/














































































































































































































































































































































































































































Автор: Люгер Джордж Ф.
Теги: компьютерные технологии искусственный интеллект
ISBN: 5-8459-0437-4
Год: 2003




Текст
Artificial
Intelligence
Structures and Strategies
for Complex Problem Solving
Fourth Edition
George F. Luger
▲
TT
ADDISON
WESLEY
AN Ш?WNT OF PEARSON EDUCATION
Boston • HarUnv, England • London • New YoHi ■ Reading, Massachusetts • San Francisco
Toronlo • Don Miib, Ontario ■ Sydney ■ Tokyo - Singapore ■ Hong Kong • Seoul • Taipei
Cape Гоня» ■ Madrid - Mexico City • Amsterdam ■ Munich • Paris • Milan
Искусственный
интеллект
Стратегии и методы решения
сложных проблем
Четвертое издание
Джордж Ф.Люгер
Москва ■ Санкт-
Петербург Киев
ББК 32.973.26-018.2.75
Л83
УДК 681.3.07
Издательский дом "Вильяме
Зав. редакцией СИ. Тригуб
Перевод е .итл»Яси.ге| Н.И. Гадпша [. КД. Протасовой,
докт. техн. наук ИМ. Куссуль
Под редакцией докт. техн. наук Н.Н. Куссуяь
По общим вопросам обращайтесь в Издательский дом "Вильяме" по адресу:
info@williamspublishing.com, h^://w\vw.williamspiiblishing.com
Люгер, Джордж, Ф.
Л83 Искусственный интеллект: стратегии и методы решения сложных проблем, 4-е издание. :
Пер. с англ. — М.: Издательский дом "Вильяме", 2003. — 864 с.: ил. — Парал. тит. англ.
ISBN 5-8459-0437-4 (рус.)
Данная книга посвяшена одной из наиболее перспективных и привлекательных
областей развития научного знания — методологии искусственного интеллекта. В ней детально
описываются как теоретические основы искусственного интеллекта, так и примеры
построения конкретных прикладных систем. Книга дает полное представление о
современном состоянии развития этой области науки.
Книга будет полезна как опытным специалистам в области искусственного
интеллекта, так и студентам и начинающим ученым.
ББК 32.973.26-018.2.75
Все названия программны* продуктов являются зарегистрированными торговыми марками соотвеплвузощих фирм.
Никакая часть настоящего издания ни в кахад целях не ш*ет быть воспроизведена в какой бы го нн было
форме и какими бы то ни было средствами, будь то электронные или механические, включая фотокопирование и
запись н» магнитный носитель, если на это нет письменного разрешения издательства Addison-Wcsley UK.
CopyrS^lom'"'*1'™ '""" "" E°g''*h '"e"S' "Ш°" poblishcd Ь» Addison-Wesley Publishing Company. Inc.,
n^etoLHS, *r^*i"M ™±? П=Р™"*«1 «"Ч » «4™l 4*m <• IransmMcd in any Гопт. or by an,
ЛСД* '" ""am* РиМ,Ы°Е H°"Se ""•** "• «« A*"™' "'h ■«" Emerprises
ISBN 5.1459-0437.4 (рус.)
ISBN 0-201-64866-0 (англ.) ® Издательский дом "Вильяме", 2003
О Pearson Education Limited 2002
Оглавление
Предисловие
Часть I. Искусственный интеллект: его истоки и проблемы
Глава I- Искусственный интеллект: история развития и области приложения
Часть II. Искусственный интеллект как представление и поиск
Глава 2. Исчисление предикатов
Глава 3. Структуры и стратегии поиска в пространстве состояний
Глава 4. Эвристический поиск
Глава 5. Управление поиском и его реализация в пространстве состояний
Часть III. Представление и разум в ракурсе искусственного
интеллекта
Глава 6. Представление знаний
Глава 7. Сильные методы решения задач
Глава 8. Рассуждения в условиях неопределенности
Часть IV. Машинное обучение
Глава 9. Машинное обучение, основанное на символьном представлении
информации
Глава 10. Машинное обучение на основе связей
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов
Часть V. Дополнительные вопросы решения задач
искусственного интеллекта
Глава 12. Автоматические рассуждения
Глава 13. Понимание естественного языка
Часть VI. Языки н технологии программирования для
искусственного интеллекта
Глава 14. Введение в PROLOG
Глава 15. Введение в LISP
Часть VII. ЭПИЛОГ ,ч„„р11ческая проблема
Гла..16.Иск7сст.=«нь."|.«™^'--1к
Библиограф™
Алфавитный указатель аиоров
Предметный указатель
777
779
809
841
Оглавление
Содержание
Предисловие
Добро пожаловать в четвертое издание!
Что нового в этом издании ^
Содержание книги "
Использование книги „,
Дополнительный материал, доступный через Internet 05
Благодарности 25
Часть I. Искусственный интеллект: его истоки и проблемы 27
Попытка дать определение искусственному интеллекту 27
Глава 1. Искусственный интеллект: история развития и области приложения 29
1.1. Отношение к интеллекту, знанию и человеческому мастерству 29
1.1.1. Историческая подоплека
1.1.2. Развитие логики
1.1.3. Тест Тьюринга
1.1.4. Биологические и социальные модели интеллекта: агенты
1.2. Обзор прикладных областей искусственного интеллекта
1.2.1. Ведение игр
1.2.2. Автоматические рассуждения и доказательство теорем
1.2.3. Экспертные системы
1.2.4. Понимание естественных языков и семантическое моделирование 46
1.2.5. Моделирование работы человеческого интеллекта 47
1.2.6. Планирование н робототехника ™
1.2.7. Языки н среды ИИ 49
1.2.8. Машинное обучение
1.2.9. Альтернативные представления: нейронные сети и генетические алгоритмы 51
1.2.10. Искусственный интеллект и философия *-
1.3. Искусственный интеллект — заключительные замечания 5 J
1.4. Резюме и дополнительная литература "
1.5. Упражнения
Часть II. Искусственный интеллект как представление и поиск 57
Введение в представление знаний 61
Обработка знаний, выраженных в качественной форме
Логическое получение новых знаний из набора фактов и правил
47
о-^~-=даг"- "пут г
Глава 2. Исчисление np^aT0B 73
2.0. Введение
2 1 Исчисление высказывании 73
211 Символы и предложения 75
2 I 'i' Семантика исчисления высказывании ??
2 2. Основы исчислена- "l*^raTO" меН||й 78
291 Синтаксис предикатов и предложении g3
-> 2 2. Семантика исчисления предикатов g7
2"'з Значение семантики на примере 'мира блоков 89
2.3. Правила вывода в исчислении предикатов g9
2.3.1. Правила вывода 92
2.3.2. Унификация 96
1 3.3. Пример унификации
2.4. Приложение: финансовый советник на основе лотки
2.5. Резюме и дополнительная литература
2.6 Упражнения
Глава 3. Структуры н стратегии поиска в пространстве состояний
3.0. Введение
3.1. Теория графов ^
3.1.1. Структуры данных для поиска в пространстве состояний UU
3.1.2. Представление задачи в пространстве состоянии П2
3.2. Стратегии поиска в пространстве состояний 1 ^
3.2.1. Поиск на основе данных и от цели И°
3.2.2. Реализация поиска на графах 121
3.2.3. Поиск в глубину и в ширину 124
3.2.4. Поиск в глубину с итерационным заглублением 131
3.3. Представление рассуждении в пространстве состояний на основе
исчисления предикатов 132
3.3.1. Описание
100
103
104
107
107
110
пространства состоянии логической системы 132
146
149
133
3.3.2- Графы И/ИЛИ j35
3.3.3. Примеры и приложения ,
3.4. Резюме и дополнительная литература
3.5. Упражнения
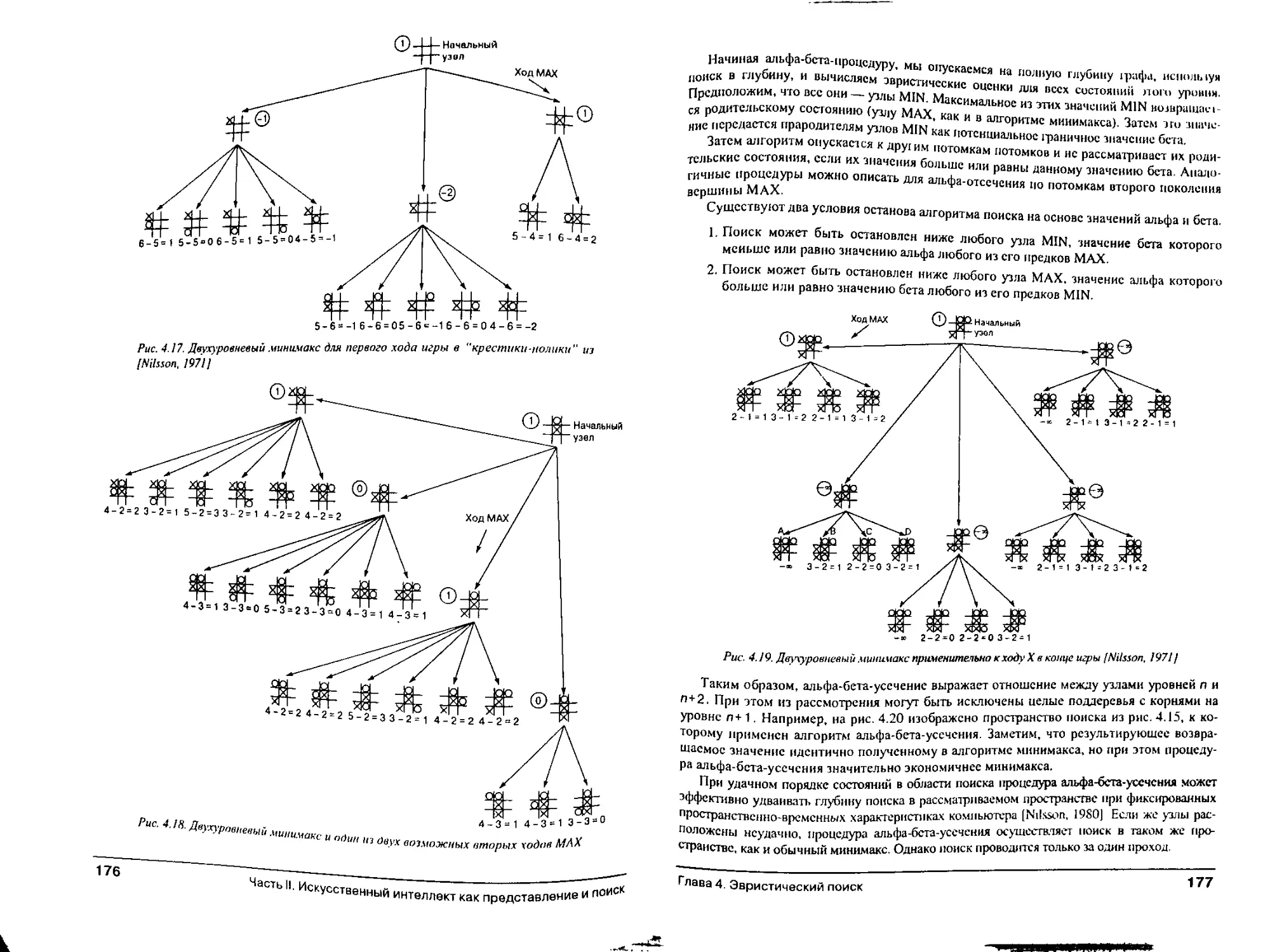
Глава 4. Эвристический поиск
4.0. Введение *4У
4.1. Алгоритм эвристического поиска *"
4.1.1. "Жадный" алгоритм поиска 1"
4.1.2. Функции эвристической оценки состояний '^
4.1.3. Эвристический поиск и экспертные системы 1^3
4.2. Допустимость, монотонность и информированность 1^4
Содержание
4.2.1. Мера допустимости
4.2.2. Монотонность '^5
4.2.3. Информированные эвристики
4.3. Использование эвристик в играх
4.3.1- Процедура минимакса на графах, допускающих полный перебор
4.3.2. Минимакс при фиксированной глубине поиска
4.3.3. Процедура альфа-бета-усечения
4.4. Проблемы сложности
4.5. Резюме и дополнительная литература
4.6. Упражнения
166
167
169
169
171
175
178
181
181
185
185
186
Глава 5. Управление поиском и его реализация в пространстве состояний
5.0. Введение
5.1. Рекурсивный поиск
5.1.1- Рекурсия
5.12. Рекурсивный поиск Ig-j
5.2. Поиск по образцу 190
5.2.1. Пример рекурсивного поиска: вариант задачи хода конем 191
5.2.2. Усовершенствование алгоритма поиска по образцу 194
5.3. Продукционные системы [96
5.3.1. Определение и история развития 196
5.3.2. Примеры продукционных систем 200
5.3.3. Управление поиском в продукционных системах 205
5.3.4. Преимущества продукционных систем для ИИ 211
5.4. Архитектура "классной доски" 212
5.5. Резюме и дополнительная литература 215
5.6. Упражнения -'°
Часть III. Представление и разум в ракурсе искусственного
интеллекта
Представление и интеллект
Глава 6. Представление знаний
6.0. Вопросы представления знаний
6.1. Краткая история схем представления ИИ
6.1.1. Ассоцнонистские теории смысла ~^"
s I i п ,- е „„. .-..■ri.iiei-b'irv ГРТРЙ •"«
232
237
241
219
219
225
225
226
226
6.1.2. Ранние работы в области семантических сетей
6.1.3. Стандартизация сетевых отношений
6.1.4. Сценарии
6.1.5. Фреймы 245
6.2. Концептуальные графы: сетевой язык ^
6.2.1. Введение в теорию концептуальных графов -^
6.2.2. Типы, экземпляры и имена 249
6.2.3. Иерархия типов 250
6.2.4. Обобщение и специализация 253
6.2.5. Пропозициональные узлы 253
62.6. Концептуальные графы и логика 255
°.3. Альтернативы явному предстааленню
Содержание
9
=tfcfc.
6.3.1. Гипотезы Брукса и категориальная архитектура
6.3.2. Архитектура Copycat 0-
6.4. Агентно-ориентированное и распределенное решение проблем ~
6.4.1. Агентно-ориектированное решение задач: определение
6.4.2. Примеры и проблемы агентно-ориентированной парадигмы
—"""«литература
262
264
266
269
6 6 Упражнения 273
Глав» 7. Сильные методы решения задач 273
292
296
299
303
307
307
275
,:,: Sp" — ЖП1™" с^Госиованных на правилах 275
7 1 1 Разработка экспертных систем, о 276
Г i Вы£ор задачи » "Р<-« ''™е" д ' ^ етении знаний 279
7.1.3.Конисптуальныемоделиипхрольвпр, р ж
7.2. Экспертные системы, основанные »*"£■»»» цеш, 282
7.2.,. Продукционна, система и решениезадала ос ^
7 2.2. Объяснения « прозрачность при рассуждени
М.З. Использование продукционной системы для рассуждении ^
на основе данных oqq
7 2 4 Эввистнки и управление в экспертных системах
7 3. Рассужен™ на основе моделей, на базе опыта „ гибридные системы 292
7.3.1. Введение в рассуждения на основе модели
7.3.2. Рассуждения на основе моделей: пример NASA
7.3.3. Введение в рассуждения на основе опыта
7.3.4. Гибридные системы: достоинства и недостатки систем
с сильными методами
7.4. Планирование
7.4.1. Введение
7.4.2. Использование макросов планирования: STRIPS 311
7.4.3. Адаптивное планирование ^16
7.4.4. Планирование: пример NASA 318
7.5. Резюме и дополнительная литература 3"'
7.6. Упражнения 3-2
Глава 8. Рассуждения в условиях неопределенности 325
8.0. Введение 325
8.1. Абдуктивный вывод, основанный на логике 327
8.1.1. Логика немонотонных рассуждений 327
8.1.2. Системы поддержки истинности 331
8.1.3. Логики, основанные на минимальных моделях 336
8.1.4. Множественное покрытие и логическая абдукция 338
8.2. Абдукция: альтернативы логическому подходу 341
8.2.1. Неточный вывод на основе фактора уверенности 342
8.2.2. Рассуждения с нечеткими множествами 344
8.2.3. Теория доказательства Демпстера-Шафера 350
8.3. Стохастический подход к описанию неопределенности 354
6.3.1. Ьанесовские рассуждения 355
8.3.2. Байесовские сети доверия 359
8.4. Резюме и дополнительная литература
8.5 Упражнения
365
367
371
371
374
380
380
381
Часть IV. Машинное обучение ,,,
Символьное, нейросетевое и змерджентное обучение 369
Глава 9. Машинное обучение, основанное на символьном представлении
информации
9.0. Введение
9.1. Символьное обучение
9.2. Поиск в пространстве версий
9.2.1. Операция обобщения и пространство понятий
9.2.2. Алгоритм исключения кандидата
9.2.3. Программа LEX: индуктивное изучение эвристик поиска 388
9.2.4. Обсуждение алгоритма исключения кандидата 391
9.3- Индуктивный алгоритм построения дерева решений ID3 392
9.3.1. Построение дерева решений сверху вниз 394
9.3.2. Выбор свойств на основе теорни информации 396
9.3.3. Анализ алгоритма ШЗ 398
9.3.4. Вопросы обработки данных для построения дерева решении 399
9.4. Индуктивный порог и возможности обучения 400
9.4.1. Индуктивный порог 400
9.4.2. Теория изучаемости 403
9.5. Знания и обучение 405
9.5.1. Алгоритм Meta-DENDRAL 406
9.5.2. Обучение на основе объяснения 407
9.5.3. Алгоритм EBL и обучение на уровне знаний 411
9.5.4. Обоснование по аналогии 412
9.6. Обучение без учителя 415
9.6.1. Научная деятельность и обучение без учителя
9.6.2. Концептуальная кластеризация
9.6.3. Программа СОВ-WEB и структурные таксономические знания
9.7. Обучение с подкреплением 4-4
9.7.1. Компоненты обучения с подкреплением 425
9.7.2. Пример: снова "крестики-нолики" 4-?
9.7.3. Алгоритмы вывода и их применение к обучению с подкреплением 429
9.8. Резюме и ссылки "
9.9. Упражнения
Глава 10. Машинное обучение на основе связей
10.0. Введение
10.1. Основы теории сетей связей
10.1.1. Ранняя история
Ш.2. Обучение персептрона
10.2.1. Алгоритм обучения персептрона *„„„„,, пйпамв
Ю.2.2. Пример: использование персептронной се™ для классификации образов
10.2.3. Обобщенное дельта-правило
Ю.З. Обучение по методу обратного распространения
Содержание
415
417
419
435
435
437
437
439
439
442
448
10.З.З.Пр..»ен™всмегол»«р 455
,^«г=&—-—-•—"имссиф' ""S
,0.5.1. В«Д«»= о6я„„я Хебба без учителя ш
1(15'' Пример алгоритм» " '
fc]. Обучение Хебба ^ неЙ1ШЙ ассоциатор
!аб.З. Йрнмер-. о**» »Х с тТх"*лдв 4"
10 64 Автоассошвтнвная память и сети ли. ч 48 [
10.7. Резкзме и дополнительная литература 482
10.8. Упражнения
Глав. П. Мвшииное «бучение „а основе социальных и змер«же„тиь,х ^
принципов 483
11 о Социальные и змерджентные модели обучения 4g5
''ЧиТд^.Ге^исаниеза.ачивконьнзикти.ио.Знормвльной
форме и задача коммивояжера ^ 1
1114. Обсуждение генетического алгоритма 4дд
11.2. Системы классификации и генетическое программирование ^
11.2.1. Системы классификации .
! 1.22. Программирование с использованием генетических операторов эии
11.3. Искусственная жизнь и эмерджентное обучение
11.3.1.Игра-Жизнь" ^
11.3.2. Эволюционное программирование ~
11.3.3. Пример эмерджентностн -11
11.4. Резюме и дополнительная литература 5 ^
11.5. Упражнения 516
Часть V. Дополнительные вопросы решения задач
искусственного интеллекта 519
Автоматические рассуждения и естественный язык 519
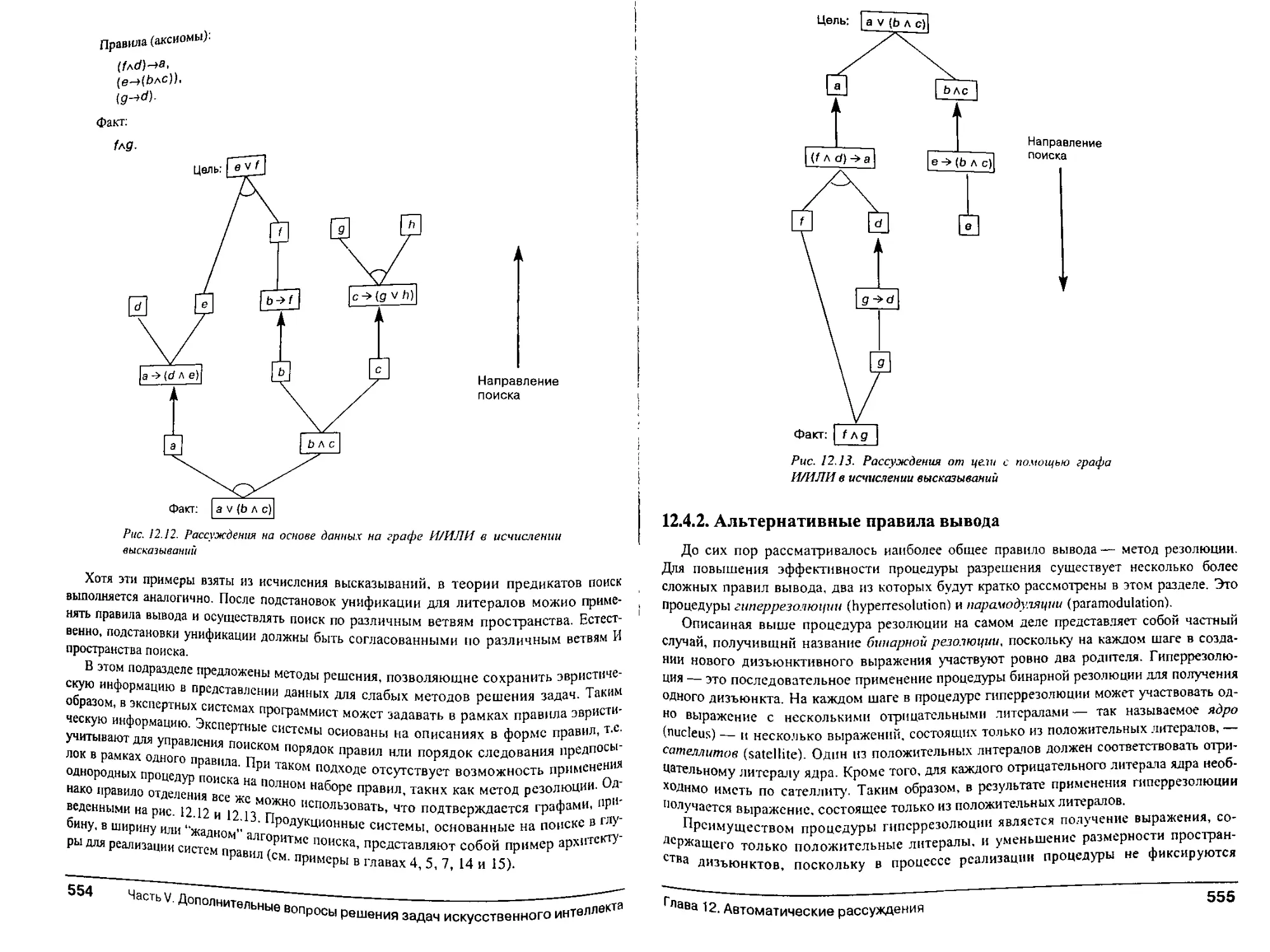
Глава 12. Автоматические рассуждения 521
12.0. Введение в слабые методы доказательства теорем 521
12.1. Система решения общих задач и таблицы отличий 522
12.2. Доказательство теорем методом резолюции 528
12.2.1. Введение 528
Содержание
12.2.2. Построение дизъюнктивной формы для опровержения разрешения 530
12.2.3. Процедура доказательства на основе бинарной резолюции 533
12.2.4. Стратегии и методы упрощения резолюции 538
12.2.5. Извлечение ответов в процессе опровержения 543
12.3. Язык PROLOG и автоматические рассуждения 546
12.3.1. Введение edfi
12.3.2. Логическое программирование и язык PROLOG 547
12.4. Дополнительные вопросы автоматических рассуждений 552
12.4.1. Единое представление для реализации слабых методов решения 552
12.4.2. Альтернативные правила вывода 555
12.4.3. Стратегии поиска и их использование 557
12.5. Резюме и дополнительная литература 558
12.6. Упражнения 559
Глава 13. Понимание естественного языка 561
13.0. Проблема понимания естественного языка 561
13.1. Разбор языка: символьный анвлиз 564
13.1.1. Введение 564
13.1.2. Стадии анализа языка 565
13.2. Синтаксический анвлиз 567
13.2.1. Спецификация и синтаксический анализ с использованием
контекстно-свободных грамматик 567
13.2.2. Анализаторы на основе сети переходов 569
13.2.3. Иерархия Хомского и контекстно-зависимые грамматики 573
13.3. Синтаксис и знания в ATN-анвлизаторах 576
13.3.1. Анализаторы на основе расширенных сетей переходов 576
13.3.2. Объединение знаний о синтаксисе и семантике 580
13.4- Стохастический подход к анализу языка 585
13.4.1. Введение 585
13.4.2. Подход на основе марковских моделей 586
13.4.3. Подход на основе дерева решений 588
13.4.4. Грамматический анализ и другие приложения стохастического подхода 590
13.5. Приложения задачи анализа естественного языка 592
13.5.1. Обучение и ответы на вопросы 592
13.5.2. Интерфейс для базы данных 592
13.5.3. Извлечение информации и системы автоматического
резюмирования для Web
13.5.4. Использование алгоритмов обучения для обобщения изалеченнои
информации „.
13.6. Резюме и дополнительная литература
13.7. Упражнения
Часть VI. Языки и технологии программирования
для искусственного интеллекта
600
603
64)6
Обзор языков PROLOG и LISP 606
PROLOG 607
LISP
Выбор языка реализации
Содержание
608
609
Г™..4..—-«0,Л0 6Ш
140. Введено м1ф0Юн-» «™кн предик»™ ш
, »зыке PROLOG
,4.2. Абстрактные тины данных в PROLOO
14.2.1. Стек
,4 2.2. Очередь
,4 •> 3 Приоритетная очередь 625
.^^ноПснете^наязы.РЯОЬОО ™
14.4
622
622
624
624
у в языке PROLOG
нГз. Реатизацня'-жадного" алгоритма поиска на языке г „^™ ^
14 5 Реализация планировщика на языке PROLOO
lit Метапредикаты, типы и подстановки унификации в языке PROLOG «^
J4.6.I. Металогические предикаты ^
14 6 2. Тшы данных в языке PROLOG ,
14.6-3. Унификация, механизм проверки соответствия предикатов и оценка ^
14.7. Метаинтерпретаторы в языке PROLOG
14.7.1. Введение в метаинтерпретаторы: PROLOG в языке PROLOU ото
14.7.2. Оболочка для экспертной системы на основе правил °4
14.7.3. Семантические сети в языке PROLOG
14.7.4. Фреймы и схемы в языке PROLOG
14.8. Алгоритмы обучения в PROLOG 661
14.8.1- Поиск в пространстве версий языка PROLOG ""'
14.8.2. Алгоритм исключения кандидата 666
14.8.3. Реализация обучения на основе пояснения на языке PROLOG 668
14.9. Обработка естественного языка на PROLOG 671
14.9.1. Семантические представления для обработки естественного языка 671
14.9.2. Рекурсивный анализатор на языке PROLOG 672
14.9.3. Рекурсивный анализатор на основе семантических сетей 675
14.10. Резюме и дополнительная литература 678
14.11. Упражнения 680
Глава 15. Введение в LISP 685
15.0. Введение ^о«
15.1. LISP: краткий обзор 6S6
15.1.1. Символьные выражения как синтаксическая основа LISP 686
5. ... Управление оцениванием в LISP: функшт quote и eval
13.1.5. ПрОГОаММИПОйЯинр l,i Т ,CD.
3... программирование на LISP: создание новых функций
15.1.4. Управление программой в LISP- условия и ппелнкат,,
690
условия и предикаты 692
705
15.1.5. Функции, списки и символьные вычисления 694
15.1.6. Списки как рекурсивные структуры 696
15.1.7. Вложенные списки, структуры и рекурсия car-cdr 698
15.1.8. Связывание переменных с помощью функции sec 701
15.1.9. Определение локальных переменных с помощью функции let 703
15J .10. Типы данных в Common LISP
15.2. Поиск в LISP: функциональный подход к решению задачи переправы
человека, волка, козы и капусты 706
15.3. Функции п абстракции высшего порядка 7 i 1
15.3.1. Отображения и фильтры 711
15.3.2. Функциональные аргументы и лямбда-выражения 713
15.4. Стратегии поиска в LISP 714
15.4.1. Поиск в ширину и в глубину 714
15.4.2. "Жадный" алгоритм поиска 717
15.5. Проверка соответствия шаблонам LISP 718
15-6. Рекурсивная функция унификации 720
15.7. Интерпретаторы и внедренные языки 724
15.8. Логическое программирование на языке LISP 727
15.8.1. Простой язык логического программирования 727
15.8.2. Потоки и их обработка 729
15.8.3. Интерпретатор для задач логического программирования
на основе потоков 731
15.9. Потоки и оценивание с задержкой 736
15.10. Оболочка экспертной системы на LISP 739
15.10.1. Реализация факторов достоверности 740
15.10.2. Архитектура оболочки lisp-shell 741
15.10.3. Классификация с использованием оболочки lisp-shell 744
15.11. Семантические сети и наследование в LISP 746
15.12. Объектно-ориентированное программирование с использованием CLOS 749
15.12.1. Определение классов и экземпляров в CLOS 751
15.12.2. Определение родовых функций и методов
15.12.3. Наследование в CLOS
15.12.4. Пример: моделирование термостата
15.13. Обучение в LISp: алгоритм ID3
15.13.1. Определение структуре помошью функции defstruct
15.13.2. Алгоритм ЮЗ
15.14. Резюме и дополнительная литература
15.15. Упражнения
753
755
756
761
761
767
772
773
Часть VII. Эпилог ^
Рассуждения о природе интеллекта
Глава 16. Искусственный интеллект как эмпирическая проблема
16.0. Введение
16.1. Искусственный интеллект: пересмотренное определение
16.1.1. Интеллект и гипотеза о физической символьной системе
16.1.2. Коннекционисгскпе. или нейросетевые. вычислительные системы
777
779
779
7SI
781
786
Содержание
15
789
792
, л, Теория иитешк"» MOrnH '"
841
Библиограф""
• а указатель авторов g4s
Алфавитный )каза
ПрМ.,я»ьп-.У»«МЬ
г, Кэтлин, и нашим детям — Саре, Дэвиду и Питеру-
:> Ч"Ш est in me ingenii, judices ..
Цицерон (Cicero)
— Джордж Люгер (George Luger)
Предисловие
Чтобы научиться что-то делить,
undo deiamb это
— Аристотель (Aristotle), Этика
Добро пожаловать в четвертое издание!
Предложение о выпуске четвертого издания книги по искусственному интеллекту я
принял с удовольствием. Я расценил его как комплимент предыдущим изданиям, первое
из которых вышло более десяти лет назад. Это предложение означает, что наш подход к
искусственному интеллекту был широко поддержан. В новом издании представлены
самые современные наработки в этой области. Спасибо читателям, коллегам и студентам
за высокую оценку книги и неослабевающий интерес к ее теме.
Многие разделы прежних изданий замечательно выдержали проверку временем. Это
главы, посвященные логике, алгоритмам поиска, представлению знаний, продукционным
системам, машинному обучению и технологиям программирования на языках LISP и
PROLOG. Эти вопросы остаются центральными в области искусственного интеллекта,
поэтому существенной доработки соответствующих глав не потребовалось. Однако
некоторые главы, в том числе связанные с вопросами понимания естественного языка,
обучения с подкреплением н неточными рассуждениями, были подвергнуты значительной
переработке. Часть вопросов, которые в первых изданиях были лишь слегка затронуты,
но впоследствии доказали свою актуальность, описаны более детально. К ним относятся
эволюционирующие вычисления, рассуждения на основе логических доказательств и
решение задач на базе моделей. Эти изменения отражают современные тенденции и
состояние области искусственного интеллекта.
В ходе проекта мы получили поддержку от наших издателей, редакторов, друзей,
коллег, а главное — читателей, которым наша работа обязана своей долгой и
продуктивной жизнью. Мы были очень рады представившейся возможности — ученым очень
редко удается вырваться за рамки своей узкой специализации. Благодаря издателям и
читателям у нас это получилось.
Несмотря на то что искусственный интеллект, как и большинство инженерны*
дисциплин, должен подтвердить свою значимость в коммерческом мире путем решения
важных практических задач, мы рассматриваем его с тех же позиций, что а многие наши
коллеги и студенты. Мы хотим понять и исследовать механизмы работы мозга,
обеспечивающие возможности интеллектуального мышления и осмысленной деятельности.
Отвергая несколько наивное утверждение о том. что интеллект - это исключительная прс-
„„, возможность эффективного исследования 0бласти
гждачмо.да>'"^7,йдасяумь»"'' артефактов. в "Р'Дмдущих издан„Д
Sktb. • ™*е ра3раб°^ »ыГчертГпреДлагаемого подход, к изучению и ^
^"отмечены три ™™"^„ £„ь,сл в предисловии к четвертому „здан„ю
ешого »«"•"»-"■ П°'Т асколько наши взгляды выдержали проверку .ремене,Д
L«e« активного Р"»"™»™, ..о6ъединение разрозненных областей искусственно,.
Основной целью мы 'J"™" ош,сания его теоретических основ . В „роцессе
„ителлекта с помощью »™ проблема - примирить исследователей, уделяк,щнх
реализации оказалось, что г ^^ разл„чных теорий интеллекта (чиады, m
основное внимание "3y4t , вак)ш„мн интеллект как средство решения конкретных
тиков), с их коллегами, р с-и _^ простая д„хотомия оказалась на деле далеко не та
прикладными w—^ mu „CKyccTBe„„oro интеллекта жаркие с0„ры
кой простои. ™ ^практиками „едутся по множеству вопросов „з самых разных об-
меяаутеордап ^^ „одхши шорят е почитателями нейронных сетей,
истей. Приер с „работникам!, форм искусственной жизни, эволюцией,,.
^еТ«и логическим принципам, архитекторы экспертных систем противо^
„ГоЛтчик» программ на основе логических доказательств. И, наконец, самые „е„р„.
мишмые дебаты ведутся между теми, кто считает задачу создания искусственного
интеллекта уже решенной, и пессимистами, вообще не верящими в возможность ее
решения Наше исходное видение искусственного интеллекта как пограничной области науки,
тжшнной укротить бунтовщиков, прорицателей, старателей и других безудержных
мечтателей с помощью формализма и эмпиризма, трансформировалось в другую
метафору. Искусственный интеллект — это большой, хаотичный, но в целом мирный город,
который законопослушные горожане разделили на отдельные деловые и богемные
районы в соответствии со своими жизненными принципами. За годы работы над разными
изданиями книги у авторов начинает появляться общее видение архитектуры
искусственного интеллекта, отражающее структуру, культуру и жизненный уклад этого города.
Интеллект— это очень сложная область знаний, которую невозможно описать с
помощью какой-то одной теории. Ученые строят целую иерархию теорий,
характеризующих его на разных уровнях абстракции. На самом нижнем уровне этой иерархии
находятся нейронные сети, генетические алгоритмы и другие формы эволюционирующих
вычислении, позволяющие понять процессы адаптации, восприятия, воплощения и
взаимодействия с физическим миром, лежащим в основе любой формы интеллектуальной
деятельности, с помощью некоторого частично поиятиого процесса разрешения эта
хаотическая популяши "слепых" и примитивных действующих лиц превращается в более
строгие шаблоны логического вывода. Работая на этом уровне, последователи Аристоте-
Ги^Г™ С<еМЬ' лмукшш- абдукции, индукции, поддержки истинности и другие бес-
оабсГ™ М0Де'™ " щ,тшш Рассуждений. На более высоком уровне абстракции ро-
но ™"Г™ЫХ C"mM' "«актуальных агентов, систем понимай™ естестм-
подкрепленн»7*ш£ 1ТЛИТ Р°ЛЬ с01<иаль11ы* процессов в создании, передаче и
™и искусственного инте1™ " тШ"т ишги МЬ| Рассмотрим все эти уровни нерар-
"расширенных формата?™'''" " |Ч*ль1дУ,чих изданиях, касался центральной Р<»»
венного ишел.,1па Это"™ "рея_гешлп,и» " стратегий поиска" в методологии искуси-
«аений и раннего этапа ' "°'ки'уи- наиболее спорный аспект наших предыдущих раКУ
развития искусственного интеллекта вообще. Многие „сследоМ-
ПоедислМ"8
„ли, работающие в области эволюционирующих ш»™ -
символьных рассуждений и семантики ссьшГс „„Тес Г ™" Г С°М"С"Ие P°"b
„дся представлен™ как процедуры присвой, имей „е2Гь,"2, "^ " ™ ™
ратила свою уникальность с появлением „еяТньгх „гÄР- ^" "° МН°Г°М УГ'
^„сетевыми моделями „ли системами иску^ГиоТжиТ'™"""- °6еСпет"ме«ы« »*
„„е вопросов представлен,,,,, ™^~^?^™:ГХ™2
специалистов-практиков в области искусственного интеллекта. Более того ZZZZ
и, что навыки и знания, приобретенные „р„ „зу^нии способов иредстаале^ и ыеТа
„измов пояска, являются неоценимым средством анализа таких аспектов „ееи1оГ„ых
областей искусственного „нтеллекта, как нейронные сети или генетические алгоритмы
Сравнение, противопоставление и критические замечания в адрес различных подходов
современного искусственного интеллекта приводятся в главе 16.
Третье утверждение, сформулированное в начале жизненного цикла этой книги -
"рассматривать искусственный интеллект в контексте эмпирической науки"
осталось'неизменным. Здесь уместно привести цитату из предисловия к третьему изданию. Автор
продолжает верить, что искусственный интеллект — это не
"...некое странное ответвление от научной градации, а... часть общего пути к знанию и
пониманию самого „нтеллекта Более того, наши программные средства искусственного
интеллекта наряду с исследованием методологии программирования... идеально подходят для
изучения окружающего мира Эти средства создают почву н для понимания и хи
появления вопросов. Мы приходим к оценке н знанию феномена конструктивно, т.е. путем
последовательной аппроксимации.
Каждую разработку и программу можно рассматривать как эксперимент с природой- мы
предлагаем представление, генерируем алгоритм поиска, а затем ставим вопрос об адекватности нашей
характеристики некоторой части феномена интеллекта И реальный мир дает ответ на этот
вопрос. Наш эксперимент можно проанализировать, модифицировать, расширить и возобновить
Нашу модеть можно подкорректировал,, а понимание — расширить'.
Что нового в этом издании
Я, Джордж Люгер (George Luger). — единственный автор четвертого издания. Несмотря
на то что интересы Билла Стабблефилла (Bill Stubblefield) сместились в сторону новых
областей компьютерных наук, его след останется н в настоящем, и в последующих изданиях
книги. На самом деле эта книга является результатом моей работы в качестве профессора
компьютерных наук- в университете Нью-Мексико и труда моих коллег, аегшрантов и
друзей — членов сообщества специалистов в области искусственного интеллекта, а также
многих читателей, направивших по электронной почте свои комментарии, пожелания и
уточнения. Данная книга продолжает традиции предыдущих изданий, поэтому, чтобы отразить
коллективный вклад в ее написание, при изложении материала я буду по-прежнему
употреблять местоимение "мы". Отдельные слова благодарности за участие в подготовке
четвертого издания приводятся в соответствующем разделе этого предисловия.
Мы переделали многие раздеты этой книги, чтобы отразить ■«Р*™3 Гт
агентного подхода к решению задач как новой технологии искусственного "^™«?
(ИИ). При обсужденш, основ ИИ мы определяем интеллект ^*«™ ^зтмТ
и расположенный в природном и социальном мире контекст. В соолзетствни с шш
ределеннем в главе 6 описываете, эволюция схем представления ИИ. начина, от ассо-
Предисловие
п ставлений через слабые и сильные методы реше-
циативного и раннего логического Р ентнь1е м„лели, и заканчивая ситуативными и
нш. включая коннекнионистские и . р ^ содержатся критические заме-
социальными подходами к решению задач ии.
чания по каждой го парадигм. проанализировали все вопросы, представ-
При работе над «™*™"££"ТремеГой интерпретации. В частности, в тлаву 9
лен„Ые ранее. „ изложили их в более совр м 0шсаны тмы такого
добавлен раздел, посвяшенны„ обучению .« получающие сигналы из внешней
обучения (метод временных разностей и у ооучен „'„„„»
среды и формирующие на их основе политику изменения состоянии.
Помимо'содержащегося в предыдущих изданиях анализа систем вывода от данных и
от цел* в главе 7 представлены рассуждения на основе модели и опыта, в том числе
примеры из космической программы NASA. В эту главу добавлен раздел, посвященный
обсуждению преимуществ и недостатков каждого из этих подходов для решения задач,
интенсивно использующих знания.
В главе 8 описан подход к реализации рассуждений при неточной илн неполной
информации. Предстаалено множество важных подходов к решению этой задачи, включая
байесовский подход к рассуждениям, сети доверия (belief network), модель Демпстера-
Шафера и неточный вывод с использованием фактора уверенности. Описаны также
приемы поддержания истинности в немонотонных ситуациях, а также рассуждения на
основе минимальных моделей и логической абдукции. В заключении гдавы глубоко
проанализированы байесовские сети доверия и алгоритм дерева клик для распространения
меры правдоподобия по сети доверия в контексте новой ииформацин.
В главе 13 обсуждаются вопросы понимания естественного языка, включая раздел по
стохастическим моделям для постижения языка. Здесь описаны марковские модели,
CART-деревья, метод взаимной кластеризации информации и статистического
грамматического разбора. В заключении главы приводится несколько примеров, в том чнеле
приложения по восполнению тексте и методы реферирования текстов для WWW.
И, наконец, в обновленной главе 16 мы снова возвращаемся к вопросам природы
интеллекта и возможности создания интеллектуальных машин. Последние достижения ИИ
рассматриваются с точки зрения психологии, философии и нейрофизиологии.
Содержание книги
койВист^и,йДае1СЯ ВВеЛСНИС В Те°РИЮ '«^'"венного интеллекта, предваренное крат-
ГГс"Ги" „ZZh"0""" ПРИНЦИПЬ' Pa60™ ММга " СУЩ"0СТЬ ">"™ с ™
™пяп, "сихологаи " ДР>™ "аук. Важно понимать, что ИИ- „о старая иаука.
ГГу7РоГ™„Т„Гк вддам Ар™ 0см™е - ™° ™Z %£
привод об^ор™^^ В этой главе тТкже
у ~ Тз Z ?Ге Тлшк теор™" < "~,,ГЫ' -0беспечить осяо-
(глава2,.^mm^ZZZZ,ZT""' """"Г" ""*"" "Р™<™>" власти
-горит™ и структуры ла^ГиГо!^" ™* 0ПНвИИХ (maM 3)' a ™*е
обсуждается важная роль эвристик в Sc„T„. реаЛшации ™го поиска. В главах 4 и 5
явлено множеств ГрхтскгуГпред^ТаГГ " "^те"т "^странетва поиска. Пред-
™^доло™ю.^с„ойГ^:^ГьГ„ГГНИЯ *~ — ™-
3
Предисловие
Главы 6. 7 и 8 составляют третью часть книги, в „их 0„псани
дач искусственного интеллекта и „иоды решеши * "писаны представлен,» дл, м.
".■я В главе 6 рассматривается эволюция схем представ,™ - исл°л"ующнх
знайся семантические сети и расширение этой мо™Гр„Т "" С"М" *»»
"„„ости, фреймы и сценарии. Затем глубоко аналтир,^" ™"""Т""""' М,И-
«оннептуальнь.е графы. Основное внимание уделяете, воТп'Т" Ь>малиэм -
SUe представления знаний „ решеник) У, ™ро2°^J*"""""* "°В""Й '
^„ения. В главе 13 показано, как концептуальные ФТы можно' 1""™ **"" "РСД-
^ш.. интерфейса с базой да„НЫх. работающего „ГиовТе" ™ ГяТыГв'за"
учении глань, 6 рассмотрены более современные подходы к предста л „ню включи
агентно-ориентироваиные архитектуры и систему Copycat "ставлению, включая
В главе 7 рассмотрена основанная „а правилах экспертная система а также системы
рассуждении иа основе моделей и опыта, включая „р„„еры из космической „рогр^мГ,
NASA. Эти подходы к решению задачи представлены как естественное продолжение
материала, изложенного в первых пяти главах книга: продукционная система на основе
выражений из теории предикатов гармонично сочетается с алгоритмами поиска на графах
В заключении главы анализируются преимущества и недостатки каждого из этих
подходов к решению задач, интенсивно использующих знания.
В главе 8 приводятся модели рассуждений в условиях неопределенности и методы
использования ненадежной информации. Здесь обсуждаются байесовские модели, сети
доверия (belief network), модель Демпстера-Шафера и неточный вывод с учетом фактора
уверенности, применяемые для рассуждения в условиях неопределенности. Описаны
приемы поддержания истинности, рассуждения на основе минимальных моделей и
логической абдукции, а также алгоритм дерева клик для байесовских сетей доверия.
В части IV (главы 9-11) подробно изложены вопросы машинного обучения. В главе 9
детально изучаются алгоритмы символьного обучения — обширной области
исследований, связанной с решением множества различных задач. Эти алгоритмы различаются по
своему назначению, используемым обучающим данным, стратегиям обучения и
представлениям знаний. К символьным алгоритмам обучения относятся индукция,
концептуальное обучение, поиск в пространстве версий и ШЗ. Подчеркивается роль индуктивного
порога, обобщения на основе реальных данных и эффективного использования знании
при обучении на единственном примере на основе объяснения. Изучение категории и
кластеризация понятий представлены в ракурсе обучения без учителя. Главу завершает
раздел, посвященный обучению с подкреплением. - способности интегрировать
обратную связь от внешней среды и политику принятия новых решений.
В главе 10 описаны нейронные сети, которые зачастую называют с,о-а««™«*«<.
«ли мнчвошшеш». моделям!, обучен,тя. В нейронной сети информация^структу
рпрована неявно. Она распространяется между набором взаимосвязанных „pottссоро. с
Учетом весовых коэффнциеитоГ, а обучение сводите, к пересортицвке и^-Ф—
весов узлов сети. Рассмотрено множество „ейроподобнь,■^^^^вЯ..
персептрона, метод обратного распространения ошиоки * „ асс0-
Изучень, „одели Кохонсна. Гроссберга и Хебба. Описана аттрзкшрная
Чнативное обучение, в том числе сети Хопфилда. обучению представлены в
Генетические алгоритмы и эмерджентныи подхо ш
и ЭВ01ЮЦИИ- После не-
г"аве 11. с этой точки зрения обучение - это процесс ада ^ рзссма1р„мется
«ольких примеров решения задач на основе генетнче ^^ ^„.км. К ним
возможность применения этой методологии для решен,
Предисловие
еское программирование. Затем описывает-
иассифнга""" « гоИТВ!!йвсти "искусственной жизни". В заключе-
относятся системы с примерам" »иГ,, рсалюова„„ых в институте Сайта.
м "социальное^ о^ эмсрД«"да1,'о^ст1вл),ются три подхода к машинному обучс-
*'• В ""'^ньГконне^оннстский ""'^ „"""„„с важных областей применен™
m"lC"Z V главы 12 и 13) °Р0ДОМ1апг"а JB явиетхя автоматическое доказательство
вчагГй и одной »' ™рейш"х^"«^""'^ж')е""я,га- в глаю 12 °°«-
„хиологии № » нцывают««««"" включая LoEic Theorist и Gen.
ГатГыеа. Solver. В я» «»»^„р, „а основе опровержения. Рассмотри
1 доказательства т»Р«» «7U"да "а основе гнперреэолюции и парамодуляции. в
„^ебояее сложные метм^* ^ ^^ выюда ю ос„ове хорновских
заключении интерпретатор ™*» да PROLOG- как пример парадигмы логнче-
выражений и резолюции а вычисл
ского программирования. ПОИ1маН111 естественного языка. Традиционный под-
Глава 13 поемшена проедем аниый с ИС110пьзованием многих описанных в
ход к пониманию языка, "Р0"™10"^^ „здании дополнен описанием стохастического
главе 6 семантических структур. ^ CART-деревья, метод взаимной класте-
подход». 3«'Р»""7™тиТч°ско о грамматического разбора. В заключении главы
„Ги^ГяГоГпрГр0:, включая^— ™ « — " "™"
рефериро.аин. текстов для ™"°^£ в глюе 14 расшатр,,ваетс» PROLOO. а в
JCT1 ГГ^Гпptc—к средства /сшепия задач искусе—
„тел!, «основе изложенных а предыдущих главах методов поиска, включая алго-
™ск.. ширину, глубину и ■■жадный" алгоритм. Реализация ™ "оиск
проблемно-независима, позтому ее можно применять для создания оболочекпоиска в
экспертных системах на основе правил построения семантических сетей, систем
понимания естественного языка и обучения.
И, наконец, глава 16 служит эпилогом этой книги. В ней рассмотрены возможности
науки об интеллектуальных системах, а также альтернативные современные подходы.
Обсуждаются современные рамки искусственного интеллекта и перспективы его развития.
Использование книги
Искусственный интеллект — это обширная область, поэтому объем этой книги
достаточно велик. Хотя для детального изучения всего материала потребуется не один
семестр, мы скомпоновали книгу таким образом, чтобы ее можно было читать по частям.
Выбирая «дельные часта материала, можно сформировать семестровый и годичный
(двухсемесгровьгй) курс изучения предмета.
Предполагается, что студенты уже прослушали курсы дискретной математики,
включая теорию предикатов и теорию графов. Если это не так, то при изучении начальных
риделов (2.1 и 3.1) необходимо уделить этим теориям больше внимания. Надеемся так-
ъС^**""* "ЗУЧИЛ" КУРС "° "И"»» Диньгх, в том числе деревьям, графам, ме-
™„?™Т7ГО П°"СИ С "°М0ШЬЮ ™т- °"4>«* » приоритетных очереден. Если
°ИК'Т° °6раТ"ге «<** ™,маннс на начальные разделы глав 3, 4 и 5.
Предисповие
PROLOG и LISP (часть VI, и требуем отсХХ Г™ ™™ Ш' 3тМ "" ЮуЧаеМ
р^изации стратегий ^^ош^^.Т^^^^Г^ ,*вв""""» "
PROLOG, можно ввести в первой части wca а затГ? ' "' Я'"К0В' " "Р"МрУ
г курса, а затем использовать его ггои изучении
„руктур дан„ь,х и алгоритмов поиска. По нашему миеиню, полезным средсГч „ЦТ
„„я систем решения задач иа основе правил и знаний являются метанн^Трпгя^горьГГд-
давленные в главе, посвяшеннои обработке естественного языка. PROLOG в свою
очередь, - отличное средство для построения систем понимания естественного языка
В двухсеместровом курсе имеется возможность рассмотреть области применен™ НИ,
описанные в частях IV и V. Особенно это касается машинного обучен™. Кроме того
студенты реализуют гораздо более серьезные программные проекты. На наш взгляд во
втором семестре очень важно, чтобы студенты познакомились с основными
первоисточниками знаний по искусственному интеллекту. Студенты должны понимать, где мы
находимся в данный момент, как мы к этому пришли, и представлять себе перспективы
развития ИИ. Для этой цели мы используем обзор [Luger, 1995].
Упомянутые в книге алгоритмы написаны на паскалеподобном псевдокоде. При этом
используются управляющие структуры языка Паскаль (Pascal) и описания проверок и
операций на родном языке. К числу управляющих структур Паскаля мы добавили две
новые полезные конструкции. Первая из них — модифицированный оператор case,
который не просто сравнивает значение переменной с постоянной меткой, как в обычном
Паскале, но и позволяет связывать с каждым элементом произволънуэо логическую
проверку. Оператор case по порядку выполняет эти проверки до тех пор, пока результат
одной из них не примет значение "истина". Тогда выполняется соотаетствуюшее
действие. Все остальные действия игнорируются. Читатели, знакомые с языком LISP, сразу же
заметят, что этот оператор обладает той же семантикой, что и оператор cond из LISP.
Вторым нововведением является оператор return, зависящий от одного аргумента.
Он может встречаться в любом месте процедуры или функции. При достижении этого
оператора программа немедленно завершает выполнение функции и возвращает
результат. Остальной стиль псевдокода соответствует синтаксису языка Pascal
Дополнительный материал, доступный через Internet
Представленный в книге код на языках PROLOG и USP чшатели могут пот/чить через
Internet Там же можно найти подробные методические рекомендации по использованию этан
книги для преподавателей Эти файлы находятся по адресу www.booksites.net/luger
ИЛИ на личной странице автора www. cs .unm. edu/ -luger/.
Дополнительные материалы и программные средства, в том числе публикуемые шла-
тельствам., Addison-Wesley и Pearson Educalion. находятся по адресу www. aw. com/ cs /
и www.pearsor.educ . com/computing. .Автор с удовольствием ожидает электронных
писем читателей по адресу luger@cs . unm. edu.
Бла
годарности
Во-первых, мы хотим поблагодарить Билза Стаббтеф.щда - соавтора первых треч
изданий за более чем десятилетний труд над этой книгой. Спасибо также многим рецензен-
пРедисловие
им в их числе Дзннис Ьахлср (Dennis
.„, „одготовт, зти четыре. ^ ^ ^ п.пгер К«™нг,УМР«=г
гам, которые помогли nc™"'"-„nn ., фцлипп чей ir....... -
ВаЫег). Скона Бритта. ,ъи™°™™„М) Сара Дуглас (Sarah Douglas). Кристоф Жирсд.
Collingwood)- Джои Дональд У<™ t* 'Кжараю (Andrew Kosoresov). Крис Малкольм
Карьер (Chnstophc Giraud Cam"'; n TC[) ,Вгасс Porter). Джуд Шаалик (Jude
(Chris Malcolm). Рэ« Мунн (Ray Модац ^ J^ (Mam, Va,10rla) „ Б„б Верофф (Bob Ver-
Shavlik), Карл Стерн (Carl Sceml. м l предложения и комментарии, направляемые
off, МЫ также благодарны за ««^^ Миренной почте.
непосредственно авторам ьнип ' ^^ |1р,0нателен своим аспирантам. Благодаря им
За помошь в реоргамоаапп ь р ■_ ^^^ ^^ ОТОЛ|ОЦ|И скм представлений для
Га:г^,г—.сГо— ^г;ГпТ^аГд;'1'д-
^^^^Гад^п-о^Ср-апоаадутспгвно^ыводу^гл^
встану Carl Stem) за помошь в написании главы 10, посвяшеннои коннекцнонметско-
т^кикю Яро, Сайа (Jared Sara) за помощь в описании стохастических моделей для
главы И ■Внещинми" «псюснтами четвертого гадания стали Леон ван дер Торрс (Uon van der
Torre) и Меди дотит (Mehdi Daslani) из Н|Шерландов, а также Леонардо Боттачн (Leonardo
Boitaci) и Джулиан Ричардсон (Julian Richardson) из Великобритании. Среди американских
рецензентов следует отметить Марека Псрковскп (Marek Perkowski) из портлендского
университета и Джона Шсппарда (John Sheppard) из университета имени Джона Хопкинса. Барак
Пермуттер (Barak Peatmuller) рецензировал главы по машинному обучению. И. наконец,
Джозеф Льюис (Joseph Lewis), Крис Малколм (Chris Malcolm), Брэнден Мак-Гоннигл (Brendan
McGonnigle) и Акаша Танг (Akasha Tang) приняли участие в обсуждении главы 16.
Автор благодарен издательству Academic Press за разрешение на перепечатку
большей части материала из главы 10. которая была ранее опубликована в [Luger, 1994]. И,
наконец, большое спасибо студентам университета Нью-Мексико, которые более десяти
лет изучали эту книгу и описанные в ней программные средства. Они существенно
расширили наш горизонт, а также позволили избавиться от опечаток и неточностей.
Спасибо моим друзьям из издательства Addison-Wesley за поддержку при написании
книги, особенно Алану Апту (Alan Apt) за помощь в подготовке первого издания. Лизе
Моллер (Lisa Moller) и Мэри Тюдор (Mary Tudor) за участие в подготовке второго,
Виктории Хендерсон (Victoria Henderson), Луизе Вилсон (Lou.se Wilson) и Карен Мосман
(Karen Mosman) за содействие в работе над третьим, а также Кэйт Мансфилд (Keith
Mansfield), Карен Сюзерланд (Karen Sutherland) и Аните Аткинсон (Anite Atkinson) за
поддержку этого четвертого издания. Особая благодарность Линде Цицарелле (Linda Ci-
carella) „з университета Нью-Мексико за помошь в подготовке рисунков
н„к,"иг^Г""* Т0М1СУ ВЗРР°У (Th0maS Barrmv> - "™»»Р»° признанному худож-
фиГляТо*.™ГиИСКУСПВ УКИВСРСНтеИ Н-М-ико. кото/ьш с/елал секДотогра-
блаХ^в™;^,:™:;:'™" р"сунки и цитаты т рабэт ч*™* ™°*°"-мы
Искусственный „нт"Ге™- ЦТ "а '«пользование этого материала.
егоси,уИГлуб„„у,вы„0^,туаоГ™™Гз^ТйГиГЦИШ,,ШаОСОЗВаВ
Джордж Люгер
1 июля 2001 года
Часть I
Искусственный
интеллект: его
истоки и проблемы
Всему есть начало, как говорил Санчо Панса, и это начало должно
опираться на нечто, ему предшествующее. Индусы придумали слона, кото-
рый удерживал мир, но им пришлось поставить его на черепаху. Нужно
отметить, что изобретение состоит в сотворении не из пустоты, но из
хаоса: в первую очередь следует позаботиться о материале...
— Мэри Шелл» (Mary Shelley), Франкенштейн
Попытка дать определение искусственному интеллекту
Искусственный интеллект (ИИ) можно определить как область компьютерной
науки, занимающуюся автоматизацией разумного поведения. Это определение наиболее
точно соответствует содержанию дайной книги, поскольку в ней ИИ рассматривается как
часть компьютерной науки, которая опирается на ее теоретические и прикладные
принципы. Эти принципы сводятся к структурам данных, используемым для представления
знаний, алгоритмам применения этих знаний, а также языкам и методикам
программирования, используемым при их реализации.
Тем не менее это определение имеет существенный недостаток, поскольку само
понятие интеллекта не очень понятно и четко сформулировано. Большинство из нас увере-
когда с ним столкнутся. Однако вряд ли
ны, что смогут отличить "разумное поведение „,„„™
кто-нибудь сможет дать интеллекту определение. Достаточно конкретно = « »«
предположительно разумной компьютерной программы и одновременно отражающее
жизнеспособность и сложность человеческого разума. ™я„„е опое-
Итак, проблема определения <«^^^^^^t^^
, Чт0 именно происходит при таком создании? Что такое
кой он существует априори? Что имени ^ 0 ншшчии интеллекта только по на-
творчество? Что такое интуиция. Можн ^^^ нал„ч1М некоего скрытого ме-
блюдаемому поведению, или же треоу ^ тканях ЖИВЬ1Х существ, и как можно
ханизма? Как представляются знания J' нь|х уС1р01-,ств? Что такое самоанализ „
применить это в проектировании нн нео6ход„мо ли создавать интеллектуальную
как он связан с разумностью. И, оолс • ю человеческого разума, или же достаток-
компьютерную программу по образ,' ■ 6ще ДОСТИчь разумности посредст-
„о строго "инженерното" подхода? Возможно ^ ^^ ^^ ^^ н
вом компьютерной техники, или же сушно
опьг™, присушетолшпь биологически», сушеств. ^ сформировать задачи „
На эти вопросы ответа пока ве "^н0-"° ш1 Отчасти привлекательность „с-
^^^Sr^S^TT^™ оригинальным и мощным ору-
дГеГдТис^едования именно этих проблем. ИИ предоставляет средство и нспытатель-
1о мСль для теорий интеллекта: такие теории могут быть переформулированы „а
языке компьютерных программ, а затем испытаны при их выполнении.
По этим причинам наше первоначальное определение, очевидно, не дает однозначной
характеристики для этой области науки. Оно лишь ставит новые вопросы и открывает
парадоксы в области, одной из главных задач которой является поиск самоопределения.
Однако проблема поиска точного определения ИИ вполне объяснима. Изучение
искусственного интеллекта— еще молодая дисциплина, и ее структура, круг вопросов и
методики не так четко определены, как в более зрелых науках, например, физике.
Искусственный интеллект призван расширить возможности компьютерных наук, а не
определить их границы. Одной из важных задач, стоящих перед исследователями,
является поддержание этих усилий ясными теоретическими принципами.
Из-за специфики проблем и целей искусственный интеллект не поддается простому
определению. Поэтому на первых порах просто опишем его как спектр проблем и
методологий, изучаемых разработчиками систем искусственного интеллекта. Это
определение может показаться глупым и бессмысленным, но оно отражает важный факт:
искусственный интеллект, как и любая наука, является сферой интересов человека, и лучше
всего рассматривать его в этом контексте.
Любая наука, включая ИИ, рассматривает некоторый круг проблем и разрабатывает
подходы к их решению. Краткое изложение истории искусственного интеллекта, рассказ
о личностях и их гипотезах, положенных в основу этой науки, поясняет, почему
некоторые проблемы стали доминировать в этой области и почему для их решения были взяты
на вооружение методы, описываемые в этой книге.
28
'■ Иск^ственный интеллект: его истоки и проблемы
Искусственный
интеллект: история
развития и области
приложения
Слушайте далее и вы еще более изумитесь ремеслам и богатствам природы,
открытым мною. Величайшим было такое: в старину, если человек заболевал, у него
не было защиты против болезни, ни исцеляющей еды, ни питья, ни мази; люди вы-
мирали от отсутствия лекарств, но я показал им. как смешивать мягкие
ингредиенты, чтобы изгонять всяческие хвори...
Это я сделал видимыми для человеческих очей пылающие знаки в небесах, что до
тех пор были в тумане. Недра зелии, скрытое благословение человечества, медь,
железо, серебро и золото — осмелится ли кто-нибудь заявить, что он открыл их
ранее меня? Я уверен, никто, ест он не лжей. Говоря кратко: все ремесла, что
есть v смертных, идут от Прометея.
Эсхил (Aeschylus), Прикованный Прометей
1.1. Отношение к интеллекту, знанию и человеческому
мастерству
П„, говорит о результатах своего —°^^^^™
не только украсть огонь для людей, но и просветить '^Р™^ окком техноло-
"сообразительности". Интеллект является основой «°ч££^ „.^„.ует
™н н цивилизации вообще. Работа классического П*46" Искусственный интеллект
глубокую и давнюю уверенность в необычайной силе^ ^—^ 6иолопш, астоо-
применяется во всех сферах наследия Прометея, мел '^ 6ш «& представить,
"омии, геологии и многих областях науки, которые •*_ ю он навлек на „его гнев Зев-
Хотя поступок Прометея освободил людей от нев i ^ ^ nfUKBWI „рико-
<*■ За кражу знании, прежде принадлежавших лишь о . ^ страд1Ш„я. Мысль о
*№■ Прометея к голой скале, чтобы стихни причиной ■- ^ перед богаш, „ли
™«. что человеческое стремление к знаниям "^™" " -, основа„а история Эдема,
"РИродой, прочно укоренилась в западной философии.
„„, „аятс „ Мильтона. И Шекспир, и древнегреческие зрапад
она пронизывает сочинения д ^ бедствий. Упорная вера в то, что жажда знаний
считали амбиции разума пр , псрстт „ эпоху Возрождения, и век Просве-
в конечном счете приведет ккаистр Ф j ^ ^ ^ ^^ ^ ^
^е^^^оГн^ГГшествеГнь, крузттх не утихает сурна, полемика „„
"Тв^Х^-^Глопн, не развеяла древний страх губительнььх послед-
ствйй »Z ктуального честолюбия, она, скорее сделала „х более вероятными, а мо-
жТ, неотвратимым,,. Легенды о Прометее, Еве, Фаусте пересказываются „а языке тех-
ZorUecKoro общества. В своем предисловии к работе ■ Франкенштейн (которая,
кстати, носит подзаголовок "Современный Прометей") Мэри Шелли пишет:
-Я была верным молчаливым слушателем долгих бесед между лордом Байроном и
Шстли В одной из них обсуждались различные философские доктрины, в частности,
сущность первопричин жизни, возможность их постижения II изучения. Они говорили об
экспериментах доктора Дарвина (я имею в виду не то, что действительно делал доктор, а то,
что ему приписывали), который хранил вермишель в стеклянной емкости, пока она не
начала сама двигаться каким-то непостижимым образом. Это не значит, что таким образом
можно дать жизнь. Но, должно быть, возможно оживить труп. Об этом свидетельствует
гальванизм- может быть, и можно изготовить составные части создания, соединить их
вместе и наполнить живительным теплом". [Bultler, 1998)
Шелли демонстрирует нам, в какой мере научные достижения, такие как работы
Дарвина и открытие электричества, убедили даже далеких от науки людей в том, что
творения природы не являются божественной тайной — их можно "разбирать" и
систематически изучать. Чудовище Франкенштейна — не продукт шаманских заклинании пли сделок
с преисподней; его собрали из отдельно "изготовленных" компонентов и наполнили
живительной силой электричества. Хотя наука девятнадцатого века не способна была
понять цель изучения принципов и создания в полной мере разумного агента, она
признавала мысль, что тайны жизни и разума можно приоткрыть с помощью научного анализа.
1.1.1. Историческая подоплека
К тому времени как Мэри Шелли окончательно и, вероятно бесповоротно соединила
современную науку с мифом о Прометее, философские корни современных работ в сфе-
f "с^с"иого',телл<:'т Р™™»™" У*е несколько тысячелетий. Хотя моральные
данТоПГл™ "" Г""' "°ДШт"е ""У"™™-™ интеллектом, интересны и важиы,
Г»»Х:,-,аС,Ш" КаСаСТСЯ «актуального наследия ИИ. Логнчс-
ывад Z™ ™Ч!°И ЭТ°" """Р"» можно считать гений Аристотеля, или, как его „а-
таГЛ Федчу.™ ТСХ' ™ ,НаСТ"" Ар"И0тель "^««нил интуитивное понимание,
мыцшеинсГ™yyZZ'Cr* ^тШ ° ™~,ь7™ ■■ «npon-
Дл» Аристотеля нГйоТ Стать ""«Ч™* Для современной наук,,,
работе -IZZ 2™ТТШ аС"еК1°М П™°™ «"» - изменчивость. В
ся вешей". Он делал ра,„ичис' с ° v ,Ф""°С0*,"° "Р"Р°Ды" как "изучение изменяющих-
из материи бронзы и цмсст ,(,„,„77 '"°'"еР"™ и формой: например, скульптура сделана
бронзе придают другую форму Ра ЧС"°ВСКа Изменен„с происходит в тот момент, когда
базис для современных научных ^"'"""."""Р1"1 и формы представляет философский
ракпня данных. В любом исч.,с„„„ ,"ЦИ"' таи,х как символьное исчисление или абст-
-исдеиин (даже в работе с числам,,!) мы манипулируем
образами, которые являются формой электромагнитной материи, а изменения формы этой
материи передают аспекты процесса решения. Абстрагирование формы" среднее
представления не только позволяет производить вычисления „ад этой формой ноТслу!
ж„т-«новой теории структур данных _ ,дра современных компьютерных наук
В своей работе Метафизика" Аристотель разработал теории неизменных вещей -
космологию н теологию. Но ближе всего к искусственному интеллекту подходит арнстоте-
„евская эпистемология, или наука познания, обсуждаемая в его "Логике" Аристотель
считал эту книгу важным инструментом познания, поскольку чувствовал, что основой знания
является изучение самой мысли. В "Логике" рассматриваются вопросы истинности
суждений на основе их взаимосвязи с другими истинными утверждениями. Например если
известно, что "все люди смертны" и "Сократ— человек", то можно заключить, что
"Сократ — смертен". В этом примере силлогизма используется дедуктивное правило modus
ропет. Хотя формальная аксиоматизация логических рассуждений в полном объеме
представлена лишь в работах Готлоба Фреге, Бертрана Рассела. Курта Геделя, Алана Тьюринга.
Альфреда Тарского и других, корни этих работ можно проследить вплоть до Аристотеля.
Идеи Ренессанса, основанные на греческой традиции, дали толчок развитию иного,
мощного представления о человечестве и его роли в природе. На смену мистицизму как
средству объяснения вселенной пришел эмпиризм. Часы (а следовательно, и расписание
работы фабрик) заменили собой ритм природы для тысяч городских жителей. Большинство
современных социальных и физических теорий уходят корнями к идее о возможности
математического анализа и достижимости природных или искусственных процессов. В
частности, ученые и философы поняли, что мышление само по себе как образ представления
знаний является трудным, но принципиальным предметом для научного изучения.
Должно быть, главным событием в развитии современных представлении стала
революция, произведенная Коперником,— замена древней геоцектрической модели
вселенной, где Земля и другие планеты на самом деле врашаются вокруг Солнца. После
столетий господства "очевидности", в которой научное объяснение природы и космоса
согласовывалось с религиозным учением и здравым смыслом, была предложена радикально
иная (и вовсе не очевидная) модель, объясняющая движение небесных тел. Возможно в
первый раз наши представления о мире рассматривались как фундаментально
отличные от их видшюсти. Этот разрыв между человеческим разумом и окружающей его
реальностью, между понятиями о вещах и самими вещами принципиален для современной
теории интеллекта и его организации. Эта брешь была расширена работами Галилея, чьи
научные наблюдения еще более расходились с "очевидными" истинами о мире, и чье
развитие математики как инструмента для описания мира усилило разрыв между миром
и нашими идеями о нем. Именно из этой "бреши" развивалось современное "P"™"'-
ние о формировании разума: самоанализ стал важным мотивом в литературе, философы
начали изучать эпистемологию и математику, и систематизированное применение
научного метода стало соперничать с чувствами как орудиями познания мира-
Хотя в XVI! и XVIII столетиях было получено немало результатов в эпистемологии
смежных областях, ограничимся рассмотрением работ Рене Декарта. Д^""*™""]
тральной фигурой в развитии современных концепции мышления и разума. ^«^
нитых "Р*мыц|лен„,х" Декарт сделая попытку найти основу реальное™ »^°™™£
методами когнитивной интроспекции. Отвергая информацию, "<*^>~ °^™В
чувств, как неблагонадежную, Декарт был вынужден подвергнуть ™—>*£ ^.
воваиие физического ^<™^£Z^^£Z£ZSZ
вать существование самого себя: XJogilo ergo sum I ^
Глава 1. Искусственный интеллект история развития и
31
„v пи лостовсоно установил свое собственное существование как мыс-
„к,"). Поел;^го как» ло™.^ Б0П1 как таорца „, в конечном счсге
лящей сушности. Дегарт вывел =>™ необходимого творения Господа.
"ГьГжГлГГ^ресГбдения. Во-первь,, раскол МежДу фи,„че.
скш Гром иего" ятеллетгуальнь,.. осмысленно, стал гвким значительным, что „оя,„.
лаеьво можноеть рассматривать процесс мышления отдельно от чувственного еоегф,,.
ятт или предмета осмысления. Во-вторых, связь между разумом и физическим м„р„м
стала столь тонкой, что понадобилось вмешательство всемилостивого Бога, чтобы дать
достоверное знание о физическом мире! Это понимание дуализма разума и физического
мира пронизывает всю картезианскую мысль, включая открытие аналитической геомет-
рин Как иначе Декарт мог объединить столь "практичную" область математики, как
геометрия, с таким абстрактным математическим основанием, как алгебра?
Почему зга философская дискуссия включена в книгу по искусственному интеллекту?
Для ИИ особое значение имеют два важных следствия этих работ.
1. Разделив разум и физический мир, Декарт и его последователи установили, что
строение идеи о мире не обязательно соответствует изучаемому предмету. На этом
основывается методология ИИ, а также эпистемологии, психологии, большей части
высшей математики и современной литературы: ментальные процессы существуют
сами по себе, подчиняются своим законам и могут изучаться посредством себя же.
2. Поскольку разум и тело оказались разделенными, философы сочли нужным найти
способ воссоединить их, ведь взаимодействие между умственным, res cogitans, и
физическим, res exlensa, необходимо для человеческого существования.
По поводу проблемы "ума и тела" были написаны миллионы трудов и было
предложено множество решений, однако ни одно из них не смогло успешно объяснить
очевидные взаимодействия между умственными состояниями и физическими действиями.
Наиболее приемлемый ответ на этот вопрос, дающий необходимое основание для изучения
ИИ. состоит в том, что ум и тело вовсе не принципиально разные сущности. Согласно
этой точке зрения ментальные процессы происходят в таких физических системах, как
мозг (или компьютер). Умственные процессы, как и физические, можно в конечном
счете охарактеризовать с помощью формальной математики. Или, как сказал философ
XVII века Гоббе (1651), "мышление есть лишь расчет",
1.1.2. Развитие логики
ща"Г.Л^ :™иееГи°ГССМа,РМаТЬСЯ ^ Ф°рМа "ни, последующими
ГотфрЯдВильтеГЛо'^кФОРМаЛ1,3аиНЯ " око™"^«м механизация. В XVIU в.
еиетТму ^:^Z^:i!tZ^,C"IUS РМ°^'"-" "-™1 ■">»»"
ний [Leibniz 18871 lan<-„ „' С00РУДИл машину для автоматизации ее вычисле-
ннгсбергских мостах (см введ37°СеМТаТ0Г° ММ " С"КМ аНал,,зе ИдаЧ" ° "'
абстрактно отражают струи™,.,,,, ГЛШу 7 сошал 5™"™ о представлениях, которые
Формализация теорГ ДУ„ ^Г"™ V™tmm M""a |Еи1ет' ,7351'
стояний (stale space search) _ сделала возможным поиск в пространстве со-
интеллскта. Графы можно исшил,™"""1 коииспТУальныП инструмент искусственного
Узлы графа состояний (stale soace п\Т* МОДСЛ"1»шния скрытой структуры задачи.
»» задачи; ребра графа „™я JIZ I.T' "Р №та<™°т собой возможные стадии реше-
тражают умозаключения, ходы в И1ре 1[ЛИ друп)С шап( в реше-
Часть |. Искусственный интеллект: его истоки и проблемы
нии. Решение задачи-- это пр0цесс поиска пути к решению на графе состоянии
(см. раздел 1.3 и главу 3). Описывал все пространство решений задачи, графы состоянии
предоставляют мощный инструмент для измерения структурированности и сложности
проблем, анализа эффективности, корректности и общности стратегий решения
Как один из основоположников науки исследования операций, а также разработчик
первых программируемых механических вычислительных устройств, математик XIX в
Чарльз Бэббидж может также считаться одним из первых практиков искусственного
интеллекта [Morrison и Morrison, 1961]. "Разностная машина" Бэббиджа являлась
специализированным устройством для вычисления значений некоторых полиномиальных
функций и была предшественницей его "аналитической машины". Аналитическая машина,
спроектированная, но не построенная при жизни Бэббиджа. была универсальным
программируемым вычислительным устройством, которое предвосхитило многие
архитектурные положения современных компьютеров.
Описывая аналитическую машину, Ада Лавленс [Lovelace. 1961]. друг Бэббиджа. его
помощница и единомышленница, отмечала:
"Можно сказать, что аналитическая машина плетет алтебршеческне узоры подобно тому, как
станок Жаккарда ткет узоры из цветов и листьев. В этом, как нам кажется, заключается куда
больше оригинальности, чем в том, на что могла бы претендовать разностная машина".
Бэббиджа вдохновляло желание применить технологию его времени для
освобождения людей от рутины арифметических вычислений. В этом отношении, как и в
представлении о вычислительных машинах как механических устройствах, Бэббидж рассуждал
всецело с позиций XIX века. Тем не менее его аналитическая машина также
основывалась на многих идеях современности, таких как разделение памяти и процессора ("склад"
и "мельница", в терминах Бэббиджа), концепция цифровой, а не аналоговой машины и
программируем ость, основанная на выполнении серий операции, закодированных на
картонных перфокартах. Отличительная черта описания Ады Лавлейс и работы
Бэббиджа в целом — это отношение к "узорам" алгебраических взаимосвязей как сущностям,
которые могут быть изучены, охарактеризованы, наконец, реализованы и подвергнуты
механическим манипуляциям без заботы о конкретных значениях, которые проходят
через "мельницу" вычислительной машины. Это и есть реализация принципа "абстракшш и
маннпуляшш формой", впервые описанного Аристотелем.
Целью создания формального языка для описания мышления задавался также
Джордж Буль, математик XIX столетия, чью работу необходимо упомянуть при
рассмотрении истоков искусственного интеллекта [Boole, 1S47, 1854]. Хотя Буль внес вклад во
множество областей математики, его наиболее известным открытием стала
математическая формализация законов логики— свершение, сформировавшее самую сердцевину
современных компьютерных наук. Роль булевом алгебры в проектировании логический
цепей хорошо всем известна, однако цели самого Буля в разработке его системы по духу
ближе к современному ИИ. В первой главе книги "Исследование законов мышления, на
которых основываются математические теории логики и вероятностей" Буль описывает
свои цели следующим образом.
Исследовать фунда ментальны с законы таких олерашш разума, какими совершается
рассуждением дать им выражение в символическом «ь*е исчисления н на этом основании
воздвигнуть науку логики и обучать логическому методу: . .наконец, из различных элементов
истины, усмотренной в зтих изысканиях, составить некоторые вероятные допцкк
касательно природы к склада человеческого ума.
Глава 1. Искусственный интеллект: история развития и области приложения
„™„т > необычайной силе « простоте предложенной им
Значимость работа вУ™с°£°!"ии, . шш л). "ИЛИ" (обозначаемая + или v) и
системы. Трн оперши»: И (ос* ю щ(Ю его лог„чсского исчисления. Эти
■НЕ" (обозначаемая символом -,1 ^ т1д формальном логики, включая разра-
операции стали базой ал» поел к» ^ щипни этих символов практически идсн-
ботку современных """"'""^ „ „„ершиям. Буль отмечал, что "символы логики
„иными соответствующим ло символы количества как таковые не имеют
относи, к спеш.альномузакону^которо^У^ ^ ^^ х ^^ х>х=х
отношения . Этот ЭДкон . и повторение не может изменить это знание),
(поскольку мы знаем »™шя°™ ,ние„„н всего до двух чисел, которые удовлство-
Р^тоТ^ГГ-" и"». Стандартные определения операций булевого умиоже-
„„Гат,слом (ИЛИ) следуют из этих соображении.
Бу е»"«"мГ™ только легла в основу двоичной арифметики, но и „оказала, что
„событие простая формаяьная система может передать полную мощь логики. Это
дад™«ниГГсист.»,а. разработанная Булем для демонстрации этого факта, стали
Еамеитом для всех попыток современной» формал,гзовать логику, от работы
rwhitetad и Russell. 1950]. последующих работ Тьюринга и Геделл до современных
систем автоматических рассуждении.
Готлоб Фрегс (Ftege) в своих 'Основах арифметики' [Frege. 1884] создал ясный и
точный язык специфи™""11 аля описания основ арифметики. С помощью этого языка Фрегс
формализовал многие вопросы, затронутые ранее в аристотелевской "Логике". Язык Фрегс,
сейчас именуемый исчислением предикатов первого порядка, служит инструментом для
записи теорем и задания значении истинности, которые образуют элементы
математических умозаключении и описывают аксиоматический базис "смысла" этих выражений.
Предполагалось, что формальная система исчисления предикатов, которая включает
символы предикатов, теорию функций и квантнроавнных переменных, станет языком для
описания математики и ее философских основ. Она также сыграла принципиальную роль в
создании теории представления для искусственного интеллекта (см. главу 2). Исчисление
предикатов первого порядка обеспечивает средства автоматизации рассуждений: язык для
построения выражений, теорию, позволяющую судить об их смысле, и логически
безупречное исчисление для вывода новых истинных выражении.
Работа Рассела и Уайтхеда особенно важна для фундаментальных принципов ИИ,
поскольку заявленной ими целью было вывести из набора аксиом путем формальных
операций всю математику. Хотя многие математические системы строились на основе
аксиом, интересно отношение Рассела и Уайтхеда к математике как к чисто формальной
системе. Это означает, что аксиомы и теоремы должны рассматриваться исключительно как
наборы символов: доказательства должны выводиться лишь посредством применения
строго определенных правил для манипулирования такими строками. При этом
исключается использование интуиция или "смысла" теорем в качестве основы доказательств.
Каждый шаг доказательства следует из строгого применения формальных
(синтаксических) правил к аксиомам или уже выведенным теоремам, даже если в
традиционных доказательствах этот шаг назывался "очевидным". Смысл содержащийся »
теорема, „ аксиомах системы, имеет отношение только к внешнему миру и совершенно
,™ " "™Г™!!,ВВД1?"* ■"""«» Ф°Р—и, (реализуемый технн-
ческнми средствами) подход
к математическим умозаключениям предоставил сушест-
ГкийТннтГсис ГГ™ »и™«"*«™ » Реальных вычислительных машинах.
Логический синтаксис и формальные правила вывода, разработанные Расселом и Уайтхедом.
лежат в основе систем автоматического доказательства теорем, рассматриваемых в
главе 12, а также составляют теоретические основы искусственного интеллекта.
Альфред Тарский (Tarski) — еще один математик, чьи работы сыграли
принципиальную роль в процессе формирования искусственного интеллекта. Тарский
(Tarski. I944, 1956] создал теорию ссылок (theory of reference), согласно которой
правильно построенные формулы (well-formed formulae) Фреге или Рассела-Уайтхсдя
определенным образом ссылаются на объекты реального мира (см. главу 2). Эта концепция
лежит в основе большинства теорий формальной семантики. В работе "Семантическая
концепция истинности и основание семантика" Тарский описывает свою теорию ссылок
и взаимосвязей между значениями истинности. Современные исследователи
компьютерных наук связали эту теорию с языками программирования и другими компьютерными
реалиями [Burstall и Darlington, 1977).
Хотя в XVH1-XIX вв. и начале XX в. формализация науки и математики создала
интеллектуальные предпосылки для изучения искусственного интеллекта, он не стал
жизнеспособной научной дисциплиной до появления цифровых вычислительных машин. К
концу 1940-х гг. электронные цифровые компьютеры продемонстрировали свои
возможности в предоставлении памяти и процессорной мощности, требуемой для
интеллектуальных программ. Стало возможным реализовать формальные системы рассуждений в
машине и эмпирически испытать их достаточность для проявления разумности.
Существенной составляющей теории искусственного интеллекта является взгляд на цифровые
компьютеры как на средство создания и проверки теорий интеллекта.
Но цифровые компьютеры — не только рабочая лошадка для испытания теорий
интеллекта. Их архитектура наталкивает на специфичное представление таких теорий:
интеллект — это способ обработки информации. Например, концепция поиска как методики
решения задач обязана своим появлением в большей степени последовательному характеру
компьютерных операции, нежели какой-либо биологической модели интеллекта.
Большинство программ ИИ представляют знания на некотором формальном языке, а затем
обрабатывают их в соответствии с алгоритмами, следуя заложенному сше фон Нейманом
принципу разделения данных и программы. Формальная лотка возникла как важный инструмент
представления для исследований ИИ. равно как теория графов играет неоценимую роль в
анализе пространства, а также предоставляет основу для семантических сетей и схожих
моделей. Эти методы и формализмы детально обсуждаются в последующих главах книги.
Здесь они упоминаются для подчеркивания симбиотнческих отношений между цифровыми
компьютерами и теоретическими основами искусственного интеллекта.
Мы часто забываем, что инструменты, которые мы создаем для своих целен, влияют
своим устройством и ограничениями на формирование наших представлений о мире.
Такое казалось бы стесняющее наш кругозор взаимодействие является важным аспектом
развития человеческого знания: инструмент (а научные теории, в конечном счете, тоже
инструменты) создается для решения конкретной проблемы По мере применения и
совершенствования инструмент подсказывает другие способы его использования, которые
приводят к новым вопросам и. в конце концов, разработке новых инструментов.
1.1.3. Тест Тьюринга
Одна из первых работ, посвященных вопросу о машинном разуме в отношении
современных цифровых компьютеров. "Вычислительные машины и интеллект" была
написана в 1950 г. британским математиком Аланом Тьюрингом н опубликована в журнале
Глава 1. Искусственный интеллект: история развития и области приложения
3S
ак-гуальиоста. как по часта аргументов против вю.
•Mind" [Turin?. |9501 ОН'"п"Рчисл„тсльноП машины, гак н по части ответов „а „их.
„ожности сомали. Р"*»""" 6„„омр, своим трудам по теории вычислимости, рас.
Тьюринг, «местный а мж1"1 'ь мшшшу действительно думать. Отмсчм, что
смогом вопрос о том. можно л ^ ^^м „опросе (что такое "думать-? что такое
фундаментальна. """Г'3"1'" -шинельного ответа, он предложил заменить в„.
^:^лГ^Гч!Го°лрсД-ннымз> рнческимтестом.
Рис. 1.1. Тест Тьюринга
Тест Тьюринга сравнивает способности предположительно разумной машины со
способностями человека— лучшим и единственным стандартом разумного поведения. В
тесте, который Тьюринг назвал "имитационной игрой", машину и ее человеческого
соперника (следователя) помешают в разные комнаты, отделенные от комнаты, в которой
находится "имитатор" (рис. 1.1). Следователь не должен видеть их или говорить с ними
напрямую— он сообщается с ними исключительно с помощью текстового устройства,
например, компьютерного терминала. Следователь должен отличить компьютер от
человека исключительно на основе их ответов на вопросы, задаваемые через это устройство.
Если же следователь не может отличить машину от человека, тогда, утверждает
Тьюринг, машину можно считать разумной.
Изолируя следователя от машины и другого человека, тест исключает предвзятое
отношение— на решение следователя не будет влиять вид машины или ее электронный
голос. Следователь волен задавать любые вопросы, не важно, насколько окольные или
косвенные, пытаясь раскрыть "личность" компьютера. Например, следователь может
попросить обоих подопытных осуществить довольно сложный арифметический подсчет,
предполагая, что компьютер скорее даст верный ответ, чем человек. Чтобы обмануть эту
стратешю, компьютер должен знать, когда ему следует выдать ошибочное число, чтобы
показаться человеком. Чтобы обнаружить человеческое поведение на основе
эмоциональной природы, следователь может попросить обоих субъектов высказаться по поводу
стихотворения или картины. Компьютер в таком случае должен знать об эмоциональном
складе человеческих существ.
Этот тест имеет следующие важные особенности.
1. Дает объективное понятие об интеллекте, т.е. реакции заведомо разумного
существа на определенный набор вопросов. Таким образом, вводится стандарт для
определения интеллекта, который предотвращает неминуемые дебаты об "истинности"
его природы.
^ У »«*«'» нас в туник сбивающими с толку и пока безответными
вопросами, такими как: должен ли компьютер использовать какие-то конкретные внутренние
процессы, нлн же должна ли машина по-настоящему осознавать свои действия
3. Исключает предвзятость в пользу живых существ, заставляя опрашивающего
сфокусироваться исключительно на содержании ответов на вопросы.
Благодаря этим преимуществам, тест Тьюринга представляет собой хорошую основу
для многих схем, которые используются на практике для испытания современных
интеллектуальных программ. Программа, потенциально достигшая разумности в какой-либо
предметной области, может быть испытана сравнением ее способностей по решению
данного множества проблем со способностями человеческого эксперта. Этот метод
испытания всего лишь вариация на тему теста Тьюринга, группу людей просят сравнить
"вслепую" ответы компьютера и человека. Как видим, эта методика стала неотъемлемым
инструментом как при разработке, так и при проверке современных экспертных систем.
Тест Тьюринга, несмотря на свою интуитивную притягательность, уязвим для многих
оправданных нападок. Одно из наиболее слабых мест— пристрастие в пользу чисто
символьных задач. Тест не затрагивает способностей, требующих навыков перцепции или ловкости
рук, хотя подобные аспекты являются важными составляющими человеческого интеллекта.
Иногда же, напротив, тест Тьюринга обвиняют в попытках втиснуть машинный интеллект в
форму интеллекта человеческого. Быть может, машинный интеллект просто настолько
отличается от человеческого, что проверять его человеческими критериями — фундаментальная
ошибка? Нужна ли нам, в самом деле, машина, которая бы решала матемалгческие задачи так
же медленно и неточно, как человек'? Не должна ли разумная машина извлекать выгоду из
своих преимуществ, таких как большая, быстрая, надежная память, и не пытаться
сымитировать человеческое познание? На самом деле, многие современные практики ИИ (например
[Ford и Hayes, 1995]) говорят, что разработка систем, которые бы выдерживали всесторонний
тест Тьюринга, — это ошибка, отвлекающая нас от более важных, насущных задач:
разработки универсальных теорий, объясняющих механизмы интеллекта людей и машин и
применение этих теорий к проектированию инструментов для решения конкретных практических
проблем. Все же тест Тьюринга представляется нам важной составляющей в тестировании и
"аттесташш" современных интеллектуальных программ.
Тьюринг также затронул проблему осуществимости построения интеллектуальной
программы на базе цифрового компьютера. Размышляя в терминах конкретной
вычислительной модели (электронной цифровой машины с дискретными состояниями), он
сделал несколько хорошо обоснованных предположении касательно ее объема памяти,
сложности программы и основных принципов проектирования такой системы. Наконец,
он рассмотрел множество моральных, философских н научных возражений возможности
создания такой программы средствами современной технологии. Отсылаем читателя к
статье Тьюринга за познавательным и все еще актуальным изложением сути споров о
возможностях интеллектуальных машин.
Два возражения, приведенных Тьюрингом, стоит рассмотреть детально. "Возражение
леди ЛавлеЙс". впервые сформулированное Адой Лавлсйс, сводится к тому, что
компьютеры могут делать лишь то, что им укажут, и, следовательно, не могут выполнять
оригинальные (читай: разумные) действия. Однако экспертные системы (см. подраздел 1.2.3 и
главу 7), особенно в области диагностики, могут формулировать выводы, которые не
были заложены в них разработчиками. Многие исследователи считают, что творческие
способности можно реализовать программно.
Глава 1. Искусственный интеллект: история развития и области приложения
„„„„„ости поведения", связано с невозможностью
другое возражение, "аргумент естеств „нд„видуу„у. что в точности нужно де
--им правил, которые бы гов°>' Действительно, гибкость, позво
другоевозр««. -г - , говорили ищи.»"*//-/. —
создания набора "РМИ"0™Р"СЧ'(,„ о6стоятсльств. Действительно, гибкость, позво.
лить при каждом возможном стс практически на бесконечное количество
ляюша, 6»°»°™4KKOMy0MP"^/cCe™PZe и «с оптимальным образом - отличитель-
различны* ситуации „риемлемым еслм» что ощм ис
на, черта разумного "^'^"Р*"^ тт ьт программ, не проявляет вели.
ГК: ГГ^рГГ:: неверно. что все программы должны писаться
„„"обнь м^разом. Большая часть работ в сфере ИИ за последние 25 лет была
направлена „а рГаботку таких языков программирования и моделей, призванных устранить
Помянутый недостаток, как продукционные системы, объектные системы, сетевые
представления и другие модели, обсуждаемые в этой книге.
Современные программы ИИ обычно состоят из набора модульных компонентов, или
правил поведения, которые не выполняются в жестко заданном порядке, а активизируются
по мерс надобности в зависимости от структуры конкретной задачи. Системы обнаружения
совпадений позволяют применять общие правила к целому диапазону задач. Эти системы
необычайно гибки, что позволяет относительно маленьким программам проявлять
разнообразное поведение в широких пределах, реагируя на различные задачи и ситуации.
Можно ли довести гибкость таких программ до уровня живых организмов, все еще
предмет жарких еппров. Нобелевский лауреат Герберт Саймон сказал, что большей частью
своеобразие и изменчивость поведения, присущие живым существам, возникли скорее
благодаря сложности их окружающей ереды, чем благодаря сложности их внутренних
"программ". 8 [Simon. 1981] Саймон описывает муравья, петляющего по неровной,
пересеченной поверхности. Хотя путь муравья кажется довольно сложным, Саймон утверждает,
что цель муравья очень проста- вернуться как можно скорее в колонию. Изгибы и повороты
его пути вызваны встречаемыми препятствиями. Саймон заключает, что:
"Муравей, рассматриваемый в качестве проявляющей разумное поведение системы, на
самом деле очень прост. Кажущаяся сложность его поведения в большей степени отражает
сложность среды, в которой он существует".
Эта идея, если удастся доказать применимость ее к организмам с более сложным
интеллектом, составит сильный аргумент в пользу простоты, а следовательно, постижимо-
сти интеллектуальных систем. Любопытно, что, применив эту идею к человеку, мы
придем к выводу об огромной значимости культуры в формировании интеллекта. Интеллект,
похоже, не взращивается во тьме, как грибы. Для его развития необходимо
взаимодействие с достаточно богатой окружающей средой. Культура так же необходима для
создания человеческих существ, как и человеческие существа для создания культуры. Эта
мысль не умаляет могущества наших интеллектов, но подчеркивает удивительное
богатство и связь различных культур, сформировавших жизни отдельных людей. Фактически
на идее о том, что интеллект возникает из взаимодействий индивидуальных элементов
общества, основывается подход к ИИ. представленный в следующем разделе.
1.1.4. Биологические и социальные модели интеллекта: агенты
vct^S.M^|BCCM°,P<:"" иэт'!Ма™ЧС<:кий "<«од к задаче построения интеллеюуальиых
лХиТ'а^ГТ"111*-™ °СН0В0Й ЫИ0Г° Инте«™ »™«-я логические умозак-
ГгГдна IZZ\Г0"""1""" "" "о6к™»«^- самих логических рассуждений. Этот
взгляд „а „анис, язык „ мишЛс„нс ^^ ^^ ^^ ' ^ фШ]0соф,ш,
38
Часть I. Искусственный интеллект: его истоки и проблег
развитую в работах Пляши, Галилея. Декарта, Лейбниц» и многих других философов
упомянутых ранее в этой главе. Также он отражает неявные предположен! тесп^ыЗ*. Jet
бенно его взгляд на символьные рассуждения как критерий интеллекта, и веру что 'лобовое"
сравнение с человеческим поведением пригодно для подтверждения интеллекта машины
Опора на логику как способ представлення языка и логические выводы как основной
механизм разумных рассуждений настолько доминирует в западной философии что их
"истинность часто кажется очевидной и неоспоримой. Петому не удивительно что
подходы, основанные на этих предположениях, главенствуют в науке искусственного
интеллекта от ее зарождения до сегодняшнего дня.
Во второй половине XX века устои рационализма пошатнулись. Философский
релятивизм в разных своих формах задавался вопросом об объективном бвзисс языка, науки,
общества н самой мысли. Философия поздних работ Витттенштсйна [Wittgenstein. 1953J
вынудила пересмотреть понятие смысла в естественных и формальных языках. Труды
Гсделя и Тьюринга подвергли сомнению основания самой математики.
Постмодернистские идеи изменили наши взгляды на значимость н ценность в художественном и
социальном контекстах. Искусственный интеллект также стал жертвой подобной критики
Действительно, трудности, которые встали на пути ИИ к его целям, часто
рассматриваются как свидетельства ошибочности рационалистического взгляда [Winograd и
Flores, 1986], [Lakoff и Johnson, 1999].
Две философские традиции — ВитттенштеЙна с Хассерлом [Husserl, 1970,1972] и
Хайдегтера [Heidegger, I962] являются основополагающими в этом пересмотре западной
философии. В своей работе Виттгенштейн затронул многие допущения рационалистской
традиции, включая основания языка, науки и знания. Естественный язык был главным
предметом анализа ВитттенштеЙна. Этот философ опровергает мнение, что смысл
человеческого языка можно вывести из каких-либо объективных основ.
В трудах В иттген штейна, как и в теории речи (speech act theory), развитой Остином
[Austin, 1962] и его последователями [Grice. 1975]. [Searle. 1969], значение любого
высказывания зависит от человеческого, культурного контекста. Значение слова "сиденье",
к примеру, зависит от наличия физического объекта, который можно применить для
сидения на нем, а также культурных соглашений об использовании сидений Когда,
например, большой плоский камень можно назвать сиденьем? Почему нелепо так называть
королевский трон? Какая разница между человеческим пониманием "сиденья" и
пониманием кота или собаки, которые в человеческом смысле сидеть не могут? Атакуя основы
смысла. Виттгенштейн утверждал, что мы должны рассматривать использование языка
посредством выбора и действий в изменчивом культурном контексте. Виттгенштейн
даже распространил свою критику на науку н математику, утверждая, что они в такой же
мере общественные конструкции, как и языки.
Хассерл. отец феноменологии, рассматривал абстракции как объекты, укоренившиеся
в конкретном "жизненном мире": рационалистская модель отодвигает конкретный
поддерживающий ее мир на второй план. Для Хассерла. как и для его ученика Хайдегтера и
их сторонника Мерло-Понти [Merleau-Ponty. 1962J. интеллект заключался не в знании
истины, а в знании, как вести себя в постоянно меняющемся и развивающемся мире 1а-
кнм образом, в экзистенциалистско-фсномснологической традиции интеллект
рассматривается скорее с точки зрения выживания в мире, чем как набор логических
утверждений о мире (в сочетании со схемой вывода).
Многие ааторы. например Дрейфусы [Dreyfus и Dreyfus. 1985[._а также Виноград и
Флорес [Winograd и Flores, 1986), опирались на работы Витггенштеина, Хассерла и Хаи-
Глава 1 Искусственный интеллект история развития и области приложения
-.ктики ИИ продолжают разработку рацио-
в гвоей критике ИИ- Хотя многие нра й как G0FAI. или Good Old
SS^SS ^Т°*^^юшк число исследователей этой об-
тГыппео AI- старый-Добрый ИИ). >«F занимательные модели интеллекта.
^Гприн- во внимание эту ^^'^Zon^^ ^VfP^ ^^-ш^
^^^^^^ интеллектуального поведения, иногда называе-
™ ««^"««wi*™- пП(ческому подходу - исследования в области коннекциони-
Пример альтернативы логическому ^ ^ ^^ логике н ра6оте рациональ.
стского обучения (см. «ОД!»»*1; 1"^ н0 сделана попытка достичь разумности посред-
ного разума уделяется мало внимав .Q ^^ q нейроннЬ]Х моделях интеллекта
с-гвом моделирования ^'^адаптироваться к миру, в котором он существует, с
упор делается на ™™™^J^ отдельными нейронами. Знание в т-ких системах не
:ы;аГ~^^^^ а ч**™-™в неявнои форме-как
свойство конфиорацинтаки^^^^ навсяна процессами Marrraillll
ИНШ1Т,^^ZZ r££Z искусственной жизни и генетических адгорит-
видов к окружающей среде- В разраошк* ' ' „„„меняются для решения сложных
-(см. главу U)np™«
^^S^SS м^ собо^ешений-кандидатов и заставляют их
^С^овГсГе помощТ процессов, имитирующих биологическую эволюцию: не-
удачные~ы на решена отмирают, в то время как подающие надежды выживают и
воспроизводятся путем создания новых решений из частей "успешных родителей.
Социальные системы дают еще одно модельное представление интеллекта с помощью
глобального поведения, которое позволяет им решать проблемы, которые бы не удалось
решить отдельным их членам. Например, хотя ни один индивидуум не в состоянии точно
предсказать количество буханок хлеба, которое потребит в заданный день Нью-Йорк,
система всех нью-йоркских пекарен отлично справляется со снабжением города хлебом и
делает это с минимальными затратами. Рынок акций отлично устанавливает относительную
ценность сотен компаний, хотя каждый отдельный инвестор имеет лишь ограниченное
знание о нескольких компаниях. Можно привести также пример из современной науки.
Отдельные исследователи из университетской, производственной или правительственной
среды сосредоточиваются на решении общих проблем. С помощью конференций и журналов,
служащих основным средством сообщения, важные для общества в целом проблемы
рассматриваются и решаются отдельными агентами, работающими отчасти независимо, хотя
прогресс во многих случаях также направляется субсидиями.
Эти примеры имеют два общих аспекта. Во-первых, корни интеллекта связаны с
культурой и обществом, а следовательно, разум является эмерджентным (emergent). Во-
вторых, разумное поведение формируется совместными действиями большого числа
очень простых взаимодействующих полуавтономных индивидуумов, или агентов.
Являются агенты нервными клетками, индивидуальными особями биологического вида или
же отдельными личностями в обществе, их взаимодействие создаст интеллект.
Рассмотрим основные аспекты агентских и эчерджентных взглядов на интеллект.
1. Агенты автономны или полуавтономны. Следовательно, у каждого агента есть
определенный круг подзадач, причем он располагает малым знанием (или вовсе
не располагает знанием) о том, что делают другие агенты или как они это дела-
40
Часть 1. Искусственный интеллект: его истоки и проблемы
выдаст собственно результат (что-то совершает) либо сообщает результат
другим агентам.
2. Агенты являются "внедренными". Каждый агент чувствителен к своей
окружающей среде и (обычно) не знает о состоянии полной области существования агентов.
Таким образом, знание агента ограничено его текущими задачами: "файл, который
я обрабатываю" или "стенка рядом со мной", агент не владеет информацией обо
всех файлах одновременно или физических границах предметной области.
3. Агенты взаимодействуют. Они формируют коллектив индивидуумов, которые
сотрудничают над решением задачи. В этом смысле их можно рассматривать как
"сообщество". Как и в человеческом обществе, знания, умения и обязанности
распределяются среди отдельных индивидуумов.
4. Сообщество агентов структурировано. В большинстве агентно-ориентированных
методов решения проблем каждый индивидуум, работая со своим собственным
окружением и навыками, координирует общий ход решения с другими агентами.
Таким образом, окончательное решение можно назвать не только коллективным, но и
кооперативным.
5. Наконец, явление интеллекта в этой среде является "эмерджентным". Хотя
индивидуальные агенты обладают некоторыми совокупностями навыков и
обязанностей, общий, совместный, результат сообщества агентов следует рассматривать как
нечто большее, чем сумма отдельных вкладов. Интеллект рассматривается как
явление, возникающее в сообществе, а не как свойство отдельного агента.
Основываясь на этих наблюдениях, определим агента как элемент сообщества,
который может воспринимать (часто ограниченно) аспекты своего окружения и
взаимодействовать с этой окружающей средой либо непосредственно, либо путем сотрудничества с
другими агентами. Большинство интеллектуальных методов решений требуют наличия
рвзнообрвзных агентов. Это могут быть простые агенты-механизмы, задача которых —
собирать и передавать информацию; агенты-координаторы, которые обеспечивают
взаимодействие между другими агентами; агенты поиска, которые перебирают пакеты
информации и возвращают какие-то избранные частицы: обучающие агенты, которые на
основе полученной информации формируют обобщающие концепции; и агенты,
принимающие решения, которые раздают задания и делают выводы на основе ограниченной
информации и обработки. Возвращаясь к старому определению интеллекта, агенты
можно рассматривать как механизмы, обеспечивающие выработку решения в условиях
ограниченных ресурсов и процессорных мощностей.
Для разработки и построения таких сообществ необходимы следующие компоненты.
1. Структуры для предстааления информации.
2. Стратегии поиска в пространстве альтернативных решений.
3. Архитектура, обеспечивающая взаимодействие агентов.
В последующих главах, в частности в разделе 6.4. приводятся рекомендации для
создания средств поддержки таких агентских сообществ.
Это предварительное рассмотрение возможностей теории автоматизированного
интеллекта ни в коей мерс не ставит себе целью преувеличить достижения, полученные до
настоящего времени или преуменьшить работу, которую еще предстоит проделать, в
этой книге постоянно подчеркивается, как важно четко представлять себе границы на-
Глава 1 Искусственный интеллект- история развитии и области приложения
„„. сверШен1.й. Например, очень ограниченные
„„^ожностсй и сегодняши"* к -ушться" в интересном для че-
""XTTi Гноении прогтамм. ^^ Мелировании семантической
скости естественных языков к при» P сложностью и корректность»
2™, тзкнх как °?™»™"*™Т„Г .^большой базы знании), требуются
значи«льные дальнейшие исследован^ °™°» сний в качестве и общности своих
коммерческого успеха, имеют все идьмн V ^ ^^ . „ смыыи„
выводов. В частности, они не спосо р^ ^ просте,-1цшх своистви реального
(commonsense reasoning) или *е про п1 разнЬ1е вещи.
мира, например, о том. как "™=™ю" J^,,. обозреть достижении искусственного
Но следует сохранять трезвый вз 6 в следующем разделе мы
1.2. Обзор прикладных областей искусственного
интеллекта
не превосходят наших знаний о том. как приказать ей что-либо исполнить
— Ада Байрон (Ada Byron), графиил Лавлеис
Прости, Дейв, я не могу позволить тебе это сделать...
— HAL 9000, компьютер из фильма 200/: Космическая одиссея
Вернемся к заявленной пели дать определение искусственному интеллекту путем
обозрения стремлений и достижений исследователей этой области. Две наиболее
фундаментальные проблемы, занимающие разработчиков ИИ, — это представление
знаний (knowledge representation) и почек (search). Первая относится к проблеме
получения новых знаний с помощью формального языка, подходящего для
компьютерных манипуляций, всего спектра знаний, требуемых для формирования
разумного поведения. В главе 2 рассматривается исчисление предикатов как язык описания
свойств и отношений между объектами предметной области. Здесь для решен
нужны скорее рассуждения качественного характера, чем арифметические расчеты.
В главах 6-8 обсуждаются языки, разработанные для отражения неопределенностей
и структурной сложности таких областей, как рассуждения на основе "здравого
смысла" и понимание естественных языков. В главах 14 и 15 демонстрируется
использование языков LISP и PROLOG для реализации этих представлений.
Поиск— это метод решения проблемы, в котором систематически просматривается
пространство состояний задачи (problem stales), т.е. альтернативных стадии се решения.
Примеры состояний задачи: различные размещения фигур на доске в игре или же
промежуточные шаги логического обоснования. Затем в этом пространстве альтернативных
решений производится перебор в поисках окончательного ответа. Ньюэлл и Саймон
[Newell и Simon, 1976] утверждают, что эта техника лежит в основе человеческого
способа решения различных задач. Действительно, когда игрок в шахматы анализирует
последствия различных ходов или врач обдумывает различные альтернативные диагнозы.
42 Часть!. Искусственный интеллект: его истоки и проблемы
они производят перебор среди альтернатив. Результаты применения этой модели и
средства ее реализации обсуждаются в главах 3, 4, 5 и 16.
Как и большая часть наук, ИИ разбивается на множество поддисциплин, которые
разделяя основной подход к решению проблем, нашли себе различные применения'
Очертим в этом разделе некоторые из основных сфер применения этих отраслей и их
вклад в искусственный интеллект вообще.
1.2.1. Ведение игр
Многие ранние исследования в области поиска в пространстве состоянии
совершались на основе таких распространенных настольных игр, как шашки, шахматы и
пятнашки. Вдобавок к свойственному им "интеллектуальному" характеру такие игры имеют
некоторые свойства, делаюшие их идеальным объектом для экспериментов. Большинство
игр ведутся с использованием четко определенного набора правил: это позволяет легко
строить пространство поиска и избавляет исследователя от неясности и путаницы,
присущих менее структурированным проблемам. Позиции фигур легко представимы в
компьютерной программе, они не требуют создания сложных формализмов, необходимых
для передачи семантических тонкостей более сложных предметных областей.
Тестирование игровых программ не порождает никаких финансовых или этических проблем.
Поиск в пространстве состояний — принцип, лежащий в основе большинства
исследований в области ведения игр, — представлен в главах 3 и 4.
Игры могут порождать необычайно большие пространства состояний. Для поиска в
них требуются мошные методики, определяющие, какие альтернативы следует
рассматривать. Такие методики называются эвристиками и составляют значительную область
исследований ИИ. Эвристика — стратегия полезная, но потенциально способная
упустить правильное решение. Примером эвристики может быть рекомендация проверять,
включен ли прибор в розетку, прежде чем делать предположения о его поломке, или
выполнять рокировку в шахматной игре, чтобы попытаться уберечь короля от шаха.
Большая часть того, что мы называем разумностью, по-видимому, опирается на эвристики,
которые люди используют в решении задач.
Поскольку у большинства из нас есть опыт в этих простых играх, можно попробовать
разработать своп эвристики и испытать их эффективность. Для этого нам не нужны
консультации экспертов в каких-то темных для непосвященных областях, вроде медицины
или математики. Поэтому игры являются хорошей основой для изучения эвристического
поиска. Глава 4 рассказывает об эвристиках на примере этих простых игр; в главе 7 их
использование распространяется на построение экспертных систем. Программы ведения
игр, несмотря на их простоту, ставят перед исследователями новые вопросы, включая
вариант, при котором ходы противника невозможно детерминировано предугадать
(см. главу 8). Наличие противника усложняет структуру программы, добавляя в нее
элемент непредсказуемости и потребность уделять внимание психологическим и
тактическим факторам игровой стратегии.
1.2.2. Автоматические рассуждения и доказательство теорем
Можно сказать, что автоматическое доказательство теорем — одна из старела
частей искусственного интеллекта, корни которой уходят к системам Logic »r"^nsl
(логический теоретик) Ньюэлла и Саймона [Newell и Simon. 1963л] и General Problem
Глава 1. Искусственный интеллект: история развития и области приложения 43
ь задач) [№
■well и Simon, 19636] и далее, к попыткам Рас-
Sdver (универсальный решатель задач, .^ ^^ форм х выводов „ т
села и Уайтхеда построить всю матем ^ пртест „аиболес богатые плоды. Благо-
„ачальных аксиом. В любом случаю теорем 6ьцш формализованы алгоритмы
даря исследованиям в области ^ едставлений, такие как исчисление предика-
„оиска и разработаны *«^Д«-" РК0Ш° (™M '4)'
тов (см. главу 2) и логический яз н доказательства теорем основана на строгости и общ-
Привлекателъностъ автом„ е логика располагает к автоматизации. Разнообразные
нести логики. В формальной си СТшт описание задачи и существенную относя-
проблемы можно попытаться ре ^^^ ^„^ „ рассматривая различные случаи задачи
шуюся к ней информацию в вид принцип лежит в основе автоматического доказа-
как теоремы, которые ^^и« „Званий (cm. главу 12).
^ЗГ:"п;Гн-,сать„ро^Му№автома™ческогодоказГЯва
не у^™&т1 систему, которая бы единообразно решала сложные задачи. Это было
оЗГено^особностью любой относительно сложной логической системы сгенерировать
бесконечное количество доказуемых теорем: без мошных методик (эвристик), которые бы „а-
правляли поиск, программы доказывали большие количества не относящихся к делу теорем,
пока не натыкались на нужную. Из-за этой неэффективности многие утверждают, что чисто
формальные синтаксические методы управления поиском в принципе не способны
справиться с такими большими пространствами, и единственная альтернатива этому — положиться на
неформальные, специально подобранные к случаю (лат. "ad hoc") стратегии, как это, похоже,
делают люди. Это один из подходов, лежащих в основе экспертных систем (см. главу 7), и он
оказался достаточно плодотворным.
Все же привлекательность рассуждений, основанных на формальной логике, слишком
сильна, чтобы ее игнорировать. Многие важные проблемы, такие как проектирование и
проверка логических цепей, проверка корректности компьютерных программ и управление
сложными системами, по-видимому, поддаются такому подходу. Вдобавок исследователям
автоматического доказательства удалось разработать мощные эвристики, основанные на
оценке синтаксической формы логического выражения, которые в результате понижают
сложность пространства поиска, не прибегая к используемым людьми методам "ad hoc".
Еще одной причиной неувядающего интереса к автоматическому доказательству теорем
является понимание, что системе не обязательно решать особо сложные проблемы без
человеческого вмешательства. Многие современные программы доказательств работают как ум-
ки'^П'ЗГ'1,рСД0Сгавляя людям Рш6™ *дачи на подзадачи и продумывать эвристи-
Гока^З™Р^ПРО<ЛРа"?С вюмо™ «беснований. Программа для автоматического
шее™™ РСШЗ" простые задачи доказательства лемм, проверки менее су-
1.2.3. Экспертные системы
с.,сциф„ч„ГоГд^Пр"даТ^Х1ст>,7Г ИССЛеД™аш,Г' по ИИ стало осознание важности
агнесгарует болезни не потому чт„™ "t,oma">sPe<:irK) знания. Врач, к примеру, хорошо
диетами к решению задач а потому что '°Лагает неки™ врожденными общими способно-
тивно находит залежей ископаемых „„'Г™ 2"Ю ° Mm"»mt. Точно так же геолог эффек-
ские и практические знания о геологГ'5' ™ °" СПОСОбеН применить богатые теорегичс
™лоп,и к текущей проблеме. Экспертное знание- это
Часть I. Искусственный интеллект: его истоки и проблемы
сочетание теоретического понимания проблемы и ияй™,,
Z», которые, как показывает опыт. эфГ^ны TZZ?*"™*""? "<*""" """ М РСШе-
с^гемы создаются с помощью заимствовав„аниП че Г™°" ^^ ЭКСПСртНЫе
„^вформу.которую компьютер может п^,У£ГГ°п^" "^
Стратегии экспертных систем основаны на знаниях „„».„ проблемам,
^аммы пишутся самнмн„осителяИиэт„„йо;™^^^^^
^^ - с ~_ эксперт предоставляет необходимые знания о
предметно,, области, опись», свои методы принят™ решении и демонстрируя эти навыки „а
„дательно отобранных примерах. Специалист по ИИ, или инженер посияй (taowtafce
engineer), как часто называют разработчиков экспертных систем, отвечает за реализацию
этого знания в программе, которая должна работать эффективно и внешне разумно. Экспертные
способности программы проверяют, давая ей решать пробные задачи. Эксперт подвергает
критике поведение программы, н в ее базу знаний вносятся необходимые изменения. Процесс
повторяется, пока программа не достигнет требуемого уровня работоспособности.
Одной нз первых систем, использовавши специфичные для предметной области знания,
была система DENDRAL, разработанная в Стэнфорде в конце 1960-х [Lindsay и др., 1980]!
DENDRAL была задумана для определения строения органических молекул из химических
формул и спектрографических данных о химических связях в молекулах. Поскольку
органические молекулы обычно очень велики, число возможных структур этих молекул также
весьма внушительно. DENDRAL решает проблему большого пространства перебора применяя
эвристические знания экспертов-химиков к решению задачи определения структуры. Методы
DENDRAL оказались весьма работоспособными. Она методично находит правильное
строение из миллионов возможных всего за несколько попыток. Данный подход оказался столь
эффективным, что "потомки" этой системы до сих пор используются в химических и
фармацевтических лабораториях по всему миру.
Программа DENDRAL одной из первых использовала специфичное знание для
достижения уровня эксперта в решении задач, однако методика современных экспертных
систем связана с другой программой — MYCIN [Buchanan и Shortliffe, 1984]. В ней
использовались знания экспертов медицины для диагностики и лечения спияального
менингита и бактериальных инфекций крови.
Программа MYCIN, разработанная в Стэнфорде в середине 1970-х, одной из первых
обратилась к проблеме принятия решений на основе ненадежной или недостаточной информадии.
Она выводит ясные и логичные пояснения своих рассуждений, используя структуру
управляющей логики, соответствующую специфике предметной области, и критерии для надежной
оценки своей работы. Многие методики разработки экспертных систем, ислольэуюшнеся
сегодня, были впервые разработаны в рамках проекта MYCIN (см. главу 7).
К числу других классических экспертных систем относится программа
PROSPECTOR, определяющая предполагаемые рудные месторождения и их
^основываясь на геологических данных о местности (Duda„JP.. 1979.. l»™^^
INTERNIST, применяемая для диагностики в сфере медицины »Н>^Т" "f™^,
грамма Dipmeter Advisor, интерпретирующая протоколы буренш «*™^^™
[Smith и Baker, 1983J; и XCON, используемая для настройки -«пьютеров^«^_
Тамма XCON была разработана в .981 г.. и одно время все маши ы »Лр^
«-емые компанией Digital Equ.pment, настраивались это ^м ^<но
экспертные системы решают в настоящее время задачи в^таких об. а
образование, бизнес, дизайн и научные исследования (Waterman. 19М». |u
'«а 1. Искусственный интеллект: история развитин и области приложения
45
экспертных систем были написаны дм спе-
л™етить. что большинство довольно хорошо изучены и распо-
И"ТереС"° Гпр™«««ь.х областей. Эти облает д п 6ле„ы, определенны,
"ГтТГ Дленными стратег-н;Р™ииР средствами решить сложнее. Не-
Г^еткой основе "-Р—° "^ вь1 "инертных систем, было бы „шибкой „ере.
смотр, на .оодуше— «£*^ ^^ Проблемь1 перечислены „„же.
оценивать возможности _ предметной области. Системе MYCIN, к
1 Трудности в передаче "глубоки ^^ ЧСЛОВечсской физиологии. Она „е
примеру, не достает действ. или СПИНИ0Г0 мозга. Ходит предание,
знает, какова фуншия 4ю» »°c"°" и менингита. MYCIN спросила, бере-
что однажды, подбирая лекарство дзи ^ ^ .„„„,.„„„ ппла Кыло это и* ^...»..
знает,
4TOOJ
мен ли
нл.
„ости знаний экспертной системы.
что однажды, подоирая^»»!»--- -^- пациент муЖского пола. Было это на самом
деле юл, нет, „=нзвес™о,'„^то хорошая иллюстрация потенциальной ограничен-
„аииект, хотя ей указали, что г
НОСТН JHUnn»-""■—г-
2 Недостаток здравомыслия „ гибкости. Если людей поставить перед задачей, кото-
„то ™ не в состоянии решить немедленно, то они обычио исследуют сперва ос-
„овные принципы и вырабатывают какую-то стратегию для подхода к проблеме.
Экспертным системам этой способности не хватает.
3 Неспособность предоставлять осмысленные объяснения. Поскольку экспертные систе-
мы не владеют глубоким знанием своей предметной области, „х пояснения обычно
ограничиваются описанием шагов, которые система предприняла в поиске решения. Но
они зачастую не могут пояснить, "почему" был выбран конкретный подход.
4. Трудности в тестировании. Хотя обоснование корректности любой большой
компьютерной системы достаточно трудоемко, экспертные системы проверять
особенно тяжело. Это серьезная проблема, поскольку технологии экспертных систем
применяются для таких критичных задач, как управление воздушным движением,
ядерными реакторами и системами оружия.
5. Ограниченные возможности обучения на опыте. Сегодняшние экспертные системы
делаются "вручную"; производительность разработанной системы не будет
возрастать до следующего вмешательства программистов. Это заставляет серьезно
усомниться в разумности таких систем.
Несмотря на эти ограничения, экспертные системы доказали свою ценность во
многих важных приложениях. Будем надеяться, что недоработки сподвигнут студентов
заняться этой важной отраслью компьютерных наук. Экспертные системы — одна из
основных тем этой книги Они подробно обсуждаются в главах 6 и 7.
1.2.4. Понимание естественных языков и семантическое моделирование
г,амГ™особД„°ьГСРОЧ"ЫХ ЦМеЙ "скУс™™»ого интеллекта является создание про-
1,м ШГ„ „1ГИШТЬ ,е"0Ве'1,:™'й ™" » строить фразы „а „ем. Способность
ч«огоТнт"ГкТа ССТССТВеКНЫ" "« ™™ Фундаментальным аспектом человс-
ности сам^ТоГью" ВУСМ„Г ~Г "^ «* " —^ ^"В'
нимаюшнхестеСТве„„ьи1язьГх"ТяГи "Г" ™ТР™'"" "' НаПИСаН"е "Р°'ТаММ'
контекстах, системы использую пРогРаммы и достигли успеха в ограниченных
рактерной для человеческой ~,J""'"атуРальмые «ыки с гибкостью и общностью, ха-
рсчи, лежат за пределами сегодняшних методологий.
46
I. Искусственный интеллект: его истоки и проблем"
Понимание естественного языка включая- с
индивидуальные части речи и поиск ,„,„ - 6мьше' чем разбор предложений на
„ом фоновом знании о прелме ™ беседь, „'ГнГ " ™^ °"° Ь^™ "а °6шир"
же. как н „а способности np„„0„»Tbo6'LT ис"м»У="ь,х в этой области, так
домолвок„неяс„осте,г„р„сРуГк^
а .. ,, "сторин и игроках. Способен ли такой человек понял,
смысл фразы: 'в центре Иванов пеоехпятиг, „-„„.,, к понять
,. перехватил верхнюю передачу— мяч полетел к шттсиЬной
соперника, там за него на втором этаже" ™к™лп,„. пЛ ^ штрафной
к „ - , ' м зтаже поооролись Петров и Сидоров, после чего был
сделан пас на Васина в штрафную, который из-под защитника по^мом^обнл точно в дальне
угол ? Хотя каждое отдельное слово в этом предложении можно понять, фраза звучит
совершенной тарабаршинои для любого нефаната, будь он хоть семи пядей во лбГ
Задача сбора и организации этого фонового знания, чтобы его можно было
применить к осмыслению языка, составляет значительную проблему в автоматизации
понимания естественного языка. Для ее решения исследователи разработали множество методов
структурирования семантических значений, используемых повсеместно в искусственном
интеллекте (см. главы 6. 7 и 13).
Из-за огромных объемов знаний, требуемых для понимания естественного языка, большая
часть работы ведется в хорошо понимаемых, специализированных проблемных областях.
Одной из первых программ, использовавших такую методику •'микромира", была программа
Винограда SHRDLU — система понимания естественного языка, которая могла ••беседовать''
о простом взаимном расположении блоков разных форм и цветов [Winograd, 1973]
Программа SHRDLU могла отвечать на вопросы типа: "какого цвета блок на синем кубике?", а также
планировать действия вроде "передвинь красную пирамидку на зеленый брусок". Задачи
этого рода, включая управление размещением блоков к их описание, на удивление часто
всплывали в исследованиях ИИ и получили название проблем "мира блоков".
Несмотря на успехи программы SHRDLU в разговорах о расположении блоков, она
была не способна абстрагироваться от мира блоков. Методики представления,
использованные в программе, были слишком просты, чтобы передать семантическую организацию
более богатых и сложных предметных областей. Основная часть текущих работ в области
понимания естественных языков направлена на поиск формализмов представления, которые
должны быть достаточно общими, чтобы применяться в широком круге приложений и
уметь адаптироваться к специфичной структуре заданной области. Множество
разнообразных методик (большинство из которых являются развитием или модификацией
семантических сетей) исследуются с этой целью и используются при разработке программ,
способных понимать естественный язык в ограниченных, но достаточно интересных предметных
областях. Наконец, в текущих исследованиях [Marcus. 1980], (Manning и Schutze. 1999].
[Jurafsky и Martin. 2000) стохастические модели, опнсываюшис совместное использование
слов в языке, применяются для характеристики как синтаксиса. 1ак я семантики. Полное
понимание языка на вычислительной основе все же остается далеко за пределами ,овпе-
менных возможностей.
1.2.5. Моделирование работы человеческого интеллекта
В большей части рассмотренного выше материала ™°^™™^™ZZ
ж„т отправной точкой в создании искусственного, однако это не означит что пр
гра .должны формироваться „о образу „ подобию человеческою раз>ма Дейч
Глава 1. Искусственный интеллект: история развития и соласги приложения
47
„тся ДМ решения каких-то насущных задач
, программы ИИ с.оМа"тсктуры. Даже экспертные системы, за„„.
„„тельно. многие: V мся1альнои арм в.людей, не пытаются моделировать
6„ учета чел0" ь „осго знания у ^^ производительность системы _ это
дауя большукI ^ человеческого ум мо6ых ос„ованин имитировать человече-
внутреннне пр . се качества, "е которые используют несвойственные
единстве»"»»! v ^ решен1Ш. Програ . . ^ человеческие соперники. Тем не
ские методуi пр ^^ шк успешны. дстальн0 модел„р0валн какой-либо ас-
ГиГкГструированне систем^ ^ плодотворной областью исследований как в
„ект работ" интеллекта че ^ холог1,и.
„ к^сственном "««»е1а,еч™ в ческото разум» помимо обеспечения ИИ его основной
Моделирование работы ™°8 Ч м для формулирования и испытан™ теорий
„етодологией оказалось мощи™ Р |Ц, решений, разработанные теоретиками
человеческого познан,!». Ме™° ю от„равную точку для исследования человс-
компьютерны" наук, дали пенхо ^ ^^ п03„ания на неясном языке ранних
ческого разума. Вместо ™™\ попшк|, ого1Сания внутренних механизмов человече-
„кледований или вообще ос, ^mmmn[ m изучению поведения), многие психо-
сюго интеллекта (как ^м» компьютерной науки для разработки моделей челове-
лоп, приспособил,. » Р тмько даю1 новую терм„нологию для характеристики
ческого разума, i акие м реализация этих теорий предоставляет психо-
-овеческого интеллекта. К мпьютернJ ковать „ уточнять „х идеи
££ ~^™~™* «еад ИИ „ попытками понять человеческий р,
зум приводится ниже и резюмируется в главе 16.
1.2.6. Планирование и робототехника
Исследования в области планирования начались с попытки сконструировать роботов,
которые бы выполняли свои задачи с некоторой степенью гибкости н способностью
реагировать на окружающий мир. Планирование предполагает, что робот должен уметь
выполнять некоторые элементарные действия. Он пытается найтн последовательность
таких действий, с помощью которой можно выполнить более сложную задачу, например,
двигаться по комнате, заполненной препятствиями.
Планирование по ряду причин является сложной проблемой, не малую роль в
этом играет размер пространства возможных последовательностей шагов. Даж_
очень простой робот способен породить огромное число различных комбинации
элементарных движений. Представьте себе, к примеру, робота, который может
передвигаться вперед, назад, влево и вправо, и вообразите, сколькими различными
путями он может двигаться по комнате. Представьте также, что в комнате есть
препятствия, и что робот должен выбирать путь вокруг них некоторым оптимальным
образом. Для написания программы, которая могла бы разумно определить лучший путь
из всех вариантов, и не была бы при этом перегружена огромным их числом,
потребуются сложные метопч цпп „„
• ■ - "™ь "еюды для представления пространственного знания и управления
перебором в пространстве апчт..™.
Одним из методов.
я сложные методы для при
е альтернатив.
~~""™ " "стожш- применяемых человеческими существами при планировании, яв-
гГп^Г'^Т дект,"™"1«» ™>ач„ (hierarchical problem decomposition). Плани-
ции гкГтеГг? " Д°Н- ■""• СК°РСе ВСег0' мйм««=ь °™»™° проблемами
организации перелета, поездки до аэропорта, самого полета и поиска подходящего вида транс-
48
I- Искусственный интеллект: его истоки и проблем*
порта в Лондоне, хотя все они яич<и™.
задач может сама быть раз6ииГа\ ™Г"""" Ш°Г° °бЩеГ° ПЛаНа' К™м '" ™
да, преодоление лабиринта лГний ,сГ„ "' ^ "аПрИМер- П0КуПЮ Юр™ ™Р°-
только эффективно ограничивает о'Т "<*"™н«" пивной. Такой подход пе
рзмеР пространства поиска но и позволяет сохпяиятк
часто используемые маршруты для дальнейшего применения Р
В то время как люди разрабатывают планы безо всяких усилий создание компьютер
„ои программы, которая бь, занималась тем же - сложная проблема. КаТГось бы 3
простая вешь, как разбиение задачи „а независимые подзадачи, „а самом деле tpZt
изощренных эвристик и обширного знания об области планирования. Не менее сГжнаэ,
проблема - определить, какие планы следует сохранить, и как их обобщить для иеполь-
зования в будущем.
Робот, слепо выполняющий последовательности действий, не реагируя на изменения
в своем окружении, или неспособный обнаруживать и исправлять ошибки в своем
собственном плане, едва ли может считаться разумным. Зачастую от робота требуют
сформировать план, основанный на недостаточной информации, и откорректировать свое
поведение по мере его выполнения. Робот может не располагать адекватными сенсорами для
того, чтобы обнаружить все препятствия на проектируемом пути. Такой робот должен
начать двигаться по комнате, основываясь на "воспринимаемых"' им данных, и
корректировать свой путь по мере того, как выявляются другие препятствия. Организация
планов, позволяющая реагировать на изменение условий окружающей среды, — основная
проблема планирования [Lewis и Luger, 2000].
Наконец, робототехника была одной из областей исследований ИИ. породившей
множество концепций, лежащих в основе агентно-ориентированного принятия решений
(см. подраздел 1.1.4). Исследователи, потерпевшие неудачу при решении проблем,
связанных с большими пространствами представлений и разработкой алгоритмов поиска для
традиционного планирования, переформулировали задачу в терминах взаимодействия
полуавтономных агентов [Agre и Chapman, 1987], [Brooks, 199 In]. Каждый агент отвечает за свою
часть задания, и общее решение возникает в результате их скоординированных действий.
Элементы алгоритмов планирования будут представлены в главах 6.7 и 14.
Исследования в области планирования сегодня вышли за пределы робототехники,
теперь онн включают также координацию любых сложных систем задач и целей.
Современные планировщики применяются в агентских средах [Nilsson, 1994], а также для
управления ускорителями частиц [Klein и др., 1999, 2000].
1.2.7. Языки и среды ИИ
Одним из наиболее важных побочных продуктов исследований ИИ ста.™ достижения
в сфере языков программирования и средах разработки программного обеспе^ния. По
множеству причин, включая размеры многих прикладных программ ИИ.
важность.методологии Создания прототипов", тенденцию алгоритмов поиска порождать чересчур
большие пространства и трудности в предсказании поведения "Р"™~»££££
программистам искусственного интеллекта пришлось разработать мощную систему
методологий программировали». стрмсгяигровати знаний, как
Средства программ„роваиия включаюн^кГасы ^пертьГсистем (они обсу-
обьектно-орментироваиное программиро анне и«ркж- р ^ [у>
ждаются в части III). Высокоуровневые язы "^J^ , с ^tpua „
которые обеспечивают модульную разраоотку, и«~
Глава 1. Искусственный интеллект: история развития и
49
метровки позволяют программистам реконст-
„ью программ. Пакеты 'Р«"в JL, „ разобраться в сложных структурах эвр„.
C^^:^i:::::^^^ ••мсгодик °ряд ли удщ,ось 6ы пои1ю-
отческого "=PJ системы ИИ. стандартными методами разработки про-
"ТЬ:=: Гзтнх метода --"ГяТоеГовам: теории ИИ. Другие же. такие как
граммкого обеспечена ..мм» coo £| имеют ЗН0ЧИТСЛЬНЬ1Н теоретический „
объектно-ориентированное програр ,„„„, ии „„час реализуются на таких
практический интерес. На^"' ^ яшаХ1 как с++ „ Java,
традиционных для вычислительно, шия т iQcm с|мзань1 с теоретической
Язык.., РшРаботанНЫеЛн„?иТните рассматривается и LISP, и PROLOG, и мы ста-
структурой этой области, в дан ^ ^ ^ относительных достоинствах, склоня-
рались удержаться от религии ь ^ ра6отник должен знать все инструменты".
TSi:^:Z»Zn программирования ,14 и ,5, рассматривают преимуЩсства
„рГнеГразличиых языков для решения конкретных задач.
1.2.8. Машинное обучение
Обучение остается "крепким орешком" искусственного интеллекта. Важность
обучения тем не менее, несомненна, поскольку эта способность является одной из главных
составляющих разумного поведения. Экспертная система может выполнять долгие и
трудоемкие вычисления для решения проблем. Но, в отличие от человеческих существ,
если дать ей такую же или подобную проблему второй раз, она не "вспомнит" решение.
Она каждый раз вновь будет выполнять те же вычисления — едва лн это похоже на
разумное поведение.
Большинство экспертных систем ограничены негибкостью их стратегий принятия
решений и трудностью модификации больших объемов кода. Очевидное решение этих
проблем — заставить программы учиться самим на опыте, аналогиях или примерах.
Хотя обучение является трудной областью, существуют некоторые программы,
которые опровергают опасения о ее неприступности. Одной из таких программ является
AM — Автоматизированный Математик, разработанный для открытия математических
законов [Lenat, 1977, 1982]. Отталкиваясь от заложенных в него понятий и аксиом
теории множеств, Математику удалось вывести из них такие важные математические
концепции, как мощность множества, целочисленная арифметика и многие результаты тео-
Рч™ ™ СТР0"Я те°РеМЫ' ««"ФииВД» свою базу знаний, и использовал эвристи-
Из вела ™ " ^ """^ нанл*чших ю «"ожестаа возможных альтернативных теорем.
р™р™ет " тсресныГ ° 0ТМЯтЬ ПР0ГРа™* К™ lC0tto" " «Р- М0°1- К0Т°-
о нсют интересные целочисленные последовательности
лоьанГГнГ "„Го"™ ГсГЕННМ ^ " *» °6"^ ~°* "^
боров "М„ра блоков" [Winston , "Х ^fW™ понятий, как построение "арок" из на-
обших принципов из разных п'п Алгоритм ID1 проявил способности в выделении
лит правила интерпретации ст^Т™ ' 1Ш"]- Си™ма Mela-DENDRAL выво-
мерах информации о веществах с 0Граф""сских «а"ных в органической химии на прн-
туальный ••интерфейс" для экспо С™°" стРУ«турой. Система Teiresias — интеллек-
уровневом языке в новые поавилГГГ-^™" ~ "Ре°бразуст сообщения на высоко-
"роитплаНь,лля„аиипу„ящ,йв«м„ д ЩЫ ЗНаний lDa«s, 1982). Программа Hacker
нре блоков" посредством итеративного процесса вы-
50
I- Искусственный интеллект: его истоки и проблемы
работки плана, его испытания „ коррекции выявленных недостатков |SUSSman, 1975].
Работа в сфере обучения, основанного „а ••пояснениях", продемонстрировала эффектна-
„ость для обучения априорному знанию [Mitchell и др., 1986], [DeJong и Моопеу. 1986].
Сегодня известно также много важных биологических и социологических моделей
обучения. Они будут рассмотрены в главах, посвященных коннекционистскому и змерд-
жентному обучению.
Успешность программ машинного обучения наводит на мысль о существовании
универсальных принципов, открытие которых позволило бы конструировать программы,
способные обучаться в реальных проблемных областях. Некоторые подходы к обучению
будут представлены в главах 9-11.
1.2.9. Альтернативные представления: нейронные сети
н генетические алгоритмы
В большей части методик, представленных в этой книге, для реализации интеллекта
используются явные представления знаний и тщательно спроектированные алгоритмы
перебора. Совершенно отличный подход состоит в построении интеллектуальных
программ с использованием моделей, имитирующих структуры нейронов в человеческом
мозге или эволюцию разных альтернативных конфигураций, как это делается в
генетических алгоритмах и искусственной жизни.
^Дендрит
Рис. 1.2. Упрощенная схема нейрона
Схематическое представление нейрона (рис. 1.2) состоит из клетки, которая имеет
множество разветвленных отростков, называемых бенари^ш, и одну етвь- ,»«>»
Дендрнть, принимают сигналы от других нейронов. Когда сумма =™ «"^f"^
шаст некоторую границу, нейрон сам возбуждается, и импульс шш си «°™
по аксону. Разветвления на конце аксона образуют снапсь, <•*%££?££££>■
нов. Синапс - это точка контакта между нейронами. Синапсы »°^6"™ш*ш,* ли
щими (excitatory) или т>р>,о*,щш,« (inhibitory), в зависимости от того, увеличиваю
они результирующий сигнал. передает основные черты, суще-
Такое описание нейрона необычайно^"^ каждый вычислительный
ственные в нейронных вычислительных моделях- результат к
элемент подсчитывает значение «««орои функции «оих в^J^^ ^.^.^ „,
присоединенным к нему элементам ест, к » ненронным„ соединснм-
раллсльной и распределенной обработки в сети, о i
ми н пороговыми значениями. средства реализации интеллекта по
Нейронные архитектуры привлекательны как PJ- ^ ^^ неустойчивы „
многим причинам. Традиционные программы , ^^ обработке такой
чувствительны к шуму. Человеческий интеллект куда
темненной комнате или разговор на шумной ве-
зашумлекной информации, каклиио, в » ^ пригодны для сопоставления эашум.
чсринке. Н^0""^^;^ поскольку они хранят знания в виде большого числа
мелких элементов, распределении»ino с™отдак „скусстве„„0й жизни мы вырабатываем
С помошью генетических алгорн^и „едьшущю решений. Генетические операторы, та-
иовые решения проблем из компонс н ^^ эишваюггам в реальном мире, вырабаты-
кие как скрещивание или МУПЩ|™Л''е „Шения. В искусственной жизни новые поколения
вают с каждым поколением все луш 1^^ ^ментов в прежних поколениях,
создаются на основе функции та алгоритмы дают естественные модели па-
И нейронные архитектуры, ™= ^^ нейрон или сегмент решения пред.
раллельной обработки *"»"«• f [Hiffis, 1985] отметил, что люди быстрее
сГраГютс Тз Г;™: Гда~ют ^ информации, . то врем, как комиьнэте-
Гь „аХрот замедляют работу. Это замедление происходит за счет увеличения време-
и 'последовательного поиска в базе знаний. Архитектура с массовым параллелизмом,
и пример человеческий мозг, не страдает таким недостатком. Наконец, есть нечто очень
привлекательное в подходе к проблемам интеллекта с позиции нервной системы или
генетики В конце концов, мозг есть результат эволюции, он проявляет разумное
поведение и делает это посредством нейронной архитектуры. Нейронные сети, генетические
алгоритмы и искусственная жизнь рассматриваются в главах 10и 11.
1.2.10. Искусственный интеллект и философия
В разделе 1.1 мы представили философские, математические и социологические
истоки искусственного интеллекта. Важно осознавать, что современный ИИ не только
наследует эту богатую интеллектуальную традицию, но и делает свой вклад в нее.
Например, поставленный Тьюрингом вопрос о разумности программ отражает наше
понимание самой концепции разумности. Что такое разумность, как ее описать? Какова
природа знания? Можно ли его представить в устройствах? Что такое навыки? Может ли
знание в прикладной области соотносится с навыком принятия решений в этой среде?
Как знание о том, что есть истина (аристотелевская "теория"), соотносится со знанием,
как это сделать ("практика")?
Ответы на эти вопросы составляют важную часть работы исследователей и
разработчиков ИИ. В научном смысле программы ИИ можно рассматривать как эксперименты.
э1с°пеГмТГр°"ТНУЮ Рсалюащм » ™« программы, и программа выполняется как
гр ммь и „о ^ "^ ПР0ГРШМЫ ШуЧаЮТ Р"*™™. » затем перестраивают про-
Гши р дста™ еГи аЭ„ГеР"Ме"Т' TaK™ 0браЗОМ вомо™° определи являются ли
в своей тьюрииговской лекщЛэт'б г ПреШЮ*и™ этот "°»°Д « научному познанию
Ф^есГй" ^оТн^истГГГГ 6°ЯЮ СИЛЬНУЮ М°ДМЬ ™™™ » »«й гипотезе о
только тогда, когда она является Zimr^ СИСТСма проявляет разумное поведение тогда и
сматривается практический смысл этой те С"МВ0"ЬН0Й систс«ой. В главе 16 подробно рас-
Многие применения ИИ подняли rnvf^P""'* Т№"К кРи™чсскне замечания в ее адрес.
заявить, что компьютер "понимает" ■taT"™ филосоФсв": вопросы. В каком смысле можно
ние языка требует толкован™ символов н еСТСС1в,:т,ого «"ка? Продуцирование и понима-
■ недостаточно правильно сформировать строку
символов. Механизм понимания должен wm ™..л.
символ в зависимое™ от контекстеЧтоГ П?ШатТГ- т смысл "™ "нтсрпреп,ров01ь
гт „к-. ,,.*„„„ и'контскста. Что такое смысл? Что такое интерпретация?
Подоб„ь,е философские вопросы встают во многих областях пр„„,я ИИ будь то
„„строение экспертных систем „ли разрабо™ алгоритмов машинного обучения Зз™
вопросы будут рассмотрены в данной книге „о „ере их появления. ФнлософсГие acne™
ИИ обсуждаются также в главе 16.
1.3. Искусственный интеллект — заключительные
замечания
Мы попытались дать определение искусственному интеллекту путем рассмотрения
основных областей его исследования и применения. Этот обзор обнаружил молодую и
многообещающую область науки, основная цель которой - найти эффективный способ понимания и
применения интеллектуального решения проблем, планирования и навыков общения к
широкому кругу практических задач. Несмотря на разнообразие проблем, затрагиваемых
исследованиями ИИ, во всех отраслях згой сферы наблюдаются некоторые общие черты.
1. Использование компьютеров для доказательства теорем, распознавания образов,
обучения и других форм рассуждений.
2. Внимание к проблемам, не поддающимся алгоритмическим решениям. Отсюда —
эвристический поиск как основа методики решения задач в ИИ.
3. Принятие решений на основе неточной, недостаточной нли плохо определенной
информации и применение формализмов представлений, помогающих
программисту справляться с этими недостатками.
4. Выделение значительных качественных характеристик ситуации.
5. Попытка решить вопросы семантического смысла, равно как и синтаксической формы.
6. Ответы, которые нельзя отнести к точным нли оптимальным, но которые в каком-
то смысле "достаточно хороши". Это результат применения эвристических
методов в ситуациях, когда получение 0[ггимальных нли точных ответов слишком
трудоемко или невозможно вовсе.
7. Использование большого количества специфичных знаний в принятии решений.
Это основа экспертных систем.
8. Использование знаний метауровня для более совершенного управления
стратегиями принятия решений. Хотя это очень сложная проблема, затронутая лишь
несколькими современными системами, она постепенно становится важной областью
исследований.
Надеемся, что это введение даст некоторое понятие об обшей структуре и значимости
искусственного интеллекта. Предполагаем, что краткое обсуждение таких технических
вопросов, как перебор и представления, не были излишне поверхностными и неясным...
детальнее они будут рассмотрены впоследствии. Здесь они приведены для демонстрации
их значимости в обшей организации этой области. „„„,/:_.
Как мы отмечали при обсуждении агентского решения проблем, объекты „р, обр.
тают смысл при взаимоотношении с другими объектами. Это не менее сПР"«^™° »
отношении фактов, теорий и методов, образующих любую научную область. Мы по
Глава 1. Искусственный интеллект история развития и области приложения 53
- тяк что, когда будут представлены отд
, таких м»"МОСВ"3е":,„те„ле1Ста, они займут свое место в по
_™гь дать понятие сственного Ш" сферы. Мы руководству.
наблюден» • .„учения, и вы неизбежно разрушит
[ВаК „.vmW о6ьединяЮшУ»>"РдаетЫ",Я
-Разрушьте crpyKHW-
его качество".
отдель-
место в посте-
/коволстяуемся
гсону
" " ~ Г~~^ ИИ отражает некоторые из древнейших вопросов, занимав-
Псрслеш.вная область ^ ного ВЫЧИСлительного моделирования. Понятия
ших западную мысль и ^ мышления сейЧас находятся, вероятно, под более при-
рациональности, пред ^ ^ ^^ времена_ ПОСКОЛьку компьютерная наука
ГбГГгхРГор°™иЧеского понимания! В то же время политические, экономические и
мчеГкне рамки мира людей заставляют нас помнить об ответственности за последствия
„Гших творении. Надеемся, последующие главы помогут вам лучше понять современные
методики ИИ и извечность проблем этой области.
Отличными источниками по вопросам, поднятым в этой главе, являются труды
[Haugeland, 1997.1985], [Dennett, 1978, 1984, 1991, 1995]. Использованы такие
первоисточники, как "Физика". "Метафизика" и "Логика" Аристотеля; работы Фреге; труды Бзб-
биджа, Буля, Рассела и Уайтхеда. Весьма интересны работы Тьюринга, особенно его
представления о природе интеллекта и возможности разработки интеллектуальных
программ [Turing, 1950]. Биография Тьюринга [Hodges, 1983] представляет собой отличное
чтение. Критика теста Тьюринга может быть найдена в [Ford и Hayes, 1995].
Работы [Weizenbaum, 1976] и [Winograd и Flores, 1986] дают трезвую оценку
ограничениям и этическим аспектам ИИ. Саймон [Simon, 1981] положительно высказывается
об осуществимости искусственного интеллекта и его роли в обществе.
Упомянутые в разделе 1.2 применения ИИ призваны показать широту интересов
исследователей ИИ и сформулировать многие изучаемые ныне вопросы. Учебник [Вагг и
Feigenbaum. 1989] содержит введение в эти области. Кроме того, рекомендуем книги
[Nilsson, 1998] и [Pearl, 1984]. В них подробно рассмотрены вопросы ведения игр.
которые затронуты в швах 2-5. В главах2, 3 и 12 обсуждается проблема автоматических
msTnTT' Не"°,Т°РМ "Данная литература по этой теме включает труды [Wos и др.,
1984], [Bledsoe, 1977], [Boyer и Moore, 1979] [Veroff 1977]
нь,хс„°™«Т,Ь„16 щ - Ч"таТеЛЬ М°Жет "0ЛУЧ,,ТЬ хоР°шее представление об эксиерт-
IDurto™" 1НаГт°" " Ю"8' 1985'' [НЧСИКЙ. и др., 1984]. [Waterman, 1986] «
рые №!Гвз™ТнаНЫиХ/ЗЫК0,>- °бласть ^прекращающегося изучения, некото-
Colby. .973], [Wife .9721 [иьТиТГ ' №П' '"5>' Winograd, 1983]. [Schank .
^ область представлено в „„А'^ 19М1- 1]«^У и Martin, 2000); введение »
Использование компьютер ™" "НИГ"'
"писанное в главе 16, более nrTJrT м°делиР0™™ работы человеческого разума, кратк»
(Anderson ,9781 и [Luger щоТп °&уждастс« ' [N™ell и Simon, 1972], [PylyAyn. 1984].
»=»"»т. 3 к,,,,™[Ватт„Feigs„0'' „ ТояТГ " 1">бот<™™ка (см. главы 7 и 14) предста»-
_ ' т1]- 1Вго°Ь, 1991о] и [Lewis н Luger. 2000].
Часты.
Искусственный интелпвкт: его истоки и пробле
ИИ-орнентированныс языки и среды паз бт*
книги, а также в [Forbus и deKleer 19931 МашиТ ^""Р™010™ ■ ™*к 14 и 15 тон
многотомном издании [MichalskiHap тэт tossirt "Т™ ^У™™ в главах 9-11;
Journal of Artificial ln,el,iSe„ce и JoJral ofMac^^rl " ^"^ 1W°1; ЖурНШ"
никами информации но этой теме. ™'"с "а™'"8 также ягшкггея важными источ-
Главы 10 и 11 представляют взгляд на интепт,„,~ „
„ адаптацию в социальном и прироГГ"'. Ж ^^^Г
Книга [Shap.ro. 1992] дает ясное и всестороннее описание области искусственного
интеллекта. Эта энциклопедия также проводит детальный анализ многих разных
подходов и противоречии, образующих текущее состояние этой дисциплины.
1.5. Упражнения
1. Предложите и аргументируйте собственное определение искусственного интеллекта.
2. Приведите несколько дополнительных примеров аристотелевского различия между
"материей" и "формой". Можете ли вы показать, как ваши примеры вписываются в
теорию абстракции?
3. Западная философская традиция во многом выросла из проблемы взаимоотношения
разума и тела. По вашему мнению:
а) разум и тело — сущности разной природы, каким-то образом взаимодействующие;
б) разум — всего лишь результат "физических процессов";
в) тело — лишь иллюзия мысли?
Обсудите ваши мысли по поводу проблемы разума и тела и ее важность для теории
искусственного интеллекта.
4. Приведите критические замечания по поводу тьюринтовского критерия
"разумности" компьютерной программы.
5. Сформулируйте ваш собственный критерий "разумности" компьютерной программы.
6. Хотя вычислительная техника — относительно молодая дисциплина, философы и
математики размышляли о вопросах, существенных для автоматического решения
задач, на протяжении тысяч лет. Каково ваше мнение о существенности этих
философских вопросов по отношению к проектированию устройств интеллектуального
решения проблем? Аргументируйте свой ответ.
7. Рассмотрев различия между архитектурам., современных «^»™«*
ского кшзга, поясните, какое значение имеет исследование *"»^Г££3-
туры и функции биологических систем для разработки программ ИИ. Аргумент»
руйте свой ответ. ,-__,
8. Выберите проблемную область, в ^^^^^EST
экспертной системы были бы ""P^'j^^ приятия решений будет „аи-
11а основании своей интуиции скажите, какие аспекты пр
более сложно автоматизировать?
■истом кроме уже перечисленных в тек-
тмвсушеспи'к"4""^....^ социальных ■шн экономических
^« ктао„еложно,,проблеМумашннногооо™„п, _
10 ^-«.«««У"»"-"™ мпьютсра понимать ,. использовать естественны,,
„ Считаете .а„=ь.=™даЫ
1чда«<-»»»! ьв0 негаП,вкых послелст.,* развит,, искусствен-
Р Выимтипоююпедю"»"»"
но™ интеллекта шобшест.
56
1 Искусственный интеллект: его истоки и пробле!
Часть II
Искусственный
интеллект как
представление
и поиск
Все науки описывают основные характеристики систем, изучаемых ими. Эти
характеристики неизменно являются качественными по своей природе, поскольку
они задают термины, оперируя которыми, можно развить данную область науки
более детально^
Изучение логики и компьютеров показало, что интеллект присущ физическим сим-
вольным системам. В качественной струюнуре заключается основной принцип
теории вычислительных систем Символьные системы — это наборы комбинаций
символов (шаблонов) и способов их обработки (процессов), которые в то же время
описывают способы создания, разрушения и изменения символов. Наиболее важное
свойство наборов символов заключается в том, что с их помощью можно
определять объекты, процессы или другие наборы символов. Процессы яри этом могут
быть интерпретированы.^
Второй принцип качественной агюуктуры искусственного интеллекта заключается в
таи, что символьные системы решают задачи путем генерации возможных решений, а
затем проверяют их в процессепоиска(иги перебора вфкяапов). Для решета задачи
обычно создаются символьные выражения, а зянем они поекдоватаьыо
модмфтпфЮтсядотехпоргюканеЬдлтдостигттыус^^
— Ньюэял (Newell) и Саймон (Simon), лекция по случаю вручения прети
Тьюринга в Ассоциации специалистов по каипьютерноы технике, 1976
В^ешк-Щ^"^^
„ спймон доказывают, что шггсллекгуальнал деятель-
В вышеупомянутой лекции нь* ^-щио, с использованием следующих средств,
„ость гак человека, так и машины, осуив.
" , „.йшгаиии символов), предназначенные для описания
'ГГГГогГ—сни, задачи.
,.Грации с зт, шаблонами, позволяющие генерировать потенциальные реше-
нил проблем.
, Поиск е целью выбора решен™ из числа всех возможных.
Описанные предположения формируют базие гипотезы о физической аштшюй сие-
JeZZZol M /J*-) <P™- 16.1). Эта гипотеза лежит в основе наших
Гпьпок создания умных маши» и делает очевидными основные предположен.» в
исследовании искусственного интеллекта. Гипотеза о физической символьной системе неявно
различает понятая шабпотв (patterns), сформированных путем упорядочения символов, и
среды (medium), в которой они реализованы. Если уровень интеллекта определяется не-
ключнтельно структурой системы символов, то любая среда, которая успешно реализует
прваильные шаблоны и процессы, достигнет згого уровня интеллекта, независимо от того,
составлена она in нейронов, логических цепей, или зто просто механическая игрушка.
Возможность построения машины, которая бы прошла тест Тьюринга, зависит от
вышеупомянутого разграничения. Согласно тезису Черча о вычислимости по Тьюрингу [Machtey
н Young. 1979] компьютеры способны осуществить любой эффективно описанный процесс
обработки символьной информации. Разве из этого не следует, что должным образом
запрограммированный цифровой компьютер обладает интеллектом?
Гипотеза о физической символьной системе также вкратце описывает главные вопросы
исследования в области искусстаенного интеллекта и разработки его приложений. К ним
относится определение структур символов и операции, необходимых для
интеллектуального решения задачи, а также разработка стратегий для эффективного и правильного поиска
потенциальных решений, сгенерированных этими структурами и операциями. Эта
взаимосвязанные проблемы представления знания и поиска (knowledge representation and search)
лежат в основе современных исследований в области искусственного интеллекта.
Гипотеза физической символьной системы оспаривается критиками, которые
утверждают, что интеллект является наследственно биологическим и экзистенциальным и не
^Г™ЮФ"Шф°Ю"С°0"ОШЬЮС""волов IS™''. "«О], [Winograd и Flores, 1986].
«сстаГипГ °™°ИТС" " roc"°"«>№My направлению исследован,,,, в области да-
ие^о", и ° йо ™' °К" °"Р™™^ ™«<= направления исследований, как разви-
z:z::::zz::s:„:^rm ™~«аге„тно-орие„тир„ва„„ых»
»ия гипотезы фшическойТи J' .mv" на »"™уютаниь,е возражения, предположе-
» теоретических абоТвэксГпт'Г СИСТеМЫ ЛИЯТ " °СН0Ве "°™ "^ «Р»™ЧССКИХ
«ого языка. Эти „роблемь в„ системах, в планировании и понимании естествен-
Залача любой схеиы ,' "W Расс"°трсны в главе 16.
ку облает,, определения зад,^,Вс„Гт5!'К"ЮЧаСКЯ ' ТОМ' ',тобы фиксировать специфн-
н,и проблемы. Очевидно что '^ ""формацию доступной для механизма реше-
жать знания, необходимые для "* "l**™™™" Должен позволять „рофаниисту выра-
ние только той информации котоп» fm"' АбстР"к11ия (abstraction), т.е. представле-
• огорая необходима для достижения заданной цели, является
Часть II. Искусственный интеллект как представление и поиск
необходимым средством управления сложными
граммы должны быть рациональными в вычисли™!™'10''*"'' Кр°т ТОГО' ко"е'""* "Р°"
Маттюсть являются взаимосвязан,,, ,„„ ,„™ <т|ошс""" Выразительность и
л"™ знаний. Многие достаточно ш^^Т™!^"™"" °"Пт """" "^'^
совсем неэффективны в других классГзаГю ™ 'Г™™™"" " '""""' ™*'Ш
вать в пользу эффективности. В то же вр™ ,,™Г„ ° Ф ° "°*"° "<ЩфП,°"
браженн, позволяв™ фиксировать =^^^^
му решению конкретной задачи. Разумный KOMnnnut,™ „™п л. и эффективно
31 ' шумный компромисс между эффективностью и
выразительностью - нетривиальная задача для разработчиков интеллектуальиьо, систем
Языки представления знаний являются средством, позволяющим решать задачи По
сушеству, способ представления знания должен обеспечить естественную структуру
выражения знания, позволяющую решить проблему. Способ представления должен сделать
это знание доступным компьютеру и помочь программисту описать его структуру.
Эти взаимные компромиссы в выборе способа представления знания можно показать на
примере представления чисел с плавающей точкой в компьютере (рис. 11.1]. Вообще, для
полного описания вещественного числа требуется бесконечный ряд цифр, что не может
быть выполнено на конечном устройстве, т.е. на машине с конечным числом состояний.
Единственное решение этой дилеммы — представление числа в виде двух частей: его
значащих цифр и положения десятичной точки в пределах этих цифр. Несмотря на то что
вещественное число без искажения нельзя хранить в компьютере, можно создать его
представление, адекватно функционирующее в большинстве практических приложений.
Вещественное число: г.
Десятичный эквивалент. 3,1415927 ...
Представление с плавающей точкой: | 31416 \ ! |
Т г Экспонента
1100010
- Мантисса
Представление в памяти компьютера:
Рис II. I. Рапичные представления вещественного числа я
Представление числа с плавающей точкой уступает в выразительности, но вьшгрыва-
ет в эффективности. Такое представление позволяет выполнять многократные арифме-
тичеекпе операции, обеспечивает эффективность их выполнения не Оф»»"ч™»>» ™"
ноетыо вычислений с предельной ошибкой округления „рН любой "Р^Р™Ь"° »
данной погрешности. Представление числа с плавающей точкой такжеп^оляет
анализировать ошибки округления. Подобно всем представление это лишь"б^Ц"*.
символьный шаблон, определяющий желаемый логический обьскт. но не сам обьскт
посредственно. „„„„тос в теории вычислительных систем. Для
Массив - еще одно представление, принятое в кори• рсашоован-
«ногих задач оно более с™=^»^Г^^Г^ оказыааеГестеет-
ная в аппаратных средствах. Это предетавспиоп]| что HarMa„o „оказано на
псиным и эффективным, уступая при этом в аыр ^ ^ ^ оцифрованное изображе-
елсдуюшем примере обработки "ю6Р"С"""„' „исссс обработки изображения опредс-
нис хромосом человека на стадии мстафазы. и и .„„ивы. отсутствующие фраг-
«яютея номер и структура хромосомы, обнаруживаются р р
менты и другие аномалии.
Введение в представление знаний
Рис II2. Оцифрованное изображение хромосом в метафазе
Визуальная сцена состоит из точек изображения. Каждая точка, или пиксель,
характеризуется расположением и числовым значением, представляющим уровень
серого цвета. Поэтому всю сцену вполне естественно представить в виде двухмерного
массива, где номер строки и столбца элемента массива определяет место
расположения пикселя (координаты X и У), а сам элемент массива — уровень серого цвета в
этой точке. Для обработки подобного изображения необходимо реализовать такие
операции, как поиск изолированных точек для удаления шума из образа, нахождение
пороговых уровнен для распознаваемых объектов и их границ, суммирование
непрерывных элементов для определения размеров и плотности образов, Затем
полученные данные, описывающие изображения, могут быть преобразованы. Этот алгоритм
удобно программировать на языке FORTRAN, в котором непосредственно
реализованы операции с массивами. Однако программа была бы слишком громоздкой, если
бы в ней использовались такие средства, как исчисление предикатов, записи или
ассемблерный код, потому что они не обеспечивают естественного представления
данного материала.
(J^ITT** И10бражсние в В»ДС массива пикселей, мы жертвуем разрешением
леГнЛ. 0ГРЗфНЮ В теТС С исх°Д»Ь'м изображением). Кроме того, массивы пнксе-
Z mZT Д0СгаТ1ЧН0 точно Сражать семантическую организацию образа. Напри-
таи™ГеЯеИ Не.М0;КСТ "Рсдстав™- организацию хромосом в отдельном ядре
"с фикеир0вТТСКУЮ ФУ',КЦИЮ ШШ Р°ЛЬ метаФиы в **«"« ■««*»■ Э™ 3'1аНИЯ ЛСГ'
«»1н*^7ГЛ)" ™с по,,ятия'как ,,счисление <w™ <глава2) 1ШИ сс"
Схема
к-ния знания должна удовлетворять следующим условиям.
Часть II. Искусственный интеллект как представление и поиск
1. Адекватно выражать всю необходимую информацию.
2. Поддерживать эффективное выполнение конечного кода.
3. Обеспечивать естественный способ выражения необходимых знаний.
Мак-Дсрмотт (McDermott) и его последователи утверждают, что секрет
написания хорошей программы, основанной на знаниях, заключается в выборе подходящих
средств представления. Программисты, специализирующиеся на языках низкого
уровня (Basic, FORTRAN, С и т.д.), порой строят неудачные экспертные системы
только потому, что эти языки не обладают достаточной выразительностью и не
обеспечивают модульность, необходимую для программирования на основе знании
(McDermott, 1981).
Вообще говоря, задачи ИИ не решают путем их упрощения и "подгонки" к уже
имеющимся понятиям, предлагаемым традиционными формальными системами, на-
пример массивам. Эти задачи связаны скорее с качественными, а не количествен,
ными проблемами, с аргументацией, а не вычислениями, с организацией больших
объемов знаний, а не реализацией отдельного четкого алгоритма. Чтобы
удовлетворять этим требованиям, язык представлений искусственного интеллекта должен
обладать следующими свойствами.
1. Обрабатывать знания, выраженные в качественной форме.
2. Получать новые знания из набора фактов и правил.
3. Отображать общие принципы и конкретные ситуации.
4. Передавать сложные семантические значения.
5. Обеспечивать рассуждения на метауровне.
Рассмотрим этот перечень более подробно.
Обработка знаний, выраженных в качественной форме
ь-га тоебует средств фиксации
Программирование ^™и«°™«™^?> простой при-
(выражения) и рассуждений о качестенншаспектах зад
мер — размещение блоков на столе (рис 1I.J).
Рис-11 -'■ MUP 6wKoe
Дл, представления расположения ^^^^^^ZZi
координат, где значения X и У задают ко рд « правильным Ч«*™££
подход описывает мир блоков и являете ^^ „с позволяет иеи«рсл'
ДЛЯ многих задач, в данном случае он неуд вмь1е для каче^енных
аенно зафиксировать свойства » 0™^'жены друг -а друга « «кис имеют
дов. Это выводы о том, какие из Л1 . _-
61
Введение в представление знаний
о было взять и поднять. Исчисление предикат,,,,
крытый верк, чтобы и>^ "0*" фМКС1фуст эту наглядную информацию. В „с.
(predicate calculus} яеаосредствс> v ^^ догическими утверждениями:
числении предикатов ыир блоков мож
dearie)
clear(a)
ontebte{a)
ontable{b)
on{c, b)
cube{b)
cube(a)
pyramld{c)
Первое слово каждого выражения (on, clBar » т.д.) - предикат (predicate), обоэщ.
чающий некоторое свойство или соотношение его параметров, приведенных в круглых
laiULUIlH "V V „Й.Л1ГГ11 Cft lull/ill И 1In/in>l,VT-imii „К
скобках. Параметры — это символы,
обозначающие объекты (блоки) в предметной
области Совокупность логических предложении описывает важные свойства и соотношения
мира блоков. Исчисление предикатов предоставляет программистам задач искусственного
интеллекта четкий язык описания и способ рассуждений относительно качественных аспектов
системы. Исчисление предикатов не единственный способ представления, но этот подход,
вероятно, наиболее понятен для многих задач. Кроме того, он является достаточно общим,
чтобы служить основой для других формальных моделей представления знания.
Исчисление предикатов подробно рассматривается в главе 2.
Вышеупомянутый пример иллюстрирует точное представление блоков на рис. Н.З.
Это явное представление, поскольку очевидна связь между его элементами и нашим
собственным пониманием "мира" блоков. Знание можно также представлять неявно.
Например, с помощью нейронной сети (глава 10) можно представить эту конфигурацию
блоков в виде шаблонов взаимодействия между искусственными нейронами.
Соотношения между этими шаблонами и элементами мира блоков не очевидны. В большинстве
случаев единственный способ понять, какие знания содержатся в сети, — это
рассмотреть ее работу на примерах. Тем не менее возникает вопрос о соответствии неявных
представлений их явным эквивалентам: способна ли данная модель нейронной сети
передать все знания, которые необходимы в задаче? Сможет ли компьютер получать
доступ и эффективно управлять этими знаниями? Можно ли гарантировать правильность
логических выводов, сделанных нейронной сетью?
Логическое получение новых знаний из набора фактов и правил
допо«льшсЛзе„3ЬШЙ °6М'" т"Ш" °6"адать способностью логически получать
z™"" carrr™аттарсальног°мира'лвди-напримср'нс
рее. мы способньГраеZ t ™ 1 ТГИТ°Г' ^^ Ы ™ " '—можно). О»-
И язык представления зЗи, а|*трает«ых описаниях классов объектов и состояний.
В ..рГрТ„ГГ„а 6„о ° С"С"ИТЬ ^ "О'можиость.
блок скрыты» те не распела °"рСДСЛ"ТЬ тсст- Устанавливающий, является ли
ныи вопрос для робототсхничсскоГ* "" "3 №0 ВеРХ"СЙ фа"" другой объскт' Эт0 "Ш'
блоки или укладывать их друг на л ""■ ' кот°РОй рука робота должна поднимать
каждому блоку. Можно опоев™.. в CBOiiCT»o не обязательно явно приписывать
редслить общее правило, которос |103мляст мс делать
логические выводы из имеющихся фактов, в исчислен,..,
выглядеть так. та .иелсиии пришито, п„ „р„„„„„ „„^ ,
УХ^ЭУоп(У.Х)=с/евг(Х).
Оно означает следующее: для любого элемеюа X э,,»м™ у
существует такого У, что у „входите, „а X эТн™шГм™IT™" °"'"""TUM''"'" "°
ситуациях при замене значений X и У. Позволяв„ oZmZT "Р""С,МГЬС" "Личных
правила вывода, исчисление предикатов Z^ZlZZ^lZ^Z
знания. Кроме того, „счисление предикатов даст возможность проект^, и 1Тд„
„точно общие системы, умеющие действовать разумно в раш,ч,Шх ситуации
Нейронные сети тоже выводят новые знаии, из имеющихся фактов, хот, правила „е-
пользуемые ими. скрыты. Классификация - зто общепринята, форма логического
вывода, выполняемого такими системами. Например, нейронную есть можно обучить
узнавать все конфигурации блоков, в которых пирамида располагается поверх блока,
имеющего форму куба.
Отображение общих принципов наряду с конкретными ситуациями
В предыдущем разделе было продемонстрировано применение логических правил для
вывода дополнительных знаний из основных фактов. Кроме того, на примере с блоками
было показано, как использовать переменные в исчислении предикатов. Поскольку интсл-
лсктуальнал система должна быть максимально общей, любой хороший язык
представления нуждается в переменных. Необходимость качественных рассуждений делает
использование и реализацию переменных чрезвычайно сложной и тонкой задачей но сравнению с
их трактовкой в традиционных языках программирования. Значения, типы и правила
обработки данных в языках программирования, ориентированных на вычисления, чрезвычайно
ограничены и нс годятся для реализации интеллектуальных систем. Для обработки связан
ных переменных и объектов существуют специальные языки представления знаний
(главы 2. 14, и 15). Высокая способность обобщения — это ключевое свойство нейронных
сетей, систем обучения и других адаптивных систем. Эффективное обучение системы-
агента заключается в том, чтобы научиться обобщать данные, полученные в процессе
такого обучения, а затем правильно применить полученные знания в новых ситуациях.
Передача сложных семантических значений
Во многих областях искусственного штгедлекта решение задачи требует «™°<*»*«™
высокосгрук-гурирошзнных взаимосвязанных знаний. Например, чтобы ""^"^Г
нсдссГчГГеДчисзпгтъ его сонные «»£-»~д=п-™
же способ соединения и взаимодействия этих« ^^кГсистТма классификации рас-
во многих задачах, начиная с таких ткеономических систем.^ак ^_^ ^ ^
во многих задачах, начиная с таких ™™™™^тхш« таких сложных объектов, как дн-
тении по .идам и родам, и заканчивая ^™^^а11гактя их частей. В примере
зольный двигатель luni человеческое тело в терминах с0™»": ^_
блоков осиовой полного описай™ расположен» бьшп~<£££££*» «-У
Семантические от„оШе„н,та^с„ео^ди»ы=пис»и,:Р ^ „
событиями. Они позволяют понять "Р"™" Р"""^,,, ,Рлс«ентарных дейеттшй. ко-
представнть план действии робота как пиждомтешисть
«плинш ПООЯЛКС.
Введение в представление знаний
к„_ „„доавлсны в виде совокупности предикатов или
Хотя все эти сягуации могут »тР ^^ „„еющего дело со сложными понятия,
адекватных им Ф°РММ"ШМ'.™ ;оп,|С1Ш1,е процессов в программе, необходимо
«коми и сгремяшегося дать У™Л ,-труктуры процесса.
торое высокоуровневое преде.». ^ ^ Ка1врейка_ ,то маленькая желтенькая
Например. канарейку можно „озвоночнос животное. Эта формулировка
ГетИ6ьГ:;^:а^^Р--еск„к предикатов:
tiassl&tcanary, small)
hascoveringWd, feathers)
nasccloricanary, yellow)
hasproperty(bird. flies)
isa{canary, bird)
isa(bird, vertebrate)
Предикатное описание можно представить графически, используя для отображения
предикатов определяющих отношения, дуги (arc) или связи (link) графа {рис. И.4). Такое
описание называемое семантической сетью (semantic network), является фундаментальной
методикой представления семантического значения. Поскольку отношения явно выражены
связями графа, алгоритм рассуждений о предметной области может строить
соответствующие ассоциации, просто следуя по связям. В примере с канарейкой системе нужно
проследовать только по двум дугам, чтобы решить, что канарейка — это позвоночное
животное. Это значительно эффективнее, чем утомительный исчерпывающий поиск в базе
данных, содержащей описания на языке исчисления предикатов вида isa(X, V).
■ . h assize i
I 5ma" H [bluebird
Рис. 11 4. Описание семантической а
. ..^. ., ,. wtHLUMue семантической сети для канарейки
Кроме того, знания „огуг быть организованы так, чтобы отражать естественную
мГЗ„,8ТиМПЛЯРа,Г/ССа т Да"К0Й "Рс»""»°й области. Некоторые связи, напри-
рактерГ.2огГ У"аЬ""т "' "1>»>™«*н„сть к классу „ задают свойства, ха-
ГанГи еГло.г;г4Г.го,гсса'которь,е "™*- вс= ■— ™—■эт ж-
самом высоком ур Л™кш"f^™™"™ « "™ол.ет сохранять знания на
«омической <»а1ф„шрХ„™ сто кт10МШ'С" "НС,РУМе"Т "Р<»™»»м таКС°-
рует ,то.сСТиь,1сса^6лГк,,тХЗ:РГ™:ГНфОР"аЩИ' МТОРЫЙ гаРаН™"
Теория графов эффективно и с-тр-Г св°иствами.
Кроме того, она позволяет от СТССТаенно вьфажает сложные семантические знания.
чесуис сети - это достойная а ^ стР>'ктУРнУ1о организацию базы знаний. Семаити-
достоннад альтернатива исчислению предикатов.
I ■ Искусственный интеллект как представление и поиск
Возможно, наиболее важное свойство
сывать семантические значения для систеССМантичсскн* сетей— это способность опи-
ссли необходимо понять детскую сказюГ П0НИМаНИЯ сс™ггвснного языка. Например,
страницы, то в соответствующей пт.клап™?ГШЬНУЮ тТЪЮ "ЛН С0ДеРжа««с Web-
ческую информацию и oLZtJ~Z°Z^ ST """^ """"^
дяший для этого механизм. Они обсХаюЗвгл^' СшанТические «™ ~ «»
задач понимания естественного языка-в™ве ,з "* пРИМСнение *» о™"»»
рассуждения на метауровне
Интеллектуальная система должна не только знать примет, но также знать о том. что
она знает этот предмет. Она должна быть способна решать задачи и объяснять этн
решения. Система должна описывать свои знания как в конкретных, так и в обобщенных
терминах, узнавать их ограничения н учиться в процессе взаимодействия с миром. Эта
"осведомленность о своих знаниях" составляет более высокий уровень знании
называемых метазнаниями, необходимых для проектирования н адекватного описания
интеллектуальных систем.
Проблему формализации метазнаний впервые исследовал Бертран Рассел (Russell) в
своей теории логических типов. Кратко ее можно описать так: если множества могут быть
членами друптх множеств (ситуация, аналогичная обладанию знанием о знании), то могут
существовать множества, которые являются членами самих себя. Согласно теории Рассела
это ведет к неразрешимым парадоксам. Рассел отверг эти парадоксы, классифицируя
множества как относящиеся к различным типам, в зависимости от того, содержат они
отдельные элементы 1£ли .«.тожества элементов л т.д. Множества не могут быть членами
множеств, относящихся к типу меньшего или равного значения. Это соответствует различиям
между знаниями и метазнаниями. Но при попытке формально описать эта рассуждения
Рассел столкнулся с многочисленными трудностями [Whitehead и Russell. 1950].
Способность обучаться на примерах, опыте или Понимать инструкции высокого
уровня (в отличие от жесткого программирования) зависит от применения метазнаний.
Методы представления знаний, разработанные для программирования задач
искусственного интеллекта, обеспечивают возможность адаптации и модификации, так
необходимую для обучающихся систем, и формируют основу для дальнейших
исследований (главы 9-П).
Чтобы удовлетворять требованиям символьных вычислений, искусственный
интеллект должен обладать такими средствами, как языки представления, например,
исчисление предикатов, семантические сети, фреймы и объекты (главы 2 и б). LISP н
PROLOG — языки для реализации этих и других представлений. Все эта
инструментальные средства подробно рассматриваются в книге. _
Как следует го приведенных выше рассуждений о необходимых сойотах языка
представлен.» знаний, решение задан,, искусственного интеллект, можно свести,,,аьгбо-
РУ представления cpei, возможных альтернатив. Выбор подходящего "Р"*™™
весьма важен для разработчиков компьютерных программ. ^"«7™ ™
-™ ««-«/.тля на большое разнообразие языков представ
зала, искусственного „нтеллекга. Нкио^ ""°™ OHI|PJ0OTHb, удовлетворять общим
ленив, используемых в »^—С^Ги ™н«ут»»ы* "—■
требованиям выразительное™, зфф*™»"*™^"J^, м,ча как для исследователей.
Выбор и оценка языков представлении — весьма важная »ш
так и для программистов.
Введение в представление знаний
65
шетодомп??5™-
J^eUICH"^JW<_2_ _ системе Ныоэлла и Саймона является
вт„рым аспектом гипотезы » ^Т»""" вариантов. С точки зрения простоте
„„„с решения зад.-» Ф*« w "f" „„скольку имен™ так задачи решает чсло.
Г.Ю™™"м»эта"ЫГТ„"-ии»нш'Юр«»»™^ мы "ЫТаСМСЯ РСШИТЬ "Р0блсмУ-
ск Рассматривая ряд "«"Р"*™'"' ходы и выбирает оптимальные согласно та-
Шахматист обычно изучает возмо* ^ ш^ или которая глобальная
стратега», критериям, как веР°»™ыеJ™ ы. Игрок также рассматривает преимуще-
тия, поддерживаемая на кажя0> , -11мср, взятие ферзя противника), возможно-
ства в краткосрочных стРатсг' ;,онвос преимущество или строит предположения
ста пожертвовать фигуру за по mi)j|j прот„вника, сто опыта и умения. Матс-
отноентельио психологической ^ ми вы(5„рает свою линию среди большого
матик при доказательстве тру ^ СИСТсматично рассматривать ряд возможных
iToYo^^ поведенис лсжит в 0СН08е методики поиска
^ТГчГсГ^Г^Гп'ГерГрассмотрим игру "крестики-нолики" Для любой
заданной ситуации всегда существует только конечное число допустимых ходов
игрока Первый игрок может разместить крестик в любой из девяти клеточек пустой
игровой доски. Каждый из таких шагов порождает различные варианты заполнения
игровой доски, которые позволяют противнику сделать восемь возможных ответных
ходов и т.д. Эту совокупность (в зависимости от возможной конфигурации игровой
доски) можно представить в виде вершин графа. Дуги графа представляют
разрешенные ходы, приводящие от одной конфигурации игровой доски к другой. Узлы
этого графа соответствуют различным состояниям игрового поля. Результирующая
структура называется графом пространства состояний.
Можно построить граф пространства состояний для игры "крестики-нолики"
(рис. И.5). Корневая вершина этого графа будет соответствовать пустой игровой
доске, указывающей на начало игры. Каждый следующий узел графа будет
представлять состояние игровой доски, возникающее в процессе игры в результате
допустимых ходов, а дуги между ними— связи между вершинами. Значение этого
графа состоит в том. что он дает возможность проследить последовательность шагов
в любой игре. Проход начинается с вершины, представляющей пустую игровую
доску, а перемещения по лугам приводят к вершинам-состояниям, представляющим или
очередной ход, или победу. Представление в пространстве состояний, таким обра-
ГазлиГГГ раССМТ"а7Ь ВСС "»«<>*«« »»рианты игры "крестикн-иолики" как
различные пути на графе пространства состояний
ну» и^Г^теп^6^0"- М0ЖН° С П0М0ЩЬЮ "оиска «а П*фе найти эффектив-
шему ZZ"J^^™™™«- «Ф^ть -се пути, «душие к
наибольшего оудеУт n*^"^^***™* " «6Р«ъ такук, игру, которая
Возможность выбора эффекТ1ш"ой °ЯН°МУ "3 оптима*ьных для нас путей,
графа. Регулярность и точность СтратеГИ" ~~ это не единственное преимущество
непосредственно реализовать "редставлсния пространства состоянии позволяют
шру на компьютере.
Рис. 11.5. Фрагмент пространства состояний для игры "крестики-нолики"
В качестве примера использования поиска для решения более сложной проблемы
рассмотрим задачу диагностирования механических неполадок в автомобиле. Хотя эта
проблема на первый взгляд и не кажется такой же легкой задачей поиска в
пространстве состояний, как игра "крестики-нолики" или шахматы, на самом деле она очень
хорошо подходит для этой стратегии. Вместо того, чтобы каждой вершине графа
пространства состояний ставить в соответствие "состояние игровой доски", будем
приписывать вершинам графа состояния частичного знания о механических неполадках
автомобиля. Процесс исследования признаков неполадок и устранения их причины
может быть представлен как поиск по всем состояниям, расширяющий наши знания о
них. Начальная вершина графа пуста, она указывает на то, что о причинах неполадок
ничего не известно. Первый вопрос, который механик мог бы задать клиенту, сводится
к следующему: какие основные части системы (двигатель, коробка передач, рулевое
управление, тормоза и т.д.), возможно, неисправны. Этот фрагмент диалога
представлен в виде совокупности дуг, ведущих от начального состояния к состояниям,
соответствующим отдельным подсистемам автомобиля (рис. И.6).
Рвшениэ задачи методом поиска
^~~7^ ' ,„1 состояний но первом этапе feme-
" и (соответствующие основным диагностичс.
Скш.««»отяньеи^*СГсТ™яши1»'. представляющим уточненные знания ,
сюш проверка..), которыеведут „е11С„равности двигателя связан с уз„ами
процессе диагностик Н"Р""^„е запускается". От узла двигатель не запускает.
'■двигатель запускается я дя»га .. заводится". Узел "не заводится" свя-
I первый вопрос: в чем
неисправность? |
Двигатель не запускается
Вопрос: заводится
ли машина? |
ы ^ивработает^ Ч^порядке^У
ктие пространства состояний в задаче диагностики неполадок автомобиля
Можно постпи-п. —j. -.
яяюшие заГв?и0т"1ытеФ„',,ВИК'ЧаК'Щ''Й Ке во™ожные вопросы и вершины. предст№
ностировать аюомоб™. „„,^агно™™ские выводы. Решающее устройство сможет д«»г
Ые не"»»ади. находя путь в этом графе. Заметим, что кон-
ЧаСТЬ "' и«УсстввнНЫй интеллект как представление и поиск
крстные вопросы, задаваемые в данном „„„мере, определяют „уть на графе. При этом
каждый следующий ответ удаляет „з рассмотрения ненужные вопросы. Хотя эта задГа
очень отличается от алгоритма нахождения оптимального пути в игре "крестики-
„олики , она тоже решается путем поиска в пространстве состоянии.
Нейронные сети и другие адаптивные системы также выполняют поиск, особенно по
время обучения и адаптации. Всевозможные обобщения данных, которые
самообучающаяся программа может сформировать в процессе обучения, можно представить себе как эле-
менты пространства. Задача алгоритма обучения состоит в использовании обучающих
данных для поиска в этом пространстве. В нейронной сети, например, пространством поиска
является множество всех наборов возможных весов связей сети. В процессе поиска набора
связей, которые максимально соответствуют обучающим данным, эти веса изменяются.
Несмотря на эту очевидную универсальность, поиска в пространстве состояний не
достаточно для автоматизации интеллектуального поведения, обеспечивающего
(автоматическое) решение проблем. Но это важный инструмент для проектирования
интеллектуальных программ. Если бы поиска в пространстве состояний было достаточно,
то было бы довольно просто написать программу, играющую в шахматы. Для
определения последовательности ходов, ведущих к победе, на каждом этапе игры нужно было бы
осуществлять полный поиск по всему пространству состояний. Этот метод решения
задач известен как исчерпывающий поиск (exhaustive search), или поиск методом полного
перебора. Хотя полный перебор может применяться в любом пространстве состояний,
огромный размер пространства для интересных задач делает этот подход практически
неприемлемым. Игре в шахматы, например, соответствует приблизительно 10120
различных состояний игровой доски. Это на порядок больше, чем число молекул во Вселенной
или число наносекунд, которые минули с "большого взрыва" (момента создания
Вселенной). Поиск в таком пространстве состояний выходит за рамки возможностей любого
вычислительного устройства, размеры которого должны быть ограничены до известной
области мироздания, а реализация должна быть закончена прежде, чем эта область
подвергнется разрушительному действию энтропии.
В этой книге будет показано, как поиск в пространстве состояний можно
использовать для практического подхода к любой проблеме. Поиск обеспечивает структуру для
автоматизации решения задач, но эта структура лишена интеллекта. Такой подход не
дает возможности формально описать задачу. Кроме того, простой полный перебор
большого пространства вообще практически неосуществим и непригоден для описания
сущности разумной деятельности.
Однако в реальной жизни люди используют поиск: шахматист рассматривает ряд
возможных ходов, доктор исследует несколько возможных диагнозов, ученый-
программист принимает во внимание различные варианты проекта перед тем, как
приступить к написанию кода. Однако люди не используют полный перебор: шахматист
исследует только те ходы, которые, как свидетельствует опыт, должны быть
эффективными, доктор не требует проведения всех возможных анализов, которые не связаны каким
либо образом с имеющимися симптомами болезни. Проектируя программные средства,
математик руководствуется опытом и теоретическими знаниями. Итак, решение задачи
человеком основано на субъективных правилах, направляющих поиск к тем частям
пространства состояний, которые по каким-то причинам кажутся "обещающими \
Эти правила известны под названием эвриспик (heuristics). Они составляют одну из
центральных тем исследований в области искусственного интеллекта. Эвристика (термин
возник от греческого слова "находить") - это стратегия для выборочного поиска в про-
Решение задачи методом поиска
69
поиск №>»' ,ШН"Л' имеющих ""сотую 8сро,т.
_„,-,. Она «^^Гватслл от потраченных впустую „ли очсв„дао
^"ОТ\^»1.''Э10М"СС1С" количество эвристик в решении задач. ЕсЛ1,
яотУсп«а У."»» тдьзуют большое тся, он м„жет сказать что-то ™„a.
"ВХ У° J ханика, почему »ro"°^Zocm". Если спросить доктора, что могло
X» «^T^f^"-что эго "вероятн0, кишечнь,й П,ИП"""
°Ь0М1Т^да»£"- , Лаже лучшая игровая стратегия может быть „обе-
""С^ »6™Ю™° "Ге™ е Гдства. разработанные опытными врачами, „„„.
„даа противником. ^я0™"«^тики порой не в состоянии доказать трудную теоре.
т терлят неудачу.0ПВ™"'" эврястячикий подход может и должен приблизить „ас к
-«"^tl^H» проблемы- -
„у. шг гаранта, что хороший '"^^ц/Ha,l6oJKe важно то, что эвристика
испольному о^'ММЬН™ ^^эффективного поиска решения.
,ует знание о "Р110™ тсютй обеспечивает средства формализации процесса решения
Поиск в прост^ ПШВ0ЛЯК)Т привносить интеллект в этот формализм. Эти методы „од-
^Т^Гтся в начальных главах этой книга и по-прежнему лежат в основе самых га-
«Гииработок в области искусственного интеллекта. В заключение заметим, что поиск в
„ХтшетГсостояшш - это формализм, независимый от каких-либо особых стратегий
поив, дальзуемьш как отправная точка во многих подходах к решению задач.
В этой книге будут исследованы теоретические аспекты представления знаний и
поиска, а также рассмотрены вопросы применения этой теории для создания эффективных
программ. Описание способов представления знаний начинается с исчисления
Предикатов (глава 2). Хотя исчисление предикатов — только одна из схем, используемых в
представлении знании, оно обладает преимуществом четкой семантики и доказуемости
правильности высказываний, полученных с помощью правил вывода (inference rule). На
примере логики предикатов читатель познакомится с проблемами представления знаний
и их отношением к поиску. Затем будут продемонстрированы ограничения исчисления
предикатов и введены альтернативные схемы представления (главы 6-8).
Глава 3 знакомит с поиском в контексте простых игр. На примере нгр можно изучать
вопросы, относящиеся к поиску в пространстве состояний, при этом не рассматривать
пока проблемы, связанные с представлением знаний в более сложных системах. Эта
методика затем применяется к пространствам состояний, определенным логическими
решающими устройствами и экспертными системами (главы 4 5, 7 и 12).
oco(J°Z„ ЖД"ОТСЯ В0Пр°сы "Рик1сн™ия алгоритмов поиска. При этом мы обратим
вакГ» IZT ™ "Ш0ЛЬЮ»ан"Е »Р-«ик «и управления поиском. В главе 5
рассматривай IZTZ ГляТМЬ^С-0ВШНЫе "а Ч*"™"™» знаний в виде продукнион-
нове поиска г^ТГеГ °бо6ще»"У» " "ошлую модель решения задач на ое-
дологии "классной джиг?™" ^^ СПОСобь1 Решения задач, включая описание мсто-
разиородных источников 34™"'" решенш сложных системных задач с привлечением
нании, взаимодействующих через общее информационное поле).
Г^ушрЛСПИИ
"^иад^^п^^ ВВеДеНИе В чувственный интеллект так, чтобы показать
таиеиа была, 1лавньщ у' "а н™ьных стадиях работа в области искусственного ин-
V ЮМ. мотивирована и обоснована философской перенскти-
ЧЗСТЬ "• ИскУсственный интеллект как представление и по**
Вон пмотиыо физической символьной системе Ньюэлла и Саймона (Newell и
Simon, 1976]. В свете этой теории при разработке интеллектуальных искусственных
объектов преимущественное значение нмелн формальная логика и поиск. На протяжении
веси книги, главным образом во второй ее части, будет представлено немало успешных
результатов применения этих методик и инструментальных средств, основанных на
символьном представлении.
Однако существует много других подходов к представлению. В части 3 (глава 6)
рассказывается о том, как первые простые системы усложнялись по мере решения более
трудных задач. Появились нейросстевой, эволюционный, агентно-ориснтированный н
другие подходы к задаче представления.
Обучающиеся машины отражают требования, выдвигаемые к более сложным
представлениям. В главе 9 будут рассмотрены традиционные подходы к обучению, основанные на
символьном представлении информации. Глава 10 посвящена нейросетевому общению,
иногда называемому коннекционистеким (connectionist). Глава 11 знакомит читателя с
социальными и эмерджентными моделями обучения, которые нашли свое отражение в
генетических алгоритмах, генетическом программировании и искусственной жизни.
Наконец, в настоящее время активно развивается стохастическое направление
исследований. Эти методы, основанные на теории Байеса, часто используются в таких
областях, как абдуктивные суждения (abductive inference), обучение с подкреплением
(reinforcement learning) и понимание естественного языка. Абдуктивные суждения важны
в "обосновании наилучшей трактовки". В областях неточных знаний стохастические
модели и связанные с ними алгоритмы вывода обеспечивают механизм логических
рассуждений и механизм, учитывающий новую информацию для достижения максимально
вероятного заключения. Например, в главе 8 представлены сети доверия (belief networks)
Байеса, используемые для диагностики.
Понимание естественного языка — это еще один пример задачи, решаемой на основе
шаблонов. Они могут быть представлены в виде множества фонем, последовательностей
слов или образцов рассуждений. Таким образом, вероятностный анализ шаблонов важен
как для понимания, так и для порождения естественного языка. В последнее время
исследователи привнесли стохастические методы и в эту научную область. Задача
понимания естественного языка рассматривается в главе 13.
В части II начинается рассмотрение схем представления.
Альтернативные схемы представления
71
Исчисление
предикатов
Наконец мы е паяной мере освоили возможности графического
изображения логического вывода — последней т наших способностей
Это не столько естественный дар, сколько долгий и напряженный труд
— Пирс (Pierce)
Существенное качество доказательства состоит а том,
чтобы заставить поверить
— Ферма (Fermat)
2.0. Введение
В этой главе мы рассматриваем исчисление предикатов как язык представления
искусственного интеллекта. Достоинства исчисления предикатов описывались во введении а часть II.
Их ггреимущества заключаются в четко сформулированной формальной семантике,
обоснованности и полноте правил вывода. Эта глава начинается с краткого обзора исчисления
высказываний (раздел 2.1). В разделе 2.2 определяется синтаксис и семантика исчисления
предикатов. В разделе 2.3 мы обсуждаем правила вывода исчисления предикатов и их
применение в решении задач. В заключении этой главы демонстрируется использование исчисления
предикатов для реализации базы знаний финансового инвестиционного совета.
2.1. Исчисление высказываний
2.1.1. Символы и предложения
Исчисление высказываний и исчисление предикатов, рассматриваемое в следующем
подразделе, являются, прежде всего, языками. Используя их слова, фразы и
предложения, мы можем представлять свойства и отношения в окружающем мире и рассуждать о
них. Первый шаг в описании языка — это знакомство с его составляющими, т.е. набором
символов языка.
0ПРЕДЕ1шСШ,СЛЕНИЯВЫС1СЛЗЬШАНИЙ
СИМВОЛЫ И1.Ч1К- _ символы высказывании
Си,даЫ ..сияния Вь,сказша„„,-Э
р, О, Я, S
значения истинности
frue (истина). Га/5б (ложь)
и погичсские связки
л, v, -п. ->■ Е
- Гппопозицнональные символы) составляют высказывания
Символы высказыванш t P^^^ некоторого мира. Они могут быть как ис-
(pmposition) или утвержд .1автомобиль красный" или "вода мокрая". Высказывания
шины, так и ложны, напри р. ^ начинаются буквой, расположенной в конце анг-
^ГГгГа^^вГ^чиолений высказываний предложения формируются из
элементарных символов согласно следующим правилам.
ОПРЕДЕЛЕНИЕ
ПРЕДЛОЖЕНИЯ ИСЧИСЛЕНИЯ ВЫСКАЗЫВАНИИ
Каждый логический символ и символ истинности являются предложением.
Например: (rue, P, О и Я — предложения.
Отрицание предложения есть предложение.
Например: -. Р и -. false есть предложения.
Конъюнкция (логическое умножение), или операция И, двух предложений есть
предложение.
Например: Рл^Р является предложением.
Дизъюнкция (логическое сложение), или операция ИЛИ, двух предложении есть
предложение.
Например: Pv-iP является предложением.
Импликация (включение) одного предложения в другое есть предложение.
Например: P^Q является предложением.
Эквивалентность двух предложений есть предложение.
Например: PvQ sR является предложением.
Легитимные предложения также называются правильно построенными формулами
(well-formed formulas — WFF), или ППФ.
В выражениях вида РлО элементы Р и О называются конъюнктами (членами
конъюнктивных выражений). В выражениях вида PvQ элементы Р и О называются
дизъюнктами. В импликации P^Q,P- предпосылка (premise), или антецедент (antecedent),
О - заключение, или логическое следствие
пой!иПг«ГЖеНИЯХ ИСЧИСЛен,1Я высказываний знаки ( ) „ [ ] используются для Фуп№
Г:В:0В В "Сражения и, таким образом, дают озможиость упра"»^
рядком их оценки и присваивания значений. Например. {PvQ)sR весьма отличается от
74
Часть И. Искусственный интеллект как представление и поис
pv(QzR), что можно продемонстрировать с помощью таблиц истинности (см.
подраздел 2.1.2).
Выражение является предложением или правильно построенной формулой (ППФ)
исчисления высказываний тогда и только тогда, когда оно может быть сформулировано в
виде некоторой последовательности допустимых символов согласно установленным
правилам. Например,
((РлО)->Я)^Ру^ОуЯ
является правильно построенным предложением в исчислении высказываний, поскольку:
Р, О, и Я — высказывания и поэтому предложения;
РлО - конъюнкция двух предложений, поэтому является предложением;
(РлО)->Я — импликация одного предложения в другое, т.е. предложение;
-.Р и -.О — отрицания предложений, являющиеся предложениями;
-.PV-.Q — дизъюнкция двух предложений, поэтому является предложением;
-iPv-iQvfl — дизъюнкция двух предложений, т.е. предложение;
((PAQ)->fl)s-,Pv-,Qvfl— эквивалентность двух предложений, являющаяся
предложением.
Мы получили первоначальное предложение, которое было создано путем применения
ряда законных правил и поэтому является "правильно построенной формулой".
2.1.2. Семантика исчисления высказываний
В подразделе 2.1.1 мы познакомились с синтаксисом исчисления высказываний и
определили набор правил для создания допустимых предложений. В этом разделе мы
формально определим семантику ("значение") этих предложений. Поскольку программы
искусственного интеллекта должны быть согласованы с представляющими их
структурами, весьма важно продемонстрировать, что правдивость их заключений зависит только
от правдивости начального знания, т.е. что процедуры вывода не содержат логических
ошибок. Для этого весьма необходима точная интерпретация семантики.
Символ предложения соответствует утверждению относительно мироздания.
Например, Р может обозначать высказывание "идет дождь", а О — высказывание "Я живу в
коричневом доме". Предложение, давая некоторое описание мира, может быть как
истинным, так и ложным. Присвоение значения истинности логическим предложениям
называется интерпретацией. Следовательно, интерпретация (interpretation)— это
утверждение относительно правдивости предложения в некотором возможном мире.
Формально интерпретация — это отображение логических символов на множество
{Г, F) (true — истина, false - ложь). Как упомянуто в предыдущем разделе, символы true и
false являются также частями ряда ППФ исчисления высказываний; т.е. значения ППФ
отличны от значения истинности, присвоенного предложению. Чтобы подчеркнуть это
различие, для присвоения значения истинности используются символы 7" и F.
Каждое возможное отображение значения истинности высказывания соответствует
возможной интерпретации мира. Например, если Р обозначает высказывание ■■идет
дождь", а О — "я на работе", то набор высказываний [Р.О] имеет четыре различных
функциональных отображения в таблице истинности {T.F}. Эти отображения
соответствуют четырем различным интерпретациям. Семантика исчисления высказываний,
подобно его синтаксису, определена индуктивно.
Глава 2. Исчисление предикатов
75
Те— ,;,сЧ11слвниявь,скл,ьшлний
Ze„e„^ набора «—«'» "™ ~ ""—■ '-
«™- ™ з-ачГкя ,!стнн„ости. предложений (ППФ) определен. еле„ую;
^«'истинности ^«ч».» -Р. то Р- это любой препозиционный с„м.
^ос^е^Гтс» так. Высказывание -,Р есть F, если Р имеет значение Т; „ выска.
зыв'анне ^Р есть 7. если Р имеет значение Р.
Определение истинное™ конъюнкт л осуществляется так: высказывание имеет
значение Т, только если оба конъюнкта имеют значение Т; иначе выражение имеет
значение F.
Определение истинности дизъюнкции v осуществляется так: высказывание имеет
значение F, только если оба дизъюнкта имеют значение F; иначе выражение имеет
значение 7.
Определение истинности импликации -» осуществляется так: высказывание имеет
значение F только тогда, когда предпосылка (символ перед импликацией) есть Г, и
значение истинности следствия (символа после импликации) есть F; иначе выражение
имеет значение 7".
Истинность эквивалентности = определяется так: высказывание эквивалентности
имеет значение Т только тогда, когда оба выражения имеют одинаковое значение
истинности для всех возможных интерпретаций; иначе выражение эквивалентности
имеет значение F.
Значения истинности сложных выражений часто описываются таблицами
истинности. Таблица истинности содержит все возможные варианты значения истинности для
элементарных суждений (атомарных формул), составляющих большие выражения, и
задает значение истинности выражениям для каждой возможной интерпретации. Таким
образом, в таблице истинности перечисляются все возможные варианты интерпретации
данного выражения. Например, таблица истинности для РаО (рис. 2.1) даст значения
истинности выражения для каждого возможного значения операнда. Выражение Рлй
истинно только тогда, когда и Р, и О имеют значение Т. Операции "или" (v), "не" Ь)>
"импликация" (-») и "эквивалентность" (=) определены аналогичным образом,
Построение их таблиц истинности предлагается выполнить в качестве упражнений.
Два выражения в исчислении высказываний эквивалентны если они имеют одни и те
же значения при всех возможных значениях элементов, составляющих выражение. Эта
пТ,ГеНТН°СТЬ М°ЖеТ 6ЫТЬ "Родамонстрирована с помощью таблиц истинности.
Насти И0^™Г"еЛЬ™™,шад«™«и Р-0 и ^Q определяется таблицей истинно-
сти, показанной на рис. 2.2,
иcч*ГeГ™V,Дe"TИ-"0CI,, Та6л'Щ "«"иности для двух различных предложений в
^Р)*р
76
Часть II. Искусственный интеллект как представление и
Закон контрапозицин импликации: P-^Q = (-.Q-»-,P).
Закон Моргана:-,(PvQ)s(-,pA_TQ) и-,(PaO)s(-,Pv-,Q).
Законы коммутативности: (PaQ) = (QaP) и (PvQ)h(QvP).
Ассоциативный закон: ((PaQ)aR) = (Pa(QaR)).
Ассоциативный закон: ((PvQ)vR)e{pv(QvR)).
Дистрибутивный закон: Pv(ОлR) = (pvQ)л(PvR).
Дистрибутивный закон: Pa(OvR)s(PaQ)v(PaR).
Эти тождества могут быть использованы для приведения выражения исчисления
высказываний к синтаксически различным, но логически эквивалентным формам. Используя эти
тождества вместо таблиц истинности данных выражении, докажите эквивалентность
выражений, преобразуя одно выражение в другое через последовательность эквивалентных
выражений. Первая программа искусственного интеллекта Logic Theorist (Логический
теоретик) [Newell и Simon, 1956], разработанная Ньюэллом. Саймоном и Шоу, использовала
преобразования эквивалентных форм выражений для доказательства многих теорем из
[Whitehead и Russell, 1950], Правила вывода дают возможность заменять логическое
выражение другими формами с эквивалентными значениями истинности, что очень важно. Для
использования правил modus poneiu (раздел 2.3) и резолюции (resolution) (глава 12)
необходимо, чтобы выражения были заданы в определенной форме.
-Р -,fKO P=>Q {-Р:0)-[Р^О)
Т F F
F Т F
F F F
Т Т F Т Т Т
Т F F F F Т
F_ JT Т Т Т Т
F F Т Т Т Т
Рис. 2.1. Таблица
истинности для
оператора л
Рис. 2.2. Таблица истинности,
демонстрирующая тождественность выражений
P-iQ и -^PvQ
2.2. Основы исчисления предикатов
В исчислении высказываний каждый атомарный (элементарный) символ (Р. О и т.д,1
обозначает высказывание некоторой сложности. При этом не существует способа
получить доступ к компонентам отдельного суждения. Исчисление предикатов предоставляет
эту возможность. Например, вместо того, чтобы разрешить единственный символ
высказывания Р, обозначив все предложение "во вторник шел дождь", мы можем создать
предикат погода или weather, который описывает отношения между датой и погодой-
погода(вторник, дождь) или weather(tuesday, rain). Посредством правил вывода
можно изменять выражения исчислений предикатов, непосредственно обращаясь к их
компонентам и выводя новые предложения.
Кроме того, исчисление предикатов позволяет включать в выражения переменные,
Переменные помогают создавать обобщенные утверждения относительно классов
логических объектов. Например, можно заявить, что для всех значений X, где X— день
недели, утверждение логода(Х, дождь) или weather(X, rain) есть истина; т.е. каждый день
идет дождь. Как и при исчислении высказываний, сначала определим синтаксис языкв
предикатов, а затем обсуднм его семантику.
Глава 2. Исчисление предикатов
77
и предложении
2.2.1. Синтаксис пред правш1ьных выражений в исчислении предика.
Пепел тем как определить сикт сюдаши символов „ыка. Это соответствует
тов, определи" алфавит и града ^ ,1рогра„мирования. Символы исчислен™ „ре.
лексическому аспекту определе амШф0Ваиия, являются неприводимыми
дакатов. подобно лексемам в тши. они не мо1уг быть разбиты операциями
(минимальными) синтаксическими
языка на составляющие. символы исчисления предикатов как строки букв „
в этой книге мы представ. ц и неалфа8ИТНо-цифровые символы использовать
цифр, начинающиеся с буквы, р ИСПользоваться для удобства чтения.
нельзя, хотя символ подчеркивания (_)
ОПРЕДЕЛЕНИЕ
СИМВОЛЫ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Алфавит „счисления предикатов состоит из следующих элементов.
L Набор букв английского алфавита как верхнего, так и нижнего регистра.
2. Набор цифр — 0, 1.....9.
3 Символ подчеркивания _.
Символы в „счислении предикатов начинаются с буквы, за которой следует
последовательность перечисленных выше знаков.
Приведем пример допустимых знаков в алфавите „счисления предикатов.
аН69р_z
Вот пример недопустимых знаков в алфавите исчисления предикатов.
# %@/& ""
К допустимым символам исчисления предикатов относятся следующие.
George пгеЗ хот and Jerry bill XXXX friends _of
Приведем примеры строк, содержащих неразрешенные знаки.
3/аск"по blanks allowed" ab%cd *"*71 с/иск!!!
Символы (или идентификаторы), как будет показано в подразделе 2.2.2,
используются для обозначения объектов, свойств или отношений в области рассуждения. Как и в
большинстве языков программирования, использование "слов", которые имеют
зарезервированное значение, помогает понимать программный код. Например, выражения
л(д,к) и любит(Д*ордж,Кейт) формально эквивалентны (т.е. имеют одинаковую
структуру). Однако второй вариант может быть удобнее для понимания (людьми-
читателями) смысла отношений, описанных этим выражением. Следует подчеркнуть, что
такие подробные имена предназначены исключительно для улучшения удобочитаемости
выражений. Единственное значение, которое может иметь выражение исчисления
предикатов, - это значение, определяемое их формальной семантикой.
Круглые скобки, запятые (,) и точки (.) используются исключительно для правильного
построгай» выражений и не обозначают объекты или отношения из области
рассуждения. Они называются иесобст.елны™ симвотчи (improper symbol).
78
Часть И. Искусственный интеллект как представление и
Символы исчисления предикатов могут представлять переменные, константы,
функции или предикаты. Константами называют определенные объекты или свойства из
области рассуждения. Символьные константы должны начинаться со строчной буквы
(буквы нижнего регистра). Таким образом, george. tree, tell и blue - примеры
правильных символьных констант. Константы true (истина) и false (ложь) зарезервированы
как символы истинности.
Идентификаторы переменных используются для обозначения общих классов
объектов или свойств из области рассуждения. Переменные представляются
идентификаторами, начинающимися с прописной буквы. Так, George, BILL и Kate — допустимые
переменные, в то время как geORGE и bill — нет.
Исчисление предикатов также допускает существование функций для объектов из
некоторой области рассмотрения. Идентификаторы функций (подобно константам)
начинаются с символа нижнего регистра (строчной буквы). Функции обозначают
отображение одного или нескольких элементов множества (называемого областью
определения функции) в однозначно определяемый элемент другого множества
(множества значений функции). Элементы определения и множества значений —
это объекты из области рассмотрения. Помимо обычных арифметических функций,
таких как сложение и умножение, функции могут определять отображения между
нечисловыми областями.
Заметим, что наше определение символов исчисления предикатов не содержит чисел
или арифметических операторов. Система счисления не включена в примитивы
исчисления предикатов. Мы лишь аксиоматически определили "базовое" исчисление предикатов
[Маппа и Waldinger, 1985]. Его производные представляют теоретический интерес, но
они менее важны в применении исчисления предикатов в качестве модели представления
искусственного интеллекта. Для удобства включим арифметику в язык описания.
Каждый функциональный символ связан с арностью larily), указывающей на
количество параметров этой функциональной зависимости. Так, например, символ father мог бы
обозначать функцию арности I. которая позволяет определить отца, a plus мог бы быть
функцией арности 2, которая отображает два числа в их арифметическую сумму.
Функциональное выражение — это идентификатор функции, за которым следуют его
аргументы (или параметры). Аргументы — это элементы области определения функции.
Число аргументов равно арности функции. Аргументы заключаются в круглые скобки и
разделяются запятыми. Например.
W.Y)
father(david)
price(bananas)
Все эти выражения являются правильно определенными функциональными
выражениями.
Каждое функциональное выражение обозначает отображение аргументов в
единственный объект множества значении, называемый значение.» функции. Например, если
father— это унарная функция, то father(davld) является функциональным
выражением, значением которого (по желанию автора) есть george. Если plus — это функция
арности 2. определенная на множестве целых чисел, то plus(2,3) является
функциональным выражением, значением которого является целое число 5. Замена функции се
значением называется се оцениванием (evaluation).
Понятие символа исчисления предикатов, или терма, формализовано следующим
определением.
Глава 2. Исчисление предикатов
79
„ true и false. Это зарезервированные символы.
ОПРЕДЕЛЕНИЕ
СИМВОЛЫ И ТЕРМЫ
^мволам исчисления предикатов относятся следуйте.
1 Символы истинности ч
символьные выражения, начинающиеся с символа
2 Символы констант— эти <-"
нижнего регистра (строчный символ).
а„и,,г~ это символьные выражения, начинающиеся с символа
3. Символы переменны-*
верхнего регистра (прописной символ).
4 Ф„-— «««»«- «о символьные выражешн,, начинающиеся с сим-
вола нижнего регистра (строчный символ). С функциями связывается арность,
указывающая на число их аргументов.
Ф^.„к1„юиа,ыюе выражение (function expression) состоит из функциональной
константы арности л, за которой следуют п термов г,, h (», заключенных а
круглые скобки и отделенных друг от друга запятыми.
Терм исчисления предикатов может быть константой, переменной или
функциональным выражением.
Таким образом, термом исчисления предикатов обозначают объекты и свойства из
области определения данной задачи. Примеры термов:
cat
Hmes(2.3)
X
blue
тоШегЦапе)
kate
Символы в исчислении предикатов могут также представлять предикаты.
Предикатные символы, подобно константам и именам функций, начинаются с буквы нижнего
регистра. Предикат указывает на отношения между несколькими объектами (в том числе
нулевым числом объектов) в мире. Количество объектов, связанных таким образом,
определяет арность предиката. Примеры предикатов:
like equals on near part_of
Атомарное высказывание (атомарная формула) (atomic sentence), самая
примитивная единица языка исчислений предикатов, является предикатом арности п, за которым
следует г, термов, заключенных в круглые скобки и разделенных запятыми. Вот примеры
атомарных высказываний.
Wraaeorge.susie) likes(X X)
ПСИХ?' ^умытегЫ^^.ШПег.оПапФеМ
...youruei /ielps(rlchard bill)
предЗТожПетРСбыГиВ * ™ ™*™»™ ™ются likes, friends и helps. О***
^^^^^^Л90'"^ ЧИСЛ°М а^МСНТ0В" В ЭТ°Т "^
различных предиката /*в8, 0д1Ш щ которь1Х завис1)Т от двух, а другой-
от трех аргументов. Если символ предиката используется в предложениях с различной
арностью, то считается, что он представляет два различных отношения. Таким образом,
отношение предиката определяется его именем и арностью. Два отличных предиката
likes могли бы составлять часть одного и того же описания мира; однако этого избегают
так как могут возникнуть недоразумения.
В приведенных выше примерах предикатов bill, деогде и Rate являются
постоянными символами и представляют объекты из области определения задачи. Аргументы
предиката являются термами и могут также содержать переменные или функциональные
выражения. Например,
friends{father_of(david),father_of(andrew))
является предикатом, описывающим отношения между двумя объектами из области
рассуждения. Аргументы здесь представлены как функциональные выражения, значения
которых (будем считать, что father_of{david] есть деогде и father of(andrew) есть
alien) являются параметрами предиката. После оценки функциональных выражений
представленное выше выражение примет вид.
friends(george, alien)
Эти идеи формализованы в следующем определении.
ОПРЕДЕЛЕНИЕ
ПРЕДИКАТЫ И АТОМАРНЫЕ ПРЕДЛОЖЕНИЯ
Символы предиката — это символы, начинающиеся с символа нижнего регистра.
Предикаты связаны с положительным целым числом, определяющим арность, или
"число аргументов", предиката. Предикаты с одинаковым именем, но различной
арностью считаются различными.
Атомарное предложение— это предикатная константа арности л, за которой
следуют п термов fj, tz,.... („, заключенных в круглые скобки и отделенных запятыми.
Значения истинности true и false тоже являются атомарными предложениями.
Атомарные предложения также называются атомарными выражениями, атомами
или предложениями.
Мы можем комбинировать атомарные предложения и формировать предложения в
исчислении предикатов, используя логические операторы. Это те же самые логические
связки, которые используются в исчислении высказываний
Л, V, -1, —> И S.
Переменная, встречающаяся в предложении в качестве параметра (аргумента),
относится к неопределенным объектам в области определения. Исчисление предикатов
первого порядка (подраздел 2.2.2) включает два символа: кванторы переменных (variable
quantifier) V и 3. Они ограничивают значение предложения, содержащего переменную.
За квантором следует переменная и предложение, как показано ниже.
ЗУ friends(Y,peter)
VX likes{X,ice_cream)
Квантор всеобщности V означает, что предложение истинно для всех значений
переменной. В примере VX likes[X.ice cream) выражение истинно для всех значений X в
области определения X. Квантор сл-ществования 3 указывает, что предложение истинно
Глава 2. Исчисление предикатов
81
течения в области определения. Выражение Зу
„о крайней мере для одн я П0 ^аГшей мере один объект У, который ми,.
friends(Y.peter) истинно. есл ткт00ы рассматриваются в подразделе 2.2.2.
ОПРЕДЕЛЕНИЕ
ПРЕДЛОЖЕНИЯ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Каждое атамарное предложение есть предложение.
1 Если » - предложение, та его отрицание -* тоже является предложением.
V Если s, и % - предложения, та их конъюнкция s, л s2 тоже является предложением.
I Если S, и s, - предложения, то их дизъюнкция s,vS, гоже является предложением.
4. Если s, и s, - предложения, то .к импликация я,->%тожс является предложением.
5. Если s, и s2 — предложения, то их эквивалентность s,es2 тоже является
предложением.
6. Если X — переменная и s предложение, то VX s есть предложение.
7. Если X — переменная и s предложение, то ЗХ s есть предложение.
Даяее следуют примеры правильно построенных предложении.
Пусть rimes (умножить) и plus (сложить) — символы функций арности 2 и пусть
equal (равно) и too являются предикатными символами арности 2 и 3 соответственно.
p/us(two,three) (сложить два и три) — это функция, т.е. не атомарное предложение.
equal [plus[two,three), five) — это атомарное предложение.
egua/(p/us(2,3), seven)— это атомарное предложение. Заметим, что это
предложение при стандартной интерпретации операций сложения и уравнивания является
ложным. Формальная правильность и истинность значения — независимые понятия.
ЗХ too(X,twoj>lus[two,three))Aequal{plus(two,three),five) — предложение,
потому что оба конъюнкта являются предложениями.
Vooltwo,two,plwllm>,three)))-tequaHplusltwo,thme).flve)strue) — это
предложение, потому что все его компоненты — предложения, связанные логическими
операторами.
Определение предложений исчисления предикатов и приведенные примеры приводи
к мысли о необходимости проверки: является ли выражение предложением. Метод такой
проверки можно записать в виде рекурсивной функции verify_sentence, которая
получает в качестве параметра рассматриваемое выражение и возвращает значение
success (успех), если выражение является предложением.
Ьед!="ОП "erify.sentence (expression) ,
case
Zre™e "ЛЯет" "парным предложением: return SUCCESS;
ТсГ"егТт1еТаеТ ° Х *' Гда ° " »«*> V ™6° Э.а X - переменная,
tCr«ur^c!sse,e) B°3*e»^ ACCESS
else return РАН;
выражение имеет вид ^s.
it veri£y_sentence(s)- возвращает ,,
then return SUCCESS
else return FAll;
выражение имеет вид s, od s nno ,-,,-,
оператор: l P 2' ГД6 °Р ~ Унарный логический
if verify.sentencefs,) возвращает SUCCESS и
verify^sentence{s2) возвращает SUCCESS
then return SUCCESS
else return FAIL;
в остальных случаях: return FAIL
end
end.
В заключение этого раздела приведем пример использования исчисления предикатов
Рассмотрим модель простого мира. Рассматриваемая область определения - набор
семейных отношений в библейской генеалогии.
mother{eve,abel)
mother[eve,cain)
father(adam,abel)
father(adam,cain)
VXVY father{X, Y)^mother{X, Y)->parent{X, Y}
VXVYVZparent(X,Y}Aparent(X,Z)^siblinglY,Z)
В этом примере для определения набора отношений родителей и детей использованы
предикаты mother (мать) и father (отец). В терминах этих предикатов импликация дает
общее определение других отношений, в том числе родительских и братских. Интуиция
подсказывает, что импликацию можно использовать для описания братских отношении.
например sibling(cain, abel). Для реализации этого процесса на компьютере
необходимо его формализовать, т.е. определить алгоритмы вывода. При задании этих алгоритмов
нужно соблюдать осторожность, поскольку они действительно должны выводить
правильные заключения из данного набора утверждений исчисления предикатов. Для того
чтобы это было именно так, вначаяе определим семантику исчисления предикатов
(подраздел 2.2.2), а затем перейдем к правилам вывода (раздел 2.3).
