функция возвращает результат фильтрации отрицательных элементов хвоста
списка, определяемого функцией cdr. Если первый элемент списка положителен, он
включается в результат фильтрации отрицательных чисел хвоста.
((defun filter-negatives (number-list)
(cond ((null number-list) nil)
/условие останова
((plusp (car number-list)) (cons (car number-list)
(filter-negatives
(cdr number-list))))
(t (filter-negatives (cdr number-list)))))
Вот пример вызова этой функции.
> (filter-negatives 'A-12-23 -4))
A 2 3)
Это типичный пример использования функции cons в рекурсивных функциях над
списками. Функции саг и cdr делят список на части и "управляют" рекурсией, a cons
формирует результат по мере "развертывания" рекурсии. Еще один пример
использования функции cons — переопределение встроенной функции append.
(defun my-append (listl list2)
(cond ((null listl) list2)
(t (cons (car listl) (my-append (cdr listl) list2)))))
Проиллюстрируем вызов этой функции.
> (my-append 'A2 3) 'D56))
A2 3 4 5 6)
Заметим, что по такой же рекурсивной схеме строятся определения функций my-
append, my-length и my-member. В каждом из этих определений для удаления
элемента из списка используется функция cdr. Это обеспечивает возможность
рекурсивного вызова укороченного списка. Рекурсия завершается, если список пуст. В процессе
рекурсии функция cons перестраивает решение. Эта схема зачастую называется cdr-
рекурсией (cdr-recursion) или хвостовой рекурсией (tail resursion), поскольку функция
cdr используется для получения хвоста списка.
15.1.7. Вложенные списки, структуры и рекурсия car-cdr
Хотя обе функции cons и append предназначены для объединения небольших списков,
важно понимать различие между ними. При вызове функции cons ее параметрами являются
698 Часть VI. Языки и технологии программирования для искусственного интеллекта
два списка. Первый из них становится первым элементом второго списка. Функция append
возвращает список, членами которого являются элементы обоих аргументов.
> (cons 'A2) 'C4))
(A 2) 3 4)
> (append 'A2) 'C 4))
A2 3 4)
Списки A 2 3 4)и(A 2) 3 4) имеют принципиально разную структуру. Это
различие можно отобразить графически, установив изоморфизм между списками и
деревьями. Простейший способ построения соответствия между списками и деревьями —
создание для каждого списка узла без метки, потомками которого являются элементы
этого списка. Это правило рекурсивно применяется ко
всем элементам списка, которые сами являются
списками. Атомарные элементы становятся листовыми узлами
дерева. При таком построении два указанных выше
списка генерируют деревья различной структуры (рис. 15.2). f 2 з" 4 12 3 4
Этот пример иллюстрирует широкие возможности спи- П23 4) К 12K 4)
сков по представлению данных. В частности, их можно ис-
с- ~ - Рис. 15.2. Представление списков
пользовать как средство представления любой древовидной . . ^ .
в виде деревьев для отоораже-
структуры, в том числе дерева поиска или дерева граммати- ~
rj JV r <^rr ния различии в их структуре
ческого разбора (рис. 15.1). Кроме того, вложенные списки
обеспечивают возможность иерархического
структурирования сложных данных. В примере с записями о сотрудниках из подраздела 15 1.4 поле имени
само является списком, состоящим из собственно имени и фамилии. Этот список можно
рассматривать как единую сущность, а можно получать доступ к каждому его компоненту.
Простой схемы cdr-рекурсии, описанной в предыдущем разделе, недостаточно для
реализации всех операций над вложенными списками, поскольку в ней не различаются
списочные и атомарные элементы. Например, допустим, что функция length,
определенная в подразделе 15.1.6, применяется к иерархической списочной структуре.
> (length '(A2) 3 A D E)))))
3
Функция length возвращает значение 3, поскольку список состоит из 3 элементов: A
2), 3 и A D E))). Это, конечно, правильно, и такое поведение функции корректно.
С другой стороны, если требуется подсчитать количество атомов в списке,
необходимо определить другую схему рекурсии, которая при сканировании элементов списка
будет "вскрывать" неатомарные элементы списка и рекурсивно выполнять операции по
подсчету атомов. Эту функцию можно определить так.
(defun count-atoms (my-list)
(cond ((null my-list) 0)
((atom my-list) 1)
(t (+ (count-atoms (car my-list))
;вскрываем элемент
(count-atoms (cdr my-list))))))
;сканируем список
> (count-atoms '(A 2) 3 ((D 5 F))))))
6
Это определение— пример рекурсии car-cdr. Помимо рекурсивного прохода по
списку с помощью формы cdr, функция count-atoms выполняет рекурсию по перво-
Глава 15. Введение в LISP 699
му элементу, получаемому с помощью формы саг. Затем функция + комбинирует оба
результата при формировании ответа. Рекурсия завершается при достижении атома или
конца списка. Такую схему можно рассматривать как добавление второго измерения к
простой cdr-рекурсии, обеспечивающего "заглубление" в каждый из элементов списка.
Сравните диаграммы вызовов функций length и count-atoms, представленные на
рис. 15.3. Обратите внимание на сходство рекурсии car-cdr и рекурсивного
определения s-выражений в подразделе 15.1.1.
Линейная, или cdr-рекурсия (length(A 2) 3 ADE)))))
(lengthC ADE)))))
+
(length(ADE)))))
(lengthO)
Рекурсия по дереву, или car-cdr-рекурсия: (count-atoms(A 2) 3ADE)))))
(count-atomsA 2)) (count-atomsCADE)))))
1 (count-atomsB)) 1 (count-atoms(ADE)))))
+ +
1 (count-atoms(DE))))
(count-atomsDE))) 0
(count-atoms(E)))
(count-atomsE))
+
1 0
Рис. 15 3. Диаграммы линейной и древовидной схемы рекурсии
700 Часть VI. Языки и технологии программирования для искусственного интеллекта
Еще одним примером использования рекурсии car-cdr является определение
функции flatten. Она зависит от одного аргумента, представляющего собой список
произвольных структур, и возвращает неиерархический список, состоящий из тех же
атомов, расположенных в том же порядке. Обратите внимание на аналогию определений
функций flatten и count-atoms. В обеих функциях для разбиения списков и
управления рекурсией используется схема car-cdr, рекурсия прекращается при достижении
нулевого или атомарного элемента, и для построения ответа по результатам рекурсивных
вызовов в обоих случаях применяется вторая функция (append или +).
(defun flatten Ast)
(cond ((null 1st) nil)
((atom 1st) (list 1st))
(t (append (flatten (car 1st))(flatten (cdr 1st))))))
Вот пример вызова функции flatten.
> (flatten Ma (be) (((d) e f) ) ) )
(a b с d e f)
> (flatten '(a b с)) ;этот список уже не содержит иерархии
(a b с)
> (flatten ' A B 3) D E 6) 7) ) )
A2 3 4 5 6 7)
Рекурсия car-cdr является основой реализации процедуры унификации в разделе 15.6.
15.1.8. Связывание переменных с помощью функции set
Язык LISP строится на теории рекурсивных функций. Ранние его версии могут
служить примером функционального или прикладного языка программирования. Важным
аспектом чисто функциональных языков является отсутствие побочных эффектов в
результате выполнения функций. Это означает, что возвращаемое функцией значение
зависит только от определения функции и фактических параметров при се вызове. Хотя LISP
основывается на математических функциях, можно определить формы, нарушающие это
свойство. Рассмотрим следующие команды LISP.
> (f 4)
5
> (f 4)
б
> (f 4)
7
Заметим, что f не является полноценной функцией, поскольку ее результат
определяется не только фактическим параметром: различные вызовы с параметром 4 возвращают
разные значения. Дело в том, что при выполнении этой функции создается побочный
эффект, который сказывается на се поведении при последующих вызовах. Функция f
реализована с помощью встроенной в LISP функции set.
(defun f (x)
(set 'inc (+ inc 1))
(+ x inc))
Функция set зависит от двух аргументов. Результатом оценивания первого должен
являться символ, а вторым параметром может быть произвольное s-выражение. Функция
set оценивает второй аргумент и присваивает полученное значение символу, опреде-
Глава 15. Введение в LISP
701
ленному первым аргументом. Если в рассмотренном примере значение переменной inc
инициализировать нулем с помощью вызова (set 'inc 0), то при последующих
вызовах значение этого параметра будет увеличиваться на 1.
Результатом оценивания первого аргумента функции set обязательно должен быть
символ. Зачастую первым параметром является просто квотированный символ.
Поскольку такая ситуация встречается очень часто, в LISP существует альтернативная форма
этой функции setq, при вызове которой первый параметр не оценивается. Для
использования функции setq необходимо, чтобы ее первый параметр был символом.
Например, следующие формы эквивалентны.
> (set 'х 0)
0
> (setq х 0)
0
Хотя использование функции set позволяет создавать в LISP объекты, не
являющиеся чистыми функциями в строго математическом смысле, возможность связывания
значения с переменной глобального окружения — очень полезное свойство. Многие задачи
программирования наиболее естественно реализовать на основе определения объектов,
состояние которых сохраняется между вызовами функции. Классическим примером
таких объектов является начальное число, используемое генератором случайных чисел.
Его значение изменяется и сохраняется при каждом вызове функции. Аналогично в
системе управления базой данных (в частности, описанной в подразделе 15.1.3) естественно
хранить базу данных, связав ее с переменной в глобальной среде.
Таким образом, существует два способа присваивания значения символу: явный — с
помощью функции set или setq, и неявный, когда при вызове функции фактические
параметры вызова связываются с формальными параметрами в определении функции. В
рассмотренных выше примерах все переменные в теле функции были либо связанными (bound variable)
либо свободными (free variable). Связанная переменная — это переменная, используемая в
качестве формального параметра в определении функции, а свободная переменная встречается в
теле функции, но не является формальным параметром. При вызове функции все связи
переменной в глобальной среде сохраняются, а сама связанная переменная ассоциируется с
фактическим параметром. После завершения выполнения функции исходные связи
восстанавливаются. Поэтому присваивание значений связанной переменной в теле функции не влияет на
глобальные связи этой переменной. Это видно из следующего примера.
> (defun foo (x)
(setq x (+ х 1)) ;инкрементирование связанной переменной х
х)
/возврат значения
foo
> (setq у 1)
1
> (foo у)
2
> у ;значение у не изменилось
1
В примере, приведенном в начале этого раздела, в функции f переменная х была
связанной, а переменная inc — свободной. Как ясно из этого примера, свободные
переменные в определении функции — прямой источник побочных эффектов.
702 Часть VI. Языки и технологии программирования для искусственного интеллекта
Интересной альтернативой для формы set или setq является обобщенная функция
присваивания setf. Эта функция не присваивает значения символу, а оценивает свой
первый аргумент с целью получения адреса в памяти и помещает по этому адресу
значение второго аргумента. При связывании значения с символом функция setf ведет себя
аналогично setq.
> (setq x 0)
0
> (setf x 0)
0
Однако, поскольку функцию setf можно вызвать для любой формы описания
местоположения в памяти, она допускает более общую семантику. Например, если первым
параметром функции setf является вызов функции саг, то setf заменяет первый
элемент списка. Если первым аргументом функции setf является вызов cdr, то заменяется
хвост этого списка. Например, так.
> (setf х '(a b с)) ;х связывается со списком
(a b с)
> х /значение х - это список
(a b с)
> (setf (car x) 1) ;результат вызова функции саг для х соответствует
1
/адресу в памяти
> х /функция setf изменила значение первого элемента х
A b с)
> (setf (cdr x) 'B 3))
B 3)
> х /теперь у х изменился хвост
A 2 3)
Функцию setf можно вызывать для большинства форм LISP, соответствующих адресу
в памяти. В качестве первого параметра могут выступать символы и функции, в частное га,
car, cdr и nth. Таким образом, функция setf обеспечивает большую гибкость при
создании структур данных LISP, управлении ими и даже замене их компонентов.
15.1.9. Определение локальных переменных с помощью функции let
Функция let — это еще одна полезная форма явного управления связыванием
переменных. Она позволяет создавать локальные переменные. В качестве примера использования
функции let рассмотрим функцию вычисления корней квадратного уравнения. Функция
quad-roots зависит от трех параметров a, b и с уравнения ах2+Ьх+с=0 и возвращает
список, состоящий из двух корней этого уравнения. Корни вычисляются по формуле
-Ь±>/Ь2-4ас
х= .
2а
Например, так.
> (quad-roots 12 1)
(-1,0 -1,0)
> (quad-roots 16 8)
(-2,0 -4,0)
Глава 15. Введение в LISP
703
При вычислении значения функции quad-roots значение выражения
ylb2-4ac
используется дважды. Из соображений эффективности и элегантности это значение можно
вычислить один раз и сохранить его в локальной переменной для вычисления обоих
корней. Поэтому исходная реализация функции quad-roots может иметь такой вид.
(defun quad-roots-1 (a b с)
(setq temp (sqrt ( - (* b b) (* 4 a c))))
(list (/ ( + (- b) temp) (* 2 a) )
(/ (- (- b) temp) (* 2 a)) ))
Заметим, что при такой реализации предполагается отсутствие мнимых корней
уравнения. Попытка вычислить квадратный корень из отрицательного числа приведет к
неудачному завершению функции sqrt с кодом ошибки. Модификация кода с целью
обработки этой ситуации не имеет прямого отношения к рассматриваемому вопросу.
Хотя с учетом этого исключения код функции корректен, оценивание тела приведет к
побочному эффекту установки значения переменной temp в глобальном окружении.
> (quad-roots-1 12 1)
(-1,0 -1,0)
> temp
0.0
Более предпочтительно сделать переменную temp локальной для функции quad-
roots и исключить этот побочный эффект. Для этого можно использовать блок let.
Вот синтаксис этого выражения.
(let {<локальные-переменные>) <выражения>)
Элементы списка (<локальные-переменные>) — это либо символьные атомы либо
пары вида
(<символ> <выражение>)
При оценивании формы (или блока) let устанавливается локальное окружение,
состоящее из всех символов списка (<локальные-переменные>). Если некоторый символ
является первым элементом пары, то второй элемент оценивается, и результат оценки
связывается с этим символом. Символы, не включенные в пары, связываются со
значением nil. Если некоторые из этих символов уже связаны в глобальном окружении, то
глобальные связи сохраняются и восстанавливаются при выходе из блока let.
После установки этих локальных связей задаваемые вторым параметром формы let
<выражения> по порядку оцениваются в этом окружении. При выходе из блока let
возвращается значение последнего выражения, оцененного в этом блоке.
Поведение блока let можно проиллюстрировать на следующем примере.
> (setq a 0)
0
> (let ( (а 3) Ь)
(setq b 4)
( + а Ь))
7
> а
0
> b
ERROR - b is not bound at top level.
704 Часть VI. Языки и технологии программирования для искусственного интеллекта
В этом примере до выполнения блока let переменная а связана со значением 0, a b —
не связана на верхнем уровне окружения. При оценивании формы let а связывается со
значением 3, a b — с nil. Функция setq присваивает переменной b значение 4, после
чего оператор let возвращает значение суммы а и Ь. После завершения работы формы let
восстанавливаются предыдущие значения переменных а и Ь, в том числе несвязанный
статус переменной Ь.
С помощью оператора let функцию quad-roots можно реализовать без
глобальных побочных эффектов.
(defun quad-roots-2 (a b с)
(let (temp)
(setq temp (sqrt (- (* b b) (* 4 a c))))
(list (/ ( + (- b) temp) (* 2 a) )
(/ (- (- b) temp) (* 2 a)))))
Переменную temp можно также связать при ее объявлении в операторе let. Это
обеспечит более согласованную реализацию функции quad-roots. В этой
окончательной версии знаменатель формулы 2а тоже вычисляется однократно и сохраняется в
локальной переменной denom.
(defun quad-roots-3 (a b с)
(let ((temp (sqrt (- (* b b) (* 4 a c) ) ) )
(denom (* 2 a) ) )
(list (/ (+ (- b) temp) denom)
(/ (- (- b) temp) denom))))
Помимо устранения побочных эффектов версия quad-roots-З наиболее
эффективна среди всех реализаций, поскольку в ней отсутствуют повторные вычисления
одинаковых значений.
15.1.10. Типы данных в Common LISP
Язык LISP включает большое количество встроенных типов данных. К ним относятся
целые числа, числа с плавающей точкой, строки и символы. В LISP также содержатся
такие структурированные типы, как массивы, хэш-таблицы, множества и структуры.
Со всеми этими типами связаны соответствующие операции и предикаты проверки
принадлежности объектов данному типу. Например, для списков поддерживаются функции
идентификации объекта как списка listp, определения пустоты списка null, а также
конструкторы и функции доступа list, nth, car и cdr.
Однако в отличие от таких строго типизированных языков, как С или Pascal, в которых
проверка типов всех выражений может быть сделана до начала выполнения программы, в
LISP типы относятся к объектам данных, а не к переменным. Любой символ LISP можно
связать с любым объектом. При этом программист получает возможности типизации, не
ограничивая гибкость работы с объектами различных или даже неизвестных типов.
Например, любой объект можно связать с любой переменной во время выполнения программы.
Это позволяет определять такие структуры данных, как фреймы, без полной спецификации
типов хранящихся в них значений. Для поддержки этой гибкости в LISP реализована
проверка соответствия типов во время выполнения программы. Таким образом, если связать
переменную с символом и попытаться некорректно использовать это значение во время
выполнения программы, интерпретатор LISP выдаст ошибку.
Глава 15. Введение в LISP
705
> (setq x 'a)
a
> (+ x 2)
> > Error: a is not a valid argument to +.
> > While executing: +
Пользователи могут реализовывать свои собственные функции проверки
соответствия типов на основе встроенных или пользовательских предикатов. Это позволяет
определять ошибки, связанные с использованием типов.
Этот раздел не претендует на полное описание возможностей LISP. Автор лишь
старался ознакомить читателя с интересными свойствами языка, которые будут
использоваться при реализации структур данных и алгоритмов искусственного интеллекта. К этим
свойствам относятся следующие.
1. Естественная поддержка абстрактных типов данных.
2. Использование списков для создания символьных структур данных.
3. Использование функции cond и рекурсии для управления программой.
4. Рекурсивная природа списочных структур и рекурсивные схемы управления ими.
5. Использование функций quote и eval для управления оцениванием форм.
6. Использование функций set и let для управления связыванием переменных и
побочными эффектами.
В оставшейся части этой главы эти идеи использованы для иллюстрации решения
задач искусственного интеллекта на языке LISP, в том числе для реализации алгоритмов
поиска и проверки соответствия шаблонам.
15.2. Поиск в LISP: функциональный подход к
решению задачи переправы человека, волка, козы
и капусты
Чтобы продемонстрировать возможности программного решения задач искусственного
интеллекта на языке LISP, вернемся к задаче перевозки человека, волка, козы и капусты.
Человеку требуется переправиться через реку и перевезти с собой волка, козу и капусту.
На берегу реки находится лодка, которой должен управлять человек. Лодка одновременно
может перевозить не более двух пассажиров (включая лодочника). Если волк останется на
берегу с козой, то он ее съест. Если коза останется на берегу с капустой, то она уничтожит
капусту. Требуется выработать последовательность переправки через реку таким образом,
чтобы все четыре пассажира были доставлены в целости и сохранности на другой берег реки.
Решение этой задачи на языке PROLOG было описано в разделе 14.3. При программной
реализации на языке LISP поиск выполняется в том же пространстве. Но наряду со
структурной аналогией с решением на PROLOG, программная реализация на LISP отражает
функциональную ориентацию этого языка программирования. Здесь используется поиск в глубину, а
для предотвращения циклов используются списки посещенных состояний.
Ядром программы является набор функций, определяющих состояния мира как
абстрактный тип данных. В этих функциях внутреннее представление состояний скрыто от
программных компонентов более высокого уровня. Состояния представляются в виде списков
706 Часть VI. Языки и технологии программирования для искусственного интеллекта
из четырех элементов, в которых каждый компонент обозначает местоположение человека,
волка, козы и капусты соответственно. Так, список (е w e w) задает состояние, при
котором человек (первый элемент) и коза (третий элемент) находятся на восточном берегу,
а волк и капуста — на западном. Базовыми функциями, определяющими состояние данных
этого типа, являются конструктор make-state и четыре функции. доступа farmer-
side, wolf-side, goat-side и cabbage-side. Параметром конструктора является
местоположение человека, волка, козы и капусты. Эта функция возвращает состояние.
Параметрами функций доступа является состояние, а возвращаемым значением —
местоположение объекта. Эти функции можно определить так.
(defun make-state (f w g с) (list f w g с))
(defun farmer-side (state)
(nth 0 state))
(defun wolf-side (state)
(nth 1 state))
(defun goat-side (state)
(nth 2 state))
(defun cabbage-side (state)
(nth 3 state))
Оставшаяся часть программы основывается на этих функциях. В частности, они
применяются для реализации четырех возможных действий человека: переправы через реку
в одиночку или с одним из пассажиров.
При каждом переходе в новое состояние функции доступа используются для
разделения состояния на его компоненты. Функция opposite (которая вскоре будет
определена), задает новое местоположение объектов, пересекающих реку, а функция make-
state— трансформирует его в новое состояние. Например, функцию farmer-
takes-self можно определить так.
(defun farmer-takes-self (state)
(make-state (opposite (farmer-side state))
(wolf-side state)
(goat-side state)
(cabbage-side state)))
Заметим, что эта функция возвращает новое состояние без учета его безопасности.
Состояние является небезопасным, если человек оставит на берегу козу с капустой или
волка с козой. Программа должна найти путь решения, не допускающий "опасных"
состояний. Проверку состояния на его "безопасность" можно проводить на многих этапах
выполнения программы. Мы будем выполнять ее в функциях перемещения с помощью
формы safe, которая вскоре будет определена. Вот пример ее использования.
> (safe ' (w w w w)) ;состояние безопасно, возвращается без изменений
(w w w w)
> (safe '(е w w e)) ;волк съест козу, вернуть nil
nil
> (safe '(w w e e)) ;коза съест капусту, вернуть nil
Функция safe используется в каждой функции перехода для фильтрации опасных
состояний. Так, любой переход, приводящий к "небезопасному" состоянию, возвращает
не это состояние, а значение nil. Рекурсивный алгоритм вычисления пути проверяет
возвращаемое значение, и, если оно равно nil, отбрасывает это состояние. Таким
образом функция safe обеспечивает реализацию проверки условия до определения возмож-
Глава 15. Введение в LISP
707
ности применения правила перехода. Этот стиль используется при создании
продукционных систем. С учетом функции safe четыре формы перехода можно определить
следующим образом.
(defun farmer-takes-self (state)
(safe (make-state (opposite (farmer-side state))
(wolf-side state)
(goat-side state)
(cabbage-side state))))
(defun farmer-takes-wolf (state)
(cond ((equal (farmer-side state) (wolf-side state))
(safe (make-state (opposite (farmer-side state))
(opposite (wolf-side state))
(goat-side state)
(cabbage-side state))))
(t nil)))
(defun farmer-takes-goat (state)
(cond ((equal (farmer-side state) (goat-side state))
(safe (make-state (opposite (farmer-side state))
(wolf-side state)
(opposite (goat-side state))
(cabbage-side state))))
(t nil)))
(defun farmer-takes-cabbage (state)
(cond ((equal (farmer-side state) (cabbage-side state))
(safe (make-state (opposite (farmer-side state))
(wolf-side state)
(goat-side state)
(opposite (cabbage-side
state)))))
(t nil)))
Заметим, что три последние функции перехода включают проверку условия для
определения, находятся ли человек и его предполагаемый пассажир на одном и том же берегу
реки. Если нет, то эти функции возвращают nil. В функциях перехода используются
представленные выше формы обработки состояний, а также функция opposite,
возвращающая местоположение, противоположное текущему.
defun opposite (side)
(cond ((equal side 'e) 'w)
((equal side 'w) 'e)))
В LISP существует множество различных предикатов для проверки равенства.
Наиболее простой — eq — возвращает значение "истина" только в том случае, если его
аргументы соответствуют одному и тому же объекту, т.е. указывают на одну и ту же
область памяти. Более сложным является предикат equal, для истинности которого все
его аргументы должны быть синтаксически идентичными.
> (setq |1 'A 2 3))
A 2 3)
> (setq |2 'A23))
A 2 3)
> (equal |l |2)
t
> (eq |1 |2)
708 Часть VI. Языки и технологии программирования для искусственного интеллекта
nil
> (setq |3 |1)
A 2 3)
> (eq |1 |3)
t
Функция safe определена на основе формы cond. Это позволяет проверить два
"опасных" условия: человек расположен на противоположном берегу от волка и козы, и
человек находится на противоположном берегу от козы и капусты. Если состояние безопасно,
функция safe возвращает его неизменным, в противном случае она возвращает nil.
(defun safe (state)
(cond ((and (equal (goat-side state) (wolf-side state))
;волк съест козу
(not (equal (farmer-side state) (wolf-side state)))) nil)
((and (equal (goat-side state) (cabbage-side state))
;коза съест капусту
(not (equal (farmer-side state) (goat-side state)))) nil)
(t state)))
Функция path реализует поиск с возвратами в пространстве состояний. Ее
аргументами являются исходное и целевое состояния. Сначала проверяется равенство этих
состояний. Если они равны, то поиск завершается успешно. Если эти состояния не равны,
функция path генерирует все четыре соседних состояния на графе состояний и
рекурсивно вызывает сама себя для каждого из них, пытаясь найти путь к цели. Это
определение на LISP можно записать так.
(defun path (state goal)
(cond ((equal state goal) 'success)
(t (or (path (farmer-takes-self state) goal)
(path (farmer-takes-wolf state) goal)
(path (farmer-takes-goat state) goal)
(path (farmer-takes-cabbage state) goal)))))
Эта версия функции path представляет собой простой перевод рекурсивного
алгоритма поиска пути с "человеческого" языка на LISP. Она содержит несколько ошибок,
которые необходимо устранить. Однако эта версия отражает основную структуру алгоритма,
поэтому до начала устранения ошибок ее следует проанализировать подробнее. Первый
оператор cond служит для проверки успешного завершения алгоритма поиска. При
соответствии исходного состояния целевому equal state goal рекурсия прекращается и
возвращается атом success. В противном случае функция path генерирует 4 дочерних
узла на графе поиска, а затем вызывает сама себя для каждого из этих узлов.
Обратите внимание на использование формы or для управления оцениванием
аргументов. Напомним, что функция or оценивает свои аргументы до тех пор, пока один из них не
возвращает значение, отличное от nil. В этом случае вызов функции or прекращается,
остальные ее аргументы не оцениваются, а результатом считается это ненулевое значение.
Таким образом, функция or не только используется как логический оператор, но и
обеспечивает способ управления ветвлением в пространстве поиска. Здесь применяется форма or,
а не cond, поскольку проверяемое и возвращаемое ненулевое значение совпадают.
Неудобство этого определения состоит в том, что функция перехода может возвращать
значение nil, если переход невозможен или ведет к "опасному" состоянию. Чтобы
предотвратить генерацию узла-потомка для состояния nil, необходимо сначала проверить, является
ли текущее состояние нулевым. Если да, то функция path должна возвращать nil.
Глава 15. Введение в LISP
709
Еще одним вопросом, требующим решения при реализации функции path, является
выявление потенциальных циклов в пространстве поиска. Через несколько шагов работы
описанной выше функции path человек будет возить себя самого с одного берега на
другой. Следовательно, алгоритм попадет в бесконечный цикл между идентичными
состояниями, которые уже были посещены. Для предотвращения такой ситуации в
функцию path нужно добавить третий параметр been-list, представляющий список уже
посещенных состояний. При каждом рекурсивном вызове функции path для нового
состояния мира родительское состояние будет добавляться в список been-list. Для
проверки отсутствия в этом списке текущего состояния можно использовать предикат
member. Вот новое определение функции path.
(defun path (state goal been-list)
(cond ((null state) nil)
((equal state goal) (reverse (cons state been-list)))
((not (member state been-list :test #'equal))
(or (path (farmer-takes-self state) goal
(cons state been-list))
(path (farmer-takes-wolf state) goal
(cons state been-list))
(path (farmer-takes-goat state) goal
(cons state been-list))
(path (farmer-takes-cabbage state) goal
(cons state been-list))))))
Здесь member — это встроенная функция Common LISP, которая ведет себя так же,
как и пользовательская функция my-member, определенная выше в этой главе.
Единственным различием между этими функциями является включение в список аргументов
параметра : test # ' equal. В отличие от "доморощенной" функции my-member,
такая форма позволяет программисту указать функцию, которая будет использоваться для
проверки принадлежности элемента списку. Это повышает гибкость функции, но не
играет существенной роли в настоящем обсуждении.
Вместо того, чтобы возвращать атомарное значение success, лучше передавать из
функции найденный путь решения. Поскольку последовательность состояний в пути
решения уже содержится в списке been-list, список возвращается в новой версии
функции. Поскольку этот список построен в обратном порядке (начальное состояние
является его последним элементом), он сначала обращается (перестраивается в обратном
порядке с использованием встроенной функции LISP reverse).
И, наконец, поскольку параметр been-lisp желательно скрыть от пользователя,
целесообразно создать вызывающую функцию верхнего уровня, параметрами которой
будут являться начальное и целевое состояние. Она будут вызывать функцию path со
значением параметра been-list равным nil.
(defun solve-fwgc (state goal) (path state goal nil))
Давайте сравним версии программ решения задачи перевозки человека, волка, козы и
капусты, написанные на LISP и PROLOG (программа на PROLOG описана в
разделе 14.3). Программа на LISP не только решает ту же задачу, но и выполняет поиск
в том же пространстве состояний, что и версия на PROLOG. Это служит
подтверждением той мысли, что концептуализация задачи в пространстве состояний не зависит от
реализации программы поиска в этом пространстве. Поскольку обе программы выполняют
поиск в одном и том же пространстве состояний, эти реализации имеют много общего.
710 Часть VI. Языки и технологии программирования для искусственного интеллекта
Различия между ними очень тонки, но позволяют подчеркнуть разницу между
декларативным и процедурным стилями программирования.
Состояния в версии PROLOG представляются с помощью предиката state(e,e,e,e),
а в LISP задаются с помощью списка. Эти два представления не просто являются
синтаксическими вариациями друг друга. Представление состояния в LISP определяется не только
синтаксисом списков, но и функциями доступа и переходов, описывающими абстрактный
тип данных "состояние". В версии PROLOG состояния являются шаблонами. Их значение
определяется способом проверки соответствия другим шаблонам правил в PROLOG,
которые тоже могут быть списками.
Версия LISP функции path несколько длиннее, чем ее реализация на PROLOG. Это
связано с тем, что на LISP приходится реализовывать стратегию поиска, в то время как PROLOG
использует встроенный алгоритм поиска. Алгоритм управления в LISP задается явно,
а в PROLOG — неявно. Поскольку PROLOG строится на декларативном представлении и
методах доказательства теорем, написанные на нем программы более лаконичны и напоминают
описание предметной области задачи. В них алгоритмы поиска не нужно реализовывать
напрямую. Обратной стороной медали является "сокрытие" поведения программы,
определяемого встроенными стратегиями вывода PROLOG. Кроме того, над программистами
"довлеют" формализм представления и стратегии поиска, заложенные в PROLOG. В свою
очередь, LISP допускает большую гибкость в представлении и свободу действий
программиста. Однако здесь программисту приходится явно реализовывать стратегию поиска.
15.3. Функции и абстракции высшего порядка
Одним из главных преимуществ LISP и других функциональных языков
программирования является возможность определения функций, параметрами которых являются
другие функции, а также функций, возвращающих функцию в качестве результата. Такие
функции называются функциями высшего порядка (higher-order functions) и составляют
важное средство реализации процедурной абстракции.
15.3.1. Отображения и фильтры
Фильтр (filter) — это функция, проверяющая элементы списка на предмет
соответствия некоторому условию и удаляющая "отбракованные" элементы. Примером фильтра
является описанная выше в этой главе функция filter-negatives. Отображения
(тар) — выполняют некоторые действия над списком объектов данных и возвращают
список результатов. Эту идею можно развить и ввести понятия обобщенных
отображений и фильтров, получающих в качестве параметров списки и функции и проверяющих
применимость функций к элементам списков.
В качестве примера рассмотрим упомянутую в подразделе 15.1.6 функцию filter-
negatives. Ей в качестве параметра передается числовой список, а в результате ее
выполнения возвращается этот же список, но без отрицательных элементов. Аналогично
можно определить функцию-фильтр для удаления четных чисел из списка.
(defun filter-evens (number-list)
/условие останова
(cond ((null number-list) nil)
((oddp (car number-list))
Глава 15. Введение в LISP
711
(cons (car number-list) (filter-evens
(cdr number-list))))
(t (filter-evens (cdr number-list)))))
Поскольку эти функции отличаются друг от друга только именем предиката,
используемого для фильтрации элементов списка, логично объединить их в единую функцию,
вторым параметром которой является предикат-фильтр.
Это можно сделать с помощью формы LISP f uncall, параметрами которой
являются функция и последовательность аргументов, к которым эта функция и применяется.
((defun filter (list-of-elements test)
(cond ((null list-of-elements) nil)
((funcall test (car list-of-elements))
(cons (car list-of-elements) (filter
(cdr list-of-elements) test)))
(t (filter (cdr list-of-elements) test))))
Функция filter проверяет условие test для первого элемента списка. Если
результат проверки отличен от nil, он добавляется к результату фильтрации хвоста списка
с помощью функции cons. В противном случае возвращается отфильтрованный хвост
списка. При использовании этой функции ей можно передавать в качестве параметра
различные предикаты. Тогда она будет решать разные задачи фильтрации.
> (filter 'A3-95-2 -7 б) #'plusp) ;Фильтрация
;отрицательных чисел
A3 5 6)
> (filter 'A23456789) #'evenp) /Фильтрация всех
;нечетных чисел
B 4 6 8)
> (filter 'A a b 3 с 4 7 d) #'numberp)
A 3 4 7) ;Фильтрация нечисловых
;элементов списка
При передаче функции в качестве параметра, как в приведенном примере, перед ее
именем нужно указывать # ', а не просто символ '. Это делается для того, чтобы интерпретатор
LISP мог соответствующим образом обрабатывать этот аргумент. В частности, при передаче
функции в качестве параметра в Common LISP сохраняются все связи се свободных
переменных (если таковые существуют). Такое сочетание определения функции со связыванием
свободных переменных называется лексическим замыканием (lexical closure). Флаг # '
уведомляет интерпретатор LISP о необходимости построения лексического замыкания и передачи его в
функцию. Более строго funcall определяется следующим образом.
(funcall <функция> <арг± > < арг2 > . . . < аргп >)
В этом определении <функция> — это функция LISP, а <арг{>. . . <аргп> — нуль
или более аргументов функции. Результат оценивания funcall совпадает с результатом
вызова функции <функция>, если указанные аргументы передаются ей в качестве
фактических параметров.
Функция apply выполняет ту же задачу, что и funcall, но ее аргументы должны
передаваться в виде списка. Это единственное синтаксическое отличие между функциями apply
и funcall. Программист может выбирать одну из функций по своему усмотрению. Эти
функции аналогичны функции eval, поскольку все три позволяют пользователю управлять
оцениванием функций. Различие между ними состоит в том, что параметрами функции eval
712 Часть VI. Языки и технологии программирования для искусственного интеллекта
являются оцениваемые s-выражения, а функциям apply и f uncall передаются сама
функция и ее параметры. Вот примеры использования этих функций.
> (funcall #'plus2 3)
5
> (apply #'plus'B 3))
5
> (eval '(plus 2 3))
5
> (funcall #'car '(a b c))
a
> (apply #'car '((a b c)))
a
Еще одним важным классом функций высшего порядка являются отображения, т.е.
функции, применяющие заданную функцию ко всем элементам списка. На основе funcall
можно определить простую функцию-отображение map-simple, возвращающую список
результатов применения некоторого функционала ко всем элементам исходного списка.
(defun map-simple (func list)
(cond ((null list) nil)
((t (cons (funcall func (car list))
(map-simple func (cdr list))))))
> (map-simple #'1+ 'A23456))
B34567)
> (map-simple #'listp A2 C 4) 5 F78)))
(nil nil t nil t)
Это упрощенная версия встроенной в LISP функции mapcar, допускающая
использование нескольких списков аргументов. Тогда к соответствующим элементам
нескольких списков можно применять функции нескольких аргументов.
> (mapcar #'1+'A 2 3 4 5 6)) ;та же функция, что и map-simple
B34567)
>(mapcar #'+'A234) 'E678))
F 8 10 12)
> (mapcar #'max'C 9 17) 'B568))
C 9 6 8)
Функция mapcar — лишь одна из многих встроенных функций-отображений в LISP,
а значит, одна из многих функций высшего порядка.
15.3.2. Функциональные аргументы и лямбда-выражения
В предыдущих примерах аргументы-функции передавались по имени и применялись к
другим аргументам. Для этого функции-аргументы нужно было определять заранее в
глобальной среде. Однако зачастую желательно передавать в качестве параметра само
определение функции, не определяя се глобально. Осуществить это позволяют лямбда-выражения.
Выражение lambda позволяет отделить определение функции от ее имени. Истоки
лямбда-выражений связаны с лямбда-исчислением (lambda-calculus) — математической моделью
вычислений, обеспечивающей (среди всего прочего) особенно четкое разграничение между
объектом и его именем. Синтаксис лямбда-выражения аналогичен определению функции de-
f un, однако имя функции здесь заменяется ключевым словом lambda.
Глава 15. Введение в LISP
713
(lambda (<формальные-параметры>) <тело>)
Лямбда-выражения можно использовать вместо имени функции в спецификации
funcall или apply. Функция funcall выполнит тело лямбда-выражения, при этом
аргументы будут связаны с параметрами funcall. Как и при использовании функции,
количества формальных и фактических параметров должны совпадать. Например,
> (funcall #'(lambda (x) (* х х)) 4)
16
Здесь переменная х связывается со значением 4, а затем оценивается тело лямбда-
выражения. Функция funcall возвращает квадрат числа 4. Приведем еще несколько
примеров использования лямбда-выражений в функциях funcall и apply.
> (apply #'(lambda (х у) (+ (* х х) у)) 'B 3))
7
> (funcall #'(lambda (x) (append x x)) '(a b с))
(a b с a b с)
> (funcall #'(lambda (xl x2) (append (reverse xl) x2)) '(a b c)
' (d e f) )
(c b a d e f)
Лямбда-выражения можно использовать и в функциях высшего порядка наподобие
mapcar вместо имени глобально определенной функции. Вот пример.
>(mapcar #Mlambda (х) (* х х)) 'A2345))
A 4 9 16 25)
> (mapcar #'(lambda (x) (* х 2)) 'A2 3 4 5))
B468 10)
> (mapcar #'(lambda (x) (and (> x 0) (< х 10))) 'A 24 5 -9 8 23))
(t nil t nil t nil)
Если бы не существовало лямбда-выражений, программисту пришлось бы определять
все функции в глобальной среде с помощью функции defun, даже если они подлежат
однократному использованию. Лямбда-выражения освобождают программиста от такой
необходимости. Чтобы возвести в квадрат все элементы списка, достаточно передать
лямбда-форму функции mapcar. Это иллюстрируют приведенные выше примеры. При
этом не нужно заранее определять функцию возведения в квадрат.
15.4. Стратегии поиска в LISP
Функции высшего порядка являются мощным средством процедурной абстракции. В этом
разделе приемы абстрагирования будут применяться для реализации общих алгоритмов
поиска в ширину, глубину и "жадного" алгоритма поиска, описанных в главах 3 и 4. Для
управления поиском в пространстве состояний будут использованы списки open и closed.
15.4.1. Поиск в ширину и в глубину
Реализация алгоритма поиска в ширину базируется на использовании списка open в
качестве структуры FIFO (очереди). Списки open и closed определяются как
глобальные переменные. На то есть несколько причин. Во-первых, мы хотим
продемонстрировать использование глобальных структур в LISP. Во-вторых, целесообразно сравнить
714 Часть VI. Языки и технологии программирования для искусственного интеллекта
программное решение на LISP с программой на языке PROLOG. В-третьих, поскольку
основная задача этой программы— решать проблему поиска, то пространство поиска
следует определить глобально. И, наконец, списки open и closed разумно объявить
глобальными переменными, поскольку они могут оказаться большими. В целом
целесообразность использования локальных и глобальных переменных зависит от деталей
реализации конкретного языка программирования. Глобальные переменные в Common LISP
выделяются слева и справа символом *. Функции поиска в ширину можно определить
следующим образом.
(defun breadth-first ( )
(cond ((null *open*) nil)
(t (let ((state (car *open*)))
( cond ((equal state *goal*) 'success)
(t (setq *closed* (cons state *closed*))
(setq *open* (append (cdr *open*)
(generate-descendants state *moves*)))
(breadth-first)))))))
(defun run-breadth (start goal)
(setq *open* (list start))
(setq *closed* nil)
(setq *goal* goal)
(breadth-first))
В этой реализации проверяется наличие элементов в списке *ореп*. Если список
пуст, то алгоритм возвращает значение nil, означающее неудачное завершение
алгоритма. В противном случае проверяется первый элемент списка *ореп*. Если он
соответствует целевому узлу, то алгоритм завершается и возвращает значение success.
В противном случае для получения потомков текущего состояния вызывается функция
generate-descendants, узлы-потомки добавляются в список *ореп*, и функция
breadth-first рекурсивно вызывает сама себя. Функция run-breadth— это
процедура инициализации, в которой задаются исходные значения переменных *ореп*,
*closed* и *goal*. Функции generate-descendants в качестве параметров
передаются состояние state и список функций *moves*, генерирующих переходы. В
задаче перевозки человека, волка, козы и капусты с учетом определений переходов из
раздела 15.2 список *moves* имеет вид.
(setq *moves*
'(farmer-takes-self farmer-takes-wolf farmer-takes-goat
farmer-takes-cabbage))
Функция generate-descendants зависит от состояния и возвращает список его
потомков. Помимо генерации списка потомков она предотвращает дублирование
элементов в этом списке и исключает узлы, уже присутствующие в списке *ореп* или
*closed*. Кроме состояния функции generate-descendants передается список
переходов. Это могут быть имена уже определенных функций или лямбда-определения.
Для сохранения результатов перехода в локальной переменной child используется блок
let. Определение функции generate-descendants может иметь следующий вид.
(defun generate-descendants (state moves)
(cond ((null moves) nil)
(t (let ((child (funcall (car moves) state))
(rest (generate-descendants state (cdr moves))))
Глава 15. Введение в LISP
715
(cond ((null child)-rest)
((member child rest :test #'equal) rest)
((member child *open* :test #'equal) rest)
((member child *closed* :test #'equal) rest)
(t (cons child rest)))))))
При вызове функции member используется дополнительный параметр :test
#' equal, который впервые упоминался в разделе 15.2. Функция member позволяет
пользователю задавать любую процедуру проверки наличия элемента в списке. Для этой
цели можно использовать предикаты любой сложности и семантики. Однако LISP не
требует обязательного задания такой функции: по умолчанию используется предикат eq.
При использовании этого предиката два объекта считаются идентичными, если они
занимают одно и то же местоположение в памяти. Мы используем более слабую функцию
сравнения equal, в которой два объекта считаются равными, если они имеют одно и то
же значение. Поскольку глобальная переменная *moves* связывается с
соответствующим набором функций переходов, то описанный алгоритм поиска можно применять для
поиска в ширину на любом графе состояний.
Единственной проблемой этой реализации является невозможность вывода списка
состояний, расположенных вдоль пути решения от начала и до конца. Хотя при
завершении алгоритма все ведущие к цели состояния содержатся в списке *closed*, в нем
также находятся все остальные состояния, пройденные на предыдущих уровнях поиска.
Чтобы решить эту проблему, для каждого состояния нужно записывать и его предка.
Когда текущее состояние будет соответствовать целевому, информацию о предках
можно будет использовать для построения пути от целевого состояния к исходному. Эта
расширенная версия поиска в ширину начинается с определения абстрактного типа
данных записи состояния.
(defun build-record (state parent) (list state parent))
(defun get-state (state-tuple) (nth 0 state-tuple))
(defun get-parent (state-tuple) (nth 1 state-tuple))
(defun retrieve-by-state (state list)
(cond ((null list) nil)
((equal state (get-state (car list))) (car list))
(t (retrieve-by-state state (cdr list)))))
Функция build-record строит пару (<состоянаехпредок>). Функции get-state и
get-parent обеспечивают доступ к соответствующим полям записи. Функция retrieve-
by-state получает в качестве параметров состояние и список записей состояния, а
возвращает запись, поле состояния которой соответствует данному состоянию.
Функция build-solution использует форму retrieve-by-state для
восстановления родительского состояния и построения списка состояний, ведущих к целевому. При
инициализации списка *ореп* родительским состоянием для начального является nil. Функция
build-solution прекращает свою работу после перехода к нулевому состоянию.
(defun build-solution (state)
(cond ((null state) nil)
(t (cons state (build-solution (get-parent (retrieve-by-state
state *closed*)))))))
Остальная часть алгоритма аналогична реализации поиска в ширину из раздела 3.2.
(defun run-breadth (start goal)
(setq *open* (list (build-record start nil)))
716 Часть VI. Языки и технологии программирования для искусственного интеллекта
(setq *closed* nil)
(setq *goal* goal)
(breadth-first))
(defun breadth-first ( )
(cond ((null *open*) nil)
(t (let ((state (car *open*)))
(setq *closed* (cons state *closed*))
(cond ((equal (get-state state) *goal*)
(build-solution *goal*))
(t (setq *open* (append (cdr *open*)
(generate-descendants (get-state state)
*moves*)))
(breadth-first)))))))
(defun generate-descendants (state moves)
(cond ((null moves) nil)
(t (let ((child (funcall (car moves) state))
(rest (generate-descendants state (cdr moves))))
(cond ((null child) rest)
((retrieve-by-state child rest) rest)
((retrieve-by-state child *open*) rest)
((retrieve-by-state child *closed*) rest)
(t (cons (build-record child state) rest)))))))
Поиск в глубину можно обеспечить путем модификации процедуры поиска в ширину
и реализации списка open в виде стека. Для этого нужно всего лишь изменить порядок
следования аргументов функции append.
15.4.2. "Жадный" алгоритм поиска
"Жадный" алгоритм поиска можно реализовать с помощью простой модификации
поиска в ширину. Вместе с каждым состоянием нужно сохранять его эвристическую
оценку. Затем кортежи *ореп* следует отсортировать по этой оценке. Для записей
состояний потребуются типы данных, основанные на типах данных из реализации
алгоритма поиска в ширину.
(defun build-record (state parent depth weight)
(list state parent depth weight))
(defun get-state (state-tuple) (nth 0 state-tuple))
(defun get-parent (state-tuple) (nth 1 state-tuple))
(defun get-depth (state-tuple) (nth 2 state-tuple))
(defun get-weight (state-tuple) (nth 3 state-tuple))
(defun retrieve-by-state (state list)
(cond ((null list) nil)
((equal state (get-state (car list))) (car list))
(t (retrieve-by-state state (cdr list)))))
Функции best-first и generate-descendants определены следующим образом.
(defun best-first ( )
(cond ((null *open*) nil)
(t (let ((state (car *open*)))
(setq *closed* (cons state *closed*))
(cond ((equal (get-state state) *goal*) (build-solution
*goal*))
(t (setq *open*
Глава 15. Введение в LISP 717
(insert-by-weight
(generate-descendants (get-state state)
(+ 1 (get-depth state)) *moves*)
(cdr *open*)))
(best-first)))))))
(defun generate-descendants (state depth moves)
(cond ((null moves) nil)
(t (let ((child (funcall (car moves) state))
(rest (generate-descendants state depth (cdr moves))) )
(cond ((null child) rest)
((retrieve-by-state child rest) rest)
((retrieve-by-state child *open*) rest)
((retrieve-by-state child *closed*) rest)
(t (cons (build-record child state depth
(+ depth (heuristic child))) rest)))))))
Единственным отличием процедур поиска best-first от breadth-first
является использование функции insert-by-weight для сортировки записей списка
*ореп* по эвристическим весам и вычисление глубины поиска и этих весов с помощью
функции generate-descendants.
Для завершения процедуры поиска best-first требуется определить функцию
insert-by-weight. Она получает в качестве параметра не сортированный список
записей состояний и вставляет их по одному в соответствующие позиции списка *ореп*.
При этом также требуется с учетом специфики задачи определить функцию heuristic.
Ее параметром является состояние, для которого вычисляется эвристический вес с
помощью глобальной переменной *goal*. Определить эти функции читателю
предлагается в качестве упражнения.
15.5. Проверка соответствия шаблонам LISP
Проверка соответствия шаблонам — это важная методология искусственного
интеллекта, которая уже была описана в главах, посвященных языку PROLOG и
продукционным системам. В этом разделе будет представлена реализация рекурсивной процедуры
проверки соответствия шаблонам и рассмотрено ее использование для построения
функции извлечения информации по шаблону из простой базы данных.
Ядром системы восстановления информации служит функция match, параметрами
которой являются два s-выражения, а возвращаемым значением — t, если эти выражения
соответствуют друг другу. При этом оба выражения должны иметь одинаковую структуру, а
также содержать идентичные атомы в соответствующих позициях. Функция match
допускает использование в s-выражениях переменных, обозначенных символом ?. Переменные
соответствуют любому s-выражению (списку или атому), но не сохраняют связывания, как
при полной унификации. Ниже приводятся примеры требуемого поведения функции
match. Эти примеры напоминают соответствующие примеры на языке PROLOG из
главы 14, поскольку функция match на самом деле является упрощенной версией алгоритма
унификации, положенного в основу языка PROLOG, а также многих других систем
искусственного интеллекта, основанных на шаблонах. В разделе 15.6 функция match будет
доведена до полноценной реализации алгоритма унификации за счет добавления
возможности использования имен переменных и возвращения списка связей.
718 Часть VI. Языки и технологии программирования для искусственного интеллекта
> (match'(likes bill wine)'(likes bill wine))
t
> (match'(likes bill wine)'(likes bill milk))
nil
> (match'(likes bill ?)'(likes bill wine)) /пример с переменной
t
> (match'(likes ? wine)'(likes bill ?)) /переменные в обоих
;выражениях
t
> (match'(likes bill ?)'(likes bill (prolog lisp Smalltalk))
t
> (match'(likes ?)'(likes bill wine))
nil
Функция match используется для определения формы get-matches, параметрами
которой являются два s-выражения. Первый аргумент — это шаблон, с которым
сравниваются элементы второго s-выражения, представляющего собой список. Функция get-
matches возвращает перечень элементов списка, соответствующих первому аргументу.
В приведенном ниже примере функция get-matches используется для извлечения
записей из базы данных сотрудников, описанной выше в этой главе.
Поскольку база данных велика и содержит относительно сложные s-выражения, ее
целесообразно связать с глобальной переменной * database* и использовать эту
переменную в качестве аргумента функции get-matches. Это существенно повышает
читабельность примеров.
> (setq ^database* '(((lovelace ada) 50000.00 1234)
((turing alan) 45000.00 3927)
((shelley тагу) 35000.00 2850)
((vonNeumann John) 40000.00 7955)
((simon herbert) 50000.00 1374)
((mccarthy John) 48000.00 2864)
((russell bertrand) 35000.00 2950))
^database*
> (get-matches '((turing alan) 45000.00 3927) ^database*)
((turing alan) 45000.00 3927)
> (get-matches '(? 50000.00 ?) ^database*) ;все сотрудники
с зарплатой 50000
(((lovelace ada) 50000.00 1234) ((simon herbert) 50000.00 1374))
> (get-matches '((? John) ? ?) ^database*) ;все сотрудники
с именем John
(((vonNeumann John) 40000.00 7955) ((mccarthy John) 48000.00 2864))
Функция get-matches реализована рекурсивно. Это обеспечивает поиск
элементов, соответствующих первому аргументу (шаблону). Все элементы базы данных,
соответствующие этому шаблону, объединяются с помощью функции cons и передаются в
качестве результата. Определение функции get-matches имеет следующий вид.
((defun get-matches (pattern database)
(cond ((null database) ( ))
;соответствие найдено,
((match pattern (car database)) ;добавление к результату
(cons (car database) (get-matches pattern
(cdr database))))
(t (get-matches pattern (cdr database)))))
Глава 15. Введение в LISP
719
Основой данной системы является функция match. Она представляет собой предикат,
определяющий, соответствуют ли друг другу два s-выражения с переменными. Работа функции
match основана на утверждении, что два списка соответствуют друг другу в том и только том
случае, если друг другу соответствуют их головы и хвосты. Поэтому для реализации данного
алгоритма применена рекурсивная схема car-cdr. Рекурсия завершается, когда один из
аргументов становится атомом (в том числе пустым списком nil, который является
одновременно и атомом, и списком). Если оба аргумента представляют собой один и тот же атом, или
один из шаблонов представляет собой атомарную переменную ? (соответствующую
произвольному шаблону), то рекурсия завершается успешно. В противном случае проверка
соответствия завершается с отрицательным результатом. Заметим, что если один из шаблонов
является переменной, то второй необязательно должен быть атомарным, поскольку переменные
могут соответствовать s-выражениям произвольной сложности.
Поскольку обработка условий завершения очень сложна, то в реализации функции
match используется функция match-atom, зависящая от двух аргументов, хотя бы
один из которых является атомом. Она и проверяет соответствие шаблонам. Поскольку
сложность реализации процедуры скрыта в функции match-atom, структура рекурсии
car-cdr в функции match выглядит более наглядно.
(defun match (patternl pattern2)
(cond (or (atom patternl) (atom pattern2) ) ;один из шаблонов - атом
(match-atom patternl pattern2)) ;вызов match-atom,
;в противном случае
(t (and (match (car patternl) (car pattern2))
/проверка соответствия car и
(match (cdr patternl) (cdr pattern2))))))
;cdr
При реализации функции match-atom учитывается тот факт, что при вызове этой
функции один из ее аргументов — атом. Благодаря этому предположению упрощается
проверка соответствия шаблонов друг другу, поскольку требуется лишь удостовериться,
что оба они представляют собой один и тот же атом (возможно, переменную). Эта
функция завершается неудачей, если шаблоны представляют собой различные атомы, либо
один из них является неатомарным. Если первая проверка завершается неудачей, то
соответствие шаблону может быть достигнуто, только если один из шаблонов является
переменной. Эта проверка и составляет заключительную часть определения функции. И,
наконец, функция variable-р предназначена для проверки того, является ли шаблон
переменной. Обработка переменных как экземпляров абстрактного типа данных
упрощает дальнейшее расширение функции (например, распространение этой функции на
именованные переменные подобно тому, как это было реализовано в языке PROLOG).
((defun match-atom (patternl pattern2)
(or (equal patternl pattern2) ;шаблоны совпадают, или
(variable-p patternl) ;один из них является переменной.
(variable-p pattern2)))
(defun variable-p (x) (equal x '?))
15.6. Рекурсивная функция унификации
В разделе 15.5 реализован рекурсивный алгоритм проверки соответствия шаблонам,
позволяющий включать в шаблоны неименованные переменные. Расширим эту простую систе-
720 Часть VI. Языки и технологии программирования для искусственного интеллекта
му до реализации полного алгоритма унификации, описанного в главе 2. Функция unify
допускает использование именованных переменных в обоих выражениях и возвращает список
связанных переменных, соответствующих данному шаблону. Эта функция унификации
составляет основу систем вывода, которые будут разработаны ниже в этой главе.