2.2.2. Семантика исчисления предикатов
Определив правильно построенные выражения в нечислении предикатов, важно
задать их значения в терминах объектов, свойств м отношений в некотором мире.
Семантика исчисления предикатов обеспечивает формальную основу для определения
значений истинности корректно построенных выражений.
Истинность выражений зависит от соответствия констант, переменных, предикатов и
Функций объектам и отношениям в области определения. Из истинности отношении в
области определения следует истинность соответствующих выражений.
Например, информация относительно некоторого человека Джорджа и его друзей
Кейт и Сыози может быть выражена так.
friends{george,susie)
friends(george.kate)
И сел., Джордж действительно друг Сыози и Кейт, то каждое из этих выражений 6у
Д" иметь значение истинности Г. Если же Джордж - друг Сыти, но не Кейт, то первое
выражение будет иметь значение истинности Т. а второе - значение истинности F
Лава 2. Исчисление предикатов
«п. исчисление предикатов для решения задач, объекты и отношения
Чтобы использо ™^„™деления описываются с помощью набора корректны,
в интерпретируемой om:icv"m^Tm вь,ражений обозначают объекты и отношения в об-
выражений. Термы и' ЛРС*"К 6ата данных выражений исчисления предикатов,
ласти опален»». ™ Сение истинности 7. описывает "состояние мира". Описание
Zp^h сГдРЯСЙ - Густой пример такой базы данных. Другой пример - мнр
6ЛГ„Г~В:—:::рЧеа^"" »«™у „счисления,пр„в ф0рмадЬН0.
Снач! определим интерпретацию в области определения D. Затем, используя зту „„.
терцию, определим присвоение значений истинности предложениям языка.
ОПРЕДЕЛЕНИЕ
ИНТЕРПРЕТАЦИЯ
Пусть область определения D — некоторое непустое множество.
Интерпретация на D — это связывание логических объектов из D с каждой
константой, переменной, предикатом и функциональным символом в выражении исчисления
предикатов на основе следующих правил.
1. Каждой константе ставится в соответствие элемент из D.
2. Каждой переменной ставится в соответствие непустое подмножество из D; оно
является областью допустимых значений для этой переменной.
3. Каждая функция f арности (числа операндов) т определяется для т параметров
из D и задает отображение из Dm в D.
4. Каждый предикат р арности л определяется для п параметров из D и задает
отображение из D" в {7", F).
При таком определении интерпретации, чтобы получить значение выражения,
следует присвоить выражению значение истинности на этой интерпретации.
ОПРЕДЕЛЕНИЕ
ЗНАЧЕНИЯ ИСТИННОСТИ ВЫРАЖЕНИЙ ИСЧИСЛЕНИЯ ПРЕДИКАТОВ
Пусть существует выражение Е и интерпретация / для £ на непустой области
определенна D. Значение истинности для Е определяется так.
1. Значение константы- это элемент из D. которому соответствует данная
константа в интерпретации /.
2. Значение переменной - это множество элементов из D, которые соответствуют
данной переменной в интерпретации /.
3' чает*сяТ „Ф(ГШ'<,наль"°го ™V™««* ~ "о такой элемент из D, который полу-
ГукГи™ °Ц£нива1™ ФУ«<шш для значений параметров, соответст-
вующих интерпретации.
4. Значение символа истинности 1ше - это Т a false - F
5 nHpeTa":sa,TOMaPHOr° "»«»"»"« Р-» *«бо Т, либо F, н опредедяется интер-
'" «: о°™ ~""" РаВ"° Г- -» »«»" предложения равно* -
триоани» предложения равно F, если значение предложения равно Г.
Часть II. Искусственный интеллект как представление и пои«
7. Значение конъюнкции двух предложений п>»ип т г
мают значение Т. иначе оно равн^Г Р ' ^ "^ "Р™"*'»- "Р™"'
8 -10. Значение истинности выражений, Использующих операции v - „ -
определяется значениями их операндов, как описано в подразделе 2.1.2. '
Наконец, для переменной X и предложения S, содержащего X. выполняются елс-
дуюшие соотношения.
11. Значение выражения 4XS равно Т, если S равно Т для всех значений X из I. иначе
оно равно F.
12. Значение 3XS равно Г, если в интерпретации существует значение X. для
которого S равно 7"; иначе оно равно F.
Квантификация переменных — это важная часть семантики исчисления предикатов. Если
переменная используется в предложении, например, X в предложении likes{george,X), то
она выполняет роль заполнителя и обозначает знакоместо. На это место в выражении
может быть подставлена любая константа, допускаемая интерпретацией. Заменяя
переменную X в предложении tikes(george.X) значением kate или susie. получим
утверждения likes(george.kate) и likes(george,susie). Переменная X может быть замешена
любыми допустимыми константами. Данное имя переменной можно заменить любым
другим именем переменной, например У или PEOPLE, при этом значение выражения не
изменится. Таким образом, переменная является шаблоном для подстановка В
исчислении предикатов переменные должны быть связаны одним из двух кванторов:
универсальности или существования. Переменная считается свободной, если она не связана
Квантором универсальности или существования. Выражение считается замкнутым
(closed), если все его переменные связаны кванторами. Основное выражение (^ound
expression) вообше не имеет никаких переменных. В исчислении предикатов все
переменные должны быть связаны кванторами.
Для обозначения квантора всеобщности применяется символ V. Для указания
области действия квантора, т.е. выделения имей переменных, на которые
распространяется действие квантора, часто используются круглые скобки. Так, например.
VX(p(X)vq{n-»r(X))
Указывает, что переменная X связана квантором всеобщности в р(Х) н в г(Х).
Квантор всеобщности усложняет вычисление значения истинности предложения,
потому что для определения истинности выражения необходимо проверить все возможные
значения переменной. Например, чтобы определить значение истинности УХ
likesigeorge.X), где переменная X задана на множестве всех людей, необходимо
проверить все возможные значениях.
Если область определения интерпретации бесконечна, исчерпывающая проверка всех
подстановок переменной, связанной квантором всеобщности, в вычислительном
отношении совершенно невозможна, так как алгоритм никогда не остановится. Из-за этой
проблемы исчисление предикатов считают неразрешимым.
Поскольку исчисление высказываний не использует переменные, предложения имеют
Только конечное число возможных значений истинности, н их можно проверить полным
Черсбором. Для этого используются таблицы истинности.
Переменные также могут быть связаны квантором существования. В этом случае
выражение с переменной считается истинным, если оно истинно по крайней мере для
лава 2. Исчисление предикатов
85
„„„деления переменной. Квантор существовав
одного значения » °^!TKBatopa существования также задастся кругль1М1,, *'»»-
алея Э Область лсис™« к" коП считаются связанными этим квантором. Щ-
, „сюрих »« ""^""^ения. содержащего переменную, связанную Kaa
Анализ истинности выр ^ qeM оценнванис выражении, содержащих „2
шество»ания. "°ж" ^о6цщостн. Предположим, необходимо определить ,lcra„„Z;
„евные под «ктором « о |юдсга№1ТЬ в нсг0 различные значения каждой nepeZ
выражен,» Дл» "°™ " „кое, которое делает выражение истинным. Если обла!
"* ""непременной бесконечна, и выражение ложно при всех подстановках 5ваче.
„ш!,алгорит».никогда.не^"^"занмосвязи между операцией отрицания „ кванту.
ТбшносГи«шесТвования. Эти соотношения используются в системах o„p„Sep,
"" Полю^Г, описанных в главе 12. В приведенных соотношениях им, псрсме„„„й
Р™ ичестве формал|,ного символа, который заменяет набор констант. д>
^дГатовр и q и переменных X и У выполняются следующие соотношения.
-,3XpW*MSDW
^vxp№3X-^p(X)
эхр№ЭУр(г1
vxafXlsVKam
VX(p(XlAq(Xl)SVXp(X)AVy4m
3X(p(X)vq(X))=3Xp(X)v3yq(y)
На определенном нами языке переменные, связанные квантором всеобщности и
квантором существования, могут ссылаться только на объекты (или константы) из
рассматриваемой области определения. Имена предикатов и имена функций не могут быть
заменены именами переменных, стоящих под знаком квантора. Этот язык называется
исчисление.» предикатов первого порядка (first-order predicate calculus).
ОПРЕДЕЛЕНИЕ
ИСЧИСЛЕНИЕ ПРЕДИКАТОВ ПЕРВОГО ПОРЯДКА
Исчисление предикатов первого порядка позволяет связывать знаком квантора
переменные, соответствующие объектам из предметной области, но не предикаты или функции.
Например,
V(LiKes)likes(george,Irate)
не является правильно построенным выражением в исчислении предикатов первого пор№
Ип„,ГГСП!УЮТ исчислен1и предикатов высших порядков, в которых такие выражен»
польТГ ""Ч'"'*™™- Некоторые исследователи [McCarthy. 1968], [Appdl. 1985) »',
ест^огоЬГГСШИХ П0РЯДКОв' Ч10бЬ' "Р^"™ знания в программах понимай»
етаГленГв ZT"'"*™ "f"™»™" английские предложения могут быть ор№
'""воль ьх" Г""" ПРеДИКаТОв "=РВ°ГО »«*•»■ с помощью символов, евязо
льны, переменных, определенных в этом „азлеле. Важно заметить, что не *
шествует ™т>-.„ определенных в этом разделе. Важно заметить. ч.«
™«- Англи'йскоТи™™ °ТОбраЖе"ИЯ "Р=Д-же„ий в выражения исчисления пр »
*«™ -чиГе„"„р гр;::,::;7г—™** —° р— п^сг:::*
»ов, оптимальГГ* таЮ,ючастс» в том, чтобы найти схему использования
УЮ С Пч™ Четия выразительности и эффективности оке
Часть II. Искусственный интеллект как представление и
тельного представления. Приведем пойме™ Я1„-„..г. .„
1 примеры английских и русских предложении
представленных средствами исчисления предикатов. оженип,
If it doesn't rain on Monday, Tom will eotn ihc mfu.n.^.n. *r
дя, Том пойдет в горы.) S "Kmntams. (Если в понедельник „с будет лож-
^wee№er(ram,mono'ay)-igo(tom,mountalns)
Emma is a Doberman pinscher and a pood rlrm Пи», .™ -„е-
к ,ч ш,и 4 guuu uog. (JMMa __ эт0 no6cpMaH-nHH4ep н хорошая собака)
gooddog(emma)Alsa(emma, doberman)
All basketball players arc tall. (Все баскетболисты — высокие.)
VX(baskelball_player(X)-itall(X))
Some people like anchovies. (Некоторые люди любят анчоусы.)
3X(person(X)Alikes{X,anchovies))
If wishes were horses, beggars would ride. (Если бы желания были лошадьми, то нишне бы
ездили верхом.)
equat(wishes,horses)-iride(beggars)
Nobody likes taxes. (Никто не любит налоги.)
-,ЗХ likes(X. taxes)
2.2.3. Значение семантики на примере "мира блоков"
В заключение этого раздела рассмотрим вопросы присвоения значений истинности
некоторым выражениям исчисления предикатов на примере из "мира блоков".
Предположим, мы хотим промоделировать мир блоков, изображенный на рис. 2.3, и
сконструировать алгоритм управления для руки робота. Для представления качественных
отношений в этом мире можно использовать предложения исчисления предикатов. С помощью
этих предложений нужно описать, свободна ли верхняя грань данного блока, можно ли
взять блок а, и т.д. Предположим, что компьютер обладает знаниями о расположении
каждого блока и руки, а также способен отслеживать перемещение блоков на столе
(используя трехмерную систему координат).
В этом примере из "мира блоков" нужно очень точно определить свои действия.
Сначала необходимо создать набор выражении исчисления предикатов, который должен
фиксировать текущее состояние мира блоков в рассматриваемой предметной области. В
разделе 2.3 будет представлена интерпретация и возможная модель мира блоков,
описанная набором выражений исчисления предикатов.
Исчисление предикатов декларативно, т.е. не существует никакой принятой
синхронизации или порядка рассмотрения каждого выражения. Тем не менее в разделе 7.4 мы
Дополнительно рассмотрим процедурную семантику (procedural semantics) или ясно
определенную методологию для оценки этих выражений во времени. Конкретный пример
процедурной семантики для выражений исчисления предикатов— это язык PROLOG
(глава 14). Создаваемое нами ситуационное исчисление связано с рядом вопросов,
включающих проблему фреймов и немонотонности логических интерпретаций. Эти вопросы
будут представлены на рассмотрение позже. Для этого примера достаточно сказать, что
выражения исчисления предикатов будут оцениваться слева направо.
2. Исчисление предикатов
87
л
с
а
b
d
оп{с,а)
on(b.d)
ontablo(a)
ontableW)
clearib)
clear(c)
hand_empty
Рис. 2.3. Мир блоков и его описание
а исчислении предикатна
Здесь оп(с а) означает, что блок с находится на блоке a; ontable(a) ~ блок а лежит
на столе- dearie) - на блоке с нет других блоков; hand_empty — рука пуста.
Чтобы можно было поднять один блок и поставить его на другой, оба блока должны
быть свободными (открытыми для руки). На рис. 2.3 блок а не свободен. Поскольку руи
может перемешать блоки, она может изменять состояние мира и освобождать их.
Предположим, она снимает блок с с блока а и обновляет базу знаний, удалив из нее
утверждение ол(с,а). npoi-рамма при этом должна сделать логический вывод, что блок а
теперь свободен,
Следующее правило описывает действие "блок стал свободным".
УХ(-.ЭУол(У,Х)->с/еаг(Х))
Следовательно, для любого X X свободен, если не существует У такого, что V
находится на X.
Это правило определяет не только значение "блок свободен", но и действие
"освободить блоки". Например, блок d не свободен, потому что, если переменная X
принимает значение d, а У — Ь, то предложение является ложным. Чтобы сделать это
определение истинным, блок b следует удалить с блока d. Это легко сделать, потому что в
компьютере записано местоположение всех блоков.
Помимо
использования вышеописанного правила для определения
условия
освобождения блока, можно добавить друще правила, описывающие операции укладки одного
блока на другой. Например: чтобы положить X на Y, сначала нужно освободить руку,
затем освободить X. У и уЖ потом взять X (p/cfc_up(X)J и поставить (put_down) его на У.
VMY{{hBnd_emptyAClear{X)Aclear{Y)*pick_up(X)*put_down{X,Y))--
stacfc(X, Y))
Заметим, что в
вышеупомянутом описании необходимо связать с кажды
„ предав»™»
действие рук„ робота, например р/ск_ир(х> (взять X). Как отмечалось ранее, для з"™
ммпмГТ Д0"°""ИТ'' ССШ"™К>' '"Мления предикатов требованием, чтобы де««»'
б м v Г" " Т0М "°РЯДКС' » К°™Р°М °"" предписываются правилами. Однако эту про
^«"Улучаю рассмотреть отдельно.
88
Часть II. Искусственный интеллект как
представление
I П0И<*
На рис. 2.3 представлена семантическая инте„„г,
н„я предикатов. Она отображает константы и Р """ этнх ""Ра*сний исчисле-
„асти определения D (в данном случае это fin "редииат" в иа6оР выражений из об-
„ретация сопоставляет значение истинное™Г с " °™0UKm" МСЖДУ """"> Интер.
Для ДРУГ"11 наборов блоков, находящихся » ™v™ """ выРажс"иш в описании,
„ср. для группы и, четырех акробатов, мог". КтьГеГЖеНИ"- """ ^ Ю^
„ция. Вопрос заключается не в уникальностиI™ "Р™0*™* Другая интерпре-
Тцйя должна обеспечивать значение истиннс™ ГвсГ.Г" **' Г™™
выражения должны достаточно детально описьшатГм! Р " "а6°РС' ' С"МИ
ди„ь,е выводы. В елсдукощем разделе wZ^ZZL^tTT™ '" "С°6Х°'
вы правил вывода исчисления предикатов. ИСП0""УЮТС» **» формальной осио-
2.3. Правила вывода в исчислении предикатов
2.3.1. Правила вывода
Семантика исчисления предикатов обеспечивает основу для формализации теории
логического вывода (logical inference). Возможность логически выводить новые
правильные выражения из набора истинных утверждений — это важное свойство исчисления
предикатов. Логически выведенные выражения корректны, потому что они совместимы
со всеми предыдущими интерпретациями первоначального набора выражений. Вначале
обсудим вышесказанное неформально, а затем введем ряд определений для
формализации этих утверждений.
Говорят, что интерпретация, которая делает предложение истинным,
удовлетворяет этому предложению. Если интерпретация удовлетворяет каждому элементу
набора выражений, то говорят, что она удовлетворяет набору. Выражение X логически
следует из набора выражений S исчисления предикатов, если каждая интерпретация,
которая удовлетворяет S, удовлетворяет и X. Это утверждение дает основание для
проверки правильности правил вывода: функция логического вывода должна
производить новые предложения, которые логически следуют из данного набора
предложений исчисления предикатов.
Важно верно понимать значение слов логически следует: логическое следование
выражения X из S означает, что оно должно быть истинным для каждой интерпретации,
которая удовлетворяет первоначальному набору выражений S. Это означает, например, что
любое новое выражение исчисления предикатов, добавленное к миру блоков на рис. 2.3,
должно быть истинным в этом мире. Оно должно быть истинным и при любой другой
интерпретации, которую мог бы иметь этот набор выражении.
Термин логически екдп-т вовсе не означает, что X выведено из S. или что его можно
вывести из S. Это просто означает, что X истинно для каждой интерпретации
(потенциально до бесконечности), которая удовлетворяет S. Однако системы предикатов
могут иметь бесконечное число возможных интерпретаций, поэтому практическая
необходимость проверять все интерпретации возникает весьма редко. В вычислительном
отношении „равша вывода (inference rule) позволяют определять, когда выражение как
компонент интерпретации логически следует из этой интерпретации.
Понятие логически следует обеспечивает формальное основание для доказательства
разумности и правильности правил вывода.
Глава 2. Исчисление предикатов
89
обеспечивает создание новых предложении исчисления „рс
„р„„„„ с11Яв Следовательно, правило вывода производят новые
основе данных "Рслл0* кс,,,,сской форме данных логических утверждении
„„жения. »СН0М"Н"С ™,onvxeiiHoe с иомошыо некоторого правила вывода „а мио
КТло,Х«Г;ь,раженн,Ггакже логически следует и, S. то говорят, что ,т„ ,1ра„ *
Правило вывода о6тк* следовательно, правила вывода производят новые „„,
""Тнгыс^с тлкенческой форме данных логических ут„срждс1|и1, £
„„женвя. основанные »» ° с „омошыо некоторого правила вывода „а „, '"
каждое предложение X, нолуче „„„„ ui .ч m гпя,»» .„ ™-"'
яе S логических
вывода обосновано (sound)
;'1ТеГвГ"'.'"я'™"го»орят;'что эта система правил вывода является пото6.
п ,„ «иже правило ».«/,« ро««» " при™"" Ротации (rcsolu.ton). „редей».
Приведенное ниже пгывп» < u.u,M,«m ппявил дмапш vm™,... _.
ГГеискм Р »■"■ »»»ода способна произвести каждое выражение, которое „ож„
Если система ир. ^ эта систсма правш1 ВЬ1Вода „„„„^
"""с"» Г жеправило ««А»>.«' и принцип /—>'(»" (resolution). „рс^
«Тв ла„е 12, яш.ягстся примерам., обосновшшых правил вывода, которые ,щ т.
Z«.,«u соответствующих стратегий полны. Логические системы вывода обычно
смотриГэвристнческие рассуждения и рассуждения на основе здравого смысла, которые
опускают это требование.
Формализуем эти мысли е помощью следующих определении.
ОПРЕДЕЛЕНИЕ
УДОВЛЕТВОРЯТЬ. МОДЕЛЬ, АДЕКВАТНОСТЬ
Для выражения X исчисления предикатов и интерпретации / имеют место следующие
определения.
Если X имеет значение Т на / при конкретных значениях переменных, то говорят, что
/ удовлетворяет X.
Если / удовлетворяет X при всех значениях переменных, то / является моделью X.
X выполнимо (salifiable) тогда и только тогда, когда существуют такая интерпретация
и значение переменной, которые ему удовлетворяют-, в противном случае X
невыполнимо (unsatisfiable).
Набор выражений выполним тогда н только тогда, когда существуют интерпретация и
значения переменных, которые удовлетворяют каждому элементу.
Если набор выражении невыполним, то говорят, что он противоречив (inconsistent).
Если X имеет значение Т для всех возможных интерпретаций, то говорят, что X имеет
силу, или адекватно (valid).
В примере на рис. 2.3 мир блоков является моделью для логического описания. При
этой интерпретации все предложения в примере были истинными. Если база знаний
реализована как набор истинных утверждений для предметной области задачи, то
предметная область служит моделью для базы знаний.
Выражение ЭХ(р(Х) л ^р(Х)) противоречиво, потому что оно не может быть уд»»'
летвореио ни при какой интерпретации или значениях переменных. С другой стороны-
выражение VX (p(X) v -,р(Х)) адекватно.
Для проверки адекватное™ выражений, не содержащих переменных, можно исполь
зовать метод таблиц истинности. Поскольку не всегда можно определить, адекватно л
выражение, содержащее переменные (как говорилось выше, процесс может не »«°«
ZZ ',ТР"Т' ™ "°""°С нсч"^ение предикатов "неразрешимо". Однако еушесг.)*
'™п2£Г°тЫ:та' К0Т°РЬ1С l,03D0™OT генерировать любое выражение, логичес»
90
Часть ||. Искусственный интеллект как представление и
ОПРЕДЕЛЕНИЕ
ПРОЦЕДУРА ДОКАЗАТЕЛЬСТВА
Процедура доказательства (proof procedure) - это „„„г,
.оритма применения этих правил к набору логически ." Т™ ШВВД0 " ш'
аых предложений. р' "u"™ec™x выражений для создания но-
В главе 11 представлены процедуры доказат...^,-™,
inference rule). W Доказательства для правил резолюции (resolution
Используя эти определения, можно формально определить термин "логически следует"
ОПРЕДЕЛЕНИЕ
ЛОГИЧЕСКИ СЛЕДУЕТ, ОБОСНОВАННЫЙ И ПОЛНЫЙ
Выражение исчисления предикатов X логически следует из набора S выражений не-
числения предикатов, если каждая интерпретация и значения переменных которые
удовлетворяет S, удовлетворяют и X.
Правило вывода обосновано (sound), если каждое выражение исчисления предикатов
полученное в соответствии с правилом из множества S выражений исчисления
предикатов, также логически следует из S.
Правило вывода полно (complete), если на данном множестве S выражений исчисления
предикатов правило позволяет вывести любое выражение, которое логически следует из S.
Правило modus ponens (правило отделения, или модус поненс) — это обоснованное
правило вывода. Если дано выражение вида P-*Q и другое выражение вида Р. и оба
выражения истинны на интерпретации /. то modus ponens позволяет нам сделать вывод,
что О тоже истинно на этой интерпретации. Действительно, поскольку modus ponens
является обоснованным правилом, О истинно для всех интерпретаций, для которых Р и
Р->0 являются истинными.
Определения правила modus ponens и ряда других полезных правил вывода ланы ниже.
ОПРЕДЕЛЕНИЕ
МОДУС ПОНЕНС, МОДУС ТОЛЛЕНС. ИСКЛЮЧЕНИЕ "II", ВВЕДЕНИЕ "И",
УНИВЕРСАЛЬНОЕ ИНСТАНЦИРОВАНИЕ
Если известно, что предложения Р н Р->0 истинны, то.иодуе понеис позволяет
вывести О.
Согласно правилу вывода модус mauwc (modus tollens), если известно, что Р->0
является истинным и О ложно, можно вывести ^Р.
Исключение "И" - правило, позволяющее вывести истинность обоих конъюнктов на
основе истинности конъюнктивного предложения. Например, если РлО истинно,
можно сделать вывод, что Р и О истинны.
Введение "И" позволяет вывести истинность конъюнкции из истинности ее
конъюнктов. Например, если Р и О истинны, то конъюнкция РдО истинна.
Уншерссьнос инстониироеанис сводится к следящему: если ■£££*£££
сто,щую „0д кюптором ^общности в истинном ^°**""ш"2«Т1 -
ответетвующим тсД, из области определен^ то pc=^=^ |(
"стннно. Таким образом, если а принадлежит той *с ооласти г
V*P(X), то можно вывести р(а).
лава 2. Исчисление предикатов
91
„пмснсння правила модус попоне и исчислении
В качеств нросГО™^;а,1;ожсн,,я; •■если .шсг дождь. то земля буд,,,. ^
юм„ий рассмотри" ™ ^^„ст "идет дождь и О ест,, земля, „лажная",,,, £
-""""ДС,Т:» *« • »'да Р"° n°CK"""KV m"U"'-IU"""№ "«"ас ,„£
p->0
Применив правило -««>^^ * "^ """""" ВЫ1МЖСН""' """" *** *•
факт, что км»» J»™^'™'"" „ожет быть применено к выражениям, содержав,,,»,
Правило .«^с» к сра о6ычный с, лопш, ..цсс люди
Т'Ткрзт- ел1-к. поэтому Сократ- смертен". Высказывание "Все ,„„„„
смертны" может быть представлено в исчислении предикатов (по-русски „ „0.
английски)так.
УХ(ЧвЛОВвК(Х)->СМврГНЬН1(Х)).
VX(man(X)-»moria)(X)).
"Сократ — человек"
челоавк(сокраг).
man(socrales).
Поскольку'X в выражении сюн, под знаком квантора всеобщности, сто можно заме-
нить любым значением из обласгп определения X, и при этом утверждение будет
сохранять истинное значение согласно правилу универсального инстаицпрования. Заменив в
выражении Хна сокраг, получим следующее утверждение.
челсеек(сократ)->смертный (сокраг).
man(socrates)->morta/(socraies).
Применив правило модус поненс. приходим к выводу mortat(sacretes). Он может
быть добавлено к набору выражений, которые логически следуют из
первоначальных утверждений. Можно использовать так называемый алгоритм унификации да»
определения автоматическим решающим устройством правомочности замены X на
socrates и возможности применения правила модус поненс. Унификация
обсуждается в подразделе 2,3.2.
В главе 12 обсуждается более строгое правило вывода, называемое правилом ре
золю!/»» (resolution), которое является основой многих интеллектуальных
автоматических систем,
2.3.2. Унификация
умеЧтГ!1"Р"МСН',Т1' "РМИЛа "ывода ™"» J'°<>K поисис. система вывод» Д»»*'*
ZTu !Г' К°ГДа Л"а "Ьфаження являются эквивалентными, пли /и**» * .
Г т!лГт„Г' °Ь~'" ™ тр„.и.льно: два выражения Р»«°с«ли££
определи" К°ГДа °НИ сит™»™«и идентичны. В исчислении пред»*
Прави Г" геРеапВ"0СИЛЬН0СТ'' МУХ "«•«"•«"ий усложняется наличием пером*' ,,
Р веео5щ„„сти термами из области определения. Необходим" «'г
Часть II. Искусственный интеллект как представление и г
нить процесс замены переменных, пни кпшппи ..
„тпчпымп (обычно для того, чтоб „Гпо Z, ГК"Ш'К" '""""Же "'"*' 01"а
""'унификация - это алгоритм оиред ,ё,Г 1-оГл м,',?''"1'' """""'"' " """1
,)lWW „ [otumtcucmmtc двух выражении ис п л 1, и ""'"j™"»""" < '»'"•'» "/""«'-
:1р"«- • -~ —. - ^::;:;:т: ':, йчк
был использован в качее.ве подстановки для X в выражен,,,, VXl^SZfl
.„„ подстановка позволил» применить „p«„„„„ „одус ,101,, с „ ю ,™'", * ,
т0Гг.1(.Осг.|в.). E,ue один пример унификации был рассмотрен „„„„с. кош, обсужда
„,,сь фиктивные переменные (dummy). Поскольку р(х) „р(у, эквивалент для
приведения предложений в соответствие (match) друг другу У можно заменит,, на X
Унификация п такие правила вывода, как модус поневе, позволяют делать выводы на
множестве логических у.верждепнй. Для этого логическая база данных должна быть
выражена в соответствующей форме.
Весьма важный аспект этом формы заключается в требовании, чтобы вес переменные
стояли под знаком квантора всеобщности. Это обеспечивает полную свободу в
выполнении подстановок. Переменные, стоящие поя квантором существования, можно устрашив
из предложений в базе данных, заменив их константами, обеспечивающими истинное,ь
предложения. Например. ЗХ paren((X,(om) может быть заменено выражением
parent(bob.tom) или рагел((тагу,(от), принимая во внимание, что Боб (bob) н М ipi,
(тагу) являются родителями Тома ((от) в этой интерпретации.
Процесс удаления переменных, связанных квантором существования, усложнен тем
фактом, что значение этих подстановок может зависеть от значения других переменных
в выражении. Например, в высказывании VX ЭУ то(лег(Х,У) значение переменной У
под квантором существования зависит от значения X, Ско.челипицин (skolcmization) —
это замена каждой переменной, связанной квантором существования, функцией
нескольких или всех имеющихся в предложении переменных, которая возвращает
соответствующую константу. В вышеупомянутом примере, поскольку значение У зависит от X, У
можно заменить сколсмоаский функцией (skolcm function) f отX, Это порождает предикат
VX mother(X,tt,X)). Сколемизация — это процесс, который также позволяет связывать
переменные, стоящие под квантором всеобщности, с константами. Этот аспект подробно
обсуждается в главе 12.
После удаления из логической базы данных переменных, связанных квантором
существования, можно применить унификацию и привести предложения в форму,
необходимую для применения таких правил вывода, как модус mutate.
Процесс унификации осложняется тем фактом, что переменная может быть заменена
любым термом, включая другие переменные и функциональные выражения
произвольной сложности Эти выражения MOiyr тоже содержат,, переменные. Например
'alhariyart) можно использовать в качестве подстановки для X в выраже таП(Х)
для получения вывода, что отец Джека смертей
Приведем несколько рсалшации выражения
пэо(Х,а,доо(У)).
Их можно получить пя'см следующих подстановок
1. foo(tred,a,goo(Z))
2. roo(W,e, goo(/acM)
3. too(Z,a,goo(moo{Z)))
'лава 2. Исчисление предикатов
93
„оы подстановки, или унификации, которые ;1сла,.
И '""" "Р''Тснт"шым каждому из трех, можно записан, в виде 10т «Щ,,
<tred/X,Z/Y)
I7IX тоо{2)/У)
„-пет что X является подстановкой для переменной У „ ,.„„
Запись Х/У. - «..а»; такжс называется «яэыгшш,™. Говорят, что „Г*'
•ильном выражении. "^™1|0ЛЬЗусмым в качестве подстановки. "*»»
ная сшзв'Ш со значенi , „_ КОТОрый вычисляет подстановки, нсобх».,,.
При создании ^™Р;™"жУс';1Н? возшка,0т некоторые проблемы. ЙХ0Д""«
^ТковстангСможно систематически использовать в качестве подстановки^.
Лоба коистанта рассматривается как "базовый экземпляр" и не может 6^
СГа Н=1зя ™»е два'различных "базовых экземпляра" использовать в к,,^
плотники для одной и той же переменной.
пГсмснная не «ожег быть унифицирована с термом, содержащим ее. Поэтому „срс.
пи, ая X не может быть заменена на р(Х), поскольку это порождает бесконечное выра.
женис- pWplpl...X)...)- Тест Л"» этой С"ТУ™И" называется приверти выждет
(occurs check).
Вообще, процесс решения задачи требует рада выводов и. следовательно, ряда лота»
тельных унификаций. Логические решающие устройства задач должны поддерживать сощ
сованность подстановок для переменных. Важно, чтобы любая унифицирующая подстамовв
была сделана согласованно по всем вхождениям этой переменной во все выражения. А вир.
жеши должны быть приведены в соответствие друг другу. Эта ситуация уже встречалась, н>
гда терм Сократ использовался не только в качестве подстановки для переменной X в
предложении человек(Х). но и для переменной X в выражении смертен{Х).
Если переменная связана, все последующие унификации и процедуры вывода
должны учитывать это. Если переменная связана с константой, се уже нельзя
связывать с другим термом при последующих унификациях. Если переменная X] неполно
валась в качестве подстановки для другой переменной Xi, а затем была заменена
константой, то вХ2тоже необходимо отразить это связывание. Множество замен, не-
пользуемых в последовательности выводов, играет важную роль, потому что она
может содержать ответ на первоначальный вопрос (подраздел 12.2.5). Например."
лир(э.Х) унифицировать с предпосылкой правила p(y,Z)=>q(V.Z) при помощи»»*
становки (a/r.X/Z), модус понсце позволяет вывести q(a,X) При тон же иодсп"»
кс. Если мы сопоставим этот результат с предпосылкой правила q( lny,b)=>nW>1' "
выведем г(о,Ь) с учетом множества подстановок [a/W.b/X). ....
Другое важное понятие - это композиция подстановок унификации. Если S « "
мт» двумя множествами подстановок, то композиция S и S' (пишется SS) по»У«\
ком тГМИЮ""" S' " Э,'СМС"ТаМ S " Убавления результата к S. Рассмотрим »Р»>
к0""°"™«" последовательности подстановок
W.W/Z), (1//X), (а/|/, 4b)/W)
Они эквивалентны единственной подстановке
^T^S™'0™116™ »"»едена пугем компоновки (Х/Г, vV/Z) с № <"
' ' ' " №,'"<>"<™и результата е (a/I/, f{b)/W) для получения («Д. «""
-■=А.
Композиция подстановок— это метоп * „„
„овки унификации. Его можно V^Z^ ~?™^™ объединяются „одста-
горм представлена ниже. Можно показав то ком„ 3ииГ ™Г ^"^ """"г ~
„^„мутатнвной^ упражнениях эти вопр^ГотрТы"л^Г™"* "°
Последнее требование алгоритма унификации- униф„катоГ<„„,Сдолжен быть
максимально общим, т.е. для любы, двух выражеиий должен быть „айдTZsT^Z
ф, унификатор. Это очень важно, поскольку при потере общности в пропев решения
уменьшается вероятность достижения окончательного решения „ли такая возможность
исчезает полностью.
Например, предложения р(Х) и р( У) можно ^„^^ лю6ь|„ константаым „„,.
ражением вида {fred/X. fred/Y,. Однако fred не является наиболее общим
унификатором. Используя в качестве унификатора любую переменную, можно получить более
общее выражение: (Z/X, Z/Y). Решения, полученные при использовании первой
подстановки, всегда будут ограничены содержащейся в них константой fred. лимитирующей
логические выводы. Следовательно, fred можно использовать в качестве унификатора,
но это снижает универсальность результата.
ОПРЕДЕЛЕНИЕ
НАИБОЛЕЕ ОБЩИЙ УНИФИКАТОР
Если s — произвольный унификатор выражения Е. a g - наиболее общий
унификатор (mosl general unifier — mgu) этого набора выражений, то в случае применения s к
Е будет существовать еще один унификатор s' такой, что Es=Egs'. глс Es и Egs' —
композиции унификаций, примененные к выражению Е.
Наиболее общий унификатор для набора выражений определяется с точностью до
обозначения. В конечном счете, не имеет никакого значения, как называется
переменная — X или У, поскольку это не снижает общности для результирующей унификации.
Унификация важна для любой системы решения задач искусственного интеллекта,
использующей в качестве средства представления исчисление предикатов.
Унификация определяет условия, при которых два (или больше) выражения исчисления
предикатов могут быть эквивалентными. Это позволяет использовать для логического
представления такие правила вывода, как резолюция (resolution), хотя этот процесс часто
требует поиска с возвратом (backtracking) для нахождения всех возможных
интерпретаций (см. главу 14).
Ниже будет представлен псевдокод для функции unity (унифицировать), которая
вычисляет подстановки унификации (если зго возможно) для двух выражений исчисления
предикатов. Функция unity получаст в качестве параметров два выражения исчисления
предикатов и возвращает либо наиболее обшую подстановку унификации, либо
константу FAIL (отказ), если унификация невозможна. Эта функция определена рекурсивно:
вначале оиа пытается рекурсивно унифицировал, исходные компоненты выражении Если
это удается, все подстановки, возвращаемые в результате этой унификации,
применяются к остальным выражениям. Затем выполняется второй рекурсивный вызов функции
un/fy, в котором завершается унификация Рекурсия прекращаете., когда параметром
становится символ („редикат. имя функции, константа или переменная), или когда все
элементы выражения приводятся в соответствие.
Чтобы упросить рабол- е выражениями, в алгоритме -P»""™ ^<™ '™"'
«™ш„ синтаксис Поскольку функция unity просто проверяет синтаксическое еоот-
■ ~ 95
(p (£ a) (g /■ 4\ I
(equal eve (mother cain) )
„„over различия между предикатами, функциями и па
„егствис шаблону, она и™0^/ ю предикатов. Представляя выражение в видс
раметрами. свойственны^ис последовательности элементов, первым и, которы1(
„u«a (list)—упорялоченно ^ ^ парамстры, мы упрощаем работу с ,ы.
является предикат, за котор сам11 параметры являются предикатами „„„
ражениями. Выражения. В / едставлеиы как списки в списках. Таким обра-
функциональными выражен ^ ' ни)^ Списки заключены в круглые скобки (), ,
зом сохраняется структура р ^ ^ пробелами. Примеры выражений как в ис-
элементы списка отделены дру ме спнсков представлены ниже,
числении предикатов, так и
„„„игатов Синтаксис списка
Синтаксис исчисления предикатов ^ ^ ^
р{а,Ь)
pihaigtX.Y))
equahevejnothencain»
Представим функцию unify.
function unify(El,E2);
begin
СЕ16и Е2 - константы или пустые списки
if E1=E2 then return О
else return FAIL;
El - переменная:
if El входит в Е2 then return FAIL
else return {E2/E1};
E2 - переменная:
if E2 входит в El then return FAIL
else return {E1/E2}
El или Е2 - nyci then return FAIL
otherwise:
begin
НЕ1:=первый элемент El;
HE2:= первый элемент Е2;
SUBS1:=unifу(HE1,HE2);
if SUBS1:=FAIL then return FAIL;
TEl:=apply(SUBSl,хвост El);
TE2:=apply(SUBS1,хвост Е2);
SUBS2:=unify(TEl,TE2);
if SUBS2=FAIL then return FAIL;
else return composition SUBS 1, SUBS2
end
end
%конец case
end
%рекурсия завершается
%списки различных размеров
%Е1 и Е2 списки
23.3. Пример унификации
Поведение вышеописанного алгоритма можно понять, проследив обработку
unify((parents X (fatherX) (mother bill)), (parents bill (father ЫШ Y))
запрос*
Часть II Искусственный интеллект как представлен
Поскольку ии один параметр не является атомарным символом, при первом вызове
функции unify она будет пытаться рекурсивно унифицировать первые элементы каждого
выражения с помощью вызова
unify(parents, parents).
Эта унификация успешно выполнится и возвратит пустую подстановку 11
Применение ее к остальным выражениям не вызовет никаких изменений; затем вызывается
unify((X(father X) (mother bill)), (bill (father bill) Y)).
Древовидное описание выполнения алгоритма на этой стадии представлено на рис. 2,4.
Во втором вызове unify ни одно выражение не является атомарным, поэтому
алгоритм разделяет каждое выражение на его первый компонент и остальную часть. Затем
следует вызов
unify(X. bill).
Этот вызов завершается успешно, поскольку оба выражения атомарные, и одно из них —
переменная. В результате вызова возвращается подстановка (ЫП/Х). Она применяется к
"хвосту" каждого выражения, а функция unify — к результатам подстановки (рис. 2.5>.
unifyMfather bill) (mother bill)), ((father bill)Y)).
В результате этого вызова должна быть получена унификация (lather bill) с (father
bill). Это порождает вызовы
unify(father. father)
unifytbill, bill)
unifyU ),())
Все оин успешно завершаются, еозврашая пустое множество подстановок, как
показано на рис. 2.6.
Затем функция unify вызывается для оставшихся выражений
unlfy(((mother bill)). (У)).
Это, в свою очередь, приводит к вызовам
unity((mother bill), Y)
unlfytt ).( )).
В первом из них (mother bill) унифицируется с У. Заметам, что а процессе
унификации вместо переменной Y подставляется цела» структура (mother bill). Таким образом,
унификация завершается успешно и возвращает подстановку ((mother ЫП)/У). Вызов
unlfy(O.O)
возвращает (>. В результате комбииашш с полученной ранее подстановкой (bill/X)
приходим к ответу (bill/X (mother bill)/Y). Весь процесс подстановок лътюггрируется на
рис. 2.6. Вызовы пронумерованы, чтобы указать порядок их выполнения. Подстановки,
возвращенные каждым запросом, помечены на лугах дерева.
Глава 2 Исчисление предикатов
97
унифицирую»" s
' пвриы»™»"""1"
4 И ПрИМИИИТ!.
' подст»»°»|'И
к остальным
/''' 3u„mxV„lU,„X)U,,,,llmhlll))AblllUuU««l,im))
, ,,„IWOT«'».P'"»"'") <,„„rn„l» X ((»l).»r X) (moll,,,,
.„„.„ niiiillll""!'»1 «"I"""""" "'
/w„ x(M№x «-.««- """• fw"m'
унифициршшь
/^ и примешь ^ч
/ ,' ГЮДМЯНОВКИ >v
/ *' косгальиым \v
7, unltyfaatentu, ршппШ)
3. unl(y({X(lutlif)t X) (rnul/jw Ы\\)),(ЬШ (tathnt bill) Y))
Уиифицироинп.
/ пврньш элементы \
S,* и применить \
/тш\ (bitl/X) \
,„„«« в. «*««*«« Ш.„Ы11))МШ,,Ы1^
,-„,■ 2 ■, л,,,,,,,,,-,,,,™- ,«».•» w<«*«™*»« м/«ш™,й ((P»r<"><« x (!«""'' *> (m""'°r
l,lll)),i(|,,„,,»i" l'»l ('"!'"" ''»') y>
ge
ь П. Иокуоптаяннмй интпллпкт кпк продстввл»и
I. tmlWtP*mil*X№llmX)toiullinrblll>), irmmnlt Ь11ЦШ1юг Ull) (•))
? linltyltJntimiii, tiitriinltt)
Унифицирован, s
' nopDbie алименты \
if и применит,.
'' EKES V-«—m,^.w«i
л
3, un)ty(0< Vnthar X) (mother bill)), ЦмШЫЬчг ыц <>}
Унифицировать
ПврВЫЧ 1ЛОМОНТЫ N
S и применить
»ю/улон.-л«и
с остальным
Return \(то1Ыг bill)/Y)
5. wltyUUatrmr bill) (rnothw bill)). (((ethor bill) Y))
Унифицируют*. v
первые элементы \
и применить
подстановки .
к остальным \otu/n ((mother ы»)/У
6. unltyUfitthor bill), (fattwrUll))
Унифицировать
11 i
первые элементы
и приманить
/ подетннопки \
к остальным
ufyiiimottwЬЩ). (У))
\
ratum ()
Унифицировать
' морныо элементы
и применить
подстановки
к остальным
' MtUm (f люГ/»« h,ll)/Yi
7. unttyitnttwr, ttithor)
I iimtyUbilt), Will)} t? unity((mo4vi Nil). Y)
Унифицировать
порныо лломинты т
И приманить \
* ПОДГЛПКОУКИ \ »
к остальным у«'""Н)
' return () \ \
IJ iinityu) |jj
/'it, , f. I,ihптыитгчьпыс tuit.it унификации аы/ы*
Unnthar bill)) и (parents bill (lather bill) Y)
((parents X (father X)
Глава 2 Исчисление предикатов
00
2.4ЛТрилож«ш£фин^^
~ ИГпшшсоа использования исчисления предикатов для ..„„
в качсстве последнего ^ „ Hcfl разра6отаем „ростую си^"^
ления предметй обл-^Р^^ совет„,1Ю,.. Хотя „ Пр„ст ^
ГиГуетСого проблемсвязанных с реальными приложениями.
^з!""советника"- помочь пользователю решить, положить деньги „а с(5с
тельной чет ил,. вложить их в акции. Некоторые инвесторы, возможно, захотят распре.
лГить свой капитал между двумя вариантами. Рекомендации отдельным инвестор,,,
должны зависеть от их дохода и текущей накопленной суммы, т. е. удовлетворять с„е.
дуюшим требованиям.
1.Лица с недостаточными накоплениями должны в первую очередь увеличивать
сумму на счету, независимо от их дохода.
2. Лица с достаточными накоплениями н стабильным доходом должны
рассматривать более рискованные, но потенциально более выгодные инвестиции.
3. Лица с недостаточно высоким доходом, но уже имеющие значительные накошк.
ния, могут захотеть рассмотреть возможность распределения их дохода между
накоплениями и акциями, чтобы, с одной стороны, оградить себя от потерь при
попытке увеличить доход за счет акций, а с другой, рискнуть и значительно
увеличить прибыль.
Соответствие между накоплением и доходом определяется числом иждивенцев,
которых данное лицо должно содержать. На каждого иждивенца необходимо иметь в банке
по крайней мере S5000. Достаточным считается стабильный доход, составляющий по
крайней мере S15000 в год плюс S4000 на каждого иждивенца.
Чтобы автоматизировать эти рекомендации, запишем их на языке нечисления
предикатов. Вначале необходимо выделить главное требование, которые следует принять во
внимание. Поэтому первое требование — это достаточность сбережений и дохода. Их
можно представить с помощью Предикатов savings_account (сберегательный счет) и
income (доход) соответственно. Это унарные предикаты, параметром которых может
быть значение adequate (достаточен) или inadequate (недостаточен). Таким образом,
возможны следующие комбинации.
savmgs_account(adequate).
savmgs_account(/nadequate).
i'ncome(adequate).
l'ncome(madequate).
Заключения представим унарным предикатом investment (инвестиции), параметр
которого может принимать значения: stocks (акции), savings (сбережения) «""
combtnafton (сочетание - т.е. разбиение инвестиций).
онныеТ?У" Э™ "рсдикаты и "мпликаиию, можно представить различные инвест""
точ"ым?"е™И' Пр"°Рит«™е -I»»™. которому должны следовать лица с ив**»
точными средствами, - это увеличение сбережений на счету. Его можно записать так.
s™"gs_accoum(madeqUate) ^ inmstrnenUsavjngs)
ДУюш™браз0„ГРаНеШ,; ДВУХ ""мс™™°""ь.х альтернатив можно представ *'
savings__account(adequate) л income{adequate) -> investment{stocks).
savings_account{adequate) л income(inadequate)
-* investmenticombination).
Затем, советник должен определить, достаточны ли сбережения и доходы. Это также
можно записать с помощью импликации. Потребность в арифметических вычислениях
приводит к использованию функций. Для определения минимума достаточных
сбережений создадим функцию minsavings. Функция minsavings зависит от одного
параметра, соответствующего числу иждивенцев, и возвращает результат умножения этого
параметра на 5000.
Используя функцию minsavings, достаточность сбережений можно определить
правилами
\fX amount _saved(X) л ЗУ (dependents(Y) Agreater(X, mlnsavings(Y)))
-» savings_account(adequate).
VXamount_saved{X) л ЗУ {dependents{Y] л -,greater{X,minsavings{Y)))
-» savings_account(inadequate),
где
minsavings{X) =5000 * X.
При этих определениях amount saved(X) и dependents^ Y] означают текущую
сумму сбережений и число иждивенцев {dependents) инвестора. Здесь greater(X,Y) —
стандартная арифметическая проверка, определяющая, что больше: X или У. В этом
примере данная функция формально не определена.
Аналогично функцию minincome можно определить так.
minincome{X) =15000 +(4000 - X).
Функция minincome используется для вычисления минимального приемлемого
дохода в зависимости от числа иждивенцев. Текущий доход инвестора представлен
предикатом earnings (доходы). Поскольку достаточный доход должен быть стабилен
и превышать минимально допустимое значение, earnings имеет два параметра.
Первый параметр— заработанная сумма, а второй может принимать значение steady
(стабильный) или unsteady (нестабильный). Приведем правила работы советника,
описывающего эту ситуацию.
yXearnings(X, steady) л ЗУ {dependents(Y) л greater(X, minincomelY)))
-ь income{adequate).
yXearnings(X, steady) л ЗУ (dependents(Y) л^дгеа1ег(Х, inmcome(Y)))
-ь mcome(madequate).
VXearnings(X, unsteady) -* income(madequate).
Чтобы давать консультации, необходимо добавить к этому набор)' предложений
исчисления предикатов описание конкретного инвестора. Это — предикаты amount_saved (сумма
на счету), earnings (доходы) и dependents (иждивенцы). Например, человека с тремя
иждивенцами, имеющего $22000 в сбережениях, н с устойчивым доходом в $25000
можно описать так.
amount_saved (22000).
earnings(25000, steady)
dependents{3).
Глава 2. Исчисление предикатов
„пста0Шш логическую систему, состоящую ю следующих „реа.
Таким образом, мы построили
Л0Же""Й ,, а1*ш«») - inwstmennsavings).
1. savings.accounwi ,.ncome(ade,uete) - //.w>stmem(s,o<*S).
^i::r:::::;;:::ir--—'
, ini/estmenticombination).
-„nvestmen dents{Y) * greater{X,mmsavings{Y)))
4 v amounLsa»/ed{X) д ^ ' I"»''
'-* savings account(adequate).
t uohix\ a 3 Y(dependents(Y)A - greater(X, m/nsawngs(V)))
5 yxamount saved{X) л a j wm
'_»sewngs accounf(/nadequate).
6. vXearnin'gsiX, steady) лЗ У (dependants (У) л greater(X. mmincome(Y)))
^lncome(adequate).
7. vXearn/ngsfX, steady) л 3 Y (dependents*/) л^ greater(X, imn/ncomeiyj»
-»income(inadequate).
&.VXearnings(X, unsteady) - ,ncome{/nadequafe).
9. amounLsaved(22000).
10. earn/ngs{25000, steady).
11. dependents(3).
Здесь
minsavings(X) - 5000 ' X
и
m;mncome(X) = 15000 + (4000 * X).
Этот набор логических предложений описывает предметную область задачи.
Утверждения пронумерованы, поэтому на них можно ссылаться, описывая ход рассуждении.
Используя унификацию и правило модус поненс, можно вывести правильную
инвестиционную стратегию для этого лица как логическое следствие данных выше описании.
На первом шаге нужно унифицировать конъюнкцию высказываний 10 и 11 с первыми
двумя компонентами предпосылки из 7. Иными словами,
earn/ngs(25000,sleady) л dependents^)
нужно объединить с
earnings(X,steady) л dependents(Y)
с учетом подстановки (25000/Х, 3/У). Эта подстановка порождает новую импликацию.
earmngs(25000, steady) л dependents(Z) л -,
greater(25000, mm/ncome(3)) -»income{inadequate).
Оценивая функцию minincome, приходим к выражению
earmngs(25000, steady) л dependents(3) л -, greafer(25000, 27000) -+
/ncome(;nadequafe).
Поскольку в этом частном случае все три компонента предпосылки истинны согл»сЯ<>
предложениям 10, 11 и математическому определению функции greater (больше)-•
конъюнкция тоже истинна. Иг этот следует, что истинна и вся предпосылка- Поэтов
102
Часть II. Искусственный интеллект как представление и п
можно применить правило модус поненс и получить заключение income(inadequate),
означающее, что доход недостаточен. Добавим этот вывод к набору предложений,
присвоив ему номер 12.
12. income(inadequate).
Аналогично, унифицируя
amount_saved{22000) л dependents^)
с первыми двумя элементами предпосылки утверждения 4 с учетом подстановки
{22000/Х, 3/У), получим импликацию
amount_saved(22000) л dependents^) л greater{22000, minsavings{3))
-» savings_account(adequate),
Оценивая функцию minsavings(3), приходим к выражению
amount_saved(22000) л dependents^) л greater(22000, 15000)
-» savings_account{adequate).
Опять же, поскольку все компоненты предпосылки этой импликации истинны, то вся
предпосылка истинна, поэтому можно снова применить модус поненс и получить
заключение savings_account(adequate). Представим его как предложение 13.
13. savings_accounf{ adequate).
Анализируя выражения 3, 12 и 13, делаем вывод, что предпосылка в выражении 3
также истинна. Применив модус поиенс в третий раз. получаем результат
investment(combination). Это предложение и есть рекомендация по инвестициям для
данного лица.
На этом примере мы показали использование исчисления предикатов ддя описания
реальной проблемы. Кроме того, мы сделали логические выводы на основе применения
правил вывода к исходному описанию задачи. Мы все же не обсуждали, как обеспечить
корректность вывода и реализовать этот алгоритм на компьютере. Эти вопросы будут
рассмотрены в главах 3, 4 и 5.
2.5. Резюме и дополнительная литература
В этой главе было рассмотрено исчисление предикатов как язык представления для
решения задач искусственного интеллекта. Были описаны и определены символы, термы,
выражения и семантика языка. Основываясь на семантике исчисления предикатов, мы
определили правила вывода, позволяющие получать предложения, логически следующие
из данного набора выражений. Мы описали атгоритм унификации, определяющий
подстановки переменных, которые приводят в соответствие два выражения, что весьма
важно для применения правил вывода. II в заключение главы мы привели пример системы,
выполняющей роль финансового советника В ней знания о предметной области
представлены на языке исчисления предикатов, а в качестве методики решения задач
используется логический вывод.
Исчисление предикатов подробно обсуждается в ряде книг по теории вычнетнтельных
машин и систем, в том числе в [Manna и Waldmger, 1985]. [Gallier. 19S6]. [Chang и Lee. 1973].
[Andews, 1986]. Современные методы доказательства будут представлены в главе 12.
Глава 2. Исчисление предикатов
103
. ппедикатов как языка представления для задач искусства.
Применение исчислены "^^ „ Nilsson. 1987). [Nilsson. 1998]. [Wcs, 1995,
„ого интеллекта описано И 1985] Интересные современные приложе^
2.<кУпражнення ___
"^^я^—■ докажите тождества „з подраздела 2.1.2.
2. Новый оператор в (читается "исключающее ИЛИ ) можно определить следующей
твблнцей истинности.
р О Р®0
Создайте выражение „ечнелен.о, высказываний, эквивалентное Р S О, используя
только операции л, v и -i.
Докажите их эквивалентность с помощью таблиц истинности.
3 Логический оператор « означает *Чогда и только тогда". Выражение Р^О эквива-
' лентно (р _> 0)л (О -» Р). Базируясь на этом определении, докажите, что Р о О
логически эквивалентно (Р v О) -» (Р а Q).
3.1. Используйте при этом таблицы истинности.
3.2. Воспользуйтесь последовательностью подстановок с учетом тождеств,
приведенных в подразделе 2.1.2.
4. Докажите, что в исчислении высказываний импликация транзитивна, т.е. что ((Р -»
О) л(0->Я))-»(Р-»Я).
5. я. Докажите, что правило модус поненс для нечисления высказываний обоснованно.
Подсказка: используйте таблицы истинности и рассмотрите все возможные
интерпретации.
б. Абдукция (abduction) — это правило, которое позволяет вывести Р из Р —*
Покажите, что абдукция необоснована (см. главу 7).
в. Покажите, что правило .модус то.гъенс (modus tollens) ((P —> О) л-1 О) —» -1
гично.
6. Попытайтесь унифицировать следующие пары выражений. Найдите их наиооле
щие унификаторы или же объясните, почему они не могут быть унифицированы:
a)p(X,Y)Hp(a,Z);
б)р(Х, Х)ир(а,Ь);
в) ancestor(X, У) и ancestor(Ь///,father)bill));
r) ancestor{X,father(X)) и ancestor(david.george),
u)q(X) и-.д(а).
7. а-Скомпонуйте множества подстановок {а/Х, Y/Z) и {X/W, Ь/У).
104
Часть II. Искусственный интеллект как представление
б. Докажите, что композиция множеств подстановок ассоциативна.
в. Постройте пример, демонстрирующий, что композиция не коммутативна.
8. Реализуйте алгоритм unify (подраздел 2.3.2) на выбранном вами языке
программирования.
9. Приведите две альтернативные интерпретации для описания мира блоков (рис. 2.3).
10. Джейн Доу содержит четырех иждивенцев, имеет стабильный доход $30000 и $ 15000
на сберегательном счету. Составьте соответствующие предикаты, описывающие эту
ситуацию для системы финансового советника, рассмотренной в разделе 2.4,
выполните унификацию и получите выводы, необходимые для выдачи рекомендаций по
инвестициям.
11. Запишите набор логических предикатов, выполняющих простую диагностику
неисправностей автомобиля (если двигатель не заводится и фары не горят, значит,
неисправен аккумулятор). Не старайтесь слишком усложнять ситуацию, но рассмотрите
варианты поломки аккумулятора, отсутствия бензина, неисправности свечей
зажигания и стартера.
12. Следующий пример взят из книги [Wirth, 1976].
Я женился на вдове (давайте назовем ее W), которая имеет взрослую дочь (назовем
ее D). Мой отец (F)- который весьма часто навещал нас, влюбился в мою падчерицу и
женился на ней. Поэтому мой отец стал моим зятем, а моя падчерица стала моей
мачехой. Спустя несколько месяцев моя жена родила сына (Si), который стал шурином
(зятем) моему отцу, а потому моим дядей. Жена моего отца, т.е. моя падчерица, тоже
родила сына (S2)-
Используя исчисление предикатов, создайте набор выражений, описывающих
данную ситуацию. Добавьте выражения, определяющие основные отношения в семье, в
том числе определение тестя (или свекра), и. используя правило модус поненс.
докажите заключение "Я сам себе дедушка".
Глава 2. Исчисление предикатов
105
Структуры
и стратегии поиска
в пространстве
состояний
Для того чтобы выжить, организм должен либо защитить себя броней (подобно
дереву или моллюску) и "надеяться на лучшее ", либо развивать способность избегать
опасных путей и стремиться к безопаснолу соседству. Если он предпочел второе, ему
придется постоянно задавать себе основополагающий вопрос: "Что я сейчас делаю?".
— Даниэл С. Деннет (Daniel С. Dennett), Объяснение подсознания
Две дороги расходятся в желтом лесу,
Жаль, не могу я пройти по каждой из них.
Был одиноким я странником в этом лесу,
Долго стояч и смотрел на одну из них.
На ту, уходящую в даль, туда, где она исчезает вдали;
Затем я пошел по дороге другой...
— Роберт Фрост ("Robert Frost), Невыбранная дорога
3.0. Введение _____
В главе 2 описано исчисление предикатов — пример языка представления в
искусственном интеллекте. Правильно составленные выражения исчисления предикатов позволяют
описывать объекты и отношения в области определения, а правила вывода (например, правило
отделения modus ропеш) - логически получать новые знания из имеющихся описании. Эти
правила вывода определяют пространство, в котором ведется поиск решения задачи. I лава 5
является введением в теорию поиска в пространстве состояннн.
Чтобы разрабатывать и внедрять алгоритмы поиска, разработчик должен уметь
анализировать и прогнозировать их поведение. При этом перед ним стоят такие вопросы.
Гарантировано ли нахождение решения в процессе поиска?
Является поиск конечным, нли в нем возможны зацикливания?
Если решение найдено, является ли оно оптимальным?
щ
.„смени выполнения и используемой памяти?
КЖ "^"Гм'оГ— зффек-тнвно упростить поиск.
Как интерпретатор м „шболсе эффективного использования языка
Как разработать интерпретатор ДЛЯ «о
представления? ссет(шш» (slate space search) дает ответь, „а эти м.
Теория поиска в простри пространства состоянии, можно использовать
просы. Представив задачу в "J ч- сжшност„ как самой задачи, так и процедуры
„«рт» W°«»"»анал":| w
поиска ее решения. ве„шци и дуг, соединяющих пары вершин. В модели прс-
Граф cocTOirr in _множе"° _ ^a41, верш„ны графа представляют дискретные и-
егранства состоянии реша и результаты логического вывода или различные
стояния процесса решения, и пр . опишвают 1|ереходы между состояниями. Эти
конфигурации игровой доска ™ы(м1;а^то)Ч(.11,им |иш допустимым ходам в игре. Так,,
переходы еоотв^тствук. ошш^т тшм „ задаче „а определенном этапе „с
экспертных ™пе«\ 1аключеН|И в форме правил "если .... то позволяют получить
„^ор^" ^ый^ай применения правила представляется как
^тГоГ^фГяГ^я на.шучшим инструментом исследования структуры объектов »
их отХен^и Именно этр и привело к созданию теории графов в начале восемнадцатого
в^кГХиттаккн, математик Леонард Эйлер, .изобрел теорию графов, чтобы решжь
^ачГГкешн^ргскнх мостах". Город Кенигсберг расположен „а двух берегах реки и
2^Г5. и берега реки соединены семью мостами, как показано „а рис. 3.1.
Берег реки 1
Берег реки 2
Рис. 3.1. Город Кенигсберг
Задача о кенигсбергскнх мостах формулируется следующим образом, Lyiu ^ ^
маршрут обхода города, при котором каждый мост пересекается ровно один р - ^
местные жители после безуспешных попыток найти такой маршрут УС0МН,,^!С ^.
существовании, никто не мог доказать его отсутствие. Создав модель графа, J' ^^и
лизовал альтернативное представление карты города (рис. 3.2). Берега реки (го ^
острова (М и (2) описываются вершинами графа; мосты представлены помеченн ^
гами между вершинами (Ы , Ь2, ..., Ы). Представление в виде графа сохраняет ^^
венную информацию (структуру системы мостов), а несущественные данные (рас
и направление) игнорируются.
Часть II. Искусственный интеллект как представление
Рис. 3.2. Граф системы мостов города Кенигсберга
Кроме того, систему кенигсбергскнх мостов можно представить в терминах
исчисления предикатов. Предикат connect (соединить) соответствует дуге графа и утверждает,
что берега реки или острова связаны некоторым мостом. Для каждого моста необходимо
задать два предиката connect — по одному для каждого направления движения по мосту.
connect(i\,i2,b\) connect{i2,n,fr\)
соппесЦгЫ ,/1 ,Ь2) соллесг((1 ,лМ ,о2)
connect{rb-\,i-\,b3) соллесЦЛ ,гЫ ,ЬЗ)
саллесг(гЫ,/2,Ь4) соплесг(,'2,гЫ ,Ь4)
соллесГ(/"Ь2,Л ,Ь5) солпвсГ(/'1,гЬ2,й5)
соллесГ(лЬ2,М,Ь6) соллесг(,'1 ,гЬ2,Ь6)
connect(rb2,i2,b7) connect(i2,rb2,bl)
Выражение connect(X,Y,Z) = connect(Y,X,Z), указывающее на то, что каждый мост
может быть пройден в любом направлении, позволяет исключить половину предикатов.
Представление с помощью предикатов эквивалентно представлению в виде графа в
смысле сохранения связности. Однако никакой алгоритм не может преобразовать одно
представление знаний в другое без потери информации. Структура задачи более
естественно отражается в представлении на основе графа. Доказательство Эйлера
иллюстрирует эти различия.
Чтобы доказать невозможность существования нужного маршрута, Эйлер вводит
понятие степени вершины графа, замечая, что каждая вершина может иметь четную лноо
нечетную степень. Вершина четной степени имеет четное число дут. соединяющих ее с
соседними вершинами. Вершина нечетной степени имеет нечетное число таких дут.
Вершины нечетной степени могут использоваться только как начало либо ках конец
маршрута. Все остальные вершины должны иметь четную степень, поскольку искомый
маршрут должен входить в каждую такую вершину и выходить из нее. Иначе пимкр-
шины будут пройдены определенное число раз. а затем окажутся тупиковыми.
Путешественник не сможет покинуть вершину, не используя еше раз уже проидеиную *>£-
Эйлер заметил, что если число вершин нечетной степени не Рано^-™ ™* ">£
то маршрут невозможен. Если сушеств>ют ровно две вершины нечетной ™«м. «
можно начать путь в одной из них и закончить в другое. Если же вершин нечетной
степени не существует, то маршрут может начаться и закончиться в одной и той же
Глава 3. Структуры и стратегии поиска в пространстве состоянии
109
возможен если число вершин нечетной степени графа от
вершине. Итак, маршрут-не ^ ксниге6сргских „остах. Эта задача называется эаданс,
лично от 0 или 2, как в зад
поисками» Эйлера на T>a' mMH(lc оп11СЫвает отношения между мостами, берега.
Хотя предикатное пр д ^^ |]0НЯТ|,е степени вершины. Представление в в„дс
ми и островами, оно н > связь кажд0„ вершины с дугами, в отличие от ар.
графа обеспечивает од „оэтому представление с помощью графа приводит к
гументов пРсдикат°°;,1|ШЫ ает ключевую роль в доказательстве Эйлера. В этом
«ч-сПрТнГуСво теории графов с точки зрения анализа структуры „бмк.
ТОУ:™Гг^1ёТс„°аШГаГприводитея краткий обзор основ теории графов, а затем-
„писание пространства состояний задачи и поиска на графах. Поиск в глубину и поиск
Г,п„п„„1 - это две стратегии поиска в пространстве состоянии. Мы сравним „х, от-
„eTJразличия между поиском от цели и поиском иа основе данных. В разделе 3 3
шисГис в пространстве состояний используется для вывода логических заключении.
На протяжении всей главы теория графов будет использована для анализа структуры и
сложности различных задач.
сложности различных задач
3.1. Теория графов
3.1.1. Структуры данных для поиска в пространстве состоянии
Граф — это множество вершин и дуг между ними. В размеченном графе для каждой
вершины задается один или несколько дескрипторов (меток), которые позволяют
отличить одну вершину графа от другой. На графе пространства состояний эти дескриптор
идентифицируют состояния в процессе решения задачи. Если дескрипторы двух верш
не различаются, то эти вершины считаются одинаковыми. Дута между двумя верши
определяется метками этих вершин.
Дуги графа также могут быть размеченными. Метка дуги используется для з Д
именованного отношения (как в семантических сетях) либо веса дуги (как в зад
коммивояжере). Дуги между двумя вершинами тоже можно различать с помощью
ток (см. рис. 3.2).
Граф называется ориентированным, если каждой дуге приписано определенное
правление. Дуги в ориентированном графе обычно содержат стрелки, определяю
ориентацию дуги. Дуги, которые можно проходить в любом из двух направлений, мо>7
содержать две стрелки-указателя, но чаще вовсе не имеют стрелок. На рис. 3.3 изо Р
жен размеченный ориентированный граф. По дуге (а.Ь) можно двигаться лишь «
шины а к вершине о, по дуге (Ь,с) можно двигаться в любом из двух направлении.
Путь (path) на графе — это последовательность дуг, соединяющих соседние вер
ны. Путь представляется списком дуг, систематизированным в порядке их след"» rf p
На рис. 3.3 список [а.Ь.с.Ч] представляет путь, проходящий через вершины а,о. ■
указанном порядке.
Корневой граф содержит единственную вершину, от которой существует пу»>< "^
бон вершине графа. Эта вершина называется корнем (root). При изображении корн»
нами. Граф пространства состояний любой игры обь о является корневым П»Ф
Часть II. Искусственный интеллект как представление и
причем в качестве корня выступает начальное состояние игры. Начальные ходы в
"крестики-нолики представлены в корневом графе „а рис. U.S. Г>го ориентированный
граф. в котором все дуги являются однонаправленными. Заметим, что этот граф не имеет
циклов; игроки не могут (как бы они этого не хотели) аннулировать ходы.
Дерево (tree) — это граф, на котором для любых двух вершин существует не более
одного пути между ними. Деревья обычно имеют корни, которые изображаются в
верхней части рисунка, как и для корневых графов. Поскольку для каждой вершины дерева
существует не более одного пути в эту вершину из любой другой вершины, то не
существует путей, содержащих петли или циклы.
Для корневых деревьев или графов отношения между вершинами описываются
понятиями родителя, потомка и вершин-братьев (siblings) — вершин дерева, имеющих
общую вершину-родителя. Они используются в обычном смысле наследования: при
проходе вдоль направленной дуги родитель предшествует потомку. Концы всех направленных
дуг, исходящих из одной вершины, называются вершинами-братьями. Аналогично на
пути ориентированного графа предок предшествует потомку. На рис. 3.4 вершина Ь
является родителем вершин в и f (которые являются потомками to и вершинами-
братьями). Вершины а и с являются предками вершин д, л, I, а вершины g,h,i являются
потомками а и с.
Узлы = {a,b,c,d.e\
flyrH = ((a,b|,(a,d],(D,c),(c,bl,(c,a),(d,a|.ltf.e),(e,c|,|e,dl)
Рис. 3.3. Размеренный ориентированный граф
9
Рис. 3.4. Корнет, дерево как пример семейных отношений
Прежде чем ввеоти определенно пространства состояний задачи, приведем формать-
ные определения рассмотренных выше понятий.
ОПРЕДЕЛЕНИЕ
ГРАФ
a/ w Л/ которое не обязано быть конечным.
Граф состоит из множества вершин N,, «2 «.• котор<-е
и множества dw, соединяющих некоторые пары вершин.
Глава 3. Структуры и стратегии поиска в пространстве
,,„ „„„„ми вершин: т.е. луг» <N<, N4) соединяет всрщ„„
Душ «циклен упоР'Л" ''"" ■ ■ с Ni ссли (Nl м,) „с является дугой, ц „ротш,-
N, е всрнинюИ N4. "О >«= "Ч"""'' N »„„„стся нснлираилснноН.
Упорядоченная носдедоватшыюсть вершин [N,. N, N.. -. N.I. W а»*Д»я ,,„|и
II М.ПНСШ.М графе вершин» называете» «(>«>№*( всех вершин, расположенных после
псе (правее нее), и в то же время потомком всех вершин, расположенных „а „уга к
ней (левее нес).
Если нута включает некоторую вершину более одного раза (т.е. и приведенном выше
определении пути некоторая вершина N, повторяется), то говорят, что путь содержит
HfHMW. ИЛИ ((НО.
Дсргм — это граф. в котором существует единственный чуть между любыми двумн
вершинами. (Следовательно, нуги в дереве не содержат циклов,)
Ребра в корневом дереве ориентированы от корня. Каждая вершина и корневом
дереве имеет единственного родителя.
Две вершины называются еяязньищ, если существует пуп., содержащий т ги вершины,
3.1.2. Представление задачи в пространстве состояний
В пространстве состояний задачи вершины графа соответствуют состоятшм
решения частных задач, а дуги — этапам решения задачи. Одно или несколько начальных
состояний, соответствующих исходной информации поставленной задачи, образуют
корень дерева. Граф также включает одно или несколько целевых условий, которые сос-т-
ветствуюг решениям исходной задачи. Яонск в пространстве состояний характеризует
решение задачи как процесс нахождения пути решения (цепочки, ведущей к решению
задачи) от исходного состояния к целевому.
Определим представление задачи в пространстве состояний более формально.
ОПРЕДЕЛЕНИЕ
ПОИСК В ПРОСТРАНСТВЕ СОСТОЯНИЙ
otamemZu С°С"""""""' "Р'»™»™'™» четверкой [NAS.GD] со следующими
А - множество °аГ"" П"Ф" """ И"™"""' " "Р0""" Р™«'™ *«■"•,..
задачи W ВДУ п^штт"' соответствующих шагам в процессе решена"
S - это непустое множество начальных состояний задачи
112
^ 14 ПОИС.
I. Искусственный интеллект как представление
1. Измеряемыми свойствами состояний „™
„ „ ,. , -состояний, встречающихся в процессе поиска
2. Свойствами путей, возникаю v „ ""иша.
ремещения по дугам „™, Р°"ССИ "°"Сга' "<"""'"<*■ стоимостью „е-
ПоПУСППШЫй путь — ЭТО IIYll, Hi ni-mi.....
М У "У™ и, вершины множества S в вершину Нч множества GD.
Цель может описывать состояние Mit.n..»„»
.■крестики-нолики" (рис, .,,5, или^тнаш ™ с 3ЬТсШ„ГоВКО"ФИПфа',,,Ю " ~»
„сывагь некоторые свой™ допустимых ^ZZXZ^^TTn
.,.8, поиск заканчиваем при нахождении кратчайшего „утн „срез асе вершин, рафа
ади„с грамма,нческо,о анализа (раздел 3,3, поиск завершается нахождением пУГу
iiCHiHoio анализа предложения. у у
Дуги в пространстве состояний соответствуют шагам процесса решения, а пути
представляют решения на различной стадии завершения. Путь является целью поиска. Он
начинается из исходного состояния и продолжается до тех пор. пока не будет достигнут
условие пели. Порождение новых состояний вдоль пути обеспечивается такими
операторами, как "допустимые ходы"' в игре или правила вывода в логической задаче или
экспертной системе.
Задача алгоритма поиска состоит в нахождении допустимого пути в пространстве
состояний. Алгоритмы поиска должны направлять пути от начальной вершины к целевой,
поскольку именно они содержат цепочку операций, ведущую к решению задачи.
Одна из обших особенностей графа и одна из проблем, возникающих при создании
алгоритма поиска на |рифс, состоит в том, что состояния иногда могут быть достигнуты
разными путями. Например, на рис, 3.3 путь от вершины а к вершине d может проходить
через вершины b ч с либо непосредственно от в к с/. Поэтому важно выбрать
оптимальный путь решения данной задачи. Кроме того, множественные пути к состоянию могут
привести к петлям или циклам. Тогда алгоритм никогда не достигнет цели. Если в
качестве целевой вершины на рис. 3,3 выбрать вершину в, а в качестве начальной —
вершину а, то образуется циклический путь abedabedabed...
Если пространство поиска описывается деревом, как на рис. 3.4, проблема зацикли-
вония не возникает. Именно поэтому важно отличать задачи поиска на деревьях от задач
поиска на графах с петлями. Алгоритмы поиска на произвольных графах должны
обнаруживать и устранять петли в допустимых путях. При этом алгоритмы поиска на
деревьях выигрывают в эффективности за счет отсутствия этих тестов и затрат на них.
Игры в "крестики-ноликн" и "пятнашки" можно использовать для иллюстрации поиска
в пространстве состояний. Оба эти примера объясняют смысл условия 1 в предыдущем
определении. В задаче о коммивояжере (пример 3.1.3) цель описывается условием аила 2.
ПРИМЕР 3.1.1. "Крестики-ноликн"
Пространство состояний игры ■^^^^ZZcZ^t^^
состоянием является пуста. <^°^££2£££Я^^Ч^
Доска, на которой в одной строке, столбил или под 1 состояния в
X (предполагается, что целью является победа игрока X). "У^^х
конечное содержит последовательность ходов. j")™^ K0H*lirypMU,„ из крестиков и
Состояниями в пространстве являются »к'"'^еГ 6ольш,шсг1» из .озио*-
ноликов, которые могут возникнуть в процессе р ^ ^ девяти клетках никогда не
ных 3" вариантов расположения символов (пус о, ' ходаш, игры, которые со-
оозникает в реальной игре. Душ определяются допуе
Глава 3, Структуры и стратегии поиска в пространстве состоят.
„Г.." »»««««»»"м''""■''; 1 ,/ми«у.«ми."/«.»«.,»,.P.«..i»..u«ск,„»„ий
. ,JH»,Y> Ь»™'"»""'"" P ,Ги .риф" •« |1<п»>я«»" »"-'»|Я"""м« » У«
1
1?
10
2
13
■
!
:i
м
"к.
л
4
/
/■да, ,U. Нтшштшии и Н.чжшшшки
,.™ скпмний ласт ютммююеп. плреда/iim. еляююеп, плачи. П иррс
«m, И,ши* .тнмн^кую^ориалытую «яи чштпишишн.иую «„«..«JjJ.^
тория >и мною wipwwHi нише, -.см и -пои слуис, 1 Ыримср, » шахмггм имеется I» ю*
»* mp» « nyicfii я ипштх КГ4", причем исплорме m ни* никч/ш нс ишнимиг ■
реальных итркх Л акис нрострвшпяи чргш айио сшгжим, и их нетючможно исслеломпь
простым iKpefiHfKiM иариашш (' jpmenw поиска в ппостракс-иш больших размеров иегюяюуая
'гвристики, нтноляюлше умсныштп. сложность поиска (слала 4).
ПРИМКР 3.1,2, Н-тлокшшмкв
Н Hipc » "пятнашки" с ншияднлтыо фишками, или /1 мпшотшке, на рис. 1 *> ня'И»'
дщггь проиумероианшлх фишек ра-тмещены ли ноле т \(> клеток. Одна клока ociacK
нусгоЙ, гак что фишки можно лиипгть и получить их различные коифмурации. Цель иг
ры - найти такую ноиюлоиашншоси. перемещений фишек и пустую клетку, котирм
привела бы к шрпнес та/шцной пелсвой конфит урннии. '*ю популярная И1[»:«. кошро
оольшинемю hi nut чаомля/юи и детине 01 помню фсхдюймолый ишлрат << красными
и оенмми фишками, окайилснимми черным шипом). ,
НегнгМфМе NVIICK IM НОЙ Иф1,| ОИППЛИС1. (1СС),Mil ИРПСрССНЫМИ ДЛЯ ИССЛСЛОМЙНИЙ " '
11ШИ ИСКушИКННЩП ИНТСЛЛСКтй. С ОДНОЙ СЮроИЫ, ПроСТрВНСТНП СОСТОЯНИЙ »«)Й И'ТЫ
яилясте» л'кнпочно большим, чювы мрс/илннляп, ншерес, а с другой — вполне /««■
iyniiMM im иналтв («.исл.» жг,м<г*ш.1х шсшмннй мешилип Iftl, если рачличаи- «^
м-мричнме wtrriMiuM), (U-юяиия и.„м ле,ко нрелсаиимм. И.ра досюючио боля» *""
ИНФЛЯЦИИ ИШСрссНЫХ 'НфИСГИК (СМ, I лицу 4),
К■юж.ммшкн - ти, иерсия I^.гняоиштмки рйчмспцм^н */1, И и..й м»л«но«оМ,й в
фишек иокю нерцижт, « простри,,. И1, „, ч „„.,„; |,„i;|(fHII,ky „рпирн.кги» «■•°с,и1"
Часть II, Иадуоотмнный инюллокт как првдогаолонив и
'"М Н и^адияввои,^ И|Ш)НЙ ^ мм ^^ Ш(№|(№ ^ ^
КИЙ ТЮЙ И1|)М МСИЫ/1
с/инушишя примерах
|» peuibMnft жи-ши млы г, юдеяюяомкв шипошлея
(-„«рсл«ииуп. фишку 7 ннраяо при уСЯ(«ии, w, нупш ,,,.-,
нес" или "пср«мсс-шп, фишку Ъ mm"), однак/, чн,
"перемещении пусюй кленки". >(f> уцргяя^ет «прелс»-»,'
К фишек и 1(»п.кио/ша пусти юипка,/(«пуиимыми яс.;>
Переместись пустую клетку вверх Т
Персмсс-тип. пустую клетку мирам» -»
ПсрСМСШИТ!, Пустую КЛСТКу ВКИ'1 t
I IcpCMecJ ич fc пустую uncwy к new t-
Чччйы сделан, ч'Щи:)ш>>й хад. но/жодлмо /,
до »а пределы HipoifJi'i поля, {\>гги,му ь ottp>,
xo/iifft мотут икь-тмя недонуиичмчи Напри<" ,
И'( утлой, то допустимы лишь два хода, Ьсли (/нре^-лим начальное и
икс к Н'|оло0одомке, ю п^лихс решения чадачи можно опиат. яв№^'
иия ониеыиаюк:я массивом рачмерносги Ч/Э Ирсэиквтжл ир
нош/юна кия предиката состояния с ;шня1ЪИ) парамгфаии ^i /
доске), Дут и и upocrpaifcfM: 1ахлг,яниЙ опр«,1слякя четыре ь;
шпчо/кимс перемещения пустой клетки.
перемещении фишек
:*.'-«о;|/лкеиа епрш» m
' "-Л ГЧПОрИП, О
, wpe уч«г(«ук/г
-"'' I Iixh пунмн
к.« „ „ри „,Рс. ••«,»««.«■".»««« -"г^р;"; ; Мо..
Т«фом. во»|.шиис1>а ■ерши» ■""«!»"■ в"с" „„„U .«.«»»
'■п.«ог„0„„,„„, » „ом .р.фс «шможиы »"""" |
""«- 3. Струпу,™ и «р«.гии пои«« ■ пр^Р"*™-"»"»"""
й Если одно из них встречается на пути,
GD._ „о особое множество ::;Ф;>ГГ:рШи„Ы . —У» - искомая послед,
поиск прекращается. ) состояний 8-головоломки или 15-
тельность ходовэт то полное простран ,|Нак0во|-о размера). Отсюда сле-
СЛСДУСТ ГСз двух несв.»"* 'w^* ^„мымп из любой заданной на-
"•—""L о Голо нна состоянии являют.. ».«° ,, двс сосед„ие фишки, все
Г;Х^Г-Г^^^ •
состояния из другои части нр
ПРИМЕР 3.1.3. Зад»1"1 коммивояжер. ^ ^ городов „ возвратиться до-
Предположим. коммивояжер »* айш„й „уть. На рис. 3.7 дан пример
,,„Г, Задача состоит в ""J^Ut города, а метка „а каждой дуге
указывали задачи. Вершины графа представ п можст означать дл„ну отрезка пути
от стоимость путешествия во ней J штомо6„лсм, пли цену авиабилета при не-
в милях, если коммивояжер пользу Ж11Н, что коммивояжер проживает в
пользовании самолета. Для УЛ0<* / предположение попросту сводит задачу с
, „роде я и должен вернуться в город Л. ело р
. " „„., к проблеме с п-1 городом.
ОРОДС Я И ДОЛЖСМ D.p.-j
-городами к проблеме с п-1 городом.
50"
О
Рис. 3.7. Пример пути в задаче коммивояжера
Рассмотрим один из возможных путей [А.О,С,В,Е,А] длиной (стоимостью путе
вня) в 450 миль. Целью является нахождение пути кратчайшей длины, т.е. построен
цепочки с минимальной стоимостью. Заметим, что цель — это глобальное свойство гр
фа, а не свойство отдельного состояния. Это пример целевого состояния вида 2 из
определения поиска в пространстве состояний.
На рис. 3.8 указан способ представления возможных путей решения задачи
приведены результаты их сравнения. Начиная от вершины А, к пути добавляются
возможные следующие состояния до тех пор, пока не исчерпается список городов и
путь возвратится в исходную точку. Целью является нахождение пути кратчапшен
длины (минимальной стоимости).
пЛ2 7Г,"и "* Р"С-18' '«^""ваюшпй „„пек в задаче коммивояжера состоит »
ВОЛОВ мо1 ' МР"а"Т0В' ГЖ N - Ч1»° "*"■"» Т* ("ЛИ ЧИСЛО ГОрОДОВ). Д"» " *
родов можно непосредствеиио проверить все вершины. Но в реальных ситуация*. "»'
116
»■ Искусственный интеллект как представление и
пример для 50 городов, непосредственный перебор невозможен. На самом деле
сложность вычислении N! растет столь быстро, что очень скоро прямой перебор всех
вариантов станет неосуществимым.
Путь:
ABCDEA
Путь- Путь-
ABCEDA ABDCEA
Стоимость: Стои|
375 425
юсть: Стоимость:
475
Рис 3 8 Поиск в задаче котшвояжера. Метка каждой дуги соответствует
суммарному весу всего пути от начатой вершины А до »„«„ точки дуги
Разработано множество методов сохших ^^^"J-
т метод вепееи и границ [Ho.ow.tt и Sata 19T^^ на|ОТЧШ„й ,„ ^
рождается один из возможных вариантов пут при >™ У™ Kaim.
„ее построенных путей. Этот путь 'КП0'Ь^™ В^! ^ Грод ангора ана.з,™рует
датов. Поскольк-у „а каждом шаге к пути «« -"всевозможные продолжения
все возможные продолжения. Если оонаружи" „„„|1ТМ уничтожает 3tv ветвь и
некоторого пути (ветвь) дороже чем заданна» грашца^ J^ спцсст8СНН0 сокрашает-
«се возможные ее продолжения. В резульи тс ^ (
остается экспоненциальной(..^° » пп „„„аилу 'идти в блн-
рис. 3.7 — это
ся, но все же остается экспоненциальной
Еще одна с-
:тается экспоненты,..,,™... . п0 правилу
стратегия »" «Г пешему ^J. Ha f
—.- ■-" г- ., к —ближайшему соседу
жаиший не посещенный город . путь к ^ высоко эффективен. гак как
М, £, D, в, С, А), сю стоимость 375 миль^ J ^ сожшен.1Ю. эвристика поиска
на каждом шаге выбирается лишь один в р ю пут„ кратчайшей длины, как
ближайшего соседа не всегда приводит к п0 - цм коыпромиссом в случае, если
показано на рис. 3.9. Однако она является во
полный перебор неосуществим практически. е СОСгоянин.
В разделе 3.2 исследуются стратегии поиска в пр* Р
Глава 3. Структуры и стратегии поиска в простран
Рис. 3.9. Пример пути в задаче коммивояжера,
полученный на основе поиска ближайшего соседа.
Заметим, что этот путь (A,E,D,B,C,A) имеет
стоимость 550 и не является кратчайшими.
Сравнительно высокая стоимость дуги {С,А) не
учитывается эвристикой
3.2. Стратегии поиска в пространстве состояний
3.2.1. Поиск на основе данных н от цели
Поиск в пространстве состояний можно вести в двух направлениях: от исходных
данных задачи к цели и в обратном направлении от цели к исходным данным.
При поиске на основе данных {data-driven search — поиск, управляемый данными),
который иногда называют прямой цепочкой (forward chaining), исследователь начинает
процесс решения задачи, анализируя ее условие, а затем применяет допустимые ходы или
правила изменения состояния. В процессе поиска правила применяются к известным фактам
для получения новых фактов, которые, в свою очередь, используются для генерации новых
фактов. Этот процесс продолжается до тех пор, пока мы, если повезет не достигнем цели.
Возможен ., альтернативный подход. Рассмотрим цель, которую мы хотим достичь.
Проанализируем правила или допустимые ходы, ведущие к цели, и определим условия
их применения. Эти условия становятся новыми целями, или подцелями, поиска. Поиск
ТезТмТГ Ра™0М Напраме»"и от Д°«игнутых подцелей до тех пор, пока (если
«к пели М ИСХ0ДНЫХ Да"НЫХ Задачи' Так™ °6Разом определяется путь от
иазьтается Г,;Г7ЫИ "" "" ДМе С11ЮИТСЯ в °бр™ направлении. Этот подход
трГ™;ч=;г:ГскГв:,::::;'1гочгай'0н напо™простой детский
заданному начальному. лабиринта из конечного искомого состояния к
путеГпр™енешГпра°в"илК^Т^""""" Начинается с Уровни задачи и выполняется
к цели. Поиск от цепи начинаетсяГГ ™Л°% """ П0ЛУЧСНИЯ «овых фактов, ведущих
ния правил, которые могут привести раЩСН"я к це,ш и продолжается путем опредсле-
исходным данным задачи. " W""' " построения цепочки подцелей, ведущей к
118 Ча
аоть И. Искусственный интеллект как представление и поиск
Наконец заметим, что в обоих случаях (и пш
от цели) исследователь работает с одним и тем ж"°1* "" """""' даты* « "Р« поиск,
нак0 порядок и число состояний в процессе „„ *мТ^Т^"™ «°£%Z
п0Иска предпочесть, зависит от самой задачи. При э™ г аТЬС"' ^стратег!
„равил, "Форму пространства состояний, природ^ д~Дует ™™вать Zj£
может изменяться от задачи к задаче. У Доступность да„ных задач|| Все ^
Как пример зависимости сложности поиска от выбп™ ™
которой нужно подтвердить или опровергнуть ™ег1?>аТтШ рассмотР™ задачу, в
джефферсона". Положительным решением является Л?Т Потомок Томаса
..я- до "Томас Джвфферсон". Поиск на этом графе м»Г„Ге"еаЛО™,е1:КОМу деРевУ от
начиная от вершины "Я" строить цепочку предков к ветГ ""?" * *т на"Раш™|«х:
или начиная с вершины "Томас Джвфферсон" анали™ """^ ТШЭС Дже**еРсон",
Простая оценка позволяет сравнить сложность n0™P ™ цепочк>'его потомков.
Джефферсон родился примерно 250 лет назад Если считИ^Г" Направленш«- Томас
дается каждые 25 лет, то длина искомого „у™ составляли"» шГГГ
дыи потомок имеет двух родителей, то путь от "Я" требует анализ э' Стл^ ка*-
стояини, поскольку родители обычно имеют более двух детей (особенно это ,1" Г
семнадцатого и девятнадцатого столетий). Если допустить, что каждая семья ™еет в
среднем троих детен, то в процессе поиска нужно проанализировать Зш вершин генеало
гического дерева. Таким образом, этот путь сложнее. Заметим, однако, что оба способа
поиска имеют экспоненциальную сложность.
Модуль решения задачи может использовать как стратегию поиска на основе данных
так и на основе цели. Выбор зависит от структуры решаемой задачи. Процесс поиска от
цели рекомендован в следующих случаях.
1. Цель поиска (или гипотеза) явно присутствует в постановке задачи или может быть
легко сформулирована. Например, если задача состоит в доказательстве
математической теоремы, то целью является сама теорема. Многие диагностические
системы рассматривают возможные диагнозы, систематически подтверждая или
отвергая некоторые из них способом поиска от цели.
2. Имеется большое число правил, которые на основе полученных фактов позволяют
продуцировать возрастающее число заключений или целей. Своевременный отбор
целей позволяет отсеять множество возможных ветвей, что делает процесс поиска
в пространстве состояний более эффективным (рис. 3.10). Например, в процессе
доказательства математических теорем число используемых правил вывода
теоремы обычно значительно меньше количества, формируемого на основе полной
системы аксиом.
3. Hnv„ _ „ ,„„.„» „о потааэумевается. что они должны
3. Исходные данные не приводятся в задаче, но подразумевается, что они
добыть известны решателю. В этом случае поиск от целя может служит*.руьс*._
яством ^ пра1ьной постановки задачи. В "№««—-' ^еЛз
кн, например, имеются всевозможные Д"^0™46™"^™^ ко„кт*-шую ги-
мх только те, которые позволяют подтвердить или опровергнуть т- .
потезу о состоянии пациента.
Таю1м образом, при поиске от цели подходящие правша применяются
" ^перспективных ветвей поиска.
Данные
Рис 110 Пространство состояний, в котором при
„„иске от цели .emeu ненужных направлении поиска
эффективно отсекаются
Цель
Данные
Рис. 3.11. Пространство состоянии, п котором поиск па
оспине банных отсекает ненужные данные и их логические
следствия и позволяет определить одну ш нескольких нот-
можных целей
Поиск на основе данных применим к решению задачи в следующих случаях.
) Все или большинство исходных данных заданы в постановке задачи. Задача
интерпретации состоит о выборе этих данных и их представлении в виде, подходящем
для использования в интерпретирующих системах более высокого уровня. На
стратегии поиска от данных основаны системы анализа данных определенною типа.
Ъо такие системы, как PROSPECTOR или Dipmelcr. анализаторы геологических
Данных, определяющие, какие минералы с наибольшей вероятностью могут быть
найдены в некотором месте.
2' боТппГГ """'Г' ЧИШ0 "°™"«а"ьных иелей, „о всего лишь несколько спосо-
™Г ',?"" " "Р"»™— «"Формации о конкретном примере з*»"
кс cL» L P"MqMM ТГ0Г0 ™"а ™««- »»«»стс» программа DENDRAL'
.«.«Фтиа, сисема исслелования молекулярных структур орга сек..* сосди"-
Часть II. Искусственный интеллект как представление и по**
иий на основе формул, данных масс сп
органического соединения су,д<;сге" „ ^ " ,на,|ий ю """"и. Для любого
структур. Однако данные масс-спск™, JZ""^"" Г*">ьш'х числ" возможных
завить лишь небольшое число WnZ^™™™ "^^^ D№DRAL °*
3. Сформировать цель или гипотезы очень тг~,™„ и
системы DENDRAL изначально м"жГб,т На"РимеР- "Р" использовании
структуре соединения. *" 6ЫТЬ 0,еНЬ Мал0 ""Ф«Р«*ши о возможной
При поиске на основе данных знания „ ограничения, заложенные в исходной
„остановке задачи, используются для нахождения пути к решению ""одной поста
Подводя „тог замезим, что ничто не заменит тщательного анализа каждой «отрет-
„ой задачи. Необходимо учитывать такие особенности, как фактор ветвления J*Z-
пользовании правил, доступность данных и простота определения потенциальных целей
В главе 4 рассказывается о том, сколько новых состояний возникает в результате
применения правил поиска в обоих направлениях.
3.2.2. Реализация поиска на графах
При решении задач путем поиска на основе данных либо от цели требуется найти
путь от начального состояния к целевому на графе пространства состояний.
Последовательность дуг этого пути соответствует упорядоченной последовательности этапов
решения задачи. Если решатель задач имеет в своем распоряжении оракула или иное
непогрешимое средство предсказания для построения пути решения, то и поиска не
требуется. Модуль решения задачи должен безошибочно двигаться прямо к цели, запоминая
путь движения. Поскольку для интересных задач оракулов не существует, решатель дат-
жен рассматривать различные пути до тех пор, пока не достигнет цели. Поиск с
возвратами {backtracking) — это метод систематической проверки различных путей в
пространстве состояний.
Начнем рассмотрение алгоритмов с поиска с возвратами, поскольку это один из
первых алгоритмов поиска в информатике, который допускает естественную реализацию в
рекурсивной среде, ориентированной на использование стеков (раздел 5.1). Упрошенная
версия поиска с возвратами на примере поиска « глубит (раздет 5.1) будет реализована в
части VI на языках LISP и PROLOG.
Алгоритм поиска с возвратами запускается из начального состояния и езедует noj«oro-
рому пути до тех пор, пока не достигнет цели -либо не упрется в тупик. Если "£ »™"*£
поиск завершается, и в качестве решен*, задачи возвращается путь к *™J*™~'™»
привел в токовую вершину, тоJ——^,^Г„З^Л
шин и исследует все ее вершины-братья, а затем с^|аэт^^1_яжж(
вершины-брата. Этот процесс описываете, следующим рекурсивным правилом.
_ ~^>uuiiiti иста то hi списка о;' ■ потомков
Если „сходное состояние S не удовлетворяет Ч**»"""" . . „,.
выбираем первый SM. и к згой вершине W»" Т£™с, <*"
вратами Если в результате понев с -о.-Р»™ ■ "^ \К' vjm,
ружеиа. то повторяем процедуру Для ^Ш"™'ТЛ „ -то. иасш
ло тех пор. пока один из потомков расемагри» w ^Ш1111Ш.
узлом, либо пе выясните., что v>"«^"^" s Hl ,„..,„ ..-.. ,™,. .
брать,, Если же ни одна и, вершиибр.™" «Р j^, s „ ,
прелку вершины S и повторим процедуру ' «*
;»"л^асчс>
г"ава 3. Структуры и стратегии поиска в пространств сс~гаян»
121
„ пока не достигнет цели либо не исследует все про.
Алгоритм работает до тек пор. жп |1роцссс поиска с возвратами в гипотеги.
етронсзво состояний. На рис. >■ юс ^^т в дереве указывают направление
ческом пространстве состояп ни. '^ (Ш|Ю или ввсрх). Числа возле каждой верши-
проиесса поиска в пространстве ^^ приведем алгоритм поиска с возвратами,
ш указывают порядок их носсш ' ЮЩ11Х запоминать путь от узла к узлу в про-
В нем используются три списка, по
сранстве с0"от"и"- исспед0Ванных состояний рассматриваемого пути. Если цель
% 1е;:^Гр»тс1соксосто,н„Г,„УтирсШсн„я.
Г« (New Sunc Lis.) - список новь,х состояний, он содержит вершины, подлежащие
pacc„oZu,r« список вершин, потомки которых еЩе „с были порождены „ „ас
смотрены.
DE (Dead Ends) - список тупиков, т.е. список вершин, потомки которых уже были ис
слсло^мь, но не приведи к цели. Если состояние из этого списка снова встречается в
процессе поиска, то оно обнаруживается в списке DE и исключается из рассмотрения.
При описании алгоритма поиска с возвратами на графах общего вида (не только для
деревьев) необходимо учитывать возможность повторного появления состоянии, чтобы
избежать их повторного рассмотрения, а также петель, ведущих к зацикливанию
алгоритма поиска пути, ^то обеспечивается проверкой каждой вновь порожденной вершины
на ее вхождение в один из трех вышеуказанных списков. Если новое состояние
обнаружится хотя бы в одном из дьух списков SL или DE, значит, оно уже рассматривалось, и
его следует проигнорировать.
function backtrack;
begin
SL: = [Start];NSL: = [Start];DE: = {];CS;=Start;
^инициализация:
while NSL*H do %пока существуют неисследованные состояния
begin
if С8=доа1(или удовлетворяет описанию цели)
then return SL; %при нахождении цели вернуть список
%состояний пути.
if CS но имеет потомков (исключая узлы, входящие в DE, SL, and NSL)
then begin
while SL не пуст и С5=первый элемент списка SL do
begin
добавить CS в DE; %внести состояние в список
%тупиков
удалить первый элемент из SL; %воэврат
удалить первый элемент из HSL,-
CS;s первый элемент NSL;
end
добавить CS в SL;
end
else begin
поместить потомок CS(кроме узлов, „а содержащихся в DE,
cs:= первый элемент Nst"™ "SL> " NSL'
добавить CS в SL
122
'■ ^кУхтввнный интеллект как представление и поиск
end
end;
return FAIL;
end.
Обозначим текущее состояние „р„ n[1„CK. . „„,„
иоя„ие CS всегда равно последнему и, состояние """ °S (CU"en'sta,e)' C°-
Мет ■■фронтальную" вершину на Jcrpo Г„м в ^ ГГ" * '""""г,^ " ПРИЯаВ-
ходь, в и,ре или н„ь,е соответствующие операторь, I'1 "^ ^^ "ЫВОй*-
поются к CS. В результате возникает ^ГвПГжГвГнГTZ7Zй
потомков CS. Первый из зтнх потомков объявляете, новым текущим "о" оян^ Тос
тальные заносятся в список новых состояний NSL для дальнейшего изучТиил Новое
текущее состояние заносится в список состояний SL. и поиск пролезете,. Если текущее
состояние CS не имеет потомков, то оно удаляется из списка состояний SL (именно в
этот момент алгоритм 'возвращается назад"), и исследуется какой-либо из оставшихся
потомков его предка в списке состояний SL.
Алгоритм поиска с возвратами на графе из рис. 3.12 работает следующим образом.
Инициализируем списки.
SL=[A); NSL=[A1; DE=[]; CS=A;
После Текущее Список Новые состояния Тупики
итерации состояние состояний NSL DE
CS SL
0 А [А] [А] []
1 В [ВА] [BCDA] []
2 Е [ЕВА] [EFBCDA] []
3 Н [НЕВА] [HIEFBCDA] [1
4 / [IEBA] [IEFBCDA] [Н]
5 F [FBA] [FBCDA] [EIH]
6 J [JFBA] [JFBCDA] [EIH]
7 С [СА] \CDA] [BFJEIH]
8 G [ССД] [GCDA] [BFJEIH]
Поиск с возврата.™ в данном случае является поиском на основе данных, при
котором корень дерева связывается с начальным состоянием, а потомки узлов анализируются
ДЛЯ построения пути к цел». Этот же алгоритм можно интерпретировать и как поиекот
пели. Для этого целевую вершину следует взять в качестве корил дерева и ™^Ф°«™
совокупность предков длл нахождения пути к начальному «"^^^^Г
«ни цели вида 2 (см. подраздел 3.1.2) этот «гори™ должен определить целевое состоя
нис, исследуя путь для SL. ^ пространства состояний.
Поиск с «чш» ЦжкгаЛ) - это алгоритм поиска на граф* 4-* 1 ^.
АлГОри™ь, поис^ „а графах, которые будут рассм„p»mc, ^™^Х», W-
Wpth-fim), поиск в ширит (bmrthjm) и поиск т первачу «™>>
У!ш1ад^,).испс,1ьзуют,данпоискае.озЧ»тами..™мч,«ееледук,Щие.
..Формируется список неисследованных состояний (NSU. « »» чтс*ы иметь
возможность возвратиться к любому из «* т цгор||тн эт
2. Поддерживается список "неудачных соспмни.
проверки бесполезных путей.
Глава 3. Структуры и стратегии поиска в пространстве состснии
123
Рис. 3.12. Поиск с возвратами в
гипотетическом пространстве состояний
3. Поддерживается список узлов (SL) текущего пути, который возвращается по
достижении цели.
4. Каждое новое состояние проверяется на вхождение в эти списки, чтобы
предотвратить зацикливание.
В следующем разделе рассматриваются алгоритмы с использованием списков,
подобные алгоритму поиска с возвратами. Эти алгоритмы, среди которых поиск в глубину,
поиск в ширину и поиск по первому наилучшему совпадению (глава 4), отличаются от
поиска с возвратами более гибкими средствами и стратегиями поиска.
3.2.3. Поиск в глубину и в ширину
Определив направление поиска (от данных или от цели), алгоритм поиска должен
определить порядок исследования состояний дерева или графа. В зтом разделе
рассматриваются два возможных варианта последовательности обхода узлов графа: поиск в глубину
{depth-fist) и поиск в ширину {breadth-first).
Рассмотрим граф, представленный на рис. 3.13. Состояния в нем обозначены буквамн
(А. В. С, ...), чтобы на них можно было сослаться в следующих рассуждениях. При поиске в
глубину после исследования состояния сначала необходимо оценить все его потомки и их
потомки, а затем исследовать любую in вершин-братьев. Поиск в глубину по возможности
углубляется в область поиска. Если дальнейшие потомки состояния не найдены,
рассматриваются вершины-братья Поиск в глубину исследует состояния графа на рис. 3.13 в таком
порядке: А. В, Е. К, S. L, T, F, М. С. G. N, Н, О, P. U, D I, Q J R. Алгоритм поиска с
«сиротами, рассмотренный в подразделе 3.2.2, осуществляет поиск в глубину.
Поиск в ширину, на-
другим. И только если
ширину, напротив, исследует пространство состояний по уровням, один за
олько если состояний на данном уровне больше нет алгоритм переходит к
следующему уровню. При поиске в ширину на графе из рис. З.В состояния
рассматриваются в таком порядке: А, В. С, О, Е. F. G. И. ,. Л, L М N О Р. О R. S. Т. U.
ляю,ш> .1Ш1фИНУ°СУЩеСТВПЯеТСЯ С «'полиованисм списков open и closed, позво-
NSLТалгапГ1'1^ Продвнжен«с в пространстве состояний. Список open, подобно
коТоры" Г^ бГМв С в03врат™1'- «»Ч™ сгенерированные состоя»,.*, потомки
лЗоряо« „оЗв ЛеД°ВаНЫ- П°РЯД0К Удален»я «™нИй из списка open опре-
сок closedL ооГ™ С[ШС0К Cl°Sed Шюс™ У™ исследованные состояния. Спи-
объединяет списки ОЕ и SL. используемые в алгоритме поиска с возврати-
Часть II. Искусственный интеллект как представление и поиск
К» L. М. N* ol P. Q. я.
«1 г! J
Рис 3.13. Граф, демонстрирующий работу
алгоритмов поиска в глубину и в ширину
function breadth_first_search;
begin
open: = I Start ] ; %иниииализация
closed := [ ] ;
while open * [ ] do %есть состояния
begin
удалить крайнее слева состояние из open, скажем X,-
if X - цель then return SUCCESS %цель найдена
else begin
сгенерировать потомок X:
поместить X в список closed;
исключить потомок X, если он уже в списке
open или closed; %промрка на цик-т
поместить остальные потомки в
правый конец списка open %очередь
end
end %состояикй не остался
return FAIL
end.
Дочерипе состоя»,,* -риру^п^ Гк^П^^^
ры. или другими операциями перехода с°"° в „. Заметим, что список
ся вес дочерние вершины состояния X и запи поступления («лн
open действует как очередь "°6Р"6,™Ю" """ ^ £•«« FIFO firs,.in.fir«-
"первым поступил — первым обслужен ^ „адаугся слева. Таким образом в
ош. Состояния добавляются в список спРаВятся в сппске 0реп дольше всего, обес-
поиске участвуют состояния, которые наход м 6ыли у1Ке „писаны в списки
„яния. которые наход ^ ^ ^„^ „ £Ш
,у. Дочерние состоя»"». / ктс1 ,„.,, „свыполн,
>вая поиск в ширину. Дочерние c°CIMH"*o M ,аверШаетс1 из-за невыполнения
open или closed, отбрасываются. Если а. 1 ' весь граф „следовав •-
гц M МОЖНО Заключит.
условия цикла while lopen=U)-lu' поиск потерпел ие>дачу.
желаема» цель не достигнута. Следовательно, поиск тер
~" — _ пространств»? с
Глава 3. Структуры и стратегии поиска в i*~
„„„тма поиска в ширину breadth_£irst_search „а граф
Проследим путь алгоритма ^ ъ ^ означают номер шерации цикла while При
ГГ-ГжХое'иелеГесо^иие.
3. оре„= C,D,E,Fb d=[c,B,Al
«• ореП= °'г'г н I J]' closed=[D,C,B,A]
5. open=[E,F,G,H,I,JJ.^ d=[E| D/C, В, А]
open); closed=[F,E,D,C,B,A]
,K,L1;
6. open=[F,G,H,I,J
7. open=[G,H,I,J,K,L,M] {так как L уже
" M1 ■ closed=(G,F,E,D,C,B,A
open=[H,I,J.K.b;«.^ ----eH0; ,„„ open,„
9 И так далее.
На рис 3 14 показан граф. изображенный на рис. 3.13 после шест» итераций поиска в цщ.
щГсостояния из списков open н closed на рио. 3.14 выделены цветом. Не выделенные
состояния не били исследованы алгоритмом. Заметим, что тюграничные состояния поиска
налкАПаадиизаписываются в open.а ужерассмотренные - в closed.
Поскольку при поиске в ширину узлы графа рассматриваются по уровням, сначала
исследуются те состояния, пути к которым короче. Поиск в ширину, таким образом,
гарантирует нахождение кратчайшего пути от начального состояния к цели. Более того,
поскольку вначале исследуются состояния, найденные по кратчайшему пути, при
повторном проходе это состояние отбрасывается.
Иногда помимо имен состояний в open и closed необходимо хранить дополнительную
информацию. Например, заметим, что алгоритм поиска в ширину не поддерживает список
состояний на текущем пути к цели, как это делалось при поиске с возвратами {backtrack) в
списке Si.. Все посещенные состояния хранятся в closed. Если путь является
решением, то он возвращается алгоритмом. Это может быть сделано путем накопления
информации о предках для каждого состояния. Состояние хранится вместе с записью
родительского состояния, т.е. в виде пары (состояние, родитель). Для графа на рис. 3.13
содержание списков open и closed на четвертой итерации было бы следующим.
open=[(D,A), (E,B), (F.B), (G.C), (H,C)1; closed» [ (С, А) , (В, А), (А,пШ]
S"
I Г
. closed
Рис. 3.14. Граф из вис ? п и л
горшпма поиска V шерации выполнения ал-
""wax open и rl*HUPJ"ty\Состаяния- содержащиеся в
closed, выделены цветом
В списке open
асть ц. Искусственный интеллект как представление и г
Используя эту информацию, можно легко построить путь (А в F) ведущий от A kF
Когда цель найдена, алгоритм может восстановите ™т ведущий от л к h.
„и ияппяялешш пт „е„ы . восстановить путь решения, прослеживая его в
обратном направлении от цели к начальному состоянию по родительским состояниям. За-
метим, что состояние А имеет родителя п„ (нуль), т.е. «веется начальным сосТяниеч
Это служит сигналом прекращения восстановления пути. Поскольку поиск в Грину н^
ходит каждое состояние по кратчайшему пути и сохраняет первую версию какого
состояния, этот путь от начала до цели является самым коротким
На рис. 3.15 показаны состояния, удаленные из open и исследованные алгоритмом поиска
в ширину для 8-головоломки. Как и прежде, дуги соответствуют перемещению пустой клетки
вправо, вниз и влево. Номер рядом с каждым состоянием указывает порядок удаления из
open. В графе не показаны состояния, оставшиеся в open по завершении алгоритма.
Опишем алгоритм поиска в глубину — упрощенный алгоритм поиска с возвратами, уже
представленный в подразделе 3.23. В этом алгоритме состояния-потомки добавляются и
удаляются с левого конца списка open, т.е. список open реализован как стек магазинного типа
или структура LIFO — "last-in-first-ош" ("последним пришел — первым обслужен"). При
организации списка open в виде стека предпочтение отдается самым "молодым" (недавно
сгенерированным состояниям), т.е. осуществляется принцип поиска в глубину.
function depth_first_search;
begin
open:=[Start];
% и нициализ ация
closed:=t);
while open Ф [ ] do %есть состояния
begin
удалить крайнее слева состояние из open, скажем X;
if X - цель then return SUCCESS %цель достигнута
else begin
сгенерировать потомок X,-
поместить X в список closed;
исключить потомок X, если он уже в open или closed;
%проверка цикла
поместить остальные потомки в левый коней списка open
%стек
end
return FAIL %cocto,h™ не оста.-сеь
end.
Ниже показан процесс реализации алгоритма depth.f irst_search для графа из
рис. 3.13. Каждая успешная итерация цикла ,,«/<• описана одной строкой (2,3.4^
Начальные состояния стеков open и closed указаны в строке 1. Пуст. U- целевое состоя™*.
1. open=[AJ; closed=[]
2. open=[B,C,D]; closed=[A]
3- open=[E,F,C,D]; closed=[B,A]
4. open=[K,L,F,C,D]; closed=[E,Б,A]
5. open=(S,L,F,C,D]; closed=(K,E,B,A]
6. open=[L,F,C,D] ; closed=[S,K,E,B, A]
1- open=[T,F,C,D] ; closed= [L, S,K,E, B.A]
8. open=[F,C,D); closed=(T,L,S K,E В A] ciosed=[F, T, L, S.K.E.B, A]
9. open=[M,C,DJ, as L is already on closed, cio
Глава 3. Структуры и стратегии поиска в пространстве состояний
127
10. open=[c,Dl; closeoXM, F,T,L,S, K,E,B,A]
11. open=[G,H,Dl; closed>[C,M,F,T,L, S, K,E,B, A]
И так далее, пока не будет обнаружено состояние U, или ореп=[
34 35 36 37 38 39 40 41 42 43 44 45 46
Цель
Рис 3.15. Поиск в ширину, демонстрирующий порядок удаления состояний из списка
open, в 8-головолоике
Как и при поиске в ширину, в списке open перечислены все обнаруженные, но еще
не оцененные, состояния (текущая "граница" поиска), а в closed записаны уже
рассмотренные состояния. На рис. 3.16 показан граф, изображенный на рис. 3.13, после
выполнения шести итераций функции depth_f irst_search. Списки open и closed на
рис. 3.16 выделены цветом. Как и при поиске в ширину breadth_f irst_search, в
данном алгоритме можно сохранять для каждого состояния записи о родителях. Это
позволит алгоритму восстановить путь, ведущий от начального состояния к целевому.
В отличие от поиска в ширину, поиск в глубину не гарантирует нахождение
оптимального пути к состоянию, если оно встретилось впервые. Позже в процессе поиска
могут быть найдены различные пути к любому состоянию. Если длина пути имеет значение
в решении задачи, то в случае нахождения алгоритмом некоторого состояния повторно
необходимо сохранить именно тот путь, который оказался короче. Это можно сделать.
„1™7пЛЛЯКаЖД0ГОС0СТ0Я"ИЯТр0ЙКУ3"аЧ1:»иП (состояние, родитель, длина
на едини Г ГСИеРаШШ Д°,СРНИХ МСМСНТ0В ™™»™ « пути просто увеличивается
m,oZ г1мСТ"7СЯ BM£CIe C "°™™«. Если дочернее состояние достигнуто"»
многим „утям, эту информацию нужно использовать для сохранения лучшей версии. Эта
128
II. Искусственный интеллект как представление и
ГраГиГл^ше7:еррГс:г:Гп;т=^ {а1°°г,,ы*>■ -««■з— -
Г™ цель бГдет лоскута ГнГпТкр^ще™™ "^ """ " ""
В списке closed
В списке open
Рис. 3.16. Граф, изображенный на рис 3.13. после
выполнения шести итераций depth_first__searcK
Состояния, содержащиеся в списках open и closed,
выделены цветом
На рис. 3.17 рассмотрен поиск в глубину на примере головоломки с 8 фишками. Как
отмечалось ранее, пустая клетка передвигается согласно одному из четырех возможных
правил (вверх, вниз, влево и вправо). Числа рядом с состояниями указывают порядок, в
котором они были рассмотрены и удалены из списка open. He показаны состояния,
находящиеся в open, когда цель уже найдена. Глубина поиска в данном случае была
ограничена пятью уровнями, чтобы не "затеряться в глубинах" пространства состояний.
После выбора стратегии поиска (на основе данных или от цели), оценки графа и
выбора метода поиска (в глубину или в ширину) дальнейший ход решения будет зависеть
от конкретной задачи. Влилть на выбор стратегии поиска может необходимость обнар>-
жения именно кротчайшего пути к цели, коэс
фицнент ветвления пространства, доспи-
ное время вычислений и возможности пространства, средняя длина пути к целевой
вершине графа, а также необходимость получения всех решений или только первогоЛТри
выборе метода поиска несложно убедиться, что у любого подхода всегда имеются опре-
Деленные преимущества и недостатки. „„„„^ „+i Btw1s
Поиск в ширину. Поскольку при таком подходе до перехода к уро ик»^"™
исследуются вес узлы „а уровне п. поиск в ширину всегда »»™^"Г^Гет на£
к Целевой вершине Если ^задаче существует ^^"^Z^Z-
*». К сожалению, при большом коэффициенте^ ™ ния «. ^^ ^
- среднее число потомков, комбинаторный
Решения. Это происходит потому, что все пер.
активные и неперспективные вершины
Глава 3. Структуры и стратегии поиска в пространстве
129
„тся в списке open. Для глубокого поиска (когда цель
да, каждого уровня поиска находсостояний с высоким коэффициент™ ветв.
Цель
Рыс .?J7. Яоисквглбшо'йгяцгрыв "пятнашки" с8фишками, ограниченный 5уровнями
Степень использования пространства при поиске в ширину измеряется в терминах
числа состояний в списке open и является экспоненциальной функцией длины пути в
любой момент времени. Если каждое состояние порождает в среднем В дочерних
состояний, то общее число состояний на данном уровне определяется умножением В на
число состояний предыдущего уровня. Значит, на уровне п число состояний составляет
В". При исследовании уровня п методом поиска в ширину все состояния помещаются в
open, что может быть нежелательно, если путь к решению достаточно длинный.
Поиск в глубину быстро проникает в глубины пространства. Если известно, что путь
решения будет длинным, то поиск в глубину не будет тратить время на поиск большого
количества -поверхностных- состояний на графе. С другой стороны, поиск в глубину
может затеряться в глубинах" графа, пропуская более короткие пути к цели, или даже
•застрять на не ведущем к цели бесконечно длинном пути.
томучтоКеВм7н°11НУ Эффе[СП1Вен тя <**««* войска с высокой степенью связности, по-
™о^нГппп "УЖН0 П°МНИТЬ ВСС У1ЛЫ Данного УР°ВН* * списке open. Степень не
2ныХ? Н>Т"™ С0СТ0ЯННЙ В CJI>"*ae по««« в дубину - это линейная функи"»
^^TS; ЛЮЮе В °РеП С0*Р" ™L дочерние вершины единст-
Wmmm- ЕСЛИ У Ка**™ аршины графа имеется в среднем В дочерних вер-
130
I- Искусственный интеллект как представление и поиск
шин, и если поиск продвигается на п уровней вглубь пространства, то уровень
использования пространства составляет Вхп.
Так что же лучше: поиск в глубину или поиск в ширину? На этот вопрос можно
ответить так. Необходимо исследовать пространство состояний и проконсультироваться с
экспертами в данной области. В шахматах, например, поиск в ширину просто
невозможен. В более простых играх поиск в ширину не только возможен, но даже может
оказаться единственным способом избежать проигрышей или потерь в игре.
3.2.4. Поиск в глубину с итерационным заглублением
Хорошим решением проблем поиска в глубину является использование предельного
значения глубины поиска. Предельная глубина позволяет ограничить поиск только
заданным числом уровней. Это обеспечивает некоторое подобие "развертки" области
поиска в ширину при поиске в глубину.
Ограниченный поиск в глубину наиболее полезен, если известно, что решение
находится в пределах некоторой глубины, имеются ограничения во времени или пространство
состояний чрезвычайно велико (как в шахматах). В таких задачах число рассматриваемых
состояний ограничивают предельной глубиной поиска. На рис. 3.17 показан поиск в глубину
для 8-головоломки, для которого предельная глубина ограничена пятью уровнями.
Поэтому именно на этой глубине возникает поперечная развертка пространства.
Такая модификация позволяет исправить немало недостатков как поиска в глубину,
так и поиска в ширину. Итерационным заглубление.^ [Korf, 1987] называется поиск в
глубину, первая итерация которого ограничена 1 уровнем. Если цель не найдена,
выполняется еще один шаг с предельной глубиной 2. В процессе поиска предельная глубина
увеличивается на 1 нэ каждой irrepaionf. На каждой итерацни алгоритм выполняет поиск
в глубину с учетом текущего предельного числа уровнен. При этом при переходе от
одной итерации к другой информация о пространстве состояний не сохраняется.
Поскольку алгоритм исследует пространство "по уровням", он может гарантировать
нахождение кратчайшего пути к цели Поскольку на каждой итерацни осуществляется
только поиск в глубину, степень использования пространства на каждом уровне п
составляет Вхп, где S — среднее число дочерних состояний вершины.
На первый взгляд кажется, что итерационное продвижение в глубину менее
эффективно по времени, чем поиск глубину или в ширину. Однако временная сложность
алгоритма (время выполнения алгоритма в зависимости от размерности задачи) в
действительности имеет тот же самый порядок величины, что и каждый из этих алгоритмов —
0{ В"). Объяснение этого кажущегося парадокса приведено в [Korf. 19S7].
Поскольку число вершин на данном уровне дерева растет экспоненциально с увеличением
глубины, почти все время вычислений тратится на самом глубоком уровне
К сожалению, можно показать, что в наихудшем случае все рассмотренные в этой
главе стратегии поиска (поиск в глубину, в ширину и итерационное заглубление)
обладают экспоненциальной сложностью. Это характерно для всех неинформированных
алгоритмов поиска. Для снижения временной сложности алгоритмов поиска
используют направляющие эвристики. Поиск по первому наип-чшему совпадению — это
алгоритм поиска, подобный представленным выше алгоритмам поиска в глубину и в
ширину. Однако в процессе поиска по первому наилучшему совпадению состояния в
списке open, определяющие текущую границу поиска, >порядочиваются согласно
Глава 3 Структуры и стратегии поиска в пространстве состояний
131
„мистическому показателю качества. На каждой итерации „0„ск ра
"ТГсамыГгГуооГе, а самые "лучшие" состояния. Поиск по первому наилучц,,
„"совпадению _ центральная тема главы 4.
3 3 Представление рассуждений в пространстве
г^^птшй^н^основе^счисления предикатов
3.3.1. Описание пространства состояний логической системы
В разделе 31 при определении графа пространства состояний было отмечено, что его
вершины должны отличаться друг от друга, поскольку каждый узел представляет некоторое
состояние процесса решения. В качестве формального языка для описания этих различий и
отображения узлов графа в пространство состояний можно использовать исчисление преда,
катов. Более того, для создания дуг и описания связей между состояниями можно
использовать правила вывода Тогда методами поиска могут быть решены некоторые проблемы
исчисления предикатов. Например, таким образом можно определить, является ли некоторое
конкретное выражение логическим следствием данного набора утверждений.
Корректность и полнота правил вывода исчисления предикатов обеспечивает
корректность подобных заключений. Возможность получить формальное доказательство
целостности решения задачи с помощью алгоритма решения самой задачи является
уникальным преимуществом многих методов искусственного интеллекта.
Хотя состояния многих задач (например, "крестики-нолики") более естественно
описываются другими структурами данных (например, массивами), общая логика н
специфика решения многих задач ИИ приводят к использованию исчисления предикатов и
других моделей представления знании, в том числе правил вывода (глава 7),
семантических сетей и фреймов (глава 6). Для всех этих моделей представления знаний можно
использовать стратегии поиска, аналогичные представленным выше.
Пример 3.3.1. Исчисление высказываний
В качестве первого примера рассмотрим задачу построения графа на основе набора
логических отношений из исчисления высказываний. Пусть p. Q, г, ... — высказывания.
Рассмотрим следующие утверждения.
Р->р
г->р
v-*q
s^r
г->г
s->u
s
t
Из этого набора утверждений иа основе правила модус поненс могут быть выведе!
определенные высказывания, в том числе р, г и и. Другие высказывания, в частности,
Я. не могут быть выведены таким способом. Действительно они логически не СЛЕДУ
из этих утверждений. Отношения между начальными утверждениями и выведенными
них описаны „а рис. 3.18 с помощью ориентированного графа.
132
Часть II. Искусственный интеллект как представление и
и и
А
Рис. 3.18. Граф пространства Рис. 3.19- Граф И/ИЛИ дчя
состоянии набора импликаций в выражения q^r^p
исчислении высказываний
Дуги на рис. 3.18 соответствуют логическим импликациям (-*). Утверждения,
которые считаю гея истинными (s и 1), соответствуют исходным данным задачи. Логические
следствия из данного набора утверждений соответствуют достижимым узлам. Путь на
графе отражает последовательность применения правила модус поненс. Например, путь
[s, г, р] соответствует такому ряду логических выводов.
Из s и s —» г следует г.
Из г и г -» р следует р.
Такой способ логического вывода информации сводится к нахождению пути от
вершины, помеченной квадратиком {начального узла), к целевому высказыванию. Таким
образом, задача логического вывода сводится к проблеме поиска на графе. При этом
используется поиск на основе данных— строится путь от известных (истинных)
высказываний к целевым утверждениям. К этому же пространству состояний можно применить и
стратегию поиска от цели. Поиск от целевого высказывания позволяет прийти к
обоснованию этой цели в классе истинных высказываний. Полученное пространство логических
следствий можно исследовать методом поиска как в глубину, так и в ширину.
3.3.2. Графы И/ИЛИ
В предыдущем примере вес утверждения представляли собой импликации вида p-*q.
Способ представления логических операторов И и ИЛИ в таком графе не обсуждался.
Представление логических связей, определенных этими операторами, требует
расширения понятия модели графа. Граф. отражающий подобные взаимосвязи, называется
графом И/ИЛИ. Графы И/ИЛИ являются важным инструментом для описания областей
поиска, порожденных многими проблемами искусственного интеллекта, в том числе
задачами автоматического доказательства логических теорем и экспертными системами,
В выражениях вида q*r^>p для обеспечения истинности р должны быть истинны как
Q, так и г. В выражениях вида qvr^p истинность q или г достаточна для доказательства
того, что р— истина. Поскольку импликации <-»). содержащие дизъюнктивные (v)
предпосылки, могут быть записаны как пзры отдельных импликаций, это выражение
часто записывается в виде q^p, г-»р. Чтобы представить различные
отношения графи-
чески, на графах ШИЛИ различают узлы и (and) и или (or). Если предпосылки
имитаций связаны оператором л. они называются и-узпами графа, а дуги, ведущие от этих умов.
соединяются кривой. На рис. 3.19 в виде графа 11ЛШ1 представлено выражение <"'->*
Кривая, соединяющая дуги на рис. 3.19, означает, что для доказательства р должны
быть истинными обе предпосылки: я « '■ Если предпосылки соединены ™ератором
ИЛИ, на графе они представляются узлами или. Дуги, ведущие от узлов или к акд>к.-
Глава 3. Структуры и стратегии поиска в пространстве ее
„„„аяются кривой (рис. 3.20). Это указывает „а то, что истина лю6ой
шей вершине, не с^им"™"„ч11ь1м условием для истинности заключения,
„предпосылок является д гтерграфа. в котором узлы соединив
Граф ШЛИ »«"тя^""" 'приведем определение гиперграфа,
„дальними дугами, в множеством
ОПРЕДЕЛЕНИЕ
ГИПЕРГРАФ
Гиперграф состоит из следующих злемситов.
w - множество вершин.
н множество пшердуг. Пшердуга задастся упорядоченной парой, в которой первый
злсГ.еТявляется отдельной вершиной из N. а второй -подмножеством множества N.
Обычный граф- это частный случай гиперграфа, в котором все множества
порожденных вершин (узлов-потомков) имеют мощность 1.
Гипердуги также называют к-коннекторами. где к - мощность множества
порожденных вершин. Если к= 1. то можно считать, что потомок является вершиной ИЛИ. Ее-
ли к> 1, то элементы множества потомков являются вершинами и. В этом случае
коннекторы изображаются в виде отдельных ребер, ведущих от родителя к каждой из
порожденных вершин и соединенных изогнутой линией (см. рис. 3.19).
у
/
л
Рис. 3.20. Граф И/ИЛИ выра- Рис. .1.21. Граф И/ИЛИ'дт на-
женш qvr~*p бора выражений из исчисления
высказываний
ПРИМЕР 3.3.2. Поиск- на графе И/ИЛИ
Второй пример тоже относится к исчислению высказываний. Сгенерируем граф, i
держащий оба вида потомков: и и или. Предположим, в некотором мире истинны с)
дующие предложения.
влс-»е
bAd->f
але-»/]
Этот набор утверждений определяет граф И/ИЛИ. показанный на рис. 3 21
С помощью поиска на этом графе можно получить (вывести) ответы на следую-
щие вопросы. М}
1. Истинно ли hi
2. Является ли h истиной, если Ь больше не истина?
3. Каков кратчайший путь, доказывающий, что некоторое высказывание X истинно?
4. Показать, что высказывание р (не используемое в наборе исходных высказываний)
есть ложь. Что это значит? Что необходимо знать для получения этого заключения?
Поиск на графе ШИЛИ требует хранения большего объема информации, чем поиск
на регулярных (однородных) графах. В качестве примера рассмотрим описанный выше
алгоритм поиска с возвратами. Потомки или проверяются в точном соответствии с этим
алгоритмом. А именно, если найден путь, проходящий через вершины или и
соединяющий цель с начальной вершиной, — задача решена. Если же некоторый путь не ведет к
целевой вершине, алгоритм возвращается и исследует другую ветвь. Однако при
исследовании вопроса об истинности родительской вершины узлов и необходимо доказать
истинность всех и-потомков.
В примере, показанном на рис. 3.21, для определения истинности h с помощью
стратегии поиска от цепи (goal-directed strategy) сначала доказывается истинность
а и е. Истинность а очевидна, а выражение в истинно, если истинны и с и а, что
дано по условию задачи. Решающее устройство прослеживает все дуги, ведущие к
истинным предложениям. Затем истинные значения передаются и-узлу для
доказательства истинности /i.
Стратегия определения истинности h на основе данных предполагает обработку
исходных данных (с, а и Ь) и добавление новых высказываний к набору известных фактов
в соответствии со связями графа ШИЛИ. Сначала к набору фактов добавляется
высказывание в или d. Это дает возможность вывести новые факты. Процесс продолжается до
тех пор, пока не будет проверена желаемая цель h.
Поиск на графе И/ИЛИ можно рассматривать следующим образом. Операторы л (и-
узлы графа) означают декомпозицию задачи. Иными словами, задача разбивается на
подзадачи, которые должны быть решены для решения исходной проблемы. Оператор v
(или) в представлении на основе исчисления предикатов определяет точку выбора между
альтернативными путями решения задачи, или стратегиями. Нахождение пути к цели
вдоль любой из ветвей является достаточным условием для решения общей задачи.
3.3.3. Примеры и приложения
ПРИМЕР 3.3.3. Система MACSYMA
Приведем сше один пример графа ИЛ1ЛН. Им является программа символьного
интегрирования математических функций. MACSYMA— это известная программа,
которая широко используется математиками. Логические рассуждения в системе MACSYMA
могут быть представлены в виде графа ШИЛИ. Процесс интегрирования затрагивает
один важный класс залач, в которых выражение разбивается на подвыражения. Эти
подвыражения могут быть проинтегрированы независимо друг от друга, затем результат
алгебраически объединяется в конечное выражение. К примерам этой стратегии относится
правило интегрирования по частям и правило разложения интеграла суммы на сумму ин-
Гпава 3, Структуры и стратегии поиска в пространстве состоянии
стратегии обеспечивающие декомпозицию задачи
„градов отдельны* "—фТмс^быть представлены узлами и.
„а независимые подзадачи, в rp* _
л dz
J i-!
z = tan w
/*
Рис. 5.22. фрагмент пространства состояний графа И/ИЛИ для системы интегрирования
INilsson. 1971I
Еще одна стратегия заключается в упрощении выражения с использованием
различных алгебраических подстановок. Поскольку любое выражение может допускать ряд
замен, а каждая замена представляет независимую стратегию решения, то эти стратеги"
представлены на графе вершинами и™. На рис. 3.22 показано подобное пространство
состоянии. Поиск на зтом графе ведется от цели. Он начинается с запроса иа вычисление
интеграла конкретной функции, а затем направляется вниз к алгебраическим выражени-
™aTeST№M ^ ""^^ Зшетим- ™ "<=«■ ™"™ °* «<™ явлЯОТЯ "^Т
сГ ыоа^ГТ^ усЧ,оИ"»У "Расчески невозможно определить алгебр»*^
~™^.*ЗГ*заданный интс w те на1,рмив понск от запроса м
Часть II. Искусственный интеллект как представление и поиск
ПРИМЕР 3.3.4. Поиск от цели на графе И/ИЛИ
Этот пример взят из исчисления предикатов и представляет поиск от цели на графе.
Цель, истинность которой должна быть доказана, в этом случае представляет собой
выражение исчисления предикатов, содержащее переменные. В этой задаче аксиомы — это
логические описания отношений между собакой Фредом и его хозяином Сэмом. При
этом мы предполагаем, что холодный день — это не теплый день. Кроме того, в зтом
примере не рассматривается проблема, вызванная эквивалентными выражениями
предикатов. Она будет обсуждаться далее в главах 6 и 12. Факты и правила в этом
представлении даны в виде предложений на английском (и русском) языке, за которыми следуют их
представления на языке исчисления предикатов.
1. Fred is a collie. (Фред — это колли.)
co///e(fred).
колли(Фред).
2. Sam is Fred's master. (Сэм — хозяин Фреда.)
masfer(fred.sam).
day(sarurday).
3. The day is Saturday. (Сегодня суббота).
day(saturday).
4. It is cold on Saturday. (Холодно в субботу.)
-<(warm{saturday)).
5. Fred is trained. (Фред дрессированный.)
trained(fred).
6. Spaniels are good dogs and so are trained collies. (Спаниели — хорошие собачки, а
колли такие же обученные.)
VX[spam'e/(X)v(coHie(X)Atrained(X))->gooddog(X)]
7. If a dog is a good dog and has a master then he will be with his master. (Если собака
хорошая и имеет хозяина, тогда она находится рядом с хозяином.)
V(X.Y.Z) [gooddog(X)Amasrer(X,V>/ocar/"on(y,Z)->tocaMori(X,Z)]
8. If it is Saturday and warm, then Sam is at the park. (Если в субботу тепло, го Сэм
находится в парке.)
(day(serurday)Aivarrn(saturday))->/ocanon(sam,par/<).
9. If it is Saturday and not warm, then Sam is at the museum. (Если в субботу не тепло, то
Сэм находится в музее.)
(day(sa(urday)A-n(ivarm(saturday)))->locatran(sam, museum).
Цель— это выражение ЭХ location{fred,X) или ЭХ месго(фред.Х), означающее
"Where is Fred?" (Где же Фред?). Алгоритм с возвратами исследует альтернативные
значения этой порожденной цели: "if fred is a good dog and fred has a master and fred's master
is at a location then fred is at that location also." (Если Фред хороший пес. и Фред имеет
хозяина, и хозяин Фреда находится в некотором месте, то Фред находится в том же месте.)
Исследуются предпосылки этого правила: что значит "good dog" (хороший пес) и т.д.
Таким образом создастся граф Ц/ИЛИ, показанный на рис. 3.23.
Рассмотрим этот поиск детально. Это пример поиска от цеди с использованием
исчисления предикатов. Он иллюстрирует роль унификации (объединения) при порожде-
Глава 3. Структуры и стратегии поиска 8 пространстве состоят
137
« л,,мо реш.«ь задачу: "Где же Фред?". Эту Звд
тяда Необходимо ре -еменной X, если оиа существует „„
Jx утверждений. ь расположение Фреда, то первыми будут исследована,
Раз уж необходимо °пРедел" „рых содержится выражение Месго(/оса«о„). и™
те „редложения. в з^е"Ш выскюывание ? Заключение этого высказывание
первым будет рассыотрен ^^ о6ъед„„яется с выражением locatfon(,fred,X) .
location(KZ) (или ме ,,„ ' J х/д). Предпосылки этого правила при том же набоп.
ГГГ=г(:—,основноЙЦел;;
тановоксоставл»™'»"—
„ Л1 master(fredY)Alocatlon{Y,X).
Направление
поиска
V
( cofeM ] f !ramed(X) 1 fmaster(fred,sam)j Г daylsaturday) J f-n (ivarm(saturdayl)l
[ co//i'e(fred)
Подстановки = lfred/x, sam/Y, museum/Z}
Рис. 3.23. Подграф решения, показывающий, что Фред в музее
Это выражение можно интерпретировать так: один из путей нахождения Фреда со-
шпГ ктоЛеДУЮЩе£ НУЖ"° У66™1"0"- »»™™ лн Фред хорошей собакой, затем выяс-
иель'такнГлТ"' PMa' а ^ затем опРЗДелить местонахождение хозяина. Начальная
»ее д.оХы 6«"™ГСЯ ""'" "0ДиеЛЯМ"- °НИ ЯВЛЯЮТСЯ «-Ч»™»"»' П0ЭТ0МУ
с<й1™й.Ь'^ЗРс^1!™ "°дцсли- Р"""™* сначала определяет, является ли Фред хорошей
1^/хуПре„пГь^^МКЛЮЧешЮ в«™ывания 6, затем используется подстановка
Р д ссылка высказь1вания 6 - это логическая сумма (или) двух выражении:
^»^.«^o™lZ12Z^~~Pan'el{fred)- База дан""х не содержит этого У&Г
вершина- зто (соШеПгеТТ'!"™ Д°ЛЖН0 предположить, что это ложь. ДРУ«» "»"■
»»■ Обе эти предпосьшк'должи "f(fred)K ТА Ф^~ ™ колл» " ФРеД ""^
»а»ия»,„ 1И5. до™"" быть истинны. Так и есть в соответствии с выск»*
Итак, доказано, что выражение goodd0gtfreds „
исследует вторую предпосылку высказывания 7 тем Решающее устройство
{fred/X) к выражению masteriX.Y). получим maTf.rtf'w^' Применяя подстановку
выражение с фактом master{fred,sam) (высказ ' °'r)' a затем объединим это
ванную (обобщающую) замену {sam/Y) кот Ь'ВаКИе '' Это п°Р°ждает унифициро-
третьей подцели высказывания 7, создавая „овуюТелГ/Га^ГшТ 3"аЧеНИе "т
Разрешая эту цель, предположим, что решают» "".0П|5ат'*>-
порядку. Цель /ocat/onfsam.X) вначале буд™ ^иГТ™0 "^^ "^^ "°
вания 7. Заметим, что каждый раз исследуй о1о7тГ ° 3аКШОЧеН"еМ ВЬ,СКИЬ-
неииями связывания для X. Напомним, ZГх явТется!" "РШШ° ' рШЛИЧНЫМИ »»
то она может иметь любое значение (любой Z Ф " псРемеи'0Й <гаа»а 2),
„ - ""чсние (любой ряд, начинающийся с прописной буквы!
Поскольку диапазон действия конкретного значения какой-либо перечной о„-
вается пределами предложения, в котором содержится эта переменная, то исчисление
предикатов не имеет никаких глобальных переменных. Иначе эту мысль можно выразить
так: значения переменных передаются другим предложениям как параметры не
имеющие фиксированной области действия (памяти). Таким образом, многократные
повторения X в различных правилах в этом примере указывают на различные формальные
параметры (раздел 12.3).
Разрешая предпосылки правила 7 с вновь выведенными значениями связывания,
решатель отвергнет их, потому что Сэм не является хорошей собакой. Здесь алгоритм
поиска вернется назад к цели iocation(sam,X) и проверит заключение правила 8. Но и эта
попытка потерпит неудачу, вызывая еще одни возврат назад. Затем последует
объединение (унификация) с заключением высказывания 9 locationisam,museum).
Поскольку предпосылки предложения 9 подтверждаются другими высказываниями
(предложения 3 и 4), то заключение 9 истинно. Результаты унификации передаются
вверх по дереву и приводят к заключительному ответу ЭХ tocation(fred,X), откуда
получим /ocaf/on(fred, museum).
Важно тщательно исследовать природу поиска на графе от цели и сравнить его с
поиском на основе данных из примера 3.3.2. Дальнейшее обсуждение этой
проблемы, включая более строгое сравнение этих методов поиска на графах, рассмотрим
на следующем примере. Но детальное описание приводится только при обсуждении
продукционной системы (основанной на представлении знаний в виде
продукционных правил) в главе 5 и в приложении, описанном в части IV. Еще одна мысль,
неявно использованная в этом примере, заключается в том. что порядок высказывании
влияет на порядок поиска. В рассмотренном выше примере были по порядку
исследованы все имеющиеся предложения, указывающие на рясположеняе обьеиа^Прн
этом использовался поиск с возвратами и отвергались утверждения, истинность ко-
торых была опровергнута.
ПРИМЕР 3.3.5. Финансовый советник (повторно)
В последнем примере из главы 2 ~™Z^^—^
представления набора правил, описывающих де ^^ ^ форм„р0вания
встника. В том примере использовалось пРави™6е инвсст1Ш„й. Мы не обсуждали
совета конкретному человеку о наилучшем ™° ТВ>,ЮШ11М выводам. Это задача
"Уть решения, проделанный программой к соо ^^ ^ осуществлению логиче-
«оиска. Данный пример иллюстрирует лишь оди и; Здесь используется
<*» обоснованного поиска в системе финансовог ^^^
. —. * " 139
г"«а 3. Структуры и стратегии поиска в пространстве состояний
.. „„«патами. В рассуждениях будем использовать преди.
„„ИСК ОГ „СЛИ В ГЛубННу И С '""Р"""" L™ здссь „е дуб„НруЮга,
каты, составленные в разделе/ ^ н „,„„, вмад в размере $20000 и устой.
П!МП^йюГ. "I- 2 бьозо сказано, что к набору уже существуй вы.
ГеГий Ч« Скатов можно добавить новые. И. наоборот, программа может
™ поиск to этойТонкретной информации, запрашивая у пользователя необходимые
дТоГнГльные сведения. Преимущество этого метода состоит о том, что можно не
хранТьТеиужныс данные, которые не будут полезными для решения. Этот подход часте
используют в экспертных системах. _
Цель ьонсультаднй состоит в том, чтобы определить наилучший способ инвестиций.
Это представлено выражением исчисления предикатов ЭХ investment^), где Х~
целевая переменная, которую мы стремимся связать. Были приведены три правила (I, 2 и 3)
которые дают заключения об инвестициях, поэтому запрос будет унифицирован
(объединен) с заключениями этих правил. Если для первоначального исследования
выбрать правило I, то его предпосылка savings_account{inadequate) становится
подцелью, т.е. дочерней вершиной, которую необходимо достичь.
Для получения дочерних узлов подцели savings account(inadequate) применяется
единственно возможное правило 5, которое порождает «-вершину.
amount_saved№*dependents(Y)*-,greater(X,mtnsevingslY})
Если доказывать составляющие этого выражения слева направо, то компонент
amount^saved(X) будет рассмотрен первым. Поскольку приведенные ранее правила не
содержат этой подцели, система запрашивает пользователя о дополнительных данных.
После чего к имеющемуся списку добавляется предикат amounf_sai'ed(20000) с
унифицирующей заменой 20000 вместо X, и первая подцель становится истинной.
Поскольку мы исследуем вершину и, в случае неудачи с первым компонентом нам не
понадобилось бы исследовать остальные две подцели.
Аналогично подцель dependents! У) ведет к запросу пользователя, затем ответ
dependen(s(2) (иждивенцев 2) добавляется к логическому описанию. Подцель ставится
в соответствие выражению путем подстановки (2/V). Затем алгоритм поиска оценивает
истинность выражения ^greater(X,mi'nsaWngs(У)).
Оценка этого выражения приводит к значению "ложь" и невыполнению подцели,
определяемой всей вершиной и. Затем алгоритм поиска возвращается к
родительской вершине sawnos_accounf(/nadequafe) и пытается найти альтернативный
вариант доказательства истинности этой вершины. Эта попытка приводит к
генерированию следующей дочерней вершины и продолжению поиска. Поскольку нет прави-
вепхТгТ™"0-34' "0ДЦСЛ!" "отк завеРш«тся неудачей и возвращается к цели
приводя ЛовГ, reS'men',X)- С ЭТ0Й атю У™Ф«Ц"РУЮгся заключения правила 2,
приводя к новым подцелям
Baw„gs_aeooont(adeqUate)Aincome(adeqnaie)
4e„^:;r^nc:ra::;uzscaw"ss-accou'''(ade^ate' ™>км заы:
оставлены „а рассмотрен,!. °.~- ' "^ т "Ра8ш1а 6' Дальнейшие детали поиска
виде приведен на рис. 3.
ние читателю, а исследуемый граф И/ИЛИ в его окончательном
140
I- Искусственный интеллект как представление и поиск
investments
(InvestmenHsavmgl)]
{Mvings_accot,„,u„ademal^\
G™Ep™>) Gi«^ G^i^^imr]
, у
\amcunt_saved(200oaj\ I tfeoeMen!B(2| I эдвсь
алгоритм заходит в тупик
v I и возвращается назад
[ invtsstmentlstocks})
(amounf_»№dw) ( dependents^ ] [greater, minsavi^)]
[amount_saved(20000)') { dependentl{2)~)
\^eamtngs(X,steady) J f defjendents(Y) ] (дгеа(ег(Х,тт<гкоте(У)) "]
[earnfngsQOOOO, steady) J f dependents{2) ]
Рис. 3.24. Поиск, осуществляемый системой финансового советника на графе И/ИЛИ
ПРИМЕР 33.6. Синтаксический анализатор м генератор предложений
Заключительны» пример не относится к исчислению предикатов. Рассмотрим
набор правил подстановки (rewrite rule) для синтаксического анализа предложений
(парсинга) на подмножестве правил английской грамматики. Правила подстановки
преобразуют исходное выражение путем замены набора символов в предложении,
соответствующего некоторому шаблону, находящемуся по одну сторону стрелки {*-*>,
шаблоном из другой части правила. Например, можно определить набор правил
подстановки для замены выражения на одном языке {например, английском)
выражением на другом языке (например, французском или языке исчисления
предикатов). Приведенные здесь правила подстановки преобразуют подмножество
английских предложений в грамматические конструкции более высокого уровня, такие как
Глава 3, Структуры и стратегии поиска а пространстве состояний
141
ция „ предложение. Эти правила используются для
именная или г™™"^" K°" вательности слов в предложении, т.е. для опреде-
™=Гоос^^^^^
1 Предложение- это именная конструкция пр („о»» phrase), за которой следует
' глагольная конструкция vp {verb phrase).
sentence <-> пр vp
2. Именная конструкция - это существительное (п).
3. Именная конструкция пр - это артикпь art, за которым следует существительное п.
4. Глагольная конструкция vp (verb phrase) — это глагол.
5. Глагольная конструкция — это глагол, за которым следует именная конструкция.
vpi^vnp
Кроме этих правил грамматики, синтаксический анализатор использует словарь
данного языка. Эти слова называются терминалами {terminals). В правилах подстановки они
определены как части речи. В нашем небольшом "словаре" имеются такие слова: a, the
(артикли), man (человек), dog (пес), likes (любит) и bites (кусает). Они являются
терминалами простой грамматики.
6. а — артикль.
arf<->a
7. the — артикль.
art*r^the
8. Человек — существительное.
tinman
9. Собака — существительное.
n<~>dog
10. Любить — глагол (verb).
11. Кусать — глагол.
v&bites
Sen^,e7ce7uZl ШШ ТВИЛа под™и°™н определяют граф И/ИЛИ (рнс. 3.25).
символов Пр., этс^ЛГИИЫЮ "остР°я'"«". ™и оно состоит только из терминальных
прав™ ВьШ„да преоСзХ "гГ 4™<гп*ет Рад подстановок, которые путем применен™
Р Уют его в символ sentence (предложение). И, наоборот, анализ
142
Часть II. Искусственный интеллект как представление и
можно рассматривать как построение дерева синтаксического анализа, у которого
листьями являются слова рассматриваемого выражения, а символ sentence _ его корнем.
[sentence)
man dog a the man dog
Рис. 3.25. Граф И/ИЛИ для простой грашттики из примера 3.3.6. Для
упрощения графа некоторые вершины (пр. ап и т.д.) дублируются
Синтаксический анализ предложения "7ле dog bites the топ" с помощью дерева
грамматического разбора приведен на рис. 3.26. Это дерево является поддеревом графа 11ЯШИ,
показанного на рис. 3.25, н построено в процессе поиска. Алгоритм синтаксического анализа на
основе данных осуществляет поиск путем сопоставления правых частей правил подстановки с
элементами предложения и пробует найти одинаковые пары. Как только соответствие
найдено, часть выражения, соответствующая правой части правила, заменяется образцом из его
левой части. Это продолжается до тех пор. пока предложение не будет сведено к символу
sentence (указывающему на успешное завершение синтаксического анализа), или пока не
будут исчерпаны правила, которые можно применить к предложению (что указывает на
неудачу). Проследим путь синтаксического анализа предложения -The dog hues the man .
1. Прав,™ 7 - это первое правило, которое можно применить, записывая the как art
(артикль). Получаем предложение: art dog bites the man.
2. Правило 7 применяется на следующей итерации и получается art dog bues at, man.
3. Применение правила 8 порождает предложение art dog biles art n.
4. Правило З выводит предложение art dog biles np.
5. Правило 9 порождает art n bites np.
6. В результате применения правила 3 получим пр biles пр.
7. Правило 11 порождает npvnp.
8. Правило 5 порождает пр vp.
„„,. „ включению sentence, подтверждая кор-
9. Правило 1 приводит это предложение к заключению
ректность первоначального предложения. ^
Глава 3. Структуры и стратегии поиска в пространстве
состояний
йе dog Mes trie man
ivjm Предстанете предложения "Пе
%L,s .He'ZF* еиде дереео Ч""«Г»^
„„Лкрево графа, потайного ко рис. J—
можно выполнить путем поиска от цел... Тогда ™™™J™ часгам „разил. Pu
«^нкккых ш» [Aho и UHman. 1977]. В литературе можно н^ >ЗГГоритмы
синтаксического анализа для всех классов языков. Например, Ф«^££££
синтаксического анализа от цели, которые умеют заглядывать вперед, «ггобы опред
какое правило нз входного потока нужно применить следующим. да
В приведенном выше примере мы рассмотрели очень простои алгоритм пс"^
графе 11ЛЦП1 — нишфоршфованный метод. Однако для этого примера можно У^
вать очень интересную стратегию поиска. Метод хранения текущего выражения н )«н_
доченное нахождение подходящих правил— примеры использования продукци
аюпемы для осуществления поиска и основная тема главы 5-
Правила подстановки также используются хтя генерирования допустимых пре
кии согласно правилам грамматики. Предложения могут быть сгенерированы путе
иска от цели верхнего уровня sentence. Этот поиск заканчивается, если больше
вид. которое можно было бы применить. Поиск приводит к цепочке терминальны*-
волов, которая является допустимым предложением в данной грамматике. Напрнм р*
sentence — это пр. за которым следует vp (правило 1).
Заменяя пр на п (правило 2), получаем п vp.
Подстановка man— первого значения из множества л (правило 8)— приво
man vp.
144
Часть 11. Искуостветый интеллект как представ»1**6 и
££ ™ Л. П°"СК УСПСШСН- " »~>— vp. Правнао з заменяет * „а ,. „„.
Правило 10 заменяет v на tikes.
man tikes найдено как первое допустимое предложение.
Если необходимо получить все допустимые предложения, этот поиск можно система-
тично повторять, пока не будут испытаны все варианты, т.е. пока не будет исследовано
все пространство состояний. Затем можно генерировать предложения "a man likes"
-the man tikes" и т.д. Всего при исчерпывающем поиске (полном переборе; можно
построить 84 корректных предложения. Они включают такие семантические аномалии, как
"the man bites the dog" (человек кусает собаку;.
Синтаксический анализ и генерирование предложений могут использоваться при
решении различных задач Например, если нужно найти все предложения, завершающие
фразу "the man", решателю можно представить незаконченный ряд "rhe man...". Поиск
на основе данных можно направить вверх и вывести завершающее предложение
sentence (правило 1). Затем пр заменяется rhe man, и поиск от цели определяет все
возможные vp, которые завершают предложение. Этот алгоритм поиска позволяет
построить предложения типа "the man likes", 'The man bites the man" (человек кусает
человека) и т.д. В этих примерах мы имеем дело только с синтаксической
корректностью. Проблема семантики — это иная задача. В главе 2 исследована проблема
построения семантики выражений формальной логики и выражений естественного языка. Эта
проблема значительно сложнее, она будет обсуждаться в главе 13.
Последний пример иллюстрирует чрезвычайную гибкость исследования пространства
состояний. В следующей главе мы обсудим использование эвристик для фокусировки
поиска на минимальной области пространства состояний. В главе 5 рассмотрим
продукционные системы и другие формализмы управления методами поиска, а также иные
приемы поиска н языки представления.
3.4. Резюме и дополнительная литература
Глава 3 познакомила читателя с теоретическими основами поиска в ДО»""*
стояний. При этом для анализа структуры и сложности стратегии поиска при решении
задач использовалась теория графов. Рассматривая основы теории nH£""J^^
пути ее применения для решения задач на основе поиска на H^^Z^or^
кий. Кроме того, в этой главе приводится сравнение поиска на основе данных и от оелж.
поиска в глубину и в ширин)'. „™тиястве состояний, реализуя
Граф. И/ИЛИ °°--™™Г£>ньГг^6ыГо^^
логнчеосие рассужпеии.. Стратеги пя™м™™^ы j^^^oro сшешиа.
превши рядом примеров, в том таете на примере системы фн1и~—
ставленного в главе 2. .,__ , учсВшш по тар» игоршм». •
Основныепрившшыпоисн«•"Ф"^1^, fwTWW. (SedenHA 19ВД.
том числе а [Connen. Leisereon. Rn«. '^^Г^ш—ям., ив в як 11
[Horovra: н Sahm, 1978]. Алгоритмы поиси т1^ГГ^^^
»ги.™....„„ тгятКЯНЫХВЛЫНМРКиЬи"""»
и реализованы в пива*, поаяшеяных иынм ""'"^ -яет, «техжктуиым i
Рассмотрены в [Newell н Simon, 1
Глава з Структуры и стратегии поиска в пространстве
И 1985] В [Pearl. 1984] представлены
■Winston. 19921 и [С^к " ™Ц, приведенного в главе 4. Развитие новь
„сГка " «»—■ Сонная и широко обсуждаема тема „а ежегод
поиска на графах—'™ V
поиска на . .
ренциях по ИИ.
алгоритмы
новых приемов
ежегодных конфс-
_ это путь, проходящий через каждую вершину графа только
'■ „да™™Какие услов.И необходимы для существования такого пути? Существует ли
такой путь на карте Кенигсберга?
2 Поедставьте в виде графа задачу переправы человека, волка, козы и капусты из
раздела 143 (см. рис. 14.1 и 14.2). Пусть узлы представляют расположение объектов
в пространстве. Например, человек и коза находятся на западном берегу реки, а волк
и капуста — на восточном. Приведите преимущества стратегий поиска в ширину и в
глубину для этого пространства.
3. Приведите пример задачи о коммивояжере, в которой стратегия ближайшего соседа
при нахождении оптимального пути приводит к неудаче. Предложите другую
эвристику для этой задачи.
4. Пройдите "вручную'' алгоритм с возвратами для графа, показанного на рис. 3.27. Начните
с состояния А. Проследите значения списков NSL.SL, CS по пути к решению.
5. Реализуйте алгоритм поиска с возвратами на языке программирования по вашему
выбору.
6. Определите, какой алгоритм поиска (от цели или на основе данных)
предпочтительнее для решения каждой из следующих задач. Обоснуйте ваш ответ.
6.1. Диагностика неисправностей автомобиля.
6.2. Вы встретили даму, которая утверждает, что она ваша дальняя родственница и у
вас есть общий предок по имени адмирал Ушаков. Вы хотели бы проверить ее
заявление.
6.3. Один человек утверждает, что он приходится вам дальним родственником. Он не
знает имени вашего общего предка, но знает, что это было не более восьми
поколении назад. Вы хотели бы найти этого предка или доказать, что его не существовало.
64. Программа автоматического доказательства теорем для планиметрии.
6.5. Программа интерпретации звуковых сигналов, отличающая звуки большой под-
водно,, „одК„ от M№0]- су6мар1шы кнта от стаи ры6
шду.'рвду'итТ™' К°Т0РМ "0тЖ" ЧеЛ0ВеКу ^ифицироватъ Расте""* "°
8 fcZf" "Ыб0Р "°"СКа " ШИР""У """ в Г^""У ™ "Р>"*Са "3 упражнения 6.
9 Рещ~°Р"™ С В<ШРат,И *» "»♦• И/ИЛИ.
основе даГыГ Х°Р°ШеИ С°Ы*С т ПРимсРа Ш <= помощью стратегии поиска ва
«еитпХ^ства'шиТкТ0'' 3"ДаЧИ "°"CKa "а Т* 1ШЛИ " сформируйте ФР>""
II. Искусственный интеллект как представление и
,,. Проследите траекторию выполнен™ алгоритма на основе данных для системы
-финансового советника'описанной в примере 3.3.5. для клиента с четырьмя
иждивенцами, имеющего $18000 на счету в банке и устойчивый доход $25000 в год
Основываясь на сравнении этой задачи с примером в тексте главы, предложите
наилучшую стратегию для решения задачи в общем виде.
12. Добавьте к правилам английской грамматики, описанным в примере 3.3.6, правила
для прилагательных и наречий.
13. Добавьте к описанию английской грамматики из примера 3.3.6 правила для фраз с
предлогами.
14. Добавьте правила составления сложноподчиненных предложений вида
sentence *-* sentence и sentence.
Al AT
К L M
Рис. 3.27. Поиск на zj
Глава 3. Структуры и стратегии поиска в пространстве с
Эвристический
поиск
:-- •■ •,"--:'-
Проблема, с которой сталкивается символьная система при решении
поставленной задачи, заключается в том, чтобы, используя ограниченные ресурсы обработки,
найти решение, удовлетворяющее определенному условию. Если бы символьная
система могла управлять порядком генерации потенциальных решений, то следовало бы
добиться того, чтобы нужные решения появлячись как молено раньше. Символьной
системе необходимо проявлять интеллект для успешного решения этой проблем'.
Интеллект для системы с ограниченными ресурсами обработки — это пот
разумной последовательности действий..
— Ньюэлл и Саймон, лекция по случаю вручения премии Тьюринга, 1976
Я аккуратный
Аккуратный... О. да
Аккуратный во всех отношениях...
— Либер и Столлер (Lieber и Stoller)
4.0. Введение
В [Polya, 1945] эвристика определяется как "изучение методов и правил открытий и
изобретений". Это слово имеет греческий корень, глагол eurisco означает "исследовать"
Когда Архимед выскочил из ванны, держа золотой веиец, он закричал -Эврика!", что
значит "Я нашел'" В пространстве состояний поиска эвристика определяется как набор
правил для выбора тех ветвей из пространства состояний, которые с наибольшей
вероятностью приведут к приемлемому решению проблемы.
Специалисты по искусственному интеллекту используют эвристику в двух ситуациях.
1. Проблема может „е „меть точного решения из-за ""•Ч*"»"»™ » «^
новке задачи и/или в исходных данных. Медицинская "™- " £"" *
с rs ,„,„и1.,й нзбог) признаков может иметь несколько при
такой проблемы. Определенный наб Р ^^ ^ ^^
чин; поэтому врачи используют «Р»с™кУ- Система тех„„ческого
диагноз и подобрать ™™"Z^^™ Визуальные сцены час
зрения-другой ^""^^""'"^"асто не связанные друг с другом,
то неоднозначны, вызывают различиi l пцт о6ьектов. Оптиче-
предположения относительно nPor**™H лвтс„ысленностей. Системы тех-
ский обман - хорошая иллюстрация таких двусмыс.
„ чзсто используют эвристику для выбора наиболее 8сроятн
«»««ОГОЗР::'Гзескольк„Х возможных. «
„нтерпретаии" ^ решение, но стоимость его поиска может бы
2. проблема может_ «£* зодачм (например, игра в шахматы) рост просС
слишком высокой, во носмт эксп0НС1Ш,,альиыи характер, дру,ими > »•
„ва возможных соя■ _. растет экспоне„ц„ально с увеличением п,у6„нь,, "'
число возможных с ^ аакт решеша ■; „об" типа поиска в глубину или »
„ска. В этих случа* ^ ^^ временн. Эвристика позволяет избежать этой
ширину могут зан ^ на„6олее "перспективному" пути, исключая из рас
сложности » всс Т|шные состояния и их потомки. Эвристические алгоритм,,
смотрения не ^ ^ ^ ^^ проектировщики) остановить этот
комбинаты,, рост и найти приемлемое решение.
„ калению подобно всем правилам открытия и изобретения, эвристика может
В Эвристика - это только предложение следующего шага, который будет еде-
пГнТпути решения проблемы. Такие предположения часто основываются на опыте „л„
„нтуииии Поскольку эвристика использует такую ограниченную информацию, как
описание текущих состояний в списке open, то она редко способна предсказать дальнейшее
поведение пространства состояний. Эвристика может привести алгоритм поиска к субоп-
тнмальному решению или не найти решение вообще. Это ограничение присуще
эвристическому поиску и не может быть устранено "лучшей" эвристикой или более
эффективным алгоритмом поиска [Garey и Johnson, 1979].
Эвристика и разработка алгоритмов для эвристического поиска в течение
достаточно долгого времени остаются основным объектом исследования в проблемах
искусственного интеллекта. Игра и доказательство теорем — два самых старых
приложения в области искусственного интеллекта; оба они нуждаются в эвристике для
сокращения числа состояний в пространстве поиска. Невозможно рассмотреть
каждый вывод, который может быть сделан в той или иной области математики, или
каждый возможный ход на шахматной доске. Эвристический поиск — часто
единственный практический метод решения таких проблем.
Исследование в области экспертных систем подтвердило важность эвристики как
основного компонента при решении задач. Эксперт-человек, решая проблему, анализируя
доступную информацию и делает вывод. Интуитивные правила ("rules of thumb"),
которые использует эксперт, чтобы эффективно решить ту или иную проблему, в
значительной степени эирнстичны по природе. Такие эвристики были созданы и формализованы
разработчиками экспертных систем.
ма^ГогГйТ' аЛГ°ри™ь' с°«°»т и двух частей: эвристической меры и
алгоритмы р ссГтв! ЛИУеТ К т П0ИСКа в пР^транстве состояний. В подразделе 4.U
"жаан^аГоритГь ,"г ЭВР"™4-™ алгоритмов поиска- так называемы»
еанывконГзтойглавы '' РаЗРа6°ТКа ЭВрИСТИК И 0Ц<=НКа Их эффективности °
Р«оГюр™то„"7зтвог!!еСТ"КИ'"ОЛ"КИ" (Р"С- IL5>' Исчерпывающий поиск (полный tie-
ходов существует всеем,. Т ""РЮ""™™, но возможен. На каждый из девяти пер»
т"ть семью различны "°°ЗМ0Ж1,Ь'Х отвстов- На которые, в свою очередь, можно от»
возможных состоянГ КГ"™'" " ТД' П"остай ^"3 позволяет найти обшее число
9*8*7х...,илн9!. ' КОторь,с ^Ует рассмотреть в исчерпывающем поиске.
#
* # #
****#*#*####
Рис. 4.1. Первые три уровня пространства состояний в игре "крестики-нолики",
редуцированные с учетом симметрии
Учитывая симметрию задачи, можно уменьшить пространство поиска. Проблема
множества возможных конфигураций в действительности сводится к поиску возможных
симметричных конфигураций игровой доски. Таким образом, существует не Девятьа
только три возможных первых хода - в угол, на верхнюю центральную клетку н в центр
решетки. Редукции на втором уровне и далее сокращают размерность пространства до
12X7!. как показано на рис. 4.1. Симметрия игрового пространства, подобная, рассмот-
ренной выше, может быть описана как математический инвариант, и если °"* ^™*_
ет в задаче, то может быть успешно использована для значительногсумньше ^про
странства состояний. Простая эвристику^может свести, „a === —_
но таким образом рис. 4,.) Если ™^^£^£™^" ™
таких состояний. Затем алгоритм выбирает С°СТГН' этом от6рась,ваются не
чением. Для хода X берем центральную клетку, ^ш I ^ ^ п£рвого
только остальные возможные ходы, но и их «"«^j (рис:4.3).
хода размерность пространства состоянии У"ен™а ю двух в03„0жных ответных хо-
Оппонснт после первого хода может выора - опультируюшему состоя-
Дов (как показано на рис. 4.3). Что бы ни выбрал оппон^ ^^^ ..наи6ольш1!го
нию игры может быть применена эвристика. Р^ ходов наялучший. При продол-
числа выигрышных линий" выбирает среди в03 |Ш0СТЬ обработки потомков огбро-
жении поиска каждый новый ход устраняет не ' уется На рнс. 4.3 продемонстри-
шенных узлов, таким образом, полный переоор^ и^ы'К!акДое СОСТОянис игры помече-
рован редукционный поиск на первых трех ш*
по соответствующим ему эвристическим энач1
Глава 4. Эвристический поиск
151
„итляпкно Две потенциально
тр„потенциально ^™ZZ™ выигрышные линии,
выигрышные линии, ™Ц"°Гтв чврез проходящие через
%й£Г Г&»™ SSS
.«.шатки "«яибмыяего числа еыигрышных
©00© ©00©
Р»с. 43. Эвристическая редукция пространства состояний в игре
"крестики-нолики"
Хотя тачное количество возможных состояний в игре вычислить трудно, верхний
предел этого количества состояний может быть вычислен, если допустить, что макс
мальное число ходов в игре - 9, и каждый ход имеет по 8 потомков. В действительное™
число состояний будет гораздо меньше, так как доска заполняется, и с каждым ходом
число возможных ответов уменьшается. Более того, оппонент делает половину всех хо
Г„ьшеСГ7Я "а Г ФУбЫЙ ВерХНИЙ "Радел - 9*8. или 72 состояния, что на 4 поряди
меньше величины 9!.
152
Часть II. Искусственный интеллект как представление и
В следующем разделе (разделе 4.1) представлен алгоритм т,„„
продемонстрированы его характеристики с использованием™ ™РИС™ЧСС"»™ поиск» и
Z в -пятнашки" над 8 числами (назовем ее 8 rZ. Р™'™'"* мристик дп« „г.
Se теоретические понятия, относящиеся эв „с ГГ'' В РП"те " МЫ "*»*»•
"1--™ В разделе 4.3 P^ZllT^ZZZ^IT *" ая»и™и»»»
„ф-беш-усечешо, для эвристик в ипрах со многим"„ амТ'вТГ П°ЯМД" "
разделе проверяется общность эвристического поиска и^™0CLвГ"Г
ществеиная роль в решении задач искусственного интеллекта. основымет|:я е"> °У-
4ХАлгоритм эвристического поиска
4.1.1. "Жадный" алгоритм поиска
Наиболее простой путь эвристического поиска— это применение процедуры поиска
экстремума (hill climbing). Стратегии, основанные на поиске экстремума, оценивают не
только текущее состояние поиска, но и его потомков. Для дальнейшего поиска выбирается
наилучший потомок; при этом о его братьях и родителях просто забывают. Поиск
прекращается, когда достигается состояние, которое лучше чем любой из его наследников. Поиск
экстремума — название стратегии, которая может быть использована энергичным, но
слепым альпинистом, поднимающимся вдоль наиболее крутого склона до тех пор. пока он не
сможет идти дальше. Так как в этой стратегии данные о предыдущих состояниях не
сохраняются, то алгоритм не может быть восстановлен из точки, которая привела к "неудаче".
Основная проблема стратегий поиска экстремума — это их тенденция
останавливаться в локальном максимуме. Другими словами, как только они достигают состояния,
имеющего лучшую оценку, чем его потомки, алгоритм завершается. Если это состояние
является не решением задачи, а только локальным максимумом, то такой алгоритм
неприемлем для данной задачи. Это значит, что решение может быть оптимальным на
ограниченном множестве, но из-за формы всего пространства, возможно, никогда не будет
выбрано наилучшее решение. Пример такого локального экстремума появляется в игре в
"пятиашки". Часто для того, чтобы передвинуть фишку в нужную позицию, необходимо
сдвинуть фишку, находящуюся в наилучшей позиция. Без этого невозможно решить
головоломку, но в то же время иа данном этапе это ухудшает состояние системы. Дело в
том, что "лучший" не означает "идеальный". Методы поиска без механизмов возврата
или других приемов восстановления не могут отличить локальный максимум от
глобального. Существуют методы приближенного решения этой проблемы, например, случайное
возмущение оценки. Однако гарантированно решать задачи с использованием техники
поиска экстремума нельзя. Вариант алгоритма поиска экстремума предлагается в
тестовой программе, описанной в подразделе 4.3.2. „„,„,.,,»,
Несмотря на эти ограничения, алгоритм поиска экстремума может быть достаточно
эффективным, если оценивающая функция позволяет избежать локального максимум , » :и-
ВДкливання алгоритма. В общем, однако, эвристический поиск требует бол* ™окога ме-
™Д*. предусмотренного в "жадном" алгоритме поиска, где при использо^ии приоритет
«ой очереди возможно восстановление алгоритма из точки ЛОИЛЬНОГОшЗТ„санным в
Подобно алгоритмам поиска в глубину и алгоритмам поиск в щирину^опиданным
^ез, "жадный^ алгоритм поиска использует списки сохра^-^™ ~
°Реп отслеживает текущее состояние поиска, а в и™~
153
Глава 4. Эвристический поиск
„то записывает в список open состояние с учетом
кЬ::—•"""'""""",,"*"н
. а~*+- search;
для фуилц»». г— -
function bescfirst-search;
begin
open := [Start].
%инициализация
closed := M ; %оставшиеся состояния
while open * I 1 d°
begin „„ гпстояние X из списка open;
удалить первое состояние
if x=goal, return путь от Start
else begin
сгенерировать потомок x;
for каждого потомка X do
"потомок не содержится в списке open или closed:
Освоить потомку эвристическое значение;
добавить потомок в список open
end;
потомок уже содержится в списке open;
if потомок был достигнут по кратчайшему пути
then записать это состояние в список open
потомок уже содержится в списке closed;
if потомок был достигнут по кратчайшему пути then
begin
удалить состояние из списка closed;
добавить потомок в список open
end;
end; %case
поместить X в список closed;
переупорядочить состояния в списке open в соответствии
с эвристикой (лучшие слева)
end;
return FAIL %список OPEN пуст
end.
На каждой итерации функция best_£irst_search удаляет первый элемент из
списка open. Достигнув цели, алгоритм возвращает путь, который ведет к решению.
Заметим, что каждое состояние сохраняет информацию о предшествующем состоянии,
чтобы впоследствии восстановить его и позволить алгоритму иайти кратчайший путь к
решению (см. подраздел 3.2.3.).
Если первый элемент в списке open не является решением то алгоритм использует
продукционные правила проверки соответствия и операции, чтобы сгенерировать все возможные
потомки дащого элемента. Если потомок уже находится в списке open или closed, то
алгоритм выбирает кратчайший из двух возможных путей достижения этого состояния,
списке I"" J irst-se«ch вычисляет эвристическую оценку состоянии в
этом ^nl"C°P™PyCT С"ИС0К " с°™<=™' с этим,, эвристическим значениям. Пр»
этом лучшие состояния ставятся в начало списка. Заметим, что из-за эвристической
154
I. Искусственный интеллект как представление и
„„„роды оценивания следующее состояние должно проверяться „а любом уровне „ро-
^Гиства состоянии. Отсортированный список open часто называют npZpZlZu
1ведыо(.рпоп1у queue).
очередь<
А-5
А ;\
3-4 Н-3 / J
е-5 F-5 G-4 Н-3 / J
к L М N 0-2 Р-З О Д
< I
V т
S т
Рис. 4.4. Эвристический поиск в гипотетическом
пространстве состояний
На рис. 4.4 показано пшотетическое пространство с эвристическими оценками
некоторых из его состоянии. Состояния, рядом с которыми стоит их эвристическая оценка, были
сгенерированы функцией best_£irst_search. Состояния, по которым велся
эвристический поиск, отмечены полужирном шрифтом: заметьте, что поиск не ведется по всему
пространству. Другими словами, цель "жадного" алгоритма поиска состоит в том, чтобы
прийти к целевому состоянию кратчайшим путем. Чем более обоснованной является
эвристика (см. подраздел 4.2.3), тем меньше состояний нужно проверить при поиске цели.
Путь, по которому функция best_f irst_search находит целевое состояние,
показан на рисунке жирными стрелками. Предположим, что Р — целевое состояние (см.
рис. 4.4). Поскольку Р — цель, состояния иа пути к Р имеют низкие эвристические
значен™. Эвристика подвержена ошибкам, состояние О имеет более низкое эвристическое
значение, чем целевое, и поэтому было исследовано ранее. В отличие от поиска
экстремума, который не сохраняет приоритетную очередь для отбора "следующих" состояний,
данный алгоритм восстанавливается после ошибки и находит целевое состояние.
l.open = [А-5]. closed = [].
2. Вычисляем Д-5;орел = [В-4, С-4, D-6]:closed= [А-5].
3. Вычисляем а-4; орел = [С-4 £-5, F-5. D-6];c/osed= [B-4, А-5].
4. Вычисляем С-4; орел = [Н-3, G-4, £-5, F-5, D'6); c/osed= [С-4. S-4, А-5].
5. Вычисляем Н-3; орел = [0-2, Р-З, G-4, Е-5. F-5, D-6];
closed = [Н-3, С-4, Э-4, А-5].
6. Вычисляем 0-2; орел = [Р-З. G-4, Е-5. F-5, D-6];
closed = [0-2, Н-3, С-4. S-4, А-5].
1- Вычисляем Р-З; решение найдено1.
Глава 4. Эвристический поиск
ел °-f
Л Л К
£-5 F-5 G-4 Н-3 I J
ЛЛ I /\/\
К L М N 0-2 Р-3 0
"
»
Состояния из списка open Состояния из списка closed
Рис. 4.5. Эвристический поиск в гипотетическом про-
странстве состояний. Состояния из списков open и
closed выделены
На рис. 4.5 показано пространство после пятой итерации цикла while. Здесь
показаны состояния, содержащиеся в списках open н closed. В open сохраняется текущая
граница поиска, а в closed— уже рассмотренные состояния. Заметьте, что граница
поиска очень искривлена, отражая тем самым приспособленческую природу "жадного"
алгоритма поиска.
"Жадный" алгоритм поиска всегда выбирает наиболее перспективное состояние в
open для продолжения. Однако, поскольку при выборе состояния используется
эвристика, которая может оказаться ошибочной, алгоритм не отказывается от остальных
состояний, и сохраняет их в списке open. В данном случае эвристика обеспечивает
поиск вниз; этот путь оказывается ошибочным, но алгоритм в итоге возвращается к
некоторому ранее сгенерированному "лучшему" состоянию в open и затем
продолжает поиск в другой части пространства. В примере на рнс. 4.4 после нахождения
потомков состояния 6 казалось, что они имеют плохие эвристические оценки, н поэтому
поиск сместился к состоянию С. При этом потомки состояния 8 были сохранены в open
на случай, если алгоритму необходимо будет вернуться к ним позже. В функции
best_first_search. как и в алгоритмах нз главы 3, список open позволяет
возвращаться назад по ошибочному пути.
4.1.2. Функции эвристической оценки состоянии
8-г1ГоТо^%аЭФпФе7ГОСТЬ Несколькнх Различных эвристик для решения
в^Тпео^Тм П0К£ШН° НЭЧаЛЬНОе И целевое состоян»е "» 8-головоломки
^LT^^"™110*™ С0С™н™и, сгенерированными в процессе поиска.
156
I. Искусственный интеллект как представление и поиск
Рис. 4.6. Начальное состояние, набор возможных
первых ходов и целевое состояние в игре "8-головоломка"
Состояние с меньшим числом фишек, находящихся не на своих местах, расположено
ближе к целевому состоянию, и поэтому булет рассмотрено первым.
Однако зга эвристика не использует всю имеющуюся информацию, потому что она не
принимает во внимание расстояние, на которое фишки должны быть перемешены. Лучшая
эвристика суммировала бы все расстояния между фишкой, находящейся не на своем месте, и
полем, в которое она должна быть перемещена для достижения целевого состояния.
Обе эти эвристики можно критиковать за то, что они не учитывают W»™J
перестановке фишек. Другими словами, если для достижения целевого вкгоянш
необходимо переставить двГрядом стоящие фишки, то это потреоует более двух ходов, так
как для такой перестановки фишки должны "обойти ' Друг ДРУ™ (рис
Рис 4.7. Целевое состояние настояние
с двумя перестановками: 1 и 2. 5 и 6
тот Аакт для каждой инверсии (когда для
Эвристика, принимающая во внимание * ' м„ две рядом стоящие фиш-
Достижения целевого состояния необходимо ™меня (например 2). На рис. 4.8
«и) должна умножать эвристическое значение на малое числ
Глава 4. Эвристический поиск
-„„пи из зтях грех эвристик к ТР™ потомкам, изобра.
„оказан результат применения каждо
женным на рис. 4.6. пр„Мс„ення оценивающих функции. Эвристика суммы рас
На рис. 4.8 показан результат v ^^ точную оценку затрат, чем простои подсчет чис-
стояний", кажется, дейстаггсльне, д ^_^ Эвристика перестановки фишек не может „aim,
„а фишек, находящихся не на даюя „„дому из них оценку, равную нулю. Эвристика
рашичий между этими состоя! ' mll0i ^ как „и одно из этих состояний не содержит
"суммы состояний" не [Ч",В°™)^1Й вариант эвристики, преодолевающий ограничения, на-
ни одной прямой инверсии. ?<™£иновки фишек-, — сложить расстояния между фишками,
кладываемыс на эвристику " Р^^ которые должны быть взаимно переставлены,
удвоив расстояния МИШУ™- шсколько „удцо найти хорошую эвристику. Наша цель
Этот пример иллюстг.ир., сн „„формацию, содержащуюся в описании
состоит в том. чтобы ипольуJ ный вы6ор. Каждая из эвристик, предло-
ГГГыГ ™; у" иск" орые к^нческие элементы информации, и поэтому
«ожсГбьггь улучшена. Разработка хорошей эвристики - это эмпирическая проблема, в
решении которой помогают рассуждения и интуиция. Но все же решающи,, критерий
оценки эвристики - это ее эффективность при решении практических задач.
Поскольку эвристика может быть ошибочной, существует вероятность, что алгоритм
поиска может пойти „о ложному пути. Эта проблема возникала при поиске в глубину, где
подсчет глубины использовался для того, чтобы определить ложные пути. Эта идея может
быть также применена в эвристическом поиске. Если два состояния имеют одинаковые или
почти одинаковые эвристические значения, то предпочтительнее исследовать состояние,
которое расположено ближе к корневому состоянию графа. Это состояние с большей
вероятностью расположено на пути к цели. Расстояние от начального состояния к его потомкам
может быть измерено путем вычисления уровня глубины для каждого состояния.
-JL1
1 6 4
771
Фишки,
находящиеся
не на своих
местах
Рис. 4.8 Три
Сумма
расстояний
до целевого I
состояния
Для фишек,
находящихся
не на своих местах
Удвоенное
число
прямых
перестановок
фишек
возможных варианта эристики в 8-г.
■оловоломке
Часть Ц. Искусственный интеллект как представление и поиск
для начального состояния это значение равно 0 и увеличивается на 1 для каждою
уровня поиска. Это позволяет записать фактическое число шагов, необходимых для
достижения в процессе поиска из стартового состояния любого из его потомков. Это
значение может быть добавлено к эвристической оценке каждого состояния для того, чтобы
сместить поиск к наиболее подходящим состояниям.
Таким образом, оценивающая функция f состоит из двух компонентов:
f(n) = g{n) + h(n),
где д(п)— фактическая длина пути от произвольного состояния л к начаяьному, а
П(П) — эвристическая оценка расстояния от состояния л к цели.
Например, в 8-головоломке значением п(л) можно считать число фишек,
находящихся не на своих местах. Если рассмотреть состояния, изображенные на рис. 4.6, то
значения f для каждого из них будут равны 6, 4 и 6 соответственно (рис. 4.9).
На рис. 4.10 показано значение f для каждого состояния графа "жадного"
алгоритма поиска для 8-головоломки. Рядом с каждым состоянием указан его
эвристический вес f(n) = д(л) + п(л). Номер в верхней части состояния указывает порядок, в
котором это состояние было взято из списка open. Некоторые состояния
(ft, g, to, d, л, к и /) не пронумерованы, так как они оставались в списке open на
момент завершения алгоритма.
д(п) = 0
Значение f{n) для каждого состояния, 6
где7(л) = д(л)+л(л),
д{п) = реальное расстояние от п до начального состояния.
л(л) = число фишек, находящихся не на своих местах
Рис. 4.9. Эвристика f для состояний в игре "S-гаювоюмка "
Глава 4 Эвристический поиск
d которые генерируют этот граф, приведено ниже.
Содериннесписка» open и close .
„„_1я41 closed - [ ]■
r.s я Ь6 d6.g6];c/osed = [a4,c4].
3. оре„ = [e5, ft. №. oo. i =
, „pen . (,5, M. сб. Л. 06. «7, »Л: с»»- = [a4. c4. .5. Г5. У5].
7; open = [mS. MS, № Л. об, п7. *7. <7]; dosed = [а4, 04, .5. Я. /5, ,5].
8, Найдено решение m = цель!.
На 3 шаге состояния е и f имеют эвристическое значение, равное 5. Состояние е
было поовспено первым, его потомками являются л и /. Хотя п является потомком е, для
него число фишек, расположенных не на своих местах, соответствует состоянию f; при
этом данное состояние находится на один уровень ниже в пространстве состояний. Мера
глубины, g(n), заставляет алгоритм выбирать 1 в качестве оценки на шаге 4. Поэтому
алгоритм возвращается к состоянию I, находящемуся на один уровень выше, и затем
продолжает двигаться к цели по другой ветке. Граф пространства состояний на этой стадии
поиска показан на рис. 4.11. Здесь закрашены области, в которых находятся состояния из
списков open и closed. Обратите внимание на приспособленческую природу поиска
до первого наилучшего совпадения.
В действительности компонент g(n) функции оценки придает нашему поиску
свойства поиска в ширину. Он предотвращает возможность заблуждения из-за ошибочной
оценки: если эвристика непрерывно возвращает "хорошие" оценки для состояний на
пути, не ведущем к цели, то значение g будет расти и доминировать над h, возвращая
процедуру поиска к кратчайшему пути. Это избавляет алгоритм от зацикливания. В
разделе 4.2 рассмотрены условия, при которых "жадный" алгоритм поиска с использованием
функции оценки гарантирует выбор кратчайшего пути к цели.
Подведем итог.
1. Операции над состояниями позволяют генерировать потомков текущего состояния.
2. Каждое новое состояние проверяется на предмет того, встречалось ли оно раньше
(т.е. находится ли оно в списках open илн closed). Таким образом
предотвращаются ЦИКЛЫ.
3. Каждому состоянию п соответствует значение f, равное сумме его глубины в про-
^>ГыВе11'0п"СКа 8<П) " некотоР°й эвристической оценки расстояния от него ДО
„„l1 Друп,м" с»оюми. h ведет алгоритм поиска к эвристически наиболее
™о™г,™ТЫМ C0C™m™' B ™ вР<™я как значение g удерживает алгоритм от
1 порного следования по неверному пути.
4' с^нГвсГ™ °РеП^'Руклся в соответствии со значениями f. Сохраняя все
5 ЭФ* °РеП' а"ГОр"™ сможет Уберечь себя от неудачного завершения.
ор°п™То^ТГ„''™а Т" 6ыгь ^™чена за счет представления списков
^ ^ виде куч,, (heap) или левостороннего дерева (leftist trees).
любом 'ТафепрТтТнстваТ^- "° °бЩИ" ШГ0РИ™ Д™ эвристического поиска т
рассмотренные ранее). остоя™и (как и алгоритмы поиска в ширину или в глубину.
к
160
Часть II, Искусственный интеллект как представление и
Уровень поиска
состояние
Рис. 4.Ю. Проа„ра„стт сосаний, сгетрирс^ое при «р^и^о, « ™ -Т»**' -.-ры
в "пятнашки "
Этот_Р,т,водинаковой=:=^
Дачи, поддерживает различные функции ™е™^ (разделе). Благодаря своей уни-
иие эвр„сг,,,еского алгоритма "««« » W™ SJS с разыми эвриотшоши.
версальностн "жадный' алгоритм поиска может , иканчшия сложными критериями
начиная от субъективных оценок "хороших сос™""
оценки состояшш. ведущих к цели, на основе вероятностного подхода.
Глава 4. Эвристический поиск
161
Важным пример»" этого г
критерии (глава 7).
вляюгся байесовские (Bayesian) статистические
Состояние f
2
«
i
J
ч
б ^П Состояние d
1 fld) = 6
Состояниед
Состояниеh 71 4 Состояние) ,84
2 6 3
7 1 4
■71
Рис. 4.11. Вид списков open и closed после третьей итерации эвристического поиска
Другой интересный подход к реализации эвристики - использовать меру доверия в
экспертных системах для анализа результатов того или иного правила. Человек-эксперт,
используя эвристику, обычно способен дать квалифицированную оценку степени дове-
Z вьГпаВтГпаМ- ""^ ^ ИСП™ 4* dZpu* (confidence measure,
для выбора те, результатов, которые имеют наивысшую вероятность успеха. Состояния
162
I- Искусственный интеллект как представление и поиск
с наиболее низкой мерой доверия могут быть полностью исключены из рассмотрении.
Этот подход к эвристическому поиску будет рассмотрен в следующем разделе.
4.1.3. Эвристический поиск и экспертные системы
Простые игры типа "пятнашек" по ряду причин являются идеальными примерами для
исследования поведения алгоритмов эвристического поиска.
1. Области поиска достаточно обширны, чтобы использовать эвристические упрощения.
2. Большинство игр достаточно сложны и допускают большое разнообразие
эвристических оценок для сравнения и анализа.
3. Игры, как правило, описываются достаточно просто. Описание пространства
состояний игровой доски может быть сделано явно. Это позволяет исследователям
сосредоточиться на поведении эвристики, а не на проблеме описания задачи.
4. Поскольку каждый элемент пространства состояний имеет одно представление
(описание доски), одна эвристика может применяться во всей области поиска. Это
отличает алгоритмы эвристического поиска от систем типа финансового
советника, где каждый элемент представляет собой подцель с собственным явным
представлением.
Более реалистические проблемы затрудняют выполнение и анализ эвристического
поиска, требуя сложной эвристики, которая имеет дело с различными ситуациями в
пространстве состояний. Однако результаты, полученные в простых играх, могут быть
использованы при решении проблем, возникающих в экспертных системах, планировании,
интеллектуальном управлении и машинном обучении. В отличие от игры в "пятнашки", в
этих системах к каждому состоянию не может быть применена одна и та же эвристика.
Эвристики, решающие специфические задачи, "зашиваются" в синтаксис и семантику
соответствующих операторов решения данной задачи. На каждом шаге решения
определяется, какую эвристику следует использовать. Операция (эвристика), которая должна
быть применена к тому или иному состоянию в пространстве, определяется в процессе
проверки соответствия шаблону.
Пример 4.1.1. Модификация системы финансового советника
Эвристические критерии поиска традиционно используются при решении задач ИИ.
Вернемся к задаче разработки финансового советника, рассмотренной в главах 2 и 3. где
база зиаиий представляет собой набор логических заключений, принимающих значения
"истина" или "ложь". В действительности эти правила эвристичны по своей природе.
Например, одно из правил гласит, что человеку с достаточными сбережениями и
доходом следует вложить свой капитал в акции:
savings^accounUadequate) Aincome{adequate) => investment(stocks).
На самом деле такой человек предпочтет более безопасную комбинированную
стратегию или вообще не будет трогать свои сбережения. Таким образом, данное правило
эвристично, и при решении проблемы необходимо попытаться учесть эту
неопределенность. Можно принимать во внимание дополнительные факторы, такие как возраст
инвестора, его карьеру и другие вопросы. Однако все это существенно не влияет на
эвристическую природу финансового совета.
Глава 4. Эвристический поиск
„,-, проблемы в экспертных системах состоит в Том, что.
Один из путей решения данно пр ^^ коэфф,щиент (называемый мерой 60ее.
бы с каждым правилом вывода см | ,„„„ (cena,nly factor)). Это дает возмо*.
,*» (confidence measure) или ^""^кдому такому выводу. _ _
„ость измерить степень доверия к ^^ представляк)щс1, собой вещественное
Каждое заключение с™зь"р°т , (истт) соответствует полному доверию, а -1
число из интервала [-1; U- Р1' ю соответсгвуют степени доверия выводу. На-
(ложь) - недоверию. Значения , ^^ ^ ^^ Q& 01palKaSi таюш образом, малую
пример, приведенному выше пр /■ заключениям можно присвоить другие веса.
вероятность того, что оно не верно, иста
savings accentuate) л inadequate)
iZestmenlistocks) with conftdence - 0,8.
avings_account{adequate) ,
incoi
me{adequate)
э inV'estmen,(comb,nation) with confidence' 0 5.
savings accountladequata) A-ncomeladecuate)
=, iwesfmentlsavmgs) Mfft confidence -0,1.
Эти правила отражают следующую общую стратегию. Человеку с достаточным,, сбе-
пежениями и доходом настоятельно советуют вложить капитал в акции, но существует
некоторая возможность (и комбинированная стратегия должна учитывать ее) того, что он
может по-прежнему оставлять средства в банке. Эвристические алгоритмы поиска могут
использовать эти факторы уверенности по-разному. Например, можно вычислять
результаты применения всех правил с учетом степени доверия к ним. Такой полный перебор
всех возможностей может быть полезен, например, в медицине. Или программа может
возвращать только результат с наибольшим фактором уверенности, если остальные
решения не представляют интереса. Это позволит ей игнорировать другие правила,
радикально сужая область поиска. Можно также игнорировать правила с низкой мерой
доверия, например, не выше 0,2. Это позволит медленнее сужать пространство поиска.
При использовании меры доверия возникает ряд важных вопросов. Что понимается под
"числовой мерой доверия"? Например, как рассчитать степень доверия, если один вывод
используется как предпосылка для других? Как объединять меры доверия, если к одному и тому
же выводу можно прийти несколькими путями? Как назначать меру доверия
основополагающим правилам? Эти проблемы более подробно будут обсуждаться в главе 7.
4.2. Допустимость, монотонность и информированность
Поведение эвристики можно оценивать по ряду параметров. Например, наряду с
решением задачи может понадобиться алгоритм нахождения кратчайшего пути к нему. Это
важно, когда каждый дополнительный шаг к цели имеет очень высокую стоимость,
например, при шинировании пути для автономного робота в опасной среде. Эвристика, ко-
гихТГпТ СаМЬ"' К°Р0ТКИЙ "У,Ь К ЦСШ- ""ьтается допустимой (admissible). В ДРУ
zz™™™:™ пугь к решеш,ю может быть ж ™ ■"■""•как обшм 5ф"
риет!г":;:Гд;7о„"вуэтое"вуют ли луг,с ,вр"с™к"? и в как°м смь,слс олка т
Можно „и гара^ровать ч ' г"'" ""*°1»"'Р°<>°""ость (informedness) эвристику
стояние нельзя LIT- обнаР№н«>е „ процессе эвристического поиска со
называет;:':::::::, ™ ?токгкому,г от начального с°стаян"я? эта сюйс£
эффективностью эвр, ст соГ ^ °Т""Ы На ЭТИ и ДР>™ В0"Р0СЫ' С1Ша"
Р_™' со™вляют содержание этого раздела.
Часть и. Искусственный интеллект как представление и поиск
4.2.1. Мера допустимости
Алгоритм поиска называется допустимым, или приемлемым (admissible), если
гарантирует нахождение кратчайшего пути к решению. Поиск в ширину является допустимой
стратегией поиска. Поскольку сначала рассматриваются все состояния графа на уровне п
и лишь затем состояния на уровне п+1, то целевые состояния будут найдены по
кратчайшему „з возможных путей. К сожалению, поиск в ширину часто слишком
неэффективен при практическом использовании.
Используя функцию оценки f(n)=g(n)+/i(n), введенную в предыдущем разделе, можно
охарактеризовать класс допустимых эвристических стратегий поиска. Если п — узел графа
пространства состояний, то д(п) представляет глубину, на которой это состояние было
найдено, а Л(п) — эвристическую оценку расстояния от узла п до цели. В этом смысле
1{п) оценивает общую стоимость пути от начального состояния к целевому через узел п.
При определении свойств допустимой эвристики определим функцию оценки Г так:
f't.n)=g-{n)*h-{n),
где д*{п) — стоимость кратчайшего пути от начального узла к узлу п, а г?' —
фактическая стоимость кратчайшего пути от узла п до цели. Отсюда следует, что f'{n) —
фактическая стоимость оптимального пути от начального узла до целевого через узел п.
В дальнейшем мы увидим, что при использовании функции best_f irst_search с
функцией оценки f результирующая стратегия поиска будет допустимой. Поскольку
такие "оракулы" как С для большинства реальных проблем не существуют, будем
использовать функцию оценки f как наиболее близкую к f*. В алгоритме А д(п) — стоимость
текущего пути к состоянию п является разумной заменой оценки д', но онн не равны:
д[п)>д*(п). Они равны только в том случае, если на графе найден оптимальный путь к п.
Аналогично заменим h*[n) на h(n) — эвристическую оценку минимальной
стоимости достижения целевого состояния из узла п. Как npaeino. вычислить л* невозможно,
но достаточно часто можно определить, действительно ли эвристическая оценка h{n)
ограничена сверху, т.е. действительно лн h{n) h*(n) не превосходит фактической
стоимости кратчайшего пути п"(п). Если алгоритм использует функцию оценки f, в которой
h{n) < h*{n), то он называется алгоритмом А*.
ОПРЕДЕЛЕНИЕ
АЛГОРИТМ А, ДОПУСТИМОСТЬ, АЛГОРИТМ А*
Рассмотрим функцию оценки 1 (п) = д (n) + h (п), где
л — любое состояние, достижимое в процессе поиска,
д (п) — стоимость пути из начального состояния к узлу п,
h (п) — эвристическая оценка стоимости пути от п к цели.
Если эта функция оценки используется в алгоритме best_f irsc_search
(раздел 4.1), результирующий алгоритм называется алгоритмом А.
Поисковый алгоритм является допустимы.», если для любого графа он всегда
выбирает оптимальный путь к решению.
Если в алгоритме А используется функция оценки, в которой значение fl(n) меньше
или равно стоимости минимального пути от п до цели, такой алгоритм поиска
называется алгоритмом А * (произносится "А со звездочкой").
Теперь можно сформулировать свойство алгоритмов А*.
Все алгоритмы А* допустимы.
Глава 4. Эвристический поиск
_. «опемой, которую читателю предлагается до-
д„„ус ость алгоритмс-в А* «*£^£ такжс |Nilsso,, I980|. е. 76-78) Теорем.
Ль .рамках ««"«'',*^; „спользующни такую эристику л(л). ,|р„
„.сит, что любой алгоритм А (т.е. Р ||ахождс„„с „„„„мольного пути от л до цс.
П /1[Л)£Л'(Л) ДЛЯ Пссх л' твриимч.»
,Тссли такой путыюоб,це сушеству^г. ^^ mmKKpKiom, как алгоритм A», в кото-
Заметим, что поиск п ширину м каждого состояния принимается исключи-
ром пп) - 9(п)*0. Решение о Р»«"3,,.0го состояния. В подразделе 4.2.3 будет нока-
тслыю с учетом со расстояния ° алгоритмом А*, - это подмножество со-
•шио. что множество узлов, раььматтн^ ши
стояний.рассматриппемых при"°"^" , .KOTOpuc эвристики, применяемые для игры в
Примерами алгоритмов А »"'" „„..„слить значение л*(л), по можно показать,
■•„ятнаьчкн" Для этой задачи не» можно вы > rmli„,cro „ути к цели.
нто-P^i-on-"-^^^^^^, Репине или равно числу шагов,
треб'ДГГГс 1 Ге^^::: н-ау,о позицию. Таким образом, гака., эвристика до-
ГстиГГр пируем "вхождение оптимального (или кратчайшего) „ути решения.
C™L прямы расстояний фишек, находящихся не на своих местах, до их целевой
позиции также меньше или равна минимальному фактическому пуп. их перемещения в
„елевое состояние. Использование малых множителей для прямых перестановок фишек
является допустимой эвристикой.
Такой подход к доказательству допустимости эвристик может применяться в
любых задачах эвристического поиска. Даже если не всегда можно вычислить
фактическую стоимость кратчайшего пути к „ели, довольно часто удастся доказать, что
эвристика ограничена сверху этим самым значением. Если этот факт будет доказан, то
результирующий поиск будет ограничен сверху кратчайшим путем к „ели в случае
существования такого пути.
4.2.2. Монотонность
Напомним, что определение алгоритмов А* не требует, чтобы д(п) было равно д"(п).
Это означает, что допустимая эвристика может первоначально достигать "нецелевых"
состояний, следуя но субонтималыюму пути, но в конечном счете алгоритм найдет
оптимальный путь ко всем состояниям, лежащим на пути к цели. Естественно спросить,
существует ли эвристика, которая является "локально допустимой", т.е. позволяет
последовательно находить кратчайший путь к каждому состоянию, которое встречается в
процессе поиска. Это свойство называется мтттттоатм (monolonieily).
ОПРЕДЕЛЕНИЕ
МОНОТОННОСТЬ
Эвристическая функция л моноюнна. если
1. Для всех состояний п, и п,. где п, - потомок л,,
п(п,) - л(п,) s соЩп,, п)
со™яГ,'п"к "4 ~ ф1"т",ССКая """"<«»■ (количество ша.о.0 перемещения от
2- Эвристическая оценка ттлп „,„„„„„„ ^ ^ ^ ^^ = Q
166
I- Искусственный интеллект как представление и поиск
Один из способов описания свойства монотонности состоит в том, чтобы считан,
область поиска всюду локально совместимой с используемой эвристикой. Разноси,
между эвристическими значениями некоторого состояния и любого из его потомков
связана с фактической стоимостью перемещения между ними. Это говорит о том,
что эвристика всюду допустима и достигает каждого состояния по кратчайшему
пути от его предка.
Если "жадный" алгоритм поиска па графе использует монотонную эвристику, то
некоторыми важными шагами можно пренебречь. Поскольку такая эвристика
находи! кратчайший путь к любому состоянию при первом проходе через него, то
исчезает необходимость вычисления пути к этому же состоянию при последующих про
ходах, поскольку новый путь заведомо не будет короче. Это позволяет огбрасыватк
любое состояние, через которое алгоритм проходит во второй раз, без модификации
информации в списке open или closed.
При использовании монотонной эвристики в процессе поиска в пространстве состоя
пин эвристическое значение для каждого состояния л заменяется фактической
стоимостью пути к п. Поскольку реальная стоимость в каждой точке пространства не меньше
эвристической оценки, 1 не уменьшается. Таким образом, функция t является монотонно
неубывающей (в соответствии с названием).
Докажем, что любая монотонная эвристика допустима. Представим любой путь в
пространстве в виде последовательности состояний St, S2.... SK, где S| — начальное
состояние, a S, — целевое. Рассмотрим последовательность шагов по произвольно
выбранному пути.
OtS, к Sj h(St)-h(S2) < costiSi. S2) по свойству монотонности
OtS2kSi h(S2)-h(Sy) <cosi(S2, S3) по свойству монотонности
От Si к S4 n(S3)-n(S*) < cost(Sy, S4) по свойству монотонности
по свойству монотонности
по свойству монотонности
От S„._[ к Sx n(S„_i)-n(S,) < cosf(S„_i, S„) no свойству монотонности
Суммируя каждый столбец и используя свойство монотонности n(Sf)=0, получим
От S, к S, h(S|)-r>(S,) < cosUSt, S,)
Это означает, что монотонная эвристика л является эвристикой А* и она допустима.
Оставим в качестве упражнения проверку утверждения, что допустимость эвристики
означает се монотонность.
4.2.3. Информированные эвристики
Заключительный вопрос этого раздела— сравнительный анализ способности двух
эвристик найти кратчайший путь. Рассмотрим эвристику А*.
ОПРЕДЕЛЕНИЕ
ИНФОРМИРОВАННОСТЬ
Если для двух А*-эврнстпк п, и л:для всех состояний л в пространстве поиска
выполняется неравенство /Ji<") *- л.-(л), то тврнстика п. называется более
информированной, чем л.
Глава 4. Эвристический поиск
167
мокно использовать при сравнении эвристик для игри 8
Это определение можно в ширину экшшаЛентен алгоритму А* с эв.
"пятнашки". Как бь.,0 сказано аыш^ ^^ ^ ^^ ^ ^ ^
ристикои Л,. ПР.,^которой М ftb иаходящихся не на С80ИХ мсс
меньше, чем /,«. Мы такжедоказал Л,^^/.*. Таким образом. эвр„.
так. является нижней гранниьи ДО» » ^ » на ^ жтх ^^ Р"
=;=:ГЧ: Г. tl и: * Р- 4.12 показа,,, пространства поиска этих
д^эврТГк. Обе эвристики /.,../., находят оптимальный путь к решения,, „о „2 в Пр0.
цессе поиска оценивает намного меньше состоянии.
Точно так же можно доказать, что вычисление суммы расстоянии между фишками,
находящимися не на своих местах, является более информированной эвристикой, чем
определение числа фишек, находящихся не на своих местах. Для этого можно изобразить
последовательность областей поиска (каждая последующая меньше предыдущей),
сходящуюся к прямому оптимальному пути решения.
Если эвристика /ь более информирована, чем Л,, то множество состояний,
проверяемых эвристикой h2. является подмножеством состояний, проверяемых /,, Это можно
доказать методом "от обратного". Предположил,, что существует „о крайней мере одно
состояние, проверяемое /ъ а не г),. Поскольку h2— более информированная эвристика,
чем /?,, то для любого п rb(n)</i[{n). Кроме того, обе эти эвристики ограничены
вышеупомянутым значением /,*. Следовательно, наше предположение неверно.
Вообще, чем более информирован алгоритм А*, тем меньше состояний требуется
проверить, чтобы получить оптимальное решение.
Однако следует быть осторожным, так как при использовании более
информированной эвристик,, уменьшение числа состояний в пространстве поиска может потребовать
неоправданно больших объемов вычислений.
Интересным примером подобной ситуации являются компьютерные программы
игры в шахматы. Один из возможных подходов к такой программе — использование
простых эвристик и поиск в глубину в расчете на быстродействие компьютера. Для
оценки состояния и увеличения глубины поиска такие программы часто используют
специализированные аппаратные средства. Другой подход состоит в применении
более сложной эвристики и уменьшении числа просматриваемых состояний. Эта
эвристика вычисляет тактическое преимущество, рассматривает позиции фигур,
возможность атак, учитывает проходные пешки и так далее. Сложность вычислений
в ИТп'ЛУпИКе "0Ж" РМТ" экс™»е«шш,ьно (эта проблема будет обсуждаться
оп™м„зВ„„»я^0,:'<0"ЬКУ °бЩее ВреМ" ДЛЯ пе»вых 40 ша' °* »П>ь. ограничено, важно
оцГой Опт„„гУ"™' КОМпР°м'«™ь« Решений между поиском и эвристической
~о^—::~,,оиска -3™-——«««■•* -
168
I. Искусственный интеллект как представление и поиск
Целевое
состояние
Рис. 4.12. Сравнение пространств состояний, просматриваемых при использовании
эвристического поиска и поиска в ширину. Часть графа, просматриваемая при использовании
эвристического поиска, затемнена. Оптимальное решение выделено жирной линией.
Эвристика представляет собой функцию J[n)=g(n)+h{n), где h(n)— чисю фишек. находя~
щихся не на своих местах
43. Использование эвристик в играх
В то время две противоположные концепции вызван/ многочисленные споры. Лучшие
игроки различали ави принципиальных типа Игры — формальный и психологический.
— Герман Гессе (Hermann Hesse). Магистр Луди (Игра в бисер)
4.3.1. Процедура ми ни макса иа графах, допускающих полный перебор
Игры всегда были важной прикладной областью для эвристических алгоритмов. Итры
мя двух человек более сложны, чем простые головоломки из-за существования
"враждебного" if, no существу, непредсказуемого противник.] Такие игры не только
Глава 4 Эвристический поиск
„n-сныс возможности для развития эвристик, но и создают
обеспечивают некоторые■ интер „„ „оиска.
большие трудности в разраои. ^ьш1]М пространством состояний, обеспечивающим
Сначала рассмотрим игры ^^ ^ шя 11грах проблема решается систсматичс.
возможность ||СЧСРПЬ1МЮ'"'' ов „ контрмер противника. Затем рассмотрим игры
еким <***%££2Х невозможен, либо нежелателен. Поскольку в таких т-
чергГаюшнй поиск. В этой игре на стол между двумя противниками выкладываете, „е-
кГрос ч.Гсло фишек. При каждом ходе игрок должен разделить кучку фишек „а два
непустых набора разных размеров. Например, 6 фишек можно разделить „а группы 5 и I
„ли 4 и '■> но не ? и 1. Первый игрок, который не сможет больше сделать ход,
проигрывает Для разумного числа фишек в пространстве состояний этой игры можно
реализовать полный перебор. На рис. 4.13 показано пространство состояний для 7 фишек.
В играх, не допускающих исчерпывающего описания пространства состояний,
основная трудность заключается в предсказании действий противника. Простой способ учесть
такие действия — предположить, что ваш противник использует то же самые знания о
пространстве состояний, что и вы, и применяет эти знания для своей победы. Хотя это
предположение имеет свои ограничения (которые будут обсуждаться в подразделе 4.3.2),
оно дает разумную основу для предсказания поведения противника. Метод лптшшнеа
реализует поиск в игровом пространстве с учетом этого предположения.
Назовем противников витое MTN „ mav -,
„ам: МАХ представляет игрока иь,таю,^гП ™а ""брань, по следующим при-ш-
„реимушество. a MIN _ „рГивник Г '""^ """ "<"™'"*"'0<1<"'"' <"«
оппонента. Прад.щ^^^ис^!^"'^ • Т4-"™ СЧСТ С»МГО
таете» достичь наихудшего ддяМдх соГянГ * " "*" И"Ф°""W " ■»» ™"
При реализации стратегии м„„„„акса пометим каждый уровень в области поиска
именем игрока, ^полняюшего очередной ход: MIN или м/£ В примере Грис 4 4
первый ход делает MIN. Каждому „иетовому узлу присвоим значение 1 L О, в з виси
M"'JZ „,1СДяИТ'!ЛЯ: ШК MIN В Пр°ЦеССе Р-™-™ Ч»"»»" «""«макса ,ти
значения передаются вверх по графу согласно следующему правилу.
fl"l°,a"J!^!:T СОСТОЯНИе "ВШ1етс* У™°« МАХ, то ему присваивают макси-
узел MIN, то ему присваивают минимальное
мальное значение.
Если родительское состояние
значение.
мм'13' ПросЬ,ра"Ство со"»ояшш дм одного из вари-
лятся на несколько кучек
Значение, связываемое таким образом с каждым состоянием, отражает наилучшее
состояние, которого этот игрок может достичь (принимал во внимание действия
противника в соответствии с алгоритмом минимакса). Таким образом, полученные значения
используются для того, чтобы выбрать наилучший среди возможных шагов. Результат
применения алгоритма минимакса к графу пространства состояний для игры "ним"
показан на рис 4.14.
Значения вершинам присваиваются снизу вверх на основе принципа минимакса.
Поскольку любой из возможных первых шагов MIN ведет к вершинам со значением 1, второй
игрок, МАХ, всегда может победить, независимо от первого хода MIN. MIN может
победить только в том случае, если МАХ допустит ошибку. На рис. 4.14 видно, что MEN может
выбрать любой из возможных вариантов первого хода— все они открывают возможные
пути победы МАХ, отмеченные на рисунке полужирными линиями со стрелками.
Хотя существуют игры, где возможен полный перебор, все же наиболее интересными
являются случаи, в которых он неприменим. В следующем разделе будет рассмотрено
эвристическое приложение минимакса.
4.3.2. Минимакс при фиксированной глубине поиска
При использовании минимакса в более сложных играх редко удается построить
полный граф пространства состояний. Обычно поиск выполняют вглубь на определенное
число уровней, которое определяется располагаемыми ресурсами времени и памяти
компьютера. Эта стратегия называется прогнозированием п-го слоя (n-ply look-ahead), где
п — число исследуемых уровней. Такой подграф не отражает всех состояний игры, и
поэтому его узлам невозможно присвоить значения, отражающие победу или поражение.
Поэтому с каждой вершиной связывают значение, определяемое некоторой
эвристической функцией оценки. Значение, которое присваивается каждой из л вершин на пути от
корневой вершины,— не показатель возможности достичь победы (как в предыдущем
примере). Это просто эвристическое значение оптимального состояния, которое может
быть достигнуто за п шагов от этой корневой вершины. Прогнозирование увеличивает
силу эвристики, позволяя применить ее на большей области пространства состояний.
Стратегия минимакса интегрирует эти отдельные оценки в значение, которое
присваивается родительскому состоянию.
Часть!!. Искусственный
интеллект как представление
и поиск
Глава 4. Эврисп
ическии поиск
Рис. 4.14, Принцип мишиакса для игры "ним". Жирные линии показывают
пути к победе МАХ Каждому уыу присвоено значение 0 или 1 в
соответствии с процедурой .иынииакса
В конфликтной игре каждый игрок пытается переиграть другого, и многие игровые
эвристики прямо измеряют преимущество одного игрока над другим. В шахматах очень
важно иметь преимущество в какой-либо части игровой доски, так что простая эвристика
может учитывать разность количества частей, где имеют пренммдество либо МАХ, либо
MIN. и максимизировать ее. Можно применить и более сложную стратегию —
присваивать различные значения частям доски, в зависимости от позиции фигур на доске
(например, ферзь против пешки или король против пешки)- Большинство игр дают оез-
граннчные возможности для создания всевозможных эвристик.
Графы игр рассматриваются по уровням. Как показано на рис. 4.14, МАХ и MIN
делают шаги поочередно. Каждой ход игрока определяет новый уровень графа. Типичная
игровая программа предсказывает ходы до определенной фиксированной глубины,
которая определяется пространственными иди временными ограничениями компьютера.
Состояния до этой глубины оцениваются эвристикой и иа основе миннмакса
распространяются ооратно к начальному состоянию. Алгоритм поиска затем использует эта про*
ZZ272 * ВЫ6РЭТЪ "^ш* ^ возможны, ходов.
Ч«ш^Г^' КаЖЛ°М>' СОСТ0ЯЮ'Ю ВЫбРанн01-° ™». программа передает это зна-
™L^STUГп^Г™^ СОСТ0ЯНШ°- ЕС™ РОл.пе.дьское состояние относите* к
х^ ^ние^™ "ш,в"« » «СГО.НИЙ всех его потомков. Если
ранние ю^се^^Г ПЮИи МАХ' МЙННМаКС назначает емУ максимальное
значена -ТГа^Г^^^-- >— МАХ и одновременно минимиз,^
™? лм осуществляет проход по графу, присваивая значения потомка» *
кушсго состояния. Затем эти значения испочьтопт™ япг., *
„~, ™™„„т „ _„ ^-"»* "^-пользуются алгор1ггмом для выбора наилучшего
потомка текущего состояния. На рис 4 15 unmimi .
,...,„„ , „ p»t -*. 1Э алгор1ггм мннимакса проиллюстрирован на
гипотетическом пространстве состояний с четырьмя уровнями
Самые ранние работы по ИИ в это» nfi-neru ^™
* . с ,, " ЭТ01' 00;1астн — это программа игры в шашки,
созданная Самюэлем (Samuel) в 1959 году. Эта программа был. исключением для того време-
ни, особенно учитывая существующие ограничения для компьютеров 50-х годов. Мало
того, что эта программа игры в шашки применяла эвристический поиск, в ней также
присутствовал простои алгоритм обучения. Эта программа была во многом пионерской.
„ ее все ешс используют при создании игровых и обучающихся программ.
Программа Сэмюэля оценивала состояние доски, используя взвешенно сумму
нескольких различных эвристических значений
В этой сумме х, представляет такие особенности состояния игровой доски, как
тактические преимущества, расположение фигур, ситуация в центре доски, возможность
жертвовать фигурами за тактическое преимущество и даже тенденцию перемещения
фигур одного из игроков у края доски. Коэффициенты при х\ специально настраиваются
таким образом, чтобы отражать вклад каждого фактора в общую опенку ситуации. Таким
образом, если преимущество в какой-либо части доски важнее, чем. скажем, в центре, то
это отражает соответствующий коэффициент.
Программа Самюэля позволяет рассматривать необходимое число уровней (обычно
ограниченное возможностями компьютера) и оценивает все состояния на данном уровне,
используя полиномиальную оценку- Затем с помощью различных вариации алгоритма
мшшмакса эти значения распространяются по графу в обратном направлении. После
этого игрок может делать ход в наилучшее состояние с учетом хода противника. Затем
весь проиесс повторяется.
Если в процессе полиномиального оценивания некоторые ходы теряются, то программа
настраивает коэффициенты, чтобы повысить эффективность. Другими словами, большие
весовые коэффициенты уменьшаются (поскольку они вносят максимальный вклад в
неправильную оценку), а меньшие веса оценок увеличиваются, чтобы усилить их влияние. Если
программа побеждает, то противник, соответственно, проигрывает. Программа обучается,
играя против человека или против другой версии такой же программы.
Таким образом, программа Сэмюэля использовала алгоритм поиска экстремума для
обучения, пытаясь улучшить эффективность и сделать локальные уточнения в
полиномиальной оценке. Самюэль ограничил алгоритм поиска экстремума, введя проверку
эффективности индивидуальных взвешенных эвристических оиенок н удалял наименее
эффективные. Программа имеет некоторые интересные особенности. Например, из-за
ограниченности глобальной стратегии она чувствительна к функциям оценки, приводящим
к ловушкам. Модуль самообучения программы уязвим в случае противоречивой игры
оппонента. Например, если противник широко использовал различные стратегии или
просто играл "по-дурацки", то веса в полиномиальной оценке начинали принимать
"случайные"' значения, что приводило к полному снижению эффективности.
Сделаем несколько заключительных замечаний о процедуре мннимакса. Прежде
всего следует заметить, что оценки любого (предварительно выбранного) уровня
могут быть неверными. При использовании эвристики с ограниченным
прогнозированием сохраняется вероятность, что путь, приводящий в дальнейшем к плохой си-
Глава 4. Эвристический поиск
173
овоемя Если ваш противник по шахматам предлагает
туаиии. не будет обнаружен р^ • ^ ^^ ферм_ а оценка т ндат ^^
ладью в качестве приманки „стояния будет наилучшая оценка
«гоуроанялдепредяргает^«J,,, мож„ „рмвсст„ к 10Му. что ,„.ра ^
К сожалейию. под бны„ » ^гим, гар11Ю„т„. Для протиаостояния та-
ГГакоС 7ZZZГоГ SS- У- горизонта, так как поиск асе
^ано долж» остановиться в какой-нибудь точке и. следовательно, останется слеп к
состояниям, лежащим за ее пределами.
Л/с. 4.15. Минюшкс в гипотетическом пространстве состоянии
В алгоритме мннимакса существует и другой эффект, связанный с эвристическими
оценками. Оценки, которые находятся очень глубоко в пространстве, могут не
приниматься во внимание из-за их большой глубины [Pearl, 1984]. Подобно тому, как среднее
произведении отличается от произведения средних, оценка минимакса (которую мы
хотим получить) отличается от минимаксной оценки (которую мы получаем). В этом
смысле обычно (хотя и не всегда) лучше использовать более глубокий поиск с оценкой
состояний и алгоритмом минимакса. Детальное обсуждение этой проблемы и средств ее
решения можно найти в (Pearl, 1984J.
В завершение обсуждения алгоритма минимакса представим его приложение к
игре в "крестики-нолики" (раздел 4.1), описанное в [Nilsson, 1980]. Здесь
используется чуть более сложная эвристика, позволяющая измерить конфликт в игре. Эта
эвристика состоит в следующем. Выбирается состояние, которое необходимо оценить,
находятся все победные строки для МАХ, а затем из их числа вычитается общее ко-
личество победных строк для MIN. Алгоритм поиска пытается максимизировать эту
разность. Если данное состояние приводит к победе МАХ то оно оценивается как
+-;_а если оно приводит к победе MIN _ как -«. На рис. 4.16 показано применение
этой эвристики к нескольким состояниям.
На рис. 4.17, 4.18 и 4.19 показано применение эвристики, представленной на
рис. 4.16, в алгоритме двухуровневого минимакса. На этих рисунках продемонстри-
т'Г,"ЛЭВРИСТИЧ£СКаЯ °ЦеНКа' В038РЭТ На осном минимакса, ход МАХ, а также
некоторые ограничения на ходы с равными эвристическими значениями [Nilsson, 1971].
174
I. Искусственный
интеллект как представление и поиск
Для X существует 6
возможных вариантов
победы
Для О существует 5
^ возможных вариантов
победы
Bin) = 6-5=1
м
t
ы
~
О
■*_
-L
Х_ ;
--' о
Для X существует 4 возможных варианта победы
Для О имеется 6 возможных вариантов победы
£(п)=4-6 = -2
О Д"я * имеется 5 возможных вариантов победы
Для О существует 4 возможных варианта победы
Эвристика - £(л)=М(л)-0(л)
где М{п) — общее число возможных вариантов моей победы;
О(л) — общее число возможных вариантов победы оппонента;
£(л) — общая оценка состояния л.
Рис. 4.16. Эвристика, учитывающая конфликт в игре
"крестики-нолики "
4.3.3. Процедура альфа-бета-усечення
Прямой алгоритм минимакса требует двух проходов по области поиска. Первый
позволяет пройти вглубь области поиска и там применить эвристику, а второй —
присвоить эвристические значения состояниям, следуя вверх по дереву. Минимакс
рассматривает все ветви в пространстве поиска, включая те из них, которые могли
быть исключены более интеллектуальным алгоритмом. Разработчики игровых
стратегий в конце 1950-х годов создали алгоритм [Newell и Simon. 1976]. который
получил название альфа-бета-усечения и позволил повысить эффективность поиска в
играх с двумя участниками [Pearl, 1984].
Идея альфа-бета-поиска проста: вместо того, чтобы рассматривать все состояния
некоторого уровня графа, алгоритм выполняет поиск в глубину. В процессе поиска
участвуют два значения, называемые аыфи (alpha) и бета (beta). Значение альфа,
связанное с узлами МАХ, никогда не уменьшается, а значение бета, связанное с
узлами MIN, никогда не увеличивается. Предположим, что для некоторого узла МАХ
значение альфа равно 6. Тогда МАХ может не рассматривать состояния, которые
связаны с нижележащими узлами MIN и имеют значения меньше или равные 6
Альфа — самое плохое значение, которое может принимать МАХ, если MIN будет
придерживаться "наилучшей" стратегии. Точно так же. если значение бета для узла
MIN равно 6, то не следует рассматривать нижележащие вершины МАХ. с которыми
связаны значения 6 или более.
Глава 4. Эвристический поиск
Qj - I ■!— Начальный
-J-j-узол
Ход MAX
5-6= -16-6 = 05 -6 = -16-6 = 04-6 = -2
Рис. 4. 17. Двухуровневый минимакс для первого хода игры в "крестики-нолики " из
[Nilsson, !97lJ
''«^.«.ДТО»,,»,,,.,.,, 4-3=14-3 = 1 3-3-0
"" '" "">'■' чтюжных вторых ходов МАХ
ЧЭСТЬ "■ Иск"сс™нный интеллект как представление и поиск
Начиная альфа-бста-ироцсдуру мь, „,„
поиск в глубину, и вычисляем мристичесиГГ" "" "Ш"'УЮ Г"У°И"У Ч""1'"- "С"""Ь1У»
Прсдположим, что вес они — узлы мш м иснки шя »ссх состояний лот уровня.
„ родительскому состоянию (узлу МАХ™'ИМаЛЬНОе Ш Э™1 ™'1С|1ИЙ M'N «ojupaiuiK,-
яне передастся прародителям узлов MIN mT.t" аЛГОрИТМС ""»"«»««). Затем iro зпачо-
Затсм алгоритм опускастсГк дру^ « 2"тГ,1МИ1""™"- ^
тельскис состояния, если их тначения больше „» " "С Рассма1Т»»^ »* Р™-
гичные процедуры можно описать для ГГ 2 " Да""°МУ 3"а"С""Ю 6ста' А|Ш|°'
вершины МАХ. альфа-отсечения ио потомкам второго поколения
Существуют два условия останова алгоритма „оиека „а основе значений альфа и бета
1. Поиск может быть остановлен „иже любого узла MIN, значение бета которого
меньше или равно значению альфа любого из его предков МаТ "
2. Поиск может быть остановлен ниже любого узла МАХ. значение альфа которого
больше или равно значению бета любого из его предков MIN.
CD -Ёр Начальный
ЯГГУЭвл
Рис. 4.19. Двухуровн
чевыи минимакс
применительно кхоау X в конце игры [Nilsson, 1971}
Таким образом, альфа-бета-усечение выражает отношение между узлами уровней л и
п+2. При этом из рассмотрения могут быть исключены целые поддеревья с корнями на
уровне п+ 1. Например, на рис. 4.20 изображено пространство поиска из рис. 4.15, к
которому применен алгоритм альфа-бета-усечсния. Заметим, что результирующее
возвращаемое значение идентично полученному в алгоритме миннмакса, но при этом
процедура альфа-бета-усечсния значительно экономичнее минимакса.
При удачном порядке состоянии в области поиска процедура альфа-бета-усечсния может
эффективно удваивать глубину поиска в рассматриваемом пространстве при фиксированных
пространственно-временных характеристиках компьютера [Nilsson, 1980] Если же узлы
расположены неудачно, процедура альфа-бета-усечения осуществляет поиск в таком же
пространстве, как и обычный минимакс. Однако поиск проводится только за один проход.
Глава 4. Эвристический поиск
177
4 4. Проблемысложяости —__
комбинаторных задач является экспоненциальны* рос
Наиболее сж*^****Г£частук не учитывают разработчики программ. Поскольку
чюармпв """^^^яатезмости (вычислительной и другой) происходят в ли-
оаюмые виды ,аме,вСЖ0^^стамп. себе якооненшильный рост. Мы часто слышим
яеЯяя, времся*, вам ,вс™?ТГмошяый (или быстрый или высоко ггроюводительныв)
жалобу: -Если б^\"ЖЗ g^Tg,, „епкяа" Такие жалобы, часто вызываемые проблемой
„ыпыотгр. мои °<ю6ЖШ"!~шй1. обычно бесоочвениы Просто проблема была понята
-взрывного" Р^^^^П-елпрши™ лействи. по ее решению,
вс досшичвоглупев"" ^_^.2-г Было поаяино. что количество состояний, проемзтрн-
Ком6им'°Ря* „^1б»еТдастранстве возможны* шахматных ходов, составляет 10>а
^^^Х^^вГбмы!» шжчество"- зто число сооостаинмо с числом молекул »
Э» непросто °~и6^^п(ККЗС!^пос.ж-бо.тыВоговзрыва".
£гя А аечемие ^=3'/ б^;^т не 6o.ibuje. ^еы 3)
S яаяяетсе £--^ече**тым, таг *ajr 5>3
£л» С 3^a"-e>-ye 3=3 'С будет не меньше, чемЗ)
О явгя=тся а-уС€*е»-"аа/, та* кэ* 0^3
£ являете? с1-/^=^е"*ъл|, та* кй/ 2<3
С тс*»*«ает з-э-^еа-*е З
Ac 4-20. Ллфа-бона-усечеюе гфименшнежьио к щюсщшнату со-
аттяишрис415.Сжяюяа1я6езчиаовыхметокнеоценивашсь
Были предложены несколько метрик для вычисления сложности. Одна из них —
фактор «еашашя пространства, фактор ветвления определяется как среднее
количество ветвей (потомков), выходящих из любого состояния в пространстве поиска. Число
состояний на глубине л поиска равно фактору ветвления, возведенному в л-ю степень.
После вычисления фактора ветвления можно оценить стоимость поиска путн любой длины.
На рис. 4.21 показана зависимость между 4актором ветвления В, длиной пути L и обоям
юшместаом состояний Т в процессе поиска для малых значений. Графики представлены
в логарифмическом масштабе. Поэтояу L _ ш прюая лииия_
ти f^TT- "!*™^Г~ ■■". --- -„кукка показывают, как плохи дела на самом деле- Ь-
ггггейщ - ° ,Кр' в 6иН2Рном дереве), то для исследования все*
IV) состм» • iC™ поиаа требуется рассмотреть приблизительно
сто.™*Fr™«™Il''': ■'-'■'•' *л 12 Уровней требуется рассмотреть около 10000
состояний. Если Виктор ветвления может быть уменьшен до iS^c гк«ошью звристики «л»
178
В. Исгусственный интеллект как представление и
«регулировки задачи,, то при том « коли-.,™
пути может быть удвоена. "личеетве
Математическая формула заккимоств.
Г=в* В' *В' * *в*
где 7 — общее количество
"Релстшлеииой к
i рис. 4.21, имеет I
ГДС i — wmvt ки.шчесТВО СОСТОЯНИЙ L
Это уравнение можно привести к виду ДЯЮИ "*"'' *В~ «"♦фимиеит i
Т=В1В- - 1)/(В- 1).
Рис 4.21. Число сгенерированных yuoe i
длины пути решения L Соответствующее
INiliMon. I9»j
Измерение пространства пояска — змшижчесу-.'
знакомства с задачей и проверки различных ее вар»:..
требуется ■■■■'— -
ло возмог
ПОЗ — дл;
зом, всего получается 24 хода. Разделив это число на 9 *ьч.
иьгх местоположений пустой глетги!. получим, что среди
2,67. Как показано на f. 1 . очень хорошее зва-.
Если не принимать в- -i.-. ведущие назад »
(используемые в алгор;;..._ ..... .писанных в зтой гЗ£.-
оудет на один ход меньше. В этом случае фактор ветвления равен
""жным полный перебор (в некоторых пространствах состояний i
Как было показано в главе 3, сложность ал: '
тисков closed и open. Чтобы пох-сржнват
ЛавЖ. Эвристический поиск
179
Стоимость
применения правила
О "Информированность
г поиска н стоимости
Рис 4 " Неформальный график стоимости >
вычиаения эеристтеской оценки в зависимости от
информированности эвристики (Nilsson. 1980]
При попытке снижения ветвления алгоритма поиска или сужения пространствапоиска
мы ввели понятие -более информированной" эвристики. Более „„формированный поиск
дает возможность рассматривать меньшую область для нахождения минимального пути
решению. В разделе 4.3 было показано, что цена дополнительной информации,
необходимой для сокращения пространства поиска, не всегда приемлема. При решении задачи на
компьютере не достаточно найти минимальный путь. Необходимо также сократить
количество операций, выполняемых компьютером в процессе нахождения решения.
На рис. 4.22, взятом из [Nilsson, 1980], представлен неформальный результат
анализа этих вопросов. По оси абсцисс отложено количество информации, которая уч
в эвристике для улучшения ее эффективности. По оси ординат показаны затраты пр
цессора на осуществление поиска. Если эвристика становится более информиров
нон, затраты процессорного времени на рассмотрение состояний уменьшаются, пот
му что необходимо просматривать меньшее количество состояний. Обшая стоимос
нахождения пути решения — это общая стоимость эвристических вычислений плюс
стоимость просмотра пространства поиска. Желательно, чтобы обшая стоимость
такого поиска была минимальной.
В заключение следует отметить, что важной областью исследований является
эвристический поиск на графах НЛШИ, так как подобную форму имеет пространство
состояний для экспертных систем. Поиск на этих структурах включает компоненты,
обсуждавшиеся в этой и предыдущей главах. Поскольку для нахождения пути к цели необходим
просмотреть все потомки узлов И. эвристическая оценка стоимости поиска для У^"
представляет собой сумму оценок поиска его потомков
180
Часть И. Искусственный интеллект как представление и
43. Резюме и Дополнт^льняГ^1::г^
Р«-Г РК"И МДаЧ °6ЫЧНП >'»™«™ экспоненциально
Эвристический поиск- это основной инструмент для управления таким "комбинаторным
„зрывом . В данной главе представлен "жадный" алгоритм поиска, а затем проанаднш-
ровано поведение эвристических алгоритмов. Мы рассмотрели такие их свойства, как
допустимость, монотонность и информированность. Эвристический поиск был рассмо,-
рен на простых примерах типа игры в "пятнашки", а затем распространен на более слож-
„ые пространства состояний, возникающие при проектирован,,,, экспертной системы
(глава 6). В данной главе также была рассмотрена эвристика, применяемая в играх с
двумя участниками. Она использует процедуру минимакса и альфа-бета-усечеипя дм
предсказания ходов противника. Теория сложности играет важную роль почти в каждой
области информатики, особенно при анализе роста пространства состояний и
эвристическом усечении. Теория сложности исследует сложность задач (в противоположность
алгоритмам). Ключевая посылка теории сложности состоит в наличии класса существенно
сложных задач. Этот класс, получивший название класса NP-аожных задач
(Nondeterministicaliy Polynomial), включает проблемы, которые не могут быть решены в
разумное время без использования эвристики. Этому классу принадлежат почти все
задачи поиска. По этой проблеме мы особенно рекомендуем книги [Garey и Johnson, 19791
и [Moret и Shapiro, 1991].
В [Pearl, 1984] детально описаны такие вопросы, как разработка „ анализ эвристик. В
[Korf, 1987, 1998, 1999] продолжено исследование алгоритмов поиска, в том числе
описан алгоритм IDA*. Программы игры в шахматы вызывают постоянный интерес на
протяжении всей истории развития искусственного интеллекта. Новые результаты в этой
области часто представляются и обсуждаются на ежегодных конференциях.
Автор благодарит Нильса Нильсона [Nilsson. I9S0] за его подход и примеры, которые
были использованы в этой главе.
4.6. Упражнения
1. Придумайте эвристику, которую можно было бы использовать в программе размс
щення блоков для решения задач,, "поставить блок X на блок Y". Будет ли такая
эвристика допустимой? Монотонной?
2. Головоломка скользящих фишек включает три черные и три белые фишки, а также
пустую клетку, как показано на рис. 4.23.
В этой головоломке допустимы два хода с соответствующей стоимостью.
Фишку можно передвинуть в соседнюю пустую полщию. Этот ход стоит 1. Фиши
может перепрыгивать на пустое место через одну или две другие фишки. Стоимость этого
хода равна количеству перепрыгнутых фишек.
Цель игры состоит в том. чтобы все белые фишки расположить слева, а черные -
справа. Местоположение пустой клетки не важно.
2.1. Проанализируйте сложность пространства состоянии „ наличие циклов.
2.2. Предложите эвристику для решения этой проблемы и проанализируйте се на
допустимость, монотонность и информированность.
Глава 4. Эвристический поиск
181
в в в
w ' w \ w
р^ 4-23- Г<аол--.'- •-■-—' -*'■' - "
_«™ш для игры в типошв.- (с», рис. 4.S) с эвристикой щ^
; Сравните тр» »^~ находящихся не на свою местах, с удвоенным число*
^^Г^Ср^-хооолелулошим крктер.и»:
^^ Т™«н расстояния к ц=» Д» этого тРес> ™ нанта Ччпаившй „^ ,
- информированность. Какая нэ упомянутых эвристик наиоолее эффективно
сокращает простраяство состояний?
в) мяютонвость дм игры в титнашки";
допустимость Какал из этих эвристик ограничена сверху фактической стоимостью
пути к пели? Обоснуйте свои предположения для общего случая или приведите
контрпример.
4 о. Как было сказано выше. -жадный" алгоритм поиска для предотвращения
зацикливания использует список closed. А что если отказаться от этого теста и определять
зацикливания на основе д(л)? Сравните эффективность этих двух подходов,
б. Функция toest_f Irst^search не проверяет, является ли состояние пелевым.
пока оно не удалено из списка open. Эту проверку можно выполнять при
рассмотрении новых состояний. Как это отразится на эффективности алгоритма? На
допустимости?
5. Докажите, что алгоритм А* допустим. Подсказка: при доказательстве следует
показать, что:
а) для алгоритма А' поиск закончится;
б) в списке open всегда существует узел, который находится на оптимальном пути
к цели;
в) если путь к цели существует, то алгоритм А* закончится нахождением оптимать-
ного пути к цели.
6. Подразумевает ли допустимость выполнение свойства монотонности эвристики?
Если нет, опишите, когда допустимость подразумевает монотонность.
7. Докажите, что набор состояний, рассмотренных в алгоритме А* является
подмножеством состояний поиска в ширину.
8 tt^T' "ТОпболее "«Формированная эвристика просматривает более узкую об-
££*« Г*" 0ДСКаЗКа: ФОР-""")*™ доказательство, представленное в подраз-
9 стан^вкаГал^Л0 ПР0С™ ЖМ кодирования, основанная на циклически* пере-
НапР„м^ЗистКэ™'т>Р0Й '"Й СИМВ0Л «Ф™» заменяется (,+п)-м си*»»
как :-Gew" "™u>w831"u' Ш«ФР* Цезаря со сдвигом 4 слово "Caesar" запиш
9Л'р?Ц^ТРК'ВР"СТИКИ- КЭТ°Рые *°*н° использовать для расшифровки и"*"
92- В простом шифре подстановки кажл - -
торого произвольного взаниил ,,„ символ заменяется другим us оснок- ною-
ггредложенных дл, пшфр?^1,Т^^Г™ ™*"™« К
шифра" Обьясшгте. (СгГибо^ м «пользоваться дл» ,
ч-к- "'-■моюо Дону Моррисону (Don Momson. i
10. Реализуйте стратепио миннмакса ыа т~.„ ' ~
'""макса на дереве, показанном на рис 4 14
11. Выполните альфз-бета-усечение ctw*r* i~™«~.
на этом же дереве vce4eH„e с^^Го£ *" *■*" " il^BKaa 10 В""0"™»"
f~ . ^"P^ налево. Ооьясшгге, почему результаты отличаются.
12. Рассмотрите трехмерную игру , "крестики-нолик,,-. Проанашз.шуйте сложность
пространства состояний. Прехтожите эвристику для этой %£Г^^ СЛОМОСТЬ
13. Выполни* атьфа-бета-усече™К для игры в "кресшки-нолики' ,см. рис 4.17 4 18 и 4 №
Сколько вершин можно устранить в каждом случае?
14. а. Создайте алгоритм для эвристического поиска на графе МШИ. Обратите
внимание на то. что для определения значения родительского узла необходимо
просмотреть значения всех его потомков. Таким образом, при вычислении эвристических
оценок стоимости пути к цели оценка стоимости узла AND состоит (как минимум) из
суммы оценок стоимости различных ветвей.
6. Используйте этот алгоритм для поиска на графе (рис. 4.251.
Рис 4.24. Дерево для применения
принципа минимакса
W) = 1
WS) = 2
«CI =5
«0| = 3
Л(Я = 2
№ = 5
«G)=1
ft(H) = 3
m/i = 1
Рис. 4.25. Пример графа для поиска
Глава 4. Эвристический поиск
183
Ь--
Управление поиском
и его реализация
в пространстве
состояний
Если мы аккуратно отделим влияние среды, в которой выполняется задача, от
влияния аппаратных компонентов и организации, то поучим истинную простоту
адаптивной сиапе мы. Как мы видели, для описания способа решения человекам таких задач, как
шахматы, логика и криптоарифметика (cryptarilhmelk), необходимо постулировать
только очень простую систему обработки информации. Очевидно сложное поведение
системы обработки информации в данной среде обусловлено взаимодействием
требований среды с несколькими основными параметрами системы, в частности,
характеристиками ее блоков памяти.
— А. Ньюэлл и Н. А. Саймон, Решение проблем человеком, 1972
То, что мы называем началом, часто будет концам,
Пргаодя к концу, мы приходим к началу.
Конец — это чаше начало...
— Т. С. Элиот (Т. S. Eliot), Четыре квартета
5.0. Введение
В главах Л п 4 представлены задачи, решаемые методом поиска в пространстве
состояний. Этот подход "пространства состояний" к решению задачи позволяет
использовать теорию графов для создания и анализа компьютерных программ. В главе 3
определен общий алгоритм поиска с возвратами , а также алгоритмы поиска в глубину „ в
ширину. Эвристический поиск был представлен в главе 4. Следующие понятия
характеризуют данные и управляющие структуры, используемые для реализации поиска
в пространстве состоянии.
1. Представление решения задачи в виде „у. от начального состояния к целевому.
2. Алгоритм поиска, систематически проверяют,,,', иалпчне азьгернатнвныл путей к цен,
,™ лпугой мехашгзм. позволяют,,.! выходить „, тупиковых
3. Поиск с возвратам» '^Р/цсл„.
состояний и находить у ^ |Шформац1,ю о рассматриваемых в данный момент
состояниях, в то^Ч"вС^ющиП ^„ритму в случае необходимости исследовать ра.
„ее не рассмотренные с0"°*н|1*' енные состояния. Он позволяет алгоритму
6) список Cosed. »^Р»7,™ваТтТпиковые пути,
избегать зацикливании >' ^ ^ стек Ш1Я поиска в глубину, очереоь m
5' ^Гв .и^уплн :р„оР„теш,уЮ очеребь для Жадного" алгоритма поиска.
„„„яг™ высокоуровневые методы для построения алгоритмов поиска.
В данной ™« » ^^ „"„..Гопределяющий поиск в глубину с возврата™ более
Первый из них— рскУк"'° ^ ^ж ^ ЭюТ механшм составляет основу многих
кратким и «^еств»""" С"^™еН1,е у„„ф„кацни в процессе поиска в пространстве сосго».
алгор,т.оввразделе5.1.При.менен,еу Ф алгоритм поиска по образцу
мин ПаСШГОЯеГ ВОЗМОЖНОСТИ реКурСИВНОГО ПОШЛО. Г V 4J
?аздГ5Тио"оже„ в основу языка PROLOG, описанного в главе 14. „ многих экспертных
систем оасемотрен,шх в главе 7. Раздел 5.3 посвящен так называемым продущиотш, ее-
«Это общая архитектура для решения образно-ориентированных проблем, которая
широко используется как для моделирования человеческого образа мьшшсиия при решении
многих задач так и для построения экспертных систем и других приложении ИИ. Наконец, в
разделе 5.4 рассматривается еще одно представление для решения задач искусственного
интеллекта — так называемая модель классной доски (blackboard).
5.1. Рекурсивный поиск
5.1.1. Рекурсия
В математике рекурсивное определение объекта — это его описание в терминах
частей этого же определения. В информатике рекурсия используется для определения и
анализа структур данных и процедур. Рекурсивная процедура состоит из следующих этапов.
1. Рекурсивный шаг: вызов процедуры из этой же процедуры для повторения
последовательности действий.
2. Условие, которое обеспечивает выход из процедуры и таким образом
предотвращает зацикливание (рекурсивная версия бесконечного цикла).
Оба этих компонента необходимы и появляются во всех рекурсивных определениях и
алгоритмах. Рекурсия — естественный инструмент управления массивами данных,
которые имеют правильную структуру и неопределенный размер, например, списками,
деревьями и графами. Рекурсия особенно удобна для поиска в пространстве состояний.
Простои пример — алгоритм определения принадлежности данного элемента списку.
итемм (|,я) называют упорядоченную последовательность элементов и фуидаменталь-
Г„1ТИ™"''""Х СПРУИУР ДаННЫХ- С"иски "снользовались как альтернативна»
open „227»™™™ "Сю™ «Ч*™-™» <™ава 2) и для представления списков
г:;та1Гу^:гг,гска из п,авыз- пр°ц^а ^ -р—ност"
186
'• Искусственный интеллект как представление и поИ<*
function member(item, list);
begin
if список пуст
then return FAIL
else %останов
if item = первому элементу списка
then return SUCCESS
else ^останов
begin
ll^ictZ"Te удаленил первого элемента;
end %рекурсия
end.
Эта процедура сначала проверяет, пуст ли список, и, если да, алгоритм возвращает
ошибку. В противном случае он сравнивает выбранный элемент с первым элементом
списка. Если они равны, происходит успешное завершение процедуры. Таким образом, это
условия завершения процедуры. Если ни одно из приведенных выше условий завершения не
выполнено, процедура удаляет первый элемент из списка и снова вызывает сама себя для
сокращенного списка. Это позволяет исследовать каждый элемент списка по очереди.
Обратите внимание на то, что список конечен, и каждый шаг рекурсии уменьшает его размер
на одни элемент. Это означает, что данный алгоритм не приведет к зацикливанию.
В приведенном выше алгоритме используются две фундаментальные операции со
списком: первая из них (head) возвращает первый элемент списка, вторая операция (tail)
возвращает список, полученный после удаления первого элемента. Эти операции наряду
с рекурсией составляют основу высокоуровневых операций со списком типа member.
Данные операции поддерживаются языками обработки списков LISP и PROLOG и
подробно описаны в главах, посвященных каждому из этих языков.
Рекурсия, поддерживаемая каким-либо языком программирования, расширяет
возможности более традиционных управляющих конструкций, например, циклов и
условных операции. Другими словами, любая итерационная процедура может быть также
реализована рекурсивно. Удобство рекурсивных формулировок — ясность и компактность
выражения. Математические понятия логики или функций не поддерживают таких
механизмов, как упорядочение, ветвление и итерация. Для индикации повторения можно
использовать рекурсию. Поскольку рекурсию проше описать математически, чем явные
итерации, то легче формально проанализировать правильность и сложность рекурсивных
алгоритмов. Рекурсия часто используется в системах автоматической генерации или
верификации программ, необходимых при создании компиляторов и интерпретаторов.
Однако более важным является тот факт, что рекурсия — это естественный способ
реализации таких стратегий искусственного интеллекта, как поиск на графе.
5.1.2. Рекурсивный поиск
Прямое преобразование описанного в главе 3 алгоритма поиска в глубину в
рекурсивную форму иллюстрирует эквивалентность рекурсии и итерационного подхода.
Этот алгоритм для поддержки списка состояний использует глобальные переменные
open и closed.
function depthsearch; «переменные open и closed глобальные
begin
Глава 5, Управление поиском и его реализация в пространстве
187
Л ^еГге?«Л№ т сп„ска open;
„rreS tate :> "^ГиелевомУ состояние
И CSr«»a»sSccHSS
else
begin списка open;
open := xB0" ^d с добавлением current_state;
closed := cl°;L,4Ka current_state
для каждого ли • losed ши ореп
if не в списке %построение стека
then добавив потомок в начало списка open
end; %рекурсивный вызов
depthsearch
end' сать фактически тем же самым алгоритмом. При этом не-
Поиск в ширину можно onii ч- бальную структуру данных и рассматривать
обходимо сохранять список с 1°^е^аК
список open как очередь, а ие к ^ ^^ ^ глубину ие использует все возмож-
„з "Р«™„оцёд^уСно упростить, используя рекурсию непосредственно ,.
„ости рекурсии. Процеду» состоян1,й „ нахождения путей в их простран-
„е через список openдшР* тр ш clQsed используется для oft*
^„Г„Х—Г—™би предотвращения ци^ов. Список open неявно „с-
пользуется в записях активации рекурсивной среды.
function depthsearch (current.state) ^^ _ гловальная переменная
begin
if current_state равно целевому состоянию
then return SUCCESS;
добавить current_state в список closed;
while current_state ииеет непроверенные потомки
begin
child := следующий непроверенный потомок;
if потомок не член списка closed
then if depthsearch (child) = SUCCESS
then return SUCCESS
end; „au
return FAIL «поиск исчерпай
end
Вместо того чтобы находить все потомки данного состояния, а затем помешать^ ■
список open, этот алгоритм рассматривает потомки по одному. Для каждого из wa
курсивно находятся все потомки, а затем рассматривается очередной потомок "сх0*
состояния. Следует заметить, что алгоритм предполагает определенный порядок о
торов генерации состояний. Если при рекурсивном поиске некоторый потомок явл
целевым состоянием, то процедура поиска успешно завершается, и, естественно. ^
ритм игнорирует братьев данного потомка. Если рекурсивный вызов для одного и ^
томков приведет в тупик, то будет рассмотрен брат этого потомка, а также все ег
том«и Таким образом, алгоритм обходит весь граф аналогично алгоритму .ю»«а '
бину (см. подраздел 3.2.3). Читателю рекомендуется проверить это утверждение-
Часть II. Искусственный интеллект как представление
Рекурсия позволяет обойтись без списка ооег, м
„о реализовать рекурсию на каком-либо язык, Хакизм' посредством которого мож-
делыгую запись активации (activation record) ,ед,Прог^а™иРова™- «лжей включать от-
„ого вызова. Каждая такая запись акзт^ш ^1" 1Швт- 1977) ™ кавд°го Р»^1»"
состояние выполнения для каждого вь130в. ""f13 содержать локальные переменные и
процедуры с новым состоянием новаТ аГь™ и„ "" "^ ""N*1™"' "ш°"е
(состояние), все локальные переменные™ кудГ^ ^" "^"Т "^^^
UpHTMe поиска состояния, находящиеся иа^сма™"™ ВЫП0™еШ,Я' В l»W™««
довательности записей ак™вац,Шрт^„ьГ.1^Г^ ПУга'С0ХраНЯЮТСЯ в после'
.акже последнюю операцию. которая^Г де"" °„ геТ" т°Ю "П°" ^^
„ F UbUld сделана при генерации соответствующего по-
юмка. Это позволяет генерировать при необходимости брата данного потомка
Возврат производится, если „и один из потомков данного состояния ие привел к
цели, что послужило причиной неудачного завершения процедуры. В этом случае в
процедуру генерации потомков возвращается значение FAIL. Затем эта процедура
применяется к брату данного состояния. В рассматриваемом случае внутренние
механизмы рекурсии заменяют список open, который был использован в итерационной
версии алгоритма. Рекурсивная реализация позволяет программисту ограничить
рассмотрение единственным состоянием и его потомками, а не иметь дело со всем
списком open. Возможность рекурсии выражать глобальные понятия в простой форме —
главный источник ее удобства.
Поиск в пространстве состояний — процесс рекурсивный по природе. Чтобы иайти
путь от текущего состояния к цели, необходимо двигаться в дочернее состояние, затем из
него перейти к потомку и так далее. Если соответствующее дочернее состояние ие ведет
к цели, то необходимо рассмотреть состояние того же уровня, на котором находится
родительское состояние. Рекурсия разбивает большую и трудную проблему (поиск во всем
пространстве состояний) на более простые части (генерирование потомков отдельного
состояния), а затем применяет (рекурсивно) эту стратегию к каждому потомку. Этот
процесс продолжается до тех пор, пока не будет найдено целевое состояние или
исчерпано все пространство состояний.
Задача символьного интегрирования, рассмотренная в подразделе 3.3.3. является
превосходным примером мощности рекурсивного подхода в задачах поиска. При
интегрировании выражения обычно выполняется замена переменных или декомпозиция
интеграла, сведение его к совокупности более простых интегралов (подзадач). Эти
подзадачи также могут быть решены рекурсивно с последующим объединением
результатов в решении исходной задачи. Например, после применения правила суммы
интегралов (интеграл суммы равняется сумме интегралов) можно попытаться
рекурсивно проинтегрировать каждое из слагаемых. В дальнейшем можно снова применять
декомпозицию и замену, пока не будет проинтегрирован каждый из членов. Затем
результаты интеграции объединяются (посредством суммирования) в конечный
результат. Таким образом, рекурсия- это естественный инструмент хи систематической
Декомпозиции задачи с последующим объединением результатов решения частных
задач для решения исходной проблемы. „„.„„„.,„, ■.„„
г. -.-.„„-KRHufi подход будет расширен до некоторого кон-
В следующем разделе этот рекурсивный подход uJJC v v „ „ „...Г, ■,,. re
троллера логического решателя задач, который использует >™Ф>'™™ » •""££
нерашш пространства логических отношений и поиска в „ем. *™Р™ ™^*™^
операцию логического умножения нескольких целей and, а также построение обратных
цепочек от цели к предпосылкам.
Глава 5. Управление поиском и его реализация в пространстве
189
3 выво-
Допустим. не.—... "чесом следствием н«и.иИи.и nawp<. утверждений
женис исчисления предикато неннем „равпл модус понеис, определяющих пе-
Это предполагает поиск от цси^ь (типар(а)), алгоритм использует унификацию
реходь. между состояниям. • ^ которь]Х соответствуют цели (например, q{X) ^
для выбора импликации. обоабатьшает импликации как потенциальные правила т
р1Х)). Поскольку ^ ^"^азывают просто правгиалш. После унификации цели е за-
разрешения запроса, их ча > и применения результирующих подстановок ко
гением -"-— а тГ Р-^ае^новится новой целью (,(а)). Ее называв
ба е нани-i поиск прекращается. Последовательность выводов, ведущая от „сходной
цели к данным фактам, доказывает истинность первоначальной цели.
function pattern_search (current.goal) ;
begin . ,
if current_goal содержится в списке closed
%проверка на зацикливание
then return FAIL
else добавить current_goal в список closed;
while в базе данных остаются правила или факты для унификации do
begin
case
current_goal унифицируется с фактом:
return SUCCESS;
current_goal - это конъюнкция (р л . . .) ;
begin
for каждого конъюнкта do
вызвать pattern_search для конъюнкта;
if pattern_search успешно завершается для всех
конъюнктов
then return SUCCESS
else return FAIL
end;
current_goal унифицируется с заключением правила
(р в q -» Р) :
begin
применить подстановку унификации цели
к предпосылке
вызвать pattern_search для предпосылки;
" Pattern_search завершен успешно
then return SUCCESS
else return FAIL
end;
end; %конец оператора
return FAIL
case
190
L ИскУсственный интеллект как представление и поиск
В функции pattern„search поиги „...„
вереи"рекурсивного „^ ""ь" ™"°>™<™* с помощью модифицированном
-. использует vhhA»«»,.„J, 7 КОТОрь"1' что6ы Установить соответствие двух выражс-
„ило ТГс no"tТ™ <П°ДраЗДеЛ 23'2>' " <™ «"Дания потомков состояний -
"Р TIZ Рели Т ^ С0С™НИе П0ИСКа "РОД^влено переменной cur-
ГВ«- „til -9M1 -ответствует факту, алгоритм возвращает
SUCCESS. В противном случае алгоритм пытается сопоставить current goal с
заключением некоторого правила, рекурсивно просматривая все предпосылки. Если cur-
rent_goal не согласуется ни с одним нз утверждений, алгоритм возвращает FAIL.
Этот алгоритм также обрабатывает конъюнктивные цели, которые часто встречаются в
предпосылках правила.
Для простоты этот алгоритм не решает проблему согласования подстановок
переменных при унификации. Это важно при разрешении конъюнктивных запросов с общими
переменными (например р(Х)ла(Х)). Оба конъюнкта должны быть согласованы не
только между собой, но и с унифицированными значениями переменной X
(подраздел 2.3.2). Эту проблему мы рассмотрим в конце раздела.
Главное преимущество использования таких общих методов, как унификация и
правило модус попеис, для генерации состояний заключается в том, что
результирующий алгоритм может просматривать любое пространство логических выводов.
Специфические проблемы описываются утверждениями исчисления предикатов. Таким
образом, знания о задаче отделяются от реализации ее решения на компьютере. Функция
pattern_search обеспечивает первую реализацию такого отделения знаний от
управления.
5.2.1. Пример рекурсивного поиска: вариант задачи хода конем
Использование исчисления предикатов с общим контроллером для решения задач
поиска можно проиллюстрировать на примере упрощенной версии задачи хода конем
(knight's tour problem). В шахматах конь может перемещаться на два поля по горизонтали
или вертикали и на одно поле в перпендикулярном направлении. При этом он не должен
выйти за пределы шахматной доски. Таким образом, в самом общем случае существует
не более восьми возможных ходов (рис. 5.1).
Традиционная формулировка задачи заключается в том. чтобы найти такую поогсдо-
вательность ходов конем, при которой он становится на каждую клетку только один раз.
Эта задача дала толчок к развитию и представлению алгоритмов поиска. Пример,
который мы используем в этом разделе. — упрощенная версия задачи хода конем. Здесь
необходимо найти такую последовательность ходов, при которой конь побывал бы в
каждом поле уменьшенной шахматной доски (3x3) только один раз. (Полная задача хода
конем рассмотрена в подразделе 5.3.2.)
На рис. 5.2 показана шахматная доска, размером 3x3, где каждая клетка помечена
целым числом от 1 до 9. Для простоты эта схема маркировки будет использоваться вместо
более общей схемы в которой каждая клетка маркируется двумя цифрами, номером
строки и номером столбца. Поскольку размер шахматной доски уменьшен, мы просто
перечислим возможные ходы, а не будем разрабатывать общий оператор перемещения.
В этом случае допустимые ходы на доске можно описать с помощью предиката move,
параметрами которого являются номера начальной и конечной клетки допустимого хода.
Например, тоге( 1 8) перемещает коня из верхнего левого угла в середину нижнего
ряда. Предикаты на рис. 5.2 описывают все возможные ходы для шахматной доски 3x3.
Рис. $.1. Допустимые ходы конем на шахматной доске
movsM.8)
more( 1,6)
move(2,9)
move{2J)
move(3,4)
move{3,8)
move(4,9)
move(4,3)
move(6,1)
move(6,7)
move(7,2)
move{13)
move(8,3)
move(8,1)
move(9,2)
move(9,4)
1
4
7
2
5
8
3
6
9 I
Рис. 5.2. Шахматная доска 3*3 с допустимыми ходами
для упрощенной задачи хода конем
. п качестве примера
Эти предикаты составляют базу знании для задачи хода конем, а кя ВОвание
использования унификации для обращения к этой базе знаний проверим су ^^
различных ходов на шахматной доске. Для определения возможности пер . ^
из клетки 1 в клетку 8 будем вызывать процедуру pattern_searclfi^mo ,'я воз-
Поскольку данная цель унифицируется с фактом move( 1,8) в базе знании, фУ
вращает значение SUCCESS без каких-либо подстановок переменных. тооого
Другой запрос позволяет определить, куда конь может переместиться из н _я
8(2,Х)унифии№^
{7/Х1и{9/Х1-Д^
ли move(2,3) результатом будет FAIL, так как в базе знаний не существует эЯ^^
move(2,3). Ответом на запрос move(5, V) тоже будет FAIL, потому что не суШ
утверждении, задающих перемещение из клетки 5
,„^..„ „„.„.„о ппа пппелеле
j IIC4HCJ
местоположения, например, из клетки 2. В этом случае цель morel 2, X) унифш» V ^
с двумя различными предикатами в базе знаний с подстановками (7/Х) и (9/Х) '^мента
M,..,uw....,, .адаппши перемещение из клетки У ^ц п°'
Следующая задача состоит в построении алгоритма поиска для определения W ,,,„
следователях шагов по доске. Это можно сделать с I
, импликации i
192
Часть II. Искусственный интеллект как представление
"РТГшагов ЧтобыГ™ К бМе ЗНа"ИЙ как -*»-« «- «здания путей последова-
" Г ли напоавление ^^Т™ ™ "" ПраВИЛа °^псч„вают поиск от цели, мы
^:внГГ^П0ГГаИМШ,ИКаЦИН- С—ь„о, прав,™ будем писать как
Например, путь с двумя ходами можно записать так.
V X, У [ра(л2(Х, У) <- 3 Z [more(X, Z^movetf, У)]].
Это правило утверждает, что для веек клеток X и У существует путь с двумя ходами,
если существует такая клетка Z, что конь может переместиться из X в Z, а затем - из Z в У
Общее правило ра№2 можно применять различными способами. Например, оно
подходит для проверки существования двухходового пути из одной клетки в другую. Если
функция pattern_search вызывается для цели ра(л2(1,3), то проверяется
соответствие этой цели последовательности правил ра(л2(Х, У). При этом выполняются
подстановки для предпосылок правила. Результатом является конкретное правило, которое
определяет условия, необходимые для такого пути.
рагл2(1,3) <- 3Z [more( 1, Z) л more(Z, 3)].
Затем функция pattern_search вызывает сама себя с этим параметром.
Поскольку это конъюнкция двух выражений, pattern_search пытается разрешить каждую
подцель отдельно. Это требует не только согласованности обеих подцелей, ио и
непротиворечивости связывания всех переменных. Подстановка 8 вместо Z дает возможность
согласовать обе подцели.
Другой запрос может состоять в том, чтобы найти все клетки, которые могут быть
достигнуты из клетки 2 за два хода. Это достигается вызовом pattern_search для
цели ра!л2(2, У). Используя подобный процесс, можно найти все возможные
подстановки, включая {6/У) и{2/У} (с промежуточным значением Z. равным 7), а также {2/У)
и {4/У) (с промежуточным значением 9). Дальнейшие запросы могут состоять в том,
чтобы найти путь за два хода из клетки с некоторым номером в ту же самую клетку, из любой
клетки в клетку 5 и так далее. Обратите внимание на одно из преимуществ поиска по
образцу: в качестве начальной цели могут быть взяты самые разнообразные запросы.
Аналогично путь с тремя ходами проходит через две промежуточные клетки, которые
являются частью пути от начального состояния к цели. Такой путь может быть
определен следующим образом.
VX, у[ра№3(Х, У) <-3Z, LV[more(X, Z) л moi<e(Z, W) л move{W.Y)]).
Используя это определение, можно рассматривать такие задачи, как ратЗ(1,2),
Ра№3( 1 ,Х) или даже раГлЗ(Х, У). Эти задачи мы оставляем читателю в качестве
упражнений.
Очевидно, что аналогичным способом можно решать задачи нахождения пути
произвольной длины. Просто необходимо указать соответствующее количество
промежуточных мест "приземления". Также очевидно, что путь большей длины может быть
определен в терминах пути меньшей длины.
VX, У[ра(лЗ(Х, У) <- 3Z [move(X, Z) л path2(Z, У)]].
Это дает возможность получить общее рекурсивное правило.
V X, У [раЩХ, У) <- 3Z [more(X, Z) л parn(Z, У)]]-
Последнее правило можно использовать для проверки существования пути
произвольной длины. Такая задача может быть сформулирована следующим образом. Найти
Глава 5. Управление поиском и его реализация в пространстве
193
„ -.том чод из начальной клетки в промежуточ-
другую делая при j^
Это рекурсивное пРав11Л0 "^" "„ёш попытка определить путь к цели, использу,
ловис выхода из PcWJj™- потому что каждая попытка иайти промежуточный
предикат р.№ будет безусп« J вшову ра№(2, Y). Это объясняется тем, Что
пул,, снова будет пртоДИ^креВД состояи„я. Этот недостаток „ожег быть
„е определено услов,едоотнжен]ера(/)(х ^ Поскольку ра№(х Х)
„справлен, если к баззнай,,м тип ^,3,3) или ра№(5,5). то оио определяет „е.
^ГуГоГГзавершення рекурсии. Тотда обидее рекурсивное определение пути
задается двумя формулами исчисления предикатов.
V хГУ [pat/XX, У) <- 3 2 lmove(X, Z) л ра№. У)]].
Еще раз обратите внимание на элегантность и простоту рекурсивной формулировки.
Если объединить приведенные выше условия с рекурсивной процедурой pat-
tern_search, то эти правила позволяют найти всевозможные пути в задаче хода
конем. Объединяя их с правилами перемещения коня, получим полное описание задачи
(или базы знаний).
more(1,8) move(1.6) more(2, 9) move(2, 7)
more(3,4) more(3,8) move(i, 9) mowj(4, 3)
п?оке(6. 1) moire(6, 7) move(7, 2) move(7, 6)
move(8,3) moire(8,1) mo«!(9, 2) move(9, 4)
VXpatft(X, X)
VX, Y[path(X, У) <-3 Z [more(X, Z) л pafn(Z, Y)]].
Следует заметить, что при решении задачи использовались логические описания,
определяющие пространство состояний, и процедура pattem_search поиска в этом
пространстве. Хотя правило path достаточно удовлетворительно определяет путь, оио не
указывает, как найти этот путь. Действительно, на шахматной доске существует много других
путей, которые не ведут к цели, но, тем не менее, удовлетворяют этому определению.
Например, если не принимать во внимание механизм предотвращения зацишшвания, то поиск
целира(п(1,3) может привести к зацикливанию между клетками 1 и 8. вместо
нахождения правильного пути 1->8->3. Таким образом, логическими следствиями базы знаний
являются и цикл, и правильный (допустимый) путь. Аналогично, если рекурсивное
правило будет проверяться перед условием выхода из рекурсии, то условие выхода из
рекурсии рагп(З.З) будет проигнорировано, и поиск продолжится безо всякого смысла.
5.2.2. Усовершенствование алгоритма поиска по образцу
алтп01,™КаЧги,ЬНаЯ "ePCM ФуНКЦИИ Pa"em_search определяет правильное поведение
Гиеко™ZT "" Ш"жик" "счисления предикатов, все же стоит обратить внимай"»
корпев „„ Г™" °НИ ВЮ,К>ЧаЮТ ТОрЯДОК Р^мотрения альтернативных варианте» »
^иТеГрS Г Г"0™ На6°ра "°™— °™Р«°Р°° (а- v и -)■ Логика по с»«
Для ремизами» ™ УказЬ1ю" решателю, как вьщелить из него полезные.
1»-СГ5Гсрсдствами исчисления "радикатав иео6ходИМ Т
' 0РЬ'И °ЧВДствляет систематический поиск в пространстве, и «f
Часть II. Искусственный интеллект как представление и по**
зтом позволяет избежать тупиковых „утей и зацикливания. Алгоритм управления типа
pattem_search должен пытаться найти альтернативные пути в некоторой
последовательности. Знание этой последовательности позволяет разработчику программы
управлять поиском, должным образом систематизируя правила в базе знаний. Самый
простой способ определения такой последовательности - потребовать, чтобы алгоритм
проверял правила и факты в том порядке, в котором они встречаются в базе знаний
В задаче хода конем это гарантирует, что условие выхода из рекурсии path(X, X) будет
рассматриваться перед следующим рекурсивным шагом.
Другая проблема заключается в наличии логических связок в предпосылках правил,
например, в импликациях вида: р^ялг или p<-qA(rvs). Оператор л означает, что
результат будет истиной, если выражения q и г тоже истинны. Кроме того, конъюнкты в
выражениях должны разрешаться с помощью согласованных значений переменных. Так,
чтобы найти значение выражения р(Х)лд(Х), не достаточно разрешить р(Х) и q{X).
используя подстановку {а/Х} и {Ь/Х}. Оба конъюнкта должны быть разрешены с помощью
одного и того же соответствующего значения переменной X. С другой стороны, оператор
v (или) обеспечивает истинность для всего выражения, если хотя бы одна из его частей
является истиной. Алгоритм поиска должен принимать это во внимание.
Последнее дополнение к рассмотренному алгоритму — это его способность находить
цель, используя логическое отрицание ~>. Функция pattem_search обрабатывает
инвертированные цели, разрешая вначале операнд отрицания -». Если эта подцель
достижима, то процедура pattern_search возвращает FAIL. Если же эта цель
недостижима, то pattern^search возвращает пустое множество подстановок, указывающих на
успех. Обратите внимание на то, что даже если подцель содержит переменные, то
результат разрешения ее отрицания не может содержать никаких подстановок. Это связано
с тем, что отрицание —i принимает значение "истина", только если его операнд не
удовлетворяется. Следовательно, операция отрицания не может возвращать никаких
значений связывания для этого операнда.
Наконец, алгоритм должен возвращать не значение SUCCESS, а те значения связывания,
которые использовались при решении Например, для нахождения пути move( 1, X)
существенной частью решения являются подстановки {6/Х} и {8/Х}.
Окончательная версия функции pattern_search, возвращающая множество
унификаций, удовлетворяющих каждой подцели, имеет следующий вид.
function pattern_search(current_goal) ;
begin
if current_goal содержится в closed %проверка на зацикливание
then return FAIL
else добавить current_goal в список closed;
while остаются унифицирующие факты или правила do
begin
case
current_goal унифицируется с фактом:
return унифицирующие подстановки;
current_goal инвертирована (-■ р) ■'
begin
вызвать pattern_search для р;
if pattern^search возвращает FAIL
ава 5. Управление поиском и его реализация в пространстве состояний
195
^
^отрицание истинно
then return О;
else return FAIL.
end; , ) :
я1 _ это конъюнкция (p л ...
current_goal эт
Ь£?гПка»0ГО кои^н-а do
begin „,„,~ search ДЛЯ конъюнкта;
=f^terSScno3Bpa,aeTrML
Tsl n^eHHTf подстановки к «руги- конъюнктам;
end; . ип„воашает SUCCESS ДЛЯ всех конъюнктов
else return FAIL;
end;
current_goal - это дизъюнкция (P v . . .) :
"repeat for каждого дизъюнкта
*2£«ь pattern_search для диз-к
until больше нет дизъюнктов или ^CESS,
if pattern_search возвращает SUCCESS
then return подстановки
else return FAIL;
end;
current_goal унифицируется с заключением (р in p<-q) :
Ьпри2енить подстановки унификации цели к предпосылке (q) ;
вызвать pattern_search для предпосылки;
if pattera_search возвращает SUCCESS
then return объединение подстановок р и q
else return FAIL;
end; „~
ead: %окончаиие оператора case
end «окончание цикла while
return FAIL
end.
Этот алгоритм поиска в пространстве правил исчисления предикатов и фактов
жен в основу языка PROLOG (в котором используется хорновская форма предик ■
см. подраздел 12.3) и многих оболочек экспертных систем, работающих от
(см. часть VI). Альтернативный принцип управления поиском по образцу обеспечи
продукционные системы, которые будут рассмотрены в следующем разделе.
5.3. Продукционные системы ^^________—
5.3.1. Определение и история развития
Продукционная система (production system) — это модель вычислений, игТа^
особо важную роль в задачах искусственного интеллекта как для создания алгор^
Часть II. Искусственный интеллект как представление и п
поиска, так и для моделирования решения задач человеком. Продукционна» система
обеспечивает управление процессом решения задачи по образцу и состоит из набора
продукционных правил (production rule), рабочей памяти (working memory) и цикла
управления распознавание-действие".
ОПРЕДЕЛЕНИЕ
ПРОДУКЦИОННАЯ СИСТЕМА
Продукционную систему можно определить на основе следующих категорий.
{.Набор продукционных правил. Их часто просто называют продукциями
{productions). Продукция — это пара "условие-действие", которая определяет одну
порцию знаний, необходимых для решения задачи. Условная часть правила — это
образец (шаблон), который определяет, когда это правило может быть применено
для решения какого-либо этапа задачи. Часть действия определяет
соответствующий шаг в решении задачи.
2. Рабочая память (working memory) содержит описание текущего состояния
мира в процессе рассуждений. Это описание является образцом, который
сопоставляется с условной частью продукции с целью выбора соответствующих действий
при решении задачи. Если условие некоторого правила соответствует
содержимому рабочей памяти, то может выполняться действие, связанное с этим
условием. Действия продукционных правил предназначены для изменения содержания
рабочей памяти.
3. Цикл "распознавание-действие". Управляющая структура продукционной
системы проста: рабочая память инициализируется начальным описанием задачи.
Текущее состояние решения задачи представляется набором образцов в рабочей
памяти. Эти образцы сопоставляются с условиями продукционных правил; что
порождает подмножество правил вывода, называемое конфликтным
множеством (conflict set). Условия этих правил согласованы с образцами в рабочей
памяти. Продукции, содержащиеся в конфликтном множестве, называют
допустимыми. Выбирается и активизируется одна из продукций конфликтного
множества {разрешение конфликта). Активизация правила означает выполнение его
действия. При этом изменяется содержание рабочей памяти. После того как
выбранное правило сработало, цикл управления повторяется для
модифицированной рабочей памяти. Процесс заканчивается, если содержимое рабочей памяти
не соответствует никаким условиям.
В процессе разрешения конфликтов (conflict resolution) выбирается для выполнения
правило из конфликтного множества. Стратегии разрешения конфликтов могут быть
достаточно простыми, например, выбор первого правила, условие которого
соответствует состоянию мира. Можно для такого выбора использовать сложную эвристику.
Следует подчеркнуть, что продукционная система допускает использование
дополнительных эвристик для управления алгоритмом поиска.
Чистая продукционная модель не имеет никакого механизма выхода нз тупиковых
состояний в процессе поиска; она просто продолжает работать до тех пор, пока не
будут исчерпаны все допустимые продукции. Многие практические реализации
продукционных систем содержат механизмы возврата в предыдущее состояние
рабочей памяти.
Глава 5. Управление поиском и его реализация в пространстве состояний 197
„подстав»»™ на р»с. 5.3.
Схсм»,.родУК""»""»"!"С;,""1ук,,„„„но« систем,, представлен на рие. 5,4. д
ПР„сго,1 щн-мер I-"•« ^Л^оку. состоящую '» ««»»«»» «. Ь .. с в „£ *•
продукционная си^ма^-VW осл„ ее условие еоогветствуст части строк,, ,*"
,^,ф«»»«""ят,° , „ранила подстрока, которая соотпетс,„овала с,„ Р '
»„»,эп«С11«««^к'^'жег быть запрограммирована для выполнения каад
модель вычислен,,,, копр ностоящсс Сс предназначение - это реализация „,,
либо задачи „а компьютер".- „,-
тсллсктуальвыхсст»". компьютерных вычислении, основ„,„1ад
.. В"СР:1Гвр» W ,.«я1,ась в [PI*. 1943). В этоП работ, модель „р„дук,(„0
"Тая л ГдлТжепо в качестве формальной теории вычислении. Основа ,гой тао.
Г Рн1 прГвил вывода для еттхзк. во многом аналогичны,! правилам сиитлкс,™.
скогГаИ „з примера 3.3.6. Эта теория также тесно связана с алгоритмами Марко»
Mai" 1954] „ подобно „м эквивалентна машине Тьюринга.
Интересное приложение продукционных правил к моделированию человеческого
мышления описано в работах Нюэлла и Саймона из технологического институт.
Carnegie Institute of Technology (теперь - Carnegie Mellon University) в 1960-1970-х
годах. Программы, которые они разработали, включая Универсальный решатель задач
(General Problem Solver), послужили важным приложением продукционных систем в
искусственном интеллекте. Авторы исследовали человеческое мышление в процессе
решения различных задач, таких как задачи по логике предикатов или игре в шахматы.
Были составлены н разобраны на элементарные компоненты протоколы (образцы
поведения, включая словесные описания процесса решения задачи, движения глаз и т.д.)
решения различных задач. Эти компоненты рассматривались как основные биты
знания о методах решения задач человеком, для которых был реализован поиск на графе
(так называемом графе поведения задачи). Для осуществления поиска в этом графе
использовалась продукционная система.
Продукционные правила представляли множество навыков человека при решении
задач. Текущий фокус внимания был описан как текущее состояние мира. При работе
продукционной системы "внимание" (или "текущий фокус") решателя задачи
сопоставляется с продукционным правилом, которое изменяет состояние "внимания" и
приводит его к соответствию с другим продукционным правилом (представляющим
некоторый навык), н так далее.
Следует заметить, что в работе Ныоэлла и Саймона продукционная система
использовалась не только для реализации поиска на графе, но и для представления модели че-
Г ПГ"'™ "Р" РСШСНИ" задач"- Продукции соответствуют навыкам рМК-
ZZlltT0'1'0''''0'' '"""""" ЧеЯмека- ^бно навыкам в долгосрочной „»"«»
данное Ген!":'"Т"™ Ч» работе системы. Они „ызываются по "образцу" »
шег, fe* Г ПР°бЛШЫ' « Н08ые ''»««» мо,у, быть добавлены к суп.ест»У»9
системы сСтае ™1,С00ТВеТСТВуЮ1ЦСЙ ттн»ы ™™™. Рабочая память „родукн"°«»°«
». « описывает tckvIT"'™4™4''0'' "ш,я" ,ли ««У™* области внимания челок
Решения задач,, не сохраняем1"0 РеШСНИЯ задачн' Содержание рабочей памяти в
lUger, ST"™ °""Са"ы а и-ишх [Newell и Simon, 1972] и ILug*. ^
Шаблон
рабочей
памяти
С1-А1
С2-»А2
С3-*АЗ
Шаблон-*Д8йствио
Сл-»Ал
Рис. 5..?. Продукционная система. Цикл
выполняется до тех пар, пока образец рабочей памяти не
будет более соответствовать ни одному из
условий продукционных правил
Набор продукций:
1. Ьа -* а£>
2. еа -*■ ас
3. cb -» be
Конфликтное Применение
Итерация tt Рабочая память множество правила
0
1
2
3
4
5
6
cbaca
саЬса
acbca
acbac
acabc
аасЬс
ааЬсс
1.2,3
2
2,3
'.3
2
3
О
1
2
2
1
2
3
Останов
Рис. 5.4. Работа простой продукционной системы
Ныоэлл, Саймон и другие исследователи использовали продукционные правила для
моделирования различия между новичками и экспертами ((Larkin и др., 1980]. [Simon и
Simon, 1978]) в таких областях, как решение алгебраических и физических задач.
Продукционные системы также составляют основу для изучения человеческого и
компьютерного обучения [Klahr и др.. 1987]. На этой традиции построены системы ACT*
[Anderson, 19836] и SOAR [Newell, 1990].
Продукционные системы обеспечивают модель представления человеческого
опыта в форме правил и позволяют разрабатывать алгоритмы поиска по образцу —
центральный элемент основанных на правилах экспертных систем. В экспертных
системах продукционные модели не обязательно являются точной реализацией
человеческого подхода к решению задачи. Однако существуют такие аспекты
продукционных систем, которые делают их полезными в качестве потенциальной модели
Глава 5. Управление поиском и его реализация в пространстве состояний 199
.„ость правил, разделение знания „ управ„ени
решения зал- человеком («о^- решении задач,. Это служит „деальнь-,
^результате исследован ипр°ДУважное семейство языков для с„стем „
,„ (Carnegie Mellon ""'^tIk называемые OPS-язъш, официальны* продущт
интеллекта. Зто за» _^ v„t« сначала они предназначались дл, Мо
лон (Carnegie Mellon Universну; . называемые 0PS.„b
„усственного интеллекта л у Хотя сначала и™ .т-»«п.™1и[ь д
/„ систем (Official Product,»"^ У ^ ю задаЧ| эти языкн оказались ^
делирования «ловеческого^од Д экспертиь1х снстем и других приложений ис.
эффективными для программнро^ ^ реализацин для VAX-конфнгуратора XC0N
«усственного интеллекта, иг анных в Корпорации цифрового оборудован»,,
„№уттэкспертш*с„стыЦ mottmum2], [Soloway „ др., 1987)
(Digital Equipment Corpora; ^ остранены OPS-интерпретаторы для „ер.
кусственного 1
н других экспек...— --- - [McDermou, ivoi, i^-j. i- л - др., i
(Digital Equipment Corpora; ^ остранены OPS-интерпретаторы для „ер.
[Barker и O'Connor, 1У»у). "^^ станций. Активно используется созданная в НА.
сональных компьютеров и ра пподукцнонной системы CLIPS, реализовав-
СА объектно-ориентированная версия р
НТХюшТм0"мырассмотрим примеры использования продукционных с*
тем для решения разнообразных задач поиска.
5.3.2. Примеры продукционных систем
ПРИМЕР 5.3.1. И снова "8-головоломка'"
Пространство поиска для задачи
'8-головоломка", описанной в главе 3, является дос-
сложным и интересным. В то же время оно настолько мало, что не вызывает
особых трудностей в рассмотрении. '
головоломка" часто используется для изучения
различных стратегий поиска, например, поиска в глубину и в ширину, а также
эвристических стратегий (см. главу 4). Здесь мы рассмотрим продукционную систему.
Не уменьшая общности, будем говорить о "перемещении пустой клетки"J^™^
[ЫВ«
хода,
можно создать
ремешения пронумерованной фишки. Допустимые ходы определены продукциями,
занными на рнс. 5.5. Естественно, если пустая клетка находится в центре, Л°"Утшы^
четыре хода. Если пустая клетка находится в одном из углов, возможны только д
Если начальное и целевое состояние для "8-головоломки" определены, то i
продукционную систему, просматривающую пространство поиска задачи. ^
В реализации решения этой задачи каждую конфигурацию иа нгрово
можно представить с помощью предиката состояния с девятью параметрам
девяти возможных положений восьми фишек и пустой клетки). Правила
представить как импликации, предпосылки которых обеспечивают проверку и
димых условий. С другой стороны, для описания состояния игровой доски
использовать массивы или списки.
дань"1
Пример решения этой задачи на основе поиска в пространстве состояний, опис^
в [Nilsson, 1980], проиллюстрирован на рнс. 5.5 и 5.6. Поскольку путь к решению
находиться очень глубоко, если его не направлять, поиск был ограничен пределы .
бииои. Простои прием для реализации предельной глубины поиска — следить за *
текущего пути, и в случае превышения предельной длины отслеживать путь в о р
направлении, т.е. запускать механизм поиска с возвратом. На рис. 5.6 предельная ^
на поиска равна 5. Заметим, что число возможных состояний рабочей памяти Р^
поненциально с увеличением глубины поиска
200
Часть II. Искусственный интеллект как представление
Начальное
состояние
Продукционное множество
Целевое
состояние к
целевое состояние в рабочей памяти - останов
™™ Г"-"" "" ВМ"е "МОЙ гран"иы * переместил, пустую ячейку влево
пустая ячейка не возле верхней границы - переместить пустую ячейку вверх
пустая ячейка не возле правой границы - переместить пустую ячейку вправо
пустая ячейка не возле нижней границы - переместить пустую ячейку вниз
Рабочая память содержит текущее и целевое состояние игровой доски.
Режим управления
1. Испытать каждое правило по порядку.
2. Не допускать циклов.
3. Завершить работу при нахождении цели.
Рис. 5.5. "8-головоломка " как продукционная система
„■■ ,. л,,и,шып продукционной системы, в
Рис. 5.6. Решение задачи -»л..яш«» с ла.гач<.« "Г
которой поиск ограничен гпбиной 5 IMsson. 1Ш11
Глава 5. Управление поиском и его реализации в пространстве состояний 201
ПРИМЕР 5.3.2. Задача \ ^ ^ представленная в разделе 5.2, может быть
Задача хода конем на доске РазмеР м g этом случае каждый ход можно предста-
пешена с помошью "P°WKU1<OHH"XTODOro списывают расположение коня в конкретной
вить как правило, предпосылкиiw ^ ^^ Все возможнь,е ходы коня опись,-
клетке, а действие «Р»*™ „„„„ионных правил.
ваются с помошью шестнадцати пр т ^ ^^ состояни(, доски. в режиме упрща_
Рабочая память содержит и тс > ^ 1екущее состояние не уравняется с целевым.
ния правила применяются до тех п р. _ ^^ разрешення ко„фЛиктов запускается
Тогда процесс останавливаета_ ^ Зациклнвания поиска. Поиск может привести к
первое же правило, которое не ^^ возможное перемещение приводит в уже по-
тупиковым состояниям, из кот°Рльно вь13ьшает зацикливание. Поэтому режим уггравле-
сешенное состояние и. следоват • . продукционной системы прн определе-
ss^^^'^24 *"■
Действие
Условие "
№ правила х поле g
, Конь в поле 1 -> ~ А
,г ™ 1 _^ Ход конем в поле 6
7 Конь в поле 1 -» 2 ■ п
„ ,,,. ■> _> Ход конем в поле 9
ч Конь в поле L -» w"
,^ Q ч _* Ход конем в поле 7
i Конь в поле 2 —> л "
„ „„„ 1 _> Ход конем в поле 4
<; Конь в поле J —> л
6 Конь в полеЗ^ Ход конем в поле 8
7 Конь в поле 4-> Ход конем в поле 9
8 Конь в поле 4^ Ход конем в поле 3
9 Конь в поле 6-* Ход конем в поле 1
Ш Конь в поле 6-> Ход конем в поле 7
И Конь в поле 7^ Ход конем в поле 2
12 Конь в поле 7^ Ход конем в поле 6
13 Конь в поле 8^ Ход конем в поле 3
14 Конь в поле 8^ Ход конем в поле 1
15 Конь в поле 9^ Ход конем в поле 2
16 Конь в поле 9-* Ход конем в поле 4
Интересно заметить, что реализация предиката пути path в задаче хода конем^ ^
дела5.2 фактически обеспечивает построение продукционной системы. С эт КН
зрения pattern_search— это просто интерпретатор, а реальный поиск фа ^
осуществляется с помощью предиката path. Продукционные правила эт ф
ремешений move, первый параметр которых определяет условие (на доске до ^
достаточно места, чтобы сделать ход), а второй — действие (поле, в которое к
перейти). Цикл "распознавание-действие" (recognize-act) реализуется с помошь V ^
сивного предиката пути path. Рабочая память содержит текущее и желаемое цел ^
стояние. Ее можно представить параметрами предиката пути path. На данной i сдС
конфликтное множество — это все выражения перемещений, которые УниФииИр^фЛ„к.
целью more(X.Z). Эта программа использует простую стратегию разрешения к0 ИЙ1
тов, состоящую в выборе и активизации первого предиката перемещения в базе • ^ ^
который не ведет к повторному состоянию. Контроллер также осуществляет возвр
Часть II. Искусственный интеллект как
представление
и пои»
предиката path для продукциош
Таблица 5.1. ^^^о'^о^тома^р^^^^^^
№ итерации Рабочая память
Текущее поле Целевое поле
конем на поле 3x3
Конфликтное
множество
ле (№ правила)
1.2
13.14
5,6
7,8
15.16
Активизация
правила
13
5
7
15
Выход
Рекурсивный вызов path[X, Y) приводит
к выполнению очередной итерации
Попытка унификации рабочей
памяти с использованием
вызова раЩХ, Y)
Сравнение move(XZ)
с продукциями
Рабочая память
раЩХ.У)
В рабочей памяти присвоитьХ
значение Z (т.е. вызвать parn(Z, У))
Продукции
move( 1,8)
move( 1,6)
move(2,7)
move{2,9)
mo ve (9,2)
Разрешение конфликтов:
сначала
выполняйте сравнения,
I не приводящие к циклам J
Рис. 5.7. Рекурсивный алгоритм вычисления пути в продукционной системе
Продукционные системы могут порождать бесконечные циклы при поиске на графе
пространства состояний. Эти циклы особенно трудно определить в продукционной системе,
потому что правила могут активизироваться в любом порядке. Следовательно, зашшлнвание
может появиться при работе системы, но его не легко обнаружить путем проверки синтаксиса
набора правил. Например, при использовании порядка следования правил move в задаче хода
конем, описанного в разделе 5.2. и стратегий разрешения конфликтов путем выбора первого
соответствующего правила образец move(2,X) будет соответствовать факту ™ve<2.9).
Указывая на перемещение в поле 9. На следующей итерации образец /потеО.Х) 6>дет
сопоставлен с move(9,2). Алгоритм снова вернется в поле 2. обРаз>я цикл.
Глава 5. Управление поиском и его реализация в пространстве
203
„™ть зацикливание, функция pattern^search проверяла гло6ал1,
Чтобы предотвратитьОСТОя„ий closed. Стратегия разрешения конф„Иктов СИГ
„ый список 2С™СТьгб.фалоеь первое соотвегетвующее перемещение, которое веое^
ещепе "oc™'c""°"s°""«"«nHeoK уже обследованных состояний closed „е являете»
В продукционнаэй ™™ „епосредственно в рабочей памяти. Предикат rZ
™™оХйф"ГроВат' т,ким образом, чтобы использовать рабочую „амя1ь £
°бНЕПоложиГ™ функция pattern_search не поддерживает глобальный список
closed и не выполняет проверку на наличие циклов. Предположим также что язык ис.
числения предикатов расширен специальной конструкцией eM.rt(X) (добавить угвСр.
Гение в базу знаний), которая заносит в рабочую память свои параметр X. Конструкция
assert - не обычный предикат, а выполняемое действие, следовательно, assert всегда
завершается успешно.
Предикат assert используется для помещения в рабочую память маркера",
указывающего на проверенное состояние. Этот маркер представляется унарным предикатом
Ьеел(Х), параметром которого является поле игровой доски. Маркер Ьеел(Х)
добавляется к рабочей памяти после посещения нового состояния X. Для разрешения
конфликтов можно потребовать, чтобы при реализации правила moi/e(X,Z) в рабочей памяти
отсутствовал маркер been(Z). Для конкретного значения Z это можно проверить,
сопоставив образец с содержимым рабочей памяти.
Модифицированное рекурсивное определение пути выглядит так.
VXpatfi(X,X)
VX,ypatr)(X,y)<-3Zmoire(X, Z) A-,(been(Z)) л assert(been(Z)) л patti(Z,V).
В этом определении move(X,Z) успешно выполнится при первом совпадении с
предикатом move. При этом переменная Z станет связанной. Если предикат been[Z)
соответствует элементу рабочей памяти, то -. (been(Z)) принимает значение
"ложь". Тогда функция patem_search возвращается и ищет другое соответствие
для move(X,Z). Если клетка Z является новым состоянием, то поиск продолжается,
a been(Z) добавляется в рабочую память для предотвращения дальнейших
зацикливаний. Реальная активизация продукционного правила происходит на следующем
шаге рекурсии. Таким образом, наличие предикатов been в рабочей памяти
обеспечивает обнаружение зацикливаний в продукционной системе.
заметим, что исчисление предикатов используется как язык описания продукционных
правил и элементов рабочей памяти. Процедурная сущность продукционных систем тре-
поГ.'„Г,ш Ue"" " опр1:дслен»и предиката path были исследованы слева направо. Этот
порядок интерпретации обеспечивается функцией patern.search.
ПРИМЕР 5.3.3. Полная задача хода конем
мероГвхГпоТГ Х°Да К0Н№ М0ЖН° °Шщ™ «" ™ли°й шахма™'' Д°СК" лче'
замшим uZZбогГ "Т СМЫСМ "*"еР<»«ь ходы в такой сложной ***
«*» (ироду™, „Г*!" Ш 8 ПраВШ' ™ерирУющих допустимые ходы конем. Э
(см.рИе.5лГ СООТВ"с™У°т 8 возможным вариантам перемещения «<"'
"wZl^pLTo?0"' " СТШ'6ЦЬ' шахмэт'™« доски, то можно сформулиро*"'
Хода конем: вниз на две клетки и вправо на одну.
Часть II. Искусственный интеллект как представление и п<*
УпС^т^СиГГвП' Г™-6 л current с°'™«7
ДЕЙСТВИЕ: леи, row = current rOW ♦ 2 л new column = cumm
Если для представления продукций использовать исчисление предикатов то игровую
Д0ску можно определить предикатом saoare(R,C> („ли кеаорат^С» где В -^Г
с_ столбец шахматной доски. Приведенное выше правило может быть записаноТис
числении предикатов следующим образом.
moi/e(sauare(flow, Column). square(Newrow, Newcolumn)) ^
less_than_or_equals(Row, 6) л
equals{Newrow, plus(Row, 2)) л
less_than_or_equals(Column, 7) л
equals[Newcolumn, plus{Column, 1))
Здесь plus (плюс) — функция сложения, /ess_rrian_or_eo;ua/s (меньше или равно) и
equals (равно) тоже имеют очевидную арифметическую интерпретацию. Это правило
можно дополнить, написав еще семь правил для определения оставшихся допустимых
ходов. Эти правила заменяют факты move в версии задачи 3x3.
Функция patri (путь) в примере 3x3 определяет цикл управления в этой задаче. Как
мы уже видели, при процедурной интерпретации описаний в исчислении предикатов,
например с помощью алгоритма pattern ^search, семантика исчисления предикатов слегка
изменяется. Одно из таких изменений — это последовательность разрешения целей. При
этом к выражениям исчисления предикатов добавляется процедурная семантика (или
упорядочение). Еще один пример изменений — введение таких металогических
предикатов, как assert (утверждать), которые указывают на действия вне интерпретации
значений истинности для выражений исчисления предикатов. Эти проблемы более детально
обсуждаются при рассмотрении языка PROLOG в главе 14, а также при описании
реализации механизма логического программирования в LISP в главе 15.
ПРИМЕР 5.3.4. Финансовый советник как продукционная система
Во второй и третьей главе мы разработали модель небольшой системы "финансового
советника". Для представления знаний о финансовом состоянии вкладчика было
использовано исчисление предикатов, а для определения наилучшего способа вложения денег
применялся поиск на графе. Продукционная система является естественным средством
для реализации такой модели. Импликации логических описаний составляют
продукционные правила. Вся конкретная информация, в том числе зарплата клиента, число
иждивенцев и т.п., помещается в рабочую (оперативную) память. Правила начинают
функционировать, как только удовлетворяются их предпосылки. Из противоречивой
совокупности правил выбирается некоторое правило. Оно выполняется, а его заключение
добавляется в рабочую память. Это продолжается до тех пор, пока в рабочую память не
будут добавлены все возможные заключения верхнего уровня. Действительно, многие
оболочки экспертных систем являются продукционными системами с поддержкой
дополнительных возможностей. Среди них: интерфейс пользователя, поддержка
рассуждений с неопределенностью, редактирование базы знаний и контроль выполнения понска.
S.3.3. Управление поиском в продукционных системах
Модели продукционных систем предоставляют *°n°™^™Z°™™™ZZ
бавлению эвристического управления к алгоритму поиска. Эти дополнительные удобства
Глава 5. Управление поиском и его реализация в пространстве
205
« -тоатегни (на основе данных или от цели,, выбор самой струк-^,
Г^Г^кш»-. конфликтов.
вил
у „явление посредством выбор» стратегии поиски: « основе данных Илн от
Управление у „-„.„мстся с описания задачи (например, в виде набг>„
' "ТГвать см »э имеющихся данных выводятся новые знания. Это осущ,,^
1ем п м не ■« правил вывода, например, допустимых ходов в игре „ли друтих 0,к"
„шин е ер,ФУюшпх новые состояния в текущем описании мира. „ добавлена роул,
Zb к о"— рассматриваемой задами. Этот процесс продолжается до тех пор, пока
не будет достигнуто целевое состояние.
Такое представление рассуждении на основе данных подчеркивает их соответствие
модели продукционной системы. -'Текущее состояние мира" (это исходные данные, которые
приняты как и^на или выведены как истина с помощью правил вывода) помещается в ра-
бочую память Затем в цикле "распознавание-действие" текущее состояние сравнивается с
(упорядоченным) набором продукций. Если эти данные соответствуют условиям одного из
правил вывода (унифицируются с ними), применение этого правила добавляет новую
порцию информации к текущему состоянию мира (изменяя рабочую память).
Все продукционные правила имеют форму CONDITION —> ACTION (условие-»
действие). Если условие CONDITION соответствует некоторым элементам рабочей
памяти, выполняется действие ACTION. Если продукционные правила
сформулированы как логические импликации и действие ACTION добавляет утверждения в
рабочую память, то активизация правила соответствует применению модус поненс. При
этом на графе создается новое состояние.
На рис. 5.8 представлен простой пример поиска на основе данных для набора
продукционных правил, записанных в виде импликаций исчисления высказывания.
Стратегия разрешения конфликтов — это простая стратегия выбора допустимого
правила, которое сработало раньше всего (или совсем не активизировалось). Поиск
прекращается, когда цель достигнута. Кроме того, на рисунке также представлены
порядок активизации правил и состояния рабочей памяти в процессе выполнения, а
также граф пространства поиска.
До сих пор мы рассматривали функционирование продукционных систем на основе
данных. Однако существуют продукционные системы, осуществляющие поиск от цели-
В главе 3 говорилось о том, что поиск от цели начинается с цели и возвращается назад к
фактам, соответствующим данной цели. Чтобы реализовать это в продукционной
системе, цель помещается в рабочую память, а затем проверяется ее соответствие дсйя»»»
ACTION правил вывода. Проверка с00тветствия деПствшш вьшолняется точно так *jj
Z2L Ж М °СН0Ве ЯаННЫХ "Р^Ряется выполнение условий CONDITIO»
ИСТ/oZo "ТШШ *Н"Ф'«<™«)- Все продукционные правила, заключен.»
После: ппове™ С°0ТВетств^т *=™. Формируют конфликтное множество.
в раСг:г ф0°ггвия яе''ствий act'on нх" conoition до6
Затем проверяете? оТ ""^ П°ЯЦ<:Л" (ШШ »™»»») ™иска.
продукцией^ рав ш эГ™" Н0ВЫХ С°СТ0ЯШ,Й ^—ениям ACTION ост^
Факт, содержащий', ВН^Г Пр°ЦеСС "Р^^ется Д° «х пор, пока ие будет -
системах, факГ™ п«мд °" °П"Сани" зада™. ™«- как часто бывает в экспер™.
«ой информашш. Поиск „г,"611"0 пол>ченИ1'1» путем запроса у пользователя в'0 с.
"Ск "РекРа^«ся, когда условия всех продукционных "PaB""'
Часть II. Искусственный интеллект как представление и
пользованных (активизированных) в процессе
п цепочка правил, ведущих к исходной ,„.„„ „ "00°™' окяжУк* истинными. Эти условия
цели, составляют доказательство се истинности.
Продукционное множество: Послало.™
1.рло-щель '°<=лед°еательность выполнения:
2. ГЛ5-ф ' ■
3. wAr-»g
4.1ли->р
5. v->s
6. начало-^улглд
Просмотренная часть пространства:
начало
направление
поиска
V
Рис. 5.8. Поиск на основе данных в продукционной системе
На рис. 5.9 дан пример рассуждений от цели на том же наборе продукционных правил,
который показан на рис. 5.8. Заметим, что в процессе поиска от цели активизируется
совсем другая последовательность продукционных правил и исследуется не то
пространство, что в версии поиска на основе данных.
Как следует из вышеописанных примеров, продукционная система обеспечивает
естественную реализацию поиска от цели и на основе данных. Продукционные
правила — это закодированный набор правил вывода (знаний в экспертной системе,
основанной на правилах) для изменения состояния внутри графа. Если текущее
состояние мира (набор истинных утверждений, описывающих мир) соответствует
условиям CONDITION продукционного правила, то действие ACTION этого правила
определяет новое (истинное) описание существующего мира. Этот процесс
рассматривается как поиск отданных.
С другой стороны, если проверяется соответствие цели части ACTION набора
продукционных правил, а затем в качестве подцелей выбираются условия
CONDITION, истинность которых должна быть доказана (путем сопоставления
заключений ACTION в следующем цикле работы продукционной системы), то задача
решается путем поиска от цели.
Поскольку набор правил может активизироваться илн на основе данных или от
пели, можно сравнить эффективность этих подходов. Сложность поиска для обеих
стратегии измеряется таким понятием, как коэффициент ветвлении (branching Jac-
Глава 5. Управление поиском и его реализация в пространстве состояний
207
Л
ости поиска позволяет оценить стоимость
,ог) (раздел 4.4). Этот <^^ ос„овс данных „ли от цели, и выбрать „а„.
обеих версий решения задачи
более эффективную стратегию стратегий. Например, вначале вести по-
6 Можно также использовать «ивнн-ш. ^тр^ ^ ^ состмний не ^
иск в прямом направлении от Д" тт поиска, направив его от цели, „
достаточно большим. Затем и мен, ^ ^^ состоянии. Опасность такого
использовать возможные подцели * WM эвристического, или жадного", ал,
подхода состоит в том что "Р" и части графа могут не совпасть друг с дру.
горитма поиска (глава 4) просмоРный ^^ цт при простом подходе
том. Тогда потребуется болед ^^^ пр0СтраНства не изменяется и ис-
(рис.5.10). Однако если *о'ФФ " 6 ванная стратегия поиска может значи-
...» пипппнвния:
Продукционное
множество:
1. рло-*цель
2.ГЛ5-+Р
3 wAr-n}
4.1 л u-»q
5. v-*s
6. начало-и'Лглд
Последоват
Номер
итерации
0
2
3
4
5
°
Рабочая память
цель
цель, р, Q
цель,р,д,г, s
цель, p,g,r, s, w
цель,р,д,г, s,w, t, и
цель,р,д,г, s, w, f, u, v
цель, p, g, r, s, w, t, u, v, начало
Множество
конфликтов
1
1,2,3,4
1,2,3,4,5
1,2,3,4,5
1,2,3,4,5
1,2,3,4,5,6
1,2,3,4,5,6
Примененное
правило
1
2
3
4
5
6
останов
Просмотренная часть пространства:
цель
направление
поиска
V
Рис. 5.9. Поиск от цели в продукционной системе
208
Часть II. Искусственный интеллект как представление
и попе*
Начало
Цель
Рис. 5.10. Двунаправленный расширенный поиск
Начало
Состояния, проверенные
в процессе прямого поиска
Состояния, проверенные
в процессе обратного поиска
Состояния, проверенные лишь
в процессе прямого поиска
Состояния, проверенные как
в процессе прямого поиска,
так и при поиске в обратном
цель направлении
Рос. .4.11. Двунапрашмнный поиск, опекающий бшьш» ■«•cm- проащншета,. »сае,уг-
Щ'ю при однонаправленном поиске
Глава 5. Управление поиском и его реализация в пространстве
состояний
г поиском с помощью структуры правил
Управление поиском у■""""—^ с||СТСМС, включая различия между условием „
Структура правил в ПР™У условий, определяет метод исследования про-
действием. а™» "££„J, предикатов как язык представления, мы подчерк,1ва.
странетва. Описывая неч сешнтикн. Такнм образом, выражения исчисления
ли декларативный харак Г ИСТ11ННЬ1С отношения в области формулировки за-
предикатов веете> ™^ь °^д й от„0сительно порядка „нтерпрстации их ком-
::;:„;:: ^~ ел». «■ ^°»»°——■»«w <">«><*> *
ТГхГ^тоот) Согласно правилам исчисления предикатов альтернативная ф„рщ
Z же—"„жег быть такой VX (foo(X) -> moo(X, v .0оо(Х),. Эквивалент-
Гость этих двух выражений может быть продемонстрирована с помощью таблицы
истинности (раздел 2.1).
Хотя эти формулировки логически эквивалентны, они не ведут к одинаковым
результатам если интерпретируются как продукции (продукционные правила), потому что
реализация продукционной системы обеспечивает определенный порядок проверки
соответствия и активизации правил. По этой причине форма представления правил
определяется удобством (или возможностями) проверки соответствия правилам в конкретной
задаче. Это является результатом выбора способа интерпретации правил продукционной
системой. Продукционная система налагает на декларативный язык описания правил
процедурную семантику.
Поскольку продукционная система проверяет правила в определенном порядке,
программист может управлять поиском через структуру и порядок следования правил в
продукционном наборе.
Несмогря на то что выражения VX(foo(X) л доо(Х) -> тоо(Х)) и VX (foo(X) ->
тоо(Х) v -,доо(Х)) логически эквивалентны, при реализации поиска они
обрабатываются не одинаково.
Квалифицированные специалисты кодируют наиболее значащие (ключевые)
эвристики, руководствуясь своими профессиональными знаниями. В очередности
предпосылок содержится важная процедурная информация, необходимая для
успешного решения проблемы. Очень важно, чтобы эта формулировка (форма
выражения) сохранялась при написании программы. Например, когда механик говорит:
"Если двигатель не вращается, и фары не горят, проверьте аккумулятор", водителю
предлагается определенная последовательность действий. В логически
эквивалентном предложении "Двигатель вращается или фары горят, иян проверьте
аккумулятор эта информация теряется. Такая формулировка правил не выдерживает
критики, так как при управлении поиском необходимо, чтобы система вела себя логично,
а последовательность активизации правил была понятной.
Управление поиском через разрешение конфликтов
пРеПд™вГтГэвНп1СИСТеМЬ' (КаК " ВСе СИСТемы' ^«ванные на знаниях, позволяют
т^оои, „реХ«К1,7е"0СРеДСТВеНН0 В П"ав,'л^ описывающих знания. Кроме
ко„ф„„™ТСс« ш яп" Т°Д '""'""-««о ™ Управления - через разрешение
вое соответствующее поавГ" l^"""* СВ°ДИТСЯ к ™»У- -™6н выбирать пер-
тов (со„Шс, reLlu,io„7no еНцИиалРка„п°Ч,;Й ""Т"' °ЛНаК0 для Решения конфл" ;
пример, в OPS5 подлетЛ М0ЖеТ бь1ТЬ пР™енена любая стратегия. На
[Вгочушопидр., 198™,Р иваются бедующие стратегии разрешения конфликт"»
210
I- Искусственный интеллект как представление и
1 Z^^srzzzsr—-т —• •
ствующис его условиям. Рефрак™"^™ в'ГГ" """* ™
2. Иовюна (recency). Стратегия новизны отдает предпочтение правилам, условия
которых соответствуют образцам, добавленным в рабочую память последними Z
позволяет сосредоточить поиск на одной линии рассуждения.
3. Специфичность (specify) Согласно этой стратегии целесообразнее использовать
более конкретное, а не более общее правило. Одно правило более специфично
(конкретно) чем другое, если оно содержит больше условий, а значит,
соответствует меньшему количеству образцов в рабочей памяти.
5.3.4. Преимущества продукционных систем для ИИ
Как видно нз предыдущих примеров, продукционная система обеспечивает общую
структуру осуществления поиска. Благодаря ее простоте, модифицируемости и гибкости в
применении знаний для решения задач продукционная система, как оказалось, может быть важным
механизмом для конструирования экспертных систем и других пршюжений НИ. Главные
преимущества продукционных систем искусственного интеллекта описаны ниже
Разделенпе знапня и управления. Продукционная система — изящная модель
разделения знания и управления в компьютерной программе. Управление обеспечивается
циклом "распознание-действие" продукционной системы. При этом знания о методах
решения задач сосредоточены непосредственно в правилах. Преимущество такого
разделения заключается в простоте изменения базы знаний, при котором не требуется
изменять код программы управления. И. наоборот, это позволяет изменять код управляющей
части программы, ие трогая набор правил вывода.
Естественное соответствие поиску в пространстве состояний. Компоненты
продукционной системы естественно отображаются в логическую структуру поиска в пространстве
состояний. Последовательные состояния рабочей памяти составляют вершины графа
пространства состояний. Правила вывода — набор возможных переходов между состояниями.
Разрешение конфликтов обеспечивает выбор перехода (ветви) в пространстве состояний. Эти
правила упрощают выполнение, отладку и документирование алгоритмов поиска.
Модульность продукционных правил. Важный аспект в моделировании
продукционных систем это отсутствие синтаксического взаимодействия между
продукционными правилами. Правила могут только влиять на активизацию других правил, изменяя
образец в рабочей памяти. Правила не могут "вызывать" другие правила непосредственно,
как подпрограммы. При этом они не могут устанавливать значения переменных в других
продукционных правилах. Область действия переменных этих правил ограничена
отдельным правилом Эта синтаксическая независимость способствует инкрементальной
разработке экспертных систем путем последовательного добавления, удаления или
изменения знаний (правил) системы.
Управление иа основе образцов (pattern-directed control). Задачи, решаемые с
помощью программ ИИ требуют особой гибкости при выполнении программы. Это
вызвано еще и тем фактом что правила в продукционной системе могут запускаться в любой
последовательности. Описание задачи, представляющее текущее состояние мира,
определяет конфликтное множество и. следовательно, конкретный путь поиска „ решения.
И„, . „™ .'■•паппРИНЯ ПОИСКОМ. НеСКОЛЬКО МеТОДОВ ЭВрИСТИ-
Возможностн эвристического управления пиичч™ г
ческого управления были описаны в предыдущем разделе.
Глава 5. Управление поиском и его реализация в пространстве
211
.„„..товка Модульность правил и итерационный характер „„ ВЬ1.
Тр.ссировка и тракт ^ g „редакционной системы. На каждой стад„„
„олнения облегчают кои у а1рнвается некоторое правило. Поскольку каждое
цикла "распознание-де. г ни,. (chunk) ЗН1Ш11„ о методах решения задач, со-
правило к»™"-™^* ть ясную интерпретацию текущего состоянии системы и
^Г ГГтГ^почо прав^пеноль^мых в процессе решения, отражает как
СТграГе «к и'"иепочку рассудит,", приводящую к решению задачи человека-
™« В тлаве 7 это будет описано детально. Напротив, единая линия управления ,и,„
процедура, написанная „а традиционном языке программирования, например, Pascal „ли
FORTRAN, фактически бессмысленна.
Независимость от выбора языка. Модель управления продукционной системой не
зависит от представлена правил и рабочей памяти, если это представление поддержива.
ет сравнение с образцами. Мы описали продукционные правила как импликации
исчисления предикатов вида А => В, где истинность А и правило вывода модус поненс
позволяют сделать заключение е. Существует немало преимуществ применения логического
представления знаний и обоснования правил вывода, однако модель продукционной
системы может работать и с другими представлениями.
Исчисление предикатов обеспечивает преимущество логически обоснованного
вывода, однако немало задач требует рассуждений, которые не обоснованы в логическом
смысле. Для иих необходимы вероятностные рассуждения, правила умолчания и
недостоверные свидетельства. В главах 6, 7 и 8 мы обсудим альтернативные правила вывода,
предоставляющие такие возможности. Независимо от типа используемых правил вывода,
продукционная система обеспечивает средства поиска в пространстве состояний.
Правдоподобная модель решения задачи человеком. Среди первых моделей,
использующих продукционные системы, были модели нахождения решения задач человеком
[Newell и Simon, 1972]. Эти системы, главным образом, использовались в качестве модели
человеческой деятельности в различных областях научных исследований (глава 16).
Поиск на основе образцов (pattern-directed search) позволяет исследовать
пространство логического вывода в исчислении предикатов. На этой методике основано немало
задач. В инх исчисление предикатов используется для моделирования таких
специфических аспектов мира, как время и изменения. В следующем разделе представлена
методология "классной доски" как разновидность продукционной системы. В методологии
"классной доски" группы однотипных продукционных правил объединены в источники
знаний, которые участвуют в решении задачи путем общения через глобальную рабочую
память "классной доски".
5.4. Архитектура "классной доски"
™™Д0Л0™ "классиой досм<" (blackboard)- заключительный механизм (алгоритм)
сЗн^'™ДтаШеН"Ьт " ЭТОЙ ГЛаве' Если необходимо исследовать состояния в про-
дГигГ„ьгхсГ^К0Г0,ВЬ'В0ДаНеК01ОрЬ,м Д™Р»<нированным способом, применение про-
^ГвРабТчей гГГ^ГСПечИвает а»™™-"*» "шкость, ПОЗВОляя одновременно предс™-
рГреш»Г1ТГоГм е™° ЧаСТНЫХ реШеНИЙ и Убрать следующее состояние путем
циоГь^Гистем Г»„п Мет°Дология "кла«™й доски" расширяет возможности продук-
ДьШизГт™гоХ™уÄÄà Раб°ЧУЮ "" В"- ОТД™ """"""С
ветствует подмножеству продукционных правил. "Классная доска и"
тегрирует отдельные наборы продукционных ппят™ „ „
1L,> решателей задач в nneni™.„ , "равил и координирует действия
малочисленных решателей задач в пределах единой глобальной стпукттоы
Решение многих задач требует координации ряда^шичных типов знания Па-
пример, программа понимания (распознавания) речи должна сначала обр б„ а и
фрагменты речи, представленные в виде оцифрованной волны. Далее в 'роц
распознавания необходимо выделить в этом речевом фрагменте отдельные "лова
сформировать их в предложения и, наконец, синтезировать семантическое представ!
ленис полученного значения. ^
При взаимодействии множества процессов в ходе решения одной большой задачи
может возникнуть немало сопутствующих проблем. Примером этого служит задача
слияния (объединения) показаний датчиков [Lesser и Corkill. 1983]. Предположим
имеется сеть датчиков, соответствующих различным процессам. Предположим так!
же, что процессы могут сообщаться. Поэтому соответствующая интерпретация
данных каждого отдельного датчика зависит от данных, полученных другими
датчиками этой единой сети. Эта проблема возникает и в задаче управления траекторией
движения самолета, находящегося в поле обзора многочисленных радарных
установок с последующим объединением показаний всех датчиков в процессе обработки
информации.
Архитектура "классной доски" (стратегия решения сложных системных задач с
привлечением разнородных источников знаний, взаимодействующих через обшее
информационное поле) — модель управления, которая успешно применяется для решения этой и
других задач, требующих координации различных процессов или источников знания.
"Классная доска" — центральная глобальная база данных, предназначенная для связи
независимых асинхронных источников знаний. На рис. 5.12 дано схематичное
представление архитектуры "классной доски".
На рис. 5.12 каждый источник знаний KS, (knowledge source) получает свои данные
от "классиой доски", обрабатывает их и возвращает результаты "классной доске" для нх
дальнейшего использования другими источниками знаний. Это изолированные
процессы, действующие согласно своим собственным спецификациям (описанию). Поэтому при
параллельной обработке информации или мультипроцессорной системы эти системы
участвуют в решении единой задачи независимо друг от друга. Это асинхронная система,
поскольку каждый источник знаний KS, начинает свою работу, когда находит
соответствующие входные данные на "классной доске". Закончив обработку данных, он
возвращает свои результаты и ожидает новых входных данных.
Подход "классной доски" к организации большой программы изначально был
реализован в системе HEARSAY-II [Еггаап и др., 1980]. [Reddy, 1976]. HEARSAY-II -
это программа понимания речи. Первоначально она была разработана как внешний
интерфейс длл базы данных публикаций по теории вычислительных систем.
Предполагалось что абонент библиотеки может обратиться к компьютеру на английском
языке с запросом типа: "Есть ли у вас какие-нибудь работы авторов Феигенбаума
(Feigenbaum) и Фельдмана (Feldman)?". Компьютер должен ответить на этот вопрос,
предоставив информацию из базы данных библиотеки. Понимание речи требует
интеграции ряда различных процессов, которым необходимы различные знания и
алгоритмы. Сложность этих алгоритмов и знаний может расти экспоненциально.
Обработка сигналов, распознавание фонем, слогов и слов, синтаксический анализ и
семантический анализ- все эти процессы связаны друг с другом в процессе
интерпретации речи.
Глава 5. Управление поиском и его реализация в пространстве
213
Глобальная
классная доска"
: 5.12. Архитектура "классной доски"
Архитектура "классной доски
позволила скоординировать в системе HEARSAY-II
несколько различных источников знания, необходимых для этой сложной задачи.
"Классная доска" обычно организована в двух измерениях. В HEARSAY-U этнмн
измерениями были время, в течение которого звучала речь, и уровень анализа фрагмента
активной речи. Каждый уровень анализа реализовывался различными классами источников
знания. Эти уровни анализа таковы.
KS, Форма волны (временная диаграмма) акустического сигнала.
KS. Фонемы или возможные звуковые сегменты акустического сигнала.
KS3 Слоги, которые могут быть составлены нз фонем.
KS* Возможные слова, результат анализа первого KS,-.
KSS Возможные слова, результат анализа второго KS (обычно рассматриваются
слова из различных частей данных).
KSf, Генерация возможных последовательностей слов.
KS^ Связывание последовательности слов в фразы.
Эти процессы можно визуализировать в виде компонентов (см. рнс. 5.12). При
обработке устной речи форма волны произнесенного сигнала рассматривается на самом
нижнем уровне. Обработку этих данных выполняют определенные источники знаний.
Результаты их анализа переносятся на доску и используются другими процессами. Из-за
неоднозначности разговорного языка на каждом уровне доскн могут присутствовать
многочисленные конкурирующие гипотезы. Источники знаний более высоких уровней
пытаются устранить неоднозначности конкурирующих гипотез.
Процесс анализа в HEARSAY-U не следует рассматривать просто как
последовательность этапов анализа на низком уровне и создания данных, которые затем могут быть
проанализированы на более высоком уровне. Система HEARSAY-II значительно
сложнее. Если KS на одном уровне не может обработать (осмыслить) переданные ему данные,
то он делает запрос к соответствующему источнику о новых данных. Затем, получив
новые данные, делает еще одну попытку их обработки или принимает другую гипотезу от-
Z мГГ° "ерВ°НаЧаЛЬН0 полУче«иь.х данных. Кроме того, различные KS, могут одно-
IZZT, Г "ад Ра™"ШИ V™™™" Речи. Все процессы, как было уже сказано.
ниПх"„1НХРОтЬШ" " W*1»»»*» «a основе данных. Они запускаются с появле-
ют "вГГу"ГКЬ'Х " ПР°Д0ЛЖ!"ОТ Раб<">. "»а не закончат задание, затем воэвраша-
ют свои результаты и ждут следующего задания.
обраСГ„„/о';ГЫВаеМЫЙ m""'V""'^oM, обрабатывает сообщения о результатах
Р ботки информации, передаваемые между другам„ KSj. Планировщик ранжирует Р="
214
I. Искусственный интеллект как представление и
зультаты деятельности каждого KS, и с помои.кт пп,.„
' „ ' помощью приоритетной очереди обеспечивает
некоторое направление решения задачи Если ни r,„„u „, .,„ «ччлди ишыкчшш.!
.,..„ п»,„»„т ,„„ *ч*™. если ни один из источников знани не активен,
планировщик решаемо задача завершена, н прекрашает свою работу
Когда программа. HEARSAY содержала базу данных около 1Ш слов, она работала
достаточно хорошо, хотя немного медленно. Когда же база данных была расширена, данные
оказались слишком сложными для источников знания, и KS, не могли их обработать.
Система HEARSAY-Ш Baize, н другие, 1980], [Еггшш и др., 1981] - это обобщение подхода,
принятого в HEARSAY-II. Временное измерение в HEARSAY-Ш ие используется, но
различные уровни анализа сохранены. -Классная доска" в HEARSAY-Ш предназначена для
взаимодействия с реляционной базой данных общего назначения. На самом деле, HEARSAY-Ш —
это оболочка для проектирования экспертных систем (см. подраздел 7.1.1).
Важным нововведением в HEARSAY-Ш стало отделение планировщика н превращение
его в контроллер ("классную доску") для первичной классной доски предметной области.
Появление второй "классной доски" позволило разделить процесс планирования и реализовать
его с помощью многочисленных источников знаний подобно тому, как сама задача
разделяется на различные уровни анализа. За разные аспекты процедуры решения (например, когда и
как применять знания о предметной области) стали отвечать различные KS,. Таким образом,
вторая "классная доска" позволяет сравнить и сбалансировать разные решения отдельных
задач [Nii н AieHo, 1979], [Nii, 1986a], [Nii, 19866]. Существует и альтернативная модель
"классной доски", согласно которой важные части базы знаний остаются на "классной доске",
а не распределяются по источникам знаний [Skinner и Luger, 1991].
5.5. Резюме и дополнительная литература
В главе 5 обсуждалась реализация стратегий поиска, описанных в главах 3 и 4. Таким
образом, ссылки, перечисленные в заключительной части глав 3 и 4, относятся также и к
этой главе. В главе 5 представлена рекурсия как важный инструмент программирования
поиска на графе, а затем в рекурсивной форме реализован алгоритм поиска с возвратами
(backtrack algorithm) из главы 3. Поиск по образцу (pattern-directed search) с
использованием унификации и правил вывода упрощает реализацию поиска в пространстве
логического вывода.
Было показано что продукционная система является естественной структурой для
моделирования решения задач и реализации алгоритмов поиска. Эта глава завершается
примерами реализации продукционных систем, осуществляющих поиск на основе
данных и от цели. Действительно продукционные системы всегда были важной парадигмой
Для программирования задач ИИ. начиная с работ Ньюэлла и Саймона и их коллег из
Carnegie Mellon University [Newell и Stmon, 1976]. [Klahr и др.. 19S7]. Продукционная
система также является важной структурой, поддерживающей исследования в области
когнитивистнки (науки о мышлении) [Newell и Simon. 1972]. [Luger. 1994].
Конкретные реализации продукционных систем описаны в [Brownston и др.. 19SM и
[Waterman „ Havc-Roth, 197S]. в посмшенныч
Ранние исследования по модели -классной доски _'',„,„, „.,,„„.„ „,„.
системе HEARSAY-П, - [teddy. .976], [Erman и др.. 1980]. Д,„ ..шее раза™,
методологии "классной доски" описано в работах [Lesser и CorUl. 19S, . [Nn, IQR^l.
INii. 19866], посвященных системе HEARSAY-HI. и [Engelmore и Morgan. 1988].
Глава 5. Управление поиском и его реализация в пространств,
215
гаонным системам, планированию и структурам "классной
Исследования по "Р0*™ исследований в искусственном интеллекте. Интере-
доски" остаются областью а о6 тнться к последним трудам конференций Ameri-
суюшемуся чи™тел"Р^°"™|ИоеПсе Conference и International Joint Conference on Arti-
п'ппыТ^Сн Кауфман (Morgan Kaufmann, издал труды конференций, а
также сборник докладов по вопросам ИИ.
5.6. Упражнения
1. Алгоритм проверки вхождения из подраздела 5.1.1 рекурсивно определяет, является
ли данный элемент членом списка.
1.1. Составьте алгоритм, вычисляющий число элементов в списке.
1.2. Составьте алгоритм, вычисляющий число атомов в списке.
Различие между атомами н элементами состоит в том, что элемент сам может быть
списком. (Дополнительная информация содержится в разделе 15.1.)
2. Напишите рекурсивный алгоритм поиска в ширину (с использованием списков open
и closed). Можно ли с учетом рекурсии обойтись при поиске в ширину без списка
open? Объясните.
3. Проследите выполнение рекурсивного алгоритма поиска в глубину (без
использования списка орел) в пространстве состояний, показанном на рис. 3.10.
4. В древнеиндийской чайной церемонии принимают участие три человека: взросльш, слуга
и ребенок. Они выполняют четыре задачи: поддерживают огонь, подают тгрожки,
наливают чай и читают стихи. Эти задачи перечислены в порядке убывания важности. В
начале церемонии все четыре задачи выполняет ребенок. Затем они по одной переходят к
слуге и взрослому. В конце церемошш все четыре задачи выполняет взрослый. Никто не
может браться за менее важную задачу, чем те, которые он уже выполняет. Сгенер1груйте
последовательность шагов передачи задач от ребенка к взрослому. Запишите
рекурсивный алгоритм выполнения последовательности этих шагов.
5. Используя определения перемещения н пути для задачи хода конем из раздела 5.2,
проследите выполнение алгоритма pa»ern_search для следующих целей:
а)рагп(1,9);
б)рат(1,5);
в)ра!п(7,6).
Если предикаты mow, выполняются по порядку, то в алгоритме поиска часто быва-
ют зацикливания. Как обнаружить цикл „ реализовать возврат в этом случае?
pZ71ёл%ТпПСевД0К0Да ВерС1"° ""Ч*™1 "а»<™ —rch с поиском в иш-
горитма "Те "реттУю и пространственную" эффективность этого ал-
хоГрТшен^гол" "аЧаЛЬТ мстояния, показанные на рнс. 5.5, промоделируй"
Щнх стратегий: продукционной системой с использованием следую-
216
I- Искусственный интеллект как представление и поиск
а) поиск от цели;
б) поиск на основе данных.
9. Рассмотрите задачу финансового советника, описанную в главах 2 3 и 4 Используя
исчисление предикатов в качестве языка ггоелстатчч.,™ „„„ используя
л^ыкч представления, решите следующие задачи.
9.1. Опишите задачу явно в виде продукционной системы.
9.2. Сгенерируйте пространство состояний и содержимое рабочей памяти при реше-
иии задачи, описанной в примере из главы 3, на основе данных.
9.3. Решите эту же задачу, используя стратегию поиска от цели.
10. В подразделе 5.3.3 представлены общие стратегии разрешения конфликтов на основе
рефракции (refraction), новизны (recency) и специфичности (specificity). Предложите
н обоснуйте еще две такие стратегии.
11. Предложите две прикладные задачи, для решения которых можно использовать
структуру "классной доски". Кратко охарактеризуйте организацию "классной доски"
и источников знания для каждой задачи.
Глава 5. Управление поиском и его реализация в пространстве
217
Часть ill
Представление
и разум в ракурсе
искусственного
интеллекта
Наш век беспокойства в значительной мере является результатом попыток
выполнять сегодняшнюю работу вчерашними средствами...
— Маршалл Мак-Люган (Marshall McLugan)
Может быть, стоит рассматривать мозг как набор контроллеров для
осуществляемой деятельности? Этот небольшой сдвиг в перспективе окажет большое влияние на то,
как мы конструируя.» науку о мышлении. На самом деле это требует больших изменений
в нашем ходе мыслей об интеллектуальном поведении. Необходимо отказаться от:
мыслей (привычных со времен Декарта) о разуме как сфере, отличной от сферы тела;
разделения восприятия, познания и действия; идеи исполнительного центра, где мозг
выполняет высокоуровневые рассуждения; и, более того, отказаться от исследовательских
методов, которые искусственно отделяют мысль от осуществляемого действия.
— Энди Кларк (Andy Clark), Being There
Представление и интеллект
и , . ,„,;Л„\ кяк наилучшего способа фиксации критиче-
ТЬ|х в настоящее впемя исследователями ИИ. Первый иидлид, т к i i
» настоящее время исследим 6„ .связанной с программой Logic
'950-х и 1960-х годах Ньюэллом и Са™он°М ° "^ШЗя]. состоит в использовании
Theorist (Логический теоретик) [Newell и Simon. TOO, itojdi.
тобвея (weak problem-solving method). Второй подход
слабых методов решения р^_^ ^ mf)^ годах и поддерживаемый разработки
чивший Ра™Р°^хаНсе""см св„дится к применению сильных методов решения „ро(>
первых 'ксп^ны* C"L . начале главы 7). В более современных исследования* „
Г То^яТробГо™™,», и агентных методов [Brooks. 1987, ,989,, [а^{
бенно в областях рос» тш и внедрениых представлениях интеллекта ''
«"SS-Toil из этих методологий представления интеллекта. Три гаавы
[Юзнакоми вкяючают более детальные описания этих подходов.
■*№ " -чале .960-х Алан Ньюэлл (А,ап Newell) и Герберт Са„ион
(Herbert Simon) написали несколько компьютерных программ для проверки гипотезы 0
то,, что интеллектуальное поведение является результатом эвристического поиска. Про-
грамма Lo»ic Theorist, разработанная совместно с Дж. Шоу (J. С. Show) [Newell и Simon
1963а] доказывала теоремы из области элементарной логики с помощью системы обо.'
значений и аксиом, описанных в [Whitehead и Russell, 1950]. Авторы характеризуют свое
исследование как ориентированное на понимание
"...сложных гфопессов (эвристик), которые эффективны при решении проблем.
Следовательно, мы не заинтересованы в методах, которые гарантируют решение, но требуют большого
количества вычислений. Скорее, мы желаем понять, как математик должен доказывать теоре-
му, даже когда в начале или в процессе доказательства он не знает, как достичь цели."
В более поздней программе GPS (General Problem Solver) Ньюэлл и Саймой [Newell и
Simon, 1963e], [Newell и Simon, 1972] продолжили поиск общих принципов
интеллектуального решения проблем. Система GPS решала задачи, сформулированные как проблемы поиска в
пространстве состояний. При этом в процессе решения задачи выполнялось множество
операций для изменения представления состояний. Система GPS искала последовательность
операций, которая могла бы преобразовать исходное состояние в целевое, осуществляя поиск
таким же образом, как и алгоритмы, рассмотренные в предыдущих главах.
Для управления поиском в пространстве состояний система GPS использовала аналю
целей и средств (means-aids analysis) — общую эвристику для выбора среди
альтернативных операций преобразования состояния. В процессе анализа целей и средств
проверяются синтаксические различия между текущим и целевым состояниями и выбирается
оператор, который может уменьшить эти различия. Предположим, например, что систе-
иге пытается доказать эквивалентность двух логических выражений. Если текущее
состояние содержит оператор л, а у цели нет этого оператора, то в процессе анализа це-
преобпа,™ УШК"'" ЗТОГ0 опеРат°Ра из выражений можно выбрать соответствующее
преобразование, например закон де Моргана (см. раздел 12 1)
го ре^ГС„ооГеСИС1еШ GPS СМ°ЖЭТ ™- о6щей архитектурой для „нтеллекгуально-
которГпТовеояет Г' "™т° ™ ^"^ П0<Ж°ЛЬКу » "^пользуется »Р«спв.
ограГченц7"Т" """"""«Ч» Ф°Р"У состояний. Программы подобные GPS.
РазнообразГ,™,"' '"' °СН°Ванными иа синтаксисе, и ориентированные на шир"»
(^m«WPSrXVrUBa,<>TC" РеШатеЛялт 3od<"< "" основе слабых »-*
•» »«м иреГет'иь^.о^аетя^Г™ Зврнстики. "™рая ""*" успешно Щ>«»<"'™1
проблемы, используют 6W Ше" СЛучае мет0™. с помощью которь,х мы реш»еп
"ировать болезни так IT К0Л1™С™ знаний о ситуации. Врачи способны П"<*"°
обширные мед„ц„нск ,Г3К„Л™Ш,НАИтеЛЬН0 к °б«™ возможностям решения задан и» »
3"ан„,мн в области т^Л""™0"" "актируют дома потому, что об».«
^^озе.„огут6ь1тьЦтск^ь- Безусловно, эвристики, используемые в мед.шп»»0'
петыми при проектировании офисного здания.
Часть II
Представление и разум в ракурсе искусственного инг*.
.ллекта
Слабые методы значительно отличаются т- г.,^,
вЫс используют точные знания частной проблемной Z"*" 7 <*"W"! таШ>- к010'
системы диагностики автомобилей. Пр°6лем"°" °6"«™. Рассмотрим правило для
если
двигатель не заводится и
фары не горят,
то
проблема в аккумуляторе или в проводах (0.8)
Эта эвристика, перефразированная как правило "если..., то..Л фокусирует поиск на
подсистеме аккумулятора автомобиля, исключая другие компоненты и уменьшая
пространство поиска. Отметим, что эта частная эвристика, в отличие от анализа целей и
средств, использует знание о функционировании автомобиля, а также знание о
взаимосвязях между аккумулятором, фарами и стартером. Она бесполезна в любой проблемной
области, за исключением авторемонта.
Решатели задач иа основе сильных методов не только используют специфические
знания о предметной области, но и требуют большого количества таких знаний.
Например, эвристика "неисправен аккумулятор" не слишком полезна при диагностике
поломки карбюратора и может быть вообше бесполезной в любой области, выходящей
за рамки диагностики автомобилей. Таким образом, главной проблемой при
разработке программы, основанной на знаниях, есть проблема извлечения и организации
больших объемов специфических знаний о предметной области. Правила могут также
содержать меру (0,8 в приведенном выше правиле), чтобы отразить достоверность
этой части зиаииЙ о предметной области.
При использовании подхода на основе сильных методов разработчик программы
делает определенные предположения о природе интеллектуальной системы. Эти
предположения формализованы Брайаном Смитом (Brian Smith) [Smiih, 1985] в виде гипотезы
о представлении знаний (knowledge representation hypothesis). Согласно этой гипотезе
"...любой механически материализованный интеллект>-а.тьный процесс будет состоять нз
компонентов, которые а) мы, как внешние наблюдатели, естественно выбираем хтя
представления пропозиционального учета знания всего этого процесса, и б) независимо от
внешнего семантического свойства играют формальную роль в реалнзашт повеления,
соответствующего этому знанию."
Важным аспектом этой гипотезы является предположение, что знание будет
представлено пропозиционалъно. т.е. в форме, которая точно представляет знание вопроса и
которая может рассматриваться внешним наблюдателем как "естественное описание
этого знания. Второе важное предположение состоит в том, что поведение системы
Должно определяться предложениями базы знаний, и что это поведение должно
соответствовать воспринятому смыслу этих предложений.
В последнее время при описании вопросов предстанлеиия в ИИ часто используются
такие термины как агентное, внедренное (воплощенное), или жрджентное реи^ние
**». Некоторые исследователи. Р^"^" ^
«а. разработка игр и Interne!, включая [Brooks, 19Ы. f» I- ' » „„„„„, ..,.„«
[Jennings, 1995] и [Wooldridge. 2000]. подвергли сомнению требование „ал,™ к^он
«ибо централизованной базы знаний ил» общецслевои схемы вы вол». Решали задач
Разрабатываются как васпредаенные агенты: ситуативные, автанаины, и.иокие.
н«иа.ываются какрасл/tcre,..: „„.-гиятонвается как распределенный процесс
С этой точки зрения решение задач рассматривается как р г-- о6*тЯ
«анмодейсгвня агентов, решающих задачи в различных подконтекстач своих областей.
Представление и интеллект
, „ брокера или arc,™ безопасности. Процесс решения pa,6H„acTC>, „а
„.пример, mtemet-броузсрв шо|( или ВОЕ1СС отсутствующей координацией эа
несколько компонентов щсстолять сенсорное восприятие своего окружения а
дач.Ситуативнын агент м ^ 6с1 ожидания инструкции от некоторого обще',»
также рсагиро»^ » ||ВН0Й ,прс агент может решать локальную задачу п.
контроллера. Наприм ,._ ^^ 1]Од0ЧИ сипшш без общего обзора всей ситуации,
па зашиты от коикр ' ^^ должны деПстоовать бет прямого вмешательства
J£Z ZZ п авляюшего процесса. Таким образом, автономные агент,,, у1|рав.
яю—Стенными действиями и внутренним состоянием. Кроме того, гибкие
ашггь должны чувствовать ситуацию их локального окружения, а также быть „реду.
сыотрнтсльными - должны уметь предвидеть ситуации. И, наконец, они должны гибко
отвечать другим агентам проблемной области, переговариваясь о задачах, целях и соот-
ветствующих процессах.
Некоторые исследователи в области роботики создали озон агентные системы. Родни
Брукс (Rodney Brooks) из лаборатории MIT Robotics Laboratory разработал так
называемую категориальную архитектуру (subsumplion architecture) — многослойную
последовательность конечных автоматов, каждый из которых действует в своем собственном
контексте, поддерживая также функциональность иа более высоких уровнях. Мануэла
Велосо (Manuela Veloso) из лаборатории роботики Карнэги Мешюн создала команду
футбольных роботов-агентов, которые взаимодействуют в рамках футбольных турниров.
И, наконец, этот ситуативный и внедренный подход к представлению
описывается некоторыми философами, включая [Dennett, 1991, 1995] н [Clark, 1997], как
соответствующая характеристика человеческого интеллекта. Ниже в этой книге будут
приведены дополнительные схемы представлений, включая коннекционистский
(глава 10) и генетический (глава 11) подходы. Общие вопросы представления снова
обсуждаются в главе 16.
В главе 6 в деталях исследуются основные подходы к представлению, принятые в
ИИ. Мы начинаем с ранних представлений, включающих семантические сети,
сценарии, фреймы и объекты. Эти схемы рассматриваются с эволюционной точки зрения,
показывая путь развития от самых ранних исследований ИИ до современных средств.
Далее описываются концептуальные графы Джона Сова (John Sowa) — представление,
используемое для понимания естественного языка. Наконец приводятся агентный и
ситуативный подходы к представлению. В частности, рассматривается категориальной
архитектура Родни Брукса, которая ставит под вопрос необходимость центральной базы
точных знаний используемой с обшецслевым контроллером.
пп„оВГ„ 7ЖЛа'°ТСЯ СИСТСМЫ' ^"'"ыс знаниями, и рассматриваются проблемы
вывода"™? Ф°рмал,тш|" » °™дки баз знаний. Мы представляем различные схемы
оёГанГх „Г" "РШ""' В,Ш0ЧаЯ Ра«^=н„я, от цели и от данных. Кроме систем.
"римерГ;:;^::;^6^ '4**™™ны рассуждения, основанные на модели "
ноеть области 1ZT П''"° прслстав1™ теоретические основы и функциональ-
Данных оГсываюп" юР' ЭЛСКТ°Н1ШХ <*»<*■ » ™ время как вторые строят точку» баз
области ГбьГпГо" У™"*™»* Ус"«™ыс и неудачные ,!рнмерь, из проблем"
'^upJ^lZZ) Г"™ "РИ РСШС"ИИ ""06"см- Г*™ 7 --ршается обзору
^"Управлятьpel™ "Г г """ Т°ЧНЬ,е "iaH"» «°™нь, быть организованы так.
Глава 8 описывает ря" Г " ТаКНХ с"°ж""х областях, как роботика.
™* в условиях не.Где Т?"0*' «°Т0*кк ««прилены на представление реш
«'^деленное™ „ неуверенное™. В этих ситуациях мы пытаем"
^сть «1. Представление и разум в ракурсв искусственного интелл^"
как можно лучше объяснить часто неоднозначную информацию. Этот тип рассужде-
„„й часто называют аПоуктшиьши (abduaive reasoning,. Сначала будет
представлена немонотонная логика и логика поддержки истинности, расширяющая ло.ику
предикатов за счет включения ситуаций с неопределенностью. Однако решение
многих интересных и важных проблем не всегда можно свести к дедуктивной логике.
Для рассуждении в этих условиях вводится ряд других эффективных средств,
включая байесовский подход, подход Дсмстсра-Шафера и неточный вывод на основе
фактора уверенности. Глава содержит также раздел по нечетким рассуждениям и
завершается кратким описанием стохастических агентов.
В части VI многие из этих представлений реализованы на языках LISP H PROLOO.
Представление и интеллект
223
Представление
знаний
Эта грандиозная книга, универсум, написана на языке математики, и ее символами
служат треугольники, круги и другие геометрические фигуры, без коаюрых невозможно
понять ее слово — без них бродишь в темноте лабиринта...
— Галилео Галилей (Galileo Galilei). 1638
Поскольку нет организма, который может покрыть бесконечное разнообразие, одной
из основных функций всех организмов есть разбиение окружения на классы, при котором
неидентичные стимулы могут трактоваться как эквивалентные...
— Элеанор Рош (Eleanor Rosch), Принципы категоризации, 1978
Мы всегда имеем два универсума рассуждений — назовем их "физический " и
"феноменальный " (или, как вы желаете) — один связан с вопросами количества и
формальной структуры, другой — с теми качествами, которые соответствуют слову
"мир ". Каждый из нас имеет собственные ментальные миры, собственные внутренние
маршруты и ландшафты, и они не требуют ясной нейрологической "корреляции ".
— Оливер Сакс (Oliver Sacks),
Человек, который ошибочно принял свою жену за шляпу, 1987
6.0. Вопросы представления знаний
Представление информации для решения интеллектуальных проблем — важная и трудная
задача, лежащая в основе ИИ. Раздел 6.1 содержит краткую историческую ретроспективу
ранних исследований по представлениям: в нее включены семантические сети (semantic
networks), концептуальные зависимости {conceptual dependency), сценарии (script) и фреймы
(frame). Раздел 6.2 посвящен более современным представлениям — концептуальный графам
(conceptual graph), предназначенным для решения задач понимания естественного языка. В
разделе 6.3 обсуждается требование создания централизованных и явных схем представления.
Альтернативой является категориальная архитектура (subsumption architecture) Брукса для
роботов. В разделе 6.4 представлены агенты— другая альтернатива централизованному
Убавлению. В последующих главах приведено расширенное обсуждение представлений,
включая стохастическое (раздел 8.3), коннекционистское (глава 10) и генетическое
(эмерджентное) (глава 11).
, обсуждение с исторической ретроспективы, в которой база зна„„й
Начинаем наше °6c^"f £ „ от„„шеннй предметной области в вь "И
°ПИСЬШаХКкть, и^огрГшные отношен,. [Bobrow. .975]. Результаты вывода в 6щ'е
КЛЬН"^™иы оответствовать результатам действии или наблюдении в мире. Вь,ч„с.
лнтеГи"™, отношения и выводы, привычные программисту, выражай™, „зы.
"Z^rSe^uTb, организапии знаний, которые применяются в Разл„чных
„блаГхТмТгут врио поддерживаться языком представления. Например, иерарх™, класив
«Hata, как в научных, так и в общесмысловых классификационных системах. Но как
оточить „бщнй механизм для их представления? Как представить определен™? Иеювоче-
„,«■> Как научить интеллектуальную систему по умолчанию делать предположения о
недостающей информации и проверять истинность подобных предположений? Как наилучшим
образом предстаешь время? Причинность? Неопределенность? Прогресс в создании интеллек-
туальных систем зависит от открытия принципов Организации знаний и от поддержки их
высокоуровневыми средствами представления.
Полезно делать различие между схемой представления и средой ее выполнения. Эта
подобно различию между структурами данных и языками программирования. Языки
программирования являются средой выполнения; структурой даниых служит схема.
Обычно языки представления знаний являются более ограниченными, чем исчисление
предикатов или языки программирования. Эти ограничения принимают форму точных
структур для представления категорий знания. Средой, в которой они выполняются,
могут быть PROLOG, LISP либо такие языки, как C++ или Java.
Обсуждение данных вопросов иллюстрирует традиционный обзор схем
представления ИИ, приведенный в разделах 6.1 и 6.2. Этот обзор, как правило, включает
глобальную базу знании из языковых структур, отражающих статику и "предопределенные
центры реального мира". Более поздние исследования в области роботики [Brooks, 1991fl],
[Lewis и Luger, 2000], ситуативного познания [Agre и Chapman, 1987], (Lakoff и
Johnson, 1999], агентиого решения проблем [Jennings и др., 1998], [Wooldridge, 2000] и
философии [Clark, 1997] бросили вызов традиционному подходу. Эти проблемные
области требуют распределенного знания; мира, который сам может быть использован как
частная структура знания; возможности рассуждать при иеполиой информации и даже на
основе представлений, которые изменяются в процессе экспериментов в проблемной
области. Эти подходы приводятся разделах 6.3 и 6.4.
6.1. Краткая историяосем представления ИИ __
6.1.1. Ассоционистские теории смысла
поз1оСляет,Мх'я„Ф^ОС°ФОВ " матем"«ков Уровень логических представлений возрос »
лГиГ"„азР„1еРНЗГаТЬ ПРИНЦИПЫ Ч-ильиого рассуждения. Основная задач
полнь! п„а1аТ Ф°РМаЛЬНЫХ »«»» представлеиияТиаинй с совершенным» .
ное вГи ,а„Р е И;даеляеТВЬ№0Да' П°"°МУ В "м™ках исчисления предикатов осно,
ных выраж Н1,ях В'"'J™*"""*"™ «ститосми операций „а корректно построе»
человеческого „0ИИмРУТаТе УСШШЙ пс>™»°«>в и лингвистов по оценке пр..Р°»в
ше связана со стан Г, В°3"ИКЛа м"Ч>"«11вИая линия исследований. Она меиь
становлением науки корректных рассуждений, а больше тяготеет ь
Часть in. Представление и разум в ракурсе искусственного интелл»""
>|
оп„санию способ побретсния и „^^ знаний
Ка38Л- и пасс" жленнй Z "РИМСИС"ИЯ ™ в области понимания естественных
языков и рассуждении на основе здравого смысла
Существует много проблем, которые возникают при отображении рассуждений на
основе здравого смысла в формальную логику. Например, обычно примято думать, что
операторы v и -> соответствуют конструкциям русского языка •■или" и "если... то "
Однако эти операторы в логике связаны только со значениями истинности и игнорируют
специфическую взаимосвязь между посылками и заключением конструкции "если
то..." (скорее корреляционную, чем причинную). Например, предложение "Если
птица— кардинал, то ее цвет— красный" (ассоциация птицы с красным цветом) может
быть описано в исчислении предикатов следующим образом.
УХ((кардинал(Х) -» красный(Х)).
Это предложение может быть заменено логически эквивалентным выражением
посредством ряда сохраняющих истинность операций из главы 2:
VX (—1Красный(Х) -> -^ардинал(Х)).
Второе выражение истинно тогда и только тогда, когда истинно первое. Однако
эквивалентность значений истинности в данном случае не сохраняется. Если
рассматривать физическую основу истинности этих выражений, то факт, что лист
бумаги ие красный и не является птицей-кардииалом, служит основой для истинности
второго выражения. Из эквивалентности двух выражений следует, что второе
является также основой для истинностн первого. Это приводит к заключению, что белый
цвет листа бумаги служит причиной того, что кардиналы красные. Эта линия
рассуждений представляется лишенной смысла и довольно глупой. Причина такой
бессвязности в том, что логическая импликация лишь выражает связь между
значениями истинности своих операндов, в то время как выражение в русском языке
предполагает положительную корреляцию между членством в классе и обладанием
свойствами этого класса. Действительно, определенный цвет птицы связан с ее
генетическим строением. Эта связь теряется во второй версии выражения. Хотя факт,
что бумага ие красная, обеспечивает истинность обоих выражений, но ие отражает
причинную природу цвета птиц.
Ассоционистские (associationist theory) теории определяют значение объекта в
терминах сети ассоциаций с другими объектами. С точки зрения такой теории восприятие
объекта происходит через понятия. Понятия являются частью всего нашего знания о мире и
связываются соответствующими ассоциациями с другими понятиями. Эти связи
представляют свойства и поведение объекта. Например, на основании опыта мы ассоциируем
понятие "снег" с другими, такими как "холод", "белый", "снежный человек", "скользкий"
и "лел". Наше знание о снеге и истинность утверждений типа "снег белый" возникают из
этой сети ассоциаций.
Из психологин гавестно, что люди ассоциируют понятия, а также иерархически
организуют свои знания с помощью информации самых верхних уровней классификационной
иерархии. Коллиис (Collins) и Квиллиан (Quillian) [Collins и Quillian. I969] моделировали хранение
информации человеком и управление ею, используя семантическую сеть (рис. 6.1). Структура
этой иерархии была получена в лаборатории в результате тестирования групп людей.
Субъектам задавались вопросы о различных свойствах птиц, такие как "Канарейка — это пти-
иа?" или "Канарейка может петь?" или "Канарейка может летать?".
Глава 6. Представление знаний
227
!££=£»
Канарейка имеет кожу
Канарейка — это животное
Рис 6 1 Семантическая сеть, разработанная Кошинсом и Каиш^ш в их исследовании по
хранению информации и времени отклика человека {Harmon и King, УУЬОУ
Хотя ответы на эти вопросы, возможно, просты, изучение времен,, реакции показало
что при ответе на вопрос "Может ли канарейка летать?" оно больше, чем на вопрос
"Может лн канарейка петь?". Коллинс и Квиллиаи объясняют эту разницу во врет
ответа тем, что люди запоминают информацию на самом абстрактном уровне, в ^
того, чтобы запоминать конкретные свойства для каждой птицы (канарейки л ^
дрозды летают, ласточки летают), люди запоминают, что канарейки птицы, а
(обычно) имеют свойство летать. Даже более общие свойства, такие как питание, д
ние и движение запоминаются на уровне "животное". Таким образом, попыт
нить, может ли канарейка дышать, занимает больше времени, чем воспомин i -
ли канарейка летать. Это, конечно, происходит из-за того, что для получения
ловек должен дольше путешествовать по иерархии структур памяти. л()
Быстрее всего вспоминаются самые конкретные свойства птицы, скажем, *> е.
она петь или является ли она желтой. Оказалось, что отрицательная трактовка та ^
лалась на наиболее детальном уровне. Когда субъекта спрашивают, может ли стр У^^
тать, он отвечает быстрее, чем когда его спрашивают, может ли страус дышать. ^ ^
образом, иерархия страус ->птица -> животное не прослеживалась, чтобы п°л^ орга.
рицательную информацию,— она запоминалась наряду с понятием "страус"- Э
,с0коМ
ннзация знаний была формализована в системах наследования.
Системы наследования позволяют нам запоминать информацию на самом i
эовне абстракци " "' "™
ни. Например, е
общие для всех птиц, например способность летать или иметь родителей, для ^-^
класса птиц BIRD и разрешаем частным представителям птиц наследовать т*«»
уровне абстракции, что уменьшает размер баз знаний и помогает избежать nP°oftcTBa,
чий. Например, если мы строим базу знаний о птицах, то можем определить ев
общие для всех птич ияпвн.,«, с... ,Tenpu. для ши" *
228 Часть Ш. Представление и разум в ракурсе искусственного иите
ва. Это уменьшает размер базы знаний за счет требования определять существенные
свойства лишь один раз и не определять их для каждого объекта. Наследование также
помогает поддерживать непротиворечивость базы знаний при добавлении новых классов
и объекта. Предположим, в существующую базу знаний добавляется вид ROBIN (дрозд).
Когда мы утверждаем, что ROBIN — это подкласс класса SONGBIRD (певчие птицы),
дрозд наследует все общие свойства как певчих птиц, так и птиц вообще. Программисту
не требуется запоминать (или забывать!) эту информацию.
Графы оказались идеальным средством для формализации ассоционистских теорий
знаний за счет точного представления отношений посредством дуг и узлов.
Семантическая сеть (semantic network) представляет знания в виде графа, узлы которого
соответствуют фактам или понятиям, а дуги — отношениям или ассоциациям между понятиями.
Как узлы, так и связи обычно имеют метки.
Семантическая сеть, которая определяет свойства понятий "снег" и "лед", показана на
рис. 6.2. Эту сеть можно использовать (с соответствующими правилами вывода) для
ответов на вопросы о снеге, льде и снежном человеке. Выводы делаются путем
прослеживания связей с соответствующими понятиями. Семантические сети также реализуют
наследование: например, объект frosty (морозный) наследует свойства объекта
snowman (снежный человек).
| снежная фигура |—
температура
скользкий
холодный
-и прозрачный
Рис. 6.2. Сетевое представление свойств снега и льда
Термин "семантическая сеть" обозначает семейство представлений, основанных на
графах. Эти представления отличаются главным образом именами шов. связей и выво-
Глава 6. Представление знаний
™„ыс можно делать в этих структурах. Однако общее множество предположе
дамн, которые можно я представления сетей. Это иллюеттш,,,
„„„ „ *-™^:; 1 6.2 будут рассмотрены ^еп^^Г
^;;Т"бое^време„нЫРП язык сетевого -4™™, который „,»££
многие из этих идей.
6.1.2. Ранние работы в области семантических сетей
Сетевые представления имеют почти такую же длинную историю, как и логика. фре.
re (Frege) например, разработал три системы обозначении для логических выражений
Возможно, наиболее ранней работой, имеющей прямое влияние иа современные
семантические сети, была система экзистенциальных графов, разработанная Чарльзом Пирсом
(Charles Peirce) в девятнадцатом столетни [Roberts, 1973]. Теория Пнрса использовала
всю выразительную силу исчисления предикатов первого порядка с аксиоматической
основой и формальными правилами вывода.
Графы давно используются в психологии для представления структур понятий и
ассоциаций. Пионером в этой области был Сэлз [Selz, 1913, 1922], который использовал
графы для представления иерархии понятий и наследования свойств. Ои также
разработал теорию схематического упреждения, которая повлияла на работы по фреймам и
схемам в ИИ. Андерсон (Anderson), Норман (Norman), Румельхарт (Rumelhart) и другие
использовали сети, чтобы моделировать человеческую память и интеллектуальные
проявления [Anderson и Bower, 1973], [Norman и др., 1975].
Много исследований на основе сетевых представлений было сделано в области
понимания естественных языков. В общем случае для понимания естественных языков
требуется намного больше знаний, чем для работы специализированных экспертных систем.
Оно включает понимание общего смысла, принципов действия физических объектов,
взаимодействий, происходящих между людьми, и принципов организации коллективов
людей. Программа должна понимать намерения, убеждения, гипотетические
рассуждения, планы и цели. Из-за требований большого количества необходимых знаинй
проблема понимания естественных языков всегда являлась движущей силой исследований в
области представления знаний.
Первые компьютерные реализации семантических сетей были созданы в начале 1960-
х для использования в системах автоматического (машинного) перевода. В работе
IMasterman, 1961] Мастерман определил множество из 100 примитивных типов понятий
и использовал их в словаре из 15000 понятий. В [Wilks, 1972] продолжено построение
систем понимания естественных языков на основе работы Мастермана (Masterman) в об-
з™ш,ГаГ,ЧККИХ СеТеЙ' В Ч"СЛе ДР>™ Р™и* Работ "° исследованию ИИ, исиоль-
ЕГп 965ЫАПРеДгаоЛеННЯ' М0Ж™ ™ [Ceccato, 1961], [Raphael, 1968L
LKeuman, 1965], [Simmons, 1966].
Kol2Z^ZVlZmmC™a ИЗВеСТНаЯ Чюграи*, которая иллюстрирует многие
ла англи^ГслГ," ССКИХ CeTeil tQuillian- l967l- ** программа характеризовав
ляется Гтер1нГ;ГГсРН° ™M « °^^ "» ™ ™^ словарь: слово
олений. В отличие от 1ош^ " ™ *° Ф°Р"УлнРУ°тся составляющие этих опреД^
Формулировка просто Ве1К|° °ПРеделен»я слов в терминах базовых аксиом **£
но, окольными путями Пм определениям, неструктурированными и, возма»
пока не убедимся что пЛ просмотРе слова мы прослеживаем эту цепочку до тех " V-
понимаем первоначальное слово.
Каждый узел в сети Куиллиана соответствует словесному понятию, имеющему
ассоциативные связи с другими понятиями, из которых формируется его определение. База
знаний организована в плоскости, каждая из которых является графом,
характеризующим одно слово. На рис. 6.3, взятом из статьи [Quillan, 1967], показаны три плоскости,
задающие трн различных определения слова "plant": plant 1 (растение), plant 2
(место, где работают люди) и plant 3 (процесс помещения семени в землю).
Plant' 1. Живая структура, которая не является животным,
часто с листьями, получающая пищу из воздуха, воды и земли.
2. Оборудование, используемое для некоторого
производственного процесса.
3. Помещать (семя, растение и т.п.) в землю
для выращивания.
1 person
4""" 1 seed paTh ob|ect
L~eanh~""- : i
'1;
1—r
-ГТ-
Рис. 6.3. Три плоскости, представляющие три определения слова "planf [Quillian. 1967j
Программа использовала эту базу знаний для поиска отношений между парами
английских слов. Получив два слова, она осуществляла на графах поиск в ширину для
нахождения общего понятия, или узла пересечения. Пути к общему узлу представляли
отношение между словесными понятиями. Например, на рис. 6.4, взятом из той же статьи,
показана точка пересечения путей, ведущих от понятии cry (плач) и comfort (покой).
Используя пересечение этих путей, программа смогла заключить следуюшее.
Плач (cry 2), помимо всего прочего, связан с производством печальных звуков. Покой
(comfort 3) может уменьшить печаль [Quillan. 1967].
Числа в ответах указывают, какие именно значения слов выбрала программа.
Кунллиан предполагал, что этот подход к семантике обеспечит следующие
возможности систем понимания естественных языков.
1. Определять смысл английского текста путем построения совокупности узлов
пересечения.
2. Выбирать смысл слов, находя самые короткие пут к точкам пересечения с путями для
других слов предложения. Например, в английском предложении 'Tom went home to
Глава 6. Представление знаний
231
жмой полить свое нове« растение) система сможп
^в hs or» (to«" 1"Тс!^*^ясвя»сь к» пересечении понятий -»«ег" „ -ph,,-
1ы6рт,зноте«<ссж**"р^ ' ывмсь на ассоциации между понятиями в во-
, Гибко оп*т«ь ю «Ч*"-*"1
"Bps»",c,":TOK'
Fui. 6.А 17<f«w«* >•>"<*■ S°J?'~:
L«~:^i cry (ладч) и conif ore im»r»u) [QuWan, 19671
Хот, зта и лр>тне Р-« prf™ ^ силу ^^^Р-Г^ЛХ
,„„„, ошсда. они бьои ограничены чрезмерной общнсчтью формал.ам
S стр^нровалось в терминах специфических отношен,™_таи х ^ье^
25^ гасс-^ооднзсс и агент-глагат-сбъегт. Исследования в области сетевых пред
спшзашй часто фок>харовалнсь та спецификации этих отношении.
6.1-J. Ставдартизадпя сетевых отношений
Само no себе представление отношен™ в Blue графов имеет мало "Р*11"^.,^,,.
вел исчислением предикатов — это только другая ззгшсь отношений между i [[д №
Сиза сетевых, представлений состоит в определении связен и специфических гда
аа. определяемых механизмом наследования.
Хотя ранняя работа Купхтиана установила такие наиболее
вола, определяемых механизмом наследования. -j^hhocth
^ - значительные _'*^£в.
формализма семантических сетей, как помеченные дути и связи, иерархи -южность
ванне н вывод аа основе ассоциативных связен, она не позволяла преодоле ^ - ^^ _^
многих проблемных областей. Одной го главных причин зтого была ограничу .^^ща!
эсн. которые не охватывали более глубоких семантических аспектов знании ^^j
часть связей представляла общие ассоциации между узлами и не обеспешгез. ^ ^н
основы для структурирования семантических отношений. Та же проблема во ^^ даТ
попытке использовать исчисление предикатов для охвата семантики смыС"и- '^й «и
фогяалом является очень выразительным и позволяет представлять почти -^^ м110.
званий, он слишком общий и переносит бремя конструирования соответствую
хества фактов и правил на программиста. клт11"*1"
Бсяьшннство работ по сетевым представлениям, развивающих работ" . ^-е
сводились к определению обширного множества меток связен i отношении >^_
иитвn*,c^•,
полного моделирования семантики естественного языка. За счет реализации базовых
семантических отношений естественного языка как части формаш±ма. а не как части
знаний о приметной области, базы знаний позволяют автоматизировать работа и
обеспечивают большую общность и непротиворечивость.
В [Brachman. 1979] отмечено следующее.
Ключевым вопросом здесь является выделение примитивов для языков семантических
сетей. Примитивами сетевого языка являются те понятия, для понимания которых
интерпретатор программируется заранее, н которые (обычно) не представлены в самом
сетевом языке.
В [Simmons, 1973] подчеркнута необходимость стандартизации отношений с
учетом грамматики английского языка. В этом подходе, основанном на работе
[Fillmore. 19о$]. связи определяются ролью существительных и групп
существительных в действии, описываемом предложением. К числу возможных ролей
(падежных отношений) относятся агент, объект, инструмент, место и время.
Предложение представляется как набор узлов, олнн из которых соответствует
глаголу, з остальные связанные с ним узлы представляют других участников действия.
Эта стр\ктурз называется падежным фреймам (case frame). При разборе
предложения программа находит глагол и ищет в базе знаний соответствующий ему
падежный фрейм. Затем она связывает значения агента, объекта н тому подобного с
соответствующими узлами падежного фрейма. Используя этот подход, предложение
"Sarah fixed the chair with glue" ("Сара укрепила стул клеем") можно представить
сетью, показанной на рис. о.5,
Рис. 6.5. Падежный фрейм. предста&ъюифы
предложение "Сара укрелиьз стул K.iee.u ~
Таким образом, сам язык представления включает многие глубинные связи
естественного языка, такие как отношение между глаголом н его субъектом (агентное
отношение) или глаголом и его объектом. Знание падежной структуры английского
языка является частью самого сетевого формализма. При разборе отдельного
предложения стэнов»ггся ясно, что Сара— это человек, производящий укрепление, а
клей используется для соединения частей стула. Отметим, что эти атеистические
отношения запоминаются отдеъъно (независимо! от реального предложения ы
даже от языка, на котором сфор.иухировано предложение. Подобный подход принят
в сетевых языках, предложенных в [Norman. 1972]. [Rumelhan и др.. 1972] и
[Rumelhan и др., 19">3].
Ряд исследователей уделяли большое внимание дальнейшей стандартизации имен
связей [Masterman. l%t]. [Wills. 1972]. [Schank и Colby. 1973]. [Sdmk и Nash-
Webber. 1975]. Каждое исследование было направлено на установление полного множе-
Глава 6. Представление знаний
233
232
Часть 111. Представление и разум в ракурсе
искусственного»
. л„я единообразного представления семантической структуры вь,РВДе.
ста примитивов для едино р' а изюнь1 помочь в реализации рассуждений с
^олХГмТеГовТзыка. Они должны быть независимы от индивиду
"IrlTo Zl^aMC—ой Гпыткой формального моделирования глубшшых
Возможно н г0 языка является теория концептуальной зависимо-
Г(" 1 aTpSnc^P^pa (Rieger) и Шснка (Schank) [Schank и Rieger, ,974, B
ошкаГтеории концептуальной зависнмост,. рассматриваются четыре типа прими™*»,
„Ткоторых определяется смысл выражений. К „им относятся:
■ ACT — действия (actions);
• РР — объекты (picture producers);
. АА — модификаторы действий (action aiders);
• PA — модификаторы объектов (picture aiders).
Предполагается, что каждое из действий должно Приводить к созданию одного или
нескольких примитивов ACT. Перечисленные ниже примитивы выбраны в качестве
основных компонентов действия.
• ATRANS — передавать отношение (давать).
• PTRANS — передавать физическое расположение объекта (идти).
• PROPEL — применять физическую силу к объекту (толкать).
• MOVE — перемещать часть тела (владельцем).
• GRASP — захватывать объект (исполнителем).
• INGEST — поглощать объект (есть).
• EXPEL — издавать звуки (кричать),
• MTRANS — передавать ментальную информацию (сказать).
• MBU1XD — создавать новую ментальную информацию (решать).
• CONC — осмысливать идею (думать).
• SPEAK — производить звук (говорить).
• ATTEND — слушать.
Эти примитивы используются для определения отношений концептуальной зава-
Z7C"'"' ТРЫе 0ПИСЬ1вают «ысловые структуры, такие как надежные отношения
ZmT" К™ " значсний- Отношения концептуальной зависимости - это ю>«-
соотвеТе™! Т"""!"",еские "Р<">"»"- к«°Р"е выражают семантические связи в
коистгГГ! гРамма™к°й «зыка. Эти отношения могут быть использованы ДЛ»
пред™Г„ ТГ™0"""0 Ч»»™™««« английского предложения. На рис М
2 ЦТ 41 Эти 0С"0ВНЬ1Х к°и^птуальных зависимостей [Schank «
eger, 1974]. Эти зависимости охватывают базовые семантические структуры
естественного языка. Например, первая концептуальная зависимость на рис. 6.6 оп
вает отношение между подлежащим и сказуемым, а третья - отношение гл
объект. Они могут сочетаться и представлять простые транзитивные пред'»*
такие как "John throws the ball" ("Джон бросает мяч") (рис. 6.7).
РР * ACT указывает, что исполнитель действует
РР • рд указывает, что обьект имеет определенный признан
О
АСТ<- РР означает обьект действия
Ri—*рр
ACT <- обозначает реципиента и донора для обьекта действия
1—»-РР
D,—*рр
ACT <- указывает направление объекта действия
1—*РР
ACT <- 0 означает инструментальную концептуализацию действии
X
| указывает, что X вызывается Y
Y
СРА2
указывает изменение состояния объекта
РА1
РР1 <-рр2 указывает, что РР2 является либо частью, либо владельцем РР1
Рис. 6.6. Концептуальные зависимости [Schank и Rieger, 1974}
John <
> * PROPEL'
f^
Рис. 6.7. Представление концептуальных зависимостей в
предложении "John throws the ball"
1. PP<»ACT
2. РР «►Рд
3. РР**РР
4. РР
Т
РА
5. РР
ft
7 АСТ?Г*РР
I—<РР
Джон о PTRANS
John «► height (>average)
John ■** doctor
t
dog
ft POSS-BY
John «PROPEL*1 carl
John » ATRANS *H Джон взял книгу у Мэри
Джон бежал.
Джон высокий.
Джон — доктор.
Милый мальчик.
Собака Джона.
Джон двигал гележку
VTRANS *Н
<£ I—«Магу
лег
■%2
book
John <=■ INGEST <^ (|
ТУ do
spoon
a—Held
John «PTRANS H
^ l—<bag
fertilizer
Джон сьел мороженое
Джон удобрил поле
10. РР
11. (а)-» (Ь) о
Г.РА1
-•с:
*»PROPEL^ bullet
•heaJlh(-10f
,2 T yesterday
* John* PTRANS
Рис. 6.8. Некоторые базовые концептуальные зависимости, взятые
из работы (Schank и Colby, I973}, и их использование дгя
представления более сложных английских предложений
Растения выросли,
^v-fr Bob Билл застрелил Боба
В черв Джон бежал
234
Часть III. Представление и разум в ракурсе искусственного
Интел"
Глава 6. Представление знаний
.„кчепиий может быть добавлена временная „ модальна,
И наконец, ко множеству ко « спвсок модиф„катороВ отношений.
„иформапия.Шенк приводит следу
. р_ прошедшее время
• f — будушее время
. г — передача
. к — продолжительность
. ( — начало передачи
• ? — вопрос
. (/_ окончание передачи
• с — условие
• /—отрицание
• nil — настоящее время
• delta 1 — независимость от времени
В памках теории от отношения считаются конструкциями первого уровня- просгейш,.
ми септическими отношениями, на основе которых могут быть построены более сложные
структуры Примеры того, как эти базовые концептуальные зависимости могут сочетаться т
подставления смысла простых английских предложений, показаны на рис. 6.8.
На рис. 6.9 показано, как на основе этих примитивов представляется выражение Ш
ate the egg" ("Джон съел яйцо"). Символы здесь имеют следующий смысл:
• < указывает направление зависимости;
• « — обозначает отношение агент-тлагол;
• р — указывает на прошедшее время;
• INGEST — определяет примитивное действие теорнн;
• О — обозначает объектное отношение;
• D — указывает направление объекта прн выполнении действия.
Другим примером структур, которые могут быть построены на основе концепту
ных зависимостей, является графическое представление предложения "John preve
Магу from giving a book to bill" ("Джон предостерег Мэри, чтобы она не давала книгу
Биллу") (рис. 6.10). Этот частный пример интересен тем, что ои демонстрирует пре
ставление причинности.
Р
John «* 'DO'
*
с/
John «* 'ATRANS
Egg
•'INSIDE'
— John
—John
—«'MOUTH'-* John
Рис. 6.9. Концептуальная зависимость прев-
стамюща, выражение -John а,е ,Не е„"
/Sc/iant и Rieger.1974]
ч:
^Воок
Рис. 6.10. Представление MH4f"",^,i,'J
виашости для предложения ''J° " ,<-с11аПк "
Магу from civiiiB a book to Ьш
Mary from giving
Rieger, 1974]
Часть III. Представление и разум в ракурсе искусственного и
Теория концептуальной зависимости имеет ряд важных преимуществ. Во-первых,
за счет построения формальной теории семантик естественного языка уменьшаются
проблемы, связанные с двусмысленностью. Во-вторых, само представление в
процессе построения канонической формы смысла выражений охватывает много
естественно-языковых семантик. Это означает, что все выражения, которые имеют один
и тот же смысл, будут внутренне представлены синтаксически идентичными, а не
только семантически эквивалентными графами. Это каноническое представление —
попытка упростить выводы, требуемые для понимания. Например, мы можем
продемонстрировать, что два выражения означают одну и ту же сущность, с помощью
простого сопоставления графов концептуальной зависимости. Представление,
которое не обеспечивает канонической формы, может потребовать большого количества
операций на графах различной структуры.
К сожалению, процесс преобразования выражений в каноническую форму вряд ли
можно полностью алгоритмизировать. Как отмечено в [Woods, 1985} и других работах,
преобразование в каноническую форму нельзя реализовать даже для моноидов —
алгебраических групп, которые значительно проще, чем естественный язык. Более того, нет
уверенности, что люди запоминают свои знания в какой-нибудь канонической форме.
Критические замечания высказывались также по поводу вычислительной
сложности преобразования предложения в набор примитивов низкого уровня. Кроме
того, сами примитивы не позволяют охватить многие более тонкие понятия, играющие
важную роль в использовании естественного языка. Например, представление слова
"tall" ("высокий") во втором выражении на рис. 6.8 не учитывает неопределенность
этого термина, как это делается в системах нечеткой логики [Zadeh, 1983],
описанных в разделе 7.3.
Однако нельзя сказать, что модель концептуальной зависимости интенсивно не
изучалась и не была хорошо понята. Уточнение и расширение этой модели
продолжалось более десяти лет. Важными для развития теории концептуальных
зависимостей являются работы, посвященные сценариям н пакетам организации памяти.
Работы по сценариям связаны с изучением организации знаний в памяти н ее роли в
рассуждениях (см. подраздел 6.1.4). Пакеты организации памяти стали одной из
вспомогательных исследовательских областей для разработки механизмов
рассуждений, основанных на опыте (раздел 7.3). Теория концептуальной зависимости
является полностью разработанной моделью семантики естественного языка. Она
широко применяется и дает непротиворечивые результаты.
6.1.4. Сценарии
Программа, понимающая естественный язык, должна использовать большое
количество исходных знаний, чтобы понять даже простейший разговор (раздел 13.0).
Согласно экспериментальным данным люди организуют это знание в структуры,
соответствующие типовым ситуациям [Bartlett, 1932]. Читая статью о ресторанах,
бейсболе или политике, мы устраняем любые двусмысленности в тексте с учетом
тематики статьи. Если сюжет статьи неожиданно меняется, человек делает краткую
паузу в процессе чтения, необходимую для модификации структуры знания-
Возможно, слабо структурированный текст тяжело понять именно потому, что мы не
можем с легкостью связать его с какой-нибудь нз структур знания. В этом случае
ошибки понимания возникают из-за того, что мы не можем решить, какой контекст
Глава 6. Представление знаний
237
. „азрешенн* неопределенных местоимении и других двусмыслен,
использовать для P-W
ностей разговора. ^ структурированное представление, описывающее стереотип.
Сценарии <КП''" со6ытай в частном контексте. Сценарии первоначально 6ыл„
кую "^^^"Т^ Abe|so„ 1977] как средство для организации структур копией.
предложены в [Sena опнсанни типовых ситуаций. Сценарии используются в систе-
„ГГннмГГе^теТтвенного языка для организации базы знаний в терминах ситуаций,
"ТотьшТст^люХГ^с полностью спокойны (т.е. они знают, чего ожидать „
„я, Гйсгвовать) Их либо встречают на входе, либо знак указывает, куда они д„таны
Гп£Й чтобы сесть. Меню либо лежит на столе, либо предоставляется официантом, „,.
бо посетитель его просит. Мы понимаем процедуры для заказа еды, принятия пищи, он-
латы счета и ухода
В действительности ресторанный сценарии совершенно отличается от других
сценариев принятия пиши, например, в ресторанах "быстрого обслуживания" илн в рамках
"официального семенного обеда". В сети ресторанов "быстрого обслуживания" заказчик
входит, становится в очередь, оплачивает заказ (до принятия пищн), ожидает подноса с
едой, берет поднос, пытается найти свободный стол и т.д. Это — две различные после-
довательности событий, и каждая имеет отдельный сценарий. Сценарий включает
следующие компоненты.
• Начшьные условия, которые должны быть истинными при вызове сценария. В
этом сценарии они включают открытый ресторан и голодного посетителя,
имеющего некоторую сумму денег.
• Результаты или факты, которые являются истинными, когда сценарий
завершается; например, клиент сыт и его деньги потрачены, владелец ресторана имеет
больше денег.
• Предположения, которые поддерживают контекст сценария. Они могут включать
столы, официантов и меню. Множество предположений описывают принятые по
умолчанию условия реализации сценария. Например, предполагается, что
ресторан должен иметь столы и стулья, если не указано противоположное.
• Роли являются действиями, которые совершают отдельные участники.
Официант принимает заказы, доставляет пищу и выставляет счет. Клиент делает
заказ, ест и платит.
' Сцены. Шенк (Schank) разбивает сценарий на последовательность сцен, каждая я
которых представляет временные аспекты сценария. Сценарий похода в рестоР»
включает следующие сцены: вход, заказ, приятие пиши и т д.
с» ^7^Т117^Н0ШЫе ""а"И" «-и—кого значения- представл.»^
■пруктде оГГе"^ °" 3а""СИМ0С™- Собранные вместе во фреймоподобно
вышесценапий ппген»,,.
последовательность значений или событий. Описании
ешения ресторана представлен на рис. 6.11.
Сценарий- РЕСТОРАН
Аналог; Кафе
Реквизиты: Столы
Меню
F = Пища
Чек
Деньги
Роли. S = Заказчик
W = Официант
С = Повар
М = Кассир
О = Владелец
Начальные условия' S голоден
у S есть деньги
Результаты' у S стало меньше денег
у О стало больше денег
S не голоден
S доволен (не обязагельно)
Сцена 1 ■ Вюд
S PTRANS S в ресторан
S ATTEND смотрит на столы
S MBUILO куда сесть
S PTRANS S за стол
S MOVE S а сидячее положение
Сцена 2 Заказ
Меню на столе
W приносит меню S просит меню
S PTRANS меню S / S ^MNS сигнал W
У W PTRANS W к столу
\ S S MTRANS отдельный saxaaW
\ / W PTRANS W к меню
\ W PTRANS W к столу
\ W ATRANS меню S
\ /
S MTPANS список блюд в СР (S)
'SMBUILD выбор F
S MTRANS сигнал W
W PTRANS W к столу
S MTRANS "я хочу Р W
"■*"—- WPTRANS WkС
^^ W MTRANS (ATRANS F) С
С MTRANS "нет F'W \
W PTRANS WS \
W MTRANS 'нет Г S \
вернуться к * или \
перейти к сцене 4 С DO (сценарий "приготовить F")
(путь без оплаты) к сцене 3
Сцена 3' Употребление пищи
С ATRANS FW
W ATRANS FS
S INGEST F
Вариант- Вернутьсв к сцене 2. чтобы заказать еще раз.
иначе перейти к сцене Л \
Сцена 4; Выход \
SMTRANSW
/ (W ATRANS чек S)
WMOVE выписывает чек
WPTRANSWkS
W ATRANS чежБ
S ATRANS чаевые W
SPTRANSSkM
S ATRANS деньги М
S PTRANS S к выходу из ресторана
Путь без оплаты
Рис. 6.11, Сценарии! посещения ресторана [Schank и Abefson. 1917]
Описанная в [Schank и Abelson, 1911] программа читает небольшой рассказ о
ресторанах н преобразует его во внутреннее прслставление концептуальной зависимости. По-
скольк7 ключевые понятия этого внутреннего описания сопоставляются с начальными
Ja 6. Представление знаний
239
мя связывает объекты, представленные в рассказе, с РОДя.
„,„„ сценария. W^»*", „ шснарин. Результатом является расширь
Т*Z положен.—. ^^,' „льзуюшее сценарий для заполнена» отсутс^
Чтение контекста разкам. нию. Затем программа отвечает на вопро-
^„нформаиии » "реЛПТи!нарий. Сценарий допускает рациональные предположен»,
ш „ рассказе. «ьи11ЯСЬНа^т;я существенным* в понимании естественного яэыа.
™сСГ—tplepoB.
Пример 6.Ы ^ Не ordmd steak. When he paid he noticed he was
John went Ю a restaurant as ^^ ^ ^ ^ ^^ ю mjn {джон зашея g рестрш
naming out of money. He hum да рассчитываясь, он заметил, что остался бег
прошлых вечером. °«™^ 1иачаяся Ьождъ.)
денег. Он поспешил оомои, правильно ответить на вопросы о том, обедал ля
Используя сценарии, систем * ет это), чт0 использовал Джон: «а-
джо„ "РО^ "^» Р"« *о„ получил меню, что ои купил.
личные или
^^Гар^-^о;^-^, что он купил.
Пример 6.1.2
Sue wen, ои, to lunch. She ш, a. a table and called a waitress, who brought her a теш
SheoJerTaZdwick (Сью noma ^ ланч. Она села за стол и позвала официанту,
которая притаю ей меню. Она заказала сэндвич.) n„„™v ndmtm-
пГповоду этого текста логично задавать следующие вопросы Почему офици
антка принесла меню Сью? Была ли Сью в ресторане? Кто платил? Кто заказал ни
двич? Последний вопрос достаточно сложен. Ответ "официантка" (упомянутая
следней женщина) является неправильным. Роли сценария помогают разре i^
ссылки на местоимения и другие двусмысленности. Сценарии также могут
пользованы для интерпретации неожиданных результатов или прерывания д
насти по написанному сценарию.
Пример 6.1.3
Kate went to a restaurant. She was shown to a table and ordered steak from a "''"'"",
sat there and waited for a long lime. Finally, she got mad and left. (Кейт вошла в pec ^
Ей указали стоя, и она заказала бифштекс у официантки. Она села и долгое ера
ш Наконец она разозлилась и ушла.} м
На основе этого рассказа можно сформулировать следующие вопросы. Кт0д111С.
и ждал. Почему она ждала? Кто разозлился и ушел? Почему она разозлилась • ^
тим, что существуют и другие вопросы, на которые нельзя ответить с помои* не
поиГолитГп Т"™ "«^Щий- Почему людн злятся, когда официант-д да.
ли™71 f Н° °Юб0Й ™стеме. "снованной на знаниях, сценарии требУ»
Рир™а„„11,0Т!Х°ДИМ0Й баМВОЙ "«Формации. Подобно фреймам и ДР^"^»"
проблема™ У"™™»"»" исп°»«ова„„е сценариев сопряжено с «nff''^-
«рта. Контекст,' св»занный со сценарием посещения ресторан»' цк
с-« в ресторане ГСЬ "т" ВаЖную Роль' так как слово "bill" может оэ»
T0DMe.™ и программу концерта
Пример 6.1.4
John visited his favorite restaurant on the way to the concert. He was pleased by the bill
because he liked Mozart. (По пути на концерт Джон посетил свой любимый ресторан.
Он был доволен программой, так как любил Моцарта.)
Поскольку выбор сценария обычно основан на соответствии "ключевых" слов, часто
трудно определить, какой из двух или более сценариев следует использовать. Проблема
соответствия сценария является "глубинной", т.е. не существует алгоритма,
гарантирующего правильный выбор. Она требует эвристических знаний об организации мира, а
сценарии помогают лишь в организации этого знания. Проблема чтения между строк
тоже очень сложна: нельзя наперед указать возможные случаи, которые могут нарушить
сценарий. Например, рассмотрим следующую ситуацию.
Пример 6.1.5
Melissa was eating dinner at her favorite restaurant when a large piece of plaster fell from
the ceiling and landed on her date. (Мелисса обедала в своем любимом ресторане, когда
большой кусок штукатурки omeaiwicx с потолка и упал на ее финики.)
Здесь уместны следующие вопросы. Ела ли Мелисса финиковый салат? Что она
делала дальше? Были ли финики Мелиссы запачканы? Как показывает этот пример,
структурированные представления могут быть негибкими. Рассуждения могут быть
локализованы в одном сценарии, даже если он не соответствует ситуации.
Пакеты организации памяти решают проблему негибкости сценария, представляя
знания с помощью более мелких компонентов вместе с правилами для их динамического
связывания в схемы, соответствуюшие текущей ситуации [Schank. I982]. Организация
памяти знаний особенно важна для реализации рассуждений, основанных на опыте, в
которых решатель должен эффективно находить в памяти подходящее решение прежней
проблемы [Kolodner, 1988a] (раздел 7.3).
Проблемы организации и поиска знаний очень трудны и характерны для
моделирования семантического значения. Евгений Черняк [Chamiak, 1972] показал, какое
количество знаний требуется для понимания даже простых детских рассказов. Рассмотрим
фрагмент текста, описывающий вечеринку в честь дня рождения: "Магу was given two kites for
her birthday so she took one back to the store" ("В день рождения Мэри подарили два воз-
Душных змея, поэтому она вернула один из них в магазин"). Мы должны знать о
традиции дарить подарки в день рождения: знать, что такое воздушный змей и почему Мэри
могла ие захотеть иметь двух змеев. Мы должны знать о магазинах и их политике
обмена. Несмотря на эти проблемы, программы, использующие сценарии и другие
семантические представления, могут понимать естественный язык в ограниченных предметных
областях. Примером может служить программа, которая интерпретирует сообщения,
поступающие по каналам новостей. Благодаря использованию сценариев природных
катастроф, успешных сделок и других стереотипных историй программа достигла заметных
Успехов в этой ограниченной, ио реальной области [Schank u Riesbeck. 1981].
6.1.5. Фреймы
Фре(шы (frame) — это другая схема представления, во многом подобная сценариям и
ориентированная на включение в строго организованные структуры данных неявных
(подразумеваемых) информационных связей, существующих в предметной области. Это
6. Представление знаний
241
„оживает орпш..заш.ю знании в более сложные единицы, к^
^едс^ение поддерживав Pjron о,ласп|
отображают яруиУРУ'°™ -1МЫ оп„сываются следующим образом.
R статье [Minsky. i="->J vf1-
Когда некто встречается с новой ситуацией (или существе.
В статье [Mi
Вот суть
меняет »Г ™^Г„7нкый ирие при необходимости должен быть адаптароздТ^
Г™.™..,,.™ изменением деталей [Minsky. 1975]
Вот суп, теории.фрей ^ ^ ^ 0„ вы6„рает ,„ „амяти структуру, итааЮ1£
„ - ■ Л^Гсохраненкь,,-. карие при необходимости должен бьт. пла„™„„.,...
'^Т^г^иеГреальньг., изменением деталей |
Я соответствии с [Minsky. 1975] фрейм может рассматриваться как статическая струк-
™,f ГнТиспользуемая для представления хорошо понятных стереотипных ситуаций.
нТможно наше собственное знание о мире тоже организовано во фреиыоподобные струк-
™ы Мы'приспосабливаемся к каждой новой апуации, вызывая информацию, основан,
„ук, на опыте Затем мы адаптируем эти знания в соответствии с новой ситуацией.
Например достаточно один раз остановиться в гостинице, чтобы составить
представление о всех гостиничных номерах. Там почти всегда есть кровать, ванная, место для че.
модана. телефон, аварийно-эвакуационная информация на внутренней стороне двери и
т.д. Детали каждого номера при необходимости могут изменяться. Может варьироваться
цвет портьер, расположение и тип выключателей и т.п. С фреймом гостиничного номера
связана также информация, принимаемая по умолчанию. Если нет простыней, нужно
вызвать горничную, если нужен лед. необходимо посмотреть в холле и т.д. Нам не надо
подстраивать сознание для каждого нового гостиничного номера. Все элементы
обобщенного номера организуются в концептуальную структуру, к которой мы обращаемся,
когда останавливаемся в гостинице.
Эта высокоуровневые структуры можно представить в семантической сети, организуя
ее как совокупность отдельных сетей, каждая нз которых представляет некоторую
стереотипную ситуацию. фреймы так же, как объектно-ориентированные системы,
обеспечивают механизм подобной организации, представляя сущности как
структурированные объекты с поименованными ячейками и связанными с ними значениями. Таким
образом, фрейм или схема рассматривается как единая сложная сущность.
Например, гостиничный номер н его компоненты могут быть описаны рядом
отдельных фреймов. Помимо кровати во фрейме должен быть представлен стул: ожидаемая
m л" 2° ^!4° СМ' ™"° Ножек ~~ 4' значе™е по умолчанию — предназначен ля
Aral™1' ФРШМ пред™,,е1 гостиничный телефон: это вариант обычного «.«•
шГсЗГ М ПереГОВО')ы ^взывается с оплатой гостиничного номера. По у**»
™ 2 f™5" cne™^"HH гостиничный коммутатор и человек может нспользо»?
этот телефон для заказа еды i
рис. 6.12
Каждый
изооражен фрейм, подставляющий
номер, внешних звонков и получения других услуг-
гостиничный номер.
поле™™ 'оо-"™^^ """к! раССМЭТР™™ ■« «РУ*^РУ ^нньгх. во и*
™» Ячейки AndhL ' и"Ф°Рмаиией. соответствующей стереотипным суш»
«и фрейма содержат такую информацию
\Я°т»'^ентифшш<иифр&ца
'■■ Вюил
мосгязь мого фрейм.
■МО**1
«Ч-п* с„еци1Гным ГкзГ ' ^^ Ф"Лшт- 'Гостиничный телефон ^
^■житьпГямером™меха^^аМРОМ l""™*0113". который, в свою очередь- «
31есдПГсГеГ^Г;^фрАт-С^- »«р"«р- —высоту "ST*
■млиоищдл, 0Г™Частъ »ьще 60 см. „ т.д. э™ требования могут бы"
^ .^^^^^^^«я „овых обге1с10Рв стереотипу фре"*^
ость '"■ Представление и разум „ рак№се искусСтвенного и
гостиничный номер
специализация- номер
положение: гостиница
содержит гостиничный стул
гостиничный телефон
гостиничная кровать
гостиничный стул
специализация- стул
высота 20-40 см
назначения: для сидения
гостиничный телефон
специализация телефон
назначение: заказы в номер
расчет: вместе с оплатой номера
гостиничная кровать
суперкласс кровать
назначение-спать
размер: королевский
1 *"
суперкласс подушка
изготовите/* фирма
Рис-6.12. Часть фрейма, описывающего гостиничный номер. "Специализированный"
класс содержит указатель на суперкласс
4. Процедурная информация об использовании описанной структуры. Важной
особенностью фреймов является возможность присоединить к ячейке процедурный код.
5. Информация по умолчанию. Это значения ячейки, которые должны быть
истинными, если не найдены противоположные. Например, стулья имеют 4 ножки, на
телефонах есть кнопки, гостиничные кровати заправляются персоналом.
6. Информация для нового экземпляра. Многие ячейки фрейма могут оставаться
незаполненными, пока не указано значение для отдельного экземпляра илн пока они
не понадобятся для некоторого аспекта решения задачи. Например, цвет кровати
может оставаться неопределенным.
Фреймы расширяют возможности семантических сетей рядом важных
особенностей. Хотя
реймовое описание гостиничных кроватей на рнс. 6.12 может быть эквн-
чентио сетевому описанию, фреймовая версия намного яснее той, в которой кровать
исывается с помощью ее различных атрибутов. В сетевой версии существует просто
купность узлов. Такое представление в значительной степени зависит от иитер-
ретацни структуры. Возможность организации знаний в такие структуры является
важным свойством баз знании.
рсимы позволяют организовать иерархию знаний. В сети каждое понятие прелстав-
с« узлами и связями на одном н том же уровне детализашш. Однако очень часто для
и* целей объект необходимо рассматривать как единую сущность, а для других —
ватъ детали его внутренней структуры. Например, обычно нас ие интересует меха-
к»е устройство автомобиля, пока что-то ие сломается. При обнаружении поломки
достаем схему автомобильного двигателя и пытаемся устранить проблему.
роцедурные вложения являются важным свойством фреймов, таг как онн по-
т связать фрагменты программного кода с соответствующими сущностями
^ва 6. Представление знаний
243
„пения Например, в базу знании можно включить возмож„0ст.
фреймового прелстав«е«и озы Для этого больше подходит графический Я1ь,к
генерировать графичес ' ых вложсний можно создавать демоны (demon)'
чем сетевой. С помош V ^^ побочным эффектом некоторого дру'
Демон- это процедур . ^ каждом измсне„„и определенной ячейк,, „
ГПо^Гзапуекать процедуру контроля соответствия типов или тест непр„т,
ВОРС|,'сте°м™фреГшов поддерживают наследование классов. Значения ячеек и ис„о,1иуе-
, Z.Гшолчанню значения класса наследуются через иерархию класс/подкласс „
кпасс/аден Например, гостиничный телефон можно реализовать как подкласс обычного
телефона обладающий следующими особенностями: внешние звонки проходят через
коммутатор гостиницы (для расчета), и гостиничные услуги можно заказывать по пр„.
мому номеру. Некоторым ячейкам можно присвоить значения по умолчанию. Они не-
пользуются, если нет другой информации. Например, в гостнннчных номерах стоят кро-
вати. поэтому туда необходимо идти, если вы хотите спать. Если вы не знаете, как по-
звонить портье, попытайтесь набрать "нуль".
Когда создается экземпляр фрейма класса, система будет пытаться заполнить его
ячейки либо заданными пользователем значениями, либо значениями по умолчанию,
взятыми из фрейма класса, либо выполнит некоторую процедуру или демон для
получения значения экземпляра. Как и в семантических сетях, ячейки и значения по умолчанию
наследуются через иерархию класс/подкласс. Конечно, используемая по умолчанию
информация может привести к немонотонности описания данных, поскольку корректность
такой информации не всегда можно доказать (см. раздел 8.1).
В работе [Minsky, 1975] приводится пример использования фреймов в рассуждениях
по умолчанию. Рассматривается задача выявления ситуации, в которой различные
проекции объекта на самом деле представляют один н тот же объект. Например, три
проекции куба на рис. 6.13 действительно выглядят различными. В [Minsky, 1975] предложена
система фреймов, которая распознает их как проекции одного и того же объекта, по
умолчанию учитывая наличие
невидимых сторон.
Система фреймов на рис. 6.13 представляет четыре плоскости куба. Штриховые
линии показывают плоскости, невидимые в этой проекции. Связи между фреймами
отражают-отношения между видами, которые представлены фреймами. Конечно, если
6« ГГТ"Ш ""Формация о цветах или узорах граней, узлы бы*
за ель а лГ„ТГ' ? да«™™ности каждая ячейка фрейма может содержать j^
олж и те же данныГ'"' ^ П°Ш°ЛИТ ИЗбе™ избыточности информации, поскольк
Енарие 6"Г М°Ж"° ИСПОЛ"°*«ь в нескольких различных ячейках (плоское»
"ыеФоР6ье!гтьГнТвИ1Т„Т/г°ЗМОЖНОСТ1' сем^™чееких сетей, позволяя представлять елс*
(Фрейма). Это также'„,« ссм!1н™"кской структуры, а в виде единой суш.ю "
««. классы, наследован еТз^ еСТеСТвенным образом представить стереотипные суй» ^
" сетевым представлениям Чения п0 Умолчанию. Хотя фреймы, подобно яоП'чк
сложных баз знаний все ж!' Г™™1 М0ЩНЫМ средством, многие проблемы орган"
Исследован^ проведенные вТтп РСШаТЬСЯ На °сно8е опыта » ИНТ>"ЩИ" '"""^„с" «Г
* " ик"«°»ательском ц н'1'™^ Г0ДИ » Массачусетсом технологическом .и*"™
*ш'°соф„„ о6ъект,,0.ориЦ™^ Хего* Palo Alto Research Center, привели к раз»*
Рг»изацн„,вкдючм5Р^™Рова„иого программирования и созданию важных »*>
■ ava- C++ и, наконец, CLOS (раздел 15.12).
' разум в ракурсе искусственного ►
Е \
В
Вправо
Г1
В
Вправо
/Т~Л
в
/
Пространственный фрейм
Аксонометрические фреймы
Маркеры отношений в
общетерминальной структуре могут
представлять больше инвариантных
(в том числе пространственных) свойств
Рис. 6.13. Пространственный фрейм для представления куба [Minsky, 1975a}
6.2. Концептуальные графы: сетевой язык
Вслед за первыми работами по созданию схем представления в ИИ (раздел 6.1) был
предложен ряд сетевых языков для моделирования семантики естественного языка и
других областей. В этом разделе мы детально рассмотрим конкретный формализм,
чтобы показать, как этими средствами решаются задачи представления смысла. Примером
сетевого языка представления являются концептуальные графы [Sowа, 1984]. Мы
определим правила формирования концептуальных графов н манипулирования имн, а также
опишем соглашения для представления классов, экземпляров н отношений. В
подразделе 13.3.2 показывается, как этот формализм может быть использован для представления
смысла в задачах понимания естественного языка.
О.2.1. Введение в теорию концептуальных графов
Концептуальный граф (conceptual graph) — это конечный, связанный, двудольный
граф. Узлы графа представляют понятия, или концептуальные отношения. В
концептуальных графах метки дуг не используются. Отношения между понятиями предегавляют-
ся узлами концептуальных отношений. На рис. 6.14 узлы dog (собака) и brown
(коричневый) представляют понятия, a color (цвет)— концептуальное отношение,
тобы различать эти типы узлов, узлы понятий будем представлять прямоугольниками, а
концептуальные отношения — эллипсами.
° концептуальных графах узлы понятнп представляют либо конкретные, либо
абстрактные объекты в мире рассуждении. Конкретные понятия, такие как кошка, телефон
,Ли Ресторан. характеризуются нашей способностью сформировать их образ. Отметим,
т° к конкретным относятся обобщенные понятия, например, cat (кощка) или
restaurant (ресторан), а также понятия конкретных кошек и ресторанов. Мы можем также
формировать образ обобщенной кошки. Абстрактные понятия включают такие абеграк-
ии Как любовь, красота, верность, для которых не существ\ет образов в нашем вообра-
'■ Представление знаний
245
ошений описывают отношения, включающие одно wu,
женин. Умы концептуальных о™ концептуальных графов без использовав,,,
Сколько понятий. Одним из пр >?едстзвления от„ошений любой арности. N-ap„oe
помеченных дуг является просто ^^^^ отношения, имеющего N дуг, как по-
„гношсние представляется узл
казано на рис. 6.14. представляет одно высказывание. Типовая база знаний
Каждый концептуальный гр чг ^^ быть произвольной сложности, но они
будет состоять из ряда «ких граф • ^ ^ 6М представляет высказывание "А
должны быть конечюми/ „^да коричневого цвета"). На рис. 6.15 изображен более
dog has a cote of brawn ( ^^^ .Шгу gave John the book" ("Мэри да„а
сложный граф, предси концептуальные отношения используются для представле-
Джону книгу"). В этом гР * и примера ясно, как концептуальные графы
flies (летает) - унарное отношение
color (цвет) — бинарное отношение
parents (родители) — тернарное отношение
Рис 6.14. Концептуальные отношения разной арности
object
person: Mary h
give
person John h
Рис. 6.15. Граф предложения "Магу gave John the book"
6.2.2. Типы, экземпляры и имена
отиошен^Г "еРВЫХ семан™^*их «в* в основном не заботились об олреп^
Г1зГчно" ТМе'1Т Н —^С в результате чего возникала св«нп^
°™™ZZmZ™VT^ М£ЖД* ^емпляром и его классом *****%*
зом одни ев *7а Г„Г:: (С°баКа) " его суперклассом (плотоядные). Подобнь м ^
представление дГя^оХ?31 ЭКЗеМШ1ЯРам- а ДРУ™ " самим классам. В связи
« "любить ко4 0™0tT Г""' МСХаНИЗМ *" таК0Г0 РаЗЛНЧ11Я- СВ°ЙСТВа *?&**
свойствами "иметь мех" к1(0тлсльным собакам, а сам класс
"собака не ^
включают имена и места . °т чт0 Уг°Дк°". Свойства, соответствуют"0
место в зоологической классификации.
ЧЭСТЬ '"■ Пр8«"авление и разум а ракурсе искусственного и
В концептуальныхграфах каждое понятие является уникальным экземпляром
конкретного типа. Каждый прямоугольник понятия снабжается меткой типа, определяющей
класс или тип экземпляра, представленного этим узлом. Таким образом, узел,
снабженный меткой dog (собака), представляет некоторый обьект этого типа. Типы имеют
иерархическую структуру. Тип dog (собака) является подтипом типа carnivore
(плотоядные), который, в свою очередь, является подтипом nammal (млекопитающие) и
т.д. Прямоугольники с одной и той же меткой типа отражают понятия одного и того же
типа. Однако эти прямоугольники могут либо представлять, либо не представлять одно н
то же индивидуальное понятие.
Каждый прямоугольник понятия помечается именами типа и экземпляра. Метки типа
и экземпляра отделяются двоеточием. Граф на рнс. 6.16 показывает, что собака Emma —
коричневая. Граф на рис. 6.17 означает, что некая иеспецифицированная сущность типа
dog имеет коричневый цвет. Если экземпляр не указан, понятие представляет неспеци-
фнцированный индивидуум этого типа.
Концептуальные графы позволяют также описывать конкретные, но неименованные
экземпляры. Для обозначения каждого экземпляра в мнре рассуждений используется
уникальный дескриптор, называемый маркером (marker). Он представляет собой число,
перед которым расположен символ "#". Маркеры отличаются от имен тем, что оии
являются уникальными: экземпляр может иметь одно имя, несколько имен или вовсе быть
безымянным, но он имеет ровно один маркер. Подобным образом различные экземпляры
могут быть тезками, ио не могут иметь один н тот же маркер. Это различие дает
возможность преодолевать семантические неоднозначности, возникающие при именовании
объектов. Граф на рис. 6.17 означает, что конкретная собака #1352 — коричневая.
♦(fcoforj) 4
Рис. 6.16. Концептуальный граф. показывающий,
что собака Emma — коричневого цвета
dog. «1352 I K^cotor^) »|^
Рис. 6.17. Концептуальный граф. показывающий,
что отдельная (но безымянная) собака —
коричневого цвета
Маркеры позволяют отделить экземпляры от их имен. Если собака #1352 имеет имя
Эмма, для его описания можно использовать концептуальное отношение паше (имя).
Результатом является граф на рис. 6.18. Имя. заключенное в двойные кавычки, указывает,
что это строка. Там, где не возникает опасность неоднозначности, мы можем упростить
Таф и ссылаться на экземпляр прямо по имени. При таком соглашении граф на рис. 6.18
эквивалентен графу на рис. 6.16.
Рис 6 IS. Концептпмъный граф. указывающий,
что собака с именем Етлш - коричневого цвета
1а 6. Представление знаний
247
,й печи так и в формальном представлении мы часто „гно
Хоп, как в Р»™В0Р"°" ^ „ его именем, оно является важным „должно быть „оад
-.и* между «еМмТГнапри«'Р. «ли мы говорим, что John - обычное му^
^,0 языком представ»* ^ са|1ЮГ0 име„„, а не какого-нибудь экземпляр „ ..'
имя, мы утверждаем, т™ ^^ анпгайские выражения, как "Ch
нем John-Это позволит пРД1внзеявш1ется ,|менсм вида Примат0|П.
имя, мы утверждаем, что » тавк анпгайские выражения, как "Chimpanzee'
„ем John. Это позволяет прд^(]инзеявляе1СЯ ,|менсм вида приштв"). Подобнь
name of species of pnmate.s , ^^ ^ ^^ нсскольких имсн Граф ^ ^
разом можно представ иг * ^ лиричсской песне Лсннона и Маккартни (1968 г
.поставляет с..туашгю, называла себя Lil, но все ее знали как Nancy.
„ ,в <• именем Mculll, киюрол
Рис. 6.19. Концептуальный граф для
представления человека с тремя именами
Вместо обращения к объекту по маркеру илн по имени можно использовать
обобщенный маркер * для определения неспецифнцированных экземпляров. Эта информация
часто опускается в метках понятий: узел, заданный только меткой типа dog,
эквивалентен узлу dog: *. Дополнительно к обобщенному маркеру концептуальные графы
позволяют использовать именованные переменные. Они представляются звездочкой, за
которой следует имя переменной (например, *Х или *f оо). Это полезно, если два
отдельных узла должны обозначать один и тот же, но не указанный экземпляр. Граф "•
рис. 6.20 представляет утверждение "The dog scratches its ear with its paw" ("Собака чешет
ухо лапой"). Хотя мы не знаем, какая собака чешет свое ухо, переменная *Х указыв»".
что лапа и ухо принадлежат одной и той же собаке, которая чешется.
Итак, каждый узел понятия означает экземпляр определенного типа. Это объект,
относящийся к данному понятию, или объект ссылки (referent). Ссылка задается либо
индивидуально, либо
Для всех экземпляров в целом. Если l
Гесылки используй»
..„„„„„ uw(JUD и целом, если для объекта C--
"аГ, р„доВМьГРа' ,,0НЯ™е "ВЯЯетСЯ K0H4>e™"«. * если общий маркер - понятие с
"I*lisрач°'"1е"щ'т"^ граф дм „редтжент^Z^og scratches Ш ear
6.2.3. Иерархия типов
Как показано на рис. 6.21, иерархия типов —
множестве типов, которое можно обозначить символе ^™~ У"°Р"*"™и« ...
t < s, то говорят, что t - это подтип в a s _ ~ ССТЬ Т""Ы "
Рис. 6.21. Иерархия типов, иллюстрирующая
подтипы, супертипы, универсальный и
абсурдный тип. Дуги представляют отношения
Иерархия типов концептуальных графов представляет собой решетку, описывающую
Щии вид системы множественного наследования. В этой решетке типы могут иметь
множество родителей и детей. Однако каждая пара типов должна иметь минимальный
0 Щии супертип и максимальный общий подтип. Тип v является минимальным общим
Упертипом для типов s и и, если s<v и u<v и для любого общего супертипа w типов s и
v^w. Максимальный общий подтип имеет аналогичное определение. Минимальный
общий
супертип совокупности типов служит для определения свойств, присушил только
им типам. Поскольку многие типы, такие как emotion (эмоция) и rock (рок), не
имеют общих супертипов или подтипов, необходимо добавлять типы, которые выполня-
т эти роли. Чтобы иерархия типов действительно стала решеткой, в концептуальные
Тафы включают два специальных типа. Универсальный тип (universal type) обозначает-
СЯ Символом 1~и является супертипом всех типов. Абсурдный тип (absurd type) обоэна-
ется с"мволом ± и является подтипом всех типов.
>■ Представление знаний
249
6 2 4. Обобщение н специализация
„„™,„ьНых графов включает ряд операции для создания новых пми,
Те0Р"\™ твГш ol позволяют генерировать новый граф путем либТ*°в
на основе существующих „.шествующего графа, и очень важны для предста»
£^£ГГ£^«* ™'четырс °— • -SSr
ZpZale, огРа,ш<е,ше, обвинение „упрощение. Предположим, что „, „ д^^
^П^шошТоо"»"" "юволяет сформировать НОВЫЙ Т"* 9' кот°Рый «"ляется точ.
ной копией д\. „ ,
Ограничение позволяет заменить узлы понятии графа узлами, представляющим ^
специализацию. Возможны две ситуации.
1. Если понятие помечено общим маркером, то общий маркер может быть заменен
индивидуальным.
2. Метка типа может быть заменена одной нз меток его подтипов, если это
соответствует объекту ссылки понятия. На рнс. 6.22 мы можем изменить animal
(животное) на dog (собака).
Правило объединения позволяет интегрировать два графа в одни. Если узел
понятия С| графа s, идентичен узлу понятия сг графа s2, то можно сформировать новый
граф, вычеркивая с2 н связывая все его отношения с с,. Объединение — это правило
специализации, так как результирующий граф является менее общим, чем любой из его
компонентов.
Если граф содержит два одинаковых отношения, то одно нз них может быть
вычеркнуто вместе со всеми его дугами. В этом заключается правило упрощения.
Дублирующиеся отношения часто возникают в результате операции объединения, как на
графе gij на рис. 6.22.
D°D— ►с^г>_
gz: \anlmal: "emma"\
QcohrJ) J~
Ограничение g2:
g3: dog. ~emma'
Обьединение g, и g3-
g4: (jigenT)*-
1
dog: 'emma"
r
color ) ( color
Упрощение gA:
gs: (^ agent
Рис. 0.22. Призеры операций ограничит, объединения „упрощения
6. Представление знаний
251
„„л ограничения необходимо так сопоставить два „
д., использования врав™ г ^ ПОЭВОЛНт реализовать наследование и, '"".
чтХ их можно было обь* индивидуальным реализует наследование ж,^,
зшена обобшенно о мар Р^ ^^ ^^ опрСделлет наследование „ **»-
свойств типа. 3«мсн»£« о6кдя1гС„„, одного графа с другим и ограничения оп^
сом и суперклассом _пут отать наследование различных свойств. На р„71^
„енвых уз»о= понятии можно^^ст ^.^ „иметь pyRy„ qt щщ ^рим.а
n0Ka38"!,\ пои зГене метки типа меткой подтипа. Кроме того, на рисунке показано ^
эимпляр1во"Гнаследуетзто свойство с помощью инстанцироваиия общего пощ,^"
chimpanzee t-
Наследоеание свойства подклассом
\chimpanieBbonzo\-
♦f^parrj)-
Наследование свойства экземпляром
Рис. 6 23. Наследование в концептуальных графах
Таким же образом объединение и ограничение можно применять для реализации
правдоподобных высказываний, обычно используемых для понимания языка. Если мы
говорим "Магу and Tom went out for pizza together" ("Мэри н Том пошли вместе в
пиццерию"), то автоматически делаем ряд предположений: он» ели круглый итальянский хлеб,
покрытый сыром и томатным соусом. Они ели его в ресторане и каким-то образом
рассчитались за него. Это рассуждение может быть сделано иа основе объединения и
ограничения. Мы формируем концептуальный граф выражения и объединяем его с
концептуальными графами (из базы знаний) для пиццы и рестораиов Результирующий граф
позволяет предположить, что они ели томатный соус и оплатили счет,
част™"™""' " 0граничение "»1яются правилами специализации. Они определи»
ЦиГиза1Г„РЯД0ЧеШ,е "а МК°ЖеСтае ручейных П>афов. Если граф д, являете, спе-
^вГ™™0 "Ы ММСМ Г0В°РИТЬ' ™ в,- обобщение Э|. Иерархия обобше*
™"с :Г,У1РГс;е"ГДСТаВЛеНИИ ЗИаН™- Ш™™ °б°б^™Я используется **»
™ог„х мегоГ 0Нб;Л „Д Г™ " ад™ общесмысловых схем рассуждения, а га*
■«сние на основе J™ Т ™ "ам' "апр™ер, конструировать обобщенное Я1 С
Ь. .гранил, не я1Г °6уЧающе™ "Р™ера.
Фов будут вьшодитьсяи™„ЙГВШ,аМН ВЬ'В0да- °ИИ ие гарантируют, что из истинны^
'""'" ТаФы- Например, при ограничении графа на рис.
*— Emma может быть кошкой. Подобным же
г~ - ™„и „orvr f\u T°'*e m сохРаняет истинность: собака на крылы
**"" "Ржшыц А0„Г № Ручными животными. Эти операции являются *«
зм „к.—. Ч"'1>миР™ания (canonist г • . , , .. _.. „ гохпаия» И1Л ...
образ»»
зультат может не быть всгГЬ'е фа*Ы' НапР"меР- при ограничении граф;
пример гАсди„ениян™ньш-Emma может быть кошкой. Подобным же
га, которая ест кости и о™-к T°'*e m сохРаняст истинность: собака на крыльце
' ^ быть "«личными животными. Эти операции являются «*»
' (canonical formation rule), и, даже ие сохра»
1 свойством — сохраняют "осмысленность". -
ЧЭСТЬ'"' Пре^"^у^а^^^
ность. ош, обладают „„"^a"M (Can°nical formati°" ™le), и, даже ие сохраняя"^,
МНИМЫМ СВОЙг-rnni. _ .. . .. „unf-n". -^
j;r;Z~:CП1УШ,ЬНЫХ ГРаФ°В ' -»- "— —„„ого языка. Рае-
^„тГлГГГ'"",hC ^ °Г re'a,iVi,y (A»^ ЭЙ™ей„ сформулировал теорию
Albert Einstein plays center for the Los Aneclcs I -iWrrs (ЛтК™ ->-
команде Los Angeles Lakers.) 8 ^^ (Аль6срт э™тси„ - центровой в
Conceptual graphs arc yellow Dying policies. (Концептуальные графы являются желтыми
летающими мюмзиками.)
Первое выражение является истинным, а второе — ложным. Третья фаза вообще
бессодержательна: грамматически правильная, оно не имеет смысла Второе предложение, хоть и
ложное, является осмысленным. Я могу представить Альберта Эйнштейна на баскетбольной
площадке. Канонические правила формирования накладывают ограничения на семантику
смысла, т.е. не позволяют формировать бессмысленные графы на основе осмысленных. Не
являясь смысловыми правилами вывода, они формируют основу для многих правдоподобных
рассуждении в системах понимания естественного языка и для общесмысловых рассуждений.
6.2.5. Пропозициональные узлы
Графы можно использовать для определения отношений между объектами мира, а
также между высказываниями. Рассмотрим, например, утверждение 'Tom believes that
Jane likes pizza" ("Том верит, что Джейи любит пиццу"). Здесь believes — это
отношение, аргументом которого является высказывание. Концептуальные графы включают
тип понятий proposition (высказывание), объектом ссылки которого является
множество концептуальных графов. Это позволяет определить отношения, включающие
высказывания. Понятия высказываний, или пропозициональные понятия, изображаются
прямоугольником, содержащим другой концептуальный граф. Эти понятия с
соответствующими отношениями могут использоваться для представления знаний о
высказываниях. На рис. 6.24 показан концептуальный граф для приведенного выше утверждения.
Отношение experiencer (чувствующий) аналогично отношению agent (агент) — оно
тоже связывает субъект с глаголом. Связь experiencer используется для состояний
доверия, которые основываются скорее на интуиции, чем на действиях.
На рис. 6.24 показано, как концептуальные графы с пропозициональными узлами
могут использоваться для выражения модальных понятий знания и доверия. Модальные
логики (modal logic) связаны с различными типами высказываний. Они позволяют выразить
то. во что верится, возможное, вероятное или обязательно истинное, подразумеваемое
как результат действия или противоречащее фактам [Turner, 1984].
6.2.6. Концептуальные графы и логика
Используя коицептуальные графы, можно легко представить такие конъюнктивные
"онятия, как "The dog is big and hungry" ("Собака большая и голодная ), но это
представление не позволяет описать отрицание или дизъюнкцию. Не решен также вопрос кван-
тификацни переменных.
Мы можем реализовать отрицание, используя пропозициональные понятия и унарную
операцию пе3. Ее аргументом является пропозициональное понятие, которое в
результат применения операции пед становится ложным. В концептуальном графе на
Лава 6. Представление знаний
253
высказывание
pgrson:Jane 1
1 L
Рнс. 6.24. Концептуальный граф утверждения "Тот
believes that Jane likes pizza", иллюстрирующий
использование понятий высказываний
Используя отрицание и конъюнкцию, можно формировать графы для представ»
дизъюнктивных утверждений в соответствии с правилами логики. Чтобы упростить""*
процедуру, можно определить отношение or, включающее два высказывания и г, '^
ставляющее их дизъюнкцию.
Предполагается, что в концептуальных графах родовые понятия связаны квантором
существования. Например, родовое понятие "dog" ("собака") на графе, представленном
на рис. 6.14, действительно представляет переменную, связанную квантором существо,
вания. Этот граф соответствует логическому выражению
ЗХЗУ((1од(Х)лсо1ог(Х, Y)*brown(Y)).
Используя отрицание и квантор существования (подраздел 2.2.2), можно также
представить квантор всеобщности. Например, граф на рис. 6.25 можно рассматривать как
представление логического утверждения
ЧХЧПН</од[Х)лсо1о«Х,У)лР1пк{Г))).
f»c 6.25. Концептуальный граф утверждения "Viere
o'enopmtdogs"
ликатов. Как видно 7,^Ы "° С"СеЙ вЬ1Рази™ьной силе эквивалентны исчислению пр«-
концептуальных г™*„ 3™" пРнмеР°в. существует прямое соответствие предсДОИ"
Т>афов системе обозначений исчисления предикатов. В [Sowa, 1«
предложен следующий алгоритм преобразован,,» »
исчисления предикатов. и концептуального графа д в выражение
,. Каждое из п родовых понятий ^ д
2. Каждое конкретное понятие в a „,™ , переменной х„х2, ...,х,.
может быть просто именем или мар™ом 0™МЬН0И к°"<™™»- Эта константа
ссылки для данного понятия. используемым для указания объекта
3. Представить каждый узел понятия vnanuu» „„„
вует типу этого узла, и аргументом КГ™ "реДИКатом' «"» "т^" ™™™-
данного узла. аргументом которого является переменная или константа
4. Представить каждое „-арное концептуальное отношение на графе о „-арным
предикатом стем же именем. Каждый аргумент предиката являетсУ переменной или
константой, соответствующей узлу понятия, связанного с этим отношением.
5. Сформировать тело выражения исчисления предикатов в виде конъюнкции все.,
атомарных выражений, построенных в пп.З и 4. Все переменные в выражении
считаются связанными квантором существования. Например, граф на рис. 6.16
представляется выражением исчисления предикатов вида
ЗХ,(с/од(Етта)лсо/ог(Етта,Х,)лЬгои,„(Х,)).
Хотя концептуальные графы можно описать в синтаксисе исчисления предикатов.
онн поддерживают ряд специальных механизмов вывода, таких как объединение и
ограничение, не являющихся частью исчисления предикатов.
Мы представили синтаксис концептуальных графов и определили операцию
ограничения как средство реализации наследования. Однако это не весь спектр операций и
правил вывода, которые можно реализовать на таких графах. Кроме того, до сих пор не
рассматривалась проблема определения необходимых понятий и отношений для такой
предметной области, как естественный язык. Мы вернемся к этим вопросам в
подразделе 13.3.2 и используем концептуальные графы для реализации базы знаний простой
программы понимания естественного языка.
6.3. Альтернативы явному представлению
В последние годы исследователи ИИ продолжали изучать роль представления в
реализации интеллекта. Кроме коннекцпоиистского и эмерджентного подходов,
рассматриваемых в главах 10 и 11. наиболее достойной альтернативой явному представлению
является методология, описанная в работах Брукса из Массачусетса технологического
института [Brooks, 1991а]. Брукс ставит под сомнение необходимость какой-либо
централизованной схемы представлен™ и с помощью своей категориальной архитектуры
(sobsamp.ion architecture) показывает, как интеллектуальные сущности могут развиваться
из более низких вспомогательных форм интеллекта. „„_.„ „ „f^.
Другой взгляд „а проблему явного и статического предавления »^-»^
тах Меланн Митчелл (Melanie Mitchell) и Дугласа Хофстадтера (Dougta> НоЫаЛегЬ*
университета щтата Индиана. Архитектора Соруса, <"^^aK?b"^^,^n'™
развивающаяся есть, которая адаптируется к смыслу отношении, открываемых в процес
се экспериментирования с внешним ««Ф™- „ Мтчелл яаш<тея то. „г» „х
Важным прикладным аспектом «^°В™^Сзатсм проверял„сь с некоторыми
идеи были разработаны на искусственных объектах, а «, н
- ~ isi
Глава 6. Представление знаний
- irrvauHH Как отмечается во введении к главе 16, это
ограничениями в реальной ситу ' ких „аук: их эксперименты разрабо™ "
работы Брукса и М«^^^,^и подтверждены или отвергнуть,' „ «^ »
Г-^зо^Гс^-^лениезкспериментов.
6.3.1. Гипотез Брукс. . категориальная архитектура
Брукс выдвинул гипотезу о том
что интеллект и рациональное поведение не
возник.
:ГЗыГ н^плошенных) системах, подобных системам доказате^
теорем* ил"д Гв традиционных экспертных системах (раздел 7.2). Эту гипотезу а.™
подтай на примерах созданных им роботов. Брукссчитает, что „нтеллект ,ВИстс
продам взанТодейста™ определенной „нотослоннои системы со своим окру^
ZnZroro. Брукс придерживается точки зрения, что интеллектуальное поведение воз,,»,
кает при взаимодействии архитектур, организованных из более простых сущностей. В
этом состоит основная идея его категориальной архитектуры (subsumption architecture)
Категориальная архитектура реализована Бруксом в системе управления роботом. Эта
архитектура представляет собой совокупность объектов-обработчиков, предназначении
для решения отдельных задач. Каждый такой объект является конечным автоматом, ко.
торый непрерывно преобразует воспринимаемую входную информацию в выходное
управляющее воздействие и зачастую реализуется с помощью простого множества
продукционных правил типа условие-*двйствив (раздел 5.3). С помощью этих правил
можно определить (случайным образом, т.е. без знания глобального состояния), какие
действия соответствуют текущему состоянию подсистемы. Брукс допускает некую
обратную связь от более низких уровней системы.
Перед тем как представить прнмер архитектуры Брукса на рис. 6.26,
познакомимся с его философией. Брукс полагает, что "при построении больших
интеллектуальных систем представление является неправильной единицей абстракции".
Следовательно "явные представления н модели мира можно строить лишь на низших
уровнях интеллекта. Оказывается, в качестве модели мира лучше использовать сам
мир" [Brooks, 1991a]. Таким образом, Брукс рассчитывает строить
интеллектуальные системы инкрементально. На каждом этапе архитектуры он предлагает создать
завершенную систему и обеспечить надежность фуикциоиировання ее составных
частей и их интерфейсов. На каждом шаге проектирования он строит завершенные
интеллектуальные системы, которые тестируются в мире, требующем
действительного восприятия и действия [Brooks, 1991a].
На рис. 6.26, взятом из работы [Brooks, 1991a], показана трехуровневая
категориальная архитектура. Каждый уровень представляет собой сеть фиксированной топологии,
состоящую из простых конечных автоматов, имеющих несколько состояний, один или
два внутренних регистра, один или два таймера и доступ к простым вычислительным
устройствам, позволяющим, например, вычислить сумму векторов. Этн конечные
автоматы работают асинхронно, посылая и получая сообщения фиксированной длины. В
системе нет централизованного управления. Наоборот, каждый конечный автомат управ««-
ется данными, получаемыми им через сообщения. При получении сообщения или завер-
™oZZMeH"°r0 'КР"°Да °ЖИдания ^стояние автомата изменяется. В системе нет
еГтГГ Г1""* "ЛИ Каких-,шб° Динамически создаваемых коммуникационных свя-
J равноправны и являются
пленниками своей связности.
256
I- Представление и разум в ракурсе искусственного интелло*1"
-нь---
Рис. 6.26. Фужит „раурошг,ой категор^ьтй
тектуры и, рабом (ВгооЬ I99hj. VpLu ,«*U
функции AVOID (избегать), иаюец („вращаться) "ет-
PLORE (исследовать)
На рис. 6.26 представлено подмножество функций трехслойной архитектуры,
реализованной в одном из первых роботов [Brooks. 1991а]. Робот был оснащен кольцом из
двенадцати сонарных датчиков. Каждую секунду эти датчики давали двенадцать радиальных
измерений расстояния до препятствия. На самом низком уровне категориальной архитектуры
реализуется функция AVOID (избежать), которая предотвращает столкновение робота с
объектами, вне зависимости от того, являются они статическими или движущимися.
Автомат с меткой, помеченный sonar data (сонарные данные), выдает мгновенную
информацию тар, которая передается на автоматы collide (столкновение) и feedforce
(ощущение препятствия), первый из которых способен генерировать сообщение halt
(остановиться) для автомата, отвечающего за перемещение робота вперед. При
активизации автомата feedforce он способен генерировать инструкции runaway (уйти прочь)
или avoid (обойти), чтобы избежать опасности.
Эта сеть конечных автоматов самого низкого уровня генерирует инструкции halt
(остановиться) и avoid (обойти) для всей системы. Следующий слой WANDER
(перемещение) определяет способ перемещения системы, генерируя для робота
случайное направление heading каждые 10 секунд. Автомат AVOID (нижний уровень)
получает направление heading от автомата WANDER и связывает его с результатами работы
уровня AVOID. Автомат WANDER использует этот результат для подавления поведения
более низкого уровня, заставляя робота двигаться в направлении, близком к заданному, и
в то же время избегать столкновения со всеми препятствиями. И. наконец,
активизируясь, автоматы turn (повернуть) и forward (прямо) (на верхнем уровне архитектуры)
будут подавлять любые новые импульсы, присланные от автомата WANDER.
Верхний уровень EXPLORE (исследовать) позволяет изучить окружение робота. При
этом он осматривает (1оок) отдаленные места и достигает их, планируя путь plan. Этот
уровень способен подавлять инструкции автомата WANDER и наблюдать за тем. как
усилиями нижнего уровня робот огибает препятствия. Он корректирует отклонения и фоку-
сирует робота на достижении цели, сдерживая блуждающее поведение, но разрешает
автомату самого низкого давня уклоняться от препятствий на пути. При реализации
отклонений, сгенерированных на более низком уровне, уровень EXPLORE вызывает
автомат plan, чтобы вновь сориентировать
систему на достижение цели. Основой кате-
Глава 6. Представление знаний
257
„>ется то. что система не требует Централизован,,.,,
„риальной архитектору^, явля свои дейстшм без по„ска сред„ „ ^
символьных ра-Я»?""!'" S конечный автомат генерирует инструкции дл, т*
следующих состоянии. Хот,£■£„„,„„, „обальио система действует „а ос„ове
в„й исходя из своего пкуш
„одействия нижних ™-а^УРС|лура ията ю раннего прое1сга Брукса по
Представленная трехслойна» и „ослсдние годы его исследовательская труп,.,
ботке робота. п^"™"*^^., количеством уровней [Brooks, 1993], [Вг^
разработала сложные с,,стем путешествовать по лаборатории роботики Массачу
Stein, 1994]. Одна систем*, сг.. ^ ^^ пу(;ть1х щ!ЮИИН„евых банок на рабочих
сетского технологического ^ ^ дш открь,гия дверей офисов поиска ^
Тстол!вТр"аспознаваНия банок. Другие уровни отвечают за управление рукой ро6ой
ДЛЯг.Сб°РаГ™™ ^СвёГниТвертего уровня возникает в результате разработки»
Брукс утверждав, что i архитектуры. Четкое окончательное по.
тестирования отдельных слоев бол» "'^Д^ CM3cR, формируется в „р^ ^
ЕеДеШ"^Шоб™Тте™"ал1„Лектура успешно реализована в несколь^
!=„рТГ^^те«кихс„стемах[Вгс»Ь. 1989]. [Brooks. «91а].
^атеториальноГархитектурой « другими подходами к проектированию систем
управления связано несколько важных проблем (см. также раздел 16.2).
1 Существует проблема достаточности локальной информации на каждом уровне
системы. Поскольку иа каждом уровне чисто реактивные конечные автоматы
принимают решения по локальной информации, т.е. по данным текущего уровня, в
процессе принятия решений ие учитывается информация с других локальных
уровнен. По определению такое решение будет недальновидным.
2. Если не существует абсолютного "знания" или "модели" сложного окружения, как
можно иа основе локальной входной информации об ограниченной ситуации
сгенерировать инструкции для выполнения глобально приемлемых действий? Как
может верхний уровень согласовывать возможные результаты?
3. Как чисто реактивный компонент с очень ограниченным набором состояний может
обучаться в своей среде? Если агент должен быть интеллектуальным, иа некотором
уровне системы нужна достаточная информация для реализации механизмов обучения.
4. Существует проблема масштабирования. Хотя Брукс и его помощники объявили о
реализации категориальных архитектур из шести и даже десяти уровней, необходимо
сформулировать принципы дальнейшего масштабирования интересного поведения.
Может ли этот подход быть обобщен на очень большие и сложные системы?
Наконец, мы должны задать вопрос: что такое "эмерджеитность"? Не мистика ли это?
На настоящем этапе развития науки эмерджеитность относится к явлениям, с которыми
мы можем только считаться. Нам поставили задачу разработать систему, обладаю!")10
интеллектом, и испытать ее. К сожалению, без дальнейшей разработки этой инструкции
эмерджеитность остается только словом, описывающим то. что мы еще не можем
понять. В результате очень трудно определить, как можно использовать эту технологи»
для дальнейшего построения более сложных систем. В следующем разделе мы опишем
гибриднук, архитектуру Copycat, позволяющую открывать инварианты в проблемной о°
ласти исследовательским путем.
258
Часть III. Представление и разум в ракурсе искусственного интеллек*1
6.3.2. Архитектура Copycat
Часто приходится слышать критические чаи».*.,...
„ии« ИИ г..™«и. "■'"'.скис замечания в адрес традиционных схем
представления ИИ, связанные с их статичнпсткю ч ии~„~.. с
„„„ „mimnu™ г.- *-"»тичн°стыо и неспособностью отражать динамическую
природу мыслительных процессов и интелпего, и»п„
человек часто бывает поражен ее сходств Г' Ш"Р"Ж!>' попадая в вов>™ «"У*"».».
„„„ „„ сходством с уже известными ситуациями. Часто
отмелется, что человек получает информацию как снизу вверх, т.е. Эмулируется новыми
образами окружения, так и сверху вниз, т.е. связывается с ожидаемым результатом.
"STn" "° aPX1,TCKWa Р«Ш|=ния задач, разработанная в диссертации Мелани
Митчелл [M.tchell, 1993] под руководством Дугласа Хофстадтера [Hofsladter. 1995] в Индиан-
ском университете. Архитектура Copycat основывается иа многих предшествующих ей
техниках представления, включая модели классной доски (раздел 5.4). семантические сети
(раздел 6.2), сети связей (глава 10) и системы классификации [Holland, 1986]. Она также
использует подход Брукса к решению задач, состоящий в активном взаимодействии с
предметной областью. Однако в отличие от моделей Брукса и сетей связей в Copycat в
состав решателя задач входит глобальное "состояние". Более того, представление является
его динамической характеристикой. Copycat поддерживает механизм, подобный
семантической сети, который растет и изменяется в процессе непрерывного взаимодействия со
своим окружением. Таким образом, представление является менее хрупким и более
обтекаемым — оно включает ту информацию, которую счел важной сам агент, а не ту, которую
считал важной разработчик программы. И, наконец, компоненты Copycat позволяют
изучать ситуацию сверху вниз и снизу вверх, а также устанавливают аналогии.
Изначально задачей Copycat являлось восприятие и определение простых аналогий. В
этом смысле архитектура базируется на раииих работах [Evans, 1968] и [Reitman, 1965].
Примером такой задачи является комплектация групп взаимосвязанных понятии: /юг
(горячий) и cold (холодный), tall (высокий) и wall (стена), snort (короткий), wet
(мокрый), hold (крепость) или построение групп понятий на основе иерархической
организации мира, в частности, bear (медведь) и pig (свинья), либо chair (стул) и foot
(ножка), table (стол), coffee (кофе), strawberry (земляника). Архитектура Copycat
применялась для завершения упорядоченных в алфавитном порядке строк, таких как: abc и
abd win ijk и ?, либо abc и abd или ii/jkk и ?.
Copycat включает трн основных компонента: рабочее пространство (workspace),
гибкую сеть (slipnet), блок кодов (coderack). Эти составляющие взаимодействуют через
подсистему измерения температуры. Температурный механизм включает степень
восприятия в системе, а также управляет степенью случайности при принятии решения.
Высокая температура свидетельствует, что информации для принятия решения мало, низкая
температура означает противоположное. Таким образом, при высоких температурах
решения более случайны, а при понижении температуры система достигает консенсуса. И,
наконец, низкая температура говорит о "созревании" решения, а также отражает его
"достоверность".
Рабочее пространство — это глобальная структура, подобная классной доске,
описанной в разделе 5.5. предназначенная для создания объектов, инспектируемых другими
компонентами системы. В этом смысле оно во многом подобно области сообщений в
классификационной системе Холланда [Holland. 1986]. В рабочем пространстве организуется
иерархия воспринимаемых структур (три строки алфавитных символов). На рис. 6.27
представлено возможное состояние рабочего пространства со связями (стрелками) между
соответствующими компонентами строк. Обратите внимание на го. что на ранних стадиях
построена аналогии образуется связь между элементом с и парой Мс.
Глава 6. Представление знаний
259
ИЗ-
rmosi->-rmost
leiter -*■ 9r0UP
Рис 6 27 Возможное состояние рабочего проапры
ста Соруса,. Погано несколько примера, связей
л,ежду буквами (Milchel. 1993I
Гибка» сеть (slipne.) отражает набор понятий или потенциальных ассоциаций „
компонГтов аналогии (рис. 6.28). Ее можно рассматривать как динамически перестраи
Гмую емантическую сеть, каждый из узлов которой имеет свои уровень активации
Свя"и в сети могут быть помечены именами других узлов. В соответствии с уровнем ак
тнвации помеченных узлов связанные узлы увеличиваются или сокращаются. Таким об
разом система изменяет степень ассоциации между узлами в зависимости от контекста
Это важно при построении текущего решения. Для узлов, более тесио связанных в теку
щем контексте, уровень активации возрастает.
0
0^:0^:0
Рис. 6.28. Небольшая часть гибкой сети Соруса! с узлами, связями и
метками; адаптировано из IMilchell 19931
щая "т неб„1(м!1еТк) ~ ЭТ° аПрИОр" организованная вероятностная очередь, состоя-
ГнмоХ:Гс 0б!еР11НТОВбИСПОЛНЯСМЫХ КОД0В (1-^>- >феДИазнаРченных т
Формируемого решс„ияТа "Г ° "Р°"?т™ « расширяющих некоторую часть
теме, описанной в [Holland 19861 СС"ед.0вания Различных аспектов пространства. В сис-
Узлы гибкой сети генерип кг "'л <""т ,|охожи "а отдельные классификаторы. _
оценкой исполнения. Таким об ' " ' " яаправля10т и* в блок кодов с вероятностно"
менты, конкурирующие между соб""' СИСТСМа "одерживает параллельные кодовые сег-
рабочего про™; ~ ^Т™'" 1а ""Ложность
оонаружитъ и лостроить струи'У к
°ЛЬ1 соотв«ствуют породившим их узлам. В поиске приме-
ров уже сгенерированных сущностей согтпчт „.к
Р^ать и наладить отношения, ZZm~* "Ч"™ Пы™" идентнфнци-
ства, «-«оды могут также работать С„У»^Х "" " ° "Р°'Щ"1"'
n°JZJ гГе'™1ТУЮ7Р в Ра6°ЧСМ пР°"Ра„ст»е повышается степень активации
узлов, которые .снерирукгг исполнительные кодь,. ">то позволяет в контексте текущего
сования решения проблемы влиять „а будущее поведение системы. Важным заемном ар-
хитсктурь. Copycat является использование случайное™. Большинство решений
принимается случайно, а вероятность выбора действия или структуры определяется соответствием
ЭТ0Й сущности текущему состоянию решения задачи. Фактор случайное™ также
предохраняет программу от попадания в "тупиковые ситуации". Более того, выбранный наугад
"ошибочный элемент (очевидно, не относящийся к текущему пути) открывает
возможность перехода к другим потенциальным путям решения. Это помогает решать проблему
"эффекта горизонта (раздел 4.3), когда неудачиость текущего пути изначально невидима.
Случайность, таким образом, привносит неоднородность в пространство поиска, что
является одним из преимуществ генетических алгоритмов (глава 11).
И, наконец, температура служит механизмом обратной связи, определяющим степень
"зацепления" структур, построенных в рабочем пространстве. При низкой степени
зацепления вероятностный характер выбора, сделанного системой, не столь важен, поскольку
оба варианта одинаково приемлемы. При высокой степени зацепления с внутренне
непротиворечивым решением влияние вероятностного выбора возрастает, поскольку
варианты теснее связаны с формируемым решением.
Copycat представляет собой гибкую архитектуру, структуры которой развиваются как
на основе данных, так и с учетом ожидаемого результата, поэтому отражают инварианты
своего окружения. Однако эта архитектура имеет ряд недостатков. Во-первых, несмотря
иа то, что рассуждения по аналогии являются обшей и важной особенностью интеллекта,
алфавитная предметная область Copycat настолько семантически слаба, что результаты
рассуждений по аналогии мало понятны. Это превращает данную архитектуру в
игрушечную систему. Во-вторых, Copycat ие дообучается. С каждым новым образом она
пытается сформировать строки шаблонов. Для рассуждений по аналогии требуется, чтобы
система интегрировала новые знания в уже существующую в ней систему понятий,
развивая силу аналогии при каждом столкновении с окружающим миром.
Известно несколько новых проектов, развивающих Copycat и предназначенных для
проверки архитектуры в более сложной среде. В [Marshall, 1999] продолжено
моделирование связей по аналогии. В [Uwis и Luger, 2000] архитектура Copycat расширена для
использования в системе управления мобильным роботом. Таким образом, система
Copycat значительно развита за счет взаимодействия с конкретным окружением с целью
обучения. Результатом этого взаимодействия является карта пространства, исследуемого
роботом. Объекты обнаруживаются и наносятся иа карту, а заодно планируются и пере-
планнруются маршруты движения между объектами. В следующем разделе будут рас-
смотрены агентно-ориентированный и компонентный подходы к решению задач.
6.4. Агентно-ориентированное и распределенное
решение проблем
В 1980-е годы исследователями ИИ было сделано два открытия, которые имели важ-
нос значение для последующего анализа роли представлен, в интеллектуальном реше-
Глава 6. Представление знаний
261
1.
л,„ие традиций распределенного искусственного интел-
„„„ проблем. Первым было "°"^„ар по РИИ состоялся в Массачусетсском техно„оги.
лето (РИИ). Первый рабочий «^мшев вопросам, связанным с интеллектуальна
ческом институте в 1980году и№^ ю „„ожества решателей. Исследователями
решением задач системами, сое■ икне вопросы параллелизма низкого уровня,
РИИ было решено, что их не инт н^ маш„„ах или распараллеливание сложных
как распределенная обработка на мен11ьге решатели можно эффективно ско-
алгоритмов. Они хотели понять, шя „роблем. Фактически это было началом
ординировать для интеллектуалы (хпхш<м интеллекте с использованием и коорди-
зры распределенной обработки в (dacmon) и разработкой систем классной доски
нацией исполнителей (actor) и <»'«
рассмотренных в разделе 5.4. _ ^^ ^ представленным в разделе 6.3, стали ра-
Вторым открытием исследова ' 0|(азала большое влияние на традиционный
боты Брукса и его группы. ™°"^J]e„M „ ^суждения (рами. 6.3.1), Во-первых,
взгляд исследователей ИИ т_р ^ ^ npo6j]eM не ^^^ ЦеНтрализс,ванн0Г0
понимание того что """баемых некоторой общецелевой схемой вывода, привело к
запоминай^, знании, обрабатьшае. ^ „^^ где каждый
Г££2£Г£^ отв/чает за собственный компонент процесса ре-
шення проблемы. Во-вторых, факт, что интеллект является ситуативным и активным, в
контексте отдельных задач позволяет решателю перевести часть процесса решения в
окружающую среду. Это дает возможность каждому решателю решать поступающую
задачу ничего не зная о процессе решения в остальной части системы. Таким образом, один
Web-агент может проверять список товаров, в то время как другой проверяет
кредитоспособность заказчика. При этом оба агента не осведомлены о принятии решения на
более высоком уровне, например: разрешить или не разрешить покупку.
Оба эти направления 1980-х годов повлияли на текущее состояние разработок и
использование интеллектуальных агентов.
6.4.1. Агентно-ориентнрованное решение задач: определение
Прежде чем двигаться дальше, определим, что мы подразумеваем под словами
"агент", "агентно-ориентированнэя система" и "мультиагентная система". Однако это
несколько проблематично, так как мнения различных групп исследователей по этому
вопросу расходятся. Наше определение и обсуждение базируется на работах [Jennings,
Sycara и Wooldridge, 1998), [Wooldridge, 2000], (Lewis и Luger, 2000].
Будем считать, что мультиагентнал система— это вычислительная программа, блоки
решения задач (решатели) которой расположены в некоторой среде, и каждый из них
способен к гибким, автономным и социально организованным действиям, направленным
(либо нет) на предопределенные реалии или цели. Таким образом, четырьмя свойствами
интеллектуальной агентной системы, включающей программные решатели задач,
являются: ситуативность, автономность, гибкость и социальность.
Ситуативность (situaledness) интеллектуального агента означает что он воспринимает
окружение, в котором действует, и может изменять это окружение. Примеры окружения
Г™™"'" агс,,10в- ™ "к™, среда ведения игры „ли "обитания" робота. Кон-
РооГо,ZuarZZT М°Жет С"УЖ"ТЬ '"?ок » «иртуальный футбол в соревнованиях
против „ком "с? ' Х° " ДР"20001' т«^ д°л*- ."аимоденствовать с мячом ..
противником, „с зная размещения, намерений и успехов других игроков. Это понятие си-
Часть III. Представление и разум в ракурсе искусственного интеллекта
--Г-ЗНЬ-
, таких как
^аГоовГик STRUTS ПРтТГО В 6°"СС ^а*™ 1»-™- -дач. та
планировщик STRIPS (раздел 7.4) или экспертная система MYCIN (раздел 7.3) которые
поддерживали централизованные и исчерпывающие знания о своих „p„Uu,b,x облГГ
Автономная система (autonomous system) может взаимодействовать со своим
окружением без прямого вмешательства других агентов. Для -лого оиа должна коктро1,„^.
вать свои действия и внутренние состояния. Некоторые автономные агенты могут также
обучаться на своем опыте, чтобы улучшить свое поведение в дальнейшем (см. часть IV)
В Interne, автономный агент мог бы распознавать кредитную карточку вне зависимости
от решения других вопросов электронной коммерции. В системе ROBOCUP агент
должен передать мяч партнеру или забить гол (в зависимости от конкретной ситуации)
Гибкий агент (Пех.Ые agent) должен демонстрировать качества отзывчивости или
предусмотрительности (в зависимости от ситуации). Отзывчивый агент получает стимулы от
своего окружения и вовремя отвечает на них соответствующим образом.