Как и в разделе 15.5, будем рассматривать шаблоны, представляющие собой константы,
переменные или списочные структуры. В полном алгоритме унификации переменные могут
отличаться друг от друга своими именами. Именованные переменные логично представлять в
виде списков (var <имя>), где имя — это, как правило, атомарный символ. Примерами
допустимых переменных являются (var x), (var у) и (var newstate).
Параметрами функции unify являются два шаблона, подлежащих сравнению между
собой, и набор подстановок (связанных переменных). В общем случае при первом
вызове функции это множество будет пустым (nil). Если проверка соответствия завершается
успешно, функция unify возвращает множество подстановок (возможно, пустое),
необходимых для соответствия шаблону. Если соответствия не найдены, то функция unify
возвращает символ failed. Значение nil используется для обозначения пустого
множества подстановок, т.е. соответствий, не требующих никаких подстановок. Вот
примеры использования функции unify.
Ь) ( ))
> (unify'(p a (var x))
Ь))
(р а
( ( (var x)
;(var x)
> (unify'(p
(((var x) .
> (unify'(p
(var у) b) ' (p a (var х) ) ( ) )
;возвращает подстановку
;Ь для переменной
;переменные в обоих
;шаблонах
b) ((var у)
(var х)) ' (р
• а))
(q a (var у) )
) (
));переменная,
;с более
связанная
(((var x) q a (var у))]
;сложным шаблоном
> (unify' (p а) ' (р а) (
))
nil
> (unify
failed
(pa) '(q a) ( ))
;nil означает, что
;подстановки не требуются
/возвращает атом
;failed, означающий
;неудачное завершение
Обратите внимание на использование в этих вызовах символа ., например, в
выражении ((var x) .b). Это обозначение будет обсуждаться после описания функции
unify. В ней, подобно системе проверки соответствия шаблонам из раздела 15.5,
используется схема рекурсии car-cdr.
(defun unify (patternl pattern2 substitution-list)
(cond ((equal substitution-list 'failed) 'failed)
((varp patternl) (match-var patternl pattern2
substitution-list))
;проверка на наличие переменной
((varp pattern2) (match-var pattern2 patternl
substitution-list))
((is-constant-p patternl)
(cond ((equal patternl pattern2) substitution-list)
(t 'failed)))
((is-constant-p pattern2) 'failed)
(t (unify (cdr patternl) (cdr pattern2)
Глава 15. Введение в LISP
721
(unify (car patternl) (car pattern2)
substitution-list)))))
При вызове функции unify сначала проверяется соответствие списка подстановки
значению failed. Эта ситуация возможна в том случае, если первая попытка
унификации начальных элементов двух шаблонов завершается неудачно. При выполнении этого
условия функция возвращает значение failed.
Затем, если один из шаблонов является переменной, вызывается функция match-var,
выполняющая дальнейшую проверку и возможное добавление новых связанных переменных
в список подстановки. Если ни один из шаблонов не является переменной, то функция unify
проверяет наличие констант. При совпадении констант список подстановки возвращается
неизменным, в противном случае возвращается значение failed.
Последним элементом оператора cond является декомпозиция задачи по дереву
рекурсии. Сначала проводится унификация первых элементов с помощью связанных переменных
из списка подстановки substitution-list. Результат передается в качестве третьего
аргумента функции unify для унификации хвостов списков шаблонов. Это позволяет
использовать подстановки переменных, сделанные при проверке соответствия первых элементов, и
проверять вхождение этих переменных в оставшейся части обоих шаблонов.
Вот пример определения функции match-var.
(defun match-var (var pattern substitution-list)
(cond ((equal var pattern) substitution-list)
(t (let ((binding (get-binding var substitution-list)))
(cond (binding (unify (get-binding-value binding) pattern
substitution-list))
((occursp var pattern) 'failed)
(t (add-substitution var pattern substitution-list)))))))
Эта функция сначала проверяет соответствие переменной шаблону. При
самоунификации переменной подстановки не требуются, поэтому список substitution-list
возвращается неизменным.
Если параметры var и pattern не совпадают, выполняется проверка связанности
переменной. Если переменная связана, то функция unify рекурсивно вызывается для проверки
соответствия значений указанному шаблону pattern. Заметим, что значение связанной
переменной может быть константой, переменной или шаблоном произвольной сложности.
Поэтому для завершения проверки требуется вызов полного алгоритма унификации.
Если переменная var не связана ни с какими значениями, вызывается функция
occursp, с помощью которой проверяется наличие var в шаблоне pattern. Проверку
вхождения (occurs check) необходимо выполнять для предотвращения попыток
унификации переменной с содержащим ее шаблоном, которые могут привести к появлению
циклов. Например, если переменная (var x) связана с выражением (р (var x) ), то
любая попытка применения этих подстановок к шаблону приведет к бесконечному
циклу. Если в шаблоне pattern встречается фрагмент var, функция match-var
возвращает значение failed. В противном случае новая пара подстановки добавляется в
список substitution-list с помощью функции add-substitution.
Функции unify и match-var составляют основу алгоритма унификации. Ниже
описаны функция occursp (выполняющая проход по дереву шаблона в поисках
вхождений в него заданной переменной), varp и is -constant -p (проверяющая, чем
является аргумент: переменной или константой). Затем будут рассмотрены функции
обработки множества подстановок.
722 Часть VI. Языки и технологии программирования для искусственного интеллекта
(defun occursp (var pattern)
(cond ((equal var pattern) t)
((or (varp pattern) (is-constant-p pattern)) nil)
(t (or (occursp var (car pattern))
(occursp var (cdr pattern))))))
(defun is-constant-p (item)
(atom item))
(defun varp (item)
(and (listp item)
(equal (length item) 2)
(equal (car item) 'var)))
Множества подстановок можно представить с помощью встроенного в LISP типа
данных, известного под названием ассоциативного списка (association list) или а-списка
(a-list). Работа с такими структурами данных положена в основу функций add-
substitutions, get-binding и binding-value. Ассоциативный список— это
список записей данных или пар ключ-значение (key/data). Первый элемент каждой
записи — это ключ для ее восстановления, а оставшаяся часть записи содержит данные,
которые могут представлять собой либо список значений, либо отдельный атом. Извлечение
данных осуществляется с помощью функции ass ос, параметрами которой являются
ключ и ассоциативный список, а возвращаемым значением — первый элемент
ассоциативного списка, соответствующий данному ключу. При вызове функции assoc можно
дополнительно указать третий аргумент, означающий тип проверки, используемой для
сравнения ключей. По умолчанию для проверки в Common LISP используется функция
eql, согласно которой равенство двух аргументов означает, что они указывают на один
и тот же объект (т.е. занимают одну и ту же область памяти или принимают одинаковое
числовое значение). При реализации множеств подстановок будем использовать менее
жесткий тест equal, проверяющий синтаксическое соответствие аргументов
(идентичность имен). Приведем примеры использования функции assoc.
> (assoc 3 '((la) B b) C с) D d) ) )
C с)
> (assoc 'd '((a b с) (b с d e) (d e f) (c d e)) :test #'equal)
(d e f)
> (assoc 'c '((a . 1) (b . 2) (c .3) (d . 4)) :test #'equal)
(c . 3)
Заметим, что функция assoc возвращает всю запись, соответствующую указанному
ключу. Данные из этого списка можно извлечь с помощью функции cdr. Заметим также,
что в последнем вызове элементами а-списка являются не списки, а структуры,
получившие название точечных пар (dotted pair), например (а . 1).
Точечная пара — это базовый конструктор в LISP. Она является результатом
объединения двух s-выражений. Обозначение списка, используемое в этой главе, —
это лишь один из вариантов точечных пар. Например, при вызове (cons 1 nil)
на самом деле возвращается значение A . nil), что эквивалентно A).
Аналогично список A 2 3) можно записать в виде точечных пар A . B . C .
nil) ) ). Хотя на самом деле функция cons создает точечные пары, списочные
обозначения гораздо понятнее, а потому предпочтительнее.
При объединении двух атомов результат всегда записывается в обозначениях
точечных пар. Хвост точечной пары — это ее второй элемент, а не список, содержащий
второй атом. Например,
Глава 15. Введение в LISP
723
> (cons 'a 'b)
(a . b)
> (car '(a . b))
a
> (cdr '(a . b))
b
Точечные пары естественным образом входят в состав ассоциативных списков (когда
один атом используется в качестве ключа для извлечения другого атома), а также
применяются в других приложениях, требующих работы с парами атомарных символов.
Поскольку в процессе унификации вместо переменной зачастую подставляется отдельный
атом, точечные пары нередко встречаются в ассоциативных списках, возвращаемых
функцией унификации.
Наряду с assoc в Common LISP определена функция aeons, аргументами которой
являются ключ, данные и ассоциативный список, а возвращаемым значением — новый
ассоциативный список, первый элемент которого — это результат объединения ключа и
данных. Например,
> (aeons 'a 1 nil)
((а . 1) )
Заметим, что если в функцию aeons передаются два атома, то в ассоциативный
список добавляется их объединение.
> (aeons 'pets '(emma jack clyde)
'((name . bill) (hobbies music skiing movies)
(job . programmer)))
((pets emma jack clyde) (name . bill) (hobbies music skiing movies)
(job . programmer))
Элементами ассоциативного списка могут быть точечные пары и списки.
Ассоциативные списки обеспечивают удобный способ реализации различных таблиц
и других простых схем извлечения данных. При реализации алгоритма унификации
ассоциативные списки используются для представления множеств подстановок: ключи
соответствуют переменным, а данные — их значениям. Данные могут представлять собой
простую переменную, константу либо более сложную структуру.
С помощью ассоциативных списков функции работы со множеством подстановок
можно определить следующим образом.
(defun get-binding (var substitution-list)
(assoc var substitution-list :test #'equal))
(defun get-binding-value (binding) (cdr binding))
(defun add-substitution (var pattern substitution-list)
(aeons var pattern substitution-list))
На этом реализация алгоритма унификации завершена. Она будет использована в
разделе 15.8 для реализации простого интерпретатора для языка PROLOG и в разделе 15.10
для построения оболочки экспертной системы.
15.7. Интерпретаторы и внедренные языки
Верхний уровень интерпретатора LISP называется циклом read-eval-print. Это
название отражает функции интерпретатора по чтению, оцениванию и выводу значений
724 Часть VI. Языки и технологии программирования для искусственного интеллекта
s-выражений, введенных пользователем. Функция eval, определенная в
подразделе 15.1.4, составляет основу интерпретатора LISP. С ее помощью цикл read-eval-
print можно написать на самом языке LISP. В следующем примере будет разработана
упрощенная версия этого цикла. Упрощение состоит в отсутствии обработки ошибок,
хотя LISP обеспечивает средства, необходимые для ее реализации.
Для создания цикла read-eval-print воспользуемся двумя функциями LISP
read и print. Первая из них не зависит от параметров и возвращает следующее
s-выражение, введенное с клавиатуры. Функция print зависит от одного аргумента,
оценивает его и выводит результат в стандартный поток вывода. При этом нам
понадобится также функция terpri, не зависящая от аргументов и выводящая в стандартный
поток символ новой строки newline. По завершении вызова функция terpri
возвращает значение nil. Цикл read-eval-print реализуется как вложенное s-выражение.
(print (eval (read)))
При этом сначала оценивается s-выражение самого глубокого уровня вложенности
(read). Возвращаемое этой функцией значение (следующее введенное пользователем
s-выражение) передается функции eval для оценки, результат которой в свою очередь
передается функции print и выводится на экран. В завершение цикла выводится
приглашение, а с помощью функции terpri после отображения результатов выводится
символ newline, и цикл рекурсивно повторяется. Таким образом, окончательно
определение цикла read-eval-print имеет вид.
(defun my-read-eval-print ( ) ;не зависит от аргументов
(print':) /вывод приглашения :
(print (eval (read))) /цикл read-eval-print
(terpri) /вывод символа newline
(my-read-eval-print)) /повтор цикла
Этот цикл можно использовать "поверх" встроенного интерпретатора.
> (my-read-eval-print)
: ( + 1 2) /новое приглашение
3
: ; и т . д .
Из этого примера видно, что функции, подобные quote и eval, обеспечивают
программисту на LISP широкие возможности управления обработкой функций. Поскольку
программы и данные LISP представляются в виде s-выражсний, можно написать
программу, выполняющую любые действия над выражениями LISP до их оценки. В этом состоит
преимущество LISP как процедурного языка представления: произвольный код LISP
можно хранить, модифицировать и оценивать при необходимости. Это свойство также
упрощает написание специализированных интерпретаторов, расширяющих или модифицирующих
поведение встроенного интерпретатора LISP. Эта возможность положена в основу многих
экспертных систем, написанных на языке LISP, считывающих запросы пользователя и
отвечающих на них в соответствии с результатами анализа базы знаний.
Примером реализации подобного специализированного интерпретатора на LISP
может служить модификация цикла my-read-eval-print, позволяющая оценивать
арифметические выражения в инфиксной, а не префиксной системе обозначений. Работа
такого интерпретатора показана на следующем примере (обратите внимание на
модифицированное приглашение infix->).
Глава 15. Введение в LISP
725
infix-> A+2)
3
infix-> G-2)
5
infix-> (E+2) * C-1)) ;цикл должен допускать вложенные выражения
14
В целях простоты инфиксный интерпретатор обрабатывает только арифметические
выражения. Можно его дополнительно упростить, ограничив его возможности обработкой
бинарных операций и требованием заключения выражений в скобки. Это позволяет избежать
необходимости применения более сложных технологий грамматического разбора и не требует
учета приоритета операций. При этом интерпретатор допускает вложенные выражения
произвольной глубины и выполняет обработку бинарных арифметических операций.
Модифицируем разработанный ранее цикл read-eval-print, добавив функцию,
переводящую инфиксные выражения в префиксную форму перед их передачей функции
eval. Первая попытка определения этой функции может иметь такой вид.
(defun simple-in-to-pre (exp)
(list (nth 1 exp) /средний элемент (символ операции)
;становится первым
(nth 0 ехр) /первый операнд
(nth 2 ехр) /второй операнд
Функцию simple-in-to-pre удобно применять для преобразования простых
выражений. Однако с ее помощью не удастся корректно обработать вложенные выражения,
в которых операнды сами являются инфиксными выражениями. Для решения этой
проблемы операнды необходимо транслировать в префиксную форму. Рекурсия завершается
проверкой типа аргумента: если он представляет собой число, то оно возвращается
неизменным. Полная версия транслятора из инфиксной в префиксную форму имеет вид.
(defun in-to-pre (exp)
(cond ((numberp exp) exp)
(t (list (nth 1 exp)
(in-to-pre (nth 0 exp))
(in-to-pre (nth 2 exp))))))
С помощью этого транслятора можно модифицировать цикл read-eval-print и
обеспечить интерпретацию инфиксных выражений. Например, так.
(defun in-eval ( )
(print 'infix->)
(print (eval (in-to-pre (read))))
(terpri)
(in-eval))
С помощью такого интерпретатора можно обрабатывать бинарные выражения в
инфиксной форме.
> (in-eval)
infix->B + 2)
4
infix->(C * 4) - 5)
7
В приведенном примере на LISP реализован новый язык — язык инфиксной
арифметики. Поскольку наряду с символьными вычислениями (списочными структурами и
726 Часть VI. Языки и технологии программирования для искусственного интеллекта
функциями их обработки) LISP поддерживает управление оценкой, то решить эту задачу
на LISP гораздо легче, чем на многих других языках. Этот пример иллюстрирует важную
методологию программирования задач искусственного интеллекта, получившую
название металингвистической абстракции (meta-linguistic abstraction). При решении задач
искусственного интеллекта зачастую встречаются ситуации, когда не вполне понятна
сама задача, или требуемая для ее решения программа слишком сложна. В рамках подхода
металингвистической абстракции базовый язык программирования (в данном случае
LISP) применяется для реализации специализированного высокоуровневого языка,
который может быть более эффективным для решения конкретного класса задач. Термин
металингвистическая абстракция означает использование базового языка для
реализации другого языка программирования, а не решения самой задачи. Как показано в
разделе 14.6, PROLOG тоже позволяет программисту создавать интерпретаторы метауровня.
Преимущества метаинтерпретаторов с точки зрения поддержки программирования задач
из сложных предметных областей обсуждались также во введении к части VI.
15.8. Логическое программирование на языке LISP
В качестве примера металингвистической абстракции разработаем на LISP
интерпретатор для задач логического программирования, используя для этого алгоритм
унификации из раздела 15.6. Подобно логическим программам на языке PROLOG логические
программы в данном случае тоже состоят из баз данных фактов и правил из области
исчисления предикатов. Интерпретатор обрабатывает запросы (или цели) за счет их
унификации с элементами логической базы данных. Если цель унифицируется с одним
простым фактом, процесс завершается успешно. Решением в этом случае является
множество связанных переменных, сгенерированное в процессе проверки соответствия. Если
цель соответствует голове правила, интерпретатор рекурсивно пытается соответствовать
предпосылке правила, используя при этом метод поиска в глубину и связанные
переменные, сгенерированные в процессе проверки. В случае успеха интерпретатор выводит
исходную цель, в которой переменные заменены соответствующими значениями.
Для простоты этот интерпретатор поддерживает конъюнктивные цели и импликации,
операторы or и not в нем не определены, как не определены и арифметические
операции, операторы ввода-вывода и другие встроенные в PROLOG предикаты. Мы не
пытаемся реализовать полную версию PROLOG и отследить все особенности поиска.
Отсутствие оператора отсечения не позволяет корректно обрабатывать рекурсивные
предикаты. Тем не менее предлагаемая оболочка иллюстрирует основные функции языков
логического программирования. Читатель может добавить к интерпретатору
перечисленные свойства в качестве интересного упражнения.
15.8.1. Простой язык логического программирования
Предлагаемый интерпретатор для задач логического программирования
поддерживает хорновские выражения — подмножество выражений, применяемых в полном
исчислении предикатов. Корректно определенные формулы состоят из термов,
конъюнктивных выражений и правил, написанных в стиле LISP. Составной терм — это список,
первым элементом которого является имя предиката, а остальные элементы соответствуют
аргументам. В качестве аргумента могут выступать константы, переменные или другие
Глава 15. Введение в LISP
727
составные термы. Как и при описании функции unify, переменные будем представлять
списками из двух элементов. Первым элементом является слово var, а вторым — имя
переменной. Рассмотрим несколько примеров термов.
(likes bill music)
(on block (var x))
(friend bill (father robert))
Конъюнктивное выражение — это список, первым элементом которого является
слово and, а последующими — простые термы или конъюнктивные выражения.
(and (smaller david sarah) (smaller peter david))
(and (likes (var x) (var y)) (likes (var z) (var y)))
(and (hand-empty) (and (on block-1 block-2) (on block-2 table)))
Импликация выражается в синтаксически ясной форме, что упрощает се запись и
распознавание.
(rule if <предпосылка> then <заключение>)
Здесь <предпосылка> — это либо простое, либо конъюнктивное предложение,
а <заключе}ше> — всегда простое предложение. Приведем несколько примеров правил.
(rule if (and (likes (var x) (var z))
(likes (var y) (var z)))
then (friend (var x) (var y)))
(rule if (and (size (var x) small)
(color (var x) red)
(smell (var x) fragrant))
then (kind (var x) rose))
Логическая база данных — это список фактов и правил, связанных с глобальной
переменной ^assertions*. Приведем пример базы данных об отношениях симпатии, основанный
на вызове функции setq (можно было бы воспользоваться и функцией def var).
(setq ^assertions*
'((likes george beer)
(likes george kate)
(likes george kids)
(likes bill kids)
(likes bill music)
(likes bill pizza)
(likes bill wine)
(rule
if (and (likes (var x) (var z))
(likes (var y) (var z)))
then (friend (var x) (var y)))))
На верхнем уровне интерпретатора используется функция logic-shell, которая
считывает целевые выражения и пытается удовлетворить их на основе логической базы
данных, связанной с переменной * assert ions*. При работе с приведенной выше
базой данных функция logic-shell должна демонстрировать следующее поведение
(символом ; отмечены комментарии).
>(logic-shell) ;вывод приглашения ?
?(likes bill (var x)) /успешно выполненные запросы выводятся
;с подстановками
728 Часть VI. Языки и технологии программирования для искусственного интеллекта
(likes bill kids)
(likes bill music)
(likes bill pizza)
(likes bill wine)
?(likes george kate)
(likes george kate)
?(likes george taxes)
?(friend bill george)
(friend bill george)
?(friend bill roy)
?(friend bill (var x
(friend bill
(friend
(friend
(friend
(friend
?quit
bye
bill
bill
bill
bill
george)
bill)
bill)
bill)
bill)
;если запрос не выполнен,
;возвращается
ничего не
;из (and(likes bill kids)(likes george kids)
;roy не существует в базе знаний, запрос
;не выполнен
;из (and(likes bill kids)(likes george kids)
;из (and(likes bill kids)(likes bill kids))
;из (and(likes bill music)(likes bill music)
;из (and(likes bill pizza)(likes bill pizza)
;из (and(likes bill wine)(likes bill wine))
Прежде чем переходить к обсуждению реализации интерпретатора для решения задач
логического программирования, рассмотрим тип данных потока stream.
15.8.2. Потоки и их обработка
Как видно из предыдущего примера, даже небольшая база данных требует сложной
обработки. Необходимо не только определять выполнение или невыполнение целевого
выражения, но и находить в базе данных подстановки, обеспечивающие истинность
целевого выражения.
Одному целевому выражению могут соответствовать различные факты, а значит,
и разные множества подстановок. При использовании конъюнкции целей необходимо
удовлетворить всем конъюнктам, а также обеспечить согласованность связанных
переменных. Аналогично при обработке правил необходимо, чтобы подстановки,
сформированные в процессе проверки соответствия заключения правила целевому выражению,
были внесены в левую часть правила. Необходимость управления различными
множествами подстановок — основной источник сложности интерпретатора. Эту проблему
помогают решить потоки. Они позволяют сконцентрировать внимание на изменении
последовательности подстановок-кандидатов в рамках ограничений, определяемых
логической базой данных.
Поток (stream) — это последовательность объектов данных. Наиболее типичным
примером обработки потоков является обычная интерактивная программа. Поступающие
с клавиатуры данные рассматриваются как бесконечная последовательность символов,
а программа считывает и обрабатывает текущий символ из потока ввода. Обработка
потоков — это обобщение этой идеи: потоки не обязательно создаются пользователями. Их
могут генерировать и модифицировать функции. Генератор (generator) — это функция,
создающая непрерывный поток объектов данных. Функция отображения (map function)
выполняет некоторое преобразование над каждым элементом потока. Фильтр (filter)
исключает некоторые элементы из потока по условиям, заданным некоторым предикатом.
Глава 15. Введение в LISP
729
Решения, возвращаемые механизмом вывода, можно представить в виде потока
различных подстановок переменных, при которых целевое утверждение следует из базы
знаний. Ограничения, определяемые базой знаний, используются для модификации и
фильтрации потока подстановок-кандидатов и получения результата. Рассмотрим,
например, конъюнктивное целевое утверждение.
(and (likes bill (var z))
(likes george (var z)))
Воспользуемся логической базой данных из предыдущего раздела. С точки зрения
потоков каждый конъюнкт в этом выражении можно рассматривать как фильтр для
потока множеств подстановок. Каждое множество подстановок переменных в потоке
применяется к этому конъюнкту, а результат сверяется с базой знаний.
При отсутствии соответствия множество подстановок исключается
из потока. Если же соответствие найдено, создаются новые
множества подстановок за счет добавления новых связанных переменных
к исходному множеству.
На рис. 15.4 показана обработка потока подстановок с
помощью этого конъюнктивного целевого выражения. Сначала поток
подстановок-кандидатов содержит только пустое множество
подстановок. Он расширяется после появления первого соответствия
предложения множеству элементов базы данных. После
исключения подстановок, не удовлетворяющих второму конъюнкту
(likes george (var z) ), в потоке остается одно множество
подстановок. Результирующий поток ( ( ( (var z) . kids) ) )
содержит единственную подстановку переменной, обеспечивающую
соответствие обеих подцелей базе знаний.
Как видно из этого примера, одна цель и единственное
множество подстановок позволяют сгенерировать несколько новых
множеств подстановок, по одному для каждого соответствия
базе знаний. Кроме того, с помощью целевого утверждения
можно исключить множество подстановок из потока, если
соответствие не найдено. Поток множеств подстановок может
расширяться и сужаться в процессе обработки
последовательности конъюнктов.
В основе обработки потоков лежат функции создания,
расширения и доступа к элементам потока. Простой набор функций
обработки потоков можно определить на основе списков и
стандартных операций над ними.
; добавляет в поток новый первый элемент
(defun cons-stream (element stream) (cons element stream))
; возвращает первый элемент потока
(defun head-st ream (stream) (car stream))
; возвращает поток, из которого удален первый элемент
(defun tail-stream (stream) (cdr stream))
; возвращает значение "истина", если поток пуст
(defun empty-stream-p (stream) (null stream))
; создает пустой поток
( 3(defun make-empty-stream ( ) nil)
; объединяет два потока
@)
(likes bill (var z))
(((varz) kids)
((varz). music)
((varz). pizza)
((varz) wine))
(likes george (varz))
((((varz). kids)))
Рис. 15.4. Фильтрация
потока подстановок
переменных в
соответствии с
конъюнкцией целей
730 Часть VI. Языки и технологии программирования для искусственного интеллекта
(defun combine-streams (streaml stream2)
(cond ((empty-stream-p streaml) stream2)
(t (cons-stream (head-stream streaml)
(combine-streams
(tail-stream stream 1)
stream2)))))
Хотя реализация потоков в виде списков не обеспечивает всех возможностей
потоковых типов данных, такое определение позволяет посмотреть на программу с точки
зрения обработки потоков. Во многих задачах, в частности, при создании интерпретатора
для задач логического программирования из раздела 15.8.3 это дает программисту
мощное средство организации и упрощения кода. В разделе 15.9 обсуждаются некоторые
ограничения списочной реализации потоков, а также предлагается альтернативный подход
к использованию потоков при оценивании с задержкой.
15.8.3. Интерпретатор для задач логического программирования
на основе потоков
Реализуем интерпретатор с помощью функции logic-shell, которая является
упрощенным вариантом цикла read-eval-print, описанного в разделе 15.7. После
вывода приглашения ? эта функция считывает следующее введенное пользователем
s-выражение и связывает его с символом goal. Если целевое утверждение goal
соответствует значению quit, функция завершает работу. В противном случае она вызывает
функцию solve для генерации потока множеств подстановок, удовлетворяющих
данному целевому утверждению. Этот поток передается в функцию print-solutions, которая
выводит целевое утверждение с каждой из найденных подстановок. Затем функция
рекурсивно вызывает сама себя. Вот определение функции logic-shell.
(defun logic-shell ( )
(print '? )
(let ((goal (read)))
(cond ((equal goal 'quit) 'bye)
(t (print-solutions goal (solve goal nil))
(terpri)
(logic-shell)))))
Основой интерпретатора является функция solve. Она получает целевое
утверждение и набор подстановок и находит все решения, согласованные с содержимым базы
знаний. Эти решения возвращаются как поток множеств подстановок. Если соответствия
не найдены, функция solve возвращает пустой поток. С точки зрения обработки
потоков функция solve является источником (source), или генератором (generator), потока
решений. Вот ее определение.
(defun solve (goal substitutions)
(declare (special ^assertions*))
(if (conjunctive-goal-p goal)
(filter-through-conj-goals (body goal)
(cons-stream substitutions (make-empty-stream)))
(infer goal substitutions ^assertions*)))
Ключевое слово special означает, что переменная * assert ions* является
специальной (special), или глобальной (global), и будет динамически связываться со средой,
Глава 15. Введение в LISP
731
в которой вызывается функция solve. (Во многих современных версиях LISP
объявления special не требуется.)
Функция solve сначала проверяет, является ли цель конъюнктивной. Если да, то
вызывается функция filter-through-conj -goals, выполняющая описанную в
подразделе 15.8.2 фильтрацию. Если целевое утверждение goal не конъюнктивно, вызывается
функция, определенная ниже infer, выполняющая разрешение цели с помощью базы знаний.
Функция f ilter-through-conj -goals вызывается для тела конъюнкции
(т.е. последовательности конъюнктов, из которой удален оператор and) и потока,
содержащего только исходное множество подстановок. Результатом ее работы является
поток подстановок, представляющий все решения для данного целевого утверждения.
Приведем определение функции f ilter-through-conj -goals.
(defun filter-through-conj-goals (goals substitution-stream)
(if (null goals)
substitution-stream
(filter-through-conj-goals (cdr goals)
(filter-through-goal (car goals) substitution-stream))))
Если список целей пуст, функция завершает работу и возвращает поток
substitution-stream без изменений. В противном случае вызывается функция filter-
through-goal для фильтрации потока подстановок на основе первого целевого
выражения в списке. Результат ее работы передается вызываемой рекурсивно функции f
ilter-through-conj -goals для обработки оставшейся части списка целей. Таким
образом поток передается по списку целей слева направо, расширяясь и сужаясь при
обработке каждого целевого утверждения.
Функция filter-through-goal зависит от одного параметра (целевого
утверждения), который используется в качестве фильтра для потока подстановок. Такая
фильтрация выполняется с помощью вызова функции solve, параметрами которой
являются целевое утверждение и первое множество подстановок в потоке. Результатом
вызова этой функции является поток подстановок, полученный в результате проверки
соответствия целевого утверждения базе знаний. Этот поток может быть пустым, если
целевому утверждению не удовлетворяет ни одна из подстановок в потоке, либо содержать
несколько наборов подстановок, представляющих альтернативные значения переменных.
Полученный поток объединяется с результатом фильтрации хвоста входного потока.
(defun filter-through-goal (goal substitution-stream)
(if (empty-stream-p substitution-stream)
(make-empty-stream)
(combine-streams
(solve goal (head-stream substitution-stream))
(filter-through-goal goal (tail-stream
substitution-stream)))))
Таким образом в функции f ilter-through-conj-goals поток множеств
подстановок передается последовательности целевых утверждений, а функция filter-
through-goal обрабатывает этот поток для каждой конкретной цели. Рекурсивный
вызов функции solve обеспечивает разрешение цели для каждого набора подстановок.
Если конъюнктивные цели обрабатываются в функции solve с помощью вызова
f ilter-through-conj -goals, то отдельные цели разрешаются с помощью
определенной ниже функции infer, которая получает целевое утверждение и набор подстано-
732 Часть VI. Языки и технологии программирования для искусственного интеллекта
вок, а возвращает все решения, найденные в базе знаний. Третий параметр kb функции
infer — это база знаний логических выражений. При первом вызове infer из
функции solve ей передается база знаний, связанная с глобальной переменной
^assertions*. Функция infer последовательно выполняет поиск в базе знаний kb,
сверяя соответствие целевого утверждения каждому факту или заключению правила.
Такая рекурсивная реализация функции infer обеспечивает обратный вывод,
свойственный интерпретатору PROLOG и многим оболочкам экспертных систем. Сначала
проверяется, не пуста ли база знаний kb, и, если да, возвращается пустой поток. В
противном случае первый элемент базы знаний kb связывается с символом assertion
с помощью блока let*. Этот блок аналогичен блоку let, но при этом гарантированно
оценивает исходные значения локальных переменных в последовательно вложенных
контекстах, т.е. обеспечивает порядок связывания и видимость предыдущих переменных.
В нем также определяется переменная match. Если assertion— это правило,
переменная match инициализируется подстановкой, требуемой для унификации цели с
заключением этого правила. Если же assertion — это факт, переменная match
инициализируется подстановкой, требуемой для унификации assertion с целевым
утверждением. После унификации цели с первым элементом базы знаний функция infer
проверяет, удалась ли она. Если соответствие не найдено, она рекурсивно вызывает сама
себя, пытаясь разрешить целевое утверждение с помощью оставшейся части базы
знаний. Если же унификация завершилась успешно, a assertion — это правило, функция
infer вызывает функцию solve для предпосылки этого правила, причем множество
подстановок связывается с переменной match. Функция combine-stream объединяет
полученный поток решений с потоком, построенным функцией infer при обработке
оставшейся части базы знаний. Если assertion — не правило, значит, это факт. Тогда
функция infer добавляет решение, связанное с переменной match, к решению,
полученному при обработке оставшейся части базы знаний. На этом поиск прекращается.
Приведем определение функции infer.
(defun infer (goal substitutions kb)
(if (null kb)
(make-empty-stream)
(let* ((assertion (rename-variables (car kb)))
(match (if (rulep assertion)
(unify goal (conclusion assertion) substitutions)
(unify goal assertion substitutions))))
(if (equal match 'failed)
(infer goal substitutions (cdr kb))
(if (rulep assertion)
(combine-streams
(solve (premise assertion) match)
(infer goal substitutions (cdr kb)))
(cons-stream match (infer goal substitutions
(cdr kb))))))))
Перед связыванием первого элемента базы данных kb с переменной assertion он
передается в функцию rename-variables, где каждой переменной присваивается
уникальное имя. Это позволяет предотвратить конфликт имен между переменными в
целевом утверждении и базе знаний. В частности, если в целевом утверждении встречается
фрагмент (var x), его нужно обрабатывать как переменную, отличную от (var x)
в описании правила или факта. Решить эту проблему проще всего путем переименования
Глава 15. Введение в LISP
733
всех переменных в базе знаний и присвоения им уникальных имен. Определение
функции rename-variables будет приведено в конце этого раздела.
На этом реализация ядра интерпретатора для решения задач логического
программирования завершена. Итак, solve — это высокоуровневая функция, которая генерирует поток
множеств подстановок, представляющих решения для целевого утверждения, полученные с
использованием базы знаний. Функция filter-through-conj-goals разрешает
конъюнктивные цели слева направо, при этом каждая цель выступает в качестве фильтра
для потока решений-кандидатов. Если целевое утверждение не принимает значение
"истина" с учетом базы знаний для потока множеств подстановок, функция f ilter-
through-conj -goals удаляет эти подстановки из потока. Если целевое утверждение —
это простой литерал, функция solve вызывает функцию infer для генерации потока
всех подстановок, удовлетворяющих целевому утверждению с учетом базы знаний.
Подобно PROLOG, полученный интерпретатор для заданного целевого утверждения находит все
удовлетворяющие ему связанные переменные из имеющейся базы знаний.
Осталось определить функции доступа к элементам базы знаний, управления
подстановками и вывода решения. Параметрами функции print-solutions являются
целевое утверждение и поток подстановок. Для каждого множества подстановок в потоке эта
функция выводит целевое утверждение, в котором переменные заменены их значениями
из этого множества.
(defun print-solutions (goal substitution-stream)
(cond ((empty-stream-p substitution-stream) nil)
(t (print (apply-substitutions goal (head-stream
substitution-stream)))
(terpri)
(print-solutions goal (tail-stream
substitution-stream)))))
Замена переменных значениями из множеств подстановок осуществляется с
помощью функции apply-substitutions, выполняющей рекурсивный проход по дереву
шаблона. Если шаблон является константой, он возвращается без изменений. Если же это
переменная, функция apply-substitutions рекурсивно вызывает сама себя для
данного значения. Заметим, что связанное значение может быть либо константой, либо
переменной, либо шаблоном любой сложности.
(defun apply-substitutions (pattern substitution-list)
(cond ((is-constant-p pattern) pattern)
((varp pattern)
(let ((binding (get-binding pattern substitution-list)))
(cond (binding (apply-substitutions (get-binding-value
binding)
substitution-list))
(t pattern))))
(t (cons (apply-substitutions (car pattern) substitution-list)
(apply-substitutions (cdr pattern) substitution-list))) ) )
Функция infer переименовывает переменные в базе знаний до проверки их соответствия
целевому утверждению. Это необходимо для предотвращения нежелательных конфликтов
имен. Например, целевое утверждение (р a (var x) ) должно соответствовать элементу
базы знаний (р (var x) b), поскольку область видимости каждой переменной (var x)
ограничена одним выражением. Однако при унификации это соответствие не требуется. Кон-
734 Часть VI. Языки и технологии программирования для искусственного интеллекта
фликт имен можно предотвратить за счет присвоения каждой переменной уникального
имени. В основу схемы переименования можно положить встроенную функцию Common LISP
gensym, не зависящую от аргументов. При каждом вызове она возвращает уникальный
символ, состоящий из числа с префиксом # : G. Например,
> (gensym)
#:G4
> (gensym)
#:G5
> (gensym)
#:G6
>
В процессе переименования имя каждой переменной в выражении заменяется результатом
вызова функции gensym. Функция rename-variables выполняет необходимую
инициализацию (описанную ниже) и вызывает функцию rename-гее для рекурсивного
выполнения подстановок в шаблоне. Когда встречается переменная, вызывается функция rename,
возвращающая ее новое имя. Чтобы при нескольких вхождениях в шаблон одной и той же
переменной ей было присвоено одно имя, при каждом переименовании переменной ее имя
помещается в ассоциативный список, связанный со специальной переменной * name-list*.
Благодаря объявлению этой переменной как специальной все ссылки на нее являются
динамическими, и их можно использовать в различных функциях. Так, при каждом обращении к
переменной * name-list* в функции rename мы получаем доступ к экземпляру этой
переменной, объявленному в функции rename-variables. При первом вызове для данного
выражения функция rename-variables инициализирует переменную *name-list*
значением nil. Приведем определения этих функций.
(defun rename-variables (assertion)
(declare (special *name-list*))
(setq *name-list* nil)
(rename-rec assertion))
(defun rename-rec (exp)
(declare (special *name-list*))
(cond ((is-constant-p exp) exp)
((varp exp) (rename exp))
(t (cons (rename-rec (car exp))(rename-rec (cdr exp))))))
(defun rename (var)
(declare (special *name-list*))
(list 'var (or (cdr (assoc var *name-list* :test#'equal))
(let ((name (gensym)))
(setq *name-list* (aeons var name *name-list*))name))))
Функции доступа к компонентам правил и целевых утверждений не требуют
дополнительных пояснений.
(defun premise (rule) (nth 2 rule))
(defun conclusion (rule) (nth 4 rule))
(defun rulep (pattern)
(and (listp pattern)
(equal (nth 0 pattern)'rule)))
(defun conjunctive-goal-p (goal)
(and (listp goal)
(equal (car goal)'and)))
(defun body (goal) (cdr goal))
Глава 15. Введение в LISP
735
15.9. Потоки и оценивание с задержкой
При описании реализации оболочки logic-shell было показано, что использование
потоков облегчает написание сложных программ. Однако реализация потоков в виде списков
не обеспечивает всех возможностей работы с потоками. В частности, такая реализация не
достаточно эффективна и не позволяет обрабатывать потоки данных большой длины.
При списочной реализации потоков все элементы необходимо обрабатывать до
передачи этого потока (списка) в следующую функцию. В оболочке logic-shell это
приводит к полному перебору базы знаний для каждого промежуточного целевого
утверждения. Чтобы сформировать первое решение для цели высокого уровня, программа
должна получить список всех решений. Даже если нам требуется лишь первое решение
из этого списка, программа должна выполнить поиск во всем пространстве решений.
Гораздо предпочтительнее реализовать эту функцию таким образом, чтобы поиск первого
решения осуществлялся только в определенной части пространства, а нахождение
остальных решений было отложено до нужного момента.
Вторая проблема — невозможность обработки потоков сколь угодно большой длины.
Хотя эта проблема в программе logic-shell не возникает, с ней приходится
сталкиваться при решении многих важных задач. Предположим, что нужно написать функцию,
возвращающую поток из первых п нечетных чисел Фибоначчи. Для этого можно
использовать генератор потока чисел Фибоначчи, фильтр для удаления из него четных чисел и
функцию для накопления полученных решений в списке из п элементов (рис. 15.5).
К сожалению, длина потока чисел Фибоначчи неизвестна, поскольку неясно, сколько
чисел потребуется для получения первых п нечетных чисел.
Поэтому лучше создать генератор, выдающий числа Фибоначчи по одному и
пропускающий их через фильтр до тех пор, пока не будут получены первые п нечетных чисел. Такой
подход более близок интуитивному представлению об оценке потоков, чем используемый при
их списочной реализации. Будем называть его оцениванием с задержкой (delayed evaluation).
Вместо того, чтобы генерировать весь поток решений, функция-генератор должна
находить первый элемент потока и приостанавливать свое выполнение до тех пор, пока не
потребуется следующий элемент. Когда программе требуется следующий элемент,
работа генератора продолжается. Он находит очередной элемент и снова приостанавливает
оценивание оставшейся части потока. Тогда поток будет состоять не из всего списка
чисел, а лишь из двух компонентов — первого элемента и элемента, на котором процесс
генерации был приостановлен (рис. 15.6).
Для оценивания с задержкой воспользуемся замыканием функции (function closure).
Замыкание включает функцию и все ее связанные переменные в текущей среде. Такое
замыкание можно связать с переменной или передать его в качестве параметра и
обрабатывать с помощью функции funcall. По существу, замыкание "замораживает"
выполнение функции до нужного момента. Замыкание можно создать с помощью формы LISP
function. Например, рассмотрим следующую запись на LISP.
> (setq v 10)
10
> (let ((v 20)) (setq f_closure (function (lambda ( ) v))))
#<COMPILED-LEXICAL-CLOSURE #x28641E>
> (funcall f_closure)
20
>v
10
736 Часть VI. Языки и технологии программирования для искусственного интеллекта
Генератор
Порождает поток
чисел Фибоначчи
у
Фильтр
Удаляет из потока
четные числа
У
Накопитель
Накапливает первые л
чисел из потока
Рис. 15.5. Потоковая
реализация программы поиска первых
п нечетных чисел Фибоначчи
Поток на основе списка, содержащий неопределенное число элементов
<е1 e2e3V-->
Поток с отложенным оцениванием хвостовой части содержит только два элемента,
но может включать любое число элементов
(е1 . <отложенное оценивание хвостовой части потока>)
Рис. 15.6. Реализация потоков на основе списков и оценивания с задержкой
Изначально функция setq связывает переменную v со значением 10 в глобальной
среде. В блоке let переменная v локально связывается со значением 20 и создается
замыкание функции, возвращающей это значение переменной v. Интересно отметить, что
при выходе из блока let это связанное значение переменной v не исчезает, поскольку
оно сохраняется в замыкании функции, связанном с переменной f_closure. Однако
это лексическое связывание не имеет отношения к глобальному связыванию переменной
v. Следовательно, если оценить это замыкание, будет возвращено значение 2 0
локальной переменной v, хотя глобальная переменная v по прежнему принимает значение 10.
Эта реализация потоков основана на паре функций delay и force. Первая из них
получает в качестве параметра выражение и не оценивает его, а возвращает замыкание.
Функция force получает замыкание в качестве аргумента и запускает его с помощью
функции f uncall. Приведем определения этих функций.
(defmacro delay (exp) '(function (lambda (), exp)))
(defun force (function-closure)
(funcall function-closure)
Глава 15. Введение в LISP
737
Функция delay— это пример формы LISP, получившей название макроса (macro).
Эту функцию нельзя определить с помощью функции def un, поскольку определенные
таким образом формы оценивают свои аргументы до выполнения тела. Макросы
обеспечивают программистам полный контроль над оцениванием параметров. Макрос
определяется с помощью формы def macro. При его выполнении аргументы не оцениваются,
а исходные s-выражения при вызове связываются с формальными параметрами, и тело
макроса оценивается дважды. Первый этап оценивания называется макрорасширением
(macro-expansion), а второй состоит в оценке полученной формы.
Чтобы определить макрос delay, мы ввели еще одну форму LISP— обратную
кавычку х. Эта форма, подобно функции quote, предотвращает анализ параметров, но
допускает оценивание выбранных элементов выражений. Любой элемент s-выражения,
следующий за обратной кавычкой и расположенный после запятой, оценивается, и его
значение вставляется в результирующее выражение.
Например, рассмотрим вызов (delay ( + 2 3)). Выражение (+2 3) не
оценивается, а связывается с формальным параметром ехр. При первом оценивании макроса
возвращается выражение, следующее за обратной кавычкой, в котором формальный
параметр ехр заменен его значением — неоцененным s-выражением (+ 2 3 ). Получится
выражение (function (lambda () (+2 3 ))). Оно снова оценивается, и
возвращается замыкание функции.
Если позднее передать это замыкание в функцию force, то будет оцениваться выражение
(lambda () (+23)). Это функция, не зависящая от аргументов, тело которой
соответствует значению 5. С помощью функций force и delay можно реализовать потоки на
основе оценки с задержкой. Перепишем функцию cons-stream в виде макроса, зависящего
от двух аргументов. Этот макрос должен присоединять значение первого к оценке второго.
При этом второй аргумент оценивается с задержкой и может возвращать поток любой длины.
Определим функцию tail-stream, оценивающую хвост потока.
(defmacro cons-stream (ехр stream) x(cons, ехр (delay, stream)))
(defun tail-stream (stream) (force (cdr stream)))
Переопределим также в виде макроса функцию combine-streams. Она должна
получать два аргумента, но не оценивать их. В этом макросе для создания замыкания
второго потока используется функция delay. Полученный результат вместе с первым
потоком передается в функцию comb-f, аналогичную определенной ранее функции
combine-streams. Однако, если первый поток оказывается пустым, то новая функция
оценивает второй поток. Если первый поток не пуст, выполняется рекурсивный вызов
функции comb-f с помощью обновленной версии cons-stream. При этом
рекурсивный вызов в замыкании "замораживается" для дальнейшей оценки.
(defmacro combine-streams (streaml stream2)
4(comb-f ,streaml (delay ,stream2)))
(defun comb-f (streaml stream2)
(if (empty-stream-p streaml)
(force stream2)
(cons-stream (head-stream streaml)
(comb-f (tail-stream streaml) stream2))))
Если эти определения добавить к версиям функций head-stream, make-empty-
stream и empty-stream-p из подраздела 15.8.2, получим полную реализацию
потоков на основе оценивания с задержкой.
738 Часть VI. Языки и технологии программирования для искусственного интеллекта
Эти функции можно использовать для решения задачи получения первых п нечетных
чисел Фибоначчи. Функция f ibonacci-stream возвращает поток всех чисел
Фибоначчи. Заметим, что это бесконечная рекурсивная функция. Бесконечный цикл
предотвращается за счет оценивания с задержкой, поскольку следующий элемент вычисляется
только в случае необходимости. Функция filter-odds получает поток целых чисел и
исключает из него четные элементы. Функция accumulate получает поток и число п
и возвращает список, состоящий из первых п элементов потока.
(defun fibonacci-stream (fibonacci-1 fibonacci-2)
(cons-stream (+ fibonacci-1 fibonacci-2)
(fibonacci-stream fibonacci-2 (+ fibonacci-1 fibonacci-2))))
(defun filter-odds (stream)
(cond ((evenp (head-stream stream)) (filter-odds (tail-stream
stream)))
(t (cons-stream (head-stream stream) (filter-odds
(tail-stream stream))))))
((defun accumulate-into-list (n stream)
(cond ((zerop n) nil)
(t (cons (head-stream stream) (accumulate-into-list
(- n 1)(tail-stream stream))))))
Для получения списка первых 25 нечетных чисел Фибоначчи можно воспользоваться
следующим вызовом.
(accumulate-into-list 25 (filter-odds (fibonacci-stream 0 1)))
Эти функции работы с потоками можно использовать в определении интерпретатора для
решения задач логического программирования из раздела 15.8. Это позволит в некоторых
случаях повысить его эффективность. Предположим, необходимо модифицировать функцию
print-solutions, чтобы она выводила не все решения, а лишь первое из них, и ожидала
дополнительного запроса пользователя. Если потоки реализованы в виде списков, то перед
выводом первого решения необходимо найти их все. При оценивании с задержкой первое
решение можно найти отдельно, а затем при желании вычислять остальные решения.
В следующем разделе интерпретатор для решения задач логического
программирования будет модифицирован в оболочку экспертной системы. Однако сначала будут
введены две дополнительные функции работы с потоками, используемые впоследствии в
реализации оболочки. В разделе 15.3 были представлены обобщенные функции
отображения и фильтрации списков. Эти функции map-simple и filter можно
модифицировать для работы с потоками. В следующем разделе будут использоваться функции
filter-stream и map-stream. Их реализацию предлагается разработать читателю
в качестве упражнения.
15.10. Оболочка экспертной системы на LISP
Оболочка экспертной системы, разрабатываемая в этом разделе, является
обобщением механизма обратного вывода, описанного в разделе 15.8. Основные модификации
сводятся к использованию факторов достоверности для управления неопределенными
рассуждениями, возможности обращения к пользователю для получения неизвестных
фактов и использованию рабочей памяти для хранения ответов пользователя. Эта
оболочка экспертной системы называется lisp-shell.
Глава 15. Введение в LISP
739
15.10.1. Реализация факторов достоверности
Разработанный выше интерпретатор для решения задач логического
программирования возвращал множества подстановок, при которых целевое утверждение логически
следует из базы знаний. Связанные переменные, не обеспечивающие согласованность
целевого утверждения с базой знаний, либо удалялись из потока, либо вообще не
генерировались. Однако при реализации рассуждений с факторами достоверности простые
истинные значения заменяются числовыми значениями из диапазона от -1 до +1.
Поэтому поток решений должен содержать не только связанные переменные,
обеспечивающие реализацию цели, но и включать степень доверия, с которой каждое решение следует
из базы знаний. Следовательно, оболочка lisp-she 11 должна обрабатывать не потоки
множеств подстановок, а потоки пар, состоящих из множества подстановки и числа,
представляющего степень истинности целевого утверждения при данной подстановке.
Элементы потока реализуем как абстрактный тип данных. Для управления подстановками
и факторами достоверности используем функции subst-record, subst-list и subst-
cf. Первая из них строит пару, состоящую из множества подстановок и фактора
достоверности, вторая возвращает множество связанных переменных для этой пары, а третья — фактор
достоверности. Записи будут представлены как точечные пары вида (<список
подстановки> . <фактор достоверности>). Приведем определения этих функций.
;Возвращает список связанных переменных на основе пары
;подстановка-фактор достоверности,
(defun subst-list (substitutions)
(car substitutions))
;Возвращает фактор достоверности на основе пары подстановка-фактор
;достоверности.
(defun subst-cf (substitutions)
(cdr substitutions))
;Формирует пару множество подстановки-фактор достоверности,
(defun subst-record (substitutions cf)
(cons substitutions cf))
Правила и факты в базе знаний тоже связаны с фактором достоверности. Факты
представляются точечными парами (<утверждение>. <фактор достоверности>), где
<утверждение> — это положительный литерал, а <фактор достоверности> — мера
его определенности. Правила записываются в формате (rule if <предпосылка>
then <заключение> <фактор достоверности>). Приведем пример правила из
предметной области описания цветов.
(rule
if (and (rose (var x)) (color (var x) red))
then (kind (var x) american-beauty) 1)
Определим функции для обработки правил и фактов.
;Возвращает предпосылку правила,
(defun premise (rule)
(nth 2 rule))
; Возвращает заключение правила,
(defun conclusion (rule)
(nth 4 rule))
; Возвращает фактор достоверности правила,
(defun rule-cf (rule)
740 Часть VI. Языки и технологии программирования для искусственного интеллекта
(nth 5 rule))
/Проверяет, является ли данный шаблон правилом,
(defun rulep (pattern)
(and (listp pattern)
(equal (nth 0 pattern) 'rule)))
/Возвращает часть факта, являющуюся шаблоном,
(defun fact-pattern (fact)
(car fact))
/Возвращает фактор достоверности факта,
(defun fact-cf (fact)
(cdr fact))
С помощью этих функций можно реализовать интерпретатор правил путем модификации
интерпретатора для решения задач логического программирования из раздела 15.8.
15.10.2. Архитектура оболочки lisp-shell
Основу оболочки lisp-she 11 составляет функция solve. Она не возвращает
поток решения напрямую, а сначала пропускает его через фильтр, удаляющий любые
подстановки, фактор достоверности которых ниже, чем 0,2. Таким образом удаляются
результаты с невысокой степенью доверия.
(defun solve (goal substitutions)
(filter-stream
(if (conjunctive-goal-p goal)
(filter-through-conj-goals
(cdr (body goal))
(solve (car (body goal)) substitutions))
(solve-simple-goal goal substitutions))
#'(lambda (x) (< 0.2 (subst-cf x)))))
Это определение мало отличается от определения функции solve в оболочке
logic-shell. Эта функция по-прежнему содержит условный оператор, выделяющий
простые и конъюнктивные цели. Различие состоит в использовании обобщенного
фильтра filter-stream, удаляющего любые решения, фактор достоверности которых
оказывается ниже заданного значения. Эта проверка реализуется с помощью лямбда-
выражения. Второе отличие состоит в использовании функции solve-simple-goal
вместо формы infer. Обработка простых целей усложняется за счет возможности
запросов к пользователю.
(defun solve-simple-goal (goal substitutions)
(declare (special ^assertions*))
(declare (special *case-specific-data*))
(or (told goal substitutions *case-specific-data*)
(infer goal substitutions *assertions*)
(ask-for goal substitutions)))
В этой функции для поочередного использования трех различных стратегий применяется
форма or. Сначала вызывается функция told, проверяющая, было ли данное целевое
утверждение уже разрешено пользователем в ответ на предыдущий запрос. Ответы пользователя
связываются с глобальной переменной *case-specif ic-data*. Функция told
просматривает этот список в поисках соответствия целевому утверждению. Благодаря этому оболочка
lisp-she 11 не запрашивает дважды одну и ту же информацию. Если целевое утверждение
Глава 15. Введение в LISP
741
в списке ответов не найдено, функция solve-simple-goal пытается вывести это
утверждение с помощью правил из базы данных ^assertions*. И, наконец, если это не удается,
вызывается функция ask-for, отправляющая пользователю запрос на получение
информации. Эти функции определены ниже.
Цикл верхнего уровня read-solve-print изменился мало. В него лишь добавлен
оператор инициализации переменной *case-specif ic-data* значением nil перед
разрешением нового целевого утверждения. Заметим, что при первом вызове функции
solve ей передается не просто пустое множество подстановок, а пара, состоящая из
пустого множества подстановок и фактора достоверности cf, принимающего значение
0. Это число не имеет реального значения. Оно лишь включается для согласованности
синтаксиса и заменяется реальным фактором достоверности, введенным пользователем
или полученным из базы знаний.
(defun lisp-shell ()
(declare (special *case-specific-data*))
(setq *case-specific-data* ( ))
(prinl /lisp-shell> ) ;prinl не выводит новую строку
(let ((goal (read)))
(terpri)
(cond ((equal goal 'quit) 'bye)
(t (print-solutions goal (solve goal (subst-record nil 0)))
(terpri)
(lisp-shell)))))
Функция f ilter-through-conj -goals не меняется, а функция filter-
through-goal должна вычислять фактор достоверности конъюнктивного выражения
как минимум соответствующих факторов-конъюнктов. Для этого первый элемент потока
substituion-stream связывается с символом subs в блоке let. Затем вызывается
функция solve для данного целевого утверждения goal и множества подстановок.
Результат передается в обобщенную функцию отображения map-stream, которая
получает поток пар подстановок, возвращаемых функцией solve, и пересчитывает их факторы
достоверности. Приведем определения этих функций.
(defun filter-through-conj-goals (goals substitution-stream)
(if (null goals)
substitution-stream
(filter-through-conj-goals (cdr goals)
(filter-through-goal (car goals) substitution-stream))))
(defun filter-through-goal (goal substitution-stream)
(if (empty-stream-p substitution-stream)
(make-empty-stream)
(let ((subs (head-stream substitution-stream)))
(combine-streams
(map-stream (solve goal subs)
#'(lambda (x) (subst-record (subst-list x)
(min (subst-cf x)
(subst-cf subs)))))
(filter-through-goal goal (tail-stream
substitution-stream))))))
Определение функции infer изменяется с учетом факторов достоверности. Хотя
общая структура этой функции соответствует ее версии, написанной для интерпретатора
раздела 15.8, теперь в этой функции вычисляется фактор достоверности решений на ос-
742 Часть VI. Языки и технологии программирования для искусственного интеллекта
нове факторов достоверности правил и степени соответствия решений предпосылкам
правил. Функция solve-rule вызывает функцию solve для нахождения всех
решений на основе предпосылок правил и использует функцию map-stream для вычисления
результирующего фактора достоверности для заключения этого правила.
(defun infer (goal substitutions kb)
(if (null kb)
(make-empty-stream)
(let* ((assertion (rename-variables (car kb)))
(match (if (rulep assertion)
(unify goal conclusion assertion)
(subst-list substitutions))
(unify goal assertion (subst-list
substitutions)))))
(if (equal match 'failed)
(infer goal substitutions (cdr kb))
(if (rulep assertion)
(combine-streams
(solve-rule assertion (subst-record match
(subst-cf substitutions)))
(infer goal substitutions (cdr kb)))
(cons-stream (subst-record match
(fact-cf assertion))
(infer goal substitutions (cdr kb))))))))
((defun solve-rule (rule substitutions)
(map-stream (solve (premise rule) substitutions)
#'(lambda (x) (subst-record
(subst-list x)
(* (subst-cf x) (rule-cf rule))))))
И, наконец, с учетом факторов достоверности модифицируется функция print-
solutions.
(defun print-solutions (goal substitution-stream)
(cond ((empty-stream-p substitution-stream) nil)
(t (print (apply-substitutions goal (subst-list
(head-stream substitution-stream) )))
(write-string "cf = ")
(prinl (subst-cf (head-stream substitution-stream)))
(terpri)
(print-solutions goal (tail-stream
substitution-stream)))))
Остальные функции, в том числе apply-substitutions и функции доступа
к компонентам правил и целевых утверждений, остаются неизменными. Их определения
приведены в разделе 15.8.
Для реализации оболочки lisp-shell остается определить функции ask-for и
told, обрабатывающие взаимодействие с пользователем. Они определяются достаточно
просто, однако читатель должен понимать, что при их описании сделаны некоторые
упрощающие предположения. В частности, в ответ на запросы можно вводить лишь
значения у или п, соответствующие значениям фактора достоверности 1 и -1. Пользователь
не может дать недостоверный ответ на запрос. Функция ask-гее выводит запрос и
считывает ответ. Эти действия повторяются до тех пор, пока пользователь не ответит у или
п. Читатель может дополнить функцию ask-гее таким образом, чтобы принимались
Глава 15. Введение в LISP
743
любые значения из диапазона от -1 до 1. (Этот диапазон, конечно же, выбран
произвольно. В других приложениях можно выбирать другие диапазоны.)
Функция askable проверяет, можно ли задать вопрос пользователю по поводу
данного целевого утверждения. Для этого вводится глобальный список *askables*. С его
помощью архитектор экспертной системы может определить, для каких целевых
утверждений допустимы запросы к пользователю, а какие должны выводиться только из базы
знаний. Функция told выполняет поиск элементов в глобальном списке *case-
speci fie -data*, содержащем запросы, на которые пользователь уже отвечал. Ее
реализация аналогична определению функции infer с учетом того, что в списке *case-
specif ic-data* хранятся только факты. Приведем определения этих функций.
(defun ask-for (goal substitutions)
(declare (special *askables*))
(declare (special *case-specific-data*))
(if (askable goal *askables*)
(let* ((query (apply-substitutions goal (subst-list
substitutions)))
(result (ask-rec query)))
((setq *case-specific-data* (cons (subst-record query
result)
*case-specific-data*))
(cons-stream (subst-record (subst-list substitutions)
result)
(make-empty-stream)))))
(defun ask-rec (query)
(prinl query)
(write-string ">")
(let ((answer (read)))
(cond ((equal answer 'y) 1)
((equal answer 'n) - 1)
(t (print "введите у или п")
(terpri)
(ask-rec query)))))
(defun askable (goal askables)
(cond ((null askables) nil)
((not (equal (unify goal (car askables) ( )) 'failed)) t)
(t (askable goal (cdr askables)))))
(defun told (goal substitutions case-specific-data)
(cond ((null case-specific-data) (make-empty-stream))
(t (combine-streams
(use-fact goal (car case-specific-data)
substitutions)
(told goal substitutions (cdr case-specific-data))))) )
На этом реализация оболочки экспертной системы на основе LISP завершена. В
следующем разделе эта оболочка будет использована для построения простой экспертной
системы классификации.
15.10.3. Классификация с использованием оболочки lisp-shell
Рассмотрим небольшую экспертную систему для классификации деревьев и кустов.
Хотя эта система не претендует на полноту с точки зрения ботаники, она иллюстрирует
744 Часть VI. Языки и технологии программирования для искусственного интеллекта
основные свойства экспертных систем. База знаний связана с двумя глобальными
переменными: ^assertions* и *askables*. С первой из них связана база данных правил
и фактов, а со второй — список целевых утверждений, по которым можно задавать
вопросы пользователю. Используемая в этом примере база знаний строится с помощью
двух вызовов функции setq.
(setq ^assertions*'(
(rule
if (and (size (var x) tall) (woody (var x)))
then (tree (var x)) .9)
(rule
if (and (size (var x) small) (woody (var x)))
then (bush (var x)) .9)
(rule
if (and (tree (var x)) (evergreen (var x))(color (var x)
blue))
then (kind (var x) spruce) .8)
(rule
if (and (tree (var x)) (evergreen (var x))(color (var x)
green))
then (kind (var x) pine) .9)
(rule
if (and (tree (var x)) (deciduous (var x)) (bears (var x)
fruit))
then (fruit-tree (var x)) 1)
(rule
if (and (fruit-tree (var x)) (color fruit red) (taste fruit
sweet))
then (kind (var x) apple-tree) .9)
(rule
if (and (fruit-tree (var x)) (color fruit yellow) (taste
fruit sour))
then (kind (var x) lemon-tree) .8)
(rule
if (and (bush (var x)) (flowering (var x)) (thorny (var x)))
then (rose (var x)) 1)
(rule
if (and (rose (var x)) (color (var x) red))
then (kind (var x) american-beauty) 1)))
(setq *askables*'(
(size (var x) (var y))
(woody (var x))
(soft (var x))
(color (var x) (var y))
(evergreen (var x))
(thorny (var x))
(deciduous (var x))
(bears (var x) (var y))
(taste (var x) (var y))
(flowering (var x))))
Приведем пример работы системы с этой базой знаний. Читателю предлагается
проследить порядок обработки правил, изменения факторов достоверности, а также
возможность удаления подстановок, не обеспечивающих истинность целевого утверждения.
Глава 15. Введение в LISP
745
> (lisp-shell)
lisp-shell>(kind tree-1 (var x) )
(size tree-1 tall) >y
(woody tree-1) >y
(evergreen tree-1) >y
(color tree-1 blue) >n
color tree-1 green) >y
(kind tree-1 pine) cf 0.81
(deciduous tree-1) >n
(size tree-1 small) >n
lisp-shell>(kind bush-2 (var x))
(size bush-2 tall) >n
(size bush-2 small) >y
(woody bush-2) >y
(flowering bush-2) >y
(thorny bush-2) >y
(color bush-2 red) >y
(kind bush-2 american-beauty) cf 0.9
lisp-shell>(kind tree-3 (var x))
(size tree-3 tall) >y
(woody tree-3) >y
(evergreen tree-3) > n
(deciduous tree-3) >y
(bears tree-3 fruit) >y
(color fruit red) >n
(color fruit yellow) >y
(taste fruit sour) >y
(kind tree-3 lemon-tree) cf 0.72
(size tree-3 small) >n
lisp-shell>quit
bye
•p
В этом примере можно заметить несколько аномалий. Например, система задает
пользователю вопрос о том, является ли дерево низким, хотя уже сообщалось, что оно высокое.
В другом случае пользователю задается вопрос о том, является ли дерево лиственным, хотя
оно уже охарактеризовано как вечнозеленое. Это типичные примеры поведения экспертной
системы. В базе знаний не содержится никакой информации о взаимосвязи понятий
"высокий" и "низкий" (определяемых литералами tall и small) или "лиственный" и
"вечнозеленый" (deciduous и evergreen). С точки зрения базы знаний это лишь
шаблоны для проверки соответствия. Поскольку поиск выполняется полным перебором, то
проверяются все правила. Для того чтобы система демонстрировала более глубокие знания, в базе
знаний необходимо закодировать и отношения между понятиями. Например, можно написать
правило, утверждающее, что small соответствует not tall. В рассматриваемом примере
такие отношения не представлены, поскольку в системе lisp-shell не реализован
оператор not. Читателю предлагается реализовать его в качестве упражнения.
15.11. Семантические сети и наследование в LISP
В этом разделе будет представлена реализация семантических сетей на языке LISP.
Как семейство представлений семантические сети обеспечивают базис для разнообраз-
746 Часть VI. Языки и технологии программирования для искусственного интеллекта
ных систем вывода. Мы не будем обсуждать все возможные варианты, а сконцентрируем
внимание на основном подходе к построению сетевых представлений с помощью
списков свойств (property list). После их использования для определения простой
семантической сети будет введена функция для реализации наследования классов. Изложенные в
этом разделе идеи являются важным источником развития объектно-ориентированной
методологии программирования, описанной в разделе 15.12.
LISP — это удобный язык для представления графов любой структуры, включая
семантические сети. Списки обеспечивают возможность создания вычислительных
объектов произвольной сложности. Эти объекты могут быть связаны с именами,
обеспечивающими простоту ссылок и определение взаимосвязей между объектами. На самом
деле все структуры данных LISP основаны на внутреннем представлении в виде цепочек
указателей, которое изоморфно структуре графов.
Например, граф с метками можно представить с помощью ассоциативного списка.
Каждый узел — это элемент ассоциативного списка, в котором все исходящие из этого
узла дуги хранятся в разделе данных в виде другого ассоциативного списка. Дуги
описываются с помощью элемента ассоциативного списка, ключом которого является имя
дуги, а данными — узел назначения. При таком представлении для поиска узла назначения
некоторой дуги выбранного узла можно использовать встроенные функции работы с
ассоциативными списками. Например, маркированный направленный граф, показанный на
рис. 15.7, можно представить с помощью ассоциативного списка вида
((а A . Ь))
(Ь B . с))
(с B . Ь) C . а)))
с
Рис. 15.7. Простой маркированный направленный граф
Такой подход положен в основу многих сетевых реализаций. Однако семантические
сети можно реализовать и на основе списков свойств (property list).
По существу, списки свойств — это встроенное средство LISP, позволяющее
связывать символы с именованными отношениями. При использовании списков свойств
объектам в глобальной среде можно напрямую сопоставить именованные атрибуты (без
применения функции setq). Такие связи с символом рассматриваются не как значения,
а как дополнительный компонент — список свойств.
Для управления списками свойств используются функции get, setf, remprop и
plist. Функция get вида
(get <символ> <имя-свойства>)
позволяет получить свойство объекта <символ> по его имени. Например, если для
символа rose свойство color принимает значение red, а свойство smell — значение
sweet, значит, функция get будет вести себя следующим образом.
(get 'rose 'color)
red
(get 'rose 'smell)
Глава 15. Введение в LISP
747
sweet
(get 'rose 'party-affiliation)
nil
Из последнего вызова видно, что при попытке получить значение несуществующего
свойства (отсутствующего в списке свойств) функция get возвращает значение nil.
Свойства связываются с объектами с помощью функции setf, имеющей следующий
синтаксис.
(setf <форма><значение»
Эта функция является обобщением функции setq. Первый аргумент функции setf
берется из большого, но конкретного списка форм. Функция setf использует не
значение формы, а место его хранения. В список форм включены функции саг и cdr.
Функция setf помещает значение своего второго аргумента в указанное место. Например,
функцию setf наряду с другими функциями работы со списками можно использовать
для модификации списков в глобальной среде. Это видно из следующего примера.
? (setq х' (a b с d e) )
(a b с d е)
? (setf (nth 2 х) 3)
3
? х
(а Ь 3 d e)
Функция setf наряду с функцией get используется для изменения значений
свойств. Например, свойства розы можно определить следующим образом.
> (setf (get 'rose 'color) 'red)
red
> (setf (get 'rose 'smell) 'sweet)
sweet
Параметрами функции remprop, удаляющей именованное свойство, являются
символ и имя свойства. Например,
> (get 'rose 'color)
red
> (remprop 'rose 'color)
color
> (get 'rose 'color)
nil
Функция plist получает в качестве аргумента символ и возвращает список его
свойств. Например,
> (setf (get 'rose 'color) 'red)
red
> (setf (get 'rose 'smell) 'sweet)
sweet
> (plist 'rose)
(smell sweet color red)
С помощью списков свойств достаточно просто реализовать семантическую сеть.
Например, следующие вызовы функции setf определяют описание семантической сети
видов птиц, показанной на рис. 14.7. Отношение isa определяет связи наследования.
748 Часть VI. Языки и технологии программирования для искусственного интеллекта
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf (
(setf (
get
get
get
get
get
get
(get
get
get
get
get
get
get
get
get
get
get
get
get
get
'animal 'covering) 'skin)
'bird 'covering) 'feathers)
'bird 'travel) 'flies)
'bird 'isa) 'animal)
'fish 'isa) 'animal)
'fish 'travel) 'swim)
'ostrich 'isa) 'bird)
'ostrich 'travel) 'walk)
'penguin 'isa) 'bird)
'penguin 'travel) 'walk)
'penguin 'color) 'brown)
'opus 'isa) 'penguin)
'canary 'isa) 'bird)
'canary 'color) 'yellow)
'canary 'sound) 'sing)
'tweety 'isa) 'canary)
'tweety 'color) 'white)
'robin 'isa) 'bird)
'robin 'sound) 'sings)
'robin 'color) 'red)
В этом представлении семантической сети уже определена иерархия наследования.
Если выполнить поиск по связи isa, то можно определить родительский объект по
заданному свойству. Для нахождения родительских объектов используется поиск в
глубину, который прекращается при нахождении экземпляра заданного свойства. Такой
подход обычно используется во многих коммерческих системах. В качестве стратегии
поиска можно также использовать поиск в ширину.
Функция inherit-get — это вариация функции get, которая сначала пытается
получить свойство данного символа. Если это свойство отсутствует, функция inherit-get
вызывает функцию get-f rom-parents для реализации поиска. Первым параметром функции
get-f rom-parents является либо один родительский объект, либо список таких объектов,
а вторым параметром— имя свойства. Если параметр parents принимает значение nil,
поиск завершается неудачно. Если родительским объектом является атом, для него
вызывается функция inherit-get для получения свойства самого родительского объекта либо
продолжения поиска. Если в качестве параметра указан список родителей, функция get-f rom-
parents рекурсивно вызывает сама себя для головы и хвоста этого списка. Функция
прохода по дереву inherit-get определяется следующим образом.
(defun inherit-get (object property)
(or (get object property)
(get-from-parents (get object 'isa) property)))
(defun get-from-parents (parents property)
(cond ((null parents) nil)
((atom parents) (inherit-get parents property))
(t (or (get-from-parents (car parents) property)
(get-from-parents (cdr parents) property)))))
15.12. Объектно-ориентированное программирование
с использованием CLOS
Несмотря на многочисленные преимущества функционального программирования,
некоторые задачи лучше решать в терминах объектов, состояние которых изменяется со
Глава 15. Введение в LISP
749
временем. К такому типу обычно относятся задачи моделирования. Представьте себе
программу, моделирующую систему обогрева большого здания. Если рассматривать эту
систему как множество взаимодействующих между собой объектов (комнаты,
термостаты, бойлеры, трубопроводы и т.д.) с целью изменения температуры и состояния друг
друга, то задачу можно значительно упростить. Объектно-ориентированные языки
поддерживают такой подход к решению задачи, при котором задача разбивается на набор
взаимодействующих между собой объектов. Она обладает состоянием, которое может
изменяться со временем, и множеством функций, определяющих их поведение. По
существу, объектно-ориентированное программирование позволяет решать задачи путем
моделирования их предметной области. Такой модельный метод решения задач
естественным образом подходит для искусственного интеллекта. Это эффективная методология
программирования, предоставляющая мощные средства для решения сложных задач.
Объектно-ориентированное программирование поддерживают многие языки, в том
числе Smalltalk, C++, Java и Common LISP Object System (CLOS). На первый взгляд LISP
уходит корнями в функциональное программирование, а объектная ориентация с
созданием объектов, сохраняющих со временем свое состояние, не вписывается в его
исходную концепцию. Однако многие средства языка, в том числе динамическая проверка
соответствия типов и возможность динамического создания и разрушения объектов,
делают его идеальной основой для создания объектно-ориентированного языка. LISP лежит в
основе многих ранних объектно-ориентированных языков, таких как Flavors, KEE и
ART. После разработки стандарта Common LISP сообщество его почитателей
предложило систему CLOS как средство объектно-ориентированного программирования на LISP.
Чтобы называться объектно-ориентированным, язык программирования должен
обеспечивать три возможности: инкапсуляцию (encapsulation), полиморфизм (polymorphism) и
наследование (inheritance). Определим эти возможности более детально и опишем, как их
поддерживает система CLOS.
1. Инкапсуляция. Все современные языки программирования позволяют создавать
сложные структуры данных, в которых элементарные (атомарные) элементы
объединяются в одну структуру. Объектно-ориентированная инкапсуляция — это
сочетание в одной структуре элементов данных и процедур для их обработки. Такие
структуры называются классами (class). Например, рассмотренные в разделе 14.2
абстрактные типы данных вполне обоснованно можно считать классами. В таких
объектно-ориентированных языках, как Smalltalk, инкапсуляция процедур (или
методов) в определении объекта реализуется явно. В CLOS принят другой подход.
Эта возможность реализуется за счет проверки соответствия типов. Здесь
поддерживаются методы, получившие название родовых функций (generic function). Они
проверяют типы своих параметров и тем самым гарантируют, что их можно
применять только к экземплярам заданного класса объектов. Это можно
рассматривать как логическую связь методов со своими объектами.
2. Полиморфизм. Слово "полиморфизм" произошло от двух корней: "поли",
означающего "много", и "морф" — "форма". Функция считается полиморфной, если
она демонстрирует различное поведение в зависимости от типов своих аргументов.
Наиболее типичный пример полиморфных функций и их важной роли дают
простые графические редакторы. Допустим, для каждой фигуры (квадрат, круг,
прямая) определен свой объект. Для изображения этих объектов естественно в каждом
классе определить метод draw. Каждый метод должен работать по-разному (в
зависимости от изображаемой фигуры), однако имя у всех одно. Для каждого объек-
750 Часть VI. Языки и технологии программирования для искусственного интеллекта
та в такой системе будет существовать метод draw. Это гораздо проще, чем
определять отдельные функции draw-square, draw-circle и т.д. Система CLOS
поддерживает полиморфизм за счет механизма родовых функций, поведение
которых определяется типами их аргументов. В примере с графическим редактором
можно определить функцию draw, включающую код для изображения всех
определенных в программе фигур. При оценивании будет проверен тип аргумента и
автоматически выполнен соответствующий код.
3. Наследование. Наследование — это механизм для поддержки языком
программирования абстрактных классов. Оно позволяет определить общие классы и задать структуру и
поведение их специализаций. Так, класс деревьев tree может описывать свойства
сосен, тополей, дубов и других видов деревьев. В разделе 15.11 был построен алгоритм
наследования для семантических сетей. Он иллюстрирует простоту реализации
наследования с помощью встроенных в LISP структур данных. Система CLOS обеспечивает
более робастный и выразительный встроенный алгоритм наследования.
15.12.1. Определение классов и экземпляров в CLOS
Базовой структурой данных в CLOS являются классы. Класс — это описание
множества экземпляров объектов. Классы определяются с помощью макроса defclass,
имеющего следующий синтаксис.
(defclass <имя-класса> {<имя-суперкласса>*)
(<спецификатор-элемента>*) )
Здесь <гшя-класса> — это символ, за которым следует список прямых суперклассов,
т.е. непосредственных предков данного класса в иерархии наследования. Этот список
может быть пустым. За списком родительских классов следует список (возможно,
пустой) спецификаторов элементов. Спецификатор элемента — это либо имя элемента, либо
список, состоящий из имени элемента и одного или нескольких параметров.
Спецификатор-элемента ::= имя-элемента\ {имя-элемента [параметр])
Например, можно определить класс прямоугольников rectangle, сегментами
которого являются длина length и ширина width.
> (defclass rectangle()
(length width))
#<standard-class rectangle>
Функция make-instance позволяет создавать экземпляры класса. Ее параметром
является имя класса, а возвращаемым значением — его экземпляр. В экземплярах класса
хранятся реальные данные. Символ rect можно связать с экземпляром класса
rectangle с помощью функций make-instance и setq.
> (setq rect (make-instance 'rectangle))
#<rectangle #x286ACl>
Параметры элементов в определении класса задавать необязательно. Они имеют
следующий синтаксис (где символ | означает альтернативные варианты).
параметр :: = :reader <имя-функции-чтения> \
:writer <имя-функции-записи> \
:accessor <имя-функции-чтения> \
Глава 15. Введение в LISP
751
:allocation <тип-размещения> \
:initarg <имя> \
:initform <форма>
Параметры элементов задаются с помощью ключей. Ключ — это вид
необязательного параметра в функции LISP. Перед значением ключа указывается ключевое слово,
которое всегда начинается с символа :. Параметры элементов обеспечивают доступ к ним.
Ключ : reader определяет имя функции, возвращающей значение данного элемента для
конкретного экземпляра. Ключ :writer задает имя функции записи элемента. Ключ
•.accessor определяет функцию, которая может использоваться для считывания
значения элемента или изменения его значения (с помощью функции setq). В следующем
примере определяется класс прямоугольников rectangle, элементами которого
являются длина length и ширина width с функциями доступа get-length и get-
width соответственно. Связав символ rect с экземпляром класса прямоугольников с
помощью функции make-instance, воспользуемся функцией доступа get-length
для присваивания с помощью функции setq элементу length значения 10. Для
считывания этого значения снова воспользуемся функцией доступа.
> (defclass rectangle ()
((length :accessor get-length)
(width :accessor get-width)))
#<standard-class rectangle>
> (setq rect (make-instance 'rectangle))
#<rectangle #x289159>
> (setf (get-length rect) 10)
10
> (get-length rect)
10
Помимо функций доступа для обращения к элементам класса можно использовать
функцию-примитив slot-value. Она определена для всех элементов. Ее параметром
является экземпляр класса и имя элемента, а возвращаемым значением — значение этого
элемента. Эту функцию можно использовать совместно с setq для изменения значения
элемента. Например, функцию slot-value можно применить для получения значения
элемента width экземпляра rect.
> (setf (slot-value rect 'width) 5)
5
> (slot-value rect 'width)
5
Функция : allocation определяет размещение элемента в памяти. Существует два
возможных типа размещения : instance и : class. В первом случае система CLOS
размещает элементы класса локально для каждого экземпляра, а во втором — все
экземпляры используют один и тот же элемент. Если в качестве типа размещения выбран
: class, то значения данного элемента для всех экземпляров совпадают, а его
изменения отражаются на всех экземплярах класса. По умолчанию используется тип
размещения : instance.
Ключ : initarg позволяет указать аргумент, который будет использоваться
функцией make-instance для задания начального значения элемента. Например, можно
модифицировать определение класса rectangle, инициализируя значения элементов
legth и width его экземпляров.
752 Часть VI. Языки и технологии программирования для искусственного интеллекта
> (defclass rectangle ()
((length :accessor get-length :initarg init-length)
(width : accessor get-width .-initarg init-width) ) )
#<standard-class rectangle>
>(setq rect (make-instance 'rectangle 'init-length 100
'init-width 50))
#<rectangle #x28D081>
> (get-length rect)
100
> (get-width rect)
50
Ключ rinitform позволяет задавать форму, оцениваемую при каждом обращении к
функции make-instance для вычисления начального значения элемента. Например, можно
написать программу, запрашивающую у пользователя значения элементов каждого нового
экземпляра прямоугольника. Это можно сделать с помощью ключа : initf orm.
> (defun read-value (query) (print query)(read))
read-value
> (defclass rectangle ()
((length :accessor get-length rinitform
(read-value "введите длину"))
(width .-accessor get-width rinitform (read-value
"введите ширину"))))
#<standard-class rectangle>
> (setq rect (make-instance 'rectangle))
"введите длину" 100
"введите ширину" 50
#<rectangle #x290461>
> (get-length rect)
100
> (get-width rect)
50
15.12.2. Определение родовых функций и методов
Родовая функция — это функция, поведение которой зависит от типа ее аргументов.
В CLOS родовые функции содержат множество методов (method), индексированных по
типу аргументов. Вызов родовой функции аналогичен вызову обычной функции. Просто
при ее вызове реализуется метод, связанный с данным типом аргументов.
При выборе метода родовой функции используется структура иерархии классов. Если
не существует метода, определенного напрямую для аргумента данного класса,
используется метод, связанный с "ближайшим" предком в дереве иерархии. Родовые функции
обеспечивают основные преимущества классического объектно-ориентированного
подхода и передачи сообщений, включая наследование и перегрузку. Однако по духу они
гораздо ближе к парадигме функционального программирования, составляющей основу
LISP. Например, родовые функции можно использовать наряду с такими конструкциями
высокого уровня языка LISP, как mapcar иди f uncall.
Родовые функции определяются с помощью функций def generic или defmethod.
Функция def generic позволяет определять родовую функцию и несколько методов с
помощью одной формы. Функция defmethod определяет отдельные методы, которые
Глава 15. Введение в LISP
753
затем система CLOS объединяет в общую родовую функцию. Приведем упрощенный
синтаксис функции def generic.
(defgeneric имя-функции лямбда-список <описание-метода>*)
<описание-метода> ::= (:method специализированный-лямбда-список форма)
Параметрами функции def generic являются имя функции, лямбда-список ее
аргументов и последовательность (возможно, пустая) описаний методов. В описании метода спецш-
лизированный-лямбда-сгшсок — это обычный лямбда-список из определения функции, в
котором формальный параметр может быть заменен парой (символ ушочненный-параметр), в
которой символ — это имя параметра, а уточненный параметр — класс аргумента. Если
параметр метода не содержит уточнений, по умолчанию его типом считается t — наиболее
общий класс в иерархии CLOS. Параметры типа t могут быть связаны с любым объектом.
Количество элементов специализированного лямбда-списка должно совпадать с числом
аргументов лямбда-списка в функции def generic. Эта функция создает обобщенную функцию,
методы которой заменяют любую существующую родовую функцию.
В качестве примера использования родовой функции можно определить классы
прямоугольника и окружности и реализовать в них соответствующие методы вычисления площади.
(defclass rectangle ()
((length .-accessor get-length : initarg init-length)
(width :accessor get-width .-initarg init-width) ) )
(defclass circle ()
((radius :accessor get-radius :initarg init-radius)))
(defgeneric area (shape)
(:method ((shape rectangle))
(* (get-length shape)
(get-width shape)))
(:method ((shape circle))
(* (get-radius shape) (get-radius shape) pi)))
(setq rect (make-instance 'rectangle 'init-length 10 'init-width 5))
(setq circ (make-instance 'circle 'init-radius 7))
Функцию area теперь можно использовать для вычисления площади любой фигуры.
> (area rect)
50
> (area circ)
153.93804002589985
Методы определяются с помощью функции def method, синтаксис которой
напоминает синтаксис функции defun. Однако здесь для объявления класса, к которому
принадлежат аргументы, используется специализированный лямбда-список. Если при
определении функции с помощью def method не существует родовой функции с таким
именем, она создается. Если же родовая функция с таким именем уже существует, то новый
метод добавляется к ней. Например, к приведенному выше определению можно добавить
класс квадратов square.
(defclass square ()
((side :accessor get-side :initarg init-side)))
(defmethod area ((shape square))
(* (get-side shape)
(get-side shape)))
(setq sqr (make-instance 'square 'init-side 6))
754 Часть VI. Языки и технологии программирования для искусственного интеллекта
Функция defmethod не изменяет существовавших ранее определений для
вычисления площадей фигур, а лишь добавляет новый метод к родовой функции.
> (area sqr)
36
> (area rect)
50
> (area circ)
153.93804002589985
15.12.3. Наследование в CLOS
Язык CLOS поддерживает множественное наследование. Наряду с гибкой схемой
представления данных множественное наследование таит опасность возникновения
аномалий, связанных с наследованием элементов и методов. Если для двух предков
определен один и тот же метод, то важно знать, какой из них наследуется. Возможные
неоднозначности устраняются в CLOS за счет определения списка приоритетности классов
(class precedence), в котором упорядочиваются все классы иерархии.
При определении класса с помощью функции def class все его прямые предки
упорядочиваются слева направо. На основе этой информации система CLOS определяет
порядок всех классов в иерархии наследования, на базе которого формируется список
приоритетности классов. Список приоритетности классов удовлетворяет двум правилам.
1. Любой прямой родительский класс предшествует любому более дальнему предку.
2. Порядок приоритетности непосредственных родительских классов соответствует
их указанию при вызове функции def class слева направо.
Система CLOS строит список приоритетности классов для любого объекта путем
топологической сортировки его родительских классов согласно следующему алгоритму.
Пусть С — это класс, для которого требуется определить список приоритетности.
1. Пусть Sr — это множество, состоящее из С и всех его суперклассов.
2. Для каждого класса с из Sr определяется множество упорядоченных пар
Яс = {(с|с1)|(с11с2)|(с21с3)...(сп_1,сл)},
где с{ ...,сп— прямые предки класса с в порядке их перечисления в определении
def class. Заметим, что для каждого множества Яг определен глобальный порядок.
3. Пусть Я— это объединение множеств Яг, составленных для всех элементов S(.
Оно может быть, а может и не быть частично упорядоченным. Если оно не является
частично упорядоченным, то иерархия не согласована, и алгоритм это определит.
4. Выполняется топологическая сортировка элементов Я следующим образом.
4.1. Строится пустой список приоритетности Р.
4.2. Находится класс в Я, не имеющий предков. Он добавляется в конец списка Р и
удаляется из множества Sr, а все содержащие его пары удаляются из Я. Если в
Sr содержится несколько классов, не имеющих предков, то выбирается тот из
них, прямой производный класс которого расположен ближе всего к концу
текущей версии списка Р.
4.3. Пункты 4.1 и 4.2 повторяются до тех пор, пока не будут исчерпаны все
элементы из Я, не имеющие предков.
Глава 15. Введение в LISP
755
5. Если множество Sc не пусто, значит, иерархия не согласована. В ней могут
содержаться неоднозначности, которые нельзя разрешить с помощью данной методологии.
Поскольку полученный в результате список приоритетности полностью упорядочен, с
его помощью можно разрешать любые неоднозначности в существующей иерархии
классов. Список приоритетности классов используется в системе CLOS при реализации
наследования элементов и выборе методов.
При выборе метода, применяемого при данном вызове родовой функции, система
CLOS сначала находит все подходящие методы. Метод считается подходящим для
данного вызова родовой функции, если каждый специализированный параметр метода
согласуется с типом соответствующего аргумента в вызове родовой функции.
Специализированный параметр согласован с аргументом, если он соответствует классу этого
аргумента или классу одного из его предков.
Затем система CLOS сортирует все подходящие методы с учетом списков приоритетности
аргументов. Путем сравнения специализированных параметров слева направо определяется,
какой из двух методов должен стоять первым. Если первая пара соответствующих
специализированных параметров совпадает, система CLOS сравнивает вторую пару. Этот процесс
продолжается до тех пор, пока не будет найдена пара различающихся специализированных
параметров. Среди них более специализированным считается метод, параметр которого находится
левее в списке приоритетности соответствующего аргумента. После сортировки всех
подходящих методов по умолчанию применяется наиболее специализированный метод для данных
аргументов. Более подробно эта процедура описана в работе [Steele, 1990].
15.12.4. Пример: моделирование термостата
Объектно-ориентированный подход к программированию, обеспечивающий
естественный способ организации больших и сложных программ, в равной степени применим
и для разработки баз знаний. Помимо преимуществ наследования классов для
представления классифицированных знаний, принципы передачи сообщений в объектно-
ориентированных системах упрощают представление взаимодействия компонентов.
В качестве простого примера рассмотрим задачу моделирования системы парового
отопления для небольшого офисного здания. Эту проблему можно естественным
образом описать в терминах взаимодействия компонентов, например, так.
В каждом офисе есть термостат, включающий и выключающий систему обогрева офиса.
Он работает независимо от термостатов в других офисах.
Бойлер для теплоцентрали включается и выключается по требованию, поступающему из офисов
Когда нагрузка на бойлер возрастает, может потребоваться некоторое время для генерации
нужного объема пара.
Различные офисы передают в систему разные требования. Например, угловые комнаты с
большими окнами охлаждаются быстрее, чем внутренние. Внутренние помещения могут
нагреваться даже от соседних комнат.
Объем пара, направляемый системой в каждый офис, зависит от общих требований к системе.
Это лишь некоторые аспекты, которые необходимо принимать во внимание при
моделировании такой системы. На самом деле взаимодействие между компонентами
гораздо сложнее. Объектно-ориентированное представление позволяет разработчику
сконцентрировать внимание на описании конкретного класса объектов. Термостат можно пред-
756 Часть VI. Языки и технологии программирования для искусственного интеллекта
ставить температурой, до которой он нагревает воду, а также скоростью его реакции на
изменение температуры.
Теплоцентраль можно охарактеризовать в терминах максимального количества тепла,
которое она может производить, количества топлива, используемого для его получения,
времени, затрачиваемого на выполнение поступающих к системе требований, а также
скорости потребления воды.
Комната характеризуется объемом, теплопотерями через стены и окна, количеством тепла,
поступающего из соседних комнат и скоростью поступления тепла в комнату через радиатор.
База знаний должна описывать информацию, хранящуюся в классах room и
thermostat, экземплярами которых являются объекты room-322 и thermostat-211
соответственно.
Взаимодействие между компонентами описывается в терминах передачи сообщений
между объектами. Например, при изменении температуры в комнате передается
сообщение экземпляру класса thermostat. Если эта температура достаточно низка, термостат
после некоторой задержки должен включиться. При этом объекту теплоцентрали
передается сообщение с запросом большего количества тепла. При этом теплоцентраль
потребляет больше топлива или, если она уже функционирует на пределе своих возможностей,
некоторая часть тепла, передаваемого в другие комнаты, перенаправляется в ответ на
новое требование. Это может привести к включению других термостатов и т.д.
Такое моделирование позволяет проверить работоспособность системы в
экстремальных ситуациях, оценить потери тепла и эффективность самой системы обогрева.
Полученную модель можно использовать для диагностики неисправностей в системе и
выявления их симптомов. Например, если есть основания считать, что проблемы с
обогревом вызваны неисправностью теплотрассы, можно ввести в модель соответствующие
характеристики и проверить свои предположения в модельном режиме.
Основу реализации этой модели составляет набор определений классов. Класс
термостатов имеет один элемент— setting. Для каждого экземпляра он инициализируется
значением 65 с помощью функции initf orm. Для класса thermostat определен
производный класс heater-thermostat для управления радиаторами (в противовес
кондиционерам воздуха). Единственный элемент этого класса связывается с экземпляром класса
heater. Заметим, что элемент класса heater имеет тип размещения : class. Это
означает, что термостаты в разных комнатах управляют общим на все здание радиатором.
(defclass thermostat ()
((setting :initform 65
:accessor therm-setting)))
(defclass heater-thermostat (thermostat)
((heater :allocation :class
:initarg heater-obj)))
Класс heater обладает состоянием (on или off), которое изначально принимает
значение off, и характеризуется местоположением. Он также включает элемент
rooms-heater, связанный со списком объектов типа room. Заметим, что экземпляры
классов, как и другие структуры данных LISP, могут быть элементами списков.
(defclass heater ()
((state :initform 'off
:accessor heater-state)
(location :initarg loc)
(rooms-heated)))
Глава 15. Введение в LISP
757
Элементами класса room являются temperature, принимающий начальное
значение 65, thermostat, связанный с экземпляром класса thermostat, и name,
описывающий имя комнаты.
(defclass room ()
((temperature :initform 65
:accessor room-temp)
(thermostat :initarg therm
:accessor room-thermostat)
(name -.initarg name
•.accessor room-name)))
Иерархия описанных классов приводится на рис. 15.8.
Class: standard-object
Class: thermostat
setting
Class: heater
state
location
rooms-heated
Class: room
temperature
thermostat
Class: heater-thermostat
heater
Рис. 15.8. Иерархия классов в модели термостата
При моделировании поведения термостата используются конкретные экземпляры
этих классов. Реализуем систему, состоящую из одной комнаты, одного нагревателя и
одного термостата.
(setf office-heater (make-instance 'heater 'loc 'office))
(setf room-325 (make-instance 'room
'therm (make-instance 'heater-thermostat
'heater-obj office-heater)
'name 'room-325))
(setf (slot-value office-heater 'rooms-heated) (list room-325))
Определения экземпляров и связи между ними показаны на рис. 15.9.
Поведение комнат описывается методами change-temp, check-temp и change-
setting. Метод change-temp устанавливает новое значение температуры в комнате,
выводит сообщение пользователю и вызывает метод check-temp, чтобы проверить, не
нужно ли включить радиатор. Аналогично метод change-set ting изменяет установку
термостата и вызывает метод check-temp, моделирующий функцию термостата. Если
температура в комнате ниже установки термостата, он передает обогревателю
сообщение о включении. В противном случае передается сообщение об отключении.
758 Часть VI. Языки и технологии программирования для искусственного интеллекта
instance
setting: 65
^ J
i
i
instance: office-heater
state: off
location: office
rooms-heated: (.)
1—>
instance: room-325
temperature: 65
name: room-325
Рис. 15.9. Экземпляры классов в модели термостата с исходными значениями и
указанием типа размещения элементов
(defmethod change-temp ((place room) temp-change)
(let ((new-temp (+ (room-temp place) temp-change)))
(setf (room-temp place) new-temp)
(terpri)
(prinl "температура в")
(prinl (room-name place))
(prinl "составляет")
(prinl new-temp)
(terpri)
(check-temp place)))
(defmethod change-setting ((room room) new-setting)
((let ((therm (room-thermostat room)))
(setf (therm-setting therm) new-setting)
(prinl "изменение установки термостата в")
(prinl (room-name room))
(prinl "на")
(prinl new-setting)
(terpri)
(check-temp room)))
(defmethod check-temp ((room room))
(let* ((therm (room-thermostat room))
(heater (slot-value therm 'heater)))
(cond ((> (therm-setting therm) (room-temp room))
(send-heater heater 'on))
(t (send-heater heater 'off)))))
Глава 15. Введение в LISP
759
Методы класса heater управляют состоянием обогревателя и изменением
температуры в комнатах. Аргументами метода send-heater являются экземпляр обогревателя
и сообщение, передающее новое состояние. Если новым состоянием является on,
вызывается метод turn-on включения обогревателя, в противном случае вызывается метод
его отключения turn-off. После включения обогревателя вызывается метод heat-
rooms для повышения температуры в комнатах на 1 градус.
(defmethod send-heater ((heater heater) new-state)
(case new-state
(on (if (equal (heater-state heater) 'off)
(turn-on heater))
(heat-rooms (slot-value heater 'rooms-heated) 1))
(off (if (equal (heater-state heater) 'on)
(turn-off heater)))))
(defmethod turn-on ((heater heater))
(setf (heater-state heater) 'on)
(prinl "включение обогревателя в")
(prinl (slot-value heater 'location))
(terpri))
(defmethod turn-off ((heater heater))
(setf (heater-state heater) 'off)
(prinl "отключение обогревателя в")
(prinl (slot-value heater 'location))
(terpri))
(defun heat-rooms (rooms amount)
(cond ((null rooms) nil)
(t (change-temp (car rooms) amount)
(heat-rooms (cdr rooms) amount))))
Приведем пример работы модели.
> (change-temp room-325 5)
"температура в "room-325" составляет 0
"включение обогревателя в "office
"температура в "room-325" составляет 1
"температура в "room-325" составляет 2
"температура в "room-325" составляет 3
"температура в "room-325" составляет 4
"температура в "room-325" составляет 5
"отключение обогревателя в "office
nil
> (change-setting room-325 70)
"изменение установки термостата в "room-325" на 0
"включение обогревателя в "office
"температура в "room-325" составляет 6
"температура в "room-325" составляет 7
"температура в "room-325" составляет 8
"температура в "room-325" составляет 9
"температура в "room-325" составляет 0
"отключение обогревателя в "office
nil
760 Часть VI. Языки и технологии программирования для искусственного интеллекта
15.13. Обучение в LISP: алгоритм ID3
В этом разделе будет описана реализация алгоритма ID3 из раздела 9.3. Согласно
этому алгоритму на основе множества обучающих примеров строятся деревья решений,
обеспечивающие классификацию объекта по его свойствам. Каждый внутренний узел
дерева решений отвечает за одно из свойств объекта-кандидата и использует его
значение для выбора следующей ветви дерева. В процессе прохода по дереву проверяются
различные свойства. Эта процедура продолжается до тех пор, пока не будет достигнут
один из листов дерева, означающий класс, к которому относится данный объект. В
алгоритме ID3 для упорядочения тестов и построения (почти) оптимального дерева решений
используется функция выбора тестов, построенная на основе теории информации.
В алгоритме ID3 задействованы сложные структуры данных, в том числе объекты,
свойства, множества и деревья решений. Основу его реализации составляет набор
определений структур — агрегатных типов данных, аналогичных записям в языке Pascal или
структурам в С. С помощью функции def struct в Common LISP можно определить
тип данных как набор именованных элементов. Форма def struct строит функции,
необходимые для создания и управления объектами данного типа.
Наряду с использованием структур для определения типов данных при реализации
алгоритма будут использованы такие функции высокого уровня, как mapcar. Как стало ясно при
реализации оболочки экспертной системы, использование отображений и фильтров для
выполнения функций над списками объектов обеспечивает большую прозрачность подхода к
программированию на основе потоков данных по сравнению с другими принципами
программирования. Возможность обработки функций как данных и построения замыканий
функций — краеугольный камень стиля программирования на языке LISP.
15.13.1. Определение структур с помощью функции def struct
С помощью функции def struct можно определить новый тип данных (data type)
сотрудников — employee.
(defstruct employee
name
address
serial-number
department
salary)
Здесь employee — это имя типа, name, address, serial-number, department
и salary— имена его элементов. При оценивании формы defstruct не создается
никаких экземпляров записей о сотрудниках. Определяются лишь тип и функции,
необходимые для создания и управления его элементами. Параметрами функции defstruct
являются символ, который становится именем нового типа, и количество
спецификаторов элементов. В данном случае 5 элементов определены по имени. Спецификаторы
элементов позволяют также определять различные свойства элементов, включая их тип и
информацию для инициализации [Steele, 1990].
Оценивание формы defstruct приводит к нескольким результатам. Рассмотрим
для примера следующее определение.
Глава 15. Введение в LISP
761
(defstruct <имя типа>
<имя элемента 1>
<имя элемента 2>
<имя элемента п>)
Эта форма определяет функцию, имя которой формируется по принципу make-<имя
muna>. Это позволяет создавать экземпляры данного типа. Например, после определения
структуры employee с объектом этого типа можно связать имя new-employee.
(setq new-employee (make-employee))
Имена элементов можно использовать в качестве ключей при создании функции. С их
помощью элементам экземпляров можно присваивать начальные значения. Например, так.
(setq new-employee
(make-employee
:name '(Doe Jane)
:address 234 Main, Randolph, Vt"
:serial-number 98765
.•department 'Sales
.•salary 4500.00) )
При оценивании функции def struct <имя muna> становится названием типа
данных. Это имя можно использовать в функции typep для проверки принадлежности
объекта к некоторому типу. Например, так.
> (typep new-employee 'employee)
t
Более того, def struct определяет функцию <имя muna>-p, которую тоже можно
использовать для проверки принадлежности объекта к данному типу.
> (employee-p new-employee)
t
> (employee-p '(Doe Jane))
nil
И, наконец, def struct определяет функции доступа к каждому элементу
структуры. Их имена формируются по схеме
<имя типа> <имя элемента>
В рассматриваемом примере доступ к значениям различных элементов объекта new-
employee можно получить следующим образом.
> (employее-name new-employee)
(Doe Jane)
> (employee-address new-employee)
234 Main, Randolph, Vt"
> (employee-department new-employee)
Sales
Эти функции доступа можно использовать совместно с setf для изменения значений
элементов экземпляра. Приведем пример.
> (employee-salary new-employee)
4500.0
> (setf (employee-salary new-employee) 5000.00)
762 Часть VI. Языки и технологии программирования для искусственного интеллекта
5000.0
> (employee-salary new-employee)
5000.0
Таким образом, с помощью структур можно определять предикаты и функции
доступа к объекту данного типа в одной и той же форме LISP. Эти определения будут играть
ключевую роль при реализации алгоритма ID3.
На основе множества примеров, относящихся к известным классам, алгоритм ID3
строит дерево, позволяющее корректно классифицировать все обучающие примеры и (с
высокой вероятностью) неизвестные объекты. При изучении алгоритма ID3 в разделе 9.3
обучающие примеры были представлены в табличной форме с явным перечислением
свойств и их значений для каждого примера. Например, в табл. 9.1 приведен список
свойств обучающих примеров, используемых для прогнозирования кредитного риска.
В данном разделе мы снова обратимся к этой задаче.
Таблицы — это лишь один из способов представления примеров. В более общем
случае их можно рассматривать как объекты, обладающие различными свойствами.
Сделаем несколько предположений о представлении объектов. Для каждого свойства
определим функцию, зависящую от одного аргумента и применяемую для получения значения
этого свойства. Например, если объект credit -prof ile-1 связан с первым примером
из табл. 9.1, a history — функция, возвращающая значение кредитной истории, то при
вызове этой функции для указанного объекта будет получен следующий результат.
> (history credit-profile-1)
bad
Аналогично зададим функции для других свойств кредитного профиля.
> (debt credit-profile-1)
high
> (collateral credit-profile-1)
none
> (income credit-profile-1)
0-to-15k
> (risk credit-profile-1)
high
Выберем представление для базы знаний из данного примера. Представим объекты в
виде ассоциативных списков, в которых ключами являются имена свойств, а данными —
соответствующие значения. В частности, первый пример из табл. 9.1 можно представить
в виде ассоциативного списка.
((risk.high) (history.bad) (debt.high)(collateral.none)
(income.0-15k))
Для определения примеров из табл. 9.1 в виде структур воспользуемся функцией
def struct. Полный набор обучающих примеров представим в виде списка
ассоциативных списков и свяжем этот список с именем examples.
(setq examples
' ( ( (risk . high) (history . bad) (debt . high) (collateral . none)
(income . 0-15k))
( (risk . high) (history . unknown) (debt . high)
(collateral . none) (income . 15k-35k))
( (risk . moderate) (history . unknown) (debt . low)
(collateral . none)(income . 15k-35k))
Глава 15. Введение в LISP
763
((risk . high) (history . unknown) (debt . low) (collateral . none)
(income . 0-15k))
((risk . low) (history . unknown) (debt . low) (collateral . none)
(income . over-35k))
( (risk . low) (history . unknown) (debt . low) (collateral . adequate)
(income . over-35k))
((risk . high) (history . bad) (debt . low) (collateral . none)
(income . 0-15k))
((risk . moderate) (history . bad) (debt . low)
(collateral . adequate) (income . over-35k))
((risk . low) (history . good) (debt . low) (collateral . none)
(income . over-35k))
((risk . low) (history . good) (debt . high) (collateral . adequate)
(income . over-35k))
((risk . high) (history . good) (debt . high) (collateral . none)
(income . 0-15k))
((risk . moderate) (history . good) (debt . high) (collateral . none)
(income . 15k-35k))
((risk . low) (history . good) (debt . high) (collateral . none)
(income . over-35k))
((risk . high) (history . bad) (debt . high) (collateral . none)
(income . 15k-35k))))
Поскольку задачей дерева решений является определение риска для новых примеров,
в процессе проверки используются все свойства, за исключением значения риска.
(setq test-instance
'((history . good) (debt . low) (collateral . none)
(income . 15k-35k)))
Определим свойства для такого представления объектов.
(defun history (object)
(cdr (assoc 'history object .-test #'equal)))
(defun debt (object)
(cdr (assoc 'debt object :test #'equal)))
(defun collateral (object)
(cdr (assoc 'collateral object :test #'equal)))
(defun income (object)
(cdr (assoc 'income object :test #'equal)))
(defun risk (object)
(cdr (assoc 'risk object :test #'equal)))
Свойство property — это функция, определенная над объектами. Такие функции
представляются в виде элементов структуры, включающей другую полезную информацию.
(defstruct property
name
test
values)
Элемент test экземпляра property связан с функцией, возвращающей значение
свойства, name — это имя свойства. Оно включается исключительно для удобства
пользователя. Элемент values — это список всех значений, которые могут возвращаться
функцией test. Требование заблаговременного определения диапазона значений
свойства значительно упрощает реализацию.
764 Часть VI. Языки и технологии программирования для искусственного интеллекта
Деревья решений можно определить с помощью следующей структуры.
(def struct decision-tree
test-name
test
branches)
(defstruct leaf
values)
Таким образом, дерево поиска является экземпляром структуры decision-tree
или leaf. Структура leaf состоит из одного элемента value, определяющего класс
объекта. Экземпляры типа dec is ion-tree представляют внутренние узлы дерева.
Их элементами являются test, test-name и множество ветвей branches. Функция
test зависит от одного аргумента— объекта— и возвращает значение свойства. При
классификации объекта с помощью f uncall вызывается функция test. Возвращаемое
ею значение применяется для выбора ветви дерева. Имя этого свойства задает элемент
test-name. Этот элемент облегчает пользователю контроль дерева решений. При
выполнении программы он не играет никакой существенной роли. Элемент branches —
это ассоциативный список поддеревьев. Ключами являются возможные значения,
возвращаемые функцией test, а данными — сами поддеревья.
Например, дерево на рис. 9.13 соответствует следующему набору вложенных
структур. Обозначение #S применяется при реализации ввода-вывода в Common LISP. Оно
означает, что данное s-выражение представляет структуру.
#S(decision-tree
: test-name income
.-test #<Compiled-function income #x3525CE>
:branches
(@-15k . #S(leaf rvalue high))
A5k-35k .
#S(decision-tree
:test-name history
:test #<Compiled-function history #x3514D6>
:branches
((good . #S(leaf rvalue moderate))
(bad . #S(leaf rvalue high))
(unknown .
#S(decision-tree
:test-name debt
:test #<Compiled-function debt #x35lA7E>
:branches
((high . #S(leaf rvalue high))
(low.#S(leaf rvalue moderate))))))))
(over-35k .
#S (decision-tree -.test-name
history
:test #<Co...d-fun.. history
#x3514D6>
:branches
((good . #S(leaf rvalue
low))
(bad . #S(leaf rvalue
moderate))
(unknown . #S(leaf
rvalue low)))))))
Глава 15. Введение в LISP
765
Хотя набор обучающих примеров по существу представляет собой лишь множество
объектов, будем рассматривать его как часть структуры, включающей элементы другой
информации, используемой в алгоритме. Определим структуру example-frame
следующим образом.
(defstruct example-frame
instances
properties
classifier
size
information)
Здесь instances — это список объектов, для которых известно, к какому классу
они принадлежат. Эти данные используются в качестве обучающего множества для
построения дерева решения. Элемент properties — это список объектов типа
property, включающий свойства, которые можно использовать при проходе узлов
дерева. Элемент classifier— это тоже экземпляр типа property. Он
представляет классификацию, которую должен изучить алгоритм ID3. Поскольку известно, к
каким классам принадлежат обучающие примеры, эту информацию можно включить в
качестве еще одного свойства. Элемент size задает количество примеров в списке
instances, a information — это содержимое данного множества примеров.
Значения size и information определяются из примеров. Поскольку их вычисление
занимает определенное время, а эти данные используются многократно, имеет смысл
сохранить их в отдельных элементах.
Напомним, что алгоритм ID3 строит деревья решений рекурсивно. Для каждого
экземпляра структуры example-frame выбирается свойство, которое используется для
разбиения обучающего множества на непересекающиеся подмножества. Каждое
подмножество содержит все экземпляры, для которых данное свойство принимает одно и
то же значение. Выбранное свойство используется в качестве теста для данного узла
дерева. Для каждого подмножества в этом разбиении алгоритм ID3 рекурсивно строит
поддерево с учетом остальных свойств. Алгоритм прекращает свою работу, если
оставшееся множество примеров принадлежит к одному и тому же классу. Для него
создается лист дерева.
Определим структуру partition, которая разбивает множество примеров на
подмножества с использованием заданного свойства.
(defstruct partition
test-name
test
components
info-gain)
Элемент test экземпляра структуры partition связан со свойством,
используемым для создания разбиения, test-name— это имя теста, включенное для удобства
пользователя. Элемент components связывается с подмножествами разбиения. В
данной реализации components — это ассоциативный список. Ключами являются
различные значения выбранного свойства, а данными— экземпляр структуры example-
frame. Элемент gain-info отвечает за информацию, получаемую в результате
применения теста для данного узла дерева. Подобно элементам size и information
структуры example-frame этот элемент содержит вычисляемое значение,
многократно используемое в алгоритме. Благодаря этим типам данных реализация алгоритма более
точно отражает его структуру.
766 Часть VI. Языки и технологии программирования для искусственного интеллекта
15.13.2. Алгоритм ID3
Основу реализации алгоритма ID3 составляет рекурсивная функция построения
дерева build-tree, параметром которой является структура example-frame.
(defun build-tree (training-frame)
(cond
; Вариант 1: пустое множество примеров
((null (example-frame-instances training-frame))
(make-leaf rvalue "невозможно классифицировать: нет
примеров"))
; Вариант 2: использованы все тесты
((null (example-frame-properties training-frame))
(make-leaf rvalue (list-classes training-frame)))
; Вариант З: все примеры принадлежат одному классу
((zerop (example-frame-information training-frame))
(make-leaf .-value (funcall
(property-test (example-frame-classifier
training-frame))
(car (example-frame-instances training-frame)))))
; Вариант 4: выбор теста и рекурсивный вызов
(t (let ((part (choose-partition (gen-partitions
training-frame))))
(make-decision-tree
:test-name (partition-test-name part)
.•test (partition-test part)
•.branches (mapcar #' (lambda (x)
(cons (car x) (build-tree (cdr x))))
(partition-components part)))))))
С помощью конструкции cond функция build-tree анализирует четыре
возможных случая. В первом случае структура training-frame не содержит обучающих
примеров. Такая ситуация может встретиться в том случае, если множество обучающих
примеров алгоритма ID3 неполно — в нем отсутствуют экземпляры с указанным
значением данного свойства. В этом случае создается лист, содержащий сообщение
"невозможно классифицировать: нет примеров".
Второму случаю соответствует ситуация, когда элемент свойств структуры
training-frame пуст. При рекурсивном построении дерева решений после выбора свойства
оно удаляется из списка свойств данного экземпляра example-frame для всех
поддеревьев. Если множество примеров не согласовано, список свойств может исчерпаться до
построения однозначной классификации обучающего множества. В этом случае
создается лист, значением которого является список всех классов, к которым могут относиться
обучающие примеры.