Предусмотрительный агент не просто реагирует на ситуацию в свеем окружении, ио и адаптируется,
целенаправленно действует и выбирает альтернативы в различных ситуациях. Агент по
поиску кредитора, например, должен уметь предоставить пользователю несколько вариантов
или найти другое кредитное агентство, если недостаточно одной альтернативы.
Футбольный агент должен изменить свою тактику игры в зависимости от замысла противника.
И, наконец, агент является социальным (social agent), если он может
соответствующим образом взаимодействовать с другими программными или человеческими агентами.
После всего сказанного становится ясно, что агент является лишь частью сложного
процесса решения проблем. Взаимодействия социального агента ориентированы на
достижение целей более крупной мультиагентной системы. Эта социальная направленность
агентной системы должна решать много проблем, в том числе такие Как различные
агенты выделяют подзадачи при решении проблем? Как агенты могут взаимодействовать
друг с другом, чтобы облегчить решение системной задачи более высокого уровня (в
системе ROBOCUP. например, вести счет)? Как один агент может поддерживать цели
другого агента (например, управлять вопросами безопасности в Internet)? Все эти
вопросы социальной направленности являются предметом современных исследований.
Мы описали основы создания мультиагентных систем. Мультиагентиые системы
идеально подходят для решения проблем, включающих большое количество методов
решения, точек зрения и сущностей. В этих областях мультиагентные системы имеют
преимущества распределенного и конкурентного решения проблем, в том числе за счет
реализации сложных схем взаимодействия. Примеры взанмодействня показывают
совместные действия по достижению обшей цели. В этом и состоит гибкость
социальных взаимодействий, которая отличает мультиагентные системы от традиционного
программного обеспечения и обусловливает интерес к агентной парадигме.
В последние годы термин мультиагентная система относят ко всем типам
программных систем, составленных из множества полуавтономных компонентов.
Распределенная агентнал система рассматривает пути решения частных задач с помощью ряда
модулей (агентов) которые взаимодействуют на основе совместного использования
знаний о задаче в процессе решения. Исследования в области мультиагентных систем
сосредоточены на синтезе поведения множества иногда уже существующих автономных
агентов, ориентированных |.а решение данной проблемы. Мультиагентная система
может рассматриваться как сильно связанная сеть решателей, совместно работающих над
проблемами, которые могут выходить за рамки возможностей индивидуальных агентов
[Durfee и Lesser. I989].
Глава 6. Представление знаний
263
„мяясь автономными, могут в то же время быть нс-
Рсшатели мультиагектной c»OT^'^Wooldridge. 1998] можно выделить четыре важ.
однородными. На основе V™^^m проблем. Во-первых, каждый агент имеет не.
Z «ракгерис™, ^™^™°™еСможност,, для решения всей задачи, вследствие че-
подную информашгю и недостойны ■> ^ сушесгаует гаобального системного
го страдает от ограшпенносга зшгнпи ^ знаИ1Я „ вход„ь,е данные задачи тоже
контроллера для решен,» всей "P<** c рдения часто является асинхронным,
декентрал.шваны. и. в'че1верт,*'сТ,ьв о6ъектно-ориент.Фованных систем не видят ничего
Наконец, разработчики традшши ^ ^ ^^ понять, если рассматривать свойства
нового в аген™0-°Р'к™,р<"И,^ГеСк1Ы определяются как вычислительные системы с инкап-
отдедьных агентов и объектов, и ^ методам„, связанныШ1 с этим состоянием, и совер-
суднрованным состоянием, они от ^^^ ищшодейстауют, передавая сообщения,
шают действия в окружающей ^ ' j COCIOirr в том, что объекты редко контролируют
Разлнчне между объектами и аг ^ ^ ^ сушност„, вызывающие конкретные
свое поведение. Агеиш следует^ Р^ ^ вьшолнение необходимых дейст-
Г^ ™^югся п,6и»и. т.е. чутко реагирующими „а изменение внешней средь,,
вии. Далее, агенты яв"™° настроенными. И, наконец, прн взаимодействии агентов
ГаС« ГГ °сГ ГеГе потоки утгр_ Все эти разя,™ не означ,
"X что такой объек-шо-орнен.фованньи, язык, как CLOS, рассматриваемый в
разделе 12, не является подходящей средой для построения агентнои системы. Наоборот, сила н
гибкость CLOS делает его идеальным для решения этой задачи.
6.4.2. Примеры и проблемы агеитио-ориеитированной парадигмы
Чтобы конкретизировать идеи предьщущего раздела, опишем ряд прикладных
областей, в которых целесообразно использовать агентно-ориентированное решение задач.
Заодно приведем ссылки на исследования в этих проблемных областях.
• Производство. Производственная область может моделироваться как иерархия
рабочих областей. Можно рассматривать рабочие области для мукомольного
производства, штукатурных, малярных работ, сборки и т.д. Эти рабочие области
затем можно сгруппировать в производственные подсистемы. Каждая из подсистем
функционирует внутри некоторого производственного процесса. Впоследствии
эти подсистемы можно объединить в фабрику. Еще более крупная сущность —
компания — может контролировать деятельность каждой из этих фабрик,
например, управлять заказами, учетом товаров, ростом производства, прибылью и т.п.
Литературные ссылки на агентно-ориентированное производство включают
работы по формированию последовательности производственных процессов [Chung и
Wu, 1997], производственных операций [Oliveira и др., 1997] и совместному
созданию продукции [Cutosky н др., 1993], [Darr и Birmingham, 1996].
• Автоматическое управление. Поскольку контроллеры процессов обычно
являются автономными, реактивными и зачастую распределенными системами, ж
удивительно, что агентные модели приобретают в этой области важное значение
существуют исследования „о управлению транспортными системами [Согега ч
ДР. 1996], управлению космическими аппаратами [Schwuttke и Quan, 1993], эл*
7„Г;,ТеВЬ'МИ уск°Рита™" Ibmolat и др., 1996], [Klein и др., 2000],
управлении, воздушным транспортом [Ljunberg и Lucas, 1992] и другие.
264
I- Представление и разум в ракурсе искусственного интеллекта
' ^Генн1Гс!етя:иТеЛС'<0№'УН"Каи"ОННЬ'<: ~' »»™» «"—ими рае-
тоебу^ГтоТн™ С0СГОЯЩИМ" "3 взаимодействующих компонентов, которые
„п 19971 ГДН1. ^'Иеюго5^^«ния и менеджмента [Schoonderwoerd и
Р ' 993 'и б ДР" 19891' трСДаЧ" ""ФОРМАЦИИ, переключения [Nishibe и
др., 1993] и обслуживания [Busuoic и Griffiths, 1994]. Более полный обзор
приложении в этой области содержится в [Veloco и др., 1994].
. Транспортные системы. Системы грузоперевозок едва ли „е по определению
являются распределенными, ситуативными и автономными. Приложения в этой
области включают управление пассажиропотоками и транспортом для транспортных
баз [Burme.ster и др., 1997] и кооперативное составление транспортных
расписаний (Fischer н др., 1996].
. Информационный менеджмент. Изобилие, разнообразие и сложность
информации в современном обществе почти безграничны. Агеитные системы могут
обеспечить интеллектуальный информационный менеджмент, особенно в Internet. Как
человеческий фактор, так и информационная организация как будто сговорились
против комфортного доступа к информации. Двумя критическими агентными
задачами являются фильтрация данных — получение из всей доступной
информации лишь той небольшой порции, которая нас действительно интересует, и сбор
информации — задача накопления и определения приоритетов среди отобранных
порций информации. Среди приложений можно отметить WEBMATE [Chen и
Sycara, 1998], систему фильтрации электронной почты [Maes, 1994], поиск в Web
[Lieberman, 1995] и агент поиска эксперта [Kautz н др., 1997].
• Электронная коммерция. Современная коммерческая деятельность
осуществляется под управлением человека: мы решаем, когда купить или продать, какое
количество и по каким ценам, и даже, какая информация необходима нам к
определенному времени. Несомненно, коммерция является областью, подходящей для
агентных моделей. Хотя полная разработка электронных коммерческих агентов
может быть осуществлена только в будущем, несколько систем уже реализовано.
Например, современные программы могут принимать решения по многим
покупкам и продажам на основании большого количестаа разнородной и
распределенной информации. Было разработано несколько агентных систем для управления
портфелем ценных бумаг (Sycara н др., 1996]. системы— помощники покупателя
[Doorenbos и др., 1997], [KruKvich. 1996] и интерактивные каталоги [Schrooten и
van de Velde, 1997], (Takahashi и др., 1997].
• Интерактивные игры и театр. Участники игр и театральные герои
функционируют в богатой интерактивной среде. Игровые агенты могут втягивать нас в
военные игры, в сценарии управления финансами и даже в спортивные состязания.
Театральные агенты играют роль человеческих прототипов и могут создавать
иллюзию жизни в эмоциональных ситуациях, при моделировании критических
ситуаций в медицине или при обучении разнородным задачам. Исследования в
этой области включают компьютерные игры [Wavish и Graham, 1996] и
интерактивные модели личностей [Hayes-Roth, 1995], [Trappl и РеПа, 1997].
Разумеется, сушествует много других областей, для которых подходит агентно-
орнентнрованная парадигма реализации. Несмотря на то что агентная технология имеет
много потенциальных преимуществ, для интеллектуального решения проблем еще нсоб-
Глава 6. Представление знаний
^gR"-'--
- пп.тсленный ниже список вопросов сформулирован
ходи«о преодолеть Р« W— innings и ДР-. 19981. [Bond и Gasscr. ,988).
на основе идеи, излом и оМТЬ распределить задачи агентов? Более тощ
. Как систематизировать,Ф°Р» ^„„„вять результаты их решения?
кпк соответствуют- образом с, ^ ^^^ ш.е„тов? Кшж ^^^
' ^""фо^оГпереД-"' -°6ЩСН",Т' Ч™ " K0™ М0ЖН° "аЗМТЬ П0ДХ0"
лишен информацией? „
„.-„„сованнос поведение агентов при выборе действии и приш,-
' Г «^ снрГГся с нелокалиэоваиным,, воздействиями и избегать
вредных взаимодействии с агентами?
. Как отдельные агенты могут представлять и обрабатывать ..„формацию о дейст.
вг! планах „ знаниях других агентов для их координации I Как агенты Moiyr су.
д,ггь о состоянии координируемых ими процессов.
. Как распознать и скоординировать различные точки зрения и конфликтные
намерения агентов?
. Как распознать опасное поведение всей системы, например, хаотичное или
вибрирующее, и избежать его?
• Как распределять и контролировать ограниченные ресурсы как отдельного агента,
так и системы в целом?
• И, наконец, какие технические средства и программные технологии существуют
для разработки и поддержки агентных систем?
Методы разработки интеллектуального программного обеспечения, необходимые для
поддержки агентных технологий решения проблем, можно встретить на протяжении всей
книги. Во-первых, требования к представлению процесса интеллектуального решения
проблем стали постоянной темой нашего изложения. Во-вторых, вопросы поиска,
особенно эвристического, можно найти в части II. В-третьих, область планирования,
представленная в разделе 7.4, обеспечивает технологию упорядочения и координацию
подцелей при организации решения проблем. В-четвертых, мы представляем идею
стохастических агентных рассуждений в условиях неопределенности в разделе 8.3. И. наконец,
вопросы обучения в областях автоматизированных рассуждений и понимания
естественного языка рассматриваются в частях V и IV. Эти подобласти традиционного
искусственного интеллекта важны для создан™ агентных архитектур.
Существует ряд других вопросов разработки агентных моделей, которые находятся вне
сферы этой книга, например, языки коммуникаций, схемы взаимодействия и методы
распределенного управления. Они рассматриваются в [Jennings, Sycara и Wooldridge, 1998) и в
трудах соответствующих конфсрсишйЦАЛАЛ.1ICAI и ХЗМ).
**^??^ммпп^^
ний^^чаПсноли'о^ие!"''.,''0 '° °С"°В"иХ шьтеР™™» Д"» представления зна-
го, описаны системы без йен™ РШ"Л' «ман™чсских сетей и фреймов. Кроме то-
ждений. Наконец мы пассмП™Г'ТОВаНН0Й базы зиа""" «ли общецелевой схемы расе)"
I емотрелн распределенное решение проблем с агентам... Резуль-
Часть ш. ПрвДС1авлвнив и ра_ум в раедка искусстввнног.0 интеллекта
таты тщательного изучения показыияшт unnt„-, ,m„
„„чений каждого из этих noZSZ^Z^^T"" "Т*™ " °П""
ecTC™^ tTвиос™И -="^^^
ГрГтавТен'и^на^Г " °^»™ ™ «™ ™ в области
Первый из них -это выбор и степень детализации атомарных ш,«а,и для
представления знании. Объекты мира составляют область определения отображения-,
вычислительные объекты в базе знаний являются его областью значений. Природа атомарных
элементов языка в значительной степени определяет форму описания мира, например,
если "автомобиль - это наименьший атом представления, то система не может
рассуждать о двигателях, колесах и какой-либо другой части автомобиля. Однако, если этим
частям соответствуют атомы, то для представления "автомобиля" как единого понятия
может потребоваться более крупная структура со своими способами управления.
Другой пример компромиссного решения при выборе символов может быть найден в
работах, посвященных пониманию естественного языка. Сложные понятия, значение
которых не описывается одним словом, нельзя представить с помощью программ,
использующих отдельные слова в качестве элементов смысла. Существуют также определенные
трудности в выделении разного смысла одного н того же слова или разных слов с одним
и тем же смыслом. Один из подходов к этой проблеме заключается в использовании
семантических примитивов — независимых от языка концептуальных единиц,
используемых в качестве основы для представления естественного языка. Хотя эта точка зрения
устраняет проблему использования отдельных слов как единиц смысла, возникают
другие проблемы: многие слова требуют сложных структур для их определения; кроме того,
при небольшом множестве примитивов сложно уловить тонкие различия, такие как
"push" и "shove" (толкать) или "yell" и "scream" (пронзительный крик).
Полнота — свойство базы знашп., которое обеспечивается подходящим
представлением. Отображение является полным по отношению к свойству или классу объектов, если все
вхождения точно соответствуют элементу представления. Предполагается, что
географические карты должны быть полными иа некотором уровне детализации. Карту, на которой
упущен город илн река, нельзя рассматривать как навигационную. Хотя большинство баз
знаний не полны, полнота относительно определенных свойств илн объектов является
обязательной. Например, предположение полноты представления позволяет планировщику
игнорировать возможные эффекты проблемы границ (frame problem).
При описании задачи как последовательности состояний мира, вызываемых
некоторыми действиями или событиями, нужно учитывать, что этн действия или события
изменяют лишь небольшую часть компонентов описания. Программа должна иметь
возможность выявить побочные эффекты и подразумеваемые изменения в описании мира.
Проблема описания побочных явлений действий называется проблемой границ. Например,
робот, складывающий тяжелые яшики на грузовик, должен учитывать понижение уровня
дна автомобиля с каждым новым ящиком. Если представление является полным, то
неопределенных побочных эффектов не будет, н проблема границ исчезает. Трудность
проблемы границ является следствием того, что для большинства областей невозможно
построить полнута базу знаний. Язык представления должен помогать программисту в
решении вопросов, какие знания можно опустить без потери информации.
С проблемой полноты связан вопрос пластичности илн модифицируемости пред-
стаалеиия. при отсутствии полноты необходимо восполнить отсутствующие знания.
Поскольку большинство баз знании являются неполными, желательно, чтеюы процесс мо-
Глава 6, Представление знаний
267
был простым. Кроме синтаксической простоты пРоцесса Вос.
Ликации ял» адмгпшии был про „„ровать непротиворечивость базы №
S&-* ^Г» Р^*» 'наследование является примером того, Z
Z, добавлении и УДшея""Гс*£Ч„ть непротиворечивость.
сТма представления может обеспе ,_ ^ решш]и ВО[]рос „„^^
Несколько систем, в™^-гуп которые изменяются и развиваются, встречаясь с ог-
счет разработки сетевых "РУ'^В да системах представление является результате,
раничениями естественно™ „„строения снизу вверх) с учетом ожидаемого результата
приобретения новых данных ( ^ рассуждение п0 аналогии.
Примером систем этого та дсганлеиш1, связанным с отображением мира в базу
Другим полезным сюи в данном случае гомоморфизм означает однозначное
знаний, является да"°"°'Тш и действиями мира и вычислительными объектами и one-
соответствие между ооъе^ 01о6раже„ии база знаний отражает воспринятую
рациями языка, при ' ^ оШоваиа более естественным образом,
структуру области и мо сти и легкости использования схемы предегавле-
Кроме «теот»"°в™ ОДп"о их еышсипсьной эффективности. В [Levesque „
ZJZZim обсуждается компромисс между выразительностью н эффективностью.
кГгла в качестве схемы представления используется логика, система является высоко
выразительной вследствие полноты. Однако системы основанные на неограниченной
логике, как правило, не очень эффективны (см. главу 12). _
Большинство вопросов представления относятся к любой информации, накапливаемой и
используемой ко.мпыотером. Существует еще ряд вопросов, которые должны решаться
разработчиками распределенных и агентньгх систем. Многие из этих вопросов относятся к
принятию решений на основе частной (локальной) информации, распределенной относительно
выполняемых задач. Эти вопросы решаются с помощью агентных языков передачи
сообщений и разработки алгоритмов для кооперации и совместного использования информации
агентами. Большинство этих вопросов представлено в разделе 6.4. И, наконец, совершенно
новые языки и представления могут потребоваться при реализации философских аспектов
распределенного, основанного на окружении интеллекта, предложенных в [Clark, 1997],
[Haugeland, 1997] и [Dennett, 1991,1995], где так называемые "неплотные" системы
используют окружение и других агентов в качестве критической среды для запоминания и
использования знаний. Необходимы также средства представления и поддержки, которые в
соответствии с [Brooks, 1991а] "используют мир в качестве модели".
В заключение расширим ссылки на материалы, представленные в главе 6. Ассоцианист-
ские теории как модели компьютерной и человеческой памяти и рассуждений изучались в
[Selz, 1913,1922], [Anderson и Bower, 1973], [Sowa, 1984], [Collins и Quillian, 1069].
Важным результатом в области разработки языков структурированного
представления знаний являются языки представления KRL [Bobrow н Winograd, 1977] и KL-0№
lurachman. 1979], которые играют особую роль как семантические основы
структурированных представлений.
ОтсьГе™ 0НЦегауальньа ПН»» в значительной степени основан иа книге [Sowa, 19841.
«ZeZZr Т°Щ ИЗДаНИ° *"" 6олее «ильного знакомства. Согласно этой работе
"Г„"^ГЧга,ОТ ВЫР™-"^ силу „счисления предикатов, *»»«"*;
»«* пол™Гх 7 П°РЯДК0В С б0гатсге°м ™™«™. встроенных понятии и onto
СушеГуИял' «емологии, психологии и линлшстики.
Файкс и ЛивГки noeZ* ИНКреСНЬ1Х ПОдходов к представлению. Например, ЕР»»*
"с™ предложили представление, которое подчеркивает функционале
Представление и разум в ракурсе искусственного интеллек*
1Т№Я^*9МГ 3а"РаШ—Й ™" 4»™* - базе знаний [ВгасЬшап
1ВГавсьГ:^;т;9^ГетсТ1мвп°гг-может помочь рш № ™
1 . ' *ш1ястся компиляцией важных статей на эту тему Многие
И3 "ТЗ ССЫЛаСТСЯ Да"НаЯ ГЛаВа' М°^ 6ЫТЬ ™" там^хоГссылТиа
ItT Toon, ,12 Пер°ðЧ"ИКИ' Поли»ым" »ТТ стать [Bobrow и Collins, 1975,,
[Devts, 1990]. [Weld и deKleer, 1990] и труды любой из конференций „о ИИ вообще, или
по представлению знании в частности, например [Brachman и др 1990]
В настоящее время существует значительное количество статей, развивающих
направления, предложенные Бруксом по категориальной архитектуре. Особое внимание
стоит уделить работам [Brooks, 1991a], [Brooks и Stein, 1994], [Maes 1994] [Veloco и
др., 2000]. Дальнейшие исследования поддерживают философскую точку зрения о
распределенной и материализованной природе знаний и интеллекта. Особый интерес
представляет работа [Clark, 1997].
Агеитно-ориентированные исследования являются достаточно популярными в
современном ИИ [Jennings и др., 1998]. На ежегодных конференциях по ИИ (IAAI. UCAI)
агеитным исследованиям посвящены целые секции. Для ознакомления с новейшнмн
достижениями в этой области мы бы порекомендовали изучить последние труды этих
конференций. Кроме того, следует ознакомиться с трудами конференции в области
распределенного искусственного интеллекта (РИИ). Обзор н ссьшки на важные прикладные
области агентно-ориентированиых исследований были представлены в разделе 6.4.
Вопросы представления знаний находятся иа стыке искусственного интеллекта и ког-
иитологии [Luger, 1994] и [Clark, 1997]. Книга [Luger, 1995] объединяет классические
статьи, которые освещают разработку многих схем представления знаний.
6.6. Упражнения
1. В общесмысловых рассуждениях такие понятия, как причинность, аналогия,
эквивалентность используют не так, как в формальных языках. Например, если мы говорим
"Инфляция заставила Джейи просить о повышении", то предполагаем более сложные
причинные зависимости, чем в простых физических законах. Если мы говорим
"Используйте нож или стамеску для подрезки дерева", то предполагаем важное
понятие эквивалентности. Приведите примеры трансляции этих и других понятий в
формальный язык.
2. В подразделе 6.2.1 приведены некоторые аргументы против использования логики
для представления общесмысловых знаний. Приведите аргумент в пользу
использования логики для представления этих знаний.
3. Запищите каждое из этих выражений в терминах исчисления предикатов,
концептуальных зависимостей и концептуальных графов.
"Jane gave Tom an ice cream cone" ("Джейн дала Тому порцию мороженого").
"Basketball players are tall" (•Баскетболистывысокие").
"Paul cut down the tree with an axe" ("Пол срубил дерево топором").
"Place all the ingredients in a bowl and mix thoroughly" ("Помесит все ингредиенты в миску
» тщательно перемешайте").
Глава 6. Представление знаний
rWonds 1985]. Раздш 'V "ои статьи содержит описание ряда
4. Прочитайте статью [wooub, „ожиге решение каждой из этих проблем, ис.
„роблем в представлении знании, i P фреймов.
пользуя логику, концептуальные графы и понятие фр
пользуя логику. естественном языке.
Ч Опишите концептуальные графы (рис. о .от
3. шиш.» , restrict (ограничить) определяют обобщенное
6' °^Z^l "тщьных графах. Покажите, что отногцение обобщения ,в.
ляется транзитивным.
7 Специализация концептуальных графов, использующая операции объединения „ огр1.
„„«является операцией, не сохраняющей истинность Приведите пример, кото.
рыи демонстрирует, что ограничение истинного графа не обязательно является истин-
Г« Однак7обобщенпе истинного графа всегда являегся истинным. Докажите это.
8 Определите специализированный язык для описания деятельности общественной
' библиотеки. Этот язык должен содержать множество понятии и отношений и
основываться на использовании концептуальных графов. Сделайте то же самое для пред.
приятия розничной торгоали. Какие поиятия и отношения могли бы быть общиыи в
этих двух языках? Какие из них могли бы существовать в обоих языках, но иметь
различный смысл?
9. Транслируйте концептуальные графы (рис. 6.29) в исчисление предикатов.
—и soup
^instrument)
высказывание
высказывание
1 likes 1
*■ Qwperien cen
(оЦо«)
—»| /ota |
-H pizza
Puc. 6.29. Два
естественном
10. Представьте базу знании
ecmecmee^ZZr^""" *W*°' ^^^ "ео6ход"л<° °»»™>"b "а
ального графа.
финансового советника (раздел 2.4) в виде концепту-
270
ль III. Представление и разум а ракурсе искусственного интеллекта
П. Приведите пример из вашего опыта *<™п..„-, ™
_„т п„ ти„„ „„.,,„„ "ь|та- «сторыи говорит об организации человеческой
памяти по типу сценариев или фреймов.
12. Используя концептуальные зависимости, определите сценарий для:
а) ресторана быстрого приготовления пищи;
б) обшения с продавцом бывших в употреблении автомобилей;
в) похода в оперный театр.
13. Постройте иерархию подтипов для поиятия транспортное средство например,
его подтипами могли бы быть наземное транспортное средство или морское
транспортное средство. Они, в свою очередь, могли бы иметь свои подтипы.
Сделайте то же самое для понятий перемещаться и сердитый.
14. Постройте иерархию типов, в которой некоторые типы не имеют общего супертипа
Дополните множество типов таким образом, чтобы иерархия превратилась в
решетку. Может ли эта иерархия быть выражена с помощью дерева наследования? Какие
проблемы могут возникнуть при этом?
15. Каждая из следующих последовательностей символов генерируется в соответствии с
некоторым правилом. Опишите представление правил или отношений, необходимых
для продолжения каждой последовательности:
а) 2, 4, 6, 8, ...
б) 1,2,4.8, 16, ...
в) 1,1,2,3,5,8,...
г) 1,а, 2, с, 3. f,4, ...
д)о, 1.1, f, f, s, s,...
16. В разделе 6.3 было представлено два примера рассуждений по аналогии. Опишите
соответствующее представление и стратегию поиска, позволяющие сделать
оптимальный выбор. Приведите несколько примеров аналогий, которые можно
реализовать на основе прешюженного вами представления.
а) hot (горячий) и cold (холодный), tall (высокий) и wall (стена), short (короткий),
wet (мокрый), hold (крепость)
б) bear (медведь) и pig (свинья); chair (стул) и foot (ножка), table (стол), cotlee
(кофе), strawberry (земляника)
17. Опишите представление, которое могло бы использоваться в программе решения по
аналогии проблем, подобных показанным на рис. 6.30. Этот класс задач изучался в
работе [Evans, 1968]. Представление должно учитывать такие существенные
признаки, как размер, форма и относительное местоположение.
18. В статье [Brooks. 1991a] содержится обсуждение роли предстааления в
традиционном ИИ. Прочтите эту статью и прокомментируйте ограничения явной и обшецеде-
вой схем представления.
19. В конце подраздела 6.3.1 содержится пять вопросов, которые должны быть решены для
успешного решения задач на основе категориальной архитектуры [Brooks. 1991oJ.
Прокомментирулгте хотя бы один из этих вопросов.
20. Определите пять свойств, которые должен иметь язык для реализации агентно-
ориентированной службы Internet. Прокомментируйте роль языка Java как обшеце-
Глана 6. Представление знаний
271
таботки служб Internet. Согласны ли вы, что подоб-
левого агентного языка для рюр , №обилие информации по этому вопро-
„ую роль выполняет и язык CLOS -и
су находится в самой Internet. ^ |
д-@
л
Выберите один
Рис 6.30. Пример задачи, решаемой по аналогии
21. Ряд важных вопросов, относящихся к агентно-ориентированному решению задач,
был представлен почти в самом конце раздела 6.4. Обсудите один из ннх.
22. Предположим, вы разработали агентную систему для представления командной игры
в американский футбол. Для взаимодействия агентов в защите или нападении они
должны иметь представление о планах других агентов и возможных ответах на
создавшуюся ситуацию. Как бы вы построили модель целей и планов других
взаимодействующих агентов?
23. Выберите одну из прикладных областей для агентных архитектур, описанных в
главе 6.4. Выберите статью исследовательского или прикладного характера нз этой
области. Разработайте структуру агентов, которые могли бы решать задачу. Разбейте
проблему так, чтобы определить ответственность каждого агента. Составьте список
соответствующих процедур взаимодействия.
\4 *«*«$
Сильные методы
решения задач
Основным принципом инженерии знаний является то, что возможности решателя
задач интеллектуального агента в первую очередь определяются его информационной
базой и лишь во вторую - используе.мы.» методом вывода. Экспертные системы должны
быть сильны знаниями, даже если они слабы методами. Это важный вывод, который
лишь недавно по достоинству оценили исследователи ИИ. Долгое время они занимались
почти исключительно разработкой различных методов вывода. Но можно использовать
почти любой метод. Сила заключается в знаниях.
— Эдвард Фейгенбаум (Edward Feigenbaum), Стэндфордскнй университет
Nam et ipsa scienlia potestas est (Знание ~ сила).
— Фрэнсис Бэкон (Francis Bacon)
7,0. Введение
Продолжая изучать вопросы представления и интеллекта, рассмотрим важный
компонент ИИ — сильные методы решения задач, или методы, основанные на знаниях.
Человек-эксперт способен действовать на высоком уровне, так как много знает об
области своей деятельности. Это простое наблюдение является главным обоснованием ятя
разработки сильных методов, или решателей проблем, основанных на знаниях (см.
введение к части III). Экспертные системы используют знания специфичной предметной
области. Обычно разработчики экспертной системы приобретают эти знания с помошью
экспертов, методологию и деятельность которых затем эмулирует система. Так же, как опытные
люди, экспертные системы являются "специалистами" по узкому кругу проблем. Подобно
людям, они обладают как теоретическими, так и практическими знаниями: человек-
эксперт, обеспечивающий систему знаниями, обычно привносит собственное
теоретическое понимание предметной области, а также снабжает систему "хитростями",
кратчайшими путями решения и эвристикам», полученными из опыта решения проблем.
Экспертные системы обычно предоставляют следующие возможности.
1. Отслеживают свои процессы рассуждения, выводя промежуточные результаты и
отвечая на вопросы о процессе решения.
2. Позволяют несколько модифицировать базу знании (добавлять и удалять информацию).
3. Рассуждают эвристически, используя для получения полезных решений во многом
несовершенные знания.
г-^И^^и.
а системы лолжсн быть открыт для проверки, „бес-
Процесс рассуждения '""«Р™™" проблемы и объясняя выборы и решения, ко-
„ечяаая информацию о состоянии p..UJi ^ челомкаокспсрта. например врача иди
торые делает программа. 06ьяс"еН1„..,омендаш,ю компьютера. В самом деле, мало кто
инженера, если он должен принять р ^^ нс говоря ужс 0 том что6ы следо
из экспертов будет принимать сове В(ю Как |( лю6ые программные средства,
вать совету машины, не учитывая j^ ^„„„^ „рототипнровання, тестирования и
экспертные системы должны о л t методоЛопш разработки используются языки и
изменения. Для поддержки нпра продукционной системе, например, мо-
срсдства программирован,* задач:Ш ■ х синтаксических побочных эффектов,
дификацня одного правила не 'м«* необходимости дальнейших изменений
Правила могут «^^^*^ c,fCTeMU часто объясняют, что леткость мо-
д:1Г^ьТзГ,~,'т:^Г фактором производства успешных программ.
Фс"шеП особенностью экспертных систем является использование эвристически
методов" решети, проблем. Разработчики экспертных систем установили, что „ефор-
мальные 'трюки" и "интуитивные правила" являются существенным дополнением к
стандартной теория, предоставляемой учебниками и курсами. Иногда эти правша
усиливают теоретические знания с учетом здравого смысла, а зачастую они просто дают
кратчайший путь к решению.
Экспертные системы строятся для решения широкого круга проблем в таких
областях, как медицина, математика, машиностроение, химия, геология, вычислительная
техника, бизнес, законодательство, оборона и образование. Эти программы решают
разнообразные проблемы. Следующий список из работы [Waterman, 1986] является полезным
конспектом общих задач экспертных систем.
• Интерпретация— формирование высокоуровневых выводов из наборов строк
данных.
• Прогнозирование — проектирование возможных последствий данной ситуации.
• Диагностика — определение причин неисправностей в сложных ситуациях на
основе наблюдаемых симптомов.
• Проектирование— нахождение конфигурации компонентов системы, которая
удовлетворяет целевым условиям и множеству проектных ограничений.
• Планирование— разработка последовательности действий для достижения
множества целей при данных начальных условиях и временных ограничениях.
• Мониторинг — сравнение наблюдаемого I
ведением.
' с^ГсГ^-" "°М0ЩЬ " с6Разователь™м процессе по изучению техниче-
• Упрощение - управление поведением сложной среды
бле^ссГвеТнатГГуГщГиГ ~™°' ""*" »" ™°™ >«» ^
кого круга проблем- от выбора инженеРия знан™ Должна обеспечивать решение широ-
малнзации знаний по решению ™та^ствУющей прикладной области до извлечения и Ф°Р"
на правилах. При этом продукиио ^ ,МЗЛеЛС 7 2 6удут рассмотрены системы, основанные
тура для реализации процессов оегГ™!!™^ 6УД" "P^™™™ как программная архшек-
решения и анализа. В разделе 7.3 рассматриваются приемы
Частый. Представлением
Разум в ракурсе искусственного интеллекта
рассуждении на основе моделей и опыта. Раздел 7 А „<*».
ганизацин частей знаний в непротиворечивую пишеГ^Г" та""ров"тю ~ M1K,№CCV °Р'
„ели. Приемы рассуждения в неопределим сиЗГ^"0™ ЛС"™"4 "° а°™жтт
для разработки решателей задач »Zm,™2,2«7eZml ' " ""' * '""" ^
7.1. Обзор технологииэкспертных систем
7.1.1. Разработка экспертных систем, основанных на правилах
На рис. 7.1 показаны модули, которые составляют типичную экспертную систему
Пользователь взаимодействует с системой через пользовательский интерфейс, который
скрывает многие сложности, в том числе внутреннюю структуру базы правил. При
разработке интерфейса экспертной системы используют разнообразие стилей, включая
"вопрос-ответ , меню управления или графический интерфейс. Тип интерфейса
определяется потребностями пользователя и требованиями базы знаний и системы вывода.
Ядром экспертной системы является база знаний, которая содержит знание из частной
прикладной области. В экспертной системе, основанной на правилах, это знание
представляется в форме правил ест..., то..., как в примерах из раздела 7.2. База знаний
содержит как общие знания, так и информацию о частных случаях.
Механизм вывода применяет знания при решении реальных задач. По существу, он
является интерпретатором базы знаний. В продукционной системе механизм вывода
совершает цикл распознавание-действие. Процедуры, которые выполняют этот
управляющий цикл, отделены от самих продукционных правил. Такое разделение механизма
вывода и базы знаний важно поддерживать по нескольким причинам.
1. Оно дает возможность представить знания более естественным образом.
Например, правила если..., то... точнее описывают навыки человека по решению задач,
чем компьютерный код более низкого уровня.
2. В связи с тем, что база знании отделяется от программных управляющих структур
более низкого уровня, разработчики экспертной системы могут сосредоточиться на
накоплении и организации знаний, а не на деталях их компьютерной реализации.
3. В идеале разделение знаний н управления позволяет вносить изменения в одну
часть базы знаний без создания побочных эффектов в других.
4. Разделение знаний и управляющих элементов программы позволяет использовать
в различных системах одни и те же модули управления и интерфейса пользователя.
Оболочка экспертной системы включает все компоненты, показанные на рис. 7.1.
а база знаний и данные о частных случаях могут пополняться для новых
приложений. Штриховые линии на рнс. 7.1 ограничивают модули оболочки.
Экспертная система должна сохранять информацию о частных случаях, в том числе
факты и выводы. Сюда включаются данные, полученные в отдельном случае решения
задачи, частные заключения, степени доверия к заключениям н тупики в процессе
поиска. Эта информация отделяется от общей базы знаний.
Подсистема объяснений позволяет программе пояснить свое рассуждение лользова-
телю. Она обеспечивает обоснования, заключений системы в ответ на вопросы как.
(раздел 7.2). объяснение необходимости конкретных данных, а также ответы на вопросы
"почему.'" (раздел 7.2).
Глава 7. Сильные методы решения задач
275
Рис. 7.1. Архитектура типовой экспертной систем для конкретной
предметной области
Многие системы включают также редактор базы знаний. Редакторы баз знаний
помогают программистам локализовать и откорректировать сбои в действиях программы,
используя информацию, обеспечиваемую подсистемой объяснении. Кроме того, они
могут помочь в пополнении новых знаний, поддержке корректности синтаксиса правил и в
проверке на непротиворечивость при изменениях в базе знаний.
Важной причиной сокращения времени разработки и настройки современных
экспертных систем является наличие оболочек. В Internet можно найти оболочки CLIPS,
JASS, а в части VI предлагаются оболочки для LISP и PROLOG. К сожалению,
программные оболочки не решают всех проблем, возникающих при разработке экспертных
систем. Хотя разделение знаний и уровня управления, модульность архитектуры
продукционной системы и использование соответствующего языка представления знаний
помогают при построении экспертной системы, извлечение и формализация знаний для
конкретной области остаются пока очень трудными задачами.
7.1.2. Выбор задачи н процесс инженерии знаний
Экспертные системы приалекают значительные денежные инвестиции и человеческие
усилия. Попытки решить слишком сложную, малопонятную или, другими словами, не
соответствующую имеющейся технологии проблему могут привести к дорогостоящим и
постыдным неудачам. Поэтому были выработаны критерии оправданности решения
данной задачи с помощью экспертной системы.
1. Необходимость решения оправдывает стоимость и усилия по разработке
экспертной системы. Многие экспертные системы были построены в таких областях,
как разведка минералов, бизнес, оборона и медицина, где существует большой
потенциал для экономии денег, времени и защиты человеческой жизни.
1 ™„>нмС1„ВИГЬ1°"ЧеСК0Г«0 °ПЫТа в ситУа"иях, где он необходим. В геологи,..
нГгеолоГи^Г Нео6ход™°"ь Удаленной экспертизы минирования и бурс-
большимн за1Г РЫ Ча™ ИМИ ПР°Х0ДЯТ 6°льш»с расстояния, что связано с
'ГгГ: о^ы^нГДоТГ""' "К" "» >™>*
v 'валенных районов могут быть решены без их посещения.
'^^Zr^ZZZlV^r11"^^ символьны* рассуй-
н олемы не требует физической ловкости или конкретных на-
276
асть III. Представление и разум в ракурсе искусственного интеллекта
выков. Современным роботам и систем™
присущих человеку. ' 3Рения не хватает ума и тбкосги,
4 Проблемная область является vm,n„.„ „
суждении „а основе здраво" 271 Ц™!™"™"** '" '"^ Р°С"
удобны для изучения и формализации- для „МчК™НОЛОГИЧ"и<: о6"аст" ™»'
построены ясные и конкретные коннепТаГ 0"Рс*ел™а терминология и
-.правого смысла ™,," ™»иептуальные модели. Рассуждения па основе
здравого смысла трудно автоматизировать.
5. Проблема не может быть решена тпа™..„,,,.„,
-г Fcu"-"<i ■раднционными вычислительными мето-
дами. Технология экспертных систем не „„„„ """
, vшыл систем не должна использоваться там, где это не
является необходимостью. Если проблема может быть удовлетворительно решена
более традиционными методами, она не должна рассматриваться как кандидат для
решения экспертными системами.
6. Известны эксперты, способные взаимодействовать между собой и четко вы-
ражать свои мысли. Знания, используемые экспертными системами, формируют-
ся из опыта и суждений людей, работающих в данной области. Важно, чтобы эти
эксперты не только хотели, ио и были способны поделиться знаниями.
7. Проблема имеет приемлемые размеры и границы. Например, программа,
пытающаяся воплотить весь опыт врача, нереальна. Программа, подсказывающая
медицинские решения по использованию конкретного медицинского оборудования
или конкретного множества диагнозов, более практична.
К разработке экспертной системы необходимо привлекать инженеров по знания.^,
экспертов в данной предметной области и конечных пользователей. Инженер по
знаниям является экспертом по языку ИИ и представлению. Его главная задача— выбрать
программный и аппаратный инструментарий для проекта, помочь эксперту в данной
области членораздельно сформулировать необходимую информацию, а также реализовать
ее в корректной и эффективной базе знаний. Часто инженер по знаниям изначально не
знаком с прикладной областью.
Знания о предметной области обеспечивает эксперт. Экспертом предметной
области обычно является тот человек, который работал в этой области и понимает
принципы решения ее задач, знает приемы решения, может обеспечить управление
неточными данными, оценку частичных решений и имеет другие навыки, делающие
его экспертом. Эксперт в предметной области отвечает за передачу этих навыков
инженеру по знаниям.
В большинстве приложений основные проектные ограничения определяет конечный
пользователь. Обычно разработка продолжается до тех пор. пока пользователь не будет
удовлетворен. Навыки и потребности пользователя учитываются в течение всего цикла
разработки. Постоянно отслеживаются следующие вопросы. Делает ли программа
работу пользователя более легкой, быстрой, удобной? Какой уровень объяснения необходим
пользователю? Может ли пользователь предоставить системе корректную информацию?
Является ли адекватным интерфейс? Соответствует ли рабочая среда пользователя
ограничениям на использование программ? Например, интерфейс, треоуюшни ввода данных
с клавиатуры, ие подходит для использования в кабине истребителя.
Так же как и большинство разработок ИИ, экспертные системы требуют
нетрадиционного жизненного цикла разработки, основанного на раннем прототипировании и
постепенной модификации кода. Обычно работа с системой начинается с попытки
инженера по знаниям описать процессы, происходящие в данной предметной области Этому
Глава 7. Сильные методы решения задач
277
„ в ланкой области. Адекватность описания дости-
помогает взаимодействие с экспертом в д ^ эксперга„„ и наблюдения за ним,, „
гаотя с помощью предварительных ^ и экспер1 нач„„ают процесс извлечения
процессе работы. Далее инженер п задается ряд простых задач, которые он
знаний по решению проблем. Для э приемы. Зачастую этот процесс за-
пытастся решить, объясняя используемые при
писывают на видео- и аудиокассеты^ №т 6ыл НОВНчком в предметной области.
Иногда полезно, чтобы »»*енеР всегда может пчт объяснить ход решения
Общеизвестно, что «Ко^мет упошнуть шаги, которые за годы работы в
сложной проблемы. Часто о»' 3»"м^J '„ шн даЖе автоматическими. В силу
этой области стали для не о впол оче »™ ^^ ^^ ^ ^У
:Г;\ГтГГГЦбе„Г;»Г азрыв!, и попросить о помошн. Котда инженер
„з—, случит общее представление о предметной области „ проведет несколько
сеансов решеннГзадач с экспертом, он сможет приступить к разработке системы:
выбрать способ представления знаний (например, правила илн фреймы), определить
стратегию поиска (прямой, обратный, в глубину, в ширину н т.п.), разработать
пользовательский интерфейс. После выполнения этих обязательных этапов инженер по
знаниям строит прототип.
Этот прототип должен быть способен решить проблемы из данной предметной
области и обеспечить испытательный стенд для проверки предварительных проектных
решений. Когда прототип готов, инженер по знаниям и эксперт в предметной области
испытывают и уточняют знания путем решения конкретных задач и устранения дефектов.
Если предположения, сделанные при проектировании прототипа, оказываются
корректными, прототип можно поступательно расширять до тех пор, пока он не превратится в
окончательную систему.
Экспертные системы строятся методом последовательных приближений.
Выявляемые ошибки приводят к коррекции и наращиванию базы знаний. В этом смысле база
знаний скорее "растет", чем конструируется. На рис. 7.2 представлена блок-схема,
описывающая исследовательский цикл разработки программы. Этот подход к
программированию был изучен Сеймуром Папертом (Seymour Papert) с помощью его
языка LOGO [Papert, 1980], а также Аланом Кэем (Alan Key). Согласно философии LOGO
отслеживание откликов компьютера на некорректное представление идей в
программном коде приводит к коррекции кода (.отладке) и преобразованию в более точный код.
Этот процесс проб и корректировки проектов-кандидатов является общепринятым в
разработке экспертных систем и кардинально отличается от таких проработанных
иерархических процессов, как проектирование сверху вниз
полхГЛГпГ" СТаЛ СЛИШК0М Т™03»™". "ли проектировщики решили изменить
ботчика, ТсслеТ; ""Т М0ЖН° ПР°СТ0 '"вросигь. Прототип позволяет разра-
Другой важной особенностью «<-„«,
не должна рассматриваться каГ ертаьк снсгем является то, что программа никогда
иметь ограниченные bojn^hoc^MoZIT' Эврисгаче<:кая база знаний всегда будет
ляст естественным образом добавить Ь Модели продукционной системы позво-
вать существующую базу правил """"^ Правила шш в ™бое время подкорректнро-
Часть ш. Представление и разум в ракурсе искусственного интеллекта
i
( Начало J
Определение
задач и целей
Разработка
и создание прототипа
Тестирование/использование
системы
Анализ и исправление
недостатков
УТу-
I успешно
Рис. 7.2. Исследовательский цикл разработки
7.1.3. Концептуальные модели и их роль в приобретении знаний
На рнс. 7.3 представлена упрошенная модель процесса извлечения знаний, которая
могла бы служить первой аппроксимацией для понимания задач приобретен,» и
формализации человеческого опыта. Человек-эксперт, работая в прикладной области,
оперирует знанием, мастерством и практическими навыками. Это знание часто является
неопределенным н неточным. Инженер по знаниям должен транслировать этот Мюрма.™"..
опыт в формальный язык вычислительной системы. В процессе формализации
практической деятельности человека возникает ряд важных вопросов.
1. Человеческое мастерство часто недоступно для °™™^™*ZIZ?J
Аристотель в своей -Этике": "Все. чему мы должны научиться, мы изучаем на cob
Аристотель в своей лике „ulmwvTC. ,. годы обучения в интернатуре и в
ственном опыте". Навыки вРа-П^лем^оле™й работы эти навыки становятся
процессе работы с паииенгам,. После много ^ подсмнанм. эксперты
интегрированными и существуют в о«°»ном^ ур ^
могут затрудняться точно описать то, что они дслаюгпр и и»
Глава 7. Сильные методы решения задач
Извлечение знаний
Опья реализованная система
Рис. 7.3. Стандартный «*»> на построение экспертной сапсш
■, человеческий опыт часто принимает форму знания о том, ш справиться с ситуа-
" ц„Г „с о L. какош рационмьные характеристики этой ситуации. Мы выраба-
Гваем сложные механизмы действия, а не формируем фундаментальное
понимание этих механизмов. Наглядным примером этого является уникальная
последовательность действий при верховой езде: опытный наездник для поддержания
равновесия не решает в реальном времени многочисленные системы
дифференциальных уравнений, а использует интуитивное ощущение гравитации, момента и
инерции для формирования адекватной управляющей процедуры.
3. Приобретение знаний часто рассматривается как получение фактических
знаний об объективной реальности так называемого "реального мира". Как
показано в теории и на практике, человеческий опыт представляет модели мира,
формируемые отдельным человеком или группой людей. Такие модели
создаются под воздействием социальных процессов, скрытых закономерностей и
эмпирических методологий.
4. Опыт накапливается. Люди не только получают новые знания, но и
перерабатывают существующие, что сопровождается продолжительными дебатами в науке.
Следовательно, инженерия знаний является сложной задачей, связанной с жизненным
циклом любой экспертной системы. Чтобы упростить эту задачу, полезно создать
концептуальную модель — прослойку между человеческим опытом и реализованной
программой (рис. 7.4). Под концептуальной моделью понимается концепция знаний о
данной области, построенная инженером по знаниям. Несомненно, отличаясь от модели
эксперта в данной области, концептуальная модель действительно определяет структуру
формальной базы знаний.
„ель,™™0"" 6ольш"нства интересных областей этот промежуточный результат
рГатьГпеоеЗВаТЬ '" °КОНЧ№ы"- Инжокры по знаниям должнь, задокументи-
проектгоо Z „no ПреД<?мение • предметной области с помощью общих методов
;°6oZuT"сте'ГГак Р" РШРаб0ТКС ЭКСПер™0Й "™ необходимо описать
-кспертГй сисГе до™ Г: Г""*'"1" ™eH"°r0 ™кла разработки требования
Фическне •V^J^^^Z'mm. C "Р-°™°м. Словари терминов, гра^
частью этой модели. ПубликТэтГпп "' " комментаР™ в коде сами являются
6ок как „р„ „„„, та j пр/с~1 нр„7пр0иг;а'::геньшасмколичествоош'"
Концептуальная модель г-,
ф 5
Извлечение знаний
Опыт Реализованная система
Рис. 7.4. Роль ментальных или концептуальных моделей в решении проблем
Инженеры по знаниям должны сохранять записи своих интервью с экспертами по
предметной области. Часто по мере улучшения понимания проблемной области инженеры
по знаниям формируют новые интерпретации или открывают новую информацию. Записи
наряду с документированием данных и интерпретаций играют важную роль при
рассмотрении проектных решений и тестировании прототипов. Наконец, эта модель играет
промежуточную роль при формализации знаний. Выбор языка представления оказывает
значительное влияние на модель предметной области, создаваемую инженером по знаниям.
Концептуальная модель не является формальной или исполняемой на компьютере.
Это промежуточное проектное решение, шаблон для начала процесса кодирования
человеческого опыта. Если инженер по знаниям использует модель исчисления предикатов,
она может быть представлена в виде набора простых сетей, определяющих состояния
рассуждений посредством типичных способов решения проблем.^ Лишь после
дальнейших уточнений эта сеть превратится в набор правгш "ест..., то..: .
При создании концептуальной модели рассматриваются следующие вопросы.
Является ли решение проблемы детерминированным или оно основано на поиске. Как
выполняется рассуждение: на основе данных (возможно, с генерацией и
тестированием) „лн на основе цели (с учетом некоторого множества вероятных гипотез)?
Существуют ли стадии рассуждения? Хорошо лн изучена область и может ли она
обеспечить глубокие прогнозирующие модели, или все знание существенно »Р«™™*
Можно ли для решения новых проблем использовать примеры прежнн-задач: н их
Решений, „ли сначала необходимо преобразовать эти примеры в общееправило?
Является ли знание точным, нли оно "размытое" к приближенное, и для него
используются числе ные оценки определенности (глава 8)? Позволяв стратег рас-
суждений делать стабильные выводы или внутренняя ^^^"^ZZ
гребует немонотонного рассуждения, возможности формулиро ать утв рждения. ко
™Рые впоследствии могут «°Д"Ф"""Р" ^"^ яГвыво'а н™
иец. требует ли структура знании о данной области отк^«
281
„„„ схем, как нейронные сети или генетические
прав„л в пользу таких альтернативных
Хоришы (часть IV)? жны также учитываться потребности конеч.
В контексте концептуальной молот шкцтЯ программы? Каков уровень их опы-
„ых пользователей. Чего они ожид ^^ Ктк yp0BHi, объяснений нм требуют.
ш новичок, средний «Mb30Ba™6MMM удовлетворяет их нужды?
с? Какой интерфейс наилучшим г BonpocUi a ^ж знания о предметной области.
Получив ответы на эти и ДРУконце|Пуальной модели, а затем и самой экспертной
можно приступать к Р^Р*60^ системы, впервые представленные в главе 5, пред-
снетемы. Поскольку ПР0ДУКЦ" организации и применен™ знаний, онн часто
латают собственные М°ЩНЫ"Р™ „„едставления знаний в экспертных системах,
используются в качестве платформы для пред
7!21ЭкспеЕпшеснс^^
В экспертных системах, основанных на правилах, знания о решении задач представ-
ляют в вще прав™ "если..., то...". Этот подход, являясь одним из старейших методов
представления знаний о предметной области в экспертной системе, применяется в
системах, архитектура которых показана на рнс. 7.1. Как один из наиболее естественных он
широко используется в коммерческих и экспериментальных экспертных системах.
7.2.1. Продукционная система и решение задач на основе цели
Архитектура экспертной системы, основанной на правилах, может быть рассмотрена в
терминах модели продукционной системы решения задач, представленной в части П. Между
ними есть большое сходство: продукционная система считается интеллектуальным
предшественником архитектуры современных экспертных систем, в которой продукционные правила
позволяют лучше понять конкретную аггуацию. Когда Ньюэлл и Саймон разрабатывали
продукционную систему, их целью было моделирование деятельности человека при решении
задач. Если экспертную систему на рис. 7.1 рассматривать как продукционную, то базу знаний о
предметной области можно считать набором продукционных прав™. В системе, основанной
на правилах, пары "условие-действие" представляются правилами "если..., то...", в которых
посылка (часть если) соответствует условию, а заключение (часть то) — действию. Если
условие удовлетворяется, экспертная система осуществляет действие означающее истинность
закшочения. Данные частных случаев можно хранить в рабочей памяти. Механизм вывода
m^^ZZT" ПрОД>вдио,шой ^стемы -'распознавацие-действие". При этом управление
мож„осуЩестзлятьсялибо„аос„оведа„га>к,л„6онаосновецели.
npotr иГрГрГ^боГая6:::™ <~вуют —*m-^Hanp,,M£p'в
ные, при этом часто™ Т "Ь инФ°Р»ацин представляет собой исходные дан-
проиД ас" ^нГД„ГФОРМУЛИР,0ВаТЬ ГИПОгаЫ "™ »"*■ Эт° »Р™°»»Т к ПРЯМ0МУ
^^^Ч,'^Ю^^™ П0МИ™ГИ ° Раб°ЧУЮ ПаМЯТЬ' " СИСТ"'а
жение. Система сопостТвлГеГ"01"2 Ue™ " рабочую память помещается целевое выро-
их предпосылки в рабочую паМКЛ№"ш,я правил с целевым выражением и помешает
лее простые подцел,, На cae^"' - С00тветствУст декомпозиции проблемы на бо-
цесс продолжается, ,т„ ПпеЛп„ '" итерации Работы продукционной системы про-
сылки становятся новыми подцелями, которые сопос
Представление и разум в ракурсе искусственного интеллекта
гавляются с заключениями правил. Система работа
рабочей памяти не станут истинными, подтвепж„?Г "° ™ ПОр' П°Ка "Се подцеяи »
НЫЙ поиск в экспертной системе приближенно Z "У' ТаКИМ °6раЗОМ> о6рат'
"ез прн решении проблем человеком С00Твет"аУ« "РОЦесеу проверки гипо-
В экспертной системе, чтобы достичь nnmn-i™ „»
,„ В некоторых экспертных систГ^Г Z—^ZIUZ
" ГиГГтут^^Ри°Г„нПГОВаТеЛЮ' *»"* ^^"ZraVZ:
Гелю, если не могут вывести истинность подцеяи на основе правил из базы знаний
В качестве примера решения задач „а основе цели с запросами к пользователю
рассмотрим небольшую экспертную систему диагностики автомобиля. Это не полная
система диагностики, так как она содержит всего четыре очень простых правила. Она
приводятся как пример, демонстрирующий образование цепочек правил, интеграцию новых
данных и использование возможностей объяснения
Правило 1: если
топливо поступает в двигатель и
двигатель вращается,
то
проблема в свечах зазкигания.
Правило 2: если
двигатель не вращается и
фары не горят,
то
проблема в аккумуляторе или проводке.
Правило 3: если
двигатель не вращается и
фары горят,
то
проблема в стартере.
Правило 4: если
в баке есть топливо и
топливо поступает в карбюратор,
то
топливо поступает в двигатель.
Для работы с этой базой знаний цель верхнего уровня проблема в X помещается в
рабочую память, как показано на рнс. 7.5. Здесь X — переменная, которая может
сопоставляться с любой фразой, например, проблема в аккумуляторе или проводке.
В процессе решения задачи она будет связана с некоторым значением. С выражением в
рабочей памяти сопоставляются три правила: правило 1, правило 2 и правило 3. Если мы
разрешаем конфликты, предпочитая правила с наименьшим номером, будет
активизироваться правило 1. При этом X связывается со значением свечи зажигания, и
предпосылки правила 1 помещаются в рабочую память (рис. 7.6). Таким образом, система
выбирает для исследования гипотезу о неисправности свечей зажигания. Это можно
рассматривать как выбор системой ветви ИЛИ на графе ШИЛИ (глава 3).
Отмстим, что для истинности заключения правила 1 должны быть удовлетворены две
предпосылки, Они являются ветвями И графа поиска, представляюшего декомпозицию
задачи (действительно ли проблема в свечах зажигания) на две подзадачи (топливо
поступает в двигатель и двигатель вращается). Затем можно активировать
правило 4, заключение которого сопоставляется с целевым утверждением топливо
поступает в двигатель, и его предпосылки помещаются в рабочую память (р*. 7.7).
Глава 7. Сильные методы решения задач
283
Рис. 7.5. Начало работы продукционной
системы диагностики неисправностей
автомобиля
Рабочая память
топливо поступает
в двигатель
двигатель
вращается
проблема
в свечах зажигания
!
1
Продукционные
правила
Правило 2
Правило 3
Правило 4
Рис. 7.6. Продукционная система после
активизации правила 1
Рабочая память
вбаке9стьтопливо
топливо поступает
в карбюратор
проблема
в свечах зажигания
L
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
Рис. 7.7. Система после активизации правша 4.
Обратите внешние на использование стека в
процессе приведения цели
284
Часть III. Представление и ра.ум в ракурсе искусственного интеллекта
Рис. 7.8. Граф И/ИЛИ при сравнении заключения правша 4 с первой предпосылкой правша 1 в
примере диагностики автомобиля
Теперь в рабочей памяти существуют три элемента, которые не соответствуют ни
одному из заключений в наборе правил. В подобной ситуации экспертная система будет
запрашивать пользователя. Если пользователь подтвердит истинность всех трех подцелей,
экспертная система успешно определит, что автомобиль не заводится из-за
неисправности свечей зажигания. При поиске этого решения система исследовала крайнюю слева
ветвь графа И/ИЛИ, показанного на рис. 7.8.
Конечно, это очень простой пример. И не только потому, что база знаний об
автомобиле ограничена а также потому, что в этом примере не учитывается ряд важных
аспектов реализации. Правила описаны на русском, а не на формальном языке. При
обнаружении решения реальная экспертная система сообшит пользователю свои диагноз (наша
модель просто останавливается). Необходимо также поддерживать достаточно длинную
историю рассуждений, чтобы в случае необходимости возвратиться назад. Если вывод о
неисправности свечей зажигания окажется неудачным, нужно иметь возможность
возвратиться „а второй уровень и проверить правило 2. Заметим, что информация по
упорядочению подцелей в рабочей памяти на рис. 7.7 и на графе, представленном „а рис. 7.8,
явно „е выражена. Однако, несмотря „а простоту, этот пример подчеркивает важность
поиска „а основе продукционной системы и его представления графом 11/ШШ в экс-
пертных системах, основанных на правилах. _ „„„„„„
Ранее мы подчеркивали, что экспертная система должна »»»Ч»°»»»™-
™рования, легко модифицируемой и эвристической по природе. Архиге^р.
продукционной системы являете важным фактором для каждого из этих требовании. Легкость
Глава 7. Сильные методы решения задач
285
...таКСИЧССКОЙ НС1ЯВИСИМОСТЫО продукционных
моляфика,и.и. например, определяется сии, й, Kimpa» ножа модифицироваться
молн'Р"1 ,тЧцило является пи»»»»» _ „1JliU поскольку иплинилули..
,,„„„,: каждое правило является ™»- офа„„чсиия, поскольку индивиду»,,,,.
*1си«о. Однако сушествукнмаити ж„„ Г„„ть согласованы .любом пропсе
1Ы, правила «м««и по смыслу 3™ ' ижс ми обсудим генерации, rfuoHHt и у„ра„.
ее редактирования или модификации.
лепис выводом.
„т. ппн пассуждсииих на оспине цели
7 2 2. Объяснения и прозрачность при рассужд
я(г, „„иск на графе. Профаммы подсистемы объ-
Пролукпионная система «^lc""" ||0ИСКа „а ,-рафс и исполмуют '.ту информа-
яснений на рис. 7.1 отслеживаю, с М(1ШЫ„ продукционных прапил каж-
ш„о, чтобы отвечать па вопрос ьп ю»«»™ а|пома,И„ССКИ.
Л,.,Й ша, процесса Ра«^'|ИЙ*7сГ1 пне па правилах, отвечают „а дна вопроса _
°б"ТЖТ"ив::рГ^ -шкает, когда проф.-. опрашивает „„.
"почему/ и как. . во ip / 0,„,.,вет "почему вы запрашиваете -.ту ипфор-
!Го'ГоС:Г=:Гуи:Г:ра„ило, которое система пытается акзивизиро-
^Ответом на вопрос "как вы получили этот результат?" является последовал,.-
ность правил, использованных для достижения цели.
Предположим, автомобильная опершая система имеет средства объяснения, и
в процессе работы дости.ла стадии, представленной конфигурацией рабочей памяти
на рис 7.7. Приведенный ниже диало, начинается с вопроса компьютера к
пользователю о целях, представленных в рабочей памяти. Ответы пельзоназеля выделены
жирным шрифтом,
в баке есть топливо?
да
топливо поступает в ?■•• г-«-\> '.!•'*
да
двигатель вращается'.'
почему
Здесь пользователь задаст вопрос: "Ничему вы xothic знать, вращается ли
двигатель?". Система отвечает с помощью символьною представления правила, к которому
относится нопрос.
Выло установлено, что:
1. топливо поступает в двигатель,
поэтому если
2. двигатель вращается,
то проблема в свечах зажигания.
Поскольку пользователь на первые два вопроса ответит! "да", это дало возможность
вГм"и!Т™а"' "Ра"И"" ' " "Р""СрИГ" cro "W0 предпосылку. Отмстим, что обмене-
сив ZZ,2Um"U Тт" ™'bKU тти ""а"и"а' К»™Р<* ««■«"■« » Рассм0Т'
ч му„ „па„„1»„ч ""аК° ЭТ° °б=и'<""™« адекватное объяснение причин, по-
Г'ГаТ ГГ:^:™т яви,ата""п тт ш "°"рос "|Ю"сму"систс'
"ользо,шсль далее спрашнвГ '" """У"™ " " matt" "Р™'"""*""'
как топливо
поступает в ,nMVii
286
I. Представление и разум в ракурсе искусственного интеллекта
Ответом являс-теа последовательность рассуждений, приведшая к этому заключению
0на „осстанавливатггсяобратным „риходом „ цс„„ J^ JT^nTyZ.H „ ZTo
информации, введенной пользователем. ""нигготвукиних „рави/i до
Из правила 4 следует:
если
в Саке есть топливо и
топливо поступает о карбюратор,
то
топливо поступает в двигатель.
в баке есть топливо - указано пользователем
топливо поступает в карбюратор - указано пользователем
Таким образом, архитектура продукционной системы обеспечивает основу для этих
объяснений. I) каждом цикле управления выбирается и активизируется новое правило.
После каждого цикла протрамма может быть остановлена и проинспектирована.
Поскольку каждое правило представляет "глыбу" знаний „о решению проблемы, текущее
правило обеспечивает контскс, для объяснения, >гим продукционный подход
отличается от более традиционных архитектур: если программу на С или C++ остановить во
время исполнения, то вряд ли текущее выражение будет иметь мною смысла.
Итак, система, основанная на знаниях, отвечает на вопросы "почему?", отображая
текущее правило, которое она пытается активизировать. В ответ на вопросы "как?" она
предоставляет последовательность рассуждений, которая привела к цели. Хотя эти
механизмы являются концептуально простыми, они обладают хорошими возможностями
объяснений, если база знаний организована логически трамоттю. Главы по языкам LISP и
PROLOG в части IV демонстрируют использование стеков правил и деревьев
доказательств для объяснений. Ьсли объяснения должны быть ло, ичными. важно не только,
чтобы база знаний выдавала корректный ответ, но и чтобы каждое правило
соответствовало одному шагу процесса решения проблемы. Если в одном правиле базы знаний
заключено несколько шагов или правила сформулированы произвольным образом,
получить правильные ответы на вопросы "как?" и "почему?" будет сложнее. Это не только
подрывает доверие пользователя к системе, но и делает программу более трудной для
понимания и модификации разработчиками.
7.2.3. Испои,.питание продукционной системы дли рассуждений
на осноне данных
Пример диагностики автомобиля в подразделе 7.2.1 иллюстрирует использование
продукционной системы дття реализации поиска на основе цели. В этом примере использовался
поиск в глубину, так как перед переходом к соседним целям для каждой обнаруженной в
базе правил подцели производился исчерпывающий поиск. Однако, как мы видели в
разделе 5.3, продукционная система является также идеальной архитектурой и для рассуждений
на основе данных В примере 5.3.1 этот процесс был продемонстрирован для игры в
"пятнашки", а в примерах 5.3.2 и 5.3.3 - для задачи о ходе конем. В каждом из этих
примеров конфликт разрешался посредством извлечения и применения первою
обнаруженного в базе знаний правила. При этом выполнялся поиск в глубину, хотя в этих примерах не
было механизма возврата для выхода из '-тупиковых состояний" в пространстве поиска.
В рассуждениях на основе данных чаше применяется поиск в ширину. Алгоритм
очень прост: содержимое рабочей памяти сравнивается с предпосылками каждого пра-
Глава 7, Сильные методы решения задач
287
анные в рабочей памяти приводят к активиза-
в„л. » упорядоченной базе W™"^™» память, „ управление передается следу».
ц „ правила, результат помещается в£ ^ ^ повторяется сначала,
шему правилу. После Р^'^^мобильной диагностики на основе правил из под.
Рассмотрим, например, задачуавто ^ выводится ю друтих правил, то иедостаю-
раздела 7.2.1. Если предпосылка пр| димости Например, предпосылка правила 1
щая информация запрашивается пр является запрашиваемой, так как этот факт
топливо поступает в явиг"" „менно- правила 4.
является заключением другого пра начинается ю состояния, показанного на рис. 7.9.
Поиск в ширину на основе д™ еиное на рис. 7.5. Отличие состоит лишь в от-
Оно очень напоминает состояни • ^ Предпосылки четырех правил проверяются на
сутствии информации в рабочей ^ Предпосылка топливо поступает в
ПРвИЯ ГГяГГ^Р—ok позт^,у правило 1 применить нельзя, и управ-
двигатель не является ■""!""" „нигатель не вращается является за-
„енне переходит к правилу 2. нфор <*ш* в-ате J^ тогда в ^тую ^
прашиваемон. Предположим, ответом на это р у ^ ? ^
мять заносится фраза двигатель вращается, к
Рабочая память
Продукционные
правила
Рабочая память
Продукционные
правила
Правило 1
Правило 2
Правило 3
Правило 4
двигатель
вращается
Празило 1
*■ Правило 2
Правило 3
Правило 4
Рис. 7.9. Продукционная система в
начале процесса рассуждения на
основе данных
Рабочая память
Рис. 7.10. Продукционная система
после оценки первой предпосылки
правила 2, которая оказалась ложной
Продукционные
Правила
Топливо поступает
в карбюратор
Двигатель
вращается
Правило 1
Правило 2
Правило 3
Правило 4
Рис 7.11. Основанная на данных
продукционная система после рассмотрения правила
4 начинает второй проход по правилам
Но правило 2 применить нельзя, поскольку первая нз двух конъюнктивных
предпосылок является ложной. Управление переходит к правилу 3, в котором первая посылка снова
принимает значение "ложь". В правиле 4 обе предпосылки являются запрашиваемы*»-
Предположим, ответом на оба вопроса будет "истина", тогда предложения в баке есть
топливо и топливо поступает в карбюратор помещаются в рабочую память.
Туда же заносится и заключение правила - топливо поступает в двигатель.
288
I. Представление и разум в ракурсе искусственного интелле!
Итак, по первому разу все правила рассмотрены, и начинается повторное
рассмотрение правил с учетом нового содержания рабочей памяти. Как показано на рис 7.11, при
сопоставлении правила 1 с данными в рабочей памяти его заключение - проблема в
сВечах зажигания - помещается в рабочую память. Больше никаких правил
применить нельзя, и сеанс решения задачи завершается. На рис. 7.12 показан граф поиска, узлы
которого содержат информацию, находящуюся в рабочей памяти (РП).
Первый проход
по правилам
Правило Правило Правило Правило
е применимо неприменимо неприменимо активизируется
Второй проход
по правилам
как на
рис. 7.11, плюс
проблема в свечах
зажигания
Останов в связи с отсутствием
подходящих правил
Правило
активизируется
Рис 7 12. Граф поиска , ширину на основе данных, р.». ноторого
явмется информация из рабочей памяти (РП)
Важной модификацией используемой в ^^^Cl^Z^^Z:
рину является так "-ваемьше== ^ »**»»"
всякий раз при активизации правила Я™ вшо*, но ^ ^ Следовательно,
к правилу, содержащему эту новую информацию в качестве^д. обработки
любая вновь ценная информация роется - ^fj™ S да отделения
запрашиваемых" предпосылок не ю"™™"' , „едовани. правил пред-
акшвнзируемых в дальнейшем правил. ™J""> и оппоргу11ИсГн,е«им.
ставленный пример, сам по себе очень ПР°<™'' на мвок да„иых, затронем во-
В завершение раздела, п-вяшенно^а^еиия ^ ^ ^^
чросы объяснений и прозрачности в системах пр»мо
289
Глава 7. Сильные методы решения задач
„ (подразделы 7.2.1, 7.2.2), рассуждения иа основе да„.
с „семами, основанными на <«^™я Прич„„а этого очевидна - в системе, 0сно.
„их выполняются менее ^"^ено на решение конкретной задачи, которая раз6н.
ванной на цели, рассуждение направл ^ ^ очередЬ| могут дро6нться дальше в ре
вается на более мелкие, и эти »«' ведущсй от этой цели к ее составляющим,
зультате поиск всегда направленпк,^ ^ 0ТсутсгВует. Поиск выполняется по де,
В системах на основе данных ори нця правил „ появления новой информации. В
реву, зависящему лишь от П0РЯ^ „ асплывчатым" и несфокусированным,
итоге процесс поиска часто хтт ^и рмультатом только что сказанного, пояснения,
Во-вторых, и это являетс" "Р пщкка в(!(;ьма ограничены. В системах на основе
выдаваемые пользователю в "Р п0льз08ателю представляется рассматриваемое пра-
правил в ответ на вопрос тюча^. ^ последоватеЛьность правил точно не отслежива-
вило (см. подраздел l.l.J.)- и. ■ ого поиска), это объяснение нельзя раэ-
ется (например, с -*»-^нове данных затрудняет подобные объяснения. И,
вить. "Расплывчатость поиска в^основе д J ,ывающее объяснение в ответ
ия«т»нри пли достижении иели системе труд™ д v
„вопрос 3" В качестве частичного или полного объяснения можно лишь нсполь-
"овать содержимое рабочей намят,, или список активизированных Правил. Но опять-таки
эти пояснения не дают полного согласованного обоснования, которое мы наблюдали в
рассуждениях на основе цели.
7.2.4. Эвристики и управление в экспертных системах
Вследствие разделения базы знаний и механизма вывода, а также особенностей
работы механизма вывода важным методом программного управления поиском является
структурирование и упорядочение правил в базе знаний. Такое мнкроуправление на
множестве правил открывает новые возможности, особенно с учетом зависимости
стратегий управления от специфики предметной области и объема знании. Хотя правило вида
if p, q, and r then s (если р, q и г, то s) напоминает логическое выражение, оно
может быть интерпретировано как последовательность процедур или шагов решения
задачи: "чтобы получить s, сначала нужно выполнить р, затем q, затем г". Важность
упорядочения правил и их предпосылок была неявно продемонстрирована в только что
рассмотренных примерах из раздела 7.2.
Этот процедурный метод интерпретации правил является существенным
компонентом практического использования знаний и часто отражает стратегию решения задачи
человеком-экспертом. Например, предпосьшки правила можно упорядочить таким
образом, что наиболее вероятные отрицательные ответы или простые подтверждения истины
будут проверяться первыми. Это дает возможность отбросить правило (и, следовательно,
отсечь часть пространства поиска) как можно раньше. Правило 1 в примере с
автомобилем предполагает ответь, „а вопрось, в такой последовательности: сначала требуется оп-
2™„П0СТУПаеТ Л" Т0Ш1ИВ° В ДВИГагель' а загем - "Р^тся ™ Двигатель. Это
веетсяTZ' Т КаК "РИ П°ПЫТКе ВЬ1ЯСНПТЬ' по^па« ™ ™пл„во в двигатель, вьгэыва-
^пооеа П„„РТ°' "' " К'"К'1тМ СЧ"е' "°*ьзователь Д°™е„ ответить еше на да»
• рашаетс, ли "ГгатТ" ""^ Ч*<™*™» отрицательный ответ на вопрос
^^zy:zrz:z:4zr правил°т ^^^ >° •*>«*»шсе
Есть еще одна ипИч,!1 эФФ=™вность системы повышается,
имеет зиа^ГГпо™ «Г УП°«—' Е<™ Д-атель не враптается,
ступает ли в него топливо. В правиле 4 пользователя сначала пр<**
проверить наличие топлива в баке, а затем е™ „„™
"f,„ первая проверка легче второй ТакГ „7 П0С^ПЛ1™С » карбюратор. В этой си.уа
U" \.L „.'.,. « Р КИМ обРЩ°", Для повышения обшей эАЛиггивм»
проверить наличие топлива в баке,
цни первая проверка легче второй.
ст„ системы должны быть рассмотрены все'аТпе'кты "„„„'ГГ™"* "^ *ЮскпшИ°-
110Сьшо, стоимость каждой проверки, разме Гекае^о"™ Иска '„а'Г
лее типичные случаи и т.д. ^^фансва поиска, наиоо
Планирование порядка правил, организация nneinnn...,,,,
г • н «ппзйция предпосылок в правилах и определение
стоимости различных проверок —действия ,.„„„„„„, . «.рчшшт
*• f к дчл 1вия, эвристичные по своей природе. В больший-
„во экспертных систем, основанных на правилах, эти эвристики отражают подходы
человека-эксперта и, несомненно, могут давать ошибочные результаты. В нашем примере,
если топливо поступает в двигатель и двигатель вращается, проблема может заключаться
в распределителе, а не свечах зажигания.
Рассуждения на основе данных создают дополнительные проблемы и обеспечивают
новые возможности управления. К ним относятся эвристики высокого уровня, такие как
рефракция, оппортунистический поиск и учет особенностей предметной области,
представленные в подразделе 5.3.3. При более специфичном подходе множества правил
группируются в соответствии со стадиями процесса решения. Например, в задаче
диагностики автомобиля можно выделить четыре различные стадии: формирование
ситуации, сбор данных, анализ (возможность возникновения нескольких проблем
одновременно), заключение и рекомендации по ремонту.
Для такого поэтапного решения задачи следует создать описание для каждой стадии
решения и использовать их в качестве первой предпосьшки всех правил, относяшихся к
этой стадии. Например, сначала в рабочую память можно поместить утверждение
стадия — формирование ситуации. Если в рабочей памяти нет описания других
стадии, то будут активизироваться лишь правила, содержащие в качестве предпосьшки
факт стадия — формирование ситуации. Разумеется, в каждом правиле эта
предпосылка должна располагаться первой. Для перехода к следующей стадии при
активизации последнего правила факт стадия - формирование ситуации нужно
вычеркнуть и заменить его фактом, определяющим стадию сбора данных. Первой
предпосылкой всех правил, относяшихся к стадии сбора информации, должна быть следующая:
если стадия — сбор данных и .... По окончании стадии сбора данных
последнее правило должно вычеркивать этот факт и дописывать в рабочую память факт
перехода к стадии анализа данных. На этой стадии будут обрабатываться лишь те правша,
первой предпосылкой которых является факт если стадия - анализ данных....
До сих пор в своем обсуждении мы описывали поведение продукционной системы в
терминах исчерпывающего рассмотрения базы правил. Хотя такое поведение является
достаточно дорогостоящим, оно включает внутреннюю семантику продукционной
системы. Однако существует ряд алгоритмов, таких как RETE [Forgy. 1982]. которые могут
быть использованы для оптимизации поиска потенциально полезных правил. По
существу, алгоритм RETE интегрирует правила в сетевую структуру, позволяющую системе
сопоставлять правила с данными, прямо указывающими на правило. Этот алгоритм
значительно ускоряет выполнение, особенно для больших множеств правил, в то же время
сохраняя семантику поведения, описанную в данном разделе.
И в заключение правила были и остаются важным средством построения решателей
задач, основанных на знаниях. Правила экспертной системы содержат знания людей-
экспертов в том виде в котором они используются на практике. Поэтому они часто
явится смесью теоретических знаний, полученных из опыта эвристик и специальных
правил управления нерегулярным,, случаями и другими исключениями. Во многих си-
Глава 7. Сильные методы решения задач
291
„ „оказал свою эффективность. Тем не менее эвристические системь,
туациях этот подход доказал ecJЗадача не соответствует ни одному из имеющихся
могут давать сбои в том случ^ 0Шиб0ЧН0 применяется к неподходящей ситуации,
правил, или эвР"стиче™п.^ ПОдо6ных проблем, потому что обладает более глубоким
Человек-эксперт не испыт й о6ластн> позволяющим осмысленно применять
теоретическим понимайнем пр « ^ ^^ СИ1уащмх к рассужДе„иям „а основе 6а-
эвристические правилаитщ П0драз„еле 7.3.1 подходы, основанные „„моде-
зовых принципов. 0шк,ыва'""емДожнос1Н для экспертных систем.
^В^ГоГоб^сГнГ: и!^ является друге* человеческой способ„ость,о,
котооТзмулируюЛнстемы решения задач, основанные „а знаниях. Рассуди» т
Г1« (лодраздел 7.3.3) поддерживают базу знании примеров решения задач.
При сГлГовении с новой проблемой механизм рассуждении выбирает из сохраненного
множества случай, напоминающий решаемую задачу, и затем пытается применить его
стратегию решения к новой проблеме. В юриспруденции примером рассуждений на
основе опыта является доказательство по прецеденту.
7.3. Рассуждения на основе моделей, на базе опыта
и гибридные системы
7.3.1. Введение в рассуждения на основе модели
Человеческий опыт — это чрезвычайно сложная смесь теоретических знаний,
эвристик решения задач, примеров прошлых проблем и нх решений, навыков восприятия и
интерпретации, а также других аспектов, которые можно описать лишь как интуитивные.
С годами человек-эксперт вырабатывает очень точные правила поведения в обычных
ситуациях. Часто эти правила принимают форму прямых ассоциаций между
наблюдаемыми симптомами и окончательными диагнозами, скрывая их более глубокие причинно-
следственные связи.
Например, экспертная система MYCIN может предложить диагноз, исходя из таких
симптомов, как "головная боль", "тошнота" или "жар". Хотя эти параметры могут быть
индикаторами болезни, правила, напрямую связывающие их с диагнозами, не отражают
более глубокого причинного понимания человеческой физиологии. Правила системы
MYCIN позволяют определить название болезни, но не объясняют ее причины. Подход,
основанный на более глубоких объяснениях, должен учитывать присутствие
инфекционных агентов, результирующее воспаление содержимого клетки, наличие
внутричерепного давления и причинную связь с наблюдаемыми симптомами головной боли,
повышенной температуры и тошноты.
стнНпгХ'ÄЄ'п! ЭКСПертной систем^ предназначенной для анализа причин неисправно-
™Г„Т„ГГа "а °СН08е ^"^ опис™ль„ый подход позволит строить „иагне
ZZoZTZZr" 7 ШКт С"МПТОмах' как обесцвечивание компонентов
UeZ;ra^T„r;„roP„Sa'cTOP1U M™»™* ' »<*■*"» "^ "Г
ходы, которые испольТуют „Т ЩЬК> MemP°™oro микроскопа. Однако под-
полезными'™^ глубо?„Га """ СМЗИ м6™«ний с диагнозами, являются бес
объяснение могло б" h^IT"" СТРУКТУРЫ " ФуИКЦИЙ Пр"6°ра' Б°Лее """I
структуры цепи „ уравнений опись "l""06""" яетаЛ1™Р™™"°й "°Д<™ Ф'««ческ°"
нии, описывающих ожидаемое поведение каждого компонента
Представление и разум в ракурсе искусственного интеллекта
цепи и нх взаимодействия. Диагнозы могли бы основываться на сигналах, полученных из
различных точек, „ модели цепи для определения точных мест неисправности.
Поскольку экспертные системы первого поколения основывались на эвристических
правилах, полученных нз описаний методов решения задач человеком-экспертом, они
обладали рядом ограничений [Clancy, 1985]. Если ситуация не соответствовала
заложенным в систему эвристикам, она просто терпела неудачу, хотя более строгий
теоретический анализ мог бы привести к успешному решению. Часто экспертные системы
применяли эвристики в несоответствующих ситуациях, в которых более глубокое понимание
проблемы могло бы указать другой курс. Эти ограничения позволяют преодолеть
подходы, основанные на моделях. Механизм рассуждения, который базируется на
спецификации и функциональности физической системы, называется системой на основе модели.
Система рассуждений на основе модели осуществляет программное моделирование тех
функций, которые необходимо понять или зафиксировать. (Существуют, конечно, и
другие типы систем, основанных на моделях, в частности, логические и стохастические. Они
будут рассмотрены в главе 8.)
Первые системы рассуждений на основе моделей появились в середине 1970-х и
продолжали развиваться в 1980-х годах [Davis и Harascher, 1992]. Интересно отметить, что
некоторые из наиболее ранних работ были направлены на создание программных
моделей различных физических приборов, таких как электронные цепи, с целью их изучения
[deKleer, 1976], [Brown и др., 1982]. В этих работах прибор или цепи описывались в виде
набора правил, например, законов Кирхгофа и Ома. Обучающая система могла
проверить знания студента в данной области, а также передать ему недостающие данные.
Правила, с одной стороны, обеспечивали представление функциональности, а с другой —
представляли собой среду для передачи знания студенту. Развитием этих ранних
обучающих систем, задача которых сводилась к моделированию и обучению
функциональности системы, стали системы рассуждения на основе моделей, предназначенные для
устранения неисправностей. Прн выявлении неисправности в физической системе
модель предлагает множество прогнозируемых вариантов поведения. Неисправность
отражается в различии между ожидаемым и наблюдаемым поведением. Система, основанная
на модели, сообщает пользователю, чего ожидать, а различия между наблюдаемым и
ожидаемым поведением приводят к идентификации неисправностей.
Качественные рассуждения на основе моделей включают следующие аспекты.
1. Описанне каждого компонента прибора, позволяющее моделировать их поведение.
2. Описание внутренней структуры прибора. Оно обычно содержит представление
компонентов и их взаимосвязей наряду с возможностью моделировать их
взаимодействие. Требуемая степень знаний внутренней структуры зависит от
применяемого уровня абстракции и ожидаемого диагноза.
3. Диагностика частной проблемы. Это требует наблюдений реального поведения
прибора, обычно — измерения его входов и выходов. Входные и выходные
измерения получить легче всего.
Задача заключается в определен еисправных компонентов с учетом наблюдаемого
поведения. Это требует дополнительных правит, описывающих известные формы
неисправностей для различных компонентов и нх комбинаций. Система рассуждений должна обнаружить
наиболее вероятные неисправности, объясняющие наблюдаемое повеление системы.
Для представления причинно-следственной и структурной информации в моделях
можно использовать различные структуры данных. Дтя отражения причинности и функ-
Глава 7 Сильные методы решения задач
293
f. , » поограмме рассуждении на основе моделей зачастую „сп
„„ональности прибора в "Р0ГР 'пользоваться для фиксации отношении Мйкд '
т правила. Правила «°^ «^^ с]|стемы (см. раздел 15.12) также является „""
„онентамн. 06ыкгт^2й устройства и внутренней структуры компонентов «одели
красным средством описа.у ^^ дсташиют устройство или состояние компо^
При этом переменные — член нальность устройства.
„ентов. а методы определяют ФУ к„ „ описан™ модели, рассмотри не.
Чтобы »»»%™*»™*™. « Цепей, взятых из работы (Davis и Hamsche,
Чтобы конкретизировать проц ^Г ^ „3 |Davis „ ^ -- »-
с^»^^"^^^,^^». выражений. определяющих оти^ени,
мП^С:1Г„Г:™ГмС:::ТрибоРа. Дл» сумматора, „оказанното на рис. „3, 2
выражения имеют такой вид.
Если известны значения в точках А и В. то значение в точке С
вычисляется как MB (сплошная линия.. Бычисляется _ с_д
Если известны С и А, значение
(KDvnHbm пунктир).
Если известны значения С и В. значение в точке А вычисляется
как С-В (пунктир).
Рис. 7.1.1 Описание поведения сумматора из [Shrobe (ред.), 1988]
Для представления этих отношений иет необходимости использовать алгебраическую
форму записи. С таким же успехом могут быть использованы кортежи отношений, а
ограничения могут быть представлены с помощью функций LISP. Целью рассуждении на
основе модели является представление знаний, определяющих функциональность сумматора.
В качестве второго примера рассмотрим схему из трех мультиплексоров и двух
сумматоров (рис. 7.14). В этом примере входные значения задаются в точках А -Е, а
выходные вычисляются в точках F и G. Ожидаемые выходные значения задаются а круглых
скобках, а действительные выходы — в квадратных. Задача заключается в определении
неисправности, объясняющей различие между этими значениями. В точке F наблюдается
конфликт: ожидаемым выходным значением является 12, а реально полученным - Ю.
проверяя зависимости в этой точке, определяем, что значение в точке F вычисляется как
Функция от add-1. Это значение, в свою очередь, зависит от выходов MULT-1 и MULT-
c,,„Z°J" ЭТИХ уСтройств ««Держит неисправность, следовательно, необходимо рас-
дяекя одиТ,'пПШОтаЫ: ЛИб° П°ВедеН"е СуМмат°Ра '«адекватно, либо некорректны», яв-
ЕслГ, "xl Г еГ° 8Х0Л0В' Т°ГДа "р0бЛеМу иад° — дальше в цепи
значение 6 То «Г™ ' (3'МЧС""Я Ю) пРе™™°™, что поведение add-1 и
(обозначим его ^долГоГ"" Х К°РрСКТНЫ' то значение "а -тором »*°к М*5'1
являющемуся результатом „ Г РаВ"° " Н° ЭТ° пР°™воречит ожидаемому значению 6.
«- за этими^" зГеГГ" "°вСДеИ"Я ^^ и ВМД°В В " D' M"' "^
знаем, что иа них поступали правильные значения.
Следовательно, неисправен модуль MULT-2. Вариантом второй гипотезы можс! быгь
предположение, что модуль ADD-1 исправен, а неисправен компонент MULT-1.
Продолжая рассуждения, приходим к выводу, что если на первый вход X модуля
ADD-1 поступает корректное значение и сам ADD-1 работает корректно, то значение
второго входа У должно быть равно 4. Если это так, то G должно принимать значение
10. а не 12. так что выход MULT-2 должен равняться 6 и быть корректным. Здесь мы
отбрасываем гипотезу, что неисправность содержится в MULT-1 или в ADD-1. Эти
модули можно рассмотреть при дальнейшем тестировании.
В рассуждениях о ситуации, показанной на рис. 7.14, рассматривались три задачи.
1. Создание гипотезы о том, какие компоненты устройства могли вызвать
расхождение ожидаемого и реального значений.
2. Проверка гипотезы, в процессе которой при заданной совокупности потенциально
неисправных компонентов определяется, какой из них может объяснить
наблюдаемое поведение.
3. Выделение гипотез, когда в результате тестирования остается несколько версий
(как на рис. 7.14) и необходимо определить, какая дополнительная информация
может помочь выявить неисправность.
в=з —
D=2
п
L
г
MULT-1
MULT-2
J
L^
MULT-3
ADD-1
ADD-2
(F=12|
IG=12)
[G-12]
Puc. 7.14. Направленные информационные потоки;
из работы [Shrobe (ред.). 19S8)
И, наконец мы должны отметить, что в примере на рис. 7 14 предполагается, что
неисправен единственный модуль. Мир не всегда так прост, хотя предположение о
единственной неисправности является полезной и часто корректной эвристикой.
Поскольку методы, основанные на качественных моделях, требуют понимания
принципов функционирования рассматриваемых устройств, они устраняют многие из
ограничений эвристических подходов. Подходы, основанные на моделях, позволяют
представить устройства и схемы на причинном и функциональном уровне, а не_ рассуждать о
причинах неисправностей на основе наблюдаемых явлений. Программный код отражает
как функции модулей, так и внутренние зависимости системы. Такие модели часто более
надежны, чем эвристические подходы. Однако обратной стороной такого точного
моделирования является то. что стадия извлечения знаний требует большой скрупулезности, а
Глава 7. Сильные методы решения задач
295
„казаться громоздкой и медлительной. Поскольку эв
резульгируюшая программно* распространен„ые случаи в общее правило, 0„„
риетнческне подходы к
зачастую более эффективны. ^ связаны б0лее глубокие проблемы. Как и рас.
Однако с подходом на осно сйСКШ _ эт0 всего лишь модель. Она является не-
суждения на основе правил, мод ^ няютором уровне детализации становится некор
обходимой абстракциейсистем ^^ ^ т ?т 7Л4. Мы считалн эти значещя
ректной. Например, расе v я состояние сам„х шин и контактов с мультиплек-
заданными и ^""ждень. провода или неисправны контакты? Если пользователь ие
сорамн. А если "0ВР™ £ соответствовать действительному устройству.
^:tlZ2Z£ „денную ситуацию. т.е. предполагаемые действия снеге-
„ьЛ не о альные. Неисправным соединением считается контактная точка в системе, в
которой „ебртжно соединены два провода или устройства (например, когда два провода
соединены плохим припоем). Большинство рассуждении, основанных на моделях, „с
обеспечивают диагностику неисправности соединения из-за априорных предположений
базовой модели и заложенных в иих методов поиска для определения аномалий.
Дефекты соединений можно просто считать новыми проводами, которые не являются частью
первоначального проекта. В этом состоит неявное "предположение о замкнутости мира"
(раздел S.1). согласно которому структура описания модели предполагается полной, и
все, что не описано в модели, просто не существует.
Но, несмотря на эти недостатки, рассуждения на основе моделей являются важным
дополнением к инструментальным средствам инженера по знаниям. Исследователи
продолжают углублять наше понимание диагностики за счет исследования принципов
эффективного решения этой задачи человеком-экспертом, а также улучшения машинной
реализации алгоритмов [Stern и Luger, 1997].
7.3.2. Рассуждения на основе моделей: пример NASA
В настоящее время NASA разрабатывает флотилию интеллектуальных космических
зондов, предназначенных для автономного исследования солнечной снетемы [Williams и
Nayak, 1996], [Bernard и др., 1998]. Этот проект начался с разработки программного
обеспечения для первого зонда в 1997 и запуска аппарата Deep Space 1 в 1998 году. Для
успешной работы в суровых условиях космического путешествия космический корабль в ответ на
неудачи должен уметь радикально перестраивать свой режим управления и учитывать эти
неудачи при планировании оставшейся части полета. Для обеспечения приемлемой
стоимости и скорости реконфигурации необходимо быстро подключать стандартные модули,
которые составляет программное обеспечение полета. Кроме того, NASA считает, что
шльТовГт! Т*"*"" СЦеКар"еВ " аозм<™ ответов будет слишком большим, чтобы ис-
ZnSSTп„ГеНЬ.ГХ В°ЗМ0ЖНЫХ C^aeB- Космический корабль должен
реактивно размышлять при реконфигурации своей снетемы убавления
~mTopL~ГliamS " №* ^ Ре—Гключевые Функции pea,
селения рассуГенйТ аВТОНОМНЬК си™=м, основанных на моделях. Языком пред-
числение. Обратите »и„к.о°СН0Ве моделен а Livingstone является пропозициональное ис-
(глава2)-триш0„„„Г.Н,Ие "" °™Д 0Т "™сле„„я предикатов первого порядка
Основываясь иа своих поел предпавлс"и» в задачах диагностики на основе моделей,
нальной логики для конА.ш.Т™' "^""«ниях по разработке быстрой пропозишю-
Ф"ИИНШ ^"Ритмов диагностики, Вильяме (Williams) и Наян
296 _——■
асть III. Представление и разум в ракурсе искусственного интеллекта
(Nayak) решили, что пришло время для построения быстрой реактивной системы,
реализующей дедукцию в цикле восприятие-реакция. Дальновидные рассуждения модели
должны поддерживать единую централизованную модель для решения различных инженерных
задач. В автономных системах это означает использование единой модели для поддержки
выполнения различных задач. Такие задачи включают поддержку истории
разрабатываемых планов (раздел 7.4), поддержку аппаратных режимов, аппаратуру для реконфигурации,
определение аномалии, диагностику, устранение неисправностей. В системе Livingstone все
эти задачи автоматизированы с помощью единой модели и общего корневого алгоритма.
Это значительно расширяет возможности решателей задач, основанных иа моделях.
На рис. 7.15 показана упрощенная схема подсистемы главного двигателя космического
корабля Cassini — наиболее сложного из построенных к настоящему времени. Он состоит
из гелиевого, топливного, кислородного баков, пары главных двигателей, регуляторов,
клапанов, пироклапанов и трубопроводов. Гелиевый бак поддерживает давление в двух
топливных баках с помощью регуляторов, понижающих высокое давление гелия до рабочего
уровня. Когда топливные пути к главному двигателю открываются (изображение клапана
не заштриховано), в главный двигатель подаются топливо и кислород. Там они
смешиваются, смесь воспламеняется, и этот процесс сопровождается толчком. Пироклапаны могут
активизироваться (т.е. изменить состояние) только один раз, переходя нз открытого к
закрытому состоянию или наоборот. Их функцией является временная изоляция частей
подсистемы главного двигателя или постоянная изоляция отказавших компонентов. Клапанами
управляют специальные драйверы (на рис. 7.15 ие показаны) и акселерометр, который
измеряет ускорение, сгенерированное двигателями.
Условные обозначения
J Клапан {закрыт)
J Пироклапан (закрыт)
Рис. 7,15. Упрощенная схема системы двигателей Livingstone
из работы [Williams и Nay'ak 1996]
Высокоуровневой целью системы является выполнение толчка из начального
положения, показанного на рис. 7.15. Эта цель может быть достигнута различными
способами: толчок обеспечивается или главными двигателями, или открытием топливных путей
к главному двигателю. Например, для толчка можно открыть клапаны, ведущие к левому
двигателю, или активизировать пару пироклапанов и открыть клапаны, ведущие к
правому двигателю. Другие конфигурации соответствуют различным комбинациям
активизации пироклапанов. Эти конфигурации имеют различные характеристики, поскольку
активизация пироклапанов является необратимым действием и требует зиач.ггельно
больше энергии, чем открытие или закрытие клапанов.
Глава 7. Сильные методы решения задач
297
. -U I 1Ш11И II I III 1'Ч I
„шого двигателя была сконфигурирована так, чтобь,
Предположим, подсистема глав" гателя пуТсм открытия ведущих к нему клапа.
обеспечить толчок от левого главно ^ напр,Шср перегрет, и не может обеспе-
нов. Допустим, что этот двигатель ^ 0gccnc4llTb необходимый толчок даже в этой си-
чить требуемый толчок. Для того ч ^^ в ||0вое СОСТОяние, в котором толчок де.
хуации, космический корабл,■ ™W ;ым с „равой СТОр0ны. В идеале это достигается
лается главным двигателем, р й чвсти системы, и открытием остав-
активизацией двух ппроклапанов. вслутдI. д Р
.„хеяклапаиовбеза^апии^ни^ космическнй _
Дш^чЧР '°"ФГ>'т<""™2 котором достигается множество динамически иэме-
—х^ТГГв^Г^'ГкотГорабль обоняется от вь.бранного ,гутн м
ГР™ен,и1. диспетчер анализирует сенсорные данные, чтобы определить текущую кон-
ГгСик, корабля, а затем переводит его в новое состояние, чтобы достичь цели. Дисиет-
LТокфитуранда является дискретной системой управления, которая обеспечивает
конфигурацию необходимую для достижения множества целей. Алгоритм планирования, под-
доживающий работу диспетчера конфигурации, представлен в подразделе 7.4.4.
Рассуждения о конфигурациях и автономных реконфигурациях в системе требуют
использования понятий рабочего и аварийного режимов, устранения неисправностей и
изменения конфигурации. В системе NASA эти понятия описываются с помощью
диаграммы состояний: устраняемые неисправности — это переходы от неисправного
состояния к рабочему. К рабочему состоянию применимы изменения конфигурации.
Неисправности — это переходы от нормального к аварийному состоянию.
В работе (Williams и Nayak, 1996] управление автономной системой осуществляется с
помощью реактивного диспетчера конфигурации и планировщика высокого уровня.
Планировщик (раздел 7.4) генерирует последовательность целей по реконфигурации
системы. Диспетчер конфигурации отслеживает переходы системы (в нашем случае —
системы двигателей космического корабля) вдоль желаемой траектории. Таким образом,
унрааление конфигурацией осуществляется посредством наблюдения н управления
переходами между состояниями системы.
Чтобы определить необходимую последовательность управляющих воздействий,
диспетчер конфигурации на основе моделей использует спецификацию переходов
системы. В примере на рис. 7.15 каждый элемент схемы моделируется системой переходов.
Взаимодействие компонентов, показанное на рисунке помощью связей, моделируется с
помощью переменных, используемых в соответствующих компонентах системы.
Диспетчер конфигурации интенсивно использует модель для определения текущего
состояния системы и выбора оптимальных управляющих воздействий для достижения
дов^пГГ„ Г1""60™""0 " C1"W"^ B *°™рых при использовании простых мето-
™Ги нс„Г КаМа" нет™°"ь может привести к катастрофе. Диспетчер конфи-
ZZ^ZZ:'™" *" П0ОР°еН"Я Же"аеМ0Й п°следов™те1„ост„ управлений с
п»Г„о «ГоГГ 0UeHK" " Р^Ф-ГУрацни (РО н РР „а рис. 7.16) Модуль РО
" еГ/ов™ 'дУ аГГтГю ™аСИСТе-НЫХ ^* ^™ °
пользует модель LeZr к упРавл<:н"" « измеренных значений. Модуль РР ис-
ные РО в те^шш с™ ,ь!Г УПраВЛИ™ « *Р"«™ траекторий, сгенерирован-
при которых конфигтоапионн опРеделси"я множества таких управляющих значении.
РР являются реактивными СсГе ^In™™" " ™аУю^ состоянии. Модули РО >■
дыдушего и текущих наблюдс i - м °"Рсдсляет текущее состояние на основе пре-
лостигают ко«Ьип.п,, „ ' ™ МоДУль РР рассматривает лишь действия, которые
1 в следующем состоянии.
Представление и разум в ракурсе искусственного интеллекта
Цели высокого _
Уровня
Подтверждение
Диспетчер
конфигурацт
Планировщик
Наблюдаемые
значения
Цепи
конфигурации
Рис. 7.16. Конфигурационная система управления на
основе модели [Williams и Nayak, 1996}
В следующем разделе будут рассмотрены рассуждения иа основе опыта — прием,
позволяющий использовать прошлый опыт работы в данной предметной области в новых
ситуациях. В разделе 7.4 представлены вопросы планирования и снова рассмотрен
пример системы, разработанной NASA.
7.3.3. Введение в рассуждения на основе опыта
Эвристические правила и теоретические модели — вот два типа информации,
которые человек-эксперт использует для решения проблем. Еще одной мошной стратегией,
используемой экспертами, является рассуждение на основе опыта решения задач. В
рассуждениях на основе опыта для решения новых проблем используется детальная база
данных, содержащая известные решения задач. Эти решения могут быть собраны
экспертами в области знаний или могут отображать результаты предыдущих успешных и
неудачных попыток поиска решения. Например, медицинская диагностика основывается
ие только на теоретических моделях болезней, анатомии и физиологии, но и на изучении
истории болезни н врачебного опыта, приобретенного при лечении других пациентов.
Системы CASEY [Koton, 1988a, 19885] и PROTOS [Bareiss и др., 1988] являются
примерами рассуждений на основе опыта в медицине.
Юристы тоже подыскивают прецеденты и пытаются убедить суд, что нужно
действовать по аналогии с известной ситуацией. Хотя общие законы вырабатываются в
рамках демократических процессов, их интерпретация обычно основана на
прецедентах. Интерпретация закона в некоторой предыдущей ситуации определяет его текущую
интерпретацию. Таким образом, важным компонентом правовых рассуждений
является идентификация прецедента для принятия решения в конкретном случае. В работах
[Rissland, 1983] и [Rissland и Ashly, 1987] предложены механизмы рассуждений на
основе опыта, предназначенные для поддержки правовых споров.
Программисты часто повторно используют старые программы для адаптации
существующих структур к похожей новой ситуации. Архитекторы используют свои знания об
эстетической привлекательности и полезности существующих сооружений для разработки
новых здании, которые будут восприняты современниками как красивые и удобные.
Историки используют исторические факты, чтобы помочь государственным деятелям,
чиновникам и гражданам понять прошлые события и планировать будущее. Возможность
рассуждать на основе опыта является краеугольным камнем человеческого интеллекта.
Другие области рассуждения на основе опыта включают проектирование, где
успешно выполненный проект может использоваться в новой ситуации, и диагностику, где час-
Глаеа 7. Сильные методы решения задач
299
„.„„ого Хорошим примером этого является таюкс тап1
то приходят на ум неудачи прошл -^ о6тст ^ решения текущей проблемы^""
стека аппаратных средств. Мстер' знаний п0 электронике и механическим с»
мимо использования богатых тс р ого РассуЖдения на основе опыта составя,^
темам учитывает успехи и «уда ^^^^^ систем включая №СТеыы диаг ""
важный компонент мяопк * „ Luger, I992J и анализа неисправностей пол™,,
спутникового оборудования [Skmner и ^ лу„ро.
водииковыхкомпонентов! е обеспечиаают ряд преимуществ для разработки экс
Рассуждения наихиов о ^ может 6ыть „,,, если механизм £
—^———^
гггхп^^——:•—-----^
"РГ;:™ПкГра^Гм позволяют экспертной системе учиться „а ce0tt,
опы^Тоеле решения задачи путем поиска система может сохранить это решение, что-
„^пользоваться им при возникновении подобной ситуации (без привлечения поиска),
too запоминать информацию как об успешных, гак и о неудачных попытках решения.
Таким образом, рассуждения на основе опыта являются мощным средством для о6уче.
ния Одним из первых примеров таких систем является программа для игры в шашки
[Samuel 1959] (см. подраздел 4.3.2), где важные позиции на доске, наиденные
посредством поиска или эксперимента, запоминались для последующего использования.
Механизм рассуждения на основе опыта функционирует следующим образом.
1. Находит подходящие случаи в памяти. Случай является подходящим, если
решение может быть успешно применено в новой ситуации. Поскольку механизмы
рассуждения не могут знать этого наперед, для выбора случаев обычно
используются эвристики. Как люди, так и искусственные механизмы рассуждения,
определяют подобие на основе общих признаков: например, если у двух пациентов
наблюдается ряд общих признаков, связанных с симптомами и историей болезни, то
велика вероятность, что у них одно и то же заболевание, н им подходит один и тот
же курс лечения. Для эффективного поиска случаев память должна быть
организована соответствующим образом. Обычно ситуации индексируются по их
существенным признакам, что обеспечивает эффективный поиск аналогичных случаев.
Идентификация существенных признаков зависит от ситуации.
2. Приспосабливает найденную ситуацию к текущей. Обычно случай— это
последовательность операций, преобразующих начальное состояние в целевое. Механизм
рассуждения должен модифицировать некоторые операции в сохраненном решении с
учетом специфики текущей проблемы. Здесь могут быть полезны такие
аналитические методы, как подбор зависимости параметров, общих для сохраненных случаев и
новой проблемы. Если аналитические связи между ситуациями отсутствуют, могут
использоваться более эвристические методы - например, справочники.
3. Применяет преобразованное решение. Модификация известного случая не
обязательно гарантирует удовлетворительное решение проблемы. Может
потребоваться еще одна итерация выполнения первых трех шагов.
Со°х?аТ^>,СПеШНОе ШШ ие№ач1™ Решение длн дальнейшего использования.
спе™ХеНмГ„СЛУЧаеВ Тре6уеТ адашации ин«сн™ структуры. Существ^
ЦииТиеТ 9*7? П0АДеРЖКИ ИНДекСов- К ■»» «носятся азц-ор.гшы кластер-
' ' '987] Идр>™е пРие™ машинного обучения [Stubblefield и Luger, I996].
Часть III. Представление и разум в ракурсе искусственного интеллекта
Для реализации рассуждения на основе случая
туры данных. В простейшей ситуации случаи ""^ потре6оваться специальные струк-
одни аргументы описывают сопоставляемые 3апомииакяся как кортежи отношений, где
„огут представляться и более сложными сто™Г ™f *™ ~ ™" ^Ш""" СлуЧаИ
случай запоминается как множество правил tZ^-Z' ™ ^ ДЧЖВЬЯ ВЬШ0Да- °бычн°
ситуацию, являются существенными LZkZ.С"^™'»г»™"= **™. описывающие
шие действия, описывают преобразования „Z„™ "^ * 0ПеРат0Ры' "Р<=Д«авляю.
ван„и такого представления дляТгГиГа™ "Г^! " "^ "^^ ПрИ ИСП0ЛЫ°-
организации и оптимизации поиска попхопяших гпучяеп
могут применяться такие алгоритмы, как RETE [Forgy 1982] ш™°'и™<* случаев
"ств^Л™ В0ПР°С0М ' РеШ£НИИ Пр0бЛеМ "а °™°»= о""-™ является выбор
существеиных признаков для индексирования и „„„ска ситуаций. В (Kolcdner и
Др„ 1993] при решении задач „а основе случаев считается, что они должны быть
организованы в соответствии с целями н потребностями решателя проблем. Это означает, что
необходимо выполнить тщательный анализ дескрипторов ситуации в контексте того как
эти случаи должны быть использованы в процессе решения.
Например, рассмотрим проблему слабого коммуникационного сигнала на спутнике в
момент времени 10:24:35 GMT. На основе анализа определяется, что. кроме всего прочего,
система имеет низкую мощность. Низкая мощность может быть следствием того, что
солнечные батареи неправильно ориентированы по отношению к Солнцу. Наземные
контроллеры регулируют ориентацию спутника, мощность увеличивается, и коммуникационный
сигнал снова становится сильным. Для записи этого случая можно использовать ряд
существенных признаков. Наиболее важным из них является слабый коммуникационный сигнал
или низкий ресурс мощности. Другой существенный признак — время возникновения
проблемы (10:24:35). В соответствии с целями и потребностями решателя задач
существенными признаками являются слабый коммуникационный сигнал и низкий ресурс мощности.
Время события может не иметь никакого значения, за исключением случая, если поломка
произошла именно после того, как Солнце скрылось за горизонтом [Skinner и Luger, 1995].
Другой существенной проблемой является представление таких понятий, как слабый
сигнал или низкая мощность. Поскольку эта ситуация вряд ли повторится в точности, то
значение сигнала целесообразно представлять интервалами действительных чисел,
определяющими хороший, граничный, слабый и опасный уровни.
В работе [Kolodner, 1993] предлагается множество возможных эвристик для
организации, хранения и поиска ситуаций. К ним относятся следующие.
1. Упорядочение на основе целей. Случаи систематизируются, по крайней мере
частично, на основе описания цели. Выполняется поиск случаев, цель которых
соответствует текущей ситуации.
2. Упорядочение по существенным признакам. Выбираются случаи, для которых
наиболее важные признаки (или большинство важных признаков) совпадают.
3. Предпочтение точных совпадений. Сначала рассматриваются все случаи точного
совпадения признаков, а затем более общие соответствия.
4. Частотное предпочтете. Сначала проверяются наиболее типичные случаи.
5. Предпочтение новизны. Предпочтение отдается случаям, которые использовались
последними.
6. Предпочтение легкости адаптации. Используются первые, наиболее легко адап-
тируемые к текущей ситуации, случаи.
Глава 7. Сильные методы решения задач
301
основе опыта имеют ряд преимуществ при разработке эксперт
Рассуждения на °™<« ^^ оста„0811лнсь на некотором представ' ""Х
систем. Как только h""bcP мав[1Й „е ,|редставляст труда^ Оно сводится к "»и
случая, дальнейшее иэвл Описания случаев могут быть найдены в истоп„и
сохранению накопленных ситу ^ц ^^^ „влений. Р"Че.
ских записях или при подн„мают ряд важных теоретических вопросов, тио
Рассуждения на основе оп „умениям. Одним из наиболее острых и ™
, к человеческому обучению и р у пгатК„Г* " "P""
сяшихся к человеческ , у ' степени подобия. Хотя меру подобия двух .„
„ческих вопросов являете, опредсл qt числа о6щих ,„„ >^Щ.
Чаев можно °™™°™^^."например'большинство объектов „ ситуациГ^
„ожио описывать как функцию, зависящую от числа общих признаков, такое „ред.
^содержит ряд тонкостей. Например, большинство объектов „ ситуаций „„"£
ZZ оечГо с ойств. Однако механизм рассуждении на основе опыта, как mZ
,„мет случа„ „з очень небольшого архива поиска, составляемого инженером ,,0
ло. выбирает случ исследования возможности решателя определять соот-
Г— рГнакн :,з своего собственного опыт. [S.ubblefield, 1995), определение
„нГрГтквности признаков остается сложной проблемой.
Zro,. важной проблемой, с которой сталкиваются специалисты прн реализации рас,
суждений на основе опыта, является проблема компромисса между запоминанием и вычис
лением По мере запоминания новых случаев механизм рассуждении становится все более
интеллектуальным, способным лучше решать различные проблемы. Действительно по мере
добавления в память новых случаев результаты рассуждений до некоторого момента будет
улучшаться. Но по мере роста базы данных время, необходимое для поиска и обработки
информации о прецедентах, тоже растет. Снижение эффективности для больших баз
данных также может объясняться пересечением понятий и другими помехами. Одним из
решений этой проблемы является хранение лишь "наилучших" или "прототнпиых" случаев и
вычеркивание тех, которые являются избыточными или редко используемыми.
Следовательно, система рассуждений должна забывать случаи, которые не доказали свою
полезность. Примером ранних работ в этой области может служить алгоритм запоминания
позиций на шашечной доске [Samuel. 1959]. Однако в общем случае не ясно, как можно
автоматизировать такие решения. Это остается областью активного поиска [Kolodner, 1993].
Автоматизированные объяснения рекомендаций — еще один тип рассуждения на
основе опыта. В ответ на вопрос, почему в данной ситуации рекомендуется принимать
именно это лекарство, единственным объяснением системы является то, что именно это
назначение было сделано в предыдущий период времени. Иногда используются
объяснения, основанные на сходстве описаний текущей и предыдущей ситуаций. В примере
задачи спутниковой коммуникации подходящий случай был выбран на основе слабого
коммуникационного сигнала. Этот способ рассуждения тоже не обеспечивает более
глубокого объяснения, чем то, которое было выработано ранее в подобной ситуации. Но
зачастую этого может быть достаточно.
Однако многие исследователи убеждены, что простое повторение целей высокого
Г" "Дуемых случаев является недостаточным объяснением [Leake. 19921.
та,,™ г„™ -* Верншся к ситуации со спутником. Предположим, что переориен-
снова 22» Т" П0М0Га£Т Ул^ш"ть кате"во сигнала, но через три часа сигнал
пер™Ри72Т " ИСПШ,ИУЯ ЧаИ0™Ую Ч.«™У и эристику "овизиы, мы ено-
ждые трТчТса Р„ь " ШеЧ'^° ^^ Ч^ Ч» ча« слабый сигнал повторяется.
Каной сиГаци? " ™ "ЬйЗУеМ 0Д"° " ™ ж значение. Этот пример основан на рс*"
".роск™ да ГГГ ШИ 06Ha№Ha 6°л« c"°™ причин., а именно: перегр*
Давал „скаженные данные об ориентации спутника. Окончательно реши»
Часть III. Представление и разум в ракурсе искусственного интеллект"
проблему и определить причину слабого ,„„„™
помощью рассуждений „а основ! модели: „о 31""^™ УДаЛ°С" "ИШЬ С
Рассуждения „а основе опыта o6ecneIZT „Г ' " LUgCr' 1M5!'
пользования прошлого опыта необходимо Тп УЧеН"С П° аНаЛ0ГШ- ^ "°™Р»°™ «с-
гуации и построить отобРаже„„ГГвГю^ТшмГ'™"""' ЩИЯт ПрОШЛ°Й <""
Примером подхода к решению задач „аТсГве „Гта я. ™Т """/ ^^ ^"^
rr,rhnnpll IQR31 н„.„ , основе опыта является трансформационная
аналогия [Carbonell. 1983]. Новая задача решается путем модификации существующих решений
до тех пор, пока их „ельзя будет применить к дайной ситуации Опе^тГьГкотТрыемоди
фнипруют решение задачи, определяют абстракцию &лее высоко™ уровГн! "-
пространство в котором состояниями служат решения задачи, подлежащие
преобразованию (рис. 7.17). Целью является преобразование „сходного решен™ в возможное решение
поставленной проблемы. Для модификации решен™ можно его исключить
переупорядочить шагн в решении, соединить новые решения или изменить параметры в текущем
решении. Трансформационная аналогия - типичный пример решения задач на основе опыта.
Более поздние работы уточняют этот подход. В них рассматриваются такие вопросы, как
представление случаев, стратегии организации памяти случаев, поиск подходящих
ситуаций и использование их для решения новых задач. Более полная информация о
рассуждениях на основе опыта содержится в [Hammond, 1989]. [Kolodner, 1988a] и
[Kolodner, 1988сТ]. Исследования по аналогии рассматриваются далее в контексте
машинного обучения на основе символов (см. подраздел 9.5.4).
Исходное
пространство
Т-пространство
Рис. 7.17. Трансформационная аналогия из [Carbonell. 198.4
7.3.4. Гибридные системы: достоинства и недостатки систем
с сильными методами
Успехи построения экспертных систем для решения сложных практическ,« преЧшеи
продемонстрировали работоспособность основной идеи построения систем на^основе
знаний. Эффективность механизма рассуждения определяете, его знаниями, а™^™
а не модами рассуждения. Это наблюдение, впрочем, поднимает од н из лавиьх вопр*
сов искусственного^мтедлекта- вопрос представления знании. На практическом уровне
Глава 7. Сильные методы решения задач
303
.... „ппжен выбрать наиболее эффективный способ их прсдста».
каждый инженер по знаниям дол ^^ ^ р(|дам таык теорстичсски важ11Ь1х „ и
ления. Представление знании связа ете недостающей и неопределенной информа-
„ектуально шожнь,^^.ности представления, отношение между языком предетаале.
иней, определение №РШИ™Ь"° тннй и Эффективностью механизма рассуждения.
нм„о6уче„„еМ.^обретен™3на„^ ФФьи ^^ r прсдспшленжо ^^
пе„™"1 с ва „ГнаГав-х. «-иэмь, рассуждений „а основе моделей
и oZ™ Подь'ожим достоинства и недостатки каждого из перечисленных подходов к
решению проблем.
Рассуждения на основе правил
Преимущества этого подхода сводятся к следующему.
1 Возможность использовать знания экспертов в очень простой форме. Это важно в
областях, зависящих от эвристик управления сложной и/или отсутствующей
информацией.
2. Правила отображаются в пространство состояний поиска. Возможности
объяснения облегчают отладку программ.
3. Отделение знаний от управления упрощает разработку экспертной системы,
обеспечивая итеративный процесс разработки, в котором инженер накапливает,
реализует и тестирует отдельные правила.
4. В ограниченных предметных областях возможны хорошие результаты. Поскольку
для интеллектуального решения задачи требуется большой объем знаний,
экспертные системы ограничиваются узкими областями. Однако существует много
областей, в которых разработка подобных систем оказалась чрезвычайно полезной.
5. Хорошие возможности объяснения. Хотя системы на основе правил поддерживают
гибкие, проблемно-зависимые объяснения, необходимо отметить, что максимальное
качество этих объяснений зависит от структуры и содержания правил. Возможности
объяснения в системах, основанных на данных и на целях, сильно различаются.
Недостатки рассуждений, основанных на правилах.
1. Правила, полученные от экспертов, часто являются эвристическими по природе и
не охватывают функциональных знаний или знаний, основанных на моделях.
2. Эвристические правила обычно не являются робастными и не позволяют управлять
отсутствующей информацией или неожиданными значениями данных.
1 оеГГнГв "Н0СТЬЮ ПраВИЛ ЯМЯется их «применимость на границе области on-
вым,Гпп„к! °ТЛИЧ"ег0Т ЛЮДей' снстемы "а основе правил при столкновении с но-
m:z:T;z:^rне способны возврат'™ --« -р—-
'^Г^ствуГэтГ ЛИШЬ "а 0Писа™ьи„м уровне. Теоретические обоснова-
вавэт симптомы с Решен„Яя3Г„С,ТСМй' ™ 3BP"C™4CCK"= правила напрямую связь,-
5. Знания являются п„о6, Г °6еспе™»™^ более глубоких рассуждении,
предметной области °,''мн°-мвиси'™"". Формализованные знания о некоторой
ной области. Современнь, аВ11Л0' °''С"Ь СПСЦИФичны и применимы только к да""
"и, присущей человеку ° "Ы"" Прсдстаолс"ия знаний не обеспечивают гибко-
"■ Првдстав™"ие и разум в ракурса искусственного интеллект;
Рассуждения на основе опыта
Преимущества рассуждений „а основе опыта сводятся к следующему
1 r=yr:^:rrr ™" °- в°——-
риалов, записей или других источник™ п™ СушсС1вУю1«"х исторических мате-
дивного n^pc-rcl знаиТ™*,"^l?™™"^— "*
2. Возможность сокращения рассуждений Frnu ■,■,„.„
i ра^^ждении. пели известен аналогичный случай новые
задачи решаются гораздо быстосе чем л™ .«■„„ случаи, новые
F иистрсс, чем при использовании правил или моделей
3. Рассуждения на основе опыта позволяют избежать прошлых ошибок и использовать
прошлые успехи. Они обеспечивают модель обучения, как интересную с теоретической
точки зрения, так и достаточно практичную для применения в сложных ситуациях.
4. Не требуется всестороннего анализа знаний о данной области. В отличие от систем
основанных на правилах, где инженер по знаниям должен описать взаимодействие
правил, рассуждения на основе опыта обеспечивают простую аддитивную модель
приобретения знании. Для использования этого подхода необходимо обеспечить
соответствующее представление случаев, индексирование данных и стратегию адаптации.
5. Соответствующие стратегии индексирования повышают эффективность решения
задач. Мощность механизма рассуждений на основе опыта определяется
возможностью выявлять отличительные особенности целевой проблемы и выбирать
соответствующий случай из базы данных. Алгоритмы индексации часто обеспечивают
эту функциональность автоматически.
Рассмотрим недостатки рассуждений на основе опыта.
1. Описания случаев обычно не учитывают более глубокие знания о предметной области.
Это снижает качество объяснения и во многих ситуациях приводит к ошибочному
применению опыта, а значит, к неправильным или низкокачественным советам.
2. Большая база данных может привести к снижению производительности системы.
3. Трудно определить хороший критерий для индексирования и сравнения случаев.
Словари поиска и алгоритмы определения подобия необходимо тщательно
отлаживать вручную. Это может нейтрализовать многие из преимуществ, присущих
рассуждениям на основе опыта.
Рассуждения иа основе моделей
Преимущества рассуждений на основе моделей сводятся к с |ед>к.щсм>.
1. Возможность использовать при решении задач функциональные и структурные
знания о предметной области. Это увеличивает эффективность механизма рассуж-
дений при решении различных задач, включая те. которые не были предусмотрены
при разработке системы.
2. Механизмы рассуждений на основе моделей обычно очень эффек-п-вны. Они
являются мощными и гибкими средствами решения задач, поскольку^ и люди,
часто возвращаются к исходным данным при столкновении с новой проблемой.
~. г. niiut-гч ипаияч Системы рзсс\жденин на
3. Некоторые знания можно использовать в разных задачах. L иск ,
- «, й-,,|.пуются на теоретических научных знаниях. По-
основе моделей зачастую базируют". н р „м^^ чзсто рас-
скольку наука обычно оперирует общими теориями, так
ширяет возможности механизма рассужде на основе моделей.
Глава 7 Сильные методы решения задач
305
,™*лений основанные на моделях, обеспечивают причинные
4. Обычно системы Рас^*^ полыователям можно передать более глубокое пот,,
обьяснеиия. Так™с°™вност„. которое может сыграть важную образователЬ„ую
роль (см. также раздел 16.2).
Недостатки рассуждений „а основе моделей таковы.
„■.„■шентального (описательного) знания предметной области. Эв-
' p0Jc™^e"U иГльзуемые при рассуждениях на основе правил, отражав
важный класс экспертных оценок.
, Необходимость точной модели предметной области. Знания из многих областей
™ёют стГгую научную основу, которую можно использовать в рассуждениях на
основе моделей Однако во многих сферах, например, в некоторых мед„ц„„ских
направлениях большинстве проблем проектирован™ или финансовых .гриложени-
ях хорошо определенная научная теория отсутствует. В таких случаях подходы,
основанные на моделях, ие могут быть использованы.
3 Высокая сложность. Рассуждения, основанные иа моделях, обычно ведутся на
детализированном уровне, что приводит к значительным усложнениям. Именно по
этой причине эксперты в первую очередь разрабатывают эвристики.
4. Исключительные ситуации. Необычные обстоятельства, например, замыкание или
взаимодействие множества неисправностей электронных компонентов, могут
изменить функциональность системы таким образом, что ее трудно будет предсказать.
Гибридные системы
Важной областью исследований является комбинация различных моделей
рассуждений. В гибридной архитектуре, объединяющей несколько парадигм, эффективность
одного подхода может компенсировать слабости другого. Комбинируя различные подходы,
можно обойти недостатки, присущие каждому из них в отдельности.
Например, сочетание рассуждений на основе правил и опыта может обеспечить
следующие преимущества.
1. Просмотр известных случаев до начала рассуждений иа основе правил позволяет
снизить затраты иа поиск.
2. Примеры и исключения можно сохранять в базе данных ситуаций.
3. Результаты поиска можно сохранить для будущего использования. При этом
механизм рассуждений позволит избежать затрат на повторный поиск.
можн°о^тиИаЦИЯ раССуЖцений на ос"°»е правил н моделей открывает следующие воз-
'' об^ющ^сГстГаГ™ ФуНКЦИО"альнымн знаниями. Это может быть полезно в
2прГ™Те„Я„лУь<зТ°ЙЧИВОСТЬ С"СТеМЬ' ПРИ °™за- ПРи отсутствии эвристических
з ~и:,Ги™^ может прибегнуть
мо^Т^ожиых оасГ" ДОПОДНЯется эвристическим поиском. Это может по-
можность выбора УЖДениях' основанных на модели, и обеспечивает воз-
Часть III. Представление и разум в ракурсе искусственного интеллекта
Комбинация рассуждений иа основе моделей и опыта „„„
далей и опыта дает следующие преимущества.
1. Более разумное объяснение ситуации.
2. Проверка аналогичных случаев до начала бол» ™,™
„ 1,„,;„т1 - начала более экстенсивного поиска посредством
рассуждении на основе моделей.
3. Обеспечение записи примеров и исключений а sa„, „
^ ^ н исключении в базу данных случаев, которые
могут быть использованы для управления выводом на основе модели.
4. Запись результатов вывода иа основе моделей для будущего использования.
Гибридные методы заслуживают внимания как исследователей, так и разработчиков при-
кеиий. Однако построение таких систем требует решения целого ряда проблем. Необходи-
определлть метод рассуждения для данной ситуации, момент изменения метода рассужде-
„л, выяснить различия между методами рассуждения, разработать представления,
обеспечивающие совместное использование знаний. Далее будут рассмотрены вопросы планирования
или организации частей знаний для решения более сложных проблем.
ложеиий
МО'
ния
7.4. Планирование
7.4.1. Введение
Задача планировщика — определить последовательность действий модуля решения,
например системы управления. Традиционное планирование основано иа знаниях,
поскольку создание плана требует организации частей знаний и частичных планов в
процедуру решения. Планирование используется в экспертных системах при рассуждении о
событиях, происходящих во времени. Планирование находит приложения как в
производстве, так и в управлении. Оно также важно в задачах понимания естественного языка,
поскольку люди часто обсуждают планы, цели и намерения.
В этом разделе будут использованы примеры из традиционной робототехники.
(Современная робототехника, как указано в разделе 6.3, во многом основывается на
реактивном управлении, а ие иа планировании.) Пункты плана определяют атомарные
действия робота. Однако при описании плана нет необходимости опускаться до
аппаратного уровня (или микроуровня) и говорить о таких деталях, как "поворот шестого
шагового двигателя иа один оборот". Планировщики описывают действия на более
высоком уровне в терминах их воздействий на мир. Например, планировщик для робота из
мира блоков может оперировать такими действиями, как "взять ооьект а или перента в
местоположение х". На таких планах высокого уровня строится управление действиями
"Тп^дГ реализации пункта плана "принести блок а из комнаты «Г требуется
следующая последовательность действий.
1 ■ Положить все, что есть в руке.
2. Пройти в комнату б.
3. Подойти к блоку а.
4. Взять блок а.
5. Выйти из комнаты б.
6- Вернуться в первоначальное местоположение. ^
307
■"лава 7. Сильные методы решения задач
„ пространстве возможных действии до тех пор „ок
Планы создаются путем п°"с „собходимая для решения задачи. Это прост™,,
„е будет найдена последова которые изменяются при выполнении каждого дейст
ство "Релотвшетсо™Я"™ д'ост„гастся целевое состояние (описание мира). ТакИм
вия. Поиск зак^™™"пы эвристического поиска, включая алгоритмы решения А»,
подходят и для планирования^ существования реального робота. Изначально
,. .Ге"^— ^компьютерного планирования полныепланы фор^
(в 1960-е годы; при р. совершал свое первое действие. Таким образом
Z:^ZZr:Z — робота вообще! В последнее время благодаря ^
зТшш сложных механизмов восприятия и реагирования исследователи сфокусировались
„а более интегрированной последовательности план-деиствне.
Планирование зависит от методов поиска и поднимает ряд уникальных вопросов. На-
пример описание состояний мира может быть значительно сложнее, чем в предыдущих
примерах поиска. Рассмотрим ряд предикатов, необходимых для описания комнат,
коридоров и объектов в окружении робота. При этом необходимо представить не только мир
робота, но и воздействие его атомарных действий на этот мир. Полное описание каждого
состояния задачи может быть очень громоздким.
Другой отличительной особенностью планирования является необходимость
характеризовать сложные неатомарные состояния и действия. Захват объекта означает
изменение его местоположения и состояния руки робота (теперь она сжимает объект). При этом
не изменяется местоположение дверей, комнат илн других объектов. Описание того, что
истинно в одном состоянии мира и изменяется при выполнении некоторого действия,
называется проблемой границ [McCarthy, 1980], [McCarthy и Hayes, 1969]. По мере
усложнения пространства состояний задачи вопрос поддержки истории изменений, связанных
с каждым действием, и инвариантных признаков описания состояния становится все
более важным. В этой главе будут представлены два подхода к проблеме границ, но, как
показано ниже, ни один из них не является полностью удовлетворительным.
Другие важные вопросы включают генерацию планов, хранение и обобщение хороших
планов, восстаноаление системы после неожиданных сбоев (часть мира могла оказаться не
такой, как ожидалось, возможно вследствие случайного сдвига относительно прежнего
местоположения) и поддержку соответствия между миром и его программной моделью.
b е
а с н
''«с 7.IS Мир Ох
В примерах этого раздела мы ограничим мир робота и,™
„ости стола и действиями руки робота кото™ 11° мно*еств°м 6»™°» "" "оверх-
зя" верхний блок и переместить блоЕ™™"„"оГнГ "'ТГ" "W"*
1, h r d в vrmunon». "("-делах стола. На рис. 7.18 показаны пять
6Т°" ™'о, о пазГГ и т ВСРХ"СЙ ""«Т»™™ стола. Все блоки являются
кубами °Д"°' о Р^мера. Некоторые блоки располагаются непосредственно «руг на
друге, образуя стеки. Рука робота имеет захват, который может схватить любой
свободой блок (тот, который не имеет блоков на своей верхней грани) и переместить его в лю-
бое место на поверхности стола или на верхнюю грань любого другого свободного блока.
Рука робота может выполнять следующие задания Ш, V, W, X, У и Z — переменные).
goto(X,VZ) Перейти в местоположение, описанное координатами X, У и Z. Это
местоположение может быть неявно задано в команде pickupW), где
блок W имеет координаты X, У, Z.
pickup(W) Взять блок W нз его текущего местоположения и держать его.
Предполагается, что блок является свободным, захват в это время пуст и
компьютер знает текущее местоположение блока IV.
putdown(VJ) Опустить блок W в некоторой точке на столе. Записать новое
местоположение для IV. При выполнении дайной задачи предполагается,
что в данный момент блок IV удерживается захватом.
stackiUM) Поместить блок U иа верхнюю грань блока V. При этом захват должен
держать блок U, и верхняя грань V должна быть свободна.
unstack(U,V) Убрать блок U с верхней грани 1/. Перед выполнением этой команды
блок U должен быть свободен, располагаться на верхней поверхности
блока 1/, н рука должна быть пустой.
Состояние мира описывается множеством предикатов и отношений между ними.
/ocaf/on(W,X,y,Z) Блок W имеет координаты X, У, Z.
on{X,Y) Блок X находится непосредственно на верхней поверхности блока У.
clear(X) Верхняя грань блока X пуста.
gripping(X) Захват робота удерживает блок X.
grippingO Захват робота пуст.
ontableiW) Блок W находится на столе.
Запись ontable(W) является короткой формой предиката location<WXYT), где Z -
уровень стола. Предикат оП(Х,У) указывает, что нижняя часть блока X нмолитана
верхней грани блока У. Если местоположение каждого блока и информация об их,лере-
мещении в новое место записаны в компьютере, то описание мира ""^™™»»
упростить. При этом устраняется необходимость в команде, поскольку такие команды.
■*« "»» «"«*>• НеЯТС0ДГЛ"жТбыть представ множеством
Тогда мир блоков, показанный на рис. 7.18. может оыть up J
предикатов Состояние!. Поскольку предикаты, бывающие с~^ м„ра „а
рис. 7.18, являются истинными одновременно, полное описание состояния является
конъюнкцией (л) всех этих предикатов.
Состояние 1
ontab/e(a). ол(Ь.з) Ыеагф).
Ontable(c). ome.d). clealic).
Ontable(d). grippingO. dearie).
Глава 7. Сильные методы решения задач
309
, „rfM antable(B) и gripping!) опишем ряд истинных отношений (в
ДеЛ:Гв„«Гсле)'ил0:„равиЛВьт0л„е„ия(впроЦелУрном смысле,.
1. (vx) (ctearw <-- (amo"^»
2. (V*0 (VX) -, (on(YJQ <- (олИйИ W
3. (V*0 ЭФР/ВДО <"» - (ЯФРШУ))-
Согласно первому утверждению, если блок X свободен, то не существует блока Y,
„аспол—Za верхней грани X. Процедурно его можно интерпретировать так: "Дд,
Z2ZZ'блока х'нужно Убрать любой блок У. который может находиться „а верх-
""'тТпеТь^разработаем правила, воздействующие на состояния и приводящие к новым
состояниям С этой целью снова введем процедурную семантику для логического
представления предикатов. Операторы {pickup, putdown, stack, unstack) определяются
следующим образом.
4. (VX) (pickupW -»Igrippingm <- (дг!рртд0лс1еаг(Х)л ontable(X)))).
5. (VX) tputdownW -»((gripping!) л опгаЫе(Х) л c/ear(X)) <r- gripping'X))).
6. (VX) (VV0 (stack(X,V) -» «on(X,V0 л gripping') л c/ear(X)) <- (ctear(y) л
gnppmrj(X)))).
7. (VX) (V/) (unstack(X,V) -> (!clear(Y) л gripping(X)) *- (ол(Х,Г)лс/еаг(Х) л
дфр/ngO)).
Рассмотрим четвертое правило: для всех блоков X pickup(X) означает gripping(X),
если рука пуста и блок X свободен. Отметим форму этого правила: A—>(Bt-C). Это
означает, что из А следует новый предикат В, если условие С истинно. Это правило можно
использовать для генерации новых состояний в пространстве. Если предикат С является
истинным, то в наследуемом состоянии В тоже является истинным. Другими словами,
оператор А может быть использован для создания нового состояния, описываемого
предикатом В, если предикат С является истинным. Для создания этих операторов можно
использовать и альтернативные подходы, описанные в подразделе 7.4.2, [Nilsson, 19S0] и
[Rich и Knight, 1991].
Прежде чем использовать эти правила взаимосвязи для генерации новых состояний
мира блоков, надо обратиться к проблеме грант,. Прн описании нового состояния мира
ГимГпГГ аКСи0МЫ гРШЩ~ ПрШтла' определяющие инвариантные предикаты. На-
«7, я ТсГ"™"? °"еРатар Pi°kUp " бюхУ S «а рис. 7.18, то все предикаты, отно-
бГко„ожГГШМ ' ° След*Ю№н "стоянии останутся истинными. Для мира
олоков можно описать несколько правил границ.
* <VX> (Vy) (VZ) (s,ack<V^ ^ {ontable(X) _ ontablem);'
Эти правила означают, что ппеликат п„«ы
рам stack и unstack Это исти ontable инвариантен по отношению к операто-
этих выражений ие будет истинны "*** "РИ Идентичиос™ х и Z; если же Y=Z, то одно из
Другие аксиомы границ сводятся » ,
значения предикатов оп и с/еаг У' Ч™ опеРатоРЫ stack н unstack изменяют
оператор unstackfc d) „c , ™b ДЛЯ некотарых параметров. Так, в нашем примере
затрагивает значение оп(Ь,а). Аналогично оператор
Частым. Представление и
Разум в ракурсе искусственного интеллект8
gripping!*) не затрагивает отношение с/еаг(Х) даже сг„„ у у
gripping!)- Кроме того, оператор олрр/по ,.™ """ "С™НН° выР"жение
Г„ГаЫв(Х),гдеХ-удерж„вае„ый^кСм2яГ"" "= °™°Ш™": ""^ '
м0 описать ряд аксиом границ. "М °бра30м- *"" «™его примера „собходи-
Операторы и аксиомы границ определяют ,™™
стояние определяемое оператором ппз/асГ Для^п""" C0CT°™*' Рассмот""м с0"
1И1Ж" для выполнения опсоатопа unstacklX Y\
должны выполняться три условия одновременно, а именно: ап{х7> grppfng!) и
c/MrtX). Когда эти ,ып тся, примененис оп '„i^^,,^;
новым предикатам опрр,пд(х, и с/еаг(у). Остальные предикаты описывающие
состояние 1, останься истинными н в состоянии 2. Переход к состоянию 2 осуществляется
посредством применения оператора unstack и аксиом границ к предикатам состояния 1.
Состояние 2
ontable!a). оп(Ь,а). с/еаг(р).
ontable!c). clear!c). clear!d).
ontable!d). gripping!e).clear!e).
Подведем итоги.
1. Планирование можно рассматривать как поиск в пространстве состояний.
2. Новые состояния определяются такими общими операторами, как stack и
unstack, и правилами границ.
3. Для нахождения пути из начального состояния к целевому могут применяться
методы поиска на графах. Операции переходов для этого пути составляют план.
На рнс. 7.19 показан пример пространства состояний, в котором поиск выполняется с
применением описанных выше операторов. Если к этому процессу решения задачи
добавить описание цели, то план можно рассматривать как множество операторов,
описывающих путь от текущего состояния этого графа к целевому (см. подраздел 3.1.2.).
Такое описание задачи планирования позволяет определить ее теоретические
кории. Это — поиск в пространстве состояний и исчисление предикатов. Однако
такой способ решения может быть очень сложным. В частности, использование
правил границ для вычисления инвариантов может экспоненциально усложнить поиск,
что видно на примере очень простой задачи из мира блоков. Действительно, если
ввести новый предикат для описания цвета, формы или размера, необходимо
определить новые правила границ, которые должны быть связаны со всеми
соответствующими действиями!
Предполагается также, что подзадачи общей задачи являются независимыми и могут
быть решены в произвольном порядке. В интересных и сложных предметных областях
это условие выполняется редко. Обычно предусловия и действия, необходимые для
достижения одной подцели, противоречат предусловиям и действиям, необходимым дл.
Достижения другой. Проиллюстрируем эти проблемы и опишем подход к планированию,
который в значительно мере помогает их преодолеть.
7-4.2. Использование макросов планирования: STRIPS
~ „ qrt International) — это система пла-
Система STRIPS (современное название - SKI Inlernami (Stanford
нирования, разработ1„на^ в C^^^^^^X^
нирования, разработанная в Стандфордском исследоштелыс «^"-• ■» э-> -
Research Institute Planning System) [Fikes и Nil.™. 197Ц. |F,Us и др . 197_]. В нач
Глава 7. Сильные методы решения задач
311
™„1лер использовался для управления роботом ».,.,
ле 1970-х годов этот конгроу ффективного представления знаний н вь,п„„
Система STKll-э Р™"" "' с учетом противоречивости подцелей и обеспечи "
„„я операций ™а»"Р° ™' ** "шные планы сохранялись и обобщались как „^
начальную модель °°/V Н0ГЛ11 6ыть использованы в подобных ситуациях в Г
роопсраторы. которые з описывается использованный в STRIPS подход к ° '
тавшенс» части >"" Р^ „юбл„„ы - структуры данных, используемые тя '
^—нани.макроопсраиий.
&\
b
а
Н
е
d
"nstack опиаюютсТтооЛкГми' 6Л0К!,МИ чегыРе ™«=ратора pickup, putdown, stack я
™° »/>ф„,в„Й (П) ко ™, элшен™=- Первым элементом тройки является мноЖ-
в™рой злемент тройки _СР„ПД0"ЖСН №™™творять мир д», применения оператор»-
к описанию состояния, которые я
исТ""' К0Т0Р№ w™»" of0113' И' НаК0Не^ ™"«* ™'<е/жш<™ш (В) состой
=„ГСКЛЮЧаЮТ "водимое , Г03""" С0Стая™я после применения оператора- Эт
"»« "пераТ0ры можно™ "'"ЛЬ30Вания °™-ных аксиом границ. Рюс-Ч""
вставить следующим образом.
П: gripping^ ) лс/еаг(Х) дошлый
p,cWP(X) R.gripplngiX) 'л'л°л<аЬ/е(Х)
В: onfabfe(X) л gripping, ,
П: gripping(X)
pU,dowr,{X) Д: ontabiefX) л gripp,-ng( , л 0,
В: gripping^) ( '
П
stac/c(X,V) д
В
с(еаг( Г) л gripping)*)
оп(Х, У) л gripping) ) л с/еаг(Х)
с/еал( У) л gripping(X)
П: c/ear(X) Agrippingl ) лоп(Х.У)
unstaoK(X, У) Д: grfpping(X) л с/еаг(У)
В: gripping( ) лоп(Х,У)
Важной особенностью списков добавления и вычеркивания является то, что они
описывают аксиомы границ. Подходу, основанному на списках добавления и вычеркивания,
присуща некоторая избыточность. Например, в операторе unstack добавление
grippmg(X) может подразумевать вычеркивание grippingQ. Однако эта избыточность
имеет свои преимущества. Каждый дескриптор состояния, который не упоминается в
списке добавления нли вычеркивания, остается истинным в описании нового состояния.
К недостаткам подхода, основанного на списках добавления и вычеркивания, можно
отнести следующее. Здесь для формирования нового состояния не используется процесс
доказательства теорем. Однако это не является серьезной проблемой, так как
доказательство эквивалентности двух подходов может гарантировать корректность метода списков
добавления и вычеркивания.
Подход, основанный на списках добавления и вычеркивания, в нашем примере дает
те же результаты, что н правила вывода с аксиомами границ. Поиск в пространстве
состояний (см. рис. 7.19) для обоих подходов реализуется одинаково.
Некоторые проблемы планирования не решает ни один из этих двух подходов. При
решении задачи ее зачастую делят на подзадачи, например unstack(e.d) н unstack(b,a).
Попытка независимого достижения этих подцелей может вызвать проблемы, если
действия, необходимые для достижения одной цели, направлены на разрушение другой.
Несовместимость подцелей может быть результатом неправильного предположения о
линейности (независимости) подцелей. Нелинейность пространства план-действие может сделать
поиск решений чрезмерно трудным или даже невозможным. Приведем простой пример
несовместимых подцелей. Используем исходное состояние 1, показанное на рис. 7.1S.
Предположим, что целью планирования является состояние G. показанное на рис. 7.20. в кото-
Ром ол(Ь, а)лоп(а, с), а блоки due остаются в том же положении, что и в состоянии I.
Можно отметить что одна из частей конъюнктивной цели ол(Ь.а)лол(а.с) — ол«з,а) —
» состоянии 1 истинна. Для достижения второй подцели ол(а, с) это условие должно
быть нарушено
Представление данных в виде трфгольной табтиы [Fikes н Nilsson, I97I],
INilsson, 1980] позволяет смягчить некоторые последствия этих аномалий. Треугольна,
"блица является структурой данных для организации последовательности действии,
"ключа, потенциально несовместимые подцели. Она решает проблему противоречиво-
7. Сильные методы решения задач
313
- посредством представления глобального
„и подцелей внутри .^^рац,,й. В треугольной таблице
действия последовательностей Нв^ми ^^ до6авлсння и в,
„ействия сопоставляются с посту
действия nouiw
действ,.» сопоставляются с по,
ствуюшего действия.
,„сраций посредством представления глобального взаИМо.
и операций. В треугольной таблице предусловия одного
условиями списков добавления и вычеркивания преДШЕ
Рис. 7.20. Целевое состояние Оля мира блоков
Треугольные таблицы служат для определения применимости макрооператора при
построении плана. Повторное использование этих макрооператоров увеличивает
эффективность поиска при планировании в STRIPS. Действительно макрооператор можно
обобщить, заменяя названия блоков в частном примере именами переменных. Затем для
сокращения поиска можно вызвать новый обобщенный макрооператор. В главе 9 методы
обобщения макроопераций обсуждаются при описании обучения на основе символов.
Повторное использование макрооператоров помогает также решить проблему
противоречивости подцелей. Если планировщик разработал план достижения целей вида
stack(X, Y)AStack(Y, Z), то этот план можно запомнить и использовать повторно. Это
исключает необходимость разбивать цель на подцели н позволяет избежать
возможных усложнений.
На рис. 7.21 представлена треугольная таблица для макрооператора stacW,
Y)*stack(Y, Z). Этот макрооператор можно применять в состояниях, для которых
истинно выражение оп(Х, У)лс/еаг(Х)лс/еаг(2). Эта треугольная таблица соответствует
начальному состоянию 1 при X=d, Y=a и Z=c.
(DjrAr„MaP"»w т""Вт "Лана ^исываются ВДоль диагонали. Эти четыре действия
t^7ZT„™k) р-ссттш раное в данном ршдслс' Мнмес™°
1
2
3
4
5
6
7
gripping^
cteartX)
ол(Х.У)
ontableiY)
clear(Z)
unstack{X,Y)
grippmg{X)
cleariY)
putdownW)
gripping^)
cleartX)
ontablelX)
pickup(Y)
grippingiY)
slack(YZl
grippingi)
cleariY)
on{YZ)
pictcupiX)
gripplngiX)
stackOi.Y)
i
Действию, а „оГсл",™ ДС"СТВ"Й т"™°*™ » строке, соответствующей этому *С™™« ".Ч»*™? ^Г^Г—, в мир при выполнении макрооперагора. Тре-
Филя „ в соответствующем crrnnfSiip i-iarmnnfn d гтпоке 5
содер- ""■"« в самой нижней строке *и-»™ - —- "г „.„„„,„„ .„ „о.™ собственным
1 2 3 4 5 6 7
Рис. 7.21. Треугольная таблица
Одним из преимуществ треугольных таблиц является возможность преодоления
неожиданных или аварийных спуаций, таких как сдвиг блока. Часто в случае аварии для
продолжения реализации плана требуется вернуться на несколько шагов назад. При необходимости
планировщик может возвратиться назад к нужным строкам и столбцам таблицы, чтобы
проверить, какие подцели еще истинны. После такой проверки планировщик знает, каким должен
быть следующий шаг решения. Это формализуется с помощью понятия ядра.
Ядро п-го порядка, или п-е ядро, - это пересечение всех строк, начиная с n-й. с л
столбцами, начиная с крайнего слева. На рис. 7.21 мы очертили третье ядро жирной
линией. При выполнении плана, представленного треугольной таблицей, 1-я операция (т.е.
операция в ,-й строке) может быть выполнена, если все предикаты, содержащиеся в ,-м
ядре, истинны. Это позволяет проверить, какой шаг может быть выполнен, и
восстановить выполнение плана при его нарушении. Для этого в треугольной таодаценужно
найти и выполнить действие, соответствующее ядру максимального порядка. Это
дает^возможность не только возвратиться к предыдущим шагам плана, но и скачкообразно не-
рейти вперед после неожиданного события. _ „„_„„ v,-
Условия в крайнем слева столбце - это предусловия для «акродеиствияв ц.том.Ус
соответствующем столбце. Например, в строке 5 содер;
(списки добавления и вычеркива.
ння)
жатся предусловия, а в столбце б „„,
™ оператора p,ckUD,X) П ПТУСЛМИЯ
™х (дальнейших! Ilj' остусловия одних действий являются предусловиями ДРУ
„„„„х,. „„....._'' Цель Чкуольной таблипы - ™™„„ .... образом упорЯ;
■ соответствующим
«'«и. Таким образом тр"^™ „""-..а*Д°Г° дс"«вня при достижении более круп"»»
УРовне макроопТ" -Z? '""" решают B0"P°™ нелинейности планир""
'• ' ™" ,Г„™ Г' ЭГИ те ВОПР°<=ь, «»*но решить и на основе ДРУ™
I Russell и Norvig, 1995]. "С"0Л"0МК"« частично упорядоченных планировщик»
Угольная таблица может быть сохранена как мак^операпшр со своим собственным
множеством предусловий и списками **^™£^£^ скрывает сематнку
Разумеется, подход на основе треугольной таблицы с оль^£ ^
предыдущих моделей планирования. Например в ™™^^шпх денствш-, Таким
еловия, которые одновременно являются "Р^—иш^^ верификацня
образом, для получения корректного результата "«^ fl позволяющей
треугольных таблиц, возможно, с учетом дополнительной инфер
еформнровать последовательности треугольных таблиц
аоть III. Представление и ра3у„ в ракурсе искусстввнного интелл.
Глава 7. Сильные методы решения задач
315
в „озникают и другие проблемы. С увеличение
При использовании «^оопер"Р1СП0Льзует более сложные операции, а размер „с"
числа макрооператоров план"р°™ ™е„ьшается. К сожалению, предусловия всех 0Пе"
следуемого пространства состояв j^ ^ ^^ Необходнмо(, для определен,,,
раторов необходимо проверя ^ с о6разцом может значительно усложнить про
применимости оператора соп ства маКроопераций. Проблемы необходимости
цссс поиска и свести на не V т следующег0 оператора остаются предметом
сохранения m^°°7r " уюшем разделе будет описан алгоритм адаптивного плана-
многих исследовании. В ж™ * удовлетворяться несколько подцелей,
роваиия, при котором одновременно могут уд
7.4.3. Адаптивное планирование
С момента появления ранних работ по планированию, описанных в предыдущем
оазлеле [Fikes и Nilsson, 1971], в этой области был получен ряд значительных резуль-
тагов Многие из них не связаны с конкретной предметной областью. Но в последнее
время особое значение приобретает планирование в специфических областях, где
используется распределенный механизм "восприятие-реакция". В следующих разделах
будет описана не зависящая от предметной области система адаптивного
планирования, а также более специфический планировщик Бартона (Burton) из NASA. В качестве
дополнительной литературы по исследованиям в области планирования рекомендуем
книгу [Allen и др., 1990].
Адаптивное, или телео-реашивное, планирование (АП) впервые было предложено в
[Nilsson, 1994] и [Benson, 1995]. Принцип АП может применяться во многих областях,
требующих скоординированного управления сложными подсистемами для достижения
целей более высокого уровня. Здесь иерархическая архитектура управления (сверху
вниз) соединяется с агентным подходом (раздел 6.4) или управлением снизу вверх.
Результатом является система, которая может решать сложные проблемы посредством
координации простых проблемно-ориентированных агентов. Такой подход можно
обосновать следующим образом. Простые агенты хорошо работают в ограниченных
пространствах. С другой стороны, контроллер более высокого уровня может делать более общие
заключения, относящиеся ко всей системе. Например, он позволяет оценить, как текущее
локальное решение воздействует на процесс решения общей задачи.
Адаптивное управление объединяет аспекты управления по обратной связи и
планирование конкретных действий. Адаптивная программа — это
последовательность действии, обеспечивающих выполнение целенаправленного плана. В отличие
лепГтГ, ™аД"и"°ННЫХ СР£Д интелле"уального планирования [Weld, 1994] здесь не
Го"предскГеГсГИЙ ° ™CKpe™0™ * непрерывности действий, а также о пол-
поГе ж!атьУся тен^ГГ™' На°б°Р0Т' «—Р™ действия могут
до тех пор пока v» дл"тельиого периода времени, т.е. действие выполняется
цель В [Niisson 1904, ТВ°РЯЮТСЯ nPeW-°™ и не достигнута соответствующе
могут б™ прервань 1:КГ„*ТВМ Ш"™ -^МжииеГны«« Wur.«ive). Они
цели верхнего уровня п„ некоторого другого действия, более близкого к
ются, отражая новое 0Х"ЗМе1ЮИ"" среды Управляющие действия быстро измен»-
Последовательности Т P™""™ пРоблемы.
структурами данных _т1Р0Д0ЛЖИТеяьнЬ1х дей«вий представляются специальным"
пар условие-действие „т,™1"™" <РИС' 12Г>- TR-Дсрево описывается множеством
«*« продукционными правилами (раздел 5.3). Например,
Часть III. Првдставл^^зум в ракурсе искусственног7и~нтеллектз
с,->А.
Сп-><ч„.
где С,- условия, а А,- соответствующие им действия. с„- это ссылка на цель верх-
нег0 уровня дерева, а А„ — нулевое действие, показывающее, что при достижении цели
верхнего уровня никаких действий не требуется. На каждом цикле работы такой системы
условия С, оцениваются сверху вниз (Со, С,, ..., с„) до тех пор, пока не находится первое
истинное условие, и действие, связанное с этим условием, выполняется. Затем цикл
повторяется. Частота повторения определяется скоростью реакции контура управления.
V©
0
Рис. 7.22. Простое TR-дерево,
содержащее правила условие—^действие для
достижения цели верхнего уровня
[Klein и др., 20001
Ппопукчии С^А организуются таким образом, что каждое действие А,, если оно не-
прер^Р^^^^
кГаГп^н^^^
ет результат предыдущих дей"^ —^=—™^о уровня во/обнов-
более низкого уровня, и работа пUW»»™ „ нечт0 непреДвиденное.
ляется. Аналогично, если в среде вьшолнен,я д^ ^„^ с „СТИН|ШМ условием,
то управление автоматически переидеткл ^ планирования, которые испольэу-
TR-деревья могут создаваться с помощью"™Р™ ^ цм^ Начиная от цели
ют общепринятые в искусственном инт _ результат которых приводит к досги-
верхнего уровня, планировщик находит деист^ -^^ новое множесгво подцелей, и
жению этой цели. Предусловия этих ^"c™"" завершается, когда предусловия конеч-
эта процедура исполняется рекурсивно, lipou к j^pmM планирования выпол-
ных узлов выполняются в текущей среде, аы. ^стоянию Конечно. действия часто
няет редукцию цели верхнего уровня к «куш J тщательн0 следнть за тем, чтобы ка-
нмеют побочные эффекты, и планировщик дол* высокого уровня TR-дерева. Та-
ждое действие не изменяло предусловия №"^"те,1 ограничений за счет использо-
ким образом, редукция целен связана с >Д -,
вания различных стратегий переупорядочен«да построения п.ланов, листья ко-
Итак, алгоритмы ТЯ-план.фован.гя исполи юте ^^ ^ ^ пмвомют строит1
торых соответствуют текущему состоянию ср д
Глава?. Сильные методы решения
„ые можно реализовывать из любого состояния мира, так как под„б11Ь||1
ы, которые можно р [(.„(„[„.„„„„ого выполнен,,» эт W">H n
яки для запоминания г
) выполнения. Это с
' "ЗДяю
„ы слишком ■™ик" ^^„„„е события морд' привести мир в состояние, не С-Т""' "»'
Рова„Ис. к
скольку
иногда в
Мовде,
, TR-дерева. В этом случае потребуется перепланирование"^0'
^.зт^Гприповтори^^
В [Benson.
I994J и [Nilsson, 1995] описывается использование адаптивного пла„
областей, включая управление распределенными ■.
—~ ЛК££££ ~ « вт™» ■-iTissusr. ;r *
роботами i
■ 20001
адаптивный планировщик используется для построения и испытания портативной ут,
ляющей системы для ускорителя пучков заряженных частиц. В этих работах „Ц*
применения адаптивного планирования обосновывается следующим образом. '
1. Ускоритель пучков — это динамическая и зашумленная система.
2. На процесс настройки ускорителя часто влияют стохастические процессы, рад„
помехи или осцилляция источника пучков. ' ю'
3. Многие действия в процессе настройки являются продолжительными. Это особе
но касается процедур тонкой настройки и оптимизации, которые продолжаются
тех пор. пока не будут достигнуты некоторые критерии.
4. TR-деревья обеспечивают естественный способ описания планов настройки
латаемых физиками. В самом деле, при небольшом содействии физики сами мот
разработать собственные TR-деревья.
Более подробное описание этих приложений можно иайти в литературе, указанной в
заключительной часта главы. В следующем разделе мы вернемся к примеру рассужде
нии на основе модели из раздела 7.3 и опишем алгоритмы управления-планирования для
двигательной установки космического аппарата.
7.4.4. Планирование: пример NASA
дел*,в!Т!Г УЯ" °™СаН maH"P°™™ *™ механизма рассуждений на основе мо-
c"uZL"-"m " [Wi"iamS " Na^ 19961- описанному в подразделе 7.3.2.
нентную модель двшжельТй'С™НЬШ Д"СПетчеР конфигурации, использующий компо-
в""ноеереконф^~рИс 7™" К°СМтеСКОГО *°Ра6"я «« определения дейа-
Космический
корабль
Команды
Рис. 7.21 Реакт | корабль р
"М-** >996„7'""">"""""<!т"'<оифигура„ией 1Ш осиоеемодеш и, [William
Каждый компонент системы двигателей можно „,,,„
тельностн переходов, описывающей поведение з пРеДставить в виде поелсдова-
-ежимах и переходы между этими режимами 7°™ Злемснта в рабочем, аварийном
входов (рис. 7.24). На рис. 7.24 элементы open ITZseT"""" " ВСр0Я™сть пе-
рабочие режимы, a stuck орел и stuck closed _ „Г представляют нормальные
„ич„ую стоимость и вызывает переход „т режима сГ^Т'' *** °Рв" ""'" *
наоборот. Аварийные переходы переводят Гапан Till ""^ * Г™" "*—
один из аварийных режимов с вероятностно? Н°рМаЛЬНОГО Ра6очет° Р™а °
°Реп 0,01 stuck open
^ Нормальный переход
со стоимостью. .
, Аварийный переход
с вероятностью ..
closed 0,01 stuckclosed
Рис. 7.24. Модель системы переходов ыапана ю
[Williams и Nayak, 1996a]
Поведение элемента в каждом из режимов описывается формулами
пропозициональной логики, а переходы между режимами — формулами пропозициональной логики при
ограниченном времени. Это описание можно использовать для моделирования цифровых
и аналоговых устройств [deKleer и Williams, 1991], [Weld и deKleer. 1990]. а также
программного обеспечения реального времени на основе модели параллельных реактивных
систем [Маппа и Penueli, 1992]. Модель системы переходов космического корабля — это
композиция систем переходов его компонентов. При этом множество состояний
конфигурации космического корабля определяется как прямое произведение состояний его
компонентов. Предполагается, что системы переходов всех компонентов действуют
синхронно, т.е. каждый переход состояний космического корабля связан с переходом
состояний его компонентов. Диспетчер конфигурации, основанный на модели, использует
модель переходов системы как для идентификации текущей конфигурации космического
корабля в режиме оценивания (РО), так и для перевода корабля в новое состояние в
режиме реконфигурации (РР). В РО поэтапно генерируются все переходы космического
корабля в состояние, совместимое с текущими наблюдениями. Например, на рис. 7.25
показана ситуация, при которой в предыдущем состоянии левый двигатель запускается
нормально, а в текущем состоянии отсутствует тяга. Задача РО — идентифицировать
состояние, в которое может перейти корабль с учетом этого наблюдения. На рисунке
показаны два возможных перехода, соответствующих неисправности одного из клапанов
главного двигателя. Неисправные клапаны обведены кружочками. При этом можно
также учитывать многие другие переходы, включая маловероятные двойные отказы.
В РР определяются команды, переводящие корабль в состояние для достижения цели
(рис. 7.26). Этот рисунок соответствует ситуации, в которой в режиме идентификации
обнаружена неисправность клапана, ведущего клевому двигателю. В РР предполагается,
что дл, восстановления нормальной тяги в следующем состоянии несводимо открыть
соответствующий набор клапанов, ведущих к правому двигателю. На рисунке показаны
Две из множества конфигураций, позволяющих достичь желаемой цели при изменении
состояния клапанов, обведенных кружками. Переход к верхней конфигурации Дсшевл.
так как для него необходимо лишь активизировать пироклапаны ,см. подраздел 7.3-)-
Глава 7. Сильные методы решения задач
319
„евому двигателю, перекрываются, и система продолу
тогда клапаны, ведушие "^ование моде» космического корабля как в РО, так
^однвмДви-^^Г^ние целей конфигурации.
РР обеспечивает корректно
а
такНа
Текущая конфигурация
Возможны следующие
конфигурации,
обеспечивающие
'нормальную тягу"
Рис. 7.26. Режим реконфигурации из [Williams и Nayak, 1996a]
Оба режима (РО и РР) являются реактивными (см. раздел 6.4). В РО текущая
конфигурация определяется на основе предыдущей конфигурации и текущих наблюдений.
В РР рассматриваются лишь те команды, которые обеспечивают достижение цели в
следующем состоянии. При этом ключевую роль играет предположение о синхронности
переходов. Альтернативой является последовательное моделирование множест
переходов дд» отдельных компонентов. Однако в этом случае текущая и цел""
ТоТвГ"' ТУТ °Ка3аТЬСЯ Далеко Ч>У « ДРУга, и возможность ограничить в"
модели Г"" фиКС">>°ва™ь,м числом'состояний удет сведена на нет. Поэтом »
прат„0?TU СЧИТаЮТСЯ с-н"РОнными. Если переходы в программ
2Z ™ все Г6""™ не ™»Ч.оннн. система Livingstone исходит из пред о»
,0 ВСе ,юочеРеяные переходы корректны и поддерживают достижение »
' Представление и разум в ракурсе искусственного интелл
Ж
„аемой конфигурации. В системе Burton па™»,
, ivingstone. это предположение отсутствует В систем! IT™ основные возможности
Ь .„едоватсльность управляющих воздействий ппоиТ» """""Ровщик определяет
:...".. N„„»b 10071 ылчд ™ИИ'nP°mB0^iUHX все желаемые пепехши.,
П0СЛ1
[Williams и Nayak, 1997]. NASA использует апхитектГТ'1"" ВСе же"аемые переходы
1 в системе Living*™ не нужно re„eL„BT гГ!®""0" ' ПрметеТ^ Sa' 21-
мк»цНе команда. Требуются только наиболее вероятны пепГолы ™OTBeIC™!HH0' ™™-
управления. Для их эффективного вычисления задачи ро^р I оптимальная команда
^вать как задачи комбинаторной оптимизации ТГой! HOo6x°r'° ™1*Ф°Р"*™-
^тся наиболее вероятные траектории ^бл! ^ "^II™^
меньшей стоимости, которая переводит корабль из наиболее вероТоГек^еПонфи^
рации к конфигурации, соответствующей желаемой цели Задачи Шорной
оптимизации решаются с помощью алгоритма поиска до первого наилучшего соответствия
(best-first). Более формальное описание РО и РР, а также детальное описание алгоритмов
поиска и планирования содержится в [Williams и Nayak, 1996,1996а].
7.5. Резюме и дополнительная литература
Экспертные системы, основанные на правилах, строятся в виде продукционных
систем. Вне зависимости от того, основан конечный продукт на данных или на цели,
моделью программы является продукционная система, генерирующая граф поиска (глава 5).
В главах 14 и 15 будут представлены оболочки экспертных продукционных систем,
написанные на языках PROLOG и LISP соответственно. Эти оболочки позволяют
реализовать поиск на основе цели. Правила могут включать степень надежности, что
обеспечивает возможность эвристического поиска.
Представленный в этой главе материал можно дополнить рядом работ. Особенно
рекомендуем подборку оригинальных публикаций по системе MYCIN [Buchanan и Shor-
tliffe, 1984]. Для робастной реализации поиска на основе данных можно использовать
программное обеспечение CLIPS, распространяемое NASA [Giarratano и Riley, 1989].
К важным книгам по общей инженерии знаний относятся [Hayes-Roth и др., 1984].
(Waterman, 1986], [Alty и Coombs, 1984]. [Johnson и Keravnou, 1985], [Harmon и др.. 1988]
и [Negoita, 1985). Советуем также прочитать (Ignizio, 1991], [Mockler и Dologite, 1992] и
[Durkin, 1994].
Поскольку экспертные системы должны обладать обширными знаниями в конкретной
предметной области, важным источником знаний для них являются описания примеров
из этой области. Книги из этой категории включают [Klahr и Waterman, 1986], [Кетаиюи
и Johnson, 1986] [Smart н Langeland-Knudsen, 19S6], [Coombs, 1984], [Prerau, 1990]. Осо-
бенно рекомендуем книгу [Durkin, 1994] из-за ее многочисленных практических
предложений по созданию экспертных систем.
Разработан ряд методов для извлечения знаний. Подробная информация по
отдельным методологиям представлена в [McGraw и Harbison-Bnggs. .989] и [Chorafas, 1990],
а также в [Mockler и Dologite, 1992]. „„„„„„„„о
Рассуэкдсння на основе примеров являются ответвлением более |"™^
труппы Шенка (Schank) из Йельского университета по сценариям (см. ™Ф°*™£\
« 6.1.4). Книг. [Kolodne, 1993] является всеобьемлюшнм введением ****££%£
также предлагает ценные взгляды „а разработку и проекпгроваш.е ™**£^f ££
тах [Leake, 1992. 1996] содержатся важные комментарии по реализации „6ьяснени„ систе-
г"ава 7. Сильные методы решения задач
, В настоящее время существует ряд коммерческих прот
к основанных на примерах. к1шолоп1Ю сшггем. основанных на примерах. тщ-
xnix.flyKroB.noa»ep»BaK™^a. ^^ ^^ „ Я8Н0М представлении логически,
ставлены a |Н^»£^'££и „^orvg. .995] описываю^ ги6р^ь ^
^т«^^^^аЮ' МН°ЖеСТВа П0ДХ0Д°В К РеШеНИЮ "^
T^TSS^^m описаны некоторые ш структур д
метоУГпГска, предназначенные для создания планировщиков общего „^наченш, По
Ттематике можно также порекомендоватьописание_ ABSTRIPSили. ABstrac, т ^
„ератора отношений STRIPS [Sacerdom, 19741и „стемы NOAH для нел„„е„„„г0 1ищ
иерархического санирования [Sacerdott, , 1975USacerdott, 1977 Более совреме„„ыс
гшанпровшики описаны в разделе 15.3 и работе [Benson и Nilsscm. 1995].
Метапланирование — это метод рассуждения не только о плане, но и о процессе
планирования. Это штмет важную роль в разработке экспертных систем. В качестве первоисточников
можно посоветовать литературу по системам Meta-DENDRAL [Lindsay и др., 1980] и Teiresias
[Devis, 1982]. Непрерывно взаимодействующие с окружающей средой планировщики, т.е.
системы, моделирующие изменяющееся окружение, описаны в [McDermott, 1978].
Дальнейшие исследования включают оппортунистическое планирование, использующее
метод классной доски, и планирование, основанное на объектно-ориентированном описании
[Smoliar, 1985]. Несколько обзоров по области планирования содержатся в словарях [Ватт и
Feigenbaum, 1989] [Cohen и Feigenbaum, 1982] и энциклопедии по искусственному интеллекту
[Shapiro, 1987]. Вопросы нелинейного и частично упорядоченного планирования
представлены в [Russel и Norvig, 1985]. К этой области относится и работа [Allen и др., 1990].
Наше описание и анализ рассуждений на основе моделей, а также алгоритмы
планирования взяты из [Williams и Nayak, 1996,1996а]. Мы благодарны авторам, а также издательству
ААА1 Press за разрешение описать эти исследования в своей книге.
7.6. Упражнения
1. В разделе 7.2 мы ввели набор правил для диагностики автомобиля. Определите
возможных инженеров по знаниям, экспертов в данной предметной области и
потенциальных конечных пользователей для такого приложения. Опишите ожидания,
возможности и потребности каждой из этих групп
2' шГ'П^™"2™0 '• С°3даЙТе на РУССК°М ™™ или псевдокоде 15 правил "ест.-.
метлой'""rS^Z,' РаЗДСЛе 7'2) "" Ч*»™™»™ °™Ш<:ИИЙ В ОТЙ ■**
"«-троите граф, представляющий взаимосвязи этих 15 правил.
' оГовеТн!?!,!,"3 УПражнеН1и 2- Какой поиск вн рекомендуете использовать: в.
-ж^гй?в ш,,рину или ■глубину9 как,,м обр
4 Выбепите И"сгики поиска? Обоснуйте ответы на эта вопросы.
' 1-3 для3™™^^™.''"'' РШрабтт «спергиой системы. Ответьте на вопрос*
комендуем о^мочетГЧ тЛ^' НСП0Л"УЯ коммерческую оболочку. Особенно Г
' LLlK> IGianatano и Riley, 1989].
I Представление и разум в ракурсе искусственного интел*»^
Часть II
6, Оцените оболочку, которую вы использовали „„„ .
ее сильные и слабые стороны' Что . „»- Р выг,олнен"» упражнения 5. Каковы
шеиия вашей задачи? Для каких залач2 М°ЖН° уЛучшитъ? Подходит лн она для ре-
каких задач предназначен этот инструментарий'
7 Гм^ирХ"ер=е:11г°:„бГ ™ ™—«**
8. Прочтите и прокомментируйте статью [Devis и др., 1982].
9. Прочтите одну из ранних статей о naccvatncuu.v
: '. - , рассуждениях на основе моделей, посвященную
обучению детей арифметике IBrnwn и Run™ irnei гл
,,ii, mom гт lorown и burton, 1978] или электронике [Brown и
VanLehn, 1980]. Прокомментируйте этот подход.
10. Постройте механизм рассуждений „а примерах для произвольно выбранного
приложения, например, задачи выбора курсов по вычислительной технике и компьютерным
наукам при изучении базовых университетских дисциплин ш получении степени магистра.
11. Используйте коммерческое программное обеспечение (найдите в Internet) для построения
системы рассуждений на примерах из упражнения 10. Если нет готового программного
обеспечения, постройте такую систему на языках PROLOG, LISP или Java
12. Прочтите и прокомментируйте статью [Kolodner, 1991a].
13. Опишите остальные аксиомы границ, необходимые для четырех операторов
pickup, putdown, stack и unstack, упомянутых в правилах 4-7 из раздела 7.4.
14. Используйте операторы н аксиомы границ из предыдущего упражнения для
генерации пространства поиска, показанного на рис. 7.19.
15. Покажите, как можно использовать списки add н delete для замены аксиом
границ при генерации состояния 2 на основе состояния 1 в разделе 7.4.
16. Используйте списки добавления и вычеркивания для генеращш пространства поиска
из рис. 7.19.
17. Спроектируйте автоматический контроллер, который мог бы использовать списки
добавления и вычеркивания для генерации графа поиска, подобного
представленному на рис. 7.19.
18. Укажите не менее двух несовместимых (по предусловиям) подцелей в операторах из
мира блоков (рис. 7.19).
19. Прочтите исследование ABSTRIPS [Sacerdotti, 1974] и обьясните. как управлять
линейными (или несовместимыми) подцелями при планировании задач.
20. В подразделе 7.4.3 был представлен планировщик, созданный Нильсоном и его
учениками в Стэндфордском университете [Benson и Nilison, 1985]. Адаптивное
планирование позволяет описывать продолжительные действия, т.е. такие, которые
остаются истинными в течение определенных временных периодов. Почему системы
адаптивного планирования предпочтительнее планировщиков типа STRIPS.
Постройте адаптивный планировщик на языках PROLOG. LISP или Java.
21. Прочтите статьи [Williams и Nayak. 1996], [Williams и Nayak, 1996ч,] и обсудите сие-
темы планирования на основе моделей.
22. Расширьте схему представления в пропозициональном „счислении, введенную в
[Williams и Nayak, 1996а. С. 973] для описания переходов состоянии двигательной
установки.
Глава 7. Сильные методы решения задач
323
Рассуждения
в условиях
неопределенности
Любая традиционная логика обычно предполагает использование точных
символов. Поэтому она применима не к земной жизни, а лишь к
воображаемому небесному существованию.
— Бертран Рассел (Bertrand Russel)
Свойством разума является удовлетворенность той степенью точности,
которую допускает природа субъекта, а не ожидание точности там, где
возможно лишь приближение к истине.
— Аристотель (Aristotle)
Если законы математики опираются на реальность, они я&тяются
неопределенными. А коль скоро они точны, они не отражают реальность.
— Альберт Эйнштейн (Albert Einstein)
8.0. Введение
Процедуры вывода, описанные в частях I и II, а также большинство процедур из
части III основаны на модели рассуждения, используемой в исчислении предикатов: из
корректных предпосылок с помощью обоснованных правил вывода можно получить новые
гарантированно корректные заключения. Однако, как было показано в главе 7,
существует много ситуаций, для которых такой подход не годится. Зачастую полезные
заключения должны быть получены из неудачно сформулированных и неопределенных данных с
использованием несовершенных правил вывода.
Извлечение полезных заключений из неполных и неточных данных с помошью
несовершенного вывода является неразрешимой задачей, однако человек в повседневной
жизни справляется с этим достаточно успешно. Мы ставим корректные медицинские
диагнозы и рекомендуем лечение на основании неоднозначных симптомов; анализируем
автомобильные проблемы; понимаем языковые выражения, часто являющиеся
неполными или двусмысленными; узнаем друзей по голосу или по походке и т.д.
, „ассуждения в условиях неопределенности рассмогг™
дм демонстрации пРоОЛ " ;гност„кн автомобиля, представленной в разделе 7 2
правило 2 экспертной системы д
двигатель не врашается и
фары не горят,
пТр°0олема в аккумуляторе или проводке.
и „,™й взгляд это правило напоминает обычное предикатное выражение, исполь.
РГГ,ГГв'одГшЛг «0к«к. Однако это не так - оно эвристнчно по пр„р0Д(,
ГМГ„7 о" и м^ероятно, что аккумулятор и проводка исправны, просто у авто;
.щоХповрёжден стартер и перегорели фары. Невозможность завести двигатель „ от.
сГГие света не обязательно означают неисправность аккумулятора „ли проводки.
Интересно, что обратное утверждение правила истинно.
проблема в аккумуляторе или проводке,
то двигатель не вращается и фары не горят.
Если чудо не произойдет, при неисправном аккумуляторе ни освещение, ни двигатель
работать не будут!
Эта экспертная система обеспечивает пример абдуктивного рассуждения. Формально
абдукция означает, что из Р->0 и О можно вывести Р. Абдукция является
необоснованным (unsound) правилом вывода, означающим, что заключение не обязательно истинно
для каждой интерпретации, при которой истинны предпосылки (раздел 2.2).
Хотя абдукция и является необоснованной, она часто используется при решении
проблем. "Логически корректная" версия правила об аккумуляторе не очень важна при
диагностике автомобильных неисправностей, поскольку предпосылка "проблема в
аккумуляторе" в реальной задаче является целью, а заключение — наблюдаемыми симптомами,
с которыми необходимо работать. Тем не менее правило может быть использовано аб-
дуктивно, подобно правилам во многих экспертных системах. Неисправности или
болезни вызывают (имплицируют) симптомы, а не наоборот; но диагноз должен ставиться от
симптомов к причинам, их вызвавшим.
В системах, основанных на знаниях, с правилом часто связывается фактор
уверенности для измерения степени доверия его заключению. Например, правило P->Q (■')
выражает следующее: "Если вы верите, что Р истинно, то О будет выполняться в 90%
случаев . Таким образом, эвристические правила могут выражать политику доверия.
Следующая проблема рассуждений в экспертных системах — как извлечь полезные
ЦТ"" Ю ДаШЫХ С непшшой ""и некорректной информацией. Для отражения досто-
"освеиТн,ГТ М0ЖН° исполи°в«ь меру неопределенности, например, утверждение
бо Zv ло^Г" "а П°ЛНУЮ М°ШН0СТЬ <-2)" >™вает, что фары горят, но очень с*
В этой ™„ Р« " " НесовеР™ва данных можно учест! в правилах,
неопредел™ стью"* "Т™" СП°СОбОВ уП"аМенм *бдуктнвным выводом .
Вразделе8Г„ок1вТ °6ра3°М ПрИ решени" ™т- основанных на знав" -
абдуктивных зад в "' КаДло™чес>™ Формализмы можно развить для решен
подходу, в том ч„сл! н'еТ; " РтетР™«« несколько альтернатив логически
суждения „ теория 1"!Г,ВЫВ°Д ™ °Снове Фак™ра уверенности, "нечеткие Р
шения некоторь'Гп™ Г Г Фера' Э™ Пр0С™е "Р""" разработань, для Р«
пертных систем. байесовского подхода, всплывающих при построении э»
Часть ш. Представление и разум в ракурсе искусственного интел^»
nib, ГтеоремеГайес СТ0ХаСТ"ТОЮ* "°™>Д" к неточному выводу. Эти приемы
основаны на теореме Баиеса, относящейся к рассуждениям о частоте событий „а основе
априорной „„формации „ „их. в замючение ^ „^^ тд^ ™Д_
ставленные с помощью байесовских сетей доверия (belief network). 'P
8.1. Абдуктивный вывод, основанный на логике
До сих пор в основном рассматривались логические подходы к решению задач при
которых часть знании явно используется в рассуждениях, и, как явствует из главы 7
может обеспечить объяснения для выведенных заключений. Но традиционная логика имеет
и свои ограничения, особенно в условиях неполной или неопределенной информации.
В этих ситуациях традиционные процедуры вывода не могут быть использованы. В
разделе 8.1 приводится несколько расширений традиционной логики, позволяющих
поддерживать абдуктивный вывод.
В подразделе 8.1.1 логический подход расширяется для описания мира изменяющейся
информации и степени доверия ей. Традиционная математическая логика является
монотонной. Она основана на множестве аксиом, принимаемых за истинные, из которых выводятся
следствия. Добавленне в эту систему новой информации может вызвать только увеличение
множества истинных утверждений. Добавление знаний никогда не приводит к уменьшению
множества истинных утверждений. Это свойство монотонности приводит к проблемам при
моделировании рассуждений, основанных на доверии (belief) и предположениях. При
рассуждении в условиях неопределенности человек делает выводы на основе текущей информации н
степени уверенности в ней. Однако, в отличие от математических аксиом, мера доверия и
выводы могут изменяться по мере накопления информации.
Проблему изменяющейся степени доверия решают немонотонные рассуждения.
Система немонотонных рассуждений управляет степенью неопределенности, делая
наиболее обоснованные предположения в условиях неопределенной информации. Затем
выполняется вывод на основе этих предположений, принимаемых за истинные. Позже мера
доверия может измениться и потребовать перепроверки всех заключений, выведенных с
ее использованием. Затем для сохранения непротиворечивости базы знаний могут быть
использованы алгоритмы поддержки истинности (подраздел S.1.2). Другие расширения
логического подхода включают "минимальные модели" (подраздел 8.1 3* и метод,
основанный на множественном покрытии (подраздел 8.1.4).
8.1.1. Логика немонотонных рассуждений
Немонотонность является важной особенностью общесмысловых рассуждений и
решения задач человеком. В большинстве случаев при планировании мы летаем
многочисленные предположения. Например, выезжая на автомобиле, следует учитывать состояние
дорог и транспорта. Прн нарушении одного из предположений, например, из-за аварии
на обычном маршруте планы изменяются и выбирается альтернативный маршрут.
Традиционные рассуждения, использующие логику предикатов, основываются на
грех важных предположена. Во-первых, выражения теории предикатов должны
адекватно описывать соответствующую предметную область. Следовательно, в виде
предикатов должна быть представлена вся информация, необходимая для решения задачи. Во-
вторых, информационная база должна быть непротиворечивой, т.е. части знании не
должны противоречить друг другу. 11. наконец, с использованием правил вывода
количества 8. Рассуждения в условиях неопределенности
327
о. „„„и увеличивается монотонно. При невыполнении хотя бы „.„„
ство известной информации У ^ ^„ционный подход работать не будет.
го из эти* правил оснианн са Во-первых, системы рассужде„„й
НеМ0"01°ГсяСсТт"е« знаинТо предметной области. В данном сл~
часто ^кива"™ "ж^, у „ае нет знаний о предикате р. Отсутствие знания означ™
знания важны. Предам ' Л(Ы vecpe„b,, что p не является истинны»! На
"•™0ГоГГио отвГь-колькимн способами. Система PROLOG (см. ГЛМу *
™1™^ "сложение о мтутоши мира и считает ложью все тс утверждения,
Тть которых „е может доказать. Человек часто выбирает альтернативный „одХОд,
истинно которь^ нт пои не 6удет доказаН0 о6ратное.
"XwoN "одход к проблеме отсутствия знания заключается в точном определении „с
тины В человеческих отношениях применяется принцип презумпции невиновности. Ре-
ZbraT этих ограничивающих предположений позволяет эффективно восполнить упу.
шейные детали нашего знания, продолжить рассуждения и получить новые заключения,
основанные на этих предположениях. Предположение о замкнутости мира и его
альтернативы обсуждаются в подразделе 8.1.3.
Основа человеческих рассуждений — знание о традиционном ходе вещей в мире.
Большинство птиц летает. Родители, как правило, любят и поддерживают своих детей. Выводы
делаются на основе непротиворечивости рассуждения с предположениями о мире. В этом
разделе обсуждаются модальные операторы, такие как Is consistent with (согласуется с) и
unless (если не) для реализации рассуждений, основанных иа предположениях.
Второе предположение, используемое в системах, основанных на традиционной логике,
заключается в том, что знание, на котором строятся рассуждения, непротиворечиво. Для
человеческих рассуждешш это очень ограничительное предположение. В задачах диагностики
часто принимается во внимание множество возможных объяснений ситуации,
предполагается, что некоторые из них истинны, пока не подтверждаются альтернативные предположения.
При анализе авиакатастроф эксперт рассматривает ряд альтернативных прични, исключая
некоторые из них по мере появления новой информации. При рассмотрении альтернативных
сценариев люди используют знание о том, каков этот мир обычно. Желательно, чтобы
логические системы тоже могли принимать во внимание альтернативные гипотезы.
И, наконец, для использования логики необходимо решить проблему адаптации базы
знаний. При этом возникают два вопроса. Первый — как добавлять в базу знания,
которые основываются только иа предположениях, и второй — что необходимо делать, если
одно из предположений окажется некорректным. Для решения первого вопроса можно
обеспечить добавление нового знания иа основе предположений. Это новое знание
априори может считаться корректным н, в свою очередь, использоваться для вывода
нового знания. Цена этого подхода- необходимость отслеживать весь ход рассуждений и
доказательств, основанных на предположениях. Мы должны быть готовы к пересмотру
любого знания, основанного „а этих предположениях
ваютсГГ^ 3аКЛЮЧения ин°™ пересматриваются, немонотонные рассуждения назы-
татТсттэГГ™"™' Te "°8аЯ "»Ф°Р»«Ция может свести на иет предыдущие резу»'"
ГичесК0^3' "реДгаВЛеНИЯ " "Рождурь, поиска, отслеживающие рассуждения ло-
нуГир™^^ГнГспи аКта"Ю "°ддерЖК" —• «ли СПИ. При а^
заключения котоС2„ Ст?™»™ непротиворечивость базы знаний, отсле*^
несколько поГдоТк поГ/ ""^ '^ °СП°реНЫ- В "»«••»»« 8.1.2 рассматриваем
аннулируемое £Д£ЗГ "с™™°™. Рассмотрим операторы, обеспечивав»
V суждении в системах, основанных на традиционной логике.
gog ^ ______
Часть щ. Представление и разум в ракурсе искусственного интелл*"»
"аРт^ТГз"ИИэГоГТ°ИНОГО РаССУЖЛеИНЯ M°™ »™Р™ «««У с помощью
ZеЗ ДоГстнм^меГ Р П0ДДеРЖшиет ""вод „а основе .гредположснн» о ложности
аргумента. Допустим, имеется следующее множество выражений из логики предикатов.
р(Х) unless <j(X) -) г(Х)
P(Z),
r(W)-» s(W).
Первое правило означает, что г(Х) можно вывести, если истинно р(Х), и мы не
верим, что истинно о(Х). Если эти условия выполняются, мы выводим г(Х), а используя
Г(Х), можем вывести s(X). Впоследствии, если обнаружится, что о(Х) истинно, г(Х) и
s(X) должны быть отменены. Заметим, что оператор unless связан скорее с понятием
веры, чем истинности. Впоследствии изменение значения аргумента с "вероятно ложь
либо неизвестно" на "точно либо вероятно истина" может вызвать отмену всех выводов,
зависящих от этих предположений. Расширяя логику за счет рассуждений на основе
предположений, которые позже могут быть отменены, мы вводим в механизм
рассуждений элемент немонотонности.
Описанная выше схема рассуждений может быть использована также для описания
правил умолчания [Reiter, 1980]. Замена р(Х) unless <j(X) -> г(Х) на р(Х) unless ab
р(Х) -» г(Х), где аор(Х) —это abnormal р(Х), означает, что при отсутствии аномалии,
такой как птнца с перебитым крылом, можно сделать вывод, что если X — птица, то X
может летать.
Другой модальный оператор для расширения логических систем рассматривается в
[McPermotl н Doyle, 1980]. Авторы усиливают логику предикатов первого порядка
модальным оператором М, который помещается перед предикатом и читается как "не
противоречит". Введем следующие предикаты: good^student— быть хорошим студентом,
study_hard — прилежно учиться, graduates — окончить ВУЗ. Тогда предложение
VX goodstudenUX) л М study_hard(X) -> graduates^
может быть прочитано следующим образом: для любого X, где X — хороший студент,
если факт, что X прилежно учится, не противоречит остальной информации, то X закончит
ВУЗ. Конечно, основной проблемой здесь является точное определение значения "не
противоречит остальной информации".
Сначала заметим, что утверждение "не противоречит остальной информации" может
оказаться неразрешимым. Причина в том. что модальный оператор формирует
супермножество для уже неразрешимой системы (см. подраздел 2.2.2), и таким образом сам
будет неразрешимым. Существуют два способа преодоления неразрешимости.
Первый — использование метода доказательства от противного. В нашем примере можно
попробовать доказать выражение not'study_hard(X)). Если не удастся доказать, что X
не учится, то можно предположить, что X учится. Этот подход часто используется в
PROLOG-подобиой реализации логики предикатов. К сожалению, метод доказательства
от противного может слишком ограничить область интерпретации.
Второй подход к проблеме непротиворечивости заключается в выполнении эврв-
стического и ограниченного (по времени нли по памяти) поиска истинности предиката
(в нашем примере- studyJiard(XI). Если поиск не приводит к доказательству
ложности предиката, можно предположить, что он истинен. При этом следует понимать,
что утверждение graduates и все основанные на нем заключения в дальнейшем
могут быть отменены.
' ' " 329
Глава 8. Рассуждений в условиях неопределенности
.. п„отиворечит". можно получить противоречивые резул.
Используя оператор нер хорощим студентом, но любит вечеринки. Тогда л?"
ты. Предположим. Петр я» следующее множество предикатов. ш1я
оиисанияситуаиииможноиспо „ard(X, - gradua,esW
ZZniTeZ^) " Мло«.Г«*_/»««Х)> - „of<9redU.,e.W)
9ood_s(uc/efi'(Pe'erl
parry_person(per<"").
. „ert„ person - любитель вечеринок. Из этого множества выражений можно вывести
как Сю^ние что он окончит ВУЗ. так и заключение, что он его не окончит (сели нп 6о.
л'Гиой инф рмации о привычка.. Петра и не известно, прилежен ли он в учебе)!
Одним „"методов рассуждения, позволяющих избежать таких противоречивых рс.
■мьтатов является отслеживание связывания переменных, используемых в модальном
операторе "не противоречит". Таким образом, единожды связав значение peter с пред„.
катом study hard или „of(sfudyjiard), система должна предотвратить связывание это-
го значения с противоположным по смыслу предикатом. Другие системы немонотонной
логики [Mcdermott и Doyle, 1980] являются еще более консервативными и предотвращу
ют любые заключения нз таких потенциально противоречивых множеств выражений.
Возможна и другая аномалия.
VYvery_smart(Y) л Мnot{study_hard(Y)) -> not{study_hard{Y))
VXnot[very_smart{X)) л M not{study_hardiX)) -> not{study_hard{X)),
где very^smart — очень умный.
Из этих выражений можно вывести новое выражение.
VZMnot{study_hard(Z)) -> not(study_hard(Z)).
Последующие исследования семантики оператора "не противоречит" направлены
на решение проблем с такими аномальными рассуждениями. Одним нз дальнейших
расширений является логика, обеспечивающая автоматическое образование понятии
(autoepistemic logic) [Moore, 1985].
Другой немонотонной логической системой является логика умолчания (default logic),
созданная Рейтером [Reiter, 1980]. Логика умолчания использует новое множество
правил вывода вида
A{Z) л: B(Z) -> C(Z),
которое читается так: если Atf) доказуемо и если оно не противоречит знаниям,
позволяющим предположить B{Z), можно вывести C(Z).
На первый взгляд, логика умолчания во многом подобна описанной выше иемоио-
ГП Мак'ДеРмо™ " До"™- Важным различием между ними является метод, с
™ьиь?е пТ°Р0ГО совеРшается Рассуждение. В логике умолчания используются специ-
оХооемРк ж1вЫВ°Да пРав»"°Д°бного расширения исходного множества «я»
™£%^Z ЕГ"*"? С°ЗДаеТСЯ ПУГСМ "™-ьзования одного иэ правил вывода
Та—азе» естГ "' ПРедс™л™"Ь,х „сходным множеством аксиом/теоР*
знаний Это м„ж„?„ П°ЛуЧаеТСЯ РВД правдоподобных расширений исходной базы
Это можно продемонстрировать на следующем примере.
Каждое вь, a- "^-"агсЦУ)) _» по(( graduates) Г)).
Расш„РФННЯ, основаТногоГ0 ИСПОЛИОВеть для создания уникального правдоподоб^0
"ованно, о иа исходном множестве знаний.
ЧЭСТЬ '"■ ^^авление и разум в ракурсе искусственного интелл^3
Логика умолчания позволяет использовать » „„.,„
суждений любую теорему. выведенную врамк» ПГ„ Т" "" Дальнейш,,'( »°с-
6ы установить, какое расширение должно „ГиГль™0"™06"0™ РасшиРсния' "»• ™"
дач„, необходимо обеспечить упра~пГЦесс° """ """^Г" реШСНИ" За"
„ия ничего не говорит о выборев„Тмож„ЬгГIT™? P£"C™"' Л°™ка *м°™-
„„„„и Полпобнег- ,™ ™ . возм°жнь1х правдоподобных расширений из базы
[тоиге.гку,Т9Р86, ™ ТеМЫ РаССМ01Ре"Ы В Раб°- »*« и Criscuo.0, .98.) и
Наконец, существует способ иемоиотоиных рассуждений „а основе множественного
наследования. Упомянутый выше Петр (хороший студент и любитель вечеринок) мог
наследовать лишь одно из множества свойств. Поскольку он - хороший студент, то,
вероятно, ои окончит ВУЗ. Но он может наследовать и другое свойство (в данном случае
частично противоречащее первому) - быть любителем вечеринок. Следовательно, ои мо-
жет и не окончить ВУЗ.
Важной проблемой, с которой сталкиваются системы немонотонного рассуждения,
является эффективная проверка множества заключений в свете изменяющихся
предположений. Например, если для вывода s используется предикат г, то отмена г исключает
также s, а равно и любое другое заключение, использующее s. Если отсутствует
независимый вывод s, s должно быть исключено из списка корректных утверждений.
Реализация этого процесса в худшем случае требует пересчета всех заключений при каждом
изменении предположений. Представляемые ниже системы поддержки истинности
обеспечивают механизм для поддержки непротиворечивости базы знаний.
8.1.2. Системы поддержки истинности
Система поддержки истинности (СПИ) может использоваться для защиты
логической целостности заключений системы вывода. Как отмечалось в предыдущем разделе,
всякий раз, когда изменяются предположения в базе знаний, необходимо заново
проверить все заключения. Системы поддержки рассуждений решают эту проблему,
пересматривая заключения в свете новых предположений.
Один из способов решения этой проблемы обеспечивает алгоритм возврата, впервые
предложенный в подразделе 3.2.2. Возврат к предыдущему состоянию является
систематическим методом для исследования всех альтернатив в точках ветвления при решении задач
иа основе поиска. Однако существенным недостатком такого алгоритма поиска является
способ систематического выхода из тупиков пространства состояний и просмотра
последних вариантов переходов. Этот подход иногда называется хронологически» возвратам к
предыдущему состоянию. Алгоритм хронологических возвратов систематически проверяет
все альтернативы в пространстве, однако способ реализации этого механизма является
затратным по времени, неэффективным, а при очень большом пространстве - бесполезным.
В процессе поиска желательно отступить назад прямо в точку пространства, где
возникла проблема, и откорректировать решение в этом состоянии. Этот подход называется
возвратом с учетом зависшюстей. Рассмотрим пример немонотонного рассуждения.
Нам необходимо прийти к заключению р. которое мы не можем вывести прямо. Однако
существует правдоподобное предположение с, которое, будучи "™нны"; П^В0Я"Т "£
Таким образом, предполагая , истинным, мы выводим р. Прол—,^-сужден- „ на
основе истинности р выводим г и .. Двигаясь еше дальше, уже без У™*^*™,
Дим истинность г ни. И. наконец, доказываем, что прежнее предположение , является
ложным. Что делать в даииой ситуации?
Глава 8. Рассуждения в условиях неопределенности
331
, монологическими возвратами должен пройти все шаги paccy*^.
Алгоритм поиска с хроно ^ ^^ зависимостей обеспечивает переход „е„0
ния в обратном порядке, в J" цивой „„формации, а именно — к первому предпо
средственно к источнику_"Р над0 ДВ11П1ТЬСЯ вперед, отменяя истинность Р, г и s B
fi „™нности Q. д иогуг ли f и s 6ыть выведеиь, независимо от р „ „. То
" к ™ пл*> пппппження. не означает, что они нр ..„-_
ложению
это же время можно пр к ЬН0Г0 предположения, не означает, что они не м01ут
6Гть°ГоГ::ГоЫор- И. наконец, так как , „ , были выведены без р, , „^
ПеРдГ„Тп1ГванНияНв"истеме рассуждения алгоритма возврата с учетом зависимостей
необходимо выполнить следующие действия.
, Связать с каждым выполняемым заключением его обоснование. Это обоснование
описывает процесс вывода данного заключения. Обоснование должно содержал,
все факты, правила и предположения, используемые для получения заключения.
2 Обеспечить механизм нахождения множества ложных предположений в рамках
обоснования, которое привело к противоречию.
3. Отменить ложные предположения.
4. Создать механизм, отслеживающий отмененные предположения и отменяющий
все заключения, которые используют в своих обоснованиях отмененные ложные
предположения.
Конечно, отмененные заключения не обязательно являются ложными, так что
необходимо перепроверить, могут ли они быть выведены независимо от отмененных
предпосылок. Ниже приводится два метода построения систем возврата с учетом зависимостей.
В [Doyle, 1979] описана одна из первых систем поддержки истинности, названная
системой поддержки истинности с учетом обоснования (justification based truth maintenance
system), или СПИО. Джон Дойл (Jon Doyle) был первым исследователем, который явно
отделил систему поддержки истинности, сеть предположений и их обоснования от системы
рассуждений, действующей в некоторой предметной области. Результатом этого
разделения является то, что СПИО взаимодействует с решателем задач (возможно, системой
автоматического доказательства теорем), получая информацию о новых предположениях и
обоснованиях и, в свою очередь, поставляя решателю задач информацию о
предположениях, которые должны быть достоверными с учетом существуюших обоснований.
СПИО выполняет трн основные операции. Первая — проверка сети обоснований. Эту
проверку может инициировать решатель задач с помощью запросов вида: "Должен ли я
доверять предположению р? Почему я должен доверять предположению pi Какие
предположения лежат в основе р?'\
*™!,ТЙ 0ПеРаЦ"£Й СПИ° ЯВЛЯСГСЯ "°лификация сети зависимостей на основе ин-
!°?„Г ПОСТавляемои Р^телем задач. Модификация подразумевает введение новых
обГ„ТпрелГ™""- т" УСТраНе""С ^посылок, дополнение противоречий .
™Z~Z7™2Jl~u операцией спио явл*етсяадаптаЦ1И сет,оп:
рация адаптации „J, Р Да пРоисх»Дит изменение сети зависимостей. One
обГновГиямТ "ереСМа1Т™а« •« предположения в соответствии с существующими
мод^„Г:„ер!Г;'мС™ «°;СТРУ,-,РУеМ ПР°^ ^ зависимостей. Рассмотрим
предикатом „ читается 'а Р'„™1Й " n°W=*<= 8.L1, который помещается перед
тается как „е противоречит". Например,
Часть III. Представление и разум в ракурсе искусственного интеллекта
Wparty_person(Y) -» „0ц study hard\Y)) ay-"ard<x>
goodsfudenf(daWd)
Поместим это множество предположений в сеть обоснований
В СПИО каждый предикат, представляющий предположение, связывается е двумя
другими множествами предположений. Первое множество, помеченное на рис. 8 I
меткой IN, является множеством предположений, которые должны быть достоверными для
рассматриваемого предположения. Второе множество OUT является множеством
предположении, которые не должны быть истинными для рассматриваемого предположения.
На рис. 8.1 представлено обоснование предиката study_hard(davidu выведенного из
предоставленных выше предикатов. Обозначения на рис. 8.1 адаптированы из работы
[Goodwin, 1982] и объясняются на рис. 8.2. Предпосылки обоснований помечаются в
соответствии с рис. 8.2, а, а комбинации предположений, приводящих к заключению, обо-
оияцяются в соответствии с. пне Я1 й
значаются в соответствии с рнс. 8.2, б
J *■( good_student{dBvKf)
OUT
[J) >-( рагГу_рег50п(У) ^-
Puc. 8.1. Сеть обоснований утверждения о том, что Давид учится
прилежно
D—О
Рис. 8.2. Обоснование предпосылки и конъюнкция двух
предположений а и not(b). доказывающих с [Goodwin, I9821
Из информации, приведенной на рис. 8.1. решатель задач может заключить, что
study_hard(daWd) истинно, так как предпосылка good_student(david) считается
истинной и совместимой с фактом, что хорошие студенты прилежно учатся. К тому же в
этом примере нет информации о том, что Давид не учится прилежно.
Добавим предпосылку partyjersonidavid). Это дополнение позволяет вывести
not(study hard(dawd)), и предпосылка study.Hardldawd) больше не поддерживается.
Обоснования для этой новой ситуации отражены на рис. 8.3. Обратите внимание на мет-
ки IN и OUT
Как свидетельствуют рнс. 8.1 и 8.3, в СПИО предикатные отношения явно не
выражаются через начальное множество предположений. СПИО - это тресте, ее*
позволяющая рассматривать лишь отношен.» между атомарными предположениями и их
отрицаниями и ишользующая эти данные для подтверждения предполож ни , .Полное
, „.тппя (VX л v —* и т.д.) используется в самом
множество предикатных связей и схе■"»££££ 1978) „ [Martins „ Shap.ro. 1988).
решателе задач. В системах, описанных в [МсАпеми, .»/<>, .
СПИО и решатель задач объединены в рамках обшего представления.
Глава 8. Рассуждения в условиях неопределенности
ИР1И
Fuc S ? Новая разметка информации,
приведенной на рис. 8.1, связанная с новой предпосылкой
pany_person{david)
СПИО описывает лишь зависимости между предположениями, но не содержимое
этих предположений. Поэтому предположения заменяются идентификаторами, часто
имеющими вид л„ л,, .... которые ассоциируются с объектами (узлами) сети. Тогда
алгебра множеств IN и OUT позволяет СПИО рассуждать о поддержке предположений.
Итак, СПИО работает со множествами узлов и обоснований. Узлы означают
предположения, а обоснования поддерживают их. С узлами ассоциированы метки Ш
и OUT, указывающие статус предположения для данного узла. Мы можем
рассуждать о поддержке любого узла посредством отнесеиня его ко множествам IN и OUT
других узлов, составляющих их обоснования. Первичными операциями алгебры
СПИО являются операторы проверки, модификации и адаптации, указанные выше.
И, наконец, поскольку проверка обоснования производится путем обратного
просмотра связей самой сети обоснований — это пример возврата с учетом
зависимостей. Для получения более полной информации об этом подходе в СПИО читайте
[Doyle, 1983] или [Reinfrank, 1989].
Другим типом системы поддержки истинности является система поддержки
истинности на основе предположений (СПИП). Термин "на основе предположений" впервые
был введен в работе (deKleer, 1984], хотя подобные идеи можно отыскать и в [Martins и
Shapiro, 1983]. В этих системах для узлов сети не используются метки IN и OUT. Узлы
скорее являются множествами предпосылок (предположений), лежащих в основе их
вывода. В [deKleer, 1984] также учитывается различие между узлами-предпосылками,
являющимися истинными везде, и узлами, которые могут описывать предположения
решателя задач, которые позже могут быть отменены.
Прглгмущество СПИП по отношению к СПИО состоит в дополнительной гибкости,
которую обеспечивает СПИП. работая со множеством возможных состояний предположений,
пометив предположения с помощью множеств предпосылок, при которых оии истинны, по-
ньГ co™Z"°e С°ТЯ"Ие пРедположе"и« (в СПИО все узлы IN), а скорее ряд возмож-
Гличнш „„„Гест °Р ВССХ П0ДМН<ЖС™. поддерживающих предпосылки. Создание
^"',"™ предположений „ли возможных миров позволяет сравнивать ре-
ГбГлятьсяТ их "Г РМНЫХ Пр™°™л<^ обнаруживать противореча и
К недостаткам СПИП отнеся „СГЧНВаеТ Сушеств°ва™ Различных решений задачи.
которые сами являются немонот„ни "°CTb г,Редстав™"и" множества предпосылок,
Взаимодействие между СПИП " упРавлення ими <= помощью решателя задач,
ме СПИО. Оно основано на о " решателем за«ач реализовано аналогично
естественное различие состоит в ™РаТ°раХ пРОЙеР«и, модификации и адаптации.
Бдения, а есть подмножества потен"' ЧТ° " СПИП иет единого состояния предположе-
мальные множества ппеиппги„ЦИаЛЬНЫХ пРе«посылок. Цель СПИП — иайти мп""-
"Редпосылок, достаточные дл, поддержки каждого узла. Эп.
;Т"'"' ПреАстав"е"ие и разум в ракурсе искусстве„„0го интеллекта
вычисления производятся путем распространения н кпмй„и,,„
с меток предпосылок. ранения н комбинирования меток, начиная
Ниже детально описывается пример из [Martins, 1992]. Предположим что существует
с„ь ПСПИ, представленная на рис. 8.4. В этой сети л п п „ „ существует
*-w „ к "н LeTH ль пъ л4 и п5 являются предпосыл-
ками. которые по предположению являются истинными. Сеть зависимостей отражает тот
факт, что с помощью посылок л, и л2 выводится п,. с помощью л, и л4 выводится л, с
помощью л, и л5 выводится п6, и, наконец, с помощью л6 выводится л7.
Рис. 8.4. Разметка узлов в сети зависимостей ПСПИ
На рис. 8.5 представлена решетка зависимостей предпосылок (подмножество/
супермножество), показанных на рис. 8.4. Эта решетка подмножеств обеспечивает
хороший способ визуализации пространства комбинаций предпосылок. Если
некоторые предпосылки вызывают подозрение, СПИП сможет определить, как они
соотносятся с другими предпосылками подмножеств. Например, узел л3 на рис. 8.4
поддерживается всеми множествами предпосылок, которые находятся выше {л,, nj в
решетке на рис. 8.5.
Механизм рассуждения СПИП избавляется от противоречий путем удаления из узлов
тех множеств предпосылок, которые являются несовместимыми. Предположим,
например, что необходимо проверить рассуждения, представленные на рис. 8.4. в связи с
противоречивостью узла л3. Поскольку меткой л3 является множество (л,, nj. это
множество предпосылок определяется как противоречивое. Когда эта противоречие
обнаруживается, все множества предпосылок, относящиеся к супермиожеству (л,, nj.
помечаются как противоречивые и удаляются из сети зависимостей. В этой ситуации
должна быть удалена одна из возможных меток, ведущих к л,. Полное описание
алгоритма устранения противоречий можно иайти в [deKleer, 1986].
Существует несколько других важных подходов к рассуждениям с помощью СПИ.
Логические систры поддержки истинности (ЛСПГО строятся на результатах работы
[McAllester 1978] В ЛСПИ отношения между предположениями представляются с
помощью выражений (дизъюнктов), которые можно использовать для вывода значении нс-
тинности соответствующих предложений. Другой подход- .ехашам Р°^д™"» ™
основе множественной достоверности (МДР) - подобен механизму ракуждени
СПИП за исключением того, что решатель задач и система ™^P^J^™"° ™^
динены в одну систему МДР основывается на логическом языке SWM'. «питающем
состояния знаний Каждое состояние знаний описывается парой д^крипторов^п вы ,
отражает базу знаний, а второй - набор множеств в этой базе знанит, ^^оцессе
торых являются несовместимыми. Алгоритмы проверки на несовместимость в процессе
Рассуждений можно найти в |Martins, 1992].
Глава 8. Рассуждения в условиях неопределенности
335
Рис 8.5. Решетка предпосылок сети, показанной на рис. 8.4. Множества в
рамках со скругленными углами определяют иерархию несовместимости
[Martins. 1997]
8.1.3. Логики, основанные на минимальных моделях
В предыдущих разделах мы расширили логику с помощью нескольких модальных
операторов, которые были специально разработаны для рассуждений об обычных
состояниях мира. Это позволяет ослабить требования к полноте наших знаний о мире.
Модальные операторы появились вследствие необходимости создания более гибкого и
изменчивого описания мира. В этом разделе представляются логики, специально
разработанные для рассуждения в двух ситуациях: когда множество утверждений описывая
лишь истинные положения, и когда из-за природы решаемой задачи множества
предположении являются истинными в большинстве случаев. В первой ситуации используется
предположение о замкнутости мира, во пор,*-ограничения. Эти подходы часто иа-
жыт рассуждениями на минимальных моделях (reasoning over minimum models).
твоп^-УтЫВаЛ0СЬ " РШДеЛе2Х модыш читается интерпретация, которая уд°вж-
^ZZcZTu^ Предикатньк выражений S для всех значений переменных. Суше«-
ZL какГГ °"реДеЛе"ИЙ мт™°»-»°й "одели. Автор определяет минимальную »о-
~Г/Г1? тт0Р°й "е ^™°Ует подмоделей, удовлетворяющих м*****
выражении S при всех значениях переменных
Дикатов. Напоимег, „„■ Р чествует (потенциально) бесконечное числе, ПР
Например, для описания ситуаций в задаче о миссионерах и каннибала*
336
Представление и разум в ракурсе искусственного ингелл^3
(раздел 14.10, упражнение 7) можно испольэо»»,-.. и»„™
„ и„гле следующие- fii-m-™ „„ "Пользовать неограниченное число предикатов, в
том числе следующие, берега реки находятся достаточно близко друг от друга ветер и
течение являются несущественными факторами и т л П™ ™ „
р д- иРи определении задачи мы
довольно экономны в своих описаниях. Мы иепши.™..* „„„,! j.
димые для решения задачи предикаты ИСП°Л"уеМ ™ШЬ информативные и нсобхо-
Предположение о замкнутости мира основывается на минимальной модели мира.
Используются только предикаты, необходимые для решения. Предположение
замкнутости влияет на семантику отрицания в рассуждении. Например, если мы хотим
определить, является ли студент членом группы, то можем просмотреть список (базу данных)
этой группы. Коль скоро студент явно не помещен в эту базу данных (минимальная
модель), он не является членом класса. Аналогично, если необходимо узнать, существует
ли авиасообщение между двумя городами, необходимо просмотреть список всех рейсов.
Если прямой рейс туда не помещен, то он не существует.
Предположение о замкнутости мира сводится к следующему. Если вычислительная
система не может сделать заключения об истинности Р(Х), то истинно ло((р(Х)). Как
будет показано в разделе 12.4. на предположении о замкнутости мира строится вывод в
системе PROLOG. В разделе 12.4 при использовании минимальных моделей неявно
учитываются три предположения (аксиомы). Этими аксиомами являются уникальность имен,
замкнутость мира и замкнутость предметной области. Уникальность имен означает, что все
атомы с различными именами являются различными. Замкнутость мира приводит к тому, что
экземплярами отношешш являются лишь те, которые выведены из имеющихся выражений
(дизъюнктов). Замкнутость предметной области означает, что атомарными предложениями
в предметной области являются только те. которые принадлежат модели. Если эти три
предположения подтверждаются, минимальная модель является полной логической
спецификацией. В противном случае требуется алгоритм поддержки истинности.
Если для использования предположения о замкнутости мира требуется, чтобы были
определены все предикаты, составляющие модель, то для алгебры ограничений
[McCarthy, 1980], [Lifschitz. 19S4|, [McCarthy, 1986] необходимо, чтобы были
определены только предикаты, существенные для решения задачи. В алгебре ограничений в
систему добавляются аксиомы, определяюшие минимальную интерпретацию на предикатах
нз базы знаний. Эти "метапредикаты" (предикаты над предикатами утверждеюш задачи)
описывают способ интерпретации конкретных предикатов. Таким образом, они
определяют границы (или ограничивают) возможные интерпретации предикатов.
В работе [McCarthy, 1980] идея ограничения используется в задаче о миссионерах и
каннибалах. Для решения этой задачи необходимо разработать последовательность
ходов (по переправе лодки через реку) для шести символов при множестве ограничении. В
[McCarthy 1980] приводится большое число абсурдных ситуаций, которые вполне могли
быть использованы при формулировке задачи. Некоторые из них, такие как фактор
ветра, уже были упомянуты в этом разделе. Несмотря на то что человек рассматривает эти
ситуации как абсурдные, соответствующие рассуждения не столь очев.циы. Аксиомы
ограничений, которые Мак-Карти (McCarthy) предлагает Добавить в описание задачи,
позволяют точно ограничить множество предикатов.
В качестве другого примера ограничений рассмотрим предикатное выражение из
объектно-ориентированной спецификации рассуждений на основе здравого смысла (раздел 8 5).
VX ЫгсЦХ) л not (abnorma/(X)) -» ftes(X).
где bird — птица
Глава 8. Рассуждения в условиях неопределенности
337
метиться в рассуждениях, в которых одним из свойств пти
Это выражение может^встр юнавдст ^дикат abnormal (аномальный)? То, что
цы является flies (летает). q ^ она мертва? Спецификация предиката
птица— пингвин, у нес пен
аЬполта/принципи№НОН«юмож"с ^ множество метаправил, в рамках „с
В алгебре ограничении система генерации предикатов для некого
леиия "Р-«-™В^ГОс ^Гп; в,, обеспечивает наименьшее расширение дляо"
рой предметной области. С, сте^ пр ^^ ^^ предшложений ^
Sine оФ„ ГрГ и'знГ из предметной области „,„ о предикате Р. то р можно
считать^минимизированным в том смысле, что минимально возможное количество ато-
мовТ удовлетворяющее р(а,), является также совместимым с Мр) и К. Знание „ира к
вместе' с Alp) и схемой ограничения используются для вывода заключении в стандарт,
„ом „счислении предикатов первого порядка. Эти заключения затем добавляются в сие-
тему предположений В.
Допустим, для мира блоков из раздела 5.4 имеется выражение
isblocklA) л Isblock(B) л IsblockiC).
утверждающее, что А, В и С являются блоками. Ограничение предиката isblock
приводит к утверждению
VX(isblocklX) <- ((X=/t) v (X=8)v (Х=С))).
Это выражение означает, что блоками являются только А, В и С, т.е. только те объекты,
которые считаются блоками согласно предикату isblock. Подобным образом предикат
isblock{A) v isblock(B)
может быть ограничен утверждением
VX(/sd/ock(X) <- ((XM)v (X=S))).
Более подробная информация об использовании схемы аксиом для вывода результатов
содержится в [McCarthy, 1980] (раздел 4).
Использование ограничений для таких операторов, как abnormal, аналогично
предположению о замкнутости мира, так как допустимы только те связывания переменных,
которые может поддерживать abnormal. Алгебра ограничений, однако, позволяет
расширить процесс рассуждений посредством предикатного представления. Если имеется
™o6nIP М0ЖН° огРаничить ™6° предикат р, либо о, либо оба сразу. Та-
i отличие от предположения
замкнутости мира, алгебра ограничений г
То"Гпо "и?03"0*""6 СВЯЗЬШаШЯ пеР^»„ь,х через набор предикатов.
Nils™ ,9871 й! Р"У№1" °бЛаСТИ Л0ГИК" °Т<шичений можно найти в [Genesereth ..
™еТчеч„„П оГ„,ченнеоГтаТ """^ ' "^ **«***■ 19^ Т™ в« "№
каты „их возможные Гем, K°™a Мин"мальная м0Д^ь описывает отдельные предн-
™ приведен в работе (Perils Tg'ssi "' ВСЮ nPe"Me™W> класть. Другой важный резуль-
ствии знаний у отдельного агента ЛаСН° К0Т0Р0" возможны рассуждения об отсут-
8Лк!;!гественное покрь,тие и логи— Нунция
К-ак отмечалось во введении к зтой .
ваются правила типа р=0 „ * Главе' ПРН абдуктивных рассуждениях рассматри-
ч. которых о является обоснованным предположением. Тре-
аСТЬ'"' Првдстав™ние и разум в ракурсе искусственного интеллекта
буется найти пример истинности преликатя л дк-
,„„„и„, „, „„„то „„ еднката р. Абдуктивные рассуждения не являются
традпц..оннь™и^„х часто называют обоснованием нашуншего объяснения данных о. В
этом разделе детально рассматриваете, процесс генерации объяснений в области абдук-
тивного вывода. Mjr
В дополнение к уже представленным методам абдуктивных рассуждений исследователи
ИИ используют также множественное покрытие и логический анализ. Подход к абдукции
„а основе множественного покрытия объясняет принятие некоторого предположен™ в
рамках некоторой поясняющей гипотезы тем, что это единственный способ обоснован™
необъяснимого множества фактов. Основанный на логике подход к абдукции описывает
правила вывода для абдукции вместе с определением допустимых форм их использования.
В рамках множественного покрытия абдуктивное объяснение определяется как покрытие
предикатов, описывающих наблюдения, с помощью предикатов, описываюплгх гипотезы. В
работе [Reggia и др., 1983] описывается покрытие, основанное на бинарном причинном
отношении Я, где Я является подмножеством множества (ГипотеэыхНаблюдения).
Таким образом, абдуктивным объяснением множества наблюдений S2 является множество
гипотез S1, достаточное для объяснен™ S2. Оптимальным является минимальное
покрытие множества S2. Слабость этого подхода заключается в том. что он сводит
объяснение к простому списку гипотез S1. В ситуациях, где существуют взаимосвязанные или
взаимодействующие причины, или где требуется понимание структуры или
последовательности причинных взаимодействий, модель множественного покрытия является неадекватной.
Логические подходы к абдукции основаны на более сложной модели объяснения. В
работе [Levesque, 1989] абдуктивным объяснением некоторого ранее необъясненного
множества наблюдений О считается минимальное множество пшотез Н, совместимых с
исходными знаниями агента К. Из гипотез Н и исходных знаний К должны следовать
наблюдения О. Более формально
abduce{K,0) = Н тогда и только тогда, когда
а) из К не следует О,
б) из НиК следует О,
в) НиК не противоречиво,
г) не существует подмножества Н, обладающего свойствами 1. 2 н 3.
Отметим, что в общем случае для данного множества наблюдений О может
существовать несколько множеств гипотез или потенциальных объяснений.
Логическое определение абдуктивного объяснен™ обеспечивает соответствующий
механизм получения объяснения в контексте системы баз знаний. Если из поясняющих
гипотез должны следовать наблюден™ О, то для построен™ полного объяснения нужно
рассуждать в обратном направлении от О. Как было показано в разделах 3.3 и 6.2, можно начать
с конъюнктивных компонентов О и проводить рассужден™ от заключении к антецедентам.
Этот подход, основанный на построении обратной цепочки вывода, также кажется
естественным, так как условия, поддерживающие этот обратный процесс, вероятно, можно рас-
сматриватъ как причинные законы, играющие основную роль, каковую играют причинные
знан™ в конструировании объяснении. Модель является удобной, поскольку она напоминает
хорошо знакомые исследователям ИИ обратный вывод и вычислительные модели дедукции.
Существуют также интеллектуальные способы нахождения полного множества аб-
дуктпвных объяснений. Системы поддержки истинности, основанные иа
предположениях (СГШП) ([deKleer, 19S6], подраздел 7.2.3), реализуют алгоритм вычисления мини-
Глава 8 Рассуждения в условиях неопределенности
339
„„„лепжки- множества высказывании (не аксиом), из которых ло-
мальных множеств поддер ие Все возможные индуктивные объяснения множе-
гическн следует данное пред ^^_ декартов0 произведение множеств поддержки
ства наблюдений гфедсташ,яь ^ ^^ логнческой абдукции, ей присущи два
Несмотря на "Р0"0^ высокм вь1Чнслительная сложность и семантическая сла-
взаимосвязанных недич ■ .„„„, установлено, что сложность задач абдукции
6ост, В ^^TZ^Z множеств поддержки ШИП. Стандартное Z2Z
аналогична сложноет^ ^^ 1ИЯ1, NP-еложной, основывается „а существо-
ГииТрГеров задач с экспоненциальным числом решений. Авторы не рассматривают
вопрос о потенциальной сложности ряда задач, сводяэту проблему к нахождению мень-
шего множества NP-сложных решений. Для заданной базы знании хорновских
выражений (см раздел 12 2) авторы приводят алгоритм нахождения единственного объяснения
порядка СЦк'п), где X - число пропозициональных переменных, а л - число вхождений
литералов. Однако, если ввести ограничение на типы искомых объяснений, задача снова
становится NP-сложной даже для хорновских дизъюнктов.
Одним из интересных результатов работы [Selman н Levesque, 1990] является тот
факт, что добааление определенных типов целей или ограничений в задачу абдукции
действительно значительно усложняет вычисление. С точки зрения решения задач
человеком эта дополнительная сложность удивляет — для человека добавление
дополнительных ограничений на поиск объяснений упрощает задачу. Причина усложнения задачи в
логической модели абдукции заключается в том, что добавление ограничений приводит к
появлению дополнительных дизъюнктов задачи, а не к модификации структуры задачи,
упрощающей вывод решения.
Поиск объяснения в логической модели можно описать как задачу нахождения
множества гипотез с определенными логическими свойствами. Эти свойства, включая
совместимость с исходными знаниями и выводимость того, что должно быть объяснено,
предназначены для накопления необходимых условий объяснений, т.е. минимальных
условий, которым должны удовлетворять объясняющие гипотезы, претендующие на роль
абдуктивных объяснений.
Одной из простых стратегий получения качественных объяснений является
определение абдуктивного множества фактов, т.е. множества дизъюнктов, из которого должны
выоираться гипотезы-кандидаты. Это множество дизъюнктов позволяет заранее
ограничить поиск теми факторами, которые потенциально могут играть существенную роль в
выбранной области. Другой стратегией является добавление критерия отбора для оценки
и выоора объяснений. Были предложены различные стратегии отбора, включая мти-
'Г™„ТЬ„""°ЖеС'"М' С0ГЛаСН° ЭТ0Й с,Татег™ из »ух согласованных множеств пред-
просто™„ТвсГ МШ"мальном* "• ™у, которое содержится в другом. Критерий
Г„™^епТвГнчТ ^!Г°Н0МНЬВ,.М"0Ж-™ ™"°-, т.е. ™их, Горые содержат
> бКр™еы'окк"„аТЬ"ОСТН " ПР°СТ0Т'" М0ЖН0
приводит к усечению ^^'KS"'TemJ'mKU'u,WOQ™ множества практически
па бритвы Оккама. К сож^и"™' ™Ж"° Рас«атривать как реализацию принци-
Ме™™"Р.0.В!РеННЫХП1'едпол№™»й (Levesque, 1989].
ожно рассматт.
объясне"нм Уявляюш11еПсРя°ГРаНСТВа "°"CKa- Ег0 пРи«енениё'лишГ1кгаючас7ф|1нальнь1е
себе критерий простоты тоУ"ермножествам« ДРУ™х существующих объяснений. Сам по
сконструировать примеры Гк Да6Т СОШ'ительные преимущества при поиске. Несложно
тез, является более предиочтИтТОРЬ,Х °бьяснсн"е. требующее большего множества гипо-
Действительно сложные ппичи"" П° сРавна"«° е некоторым простым множеством-
причинные механизмы, как правило, требуют большего количс-
Часть III. Представление и разум в ракурсе искусственного интеллекта
ства гипотез, однако абдукция таких мтиш„АП г
"* механизмов может быть хорошо обоснованной
особенно если присутствуют определенные ключ™.. ,„„ хоР°шо оооснованнои,
проверенные с помощью наблюдения. "' MeMCH™ ЭТ°Г° »ем™3»' У*°
Интереснымн являются и два следующих механизма выбора объяснения,
принимающие во внимание как свойства множества гипотез, так и свойства процедуры
доказательства. Первый - абдукция „а основе стоимости - сводится к оценке стоимости
потенциальных гипотез и правил. Общая стоимость объяснения вычисляется как сумма общей
стоимости и правил, используемых для абдукции. Затем конкурирующие множества
гипотез сравниваются по стоимости. Одной из естественных семантик, которые могут быть
добавлены к этой схеме, является вероятностная семантика [Charniak и Shimony, 1990]
(раздел 13.4). Чем выше стоимость гипотезы, тем ниже вероятность событий; чем выше
стоимость правил, тем менее вероятны причинные механизмы. Метрики, основанные на
стоимости, можно использовать в сочетании с алгоритмами поиска наименьшей
стоимости, такими как поиск до первого наилучшего совпадения (см. главу 4), значительно
уменьшающими вычислительную сложность задачи.
Второй механизм — выбор на основе когерентности — применяют в том случае, когда
необходимо объяснить не простое высказывание, а множество высказываний. В работе [Ng н
Моопеу, 1990] доказано, что метрика когерентности лучше метрики простоты для выбора
объяснений при анализе естественно-языковых текстов. Авторы определяют когерентность
как свойство графа доказательства. Более когерентными считаются объяснения с большим
количеством связей между парами наблюдений и меньшим числом непересекающихся
разбиений. Критерий когерентности основан на эвристическом предположении о том. является
ли предмет объяснения единственным событием или действием с различными аспектами.
Обоснование метрики когерентности в задачах понимания естественного языка строится на
"принципе красноречия", который говорит о том, что речь оратора должна быть связной и
предметной [Gnce, 1975]. Не трудно распространить этот подход на другие ситуации.
Например, в задаче диагностию! все наблюдения рассматриваются в комплексе, поскольку
предполагается, что они являются проявлениями одной и той же неисправности.
В разделе 8.1 мы рассмотрели расширения традиционной логики, поддерживающие
рассуждения с неопределенными или недостающими данными. Ниже будут описаны не-
логнческие подходы к рассуждениям в ситуациях неопределенности, в том числе Стэнд-
фордская алгебра фактора уверенности, рассуждения с использованием нечетких
множеств и теории обоснования Демпстера-Шафера.
8.2. Абдукция: альтернативы логическому подходу
Логические подходы, описанные в разделе 8.1, являются громоздкими и вычислительно
сложными, особенно при их использовании в экспертных системах. В качестве альтернативы
в некоторых ранн.гх экспертных системах (например PROSPECTOR) была сделана попытка
применить для абдуктивного вывода байесовские методы (раздел S3). Однако .грнменнмость
этого подхода ограничивается предположен,.*™ о независимости, непрерывности
обновления статистических данных и сложностью вычислений для поддержки стохастического
вывода. Альтернативное решение было использовано в Стэндфорде для разработки раншгх
экспертных систем в том числе MYCIN [Buchanan и Shorthffe, 1984]. , t , „„
п ,„„,„-t,,4(vkiix знаний человек-эксперт может дать адек-
При рассуждениях на основе эвристических знании -.w r ,,,.„„„.„„, ,.
г г j-^y „-,.,. ^..птченпя Пюдп оценивают заключение с
ватные и полезные оценки достоверности заключения, -jiuj..
Глава 8. Рассуждения в условиях неопределенности
341
аминов как "весьма вероятно", "маловероятно , почти навер„,ка,
помощью таких терминов к ициенты" „е основаны на тщательном вероятност-
„ли "возможно . Ли весов эвристякамн. выведенными из опыта рассуждений 0
„ом анализе. Они сами являю™ ^ Р^^ ^ методолопш абдуктивного вывода-
предметной области. »М • на основе факгора уверенности, нечеткие рас.
SS^SS* В разделе 8.3 представлены стохастические под.
ходы к описанию неопределенностей.
8.2.1. Неточный вывод на основе фактора уверенности
Оюндфордская „торги, фактора уверенности основывается „а ряде наблюдений.
Во-первых в традиционной теории вероятностей сумма вероятностей отношения „ его
отрицания должна равняться единице. Однако нередки ситуации, при которых человек-
эксперт, оценив вероятность (достоверность) некоторого отношения значением 0.7,
полагает, что отношение истинно, и вовсе не учитывает, что оно может быть ложным. Еще
одно предположение, подкрепляющее теорию фактора уверенности, состоит в том, что
знание самих правил намного важнее, чем знание алгебры для вычисления нх
достоверности. Мера уверенности (или доверия) — это неформальная оценка, которую человек-
эксперт добавляет к заключению, например: "вероятно, это так", "почти наверняка, это
так" или "это совершенно невероятно".
Стэндфордская теория фактора уверенности вводит некоторые простые
предположения о мере доверия и предлагает правила для объединения свидетельств при выводе
заключений. Первым допущением является разделение меры доверия и недоверия ("за" и
"против") для каждого отношения.
Пусть МВ{Н\ Е) — мера уверенности в гипотезе Н при заданном свидетельстве Е.
Обозначим через MD(H\E) меру недостоверности гипотезы Н при заданном
свидетельстве Е.
Тогда:
1 > МВ{Н\Е) > 0, еслиМО(Н|Е) = 0,
или
1 > MD(H|E) > 0, если МВ[Н\Е)=0.
Эти две меры накладывают ограничения друг на друга, так как заданной считается часть
свидетельства в пользу данной гипотезы, либо против нее. В этом состоит важное различие
между алгеорои уверенности и теорией вероятности. Если связь между мерами доверия и
недостоверности установлена, их можно снова объединить следующим образом.
CF(H|E) = MB(H|E)-MD(H|E).
^о^^^сТГГ™ °F ШЗШУ faC,°r) K ' УСИЛИ8аеТСЯ Д0МР"е К
что доказательств I ~~ ™ отРи«а™<;- Близость значения CF к 0 означает,
сбалансн^Г Я"ЗУ ™°№ И ПР°™ "" <™ш»м «ало, либо эти свидетельства
ределенно^значениеТГгТ" ^r "mm' °"Н сопоста-вляют с каждым правилом оп-
Меры уверенности позволяю^» отРажает нх уверенность в надежности правила,
вариации мерь, доверия o^nJ реГ7ЛИР0вать производительность системы, хотя слабые
роль меры доверия подтвео™ Т° ВЛИШ°Т "а °6щук> Результативность. Эта вторая
наилучшей гарантией KoppeZocr,, „Г™°' ""• "Т° "знани<=- оила". Другими словами,
РР ктности диагностики является целостность самих знаний.
Часть |||. Представление и разум в ракурсе искусственного интеллекта
Предпосылка каждого правила состоит из ояпа А»™
.онкции и дизъюнкции. При использовании nrjonwT св»™ных операплями конъ-
торь, доверия, связанные с каждым условн!п■, ™ "РШт° У4"™™™» Ф»-
р°уРдовсрияРвсей пред„осьшке^едующГ„орХмД1,ОСЬШКИ' ^ '"^^ """^^ "*
Для предпосылок Р\ и Р2
СЯР1 and Р2) = M/N(CF(P1), CF(P2))
н
Cf(P1 orP2) = MAX(CF(P\), CF(P2)).
Для получения фактора уверенности в заключении правила объединенный фактор
уверенности в предпосылках CF, полученный с помощью приведенных выше правил
умножается на CF самого правила.
Рассмотрим, например, следующее правило базы знаний
(Р1 and Р2) or РЗ -» fl1(0,7)andfl2(0,3),
где Р1, Р2 н РЗ — предпосылки, а Я1 и Я2 — заключения правила с фактором доверия
CF, равным 0,7 и 0,3 соответственно. Эти числа добавляются к правилу при его
разработке и представляют уверенность эксперта в выводе, если все предпосылки известны с
полной определенностью. Если в процессе выполнения программы для PI, P2 и РЗ
получены значения CF, равные 0,6, 0,4 и 0.2 соответственно, то в данном случае Я1 и Я2
следует учитывать с факторами доверия CF, равными 0,28 и 0,12 соответственно. Ниже
приводятся вычисления для этого примера.
CF(Pt{0,6) алс/Р2(0,4)) = МЩ0.6, 0,4) = 0,4
CF((0,4) огРЗ(0,2)) = ШХ(0,4; 0,2) = 0,4
Значение CF для Я1 в описании правила равно 0,7, так что Я1 добавляется ко
множеству конкретных знаний о данной ситуации со значением CF= (0,7) "(0,4) = 0,28.
Значение CF для Я2 в общем правиле равно 0,3, так что Я2 добавляется ко множеству
знаний о данной ситуации со значением CF (0.3) * (0.4) = 0,12.
Требуется определить еще одну метрику. Как объединить несколько значений CF,
если два или более правил приводят к одному и тому же результату Я? Правило для этого
случая отражает аналогию алгебры достоверности с теорией вероятности. Меры доверия
прн объединении независимых свидетельств перемножаются. Многократно используя
это правило, можно объединять результаты любого количества правил, используемых
Для определения результата Я. Если CF( P1) представляет фактор доверия результату Я. а
ранее не использованное правило приводит к результату Я (снова) со значением СЯЯ-).
то новое значение CF результата Я вычисляется следующим образом:
CF(fl1) + CF(fl2) - (СР(Я1)-СЯЯ2)).
если CFffll) и CF(Я2) положительны.
СР(Я1) + CF(Я2) + (CF(fl1) * СЯЯ2)),
если CF(fll) и CF( Я2) отрицательны и
CF(fl1) + CF(P2)
1-M/N(|CF(fl1)|,|CF(fl2)|)
во всех остальных случаях, где |Х| - абсолютное значение X.
Глава 8. Рассуждения в условиях неопределенности
ит, эти комбинационные уравнения имеют другие По
Кроме легкости вычислен.< е фактора CF. вычисленное согласно этому
лезные свойства. Во-первых. ( ^ { Во_вторых, в результате объединения
правилу, всегда будет лежат ащаются, что тоже является положительным
противоположные зна,енИ" „ ова„„а« мера CF является монотонно возрастаю,
моментом. И, наконец, ко г „„кой-то мере и следовало ожидать для обобщен
Шей (убывающей) функцией, что в какой още„.
„ого свидетельства ^„дфордской алгебры описывает человеческую
Итак, мера >™Р~ „^^ояхностной меры. Как указывалось в подраздГ
ле^ТГХ —ЕоГком подходе, если А, В » С вл.тяют на О, то „ри рассу.
жд нии о D и" бходимо выделить и скомбинировать все априорные н апостер„„рные в,
Гтности включая\<D). П0\А). РР\В). РЮ\С), ПА\0). Подход, основанный „а
стэндфордском факторе уверенностн. позволяет специалисту по знан.гям описать все эти
_вяз„ одним фактором CF доверия правилу, т.е. ,f A and В and С then DlCF).^
простая алгебра лучше отражает способ мышления человека-эксперта.
Теория фактора уверенностн может быть подвергнута критике как
необоснованная. Несмотря на то что она определяется в рамках формальной алгебры, значение
меры доверия не так строго обосновано, как в теории вероятностей. Однако теория
фактора уверенности не пытается строить алгебру для "корректного" рассуждения.
Она обеспечивает компромисс, позволяющий экспертной системе объединять
свидетельства по мере решения задачи. Эти меры являются эвристическими в том
смысле, что уверенность эксперта в результатах является неполной, эвристической и
неформальной. В системе MYCIN факторы CF используются при эвристическом
поиске для установки приоритетов целей и определения точки отсечения, после которой
цель не должна более рассматриваться. Но, несмотря на использование факторов CF
для поддержки выполнения программы н сбора информации, производительность
программы определяется качеством правил.
8.2.2. Рассуждения с нечеткими множествами
Традиционная формальная логика основывается на двух предположениях. Первое
связано с установлением принадлежности— для любого элемента и множества,
принадлежащего некоторому универсуму, элемент является либо членом множества,
либо членом дополнения множества. Второе предположение основано на законе не-
кпючент третьего (the law of excluded middle), утверждающем, что элемент не мо-
*!и„°Г„°ВРеМеН110 пР"надле™ множеству и его дополнению. Оба этих предполо-
точки зпе„„?ЮТСЯ " те°Р"" "e4™'KUV тожеств (fuzzy set theory) Лофтн Заде. С
иионн„3ГлГ„кНи1еГаГГ™ ГЖСТВа " 3аК°НЬ' РаССУЖДеН"Й В "аМКаХ ТРаЯ""
стейТвГетс^^пТ"''6 *"* ^^ Ш3] ««"'орется в том, что теория вероятно-
не подходит для Г'Т "Нструментам Д"» измерения случайности информации, но
кающая при испп„„' "" СМЫСЛа "нФ°Р"ации. В самом деле, путаница,
возникнем ясности („еоп°ГН" СЛ°В " *Ра3 ест«™е""ото языка, связана скорее с отсут-
точкой для анал", а "Р, f ЛеН"°СТЬ)' ЧСМ с0 слУ"ай„остью. Это является критической
достоверности ппшкк.тп структИ> и играет важную роль для определения меры
"редукционных „рав„я. д,, 1пмерен^ неРопрсдслсинРости заде пр№
'"' Предатав"ение и разум в ракурсе искусственного интеллекта
„агает теорию возможностей, в то время как т-пп„.
делить меру случайности. ория вероятностей позволяет опре-
Теория Заде дает количественное выпажен»» „™
W принадлежности множеству, котор^ГжТпп^маГ *" ЭТ°Г° """"^ ФУ"К"
вале между 0 н 1. Понятие нечетког!7,н0жеа™7гпГ 'Г""*™ Г™"" " ""IeP"
дуюшим образом: пусть S - множество aT"™JентГ" """' 6bm°™CaH° СЛе"
„иожество F множества S определяется фуикц^еГппии™ ™ тож™"™ «*
.■степень" принадлежности s к F ^ принадлежности mFis), задающей
На рис. 8.6 представлен стандартный пример нечеткого множества, где S-
множество положительных чисел, a F- нечотое подмножество S, называемое множеством
малых чисел. Приведенные ниже различные числовые значения могут иметь распределе-
иие "возможности определяющее их "нечеткую принадлежность" множеству малых
чисел: mF(l) = 1,0, mF(2) = 1,0, mF(3) = 0,9, mF(4)= 0,8 mF(50) = 0001 и тд
Для описания принадлежности положительного числа X множеству малых чисел
создается распределение mF возможности для всего множества положительных чисел S.
Теория нечетких множеств связана не с созданием этих распределений, а скорее с
правилами вычисления комбинированных возможностей на выражениях, содержащих
нечеткие переменные. Таким образом, она включает правила сочетания мер
возможности для выражений, содержащих нечеткие переменные. Законы изменения меры
возможности для операций or, and н not над этими выражениями напоминают
соответствующие соотношения из стэндфордской алгебры фактора уверенности (см.
подраздел 8.2.1).
Для нечеткого множества, представленного множеством малых чисел на рис. 8.6,
каждое число принадлежит этому множеству с соответствующей мерой достоверности. В
традиционной логике "четких" множеств достоверность того, что элемент принадлежит
множеству, равна либо 1, либо 0. На рис. 8.7 представлена функция принадлежности
множествам понятий "низкие, средние н высокие мужчины". Отметим, что любой
элемент может принадлежать более чем одному множеству. Например, мужчина ростом
5'10" принадлежит как множеству средних, так и множеству высоких мужчин.
средний высокий
Рис. S.6. Нечеткое .множество, представ- Рис. 8.7. Нечеткие множества,
представляющее "ма.1ые цечые чиаа " зяющие низких, средних и высоких .щжчт
Далее приводятся правила для сочетания н передачи нечетких мер для задачи,
ставшей уже классической в литературе по нечетким множествам, — задачи >тгравления
перевернутым маятником. На рис. 8.8 представлен перевернутый маятник, который
необходимо удерживать в вертикальном положении. Положение маятника регулируется
посредством перемещения основания системы в направлении отклонения маятника и
Действием силы тяжести. Детерминированный способ решения задачи стабшивацни
маятника в состоянии равновесия может быть описан с помощью набора
дифференциальных уравнении [Ross 1995]. Преимущество нечеткого подхода к управлению мая™.ко-
аоп системой состоит в том. что можно описать алгоритм эффективного управления
системой в реальном времени. Этот алгоритм управления приводится ниже.
Глава 8. Рассуждения в условиях неопределенности
345
„.. маятника, рассматривая ее в двухмерном пространст.
Упростим задачу стабилизации м ^^ значений контроллера используются две
ве Как показано на рис. 8.8, в кач отклонения „аятника от вертикали в, а вторая -
измеряемые величины', первая У т. Обе эти величины положительны в правом
скорость de/dt. с которой движет ^ значения подаются на вход нечеткого кон-
квадранте и отрицательны в лев_ системы. Выходом котроллера являются величина
троллера на каждой итерации р снстемы. Команды по перемещению с указанием
„ направление „еремешения °«» е маят„ика.
его направления обеспечивают сохранение р
Рис. S.S. Перевернутый
маятник и входные значения 9 и dB/dt
Для объяснения работы нечеткого контроллера опишем процесс решения задачи на
основе нечетких множеств. Данные, описывающие состояние маятника (6 и de/dt),
интерпретируются как нечеткие меры (рис. 8.9). которые используются во множестве
нечетких правил. Этот шаг может быть очень эффективно реализован за счет
использования нечеткой ассоциативной матрицы (НАМ) (fuzzy associative matrix), показанной на
рис. 8.12. В НАМ отношения вход-выход кодируются напрямую. Правила не
объединяются, как при традиционном решении задач на основе правил. Все применимые правила
активизируются, а затем их результаты объединяются. Общий результат обычно задается
областью пространства нечетких выходных параметров (рис. 8.10), который затем
подвергается дефаззификации для получения "четкого" управляющего воздействия.
Заметим, что и входные, и выходные значения контроллера являются "четкими" значениями.
Они представляют точные показания некоторого монитора на входах и точные команды
управления на выходе.
Опишем нечеткие области входных значений, 9 и с/8/Л. В этом примере для ряда
нечетких областей входных значений ситуация упрощена, но показан полный цикл
применения правил и получения результата контроллера. Диапазон входных значений 9 (от -2
до +2 радиан) разделяется на три области: область отрицательных чисел N (Negative).
окрестность нуля Z (Zero) и область положительных чисел Р (Positive) (рис. 8.9, а). На
рис. 8.9, 6 представлены трн области, на которые разбивается диапазон изменения (от-5
Н™»°,пВ ССКУ"ДУ) ВТ0Р0Г° ВХ0ДН0Г0 значе™я «/Л: N. Р и Z.
«ое NB meJta в°ГвЛе"Ы подмножа™ ™*°Д"ь.х значений: большое отрицав
ffosUivenбLn Е)' °трицапш™°' N (Negative), нулевое Z (Zero), положительное ?
~itr;::roro^B„(+p2Tl,ve Bis)'Ве™ -напрзвлсннс пер
• Представление и разум „ ракурсе искусственного интелле^
Рис. 8.9. Нечеткие области для входных значений в (а) и dQ/dt (б)
Рис. S.I0. Нечеткие области изменения .ыюдного значения, отражающие перемещение
основания маятника
Предположим, сначала контроллеру передаются значения в--1 ■ dS^^Ha
рис. 8.1, иллюстрируется процесс *^2~*Z"^™™
нос значение можно отнести к двумнечетким «£££•» * „^ £,* прннадле-
области нуля и области положительнычисел сосгаа а ннаа ф^
жит области N с мерой 0,8 и Z с мерой 0Л_ Ш рис. 8 1 jc ^ ^ e ^ ^ ^
нечеткой ассоциативной матрицы для этой змач* ^^ ^
ны в первом столбце, а для de/dt или X, --в ■ерхн,^ ^ }>J „ р
ния представлены в правом нижнем квадранте матрицы п t
Глава 8. Рассуждения в условиях неопределенности
347
N НдМ возвращает значение Z. После этого
необ.
х,[01 = 1
N
*
jjj^
i i i~~"-~~~
0,Г~"~~-~.
0.2 ^^
-3 -2-10 1
I
2
I
3
I
4
P
£
,
x,(0) = -4
б
Рис. 8.11. Фаззификация входных значений Х) = 1, х-> - -4
х1
р
2
N
Р
РВ
Р
г
z
р
г
N
N
Z
N
NB
Рис. 8.12. Нечеткая ассоциативная
матрица (НАМ) для задачи
стабилизации перевернутого маятника. Входные
значения указаны в левом столбце и
верхней строке
bxoLZTJT*' П0СК°ЛЬКУ ВХ°Д"Ь,е значеиия относятся к двум нечетким областям
объГдГенТпТаГ™' Ж°Ьыт"° ПрИМеНЯТЬ 4<™PC "P»"™- *» отмечалось вь,ш=.
рГфаГоГ Z """" НСЧеТКИХ СИСТСМ «нается аналогично стэидфордской алгеб-
еслир„;г гГжГст™ком6инаиин прмм™-гсбр- -ч"ик рассужде::
правил,берется ГнТ„° " ^ пРелпос"™« вязаны конъюнкцией, в качестве меры
в качестве мерь, итт1 г, МСР' " меРы ДВУ* предпосылок связаны дизъюнкии •
Р "равила берется максимум из этих мер.
Часть III. Представление и разум в ракурсе искусственного инте.
,ллекта
В нашем примере вес пары связаны конъюнкт,™ ™
берется минимум их мер: конъюнкцией, так что в качестве меры правило
IF х, = Рandx2= ZTHEN и = р
m/n(0.5; 0,2) = 0,2 Р
IFx, = РandX,= NTHEN u = Z
m/n(0,5; 0,8)=0,5Z
IFx, = Zandx; = ZTHEN u=Z
m/n(0,5; 0,21=0,2 Z
IFx, = Z and x,= N THEN u = N
m/n(0,5; 0,8)=0,5N
Затем полученные результаты объединяются (выполняется дефаззификация). В нашем
примере объединяются две области, показанные на рис. 8.10, полученные в результате
активизации этого множества правил. Существует ряд методов дефаззификации [Ross, 1995].
Выберем один из наиболее известных — метод центра тяжести. При использовании этого
метода окончательным выходным значением контроллера, применяемым к маятнику, является
значение центра тяжести объединения областей выходных значений. На рис. 8.13
представлены и само объединение и центр тяжести объединения областей. Этот выход или результат
применяется к системе, снова измеряются значения q и dq/dt, и цикл управления повторяется.
N Z
/ Лс
,/ , ,/ , \
р
1.0
/ , \, , \
-16 -12 -8-4 0
IV
Рис 8 11 Нечеткие коисетентъ, (а) и т объединения 16).
Центр „игжести объединения (-2) является четки.» .шодо»
При описании систем нечетких рассуждений мы не рассматривали ряд вопросов,
включая колебания в процессе сходимости и выбор оптимальных "ОэфФ"^'™ с не
четкие системы предоставляют инженерам мощный инструментарий дл, борьбы с
неточностью измерений, особенно в области управления.
Глава 8. Рассуждения в условиях неопределенности
349
g 2 3 Теория доказательства Демпстера-Шафера
' „ мы описывали методы, которые рассматривают отдельные вь,сказь,ва1|и
Д° С"Х " ненки степени достоверности. Одним из ограничении вероятностные ""«
,, числовые оценки чт0 они используют единственную колич^ Д"
^ К "еГ:«", с" -жег оказаться очень сложной задачей. Это ^
ВЫЧ11Ы _^ „.ими ппн ОТСУТСТВИИ попжчпгг, „е- п° С
ную меру. в^'';;;'"р"иультата объединена прн отсутствии должного обосвдвГ„С
^сьшоГнГследсванием ограничений эвристических правил и огра„„ченао^
НТл?теоГа™"ныП3Гд"оД. называемый теорией обоснования Делтшера-Щаф
оас~ас' «"°«™ предположений и ставит в соответствие каждому ю Н1)х ,£
Со тньп. интервал доверия (правдоподобия^ которому должна принадлежать „«4
Юности в каждом предположении. Мера доверия обозначается Ье, и изменяете, от
™ что указывает на отсутствие свидетельств в пользу множества предположений до
единицы, означающей определенность. Мера правдоподобия предположения р - р/(р)
определяется следующим образом:
р/(р)= 1 -be/(nof(p)).
Таким образом, правдоподобие также изменяется от нуля до единицы н вычисляется
на основе меры доверия предположению лоГ(р). Если лог(р) вполне обоснованно, то
be/(nof(p))= 1. ар/(Р) равно 0. Единственно возможным значением для ЬеЦр) -аше
является нуль.
Предположим, что существуют две конкурирующие гипотезы л, и л2. Прн отсутствии
информации, поддерживающей эти гипотезы, мера доверия и правдоподобия каждой из
них принадлежат отрезку [0; 1]. По мере накопления информации эти интервалы будут
уменьшаться, а доверие гипотезам — увеличиваться. Согласно байесовскому подходу
(при отсутствии свидетельств) априорные вероятности распределяются поровну между
двумя гипотезами: Р(п,) = 0,5. Подход Демпстера-Шафера также подразумевает это. С
другой стороны, байесовский подход может привести к такой же вероятностной мере независимо
от количества имеющихся данных. Таюш образом, подход Демпстера-Шафера может быть
очень полезен, когда необходимо принимать решение на основе накопленных данных.
Итак, подход Демпстера-Шафера решает проблему измерения достоверности, делал
коренное различие между отсутствием уверенности н незнанием. В теории вероятностей
мы вынуждены выражать степень нашего знания о гипотезе л единствеииым числом
P{h). Проблема такого подхода, по мнению Демпстера-Шафера, заключается в том, что
мы просто не всегда можем зиать значения вероятностей, и поэтому не любой выбор
Р(л) может быть обоснован.
Функция доверия Демпстера-Шафера удовлетворяет аксиомам, которые слабее
аксиом теории вероятности, н сводится к теории вероятности, если все вероятности известны.
Функции доверия позволяют использовать имеющиеся знания для ограничения
вероятностей событий при отсутствии точных значений вероятностей.
Теория Демпстера-Шафера основана на двух идеях. Первая- получение степени
доверия для данной задачи из субъективных свидетельств о связанных с ней проблемах,
и вторая - использование правша объединения свидетельств если они основаны на «е-
оом7гГХ TZ^° ПраВНЛ° "^'"«ния первоначально было предложено ДемпсИ-
стеоа^Т '' ДМее Ч*»™"™ неформальный пример рассуждения №"*
SS^S^r^T. Гвило Деш,™ра 0бъсдинения свидстельств"'
jioi и правила к более жизненной ситуации.
350
!■ Представление и разум в ракурсе искусственного инт<
Рассмотрим субъективные вероятности прав
лиссы. Вероятность того, что ей можно верить Я"°љ свиД«ельств моей полруги Мс-
зя. — 0,1. Предположим, Мелисса говорит что' "f™"™" °'9' а т°г°. что верить нель-
„ие истинно, если Мелиссе можно верить 'но оно и.К°""ьютер сл°мался. Это утвержде-
нельзя. Таким образом, утверждение Мелиссы что °- ™ь"° ложн°. если ей верить
вается с достоверностью 0.9, а то что он исп "°" К0МПЬКУТСР сломался, обосновы-
„ость 0,0 не означает уверенности в том что к™!™ ДОС™еРютю °.°- Достовср-
6ы вероятность 0.0. Это просто означает ™ Z^Z^u"""^ "" ™ ""^
р„ть, что мой компьютер Несд0мМм.Мера„рГпГГ:Гзт„^^ИТ-В£"
р/<комльк,гер_Сло„ался) =, - Ьв„По,(темльюгеР_сломался))=1 - 0 0
„ли 1,0, и моя мера доверия Мелиссе есть [0,9; 1,0]. Заметим, что еще нет основания
считать, что мои компьютер не сломался.
Далее рассмотрим правило Демлсгера для объединения свидетельств. Допустим мой
друг Билл также говорит, что мой компьютер сломался. Предположим, вероятность того
что Биллу можно верить, составляет 0,8, а что верить нельзя— 0,2 Я также должен
предположить, что утверждения Билла и Мелиссы о моем компьютере независимы друг
от друга, т.е. они вызваны разными причинами. Событие 'Билл заслуживает доверия"
также должно быть независимо от события, определяющего степень доверия Мелиссе.
Вероятность правдивости и Билла и Мелиссы равна произведению та вероятностей —
0,72; вероятность неправдивости обоих —0,02. Вероятность того, что верить можно по
крайней мере одному из них — 1-0,02 = 0,98. Поскольку оба они говорят, что мой
компьютер сломался, и вероятность того, что по крайней мере один из них заслуживает
доверия, равна 0,98, можно установить степень достоверности события поломки
компьютера [0,98; 1,0].
Предположим, Билл и Мелисса расходятся в том, что мой компьютер сломался:
Мелисса утверждает, что он сломался, а Билл говорит, что нет. В этом случае они оба
одновременно не могут говорить правду и не могут оба вызывать доверие. Либо обоим им
нельзя верить, либо нельзя верить одному из них. Априорная вероятность того, что
можно верить лишь Мелиссе, составляет 0,9*(Т - 0,8) = 0,18. а того, что верить можно только
Биллу, — 0,8*(1 - 0,9) = 0,08. а того, что ни одному из них верить нельзя. — 0,2*0.1 =
0,02. Имея вероятность того, что по крайней мере одному из друзей верить нельзя. (0.18
+ 0 08 + 0,02) = 0 28, можно вычислить апостериорную вероятность того, что верить
можно лишь Мелиссе, и мой компьютер сломан - 0,18/0,28 = 0.643: или апостериорную
вероятность того, что прав лишь Билл, и мой компьютер исправен — 0.OS/O.28 - 0.286.
При этом было использовано правило Демлсгера для объединения свидетельств. После
заявлен™ Мелиссы и Билла о том, что компьютер сломан, мы рассмотрели три
гипотетические ситуации, связанные с поломкой: Билл)' и Мелиссе можно верить; Биллу можно
верить, а Мелиссе нет; Мелиссе можно верить, а Биллу нет. Доверие результату анализ,
возможных гипотетических сценариев составила 0.98. При втором и™"^™
Демпстера свидетельства расходились. Снова были проаналтгзировань, все вшмо^кные сн -
нарии. Исключалась единственная сигуашья. связанная с тем. что ■Ч"»*™*'»'£
г - w „„mm. я Биллл- нет, либо можно верить biLXT>. а не ме-
ким образом, либо Мелиссе можно верить, а ьилл> ни. "плШ1... составила
' ,rt них Суммарная достоверность поломки составила
лиссе; либо нельзя верить никому из них. ^У"^" " г Kiiini> — (Р86
0,6, Достоверность tL. что «"^^Х^-^! мера^
Поскольку правдоподобие поломки составляет i и» >
верия принадлежит интервалу [0,28; 0,714].
Глава 8. Рассуждения в условиях неопределенности
351
можно получить меру доверия для одной
Используя nPaBH"°*""w,3 вероятности для другой (Является ли свидсте^"
(Бы„ ли компьютер сломан. нео6ход„„о предположить, что задачи,^
адежным?). Для "Р™^, ^зависимы, но эта независимость лишь а„риор£"
которых известны "Р'»тк0 конфликт между различными атомами обоснования
Она исчезает, когда возни стера_Шафера в каждой ситуации приводит к ое
Использование подход « ^ Во.первых, мы разделяем неопределенность сиг»!"
шению двух связанных пр ^^ Во-вторых, применяем правило Дем„с ' "
ции на априорно неза предположим опять-таки, что Билл и Мелисса неза'
Эти две задачи юаим° , чт0 0ни были уверены в том, что мой компьютер сд„
висимо друг от друга ■ ^ вызвал маСтера для проверки компьютера, и что оба
„а„. Предположим такж^ ^^^ этого. и,.м этого общег0 со6ыт„„
(„ Билл, и Мелисса' степени доверия. Однако, явно учитывая возможность
: больше сравниваю
а, можи
правдивость Мелиссы, правдивость Билла
можем больше ср ^^ получить три независимых атомарных обоснования,
приглашения мае р^. див0(.ть Билла „ основание для присутствия мастера, ко.
затем объединить с помощью правила Демпстера.
торые можно з ^ исч<.рпЫвающее множество взаимоисключающих гипотез.
06о?наСмЛе°гЖо"через О. Наша цель - приписать некоторую меру доверия гп различи^
Обозначим / тжестю 0; т „ногда называют вероятностной функцией чуестт-
подмножествам Z множества (
тюъиости (probability density
держивают не все
function) подмножества О. Реально свидетельства под-
элементы О. В основном поддерживаются различные подмноже-
ства Z множества О. Более того, поскольку элементы О предполагаются
взаимоисключающими, доказательство в пользу одного из них может оказывать влияние на
доверие другим элементам. В чисто байесовской системе (раздел 8.3) обе эти
ситуации разрешаются за счет рассмотрения всех комбинаций условных вероятностей. В
системе Демпстера-Шафера эти взаимодействия учитываются напрямую путем
непосредственного манипулирования множествами гипотез. Величина m„{Z) означает
степень доверия, связанную с подмножеством пшотез Z, а п представляет число
источников свидетельств. Правило Демпстера имеет вид
mJZ):
S»nr.z"V;(X)m„_,(y)
1-^п»,,т„.г(Х)тл.,(У)'
Например, мерой доверия m„(Z) гипотезе Z для л=3 источников свидетельств сч
ется сумма произведений гипотетических мер доверия т |(Х) и т2{ Y), совместное вх
дение которых поддерживает Z, т.е. Хп Y=Z. Как видно из примера, знаменатель правВ
Демпстера допускает пустое пересечение X и У, а сумма мер доверия должна быть и г
мализована.
Применим правило Демпстера к задаче медицинской диагностики. Предположим,
рассматривается область О, содержащая четыре гипотезы: пациент был без сознания (•
у него был грипп (F), мигрень (Н) или менингит (М). Наша задача — связать меры д
рия со множествами гипотез в рамках О. Как отмечалось выше, это именно мно»
гипотез, поскольку они ничем не обоснованы. Например, лихорадка свидетсльс^
пмьзу (C,F,M). Поскольку элементы О трактуются как взаимоисключающие пш
подтверждение „д„„й из „их может влиять т достов ость других. Как уже го >J
ботки °Г" ДемпстеРа-Шафера разрешает взаимодействие посредством прямо"
Для вероятностной функции чувствительности т
значение m(g,) представляет меру доверия кот " ""^ ПОДМНОЖ|:СТВ z множества О
чем сумма всех m{q,) равна 1. Если О содержи°РМ "аЗНача|лся ка*Д°му о, из О. При-
жеств О — это очень много. Проблема улрощается'зТ'*"™' " существУет 2" П°ДМ"°-
жеств недопустимы. Таким образом существует "" Т°Г°' ЧТ° многне т п°Дмно-
значения могут быть проигнорированы И L^™™^ упрощение- и невозможные
Хт(Ч,), где Ч:-множество гипотез, имеюЩиГ„еГтоГВД°ПОДОбИе ° ^ Р"0)='-
отсутствии информации о некоторых гипотезах ™ РУ веРга™°«ь поддержки. При
са диагностики, р« О) = 1.0. ™"Олезах, что чаще всего бывает в начале проще
Предположим, первая часть свидетельства v „
вает IC.FM с вероятностью 0,6. нГовемТоТеовоГ™ "^^ °" ""^^
лишь гипотеза, то m,fC,F,M1=0.6 Ге m (O1-04 л" ? ЛЮЧ"И ""' ЕСШ ЭТ° "СеГ°
доверия. Важно отметить, что m (О) = 0 4 ппед™етос Г°СЯ Р""**"™" "^
F " ' ил представляет оставшуюся часть распределения
достоверности, т.е. все другие возможные мерь, доверия О. а не доетоверн'ость допо.Г-
ния (C,F,M).
Предположим теперь, что мы получили некоторые новые данные для постановки
диагноза. К примеру, у пациента сильная рвота, которая свидетельствует о (С F Н) со
степенью доверия 0,7. Назовем меру доверия этому свидетельству ль. Для нее мы имеем
m2{C,F,H}=0,7 и m2{Q)-0,3. Используем правило Демпстера для объединения этих двух
свидетельств т, и ггь. Пусть X— набор подмножеств О. на котором т, принимает
ненулевые значения, и У- набор подмножеств О, на котором т2 принимает ненулевые
значения. Затем по правилу Демпстера определим объединенную меру доверия т, на
подмножествах Z множества О.
При его применении к диагнозам прежде всего отметим, что не существует пустых
множеств Хп У, так что знаменатель равен 1. Распределение вероятностей т3 приведено в
табл. 8.1.
Таблица 8.1. Использование правила Демпстера объединения свидетельств
tri\ m2 m3
m,{C,F.M)=0,6
m,(O)=0.4
m,(C,F,M)=0,6
m,(O)=0,4
m2(C,F,H)=0,7
m5(C.F,H)=0,7
m,(O|=0.3
m,(O)=0,3
m3(C,F)=0,42
m3{C,F,Hl=0,28
m,(C.F.M)=0,18
m3(Q)=0,12
Четыре множества Z, представляющие все возможные способы пересечения X и У
согласно правилу Демпстера, составляют крайний справа столбец табл. 8.1. Степень
доверия вычисляется перемножением мер достоверности элементов X и У, для которых
заданы т, и Л12. Отметим, что в этом примере каждое множество в Z уникально, что ие
является частым случаем.
Расширим пример, чтобы показать, как в процессе анализа факторизуются пустые
множества достоверности. Предположим, получен новый факт, отражающий результаты
лабораторного анализа, который связан с менингитом. Теперь т,{М\= 0,8 и m,{0)- 0.2.
Чтобы объединить результаты предыдущего анализа т3 с т.для получения т,. можно
использовать формулу Демпстера (табл. S.2).
Часть III. Представление и разум в ракурсе искусственного
интв"лв"
Глава 8. Рассуждения в условиях неопределенности
353
Таблица 8.2. и
|C,f)=0.42
{О)=0,12
(C,f.m=°-28
{C,f,Ml=0,18
(C,f.H|=0,28
C.f.M|=0,18
m4{M)=0,S
ц(М1=0,8
m4(O)=0,2
m4{O)=0,2
m4{M)=0,8
m4(M 1=0.8
m4{Q 1=0.2
m4{O)=0.2
m5{ 1=0,336
m 5 (M) =0,096
m,|C, F)=0,084
ms\ Q )=0,024
m5( 1=0,224
m5(/W)=0,144
m5{C,F,«)=0,0S6
m,(C,F,M)=0,036
„„„«ib поэтому общая вероятность гл5<м, = и,хчи. ^оме lu,„, ь результате перед,,
множеств поз У получается пустое множество {}. Таким образом, знаие,,
Г;: не»: ДеСтера равен . - (0,336 ♦ 0,224) = 1 - 0,56 = 0,44. Окончат^
ZZ» Функции доверия гл5 будут иметь вид
т,(С,г1 =0,191
ms{C,F,/W} =0,082
m5{ ) =0,56
m5{Q) =0,055
ms(M)= 0,545
ms(C,F,H)= 0,127
Во-первых высокая достоверность пустого множества m5 ( } - 0,56 означает
существование конфликта свидетельств на множестве мер доверия т,. Данный пример rami»
ет показать несколько особенностей рассуждения Демпстера-Шафера, поэтому в таив-
тор пожертвовал медицинской согласованностью. Во-вторых, при существовании
больших множеств гипотез, а также сложного множества свидетельств вычисление мер
доверия может оказаться громоздким, хотя, как уже отмечалось, количество
рассуждений все же значительно меньше, чем при использовании байесовского подхода. И
последнее, подход Демпстера-Шафера является очень полезным инструментом, когда
более строгие байесовские рассуждения себя не оправдывают.
Подход Демпстера-Шафера является примером алгебры, поддерживающей в
рассуждении субъективные вероятности, в противоположность объективным вероятностям
еса. В субъективной теории вероятностей мы стронм алгебру рассуждений, часто осла
ляя некоторые ограничения Байеса. Иногда субъективные вероятности лучше отражают
рассуждения эксперта-человека. В последнем разделе главы 8 будут рассмотрены ак-
совские рассуждения, включая использование сетей доверия.
8.3. Стохастический подход к описанию
неопределенности
В рамках теории вероятностей можно определить (зачастую априори) шансы
ления событий. Можно также описать, как комбинации событий влияют друг »» '
летя последние достижения в области теории вероятностен были получены ма«
Г." ™ двад««°™ столетня, включая Фишера, Неймана н Пирсона, попь"^
Т КОПНЯМН чрпп r-n^nviun ярь-Я К грекам, вклю-"" -дп0
коми,.-» „ ~ -""«им, включая Фишера, Неймана н Пирсон». п0ПЬ1Тка дол.*
комбинаторную алгебру ухОДИТ корнямн черсзРсрсдннс века к грекам, «*«££
и др., 1995а]. Теория вероятностей строится
ПооА«™. . п РУ уходит ^Рчямн через средние века к гре
Порфирия и Платона [Glymour и др., 1995о]Р Тс0Ррия вероятностей
Часть III. Представление и разум в ракурсе искусственного и
ложении о том, что, зная частоту насгуплени» rr.fi -
следующих комбинаций событий Напп.ш та°ытии. можно рассуждать о частоте по-
терсе или в игре в покер. Р Р' тжт вь™лить шансы на выигрыш в ло-
СРед?тГ Гп^вьГэГГрГ: =грмадный а™——
„1, как при игре хорошо „ep^ct2 ZiкГмГГлГТ ЖЙ™ ™^
„„„ крупье. В картах, например, следующГ каГ влГг Т ^Г""*™0" поведе-
уже вь,тянутьтх карт. Во-вторых этот „олТп */У«™.«™ от типа колоды и
Spa. Хотя события в мире мо™ не 6ьГс1 P"MeH"M """ °П"СШ™ ""°"мал'>»°г°"
события часто неизвестными! ^ их в аиЗГ'Г "^ШЫ^ ™ "Р«™
и ' и их взаимосвязь. Статистические корреляции явля-
Г" "ТоТ ,ГТ™ "■"""'"""-энного анализа, хотя в работах [оТутпоиг и
Cooper, 1999], [Pearl, 2000] делается попытка связать понятия вероятности и
причинности. Дальнейшее использование вероятностей позволяет вьшвнть возможные
исключения в общих взаимосвязях. Статистический подход группирует все исключения, а затем
использует эту меру для описания исключения общего вида. Другая важная роль
статистики — это основа для индукции и обучения (например, алгоритм ШЗ из раздела 9 3)
При решении задач, основанных на знаниях (глава 7), часто приходится проводить
рассуждения с ограниченными знаниями и неполной информацией. Многие
исследовательские группы направляли свои усилия иа изучение различных форм вероятностных
рассуждений. В этом разделе сначала описывается полный байесовский анализ, а затем
ограниченная форма байесовского вывода, называемая сетям доверия.
8.3.1. Байесовские рассуждения
Байесовские рассуждения основаны на формальной теории вероятностен и
интенсивно используются в некоторых современных областях исследований, включая
распознавание образов и классификацию. Теория Байеса обеспечивает вычисление сложных
вероятностей на основе случайной выборки событий. Например, в рамках простых
вероятностных вычислений можно определить, как карты могут распределяться среди игроков.
Предположим, я — один из четырех игроков в карточной игре, в которой все карты
распределены равномерно. Если у меня нет пиковой дамы, я могу заключить, что
вероятность ее нахождения у каждого из остальных игроков равна 1/3. Аналогично можно
заключить, что вероятность нахождения у каждого из игроков червового туза также
составляет 1/3, и что любой игрок имеет обе карты с вероятностью 1/3*1/3 или 1/9,
предположив, что события получения двух карт являются независимыми.
В математической теории вероятностей отдельные вероятности вычисляются либо
аналитически комбинаторными методами, либо эмпирически. Если известно, что А и В
независимы, вероятность их комбинации вычисляется по следующему правилу:
вероРТносгь(Д&В) = вероягносгьИ) * вероягносгь(В)
ОПРЕДЕЛЕНИЕ
АПРИОРНАЯ ВЕРОЯТНОСТЬ
Априорная вероятность (prior probability), часто называемая безусювной
вероятностью (unconditional probability) события, - это вероятность, присвоенная событию
при отсутствии знания, поддерживающего его наступление. Следовательно, это
вероятность события, предшествующего какой-либо основе. Априорная вероятность со-
бытия обозначается Р(событие).
Глава 8. Рассуждения в условиях неопределенности
АПОСТЕРИОРНАЯВЕРОЯТШСТЬ
.„„ость (posterior probability), часто называемая уатнай „
Anocmepwp^sepo^ собьгтя,- это вероятность события при некото,2°'"*и-
стью (со^'%^терИорнаЯ вероятность обозначается Р( событие |
кос-
„ом основании
ь выпадения двойки или тройки при бросании игр^.
Априорная *£™ мюи10С1е„, деленная на общее число возможных альт"!
та_ это сумма W 6олезни отдельного человека равна чнелу людей г '
т.е. 2/6. Априорная "4»™°^ люд<А намдяш„Хся под наблюдением. С >"«<
заболеванием, дие""о* заболевания d у человека с симптомом s равна-
Апостериорная верииш
P(d|s> = |dns|/|sl.
„„.А™ обозначают чисто элементов множества. В правой части этого v»
"Г^ "дей. .—х как заболевание d, так и симптом .. дел ^
^е^юдей с симптомом ,. Расширим это уравнение
Hd\s) = Hd n s) / P(s)
и получим эквивалентное соотношение для Р( s | d) и Р( d n s):
p(s|d) = P(dns)/P(d),
P(dns) = P(s|d|-P(d).
Подстановка этого результата в соотношение Р(d| s) дает теорему Байеса (для одной
болезни и одного симптома):
P(d|s) = (P(s|d)-P(d))/P(s).
Важной особенностью теоремы Байеса является то, что числа в правой части уравнения
получить легче, чем значение в его левой части. Например, вследствие меньшей популяции
намного легче определить число больных менингитом, имеющих головные боли, чем процент
бо.тьных менингитом ю общего числа страдающих головной болью. Более важной
особенностью теоремы Байеса является то. что для простого случая одной болезни и одного симптома
в вычислениях участвует не очень много чисел. Трудности начинаются, когда мы
рассматриваем комплексные заболевания dm нз области заболеваний D и комплексные симптомы s,
из множества возможных симптомов S. Прн рассмотрении каждой болезни из О и каждого
симптома из S отдельно необходимо собрать н интегрировать тхп измерений. (В
действительности тхл апостериорных вероятностей плюс (т+п) априорных вероятностей)
К сожалению, анатиз при этом становится намного сложнее. До сих пор мы
рассматривали симптомы отдельно. В действительности отдельные симптомы встречаются редко. Нант*
мер, когда врач осматривает пациента, он должен учитывать много различных комбината"
симптомов. Эту ситуацию описывает форма правила Байеса с комплексными симптомами.
P(d|s,& $г &...& 5.) = (P(d)*P(s,& s2b...b sjd)) / P(s& Sj&...& s„).
Для обработки одного заболевания с одним симптомом необходимо лишь mxn «*
£ Z ^(ГГ, Т СИИПТОМ08 =. " »; и болезни d необходимо знать как Р<* * £
приблизительно п' F ™ S СОаержит " симптомов, число таких пар будет "'<"-";,„.
ч^Тото г™ ' * М" 3аХ°™М в°с"°л«оваться правилом Байеса, то прИД*«'
™™Z7JZ?Z7r ТГ* + ("2 вероятностей симптомов, **£
«сойсистеме 2т]21 ^ тхп+п+»> «иняц информации. В Р^Г^о!
Я заболеваниям, и 2000 симптомами -vrn значение ппевышаст 80000W*
Э симптомами это значение превышает о
Часть |||. Представление и разум в ракурсе искусственного инте**
Однако есть некоторая нале»ля ,.,,,
T.e.P(sJs,)=P(B,,.He3a™„„„^3„a4L "Те"3 ™ ** *Ут "—«««•
дицине большинство симптомов ие си"™' нТГ"^ "' " *""'"" " S'' B ""
если десять процентов симптомов зависимы ZZk °ЪШСМт с кашлем" Н° »™
80000000 отношений. зависимы, необходимо рассматривать около
Во многих задачах диагностики поихппитг-о .,..„
ей. когда симптом у пащ.е„тГотТутстГуетТ„а^Г ЛеЛ° ' 01ртит^"ой информаци-
случаях необходимо, чтобы °ТСуТСТВуст (™№V. низкое давление кровн,. В обоих
p(not s) = 1 - P(S) и р(поГ d| s)= , _ p(d| s)
Наконец, следует отметить, что P(s|d) и P(d|s) - это „е одно и то же, и в любой
ситуации эти величины будут „„еть различные значения. Эти отношения „ попытка
избежать циклических рассуждений являются важными при разработке байесовских сетей
доверия (подраздел 8.3.2).
Далее будет представлен один из наиболее важных результатов теории
вероятностей — теорема Банеса в общей форме. Она обеспечивает способ вычисления
вероятности гипотезы Н„ следующей из отдельного основания, если даиы лишь вероятности
основания, следующего из реальных причин (гипотез).
p(4|F)- P(E\H,)-P(HJ
ХР(Е|НЛ-Р(Н»)
где
P(Hjf) — вероятность истинности Н, при заданном основании £7;
Р(Н,) — вероятность истинности Н, вообще;
Р(Е\ HJ — вероятность наблюдения основания, если истинно Н,;
п — число возможных гипотез.
Предположим, необходимо определить вероятность обнаружения меди на основе
пробы грунта. Для этого нужно знать наперед вероятность обнаружения каждого из
множества минералов и вероятность определенного грунта при обнаружении каждого
отдельного минерала. Тогда можно использовгть теорему Байеса для определения
вероятности присутствия меди на основе пробы грунта. Этот подход используется в системе
PROSPECTOR, созданной в Стэндфордском университете и применяемой для
геологоразведки (медн, молибдена и др.). Система PROSPECTOR позволила обнаружить
коммерчески значимые залежи минералов в нескольких местах (Duda и др., 1919а].
Для использования теоремы Байеса существует два главных требования. Первое
заключается в том, что должны быть известны вероятности взаимосвязи основания с различными
гипотезами, а также вероятности взаимосвязи различных частей основания. Второе, и иногда
более трудное в определении, требование заключается в том. что должны быть вычислены все
взаимосвязи между основанием и гипотезами или Р(£| Н.). Вообще и особенно в таких
областях, как медицина, предположение независимости не может быть априори обоснованным.
Последняя проблема, затрудняющая использование сложных байесовских систем,
заключается в переопределении таблицы вероятностей при выявлении новых взаимосвязей
между гипотезами и обоснованиями. В таких активных исследовательских областях, как
медицина, новые открытия осуществляются непрерывно. Для корректности заключении
байесовских рассуждений требуется (постоянное) вычисление полных вероятностей,
включая объединенные вероятности. Во многих областях такой ооширныи сбор данных и
Глава 8. Рассуждения в условиях неопределенности
357
верификация
t возможны, а если hi
и возможны, го стоят очень дорого. Там. где эти
"Редпо-
байесовский подход обеспечивает математически хорошо ^
ложения выполняются, о аотю Большинство областей экспертных систсГ"0'
МШОе ZZ Trl тениям и долж», опираться „а эвристический „„лход. Нол," £
удовлетворяют этим тр „ошные компьютеры не могут использовать 6ай№
сХ™ы"но^
приведем
'йебольшой пр.шер, позволяющий показать, как полный байесовский
ПОДХод
приведем нсиил»- г взаимосвязейгипотезаоснование.
"° ПрГоГоГ «Г"аГмобидь „о скоростной трассе и осознан, что суЩсс,
венно ГГете скорость из-за большого ™™™Z7ZT™*™J.l"b™mch найти
возможное объяснение снижения скорости. Может, ™™™™°*;™™» дороги, Бь[.
езжаетс мимо группы дорожных рабочих в оранжевых комбинезонах, расположившихся
а ашпжя' Возможно, существуют и другие объяснения. Через несколько минут вь, Пр0.
езжаетс мимо группы дорожных рабочих в оранжевых комбинезонах, расположивши
посреди дорога. В этот момент вы решаете, что наилучшим объяснением является ре.
монт дорога И альтернативная гипотеза аварии отбрасывается. Аналогично, если бы
вы увидели впереди "мигалку" автомобиля автоинспекции или скорой помощи, наилуч-
шим объяснением этой ситуации стала бы транспортная авария, позволяющая опросить
версию о ремонте дороги. Отказ от гипотезы вовсе не означает, что она вообще
невозможна. Скорее, в контексте нового основания она имеет намного меньшую вероятность.
На рис. 8.14 представлена байесовская интерпретация этой ситуации. Ремонт дороги
связывается с оранжевылш комбинезонами и замедленным движением. Аналогично
авария связывается с мигалкой и замедленным движением. Далее согласно рис. 8.14
строится объединенное вероятностное распределение для отношения ремонт дороги и
замедленное движение. Упрощенно предположим, что эти переменные могут принимать
значения true (l) или false (f). Вероятностные распределения для этого случал показаны на
рис. 8.15. Отметим, что, если ремонт имеет значение г, замедленное движение
невозможно, а при значении f — возможно. Отметим также, что вероятность того, что дорога
сконструирована как скоростнав С = true, равна 0,5, а вероятность замедленного
передвижения Г = true равна 0,4 (это относится к штату Нью-Мексико).
Рис- 8.14. Байесовское представление
транспортной проблемы с возможными объяснениями
С
Т
р
о.з-
0,2
0,1 -
0.4
Рис. S.1S. Распределение объед,
™ "ерелинных из рис. 8.14
пшенной вероятности
Часть in. ПрвдстаВлвнив и разум а ракурсе искусственного интвлл*»
Далее рассматривается вероятность п*»™™,, л
,,„ Р1Г1 Т\ nr Ptr-,it .,,, Р доРоги ПРИ Условии замедленного деи-
жения - Р( С | Г) от Р( С-, | т= г). Используя упрощенное правило Байееа. получим
Р(С| Т) = P(C=,,T=t)/(P(c=, т=() + P[c,,T,t)) ,0,3/,o,3+0,1)-o,75.
Так что теперь вероятность ремонта дороги при замедленном делении возрастает с
0,5 до 0.75. Аналогично эта вероятность возрастет еще больше при наличии
комбинезонов, позволяющих напрочь отбросить гипотезу аварии
Кроме необходимости знать значение любого из параметров в каждом состоянии
следует учитывать вопросы сложности. Рассмотрим вычисление объединенной
вероятности для всех параметров, показанных на рис. 8.14 (используя топологическую
сортировку неременных).
Р(САВ,Т,/)=Р(С)-р(Л|С)-Р(В|С,Л)-Р(Г|САв)-Р((.|САв.Т).
Это, конечно, общая декомпозиция вероятностных мер. которая всегда истинна.
Стоимость генерации таблицы объединенной вероятности экспоненциально возрастает с
ростом числа параметров. В данном случае требуется таблица размером 25. или 32. Мы
рассматриваем игрушечную проблему лишь с пятью параметрами. Для более интересной
ситуации, скажем, с тридцатью или более параметрами потребуется таблица
объединенной вероятности с биллионом элементов. Байесовские сети доверия позволяют решить
вопросы представления и сложности вычислений.
8.3.2. Байесовские сети доверия
Несмотря на то, что байесовскал теория вероятностей обеспечивает математическую
основу для рассуждений в условиях неопределенности, сложность, возникающая при се
применении к реальным предметным областям, может оказаться недопустимой. К
счастью, мы можем уменьшить эту сложность, сфокусировав поиск на меньшем множестве
наиболее адекватных событии и свидетельств. Подход, называемый байесовскими
сетями доверия fBayesian belief network) [Pearl, 1988], предлагает вычислительную модель
рассуждения с наилучшим объяснением множества данных в контексте ожидаемых
причинных связен в предметной области.
Байесовские сети доверия ослабляют многие ограничения полной байесовской
модели и показывают, как данные из предметной области (или даже отсутствующие данные!)
позволяют разделять и фокусировать рассуждения. Наблюдения показывают, что
модульность предметной области часто позволяет ослабить многие ограничения зависимо-
сти/незавнепмости, требуемые для правила Байсса. В большинстве ситуаций не надо
строить большую таблицу объединенной вероятности, содержащую вероятности всех
возможных комбинаций событий и свидетельств. Человек-эксперт выбирает локальные
явления, которые заведомо связаны друг с другом, и получает вероятности или меры
влияния, которые отражают лишь эти кластеры событий. Эксперты предполагают, что
остальные события или условно независимы, или их корреляции настолько малы, что
ими можно пренебречь.
Рассмотрим снова пример транспортной задачи, показанный на рис. 8.14. Если
предположить, что параметры зависят только от вероятностей их родителей, т.е. допустить,
что при наличии знания о родителях узлы являются независимыми от других
предшественников, то вычисление PICAS, T.L) выполняется следующим образом,-
Р(С,Л.В,Т,и = Р(С)-Р(Л)*Р(В|С)4Р(Т|СЛ)-Р{1.!Л)
Глава 8 Рассуждения в условиях неопределенности
™ топать сделанное нами упрощение, рассмотрим всроят.
Чтобы лучше прояялюстрнро» шн(,ния в п0Следнем уравнении мы ослабили ее до
ность НВ\ С А) из "Рсдащ^еГ° ^„ложени!!. что авария не влияет на ремонт дорог,,
Р(В| С). Это основываем на пр |(е Ш|(яет замедленное движение, но ремонт и
Аналогично на •■оранжевые комопн ^ ^ ^ г| с д 8) Наконец, рЩС.А.В.Т) оелабад.
«мчркя учитываются в П /|U '• дм Р(С,Л,В, Г,/.) теперь имеет всего 20
ется до PHW. ^^Т11пЛбоЯ№ жизненной проблеме, скажем, с 30 перемен
параметров (а не «•"Р ' максимум двух родителей, в распределении 6уде1
„ыми. где ^" ^"^Le состояние имеет трех родителей, в распределении бу.
дГма~«0 «оГ значительно меньше, чем билдион, требуемый для ^
"Т^оГмГбоГГть зависимость узла сети доверия от родительских узлов. Связ„
межГузТми сети доверия представляют условные вероятности причинного влияния. В
рождении эксперта, „спользуюшего причинно-следственный вывод, неявно
предполагается что эти влияния являются направленными, т.е. реализация некоторого события
вызывает другие события в сети. Кроме того, рассуждение причинного влияния не
является цикличным а раз так, воздействие не может вернуться назад, чтобы вызвать себя.
По этим причинам байесовские сети доверия могут быть естественным образом
представлены в виде ациклического направленного графа (АНГ) (подраздел 3.1.1), где лога-
чески последовательные рассуждения отображаются как пути, проходящие через дуги
причина-симптом.
В транспортном примере мы имеем даже более устойчивую ситуацию — здесь нет
ненаправленных циклов. Это позволяет очень просто вычислять вероятностное
распределение в каждом узле. Распределение узлов, не имеющих родителей, находится
непосредственно. Значения узлов-наследников вычисляются на основе вероятностного
распределения каждого из родителей путем соответствующих вычислений по таблицам
условных вероятностей. Это возможно потому, что мы не заботимся о корреляциях между
родителями любого узла (поскольку сеть задается как ациклический направленный
граф). Это обеспечивает естественное абдуктивное отделение, прн котором авария
совсем не коррелирует с наличием "оранжевых комбинезонов" (см. рис. 8.14).
Далее рассмотрим предположение, неявно используемое в рассуждениях многих
экспертов: присутствие или отсутствие данных об области может разделять н фокусировать
поиск объяснений. Этот факт имеет важные комплексные последствия для пространства
поиска. Приведем несколько примеров и концепцию ^отделения (d-separation),
поддерживающую эти интуитивные рассуждения.
Сначала рассмотрим задачу диагностики наличия масла в автомобиле: предположим,
старые поршневые кольца вызывают чрезмерное потребление масла, что, в свою
очередь, приводит к нткому уровню масла. Эта ситуация отображается на рис. 8.16, а, где
вень^™ Г™"1"' К°ЛЬЦа' V ~ ЧР™Ч>"°<= потребление масла и В - низкий ур°-
отюшеГ \2 "С ™М ° "P™"?»™ потреблении масла, мы получаем причинное
ГГ„"1 „Z CIaP'"M" тртж™"» «""«ими и низким уровнем масла. Однако, ес-
Кольца,1„Изк„йуРове„ГаГ::^„г;р;::;;гисывающнестарь,епорш
ннзкиТу^Гнь^Г^ ПОрЩ"еВЬ,е К°ЛЬЩ "^ ".звать как синий выхлоп, «к »
кольца,1_ сиииГвы^п ТГ^Г " ^ ^ * ™ *-"*"* ""^
низкий уровень масла. Не зная, какое значение »«etl
Часть III. Представление и разум в ракурсе искусственного интеллек*
переменная В - true или false, — мы не
хлоп) и В (низкий уровень масла) коррелирован,, ТСЯ ли пеРеменные А (синий аы-
ной V (старые поршневые кольца) означав UTn наличие информации о
переменяет, что эти переменные не корродированы.
Рис. 8.16. Последовательная связь узлов (о}, в
которых влияние распространяется от А к В до тех пор,
пока существует V; расходящаяся связь (6), где
информация распространяется к наследникам V до тех
пор, пока определено значение V; сходящаяся связь (в);
если ничего не известно о V, то его родители
независимы, в противном сяучае между родителями
существует корреляция
И, наконец, если низкий уровень масла вызван либо чрезмерным его потреблением,
либо утечкой, то при наличии данных о низком уровне масла эти две возможные
причины являются коррелированными. Более того, если переменная V (низкий уровень масла)
истинна (рис. 8.16, в), то утечка масла объясняет его чрезмерное потребление. Если же
состояние переменной V (низкий уровень масла) неизвестно, то эти две возможные
причины являются независимыми. В любом случае информация о низком уровне масла
является ключевым элементом в процессе рассуждения. Эта ситуация изображена на
рис. 8.15, в, где переменная А означает чрезмерное потребление масла, В —утечку и V —
низкий уровень масла.
Уточним эти интуитивные представления, определив ^-отделение узлов в сети
доверия [perl, 1988].
ОПРЕДЕЛЕНИЕ
^-ОТДЕЛЕНИЕ
Два узла А и В в ациклическом направленном графе являются d-отделенными, если
все пути между ними блокированы. Путь — это любая непрерывная
последовательность связей на графе (связывающая узлы в любом направлении, например, на
рис. 8.17. 6 путь от А к В). Путь является блокированным, если существует
промежуточный узел V, обладающий одним из следующих свойств:
связь является последовательной иди расходящейся, и состояние V известно;
связь является сходящейся, и ни V, ни любой из наследников V не имеют
обоснования.
Глава 8. Рассуждения в условиях неопределенности
361
™.t последовательных, расходящихся и сходящихся отноц,.
дополнительные примеры № этого pl,cyMKa видно, как d-orasneuu.
кий между У*™" приводятся на рис •
влияет на построение путей ^ ^^ на рис 8 16 по„ажем, как предпол,,.
Перед тем как зак°т" J „решают вычисления условных вероятностей. По за
женил байесовской сети доверия у»г __ „„„„„типстей может »™„
Т Уединенное распределение вероятностей может рассматриваться
' m™;S^--™™<>"^ * Р"С- 8'6' " УСЛ°ВНМ ВСР°ЯТН0СТ1' »» "VT,"
отЛдо1/нот1^до£
кону ьаисса jjiw"- - „„типг-гей На рис. о.»«
■ Р{В\АУ\-
Используем предположение байесовской сети доверил, что условная вероятность „с.
Использ5е.1 Р» вероятностей всех ее предшественников равна yc„oe.
ремсинои пряных »™ ^ лишь дая р0яителей. в ре3ультдте в пР„всде„.
Z ГыГ;—и Ж заменяется „a ПВ| V). поскольку „ являете, иря„Ым ро.
ителем В а А - нет Объединенные вероятностные распредепения для трех сетей,
показанных на рис. 8.16, вычисляются следующим образом.
a)PlA.V.B) = PIA)-PlV\A)-P<B\V),
6)PiV.A.B)'P(V) •P{A\V)-P(B\V).
b)P(A,B,V) = P[A)-PIB) •PiVlA.B).
Как показывает транспортный пример (см. рис. 8.14), в более масштабных
байесовских сетях доверия многие переменные условных вероятностей могут быть исключены.
Это делает сети доверия значительно более простыми в реализации, чем полный
байесовский анализ.
В следующем примере [Pearl, 19881 рассматривается более сложная байесовская сеть.
Как показано на рис. 8.17, переменная season (сезон) определяет вероятность rain (идет
дождь), а также вероятность waler (вода поступает из поливной системы). Переменная Wet
sidewalk (мокрый тротуар) будет коррелировать с дождем или водой из поливной системы.
Наконец, тротуар будет slick (блестящим) в зависимости от того, мокрый он или нет. На
рисунке показаны вероятностные отношения для этой ситуации. Отметим также, что в отличие
от транспортного примера в данном графе имеется ненаправленный цикл.
Теперь зададим вопрос, как может быть описана вероятность мокрого тротуара
Р( WS) Это не может быть сделано так, как было описано выше, т.е. Р( W) - Р( W| S) *
P(S) или P(R) = P(R|S) * P(S). Обе причины WS являются взаимно независимыми,
например: если время года — это лето, то можно использовать как Р( W), так и Р( Я) ■
Таким образом, должны быть вычислены полные корреляции двух переменных, а также и
корреляция с S. В данной ситуации это возможно, но сложность таких вычислений
экспоненциально зависит от числа возможных причин WS. Результаты вычислений
представлены на рис. 8.18. Здесь вычисляется один элемент* При истинных значениях R и »■
для простоты предполагается, что переменная S (время года) может принимать значен.»,
либо ha (теплое), либо cold (холодное).
P(S - оси • рш V,! S = h0'l' РW = М S = hot) +
рис^Т8° пГГм'поГГТ ВЫЧИСЛ"ТЬ 0С™е 3"<™н„я тдблицы,
темы. Такой "м;0э;еС'пДИНеННУЮ ВеР°ЯТН°СТЬ т " В°ДЫ "' "^ -
акроэлемент представляет P((VS) = P[WS | R,W) • Р( Я, W). Эта задача
ЧаСТ" '"■ "РЗД^авлвние „ разум а раКурсе „„усс-твенного интелл^8
решена в рамках приемлемых объемов вычислен -
ем вычислений экспоненциально увеличи.я„ "° ПР0блема состоит в том, что объ-
увеличивастся е ростом числа родителей состояния.
PIR\$) С Я ) Дождь P(tV|S} (tv) ?0да
' .поливная система)
Мокрый тротуар
P(SL|IVS) (SL) Блестнщийтротуар
f
г
г
W
t
1
(
р
■{
PUC.S.17. Прш.ер байесовской сета Ооеерш. где Рис. 8.18. Распределение крайностей
вероятностные 3a.ucu.mcmu указаны рядом с ка- д„ P(WS) как функиия от P(W) a PIP.)
ждш, узлом. Этот пример взят ш [Pearl 1988] „ри заданном „,™™u S. Вынется
влияние х при R=i и W= /
Назовем этот макроэлемент объединенной переменной для вычисления P(WS).
Теперь введем понятие клики, чтобы заменить ограничения АНГ из рис. 8.17
ациклическим деревом клик, которое показано на рис. 8.19. Прямоугольники означают
переменные, выше н ниже которых находятся клики. Размер таблицы, описывающей
передачу параметров через следующую клику, экспоненциально зависит от числа этих
параметров. Необходимо отметить, что в клике должна быть представлена связанная
переменная вместе с ее родителями. Таким образом, при построении сети доверия
(процесс инженерии знаний) необходимо задумываться о количестве родителей
каждого состояния. Как показано на рис. 8.19, б, клики могут пересекаться и передавать
информацию через полное дерево клик, называемое объединенным деревом.
Представим алгоритм создания объединенного дерева на основе сети доверия. Этот алгоритм
разработан в [Lauritzen н Spiegelhalter, 1988J.
1. Для всех узлов сети доверия сделать все направленные связи ненаправленными.
2. Для каждого узла начертить связи между всеми его родителями (штриховая линия
между узлами R и IV на рис. S. 19, б).
3. Просмотреть каждый цикл в результирующем графе длины >3 и добавить
дополнительные связи, ослабляющие этот цикл до дерева. Этот процесс называется
триангуляцией и не является необходимым для примера, показанного на рис. 8.19, б.
4. Сформировать объединенное дерево из результирующих триангулярных структур.
Это делается с помошью выявления максимальных клик (клик, являющихся
полными подграфами, а не подграфами больших клик). Переменные в эти\ кликах
объединяются, и создается результирующее объединенное дерево. В нем
соединяются любые два объединения, содержащих по крайней мере одну общую
переменную, как показано на рис. 8.19, а.
Процесс триангуляции, описанный в п. 3, является критическим, гак как- при распро
странен,,,, „„формации результирующее обьединенное дерево должно иметь
минимально вычислительную стоимость. К сожалению, это решение является NP-сложным. Но.
к счастью, для получения результата часто достаточно применить несложный о.ранн-
Глава 8. Рассуждения в условиях неопределенное.
363
„„•.mcdu таблиц, необходимых для обработки объсд,,,
чснный алгоритм. Отметим «0 1»-* ^^ 2,2.2, 2.2»2 „ 2.2 соотистст„
„сииого дерева, показанного на рис. ^
•снио
Р„с 8 19 Объединенное дерево (а) дм
байесовской вероятностной сети (б). Отмет,ш, что мы
начали конструировать таблицу переходов для
прямоугольника, содержащего Я. W
И наконец, рассмотрим пример сети на рис. 8.17 и вернемся к вопросу d-отделснш,.
Напомним что при наличии некоторой информации d-отдсление позволяет проигнор,,-
ровать при'вычислении вероятностных распределений часть сети доверия.
1. SL d-отделимо от Я. S, W, если известно WS.
2. d-отделение является симметричным, т.е. S также d-отдслпмо (и не является
объяснением Si.) при знании WS.
3. Я и W являются зависимыми вследствие S, но значения S, Я и W являются d-
от деленными.
4. Если известно значение WS, то Я и W не являются d-отделимыми, сели же
значение WS не известно — являются.
5. При заданной цепочке R->WS->Si, если известно WS. то Я и SL являются d-
отделимыми.
Мы должны быть осторожны, если известна информация о наследниках некоторого
состояния. Например, если известно SL, то Я и IV не являются d-отделимымн, поскольку
SL коррелируег с WS, a WS, Я и IV не являются d-отделимыми.
Заключительный комментарий: байесовские сети доверия отражают рассуждения
человека о сложных областях, где некоторые факторы известны и априори связаны с другими
Поскольку рассуждение реализуется при постепенной конкретизации информации,
последующий поиск ограничивается, и в результате оказывается более эффективным. Эта
эффективность поиска сильно контрастирует с представлением (поддерживаемым
применением точного закона Байеса) о том, что добавление информации вызывает экспоненциаль-
"™rw ™1^г™чсских сношений и расширение результирующей области поиска,
vinp^™., , итмов для построения с
вого основания. Автор i
«mi, изложенный в [Ре-.., ,,оо,, а также ме.ид ту .,,
дерево клик, предложенный в работе [Laurintzen и Spiegelhaller. 1988). В работе [Druzdel
—..„„ ,, расширение результирующей области поиска.
Существует ряд алгоритмов для построения сетей доверия и распространения и"Ф°г"
ации при получении нового основания. Автор особенно рекомендует подход. осноЮН-
иыи „а передаче сообщений, изложенный в [Pearl, 1988] а также метод mptW'™"".
364
!■ Представление и разум в ракурсе искусственного интелле
и Henrion, 1993) также представлены алгооитмм ,,п™~
' „с влияния , сети. В работе [Dcchrer, !99б7IуГиГГ Т раС"Р0С11""'С-
л:ст„ого вывода положен алгоритм сегмеиiZZlTj""""^ '""'"" "СР°"Т"
Однако при ™™'И""И ОТСЙ ,ЮВ^ °™<™ «™го „граничении как с точки зре-
„ия инженерии знании гак и,= точки зрения вычислительной сложности [Х,але и др.. 1993).
1UsKey и Mahoney, 19Л[. Эти ограничения мотивированы разнообразием исследований в
иерархических и компонуемых байесовских моделях [Koller и Pfeffer 1997 19981 [Pfeffer и
др., 19W]. 1Х|а"В " ДР-.2000]. Эти новые формализмы моделирования поддерживают
декомпозицию модели подобно объектно-ориентированному проектированию программною
обеспечения. Дальнейшие расширения до полных стохастических моделей Тьюринга
можно найти в [Koller и Pfeffer, 1997|, [Pless и др., 2000]. В работе [Pearl. 20O0] используются
стохастические методы поддержания философской идеи причинности.
Стохастические методы играют важную роль в области искусственного интеллекта,
например, в решении задач с вероятностными агентами [Kosoresow, 1993]. Со
стохастическими методами мы снова встретимся при рассмотрении проблем обучения
(раздел 9.7) и задач понимания естественного языка (глава 13).
8.4. Резюме и дополнительная литература
С самого начала исследований в области искусственною интеллекта существовал
круг ученых, хорошо чувствовавших логику и предлагавших ее расширения,
достаточные для представления интеллекта. Для описания рассуждений в условиях
неопределенности были предложены важные альтернативы исчислению предикатов первого порядка,
1. Многозначные логики расширили лотку путем добавления к стандартным
значениям frue и false таких новых значений истинности, как unknown. Это может
обеспечить механизм для отделения ложных утверждений от утверждений,
истинность которых просто неизвестна.
2. Модальные логики добавляют операторы, которые позволяют решать проблемы,
связанные со знаниями, их достоверностью, необходимостью и возможностью.
В данной главе обсуждались модальные операторы unless и consistent with.
3. Временные логики дают возможность квантифицировать выражения
относительно логики, указывая, например, что выражение всегда истинно или будет истинно
в определенное время в будущем.
4. Логики более высокого порядка. Многие категории знаний включают понятия
более высокого порядка, в которых под знаком квантора могут находиться не
только переменные, но и предикаты. Действительно для работы с этими знаниями
нужны логики более высокого порядка или достаточно логики первого порядка?
Если они нужны, как их описать наилучшим образом?
5. Логические формулировки определений, прототипов и исключений
Исключения часто рассматриваются как необходимая особенность системы определении.
Однако неосторожное использование исключений подрывает семантику
представления. Другим вопросом является различие между определением и прототипом или
описанием типичны, представителей. Какова разница между <~«"»Г"»"
типичного представителя? Как должны быть представлены прототипы? Когда
прототип является более адекватным представлением, чем определение.
365
I
Глава 8. Рассуждения в условиях неопределенности
„ ..« пошке продолжают оставаться важной областью иг.
ЖМГ!^ ШЖ №* .980, ^ .982, [Типте,™^
вании [Мссапп). « j.1 j_ „ост„жения в области систем рассуждений с по,,»
Сушестеуютнлрут еааж^Д^^ ^ ^ ^ (ЛСПИ) ^^ под,
ISLST^J В™ст?«-™- -^ предположениями представляют^ Г
L"^ о'орьш могут быть использованы для вывода значен,,,, истинности „.„^
юнктами, ко р ' ом ЯВЛяется мехтти рассуждении „а основе мпож-Г
*VCW°ZcTowZZZZo^« —™»-V Р-У*>™ий СПИП IdeK,ee,T9 Г
ZZr,Z™"гут 6-„видены ■ Iм-"- " Я»Р*».'»»]. МДР основывает'^
логическом языке SWM*. описывающем состояния знании. Алгоритмы для „р„в<.рк„
„„отиворсчивостн базы знаний в процессе рассуждения приводятся в [Martins, 1991]. Б„.
лее полная информация по алгебре узлов содержится в [Doyle, 1983] т
fReinfrank 1989]. Логика умолчания позволяет рассматривать любую теорему, выведи.
L в „асширснип системы, в качестве аксиомы для дальнейших рассуждений. Эти
Гсы усматриваются в [Rener,. Criscnolo. 1981] и (Tooretzky, 1986].
В области немонотонных рассуждений, логики достоверности и поддержки
истинности кроме оригинальных статей, существует обширная литература [Doyle, 1979]
[Reicer 1985], [deKleer, 1986], [McCarthy. 1980]. Стохастические модели описаны ,'
(Pearl, 1988], (Shafer и Pearl 1990). [Davis, 1990] и многочисленных докладах последних
конференций ААА1 и 1JCAI. Автор рекомендует также энциклопедию искусственного
интеллекта (Shapiro. 1992]. Обширный материал собран в книгах [Josephson и Josephson,
1994] и [Hobbs н Moore, 1985]. Работа (Pearl 2O00] вносит свой вклад в понимание при-
чинно-следственных отношений в мире.
Дальнейшие исследования по ограничениям и минимизации логической модели
можно найти в [Genesereth и Nilsson. 1987], [Lifschitz, 1986] и [McCarthy, 1986]. Важный
вклад в развитие ограниченного вывода вносит работа [Perils, 1988], учитывающая
отсутствие знании у отдельного агента. Важная коллекция статей по немонотонным
системам собрана в книге [Ginsburg, 1987}.
В качестве литературы по нечетким системам мы бы рекомендовали оригинальную
статью [Zadeh, 1983]. Более современные реализации этого подхода можно найти в
работах (Yager и Zadeh, 1994] и [Ross, 1995]. Задача перевернутого маятника, представленная
в подразделе 8.2.2, взята из [Ross, 1995].
Алгоритмы реализации байесовских сетей доверия на основе передачи сообщений
изложены в [Pear], 1988], а метод триангуляции клик (раздел 8.3) изложен в [Lauritzeait
Spiegelhaltei, 1988, Этот алгоритм обсуждается в [Shapiro, 1992]. Введение в
байесовские сети доверия содержится в [van der Gaag, 1996], а обсуждение качественных
вероятностных сетей приводится в [Druzdel, 1996].
Стохастические представления и алгоритмы продолжают оставаться очень
актуальной областью исследований [Xiang и др., 1993], [Laskey и Мапопеу, 1997]. Ограничения
байесовского представления обусловили исследования по иерархическим и компонуе-
МЬ'" °™ге°вс«™ моделям [Koller и Pfeffer, 1997, 1998, [Pfeffer и др.,1999], [Xiang »
др 2ШЦ] Дальнейшее расширение этих результатов до полных моделей Тьюрии"
можно найти в [Pless и др., 2000].
366
I. Представление и разум в ракурсе искусственного интелле*"1
8.5. Упражнения
1. Укажите зри прикладные области, в котооых „. F.
неопределенности. Выберите одну из этих "."""" P^S™5""» » условиях
вывода, отражающих рассуждения в ней ° ЛаС™ " Работайте шесть правил
Z Т^рГой ZZT"- "Р"МСМеМЫС = «-Р»* ™ Реющей „а осно-
А л no«B) => C(0,9)C v D => £(0,75)
F=>/1(0,6)
G => D(0.8)
Система может вывести следующие факты (с заданной достоверностью)
«0,9)
В(-0,8)
G(0.7)
Используйте стэндфордскую алгебру фактора уверенности для определения Е и его
достоверности.
3. Рассмотрите простое MYCIN-подобное правило: it А л (В v С) => D(0,9) л Е(0.75).
Обсудите вопросы, возникающие при работе с такими неопределенностями в
контексте байесовского подхода. Как это правило можно использовать в рассуждениях
Демпстсра-Шафера?
4. Приведите новый пример диагностических рассуждений и используйте уравнение
Демпстера-Шафера из подраздела 8.2.3 для объединения свидетельств, аналогичного
приведенному в табл. 8.1 и 8.2.
5. Используйте схему аксиом, представленную в работе [McCarthy, 1980, раздел 4], для
воссоздания результатов, приведенных в разделе 8.1.3.
6. Создайте сеть рассуждений, подобную представленной на рис. 8.4, и постройте
решетку зависимостей для ее посылок, как это сделано на рис. 8.5.
7. Рассуждения на минимальных моделях являются важными в повседневной жизни
человека. Приведите не менее двух примеров, предполагающих использование
минимальных моделей.
8. Вернитесь к примеру перевернутого маятника из пода 8.2.2. Воспроизведите не
менее двух итераций работы нечеткого контроллера.
9. Напишите программу, реализующую нечеткий контроллер из подраздела 8.2.2.
10. С использованием литературных источников (например [Ross, 1995]) опишите две
области, в которых применимо нечеткое управление. Разработайте множество нечет-
кнх правил для этих областей.
П. Добавьте некоторую новую связь на рис. 8.26. скажем, соединяющую сезон е
тротуаром, и создайте дерево клик для представлен™ этой ситуации. Сопоставьте
сложность этой задачи с той, которая представлена деревом клик на рис. 8.17.
12. Добавьте оценки, необходимые для завершения табл. 8.4.
„. . „ я.ли-овских сетей доверия и примените его к задаче
13. Создайте алгоритм реализации байесовских сиси и г „.„.,_„. пепелачи со-
оз-> можно использовать подход передачи со
скользкого тротуара из подраздела ».-'.- то*™
Глава 8 Рассуждения в условиях неопределенности
- tP,ir1 1988]. или метод триангуляции клик, предложен,,,,,,,
о6ше„ий. .пложенный «jPearbl
„ [Uurilzen и Spiege • я ^ новой области применения (наприм
,4 Создайте граф байесовской годки |ш) а1,шша автомо6и11ьных „^^
медицинской диагност,<ки, d отдСЛСНИЯ „ создайте дерево клик для этой сет,,.
„остей). Обратитесь к при ^ дерев0 для ситуации, показанной на рис. 8 20
15. Создайте дерево клик и оо д е __ всс эт0 МОЖет вызвать
О^'^Гм^по—ьнойоп; ■-—"»»"■ "■"
СОЗДШ..Ч.-Г- землетрясение— ■>' —- тревогу в домс
Ограбление, вандализм й опасности района, где расположен д—
Сушествуеттакже «ера пот. ^ приоедснные в по
Ограолснмс "-"-- потенииальной опасности ра»^. ■ «- н
Существует также м р рдения, приведенные в подразделе
16. Рассмотрите диагностическ, р _ Сопоставьте эти два под
„авьте их в виде байесовской
диагностики.
N ) Качество районе
И ДОМ.
1.2.3,
и пред.
подхода к задаче
Землетрясение
Рис. 8.20. Сеть доверия, иллюстрирующая
вохчожность тревоги доме в зависимости
от различных опасностей
368
Часть III. Представление и разум в ракурсе искусственного инт
Часть IV
Машинное обучение
Точность — это не истина...
— Генри Матисс (Henri Matisse)
Настоящее и будущее являются настоящим с точки зрения будущего и будущим с
точки зрения прошедшего...
— Т. С. Элиот (Т. S.EHot)
...Каждый крупный результат является конечны.» продуктом длинной
последовательности маленьких действий.
— Кристофер Александер (Christopher Alexander)
Символьное, нейросетевое и эмерджентное обучение
В ответ на вопрос о том, какие проявления интеллекта, ™""Z2T™11™
„ее всего компьютеризировать, помимо творческих ™^«°"^™J™nHZ
решений и социальной T^^^^^Z^^ «ьЮ и
языка н способность к обучению. В течение мн°™* 0 й т причин слож-
камнем преткновения для развития »^~°о™2« то, чт/эти облает,
ности и важности исследован,» языка и процесса_°4£e^ ^^ Сятм. обла-
связаны со многими другими проявлениями чел ц ^ челокческ0м языке на
дающая искусственным интеллектом Долж^р ^ тсорем. в част„ IV они-
основе машинного обучен™ и штош™ , нц„ в части V рассмотрены вопросы ав-
сано несколько подходов к машинному о ^ естественного языка,
тематического доказательства теорем и пони. £ т c|IHBOmL Сначала рассматри-
В главе 9 описываются методы обучения.,зс жыт жжду Ш1М„ в области их
вается набор символов, представляющих ^°обКтч»тк,т возможность корректного и
определения. Символьные алгоритмы ооуч терминах эле символов,
полезного обобщения, которое тоже можно вырааип, J ^ ^ предП0 т оп„Са-
Подходы к обучению на основе связей ™°*=НС0СТ011ШИХ „, отдельных небольших
нне знаний в виде примеров деятельност,, в «тях.^ ^^ ^ ^ о6учшотся За
обрабатывающих элементов. По примеру .
нии обучающей
символьного npw* м„«-,и„тъ их в структуре сети.
*—=^^^^^
„ов^ ан^и эмерджентных молелен, рассмотренных в главе 11, явлЯЮТСя генети.
ческиГи эволюционные процессы. Генетические алгоритмы начинают свою работу с ^
лои популяции кандидатов на решение проблемы. Решения оцениваются по некоторому
критерию позволяющему отобрать наилучшие. Комбинация таких претендентов состав-
ляст новое поколение возможных решений. Таким образом по принципу Дарвина стр0.
ится последовательность все более точных решений. Этот подход предполагает поиск
источника интеллекта в самом процессе развития, который (хотя некоторые это и
оспаривают) стал источником самой жизни.
Машинное обучение связано со множеством важных философских проблем i,
проблем образования понятий. К ним относятся проблема обобщения — как машина может
идентифицировать инвариантные фрагменты данных и в дальнейшем использовать их
для решения интеллектуальных проблем, например, для работы с новыми, не
известными ранее данными. Вторая проблема машинного обучения — природа индуктивного
порога. Этот порог наломинает использование разработчиками программ собственной
интуиции и эвристик в моделировании, представлении и алгоритмизации процесса
обучения. Примерами таких проявлений являются выделение "важных" понятий в области
определения, использование конкретного алгоритма поиска или выбор архитектуры
нейронной сети для обучения. Индуктивный порог с одной стороны обеспечивает процесс
обучения, а с другой — ограничивает информационную емкость системы. И последний
философский вопрос, получивший название эмпирической дилеммы, открывает вторую
сторону медали: если в обучающейся системе нет заданных наперед индуктивных поро-
гог.. как можно научиться чему-то полезному, или даже вредному? Как вообще можно
узнать, что система чему-то научилась? Этот вопрос зачастую возникает в эмерджентных
моделях и моделях обучения без учителя. Эти три вопроса более подробно обсуждаются
в разделе 16.2.
Машинное обучение,
основанное
на символьном
представлении
информации
Разум, как я и утверждал, в процессе наполнения большим количество.» простых
идей, переданных через органы чувств из внешнего мира или сформированных как
отражение собственных операций, получает также информацию о том, что
некоторые из этих простых идей тесно связаны друг с другом..., что впоследствии по
невнимательности мы екзонны трактовать как одну простую идею.
— Джон Лок (John Locke)
Простое созерцание мира ничего не значит. Созерцание переходит в наблюдение.
наблюдение — в осмыезение, осмысление — в установление связей, поэтому можно
сказать, что каждый внимательный взгляд в мир является актом теоретшации.
Однако это надо делать сознательно, с дспей самокритики, свободой мышления, не
боясь сиелых высказываний и иронии.
— Гете (Goethe)
9.0. Введение
Способность к „бучению присуща любой системе, °6™ZfJ^™™£°™-
ше„ мире символов ,Z »™^"^Z~"ZZ ,„7,;,
воестественнь,». Интеллектуальные агенты »™ ™ приоб1)етен„я опьга „а осно-
взишодсиствин с окружающим мнром. а иил. ^едуюшие главы будут посвящены
в= св„„х внутренних -стоянии и Д^с™^ Три подхода к 310Й ^^ „ервый-
проблеме машинного обучения. Они отражакр _ ^ ^^ и ]реПШ
на основе символьного представления информации.^второ
основан на принципах генетики или эволюционной Р ^^ ИСИОТЖниого интел-
Обучение играет важную роль в "Ра™4" №forducW „ 198З году назвали про-
лекта. Фейгснбаум (Feigenbaum) и Мак-портi i ^ K0MV распространению ин-
омму машинного обучения основным прештч
v ,-истем Эта проблема возникает при создании экспертных снос, ,
теллекгуальных систем' знаний, описанного в разделе 7.1. Одним и, „ " °с-
-TSSSU обучения „а примерах с у.„ТелемZ?*£»*
этой проблемь, является в ^^ определення. °«ю»с
В"^РбеНрт СимДон"^leXr. Simon) определил обучение следующим образом.
^"Обучение- это любое изменение в системе, приводящее к улучшению рсщОТ1я
„^повторном предъявлении или к решению друго,, задачи „а основе тех же да"*»
[Simon, 1983]
Это краткое определение затрагивает множество вопросов, связанных с раэработвд
обучаемых программ. Обучение подразумевает обобщение на основе опыта. Пр0„Мо™
хеГность системы должна повышаться не только при повторном решении одной „ той™
задачи но и при решении аналогичных задач из той же предметной области. Поскольку об
ласть определения обучающих данных обычно достаточно широка, то обучаемая система
зачастую может обработать не все возможные примеры, и этот ограниченный опыт она
должна корректно распространить на недостающие примеры. Такая задача индущш
(induction) является центральной для обучения. Для большинства задач имеющихся в
наличии данных недостаточно, чтобы гарантировать оптимальное обобщение независимо от
типа используемого алгоритма. Обучаемые системы должны обобщать информацию эври.
стически, т.е. отбирать те аспекты, которые вероятнее всего окажутся полезными в буду,
щем. Такой критерий отбора называется индуктивным порогом (inductive bias).
Определение Симона описывает обучение как свойство системы улучшить повторное
решение задачи. Как следует из вышесказанного, формирование возможных изменений,
приводящих к такому улучшению, — это сложная задача. При исследовании природы
обучения может оказаться, что подобные изменения на самом деле снижают
производительность системы. Поэтому предотвращение и выявление таких проблем — это еще
одна задача алгоритма обучения.
Обучение приводит к изменениям в обучаемой системе. Это несомненно. Однако
точная природа этих изменений и наилучший способ их представления далеко не так
очевидны. Один из подходов к обучению сводится к явному представлению в системе
знаний об области определения задачи. На основе своего опыта обучаемая система
строит или модифицирует выражение на формальном языке и сохраняет эти знания для
последующего использования. Символьные подходы, описанные в разделах 9.2-9.6,
строятся на предположении, что основное влияние на поведение системы оказывают знания
об области определения в их явном представлении.
Нейронные сети (neural network), или сети связей (connectionist network), обучаются не
на основе символьного языка. Подобно мозгу живых организмов, состоящему из
огромного количества нервных клеток, нейронные сети — это системы взаимосвязанных
искусственных нейронов. Знания программы неявно представлены в общей организации и
взаимодействии этих нейронов. Такие системы не строят явную модель мира, они сами
принимают его форму. Нейронные сети обучаются не за счет добавления новой информации в свою
базу знаний, а за счет модификации своей общей структуры в отает на получаемую юане
информацию. Нейросетевой подход к обучению будет рассмотрен в главе 10.
В главе 11 описывается генетическое (genetic learning), или эволюционное, обуете
(evolutionary learning). Естественно, наиболее впечатляющим примером обучаемой
системы является организм человека или животного, который эволюционировал вместе с
ЗкеиТ" МИР°М' Э'т ,Me»™e"™«" подход к обучению, основанный на адапгаш
иТу^ннТйж™ 1ЛГ°Р"™аХ' ГСНет"—' "Гограммированпи н исследо—
372
Часть IV. Машинное обучен'
Машинное обучение — это общинная гЛ
„„честно проблем и алгоритмов их решеи™"^ ""Т*™"*- "^'™ma, большое КС-
исходными данными, стратегиями обучен™ „ слоЗТ' РИ,шча'№я ■="■>"«" задачами.
„„„ сводятся к поиску полезной информаи™ в июетг!^!''0™-'1™1"' мй °»»° «*
рапному обобщению. В разделе 9.1 6удст paccJr"f™OTc Нежных понятия „ ее кор-
чения, в рамках которого будут введены обшщ. ™, "^ с,1мвольного машинного обу-
В разделе 9.1 рассматриваются различные^лаТпГ"'' ™ *Г°Й 0&ис™ энаиий-
основном индуктивному обучению. Индукция (ел д *"""• "° "°свяшсиа эта глава в
жества примеров) — одна из наиболее фУняа«^? Ь о6о6щеиия "а основе мно-
дачей индуктивного обучения является пучение™ * МЛач 0б^ен"я Типичной м-
на основе примеров некоторого понятия выводитг^™"" <C0IMpl leai™n8>. "рн котором
душем корректно распозиавать экземпляры iLoZZZ^Z"0™™™? *
вавия" или "удачное вложение акций-. В разделах 9 эТд V Z ' ""' Мб°Ле"
концептуальной индукции: „овд^«^
В разделе 9.4 рассматривается роль шоушивиого порога в ироце^уч!"
Пространство поиска в эадачахобучения обычно чрезвычайно велико Эта пробГГ ложГо-
ста усугубляется проблемой выбора наилучшего варианта обобщен™ шГоснове
обучающих данных. Индуктивный порог используется во всех методах для ограничен™ ггросгран-
ства возможных обобщений. Алгоритмы из разделов 9.2 и 9.3 основаны на данных Они не
используют априорных знаний об изучаемой предметной области, а определяют главные
свойства общего понятия на основе большого количества примеров. Алгоритмы,
выполняющие обобщение на базе обучающих данных, называются алгоритмами обучения на
основе нодобшч (similarity-based learning). В отличие от таких методов, человек в процессе
обучения может использовать априорные знания о предметной области. Например, для
эффективного обучения человеку не требуется большого количества примеров. Зачастую
одного примера, аналогии или пространного намека вполне достаточно для формирования
общего понятия. Эффективное использование таких знаний повышает результативность
обучения и снижает вероятность ошибок. В разделе 9.5 рассматривается обучение на основе
объяснения (explanation-based learning), обучение по аналогии и другие приемы,
использующие априорные знания для обучен™ с помощью ограниченного чиста примеров.
Алгоритмы, представленные в разделах 9.2-9.5, отличаются друг от друга
стратегиями поиска, языками представления и обьемом используемых априорных знаний. Однако
все они предполагают, что обучающие данные классифицированы. Обучаемой системе
сообщается, к какому классу относится данный пример Такой подход, предполагающий
наличие информации о классификации обучающих данных, называется обучением с
учителем (supervised learning).
В разделе 9.6 продолжается изучение индуктивных методов обучения. Здесь
рассматривается обучение бе, учите.» (unsupervised learning), предполагающее^извлечен*
полезной информации интеллектуальным агентом при отсутствии ^™°J^™*^
рованных Мучающих --" ^Г %%£S^££
формирование категории (category f«™'10"''„ .олже„ разДел„ть объекты на полез-
(conceptual clustering). Как ««-™b™"« ли эта категория? В этом разлете будут
ные категории? Как вообще определить, полезна ли ^ CLT}STER/2 „ COB-WEB. II.
рассмотрены два алгоритма формирования к"е™р Л1Ста1 ,re,nforcemem learning),
наконец, в разделе 9.7 представлено обучение "г^ ^ „„ Процесс обучен™
при котором агент помешается в среду " п \у тщт обратной связи, получен-
предполагает активную
деятельность агента и """Г^-^, ог ^„ени. с учите-
ной в ответ на его действия. Обучение с подкреплением от.т
Глава 9. Машинное обучение, основанное на
символьном представлении
„, «частвует учитель, напрямую оценивающий каждое действие,
лем тем, что в нем не■■ГаспУ™ У*' и1трпротции обратной связи.
Агент сам должен выработать пол у^^ ^ обучению обладают общим свойством
Все представленные в „ои -в в „„„„ранстве состояний. Даже в af0ttK-
Их можно рассматривать как вар значимости в пространстве состояний
се обучения с подкреплением^лроиМЯ ива1ЬСЯ в общем контексте „o„CKa
Далее проблема машинного обучения оуд>я р
9.1. Символьноеобученне___ ___
Алгоритмы обучения можно охарактеризовать с нескольких точек зрения (рис. 9.1).
I Данные и цели задачи обучения. Одной из основных характеристик обучения
является его цель и имеющиеся данные. Например, алгоритмы изучения понятий,
описанные в разделах 9.2 и 9.3, начинают свою работу с набора положительных (и
зачастую отрицательных) примеров целевого класса. Обучение должно
сформировать общее определение, позволяющее в дальнейшем распознавать экземпляры
этого класса. В отличие от обучения, основанного на данных, обучение на основе
объяснения (раздел 9.5) предполагает извлечение общего знания нз каждого
обучающего примера н наличие исходной базы знаний о конкретной области
определения. Алгоритмы концептуальной кластеризации, описанные в разделе 9.6,
иллюстрируют еще один вариант проблемы индукции. Они начинают свою работу с
набора неклассифицированных экземпляров. Их задачей является категоризация этих
данных, имеющая определенный смысл для обучаемой системы.
Язык представления
Пространство понятий
Данные и цели
задачи обученит
Рис. 9.1. Общая
модель процесса обучени
374
Часть IV. Машинное обучение
Примеры — не единственный источник даннч, „ *
мер. зачастую обучается на основе высоко™ обУчени»' Человек, напрп-
ченни программирования преподаватель ^ °"с,ш* Рекомендаций. При иэу-
цикле всегда должно достигаться условие ° своим ^лентам, что в
ректный совет напрямую „епримеииГ Ег оНТ""" ЭТ°Т бМуСЛ0ВН° к0"-
конкретных правил управления счетчиками ц„".Х0ДИМ0 реалт°в«ь ' ви"
языке программирования. Еще одним"™" „ Г »°™ческих условий „а
догня (подраздел 9.5.4), которук„ёобГоГмксГГ """"* '*™™ *
начала использования. Если Z^^r^^ZT^T^Z
чество напоминает воду, студенты яолжнм ™п„^т -"лсктри
mj, смежны должны корректно интерпретировать эту
аналогию - электричество распространяется по проводам, как жидкость в
водопроводе. Как и для потока жидкости можно измерить количество
электричества (силу тока) и его давление в потоке (напряжение). Однако, в отличие от
воды, электричество не увлажняет вещи и не помогает мыть руки.
Интерпретируя аналогию, следует выявить осмысленное сходство и исключить ложные
или несущественные детали.
Характеристикой алгоритма обучения также является его цель (target). Цель
многих алгоритмов — понятие (concept), или общее описание класса объектов.
Алгоритмы обучения также могут использовать планы, эвристики решения проблемы
или другие формы процедурного знания.
Свойства н качество обучающих данных — это еще одно направление для
классификации задач обучения. Данные могут поступать от учителя из окружающей
среды илн генерироваться самой программой. Они могут быть достоверными или
непроверенными, структурированными или неорганизованными. Данные могут
включать как положительные, так и отрицательные примеры, или состоять только
из положительных примеров. Данные могут быть подготовлены либо требовать
дополнительных экспериментов по их извлечению.
2. Представление полученных знаний. Программы машинного обучения могут
использовать любые языки представления, описанные в этой книге. Например, в
программах, обучаемых классификации объектов, понятия могут быть представлены
выражениями из теории предикатов или с помощью фреймов и объектов. Шалы
могут описываться как последовательности операций или треугольные таблицы.
Эвристики представляются в виде правил вывода.
Для того чтобы сформулировать проблему изучения понятий следует представить
экземпляры понятий в виде конъюнктивных выражений с параметрами. Например,
два экземпляра понятия "мяч" (которых недостаточно для изучения самого
понятия) можно представить в следующем виде.
s/ze(oDyi, small) л со/ог(оЬУ1, red) л shapeiobj) round)
slze(obj2, large) л color{obj2. red) л shape{obl2. round)
Общее понятие "мяч" можно описать так.
s/ze(X, У) л co/or(X, Z) л shape(X, round)
„„„mince этому общему определению, представ-
Тогда любое выражение, удовлетворяющее этому оищ ,
Г -"Т^оТнГсимвольном представлении
Глава 9. Машинное обучение, основанное на
, u„™ набор экземпляров для обучения, система должна поеттю-
3. Набор операций Имея набор э ^ _ удовлстворяющие ее «»
,ггь обобщение, эвристичсос пр роваТь представлениями. К т„п„ч
решена этой задачи -6 мо^ ^ Jmmm еитошта ^п -
"Тт^йка Го кГро^оп сети или другая модификация представлен™ дащщх в
ГоГГме В рас'штренном выше примере изучения понятий обучаемая система
ГжТЛывес™ определение, заменив конкретное значение переменными. Рас.
смотрим первое выражение.
зЫоЬП. small) л со/ог(ой/1. red) л sr,ape(ou,1. round)
Если заменить одну константу переменной, получим следующее обобщение.
sfcelob/1, X) л color(obi1. red) л shape{obn, round)
sizeiobjl. small) л co/or(ob/l, X) л shape(ob,1, round)
sizeiobn, small) л co/or(ob)1, red) л shape(oo;1, X)
size{X, small) л co/or(X, red) л shape(X, round)
4. Пространство понятий. Язык представления наряду с описанными выше
операциями определяет пространство потенциальных определений понятий.
Обучаемая система, чтобы найти нужное понятие, должна выделить это
пространство. Сложность такого пространства понятий — основная мера сложности
задачи обучения.
5. Эвристический поиск. Обучаемые программы должны учитывать направление и
порядок поиска, а также для повышения эффективности поиска использовать
имеющиеся в наличии обучающие данные и эвристики. В рассмотренном выше
примере изучения понятия "мяч" алгоритм может выбрать первое выражение в
качестве кандидата и включить его в последующие примеры. Например, имея
единственный обучающий пример
sizelobjl. small) л color(obj), red) л snape(oo/1, round),
обучаемая система выберет его в качестве кандидата на определение понятия. Этот
пример корректно описывает лищь одни экземпляр.
Если алгоритму предъявить второй экземпляр этого понятия
sfee(ouj2, large) л color(obj2, red) л shape(ob;2, round),
обучаемая система может обобщить понятие-кандидат, заменив конкретные
значения переменными, и сформировать понятие, удовлетворяющее описаниям обоих
экземпляров. В результате получится более общее понятие-кандидат, точнее
соответствующее целевому понятию "мяч''.
size{X, У) д соЮг(Х, red) л shape(X, round)
описГвТй^ г.4""""*" П0НЯ™Й "а положительных и отрицательных примерах
о Р д ле«"аТРНКа ВШСТ°"а 'Wi™™. 1975„]. Его программа строи? обшне
ОбРучающГд^ ,еСТРУК,ТУРКЫХ П<™™Й' ™ Ч». —вая их составные части,
примеров „„„„ти" Это псТ„0„еП„0к,ЛеЛОВаТеЛЬН°СТЬ "И0МГЕ№»« и отрицательных
земпляры для поинЯП„^ оч™ Удовлетворительными" считаются эк-
отношения "Почти ™Г " катег0Р"» вторым не хватает одного свойства ил"
^Удовлетворительные" экземпляры позволяют программе выде-
376
Часть IV. Машинное обучение
лить
свойства, которые можно использовать лл
,,з целевого понятия. На рис. 9.2 показан^ "Стючения отрицательных примс-
„етворительные" экземпляры понятия "арка" Житепь1шс примеры и "почти
Почти удовлетворительный
пример
Почти удовлетворительный
пример
Рис. 9.2. Хорошие и "почти удовлетворительные"
примеры понятия "арка"
Программа представляет понятия в виде семантической сети (рис. 9.3). Она
обучается, уточняя описание кандидата на роль целевого понятия на основе обучающих данных.
Программа Винстона уточняет описание кандидата с помощью обобщения и
специализации. Обобщение приводит к такому изменению графа, которое обеспечивает
соответствие графу новых экземпляров понятия. На рис. 9.3, а показана арка из трех блоков и
представляющий ее граф. В следующем обучающем примере (рнс. 9.3, 6) перекладиной
арки служит пирамида, а не блок. Этот пример не соответствует описанию понятия-
кандидата. Программа сопоставляет эти графы, пытаясь определить степень их
изоморфизма, с помощью имен узлов. После сопоставления графов программа может выявить
различия между ними. На рис. 9.3 графы соответствуют друг другу по всем компонентам
за исключением верхнего элемента: в первом графе этому элементу соответствует узел
brick (блок), а во втором — узел pyramid (пирамида). На рнс. 9.3. в показана иерархия
обобщения этих понятий. Программа строит обобщенный граф, заменяя
соответствующий узел ближайшим общим супертипом дта объектов brick и pyramid. В данном
примере это polygon (многогранник). В результате получается понятие, представленное
графом на рис. 9.3, г.
^ва 9. Машинное обучение, основанное на символьном представлении.
377
i. Пример арки
и ее сетевого описания
). Пример другой арки с сетевым описанием
в. Базовые знания о том, что блок и пирамида являются частным случаем
многогранника
г. Обобщение, включающее оба примера
С part 1 »-{ polygon rj '
Рис. 9.3. Обобщение описания, позволяющее исключить множественное представление
"Почти удовлетворительные" примепы оттши*™-™ „т .«„„„„ „™в ппним свой-
-, ..«„W„WU{CC исключить множественное npeucmuw
"Почти удовлетворительные" примеры отличаются от целевого понятия одним см*
Ш шсТд ИСЕЛЮЧенм "I"»?3"» выполняет специализацию описания кандидате»
удов™„телГ„г™МеНО 0ПИСаНИ,: ™"*™-ндидата. Оно отличается от -W"»
оГсаГТрГаммт Г"4" "а Р"С'94' 6 ""гением touch (касается) в послел»'
ДОЛЖНО К асаться) Гпиг ъа"\спсц"ализаПию графа, добавляя связь must-not-louch(
эости отрицательных '„„„'„-, ""' ™ этот ^ropi™ существенно зависит от №. ■
тельиоеТвойство.ГоГмТ т°Му П0Шт,ю- °"Р« единственное <г*««
' у "яет понятие-кандидат.
Часть IV. Машинное обу*
а. Вариант описания арки
6. "Почти удовлетворительный" пример и его описание
в. Специализированное описание арки, исключающее "почти удовлетворительный"
пример
Рис. 9.4. Специализация описания с целью исключить "почти удоаетеорительные"
примеры. Но рис. 9.4. в к графу, предстанемте «а рис. 9.4. а. добавлены ограничения, ис-
кмочающие его соответствие графу на рис. 9.4, о
Эти операции- специализация сети за счет добавления связей и обобщение путем
замены имени узла или связи более общим понятием - задают пространство возможных
определений понятия. Программа Вннстона выполняет поиск экстремума в пространстве
понятий на основе обучающих данных. Поскольку программа не отслеживает маршрут
поиска, ее производительность существенно зависит от порядка^ш^^Г^
Щих примеров. Неудачный порядок может завести программу в тупик пространства по
иска. Обучающие примеры необходимо предъявлять программе п°р«кс nocota
Гщем извиню /анното понятия, "^^^ГДГ^
снятия со студентами. Качество и порядок с— >о сопоставлен,м ,тафь1 «
та«е для алгоритма сопоставления графов, для згофемн
Должны сильно различаться.
Глава 9. Машинное обучение, основанное на символьном представлении... 379
- „.„вы, реализаций принципа индуктивного обучения, программа
Являясь одной из первых ре 6лемы большинства подходов к машинному обу-
Винстона.шлюстрнрустсвои J^^,,, „ специализации, чтобы определить Про.
че„„ю. Они используют опери ^ ^ ^ пространстве осуществляется „а основе
странам возможных понят ■ гаМ зависят от качества обучающих данных. В сле-
данных. и все эти ""^'^„j эт1, проблемы и приемы их решения в системах ма-
шинного обучения.
9.2. Поиск впространств^версий
„re иерсий (version space search) [Mitchell 1978, 1982] иллюстри-
mef нХивГоГ^ение как реализацию поиска в пространстве понятий. Поиск в
пгДттГ™ версий основан на том, что операция обобщения упорядочивает понятия в
п^тр^стве поиска. Затем згот порядок используется для выоора направления поиска.
9Л.1. Операция обобщения и пространство понятий
Обобщение и специализация— самые типичные операции при определении
пространства понятий, К основным операциям обобщения, применяемым в машинном
обучении, относятся следующие.
1. Замена конкретных значений переменными. Например.
colorlball, red)
приводится к виду
co/or(X, red).
2. Исключение условш, из конъюнктивных выражений. Так,
shape[X, round) л size{X, smalt) л color{X, red)
сводится к выражению
shape{X, round) л co/or(x, red).
3. Добавление в выражение операшп, дизъюнкшш. Например,
sftape(X, round) л size{X, small) л co/or(X, red)
приводится к
s/iape(X, round) л size[X, small) л (co/or(X, red) v color(X, blue)).
4. Замена свойства родительским объектом согласно иерархии классов. Если объект
рптагусо/ог (основной цвет) является суперклассом для свойства red (красный), то
co/or(X, red)
заменяется на
color(X, prfmaryco/or).
мно°"™Тк^6ГНМ М0ЖН° °П"СЭТЬ » Те>"'™» ™»ии множеств. Пусть Р н 0-
ответГнГвСГн'и/ГГ'^'ГХ "*™™* ' " " '" ™'"" ПРСД,,ИПв1
выще примерах^™2 ^ °бШ"М' ЧеМ «• «™ Р=°- В "Р"8"""rf,
включает набор ззементГ "Рг110ж£иий- Удовлетворяющих выражению colore. '«"■
Р элементов, удовлетворяющих выражению colorlball. red). Аналоги""»1
Часть IV. Машинное обучен*"
, примере 2 множество круглых и красных объектов являете, fi
„„о маленьких красных и круглых объектов Замети ""' ЧеМ Множе"
дозволяет упорядочить логические предложения в соо"' ™ °™ошение "6олсе общий"
отношение можно обозначить символом ••>" т е о> 'гтс1в>пощем пространстве. Это
а более общим, чем о. Такая систематизация суше™!"™"' ™ ""Р3*™"6 Р "™«-
выполняемого алгоритмом обучения /«есгвенно сужает направление поиска,
бой положительные примерь, понятия. Друпш11 словами ^лГХ^ *
"W^f1 " Q<*>-P^U). Говорят, что р покрывает g если
q<x)-*posmveU) является логическим следствием p(x)-»posrt/ve(x)
Например, Color(X, Y) покрывает co/or(6aff. Z), которое, в свою очередь, покрывает
coloriball, red), В качестве простого примера рассмотрим множество объектов со
следующими свойствами.
Sizes = {large, small)
Colors = [red, white, blue)
Shapes = {ball, brick, cube)
Эти объекты можно представить с помощью предиката obj{Sizes, Colors, Shapes).
Операция обобщения, осуществляемая путем замены конкретных значений
переменными, определяет пространство, представленное на рис. 9 5. Индуктивное обучение можно
рассматривать как поиск в этом пространстве понятия, удовлетворяющего всем
обучающим примерам.
9.2.2. Алгоритм исключения кандидата
В этом разделе представлены три алгоритма [Mitchell. 1982] поиска в пространстве
понятий. Эти алгоритмы основываются на понятии пространства еерсий Version фасе),
представляющем собой множество всех описаний понятия, согласующихся с об>чающимн
примерами. Эти алгоритмы работают за счет сужения пространства версий с появлением новых
примеров. Первые два алгоритма обеспечивают сужение пространства версий в направлении
от частного к общему и от общего к частному соответственно. Третий алгоритм, нззыж ~~-
алгорюпмом исключения кандидата (candidate elimination), объедзошет оба подхода н
зует двунаправленный поиск.
Эти алгоритмы основаны на данных. Обобщение выполняется на основе
обнаруженных в обучающих данных закономерностей. Кроме того, поскольку в этих алгоритмах
используются классифицированные обучающие данные, их можно считать
разновидностью общения с учителем (supervised learning).
Как и программа Вннстона, реализующая обучение на основе структурных описании,
алгоритмы поТ.ска в пространстве версий используют и положите, и от^тель-
»ые примеры целевое! понятия. Хот, операцию обобщения ™™^
на по_ль„ых примерах. о^™^^™™-^^^^
« обобцгение. Изученное ™**™*°™^2^ исключить „с отрицятеть-
вать всем положительным примерам, но и части положительных экзем-
"ьк. В пространстве, представленном на рис. 9-5. все множество
пляров покрывается понятием obj{X. V, Z).
только
излит-
Г"ава 9. Машинное обучение, основанное на символьно» представлении
objlK Y- &
^ red. ball) °W"^
objismall, red, bait)
obRlatge, red, ball) оЩетаЧ, white, ball)
Рис. 9.5. Пространство понятии
Однако это понятие является слишком общим, поскольку включает все существующие
экземпляры. Чтобы избежать излишнего обобщения, необходимо систематизировать
обучающие данные в минимально возможной степени, чтобы покрыть лишь
положительные примеры, либо использовать отрицательные примеры для исключения лишних
объектов. Как показано на рис. 9.6, отрицательные примеры предотвращают избыточное
обобщение за счет специализации понятий и исключения отрицательных примеров.
Предстааленные в этом разделе алгоритмы используют оба приема. Поиск от частного к
общему на множестве гипотез S выполняется следующим образом.
Begin
Инициализировать S первым положительным обучающим примером;
N
множество веек отрицательных примеров.
Для каждого положительного примера р
Begin
Для каждого seS, не удовлетворяющего примеру р, заменить
s минимальным более общим понятием.
Удовлетворяющим примеру р,
Удалить из S все гипотезы, более общие, чем некоторые
другие гипотезы из S;
далить из S все гипотезы, удовлетворяющие рассмотренному
Ранее отрицательному примеру „3 N;
to каждого отрицательного
begin
примера п
End
^«-ьТвТножёство £. Удовлетворяв ";
м;и„отез „а „редмет ^^проверк^последующи,
Понятие, составленное только Понятие nnr~r™QU1J«r, c
из положительных примеров ' „° ^ГГ„! положительных
м ^ и отрицательных примеров
Рис. 9.6. Роль отрицательных примера, . „редот.ращенш, иттнего обабщенш
В алгоритме поиска от частного к общему используется множество гипотез S
элементами которого являются кандидаты на определение понятия. Чтобы избежать
излишнего обобщения, эти определения-кандидаты формируются как максимально
конкретные обобщения (maximally specific generalization) исходных обучающих данных. Понятие
с является максимально конкретным, если оно покрывает все положительные примеры,
не удовлетворяет ин одному отрицательному, и для любого другого понятия с'
покрывающего все положительные примеры, С> с. На рис. 9.7 представлен пример
применения этого алгоритма к пространству версий из рис. 9.5. В подразделе 14.8.1 алгоритм
поиска в пространстве версий от частного к общему реализован на языке PROLOG.
S: 0 Положительный: objismall. fed, bait)
S: {ob/lsmall, red. ball))
Положительный: ob/lsmall. white, bat!)
_j
S: {objismall, X, ball))
Положительный: ob/(large, blue, bait)
S: {obHY, X, ball))
Рус. 9.7. Поиск от частного к общему в пространстве версий при «ns
нении понятия "ball"
Можно выполнять „оиск и от общего к частному. Р-™^™-^тельн™
■ДНИ множество G «акси^ьно оби,,, понятии, покрывающее положг,™ьни „и
„,„„„ .„„ понятие с является максимально общим, euin оно Ht
одного отрицательного примера. Понятие ° »Г"1 с. не ПИфЫвак>щего
"скрывает отрицательных примеров, и для ™6ош ДРУ™ " обеспечнва-
«риивтельных примеров, «С. В этом ^Р'™^™^ JT J^
^специализацию понятий-кандидатов, а положтхльн
ной конкретизации понятий.
Глава 9. Машинное обучение, основанное на символьном представлении
383
« „ее обшим понятием в пространстве;
-визировать .о--- пример.
р содермт все
„„нательного примера П
Яля каждого отрииате
Д Begin удовлетворяющего примеру п. заменить
""" ^Тнаибол'ее обией специализацией.
не УДовлетв°рЯЮИе„<>,|,, более частные, чем некоторые
mL «я G все гипотез,
удалить из Ь из G.
другие ,ип° тезЫ/ не удовлетворяющие
удалить из Ь в=е р.
некоторым примерам из Г.
End;
для каждого нелояльного примера р
удалить из G все гипотезы, не удовлетворяющие р;
Добавитъ р в множество Р;
End;
End
G:(obj(X,V,^}
Отрицательный: obj[small, red, bnck)
G: (obrf/arge. V, 2), obliK wtofe. 2).
ofcflX btoe, 2), ob](K Y, baffl. objtX Y, cube)}
Положительный: obj{large, white, ball)
I
G; (оад/arge. Y, Z).
otflX. white. Zl. obiiK Y, ball))
Отрицательный: objdarge, blue, alba)
0: {obftlarge. white, Zl.
ОЩХ, while, Zl. obj{K V, ball))
Положительный: ob;(sma«. №«. M<1
0: (ol»[x, Г, 1>а//)|
ft* 98. По»»- от общем к частному в пространстве версий при изучении понятия "ЬаИ
"■""• п° -■ перс»'
-зрие.9 5 В этПо?3а" ПРИМер "Р"»™»™ этого алгоритма к пространству «Р
5f« (Размер) Г' Р"МСре ШГ0?КШ использует базовые знания о том, что свои
*"»• 1™Лнв & ЗНачеиия <'а'9е. ""«/О. свойство со/or ("°« зн1н».
чен.щ (red w„„e ы ТЬ значеи"» «arge, sma//>. свойство color (u«'
»П»ют важную псГ \С80ИСТВ0 8^ре (форма) - {ball, brick, cube). Эти
|,|,й ^Ременным,, Ф°Рм"Р0ва„„„ „0„ятнй путем замены конкретных
, W. Машинное обУ*
Алгоритм исключения кандидата объединяет об,
правленный поиск, который дает множество п°Д*°Да и обеспечивает двуна-
Алгоритм поддерживает два множества поня"Р-ИМУЩМТВ ДЛ" обУчаем<>и системы,
симально общих понятий-кандидатов a S — тии'канД1™тов: G— множество мак-
процессе работы алгоритма специализация мн"0""'0 максиыально конкретных. В
выполняется до тех пор, пока они не сойлутг °Жества G и обобщение множества S
следующий вид.
дутся к целевому понятию. Алгоритм имеет
Begin
Инициализировать G наиболее общим понятием . „
Инициализировать S первым полосе!"™" ' "Р°СТРа—;
1ЬКЫМ Обучающим примером;
Для каждого положительного примера р
Begin
удалить все элементы G, „е удовлетворяющие примеру р-
Для каждого KS. не удовлетворяющего примеру р, заменив
S наиболее частным обобщением,
удовлетворяющим примеру р;
Удалить иэ S все гипотезы, более общие, чем некоторые
другие гипотезы из S;
Удалить из S все гипотезы, более общие, чем некоторые
гипотезы из G;
End;
Для каждого нового отрицательного примера л
Begin
Удалить все элементы S, удовлетворяющие п;
Для каждого geG, удовлетворяющего примеру л, заменить
g его наиболее общей специализацией,
не удовлетворяющей примеру л,-
Удалить из G все гипотезы, более частные, чем некоторые
другие гипотезы из G;
Удалить из G все гипотезы, более частные, чем
некоторые гипотезы из S;
End;
Если G=S и оба множества содержат по одному элементу,
значит, найдено единственное понятие, удовлетворяющее
всем данным;
Если G и S пусты, значит, не существует понятия, покрываемо
все положительные примеры и не удовлетворяющего
отрицательным;
End
На рис. 9.9 проиллюстрирована работа алгоритма исключения кандидата • простран-
«ве версии из рис. 9.5. Заметим, что здесь не показаны понятия, которые былщучены
в процессе обобщения или специализации, но „сечены „з »™^"£££
потез как слишком общие ш,и частные. Исследование этой ™"Ф™£%£^
выполнить самостоятельно в качестве упражнения^ Программная реализация зтого
алгоритма на языке PROLOG описана в подразделе U.S..
fWI Машинное обучение^снованное на символьном представлении
385
S:l)
Положительный: оЬЦвтаИ, red, ^
S;(ou;is»i««,'«'-lM/,n
0: (ob/IX, '«<■ Л)
S: (oto/{sma//. red. ball))
Отрицательный: oblismall, blue, bull)
Положительный: objUarge, red, ball)
G: \obliX, red. Я)
S: (ob/lX, led. ball))
Отрицательный: оЬЩвгде, led, cube)
0; \obilK ted, bell))
S: {оВДХ, ted, bell))
Рис. 9.9. Изучение понятия "red ball" с помощью алгоритма исключения кандидата
Объединение двух направлений поиска в одном алгоритме обеспечивает несколько
преимуществ. Множества G и S содержат обобщенную информацию об отрицательных и
положительных примерах соответственно, что устраняет необходимость хранения этих
примеров. Например, после обобщения множества S с целью покрытия очередного
положительного примера множество G используется для исключения нз S понятии,
покрывающих отрицательные примеры. Поскольку G — это множество макашально обща
понятий, не удовлетворяющих ни одному из отрицательных примеров, то элемент
множества S, более общий, чем любой элемент нз G, должен удовлетворять некоторым
отрицательным примерам. Аналогично, поскольку S — это множество максимально
конкретных обобщений, покрывающих все положительные примеры, то любой новый
элемент G, более частный, чем элемент S, не покрывает некоторые положительн
экземпляры, и его необходимо исключить.
На рис. 9.10 показано абстрактное представление алгоритма исключения канД"^;
пшТтГ" + °боз1ачень' положительные обучающие примеры, а символом "-
поГыТГ' ВНУ1ре"Нем ВДге 3™сньГвсе известные положительные примЧ»
L7"" П0М™™ S. Внешний круг соответствует множеству G; любые пр.-'
и^евое поГГ ^^ °™™™ш. Затененная часть изображения сод *
2^общГи™бо7аКЖС ЛРУ™е еГ° «**«"". которые могут оказаться либо*
™ритм™° :~ГМИ (°™еЧеНЫ —" "?"'- В ПР°ТнысР££"-
сжимается", чтобы исключить отрицательные
1 окружность '
Часть IV. Машинное
обУ*
„тоге оба процесса «одятГк еГноГ ВКЛК>ЧеНИЯ "°ВЫХ П°»°™™™"* «P«»<V>*. В
дат* позволяет опредеГть коТаТй "У "0НЯ™Ю' АЛГОрИ™ исключения канди-
понятия. Если множества S и GсоP~7„~ """^ 0П"Я™ "™Г°
шился успешно. Если G и S пСы ™™ П0НЯ™е' ЗНаЧИТ' алгоР"™ завсР-
всем положительным примере" ни оли" "' СУЩеСТВу" П0"»™- удовлетворяющего
случае противоречивостиJZ"2 пГ.7 0ТРИЦаТеЛЬН°Му ^ м°жет "Р°™й™ -
„ия (подраздел 9.2.4) """ УСЛ°В"И не>™™™ выбора языка представле-
Рис. 9.10. Изменение множеств G и S в процессе работы
алгоритма исключения кандидата
Интересным свойством алгоритма исключения кандидата является его инкременталъ-
ность. Инкрементальные алгоритмы обучения предполагают поочередную обработку
обучающих примеров и формирование удовлетворительного, хотя, возможно, н неполного,
обобщения после предъявления каждого из экземпляров. В отличие от них алгоритмы
пакетной обработки (например, ID3 из раздела 9.3) требуют наличия всех обучающих
примеров до начала обучения. Множества G и S в процессе работы алгоритма исключения
кандидата сужают множество потенциальных понятий: если с — целевое понятие, то для
всех geG и seS g>c>s. Любое понятие, более общее, чем некоторое понятие из G.
будет покрывать отрицательные примеры; любое понятие, более частное, чем
некоторое понятие из S, не покрывает некоторые положительные примеры. Это означает,
что множества G и S охватывают набор приемлемых понятий.
В следующем разделе эти рассуждения будут проиллюстрированы на примере
программы, использующей метод исключения кандидата для изучения эвристик поиска.
Программа LEX [Mitchell и др, 1983] обучается эвристикам для решения задач
символьного интегрирования. Эта профамма не только демонстрирует использование множеств
G и S для определения частных понятий, но и иллюстрирует такие вопросы, как
сложность задач многошагового обучения и взаимоотношения между компонентами
обучения и решения проблемы в сложной системе.
Глава 9. Машинное обучение, основанное на символьном представлении.
387
, 2 1 Программа LEX: индуктив-ое изучение эвристик поиска
' - 1ЬЕХиз>.аеТзВрисТиК.,^Р=:=1С==,г
Программа Lt-Л ш^ выражения методом эвристического поиска. На ос„„
Оиа интегрирует^р■ пр(жнтегрир „, С11СТСМа выполняет поиск цел11°*
выражения, которое н „„тегоала. Компонент обучения использует п,„„
„ьтаження, не содержащего знака «н Ф ,lfiv4eHlu, эвонстакам. чтп „Л**"»*'
Зп'не^р^ш-^Г^нндухгивното обучения зврнстикам, что ВД11Ш^
ЮХ"ьЁП— сХиск в пространстве, определенном операции надад
гебгГч^скими выражениями. Эти операции представляют собой типичные Преобразо^.
„олняемые при „нтетрированин. К ним относятся следующие.
ОР1.Jrnx)dx->rjf(x) <*f
ОР2: juoV-> uv- jvdu
ОРЗ: Г«х)-> Л»
ОР4: Jrf,(x)+f,(x» in KM e/x+ J f,(x) d*
Операции — это правила, в левой части которых указаны условия их использования
Однако в этих выражениях определены лишь условия, при которых можно применять
эти операции, но они не включают эвристик, определяющих, когда это нелепо делать.
Программа LEX изучает эти эвристики на собственном опыте. Эвристиками называются
выражения вида:
Если состояние текущей задачи удовлетворяет условию Р,
значит, нужно применить операцию О с ограничением б.
Например, типичной эвристикой для программы LEX является следующая.
Если состояние текущей задачи удовлетворяет условию
\х transcedental(x) dx,
значит, нужно применить операцию ОРЗ с обозначениями
U= X;
dv = transcedental(x) dx
Здесь эвристика предполагает интегрирование по частям для вычисления интеграла от
произведения х и некоторой трансцендентной (т.е. тригонометрической) функции отх.
Язык представления понятий в программе LEX состоит из символов, изображенных на
рис. 9.11. Заметим, что эти символы представлены в виде иерархии обобщения, где каждый
символ соответствует всем своим потомкам в этой иерархии. Обобщение выражений
выполняется путем замены символа его предшественником в иерархии обобщения.
j3xcos(x)dx.
Программа LEX может изменить обозначение cos на trio Тогда выражение
примет вид у
l3xtrig(x)dx.
Например, рассмотрим выражение
Кроме того, можно заменить число 3 символом к, представляющим любое целое число
Ifcxcos(x)dx.
щен^Г 9'12 ПреДСТаВлено пространство версий для ОР2, определенное этими обоб-
388 Гпб^и9
Часть IV. Машинное ооу
1 ' . ' !—*->-l-
sin cos tan In exp
Рис. 9.П. Фрагмент иерархии символов программы LEX
f poly(x) (2<x> dx
—*■ apply OP2
/iransc(x)f2{x)dx
-* apptyOP2
/ kx cos(x} dx
— apply OP2
/ 3x ing(x) dx
—* apply OP2
Puc 9.1-■ Пространство
версий для операции ОР2
Глава 9. Машинное обучение, основанное на символьном представлении
389
Программа LEX состоит из4компоиентов.
"к—<« обобщи. использующий для поиска эвристик метод тпк>ч^
3*1^ **»»■ извлскаюшнй положительные „ отрицательно Примеры ш
процессе решения задачи.
4 Lpa,„oP sate, формирующий новые задачи-кандидаты.
i рх поддерживает несколько пространств версии. Каждое из них связ,.,
с о„™'ойоп"* представляет частично изученную эвристику „ та^Г
„аГи КоГонент обобщения обрабатывает эти версии с использованием положи^.
Г. отр "тельных примеров применения операции^ сгенерированных модулем ^
™ Полнив положительный пример, программа LEX определяет, включен ли этот эк.
з^мплярв пространство версий для соответствующей операции. Положительный пр„мер
включается в пространство версий, если он покрывается некоторым понятием из G. За.
тем программа использует этот положительный пример для обновления эвристики. Если
ни одна из существующих эвристик не удовлетворяет этому примеру, создается новое
пространство версий, для которого в качестве первого положительного примера исполь-
зуется данный экземпляр. Это может привести к созданию нескольких пространств вер.
сий для одной операции с разными эвристиками.
Модуль решения задачи строит дерево поиска прн решении задачи интегрирования.
В программе процессорное время, отводимое на решение задачи, ограничено. При
этом для решения задачи используется алгоритм поиска по первому наилучшему
совпадению со специально разработанными эвристиками. Интересно, что в качестве
частных определений эвристики в программе LEX используются множества G и S. Если
для данного состояния можно применить несколько операций, выбирается та, которая
больше всего соответствует этому состоянию. Степень соответствия определяется как
процентное соотношение всех понятий, расположенных в пределах G и S,
удовлетворяющих текущему состоянию. Поскольку вычислительные затраты на проверку всех
понятий-кандидатов могут оказаться значительными, степень соответствия в
программе определяется через процентное соотношение элементов G н S, удовлетворяющих
данному состоянию. Заметим, что с уточнением эвристик производительность
системы LEX значительно повышается.
Положительные и отрицательные примеры применения операций извлекаются в
процессе решения задач в модуле решения. При отсутствии учителя программа должна сама
разделить примеры на положительные и отрицательные. Это пример решения проблемы
шдаетш кредита (credit assignment). Если обучение рассматривается в контексгс ре-
шення многошаговой задачи, то зачастую неясно, какое из действий в
последовательности отвечает за полученный результат. Если модуль решения проблемы получая невер-
кг1™Г' Т° КаК У"ИТЬ' КаК0Й т >™лькнх шагов стал причиной ошибки? В «одуле
пСГш"Р0ГРаММЫ Щ ™ Проблема Ре™«ся с помощью предположения о том, «о
cZZT~ 7 Кра"аЙШИЙ "У"- « «ли. Программа классифицирует яр»*»*
»",Ге„„~жгг кра™йшему пути как —,е *°~
Однако п™ .„ рассматривает как отрицательные. „,.
Факт, что модифицируемые эвристики необязательно являются до*
IZToXZZTCITZZ: Т" РеШгаИЯ- -6— „а самом деле
еифицированных как^тГцательн^Р " °К^"'™ <™P*«<*. <™ибоЧ„о клас-
ваются пути, »™«пГГс^^£иш „ "'^"^ "* C"™" ^"^
„v пр.мению Ofit,uun Г операции, и проверяется, не ведут ли они к
лучшему решению. Обычно в процессе решения одной задачи формируются от двух до два-
дцати обучающих примеров. Эти положительные к отрицательныеПримеры
передаются в модуль обобщения, где они используются для обновления продан™
версии соответствующих операций. ""иртчр-игаи
Модуль генератора задач - наименее развитая часть программы. Хотя для автомати-
зацни выбора задач использованы различные стратегии, большинство примеров вводится
вручную. Один из подходов к генерации примеров состоит в покрытии частных эвристик
для двух операции с целью научить программу различать эти операции.
Эмпирические тесты показывают, что программа LEX эффективно обучается
полезным эвристикам. В рамках одного исследования программе LEX было предъявлено пять
тестовых и двенадцать обучающих задач. Перед началом обучения она решала тестовые
задачи в среднем за двести шагов без использования эвристик в процессе поиска. После
формирования эвристики на основе двенадцати обучающих задач программа смогла
решить те же тестовые задачи в среднем за двадцать шагов.
В программе LEX затронуты многие аспекты обучения, в том числе такие проблемы,
как выделение кредитов, выбор обучающих примеров, взаимоотношения компонентов
решения задачи и обобщения. На примере этой программы видна роль
соответствующего представления понятий. Эффективность программы во многом обеспечивается
иерархической организацией понятий. Эта иерархия достаточно невелика, чтобы ограничить
пространство возможных эвристик и обеспечить эффективный поиск, и в то же время
достаточно богата для создания эффективных эвристик.
9.2.4. Обсуждение алгоритма исключения кандидата
Алгоритм исключения кандидата демонстрирует способ применения метода поиска в
пространстве состояний и представления знаний к решению задачи машинного обучения.
Однако, как и большинство важных научных результатов, этот алгоритм нельзя оценивать
в отрыве от других задач. Он связан со множеством задач машинного обучения.
Обучение на основе поиска, подобно другим задачам поиска, связано с операциями в
некоторых пространствах. Поскольку алгоритм исключения кандидата реализует поиск в
ширину, он может оказаться неэффективным. Если специфика задачи такова, что
множества G и S интенсивно увеличиваются, возможно, следует выработать эвристики для
исключения состояний из этих множеств на основе лучевого поиска (Ъеат search) (см. главу 4).
Еще один подход к решению этой проблемы, описанный в разделе 9.4. предполагает
использование индуктивного порога для дальнейшего уменьшения размера пространства
понятий Такие порога вносят ограничения в язык представления понятий. В программе
LEX порог создан с помощью иерархии обобщения понятий. Язык представления понятии
в этой программе достаточно строг, чтобы обеспечить формирование множества эффек-
тнвных эвристик и уменьшить пространство понятий до -обозримых размеров .
Применение порогов позволяет упростить пространство понятий, но может привести к
неспособности системы адекватно представить изучаемые понятия. Следовательно, метод исыюченн.
кандидата не сойдется к целевому понятию, а множества G и S окажется пустыми. В этом
состоит противоречие между выразительностью и эффективностью ооучения.
Глава 9. Машинное обучение, основанное на символьном представлении
391
„п.иение алгоритма может также быть вызвано шумом „ли „роти
Неудачное »»*шен"е Задача обЯен."> на зашумленных данных очень важна Z
чи,остыо обучают»*.Л"" " даиные м01уг быть неполными „ли противоречивым;
реальных "PM0*f""'^^а „ельзя назвать устойчивым к шуму. Даже од„„ „ вд
Алгоритм исключения «<™ . Mef может сделать алгоритм расходЯЩинся v°
классифицированный о У ы является использование нескольких множеств G и
ним из решении этой Р №тп ^ всех обучающих примеров, создаю^
Помимо "Р0^™ и на ос„ове всех примеров за исключением одного, двух
дополнительные "Р0^ „е сходится для „сходных множеств G „ S. его провер,.
земпляров и т.д. вся. ^^ ^ надежде, что они окажутся согласованными. К сожа
ют на "усеченных „'„АЛективен для практического использования.
«"Г Г^нании . пропессе обучения. Иерархи, „ora™„ про,
гаш„Ш основана на знаниях алгебры, „ это принципиально важно ^эффективно,
сти алгоритма. Может ли изучение области определения сделать обучение более эффек
тивным? Ответ на этот вопрос содержится в разделе 9.5.
Важное значение программы LEX состоит в выявлении взаимосвязей между пред.
ставлением знаний реализацией обобщения и поиском в процессе индуктивного
обучения Хотя исключение кандидата - это лишь один из многих алгоритмов обучения, в
нем проявляются общие проблемы обучения: сложность, обеспечение выразительности и
использование знаний и данных в процессе обобщения. Эти проблемы являются
центральными для всех алгоритмов машинного обучения. Поэтому оии еще не раз будут
упоминаться в этой главе.
9.3. Индуктивный алгоритм построения дерева
решений ID3
Алгоритм ID3 [Quinlan, 1986a] подобно методу исключения кандидата обеспечивает
изучение понятий на примерах. Особый интерес представляют способ хранения
полученных знаний, подход к управлению сложностью, эвристика для выбора понятий-
кандидатов и возможности обработки зашумленных данных. В алгоритме ID3 понятия
представляются в виде дерева решений (decision tree). Такое представление позволяет
классифицировать объект путем проверки значения определенных свойств.
Например, рассмотрим задачу оценки кредитного рнска на основе кредитной истории,
текущего долга, наличия поручительства и дохода. В табл. 9.1 представлены примеры с
известным кредитным риском. Дерево решений иа рис. 9.13 содержит приведенные в
таол. 9.1 данные и позволяет корректно классифицировать все объекты в таблице. Каждый
внутренний узел дерева решений представляет некоторое свойство, например, кредитую
лег^ТТ™ Д°Х0Д" КаВД°Му втм°ж"°"У значению этого свойства соотаетствует ветвь
ш&ж.Т™'™ ОТРаЖаК>Т Р"^"™™ классификации, в частности, низкий ил" 'Р№
вестеГл™ ^Т° ЭТ°Г° "'^ М0ЖН0 классифицировать клиента, тип которого нею-
лГдашГо" ВКУ1РеННеГ° ^ Ч»«Ч»«™ значение соответствующего с-*»
"„ „ «„Г!™™ ПСреМД П0 соответствующей ветви. Процесс завер-
Заметим что п™ Г™ ^ отделяющего класс объекта.
Дерева учтываготСнТв^г!11^""" КаЖД01'° «""фетного экземпляра с помошьк. ^
имеет хорошую кредитн™ Г™' "^«^««ые „ та6л. 9Л. Например, если чел
кредитную историю „ „изкий дол1% „ согласно 6ез учета до*»*
Часть IV. Машинное обучв"
и поручительства с иим связывается низкий пиг* ^л ™„„
, r nnjKtiH риск, ло дерево позволяет корректно
классифицировать все примеры.
Таблица 9.1. Данные о кредитной истории
№п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Риск
Высокий
Высокий
Средний
Высокий
Низкий
Низкий
Высокий
Средний
Низкий
Низкий
Высокий
Средний
Низкий
Высокий
Кредитная
Плохая
Неизвестна
Неизвестна
Неизвестна
Неизвестна
Неизвестна
Плохая
Плохая
Хорошая
Хорошая
Хорошая
Хорошая
Хорошая
Плохая
Долг
/ \
Высокий Низкий
/ \
Высокий риск
история
Долг
Высокий
Высокий
Низкий
Низкий
Низкий
Высокий
Низкий
Низкий
Низкий
Высокий
Высокий
Высокий
Высокий
Высокий
Кредитная и сгорис
Неизвестна
1 Поручительство
А
Плохая
1
П оруч иге льство
Поручительстве
Нет
Нет
Нет
Нет
Нет
Адекватное
Нет
Адекватное
Нет
Адекватное
Нет
Нет
Нет
Нет
i
Хорошая
/\
Нет Адекватное
/ \
i Доход
ото до $15
от 15 до $35
от 15 до $35
от 0 до $15
свыше $35
свыше $35
отО до $15
свыше $35
свыше $35
свыше $35
от0до$15
от 15 до $35
свыше 335
от 15 до S35
Долг
/ \
Высокий Низкий
/ \
ВыеокиВр»ск| |ср*диийРис«| Поручительство | нкмхйри«|
/\
Нет Адекватное
/ \
Д0*°Я [низкий риск]
Нет
/
Доход
Ич
Адекватное
(Низгайриск!
OT0floS15oTl5aoS35 c-areSSS orOfloSIS orl5aoS35 «um.S35
/ _| \_^_^l_,r_J——, ,-i |
|.ыс..и.,...| |]^^7] Q«3 [в^о^ [«^«г^ [н^р^
Рис. 9.;.). Дерево решении дм оценки кредитного риска
В целом, размер дерева, необходимого для ™™*»™"4ZZ^Z-
меров, варьируется в зависимости от проверяемых свойств. На рис. 9.14 псказанедере
во которое гораздо проще предыдущего, но позволяет корректно классифицировать
примеры из табл. 9.1.
Глава 9. Машинное обучение, основанное на символьном представлении.
393
] I низкий риск|
Рис. 9.14. Упрощенное дерево решений дм оценки кредитного риска
Имея набор обучающих примеров и несколько деревьев решений, позволяющих
корректно классифицировать эта примеры, следует выбрать дерево, которое с наибольшей
вероятностью позволит корректно классифицировать неизвестные экземпляры. По алгоритму
ГОЗ таким деревом считается простейшее дерево решений, покрывающее все обучающие
примеры. В основу такого предположения положена проверенная временем эвристика,
согласно которой предпочтение отдается простоте без дополнительных ограничений. Этот
принцип впервые был сформулирован в 1324 году философом-схоластом Вильямом из Ок-
кама (William of Occam) и получил название "бритвы Оккама" (Occam's Razor).
"Глупо прилагать больше усилий, чем нужно для достижения цели... Не стоит
приумножать сущности сверх необходимого."
Более современная версия этого принципа сводится к выбору простейшего ответа,
соответствующего исходным данным. В данном случае это наименьшее дерево решений,
которое позволяет корректно классифицировать все имеющиеся примеры.
Хотя принцип "бритвы Оккама" хорошо зарекомендовал себя в качестве общей
эвристики для всех видов интеллектуальной деятельности, его использование в данном
алгоритме имеет более точное обоснование. Если предположить, что существующих
примеров достаточно для построения корректного обобщения, то проблема сводится к выделе
нню необходимых свойств из дополнительных примеров. Простейшее дерево решений,
покрывающее все примеры, вероятнее всего, не будет содержать излишних ограничений.
И хотя эта идея основывается на интуитивных рассуждениях, ее можно проверить на
^ак!ике' Некот°Рые из "^их эмпирических результатов представлены в подразде-
днако, прежде чем переходить к их изучению, рассмотрим алгоритм
ШЗ.
позволяющий строить деревья решений на основе примеров.
9.3.1. Построение дерева решений сверху вниз
свой™оаС„Но°1вТГМУкГОЗ ДерСВ° решений ГП"»™ сверху внш. Заметим, что каждое
"к ка^ГиГ На6°Р «У4*™™ "P««P«» на непересекающиеся под».н°-
сво^ва пГД„™;ТзЬ'ГТН0-СЯТСЯ ВСС ПР"МСРЬ' С °ДК™ ЗНаЧеНИ-е1Г,"
ритму Ш3 Ka"«u" У*л дерева представляет некоторое свойство, и»
394
Часть IV. Машинное обУ<еН
„сновании которого выполняется разделение набора нр„мер0в. Таким о6рмом, ^„р^
рекурсивно строит поддерево для каждого раздела. Эта процедура длится до тех пор по-
ка все элементы раздела не будут отнесены к
одному и тому же классу. Этот класс стано-
в„тся конечным узлом дерева. Поскольку для построения простого дерева решений
важную роль играет порядок тестирования, в алгоритме ГОЗ реализован специальный
критерий выбора теста для корневого узла каждого поддерева. Чтобы упростить описание, в
этом разделе рассматривается алгоритм построения деревьев решений в предположении,
что существует соответствующая функция выбора. Сама эвристика выбора для
алгоритма ГОЗ рассматривается в подразделе 9.3.2.
Например, рассмотрим процесс построения дерева, представленного на рис. 9.14, на
основе данных из табл. 9.1. Имея полную таблицу примеров, алгоритм ГОЗ выбирает в
качестве корневого свойства значение дохода на основе функции выбора, описанной в
подразделе 9.3.2. При этом множество примеров делится на три части, как показано на рис. 9.15.
Элементы каждой части представлены порядковыми номерами примеров в таблице.
Доход
Примеры {1,4,7,11} Примеры {2, 3,12,14} Примеры {5, 6, 8, 9, 10, 13}
Рис. 9.15. Фрагмент дерева решений
Доход
от0до$15 от15до$35 свыше $35
Кредитная история Примеры {5, 6, 8, 9,10,13}
Примеры {2,3} Примеры {14} Примеры {12}
Рис 9 16. Еще один фрагмент дерева решений
Длгори™ индукции нанннает.о» ^^^—5^
элементов целевых категории. Алгоритм 1Ш строи д ^ t~
function lnduce_tree (exempte.se., Properties)
Be9in „„« example set принадлежат к
если все элементы набора примеров example^
одному и тому же классу, э классу,
то вернуть конечный узел, отнеся е
иначе, если »н°*еств° j!™^' именем которого являете,
то вернуть конечный узел,
„„_. на символьном представлении
Глава 9. Машинное обучение, основанное на сима
395
^пягсов в exemple set
объединение всех имен классов у _
ИНаЧвеь,Ора^ь свойство Р и назначить его корне*
удалГ^с^оТиз множества «^
У для каждого значения 1/ свойства Р
Begin „
создать ветвь дерева с меткой V;
к разделу partition, отнести
элементы множества example_set, для
которых свойство Р принимает значение V.
вызвать функцию induce_tree [partition,,
Properties), добавить результаты к ветви V
End
End
End
Согласно алгоритму ГОЗ функция induce_tree рекурсивно вызывается для
каждого раздела. Например, пусть к разделу (1,4,7, 11) относятся клиенты с высоким
риском; алгоритм ШЗ создаст соответствующий конечный узел. Затем в качестве корневого
узла поддерева раздела (2, 3, 12, 14) выбирается свойство "кредитная история". На
рис. 9.J4 элементы этого раздела в свою очередь разбиваются иа три группы: {2, 3),
{14} и {12}. Таким образом, строится дерево, представленное на рис. 9.14. Оставшуюся
часть дерева читателям предлагается построить самостоятельно. Реализация этого
алгоритма на языке LISP описана в разделе 15.13.
Прежде чем переходить к рассмотрению эвристики выбора, проанализируем
взаимосвязь алгоритма построения дерева и поиска в пространстве понятий. Набор всех
возможных деревьев решений можно рассматривать как пространство версий. Операции
перемещения в этом пространстве соответствуют добавлению частей дерева. Алгоритм
ШЗ реализует вариант поиска по первому наилучшему совпадению в пространстве всех
возможных деревьев. Он добавляет дерево к текущему поддереву и продолжает поиск,
ие возвращаясь к исходной точке. Это обеспечивает высокую эффективность алгоритма,
а также зависимость от критерия выбора свойств.
9.3.2. Выбор свойств на основе теорнн информации
Каждое свойство можно рассматривать с точки зрения его вклада в процесс
классификации. Например, если необходимо определить виды животных, то одним из
признаков классификации является откладывание яиц. Алгоритм ID3 при выборе корня текуше-
т1 оГвыГГ™" УДе"Ь"ЫЙ ВСС и«Ф°Р«а«ии, добавляемой каждым свойством. За-
Тео„"ZLTn вои™;ГеЮИее наибольшую информативность.
р=нтиГ :;;ir„ ™'скоГ ::t6ra™r —>» ™* -»г:
земпляр в пространстве воз!|е1Г' с соо6щеии<: MO™° рассматривать к* *
бору одногсLI"™!ш спТ С<Юбщений- neP<™"a сообщения соответствует .ы-
информациониую емкость" с о ""' С ""* Т°ЧШ Ч*"™ несообразно определи»
™~™™zz:ziz7c:0czn°™ от размера "р^^™и частоты
нь1хигрНУсраСвц°^ст?со0В60щГчГЫХ С00б1цсиий м°*"° 0№нить на примере азарт-
««тения с правильным прогнозом результата врашени* Р»
Часть IV. Машинное обучен"8
щении ,
„стки и подбрасывания монеты. Поскольку количеств »„
ки значительно превышает количество результатовГ1Г * C0"°""m *™ №"'
нь,й прогноз для игры в рулетку гораздо' инфо^Ги Р ГСеТоТ^вГ:^,
игре значительно выше. Следовательно, такое сообщение и™ Г л,
Роль вероятности передачи каждого coota ."„!„, Г ""*°P«
положим, что существует монета, при подбрасыванГГ™^"КауЮШГ° арШ^ Пр№
„ „„,, Е. ' н "одорасывании которой в трех из четырех случаев
выпадает решка. Если знать, что вероятность выпадания решки составляет >/4, то в >/.
случаев можно правильно угадать результат игры
Шеннон формализовал эти наблюден,»,, определив количество информации в сооб-
-чии как функцию от вероятности р передачи каждого возможного сообщения, а имен-
... -log, р. Имея пространство сообщений М={тх, тъ .... т„} „ зная вероятности р(/п,)
для каждого сообщения, информативность этих сообщений можно вычислить
следующим образом.
ЯМ] = f l>P(m,)log,(p(m,)) J = E[-log, p(m,)].
Количество информации в сообщении измеряется в битах. Например,
информативность сообщения в результате подбрасывания обычной монеты составляет
/[Co/nls-pl/ieacOlog.lpl/iearJ)) - p(ra,r)log,(p(ta"))
=-1/2log,(1/2)- 1/2 log2(1/2)
= 1 бит.
Если же монета такова, что вероятность выпадения решки составляет 75%. то
информативность сообщения равна
/[Соот]=-3/4 log,(3/4) - 1/4 log,( )/4)
=-3/4*(-0,415)-1/4-(-2)
=0,811 бит.
Это определение позволяет формализовать интуитивные рассуждения об
информативности сообщений. Теория информации широко используется в компьютерных науках
и телекоммуникациях, в том числе для определения информационной емкости
телекоммуникационных каналов, при разработке алгоритмов сжатия данных и устойчивых к
шуму коммуникационных стратегий. В алгоритме ШЗ теория информации используется для
выбора наиболее информативного свойства при классификации обучающих примеров.
Дерево решений можно рассматривать с точки зрения информации о примерах.
Информативность дерева вычисляется на основе вероятностей различных типов
классификации. Например, если предположить, что все примеры в табл. 9.1 появляются с олива-
ковой вероятностью, то
Р1ВЫСОКИЙ риск)*'/,, рЮредний P««)=V„ " Pi*»*™» Ри«)='/„.
Следовательно, информативность распределения D,„ описанного в табл. 9.1, а
значит, и любого дерева, покрывающего эти примеры, составляет
/[D.J=-6/Ulog.(6/14)-3/14logl(3/14)-5/14log,(5/14)
=-6/14-(-1.222)-3/14-(-2,222)-5/14-<-1.485)
= 1,531 бит.
Количество информации, о-^оГ^Ге^ Гф^ГвТрДеТкГ
корня текущего дерева, равно разности ооидаи ■—»> т ■-
Глава 9. Машинное обучение, основанное на символьном представлении.
397
дм завершения классификации. Количество „„,
чесгаа информации, иеоо"W" дерсва, определяется как взвешенное срсд,ес „^
„„„„, необходимое длязавр Вшешснное срСднес вычисляется как сум„а "'
формации во всех его "»а^дого поддерева и процентного соотношения пр„м ^
ведений информативна
„ом поддереве. пш<хгте, набор обучаюших примеров С. Если корнем текущсге
Предположим, что су j ^^ пр„ннмать п значений, то множество с бул„
дерева является свойство . к Информация, необходимая для завершу
разделено на подмножеств.£,С>^ р'сотвяя<г1 ■ершев»
построения дерева при выборе свойства г.
Выигоыш от использования свойства Р вычисляется как разность общей
информативности дерева и объема информации, необходимого для завершения построения дерева.
ва/п(/>)=/[С]-Е[Р]
Возвращаясь к примеру из табл. 9.1, при выборе в качестве корня дерева свойства
••доход" примеры будут разделены на три группы: С,-(1, 4, 7, 11),С2-(2, 3, 12, 14)
и С)=|5, 6, 8, 9, 10, 13). Информация, необходимая для завершения построения
дерева, составляет
Е[доход]=4/14'/[С,)+4/14*/[Сг] +6/1 4'/[С,]
=4/14 "0,0+4/14'1,0+ 6/14'0,650
=0,564 бит.
Информационный выигрыш от такого разбиения данных табл. 9.1. составляет
да/п(доход)= /[D,,] - Е[доход]
= 1.531 -0,564
= 0,967 виг.
Аналогично можно показать, что
данЦкредигная история) = 0,266
gain(debr)b = 0,581
gai'n(coHateral) = 0,576.
Поскольку доход обеспечивает наибольший информационный выигрыш, именно это
™^Г ВЬ10ирается в Ka4et™ К°Р«* Дерева решений алгоритма ID3. Такой анализ
рекурсивно выполняется для каждого поддерева до полного построения всего дерева.
93-3. Анализ алгоритма ID3
««."rnL™!??"™ юз стронт "р°стое дер"° р™-"й-совсем не очет:
примеры. Поэтому aW„™ гпТ,? М°ЖН° ЭФФе™° классифицировать некий*™*
иых приложениях Тесть, ™ протестирован на контрольных примерах и р»*
Н-ример, в работс ,Д ,СГ° "Р™*- работоспособность. ,
на пример,, задачи шасси*»., ' исслсД°вана производительность алгоритм»'"
шпилей Участвовали с^лыс Г Эндшп"лсй при игре в шахматы. В примерах ^
6bU0 н^-™« Р«п°з„аватьР„о"„пИ„ЛаДЬЯ " "ерНЫе К0Р0ЛЬ » K0HI- 3адаЧеП ""С
______^ т"ции' приводящие к поражению черных за три *<«
Течение
Часть IV. Машинное ооу
В качестве свойств использовались различные ru,-
"невозможность безопасного перемещения „ » «"УРОвневыс признаки, такие как
ных признака. 0рол" • ПР" эт°м учитывались 23 подоб-
С учетом симметрии область определения задачи в™™,,» , „
позиций, среди которых 474 ™с»чи приводятТГорГнТк, ' МИЛЛ"°"а """"л™"
ритм ЮЗ строил дерево иа случайно выбраад„м об™юГ» ^ " ^ X°M-
„а ,0000 различных комбинаций, которые тоже выбиТиГ """i"™,? ™™Р°™°-
тать, тестирования приведены в табл. 9 2. Более „oZZ l"*™™" ^ '"^
вания приводится в работе [Quinlan, 1983) ^ "" ^Ю Р"*""™» ™™Р°-
"Эти результаты подтверждаются и другими тестами и конкретными приложениями.
Существуют вариан™ алгоритма ЮЗ, позволяющие решать задачи в условиях зашум-
ленных данных „ очень больших обучающих множеств. Более подробная информация
приводится в работе (Quinlan, 1986а, б].
Таблица 9.2. Результаты тестирования алгоритма ЮЗ
Размер обучающего Процентное отно- Количество ошибок Прогнозируемый
множества шение г. размеру на 10000 примеров максимум ошибок
всего пространства
200 0,01 ,99 728
1000 0,07 33 146
5000 0,36 8 29
25000 1,79 6 7
125000 8,93 2 1
9.3.4. Вопросы обработки данных для построения дерева решений
В работе [Quinlan, 1983] впервые предлагается использовать теорию информации для
построения поддеревьев дерева решений. Именно эта работа положена в основу
приведенного выше обоснования алгоритма. Рассмотренные примеры были достаточно
понятны н просты. Однако в них не затрагивалось множество проблем, которые зачастую
возникают при работе с большими массивами данных.
1. Первая проблема — плохие данные. Это означает, что несколько наборов данных с
ндентнчнымл свойствами приводят к различному результату. Что делать при
отсутствии априорной информации о достоверности данных?
2. Данные для некоторых наборов признаков отсутствуют, возможно, нз-за очень
высокой стоимости их получения. Нужно ли проводить экстраполяцию или лучше
ввести новое значение "неизвестен"? Как обойти эту проблему?
3. Некоторые признаки могут принимать значения из непрерывного интервала. Такие
данные подлежат дискретизации и последующей группировке. Можно ли приду-
мать более эффективный подход?
4. Набор данных может быть слишком большим для алгоритма общения. Что летать
в этой ситуации?
Решение этих проблем привело к созданию нового поколения ^™ов^"™;
основанных „а построении дерева решений. Наиболее известным из н..являете» алго-
ритм С4.5 [Quinlan, i996]. Для решения этих проблем также используются такие приемы,
Глава 9. Машинное обучение, основанное на символьном предстаале,
399
„„шхся элементов (bagging) и усиление (boosting). Пос„
как добавление "О^*?™ ют собой векторы признаков „ли наборы при'^
»™a:zT^^ "Peo6poзoвaм,ям• удостовеРить^ в ««55 *
рТзул^классификад^ „ центов предполагает дублирование o6vu
Р Метод доба^ия »»^* ых о6учающих примеров. /7>„ «««*„**„„„„ ™>""»-
Ш1К множеств с заменой »™ ^ мвожества участвуют все примеры, „0 ^
„ формировании каждо , эюе„пляра в обучающем множестве. Этот вес .„,
еесового коэффициента кажло«в^вуюшето ^^ ^ ^^^ ^«Д**,
отражать ^"^„фикаторы, поскольку за счет весовых коэффициентов СИСГ
ЮТС" Т;^" — »» J»» примерах. Набор полненных классификаторов
Г„"Г« » • " бший классификатор. При использовании метода добавления „■£
™1 «я элементов вклад всех компонентных классификаторов одинаков, а в метощ
v ,шГ« классификаторы имеют различный вес, определяемый их точностью.
При работе с очень большими наборами данных их зачастую делят на подмножества, щ
одном из которых строят дерево решений. Это дерево проверяют на других подмножествах. В
настоящее врем литература по методам обучения на основе деревьев решений очень обшир.
на. Много информации содержится в Internet. Опубликовано большое количество результата,
использования алгоритмов построения деревьев поиска на этих данных.
И, наконец, достаточно просто конвертировать дерево решений в соответствующий набор
правил. Для этого каждый путь в дереве решен™ нужно описать в виде отдельного правила
Левая часть этого правила (глава 5) состоит из решений, приводящих к конечному узлу.
Действие в правой части выражения — это узел-лист или результат поиска по дереву. Затем этот
набор правил можно настроить таким образом, чтобы он описывал поддеревья дерева
решений. Впоследствии его можно применять для классификации новых данных.
9.4. Индуктивный порог и возможности обучения
В предыдущих разделах основное внимание уделялось обобщению по эмпирическим
данным. Однако важную роль в успешном индуктивном обучении играют также
априорные знания и предположения о природе изучаемых понятий. Индуктивный порог
" ' b,as)~ это лю6ой критерий, используемый обучаемой системой для ограни-
сле™ 1?°"°™ »°НЯТ"Й ИЛВ ""« выб°Ра "™*™й в Римках этого пространства. В
обычно „„1ГДеЛе УД" рассМ0тРе,и необходимость использования и типы порогов,
результате™,:Е^Г ° n°~e ^ ^"^^ ^"^
ания эффективности индуктивных порогов.
9-4.1. Индуктивный порог
Рога «^делен^об^Г "РИМеа °бычно Достаточно велико. Поэтому без некото-
Р»«могрим задачу классе!"5 ™ °СН0Ве ПОнска практически невозможно. Напри"*
*™ь"ь.х и отр;пн!":ции битовых *** е™»*«о"»» °снове %,
Роевне множества ™с Р,ер0В' П°С1»льку такая классификация- это пр«£
«Фикацни соответствует М0!ГК "* "°™«°жества. общее количество вариантов »*
рантов ™ссиф„^М~' этого м„ожества. д„ т npmgfm существу"
Д"аК0 для строки, состоящей из п битов, количество
TZ^ во вселенной. Поэтому без «^ Гри™ чZZ^—bTZ
„ожно организовать эффективный поиск в таких пространствах
Еше одним обоснованием необходимости порога служит сама природа индуктивного
обобщения. Обобщение не сохраняет истинности высказываний. Например, встретив
честного политика, нельзя утверждать, что все политики честны. Сколько честных
политиков нужно встретить, чтобы прийти к такому заключению? Несколько сотен лет назад
эта проблема была описана как задача индукции следующим образом.
"Вы говорите, что одно предложение вытекает из другого. Однако необходимо признать,
что это умозаключение не интуитивно и не демонстративно. Тогда какова же его природа?
Можно сказать, что оно проверяется экспериментально, но это слабое утешение. Все
умозаключения, основанные на опыте, предполагают, что будущее аналогично прошедшему, и
что сходные причины приведут к подобным результатам". [Hume. 1748].
В XVUl столетии эта работа считалась опасной, особенно на фоне попыток религиозного
сообщества математически доказать существование бога. Однако вернемся к индукции.
В индуктивном обучении обучающие данные — это лишь подмножество всех
экземпляров области определения. Следовательно, для любой обучающей выборки возможны
различные обобщения. Вернемся к примеру с классификацией битовых строк.
Предположим, что в качестве положительных примеров некоторого класса строк системе были
предъявлены строки {1100, 1010}. Для этого примера допустимо много различных
обобщений: все строки, начинающиеся с "1" и заканчивающиеся "0"; множество строк,
начинающихся с "1"; множество четных строк или любое другое подмножество,
включающее рассмотренный пример {1 1 00, 1 01 0}. На основе чего система может сделать
обобщение? Одних данных для этого недостаточно, поскольку все приведенные примеры
обобщений согласуются с этими данными. Обучаемая система должна сделать
дополнительные предположения о "вероятных понятиях"'.
В задачах обучения такие предположения зачастую принимают форму эвристик
выбора ветвей в пространстве поиска. Примером такой эвристики является функция выбора
на основе теории информации, используемая в алгоритме ШЗ (подраздел 9.3.2).
Алгоритм ШЗ выполняет поиск экстремума в пространстве возможных деревьев решений. На
каждом этапе он проверяет все свойства, которые можно использовать для расширения
дерева, и выбирает из них наиболее информативное. Это "жадная" эвристика, поскольку
предпочтение отдается тем ветвям в пространстве поиска, которые дают наилучший
результат в продвижении к цели. , „ _ _ажт
Такая эвристика позволяет алгоритму ШЗ выполнять эффективный поиск в
пространстве деревьев решений и решить проблему выбора приемлемого сообщения „а, осном
ограниченного "объем, данных. В алгоритме ШЗ предполагается, что мню™^;
=о, корректно класспфншфуюшее все об>чаюш„е примеры, °^™!*°С"°^1^
рехтио классифицировать!, последующие ^—^^^"ll
новано на том, что маленькие деревья, скорее всего. 6>дут соотвс^
«анным. Если же обучающее множество достаточно велико тс,™е лревь. далжны
включать все существенные признаки для «^^^^^^^t
«но в подразделе 9.3.3, это предположение »6ос^ьшается ^ J ^ „.
№. Подобное предпочтение простых определении понятии испол .
Ритмах обучения, как CLUSTER/2 из подраздела 0.6.-.
Г"ввв 9. Машинное обучение, основанное на символьном представлении..
401
„га предсгамя" собой синтаксическое огра„ич
™„ индукт»вного "оро. т„ис пороги не являются эвристиками дд, в "е
1 .^пространстве ™»«£J* „^ничейными средствами языка. НапРИМе *
IЛ^*«»»» mTaaZ бол^граничительныи язык представлен™, ч£м *
^^ГсТ^еГ/уТньшение размера пространства понятии обеспечивает ,ы"
^7ф«'™»»т^сСГпС™. К°™РЫЙ М0ЖСТ °Ка3аТЬСЯ ЭфФек™в"«« пр„
Примером синтаксического к^ ограНнчение описания примеров шаблонам,,
кдасснфивши" битовых стро . каждый ша6л0(1 определяет класс всех соответст'
состоящими ш символов (и' ' задастся следующими правилами.
^е.г.стро^.э- рокисодаржится „^ знач^
iz:jrzzzz> «»»■>»« ■<>• - >~* —•
гым в некоторой позиции шаблона строки содержится -1 -, значит,
Если в неюдч^ „„„„жать "1" в этой позиции.
и целевая строка должна содержать
Символ ■#• в некоторой позиции соответствует либо "1 - либо -О".
Налрнмер.шаблон"1##0"определяетнаборстрок(1110, 1100, 1010, 1000).
Использование классов, соответствующих таким шаблонам, значительно уменьшает
размер пространства понятий. Для строк длины п можно определить 3" различных
шаблонов. Это значительно меньше, чем 2 в степени 2" возможных понятий в
неограниченном пространстве. Порот также позволяет упростить реализацию поиска в пространстве
версий, поскольку в этом случае обобщение означает замену символов "1" или "0" в
шаблоне символом "#". Однако наличие этого порога приводит к невозможности
представления (а следовательно, и изучения) некоторых понятий. Например, с помощью
такого шаблона нельзя представить все строки, содержащие четное число нулей и единиц.
Противоречие между выразительностью и эффективностью — типичная
проблема обучения. Например, в программе LEX четные и нечетные целые не различаются.
Следовательно, она не может обучиться эвристике, основанной на этом различии. И
mUff .иГ?"1 пРогРамма* порог изменяется в соответствии с данными
иорт°"сра6а™,а?м"""В(> °буЧаШЫХ пР°П>амм основываются на фиксированном
конъюнкцией литералов Эт "JUnCllve b,as> ограничивают возможности обучения
дизъюнкции в определен.! ° ДОСтато1шо ™пичный подход, поскольку использование
предположим, что в предта П°т"" вшь1вает проблемы при обобщении. Например,
можно свободно исполып„,!"е"И" ттт" в Рамках алгоритма исключения кандидата
иш^.с BdTb операцию ДЧ--Т- --- ™. -- ..~.,*пег-
ним обобщением набора пол раш,ю Дизъюнкции. Поскольку максимально конкрет-
примеров, то обучаемая maZ*™?"* "Р^ров является простая дизъюнкция эти
"а бУДет просто до6а№т^с"а8°°6пде "е сможет выполи,
Огртте,,ш н<вы=°пеРанды [Mitchell, 1980].
■ , ~ читаемая CUCTfua в с F Л°"л^'-И 1IJJUC1UM дмлчип^ц—
™ будет „р„по до6 с»а вообще не сможет выполнить обобщение. Такая снеге-
Огртте,,ш ття 2 'Тл"П^тш 1Mitchel1. 1980].
конъюв ые пороги 2^'"""°° WmtaHon on the пптЬет of disjuncts). Чис»
выразитель n<v-r, __. wlca слишкпи-^„ „ ,-r-„.,rwTb
™слТлГ"°ПЬ "ре'1«аалешТц,СЯмГжИШ'С0М Же"КИМИ ™ ми°"« приложений. Повысить
-™° Дизъ„„пов. можно, разрешив использовать небольшое ограниченное
402
Часть IV. Машинное обучен"8
векторы признаков (feature vector)— это представлен,,. „
„наборы свойств, значения которых различны ллТТ, °писыва»шис объекты че-
^реУтавлены именно наборами^™" '"""" °бЪљ  та6" »■' °6—
JZ^~^:^ ЭТ° 4-W~— "• 'ФФ—сть кото-
Р Хорновсше выражения (Hon, clauses) налагают ограничен», „а форму вь1вода ис
подазуемую при автоматическом доказательстве. Хорновские выраже^еГьи" „™-
саны в разделе 1.2.2.
Помимо синтаксических порогов, рассмотренных в этом разделе, во многих
программах при описании области определения используются конкретные знания о ней Они
о6еспечивают чрезвычайно эффективные ограничения, или пороги В разделе 9 5 осве
шаются подходы к выбору порогов на основе знаний. Однако, прежде чем рассматривать
роль знании в обучении, кратко рассмотрим теоретические результаты, обосновывающие
эффективность индуктивных порогов (см. также раздел 16.2).
9.4.2. Теория изучаемое™
Задачей индуктивных порогов является такое ограничение множества целевых
понятий, при котором возможны эффективный поиск и формирование удачных определений
понятий. Проблема количественной оценки эффективности индуктивных порогов была
исследована теоретически.
Качество определения понятия можно выразить в терминах корректной
классификации с его помощью объектов, не включенных в обучающее множество. Несложно
написать алгоритм обучения, формирующий понятия, с помощью которых можно корректно
классифицировать все примеры из обучающей выборки. Однако, поскольку в области
определения обычно содержится большое количество экземпляров, часть из которых
может быть недоступна для обучения, алгоритм должен строить обобщения на основе
некоторой выборки нз всех возможных примеров. Поэтому чрезвычайно важную роль
играет эффективность работы алгоритма на новых данных. При тестировании алгоритма
обучения множество всех примеров обычно делится на два непересекающихся
подмножества: обучающее и тестовое. После обучения программы на обучающем множестве ее
проверяют на тестовом.
Эффективность и корректность алгоритма можно рассматривать как свойство языка
представления понятий, т.е. индуктивного порога, а не конкретного алгоритма обучения.
Алгоритмы обучения выполняют поиск в пространстве понятий. Если это пространство
хорошо структурировано и содержит удачные определения понятии, то люоои
обоснованный алгоритм обучения будет эффективно работать на этих определениях. Если же
пространство является очень сложным, то алгоритм не даст хороших результатов. Это
можно пояснить „а следующем примере. ^
Понятие "мяч" является изучаемым. Для его изучения »м. „„„„„..
описания свойств объекта. Увидев относительно небольшое -личество^мяч. ™
«жег „р„„т„ к выводу, т мяч„ круглые. ™™^—^«—
«УЧ.™. д0„устим, 1руша ЛЮДей прошла по "^^".нными объектами". По-
миллионов произвольных объектов и назвала этот класс .БыиР „пелставления
«л* "выбранный объект" не просто требует чрезвычайно сложн,огопре.™тен™.
С-рее всего, с его помощью будет невозможно »^^Z^Z^Z.
принадлежащие ко множеству выбранных. Эти рассуждения прив д
г<»ва 9. Машинное обучение, основанное на символьном представлении.
403
„ „снятие в пространстве, согласованном с m
„й^еиия находят поня иожно опретяип „ ми
- ""С? 2-" ^Гд^и "языка с порогам. При попыттЛ, С *
Понятие «w „ыраэить срсдст» длинный список всех свойств „
•^^•^'""''^Хп." жио 0„рсда,ять . терминах^'
■"* "Го класса- ПотГОИ)' "Явления понятий. В целом можно сказать ""
££ -^ ' ;:;;„Гт^Г конкретной области определения, а . £
Г^емость' Ф0РКУ"ЯИ««- » ' ,„ понятии.
„"Гси^ксичсских свойству дам0 „рииимать во внимание „е только эф.
""при определения *^ ^Uopa данных. В целом, нельзя рассчитывать Га
фективность, но и °*а"™™яого п0„ятия иа осиове случайного набора „р„М1,рое
„острое""* точного и корР атического ожидания в статистике, мь, mxomi
Скорее, подобно »ычиы™ „оятиостьк> является корректным. Следовательно, кор.
понятие, которое с высок и корре)тшй классификации экземпляра во в«„
ряотгосп. понятия — 'То всэ~
пространстве "Р""^ сяньи „отитий необходимо также учитывать вероятность
Помимо »№ск" Сушествует небольшая вероятность того, что нетипичность
вХГ; н^в "нведа к невозможности обучения. Следовательно, конкретное
оаспГе^ние положительных примеров или конкретное обучающее множество, вы-
данное ю этих примеров, могут оказаться недостаточными для формирования корреп-
ного лонятия. При этом нужно учитывать две возможности, вероятность нетипичное™
примеров и вероятность нахождения удачного понятия (обычиую ошибку оценивания). В
приведенном ниже определении РАС-изучаемости эти возможности ограничены
значениями б и £ соответственно.
Итак, итучаемость— это свойство пространства понятий, определяемое языком ил
представления. При исследовании этого пространства необходимо учитывать
вероятность нетипичности данных и вероятность, с которой результирующее понятие позволят
корректно классифицировать неизвестные экземпляры.
В 1984 году эти рассуждения были формализованы в теории приближенно
корректного с высокой вероятностью РАС-обучения (probably approximately correct learning)
[Valiant, 1984].
Класс понятий является РАС-изучаемым, если существует эффективный алгоритм,
который с высокой вероятностью находит приближенно корректное понятие. Под
приближенно корректным" понимается понятие, которое позволяет корректно клас-
высокоЛГ ВЫС°КИЙ Пр0Цт Н0ВЫХ "Римеров. Таким образом, алгоритм должен с
этомТачГоГОСТЬ10 Т" П0НЯ™е' К°™Р« ™«™ почти корректным, при
ZZZZ7*. Z71TJ**mm"m- Ин«Р«нНИ свойством этого «**
. от п°'
примеров в „Рос^а™тве"да„Г!Яп,':''ЬНО 3авИСИТ т Распределения положительны»
рога и желаемой степени v, «висит от природы языка понятий, т.е.
г»'« л желаемой степени vt "И"риды и.)ы|\а пилл»»», •-
Делении примеров зачаст! ""' К НаКонец' с"елав предположение о рК°Г
меньшим количеством „риХов"0*"0 "0ВЫСИТЬ производительность, т.е. обойтись
Формально понятие РАС-m™ ,
™,"fХКпа гюю™й о, ах-^? 0ПРедеш,ется следующим образом. Пусть<
Формально понятие РАС
о множество понятий с .'"3учаемос™ определяется следующим образом. Пусть С-
егупатьщгоритмы ш^ т^^° экземпляров. В качестве понятий могут^
™ен^рица1с,,ьныс ь, ш лругис средта ^^ ^ на ю
№орнт«,об„^ювд/с^ Множено является РАС-изучаемым, если суше^
Часть IV. Машинное
обуй8'
из
,. Если для ошибки понятия с и вероятности нена.™
горитм, который за полиномиальное время 1 /ТиТТ"' '"""""* ° с>"^т»ует ал.
ров размера п = \Х\ находит такое понятие с " "У^ной выборке примс-
С, при котором вероятность ошибки обобщения ющссс' мемеитом множества
Следовательно, для элемента у, подчиняюшегос "РСВЫШак,шм Е- меньше, чем 8.
элементы множествах, выполняется соотношение' ^^ *' распРелслеиию. ™ "
Р[Р1у неверно классИф„ц„руеТСЯ с „шощью ^^
2. Время рабслы алгоритма для л примеров «b-,.w„
, /е и 1 /8. ^ "СЯ »*»<ноыиашшм н составляет
Это определение РАС-изучаемости позволило доказать эффективность „ескоэькнх
„идутггивных порогов. Например, в работе [Valiant, 1984) тюка*шо что ^с "uZIZ
k^NF является изучаемым. Выражения k-CNF- это предложения в™™ но
„ормальнои форме с ограничением „а количество дизъюнктов. Выражения формируются
п, операторов конъюнкции с,, е„ ...с„ где с,- дизъюнктивное выраже„иГ™ее
„е более чем из К литералов. Этот теоретический результат обосновывает общепринятое
описание понятии в конъюнктивной форме, используемое во многих алгоритмах
обучения. Мы не будем приводить доказательство этого утверждения, а отошлем читателя к
исходной статье, где обосновывается этот результат, а также свойство изучаемое™ прн
использовании других порогов. Результаты исследования изучаемое™ понятий и
индуктивных порогов приводятся в работах [Haussler, 1988] и [Martin, 1997].
9.5. Знания и обучение
Алгоритмы ID3 и исключения кандидата выполняют обобщение за счет поиска
закономерностей в обучающих данных. Такие алгоритмы называют основанными на пособии
[similarity based learning), поскольку обобщение для них является функцией подобия
обучающих примеров. Пороги, реализованные в этих алгоритмах, представляют собой
синтаксические ограничения на форму представления изученных знаний. Они не предполагают
строгих офаничений для семантики области определения. В этом разделе рассматриваются
алгоритмы обучения, основанные на объяснении (explanation-based learning), которые при
обобщении руководствуются знаниями об области определения. На первый взгляд идея
использования априорных знаний в процессе обучения кажется противоречивой. Однако и в
машинном обучении и в исследованиях ученъгх-когнито.тогов известен тот факт, что
дополнительные априорные знаиия об области определения повышают эффективность
обучения. Одним из подтверждений важности знаний в процессе обучения является та что
алгоритмы обучения, основанные на подобии, опираются иа относительно бсаьщонооъем
Дающих данных. В отличие от них человек может сформировать корректные оообще-
"ия „а основе нескольких обучающих примеров. Поэтому во многих практических
приложениях такие же требования выдвигаются и к обучаемым программам.
Еше одним аргументом а пользу априорных знании "И"™J£ *^^"0£°£
множестве обучГюших примеров можно ^^^ Г^ы^л-
""И, большинство из которых окажутся либо бессмысленны порогов. В
*- "3 средств решения этой проблемы '^^^Гп^З^-.-
эт°« разделе рассматриваются алгоритмы, вы.ходяши:за "Р*^™ ^7Жгга
""» синтаксических порогов и подтверждающие роль строгих знании оо ос,
лсиия в процессе обучения.
Г"ада 9. Машинное обучение, основанное на символьном щ
405
9 51. Алгоритм Meta-DE _ зто один ш первь1х и
Lm, Меш-DENOTAL [Buchanan. M«^ ^^ Meta.DENDRAL фор^
№Си»«е,<иязнашшвиндук™^^АЬ ^с-спектрограф.гческого анализа
„рдаревпри.^ ^„о,, DENU жских молекул на ОСНоае •»
" -"""С SJS» ексТЗНШт№1^экспериментов. ™"4£
^^-"SS^- бомбардировке электронами, что пр„.
вГГсс-спекгрографе молекулы под^ Р^_ Специал„сты.химнки измеряют вес №
водит к разрыву »датар"^Гинтерпретируют эти результаты, чтобы восстановить
тавшихся фрагментов молекулы и . У DENDRAL 3„а„„я используются в ф„рме
„сходную структуру соединен'».в * ких дан„ых. Исходным предположением
правил интерпретации масс-спе у , ^ определенноГ, молекулярной структуре. Вы-
для правша служит граф. »°в >,„ мест расщепления молекулы,
водом правила являете!irpaq>У эти правила на основе результатов масс-
Алгоритм MeB-UhN^Za„lU м0лекул известной структуры. Входными данными
спектрографтескогонс ^ прущра известных соеднненнй, а также масса „
алгоритма Meta-ut«u полученных в результате спектрографической об-
ТГ шГоГ РП ^Гз'ихТиных восстанавливается исходная структура
Го^лы ОбобТение данных о нарушении структуры конкретных молекул становится
основой формирования единых правил.
Пои обучении в программе DENDRAL используется Теория полупорядка" из
органической химии. Хотя эта теория не позволяет напрямую строить правила цывода, она
поддерживает интерпретацию нарушений структуры известных молекул. Теория
полупорядка состоит из правил, ограничений и эвристик следующего вида.
Двойные и тройные связи не разрываются.
В экспериментальных данных можно наблюдать лишь фрагменты, размер
которых превышает 2 атома углерода.
На основе теории полупорядка в программе DENDRAL формируются пояснения
структурных нарушений, указывающие наиболее вероятные места расщепления, а также
направления возможного перемещения атомов вдоль линий разрывов.
Эти пояснения составляют набор положительных примеров для программы
формирования правил. Ограничения в левой части правил строятся на основе поиска от общего к
частному. Работа алгоритма начинается с рассмотрения наиболее общего описания
расщепления Х,'Х2. Этот шаблон означает, что расщепление, обозначенное символом "*",
может произойти между любыми двумя атомами. Этот шаблон уточняется таким образом:
добавление атомов: Х,*Х -> X -X "X
где оператор ". •• означает химическую связь, или
MHcn™W"««. а™°° « атрибутов атомое: X, -V _ С'Х,.
Алгоритм Meta-DENDRAT nf,
иска экстремума в ппо™ 00)™ется только на положительных примерах путем по-
тнкого ограничен™ ПгавГСТВС "°тА Излишн« обобщение предотвращается за счет
обучающих примеров в посКаНЛ"ЛаТОВ' "Р" К0Т0Р0М он" покрывают лишь половину
Уточняются путем моли*и1-,ЛеЛУК>Щ"Х М0ДУЛЯХ программы эти правила оцениваются »
Преимущество алЗгГГ TZT °6щИХ Ил" час™ь« ПР=">ИЛ-
™ определения для ,ю6.', NDRAL состоит в использовании знаний об облас-
Реобразованш, од„о„ер„ых данных в более удобную форму. Эт»
Часть IV. Машинное о
бучени»
печивает устойчивость программы к шумам за счет юклкя,™.
Жданных на основе теории, а также способность к обучеХ„а^ПСттКтлм0 ош^-
о 5.2. Обучение на основе объяснения
в обучении на основе объяснения явное представление теоретических знаний об об
0сш определения используется для построения пояснений "к обучающим np„„£pt
обычно с целью доказательства того что данный пример следует „з^той теориГфнГ
рация шума в обучении „а основе объяснения выполняется за счет обобщения пояснений
к примерам, а не на основе самих примеров. При этом выбираются соответствующие
аспекты опыта, и обучающие данные систематизируются в строгую и логически
согласованную структуру.
Существует несколько различных реализаций этой идеи. Например, она оказала
значительное влияние на представление общих операторов планирования (см. раздел 5 4 и
9.5) в программе STRIPS [Fikes и др., 1972]. В алгоритме Meta-DENDRAL тоже
использованы преимущества теоретической интерпретащш обучающих примеров. В последние
годы многие авторы предложили альтернативные формулировки этой идеи [DeJong и
Мсопеу, 1986; Minton, 1988]. Типичным примером является алгоритм обобщения на
основе объяснения, разработанный Митчеллом и его коллегами в 1986 году. В этом разделе
будет рассмотрен вариант алгоритма обучения иа основе объяснения EBL (explanation-
based learning), разработанный Депонтом и Муни (DeJong и Моопеу] в 1986 году.
Исходными данными для алгоритма EBL являются следующие.
1. Целевое понятие. Задача обучаемой системы — выработать эффективное
определение этого понятия. В зависимости от типа приложения целевым понятием может
быть система классификации, доказанная теорема, план достижения цели или
эвристика для решения задачи.
2. Обучающий пример. Это пример цели.
3. Теоретические сведения об области определения. Набор правил илн фактов,
используемых для объяснения того, почему обучающий пример является
экземпляром целевого понятия.
4. Критерий фунщионачъности. Средства описания формы, которую может
принимать определение понятия.
Для иллюстрации алгоритма EBL рассмотрим пример изучения понятия "чашка". Эта
задача была описана Вннстоном (Winston) в 1983 году н адаптирована к обучению на
основе объяснения Митчеллом и его коллегами в 1986 году. Целевым понятием в этой задаче
является правило, которое можно использовать для выяснения, является ли объект чашкой.
premiseiX) -> сир{Х),
гДе premise - это конъюнктивное выражение, содержащее переменнуюi*
Допустим, теоретические сведения о чашках представлены в виде следующих правил.
Hftablem a holds liquidlX) -> сир(Х) ,,„,„wm
Pamz. W) л concaveiW) л points_up(W) -> holds Jqu,d(Z)
»9ht(Y) л part{Y, handle) -> HftableiY)
smalHA) -»light(A)
made_of{A, features) -> light(A)
Гла<* 9. Машинное обучение, основанное на символьном представлении... 407
экземпляр целевого понятия, который в данном случае
Обучавший пример— эт0
имеет такой вид:
cuplobj))
smalllobj))
рагНоЬП, handle)
ownsibob, objV
parWbj), bottom)
part{obj\, bowl)
pointsyplbowl)
concave(bowl)
colorlobj), red).
согласно критерию функциональности целевые now,.
И, наконец, предполож , ^ ташх на6людаемых, структурных свойств объек-
тия должны определяться ^ (вогнутость). Можно сформулировать правила, позво-
^^'бучаемоГсистеме определить, является описание функциональным „ли это
"Тпо^ГэГХети-ских сведений можно обосновать тот факт, что пример
действительно является экземпляром изучаемого понятия. Такое обоснование будет
иметь вид доказательства, что целевое понятие логически вытекает из примера, как для
первого дерева на рис. 9.17. Заметам, что в этом объяснении такие несущественные при-
меры из обучающих данных, как красный цвет со)ог( оЬ/1, red), не учитываются, а
внимание акцентируется на важных свойствах изучаемого понятия.
На следующем этапе обучения объяснение следует обобщить и получить определение
понятия, которое можно использовать для распознавания других чашек. В алгоритме
EBL эта процедура реализована за счет замены переменными тех конкретных значений в
дереве доказательства, которые связаны только с конкретным обучающим примером (см.
рис. 9.17). На основе обобщенного дерева алгоритм EBL определяет новое правило,
заключением которого является корневой узел дерева, а начальными условиями —
конъюнкция листьев
smalUX) лрагЦХ, handle) л part(X,IV) л concave(lV) л points _up(W) -> cup(X).
При построении обобщенного дерева доказательства основная цель — заменить
переменными те константы, которые относятся к обучающему примеру, и оставить
конкретные значения и ограничения, которые являются частью теоретических сведений об
области определения. В этом примере значение handle (ручка) относится к теоретиче-
таТеГГ" °6ЛаСТ" т^лжпт- а ™ * обучающему экземпляру. Поэтому оно ос-
Обобщ'Г™™" «Р»™»е в окончательном правиле,
примера пазли „fePeB° ""f^™"™ «ожно построить на основе обучающего
зГльстваТ"0ZZToT " ^™ Митчелла сначала строится дерево
доноса, получившего название „ °Ра' """"^ МТем °ЪоЪ^™ <= помощью
пронесли обобщенная цель (в mL?"""" '"""' <B°al reB«ssion). В процессе регрессии ие-
казательства, при этом кон
примере сир(Х)) приравнивается к корню дерева до-
подстановки выполняются пе Кре™Ые значен"я заменяются переменными. Такие
менены вес соответствуюш„„'<УРСИВ"0 П0 """У деРевУ Д° тех пор, пока не будут №
боте [Mitchell и др. 19g6, кон«анты. Этот процесс более подробно описан в ра-
408
Часть IV. Машинное обучен*
Доказательство того, что объект оЦ1
является чашкой
cupiobjl)
/iftab/e(oby1)
holds /iquid(ob)1)
цдМоЬП) раЩоЬП, handle) ютоЦ\,Ьощ сопсащьоШ) ^ISJJp,b0»/)
stmll{obj\)
Обобщенное доказательство того, что объект X — чашк:
сир(Х)
lightiX)
part{X, handle) part[X, W) concavelW) pomts_up{W)
smalUX)
Рис. 9.17. Частное и обобщенное доказательство тот факта, что объект Xявляется чашкой
В [DeJong и Моопеу. 1986] предложен альтернативный подход, позволяющий
строить обобщенные н частные деревья одновременно. Это достигается благодаря особому
варианту дерева доказательства, содержащему правила выявления отличии цели от
понятия, сформированного за счет подстановки переменных в реальное
доказательство- Это дерево называется структурой объяснения (explanat.on structure) (рис. У. 1») н
представляет абстрактную структуру доказательства. Обучаемая система
поддерживает два различных списка подстановок для структуры объяснения: список ™^™"*
подстановок, необходимый для объясненил обучающего "Р™^"™'^™^
подстановок для обоснования обобщенной цели. Эти списки подстановок строятся
процессе создания структуры объяснения. „к™,™ Пусть s
Списки общих иТастных подстановок формируются следующ«<%££%££
» •. - списки частных и общих подстановок «^еааш^^^^.
»"№«.„„ е, и е2 в структуре объяснения s, н s, обновляются по следующему прав у
ei находится в левой части правила, а е:
tlten begi
- в его заключении.
S, и e,s, %объединить е, и е,
г> = наиболее общий унификатор из е
^ш>7нное обучение, осноТа^оТн^и^ьном представлении..
409
,. значение s,, скомпоновав его с г
при условии s, %06новить ' e,So %о0ъединить 8l и в *
Г-'н^олее с«ий уни*икаТор - ,.
пр„ условии ., %о6ЯОВИТь значение ... скомпоновав его с г>
S'°S'T' „мпя а в, - это факт из обучающего
end „лито» в лавой части правила. . ра
if е, находится
*"" begin бпшй унификатор из .А и «Л %объе„Инить в, и „,
j = наиболее общий униФи г %при условии s>
*обновить значение s„ скомпоновав его с т.
s, -s.T.
s.'S.T.
end
bghtiYl рагЧЪ '«ndte) part(Z. W) concave(W) po'mts_up(Y/)
II II II II И
6ф№ partlotyl.ta/itfe) ^^ ^^ conca«s[bowO poirtts_up<boiW)
smsfl(oty'l)
/Vc. 9. /S. Структура объяснения для примера с чашкой
В примере на рис. 9.18
i, = (ofy'1/X, оЬУ1/У, otu</4, оЬЛ/Z, bovW/W)
; = W. Y/A, X/Z).
Применяя эти подстановки к структуре объяснения, показанной на рнс. 9.18. получим
частое и общее деревья доказательства, показанные на рис. 9 17
Преимущества обучен™ „а основе объяснения сводятся к следующему.
10^ающ,е прт,еры зачастую содержат несущественную информацию, наподобие
^Гс^Г™ ТГ' Т«Р«™ские сведения об о'бласти определен».»
2 Каждый п и» 'е аТЬ Ю 0бучак>щих примеров важные аспекты.
' рых дабоТёиолонТ™^ "Н0ЖССТВ0 Ручных обобщений, большая часть кото-
РУ" заведомо адекватХ б'"Мысле1ии. ™бо ошибочна. Алгоритм EBL форм»"
«ость с теоретическими сведе°еН11Я " обеспечивает "* логическую согласован-
3. Используя знания об об
«а основе одного обу,ающ™°ПредеЛСННЯ' алгоритм EBL обеспечивает обучен*
Часть IV. Машинное обучен"15
л Построение объяснений позволяет обучаемой систем,. „„,,
й между ее целями и опытом, подобно тому каЛп^ "РеДПОЛагать н™™-= «-
оСНове се структурных свойств. У * ""Р^нис чашки создается т
Алгоритм EBL применялся для решения многочислению. •,»„.. с
„p»tep.PB Рабо- [Mi.chel, и др., ,983] обсуждается »^^Ж^
тмуЬЕХ. Допустим, первый положительный пример использован я перац и ОР,'
„ретился при вычислении интеграла W dx. Согласно алгоритму LEX этот " „„еР
с1а„ет элементом множества X, содержащего наиболее конкретные обобщения Од
нако человек сразу же определит, что используемый при решении этой задачи прием
ве зависит от значении коэффициента и показателя степени и может применяться
д„я любых вещественных зиаченнй этих переменных (за исключением показателя
степени -1). Поэтому можно обобщить этот пример и сделать вывод о том, что
операцию ОР1 необходимо применять для вычисления любых интегралов вида V2*"
" ах, где г, и гг — любые вещественные числа. Для такого обобщения алгоритм LEX
был модифицирован на базе знаний алгебры и обучения на основе объяснения.
Реализация алгоритма обучения на основе объяснения на языке PROLOG приводится в
подразделе 14.8.3.
9.5.3. Алгоритм EBL и обучение на уровне знаний
Алгоритм EBL элегантно демонстрирует роль знаний в обучении, однако при его
изучении возникает много важных вопросов. Один из самых очевидных сводится к
следующему: чему на самом деле учится система на основе объяснения? Чистый
алгоритм EBL позволяет лишь выучить правила в рамках дедуктивного замыкания
(deductive closure) существующих теоретических сведений. Это означает, что
изученные правила можно сформулировать лищь на основе базы знаний без
использования обучающих примеров вообще. Основная роль обучающего примера сводится к
фокусированию внимания обучаемой системы на существенных аспектах области
определения задачи. Следовательно, алгоритм EBL зачастую рассматривают как
одну из форм ускорения обучения или реструктуризации базы знаний. Он ускоряет
процесс обучения, поскольку не требует построения дерева доказательства,
лежащего в основе нового правила. Однако он не позволяет изучить никакой новой
информации. Это отличительное свойство алгоритма было сформулировано Дитрихом
(Dietterich) при обсуждении обучения на уровне знаний в 1986 году.
Алгоритм EBL извлекает неявную информацию из набора правил и делает ее явной.
Например, рассмотрим игру в шахматы. Минимальные знания правил этой игры в
сочетании с неограниченными возможностями просчета наперед различных комбинации
обеспечивают компьютеру чрезвычайно высокий уровень игры в шахматы. К сожале-
»ию. шахматы слишком сложны для реализации изучаемого подхода. Любая обучаемая
«а основе объяснения система, которая сможет освоить стратегию игры в шахматы, на
гамом деле получит новые (с практической точки зрения) знания.
Алгоритм EBL также позволяет отказаться от требования назичияполной икор
**™°й теории описания области определения и ^"WfZiS
Мнения неполных теоретических сведений в контексте ЕМ- Обуи-менс*«*
^fP-енг дерева решений. Ветв^^^^
Глава 9. Машинное обучение, основанное на символьном представлении.
411
яние методологии выделения кредитов и выбор „,
шью неполной теории. Ф°Р«НР0В'Я1[азательств. подлежащего исправлению,
„ого из нескольких неуспешных^ ^ о6ъяснен„я предполагает со н„те
Дальнейшее развитие °6Учен» е подо6ия. в этой области тоже было „редло.
ш,ю с подходом к обучению на ^ ^^ предполагающих использование алго-
жено множество базовых схем,, ^^ т основс теории с Последу,ощей П(,
ритма EBL для уточнен!..' «Ч£ данных компоиенту обучения иа основе под06ия
редачейзтих частично оооош ^ неудачные объяснения можно использо.
для дальнейшего оЬ°°™^оты „ории с последующим переходом к обучению на ос.
~°£ь. вопросы«аи„я =1Г- - = ^-Uj.
дТнГ^етГ^ГнГГсГериров^иых правил, подлежащих сохраиеиГ
9.5.4. Обоснование по аналогии
' Если "чистый" алгоритм EBL обеспечивает лишь дедуктивное обучение, то обосно-
ванне! аналогии - это более гибкий метод использования имеющихся знании. Обос
Гвание „о аналогии строится на следующих предпосылках. Если две ситуации сходны
некотором отношении, то весьма вероятно, что оии окажутся сходными и в других ас-
пектах Например, если два дома расположены в одной местности и похожи по
архитектуре, то они, скорее всего, имеют одинаковую стоимость. В отличие от доказательств,
используемых в алгоритме EBL, метод аналогии ие является логически строгим. В этом
смысле он подобен индукции. Как замечено в [Russell, 19891 и других работах,
аналогия — это вид индукции на основе единственного примера. В примере с домами
свойства одного дома прогнозируются на основе информации о втором.
Как было указано при рассмотрении обоснования на основе опыта (раздел 7.3),
аналогия очень полезна для применения имеющихся знаний к новым ситуациям. Например,
предположим, студент изучает свойства электричества, а преподаватель сообщает ему,
что электричество напоминает воду, причем напряжение соответствует давлению, сила
тока — величине потока, а сопротивление — пропускной способности канала. С помо
шью этой аналогии студент сможет легче понять закон Ома.
В стандартной математической модели аналогии используется источник аналогии,
который может представлять собой решение задачи, пример или относительно
понятную теорию, а также не совсем понятная цепь. Аналогия — это отображение
соответствующих элементов источника и цели. Заключение по аналогии расширяет это
отображение „а новые элементы области определения цели. Возвращаясь к аналогий
такжТс'.Г, ? " В°да' "а °С"0Ве СВеДений ° ™°™етствии напряжения и давления, а
сГб™:^Га~твУТсГдкости можио сдеяать вывол ™пропускна:
природой сопротивления У "противлению. Это поможет лучше разобраться с
При участии многочнсленнм¥ *„-.
реализации вычислительны» Т °Р ! Ш Р^Р36»™ унифицированный подход к
Cabelli, l988); IWolstencroft iggof or" 0бос"ова™ ™ аналогии [Hall, 1989J; [Kedar-
j П . . ' )иЬь,чно "от процесс состоит из следующих этапов.
источник аналог„„НаПри„еЛэетВУЮ проблсмУ, необходимо выбрать потенциальны»
которые подтверждают „ °" "УЖН° выделить те свойства цели и источника,
правдо„„до6ие аналогии, а также проиндексировать
412
Часть IV. Машинное обучен"6
знания согласно этим свойствам. В целом в п
исходные элементы отображения. ' про«сссе поиска определяются
2 Ртвитче (уточнение). Обнаружив источник зачас™
тельные свойства и отношения источника Напримеп СЛСДУ" выделить Д°"олни-
аналогии необходимо разработать специфическое Р' "Ногда в качествс базиса для
мЫ в области определения источника. ояеисние для решения нроблс-
3. Отображение и логический вывод (mapping and inference! -^
отображение атрибутов источника в область опрелел """ "Рслпола™«
ся и известные соответствия и вывод по аналогии. """ "еЛИ' 3дССЬ испол«У«"-
4. Подтверждение (justification). На этом этапе проверяется ко™
„ил. При необходимости его следует модифицировать К0РРСК™™ «ображе-
5. Обучение (learning). Полученные знания сохраняются в ™„а л.
жет быть полезна в будущем. Р ™°" Ф°Рме' ™™!>™ мо-
Эти этапы реализованы в многочисленных вычислительных моделях обоснования
„„ аналогии. Например^ теория структурного отображения (strucmre mapping Zrv
[Falkenhamer. 1990], [Falkenhamer и др., 1989], [Centner, 1983] „e только позвГяе'
решить проблему поиска полезных аналогий, но и обеспечивает правдоподобную
модель понимания аналогии человеком. Основной вопрос при использовании аналогии
заключается в том, как отличить выразительные, глубокие аналогии от поверхностных
сравнении. В своей работе Гентнер (Gentner) утверждает, что истинные аналогии
должны акцентировать внимание иа систематичных, структурных свойствах области
определения, а не иа малосущественном сходстве. Например, аналогия "атом подобен
солнечной системе" глубже, чем "подсолнух напоминает солнце", поскольку первая
отражает целую систему взаимосвязей между элементами, движущимися по своим
орбитам, а вторая описывает лишь внешнее сходство, состоящее в том, что оба объекта
имеют круглую форму и желтый цвет. Это свойство отображения аналогии называется
систематичностью (systematicity).
Теория структурного отображения формализует эти рассуждения. Рассмотрим
пример аналогии атома и солнечной системы, описанный в [Genlner. 1983] и
проиллюстрированный иа рис. 9.19. Область определения источника включает предикаты
ye//oiv(sun)
blue(eanh)
hotter-than(sun, earth)
causes(more-massive(sun, earth), attraction, earth))
causes(attract(sun. earth), revolves-arouncHearth, sun)).
Область определения цели содержит предикаты
™ore-massive(nucleus, electron)
revolves-around{electron, nucleus).
ПРИ структурном отображении задается соответствие структур источника и цели,
определяемое следующими правилами.
Гла|* 9. Машинное обучение, основанное на символьном представлении..
413
Отображение по аналогии:
Рис. 9.19. Отображение для аналогии
1. Из описания источника исключаются лишние свойства. Поскольку аналогия
концентрирует внимание на системе отношений, сначала необходимо исключить
предикаты, описывающие несущественные свойства источника. В структурном
отображении эта процедура формализуется путем исключения из описания источника
предикатов с единственным аргументом (унарных предикатов). Это обосновано
тем, что предикаты с более высокой арностью, описывающие отношения между
несколькими сущностями, содержат систематичную информацию с более высокой
степенью вероятности, что и требуется для аналогии. В нашем примере
исключаются утверждения, определяющие цвет Солнца и Земли yeffow(sun) и
Ыие(еа/1л). Заметим, что в описании источника все еще могут содержаться
утверждения, не имеющие значения для аналогии, например, утверждение о том, что
Солнце теплее Земли hotter-than{sun, earth).
2' М^п""" ОТОбражаются из °™™ил источника в описание цели без изменений.
ннкГк меГ™ ЛИШ" паРамстР" э™ отношений. В нашем примере для источ-
"ol™в„ ГоГГьГтаГ-0""" (В"Я « " ^^^
строения аналогий „ Тако" мдход используется во многих теориях №
II""" П0М0ляет "Ч*™. число возможных отображений, а так-
3. При построТнГ, „Гб ° ПРеДПОтанмх " отображении,
ношения болТвысокого п"™ " КаЧестве ег0 ФокУса целесообразно выбирать от-
порядка выступает r*„* °!""№a- B нашем примере отношением более высокого
-%_ J l*-<*useS, ПОСКОПыл/ DPn ,ппте-
3 ни™тася принципы
поскольку его аргументами являются другие отноше-
тстематтности (systematicity principle).
Часть IV. Машинное обучение
Такие правила приводят к отображению
sun -> nucleus
earth -> electron.
расширяя это отображение, приходим к выражении
causes{more-massive{nucleus. electron) attracting*., ,
causes(at,rac«nuc,eus, electron), reJ^alZZlcLl ''ZTl))
Теория структурного отображения была реализована и п„„т„т
областГх определения. Однако она еще д^а от полной т^^Г ^7,
„„зволяет решить такую проблему, как поиск источника аналогии. Она подтверждаете
„„числительным экспериментом и объясняет многие аспекты обоснования по аиТоги
свойственного человеку. И. наконец, в этом разделе уже упоминалось обоснование ,ш
основе опыта (case-based reasoning), описанное в разделе 7.3. В этом контексте при
создании и применении базы полезного опыта важная роль отводится аналогии.
9.6. Обучение без учителя
Описанные выше алгоритмы построены на принципе обучения с учителем (supervised
learning). В них предполагается существование учителя, некоторой меры соответствия
или другого внешнего метода классификации обучающих данных. Общение без учителя
(unsupervised learning) не предполагает наличия учителя и обеспечивает формирование
понятий в самой обучаемой системе. Пожалуй, лучшим примером обучения без учителя
в человеческом сообществе является наука. Ученые не получают знаний от учителя. Они
сами выдвигают гипотезы, объясняющие их наблюдения, оценивают эти гипотезы по
таким критериям, как простота, общность и элегантность, а затем тестируют их с помощью
разработанных ими экспериментов.
9.6.1. Научная деятельность н обучение без учителя
Одной из первых и наиболее успешных систем, позволяющих "открывать" новые
знания, является программа AM [Davis и Lenat, 1982]; [Lenat и Brown. 1984], которая
выводит интересные, а иногда и оригинальные, понятия в математике. Эта программа
основывается на теории множеств, операциях по созданию новых знаний путем модификации
и комбинирования существующих понятий и наборе эвристик для выявления
"интересных" понятий. За счет поиска в пространстве математических понятии
программа AM "открыла" натуральные числа и несколько важных понятии теории чисел,
например, существование простых чисел. _...„„-
Так, программа AM "открыла" натуральные числа, модифишгруя свое пред™—:
о "множествах с повторяющимися элементами". К таким множествам относу аирн-
*Р(«. а, о, с, о). При специализации определения такого множеству огород
«гея только элемент!, одного типа, возникла аналогия с натура н "^
пример, множество с повторяющимися элементами (1, 1, i. i ' f
Объединение таких множеств соответствует сложению чисел: <J^'JJ^L' ' ',
> ««» 2 + 2 = 4. В процессе дальнейшего "^^Гж»^ С —^ эвр,^ики
*™ умножен™ _ это последовательность операции <^Т±™ ™ ^ AM
"^деления новых операций путем обращения существующих пр гр
Г"ава 9. Машинное обучение, основанное на символьном представлении...
415
,„ение Затем было найдено понятие простого числа, „Mei0.
••„гкрыла" ^численное деле„и. ^
щего только два делителя (само чи м ^ оце„ивает его в соответствии с „е.
При создании нового понят ^ 0ПредеЛИТЬ ••„нтересность понятая. Прост
сколькими эвристиками, позволя мключеиие 0С1Ювано на частоте их появления. Пр„
числа оказались интересными- „„ограмма AM генерирует экземпляры базового „онл-
оценке понятия по этой эврист j определению. Если все экземпляры удовлетво-
тия и проверяет их соответ ^ ^^ Э10 тавтология, и новое понятие получает
ряют определению нового •^ ПОНятия, не соответствующие ин одному из
низкую оценку. Анал0™'* Если понятне описывает значительную часть примеров
^^^^^.•"^^г ш классифнцнруэт его как щ-
РеСнГс1™'на ™Сп"ме" А^алоГоткрыть простые числа и несколько дРу.
п,х HH«Zb"x понятий она не смогла продвинуться дальше элементарной теории ,и.
ЛГпа! н Brown 1984] были проанализированы преимущества программы и ее
ограничения Изначально считалось, что основным преимуществом программы являются
ее эвристики однако впоследствии оказалось, что своим успехом программа обязана
языку представления математических понятий. Понятия в ней представлены
рекурсивными структурами на языке программирования LISP. Поскольку описание основано на
удачно спроектированном языке программирования, в определяемом пространстве
плотность интересных понятий очень высока. Особенно это проявляется на ранних этапах
поиска. При последующем исследовании понятий пространство расширяется по законам
комбинаторики, и "доля" интересных понятий в общем пространстве уменьшается. Это
наблюдение еще раз подчеркивает связь между представлением и поиском.
Еще одной причиной, обусловившей невозможность получения дальнейших
впечатляющих результатов на основе первых достижений программы AM, является ее
неспособность "учиться учиться". В процессе приобретения математических знаний она не
выводит новых эвристик. Следовательно, качество поиска снижается с увеличением
математической сложности задач. В этом смысле программа никогда не достигнет
глубокого понимания математики. Эта проблема впоследствии была решена в программе
EVRISKO, которая способна обучиться новым эвристикам [Lenat, 1983].
Проблема автоматического обучения исследовалась во многих программах. В
программе IL [Sims, 1987] для "открытия" новых математических понятий использованы
различные приемы обучения, в том числе методы автоматического доказательства
теорем и обучения на основе объяснения (раздел 9.5). Автоматический вывод
целочисленных последовательностей олисан также в [Cotton и др 2000]
В программе BACON [Langley и др., 1987] разработаны и реализованы математические
ГГоФ(Г"Р0ВаН''Я Количе<™™ научных закономерностей. Например, на основе
СШ^пГ"""0™ Т*1 °Т СШШШ и ПеРнода ™ ЧИШИ-™ по орбитам система ВА-
м«ал"заш,ТиТа m°HU ^^ ° ДВД™« ™""- С "<•»«£» вычислительной
ловека. В си££Ж2ГГ "<***>■«-«. процессов научной деятельности *
»-оритма ЮЗ 2 по,™е,?иГ ' b,b'efle,d' 19951' l^bblefield, 1996] применен вариант
[StagerиипыГшоГп" СПОСОбнос™ Формирования полезных аналогий. В рабо*
Несмотря н. т„ что L™L"° Г0"™0 ДРУПК ^обучающихся систем,
в ней были получены очи,.. ятсльность — важная область исследования, до еих пор
незначительные результаты. Более фундаментальной про-
416
Часть IV. Машинное обучение
йпемой обучения без учителя, при решении которой бып „„
.„„яется изучение категорий. В [Lakoff, 1987] сдалаио „р^™""""^ Ч»П«с
„изапня - это основа человеческого познания: высоко™™ * ° Т°М' ™ Катег°-
,ависят от способности систематизировать конкретный опыт ? теоретиче™= ™ания
^асеификационной иерархии. Большая часть знаний человек» " согпасова"«™
йъектов. например к лошадям, а ие к отдельно взятий „„ °™осится к категориям
о Гангу или Боливару. В работе [NordhausT U„g ey ^оГГ "^ "^^
„не категорий- основа единой теории „аучныЛс^ Г^ MS?"**
„роцесеов химических реакций ученые основывались на щве™„й к„ ' И1СЛСД0ШШИИ
единений по таким категориям, как "кислота" и "щел0 J. eC™°" "^"Фикации со-
В следующем разделе рассматривается концептуальная кластеризация (conceptual
clustering)- проблема формирования полезных категорий „а основе неклаесиф™
ванных данных. ч1"" v»
9.6.2. Концептуальная кластеризация
Дм решения задачи кластеризации (clustering problem) требуются набор
неклассифицированных объектов и средства измерения подобия объектов. Целью кластеризации
является организация объектов в классы, удовлетворяющие некоторому стандарту
качества, например на основе максимального сходства объектов каждого класса.
Числовая таксономия (numeric taxonomy) — один из первых подходов к решению
задач кластеризации. Числовые методы основываются на представлении объектов с
помощью набора свойств, каждое из которых может принимать некоторое числовое значение.
При наличии корректной метрики подобия каждый объект (вектор из п значений
признаков) можно рассматривать как точку в л-мерном пространстве. Мерой сходства двух
объектов можно считать расстояние между ними в этом пространстве.
Используя метрику подобия, типичные алгоритмы кластеризации строят классы по
принципу "снизу вверх". В рамках этого подхода, зачастую называемого стратегией
накопительной кластеризации (agglomerative clustering), категории формируются следующим образом.
1. Проверяются все пары объектов, выбирается пара с максимальной степенью
подобия, которая и становится кластером.
2. Определяются свойства кластера как некоторые функции свойств элементов
(например, среднее значение), и компоненты объектов заменяются этими
значениями признаков.
3. Этот процесс повторяется до тех пор, пока все объекты не будут отнесены к одно-
му кластеру.
4. Можно сказать, что многие алгоритмы обучения без учителя оценивают плотность
по методу максимального правдоподобия (maximum likelihood dens.lv °™"^
означает построение распределения, которому с „анбольщен «1»"™*™»°^
ияются исходные данные. Пример- Р^изации такого подхода являете штерпре
тация набора фонем в приложении обработки естественного языка (глава Щ.
Результатом работы такого алгоритма является бинарное ^~™ГО ~
«ветствуютэкземплярам, а вн>арен„,.е узлы-кластерам ^бщегов^^^ ^
Этот алгоритм можно распространить на объекты,,ир ^ юмеренне
во"ьных, а не числовых, свойств. Единственной проблемой при
Гла<* 9. Машинное обучение, основанное на символьном представлении.
417
, . определенных символьными, а не числовыми, Зтче
степени подобия объектов опред^ ^^ с относ1ггель„ы„ числом совпадаю^
Логичновязать степень»-
значений признаков, ьсл. л
го можно .вести метрику подобия
ЖЖ ^«': —№Ь/ес;г оЬУес'3)=v-
™„ кластеризации на основе подобия неадекватно учитывают роль
°ДТскТзн?Г ^формировании кластеров. Например, созвездия „а небесной
*==^^,Г ==™ » " —озанием
^Г^^ГиГГрГнГвсесвоГ.ст.аиме.отодинаковыивее.Взавиеимоетиот
контек'™ каждое свойство может стать более важным, чем другие, а простая метрика
Хюбня не позволяет выделить главные признаки. Человеческие категории в гораздо
большей степени определяются целью категоризации и априорными знаниями о
предметной области а не внешним сходством. В качестве примера рассмотрим китов,
которые относятся к категории млекопитающих, а не рыб. При этом внешнее сходство не
учитывается, основное внимание уделяется задачам классификации биологических
организмов на основе физиологических признаков и с учетом эволюции.
Традиционные алгоритмы кластеризации не только не учитывают цели и базовые
знания, но и не обеспечивают осмысленное семантическое обоснование
сформированных категорий. В этих алгоритмах кластер представляется перечислением всех его
элементов. Алгоритмы не позволяют получить содержательные определения или общие
правила описания семантики категории, которые можно было бы использовать для
классификации как известных, так и неизвестных представителей этой категории. Например,
множество людей, которые избирались на пост генерального секретаря ООН, можно
представить в виде обычного списка. Содержательное определение
{X | X, которые избирались на пост генерального секретаря ООН)
позволяет выделить семантические свойства класса и классифицировать будущих
представителей этой категории.
Концептуальная кластеризация (conceptual clustering) позволяет решить эти проблемы
за счет использования методов машинного обучения для создания общих определений
понятии и применения базовых знаний при формировании этих категорий. Хорошим
примером реализации этого подхода является система CLUSTER/2 [Michalski и Stepp, 1983].
В Г nPe™SI,t^ ЮтеГ°р"Й ™"У<™я базовые знания в форме языковых порогов,
к- это TZ Формируются к категорий на базе к опорных объектов, где
кластеры выб„'„7' НаСТраИ8аемЬ|й пользователем. Программа оценивает полученные
ЖЙ^1Г.1Ги повторяет этот процесс до тех пор'пока
н ерии качества. Этот алгоритм имеет следующий вид.
а все оста^ьн°ыеТ°Г° °бЪе1Сга' ИСП0ЛЬЗУЯ е™ в качестве положительного пример»,
качестве отрицательных, создать наиболее общее определе-
Чаоть IV. Машинное обучение
ннс, покрывающее все положительные и ни одного о™
тнм, что при этом может образоваться несколько ™"'"°''0 "Р,ШСР°- JaMC-
относящимися к опорным) объектами классов, связанных с другими (ис
3. Классифицировать все объекты в соответствии г ™
ждое максимально общее определение Макс"мальнТ °ПИСаН,имн- Зта1т- №
все объекты этой категории. При этом снижаГГ КОИ1ч,етным' покрывающим
при классификации „овь^, «Z^Z^^T^ "^"^ ™
4' K" СШ5Т™2ПвРГюТаТЬСЯ ДаЖС т °6Ъ™ "«г™"»*, множества. В
систему CLUSTER/2 включен алгоритм настройки перекрывающихся определений
5. С помощью метрики расстояния выбрать элемент, ближайщий к центру каждого
класса. Метрика расстояния может напоминать описанную выше метрику поГби»
6. Используя эти центральные элементы в качестве опорных, повторить пункты 1-5
Алгоритм завершается после формирования приемлемых кластеров. Типичной
мерой качества является сложность общих описаний классов. Например согласно
принципу "бритвы Оккама" следует отдавать предпочтение кластерам с
синтаксически простыми определениями, т.е. с малым числом конъюнктов.