Третья ситуация представляет успешное завершение построения ветви дерева. Если
содержимое элемента information структуры example-frame равно нулю, значит,
все примеры принадлежат одному и тому же классу (согласно определению информации
по Шеннону, приведенному в разделе 12.3). Алгоритм завершается и возвращается
листовой узел, значение которого соответствует оставшемуся классу.
В первых трех случаях построение дерева завершается. В четвертом случае для
построения поддеревьев текущего узла рекурсивно вызывается функция build-tree.
Функция gen-partitions с учетом тестов элемента свойств генерирует список всех
возможных разбиений множества примеров, а функция choose-partition выбирает
Глава 15. Введение в LISP
767
наиболее информативный тест. После связывания в блоке let полученного разбиения с
переменной part строится узел дерева решений, которому соответствует
использованный для разбиения тест, а элемент branches связывается с ассоциативным списком
поддеревьев. Каждому ключу в списке branches соответствует значение теста, а
данные представляют собой дерево решений, построенное в процессе рекурсивного вызова
функции build-tree. Поскольку элемент components структуры part уже
представляет собой ассоциативный список, ключами которого являются значения свойств, а
данными— экземпляры example-frame, построение поддеревьев выполняется с
помощью функции mapcar, позволяющей применить функцию build-tree к каждому
объекту данных ассоциативного списка.
Функция gen-partitions зависит от одного аргумента training-frame —
объекта типа example-frame— и возвращает все разбиения соответствующего
подмножества примеров. Каждое разбиение создается с использованием некоторого
свойства из списка properties. Функция gen-partitions вызывает функцию
partition, аргументами которой являются экземпляр example-frame и выбранное
свойство. Она разбивает все множество примеров на основе значений этого свойства. Заметим,
что с помощью функции mapcar формируется разбиение для каждого элемента списка
свойств экземпляра training-frame.
((defun gen-partitions (training-frame)
(mapcar #'(lambda (x) (partition training-frame x))
(example-frame-properties training-frame)))
Функция choose-part it ion просматривает список возможных разбиений и
выбирает из них наиболее информативное.
(defun choose-partition (candidates)
(cond ((null candidates) nil)
((= (list-length candidates) 1)(car candidates))
(t (let ((best (choose-partition (cdr candidates))))
(if (> (partition-info-gain (car candidates))
(partition-info-gain best))
(car candidates)
best)))))
Самой сложной функцией при реализации алгоритма ID3 является функция
partition. Она получает в качестве параметров экземпляр exapmle- frame и некоторое
свойство property, а возвращает экземпляр структуры разбиения.
((defun partition (root-frame property)
(let ((parts (mapcar #' (lambda (x) (cons x (make-example- frame) ) )
(property-values property))))
(dolist (instance (example-frame-instances root-frame) )
(push instance (example-frame-instances
(cdr (assoc (funcall (property-test property) instance)
parts)))))
(mapcar #'(lambda (x)
(let ((frame (cdr x)))
(setf (example-frame-properties frame)
(remove property (example-frame-properties
root-frame)))
(setf (example-frame-classifier frame)
(example-frame-classifier root-frame))
768 Часть VI. Языки и технологии программирования для искусственного интеллекта
(setf (example-frame-size frame)
(list-length (example-frame-instances
frame)))
(setf (example-frame-information frame)
(compute-information
(example-frame-instances frame)
(example-frame-classifier root-frame)))))
parts)
(make-partition
:test-name (property-name property)
.-test (property-test property)
:components parts
:info-gain (compute-info-gain root-frame parts))))
В функции partition сначала в блоке let определяется локальная переменная
parts. Она инициализируется ассоциативным списком, ключами которого являются все
возможные значения свойства, используемого для теста, а данными — поддеревья
разбиения. Это делается с помощью макроса dolist, который связывает с каждым
элементом списка локальную переменную и оценивает ее. Пока элементами списка являются
пустые экземпляры структуры example-frame, элементы, соответствующие каждой
подзадаче, связываются со значением nil. С помощью формы dolist функция
partition помещает каждый элемент root-frame в соответствующий элемент
поддерева переменной parts. При этом используется макрос LISP push, модифицирующий
список за счет добавления нового первого элемента. В отличие от cons функция push
постоянно добавляет новые элементы в список.
Этот фрагмент кода отвечает за разбиение множества root-frame. По завершении
работы функции dolist переменная parts представляет ассоциативный список, в
котором каждый ключ является значением свойства, а каждый элемент данных —
множеством примеров, для которых выбранное свойство принимает данное значение. С
помощью функции mapcar пополняется информация о каждом подмножестве примеров
переменной parts. При этом соответствующие значения присваиваются элементам
properties, classifier, size и information. Затем строится экземпляр
структуры partition, элемент components которой связывается с переменной parts.
Во второй ветви функции build-tree для создания листового узла при
неоднозначной классификации используется функция list-classes. В ней для перечисления
классов, которым соответствует список примеров, применяется цикл do. В этом цикле
список classes инициализируется всеми значениями классификатора из training-
frame. Если в списке training-frame содержится элемент, принадлежащий
некоторому классу, то этот класс добавляется в список classes-present.
(defun list-classes (training-frame)
(do
((classes (property-values (example-frame-classifier
training-frame))
(cdr classes))
(classifier (property-test (example-frame-classifier
training-frame)))
classes-present) ;результаты накапливаются в локальной
переменной
((null classes) classes-present) ;выход из цикла
Глава 15. Введение в LISP
769
(if (member (car classes) (example-frame-instances
training-frame)
:test #'(lambda (x y) (equal x (funcall classifier y))))
(push (car classes) classes-present))))
Остальные функции используются для извлечения из примеров необходимой
информации. Функция compute-information определяет информационное содержимое
списка примеров. Она вычисляет количество примеров для каждого класса и долю
каждого класса во всем множестве обучающих примеров. Если предположить, что эта доля
соответствует вероятности принадлежности объекта данному классу, то можно
вычислить информативность примеров по определению Шеннона.
(defun compute-information (examples classifier)
(let ((class-count
(mapcar #'(lambda (x) (cons x 0)) (property-values
classifier)))
(size 0))
; вычисление количества примеров для каждого класса
(dolist (instance examples)
(incf size)
(incf (cdr (assoc (funcall (property-test classifier)
instance)
class-count))))
;вычисление информативности примеров
(sum #'(lambda (x) (if (= (cdr x) 0) 0
(* -1
(/ (cdr x) size)
(log (/ (cdr x) size) 2))))
class-count)))
Функция compute-info-gain вычисляет прирост информации для данного
разбиения путем вычитания взвешенного среднего информации компонентов из
соответствующего значения, полученного для родительских примеров.
(defun compute-info-gain (root parts)
(- (example-frame-information root)
(sum #' (lambda (x) (* (example-frame-information (cdr x) )
(/ (example-frame-size (cdr x))
(example-frame-size root))))
parts)))
Функция sum вычисляет значения, получаемые в результате применения функции f
ко всем элементам списка list-of-numbers.
(defun sum (f list-of-numbers)
(apply '+ (mapcar f list-of-numbers)))
На этом реализация функции build-tree завершена. Осталось реализовать
функцию classify, которая на основе дерева решений, построенного функцией build-
tree, выполняет классификацию указанного объекта путем рекурсивного прохода по
дереву. Эта функция достаточно проста. Ее выполнение завершается по достижении
листа. При этом в каждом узле проверяется значение соответствующего свойства
классифицируемого объекта, а полученный результат используется в качестве ключа для выбора
ветви при вызове функции assoc.
770 Часть VI. Языки и технологии программирования для искусственного интеллекта
(defun classify (instance tree)
(if (leaf-p tree)
(leaf-value tree)
(classify instance
(cdr (assoc (funcall (decision-tree-test tree) instance)
(decision-tree-branches tree))))))
Теперь вызовем функцию build-tree для примера из табл. 9.1. Свяжем символ
tests со списком определений свойств для кредитной истории, долга, поручительства и
дохода, а символ classifier — со значением риска для данного примера. С помощью
этих определений примеры из таблицы можно связать с экземпляром example-frame.
(setq tests
(list (make-property
:name 'history
:test #'history
:values '(good bad unknown))
(make-property
:name 'debt
:test #'debt
rvalues '(high low))
(make-property
:name 'collateral
:test #'collateral
:values '(none adequate))
(make-property
:name 'income
:test #'income
rvalues '@-to-15k 15k-to-35k over-35k))))
(setq classifier
(make-property
:name 'risk
:test #'risk
•.values ' (high moderate low) ) )
(setq credit-examples
(make-example- frame
:instances examples
:properties tests
iclassifier classifier
:size (list-length examples)
.•information (compute-information examples class)))
На основе этих определений можно построить деревья решений и использовать их
для классификации примеров по их кредитному риску.
> (setq credit-tree (build-tree credit-examples))
#S(decision-tree
: test-name income
:test #<Compiled-function income #x3525CE>
:branches
(@-to-15k . #S(leaf rvalue high))
A5k-to-35k .
#S(decision-tree
Глава 15. Введение в LISP
771
:test-паше history
:test #<Compiled-function history #x3514D6>
:branches
((good . #S(leaf rvalue moderate))
(bad . #S(leaf rvalue high))
(unknown .
#S(decision-tree
:test-name debt
:test #<Compiled-function debt #x351A7E>
:branches
(((high . #S(leaf rvalue high))
(low . #S(leaf rvalue
moderate))))))))
(over-35k .
#S(decision-tree :test-name
history
:test #<Compiled-function
history #x...6>
:branches
((good . #S(leaf rvalue
low) )
(bad . #S(leaf rvalue
moderate))
(unknown . #S(leaf
rvalue low)))))))
>(classify '((history . good) (debt . low (collateral . none)
(income . 15k-to-35k))
credit-tree) moderate
15.14. Резюме и дополнительная литература
И PROLOG и LISP основаны на формальной математической модели вычислений:
PROLOG — на логике и методах доказательства теорем, a LISP — на теории
рекурсивных функций. Указанное свойство выделяет эти языки из множества более
традиционных языков программирования, структура которых определяется архитектурой
используемых аппаратных средств. Унаследовав синтаксис и семантику от математических
рассуждений, LISP и PROLOG получили также их выразительную мощь и ясность.
В то время как PROLOG — более новый из этих двух языков — остался близок к
своим теоретическим корням, LISP развился настолько, что его уже нельзя назвать
чисто функциональным языком программирования. Прежде всего он стал
практическим языком программирования, поддерживающим полный спектр современных
технологий. К ним относятся функциональное и прикладное программирование,
абстрактные типы данных, обработка потоков, оценивание с задержкой и объектно-
ориентированное программирование.
Преимущество LISP состоит в том, что для него разработан широкий диапазон
современных методов программирования, расширяющих базовую модель
функционального программирования. Эти средства в сочетании с возможностями списков по созданию
различных символьных структур данных составляют основу современного
программирования на LISP. В этой главе авторы пытались проиллюстрировать этот стиль.
772 Часть VI. Языки и технологии программирования для искусственного интеллекта
При разработке алгоритмов для этой главы использована книга [Abelson и Sussman,
1985]. Хорошим руководством по изучению Common LISP является [Steele, 1990]. Кроме
того, можно порекомендовать такие учебники по программированию на LISP, как
[Touretzky, 1990], [Hasemer и Domingue, 1989J, [Graham, 1993] и [Graham, 1995].
Многие книги посвящены применению языка LISP для разработки систем решения
задач искусственного интеллекта. Так, [Forbus и deKleer, 1993] содержит описание
реализации известных алгоритмов ИИ на LISP и является незаменимым пособием для
специалистов по практической реализации методов искусственного интеллекта. Кроме того,
существует множество книг, посвященных общим проблемам искусственного интеллекта
и их решению на основе LISP. К ним относятся [Noyes, 1992] и [Tanimoto, 1990].
15.15. Упражнения
1. Метод Ньютона нахождения квадратного корня из числа предполагает вычисление
значения корня и проверку его точности. Если найденное решение не обладает
требуемой точностью, вычисляется новая оценка, и процесс повторяется. Псевдокод
этой процедуры имеет следующий вид.
function root-by-newtons-method (х, tolerance)
guess := 1;
repeat
guess := 1/2(guess + x/guess)
until absolute-value(x - guess * guess) < tolerance
Напишите на LISP рекурсивную функцию вычисления квадратных корней по методу
Ньютона.
2. а. Напишите на LISP рекурсивную функцию обращения элементов списка (не
используя встроенную функцию reverse). Оцените сложность реализации. Можно ли
реализовать обращение списка за линейное время?
б. Напишите на LISP рекурсивную функцию, получающую вложенный список
произвольной длины и выводящую зеркальный образ этого списка. В частности,
функция должна демонстрировать такое поведение.
> (mirror '((а Ь) (с (d е))))
(((е d) с) (Ь а))
3. Напишите на LISP генератор случайных чисел. Эта функция должна поддерживать
глобальную переменную seed и возвращать разные случайные числа при каждом вызове.
Описание алгоритма генерации случайных чисел найдите в специальной литературе.
4. Напишите функции initialize, push, top, pop и list-stack,
поддерживающие глобальный стек. Они должны вести себя следующим образом.
> (initialize)
nil
> (push 'foo)
foo
> (push 'bar)
bar
> (top)
bar
> (list-stack)
Глава 15. Введение в LISP
773
(bar foo)
> (pop)
bar
> (list-stack)
(foo)
5. Множества можно представить с помощью списков, не содержащих повторяющихся
элементов. Напишите на LISP свою реализацию операций объединения, пересечения
и вычитания множеств union, intersection и difference. (He пользуйтесь
встроенными в Common LISP версиями этих функций.)
6. Задача башен Ханоя основана на следующей легенде.
В дальневосточном монастыре существует головоломка, состоящая из трех
бриллиантовых иголок и 64 золотых дисков различного размера. Изначально диски были
нанизаны на одну иглу и упорядочены по уменьшению размера. Монахи пытаются
переместить все диски на другую иглу по следующим правилам.
6.1. Диски можно перемещать только по одному.
6.2. Ни один диск не может располагаться поверх диска меньшего размера.
Согласно легенде, когда эта задача будет решена, наступит конец света.
Напишите на LISP программу для решения этой задачи. Для простоты (и чтобы
программа завершила свою работу еще при вашей жизни), не пытайтесь решить полную
задачу о 64 дисках. Попробуйте рассмотреть 3 или 4 диска.
7. Напишите компилятор для оценки арифметических выражений вида
(оператор операнд! операнд2 ),
где оператор — это +, -, * или /, а операндами являются числа или вложенные
выражения. Примером допустимого выражения является (*(+ 3 6) (- 7 9)). Допустим,
что целевая машина поддерживает инструкции:
(move value register)
(add register-1 register-2)
(subtract register-1 register-2)
(times register-1 register-2)
(divide register-1 register-2) ЛЛ|
Результаты всех арифметических операций присваиваются аргументу, хранящемуся
в первом регистре. Для простоты количество регистров считайте неограниченным.
Компилятор должен получать арифметическое выражение и возвращать список
указанных машинных операций.
8. Реализуйте алгоритм поиска в глубину с возвратами (аналогичный использованному в
разделе 15.2 при решении задачи переправы человека, волка, козы и капусты) для
решения задачи миссионера и каннибала. Задача формулируется следующим образом.
Три миссионера и три каннибала стоят на берегу реки и хотят переправиться через
нее. У берега находится лодка, в которую могут поместиться только два человека, и
ни одна из групп не умеет плавать. Если на одном из берегов реки миссионеров
окажется больше, чем каннибалов, то каннибалы превратятся в миссионеров. Требуется
найти последовательность перемещений всех людей через реку, не влекущую за
собой никаких превращений.
9. Реализуйте алгоритм поиска в глубину для решения задачи о кувшинах с водой.
774 Часть VI. Языки и технологии программирования для искусственного интеллекта
Имеются два кувшина емкостью 3 и 5 литров воды соответственно. Их можно заполнять,
опорожнять и сливать воду из одного в другой до тех пор, пока один из них не окажется
полным или пустым. Выработайте последовательность действий, при которой в большем
кувшине окажется 4 литра воды. (Совет: используйте только целые числа.)
10. Реализуйте функции build-solution и eliminate-duplicates для
алгоритма поиска в ширину из раздела 15.3.
11. Используйте разработанный в упражнении 10 алгоритм поиска в ширину для
решения следующих задач.
11.1. Задача переправы человека, волка, козы и капусты (см. раздел 15.2).
11.2. Задача миссионера и каннибала (см. упражнение 8).
11.3. Задача о двух кувшинах (см. упражнение 9).
Сравните полученные результаты с результатами работы алгоритма поиска в
глубину. Различия должны особенно четко проявиться в задаче о двух кувшинах. Почему?
12. Завершите реализацию "жадного" алгоритма поиска из подраздела 15.3.3.
Используйте его с учетом соответствующих эвристик для решения каждой из трех задач,
перечисленных в упражнении 11.
13. Напишите на LISP программу решения задачи о 8 ферзях. (Задача состоит в
нахождении на шахматной доске такой позиции для 8 ферзей, чтобы они не могли побить
друг друга за 1 ход. Следовательно, никакие два ферзя не должны располагаться в
одном ряду, столбце или на одной диагонали.)
14. Напишите на LISP программу решения полной версии задачи о ходе конем для
доски 8x8.
15. Реализации алгоритмов поиска в ширину, в глубину и "жадного" алгоритма с
использованием списков open и closed очень близки друг другу. Они различаются
только реализацией списка open. Напишите общую функцию поиска, реализующую
любой из трех алгоритмов поиска, определив функцию поддержки списка open в
качестве параметра.
16. Перепишите функцию print-solution из реализации интерпретатора для
решения задач логического программирования таким образом, чтобы она выводила
первое решение и ожидала запроса пользователя (например, символ возврата каретки)
для вывода второго решения.
17. Модифицируйте интерпретатор для решения задач логического программирования
таким образом, чтобы он поддерживал операторы or и not. Дизъюнктивное
выражение должно принимать значение "истина", если такое значение принимает хотя бы
один из дизъюнктов. При обработке дизъюнктивных выражений интерпретатор
должен возвращать объединение всех решений, возвращаемых дизъюнктами. Отрицание
реализовать несколько сложнее, поскольку отрицание цели истинно только в том
случае, если целевое утверждение принимает значение "ложь". Поэтому для
отрицания цели нельзя возвращать никаких связанных переменных. Это результат
предположения о замкнутости мира, описанного в разделе 12.3.
18. Реализуйте общие функции отображения и фильтрации map-stream и filter-
stream, описанные в разделе 15.8.
19. Перепишите программу решения задачи поиска первых п нечетных чисел
Фибоначчи с использованием общего фильтра потока filter-stream вместо функции
Глава 15. Введение в LISP
775
filter-odds. Модифицируйте ее таким образом, чтобы программа возвращала
первые п четных чисел Фибоначчи, а затем снова измените программу для
вычисления квадратов первых п чисел Фибоначчи.
20. Дополните интерпретатор для решения задач логического программирования
операторами LISP write. Это позволит выводить сообщения непосредственно пользователю.
Совет: сначала модифицируйте функцию solve так, чтобы она проверяла, является ли
целевое утверждение оператором write. При положительном ответе оцените
функцию write и верните поток, содержащий исходное множество подстановок.
21. Дополните язык логического программирования, включив в него арифметические
операторы сравнения =, < и >. Совет: как и в упражнении 20, сначала модифицируйте
функцию solve для выявления этих операторов до вызова функции infer. Если
выражение содержит оператор сравнения, замените все переменные их значениями и
оцените это выражение. Если результатом оценивания будет nil, функция solve должна
возвратить пустой поток. В противном случае она возвращает поток, содержащий
исходное множество подстановок. Будем предполагать, что выражения не содержат
несвязанных переменных. В качестве более сложного упражнения определите оператор =
как функцию (подобно оператору is в PROLOG), присваивающую значение
несвязанной переменной и выполняющую проверку равенства, если все элементы связаны.
22. Используйте разработанные в упражнении 21 арифметические операторы в
интерпретаторе для решения задач логического программирования для решения задачи
консультанта по финансовым вопросам из главы 2.
23. Выберите задачу (например, диагностики автомобилей или классификации видов
животных) и решите ее с помощью оболочки lisp-shell.
24. Модифицируйте оболочку экспертной системы из раздела 15.10 таким образом,
чтобы в качестве ответов пользователя допускались не только значения у и п.
Например, пользователь может задать связанные переменные для целевого утверждения.
Для этого нужно изменить функцию ask-for и связанные с ней функции и
позволить пользователю вводить шаблоны, соответствующие целевому утверждению.
В случае соответствия нужно запрашивать у пользователя коэффициент достоверности.
25. Дополните оболочку lisp-she 11 оператором not. В качестве примера обработки
отрицания цели с использованием рассуждений с неопределенностью используйте материал
главы 7 и оболочку экспертной системы из главы 14, написанную на языке PROLOG.
26. Напишите ATN-анализатор (раздел 11.3) для некоторого подмножества английского
языка.
27. Добавьте в модель из раздела 15.12 систему охлаждения, понижающую температуру
в комнате, если она превышает заданное значение. Для каждой комнаты введите
коэффициент теплоемкости, чтобы степень нагревания и охлаждения комнаты зависела
от ее объема и изолированности.
28. Создайте в системе CLOS модель для другой предметной области, например для
экосистемы.
29. Примените алгоритм ШЗ для решения другой задачи, выбранной по своему усмотрению.
776 Часть VI. Языки и технологии программирования для искусственного интеллекта
Часть VII
Эпилог
Потенциал компьютерных наук (при его полном изучении и реализации) поставит нас
на более высокую ступень знания о мире. Компьютерные науки помогут нам достичь
более глубокого понимания интеллектуальных процессов. Они углубят наши знания о
процессах обучения, мышления и анализа. Мы сможем построить модели и
концептуальные средства для развития науки о познании. Подобно доминирующей роли физики
в нашем веке при изучении природы материи и начала вселенной, сегодня на первый
план выступает изучение интеллектуальной вселенной идей, структур знаний и языка.
По моему мнению, это приведет к существенным улучшениям, которые в корне
изменят нашу жизнь... Мне кажется, недалек тот час, когда мы поймем принципы
организации знаний и управления ими...
— Дж. Хопкрофт (J. Hopcroft),
лекция по случаю вручения премии Тьюринга, 1987
Что такое мышление? Нематериальная субстанция.
Что такое материя? Этого никогда не осмыслить...
— Гомер Симпсон (Homer Simpson)
Мы научимся, когда поймем, что это важно.
— Эрл Уивер (Weaver)
Рассуждения о природе интеллекта
Хотя в этой книге затрагивается множество философских аспектов искусственного
интеллекта, основное внимание сосредоточено на инженерных технологиях,
используемых для построения интеллектуальных артефактов на основе компьютера. В заключение
книги мы вернемся к более сложным вопросам философских основ искусственного
интеллекта, постараемся еще раз переосмыслить возможности науки о познании на основе
методологии ИИ, а также обсудить будущие направления развития этой дисциплины.
Как неоднократно отмечалось ранее, исследования человеческого познания и
способов решения задач человеком внесли существенный вклад в теорию искусственного
интеллекта и разработку его программного обеспечения. В свою очередь, работы в области
ИИ обеспечили возможность построения моделей и экспериментальную проверку науч-
ных результатов во многих дисциплинах, в том числе биологии, лингвистике и
психологии познания. В заключение мы обсудим такие темы, как ограниченность представлений,
важность физического овеществления процессов мышления и роль культуры в
накоплении и интерпретации знаний. Эти вопросы приводят к таким новым научным и
философским проблемам, как опровержимость моделей или природа и возможности самого
научного метода. Опыт автора привел его к междисциплинарному подходу,
объединяющему работы в области ИИ с исследованиями психологов, лингвистов, биологов,
антропологов, эпистемологов и специалистов в других областях, изучающих весь спектр
проблем человеческого мышления.
Традиционно работы в области искусственного интеллекта основывались на гипотезе
о физической символьной системе [Newell и Simon, 1976]. В рамках этого подхода были
разработаны сложные структуры данных и стратегии поиска, которые, в свою очередь,
привели к получению множества важных результатов. Были созданы системы,
обладающие элементами интеллектуального поведения, и выявлены многие компоненты,
составляющие интеллект человека. Важно отметить, что большинство результатов, основанных
на этих ранних подходах, были ограничены предположениями, вытекающими из
философии рационализма. Согласно рационалистской традиции сам интеллект
рассматривается как процесс логических рассуждений и решения научных задач, основанный на
прямом, эмпирическом подходе к пониманию вселенной. Этот философский
рационализм слишком ограничивает развитие искусственного интеллекта на современном этапе.
В книге представлено множество более современных разработок, в том числе
альтернативные модели обучения, агентно-ориентированные и распределенные системы
решения задач, подходы, связанные с овеществлением интеллекта, а также исследования по
реализации эволюционных вычислений и искусственной жизни. Эти подходы к
пониманию интеллекта обеспечивают необходимые альтернативы идеям рационалистского
редукционизма. Биологические и социальные модели интеллекта показали, что
человеческий разум во многом является продуктом нашего тела и ощущений. Он связан с
культурными и социальными традициями, навеян произведениями искусства, нашим опытом
и опытом окружающих людей. Создавая методы и компьютерные модели таких сложных
процессов, как эволюция или адаптация нейросетевых структур человеческого мозга,
исследователи в области ИИ получили множество новых мощных результатов,
дополняющих более традиционные методологии.
Искусственный интеллект, подобно самим компьютерным наукам, — довольно новая
область. Если процесс развития физики или биологии измеряется столетиями, то возраст
современных компьютерных наук исчисляется десятками лет. В главе 16 мы постараемся
интегрировать различные подходы к ИИ в единую науку создания интеллектуальных
систем. Автор считает, что эта наука, технология, философия и жизненное кредо
приведут к возможности создания новых артефактов и экспериментов, которые при
корректном использовании позволят глубже понять общие принципы построения
интеллектуальных систем. В этой главе рассматриваются предложенные в главе 1 традиции
изучения эпистемологических основ ИИ. Это делается не для того, чтобы дать достойный
ответ критикам (хотя многие из их нападок все еще требуют ответа), а с позитивной
целью — исследовать и осветить пути развития этой науки.
778
Часть VII. Эпилог
Искусственный
интеллект
как эмпирическая
проблема
Теория вычислительных систем — дисциплина эмпирическая. Молено было бы назвать
ее экспериментальной наукой, но, подобно астрономии, экономике и геологии, некоторые
из ее оригинальных форм испытаний и наблюдений невозможно втиснуть в узкий
стереотип экспериментального метода. Тем не менее это эксперименты. Конструирование
каждого нового компьютера — это эксперимент. Сам факт создания машины ставит
вопрос перед природой; и мы получаем ответ на него, наблюдая за машиной в действии,
анализируя ее всеми доступными способами. Каждая новая программа — это
эксперимент. Она ставит вопрос природе, и ее поведение дает нам ключи к разгадке. Ни машины,
ни программы не являются "черными ящиками", это творения наших рук,
спроектированные как аппаратно, так и программно; мы можем снять крышку и заглянуть внутрь.
Мы можем соотнести их структуру с поведением и извлечь множество уроков из одного-
единственного эксперимента.
— Ньюэлл (A. Newell) и Саймон (Н.A. Simon),
лекция по случаю вручения премии Тьюринга, 1976
Изучение мыслящих машин дает нам больше знаний о мозге, чем самоанализ.
Западный человек воплощает себя в устройствах.
— Уильям С. Берроуз (William Burroughs), Завтрак нагишом
Где то знание, что утеряно в информации ?
— Т. С. Элиот (T.S. Eliot), хоры из поэмы "Скала"
16.0. Введение
Для многих людей наиболее удивительным аспектом работы в сфере искусственного
интеллекта является степень, в которой ИИ, да и большая часть теории вычислительных
систем, оказывается эмпирической дисциплиной. Этот аспект удивителен, поскольку
большинство рассматривает эти области в терминах своего математического или
инженерного образования. Пунктуальным математикам свойственно желание применить к
конструированию интеллектуальных устройств привычные им логические рассуждения и
анализ. С точки зрения "неряшливых" инженеров, задача часто состоит лишь в создании
систем, которые общество назвало бы "разумными". К несчастью, а может, и наоборот
(в зависимости от точки зрения), сложность интеллектуальных программ и
неопределенность, присущая их взаимодействию с миром природы и человеческой деятельности,
делают невозможным анализ с чисто математической или чисто инженерной точек зрения.
Более того, если мы пытаемся довести исследования искусственного интеллекта до
уровня науки и сделать их неотъемлемой частью теории интеллектуальных систем
(science of intelligent systems), то в процессе конструирования, использования и анализа
артефактов должны применять смесь из аналитических и эмпирических методов. С этой
точки зрения каждая программа ИИ должна рассматриваться как эксперимент: он ставит
вопрос перед природой, и ответ на него — это результат выполнения программы. Отклик
природы на заложенные конструкторские и программные принципы формирует наше
понимание формализма, закономерностей и самой сути мышления.
В отличие от многих традиционных наук, изучающих человеческое познание,
разработчики разумных компьютерных систем могут исследовать внутренние механизмы
своих "подопытных". Они могут останавливать выполнение программы, изучать ее
внутреннее состояние и как угодно модифицировать ее структуру. Как отметили Ньюэлл и
Саймон, устройство компьютеров и компьютерных программ предопределяет их
потенциальное поведение, возможность всестороннего исследования, и доступность для
понимания. Сила компьютеров как инструментов для изучения интеллекта проистекает из
этой двойственности. Соответствующим образом запрограммированные компьютеры
способны достигнуть высокой степени сложности как в семантике, так и в поведении.
Такие системы естественно охарактеризовать в терминах физиологии. Кроме того,
можно исследовать их внутренние состояния, что в большинстве случаев не могут
осуществить ученые, занимающиеся разумными формами жизни.
К счастью для работ в сфере ИИ, равно как и для становления теории
интеллектуальных систем, современные физиологические методы, в особенности относящиеся к
нейрофизиологии, пролили свет на многие аспекты человеческого мышления. Например,
сегодня мы знаем, что функция человеческого интеллекта не цельна и однородна. Она,
скорее, является модульной и распределенной. Достоинства этого подхода проявляются
в работе органов чувств, например, сетчатки глаза, которая умеет фильтровать и
предварительно обрабатывать визуальную информацию. Точно так же обучение нельзя назвать
однородной, гомогенной способностью. Скорее, оно является функцией множества
различных систем, каждая из которых адаптирована для специфических целей. Магнитно-
резонансное сканирование, позитронная эмиссионная томография и другие методы
получения изображений нервной системы дают яркую и точную картину внутреннего
устройства естественных интеллектуальных систем.
Приближая ИИ к масштабам науки, необходимо решать важные философские
проблемы, особенно относящиеся к эпистемологии, или вопрос о том, как интеллектуальная
система "познает" свой мир. Эти проблемы варьируются от вопроса о том, что есть
предметом изучения искусственного интеллекта, до более глубоких, таких как
обоснованность и применимость гипотезы о физической символьной системе. Далее следуют
вопросы о том, что такое "символ" в символьной системе, и как символы могут
соотноситься с узлами коннекционистской модели. Рассматривается вопрос о роли
рационализма, выраженного в форме индуктивного порога и представленного в большинстве
обучающихся программ. Возникает вопрос, как соотнести это с недостаточной структу-
780
Часть VII. Эпилог
рированностью, присущей обучению без учителя, обучению с подкреплением и
эволюционным подходам. И, наконец, необходимо рассмотреть роль конструктивного
исполнения, внедрения агентов и социологических предпосылок решения задач. В заключение
дискуссии о философских вопросах будет предложена эпистемология в духе
конструктивизма, которая естественным образом согласуется с предложенным подходом к
рассмотрению ИИ как науки, так и эмпирической проблемы.
Итак, в этой заключительной главе мы вновь возвращаемся к вопросу, поставленному в
главе 1: что такое интеллект? Поддается ли он формализации? Как построить системы,
проявляющие это свойство? Каким образом искусственный и человеческий интеллект
вписываются в более широкий контекст теории интеллектуальных систем? В разделе 16.1
рассматривается пересмотренное определение искусственного интеллекта. Оно
свидетельствует о следующем. Хотя работа в области ИИ и основана на гипотезе о физической
символьной системе Ньюэлла и Саймона, сегодня набор ее средств и методов значительно
расширился. Эта область покрывает гораздо более широкий круг вопросов. Анализируются
альтернативные подходы к вопросу об интеллекте. Они рассматриваются и как средства
проектирования интеллектуальных устройств, и как составные части теории
интеллектуальных систем. В разделе 16.2 основное внимание читателя будет сконцентрировано на
использовании методов современной когнитивной психологии, нейросетевых вычислений и
эпистемологии для лучшего понимания области искусственного интеллекта.
Наконец, в разделе 16.3 обсуждаются задачи, стоящие сегодня как перед практиками
ИИ, так и перед специалистами по формированию понятий. Хотя традиционные подходы
к ИИ зачастую обвиняют в рационалистском редукционизме, новые междисциплинарные
методы тоже нередко страдают подобными недостатками. Например, разработчики
генетических алгоритмов и исследователи искусственной жизни определяют интеллект с
точки зрения дарвинизма: "Разумно то, что выживает". Знание в сложном мире
внедренных агентов часто сводится к формуле "знаю, как сделать", а не к "знаю, что делаю". Но
для ученых ответы требуют пояснений, их не устраивает одна лишь "успешность" или
"выживаемость" моделей. В этой заключительной главе мы обсудим будущее ИИ,
сформулировав насущные для создания вычислительной теории интеллекта вопросы, и
придем к выводу, что эмпирическая методология является важным, если не наилучшим
орудием для исследования природы интеллекта.
16.1. Искусственный интеллект: пересмотренное
определение
16.1.1. Интеллект и гипотеза о физической символьной системе
Основываясь на материале предыдущих 15 глав, можно сформулировать
пересмотренное определение искусственного интеллекта.
ИИ— это дисциплина, исследующая закономерности, лежащие в основе
разумного поведения, путем построения и изучения артефактов,
предопределяющих эти закономерности.
Согласно этому определению искусственный интеллект в меньшей степени представляет
собой теорию закономерностей, лежащих в основе интеллекта, и в большей — эмпирическую
методологию создания и исследования всевозможных моделей, на которые эта теория опира-
Глава 16. Искусственный интеллект как эмпирическая проблема
781
ется. s^tot вывод проистекает из научного метода проектирования и проведения
экспериментов с целью усовершенствования текущей модели и постановки дальнейших экспериментов.
Однако это определение, как и сама область ИИ, бросает вызов многовековому
философскому мракобесию в вопросе природы разума. Оно дает людям, которые жаждут понимания (что,
возможно, является главной характеристикой человека), альтернативу религии, суевериям,
картезианскому дуализму, пустым теориям нового времени или поискам разума в каких-то не
открытых еще закоулках квантовой механики [Penrose, 1989]. Если наука, исследующая
искусственный интеллект, и внесла какой-то вклад в человеческие знания, то он подтверждает
следующее. Разум — это не мистический эфир, пронизывающий людей и ангелов, а, скорее,
проявление принципов и законов, которые можно постичь и применить в конструировании
интеллектуальных машин. Необходимо отметить, что наше пересмотренное определение не
касается интеллекта, оно определяет роль искусственного интеллекта в изучении природы и
феномена разумности.
Исторически главенствующий подход к искусственному интеллекту включал
построение формальных моделей и соответствующих им механизмов рассуждений,
основанных на переборе. Ведущим принципом ранней методологии искусственного
интеллекта являлась гипотеза о физической символьной системе (physical symbol system),
впервые сформулированная Ньюэллом и Саймоном [Newell и Simon, 1976]. Эта гипотеза
гласит следующее.
Физическая система проявляет разумное в широком смысле поведение
тогда и только тогда, когда она является физической символьной системой.
Достаточность означает, что разумность может быть достигнута
каждой правильно организованной физической символьной системой.
Необходимость означает, что каждый агент, проявляющий разумность в
общепринятом смысле, должен являться физической символьной системой.
Необходимое условие этой гипотезы требует, чтобы любой разумный агент,
будь-то человек, инопланетянин или компьютер, достигал разумного
поведения путем физической реализации операций над символьными структурами.
Разумное в широком смысле поведение (general intelligent action) означает
действия, характерные для поведения человека. Физически ограниченная
система ведет себя соответственно своим целям, приспосабливаясь к
требованиям окружающей среды.
Ньюэлл и Саймон собрали аргументы в пользу необходимого и достаточного условий
[Newell и Simon, 1976]; [Newell, 1981]; [Simon, 1981]. В последующие годы специалисты
в области ИИ и когнитологии исследовали территорию, очерченную этой гипотезой.
Гипотеза о физической символьной системе привела к трем важнейшим принципам
методологии: использованию символов и символьных систем в качестве средства для
описания мира; разработке механизмов перебора, в особенности эвристического, для
исследования границ потенциальных умозаключений таких систем; отвлеченности
когнитивной архитектуры. Имеется в виду предположение о том, что правильно построенная
символьная система может проявлять интеллект в широком смысле независимо от
средств реализации. Наконец, с этой точки зрения ИИ становится эмпирической и
конструктивной дисциплиной, которая изучает интеллект, строя его действующие модели.
Языковые знаки, называемые символами, используются для обозначений или ссылок на
различные сторонние объекты. Как вербальные знаки в естественном языке, символы заме-
782
Часть VII. Эпилог
няют или ссылаются на конкретные вещи в мире разумного агента. Например, для этих
объектно-ссылочных связей можно предложить некоторый вариант семантики (см. раздел 2.3).
С точки зрения символьных систем использование символов в ИИ уходит далеко за
пределы такой семантики. Символами здесь представляются все формы знаний, опыта,
понятий и причинности. Все подобные конструктивные работы опираются на тот факт,
что символы вместе со своей семантикой могут использоваться для построения
формальных систем. Они определяют язык представления (representation language). Эта
возможность формализовать символьные модели принципиальна для моделирования
интеллекта как выполняемой компьютерной программы. В этой книге было детально изучено
несколько представлений, в том числе предикатное исчисление, семантические сети,
сценарии, концептуальные графы, фреймы и объекты.
Математика формальных систем позволяет говорить о таких вещах, как
непротиворечивость, полнота и сложность, а также обсуждать организацию знаний.
Эволюция формализмов представления позволяет установить более сложные (широкие)
семантические отношения. Например, системы наследования формируют семантическую
теорию таксономического знания и его роли в интеллекте. Формально определяя
наследование классов, такие языки облегчают построение интеллектуальных программ и
предоставляют удобно тестируемые модели организации возможных категорий интеллекта.
Схемы представления и их использование в формальных рассуждениях тесно связаны с
понятием поиска. Поиск — это поочередная проверка узлов в априори семантически
описанной сети представления на предмет нахождения решения задачи или подзадач, выявления
симметрии задачи и тому подобного (в зависимости от рассматриваемого аспекта).
Представление и поиск связаны, поскольку соотнесение задачи с конкретным
представлением определяет априорное пространство поиска. Действительно решение многих
задач можно значительно усложнить, а то и вовсе сделать невозможным, неудачно
выбрав язык представления. Последующее обсуждение индуктивного порога в этой главе
проиллюстрирует эту точку зрения.
Выразительным и часто цитируемым примером связи между поиском и
представлением, а также трудности выбора удобного представления является задача размещения
костей домино на усеченной шахматной доске. Допустим, имеется шахматная доска и
набор костей домино, причем каждая закрывает ровно две клетки на доске. Положим
также, что у доски не хватает нескольких клеток — на рис. 16.1 отсутствуют верхний
левый и нижний правый уголки.
I I I I I 1 1 ♦
1 1 1 1 I 1 1 1 ♦
Рис. 16.1. Усеченная шахматная доска с двумя клетками, закрытыми
костью домино
Глава 16. Искусственный интеллект как эмпирическая проблема
783
Задача состоит в том, чтобы установить, можно ли разместить кости домино на доске
так, чтобы все поля были закрыты, и при этом каждая кость покрывала две и только две
клетки. Можно попытаться решить проблему, перебрав все варианты расположения
костей. Это типичный пример решения на основе поиска, который является естественным
следствием представления доски в виде простой матрицы, игнорирующим такие,
казалось бы, незначительные особенности, как цвет поля. Сложность подобного поиска
просто невероятна. Для эффективного решения необходимо применение эвристических
методов. Например, можно отсечь частные решения, которые оставляют изолированными
отдельные клетки. Можно также начать с решения задачи для досок меньшего размера,
таких как 2x2, 3x3, и постараться расширить решение до ситуации 8x8.
Опираясь на более сложное представление, можно получить изящное решение. Для
этого нужно учесть тот факт, что каждая кость должна одновременно покрывать белую и
черную клетки. На усеченной доске 32 черные клетки, но лишь 30 белых, следовательно,
требуемое размещение невозможно. Таким образом, в системах, основанных на
символьных рассуждениях, возникает серьезный вопрос: существуют ли представления,
позволяющие оперировать знаниями с такой степенью гибкости и творческого подхода?
Как может конкретное представление изменять свою структуру по мере появления новых
сведений о предметной области?
Эвристика — это третий важный компонент символьного ИИ после представления и
поиска. Эвристика — это механизм организации поиска среди альтернатив,
предлагаемых конкретным представлением. Эвристики разрабатываются для преодоления
сложности полного перебора, являющейся непреодолимым барьером на пути получения
полезных решений многих классов интересных задач. В компьютерной среде, как и в
человеческом обществе, интеллект нуждается в обоснованном решении "что делать дальше".
На протяжении истории развития ИИ эвристики принимали множество форм.
Такие ранние методы решения задач, как метод поиска экстремума (hill climbing) в
шашечной программе (см. главу 4) или анализ целей и средств (means-ends analysis) в
обобщенной системе решения задач General Problem Solver (см. главу 12), пришли в ИИ
из других дисциплин, таких как исследование операций (operations research), и
постепенно выросли до общеприменимых методов решения задач ИИ. Характеристики поиска,
включая допустимость (admissibility), монотонность (monotonicity) и осведомленность
(informedness), являются важными результатами этих ранних работ. Подобные методы
часто называют слабыми (weak methods). Слабые методы были разработаны как
универсальные стратегии поиска, рассчитанные на применение в целых классах предметных
областей [Newell and Simon, 1972], [Ernst и Newell, 1969]. Эти методы и их
характеристики рассмотрены в главах 3, 4, 5 и 12.
В главах 6, 7 и 8 представлены сильные методы (strong methods) для решения задач
ИИ с использованием экспертных систем на основе продукционных правил,
рассуждений с использованием моделей (model-based reasoning) и примеров (case-based reasoning),
а также символьного обучения (symbol-based learning). В отличие от слабых, сильные
методы фокусируют внимание на информации, специфичной для каждой предметной
области, будь то медицина внутренних органов или интегральное исчисление. Сильные
методы лежат в основе экспертных систем и других подходов к решению задач с активным
усвоением знаний. В сильных методах особое значение придается количеству данных,
необходимых для решения задачи, обучению и пополнению знаний, их синтаксическому
представлению, управлению неопределенностью, а также вопросам о качестве знаний.
784
Часть VII. Эпилог
Почему до сих пор не существует действительно интеллектуальных
символьных систем
Характеристика интеллекта как физической символьной системы вызывает немало
нареканий. Большую их часть легко отвергнуть, рассмотрев вопросы семантического
значения и обоснования (grounding) концепции символов и символьных систем. Вопрос
"смысла", конечно, тоже бьет по идее интеллекта как поиска в предварительно
интерпретированных символьных структурах. Понятие смысла в традиционном ИИ развито весьма
слабо. Тем не менее искушение сдвинуться в сторону более "математизированной"
семантики, например, теории возможных миров (possible worlds), представляется ошибочным.
Такой метод уходит корнями к рационалистской идее подмены гибкого
эволюционирующего интеллекта материализованного агента миром ясных, четко определенных идей.
Обоснование смысла — это проблема, которая всегда путала планы как
приверженцев, так и критиков искусственного интеллекта, а также когнитологов. Проблема
обоснования сводится к следующему: как символы могут иметь смысл? В работе [Searle, 1980]
она рассматривается на примере так называемой "китайской комнаты". Автор помещает
себя в комнату, предназначенную для перевода китайских предложений на английский.
Ему передают набор китайских иероглифов, а он отыскивает значение иероглифов в
большом каталоге и передает на выход соответствующий набор английских символов.
Автор заявляет, что даже без знания китайского языка его "систему" можно
рассматривать как машину — переводчик с китайского на английский.
Но здесь возникает одна проблема. Любой специалист, работающий в области
машинного перевода или понимания естественных языков (см. главу 13), может возразить, что
"переводчик", слепо сопоставляющий один набор символов с другим, выдает результат
очень низкого качества. Более того, возможности текущего поколения интеллектуальных
систем по "осмысленной" интерпретации набора символов весьма ограничены. Проблема
слишком бедной опорной семантики распространяется и на вычислительно реализованные
сенсорные модальности, будь то визуальные, кинестетические или вербальные.
Что касается понимания естественного языка, Лакофф и Джонсон [Lakoff и Johnson,
1999] возражают, что способность создавать, использовать, обменивать и
интерпретировать осмысленные символы является следствием интеграции человека в изменяющуюся
социальную среду. Благодаря ей возникли человеческие способности выживания,
эволюционирования и продолжения рода. Она сделала возможными рассуждения по аналогии,
юмор, музыку и искусство. Современные средства и методы искусственного интеллекта и
впрямь весьма далеки от способности кодировать и использовать эквивалентные по
"смыслу" системы.
Прямым следствием бедной семантики является то, что методология поиска в
традиционном ИИ рассматривает лишь предварительно интерпретированные состояния и их
контексты. Это означает, что создатель программы ИИ связывает с используемыми
символами семантический смысл. Поэтому интеллектуальные системы, включая системы
обучения и понимания естественного языка, могут строить лишь некую вычисляемую
функцию в этой интерпретации. Таким образом, большая часть систем ИИ очень
ограничена в возможности построения новых смысловых ассоциаций по мере изучения
окружающего мира [Lewis и Luger, 2000].
Вследствие стесненных возможностей семантического моделирования наиболее
значительные успехи связаны с разработкой приложений, в которых можно
абстрагироваться от чересчур широкого контекста и в то же время описать основные компоненты
решения задачи с помощью заранее интерпретируемых символьных систем. Большая их часть
Глава 16. Искусственный интеллект как эмпирическая проблема
785
упоминалась в этой книге. Но и такие системы не поддерживают множественных
интерпретаций и ограничены в способности восстанавливать работоспособность после сбоя.
На протяжении всей недолгой истории искусственного интеллекта изучались
различные варианты гипотезы о физической символьной системе. Были разработаны
альтернативы этому подходу. Как показано в последних главах этой книги, символьная система и
поиск— не единственно возможные средства реализации интеллектуальной системы.
Вычислительные модели, основанные на работе органического мозга, а также на
процессах биологической эволюции, предоставляют альтернативную базу для понимания
интеллекта в терминах научно познаваемых и эмпирически воспроизводимых процессов.
Оставшаяся часть этого раздела посвящена обсуждению этих подходов.
16.1.2. Коннекционистские, или нейросетевые,
вычислительные системы
Существенной альтернативой гипотезе о физической символьной системе являются
исследования в области нейронных сетей и других, заимствованных из биологии,
вычислительных моделей. Нейронные сети, например, являются физически реализуемыми
вычислительными моделями познания, не основанными на предварительно
интерпретированных символах, которыми точно описывается предметная область. Поскольку знания в
нейронной сети распределены по всей ее структуре, зачастую сложно (а то и
невозможно) соотнести конкретные понятия с отдельными узлами или весовыми коэффициентами.
Фактически любая часть сети может служить для представления разных понятий.
Следовательно, нейронные сети являются хорошим контрпримером, по крайней мере, условию
гипотезы о физических символьных системах.
Нейронные сети и генетические алгоритмы сместили акцент исследований ИИ с
проблем символьного представления и стратегий формальных рассуждений на проблемы
обучения и адаптации. Нейронные сети, подобно человеческим существам и животным,
умеют адаптироваться к миру. Структура нейронной сети формируется не только при ее
разработке, но и при обучении. Интеллект, основанный на нейронной сети, не требует
переведения мира на язык символьной модели. Скорее, сеть формируется при
взаимодействии с миром, который отражается в неявной форме опыта. Этот подход внес
значительный вклад в наше понимание интеллекта. Он дал правдоподобное описание
механизмов, лежащих в основе физической реализации процессов мышления; более
жизнеспособную модель обучения и развития; демонстрацию возможности путем простой
локальной адаптации сформировать сложную систему, реагирующую на реальные
явления; а также мощное орудие для когнитивной теории нейронных систем (neuroscience).
Именно благодаря своей многогранности нейронные сети помогают ответить на
множество вопросов, лежащих за пределами впечатляющих возможностей символьного
ИИ. Важный класс таких вопросов касается проблемы перцепции. Природа не столь
щедра, чтобы представить работу нашего восприятия в виде набора точных формул
предикатного исчисления. Нейронные сети обеспечивают модель выделения "осмысленных"
образов из хаоса сенсорных стимулов.
Из-за своего распределенного представления нейронные сети часто более устойчивы,
нежели аналогичные символьные системы. Соответствующим образом обученная нейронная
сеть может эффективно классифицировать новые входные данные, проявляя подобное
человеческому восприятие, основанное не на строгой логике, а на "схожести". Аналогично потеря
нескольких нейронов серьезно не повлияет на производительность большой нейронной сети.
Это является следствием избыточности, часто присущей сетевым моделям.
786
Часть VII. Эпилог
Наверное, самым притягательным аспектом коннекционистских сетей является их
способность обучаться. Вместо построения подробной символьной модели мира нейронные
сети благодаря гибкости своей структуры могут адаптироваться на основе опыта. Они не
столько строят модель, сколько сами формируются под влиянием мира. Обучение является
одним из главных аспектов интеллекта. И именно из проблемы обучения вырастают
наиболее сложные вопросы, связанные с нейросетевыми вычислительными системами.
Почему мы до сих пор не создали мозг
Недавние исследования в когнитивной теории нейронных систем [Squire и
Kosslyn, 1998], [Gazzaniga, 2000] представляют новый аспект в понимании когнитивной
архитектуры человеческого мозга. В этом разделе мы кратко ознакомимся с некоторыми
открытиями в этой области, проведя параллель между ними и искусственным
интеллектом. Эти вопросы будут рассмотрены с трех позиций: на уровне, во-первых, нейрона, во-
вторых, нейронной архитектуры и, в-третьих, когнитивного представления проблемы
кодирования (encoding).
На уровне отдельного нейрона Шепард [Shephard, 1998] и Карлсон [Carlson, 1994]
определяют множество различных типов нейронной архитектуры, построенной из
клеток, каждая из которых выполняет специализированную функцию и играет свою роль в
большей системе. Они выделяют клетки рецепторов наподобие клеток кожи, которые
передают входную информацию другим скоплениям клеток, внутренним нейронам,
основная задача которых сводится к передаче информации внутри скоплений клеток, и
моторным нейронам, формирующим выход системы.
Нейронная активность имеет электрическую природу. Состояние возбуждения или
покоя определяется характером ионных потоков в нейрон и из него. У типичного
нейрона потенциал покоя составляет приблизительно -70 мВ. Когда клетка активна, окончание
аксона выделяет определенные вещества. Эти химические вещества, называемые
медиаторами (neurotransmitters), взаимодействуют с постсинаптической мембраной, обычно
вливаясь в нужные рецепторы и возбуждая тем самым дальнейшие ионные токи. Потоки
ионов, достигая критического уровня, около -50 мВ, формируют потенциал
возбуждения (action potential) — триггерный механизм, однозначно определяющий степень
возбуждения клетки. Таким образом, нейроны сообщаются, обмениваясь
последовательностями двоичных кодов.
Существует два вида постсинаптических изменений, вызванных достижением
потенциала возбуждения: тормозящие (inhibitory), наблюдаемые в основном в межнейронных
структурах клеток, и возбуждающие (excitatory). Такие положительные и отрицательные
потенциалы постоянно генерируются в синапсах дендритной системы. Когда
результирующее влияние всех этих событий изменяет потенциалы мембран соответствующих
нейронов от -70 мВ до примерно -50 мВ, пороговое значение превышается, и вновь
инициируются ионные токи в аксонах этих клеток.
На уровне нейронной архитектуры в коре головного мозга (тонком слое,
покрывающем полушария мозга) содержится приблизительно 1010 нейронов. Большая часть коры
имеет складчатую форму, что увеличивает ее площадь поверхности. С точки зрения
вычислительной системы необходимо учитывать не только количество синапсов, но и
нагрузочные способности по входу и выходу. Шепард [Shephard, 1998] примерно
оценивает оба этих параметра числом 105.
Кроме различий в клетках и архитектурах нейронных и компьютерных систем,
существует более глубокая проблема когнитивного представления. Мы, к примеру, совершен-
Глава 16. Искусственный интеллект как эмпирическая проблема
787
но ничего не знаем о том, как в коре кодируются даже простейшие воспоминания. Или
как человек узнает лица, и каким образом распознавание лица может соотноситься
агентом с чувствами радости или печали. Мы очень много знаем о физико-химических
аспектах устройства мозга, но относительно мало о том, как нервная система кодирует
сведения и использует эти образы в нужном контексте.
Один из наиболее сложных вопросов, с которым сталкиваются исследователи и
неврши.ного, и вычислительного толка, касается роли врожденного знания в обучении.
Можно ли провести эффективное обучение "с нуля", без начального знания, основываясь
исключительно на опыте; или же должен присутствовать некий индуктивный порог? Опыт
разработки обучающихся программ предполагает необходимость какого-либо начального
знания, обычно выражающегося в форме индуктивного порога. Оказалось, что способность
нейронных сетей строить осмысленное обобщение на основе обучающего множества
зависит от числа нейронов, топологии сети и специфики алгоритмов обучения. Совокупность
этих факторов составляет индуктивный порог, играющий не менее важную роль, чем в
любом символьном представлении. Например, находится все больше подтверждений тому,
что дети наследуют совокупность "аппаратно прошитых" когнитивных предпосылок
(порогов), благодаря которым возможно обучение в таких областях, как язык и
интуитивное понимание законов природы. Представление врожденных порогов в нейронных сетях
сегодня является областью активных исследований [Elman и др., 1996].
Вопрос о врожденных порогах отходит на второй план, если обратить внимание на
более сложные проблемы обучения. Предположим, нужно разработать вычислительную
модель научного открытия и смоделировать переход Коперника от геоцентрического к
гелиоцентрическому взгляду на устройство вселенной. Для этого требуется представить
в компьютерной программе теории Коперника и Птолемея. Хотя эти взгляды можно
представить в качестве активационных схем нейронной сети, такие сети ничего не
скажут о них, как о теориях. Человек предпочитает получать объяснения вроде: "Коперник
был озадачен сложностью системы Птолемея и предпочел более простую модель, в
которой планеты вращаются вокруг Солнца". Подобные объяснения требуют символьного
выражения. Очевидно, нейронные сети должны обеспечивать символьное обоснование.
В конце концов, человеческий мозг — это нейронная сеть, но она неплохо умеет
обращаться с символами. И тем не менее символьное обоснование в нейронных сетях —
важная, но все еще открытая проблема.
Еще одной проблемой является роль развития в обучении. Дети не могут просто
учиться на доступных данных. Их способность к обучению в конкретных областях
проявляется на четко определенных стадиях развития [Karmiloff-Smith, 1992]. Возникает
любопытный вопрос: является ли этот факт всецело следствием человеческой биологии,
или же он отражает некие принципиально необходимые ограничения на способность
интеллекта познавать закономерности окружающего мира? Могут ли подобные стадии
развития служить механизмом для разбиения задачи обучения на более простые подзадачи?