7. Если кластеры неприемлемы, но в течение нескольких итераций не наблюдается
никаких улучшений, выберите новые опорные объекты, ближайшие к границе
кластеров, а ие к его центру.
Этапы работы алгоритма CLUSTER/2 показаны на рис. 9.20.
После выбора опорных объектов (п. 1)
После создания общих описаний (п. 2, 3)
Заметим, что категории перекрываются
После конкретизации описания понятий (п. 4).
Пересекающиеся фрагменты все еще есть
Рис. 9.20. Этапы выполнения алгоритма CLUSTER/2
После устранения дублирования элементов (п. 5)
9.6.3. Программа СОВ-WEB и структурные таксономические знания
Многие алгоритмы кластеризации, как и многие алгоритмы ^^ «f "^
типа ,03, определяют категории в терминах „еобходт,»«. Д^ У—
принадлежности этим категориям. Эти условия представляют сооои « Р J
ков, свойственных каждому элементу категории и отличных от признаков другой ка
Глава 9. Машинное обучение, основанное на символьном представлении... 419
„чт(. многие категории, к примеру Ми„
м„ж„о описать «но ^ ^^ ^J> ^ „„
Таким обР»0" М". еческие категории не всегда соответствуй
да n^£^r~i "60лес -^
"°ГрС е- S"-«Г „,-ежкости. мы не смогли бы отличит^
мыми и достаточными ^„«ологи отмечают важное значение прототипов „ Пс«'
згой принадлежности ОДн«° мер, ^ человека малиновка - более г»*'
.еческих дахегориях jRcBcn^^ g да(. _ 6oJ]M типичныи пример дерева, чем пальма о£
ный пример птиц > Тч%1
минимум, в северных ширт_аются тирий сыайного сходстве (family reSemblan„
Эти рассуждения под ^ нн опреяеяяются сложной системой сходства меж»,
Iheory). которая ««^ и достат0чньши условиями принадлежности чле„„,
элементами, а не « категор«зацин может не существовать свойств, o6uw
[Wiltgenslem, 1953j. пр fl [Wittge„stein, 1953) приводится пример категоГ
f "f Л^яГь. предполагают наличие двух или нескольких игроков (например, коы.
игра . не все г ^^ ^ ^ четко Сф0рмулир0ваиы правила (например,
Для дет-
Т,)Тнё венгры предполагают соревнование, подобно перетягиванию каната. Тем к
„е ее та категория хорошо определена и недвусмысленна.
Человеческие категории также отличаются от большинства формальных иерар.
хий наследования (глава 8) тем, что не все уровни человеческой таксономии один»,
ково важны Психологам удалось продемонстрировать существование категорий
базового уровня (base-level category) [Rosch, 1978]. Базовая категория — это
классификация, которая чаше всего используется для описания объектов в терминах,
изученных с раннего детства, на уровне, в некотором смысле охватывающем наиболее
фундаментальные свойства объекта. Например, категория "стул" является более
базовой, чем любое ее обобщение, в частности, "мебель", или любая ее специализация,
например, "офисный стул". "Машина" — это более базовая категория, чем "седан"
или "транспортное средство".
Обычные средства представления классов или их иерархии, в том числе логическое
представление, иерархия наследования, векторы признаков или деревья решений, не
учитывают этого, хотя это очень важно не только для ученых-когиитологов, целью которых
является познание человеческого интеллекта. Это имеет большое значение и для
построения полезных приложений искусственного интеллекта. Пользователи оценивают
программу в терминах гибкости, робастности и соответствия ее поведения человеческим
стандартам. И хотя вовсе не требуется, чтобы все алгоритмы искусственного интеллекта
учитывали параллельность обработки информации мозгом человека, все алгоритмы
изучения категории должны оправдывать ожидания пользователя относительно структуры »
поведения этих категорий.
Эти проблемы учтены в системе COB-WEB [Fisher 1987]. Не претендуя на
звание модели человеческого познания, эта система учитывает категории базового
уровня и степень принадлежности элемента соответствующей категории. Кроме то-
6уюн1ТММе C°BWEB P"*™*"*» инкрементальный алгоритм обучения, не трс-
прил7же„ТГйавЛеН"Я ЕССХ °6>™'°ЩИХ примеров до начала обучения. Во многих
До"™ "Гит y4aeMM С',СТШа ПОЛ*ча« «»»« со временем. В этом случае она
"0»лятьэТо™Ле3,Ше 0пРаделе«"« "снятии „а основе исходных данных и об-
эти описания с появлением новой информации. В системе COBWEB так*=
пешена проблема определения корректно™ и^^
& формируется изначально JLZZZllZlTn '""'Ц"и""° "^
'снять это число, однако такой подход ,«,?„,'' П°я"м«ель "°*« ■«-
мси ""д*.ид нельзя назвать гибким. В системе COBWFR
лля определения количества кластеров, глубины иерархии и принГлГности катс
гор„и новых экземпляров используется глобальна, метрика качества
В отличие от рассмотренных ранее алгоритмов, в системе COBWEB реализовано
вероятностное представление категорий. Принадлежность категории определяется не
набором значении каждого свойства объекта, а вероятностью появления значен™. Напри-
мер, Plfr'„\c„) - это условная вероятность, с которой свойство I, принимает значение
у/ , если объекг относится к категории ct.
" На рис. 9.21 "Оказана система классификации программы COBWEB приведенная
в работе [German и др., 1989]. Это пример категоризации четырех одноклеточных
организмов, изображенных в нижней части рисунка. Каждый класс определяется
значениями следующих свойств: цвет, количество хвостов и ядер. Например, к
категории СЗ относятся объекты, имеющие по 2 хвоста и ядра с вероятностью 1,0, и
светлые с вероятностью 0,5.
Как видно из рис. 9.21, для каждой категории в иерархии определены вероятности
вхождения всех значений каждого свойства. Это важно как для категоризации новых
экземпляров, так и для изменения структуры категорий для более полного соответствия
свойствам их элементов. Поскольку в системе COBWEB реализован инкрементальный
алгоритм обучения, она не разделяет эти операции. При предъявлении нового
экземпляра система COBWEB оценивает качество отнесения этого примера к существующей
категории и модификации иерархии категорий в соответствии с новым представителем.
Критерием оценки качества классификации является полезность категории (category
utility) [Gluck и Corter, 1985]. Критерий полезности категории был определен при
исследовании человеческой категоризации. Он учитывает влияние категорий базового уровня
и другие аспекты структуры человеческих категорий.
Критерий полезности категории максимизирует вероятность того, что два
объекта, отнесенные к одной категории, имеют одинаковые значения свойств и значения
свойств для объектов из различных категорий отличаются. Полезность категории
определяется формулой
IXIpH = Mp(f, = v, |c, )РЮ, \f,= v,).
Значения суммируются по всем категориям с,, всем свойствам f, и всем значениям
свойств v„. Значение p(f,=v„|ci) называется предсказуемостью (predictability). Это
вероятность того, что объект, для которого свойство I, принимает значение ir„, относится к
категории с,. Чем выше это значение, тем вероятнее, что свойства двух объектов,
отнесенных к одной категории, имеют одинаковые значения. Величина p(ct\f,=v„) называется
предиктиеностьк, (predictiveness). Это вероятность того, что для объектов из категории
с, свойство I, принимает значение v„. Чем больше эта величина, тем менее вероятно, что
для объектов, не относящихся к данной категории, это свойство оудет принимать
указанное значение. Значение p(/,=v„) - это весовой коэффициент, усиливающий в—
наиболее распространенных свойств. Благодаря совместному учету этих значении
высокая полезность категории означает высокую вероятность того, что объекты из одно ^
тегории обладают одинаковыми свойствами, и низкую вероятность наличия этих свойств
у объектов из др> тих категорий.
Глава 9. Машинное обучение, основанное на символьном представлении..
421
Категория
Свойство
Хвост
Цвет
Ядро
С2 Р(С2)-1/*
Знамение р(Ис)
~0д^ ГО
Два 0.0
Светлый 1 0
Темный 0 0
Одно 1-0
Две 0.0
Три 0 0
Свойство Значение p(vlc)
Хвост Один 0.0
Одно
Два
Три
Категория
Свойство
Хвост
ц.„,
Ядро
С4 Р(С4)=1/4
Значение p(vlc}
Один 1 ,о
Два 0.0
Светлый 0.0
Темный 1,0
Одно 0.0
Два 0 0
Три 1.о
Кате гор и
Свойств
Хеост
Цвет
Ядро
С5 Р(С5)=1/4
□ Значение p(vtc)
Один 0.0
Два 1.0
Светлый 1.0
Темный 0 0
Одно 0.0
Два 10
Три 0 0
Категория С6 Р(С6)=1/4
Свойство Значение p(vlc)
Рис. 9.21. Кзастершаиия четырех одноклеточных организмов в системе COBWEB
Алгоритм COBWEB имеет следующий вид.
cobweblNode, Instance)
Begin
if узел Node-это лист^
then begin
создать два дочерних узла (., и L, для узла Nods;
задать для УЗЛа (, те ^ оероятностИ| что и для узла Node.
инициализировать вероятности для узла L2 соответствуя""»
значениями объекта /nstance-
к
Часть IV. Машинное обу*»нИ
добавить Instance к Node, обновит, „^
Node; Обновив вероятности для узла
end
else begin
доОавить Ins tan се к Node обновит. Во~
Node. ' оон°вив вероятности для уэла
для каждого дочернего узла С узла Node
вычислить полезность категории при отнесении
экземпляра Instance к категории С;
пусть S, ~ значение полезности для наилучшей
классификации С^
пусть S2 - значение для второй наилучшей
классификации С2;
пусть S3 - значение полезности для отнесения
экземпляра к новой категории;
пусть St - значение для слияния С, и С2 в одну категорию;
пусть Ss - значение для разделения d (замены
дочерними категориями);
end
if Si — наилучшее значение,
then cobweb(Cj, Instance) %отнести экземпляр к С±
else, if S3 _ наилучшее значение,
then инициализировать вероятности для новой
категории значениями Instance
else, if St _ наилучшее значение,
then begin
пусть С„ — результат слияния Сх и С2;
cobweb(C„, Instance)
end
else, if Sj _ наилучший результат,
then Begin
разделить Ci(-
cobweb(Ca, Instance)
end;
end
В системе COBWEB реализован метод поиска экстремума в пространстве возможных
кластеров с использованием критерия полезности категорий для оценки и выбора
возможных способов категоризации. Сначала вводится единственная категория, свойства
которой совпадают со свойствами первого экземпляра. Для каждого последующего
экземпляра алгоритм начинает свою работ)- с корневой категории и движется далее по
дереву. На каждом уровне выполняется оценка эффективности категоризации^ основе
полезности категории. При этом оцениваются результаты следующих операции.
1- Отнесение экземпляра к наилучшей из существующих категорий.
2. Добавление новой категории, содержащей единственный экземпляр.
3. Слияние двух существующих категорий в одну новую с добавлением в нее этого
экземпляра.
4. Разбиение существующей категории на две и отнесение экземпляра к .лучшей ю
вновь созданных категорий-
Глава 9. Машинное обучение, основанное на символьном представлении.. 423
„ п „оказаны процессы слияния ,. разделения узлов. Для слияния
На рис. 9 22.п0™а K;mnoro существующие узлы становятся дочер„„„
создастся новый узел, да ко
Двух у
торого существующие узлы становятся дочерним,,'7." Л"0а
учений вероятностей дочерних ^ _ш~™ вероятности ДЛя „„^0.
аменяется двумя дочерними. "* ° Узла.
ПР"-Сг,Гори™'досрочно эффективен и выполняет кластеризацию на разу
Этот алгорипд 1Юпользуетея вероятностное представление принял? С"
™ То^ае" е ^рииТвляютея гибкими и р„баст„ь,М„. Кроме тото. . Z^Z
™я эффект категорий базового уровня, поддерживается прототипирова„ие и ,,££*
сТстеГнь „ринадлежкост,,. Он основан не на классической логике, а, подоб„0 м„ ^
теории нечетких множеств, учитывает "неопределенность категоризации как *
мый компонент обучения и рассуждений в гибкой и интеллектуальной манере. Д"'
Дочерний уэел1
Дочерний уэел2
Рис. 9.22. Слияние и разбиение узлов
еи^ГГа*иМфР„"аДе,Ле °П"СЫВается ^унык <= подкреплением, при котором, подобно
условие-отклик v»»^™'" ™ р"дела 'L2- Д™ изучения оптимального набора отношений
отклик учитываются обратные связи с внешней средой.
'^ад ииычно обучает™
обратная связь, вызванная - пР°цессе взаимодействия с окружающим миром. Однако
Форме. Например, в человек, "**" человека. »е всегда проявляется сразу и в явной
"аютея лишь по прошествии вза|шо°™ошениях результаты наших действий скаэы-
■«гда можно пром 2 "которого времени. На примере взаимодействия с миром
'ричн™°-следственные связи [Pearl, 2000], а также после"0»»-
Лол " _
гг^,-;—^
гельности действий, приводящие к реализации слП
агенты люди вырабатывают политику своей деятеле" ЦМеЙ- Как и"™лектуальныс
этом "мир" выступает в роли учителя, но его тооки™?"™ ' окРУжаюшем их мире. При
yv ки зачастую слабы и трудно усваиваются.
9.7.1. Компоненты обучения с подкреплением
В процессе обучения с подкреплением вырабатывав
перехода от ситуации к действиям, которые максим, вычислительный алгоритм
сообщается напрямую, как поступить или какое де^еСГ"^""5' ^^ "С
своего опыта узнает, какие действия приводят Sl^4™'1 °" сам Ш °сновс
вия агента определяются не только cJS^Z р'уГтГтГ Г™*'""'"™»- Т
ствиями и случайными вознаграждениями. Эп. два свои™11 ""Г""""^ Д™"
подкрепление с задержкой) являются ^^^^^Z^^Z
леннем. Следовательно, такое обучение пеализует Km.» в «j-wi™ i. иидкреп
ритмы обучения, описанные вышГв этой Ze ЩУЮ МСТВД0Л°""°- «" №°-
Обучение с подкреплением не определяется конкретными методами обучения. Оно
характеризуется действиями объекта в среде и откликом этой среды. Любой метод,
реализующий подобное взаимодействие, относится к обучению с подкреплением. Такое
обучение отличается от обучения с учителем, при котором "учитель" с использованием
примеров напрямую инструктирует или тренирует обучаемую систему. При обучении с
подкреплением агент обучается сам с помощью проб, ошибок и обратной связи. Он
определяет оптимальную политику для достижения цели во внешней среде. (В этом смысле
данный метод напоминает обучение классификации, описанное в разделе 11.3.)
При обучении с подкреплением необходимо также учитывать не только
существующие, но и будущие знания. Чтобы оптимизировать возможное вознаграждение, агент не
только должен опираться на свои знания, но и исследовать еще неизведанную им часть
окружающего мира. Такое исследование (возможно) позволит ему сделать лучший
выбор в будущем. Однако очевидно, что одно исследование иди его полное отсутствие
дадут плохой результат. Агент должен изучить различные возможности и выбрать
наиболее перспективные. В задачах со стохаспгческнмн параметрами для получения
достоверных оценок попытки исследования должны повторяться многократно.
Многие проблемно-ориентированные алгоритмы, описанные ранее в этой книге,
включая алгоритмы планирования, методы принятия решении или алгоритмы поиска,
можно рассматривать в контексте обучения с подкреплением. Например, можно создать
план с помощью телео-реактивного контроллера (раздел 7.4), а затем оценить его на
основе алгоритма обучения с подкреплением. По существу, в алгоритме обучения с
подкреплением DYNA-Q [Sutton. 1990. 1991] модельное обучение объединено с
планированием и действием. Такое обучение с подкреплением обеспечивает метод оценки как
плана, так и модели, а также их полезности для решения задач в сложной среде.
Введем некоторые обозначения из области обучения с подкреплением.
( — дискретный момент времени в процессе решения задачи;
s, - состояние задач,, в момент времени Г, которое зависит от V, и а_„
а, — действие в момент времени t, зависящее от s,;
г, - вознаграждение в момент времени t. зависящее: о,^, ам. т
к - политика выполнения действий в зависимости от состояния.
пространства состояний в пространство действии,
л — оптимальная политика;
Глава 9. Машинное обучение, основанное на символьном
425
^„ ufs) — это ценность состояния s при использована
1/ _ функция ценности, т.е. v 1» *нии
„„литию, я- П0СТ0ЯШ0Й „on.rn.KC я описан метод *реме„„ш
В подразделе 9.7.2 при .. нш „ на основе s. ac*n
^То^^Гс^^еалением участвуют 4 компонент «ш»,, ^|кчм
В обучении под f ,„оте„„й у и, зачастую, ло<)ыь внешней среды. По,т*
f^Z '*Z С-о^нта и способ сто действия в определенное apeM^
„ литГможет быть представлена правилам,, вывода «ли простои таблицей „о„ска. ^
Ге Доминалось, в конкретной ситуации политика может выступать результатом р1с.
иГренного поиска, анализа модели или процесса планирования. Она может быть „охас
тичегеой Пол,ггака- это критичный компонент агента обучения, поскольку ее одной
достаточно для определения поведения в заданный момент времени.
функция вознагражден,* (reward function) г, задаст отношение состояние-цель т
данной задачи в момент времени Г Она определяет отображение каждого действия, или,
более точно, каждой пары "состояние-отклик", в меру вознаграждения, определяющую
степень эффективности этого действия для достижения цели. В процессе обучения с
подкреплением перед агентом ставится цель максимизации общего вознаграждения,
получаемого в результате решения задачи.
функция стоимости, или ценности (value function), V — это свойство каждого
состояния среды, определяющее величину вознаграждения, на которое может
рассчитывать система, продолжая действовать из этого состояния. Если функция вознаграждения
определяет сиюминутную эффективность пары "состояние-отклик", то функция
ценности задает долговременную перспективность состояния среды. Значение состояния
определяется как на основе его внутреннего качества, так и на основе качества состояний,
вероятно, последующих за данным, т.е. вознаграждения, получаемого при переходе в зги
состояния. Например, пара "состояние-действие" может приводить к низкому
сиюминутному вознаграждению, но иметь высокую ценность, поскольку за ней обычно
следуют другие состояния с высоким вознаграждением. Низкая ценность соответствует
состояниям, не приводящим к успешному решению задачи.
Без функции вознаграждения нельзя определить значение ценности, которую
необходимо оценить для получения более высокого вознаграждения. Однако в процессе
принятия решений нас в первую очередь интересует ценность, поскольку она определяет
состояния и их комбинации, приводящие к максимальному вознаграждению.
Вознаграждение предоставляется непосредственно внешней средой, а стоимость может многократно
ншболеГ™ С° ВРеМСНеМ "а °СН0Ве ^«"ного н ошибочного опыта. На самом деле,
27ш1ХГ"т " СЛ°Ж,ШМ М0МеНТОМ "б*4"™ с подкреплением является создание
нЗосФ„!с .Г"™ 0,1ред™"™ «"«ос™. Один „, таЛ методов - правило обуче-
ПосТеГимТТГ РМН0СТСЙ - «*» продемонстрирован в подразделе 9.7.2.
внешне^еГГдеГ-з""" MCM™°M °^"m Укреплением является.,,»^
ДЫ. Как следует ю „,-, -^ мсханизм Реализации аспектов поведения внешней ере-
сбоев, как в диагноепта М°Ле,Ш М0Ж"° "Пользовать не только для выявлен»»
нить результата возмо-™," "?" опРсделе"»и плана действий. Модели позволяв оое
основе моделей - зт„ сТ ЛИ"ЛВ"Й 6" Их Р^ьного выполнения. Планирование »
поскольку в Ран„„х систем»*"0' тп0Лтт' « парадигме обучения с подкреплен,,»
пробным,, действиями и „„„.к "'" вотнагРаждения и ценности определялись толь*
"шиоками агента
Часть IV. Машинное обучен
к
9.7.2. Пример: снова "крестики-нолнкн"
1998] для иллюстрации обученш с подкреплеГем UeZZ " [$"'Ы " ВаП°'
„одкэдеплениемслрутими подходами, .^^^.^ГГ" '
Напомним, что крестики-нолики" - это игра для двух чело'век^оторТе"о очереди
расставляют свои метки X и О в сетке, размером 3x3 (см. рис. II.V, ПоТэеждает штГ
первым составивший ряд из трех меток „ибо „о горизонтали, либо по вертикали лиоо по
диагонали. Как известно читателю из раздела 4.3, при наличии полной информации о
планах оппонента эта игра всегда завершается вничью. Однако при использовании
обучения с подкреплением можно получить более интересный результат. В этом разделе
будет показано, как можно разгадать планы соперника и выработать политику,
позволяющую максимизировать свое преимущество. Эта политика эволюционирует при измене-
нии стиля игры соперника и строится на использовании модели.
Во-первых, необходимо создать таблицу, в которой каждому возможному состоянию
игры соответствует одно число. Эти числа, определяющие ценность состояния, отражают
текущую оценку вероятности победы, если игра начинается с этого состояния. Они будут
использованы для выработки стратегии чистой победы, при которой победа соперника или
ничья рассматриваются как поражение. Такой подход позволяет сконцентрироваться на
победе, и этим он отличается от рассмотренной в разделе 4.3 модели, предполагающей 3
возможных нехода: победа, поражение и ничья. Это действительно важное отличие. В
обучении с подкреплением учитывается поведение реального соперника, а не полная
информация о действиях некоего идеализированного оппонента. В таблице значения ценности
нужно проинициализнровать следующим образом: 1 — для тех состояний, которые
приводят к победе, 0 — для приводящих к поражению или ничьей и 0.5 — для всех остальных
неизвестных позиций. Это соответствует 50^ вероятности победы для этих состояний.
Теперь нужно многократно сыграть в игру с этим противником. Для простоты
предположим, что мы ставим крестики, а наш оппонент — нолики. На рис. 9.23 показана
последовательность ходов — возможных и реализованных. Прежде чем слетать ход,
оцените каждое из возможных состояний, в которое можно перейти из данного состояния.
По таблице определите текущее значение ценности для каждого состояния. Чаше всего
придется делать "жадные" ходы, т.е. выбирать состояния с максимальным значением
функции ценности Иногда, возможно, потребуется сделать пробный ход и выбрать
следующее состояние случайным образом. Такие пробные ходы позволяют выявить
упущенные альтернативы и расширить пространство оптимизации.
В процессе игры значение фтеции юности для каждого выбранного состояния
изменяется, чтобы лучше отразить вероятность принадлежности данного состояния» тюбеднюм>
пут,,. Эта величина ранее была названа фуш-циеи т»аграж6ехи* для <^^L ™™
ценность выбранногГсостояния вычисляется как функция от «^9 ,ТГт^^-
ного состоянГкак показывают "Ч-™?^?^^^^^
rax „с „и™*™ ход соперника. Тахз,м образом. ££^2£„, цетость прель,-
етсясучетамце„ност,,постед>ТОшего(нк™сч^псяэеды ^^ цсшхп1 ^
Душего состояния изменяется на величину разности - пшучш>Ший „ива-
последовательных состояний, умноженную на некоторый ^ициент ту
ние шагового множите.*,, или параметра шага (Sep** риагпею'-
Hs.)=l/(s.)+c(Ws..,)-l'(s.))
Глава 9. Машинное обучение, основанное на символьном
427
Мой ХОД ^
Ход соперника 1 (ПОБЕДА!
Рис. 9.23. Последовательность ходов при игре в
■■крестики-нолики". Пунктирные линии со стрелкой
указывают возможные ходы, сплошные линии со
стрелкой вню задают выбранные ходы, а линии со
стрелкой вверх определяют вознаграждение при
изменении значения ценности для состоятся
»»| - состотнте°ш6па„н" ПрелСтавляет с°«°яние, выбранное в момент времени п. а
на основе временных паз " " "°"еИТ П+1' Эт0 Уравнение — пример правила ооучеит
состояния вычисляется к'аГГ" (temporal difference learning rule), поскольку изменение
ДВУХ последовательных мо ФУНКЦИЯ 0Т Ршн0™ значений ценности Vls„t,)-V(sJ V
сувдаться ниже в этой главе е"ТОВ ВреМени П+1 и "• та™е правила обучения будут об-
«»• Со временемКи!елесо:обоОЛИКИ т"т° вРше™ь" разностей достаточно эффект»»"
"бученной системы значен™ УМеНЬШИТЬ шаговый множитель с, поскольку для болм
таровать сходимость функ,,,,"0""0"" должиы изменяться меньше. Тогда можно гарав-
победь, „р„ игре с д J/ ц™ ценнос™ Для каждого состояния к значению вероятно"»
множителя „ривсдет к " °™Р»иком. Интересно отметить, что неизменность шаго>»«>
«меняться, отражая измене™ , ™Ы "ШШ™ка ™к°гда не сойдется и будет постояв
ЭВД пример „л„ю ""' <УУчшен„е) стнля игры противника.
"Ч»«х, такое обучение^" "ног° в»«ь,х свойств обучения с подкреплением. В '
в п"п'""-~ - с внешней средой, > Д«
Часть IV. Машинное обу"еИ
ном случае — с соперником. Во-вторых здесь им,
вых состояниях), и, чтобы ее лостичь необходим *BHM Цеш" Отраженная в целе-
лью обеспечить долгосрочное влияние' конк-рстнь ° ПЛа1шровать и прогнозировать с це-
с подкреплением, по существу, строит многохоло" Х0Л0В' НапРимеР. алгоритм обучения
„уть неопытного соперника. Важное свойство об ком6инации- которые могут обма-
что результата планирования и прогнозирования ГГ™ ° "одкрсплснис" с°<™ит в том,
ведение соперника и не проводя расширенный поиск "°m""'' "" M0Дeлиpy,, "вн0 п0"
В рассмотренном примере для обучения u* ™
правил' игры. (Просто все 'состояи^ ™м кГчньГин"' **"" """"• •*>"
ем 0,5.) Однако такая -уравниловка" ■^^^^ЦЗГи^
„нем можно учесть и любую реальную информации, о начальных со^ояГхКрсГе
того, при наличии данных о ситуации для значений состояний можно использовав "Ге-
ден.» из этой модели. Важно помнить, что обучение с подкреплением применимо в
любом случае, даже при отсутствии модели, однако при наличии модельной информации
ее тоже можно учесть. т г
В примере игры "крестики-нолики" вознаграждение амортизируется с каждым
следующим шагом. Здесь используется "близорукий" агент, максимизирующий только
сиюминутное вознаграждение. На самом деле, при более пристальном изучении обучения с
подкреплением необходимо учитывать "обесценивание" вознаграждения со временем. Пусть
коэффициент у представляет текущее значение будущего вознаграждения. При получении
вознаграждения на к шагов позже его стоимость снижается в у**1 раз. Такая мера
"обесценивания" важна для реализации обучения с подкреплением на базе принципа
динамического программирования. Этот подход будет описан в следующем разделе.
"Крестики-нолики" — это пример игры с участием двух соперников. Обучение с
подкреплением можно также применять при отсутствии противника, учитывая только
обратную связь с окружающей средой. Рассмотренный пример характеризуется конечным
(к тому же очень маленьким) пространством состояний. Обучение с подкреплением
можно также применять для очень больших и бесконечных пространств. В последнем
случае ценность состояния определяется только при достижении этого состояния и его
участии в решении. Например, в работе [Tesauro, 1995] упомянутое выше правило
временных разностей встроено в нейронную сеть для обучения игре в нарды. Несмотря на
то что пространство состояний игры в нарды содержит 10 значений, разработанная
программа играет на уровне лучших специалистов.
9.7.3. Алгоритмы вывода и их применение к обучению
с подкреплением
В работе [Sunon и Barto. 1998] выделены три семейства алгоритмов^общения
с^подкреплением „а основе вывода: обучение по правшу ере«т Р*»™^'™*™.
ат^.п Мпчте Knnio К этим типам сзодятся все совре-
веского программирования и »™л ^//Еды .ременных разностей основаны
менные подходы к обучению с "°лкре™=""^ ™™"„а£„ий »™"°™ «к™™» »а
на использовании известных 4»««J™ " »Ц "^.„а общения итре в "крестнки-
основе ценности последующего состояния, пример "Р™
нолики- на основе временных Р™«^°£^^"ф^кции стоимо-
Метод динамического ^^m^'"ZT,«^ стоимости „оследутошего. Со-
пи предыдущего состояния на основе значения *>""„, iU „„следующего
стояния систематически обновляются с учетом мода^ фОМН1Ц1 „„„.
состояния. Обучение с подкреплением методом динам,, ^^^
^ва 9. Машинное обучение, осТов^ноТн^ль^м представл^иГ429
еле
"Woi^
ю„о на том, что для любой политики п и любого состоян„л s выполни,
рекурсивное уравнение
где rc(a|s) - вероятность действия а для данного состояния s при использов
хастической политики п, n(s^s'| а) - вероятность перехода из состояния s ct°-
действием а. Это выражение называется "уравнением Беллмаиа для у- 0н ° Sr,0«
соотношение между стоимостью состояния и рекурсивно вычисляемыми 3 BUria*aer
стоимости его последующих состояний. На рис. 9.24. а показан первый этап вь"2401"""'"
1Ч1клений
где для состояния s рассматриваются три возможных последующих
пользовании
состояния, п,
политики л вероятность воздействия а составляет гс(а | s). Дш1 ка "W *- ^ употребляется в более 1™™"™"™' а "е шаго
тояний в результате воздействия окружающей средь, может ocvm^L™ "3 ни», в котором важную 'ГЕ!" ЗНачении «™ обозк
переход в одно из нескольких состояний, скажем, s'c вознаграждением г R ТЬс*
Беллмана эти возможности усредняются с учетом вероятности реализа ^авНении
них. Согласно этому уравнению стоимость начального состояния s п Ка*Дой из
стоимости всех последующих состоянии с коэффициентом у н вознагпа °РЦИоНальна
дель. которая может быть „е аналитической
вать траектории и может ие вы.™,.,,. ' численной Он» „„
„„а не должна обеспечивать лно l?™™' *™»Ч~T"° КЖ^
«ДО», которое требустся вдина™еРа™Ределе„„е вероятно^™"™ в„ """ °бРа3°М-
Итак, метод Монте-Карло решаГза ' ПрОПММ™Рова„и„ * тж*»™
прения результатов экспериментов Для обТ/У °бучсния <= подкрепление „„
метод Монте-Карло работает т„„„ °6ссг|СЧ[™» хорошейХ "," " м С,ст ^«не-
„тоге завершаться. Более „г Ти^иТ™" ^"^'Т^Т^™*
вершении каждого теста СлемваТ mmo™ " политики „ "НЯГ "0™"b' B
в с^ле последовательнее™^^
тую употребляется в более широкомJ™'\ !."' ™Г0В' Т=Р«"н Мол Г-^Гзачас
ченному вдоль всего пути.
полу.
^^TnlZZZ^Z^?:^0-^ "МееТ 01?а«"°е приме-
« ■■ управляющих воздействий со™»Г Идеальнои "<W™- Если количество состоя-
°™ программирована позволяет ихГГ. " " m соответс™нно, то метод динамиче-
™, несмотря на то, что „Z" "Гг№ТЬ оптимм>>нУк> политику за полиномиальное
"«е скорость д„„а,„,чк^™Л0 детеР»"«истских политик равно „". В этом
™°П<>ям™" методами поиска» пГР°ВаНИЯ экспоне„щ,ально возрастает по срав-
«ече„™ икнх же 1ебВ"тРв'ЛРаНСТВе П0ЛИ™К- "~шму прямые метода ДЛЯ
™тод Мо„тс-КаРл0 „е треб;7„' СТ°Р°ННей оце™ каждой политики.
Z»T7mm" к^» TpS-тГи! Я П0ЛИ°Й МОдели' ПРИ использовании этого
<еГл„1 Н0ВМеТИ *»«£ Функции ЗМеНеИИЯ С0С™НИЙ' « »" Результатам таких
^ нийТ'"' П0и™вателУьГ™ сТ°ПМ0СТИ' *» раб°™ "«™» Монте-Карло
ZT' ""«Ученная в резу„ь ™ " '«стояний, управляющих воздействий и воэ-
5*"" Pe№""" *c„ZMPeerHOr° «™одепств„я с .„сшей средой или
-но ем?ГЮЦ,еЙ Срад' "» поз"" "HTePeCeH тем- ™ °» « требует начальных
«°Д=льнот0 «пернм,,,^™ "«Учт оптимальный результат. Обучение
.—____^^^^ Дает хорошие результаты. При этом нужна мо-
)
„„ ,-г-™ ■ оолее широком значении для „вГ рмин М°»™-Кар™ зачас-
„»,. в котором важную роль „грает ,^**" ™бого метода" оценив .
м^одов. основанных „а уСреднениире^;Ь™к™™нс„г. Здесь он используется для
В обучении с подкреплением испо^уютсТи Л Р °В'
веешьш является Q-обучеиие [Watkins 19891 п о^ГГ ""* ЧКШ ^Р1» "»&»« из-
нове временных разностей. Название метода про^Г"0"™ С°6°Й ВарИат подхо» »* «>
это функция, отображающая пары состояние л^Г. СЛедУЮЩИШ1 соображениям. О -
О: .состояв ^оЭДейСтв№) _;—;ИЗУЧе"""""а-™™™о-
Для одного шага Q-обучени, выполняется соотношение
°(S"a')^(1-C)*0<s^' + c-^.. + rmax0(s„„a,-0(s,iar)]p
Z^o2 иГрис3 5^1 Е^иТГо"^ С0С™НШ •- М™Д Q-o6y,e„,„, ^о.ьтлзо-
торото „оказань, воз!жь;Г™^юш„е7аЧ:ийНЬШ ^ ^дпа™ет состояние, дтя ко-
проход вьшолняется ZZ ™^ПГ ^ ™ " РШШХ Q-°6y4eHlu «**™™
и,1 УЧеИ"" 0бРатный "Р»*0» осуществляется для узлов упраатения с учетом во,
награде ,я и максимума функции О по всем возможным уг^вденн,™ ы^е™
Ге узлы ГевеГ° C°C™H'U- """ ""^ №т° определенном Q-o6y,e„„„3
вательиоД?™ ЛЯ-'°ТСЯ комчными и Достишотся в результате вьшолнения
последовательности действии с учетом вознаграждения, начиная с корневого узла.
Интерактивное Q-обучение предполагает прямой проход в пространстве возможных
действии и не требует построения полной модели мира. Его также можно выполнять в пакетном
режиме. Легко видеть, что Q-обучение— это разновидность метода временных разностей
олее подробное описание этого метода приводится в [Walkins, 1989] и [Sutton и Ватто, 1998].
С помощью обучения с подкреплением решено большое количество важных задач,
включая обучение игре в нарды [Tesauro, 1994, 1995]. В (Sutton и Ватто, 1998] с точки зрения обу-
ения с подкреплением проанализирована программа irrpu в шашки, описанная в разделе 4 3.
1 же рассмотрены вопросы обучения с подкреплением для управления лифтом, динамнче-
кого выделения каналов, составления расписаний и других проблем.
^^^Резюме и ссылки
Машинное обучение — одна из наиболее привлекательных областей искусственного
'нтеллекта, призванная решить основную задачу моделирования интеллектуального по-
Часть IV. Машинное обучение
9. Машинное обучение, основанное на символьном представлении.. 431
- пбласти возникает множество вопросов, связанных с пре
ведения. В згой научной J-1 положениями самого искусственно™ „££
"„„ем —A " " Тбзора. посвяшеиных вопросам машинного обучен.,. ^
пил» Можно выделить три г [Martin, 1997].
SbUUngley. ''^1е'р„„иё обзоры [Kondra.off и Michalski. 1990,; [Michalski
Стоит отметить также (юле р ^ я|ок1, с6ор„„к статей [Shavhk u D1elterich, 19901
„ др., 1983]. [Mictol*, и <?Р;; анные, нач„„ая с 1958 года. Поместив все эти р^
включающий работы. оп>ол ^^ важнос дм0 как для специалистов в области
ты в олну книгу'- редакторы ^ ^ ^ нов„ЧКов, желающих познакомиться с этой обла
„скусственного ""^""j собраны статьи по машинному обучению, включая ра
стью знаний. В [Klahr 195 1 ному подходу.
боты, относящиеся к иш.^ _ ^ вводный обзор по всей области,
включая стохас
Раб0И Ч^ы— и •"Ч*™1 «ш™»го 06УЧ!Н'И- ЧитаТеЛ"' """Ч*»*
тнческие, «е"Р0С™в глу6оких знаний в области рассуждении по аналогии, могут обратить.
ШеВП^е"ТгжЬог!е|1^з19861; [Holyoak, 1985]; [Kedar-Cabelli, 1988]; [Thagard, 1988].
Z K "^'вошосам создания новых знании и формирования теорий содержится в [Lang|ey
"Гш""] и s"Ct " Sngley 19901. В [Hsher и др., 1991] собраны статьи по класть
™ Сшрованию.понятии и другим формам обучения без учите».
я!1т машинного обучения много работ посвящено алгоритму ШЗ и его моднфикац,.
" ^^ва^поншш и другим формам, обучения без учите».
В оамках машии.~.—j--- ■ ,-„.,.
; В [Feigenbaum и Feldman, 1963] описан алгоритм запоминания ЕРАМ, в котором исполь-
зуется специальный вид дерева решении, получивший название дискриминаттои сета
(discrimination net) и позволяющий строить последовательности бессмысленных слогов.
Квинлану (Quinlan) впервые удалось использовать теорию информации для генерирования
дочерних узлов дерева решений. В [Quinlan, 1993] и других работах описаны модификации
алгоритма ЮЗ и решены вопросы обработки зашумленных данных и атрибутов, принимаю-
ших значения из непрерывного интервала [Quinlan, 1996]; [Auer и др., 1995]. В [Stubblefield и
Luger, 1996] алгоритм ЮЗ применяется для улучшения процесса восстановления нсточнигав
задаче рассуждения по аналогии.
Первые примеры обучения с подкреплением приводятся в [Michie, 1961]; [Samuel,
1959]. Большая часть материала этой главы почерпнута из [Sutton и Barto, 1998]. Метод
СЗ-обучения более подробно описан в диссертации [Watkins, 1989]. Вопросы обучения на
основе временных разностей освещены в [Sutton, 1998], а все алгоритмы обучения с под-
креплением описаны в [Bertsebs и Tsitsiklis, 1996].
Вопросам машинного обучения посвящен журнал "Machine learning". Новые ре-
зультаты в этой области ежегодно докладываются на конференциях "International
Conference on Machine Learning", "European Conference on Machine Learning",
American Association of Artificial Intelligence Conference" и "International Joint
Conference on Artificial Intelligence".
Вопросы обучения на основе связей освещены в главе 10, а социальное обучении
сГетс^азд^бГ "' Р°ЛЬ ИНДУК™ ™Р°™ и обобщения в обучении or*
^Упражнения
''ХГ^Га-'с3^™ "0ИЯТНЙ BHHC™Ha " РаССМ0ТРНТе ^hS
иулмька Ступенька состоит из расположенных рядом маленьк
ICHlf
,кого «
Часть IV. Машинное обу*
большого блоков (рис. 9.25). Создайте семантиче
или четырех положительных и "почти удовлетв СКУЮ '*П "*" пРедатавлс>™я трех
это понятие в развитии. зрительных" примеров и покажите
Рис. 9.25. Ступенька
2. На рис. 9.9, отражающем работу алгоритма исключения кандидата „е „оказаны по
нятия, которые были сгенерированы, а потом отношены из-зТих',р змерк.™ общ-
„ости или конкретности, либо были "поглощены" другими „оиятк!,. Повтори"
процесс, отображая эти понятия и указывая причины их исключения.
3. Реализуйте алгоритм поиска в пространстве версий на языке PROLOG „ли „а любом
другом языке программирования. Если вы выбрали PROLOG, воспользуйтесь
рекомендациями из подраздела 14.14.1.
4. Используя функцию выбора на основе теории информации из подраздела 9.4.3,
покажите, как алгоритм ЮЗ строит дерево, представленное на рис. 9.14 для данных из
табл. 9.1. Учитывайте приращение информативности для каждого теста.
5. С помощью формулы Шеннона докажите, что информативность сообщения о
результатах вращения рулетки выше, чем информативность сообщения о результате
подбрасывания монеты. Что можно сказать о сообщении "не 00"?
6. В некоторой предметной области составьте таблицу примеров, наподобие
классификации животных по видам, и продемонстрируйте процесс построения дерева
решений с помощью алгоритма ID3.
7. Реализуйте алгоритм ГОЗ на любом языке программирования и протестируйте эту
программу на данных по кредитной истории, приведенных в этой главе. При
реализации на языке LISP воспользуйтесь алгоритмами и структурами данных,
приведенными в разделе 15.13.
8. Подумайте, какие проблемы возникают при использовании атрибутов, принимающих
значения из непрерывного интервата, например, из множества вещественных чисел.
Предложите свои методы решения этих проблем.
9. Еще одной проблемой для алгоритма ЮЗ являются некачественные или неполные
данные. Данные считаются некачественными, если для одного и того же набора атрнбугов
возможны несколько различных результатов. Данные называются неполными, если часть
значений атрибутов отсутствует, возможно, из-за слишком высокой стоимости их
поучения. Как решить эти проблемы за счет модификации алгоритма шз
Ю. Познакомьтесь с алгоритмом построения дерева решений С4.5 из [QuinJar, 19ЭД и
протестируйте его на одном из наборов данных. В этой работе приводится полный
текст программы и тестовые наборы данных.
П. ПодберитГтеоретическис сведения для обучения „а ^^"^Г*'
предметной области. Проследите за поведением системы в процессе <>Ч™»»
-2. Разработайте алгоритм обучения „а основе ^"^^Л^Г™
ния. Если вы выбрали PROLOG, воспользуйтесь алгоритмом из подразд
ния. Если вы выбрали PROLOG, 1
Глава 9. Машинное обучение, основанное на символьном представлении..
алго-
'Ия.
™ы в •крестики-нолики" из подраздела9.7.2. Рсали1уИтс
13 Вспомните "РйМер "^° „енных разностей на любом языке программу
ритм обуче""» на М™ с„и принять во внимание симметричность задачи?
Как изменится алгор • ^ ^^ врсмсиных разностей нз задачи 13 г,У!т
,4. Что произойдет. сс<ш
использовав п~ ^^ g точки об с „од<р
,5. Проанализируйте ^£ ^„.„тами анализа из [Sutlon и Barto. 1998).
Воспользуйтесь "Р"* „увернутого маятника, рассмотренную в подраздел. 8 2 2
16. Мо*«о ли рецепт** ^ с 110дарсш1снисм? Разработайте „росгук, Фу111<1ДИ10
(см. рис. 8-8). с пом ^^„.ь алгоритмом на основе временных разностей,
„дагтиж*™. и i«кг^ ^ ^^ £ подкрсш,еинсм явяяется так „мьшасма||
17. Еше одной тестов ^_ ^ ^ „оказана решетка размером 4x4. Две заштриховав,
проблема решетк ^ Рд^ эт0 целевые конечные состояния агента. Из любой
НЫеГГйки£ент может двигаться вверх, вниз, влево или вправо. Он не мо*и
другой »4"™ етки. при такой „„пытке состояние не изменяется. Вотнагра».
'»ТлтУвсех ходов, за исключением перехода в конечное состояние, составляет -1.
встройте решение на основе алгоритма временных разностей, описанного в
подразделе 9.7.2.
Дейс
ТВИЯ
для любого хода
Рис. 9.26 Пример решетки 4x4 из работы (Sutton и
Вапо, 1998}
Часть IV. Машинное
обу*»**
Машинное обучение
на основе связей
Кошка, которая аоиажды села на горячую печь, никогоа Co.ihuie не
сядет ни на горячую, на на заяооную...
— Марк Твен (Mark Twain;
Все неизвестное г/стаетгл неясный Oft тег пор, пока не пытаешься
его уточнить...
— Бертран Рассел (Bertrand Rnsieil)
...как Оуото еолшеоный фонарик осяещает изнутри образы на зхране
— Т. С. Элиот ITS Elioti Псгнь wA»Ji"*wMn«J»-»
10.0. Введение
В главе 9 основное внимание уделялось символьному подходу к обучению
Центральной идеей такого подхода является использование символов для обозначения
объектов и отношений между ними в некоторой предметной области. В ттой глаас будут
рассмотрены нейроподобные. или биологические, подходы к обучению.
Нейроподобиые модели, известные также как системы параллельной распределенной
обработки или системы связей, ис предполагают явного использования символьного
представления в задаче обучения. Интеллектуальные свойства тли систем
обеспечиваются взаимодействием простых компонентов (биологических или искусственных
нейронов) и настройкой связей между ними в процессе обучения или адаптации. Нейроны
организованы в несколько слоев, поэтому такие системы являются распределенными.
Информация обрабатывается параллельно, т.е. все нейроны одного ело. одияремеиио и
независимо друг от друга получают н преобразуют входные данные.
Однако в „ейросетевых моделях символьное „pejorate играет «™У»Р°» Ч»
Формировании входных векторов и интерпрстании выходных ™™±>^gJZ
"здания нейронной сети разработчик должен определить ***™«*-~'1*~
'Ш их передачи в нейронную сеть Выбор схемы кодирования может сыгрт ключей
Роль для способности Гили неспособности) сети к обучению.
""•аая СПОСООНОСТИ (ИЛИ НССПОСООпич»!-- „Я—RmiV ИН<*ООМ»Ш1Н ОД-
Сети связей выполняют параллельную и г«Р^**22Г~*
нако
"ри тгом символы ис рассматриваются как
символы. Входная информас
, „,veTca B числовые векторы. Связи между элементами «га, нсйп„
меткой области преобралуек■ ми ,начсн,им„. И, наконец, преобразована „2°'
„а,ш тоже ^^^ош% „„ераш.й. как правило, векторно-матричного ум„0)1(£„£
зов _ зто результат число» ^^^ индуктив„ь,„ порог системы. '«•
Выбранная архитектур МИЗуЮшне этот подход, не предполагают явного „п.
№Р"™" "оТн пг!о™ выбираются для обучения сети. В этом ., состоит основе
граммнромтм. » Р „„вар,щнтные свойства входной информации выящмют,„
ПреМУШеСйТ„™^ответствуюшей архитектуры и метода обучения. При этом могут m^
за счет выбора coo ^ ^^ программирс.ван|,е здесь не требуется. Именно
пяться * странные °"г '
МГс-Г;ГГпа:хГт^Р=Ше„.1яследуьоЩнхзадаЧ.
. Классификация- определение категории или группы, к которой принадлежа,
входные значения.
. Распознавание образов - идентификация структуры или шаблона данных.
. Реализация памяти,в том ч,|сле задача контекстной адресации памяти.
. Прогнозирование, например, диагностика болезни по ее симптомам, определение
следствий на основе известных причин.
• Оптимизация — поиск наилучшей структуры ограничений.
• Фильтрация — выделение полезного сигнала из фонового шума, отбрасывание
несущественных компонентов сигнала.
Описанные в этой главе методы лучше всего подходят для решения задач, которые
трудно описать символьными моделями. К ним обычно относятся задачи, предметная
область которых требует осознания либо плохо формализуется с помощью явно
определенного синтаксиса.
В разделе 10.1 рассматривается история развития нейроподобных моделей. Здесь
представлены основные компоненты, необходимые для обучения нейронной сети,
включая "механический" нейрон, а также описаны некоторые исторически значимые ранние
результаты в этой области, в том числе нейрон Мак-Каллока-Питтса (McCulloch-Pitts),
разработанный в 1943 году. Развитие этих нейросетевых парадигм в течение последних
40 лет во многом обусловило современное состояние проблемы машинного обучения,
В разделе 10.2 в историческом контексте представлено правило обучения персептро-
на (perception), или de.nma-npaeu.io (delta rule). Рассматривается пример, в котором пер-
септрон выступает в роли классификатора. В разделе 10.3 вводятся сети со скрытым»
слоями „ освещается алгоритм обучения на основе обратного распространения o««fe
тшП",? '' аР*™ЭТ>ы позволили преодолеть проблему линейной раз№
«Гс^?УШУЮ тШМ нейР°с<™ьт моделям. Алгоритм обратного распространи
Z^~72 °ШИбК" " ™ ^ ™°™°й сети с непрерывными по-
В разделе юТ' РЫе ЛаЮТ «""Рректный результат.
meehtTeta 1987Г:ГеНЫ МОД™ Кохонена [Kohonen, 1984] и Хехта-Н,^
моделях векторы ве овыхЗГГ"6 "*"""'" <coraP«ilive '«™inS) «* ^У4™""*!*
зов, а „е моишо™ св ™ ?ФфИЦИентав используются для представления самих W
аЩ выбирает узеГобГ Р"™ °буЧеННЯ "победитель забирает вес" (winner-»^
ответствует входном,„ "ОГОРОГО (вектор весовых коэффициентов) наиболее точи
более точного соответ™?^" HaclPa"Ba« эти коэффициенты для обеспечен.*
• Jto 'лгоритм обучения без учителя, поскольку ««г-
ЧастЫУ. Машинное обУ»
победитель — это просто нейрон, вектор весовых кт**
6лиз0к входному вектору. Комбинация слоев нейронов К НТ0В К0ТОР°™ наиболее
к созданию сети, которая может служить интересной мл "* " Гросс6сРга приводит
встречного распространения. моделью для обучения по методу
В разделе 10.5 представлена модель обучения г пп„„.
Хебб высказал предположение 0 том, J^^T2T^ ^ ^ 1949]
переда- ему импульса от другого нейр0на с^а^Гм^Г "?»"* ^^
^Алгоритм обучения Хебба- это простой алгор Z7c^l" Неиронами В03Расга-
„редставлеиы версии этого алгоритма L об^Гс^ГмТб Гу^ГГа 5S
линейная ассоциативная память (linear associator), основанная на моделиХебТа
В разделе 10.6 вводится очень важный тип нейроподобных моделей, получивших
название аттракторы* сетей («tractor network). В этих сетях для циклической передачи
сигналов используются обратные связи. Выходом сети является ее состояние в положе
нин равновесия. В процессе настройки весов связей формируется множество
аттракторов. При подаче на вход сети образов, относящихся к зоне притяжения аттрактора сеть
сходится к состоянию равновесия, соответствующему данному аттрактору.
Следовательно, аттракторы можно использовать для хранения образов в памяти. Тогда, имея входной
образ, можно получить либо ближайший из сохраненных образов либо ассоциированный
с ним. Первый тип сети называется автоассоциативной (autoassociative memory), а
второй — гетероассоциативной памятью (heteroassociaUve memory). В 1982 году физик-
теоретик Джон Хопфилд (John Hopfield) разработал класс аттракторных сетей,
доказательство сходимости которых сводится к минимизации функции энергии. Сети Хонфкл-
да можно использовать для решения задач оптимизации при наличии ограничений, в
частности задачи коммивояжера. При этом критерий оптимизации записывается как
функция энергии системы (подраздел 10.6.4).
В глааеН, заключительной главе части IV, представлены эволюционные модели
обучения, в том числе генетические алгоритмы и модели "искусственной жизни".
Вопросы представления информации и порогов в обучении, а также преимущества каждой из
парадигм рассматриваются в разделе 16.3.
10.1. Основы теории сетей связей
10.1.1. Ранняя история
Зачастую теорию нейронных сетей считают очень современной наукой олнаш ее
истоки относятся к периоду pal» работ в области компьютерных наугс "™'™ Ф^
Фин. Например, еще Джои фон Нейман пришел в восторг ог теории ы«™™^™^
-Фопо/обного подхода к вычислениям. ^^jZZZZ^bb.^.
»ия выполнялись под влиянием психологической теории всучен и
В этом разделе будут описаны основные -^"^Х£Г
к«я.атакже представлены исторически^™^с™С/„"1рон. „сма которого показана
Основой нейронных сетей является искусственный на j~
»>Р«с. 10.1. Искусственный нейрон имеет следующую структуру.
~-™™кчиие из окружающем среды или от
• Входные сигналы *,. Это данные. "^™ ючСний зля oavrm^ моделей мо-
Других активных нейронов. Диапазон вход тм д11сктетнь1ч„ (бинарными)
жет отличаться. Обычно входные знзченн
г"ава 10. Машинное обучение на основе связей
и определяются множествами {0,1} или
венные значения.
-1,11 либо
принимают любые веЩсст.
Рис. 10.1. Искусственный нейрон, входной вектор X,
вес связей W-и пороговая функция f. определяющая
выходное значение нейрона. Сравните эту схему с изо-
брожением реального нейрона, приведенным на рис. 1.2
• Набор вещественных весовых коэффициентов iv,. Весовые коэффициенты
определяют силу связи между нейронами.
• Уровень активация нейрона 2>л„ который определяется взвешенной суммой
его входных сигналов.
• Пороговая функция г", предназначенная для вычисления выходного значения
нейрона путем сравнения уровня активации с некоторым порогом. Пороговая
функция определяет активное или неактивное состояние нейрона.
Помимо этих свойств отдельных нейронов, нейронная сеть также характеризуется
следующими глобальными свойствами.
• Топология сети (network topology) — это шаблон, определяющий наличие связей
между отдельными нейронами. Топология является главным источником
индуктивного порога.
• Используемый алгоритм обучения (learning algorithm). В этой главе
представлены различные алгоритмы обучения.
• Схема кодирования (encoding scheme), определяющая интерпретацию данных >
сети и результатов их обработки.
[м'гТ'ь "р"мером нсйР°еетевой модели является нейрон Мак-Каллока-Питтса
IMcCalloch и Pitts. 1943]. На вход нейрона подаются биполярные сигналы (равные +1
или -1). Активационная функция— это пороговая зависимость, результат которой
вычисляется следующим образом. Если взвешенная сумма входов не меньше нуля, выход
" пС ГГММТСЯ РШНЬШ 1 • В про™ном с»Г«е - -1 • В своей работе Мак-Каллок
ФункГю сТ"' ^ "а °СН0Ве ТаКИХ нейР°"°в M°™0 построить любую логичесю»
t™l« °' СИСТеМа Щ таких «ейР°»™ обеспечивает полную вычисли-
И™^С:1Г™Р1ЫЧ"™™ «о™™™ функций И и ИЛИ с пом**
из которых здаю^аГ меТ"' КаЖДЫЙ из этих "ейронов'имеет три входа, первьк
™S)' всегда Ра«» 1 ■ Весоше to"
(bias), все™ rT"! ^Т'6"™ Функции х и у, а третий, иногда называемый троге
з состава"10
соответствен!
фициенты связей для входных нейронов с
' с_ 1огда «м "юбых входных значений х и у нейрон вычв
+У- 2. Если
это значение
меньше 0, выходным значением нейрона
1ВЛЯСК»
Часть IV. Машинное обуче
.,, в противном случае — 1 Из табл. 10.1 видно что такой „„-
ч сляет значение функции *лу. Аналогично можно уд„стове Гя"' П° ^"^ ""
„ейроннарис. 10.2 вычисляет значение логической фу'нкгщи ИлГ ™'' ™ "°?Л
Рис. 10.2. Вычисление логических функций И и ИЛИ с по-
мощью нейронов Мак-Каллока-Питтса
Таблица 10.1. Модель Мак-Каллока-Питтса для вычисления функции
логического И
х У х+у-2 выход
Несмотря иа то что Мак-Каллок и Питтс продемонстрировали возможности нейросетевых
вычислений, реальный интерес к этой области проявился только после разработки
применимых на практике алгоритмов обучения. Первые модели обучения во многом связаны с
работами специалиста по психологии Д. О. Хебба (D. О. НеЬЬ), который в 1949 году предположил,
что обучение биологических существ связано с модификацией синапсов в мозгу. Он показал,
что многократное возбуждение синапса приводит к повышению его чувствительности и
вероятности его возбуждения в будущем. Если некоторый стимул многократно приводит к
активизации группы клеток, то между эпши клетками возникает сильная ассоциативная связь.
Поэтому в будущем подобньш стмул приведет к возбуждению тех же сшпеи между
нейронами, что в свою очередь обеспечит распознавание стимула (более точно утверждение Хеоба
приводится в подразделе 10.5.1). Модель обучеюи Хебба основана только на
идее.подкрепления „ не учитьшает забывчивость, штрафы за ошибки или «нос. <»»« «»££
ныт^сь Реа_ моде, *«*» ~ п^ь ^£££££
без добавления механизма забывчивости [Koinesler и др., i?ooj lv
чения Хебба более подробно будет рассмотрена М*^^ за счет формиро-
В следующем разделе модель ^£££%£££« в^Ймодейсгвия. " —
ванил слоев взаимосвязанных нейронов и добавления ашиу Гоегсеосгоп).
версия такой „ейроподобной структуры получила название „ерсептрона (реоерош)
10.2. Обучение персептрон^
У распространения
глава 10. Машинное обучение на основе связей
, r,« в подразделе 10.2.2. Входные значения перестроив я1!ляю^
мер которого будет описи, в подр ^ _ всщсствснным чиа10м. уровень ттщ»*Ъ
биполярным" (равны - ювсшснная сумш его входов. Sx,w, Выходное значение „,„'
септрона вычислял» ^ ^^ |11)роговои функции: если уровень акт„ва„,„"
«„трона »«-«^ порогово„у значению, выход персептрона принимается раВ1Ш1,, '
превышает или рав^ i ^^ о6[ШОМ, вь1ХОдное значение персептрона вычисляет,,
„аТГвГетоТодиых значений х„ весовых коэффициентов и,, и порога f следую»,
образом.
1, если Ixw, 2 !,
-1, если 1х w, < I.
Пля настройки весов персептрона используется простой алгоритм обучения с
учителем Псрсептрон пытается решить предлагаемую задачу, „осле чего ему
предъявляется корректный результат. Затем веса персептрона изменяются таким об-
разом чтобы уменьшить ошибку на его выходе. При этом используется следующее
правило. Пусть с — постоянный коэффициент скорости обучения, ad— ожидаемое
значение выхода. Настройка весового коэффициента для 1-го компонента входного
вектора выполняется по формуле
Aw=c(d-sign(Sxw,)) хг.
Здесь sign(Ix,w,) — выходное значение персептрона, равное + 1 илн - 1. Разность
междужелаемым и реальным выходными значениями может быть равна 0, 2 или -2.
Следовательно, для каждого компонента входного вектора выполняются такие действия.
Если значения желаемого и реального выхода совпадают, ничего не происходит.
Если реальное выходное значение равно - 1, а желаемое — 1, то весовой
коэффициент для 1-го входа увеличивается на 2сх(.
Если реальное выходное значение равно -1, а желаемое — 1, то весовой
коэффициент для t'-го входа уменьшается на 2сх(.
При использовании такой процедуры получается все, минимизирующий среднюю
ошибку на всем обучающем множестве. Если существует набор весовых
коэффициентов, обеспечивающий корректное выходное значение для каждого элемента
обучающего множества, то такая процедура обучения персептрона позволяет его получить
IMrnsky и Рареп, i%9].
п™П„еРВ°Нт«ЬН0 появлен"с персептрона было встречено с большим энтузиазмом
оаннчГ ™ДУ Н"ЛЬС НИЛЬС0Н (Nils Nilss™> « Другие исследователи выявили ог-
клаёеаГГтМ0ДМ" nePc™?<>"». Они „оказали, что псрсептрон не решает целого
™м 11хот 7° СЛ0ЖНЬ,Х МЛаЧ' В котаРы* *»ные "е являются линейно раздел»'
трона в то , ч ГеДСТВ"" П°ЯВИЛИСЬ Р«лпчныс усовершенствования модели персе»;
?Регеерго„" а;;0ГОС™Г'»"= персептроны. Минский и Пейиерт в своей кн «
»о^дел„моГ;м;:;;тГр;;;:т%9Герссптрона нсльм рсшнть "ро6лсму
вом^1лео™'РХГ2°1ад?"'^'аСС"фи^ци^ "а«иы= которой не обладит с»*1'
,; " -" l™'nsKy и Paper!, 1969I
Классическим пойме™.. ,„„.. .
ой раз
„г„ „' " ""'"' ""ляется проблема "исключающего или *■-- , щ,
исключающего ИЛИ" можно „редставить с помошыо СЛсду,ошеи тао»»
ФункГю ,1'"'"""°™' ЯВЛЯтея "Р°6— "исключающего ИЛИ" («6»^°
a™„Z„ аК>ЩеГ° ИЛИ" м°*«° "Редставить с помощью следуют» "
Часть IV. Машинное обу*
т-ЙЛИМ" 1°-2- Га^Ицаисгиннос™^»ФУН«Ч.«о,с«,«,и^,.|„„
Выход
Рассмотрим псрсептрон с двумя входами х, и х,, двумя весовыми коэффициентами иг,
„ W; и пороговым значением I. Для реализации этой функции сеть должна настроить
весовые коэффициенты таким образом, чтобы выполнялись следующие неравенства
(рис. 10.3).
w/1+w/Kf (из первой строки таблицы истинности),
w," 1+0 > г (из второй строки таблицы истинности).
0+иуа* 1 > г (из первой строки таблицы истинности).
0+0 < г (т.е. положительный порог, из последней строки
таблицы истинности).
Эта система неравенств для W, и w2 и f не имеет решения. Тем самым
подтверждается, что псрсептрон не может решить проблему "исключающего ИЛ1Г. Несмотря на то
что существуют многослойные сети, способные решить згу проблему (см.
подраздел 10.3.3), алгоритм обучения персептрона предназначен только для обучения
однослойных сетей.
Невозможность решения задачи "исключающего ИТОГ для персептрона объясняется тем,
что два класса, которые должна различать сеть, не являются лшешю разданы.™ (рис. 10.3).
В двухмерном пространстве невозможно провести прямую, разделяющую множества точек е
координатами ((0,0), (1,1)) и((1,0), (0,1)).
Можно считать, что входные данные сети определяют
пространство. Каждый компонент входного вектора определяет
направление, а каждое входное значение задает точку в этом
пространстве. В задаче "исключающего ИЛИ" четыре входных
вектора с координатами X, и х, определяют точки, показанные на
рис. 10.3. Задача обучения классификации сводится к
разделению этих точек на две ^"^""^^^ Рж. Ш. **ш
етво является линейно разделимым^если его , ом „110яю«и)ч«я, ИЛИ':
классы с помощью n-мернои пшЧ»»™'' 'ш „ в4ючю,^
пространстве n-мерной гиперплоскостью явля г „„.„гюшг,
трехмерном — плоскость и т.д.) „„„.„„„и разделимости
В результате выявления проблемы —», ро^ ^
направление исследований сместилось юч '' в о6ласп1
нованных на символьном представлении, а ^^^ 0д1ШВ)
"ейросетевоп методологии '»"^^™года, показали, что
Дальнейшие исследования в 19/U-X и i*°
5та проблема является разрешимой. обратного распространения.
В разделе 10.3 будет описан метод обунени, «° Персептрона для многослойных се-
которкп'1 является обобщением алгоритм. f ^гЛ,стода. рассмотрим -Ч»™* «™
теп. Однако прежде чей переходить к изуче "О ™ р „вершение раздел. 1^
"среситроиного типа, выполняющей класс Ф ^^ ^.„a-rulo» - обобшеине алго-
будет изложено обобщенное demwa-Щ"""" (-
0(0. И
странегте не.1ЫЯ
провести пряиую, разое-
ТЯЮЩУ» МРЫ тйЧ('К
((0,1). (1,0)1 "
((0,0). (1,11)
глава 10. Машинное обучение на основе связ
„™,,и. используемое в многочисленных неиросетсвых архтс№/
ритма обучена "^оГных"" методе кратного раепростраиеиия. «*
pax, в том числе основан™
Юг^Примермипользованиеперсептроннойсетн
для классификации образов
и 10 4 показана обШая схема решения задачи классификации. Строки да„„ых щ
На рис. 10.4 показа ^ „ы6ираюТся преобразуются к новому виду D проспан.
пространства »"»""^ " щт „„, о6разов. В этом новом пространстве образов виде-
^"'"Тзиаки определяются сущности, представляемые ими. Например, расСН01.
ляются признаки и и v записанными на цифровом устройстве. Эти акусти.
а возможных точек е
ствуюших . г, ~
,ределяются сущности, представляемые имн^Например, рассмот-
„Тй ,7лаот со звуковыми сигналами,:
«шГсигналы трансформируются в амплитудно-частотное представление, а затем
г L классификации по этим признакам может распознать, кому принадлежит да„„ы„
™7с Еще одним примером задачи классификации является медицинская диагностика,
предполагающая сбор информации с помощью медицинского диагностического
оборудования и классификацию симптомов по различным категориям болезней.
Для рассматриваемого примера в блоке преобразователя и извлечения признаков
на рис 10.4 данные из предметной области задачи трансформируются в двухмерные
векторы декартова пространства. На рис. 10.5 показаны результаты анализа
информации, приведенной в табл. 10.3, с помощью персептрона с двумя входами. В
первых двух столбцах таблицы содержатся векторы данных, используемые для
обучения сети. В третьем столбце представлены ожидаемые результаты классификации,
+1 или -1, используемые для обучения сети. На рис. 10.5 показаны обучающие
данные и линия разделения классов данных, полученных после предъявления обученной
сети каждого входного образа.
Строки данных
Пространство
Преобразователь
Данные
Пространство
образов
Модуль
извлечения
признаков
Признаки
Пространство
признаков
Классификатор
Класс
Признаки
Рис. 10.4. Полная система классификации
явленнППМ"Г°ИИМС" ° °6шеЙ Те°РиеГ| ™ссиф„кации. Каждая группа данных, в"'
ном пр^а„™ФЕ"ГР0М' М°ЖеТ бЫТЬ "Ржавлена некоторой областью в миогомер-
ДеляющаТстГнь nZ""" ™С°У "' »°™ует Дискримииантная функция 9,. о^
Для об^ГГГа Л 1 С™ ЭТ0Й °блас™ CPe«" юех Днскриминаитных фУ»««""
' Макс"маль"°= значение имеет функция о,:
№)>Э,(х) для всех/, -!<,■<„,
В простом примере из табл im
первому из которых com. Двухмерные входные векторы делятся на два
«ответствует значение 1, а второму — -1
класса.
Часть IV. Машинное обуче"
100
Рис. 10.5. Данные ш табл. 10.3 в
двухмерном пространстве. Персептрон.
описанный в подразделе 10.2.1, обеспечивает
линейное разделение этого набора данных
Таблице 10.3. Набор обучающих денных для классификации с помощью
персептрона
X,
1,0
9,4
2,5
8,0
0,5
7,9
7,0
2,8
1 О
Х;
1,0
6,4
2,1
7.7
2,2
8,4
7,0
0.8
Выход
-1
-1
-1
-1
Важным частным случаем дискримннантнон функции являете.' °"™^"" J
««ложности „а основе расстояния от некоторой центральной точки облает Классифн
нация, основанная „а такой днекриминангной функции. «^""^То^оТ^-
шнш,а,ьно.«у расстоянию. Легко показать, что такую классификацию можно ре
вать для линейно разделимых классов, „«„„„„ на гше ЮЛ то существует
Если области В, и В, являются смежными, как две области „а риели
пограничная область, для которой дискриминанта» функция имеет вид
вМ-glx) или g,(x)-g,(x)=0. A„„„u оаз-
с „„,„ис I0.S, то днекриминантная ф>тш»м, раз
Если классы линейно разделимы, как на ри".- „„„vk, л,шию. т.е. функции д,
Деляющая соответствующие области, пРедс^2 мнс,жесгво точек, равноудаленных
'' S; являются линейными. Пос
1Т Двух фиксированных точек,
1Нмат-ил.-„ - „„.лат
- и™ линейно разделимы, как ""f""'"^"„"„р^™ линию, т.е. функции о,
шющая соответствующие области, представши. ^^д точ№ равноудаленных
» 9, являются линейными. Поскольку прямая э эт0 функции ми-
Двух фиксированных точек, то «^TT^^Z^
"имального расстояния от декартового центра кажде
г"ава 10. Машинное обучение на основе связей
Пока.
._ „„„едяюшую функцию можно вычислить с помощью переспи
ЛИИе"ТсРШ П^жашего два обычных входа и пороговый вход с £*■
м„„ого на рис. Ш" /ыття„ 8Ы,ШСленис по следующей формуле """"««to,
значением l.liepceinpv
Еся„Ях)=+1,тохпринадлежит одному классу, если ""Г:1 ~ЛРУ10МУ-Та№е^
„братние называете» кусочно-линейной биполярной пороговой функцией (рис. ,„ ? ° *•
ZL вхол служит для смещения пороговой функции вдоль вертикальной оси. Ве^
того смешения определяется в процессе обучен™ с помощью настройки весового^
фициекта tv3.
Используем данные из табл. 10.3 для обучения персептрона, показанного на р„с 10,
Инициализируем значения веса случайным образом, например [0,75, 0,5, -0 61
применим алгоритм обучения персептрона, описанный в подразделе 10.2.1. Верхний'"
деке переменной, в частности 1 в выражении Цпе!) , задает номер текущей нтсрациищ
горитма. Обработка данных начинается с первой строки таблицы
f(nef)'=f(0.75-1+0.5*1-0.6-1)=f<0,65)=1.
Поскольку значение 1(лет)'=1 корректно, настройка весовых коэф
на Следовательно, W2=W]. Для второго обучающего примера
f{ne()'=f(0,75-9,4+0,5-6,4-0,6'1)=f(9,65) = 1.
[шциентов не ну*.
Рис. 10.6. Персептрон для классификации
данных т табл. 10.3 с кусочно-линейной
биполярной пороговой функцией
значи? лТи? °6Г,аЮшего "РимсРа "а выходе персептрона ожидается значение -1.
под^ГшТИК" ВеѰ Не°бхОДИМО применить обучающее правило, описанное.
bwwTt'-ZLTTT™обучения'х" w~~ вект°ры входов и весовых т*
лаемый результат а момен """ УЧения' Т — символ транспонирования, о""1 — о*"'
'=2). Выход сети при (=2 о """"J5"" '"1 (или- как в Данном случае, в момент временя
иым выходом сего состав-i !v" сл«™ательно, разность между ожидаемым и реаль-
пгреептрона инкремент об™ ~sl9n(<w~>T>-X2) = -2. На самом деле для биполярного
™Р из обучающе,-,, множеств,"1? """^ составляет либо + 2 с* либо - 2 сХ. где X - к*
сгвенное число, наподобие 0 2 п°'Ффиииент «орости обучения — ото небольшое вешс-
• ■ Обновим вектор весовых коэффициентов:
.. Г П 7с "1
0,75
0,50
.-0,60
-0,4
9,4
6,4
Л°.
=
-3,01"
-гоб
-1,00
Часть IV. Машинное
обучен^
Теперь нужно вычислить выходное значение сети л
с учетом настроенных весов """ третьего обучающего примера
((Лв()'=т(-3.0Г2,5-2,06-2,1-1,0-1Н(-12,84)=-,
Это значение снова не совпадает с ожидаемым выходом На г-,,, г
а tf обновляются таким образом ' следующей итерации вс-
= W3+0,2(-1-(-1))X:' =
+ 0,4
После десяти итерации обучения сети персептрона формируется линейнс* рашме.
и„е, „оказанное на рис. 10.5. Примерно через 500 шагов обучения вектор вееГвьгх и!
фициентог. будет равен [-1,3; -1,1; 10,9]. Нас интересует ли„ей„ое1азделенГ££
„ассов. В терминах дискримииантных функций д, и д, разделяющая поверхность
представляет собой множество точек, для которых д,<х)= 9/{х) или gix) - 9/х)=0 т е
уровень активации равен 0. Уравнение функционирования сети можно записать в
терминах весов
net=w,x,+wIx1+wy
Следовательно, линейная разделяющая поверхность между двумя классами
определяется линейным уравнением
-1,3'х,+(-1,1)"х,+ 10,9=0.
10.2.3. Обобщенное дельта-правило
Для обобщения идеи сети персептрона нужно заменить его строгую пороговую
функцию активационной функцией другого типа. Например, непрерывные активациоиные
функции позволяют строить более тонкие алгоритмы обучения за счет более точного
вычисления ошибки измерения.
На рис. 10.7 показаны графики некоторых пороговых функций: кусочно-линейной
биполярной пороговой функции (рис. 10.7, а), используемой для персептрона. и
нескольких видов сигмаидальных функций (sigmoid). Сигмоидальные функции получи.™ такое
название благодаря тому, что их график напоминает латинскую букву "S" (рис. 10.7.6).
Типичная сигмоилальиая активационная функция, или логистическая функция (logisoc
function), задается уравнением
f(net)=1/(1+e '""), где net-lxy/..
Здесь, как и ранее, х, - 1-Й вход. W, - вес свят I - параметр -кривизны'. нсполь.
зуемьш для настройки формы сигмоилальиой кривой. При ^ь™^Тд^н"
сигмоиды приближаете;/обычной кусочно-линейной -РГ^ГГТна ZrXr
значений (0,1), а при значениях параметра "кривизны . близких '■
Аргументам пороговой функции является УР°«Н^™ШШ'^^ ч^по^ет
«■ ~ »ь,ход нейрона. Строгальная активационная Ф>-™»^ф"™ «™-
""•нее „цсмить 1„6ку на выходе сети. Подобно обычно^°^™£J» f ^^ „
^ьная активационная функция отображает "Гп^ои^ш сигмокд. может
"нтервала (0,1). Однако в отличие от обычной пороговой q»
Глава 10. Машинное обучение на основе связей
. „з всего интервала, т.е. она обеспечивает непрерывную Щп.
„рннимать значения из всег Парше1р Л опрсделяет .^ „ >Р0Кс,,
„з„„ю классической порогов^№т ^^^ функцш| вдоль ^ ^^ перех,
Взвешенное значени v
Их) V
"-1 ' ' Сл"'3шовЛ
«да.
i, строгая кусочно-
линейная биполярная
пороговая функция
б. Сигмоидальная
униоолярная
пороговая функция
в. Сигмоидальная сдвинутая функция
с различной"кривизной". Чем
больше значение параметра
тем точнее сигмоидальная аппроксимагш
кусочно-линейной пороговой функции
-. 10.7. Ативаиионные функции
Появление сетей с непрерывными активационными функциями исторически обусло-
вило новые подходы к обучению на основе коррекции ошибки. Так, обучающее правило
Видроу-Хоффа [Widrow и Hoff, 1960] предполагает минимизацию среднеквадратиче-
ской ошибки между ожидаемым выходным значением и уровнем активации сем
net=Wx„ независимо от вида активационной функции. Но самым важным правилом
обучения для сетей с непрерывной активационной функцией является, пожалуй, дельта-
прстею (delta-rule) (Rumelhart и др., 1986, а].
Интуитивно дельта-правило базируется иа использовании понятия поверхности
ошибки (рис. 10.8), которая представляет кумулятивную ошибку на всем наборе данных
как функцию от вееов сети. Каждая возможная конфигурация весов определяет точку
поверхности ошибки. Имея определенную конфигурацию весов, с помощью алгоритма
обучения можно найти направление на этой поверхности, вдоль которого происходит
наиболее быстрое уменьшение функции ошибки. Этот подход называется обучением по
методу градиентного спуска (gradient descent learning), поскольку градиент определяет
"наклон" поверхности в каждой ее точке.
Старое значение И/
Новое значение И/
Локальный минимум
^Поверхность ошибки
Piemen,p"^?P"W' п™еРх»°сть ошибки. Константа с оп-
» размер шага обучения
Дельта-правило предполагает использование м
аКГ„вациоиной функции. Этими свойствами обла/аТ"™"0* " д"ФФсР=«иируем„п
«екая функция. Дельта-правило для настройки / г рассмотРе""ая выше
логистики имеет вид '"™ "«ового козфф„цИе„та ,-.г„ узла
c(d,-0,)f'(nef,)x,
да с — постоянный коэффициент скорости обучения d „ п
выходы /-го нейрона, ,'_ производная ^SnU^ZZZlT'^
вход„ое значение ,-го узла Покажем, как выводите» эта форСа ^ ' ~ "*
j::;t:zz™ оши6ка на — «■ ^~ ^ «^
Error =(1/2)£(d,-0,)! ,
где с/, - ожидаемое значение выхода нейрона, а О, - его реальное значение. При
суммировании ошибки возводятся в квадрат, чтобы отрицательные и положительные
ошибки не компенсировали друг друга.
Рассмотрим случай, когда сеть состоит из единственного (выходного) слоя
нейронов. Более общий случай наличия скрытых слоев будет описан в разделе 10.3. Сначала
необходимо определить скорость изменения ошибки на каждом из выходных нейронов
сети. Для этого нужно взять частную производную (partial derivative), определяющую
скорость изменения векторной функции по одной из переменных. Частная
производная общей ошибки для каждого /-го нейрона выходного слоя составляет
ЭЕтг W/WBd.-Q,f 3(V2)'(d,-qy
дО, ЭО, ЭО,
Такое упрощение возможно, поскольку рассматриваемая сеть содержит лишь один
выходной слой нейронов, а значит, ошибка на выходе одного из узлов не влияет ни на
какие другие нейроны. Вычисляя производную, получим
эд/гщ-о,.)'
ЭО,
Определим скорость изменения ошибки для каждого из весовых коэффициентов w,
ДЛЯ 1-го узла. С этой целью вычислим частную производную функции ошиоки для
каждого из узлов по весовым коэффициентам связей *-,, ведуших к этому узлу.
дЕггог _ дЕггог . dOj
dwk dOt dwk
Учитывая предыдущее соотношение, получим
*. ...о пг пычис!яется частная произвол-
Рассмотрим правую часть этого »*^-Г%£££апш связей, ведущих к
«ая реального выхода 1-го нейрона по весовым *»**"" коэфф„ц„е„ты сле-
Мму. Выходное значение нейрона выражается через Ф*
Дующим образом:
0=f(W,X), где WtX=nett.
Глава ю. Машинное овучение на основе связей
447
, „ .„оеоывная функция, можно вычислить се производную
Поскольку» — нч'^н
oW,
Подставляя это соотношение в „редьшушее уравнение, получи»
^SHE--{d,-0,rnnet,rx,.
dw,
Для минимизации ошибки необходимо изменить значение веса в направлении ант,-
градиента. Следовательно,
,„, .^.®IHC=-cH(*,-0,)T(nef,)*x,] = c(d,-0,)-f(nef1)*x,.
Несложно заметить, что дельта-правило напоминает метод вычисления экстремума,
описанный в разделе 4.1. Там он применялся для минимизации локальной ошибки на
каждом этапе. Этот метод состоит в поиске наклона поверхности ошибки в окрестности
некоторой точки. Такое свойство приводит к неустойчивости дельта-правила, поскольку
с его помощью нельзя отличить локальный минимум от глобального.
Существенное влияние на эффективность дельта-правнла оказывает коэффициент
скорости обучения с (см. рис. 10.8). Значение этого коэффициента определяет вели-
чину изменения весов на каждом шаге обучения. Чем больше с, тем быстрее вес
приходит к оптимальному значению. Однако если коэффициент с слишком велик,
алгоритм может ''проскочить" точку экстремума или осциллировать в окрестности
этой точки. Небольшие значения коэффициента скорости обучения позволяют
устранить эту проблему, но замедляют процесс обучения. Оптимальное значение этого
коэффициента иногда определяется с учетом фактора момента [Zurada, 1992] —
параметра, настраиваемого экспериментально для каждого конкретного приложения.
Хотя дельта-правило обеспечивает возможность обучения только однослойных
сетей, его обобщение приводит к методу обратного распространения ошибки —
алгоритму обучения многослойных сетей. Этот алгоритм рассматривается в
следующем разделе.
10.3. Обучение по методу обратного распространение
Ю.3.1. Вывод алгоритма обратного распространения
ото„3иче„иГЩеГ° РаЗД£Ла ЯСН°' ™ °Д"°слойныс сети персептронного типа обладаю'
Гдобав" 'ё ВЮМ0Ж»0™™ классификации. В разделах'10.3 и 10.4 6УД« показ»
смоСь в" "еСК°ЛЬКИХ СЛ°еВ ПЮ№ о-™ эти ограничения. В разделе 16.3 F*
«.ГтГ"'Т° "0т""е мно™»°йн"е "ейрон7ые сети, эквивалентные к» О
-гоР™ГоРС„™T э° ^ ™'а ССТеЙ Д0Л™ ^ «е существовало ,фФ-*£
чивающеерешежГ, - раЗДеле описывается обобщенное дельта-правило, оое
Ней™ проблемы.
с», о ™::::z?z*ти -"—=я т „,.». ^ ю.». при*. ^
"* "«ходе сети Z ° р.5™""1 СЛ0Я "+1 - При многослойной обработке сигналаоШ>
" 6ЫТЬ »щю™ сложными процессами внутри нее. Поэтому
к ошибки в выходном <
„,„ —• сета необходимо анализиво.я-п. „
ратного распространения ошибки обеспечивает спос 7 I кошш*се. Метод об-
гослойной структуры нейронной сети. настройки весов с учетом мно-
Прямое
распространение
информации в сети
Обратное
распространение
ошибки
Рис. 10.9. Обратное распространение ошибки в нейронной
сети со скрытым слоеи
В рамках этого подхода ошибка на выходе сети распространяется в обратном
направлении к скрытым слоям. Анализируя обучение по дельта-правилу, несложно
заметить, что вся информация, необходимая для модификации весов нейрона, относится
только к этому нейрону, за исключением самой величины ошибки. Для нейронов
выходного слоя величина ошибки вычисляется просто как разность между ожидаемым и
реальным выходным значением. Для узлов скрытых слоев ошибку определить значительно
сложнее. В качестве активационной функции при использовании метода обратного
распространения обычно выбирается логистическая функция
f(net)=1/(1+e~1'""), где net=Ixw.
Применение этой функции обусловлено тремя причинами. Во-первых, она относится к
классу сигмоидных функщш. Во-вторых, поскольку она непрерывна, то ее производная
существует в каждой точке. В-третьих, поскольку максимальное значение производной
соответствует сегменту наиболее быстрого изменения функщш. то наибольшая ошибка соответствует
Умам, для которых уровень активации наименее определен. И, наконец, производная этой
Функции легко вычисляется с помощью операций умножения и вычитания
f'(net)=(1/(l+e-i'",'))'=>.(f(ne()-(1-f(ne'm.
Метод обратного распространешгя является обобщением ^Т! ™о! ZZro
лоя ошибка вычисляется на основе °ш«бы'в"7„ „™м"1онашГпо методу обратне-
бавок к весовому коэффициенту связи wb между к-м и / м неирои™
го распространения ошибки имеют вид
1. Am,=-Xc-(d,-0,)-0,(1 -0,)х, для узлов выходного моя;
2- 4^=-Лс-0Д1-О,)£Н*>"а/"'.,х' ДДЯУИ» скрытых слоев.
Часть IV. Машинное с
Глава 10, Машинное обучение на основе связей
449
Во втором соотношении 1 - индекс У™ ««У»*™ ™* «> »™Р«о раы,р0Ора
„яетсяс«гналот/-гонейроиа.и
de„a =_S&ror=(d;_о,ГО,<1-0,).
Вычислим производную от этой функции. Сначала возьмем производную для „
* Г™ весовым коэффициентам евяэей с выходным слоем. Как и ранее, r^
^ГГ " изменяя ошибки сети в зависимости от *-го веса связи ^
„йро^ом. »"" сяУчай Р»ю"пТ"ки1СЯ "Р" 8ЫВ0Де де»ьта-"РаВ|,ла в подразделе 10,23,
где было показано, что
дЕггог
dwk
-id, -О,)'I■(nef.J'x,.
Поскольку f —логистическая активационная функция, то
f(nel)=l'(V(He'""))=M(ne()*(1-f(net)).
Напомним, что f(ne(,)=0,. Подставляя это выражение в предыдущее уравнение,
получим
дЕггог
3vv„
:-/Kd,-0,)-0,(d,-0,)'x,.
Поскольку для минимизации ошибки вес должен изменяться в направлении,
обратном градиенту, то при вычислении добавки к весовому коэффициенту для 1-го неГфОна
эту производную нужно умножить на -с:
Aw,=-c"(d-0,rO,(1-OX.
Выведем формулу настройки весов для нейронов скрытого слоя. Для простоты сна-
чала предположим, что сеть содержит только один скрытый слон. Возьмем один /-Й
нейрон скрытого слоя и проанализируем его вклад в обшую ошибку на выходе сети. Для
этого рассмотрим вклад /-го нейрона в ошибку на выходе /-го нейрона выходного слоя, а
затем просуммируем этот вклад для всех элементов выходного слоя. И, наконец, учтем
вклад в обшую ошибку к-го весового коэффициента связн с i-м нейроном. Эта ситуация
изображена на рис. 10.10.
Выходной слой 01 02 0-0/ О
Скрытый слой О 01 02 -"^Xfj-- О
Видаойолой 01 02 О Ok О
Рис. W.IO. Общий вклад £-de/ra, * W, 1-го
нейрона в ошибку „а выХоде сети,
принимаемый во внимание при настройке весового
коэффициента w„
Сначала рассмотрим частную производи™ „ш„к
скрытого слоя. Для этого можно воспользоваться „.„ С™ по ВЬ"10ДУ '""> нейрона
Цепным правилом
ЗЕггог дЕггог. длег,
дО, dnet, до, '
Первый множитель в правой части этого соотно„„.„„ - ,
обозначим delta, ^отношения, взятый с обратным знаком,
de/!a=(5e-/-or)/(Snety).
Тогда предыдущее соотношение можно переписать в виде
дЕггог , ,. . Элег,
= -delta, * <-
дО, ' дО,
Напомним, что уровень активации )то нейрона net, выходного слоя вычисляется как
сумма произведении весовых коэффициентов и выходных значений узлов скрытого слоя
Поскольку частные производные вычисляются только по одному компоненту
суммы — по связи между нейронами / и /, получим
dnet,
дО, '
где W,, — вес связи между /-м нейроном скрытого слоя н у'-м нейроном выходного слоя.
Подставляя этот результат в формулу производной ошибки, получим
дЕггог , „ .
= -deta, w,.
30, ' '
Теперь просуммируем это выражение по всем связям /-го нейрона с узлами
выходного слоя
— = У -deta,' w,-.
Щ i
Это соотношение определяет чувствительность ошибки на выходе сети к выходу 1-го
нейрона скрытого слоя. Теперь определим значение delta, - чувствительность ошибки
=«и к уровню активации /-го нейрона скрытого слоя. Это даст возможность получить
чувствительность ошибки сети к весовым коэффициентам входящих связей i-го узла.
Снова воспользуемся цепным правилом
. , дЕггог дЕггог, дО,
-delta. = — = ^д -—-■
' dnet, дО, dnet,
Поскольку используется логистическая активационная функция.
^- = -10,-(1-0,).
dnet,
Гл&ва Ю. Машинное обучение на основе
„_,„ тля delta,, приходим к соотношению
Подставляя тто значение в ура»«™« *>
„„_ чувствительносп. ошибки на выходе сети к весу входящ,,
связеиТо ие^°"^г0 СЛ°' PacCMan",U "'" МЫ>ВОЙ "°,ффиЦИСт """« ». .7,
ухгнэм. Согласно цепному п|»ви-1У
„Error Жгтог. *»t=^WI(C^-=-iJe«e,,x,,
^ГсГГГс^Ге^евв^епне^^-.полуяим
*^2С = 0,(1-0,)£(-*'в; '*'.'/'
Л"» '
Поскольку для минимизации ошибки вес необходимо изменять в направлении анти-
градиента, то его настройка выполняется по формуле
Для сетей с несколькими скрытыми слоями эта процедура рекурсивно применяется
для распространения ошибки от п-ro скрытого слоя к слою п-1.
Несмотря на то что метод обратного распространения ошибки позволяет решить
проблему обучения многослойных сетей, он ие лишен своих недостатков. Поскольку он
основан на метоле поиска экстремума, то может сходиться к локальному минимуму, как ш
рис. 10.8. И, наконец- этот метод вычислительно не прост, особенно для сетей со
сложной поверхностью ошибки.
103.2. Пример применения метода обратного распространения
ошибки: система NET talk
Система NETlalk — интересный пример нейросетевого решения сложной проблемы
обучения [Sejnowski и Rosenberg, 1987]. Система NETlalk обучается произносить
английский текст. Это достаточно сложная задача для явного подхода, основанного на
символьном представлении информации, например для системы, основанной иа правилах,
посколыгу английское произношение очень нерегулярно.
Система NETlalk учится читать строку текста и возвращает фонему с сочггветствую-
шяи ударением для каждой буквы строки. Фонема - это базовая единица звука в язн«.
а ударение- относительная громкость этого звука. Поскольку произношение каж**
буквы зависит от контекста и окружающих ее букв, система NETlalk работает с окном,
«держащий семь символов. При перемещении текста в этом окне NETlalk для *»**
буквы возвращает пару фонема-ударение
шХ^^У"""" NETUlk "°™*m "* Рис 10.11. Сеть состоит из 3 слоев «<*£
Гпое^Г'" «^ствуют семи символам текстового окна. Каждая позиция •»
ГзяТиакГ™™ вадИЫИИ НСЙрОИаии- ™ <»»°"У *» "***>» 6УКВ" МФ!!^тЯ
для знаков пунктуации и „робело». Буква в каждой позиции активизирует соответ*
Часть IV. Машинное обУ***"
ВуЮШИЙ НСЙрОН УЗЛЫ ВЫХОДНОГО СЛОЯ mw™
человеческой артикуляции. Остальные 1 ГГ**"""" Фонемы с помощью 21 июйс-пм
Сеть NETlalk содержит 80 скрытых нейпг^ТТ* "£'ли,^ш >'*Ч*иие и границы ш„
мх нейрон,,., 20 выхолиых узлов и 1862» связей
26 ~"««" "«sow» COOOO О
C£J_Csd
/'«с. /ft//. Топология сети системы NZTlalk
При обучении системы NETlalk ей предъявляется окно размером 7 символов, и
система пытается произнести" среднюю букву. После сравнения ее произношения с
корректным веса системы настраиваются по метолу обратного распростраиеиия ошибки
Этот пример иллюстрирует множество интересных свойств нейронных сетей, часть
из которых отражают природу человеческого обучения. Например, в начале, когда
процентное соотношение корректных ответов невелико, процесс обучения идет достаточно
быстро и замедляется с увеличением доли правитьных ответов. Как и для человека, чем
больше слов сеть научится произносить, тем лепте ей будет выговорить неизвестные
слова. Эксперименты, в которых некоторые весовые коэффициенты случайным образом
изменялись, показал, что сеть устойчива к повреждению структуры. Исследования также
показали высокую эффективность переобучения поврежденной сети.
Еше один интересный аспект многослойных сетей — роль скрытых слоев. Любой
алгоритм обучения должен выполнять обобщение ил неизвестные сети точки предметной
области. Скрытые слои играют важную роль, позволяя сети реализовать это обобшеяие.
Подобно многим сетям, обучвечым по методу обратного распространения, в скрытом
слое системы NET talk содержится меньше нейронов, чем во входном. Это означает, что
для кодирования информации, содержащейся в обучающих образах, в скрытом сдое
используется меньше нейронов, т.е. этот слой реализует некоторую форму абстракции.
Такое сжимающее кодирование приводит к тому, что различные входные образы в скрытом
слое имеют идентичное представление. В этом и состоит обобщение-
Система NETlalk обучается достаточно эффективно, хотя для этого требуется большое
число обучающих примеров, а также многократное повторение итераций обучения на одних и
тех же обучающих данных. В работе [Shavfik и др.. 199Ц приводятся данные экспернмен-
тального сравнения результатов решения этой задачи методом обраттюгораияюиршеиия и с
помощью алгоритма ГОЗ. Оказалось, что оба алгоритма дают одинаковые результаты, хотя
по-разному обучаются и используют данные. В этом *^^"Лжш^Г°^а
ров разделялось на лес частиобучающую и тесг^ую «Лор*. Обе системы <ЗД«"°---
в разделе 9.3. и NETlalk) смогли корректно произнести 60» тестовых ^ °"~?*£""
на 500 примерах. Однако дл, обукиня системы ГОЗ "мгюбк™|^"^хГ;
му ииож^уТдл. системы NETlalk итерации обучения мзкя-шратно покорялись. В про»
ленном исследовании обучение завершилось после 100 итераций.
Как
биосвязь между подходами к обучению, оснманиы-
показывает этот пример. взаииосв«зь »«^' х ,„„«. та «„,„
ми на символьном и сетевом представлении информации, гораздо
Глава 10 Машинное обучение иа основе
463
епвый взгляд. В следуюшем примере метод обратного распростри
10 3 3 Применение метода обратного распространения для реЩеН11я
задачи "исключаюшето ИЛИ
, „юлела рассмотрим задачу "исключающего ИЛИ" и покажем
В ^ГТшитГп "нейронной сети со скрытым слоем. На р„с. Ш2^
как ее можно, решит. ^ одним скрыть,м и одним выходным элемент™
зана сеть с **^™я оговых нейрона, первый нз которых связан с единственным
Сеть™«е содержупд» « Р _ £ выходным нейроном. Уровии а1стнвации ^J
гоТвГодТо нейронов вычисляются обычным образом как скалярное произведет*
ГрГвесовых коэффициентов и входных значении. К этому значению добавляете,
веГчина порога. Веса обучаются по методу обратного распространен™ при „сполио.
вании сигмоидальвой активационной функции.
Порого.ый нейрон _^^ иц> Пороговый нейрон
Рис. 10.12. Решение задачи "исключающего ИЛИ"
методом обратного распространения. Здесь wtJ —
весовые коэффициенты связей, Н — скрытый нейрон
Следует отметить, что входные нейроны напрямую соединены обучаемыми связями с
выходным нейроном. Такие дополнительные связи зачастую позволяют снизить размерность
скрытого слоя и обеспечивают более быструю сходимость. На самом деле сеть, показанная на
рис. 10.12, не является единственно возможной. Для решения задачи "исключающего ИЛИ"
можно подобрать множество различных архитектур нейронных сетей.
Сначала веса связей инициализируются случайным образом, а затем настраиваются с
использованием данных нз таблицы истинности функции "исключающего ИЛИ"
(0;0)->0;(1;0)->1;(0; 1)-»1; (1;1)->0.
После 1400 циклов обучения для этих четырех обучающих примеров получаются
весовые коэффициенты следующего вида (значения округлены до 1 знака после запятой)
W„,=-7,0 W„„=2,6 W0,=-7 0 kV =-110
W„=-7,0 Wo>=7,0 W01=-4,rj. °"
Для входного вектора (0,0) на выходе скрытого нейрона будет получено значение
f(0*(-7,0)+0*(-7,0)+1-2,6)=f(2,6)->1.
Для этого же входного образа выходное значение сети будет вычисляться по фоР«У*
f(0-(-5,0)+0-(-4,0)+,-Mii0)+1.7|0)=fM|0h0
Для входного вектора (1,0) выходом скрытого нейрона будет
«1-<-7,0)+0-(-7,0)+1-2,бИ(-4,4Н0,
Часть IV. Машинное <з6Ге№
а на выходе сети будет получено значение
.(1-(-5,0)+0-(-4,0)+0-(-11,0)+1-7,0И,2,0Н1.
Для входного вектора (0; 1) будут получен.., а-
конец, рассмотрим входной вектор (1- п Л„„ " аналогичные выходные значения. И, на-
„-,-, 7 т.ч., у г, 'Ч-Д™ негою выходе скрытого слоя получим
а на выходе сети
f(1-(-5,0)-M-(-4,0)+0-(-11,0)+1-7,0H(-2,0H0.
Понятно, что сеть прямого распространения, обученная по методу обратного
распространения ошибки, обеспечивает нелинейное разделение этих данных. Пороговая
функция f- это сигмоида, график которой показан „а рис. 10.7,6, несколько смещенная в
положительном направлении за счет обучаемого порога
В следующем разделе будут рассмотрены модели конкурентного обучения.
10.4. Конкурентное обучение
10.4.1. Алгоритм обучения "победитель забирает все" для задачи
классификации
В алгоритме "победитель забирает все" [Kohonen, 1984]. [Hecht-Nielsen, 1987] при
предъявлении сети входного вектора возбуждается единственный нейрон, наиболее
точно соответствующий этому образу. Подобный алгоритм можно рассматривать как
реализацию механизма конкуреншш между нейронами сети (рис. 10.13). На рис. 10.13 вектор
входных значений Х=(Х|, х2, ..., хт) передается слою нейронов сети А, В N. причем
нейрон S оказывается победителем, а его выходной сигнал равен 1.
Рис. 10.13. Слой нейронов при работе
алгоритма -победитель забирает все-.
Нейрон-победитель определяется на основе
входных векторов
Глава 10. Машинное обучение на основе связей
™ "победитель забирает все" реализует принцип обучения без уц,^
Алгоритм тмят* а.1юхкя по максимальному уровню активности и»
скольку ясйрои-побелител выбираем модиф,1ц„руется для 6мее с™' Вектор
==Sil-==—•■'—■-t
AbV^tX-'-W').
г„е с _ малый положительный параметр обучения, который обычно уменьшается в про.
цсссе общения. Вектор весовых коэффициентов нейрона-победителя настраивается „у.
тем лобавления к нему Д W-
Согласно этому соотношению каждый компонент вектора весовых коэффициента,
увеличивается или уменьшается на величину *,-«-,. Целью такой настройки является
максимальное приближение нейрона-победителя к входному вектору. Алгоритм
"победитель забирает все" не требует прямого вычисления уровнен активации для „оис.
ка нейрона с наиболее сильным откликом. Уровень активации неирона напрямую
зависит от близости вектора весов входному вектору. Для /-го нейрона с нормализованным
вектором весовых коэффициентов W, уровень активации W# — это функция евклидово-
го расстояния между W, и входным образом X. В этом можно убедиться, вычислив
евклидово расстояние для нормализованного вектора W,
Из этого соотношения видно, что среди всех нормализованных векторов весовых
коэффициентов максимальный уровень активации WX соответствует векторам с
минимальным евклидовым расстоянием | |X-W| |. Во многих случаях более эффективно
определять победителя, вычисляя евклидово расстояние, а не уровни активации для
нормализованных векторов весов.
Правило обучения Кохонена "победитель забирает все" рассматривается здесь по
нескольким причинам. Во-первых, это метод классификации, который можно сравнить с
эффективностью персегпрона. Во-вторых, его можно комбинировать с другими нейросе-
тевыми архитектурами и обеспечить тем самым более сложные модели обучения. В
последующих разделах будет рассмотрена комбинация метода обучения Кохонена с
алгоритмом обучения с учителем Гроссберга. Такая комбинированная архитектура, впервые
предложенная Робертом Хехт-Нильсеном (Robert Hecht-Nielsen) [Hecht-Nielsen, 1987,
1990], называется сетью встречного распространения (counterpropagation network). Эта
неиросетевая парадигма будет рассмотрена в подразделе 10.4.3.
Прежде чем завершить это введение, следует отметить несколько важных
модификации алгоритма "победитель забирает все". Иногда в этот алгоритм добавляется
параметр совести", который обновляется на каждой итерации и препятствует слиш-
ctL?™T " аМ" °ДН"Х " тех же «Тронов. Благодаря этому параметру про-
В некоГь» л ра3°В Рав"°м'РН0 представляется всеми нейронами сети.
жТсшо бГ»М-°Д"фИКациях а"™Р'™а определяется не нейрон-победитель, а мне-
иеир^ов это™ Не"Р0НМ' " »«П»и.аю1=. весовые коэффициенты связей всех
строке ecIbxKoZ0™' ЕЩ£ °Я"Н "°Дхад «<«»«. к дифференцированно" » "
В рамках этого мет ФФИГеН™ ВСех неЙРонов '« окрестности нейрона-победителя-
ни-ми ::ZIZZZ: ГТ "" °бЫЧН° инициализируются случайными зна-
алгоритм "S™ ' '' 1992]' В ра6отс [Hecht-Nielsen, 1990) показано
обедитель забирает все" можно рассматривать в качестве эквивале»"
456
Часть IV. Машинное о(
к-зиачиого анализа множества лант.^ n -
Кохонена обучения без у,™ л. Сбе!„т ^ «™ РМЮЛе ^^ 0ПИСан ^"Р"™
решения задач кластеризации поб=™™ь забирает все", предназначенный дл»
10.4.2. Сеть Кохонена для изучения прототипов
В0ПРо0т„о™Г„СсИЛИКаЦ1"' ДаН"ЫХ " Ж™»°™«* Р°™ прототипов в обучении
традиционно относились к компетенции психологов, лингвистов, специалистов^
компьютерным наукам и теории обучения (Wittgenstein. 1953], [Rosen. 1978], [Lakoff 1987] Роль
прототиповн классификации в интеллектуальной деятельности - это также основная
тема данной книги. В разделе 9.5 описаны методы классификации, основанные на
символьном представлении информации, и вероятностные алгоритмы кластеризации,
реализованные в системах COBWEB „ CLUSTER/2. В разделе 10.2 представлен нейросетевой
алгоритм классификация с помощью персегпрона, а в этом разделе рассмотрен алгоритм
кластеризации Кохонена "победитель забирает все" [Kohonen, 1984].
На рис. 10.4 снова показаны данные из табл. 10.3. На эти точки наложены наборы
прототипов, сформированных в процессе обучения сети. В результате итерационного
обучения персептрона формируется такая конфигурация весовых коэффициентов,
которая обеспечивает линейное разделение двух классов. Как было показано, линейная
поверхность, определяемая этими весами, получается путем неявного вычисления центра
каждого кластера в евклидовом пространстве. Этот центр кластера служит прототипом
класса при решении задачи классификации с помощью персептрона.
С другой стороны, алгоритм обучения Кохонена не требует участия учителя. При
таком обучении набор прототипов создается случайным образом и уточняется до тех пор,
пока прототипы не обеспечат явного представления кластеров данных. В процессе
работы алгоритма коэффициент скорости обучения постепенно уменьшается, чтобы каждый
новый входной вектор оказывал все меньшее влияние на прототип.
В системах, обучаемых по методу Кохонена, типа CLUSTER/2, используется строгий
индуктивный порог, т.е. желаемое количество прототипов явно задается в начале работы
алгоритма, а затем постоянно уточняется. Это позволяет разработчику определить
конкретное число прототипов, представляющих каждый кластер данных. Метод встречного
распространения (подраздел 10.4.3) обеспечивает дополнительное управление
выбранным числом прототипов.
На рис. 10.15 показана сеть Кохонена, предназначенная для классификации данных из
табл. 10.3. Эти данные представлены в двухмерном декартовом пространстве, поэтому
прототипы представляющие кластеры данных, тоже являются упорядоченными парами.
Для представления кластеров данных выбрано два прототипа- по одному на каждый
кластер. Узлы А и S случайным образом инициализированы значениями (7.2) и (2,9).
Случайная инициализация подходит только для таких простых приоров, как ™^
Обычно в качестве начальных значений векторов весовых коэффипиентов выбираются
представители каждого кластера. , „ «„.™-, ,-.„„.« к R*m-
Вектор весовых коэффициентов -^:^ГГ^Гк"ьп;дан'-
ному вектору. Этот вектор весов ^Г 1"ZZ7hcLhos остаются
неизменным, в то время как весовые коэффпш «нт«ости ных .<р ^^ до
нымн. Благодаря явному вычислению
евклидова расстояния от входного вектора до
"ими. ьлагодаря явному ш™«-» „„„„„„т.ать эти векторы, как описано в
каждого из прототипов нет необходимости нормализовать аскт P
подразделе 10.4.1.
Глава 10. Машинное обучение на основе связей
457
сгвляется без учителя, а нейрон-победитель on
Обучение сети Кохонена'^"е ым вектором и каждым из прототипов. кТ^'
ется на основе
расстояния "^сп, сачооргаташт сети (self-organizing „е,™0"'
фнкацля выполняется в дом Кохонена входные данные обрабатываются „
Обычно при обучении .сети с ^ ^^ выбираться сверх>, внвд «*■
чанном порядке, однако данные из ^ ^ прототипов Иала «'
меряется расстояние от точи. ( .' М
,„,п-/,_71'+М-2)!=37,
ММ 11-17 2)11=(1-7)'+(1-2)!=37'
||,(,1,1!-»9)||-(1-г)'Ч'-«'-в5-
100-
8,0-
6.0-
4.0-
2.0-
'й 1
Прототип 2 после
10 итераций N. ■
д 1 А* .л
л ^
а й ij/
1
дД
Прототип 1 после
/ 10 итераций
iiil
Ч^-
- Точки данных
л Прототипы [
Л«г. 10.14. Обучение сети Кохонена без
учителя, при котором генерируется
последовательность прототипов,
представляющих классы из табл. 10.3
Рис. 10.15. Архитектура сети Кохонена
для классификации данных из табл. 10.3
Узел А{1\ 2) становится победителем, так как он ближе к точке (V 1). Расстояние
между этими точками- | [(1; 1)-(7; 2)||. причем квадратный корень вычислять нет
необходимости, поскольку эта функция возрастающая. Теперь для узла-победителя нужно
пересчитать значения весовых коэффициентов, установив коэффициент скорости
обучения равным 0,5. На второй итерации
WI=Wl+c(Xl-W,) =
На
«торой „теращш обучения вычисли», расстояния от точки (9.4 • 6.4):
Снова победителем является i
-9f=60,15.
составляют
1 А. Веса связей перед третьей итерацией обучен»
И"=И"+с(Х'-Цг>
=И;1,5)+0,5((9,4;6,4)-(4Ч 5п-
4S8
Часть IV. Машинное обучени
На третьей итерации для точки (2,5; 2.1) имеем
|1(2.S;2.1)-(6.7;4)||=(2.5-6.7)'+(2 1-4)'=S1 24
| |(2,5; 2,1)-(2; 9>| |=(2,5-2>'+(2,1-9)'=47,в6
Узел А снова становится победителем и для иг™ ■>
„ -u.. in 14 „,„,,„ ,„„ """™-м, н для него вычисляется новый весовой вектор.
На рис. 10.14 показана зволюция прототипов в течение 10 итераций. Алгоритм
генерации данных, представленных на рис. 10 14 выбиоам „„„ ™uuj,ni» .encya
с ,п1 „а„„ к н ' выоиРает очередные входные данные из
табл. 10.3 случайным образом, поэтому эти точки гугни, ~
. „ . . v-миму ли точки отличаются от вычисленных выше. Как
показано на рис. 10.14, в процессе обучения прототипы постепенно смешаются к центрам
кластеров. Напомним, что обучение выполняется без учителя „а основе алгоритма с под-
креплением победитель получает все". В процессе такого обучен™ строится
последовательность явных прототипов, представляющих кластеры данных. Некоторые
исследователи, в том числе Зурада [Zurada, 1992] и Хехт-Нильсен [Hecht-Nielsen. 1990], показали, что
алгоритм обучения Кохонена по существу эквивалентен к-значному анализу.
В следующем разделе будет рассмотрен модифицированный алгоритм выбора
прототипов, основанный на модели Гроссберга, являющейся расширением сети Кохонена.
10.4.3. Нейроны Гроссберга и сети встречного распространения
До сих пор рассматривалась задача кластеризации входных данных без участия
учителя. Для обучения нейронной сети при этом требуются некоторые начальные знания об
области определения задачи. В процессе определения характеристик данных, а также
истории обучения идентифицируются классы и выявляются границы между ними.
Поскольку данные классифицируются на основе подобия их векторного представления,
учитель может поспособствовать в калибровке полученных результатов или в
присвоении имен этим классам. Это можно сделать с помощью обучения с учителем, при
котором выходы слоя, обучаемого по методу "победитель забирает все", используются в
качестве входов второго слоя сети. Решения этого выходного слоя можно явно
скоординировать (подкрепить) с помощью учителя.
Такой подход позволяет, например, отобразить результаты слоя Кохонена в
выходные образы или классы. Это можно слетать с помощью алгоритма "исходящей звезды"
(оиЫаг) Гроссберга [Grossberg, 1982], [Grossberg, 1988]. Комбинированная сеть,
включающая слой нейронов Кохонена и слой Гроссберга, впервые была предложена
Робертом Хехт-Нильсеном и получила название сети встречного распространения
(counierpropagation network) [Hecht-Nielsen. 1987, 1990].
Слой Кохонена достаточно подробно рассмотрен в подразделе 10.4.2, поэтому
здесь остановимся на слое Гроссберга. На рис. 10.16 показан слой нейронов Л. В
N. один из которых — J — является победителем. Алгоритм Гроссберга предполагает
наличие обратной связи от учителя, представленной вектором Y. с целью подкрепления
весов связей от нейрона J к нейрону I выходного слоя, который должен
активизироваться. Согласно алгоритму обучения Гроссберга вес исходящей связи V», от нейрона к
нейрону / увеличивается. _ Лпмп^
В сети встречного распространения сначала обучается слон ™?ы"^°Та£
лени, „„белителя его выходное значение устанавливается равным 1 ^^е „теГн
»"« псех остальных нейронов Кохонена принимаются равными ° »^п^^
все нейроны выходного слоя, с которыми он «язан, Ф°Р^^™_"^^
""сходящую звезду" (рис. 10.16). Обучение слоя Гроссберга осуществляется для компо
нентов этой "звезды".
Г|»ва 10. Машинное обучение на основе
459
Выходной Ожидаемый
слой выход У
Рис. 10.16. -Исходящая звезда" дм нейрона J в сети,
обучаемой по .\iemodv "победитель забирает все". Вектор У— это
ожидаемый выход слоя Гроссберга. Жирной линией выделены
связи нейрона, выход которого равен 1,- выходные значения всех
остальных нейронов слоя Кохонена равны О
Если каждый кластер входных векторов представляется одним классом и всем членам
этого класса соответствует одно и то же значение выходного слоя, то в итеративном
обучении нет необходимости. Требуется лишь определить, с каким нейроном слоя Кохонена
связан каждый класс, а затем назначить веса связей между каждым нейроном-
победителем и выходным слоем на основе ассоциации между классами и ожидаемыми
выходными значениями. Например, если J-й нейрон Кохонена соответствует всем
элементам кластера, для которого ожидаемым выходом сети является /= 1, то для связи
между нейронами J и / нужно установить значение wy= 1, а для всех остальных весовых
коэффициентов исходящих связей нейрона J — wJt= 0.
Если одному кластеру могут соответствовать различные выходные нейроны, то для
настройки весовых коэффициентов "исходящей звезды" применяется итеративная
процедура обучения с учителем на основе ожидаемого вектора У. Целью процедуры
обучения является усреднение ожидаемых выходных значений для элементов каждого
кластера Веса связей нейрона-победителя с выходными нейронами настраивают»
согласно формуле
И/"=И/+с(У-и/),
где с — малый положительный коэф
еитов связей нейрона-победита
тор. Заметим, что этот
ie
победитель,
ищиент обучения, W — вектор весовых коэффп"""
ля с выходным слоем, а У— ожидаемый выходной "«"
слоя Кохонена „ , Ш|;0РИ™ обучения приводит к усилению
--/- иИ " »™>м ' выходного слоя только в том случае, если /- »е»Р»»;
связей между yM°,,J
нейро»-
ПоэтомУ
данный алгоои^м^" **** 1' а желаемь1Й выход при этом тоже равен
торому емзь ™T„ C4TOm' Ри"™иД"остькэ метода обучения Хебба, согласно^
« Хебба „0„ееГод™бн°";Ica^T" "СЯШ" ""' "РИ еС ВОЗбуЖДе'ИИ' №"
"бл. 10.3.Н1ТокадемС^еэ"ОГО распРостРа"<:ния для распознавания кластеров дан»"'[ »
«а этом примере, как реализуете, алгоритм обучения такой сет
обучен"»
Часть IV. Машинное
Допустим, параметр х, в табл. 10.3 представляет скорость двигателя в силовой
установке, ах2 — с™ температуру. Оба параметра откалиброваны таким образом, что
принимают значения из диапазона [0; 10]. Предположим, система мониторинга через заданные
интервалы времени снимает данные с двигателей, и должна рассылать уведомление, если
скорость н температура чрезмерно возрастут. Переименуем выходные значения в
табл. Ю.З следующим образом: будем считать, что значение +1 соответствует
"безопасному" состоянию, а -1 — "опасному". Сеть встречного распространения при
этом будет выглядеть примерно так, как показано на рис. 10.17.
Рис. 10.17. Сеть встречного распространения для
распознавания классов ш табл. 10.1. Обучению подлежат
весовые коэффициенты wAS и wA£1 связей узла А с
выходными нейронами
Поскольку точно известно, каким выходным значениям слоя Гроссберпu««J
ответствовать нейроны-победители слоя Кохонена, можно напрямую задать эти значе_
ZZ демонский обучепия слоя Гроссберга обучим сеть с помощью указкой
ГщеТорму! S (продольным образом, T^~Z,"^b
ходного слоя отвечает за безопасную ситуацию, а узел Dк- за она нуго
хонена. Сходимость процесса обучен*. ^°яJ^Te™" ходящихсвязей нейрона
примере в подразделе 10.4.2. Входные векторы для обучен гя „ ^ со0тветству1ощие
А имеют вид [х„ х2, 1, 0]. Здесь х, и х2 - это—^J^ ют_т ^ д ^ется
нейрону А слоя Кохонена, а два других компоне ^^^ значению "истина", а
победителем, т.е. безопасное состаяние *°'"/ca ,,смд1Ш„х связей неГгрона Л инициали-
опасное— значению "ложь" (см. рис IW- , сделаем равным 0,2
зируем значениями (0; 0] и коэффициент скорости обучения еды
W-[0; 0]+0.2[[1: ОНО; 0]1-[0: ^^^^'б'оМО.Зб; 0).
^=0,2;0]+0,2[[1;0]-[0,2,0]]=0 20№ b 0]=10.4Э; 0].
W=[o,36; o1+o,2[[i; 0]- о.зб Н 0,36. о + ,0|59. 0],
W = [0,49; 0]+0,2[[Г, 0И 0,49 Н °f: + 8 01 = Г0|67; 0].
-V40.59; 0] + 0,2[[1; 0)-[ 0,59, 0]]-[ О.ь».
Глава 10. Машинное обучение на основе связей
лепиться что в процессе обучения значения весовых коэффВЦ1
Несложно У»»™^^, „^однозначности соответствия нейрона-победи^
„"^нТвых'однот слоТможно бьшо бы просто назначить веса связей и „с „с„ользов^
алгоритм обучения воо6™ец обеспечивают адекватное функционирование cm.
Покажем, что такие значения, весов о ^ иа ш л * «» «со»
^Гз^оТГ^в'н0::",.:™^,, нейрона Л сое™» (1; I]. . „ейро„7Г
тТв еш«н^ с^ма этих значений для нейрона S выходного слоя составит ,. Если
L „схожих связей нейрона В составляют [0,1] то уровеньактнвацш, нейрона О 6у.
дГравен 0. что и требуется для данной задачи. Выбирая второй вектор из табл. 10.3, „„.
1шм уровень активации для узла А [0; 0], а для узла В - (1; 1 ]. Взвешенная сумма этих
значений для нейрона S составляет 0, а для нейрона D - 1. Аналогично можно
проверить корректность функционирования сети для всех данных из табл. 10.3.
С точки зрения теории познания для сети встречного распространения можно предложил,
ассоциативную интерпретацию. Вернемся к рис. 10.17. Обучение слоя Кохонена можно рас-
сматривать как знакомство с условным стимулом, поскольку сеть изучает образы по мере щ
поступления. Обучение слоя Гроссберга — это связывание нейронов (безусловных стимулов)
с некоторым откликом. В рассмотренном случае сеть обучится рассылать уведомление об
опасности при соответствии данных некоторому шаблону. После обучения система будет
правильно реагировать на новые данные даже без участия учителя.
Другая когнитивная интерпретация сводится к подкреплению определенных связей в
памяти для данного шаблона. Этот процесс напоминает построение таблицы поиска для
откликов на шаблоны данных.
Сеть встречного распространения имеет, в некотором смысле, значительное
преимущество перед сетью обратного распространения. Подобно сети обратного
распространения, она обучается классификации на основе нелинейного разделения. Однако делается
это за счет препроцессинга, обеспечиваемого слоем Кохонена, с помощью которого
данные делятся на кластеры. Такая кластеризация обеспечивает существенное
преимущество по сравнению с сетью обратного распространения, поскольку устраняет
необходимость выполнения поиска, требуемого для обучения скрытых слоев такой сети.
10.5. Синхронное обучение Хебба
10.5.1. Введение
в би^че^йГст?663 0СН0№вае™ »* следующем наблюдении: если одни нейрон
ми у=Гв к: r9-z;;:;^z:,атот —■то связь между"""
«XffiZ^Tpo^ZTT УЧаСТВуСТ В воз6У"<="ии клетки В, то имеет место не-
ДЯШ..Й к усиление™!™ ST""™"" raM?HeHM в °дкой ил" о6свх К"™*' "Р
ван на покГенчсскоГппГ °ШЯтт "°™точно привлекательно, поскольку он осно-
УРОвне. Нейрофизиологии С "одкРспле1™. который наблюдается на нейронном
совместном возбуждении не" НССЛедования подтвердили идею Хебба о том, что пр»
Однако этот процесс окя«пР°Н°В с"нагт™ские связи между ними могут усиливаться.
______ К!ПаЛСЯ г°»™о сложнее предположения Хебба об "усилен.."
^62
Часть IV. Машинное обучение
влияния'. Представленный в этом разделе закон обучения пг,™,
„„я Хебба, несмотря на то, что его идея оказал!? ^" "*"*"""' ме™а°бучс-
„7,ггся к категории синхпонЛ^ Г™'* несколько абстрактной. Такое обучение
относится к ка.ллорни синхронного (coincidence) поск-п™.™
„ и„ события imoucnnn«„,u» „ г . П0СК0ЛЬКУ значения весов изменяются в
ответ на события, происходящие в нейронной сети. Законы обучения относящиеся к этой
категории, описываются своими временными „ пространственны! cbcZ Г
Обучение Хебба используется в многочисленных „ейросетевых архитектурах. Оно
реализуется как в интерактивном, так „ в кумулятивном режимах. Эффект уЗния
связей между нейронами притих взаимном возбуждении можно математически
промоделировать с помощьюнастроики весов связей между ними с учетом знака произведения их
выходных значении.
Остановимся на конкретной реализации этого подхода. Предположим, что выход
нейрона I связан со входом нейрона/. Добавкой к весовому коэффициенту связи между
этими нейронами ЛИ/ можно определить коэффициент скорости обучения с. взятый со
знаком произведения (о,*о;). В табл. 10.4 приводятся данные о знаке произведения о,'о,
выходов нейронов / и j в зависимости от знака каждого из множителей. Из первой строки
таблицы видно, что если оба выхода нейронов положительны, то и весовая добавка AW
имеет знак "+". Следовательно, если нейрон / участвует в возбуждении нейрона /. то
„„mi. Mp*nv ннми усиливается.
связь между ннми усилнвается.
Таблица 10.4. Зависимость знака произведения от знаков выходных значений
нейронов
Вторая и третья строки таблицы соответствуют ситуации, когда знаки выходных
значений нейронов различаются. Поскольку знаки отличаются, необходимо уменьшить
влияние нейрона i на выход нейрона/. Следовательно, инкремент к весовому
коэффициенту связи выбирается с отрицательным знаком. И, наконец, в четвертой строке знаки
выходов нейронов . и / снова совпадают, и сила этой связи увеличивается. Такой
механизм настройки весов способствует укреплению связей между нейронами, если их
выходные сигналы имеют одинаковый знак, и уменьшению этой связи в противном.случае.
В следующих разделах рассматриваются два типа обучения Хеоба - без учителя
учителем. Сначала рассмотрим алгоритм обучения без учителя.
Ю.5.2. Пример алгоритма обучения Хебба без учителя
Напомш,, что при обу^енин ^^-^^^^^Z
используется внешнее «аденские^ »0^™еР^оГ1 сети сводйтс» к усилению от-
Формации о входах и выходах нейрона^ ^ 6удет „„.. как метод
клика сети на уже "виденные образы, в следу ^ ^_ о6успоелеш0ГО откпИЕа, ко-
Хебба используется для моделирования о > про„звольно выбранный стимул,
гда в роли условия для желаемого отклика в ту „„страивать по формуле
При обучении Хебба без учителя веса нейрон.
Глава 10. Машинное обучение на основе
463
где с—малый по.
,л„*„тель„ь,н коэффиш"«- обучен,,,. «X. Щ - выходное з„аче1Ие.
го нейрона, а Х- его мс* можно ИСПользовать для преобразования отклика t
" ровного стимул, к условному. Это позволит промоделирОШт
""" Г^и эксперимента* Павлова, когда у собаки вьфабатъшалс, УИов.
--'- ' .„ок После того, как подача шшш собаке^многократно сопровожу,,
ный рефлекс на звонок ^ ши„ншось слюноотделение. Сеть, показанная на рис. щ,.
V/7
«3
Щ
щ
\flx)=sign(x)
|
Учитель
„„; .-.— , . После ТОГО, KB» над*™ ' —- -«"уио
ный рефлекс ™ звоно^ нач„налось слюноотделение. Сеть, показанная на р„с. 10,
звонко* при звуке зв, у миронами и выходной слой с одним нейрон»,'
содержит два ™я..ходнпсл^ значение +1. соответствующее возбужденному ££
Выходной нейрон "^Т^ его «возбужденному состоянию. "**•
^ГГГффиинт скорости обучения равным 0.2. В этом призере сеть обучаете, „
J'",., _V,_1] поставляющий собой конкатенацию двух образов: [1;-,;1] „
н" -1 ]'. Образ [1 ;'-1; 1 ] соответствует безусловному стимулу, а образ [-1; 1;-1J _ новому
Слуховая
информация
Рис 10.18. Пример нейронной сети, для которой применяется
обучение Хебба безучитеяя
Предположим, сеть положительно реагирует на безусловный стимул, но не
воспринимает новый стимул. Положительный отклик сети на безусловный стимул можно
обеспечить с помощью весового вектора [ 1; -1; 1 ], в точности соответствующего входному
образу, а нейтральный отклик на новый стимул— с помощью вектора весов [0;О;О].
Конкатенация этих двух векторов весовых коэффициентов дает исходный вектор весов
сети[1;-1;1;0;0;0].
Теперь сеть нужно обучить реакции на входной образ таким образом, чтобы новая
конфигурация весов обеспечивала положительный отклик на новый стимул. На первом
шаге работы сети вычислим
^wwiMl'M,wn)t|0'M,W0,,)t'°,(-'))=
f(3)=sign(3)=1.'
Теперь определим новый вектор весовых коэффициентов W
^=И;-1;1;0;0;0]+0,2Т[1-1-1-1Т 11-
ВТ■*"" °™T""натотже вгадной образ с учетом °б»оме»»°го век1ора Еесов
f(4,S)=1. ' <°-z)+{0.2)+(0,2)=4,2.
464
Часть IV. Машинное
Определим новый вектор весовых коэффициентов И/1
W=[1.2;-),2:l.2;-0,2;0.2:-0,2I+0.2-1-[1--VV 1-1- 11
Несложно заметить, что произведение векторов WX продолжает возрастать при
зтом абсолютное значение каждого элемента вектора весовых коэффициентов в кажд!
цикле обучения увеличивается „а 0,2. После 13 итераций обучения вектор весовТко
эффнциентов примет вид v есивых ко
1У"=[3,4;-3.4;3,4;-2,4;2,4,-2,4].
Теперь этот обученный вектор весов можно использовать для тестирования отхлика
сети на два отдельных образа. При этом ожидается, что сеть будет по-прежнему
положительно реагировать на безусловный стимул, и, что гораздо важнее, будет давать положи-
тельный отклик на новый, обусловленный, стимул. Сначала проверим реакцию сети на
безусловный стимул [1;-1;1]. Три последних элемента входного вектора заполним
произвольно выбранными значениями 1 и -1. Например, определим реакцию сети на вектор
[1;-1;1;1:1:-H
sign(H'*X)=sign((3,4'1)+((-3,4)*(-1))+(3,4-1)+
+(-2,4Ч)+(2,4*|)+((-2,4)-(-1)))=
=sign(3,4+3,4+3,4-2,4+2,4+2,4)=
=sign(12,6)=+1.
Таким образом, сеть по-прежнему положительно реагирует на исходный безусловный
стимул. Теперь проверим реакцию сети на тот же безусловный стимул и другой случайно
выбранный вектор в последних трех позициях [1;-1;1;1;-1;-1]
sign(WX)=sign({3,4*1)+((-3,4)-(-1»+(3,4-1)+
+ (-2,4-1 ) + (2,4-(-1)) + ((-2,4)-(-1)))=
=sign(3,4+3,4+3,4-2,4-2,4+2,4)=
=sign(7.8)=+1.
Этот входной вектор тоже приводит к положительному отклику сети. На самом деле
эти два примера свидетельствуют о том, что сеть чувствительна к исходному стимулу,
связь с которым была усилена благодаря его многократному повторению.
Теперь определим отклик сети на новый стимул Н;1.-Ч. закодированный а
последних трех позициях входного вектора. Первые три элемента заполним случаиновыбран-
ными значениями из множества (-1;1) и проверим реакцию сета на входной вектор
И;1;1;-1;1;-1]
sign(lVX)=sign((3,4M)+((-3,4)*1)+(3,4-1)+
+(-2,4-(-1 ))+(2,4*1 )+((-2,4Г(-1)))=
=sign(3,4-3.4+3,4+2,4+2,4+2,4)=
=sign(10,6)=+1.
Второй стимул тоже успешно распознан. г-н/чай fiv-ieT
Проведем енТе один Эксперимент, слегка измени, входной -^п* ^«^
соответствовать ситуации, когда „спользуетс ™>»«™^1Д»„ мемента не совпа.
"пируем сеть на входном векторе [1;-1,-1.1,1. и, ик J /
Дают с исходным стимулом, а вторые три отличаются от обусловленного
sign(WX)=sign((3,4-1)+((-3.4)-<-!>M3.<>-<-'>>+
Глава 10. Машинное обучение на основе
465
=slgn(3,4+3,4-3,4 г,* .
=sign(5,6)=+1-
=мвп<5,8)- >• яжеслсгка отличный стимул.
Следовательно, распознан даж Хе66а? БлаГодаря многократному совмесг-
Что же получилось в резуль 6ьша с03дана ассоциация между новым стиму.
„ому появлению старого и нов ^ обеспечивать прежний отклик на новый стимул
лом и старым откликом. L"° ' нная чувствительность также позволяет сети правильно
без участия учителя. Такая " ы(. тщп Это достигается за счет синхронного обу.
лом и старым откликом. L" ' ннм чувствительность также позволяет сети правильно
без участия учителя. Такая п ы(. тщп Это достигается за счет синхронного обу.
отвечать на слегка модифиц р ^ на о6цшП о6раз увеличивается, что приво-
дГус*:;-—ГГк^йотдельнь,,-, компонептзтого образа.
10.5.3. Обучение Хебба с учителем
Правило обучения Хебба основано на принципе усиления связи между нейронами при их
взаимном возбуждении. Этот принцип можно адаптировать н к обучению с учителем, если
вес связи настраивать на ожидаемый, а не реальный выход нейрона. Например, если входной
потенциал нейрона В, поступающий от нейрона А, является положительным, и от нейрона В
ожидается положительный отклик, то связь между этими нейронами усиливается.
Проверим, как с помощью метода обучения Хебба с учителем можно научить сеть
распознавать набор ассоциаций между образами. Ассоциации задаются как набор
упорядоченных пар {<Х[,У|>, <Х2, Vi>,-.., <Xf, У,>}, где X, н V, — вектор ассоциируемых между
собой образов. Предположим, размерность вектора X, равна л, а размерность У,— т.
Построим сеть, соответствующую этой ситуации. Оиа должна состоять из двух слоев,
первый из которых содержит п нейронов, а второй — m (рис. 10.19).
Для обучения этой сети воспользуемся формулой настройки весов нз
предыдущего раздела
ДИ/=сЧ(Х,И0*Х,
где 1(Х,IV) —реальный выход нейронной сети. При обучении с учителем заменим
реальный выход нейронов ожидаемым выходным вектором D. Получим
ДИ/=с*0*Х.
Рис. 10.19 Изучение ассоциаций с помощью метода
°6Г"»<шХеб5ас,Чителел,
466
Часть IV. Машинное
^учение
-«rmzzz
Возьмем пару векторов <Х„У,> „3 набора ассоциаций и „
чения к умУ * выходного слоя ">ииации и применим это правило обу-
дИ/=с*о7
да дИ/„— весовая добавка к связи нейрона / входного слоя с „„„ ь
„*_ ожидаемый выход к-го нейрона, а5°_ ,-й эГеГвХoZZ~lZ*
„яется для настройки всех весов связей всех нейронов выходного слоя Sp"*
Л Х„>-это входной вектор X, a <d|, d, d„> _ выходной век-гор 7п2,е1
эту формулу для настройки отдельных весов связей с каждым нейроном выходного слоя
приходим к формуле модификации весов для всего выходного слоя
дИ/=с*У*Х,
где УХ - внешнее векторное произведение (outer vector product), определяемое как иатр.ща
ГУ,*1 У,*г - У,Х„
YX-
Уг", Уг*г - Уг*„
Ут-*„
Чтобы обучить сеть всему набору ассоциированных пар, нужно организовать
итерационную процедуру настройки весов для каждой пары <Х„ У,> по формуле
ИГ'=ИУ+с*У,'Хг
Для всего обучающего множества имеем
И/'=И^+с-(У,*Х,+ Y,-X,+... + Y,'X,).
где IVй — исходная конфигурация весов. Если исходные веса W инициализировать
нулевым вектором <0;0;...;0>,а коэффициент обучения с выбрать равным 1, получим
следующую формулу вычисления весов
LV=y,"X,+ У,*Хг+...+У,-Х,
Сеть, отображающая вектор входов в вектор выходов и обученная по этой формуле
настройки весов, называется линейный ассоциатором (linear associator). Как станет ясно
впоследствии, такая модель позволяет хранить множество ассоциаций в матрице связей. Это
приводит к возможности взаимодействия между сохраненными шаблонами. Проблемы,
возникающие при таком взаимодействии, будут рассмотрены в следующих разделах.
Ю.5.4. Ассоциативная память и линейный ассоциатор
Нейронная сеть, представляющая собой .шнешш ассоциатор «герме бьог^дложена
Т. Кохоненом [Kohonen. 1972] и Дж. Андерсоном [Anderson и др.. 19 7 .1> ™ ^ <£"
описана линейная ассоциативная сеть, предназначенная ^^reTc^ZZ^-
зов из памяти. Будут изучены различные Ф«Р-'«^™ГвГожнс™ „спользо-
тоассоциатнвная и интерполятивная модели. Будет ^™nJl щ ^ MfTOJa „буче-
""«. линейного ассоциатива для реализации 1"^~^£Г^.ф«|««и или помех,
«ия Хебба. в завершение раздела будут рассмотрены проблемы интерн
ВДниюющпх при хранении в .шип. нескольких офшм- „ем „„формации в памя-
Сначала введем несколько определении, связа £ векюрж. Для устранения
™. Входные образы и хранимые в памяти значения являются
Глава 10. Машинное обучение на основе
467
к но вводится индуктивный порог, предполагающий
проблемы Щ"тшсН"Я °Z„аков Хранимые в памяти ассоциации предста№1 ™-
I множества векторе,, пр»™° "<X; ,г> <Х„У,>>. Для каждой пары ^
„да набора векторнш "^^^ восстановлення образа V, Существует три типа ™_"
сопиативной памяти.
,о„ «ямять (beieroassociative memory) — это такое ото&и».
^ГСГГрГГорТх^олес близкому к X,. ставится в соответстаи?:;
вращаемый вектор У,.
, Автоассоцяативная память (autoassocranve memory) - это такое отображение,
1 котором для всех „ар Х,=У, Поскольку каждый вектор X, ассоциируй с и.
Гм собой, зта форма памяти используется в основном для восстановлена, полно.
го вектора по его части.
3 Интерполятивная память (interpolate memory)- это такое отображение Ф:
Х-»У при котором отличному от эталона вектору Х-Х.+ Д, ставится в соответствие
выходной вектор Ф(Х)=Ф(Х,+Д,)= У,+ £, где £=Ф(Д,). При интерполятивном ото-
брожении каждый из ключей эталона связывается с соответствующим образом в
памяти. Если же входной вектор отличается от эталонного на вектор Д, то выход.
ной вектор тоже отличается от эталонного иа величину Е, где Е=Ф(Д,).
Автоассоциативная и гетероассоциативная память используются для
восстановления одного из запомненных эталонов. Они моделируют память в ее исходном
значении, при котором извлекаемый образ является точной копией запомненного. Можно
также сконструировать память таким образом, чтобы выходной вектор отличался от
сохраненного в памяти в некотором семантическом смысле. В этом и состоит роль ий-
терполятивной памяти.
Линейный ассоциатор, представленный на рнс. 10.20, реализует одну нз форм интер-
полятивной памяти. Как следует из подраздела 10.5.3, его работа основаиа на модели
обучения Хебба. Веса связей инициализируются с помощью соотношения, приведенного
в подразделе 10.5.3
W=Y,'Xt+ V,*X,+... + r-,*X,.
При таких значениях весовых коэффициентов для каждого эталонного ключа сеть
будет восстанавливать точно соответствующий ему эталонный образ, в противном случае
она будет осуществлять интерполяционное отображение.
Теперь введем несколько понятий, которые помогут проанализировать поведение
этой сети. Сначала введем метрику, позволяющую определить точное расстояние между
векторам,,. Все векторы-эталоны в рассмотренном примере являются хе.ш«тговъши, т.е.
состоящими только из -1 и +1. Для описания расстояния между хемминговыми
векторами можно ввести хелтинюво расстояние (Hamming distance). Определим хеммиюово
пространство следующим образом:
Нп=(Х=(х„хг,
множества {+1;-1}.
««^""аГкГ™' 0ЧКДМЯется «*W W- любыми векторами в хемминго-
IIX. И 1= количеству различных компонентов в векторах X и У.
468
Часть IV. Машинное обуч"
Рис. 10.20. Линейная ассоциатитая сеть. На „од
сети подается вектор Х„ а на «А получается
соответствующий ему вектор У, каждый компонент
которого у, является линейной комбинацией ею*» В
процессе обучат каждый выхооиой нейрон
подкрепляется соответствующими ему корректными
выходными сигналами
Например, хеммннгово расстояние в четырехмерном хемминговом пространстве
между векторами
(1;-1;-1;1) и (1;1 ;-1;1) равно 1,
Ы;-1;-1;1)и(1;1;1-;1)равно4,
(1;-1;1;-1) и (1;-1;1;-1) равно 0.
Введем еще два определения. Дополнением хеммингового вектора называется вектор,
все компоненты которого противоположны компонентам исходного вектора. Например,
дополнением к (I,'-I,-I;-l) является вектор (-1,1; 1,1).
Определим понятие ортонормальности векторов. Ортонормальными называются
ортогональные или перпендикулярные векторы единичной длины. Покомпонентное
произведение ортонормальных векторов равно 0. Следовательно, скалярное произведение
любых двух векторов X, и X, из набора ортонормальных векторов равно 0, если эти
векторы различны:
ХХ,=5 , где 5, =1, если /=/, и 8„ =0 в остальных случаях.
Покажем, что определенный выше линейный ассоциатор обладает следующими
двумя свойствами. Пусть Ф(Х) — выполняемое сетью отображение. Во-первых, для любого
входного вектора X точно соответствующего одному из эталонов, выход сети Ф(Х,)
равен соответствующему выходному эталонному вектору У,. Во-вторых, для любого вход-
«№0 вектора Xt. не соответствующего ни одному из эталонов, выход сети Ф(Х.) равен
вектору г-,, представляющему собой интерполяцию вектора Х„ Более точно, для Х*= X,
+4„ где X, _ эталонный вектор, сеть возвращает значение
У.= У,+Е, гдв£=ф(Д,).
„од сети одного из эталонов она возпращает
С1МЧШа „окажем.™ при подачена вх Д
По определению актинии»
<Ъ{Х)*Ш,
Поскольку
W=Y,-X* Y,-X*..+У/Х,.
получим ,.у.у|У=
"д^^пос^ьку»«-»»»»--«"'™^"
по закону
По
Ф(х,иг,а„*гА,+-+у.8'+-+к8
Ф(Х,)- УД, г, „ • остальных случаях. Тогда
, условию ортонормальности 6>1 при Ч
' - ,unm BPicrona Xi. ие соответствующего нн одному
„з зГо1ТГ=ГИГе;=Го^ажение. Так. для *. X, +Д„ где
X, — один из эталонных векторов
Ф(Х,)= <t>(X,+A,)=V,+E.
где V, — вектор, связанный с X,, а
£= Ф(Д,)= (У,'Х,+ У,-Х,+- + У„*Х„) 4,.
Детали доказательства можно опустить. ^
Теперь приведем пример обработки данных с помощью линейного ассоциатора. На
рис 10 21 показана простая линейная ассоциативная сеть, отображающая
четырехмерный вектор X в трехмерный вектор У. Поскольку сеть работает в хемм.шговом
пространстве, в качестве активационной функции необходимо использовать описанную выше
функцию sign.
Уг
Рис 10.21. Линейный ассоциатор, весовая
матрица которого вычисляется по
формуле ю предыдущего раздела
Допустим, требуется запомнить две векторные ассоциации <Х„ У,>. <Х2, Ур- ™е
Х=[1;-1;-1;-1]<-,у,=[_1;1;11
x.=l-1:-i:-i;il<->y>=ii;_i-1i.
470
Часть IV. Машинное обу1
Используя определенную в предыдущем разделе »„„„„
шейного ассоциатора, получим V Д "е «"Риулу
„инейного ассоциатора, получим
W=y,*x,+ у,*х,+ у/х,+...+ул-хл.
С помощью операции внешнего векторного произведения УХ +УУ
вую матрицу сети * °'-«™ия У|Х,+У2Х2
-1 1
1 -1
инициализации весов для
вычислим весо-
1
"' ' -2002
1 -1 = 2 о 0-2
"1 1J 0-2-2 0
Проверим работу линейного ассоциатора для одного из зталонов Начнем с вектора
х=[1Н;-1;-1] из первой эталонной пары и вычислим связанный с „им веГор7 '
у,=((-2)-1Ж0-(-1)И0'(-1)И2-(-1))=-4 s|gn(-4)=-1
У,=(2'1Ж0-(-1))+(0-(-1))+((-2)-(-1))=4. signal
y,=(0-1)+((-2>-(-1))+((-2)-(-1))+(0-(-1))=4.sign<4)"=1.
Следовательно, У,=[-1;1;1] — получена вторая половина пары.
Приведем пример линейной интерполяции эталона. Рассмотрим вектор Х=[1;-Ц1;1].
y,=((-2)*1)+(0'(-1))+(0*1)+(2-l)=0,sign(0)=1,
у,=(2*1)+(0*(-1))+(0*(-1))+((-2)*1)=0, sign(0)=1,
y,=(0*1)+((-2)*(-1))+((-2)*1)+(0*1)=0,sign(0)=1.
Заметим, что вектор У=[1;1;1) не соответствует ни одному из эталонов.
Подытожим несколько наблюдений относительно линейных ассоциаторов.
Ожидаемые свойства таких сетей основываются на предположении, что эталонные экземпляры
составляют множество ортонормальных векторов. Это ограничивает их практическую
применимость по двум причинам. Во-первых, может не существовать очевидного
отображения реальной жизненной ситуации в ортонормированный набор векторов. Во-
вторых, количество сохраняемых образов ограничено размерностью векторного
пространства. Если требование ортонормированности нарушается, образы смешиваются в
памяти, что приводит к помехам (crosstalk).
Обратите внимание на то, что линейный ассоциатор восстанавливает эталонный
образ только тогда, когда входной вектор в точности соответствует эталонному. При
отсутствии точного соответствия входного вектора сеть выполняет интерполяционное
отображение. Можно возразить, что интерполяция не является памятью в прямом смысле
этого слова. Зачастую требуется реализовать истинные свойства памяти, когда при
подаче на вход приближенного ключа сеть восстанавливает точный соответствующий ему
эталонный образ. Для этого нужно ввести в рассмотрение аттракторныи радиус,
обеспечивающий притяжение векторов из некоторой окрестности.
В следующем разделе описывается аттракторная версия линейной ассоциативной сети.
IQj- Аттракторныеccrajcera^ccoggapiBHott памяти")
Ю.6Л. Введение
п * сих пор рассматривать «*. -*»- ^^^PZ^^
«work), в таких сетях данные поступают на входи^^^ней^нгГс^ей явля-
последующим слоям до выхода id сета. Еще одним важным класс*. г
Глава 1 о. Машинное обучение на основе связей
471
(feedback network). Архитектура таких сетей отличается Ки
кто, сети с обратным «ям» V ^ косвенно нтд. ко входам нейрона,
что выходной с/опал передается Р|и ^ „„j прямого распространения состо„ .
Отличия сетей с обратным.,
следующем.
, Между нейронами существуют обратные связи.
СГяне^раяар^-енн.,» задержка. т.,е„талрасгфссгранлется не мтове»,,,.
3 ь^ом сети является ее состояние по завершении процесса сходимости.
4 Полезность сет,, зависит от свойств сходимости.
Когда сеть с обратными связями приходит к неизменному состоянию, такое состояние
„азы^я^стояннем равновесия, которое н рассматривается в качестве выхода сета.
ГГх"™ратныш, связями, которые будут рассмотрены в подраздепе 10.6.2, со-
стояния™™, инициализируются входным вектором. Сеть обрабатывает этот образ, „срс.
Гвая его несколько раз от входа к выходу до тех пор. пока не достигнет состояния ра,-
„овесия Состояние равновесия сети - это и есть образ, извлеченный из памяти. В под.
разделе 10.6.3 будут рассмотрены сети, реализующие гетероассоциативную память, а в
подразделе 10.6.4 — модели автоассоциативной памяти.
Интересны и важны когнитивные аспекты этих сетей, реализующих модель
контекстно адресуемой памяти. Этот тип ассоциативных связей описывает извлечение из
долговременной памяти номера телефона, чувства досады или даже распознавания человека
по части его фотографии. Исследователи выделяют множество ассоциативных аспектов
этого типа памяти в структурах данных, основанных на символьном описании, включая
семантические сети, фреймы и объектные системы, рассмотренные в главе 6.
Аттрактор (attractor) — это состояние, к которому со временем сходятся другие
состояния из некоторой окрестности. Каждому аттрактору в сети соответствует область,
внутри которой сеть всегда эволюционирует к этому состоянию. Эта область
характеризуется аттракторным радиусом. Аттрактор может содержать одно состояние сети или
несколько состояний, по которым происходит циклическое перемещение.
Попытки понять и математически описать свойства аттракторов привели к
формированию понятия функции энергии сети [Hopfield, 1984]. Сети с обратными связями,
функция энергии которых обладает тем свойством, что любой переход состояний этой сел,
приводит к уменьшению сетевой энергии, обязательно сходятся к точке равновесия. Эти
сети будут описаны в подразделе ] 0.6.3.
Аттракторные сети можно использовать для реализации контекстно адресуемой
памяти, запоминая нужные образы в качестве аттракторов сети. Их также можно
применять для решения задач оптимизации, в том числе для задачи коммивояжера, создавая
отображения функции стоимости в задаче оптимизации в энергию сети. Решение этой
тГ^ПР"В°ДИТ " умсньшению °бщ™ энергии сети. Этот тип задач решается с
помощью так называемых сетей Хопфтда.
10.6.2. Двунаправленная ассоциативная память
состсаиТ„ХеГ„ГЦИ™В1,аЯ ПаМТЬ (ДДП>- «Ч.™ ™» ■ lKMk0' '*2'
аоаать „бра™ свГь'аГ" И0" о6^™в.ющт элементов. Может также cfl*
мерный вхР„лГйвГкт„;ПГмНееЙ Р°-а ° """" ^^ СбТЬ ДАП'
"^^Поскольку связи между неймнам»i вьк°Д"°й вектор У„, показана на рис. 10.2- .
необходимо определять ТТ '" Х и Y явмются Двунаправленными, то веса св«
щ ооонх направлений.
Часть IV. Машинное обуч"
I"0, 'ft2,o f T ДЛП дяя "*™'Р° " «*■
раздепа ,0.6.2. КажОш нсирои можт
Оыть связан с самим собой
Подобно весам в линейном ассоциаторе, веса связей в сети ДАП можно вычислить
заранее. Для определения весов используется тот же метод, ™ и в линейной ассо.ГатиТойТ
дел,. Векторы состоянии в архитектуре ДАП рассматриваются в хемминговом пространстве
Пусть даны N пар векторов, составляющих набор эталонов, которые необходимо
сохранить в памяти. Подобно описанной в подразделе 10.5.4 процедуре, веса связей вы-
числим следующим образом:
W=Y^X + Y2*Xi+... + Y;Xi.
Это соотношение позволяет вычислить веса связей от слоя Хк слою У (см. рис. 10.22).
Например, w32 — это вес связи, ведущий от третьего нейрона слоя X ко второму нейрону слоя У.
Предполагается, что между двумя нейронами существует лишь одна связь. Следовательно,
весовые коэффициенты связи между слоями X и У одинаковы в обоих направлениях, т.е.
матрица весов связей, ведущих от слоя У к слою X, является транспонированной матрицей W.
Сеть ДАП можно рассматривать как автоассоцнативную модель, если набор
ассоциаций имеет вид <Х|Л|>,<ХгЛ2>, ■■■ Поскольку в этом случае слоиХ и У идентичны, слой
У можно вообще исключить (рис. 10.23). Пример автоассоциативной сети будет
рассмотрен в подразделе 10.6.4.
Рис. 10.23. Автоассоциативная сеть со входные
вектором I,. Предполагается, что между каждыми^ двумя неи-
ронами существует одна связь, так что Wj-Wj, и
матрица весовых коэффициентов симметрична
Сеть ДАП используется для извлечения из памяти образов ^™^J?^*
»«* «а вход слоя X Если входной образ зашумлен или неполон, то сеть ДАП зачастую
«ожег восполнить этот образ и извлечь из памяти емзанныи с ним Виктор.
,ава 10. Машинное обучение на основе связей
473
,„„ые из памяти сет,. ДАП. нужно выполнить следующие дей„В1и
Ч10бЫЮЮеЧЬД " "е- — пара ветров (Х.УГ где Х-эта 0б
L ко'рт^ПосГи'вить связанный с ним эталон, а У- случайно эд^
2. Гформаиия распространяется от слоя X к елок, У, И вычисляв эначеии» нейро.
3 ГхГдГые значения нейронов ело, У передаются „а вход слоя X, и .«.^
значения нейронов этого слоя.
4 Два предыдущих действия продолжают выполняться до тех пор. пока состояние
t\ ГсХиэируется, т.е. значения векторов X и У перестанут изменяться.
Указанный алгоритм описывает распространение информации в сети ДАП в обоих
направлениях до достижения точки равновесия. Работу алгоритма можно начинать с „е-
редачи в сеть значений слоя У, тогда после сходимости можно получить значение веки,
па X Эта сеть в полном смысле является двунаправленной: в качестве входа можно
использовать вектор X и вычислять ассоциированный с ним вектор У, а можно на основа-
ним вектора У определять значение вектора X. Пример такой сети будет рассмотрен в
следующем разделе.
После сходимости процесса обработки состояние равновесия представляет собой
один из эталонов, использованных для построения исходной матрицы весов. На вход
сети подается вектор с известными свойствами: либо идентичный одному из векторов
эталонной пары, либо слегка отличный от него. Этот вектор используется для
восстановления второго вектора из эталонной пары. В качестве расстояния выбирается хеммннгово
расстояние, измеряемое как количество различающихся элементов векторов. Благодаря
свойству ортонормированностн сходимость сети ДАП к одному вектору означает также
сходнмтостъ к его дополнению. Следовательно, вектор дополнения тоже становится
аттрактором сети. Пример этой ситуации будет рассмотрен в следующем разделе.
Сходимость сети ДАП определяется несколькими факторами. Если в матрице
весов сохранено слишком много эталонов, то онн оказываются очень блнзкн друг к
другу, что приводит к появлению исевдоустойчнвых состояний в сети. Этот
феномен получил название помех, которые приводят к появлению локальных минимумов
в пространстве энергии сети.
Давайте кратко остановимся на обработке информации в сети ДАП. Умножая
входной вектор на матрицу связей, получим входные значения элементов второго слоя.
Простая пороговая функция приводит полученный результат к виду, необходимому для
хранения вектора в хемминговом пространстве.
net (У) = WX, или для каждого элемента у, net(y:) = Sw/x,.
ПопслТваяГч0!,™0™0™""6 "Ч""**™» для вычисления значения нейронов ело» X
Пороговая функция в момент времени (+1 имеет вид
(+1, если net>0,
f(net'), если net=0,
-1, если пе!<0
В следующем разделе будет рассмотрено несколько примеров работы двунапрм"1
)й ассоциативной памяти.
Часть IV. Машинное обуче
10.6.3. Примеры обработки данных в сети ДАП
На рис Ю.24 показана небольшая сеть ДАП, которая является одним „э простейших
ириантов линейного ассоциатора, представленного в подразделе 10.5.4. Эта сеть
выползет отображение четырехмерного вектора X в трехмерный вектор У и наоборот.
Допустим, требуется запомнить в сети две пары эталонов
х =[1;-1;-1;--I]«-»V,=[1;1:1],
x,=t-i;-i:-i;i]"V,=[i;-i;ii.
Веса для
— вычисления
Хнаосчс-ееГ
Рис. 10.24. Сеть ДАП дня примеров из подраздела 10.6.3
Построим матрицу весов согласно формуле, приведенной в предыдущем разделе
w=у,х;+угх;+у,х;+...+y„xi,
W-
~1 -1 -1 -1
1 -1 -1 -1
1 -1 -1 -1
-1 -1 -1 1
111-1
-1 -1 -1 1
-2 -2 0"
0 0-2
-2 -2 0
Матрица весовых коэффициентов связей слоя У со слоем X представляет собой
транспонированную матрицу для W и имеет вид
0 2 01
-2 0
-2 0
[0-2
Выберем несколько векторов и протестируем работу се™ ^^^ГГвшоде
иу из эталонных пар. подадим на вход сети вектор X и проверим, потуч
сети вектор У. ПустьХ=[1 ;-1 ;-1;-1]. Тогда
y,ц1-o,+(,-1)V2))M(-1)•(-2)И^-1™={4;it,,
у1.(1-2)+((-1)-0Ж(-1Г0И(;"J» -Д'-^Л т<4)=1-
У,=(1-0Ж(-1П-2)Ж(-1) (-2»+<(;) Чидаь 칄 в,ять этот вектор У
Итак, получен второй вектор ""™0HH°" "^„"лТченвекторХЧ!;-!:-!.-1]- v
вкачестве входного и убедиться, что на выход°>*с .',. ,._-,], а элементы вектора У
В качестве следующего примера Р30"10^"'' е сеТь выдаст результат
инициализируем произвольным образом. В э
У,=< 1 -2)+(1 -0И1 '0И(- -2> у'4 „_4)=-1.
глава 10. Машинное обучение на основе связей
того что для векторного аргумента [-4; 4; -4] зна.
Этот результат получен с учета ,, вычислим значение компонентов вектора X
ченне пороговой функции равно [-1. 1. -Ч- В" pax.
х'=( -1)'0)+(Г<-2))+«-1>-0)=-2.
Пос; применения ^^^^^^^^^.^^.
енГй пример является дополнением ко второй паре эталонов <Х2. У2>. Это еще раз
подтверждает что в еети ДАЛ для каждой пары прототипов ее дополнение тоже являет-
сГталон!. Следовательно, в сети ДАЛ записаны еще два прототипа
X,=[-i;1;1;1]wVs=[-1;-1;-1],
x.=li;i;ii-i)<->''.=[-1;1:-i]-
Выберем вектор из окрестности одного из эталонов, например Х=[1; -1; 1; -1].
Заметим, что хеммингово расстояние от этого вектора до ближайшего эталона составляет 1.
Инициализируем случайным образом вектор У=[-1;-1;-1]. Вычислим значения
нейронов второго слоя сети
у,'*,=(Г0)+((-1)-(-2))+(Г(-2))+((-1)'О) = 0,
у,ы=(1*2)-К(-1)'0)+(Г0)+((-1)Ч-2)) = 4,
уГ=(1*О)+(НП-2)|+(Г(-2))+(НГ0) = О.
Напомним, что по определению пороговой функции, приведенному в конце
подраздела 10.6.2, для у[ = 0 /(у,ж) = /(у'). Поскольку первый н третий элементы вектора У
были инициализированы случайным образом значением -1, то У=[-1; 1; -1]. Теперь
снова вычислим значение X.
х,=((-1)*0)+(1*2)+((-1)'0)=2,
хг=«-1)*(-2))+(1'0)+((-1П-2))=4,
*.=«-1П-2)Ж1'0)+«-1)-(-2))=4,
х.=((-1)*0)+(1*(-2)Ж(-1)*0)=-2.
Применяя пороговую функцию, получим вектор Х=[1; 1; 1; -1]. Повторяя этот
процесс, снова вычислим вектор У
У,=(1*0)+(1*(-2))+(1Ч-2))+((-1)«0)=-4
У.»(1*2)+(1*0)+(1*0)+((-1)*(-2))*4
У."(1*0)+(1'(-2))+(1Ч-2))+((-1)»0)=-4.
В результате применения пороговой функции получим У=[-1- 1; -1]. Этот вектор
Го»пИмеНтП,РеДЬЩУШеМУ' следова™-°. сеть перешла в устойчивое состояние. Таким
в с«„ этГо„1ДТ ПРМОД0В П° Се™ mi Синтий к I образ совпал с сохранении,.
нзо"ражГИе п1 Г™ таК ЖЕ М0ЖН° »«™»»»-ть изображение лица или любое другое
™Z™ZZ :Z"ZxT7r7частиинф0"-Хеммингово TnT-
ратном направлении, восстанавливая вектор X по исходному вектору У
476
Часть IV. Машинное обуч8Н
В работе [Hecht-N.elsen, 1990] приводятся ннтерес„ые „„„
Там показано, что свойство ортонормальностн необхг™. риульта™ анал™ еета ДЛП.
сети, для сети ДЛП является слишком ограничитесь П """ '""""''"^ асс°шю™>"°"
„роения сети требуется лишь линейная независимое " ПОКазыюет- ™ <™ по-
р^ввпростраиствеэтллоновне приставлял со=^^
10.6.4. Автоассоциативиая память и сети Хопфилда
Нейроеетевые архитектуры „„луч„лИ всеобщее признание во многом благодаря
исследованиям Джона Хопфилда, физика из Калифорнийского технологического
института. Он изучал свойства сходимости сетей на основе принципа минимизации энерпГа
также разработал на основе этого принципа семейство нейросетевых архитектур Как
физик Хопфидд рассматривал вопросы устойчивости физических объектов с точки
зрения минимизации энергии физической системы. Примером такого подхода является
моделирование отжига и охлаждения металлов.
Рассмотрим сначала основные характеристики ассоциативных сетей с обратными
связями. Начальным состоянием таких сетей является подаваемый на вход вектор. Сеть
обрабатывает этот сигнал с использованием обратных связей до тех пор, пока не
достигнет устойчивого состояния. Для того чтобы такую архитектуру можно было
использовать в качестве модели ассоциативной памяти, необходимо обеспечить выполнение двух
свойств. Во-первых, необходимо гарантировать переход сети в некоторое устойчивое
состояние из любого начального состояния. Во-вторых, это устойчивое состояние должно
быть ближайшим ко входному вектору в некоторой метрике.
Сначала рассмотрим автоассоциатнвную сеть, построенную на тех же принципах, что
и сеть ДЛП. В предыдущем разделе было отмечено, что сети ДАП можно
трансформировать в модели автоассоциативнон памяти, если в качестве X и У выбирать идентичные
векторы. В результате такого выбора, как будет ясно из дальнейшего, квадратная
матрица весов становится симметричной. Пример такой ситуации показан на рис. 10.23 и
описан в подразделе 10.6.2.
Матрица весов для автоассоциативной сети, в которой хранится набор эталонных
векторов {Х|, Х2 Х„), создается по правилу
lV = £X,X,r
узлах
При создании автоассоцнативной памяти на основе "^™°w™ZlZ "*
„ „ v т с матпипа весовых коэффициентов является
Узла х, к узлу х, равен весу связи от х, к ^Тп3ен« требуется лишь, чтобы между
симметричной. Для выполнения эт°™ ^^„ЗГзь^ ф™с,Фованньш весом. Воз-
двумя элементами сети существовала еДинствен"^СВ™ *M3a„ „апрямую сам с со-
можеи также особый случай, когда „и -»« "=«™ -задало ^
бой, т.е. связь между х, и х, отсутствует. При этом на и.»
вых коэффициентов будут располагаться «Ут- „а 0СН0Ее запоминаемых в
Как и при работе с сетью ДАП, матрица весов строитсяи эгалон_
памяти образов. Продемонстрируем это на простом примере,
ных вектора
*,=[1:-1;1
х,=[1;1;-1
.-1:И.
-1:-И.
1:1].
Глава 1 о. Машинное обучение на основе связей
Вычислим
W=
i
W =
1
-1
1
1
3
-1
-1
1
3
laTpnuy
-1
1
-1
1
-1
-1
3
-1
1
-1
1
-1
1
-1
1
-1
-1
3
-3
-1
весов n
-1 1'
1 -1
"! -!
-1 1.
1 3
1 -1
-3 -1
3 1
1 3
по формуле
W = I*,X,r
Таким
что
Будем использовать пороговую функцию
+1, если леГ>0,
f(netM)=-'(net*), если nef=0,.
-\ если леКО.
Сначала проверим результат работы сети для одного из эталонов Х,= [1;1;-1; 1;1]
Получаем
X,- И/=[7;3;-9;9;7],
а после применения пороговой функции приходим к состоянию [ 1; 1; -1; 1; 1 ]
образом, при подаче в сеть этого вектора она сразу же сходится к нему. Это значит,
эталоны сами являются устойчивыми состояниями, или аттракторами.
Теперь проверим следующий вектор, хеммингово расстояние от которого до эталона
X, равно единице. Сеть должна сойтись к этому эталону. Это означает извлечение из
памяти образа по частично искаженным данным. Выберем Х= [ 1; 1; 1; 1; 1 ] ■
Х- W=(5; 1; -3; 3; 5].
После применения пороговой функции приходим к вектору Хэ = [ 1; 1 i ~ * ■ ^; ^'
Рассмотрим третий пример, выбрав на этот раз вектор, расстояние от которого д
ближайшего прототипа равно 2, допустим, Х=[1; -1; -1; 1; -1]. Не сложно убедиться,
что этот вектор находится на расстоянии 2 от вектора Х3, на расстоянии 3 от вектора Xi и
4 от Х2. Вычислим произведение
X*W=[3;-1;-5;5;3].
а после применения пороговой функции получим [ 1;
ляется устойчивым, поэтому вычислим
[1;-1;-1; 1; 1] • W= [9; -3; -7; 7; 9],
а с учетом порога получим [1; -1; -1; 1
вым, но оно не совпадает
; -1; 1; 1 ]. Это состояние НС я
нимум функции энергии? Однако „ри ближайшем рассмотрении видно, что этот
1]. Теперь это состояние оказалось У014"'
од"» м1
вектор
ни с одним из исходных образов. Возможно, это е
478
.IV. Машинное обучен"»
является дополнением к исходному прототипу Х,=Г-1- 1- i ,
„„ативной сети ДАП, аттракторами автоассоциативной се™ ' " " гетеР0"СС0-
^««..«..«.„..^^^^-^-^
По сих пор рассматривались автоассоциативн, к- г™ „ факторов.
u,iH0„ модели нам,™. Одной из целей Д^Г^^"^^~
„„„ автоассоциативных сетей, применимой к любой однослойной сет,, собратным и Г..
мни, которая удовлетворяет набору простых ограничений. Хоифияд док™ что Z,
„ого класса однослойных сетей с обратными связями всегда существует функция
энергии сети, обеспечивающая ее сходимость к устойчивому состоянию
Еше одной целью Хопфилда было распространение дискретной модели на вариант
непрерывного времени, более точно соответствующий условиям функционирования
реальных нейронных сетей. Типичный способ моделирования непрерывного времени в
сетях Хопфилда сводится к последовательной, а не послойной обработке узлов. Это
делается с помощью процедуры случайного выбора обрабатываемого нейрона с
одновременным применением некоторого метода, позволяющего убедиться в равномерности
обработки всех нейронов сети.
Структура сети Хопфилда идентична рассмотренной выше архитектуре
автоассоциативной памяти. Она состоит из одного слоя связанных между собой нейронов (см.
рис. 10.23). Функция активации, или пороговая функция, тоже совпадает с
рассмотренной. Следовательно, для /-го узла
х""" =
И, если ^ivsx>QW>7;
<,°и, если Y*W'XT=T>-
i
-1, если Y,w>"T'<Ti
При такой архитектуре для получения сети Хопфилда необходимо обеспечить лишь
одно дополнительное ограничение. Если w„ — это вес связи от узла i к узлу /, то весовые
коэффициенты в сети Хопфилда должны удовлетворять условию
iv„=0 V/,ivu= wlt vi, J, 1*1-
Для обучения сети Хопфилда не существует никаких специальных методов. Подобно
сети ДАП, ее веса обычно вычисляются заранее.
На сегодняшний день поведение сетей Хопфилда, как и персептронов^ено гс.р*,
„п ,,~~,й ^)то СВЯЗаНО С Тем, ЧТО Поведение ccicu
до лучше, чем свойства других классов сете», ло свя.мли
Хопфилда описывается в терминах функции энергии
Н<*> =-Z 2>.*Л + 2№''
Покажем, что 'благодаря свойствам этой ^^^"^ZZ^Z"
приводит к уменьшению общей энергии сети. ^^ тттт сет11, не
Функции н „ уменьшения значения Ф>'нкц"3 юбого начального состояния,
сложно прийти к выводу, что сеть будет сходи, ,пеиекта к изменение его состояния
Сначала покажем, что для любого ^^J™™^ веяичину мнения энергии ЛН
"Риводит к уменьшению значения функции Н. Вычислим ве,
ДН=Н(Х— )-Н(Х"').
Глава 10. Машинное обучение на основе
479
Поскольку для (=* *i
Получ-"
, слагаемые, не содержащие х,, можно исключит.
_л „ к/ -м/ приходим к соотношению
Учитывая тот факт, что №,=0 и *>г»,- ПРИХ д
чпйы показать отрицательность АН, рассмотрим два случая. Сначала предположим,
что —ГГи«сь с -I «а +1. Тогда множитель в квадратных скобках должен
быть положительным. Поскольку х- -*Г - "* ■ ™ ДМ отрицательно. Теперь предполо-
жнм, что значение х, изменилось с 1 на -1. Тогда по тем же причинам ДН отрицательно.
Если жех, не изменялось, то х»"-хГ=° иДН-0.
Отсюда следует что сеть должна сходиться из любого начального состояния. Более
того состояние сети после сходимости соответствует локальному минимуму энергии.
Если это состояние еще не достигнуто, значит, существует переход, приводящий к даль-
нейшему уменьшению общей энергии сети, и согласно алгоритму обучения для
модификации выбирается именно этот узел.
Было показано, что сети Хопфилда обладают одним из двух свойств, которыми
должны обладать сети ассоциативной памяти. Однако можно показать, что сети
Хопфилда в целом не удовлетворяют второму свойству: они не всегда сходятся к
устойчивому состоянию, которое является ближайшим к исходному. Для решения этой проблемы
не существует общего метода.
Сети Хопфилда также можно применять для решения задач оптимизации, в том числе
задачи коммивояжера. Для этого разработчик должен определить отображение функции
стоимости этой задачи в функцию энергии Хопфилда. Тогда переход к минимум энергии
сети приведет также к минимизации стоимости в соответствии с состоянием дайной
задачи. Хотя для многих интересных задач, в том числе для задачи коммивояжера, такое
отображение удалось построить, в целом построение отображения из пространства
данных задачи в функцию энергии — очень сложная проблема.
В этом разделе рассмотрены гетероассоцнативные и автоассоциативиые сети с
обратными связями. Проанализированы динамические свойства этих сетей и предложены
очень простые примеры, отражающие эволюцию состояний систем к своим аттракторам,
ьыло показано, как линейную ассоциативную сеть можно модифицировать в агтрактор-
ную сеть ДАЛ. При обсуждении сетей Хопфилда, функционирующих в непрерывном
С""' «Роимонстрироваио, как поведение сети можно описать в терминах
сиГ! ZT""' СеТСЙ ХопФ"^ обладает гарантированной сходимостью, по-
ОлГкоТГо "е"е™Я ° ТШОй №™ уМеиьша" "бшую »«1»™> с«и.
ет решить „ек™"""" "" Э"ерГИИ П0ДХ0Д к «учению сетей связей все же не позволя-
тельно соответствует У,""'' ^-Ч™». Достигнутое состояние энергии не обяза-
Хопфилда не обязате^™альномУ "ииимуму для данной системы. Во-вторых, сети
осязательно сходятся к аттрактору, ближайшему к данному входному
480
Часть IV. Машинное обучение
л,оУ- с этим связаио "сУДобство их испо-,,.,
•:ГУ -ой памяти. В-третьих, „р„ испол"ь D-»«»™ реализации ко„гекстно
Р „мизош-и не существует общего метола ™ " Хо"Ф-лда для „1 ш"
*Учества минимумов энергии, которые можно сохГниТДельное ™«=«ие общ 0 к„.
ело нельзя установить точно. Эмпирическое «Т„„о "Г" " Ю,Лечь m ««• ™
„ количество аттракторов составляет лишь MaZ """" °№й омш»«^.
адт и другие связанные с ним вопросы активно и,™ еГ0 числа ^лоа а сета
,990], [Zurada. 1992] и [Freeman, Skapura, 1991] учаются в Работах [Hecht-Nielsen
В рамках таких биологических подходов, как генетические .„т
„«маты, предпринимаются попытки построить модели о£Г """Р"™" « клеточные
^форм жизни. Обработка данных в эти,• модели «Z? "* "РтЩШИ М™
■доделенной. Например, в генетических алгоритмах какл„,»Т юршлеяь»°й и рас-
^ется целая популяция образов. В процесс ZZZIZTZT™ M™
„„оиирует с учетом принципов воспроизводства, мутации и^еГоТТоГ^
подходы рассматриваются в главе 11. естественного отбора. Эти
10.7. Резюме и дополнительная литература
В этой главе были рассмотрены вопросы обучения в сетях связей. В разделе 10 1 они
описаны с исторической точки зрения. Для более подробного ознакомления с эти.™
вопросами мы рекомендуем ознакомиться с работами [McCulloch, Pitts, 1943], [Selfh'dge. 1959],
[Shannon, 1948], [Rosenblatt, 1958]. Важно также изучить физиологические модели, особенно
предложенные Дональдом Хеббом [Hebb, 1949]. Наука о познании продолжает исследовать
взаимосвязи между обучением и структурой мозга. Эти вопросы описаны в [Ballard. 1997],
[Franklin, 1995], [Jeannerod, 1997] и [Elman и др., 19961.
За рамками рассмотрения остались многие важные математические и
вычислительные аспекты сетей связей, описанные в работах [Hecht-Nielsen. 1990], [Zurada. 1992] и
[Freeman, Skapura, 1991].
Специалисты по машинному обучению должны рассматривать и множество других
вопросов, связанных как с представлением, так и с реализацией вычислений. К числу
этих проблем относятся выбор архитектуры и структуры связей сети, определение
параметров обучения и множество других. Существуют так называемые нейро-символыше
гибридные системы, которые тоже могут отражать различные аспекты интеллекта.
Сеть прямого распространения - одна из наиболее распространенных ™«^сетевь"
архитектур Поэтому в этой главе достаточно много внимай™ уделялось ее -игтокам
использованию и развитию. Введение в теорию нейронных -«^'^"ад
вычислительных средствах обучения содержится в двухтомнике [Rumelhait и др.. 19865].
Этому же вопросу посвящена работа [Grossberg. 1988). множество других во-
При использовании сетей прямого ^^^^^^^^ыирс,
просов, в том числе проблема выбора количества т использования по-
вания обучающего множества, настройки коэффнц- ^^ потш ,шдуктивного
роговых нейронов и т.д. Многие из этих вопросов вх д 1кп01Иуемьк да, решения
порога, определяющего роль знаний, наблюдении и р ^
задачи. Многие их этих вопросов рассматриваются в .
описали л\ в своих работах
Большинство разработчиков нейросетевых архше■ v 19S6]. [Hecht-Nielsen. 1989,
[Anderson и др., ,977Р]. [Grossberg, 1976, 19Й1 Р* ™, ^•,„,, „ [МЫ. 19S9]. Более
W0], [Hopfield. 1982, 1984], [Kohonen, 1972, I984J. l
г"ава 1 о. Машинное обучение на основе связей
. „„„о™ в том числе графические модели, описаны в работах (Jordan, l9w,
ISTМоГо^ореГеиловатТ!, хороший современны,-, учебник [Bishop, l995^
10.8. Упражнения^
1. Постройте „ейроТм^-Калока-Питтса, вычисляющий функцию логического
следования =>.
2 Постройте персептронную сеть на языке LISP н реализуйте в ней пример задач„
классификации, описанный в подразделе 10.2...
2 1 Сгенерируйте свой набор данных, аналогичный представленному в табл. 10.3 „
' используйте его для решения задачи классификации.
2.2. Воспользуйтесь результатами работы классификатора и весами связей для
определен™ специфики разделяющей линии.
3 Реализуйте сеть прямого распространения на языке LISP или C++ и используйте ее
для решения задачи •исключающего ИЛИ", описанной в подразделе 10.3.3. Решите
эту задачу с помощью нескольких сетей различной архитектуры, например, сета с
двумя скрытыми узлами без пороговых нейронов. Сравните скорость сходимости
разных сетевых архитектур.
4. Реализуйте сеть Кохонена на языке LISP или C++ н используйте ее для решения
задачи классификации данных из табл. 10.3. Сравните полученные результаты с
описанными в подразделах 10.2.2 и 10.4.2.
5. Реализуйте сеть встречного распространения и используйте ее для решения задачи
"исключающего ИЛИ". Сравните полученные результаты с данными для сети
прямого распространения, приведенными в подразделе 10.3.3. Используйте свою сеть
встречного распространения для разделения классов из табл. 10.3.
6. С помощью сети прямого распространения решите задачу распознавания десяти
рукописных цифр. Для этого можно размешать цифры в сетке размером 4x6. Если
фрагмент цифры попадает на данную клетку, присвойте ей значение 1, если нет —
значение 0. Этот вектор из двадцати четырех элементов можно использовать в
качестве входного вектора сети. Для построения обучающего множества можете
воспользоваться и другим подходом. Решите эту же задачу с помощью сетн встречного
распространения. Сравните полученные результаты.
7. Выберите входной образ, отличный от использованного в подразделе 10.5.2, и
примените метод обучения Хебба без учителя для распознавания этого образа.
8. В подразделе 10.5.4 для создания ассоциаций между двумя парами векторов
использован линейный ассоциатор. Выберите три новые пары векторов и решите эту же
задачу. Проверьте, обладает ли ваш линейный ассоциатор свойством интерполятивно-
сти, т.е. может ли он находить близкие к эталону векторы? Постройте автоассокда-
тивный линейный ассоциатор.
9. Вспомните сеть ДАЛ, описанную в подразделе 10.6.3. Измените пары ассоциаций.
выОранные в этом разделе, и постройте для них матрицу весов. Выберите новые
векторы и протестируйте свою сеть ДАП.
10- Опишите различия между сетью ДАЛ и линейным ассоциатором. Что такое помехи,,
как предотвратить их появление?
11. Постройте сеть Хопфилда для решения задачи коммивояжера для десяти городов.
Машинное обучение
на основе
социальных
и эмерджентных
принципов
Как можно ограничить эту энергию, действующую в течение долгих веков и
строго изучающую общую организацию, структуру и привычки каждого существа —
благословляющую на добро и отсекающую зло? Я не вижу границ этой энергии,
которая медленно, но верно адаптирует каждое создание
к самым сложным жизненным отношениям.
— Чарльз Дарвин (Charles Darwin), О происхождении видов
Первый закон пророчества:
"Когда признанный пожилой ученый утверждает, что нечто возможно, он почти всегда
прав. Если он утверждает, что нечто невозможно, он, вероятнее всего, ошибается."
Второй закон-
"Единственный способ постичь границы возможного —
отважиться на небольшой шаг за его пределы."
Третий закон:
-Любая достаточно развитая технология неотличима от магии."
— Артур Кларк (Arthur С. Clarke), Профили будущего
И.О. Социальные и эмерджентные модели обучения
1, - „,.»,-, Вл многом было обусловлено целью создания
На ранних этапах развитие сетей связен во «»<^^ 6„ологнчки1й прототип для
искусственной нервной системы. Однако это *. ^™^™' дагр|1(ш01с» алгоритмы
разработки алгоритмов машинного обучения. В го,, главе Р JP^ ^.^
обучения, основанные и» принципа «юл. ^ра"нтьнейших пред™ите.тей попу-
особей популяции в процессе ее развития Роп "*°Ра социальных процессах. пр„-
ляции ярко проявляется на примере эволюции видов, а также
482
Часть IV. Машинное
„буче.
ние
водящих к изменению н формяр._ генетичс<;ких алгоритмов, генетического ппопГ C
помошью теории клеточных авто. • , эмерДжентных вычислений. рам'
„ировання. искусственно*^из™ ^ модели (emergent model) обучения им„ТИрук>г
наиболее элегантную
ного и животного мира.
Как отметил Чарльз Дарвин, нет "границ этой энергии,
.Оптирует каждое создание к самым сложным жизненным отнотГ
^"nleTnpo - варьирования некоторых свойств наиболее жизнеспосо^
ниям . В процессе пр v дачнь1Х экземпляров повышаются адаптат,..
дение новых свойств
ют друг на друга
„,.,„ происходят в популяциях материальных особей, которые действу,
и подвергаются внешнему воздействию. Таким образом, необходи
отбора исходит не только из внешней среды, ио и от взаимодействия между членами
популяции Экосистема включает множество членов, кумулятивное поведение которых
формирует оставшуюся часть популяции н формируется под ее воздействием.
Простота процессов, лежащих в основе эволюции, обеспечивает их достаточно общее
обоснование Виды создаются в процессе биологической эволюции за счет отбора наиболее
благоприятных изменений генома. Аналогично в процессе культурной эволюции при переда-
че социально обработанных и модифицированных единиц информации формируются знания.
Генетические алгоритмы и друпк формальные эволюционные аналоги обусловливают более
точное решение задачи за счет операций над популяциями кандидатов на роль решения.
Генетический алгоритм решения задачи включает три стадии, первая из которых
предполагает представление отдельных потенциальных решений в специальном виде,
удобном для выполнения эволюционных операций изменения и отбора. Зачастую таким
представлением являются обычные битовые строки. На второй стадии реализуются
скрещивание и мутации, присущие биологическим формам жизнн, в результате которых
появляется новое поколение особей с рекомбинированными свойствами своих
родителей. И наконец на основе некоторого критерия отбора (fitness function) выбираются
"лучшие" формы жизни, т.е. наиболее точно соответствующие решению данной
проблемы. Эти особи отбираются для выживания и воспроизведения, т.е. для формирования
нового поколения потенциальных решений. В конечном счете некоторое поколение особей
и станет решением исходной задачи.
В генетических алгоритмах применяются и более сложные представления, в том
числе правила вывода, эволюционирующие в процессе взаимодействия с внешней средой.
Например, в генетическом программировании за счет комбинирования и "мутации"
фрагментов программного кода программа эволюционирует и сходится к решению
задачи, например к выделению инвариантного множества.
Примеры обучения, представляющего собой социальное взаимодействие с целью
выживания, можно найти в таких играх, как "Жизнь". Эта игра изначально была
разработана математиком Джоном Хортоном Конвеем (John Horton Conway) и представлена
широкой общественности Мартином Гарднером в журнале "Scientific American" в 1970 и
19/1 годах. В этой игре рождение, жизнь и смерть особей — это функция их собственно-
точнТн0б""" " С0СТ0Я""Я "х о™*»™"* соседей. Обычно для определения игры доета-
е ппмппгп ™„....~ . .именты с
точно небольшого количества
правил — трех илн четырех. Как показали экспер!
"Го c^Z,"' "еСМ<ПРЯ "а ЭТ> ПРОСТОТ>- в ее Рамках'могут эволюционировать чрезвы-
Го;ГнГа;\ХХопеВТ,985ГСЛе т"™ °^~< " **""**
Один из важных подходов к искусственной жизни (art T if
вании условий биологической эволюции за счет вза - состоит в моделиро-
заданных наборами состояний и правил перехода ^"олс"ств"я и>«счных автоматов,
формацию из внешней среды, в частности, от ближайшГхТ™ "Т "Р"НИМать HH"
'держат инструкции „о рождению, продолжение"ГГи сГ™ Р"™"" "СРСХ°Д°"
ких автоматов свободно действует в своей ^^^T^Z^o"
„„действовать как параллельные асинхронные агенты, то иногда можГиаблюдатьТо
лкшию практически независимых "форм жизни" наолюдать эво-
Можно привести еще один пример. В работах [Brooks, 1986, 1987) описаны простые
роботы, действующие как автономные агенты, способные решать задачи в лабораторных
условиях. При этом центральный алгоритм управления отсутствует, а кооперация от-
дельиых особей становится артефактом распределенного и автономного поведения
каждого из них. Сообщество ученых, работающих в области искусственной жизни
регулярно проводит конференции и выпускает журнал, на страницах которого обсуждаются
новейшие результаты в этой области [Langton, 1995].
В разделе 11.1 вводятся эволюционные модели и описываются генетические
алгоритмы (genetic algorithm) [Holland, 1975] — подход к обучению на основе параллелизма,
общего взаимодействия и, как правило, битового представления. В разделе 11.2
представлены системы классификации (classifier system) и генетического программирования
(genetic programming) — сравнительно новые области исследования, в которых
методология генетических алгоритмов применяется для решения более сложных задач, в
частности, для построения и уточнения наборов правил вывода [Holland и др., 1986]. а также
для создания и настройки компьютерных программ [Koza. 1992]. В разделе 11.3
представлена методология искусственной жизни [Langton, 1995]. Этот раздел начинается со
знакомства с игрой "Жизнь". В завершение раздела приводится пример "эмерджентного
поведения", описанный в [Crutchfield и Mitchell, 1995].
11.1. Генетические алгоритмы
Подобно нейронным сетям, генетические алгоритмы основываются на свойствах
биологического прототипа. В рамках этого подхода обучение рассматривается как
конкуренция внутри популяции между эволюционирующими кандидатами на роль решения
задачи. Каждое решение оценивается согласно критерию отбора. По результатам оценки
определяется, будет ли этот экземпляр участвовать в следующем „околенш, решении.
Затем с помощью операций, аналогичных трансформации генотипа в процессе оиологи-
ческого воспроизводства, создается новое поколение решений-кандидатов.
Пусть Р( г) - поколение решений-кандидатов х\ в момент времени t
p(o=(xi,xj,...x;(.
В общем виде генетический алгоритм мо
procedure genetic algorithm;
begin
установить f;=0;
инициализировать популяцию PC),
while не достигнуто условие завершения
о представить следующим образом.
Часть IV. Машинное обучение
' ,„яльнь0< и эмерДжентных принципов
Глава 11. Машинное обучение на основе социальных и эмерд»
485
""^мелить значение критерия качества для каждого члена
Госно^ Гначений критерия качества выбрать из P(f) „^
число чле"°в'' поколение с помощью генетических опеЕд, .
загнить с учето» значений критерия качества особей РаЦИЙ'
популяции Pit) их потомками;
установить время (:-(+!
end
end.
Этот алгоритм отражает основные принципы генетического обучения. Его конкп
ные реализации могут отличаться в зависимости от задачи. Какое процентное соотисГ
ние особей выживает в следующем поколении? Сколько особен участвуют в скрещи»!'
ннн? Как часто и к кому применяются генетические операторы? Процедуру "замещу
особей популяции Р(0" можно реализовать простейшим образом, заменив фиксиро-
ванное процентное соотношение слабейших кандидатов. Более сложный подход с
стоит в упорядочении популяции согласно критерию качества и удалении особей с
учетом вероятности, обратно пропорциональной значению критерия качества. Такую
меру можно использовать для выбора исключаемых особей. И хотя для наилучших
особей популяции вероятность их исключения очень низка, все же существует шанс
удаления самых "сильных" особей популяции. Преимущество этой схемы состоит в
возможности сохранения некоторых "слабых" особей, которые в дальнейшем мот
внести свой вклад в получение более точного решения. Такой алгоритм замены
известен под многими именами, в том числе как метод Монте-Карло (Monte-Carlo),
правило рулетки (roulette wheel) или алгоритм отбора пропорционально критерию
качества (fitness proportionate selection).
Несмотря на то что в подразделе 11.1.3 вводится более сложный принцип
представления при изучении генетических алгоритмов решение задачи будем описывать с
помощью обычных битовых строк. Предположим, что необходимо с помощью генетического
алгоритма научиться классифицировать строки, состоящие из единиц и нулей. В такой
задаче популяцию битовых строк можно описывать с помощью шаблона, состоящего из
\mmZT0mB К0Т°РЫе ШГуТ со<™етствовать как 1, так и 0. Следовательно, шаблон
coaZT 1реДСтаВляет все «осьмибнтовые строки, начинающиеся, заканчивающиеся 1 и
содержащие в середине строки два нуля подряд.
>шициали^р»тсяНе1ТбГК0Г0 алгор"™а порция кандидатов Р(0) некоторым образом
чисел Лл инициализация выполняется с помощью датчика случайных
шнймеГ °ЦеЖН Решений-ка,™Д"°в вводится критерий качества f(x\), определяю-
щни меру соответствия l- • г •
рой соответствия LZ ° КЗНД1,дата в "омент времени г. При классификации «е-
множестве обучающих mMm" про«ен™ое соотношение правильных ответов на
кандидату соответствует "начини08' ПРИ ТаК°М критер"" качес™а каждому решен.но-
f(*i')/m (P, t)}
мерасоответствияДизС1н'яетсНИе 'фИТСр"я качества для всех членов популяции. Обычн»
шей от стадии оешен„ " В° времен"' поэтому критерий качества может быть ФУ
"ия всей проблемы или Цх\).
После анализа каждого кандидата выбираются папм
пользуются генетические операторы, в результате в Рском6инации. При этом ис-
„олучаются путем комбинации свойств родителей К Ы"0ЛНенм К0ТОР™ новые решения
ц„н, степень участия в репродуктивном процессе для -«1"™™""°" ПР°ЦеССе ЪЪШЮ'
ченнем критерия качества: кандвдаты с более высокими кандидата определяется зна-
вуют в процессе воспроизводства с 6,J^Z£^ ГГ """'" ^
бор осуществляется на основе вероятностных законо» . к У °™ечалось. вы-
имРеют меньшую вероятность воспроизводи однГ^ГвозГ ™"И ^^
Вьгживанне некоторых слабейших особейГеет вГн„е зГ В°ЗМ°Ж"0С1Ъ не "еключается.
1,1 "меег важное значение для развития пмпляшш
поскольку они могут содержать некоторые важные компоненты решения Z,„mT фГ-
„ент битовой строки, которые могут извлекаться при воспроизводстве
Существует множество генетических операторов получения потомства,
обладающего свойствами своих родителей. Наиболее типичный нз них называется
скрещиванием (crossover). Прн скрещивании два решения-кандндата
делятся на несколько частей и обмениваются этими
частями, результатом становятся два новых кандидата. На Входные 6т™"в строки:
рис. 11.1 показана операция скрещивания шаблонов бито- 11 »0 i 1 о 1 s snoi*o*i
вых строк длины 8. Эти строки делятся на две равные час- I \ i /
ти, после чего формируются два потомка, содержащих по РвзУль™РУк»чие битовые строки:
одному сегменту каждого из родителей. Заметим, что раз- i i#o*0»1 #110101»
биение родительских особей на две равные части — это
достаточно произвольный выбор. Решения-кандидаты мо- рцС, ;;.;. Использование скре-
гут разбиваться в любой точке, которую можно выбирать щивання для двух битовых
и изменять случайным образом в ходе решения задачи. строк длины 8. Символ # озна-
Предположим, что целевой класс— это набор всех чает "произвольное значение"
строк, которые начинаются и заканчиваются единицей. Обе
родительские строки, показанные нарнс. 11.1. достаточно хорошо подходят для решения
этой задачи. Однако первый их потомок гораздо точнее соответствует критерию качества,
чем любой из родителей: с помощью этого шаблона не будет пропущен ни один из целевых
примеров, а нераспознанными останутся гораздо меньше строк, чем в реальном классе
решения. Заметим также, что его "собрат" гораздо хуже, чем любой из родителей, поэтому
этот экземпляр, скорее всего, будет исключен в одном из ближайших поколений.
Мутация (mutation) — это еще один важный генетический оператор. Она состоит в сту-
чайном выборе кандидата и случайном изменении некоторых его свойств. Например, мутация
может состоять в случайном выборе бита в шаблоне н изменении его значения с 1 на 0 или #.
Значение мутации состоит в возможном восполнении важных компонентов решения,
отсутствующих в исходной популяции. Если в рассмотренном выше примере ни один из членов
исходной популяции не содержит 1 в первой позиции, то в процессе скрещивания нельзя
получить потомка, обладающего этим свойством. Значение первого бита м°>™ "™™
вследствие мутации. Этой цели можно также достичь с помощью другого генетического one
ратора - инверсии (.nve.ion, которая будет™,.подразделе Л ^
Работ* генетического алгоритма проломаете Д° ^ пор ^ ^
условие его завершения. ""РН"^^™ ™^м ра3деле приводятся пр.-
терия качества „с превысит некоторого *["^ а такж ^„^ гене1иче.
меры кодирования информации в генети .. ^ возможности описания проблемы
ских операторов и критериев качества для двух задач^ ■
- -, *„„»,(■ н задачи коммивояжера,
в конъюнктивной нормальной форме н зада-"
Тл^а^^^^^ 4"
„ , з Два примера: описание задачи в ко„ъю„,ст„в„ой „орм
форме и задача коммивояжер! "»и
. «мчи и обсудим для них вопросы представления и выбора кгшт,
^^"^момента. Во-первых, не все задачи естествен^Г ""
«Хуровн битового представления. Во-вторь,х. генетические операторы д^ *«-
"~ь появление нежелательных взаимоотношении внутри „опУляции, """!»•
«обеспечивать присутствие и уникальность всех городов в маршруге „ «ер,
раТнаконец. следует обсудить важные взаимосвязи между значением критерия „^
для различных состояний и методом кодирования, выбранным для данной задачи. ЗДа
Описание проблемы в конъюнктивной нормальной форме
Описание в коньюнктивной нормальной форме (КНФ) — это представление выраж
ния в виде последовательности операторов, связанных отношением И (л). Каждый щ
этих операторов должен представлять собой дизъюнктивное выражение, определяемо
отношением ИЛИ (v), или литерал. Например, для литералов а, Ь, с, d, е и f выражение'
(-1avc)A(-,avcv-,e)Abbvcvc/v-,e)A(av-,bvc)A(-,evf)
является конъюнктивной нормальной формой. Это выражение представляет собой
конъюнкцию пяти операторов, каждый из которых является дизъюнкцией двух или
нескольких литералов. Понятия предложения и его представления были введены в главе 2
Там же обсуждались вопросы представления в конъюнктивной нормальной форме и
предлагался метод сокращения числа операторов в КНФ. В разделе 12.2 будет приведено
доказательство теоремы о разрешении.
Представимость в конъюнктивной нормальной форме означает существование таких
логических значений (1 или 0 либо true и false) для каждого из шести литералов, при
которых КНФ-выражение принимает значение true. Несложно проверить, что для
доказательства представимости рассмотренного выше выражения в конъюнктивной нор-
мальнон форме достаточно присвоить значение false литералам а Ь и е. Еще одно
решение обеспечивается присвоением литералу е значения false, а с — true.
Естественным представлением данных для задачи КНФ-описания является
последовательность из шести битов, каждый из которых представляет значение одного из шести
литералов а. Ь, с, d, e и f. Таким образом, выражение
1010 10
комбинации0,™4'2"1-''' а'°"е Прин,шают значение true, а Ь, d и f — false. Для такой
false Читат-ль литеРш™ приведенное выше выражение принимает значение
общее выражение иЖстТннно°еТОЯТеЛЬНО ПОДобрать такие значеиия литералов, при которых
рого КНФ-вырме'нзТ6''"'1 Генетических операторов требуется получить потомка, для кото-
генетического опеоатои , " "стишщм- Следовательно, в результате выполнения каждого
как кандидат на роль „е "*"* Получатъся б'"°вая строка, которая может рассматриваться
пор генетические опепатпп"11^34134"' Эгам свои™ом обладают все рассмотренные до я»
битовые строки, которые ч'' ЧаС™0СТИ' в Результате скрещивания и мутации получи»
гак'«'вф»ш/>овошк(1пУег,;°1ТГ,Статъ Рвением задачи. Менее типичные операторы, та"1'
на обратный) или обмен (еГь (Изменение п°Р>ика следования битов в шестибитовой ел**
чивают получение канд„лЯ„ 8С) (пеРемена мест двух произвольных битов), тоже обесп
°6еспеЧ1Пъ более удаЧНОе п™ Р0ДЬ решення КНФ-проблсмы. С этой точки зрения труД»
У °е "Радетавление данных в золаче кнт
е данных в задаче КНФ.
Выбор критерия качества для этой популяции битовых mv,
„ой стороны, задача считается решенной, если найдена ком^,"* Т™ оджпначсн- С °*
ражение принимает значение true. Поэтому на пепвый взгГ ' '*" К0Т°р0Й '""
помощью которого можно оценить "качеств битоГх стгТ ^^ 01феДеЛтЪ **т*М- С
Однако существует множество варианте (iZ отГ^Г потснцишы,ы>' Р"™™
представляет собой конъюнкцию пяти опфатороГ ПозТпмГ' ™ ""^ 1Шф-выр—"е
„Гения по шкале от 0 до 5 в зависимости оТкЗчест^опТпа °Г "^^^ ^^ ""
„,е. Тогда каждому из образов можно со„остТГоГетГуюиТ„—Г "
1 1 0 0 1 0 — рейтинг 1,
О 1 0 0 1 0 — рейтинг 2,
0 1 0 0 1 1 — рейтинг 3,
1 0 1 0 1 1 — рейтинг 5,
следовательно, эта комбинация является решением. Такой генетический алгоритм
обеспечивает разумный подход к решению КНФ-гтроблемы. Одним из важнейш.гх свойств этого
подхода является неявный параллелизм, обеспечиваемый за счет одновременной обработки
целой популяции решении. Этому представлению естественным образом соответствуют
генетические операторы. И, наконец, поиск решения выполняется по принципу разделяй и
властвуй", поскольку решение задачи делится на несколько элементов. В упражнениях к этой
главе читателю будет предложено рассмотреть другие аспекты этой проблемы.
Задача коммивояжера
Задача коммивояжера — это классический пример тестовой задачи для методов
искусственного интеллекта и компьютерных наук вообще. Впервые она упоминалась в
разделе 3.1 при описании графов. Пространство состояний этой задачи для N городов
включает АЛ возможных состояний. Было показано, что эта задача является NP-полной,
поэтому для ее решения предлагалось множество различных эвристических подходов.
Формулировка задачи достаточно проста.
Коммивояжеру требуется посетить N городов. Для каждой пары городов по маршруту
следования установлена стоимость (например расстояние). Требуется найти путь минимальной
стоимости, который начинается из некоторого города, обеспечивает посещение остальных
городов ровно по одному разу и возврат в точку отправления.
Задача коммивояжера используется на практике, в том числе обеспечивает решение
проблемы разводки электронных схем, задачи рентгеновской кристаллографии и
маршрутизации при производстве СБИС. Некоторые из этих задач в процессе прохождения
пути минимальной стоимости требуют посещения десятков тысяч точек (городов).
Большой интерес представляет анализ класса задач коммивояжера с точки зрения
эффективности их реализации. Вопрос заключается в том, стоит потратить несколько часов на
получение субоптимального решения на рабочей станции ити дешевле разработать
простой компьютер, который за несколько минут обеспечит вполне приемлемый результат.
Задача коммивояжера - это интересная и сложная проблема, затрагивающая множество
аспектов реализации стратегии поиска.
Как можно решить эту задачу с помощью генетического алгоритма? Во-первых,
можно выбрать представление для маршрута посещения городов, а такэке гюдобрать „с-
пользуемые генетические операторы. В то же время выбор критерия качества в данном
случае достаточно прост - требуется оценить лишь длину пути. После этого маршруты
«ожно упорядочить по длине - чем "j*^^^ имеют достаточно сложные
Рассмотрим несколько очевидным представлении, млирыс
последствия Предположи»,, необходимо посетить девять городов 1. 2 9. Тогда путь
Глава ,,. машинновс^учениенаосновесоциальныхиэмерджентныхпринципов 489
т „„пядоченным списком из девяти целых. Представим поп»
представить утюр-ядоч ^ ^^ ^ ^^ 1т ^^ ^ ™Р»ДКоввд ^
»выражение
льность посещения городов по возрастанию их пор
ПрМСТа8'гте„Т„бПелыТэтом выражении «отмены только для простоты восприя^^»
номеров. Прооелы использовать для решения этой задачи' Ск™
"* ""Гп— поскольку получаемая результате строка, скор^
н„е однозначно не под». д котором каждый город посещается только „ "е
Г'Г^С^»"»^города выпалут из последо ^Г
Действительно при скрш ^^ q [Ш, п «сти, а
r:S"Z:r шестого города ОНО изменится на 1. Тогда „„^
число 1110 будет соответствовать порядковому номеру 14, который не входит в допу(.
тимый перечень городов. Инвертирование городов в выражении пути в данном случае
является допустимой операцией, однако достаточно ли ее для получения необходимого
решения' Одним из способов поиска минимального пути является генерирование „
оценка всех возможных перестановок из N элементов в списке городов. Поэтому тенета-
ческие операторы должны обеспечить возможность получения этих перестановок.
Задачу коммивояжера можно решить и по-другому: проигнорировать битовое
представление и присвоить городам обычные порядковые номера 1,2,..., 9. Путь между этими городами
будет представлять собой некоторую последовательность девяти цифр, а соответствующие
генетические операторы позволят формировать новые пути. В этом случае мутация как
случайный обмен двух городов в маршруте будет допустимой операцией, но скрещивание по-
прежнему окажется бесполезным. Обмен фрагментов маршрута на другие фрагменты того же
пути либо любой оператор, меняющий местами номера городов маршрута (без удаления,
добавления или дублирования городов), окажется достаточно эффективным. Однако при таких
подходах невозможно обеспечить сочетание лучших родительских свойств в потомке,
поскольку для этого требуется формировать его на основе двух родителей.
Многие исследователи [Davis, 1985], (Oliver и др., 1987] разработали операторы
скрещивания, устраняющие эти проблемы и позволяющие работать с упорядоченным списком
посещаемых городов. Например, в работе [Davis, 1985] определен оператор, получивший
название упорядоченного скрещивания (order crossover). Допустим, имеется девять городов
1,2 .... 9, порядок следования которых представляет очередность их посещения.
В процессе упорядоченного скрещивания потомок строится путем выбора
подпоследовательности городов в пути одного из родителей. В нем также сохраняется
относительный порядок городов другого родителя. Сначала выбираются две точки сече-
тГж, ,r4eH"bK СИМВ°Л0М '' КОТ°Рые ™учайньш образом устанавливаются в одних и
Гайным Г КаЖД0Г° "3 Р°дита"*. Местоположение точек сечеиия выбирается слу-
для д ГооГ"' °T° Т КЗЖД0ГО из Родителей эти точки совпадают. Например, если
™ двух родителей pi „ р2 точки сечення располагаются после 3-го и 7-го городов
Р1=(192|4657|83),
Р2=(459|1876|23),
то два потомка cl и с2
ив копируЮТСЯ фрагмен
получаются
следующим образом. Сначала для каждого из потом-
r^-..^vparMeHTb p^u,.,. сначала для ч»д»'""--
с1=(ххх|4657|хх) Р°дителеи, расположенные между точками сечеиия.
с2=(ххх| 187б| хх)!
Затем после второй точки сечения одного из оо
ствуюшие другому родителю, с сохранением по^кТ!!*"0"6™™™' ðаДа' °0<ПШТ'
имеющиеся города пропускаются. При достижении кДш,»1,Д0ВаН"Я- Пр" ЭТ™ ^
сначала. Так, последовательность подстановки городов из рГиГеГвиГ" П*°тС™
234591876.
Поскольку города 4, 6, 5 и 7 не учитывают™ tnu„ ,
ка), получается укороченный ряд 2^39ТПотоТшТпГ^ " С°™ Т™ П0Т°М-
е„ порядка следования этих городов в Р2:' " подставляете, в cl с сохранени-
с1=(239|4657|18).
Аналогично получим второй потомок
с2=(392|1876|45).
Итак, в упорядоченном скрещивании фрагменты пути передаются от одного родителя р 1
потомку cl, при этом порядок посещения городов наследуется и от другого родителя р2
Этот подход основан иа интуитивном предположении о том, что порядок обхода городов
играет важную роль в поиске кратчайшего пути. Поэтому информация о порядке
следования сохраняется для потомков.
Алгоритм упорядоченного скрещивания гарантирует однократное посещение всех
городов. К результату этой операции мутацию следует применять крайне осторожно. Как
указывалось выше, она должна сводиться к перемене мест двух городов в рамках одного
маршрута. Инвертирование (простое изменение порядка посещения городов) в данном
случае неприменимо, поскольку при этом не формируется нового пути. Однако если в
рамках одного маршрута выбрать некий фрагмент и инвертировать его, то это может
дать хороший результат. Например, путь
с1=(239|4657|18)
после инвертирования его средней части примет вид
с1=(239|7564|18).
Можно ввести еще один оператор мутации, который состоит в случайном выборе
города и перемещении его в случайно выбранное положение в рамках маршрута. Такой
оператор мутации можно применять и для фрагмента пути, например, выбрав фрагмент
трех городов и поместив его в новое случайно выбранное положение. В упражнениях к
этой главе приводятся и другие примеры генетических операторов.
П.1.4. Обсуждение генетического алгоритма
Рассмотренные примеры подчеркивают характерные для генегнческш
атгор.ггаовпроблемы представления знании, выбора операторов и определения критерия качества.
Выбранное представление должно поддерживать генетические операторы. Иногда, как в КНФ-задаче,
естественным является битовое представление. В этом случае для получен™ потенциальных
решений можно напрямую использовать такие традиционные генепгческие операторы как
скрещивание и мутацию. В задаче коммивояжера ситуация совсем другая. ^Р»^™^
не подходит битовое представление. Во-вторых, три определении операторо-Ч™™^
скрещивания для каждой, потомка необходимо отслеживать выполнение тр^мых свойств
(присутствие в маршруте всех городов при однократном посещении каждого них).
„.„„.ланий генетических операторов существенная ин,и
"■ "^"с'я с" му поколению. Если эта информация, как в K^>
должна передаваться сладкийу ьтатс выполнения генетических о„, W"№-
смян. со««и.ie« «^ZZscJy^ поколении. В задаче коммиво ^Р»»
"XSпоследовательность городов в маршруте, поэтому потомка^"'
тич„ои являете i поел д Чтобы обсспеч„ть та *> «"
сГГГбхГГсГтвеи-нм оеразом выбрать способ предста^ениП::-
™н™ „"ескис операторы для каждой задач,, в отдельности.
Завершая обсуждение способа представления данных, рассмотрим пр0б
•■естественности" такого представлен,.*. В качестве простого но несколько искусственно,,
примера рассмотрим задачу выделения чисел б, 7, 8 и 9. Естественным представление»,'
с^спечиваюшим сортировку данных, является обычное целочисленное описание, поскольи
среди десяти цифр каждая следующая на 1 больше предыдущей. При переходе к двоичному
описанию эта естественность исчезает. Рассмотрим битовое представление чисел 6, 7, 8 и 9:
01100111 1000 1001.
Заметим, что числа 6 и 7, а также 8 и 9 отличаются друг от друга на один бит. Однако
числа 7 и 8 не имеют между собой ничего общего! Это свойство представлен™ может
вызвать большие проблемы при решении задач, требующих систематизации этих образов. Дм
решения проблемы неоднородного представления используется множество приемов,
получивших общее название кодирования Грея (gray coding). Например, код Грея для первых
шестнадцати двоичных чисел приводится в табл. 11.1. Заметим, что здесь каждое число
отличается от своих соседей ровно на одни бит. Обычно при использовании кодирования
Грея вместо обычного двоичного представления переходы между состояниями при
реализации генетических операторов являются более естественными и гладкими.
Таблица 11.1. Коды Грея для двоичных чисел О, 1, ..., 15
Двоичное число Код Грея
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111 Ю01
■ 1000
Важным
поиска. Они
0000
0001
0011
0010
0110
0111
0101
0100
1100
1101
1111
1110
1010
1011
поиска, они Dear,™'0™" ГеНетиче™ алгоритмов является параллельная пр„Р«<
сколько решений На »„,! Т М°ЩНЫХ Ф°рЫ понска экстремума, поддерживающую н
• ™ рис. 11.2, взятом из работы [Holland 1986J, показано, как мн»»ст
Часть IV. Машинное обучв"1
в0 решений сходится к точкам экстремума в пространстве поиск, н
зонтальная ось представляет возможные точки в ппос ЭТОМ ?тУжс ГОР"-
„оказано качество этих решений. Точки на кривой-э "^ рсшений' а п0 вертикали
ше„„Й-кандидатов, полученные при работе генетическогпТ"" "Т? поп>™щ,и Р*
ния равномерно распределялись в пространстве поиска П^пГ™' Изначаль"° Р"«-
^„„руютеявобластя, соответствующих ^^^Zyl^Z^ZT ^
Качество „
Качество Качество
решения
Пространство поиска Пространство поиска
а. Исходное пространство поиска б. Пространство поиска после п поколений
Рис. 11.2. Генетический алгоритм как параллельный поиск экстремума
При описании генетического алгоритма как алгоритма поиска экстремума неявно
предполагается перемещение по поверхности, определяемой критерием качества. На
этой поверхности существуют свои вершины, низменности, а также локальные
максимумы и минимумы. Нарушение непрерывности этого пространства является следствием
выбора представления и генетических операторов для конкретной задачи. Например,
такое нарушение непрерывности может быть вызвано неправильным кодированием, в том
числе без использован™ кодов Грея. Отметим также, что генетические алгоритмы, в
отличие от последовательных форм поиска экстремума, описанных в разделе 4.1. не сразу
отбрасывают бесперспективные решения. При реализации генетических операторов
даже плохие решения могут оставаться в популяции и вносить свой вклад в формирование
последующих поколений решений.
Еще одним отличием эвристического поиска в пространстве состояний, описанного в
главе 4, от генетических алгоритмов является анализ различия между текущим и
целевым состояниями. Такая информация учитывается в алгоритме А* »аздеГ-2)^!^"
шем оценки "усилий" для перехода из текущего состояния в целевое. Дтя
рабо™диетических алгоритмов такая мера не нуэкна. Просто каждое поколение ™T"™*f Ш^
оценивается с помощью некоторого критерия качества. Не П*^™"^Г,££,
«атизация последующ» состояний, как при поиске a "P^^^^S
формируется поколение решений-кандидатов, каждое из «^""f""™
в получение новых »°^^£^%^^^^
Важным источником эффективности генетичк. ^ ^^„^ состояний, в данном
лизм эволюционных операторов. В отличие от ^^ пошщпальных решений,
случае операции выполняются параллельно д. генетические алгоритмы приводят к
Ограничивая репродуктивные свойства слаоых ре ^ ^^ HanpI1Mep. если строка
исключению не только этого решения, но ^ ^^ не сможет породить
Ю1#0##1 отброшена в процессе Ра6оты^™е COOTeercTBY*T критерию качества,
строки вида 1 0 1 # .Если родительское Р™ потенциальные поточил,.
то в процессе работы алгоритма не будут рассматриваться все
Пильных и эмерджентных принципов 493
Глава 11. Машинное обучение на основе социальных ни»
„„гппитмы все шире применяются для решения п..
Поскольку «"-;«К^л°;Га"ия. в последнее врем, повышаетсГинТГ^
«a4 и «™*™^^. Естественно, возникают следующие вопрос^ * ос-
мыслению их теореш-»'
, Можно ли охарактеризовать типы задач, для которых генетические алгор„ТМь|
ботают наиболее эффективно?
2 Для каких типов задач они работают плохо?
3. Что означает высокая и низкая эффективность генетического алгоритма да реще
иия некоторого типа задач?
4 Существуют ли законы, описывающие поведение генетических алгоритМов
' макроуровне? В частности, можно ли спрогнозировать изменения значений крит"
рия качества для элементов популяции?
5 Существует ли способ описать результаты таких различных генетических о„ерато
' ров, как скрещивание, мутация, инвертирование и т.д.?
6 При каких условиях (для каких задач и генетических операторов) генетические
алгоритмы работают лучше, чем традиционные интеллектуальные методы поиска?
Многие из этих вопросов выходят за рамки тематики данной книги. В работе
[Mitchell. 1996] указано, что в теоретическом осмыслении генетических алгоритмов пока
еше больше открытых вопросов, чем приемлемых ответов. Тем не менее с момента
появления генетических алгоритмов исследователи пытаются понять принципы их работы
[Holland, 1975]. И хотя многие вопросы, как и приведенные выше, относятся к
макроуровню, их анализ начинается с микроуровня битового представления.
В [Holland, 1975] вводится понятие схемы (schema) как общего шаблона и
строительного блока решения. Схема — это шаблон битовых строк, описываемый символами 1, О
и #. Например, схема 10##01 представляет семейство шестибитовых строк,
начинающихся с фрагмента 10 и завершающихся символами 01. Поскольку центральный
фрагмент ## описывает четыре возможные комбинации битов, 00, 01, 10, 11, то вся схема
представляет четыре битовые строки, состоящие из 1 и 0. Традиционно считается, что
каждая схема описывает гиперплоскость [Goldberg, 1989]. В этом примере данная
гиперплоскость пересекает множество всех возможных шестибитовых представлений.
Центральным моментом традиционной теории генетических алгоритмов является
утверждение, что подобные схемы — это строительные блоки семейств решений. Генетические
операторы скрещивания и мутации оперируют такими схемами в процессе поиска
потенциальных решений. Эти операции описываются теоремой о схемах [Holland, 19751,
[Goldberg, 1989]. По Холланду, для повышения производительности в некоторой среде
адаптивная система должна идентифицировать, проверить и реализовать некоторые
структурные свойства, формализуемые с помощью схем.
Анализ схем Холланда предполагает, что алгоритм выбора по критерию качества
ГюТГ ТИСКУ П0ДМН0ЖССТВ » пространстве поиска, наилучшим образом
удовлетворяющих д„ному кр1трию_ СлсдоваТельно эт[( п жества ШШСЬ1Ваются схемам".
ог^ратоГв 'Г4'"1"5 КРИгерШ' КаЧес™ выш<= сРВДнего. При выполнении генетически»
ваютсяТ, СКреш"ВаНИЯ стР°>"ельные блоки с высока „L™^. .ячества
складываются вместе и формируют
что генетические особекн УлУчш«нные" строки. Мутации позволяют гарантирован-
обеспечивают переход к н„ "'будуг У«ряны в процессе поиска, т.е. эти оператор"1
ские алгоритмы можно „Г °бластям поверхности поиска. Таким образом, генети" '
1 "ожно
рассматривать как некое обобщение процесса поиска с сохра*"'
Часть IV. Машинное обучен"
ние„ важных генетических свойств. Холланд изначалькп ,„„
„ритмы иа битовом уровне. Более современные работь" расп^Т"1" генстичсскис №
г0 анализа иа другие схемы представления [Goldber» iqmiT^ риультаты эт0"
тические алгоритмы будут прнменеиы к 6олее сложном пХ-ГяГ" "^ """"
Ц.2. Системы классификации и генетическое
программирование
Первые генетические алгоритмы почти целиком базировались „а низкоусовиевом
представлении, в частности, битовых строках ,о, 1. #,. Помимо того что oZ™
к„ являются естественным представлением для реализации генетических персов.
„„„ обеспечивают для генетических алгоритмов столь же высокую производительность
как и другие иееимвольные подходы, в том числе иейросетевые. Однако существуют
задачи, например, проблема коммивояжера, для которых естественным является
кодирование иа более высоком уровне представления. При глубоком исследовании может
возникнуть вопрос о реализации генетических алгоритмов для таких высокоуровневых
представлений, как правила вывода или фрагменты программного кода. Важным аспектом
этих представлений является возможность комбинирования таких фрагментов
высокоуровневых знаний, как цепочки правил вывода или вызовы функций.
К сожалению, достаточно сложно определить генетические операторы,
поддерживающие синтаксическую и семантическую структуру логических взаимоотношений и в
то же время обеспечивающие эффективное применение скрещивания и мутации.
Одним из возможных путей совмещения преимуществ правил вывода и генетического
обучения является преобразование логических утверждений в битовые строки и
применение для них стандартного оператора скрещивания. Однако получаемые после
скрещивания и мутации битовые строки зачастую не обладают свойствами логических
выражений. В качестве альтернативы этому представлению можно определить новые
варианты скрещивания, применимые напрямую к высокоуровневым представлениям,
таким как правила вывода или фрагменты кода на высокоуровневом языке
программирования. В этом разделе описываются примеры каждого из подходов, расширяющие
возможности генетических алгоритмов.
11.2.1. Системы классификации
В [Holland 19S6] разработаны проблемно-ориентированные архитектуры,
получившие название'систел, классификации (classifier system), в которых генетическое
обучение применяется к правилам логического вывода. Система классификации включает
стандартные элементы системы вывода (рис. 11.3): правила вывода (называемые здесь
классификаторами), рабочую память, входные датчики (или декодеры) и вылодные эле-
менты (эффекторы) Отличительной особенностью системы "f^TL£££
конкурентный подход к ^^Г^^^^^^
лля обучения и алгоритма "пожарно ц "»"- ^ С ^м cJ3b с0 внешнеГ, сред0„
ления поощрений и наказании в «Р0^""6^™ Ранд11дагов, что необходимо для
Дает возможность оценить качество « сиф '*™Р ,кетная „2 р11С. ,,.з,
реализации генетического обучения. Система кллч.ф
включает следующие основные компоненты.
'ZZI^^^P^»wtM принципов
Глава 11. Машинное обучение на основе соци*
495
Правила классификации
продукционной памяти
Распределение кредитов по
принципу "пожарной цепочки"
Рис. 11.3. Взаимодействие системы классификации с внешней средой
1. Детекторы входяших сообщений от внешней среды.
2. Детекторы обратных связей со внешней средой.
3. Эффекторы, передающие результаты применения правил во внешнюю среду.
4. Набор правил вывода, представляющий собой популяцию классификаторов.
Каждому классификатору соответствует свое значение критерия качества.
5. Рабочая память для правил классификации, в которой результаты правил выбора
интегрированы с входной информацией.
6. Набор генетических операторов для модификации правил вывода.
7. Система для предоставления кредита правилам, участвующим в выполнении
успешных действий.
При решении задачи классификатор работает как традиционная система
логического вывода. На детекторы системы классификации нз внешней среды поступает
сообщение, например, информация о сделанном игроком ходе. Это событие
кодируется и помещается в качестве образа во внутренний список сообщений — рабочую
память системы вывода. Эти сообщения при обычной работе системы вывода на
основе данных соответствуют условиям правил классификации. Выбор "наиболее
активного классификатора" осуществляется по схеме аукциона, в которой
предлагаемая цена - это функция аккумулированного значения критерия качества для такого
классификатора и уровня соответствия между входным стимулом и его условием,
ким ZZm' до6авляютс» ■ Росную память классификаторов с наиболее высо-
чёпез зфГ1С„00ТВеТСТВИЯ' Из °бн°^„„ого списка сообщения могут передаваться
-S^ST ак™ровать -™правнла кл8ССИф'"
(разСд'елТ9^ 7*71™"™ Р™ЮуЮТ °ДН^ из Ф°Р" Лучения с подкреплением
значсиим Кр"тер„я Г НИф0р-",и»- "окупающей от учителя или определяемо"
чествадл" о" ляиии п '' °буЧаеМая С1,стема вычис^кгг значение кр««Р»я
него из вариаито гсНеГВИЛ"КаНДИДаТ°В " ""°»т "°»У» популяцию с помощь»
готического обучения. Системы классификации обучаются д»>
Часть IV. Машинное обучен
мя способами. Первый способ состоит в испо
стра„вающей меру качества правил классификациТ"31""1 СИ"ты поощрений,
навил и ослабления действия ошибочных Алгооит '" "" ус"ле,шя полезных пра-
часть вознаграждения или штрафа каждому поави РаСПредслсния kP«"tob передаст
участие в формировании окончательного прави ,"У классиФикаин'1. принимавшему
вознаграждений между взаимодействующими киссиШраспределеинс Риличных
стся с помощью алгоритма "пожарной цепочки" 41 РаМ" 3аЧаСТуЮ рСШ""у-
распределения кредитов и штрафов для систем вы*„ аЛГ°Р"™ РСШа" пРо6лсму
ТР0И последовательного применения наборТп^ГкТоаГ" "яюа ^""^
ду правилами зтой цепочки в случае ошибки „я f^P^""™ штрафы
межуется источником ошибки: SX" ^^Г " "ТГ™
1. м "J1" одно из предыдущих9 Апгопитм
..„„жарнои цепочки позволяет распределить кредиты и штрафы Гжду пр" ил Ги
этои последовательности в зависимости от вклада каждого правила в окончательное
решение. Аналогичное распределение поощрений и штрафов на основе ошибки на
выходе обеспечивает алгоритм обратного распространения, описанный в
разделе 10.3. Более подробная информация об этом содержится в [Holland. 1986]
Вторая форма обучения связана с модификацией самих правил на основе
генетических операторов типа мутации и скрещивания. При таком подходе выживают лучшие
правила, а в результате их комбинации формируются новые классификаторы.
Каждое правило классификации состоит из трех компонентов и работает, как
обычная система вывода: на основе некоторого условия проверяется соответствие
данных содержимому рабочей памяти. В процессе обучения генетические операторы
могут модифицировать как условия, так и действия правнла вывода. Второй
компонент правила — действие — может изменять внутренний список сообщений
(продукционную память). И, наконец, каждому правилу соответствует мера качества.
Как уже отмечалось, этот параметр изменяется как при успешном, так и при
неуспешном применении правила. Эта мера изначально присваивается каждому правилу при
его создании генетическим оператором. Например, мерой качества может служить
среднее значение качества двух родителей,
Взаимодействие этих компонентов системы классификации можно
продемонстрировать на простом примере. Предположим, набор подлежащих классификации
объектов определяется шестью атрибутами (условиями с1, с2 сб). Допустим также, что
каждый нз этих атрибутов может принимать 5 различных значений. И хотя каждый
атрибут имеет свой физический смысл (например, параметр сЗ описывает цвет, а с5 —
погоду), без потери общности допустимые значения всех атрибутов можно ошгсать целыми
числами |1,2, ..., 5). Предположим, согласно правилам вывода объекты разбиваются на
4 класса: А1,А2,АЗ,А4.
Таким образом, каждый классификатор можно описать в виде соотношения
(с1,с2,сЗ,с4, с5, сб) ->/W, где/=1,2, 3,4,
где каждое из условий с/ принимает значение из диапазона (1, 2 5' »0™""^°#
«его атрибута Обычно условию может соответствовать и про,'"^~J
мание на то, что несколько различных условных шаол - СООтветство-
иому классу, как в правилах 1 и 2, либо два одинаковых шаблона могут
вать различным классам.
Глава 11. Машинное обучение на основе социальных и эмерджентных
497
„t снстема классификации - это еще одна форма вездесущих систем,
КаКП°Ка3Г—» логического вывода. Единственным отличительным свойством
„снованных на прав псподьзованных в приведснном примере, является применение
правил ™СС"Ф' Г"в'#дм представления шаблонов условий. Такое представление ус„0.
TZечГГ Гим-иеГиетических ^ритмов в правилах логического вывода.
Zee будет исследован вопрос генетического обучения в системах классификации.
Чтобы шросгить изложение, будем рассматривать обучение системы только для класса
/U Не принимая во внимание другие классы, присвоим шаблонам условий значение 1 или 0 в
зависимости от соответствия классу /II. Заметим, что это упрощение не ограничивает
общности рассуждения, поскольку эти выкладки можно распространить на случаи обучения для
нескольких классов. Для этого достаточно ввести вектор, соответствующий конкретному
условному шаблону. Например, классификатор из табл. 11.2 можно описать в виде
(1###1#)-»(1000),
(2##3##)-»(1000),
(1#####Н(0100),
(##43##Н(0110).
Последняя строка в этом примере соответствует правилам классификации для классов
Д2 и ЛЗ, но не ,41 или М. Заменяя 0 или I подобными векторными представлениями
классов, можно оценить эффективность правила для классификации на несколько классов.
Для определения корректности классификации будем использовать правила из
табл. 11.2. А именно, будем рассматривать их в качестве учителя для оценки качества
правил в системе классификации. Как в большинстве генетических систем обучения,
выберем случайным образом исходную популяцию правил. Каждому шаблону условий
сопоставим параметр качества (fitness) или силы (strength) (вещественное число из
диапазона от 0,0 до 1,0). Этот параметр силы s будем вычислять на основе качества каждого
родительского правила с учетом предыстории.
В каждом цикле обучения с помощью правил будем пытаться классифицировать
входы и проверять качество классификации с помощью учителя ими меры качества. Напри-
„я ПОТ""0™™"' ™ "а некот°Р°» шаге получена следующая популяция кандидатов
Р зуГтатТлГ ™ССИФикац^ <™ каждого элемента которой 1 означает корректный
результат классификации, а 0 — неверный:
(###21#H1 s=06
<##3##5)-»0 s=o'5'
(#4###2)->о
5=0,4,
s=0,23.
осн*^~п„СРвГаПОСТ^"ЛО "ОВОе входное ™°Ъщыт (1 4 3 2 1 5), и учти» <»
Р правила из табл. 11.2) классифицировал этот вектор как положительны»
498
Часть IV. Машинное обучен
пример для класса А1. Посмотрим, что происходит пп„ „,„,.
память при попытке его классификации с помощьюТ рсдачс этого оСРвзп в рабочую
ответствует правилам 1 и 2. Разрешение конфликта Правш1'канд1™тов. Этот образ со-
полнястся иа основе конкуренции. В нашем приме МСЖДУ подходящ,,м" правилами
вывила вычисляется как сумма произведений степеней CTe"e"b соотвстствия каждого про-
меры качества данного правила. Неопределеинокге а^г™".™"" каждого из атрибутов и
при точном соответствии атрибута ему приеваиваетГ™!™,^™^ ЗНаЧСШС °'5, "
ценное значение делится на длину входного вектопа п J ДЛЯ "°РМ"Р0ВКИ
полуданного входного вектора дает два точных соответс™,.?** "^^ классификатор для
шая степень его соответствия входному вектору^™ ^"«7о~"о XoTit
второго классификатора тоже имеется 2 точных соотй^^», "ч "•3+i " U.W6-0.4. Для
та, поэтому его степень соответствия составляет «ТВ "Гем" „ Не°ПрСдеЛеННЫХ *^
„уреиции побежлает классификатор с максиме стГнГ оЗ^^ТГбо^ее
сложных задачах желательно учитывать некоторый порог
Таким образом, победило первое правило, в соответствии с которым предъявленный
образ относится к классу М. Поскольку это действие корректно, мера качества первого
правила увеличивается и принимает новое значение, приближенное к 1. Если бы
результат выполнения этого правила оказался некорректным, его мера качества была бы
уменьшена. Если для получения результата в системе многократно выполняется
некоторый набор правил, то определенную долю подкрепления должны получить все правила,
участвующие в получении результата. Точная процедура пересчета меры качества
определяется в зависимости от системы и может оказаться очень сложной. Она может
строиться иа основе алгоритма "пожарной цепочки" или другого метода распределения
кредитов. Более подробная информация по этому вопросу содержится в [Holland, 1986].
После вычисления меры качества правил-кандидатов в алгоритме обучения
применяются генетические операторы для создания следующего поколения правил. Сначала на
основе принципа отбора выбирается множество правил с наиболее высоким значением
критерия качества. Этот выбор базируется на значении меры качества, но может учитывать
и дополнительные случайные величины. Элемент случайности обеспечивает возможность
отбора правил с плохими показателями качества, которые, невзирая на общее
несоответствие, могут привнести полезные элементы в решение задачи. Допустим, в рассмотренном
примере для дальнейшей работы выбраны первые два правила классификации. После
случайного выбора точки скрещивания между четвертым и пятым элементами
(###2|1#)-»1 s=0,6,
(##3#|#5)->0 s=0,5,
получим потомки
(##3#|1#)->0 s=0,53,
(###2|#5)->1 s=0,57.
Мера качества каждого потомка- это взвешенная фуиющя показателей качества их
родителей. Весовые коэффициенты определяются местоположением точки скрещивания.
Первый потомок получил 1/3 информации от классификатора с мерой качества 0,6 и
М - от классификатора с мерой качества 0,5. Поэтому его мера качества составляет
(1/3*0,6)+(2/3*0 5)=0 51 С помощью аналогичных рассуждении выясним, что мера
качества второго потомка'равна 0,57. Результат выполнения правила (значение 0 или 1)
определяется соответствием большинства атрибутов. В типичных системах классификации
эти два новых правила, наряду с их родителям!
торыми работает система на следующем этапе.
«и два новых правила, наряду с их родителями, входят в набор классификаторов, с ко-
г"ава п. машинное обучение на основе социальных и эмерджентных принципов
499
, мугаЦии. Простая мутация заключается в случайной
Можно определить и °"ера™Р ^.„вольным значением из допустимого диапазона
замене любого значения атрибута у ^ ^ ^ # Как указь1валось при описании »»■
Например. 5 можно «""'^ ''„„„ призваны внести элемент случайности в 110llc"K
ческих алгоритмов. °леРа™р" J „„ванне позволяет сохранить удачные фрагменты
классификатора, в то вре я ^ ^ потомках.
данных изР°дятеМ"'",е„ достаточно прост и призван лишь проиллюстр„ровать ра6
Рассмотренный пример д ^^ф,,,.^,,,, в реальных системах может сгибать,-
основных компонен™ се они „от передавать свои результаты в рабочую память
вать несколько пРаши1' доминирования одного нз классификаторов в про
3аЧа^ГюТрГ— «е "а "алотообложен™. при которой ето мера качеств^
цессе решения применяете снижается. Здесь также не описан алгор,,™
■ZZJZZ^^Z, . P-ичной с»™», "поощрять" правила, у^
вуюшТв успешном решении задачи и передаче сообщения во внешнюю среду. Кроме
тГо как правило, генетические операторы применяются для трансформации
классификаторов не на каждом шаге работы алгоритма. Обычно существует некий общий
параметр определяемый с учетом специфики каждого приложения, в частности, иа основе
анализа обратной связи со внешней средой, иа основе которого принимается решение о
необходимости применения генетических операторов.
Описанный пример взят из работы (Holland, 1986], выполненной в университете
штага Мичиган. Такой подход можно рассматривать как численную модель позиания, в
которой знания (классификаторы) обучаемой сущности формируются в процессе
взаимодействия с внешней средой и модифицируются со временем. При этом оценивается
общая работа всей системы, а не качество отдельного классификатора. В работе [Michalski
и др., 1983], выполненной в университете Питтсбурга (Pittsburg), предложен
альтернативный подход к построению систем классификации, в котором при создании нового
поколения классификаторов основное внимание уделяется отдельным правилам. Такой
подход реализует предложенную Михальски (Michalski) модель индуктивного обучения.
В следующем разделе рассматривается еще одно интересное приложение
генетических алгоритмов, обеспечивающее эволюцию компьютерных программ.
11.2.2 Программирование с использованием генетических операторов
В нескольких предыдущих разделах рассматривалось применение генетических
алгоритмов для все более сложных структур данных. А что произойдет, если применить
генетические преобразования битовых строк к правилам "если..., то..."? Возникает
естественный вопрос, можно ли применять генетические и эволюционные операторы для
создания более крупномасштабных вычислительных средств. Известны два основных
ей сиГкГ ЭТ°И "' саязанные <= генерацией компьютерных программ и
эволюцией cb""™, реализующих конечные автоматы.
жетэволСю!т™!^п!ЫСКа3аНО пРедпол°*енне, что удачная компьютерная программа
морам»к: kToZ п И "" ПРИме»е™ генетических операторов При этом структу-
"ерархнчеГи „" Г™™ ПРИНШШЫ ™">™ского программирования, являются
п^ержГвает п™~Г ФРаГМеН™ ™П^™* "Р°£«"- ^ГОР"™ <**"*"<
способностью решать нГ ПрогРамм-каиДНдатов. Качество программы определяется ее
«ет применен™ скрещивГГ" ""^ 3аДаЧ' " м°™Ф'"«>ция программы выполняется з»
крещивання и мутации к поддеревьям программы. При генетическом
500
Часть IV. Машинное обучение
программировании поиск выполняется в пространстве ™
„ото размера и сложности. Фактически пространство „""°ТерНЬ"с '№""" разиич-
ножных компьютерных программ, составленных поиска-это множество всех воз-
„остей символов, соответствующих предметной областТ"0" функц"Г' и поелсдователь-
чение, такой поиск содержит элемент случайности г!щпп- Ка" " гснэтичсское обу-
„о, иа удивление, оказывается достаточно эффективным""
■ во многом выполняется •'вслепую",
При генетическом программировании сначалаИи'ииияпи,.. ,„
.генерированных программ, составленных из еоот^Г^™4^ Г"*"
тов. Эти фрагменты в зависимости от предметной 1"™ZZ^~^*2
дартные арифметические операции, математические и логические фуГцни ^ 2".
цифические функции для данной предметной области. В число проемных Зпо -
тов включаются данные стандартных типов: логические, целочисленные, с плавающей
точкой, векторные символьные или многозначные.
После инициализации генерируется популяция из тысяч компьютерных программ
Каждая новая программа создается с применением генетических операторов.
Скрещивание, мутация н другие обеспечивающие воспроизводство операторы необходимо
адаптировать для создания компьютерных программ. (Ниже мы кратко остановимся на
нескольких примерах.) Качество каждой новой программы определяется ее способностью
решать задачи из конкретной предметной области. Сам критерии качества тоже
формируется с учетом предметной области. Программы с высоким значением критерия
качества выживают и участвуют в формировании следующего поколения программ.
Итак, генетическое программирование включает следующие шесть компонентов,
многие из которых напоминают составные части генетических алгоритмов.
1. Набор структур, подвергающихся трансформации с помощью генетических
операторов.
2. Набор исходных структур, соответствующих предметной области.
3. Мера качества для оценки этих структур, выбираемая с учетом предметной области.
4. Набор генетических операторов для трансформации структур.
5. Описания параметров и состояний элементов каждого поколения.
6. Набор условий останова.
В следующих разделах эти компоненты будут рассмотрены более подробно.
В генетическом программировании операции выполняются над иерархически
организованными программными модулями. Основным средством представления компонентов
программных языков был и остается язык LISP. В [Koza. 1992] программные фрагменты
представлены в виде символьных выражений на языке LISP, или выражении. Описание
s-выражений, их естественное представление в виде структур деревьев, а также
эффективность такого представления более подробно рассматриваются в разделе 15.1
Генетические операторы оперируют s-выражениями. В частности они отображают
Древовидные структуры s-выраженнй (фрагменты программ на языке LISP) в но^ые
деревья (другие программы „a LISP). Хотя эти s-выражения появились еще ,.prior,[koz.
1992], другие исследователи применяли этот подход к различным парадигмам програм
мнрования и в более позднее время. ,~,„„„ н1 основе
Генетическое программирование позволяет строить полезны ршраммы а^нос
««одных данных и предикатов, описывающих предмете» оо^™ задачу Р»™* »
власти определения для поколения программ, предназначенных д.„ Р^ния н^оторо
Золимо сначала проанализировать возможные конечные з„ачс
го множества задач, неободамо ^ „ также функции, необходимые для „ "
н„я составных элементов^ам Р ^ ^,„„0, чт0 ...Пр„ использовании генеТ1,
„™ этих конечных значении^ ^^ до ^ некоторая композиция фунПшй
чеокого программирование^н „ро6ле„ы".
конечных значении привод'>" ^ ь, модифицируемые с помощью генетических one
Чтобы инициализировать и, тт1.кт. МНОжество функций F и множество конеч
раторов, необходимо сома . предмс1Н0Й области. Множество F может сост0.
ных значений Т, треоуемь. д ^ ^ ^ включать более сложные функции, такие как
ять из простых операции ' • ^ МножеСтво Г может содержать целые или вещест
sinM, cos(x) и «"P1™" J „ожные выражения. Множество символов Т должно
венные числа, матрицы или и ^
«"«^"^""^^„Г^оя.шх "программ" путем случайного выбора эле-
Затем генерируется попу^ ^ ^^ ^^ ш множества т_ мы ^^
ментов из "™"с с0С10ящее из одного корневого элемента. Более интересной явяя-
Г— Гдаснач11б„раетс, элемент нз F. скажем, н-^В этом случае
„случаев корнеГй узел дерева с двумя потенциальными потомками. Допустим, после этого в
кГчесГе первого потомка инициализатор выбирает из F операцию (с двумя
потенциальными потомками), а в качестве второго - конечное значение 6 из множества Т.
Следующими случайно выбранными элементами могут стать конечное значение 8 и функция
+ из F Допустим, процедура завершается выбором значении 5 и 7 нз множества Т.
Случайно сгенерированная таким образом программа представлена на рис. 11.4. На
рис 114о показано дерево после первого выбора операции +, на рнс. 11.4, б — после
выбора конечного значения 6, а на рис. 11.4. в — окончательная программа. Для
инициализации процесса генетического программирования формируется целое поколение
подобных программ. Для контроля размерности этой популяции можно применять ограничения,
например, на максимальную глубину программ. Описание подобных ограничений, а также
различных методов генерирования исходных популяций содержится в [Koza, 1992].
Рис. 11.4. Случайная генерация исходной
программы. Узлы, обозначенные ашволом
окружности, соответствуют функциям
До сих пор рассматривались вопросы представления (s-выражения) и древов.шные
структуры, необходимые для инициализации процесса эволюции программ. Для управления попу-
ГисиТо? Г*1*"" то6ходим° определить критерий качества. Выбор критерия качества »-
rZL эГ"1*™5" адаЧ" " °6ычно свдится « определению набора задач, которые дол**
«6еГ.иИ™ИРУ'0ЩШ Пр0ГраМма' °« Ч>™Р"И качества- это функция,
вычисляющая эффективна решен™ ^ч данной „^ Гмой. Линейный критерий качества (я»
fitne») учитывает различие между результатом выполнения ™„
ем реальной задачи. Следовательно, линейный гоитепий ЧЮГраммы и требуемым решет,-
сумму ошибок при наборе задач. Возможны также лпЧ™ еСгаа можно Рассматривать как
критерий качества подразумевает деление общего коитеп *"^Ы качества. Нормализованный
„ожных ошибок. Следовательно, нормализованный шт^*™* "* кмичгаж> всга »оз-
^апаэоне от 0 до 1. Преимущество нормализация!^™ Г"Г'°Т "ЗМе,МТЬ<:Я '
^ями программ. Мера качества учитывает размер^™^™ с tabmm" »^
„здание компактных программ небольшого размера например, можно поощрять
Генетические операторы в пространстве прогпамм го-,.™
дерева, т*к и обмен фрагментами между разл^н™^. В^кГ^ТГсГ Г
„овные преобразования, получившие название воспроизводства (reprcd^on, и ~1^»
(crossover). Воспроизводство- это выбор программ текутцего „околен™ и ££ZZZ
(to изменении) в популяцию следующего „околен™. Скрещивание полраз^еГГобм»
поддеревьев двух существующих программ. Допустим, существуют две родительские
программы, представленные на рис. 11.5, в которых символом | показаны точки скрещивай™
Дочерние деревья, полученные в результате скрещивания, изображены на рис 11 б
Скрещивание также можно использовать для преобразован™ одного родительского дерева путем
перемены мест в двух его поддеревьях. При случайном выборе точки скрещивания два
идентичных родительских дерева могут дать различное потомство. Точкой скрещиванш также
может служить корневой узел программы.
Рис. 11.5. Две программы, подлежащие скрещи- Рис. 11.6. Дочерте программы, поденные в
ванию в случайно выбранной точке \
результате скрещивания
Известно множество менее распространенных и менее полезных генетических
преобразований деревьев программ. К ним относятся мутация (mutation), при которой в
структуру программы просто вносятся случайные изменен™ (например, замена
конечного значения другим значением или поддеревом). Перестановка (permuuHton) аналогична
оператору инвертирования строк. Она тоже выполняется для отдельных программ и
состоит в перемене мест конечных символов или поддеревьев. .„„„,.„ спеш,-
т ™-и.-<,,.т состояние решения. Не существует спецн
Текущее пополнение программ ^^^™"J1PH0CT,, определяемой критерием
альных методов, позволяющих учитывать релыф "0MPVBtt напотпшаст алгоритм no-
качества. С этой точки зрения ^"^^^ZZZ^Z^ cxoL с ес-
"ска экстремума, описанный в разделе 4.1. reH™^*J^J orpaMM можно
выполненным процессом эволюции, поскольку трансформац« JJ^^ ^-ов
«ять непрерывно. Тем не менее ограниченность. вре^ от ^^ ^^
требуют задания условий останова. Такие условия ооы
качества и потребляемых вычислительных ресурсов.
Глава 11. Машинное обучение на основе социальных
и эмерджентных принципов
,„„с программирование- это метод генерирования ко„„Ь10
Поскольку генетическое^прогр ^ ^^ ^„„„„«.„„г,, программ„рования «Р-
„их программ, то его можно отн компьютервых программ на ос„овс фраг„ен2>
проблемой автоматического^с « ^ с сшого начала развития искусственного™?"
„„й информации ^"Генетическое программирование можно рассматривать как „"'
теллекта [Shap.ro, 199-J-1« „сследованиП. В конце этого раздела будет *
Эволкши» программы, моделируй,-, третий закон Кеплера о движении „ланет
иГкои 1992] описано много приложений метода генетического программирован,,»,
[^иИх решать интересные задачи. Однако большинство этих примеров слишком
„озволяюш х реш .« Р ^ „_ 1996] приводится простой „
™Г1" "н гие важные понятия генетического программирования. Третий закон
S™ о движении планет описывает функциональные зависимости между периодом
оГгы Р и средним расстоянием от этой планеты до Солнца Л.
Формула третьего закона Кеплера имеет вид
Р=сА',
где с — константа. Если считать, что единицей измерения величины Р является земной
год, а величина А — это количество средних расстояний от Земли до Солица, то с= 1. Дм
этого отношения s-выражение имеет вид
P=(sqrt(M(/M))).
Целевая программа, реализующая это соотношение, представлена в виде древовидной
структуры на рис. 11.7.
В этом примере множество конечных символов выбирается очень просто: оно
включает только одно значение А. Набор функций тоже задастся несложно, в частности {+, -,
*, /, sq, sqrt|. Создадим случайным образом популяцию программ. Исходная популяция
может иметь вид
(*Л(-(*Д d)(sqrtA))) мера качества: 1
UAUUA А)[/А А))) мера качества: 3
(+А(*( sqrtAM)) мера качества: О
Значения меры качества будут обоснованы ниже. Как указывалось выше в этом
разделе, на исходную популяцию могут накладываться ограничения по размеру и глубине
программ, определяемые знаниями о предметной области. Этн три примера
описываются деревьями программ, показанными на рис. 11.8.
Определим набор тестов для программ этой популяции. Допустим, нам известна
некоторая информация о планетах, которая должна найти свое подтверждение при работе
ZZ7„Z Пр,еДПОЯОЖИМ' и3"""" данные, приведенные в табл. 11.3. Этн сведения
получены из работы [Urey, 1952].
граммьГэта^ "^ КаЧеС™ ДШ1жна определять степень соответствия результатов про
граммы, отличающих"'» от Т"° °ПреДеЛИТЬ как количество результатов работы про
пользовано для по™, аЛ°ННЫХ даннь1х "е более '«" «а 20%. Это определение ис
Читателю предлагаете™, „ТРЫ КаЧеСТВа ТрСХ пР01Тамм, представленных на рис П.8
руировать оператор/ °Ще нескольк° элементов исходной популяции, сконст-
лен,И „рограм„, иР0прZmT""* " "^^ пюв°ля«™ие формировать новые поко-
пределить условия останова
504
Часть IV. Машинное обучение
Мера качества = 1
Рис. 11-7- Цсл^ая
программ, моделирующая
третий
шй закон Кеплера
А А д
Рис II Я И Л ^Ра «чести = з Мера качества = О
Таблиц* 11-3. Набор данных о дарении планет т работы [Urev
относительный размер главной полуоси орбиты а Р „J™ '' А~этс
Приведенный к данным дли Земли У °P6"™' " Р ~ относительный период,
Планета
А (вход)
Венера
Земля
Марс
Юпитер
Сатурн
Уран
0,72
1,0
1,52
5,2
9,53
19,1
Р (выход)
0,61
1,0
1,87
11,9
29,4
83.5
11.3. Искусственная жизнь и эмерджентное обучение
Ранее в этой главе была описана упрошенная версия игры "Жизнь". Эта игра,
которую можно эффективно визуализировать на компьютере, имеет очень простое описание.
Впервые она была предложена математиком Джоном Хортоном Конвеем (John Horton
Conway) и получила широкую популярность благодаря ее описанию в журнале Scientific
American в 1970-1971 годах. Игра "Жизнь" — это простой пример модели вычислений,
получившей название клеточных автоматов (cellular automata). Клеточный автомат —
это семейство простых конечных автоматов, демонстрирующее интересное
эмерджентное поведение при взаимодействии элементов популяции.
ОПРЕДЕЛЕНИЕ
МАШИНА С КОНЕЧНЫМ ЧИСЛОМ СОСТОЯНИЙ, или КОНЕЧНЫЙ АВТОМАТ
Понятие конечного автомата включает следующие элементы.
1 • Множество /, называемое модный алфавитом.
2 Множество S возможных состояний автомата,
3, Известное начальное состояние So-
4. Фушиш, N: Sxi^S. определяющая следующее состояние для каждой ушрядо-
ченной пары состояиис-вход.
Гя- 11. Машинное обучение „а основ, социальных и эмеоджентных принципов
505
™„M состояний— это функция текущего состояния „
Выход машины с конечны» число ^ сояояннем конечного автомата в „0MeH"t
состоянии ближайших "онеч"ь?Г™ного состояния и состояния его соседей в момент „ *
(+1 является функция от ™°°™2w™ элемента клеточного автомата со свои™, соседа.
„ени ,. Благодаря ^Mfе"^оо6разное поведение, чем поведение отдельного элемент
„,, достигается гораздо более paw и ^ ^g^ привлекательных свойств клеточных
Такая взаимозависимость являете ^ ^^ от состояиия его соседей| ЭВ0ЛЮцию
автоматов. Поскольку выход кажа ^ ^ проакс социальной адаптации,
состояний набора элементов можн ^ ^^ не вычисляется значение критерия качест
В примерах, описанных.вэ р^ Определяется как результат взаимодействия эле-
ва для каждого элемента, к р естц к "отм„ранию" отдельных автоматов. Неявно
ментов популяции, котороотдельных особей из поколения в поколение. Для кле-
качество выражается в обучение без учителя. Как и при естественной эво-
точных автоматов обычно "P™™""^, дУействш1 другихособей этой популяции.
люц„и,адапт,ш^™л™™» ^ ^^ с гло6альной, социально ориентир».
Важную роль ™кого ^ аняет необходимость концентрировать внимание
ванной точкт, зрения^ Такой подхдуеф атижтн „ ре17лярнь1е зависимости в
ГоТе"^^^^^^
И наконец, в отличие от обучения с учителем, эволюция ие должна быть направленной".
Нельзя считать что общество движется к некоторой заранее заданной точке "омега". При
явном использовании меры качества в предыдущих разделах этой главы на самом деле
ставилась задача сходимости процесса обучения. Однако, как отмечено в работах [Gould,
1977] [Gould, 1996], эволюцию нельзя рассматривать с точки зрения улучшения мнра, а
лишь с точки зрения его выживания. Единственной мерой прогресса является
продолжение существования.
11.3.1. Игра "Жизнь"
Рассмотрим простую двухмерную решетку или игровую доску, показанную на рис. 11.9.
На этом рисунке одна из клеток закрашена черным (занята), а восемь соседних —
заштрихованы. Со временем внешний вид доски изменяется, при
этом состояние каждой клетки в момент времени f+1 — это
функция ее состояния и состояний ее ближайших соседей в
момент времени t. Игра подчиняется трем простым
правилам. Во-первых, если для некоторой клетки (занятой или
свободной) ровно три ближайшие соседние клетки заняты, то
она будет занята в следующий момент времени. Во-вторых,
если для некоторой занятой клетки заняты также ровно две
соседние клетки, то она тоже будет занята в следующий
момент времени. И, наконец, во всех остальных ситуациях в
Рис. 11.9. Заштрихованная слеДУютий момент времени клетка остается свободной.
область определяет группу Одна из интерпретаций этнх правил сводится к следую'
соседей в игре "Жизнь" тему. Для каждого поколения или момента времени жизнь
u„, n „„„ „ каждой популяции (черный цвет клетки или состояние, рэв-
щем ,„ХТ ТУЛЬТаТ°М еС соб™<™™ жизни, а также жизни ее соседей в предыДУ'
Гто ) „лТпаз' "МеНН0' СЛ"ШК0М ПЛ0™ая "елейность (более трех занятых соседи"
клеток) „„„ Разреженность сосадшх ^^ ^ J* ^ ^^ времени
невозможности жизни в следующем поколении
I
ш
У/Л
ш
т.
ч
й
приводят
506
Часть IV. Машинное обуче"и
Например, рассмотрим состояние, показанное на „„„ ,, ,
(обозначенные символом X) имеют ровно по три заняты,' "' 3деСЬ ропно <»« ™<™<
„0коление показано на рис. 11.Ш, 6. Здесь также ^^"тт K"e™' С««У»««
символом Y). у которых есть три занятых соседа Н,™ КЛ™" <°6°™ачсш,ыс
.. л„„<~г циклически nw»n . " "СЛОЖНО Убепи-п.,,,, ..-
давни будет циклически переходить между рис •', 10 ™ ^ития, что состояние
ется определить следующее состояние для рис 11 п ' " ,, ,, 6' Ч"тателю предлага-
другие возможные конфигурации "мира". В работе [Pound*™!. ГоД,™ исслсд°веть
Р^нообразне и богатство структур, по'лучаем'ьгГв Ре'зТлГтатЛ™ '"S °"ИСаН° 6ольшое
фанеры (glider) - шаблоны ячеек, которые перемещайся Г!*-"''' ' ™" ""^
ряюшихся циклах изменения формы. "шипя по игровой доске в повто-
Благодаря своей способности обеспечивать разнообразное коп™,
„роцессе взаимодейств™ простых клеток клеточные авГма™™^8"" П™№ '
изучения математических принципов эмерджен™оети^ГГГ '" СреДСТВ°М
Пленных компонентов. По ™Р«»^^~^^^
идя ценой устий человека, а не природы. Как видно из
предыдущего примера,
искусственная жизнь имеет ярко_ выраженную тенденцию к развитию, т.е. система жизни с™
„тся иа основе взаимодействия ее атомов. Регулярности этой формы жизни объясняются
правилами раооты конечных автоматов.
Но как в данном случае можно воздействовать иа процесс развитая жизни''
Например, в биологии множество созданных природой живых сущностей во всей своей
сложности и многообразии подчиняется воле случая и исторической неопределенности. Мы
верим в существование логических закономерностей в работе над созданием этого
множества, однако их может и не быть. Вряд ли мы сможем исследовать общие
закономерности, ограничившись рассмотрением лишь созданных природой биологических
сущностей. Важно изучить полный набор возможных биологических закономерностей, часть из
которых может нарушаться вмешательством случая. Остается только гадать, как бы
выглядел современный мир, если бы по воле случая ие вымерли динозавры. Чтобы
построить теорию существования, необходимо понять границы возможного.
X
I
х
ЕЭЁЕЕ
Рис. 11.10. Множество соседей, создающих эффект
переключения света
Помимо известных попыток специалистов по антропологии и ^'^"^м
нить бреши в „зрении реальной эволюции, не прекращаются ди кусспн«»-™
характере самой эволюции. Что бы произошло, если оы ™™™™Ь'Ц^
начальных условий? Что бы изменилось при включении «™". ^ ^Госта-
"ашей физической и биологической среде? Как пошел б« "Р«*££»™«ле, - это
л»сь бы нетронутым? Путь развития, который реально оыл пройден
^ГмашинноеосучениенТ^ог^^^
•кторий Ответы на некоторые из этих во
лишь одна из ««""'^^Гх'оХнекоторь.е из множества возможных cht^0"
можно получить, сгенериро
■
Рис. 11.11. Что произойдет с этими образами в
следующем жизненна» цикле?
Технологи искусственной жизни- это не просто артефакт из предметной области
биологии 'или компьютерных наук. Исследователи из других областей, в том числе
специалисты по химии и фармакологии, построили синтетические артефакты, тесно
связанные со знанием реальных форм жизни в нашем мире. Например, в области химии
изучение строения вещества и многих созданных природой компонентов привело к
необходимости анализа этих компонентов, их составных частей и границ. Этот анализ и попытки
рекомбинации позволили создать многочисленные соединения, ие существующие в
природе. Знание о строительных блоках природных соединений привело к разработке их
синтетических аналогов и созданию новых, не известных ранее веществ. Благодаря
внимательному изучению естественных химических соединений люди пришли к некоторому
пониманию множества возможных соединений вообще.
Одним из средств понимания мира является моделирование и анализ общества на
основе взаимодействия и движения. Примером такой модели является игра "Жизнь".
Последовательность жизненных циклов, показанная на рнс. 11.12, иллюстрирует
упомянутую ранее структуру "планер". Планер перемещается по жизненному пространству,
циклически изменяя свою форму. За четыре такта он перемещается в новое положение со
сдвигом на одну клетку вправо и вниз
■ ■■■■
Рис. 11.12. Перемещение
Шаг!
'планера' по экрану
Шаг 4
c*SZ!LaCre™M "П"" "Ж"ЗНЬ" явля™» исследование взаимодействия различны»
3E(Z£"б:™), СЛ0ЖН° № » спрогнозировать, что произойдет при в**
ного существо!!ТГ"" '"И"»»"'- Ч™?>
имер, на рис. 11.13 показан пример
совмест-
во, .SS ЖР°В- ЧерИ че™Ре ™™ планер, передвпгшощш.ся вниз .. м-
» том числе™,еТм " """^ HHTCpecH0 °™ет™>. ™ наши отологические описан.»;
термины, как "сущность", "планер", "переключение света", "поглошастс» .
Часть IV. Машинное oi
^учение
отражают наши антропоцентрические представлени, „ *
венной, и их взаимодействии. Человеку свойственно с ЖЮШ'" там
числе ц искусст-
саихя* присущими социальным структурам. ог,еР>фовать терминами и закономерно-
Шаг 0 Шаг 1
рис. Н-13- "Поглощение" "планера" друя
Шаг 2
>ой сущностью
-J::ic
■
11.3.2. Эволюционное программирование
Игра "Жизиь" - это интуитивный описательный пример клеточного автомата.
Описание клеточных автоматов можно обобщить, охарактеризовав их как машину с конечным
числом состоянии. В этом разделе будут рассмотрены сообщества связанных друг с другом
машин с конечным числом состояний и проанализировано их взаимодействие. >га область
знаний получила название эволюционного программирования (evolutionary programming).
История эволюционного программирования возникла в момент зарождения самих
компьютеров. В 1949 году в цикле лекций Джона фон Неймана исследован вопрос о том.
какой уровень организационной сложности необходим для самовоссоздания. В [Burks,
1970] цель фон Неймана определена так: "...это не попытка моделировать
самовоспроизводство естественной системы на уровне генетики и биохимии. Автор хотел
абстрагироваться от естественной проблемы самовоспроизводства".
Не вдаваясь в химические, биологические и механические тонкости, фон Нейман
постарался представить основные требования, необходимые для самовоспроизводства. Он
разработал (но не реализовал) самовоептюнзводяшуюся автоматическую конструкцию,
представляющую собой двухмерную рещетку с большим чистом отдельных автоматов с 29
состояниями. Каждое следующее состояние отдельного автомата конструкции являлось функцией
его текущего состояния и состояний четырех ближайших соседей [Burks. 1970.1987].
Интересно, что для обеспечения функциональности универсальной машины
Тьюринга фон Нейману потребовалось спроектировать самовоспроизводящийся автомат,
содержащий около 40 000 клеток. Это универсальное вычислительное устройство было также
конструктивно универсальным в смысле его способности чтения входных данных с
магнитной ленты, их интерпретации и использования специальной руки для создания
описанной на ленте конфигурации в незанятой части клеточного пространства. Поместив на
магнитной ленте описание самого автомата, фон Нейман создал самовоспроизводящийся
автомат [Arbib, 1966].
Позднее, в 1968 году Кодд (Codd) уменьшил число состояний
самовоспроизводящегося автомата, необходимых для обеспечения вычислительной универсальности, с 9 до
«■ Однако для этого ему потребовалось примерно 100 000 000 клеток. После этого Девор
(Devore) упростил машину Кодд. и разработал автомат, содержащий пр. мерно 87 500
клеток. В последние десятилетия был разработан самовоспроизвод-Щ шс "ат™
-ящий из 1Ю клеток по 8 состояний кажд. «^^^^Z^^
сальностью [Langlon, 1986], [Hightower, 19921, [(.odd. iw-l- иодр
г"ава 11. Машинное обучение на основе социальных и эмерджентных,
509
„ « материалах конференций, посвященных пппк
„ых результат»» содержат ав« «Р оп „ др , 1992]. пробпемц
ИаУ,«тве»н"й жизни [Ungton. WWt ои,водяш„хся машнн
"ТкГобразом, Ф^££Гс результаты Демонстрируют также „,>
вглубь теории вычислении^ ycRex работь1 эт„х программ спредер
„следования Ф»Р« ИСЧС" , ""„терием качества, а простым фактом выживания ""'
вторым заранее '—^успеха является само выживание. Но суи^
„„спроизводства особ № Р естны компьютер„ые вирусы и черви, способные вь!
другая сторона медал.оВ»д|т ^ (о6ычно разрушая в памяти любую *
вать в чуждой среде, восдр 0||звадсТва) „ инфицировать другие узлы. mi
дик,, необходимую дм з 0СТ]Ш0ВИмся на двух исследовательских проектах ™„
В заключение этот радее родан Брукса ^„^ ВгооЬ) из Массачусетс^0
шну1их ра„се '"™££ /Нильса Нильсона (Nils Nilsson) и его студентов „з ^
TTSЕрукса^налась в разделе 6.3, а проект Нильсона - при описани *
Ф°Р „„яГоования в подразделе 7.4.3. В контексте данной главы этн два описания 6у.
„росов пл^Р0"™^ 3^нм искусственной жизни и феномена эмерджентност,, *
ДУГРоПСни Брукс [Brooks. 199Ы. 19916] из Массачусетса техиологнческого института
„остпоил исследовательскую программу, основываясь иа исследоваини искусственной
жизни а именно— на интеллектуальном поведении, проявляющемся при взаимоденст.
вин простых автономных агентов. Подход Брукса, зачастую называемый "интеллектом
без представления", предусматривает различные способы создания искусственного
интеллекта. Брукс утверждает следующее.
"Необходимо постепенно наращивать возможности интеллектуальной системы,
отталкиваясь на каждом шаге от полной системы, в которой автоматически обеспечивается
корректность фрагментов и их интерфейсов.
На каждом шаге необходимо строить полные интеллектуальные системы, которые можно
"выпускать" в реальный мир с реальными ощущениями и действиями. В противном случае
мы будем обманывать сами себя.
Мы следовали такому подходу и построили группы автономных мобильных роботов. При
этом мы пришли к неожиданному заключению.
При исследовании очень простых уровней интеллекта мы обнаружили необходимость
явного представления и моделей мира. Гораздо лучше использовать реальный мир в качестве
его собственной модели."
Брукс построил серию роботов, способных обнаруживать препятствия и
перемешаться вокруг офисов и зданий Массачусетса технологического института. Они могут пе-
bTZ™"' "ССЛ'Л0ЮТЬ " °6Х0ДИТЬ дРУ™е обккты- Каждая из этих сущностей осно-
вГ^гГ™""* Г" °б <*»»'»"»'№* категоризации (subsumpt.on architecture), кото-
Гт„.Г!™!1 Фронтальные идеи декомпозиции поведения на уровни .
этой сис-
постепенн»™ ™ "щ НДС" декомпозиции поведения на yi~-
темТ-1"ГаптеГ1таиИЮ ПУ1"' аПробаи™ в Р^ном мире". Интеллект это
Брукс утверждает " Т" 0рганиза«ии » взаимодействия с окружающей ср.
Управления. Каждый 17нь ''^ К°НеЧНЬ'е автомэты- разлагая ,,х "° ^
не основы»™™... .уровень строится на базе существующих. Нижние уровни
шиши»"
никогда
основьшаютеГи СГГНЬ "Р0"™ Ш бше существующих. Нижние уровни иико™
«ботах [Brooks 1987 шо'п8'1""1 высок'""- Более подробная информация содержи
НилкНильеонеосвп! К' " "Lu8er- 2°°0]- №о«
В»»п,, разработал сиГГ^™™ т ^нфорда, в частности Скоттом Ьенсо ■
стему «"«-реактивного управления агентами. По сравнению с р**-
Часть IV. Машинное обучен
„й Брукса. Нильсон предложил более глобальную агентную апкит,,™
систем, интеграция которых обеспечивает функции ш^Г архкге|аУРУ- состоящую из под-
*даствования в динамической среде. Т^Г^' ^ходилте дл, робастиого и гибкого
^ „а различньте ситуации в окружающееIkZ^ZT'0™™™^^ *°*
Тия между несколькими конкурирующими целям"Т переключение вни-
^Гситуации за onp^^Tf^ZZ^TZ^^TT^' """ "'^^ "P" "*
^ствий Д« последующего по^ння^Тн^жГ» ZT "^ ™т ""'"
Нильсон н его ученики разработали телео-пеяю-и™ „
тельств [Nilsson, 1994), [Benson, 1995], [Benson и Nilsson 1995)
Эта программа в значительной мере напоминает продукционную систему (глава 5)
„о при этом поддерживает длительные действия (durative action), т.е. действия
происходящие в течение произвольных периодов времени, такие как "двигаться вперед,
пока...". Поэтому, в отличие от обычной системы логического вывода, в данном случае
необходимо постоянно отслеживать условия и выполнять действия, в наибольшей
степени соответствующие нм. Сказанное выше можно подытожить следующим образом.
[.Данный подход поддерживает принцип планирования, требующий стереотипной
программы отклика. Эта архитектура также поддерживает планирование,
позволяющее агентам соответствующим образом быстро реагировать на типичные
ситуации (отсюда термин "реактивный"). Действия агентов также являются
динамическими н подчиняются определенным целям (поэтому "телео").
2. Агенты должны иметь возможность поддерживать несколько изменяемых во
времени целей н предпринимать действия, соответствующие организации этих целей.
3. Поскольку невозможно запомнить все стереотипные ситуации, необходимо
обеспечить агенту возможность динамического планирования (а при необходимости и
перепланирования) последовательности действий и изменения положения вещей
во внешней среде.
4. Наряду с постоянным перепланированием в соответствии со внешними
обстоятельствами важно обеспечить возможность обучения системы. В этой работе
реализованы методы обучения и адаптации, позволяющие агенту автоматически
изменять заложенную в нем программу.
Более подробная информация содержится в работах [Nilsson. 1994], [Benson. 1995].
[Benson н Nilsson, 1995], [Klein и др., 2000].
Этн две работы служат примерами огромного множества исследовательских
проектов, основанных на использовании агентов. По своей сути они являются
экспериментальными и поднимают вопросы, с которыми сталкивается естественный мир. Во
взаимодействии с внешним миром формируются и "выживают" успешные алгоритмы, а
неспособные к адаптацин системы "отмирают". Этот аспект искусственного интеллекта
более подробно будет описан в завершение главы 16.
И наконец рассмотрим научные результаты, полученные в институте Санта-Фе (Santa
Fe Institute).
П.3.3. Пример эмерджентности
В [Crotennelo и М,,сг,„, ,994, ^^^^^^ZXZZ^-
простых систем с целью формирования взаимосвязей, о^
Глава 11. Машинное обучение на основе социальных и эыерджентных
511
« finTKV информации. Эта работа содержит пример эм
.vk, коллективную обр*^ '^ен„„ в распределенной системе. состоЯЩе'Г>о.
%шг**»>" ""ТГом иеток или процессоров на основе «шпоци^1^
ГдействуюшихдругсдаУГ» ^„тяые ««ш« (emergen, computa,^'*
„"егических «Ч»™*1*^ ^уктур глобальной обработки н„формац ■> «п„.
сывает появление в '™x " даектуры н механизмов эволюции, o6ecne4„JJ>
„Гаедован™ является п^ниЦ ^^ ч«.ав%х
реализашю методов эмерд „3 6оЛьшого числа отдельных ячеек. В каждом и, „
Щеточный автом с ^ ^ ^^ ^ ^^ с 6ннарньщи ^э ра,
одариваемых "Р»меР™ "'анство без глобальной координации. Состояние каГл -
«и образуй ^^ZhZo состояния на предыдущем шаге и состояний 12°»
метки зависит от ее эволюции клеточного автомата формируется двух* *
6Л™ГГ№-н„РоНа состоит из N ячеек со случайно сгенерированными^
ная решетка тн ^ ^^ эволюцш, мелочного автомата. состоящее "
^леГт :вр1«"ячейки»>,ерутотсяс0до 148. На рис. 11.14 показаны „р0Ор°а»
тве но-вРемениь,е диаграммы возможного поведения клеточного автомата. На этих
Граммах единичные состояния представлены черными клетками, а нулевые - 6елы.
Z Различные правила выбора соседей приводят к различным конфигурациям прооран,
ствевно-временных диаграмм клеточного автомата.
Опишем набор правил, определяющих активизацию элементов клеточного автомата. На
рис. 11.15 показан одномерный клеточный автомат с бинарными состояниями, состоящий
из N=11 ячеек. Там же приведены таблица вычисления состояний и правило определе»
ближайших соседей. Показано изменение решетки за одни шаг. Эта решетка на самом деле
представляет собой цилиндр, в котором крайние слева и справа ячейки в каждый моиеят
времени считаются соседними (это важно для применения набора правил). Таблица правил
реализует правило мажоритарного голосования (majority vote): если большинство из трех
ячеек находится в единичном состоянии, то центральная ячейка на следующем шаге
переходит в состояние 1. В противном случае она переходит в состояние 0.
Время
? двух
ода»"
™"«мгалю« к <)«,„,c^uZ'^"!""e'"'i'K дшгР^<мы. отражающие поведение с .
«Р»ь". цветом, а нулевтТе п<еРджент„ое поведение. Единичные значения клеток л№
_______™"_~ °елш,. ВРЫЯ изменяется сверху вниз
Часть IV. Машинное обу*""1
Таблица правил
окрестность: пп« л„.
ре3»„ьтир»„шввэн,чвнив: 7°°0 °'о°Т ТУ Т
Решетка
Окрестность'
,=1 liliJAiiiiJjIDIIIHl]
Рис. 11.15. Пример одномерного бинарного клеточного
автомата, состоящего т Af=11 злементов. Здесь
показаны решетка и таблица правил для ее обновления.
Этот клеточный автомат является циклическим, т.е.
два крайних значения считаются соседями
В работе [Crutchfield и Mitchell, 1994] предпринята попытка построения клеточного
автомата, выполняющего следующие коллективные вычисления, получившие название
победы большинства (majority wins): если исходная решетка содержит большинство
единиц, то на следующем шаге все элементы автомата переходят в состояние 1, в
противном случае — в состояние 0. При этом были использованы клеточные автоматы, в
которых окрестность состояла из семи ячеек (по три соседа с каждой стороны от центра).
Интересным аспектом оказалось сложность построения правила, реализующего такие
вычисления. На самом деле в работе [Mitchell и др., 1996] показано, что простое правило
мажоритарного голосования для семи соседей не реализует правило победы
большинства. Для поиска требуемого правила был использован генетический алгоритм.
Описанный в разделе 11.1 генетический алгоритм применялся для создания таблицы
правил в экспериментах с клеточным автоматом. А именно, он использовался для
настройки правил преобразования одномерной бинарной популяции элементов клеточного
автомата. Критерий качества формировался с целью подкрепить правила,
обеспечивающие победу большинства для клеточного автомата.
Таким образом, со временем на основе генетического алгоритма был сформирован
набор правил, обеспечивающий победу большинства. Отобранные на основе критерия
качества элементы популяции случайным образом комбинировались с помощью
скрещивания, а затем каждый потомок с малой вероятностью подвергался мутации. Этот
процесс продолжался для ста поколений, при этом для каждого поколения вычислялся
критерий качества [Crutchfield и Mitchell, 1994].
Как определить наилучший клеточный автомат, реализующий эмерджентные
вычисления? Подобно многим пространственным естественным процессам,
конфигурация ячеек со временем зачастую образует динамически гомогенные ооласти в
пространстве. В идеале следует автоматизировать процесс анализа и определения этих
закономерностей. В работе [Hanson и Crutchfield, 1992] разработан язык минимальных
Детерминистских конечных автоматов, с помошью которого описаны области притя-
*=ния аттракторов для каждого конечного автомата. Этот язык можно использовать и
Для описания нашего примера.
Глава 11. Машинное обучение на основе социальных и эмерджентных принципов
513
,, 14 а) эти области заметны невооруженным глазом
Иногда (как на рис ' м ' т„. Обозначим эти облает,, символом Л, „ *>■
даю1 собой инвариантны ПН описать „занмоденствня, опреде'а>Ы.
дСм инвариантна »*№, ,м описаны три Л-облает„: Л», состоящ^ *■
ресечением этих области ^ ^ „держащая повторяющиеся фрагменты loW4'
Л!, состоящая из един! и, л_о6ластИ] н0 „ока они нас не интересуют. '• Hi
рис. I114'"™'™™"* элементыЛ-областей, можно отследить „х вэаимодейст,
Выделяя »"-Р»^едХвие шести Л-областей, в том числе по .раницГ^В
табл. 1М описано взводеи _ __ ^^ ^^ Ц об^
А. „л» Эта границ»^между ед в ^ [Crutchfie|d „ Mi,che||] ШС;4] ^^ ,0,
s^,™. - -;—: sr ^=r„r x(r:rr"
—;="" операм Поэтому поведение «^
„буаГено информационно-обрабатывающими элементами, представляющими собой
X* областей, их границ, частиц и взаимодействия.
таблица 7 7 4. Каталог регулярных областей, частиц (границ областей),
их скоростей (в скобках) и взаимодействий, описывающих пространственно-
временное поведение клеточного автомата на рис. 11.14, а. Запись р-л'Л"
означает, что р—зто частица, формирующая границу между регулярными
областями Л" и Л'
Регулярные области
Л»=о- л'=г л'=(Ю001г
Частицы (скорости)
сс-Л'л'П) Р-Л°Л'(0)
у-л'л'(-2) 6-Л°Л!(1/2)
П-Л'Л'(4/3) ц-Л'л'(З)
Взаимодействия
Распад а->у+ц
Реащия а+5-.ц, п+а->у, ц+г-ю
А""игил"иия г|+ц->е„у+5-.е0
На рис. 11.16 показана эмерджентная логика, представленная на рис. И.14,а. Здесь
выделены Л-области с инвариантным содержимым, а также пограничные частицы.
Увеличенные фрагменты на рис. 11.16 демонстрируют логику взаимодействия двух вне-
ГИГ ""Г"1' В ПраВ°М Верхнем W покамн° взаимодействие а+6->Ц, реализуюшее
по™»™'Г"1" mmm™^™ конфигурации сигналов а и 6 в сигнал Ц. Ниже
~тс,вХп.ГЧаСТИЦН+^а Б°Лее П°ЛНОе — в-имодействил части»
нИеИ^од„ТГсГЗУЛЬтаТОМ Ра6°ТЫ infield „ Mitchell, 1994] является «о*»
системах, с„стоя;:™з^ГТНЫХ ВЫЧИСЛеНИЙ В "Р°"Ра'™° '^Тп^
ное взаимодействие 2 ма"модействующих клеточных процессоров. Лок
сводится к изучению и!™ onPe«eju" и глобальное. Роль генетических угорит
« работке m^ZZ2T "РШШ ви™°Д™<™ия, которые в результате при^
ICnitchfield и MitchdUQgl,"Х пР°«Ра"«венно-временнЫх интервалах. В р»
"ий использованы илеи т,Г Т хаРа1сгеРистики пространственно-временных
,ИД,;и™Рии формальных языков.
Часть IV. Машинное
Время
Рис. 11.16. Анализ эмерджентной логики dVw классификации плотности областей на рис. 11.14. а.
Этот клеточный автомат характеризуется тремя А-областячи, шестью частицами и шестью
видами их взаимодействия, описанными в табл. 11.4. Области выделены с помощью нелинейного
преобразования с 18 состояниями, описанного в [Mitchell и др., 1996]
Результат эволюции клеточного автомата отражает качественно новый уровень
поведения, который отличается от низкоуровневого взаимодействия распределенных элементов.
Глобальное взаимодействие частиц иллюстрирует сложную координацию, возникающую в
результате набора простых действий. Применение генетического алгоритма для правил
изменения состояния отдельных частиц отражает процесс эволюции, реализующий новый
уровень поведения, необходимый для эффективных эмерджентных вычислений.
Значение работы [Crutchfield и Mitchell. 1994] состоит в том. что в ней с помощью
генетических алгоритмов продемонстрировано эмерджентное высокоуровневое поведение
клеточного автомата. Более того, авторы предложили вычислительные средства
описания инвариантности, построенные на основе теории формальных языков. Продолжение
исследований даст возможность изучить природу сложности: определить характеристики
жнзни и понять принципы формирования родов, видов и экосистем.
11.4. Резюме и дополнительная литература
Основоположником развило, генетических алгоритмов и ^оп„еского <*^™
Джон Холланд (John Holland) [Holland. 1975,1986]. В последней работе «да» па»™,
системы класс,фикащш. Анализ генетических систем »«^Я °J^^
1M,,che„, ,996]. [Lest и M.tchell. ^^^^Т^^Т^"
мов и „бучения проводите, также ^^J^^J 'онятие системы «оь
идсиразв^ютсяв^епЫ^и^е^
Джон Коза (John Koza) - это основной '~°^ , , „„ользевания генети-
мирования [Koza, 1992,1994]. Описанный в под!шдежл . Ф V
ческих алгоритмов для изучения третьего закона Кеплфа предложс
Тг^Гт^^ч^а^^ 515
„ была создана математиком Джоном Хортоном Конвс
И^а-жизнь"«знача*"°6_ела широкую популярность после ее обсужден 8Г<Ч
Нойон Соп«у), однако при анР|е дачнсл1ГТель„0й мощности конечных автоматов^*3*
i** A""*""' "Г08№, компьютерам. Большой вклад в эти исследования »„«*>
корням,, к первым и ФР°» е показал, ^ вычислительная мощно "«*»'<
ф0„ Нейман, которыифактич^й ^^ Тьюринга Большинство 'ко*,.
НФ0ГО автомата соотв»^ [Burks, ,966, 1970 и 1987]. Дру™ „^^
результатов представл ^^ как на осдаве этих ранннх ра6от № атзд
[Hightower. 1992^°; искусственной жизни. Вопросы искусственной ж„зн„ и™^
„матам строится моде» «СКУ сИеу „ др„ 1992]. Труды коифере1щщ. ^
"" ^лХ иГ^пнои жизни, собраны в [Ungton, 1989, 1990].
^ХГе 1995] и других работах отмечена важность эволюционной теории в рщви
В [Dennett, 19W"^ ^ - же теме „освящена работа [Gould, 1996]. Р ""
""/То^нГГрГдле 11.3 концепция атентното обучения изложена в ра6опх
[ВшоГ^""^^^!.], [Nilsson, 1994], [Benson и др., 1995]. В ^
Maes 1989] [Maes, 1990] предложена модель распределенной обработки информации,
сетях которая получила свое дальнейшее развитие в работе [Hayes-Roth и др., 1993]. ре.
зультаты, описанные в подразделе 11.3.3, базируются на работе [Crutchfield „
х*:,„|«,п IQQdl
Mitchell, 1994]
11.5. Упражнения
1. Генетический алгоритм должен поддерживать поиск в пространстве вероятных
комбинаций и обеспечивать выживание на основе генетических шаблонов. Опишите, как
эти задачи решаются с помощью различных генетических операторов.
2. Вспомните проблему разработки представления для генетических операторов при
решении задач из различных предметных областей. В чем здесь состоит роль
индуктивного порога?
3. Вернемся к задаче построения конъюнктивной нормальной формы, описанной в
подразделе 11.1.3. В чем состоит роль количества дизъюнктов, определяющих
построение конъюнктивной нормальной формы в пространстве решений? Укажите
другие возможные представления и генетические операторы для этой задачи. Можно
ли выбрать другую меру качества?
4. Постройте генетический алгоритм для решения задачи представимости в
конъюнктивной нормальной форме.
5. Подумайте над проблемой выбора соответствующего представления для зада™
коммивояжера, описанной в подразделе 11.1.3. Определите другие возможные
генетические операторы и «еры качества для этой задачи.
■ Построите генетический алгоритм поиска решения задачи коммивояжера.
страГвП Р°ЛЬ Предгавм™. в том числе кодирования Грея, для описан» Ч£
ЗЕГ.Т" ° ГеН™Ческ"х «-«ритмах. Приведите примеры дву* «pW*1*"
областей, в которых этот вопрос „грае, важную £„„,
2ГГг,сз2Г Гх"'"'•1996]'[К0- 19М!££5
эволюцию пространства решений при использовании 1««™
Часть IV. Машинное обГ
ГиГбГ™вь1Ти^Г:ГЭтаТЕОР-™---«°™-."---аЩИхкод„ро.
'■ п™Гнт„::ГоГй цепочки"№nand'i986] "■»■ -—°*— р-
10. Напишите программу, решающую задачу моделирования третьего закона Кеплера
описанную в подразделе 11.2.2,
П. Сформулируйте ограничения (упомянутые в подразделе 11.2.2) по использованию
методов генетического программирования для решения задач. Например, какие
компоненты решения не могут эволюционировать в рамках парадигмы генетического
программирования?
12. Познакомьтесь с первыми описаниями игры ''Жизнь" в журнале Scientific American.
Назовите другие структуры искусственной жизни, подобные описанному в
подразделе 11.3.1 планеру.
13. Напищнте программу моделирования искусственной жизни, реализующую
функциональность, показанную на рис. 11.10-11.13.
14. В разделе 11.3 упоминаются исследования, ориентированные на агентов.
Ознакомьтесь с публикациями по этим вопросам.
15. Определите роль индуктивного порога в выборе представления стратегий поиска н
операторов, используемых в моделях обучения из главы 11. Является ли
генетическая модель обучения изолированной илн ее можно распространить на более
широкие области?
16. Изучите глубже вопросы эволюции и эмерлжентности. Прочтите и обсудите работы
[Dennett, 1995], [Gould, 19961.
Глава 11. Машинное обучение на основе социальных и эмердаентных принципов
517
Часть V
Дополнительные
вопросы решения
задач
искусственного
интеллекта
Точность — это не истина...
— Генри Матисс (Henri Matisse)
Время настоящее и время прошедшее — это лишь настоящее для времени
будущего, а время 6ydyufee содержится в прошедшем...
— Т. С. Элнот (Т. S. Eliot), Бернт Нортон
... любой крупный результат является следствием длинной
последовательности мельчайших действий.
— Кристофер Александер (Christopher Alexander)
Автоматические рассуждения и естественный язык
В части V рассматриваются два важных приложения искусственного интеллекта:
понимание естественного языка и автоматические рассуждения. Приступая к созданию
искусственного интеллекта, необходимо решить проблемы языка, рассуждений и обучения.
Предлагаемые решения этих проблем основываются на средствах и методах,
упомянутых в предыдущих разделах этой книги. В свою очередь эти проблемы оказали
существенное влияние на развитие самого искусственного интеллекта и его методов. Во введс-
tit обсуждал"01, ПР>-» • „ких методов обусловлена сложности ^
(*ик * „1каи^>да°С1ЬЮп ш ое развитие экспертных систем „ сильны*^'»
^"^ленГнес»^» "а Сх "ео>>™ более общие подходы. На самом де^»»«
"*№Сазад". » "»0Г"Х СЛ> птных снекм* основаны „а использовании ,£?«*
ранениям*"' caj|HX экспертных быть no "fwi Me.
SS^S» в -t^ff по созданию моту, быть получены в ££*
" Многообешаюшие резУ" телы7Я(Ш m«y>aw (automated reasoning). э™ „ ",'
^'„«Т«^>«*т'"„ многих важных областях, включая оГ?"»'
Г£Г~ "Р'М£:;Ги-„ю " оказательство корректное™ програмИ^
^„ровавныхеетеи »^ Ф - аммированш! PROLOG. В главе 12 рассма^
косвенно, .три »м "' т" "ат„,ескими рассуждениями,
вопросы, связанные с авто»■ ш №,Koe при решении задач искусственно:
Соленость »0№,""""f ™ чинами. В частности, для использования языка необходим!
„.„та объясняется многим, н ^ и тьт Успешиое пон„маиие языка требует «МЫс.
большой объем знании, ^ человеческой психологии и социальных аспектов Дщ
естественного мира, ассуждений и интерпретация метафор. Из-за слож».
ш-кна реализация да. „„.„„е место выхолит nnofin™» и,.,
лення
этого нужна р<
стии
нииа реализация лошчи."" г---,-.. ш.
многогранности человеческого языка на первое место выходит проблема исследои.
™ представления званий. Попытки таких исследовании увенчались успехом лишь ,arow.
„о На основе знаний были успешно разработаны программы, понимающие естественный
язык в отдельных предметных областях. Возможность создания систем, решающих про.
блему понимания естественного языка, до сих пор является предметом споров.
Методы представления, описанные в главе 6, в том числе семантические сета, сценарии
в фреймы, играют важную роль в решении задачи понимания естественного языка. В
последнее время для решения этой задачи привлекаются методы корреляционного анализа
языковых шаблонов. Языковые конструкции — это не случайный набор звуков или слов.
Их можно моделировать на основе байесовского подхода. В главе 13 будут рассмотрены
синтаксические, семантические и стохастические методы понимания естественного языка.
С широким распространением технологий World Wide Web и интенсивным
использованием механизмов поиска вопрос понимания естественного языка стал еще важнее.
Общий поиск полезной информации в неструктурированном тексте, возможность
резюмирования информации, или "понимания" текста, — это важнейшие новые технологии.
Теоретические основы программных средств, базирующихся на символьном
представлении и стохастическом распознавании образов, представлены в главе 13.
И, наконец, в части VI будут рассмотрены многие структуры данных, используоак
при решении задач понимания естественного языка. В разделах 14.7 и 15.11 описаны
семантические сети „ фреймовые системы, а в разделе 14 9 - рекурсивный семантически»
ZZ"JUm'miT В Гтве 16 °6даются некоторые существующие проблемы в »»'
"иманнн языка, обучении „ решении слож„ь,х задач
a"bV. Дополнительные вопросы решения задач искусстве!
„но-ои*"""
Автоматические
рассуждения
Как это получается. — спросил этот проницательный человек, — когда мне
приходит идея, я могу выйти за ее рамки и связать с другими, не
содержащимися в ней, как будто эти идеи неразрывно связаны с первоначальной ?
— Иммануил Кант (Immanuel Kant),
Prolegomena to a Future Metaphysics
Любое рациональное решение можно рассматривать каквывод. полученный
на основе некоторых начальных условий... Счедовательно, поведение
рационального человека можно контролировать, если задать ему фактические
предположения, на базе которых он строит свое заключение.
— Симон (Simon),
Decision-Making and Administrative Organization, 1944
Доказательство — это искусство, а не наука...
— Вое (Wos), Automated Reasoning, 1984
12.0. Введение в слабые методы доказательства теорем
В [Wos и др., 1984] сказано, что система автоматического доказательства "применяет
однозначные описания для представления информации, точные правила вывода для
формирования заключении и внимательно сформулированные стратегии для управления этими
правилами". Авторы добавляют, что применение стратегий к правилам вывода для
получения новой информации— это искусство. "Хороший выбор представления подразумевает
использование обозначений, повышающих вероятность решения проблемы, и включение
полезной, хотя и не самой необходимой, информации. Хорошие правила вывода — это
правила, удачно использующие выбранное представление. Хорошие стратегии— это
принципы управления правилами вывода, повышающие эффективность программы
автоматических рассуждений."
Отсюда следует, что для построения систем автоматических рассуждений
используются слабые методы решения проблем. Они строятся на таком однородном
представлении, как теория предикатов первого порядка (глава 2). теория хорновских выражении
(раздел 12.3) или операторов разрешения (раздел 12.2). Правила вывода должны оыть
„„шожности поливши. В качестве общих стратегий пример
согласованными я поГ™0™^" алгоритмы поиска и. как будет вид„0 и э^«
°„„ск в ширину. = ^"„ожТсшео поддержки (se. of support) „ единичное пр^
,ы. такие эвристики, как^^^ возм„жность исчерпывающего поиска. Pi>
„„„ (unit preference^ Они о ^^ для эт„х стр _ ю ^^ ^Щ-
ботка стратегии поиска а мое решение задачи будет найдено в „""*
в0. Нельзя «ра"™Р° ^а™£нРвого о6ъема памяти. Ра«^
допустимого временя,и v ем_ эт0 ваЖное средство, а также основа для
СЛа6Ые„Г™. ««вода .. экспертные системы „а основе правил- это при^
„ь,х методов. Систем Задач. Даже если правила в системе вывода ™
реализации слабых « «J^ си„ьные проблемно-ориентированные эвристики 1
экспертной сиси.".- ^ о6щимн стратегиями вывода (слабыми методами).
4^TSSi слабых методов были в центре внимания ученых в области „с.
етс"в н то интеялекта с момент зарождения этой науки. Эти приемы зачастую от„„.
обшее название -
- автоматические рассуждения (automated reasoning). В начале
этой
главы (раздел 12 1) будут рассмотрены один из первых примеров автоматических рассу.
ждений - система для решения задач общего вида General Problem Soher, а также
использование анализа целей и средств (means-ends analysis) и таблиц отличив (difference
tables) для управления поиском.
В разделе 12.2 представлен важный результат в области автоматических рассужде-
ний — система доказательства теорем на основе резолюции (resolution theorem prover).
Будет описан язык представления, правило вывода, стратегии поиска и средства
извлечения ответов при доказательстве теорем разрешения. В качестве примера рассуждений
на основе хорновских выражений в разделе 12.3 описан механизм вывода для языка
PROLOG и показано, как этот язык реализует философию декларативного
программирования с помощью интерпретатора, основанного на доказательстве теорем разрешения. В
заключение этой главы (раздел 12.4) приводятся краткая информация о естественной
дедукции, решении уравнений и более сложных правилах вывода.
12.1. Система решения общих задач и таблицы отличий
Система решения оби/их задач GPS (General Problem Solver) [Newell и Simon, 19636],
[Ernst и Newell, 1969] стала результатом исследований Алана Ньюэлла (Allen Newell) it
lepoepra Саймона (Herbert Simon) из института технологий имени Кариеги.
Предшественницей этой системы можно считать более раннюю компьютерную программу LT
™™ 7° 1NCWe" " Simon' I963a| C «омощью программы LT были доказаны мно-
гие теоремы, приведение в [Whitehead и Russell 1950]
LT иГ„ль,0„»СТаЛЬНЬШ С"СТеШМ решсния м"ач ™ °™°ве слабых методов, в программе
та^Г1а6оГнпУ"ИФ"ЦИРОВаННОе "Руление и семантические правила вьшодМ
соГ,ГГр Г„„ ГвпТ СТРаТС™Й ™ мистических методов уп авления проиес-
medium) использовано Р ^^ LT " Качсстве сРеДства представления (represent*
-,гУпаи:г:;г^г;е,иие гказьшаиий £«».«- ^ ^°v7
ПодстановкаZZZt 13™ma ("T^emem) „ открепление (detachment^
ставляющем собой »„.„„ Заменить Л|°°ос вхождение символа в предположении, ир
аксиому тн теорему зшедомо истиииым выра^нием. НапримФ
Насть V. Допо„„ительныв вопросы рвшвния задач искусстввнноГО инталпе«та
выражение (SvS)^e вместо в можно подставить -л „
_^v-t4)->-^- «""«нить -л и получить выражение
' ТТ ТапХеоТпиТ™ ""^° ВЫРаЖеНМ СТ0 «*«*»»■« "ли
эквивалентную Форму- "-РИ^Р. "Р" логической эквивалентности выражений -vWB и А^,В вы-
ражение -iAv-iA можно заменить Д->_А
Открепление - это правило вывода, которое в главе 2 было названо правило* мо-
дус понепс.
В программе LT эти правила вывода были использованы для поиска в ширину при
доказательстве теорем. Программа пытается найти последовательности операций
приводящих к заведомо истинным аксиомам или теоремам. В исполняемом модуле LT
реализованы четыре метода.
1. Метод подстановки напрямую применяется для текущей задачи, чтобы привести ее
к известным аксиомам и теоремам.
2. Если этот метод не приводит к успешному доказательству, используются все
возможные открепления и замены, и для каждого из результатов снова применяется
метод подстановки. Если получить доказательство теоремы не удается, то все эти
результаты добавляются в список подзадач (subproblem list).
3. Затем для поиска новой подзадачи, решение которой обеспечивает доказательство
исходного утверждения, используется метод цепочки, учитывающий
транзитивность импликации. Таким образом, если для задачи а->с получено Ь—>с, то в
качестве новой подзадачи выбирается а—>Ь.
4. Если первые три метода ие приводят к ожидаемому результату, то система
выбирает следующую подзадачу из списка.
Эти четыре метода применяются до тех пор, пока не будет найдено решение, ие
исчерпается список подзадач, память или время, выделенные для решения задачи. Таким
образом, система LT выполняет поиск в ширину в пространстве задач.
В исполняемой программе подстановка, замена и открепление выполняются в рамках
процесса проверки соответствия (matching process). Допустим, необходимо доказать
утверждение p—>(q—tp). В процессе проверки соответствия сначала выявляется одна из
аксиом p-t(qvp) как наиболее соответствующая в терминах различия для данной
области определения (в данном случае в обоих выражениях совпадает основной логический
оператор ->). Затем при проверке соответствия устанавливается идентичность левых
операндов основного логического оператора обоих выражений. И, наконец, определяется
различие правых операндов. На основе различия между операторами -> и v можно
предложить очевидную замену для доказательства теоремы. Процесс проверки соответствия
помогает управлять поиском при реализации всех подстановок, замен и откреплений.
Ои гораздо более эффективен, чем простой метод проб и ошибок, что обеспечивает
успешное решение задач с помощью программы LT.
Рассмотрим эффективность проверки соответствия на примере доказательства
теоремы 2.02 из книги [Whitehead и Russell, 1950]: p-H<J->P). В процессе проверки
соответствия в качестве замены находится аксиома p->«jvp). Подстановка ы, вместо q приводит
к доказательству теоремы. Проверка соответствия, управление подстановкой и правила
замещения приводят к прямому доказательству теоремы без привлечения поиска в про-
странстве других аксиом или теорем.
Глава 12. Автоматические рассуждения
523
д.м второго .ФИ-Р- "^" ° "0М0ШЬЮ ПР0ГРаММЫ ^ Д°КаМТЬ ^-„е
""П^МЛ - в процессе проверки соответствия выявляется наилучшая акс„„Ма ^
„яти возможных.
,Mv-,.H^-подстановка вместо Л.
, ц-ЛО-.-Л- «мена v или -. на-»
4.'(p-w»-^P- подстановка р вместо Л.
Х^ГГтдСГет «у теорему на основе пяти «сном примерно за дест с,
к^Гьное доказательство выполняете, за два этапа и не требует поиска. На «^
эГе в nlecce проверки соответствия выбирается самая подходящая аксиома, посколь '
еГформГ наиболее близка к утверждению, которое требуется доказать: выраж1
„иЛпредюжение. Затем вместо А подставляется ^А. Этим определяется второй („ по.
следний) этап, который приводит к замене v на ->. Программа LT не только является пер.
вым примером системы автоматических рассуждении, но и демонстрирует роль стратегий
поиси и эвристик в средствах автоматического доказательства теорем. Во многих случаях
LT за несколько шагов приходит к таким решениям, которые с большим трудом можно
найти только путем полного перебора. Некоторые теоремы не решаются с помощью
программы LT, поэтому авторы программы внесли некоторые предложения по ее улучшению.
Примерно в это же время исследователи из технологического института Карнеги
(Carnegie Institute of Technology), а также специалисты из Иельского университета
(Мооге и Anderson. 1954] начат высказывать свои идеи о способах решения логических
задач. II хотя их основной целью было изучить процессы человеческого мышления,
решающие этот класс задач, они сравнили принципы решения задач человеком с
подходами, реализованными в компьютерных профаммах наподобие LT. Это положило начало
новой научной области, получившей современное название психологии обработки
информации (information processing psychology). Данная наука пытается объяснить
наблюдаемое поведение организмов с помощью пришттной профаммы обработки
информации, моделирующей такое поведение [Newell и др., 195S]. Это исследование также стало
одной из первых работ в области науки о мышлении — когнитологии (cognitive science),
о которой речь пойдет в разделе 16.2 (Luger, 1994].
Пристальное изучение этих первых профамм показало существенные отличия
человеческих подходов к мышлению от компьютерных реализаций наподобие LT. В
человеческом поведении прослеживается существенная роль анализа целей и средств, в
котором методы уменьшения различии (средства) тесно связаны с конкретными отличиями
(целями). По ним можно проиндексировать операторы уменьшения различий.
рассмотрим простейший пример. Если начальное утверждение имеет вид P^l- » ^
символ™ _*V"' ™ РаЗЛ"ЧИе С0СКШТ в том' что в "сходном выражении участвует
левом- ' ыВ тТ*"" ~ V U таКЖе в исх°ДНом утверждении есть выражение р. а в це-
> также удаУен „Л"™" 0TЛ1,ЧHr, Д0ЛЖНа »ДЧ>*атъ различные способы замены -> на*
Доп„„„„Уго^а„^'ЦаН"Я' ТаК"е '^образования необходимо поочередно применять
y^^Z^T:Z-^^^^ " иелевых утверждения, *£
"»ющий эти отличи, ТакГпСЛУЧае " ^""иЫ вбирается оператор, частично усП^
отличий. При этом можГ рОЦСДУ1)а применяется рекурсивно до полного уел»"
потРебоваться применение различных методов поиска.
ЧаСТЬ" А°ПОЛ™™ь„Ые вопросы рвшвния задач искусстввнного •я***"
В среднем столбце табл. 12.1 [Newell и Sim 1QA3
вил преобразован.,, для решения логических зал^ч в „ представлены Двадцать пра-
„ендации по ..х применению. ВД ' В правом """^ приводятся рско-
Твблицэ 12.1. ПР™»™преобрВЗОВВНИЯДЛЯтгическтзвДВЧ
№п/п Правило преобразован^ Рекомв^.,, пп „г „-„„„.,
1
2
3
4
5
6
7
8
9
10
11
12
Д B->BЛ
,чvB-»Bv,ч
,чзB-^-Bэ-/ч
А А<->А
AvA*-*vA
AiB С)щАВ)С
Av(BvC)mAvB)vC
AvB>->-{-A —В)
АэВи-AvB
AiBvC)>->iA ВЫАС)
Av(B-C)^AvB)iAvC)
A B-tA
AB-tB
A-^AvX
в}—
лэвЬв
ВэС
Применяется, если А и S -
два основных выражения
Применяется, если А и S - два основных выражения
Применяется только к основному выражению
Применяется, если А и >Ь8 - два основных выражения
Применяется, если ДэВ и ВэС — два основных выражения
Применяется только х основному выражению
Применяется только к основному выражению
Применяется, если А и В — два основных выражения
Применяется, если А и ЛэВ — два основных выражения
Применяется, если Az>B^Bz>C — два основных выражения
В табл. 12.2 представлено доказательство, сгенерированное человеком (Newell и
Simon, 19636]. При этом человеку, не имеющему опыта в решении задач формальной
логики, были предоставлены правила преобразования из табл. 12.1. Требовалось
преобразовать выражение (Яэ-,Р)«ЬЯэО) к вшу -.(-.ОР). В обозначениях из главы 2 символ
- обозначает -,. • обозначает л, а э >. В табл. 12.1 символ -» или <-> обозначает
корректную замену. В правом столбце табл. 12.2 указаны правила из табл. 12.1.
применяемые на каждом этапе доказательства.
Таблица 12.2. Доказательство творены на основа исчисления высказываний
N» п/п Последовательность Применение правил
преобразований .
(Rd-PH-R-Q)
(-Rv-P.(RvQ)
(-Rv-PH-RdQ)
Яэ-Р
-flv-P
-i-QP)
Правило 6 применяется х левой и правой части 1
Правило 6 применяется к левой части 1
Правило 8 применяется к 1
Правило 6 применяется к 4
Глава 12. Автоматические рассуждения
525
-^ЗО^Ютабл. ,г
Правило 8 применяется к 1 —-
Правило 6 применяется к 6
Правило 10 применяется к 5 и 7
Правило 2 применяется к 4
Правило 2 применяется к 6
Правило 12 применяется к 6 и 9
Правило 6 применяется к 11
Правило 5 применяется к 12
Правило 1 применяется к 13. Что и требовалось доказать
р „s™ rNewell и Simon, 19636] стратегии решения задач человеком названы процессом
vJLS« различий, а общий процесс использования преобразований для уменьшения раз-
уметшчп г анализом целей и средств. Алгоритм выполнения этого анализа
На рис 12 1 показаны схема функционирования и таблица связей для GPS. Требуется
преобразовать выражением в выражение В. Для этого сначала необходимо найти
различие D между А и В. Во втором блоке первой строки решается подзадача — уменьшение
D. Третий блок указывает на то, что процедура уменьшения различия является
рекурсивной. Уменьшение различий выполняется во второй строке, где для 0 выбирается
оператор О. На самом деле список операторов формируется на основе таблицы связей.
Операторы из этого списка последовательно проходят тест применимости (feasibility test). В
третьей строке на рис. 12.1 используется нужный оператор и уменьшается D.
Используемая в GPS модель решения задач основана на двух компонентах.
Первый— описанная выше общая процедура сравнения двух состояний н уменьшения их
различий. Второй— таблица связей (table of connections), описывающая взаимосвязи
между существующими различиями и конкретными преобразованиями, применяемыми
для их уменьшения. Таблица связей для 12 преобразований, описанных в табл. 12.1,
показана на рис. 12.1. Для уменьшения различий в алгебраической форме при решении
задач наподобие ханойских башен или моделировании более сложных игр, таких как
шахматы, могут применяться другие таблицы связей. Многочисленные применения системы
GPS описаны в (Ernst и Newell, 1969].
Структурирование процесса уменьшения различий для конкретной предметной области
помогает организовать поиск в пространстве состояний. Эвристический или приортетный
порядок уменьшения различий неявно определяется порядком преобразований на основе
таблицы отличии. Согласно этому порядку обычно сначала выполняются более общие преобра-
vTZ'lT" ~ Специалт"1,°ю™. Зачастую при определении порядка преобразовании
^егеГ гр'Г ЭШКРТ0В П° ДаНИ0Й предметной области.
Одним™^!4™"3 ТО"ЧК0М т Р™1™" «'следований во многих направлен*
сГГО поведеииГ „„ ВаИИе М"°а°» ™Ч*™нного интеллекта для анализа человече-
целГй ZZ ьГзГ РеШе,ШЯ 3аДаЧ' В ЧаС™0С™' используемые в GPS методы »-»*
точку. ХГоб^ГиГ ***** Л0ПМеСК0ГО ВЫВС* представляющей собой бол*
«мах правила вьшС„Х^"^
лмуются вместо отдельных элементов таблицы отличии GF^-
аль-1
С
,: преобразовать объект А в объект В
СравиитьАиВ
для поиска
отличий Р
Подзадача:
привести О
А'
Подзадача:
преобразовать
А'ъВ
Успешное завершение Неудачное завершение
i |аль: уменьшить различия О между объектами А и В
Неудачное завершение
Найти оператор О.
позволяющий
уменьшить D
Проверить
применимость
(предварительно)
Подзадача:
применить О к А
для получения Л'
Неудачное завершение
Цель: применить оператор Q к объекту А
D
Проверить
соответствие условий О для
объекта Л для поиска
отличий О
Подзадача:
уменьшить О
Подзадача:
применить Q к А'
Получить результат
А ■• Неудачное завершение
*- Успешное завершение
Неудачное завершение
Тест на применимость (предварительный) для описанной логической задачи:
Совпадает ли основной логический оператор (т.е. А-В -> В хуже, чем P:Q)?
Не слишком ли велико выражение (т.е. [A vB)-(d vC) -> Д v(B*C) хуже, чем P-Q)7
Не является ли оператор слишком простым (т.е. А -> А-А применимо к любому выражению)?
Удовлетворяются ли второстепенные условия (например, правило 8 применимо только для
основного выражения)?
я\
X
R?
X
X
R3
X
X
R4
X
R5
X
X
X
R6
X
X
R7
X
X
X
X
R8 R9 R10R11R12
X
X
X
X
X
X
X
Таблица связей
Добавить термы
Удалить термы
Изменить логический оператор
Изменить знак
Изменить знак операнда
Изменить группировку
Изменить положение
Символ "Х- означает применимость некоторого варианта правила.
Система GPS выбирает соответствующий вариант
Рис. 12.1. Схема функционирования и таблица связей дня системы GPS
Методы GPS получили свое развитие и в других интересных направлении. Так, вместо
таблицы отличии в системах STRIPS и ABSTRIPS стали использовать таолицы операции
(operator able) для тонирования (planning). Планирование - это важный аспект
управления роботами. Чтобы решить задачу, например, перейти в ^м ™е ^™™
который предмет, компьютер должен разработать план. ^^'Г^.^^^к
Сначала необходимо положить предмет, «^Р^^Л^^^£
Двери, выйти „з комнаты, найти нужную комнату, войти в нее, подойти к обьекту т.д. При
Глава 12. Автоматические рассуждения
527
uu STRIPS (Stanford Research Institute Problem Solvcrt
формировании планов для «^™ ^ая аналогом таблицы отличий GPS „£>*•
«ется таблица операци "^ Каждой операции (пр^пшшиому действии р*«»
Son,197.J972]JSac«dom.^ 1 „, аналогичных тесту примени^
в ЭТОЙ таблице «""^f!^" содержит списки добавлен™ и удаления, с „0к? »
ряс. 12.1. Таблица операции^™*... ,юсле вьшолненил операции. Система планир^Г
которых »Д*^ГС6^а°Гисана в разделе 7.4. а се реализация „а языке PRol^ £
ния, подобная ы м
дет рассмотрена в разделе __ рассуждений в области искусственного „,„.„
Итак, <*■*%£%%%£* (LJ) „ апега1 Problem Solver (GPS). В этих щ££
„екта являются системы Log^ м ^ „спользовано унифицированное пред^
мах реализованы слаоые mciwi г ипатепш применения этих правил. Эти же „л.
p^ureiГ fc« современном и мощном аппарате автоматических рассуждений.
12 2 др^ятрг^л^^орем методом резолюции
12.2.1. Введение
Резолюция — это один из приемов доказательства теорем в области исчисления
высказываний или предикатов, относящийся к сфере искусственного интеллекта с середины 60-х
годов прошлого столетия [Bledsoe, 1977], [Robinson, 1965], [Kowalski, 19796]. Резолюция — это
правило вывода используемое для построения опровержений (refutation) (подраздел 12.2.3).
Важным практическим применением метода резолюции, в частности при создании систем
опровержения, является современное поколение интерпретаторов языка PROLOG (рис. 12.2).
Принцип резолюции (или разрешения), введенный в работе [Robinson, 1965],
описывает способ обнаружения противоречий в базе данных дизъюнктивных выражений при
минимальном использовании подстановок. Опровержение разрешения — это способ
доказательства теоремы, основанный на формулировке обратного утверждения и
добавлении отрицательного высказывания к множеству известных аксном, которые по
предположению считаются истинными. Затем правило резолюции используется для
доказательства того, что такое предположение ведет к противоречию (доказательство от
обратного). Поскольку в процессе доказательства теоремы показывается, что обратное
утверждение несовместимо с существующим набором аксиом, исходное утверждение
должно быть истинным. В этом и состоит доказательство теорем.
Процесс доказательства от обратного состоит нз следующих этапов.
1. Предположения или аксиомы приводятся к дизъюнктивной форме (clause form)
(подраздел 12.2.2).
2' тив"нонРф^рмеИ°М Л°6аВЛЯеТСЯ 0WH.,e Доказываемого утверждения в дизьюнк-
3'«тсТновГосГГ™0' Ра3рСШеШе Э™ Дизъюнктов, в результате чего пол>»
4 Г ВаННЫе "а них *«™„кт„вные выражения (подраздел 12.2.3).
4. Ге„е„ пу„м выраженне означающ£е
о го», что о™ц"„ТГННЫе ДИ П°'^ен"я Ч*»™ выражения, свидетельству"'
тр"цан"я — истинно (подраздел 12.2.4).
■ А лоянительные №просы решвния задач искусственного интолл*«
резолюция - это согласованное правило вывода (см
ся полным Резолюция является пошой в ы,« mpoeepJ„2 ?e"ael0"° "Г""""'
Называний имеется противоречие, то на основе этого набо„=,Т 0рс mJ"
ть пустое или нулевое выражение. Этот вопрос более подообио^ М°ЖИ° СГСНСР"Р°-
Гни'сушествующих стратегий построения'опроГр^ГГ^СГ 12 V 7"
■„казательства от обратного требуется, чтобы аксиомы и ™ |юДР»леле 12.2.4. Для
££. б-». при«дснН к „оР,т0й дипю„;:;27Ф:Р7 х::^т°утвер-
Гвной форме логическая база данных представляется I Г„, „1в >- д'пък>"|<-
Наиболее типичная форма резолюции, получившая название бинарной резошш.и
(Ы„агу resolofon), применяется к двум выражениям, одно из которыхТвляетс л Z
лом, а другое - его отрицанием. Если литералы содержат переменные, то их „еоГоди
м0 унифицировать и привести к эквивалентному виду. Затем генерируется новое выпа-
Жение, состоящее из дизъюнктов всех предикатов этих двух выражений, за исключением
этого литерала и его отрицания, которые считаются "вычеркнутыми"
Прежде чем перейти к более строгому описанию этой методики в следующем
разделе, рассмотрим простейший пример. На основе принципа резолюции докажем
утверждение, аналогичное полученному с помощью правила модус поненс. При этом ставится
задача не показать эквивалентность правил вывода (принцип резолюции на самом деле
является более общим, чем правило отделенют модус поненс (композиционное правило)),
а лишь познакомить читателя с этим процессом.
Докажем, что утверждение "Фидо смертен" следует из утверждений "Фидо —
собака", "Собаки — это животные" н "Все животные смертны". Преобразовывая этн
предположения в предикатную форму и применяя правило отделения, получим следующее.
1. Собаки — это животные: V(X)(dog(X)->anima/(X)).
2. Фидо — собака: dog(fido).
3. На основе правила отделения и подстановки {fidoIX} получим: animal(fido).
4. Все животные смертны: V(Y)(animal(Y)-*die(Y)).
5. На основе правила отделения и подстановки [fido/Y] получим: die(fido).
По принципу резолюции этн предикаты необходимо преобразовать в
дизъюнктивную форму.
Предикатная форма Дизъюнктивная форма
V(X)(dog(X)->an/ma/(>0) ^dog(X)van/ma/(X)
dog(ffdo) dog(fido)
V(V)(amma/(r)->d;e(V)) -an/ma/(V)vdie(V)
Запишем отрицание целевого утверждения "Фидо смертен".
^die(fido) -.die(fido)
Выполняя резолюцию с использованием обратных литералов, получим новые
дизъюнктивные выражения, представленные на рис. 12.2. Этот процесс зачастую называют
созданием конфликта (clashing). - ,,_„
Символ 1 „а рис. 12.2 означает пустой дизъюнкт или противоречие. О»' ™»»™W-
« «онфликг предиката и его отрицания, т.е. наличие двух "Р°™юр™В" ™™-
« в пространстве дизъюнктов Последовательность подстановок (операции чнифика
ава 12. Автоматические рассуждения
„катов к эквивалентной форме, позволяет on» I
. ляя приведен!» преди высказываиие истинно. Hanp^fj I
делить з»»«"«" "^ ли некоторое су иа рис. 12.2 означает, что ф,,до^ |
Ц^ТГ^^^^^"- Б°Лее П°ДР ЭТ°Т "РИМер^
„зъюикгивиой формы для опровержения
12.2.2. Построение дизънШ
разрешения „„„ания всех операторов базы данных, описывающих
Метод резолюши требует гфеобраз форме. Это связано с тем, что резолюцш, - ^
JZZI стандартной Д^^яЩ*« созданию новых дизьюнктов. Такая форма
^над парой Д--"еХ—- а,-зьЮ„™ов (conjunction of disjun^.
Оставления базы данных на»*»"=„„, все вьфажеиия в базе данных о„„овре„е„.
Zo конъюнкция, поскольку по по Д ^ _ это №3ъюиКищ, поскольку каждое выражение
„о являются истинными. В то ж у Hmm TaK11M образом, всю базу данных,
предписывается с ■»«£»££ 0ПРисать в следующей форме,
ценную на рис. 12. , l{Y)vdie{Y))Aidog(fido)).
i-,doo(X)vi»"ma"x" l
1 " ver добавить (с помощью конъюнкции) отрицание целевого
К этому выражению следует образом, база данных описывается как
idog(X) van/ma/(X)
animallX) v di'e(y)
dog(fido)
(fcfo/Y)
d/'e(n'do)
ftic. /2.2. Доказательство разрешения dm задачи "смертной собаки"
530 Часть V, Дополнительные вопросы решения задач искусственного интелл^
Рассмотрим алгоритм, представляющий собой последоватеп.»
„„„ведению набора предикатов к дизъюнктивной форме вТь? ,,1реобГ°"аИиП
""„/что «кис преобразования можно использовать!^ ппивелси В "^ '№' "**
;„„ых, связанных квантором существования [Chang и Lee, 1973]. Однако приТтом
Гоняется значение истинности выражений. Следовательно, если в „сходном множестве
„редикатов есть противоречие, то оно остается „ в дизъюнктивной форме. Такие
преобразования ие нарушают полноты доказательства опровержения.
Проиллюстрируем процесс приведения к конъюнктивной нормальной форме на
конкретном примере и дадим краткое пояснение каждому из шагов. Эти пояснения не претендуют на
роль доказательства эквивалентное™ преобразований для теории предикатов в целом
В следующих выражениях согласно принятым в главе 2 соглашениям прописными
буквами обозначены переменные (W, X, У н Z), строчными буквами из середины
алфавита (/, тип)— константы и граничные значения, а начальными строчными буквами
(а, о, с, d и е) — имена предикатов. Для улучшения читабельности выражений
используется два типа скобок: круглые и квадратные. В качестве примера рассмотрим
выражение, где X, Y н Z — переменные, а / — константа.
(УХ)([а(Х)лЬ(Х)]-»[е(Х, ))a(3V)((3Z)[c(V, 2)]-»d(X, V))])v(VX)(e(X)). (i)
1. Сначала исключим оператор -> с использованием эквивалентной формы,
приведенной в главе 2: a—»b=-iavb. После этого преобразования выражение (i) примет вид
(VX)(-,[a(X)Ab(X)]v[e(X, /M3Y")(OZ)[-,e(Y", Z))vcHX, V"))])v(VX)(e(X)). (il)
2. Теперь выполним преобразование операторов отрицания. Для этого можно
воспользоваться формулами, описанными в главе 2, например такими.
-,<-,а)«а
-,(3X)a(X)s(VX)-.a(X)
ЧУХ)Ь(ХНЭХЬЬ(Х)
->{aAb)=-iav^b
-i(avb)s-,aA-ib
Используя эти тождества, формулу (ii) можно привести к виду
<VX)([-,a(X)v-,b(X)]v[c(X, /)A(3V)({3Z)bc(V, Z)]vd(X. V))])v(VX)(e(X)). (iii)
3. Теперь переименуем все переменные таким образом, чтобы переменные, ограниченные
различными кванторами, имели различные имена. (Эта операция называется <™гдар™-
зацией переменных.) Как было указано в главе 2. имя переменной - это .тишь
обозначение "знакоместа". Оно не влияет ни на истинность выражения, ни на общность
высказывания. Воспользуемся на этом шаге следующим преобразованием
((VX)a(X)v(vX)b(X)H(VX)a(X)v(W)b(V-)).
Поскольку в (iii) содержится два вхождения переменной X, переименуем ее
следующим образом ,.„, ,. .
(VX)(ba(x)v.b(X,]v[c(X, „л,ЭУ)((32,ЬС(У, Z,]vd(X. УШМ*И0(в(И0). (IV)
ава 12. Автоматические рассуждения
531
„ не изменяя порядок нх следования. Это мо».
4 Перс—" - «-ТзСГисключена возможность любого конфликт, Мо^
(VX)(3>-)(3ZK^)(H^ ^/„шой. или „/,«««*<.« „о/МЛМ1„,0Й ф
На этом шаге получено выр*е„^ ^^ шнкены в начал0 предложен,,,,
(prenex normal form), пос ествования с помощью процесса «оле^
5 Теперь исключим все квантор >|1спользуется квантор сущСствова„и» №
(skolemizarion). В »ЫР«™" * т переменную, связанную квантором суЩе„.
„енной У. Если ""Р3*,. 7 )), значит, существует значение переменной г
вования. например «' -^ Сколемнзация позволяет определить такое
„ри котором выражение u „еобязательно показывает, так получить это
значение. При этом ско .^ метадом пр,1своения имени значению, которое
значение. Она лишь мым значением является к, то указанное выражс.
Аижяо существовать, ы. ^ ^ Ит^ (3X)(dog(X)) можно заменить выра.
нне можно записать в виде ^"^^ ю области определения X для обозначения
жением dogtfdo), где и ^^ fldo назь1вается сколемовскои константой
отдельного 3K3CS"^ едикат „меет несколько аргументов, и переменная, свя-
(skolem constant). ^.^ следует За переменными, связанными квантором
^0Тш"то она должна быть функцией этих переменных. Это отражено в I
^це" е сколемнзашш. Рассмотрим выражение
(VX)(3y)(moff>er(X, V)).
Оно означает что у каждого человека есть мать. Каждый человек — это перемен-
иая X, а существование матерн - функция от конкретно взятого человека X. В ре-
зультате сколемизации получим
iyX)mother(X, m(X)).
Это означает, что у каждого X есть мать (значение т для этого X). Вот другой при- I
мер. Выражение !
<VX)(W)(3Z)<VH')(foo(X, Y.Z, W))
в результате сколемизации можно привести к виду
(VX)(W)(VW)(foo(X, У, f(X, Y), W)).
Связанные квантором существования переменные V и Z находятся под квантором
всеобщности переменной X (справа от нее), ио не под квантором всеобщности
переменной W. Поэтому каждую из этих переменных можно заменить сколемовскои ,
функцией от X. Заменяя переменную Y сколемовскои функцией f(X), a Z — gH). I
формулу (v) преобразуем к виду !
(VX)(VW)(ba(X)v-,b(X)]v[c(X, ОлЬс(т(Х), 9(X))vd(X, f(X)))]ve(W)>- Ivl)
После сколемизации можно перейти к п. 6, в котором просто удаляется префикс
6. Исключим все кванторы всеобщности. К этому моменту (после п. 5) остались лишь
переменные, связанные кванторами всеобщности, и все конфликты ntas»m
устранены (в п. 3). Следовательно, все кванторы можно опустить, поскольку л
процедура доказательства предполагает выполнение утверждения для всех V
менных. Формула (vi) примет вид
532
Часть V. Дополнительные вопросы решения задач искусственного интел/»1"8
ha(X)v^o(X)]v[c(X, /)л(-,с(,(х), B,X))vd(X. f(X)),lve(lv)
7 Теперь представим это выражение в виде конъюнюти
г п0ЛЬЗРуемся свойствами ассоциативности .^Г™""* ^ ™° **'
помним (глава 2), что Дистрибутивности операций л и v. Ha-
av(bvc)=(avb)vc,
ал(Ьлс)=(алЬ)лс.
Это означает, что операции л и v можно гттп„„„
рГрН необходимости можно ^^JZ^^Z^^ZltZ
вы 2. Поскольку выражение Аиефниугнвности из гла-
aA(twc)
уже представляет собой дизьюнктив.гую форму, его не нужно преобразовьшать. Однако
для операции дизъюнкции следует воспользоваться дистрибутивным законом
av(t>AC)=(avb)A(avc).
Окончательно выражение (vii) примет вид
ba(X)v-,b(X)vc(X, /)ve(l/V)]Aba(X)v^b(X)v^c(f(X), g(X))vd(X, f(X))ve(lV)]. (viii)
8. Теперь выделим каждый конъюнкт в отдельное выражение. Предложение (viii)
будет представлено в виде двух выражений
-*(X)v-.b(X)vc(X, /)ve(W), (jxa)
^a(X)v^b(X)v^c(f(X), g(X))vd(X, f(X))ve(W). (ixb)
9. И, наконец, снова разделим переменные, т.е. присвоим переменным в каждом
выражении, сгенерированном в п. 8, различные имена. Это делается на основе
приведенного в главе 2 тождества
(УХ)(а(Х)лЬ(Х))г(УХ)а(Х)л(УУ)Ь(Х),
которое в свою очередь следует нз того, что имена переменных — это лишь
обозначения знакомест. Теперь, вводя новые имена переменных U и V. преобразуем
формулы (ixa) и (ixb) к виду
^a(X)v-.b(X)vc(X, /)ve(lV), (xa)
-.a(U)v-,D(U)v-,c(f(U), g<U))vd(U, f(U))ve(l/). (xb)
Значение такой стандартизации станет понятно только после описания процедуры
унификации в процессе резолюции. Она сводится к поиску наиболее общей унифицированной
формы, обеспечивающей эквивалентность предикатов в двух выражениях, а затем ее
подстановке вместо всех переменных с одинаковыми именами в рамках одного выражения.
Так, если имена некоторых переменных совпадают, то в процессе унификации они могут
быть переименованы с последующей (возможной) потерей общности решений.
Описанный процесс используется для приведения любого набора выражений нз
теории предикатов к дизъюнктивной форме. При этом свойство полноты опровержения
сохраняется. Проиллюстрируем процедуру резолюции, используемую для генерации
доказательств на основе этих выражений.
!2-2.3. Процедура доказательства на основе бинарной резолюции
Процедура опровержения разрешения (resolnrion refutation) дает °™"Ж™.
г*рнРуст новый результат путем сведения набора выражении к противоречию, пред
,г- Автоматические рассуждения
533
(J) Противоречие возникает при попарной рез0„
ценному нулевым вырази • ^ ^ „ р к противоречиво *
выражений из б»Д»"^ выраж„ие -/**»ь<*«<™ (resolvent) - добавл,^
мую. то полученное в ре У лжаетсЯ.
б^уданныхвыражении.ипрои сходитпроцесс Ющ,и в исчислении пре
Прежде чем "«""VV, ,,счисления высказывании (без переменных). Рассмотрим
рассмотри пример из оол^ з о6ласти „счисления высказываний
два родительских выражения р
p1:a,va,v...ve,,.
содержГших «1 а, и Ь, при которых ^,= Ь, где 1<Кп и KySm. в резуЛьтате
бинарной резолюции получим выражение
a va,v...va,,va,.,v...va„v&,v6,v...vA,vb,.,v...v "„■
Таким образом, резольвента состоит из дизъюнкции всех литералов двух родитель-
ских выражений за исключением литералов а, и Ь,.
Простое рассуждение позволит выйти за рамки принципа резолюции. Допустим, что
ач-b и bvc — два истинных выражения. Заметим, что одио из значений Ь илн -,Ь
обязательно истинно, а второе — ложно (Ьч^Ь - это тавтология). Следовательно, значение
одного из литералов в выражении
avc
должно быть истинно. Выражение avc — это резольвента двух родительских выражений
av-ib Hfjvc.
Рассмотрим теперь пример из области исчисления высказываний. Требуется
получить значение а на основе следующих аксиом (естественно, /*—m=m—>/ для всех
предложений / и т):
at-Ьлс,
Ь,
evf,
A\-iA.
Приведем первую аксиому к дизъюнктивной форме.
а<-Ьлс,
av-,(bAC), поскольку /->ms-,/vm,
av-,bv^c, по закону де Моргана.
раж°нХИЫе аКС"°МЬ1 Пр"вояить не "У™°. поэтому получаем набор следующих вы-
av-,fjv-,c
Ь,
cv-,c/v-,e,
evf,
d,
-,f.
•женииТо&Ге^Гн^Г Р"тЮщт "°к™"° на рис. 12.3. Сначала к набору »«£
«■'Ражений еодержиТпр^ор"™™ ВЫражеН|,я а' Символ I означает, что база дан»"'
4«"bV. Дополнительные вопросы решения задач искусственного интеял^
Рис. 12.S. Доказательство теоремы методом
резолюции для примера из области исчисления
высказываний
, Для того чтобы использовать бинарную резолюцию в исчислении предикатов, при
котором каждый литерал может содержать переменные, необходимо обеспечить
эквивалентность двух литералов с различными именами переменных или одинаковым постоянным
значением. В подразделе 2.3.2 был определен процесс унификации, реализующий
согласованную и более общую подстановку для обеспечения эквивалентности предикатов.
Алгоритм резолюции в исчислении предикатов во многом аналогичен этому же
процессу для исчисления высказываний за исключением следующих моментов.
1 - Литерал и его отрицание в родительских выражениях дают резольвенту только в том
случае, если они унифицированы для некоторой подстановки а. Затем а применяется
к этой резольвенте до ее добавления к набору дизъюнктов. При этом требуется,
чтобы а была наиболее общим унификатором для родительских выражений.
2. Унифицирующие подстановки, используемые для поиска противоречий, обеспечивают
связывание переменных, при котором исходный запрос является истинным. Этот
прочесе, получивший название излечения ответа (answer extraction), будет описан ниже.
Иногда для нескольких литералов в одном выражении существует объединяющая
ПадстаНовка. При этом может не существовать опровержения для наборов дизъюнктов,
держащих это выражение, даже если этот набор является противоречивым. Например.
Р^мотрим выражения
ы Не сложно заметить что при простой резолюции эти выражения можио свести лишь
"""ивадентяой форме или тавтологии, а ие к противоречию. То есть никакая подста-
г их противоречивыми.
2 Автоматические
рассуждения
535
..„„ np.iMC""^ факторизацию выражении (factoring, Ег
<;„,,« ситуаи'"1 мож»»'' выражении имеет наиболее общий униЛ» "
B"M^WpW B НСК° Т1жно заменить новым выражением, по"!^
"°тт:е£У.^''™ '"Г.Г-зто исходное вьфажение. к котором,1"!^
НаЗВМ „вка наиболее °6ш£™*,,и р(Х) vp< fl У)) можно унифицировать е по„оЩь10 „Г
™, литерала а выражен^ в обою литсралах н пояучим .., "°Д-
рМП)»Р(«П>- '^ „лючиии» факторизацию, является полной в смысле 0 '
сщ*^**™%£, переменных (выполняемую в п 3 подраздела 12.2.2) MJHo
вержения. Стандарт,.'aun ^ снне факторизации. Факторизацию также „«,,„
]|НТСр„ретировать и»: пр^ >— в пр0цедуре гиперрезолюции (hyperresolution)
„о^гмятпивать как част v
рассмяр™»'" „-12 4''
„писанной в подраздга _ _". ра3решения из области исчисления предикатов Рас
J^S—-™ ""еита"'
* « - ^.«т который сдаст экзамен по истории и выигрывает в лотерею, - счасш,.
Любо,, cry» . ливь|й или отраТельный студент может едать все экзамены.
Л^ТГс относится к числу старательных студентов, но достаточно удачлив. Любой уда,.
™1с1уде„т»ь,„п,ь,вает.лотеРею.Счаетл„вл„Джо„?
Сначала запишем эти предложения в предикатной форме.
Любой студент, который сдаст экзамен по истории и выигрывает в лотерею, — счастлив:
VX&ass{X, history)Min{X, fortery)->/)appy(X)).
Известно, что любой удачливый или старательный студент может сдать все экзамены:
VXW(study(X)v/ucKy(X)->pass(X, У)).
Джон не относится к числу старательных студентов, но достаточно удачлив:
-TStudy(john)Aluckyyohn).
Любой удачливый студент выигрывает в лотерею:
4X[lucky{X)->v/in(X, lottery)).
Приведем эти четыре высказывания предикатов к дизъюнктивной фор*
(подраздел 12.2.2).
1--*ass(X,Wstory)v-,w/n(X,/oftery)vf,appy(X).
2.-.study(y)vpass(y,Z).
3-^ucky(W)vpass(rV, V).
4-^studyOofin).
5./ucky(j'ohn).
^-'"ckyWUwinw, lottery)
"*"'" " *"" ""Р^ниям отрицание заключения в дизъюнктивной форме
™Ppyiiohn).
'"ZZK[T?wma-показан™" •« р- >2-4- °^*aeT процссс пол!*
Довательно, доказывает, что Джон счастлив. ^^
аСТ" V' Аог,олнигельные вопросы решения задач искусственного инте""6
в качестве последнего примера рассмотрим задачу • w„ -
«««чу интересной жизни"
Все небедные и умные люди счастливы Человек чи
читать и является состоятельным человеком СчастлГ.Г"'" *"""'■ ~ жгш^ Д*°" Умеет
Можно ли указать человека, живущего интересной жимы*.*""' Ж"8УГ и1тРк"°" жизнью.
Предполагается, что
vX(smart(X)^s,up,'d(X)) и ^(и/еаУ№у(У)^р00л(у))
Тогда получим
VX(-rpoor(X)Asmart(X)-»fiappy(X)),
WlreadlVJ-jsmariiy)),
read(john)A^poor(john),
VZ(happy(Z)-»exc/(mg(Z)).
-i pass(X, history) v n mn(X, lottery) v ftappy(X)
/ucky(U) v win{U, lottery)
happytjohn)
ilohn/U)
luckytjohn) -i passljohn, history) v -i luckytjohn)
{john/V, history/W)
-i /ис*у(Ю у passW И/)
luckytjohn)
Рис. 12.4. Опровержение разрешения для задачи "счастливого студента"
Т'танне заключения имеет вид
~*3W(exciting{W)).
тивн - Преднкатные выражения для задачи "интересной жизни" приводятся к дизьюнк-
0И *°Рме следующим образом.
" Авт°матические рассуждения
537
readljohn).
^'"'"IL^^ примера показаииа рис. 12.5.
граФопр№р; ,««.-*
v -i smartlX) v happylX)
pooM^smartW -. readingsmartin
(V/X)
п роол(/олл)
poortY) v -i read! И
(/ofm/Y)
readljohn)
Рис. 12.5. Доказательство разрешения для задачи "интересной жизни"
12.2.4. Стратегии и методы упрощения резолюции
На рис. 12.6 показано отличное от представленного на рис. 12.5 дерево
доказательства для того же пространства поиска. Эти доказательства чем-то схожи, например, для
резолюции они оба требуют выполнения пяти действий. Кроме того, в обоих
доказательствах с помощью подстановки унификации получено, что Джон относится к числу людей-
живущих "интересной жизнью".
Однако такое сходство не обязательно. При определении системы резолюции
(подраздел 12.2.3) порядок комбинации дизъюнктивных выражений не устанавливал»
имеГяН^ТЬ'Г0МеНТ: eC™ В "Р°"Р»<™ дизъюнктов существует N выражен^
— то-Г ^ Ш К°МбнНад™ »« ™ первом уровне. Результирующий иабо р *
ноГ :j^e ГГ„"а° ГлГ *" ™" 2°% »"™й ^^ К ^^
больше, to больших Г ЛедуЮщем этапе -пело возможных комбинации "»"еТ
^^oZl^lZ^HmWmbHUU Р0СТ Д0СтаТОЧН° бЫСТР° "Р
Частьу.дополнительныевопросырешениязадачискусстввнногоинтвлле^
Поэтому в процедурах резолюции, которые относятся к r„ K
„ач, очень большое значение имеют эвристики по.Гп Т'" м<™Дам решений за-
ен„ым в главе 4, для каждой конкретной проблемы „„ 1одобно "Ристикам,
рассмотри наилучшей стратегии. Тем не менее существукГоб СуШе™**" строгого обоснова-
р0ТЬся с экспоненцнальньш ростом числа возможных комбни^Г™' П03а0тютт 6o'
"■ happtfZ) v excitinglZ)
РоофО V -, smartlX) V happyVO
-■ reacHY) V exciting/Y) V роо^У)
{/олп/Y}
readljohn) - readljohn) V exdthgUohn)
' poonjohn)
{john/W)
Рис. 12.6. Еще одно опровержение разрешения для задачи "интересной жизни"
Прежде чем приступить к описанию этих стратегий, необходимо сделать несколько
пояснений. Во-первых, основываясь на определении невыполнимости выражения из
главы 2, назовем набор дизъюнктивных выражений невыполнимым (a set of clauses is unsat-
isfiable), если не существует интерпретации, доказывающей выполнимость этого набора.
Во-вторых, правило вывода будем считать полным в смысле опровержения (refutation
complete), если невыполнимость набора дизъюнктивных выражений может быть
доказана с помощью одного этого правила. Этим свойством обладает процедура резолюции с
факторизацией [Chang и Lee, 1973]. И, наконец, стратегия является полной, если на ее
основе с помощью полного в смысле опровержения правила вывода можно
гарантированно найти опровержение для невыполнимого набора дизъюнктивных выражений.
Примером полной стратегии является поиск в ширину (breadth-first).
Стратегия поиска в ширину
Приведенный выше анализ сложности полного перебора дизъюнктивных выражений
°сновывается на поиске в ширину. На первом этапе выполняется бинарная резолюция
всех дизъюнктов в пространстве выражений. На следующем этапе в пространство поиска
* исходным выражениям добавляются дизъюнктивные выражения, сгенерированные при
Реаолющщ дизъюнктов. На n-м этапе обрабатываются все выражения, полученные ра-
се- а также исходное множество дизъюиктов.
- Автоматические рассуждения
539
„чень быстрому разрастанию пространства поиска, „ОЭТо,
Такая страт,™, приводе к. о«нь^ 0днак0 она ойладает интересным свойством. П
ис ™Гдтдля решения *■»»££ гарант„руст нахождение кратчайшего пути „ ред
1ГпГску в ширину. ™«?™Z*cl только с одним уровнем и ие предполагает „„,
„.„.иг на каждом эт
эму
ие ™„годяа ДЛЯ pew""» ^«да гарант„рует нахождение кратчайшего пути к реЩс.
L „ ™7ску в ширину- эта стратегия н с щннм уровнем и ие предполагает „И|н
„Гп^лГку „аТаждом ^f^, является полной, поскольку, если ее «^
Itутлубдеишт. Кроме того Данн^^^ о6наружит опровержение, если таков„е
зевать достаточно *»«\ °^я поиска в ширину является достаточно адекватад
существует. Следовательно «р» м выше. На рис 12.7 приводится „ллюсгра-
--ГГГГ^-задаЧи^ресиойжНзн„.
Рис. /2.7. Яолное пространство состояний для задачи ■'интересной жизни", полученное при
использовании стратеги поиска в ширину (для двух уровней)
Стратегия "множества поддержки"
Стратегия "множества поддержки" — это отличная стратегия поиска в больших
пространствах дизъюнктивных выражений [Wos и Robinson, 1968]. Для некоторого набора
исходных дизъюнктивных выражений S можно указать подмножество Г, называемое
множеством поддержки. Для реализации этой стратегии необходимо, чтобы одна из
резольвент в каждом опровержении имела предка из множества поддержки. Можно
доказать, что если S — невыполнимый набор дизъюнктов, a S-T— выполнимый, то
стратегия множества поддержки является полной в смысле опровержения [Wos и др., 1984].
Если исходный набор дизъюнктов является согласованным, то этим требованиям
удовлетворяет любое множество поддержки, включающее отрицание исходного запроса.
Эта стратегия основывается
на том, что добавление отрицания доказываемого
ния приводит к противоречивости пространства возможных дизъюнктов. Множество
поддержки ускоряет процесс резолюции для пар выражений, в которых одно
представляет собой отрицание цели
На рис. 12.5 приведен пример применения
или полученное на его основе дизъюнктивное выражение.
стратегии "множества поддер:
жки" Д^ Ре'
теши. Одним из способов
> опровержения, оно может составлять основу полной к
реализации такой стратегии является выполнение
поиска »
ШИРИНУ ДЛЯ Rf-PV а™ ""' ""*"" чрчИЛИИ ИИЛИС1СИ DD1""— ^.ГО"
раздо^47еГвнГ„Ь1МН°ЖеСТВ П0ДДЧ™ ^"«р-ения. Естественно, э«™
Тфективныи путь, чем поиск в ширину в пространстве всех дизъкэнктив»
Часть V. Допо„„ительные вопрош решеиия задач искусственного интелл^
|0аже"ий- Необходимо лишь удостовериться в том чт
"Тщания целевого выражения, а также все их потомки. ° Пр0Верень1 т Резольвенты or
,атегия предпочтении единичного выражения
СП»-— —■——"»
Заметим, что в приведенных выше примерах резолюции „„
„„явлении выражения, не содержащего литералов. Следоват 'Р°™в°Речие.возиикает при
„„и результирующего выражения с меньшим число^?~™T2T "'" """"'
ге„ерации выражения, не содержащего литералов вообще В ч^еттности „„„ "
жжения, состоящего из одного литерала или так „»,„.. час™ос™, получение вы-
S dause), гарантирует, что VVoJ^Z^Z^jt™"™ ™Pm*
ыражение. Страте™ предпочтения единичное выражение поелолГ" Р°ДИТеЛЬСК0Е
Пользование единичных выражений в процессе peUZГр^Гс"
проиллюстрирована для задачи "интересной жизни". Совместное применение сГТег„„
предпочтения единичного выражения и стратегии "множества поддержки" позвсГет по
„учить более эффективную полную стратегию. иимиляет по-
1 вхсШпд{ Щ -, happyiZ) v exciting[Z)
-< happyiZ) poor(X) v -, smart(X) v happy[X)
-i poor(john) poor(X) v n smart(X)
(/олл/Х)
-i smartijohn) ^ read{Y) v smart(Y)
(john/Y)
read(john)
-i readijohn)
Pile. 12.8. Использование стратегии предпочтения единичного
выражения для решения задачи 'интересной жизни"
Стратегия единичного разрешения — это близкая стратегия, требующая, чтобы одна
"] резольвент всегда представляла собой единичное выражение. Это более строгое тре-
«вание, чем требования выдвигаемые стратегией предпочтения единичного выражения.
™*но показать, что стратегия единичного разрешения не является полной. Для этого
™*но использовать тот же пример, что и для демонстрации неполноты стратегии ли-
"ей"°" входной формы.
Глава 1? л 541
хс автоматические рассуждения
Стратеги» линейной вх предполагает прямое использование отр„Цанц
с кгм линейной входной Ф^ ^ получению вого дизъю„кт„ВИоГ0 „ ^ и,
цели и исходных «Г^,^ с одной из аксиом. Полненный результат рЮрв£««
,а счет резолюции отрицания ц ^^ выражсния, которое в свою очередь **.
ся с одной из аксиом для «" продолжается до получения пустого дизъюнкта ""
ется с одной из аксиом. JT г' я да, ВНОвь полученного выражения и аксиом
сформулированноидая и . лющ|и ^ |( не используются две аксиомы вмесге ни-
когда не используются да Р ^^ в чем иесложно убедиться на npmj'
™ Л,гаеЙН00,1ГрДаТз ^Тдшъюнктпвных выражений (который, очевидно, ,££
следующего наоор' какое ||3 дизъюнктивных выражений выбрано в каЧе
S^^Гц^^гиялинейноговходанеприводигкпротиворечи.о.
-,av-J>,
av^to,
^avb,
avb.
Другие стратегии и методы упрощения
Автор не ставил перед собой задачу исчерпывающего анализа всех стратегий или
большинства сложных приемов доказательства теорем на основе логического вывода и принципа
резолюции. Они описаны в других источниках, в частности в работах [Wos, 1984] и [Wos,
1988]. Наша задача — познакомить читателя с основными средствами, разработанными для
этой области исследовашш, и показать, как их можно использовать для решения задач.
Процедура резолюции — это один из приемов, применяемых в слабых методах решения задач.
В этом смысле резолюцию можно рассматривать как механизм вывода для
исчисления предикатов, требующий дополнительного анализа и осторожного применения
различных стратегий. В представляющих интерес больших задачах случайный выбор
выражений для резолюции столь же бесперспективен, как и попытки написать хорошую
статью путем нажатия случайных комбинаций клавиш иа компьютере. Количество таких
комбинаций слишком велико!
Используемые в этой главе примеры тривиально малы и содержат все необходимые для
решения задачи дизъюнкты (и не только необходимые). Такая ситуация в реальных задачах
встречается довольно редко. Выше было рассмотрено несколько простых стратегий борьбы с
этап комбинаторной сложностью. В завершение этого подраздела приведем несколько
важных соображений, относящихся к разработке систем решения задач на основе резолюции
в разделе 12.3 будет показано, как с помощью системы опровержения разрешения при ком-
22лГ"" ПраТе™Л П0"СКа можнс обеспечить "семантику" для логического программ
Ши vZr0gramminS)'" Ча™0СТН'"" P4>a6°™ интерпретаторов для языка PROLOG.
п.юС„ГсГ„И П°ИСК0М °ЧеИЬ П0ЛИН0 к°»бинировать стратегии, например, страте-
™1 „сГк ™оЖИГ"™" С° СТРЭТе™еЙ Ч-Дпочтения единичного выражения. Э. '
право) ТаГе" Г" "*"""• В а?т выв°«а <ѰЙРУ «"Ч*"" ^ ,
Подобное ,:::™"е Ми°олее эффективно для усечен™ пространства по
«зыке PROLOG (раз„елТ23)аНИе """""" "^ ™Ж"уЮ Р°"Ь в "Р^™"1*"'*
С однойТо'р^ТнеХ!0™ Ст"атегии решения может служить общность заключен»'1
Р ны, необходимо обеспечить максимально возможную общность про*»
Насть V. Дополнительные вопросы решения задач искусственного *****
точных решений, поскольку это дает большую свободу их иеппп,.,™.
Гии Так, резолюцию дизъюнктивных выражений ™?й "'пользования при реэолю-
^зьшання переменных, »™?™cPUoh^Zs—T СПСЦИаЛИМЦ"и ™ сч"
„ ,„™, С лтптой г™™,, . неооходимо отложить на максимально
позднее время. L другой стороны, если решение требует связывания коикоетнпх „еле
„енных, как при выяснении, инфицирован ли Лжг™ тлГ конкретных пере-
\, тпгчоп) н \staohllnfertmn\\ m стафилококком, подстановки
{i°h оятность н екооо ть и ' °» "" 01Таничнт" пространство поиска и повь,-
енть вероятность и скорость нахождения решения
При выборе стратегии большое значение имеет вопрос полноты. В некоторых прило-
жен„ях очень важно знать, что решение обязательно будет найдено (если оно существу.
„), Это можно гарантировать, используя полные стратегии
Повышения эффективности можно добиться за счет ускорения проверки
соответствия. Можно исключить избыточные (н ресурсоемкие) операции унификации выражений,
которые ие приводят к получению новых резольвент, индексируя каждое дизъюнктивное
выражение по содержащимся в нем литералам и их положительным и отрицательным
значениям. Это позволяет напрямую находить потенциальные резольвенты для любого
выражения. Кроме того, некоторые выражения необходимо исключить сразу же после их
получения. Не следует рассматривать тавтологии, поскольку онн никогда не могут
принимать ложное значение, и не дают новой информации для получения решения.
Еще одним типом выражений, не несущих новой информации, являются так
называемые категоризированные (subsumed) выражения — частный случай уже
существующего более общего выражения. Например, выражение pQohn) не информативно в
пространстве, где уже существует выражение VX(p(X)). В этом случае p(john) можно
опустить без потерн общности. Это даже полезно, поскольку количество выражений в
пространстве уменьшается. Аналогично выражение р(Х) относится к категории
p(X)vq(X). Частная информация ничего ие добавляет к уже существующей общей.
И, наконец, включение процедур (procedural attachment) позволяет без дальнейшего
поиска оценить или обработать любое выражение, которое может дать новую
информацию. Оно основано на принципах арифметики и состоит в сравнении атомов или
выражений либо "запуске" любой другой детерминистской процедуры, добавляющей в
процессе решения задачи конкретную информацию или ограничения. Например, можно
использовать процедуру для вычисления связывания переменной при наличии для этого
достаточной информации. Такое связывание переменной ограничивает возможные
варианты резолюции и приводит к усечению пространства поиска.
Теперь рассмотрим, как в процессе опровержения можно извлекать ответы.
12.2.5. Извлечение ответов в процессе опровержения
Примеры, для которых гипотеза истинна, представляют собой подстановки для
поиска опровержения. Следовательно, сохраняя информацию о подстановках Унификации,
сделанных при опровержении разрешен,.*, можно получить данные для корректного
ответа. В этом подразделе будут рассмотрены три таких примера и метод учета для
излечения ответов из опровержения разрешения. -тказательсп™ за-
Метод записи ответов очень прост. Берется ^^^^^^Т^Тс,
Учение и к нему добавляется каждая ^^^^^ZГ.Д»сделан-
Резолюции. Таким образом, исходное заключение сгано» ' _н0„ реалнзацн И ЭТО
*« в процессе резолюции подстановок унификации. При ш» пьют^р Р
'»«т потребовать увеличения числа указателей, если при псп^шгр Р _
'** несколько вариантов выбора- Для получения альтернативное щ Р
ешения пона-
" "Вт°матические рассуждения
543
. например возврата. Однако при аккуратной реадщ,,
лооигся механизм >^^,Гм„жно -хранит,. ^и
•рассмотрим и«кмь">„вП^егоРинтересной жизнью, использованы подстановки *
шествования человека, «.вуш ]2 g ^т сохранить „сходную цель и примещГ;
А..„,ш„. представленные на р „„жения. мы получим ответ на воппп,- «. к
фикаш.", "Р""^1;;^" овки опровержения, мы получим ответ „а вопрос, кто „„
отму выражению все.ид ^
человек, жнвушни интересно! опровержения
разрешена рнс. 12.9 показано ^с п^ ^^^ „никт0 не живет
ния можно не только до ^ ^ опредмнть> ^ "счастливым"
интересной жизнью ло ^ ^^ результат, в котором под-
человеком является джо . опровержению, совпадают с
—^==TZ^ -ения. при которых
"Тс^ГеГГ;™-^ « простой исторне.
Сойка Фшо идет туда, куда «Дет ее хозяин Джон. Джон - в бнб-
лнотеке. Где Фидо?
Сначала представим эту историю в виде выражений
исчисления предикатов и сведем их к дизъюнктивной форме. Предикаты
имеют вид
atUohn,X)->at(fido,X),
aHjohn, library).
Дизъюнктивные выражения
-^atgohn, Y)vaWido, Y),
atljohn, library).
Отрицание заключения имеет вид
-таЦШо, Z).
Это означает, что Фидо — нигде.
На рис. 12.10 показан процесс извлечения ответа. Литерал,
отслеживающий подстановки унификации, — это исходный запрос
"Где Фидо?"
atlfido, Z).
tme раз подчеркнем, что подстановка унификации, приводящая к противоречию, со-
держит информацию об условиях выполнения исходного запроса: "Фндо в библиотеке"
Последний пример демонстрирует, как в процессе сколемюации можно получил
значение, из которого извлекается ответ. Рассмотрим следующую ситуацию.
Уиждото человека есть родитель. Родитель родителя - это дедушка. Требуется доказав
та у ковкретного человека Д*„„а ссть ^^
первтГТГ П|КДаожения »нсывак>т факты и взаимоотношения этой ситуации Во-
первых, Ук**Дого человека есть родитель"-
<«)(ЭУ)р(Х, У).
"Род^Родителя-это дедушка"-
Часть V. Дополнительные вопросы решения задач искусственного интел**"
exc/f/ng(iv)
KZ/Щ
exciting(Z]
extitingVQ
{Y/Xl
excitingiY)
ijohn/Y)
exciting(john)
{)
excitingljohn)
Рис. 12.9.
Подстановки унификации,
примененные к исходному
запросу; резолюция
которого
представлена на рис. 12.5
Требуется найти значение IV, при котором gp(john „. ,
„анием цели является предложение -aW)(gp(john Ю) KniT™ (VV)(9p0'°',n- W) 0тР""
-,gp(/ohn, W).
"■ atljohn, X) v a((fido, X)
tfjohn, library)
at(fido, library) r—i
Рис. 12.10. Прочесе извлечения ответа для задачи поиски Фиоо
В процессе приведения указанных выше предикатов к дизъюнктивной форме для
опровержения разрешения квантор существования в первом предикате "У каждого
человека есть родитель" требует построения сколемовскон функции. В данном случае она
строится достаточно просто: нужно взять конкретное значение X и найти для него
родителя. Функцию нахождения предка для X назовем ра(Х). Для Джона это будет его отец
или мать. Для данной задачи дизъюнктивная форма предикатов будет иметь вид:
р(Х,ра(Х)),
^p(W, y)v^P(y, Z)vgp(WZ),
-*gp{john, V).
Процессы опровержения разрешения н извлечения ответов для этой задачи
представлены на рис. 12.11. Отметим, что подстановки унификации при извлечении
ответа имеют вид
gpUohn. pa(paljohn))).
Ответ на вопрос о том. есть ли у Джона дедушка, состоит в нахождении "ближайшего
предка ближайшего предка Джона". Сколемизированная функция позволяет вычислить
этот результат.
Описанный выше общий процесс извлечения ответа может использоваться в любых
процедурах опровержения, где применяются подстановки унификации, показанные иа
Рис- 12.9 и 12.10, или сколемовские функции, показанные на рис. 12.11. Этот процесс
позволяет находить ответы Метод действительно очень прост: экземпляры (подстановки
Унификации), приводящие к противоречию, в то же время обеспечивают истинность
отрицания заключения (исходного запроса). Хотя в этом подразделе ие доказывается
применимость метода для тюбой задачи, работоспособность этого процесса проиллюстри-
Р°»ана иа нескольких примерах. Более подробное описание процесса извлечения ответов
"ожно найтн в [Nilsson. 19S0] и [Wos и др.. 1984].
-, gp lp"n- w
-. p(W,Y) V -. p(KZ) V gp(W.Z)
i plpaijohn), V) p(X,pa(X))
gp (/bftf. ^
(/'oftnA. psWAI
gp {John, 10
(pa(/ohn)/X,pa(X)/V)
ffp(/o/T/J.pa(paO'oftn)))
Рис 12.11. Сшкмюацш как часть процесса извлечения ответа
12.3. Язык PROLOG и автоматические рассуждения
12.3.1. Введение
Только понимание реализации языка программирования обеспечивает его корректное
использование, надежность полученных результатов и возможность устранения
побочных эффектов. В этом разделе будет описана семантика языка PROLOG и его связь с
вопросами автоматических рассуждений, рассмотренными в предыдущем разделе.
Серьезным ограничением процедуры резолюции, описанной в разделе 12.2, является
требование полной однородности базы данных задачи. В процессе приведения
предикатной формы описания нли преобразования дизъюнктивной формы может быть утеряна
важная информация о решении проблемы. Утраченная информация ие является
подтверждением или опровержением некоторой части проблемы, а скорее может служить
процедурным описанием способа использования этой информации. Например, отрицание
целевого выражения может иметь вид
av-,bvcv-,c/,
о поис-
где а, Ь, с и d — литералы. В процессе резолюции можно использовать стратегию г
ка для получения пустого дизъюнкта. Стратегию можно применять ко всем литералам, и
выЬор конкретного литерала зависит от выбора самой стратегии. Используемые для ре-
золюции стратегии являются слабыми эвристиками. Они не подразумевает глубоких
знании о конкретной предметной области задачи
обр":Гк%оеГг:йц;:;гвь,ражети в приведеином выше пр,,мере можно пг
Э(-Ьл-,СлС/.
та^;Ги~;,:°в1ШтеРПРе™Р0ВаТЬ ™: "Проверить, истинно ли .«Р»*"^
______^^^«™ с". Это правило служит для решения а и предок»
Дополнительные вопросы решения задач искусственного
интелл^а
№СТ соответствующую эвристическую информацию. На самом деле проще всего обеспе-
ЧЙТь лда"°"";мЧ!нНиИС ° яЩСГ° "РСДИКата С "ОМ°щью подцели ь. поскольку™ „„менее
ресурсоемким по времени является следующий порядок выполнен™ операций- "Проверить зна-
„енис Ь. посмотреть, ложно ли с, а затем проверить о~. Существует неявная эвристика;
сначала нужно проверить простейший способ получения ложного значения, а если он не
сработает, перейти к остальной (возможно, более сложной) часта решения. Эксперты могут
разработать процедуры и взаимоотношения, которые не только сами являются истинными,
„о и содержат информацию о том, как воспользоваться этой истиной. При решении
большинства интересных задач эти эвристики не стоит игнорировать [Kowalski 1979ff]
В следующем разделе вводятся хорновские выражения, а их процедурная
интерпретация используется в качестве точной стратегии, позволяющей сохранить эту
эвристическую информацию.
12.3.2. Логическое программирование и язык PROLOG
Чтобы понять математические основы языка PROLOG, введем определение
логического программирования (logic programming). Затем добавим к нему точную стратегию
поиска для получения аппроксимации этой стратегии поиска, которую иногда называют
процедурной семантикой (procedural semantics) языка PROLOG. Для полноты описания
языка PROLOG будет рассмотрено использование оператора not н предположения о
замкнутости мира (closed world assumption).
Рассмотрим базу данных дизъюнктивных выражений, подготовленную для
опровержения разрешения (раздел 12.2). Если ограничить это множество выражениями,
содержащими не более одного положительного литерала (а также 0 или более отрицательных
литералов), получим пространство дизъюнктов с некоторыми интересными свойствами.
Во-первых, задачи, описываемые с помощью этого набора дизъюнктов, сохраняют
свойство невыполнимости (unsatisfiability) для опровержения разрешений, т.е. являются
полными в смысле опровержения (раздел 12.2). Во-вторых, важным преимуществом
ограничения нашего представления этим подклассом всех дизъюнктов является наличие
очень эффективной стратегии поиска опровержения, основанной на использовании
линейной входной формы, предпочтении единичного выражения и сведении целевого
выражения слева направо с помощью поиска в глубину. При эффективной реализации
рекурсии (конечных рекурсивных вызовов) эта стратегия гарантирует нахождение
опровержения, если пространство дизъюнктов обладает свойством невыполнимое™ [van
Emden н Kowalski. 1976]. Хорновское выражение содержит не более одного
положительного литерала, т.е. может быть записано в форме
av-,b]v-,j32v... v-.£>„,
где а и Ь, — положительные литералы. Чтобы подчеркнуть ключевую роль
единственного положительного литерала в разрешении, хорновские выражения обычно записывают в
виде импликации с положительным литералом в качестве заключения
a<-biAfc>2A...Afc>„.
Прежде чем обсудить стратегию поиска, дадим формальное определение
подмножеству Юрноескш выражений (Horn clause). Это подмножество вместе со стратегией не
^ш»™™ приведен,* „елевого выражения называется логической программой
flogic program).
ОПРЕДЕЛЕНИЕ д
ЛОГИЧЕСКАЯ ПРОГР „0 выражении, связанных квантором всеобщ
Логическая „рограшш - № я прсд11катов первого порядка вида
„ости, записанных в форме »с
а_6,лЬ,лЬ,л...л ,. ы, к010рыс иногда называют атомарны,щ
Здесь а и Ь, - полож,т^дОВОК выражения, а конъюнкция Ь, — его тело.
.«„„. При этом a j™ 3 ЮА,„«ж«ш< вЧра»™.««« (Hon, clause) теории предика-
Такие предложения "*"' 6шъ записаны в трех формах: когда исходное
дизъюнктов первого порядка, ини. , п01]0Ж„тельны.ч литералов, когда оно не содержит отрица-
тквное выражение сш i од]1н положительный и один над несколько от-
тельных литералов и когда он ^ 6ознзчсиы ц„фрам„ 1.2»3 соответственно,
рнцвтельных литералов. Ли вариаш
ли — это так называемое беззаголовочное выражение или
проверяемые чет.
2.а,<-
а;<-
называются фактами tfact).
3. а<-Ь,л...лЬ„ называется отношением правила.
Теория хориовских выражений допускает только такие формы. Слева от символа
импликации *- может располагаться только один литерал, и он должен быть
положительным. Все литералы справа от символа <- тоже положительны. Приведение выражений,
содержащих не более одного положительного литерала, к хорновской форме,
выполняется в три этапа. Сначала выбирается положительный литерал в выражении, если он
существует, и перемещается в его левую часть (на основе коммутативного свойства
дизъюнкции). Этот единственный положительный литерал становится заголовком хорновско-
го выражения. Затем все выражение приводится к хорновской форме по правилу
ау-,й,у^Ь^...у-,Ьл.а<—^(-ib,v-,b,v...v-,6J.
И. наконец, на основе закона де Моргана эта запись приводится к виду
а<-Ь,лЬ;л...лЬп,
где для систематизации промежуточных целей Ь, используется коммутативное свойство
конъюнкции. •
из ™«™ °ШП,т- ™ П°Р°Г| невозможно преобразовать дизъюнктивные выражена
Ыг!з!,с,7 ПР0ТНС™ К Х0Р,ЮВСК™ Ф°Р-' Некоторые выражения не могут
;:™1Г' Ф°РМС' НаПР"МСР Pv"' Д"» "»«"» ханойского выражения в
Если "Г™Г*г "" Я°ЛЖН0 свдеРж«ься „е более одного положительного ливр-;
предика™юФ1Р:'Г„ВЫП0Л"ЯеТСЯ- ГО М0*« понадобиться пересмотреть исходу
вом хорновс!Г р 7, НМ "РОбЛСМЫ' *" 5У™ »"««> ™ Д-ьнейшего, преим)'^
стратегии опроВерженш-,СТавЛ<:Ш,Я ЯЙЛЯ"СЯ во™ожность реализации эффект»»»0"
Алгоритм вычисления в логической программе реализует детерминирован,,,
:„„е целевого выражения. Если целевое выражение имеет вид
UIOC lipHHt.'
дсние г~'*лилт uL'"^^n""" --- -
<—а,лагл...лап,
то на каждом шаге вычислений алгоритм произвольным образом выбирает некоторое
значение а, 1<1<п. Затем на основе недетерминированного выбора строится выражение
а'<— Ь1лЬгл...лЬп,
которое используется для приведения целевого выражения путем унификации а' и а,
с помощью подстановки <;. Новое целевое выражение принимает вид
*-(а,л...ла,.1лЬ1лЬгл...лЬпла).|л...ла )£.
Такой процесс недетерминированного приведения целевого выражения продолжается до
тех пор, пока целевое множество не окажется пустым.
Если отказаться от недетерминироваиности за счет упорядочения подзадач в процессе
приведения, то результат вычислений не изменится. Ко всем результатам, получаемым с
помошью недетерминированного поиска, можно также прийти путем полного
упорядоченного перебора. Однако, снижая уровень иедетерминированности, можно определить
стратегии, позволяющие исключить ненужные ветви из пространства поиска. Так, основная
задача практических языков логического профаммирования— обеспечить программиста
средствами контроля, а по возможности н уменьшить уровень иедетерминированности.
С помощью этих средств программист может обеспечить порядок приведения и выбрать
набор дизъюнктивных выражений, используемых для приведения каждого целевого
выражения. (Как и в алгоритмах поиска на графах, для предотвращения бесконечных циклов в
доказательствах необходимо предпринимать дополнительные меры предосторожности.)
Согласно абстрактной спецификации логическая программа должна обладать ясной
семантикой, свойственной системам опровержения разрешения. В работе [van Emden и
Kowalski, 1976] показано, что минимальной интерпретацией, при которой логическая
программа истинна, является сама интерпретация этой программы. Поэтому в
практических языках программирования, таких как PROLOG, в процессе работы программы
можно вычислить только подмножество связанных с ней интерпретаций [Shapiro. 1987].
Последовательный язык PROLOG — это аппроксимация интерпретатора для модели
логического программирования, спроектированная для эффективного выполнения на
машине фон Неймана. Этот интерпретатор применялся до cirx пор в данной книге.
Последовательный PROLOG для управления поиском в процессе доказательства использует как
порядок целей в выражении, так и порядок выражений в программе. Если известно некоторое
число целей. PROLOG всегда обрабатывает их слева направо. В процессе поиска
унифицируемого выражения имеющиеся дизъюнкты всегда проверяются в том порядке, в котором
они подаются программистом. После обработки каждого выбранного выражения к записи
унификации добавляется указатель возврата, позволяющий в случае неудачного исходного
выбора использовать другие выражения (опять же в заданном программистом порядке).
Если процесс не увенчается успехом для всех возможных выражений в пространстве
дизъюнктов, то вычисления завершаются неудачно. При использовании оператора cue для
эффективного поиска в глубину (подраздел 14.1.5) интерпретатор на самом деле может
обработать не все комбинации выражений в пространстве поиска.
Опишем работу интерпретатора более формально. Пусть имеется цель
12. Автоматические рассуждения
549
„„ PROLOG последовательно выбирает первое дизъюнкт„
„ программа P. W^ к°™Р0ГО У™*"™" "" 3*™ Э™ ВЫР^ние испол"
„ое выражение из г.
зуется для приведения пеленги
а^ь,лЬ,л...л ^ т0 цмевое выражение принимает вид
приводящее выражение для униФ
♦.(Ь,лЬ,л...лЬ„лв,ла,л...ла„)5-
mmn PROLOG пытается выполнить приведение крайней слева цели ь
Затем «"«Р^Зение программы Р, унифицирующее Ь„ Предположим, ''
используя первое выражение щ у
Ь1<-с,лсгл...лср
„р„ подстановке унификации «. Тогда целевое выражение приводится к виду
Ис,лС,л...лС,лЬ!л-лЬ»ла=ла>Л"Ла")4Ф-
Заметим что список целей обрабатывается как стек, поэтому целесообразно выполнять
поиск в глубину Если интерпретатор языка PROLOG не находит подстановку унификации,
приводящую к решению, то он возвращается к ближайшей точке выбора унификации, вое-
станавливает все установленные после этого связи и выбирает следующее выражение для
унификации (в соответствии с порядком в программе Р). Таким образом, PROLOG
реализует поиск в глубину слева направо в пространстве дизъюнктивных выражений.
Если целевое выражение приводится к нулевому предложению (J), то приводящая к
этому композиция подстановок унификации
обеспечивает интерпретацию, при которой исходное целевое выражение истинно. Помимо
возврата в соответствии с порядком следования выражений в программе, последовательный
язык PROLOG допускает использование выражения cut или !. Как описано в
подразделе 14.1.5, выражение cut можно поместить в дизъюнктивное выражение в качестве самой
цели. Тогда интерпретатор, достигнув этого выражения, фиксирует текущий путь выполнения
программы и подмножество подстановок унификации, сделанных после выбора выражения,
содержащего cut. При этом само выбранное дизъюнктивное выражение становится
единственным средством приведения целевого выражения. Если процесс приведен™ завершится
неудачно после выражения cut, то все дизъюнктивное выражение считается ложным.
На практике для реализации механизма cut необходимо хранить возвратные
указатели для участвующего в приведении выражения и всех его компонентов,
расположенных до выражения cut. Наличие выражен™ cut может означать, что вычисляются
только некоторые из возможных интерпретаций модели.
к,г,1!Д"0ДЯ "Т0Г описа"ию последовательного языка PROLOG, следует сравнить его с
моделью опровержения разрешения из раздела 12.2.
'иольТеммГ" ПрОГ?амм"Р0|«ни„ пространство дизъюнктивных выражений, ис-
возможнТт, Ре30ЛЮЦИИ' ^Ржт подмножество хорновскнх выражений. Для
чать нГбГеГоГоГоГи8 Х°РН°ВСК°Й Ф°Р№ ™ "^^ ^ ^
2 с " """"жительного литерала.
2-1. Цел7выС1РУ'ПУРЬ1 П03В0ЛЯЮТ "Р^станить задачу в хорновской форме.
*-ь,лЬ,л...лЬп_
Насть V. Дополнительные вопросы решения задач искусственного интелл^
^ITZZT^T*' К0Т°РЫе необхВДимо проверить в процессе опровер-
T„v„T *" КаЖД0Г° Э' "Р011™ «Риц«,ие. выполняются иодста-
вое сущ" твуетГ " '*""»"* "° П°ЛУЧШИЯ ПУ"°Г° ВЬфаЖеНИЯ ^Ш ""-
2.2. Факты
это отдельные выражения, используемые для резолюции.
2.3. Хорновские правила или аксиомы
позволяют выполнять приведение для соответствующих подцелей.
3. При использовании стратегии предпочтения единичных выражений, линейной
входной формы (методики предпочтения фактов и использования отрицания цели и
ее дочерних резольвент, описанной в подразделе 12.2.4) и применении принципа
поиска выражений для резолюции в глубину (с возвратом) и слева направо система
доказательства теорем на основе резолюции работает как интерпретатор языка
PROLOG. Поскольку эта стратегия является полной в смысле опровержения, она
гарантирует нахождение решения (т.е. исключает отсечение интерпретаций за счет
использования выражения cut).
4. И, наконец, комлозиц™ подстановок унификации в процессе доказательства
обеспечивает интерпретацию (ответ), для которой целевое выражение является истинным. Это
точно соответствует процессу извлечения ответа, описанному в подразделе 12.2.5.
Важным свойством современных интерпретаторов языка PROLOG является неявное
использование в его реализации предположения о замкнутости пространства (closed world
assumption). В теории предикатов доказательство -*>(Х) эквивалентно доказательству того, что
р(Х) логически ложно, т.е. выражение р(Х) ложно для каждой интерпретации, для которой
набор аксиом является истинным. Интерпретатор языка PROLOG на основе алгоритма
унификации из главы 2 дает более частный результат, чем общий принцип опровержения
разрешен™, описанный в разделе 12.2. Вместо проверки всех интерпрегшгнй он тестирует только
те выражен™, которые содержатся в базе данных в явной форме. Сформулируем эти
ограничения, чтобы четко увидеть неявную ограниченность языка PROLOG.
Предположим, что для каждого предиката о и каждой переменной X из о множество
в|, а2 а„ составляет область определения X. Работа интерпретатора PROLOG в
процессе унификации основывается на следующих принципах.
1. Аксиома об уникальности имен. Для всех элементов области определения а,*а, если
эти значениям; идентичны. Следовательно разноименные элементы различаются.
2. Аксиома замкнутости мира (closed world).
Р(Х)->р(а,Кр(агК..^р(а„).
Это означает, что возможными реализациями отношения являются только те
выражения, которые содержатся в описании задачи.
'а 12. Автоматические рассуждения
551
„Мао—.---—^"^
(X=a1)v(X=aI)v...v(X-a,b ^ содержащиеся в описании задачи, пред
Эта аксиома гаРа1""рГспис0К единственно возможных элементов.
сгавляют собой полный с™ ^ интерпретаторе языка prolog, что П0Д.
Эти три аксиомы неявно Р™» ^^ возможных интерпретаций PROLOG.
тверждается ограниченностью ^ ^^ PROLOG все целевые выражения, для кото
Неформально это означа ^ сч|гга|отся ложными. Это может привести к аномалии-
рых нельзя доказать истинно- , целевого выражения, ие содержится в тек*
если значение, о*"™^,"^ да„ное выражение ложным.
шей базе Д»«> г ^„т и другие ограничения, присущие всем языкам
В «Гн .Глее важными из них, помимо проблемы отрицания, являются
программирования^ Наибш* лог„ческого программирования. В частности, еле.
7r:Z::'Z^"o^ вождений, ™ «P™°*"T " возможности у„„ф„кац„,
ГоаГення с его подмножеством (раздел 2.3), а также использование выражения cut
Соименное поколение интерпретаторов PROLOG следует рассматривать с практиче-
ской точки зрения. Некоторые проблемы вызваны тем, что на сегодняшний день не су
шествует эффективного пути их решения (проверка вхождения). Другие связаны с по
пытками оптимизировать использование поиска в глубину с возвратом (выражение cut).
Многие аномалии языка PROLOG являются результатом попытки реализовать иедетер-
минированную семантику чистого логического программирования на последовательном
компьютере. К ним относятся проблемы, связанные с выражением cut.
В заключительном разделе главы 12 рассматриваются альтернативные схемы
логического вывода, применяемые для автоматических рассуждении.
12.4. Дополнительные вопросы автоматических
рассуждений
Мы рассмотрели слабые методы решения задач, основанные иа синтаксических
свойствах представления и применении стратегий для выбора комбинаций в процессе
полного перебора. В завершение этой главы приведем некоторые комментарии по основным
аспектам слабых методов решения.
12.4.1. Единое представление для реализации слабых методов решения
Процедура доказательства разрешения требует приведения всех аксиом к дизъюнктивно»
эвг,™ еД"НОе П1Клставлен1к позволяет разрешать выражения и упрощает разработку
пТеГГнТUKH™ ЗЩаЧ"' °СН0ВШМ ВД«™к°« этого подхода является возможность
ФогГт пТп!ИСТИЧеСК°" ш,*01>-«и.« в процессе ее единообразного кодирования.
зованГГ^а™™ ПРа"№ "еСт «■■■■■ *™*У» более'ннформативси для исп»
ДобгГ ™,™ *" РСМЮад1» "»™ в продукционной системе, чем один из п "
зовать это «о nTnv " °В' КР°МС ТОГ0' такой Ф°Р*т позволяет эффективно испол -
(разделе?~Z^^™ "f*™ абдутегивнын вывод (аЫис^е inferen-
сслакк^гулГгТТгГо,, ДвИГаТ'ШЬ ж вводится и фары не включаются, то, возм»*»»'
Р - С помощью этого правила можно проверить аккумулятор.
Часть V. Дополнительные вопросы решения задач искусственного интеллект»
При записи этого правила в дизъюнктивной форме теряется эвристическая
информация о способе его применения. Если записать это правило в предикатной форме
^wrn_over^ghts->bat,ery. то его дизъюнктивная форма будет иметь „ид
turnomrvlightss,battery. Это выражение можно записывать по-разному, причем
каждая форма записи может представлять отдельную импликацию.
(-i(urn_overA^//g/its)-> battery,
i^turn_over-^,(batteryvlights),
^batteryn^lights)~>turn_ove'r,
(-^battery->{turn ^overvlights)
и т.д.
Чтобы сохранить эвристическую информацию в процессе автоматических рассуждений
некоторые исследователи разработали методы рассуждений, предполагающие кодирование
эвристик путем формирования правил по аналогии с разработкой отношений человеком-
экспертом [Nilsson, 1980], [Bundy, 1988]. Этот подход уже был рассмотрен в разделе 3.3,
а его реализация на языке PROLOG описана в разделе 12.3. Экспертные системы на основе
правил также позволяют программисту контролировать поиск с помощью структуры
правил. Эта идея будет развита в следующих двух примерах, в которых сохраняется форма
импликации, и эта информация используется для управления поиском иа графе.
Рассмотрим задачу рассуждения на основе данных с использованием следующих
фактов, правил (аксиом) и цели.
Факт:
(av(bAC)).
Правила (аксиомы):
(а-»(<*ле)),
(c->(gv/,)).
Цель:
<-evf.
Доказательство утверждения ev/ показано на рис. 12.12. Обратите внимание на
использование связки II для отношения v и связки ПЛИ для отношения л в пространстве
поиска на основе данных. Если известно, что а или Ьлс — истинно, то необходимо
проводить рассуждения с помощью обоих дизъюнктов, чтобы гарантировать сохранение
истинности. Поэтому эти два пути соединяются. С другой стороны, если tone — истинны,
то можно продолжать исследовать любой из этих конъюнктов. В процессе проверки
соответствия любое промежуточное состояние, например с, заменяется заключением
правила, в частности, gvh. предпосылка которого соответствует этому состоянию.
Исследование обоих состояний в и f на рис. 12.12 приводит к достижению цели evf.
Аналогичным образом можно использовать проверку соответствия правил на графе
И/ИЛИ „ри рассуждениях на основе цели. Если в описании цели содержится символ v,
ик в примере иа рис 12 13 то каждую альтернативу можно исследовать независимо.
Если целевое выражение представляет собой конъюнкцию, то необходимо обрабатывать
оба конъюнкта.
Цель
(av(fc-AC))
>а12. Автоматические рассуждения
553
Правила (аксиомы):
(в_>(йлс)).
{g->d).
Направление
поиска
Рис. 12.12. Рассуждения на основе данных на графе И/ИЛИ в исчислении
высказывании
Хотя эти примеры взяты из исчисления высказываний, в теории предикатов поиск
выполняется аналогично. После подстановок унификации для литералов можно
применять правила вывода и осуществлять поиск по различным ветвям пространства.
Естественно, подстановки унификации должны быть согласованными по различным ветвям И
пространства поиска.
™Э„ТГ П°ЛрШделе "Ражены методы решения, позволяющие сохранить эвристиче-
обоазом ЛГ"Ю " Предс™'га'"" A""™* для слабых методов решения задач. Таким
cZ иI 2ZZ?mmX "РОЛ»»™* может задавать в рамках правила эвристи-
лок в рамках одного ГаГГп' П°РЯЛ°К ПравИЛ НЛН П0РЯД0К следования предпось,-
однородных процедур поискам "0М П°ДХ0де отс^твуст возможность применен»*
нако правило отделения все " "а6°Ре ПраВИЛ' такнх как мстод Р"0ЛЮЦИИ' Л"
веденными на рис. 12 12 и т^п*™ 11спользовать. чт° подтверждается графами, при-
бину, в ширину или "жадном" ' ролукционнь1е системы, основанные на поиске в
гяуры для реализации систем по аЛ™ритмс ,,0ИС1«, представляют собой пример архитекту-
Равил (см. примеры в главах 4, 5, 7, 14 и 15).
Дополнительные вопросы решения задач искусственного интеллекта
Направление
поиска
Рис. 12.13. Рассуждения от ue.ni с
И/ИЛИ в исчислении высказываний
помощью графа
12.4.2. Альтернативные правила вывода
До сих пор рассматривалось наиболее общее правило вывода— метод резолюции.
Для повышения эффективности процедуры разрешения существует несколько более
сложных правил вывода, два из которых будут кратко рассмотрены в этом разделе. Это
процедуры гиперрезолюции (hyperresolution) и парамодуляции (paramodulation).
Описанная выше процедура резолюции на самом деле представляет собой частный
случай, получивший название бинарной резолюции, поскольку на каждом шаге в
создании нового дизъюнктивного выражения участвуют ровно два родгггеля.
Гиперрезолюция — это последовательное применение процедуры бинарной резолюции для получения
одного дизъюнкта. На каждом шаге в процедуре гиперрезолюции может участвовать
одно выражение с несколькими отрицательными литералами— так называемое ядро
(nucleus) - и несколько выражений, состоящих только из положительных литералов, -
сателлитов (satellite) Один из положительных лнтерачов должен соответствовать
отрицательному литералу ядра. Кроме того, для каждого отрицательного литерапа ядра
необходимо иметь по сателлиту. Таким образом, в результате применения гиперрезолюции
получается выражение, состоящее только из положительных литералов.
Преимуществом процедуры гнперрезолюции является получение выражения,
содержащего только положительные литералы, и уменьшение размерности
пространна дизъюнктов" поскольку в процессе реализации процедуры не фиксируются
555
суточные P— »-*—■ -*"— " ™ — —>
„абор'адизьюн—.ь^е■ . ^
^arriedlX, ^m°'h*Les<Lorge, Kate),
motherikate. sara . можио пояучнть за один шаг.
Спомошьюпшерреэолюциизаключ
fstherlSeor9e,ssrah^^georSe. tar.).
является первое выражение. Два другие — сателлиты. Сател-
Ядром в этом пР"мере тсльных дизъюнктов, причем на каждый отрицательный
л^°Х"ди3тся по одному сателлиту. Заметим, что в данном случае ядро пред.
^«^дизъюнктивную форму импликации
married(X, Y)*mother(X, Z)^fathe«Y, Z).
Заключение этого правила - часть окончательного результата. Заметим, что в про-
цессе отсутствуют промежуточные результаты типа
^motherikate, Z)vfather{george, Z)vlikes{george, kate),
которые обычно получаются при использовании бинарной резолюции в том же
пространстве дизъюнктивных выражений.
Гиперрезолюция — это согласованная и полная процедура. В сочетании с другими
стратегиями, такими как стратегия "множества поддержки", свойство полноты может нарушаться
[Wos и др., 1984]. Для создания ядра и сателлитных выражений могут потребоваться
специальные стратегии поиска, хотя в большинстве случаев эти выражения легко проиндексировать
по имени и свойству положительности или отрицательности каждого литерала. Это позволяет
подготовить ядро и сателлитные выражения к процедуре гиперрезолюции.
Важным и сложным вопросом в разработке механизмов доказательства теорем является
контроль равенства. Особенно сложные задачи возникают в областях, где большинство
фактов и взаимосвязей имеют несколько представлений, например, могут быть получены путем
применения свойств ассоциативности и коммутативности выражений. Такой областью
является математика. Вот простой пример. Арифметическое выражение 3+(4+5) может был.
представлено во многих различных формах, в том числе 3+((4+0)+5). Такие выражения
сложны для использования подстановок, унификации и проверки равенства с другими
выражениями в рамках автоматического решения математических задач.
Демос-умщя (demodulation)- это процесс перефразирован™ или преобразования
выражении для их автоматической записи в выбранной канонической форме. Единичные
MeZI,'' "С"0ЛЬЗуСМЬ,е Д™ преобразования к этой форме, называются демодулятор»
ние е™ к 1„ ^Т РаВеНС™ Р"»™* выражений и позволяют заменять выраже-
сгене „рГаГнГиТ *""*■ Пр" ПРав™ьном использовании демодуляторов вся вновь
юнктивных выражении. Например, пусть имеется демодулятор
eqUal{fSthe^^rW],grandfathenX))
и новое выражение
age(father(fa(nei
'r(sarafi)),
Прежде чем добавить это выражение в пространство диз™
дулятор, и выражение добавляется в виде Дизъюнктов, применяется дсмо-
age(grandfather(sarah). 86).
В данном случае проблема равенства связана с ии™„ - ,
тельнее классифицировать человека; как ^^ZT?^ а*ЯЙ°т-
grandfather'»? Подобным образом можио указать каноне W> """ ДСДУШКУ
*СМЬ11, в частности определить, что брат отцаТоГт ,™ IT^-ZZ^lm
указав канонические „мена, под которыми должна храниться „нфорГцГ южно ™
работать демодуляторы, в частности equal, приводящие всю новую ГГмацню к
выбранной форме. Заме™», что демодуляторы - это всегда единичные вырГниГ
Парамодуляция- это обобщение подстановки равенства „а уровне термов.' Напри-
мер, пусть дано выражение '* ч»»- папр»
olderimother(Y), Y)
и отношение равенства
equal(motherisarah), kate).
Тогда можно выполнить парамодуляцию и получить
older(kate, sarah).
Заметим, что проверка соответствия и замены [sarahlY] и (mother(sarah)lkate)
выполняется иа уровне термов. Основное различие между процедурами демодуляции и парамо-
дуляции состоит в том, что последняя допускает нетривиальную замену переменных в обоих
аргументах равенства предикатов. При демодуляции замена выполняется с помощью
демодулятора. Для получения окончательного вида выражения можно использовать несколько
демодуляторов. Парамодуляция выполняется лишь один раз для любой ситуации.
Итак, рассмотрены простые примеры мощных механизмов вывода. Эти механизмы можно
рассматривать как более общие приемы резолюции в пространстве лшъюнктивных
выражений. Как и другие описанные выше правила вывода, они тесно связаны с выбором
представления, и для их реализации требуется применение соответствующих стратегий.
12.4.3. Стратегии поиска и их использование
Иногда предметная область приложения диктует специальные требования к правилам
вывода и эвристикам по их использованию. Выше уже рассматривался вопрос
использования демодуляторов для реализации равнозначных подстановок. В естественной
дедуктивной системе (natural deduction system), описанной в работе [Bledsoe, 1971],
использованы две важные стратегии доказательства теорем иа основе резолюции,
получившие название стратегий расцепления (split) И приведения (reduce).
Эти стратегии разрабатывались для использования в математике, в частности, для
применения в теории множеств. Идея этих стратегий состоит в разбиении теоремы на
части с целью ее упрощения и возможности использования таких традиционных
методов, как метод резолюции. Стратегия расщеплен.» состоит в разделении различных
математических форм „а соответствующие части. Доказательство соотношения АлВ
эквивалентно доказательству А и доказательству S. Аналогично доказательство А^В - это
Доказательство А^В нА*-В. доказательств на состав-
Стратегия приведения тоже сводится к дал'",'1°пвможио свести к доказательству
Дхюшне. Например, доказательство того, что seArS можио свести
»12. Автоматические рассуждения
557
.-.телыДО истинности некоторого свойства,
„„„й seA и «В. Или дадаа"Л'1 го свойства для -VI и для -.в "'1Щ'
^Г7" "и-™- Д°-—Меньшего объема, можно ограни^ ^
д^~ ^-"ГТвЫ, еФ №. используйся также подстановки равсист?"
^Гство поиска. В работе [ВU** ' главах, корректное использование стра.
^Как неоднократно отмечал сь >,ч* %орошего знания области приложен*,'а
кгий_ это, скорее, "*£££ш „ правил вывода. В заключение этой главь, „ри.
также соответствующего пр'ДСта осмысленном использовании могу, 0&
ведем несколько обшнх правил, и^^ ^^ нмеют сво„ исклкптт. Эти
заться очень эффективными, и нсследователей, работающих в этой области
комендации обобщают опыт. _ ^ ^^ |Wos_ 1988] а также собствен|(ь|е
[Bledsoe, 1971), lMf"-" с'ла6ьк методах решения задач. Приведем эти рекомеНда.
поедставления автора книги
цин без дополнительных комментариев.
. по возможности используйте дизъюнктивные выражения с меньшим числом ли-
тералов.
. Прежде чем применять общие правила вывода, разбивайте задачу на подзадачи.
. По возможности используйте предикаты равенства.
. Применяйте демодуляторы для создания канонических форм.
. Пользуйтесь парамодуляцией при работе с правилами вывода для предикатов
равенства
• Реализуйте стратегии, сохраняющие "полноту"'.
• Используйте стратегию "множества поддержки" в задачах, содержащих
потенциальные противоречия.
• В процесс резолюции старайтесь использовать единичные выражения.
• Выполняйте категоризацию новых выражении.
• Используйте средства упорядочения выражений и литералов в рамках более
крупных выражений, отражающие ваши интуитивные представления и опыт решения
задач из данной области.
12.5. Резюме и дополнительная литература
Системы автоматических рассуждений и другие слабые методы решения задач
составляют важную область искусственного интеллекта. Они используются для выработки
общих стратегий поиска в игровых задачах, при доказательстве теорем и для поддержки
ЕГ™™ В СИСТеМаХ "а °СН0К баз знаний- Э™ "«оды применяются для разработки
оболочек экспертных систем и механизмов вывода
Эти ™, со™„ОДЬ' ТРе6У'ОТ ВЫб°Ра "Ре«<™«»=ния, правил вывода „ стратегий поиска.
-иГ :~д:ГаНВРьГВН° СМЗаНЫ МеЖДУ СОб°Й " не ^ Р-оматриваться
некой приложен ЙГ' Р ™Х э,|еме»™в также во многом определяется специфи-
-„"1:;:~;гбору основных —»■* -б-—ре'
Резолюция— это ц редыдУш«"о раздела. с
дизъюнктивных выражений^ "°"Р°а""' возможных интерпретаций в пространств
"ражении, к которому до6авлено отрицание целсвого выражения, Д°
„-.никновения противоречия, в этой книгР un „
^опровержения разреше„„я;^:оГе:аюРтгС^Г^гВп;ТиЛГ7Г',РО-
Любознательному читателю можно порекомендовать г™, 8 ' ''
литературой- В частности, работа [Chang и Ue Т973. Т МНТЬСЯ с соответствующей
^W^tso,'^^^^
«шгленнй изложены в работах [Nilsson losm tr» ,. "'"«-'и автоматических
рассуждай™ к х innsson, 198U), [Genesereth и Ni sson, 19871, [Kowalski
19796]. [Lloyd, 1984], [Wos и др., i984, 1988], [Robinson, 1965] [Bledsoe 1977 Важный
вМад в методику доказательства теорем внесла работ. [Воует и „9'" «!
6отам в этой области относятся [Feigenbaum и Feldman, 1963) и [Newell и Simon 1972]
В течение последних двадцати пяти лет все новые результаты в области
автоматических рассуждении докладывались на конференции CADE (Conference on Automated
Deduction). В настоящее время много работ посвящены проверке соответствия моделей,
разработке систем верификации и представления иерархических знаний [McAllester
1999], [Ganzinger и др., 1999], Продолжают свои исследования Ларри Вое (Larry Wos) и
его коллеги из Аргонской национальной лаборатории. В частности, работа [Veroff. 1997]
по теории автоматических рассуждений посвящена Восу. Стоит отметить также работы
[Bundy, 1983, 1988], выполненные в Эдинбургском университете, а также [Kaufmann и
др., 2000], выполненную в университете штата Техас.
12.6. Упражнения
1. Приведите предикаты, описанные в разделе 2.4, к дизъюнктивной форме и
используйте процедуру опровержения разрешения для ответа на запрос о том, должен лн
конкретный инвестор выполнять /m/es(ment(comb/na(/on)?
2. С помощью процедуры резолюции докажите утверждение из упражнения 12 к главе 2.
3. Используйте процедуру резолюции для ответа на запрос нз примера 3.3.4.
4. В главе 5 представлена упрощенная форма игры "хода коием". Приведите правило
раглЗ к дизъюнктивной форме и с помощью процедуры резолюции получите ответ
на запрос раглЗ(3. б). Затем воспользуйтесь рекурсивным вызовом процедур в
дизъюнктивной форме.
5. Как можно использовать процедуру резолюции для реализации поиска в
продукционной системе?
6. Как с помощью резолюции реализовать рассуждения от данных? Используйте этот
метод для определения пространства поиска в упражнении 1. Какие проблемы могут
возникнуть в задачах, где пространство поиска достаточно велико?
7. Воспользуйтесь процедурой резолюции для решения задачи переправы человека,
волка, козы и капусты из раздела 14.3.
8. Воспользуйтесь методом резолюции для решен», задачи из [Wos ,, ^ '^№
вия задачи следующие. Четыре человека- «•^^ ^ рГ™.
ют „а восьми различных работах, "'Ц^^ш.с,,^. телефонист.
Они занимают следующ.,е должности, руководит Р^^ Муж руковод,т.
полицейский, учитель, актер и боксер. <-?"',™<' вьк.шего о6р:аомит. Робер-
ля - телефонист. Роберта - не боксер. Пит не имеет выси
лава 12. Автоматические рассуждения
559
„Яскнй любят вместе играть в гольф. Кто „а какой ра6
„ руководитель и «««^ задача с учетом пола каждого „з сотруд„иков *
работает? Покажите, как юц„„ гдс ядро состоит ие менее чем из .1еТь]
9. Приведите два примера п№
литералов. ыпажения sum. приводящий дизъюнктивные вира*,
,0. Напишите Л™°ДУОТГОР Tsum(6, minus(6)))) к виду equal(ans, Sum(5, 0)). Раз '
„ия вида «<jua/(a/w. «ш№3' ен1И этого результата к виду equaKans, 5).
ботайте демодулятор для ^^ т шести тнпов семенных отношений. Нам
П. Постройте "канош™^епр„ВСдения различных форм отношений к канонической
^^^^^^Тпад^^ 12.24 для решения задача
д „,.тЯ*-ение из предикатной формы к дизъюнктивной
и Ппниелнте следующее выражение иj up м
ii Создайте граф ШЛИ для решения следующей задачи на основе данных.
Факт: -rf(ev[b(r)Ac(r)].
Правила: -*ВД->-<><*) » Ь(г1-»М •■ 9(И0<-е(И0-
Доказать: -^a(Z)ve(Z).
15. Докажите, что стратегия линейной входной формы не является полной в смысле
опровержения.
16. Создайте граф 11/ИЛ11 для решения следующей задачи и объясните, почему
невозможно получить целевое выражение.
r(Z)vs(Z)?
Факт: p(X)vo(X).
Правила: р(а)->г(а) и q{b)->s(b).
17. Используйте процедуры факторизации и резолюции для опровержения следующих
выражений p{X)vp(f(Y)) и -p(W)v-p(f(Z)). Постарайтесь построить опровержение
без факторизации.
18. Альтернативной семантической моделью для логического программирования
является Flat Concurrent PROLOG [Shapiro, 1987]. Сравните эту модель с семантикой
языка PROLOG, описанной в разделе 12.3.
Дополнительные вопросы решения задач искусственного nHieJ
}лле*тэ
Понимание
естественного
языка
Чек объяснить потребность в словах?
— Теренс (Terence)
До меня доходит
Какой-то ураган в твоих словах.
Но не слова.
— Вильям Шекспир (William Shakespeare), Отелло
13.0. Проблема понимания естественного языка
Проблема понимания естественного языка, будь то текст или речь, в значительной
мере зависит от знания предметной области. Понимание языка — это не просто передача
слов. Оно требует знаний о целях говорящего, контексте, в также о данной предметной
области. Программы, реализующие понимание естественного языка, требуют
представления этих знаний и предположении. При их создании необходимо учитывать такие
аспекты, как немонотонность, изменение убеждений, иносказательность, возможность
обучения, планирования и практическая сложность человеческих взаимоотношений.
Следует отметить, что все эти проблемы являются краеугольными для самого
искусственного интеллекта в целом.
Например, рассмотрим следующие строки из восемнадцатого сонета Шекспира.
"Сравню ли с летним днем твои черты?
Но ты милей, умеренней и краше.
Ломает буря майские цветы,
И так недолговечно лето наше!"
В рамках упрощенной, буквальной трактовки каждого слова смысл этил стихов
понять невозможно. Для его понимания нужно ответить на следующие вопросы.
г „тйная пртяппельность произведении Шекспира? Чтобы „„
1 чем объясняется необыча,'»"£_ ^ №-0е человеческая любовь и каковы ее «
» эти строки, "^««Г^ „^ пытался отработать причитающийся ему го„орар
алькые традиции. шеьс v ^ вМлюбленную с летним днем? Означает ли Это
2. Почему Шекспир Чявн"'' о6щсш„, с ней кожа покрывается летним загаром, „ли
что она длится 24 часа и пр ^ ошуще|ШСМ тепла „ летней красоты?
0„а ассоциируете»,>■ м Р ^ ^ фратента, Смысл сказанного явно щ ^
3. Какие выводы можно' " ^ с помошью метафор, аналогии н базовых знац„й
ражен в тексте. "" лета ассоциируются с перипетиями человеческой
Например, буря и скоро «л
жизни и любви.
4 Как человек понимает метафоры? Слова ие просто описывают совокупность о6ъ.
™.Тк ячейки в таблице. Смысл этих стихов состоит в сопоставлении характе-
0™™его дня и возлюбленной автора. Какие из этих свойств могут быть при-
„"саны обоим объектам, а какие нет, и главное, почему некоторые свойства под.
черкиваются, а другие даже не упоминаются?
5 И наконец, должна ли компьютерная система понимания языка знать, что такое
"ямб"? Как компьютер ответит на вопрос, о чем эти стихн?
Если напрямую объединить словарные значения слов этого соиета, то это ие добавит
ясности. Чтобы уловить смысл стихов, нужно задействовать сложный механизм
понимания слов, синтаксического разбора предложения, построения представления
семантических значений и их интерпретации в свете знаний предметной области.
Рассмотрим второй пример, взятый из объявления о вакансиях на факультете
компьютерных наук.
"Факультет компьютерных наук университета Нью-Мексико... проводит конкурс на
замещение двук должностей профессора. Требуются специалисты в следующих областях:
программное обеспечение, в том числе анализ, проектирование и средства разработки...;
системы, включая архитектуру, компиляторы, сети...
Кандидаты должны иметь степень доктора наук по специальности...
На факультете выполняются международные проекты в области адаптивных вычислений,
искусственного интеллекта, поддерживаются тесные связи с институтом Санта-Фе и
несколькими национальными лабораториями..."
В связи с этим объявлением возникает несколько вопросов.
''тогофа^ьтетТ1' "Т° ™ 0бМвлен"е касается вакантных должностей именно
с™еЯ(они'явнТЛСТВа ПрограммиР°ваиия необходимо знать для работы в уннвер-
сом ппепола„я„„. УКШа"Ы " 0бъям™ии)? Человек, хорошо знакомый с процес-
PROLOG и имГ УИт^"КК' «о-ет понять, что речь идет о языках Cobol.
3. Какое отношение к этому об
и связях с другивд лабораторими?1''0 ИМСЮТ Жает<* ° "«гаународных проекта*
направить объяв™™Г'"/Г' ™ объяшен"е? Что ему необходимо знать, чтобы
боты в Web? ше1 кандидату наук, который занимается поиском р»-
По„имаиие естественных языков связано (как мииим^
„ервых. предполагается большой объем челов ческих"„а„и1 я4*™ "°"V°C,'m- Во"
" язи в сложном реальном мнре. с которыми до™ б Г °™«-»>« »»"мо-
;Г;;юЩая на понимание языка. Во-вторых, яГимееГи^— ^Г^
„оят из фонем, ... в свою очередь, составляют предложения и £рш ,S, следов!
ния фонем, слов и предложении не является случайным. Без корректно ZoZZZL
этих компонентов общение невозможно. И, наконец, языковьЛоис^™ ™п
дукт некоторого агента - человека или компьютера. Агенты внедреТв сложную среду
„ развиваются в направлениях, определяемых их индивидуальностью и социумом Язы
новые действия являются целенаправленными.
В этой главе предлагается введение в проблему понимания естественного языка и
кратко рассматриваются вычислительные средства ее решения. Хотя основное внимание
будет уделено вопросам понимания текста, разработка систем понимания и генерации
речи тоже сопряжена с решением этих проблем, а также с дополнительными
сложностями, связанными с распознаванием и выделением слов из контекста.
В первых системах искусственного интеллекта разработчики старались ограничить
предметную область системы (поскольку для успешной работы системы требуется
знание предметной области) и создавали приложения, работающие в минимальной
предметной области. К числу таких систем относится SHRDLU [Winograd, 1972], которая
могла работать с блоками различной формы и цвета и с помощью "руки" перемещать
указанный блок (рис. 13.1).
Система SHRDLU могла отвечать на заданные на английском языке вопросы типа
"Что находится на красном блоке?" или выполнять запросы вида "Поместите зеленую
пирамиду на красный брусок". Она понимала местоимения, например, могла обработать
запрос: "Есть ли здесь красный блок? Подними его". Она даже понимала эллипсис, в
частности "Какого цвета блок находится на синем бруске? Какой формы?". Поскольку мир
блоков очень прост, то система была снабжена полной базой знаний о нем.
Взаимодействие с этим "миром" не требует знания таких общих понятий, как время, возможности,
убеждения и разработки приемов представления этих знаний. Благодаря ограниченности
предметной области в системе SHRDLU достигнута интеграция синтаксиса и семантики.
Ее пример доказывает, что при достаточных знаниях о предметной области
компьютерная система может эффективно работать с естественным языком.
Ail- IX/. "Мир" б.и
'3. Понимание естественного языка
563
-™пй облает система понимания языка должна мод,
„■„его знания предмет»» Мощным средством для такого м„„.
"rlcS -Р—»i:;^KMov" bain,. Например, в язь.коаых констр^
лировать шаи марковские иетпт существительными, а не наоборот. мГ
Р 1 модели также могут отражать в которого они предназначены.
г»*'^":;:^—* пониманию языка-радл ^ -
В разделе 13.1 представлен с.м= [3 3 усматриваются вопросы моделирова.
свяшен синтаксическому анализу^ Р ^ 4 представлеи стохастический подход к выяв.
„„я синтаксиса и семантики, b paw. ениях. и наконец в разделе 13.5 расематри.
„ению закономерностей в язь'к0 ' c||creM понимания естественного языка: ответы „а
„аются несколько приложении^т ^ выполнение Web-запросов и анализ
вопросы, получение информации
текстовой информации.
13.1.1. Введение
Язык- это сложный феномен, понимание которого включает такие разнообразные
„рои "«. как распознавание звуков и печатных букв, синтаксический разбор, вывод ее-
„антик высокого уровня и даже учет эмоционального контекста, передаваемого е
помощью ритма и интонации. Для управления этой сложностью лингвисты определили раз-
личные уровни анализа естественного языка.
{.Просодия (prosody), к которой относятся анализ ритма и интонации языка. Этот
уровень анализа достаточно сложно формализуем, поэтому им зачастую
пренебрегают. Однако его значение очевидно. Сила ритма и интонации наиболее ярко
проявляется в поэзии и религиозных песнопениях. Ритмика языка играет важную роль
также в детских играх и колыбельных.
2. Фонология (phonology) — наука о звуках и их комбинациях в языковых структурах.
Эта область лингвистики играет важную роль в компьютерном распознавании к
генерации речи.
3. Морфология (morphology)— анализ компонентов (морфем), из которых состоят
слова. К этой области относятся вопросы правил формирования слов, в том чисте
использования префиксов (в английском языке ни-, поп-, апй- и др.) и суффиксов (
».S, -'.У и др.) для модификации значения корня слова. Морфологический анализ
играет важную роль в определении значения слова в предложении, в том числе
времени глагола, числа и части речи.
4. Синтаксический шшю (syntax) связан с изучением правил сочетания слов в
отдельных фразах и предложениях, а также использованием этих правил для pa*f
пей ноТГ ЛреДЛОЖ£ний- Эта область наиболее формализована, и поэтому *
пешио применяется для автоматизации лингвистического анализа.
^ ^Гп'еГед^Гв^Га" ЗНаЧ£НИС СЛ°В' Фра3 " "Р"- ' "* """
Р выражениях естественного языка,
о. Прагматика (praematicO .„ ат0«б
™ "а с,,уШатсляЕ нСпп„~ Ш ° СП°С°6аХ "сп°л»™а"™ языка и С™ *„„*«>
______J^™^HanP"Mep, с помощью прагматики можно объяснить, по'
часть V. Дополнительные вопросы решения задач искусственного ик*-»""
слово "Да" является неудовлетворительным ответом на »„„„„,. •-,
торый час?". ом на "опрос Знаете ли вы, ко-
7. Знания об окружающем мире (world knowledee) — ™ ,-..,,
ческом мире, в котором мы ж„вем, мире человечески? ° гоаЛШШ Ф'»'-
ниЯ. а также значении целей и стараний в о(SZZTTT "ТТ™0"*
„„, играют ^^MioJLn,^^-^^™
ум уровни аиаг,„за кажутся достаточно естественными „ подтверждаются с точки
зрения психологии, однако не дают полного представления о языке. От, 172по связа
„ы между собой, и даже низкоуровневые изменения интонации и ритма могут полностью
изменить значение слова. Примером этому является сарказм. Для синтаксиса „
семантики такая взаимосвязь очевидна, и хотя между этими понятиями проводится четхая линия,
„а самом деле эту границу сложно охарактеризовать. Например, предложение "Они едят
яблоки" можно интерпретировать по-разному в зависимости от контекста Синтаксис
тоже оказывает сильное влияние на семантику, что подтверждается важным значением
структуры словосочетании при интерпретации предложений.
Несмотря на то что природа различий синтаксиса и семантики является предметом
ожесточенных споров, эти различия сохраняются и играют важную роль в понимании
естественного языка. Эти глубинные вопросы будут также рассмотрены в главе 16.
13.1.2. Стадии анализа языка
Конкретная структура программ понимания естественного языка варьируется в
зависимости от используемой идеологии и целей приложения. Проблема понимания языка может
возникать при реализации интерфейса с базой данных, системы автоматического перевода-
программы интерактивного обучения и др. Во всех этих системах исходное предложение
необходимо привести к внутреннему представлению, отражающему его значение.
Основные стадии решения задачи понимания естественного языка показаны на рис. 13.2.
Первая стадия — это синтаксический разбор (parsing), т.е. анализ синтаксической
структуры. В процессе синтаксического разбора проверяется, корректно ли сформировано
предложение, и определяется его лингвистическая структура. За счет идентификации таких
основных лингвистических отношений, как подлежащее-сказуемое, сказуемое-дополнение, в
процессе синтаксического разбора строится базис для семантической интерпретации. Результаты
анализа зачастую представляются в виде дерева разбора (parse tree). В синтакигческом
анализаторе используются знания синтаксиса языка, морфологии и, частично, семантики.
Вторая стадия — это семантическая интерпретация (semantic mlerpreiauonl. в
результате которой формируется представление содержания текста. На рис- 13.2 этот
процесс показан в виде концептуального графа. К другим наиболее часто используемым
представлениям относятся концептуальные зависимости, фреймы и логические пред-
«явления. В процессе семантической интерпретации используются знания о значении
■»в „ лингвистической структуре, в том числе синонимы существительных или глаго-
»■• На рис. 13.2 показа,^ чТв программе используется знание ".^"на $е
•иеловать) для добавления в качестве используемого no >*^"» ^П£еХ
'"'» '4» (губы). На этой стадии также выполняется проверка с ««»'' ™»°"
-с™. Например, определение глагола И» -^^еТаГн X Дж1 "Z™
ге". что человек может целовать только человека, т.е. 1аРзан «cm я
не челует обезьяну Читу.
1Э. Понимание естественного языка
565
Интерпретация знаний об
окружающем мире
Расширенное представление:
possess,
fexperiencer) 1 love \—(object
person: tarzanj I person: jane]
agent )—jkiss ] ( object
Передать в блок генерации
ответов, обработчику
запросов к базе данных,
транслятору и т.д.
Рис. 13.2. Стадии создания внутреннего представления предложения
На третьей стадии структуры из базы знаний добавляются к внутреннему
представлению предложения для формирования расширенного представления значения
предложения. Для полного понимания предложения требуются знания о реальном мире, в том
числе знание того факта, что Тарзан любит Джейн, Джейн и Тарзан живут в джунглях и
обезьяна Чита - это друг Тарзана. Эта окончательная структура представляет значение
текста и используется системой для дальнейшей его обработки
ФоомиГГ' ° ИНТер*ейсе с бш°" инных "а расширенная структура используется для
иГГж" бь,тГЛСТаГНМ ЮПр0Са С уЧе™м °Р™нзац„и сbbZ». Затем этотза-
л^ьГ^ЛГ^Гв'Г С0<™^ий -прос „а языке управления базами
представлять соде„ж„„;ек?яУЧаЮЩИ'; "Р01?3™** эта расширенная структура может
«ой теме (ем обе™ Г ^^ " испол™в"ься Д™ ответов на вопрос по
задании стадии „рС™"ЦтеНар"Св в ™ве 6 и подраздел 13.5.3).
в виде программных моГеГнГ" СИСТШаХ' Х0ТЯ "^ быть по-разному реализован"
"гея в явном виде Вместо РИМер- во многах программах дерево разбора не стр»
представление. Тем не мене,.™™ напРямУю генерируется внутреннее семантическ»
ттш»« синтаксический palZTr"'™"0 У43™^ в разборе предложения. №«?/'""'
К"иртб°Р (incremental parsing) [Allen. 1987] - это типичный ИР"
в рамках которого фрагмент внутреннего представ,,...,., а
каждой существенной части предложения. Объединение Z^T™™" "P" РШб°РС
"олную структуру предложения, которая зачастГ испольГ^ ФраШСНТОВ «являет
:мЫСлен„остейнобЩегоруководствадейетвн,,Г:„Г;чХг:а^„УзГрНаСН,,ЯДОУ-
13.2. Синтаксический анализ
13.2.1. Спецификация „ синтаксический анализ с использованием
контекстно-свободных грамматик
В главах 3 и 14 вводится понятие правил вывода (rewrite rule), используемых для
определения грамматики. Перечисленные „„же правила определяют грамматику дГпро-
„ых транзитивных предложении типа "Человек любит собаку" Для удобства эти
правила перенумерованы. ' е
1. sentence<->noun_phrase verbjDhrase
2. nounjDhrasei-^noun
3. noun_phrase<rlarticle noun
4. verb_phrase<-*verb
5. verb_phrasetr*verb nounjDhrase
6. article <->a
7. arf/c/e<->the
8. noun<->man
9. noun<->dog
10. i/erfj<->likes
11. verb<->bites
В правой части правил 6-11 содержатся английские слова. Эти правила формируют
словарь доступных слов, которые могут появляться в предложении. Этн слова являются
терминалами (terminal) грамматики и определяют лексикон (lexicon). Термины,
определяющие лингвистические понятия более высокого уровня (sentence. noun_phrase), на-
зываются нетерминальными „ выделяются стилем формул. Заметим, что терминалы не
встречаются в левой часта правил.
Корректное предложение — эта любая строка терминалов, которую можно разделить
на части с помощью этих правил. Трансформация начинается с нетерминального
символа sentence и в результате серии последовательных подстановок, определенных
правила™ грамматики, приводит к формированию строки терминалов. Корректная
подстановка—это замена символа соответствующего левой части правила, символом из
правой части этого правила На промежуточных стад.гях вывода строки могут включать как
теР«иналы, так и нетерминальные выражения. Такое представление называется сентен-^
Ч^ьной формой (5еп1еп,|а| forrn). Трансформация предложения 'The man b.tes the dog
Ыгляднт следующим образом (табл. 13.1).
■ Понимание естественного языка
применяемое правило
Строка
Sentence
„ounJ>hraseverbJ>nrase ?
article noun verb Jihrase &
The noun verb jhrase 5
The men verbjihrase ,,
The man verb noun_phrase ^
The man bites nounjhrase _,
The man bitesart/cte noun g
The man biles the noun
The man bites tt
Это пример трансформации сверху
вша (top-down derivation). Она начинается с сим-
тяТзеп,епсе „завершается строкой терминалов. Трансформация снизу вверх начина-
Г со строки терминалов, включает замену элементов правой части правила соответст-
™„м„ элементами из левой части и завершается символом sentence.
Трансформацию можно представить в виде дерева, получившего название дерева
грамматического разбора (parse tree), в котором каждый узел— это символ из набора
правил грамматики. Внутренние узлы дерева — нетерминальные. Каждый узел н его
потомки — это левая и правая части некоторого правила грамматики соответственно.
Листовые узлы — это терминалы, а символ sentence — корень дерева. Дерево разбора для
предложения "The man bites the dog" показано на рис. 13.3.
Существование трансформации или дерева разбора не только доказывает
корректность предложения с точки зрения грамматики, но и определяет его структуру.
Фразовая структура грамматики {phrase structure) определяет глубинную лингвистическую
организацию языка. Например, разделение предложения на глагольную и именную
конструкции (фразы) определяет отношение между действием н его агентом. Такая
фразовая структура играет ключевую роль в семантической интерпретации, поскольку
определяет промежуточные стадии трансформации, на которых может выполняться
семантическая обработка.
Разбор предложений — это задача построения трансформации нли дерева
грамматического разбора для входной строки на основе формального определения грамматики.
Алгоритмы грамматического разбора делятся на два класса; анализаторы сверху ениз
и с™" РаГ$еГ)' К0Т°РЫе шчинают свшо Работу с высокоуровневого символа sentence
весах (НоГ?0' "ИСТЬЯ К0Т0|50Г0 оставляют целевое предложение, и анализаторы ст№
в результате^ ' Р КОТОрых "ачннается со слов предложения (терминалов), и
*ГиГ™"еГаТСЛЬНШ °,lePaUWl *°Р»»РУСтся символ sentence,
существующего ™к ^ШШ* МДа"И 'Тонического разбора состоит в выборе из
Формации При „e„nГ„„ПГ8ИЛa• Т°т ак™" использовать на каждом шаге транс-
ложеиис.Напримео ппГп Т РС анш"™тар может не распознать корректно прел-
зультате применен™ IZZ 1 \т™0Кг"™ "The dog bites" методом снизу вверх в F
этого ошибочное ппимене» УД" полУ«ена строка article noun verb. По»
«старую нельзя „р,,ВСсти Т "РаВ""а2 генерирУст строку article noun_prhase verb.
пользовать прав1,ло з Аналог,™^ Sen,ence' На самом деле анализатор должен
>чные проблемы возникают и при разборе сверху вниз
ительные вопросы решения задач искусственного интеллекта
bites the
dog
Рис. 1.13. Дерево грамматического разбора
для предложения "Tlxe man bites the dog "
Проблема выбора корректного правила на каждой стадии грамматического разбора
решается за счет установки возвратных указателей н обратного перехода к исходной ситуации при
некорректном выборе правила (подобно тому, как это происходит в рекурсивных
анализаторах спуска, описанных в разделе 14.9) или предварительной проверки исходной строки на
предмет наличия свойств, позволяющих определить выбор применяемых правил.
Обратная задача — это задача генерации (generation), или формирования, корректных
предложений на основе внутреннего семантического представления. Генерация
начинается с представления некоторого осмысленного содержимого (в частности,
семантической сети нли графа концептуальных зависимостей) и состоит в построении
грамматически корректного предложения, отражающего этот смысл. Однако генерация— это не
просто задача, обратная пониманию. При ее решении возникают отдельные сложности,
для устранения которых требуются специальные методологии.
Поскольку грамматический разбор играет особо важную роль в обработке не только
естественных, но и программных языков, ученые разработали многочисленные
алгоритмы такого анализа. Онн включают стратегии обработки информации снизу вверх и
сверху вниз. Полный обзор алгоритмов грамматического анализа выходит за рамки этой
главы, однако мы остановимся на принципах работы анализаторов на основе сети
переходов (transition network). Сети переходов не обладают достаточной мошностью для
анализа естественных языков, но онн были положены в основу расширенных сетей
переходов (augmented transition network), которые зарекомендовали себя как полезные и
мощные средства работы с естественным языком.
13.2.2. Анализаторы на основе сети переходов
Анализатор иа основе сети переходов представляет грамматику в виде набора конечных
автоматов или сетей переходов. Каждая сеть соответствует одному нетерминальному
элементу грамматики. Дуги в таких сетях помечены терминальными или нетерминальными
символами. Все пути в такой сети, ведущие от начального состояния к конечному,
соответствуют некоторому правилу для нетерминальных элементов. Последовательность меток дуг
гагого пути — это последовательность символов в правой части правила. Грамматика,
рассмотренная в подразделе П 2 1 может быть описана с помошью сетей переходов, показаи-
нь* "а р„с. 13.4. Если грамматика содержит несколько правил для нетерминальных эле-
м«"ов, то в соответствующей сети содержится несколько путей от начала к цели. Напри-
М£Р. правила noun_phrase^noun и noun_phrase^article noun изображаются в виде
Различных путей в сети noun_phrase на рис. 13.4.
'■ Понимание естественного языка
569
noun_phrasa:
дамбам S N
f s final J
verb_phrese: ^b Л >, nTJuryshrase ^^
(s final J
вы) (^^J^y
(smifial) ( sfinal J
Рис. 13.4. Определение сети переходов простой грамматики
английского языка
Поиск успешного перехода в сети для нетерминального элемента состоит в замене
этого элемента содержимым правой части грамматического правила. Например, для
разбора предложения анализатор должен найти переход в сети предложения sentence. Он
начинается с исходного состояния (S„,„„,), включает переход noun_phrase, затем
переход verbjhrase и завершается в конечном состоянии S„„„,. Этот процесс эквивалентен
замене исходного символа sentence парой символов noun_phrase и Verbj,hrase.
тепмСяГГХ0Да Л° ДУГС аналнит°Р проверяет ее метку. Если метка представляет собой
ли еле"™""" С"МЕ0Л' аНаЛ'гаТ°Р Пр0ВеРяст ™Д™Й ™™к и определяет, соответствует
л дХомеченГ ""* ДУ™' ^ °"° ю ^ответствует, переход не совершается. Ес-
~Zl м„""ГИНаЛШЫМ С"т0тЫ- аналта™Р Р=курснв„о переходит к сети
«аруже^ГрГдГ;™ Те:™" "» »*« "У* ■ ™* сети. ЕсРли путь не об-
вращается к исходной сети и УР°ВНЯ невознож™- В этом случае анализатор воз-
путь в сети sentence Если -ряет слеДУЮЩий путь. Так анализатор пытается начти
собой корректное предлож,^?™ ПУП> сУщсствУет. значит, входная строка представляет
Рассмотрим простГпГ Да1Ш°Й ^мматике.
бора этого предложения показаГы'нГ '^ ^^ ("Собака «У^ется"). Первые шаги рэз-
1 - Вызвать
noun_phrase
verb_phrase
7. Вернуть4,
success
8. Вызвать
^ verb_phrase
ч rw Ч^ 4- Вызватъ 6- ^Р^Уть
■S. Путь -ч noun sij«j<te
не найден X Success
5 Считать "dog" из
входного потока
Рис. I3.S. Анализ предложения "Dog bites " с помощью сети переходов
1. Анализатор начинает свою работу с сети sentence и пытается совершить переход
по дуге с меткой noun_phrase. Для этого он переходит к сети noun_phrase.
2. В сети noun_phrase анализатор сначала пытается совершить переход по дуге
article. Для этого он переходит к сети article.
3. В сети article нельзя найти путь к конечному узлу, поскольку ни одна из дуг не
помечена первым словом предложения "dog". В результате безуспешной попытки
поиска пути анализатор возвращается к сети noun_phrase.
4. Анализатор пытается пройти по дуге noun в сети noun_phrase и переходит к
сети поип.
5. Проход по дуге с меткой "dog" завершается успешно, а именно она соответствует
первому слову входного потока.
6. Результат поиска в сети поип положителен. Это значит, что дуга с меткой поип в
сети noun_phrase ведет к конечному состоянию.
7- Сеть noun_phrase возвращает успешный результат сети самого верхнего уровня,
разрешая переход по дуге nounjjhrase.
8- Аналогичная последовательность шагов приводит к разбору части предложения
"erbjjhrase.
Ниже приведен псевдокод работы анализатора на основе сети переходов. Этот анализатор
Сделен с помощью двух взаимно рекурсивных функций parse и transition. Аргумен-
То« Функции parse является символ грамматики. Если это терминальный символ, то функ-
ЦИЯ P«se сверяет его со следующим еловом входного потока Если он нетерминальный.
Глава 1 "5 п
J-1 внимание естественного языка
язанной с этим символом, и вызывает функцию
а. „. оагве следу" к сел. "^* С „^ transition в качестве параметр, ис.
функция parse в ^ сети, у „уп, в этой сети с помощью метода „о-
„.„vo позицию вс входном потоке;
Сохранить указатель ка T.KW-
саЕе „тся терминальным:
еиы»ол.гра«атИки ^"^ответствует следующему слову во
if символ_грамматики со
„одном потоке^^^
^"переустановить входной поток;
retum(failure)
символистики является нетерминальным:
Ьед1перейти к сети переходов, соответствующей символу
грамматики;
Состояние:=начальное состояние сети;
if tranaition(cocTOflHMe) возвращает success
then return(success)
else begin
переустановить входной поток;
return(failure)
end
end;
end
end.
function transition(TeKyuiee_coCTOHHHe);
begin
case
текущее„состояние - это конечное состояние:
return(success)
текущее_состояние - это не конечное состояние:
while существуют н^г/->г,^.1|1ие переходы из текущего
состояния
do begin
символ_граии^тики: = мотка следующего непроверенного
перехода;
it parse (символ_грамыатики) возвращает success
then begin
следующее_состояние:=состояние в конце
перехода,-
if transition(следующее_состояние)
возвращает success
then return(success)
end
Ч-ль V. Дополнительные вопросы решения задач искусственного интвлл»^
return(failure)
end
nd-
Поскольку анализатор может совершить ошибку и должен возвратиться к исходному
с0Стояник, функция perse сохраняет указатель иа текущую позишкГГ ходнем пГ
ке, позволяя переустановить входной поток в эту позиции, в случае возврата анализатора.
Такой анализатор на основе сети переходов может определить корректность прешшже-
„„,, „о не может построить дерево грамматического разбора. Для решения пой задачи
необходимо построить функцию, возвращающую поддерево дерева разбора, а не просто
символ success. Для этого процедуру анализа нужно модифицировать следующим образом.
1. При каждом вызове функции parse, параметром которой является терминальный
символ, соответствующий следующему символу входного потока, она должна
возвращать дерево, состоящее из одного листового узла, помеченного этим символом.
2. Если функция parse вызывается для нетерминального значения параметра
символ_грамматики, она вызывает функцию transition. При успешном
завершении функции transition она возвращает упорядоченный набор поддеревьев
(который будет описан ниже;. Функция parse строит на их основе дерево, корнем
которого является символ_гракматики, а дочерними элементами — поддеревья,
возвращаемые функцией transition.
3. При поиске пути в сети функция transition вызывает функцию parse для
метки каждой дуги. При успешном завершении функция parse возвращает
дерево, являющееся результатом разбора соответствующего символа. Функция
transition сохраняет эти поддеревья в виде упорядоченного набора и при
нахождении пути в сети возвращает упорядоченный набор деревьев разбора,
соответствующий последовательности меток дуг этого пути.
13.2.3. Иерархия Хомского и контекстно-зависимые грамматики
В подразделе 13.2.1 была определена малая часть правил английского языка на
основе контекстно-пезавиашой грамматики (contexl-free grammar). В такой грамматике в
левой части правил может содержаться только по одному нетерминальному символу.
Следовательно, правило можно применять к любому вхождению этого символа,
независимо от контекста. Хотя КОи1скстно-независнмые грамматики зарекомендовали себя как
мощное средство определения языков программирования и других формализмов в ком-
«иотсриых науках, есть основания считать, что сами по себе оии недостаточно
эффективны для представления правил построения естественного языка. Например,
рассмотрим, что произойдет, если добавить к описанной в подразделе 13.2.1 грамматике
существительные и глаголы не только в единственном, но и во множественном числе.
лоил*~>теп,
noun«~>dogs,
verbubite,
«srbulike.
(- ««мощью „о , ■ , .-.шатики можно осуществлять грамматический разбор
nnr,,,. мощыо чо"э'"-и.. i""" •• ,-д m,-n likes a docs", в которых артикли и
£«««еиий вида -The dogs like the men и ^^,^ 8до„ускаег такие предло-
м«°*сствсннос чии1о у,гат1,со„як,тся некорректно. Анализатор д
'3. Понимание естественного языка
573
„„авила не используют контекст для коорд„наЦ(
. поскольку сушеавуюшие прав» числа Например, правило> 0Пределя
Ж£^нИмо™Гедаш«вейного и »'но*'С™онструкцию лоЦЛ_рг,газе. за которой слсду.
ГГ;сГо""и-—се каким ^о-^ност,, числа существительного „ £
рольная verbjhrase,™^^возникает при использовании артиклей,
гола Та же проблема ™гласова""°"^висимымн грамматиками, составляют лнгнь од„„ щ
Языки, определяемые ^кС™°\ Такая иерархия называется иерархией Хамского
классов иерархии формальных язык -^ [Chomsky, ,965]. На нижнем уровне этой №.
(Chomsky hierarchy) [Hopcrott и иип ,^ ^^ toguage) рсгуляр„ь1м называется язык
рархии находится класс раумр» а с использованием конечных автоматов. Хотя
грамматика которого может оы™>^я в КОМПЬ10терных науках, они недостаточно эффек-
регулярные языки ая™"° "™ * ^ьшииства языков программирования,
тонны для представления сии ^ (contexl-free language) в иерархии Хомского распо-
Контекстно-яезатси.т' языков 0ии определяются с помощью правил вы-
ложены на уровень выше р^.^^ контекст„о-независимых правил может распола-
В°Да<"°^ГкГоаин нетерминальный символ. Класс контекстно-независимых языков
Гно Z, гзировать «I- сетей переходов. Интересно отметить, что если в ана-
л,Горе на основе сетей переходов не допускать рекурсии (т.е. дугн помечать только
терминальными символами, не приводящими к "вызову другой сети), то класс таких
языков будет соответствовать множеству регулярных выражении. Таким образом,
регулярные языки - это строгое подмножество контекстно-независимых языков.
Контекстно-заташые языки (context-sensitive language) составляют строгое
супермножество контекстно-независимых языков. Они определяются с помощью контекстно-
зависимых грашшгтк, которые допускают использование нескольких символов в левой
части правила для определения контекста применения этого правила. Таким образом,
гарантируются глобальные ограничения, в частности, согласованность единственного и
множественного числа. Единственным ограничением для правил контекстно-зависимой грамматики
является непревышение правой части правила размера его левой части [Hopcroft и Ullman, 1979].
Четвертым классом, составляющим супермножество контекстно-зависимых языков,
является класс рекурсивно-перечиелнмых языков (recursively enumerable language). Такие
языки определяются с помощью неограниченных продукционных правил. Поскольку эти
правила не такие жесткие, как контекстно-зависимые, класс рекурсивио-перечнелимых
языков является строгим супермножеством контекстно-зависимых языков. Этот класс не
представляет интереса для определения синтаксиса естественного языка хотя тоже
играет важную роль в теории компьютерных наук. Остальная часть этой главы будет
посвящена анализу английского языка, как относящегося к классу контекстно-зависимых.
Га™^^0тСК™°"Н™СИМаЯ T^™* для предложений вида article noun verb
нТчислсZГГ™ЬНОе ГЛаГ0Л)' В К0Т0РЫХ «™ова„о единственное и
множественное число артикле,, и существительных, а также существительных и глаголов, имеет вид
sentencewnounjJhrase verb_phrase
"ounjhrase^articlenum ber„"„n
n°u"-PhraSe„number„oun '
num6er«smgufar,
numbers plural
™>cle singulars singular
article smgu/arMthe singular
allele P/ura/Mthe p/Ufa,
интеллект8
singular nounoman singular.
singular noun<-»dog singular,
plural nounwmen plural,
plural noun<-)dogs plural,
singular verb_phrase^>singular verb,
plural verb_phrase<->plural verb,
singular verbt-^likes,
singular verb<->bites,
plural verbt-^like,
plural verb<->bite.
B это„ гт—ке нетерминальные символы singular и plural обеспечивав
ограничения при определении правил применения различных артиклей, существительных ..
глагольных конструкции с целью согласования форм единственного и множественного
числа. Трансформация предложения 'The dogs bite" с использованием этой грамматики
выполняется следующим образом.
sentence.
noun_phrase verb_phrase.
article plural noun verb_phrase.
The plural noun verb_phrase.
The dogs plural verb_phrase.
The dogs plural verb.
The dogs bite.
Аналогично контекстно-зависимую грамматику можно использовать для проверки
выполнения синтаксических соглашений. Например, добавив к данной грамматике нетерминальный
символ act_of_biting, можно запретить использование предложений вида "Man bites dog"
(человек кусает собаку). Этот нетерминальный символ можно использовать для
предотвращения построения предложении, в которых действие bites вьшолняет существительное man.
Контекстно-зависимые грамматики позволяют определять языковые структуры, не
охваченные контекстно-независимы ми грамматиками, но их практическое применение при
создании анализаторов сопряжено с некоторыми сложностями следующего характера.
1. При использовании контекстно-зависимых грамматик резко возрастает количество
правил и нетерминальных символов. Представьте себе сложность контекстно-
зависимой грамматики, необходимой для описания форм числа (единственного и
множественного) и лица (первого, второго и третьего), а также всех остальных
форм соглашений, принятых в английском языке.
2. В контекстно-зависимых грамматиках размывается структура фраз языка, столь
ясно представнмая с помощью контекстно-независимых правил.
3- При попытке описать более сложные соглашения и обеспечить семантическую
согласованность самой грамматики теряются многие преимущества разделения
синтаксического и семантического компонентов языка.
4- Контекстно-зависимые грамматики не решают проблемы построения
семантического представления значения текста. Анализатор, который просто принимает или
отвергает предложение, никому не нужен. Ои должен возвращать эффективное
представление семантического значения предложении.
, В следующем разделе будут рассмотрены расширенные сети переходов ATN
Kmented transition network), с помощью которых можно определять контекстно-
!- Понимание естественного языка
575
сния обладает некоторыми преимуществам,,
Мв„симь,е языки. Такой ^ХГграмматиками при разработке анализаторов,
по сравнению с контекстна
..a r ATN-анализаторах
1^мависн«ых грамматик является сохранение простой струк.
Альтернативой для контекстии *"мми11И1 „ расширение этих правил за счет добаале-
туры правил котк™^н1^И^'00'д,иые контекстуальные проверки. Такие процедуры вы-
ния процедур. выполняюш1тх неоо ^.^ ^ шалюл. Вместо использования граммати-
полняются при использовании rip_ ^ ^ единственного и множественного числа,
и, для представления такю: по _ ш]еннь1е предметы, их можно представлять с по-
времена ^Т^Гсвяз^зньгх с терминальными и нетерминальными символами грач-
:= Гв^Гс^ТлГ^Оки ттроцедуры обрашатотся к этим средствам т
«качений Гвыполиенш «обховимых проверок. К грамматикам, „спользузощим
«ния контекстно-независимых грамматик для реализации контекстной зависимости,
относятся расширенные грамматики фразовой структуры (augmented phrase structure)
(Heidorn 1975] [Sovra, 1974), расширения логических грамматик (augmentation of logic
grammar) [Allen, 1987] «расширенные сети переходов ATN (augmented transition network).
Этот раздел посвящен ATN-аналшу и вопросам разработки простых ATN-анализаторов
для предложений из "мира собак", о которых шла речь в подразделе 13.2.1. Будут
выполнены первые два шага процедуры, проиллюстрированной на рис. 13.2: создание дерева
разбора и его использование для построения представления смысла предложения. В этом
примере будут использованы концептуальные графы, хотя ATN-анализаторы можно также
строить на основе сценариев, фреймов и логических представлений.
13.3.1. Анализаторы на основе расширенных сетей переходов
Расширенные сети переходов усиливают возможности обычных сетей за счет
добавления процедур, связанных с дугами сети. Эти процедуры выполняются ATN-анализатором
при проходе соответствующих дуг. Процедуры могут присваивать значения и выполнять
проверки, приводящие к запрещению перехода при несоблюдении заданных условий
(например, соглашений об использовании форм единственного и множественного числа).
пГГ^10 УтХ "Р°иеЛУР ТаКЖС можно "?0НТЪ Д^во Разбора, применяемое для
генерации внутреннего семантического представлен,* смысла предложентп,.
лами (в тоТчЬисМл°еТйГЗЬШЭТЬСЯ ™ ° теРм»™"-ными, так и нетерминальными симво-
ванием сго м0о4олог """"^^ Пример, слово можно описывать с нспользо-
ственное или множественнГ „Т"' " ° П°М°ЩЬЮ пР01<еауры задавать часть речи, един-
описывакяся а„Шогич„0 им1 °' ™U° " тл "терминальные символы грамматик.,
ньш, его числом и лицом Ка К0НСТРУКЦИЯ описывается артиклем, существитель-
прслставить с помощью rtineiJ ТСрм"нальные. так и нетерминальные символы можно
Значения тгих ячеек мот зада ™ СТру,СТуРы с именами ячеек и их значениями
пример, „срвая ячсйка ф . мть процедуры или указатели на другие структуры. №•
именной конструкции На пиг Г™Шжения мож" содержать указатель иа определена
«nrer,ce,noUn_pnrase„Jerb oh ПЖЮты *Реймы Для нетерминальных символе»
Отдельные слова представ^™ " 0,|Исанн°й выше простой грамматике,
«варе определяется фреймов» . ' П°М0ЩЬЮ а"^о™ч„ь,х структур. Каждое слово в
_____J*PJ«^ в котором указано, к какой части речи оно относит»
576 ЧагтьУ л ' ^-—
°™"ните„ь„ыв вопросы решетя ^ искусотввнного интеллекта
уфологический корень и существенные грамматические г. -
■обходимо проверять только соответствие форм ели» С80истм- в нашем примере
В более сложных грамматиках мот vhhtu,., го и ""ожественного чис-
~-..~nV r-nnanna .. /™»ЫВаТЬСЯ Такжр птт I,
ходи"" ..Р™^-» — шли соответствие форм елингт».../— нашсм пРИ1«ре
} более сложных грамматиках могут учитывать " множественного чис-
3 этих записях словаря может содержаться оппеле л™ ^^ ЛИЦ° " ЛруГие СВ0Й"М-
нИя слова, используемое при семантической интерпое™ ' "Т6"^"101"0 Графа 1наче"
ваемой грамматики показан иарис. 13.7. полный словарь рассматри-
Именнан конструкция
Предложение
Noun phrase:
Verb phrase:
Глагольная конструшш
Verb-
Number
Object:
Рис. 13.6. Структуры Сля представления нетерминальных симюо. поео.о
женил, а также именной „ глагольной конструкций """»•"" »Р«>™
Слово
Определение
dog
dogs
PART_OF_SPEECH
article
ROOT: a
NUMBER: singular
PART_OF_SPEECH
verb
ROOT: bite
NUMBER: plural
PART_OF_ SPEECH
verb
ROOT, brie
NUMBER: singular
PART__OF_SPEECH:
noun
ROOT: dog
NUMBER: singular
PART_OF_SPEECH.
"юип
ROOT' dog
NUMBER plural
Слово
like
Определение
PART_OF_SPEECH:vero
ROOT: like
NUMBER: plural
PARTJ)F_SPEECH:verb
ROOT: like
NUMBER, singular
PARTOFSPEECH: noun
NUMBER: singular
PART OF SPEECH noun
PART OFSPEECH. article
NUMBER: plural or singular
Рис. 13.7. Записи словаря для простой ATN-сети
ATN для данной грамматки. С помощью псевдокода
На рис 13.8 показана сеть AIM Д»^ Метками дуг являются как нстерминаль..^
процедур"- выполняемые для каждой д^ ^ ^^ использусмые для указания функций,
волы грамматики (как и на рис.
волы it»- _^
процедуры, выполняемы. "-" - так и числа, используем». ^ ,-опи. функций, с„.
вТлы грамматики (как и на рис. 1 *А ^ функцш, ДОЛЖны бьпъ успешно выполнены,
зантк с каждой дугой. Для пс^одД>о ^^ аншшзаТ0р создает новый фр;
При обращении к сети нетср» создается фрейм noun_phrase. Ячсйк- -
)ейм.
При обращении к сети нс.ч- ^ создается фрейм noi/n_pnrase. Ячейки фрсй;
Например, при входе в сеть по j, ^ ^^ m(,f(KaM Moryr бь1ть присвоены значения
„а заполняются функциями а™ на компоненты синтаксической структуры (Те
грамматических свойств ..ли > ^ сншюлов vert н noun_phrase). При достиг
„:Гне^сГовян1Гетьвоз.раЩаетполученную структур,
sentence:
noun_phrasi
f.
rb_phrase^-
function sentence-1;
b6|EjN_PHRASE := структура, возвращаемая
сетью noun_pnrase;
SENTENCE.SUBJECT ;= NOUN_PHRASE;
end.
furtclion sentence-2;
begin
VERB PHRASE := структура, возвращаемая
"сетью verb_phrase network;
if NOUN PHRASE.NUMBER =
VERB_PHRASE.NUMBER
then begin
SENTENCE.VERB PHRASE :=VERB_PHRASE;
return SENTENCE
end
function noun_phrase-1;
begin
ARTICLE := фрейм определения для следующего входного слова;
if ARTICLE-PART OF SPEECH-article
then N0UN_PH~RA5E.DETERMINER := ARTICLE
else fail
function noun_phrase-2;
begin
NOUN := фрейм определения для следующего входного слова;
ifNDUN.PART OF БРЕЕСН^существительноеи
NDUN.NUMBER согласуется с
NOUN_PHRASE.DETERMlNER.NUMBER
then begin
NOUNPHRASE.NOUN ;= NOUN'
NOUN PHRASE.NUMBER := NDUN.NUMBER
returnNDUN PHRASE
end
else fail
end.
лт-грашатию, для проверкг, соответствия числа и построения дерева разбора
function noun_phrase-3
begin
«ОШ - фрейм опремлеии„ „,, CM№ulero юотого слом.
"Г.ГьеР9Г-0МРЕЕСН=«та»—
^NOUN.PHRASLNUMBER^nSuN.NUMBEB
else fell
пои n_ph rase
function verb_phrase-1
begin
VERB := фрейм определения для следующего входного слова;
if VERB.PART_OF_SPEECH=verb
then begin
VERB_PH RASE. VERB :=VERB;
VERB^PHRASE.NUMBER :=VERB.NUMBER;
end;
end.
function verb_phrase-2
begin
NOUN_PHRASE:
•■ структура, возвращаемая сетью
noun_phrase;
VERB_PHRASLOBJECT:=NOUN PHRASE;
return VERB_PHRASE
Рис. 1.18. (Окончание)
function verb_phrase-3
begin
VERB := фрейм определения для следующего входного слова;
if VERB.PART_OF_SPEECH=verb
then begin
VER8.PH RASE- VERB =VERB,
VERB PHRASE NUMBER-VERB.NUMBER;
VERB_PHRASE.OBJECT ;= unspecified;
return VERB_PH RASE;
end;
end.
При проходе дуг с метками noun, article it verb считывается следующее слово из
входного потока и извлекается его определение из словаря. Если это слово относится к
несоответствующей части речи, переход по дуге не совершается. В противном случае
возвращается фрейм определения.
На рис. 13.S фре Пмы н ячейки обозначены идентификатором ФРЕЙМ.ЯЧЕЙКА, в
частности ячейка числа фрейма глагола обозначена VERB.NUMBER. В процессе разбора
каждая функция строит л возвращает фрейм, описывающий соответствующую
синтаксическую структуру. В этой структуре содержатся указатели на структуры, возвращаемые
сетями более низкого уровня. Функция самого высокого уровня (уровня предложения)
возвращает структуру sentence, представляющую дерево разбора входного потока. Эта
"Руктура передается семантическому интерпретатору. На рис. 13.9 показано дерево
грамматического разбора, возвращаемое для предложения "The dog likes man".
На следующей стадии обработки естественного языка на основе полученного дерева
Разбора (наподобие представленного на рис. 13.9) строится семантическое
представление знаний о предметной области и смысла предложения.
1а 13. Понимание естественного языка
579
Рис. 13.9. Дерево грамматического разбора для предложения "The dog likes man ", возвращаемое
ATN-анализатором
13.3.2. Объединение знаний о синтаксисе и семантике
Семантический интерпретатор строит представление значения входной строки,
перемещаясь по дереву грамматического разбора от корневого узла sentence. В каждом узле
он рекурсивно интерпретирует его дочерние узлы и объединяет полученные результаты в
с™ „,e0rrMbH0^ ГРафС- НаПр"Мер' ««антический интерпретатор строит
пределZ n olrsZ ^ "■ Ф°РМИРУЯ ™сивные представления дочерних узлов
зультГт средня! „" 0бЪ,СШШЯЯ "Х ШШ "Ржавления глагольной конструкции. Рс-
Pewe~:p;LeeTcrCe " °6Ъ™"«™ ' представлением символаVubject.
разбора. Некоторые из них "Р" Д0СТ,ше"ии терминальных элементов дерева
лам „ прилагательным треб™™,.4"™0 С00тветс™>"<>щ„е существительным, глаго-
ности артикли, не имеют ,тГ леченмя понятий из базы знаний. Другие, в час1-
деляют другие „снятия на графе С°°ТВСТСТвия с "снятиями базы знаний, но опрс-
иий о "мире собак-ТмнГпГ СС'"а.нтичсский интерпретатор использует базу энз-
также действия like и bite. Эти i °" 5"Ы ШШ"" относятся объекты dog и man. »
понятия описываются с помощью иерархии типов.
Дополнительные вопросы решения задач искусственного нигелле
Т
on,«V slate
animals physobj
b,te dt>9 person teeth like
Рис. 13.10. Иерархия типов для
примера га "мира собак"
Помимо понятий необходимо определить отношения, которые будут нспользопаны и
концептуальных графах. В нашем примере участвуют следующие понятия.
• Символ agent (агент) связывает понятие act (действие) с понятием типа animatii
(одушевленный). Агент определяет отношение между действием и одушевленным
объектом, инициирующим это действие.
• Символ experiencer (носитель состояния) связывает понятие state (состояние) с
понятием типа animate (одушевленный). Он определяет отношение между
психическим состоянием и его носителем.
• Символ instrument (инструмент) связывает понятие act (действие) с понятием entity
(сущность) и определяет инструмент, используемый для выполнения действия.
• Символ object (объект) связывает понятие event (событие) или state (состояние)
с понятием entity (сущность) и представляет отношение "действие-объект".
• Символ part (часть) связывает понятия типа physobj (физический объект) и
определяет отношение между целым и его частью.
При построении интерпретации особо важная роль отводится глаголам, поскольку
они определяют отношения между подлежащим, дополнением и другими компонентами
предложения. Каждый глагол можно представить с помощью падеокного фрейма (case
frame), определяющего следующие данные.
1. Лингвистические отношения (агент, объект, инструмент л т.д.), соответствующие
данному глаголу. Например, транзитивные глаголы связаны с объектом, а нетраи-
зитивные— нет.
2. Ограничения на значения, которые могут присваиваться любому компоненту
падежного фрейма. Например, в падежном фрейме для глагола "biles" утверждается,
что агент должен относиться к типу dog. Тогда предложение "Man bites dog" будет
отклонено как семантически некорректное.
3. Используемые по умолчанию значения компонентов надежного фрейма. Во
фрейме глагола "bites" для понятия, связанного с отношением instrument, по умолча-
нию используется значение teeth.
13. Понимание естественного языка
581
ПМежнь,е фрей«" ^™аГОЛ0В
like и bite
показаны на рис. 13.11.
[ entity | (^рагР)
Р„с 13.11. Падежные фреймы для глаголов "like" и -bite"
Определим действия, позволяющие строить семантическое представление правил
или процедур для каждого потенциального узла дерева грамматического разбора. В
нашем примере правила описываются в виде процедур на языке псевдокода. В
каждой процедуре при неуспешном завершении конкретного теста или объединения
данная интерпретация отклоняется как семантически некорректная.
procedure sentence;
begin
вызвать процедуру noun_phrase для получения представления
подлежащего;
вызвать процедуру verb_phrase для получения представления
сказуемого с зависимыми словами;
с помощью объединения и ограничения связать понятие
существительного,
возвращаемое для подлежащего, с агентом графа
для глагольной
конструкции
end
procedure noun_phrase;
begin
вызвать процедуру noun для получения представления
существительного-
case '
Нео™гГеННЫЙ аРтикль и единственное число: понятие,
о^^Л:нЛ„Я4МО:РтСиГьСТи8ИТеЛЬНЫЫ' ЯВМеТСЯ 0б™М; маркеР •
понятирч Т dpT11KJIb и единственное число: связать маркер
-оГеяс™::„0:п^яемь,мсущест™ным'-
во множественном числе*"' ^ с>™ествительное
end case
end.
procedure verb_phrase;
begin
?Гсарлаг^мДУРУ Verb ДЛЯ пол>"«*"™ представления глагола;
if с глаголом связано дополнение
then begin
ВЫдополне^ия;ДУРУ n°Un-phrase ДЛЯ получения представления
с помощью объединения и ограничения связать понятие
определяемое дополнением, с дополнением,
соответствующим сказуемому
end
end.
procedure verb;
begin
получить падежный фрейм для глагола
end.
procedure noun;
begin
получить понятие для существительного
end.
Артикли не соответствуют понятиям в базе знаний, ио позволяют определить,
каким является понятие, связанное с данным существительным: общим нли
конкретным. Представление понятий во множественном числе в книге не рассматривается.
Их обработка с помощью концептуальных графов описывается в [Sowa, 1984].
С помощью этих процедур для иерархии понятий, показанной на рис. 13.10, н
падежных фреймов, представленных на рис. 13.11, можно описать действия
семантического интерпретатора, предпринимаемые для построения семантического
представления предложения LThe dogs like a man" на основе дерева грамматического
разбора, изображенного на рис. 13.9. Последовательность этих действий
проиллюстрирована на рис. 13.12.
Числа в скобках в следующем списке соответствуют порядковым номерам на
рис. 13.12.
1. Сначала для узла, соответствующего предложению, вызывается процедура
sentence,
2. Процедура sentence вызывает процедуру nouruphrase.
3. Процедура noun_phrase вызывает процедуру noun.
4- Процедура noun возвращает понятие, связанное с существительным dog (1 на
рис. 13.12),
5. Поскольку артикль является определенным, процедура noun_phrase связывает
маркер #1 с этим понятием (2) и возвращает данное понятие процедуре sentence.