Возможно ли, что система искусственно налагаемых ограничений на развитие
искусственной сети является необходимой основой для обучения в сложном мире?
Применение нейронных сетей для решения практических задач ставит
дополнительные проблемы перед исследователями. Те самые свойства нейронных сетей, которые
делают их такими привлекательными (способность адаптироваться, устойчивость к
недостаточности или неоднозначности данных), одновременно создают препятствия для их
практического применения. Поскольку нейронные сети обучаются, а не
программируются, их поведение сложнее предсказать. Существует несколько общих принципов проек-
788
Часть VII. Эпилог
тирования сетей, которые вели бы себя нужным образом в заданной предметной области.
Однако сложно объяснить, почему нейронная сеть пришла к определенному выводу.
Обычно такие объяснения принимают вид каких-то статистических соображений. Все
вышеперечисленные проблемы являются предметом текущих исследований.
Возникает вопрос, так ли уж различаются в качестве моделей интеллекта коннекцио-
нистские сети и символьные системы ИИ? В них достаточно много общего. В обоих
подходах процесс "мышления" сводится к вычислительным операциям, имеющим
фундаментальные и формальные ограничения, такие как описанная в главе 2 гипотеза Чер-
ча-Тьюринга (Church-Turing) [Luger, 1994]. Оба подхода предлагают модель разума,
применимую в практических задачах. Более того, оба подхода отвергают философию
дуализма и помещают истоки разума в структуру и функцию физических устройств.
Мы верим, что согласование этих двух очень разных подходов неизбежно.
Исключительным вкладом в науку стало бы построение теории преобразования символьного
представления в конфигурацию сети, и, в свою очередь, влияния на ее дальнейшую адаптацию. Такая
теория помогла бы во многих исследованиях, например, интеграции в единую
интеллектуальную систему нейросетевого восприятия и систем рассуждения на основе знаний. Тем не менее
в ближайшее время у приверженцев обоих взглядов будет достаточно работы, и мы не видим
никаких причин, мешающих им сосуществовать. Для тех же, кого смущает подобная
противоречивость двух моделей интеллекта, приведем пример из физики, в которой свет иногда
удобнее рассматривать как волну, а иногда — как поток частиц.
16.1.3. Агенты, интеллект и эволюция
Агентные вычисления и модульные теории познания ставят перед исследователями
систем ИИ интересные вопросы. Одна из известных школ когнитологии полагает, что разум
формируется из наборов специализированных функциональных элементов [Minsky, 1995],
[Fodor, 1983]. Все модули имеют четкую специализацию и используют широкий диапазон
врожденных структур и функций, от "аппаратно прошитого" решения задач до индуктивного
порога. Это связано с разнообразием проблем, которыми они как практические агенты
должны заниматься. В этом есть смысл: как можно обучить нейронную сеть заниматься и
перцепцией, и двигательными функциями, и запоминанием, и логическими рассуждениями?
Модульные теории интеллекта предоставляют базу для поиска ответа на этот вопрос, а также
направление дальнейшего исследования таких вопросов, как природа индуктивного порога в
отдельных модулях или механизмы модульного взаимодействия.
Генетические и эволюционные вычислительные модели обеспечивают новые
захватывающие подходы к пониманию как человеческого, так и искусственного разума.
Демонстрируя возможность рассмотрения разумного поведения как совокупности работы
большого числа ограниченных независимых агентов, теория генетических и
эволюционных вычислений решает проблему представления сложного разума в виде результата
взаимодействия относительно простых структур.
В работе [Holland, 1995] приведен пример, в котором механизмы обеспечения хлебом
большого города (например Нью-Йорка) демонстрируют процесс возникновения
интеллекта в агентской системе. Вряд ли можно написать централизованный планировщик,
который обеспечивал бы жителей Нью-Йорка привычным им разнообразием сортов
хлеба. Да и неудачный эксперимент коммунистического мира по внедрению
централизованного управления явно показал ограниченность такого подхода. Даже несмотря на
практические сложности написания алгоритма такого централизованного планирования, сла-
Глава 16. Искусственный интеллект как эмпирическая проблема
789
бо скоординированные в действиях городские пекари, торговцы и поставщики сырья и
так неплохо справляются с решением проблемы. Эволюционные агентские системы не
имеют центрального плана. Любой булочник владеет весьма ограниченными сведениями
о потребностях города в хлебе. Он всего лишь старается оптимизировать возможности
своего бизнеса. Решение глобальной проблемы складывается из коллективной
деятельности таких независимых локальных агентов.
Демонстрируя, как целенаправленное, устойчивое к флуктуациям и почти
оптимальное поведение может складываться из взаимодействия отдельных локальных агентов, эти
модели дают еще один ответ на старый философский вопрос о происхождении разума.
Главный урок эволюционных подходов к интеллекту состоит в том, что цельный
интеллект может возникнуть и возникает из взаимодействия множества простых, отдельных,
локальных, овеществленных агентских интеллектов.
Вторая главная особенность эволюционных моделей заключается в том, что они
опираются на дарвиновский принцип естественного отбора как на основной механизм, формирующий
поведение отдельных агентов. Возвращаясь к примеру с булочниками, трудно утверждать, что
каждый отдельный пекарь ведет себя "глобально оптимальным" образом. Источник такой
оптимальности— не централизованный проект, а простой факт. Булочники, которые плохо
удовлетворяют нужды своих покупателей, разоряются. Путем неустанных, многократных
селективных воздействий отдельные булочники приходят к модели поведения, которая
обеспечивает как их собственное выживание, так и общественную полезность.
Комбинация распределенной, агентской архитектуры и адаптивных воздействий
естественного отбора — мощная модель эволюции и работы разума. Эволюционные
психологи [Cosmides и Tooby, 1992, 1994], [Barkow и др., 1992] разработали модель
формирования врожденной структуры и индуктивного порога человеческого мозга в процессе
естественного отбора. Основа эволюционной психологии — это рассмотрение разума как
модульной системы взаимодействующих специализированных агентов. В эволюционной
психологии ум часто сравнивают со швейцарским ножом — набором
специализированных инструментов, предназначенных для решения различных задач. Появляется все
больше свидетельств тому, что человеческий интеллект действительно в высокой
степени является модульной системой. В [Fodor, 1983] приводятся философские доводы в
пользу модульной структуры интеллекта. Минский [Minsky, 1985] исследовал различные
применения теорий модульности в сфере искусственного интеллекта. Такая архитектура
имеет важное значение для теорий эволюции интеллекта. Сложно представить себе, как
эволюция могла сформировать цельную систему такой сложности, как человеческий
мозг. С другой стороны, правдоподобным выглядит тот факт, что эволюция в течение
миллионов лет могла бы успешно сформировать отдельные, специализированные
познавательные навыки. Затем она бы могла работать над комбинациями модулей, формируя
механизмы их взаимодействия, обмена информацией и сотрудничества, позволяющие в
результате решать все более сложные задачи познания [Mithen, 1996].
Теории нейронной селекции [Edelman, 1992] показывают, как эти же процессы могут
отвечать за адаптацию отдельной нервной системы. Модели нейронного дарвинизма
описывают адаптацию нейронных систем в терминах Дарвина: в процессе селекции в
ответ на воздействия внешней среды происходит усиление одних цепочек в мозге и
ослабление других. В отличие от символьных методов обучения, которые пытаются выделить
информацию из обучающих данных и использовать ее для построения модели мира,
теории нейронной селекции рассматривают влияние селективных воздействий на популяции
нейронов и их взаимодействие. Эдельман [Edelman, 1992, С. 81] утверждает:
790
Часть VII. Эпилог
Рассматривая изучение мозга как науку о познании, я подразумеваю, что познание не является
инструктивным процессом. Здесь не происходит непосредственной пересылки информации,
как ее нет в эволюционных или иммунных процессах. Напротив, познание селективно.
Агентные технологии предоставляют также модели социального взаимодействия.
Используя агентные подходы, экономисты построили информативные (если не полностью
прогнозирующие) модели экономических рынков. Агентные технологии оказывают
всевозрастающее влияние на построение распределенных компьютерных систем,
разработку средств поиска в Internet и проектирование сред совместной разработки.
Наконец, агентные модели оказали немалое влияние на теорию сознания. Например,
Даниэль Дэннетт [Dennett, 1991] рассматривает функцию и структуру сознания,
отталкиваясь от агентной архитектуры интеллекта. Он начинает с замечания, что вопрос о
местоположении сознания в мозге или разуме некорректен. Напротив, его множественная
теория сознания (multiple draft theory of consciousness) основана на рассмотрении
сознания во взаимодействии агентов в распределенной архитектуре интеллекта. Во время
перцепции, управления двигательными функциями, решения задач, обучения и другой
психической активности формируются объединения взаимодействующих агентов. Эти
сочетания очень динамичны и изменяются в зависимости от потребностей в различных
ситуациях. Сознание, по Дэннету, служит связующим механизмом этих объединений
агентов, оно поддерживает взаимодействие агентов. Совокупность агентов становится
основой когнитивной обработки данных.
Ограничения агентного представления интеллекта
Развитие эволюционного подхода привело к возникновению новых вопросов.
Например, еще предстоит понять весь путь эволюции высокоуровневых познавательных
способностей языка. Подобно попыткам палеонтологов реконструировать эволюцию видов,
отслеживание развития этих высокоуровневых проблем связано с большим объемом
кропотливой роботы. Необходимо перечислить все агенты, лежащие в основе
архитектуры разума, и отследить их эволюцию во времени.
Важная проблема для агентских теорий — объяснение взаимодействий между
модулями. Хотя модель ума как "швейцарского ножа" полезна для интуитивного понимания,
модули, из которых состоит интеллект, не так независимы, как лезвия перочинного
ножика. Разум демонстрирует широкие, весьма изменчивые взаимодействия между
когнитивными областями: мы можем говорить о вещах, которые видим, что выявляет
взаимодействие между визуальным и лингвистическим модулями. Мы можем сооружать
здания, служащие специфичным социальным целям, что свидетельствует о взаимодействии
между технической и социальной сторонами интеллекта. Поэты могут строить метафоры
для описания зрительных сцен, демонстрирующие гибкое взаимодействие между
визуальным и тактильным модулями. Исследование представлений и процессов, делающих
возможными эти межмодульные взаимодействия, является областью текущих
исследований [Karmiloff-Smith, 1992], [Mithen, 1996], [Lakoff и Johnson, 2000].
Все важнее становятся практические применения агентных технологий. Используя
компьютерное моделирование на основе агентов, можно создать сложные системы, для
которых не существует аналитического описания, и которые из-за этого ранее были недоступны
для изучения. Методы моделирования применяются для описания широкого спектра
явлений, например, адаптации человеческой иммунной системы, управления сложными
процессами, включая ускорение частиц, поведения мировых рынков валют, метеорологии.
Вопросы представления и вычислительной реализации, которые предстоит решить для созда-
Глава 16. Искусственный интеллект как эмпирическая проблема
791
ния таких моделей, определяют направление исследований в построении представлений
знаний, алгоритмов и даже разработки компьютерной аппаратуры.
Другие практические вопросы, с которыми предстоит иметь дело агентным
архитектурам, включают протоколы межагентного взаимодействия, особенно в случаях, когда
локальные агенты имеют ограниченные знания о проблеме в целом или о том, какими
знаниями уже могут обладать другие агенты. Более того, существует несколько
алгоритмов для разбиения больших задач на агентно-ориентированные подзадачи и
распределения ограниченных ресурсов между агентами. Эти и другие вопросы агентного
представления были рассмотрены в подразделе 6.4.2.
Пожалуй, наиболее увлекательный аспект эволюционной теории интеллекта— это
возможность описать различные виды психической деятельности единой моделью
возникновения порядка из хаоса. Краткий обзор, проведенный в этом разделе, позволяет
выделить работы, использующие эволюционную теорию для моделирования ряда
процессов: от эволюции интеллекта до конструирования экономических и социальных
моделей поведения. Есть нечто чрезвычайно привлекательное в той идее, что
эволюционные процессы, описываемые теорией Дарвина, могут объяснить разумное поведение во
многих масштабах: от взаимодействия индивидуальных нейронов до формирования
молекулярной структуры мозга или функционирования экономических рынков и
социальных систем. Оказывается, интеллект подобен фрактальной структуре, где одни и те же
процессы действуют в любых масштабах и во всей системе в целом.
Далее будут рассмотрены психологические и философские аспекты человеческого
мышления, которые повлияли на создание, разработку и применение теории
искусственного интеллекта.
16.2. Теория интеллектуальных систем
Основная группа исследователей искусственного интеллекта сосредоточила свою
деятельность на понимании человеческого разума совсем не случайно. Люди
обеспечивают прототипы и примеры интеллектуальных действий. Поэтому разработчики
искусственного интеллекта редко игнорируют "человеческий" подход, хотя обычно и не ставят
перед собой цели заставить программы действовать по примеру людей. Так, в
приложениях компьютерной диагностики программы зачастую моделируют рассуждения людей-
экспертов, работающих в соответствующей области. А главное, понимание
человеческого интеллекта — захватывающая и все еще открытая научная проблема.
Современная когнитология (cognitive science), или теория интеллектуальных систем
(science of intelligent systems) [Luger, 1994], возникла с изобретением цифрового
компьютера. Однако в главе 1 упоминалось, что у этой дисциплины были свои
предшественники. Их список начинается с Аристотеля, Декарта и Буля и включает многих современных
теоретиков, таких как Тьюринг, Мак-Каллок и Питтс, основоположники нейросетевых
моделей, а также Джон фон Нейман — один из первых защитников концепции
искусственной жизни. Эти исследования стали наукой лишь тогда, когда возникла возможность
ставить эксперименты, основанные на теоретических соображениях, а точнее, с
появлением компьютеров. Наконец-то можно задать вопрос: "Существует ли всеобъемлющая
теория интеллекта?". Можно также спросить: "Может ли теория интеллектуальных
систем помочь в создании искусственного разума?".
В нижеследующих разделах вкратце будет рассказано о том, как психология,
эпистемология и социология повлияли на исследования в сфере ИИ.
792
Часть VII. Эпилог
16.2.1. Ограничения психологии
Ранние когнитологические исследования касались решения логических задач человеком.
Такие системы учились играть в простые игры, планировать и осуществлять изучение
понятий [Feigenbaum и Feldman, 1963], [Newell и Simon, 1972], [Simon, 1981]. В процессе работы
над системой Logic Theorist (см. раздел 12.1) Ньюэлл и Саймон начали сравнивать свои
вычислительные подходы со стратегиями поиска, применяемыми человеком. Исходными
данными для них служили протоколы "мыслей вслух" (think-aloud protocols) — описания людьми
своих мыслей в процессе обдумывания решения задачи, например, доказательства какой-
нибудь теоремы. Ньюэлл и Саймон сравнили эти протоколы с поведением компьютерной
программы, работающей над той же задачей. Исследователи обнаружили поразительную
схожесть и интересные отличия, как в задачах, так и в субъектах исследования.
Эти ранние проекты позволили создать методологию, применяемую в когнитологии в
последующие десятилетия.
1. На основе данных, полученных от людей, решающих определенный класс
проблем, строится схема представления и соответствующая стратегия поиска для
решения задачи.
2. Отслеживается поведение компьютерной модели, решающей такую проблему.
3. Ведется наблюдение за людьми, работающими над решением задач, и
отслеживаются измеряемые параметры их процесса решения, а именно: протоколы "мыслей
вслух", движения глаз, записи промежуточных результатов.
4. Решения человека и компьютера сравниваются и анализируются.
5. Компьютерная модель пересматривается для следующего цикла экспериментов.
Эта эмпирическая методика описана в лекции Ньюэлла и Саймона, прочитанной по
случаю вручения премии Тьюринга. Ее фрагмент был выбран в качестве эпиграфа к этой
главе. Важным аспектом когнитологии является использование экспериментов для
подтверждения работоспособности архитектуры решателя, будь то продукционная система,
сеть связей или архитектура, основанная на взаимодействии распределенных агентов.
В последние годы к этим понятиям добавилось принципиально новое измерение.
Теперь в процессе решения задач можно "разбирать" и изучать не только программы, но и
людей, и другие формы жизни. Множество новых технологий получения изображений
пополнили набор средств, применяемых для изучения активности коры мозга. К этим
технологиям относится магнитная энцефалография (magnetoencephalography— MEG),
которая регистрирует магнитные поля, создаваемые группами нейронов. В отличие от
электрического магнитное поле не искажается костями и кожей черепа, следовательно,
можно получить более четкое его изображение.
Другая технология — позитронная эмиссионная томография (positron emission
tomography — PET). В кровеносный сосуд впрыскивается радиоактивное вещество, обычно О15. Когда
определенная область мозга возбуждена, чувствительными детекторами регистрируется
большее количество радиоактивного агента, чем в состоянии покоя этой области мозга.
Сравнение изображений возбужденных и находящихся в покое областей помогает обнаруживать
функциональную локализацию с разрешением примерно 1 см [Stytz и Frieder, 1990].
Еще один метод анализа нервной системы — функциональное магнитно-резонансное
сканирование (functional magnetic resonance imaging — F-MRI). Этот подход происходит
от более стандартного метода, основанного на ядерном магнитном резонансе (nuclear
Глава 16. Искусственный интеллект как эмпирическая проблема
793
magnetic resonance — NMR). Подобно методу PET, в этом подходе для выявления
функциональной локализации используется сравнение изображений возбужденных и
находящихся в покое областей мозга.
Дальнейший вклад в локализацию функций мозга сделали программные алгоритмы,
разработанные Бараком Перлмуттером и его коллегами [Pearlmutter и Рагга, 1997],
[Tang и др., 1999, 2000я, 20006]. Они тесно связаны с перечисленными выше методами.
Благодаря этим исследованиям появилась возможность получить сложные образцы
шума, часто возникающего на выходе устройств для получения изображений нервной
системы. Это важный шаг в исследованиях, поскольку такие показатели, как движения глаз,
дыхание и сердцебиение, связаны с исследуемыми схемами возбуждения нейронов.
Результаты недавних исследований в когнитивной теории нейронных систем [Squire и
Kosslyn, 1998], [Shephard, 1998], [Gazzaniga, 2000] значительно улучшили понимание
роли нейронной составляющей в интеллектуальной деятельности. Хотя анализ и критика
таких результатов выходит за пределы рассмотрения данной книги, коснемся нескольких
важных вопросов.
• В области восприятия и внимания существует проблема связывания (binding
problem). Такие исследователи, как Энн Трисмэн [Triesman, 1993, 1998], отмечают, что
представление восприятия зависит от распределенных нейронных кодов,
отвечающих за сопоставление частей и качеств объектов, и ставят вопрос о том, какие
механизмы "связывают" информацию, относящуюся к конкретному объекту, и
позволяют отличать этот объект от других.
• В области визуального поиска рассматривается вопрос о том, какие нейронные
механизмы обеспечивают восприятие объектов, входящих в большие, сложные сцены.
Некоторые эксперименты показывают, что фильтрация информации о незначительных
объектах играет важную роль в определении целей поиска [Luck, 1998]. Вопрос о том,
как мы''учимся" видеть, исследуется в работе [Sagi и Таппе, 1998].
• Работы [Gilbert, 1992, 1998] посвящены гибкости восприятия. Из них следует, что
видимая человеком картина не отражает точные физические характеристики
сцены. Она значительно зависит от процессов, с помощью которых мозг пытается
интерпретировать эту картину.
• В [Ivry, 1998] рассматривается вопрос о том, каким образом кора мозга кодирует и
индексирует соотносящуюся во времени информацию, включая интерпретацию
ощущений и двигательную активность.
• Стрессовые гормоны, вырабатываемые в состояниях эмоционального
возбуждения, влияют на процессы памяти [Cahill и McGaugh, 1998]. Это соотносится с
проблемой обоснования (grounding): почему мысли, слова, ощущения имеют
осмысленное значение для агента? В каком смысле возможна "грусть в вещах", вергили-
евская lacremae re rum?
• Акустико-фонетические аспекты речи основаны на важных организационных
принципах, связывающих исследования в области нейронных систем с
когнитивными и лингвистическими теориями [Miller и др., 1998]. В [Gazzaniga, 2000]
рассматривается вопрос о том, как синтаксические и семантические составляющие
сочетаются в коре мозга.
• Как индивидуум учится определенному языку, и какие нейрофизиологические
стадии соответствуют этому процессу? Этой проблеме посвящены работы
[Kuhl, 1993, 190Я].
794
Часть VII. Эпилог
• В [O'Leary и др., 1999] затрагиваются следующие вопросы. Как понимать
развитие, чем определяется пластичность критических периодов и реорганизации в
процессе взросления, наблюдаемых в соматосенсорных системах
млекопитающих? Критичны ли фазы развития для формирования интеллекта? Эти же вопросы
рассматриваются в [Karmiloff-Smith, 1992], [Gazzaniga, 2000] и подразделе 16.1.2.
Практическая работа в сфере искусственного интеллекта не требует обширных
познаний в вышеперечисленных и смежных нейронных и психологических областях. Но
такие знания могут помочь в разработке интеллектуальных устройств, а также в
определении места исследований ИИ в контексте общей теории интеллектуальных систем.
Наконец, синтез психологии, нейрофизиологии и компьютерных наук— по-настоящему
увлекательная задача. Но она требует детальной проработки эпистемологами, что будет
нашей следующей темой для обсуждения.
16.2.2. Вопросы эпистемологии
Если не знаешь, куда идешь, придешь не туда, куда хочешь...
— приписывается Йоги Берра (Yogi Berra)
Развитие искусственного интеллекта происходило в процессе решения множества
важных задач и вопросов. Понимание естественных языков, планирование, рассуждения
в условиях неопределенности и машинное обучение — все это типичные проблемы,
которые отражают важные аспекты разумного поведения. Интеллектуальные системы,
работающие в этих предметных областях, требуют знания целей и опыта в контексте
конкретной социальной ситуации. Для этого в программе, которую человек пытается
наделить "разумом", необходимо обеспечить возможность формирования понятий.
Процесс формирования понятий отражает как семантику, поддерживающую
использование символов, так и структуру применяемых символов. Задача состоит в том, чтобы
найти и использовать инвариантности, присущие данной предметной области. Термин
"инвариант" используется для описания регулярностей или значимых, пригодных для
использования, аспектов сложных рабочих сред. В данном рассмотрении термины
символы и символьные системы используются в широком смысле. Они включают широкий
спектр понятий: от четко определенных символов Ньюэла и Саймона [Newell и
Simon, 1976] до узлов и сетевой архитектуры систем связей, а также эволюционирующих
структур генетики и искусственной жизни.
Хотя рассматриваемые ниже вопросы характерны для большей части работ в сфере ИИ,
остановимся на проблемах машинного обучения. Это обусловлено тремя причинами.
Во-первых, довольно глубокое изучение хотя бы одной ключевой предметной
области искусственного интеллекта даст читателю более полное и точное представление о
последних достижениях ИИ. Во-вторых, успехи в машинном обучении, а особенно в
нейронных сетях, генетических алгоритмах и других эволюционных подходах,
потенциально способны совершить революцию в сфере ИИ. Наконец, обучение — это одна из
наиболее увлекательных областей исследований в искусственном интеллекте.
Несмотря на прогресс, обучение остается одной из наиболее трудных проблем,
встающих перед исследователями ИИ. Далее мы обсудим три вопроса, сдерживающих
сегодня продвижение в этой сфере: во-первых, обобщение и переобучение (generalization
and overlearning), во-вторых, роль индуктивного порога (inductive bias) в обучении, в-
третьих, дилемму эмпирика (empiricist's dilemma), или понимание эволюции без ограни-
Глава 16. Искусственный интеллект как эмпирическая проблема
795
чений. Последние две проблемы взаимосвязаны. Присущий многим алгоритмам
индуктивный порог является выражением рационалистической проблемы. Порог определяется
ожиданиями, т.е. то, чему мы обучаемся, зачастую зависит от того, чему хочется
научиться. Есть и другая проблема. Иногда мы не располагаем априорными догадками о
результате. Это, например, можно наблюдать в исследованиях, посвященных
искусственной жизни. Можно ли утверждать: "Построй это, и оно будет работать, как нужно"? Если
верить Йоги Берра (см. эпиграф к разделу), то, скорее всего, нет! Эти темы будут
затронуты в следующем разделе.
Проблема обобщения
Примеры, использованные для представления разнообразных моделей обучения
(символьных, коннекционистских и эволюционных), зачастую были слишком
неестественны. Например, архитектуры связей часто содержали всего несколько узлов или один
скрытый слой. Такие примеры уместны, поскольку основные законы обучения можно
адекватно объяснить в контексте нескольких нейронов или слоев. Но стоит помнить, что
в реальных задачах нейронные сети обычно значительно больше, и проблема масштаба
здесь имеет значение. Например, для обучения с обратным распространением ошибки
требуется большое количество обучающих примеров, а для решения сколько-нибудь
практически интересных задач нужны большие сети. Многие исследователи ([Necht-
Nielsen, 1990]; [Zurada, 1992], [Freeman и Scapura, 1991]) работали над проблемой выбора
оптимального числа входных данных, соотношения между числом входных параметров
и узлов в скрытом слое, определением количества проходов процесса обучения,
достаточного для обеспечения сходимости. Здесь мы только констатировали, что эти
проблемы сложные, важные и в большинстве случаев открытые.
Количество и качество обучающих данных важны для любого обучающего
алгоритма. Без обширных исходных знаний о предметной области алгоритм обучения может не
справиться с выделением образов при получении зашумленных, недостаточных или даже
испорченных данных.
Смежная проблема — вопрос "достаточности" в обучении. В каких случаях алгоритмы
можно назвать достаточно пригодными для выделения важных границ или инвариантов
предметной области задачи? Приберечь ли запас входных данных для тестирования
алгоритма? Отвечает ли количество имеющихся данных требуемому качеству обучения?
Должно быть, суждение о "достаточности" является в большей степени эвристическим или даже
эстетическим: мы, люди, часто рассматриваем алгоритмы как "достаточно хорошие".
Проиллюстрируем проблему обобщения на примере, используя метод обратного
распространения ошибки для нахождения функции по набору заданных точек (рис. 16.2).
Линии вокруг этого набора представляют функции,
найденные алгоритмом обучения. Напомним, что
по завершении обучения алгоритму необходимо
предоставлять новые входные данные, чтобы
проверить качество обучения.
Функция fj представляет довольно точную
аппроксимацию методом наименьших квадратов.
Дальнейшее обучение системы может дать функцию
f2, которая выглядит как достаточно "хорошая" ап-
Рис. 16.2. Набор точек данных и три проксимация набо данных. Но все же f2 не точно
аппроксимирующие функции ^ „ ~
соответствует заданным точкам. Дальнейшее ооуче-
796
Часть VII. Эпилог
ние может привести к функциям, которые точно аппроксимируют данные, но дают
ужасные обобщения для новых входных данных. Это явление называют переобучением
(overtraining) сети. Одной из сильных сторон обучения с обратным распространением
ошибки является то, что в предметных областях многих приложений оно дает эффективные
обобщения, т.е. аппроксимации функций, которые приближают обучающие данные и
корректно обрабатывают новые. Тем не менее обнаружить точку, в которой сеть переходит из
"недообученного" в переобученное состояние,— задача нетривиальная. Наивно думать,
что можно построить сеть, или вообще какой-либо обучающий инструмент, снабдить его
"сырыми" данными, а затем отойти в сторону и наблюдать за тем, как он вырабатывает
самые эффективные и полезные обобщения, применимые к новым подобным проблемам.
Подведем итог, возвращая вопрос обобщения в контекст его эпистемологии. Когда
решатель задач формирует и применяет обобщения в процессе решения, он создает
инварианты или даже системы инвариантов в области задача-решение. Таким образом,
качество и четкость таких обобщений могут быть необходимой основой для успешного
осуществления проекта. Исследования в области обобщения задачи и процесса ее
решения продолжаются.
Индуктивный порог: рационалистское априори
Методы автоматического обучения, рассмотренные в главах 9-11, и, следовательно,
большая часть методов ИИ отражают индуктивные пороги, присущие их создателям.
Проблема индуктивных порогов в том, что получаемые в результате представления и
стратегии поиска дают средство кодирования в уже интерпретированном мире. Они
редко могут предоставить механизмы для исследования наших интерпретаций, рождения
новых взглядов или отслеживания и изменения неэффективных перспектив. Такие
неявные предпосылки приводят к ловушке рационалистской эпистемологии, когда
исследуемую среду можно увидеть лишь так, как мы ожидаем или научены ее видеть.
Роль индуктивного порога должна быть явной в каждом обучающем алгоритме.
(Альтернативное утверждение гласит, что незнание индуктивного порога вовсе не
означает того, что он не существует и не влияет критически на параметры обучения.) В
символьном обучении индуктивные пороги обычно очевидны, например, использование
семантической сети для концептуального обучения. В обучающем алгоритме Уинстона
[Winston, 1975^] пороги включают представление в виде конъюнктивных связей и
использование "попаданий близ цели" для коррекции наложенных на систему ограничений.
Подобные пороги используются при реализации поиска в пространстве версий
(раздел 9Л), построении деревьев решений в алгоритме ID3 (раздел 9.3) или даже
правилах Meta-DENDRAL (раздел 9.5).
Как упоминалось в главах 10 и 11, многие аспекты стратегий коннекционистского и
генетического обучения также предполагают наличие индуктивных порогов. Например,
ограничения персептронных сетей привели к появлению скрытых слоев. Уместен вопрос
о том, какой вклад вносят скрытые узлы в получение решения. Одна из функций
скрытых узлов состоит в том, что они добавляют новые измерения в пространство
представлений. На простом примере из подраздела 10.3.3 было видно, что данные в задаче
"исключающего ИЛИ" не были линейно разделимы в двухмерном пространстве. Однако
получаемые в процессе обучения весовые коэффициенты добавляют к представлению
еще одно измерение. В трехмерном пространстве точки можно разделить двухмерной
плоскостью. Выходной слой этой сети можно рассматривать как персептрон, находящий
плоскость в трехмерном пространстве.
Глава 16. Искусственный интеллект как эмпирическая проблема
797
Стоит отметить, что многие из "различных" парадигм обучения используют (иногда
неявно) общие индуктивные пороги. Примером подобной ситуации является взаимосвязь
между кластеризацией в системе CLUSTER/2 (раздел 9.5), персептроном (раздел 10.2) и
сетями прототипов (раздел 10.3). Было отмечено, что встречное распространение
информации в дуальной сети, использующей обучение без учителя с коррекцией весов по
выходу в слое Кохонена наряду с обучением с учителем в слое Гроссберга, во многом
подобно обучению с обратным распространением ошибки.
Рассмотренные средства схожи во многих важных аспектах. Фактически даже задача
кластеризации данных является дополнением к методу аппроксимации функций. В
первом случае мы пытаемся классифицировать наборы данных; во втором строим функции,
которые однозначно отделяют кластеры данных друг от друга. Это можно наблюдать,
когда используемый персептроном алгоритм классификации на основе минимального
расстояния находит также параметры, задающие линейное разделение.
Даже задачи обобщения или построения функций можно рассматривать с различных
позиций. Например, статистические методы используются для обнаружения корреляции
данных. Итеративный вариант рядов Тейлора позволяет аппроксимировать большинство
функций. Алгоритмы полиномиальной аппроксимации на протяжении более столетия
используются для аппроксимации функций по заданным точкам.
Итак, результат обучения (символьного, коннекционистского или эволюционного) во
многом определяется принятыми предположениями о характере решения. Принимая в расчет этот
синергетический эффект в процессе разработки вычислительных решателей задач, зачастую
можно улучшить шансы на успех и более осмысленно интерпретировать результаты.
Дилемма эмпирика
Если в сегодняшних подходах к машинному обучению, особенно обучению с учителем,
главную роль играет индуктивный порог, то обучение без учителя, которое используется во
многих генетических и эволюционных подходах, сталкивается с противоположной
проблемой, которую иногда называют дилеммой эмпирика. В таких подходах считается, что
решения сложатся сами на основе эволюционирующих альтернатив, в процессе "выживания"
наиболее подходящих особей популяции. Это мощный метод, особенно в контексте
параллельных и распределенных средств поиска. Но возникает вопрос: откуда можно узнать, что
система пришла к правильному решению, если мы не знали, куда идем?
Давным-давно Платон сформулировал эту проблему словами Менона из знаменитого
диалога:
"Но каким же образом, Сократ, ты будешь искать вещь, не зная даже, что она такое? Какую из
неизвестных тебе вещей изберешь ты предметом исследования? Или, если в лучшем случае ты
даже натолкнешься на нее, откуда ты узнаешь, что она именно то, чего ты не знал?"
Несколько исследователей подтверждают слова Менона [Mitchell, 1997] и теорему
"о бесплатном сыре" Вольперта и Макреди [Wolpert, Macready, 1995]. Эмпирик
фактически нуждается в какой-то доле рационалистского априорного знания для придания
научности своим рассуждениям.
Тем не менее продолжается множество увлекательных разработок в обучении без
учителя и эволюционном обучении. Примером служит создание сетей, основанных на
моделях или минимизации энергии, которые можно рассматривать в качестве
аттракторов для сложных инвариантностей. Наблюдая, как данные ''выстраиваются" к точкам
притяжения, исследователь начинает рассматривать эти архитектуры как средства
моделирования динамических явлений. Возникает вопрос: каковы ограничения этих методов?
798
Часть VII. Эпилог
Фактически исследователи показали [Siegelman и Sontag, 1991], что рекуррентные
сети полны в смысле вычислений, т.е. эквивалентны классу машин Тьюринга. Эта
эквивалентность обобщает более ранние результаты. Колмогоров [Kolmogorov, 1957] показал,
что для каждой непрерывной функции существует нейронная сеть, реализующая ее
вычисление. Также было показано, что сеть обратного распространения ошибки с одним
скрытым слоем может аппроксимировать любую непрерывную на компакте функцию
[Necht-Nielsen, 1989]. В разделе 11.3 было указано, что фон Нейман построил полные, по
Тьюрингу, конечные автоматы. Таким образом, сети связей и конечные автоматы
оказались еще двумя классами алгоритмов, способных аппроксимировать практически любую
функцию. Кроме того, индуктивные пороги применимы к обучению без учителя, а также
к эволюционным моделям; пороги представлений применимы к построению узлов, сетей
и геномов, а алгоритмические пороги — к механизмам поиска, подкрепления и селекции.
Что в таком случае могут нам предложить коннекционистские, генетические или
эволюционные конечные автоматы в их разнообразных формах?
1. Одна из наиболее привлекательных черт нейросетевого обучения— это
возможность адаптации на основе входных данных или примеров. Таким образом, хотя их
архитектуры точно проектируются, они обучаются на примерах, обобщая данные в
конкретной предметной области. Но возникает вопрос о том, хватает ли данных и
достаточно они ли "чисты", чтобы не исказить результат решения. И может ли это
знать конструктор?
2. Генетические алгоритмы также обеспечивают мощный и гибкий механизм поиска
в пространстве параметров задачи. Генетический поиск управляется как
мутациями, так и специальными операторами (например, скрещивания или инверсии),
которые сохраняют важные аспекты родительской информации для последующих
поколений. Каким образом проектировщик программы может найти и сохранить в
нужной мере компромисс между разнообразием и постоянством?
3. Генетические алгоритмы и коннекционистские архитектуры можно рассматривать
как примеры параллельной и асинхронной обработки. Но действительно ли они
обеспечивают результаты, недостижимые в последовательном программировании?
4. Хотя нейросетевые и социологические корни не имеют принципиального
значения для многих современных практиков коннекционистского и генетического
обучения, эти методы отражают многие важные стороны естественного отбора и
эволюции. В главе 10 были рассмотрены модели обучения с уменьшением
ошибки — персептронные сети, сети с обратным распространением ошибки и
модели Хебба. В подразделе 10.3.4 описаны сети Хопфилда, предназначенные
для решения задач ассоциативной памяти. Разнообразные эволюционные модели
рассматривались в главе 11.
5. И, наконец, все методики обучения являются эмпирическими средствами.
Достаточно ли мощны и выразительны эти средства, чтобы по мере выявления инвари-
антностей нашего мира ставить дальнейшие вопросы о природе восприятия,
обучения и понимания?
В следующем разделе будет обоснован вывод о том, что конструктивистская
эпистемология, объединенная с экспериментальными методами современного искусственного
интеллекта, предлагает средства и технологии для дальнейшего построения и
исследования теории интеллектуальных систем.
Глава 16. Искусственный интеллект как эмпирическая проблема
799
Примирение с конструктивистами
Теории, как сети: кто их закидывает, у того и улов...
— Л. Виттгенштейн (L. Wittgenstein)
Конструктивисты выдвигают гипотезу о том, что всякое понимание является
результатом взаимодействия между энергетическими образами мира и ментальными
категориями, наложенными на мир разумным агентом [Piaget, 1954, 1970],
[von Glasesfeld, 1978]. В терминах Пиагета (Piaget), мы ассимилируем (assimilate)
явления внешней среды в соответствии с нашим текущим пониманием и
приспосабливаем (accommodate) наше понимание к "требованиям" явления.
Конструктивисты часто используют термин схемы (schemata) для обозначения
априорных структур, используемых в организации опытного знания о внешнем мире. Этот
термин заимствован у британского психолога Бартлетта [Bartlett, 1932] и корнями уходит
в философию Канта. С этой точки зрения наблюдение не пассивно и нейтрально, а
является активным и интерпретирующим.
Воспринятая информация (кантовское апостериорное знание) никогда не
вписывается точно в заранее составленные схемы. Поэтому пороги, основанные на схемах
и используемые субъектом для организации опытных знаний, должны быть
модифицированы, расширены или же заменены. Необходимость приспособления, вызванная
неудачными взаимодействиями с окружающей средой, служит двигателем процесса
когнитивного уравновешивания. Таким образом, конструктивистская эпистемология
является основой когнитивной эволюции и уточнения. Важным следствием теории
конструктивизма является то, что интерпретация любой ситуации подразумевает
применение понятий и категорий наблюдателя.
Когда Пиагет [Piaget, 1954, 1970] предложил конструктивистский подход к
пониманию, он назвал его генетической эпистемологией (genetic epistemology). Несоответствие
между схемой и реальным миром создает когнитивное противоречие, которое вынуждает
пересматривать схему. Исправление схемы, приспособление приводит к непрерывному
развитию понимания в сторону равновесия (equilibration).
Пересмотр схемы и движение к равновесию — это врожденная
предрасположенность, а также средство приспособления к устройству общества и окружающего мира. В
пересмотре схем объединяются обе эти силы, отражающие присущую нам склонность к
выживанию. Модификация схем априори запрограммирована нашей генетикой и в то же
время является апостериорной функцией общества и мира. Это результат нашего
воплощения в пространстве и времени.
Здесь наблюдается слияние эмпирической и рационалистической традиций. Как
материализованный объект человек может воспринимать не больше, чем
воспринимают его органы чувств. Благодаря приспособлению он выживает, изучая общие
принципы внешнего мира. Восприятие определяется нашими ожиданиями, которые, в свою
очередь, формируются восприятием. Следовательно, эти функции могут быть поняты
лишь в терминах друг друга.
Наконец, человек редко осознает схемы, обеспечивающие его взаимодействие с
миром. Он является источником предвзятости и предубеждений в науке и в обществе. Но
чаще всего человек не знает их смысла. Они формируются за счет достижения
когнитивного равновесия с миром, а не в процессе сознательного мышления.
Почему конструктивистская эпистемология особенно полезна при изучении
проблем искусственного интеллекта? Автор считает, что конструктивизм помогает в
800
Часть VII. Эпилог
рассмотрении проблемы эпистемологического доступа (epistemological access).
Более столетия в психологии идет борьба между двумя направлениями: позитивистами,
которые предлагают исследовать феномен разума, отталкиваясь от обозримого
физического поведения, и сторонниками более феноменологического подхода,
который позволяет использовать описания от первых лиц. Это разногласие существует,
поскольку оба подхода требуют некоторых предположений или толкований. По
сравнению с физическими объектами, которые считаются непосредственно
наблюдаемыми, умственные состояния и поведение субъекта четко охарактеризовать
крайне сложно. Автор полагает, что противоречие между прямым подходом к
физическим явлениям и непрямым к ментальным является иллюзорным.
Конструктивистский анализ показывает, что никакое опытное знание о предмете не возможно без
применения некоторых схем для организации этого опыта. В научных
исследованиях это подразумевает, что всякий доступ к явлениям мира происходит посредством
построения моделей, приближений и уточнений.
16.2.3. Внедренный исполнитель и экзистенциальный разум
Символьные рассуждения, нейросетевые вычисления и разнообразные формы
эволюционных стратегий являются главенствующими подходами в современном изучении ИИ.
Тем не менее, как было отмечено в предыдущем разделе, для обеспечения более высокой
эффективности эти подходы должны принимать в расчет ограничения мира, согласно
которым весь "интеллект" является овеществленным.
Теории внедренного и овеществленного действия утверждают, что интеллект не
является результатом управления моделями, построенными разумом. Его лучше
всего рассматривать в терминах действий, предпринимаемых помещенным в мир
агентом. В качестве метафоры для лучшего понимания разницы между двумя подходами
в работе [Suchman, 1987] предлагается сравнение между европейскими методами
навигации и менее формальными методами, практикуемыми полинезийскими
островитянами. Европейские навигационные методы требуют постоянного отслеживания
местонахождения корабля в каждый момент путешествия. Для этого штурманы
полагаются на обширные, детальные географические модели. Полинезийские
навигаторы, напротив, не пользуются картами и другими средствами определения своего
местонахождения. Они используют звезды, ветры и течения, чтобы продолжать
движение к своей цели, импровизируя маршрут, который непосредственно зависит
от обстоятельств их путешествия. Не полагаясь на модели мира, островитяне
рассчитывают на свое взаимодействие с ним и достигают своей цели с помощью
надежного и гибкого метода.
Теории внедренного действия утверждают, что интеллект не нужно рассматривать
как процесс построения и использования моделей мира. Это, скорее, менее
структурированный процесс выполнения действий в этом мире и реагирования на результат. Этот
подход акцентирует внимание на способности чувственного восприятия окружающего
мира, целенаправленных действиях, а также непрерывной и быстрой реакции на
изменения, происходящие в нем. В этом подходе чувства, посредством которых человек
внедряется в этот мир, имеют большее значение, нежели процессы рассуждения о них.
Важнее способность действовать, а не способность объяснять эти действия.
Влияние такой точки зрения на сети связей и агентские подходы очевидно. Оно
состоит в отказе от общих символьных методов в пользу процессов адаптации и обучения.
Глава 16. Искусственный интеллект как эмпирическая проблема
801
Работы в области искусственной жизни [Langton, 1995], должно быть, самый яркий
пример исследований, выполненных под влиянием теорий внедренного действия. Эти
модели разума повлияли на подход к робототехнике Родни Брукса [Brooks, 1989], Брендана
Мак-Гонигла [McGonigle, 1998], Льюиса и Люгера [Lewis и Luger, 2000]. Эти
исследователи утверждают, что было ошибкой начинать работы в сфере ИИ с реализации
высокоуровневых процессов рассуждений в моделируемом разуме. Этот акцент на логических
рассуждениях повел человечество неверной дорогой, отвлек внимание от
фундаментальных процессов, которые позволяют агенту внедряться в мир и действовать в нем
продуктивным образом. По мнению Брукса, нужно начинать с проектирования и исследования
небольших простых роботов, созданий, действующих на уровне насекомых. Они
позволят изучить процессы, лежащие в основе поведения как простых, так и сложных существ.
Построив множество таких простых роботов, Брукс и его коллеги пытаются применить
приобретенный опыт в конструировании более сложного робота COG, который, как
надеются разработчики, достигнет способностей человека.
Несмотря на это, теория внедренного действия также повлияла на символьные
подходы к ИИ. Например, работы в области реактивного планирования [Benson, 1995], [Benson
и Nilsson, 1995], [Klein и др., 2000] отвергают традиционные методы планирования,
предполагающие разработку полного и определенного плана, который проведет агента
по всему пути, от стартовой точки и до желаемой цели. Такие планы редко срабатывают
нужным образом, потому что на пути может возникнуть слишком много ошибок и
непредвиденных проблем. Напротив, системы реактивного планирования работают
циклами. За построением частичного плана следует его выполнение, а затем ситуации
переоценивается для построения нового плана.
Конструктивистские теории и теории внедренного действия подтверждают
многие идеи философии экзистенциализма. Экзистенциалисты считают, что человек
проявляет себя посредством своих действий в окружающем мире. То, во что люди
верят (или утверждают, что верят), куда менее важно, чем то, что они совершают в
критических ситуациях. Этот акцент весьма важен в ИИ. Исследователи постепенно
поняли, что интеллектуальные программы необходимо помещать прямо в
предметную область, а не лелеять в лаборатории. В этом причина роста интереса к
робототехнике и проблеме восприятия, а также к сети Internet. В последнее время ведутся
активные работы по созданию Web-агентов, или "софтботов", — программ, которые
выходят в сеть и совершают полезные интеллектуальные действия. Сеть
привлекательна для разработчиков ИИ прежде всего тем, что она может предложить
интеллектуальным программам мир, куда более сложный, чем построенный в
лаборатории. Этот мир, сравнимый по сложности с природой и обществом, могут населять
интеллектуальные агенты, не имеющие тел, но способные чувствовать и
действовать, как в физическом мире.
По мнению автора, теории внедренного действия будут оказывать все возрастающее
влияние на искусственный интеллект, заставляя исследователей уделять больше
внимания таким вопросам, как важность овеществления и обоснования для интеллектуального
агента. Важно также учитывать влияние социального, культурного и экономического
факторов на обучение и на способ влияния мира на рост и эволюцию внедренного
агента. [Clark, 1997], [Lakoff и Johnson, 1999].
В заключение сформулируем основные вопросы, которые как способствуют, так и
препятствуют сегодняшним усилиям специалистов в построении теории
интеллектуальных систем.
802
Часть VII. Эпилог
16.3. Искусственный интеллект: текущие задачи
и будущие направления
Как геометр, напрягший все старанья,
Чтобы измерить круг, схватить умом
Искомого не может основанья,
Таков был я при новом диве том...
— Данте (Dante), Рай
Хотя использование методик ИИ для решения практических задач
продемонстрировало его полезность, проблема их применения для построения полной теории интеллекта
сложна, и работа над ней продолжается. В этом заключительном разделе мы вернемся к
вопросам, которые привели автора к изучению проблем искусственного интеллекта и
написанию этой книги: возможно ли дать формальное математическое описание процессов,
формирующих интеллект?
Вычислительное описание интеллекта возникло с появлением абстрактных
определений вычислительных устройств. В 1930-1950-х гг. эту проблему начали исследовать
Тьюринг, Пост, Марков и Черч — все они работали над формальными системами для
описания вычислений. Целью этого исследования было не просто определить, что
подразумевать под вычислениями, но и установить рамки их применимости. Наиболее
изученным формальным описанием является универсальная машина Тьюринга [Turing, 1950],
хотя правила вывода Поста, лежащие в основе продукционных систем, тоже вносят
важный вклад в развитие этой области знаний. Модель Черча [Church, 1941], основанная на
частично рекурсивных функциях, привела к созданию современных высокоуровневых
функциональных языков, таких как Scheme и Standard ML.
Теоретики доказали, что все эти формализмы эквивалентны по своей мощности:
любая функция, вычисляемая при одном подходе, вычисляется и при остальных. На самом
деле можно показать, что универсальная машина Тьюринга эквивалента любому
современному вычислительному устройству. Исходя из этих фактов, был выдвинут тезис Чер-
ча-Тьюринга о том, что невозможно создать модель вычислительного устройства, более
мощного, чем уже известные модели. Установив эквивалентность вычислительных
моделей, мы обретаем свободу в выборе средств их технической реализации: можно
строить машины на основе электронных ламп, кремния, протоплазмы или консервных банок.
Автоматизированное проектирование в одной реализации можно рассматривать как
эквивалент других механизмов. Это делает еще более важным эмпирический метод,
поскольку исследователь может экспериментировать над системой, реализованной одними
средствами, чтобы понять систему, реализованную иными.
Хотя, возможно, универсальная машина Тьюринга и Поста чересчур универсальна.
Парадокс состоит в том, что для реализации интеллекта может потребоваться менее
мощный вычислительный механизм с большим упором на управление. В работе
[Levesque и Brachman, 1985] высказано предположение, что для реализации
человеческого интеллекта могут потребоваться вычислительно более эффективные (хотя и
менее впечатляющие) представления, в том числе основанные на использовании хорнов-
ских дизъюнктов для представления рассуждений и сужении фактического знания до
основных литералов. Агентские и эволюционные модели интеллекта также разделяют
подобную идеологию.
Глава 16. Искусственный интеллект как эмпирическая проблема
803
Еще один аспект, связанный с формальной эквивалентностью вычислительных
моделей, — это вопрос дуализма, или проблема взаимоотношения мозга и тела. По крайней
мере со времен Декарта (см. раздел 1.1) философы задавались вопросом взаимодействия
и интеграции мозга, сознания и физического тела. Философы предлагали всевозможные
объяснения, от полного материализма до отрицания материального существования,
вплоть до вмешательства бога. ИИ и когнитологические исследования отвергают
картезианский дуализм в пользу материальной модели разума, основанной на физической
реализации, или конкретизации символов, формальном описании вычислительных операций
над этими символами, эквивалентности представлений и "реализации" знаний и опыта в
овеществленных моделях. Успех таких исследований свидетельствует о справедливости
выбранной модели [Johnson-Laird, 1998], [Dennett, 1987], [Luger, 1994].
Тем не менее возникает множество вопросов, связанных с эпистемологическими
принципами организации интеллекта как физической системы. Отметим некоторые
важные проблемы.
1. Проблема представления. Ньюэлл и Саймон выдвинули гипотезу о том, что
физическая символьная система и поиск являются необходимой и достаточной
характеристикой интеллекта (см. раздел 16.1). Опровергают ли успехи нейронных сетей,
генетических и эволюционных подходов к интеллекту гипотезу о физической
символьной системе, или же они сами являются символьными системами?
Вывод о том, что физическая символьная система представляет собой достаточную
модель интеллекта, привел ко многим впечатляющим и полезным результатам в
современной науке о мышлении. Исследования показали, что можно реализовать
физическую символьную систему, которая будет проявлять разумное поведение.
Достаточность гипотезы позволяет строить и тестировать символьные модели
многих аспектов поведения человека ([Pylyshyn, 1984], [Posner, 1989]). Но теория о
том, что физическая символьная система и поиск необходимы для разумного
поведения, остается под вопросом [Searle, 1980], [Weizenbaum, 1976], [Winograd и
Flores, 1986], [Dreyfus и Dreyfus, 1985], [Penrose, 1989].
2. Роль овеществления в познании. Одним из главных предположений гипотезы о
физической символьной системе является то, что физическая реализация
символьной системы не влияет на ее функционирование. Значение имеет лишь формальная
структура. Это ставится под сомнение многими исследователями [Searle, 1980],
[Johnson, 1987], [Agre и Chapman, 1987], [Brooks, 1989], [Уаге1аидр., 1993],
которые утверждают, что разумные действия в мире требуют физического воплощения,
которое позволяет агенту объединяться с миром. Архитектура сегодняшних
компьютеров не допускает такой степени внедрения, ограничивая взаимодействие
искусственного интеллекта с миром современными устройствами ввода-вывода. Если
эти сомнения верны, то реализация машинного разума требует интерфейса, весьма
отличного от предлагаемого современными компьютерами.
3. Культура и интеллект. Традиционно упор в ИИ делался на разум отдельного
индивида как источник интеллекта. Предполагается, что изучение принципов работы
мозга (способов кодирования и манипулирования знаниями) обеспечит полное
понимание истоков интеллекта. Но можно утверждать, что знание лучше
рассматривать в контексте общества, чем как отдельную структуру.
В теории интеллекта, описанной в [Edelman, 1992], общество само является
носителем важных составляющих интеллекта. Возможно, понимание социального кон-
804
Часть VII. Эпилог
текста знания и человеческого поведения не менее важно для теории интеллекта,
чем понимание процессов отдельного разума (мозга).
4. Природа интерпретации. Большинство вычислительных моделей работают с
заранее интерпретированной предметной областью, т.е. существует неявная
априорная привязка разработчиков к контексту интерпретации. Из-за этой привязки
система ограничена в изменении целей, контекстов, представлений по мере решения
задачи. Кроме того, сегодня делается слишком мало попыток осветить процесс
построения интерпретации человеком.
Позиция Тарскиана (Tarskian), который рассматривает семантическое
приспособление как отображение множества символов на множество объектов, безусловно,
слишком слаба и не объясняет, например, тот факт, что одна предметная область
может иметь разные интерпретации в свете различных практических целей.
Лингвисты пытаются устранить ограничения такой семантики, добавляя к ней теорию
прагматики [Austin, 1962] (раздел 13.1). К этим вопросам в последнее время часто
обращаются исследователи в области анализа связной речи, поскольку здесь
важную роль играет применение символов в контексте. Однако проблема гораздо
шире — она сводится к изучению преимуществ и недостатков ссылочных средств в
целом [Lave, 1988], [Grosz и Sidner, 1990].
В традиции семиотики, основанной Пирсом [Peirse, 1958] и продолженной в
работах [Есо, 1976], [Grice, 1975], [Seboek, 1985], принимается более радикальный
подход к языку. Здесь символьные выражения рассматриваются в более широком
контексте знаков и знаковых интерпретаций. Это предполагает, что значение символа
может быть понято лишь в контексте его интерпретации и взаимодействия с
окружающей средой.
5. Неопределенность представлений. Гипотеза Андерсона о неопределенности
представлений [Anderson, 1978] гласит: принципиально невозможно определить,
какая схема представления наилучшим образом аппроксимирует решение задачи
человеком в контексте его опыта и навыков. Эта гипотеза основывается на том
факте, что всякая схема представления неразрывно связана с большей
вычислительной архитектурой и со стратегиями поиска. Детальный анализ человеческого
опыта показывает, что иногда невозможно управлять процессом решения в
степени, достаточной для определения представления, или же установить
представление, которое бы однозначно определяло процесс. Как и принцип неопределенности
в физике, где процесс измерения влияет на исследуемое явление, это соображение
важно при проектировании моделей интеллекта, но оно, как будет показано ниже,
не ограничивает их применимости.
Такие же замечания могут быть адресованы к самой вычислительной модели, где
индуктивные пороги символов и поиска в контексте гипотезы Черча-Тьюринга все
же накладывают ограничения на систему. Мысль о необходимости построения
некой оптимальной схемы представления вполне может оказаться осколком мечты
рационалиста, в то время как ученому нужна лишь модель, достаточно
качественная для рассмотрения эмпирических вопросов. Доказательством качества модели
является ее способность интерпретировать, предсказывать и адаптироваться.
6. Необходимость построения ошибочных вычислительных моделей. Поппер
[Popper, 1959] и другие утверждают, что научные теории должны ошибаться.
Следовательно, должны существовать обстоятельства, при которых модель не может
Глава 16. Искусственный интеллект как эмпирическая проблема 805
успешно аппроксимировать явление. Это связано с тем, что для подтверждения
правильности модели не достаточно никакого конечного числа подтверждающих
экспериментов. Ошибки в существующих теориях стимулируют дальнейшие
исследования.
Крайняя общность гипотезы о физической символьной системе, а также агентских
и эволюционных моделей интеллекта может привести к тому, что их будет
невозможно заставить ошибаться. Следовательно, их применимость в качестве моделей
будет ограниченной. Те же замечания можно сделать по поводу предположений
феноменологической традиции (п. 7). Некоторые структуры данных ИИ, такие как
семантические сети, тоже настолько общи, что ими можно смоделировать
практически все, что поддается описанию, или, как в универсальной машине Тьюринга,
любую вычислимую функцию. Таким образом, если исследователю ИИ или когни-
тологу задать вопрос о том, при каких условиях его модель интеллекта не будет
работать, он затруднится ответить.
7. Ограничения научного метода. Некоторые исследователи [Winograd и Flo-
res, 1986], [Weizenbaum, 1976] утверждают, что наиболее важные аспекты интеллекта
в принципе невозможно смоделировать, а в особенности с помощью символьного
представления. Эти аспекты включают обучение, понимание естественного языка и
речь. Эти вопросы корнями уходят глубоко в феноменологическую традицию.
Например, замечания Винограда (Winograd) и Флореза (Flores) основываются на
проблемах, поднятых в феноменологии [Husserl, 1970], [Heidegger, 1962].
Многие положения современной теории ИИ берут начало в работах Карнапа
(Сагпар), Фреге (Frege), Лейбница (Leibniz), а также Гоббса (Hobbes), Локка
(Locke), Гумма (Hume) и Аристотеля. В этой традиции утверждается, что
интеллектуальные процессы отвечают законам природы и в принципе постижимы.
Хайдеггер (Heidegger) и его последователи представили альтернативный подход к
пониманию интеллекта. Для Хайдеггера рефлексивная осведомленность свойственна
миру овеществленного опыта. Приверженцы этой точки зрения, включая Винограда,
Флореса и Дрейфуса (Dreyfus), говорят, что понимание личностью каких-либо
аспектов основывается на их практическом "использовании" в повседневной жизни. По
существу, мир представляет собой контекст социально организованных ролей и
целей. Эта среда и функционирование человека в ней не объясняются соотношениями и
теоремами. Это поток, который сам себя формирует и непрерывно модифицирует. В
фундаментальном смысле в мире эволюционирующих норм и неявных целей
человеческий опыт — это знание не объекта, а, скорее, способа действия. Человек по
своей сути не способен выразить большую часть своего знания и разумного поведения в
форме языка, будь то формального или естественного.
Рассмотрим эту точку зрения. Во-первых, как критика чисто рационалистской
традиции, она верна. Рационализм отстаивает позицию, что всякая человеческая
деятельность, интеллект и ответственность в принципе могут быть представлены,
формализованы и поняты. Большинство вдумчивых людей ставят это под
сомнение, отводя важную роль эмоциям, самоутверждению и обязательствам долга
(наконец-то!). Сам Аристотель говорил: ''Почему я не чувствую побуждения делать
то, что требует ответственность?". Существует множество разновидностей
человеческой деятельности, выходящих за пределы досягаемости научного метода, кото-
806
Часть VII. Эпилог
рые играют важную роль в сознательном взаимодействии людей. Их невозможно
воспроизвести в машинах.
И все же научная традиция, состоящая в изучении данных, построении моделей,
постановке экспериментов и проверке результатов с уточнением модели
дальнейших экспериментов, дала человечеству высокий уровень понимания, объяснения и
способности предсказывать. Научный метод — мощный инструмент для
улучшения понимания человека. Тем не менее в этом подходе остается множество
подводных камней.
Во-первых, ученые не должны путать модель с моделируемым явлением. Модель
позволяет постепенно аппроксимировать феномен, но всегда имеется "остаток",
который нельзя объяснить эмпирически. В этом смысле неоднозначность
представления не является проблемой. Модель используется для исследования,
объяснения и предсказания, и если она выполняет эти функции, то это — удачная
модель [Kuhn, 1962]. В самом деле разные модели могут успешно пояснять разные
аспекты одного явления, например, волновая и корпускулярная теории света.
Более того, когда исследователи утверждают, что некоторые аспекты интеллекта
находятся за рамками методов научной традиции, само это утверждение можно
проверить лишь с помощью этой традиции. Научный метод — единственный
инструмент, с помощью которого можно объяснить, в каком смысле вопросы могут
быть за пределами текущего понимания человека. Всякая логически
последовательная точка зрения, даже точка зрения феноменологической традиции, должна
соотноситься с текущими представлениями об объяснении, даже если она всего
лишь устанавливает границы, в которых феномен может быть объяснен.
Эти вопросы необходимо рассматривать для сохранения логической связности и развития
ИИ. Для того чтобы понять процесс решения задач, обучение и язык, необходимо осмыслить
представления и знания на уровне философии. Исследователям предстоит решать
аристотелевское противоречие между теорией и практикой, жить между наукой и искусством.
Ученые создают инструменты. Все наши представления, алгоритмы и языки — это
инструменты для проектирования и построения механизмов, проявляющих разумное
поведение. Посредством эксперимента можно исследовать как их вычислительную
адекватность для решения задач, так и наше собственное понимание явления интеллекта.
Мы наследники традиции Гоббса, Лейбница, Декарта, Бэббиджа, Тьюринга и других, о
чьем вкладе в науку было рассказано в главе 1. Инженерия, наука и философия; природа идей,
знаний и опыта; могущество и пределы формализма и механизма — это ограничения, с
которыми необходимо считаться и с учетом которых нужно продолжать исследования.
16.4. Резюме и дополнительная литература
Для получения дополнительной информации читатель может воспользоваться
ссылками, приведенными в конце главы 1. К ним стоит добавить работы [Pylyshyn, 1984] и
[Winograd и Flores, 1986]. Вопросы когнитологии рассматриваются в [Norman, 1983],
[Newell и Simon, 1972], [Posner, 1989], [Luger, 1994], [Ballard, 1997], [Franklin, 1995],
[Jeannerod, 1997], [Elman и др., 1996].
В работах [Haugeland, 1981, 1997], [Dennett, 1978], [Smith, 1996] описаны
философские корни теории интеллектуальных систем. Книга [Anderson, 1990] по когнитивной
Глава 16. Искусственный интеллект как эмпирическая проблема 807
психологии дает ценные примеры моделей обработки информации. В работах
[Pylyshin, 1984], [Anderson, 1978] приводится детальное описание многих
принципиальных вопросов когнитологии, включая рассмотрение неопределенности представлений. В
[Dennett, 1991] методы когнитологии применяются для исследовании структуры
сознания. Также можно порекомендовать книги по научному методу: [Popper, 1959],
[Kuhn, 1962], [Bechtel, 1988], [Hempel, 1965], [Lakatos, 1976], [Quine, 1963].
Наконец, в [Lakoff и Johnson, 1999] предложены возможные ответы на вопрос
обоснования. В книге [Clark, 1997] описаны важные аспекты овеществленности интеллекта.
Описание модели Брукса [Brooks, 199la] для решения задачи внедренного робота можно
найти в работах [McGonigle, 1990, 1998] и [Lewis и Luger, 2000].
Предлагаем читателям адреса двух известных научных групп.
The American Association for Artificial Intelligence
445 Burgess Drive
Menlo Park, CA 94025
Computer Professionals for Social Responsibility
P.O. Box 717
Palo Alto, С А 94301
808
Часть VII. Эпилог
Библиография
Abelson H., Sussman G. J. Structure and Interpretation of Computer Programs. Cambridge,
MA: MIT Press, 1985.
Ackley D. H., Hinton G. E. and Sejnowski T. J. A learning algorithm for Boltzmann machines.
Cognitive Science 9, 1985.
Ackley D. H., Littman M. Interactions between learning and evolution. In Langton et al.
A992), 1992.
Adler M. R., Davis А. В., Weihmayer R. and Worrest R. W. Conflict resolution strategies for
nonhierarchical distributed agents. Distributed Artificial Intelligence, Vol. 112. San
Francisco: Morgan Kaufmann, 1989.
Agre P. and Chapman D. Pengi: an implementation of a theory of activity. Proceedings of the
Sixth National Conference on Artificial Intelligence, pp. 268-272. CA: Morgan
Kaufmann, 1987.
Aho A. V. and Ullman J. D. Principles of Compiler Design. Reading, MA: Addison-Wesley, 1977.
Allen J. Natural Language Understanding. Menlo Park, CA: Benjamin/Cummings, 1987.
Allen J. Natural Language Understanding, 2nd ed. Menlo Park, С A: Benjamin/Cummings, 1995.
Allen J., Hendler J. and Tate A. Readings in Planning. Los Altos, С A: Morgan Kaufmann, 1990.
Alty J. L. and Coombs M. J. Expert Systems: Concepts and Examples. Manchester: NCC
Publications, 1984.
Anderson J. A., Silverstein J. W., Ritz, S. A. and Jones R. S. Distinctive features, categorical
perception and probability learning: Some applications of a neural model. Psychological
Review, 84:413-451, 1977.
Anderson J. R. Arguments concerning representations for mental imagery. Psychological
Review, 85: 249-277, 1978.
Anderson J. R. Acquisition of cognitive skill. Psychological Review, 89: 369-406, 1982.
Anderson J. R. Acquisition of proof skills in geometry. In Michalski et al. A983a), 1983a.
Anderson J. R. The Architecture of Cognition. Cambridge, MA: Harvard University Press, 19836.
Anderson J. R. Cognitive Psychology and its Implications. New York; W. H. Freeman, 1990.
Anderson J. R. and Bower G. H. Human Associative Memory. Hillsdale, NJ: Erlbaum, 1973.
Andrews P. An Introduction to Mathematical Logic and Type Theory: To Truth Through
Proof. New York: Academic Press, 1986.
Smalltalk/V: Tutorial and Programming Handbook. Los Angeles: Digitalk, 1986.
Appelt D. Planning English Sentences. London: Cambridge University Press, 1985.
Arbib M. Simple self-reproducing universal automata. Information and Control 9:177-189,1966.
Aspray W. and Burks A. W., ed. Papers of John Von Neumann on Computing and Computer
Theory. Cambridge, MA: MIT Press, 1987.
Auer P., Holte R. C. and Maass W. Theory and application of agnostic рас-learning with small
decision trees. Proceedings of the Twelfth International Conference on Machine Learning,
pp. 21-29. San Francisco: Morgan Kaufmann, 1995.
Austin J. L. How to Do Things with Words. Cambridge, MA: Harvard University Press, 1962.
Bach E. and Harms R., ed. Universals of Linguistic Theory. New York: Holt, Rinehart and
Winston, 1968.
Bachant J. and McDermott J. Rl revisited: Four years in the trenches. Al Magazine 5C), 1984.
Backus J. Can programming be liberated from the Von Neumann style? A functional style and
its algebra of programs, Communications of the ACM, 21(8): 613-641, 1978.
Ballard D. An introduction to Natural Computation. Cambridge, MA: MIT Press, 1997.
Balzer R., Erman L. D., London P. E. and Williams С HEARSAY III: A domain independent
framework for expert systems. Proceedings AAAI, 1980.
Bareiss E. R., Porter, B. W. and Weir С. С. Protos: An exemplar-based learning apprentice.
International Journal of Man-Machine Studies, 29: 549-561, 1988.
Barker V. E. and O'Connor D. E. Expert Systems for configuration at DIGITAL: XCON and
Beyond. Communications of the ACM, 32C): 298-318, 1989.
Barkow J. H., Cosmides L. and Tooby J. The Adapted Mind. New York: Oxford Univ. Press, 1992.
Barr A. and Feigenbaum E., ed. Handbook of Artificial Intelligence. Los Altos, CA: William
Kaufman, 1989.
Bartlett F. Remembering. London: Cambridge University Press, 1932.
Bateson G. Mind and Nature: A Necessary Unity. New York: Dutton, 1979.
Bechtel W. Philosophy of Mind. Hillsdale, NJ: Lawrence Erlbaum, 1988.
Bellman R. E. Dynamic Programming. Princeton, NJ: Princeton University Press, 1956.
Benson S. Action Model Learning and Action Execution in a Reactive Agent. Proceedings of
the International Joint Conference on Artificial Intelligence (IJCAI-95), 1995.
Benson S. and Nilsson N. Reacting, Planning and Learning in an Autonomous Agent. Machine
Intelligence 14. Edited by K. Furukawa, D. Michie and S. Muggleton. Oxford: Clarendon
Press, 1995.
Berger A., Brown P., Delia Pietra S., Delia Pietra V., Gillett J., Lafferty J., Mercer R., Printz H.
and Ures L. The Candide System for Machine Translation. Human Language Technology:
Proceedings of the ARPA Workshop on Speech and Natural language. San Mateo, CA:
Morgan Kaufmann, 1994.
Bernard D. E., Dorais G. A., Fry C, Gamble E. В., Kanefsky В., Kurien J., Millar W.,
Muscettola N., Nayak P. P., Pell В., Rajan K., Rouquette N., Smith B. and Williams В. С
Design of the remote agent experiment for spacecraft autonomy. Proceedings of the IEEE
Aerospace Conference, 1998.
Bertsekas D. P. and Tsitsiklis J. N. N euro-Dynamic Programming. Belmont, MA: Athena, 1996.
Bhaskar R. and Simon H. A. Problem solving in semantically rich domains. Cog. Sci. 1, 1977.
Bishop С. Н. Neural Networks for Pattern Recognition. Oxford: Oxford University Press, 1995.
810
Библиография
Bledsoe W. W. Splitting and reduction heuristics in automatic theorem proving. Artificial
Intelligence, 2: 55-77, 1971.
Bledsoe W. W. Non-resolution theorem proving. Artificial Intelligence, 9, 1977.
Bobrow D. G. Dimensions of representation. In Bobrow and Collins A975), 1975.
Bobrow D. G. and Collins A., ed. Representation and Understanding. NY: Academic Press, 1975.
Bobrow D. G. and Winograd T. An overview of K.RL, a knowledge representation language.
Cognitive Science 1A), 1977.
Bond A. H. and Gasser L., ed. Readings in Distributed Artificial Intelligence. San Francisco:
Morgan Kaufmann, 1988.
Boole G. The Mathematical Analysis of Logic. Cambridge: Macmillan, Barclay & Macmillan, 1847.
Boole G. An Investigation of the Laws of Thought. London: Walton & Maberly, 1854.
Boyer R. S. and Moore J. S. A Computational Logic. New York; Academic Press, 1979.
Brachman R. J. On the epistemological status of semantic networks. In Brachman and
LevesqueA985), 1979.
Brachman R. J. / lied about the trees. AI Magazine 6C), 1985.
Brachman R. J. and Levesque H. J. Readings in Knowledge Representation. Los Altos, CA:
Morgan Kaufmann, 1985.
Brachman R. J., Fikes R. E. and Levesque H. J. KRYPTON: A functional approach to
knowledge representation. In Brachman and Levesque A985), 1985.
Brachman R. J., Levesque H. J. and Reiter R., ed. Proceedings of the First International
Conference on Principles of Knowledge Representation and Reasoning, Los Altos, CA:
Morgan Kaufmann, 1990.
Breiman L., Friedman J., Olsen R. and Stone С Classification and Regression Trees.
Monterey, CA: Wadsworth, 1984.
Brodie M. L., Mylopoulos J. and Schmidt J. W. On Conceptual Modeling. New York:
Springer-Verlag, 1984.
Brooks R. A. A robust layered control system for a mobile robot. IEEE Journal of Robotics and
Automation. 4: 14-23, 1986.
Brooks R. A. A hardware retargetable distributed layered architecture for mobile robot
control. Proceedings IEEE Robotics and Automation, pp. 106-110. Raliegh, NC, 1987.
Brooks R. A. A robot that walks: Emergent behaviors from a carefully evolved network. Neural
Computation 1B): 253-262, 1989.
Brooks R. A. Intelligence without reason. Proceedings of IJCA1-91, pp. 569-595. San Mateo,
С A: Morgan Kaufmann, 1991a.
Brooks R. A. Challenges for complete creature architectures. In Meyer and Wilson, 1991.
Brooks R. and Stein L. Building brains for bodies. Autonomous Robots, 1: 7-25, 1994.
Brown J. S. and Burton R. R. Diagnostic models for procedural bugs in basic mathematical
skills. Cognitive Science, 2, 1978.
Brown J. S. and VanLehn K. Repair theory: A generative theory of bugs in procedural skills.
Cognitive Science, 4: 379-426, 1980.
Brown J. S., Burton R. R. and deKleer J. Pedagogical, natural language and knowledge
engineering techniques in SOPHIE. In Sleeman and Brown A982), 1982.
Библиография
811
Brownston L., Farrell R., Kant E. and Martin N. Programming Expert Systems in OPS5: An
Introduction to Rule-Based Programming. Reading, MA: Addison-Wesley, 1985.
Buchanan B. G. and Mitchell Т. М. Model-directed learning of production rules. In Waterman
and Hayes-Roth A978), 1978.
Buchanan B. G. and Shortliffe E. H. ed. Rule-Based Expert Systems: The MYCIN Experiments
of the Stanford Heuristic Programming Project. Reading, MA: Addison-Wesley, 1984.
Bundy A. Computer Modeling of Mathematical Reasoning. New York: Academic Press, 1983.
Bundy A. The use of explicit plans to guide inductive proofs. Lusk R. and Overbeek R. (ed),
Proceedings of CADE 9. pp. 111-120, New York: Springer Verlag, 1988.
Bundy A., Byrd L., Luger G., Mellish C, Milne R. and Palmer M. Solving mechanics problems
using meta-level inference. Proceedings of IJCAI-I979, pp. 1017-1027, 1979.
Bundy A. and Welham R. Using meta-level inference for selective application of multiple
rewrite rules in algebraic manipulation, Artificial Intelligence, 16: 189-212, 1981.
Burks A. W. Theory of Self Reproducing Automata. University of Illinois Press, 1966.
Burks A. W. Essays on Cellular Automata. University of Illinois Press, 1970.
Burkks A. W. Von Neumann's self-reproducing automata. In Aspray and Burks A987), 1987.
Burmeister В., Haddadi A. and Matylis G. Applications of multi-agent systems in traffic and
transportation. IEEE Transactions in Software Engineering, 144A): 51-60, 1997.
Burstall R. M. and Darlington J. A. A transformational system for developing recursive
programs. JACM, 24 (January), 1977.
Burstein M. Concept formation by incremental analogical reasoning and debugging. In
Michalskietal. A986).
Busuoic M. and Griffiths D. Cooperating intelligent agents for service management in
communications networks. Proceedings of 1993 Workshop on Cooperating Knowledge
Based Systems, University of Keele, UK, 213-226, 1994.
Butler M., ed. Frankenstein, or The Modern Prometheus: the 1818 text by Mary Shelly. New
York: Oxford University Press, 1998.
Cahill L. and McGaugh J. L. Modulation of memory storage. In Squire and Kosslyn A998), 1998.
Carbonell J. G. Learning by analogy: Formulating and generalizing plans from past
experience. In Michalski et al. A983), 1983.
Carbonell J. G. Derivational analogy: A theory of reconstructive problem solving and expertise
acquisition. In Michalski et al. A986), 1986.
Carbonell J. G., Michalski R. S. and Mitchell Т. М. An overview of machine learning. In
Michalskietal. A983), 1983.
Cardie C. Empirical methods in information extraction. Al Magazine, Winter, 65-79, 1997.
Cardie C. and Mooney R. J. Machine learning and natural language. Machine Learning, 34,
5-9, 1999.
Carlson N. R. Physiology of Behavior, 5th ed. Needham Heights MA: Allyn Bacon, 1994.
Carpenter P. A. and Just M. A. Cognitive processes in Comprehension. Hillsdale, NJ: Erlbaum,
1977.
Ceccato S. Linguistic Analysis and Programming for Mechanical Translation. New York:
Gordon & Breach, 1961.
812
Библиография
Chang С. L. and Lee R. С. Т. Symbolic Logic and Mechanical Theorem Proving. New York:
Academic Press, 1973.
Charniak E. Toward a model of children's story comprehension. Report No. TR-266, Al
Laboratory, MIT, 1972.
Charniak E. Statistical Language Learning. Cambridge, MA: MIT Press, 1993.
Charniak E., Hendrickson C, Jacobson N. and Perkowitz M. Equations for part-of speech
tagging. Proceedings of the Eleventh National Conference on Artificial Intelligence.
Menlo Park, С A; AAAI/MIT Press, 1993.
Charniak E. and McDermott D. Introduction to Artificial Intelligence. Reading, MA: Addison-
Wesley, 1985.
Charniak E., Riesbeck C. K., McDermott, D. V. and Meehan J. R. Artificial Intelligence
Programming, 2nd ed. Hillsdale, NJ: Erlbaum, 1987.
Charniak E. and Shimony S. Probabilistic semantics for cost based abduction. Proceedings of
the Eighth National Conference on Artificial Intelligence, pp. 106-111. Menlo Park, CA:
AAAI Press/ MIT Press, 1990.
Charniak E. and Wilks Y. Computational Semantics. Amsterdam: North-Holland, 1976.
Chen L. and Sycara K. Webmate: A personal agent for browsing and searching. Proceedings of
Second International Conference on Autonomous Agents (Agents 98), 1998.
Chomsky N. Aspects of the Theory of Syntax. Cambridge, MA: MIT Press, 1965.
Chorafas D. N. Knowledge Engineering. New York: Van Nostrand Reinhold, 1990.
Chung К. Т. and Wu С. Н. Dynamic scheduling with intelligent agents. Metra Application
Note 105. Palo Alto: Metra, 1997.
Church A. The calculi of lambda-conversion. Annals of Mathematical Studies. Vol. 6.
Princeton: Princeton University Press, 1941.
Churchland P. S. Neurophilosophy: Toward a Unified Science of the Mind/Brain. Cambridge,
MA: MIT Press, 1986.
Clancy W. J. The advantages of abstract control knowledge in expert system design. AAAI-3,1983.
Clancy W. J. Heuristic Classification. Artificial Intelligence, 27: 289-350, 1985.
Clancy W. J. and Shortliffe E. H. Introduction: Medical artificial intelligence programs. In
Clancy and Shortliffe A9846), 1984a.
Clancy W. J. and Shortliffe E. H., ed. Readings in Medical Artificial Intelligence: the First
Decade. Reading, MA: Addison-Wesley, 19846.
Clark A. Being There: Putting Brain, Body, and World Together Again. Cambridge, MA: MIT
Press, 1977.
Clocksin W. F. and Mellish С S. Prog, in PROLOG, 2nd ed. New York: Springer-Verlag, 1984.
Codd E. F. Cellular Automata. New York: Academic Press, 1968.
Codd E. F. Private communication to J. R. Koza. In Koza A992), 1992.
Cohen P. R. and Feigenbaum E. A. The Handbook of Artificial Intelligence. Vol. 3. Los Altos,
CA: William Kaufmann, 1982.
Cole R. A., ed. Survey of the State of the Art in Human Language Technology. New York:
Cambridge University Press, 1997.
Cole P. and Morgan J. L., ed. Studies in Syntax. Vol. 3. New York: Academic Press, 1975.
Библиография
813
Collins A. and Quillian M. R. Retrieval time from semantic memory. Journal of Verbal
Learning & Verbal Behavior, 8: 240-247, 1969.
Colmerauer A. Les Grammaires de Metamorphose, Groupe Intelligence Artificielle. Universite
Aix-Marseille II, 1975.
Colmerauer A., Kanoui H., Pasero R. and Roussel P. Un Systeme de Communication Homme-
machine en Francais. Research Report, Groupe Intelligence Artificielle, Universite Aix-
Marseille II, France, 1973.
Coombs M. J., ed. Developments in Expert Systems. New York: Academic Press, 1984.
Corera J. M., Laresgoiti I. and Jennings N. R. Using arcon, part 2: Electricity transportation
management. IEEE Expert, 11F), 71-79, 1996.
Cormen T. H., Leiserson С E. and Rivest R. J. Introduction to Algorithms. Cambridge, MA:
MIT Press, 1990.
Cosmides L. and Tooby J. Cognitive adaptations for social exc/iange. In Barkow et al. A992), 1992.
Cosmides L. and Tooby J. Origins of domain specificity: the evolution of functional
organization. In Hirschfeld and Gelman A994), 1994.
Cotton S., Bundy A. and Walsh T. Automatic invention of integer sequences. Proceedings of
the AAAI-2000, Cambridge: MIT Press, 2000.
Crick F. H. and Asanuma C. Certain aspects of the anatomy and physiology of the cerebral
cortex. In McClelland et al. A986), 1986.
Crutchfield J. P. and Mitchell M. The Evolution of Emergent Computation. Working Paper 94-
03-012. Santa Fe Institute, 1995.
Cutosky M. R., Fikes. R. E., Engelmore R. S., Genesereth M. R., Mark W. S., Gruber Т.,
Tenenbaum J. M. and Weber С J. PACT: An experiment in integrating concurrent
engineering systems. IEEE Transactions on Computers, 26A): 28-37, 1993.
Dahl V. Un Systeme Deductif d'Interrogation de Banques de Donnes en Espagnol. PhD thesis,
Universite Aix-Marseille, 1977.
Dahl V. and McCord M. C. Treating Coordination in Logic Grammars. American Journal of
Computational Linguistics, 9: 69-91, 1983.
Dallier J. H. Logic for Computer Science: Foundations of Automatic Theorem Proving. New
York: Harper & Row, 1986.
Darr T. P. and Birmingham W. P. An attribute-space representation and algorithm for
concurrent engineering. AIEDAM 10A): 21-35, 1996.
Davis E. Representations of Commonsense Knowledge. Los Altos, CA: Morgan Kaufmann, 1990.
Davis L. Applying Adaptive Algorithms to Epistatic Domains. Proceedings of the International
Joint Conference on Artificial Intelligence, pp. 162-164, 1985.
Davis R. Applications of meta level knowledge to the construction, maintenance, and use of
large knowledge bases. In Davis and Lenat A982), 1982.
Davis R. and Lenat D. B. Knowledge-based Systems in Artificial Intelligence. New York:
McGraw-Hill, 1982.
Davis R. and Hamscher W. Model-based Reasoning: Trouble Shooting. In Hamscher et al.
A992), 1992.
814
Библиография
Davis R., Shrobe H., Hamscher W., Wieckert K., Shirley M. and Polit S. Diagnosis Based on
Description of Structure and Function. Proceedings of the National Conference on
Artificial Intelligence. Menlo Park, California: AAAI Press, 1982.
Dechter R. Bucket elimination: A unifying framework for probabilistic inference. Proceedings
of Conference on Uncertainty in AI (UAI-96), 1996.
DeJong G. and Mooney R. Explanation-based learning: An alternative view. Machine
Learning, 1B): 145-176, 1986.
deKleer J. Qualitative and quantitative knowledge of classical mechanics. Technical Report
AI-TR-352, AI Laboratory, MIT, 1975.
deKleer J. Local methods for localizing faults in electronic circuits (MIT AI Memo 394).
Cambridge, MA: MIT, 1976.
deKleer J. Choices without backtracking. Proceedings of the Fourth National Conference on
Artificial Intelligence, Austin, TX, pp. 79-84. Menlo Park, CA: AAAI Press, 1984.
deKleer J. An assumption based truth maintenance system. Artificial Intelligence, 28, 1986.
deKleer J. and Williams B.C. Diagnosing multiple faults. Artificial Intelligence 32A); 92-130,
1987.
deKleer J. and Williams B.C. Diagnosis with behavioral modes. Proceedings of the
International Joint Conference on Artificial Intelligence, pp. 13124-13330. Cambridge
MA: MIT Press, 1989.
Dempster A. P. A generalization of Bayesian inference. Journal of the Royal Statistical Society,
30 (Series B): 1-38, 1968.
Dennett D. C. Brainstorms: Philosophical Essays on Mind and Psychology. Montgomery, AL:
Bradford, 1978.
Dennett D. С Elbow Room: The Varieties of Free Will Worth Wanting. London: Cambridge
University Press, 1984.
Dennett D. С The Intentional Stance. Cambridge MA: MIT Press, 1987.
Dennett D. C. Consciousness Explained. Boston: Little, Brown, 1991.
Dennett D. C. Darwin's Dangerous Idea: Evolution and the Meanings of Life. New York:
Simon & Schuster, 1995.
Dietterich T. G. Learning at the knowledge level. Machine Learning, 1C): 287-316, 1986.
Dietterich T. G. and Michalski R. S. Inductive learning of structural descriptions: Evaluation
criteria and comparative review of selected methods. Proceedings IJCAI 6, 1981.
Dietterich T. G. and Michalski R. S. Learning to predict sequences. In Michalski et al. A986), 1986.
Doorenbos R., Etzioni. O. and Weld D. A scalable comparison shopping agent for the world
wide web. Proceedings of the First International Conference on Autonomous Agents
(Agents 97), pp. 39-48, 1997.
Doyle J. A truth maintenance system. Artificial Intelligence, 12, 1979.
Doyle J. Some theories of reasoned assumptions: An essay in rational psychology. Tech.
Report CS-83-125. Pittsburgh; Carnegie Mellon University, 1983.
Dressier O. An extended basic ATMS. Proceedings of the Second International Workshop on Non-
Monotonic Reasoning, pp. 143-163. Edited by Reinfrank, deKleer, Ginsberg and Sandewall.
Lecture Notes in Artificial Intelligence 346. Heidelberg: Springer-Verlag, 1988.
Библиография
815
Dreyfus H. L. and Dreyfus S. E. Mind Over Machine. New York: Macmillan/The Free Press, 1985.
Druzdel M.J. Qualitative Verbal Explanations in Bayesian Belief Networks. AISB Quar. 1,
96, 1996.
Druzdel M. J. and Henrion M. Efficient reasoning in qualitative probabilistic networks.
Proceedings of the 11th National Conference on Artificial Intelligence (AAAI-93), pp.
548-553, 1993.
Duda R. O., Gaschnig J. and Hart P. E. Model design in the PROSPECTOR consultant system
for mineral exploration. In Michie A979), 1979я.
Duda R. O., Hart P. E., Konolige K. and Reboh R. A computer-based consultant for mineral
exploration. SRI International, 19796.
Durfee E. H. and Lesser V. Negotiating task decomposition and allocation using partial global
planning. Distributed Artificial Intelligence: Vol II, Gasser, L and Huhns, M. ed. San
Francisco: Morgan Kaufmann, 229-244, 1989.
Durkin J. Expert Systems: Design and Development. New York: Macmillan, 1994.
Eco, Umberto. A Theory of Semiotics. Bloomington, Indiana: University of Indiana Press, 1976.
Edelman G. M. Bright Air, Brilliant Fire: On the Matter of the Mind. New York: Basic Books, 1992.
Elman J. L., Bates E. A., Johnson M. A., Karmiloff-Smith A., Parisi D. and Plunkett K.
Rethinking Innateness: A Connectionist Perspective on Development. Cambridge, MA:
MIT Press, 1996.
Engelmore R. and Morgan Т., ed. Blackboard Systems, London: Addison-Wesley, 1988.
Erman L. D., Hayes-Roth F., Lesser V. and Reddy D. The HEARSAY 11 speech understanding
system: Integrating knowledge to resolve uncertainty. Computing Surveys, 12B): 213-
253,1980.
Erman L. D., London P. E. and Fickas S. F. The design and an example use of HEARSAY 111.
In Proceedings IJCAI 7, 1981.
Ernst G. W. and Newell A. GPS: A Case Study in Generality and Problem Solving. New York:
Academic Press, 1969.
Etherington D. W. and Reiter R. On inheritance hierarchies with exceptions. Proceedings
AAAI-83, pp. 104-108, 1983.
Euler L. The seven bridges ofKonigsberg. In Newman A956), 1735.
Evans T. G. A heuristic program to solve geometric analogy problems. In Minsky A968), 1968.
Falkenhainer B. Explanation and theory formation. In Shrager and Langley A990), 1990.
Falkenhainer В., Forbus K. D. and Gentner D. The structure mapping engine: Algorithm and
examples. Artificial Intelligence, 41A): 1-64, 1989.
Fass D. and Wilks Y. Preference semantics with ill-formedness and metaphor. American
Journal of Computational Linguistics IX, pp. 178-187, 1983.
Feigenbaum E. A. The simulation of verbal learning behavior. In Feigenbaum and Feldman
A963), 1963.
Feigenbaum E. A. and Feldman J., ed. Computers and Thought. New York: McGraw-Hill, 1963.
Feigenbaum E. A. and McCorduck P. The Fifth Generation: Artificial Intelligence and Japan's
Computer Challenge to the World. Reading, MA: Addison-Wesley, 1983.
816
Библиография
Fikes R. E. and Nilsson N. J. STRIPS: A new approach to the application of theorem proving
to artificial intelligence. Artificial Intelligence, 1B), 1971.
Fikes R. E., Hart P. E. and Nilsson N. J. Learning and executing generalized robot plans.
Artificial Intelligence, 3D): 251-288, 1972.
Fillmore С J. The case for case. In Bach and Harms A968), 1968.
Fischer K., Muller J. P. and Pischel M. Cooperative transportation scheduling: An application
domain for DAL Applied Artificial Intelligence, 10A): 1-34.
Fisher D. H. Knowledge acquisition via incremental conceptual clustering. Machine Learning,
2: 139-172.
Fisher D. H., Pazzani M. J. and Langley P. Concept Formation: Knowledge and Evperience in
Unsupervised Learning. San Mateo, CA: Morgan Kaufmann Publishing, 1991.
Fodor J. A. The Modularity of Mind. Cambridge, MA: MIT Press, 1983.
Forbus K. D. and deKleer J. Focusing the ATMS. Proceedings of the Seventh National
Conference on Artificial Intelligence, pp. 193-198. Menlo Park: CA, 1988.
Forbus K. D. and deKleer J. Building Problem Solvers. Cambridge, MA: MIT Press, 1993.
Ford К. М. and Hayes P. J. Turing Test Considered Harmful. Proceedings of International Joint
Conference on Artificial Intelligence, Montreal, 1995.
Ford K. M., Glymour С and Hayes P. J. Android Epistemology. Cambridge: MIT Press, 1995.
Forgy C. L. RETE: a fast algorithm for the many pattern/many object pattern match problem.
Artificial Intelligence, 19A): 17-37, 1982.
Forney G. D., Jr. The Viterbi Algorithm. Proceedings of the IEEE (March), pp. 268-278, 1973.
Forrest S. Emergent Computation: Self organizing, collective, and cooperative phenomena in
natural and artificial computing networks. Physica D, 42: 1-11, 1990.
Forrest S. and Mitchell M. What makes a problem hard for a genetic algorithm? Some
anomalous results and their explanation. Machine Learning, 13: 285-319, 1993a.
Forrest S. and Mitchell M. Relative building block fitness and the building block hypothesis. In
L.D.Whitley A993), 19936.
Franklin S. Artificial Minds. Cambridge, MA: MIT Press, 1995.
Freeman J. A. and Skapura D. M. Neural Networks: Algorithms, Applications and
Programming Techniques. New York: Addison-Wesley, 1991.
Frege G. Begriffsschrift, eine der arithmetischen nachgebildete Formelsprache des reinen
Denkens. Halle: L. Niebert, 1879.
Frege G. Die Grundlagen der Arithmetic. Breslau: W. Koeber, 1884.
Frey B. J. Graphical Models for Machine Learning and Digital Communication. Cambridge:
MIT Press, 1998.
Gadamer H. G. Philosophical Hermeneutics. Translated by D. E. Linge. Berkeley: University
of California Press, 1976.
Gallier J. H. Logic for Computer Science: Foundations of Automatic Theorem Proving. New
York: Harper and Row, 1986.
Ganzinger H., Meyer С and Veanes M. Tlie two-variable guarded fragment with transitive relations.
Proceedings of the Annual Symposium on Logic in Computer Science, pp. 24—34, 1999.
Gardner M. Mathematical Games. Scientific American (October 1970).
Библиография
817
Gardner M. Mathematical Games. Scientific American (February 1971).
Garey M. and Johnson D. Computers and Intractability: A Guide to the Theory of NP-
Completeness. San Francisco: Freeman, 1979.
Gazdar G. and Mellish C. Natural Language Processing in PROLOG: An Introduction to
Computational Linguistics. Reading, MA: Addison-Wesley, 1989.
Gazzaniga M. S., ed. Tlie New Cognitive Neurosciences Bnd ed). Cambridge: МГГ Press, 2000.
Genesereth M. and Nilsson N. Logical Foundations of Artificial Intelligence. Los Altos, CA:
Morgan Kaufmann, 1987.
Genesereth M. R. The role of plans in intelligent teaching systems. In Sleeman and Brown
A982), 1982.
Gennari J. H., Langley P. and Fisher D. Models of incremental concept formation. Artificial
Intelligence. 40A-3): 11-62, 1989.
Gentner D. Structure-mapping: A theoretical framework for analogy. Cognitive Science, 7:
155-170, 1983.
Giarratano J. and Riley G. Expert Systems: Principles and Programming. PWS-Kent
Publishing Co, 1989.
Gilbert CD. Plasticity in visula perception and physiology. In Squire and Kosslyn A998), 1998.
Gilbert C. D. Horizontal integration and cortical dynamics. Neuron, 9: 1-13, 1992.
Ginsburg M., ed. Readings in Non-monotonic Reasoning. San Francisco: Morgan Kaufmann, 1987.
Glasgow В., Mandell A., Binney D., Ghemri L. and Fisher D. MITA: An information extraction
approach to analysis of free-form text in life insurance applications. Proceedings of the
Ninth Conference of Innovative Applications of Artificial Intelligence, pp. 992-999, 1997.
Gluck M. and Corter J. Information, uncertainty and the utility of categories. Seventh Annual
Conference of the Cognitive Science Society in Irvine, Calif, 1985.
Glymour C, Ford K. and Hayes P. The Prehistory of Android Epistemology. In Glymour et al.
A9955), 1995я.
Glymour C, Ford K. and Hayes P. Android Epistemology. Menlo Park, С A: AAAI Press, 19956.
Glymour С and Cooper G. F. Computation, Causation and Discovery. Cambridge: MIT Press, 1999.
Goldberg A. and Robson D. Smalltalk 80: The Language and Its Implementation. Reading,
MA: Addison-Wesley, 1983.
Goldberg D. E. Genetic Algorithms in Search, Optimization and Machine Learning. Reading,
MA: Addison-Wesley, 1989.
Goldstine H. H. The Computer from Pascal to Von Neumann. Princeton, NJ: Princeton
University Press, 1972.
Goodman N. Fact, Fiction and Forecast, 4th ed. Cambridge, MA: Harvard University Press, 1954.
Goodwin J. An Improved Algorithm for Non-Monotonic Dependency Net Update. Technical
Report LITH-MAT-R-82-23. Department of Computer Science and Information Science,
Linkbping University, Linkoping, Sweden, 1982.
Gould S. J. Ontogeny and Phylogeny. Cambridge MA: Belknap Press, 1977.
Gould S.J. Full House: The Spread of Excellence from Plato to Darwin. NY: Harmony Books,
1996.
818
Библиография
Graham P. On LISP: Advanced Techniques for Common LISP. Englewood Cliffs, NJ: Prentice
Hall, 1993.
Graham P. ANSI Common Lisp. Englewood Cliffs, NJ: Prentice Hall, 1995.
Grice H. P. Logic and conversation. In Cole and Morgan A975), 1975.
Grossberg S. Adaptive pattern classification and universal recording. I. Parallel development
and coding of neural feature detectors. Biological Cybernetics, 23: 121-134, 1976.
Grossberg S. Studies of Mind and Brain: Neural Principles of Learning, Perception,
Development, Cognition and Motor Control. Boston: Reidel Press, 1982.
Grossberg S., ed. Neural Networks and Natural Intelligence. Cambridge, MA: MIT Press, 1988.
Grosz B. The representation and use of focus in dialogue understanding. PhD thesis,
University of California, Berkeley, 1977.
Grosz B. and Sidner C. L. Plans for discourse. Intentions in Communications, Cohen P. R. and
Pollack M. E. ed., pp. 417-444. Cambridge, MA: MIT Press, 1990.
Hall R. P. Computational approaches to analogical reasoning: A comparative analysis, 39A):
39-120, 1989.
Hammond K., ed. Case Based Reasoning Workshop. San Mateo, С A: Morgan Kaufmann, 1989.
Hamscher W., Console L. and deKleer J. Readings in Model-based Diagnosis. San Mateo:
Morgan Kaufmann, 1992.
Hanson J. E. and Crutchfield J. P. 1992. The Attractor-basin portrait of a cellular automaton.
Journal of Statistical Physics, 66E/6): 1415-1462.
Harmon P. and King D. Expert Systems: Artificial Intelligence in Business. New York: Wiley, 1985.
Harmon P., Maus, R. and Morrissey W. Expert Systems: Tools and Applications. New York:
Wiley, 1988.
Harris M. D. Introduction to Natural Language Processing. Englewood Cliffs NJ: Prentice
Hall, 1985.
Hasemer T. and Domingue J. Common LISP Programming for Artificial Intelligence. Reading,
MA: Addison-Wesley, 1989.
Haugeland J., ed. Mind Design: Philosophy, Psychology, Artificial Intelligence. Cambridge,
MA: MIT Press, 1981.
Haugeland J. Artificial Intelligence: the Very Idea. Cambridge/Bradford, MA: MIT Press, 1985.
Haugeland J., ed. Mind Design: Philosophy, Psychology, Artificial Intelligence, 2nd ed.
Cambridge, MA: MIT Press, 1997.
Haussler D. Quantifying inductive bias: AI learning algorithms and Valiant's learning
framework. Artificial Intelligence, 36:177-222, 1988.
Hayes P. J. Some problems and non-problems in representation theory. Proc. AISB Summer
Conference, pp. 63-69, University of Sussex, 1974.
Hayes P. J. In defense of logic. Proceedings IJCAI-77, pp. 559-564, Cambridge, MA, 1977.
Hayes P. J. The logic of frames. In Metzing A979), 1979.
Hayes-Roth B. Agents on stage: Advancing the state of the art in AI. Proceedings of the
Fourteenth International Joint Conference on Artificial Intelligence. Cambridge, MA. МП
Press, 967-971, 1995.
Библиография
819
Hayes-Roth В., Pfleger К., Morignot P. and Lalanda P. Plans and Behavior in Intelligent
Agents. Technical Report, Knowledge Systems Laboratory (KSL-95-35), 1993.
Hayes-Roth F. and McDermott J. An inference matching technique for inducing abstractions.
Communications of the ACM, 26: 401^10, 1983.
Hayes-Roth F., Waterman D. and Lenat D. Building Expert Systems. Reading, MA: Addison-
Wesley, 1984.
Hebb D. O. The Organization of Behavior. New York: Wiley, 1949.
Hecht-Nielsen R. Neural analog processing. Proc. SPIE, 360, pp. 180-189. Bellingham, WA, 1982.
Hecht-Nielsen R. Counterpropagation networks. Applied Optics, 26: 4979^4984 (December 1987).
Hecht-Nielsen R. Theory of the backpropagation neural network. Proceedings of the
International Joint Conference on Neural Networks, I, pp. 593-611. New York: IEEE
Press, 1989.
Hecht-Nielsen R. Neurocomputing. New York; Addison-Wesley, 1990.
Heidegger M. Being and Time. Translated by J. Masquame and E. Robinson. New York:
Harper & Row, 1962.
Heidorn G. E. Augmented phrase structure grammar. In Schank and Nash-Webber A975), 1975.
Helman P. and Veroff R. Intermediate Problem Solving and Data Structures: Walls and
Mirrors, Menlo Park, CA: Benjamin/Cummings, 1986.
Hempel С G. Aspects of Scientific Explanation. New York: The Free Press, 1965.
Henderson Peter. Functional programming: Application and Implementation. Englewood
Cliffs, NJ; Prentice-Hall, 1980.
Hightower R. The Devore universal computer constructor. Presentation at the Third Workshop
on Artificial Life, Santa Fe, NM, 1992.
Hill P. A. and Lloyd J. W. The Goedel Programming Language. Cambridge, MA: MIT Press, 1994.
Hillis D. W. The Connection Machine. Cambridge, MA: MIT Press, 1985.
Hinsley D., Hayes J. and Simon H. From words to equations: Meaning and representation in
algebra word problems. In Carpenter and Just A977), 1977.
Hinton G. E. and Sejnowski T. J. Learning and relearning in Boltzmann machines. In
McClelland et al. A986), 1986.
Hinton G. E. and Sejnowski T. J. Neural network architectures for AL Tutorial, AAAI
Conference, 1987.
Hirschfeld L. A. and Gelman S. A., ed. Mapping the Mind: Domain Specificity in Cognition
and Culture. Cambridge: Cambridge University Press, 1994.
Hobbs J. R. and Moore R. С Formal Theories of the Commonsense World. Norwood, NJ:
Ablex, 1985.
Hodges A. Alan Turing: The Enigma. New York: Simon and Schuster, 1983.
Hofstadter D. Fluid Concepts and Creative Analogies, New York: Basic Books, 1995.
Holland J. H. Adaptation in Natural and Artificial Systems. University of Michigan Press, 1975.
Holland J. H. Studies of the spontaneous emergence of self-replicating systems using cellular
automata and formal grammars. In Lindenmayer and Rozenberg A976), 1976.
Holland J. H. Escaping bhttleness: The possibilities of general purpose learning algorithms
applied to parallel rule-based systems. In Michalski et al. A986), 1986.
820
Библиография
Holland J. H. Hidden Order: How Adaptation Builds Complexity. Reading, MA: Addison-
Wesley, 1995.
Holland J. H., Holyoak K. J, Nisbett R. E. and Thagard P. R. Induction: Processes of
Inference, Learning and Discovery. Cambridge, MA: MIT Press, 1986.
Holowczak R. D. and Adam N. R. Information extraction-based multiple-category document
classification for the global legal information network. Proceedings of the Ninth
Conference on Innovative Applications of Artificial Intelligence, pp. 1013-1018, 1997.
Holyoak K. J. The pragmatics of analogical transfer. The Psychology of Learning and
Motivation, 19: 59-87, 1985.
Hopcroft J. E. and Ullman J. D. Introduction to Automata Theory, Languages and
Computation. Rending, MA: Addison-Wesley, 1979.
Hopfield J. J. Neural networks and physical systems with emergent collective computational
abilities. Proceedings of the National Academy of Sciences 79, 1982.
Hopfield J. J. Neural networks and physical systems with emergent collective computational
abilities. Proceedings of the National Academy of Sciences, 79: 2554-2558, 1984.
Horowitz E. and Sahni S. Fundamentals of Computer Algorithms. Rockville, MD: Computer
Science Press, 1978.
Hume D. An Inquiry Concerning Human Understanding. New York: Bobbs-Merrill, 1748.
Husserl E. The Crisis of European Sciences and Transcendental Phenomenology. Translated
by D. Carr. Evanston, IL: Northwestern University Press, 1970.
Husserl E. Ideas: General Introduction to Pure Phenomenology. New York: Collier, 1972.
Ignizio J. P. Introduction to Expert Systems: The Development and Implementation of Rule-
Based Expert Systems. New York: McGraw-Hill, 1991.
Ivry I. B. The representation of temporal information in perception and motor control. In
Squire and Kosslyn A998), 1998.
Jackson P. Introduction to Expert Systems. Reading, MA: Addison-Wesley, 1986.
Jeannerod M. The Cognitive Neuroscience of Action. Oxford: Blackwell, 1997.
Jennings N. R. Controlling cooperative problem solving in industrial multi-agent systems using
joint intentions. Artificial Intelligence, 75: 195-240, 1995.
Jennings N. R. and Wooldridge M. Agent Technology: Foundations, Applications, and
Markets. Jennings N. R. and Wooldridge M. ed. Berlin: Springer-Verlag, 1998.
Jennings N. R., Sycara K. P. and Wooldridge M. A roadmap for agent research and
development. Journal of Autonomous Agents and MultiAgent Systems, 1 A): 7-36, 1998.
Johnson L. and Keravnou E. T. Expert Systems Technology: A Guide. Cambridge, MA: Abacus
Press, 1985.
Johnson M. The Body in the Mind: The Bodily Basis of Meaning, Imagination and Reason.
Chicago: University of Chicago Press, 1987.
Johnson W. L. and Soloway E. Proust. Byte (April), 1985.
Johnson-Laird P. Mental Models. Cambridge, MA: Harvard University Press, 1983.
Johnson-Laird P. N. The Computer and the Mind. Cambridge, MA: Harvard University Press, 1988.
Jordan M. (ed.) Learning in Graphical Models. Boston: Kluwer Academic, 1999.
Библиография
821
Josephson J. R. and Josephson S. G., ed. Abductive Inference: Computation, Philosophy and
Technology. New York: Cambridge University Press, 1994.
Jurafsky D. and Martin J. H. Speech and Language Processing, Upper Saddle River, NJ:
Prentice Hall, 2000.
Kant I. Immanuel Kant's Critique of Pure Reason, Smith N.K. translator. New York: St
Martin's Press, 1781/1964.
Karmiloff-Smith A. Beyond Modularity: A Developmental Perspective on Cognitive Science.
Cambridge, MA: MIT Press, 1992.
Kaufmann M., Manolios P. and Moore. J. S. (ed.) Computer-Aided Reasoning: ACL2 Case
Studies. Boston: Kluwer Academic, 2000.
Kautz H., Selman B. and Shah M. The hidden web. AI Magazine 18B): 27-35, 1997.
Kedar-Cabelli S. T. Analogy — From a unified perspective. In Helman A988), 1988.
Kedar-Cabelli S. T. and McCarty L. T. Explanation based generalization as resolution theorem
proving. Proceedings of the Fourth International Workshop on Machine Learning, 1987.
Keravnou E. T. and Johnson L. Competent Expert Systems: A Case Study in Fault Diagnosis.
London: KeganPaul, 1986.
King S. H. Knowledge Systems Through PROLOG. Oxford: Oxford University Press, 1991.
Klahr D., Langley P. and Neches R., ed. Production System Models of Learning and
Development. Cambridge, MA; MIT Press, 1987.
Klahr D. and Waterman D. A. Expert Systems: Techniques, Tools and Applications. Reading,
MA: Addison-Wesley, 1986.
Klein W. В., Westervelt R. T. and Luger G. F. A general purpose intelligent control system for
particle accelerators. Journal of Intelligent & Fuzzy Systems. New York: John Wiley, 1999.
Klein W. В., Stern С R., Luger G. F. and Pless D. Teleo-reactive control for accelerator
beamline tuning. Artificial Intelligence and Soft Computing: Proceedings of the IASTED
International Conference, Anaheim: IASTED/ACTA Press, 2000.
Kodratoff Y. and Michalski R. S., ed. Machine Learning: An Artificial Intelligence Approach.
Vol. 3. Los Altos, CA: Morgan Kaufmann, 1990.
Kohonen T. Correlation matrix memories, IEEE Transactions Computers, 4: 353-359, 1972.
Kohonen T. Self-Organization and Associative Memory. Berlin: Springer-Verlag, 1984.
Koller D. and Pfeffer A. Object-oriented Bayesian networks. Proceeding of the Thirteenth
Annual Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan
Kaufmann, 1997.
Koller D. and Pfeffer A. Probabilistic frame-based systems. Proceeding of the Fifteenth Annual
Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann, 1998.
Kolmogorov A. N. On the representation of continuous functions of many variables by
superposition of continuous functions of one variable and addition (in Russian). Dokl.
Akad Nauk USSR, 114: 953-956, 1957.
Kolodner J. L. Extending problem solver capabilities through case based inference.
Proceedings of the Fourth International Workshop on Machine Learning. С A: Morgan
Kaufmann, 1987.
Kolodner J. L. Retrieving events from a case memory: A parallel implementation. Proceedings
of the Case Based Reasoning Workshop. Los Altos, CA: Morgan Kaufmann, 1988a.
822
Библиография
Kolodner J. L., ed. Case Based Reasoning Worksliop. San Mateo, CA: Morgan Kaufrnann, 19886.
Colodner J. L. Improving human decision making through case-based decision aiding. AI
Magazine, 12B): 52-68, 1991.
Kolodner J. L. Case-based Reasoning. San Mateo, С A: Morgan Kaufrnann, 1993.
Korf R. E. Search. In Shapiro A9876), 1987.
Korf R. E. Artificial intelligence search algorithms. In CRC Handbook of Algorithms and
Theory of Computation, M. J. Atallah, ed. Boca Raton, FL: CRC Press, 1998.
Korf R. E. Sliding-tile puzzles and Ruble's Cube in AI research. IEEE Intelligent Systems,
Nov, 8-12, 1999.
Kosko B. Bidirectional associative memories. IEEE Transactions Systems, Man & Cybernetics,
18:49-60,1988.
Kosoresow A. P. A fast-first cut protocol for agent coordination. Proceedings of the Eleventh
National Conference on Artificial Intelligence, pp. 237-242, Cambridge, MA: МГГ Press, 1993.
Koton P. Reasoning about evidence in causal explanation. Proceedings of AAAI-88.
Cambridge, MA: AAAI Press/MIT Press, 1988a.
Koton P. Integrating case-based and causal reasoning. Proceedings of the Tenth Annual
Conference of the Cognitive Science Society. Northdale, NJ: Erlbaum, 19886.
Kowalski R. Algorithm = Logic + Control. Communications of the ACM, 22: 424^36, 1979я.
Kowalski R. Logic for Problem Solving. Amsterdam; North-Holland, 19796.
Koza J. R. Genetic evolution and co-evolution of computer programs. In Langton et al. A991), 1991.
Koza J. R. Genetic Programming: On the Programming of Computers by Means of Natural
Selection. Cambridge, MA: MIT Press, 1992.
Koza J. R. Genetic Programming II: Automatic Discovery of Reusable Programs. Cambridge,
MA: MIT Press, 1994.
Krulwich B. The BarginFinder agent: Comparison price shopping on the internet. Bots, and
other Internet Beasties, Williams, J. ed. 257-263, Indianapolis: Macmillan, 1996.
Kuhl P. K. Innate predispositions and the effects of experience in speech perception: The
native language magnet theory. Developmental Neurocognition: Speech and Face
Processing in the First Year of Life, Boysson-Bardies В., de Schonen S., Jusczyk P.,
McNeilage P. and Morton J. ed, pp. 259-274. Netherlands: Kluwer Academic, 1993.
Kuhl P. K. Learning and representation in speech and language. In Squire and Kosslyn
A998), 1998.
Kuhn T. S. Vie Structure of Scientific Revolutions. Chicago: University of Chicago Press, 1962.
Laird J., Rosenbloom P. and Newell A. Chunking in SOAR; The Anatomy of a General
Learning Mechanism. Machine Learning 1A), 1986a.
Laird J., Rosenbloom P. and Newell A. Universal Subgoaling and Chunking: The automatic
Generation and Learning of Goal Hierarchies. Dordrecht: Kluwer, 19866.
Lakoff G. Women, Fire and Dangerous Things. Chicago: University of Chicago Press, 1987.
Lakoff G. and Johnson M. Philosophy in the Flesh, New York: Basic Books, 1999.
Lakatos I. Proofs and Refutations: The Logic of Mathematical Discovery. Cambridge
University Press, 1976.
Langley P. Elements of Machine Learning. San Francisco: Morgan Kaufrnann, 1995.
Библиография
823
Langley P., Bradshaw G. L. and Simon H. A. Bacon 5: The discovery of conservation laws.
Proceedings of the Seventh International Joint Conference on Artificial Intelligence, 1981.
Langley P., Simon H. A., Bradshaw G. L. and Zytkow J. M. Scientific Discovery: Computational
Explorations of the Creative Processes. Cambridge, MA: MIT Press, 1987.
Langley P., Zytkow J., Simon H. A. and Bradshaw G. L. The search for regularity: Four
aspects of scientific discovery. In Michalski et al. A986), 1986.
Langton С G. Studying artificial life with cellular automata. Physica D, 120-149, 1986.
Langton С G. Artificial Life: Santa Fe Institute Studies in the Sciences of Complexity, VI.
Reading, MA: Addison-Wesley, 1989.
Langton С Computation at the edge of cliaos: Phase transitions and emergent computation.
Physica D., 42: 12-37, 1990.
Langton С G. Artificial Life: An Overview. Cambridge, MA: MIT Press, 1995.
Langton С G., Taylor C, Farmer J. D. and Rasmussen S. Artificial Life II, SFI Studies in the
Sciences of Complexity. Vol. 10. Reading, MA: Addison-Wesley, 1992.
Larkin J. H., McDermott J., Simon D. P. and Simon H. A. Models of competence in solving
physics problems. Cognitive Science, 4, 1980.
Laskey K. and Mahoney S. Network fragments: Representing knowledge for constructing
probabilistic models. Proceedings of the Thirteenth Annual Conference on Uncertainty in
Artificial Intelligence. San Francisco: Morgan Kaufmann, 1997.
Lauritzen S. L. and Spiegelhalter D. J. Local computations with probabilities on graphical
structures and their application to expert systems. Journal of the Royal Statistical Society,
В 50B); 157-224, 1988.
Lave J. Cognition in Practice. Cambridge: Cambridge University Press, 1988.
Leake D. B. Constructing Explanations: A Content Theory. Northdale, NJ: Erlbaum, 1992.
Leake D. В., ed. Case-based Reasoning: Experiences, Lessons and Future Directions. Menlo
Park: AAAI Press, 1996.
Leibniz G. W. Philosophische Schriften. Berlin, 1887.
Lenat D. B. On automated scientific theory formation; a case study using the AM program.
Machine Intelligence, 9: 251-256, 1977.
Lenat D. B. AM: an artificial intelligence approach to discovery in mathematics as heuristic
search. In Davis and Lenat A982), 1982.
Lenat D. B. EURISKO: A program that learns new heuristics. Artificial Intelligence, 21A, 2):
61-98, 1983.
Lenat D. B. and Brown J. S. Why AM and Eurisko appear to work. Artificial Intelligence,
23C), 1984.
Lenat D. B. and Guha R. V. Building Large Knowledge Based Systems, Reading, MA:
Addison-Wesley, 1990.
Lennon J. and McCartney P. Rocky Raccoon. The White Album. Apple Records, 1968.
Lesser V. R. and Corkill D. D. The distributed vehicle monitoring testbed. AI Magazine, 4C), 1983.
Levesque H. Foundations of a functional approach to knowledge representation. Artificial
Intelligence, 23B), 1984.
824
Библиография
Levesque, H. J. A knowledge level account of abduction. Proceedings of the Eleventh
International Joint Conference on Artificial Intelligence, pp. 1051-1067. San Mateo, CA:
Morgan Kaufmann, 1989.
Levesque H. J. and Brachman R. J. A fundamental tradeoff in knowledge representation and
reasoning (revised version). In Brachman and Levesque A985), 1985.
Lewis J. A. and Luger G. F. A constructivist model of robot perception and performance. In
Proceedings of the Twenty Second Annual Conference of the Cognitive Science Society.
Hillsdale, NJ: Erlbaum, 2000.
Lieberman H. Letizia: An agent that assists web browsing. Proceedings of the Fourteenth
International Joint Conference on Artificial Intelligence, 924-929. Cambridge, MA: MIT
Press, 1995.
Lifschitz V. Some Results on Circumscription. AAAI 1984, 1984.
Lifschitz V. Pointwise Circumscription: Preliminary Report. Proceedings of the Fifth National
Conference on Artificial Intelligence, pp. 406^10. Menlo Park, CA: AAAI Press, 1986.
Linde C. Information structures in discourse. PhD thesis, Columbia University, 1974.
Lindenmayer A. and Rosenberg G., ed. Automata, Languages, Development. New York:
North-Holland, 1976.
Lindsay R. K., Buchanan B. G., Feigenbaum E. A. and Lederberg J. Applications of artificial
intelligence for organic chemistry: the DENDRAL project. New York: McGraw-Hill, 1980.
Ljunberg M. and Lucas A. The OASIS air traffic management system. Proceedings of the
Second Pacific Rim International Conference on AI (PRICAI-92), 1992.
Lloyd J. W. Foundations of Logic Programming. New York: Springer-Verlag, 1984.
Lovelace A. Notes upon L.F. Menabrea's sketch of the Analytical Engine invented by Charles
Babbage. In Morrison and Morrison A961), 1961.
Loveland D. W. Automated Theorem Proving: a Logical Basis. New York: North-Holland, 1978.
Lucas R. Mastering PROLOG. London: UCL Press, 1996.
Luck S. J. Cognitive and neural mechanisms in visual search. In Squire and Kosslyn A998), 1998.
Luger G. F. Formal analysis of problem solving behavior in Cognitive Psychology: Learning
and Problem Solving, Milton Keynes: Open University Press, 1978.
Luger G. F. Mathematical model building in the solution of mechanics problems: human
protocols and the MECHO trace. Cognitive Science, 5: 55-77, 1981.
Luger G. F. Cognitive Science: The Science of Intelligent Systems. San Diego and New York:
Academic Press, 1994.
Luger G. F. Computation & Intelligence: Collected Readings. С A: AAAI Press/MIT Press, 1995.
Luger G. F. and Bauer M. A. Transfer effects in isomorphic problem solving. Acta
Psychologia, 42, 1978.
Luger G. F., Wishart J. G. and Bower T. G. R. Modelling the stages of the identity theory of
object-concept development in infancy. Perception, 13: 97-115, 1984.
Machtey M. and Young P. An Introduction to the General Theory of Algorithms. Amsterdam:
North-Holland, 1979.
MacLennan B. J. Principles of Programming Languages: Design, Evaluation, and
Implementation, 2nd ed. New York: Holt, Rinehart & Winston, 1987.
Библиография
825
Maes P. The dynamics of action selection. Proceedings of the 11th International Joint Conference on
Artificial Intelligence, pp. 991-997. Los Altos, CA: Morgan Kaufrnann, 1989.
Maes P. Designing Autonomous Agents. Cambridge, MA: MIT Press, 1990.
Maes P. Agents that reduce work and information overload. Communications of the ACM,
37G): 31-40, 1994.
Magerman D. Natural Language as Statistical Pattern Recognition. PhD dissertation, Stanford
University, Department of Computer Science, 1994.
Maier D. and Warren D. S. Computing with Logic. Menlo Park, CA: Benjamin/Cummings, 1988.
Malpas J. PROLOG: A Relational Language and its Applications. Englewood Cliffs, NJ;
Prentice Hall, 1987.
Manna Z. and Waldinger R. The Logical Basis for Computer Programming. Reading, MA:
Addison-Wesley, 1985.
Manna Z. and Pnueli A. The Temporal Logic of Reactive and Concurrent Systems:
Specification. Berlin: Springer-Verlag, 1992.
Manning C. D, and Schutze H. Foundations of Statistical Natural Language Processing.
Cambridge, MA: MIT Press, 1999.
Marcus M. A Theory of Syntactic Recognition for Natural Language. Cambridge, MA: MIT
Press, 1980.
Markov A. A theory of algorithms, National Academy of Sciences, USSR, 1954.
Marshall J. B. Metacat: A Self-Watching Cognitive Architecture for Analogy-Making and
High-Level Perception. PhD dissertation, Department of Computer Science, Indiana
University, 1999.
Martin A. Computational Learning Theory: An Introduction. Cambridge: Cambridge
University Press, 1997.
Martins J. The truth, the whole truth, and nothing but the truth: an indexed bibliography to the
literature on truth maintenance systems. AI Magazine, 11E): 7-25, 1990.
Martins J. A structure for epistemic states. New Directions for Intelligent Tutoring Systems.
Costa, ed. NATO ASI Series F. Heidelberg: Springer-Verlag, 1991.
Martins J. P. Truth Maintenance Systems. In Shapiro S.C. ed. A992), 1992.
Martins J. and Shapiro S. С Reasoning in multiple belief spaces. Proceedings of the Eighth
IJCAI. San Mateo, CA: Morgan Kaufrnann, 1983.
Martins J. & Shapiro S. С A Model for Belief Revision. Artificial Intelligence. 35A): 25-79,1988.
Masterman M. Semantic message detection for machine translation, using Interlingua.
Proceedings of the 1961 International Conference on Machine Translation, 1961.
McAllester D. A. A three-valued truth maintenance system. MIT AI Lab., Memo 473, 1978.
McAllester D. A. PAC-Bayesian model averaging. Proceedings of the Twelfth ACM Annual
Conference on Computational Learning Theory COLT-99, 1999.
McCarthy J. Recursive functions of symbolic expressions and their computation by machine.
Communications of the ACM, 3D), 1960.
McCarthy J. Programs with common sense. In Minsky A968), pp. 403^418, 1968.
McCarthy J. Epistemological problems in artificial intelligence. Proceedings IJCAI-77, pp.
1038-1044, 1977.
826
Библиография
McCarthy J. Circumscription — A form of non-monotonic reasoning. Artificial Intelligence,
13, 1980.
McCarthy J. Applications of Circumscription to Formalizing Common Sense Knowledge.
Artificial Intelligence, 28: 89-116, 1986.
McCarthy J. and Hayes P. J. Some philosophical problems from the standpoint of artificial
intelligence. In Meltzer and Michie A969), 1969.
McClelland J. L., Rumelhart D. E. and The PDP Research Group. Parallel Distributed
Processing. 2 vols. Cambridge, MA: MIT Press, 1986.
McCord M. С Using slots and modifiers in logic grammars for natural language. Artificial
Intelligence, 18: 327-367, 1982.
McCord M. C. Design of a PROLOG based machine translation system. Proceedings of the
Third International Logic Programming Conference, London, 1986.
McCulloch W. S. and Pitts W. A logical calculus of the ideas immanent in nervous activity.
Bulletin of Mathematical Biophysics, 5: 115-133, 1943.
McDermott D. Planning and acting. Cognitive Science 2, 71-109, 1978.
McDermott D. and Doyle J. Non-monotonic logic I. Artificial Intelligence, 13: 14-72, 1980.
McDermott J. Rl, The formative years. AI Magazine (summer 1981), 1981.
McDermott J. Rl: A ride based configurer of computer systems. Artificial Intelligence, 19, 1982.
McDermott J. and Bachant J. Rl revisited; Four years in the trenches. AI Magazine, 5C), 1984.
McGonigle B. Incrementing intelligent systems by design. Proceedings of the First
International Conference on Simulation of Adaptive 8ehavior (SAB-90), 1990.
McGonigle B. Autonomy in the rraking: Getting robots to control themselves. International
Symposium on Autonomous Agents. Oxford: Oxford University Press, 1998.
McGraw K. L. and Harbison-Briggs K. Knowledge Acquisition: Principles and Guidelines.
Englewood Cliffs, NJ: Prentice-Hall, 1989.
Mead C. Analog VLSI and Neural Systems. Reading, MA: Addison-Wesley, 1989.
Meltzer B. and Michie D. Machine Intelligence 4. Edinburgh: Edinburgh University Press, 1969.
Merleau-Ponty M. Phenomenology of Perception. London: Routledge & Kegan Paul, 1962.
Metzing D., ed. Frame Conceptions and Text Understanding. Berlin: Walter de Gruyter and
Co, 1979.
Meyer J. A. and Wilson S. W., ed. From animals to animats. Proceedings of the First
International Conference on Simulation of Adaptive Behavior. Cambridge, MA: MIT
Press/Bradford Books, 1991.
Michalski R. S., Carbonell J. G. and Mitchell Т. М., ed. Machine Learning. An Artificial
Intelligence Approach. Vol. 1. Palo Alto, CA: Tioga, 1983.
Michalski R. S., Carbonell J. G. and Mitchell Т. М., ed. Machine Learning. An Artificial
Intelligence Approach. Vol. 2. Los Altos, CA: Morgan Kaufmann, 1986.
Michalski R. S. and Stepp R. E. Learning from observation: conceptual clustering. In
Michalski etal. A983), 1983.
Michie D. Trial and error. Science Survey, Part 2, Barnett S.A. and McClaren A., ed., 129—
145. Harmnondsworth UK: Penguin, 1961.
Michie D., ed. Expert Systems in the Micro-electronic Age. Edinburgh: Edinburgh Univ. Press, 1979.
Библиография
827
Miller S. L., Delaney T. V. and Tallal P. Speech and other central auditory processes: Insights
from cognitive neuroscience. In Squire and Kosslyn A998), 1998.
Milner R., Tofte M. and Harper R. Definition of Standard ML. Cambridge, MA: МГГ Press, 1990.
Milner R. and Tofte M. Commentary on Standard ML. Cambridge, MA: MIT Press, 1991.
Minsky M., ed. Semantic Information Processing. Cambridge, MA: MIT Press, 1968.
Minsky M. A framework for representing knowledge. In Brachman and Levesque A985), 1975.
Minsky M. in Psychology of Computer Vision by P. Winston. McGraw-Hill, 1975a.
Minsky M. The Society of Mind, New York: Simon and Schuster, 1985.
Minsky M. and Papert S. Perceptrons: An Introduction to Computational Geometry.
Cambridge, MA: MIT Press, 1969.
Minton S. Learning Search Control Knowledge. Dordrecht: Kluwer Academic Publishers, 1988.
Mitchell M. Analogy-Making as Perception. Cambridge, МАЦ MIT Press, 1993.
Mitchell M. An Introduction to Genetic Algorithms. Cambridge, MA: The MIT Press, 1996.
Mitchell M., Crutchfield J. and Das R. Evolving cellular automata with genetic algorithms: A
review of recent work. Proceedings of the First International Conference on Evolutionary
Computation and Its Applications. Moscow, Russia: Russian Academy of Sciences, 1996.
Mitchell Т. М. Version spaces: an approach to concept learning. Report No. STAN-CS-78-
711, Computer Science Dept., Stanford University, 1978.
Mitchell Т. М. An analysis of generalization as a search problem. Proceedings IJCAI, 6, 1979.
Mitchell T. M. The need for biases in learning generalizations. Technical Report CBM-TR-
177. Department of Computer Science, Rutgers University, New Brunswick, NJ, 1980.
Mitchell Т. М. Generalization as search. Artificial Intelligence, 18B): 203-226, 1982.
Mitchell Т. М. Machine Learning. New York: McGraw Hill, 1997.
Mitchell T. M., Utgoff P. E. and Banarji R. Learning by experimentation: Acquiring and
refining problem solving heuristics. In Michalski, Carbonell, and Mitchell A983), 1983.
Mitchell T. M., Keller R. M. and Kedar-Cabelli S. T. Explanation-based generalization: A
unifying view. Machine Learning, 1A): 47-80, 1986.
Mithen S. The Prehistory of the Mind. London: Thames & Hudson, 1996.
Mockler R. J. and Dologite D. G. An Introduction to Expert Systems, New York: Macmillan, 1992.
Moore O. K. and Anderson S. B. Modern logic and tasks for experiments on problem solving
behavior. Journal of Psychology, 38: 151-160, 1954.
Moore R. С The role of logic in knowledge representation and commonsense reasoning.
Proceedings AAAI-82, 1982.
Moore R. С Semantical considerations on nonmonotonic logic. Artificial Intelligence, 25A):
75-94, 1985.
Moret B.M. E. and Shapiro H. D. Algorithms from P to NP, vol 1. Redwood City, CA:
Benjamin/Cummings, 1991.
Morrison P. and Morrison E., ed. Charles Babbage and His Calculating Machines. NY: Dover,
1961.
Mostow D. J. Machine transformation of advice into a heuristic search procedure. In
Michalski etal. A983), 1983.
828
Библиография
MUC-5, Proceedings of the Fifth Message Understanding Conference, San Francisco: Morgan
Kaufmann, 1994.
Mycroft A. and O'Keefe R. A. A polymorphic type system for PROLOG. Artificial Intelligence,
23: 295-307, 1984.
Mylopoulos J. and Levesque H. J. An overview of knowledge representation in Brodie et al.
A984), 1984.
Nadathur G. and Tong G. Realizing modularity in lambda Prolog. Journal of Functional and
Logic Programming, 9, Cambridge, MA: MIT Press, 1999.
Nagel E. and Newman J. R. Godel's Proof. New York: New York University Press, 1958.
Nahm U. Y. and Mooney R. J. A mutually beneficial integration of data mining and
information extraction. Proceedings of the American Assoc, for Artificial Intelligence
Conference, pp. 627-632, 2000.
Neches R., Langley P. and Klahr D. Learning, development and production systems. In Klahr
etal. A987), 1987.
Negoita С Expert Systems and Fuzzy Systems. Menlo Park, CA: Benjamin/Cummings, 1985.
Neves J. С F. M, Luger G. F. and Carvalho J. M. A formalism for views in a logic data base.
In Proceedings of the ACM Computer Science Conference, Cincinnati, OH, 1986.
Newell A. Physical symbol systems. In Norman A981), 1981.
Newell A. The knowledge level. Artificial Intelligence, 18A): 87-127, 1982.
Newell A. Unified Theories of Cognition. Cambridge, MA: Harvard University Press, 1990.
Newell A., Rosenbloom P. S. and Laird J. E. Symbolic architectures for cognition. In Posner
A989), 1989.
Newell A., Shaw J. С and Simon H. A. Elements of a theory of human problem solving.
Psychological Review, 65: 151-166, 1958.
Newell A. and Simon H. The logic theory machine. IRE Transactions of Information Theory, 2:
61-79, 1956.
Newell A. and Simon H. GPS: a program that simulates human thought. Lernende Automaten,
H. Billing ed. pp. 109-124. Munich: R. Oldenbourg KG, 1961.
Newell A. and Simon H. Empirical explorations with the Logic Theory Machine: a case study
in heuristics. In Feigenbaum and Feldman A963), 1963a.
Newell A. and Simon H. GPS: a program that simulates human thought. In Feigenbaum and
Feldman A963), 19636.
Newell A. and Simon H. Human Problem Solving. Englewood Cliffs, NJ: Prentice Hall 1972.
Newell A. and Simon H. Computer science as empirical inquiry: symbols and search.
Communications of the ACM, 19C): 113-126, 1976.
Newman J. R. The World of Mathematics. New York: Simon and Schuster, 1956.
Ng H. T. and Mooney R. J. On the Role of Coherence in Abductive Explanation. Proceedings
of the Eighth National Conference on Artificial Intelligence, pp. 347-342. Menlo Park,
С A: AAAI Press/MIT Press, 1990.
Nii H. P. Blackboard systems: The blackboard model of problem solving and the evolution of
blackboard architectures. AI Magazine, 7B), 1986a.
Библиография
829
Nii H. P. Blackboard systems: Blackboard application systems from a knowledge based
perspective. AI Magazine, 7C), 19866.
Nii H. P. and Aiello N. AGE: A knowledge based program for building knowledge based
programs. Proceedings IJCAI 6, 1979.
Nilsson N. J. Learning Machines. New York: McGraw-Hill, 1965.
Nilsson N. J. Problem Solving Methods in Artificial Intelligence. New York: McGraw-Hill, 1971.
Nilsson N. J. Principles of Artificial Intelligence. Palo Alto, CA: Tioga, 1980.
Nilsson N. J. Teleo-Reactive Programs for Agent Control. Journal of Artificial Intelligence
Research, 1: 139-158, 1994.
Nilsson N. J. Artificial Intelligence: A New Synthesis. San Francisco: Morgan Kaufmann, 1998.
Nishibe Y., Kuwabara K., Suda T. and Ishida T. Distributed channel allocation in atm
networks. Proceedings of the IEEE Globecom Conference, 12.2.1-12.2.7, 1993.
Nordhausen B. and Langley P. An integrated approach to empirical discovery. In Shrager and
LangleyA990), 1990.
Norman D. A. Memory, knowledge and the answering of questions. CHIP Technical Report 25,
Center for Human Information Processing, University of California, San Diego, 1972.
Norman D. A. Perspectives on Cognitive Science. Hillsdale, NJ: Erlbaum, 1981.
Norman D. A., Rumelhart D. E. and the LNR Research Group. Explorations in Cognition. San
Francisco: Freeman, 1975.
Novak G. S. Computer understanding of physics problems stated in natural language.
Proceedings IJCAI 5, 1977.
Noyes J. L. Artificial Intelligence with Common LISP: Fundamentals of Symbolic and Numeric
Computing. Lexington, MA: D. С Heath and Co, 1992.
CTKeefe R. The Craft of PROLOG. Cambridge, MA: MIT Press, 1990.
O'Leary D. D. M., Yates P. and McLaughlin T. Mapping sights and smells in the brain:
distinct chanisms to achieve a common goal. Cell 96: 255-269, 1999.
Oliver I. M., Smith D. J. and Holland J. R. С A Study of Permutation Crossover Operators on
the Traveling Salesman Problem. Proceedings of the Second International Conference on
Genetic Algorithms, pp. 224-230. Hillsdale, NJ: Erlbaum & Assoc, 1987.
Oliveira E., Fonseca J. M., and Steiger-Garcao A. MACIV: A DAI based resource management
system. Applied Artificial Intelligence, 11F): 525-550, 1997.
Papert S. Mindstorms. New York: Basic Books, 1980.
Patil R., Szolovits P. and Schwartz W. Causal understanding of patient illness in medical
diagnosis. Proceedings of the International Joint Conference on Artificial Intelligence.
Palo Alto: Morgan Kaufmann, 1981.
Pearl J. Heuristics: Intelligent Strategies for Computer Problem Solving. Reading, MA:
Addison-Wesley, 1984.
Pearl J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Los
Altos, CA; Morgan Kaufmann, 1988.
Pearl J. Causality. New York: Cambridge University Press, 2000.
830
Библиография
Pearlmutter В. A. and Parra L. C. Maximum likelihood blind source separation: A context-
sensitive generalization of 1С A. Advances in Neural Information Processing Systems, 9,
Cambridge, MA: MIT Press, 1997.
Peirce С S. Collected Papers 1931-1958. Cambridge MA: Harvard University Press, 1958.
Penrose R. The Emperor's New Mind. Oxford; Oxford University Press, 1989.
Pereira L. M. and Warren D. H. D. Definite clause grammars for language analysis — A
survey of the formalism and a comparison with augmented transition networks. Artificial
Intelligence, 13: 231-278, 1980.
Pedis D. Autocircumscription. Artificial Intelligence, 36: 223-236, 1988.
Perriolat F., Sakaret P., Varga L. Z. and Jennings N. J. Using archon: Particle accelerator
Control 11F): 80-86, 1996.
Pfeffer A., Koller D., Milch B. and Takusagawa K. SPOOK: A system for probabilistic object-
oriented knowledge representation. Proceedings of the Fifteenth Annual Conference on
Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann, 1999.
Piaget J. The Construction of Reality in The Child. New York: Basic Books, 1954.
Piaget J. Structuralism. New York: Basic Books, 1970.
Pinker S. The Language Instinct. New York: William Morrow and Company, 1994.
Plato The Collected Dialogues of Plato, Hamilton E. and Cairns H. ed. Princeton: Princeton
University Press, 1961.
Pless D., Luger G. and Stern C. A new object-oriented stochastic modeling language. Artificial
Intelligence and Soft Computing: Proceedings of the IASTED International Conference.
Anaheim: IASTED/ACTA Press, 2000.
Polya G. How to Solve It. Princeton, NJ: Princeton University Press, 1945.
Popper K. R. The Logic of Scientific Discovery. London: Hutchinson, 1959.
Posner M. I. Foundations of Cognitive Science. Cambridge, MA: MIT Press, 1989.
Post E. Formal reductions of the general combinatorial problem. American Journal of
Mathematics, 65: 197-268, 1943.
Poundstone W. The Recursive Universe: Cosmic Complexity and the Limits of Scientipc
Knowledge. New York: William Morrow and Company, 1985.
Pratt T. W. Programming Languages: Design and Implementation. Englewood Cliffs, NJ:
Prentice-Hall, 1984.
Prerau D. S. Developing and Managing Expert Systems: Proven Techniques for Business and
Industry. Reading, MA: Addison-Wesley, 1990.
Pylyshyn Z. W. What the mind's eye tells the mind's brain: a critique of mental imagery.
Psychological Bulletin, 80: 1-24, 1973.
Pylyshyn Z. W. The causal power of machines. Behavioral and Brain Sciences 3: 442^44, 1980.
Pylyshyn Z. W. Computation and Cognition: Toward a Foundation for Cognitive Science.
Cambridge, MA: MIT Press, 1984.
Quillian M. R. Word concepts: A theory and simulation of some basic semantic capabilities. In
Brachman and Levesque A985), 1967.
Quine W. V. O. From a Logical Point of View. 2nd ed. New York: Harper Torchbooks, 1963.
Библиография
831
Quinlan J. R. Learning efficient classification procedures and their application to chess
endgames. In Michalski et al. A983), 1983.
Quinlan J. R. Induction of decision trees. Machine Learning, 1A): 81-106, 1986a.
Quinlan J. R. The effect of noise on concept learning. In Michalski et al. A986), 19866.
Quinlan J. R. Bagging, Boosting and CN4.5. Proceedings AAAI96. Menlo Park: AAAI Press, 1996.
Quinlan J. R. C4.5: Programs for Machine Learning. San Francisco: Morgan Kaufmann, 1993.
Quinlan P. Connectionism and Psychology. Chicago, IL: University of Chicago Press, 1991.
Raphael B. SIR: A computer program for semantic information retrieval. In Minsky A968), 1968.
Reddy D. R. Speech recognition by machine: A review. Proceedings of the IEEE 64 (May 1976),
1976.
Reggia J., Nau D. S., and Wang P. Y. Diagnostic expert systems based on a set covering
model. International Journal of Man-Machine Studies, 19E): 437^160, 1983.
Reinfrank M. Fundamental and Logical Foundations of Truth Maintenance. Linkoping Studies
in Science and Technology, Dissertation 221, Department of Computer and Information
Science, Linkoping University, Linkoping, Sweden, 1989.
Reiter R. On closed world databases. In Webber and Nilsson A981), 1978.
Reiter R. A logic for default reasoning. Artificial Intelligence, 13: 81-132, 1980.
Reiter R. On reasoning by default. In Brachman and Levesque A985), 1985.
Reiter R. and Criscuolo G. On interacting defaults. Proceedings of the International Joint
Conference on Artificial Intelligence, 1981.
Reitman W. R. Cognition and Thought. New York: Wiley, 1965.
Rendell L. A general framework for induction and a study of selective induction. Machine
Learning, 1B), 1986.
Rich E. and Knight K. Artificial Intelligence, 2nd ed. New York: McGraw-Hill, 1991.
Rissland E. L. Examples in legal reasoning: Legal hypotheticals. Proceedings of IJCAI-83. San
Mateo, С A: Morgan Kaufmann, 1983.
Rissland E. L. and Ashley K. HYPO: A case-based system for trade secrets law. Proceedings,
First International Conference on Artificial Intelligence and Law, 1987.
Roberts D. D. The Existential Graphs of Charles S. Pierce. The Hague: Mouton, 1973.
Robinson J. A. A machine-oriented logic based on the resolution principle. Journal of the
ACM, 12: 23-41, 1965.
Rochester N., Holland J. H., Haibit L. H. and Duda W. L. Test on a cell assembly theory of the
actuation of the brain, using a large digital computer. In J. A. Anderson and E. Rosenfeld, ed.
Neurocomputing: Foundations of Research. Cambridge, MA: MIT Press, 1988.
Rosch E. Principles of categorization. In Rosch and Lloyd A978), 1978.
Rosch E. and Lloyd В. В., ed. Cognition and Categorization, Hillsdale, NJ: Erlbaum, 1978.
Rosenblatt F. The perceptron: A probabilistic model for information storage and organization
in the brain. Psychological Review, 65: 386-408, 1958.
Rosenblatt F. Principles of Neurodynamics. New York: Spartan, 1962.
Rosenbloom P. S. and Newell A. The chunking of goal hierarchies: A generalized model of
practice. In Michalski et al. A986), 1986.
832
Библиография
Rosenbloom P. S. and Newell A. Learning by chunking, a production system model of
practice. In Klahr et al. A987), 1987.
Rosenbloom P. S., Lehman J. F. and Laird J. E. Overview of Soar as a unified theory of
cognition: Spring 1993. Proceedings of the Fifteenth Annual Conference of the Cognitive
Science Society. Hillsdale, NJ: Erlbaum, 1993.
Ross P. Advanced PROLOG. Reading, MA: Addison-Wesley, 1989.
Ross T. Fuzzy Logic with Engineering Applications. New York: McGraw-Hil 1, 1995.
Roussel P. PROLOG: Manuel de Reference et d'Utilisation. Groupe d'Intelligence Artificielle,
Universite d'Aix-Marseille, Luminy, France, 1975.
Rumelhart D. E., Lindsay P. H., and Norman D. A. A process model for long-term memory. In
Tulving and Donaldson A972), 1972.
Rumelhart D. E. and Norman D. A. Active semantic networks as a model of human memory.
Proceedings IJCAI-3, 1973.
Rumelhart D. E., Hinton G. E. and Williams R. J. Learning internal representations by error
propagation. In McClelland et al. A986), 1986a.
Rumelhart D. E., McClelland J. L. and The PDP Research Group. Parallel Distributed
Processing. Vol. 1. Cambridge, MA; MIT Press, 19866.
Russell S. J. The Use of Knowledge in Analogy and Induction. San Mateo, С A: Morgan
Kaufmann, 1989.
Russell S. J. and Norvig P. Artificial Intelligence. A Modern approach. Englewood Cliffs, NJ:
Prentice-Hall, 1995.
Sacerdotti E. D. Planning in a hierarchy of abstraction spaces. Artificial Intelligence, 5: 115-
135, 1974.
Sacerdotti E. D. The поп linear nature of plans. Proceedings IJCAI 4, 1975.
Sacerdotti E. D. A Structure of Plans and Behavior. New York: Elsevier, 1977.
Sagi D. and Tanne D. Perceptual learning: Learning to see. In Squire and Kosslyn A998), 1998.
Samuel A. L. Some studies in machine learning using the game of checkers. IBM Journal of R & D,
3:211-229,1959.
Schank R. С Dynamic Memory: A Theory of Reminding and Learning in Computers and
People. London: Cambridge University Press, 1982.
Schank R. С and Abelson R. Scripts, Plans, Goals and Understanding. Hillsdale, NJ:
Erlbaum, 1977.
Schank R. С and Colby К. М., ed. Computer Models of Thought and Language. San
Francisco: Freeman, 1973.
Schank R. С and Nash-Webber B. L., ed. Theoretical Issues in Natural Language Processing.
Association for Computational Linguistics, 1975.
Schank R. С and Rieger С J. Inference and the computer understanding of natural language.
Artificial Intelligence 5D): 373-412, 1974.
Schank R. C. and Riesbeck С. К., ed. Inside Computer Understanding: Five Programs Plus
Miniatures. Hillsdale, N.J.: Erlbaum, 1981.
Библиография
833
Schoonderwoerd R., Holland O. and Bruten J. Ant-like agents for load balancing in
telecommunications networks. Proceedings of the First International Conference on
Autonomous Agents (Agents-97) pp. 209-216, 1997.
Schrooten R. and van de Velde W. Software agent foundation for dynamic interactive
electronic catalogues. Applied Artificial Intelligence, 11E) pp. 459-482, 1997.
Schwuttke U. M. and Quan A. G. Enhancing performance of cooperating agents in real-time
diagnostic systems. Proceedings of the Thirteenth International Joint Conference on
Artificial Intelligence, pp. 332-337, 1993.
Searle J. Speech Acts. London: Cambridge University Press, 1969.
Searle J. R. Minds, brains and programs. The Behavioral and Brain Sciences, 3:417^24,1980.
Sebeok T. A. Contributions to the Doctrine of Signs. Lanham, MD: Univ, Press of America, 1985.
Sedgewick R. Algorithms. Reading, MA: Addison-Wesley, 1983.
Sejnowski T. J. and Rosenberg С R. Parallel networks that learn to pronounce English text.
Complex Systems, 1: 145-168, 1987.
Selfridge O. Pandemonium: A paradigm for learning. Symposium on the Mechanization of
Thought. London: HMSO, 1959.
Selman B. and Levesque H. J. Abductive and Default Reasoning: A Computational Core.
Proceedings of the Eighth National Conference on Artificial Intelligence, pp. 343-348.
Menlo Park, С A: AAAI Press/MIT Press, 1990.
Selz O. Uber die Gesetze des Geordneten Denkverlaufs. Stuttgart: Spemann, 1913.
Selz O. Zur Psychologic des Produktiven Denkens und des Irrtums. Bonn: Friedrich Cohen, 1922.
Shafer G. & Pearl J., ed. Readings in Uncertain Reasoning, Los Altos, CA: Morgan Kaufmann,
1990.
Shannon С A mathematical theory of communication. Bell System Technical Journal, 1948.
Shapiro E. Concurrent Prolog: Collected Papers, 2 vols. Cambridge, MA: MIT Press, 1987.
Shapiro S. C, ed. Encyclopedia of Artificial Intelligence. New York: Wiley-Interscience, 1987.
Shapiro S. C, ed. Encyclopedia of Artificial Intelligence. New York: Wiley, 1992.
Shavlik J. W. and Dietterich T. G., ed. Readings in Machine Learning. San Mateo, CA:
Morgan Kaufmann, 1990.
Shavlik J. W., Mooney R. J. and To well G. G. Symbolic and neural learning algorithms: An
experimental comparison. Machine Learning, 6A): 111-143, 1991.
Shephard G. M. Vie Synaptic Organization of the Brain. New York: Oxford University Press, 1998.
Shrager J. and Langley P., ed. Computational Models of Scientific Discovery and Theory
Formation. San Mateo, С A: Morgan Kaufmann, 1990.
Shrobe H. E., ed. Exploring Artificial Intelligence: Survey Talks from the National
Conferences on Artificial Intelligence, pp. 297-346. San Mateo: Morgan Kaufmann, 1998.
Siegelman H. and Sontag E. D. Neural networks are universal computing devices. Technical
Report SYCON 91-08. New Jersey: Rutgers Center for Systems and Control, 1991.
Siegler, ed. Children's Thinking: What Develops. Hillsdale, NJ: Erlbaum, 1978.
Siekmann J. H. and Wrightson G., ed. The Automation of Reasoning: Collected Papers from
1957 to 1970. Vol. I. New York: Springer-Verlag, 1983a.
834
Библиография
Siekmann J. H. and Wrightson G., ed. The Automation of Reasoning: Collected Papers from
1957 to 1970. Vol. II. New York: Springer-Verlag, 19836.
Simmons R. F. Storage and retrieval of aspects of meaning in directed graph structures.
Communications of the ACM, 9: 211-216, 1966.
Simmons R. F. Semantic networks: Their computation and use for understanding English
sentences. In Schank A972), 1973.
Simon D. P. and Simon H. A. Individual differences in solving physics problems. In Siegler
A978), 1978.
Simon H. A. Decision making and administrative organization. Public Administration Review,
4: 16-31, 1944.
Simon H. A. The functional equivalence of problem solving skills. Cognitive Psychology, 7:
268-288, 1975.
Simon H. A. The Sciences of the Artificial, 2nd ed. Cambridge, MA: MIT Press, 1981.
Simon H. A. Why should machines learn? In Michalski et al. A983), 1983.
Sims M. H. Empirical and analytic discovery in IL. Proceedings of the Fourth International
Workshop on Machine Learning. Los Altos, CA: Morgan Kaufmann, 1987.
Skinner J. M. and Luger G. F. A synergistic approach to reasoning for autonomous satellites.
Proceedings for NATO Conference of the Advisory Group for Aerospace Research and
Development, 1991.
Skinner J. M. and Luger G. F. An architecture for integrating reasoning paradigms. Principles
of Knowledge Representation and Reasoning. B. Nobel, С Rich and W. Swartout, ed. San
Mateo, С A: Morgan Kaufmann, 1992.
Skinner J. M. and Luger G. F. Contributions of a case-based reasoner to an integrated
reasoning system. Journal of Intelligent Systems. London: Freund, 1995.
Sleeman D. Assessing aspects of competence in basic algebra. In Sleeman and Brown A982),
1982.
Sleeman D. and Smith M. J. Modelling students' problem solving. AI Journal, pp. 171-187,
1981.
Sleeman D. and Brown J. S. Intelligent Tutoring Systems. New York: Academic Press, 1982.
SmalltalkN: Tutorial and Programming Handbook. Los Angeles: Digitalk, 1986.
Smart G. and Langeland-Knudsen J. The CRI Directory of Expert Systems. Oxford: Learned
Information (Europe) Ltd., 1986.
Smith B.C. Prologue to reflection and semantics in a procedural language. In Brachman and
LevesqueA985), 1985.
Smith B.C. On the Origin of Objects. Cambridge, MA: MIT Press, 1996.
Smith R. G. and Baker J. D. The dipmeter advisor system: a case study in commercial expert
system development. Proc. 8th IJCAI, pp. 122-129, 1983.
Smoliar S. W. A View of Goal-oriented Programming, Schlumberger-Doll Research Note, 1985.
Soderland S., Fisher D., Aseltine J. and Lehnert W. CRYSTAL: Inducing a conceptual
dictionary. Proceedings of the Fourteenth International Joint Conference on Artificial
Intelligence, 1314-1319, 1995.
Библиография
835
Soloway E., Rubin E., Woolf В., Bonar J. and Johnson W. L. MENO-II: an Al-based
programming tutor. Journal of Computer Based Instruction, 10A, 2), 1983.
Soloway E., Bachant J. and Jensen K. Assessing the maintainability of XCON-in-RIME:
Coping with the problems of a very large rule base. Proceedings AAAI-87. Los Altos,
CA: Morgan Kaufmann, 1987.
Somogyi Z., Henderson, F. and Conway C. Mercury: An efficient purely declarative logic
programming language. Proceedings of the Australian Computer Science Conference,
499-512, 1995.
Sowa J. F. Conceptual Structures: Information Processing in Mind and Machine. Reading,
MA: Addison-Wesley, 1984.
Squire L. R. and Kosslyn S. M., ed. Findings and Current Opinion in Cognitive Neuroscience,
Cambridge: MIT Press, 1998.
Steele G. L. Common LISP: The Language, 2nd ed. Bedford, MA: Digital Press, 1990.
Stefik M., Bobrow D., Mittal S. and Conway L. Knowledge programming in LOOPS: Report
on an experimental course. Artificial Intelligence, 4C), 1983.
Sterling L. and Shapiro E. The Art of Prolog: Advanced Programming Techniques. Cambridge,
MA: MIT Press, 1986.
Stern C. R. An Architecture for Diagnosis Employing Schema-based Abduction. PhD
dissertation, Department of Computer Science, University of New Mexico, 1996.
Stern C. R. and Luger G. F. A model for abductive problem solving based on explanation templates
and lazy evaluation. International Journal of Expert Systems, 5C): 249-265, 1992.
Stern C. R. and Luger G. F. Abduction and abstraction in diagnosis: a schema-based account,
Situated Cognition: Expertise in Context. Ford et al. ed. Cambridge, MA: MIT Press, 1997.
Stubblefield W. A. Source Retrieval in Analogical Reasoning: An Interactionist Approach.
PhD dissertation, Department of Computer Science, University of New Mexico, 1995.
Stubblefield W. A. and Luger G. F. Source Selection for Analogical Reasoning: An Empirical
Approach. Proceedings: Thirteenth National Conference on Artificial Intelligence, 1996.
Stytz M. P. and Frieder O. Three dimensional medical imagery modalities: An overview.
Critical Review of Biomedical Engineering, 18, 11-25, 1990.
Suchman L. Plans and Situated Actions: The Problem of Human Machine Communication.
Cambridge: Cambridge University Press, 1987.
Sussman G. J. A Computer Model of Skill Acquisition. Cambridge, MA: MIT Press, 1975.
Sutton R. S. Learning to predict by the method of temporal differences. Machine Learning 3,
9-44, 1988.
Sutton R. S. Integrated architectures for learning, planning, and reacting based on
approximating dynamic programming. Proceedings of the Seventh International
Conference on Machine Learning, pp. 216-224. San Francisco: Morgan Kaufmann, 1990.
Sutton R. S. Dyna: An integrated architecture for learning, planning, and reacting. SIGART
Bulletin, 2: 160-164, ACM Press, 1991.
Sutton R. S. and Barto. A. G. Reinforcement Learning. Cambridge: MIT Press, 1998.
Sycara K., Decker K., Pannu A., Williamson M. and Zeng D. Distributed intelligent agents.
IEEE Expert, 11F), 1996.
836
Библиография
Tang А. С, Pearlmutter В. A., and Zibulevsky M. Blind source separation of neuromagnetic
responses. Computational Neuroscience 1999, Proceedings published in Neurocomputing,
1999.
Tang A. C, Pearlmutter B. A., Zibulevsky M, Hely T. A., and Weisend M. A MEG study of
response latency and variability in the human visual system during a visual-motor
integration task. Advances in Neural Information Processing Systems: San Francisco:
Morgan Kaufmann, 2000a.
Tang A. C, Phung D. and Pearlmutter B. A. Direct measurement of interhemispherical transfer
time (IHTT) for natural somatasensory stimulation during voluntary movement using
MEG and blind source separation. Society of Neuroscience Abstracts, 20006.
Takahashi K., Nishibe Y., Morihara I. and Hattori F. Intelligent pp.: Collecting shop and service
information with software agents. Applied Artificial Intelligence, 11F): 489-500, 1997.
Tanimoto S. L The Elements of Artificial Intelligence using Common LISP. New York: W.H.
Freeman, 1990.
Tarski A. The semantic conception of truth and the foundations of semantics. Philos. and
Phenom. Res., 4: 341-376, 1944.
Tarski A. Logic, Semantics, Metamathematics. London: Oxford University Press, 1956.
Tesauro G. J. TD-Gammon, a self-teaching backgammon program achieves master-level play.
Neural Computation, 6B): 215-219, 1994.
Tesauro G. J. Temporal difference learning and TD-Gammon. Communications of the ACM,
38: 58-68, 1995.
Thagard P. Dimensions of analogy. In Helman A988), 1988.
Touretzky D. S. The Mathematics of Inheritance Systems. Los Altos, С A: Morgan Kaufmann, 1986.
Touretzky D. S. Common LISP: A Gentle Introduction to Symbolic Computation. Redwood
City, CA: Benjamin/Cummings, 1990.
Trappl R. andPettaP. Creating Personalities for Synthetic Actors. Berlin: Springer- Verlag, 1997.
Triesman A. The perception of features and objects. Attention: Selection, Awareness, and
Control: A Tribute to Donald Broadbent. Badderly A. and Weiskrantz L. ed, pp. 5-35.
Oxford: Clarendon Press, 1993.
Treisman A. The binding problem. In Squire and Kosslyn A998), 1998.
Tulving E. and Donaldson W. Organization of Memory. New York: Academic Press, 1972.
Turing A. A. Computing machinery and intelligence. Mind, 59: 433-460, 1950.
Turner R. Logics for Artificial Intelligence. Chichester: Ellis Horwood, 1984.
Ullman J. D. Principles of Database Systems. Rockville, MD: Computer Science Press, 1982.
Urey H. С The Planets: Their Origin and Development. Yale University Press, 1952.
Utgoff P. E. Shift of bias in inductive concept learning. In Michalski et al. A986), 1986.
Valiant L. G. A theory of the learnable. CACM, 27: 1134-1142, 1984.
van der Gaag L. C, ed. Special issue on Bayesian Belief Networks. AISB Quarterly. 94, 1996.
van Emden M. and Kowalski R. The semantics of predicate logic and a programming
language. Journal of the ACM, 23: 733-742, 1976.
VanLe T. Techniques of PROLOG Programming with Implementation of Logical Negation and
Quantified Goals. New York: Wiley, 1993.
Библиография
837
Varela F. J., Thompson E. and Rosch E. The Embodied Mind: Cognitive Science and Human
Experience. Cambridge, MA: MIT Press, 1993.
Veloso M., Bowling M., Achim S., Han K. and Stone P. CNITED-98 RoboCup-98 small robot
world champion team. AI Magazine, 21A): 29-36, 2000.
Vere S. A. Induction of concepts in the predicate calculus. Proceedings IJCAI 4, 1975.
Vere S. A. Inductive learning of relational productions. In Waterman and Hayes-Roth A978), 1978.
Veroff R., ed. Automated Reasoning and its Applications. Cambridge, MA: MIT Press, 1997.
Viterbi A. J. Error bounds for convolutional codes and an asymptotically optimum decoding
algorithm. IEEE Transactions on Information Theory, IT-13B): 260-269, 1967.
von Glaserfeld E. An introduction to radical constructivism. The Invented Reality, Watzlawick,
ed., pp. 17^0, New York: Norton, 1978.
Walker A., McCord M., Sowa J. F. and Wilson W. G. Knowledge Systems and PROLOG: A
Logical Approach to Expert Systems and Natural Language Processing. Reading, MA:
Addison-Wesley, 1987.
Warren D. H. D. Generating conditional plans and programs. Proc. AISB Summer
Conference, Edinburgh, pp. 334-354, 1976.
Warren D. H. D. Logic programming and compiler writing. Software-Practice and Experience,
10A1), 1980.
Warren D. H. D., Pereira F. and Pereira L. M. User's Guide to DEC-System 10 PROLOG.
Occasional Paper 15, Department of Artificial Intelligence, University of Edinburgh, 1979.
Warren D. H. D., Pereira L. M. and Pereira F. PROLOG— the language and its
implementation compared with LISP. Proceedings, Symposium on AI and Programming
Languages, SIG-PLAN Notices, 12:8, 1977.
Waterman D. and Hayes-Roth F. Pattern Directed Inference Systems. New York: Academic
Press, 1978.
Waterman D. A. Machine Learning of Heuristics. Report No. STAN-CS-68-118, Computer
Science Dept, Stanford University, 1968.
Waterman D. A. A Guide to Expert Systems. Reading, MA: Addison-Wesley, 1986.
Watkins С J. С. Н. Learning from Delayed Rewards. PhD Thesis, Cambridge University, 1989.
Wavish P. and Graham M. A situated action approach to implementing characters in computer
games. Applied Artificial Intelligence, 10A): 53-74, 1996.
Webber B. L. and Nilsson N. J. Readings in Artificial Intelligence. Los Altos: Tioga Press, 1981.
Weiss S. M. and Kulikowski C. A. Computer Systems that Learn. San Mateo, CA: Morgan
Kaufmann, 1991.
Weiss S. M., Kulikowski С A., Amarel S. and Safir A. A model-based method for computer-
aided medical decision-making. Artificial Intelligence, 11A-2): 145-172, 1977.
Weizenbaum J. Computer Power and Human Reason. San Francisco: W. H. Freeman, 1976.
Weld D. An introduction to least committment planning. AI Magazine 15D): 16-35, 1994.
Weld D. S. and deKleer J., ed. Readings in Qualitative Reasoning about Physical Systems. Los
Altos, С A: Morgan Kaufmann, 1990.
Welham R. Geometry Problem Solving. Research Report 14, Department of Artificial
Intelligence, University of Edinburgh, 1976.
838
Библиография
Wellman M. P. Fundamental concepts of qualitative probabilistic networks. Artificial
Intelligence, 44C): 257-303, 1990.
Weyhrauch R. W. Prolegomena to a theory of mechanized formal reasoning. Artificial
Intelligence, 13A, 2): 133-170, 1980.
Whitehead A. N. and Russell B. Principia Mathematica, 2nd ed. London: Cambridge
University Press, 1950.
Whitley L. D., ed. Foundations of Genetic Algorithms 2. Los Altos, CA: Morgan Kaufrnann, 1993.
Widrow B. and Hoff M. E. Adaptive switching circuits. 1960 IRE WESTCON Convention
Record, pp. 96-104. New York, 1960.
Wilensky R. Common LISP Craft, Norton Press, 1986.
Wilks Y. A. Grammar, Meaning and the Machine Analysis of Language. London: Routledge &
KeganPaul, 1972.
Williams В. С and Nayak P. P. Immobile robots: AI in the new millennium. AI Magazine
17C): 17-34, 1996л.
Williams В. С and Nayak P. P. A model-based approach to reactive self-configuring systems.
Proceedings of the AAAI-96, pp. 971-978. Cambridge, MA: MIT Press, 1996.
Williams В. С and Nayak P. P. A reactive planner for a model-based executive. Proceedings
of the International Joint Conference on Artificial Intelligence, Cambridge, MA: MIT
Press, 1997.
Winograd T. Understanding Natural Language. New York: Academic Press, 1972.
Winograd T. A procedural model of language understanding. In Schank and Colby A973), 1973.
Winograd T. Language as a Cognitive Process: Syntax. Reading, MA: Addison-Wesley, 1983.
Winograd T. and Flores F. Understanding Computers and Cognition. Norwood, N.J.: Ablex, 1986.
Winston P. H. Learning structural descriptions from examples. In Winston A9756), 1975a.
Winston P. H., ed. The Psychology of Computer Vision. New York: McGraw-Hill, 19756.
Winston P. H. Learning by augmenting rules and accumulating censors. In Michalski et al.
A986), 1986.
Winston P. H. Artificial Intelligence, 3rd ed. Reading, MA: Addison-Wesley, 1992.
Winston P. H., Binford T. O., Katz B. and Lowry M. Learning physical descriptions from
functional definitions, examples and precedents. National Conference on Artificial
Intelligence in Washington, D. C, Morgan Kaufrnann, pp. 433-439, 1983.
Winston P. H. and Horn B. K. P. LISP. Reading, MA: Addison-Wesley, 1984.
Winston P. H. and Prendergast K. A., ed. The AI Business. Cambridge, MA: MIT Press, 1984.
Wirth N. Algorithms + Data Structures = Programs. Englewood Cliffs, NJ: Prentice-Hall, 1976.
Wittgenstein L. Philosophical Investigations. New York: Macmillan, 1953.
Wolpert D. H. and Macready W. G. The No Free Lunch Theorems for Search, Technical
Report SFI-TR-95-02-010. Santa Fe, NM: The Santa Fe Institute, 1995.
Wolstencroft J. Restructuring, reminding and repair: What's missing from models of analogy.
AICOM, 2B): 58-71, 1989.
Wooldridge M. Agent-based computing. Interoperable Communication Networks. 1A): 71-97, 1998.
Wooldridge M. Reasoning about Rational Agents, Cambridge, MA: MIT Press, 2000.
Библиография
839
Woods W. What's in a Link: Foundations for Semantic Networks. In Brachman and Levesque
A985), 1985.
Wos L. and Robinson G. A. Paramodulation and set of support, Proceedings of the IRIA
Symposium on Automatic Demonstration, Versailles. New York: Springer-Verlag, pp.
367-410, 1968.
Wos L. Automated Reasoning, 33 Basic Research Problems. NJ: Prentice Hall, 1988.
Wos L. The field of automated reasoning. In Computers and Mathematics with Applications,
29B): xi-xiv, 1995.
Wos L., Overbeek R., Lusk E. and Boyle J. Automated Reasoning: Introduction and
Applications. Englewood Cliffs, NJ: Prentice-Hall, 1984.
Xiang Y., Poole D. and Beddoes M. Multiply sectioned Bayesian networks and junction forests
for large knowledge based systems. Computational Intelligence 9B): 171-220, 1993.
Xiang Y., Olesen K. G. and Jensen F. V. Practical issues in modeling large diagnostic systems
with multiply sectioned Bayesian networks. International Journal of Pattern Recognition
and Artificial Intelligence, 14A): 59-71, 2000.
Yager R. R. and Zadeh L. A. Fuzzy Sets, Neural Networks and Soft Computing. New York:
Van Nostrand Reinhold, 1994.
Young R. M. Sedation by Children: An Artificial Intelligence Analysis of a Piagetian Task.
Basel: Birkhauser, 1976.
Yuasa T. and Hagiya M. Introduction to Common LISP. Boston: Academic Press, 1986.
Zadeh L. Commonsense knowledge representation based on fuzzy logic. Computer, 16: 61-65,1983.
Zurada J. M. Introduction to Artificial Neural Systems. New York: West Publishing, 1992.
840
Библиография
Алфавитный
указатель авторов
Abelson, 238,239; 599; 773
Ackley, 516
Adam, 598
Adler, 265
Agre, 49, 221,226; 804
Aho, 144,189
Aiello, 215
Allen, 54,316,566; 576, 585; 598
Alty, 321
Anderson, 54,199,230, 268, 467; 481; 524; 805; 807
Andews, 103
Appelt, 86
Arbib, 509
Ashly, 299
Auer, 432
Austin, 39; 805
В
Baker, 45
Ballard, 481,807
Balzer, 215
Bareiss, 299
Barker, 2061
Barkow, 790
Barr, 54; 322
В artlett, 237; Ш
Barto, 427,429; 431; 432
В ate son, 54
Bechtel, 808
Benson, 376; 322; 577; 576; 802
Berger, 597
Bernard, 296
Bertsekas, 432
Birmingham, 264
Bishop, 482
Bledsoe, 54; 528; 557; 558
Bobrow, 226, 268
Bond, 266
Boole, 53
Bower, 230, 268
Boyer, 44; 54,559
Brachman, 104; 233; 268; 803
Brooks, 49,54; 220; 221; 226; 255; 256; 258; 268; 269;
485; 510,802; 804; 808
Brown, 293,322; 415
Brownston,270;275
Buchanan, 45, 321; 341, 348; 406
Bundy, 44; 104; 553; 559
Burks, 509; 516
Burmeister, 265
Burstall, 35
Burton, 322
Busuoic, 265
Buttler, 30
Cahill, 794
Carbonell, 303; 432
Cardie, 597
Carlson, 787
Ceccato, 230
Chang, 705; 557; 559; 559
Chapman, 49; 221; 226; 804
Charmak, 746; 247; 547; 599
Chen, 265
Chomsky, 574
Chorafas, 527
Chung, 264
Church, 607; 803
Clancy, 293
Clark, 220; 222; 268; 802; 808
Clocksin, 607; 610; 680
Codd, 509
Colby, 54; 233
Cole, 599
Collins, 227; 268
Colmerauer, 606; 680
Conway, 484; 505; 516
Coombs, 527
Cooper, 355
Corera, 264
Corkill,275;275
Cormen, 745
Cosrmdes, 790
Cotton, 50; 416
Cnscuolo, 557; 566
Crutchfield, 485; 511; 513
Cutosky, 264
D
G
Dahl, 680
Darlington, 35
Dan, 264
Davis, 50\ 293; 322; 366; 415; 490
Dechter, 365
DeJong, 57; 407; 409
deKleer, 55; 269; 293; 319; 334; 335; 339; 366; 773
Dempster, 350
Dennett, 54; 222; 268; 516; 791; 804; 807
Devis, 269; 322
Devore, 509
Dietterich, 411; 432
Dologite, 321
Domingue, 773
Doorenbos, 265
Doyle, 329; 332; 334; 366
Dreyfus, 39; 804
Druzdel, 364; 366
Duda, 45; 357
Durfee, 263
Durkin, 45; 54; 321
E
Eco, 805
Edelman, 790; 804
E\mm,481;807
Engelmore, 215
Erman, 213; 215
Ernst, 522; 526; 784
Euler, 32
Evans, 259
F
Falkenhainer, 413
Fass, 599
Feigenbaum, 54; 322; 371; 432; 559; 793
Feldman, 432; 559; 793
Fikes,311;407;528
Fillmore, 233
Fischer, 265
Fisher, 300; 420,432
Flores, 39; 54; 58; 599; 804; 806; 807
Fodor, 789; 790
Forbus, 55; 773
Ford, 37; 54; 55
Forgy, 291; 301
Forney, 587
Forrest, 575
Franklin, 481; 807
Freeman, 481; 796
Frege, 34
Frey, 482
Frieder, 793
842
Gallier, 103
Ganzinger, 559
Garey, 750; 757
Gasser, 266
Gazdar, 599; 680
Gazzaniga, 787; 794
Genesereth, 104; 338; 366; 559
Gennari, 421
Gentner, 413
Giarratano, 321
Gilbert, 794
Ginsburg, 366
Glasgow, 598
Glymour, 354
Goldberg, 494; 515
Goodwin, 333
Gould, 506; 516
Graham, 265; 773
Gnce, 39; 341; 805
Griffiths, 265
Grossberg, 459; 481
Grosz, 805
H
Hall, 412
Hammond, 303
Hamscher, 293; 322
Hanson, 573
Harbison-Briggs, 321
Harmon, 54; 228; 321
Harris, 599
Hasemer, 773
Haugeland, 54,268; 807
Haussler, 405
Hayes, 37,54; 308; 366,607
Hayes-Roth, 54,215; 265; 321; 516
Hebb, 437; 439; 462; 481
Hecht-Nielsen, 436; 456; 459; 477; 481
Heidegger, 39; 806
Heidorn, 576
Helman, 145
Hempel, 808
Henrion, 365
Hightower, 509; 516
Hill, 680
Hillis, 52
Hinton, 481
Hobbs, 366
Hodges, 54
Hoff, 446
Hofstadter, 259
Holland, 259; 485; 492; 494; 497; 499,515; 789
Holowczak, 598
Holyoak, 432
Алфавитный указатель авторов
Hopcroft, 574; 599
Hopfidd, 437; 472; 481
Horowitz, 117; 145
Hume, 401
Hussal 39; 806
I
Ignizio, 321
Ivry, 794
J
Jeannerod, 481; 807
Jennings, 221; 226; 262; 264,266
Johnson, 39; 54; 150; 181; 226,321; 785, 791; 802,
808
Johnson-Laird, 804
Jordan, 482
Josephson, 366
Jurafsky, 47; 54; 585; 588; 592,599
К
Karmiloff-Srmth, 788; 791; 795
Kaufmann, 559
Kautz, 265
Kedar-Cabelli, 412; 432,668
Keravnou, 321
King, 54,228, 680
Klahr,199;215,321,432
Klein, 49,264; 318; 511,802
Knight, 310
Kohonen, 436; 455; 457,467,481
Koller, 365
Kolmogorov, 799
Kolodner, 241; 301; 303,321
Kondratoff, 55; 432
Korf, 131; 181
Kosko, 472; 481
Kosoresow, 365
Kosslyn, 787, 794
Koton, 299
Kowalski, 528; 547; 549,606; 680
Koza, 485; 500; 501,504; 515
Krulwich, 265
Kuhl, 794
Kuhn, 807; 808
Kulikowski, 432
L
Lakatos, 808
Lakoff, 39,54,226,417,457, 785, 791; 802; 808
Langeland-Knudsen, 321
Langley, 416; 432
Langton, 55,485; 509; 516,802
Larkin, 199
Laskey, 365
Lauritzen, 363
Lave, 805
Leake, 302; 321
Lee, 103; 531; 539; 559
Leibniz, 32
Leiserson, 145
Lenat, 50; 415; 416
Lesser, 213; 215; 263
Levesque, 104; 268; 269,339; 803
Lewis, 49; 54,226; 261; 262; 510; 785; 802
Lieberman, 265
Lifschitz, 337; 338; 366
Lindsay, 45,322
Ljunberg, 264
Lloyd, 559; 607
Lovelace, 33
Loveland, 559
Lucas, 264; 680
Luck, 794
Luger, 25; 48,49; 54,198; 215; 226; 261; 262; 269; 296;
300; 302; 322,432; 510,524; 785; 789; 792; 802;
804; 807
M
Machtey, 58
Macready, 798
Maes, 265; 269,516
Magerman, 591
Mahoney, 365
Maier, 680
Malpas, 640; 680
Manna, 79; 103; 319
Manning, 47; 591,592,599
Marcus, 47
Markov, 198
Marshall, 261
Martin, 47,54; 405,432; 585,588; 592; 599
Martins, 333; 335; 366
Masterman, 230
McAllester, 333; 366; 559
McCarthy, 86; 308; 337; 366,607, 647
McCarty, 668
McCord, 680
McCorduck, 371
McCulloch, 438,481
McDermott, 61; 146; 200,322; 329
McGaugh, 794
McGomgle, 802,808
McGraw, 321
Mead, 481
Mellish, 599; 607; 610,680
Merleau-Ponty, 39
Michalski, 55; 418; 432; 500
Michie, 432
Алфавитный указатель авторов
843
Miller, 794
Minsky, 55; 242; 244; 440; 789; 790
Minton, 407
Mitchell, 57; 259; 268; 380; 381; 387; 406; 408; 411;
432; 485; 494; 504; 511; 513; 515; 669; 798
Mithen, 790; 791
Mockler, 321
Mooney, 57; 341; 407; 409; 598
Moore, 44; 54; 330; 366; 524; 559
Moret, 757
Morgan, 275
Morrison, 33
Mycroft, 640; 643; 680
N
Nadathur, 680
Nahm, 598
Nash-Webber, 233
Nayak, 296; 298; 318; 322
Necht-Nielsen, 796; 799
Negoita, 321
Neves, 640
Newell, 42; 43,52; 54; 71; 77; 145; 175; 199; 212; 215;
515; 522; 524; 525; 526; 604; 778; 784; 793; 795;
807
Ng, 341
Nii, 275
Nilsson, 49; 54; 104; 136; 145,174; 177; 181; 200; 310;
311; 316; 338; 366; 440; 510,511; 528; 545; 553;
558; 559,802
Nishibe, 265
Nordhausen, 417
Norman, 230; 233,807
Norvig, 314,322
Noyes, 773
О
O'Connor, 200
O'Keefe, 640; 643; 680
O'Leary, 795
Oliveira, 264
Oliver, 490
P
Papert, 278; 440
Parra, 794
Pearl, 54; 146; 174; 181; 355; 359; 364; 424
Pearlmutter, 794
Peirse, 805
Penrose, 782; 804
Penueli,379
Pereira, 680
Perl, 361
Pedis, 338; 366
844
Perriolat, 264
Petta, 265
Pfeffer, 365
Piaget, 800
Pitts, 438; 481
Pless, 365
Polya, 149
Popper, 805; 808
Posner, 804; 807
Post, 795
Poundstone, 484; 507
Prerau, 321
Pylyshyn, 54; 804; 807
Q
Quan, 264
Quillian, 227; 230; 268
Quine, 808
Quinlan, 50; 392; 398; 399; 432; 439
R
Raphael, 230
Reddy, 213; 215
Reggia,339
Reinfrank, 334; 366
Reiter, 329; 330; 366
Reitman, 230; 259
Rich, 310
Rieger, 234
Riesbeck, 241; 599
Riley, 321
Rissland, 299
Rivest, 145
Roberts, 230
Robinson, 528; 540; 606
Rochester, 439
Rosch, 420; 457
Rosenberg, 452
Rosenblatt, 439; 481
Rosenbloom, 575
Ross, 345; 349; 366; 680
Roussel, 606
Rumelhart, 233; 446; 481
Russell, 34; 65; 77; 220; 314; 322; 412; 522; 523
s
Sacerdotti, 322; 528
Sagi, 794
Sahni, 777; 145
Samuel, 300,302
Scapura, 796
Schank, 54,233; 238; 239; 241; 599
Schoonderwoerd, 265
Schrooten, 265
Алфавитный указатель авторов
Schutze, 47; 591; 592; 599
Schwuttke, 264
Sear\e,39;58;599;785;804
Seboek, 805
Sedgewick, 145
Sejnowski, 452
Selfridge, 481
Selman, 340
Selz, 230,268
Shafer, 366
Shannon, 396; 481
Shapiro, 55; 181; 322; 333; 366; 504; 549; 560; 680
Shw\\k,432;453
Shephard, 787, 794
Shimony, 341
Shortliffe, 45; 321; 341; 348
Shrager, 416,432
Shrobe, 294
Sidner, 805
Siegelman, 799
Siekmann, 559
Simmons, 230,233
Simon, 38; 42,43; 52; 54; 71, 77; 145; 175; 198, 215;
219; 372; 522; 525; 778, 784; 793, 795; 807
Sims, 416
Skapura, 481
Skinner, 2 75; 300; 322
Smart, 321
Smith, 45; 221; 599; 807
Smoliar, 322
Soderland, 598
Soloway, 200
Somogyi, 680
Sontag, 799
Sowa, 230; 245; 254; 268; 576; 583; 594; 599; 680
Spiegelhalter, 363
Squire, 787; 794
Steele, 756; 761; 773
Stein, 258; 269
Stepp, 418
Sterling, 680
Stern, 296; 300; 302
Stubblefield, 300; 302; 416; 432
Stytz, 793
Suchman, 801
Sussman,57; 773
Sutton, 425; 427; 429; 431; 432
Sycara, 262; 264
Takahashi, 265
Tang, 794
Tanimoto, 773
Tanne, 794
Tarski, 35
Tesauro, 429,431
Thagard, 432
Tong, 680
Tooby, 790
Touretzky, 337; 366; 773
Trappl, 265
Triesman, 794
Tsitsiklis, 432
Turing, 36; 54; 803
Turner, 253; 366
и
Ullman, 144; 189; 574; 593; 594; 599
Urey, 504
Utgoff, 402
Valiant, 404
van de Velde, 265
van der Gaag, 366
van Emden, 547; 549
VanLe, 680
VanLehn, 322
Varela, 804
Veloco, 262; 265
Veroft,44;54;104;145;559
Viterbi, 587
von Glasesfeld, 800
w
Waldinger, 79; 103
Walker, 680
Warren, 607; 680
Waterman, 45; 54; 215; 274; 321
Watkins, 437; 432
Wavish, 265
Weiss, 432
Weizenbaum, 54; 804; 806
Weld, 269; 316
Weyhrauch, 366
Whitehead, 34; 65; 77; 220; 522; 523
Widrow, 446
Wilks, 54; 230; 599
Williams, 296; 298; 318; 322
Winograd, 39; 47; 54; 58; 268; 563; 585; 598; 804;
806; 807
Winston, 50; 146; 376; 407; 797
Wirth, 705
Wittgenstein, 39; 420; 457
Wolpert, 798
Wolstencroft, 412
Woods, 237
Алфавитный указатель авторов
845
Wooldridge, 221; 226; 262; 264
Wos, 54; 104; 521; 540; 542; 545; 556; 558
Wrightson, 559
Wu, 264
X Z
Xiang, 365; 366 Zadeh, 237; 344; 366
Zurada, 448; 456; 459; 481; 796
Y
Yager, 366
Young, 58
846
Алфавитный указатель авторов
Предметы
А
Abductive inference, 77; 552
Abstract data type, 609
Abstraction, 58
ABSTRIPS, 527
Absurd type, 249
Action potential, 787
Activation record, 189
Admissibility, 784
Agglomerative clustering, 417
a-list, 723
AM, программа, 415
Anonymous variable, 617
Answer extraction, 535
Antecedent, 74
ART, 750
Artificial life, 485
Association list, 723
Associationist theory, 227
ATN, 575
Atom, 686
Atomic sentence, 80
Attractor, 472
network, 437
Attribute, 593
Augmentation of logic grammar, 576
Augmented
phrase structure, 576
transition network, 569,575; 576
Autoassociative memory, 437\ 468
Autoepistemic logic, 330
Automated reasoning, 520; 522
Autonomous system, 263
в
Backpropagation, 436
Backtracking, 121
BACON, программа, 416
Base-level category, 420
Bayesian belief network, 359
Beam search, 180
Belief network, 77,327
Best first search, 150
Bigram, 589
Binary resolution, 529
Binding problem, 794
Bound variable, 702
указатель
Branching factor, 208
Breadth-first search, 124
Bucket brigade algorithm, 495
С
C++, 608, 750
C4 5, алгоритм, 399; 598
Candidate elimination, 381
Candide, программа, 597
Canonical formation rule, 252
Case frame, 233; 581
Case-based reasoning, 415, 784
Category
formation, 373
utility, 421
cdr-рекурсия, 698
Cellular automata, 505
Certainty factor, 164; 342
Chomsky hierarchy, 574
Clashing, 529
Class, 750
precedence, 755
Classifier system, 485; 495
Clause form, 528
CLOS, 750
Closed world assumption, 547; 551; 612
CLUSTER/2, система, 373; 401; 418; 457
Clustering problem, 417
COB-WEB, система, 373; 420
Cognitive science, 524; 792
Competitive learning, 436
Complete proof procedure, 90
Concept, 375
learning, 373
Conceptual
clustering, 373,477,475
graph, 245
Condition/action pair, 692
Conditional
evaluation, 694
probability, 356
Confidence measure, 762
Conflict
resolution, 797
set, 797
Conjunction of disjuncts, 530
Conjunctive bias, 402
Connectionist network, 372
Context-free
grammar, 573
language, 574
Context-sensitive language, 574
Counterpropagation network, 456; 459
C-PROLOG, 610
Credit assignment, 390
Crossover, 487; 503
D
Data flow diagram, 594
Data-driven search, 118
Decision tree, 392; 403
Declarative
language, 685
semantics, 609
Deductive closure, 411
Default logic, 330
Definite clause grammar, 680
Delayed evaluation, 736
Delta rule, 436; 446
Demodulation, 556
Demodulator, 556
Demon, 244
DENDRAL, система, 45; 406
Depth-fist search, 124
Detachment, 522
Difference
list, 645
table, 522
Directed acyclic graph, 114
Discrimination net, 432
Dotted pair, 723
DYNA-Q, алгоритм, 425
d-отделение, 361
E
EBL,411
Elman, 788
Embedded particle oc, 514
Empiricist's dilemma, 795
Encapsulation, 750
Encoding scheme, 438
Entity-relationship diagram, 594
Evaluation, 79
Evolutionary
learning, 372
programming, 509
EVRISKO, программа, 416
Exhaustive search, 69
Explanation structure, 409
Explanation-based learning, 373; 405; 407; 661
F
Fact, 548; 612
Factor, 536
Family resemblance theory, 420
Feasibility test, 526
Feature vector, 403; 662
Feedback network, 472
Feedforward network, 471
FIFO, структура данных, 624; 714
Filter, 711; 729
First-order predicate calculus, 86
Fitness
function, 484
proportionate selection, 486
Flat Concurrent PROLOG, 560
Flavors, 750
Flexible agent, 263
F-MRI, 793
Form, 687
FORTRAN, 678
Forward chaining, 118
Frame, 241; 639
Free variable, 702
Function
closure, 736
grammar, 598
Functional
language, 685
magnetic resonance imaging, 793
Fuzzy
associative matrix, 346
set, 345
theory, 344
G
General Problem Solver, 44; 198; 220; 522; 526; 784
Generalized delta-rule, 441
Generator, 729
Generic function, 750
Genetic
algorithm, 485
epistemology, 800
learning, 372
Glider, 507
Goal regression, 408
Goal-directed strategy, 135
GOFAI, система, 40
Gradient descent learning, 446
Grammatical
marker, 598
trigram, 591
Gray coding, 492
Ground expression, 85
848
Предметный указатель
н
Hamming distance, 468
HEARSAY-П, 213
Heteroassociative memory, 437; 468
Heuristics, 69
Hierarchical
abstraction, 604
problem decomposition, 48
Higher-order function, 711
Hill climbing, 755
Horn clause, 403; 547', 612
calculus, 612
Hyperresolution, 536; 555
I
ЮЗ, алгоритм, 373; 387; 392; 394; 398; 401; 453; 591;
598; 761; 797
IDA*, алгоритм, 181
JL, программа, 416
Imperative language, 685
Improper symbol, 78
Incremental parsing, 566
Induction, 372
Inductive bias, 372; 400; 795
Inference rule, 70; 89
Information
extraction system, 596
processing psychology, 524
Informedness, 784
Inheritance, 750
Interpol ative memory, 468
Interpretation, 75
J
J ASS, 276
Java, 50; 608; 750
Justification based truth maintenance system, 332
К
KEE, 750
Knowledge representation hypothesis, 221
к-коннектор, 134
L
Lambda-calculus, 713
Lambda-PROLOG, 680
Learning algorithm, 438
LEX, 388; 402; 411
Lexical closure, 712
Lexicon, 567
LIFO, структура данных, 622
Limitation on the number of disjuncts, 402
Предметный указатель
Linear associator, 437; 467
Link grammar, 591
LISP, 50; 276; 396; 416; 501; 606; 607; 685
логическая операция, 694
связывание переменных, 701
символьные вычисления, 694
List, 186; 615; 686
Literal, 529
Logic
program, 547
programming, 542; 547
Logical inference, 89
Logistic function, 445
M
Macro, 738
Macro-expansion, 738
Magnetoencephalography, 793
Majority vote, 512
Map, 711
function, 729
Marker, 247
Markov
assumption, 587
chain, 564
Matching process, 523
Maximally specific generalization, 383
Maximum likelihood density estimation, 417
Means-aids analysis, 220
Means-ends analysis, 522; 784
Mercury, 680
Meta-DENDRAL, 797
Meta-interpreter, 609; 646; 690
Meta-linguistic abstraction, 647; 727
Metamorphosis grammar, 680
Meta-predicate, 609; 639
Modal logic, 253
Model-based reasoning, 784
Modus tollens, 91
Monotonicity, 784
Monte-Carlo, 486
Morphology, 564
Multiple draft theory of consciousness, 791
Mutation, 487; 503
Mutual information clustering, 589
MYCIN, система, 45; 650
N
NASA, 318
Natural deduction system, 557
NETtalk, система, 452
Network topology, 438
Neural network, 372
Neuroscience, 786
Neurotransmitter, 787
849
N-ply look-ahead, 777
Nuclear magnetic resonance, 794
Nucleus, 555
Numeric taxonomy, 417
о
Occurs check, 722
Operations research, 784
Operator table, 527
Order crossover, 490
Outstar, 459
P
PAC-
изучаемость, 404
обучение, 404
Paramodulation, 555
Parse tree, 568
Parsing, 565
Pascal, язык, 641; 705
Pattern, 58
Perceptron, 436; 439
Permutation, 503
Phonology, 564
Phrase structure, 568
Physical symbol system, 782
hypothesis, 58
Planning, 527
Polymorphism, 750
Positive literal, 612
Positron emission tomography, 793
Posterior probability, 356
Pragmatics, 564
Predicate, 62,692
calculus, 62
Predictability, 421
Predictiveness, 421
Prenex normal form, 532
Prior probability, 355
Priority queue, 755; 609; 624
Probability density function, 352
Probably approximately correct learning, 404
Procedural
attachment, 543
semantics, 547
Production, 197
system, 196
PROLOG, 50; 87; 276; 383,520,528, 606; 706
абстрактный тип данных, 622
множество, 625
очередь, 624
приоритетная очередь, 624
стек, 622
проверка соответствия типов, 642
реализация
обучения на основе пояснения, 668
семантических сетей, 657
создание
метаинтерпретаторов, 646
семантических сетей, 639
типы данных, 640
Property list, 747
PROSPECTOR, программа, 45
Q
Queue, 609,624
Q-обучение, 431
R
Raw fitness, 503
Read-eval-print loop, 687
Reasoning over minimum model, 336
Recursively enumerable language, 574
Reduce, 557
Refraction, 277
Refutation, 528
complete, 539
Regular language, 574
Reinforcement learning, 71; 373
Relational database, 593
Replacement, 522
Representation language, 783
Reproduction, 503
Resolution, 77; 90; 92, 95,606
inference rule, 91
proof procedure, 528
refutation, 533
system, 606
theorem prover, 522
Resolvent, 534
Reward function, 426
Rewrite rule, 567
Roulette wheel, 486
s
Satellite, 555
SCAVENGER, система, 416
Schema, 494
Schemata, 800
SCHEME, 608
Scheme, язык, 803
Science of intelligent systems, 780; 792
Script, 238
Self-organizing network, 458
Semantic
grammar, 598
interpretation, 565
network, 64; 229,639
preference theory, 599
850
Предметный указатель
Semantics, 564
Sentential form, 567
Set, 625
of support, 522
s-expression, 686
SHRDLU, 563
Sigmoid, 445
Similarity-based learning, 373; 405
Skolem
constant, 532
function, 93
Skolemization, 93,532
Smalltalk, 750
Speech act theory, 39
Split, 557
SQL, 593
Stack, 609
Standard ML, язык, 803
State space
graph, 32
search, 32; 108
Step-size parameter, 427
Stream, 729
STRIPS, 407; 528
Strong method, 784
Structure mapping theory, 413
Subproblem list, 523
Substitution, 522
Subsumption architecture, 222, 255; 510
Supervised learning, 373,381,415
Surface structure, 599
Symbol-based learning, 784
Symbolic expression, 686
Syntax, 564
Systematicity, 413
principle, 414
Systran, программа, 591
s-выражение, 501; 686; 689
ml, 686
T
Table of connections, 526
Tail resursion, 698
Target, 375
Temporal difference learning, 426
rule, 428
Terminal, 142; 567
Theorem proving, 522
Theory of reference, 35
Top-down
derivation, 568
parser, 568
Transformational grammar, 598
Transition network, 569
Tree, 777
Trigram, 588
и
Unconditional probability, 355
Unit
clause, 541
preference, 522
Universal type, 249
Unsupervised learning, 373; 415
v
Value function, 426
Variable quantifier, 81
Verb phrase, 142
Version space, 557
search, 373,380; 661
Viterbi algorithm, 587
w
Weak method, 520; 784
problem solver, 220
Well-formed formula, 74
William of Occam, 394
A
А*, алгоритм, 493
Абдуктивные рассуждения, 71; 326; 338
Абдуктивный вывод, 327; 552
Абдукция
на основе стоимости, 341
Абстрактный
класс, 757
тип данных, 609,622; 696
Абстракция, 58
данных, 30
металингвистическая, 647; 727
Абсурдный тип, 249
Автоассоциативная память, 437; 468; 477
Автомат, конечный, 574
Автоматические рассуждения, 579; 522; 559
Автоматическое
доказательство теорем, 43,369
программирование, 504
Автономная система, 263
Агент, 40; 49; 222
гибкий,263
интеллектуальный, 577
Агентная
архитектура, 792
модель, 797
Адаптивное планирование, 576
Аксиома границ, 570
Аксон, 57
Активационная функция, 445
Алгебра ограничений, 337
Предметный указатель
851
Алгоритм
А, 165
А*, 165; 493
С4.5, 399
CLUSTER/2,373
COB-WEB, 373
DYNA-Q, 425
EBL, 407; 412
ID3, 50, 373; 392; 394; 398; 453,588; 591; 761;
797
IDA*, 181
LEX, 411
Meta-DENDRAL, 406
RETE, 29U 301
Витерби, 587
возврата, 331
генетический, 481,485; 786
двухуровневого минимакса, 174
индукции, 395
исключения кандидата, 381,385; 391; 661; 666
исходящей звезды, 459
Кохонена, 457
Маркова, 198
обобщения на основе объяснения, 407
обратного распространения, 448
обучения, 438
на основе подобия, 373
на основе пояснения, 668
персептрона, 441
с учителем Гроссберга, 456
Хебба без учителя, 463
Хебба с учителем, 466
отбора пропорционально критерию
качества, 486
победитель забирает все, 455
пожарной цепочки, 495
поиска
в пространстве версий, 373
в ширину, 714
допустимый, 165
жадный, 777
построения дерева решений (ЮЗ), 392
унификации, 103; 724
устранения противоречий, 335
хронологических возвратов, 331
Альфа-бета-усечение, 175
Анализ
естественного языка, 592
лингвистический, 585
синтаксический, 564
целей и средств, 220; 522; 526; 784
Анализатор
на основе сети переходов, 573
сверху вниз, 568
Аналогия, 375; 412
Анонимная переменная, 617
Антецедент, 74
Апостериорная вероятность, 356
Априорная вероятность, 355
Арность, 79
Архитектура
Copycat, 255; 259
гибридная, 306
категориальная, 222; 255
категоризации, 510
классной доски, 213
а-список, 723
Ассоциативный список, 723, 724
Атом, 609; 686; 689
Атомарное высказывание, 80
Атрибут, 593
Аттрактор, 436; 437; 472; 513
Аттракторная сеть, 437
Аттракторный радиус, 471; 472
Ациклический
направленный граф, 360
ориентированный граф, 114
Б
База знаний, 275
Базовая категория, 420
Байесовская сеть доверия, 327; 359
Байесовский
анализ, 355
подход, 520
Безусловная вероятность, 355
Биграмма, 589
Бинарная резолюция, 529; 555
Бритва Оккама, 394
в
Вектор
весовых коэффициентов, 436
признаков, 403; 662
Вероятностная
семантика, 341
функция чувствительности, 352
Вершины-братья, 111
Весовой коэффициент, 438
Включение процедур, 543
Внедренная частица а, 514
Возврат с учетом зависимостей, 331
Воспроизводство, 503
Временная
логика, 365
разность, 426
Встроенный тип данных, 705
Входной сигнал, 437
Выбор свойств на основе теории информации, 396
Выражение
k-CNF, 405
единичное, 541
852
Предметный указатель
замкнутое, 85
категоризированное, 543
КНФ,455
конъюнктивное, 728
символьное, 686
функциональное, 79
хорновское, 547\ 727
Высказывание, атомарное, 80
Вычислимость по Тьюрингу, 58
Вычислительная эффективность, 268
г
Генератор, 729
Генерация языковых конструкций, 584
Генетическая эпистемология, 800
Генетический
алгоритм, 52; 481; 484; 485; 786
оператор, 487
инвертирования, 488
мутации, 487
обмена, 488
упорядоченного скрещивания, 490
Генетическое
обучение, 372
программирование, 484; 501
Гетероассоциативная память, 437; 468
Гибкая сеть, 260
Гибкий агент, 263
Гибридная система, 303; 306
Гиперграф, 134
Гипердуга, 134
Гиперплоскость, 441
Гиперрезолюция, 536; 555
Гипотеза, 383
Андерсона, 805
о представлении знаний, 221
о физической символьной системе, 52; 58; 778;
782
Черча-Тьюринга, 789; 805
Глагольная конструкция, 142; 568
Головоломка
15,114
S,200
Грамматика, 574
контекстно-независимая, 573
метаморфоз, 680
определенных дизъюнктов, 680
падежная, 598
преобразований, 585; 598
связей, 591
семантическая, 598
фразовая структура, 568
функциональная, 598
Грамматическая триграмма, 591
Грамматический маркер, 598
Грамматическое правило, 570
Граф, 64
ациклический
направленный, 360
ориентированный, 114
И/ИЛИ, 133; 285
и-вершина, 142
и-узел, 133
концептуальный, 222; 245; 581; 594
ориентированный, ПО
отношения между вершинами, 111
поведения задачи, 198
поиска, 283
пространства состояний, 66; 108
размеченный, ПО
состояний, 32
Д
Двоичная арифметика, 34
Двунаправленная ассоциативная память (ДАП), 472
Двунаправленный поиск, 385
Дедуктивное замыкание, 411
Дедукция, 522
Декларативная семантика, 609
Декларативное программирование, 522
Декларативность, 685
Дельта-правило, 436; 446; 449
обобщенное, 441
Демодулятор, 556
Демодуляция, 556
Демон, 244
Дендрит, 57
Дерево, 111
грамматического разбора, 568; 573; 580
разбора, 565
решений, 392; 403
построение сверху вниз, 394
Диагностика, 274
Диаграмма
потоков данных, 594
сущность-связь, 594
Дизъюнкт, 74
Дизъюнктивная форма, 528
хорновская, 612
Дизъюнкция, 74
Дилемма эмпирика, 795; 798
Динамическое программирование, 429; 587
Дискриминантная
сеть, 432
функция, 442
Добавление повторяющихся элементов, 400
Доказательство
на основе опровержения, 612
теорем, 520; 522; 528
Допустимая эвристика, 164
Допустимость, 784
Допустимый
Предметный указатель
853
алгоритм поиска, 165
путь, 113
Доступ к компонентам списка, 696
Е
Единичное
выражение, 541
предпочтение, 522
Естественная дедуктивная система, 557
Естественный язык, 519; 561
ж
Жадный алгоритм поиска, 153; 160,634
з
Задача
анализа естественного языка, 592
генерации языковых конструкций, 584
диагностики автомобиля, 287
из мира блоков, 637
индуктивных порогов, 403
индукции, 372; 401
интересной жизни, 537; 540
исключающего ИЛИ, 440; 454
классификации, 442
битовых строк, 400
эндшпилей, 395
кластеризации, 417,459
коммивояжера, 113; 116; 437; 489
о кенигсбергских мостах, 32,108
о кувшинах с водой, 681
о миссионерах и каннибалах, 336; 681
обработки естественного языка, 671
обучения классификации, 441
определения частей речи, 585
оценки кредитного риска, 392
перевозки человека, волка, козы и капусты, 626
706
планирования, 308,311
размещения костей домино, 783
смертной собаки, 530
счастливого студента, 536
управления перевернутым маятником, 345
финансового советника, 100; 139; 163
ханойских башен, 526
хода конем, 202; 618
Закон
де Моргана, 220, 548
исключения третьего, 344
Замена, 522
Замкнутость предметной области, 337
Замыкание функции, 736
Запись активации,189
Запрос SQL, 595
И
и-вершина, 138
Игра
"Жизнь", 505,506
"крестики-нолики", 113; 150; 427
"ним", 170
"пятнашки", 114
Иерархическая
абстракция, 604
декомпозиция задачи, 48
Иерархия
обобщения понятий, 391
Хомского, 574; 599
Извлечение
знаний, 279
ответа, 535
Изучаемость, 404
Изучение понятий, 373
Именная конструкция, 142; 568
Императивность, 685
Импликация, 74; 523; 728
Индуктивное обучение, 373
Индуктивный порог, 370; 372; 373; 391,400; 436;
457; 795; 797
Индукция, 372; 373; 395
Инкапсуляция, 750
Инкрементальный
алгоритм обучения, 387
синтаксический разбор, 566
Интеллектуальный агент, 371,373
Интерполятивная память, 468
Интерпретатор, 726
метауровня, 727
семантический, 580
Интерпретация, 75; 84; 274
Интерфейс взаимодействия с базой данных, 592
Инфиксный интерпретатор, 690; 726
Искусственная жизнь, 485, 508
Искусственный
интеллект, 27; 42; 781
распределенный, 262
нейрон, 372; 437
Исследование операций, 784
Исходящая звезда, 459
Исчерпывающий поиск, 69
Исчисление
высказываний, 73; 522
символы, 74
предикатов, 62; 73; 77; 103; 727
алфавит, 78
первого порядка, 34; 86
символы, 80
пропозициональное, 296
Итерационное заглубление, 131
854
Предметный указатель
к
Каноническая форма, 237
Каноническое правило формирования, 252
Категориальная архитектура, 222; 255
трехуровневая, 256
Категоризация, 417
Категоризированное выражение, 543
Категория базового уровня, 420
Квантификация переменных, 85
Квантор
всеобщности, 81'; 85
переменных, 81
существования, 81; 85
Китайская комната, 785
Класс, 750
NP-сложных задач, 181
абстрактный, 751
регулярных языков, 574
Классификатор, 400; 515
Классификация, 436
по минимальному расстоянию, 443
Классная доска, 213
Кластеризация взаимной информации, 589
Клеточный автомат, 481; 484; 505; 512
Ключ, 723; 752
КНФ, 488
Когнитология, 524; 792
Кодирование
Грея, 492
сжимающее, 453
Композиция, 94
Конечный автомат, 574
Конкурентное обучение, 455
Конкурентный метод обучения, 436
Коннекционистская модель, 780
Конструктор, 705
Контекстно-зависимый язык, 574
Контекстно-независимая грамматика, 573; 575
Контекстно-независимое правило, 598
Контекстно-независимый язык, 574
Концевая вершина, 112
Концептуальная
кластеризация, 373; 417; 418
модель, 280
Концептуальное
отношение, 245
синтаксическое правило, 234
Концептуальный граф, 222; 230,245; 581; 594
обобщение и специализация, 250
тип, 247
Концепция
d-отделения, 360
Конъюнкт, 74; 729
Конъюнктивная нормальная форма, 488
Конъюнктивное выражение, 728
Конъюнктивный порог, 402
Конъюнкция, 74
дизъюнктов, 530
Корень графа, ПО
Корневой граф, 110
Корректность понятия, 404
Коэффициент
скорости обучения, 448
Критерий отбора, 484
Кусочно-линейная биполярная пороговая функция,
445
Л
Лексикон, 567
Лексическое замыкание, 712
Лингвистический анализ, 585
Линейная
ассоциативная память, 437
входная форма, 557
Линейный
ассоциатор, 467
критерий качества, 502
Литерал, 529
положительный, 612
Логика
умолчания, 330
хорновских дизъюнктов, 612
Логистическая функция, 445; 449
Логическая
операция, 694
программа, 548; 606
система поддержки истинности, 335
Логический вывод, 89
Логическое
исчисление Буля, 34
программирование, 542; 547; 609; 727
следствие, 74
Лучевой поиск, 180
Лямбда-выражение, 713
м
Магнитная энцефалография, 793
Мажоритарное голосование, 512
Макрорасширение, 738
Макрос, 738
defclass, 751
Максимально
конкретное обобщение, 383
общее понятие, 383
Максимальное правдоподобие, 417
Максимальный общий подтип, 249
Маркер, 247
*,248
Марковская
модель, 588
цепь, 564
Предметный указатель
855
Марковское предположение, 587
Массив, 705
Математическая модель аналогии, 412
Машина Тьюринга, 448; 509; 803
Машинное обучение, 373,391; 43 J
Медиатор, 787
Мера
доверия, 762; 164,350
неопределенности, 326
правдоподобия, 350
Метазнание, 65
Метаинтерпретатор, 609; 646; 690
для LISP, 647
Металингвистическая абстракция, 647; 727
Метапланирование, 322
Метапредикат, 609, 639
Метод
Q-обучения, 431
ветвей и границ, 117
временных разностей, 426
встречного распространения, 457
градиентного спуска, 446; 449
грамматических триграмм, 591
дефаззификации, 349
динамического программирования, 429
добавления повторяющихся элементов, 400
максимального правдоподобия, 417
минимакса, 170
Монте-Карло, 429,431; 486
неточных рассуждений на основе фактора
уверенности, 652
обратного распространения ошибки, 449
обучения по методу обратного распространения,
441
основанный на знаниях, 273
поиска экстремума, 784
редукции целей, 317
сильный, 784
слабый, 784
триангуляции дерева клик, 364
центра тяжести, 349
цепочки, 523
Методология классной доски, 212
Механизм
вывода, 275
рассуждений
на основе множественной достоверности,
335,366
на основе опыта, 300
Минимальная модель мира, 337
Минимальный общий супертип, 249
Многозначная логика, 365; 612
Многослойный персептрон, 440
Множественная теория сознания, 797
Множественное наследование, 755
Множество, 622, 625, 705
поддержки, 522,540
856
Модальная логика, 253; 365
Модель, 336
автоассоциативной памяти, 477
агентная, 797
внешней среды, 426
Гроссберга, 459
искусственной жизни, 437
классной доски, 756
коннекционистская, 780
концептуальная, 280
концептуальной зависимости, 237
марковская, 564; 588
минимальная, 336
нейроподобная, 435
обоснования по аналогии, 412
обучения с подкреплением, 437
рассуждения, 325
стохастическая, 585
триграмм, 588
физиологическая, 481
Хебба, 437; 799
эмерджентная, 370; 484
Модификатор отношений, 236
Моноид, 237
Монотонность, 784
Морфема, 564
Морфология, 564
Мультиагентная система, 262
Мутация, 487,503
н
Наиболее общий унификатор, 95
Накопительная кластеризация, 417
Наследование, 64; 750
множественное, 755
11аучная деятельность, 416
Начальное состояние, 772
Нейрон, 57; 372,435
искусственный, 437
Мак-Каллока-Питса, 436; 438
Нейронная
вычислительная модель, 51
сеть, 372,435; 786
Нейрон-победитель, 437,456
Нейроподобная модель, 435
Нейро-символьная гибридная система, 481
Немонотонная система, 328
Немонотонные рассуждения, 327
Несобственный символ, 78
Нетерминальный символ, 573
Неточный вывод
на основе фактора уверенности, 326
Нечеткая ассоциативная матрица, 346
Нечеткое множество, 344
Нормализованный критерий качества, 503
Нормальная дизъюнктивная форма, 529
Предметный указатель
о
Обобщение, 370; 377; 380
максимально конкретное, 383
на основе объяснения, 407
Обобщенное дельта-правило, 441
Обобщенный граф, 377
Оболочка
CLIPS, 276
exshell, 650
Обоснование
на основе опыта, 415
по аналогии, 412
Обработка естественного языка, 671
Обратная цепочка, 118
Обратное распространение ошибки, 436
Обучение, 50; 371
без учителя, 373,415,456
генетическое, 372
индуктивное, 373
конкурентное, 455
машинное, 373; 391; 431
на основе
временных разностей, 426; 428
обратного распространения ошибки, 436
объяснения, 373,374; 405; 407
подобия, 373; 405
поиска, 391; 400
пояснения, 661, 668
на уровне знаний, 411
по аналогии, 303
по методу
градиентного спуска, 446
обратного распространения, 441; 448
с подкреплением, 71; 373; 424,437,496
с учителем, 373; 381; 415
синхронное, 463
эволюционное, 372
Общая стратегия вывода, 522
Общий подтип, 249
Объект, 750
Объектно-ориентированное
моделирование, 686
программирование, 749
Ограничение на количество дизъюнктов, 402
Однослойная нейронная сеть, 439
Оператор
cut, 549
unless, 329
генетический, 5?
отсечения, 609; 620
разрешения, 521
Операция, 388
И, 74
Опорный объект, 418
Оппортунистический поиск, 289
Оппортунистическое планирование, 322
Опровержение, 528
разрешения, 528; 533
Оптимизация, 436
Ориентированный граф, ПО
Ортонормальность векторов, 469
Осведомленность, 784
Основное выражение, 85
Открепление, 522
Отношение
концептуальное, 245
концептуальной зависимости, 234
между вершинами графа, 111
Отображение, 711
Оценивание
с задержкой, 736
функции, 79
Оценка плотности по методу максимального
правдоподобия, 417
Очередь, 125; 186; 609,622; 714
приоритетная, 155, 624
п
Падежная грамматика, 598
Падежный фрейм, 233; 581, 671
Пакет организации памяти, 237
Пара условие-действие, 692
Параметр
качества, 498
совести,456
шага, 427
Парамодуляция, 555
Парсинг, 144
Переменная, анонимная, 617
Перестановка, 503
Персептрон, 436,439, 798
многослойный, 440
Планер, 507
Планирование, 274,527
адаптивное, 316
Планировщик, 214; 307
STRIPS, 263
Поведение, 750
Поверхностная структура, 599
Поверхность ошибки, 446
Пограничная частица, 514
Подсистема объяснений, 275
Подстановка, 94,522
Подтип, 249
максимальный общий, 249
Подход Демпстера-Шафера, 350
Позитронная эмиссионная томография, 793
Поиск, 42; 783
в Web, 592
в глубину, 121; 124; 130; 611; 631; 706
предельная глубина, 131
с возвратом, 631
Предметный указатель
857
в пространстве
версий, 373; 380; 661
состояний, 32; 108; 112; 311
в ширину, 124; 129; 287; 391; 523; 539; 633; 714;
716
двунаправленный, 385
лучевой, 180
методом полного перебора, 69
на графе И/ИЛИ, 134
на основе
данных, 775; 206
образца, 272
цели, 287
оппортунистический, 289
от общего к частному, 383; 406; 665
от цели, 775
от частного к общему, 552
по ключевым словам в Web, 596
с возвратом, 95; 121
эвристический, 163
экстремума, 755
Полезность категории, 421
Полиморфизм, 750
Полиморфная функция, 750
Политика л, 426
Полный байесовский анализ, 355
Положительный литерал, 672
Помеха, 474
Понимание
естественного языка, 369; 519; 561
языка на основе шаблонов, 555
Понятие
-кандидат, 376
максимально общее, 555
Порог
индуктивный, 372; 400
конъюнктивный, 402
синтаксический, 402
Пороговая функция, 438
Построение
дерева решений сверху вниз, 394
опровержений, 525
списков, 697
Потенциал возбуждения, 757
Поток, 729
Правило, 797; 672
Meta-DENDRAL, 797
Видроу-Хоффа, 446
временных разностей, 429
вывода, 70,89; 521; 567; 574
Демпстера, 557
если..., то..., 275; 500
контекстно-независимое, 595
копирования, 250
логического вывода, 495
мажоритарного голосования, 572
модус поненс, 57; 77; 90
модус толленс, 97
обучения
Кохонена, 456
на основе временных разностей, 428
объединения, 250
отделения, 107; 523; 529
перехода, 485
преобразования, 599
продукционное, 252; 574; 784
резолюции, 77; 91; 92
рулетки, 486
специализации, 250
Правильно построенная формула, 74
Прагматика, 564
Предваренная нормальная форма, 532
Предикат, 62; 79; 685; 692
assert, 614
bagof, 633
consult, 614
щ,708
member, 676; 697
retract, 614
Предиктивность, 421
Предложение, 57; 565
Предположение о замкнутости
мира, 296; 328; 336; 547
пространства, 557
Предпосылка, 74
Предсказуемость, 421
Представление знаний, 42
иерархических, 559
Пренексная нормальная форма, 532
Приведение, 557
Принцип
бритвы Оккама, 340
Вильяма из Оккама, 394
Дарвина, 370
минимизации энергии, 477
обучения без учителя, 456
понимания языка на основе шаблонов, 555
разделения переменных, 614
резолюции, 90; 528; 534
систематичности, 414
Приоритет операций, 726
Приоритетная очередь, 755; 756; 609; 622; 624
Приоритетность классов, 755
Проблема
выделения кредита, 390
границ, 267; 308
исследования представления знаний, 520
линейной разделимости, 436; 441
машинного обучения, 577
обобщения, 370
обоснования, 794
понимания естественного языка, 567
представления знания и поиска, 55
858
Предметный указатель
связывания, 794
формализации метазнаний, 65
эпистемологического доступа, 801
Проверка
вхождения, 94; 722
соответствия
типов, 706; 750
шаблонам, 775
Прогнозирование, 274; 436
Программа
AM, 415
BACON, 416
Candide, 591
DENDRAL, 120; 406
Dipmeter Advisor, 45
EVRISKO, 416
Hacker, 50
XL, 416
INTERNIST, 45
LEX, 388; 402
компоненты, 390
Logic Theorist (LT), 219; 522
PROSPECTOR, 45
SHRDLU, 47
STRIPS, 407
Systran, 591
WEBMATE, 265
XCON, 45
AM, 50
игры в шашки, 173; 300
логическая, 548; 606
на языке PROLOG, 67 7
Программирование
автоматическое, 504
генетическое, 484
декларативное, 522
динамическое, 587
логическое, 542; 547; 609; 727
объектно-ориентированное, 749
функциональное, 607; 685
эволюционное, 509
Продукционная
память, 497
система, 144; 186; 196; 282; 511; 708
на языке PROLOG, 626
Продукционное правило, 797; 574; 784
Продукция, 797
Проект NASA, 318
Проектирование, 274
Пропозициональное исчисление, 296
Просодия, 564
Пространство
версий, 381
возможных действий, 308
понятий, 376
состояний, 772
задачи, 42
Прототип, 278
Процедура
альфа-бета-усечения, 775
гиперрезолюции, 536
доказательства теорем, разрешающая, 528
минимакса, 775
полного доказательства, 90
Процедурная семантика, 547
Процедурный
метод интерпретации правил, 290
язык, 678
Процесс
извлечения знаний, 279
проверки соответствия, 523
сколемизации, 532
триангуляции, 363
уменьшения различий, 526
Прямая цепочка, 775
Прямой процесс рассуждения, 282
Психология обработки информации, 524
Путь
допустимый, 775
на графе, 710
Разбор предложений, 568
на естественном языке, 598
Разделение переменных, 614
Различия между декларативным и процедурным
стилями программирования, 77 7
Размеченный граф, ПО
Разностный список, 645
Распознавание образов, 436
Распределенная система, 435
Распределенный искусственный интеллект, 262
Рассуждения
абдуктивные, 338
байесовские, 355
на минимальных моделях, 336
на основе
модели, 292; 305; 784
проект NASA, 296; 318
опыта, 299; 305
правил, 304
немонотонные, 327
Расширение логических грамматик, 576
Расширенная
грамматика фразовой структуры, 576
сеть переходов, 569
Расщепление, 557
Рационально-логическая программная система, 40
Реализация памяти, 436
Регрессия цели, 408
Регулярный язык, 574
Редактор базы знаний, 276
Редукция целей, 577
Предметный указатель
859
Резолюция, 77; 528; 606
бинарная, 529; 555
Резольвента, 534
Рекурсивная
процедура, 186
функция, 685
унификации, 720
Рекурсивно-перечислимый язык, 574
Рекурсивный
анализатор, 672
на основе семантических сетей, 675
поиск, 186; 187; 618
Рекурсия, 186; 615
car-cdr, 699
Реляционная база данных, 593
Рефракция, 277
Решатель задач на основе слабых методов, 220
Решение-кандидат, 40; 485
Решетка зависимостей предпосылок, 335
Родовая функция, 750; 753
Роль, 233; 240
С
C++, 50
Самовоспроизводство, 509
Самоорганизация сети, 458
Саморепликация, 484
Сателлит, 555
Свойство ортонормальности, 477
Связывание, 94
переменных, 707
Семантика, 564
вероятностная, 341
Семантическая
грамматика, 598
интерпретация, 565
сеть, 64; 229; 377; 520; 639; 658; 746
Семантический интерпретатор, 580
Сентенциальная форма, 567
Сеть
NETtalk, 455
ассоциативная с обратными связями, 477
встречного распространения, 456; 459
гибкая, 260
доверия, 71; 327; 355
Кохонена, 457
нейронная, 372; 786
обратного распространения, 799
переходов, 569; 574
расширенная, 575
прямого распространения, 477
с обратными связями, 472
связей, 372; 435; 483
семантическая, 229; 377; 639; 658; 746
Хопфилда, 437; 472; 477; 479; 799
Сжимающее кодирование, 453
Сигмоидальная функция, 445
Сильный метод, 273
решения проблем, 220
Символ, 782
истинности, 79
несобственный, 78
нетерминальный, 573
Символьная модель, 436
Символьное
выражение, 686
исчисление, 30
обучение, 784
представление, 435
Символьные вычисления, 694
Символьный анализ, 564
Синапс, 57; 439
Синтаксический
анализ, 144; 564; 567
порог, 402
разбор, 565
Синхронное обучение, 463
Система
Burton, 321
CASEY, 299
CLUSTER/2,418; 457; 798
COB-WEB, 420
DENDRAL, 45
Dipmeter, 120
exshell, 650
General Problem Solver, 522
HEARSAY-П, 213
HEARSAY-Ш, 275
Livingstone, 296; 318
Logic Theorist, 43
MACSYMA, 755
Meta-DENDRAL, 50; 322
MYCIN, 45; 263; 292; 321; 650
NETtalk, 452
PROSPECTOR, 120; 357
PROTOS, 299
ROBOCUP, 263
SCAVENGER, 476
SHRDLU, 563
STRIPS, 577; 528
Teiresias, 50
автоматической классификации юридических
документов, 598
автономная, 263
анализа медицинских карточек пациентов, 598
гибридная, 306
доказательства на основе резолюции, 522
извлечения информации, 596
классификации, 485; 495
логического вывода, 496
мультиагентная, 262
на основе модели, 293
нейро-символьная гибридная, 481
860
Предметный указатель
немонотонная, 328
объектно-ориентированная, 294
основанная на знаниях, 326
параллельной распределенной обработки, 435
поддержки истинности, 328; 331
с учетом обоснования, 332
поддержки страхования жизни, 598
продукционная, 796; 577; 626; 708
прямого поиска, 289
решения общих задач GPS, 526
с сильными методами, 303
формальная, 783
формальной логики, 32
экспертная, 37; 273; 520
Систематичность, 413
Сколемизация, 93,531
Сколемовская
константа, 532
функция, 93
Скрещивание, 487,503
Скрытый слой, 453
Слабый метод, 784
решения задач, 220; 520
Слой нейронов, 435
Создание
конфликта, 529
локальных переменных, 703
Составной терм, 727
Состояние, 108; 750
Специализация, 377, 380
Список, 607; 615, 686, 689
open, 756
ассоциативный, 723
подзадач, 523
приоритетности классов, 755
разностный, 645
свойств, 747
Способность к обучению, 369
Среднеквадратическая ошибка, 447
Стек, 609,622
Степень
вершины графа, 109
подобия, 302
Стохастическая модель, 585
Стратегия
поиска
от цели,735
экстремума, 153
прогнозирования n-го слоя, 7 71
Строгий индуктивный порог, 457
Структура, 705
объяснения, 409
Стэндфордская теория фактора уверенности, 342
Супертип,249
минимальный общий, 249
Схема
кодирования, 438
Предметный указатель
налогообложения, 500
Сценарий, 237; 238
роль,240
т
TR-дерево, 316
Таблица
истинности, 76
операций,527
отличий, 522
связей, 526
треугольная,312
Телео-реактивное планирование, 316
Теорема
Байеса, 327; 356,357
о бесплатном сыре, 798
Теория
ассоционистская, 227
Байеса, 71; 355
вероятностей,344, 354
внедренного действия, 802
возможных миров, 785
вычислимости, 36
графов, 32,108
Демпстера-Шафера, 326
интеллектуальных систем, 780; 792
информации, 396; 591
клеточных автоматов, 484
концептуальной зависимости, 234; 237
концептуальных графов, 250
логического вывода, 89
множеств, 380,415
нейронной селекции, 790
нейронных сетей, 437, 786
нечетких множеств, 344
обоснования Демпстера-Шафера, 350
обучения Хебба, 462
Пирса, 230
поиска в пространстве состояний, 108
полупорядка, 406
предикатов, 687
первого порядка, 527, 606; 612, 671
приближенно корректного с высокой
вероятностью РАС-обучения, 404
рекурсивных функций, 607; 685
речи, 39
семантического предпочтения, 599
семейного сходства, 420
сетей связей, 437
ссылок, 35
структурного отображения, 413
схематического упреждения, 230
фактора уверенности, 342
формальных языков, 574
Терм, 79
составной, 727
861
Терминал, 142; 567
Терминальный элемент дерева разбора, 580
Тест
применимости, 526
Тьюринга, 36
Тип данных, 247
встроенный, 705
определение, 767
универсальный, 249
Топология сети, 438
Точечная пара, 723
Т-пространство, 303
Трансформационная аналогия, 303
Трансформация сверху вниз, 568
Третий закон Кеплера, 504
Треугольная таблица, 312
Триангуляция, 363
Триграмма, 588
грамматическая, 591
Тьюринг, 36
у
Универсальная машина Тьюринга, 509
Универсальное инстанцирование, 91
Универсальный тип, 249
Уникальность имен, 337
Унификация, 93; 94; 139; 530; 642; 644; 687; 701
Упорядоченное скрещивание, 490
Уровень активации нейрона, 438; 445
Ускорение обучения, 411
Условная
вероятность, 356
оценка, 694
Ф
Факт, 548; 612
Фактор, 536
ветвления, 121
пространства, 775
достоверности, 740
момента, 448
уверенности, 164; 326; 342
Факторизация выражений, 536
Феноменология, 39
Физиологическая модель, 481
Физическая символьная система, 52; 782
Фильтр, 777; 729
Фильтрация, 436
шума, 407
Фонема, 452
Фонология, 564
Форма, 687; 689
if, 693
Формальная система, 783
Формирование категорий, 373
Формула, атомарная, 80
Фразовая структура грамматики, 568
Фрейм, 241; 576; 639; 659; 685; 705
падежный, 557; 677
Функциональная грамматика, 595
Функциональное
выражение, 79
магнитно-резонансное сканирование, 793
программирование, 607; 685
Функция
defun, 697
eval, 690
let, 703
list, 655
quote, 659
set, 701
serf, 695
вознаграждения, 426
высшего порядка, 777
дискриминантная, 442
доступа к компонентам списка, 696
отображения, 713; 729
полиморфная, 750
построения списков, 697
предикат, 692
принадлежности, 345
рекурсивная, 655
родовая, 750; 753
стоимости, 426
унификации, 727
фильтр, 777
ценности, 427
энергии, 437
сети, 472
х
Хвостовая рекурсия, 695
Хе66,460
Хеммингов вектор, 468
Хорновская дизъюнктивная форма, 672
Хорновский дизъюнкт, 672
Хорновское выражение, 403; 521; 547; 727
Хронологический возврат к предыдущему
состоянию, 331
Хэш-таблица, 705
Ц
Целевое условие, 772
Цикл, 693
чтения-оценки-печати, 657
ч
Числовая таксономия, 477
862
Предметный указатель
я
Шаблон, 58; 711; 718
предложений, 584
условий, 498
Шаговый множитель, 427
э
Эволюционная модель обучения, 437
Эволюционное
обучение, 372
программирование, 509
Эвристика, 43; 69; 149; 301; 784
допустимая, 164
Эвристический поиск, 153; 163; 181; 376
Эдинбургский синтаксис, 607
Эквивалентность, 74
Экспертная система, 37; 45; 273; 520; 526
MYCIN, 292
общие задачи, 274
основанная на правилах, 282
основные модули, 275
подсистема объяснений, 275
Эмерджентная модель, 3 70; 484
Эмерджентное
поведение, 485
решение задач, 221
Эмерджентность, 258
Эмерджентные вычисления, 512
Эмпирическая дилемма, 370
Эффект горизонта, 174
Ядерный магнитный резонанс, 793
Ядро, 575; 555
Язык
C++, 608; 750
Common LISP, 608; 685; 690; 697
встроенные типы данных, 705
встроенные функции, 690
глобальные переменные, 715
основные свойства, 706
C-PROLOG, 610
FORTRAN, 678
Goedel, 680
Java, 750
KL-ONE, 268
KRL, 268
Lambda-PROLOG, 680
LISP, 396; 416; 501; 607; 685
LOGO, 278
Mercury, 680
OPS, 200
Pascal, 641; 705
PROLOG, 186,383; 528,606; 706
Scheme, 803
Smalltalk, 608
SQL, 593
SWM*, 335
естественный, 519, 561
инфиксной арифметики, 726
контекстно-зависимый, 574
контекстно-независимый, 574
представления, 783
процедурный, 678
регулярный, 574
рекурсивно-перечислимый, 574
Фреге, 34
Предметный указатель
863
Научно-популярное издание
Джордж Ф. Люгер
Искусственный интеллект: стратегии и методы решения
сложных проблем, 4-е издание
Литературный редактор О.Ю. Белозовская
Верстка О.В. Линник
Художественный редактор С.А. Чернокозинский
Корректоры Л.А. Гордиенко, Т.А. Корзун, Л.В. Коровкина
О. В. Мишутина, Л В. Чернокозинская
Издательский дом "Вильяме"
101509, Москва, ул Лесная, д 43, стр. 1
Изд лиц ЛР№ 090230 от 23.06 99
Госкомитета РФ по печати.
Подписано в печать 23 06 2003 Формат 70X100/16
Гарнитура Times. Печать офсетная
Уел печ. л. 69,66. Уч.-изд. л 58,9.
Тираж 3500 экз Заказ №289
Отпечатано с диапозитивов в ФГУП "Печатный двор"
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловскийпр , 15