6- Процедура sentence вызывает процедуру verb_phrase.
*а 13, Понимание естественного языка
583
Рис. 1.112. Построение семантического представления на
основе дерева грамматического разбора
7. Процедура verb_phrase вызывает процедуру verb, позволяющую получить
падежный фрейм для глагола like (3).
8. Процедура verb_phrase вызывает процедуру noun_phrase, которая в свою
очередь вызывает процедуру noun для получения понятия, связанного с
существительным тал (4).
9. Поскольку артикль является неопределенным, процедура noun_phrase
определяет это понятие как обшее (5J.
10. Процедура verb_phrase ограничивает понятие entity в падежной рамке и
объединяет его с понятием, соответствующим существительному man (6). Это
структура возвращается процедуре sentence.
И. Процедура sentence объединяет понятие dog- #1 с узлом experiencer
падежной рамки (7).
ТеЗТ™ концет5,алы|ЫЙ П>аф представляет значение предложения,
гоам , п„„ГяЯЗЬ,К0ВЫХ K0HCTWKU"ii - "о связанная задача, решаемая с помои*» про-
с^^ГсеманГ еСТе™е'Ш°Г° ™ка Г™^™я английских выражений требует по-
шГнГпр,Z7Z K0PPek™r0 ВЫХОда на ос«°^ внутреннего представления з„а«-
"1™1'с пом° ГюеШе а9е"' МНаЧает св«ь подлежащее-сказуемое между М«»
товым ша6Л Г^Г™* П°ДХ°Д°В со°"«ствуЮщие слова присоединяются к «-
образцов предложи,;- "Р^жний. Эти шаблоны можно рассматривать в Kd
„„„ "" т ФР««ентов, в частности, глагольной и именной констру*-
584
Дополнительные вопросы решения задач искусственного инте
■ллекта
ц„й. Выходной результат строится путем прохода по концептуальному графу и
комбинирования этих фрагментов. Более сложные подходы к генерированию языковых
конструкций связаны с использованием грамматик преобразования для отображения значения
„ диапазон возможных предложений [Winograd, 1972], [Allen 1987)
В разделе 13.5 будет описан способ программного построения внутреннего представ-
„еиия текста на естественном языке. Это представление может быть использовано в
самых различных приложениях, два из которых будут представлены в разделе 13.5. Однако
сначала в разделе 13.4 будут описаны стохастические подходы выявления шаблонов и
обших закономерностей языка.
13А Стохастический подход к анализу языка
13.4.1. Введение
В разделе 13.1 был описан принцип понимания языка на основе шаблонов. В
разделах 13.2 и 13.3 отмечалось, что семантические аспекты языка и связанные с ними знания
могут быть представлены фонематическими структурами и описаниями на уровне
предложения. В этом разделе вводятся стохастические модели, поддерживающие на этих же
уровнях анализ структур иа основе шаблонов, обеспечивающий понимание языка.
Статистические языковые методы — это приемы, используемые при рассмотрении
естественного языка как случайного процесса. В обыденном смысле случайность
подразумевает отсутствие структуры, определения или понимания. Однако рассмотрение
естественного языка как случайного процесса позволяет обобщить детерминистскую точку
зрения. С помощью статистических (пли стохастических) приемов можно с достаточной
степенью точности моделировать как хорошо определенные части языка, так и аспекты,
обладающие некоторой степенью случайности.
Рассмотрение языка как случайного процесса позволяет переопределить многие
основные задачи, связанные с пониманием естественного языка, в более строгом
математическом смысле. Например, в качестве интересного упражнения можно выбрать
несколько предложений из предыдушего абзаца (включая запятые и скобки) и вывести эти
же слова в порядке, заданном генератором случайных чисел- Полученный в результате
текст вряд пи будет осмысленным. Интересно отметить [Jura/sky и Martin. 2000]. что
подобные структурные ограничения действуют на многих уровнях лингвистического
анализа, включая структуры звуков, комбинации фонем, грамматические структуры и т.д.
В качестве примера использования стохастического подхода рассмотрим задачу
определения частей речи.
Большинство людей знакомы с этой задачей со времен изучения грамматики в школе.
Для каждого слова в предложении необходимо определить, к какой части речи оно
относится. Если слово является глаголом, то можно указать его наклонение, а также
переходность. Для существительных нужно определить число. Сложности возникают при
обработке слов типа swing. В выражении "output potential swing" (перепад выходного напряжения)
это слово выступает в рол., существительного, а в выражении "swing a. the ball (ударить по
мячу) - в роли глагола. Приведем фразу Пикассо и выделим в ней части речи.
An is a lie thai '«* us SK *' T*'
г г.,.,г,-,п м^.-тпнм Глагол Артикль Суш-
СУЩ. Глагол Артикль Сущ. Местопм. Глагол Млтонм. v
Глава 13. Понимание естественного языка
585
.тем ее формально. Пусть имеется множество слов ,
т решена задачи »""ra^Jrt, .... W°te\- " "«"^тво частей речи J>
SX*. сИ",/,НаПР"М1 Приложение, состоящее из п слов. _ это последователе" *
«риторов SMU. -• '-'J^ ^ Эти переменные являются случайными во П
„з „ случайных вы,и™ „^ '^'„бое из значений множества S„. с некоторой J"'"'-
нами, поскольку могут прнни ^_ составляют последовательность случайн**"
ГХ— ГГ^СГн „оследоватсльность ,„ г, ,„, „a^-
щую значение
Р(Г=, r,=rJW,=ff • W-=W-1
Напомним (раздел 8.3), что зались Р(Х|У) означает вероятность X при условии у
частую имена случайных переменных опускают н пишут просто
Pit,. .... t,\w »„)• (1)
Заметим, что если точно известно распределение вероятности, то за достаточно дли
тельное время можно максимизировать значение вероятности по всем возможным
наборам дескрипторов и получить оптимальный результат для данной последовательности
слов. Более того, если для каждого предложения существует лишь одна корректная
последовательность дескрипторов, то с помощью данного вероятностного метода ее всегда
можно найти. Вероятность этой последовательности будет составлять 1, а вероятность
всех остальных последовательностей — 0. В этом смысле статистический подход
является обобщением детерминистского.
В реальной жизни из-за ограниченности объема памяти, данных и времени этим
точным методом воспользоваться нельзя и приходится довольствоваться аппроксимациями
Далее в этом разделе будет рассмотрено несколько способов аппроксимации (1) (в
порядке улучшения).
Для начала отметим, что (1) можно записать по-другому
рС '„к w„)=P(t, f„, w, w„)/P(w wj.
Поскольку максимум этого выражения находится за счет выбора г,, г2 ... t, его
можно упростить и записать в виде
Р(Г, t„W W) =
рс.МиМмркдЯ) ...p(f„|w и,л, f fn |)= (2)
Пр(',|'„ ...,tM,w, w,.,lP(Wl|t, ,м, w< „м)'
Заметим, что соотношение (2) эквивалентно (1).
13.4.2. Подход на основе марковских моделей
На
практике (как было
ровать вероятностные соо™™"" " тлые 8'3> обычно достаточно сложно максимизи-
таким соотношениям относит™"^' ?ВИСЯЩН<г от м"°™х случайных величин. Именно к
точно сложно хранить вероят* свяино с тремя причинами. Во-первых, дос™'
гими случайными величинами °СТЬ СлучаЙН0Й величины, обусловленную многими ДРУ"
■иьно возрастает с ростом Г' П0СК0ЛЬКУ ™сло возможных вероятностей экспонении-
—-_____J_J^"™4ecTBa определяющих факторов Во-вторых, даже сел»
586 Часть V л "—
• ополнительные вопросы решения задач искусственного интеллекта
удастся сохранить все значения вероятнос-п-й к* „««-,
Обычно делается эмпирически путем'подсч™ колТ^сГГо^е^"0,0"™''1" °UC"K"
„0„ вручную обучающем множестве. Если это собТтиеТ^"ГГольТ«Z
оценка его вероятности будет неточной. Таким обоазом „™
ncat\me), чем Р<са(|№в dog chased the) ТскольГ™, Г™ ВСро,™ОСТЪ
обучающем множестве гораздо реже и „аКо„еи Н1Т7 *"*" ^ ВС1?ечаетс" в
Гизирузощейструкт^,^),^^^^
ПОЭТО„ыГп„ГпаолаЙДеМ НеК°Т0РУЮ У—Р—'„УК, а„™кс™(?)ВвТдем
два основных предположения:
Р(',1' ',,■ w, w,.,) соответствует Р(г,|( )
и
PI1"/!' ',... w w,_,) соответствует P(w|r).
Эти предположения называются марковскшш (Markov assumption), поскольку они
предполагают, что текущее состояние зависит от предыдущих. Подставляя эти
приближения в (2), получим
ПР(',|',-,№,К). (3)
Соотношение (3) гораздо удобнее с практической точки зрения, поскольку входящие
в него вероятности можно легко оценить н хранить. Напомним, что (3) — это лишь
аппроксимация выражения Р( г, t„\w, w,), которую необходимо максимизировать
путем выбора дескрипторов Г !„. К счастью, это можно сделать с помощью
алгоритма динамического программирования, известного под названием алгоритма Витерби
(Viterbi algorithm) [Viterbi, 1967], [Forney, 1973]. Алгоритм Витерби вычисляет
вероятность последовательности дескрипторов г для каждого слова в предложении, где г —
число возможных дескрипторов. На данном шаге рассматриваемая последовательность
дескрипторов может быть записана в следующем виде.
article article {best tail)
article verb {best tail]
article noun {best tail]
noun article {best tail)
noun noun {besttail},
где {best tail} — наиболее вероятная последовательность дескрипторов, найденная
динамически для оставшихся п-2 слов и данного дескриптора л-1.
Для каждого возможного значения дескриптора под номером п-1 и дескриптора под
номером п существует своя запись в этой таблице (получается Г последовательностей
дескрипторов). На каждом шаге алгоритм находит максимальные вероятности н
добавляет по одному дескриптору к каждой последовательности |besr tail). Этот алгоритм
гарантирует нахождение последовательности дескрипторов, максимизирующей
соотношение (3) за время 0(t!s), где f- число дескрипторов, s - количество слов в
предложении. Если вероятность Р(Г,) обусловлена последними п дескрипторами, а не
последними двумя, то работа алгоритма Витерби завершится за время 0(r s) Отсюда видно,
почему зависимость от слишком большого числа предыдущих значении увеличивает время
нахождения максимума.
7 " " _ 587
1 "ава 13. Понимание естественного языка
г удовлетворит™'"0"- Для 200 возможных деев,
К счастью, аплроксимаш» О) "^ предназначенного для оценю, вероятностей, JT
„ДХьШОГО^ак.шегом^^^оры с ТОЧНОСтью 97%. нто сопостав^
JLo «ого "«ода «"^^.„ая точность марковской аппроксимации наряд, с ^
точностью раб°™ чмовск1- "1дной да использования во многих приложениях. Ъщ
простотойдсяакп-эту «OJ»* "Р";^ ^щ, используются так называемые модели "
„ер. в большинстве систем рас ы(, .^„„дгическис знания ' для прогнозиро
^ш, (Ingram), обесиечиваюш" _ „„ простая марковская модель, в кглорой
слов с учетом ум сыдаоГО,овжка двумя предыдущими словами. При работе с таки„,
вероятность текущего слова осу описанные выше приемы. Более nomwe.
Гелями используете, атгортгпм Вит £ннл Я" н ^^
Дробная информация по этому вопросу содержите
J3.4.3. Подход на основе дерева решений
Очевидной проблемой, возникающей при использовании марковского подхода, явля.
его, учет только локального контекста. Если вместо задачи определения частей речи для
слов в предложении требуется определить действующее лицо, объект действия или залог
глаголов, следует учитывать более широкий контекст. Эту проблему можно ироиллюст-
рировать на примере следующего предложения.
The policy announced in December by the President guarantees lower taxes.
(Политика, провозглашенная в декабре президентом, гарантирует снижение налогов.)
На самом деле действующим лицом в данном случае является President, однако
программа на основе марковской модели, вероятнее всего, назовет действующим лицом
policy, a announced — глаголом в действительном залоге. Естественно, если бы
программа могла задавать вопросы типа "Описывает ли данное существительное
неодушевленный предмет?" или "Встречается ли слово by на несколько слов раньше
рассматриваемого существительного?", то она определила бы действующее лицо гораздо точнее.
Напомним, что задача расстановки дескрипторов эквивалентна максимизации
выражения (2), т.е.
,.W„ ...,V^_,)P(v/\t, tM, и/,, ...,и/м)
,™1™РегГеС'Ш увеличснис «""текста позволяет находить более точные оценки веро-
з^Г^Г ЭТ°'М ""* г,тнет' "Ч>°»тностей желательно иметь возможность исполь-
СХГРИВеДе""ЫС В",Ше ^«"«ические вопросы.
мож^комГнТпоГ!",0 Р£Ш,,ТЬ нескол™"" "У™ми. Во-первых, марковский подход
разделах "ойТвы Во Г0"3™ ^«^ского разбора, описанными в предыдущих
"Да" и "Нет" с помт„!Г M°M° находить вероятности, обусловленные ответами
Реализация »«?№ ^"^^ Ш3 (КОТ0РЫЙ П°«Р°6»° ™иса„ » Р™еяе 9Х * ""
ПИ среди большого «»L "Г*™ '5 13) т" ™Д°бного ему алгоритма. В алгоритме
хорошую оценку вероятно в°Г|Р°с°в выбираются только тс, которые
обеспечивают
» там числе в задаче грамма™ С с"ожных сдачах обработки естественного яз"й'
стся работа алгоритма ID3 о,™,™ Ра3б°ра' дсРевья Р™еннй, на которых основыю-
дели. Д^ 6удет ' ™ымются более предпочтительными, чем марковские «о-
шений в задаче фаммат„ческоторИа™0Л"ОВаТЪ алГ0Ри™ "» для построения дерев» f
588 Часть V л "~~~
волнительные вопросы решения задач искусственного интеллект»
Вь1Ше уже упоминался вопрос Описывает „„ даннос существительное
неодушевленный предмет? . Подобные вопросы можно задавать только ь том случае, если известно,
какие существительные описывают одушевленные или неодушевленные предметы.
На самом деле существует способ автоматического разделения множества слов „а ,ти
классы. Этот прием получил название кластеризации взаимной информации (mutual
information clustering). Взаимная информация, распределенная между двумя случайными
величинами X и V. определяется следующим образом:
«X-.n-II^.y^^l.
Кластеризация взаимной информации для словаря слов начинается с помещения
каждого слова словаря в отдельное множество. На каждом шаге с помощью
диграммы (bigram), т.е. модели следующего слова, вычисляется средняя взаимная
информация между множествами и выбирается разбиение множеств, состоящих из двух
слов, минимизирующее потери средней взаимной информации для всех классов.
Например, пусть изначально существуют слова cat, kitten, run и green. На первом
шаге алгоритма строятся множества
{cat), (kitten), {run), {green).
Скорее всего, вероятность появления некоторого слова после слова саг примерно
равна вероятности появления этого слова после слова kitten. Другими словами.
Pfeafs | cat)-P(eets | kitten),
P{meows\cat) =P{meows\kitten).
Таким образом, для случайных величин XI, Х2. У\, V2, при которых
Х1=((саг). {kitten), {run), {green)),
V1 =слово, следующее за Х1,
X2=((cat, kitten), {run), {green)),
У2=слово, следующее за Х2.
Обшей информации в Х2 и V2 не намного меньше, чем в XI и VI. Следовательно,
слова cat н /often с большой вероятностью можно сгруппировать. Если продолжить эту
процедуру до получения комбинаций всех возможных классов, то получится бинарное
дерево. Тогда словам, расположенным в листовых узлах этого дерева, можно присвоить
двоичные коды (bit code), описывающие путь перемещения по дереву до достижении
этого слова. Такие коды отражают семантическое значение слов. Например.
caj=01100011.
Wtren=01100010.
Более того может оказаться, что коды всех слов, "напоминающих существительные",
в качестве крайнего слева бита содержат 1, а третий бит всех неодушевленных приме-
товтоже равен 1. „
Такая „овал кодировка слов словаря позволяет анализатору более эффективно зала
аатъ вопросы Заметим что при кластеризации контекст не принимается во внимание,
"оэтому слово ГоомГнига, может быть классифицировано как "напоминающее сутцеет-
»»тельиУое". хотя в предложении "book a fl.ghf (заказать билет „а самолет, его иеобхо-
д"мо рассматривать как глагол.
глава 13. Понимание естественного языка
^.Грам^ическинанализидругие приложения
стохастического подхода
стохастического подхода
использован во многих областях компьютерной
Стохастический подход уже » „ „ тех сферах, где традиционно пр„м(
гвистаки. Тем не менее его можно npl
ся символьный подход. методов в задачах грамматического разб.
Использование сгатастнчес ■ возникающей в связи с сущ,
. - „ г „„пблемой неопределенное! и. i
традиционно применял.
ся символьный подход. мотдов в задачах грамматического разбора впервые
Использование стагистичсс . wHOCnl| возникающей в связи с существованием
было связано с пРо6"е^ "'ГглциГ, данного предложения и необходимостью выбора
""и ~Т "<<' •«« *С Ше °" 1Не РПП,еГ <НаПСЧаТаЙ ** «а
„;;ГрТ--Сь%сл--„оввЩедвух деревьев, показанных „а рис. ,ЗЛЗ.
Предложение
вопРосы решения задач искусственного интеллекта
В подобной ситуации одних правил грамматики лл» n>.,fi™,„
достаточно. Необходимо учитывать „Ткоторую™^ ХГГукГГрГ
„,,ю Такую неопределенность можно разрешить с tw<™„ "-мантичскую ннформа-
10"°' J F^ с П0М°ЩЬЮ стохастических метпппп Ппя
.-.много примера можно использовать то же спе-н-™ ,™ методов, для
данп1-" г ^^> 'и Ж1. средство, что и для определения члг-и-fl пв-
чи,, алгоритм ID3. Он позволяет предсказать вероятность K„ppe™™La™
ве семантических вопросов о данном предложении. Если в прсможеиГГцХет нско-
топая синтаксическая неопределенность, то можно »ь,б„»тГ „ ™
™ „ „„™„„..„ .., „ можно выьрать представление, вероятность
корректности которого максимальна. Обычно д» использования этого подхода трсбуек,
„„еть обучающее множество предложений с их корректными представлениями
В последнее время специалисты по статистическому моделированию естественных
языков активизировали свою деятельность и стали применять статистические методы
фамматического разбора без использования грамматики. Хотя принципы работы
анализаторов, ие учитывающих грамматику, выходят за рамки данной книги, следует
отмстить, что они более близки к системам распознавания образов, чем к традиционным
принципам грамматического разбора, описанным выше в этой главе.
Разбор без учета грамматики дает достаточно хорошие результаты. В экспериментах по
сравнению его эффективности с результатами работы грамматических анализаторов на
одинаковом множестве предложений разбор без учета грамматики обеспечивает 78*
эффективности, а с учетом — 69% [Magerraan. 1994]. Эти результаты достаточно хороши, но
их нельзя считать выдающимися. Гораздо важнее другое. Описание грамматики для
традиционного анализатора требует примерно десяти лет педантичной работы грамотного
лингвиста, в то время как анализатор без учета грамматики, не использующий жестко
закодированной лингвистической информации и основанный лишь на сложных математических
моделях, может сам извлекать необходимую информацию из обучающих данных. Более
подробная информация по этому вопросу содержится в [Manning и Schutze. 1999].
Понимание речи, преобразование речи в текстовую информацию и распознавание
рукописного текста — это еще три области, имеющие богатую историю использования
стохастических методов для моделирования языка. В этих областях для прогнозирования
следующего слова чаще всего используется статистический метод на основе модели триграмм.
Эффективность этой модели объясняется ее простотой. С ее помощью можно предсказать
следующее слово по двум предыдущим. В настоящее время специалисты в области
статистической обработки языка стараются сохранить простоту и легкость использования этой
модели при добавлении грамматических ограничений и более долгосрочных зависимостей.
Этот новый подход получил название метода грамматических триграмм (grammatical
Ingram). Грамматические триграммы содержат информацию об основных связях между
парами слов (такими как подлежашее-сказуемое, артикль-существительное или сказуемое-
дополиеиие). Совокупность этих ассоциаций образует грамматику связей (link grammar).
Такую грамматику построить гораздо легче, чем традиционную. При этом для нес
достаточно эффективными оказываются вероятностные методы.
В работе [Berber и др. 1994] описана статистическая программа Cand.de.
осуществляющая перевод французского текста на английский язык. В ней для разработки
вероятностной модели процесса перевода использованы как статистические методы, так и тео-
? ™форГ;„ТяеСее обучения г^^^£%£?2££
«•«на французском и английском ^^^^„„Lh коммерческой
сопоставимы (а в некоторых случаях и превосходят^V с рс > перевода
^граммы Systran [Berger и др.. 19ЗД. ""° ™ 'r™з6оТВ „ей иГполь-
™стема Candide ие выполняет традиционного тематического pa p
3Уются только грамматические триграммы и грамматика связей.
!а 13. Понимание естественного языка
591
- в которых стохастические методы моде
«азагь несколько »S»ac™' дать хорошие результаты. К таким ЛИР0в»'
,3 51 Обучение и ответы на вопросы
—ением технолога., понимания естественного языка является написа.
Интересным прим<-"_™^отиттъ оасски ,„,„ другой фрагмент текста на естесш™^.
.может читать pacaaal
1 естественно,.
ние программы. шго1^"'0"нем в гааве 6 обсуждались некоторые вопросы предсгавлет~
языке и отвечать на в01^ ' м важность сочетания базовых знаний с ков
Г™;"™ Ф^- "£ видно из рис. Ш. программа может обьединять ее*
™Гк« ГедставленТГе входные данных со структурами концептуальных графов в базе да,,
„Творожные представления, в том числе сценарии (подраздел 6.1.4), позволяют моде
«гь более сложные ситуации, в том числе зависящие от времени.
После построения расширенного представления текста программа может интеллектуально
отвечать на вопросы о его содержании. Вопрос приводится к внутреннему представлению и
проверяется его соответствие расширенному представлению текста. Рассмотрим пример, по,
катанный на рис. 13.2. Эта программа может прочесть предложение 'Tarzan kissed Jane"
(Тарзан поцеловал Джейн) и построить его расширенное представление.
Допустим, программе задан вопрос "Who loves Jane?" (Кто любит Джейн?).
Вопросительное слово определяет сущность вопроса. При ответе на вопрос со словом who (кто)
требуется указать агента действия. Вопросы what (что) требуют найти объект действия.
Вопросы how (как) подразумевают определение средств выполнения действия и т.д.
Граф для вопроса "Who loves Jane?" показан на рис. 13.14. Узел агента на этом графе
помечен вопросительным знаком, указывающим на то, что целью вопроса является
определение агента. Затем эта структура объединяется с расширенным представлением
исходного текста. Понятие, связанное с понятием person: ? на графе запроса, дает ответ на
этот вопрос: "Tarzan loves Jane" (Тарзан любит Джейн). В качестве примера реализации
этого подхода можно рассматривать анализатор на основе рекурсивной семантической
сети спуска, реализованный на языке PROLOG и описанный в разделе 14.9.
| love
-(^objecT) ^[person: "jane")
Рис. 13.14. Концептуальный граф для вопроса "Who loves Jane?"
гНи применяются только Для узких предметных областей с *п™,„п
кой' Этому критерию удовлетворяют „р^ ~°;^"й ^
фейсов Д^ баз данных, понимающих естественный язык. НеГо™ГнТ тоТв чГ*
*аНных обычно —™нтские объемы информации, эта „££ «едо-та
ТОЦНО/е172ь7х оч^ьЗш СВЯЗЭНа С УЗК°Й ПРеДМеТН°Й °блас™. Более то сем и-
тИка ба3/а1ШЬ'^"ЬаЗ опР<«а. Эти свойства наряду с возможностью
передачи в базу данных запроса на естественном языке делают интерфейс для такой базы
даНных важным приложением технологии понимания естественного языка
Задача такого интерфейса - перевести вопрос е естественного языка в формат
стандартного запроса на «зыке базы данных. Например, с помощью такого интерфейса
вопрос "Who h<red John, Smith? (Кто нанял на работу Дж0на Смита?) можно пс;свести в
запрос на языке SQL [Ullman, 1982] следующего вида.
SELECT MANAGER
FROM MANAGER_OF_HIRE
^ERE EMPLOYEE='John Smith'
При выполнении такого преобразования программа должна не просто выполнить
исходный запрос. Ей также необходимо решить, где выполнять поиск в базе данных
(отношение MANAGER_OF_HIRE), выбрать имя поля (MANAGER) и ограничения для
данного запроса (EMPLOYEE= 'John Smith')- Эта информация не содержится в исходном
вопросе. Ее требуется найти в базе данных на основе сведении об организации этой базы
и понимания содержания вопроса.
В реляционной базе данных (relational database) данные связаны отношениями между
сущностями различных доменов. Предположим, что необходимо построить базу данных
сотрудников, в которой нужно будет находить зарплату каждого сотрудника и
определять, кто принял его иа работу. Эта база данных должна состоять из трех доменов
(domain) или наборов сущностей: менеджеров, сотрудников и зарплат. Эти данные
можно связать двумя отношениями: employee_salary, связывающим сотрудника с его
зарплатой, и manager_of_hire, связывающим сотрудника с его менеджером. В
реляционной базе данных отношения обычно представляются в виде таблиц, в которых
перечислены экземпляры реализации отношения. Столбцам таблицы прн этом присваиваются
имена, которые называются атрибутами (attribute) отношения. На рис. 13.15 показаны
таблицы для отношений employee_salary и manager_of_hire. Отношение man-
ager_of_hire имеет два атрибута — employee и manager. Значения отношения —
это пары сотрудник-менеджер.
manager_of_hire:
emp!oyee_salary:
employee
John Smith
Alex Barrero
Don Morrison
Jan Claus
Anne Cable
manager
employee
Jane Martinez
Ed Angel
Jane Martinez
Ed Angel
Bob Verott
John Smith
Alex Barrero
Don Morrison
Jan Claus
Anne Cable
salary
535,000.00
$42,000.00
$50,000 00
$40,000.00
$45,000.00
I
Рис. 13.15. Два отношения из базы данных сотрудников
№ Если Пред_, что ™^^Z!Z"^^^
неджер и зарплата, то имя сотрудника можно исполы
— 593
Глава 13. Понимание естественного языка
ary и
ar.age:
- одни атрибут может выступать icik.,01(
■ч образом определяет значения элемент,
Дл>
r^V^^^S^Hrt. Ь» "»"" возвращает указанное зна,^
да^еГе ш множество °^"" ключами н лр>™ми атрибутами „ОЖио **=
Левого атркб^В-^Г^обами. в—ая *"ЧР»«™ "^-оо,^
ершить графя"**» P"™"£Uman. ,982] я Аигр^"» "»«»»« <*оииых (dau »
^-relauon*ip d|ap^»^noixoja позво.т»к,т представить связь «„чей с „£
взааио.
yawj .-■— - -^ этя под*
бутами в виде
яын в виде —»"--, ^^_ расширял, за счс. п^.*™»
Коеиешуаяьные W" "" н £L данных, определяющее
за счет включения диаграмм этих
- обозначаем
„_*« [So.*. '9841^^евн „„ощеню. Атриб)ты отношения - это понятия а ,„».
1К>мо1Ш«|»м15^ети»^ ^щ^-кны от ключей к другим атрибутам. Графу
цептуыьвоы графе- а с i*- ^_ grrnlavee_sa~iazy и rnanager_of hi .-«Л7
-сушвость-отношевж
, отношений expl°yee_sa.iary и rnanager_of_hire г».
"Tn^oeS п^бразованм воггроса на английском языке к виду формального заоро-
^р^хжно вс^зврашагься. и значения ключей, определяющих это поле. Вместо ггр,.
мого перевода вопроса 1
а английском языке на язык базы данных его сначала
необходимо оеревестава более выразительный язык, в частности, язык концептуальных графов.
Эго^ео&юднмо поскольку многие вопросы на естественном языке могут трактоватьа
неоднозначно иди требовать дополнительной ,пггерпреташш для получения хорошо
струоурированного запроса к базе данных. Именно этому н способствуют более выразв-
тстшые mm представления.
Интерфейс взаимодействия с базой данных должен разобрать и иетерпретировать
запрос представив его в виде концептуального графа, как было описано выше в этой
гааве. Затем этот граф объединяется с информацией in базы знаний с помощью
операций объединения и ограничения. В нашем примере необходимо обрабатывать запросы
вида: "Who hired John Smith?" iKto нанял на работу Джона Смита) или "How roach
does Jolm Smith earn?" (Сколько зарабатывает Джон Смит). Для каждого
потенциального запроса нужно хранить граф. определяюшнй его сказуемое, и все связанные с
этим вопросом диаграммы "сутность-связь". Запись базы знаний хля глагола hire ве-
з на рис. 13.17.
Рж. 13.16. Зшвраммы
=--^~_.~.ге
syee^jsalsry
Рис 13.17, Запись базы знании t
просив о "нанимателе "
^У-ДОЛОЛ№И»*« вопрос* решения задач искусственного интеяя^
Семантический интерпретатор строит граф ^ ^^
£ГО с соответствующей записью из базы Знаний р^ пользователя и объединяет
„пюшение". отражающий связь ключей с целью воп^Г Cywcnc>™ П»Ф "сущиостъ-
вгП. дм формирования запроса к базе данных нЛ^,?,™ ^ шишо "«кмъзо-
w„poca "Who hind John Srnnh- ("Кто н^Гна^"^Г*™-?* """^ "
уединения с элементом базы знаний, показанной ^дш™>мнга^> и результат его
^зан запрос SQL. сформированный .^П."* £17' "* »~ 1318 ™~
с1гуюшейзаписн. целевое поле и ключ для запросавZ^^^J^ СО°ПИТ"
указаны. Эти сведения извлекаются из базы знаниГ естественном язык ве
Семантическая iwTerxveTataw
запрета ма естесгвел,»* яэв^б
Расширенньй граф запроса:
Загскх иа йзьке SO_ SELECT МДНДъ^/З
(ВЧЕЯЕЕМРИЖЕЁ = "John sr.
Рис 13.IS. Получение загцюса к базе danrntr с тигти^тг графа, прео-
став.ыющего вопрос на естественном языке
Как видно из рис. 11.18. в исходном вопросе об агенте и объекте яе содержится
никакой информации, за исключением тоге -~~ -::" ~^ -■-^^-^-= -■ ^г-. oerson. Чтобы
-е. эти с
объединить этот граф с элементом баз;
- * -—~v Дм
волы сначала необходимо привести к .
выполнения проверки типов в исходном запрос можно г,-^-"--.-аатъ иерархию тнгюв.
Если /оЛл smif/i не относится к типу emptoyee. то вопрос додан быть отнесен к разря-
ДУ некорректных, и программа должна это автоматически определить
После построения расширенного графа запроса гфогрвша пгкяи^ие-тевое о»
"«■ помеченное символом ?. и опредеиет. что огаошеи* вападег.-.. гге связы-
«" ««я с этим понятием. Посгольк) «люч>' соответствует значек
"Рос является корректным, и программа может сформировать coots . ,^
"* Данных. Преобразование графа -сущность-связь в запрос »w"- '- ■ -
^Рутюм языке выполняется достаточно просто.
„ „„ шшюстрирУ" использование подхода иа ос
,п пчень прост, он ЛЙ-ТПня с базой данных. В нашем .. е
:::;дГа^яиГС";—:,е„яться ^ ^»~т,. том -:
,.IU и системы автоматического
13.5.3. Извлечение информаиииисис
резюмирования для Web
,„ м Wide Web связано много интересных задач и возможностей
С технологией World W1™ екга „ программ понимания естественного языка
применения иекусственного ,,кТуального программного обеспечения является рез^
Одной из основных задач инт ^ ^
мнрование интересны); матер ^ п0 ^щцым словам пи с помощью других 6о-
При нахождении информац 'тстат извлечения информации (information extraction sys.
лее сложных механизмов попе ^ ^^ ^ прореферировать его с учетом заданной наперед
tern) должна получить на вход о6ласти 0на должна найти полезную информацию, связан-
"ТЕГГ^^-^^™"" —. -тема извлечения
информации "просматривает" текст в поиске соответствующих разделов „ концентриру-
етТво внимание только на обработке этих разделов. Например, система извлечения „„.
формации может резюмировать информацию из предложении о работе в области
компьютерных наук. Вернемся к примеру, приведенному в разделе 13.0.
Пример объявления о вакансиях в области компьютерных наук
"Факультет компьютерных наук университета Нью-Мексико... проводит конкурс на
замещение двух должностей профессора. Требуются специалисты в следующих областях:
программное обеспечение, в том числе анализ, проектирование и средства разработки...;
системы, включая архитектуру, компиляторы, сети...
Кандидаты должны иметь степень доктора наук по специальности.,.
На факультете выполняются международные проекты в области адаптивных вычислении,
искусственного интеллекта, поддерживаются тесные связи с институтом Санта-Фе и
несколькими национальными лабораториями..."
Система извлечения информации может получать важные сведения с помощью
подобных предложений н заполнять шаблон определенной структуры.
Пример частично заполненного шаблона
Организация: факультет компьютерных наук университета Нью-Мексико
Город: Albuquerque
Штат: NM 87I31
Описание вакансии: должность профессора
Необходимая квалификация: степень д
ь доктора наук по специальности...
умение использовать программное обеспечение и средства р
Требуемые навыки:
ки, в том числе для анализа и проектирования...
Опыт практической деятельности: ...
Сведения об организации: (текст прилагается)
„ первых системах обработки данных на естествен,,™
11Ии использовались самые разные подходы от тради,™ ЯЗЫКС """ изш";чс"1» "нформо-
„обный семантический анализ и снабженных полны*, * Ч*"™. выполняющих нод-
„„еддожения, до систем, использующих методы сравнет,".™0"40™'™ описан,км ка*Д°го
ровней лингвистического анализа и базой знаний о вых слов' не обладающих
е„стем выявились очевидные недостатки этих крайнихГаТЛ"^' ра3работки таюк
цссс извлечения информации описай в [Cardie, 1997] след^^0^ТОЧ'в,е,,Ний ПР°~
1. Текст: факультет компьютерных наук университета н^ м
конкурс на замещение двух должностей профТс" "™fiMeKC"K0" ПР0В0ДИТ
следующих областях... профессора. Требуются специалисты в
2. Разметка „ тэгироваиие: факультет/noun компьютерных/adj наук/noun
3. Диализ предложения: факультет/subj проводит/verb конкурс/obj...
4. Извлечение: Организации: факультет компьютерных наук...
Описание вакансии: должность профессора
5. Объединение: Нью-Мексико=ЫМ...
6. Генерация шаблона: результат приведен выше.
Хотя детали архитектурной реализации системы извлечения информации могут
различаться в зависимости от приложения, последовательность выполнения основных
функций при этом не изменяется.
Сначала каждое предложение, найденное на Web-узле, подлежит разметке и тэгиро-
ванию. Для решения этой задачи можно использовать стохастический подход,
описанный в разделе 13.4. Затем следует стадия анализа предложений, на которой выполняется
грамматический разбор н выделяются глагольные группы, существительные и другие
грамматические конструкции. После этого на этапе извлечения информации
выполняется поиск семантических сущностей, соответствующих данной области. В
рассматриваемом примере на этом этапе определяется название организации, вакансии, требования к
кандидату и т.д.
Стадия извлечения информации — это первый этап процесса, полностью
определяемый спецификой предметной области. На этой стадии система выявляет специфические
отношения между соответствующими компонентами текста. В нашем примере в роли
организации выступает факультет компьютерных наук, а его местоположением
считается университет Нью-Мексико. На стадии объединения строится список синонимов и
выполняется разрешение анафор. В частности, символы Нью-Мексико и NM определяются
как синонимы, а в процессе резолюции анафор факультет компьютерных иаук из первого
предложения связывается со словом "факультет" в последующем тексте.
На этапе объединения применяется вывод на уровне рассуждений, который в свою
очередь вносит вклад в генерацию шаблона. В процессе такого вывода определяется
количество различных отношений в тексте, фрагменты информации связываются с полями
шаблона, а затем строится и сам шаблон.
Несмотря „а значительный прогресс в области развития искусственного «""*•
современные системы извлечен.» информации тоже не лишены проблем. Во-первых
можно значительно улучшить точность и робастность этих систем. Ошибки впронес с
«влечения информации скорее всего связаны с недостаточным пони™ "^
«кета. Во-btoLx по^пеиие систем извлечения информации для новой предмсгнои
текста. Во-вторых, построение систем
власти может
оказаться
достаточно сложным и ресурсоемким
Часть V. Дополнительные вопросы решения задач искусственного интеллект» Г„ава 13. понимание естественного языка
процессом [Cardie, 1997J.
597
лпиеитированной на предметную область природой
Обе эт„ проблемы «««""'"речения информации можно улучшить за "*.
££*• -«форма*""- Прои« « на к0 „„у™ область, однако „оди^ '
"ойки лингвистических »ло™» _ ^ мояныи „ трудосмкии „р0цесс Ф%а,
ц^лиигвистических знании вру У вуст множество интересных прило>к
Тем ис менее в ««*Г^0|1Ч0« и др.. 1997] представлена система поддер^
описанной технологии- ВI раб" _' ]995] опнсана систсма анализа медицине^'*
страхования жизни. В [Ьоое ^^^ страхования. Известна программы анализа гГ
точек пациентов, приме!«*™ ,MUC-5, 1994], системы автоматической кла "
зетных публикации и их рок* J k „ Adam, 1997] и программы извлечен!;
сифнкации '°Р^чесКИ";;Г,с „в вакансий [Nahm и Моопеу, 2000]. "^
информации из компьютерных
13.5.4. Использование алгоритмов обучения для обобщения
извлеченной информации
Рассмотрим приложение, а котором многие описанные в этой главе ,«ей объединены с ад.
горишами машинного обучения, изложенными в разделах 9.3 и 15.13. В работах [Cardie „
Моопеу 1999] и [Nahm и Моопеу, 2000] высказана идея о том, что процесс извлечения ил.
формации из текста можно обобщить за счет применения алгоритмов машинного обучения.
Суть подхода достаточно проста. Полностью или частично заполненные шаблоны со.
бираются с соответствующих Web-узлов. Эта информация сохраняется в реляционной
базе данных, на основе которой с использованием алгоритмов обучения наподобие ЮЗ
или С4.5 строятся деревья решений. Как известно из раздепа9.3, подобные деревья ре-
шений могут отражать неявные связи в наборе данных. (Этот прием называют
"добычей" данных — data mining.) Предполагается, что эти вновь выявленные
зависимости можно использовать для уточнения исходных шаблонов и балы знаний, принимаю-
шей участие в процессе извлечения информации. Приведем пример информации, кото-
рая может быть извлечена в процессе анализа вакансий в области компьютерных наук.
Если требуется специалист на факультет компьютерных наук, значит, опыт работы с
конкретной платформой не обязателен. Или, если имеется вакансия профессора в
университете, значит, кандидат должен иметь опыт исследовательской работы. Более под-
робно эти вопросы освещены в [Nahm и Моопеу, 2000].
13.6. Резюме и дополнительная литература
пя,^Г"еДУеТ Ю ™Й ПИШ' Ч™"1*" множество подходов к определению грамматик и
™ бьт„РеД"°'ЖеНИЙ "" ССТес™"»°м «икс. В качестве типичных примеров таких подхо-
д1нГбь,т!™ЭТРСНЫ трК0ВСК"е МОде™ н ATN-аналнзаторы. Грамотные студенты
ToZZ ™SZ°Г 7 ДРУПШ" в°змс™°™м„. К ним относятся грамматики нреобра-
[Winograd 1983] Ш el ™^rar) " ФУ'^оналыше грамматик, (function gram™
ной структуры или смис,», Тематиках преобразований для представления глу№-
Такую глубинную стр™ РСД°°Жения ^пользуются контекстно-независимые прав"»
состоящего не только ш ™ M°*"0 ,,рСдставить в виде дерева грамматического ра*ор '
наборы символов именусГГ'Ш"'"'"Х " нетеР""иальных элементов, ио и включав*"^
«снуемых графическими маркертш (grammatica, marker). С пом»
э98 ЧасткУ п — — ■*■"
■ Дополнительные вопросы решеНия задач искусственного интеллекта
д)
„.«] грамматических маркеров можно представить ™„. „ -
^те^но-зазисимые аспекты ^^Т^^Т^Г^ """ "2Г
п*ейн) и Jane li*IIKUJ °У 'om I Джеки любима Томпм^ uu».» ,,
^"чнукэ поверхностную структуру. М0М) ИМеЮТ °Д»">«»У» глубинную, „о
Правила трансформации применяются к самим деревьям разбора. С их помощью
выпаяются проверки, требующие глобального контекста, „ строите удобная
поверхностная структура. Например, с помощью правила преобразования можно проверить, что число
для узла, представляющего подлежащее, соответствует числу сказуемого. С помощью
правил трансформации простую глубинную структуру можно отобразить в различные
поверхностные структуры, заменяя действительный залог страдательным или утверждение
вопросом. Хотя грамматики преобразований подробно не описаны в этой книге, они являются
важной альтернативой для грамматик описания структуры неоднозначных фраз
Исчерпывающее описание грамматик и методов разбора естественного языка
приводится в [Winograd, 1983]. В этой книге особое внимание уделено грамматикам
преобразования. В [Allen. 1997] содержится обзор проектных решений программ понимания
естественного языка. Еще одним источником по вопросам обработки естественного языка,
затронутььм в этой главе, является книга [Harris, 1985]. Рекомендуем также ознакомиться
с [Gazdar и Mellish, 1989]. В [Chamiak, 1993] представлены материалы по применению
статистических методов для анализа структуры языка.
Семантический анализ естественного языка связан с решением многих сложных
вопросов, относящихся к представлению знаний (глава 6). [Зги вопросы затрагиваются в
[Chamiak и Wilks, 1976]. Из-за сложности моделирования знаний и необходимости учета
социального контекста в процессе анализа естественного языка многие авторы
поднимают вопрос о возможности применения этой технологии за пределами ограниченных
предметных областей [Searle, 1980], [Winograd л Flores, 1986], [Smith. 1996].
В работе [Schank и Riesbeck, 1981] задачи понимания естественного языка решаются
на основе технологии концептуальной зависимости. В [Schank и Abelson, 1977]
обсуждается роль структур организации знаний более высокого уровня в программах обработки
естественного языка.
Значение контекстуальных знаний в моделировании рассуждений отмечается в [Searle,
1969]. В [Fass и Wilks, 1983] предложена теория семантического предпочтения (semantic
preference theory), которая может стать осноюй моделирования семантики естественного
языка. Семантическое предпочтение — это обобщение падежной грамматики, допускающее
преобразования падежных фреймов. Это обеспечивает большую гибкость семантики
представления, а также возможность представления таких понятий, как метафора и аналогия.
Полное описание иерархии Хомского читатель найдет в [Hopcroft и Ullman, 197Jj.
Концептуальные графы и их применение при моделировании семантики баз данных
описаны в [Sowa, 1984] , „ г 1
Современное состояние технологии обработки языка описано в работах [Jurafsky и
Martin, 2000], [Manning и Schntze. 1999], [Cole, 1997] и в зимнем номере журнала А/
^оГйщ^следования и тенденции в области понимания =™^^™
традиционной, так и со стохастической точек зрения ^^e"aJ ZZoTaZTfor
конференций „о искусственному интеллекту и журнале Journal of riu Assoc,a„on for
Computational Linguistics.
лааа 13. Понимание естественного языка
599
ХГ^Упра ^^Г^«^и как с™такс>™скн „ско
, классифипиру** кЖое"30„0 бессмысленное; осмысленное, но неверное ил„ в
'■ ^^шкеическ» ^^предложения выявляется каждая из этих Проблем,4
„„е. Когда в процессе пои.
Colorless green ideas sleep I
Fruit flics №e a banana.
0D:srw*^"»^eiwhpresiden,0f,',eUSA'
This exercise is «* ^.__ ^ ^ garlie„ i„ ,he shade.
A wan. to be tin знаниЯ1 необходимые для понимания следую.
2. Опишите структур" представлен™
ших предложений-
Mary watered [he planls.
The spirit is willing but *e flesh .s weak.
My kingdom for a horse.
1 Выполните разбор следующих предложений с использованием грамматики из "мира со-
6™ —ой в подразделе 13.2.1. Какие ш этих предложении недопустимы? Почему?
The dog bites the dog.
The big dog bites the man.
Emma likes the boy
The man likes.
Bile the man.
4. Дополните грамматику из "мира собак" таким образом, чтобы она включала
описание недопустимых предложений из упражнения 3.
5. Выполните разбор каждого из предложении с использованием контекстно-зависимой
грамматики из подраздела 13.2.3.
The men like the dog.
The dog bites the man
6. Постройте дерево грамматического разбора для каждого из следующих
предложений. При этом вам придется дополнить простые грамматики более сложными
лингвистическими конструкциями, такими как прилагательные, наречия и вводные
конструкции. Если предложение допускает несколько вариантов разбора, постройте
диаграмму для каждого из них и обьясните, какая семантическая информация нужна для
выбора правильного варианта.
Time flies like an arrow but frail flies like a banana
Tom gave [he big. red book to Mary on Tuesday
Reasoning is an art and not a science.
To en is human, to forgive divine.
7. Д°"°™нте грамматику из "мира собак", включив в нес прилагательные и именные
2™""' Ч™Те' "Т0 ^«"^«льные в английском языке не имеют числа. Со-
тоьГ лТП РСКурс,иное 4*™o adjective list, возвращающее либо пусто» Р'-
^^=^zz;z^^——хпр
Часть V. Дополнительные вопросы решения задач искусственного „„теплее
, Добавьте следующие контекстно-независимые правила „ ™. .. , .,
„з подраздела 13.2.1. Представьте результируюцТ, Г ГраМшт,ке т миРа c°6l"<
и3' v . н"ульгирующую грамматику в виде сетей перехода.
se„tence^noun_phrase verb_phrase prepositional_phrase
prepositional_phrase<->preposition noun_phrase,
preposn
;ition*->with,
preposition<->to,
prepositiom^on.
9. разработайте ATN-анализатор для грамматики из "мира собак" с прилагательными
(упражнение /) и вводными фразами (упражнение 8).
,0. Определите понятия и отношения в концептуальных графах, необходимых для
представления грамматики из упражнения 9. Определите процедуры построения
семантического представления на основе дерева грамматического разбора
ц. Дополните контекстно-зависимую грамматику из подраздела 13.2.3 для обеспечения
проверки семантического соответствия между подлежащим и сказуемым. А
именно — люди не должны кусать собак, хотя собаки могут либо любить, либо кусать
людей. Выполните соответствующую модификацию ATN-грамматики.
12. Дополните ATN-грамматику из подраздела 13.2.4, включив в нее вопросы who и what.
13. Объясните, как марковские модели из раздела 13.4 можно комбинировать с
символьными подходами к пониманию языка, описанными в разделах 13.1-13.3.
14. Дополшгге пример интерфейса взаимодействия с базой данных из подраздела 13.6.2,
чтобы иметь возможность отвечать иа вопросы вида "How much does Don Morrison earn?"'.
При этом потребуется дополнить грамматику, язык представления и базу знаний.
15. Для предыдущей задачи разместите слова, в том числе и знаки препинания, в
случайном порядке.
16. Допустим, что наряду с другими сотрудниками в отношении employee_salary
(подраздел 13.6.2) перечислены менеджеры. Дополните этот пример таким образом,
чтобы получить возможность обрабатывать запросы вида "Find any employee [hat
earns more than his or her manager" ("Найдите сотрудников, которые зарабатывают
больше, чем их работодатели").
17. Как стохастический подход из раздела 13.4 можно объедишггь с методами анализа
базы данных из раздела 13.5?
18. Использование стохастического подхода для изучения образов, содержащихся в
реляционных базах данных, — важное современное направление исследований,
которое иногда называют "добычен данных" (data mining) (см. раздел 13.3). Как можно
использовать этот подход для ответов на запросы к реляционным базам данных,
подобные приведенным в разделе 13.5?
19. На основе материала из раздела 13.5 разработайте систему излечения информации
Для некоторой области знаний, которую можно использовать в
ia 13. Понимание естественного языка
601
Часть VI
Языки и технологии
программирования
для искусственного
интеллекта
Карта — это не территория; имя — это не ca\t объект.
— Альфред Коржибски (Alfred Korzybski)
Чему я научился, кроме корректного использования нескольких средств?
— Гарн Снаддер (Gary Snyder), Языки, их понимание и уровни абстратцш
В части VI мы сначала обсудим вопросы, связанные с выбором языка
программирования для задач искусственного интеллекта. Затем в главах, посвященных языкам LISP и
PROLOG, будут рассмотрены многочисленные приемы программирования, которые
можно использовать для построения интеллектуальных систем. Основная задача
программирования искусственного интеллекта— сформировать представление и
управляющие структуры, необходимые для решения интеллектуальной задачи. Требования к
этим структурам во многом определяют необходимые свойства языка реализации. Во
ведении к этой части сначала перечисляются требования, выдвигаемые к языкам
программирования задач искусственного интеллекта, а затем вводятся языки программиро-
вания LISP и PROLOG Эти два языка чаше всего применяются для решения задач
искусственного интеллекта Их синтаксис и семантика дают богатую почву для рассужде-
т" о задачах и их решении Эти языки оказали ощутимое влияние на историю развития
^«Умственного интеллекта. Во многом это определяется их мощностью, а также
возможностью их рассмотрения как "средства мышления".
.такими высокого уровня на основе опыта _
~-ть Фор«"ро*""" I „vreil человеческого мозга. Абстракции поз»„ *
Вмя^Ги^Г,шихосоосннос^. области в общую „ракгер£*>
ЯЯГС^ ^""""ToZT^ весь спектр частностей, вь^^^
о6К3' „ оТелен.«. Он" П03В°М"0дя в незнакомый дом. человек может con % '
£п£ » «* •*,1^2', разных ломал. Для описания полно,, картииы *
Гысллть «Р;*;,Т0Гно аборакд,,. лает возможность сжато представить ва^
"wSиелого кв«а объектов ^^ ^^ чедовек на жнок CBMcn ^
Созламя теорш, хи ош ичественные и количественные характеристики класо
объектов выде-иет с>шес™ компенс„р, егея точностью описания и силой прогнозу
Отсутствие легале|< при э &1^и_ важнейшее средство понимания сложности окр»
вня корректной «"Р"'^' ^™а также управления этой сложностью. Процесс аб<т™
жаюшего нас в^ внуфе _ и С11ВН0: знания организуются в различные ур„вщ,
аПСГв^»"с ,,— выделения структуры нз хаоса и заканчивая построен
~ на^них парий. Большинство наших идеи связаны с другими идеями.
ZJm абстращю (hierarchical abstraction) - организация опыта в струи,,
pv абстрак-гаьгх классов и описаний все более высокого уровня — это важное среден»
понимания поведения и структуры сложных систем, включая компьютерные программы.
Подобно тому, как поведение животных можно изучать без учета физиологии их нервное
системы, алгоритм можно рассматривать как отдельную характеристику, не зависящую
от реализующей его программы.
Например, рассмотрим две различные реализации бинарного поиска, написанные на
языке FORTRAN с использованием массивов и C++ с использованием указателей.
По существу, эти программы эквивалентны, несмотря на различие их реализаций. Такое
отделение алгоритма от кода — лишь один нз примеров иерархической абстракции в
компьютерных науках.
В [Newell. 1982] выделены два уровня описания интеллектуальных систем: знати
(knowledge level) и символов (symbol level). Уровень символов связан с конкретными
формализмами, применяемыми для представления знаний в процессе решения задач.
Примером рассмотрения задачи на таком уровне является описание в главе 2 логога
предикатов как языка представления. Выше расположен уровень знаний, связанный с
содержанием информации и способами ее использования
разоагю^ГпГРаШЧеН"е от?ажа™я ™ архитектуре систем на основе знаний и стилей*
™^Т"У П0ВДте™ баются с программой в терминах своих знашш .
BbutZb" Р0ТнТГ№-РеГМШ" '--Усственного интеллекта должны иметь чет»
ления ZZ^ZZZ0**™* 6ЩЬ' ~ от используемой структуры ущ*
«ы на уровне з„Л,й II Ггич™' ^^ т^°^ гаР«°™чного п***»" »£
Д" базы знаний в часшостГ "" УР°*т симаол™ определяется язык предсп»*«£
»»вня знаний позвотяет п Л°™Ческие "™ продукционные правила. Его °T*"fH"
«ости и простоты прогоамГГРаММИС1у решать проблемы выразительности, эфф«»
»»- системы. Ниже уГв' ГваШ1Я' "' °ТНОС™"<;с» ■< более высоким уровням «>**
реш»™ вопросов Ра^6Гтв;™°сЛОув1Распом''ается уровень организации программ
3№Ля™^™Тот^ч°ьсГХ°Да *РЧ>*°™ систем сложно переоценить. <»*
. ложности, относящейся к нижним уровням, и
^ 'ЯЗЫКИ И ТеХН°Л0ГИИ "Р«»ммирс«ния для искусственного >«*»""
£££«. от детален конкретной реализаш и Г,^ыГ^Г"™ ""^'^ " '
Сод..Ф""«Р»ать Р^изацито, повышая ее эфГкт,внс1?7аММНрования' °"
Та-
абст-
ПОЗВОЛЯ-
портирование
Уровень знаний
Символьный уровен!
Уровень алгоритмов и структур данных
Уровень языков программирования
Уровень компоновки
Микрокод
Машинные инструкции
Уровни аппаратных средств
Рис. VI.1. Уровни системы, основанной на знаниях из [Newell, 1982}
Уровень знаний определяет возможности интеллектуальной системы. Сами знания не
зависят от формализмов, используемых для их представления, а также выразительности
выбранного языка программирования. На уровне знаний решаются следующие вопросы.
Какие запросы допустимы в системе? Какие объекты и отношения играют важную роль в
данной предметной области? Как добавить в систему новые знания? Будут ли факты
изменяться со временем? Как в системе будут реализованы рассуждения о знаниях?
Обладает ли данная предметная область хорошо понятной систематикой? Имеется ли в ней
непонятная или неполная информация? Важным шагом в разработке архитектуры
программы является внимательный анализ вопросов этого уровня и выбор конкретного
способа представления, используемого на символьном уровне.
На символьном уровне принимаются решения о структуре представления и
организации знании. Важнейшим вопросом является выбор языка программирования. Как
известно из глав 6-8, логика— это лишь один из многих формализмов представления
знаний. Язык представления должен не только давать возможность выражать
необходимые знания, но и быть согласованным, модифицируемым и вычислительно
эффективным. Ои должен помогать программисту познакомиться с организацией базы зна-
ш<й. Этн критерии зачастую противоречивы, что требует внимательного подхода к
разработке языков представления.
Подобно разделению уровней знаний и символов, в программе можно разграничить
символьный уровень алгоритмы и структуры данных, используемые для его реализации,
"■пример, поведение логической системы решения задач, основанной на юш-таа-шшх.
$*« отличаться от ее реализации на базе бинарных деревьев только быстродействием.
^ вопрос реализации, который должен оставаться прозрачным на ««вольном уровне.
М»°гие алгоритмы и структуры данных, используемые в задачах оораоотки естественного
«ьжа, сводятся к работе с деревьями и таблицами. Но есть и специфические ятя искусст-
***** интеллекта представлен.». Они приводятся в виде псевдокода во всех частях кии-
**а их реализация на языках LISP и PROLOG описана в соответствующих главах.
1ЭоР языков PROLOG и LISP
605
„vktvp данных располагается уровень языка. На ,
Ниже уровня алгоритмов негрунровання. Хотя хороший стиль „ро *»<
J* важную роль игра" иль х свойств „зыка программирован,,, „^'
^„.«прелполагаетраД^н е ^ „„„, интеллекта 1ре6ует их ^;
даяших уровней, с"™"*'" ^L языка должна удовлетворять ограничениям, 1"
взаимосвязи. Кроме того сгру W ^ компьютер„о„ архитектуры, включая „Пе '
словленным еще более й.зкн ^„„.х средств. объем памяти „ быстродей^
„ионную систему, aP^K^L0G обеспечивают реализацию требований символы '
процессора. Языки и^ 6oJlcc „.„кого уровня. Этил, объясняется их попу'
„ уч,ггывают архитектуру о■ екта. уляР'
Гсть при решении задач '-^ык ц5Р и PROLOG.
Рассмотрим основные свойства язык
Обзор HSbiKMjPROLOGjii^ISP _____
PROLOG
PROLOG— это наиболее известный пример языка логического программирована
(logic programming language). Логическая программа — это набор спецификаций в рамкк
формальной логики. PROLOG основан на теории предикатов первого порядка. Само имя
этого языка программирования расшифровывается как Programming in Logic
(Программирование в логике). При выполнении программы интерпретатор постоянно
реализует вывод на основе логических спецификаций. Шея использования возможностей
представления теории предикатов первого порядка — это одно из основных преимуществ
применения языка PROLOG для компьютерных наук вообще и искусственного интеллекта
в частности. Применение теории предикатов первого порядка в языке программирования
обеспечивает прозрачный, элегантный синтаксис и хорошо определенную семантику.
Развитие языка PROLOG уходит корнями в исследования, связанные с доказательством
теорем, а точнее, с разработкой алгоритмов опровержения резолюции [Robinson, 1965].
В этой работе разработана процедура доказательства, получившая название резолюции
(resolution), которая и стала основным методом вычислений на языке PROLOG. В главе 12,
посвященной вопросам автоматического доказательства теорем описаны системы резот-
*mZZ1°"e тгж'жт"" (ration refutation system) (см. разделы 12.2 и 12.3).
исслелТваГ *"" СВ°ЙСТВаМ PR°L0G ^Рекомендовал себя в качестве полезного средам
«Гкола^''Х,ГПеР"МС,,таЛЬНЬ,Х В0ПР°С0В программирования, как автоматическая
роваиия PROLOG 1 Ш>* "Р0^8™ " Разработка высокоуровневых языков
программный стиль .тогпамм,!»" У™ ОСНОВаннЬ|е "а ™™ке языки, поддерживает декларат»-
иевогоописания огеаГ.^^70' кокстР№°нание программы в терминах высовоур*
™ь программировав22 "J**"™0* °«га«" задачи. В отличие от него. процедУР^
инструкш,,-! „о вьшолнению Г0"3"1" Написш"е программы в виде последовательное™
общается, "что есть истина" Т™3' В логическ°м программировании компьютеру1
точиться на решсщ,и задачи „ 7 ™ ™ сделет>>"- Это позволяет программистам сосреД
™»х написан,,, „.„ко! " " ' °ЭДанки С1ки"фикац„й для предметной области, а не >»*
Первая PROLOG.npo™M " Г°Р"ТМ'1ЧССКИХ ,,н<*РУинй »'«» "™ делать дал« ■
*ki' 19"«]. Теоретич"
606
™ проекта „„ понимав,^ „ НШк™ » Ha4aJ,e 1970-х годов во Франции в Г
IKowlaki. „то», т_. ю ««спинного языка [Colmeraner и лр , 1973]. [Rous**-"S
°<™вы этого языка опнсаны в 6отах rKo«»s
Часть VI Язык "
И Те*Н°Л0ГИИ "Р^Раммирования для искусственного *****
,о7д„ 19796], [Hayes. 1977], [Lloyd, 1984]. Основной этап „,
' ится на 1975-1979 годы, когда „а кафедре искусГенн""" РК°Ш° Пр"'
&"*™ У°РР™ ^ H.D Wain", „ Си^КйГ
вечали за реализацию этого языка. Они создали первый интерпре^а™ PROLOG ™„™"
точ„о робастныи для предъявления его всей компьютерной общественности £от Z-
базировался н, системе DEC 10 и мог работать как в режиме интерпретатор так „
, режиме компилятору Описание этого кода и результаты сравнения PROLOG с я ыком
USP приводятся в [Warren „ др 977] Эъ версия стала первым стандартом языка
PROLOG и была описана в книге [Clocksm и Mellish, 1984]. В нашей книге используется
„менно этот стандарт, который известен под названием эдинбургского синтаксиса
Преимущества этого языка были продемонстрированы при разработке исследовательских
проектов, призванных оценить н повысить выразительность логического программирования
Многие приложения, реализованные на этом языке, описаны в трудах Международной
конференции по искусственному интеллекту и Симпозиума по логическому программированию.
Ссылки на дополнительную литературу приводятся к конце главы 14.
LISP
Язык LISP был впервые предложен Джоном Маккарти (John McCarty) в конце 50-х
годов. Вначале этот язык рассматривался как альтернативная модель вычислений на
основе теории рекурсивных функций. В своей первой работе [McCarthy. 1960] автор языка
сформулировал поставленную перед ним цель следующим образом. Требуется создать
язык для символьных, а ие числовых вычислений, реализующий модель вычислений на
основе теории рекурсивных функций [Church, 1941]. При этом нужно обеспечить четкое
определение синтаксиса и семантики этого языка и продемонстрировать формальную
полноту этой вычислительной модели. Хотя LISP — это один из старейших
компьютерных языков, все еще находящихся в использовании (наряду с языками FORTRAN и
COBOL), при внимательном рассмотрении его истории развития становится ясно, что он
постоянно идет в авангарде языков программирования. Эта модель программирования
зарекомендовала себя столь хорошо, что на принципах функционального
программирования были основаны многие другие языки, в том числе SCHEME, ML и FP.
Основным структурным блоком программ и данных в LISP является список. (Отсюда
и аббревиатура LISP — Lisp Processing, илн обработка списков.) LISP поддерживает
большое число встроенных функций работы со списками как со связными структурами
Указателен. LISP обеспечивает для программиста всю мощь и общность связанных
"РУкгур данных, освобождая их от необходимости явно управлять указателями н реали-
зовывать
операции с ними.
Изначально LISP был компактным языком, состоящим нз функции построения и оо-
Работки списков, позволяющим определять новые функции, проверят,^Р™° и
опекать выражен,,,. Единственными средствами управления бил. рекур -ну™»»,
"«ераторы. В терминах этих примитивов при необходимости ""Р«™ ™™
«-Функции. Однако со временем лучшие из новых ф^нкц,,,, c=ык, ~™
зданию многочисленных диалектов LISP. 3a4atT>1^ программой, реализации
2^ Функций для структурирования> ^о—Д еда^фования функций
^ественных „ целочисленных *"ч1™ени^ВВ^ы СПОС„бствовали превращению
L1!>p и трассировки выполнения программ. Эти диалекты
iQP языков PROLOG и LISP
607
,ческой модели вычислений в богатую Мо
л^™й и элегантной теор""11ЫХ систем. Из-за быстрого разрастания пЧУ*
SkTb LISP агентство аш«т-^ ^ предложшю стаНдаРтныи диалект, падуч^
need Research Projects ль
4rsrs"^^ Введение в PROLOG
хранение получили друг™ мн ^^ как для решения задач искусственного „„'
гантное переосмысление " ' щнх фундаментальных принципов программирована,
—йГб^ользоваиимеиноСотпгпопШР.
Выбор языка реализации
Искусственный интеллект сформировался как отдельная область знаний и Пр0ДВ(И|.
стриро!, свою применимость для решения многих практических задач „а основе язь,,
ков LISP и PROLOG. Однако в последнее время удельный вес этих языков при решении
задач искусственного интеллекта несколько снизился. Это объясняется требованиями к
разработке программных систем. Системы искусственного интеллекта зачастую служат
модулями других больших приложений, поэтому стандарты разработки приводят к
необходимости использования единого языка программирования всего приложения.
Современные системы искусственного интеллекта реализуют на многих языках, включая
Smalltalk. С. C++ и Java. Тем не менее LISP и PROLOG продолжают играть свою роль в
разработке прототипов программ и новых методов решения задач.
Кроме того, эти языки служат для обоснования многих средств, которые впоследствии
включаются в современные языки программирования. Наиболее ярким примером является
язык Java, в котором используются динамическое связывание, автоматическое управление
памятью и другие средства, впервые реализованные в языках программирования задач
искусственного интеллекта. Создается впечатление, что весь остальной мир
программирования до сих пор пытается перенять стандарты от языков реализации искусственного
интеллекта. С этой точки зрения ценность LISP, PROLOG или Smalltalk со временем будет
неуклонно повышаться. Автор уверен, что эти языки пригодятся читателю, даже если
впоследствии он найдет свое место в C++, Java или любом другом конкурирующем языке.
аСТЬУ1 "*"" " ТвХН°Л0ГИИ "е°ФаМмирования дая искусственного мнтлл*
Все объекты человеческих размышлений и исследований естественным образом
можно разделить на два вида: "связи идей" и "сущность фактов".
— Дэвид Хьюм (David Hume), К вопросу о человеческом разуме
Единственный способ улучшить наши рассуждения — это сделать их столь же
осязаемыми, как математические формулы, чтобы уметь найти ошибку с одного
взгляда и иметь возможность в споре с оппонентами просто сказать: "Давайте
посчитаем... и посмотрим, кто из нас прав ".
— Лейбниц (Leibniz), Искусство открытия
14.0. Введение
Как реализация принципов логического программирования язык PROLOG вносит
интересный и существенный вклад в решение задач искусственного интеллекта. Наиболее
важное значение имеет декларативная семантика (declarative semantics)— средство
прямого выражения взаимосвязей в задачах искусственного интеллекта, а также
встроенные средства унификации и некоторые приемы проверки соответствия и поиска.
В это и главе будут затронуты многие важные вопросы логического программирования н
организации языка PROLOG.
В разделе 14.1 представлены базовый синтаксис языка PROLOG и несколько простых
программ, демонстрирующих использование исчисления предикатов в качестве языка
представления. Будет показано, как отслеживать состояние среды PROLOG н использовать
оператор отсечения (cut operator) для реализации поиска в глубину на языке PROLOG.
В разделе 14.2 рассматривается вопрос создания абстрактных типов данных (АТД)
(abstract data types — ADT) на языке PROLOG. К ним относятся стеки (stack), очереди
<Ч"еие) и приоритетные очереди (priority queue), используемые для построения
продукционной системы в разделе 14.3 и разработки в разделе 14.3 управляющих структур для
^оритмов поиска, описанных в главах 3, 4, 6. В разделе 14.5 по материалам раздела 7.4
Разрабатывается планировщик (planner). В разделе 14.6 вводится понятие метапредика-
,}'ов (meta-predicate) — предикатов, область интерпретации которых составляют сами
сражения языка PROLOG Например, выражение atom(X) является истинным, если
Х-_
"ичсиия
зто атом, т.е. константа. Метапрсдикаты можно использовать для наложения огра
i при интерпретации программы
языке PROLOG. В разделе 14.7 мета-
"Р^икаты используются для построения метаинтерпретаторов (meta-interpreter)
очередь применяются для создания HHTcpnpCTaT„
„„лт лг, которые в свою о „„тотпрстаторов цепочек правил. р0»
Я3 В разд^ 14.8 »*™Х«м Дается поиск в пространстве версии „ 0бучсни^
„ня В качестве примеров Р>™°* [4 „ стр0„тся рекурсивный анализатор „,„*
1ве объяснения из главь цВ Р которого издожень1 „ П1аве 13. в эдвсрщ£
вс семантических сете , прини Ро и J]onl4CCKOro программирован»», а
обсуждаются обшие вопросы р ^^ решсния задач.
отличия этик подходов от деклар
14.1. Синтаксис для программирования логики
предикатов
14.1.1. Представление фактов и правил
Несмотря на существование многочисленных диалектов языка PROLOG, в этой книге
„спользуеТя „сходная версия языка C-PROLOG, разработанная Уорреном (Warren).
ПеоеПоой (Pereira) [Clocksin и Mellish. 1984]. Чтобы упростить представление данных на
языке PROLOG при описании логики предикатов в главе 2 используются многие
соглашения принятые в этом языке. Однако существуют многочисленные отличия синтаксиса
логики предикатов от языка PROLOG. Например, в C-PROLOG символ : - соответствует
символу <- логики предикатов первого порядка. Приведем еще несколько отличий син-
таксиса PROLOG от обозначений, используемых в главе 2.
Название операции Обозначение в логике предикатов Обозначение в языке PROLOG
или
только если
Как и в главе 2, имена предикатов и связанных переменных представляют собой
последовательности буквенно-цифровых символов, которые начинаются с буквы.
Переменные представляются в виде строк буквенно-цифровых символов, которые
начинаются (хотя бы) с прописной буквы. Так, выражение
likes(X, susie).
или, еще лучше,
likes(Everyone, susie).
«ожег представлять тот факт, что "каждый любит Сьюзи". Или
Utes (george, Y) , likes (susie Y)
Джордж любит Кейт ., п необходимо представить следующее отио
likes (george k , "^ '"°бИТ СЬЮЗИ'' ЕГ° М0ЖН0 3аГШСаТЬ " В"ДС
' а е) , likes(george susie)
Нке^е!г::М'^Г,,Юб,ГГК*ИЛ"*0Р«'"°^Сьюзи"можнопред^«1'*
______J_J^'' lik«(9eorge, susle).
^сть«,.язык„итвх„о„огиипрограммированиядляискусстввнногоинтап^
И, наконец. "Джордж любит Сьюзи. если Джордж „е любит Кейт" описывается так
iikesfgeorge, susie) :- not(likes(george, kate)) .
№ этих примеров видно, как связки л, v. ^ „ ^ и, Л0ГИКИ прсд„като„ прсдсташ,я10т.
ся на языке PROLOG. Имена предикатов (наподобие likes), количество и порядок
следования параметров и даже постоянное или переменное число параметров определяются
требованиями (неявной семантикой") конкретной задачи. В этом языке программирования
не существует никаких ограничений, кроме требования правильного построения формул.
Программа на языке PROLOG — это набор спецификаций из логики предикатов первого
порядка, описывающих объекты и отношения между ними в предметной области задачи.
Набор спецификаций называется базой данных (database) конкретной задачи. Интерпретатор
PROLOG отвечает на вопросы, касающиеся этого набора спецификаций. Запросы к базе
данных — это шаблоны, представленные в том же логическом синтаксисе, что и записи базы
данных. Интерпретатор PROLOG использует поиск на основе шаблонов для определения
того, являются ли эта запросы логическим следствием содержимого базы данных.
Интерпретатор обрабатывает запросы, выполняя поиск в базе данных в глубину слева
направо и определяя, является ли данный запрос логическим следствием спецификаций из базы
данных. PROLOG— это в основном интерпретируемый язык. Некоторые версии языка
PROLOG работают только в режиме интерпретации, другие допускают компиляцию части
или всего набора спецификаций для ускорения выполнения программы. PROLOG — это
интерактивный язык: пользователь вводит запросы в ответ на приглашение ?-.
Допустим, требуется описать "мир симпатий и антипатий" Джорджа, Кейт и Сьюзи.
База данных для этой задачи может содержать следующий набор предикатов.
likes(george, kate).
likes(george, susie).
likes(george, wine).
likes(susie, wine),
likes(kate, gin).
likestkate, susie).
Этот набор спецификаций имеет очевидную интерпретацию или отображение на
"мир" Джорджа и его друзей. Этот мир является моделью для базы данных (раздел 2.3).
Затем интерпретатору можно задавать вопросы
?- likes(george, kate).
Yes
?- likes(kate, susie).
Yes
?- likes(george, X).
x = kate
likes(george, beer),
no
Отметим несколько моментов в этих примерах. Во-первых при ^а&тке загпкка
"kes (george X) пользователь последовательно вводит приглашение ,, поэтому
"^рпрстатор31озврапВст вес термы из спецификации базы данных, которые можно
глава 14. Введение в PROLOG
„„яются в том порядке, в котором были иайде„ы „ .
„„даавить .«есто X. Они возврат a» wlne. Хотя это противоречнт «о
данных: сначала kate. ^"Детерминированный порядок - это свойство 6о '
J ,„ непроцедурны* «^^J на последовательных машинах. Программ£
1„„ства интерпрегаторо» ре» поиска мсментов в базе данных,
„а языке PROLOG должен з"^^ ^^ т запрос выдаюТся после пользовательск,,.
Заметим также, что "°«> СХОдит возврат к последнему найденному ре,у)1ь
то приглашения ; (или). "? приводят к нахождению всех возможных ответо,
тагу. Последовательны., при ^ сушсСтвует, интерпретатор выдает ответ по.
на запрос. Если решении иллюстрируют допущение замкнутости мира Mavi
Приведен^ выше — ™к*е ^ ^ „ Ыше). в „ыкс PROLOG пред,^
■«" -J" ГГеГГвляется ложным, если нельзя доказать истинность его отрицана,
ется. что лнэбое выражение |aeorge, beer) интерпретатор ищет предки,
Пос« поиск не завершается успехом, запрос считается ложным. Таким образом, в язык
PROLOG предполагается, что все знания о мире представлены в базе данных.
Допущение замкнутости мира приводит к многочисленным практическим и философ.
ским сложностям в языке. Например, невозможность включить некоторый факт в базу
данных зачастую означает, что его истинность неизвестна. Однако в силу допущения
замкнутости мира этот факт трактуется как ложный. Если некоторый предикат был
упущен или при его вводе была допущена опечатка наподобие likes (george, beeerl,
то ответом на данный запрос будет по. Аспект трактовки отрицания как лжи — очень
важный вопрос в области искусственного интеллекта. Хотя это предположение
обеспечивает простой способ решения проблемы незаданных знаний, более сложные подходы,
в том числе многозначные логики (истина, ложь, неизвестно) н немонотонные
рассуждения (см. главу 9) обеспечивают гораздо более богатый контекст для интерпретации.
Выражения PROLOG, использованные в приведенной выше базе данных, являются
примерами спецификации фактов (fact). PROLOG также позволяет определять правша
(rale), описывающие взаимосвязи между фактами с использованием логической
импликации : -. При создании правила на языке PROLOG слева от символа ; - может
располагаться только один предикат. Этот предикат должен быть положительным литерами
(positive literal), т.е. не должен представлять собой символ с отрицанием (раздел 12.3).
все выражения логики предикатов, содержащие отношения импликации или оквива-
ш,ёТ™„Т -?и" "';Д0ЛЖШ бь,ть nP"B<WHbi к этой форме, которая получила назва-
ZZZ2" 7 Ш5е)' В Х0РН0ВСК0Й Дизъюнктивной форме в левой части импли-
" «"Z Z СЛн С0ДГТЬСЯ ™"-, поло—иый литерал. Лог*
первого пор ™ „" 2 С'аШе Ca'CUlUS> эквивалентна полной теории предика"»
Допу™7 к СТЦ l'™ """ ДОК™ьств на основе опровержения (см. главу 1»
правиле ои^:„::е:;еф::::г;зп-ртдснной выше ^»-™ ^^до6а
friends (х vi pye" tro м°жно описать следующим образом.
Эговыаж :_UkeS(X' Z1' lik<^. 2).
г, ™°ХлЕт"г и У°™ГтН;';Р"РеТИрОВЭТ'- ™. "X н Y - друзья, если существует «£
*У ни в логике предикатов »„ '„ М'*н° °™с™ть два момента. Во-первых, поем-
«"««<=. то ц,ка„а (область „„„Г'0" ""* PR0L0G ие определены глобальные J
^^^oput.n^ZlT*"^- переменных X, /„ Z ограни*"" ""*"""
^ 'ЯЭЫКИ " Те"Н0Л0™и программирования для искусственного ^^
сованы по всему выражению. Обработку правила friends интерпреташрчм я^ка
PROLOG можно проиллюстрировать на следующем примере.
Если к набору спецификаций из предыдущего примера добавлено правило friends,
то интерпретатору можно передать запрос.
7- friends(george, susie).
yes
Для ответа на этот запрос PROLOG осуществляет поиск в базе данных с помощью
алгоритма с возвратом, представленного в главах 3 и 5. Запрос friends (george,
susie) унифицируется (проверяется на соответствие) с заключением правила
friends (X, Y) :- likes (X, z) , likes (Y, Z). При этом переменной X
соответствует значение george, a Y — susie. Интерпретатор ишет значение переменной Z,
для которого выражение likes (george, Z) истинно. Это выполняется с помощью
первого факта в базе данных, в котором Z соответствует kate.
Затем интерпретатор пытается определить, истинно ли выражение likes (susie,
kate). Если оно окажется ложным, то на основе допущения замкнутости мира данное
значение для Z (kate) отклоняется. Тогда интерпретатор возвращается для поиска
второго значения Z в выражении 1 ikes (george, Z).
Затем проверяется соответствие выражения 1i kes(george, Z) второму
дизъюнкту в базе данных, при этом переменная Z связывается со значением susie. После этого
интерпретатор пытается найтн соответствие для выражения likes (susie, susie).
Если эта попытка тоже завершается неудачей, то интерпретатор снова переходит к базе
данных (возвращается) в поисках следующего значения для Z. На этот раз в третьем
предикате будет найдено значение wine, и интерпретатор постарается показать, что
likes (susie, wine) истинно. В данном случае значение wine является связкой для
значений george и susie. Интерпретатор PROLOG проверяет соответствие целей
шаблонам в том порядке, в котором эти шаблоны были введены в базу данных.
Важно отметить взаимосвязь между кванторами всеобщности и существования в
логике предикатов и обработкой переменных в программе PROLOG. Если переменная
содержится в спецификации базы данных PROLOG, то предполагается, что она связана
квантором всеобщности. Например, выражение likes (susie, Y) согласно семантике
предыдущих примеров означает "Сьюзи любит каждого". В процессе интерпретации
некоторого запроса любой терм, список или предикат может быть связан с Y. Аналогично в
правиле friends (X, Y) :- likes (X, Z), likeslY, Z) допускаются любые
связанные переменные X, Y и Z, удовлетворяющие спецификации этого выражения.
Для представления на языке PROLOG переменной, связанной квантором
существования, можно использовать два подхода. Во-первых, если известно конкретное значение
переменной, то его можно ввести в базу данных напрямую. Так, likes (george,
wine) _ это экземпляр выражения likes (george, Z). и его можно ввести в базу
Данных, как это было сделано в предыдущих примерах.
Во-вторых, для поиска экземпляра переменной, доставляюшего выражению значение
"истина", можно обратиться с запросом к интерпретатору. Например, чтобы определить,
существует ли такое значение Z. при котором выражение likes (george, Z) истинно,
мот запрос можно передать интерпретатору. Он проверит, существует ли такое значение
'"Ременной Z. Некоторые интерпретаторы PROLOG находят все значения, связанные
кантором существования. Для получения всех значений с помощью интерпретатора
"--PROLOG требуется повторять пользовательское приглашение ;.
„зменениен мониторинг среды PROLOG
14.1.2. Создание, PRoLOG сначала создастся база данных СПе
При написании профамм«н^ к спецнфикац„и в интерактивной ср*
фикации. Для добаелс" «нов ых Р ^^ к(шанды
„рименяется предикат as^rt.^^^
,. assert,U1<eS,daVld'mlH1(aTlikes(david, sarah). Теперь в ответ на запрос
ксида.фикацикдобавлястсяпред.жатп Фос
?_ likes (david, X) .
будет возвращен результат
X = sarah. _
„v,™ »ssert можно контролировать добавление новых спещфи.
С „„„„шью пр дика*^ (р) до6авляет предикат Р в начало списка„р,
кации в базу данных. Предик^ ^ _ ^ ^ [ВШ предикатов Р. Это важно дл, I
cl^ITptn,, и выбора приоритетов поиска. Для удаления предиката Р из базы
«Тных используется предикат retract (Р). Следует отметить, что во многих реаш„,
циях языка PROLOG предикат assert ведет сеоя более непредсказуемо, т.е. точ„„е
время добавления нового предиката в среду может зависеть от многих других факторе,
влияющих как на порядок следования предикатов, так и иа реализацию возвратов.
Создание спецификации путем последовательного использования предикатов
assert и retract — очень утомительный процесс. Вместо этого можно создать файл,
содержащий все спецификации для языка PROLOG, с помощью обычного редактора.
После создания файла (назовем его myf ile) нужно вызвать PROLOG и поместить весь
файл в базу данных с помощью команды consult. Так, запрос
?- consult (mylilel .
yes
добавляет предикаты, содержащиеся в файле myf ile, в базу данных. Существует и
краткая форма предиката consult, которую целесообразно использовать для
добавления в базу данных нескольких файлов. При этом используется следующее обозначение
?- [nyfile] .
yes
Предикаты read и write используются для взаимодействия с пользователем.
Команда read (X) считывает следующий терм „з текущего входного потока и добавляет
Г™„й „ Т ВЬ,раЖения РВДлякзтся точкой. Команда write (X) помещает X в №-
Г„ вас Г' Х~ НС С№аННМ "венная, то выводится целое число, перед
которым располагаете, символ подчеркивания. Эт0 целое число представляет внутре"»»
^(WHmnrZZZ9™--"0*: Не°бход™ьш для работы среды доказательст.
регистрационный ]
» файл. Команда see m ИСП0Лиук,тся *« считывания информации из файла и зат
порожденный в X Если 1 °ТКрЫвает *айл * » определяет текущий входной поток,
see IX) завершаете, ГГМе"лНаЯ Х "* СВЯЗана с ^шествующим файлом, то «о-£
одного потока. ьГС„А«™™« ^манда tell ,X, открывает файл *»*
которого совпадает со с„„! сУщс™ует, то команда tell (X) создает Фаил' .
вак„соответствующиефайлТЬ'МЗНаЧеНИеМ Х' Коман"ы seen(X) » told(X) ^
Некоторые предикаты языка PROLOG помогают отслеживать состояние базы
данных, а также связанных с ней вычислений. Среди них наиболее важными являются
listing, trace н spy. При использовании команды listing Ымя_„ргдшата), где
параметром является нмя предиката, в частности member (подраздел 14.13).
интерпретатором возвращаются все дизъюнкты нз базы данных с соответствующим именем
предиката. Заметим, что в данном случае число аргументов предиката не указано, поэтому
возвращаются все варианты данного предиката, независимо от числа аргументов.
Команда trace позволяет пользователю отслеживать состояние интерпретатора
PROLOG. В процессе мониторинга в выходной файл выводятся все целевые утверждения,
обрабатываемые интерпретатором PROLOG. Зачастую этой информации для пользователя
слишком много. Возможности трассировки во многих средах PROLOG слишком сложны
для понимания н требуют дополнительного изучения и опыта. Обычно прн трассировке
работающей программы PROLOG можно получить следующую информацию.
1. Уровень глубины рекурсивных вызовов (помечается в строке слева направо).
2. Когда предпринимается первая попытка обработки целевого утверждения (иногда
используется команда call).
3. Когда цель успешно достигнута (с помощью команды exit).
4. Возможность других соответствий целевому утверждению (команда retry).
5. Невозможность достижения цели, поскольку все попытки завершились неудачно
(зачастую используется команда fail).
6. Полная трассировка прерывается командой notrace.
Если требуется более избирательный мониторинг, то применяется команда spy. Имя
отслеживаемого предиката обычно задается в качестве аргумента, но иногда оно определяется с
помощью префиксного оператора (указывается после этого оператора). Так, с помощью
команды spy member выводится информация обо всех случаях использования предиката
member. Аргументом предиката spy может быть также список предикатов с указанием irx
арности. Так. команда spy (member/2, append/3] определяет мониторинг всех случаев
использования целевого утверждения member с двумя аргументами и утверждения append с
тремя аргументами. Команда nospy удаляет все контрольные точки.
14.1.3. Списки и рекурсия в языке PROLOG
В предыдущих подразделах на нескольких простых примерах представлен синтаксис
языка PROLOG. В этих примерах PROLOG предстает как механизм вычисления на базе
выражений логики предикатов (в хориовской дизъюнктивной форме). Это согласуется со
всеми принципами вывода в рамках логики предикатов, представленными в главе 2. Для
проверки соответствия шаблонам в языке PROLOG используется унификация и
возвращаются значения переменных (связанные переменные), обеспечивающие истинность
выражения. Эти значения унифицированы с переменными в конкретном выражении, но
«с связаны в общей среде.
Ниже будет показано что основным механизмом управления при программировании
"а языке PROLOG является рекурсия. Однако сначала рассмотрим несколько несложных
"Рнмеров обработки списков. Список (list) - это структура данных, представляющая
собой Упорядоченный набор элементов (или даже самих списков). Рекурсия - это естест-
»о»ный способ обработки списочных структур. Для обработки списков в языке PROLOG
глава 14. Введение в PROLOG
615
* ании и рекурсии- Сами элементы списков заю110
,ю,ользую1 процедуры УкиФ---я дРруг от друп, запятыми. Приведем несКОЛЬКо £
квасные скобки (Ш
„еров списка на языке ге
1 ' ,„■» может отделяться от его хвоста оператором |. Хвост списга-
Первый элемент списка CHTa. Например, для списка [ torn, dick, harrv
отсписокпослеудалени,^^^ с№ а хвостом-список [dick, harry, fred^
f red] первым шем"™ унификации можно раздештгь список на компоненты,
помощью оператора | и процедуры у <г
. Еслисппсок [torn, dick, harry, fred] соответствует шаблону [X|Y,, „
х = toffiHY = [dick, harry, fred].
. Если список [torn, dick, harry, fred] соответствует шаблону [x, Y|z],TO
X = tom,Y = dick и z = [harry, fred].
. Если список [torn, dick, harry, fred] соответствует шаблону [х, у,
z|W),toX = tom,Y = dick,z = harry.W = [fred].
. Еслисппсок [torn, dick, harry, fred] соответствует шаблону [w, X, Y,
z|V],toW = tom,x = dick.Y = harry.Z = fred,V =[].
Помимо разбиения списка на отдельные элементы унификацию можно использовать
для построения списочной структуры. Например, если X = torn, Y = [dick] и L
унифицируется с [X |Y], то переменная L будет связана со списком [torn, dick]. Термы,
отделенные друг от друга запятыми н расположенные до вертикальной черты, являются
элементами списка, а находящаяся после вертикальной черты структура всегда является
списком, а точнее, его хвостом.
Рассмотрим простой пример рекурсивной обработки списка: проверку
принадлежности элемента списку с помощью предиката member. Определим предикат, позволяющий
выявить наличие элемента в списке. Предикат member должен зависеть от двух
аргументов: элемента и списка. Он принимает значение "истина", если данный элемент
содержится в списке. Например,
?- memberla, [а, Ь, с d el )
Yes ' ' ' •
'- memberla, [1, 23411
No ' J ' '
?- member (X, [a b
X = a
c]>.
Чтобы определил, пред,,,,. m к
первым элементом списка Г Рек>Т>сивно, сначала проверим, является :
"emberix, |x|T))
тв*»°логии програММирования для искусстввнного инте"леК,а
Этот предикат проверяет, идентично ли значение X первому элементу списка. Если
„ст. то естественно проверить, содержится ли X в оставшейся части (Т) списка. Это
определяется следующим образом.
member(X, [Y|T]) :- member(X, Т) .
Таким образом, проверка наличия элемента в списке на языке PROLOG выполняется
с помощью двух строк.
member(X, [Х|т]).
memberlX, [Y|Т]):- member(X, Т).
Этот пример иллюстрирует значение встроенного в PROLOG порядка поиска, при
котором условие останова помещается перед рекурсивным вызовом, а значит, проверяется
перед следующим шагом работы алгоритма. При обратном порядке следования
предикатов условие останова может никогда не проверяться. Выполним трассировку предиката
merabertc, [a, b, с] ) с нумерацией.
1: memberlX, [Х|Т]).
2: memberlX, [Y|T]):- memberlX, T) .
?- memberlc, [a, b, с]).
call 1. fail, since c*a
call 2. X = с Y = a, T = [b, c] , memberlc, [b, c]>?
call 1. fail, since c*b
call 2. X = c, Y = b, T = [c], memberlc, [c])?
call 1. success, с = с
yes (to second call 2.)
yes (to first call 2.)
yes
Хороший стиль программирования на языке PROLOG предполагает использование
анонимных переменных (anonymous variable). Они служат для указания программисту и
интерпретатору того, что определенные переменные используются исключительно для проверки
соответствия шаблону, т.е. само связывание переменных не является частью процесса
вычислений. Так, чтобы проверить, совпадает ли элемент X с первым элементом списка, обычно
используют запись member (X, [Х|_] ). Символ _ означает, что, несмотря на важное
значение хвоста списка в процессе унификации запроса, содержимое хвоста не играет роли.
Анонимные переменные необходимо также использовать в рекурсивном утверждении при
проверке наличия элемента в списке, если значение головы списка не играет роли.
memberlX, [X|_]).
memberlX, [_|т]> :- memberlX, T) .
Хорошим упражнением для углубления пошгмания природы списков и рекурсивного
Управления является запись элементов списка по одному в строке. Допустим, требуется
таким образом записать элементы списка [а, Ь, с, d]. Для этого можно определить
Р«Урснвную команду.
writelist([ ]).
writelist|[Н|Т]) :- write(H), nl, writelistIT).
Этот предикат записывает элементы списка по одному в строке, поскольку nl озна-
ча« переход на новую строку в выходном потоке. Если требуется записать элементы
с""«а в обратном порядке, то рекурсивный предикат должен следовать перед командой
14. Введение в PROLOG
617
ялантировать. что список будет пройден до конца еще д0 3
„ite. Тогла «»*»» Записан последний элемент списка „ выполнен Рекурсив„ь,
его элементов. Затем будет *™пуюшМ элементов списка. Запись списка в „6pJ
вызов процедуры ^* • юЩ„м образом,
„ом порядке определяется следу
rever6e_writellst(U)|j) : _ reverse,writelist (T) , write(H), nl.
reversa_wr1tens ть „овсде„„е этих предикатов, запустив их в рс.
Читателю предлагается про-
жиме трассировки.
14 1.4. Рекурсивный поиск в языке PROLOG
R „атлеле 5 ■> рассматривалась задача "хода конем" размерности 3x3 в рамках теории
предикГов ^'перемещения коня использовалась квадратная доска следующего вида.
Допустимые ходы можно представить на языке PROLOG с помощью предиката
move. Предикат path определяет алгоритм нахождения пути между его аргументами за
О или более ходов. Заметим, что предикат path определен рекурсивно.
moved, 6). move(3, 4).move(6, 7).move(8, 3).
move(l, 8). move(3, 81.move(6, l).move(8, 1).
move(2, 7). move(4, 3}.move(7, 6).move(9, 4}.
move(2, 9). move(4, 9).move(7, 2).move(9, 2).
path(Z, Z) .
pathlX, Y) :- move(x, W) , not (been(W)) , assert (been (W) ) , path(W, Y) .
Это определение предиката path представляет собой реализацию на языке PROLOG
алгоритма, описанного в главе5. Как было указано выше, assert — это встроенный
предикат PROLOG, который всегда имеет значение "истина" и попутно помешает свои
аргументы в базу данных спецификаций. Предикат been используется для записи
посещенных ранее состояний и предотвращения циклов
Такое использование предиката been противоречит цели разработчика программы,
состоящей всоадании спецификации логики предикатов без использования глобальных
перечный „Г"""' <3' П0Ше до6а»™«"» в базу данных представляет собой факт.
Z „Г"™ "Р0ЦСД^С В эт°й базе данных, а значит „моющий глобш^ьш
баз" ,й ,,р„„Ги,м„' Г"™* ГЛ°6аЛЬНЬК «И«Я> ^я управления программой нарушает
™™"wZ:Z2Tm ПР°ДУад'™«ь« систем" вторых логика <спсш**£
been бь! создаГк г "РСДСТВ У"ра№ния профаммой. В данном случае стру^»
нсполиеииясамХро^к™, '№Ые СПадФик^и, предназначенные для модиФ>«»да'
Как было предложено в главе 3 п„„ - „ предот-
. Z1T °™-"^„„я поеещо„нь,х состоянии ^
Такой
(W)-
вращения циклов при вызове """ отслежива"пя посещенных состояний и и
Дублированных состояний (п 1МД"Ката path м°жно использовать список. Для »ьт
подход позволяет обойти проб"" М°ЖН° В0СПШ1и°ваться предикатом member-
ly "Пользования глобального утверждения bee
" К*ттт" программирования для искусственного интел
,ле^а
По„ск в глубину с помощью алгоритма с возвратами, описан,»,,, в гттх 3 и 5 „„ я.)ыкс
PROLOG может быть реализован следующим образом.
path(Z, Z, L).
pathlX, Y, Ы:- movelx, z) , not(member(z. l) ) , path(z, Y,[Z|L]).
Здесь member — определенный выше предикат.
Третий параметр предиката path- это локальная переменная, представляющая
список уже посещенных состоянии. При генерации нового состояния (с использованием
предиката move) оно помещается в начало списка состояний [z|L] для следующего
вызова path, если оно до сих пор не содержалось в списке посещенных состояний
not(member(Z, L)).
Следует отметить, что все параметры предиката path являются локальными а их
текущее значение зависит от места вызова на графе поиска. При каждом рекурсивном
вызове к этому списку добавляется новое состояние. Если все продолжения из данного
состояния завершаются неудачей, неудачей завершается и соответствующий вызов path.
Если интерпретатор возврашается к родительскому вызову, то третий параметр,
представляющий список посещенных состояний, принимает свое предыдущее значение.
Таким образом, в процессе поиска с возвратом на графе состояния добавляются и
удаляются из этого списка.
При успешном завершении вызова path первые два параметра принимают
одинаковые значения. Третий параметр — это список посещенных состояний в пути решения, в
котором эти состояния перечислены в обратном порядке. Таким образом, можно вывести
на печать все этапы решения. Спецификацию PROLOG для задачи "хода конем" с
использованием списков н поиска в глубину с возвратами можно получить с помощью
этого определения path и приведенных выше спецификаций предикатов move и member.
Вызов интерпретатора PROLOG для команды path(X, Y, [X] ), где X и Y— это
числа из диапазона от 1 до 9, позволяет найти путь из состояния X в состояние Y, если
этот путь существует. Третий параметр инициализирует список посещенных состояний
начальным состоянием X. Заметим, что в языке PROLOG регистр символов не
учитывается. Первые два параметра должны определять любое представление состояний в
области определения задачи, а третий — список состояний. С помощью унификации
выполняется обобщенная проверка соответствия шаблонам для всех возможных типов
данных. Таким образом, path— это общий алгоритм поиска в глубину, который можно
использовать для любого графа. В разделе 14.3 он будет применен для реализации
продукционной системы решения задачи "о перевозке человека, волка, козы и капусты" с
соответствующими спецификациями состояний.
Вернемся к решению задачи "хода конем" на поле 3x3. Полную задачу "хода конем"
"а поле 8x8 на языке PROLOG читателю предлагается решить самостоятельно (см.
упражнения к главам 14 и 15). Для этого пронумеруем обе части алгоритма path.
>'■ isp^Mx/Y^u'/- move,X, z, , net (member (Z. L... Path.z, ,.[z|I.],.
?~ Path(l, з, [1]).
Выполним трассировку этой задачи.
£«;U. 3, [щ attempts to match 1 Jail 1 * 3
Path(l. 3, [1], matches 2. X is 1, * >= ^' 6 [Ш) is true,
"»ve(l, Z) matches Z as 6, not member (о,
call path(6, ЗЛ6.1П
Глава
И. Введение в PROLOG
619
„.. to match 1. fail 6*3.
,Ы6 3, t6.D) a"T=V X is 6, V is 3, L is [6,11
P-b": 3. I«.Ji> ГГаГ72'not^er,7,[6,l)), ie ^
Pmove(6.Z) ^ев Z a
Paf,,; attempts to match 1. fail 7*3.
Path<7.3.n. 6.1 rtt»P ^ x is 7, Y is 3, L is
path(7,3. 7,6.11) »a^t(member(6, [7. 6.1])) fails, backtrack,
mOVe'^ is Й' ntt (member (2. [7,6,1])) true, 3Ck!
move(7,Z) is ' -'
6,11)
fail. 2*3.
6.1]
muvei < , -<
path(2,3,[2,7
path call attempts 1,^1,^*3.^ ^
CSi'^='' not (member,...., fails, backtrack,
"ove matches Z as 9, not (member ( . . . ) ) true.
path(9,3, [9,2,7,6,1])
^th matches'^ Is 9. V i. 3. L i. [9.2.7.6.1,
move is Z = 4, not (member (...) ) true,
path(4, 3,[4,9,2.7,6,1])
path fails 1, 4*3.
path matches 2, X is 4, Y is 3, L is [4,9,2,7,6,1]
move Z = 3, not (member (...) ) true,
path(3, 3, [3,4,9,2,7,6,1])
path attempts 1, true, 3 = 3, yes
yes
yes
yes
yes
yes
yes
В заключение отметим, что рекурсивный вызов path — это оболочка (shell), или
общая управляющая структура для поиска на графе. В path (X, Y, L) X— текущее
состояние, Y — целевое. Если Хну совпадают, рекурсия прекращается. L — список
состояний в текущем пути к состоянию Y. При обнаружении каждого нового состояния Z с
помощью вызова move (X, г) это состояние помещается в список [ Z | L ]. Проверка
наличия состояния в списке выполняется с помощью вызова not (member (Z, Lll-
.Эта проверка гарантирует отсутствие циклов в найденном пути.
итличне между списком состояний L в рассмотренном алгоритме поиска пути «
Гсе"3ЫМ МНОЖССТаом closed из главы 3 состоит в том, что это множество содержит
расшиг.итТГЫе С°СТ0Я""Я- 3 В С""Ске L *Pa™ ™лько текущий путь. Желательно
cs ~zr вь,зове path'н хранить все посещениые состояв№
14'U'"™BROLOGCPaT0Pa °ТСеЧеН,,Я ДЛЯ ^РаВЛе"ИЯ П0ИСК°М
вето утвсржден^сТи™"0 "редставляется символом ! и указывается в качестве и^
аффектов. Во-первых этаГ"Т0В' ПР» этом его применение имеет несколько not» __
во-вторых, если tin,, во-<»„,!"ерЭТОр всегда выполняется прн его первом ДО«"ж1„„ с„.
8раТС "дастся невозможным вернуться к предыДУ^'У
стоянию, то все целевое утверждение, в котором содержится этот оператор счишен-я
ложным. В качестве простого примера использован,™ оператора отсечение оассГто м
реализацию вызова предиката path для поиска ДвухшТтовГго^Гв зГче Ч Га
конем . Можно создать следующий предикатрасп2.
конем" Можно создать следующий предикатpath2.
path2(X, Y) :- move(x.z), move(Z.Y)
Между точками X и Y существует двухшаговый путь, если между „ими существует
■промежуточная остановка Z. Предположим, для данного примера существует следую-
,,^я база данных ходов конем.
шая база данных ходов конем
move(1, 6)
move(1, 8)
move{6, 7)
move{6, 1)
move (8, 3)
move(8, 1)
В ответ на запрос о поиске двухшаговых путей из состояния 1 интерпретатор выдаст
четыре значения.
?- path2(l,W).
W = 7
W = 1
W = 3
W = 1
по
Если в предикате path2 используется оператор отсечения, то ответов будет только два
path2(X, Y) :- move(X.Z), !, move(Z,Y).
?- path2(l,W) .
W = 7
Это происходит потому, что переменная Z принимает только одно значение (первое
связанное с ней) — 6. Если первая подцель реализуется успешно, то переменная Z связывается со
значением б, и достигается оператор отсечения. Поэтому в дальнейшем возврат к первой
подцели не выполняется, и переменная Z не связывается с другими значениями.
Оператор отсечения в программировании используется для нескольких целей. Во-
первых, как видно из данного примера, он позволяет программисту явно управлять
формой дерева поиска. Если дальнейший поиск (полный перебор) не Ф^уется то в этой
гочке можно выполнить явное усечение дерева. При этом код на языке PROLOG напо-
М|™ет вызов функций- если предикат PROLOG (или набор предикатов) -возвращает
°™° множество значений (связей) п достигается оператор отсечения, то интерпретатор
"Е выполняет поиск для других подстановок унификации. Если это множество значении
"е приводит к решению, то поиск решения не продолжается.
14. Введение в PROLOG
621
„ „сечения позволяет управлять рекурсией. Например, пр„
Во-вгорьк. оператор отсеч
,е предиката path
Р»*«. *■ »•. ^е.Х. V,. notl.ember.Y, Ы). path(V, Zl[y|li])i ;
РаСЫХ' ' „«.чеши означает, что в результате поиска на графе будет „айдено
добавление оператора "«'"" ШШ1Я обеспеч.1вается тем, что последующие ред.
только одно решение. > "^ дИЗЪЮ„ктивного выражения path (Z, z, L). Если
„ия буд>т найдены "«■«J"^™ eHIU, то предикат path (Z, z, L)
принимает
пользователь ^™^ ,ш11ЦиирУет вызов второго предиката path для продолжен,
значение "ложь и тел ■ Еа1| оператор отсечения размещается после рекур,
поиска (полного переборана гр Ф^ ^ ^^ fab повторен (в результате flo3Bpara) >Р
снвного вызова pacn, iu ли
^В^ьГпХчтТьш зффектом использования оператора отсечен™ янллется ускорь
„ие рХы программы и зкономия памяти. Если этот оператор использован внутри пре.
ликатГто указатели в памяти, необходимые для возврата к предикатам, расположенным
слева от оператора отсечен™, не создаются. Дело в том, что они никогда ие понадобятся.
Таким образом, применение оператора отсечения приводит к нахождению желаемого
решения только при более эффективном использовании памяти.
Оператор отсечения также можно использовать при реализации рекурсии для повторной
иющиалязацни вызова path и продолжения поиска на графе. Эта возможность будет
продемонстрирована в разделе 143 при описании общего алгоритма поиска. Для реализации этого
алгоритма нам также понадобься разработать несколько абстрактных типов данных.
14.2. Абстрактные типы данных в PROLOG
Эффективность программирования в любой среде можно повысить за счет сокрытия
информации и введения процедурных абстракций. Поскольку в алгоритмах поиска на
графе, описанных в главах 3-5, используются такие структуры данных, как множество
(set), стек (slack), очередь (queue) и приоритетная очередь (priority queue), логично
ввести их в языке PROLOG, что и будет сделано в этом разделе.
Как уже отмечалось ранее, основными средствами построения структур для поиска на
графе яшмкггея рекурсия, списки и проверка соответствия шаблонам. С помощью этих
строительных блоков создаются абстрактные талы данных (АТД). Все процедуры обработки спи-
вТаЗТ™™ ВЬШШ' °"РеаымюШ"е АТД, "сокрыты" внутри этой абстракции, котора»
в значительной мере отличается от обычных стагаческих структур[данных.
14.2.1. Стек
одного конца" Сл7лтятГ'еГ,НаЯ "W1^3- Доступ к которой осуществляется только с
«ого и того же кон„я м "^ элемен™ Добавляются и удаляются из структуры с ол-
Ои.)-••последним» "™ т* назь'вают структурой данных LIFO (Las.-In-Fi*
служить алгоритм поиска „ ТТ" ВЫШСЛ" ПР™ером работы этой структуры м°«
необходимо определить СЛ1.,„ У т ""ДРИДела 3.2.3. Для функционирования сте
'•"'-дующие операции
1. Проверка наличия элемен
2- Добавление элемента ВТ°В " """ (прове1жа пУстоты стека).
3. выталкивание (или удаление) последнего элемента (верхушки) из стека.
4. Просмотр последнего элемента (верхушки) без его удаления.
5. Проверка наличия данного элемента в стеке.
6 Добавление списка элементов в стек.
Операции 5 и 6 можно определить на основании первых четырех операций
Теперь опишем эти операции на языке PROLOG, используя в качестве строительных
блоков списки.
1. empty_stack( [) ). Этот предикат можно использовать либо для проверки
пустоты стека, либо для создания нового пустого стека.
2 _ 4. stacklTop, Stack, [Top | Stack] ). Этот предикат выполняет операции
выталкивания, добавления и считывания последнего элемента стека в зависимости
от связанных переменных, передаваемых ему в качестве параметров. Например,
если первые два аргумента представляют собой связанные переменные, то в
третьем аргументе формируется новый стек. Аналогично, если третий элемент связан со
стеком, можно получить значение верхушки стека. Тогда второй аргумент будет
связан с новым стеком, из которого удален последний элемент. И. наконец, если
передать стек в качестве третьего аргумента, то через первый элемент можно по-
луч!ггь значение его верхушки.
5,member_stack(Element, Stack) :- member (Element, Stack). Это
выражение позволяет опредешггь. содержится ли данный элемент в стеке.
Естественно, этот же результат можно получить с помощью рекурсивного вызова,
просматривая следующий элемент стека, а затем, если этот элемент не соответствует
значению аргумента Element, выталкивая его из стека. Эту процедуру
необходимо выполнять до тех пор, пока предикат проверки пустоты стека не примет
значение "истина".
6. add_list_to_stack(List, Stack, Result) :- appendlList,
Stack, Result). Значение первого аргумента List добавляется к значению
второго аргумента Stack для получения нового стека Result. Эту же операцию
можно выполнить, выталкивая элементы из стека List и добавляя каждый
следующий элемент во временный стек до тех пор. пока стек List не окажется
пустым. Затем нужно выталкивать по очереди элементы из временного стека и
добавлять их в стек Stack до опорожнения временного стека. Предикат append
подробно описан в разделе 14.8.
Осталось опредешггь предикат reverse_print_stack. выводящий стек в
обратном порядке. Это очень полезно, если в стеке в обратном порядке хранится текущий путь
от начального состояния к текущему состоянию графа поиска. Несколько примеров „с
пользования этого предиката будут приведены в следующих подразделах.
reverse_print_stack(S) : - empty_stack(S) .
reverse_print_stack(S) :-
stack(E, Rest, S),
reverse_print_stack(Rest) ,
write(E), nl.
14. Введение в PROLOG
623
14.2.2. Очередь Fff0 (F^.m-F.rst-Out) - 'первым 80Швд
О,™* (queue) - ^Хпримют как список, в котором элементы УД1цп *
1 вышел". Ее зачастую Р^"31? - 0мсредь использовалась для определения „0
ГдТого -ни, а ^^Х реалСаиин очереди требуются следующие операции
„ска в ширину в главах i ^^ ^ вьшолняет провсрку очередП на ^
'^о— L,!pyeTHOBy»ny^-—"'
2.en5ueue(E, [ 1. [*»■ ^ ( _ enqueue(E, T, Tnew). Этот рекур.
enqueued, l»l'i' _„оч_едь, определяемую вторым аргументом, элементЕ
1 ретин j т, Этот предикат создает иову ю очередь (третий аргу-
3. dequeue (Е, I I ь ' удаления очередного элемента (первого аргу.
=i^SS^S^-£- вторым аргументом.
,„ rci.pl ) Этот предикат позволяет прочитать следующий эле-
4. dequeue (Е, 1Ь|и, -) ■-> v
мент Е данной очереди.
5 member oueuel Element, Queue) :- member (Element, Queue). Это
выражение проверяет, содержится ли элемент Element в очереди Queue.
6.add_list_to_queue(List, Queue, Newqueue) :- append (Queue,
List, New-queue). Очистка всех элементов очереди.
Очевидно, что операции 5 и 6 можно реализовать на основе первых четырех
операций. Предикат append описан в разделе 14.10.
14.2.3. Приоритетная очередь
В приоритетной очереди (priority queue) элементы обычной очереди упорядочены, и
каждый новый элемент добавляется в соответствующее место. Оператор удаления
элемента из очереди извлекает из нее лучший отсортированный элемент. Приоритетная
очередь была использована при разработке "жадного" алгоритма поиска в главе 4.
Поскольку приоритетная очередь — это, по существу, отсортированная обычная
очередь, многие из ее операций совпадают с операциями для обычной очереди. К таким
операциям относятся empty_queue, member_queue и dequeue (следующим
элементом для операции dequeue является "лучший" отсортированный
элемент). Операции
enqueue в приоритетной очереди соответствует операция insert_pq. поскольку
каждый новый элемент должен помещаться в отведенное для него место.
insert_pq(state, [ ], [state]) ■- i
inse^?Srs^!Ti:Siri,:-
Precedes(x, Y) :- X < у ' „ от типов
%оператор сравнения зависит
%элементов
меитГГ^еГ™ ™ГРеДИК™ - ™ — Добавляемый элемент. Вторы^
Рель. Предикат рг=срГ "Р^етная очередь, а третьим - расширение
■—sues отвечает за соблюдение порядка элементов в очереди-
Следующим оператором для приоритетной очереди является insert_Ust_pq.
Этот предикат используется для добавления несортированного списка или множества
элементов в приоритетную очередь. Это необходимо при добавлении дочернего состоя-
н„я в приоритетную очередь при реализации "жадного" алгоритма поиска (глава 4 и
подраздел 14.4.3). Оператор insert_list_pq использует оператор insert_pq для
добавления в приоритетную очередь каждого нового элемента.
insert_list_pq([ ), L, L).
insert_list_pq([State/Tail], L, New_L) :-
insert_pq(State, L, L2) ,
insert_list_pq(Tail, L2, New_L) .
14.2.4. Множество
И, наконец, опишем абстрактный тип данных множество (set). Множество — это набор
неповторяющихся элементов. Его можно использовать для объединения всех дочерних
состояний или поддержания списка closed в алгоритме поиска, представленном в главах 3 и
4. Множество элементов, например {а, Ь}, представляется в виде списка [а, Ь], в
котором порядок элементов ие играет роли. Для множества необходимо определить операции
empty__set, member_set, delete_if_in_set и add_if_not_in_set.
Потребуются также операции для объединения и сравнения множеств, включая union,
intersection, set_dif f erence, subset и equal_set.
empty_set( [ ] ) .
member_set(E, S) :-
member(E, S).
delete_if_in_set (E,
delete_if_in_set(E,
delete_if_in_set(E,
delete_if_in_set(E,
add_if_not_in_set (X,
member(X, S), !.
add_i£_not_in_set(X, S, [x|S]).
union([ ], S, S).
union([H|T], S, S_new}:-
union(T, S, S2),
add_i£_not_in_set(H, S2, S_new) ,
subset([ ], _) ,
subset([H|T], S) :-
member_set(H, S) ,
subset(T, S).
intersection![ ], _, ( 1)■
intersection»[HjT], S, [H|S_new]) :-
member_set(H, S),
intersection^, S, S_new) , I.
intersection![_|TJ, S, S_new) :-
intersection(T, S, S_new), !■
set_di£ierence([ ] , _, M> ■
set_di££erence([H|T], S, T_new) : -
member_set(H, S),
set_di£ference(T, S, T_new) , 1.
set_di££erence([H|T], S, [H|T_new])
set_di£ference(T, S, T_new) , !■
( ]
, [
[E|T],
[H|
(E,
S,
T),
T,
S)
)).
T) :- !.
[H|T_new:
T__new) ,
:-
Глава 14, Введение в PROLOG
625
J
„jwl_Mt(Sl. SI) '-
subset (SI. »'■
subset (SJ. SI)-
.тчипниойсистемы на языкеPROLOr.
ром. На самом;
■*op соогаясгеуюикго пгклставденшГ-
впь тог fan то, „mJ.nB* " даш,0Й проблемы переправы. Пока не булем учнты-
«« ^ша^^И^0"^ "aЛJnora, неустойчивым,,. На рис. 14.2 показано
«А то нет »»6.хо11пшосгГРа,РШ 'КРе3 PW>'- Поско-чь^' человек всегда улгравляет лод-
Ч» Р«- 14Л повязана часть .тхмьГ ОТ:кль"ое представление для местоположения лодки
ашащ,« «мне кпиГчв к°тороы необходимо выполнять поиск пути.
*"■* пикто" ' Чюдш^^" ВЬа0а Ч«л„ката path обеспечивает механизм утэав-
• состояния вТроцад^ ""^f Продукционные правила - это правила юме-
Постольку язык PROLOC °аре;клим их на языке PROLOG как правил» move-
em ~. """Рируег хорновскнми дизъюнктами, то продяпююп*
гаамза ш пыхе PROLOG
^'"выднбов
> напрямую описываться в хорновской лиз"-™*
14J. Пример продл.
ГбулеТ^сыотрена продукционная система для решения задачи пере-
В ,ш разделе *>**?*■ i формулируется следу ющнм образом
возки человек», воля, козы „ калууты. г— м.
„ _ „rfvera пепсптмвпк* через рек> " переката с собой волка, козу и капут. На
^"SJk^S^ V«. которое Должен управлять человек. Лодка одновременно может
К№ "^ГГболее jbvx гал-лжвто. (включая лодочника). Если волк останется на берегу c
""Т „ чн се смет Ёеи коза лтанета на берегу с капустой, то она уничтожит катету
Т^етсд'аиак'т.п. песлачшельвосп. переправки через реку таким образом, чтобы ке
wipe ШШЧ» были доставлены в целости и сохранное™ на другой оерег реки.
Рассмотрим продутаиокную систему, обеспечивающую решение этой проблемы. Во-
первых, очевидна что эту задачу можно представ,пъ как задачу поиска на графе. Для
этого нужно учесть все возможные ходы, доступные в каждый момент решения задачи.
Некоторые из этих ходов могут оказаться неудовлетворительными, поскольку приводят к
получению неузпойчнвых состояний (кто-то кого-то съест).
Для начала предположим, что все сосгоянш, устойчивы, и просто рассмотрим граф
возможных состояний. В лодке можно перевозить четыре комбинации пассажиров:
человека н волка, человека и козу, человека и капусту, а также одного человека.
Хостоянием мира" является негогорая комбинация символов на двух берегах. На
рис 14Л показаны несколько состояний процесса поиска. "Состояние мира" можно
орелегавить с помощью предиката statetF, W, G, С). в котором первый параметр
определяет местоположение человека, второй параметр — местоположение валка,
третий — козы, а четвертый — капусты. Предполагается, что река течет с севера на юг.
поэтому берега обозначим символами е (восточный) и w (западный). Таким образом,
state (v. v, v. w) означает, что все объекты расположены на западном берегу. Эта
ситуация соответствует началу решения задачи.
Следует отметить, что все описанные соглашения были произвольно выбраны авго-
** * ~ ' те. как отмечают специалисты в области искусственного интеллекта.
- зачастую наиболее критичный аспект реше-
есогаашеяня обеспечивают удобное представление логики предн-
,__ Ю Реечные состояния мира создаются в результате переправы
taTun г^^~!!ШиМОта тжааашш значений параметров предиката state
Те«1\!^^™ЖИДГО™е представления
говном форме, лноо преобразовываться к этому ^
,Проиесс приведен.и, правил "есл,,... то..~ к хадно£кР"ат>- Вы6еР<« первый вариант
„ разделе 122). В хорновскон дизъюнктивной форме п^ Л1"ъюн™!в"о" форме описан
«.стояний должны располагаться в голове дизъюн^, ™сушего и последующего
ратора : - Они являются аргументами предиката тГ""Т Выраже1™- т■«• «ева от опс-
детворять продукционное правило для возврашени. "' ВШ1' кот°Рым до.лжно удов-
а справа от оператора : -. Как будет показано в " ""^"к™ состояния, размещают-
могут быть представлены в виде ограничений униф " np,LMePe- э™ У^ювив также
statelw.w.w.w) FWGC У5В>
stale(e. w, e, w)
state(w. w. e. w|
slate(w. w, w, e]
statele ? v, el
FWC
Л*с 14.1. Пример -?ос7ал>лля£1ьяосва( перевозок die jodmv лфеярдеы
чаювека, ееика. козы и капусты
(-начала определим правша хля перевозки через реку валка. Это правило датжно учи-
тывэтъ перевозку как с левого берега на правый, так н наоборот, а также должно быть при-
еннмо. если человек и валк находятся на пгхгтивоположных берегах реки. Таким образом.
*иэ.лжно преобразовывать состояние stateie, e, G, С) в состояние state(w,
■_G< С), а состояние stateiv, w, G. С)—Bstatele, e, G. С). Дзясостоя-
state(c, w, G. С) и statetw, е, G. С) оно датжно щмашмать значение
**> . Переменные G и С представляют тот факт, что третий н четвертый параметры мо-
Л оыть связаны с .любым из значений е (аи w. Независимо от значений этих параметров
**" не изменяются после переправы человека и волка. Некоторые из полученных состоя-
могут оказаться "неустойчивыми".
(-Дедующее правило .-nove применимо только в том случае, если человек н волг вахо-
■"те» на одном и том же берегу и переправляются на птютнвоположный берег реи. За-
е™м- То местопаложение козы и капусты не изменяется.
^^Istat-v .- - - ... - ,--->-■- гт- X Y!.
«Ьва
14 Введение в PROLOG
627
^ s.a.e.evfe.w) «ft"1 ^ele.w.w.v,,
w,w) «*..«...*! ««•.«■«•-I
statele, e, e, w)
state(e. e, w, e)
t /
state{e.w, e. e,)
Рис. 14.2. Часть графа состояний для задачи переправы человека,
волка, козы и капусты с учетом неустойчивых состояний
Это правило срабатывает в том случае, если в качестве первого параметра предикату
move передается состояние (текущее положение на графе), соответствующее
одинаковому местоположению человека и волка. При активизации этого правила генерируется
новое состояние (второй параметр предиката move), в котором значение У
противоположно значению X. Для получения этого нового состояния должны быть выполнены два
условия. Во-первых, должны совпадать значения первых двух параметров, а во-вторых,
оба новых местоположения должны быть противоположны старьш.
Первое условие проверяется неявно в процессе унификации. Следовательно, если
первые два параметра не совпадают, то предикат move даже не вызывается. Эту
проверку можно явно выполнить с помощью следующего правила.
move(state(F, w, G, с), state (г, Z, G, О) :- F=W, opp(F, Z) .
В этом эквивалентном правиле move сначала проверяется равенство значений F и W, и
только при его выполнении (расположении обоих объектов на одном берегу реки) параметру
z присваивается значение, противоположное F. Заметим, что в языке PROLOG присваивание
Cb^™?"1 C П0М0ЩЫ° связы™ значений переменных в процессе унификации.
^ГиГаГлеР"П^,РаШ10та ™ ВК ««я»™ переменной в дизъюнктивном вы-
В процессе усечен^Т ПереМенно" ограничивается содержащим ее дизъюнктом.
рованГсист™ искУсствеГоКга„ВаЖНУК> Р" "^ ™°« «"«"ое средство программ -
"ояния, не удовлетвоп,», '"«сллекта, как проверка соответствия шаблонам. L°
™. В этом смысле п°РвГИе """^ ""°™™чески отсекаются для данного
проставление, поскольку есГРС"Я "РаВИЛа m°Ve обес1гечнвает более эффективное прел
унификации это состояние „l"6'""'16 ДВа паРаметра не совпадают, то в проиее
э состояние даже
1якРЬ создадим предикат
стояния, чтобы '
рассматривается,
позволяющий проверить безопасность
каждого нового
сопроцессе переправь, через реку „и одни из объектов не был съеден-
628 ЧастьУ1.Языкии
" Т6хнслог"и программирования для искусственного интелл»
безопасным является любое состояние, в котором второй и ™„т, -
f „воположнь, первому параметру, В этом случГ „лк "' "'"""Г" ™"""""ОТ
Опасным являйся и „кое состояние, „р„ которсГо ~^ *«; «■
раметры. и при этом они противоположны первому. Тогда козаТъсГк „уст7™ с
^опасные ситуации можно представить в виде следующих правил unsafe
unsa£e(state(X, Y, Y, С)) :- opp(x, Y)
unsa£e(state(X, w, Y, Y) ) :- opp(x, Y) .
Здесь необходимо отметить несколько моментов. Во-первых, если состояние -не
является небезопасным not unsafe (т.е. безопасно), то согласно определению
встроенной процедуры not в языке PROLOG для этого состояния не может быть истинным ни
один из предикатов unsafe. Следовательно, ни один из этих предикатов не может быть
унифицирован с текущим состоянием, или при унификации их условия не должны
выполняться. Во-вторых, встроенная процедура not не эквивалентна операции логического
отрицания ^ в теории предикатов первого порядка. Процедура not — это, скорее,
отрицание за счет невыполнения противоположного утверждения. Чтобы проверить, как
поведет себя предикат unsafe, необходимо протестировать множество состояний.
Добавим к предыдущему продукционному правилу проверку not unsafe.
n\ove(state(X, X, G, С), state(Y, Y, G, CI) :-
opp(X, Y) , not (unsafe(state(Y, Y, G, C) ) ) .
Процедура not unsafe проверяет приемлемость нового состояния в процессе поиска с
помощью вызова предиката unsafe. Если все критерии удовлетворяются, включая проверку
(в алгоритме path) отсутствия этого состояния в списке уже пройденных состояний, для
данного состояния вызывается (рекурсивно) алгоритм path для перехода глубже по графу. При
вызове предиката path новое состояние добавляется к списку уже пройденных.
Аналогично можно разработать три других продукционных правила,
представляющих переправу через реку человека с козой, капустой и без "пассажиров". Для вывода
результатов трассировки добавим к каждому правилу команду wri tel i s t.
Команда reverse_print_stack используется в условии останова алгоритма
path для вывода пути окончательного решения. И. наконец, добавим пятое
"псевдоправило", которое не содержит никаких условий и поэтому всегда срабатывает
при невыполнении всех предыдущих правил. Оно означает возврат вызова алгоритма
path из текущего состояния. Это псевдоправило позволяет пользователю отслеживать
поведение продукционной системы в процессе ее работы.
Теперь рассмотрим полную программу на языке PROLOG, реализующую
продукционную систему решения задачи переправы человека, волка, козы и капусты. Она должна
включать предикаты unsafe и „ritelist, а также предикаты, описывающие
абстрактный тип данных стек (подраздел 14.2.1).
ffl°ve(state(x, X, G, с) , state(Y, Y, G, с)) :-
°РР(Х, Y) not (unsafe (state (Y, Y, G, CM), v Y G CI).
writelistlt -попытка переправить человека и волка , Y. о.
"ve (state (X, w, X, с), statefY, w, Y, с)) :-
°PP(X, Y), not(unsafe(state(Y, W, Y. OH. y,w,Y,C]>.
writelistU 'попытка переправить человека и коэ>
"oveutatelx, w, G, X) , statetY, w, 0, Y)) s-
°PP(X, Y) , not(unsafe(state(Y. W, G *) < ^ KanvCTy. Y, W, G, YJ) .
writelistlt-попытка переправить человька
'м> 14. Введение в PROLOG
629
writelistll " ch..k|..
pathlGoal. Goal, Been_stack)
path(State, Goal, Been stack).
move(State, Next state Been_stack)) .
not(member_stack(wexu_» been_stack) ,
stack<Next_state, Been stack^ _ , _
path(Next_state, Goal, "-
opp(e, w).
opp(w, e).
Этот код вызывается в запросе go, инициализирующем рекурсивный вызов
алгоритма path. Чтобы упростить работу программы, можно создать предикат test,
облегчающий ввод начальных данных.
go(Start, Goal) :-
empty_stack (Empty_been_stack),
stacklStart, Empty_been_stack, Been_stack) ,
pathlstart, Goal, Been_stack) .
test :- go(state(w, w, w, w) , state(e, e, e, e) ) .
Этот алгоритм возвращается из состояний, не обеспечивающих дальнейшего
продвижения. Для мониторинга связывания различных переменных в процессе каждого вызова
алгоритма path можно использовать команду trace. Следует отметить, что эта
система является обшей программой перемещения четырех объектов из любого (допустимого)
местоположения на берегах реки в любое другое (допустимое) местоположение, включая
поиск обратного пути к начальному состоянию. Другие интересные свойства этой
продукционной системы, в том числе зависимость результатов поиска на графе от порядка
следования правил, можно проиллюстрировать в следующих упражнениях. Приведем
некоторые результаты трассировки выполнения программы, отображая лишь правила,
действительно используемые для генерации новых состояний.
?- test.
попытка переправить человека и козу е „ е w
попытка переправить одного человека »"1
попытка переправить человека и волка еее w
попытка переправить человека и к Г.
попытка переправить человека и Г
попытка переправить человека и То^
попытка переправить человека и
ВОЗВРАТ из е „ Ч1"°1ет и к°зу е „ е е
возврат „з „; „; „' *
попытка перепоаим-т..-
попытка перГр Гт 17ZI ^^
ПУТЬ решения: человека и козу е е е е
statetw,
statete,
state(w.
w)
Часть^"языки7т^л "г
m прогРаммирования для искусственного
интелле^3
state е.
state(w-
state(e,
state(w,
state(e
e, e)
^бочая память пр„енаар^
«и- продукционной системой реализуется с помощью рекурсивного вызова раТ И I -
„ец, порядок следования прав™ д™ генерации дочерних состояний (разреше! конфликте)
определяется порядком расположения этих правил в продукционной памяти.
14.4. Разработка альтернативных стратегий поиска
Как видно из предыдущего раздела, в самом языке PROLOG реализован поиск в
глубину с возвратом. Этот момент более детально будет описан в разделе 14.7. Теперь
рассмотрим, как реализовать на языке PROLOG альтернативные стратегии поиска,
описанные в главах 3-5. Для записи состояний в процессе поиска в глубину, в ширину и при
реализации алгоритма поиска будут использованы списки open и closed. В случае
неудачного завершения поиска в некоторой точке мы не будем возвращаться к
предыдущим значениям этих списков. Они будут обновляться при вызове алгоритма path, и
поиск будет продолжаться с новыми значениями. Для предотвращения хранения старых
версий списков open и closed будет использован оператор отсечения.
14.4.1. Поиск в глубину с использованием списка closed
Поскольку при возвратах в рекурсивных вызовах значения переменных
восстанавливаются, алгоритм поиска в глубину из раздела 14.3 пополняет список пройденных
состояний только состояниями, относящимися к текущему пути к цели. И хотя проверка
наличия в списке каждого нового состояния позволяет избежать циклов, она требует
повторного тестирования тех областей пространства, которые уже были достигнуты ранее
при построении других путей, но отклонены на данный момент из-за их
бесперспективности. Это более полное множество состояний составляет список, получивший название
closed в главе 3 и Closed_set в следующем алгоритме.
В множестве Closed_set хранятся все состояния текущего пути и состояния,
отвергнутые при возврате алгоритма. Следовательно, теперь оно не представляет путь от
«сходного к текущему состоянию. Для хранения информации о пути определим
упорядоченную пару [state Parent], представляющую каждое состояние и его родителя.
Начальное состояние Start будет представлено парой [Start, nil]. Эти пары 6у-
*П использованы для воссоздания пути решения из множества Closed s;et.
Опишем на языке PROLOG структуру программы для "опека в г^ш• °™-
Учения списков open и closed н проверяя каждое новое «"""о™ stack
-■- пройде„„ы.х. Алгоритм path --c^J^^X^T^T^
l-bsed_Set (обрабатываемого как множество) и целевого ее Операторы
^стояние state является следуем состоянием для Open^stack. On.p p
аск и set описаны в разделе 14.2.
Р~ ■ 631
ава 14. Введение в PROLOG
„ „о инициализирующего вызов алгоритма path. ЗаМс
Поиск начинается с предиката 9 , open_stack помещается пара, тщси
„„.что при вьшолненни команды 9свымродителсм [SCarC, nU] ^^J
Ваюшая начальное состояние
Closed_set пока пусто.
9°,S2pt;J°:=UptyT°P-;w_open, 0pen_stack) ,
stack! [Start, niU - " *
en,pty_set (Closet) e^ Qoalb
path(Open_stack, "»tu-
*t-h зависящего от трех аргументов, имеет вид.
Вызов алгоритма path, зависящее г
path(Open_stack, _, _> '■'
--TS^^:"f Ри^ли крепни.,.
pathlOpen stack, Closed_set, Goal) :
P stackustate, Parent], Rest_open_stack Open_stack)
get.chlldren(State, Rest_open_stack, Closed_set, Children),
add_list_to_stack(Children, Rest_open_stack, New_open_staok) ,
union! [[State, Parent]), Closed_set, New_closed_set) ,
path(New_operustack, New_closed_set, Goal) , ! .
get_children(State, Rest_open_stack, Closed_set, Children) :-
bagot (Child, moves (State, Rest_open_stack,
Closed_set, Child), Children).
moves(State, Rest_open_stack, Closed_set, [Next, State]) :-
move(State, Next),
not (unsafe(Next) ) , % проверка зависит от задачи
not (member_stack( [Next, _] , Rest_open_stack) ) ,
not (member_set( [Next, _] , Closed_set) ) .
Предполагается, что правила move и (при необходимости) предикат unsafe
некоторым образом определены.
move(Present_state, Next.state) :- ... % первое правило
move (Present .state, Next_state) :- ... % второе правило
При вызове первой команды path поиск прекращается, если стек Open_stack пуст
ло означает, что в списке open больше не содержатся состояния для продолжения попе-
^бопом "°"°-ВИДИеЛЬСТВуеТ ° том, что для данного графа выполнен поиск полным пс
нГпеРча^, пГ,пВШ°ВРа№3аВерШаСТСЯ "?" "вождении решения, которое и выводится
ZZTZriZГ:0™™ "Ч» поиска представлены парами [State, Parent).
„;„„, f. ,, ' "решения будет выведен в прямом порядке.
Printsolution([state „ill ,
write(state), nl '■->:-
Pnntsolution( [State' Pa
member_set( [Parent HTl Close<5-Set) :-
Printsoiution([p _ ^«ndparent] , Closed_set) ,
»rite(state), nl. OT' Grandparent] , Closed_set),
"миологии программирования для искусственного интелл»
Н третьем вызове path используется стандартный лп= uu
PROLOG предикат bagof. Ои позволяет хрГитъ 2 ""терпрешторов яэы-
'/„to шаблона в едином списке. Второй па Г^ „ ГкГСГ ^""Т "
[ орым производится сравнение в базе данных. Первый "арГм™ „ "" ™ "' "
1 хранению в списке компоненты второго парам™ нТ^ 0прсде,,ясг "одлсжа-
::,ХсРвязаиные значения для одной *^JZZ£SX2Z^^
„ервого параметра накапливаются в списке и связываются с третьим параметром
в ,тои программе предикат bagof накапливает состояния, достигнутые пр^
срабатывали всех сушествующих продукционных правил. Естественно, необходимо хранить все по-
Томк„ конкретного состояния, поэтому их можно добавить в соответствующем порядке в
список open. Вторым аргументом предиката bagof является новый предикат moves
вызывающий предикаты move для генерации всех состояний, которые могут быть достигнуты с
„омошью данного продукционного правила. Аргументами предиката moves являются
текущее состояние, списки open и closed и переменная, представляющая состояние,
достигаемое при "хорошем" ходе. Прежде чем возвратить это состояние, предикат moves проверяет,
что зто новое состояние Next не содержится в множествах rest_open_stack, open
(поскольку текущее состояние удалено) и closed_set. Предикат bagof вызывает moves и
накапливает все состояния, удовлетворяющие этим условиям. Третий аргумент предиката
bagof представляет новые состояния, помещенные в стек Open_stack.
В некоторых реализациях предикат bagof принимает значение "ложь", если для
второго аргумента не найдено никаких соответствий, а значит, третий аргумент пуст. Это
можно исправить с помощью подстановки (bagof (X, moves (S, Т, С, X) ,
List); List=[]) для текущих вызовов предиката bagof в данном коде.
Поскольку состояния поиска представлены парами "состояние-родитель", предикаты
проверки вхождения элемента во множество member_set необходимо модифицировать таким
образом, чтобы они отражали структуру проверки соответствия шаблону. Необходимо
проверить, совпадает ли пара "состояние-родитель" с первым элементом списка таких пар. и, если
нет — выполнить рекурсивное сравнение со всеми остальными элементами списка.
member_set( [state, Parent], [[state, parent] | _]) .
member^set (X, [_|T]) : - member_set(X, T) .
14.4.2. Поиск в ширину в языке PROLOG
Теперь рассмотрим оболочку (shell) алгоритма поиска в ширину, явно использующую
списки open и closed Эту оболочку совместно с правилами move и предикатами
unsafe можно применять для решения любой задачи поиска. Алгоритм вызывается
следующим образом.
9°(Start, Goal) :-
empty_queue(Empty_open_crueue). nnencmeue)
enqueue ([Start, nil], Empty_open_gueue, Open.gueuel
empty_set(Closed_set) ,
Path (Open_ queue, Closed^set, Goal)-
, 3-че„„, параметров Start „ Goal очевидны. Они ^ZTcZZT^Z-
°e состояния. В этом алгоритме, как и „рн поиске в ™>«ину. снов^саUa уп Р
кенарь, (state, Parent] Д™ хрмеии. ннфор-.^ о ™ с
Жителе. Начальное состояние Start представляется парой [Start
'4. Введение в PROLOG
633
„a nrintsolution для воссоздания пути п
фор^вя использУ«с- ^t0 l параметром предиката path являет^»»
t!oBe множен Cl0Se^,_ множсство clcsed.set, а третьим J»>*.
* очерМЬ Тпе«м"н"ь.е. значения которых не учитываются в ДизьЮ1адив^«»«
writernoncK заверш ^ ы| ;_
Path(0pen_gueue Clos ^„^це, _) , State = Goal,
dequeue![State, r ,, „i
writer^ Решена ) , ^, closed_set) .
printsolutionl [State, e^ gm1) ;_
path(Qpen_queue Open_gueue, Rest_open_queue
dequeue![State, r oueue. Closed set. rhi
Sl< st to queue (Children, Rest_open_queue, New_open_queue),
union! [[State. Parent]], ClosecLset, New closed_set) ,
path(Ne„_open_queue, New_closed_set, Goal) !
oet_children(State, Rest_open_gueue, Closed_set, Children) :-
bagoflChild, moveslstate, Rest_open_queue,
Closed_set, Child), Children),
moveslstate, Rest_open_queue, Closed_set, [Next, State]) :-
move(State, Next),
not (unsafe (Next) ) , %проверка зависит от задачи
not (member_queue ([Next, _] , Rest_open_crueue) ) ,
not (member_set ([Next, _] , Closed_set) ) .
Этот фрагмент кода назван оболочкой, поскольку здесь не описаны правила move. Их
необходимо добавить с учетом конкретной предметной области задачи. Операторы
queue и set описаны в разделе 14.2.
Первое условие останова алгоритма path определяется для случая, когда предикат
path вызывается с пустым первым аргументом Open_queue. Эта ситуация возникает,
только если для графа больше не осталось непроверенных состоянии, а решение не было
найдено. Решение находится при вызове второго предиката path, когда голова очереди
Open.queue совпадает с целевым состоянием Goal
стМн,Г„ТКе П°"СКа ПУШ пРе<™а™ bagof и moves накапливают все дочерние со-
са тТпГ^Т™ С0СТ°ЯНИЙ " п°™=Р™вак,т очередь. Работа этих предикатов оп„-
™»Z7ZTZ?tm'Что6ы воссоздать ■*"• решения- ™с состояние С0ХС
кль nil 1<я„ „„„ e' Parentl- Родителем начального состояния является ук
Л.ебУет„ек™ро° v''HM0Cb " тЯр°ЮЖ ШЛ- попаР«ое представление состоя»'
"'"vesHprintsoluti™""" Пр0ВСрк" «ответствия шаблонам в предикатах тешве .
14 ое1!ГГция "жадного" алгори™а—-— PR0L0G
"« поиска в шГриР„уЛГкЦ0"И„'*аДН0Г°'' """Р™ поиск. - это модификация лро<
«"«« пр„ор1ггетн;й очIT" откР«тая очередь для каждого нового вызова р*
чаемом аягоР„1ые зерн^чеТ,' У"°ряд°-*>™<>" по эвристическому критерию--BJ*
™ ««Риой очеред,, и ™I* «Р. неразрывно связана с каждым новы" «*,
■^--______^^*и систематизации ее элементов. Мы бу**^
" ' Язы'и и твх„о„огии программировании для искусственного Я**0*
хран.тгь информацию о родителе каждого состояния. Как и пп„ п„
„ину. она используется для построения пути решения ко Ju?~ реализащш поиска ■ ™-
Р" Чтобы отслеживать всю необходимую L поГскаГГ" PrinCsolutl°«-
.„едставим в виде списка из пяти элементов- описание "Нфоршцшо' кажД« состояние
I ое число, определяющее глубину поиска «ZZ^TJZ" ""='
еску» меру качества состояния, „ целочислешГа,суГа тр^0 """ ЭВрИОТ-
Первый и второй элементы списка находятся обычнш, обХ^JZ7"™° "^^
«„добавления единицы к предыдущей глубине ■ZZlT^ onP«™<™ ny-
Гонкретной задачи. Пятый элемент спискГиспольз^я™ ~ ^еГсоГЛГ
«рытой очереди Open_pq и вычисляется по формуле f (П)^п)Щп) (см глаГу ZT
Как и ранее, правила move не приводятся. Они определяются с учетом специфики
задачи. Операторы работы с очередью и приоритетной очередью описаны в разделе 14 2
Мера качества состояния heuristic тоже определяется с учетом специфики задачи и
отражает эвристический характер четвертого параметра в списке описаний
Этот алгоритм имеет два условия останова и вызывается следующим образом.
go(Start, Goal) :-
empty_set(Closed_set) ,
empty_j?q(Open) ,
heuristic(Start, Goal, H),
insert_pq( [Start, nil, 0, H, H] , Open, Open_pq) ,
path(Open_pq, Closed_set, Goal).
Здесь nil — это родительское состояние для состояния Start, a H — его
эвристическая мера качества. Приведем код программы, реализующей "жадный" алгоритм поиска.
path(Open„pq, _, _) :-
empty_j?q(Open_jpq) ,
write("Поиск завершен, решение не найдено.'),
path(Open_pq, Closed_set, Goal) :-
dequeue„pq{ [State, Parent, _, _, _] , Open_pg, _),
State = Goal,
write("Путь решения:'), nl,
printsolutionl [State, Parent, _, _, _] , Closed_set) .
Path(Open_pq, Closed_set, Goal) :-
dequeue_pq( [State, Parent, D, H, S] , Open_pq, Rest_open_pq) ,
get_children( [State, Parent, D, H, S] , Rest_open_pq,
Closed_set, Children, Goal),
insert_list_pq(Children, Rest_open_pq, New_open_pq) ,
union) [[State, Parent, D, H, S] ] , Closed_set, New_closea_set),
Path(New_open_pq, New_closed_set, Goal), !•
Предикат get_children генерирует все дочерние состояния для состояния State.
Как и в предыдущих алгоритмах поиска, в нем используются предикаты bagof и
m°ves. Работа этих предикатов более подробно описана в подразделе 14.4.1. Правша
"входов, проверки безопасности допустимых переходов и эвристическая "^качества
определяются с учетом конкретной задачи. Проверка принадлежности элемента множе-
С™У должна быть специально реализована для списков из пяти элементов,
^-children([State. , D. _. _] , Rest_open_pq, ClosecLset, Chil-
Xen, Goal) ■
bagof (Child, »ves( [State, _. D. _. -J- В«*_орвц-Р,.
closed_set, Child, Goal), children).
"aBa u- Введение в PROLOG
635
1 Rest_openJ?q. Closed_set,
,,„,te , Depth, -■-'' sj Goal) :-
"aVeSU melt. State, New_D, H.
„„„„(State, Next), Определяется о учетом 3,„
noUuns-felNext)), ,, Rest.open^cj) ) , 3a«^
„ot (me^ber.setl [Next, _,
№W-D " S Goal, H), %определяется с учетом задаЧи
heuristic(NexL,
нахо.
элементов i
S is New_D + H.
™„™„aDrintsolution выводит путь решения. Она рекурсивно
И. наконец, команд Р^^ ^^^ с00тветств„я первых двух мемопо1
дитпары Ibtac , элементам пятиэлементных списков, составляю,™»
«^оХёГ^ГСитГлем начального состояния является указатель nil. *
printsolutionf [State, nil, _, _, _Ь -> ;-
write (State) n 1. Closed.set)
printsolutionf [State, Parent , _, _j n '
member.setf [Parent, Grandparent, _, _, _] , Clos
printsolutionf [Parent, Grandparent, _, _, _
write(State), nl.
>sed_set) ,
Closed_set),
14.5. Реализация планировщика на языке PROLOG
В разделе 5.4 был описан алгоритм планирования на основе теории предикатов.
В нем логика предикатов использовалась как для представления состояний мира
планирования, так и для описания правил изменения таких состояний. В этом разделе будет
разработана реализация этого алгоритма на языке PROLOG.
Состояния мира, включая начальное и целевое, представим в виде списков предикатов.
В рассматриваемом примере начальное и целевое состояния можно описать таким образом.
start = [handempty, ontablefb), ontable(c), on (a, b) , clearfc),
clear(a)]
goal = [handempty, ontableia) , ontable(b), on(c, b) , clear(a),
clear(c)]
Эта состояния наряду c фра™снтом „pocpa,^ пожжа показань1 на рис. 14.3 и 14.4.
ния как в^азд1ЭТ°7Ма Г* 6"°K0S" опнсываю™ <= помощью списков добавления и уд№
ката move r ,m "РеДииты move зависят от трех аргументов. Первый - имя прсдв-
<£z::z ^rr^ ар1ужнт- эт°с=к п^°тъ-т е перечг
вило перехода было ппГ Ш " описа""'< состояния мира, чтобь, данное пра-
лення и удалешГГн ' '° " ™МУ С°"°™т- ТР™Й аргумент - это список я**
удаляются из него для «ил Прея"кэтов' «оторые добавляются к состоянию мир* |И"
«да. Заметим, что в данном """ Ͱ°ð состояния в результате применения правила перс-
Ранни над множествам,, в тпк ° П0ЛИН0 исп°льзовать абстрактные типы данных я one
применять для управления прел""™ °6ъеяинсн"е. пересечение, разность и т.д. Их уд°»
Четыре перехода в этом миге'1™"'" ^^ до6авле"»я " удаления списков.
m°ve(picV.u ,х) р можно описать следующим образом.
^(hoiain^xJJi,1
' Оологии программирования №я искусственНого интелл»^
--[ЙГап^тРсУГ^^1еа^П,Х,^^--'Ь
add(holding(X) ) ]) .
ove(putdown<x)' (holding(X)] ,
[del (holding (X) ) , add (ontable (x) )
add(olear(X)), add(handempty) ]) .
move(stack(X, Y), [holding(X), olear(Y)
[del(holding(X)), del(clear(Y) )
add(on(X, Y)), add(olear(X) ) ) ) .
add(handempty),
Начальное состояние Целевое состояние
Рис. 14.3. Начальное и целевое состояния для задачи из мира блоков
Рис. 14.4. Начальные уровни пространства состояний для миро амии
вконец, построим рекурсивный контроллер для генерации плана. Первый прели
, ' г ■г „^™„™., ппн чепешнои реализации атана
' планирования с
оответствч'ет у
словням останова при успешной реализации атана.
■ФИ достижении цели. Последний предикат означает завершение полного перебора
"«* которого дальнейшее планирование невозможно. Рск^ивньп, генератор плана
Работает следующим образом.
'4. введение в PROLOG
637
, Находим отно^^^ тяучтт подмножества проверяем, выполняются ,
ДУСЛ°в,МРГеС0Па1з"аГгенерирует новое состояние Child_state с испо%
зованиемсшска'добавления и удаления
отношение для предиката move.
2 С -М0ГгеГпГаопТ;" -иного состояния.
3. Предикат change,
1...
4 С помошьк, предиката meraber_stack проверяем, не содержится ли новое с„.
стояние в списке уже преданных.
5. Оператор £Саскдобавляет новое состояние Child^state в стек
New_move_s tack.
6. Оператор stack добавляет исходное состояние name в стек New_been_stack.
7 С помощью рекурсивного вызова предиката plan на основе дочернего состояния
Child_state и обновленных стеков New_move_stack и Been_stack
находится новое состояние.
Для реализации алгоритма требуются дополнительные утилиты, описанные при
рассмотрении абстрактных типов данных (стека и множества) в подразделах 14.2.1 и 14.2.4.
Естественно, поиск реализуется на основе стеков с помощью алгоритма поиска в глубину
с возвратами и завершается после нахождения первого пути к цели. Алгоритмы
планирования на основе поиска в ширину и "жадного" алгоритма поиска читателю предлагается
реализовать самостоятельно в качестве упражнений.
planfstate, Goal, _, Move_stack} :-
equal_set(State, Goal),
write{Переходы'), nl,
reverse_print_stack(Move_stack) .
planlstate. Goal, Been_stack, Move_stack) :-
movelName, Preconditions, Actions),
conditions_met (Preconditions, State)
change_state(State, Actions, Chlld_state)
not(meraber_stack(child_state, Been_stack) j ,
stackfflame, Been_stack, New been stack)
l^lTlVr™-^ ^ovelstack, ,
Plw<_. -. )! writer, GOa1' New-been_stack, New_move_stack), !■
conditions_met(P, s) S- " таких пеРе*одах план невозможен!').
subsetfp, s),
change_state(s t l q,
<*ange_state(s, [add(P jT, ' „ ,
change_state(s. т l2 ' S-new| '-
addj£_not_in set'lP U =
<mpty_stack(S)
«versej)ri
stack(E. test, s),
wite№"SnIPrlnt-stack(Rest) _
же
test
и, наконец, выпишем предикат go для инициализации аргум,т
„редикат test для демонстрации простого метода запуска™ прсдиката Р1ап' <■ ™-
_ _„„,. """"уска системы планирования.
ao|Start, Goal) :-
empty_stack(Move_stack) ,
empty_stack(Been_stack) ,
stack(Start, Been_stack, New_been stack)
plan(Start, Goal, New_been_stack, Move_stack).
^eirUnmPty' °ntable,b)- -table(c,, on,a, b), clear<c),
clear (сПЬ °ntable,a)' ^able(b). on(c, b), clear,a).
14.6. Метапредикаты, типы и подстановки унификации
в языке PROLOG
14.6.1. Металогические предикаты
Металогические конструкции позволяют повысить выразительность
программирования в любой среде. Такие конструкции будем называть метапредиштами (raeta-
predicate), поскольку они предназначены для проверки соответствия, формирования
запросов и управления другими предикатами, составляющими спецификацию предметной
области задачи. Их можно использовать для рассуждения о предикатах в PROLOG, а не
для обозначения термов или объектов, что свойственно обычным предикатам.
Метапредикаты в языке PROLOG служат для реализации (как минимум) пяти целен.
1. Определение "типа" выражения.
2. Добавление ограничений "типа" в логические приложения.
3. Построение, разделение и оценка структур PROLOG.
4. Сравнение значений выражений.
5. Преобразование предикатов, передаваемых в виде данных, в исполняемый код.
Выше было описано, как в программу на языке PROLOG можно ввести глобальные
«РУктуры, т.е. данные, доступные во всем множестве дизъюнктов. К текущему набору
дизъюнкт С можно добавить с помощью команды assert (С).
Использование команд assert и retract связано с некоторой опасностью.
Поскольку эти команды создают и удаляют глобальные структуры, они приводят к
побочным эффектам которые могут вызвать другие проблемы, присущие плохо
структурированным программам. Однако глобальные структуры иногда необходимо „споль-
»»ать. Это требуется при создании в среде PROLOG се,,античеашх сетей (semam.c
"«) и фРей2„ (frame) Глобальные структуры также можно использовать для описа-
>"'» новых результатов получаемых с помощью „снованной на правилах оболочки.
*• «нформацТдолжна быть глобальной, чтобы к ней мог™ получить доступ другие
"РВДнкаты „ли правила. управлении представлениями, от-
К числу других метапредикатов, применяемых л.т > v
"осятся следующие.
глава 14. Введение в PROLOG
639
var.X. принимаетзначение
•„„„на" только в том случае, если X - „есвяэа„На,
переменная. ..|Кт|Ша.. тольк0 в том случае, если пере„енв
nonvar(X) принимает
X связана
с постоянным термом-
.создает список из терма предиката.
сер. f о
Голова списка Y- -"^^^использовать для выполнения обратного действа!
ХЛ(»тяппеШ1КЙТ = ■ ■ . „i ur-ruuun ТП чняирциш. v
с)= у унифицирует Y со списком [foo, а, ь,
это имя функции, а
можно также использ
Мегапредикат - . . » ь_ с] „стинно, то значением X являете,
Например, too^ ^- ^ функц|Ш] а хвост содержит аргументы этой фущщ^
Так. если выражение J
foo(a, b, с).
» юг(А В с (принимает значение-истина, если аргумент А-это терм,
•«ы^нкторкоторо™ имеет имявиарностьс.
Напр.шер, выражение functor(£oo (а. Ы. X, Y) истинно для значений пере-
меннш Х-£оо и Y=2. Если один нз аргументов метапредиката functor (А, в, с)
является связанной переменной, то можно получить значения других переменных, в
частности, все термы с заданным именем и/или арностью.
. clause (А, В) унифицирует В с телом дизъюнкта, голова которого
унифицирована с аргументом А.
Если в базе данных существует предикат р(Х) :- q(X), то clause (р(а), YI
истинно для Y=q {а). Этот мегапредикат полезно использовать для связывания
управляющих правил в интерпретаторе.
• any „predicate (. . ., X, ...) :- X выполняет предикат X, являющийся
аргументом произвольного предиката.
Так, некоторый предикат X можно передавать в качестве параметра н выполнять в
любое удобное время. Предикат call (X), где X — дизъюнкт, тоже завершается
успешно при выполнении предиката X. Этот краткий список металогических предикатов очень
полезен при построении и интерпретации структур данных искусственного интеллекта,
описанных в предыдущих главах. Поскольку PROLOG позволяет легко управлять
собственными структурами, то несложно реализовать интерпретаторы, модифицирующие
семантику языка PROLOG. Это и будет сделано ниже.
14.6.2. Типы данных в языке PROLOG
можВет поГ^ПР"ЛОЖеНИЯХ ""Таенное использование подстановок унификации
Bnlec™v„1 B0™KH0Be»'"° ошибок. PROLOG- это нетнпизированньш язык.
вяГк 2Г* КньТнР0СТ° ПР0В£РЯеТСЯ '"ответствие шаблонам без всякой их
придите» „з онрдГеГп" ТМеР' ЗНаЧСН"е сражения append (nil. 6, 6) вьп*
наподобие Pascal"„Zov aPPend- Ha пРимеРе СТР°™ типизированных язык»
программиста, избежатьУ*°СТОВСриться 8 ™м, что проверка соответствия типов помогая
тие типов дштых (tvoel „ . °ПК "Роблем. Многие исследователи предлагают ввести "»
Типизирован,,^;"^ ™L°G ^ " -Р- 1986,, [Мусгоп и O'Keefe. М
Данных (Neves „др. 1986, гм , "° п°лезны для использования в реляционных о
м 0,-раничений для'эт,1х „'™ РЩ' 19871- Логические правила можно применять в ^
——__™ "PaB,U и ^"""зировать их, чтобы обеспечить согласованное»
КЛП ц " ~*~ . ——
*«ки „ тех„о„огии программирования для искусственного интелл^»
.исленную интерпретацию запросов. Допустим в бэт,. „,
^ния^е-ог. <„, -^ W^ST^STiSI^
(„„ар-поставщик) и т.п. Определим базу данных как множество о™още!ий"с именовав
ы„и полями, которые можно рассматривать как наборы кортежей. Напри" р оГоГние
inventory может состоять из четырехэлементных кортежей, где отношение
<Pname, Pnumber, Supplier, Weight> s inventory
„„ько в том случае, если Supplier- это „мя поставщика товара с номером
pnumber, именем Pname и весом Weight. Допустим также, что
supplier, Snumber, Status, Location> e suppliers
„лько в том случае, если Supplier- это имя поставщика с порядковым номером
Snumber, статусом status из города Location, a
«supplier, Pnumber, Cost, Department e supplier_inventory
только в том случае, если Supplier— это имя поставщика партии с номером
Pnumber, стоимостью Cost в отдел Department.
В языке PROLOG можно определить правила, реализующие различные запросы и
выполняющие проверку соответствия типов для этих отношений. Например, запрос
"располагаются ли поставщики партии товаров № 1 в Лондоне" на языке PROLOG
можно представить так.
?- getsuppliers (Supplier, l, london) .
Правило
getsuppliers (Supplier, Pnumber, City) :-
cktype(city, suppliers, city),
suppliers(Supplier, _,city),
cktype(Pnumber, inventory, number),
supplier_inventory (Supplier, Pnumber, _, _) ,
cktype(Supplier, inventory, name).
реализует этот запрос и накладывает ограничение на кортежи базы данных. Первые
переменные Pnumber и City связываются, если запрос унифицируется с головой
правила. Предикат cktype выполняет проверку принадлежности элемента Supplier
множеству suppliers, проверку легитимности 1 как инвентарного номера и проверку того,
что london — это возможное местоположение поставщика.
Пусть предикат cktype зависит от трех аргументов: значения, имени отношения и
""ени поля. Допустим, он проверяет соответствие каждого значения типу отношения.
Например, можно определить списки допустимых значений для переменных Supplier,
Pnumber н City и реализовать типизацию данных с помощью запросов проверки
прилежности предлагаемых значений этим спискам. Кроме того, можно определить до-
веские ограничения на возможные значения в рамках одного типа. Например, можно
""требовать, чтобы инвентарные номера не превышали 1000.
Необходимо понимать различия в реализации проверки соответствия тип. межда
^артиыми языками наподобие Pascal и языком PROLOG. Для «ношен» suppli-
языке Pascal можно определить следующий гни данных,
supplier = record
ers
typ,
1эва 1л а
" ">■ Введение a PROLOG
snvriter:
integer;
boolean;
lo«clon: string
^ „-, Pascal определит «°вые ™ЛЫ (B №HH°" СЛуЧЗе suTOHer) ,
Программист на языке Pas"^^^ boolean и integer. Если программист „с
терминах уже ^ееп^2т то компилятор автоматически выполняет проверку со-
шшьзует переменные этого ти1.
ответствия tiuios. „,mnUer можно представить в виде
В PROLOG отношение supplier л
suppUerlsnafflelSuppUer),
snumber ISnuraber) ,
status(Stacus),
location(Location)) .
Пооверка соответствия типов осуществляется с помощью таких правил, как getsup-
иЛГи cktype Различие проверки соответствия типов между языками Pascal „
PROLOG мю При объявлении типа в языке Pascal компилятору передаете, тш,
даш как всей структуры (record), так и ее отдельных компонентов (boolean,
integer string) При объявлении переменной указывается ее тип (record), а затем
создаются процедуры для доступа к этим типизированным структурам.
procedure changestatus (X: supplier) ;
begin
if X.status then. . . -
Поскольку PROLOG— это не процедурный язык, в нем объявление не отделяется от
использования типов данных, а проверка соответствия типов осуществляется в процессе
выполнения программы. Рассмотрим правило
supplier_name(supplier(sname(Supplier) , snumber(Snumber) ,
status(true), location (london))) :-
integer (Snumber) , write (Supplier) .
Предикат supplier_name получает в качестве аргументов экземпляр предиката
Supplier и записывает имя данного поставщика. Однако это правило успешно реалюуется
только в том случае, если номер поставщика— это целое число, переменная статуса
принимает значение true, и поставщик располагается в Лондоне. Важной особенностью проверки
соответствия типов является ее реализация с помощью алгоритма унификащш (true, lon-
don) и встроенного системного предиката integer. Можно ввести ограничение на выбор
значении из определенного списка. Например, можно потребовать, чтобы значение
переменной srumoer выбиралось из списка номеров поставщиков Ограничения на запросы к базе
иг^еГсГ^™ С П°Жтю "Р38"* ™* <*type » supplier_narr,e и pe*«™T
Пер.ьГ,\tZZ2 PaKM0TPe™ ТРИ СП°С°6а ™™ *аиньк В """ PR° 1
можны*"иачешГп " С0СТ°т ' "™*ьзованни унификации для ограничен»» ■>«
PROLOG ГогГ,Г,еК-НЫ-4' ВТ°Р°Й с™"6- применение встроенных предикат
'^тсям^^Г:" ТКРКИ -°™«"вия типов. Примерами его резли^
огра„„чени^ГЛ™У«(Х)-1^ве(Х, у, „ integer (X). Третий спои*
^^пов.ь^^*—" ■ рассмотренном примере, где проверка «
«ий Supplier Pnutnbe7ur °ЩЬК> ПравШ1' определяющих принадлежность
г н city к заданным спискам.
^ть v.. Языки „ техншюгш Программирования №я искусственнОГО Интеле™
Четвертый, более радшсальнын, подход _ т П0ЯНШ „„ соответствия типов дан-
„,„ „ предикатов, предложенная в (Mycroft и O'Keefe. I984]. В этой работе все имена пре-
ддатов связываются с определенным типом и фиксированной арностью. Более того,
типизируются и сами имена переменных. Преимущество этого подхода состой в том. что
ограничения на вложенные предикаты и переменные в программе на языке PROLOG
определяются самой программой. Несмотря на то что выполнение программы при этом
замедляется, такой подход обеспечивает очень высокий уровень безопасности типов.
Таким образом, вместо встроенной проверки соответствия типов в языке PROLOG
допускается проверка соответствия в процессе выполнения под полным контролем
программиста. Этот подход имеет множество преимуществ для разработчиков систем
искусственного интеллекта, включая следующие.
1. Программист ие должен постоянно заботиться о строгой типизации. Он может
писать программы, работающие для любых типов объектов. Например, предикат
проверки принадлежности элемента списку выполняет общую проверку,
независимо от типа элементов списка
2. Гибкость типизации помогает разрабатывать программы в новых областях знаний.
Программисты могут абстрагироваться от проверки соответствия типов на ранних
стадиях разработки программы и ввести ее для выявления ошибок прн более
глубоком понимании задачи.
3. Представления данных в области искусственного интеллекта плохо согласуются со
встроенными типами данных таких языков, как Pascal. C++ или Java. PROLOG
позволяет определять типы с использованием всей моши логики предикатов. Эта
гибкость хорошо видна на примере с базой данных.
4. Поскольку проверка соответствия типов осуществляется в процессе выполнения
программы, а не во время компиляции, то программист сам определяет, когда ее
следует начинать. Это позволяет отложить проверку соответствия типов до
момента связывания определенных переменных или до другого момента.
5. Контроль проверки соответствия типов во время исполнения позволяет писать
программы, в которых новые типы создаются в процессе выполнения. Это можно
использовать, например, в программах обучения.
14.6.3. Унификация, механизм проверки соответствия предикатов
и оценка
Важная особенность программирования на языке PROLOG состоит в том. что
интерпретатор ведет себя как система доказательства теорем на основе резолюции (см. раз-
Дел 12,3). Как система доказательства теорем PROLOG выполняет последовательность
разрешающих процедур над элементами базы данных, а не оценивает операторы н
выражения подобно компиляторам традиционных языков. Это приводит к важному
результату: переменные связываются (инстанцнругатся, принимают значения) с помощью
подстановки унификации, а не за счет оценки, если, конечно, оно не требуется явно. Такая
парадигма программирования приводит к своеобразным последствиям.
Первым, и наиболее важным, результатом является ослабление требовании к
определению переменных как входных или выходных параметров. Преимущество этого подхо-
Д» мы уже наблюдай, на примере предиката append, с помощью которого можно либо
объединять списки, либо проверять корректность их объединен,», лиоо делить список на
Глава 14. Введение в PROLOG 643
-а
^„овка унификации также будет рассмотрена как „<*
част,.. В разделе 14.9 п0Я^2Тки ограничений при грамматическом разборе „ *
проверки соответствия я обработм ра
щи предложений. экспертных систем, основанных на правилах
Унификация-это мощное р с001ВетСтвия должна присутствовать во 8С"
фреймах. Разновидность такс,, р нап„сашш таких систем на универсальных язы
продукционных системах, ii 'ттт зачастую приходится реализовывать вруч
ках программирования алг^'" ^J,,, „a язь1Ке LISP приводится в разделе 15.6).
ную (реализация алгоритма У 4- ^ основе уиифнкации и „рнменсинем более
Важное различие ме»у вы ист, _ ^ ^ унифи1ВД1И „^^ ^^
традициои„ь,х язик в ео ™ (с соответствующикш параметрами под.
^Г«0 ^и оц нТвГт выражения. Например, предположим, что требуете, со,
Пиит successor успешно выполняющийся, если его второй аргумент на еди-
X больше первого. Не понимая сущности унификации, такой предикат можно
определить следующим образом,
successor(X, Y);- V = X + 1.
Он не будет работать, поскольку оператор = не оценивает свои аргументы, а лишь
пытается унифицировать выражен.гя в левой н правой части. Этот предикат будет
успешно выполнен, если Y можно унифицировать со структурой Х+1. Поскольку 4 не
унифицируется с 3+1. то вызов successor (3, 4) завершится неудачно. С другой
стороны, с помощью оператора = можно проверять эквивалентность (определяемую путем
унификации) любых двух выражений.
Чтобы корректно определить предикат successor и другие арифметические
предикаты, необходимо оценивать значения арифметических выражении. В языке PROLOG
для этого существует оператор is. Он оценивает выражение в правой части и пытается
унифицировать результат с объектом из левой части. Так, в выражении
X is Y + Z
осуществляется унификация объекта X со значением суммы Y и Z. Поскольку при этом
выполняются арифметические вычисления, это приводит к таким последствиям.
1. Если переменные Y и Z не имеют значений (не связаны во время выполнения), то
реализация оператора is приводит к ошибке времени выполнения.
2, Аналогично, если X и Z-связанные переменные, то с помощью выражениях is Y
+ нельзя получить значение Y (как в декларативных языках программирования).
1 »я,!ðРiS Нео6ход"мо ^пользовать для оценки значений выражений,
содержащих арифметические операции +,-,»./ и mod.
тогГк'оТГо'ев^а^ГеТ' предикатов- "именные в языке PROLOG могут иметь одно и
менная получила неготовое " Пр0ЦеСсе «жшьного присваивания или унификации
перечнем случаев возврата в t^rT™6' ™ °На Не шожет принять новое значение за
исключена* градишюнномуопеоа™*""1* П°НСКа' "^«"«гельно, is - это не функция, поФ
С помощью „„ераГа^"РИСВаИваН1мВ"раже„нех is X + 1 всегда ложно.
Аименно, жно к°Рректно определить предикат successor (X, *)■
successor(X, Y) :-у
Ои будет корректно выполняться, если переменна,, у ,.-
„ .„.„пп.лппят,. „ufi„ „„ «-ременная X связана с числовым значением,
его можно использовать либо для вычисления значения v », „„.,„„ „ с
с - v ., v ^«ачения у на основе X, либо для
проверки значении X и Y. г г
?. successor (3, X).
X = 4
yes
?_ successor (3, 4).
yes
?- successor (4, 2).
no
?_ successor (Y, 4).
failure, error in arithmetic expression
Как следует из этого обсуждения, интерпретатор PROLOG не оценивает выражения
подобно тому, как это делается при использовании традиционных языков программирования.
Программист должен явно реализовать оценивание с помощью оператора is. Явное
управление оценкой, как н в LISP, упрощает обработку выражений (в том числе данных,
передаваемых в качестве параметров), а также их создание и модификацию в рамках программы.
Это свойство наряду с возможностью оперировать выражениями логики предикатов
как данными н выполнять этн выражения с помощью предиката call существенно
упрощает разработку различных интерпретаторов, таких как оболочка экспертной системы
из следующего раздела.
В завершение обсуждения преимуществ вычислений на основе унификации приведем
пример, в котором объединение строк выполняется с помощью разностных списков
(difference list). В качестве альтернативы традиционному обозначению списка в PROLOG
его можно представить в виде разности двух списков. Например, список [а, Ь]
эквивалентен списку [а, Ь| []]-[] или [а, Ь, с ]-[ с 3. Такое представление имеет
несколько преимуществ по сравиеиню с традиционным синтаксисом списков. Если
список [а, Ь] представлен в виде разности [а, Ь J Y] - Y, то он на самом деле
описывает потенциально бесконечный класс всех списков, первыми двумя элементами которых
являются а и Ь. Такое представление обладает интересным свойством сложения.
X-Z = X-Y + Y-Z
Это свойство можно использовать для определения следующей однострочной
логической программы, в которой X-Y — первый список, Y-Z — второй, a X-Z — результат
их конкатенации.
catenate(x - Y, Y-Z, X-Z).
Эта операция объединяет два списка произвольной длины за постоянное время за
ечет унификации списочных структур, а не за счет повторного присваивания,
основанного на длине списков (как при использовании предиката append). Вызов предиката
catenate дает следующие результаты.
?- catenate ([a, b|Y]-Y, [1. 2, 3] - [ ), W).
v = U, 2, 3]
W = [а, Ь, 1, 2, 3) - ( 1
Как показано „а рис. 14.5, значение (поддерево) Y во втором параметре унифицируст-
«■ с обоими вхождениями Y в первом параметре конкатенации. В этом проявл» тся сила
№"фикацШ,, которая не сводится к простой подстановке значении переменных. В
„рога 14. Введение a PROLOG
645
„„„„сока соответствия общих структур: все вхг™,
„ессе^.фикзЦИК.ь.пояня^Р; Р^ Этот пример также иллкэстр^»" V
должнь, принимать »ачеи' ^ення. Таким образом, разностные спискн „Pe*!>
„мушество корректного пред вюможные результаты конкатенации. дста%-
ют целый класс списков,;Т тлячи1етьные особенности н преимуществ
В атом раздел.• Р*™0^ к выч„слениям, основанного „а ун„ф„кации Р^о.
—-зГ^оТкя°Х--.се^иРЯОШО. Ч,
~и, тисков' После связывания Yco списком [1.2. 31.Z —
Добавлевио разностных списки». сосгисим[] и сложения:
X-Y+Y-Z х-z
3 (]
Рис. 14.5. Древовидные диаграммы конкатенации на основе разностных списков
14.7. Метаинтерпретаторы в языке PROLOG
14.7.1. Введение в метаинтерпретаторы: PROLOG в языке PROLOG
Как на Lisp, так и на PROLOG, можно писать программы для работы с выражениями,
написанными в рамках синтаксических соглашений языка. Такие программы будем на-
зыват,.метаинтерпретатора,™ (meta-interpreter). Например, оболочка экспертной сис-
Гвиля „ГРеТ"РУеТ Р "РаВИЛ " Ф™' вписывающих конкретную задачу. И хот.
теппр™ Z Г" 0ПИСЫВаются с "«мощью синтаксиса применяемого языка,
метаинтерпретатор может переопределять их семантику.
PROLO™B™M0MTb',rPRr?nr ерПргатеРа определим семантику чистого языка
solve(В
.- solve(B).
Допустим, существует следующий
о xi Y) :" Ч(Х)
q(X) :- s(x)
r(X) :- t(x)
s(a) .
r(Y) .
простой набор суждений.
технологии программирования для искусственного инте
,ллек"
с(Ы-
t(c) ■
Тогда предикат solve будет вести себя как интерпретатор PROLOG.
7. solve(p(a, b)).
^!Ssolve(p(X, vl>
x = a,
X = a,
no
Y = b;
Y = c;
solve(p(f, g)
Предикат solve реализует тот же поиск в глубину слева направо на основе цели, что
и интерпретатор PROLOG.
Возможность написания метаинтерпретаторов для языка имеет несколько
теоретических преимуществ. Например, в [McCarthy, 1960] описан простой метаинтерпретатор для
LISP, представляющий собой часть доказательства того факта, что этот язык является
полным (по Тьюриигу). С более практической точки зрения метаинтерпретаторы можно
использовать для расширения или модификации семантики базового языка для обеспечения
его более полного соответствия специфике приложения. Такал методология
программирования получила название меташнгбистической абстракции (mela-linguistic abstraction),
подразумевающей создание высокоуровневого языка для решения конкретных задач.
Например, семантику стандартного языка PROLOG можно модифицировать таким
образом, чтобы спрашивать пользователя о значении любого целевого утверждения, истинность
которого нельзя определить с помощью базы данных. Это можно обеспечить путем
добавления следуюццгх выражений в конец предыдущего определения предиката solve.
solve(A) :- askuser(A).
askuser(A) :- write(A),
write('? Введите значение true, если целевое утверждение
истинно, и false в противном случае'), nl,
read(true).
Поскольку это определение добавляется в конец списка других правил solve, оно
вызывается только в том случае, если остальные правила не срабатывают. Предикат
solve запускает предикат askuser для передачи пользователю запроса о значении
целевого утверждения А. Команда askuser выводит целевое утверждение и инструкции
пользователю. Предикат read (true) пытается унифицировать введенное
пользователем значение с термом true. Если пользователь ввел значение false (или значение,
которое нельзя унифицировать со значением true), то эта попытка завершится
неудачей. Таким образом мы расширили семантику предиката solve и изменили поведение
языка PROLOG. Приведем пример использования определенной выше простои базы
знаний, иллюстрирующий поведение дополненного предиката solve.
Мт'введите значение true, если целевое утверждение истинно,
и false в противном случае
true
ЫВ)7 Введите значение true, если целевое утверждение истинно,
и false в противном случае
true.
yes
Глав;
647
а 14. Введение в PROLOG
„пение метаинтерпретатора позволяет ему отвечать на ^
Слсдукшк* Р^;"^" задает пользователю вопрос, то пользователь Мо?°>
-Почему?". Если """^1, why (почему). Ответом на этот запрос Лол*„0 *°*tt Щ.
я. «,У встречным »°"^™рсш„т,, „ро.рамма. Это реализуется за счет?"^
кутс правило, которое, .ь суждснин в качестве второго параметра ,,Ра"с"«»
да, правил в ТС^И ' манды clause для обратной связи с целевым П«Р *"»
fl0lve. При к«ДО»^^ ,« „равнло в отек. Тогда в стеке будет £***
СМ Tnl" ZZ от исли наивысшего уровня н заканчивал текущей подцсл"ь "°•»
цепочка правил, »»чи' можст „водить два корректных ответа на запп
,s^^ —d' кота"ь|й ™б--р,иаетсЯ у?,:;*-
„С пользователем значения true (как было описано выше), либо записывает „0°*
с 1° в стек, если пользователь вводит ответ why. Предикаты respo£*
askuser являются взаимно рекурсивными, поскольку „осле вывода ответа „а за„„ "
why предикат respond вызывает askuser для вывода следующего запроса по„ц,!*
таю о значении целевого утверждения. Заметим, однако, что на этот раз ,|ри *
askuser его параметром является хвост стека правил. Таким образом, последовала,,
ность запросов why просто приводит к последовательному извлечению правил из стек,
до его опорожнения. Это позволяет пользователю отследить всю цепочку рассуждений
solveitrue, _) :- ! .
solve(notlA), Rules) :- not (solve(A, Rules)).
solve((A, B) , Rules) :- !, solve(A, Rules), solve(B, Rules).
solve(A, Rules) :- clausefA, B) , solve(B, [(A :- B)|Rules]).
solvefA, Rules) :- askuser{A, Rules).
askuserfA, Rules) :- write(A),
write("? Введите значение true, если целевое утверждение
истинно, и false в противном случае'), ril,
read(Answer) , respond (Answer, A, Rules),
respondttrue, _, _).
respondlwhy, A, [Rule|Rules]) : - wrlte(Rule) , nl
askuserfA, Rules).
respondlwhy, A, ( )) ... askuser(A, [ ]).
Например, команду solve можно выполнить для простой базы данных, введения
Г„С!™ТЭГ0М PaW"C' 06paT"TC внима"'«. насколько успешно запросы why позволяют
отследить цепочку рассуждений.
'" SOlve(p(f, g). [ ])
s(f)? Введите значение t-mа о„
Ау и false в противном случае" ЦвЛеВОе утаеРж«ение "с™"н°'
4(f) :- а(£)
S(f)? в«дите значение true »,.
why. " £alSe B "P°™b„om случае" ЦвЛеВОе Утверждение истинно,
sliVL"(ч,£)' г(*>>
841. Введите значение true
true. " £аЬе В пР°™вном случае" ЦвЛеВое Утверждение истинно,
Ив)? Введите 3„ачение
true. " е в "Ротивиом случае" ЦеЛевое Утверждение истинно,
Уев
Важным расширением предиката solve является и™-™
.„ любой успешно реализованной цели. Построение 'ZT™ "ePe"a докюа™"":тв"
£ о6олочкам.экспертных систем возможно! o^^™ Это с=
ИСПОЛЬЗУЮТСЯ
ния задачи, в частности, алгоритма обучи
„ажио для любого алгоритма, в котором используются „ассГГГ ™ ' ° °
",,я задачи, в частности, алгоритма обучения на оСв" Го,™" РИУЛЬТаТаХ ""*'
06bT±r:iTJI°PIh0^G М0Ж"° ^яифицировать за счет рекурсивного
построения дерева доказательства для целевого утверждения в случае успешного
разрешения цели. В следующем определении дерево доказательства возвращается в качестве
второго параметра предиката solve. Доказательством атомарного утверждения true
является само это утверждение. Такое свойство приводит к построению рекурсии. При
разрешении цели А с помощью правила А :-в можно построить доказательство в и
возвратить структуру (А :- Proof В). При разрешении конъюнкции целей А и В
можно просто объединить деревья доказательств для обеих целей: (Proof A, ProofB)
Определение метаинтерпретатора, обеспечивающего построение деревьев
доказательств, имеет следующий вид.
solveitrue, true) :-!.
solve(not I A) , not ProofA) :- not(solve(A, ProofA)).
solveKA, B), (ProofA, ProofB)) :- solvefA, ProofA), solvelB,
ProofB).
solvefA, (A :- ProofB)) :- clause{A, B), solvetB, ProofB).
solve (A, (A :- given)) :- askuser (A),
askuser{A, Proof) :- write(A),
write ( 'Введите значение true, если целевое утверждение истинно,
и false в противном случае'), read{true) .
Запуск этого предиката для рассмотренной выше простой базы данных дает
следующий результат.
?- solve(p(a, Ь), proof).
Proof = р(а, Ь) :-
<(<3(а) !-
s(a) :-
true)),
(Г(Ь) :-
(t(b) :-
true)))
В следующем разделе эти приемы используются для реализации оболочки экспертной
системы exshell. В ней база знаний используется в форме правил решения задачи.
Система запрашивает у пользователя необходимую информацию, записывает
специфические данные, отвечает на запросы how и why и реализует механизм неточных
рассуждений на основе фактора уверенности из главы 8. И хотя система exshell гораздо
сложнее описанных выше метаинтерпретаторов PROLOO, она является лишь
расширением этой методологии. Ее ядром служит предикат solve, реализующий обратный
почек цепочек правил н фактов.
14.7.2. Оболочка для экспертной системы на основе правил
п ™ - ,„.,„.,. ппелнкаты. используемые при построении
В этом разделе будут описаны основ^"Рп*™ой системы под управлением цели.
»' Рпретатора для основанной на "?™"™*™V™"ZHmb применения оболочки
" завершение раздела будет продемонстрирована эффект»* i
г7~ ' 64<Г
лава 14. Введение в PROLOG
я ниже заданного
порога.
„™ автомобильной диагностики. Если читатель Же
«shell дм базы знании^ ^ ^^ основных предикатов оболочки ex"he>>- '
миться с этими резу „ в конец раздела. H.ps. 1
комендуем ему загляну. u состоит нз правил и спецификаций заг,росов I
База знании *"м" да с помощью предиката rule вида щ^'Ч !
зователю. Правила пРд енис для базы знаний, записанное с помощью ' с?1
Первый naPaMeippn(;Lo0 Утверждения могут представлять собой правил,, „,?"%■
иого синтаксиса ки ^ ^ ^^ правилг1] а р _ конъюнктивный ша6Лон „ L°C
B№ {G :"„^™hho Первый параметр предиката rule может также являться ^
Snap"F характеризует степень доверия разработчика закл^^»
PROLOG. Параметр J механизм неточных рассуждений на основе /У ""
^Г™.епре"«е„С д^я систем. MYCIN, описанной в главе S. ££*
шжет изменяться в диапазоне от 100 (если факт заведомо истинный) до 400 (ди^
доме ложных фактов). Если значение параметра CF близко к нулю, значит, степень ^.
ревности для данного факта неизвестна. Приведем типичное правило нз базы знаний а,
диагностики неисправностей автомобилей.
rule((bad_component (starter) :- (bad_system(starter_system),
lights(come_on))) , 50} .
rule(£ix(starter, 'замените стартер' ) , 100).
Первое правило утверждает следующее. Если "неисправной" оказалась система
партера, и фары включаются, значит, плохим компонентом является стартер с фактором
уверенности 50. Второе утверждение означает, что починить неисправный стартер
можно путем его замены (с уверенностью 100). В оболочке exshell предикат rule
используется для извлечения правил, дающих заключение для указанной цели, подобно
тому, как в более простой версии предиката solve используется встроенный предикат
clause для извлечения правил из глобальной базы данных PROLOG.
Система exshell поддерживает запросы к пользователям о неизвестных данных.
Однако, поскольку интерпретатор не должен задавать вопросы для каждой
неразрешенной цели, программист может явно указать, какую информацию следует получить. Это
можно сделать с помощью предиката askable.
askable(car_starts) .
Этот предикат означает, что интерпретатор может запрашивать у пользователя
значение истинности цели car.starts, если необходимая информация отсутствует и не
может быть выведена с помощью базы данных
тещ ГГ 17СДеЛ°НН0Й "Рожистом базы знаний правш. и допустимых запросов, си-
ям Поскол! 7Иерживает ™" собственные данные, относящиеся к конкретным с.пуа»
хрантТоГвГГ™3 МПрашиюет У пользователя информацию, ответь, необходим»*
Хом „ZT ПР0,ТаММе ИЗбСга1Ъ "°"™рных запросов в процессе консультации-
Р« ^ментовп? РтТ°Ра eXsheU -веется предикат solve, зависящий от •*"
Ш«тьРПр:7^ш2:ТшГЖ"Т~ ™ Цемвое Утверждение, которое требуется g
™пе„ью /вер Го™?™™" ЦМН ^очка exshel 1 связывает второй *W**c
"Р»ил, применяемый 'Z о"™6™" На °СН0ве ба™ »"»*■ ТРСТИЙ арГуМС"Т " Z*
«««да и Р„чны ™: ~™ Щ И"Р-ь. why, а четвертый - порог отсе**£
ограничивать проставив °С"°ве Фа™ра уверенности. Такой подход поз»
юности) опуекаетГнГже "0,,СКа' еСЛ" ЗНачение Ф™ра уверенности (степень Д»
Ча°тьу|.Язык„„теХн0„огии
программирования для искусственной
О ИНТ!
При разрешении цели G предикат solve сначала пк,™
яи G любому факту, уже полученному от пользовате^^'Т"" с00твстстаие цс-
::с „омошью предиката known.A. СР,. Напри™. " к1"аг^агГ™Г-
"""' Ч;:с™Л85°"сГзСеСООбШИЛ ° ™' ™ -"«обтиь'запускается о' степ „ьо
г, пето верности ьэ. Ьслн значение целевого \твепжпрн,.П
Д0С1 F „„ „ У^цэждения неизвестно, предикат solve
пытается Разрешить его с помощью базы знаний. Он обрабатывает отрицание цели,
разрешая ее и умножая достоверность этой цели на -1. При Этом разрешение конъюнктив-
„ьй целен производится слева направо. Если G - это Положительный литерал, то
предикат solve проверяет все правила, голова которых соответствует G. В случае неудачного
завершения этой операции solve передает запрос Пользователю. При получении от
пользователя значения достоверности цели предикат solve добавляет эту информацию
в базу данных с помощью предиката known.
% Ситуация 1: истинное значение целевого утверждения уже известно
solve(Goal, CF, _, Threshold) :-
known(Goal, CF), !,
above_threshold(CF, Threshold) . %Проверка порога г-остоверности
% Ситуация 2: отрицание цепи
solve (not (Goal) , CF, Rules, Threshold) :-.',
invert_threshold(Threshold, New_threshold) ,
solve(Goal, CF_goal, Rules, New_threshold) ,
negate_cf(CF_goal, CF) .
% Ситуация З: конъюнктивные цели
solve ( (Goal_l, Goal_2), CF, Rules, Threshold) :- !,
solve(Goal_l, CF_1, Rules, Threshold),
above_threshold(CF_l, Threshold) ,
solve(Goal_2, CF_2, Rules, Threshold),
above_threshold(CF_2, Threshold),
and_c£(CF 1, CF_2, CF) . %Бычисление CF для конъюнкции ць.еи
% Ситуация 4:~обратная связь с правилом в базе знаний
solve (Goal, CF, Rules, Threshold) :-
rule ((Goal :- (Premise)), CF_rule) ,
solve (Premise, CF_premise, [rule ((Goal :- Premise),
CF_rule) |Rules), Threshold) ,
rule_c£(CF_rule, CF_premise, CF) ,
above_threshold(CF, Threshold).
% Ситуация 5: добавлени факта в базу знании
solve(Goal, CF, _, Threshold) •.-
rule(Goal, CF),
above_threshold(CF, Threshold).
% Ситуация 6: запрос к пользователю^
solve(Goal, CF, Rules, Threshold) :
askable(Goal),
askuserlGoal, CF, Rules), !.
assert(known(Goal, CF)) ,
above thresholdlCF, Threshold).
™-м начинаются с помощью версии предиката solv,
Консультации с пользователе "ач1Ш ве„хнсго уровня в базе знании, а в
двумя параметрами. Первый аргумент это г уверенности в цели после анализа
рой - переменна», которая будет связана с ^ ^тчьзова1СЛЮ. вызывает команду
базы знаний. Этот предикат выводит наоор и -, „„формации от преды-
retractall(known(_, _) ) для очистки любой ос
651
solve с
вто-
Глава 14. Введение в PROLOG
. запусков оболочки е:
з^мичетьфех параметров.
«shell, а затем вызывает предикат solve e cootDOTO]1
ДУШИХ
шнми
solve (Goal. CF) ■■-
print_instruotions,
Lractalll^-j ->»;
solve(Goal, CF, l i-
anopor 20
манда prlnt_instructions сообщает пользователю список допустимых „т.е.
тов на запрос exshell.
Р"ПУП^еГВоз«с,;кь,е ответь,: •).
» ' „i" -Фактор уверенное™ в истинности запроса. .,.
nl! write!' Число от -100 до 100. ),
nl! write!' how(X),'rBe X - это целевое утверждение'), Ш.
Следующий набор предикатов позволяет вычислить коэффициенты достоверности.
(В оболочке exshell используется разновидность метода неточных рассуждений на
основе фактора уверенности, представленного в подразделе 8.2.1.) Фактор уверенное™
для конъюнкции двух целей — это минимум среди факторов уверенности каждой из
целей. Фактор уверенности для отрицания факта вычисляется путем умножения фактора
уверенности этого факта на -1. Степень уверенности в гипотезе, полученной с помощью
правила, равна произведению факторов уверенности предпосылок и самого этого
правила. Предикат above_threshold определяет, превышает ли значение фактора
уверенности заданный порог. В системе exshell пороговое значение используется для
отсечения цели, если уверенность в ней слишком низка. Заметим, что предикат
above_threshold отдельно определяется для отрицательных и положительных
значении порога. При положительном значении порога отсечение выполняется в том случае,
если фактор уверенности не превышает этого порога. Отрицательное значение порога
означает, что мы пытаемся доказать ложность цели. Поэтому для отрицательных целей
поиск прерывается, если значение фактора уверенности цели превышает заданный порог.
Команда invert_threshold вызывается для умножения значения порога на -1.
and_cf{A, В, А) :-
А = < В.
and_cf(A, в, в) 1-
В < А.
negate_cf(CF, Negated_CF) :-
Negated_CF is - 1 * CF
rule_c£(CF_rule, CFjremise, CF) •-
CF is (CF_rule • CF_premise/100)
above_threshold(CF T) 71 "«"±""1.
T >= 0, CF >= i.
above_threshold(CF, T) ■-
T < 0, CF =< t'
invert_threshold(Thre4hni^ »
nN^eShoid .г?;v:^hoiгh°ld,;-
зроПпаЛ,'ьшолан™т „ей ^"^ ""Р00 " СЧ11™ва« «™* пользователя. Пред-""" "'
шолняк,тдействия, соответствующие введенной пользователем ппформ^""'
НасТьМяЭЫкиитехноЛог„ипрограыыированиядляискуссТевнногоинтелЯ*»
.„.орт (Goal, CF, Rules I ■ - »Qar,~
askUS ^Запрашивает ответ пользователя
nl, „rite ('Запрос к пользователГТ №™
write(Goal), nl, writef'?'),
read(Answer),
respond(Answer, Goal, CF, Rules).
^Обрабатывает ответ
В »^^ ™ ""«« пользователь может ввести значение параметра CF „з
диапазона от -100 до 100, отражающее степень его доверия истинности цели, запрос why
„ли how (X).
Ответом на запрос why является правило, расположенное в данный момент в верхушке
стека. Как и в предыдущей реализации, успешная обработка запросов why приводит к
последовательному извлечению правил из стека. Это позволяет восстановить всю цепочку
ряссужаений. Если ответ пользователя соответствует шаблону how(X), то предикат
respond вызывает команду build^proof для построения дерева доказательства для X и
команду write^proof для вывода этого доказательства в удобной для восприятия форме.
Все неизвестные входные значения "отлавливаются" предикатом respond.
% Ситуация 1: пользователь вводит корректный фактор уверенности
respond(CF, _, CF, _) :-
number(CF),
CF =< 100, CF >= -100.
% Ситуация 2: пользователь вводит запрос why
respond(why. Goal, CF, [Rule|Rules]) :-
write_rule(Rule),
askuser(Goal, CF, Rules),
respond(why, Goal, CF, [ ]) :-
write('Перейти к вершине стека правил. '),
askuser(Goal, CF, [ ]).
% Ситуация 3: Пользователь вводит запрос how.
% Строится и выводится доказательство
respond(how(X), Goal, CF, Rules) :-
build_proof(X, CF_X, Proof), i,
write(X), write('заключение получено с уверенностью '),
write(CF_X),nl, nl,
write('Доказательство '), nl, nl.
write_proof(Proof, 0), nl, nl,
askuser(Goal, CF, Rules).
% пользователь вводит запрос how, доказательство построить нельзя
respond(how(X), Goal, CF, Rules) :-
write('Истинность '), write(X), nl,
write('еще неизвестна. '), nl,
askuser(Goal, CF, Rules).
% Ситуация 4: неизвестный ввод
respond(_, Goal, CF, Rules) :-
write('Неизвестный отклик.'), nl,
askuser(Goal, CF, Rules).
n . ,,, „,nnf „очти полностью соответствует определению
Определение предиката buil<U>roof »очт« £ н£ спрашиюет „ользова-
предикап, solve с четырьмя ^P^c^m^x^^tt данных, соответствующих
**я о неизвестных фактах, поскольку они У™™^^ дательсгва цели,
определенным ситуациям. Предикат build_proof строит д^вс
Глава 14, Введение в PROLOG
, CF (Goal, CF :- Siven)) :-
known(Goal, CM, t proof) :-
build-Proof(not Goal CF Proof), negate c£(CF_goal|
i build-proof (Goal, "у" CF (proof_l. Proof_2)) :_ tp> ■
buildlproofUGoal 1, Goal_-^ proo£_1) ,
,, build-proof(Goai_i, proo£_2)i and_c£(CF_l, CF2 cpi
build-Proof(Goal_2, CF , ;_ proo£)) ._ - <-F).
build-proof (Goal, f; <°°f'CF rule),
„let (Goal :- Premise) - proo£),
build-proof (Premise, CFjrem
„le-Cf.CKrule -premise «);_£act)) ;_
build-proof(Goal, CF, l""«
rule(Goal, CF).
И наконец, создали» предикагы, определяющие простой интерфейс пользователя
Как правило, для его написания требуются огромные объемы кода. Сначала опреде1мм
предикат вывода правила в удобном для восприятия формате,
write-rule (rule! (Goal =- (Premise)), CF))
write(Goal), write!':-'), nl,
write_premise(Premise) , nl,
write!'CF = '), write (CF), nl.
write_rule(rule(Goal, CF)) :-
write (Goal), nl,
writeCCF = '). write(CF), nl.
Тогда предикат write_premise записывает конъюнкты из предусловий правила.
write_premise( <Premise_l, premise_2) ) :-
!, write_premise(Premise_l) ,
write-Premise(Premise_2) .
write_premise(not Premise) :-
!, write!' '), write(not), write!1 '), write (Premise) , nl.
write_premise(Premise) :-
writef' '), write(Premise) , nl.
Команда write_proof выводит доказательство с отображением структуры дерева.
writejroof ( (Goal, CF :- given). Level) :- %Выводит дерево
^доказательства
lndent(Level), write(Goal), %c указанием уровней
write С CF= ■), write (CF),
^ write(' получено от пользователя') nl '
writejroofUGoal, CF :- fact). Level) •- ' "
indent (Level), write (Goal), write (• CF = •), write(CF),
write! факт из базы знаний'), nl i
write jr„f|| Goal, CF :. Proof). Level) "-
indentaevei,, write(Goal,, write,' CF = ',, „rite(CF),
writejroofTnoteproof''T1 ]/' write-Proof(Proof. Newjevel) , !•
НеГ^П^Л-''^''-!,
indent (0). root-l. Level), write_proof (Proo£_2, Level), ■•
■ Языки и технологии программирования для искусственного и
write!' '), l_new is 1-1, indent (l_new) .
indent (1)(;-м
«) .
Для иллюстрации работы оболочки exshell пагг>,п™.
^знаний ДЛЯ диагностики неисправностей zJZ^Z^™"*
является утверждение fix. зависящее от одного параметра. С „омощ ю ь, ™ани
решение задачи разбивается „а поиск неисправной системы, поиск неисправного
компонента в рамках этой системы и построение совета по решению проблемы на
основе поставленного диагноза. Заметим, что база знаний является неполной т е
существует множество симптомов, которые невозможно диагностировать В атом
случае программа exshell попросту не работает. Расширение базы знаний на
некоторые нз этих случаев и добавление правил, срабатывающих при неприменимости
остальных правил. — это интересная задача, которую читатель может решить в
качестве упражнения.
rule((fix(Advice) :- %Запрос верхнего уровня
(bad_component (X) , fix(x. Advice) )) , 100).
rule((bad_component(starter) :-
(bad_system(starter_system) , lights (come_on))) , 50).
rule((bad_component(battery) :-
(bad_system(starter_system) , not lights(come_on) )) , 90).
rule( (bad_component (timing) :-
(bad_system(ignition_system) , not tuned_recently) ) , 80).
rule((bad_component(plugs) :-
(bad_system(ignition_system) , plugs (dirty) )) , 90).
rule ( (bad_component (ignition-Wires) :-
(bad_system(ignition_system) , not plugs(dirty) ,
tuned_recently)), 80).
rule ( (bad_system (starter_system) : -
(not car_starts, not turns_over)) , 90).
rule!(bad_system(ignition_system) :-
(not car_starts, turns_over, gas_in_carb) ) , 80).
rule( (bad_system(ignition_system) :-
(runs(rough), gas_in_carb)) , 80).
rule! (bad_system(ignition_system) -.-
(car_starts, runs(dies), gas_in_carb)) , 60).
rule(£ix(starter, 'заменить стартер'), 100).
%Совет по устранению проблемы
rule (fix (battery, ' заменить или зарядить аккумулятор') 100).
rule (fix (timing. ' настроить временные параметры , 100).
rule(fix(oluas 'заменить свечи зажигания') , 100).
ruleifixUgnitlonlwires, -проверить провода в системе зажигания .,
askable<car_starts) . ™°™° СТР0СИТЬ ™л»°"ТеЛЯ ° Ue™
askable(turns_over).
askable(lights(_)).
askable(runs(_)).
askable(gas_in_carb).
askable(tuned_recently)•
askable(plugs(_)).
Глава 14. Введение в PROLOG
655
,, .той базой знаний в работе системы exshell. H
Тетерь воспользуемся Сш10ШНой линией обозначены пройденны
<вза„о пространство поиска. _ ^^
показано пространство поиска, i,iu>uu—_
пунктирной — непройденные, а жирной — решения.
пройден,,^ Р^
soh/a{fix(X)).
fixftiming,
настроить временно
параметры').
bad_system not tuned j-ecently
(ignnion_system)
Успешное
завершение
Успешное
завершение
not starts turns
gasjn
carb
Успешное Неудачное Успешное Неудачное Успешное Успешное Успешное
завершение завершение завершение завершение завершение завершение завершение
Рис. ]4.6. Граф поиска для системы диагностики неисправностей автомобилей. Пунктирные
линии обозначают непройденные ветви, а жирные — окончательное решение
?- solve(fix(X) , CF) .
Возможные ответы:
Фактор уверенности в истинности запроса.
Число от -100 до 100.
why.
how(X), где X - это целевое утверждение
Запрос к пользователю:саг_з1;агЬ5
? -100.
Запрос к пользователю:turns over
? 85. ~
Запрос к пользователю: gas_in_carb
Запрос к пользователю:tuned_recently
X = 'настроить временные параметры' CF = 4B.0
hoJ„TvPrn МОТРИ" СИТуаЦИЮ' При К0Т°Р°» в этой же задаче используются запросы
«' рис Ш °ТВеШ С С00тветст^Щими поддеревьями и путями, показанным.
?- solve(£ix(X), CF)
Возможные ответы-
^оГ-^ 5Г-™ запрос,
л технологии программирования для искусственного инт*
:ллекта
nOW(X), где X - это целевое Утверждение
заПрОС к пользователю: car_starts
, -100.
Запрос к пользователю: turns_over
■> why-
bad_system(starter_system) :-
not car_starts
not turns_over
CF = 90
Запрос к пользователю: turns_over
? why-
bad_component(starter):-
bad_system(starter_system)
lights(come_on)
CF = 50
Запрос к пользователю:turns_over
? why.
£ix(_0) :-
bad_component(starter)
fix(starter, _0)
CF = 100
Запрос к пользователю:turns_over
? why.
Возврат к верхушке стека правил.
Запрос к пользователю:turns_over
? 85.
Запрос к пользователю:gas_in_carb
? 75.
Запрос к пользователю: tuned_recently
? why.
bad„component(timing) :-
bad_system(ignition_system)
not tuned_recently
CF = 80
Запрос к пользователю:tuned_recently
? how(bad_system(ignition_system) ) .
bad_system(ignition_system) заключение получено с
достоверностью 60.0
Доказательство
bad_system(ignition_system) CF= 60.0 :-
not car_starts CF = -100 получено от пользователя
turns_over CF = 85 получено от пользователя
gas_in_carb CF = 75 получено от пользователя
Запрос к пользователю: tuned_recently
? -90.
X = "настроить временные параметры' CF = 48.0
14.7.3. Семантические сети в языке PROLOG
В этом разделе рассмотрим реализацию наследования для простого »«ка «м™"с-
^ сетей (глава 6). Этот/зык не обладает всей мощь» и °™»0C™™^ZZ
-ниепт.альнь.е графь,. В частности, мы ™*£У£^^
кассами и их экземплярами. Однако такая ограниченность > пр ш (
» 14. Введение в PROLOG
657
- ~» показанной на рис. 14.7, узлы представляют такие „б^
в семантической сети, показан ^ ^^ ostrich ^^^ ^ (ворона) ^.
как конкретная кшаР^ ™ b„te (позвоночное). Отношение isa связывает кла«"
(дрозд), bird <птша) и ver в этой сети реализованы канонические о0„
Ручных ровней иерархии^isa(Type. Parent, указывает на то, чт„ 0^
мы представления данныхлр^^ ^ предикат hasprop(Object, Propertv
Туре является подтипе Предикат hasprop указывает и= ™ .... - у'
v^ue, описывает свойства обьектовР и№ уа1це
^^„е „йлалает свойством Property „«„„„„„.,„
ре Я»"' - ^ лЯт.ритОВ ПреДИКВ! Iiaa^uf j^^jninatf НЭ ТО
.Лие) °™<:иваетСВ™";м property со значением Value. При
Object обладает свойство 6ъединяющей их связи.
value - зто узлы сети, a Property
I animal
что oft,cln
этом Object „
covering .
| opus I I tweety I *\ white
Рис 14.7. Фрагмент семантической сети, описывающей птиц и других животных
Фрагмент списка предикатов, описывающих показанную на рнс. 14.7 иерархию птиц.
имеет вид.
isa(canary, bird).
isa(ostrich, bird).
isa(bird, animal).
isa(opus, penguin).
haspropltweety, color, white)
hasprop(canary, color, yellow)
hasprop(bird, travel fly)
hasprop(ostrich, travel, walk)
hasprop(robin, sound, sing)
hasproplbird, cover, feathers)
red) •
isa(robin, bird).
isa(penguin, bird).
isa(fish, animal).
isa(tweety, canary).
hasprop(robin, color, —■
. т„^ brown) -
hasprop(penguin, color, ^
hasproplfish, travel, svn*l.
hasprop(penguin, travel-
hasproplcanary, sound, sj™b
hasprop(animal, cover, s
пеки»
" iU' Cover' fathers). hasprop (animal, cover, sKin, •
°^ZZZo7l2 OT°PH™ П°ИСКа- "<™« определить. <*»»«£ ^
нтаческои сети указанным свойством. Свойства хранятся в сета на самом
ком уроне, на котором они „спишь,, с помощью наследования ы~
^ает свойства своего суперкласса. Так, свойство £1 0бъскт и™ подкласс приоб-
„одклассам. Исключения размешаются на отдельном СвТ™ " "^^ bird " °КМ еГ°
crich „ пингвин penguin ходят (walk), „„ „е летаютт* n™™™"' Т"К' С1рауС °3~
даает поиск с конкретного объекта. Ест, информация HarmI™ ^ hasproPerty иа"
0„ переходит по связи isa к суперклассам. Если супеокЗГгГ "' а**Ш ° ЭТ™ о6ъс,т>м-
^паяргорег^ненашел^жното свойства „Ге^^Т^^^"^-
hasproperty!Object, Property, Value)■-
hasprop(Object, Property, Value)
hasproperty(Object, Property, Value)'•-
isafObject, Parent),
hasproperty(Parent, Property, Value).
Предикат hasproperty выполняет поиск в глубину в иерархии наследования
В следующем разделе будет показано, как применять наследование предсЗнияТа
основе фреймов и реализовьшать отношена деревьев „ множественного „асГедова""
14.7.4. Фреймы и схемы в языке PROLOG
Семантические сети можно разбивать на части, добавляя к описаниям узлов
дополнительную информацию и обеспечивая тем самым фреймовую структуру. Переопределим
рассмотренный в предыдущем подразделе пример с использованием фреймов. Каждый
фрейм будет представлять набор отношений семантической сети, а ячейка isa —
определять иерархию фреймов (рис. 14.8).
В первой ячейке каждого фрейма содержится имя узла, например, name (tweety)
или name (vertebrate). Во второй ячейке определяется отношение наследования
между данным узлом и его родителями. Поскольку в нашем примере сеть имеет
древовидную структуру, каждый узел содержит лишь одну связь — предикат isa зависит от
одного аргумента. В третьей ячейке содержится список свойств, описывающих этот узел.
В этом списке можно использовать любые предикаты PROLOG, в том числе flies,
feathers или color (brown). В последней ячейке фрейма находится список
исключений и принимаемых по умолчанию значений для данного узла. Его элементы тоже
могут представлять собой либо отдельные слова, либо предикаты, описывающие свойства.
name: bird
isa: animal
properties: flies
feathers
default:
name: canary
isa: bird
properties: cotor(yeilow)
sound(sing)
default: size(small)
Рис. 14.8. Фреймы дтя базы зн
name: antma!
isa: animate
properties: eats
skin
default.
'name, tweety
isa canary
properties-
default- color(white) J
аний о птицах
лааа 14. Введение в PROLOG
- „» каждый предикат frame связывает имена ячеек. с„„ск„
На „ашем языке фреймов^^ значсн„я. Это позволяетразличать типы э„аний „
свойств и принимаемые по умолчан наслед0вания. Хотя при такой реали,
приписывать им разнос поведе«<^ ^0„х спнсков. для конкретных приложений вд.
„„"классы мотуг "«"""""Гие представления. Например, можно наследовать то„1К0
1 „казаться полезными и другие И ^ ^^ грстт список. содержащий свойств,
„шользуемыс по умолчанию зна ^^ мач1,ит и110Гда называются 3;ш,Я(аЦ)1(
самого класса, а не его ™°"а ^ сдслать так. чтобы класс canary определял вид
класса (class value). Например. ^ насЛедоваться подклассами или экземпляру.
певчей птииы. Это свойство д ьнсишсе расширение этого примера предлагает-
tweety - «с есть вид певчих птиц Д ^ ^^
ся выполнить в качестве упражнен^^ ^ ^ 14^ на m(jKe pR0L0G с помо(щю
Теперь опишем °™ошс" ' аргунентами. Для проверки соответствия типов лре-
предиката факта frame с ? к|) того, что в третьей ячейке фрейма содержится
диката frame, в частности, да • ачение т заданного диапазона свойств, можно
Гл^^ьГ^=Гв подразделе 14,,.
frame(name(bird),
isa(animal),
[travel(flies), feathers],
[ ])•
frame (name (penguin) ,
isa(bird),
[color(brown)],
[travel(walks)]) .
frame(name(canary),
iea(bird),
[color(yellow), call(sing) ] ,
[size(small)]),
frame(name(tweety) ,
isa(canary),
{ 1,
[color(white)]),
Определив для фрейма (рис. 14.8) полное множество описаний и отношений
наследования, разработаем процедуры для извлечения свойств нз этого представления.
get(Prop, Object) :-
frame(name(Object) , _, List_of_properties, _) ,
member(Prop, List_of_properties) .
get(Prop, Object) :-
frame(name(Object) , _, _, List_of_defaults) ,
member(Prop, List_of_defaults) .
get(Prop, Object) :-
frame(name(Object) , isa(Parent), _, _) ,
get(Prop, Parent).
Если структура фреймов допускает множественное наследование свойств (см. также раэ-
дел 15.12), то в наше представление и стратегию поиска необходимо внести соответствую^
изменения. Во-первых, в представлении фрейма apj-умент, связанный с предикатом isa. Д
жен содержать список суперклассов данного объекта. Каждый суперкласс этого списка-;
роди^льский класс объекта, указанного в первом аргументе предиката frame. Если с&
^artT К Г? ПИНГВИН°В Pen^uin " предс^вляет собой персонаж -У**"»"
(cartoon^char), то это можно представить следующим образом.
660 Часть VI. Языки и технологии программирования для искусственного интеллекта
£rame (name (opus),
isa([penguin, cartoon_char]),
[color(black)],
I })■
get (Prop, Object) -.-
frame(name(Object), isa(List), _, _)
get_multiple(Prop, List).
Предикат get_multiple можно определить следующим обратом.
getjnultiple(Prop, [Parent|_]) :-
get(Prop, Parent).
get_multiple(Prop, [_|Rest)) ■-
get_multiple(Prop, Rest).
В этой иерархии свойства класса penguin и его суперклассов будут проверены до
начала проверки свойств класса cartoon_char.
И, наконец, с каждой ячейкой фрейма можно связать любую процедуру на языке
PROLOG. Имея фреймовое представление для данного примера, в качестве параметра
предиката frame можно добавить правило PROLOG ияи список таких правил. Для этого
все правило нужно заключить в скобки, как это делалось при реализации оболочки ex-
shell, и включить эту структуру в список аргументов предиката frame. Например,
можно разработать список правил отклика для объекта opus, обеспечив для этого
персонажа возможность давать различные ответы на разные вопросы.
Эгиг список правил (где каждое правило заключено в скобки) должен стать параметром
предиката frame, определяющим соответствующий ответ в зависимости от значения X.
передаваемого фрейму opus. Более сложными примерами могут служить правила управления
термостатом или создания графического изображения на основе множества значений- Такие
примеры представлены в разделе 15.12. где важную роль в объектно-ориентированном
представлении играют связанные с объектами процедуры, зачастую называемые методами.
14.8. Алгоритмы обучения в PROLOG
14.8.1. Поиск в пространстве версий языка PROLOG
В главе 9 описано несколько алгоритмов символьного машинного обучения. В этом и
■«дующем разделах будут реализованы два из них: алгоритмы поиска в пространстве
>тт (version space search) и обучения на основе пояснения (explananon-based leammg).
Сами эти алгоритмы описаны в главе 9. а здесь приводится лишь их реализация на языке
PROLOG. Такой выбор языка для реализации алгоритмов машинного обучен™
обусловлен т„.. Р „„-„.„«иааст встроенные механизмы проверки
"с« тем, что он очень иллюстративен, поддерживает в<лрис„п „,„.„' „„
«^етствия шаблонам, а его возможности рассуждении на метауровне упрошают по-
«Р-нне и работу с новыми "P^^""»* а затсм _ ,юл„ый двунаправленный
Сначала реализуем поиск от частного к обшему. а заи построению
^Р'ТМ исключения кандидата. Читателю будут предложены советы построению
Лава ,4' Введение в PROLOG
, „™сий от обшсго к частному. Эти алгоритмы поиска
,, поиска в пролРанств^„ЯП1,н„я понятий, если это представление nnn —
не.
!жк-
ать
Мяч
' п „педставления понятий, если это представление поддт
зависимы от используемого"Р„, 0б06шения и специализации. Мы будем исполТзо"
«и соответствуютне оп р ^^ ^.^ Например, маленький красный '
представление объекте в списка.
можно описать с помошью следую
[small, red, ball].
Понятие маленького красного объекта можно описать с помощью списка с переме„„ой.
[small, red.X].
Такое представление называется вектором «рюнаков (feature vector). Оно менее выра.
JT„o Тем полная логика, поскольку с его помошью нельзя представить класс >„
кгГньгх и зеленых мячей". Однако оно упрощает обобщение и обеспечивает строгий „„.
Гшвнын порог (раздел 9.4). Вектор признаков можно обобщить, подставляя вместо ко„.
„анты переменные. Например, наиболее конкретным обобщением для векторов [sma/,
red ball] и [small, green, ball] является вектор [small, X, ball] ■ Этот вектор покрыв»,
ет каждую из специализаций и является наиболее конкретным из всех таких векторов.
Будем считать, что вектор признаков покрывает другой вектор признаков, если он
либо идентичен этому вектору, либо является более общим. Заметим, что в отличие от
процедуры унификации отношение покрытия covers асимметрично: существуют
значения, для которых X покрывает Y. но Y не покрывает X. Например, вектор [X, red, ball]
покрывает вектор [large, red, bait], но не наоборот. Определим предикат covers для
векторов признаков следующим образом.
coversI П . П ) •
covers![Н1|т1], [Н2|т2]) :- %переменные покрывают друг друга
var(Hl), var(H2), covers(Tl, T2).
covers![Н1|т11, [H2|T2]) :- %переменная покрывает константу
var(Hl), atom(H2), covers(Tl, T2).
covers([Hl|Tl], [Н2|т2]) :- %проверка соответствия констант
atom(HI), atom(H2), HI = H2,
covers (Tl, T2) ,
Теперь необходимо определить, является ли один вектор признаков строго более
общим, чем другой (т.е. векторы не идентичны). Определим соответствующий предикат
more_general.
more_general(X, Y) :- not (covers (Y, X)), coverslX, Y) .
Обобщение векторов признаков реализуется с помощью предиката generalize, зави-
™^°Т,ТРеХ ар^,ентов' ПЧ»™ аргумент- это вектор признаков, представляющие
гипотезу (он может содержать переменные). Второй аргумент- экземпляр, не содер»"
кГньм ГГГ"" Ре"'Й арт7№нт ПРад«™ generalize связывается с наиболее ков-
S 1о скГГ™ тП°ТеЗЬ'' ""^■"^й Данный экземпляр. Предикат generally
~ о8ГдаРГГ°РЫ "РИЗНаК°в' ^т"™ соответствующие элементы. Если д»
компонТкГвёктсГ™ Ре3уЛЬ™Р>™»"" в=™Р включается значение соответствии.*>
зицию my^ZT^ ЕС"И "" Элеме«™ •* совпадают, то в соответствуй п
зование^^ТоыГТ "^^ ™*мен""- 06ра™ге "'""^ ™ "Z «
обобщения'этоТо^'Г^^^^п^-Ргор) во втором определении пре»»««
атома без реаль„„Твып;„ТР11Ца"Ие П°3воляст проверить, можно ли унифицировать^
^ногосв„ьша„ГпГГ"ИЯ Т1*^» *™Фикац1и и формирования любого не*
' Ных- °"РВДелим предикат generalize.
6И ^"^""~^^
aeneralize((], [], П).
bZl^T^ZTnn |R!St!' '—-l-st_instl,
^eature S= Inst^rop, generali^,KeiReS„;sriiet!-^r-^" '"
эт предикаты задают основную операцию для представления векторов признаков
Остальная часть реализации не будет зависеть от конкретного представления и может
применяться к различным представлениям и операциям обобщения
Как было указано в разделе 9.2, поиск от частного к общему в пространстве понятий
можно проводить за счет поддержания списка н гипотез-кандидатов. Гипотезы в н— это
наиболее конкретные понятия, покрывающие все положительные примеры и ни одного
отрицательного. Ядром алгоритма является процедура process, зависящая от пяти
аргументов. Первый аргумент— это обучающий экземпляр positive (X) или negative (X),
указывающий на то, что X является положительным или отрицательным примером. Второй
и третий аргументы — это текущий список гипотез и список отрицательных экземпляров.
В процессе реализации предикат process связывает четвертый и пятый аргументы с
обновленными списками гипотез и отрицательных экземпляров соответственно.
Первое выражение в этом определении инициализирует пустое множество гипотез
первым положительным экземпляром. Второе обрабатывает положительные обучающие
примеры путем обобщения гипотез-кандидатов для обеспечения покрытия этих
примеров. Затем ликвидируется чрезмерное обобшение за счет удаления всех гипотез, которые
являются более общими, чем другие, а также гипотез, покрывающих некоторые
отрицательные примеры. Третье выражение в этом определении служит для обработки
отрицательных примеров за счет удаления любых гипотез, покрывающих эти экземпляры.
process (positive (Instance) , [], N, [Instance], N) .
process (positive (Instance) , H, N, Updated_H, N) :-
generalize_set(H, Gen_H, Instance),
delete(X, Gen_H, (memberlY, Gen_H) ,
more_general(X, Y) ) , Pruned_H),
delete(X, Pruned_H, ImemberlY, N) ,
covers(X, YM, Updated_H) .
process (negative) Instance) , H, N, UpdatedJ, [Instance|N] ) :-
delete (X, H, coverslX, Instance), UpdatedJ).
Process (Input, H, N, H, N):- Ктслемзаян ошбо. ввода
Input \= positive(_),
^ТеГЪъет^т^пыоум^.ъкж пример positive (Instance) либо
отрицательный negative (Instance) '), nl.
Интересным аспектом этой реализации является предикат delete, представляющий
«бой обобщение обычного процесса удаления всех повторных вхождении -шнтаю
^ека. Один из аргументов этого предикат, используется для «£~^ ^
*менть, подлежат удалению из списка. С помошью предиката bagofпредикат dele^ е
"Роверяет соответствие своего первого аргумента (который обычно Г^^^.
^ому мемет7 ВТОрого ар[ушиа (который с*«за~о»с"^^«Х
Д"» каждого такого связывания выполняется проверка. У"^™ целевых ут-
^ента. Эта проверка представляет собой любую ^™~?™™™^Л,
«РЖдснии языка PROLOG. Если список элементов таков, что данная пгх в Р
лава 14. Введение в PROLOG
663
,„кат delete исключает этот элемент из ротирующего списка. рс.
неудачно, то прелат del ^ ар1уменг. Предикат delete- это прекрас„1
зульгат возвРашагГС"Х языке PROLOG. Имея возможность передавать спецификац™"
пример »mpaccj«-" ю спнска, программист тем самым получает общ!!
элементов вторые треб, J ^^ ^ ^^^ т^ предакат ^^ ^ «
средство реашгэациице. ,юполыуе„ыс в процедуре process, в очень ком
ляет «прелелятъ Различны. 4ЛШ.1Р м о6разом.
„акшой форме. Зададим предикат dele
deletelX, L, Goal, "™-L) j" not(Goal)), New_L) ; New_L = [ ]).
(bagoflX, (member (X, L> ,
Ппе-шкат generalize^ рекурсивно сканирует список гипотез и обобщает ка*.
™ ,о них в соответствии с обучающим примером. При этом предполагается возмож-
ж существования нескольких обобщений кандидатов одновременно. На самом даи
писанное в разделе 9.2 представление в виде признаков допускает лишь одно наиболее
конкретное обобщение. Однако в целом это неверно, поэтому необходимо определить
алгоритм для общего случая.
gSeraUzelsIt! [Hypothesis"! Rest], Updated.H, Instance) :-
not (covers (Hypothesis, Instance)),
(bagofIX, generalize(Hypothesis, Instance, X), Updated_head),
Updated_head = [ ]) ,
generalize_set(Rest, Updated_rest, Instance),
append(Updated_head, Updated_rest, Updated_H) .
generalize_set( [Hypothesis|Rest] , [Hypothesis | Updated_rest] ,
Instance) :-
covers(Hypothesis, Instance),
generalize_set (Rest, Updated_rest, Instance).
Правило specif ic_to_general реализует цикл для считывания и обработки
обучающих примеров.
specific_to_general(H, N) :-
write! 'H=') ,write(H) ,nl,write! 'N=' ) .write (N) , nl,
write('Введите пример:'),
read (Instance) , processdnstance, H, N, Updated_H, Updated_N),
specific_to_general(Updated_H, Updated_N) .
Следующий пример иллюстрирует выполнение алгоритма.
?- specific_to_general([], []).
N = [)
НВ:Д[рГ?еЛап1?,18та11'Геа'Ьа111)-
Ь^ЛНеГьЙ^"1^' --' -Ье„.
[[large, green, cube]]
нТ^ЛГ^Та!^'1^11'^, brickl).
BB™ieanp^e3pre^slCt^l; l£ma11' blue- brick] ]
H= [[small, !б6 balllt "^ ' ЗГевП' Ьа1Ш-
.Языки и технологии программирования для искусственного и
N = [[large, green cube), [small
введи^пример: positive, [large, blu^ba^^'
„, [[small, blue, brick], (large_ ^^
Вторая версия алгоритма, описанного в подразделе 9 7 7
да общего к частному. В этой версии множество mno™, v' ВЬШ0-™яет ™™ " направленга,
более общим среди возможных понятий. Для пмжтаилГ" ^™aTCB "™шалиэируега наи-
•да список переменных. Затем выполняется специализа, ° П0М0ЩЬЮ К1сгоРа признаков -
шаюшая покрытие отрицательных примеров В предстам™ ПОШГпш"канД1иатов. предотвра-
да операция сводится к замене переменных константами "* °С'ЮК K™f°B признаков
тельного примера удаляются любые гипотезы кЯм™„„ Р" полУченин нового положи-
Реадизация этого алгоритма во многоеан^кГ * П0Крь,вающм <™-
„ска от частного к общему, включая использование Гщё™ ГеГка™ 'Z*™0™* П°~
деления различных фильтров для списка понятий-кандидатов ^ 0Пре"
метр-это обучающий пр»,ер ви^оЕ^„еТС1сТГ пе^е^Т^"
второй- список пшотез-кандидатов, включающий наиболее общие плюсне То™'
вакэщие отрицательных примеров. Третий параметр - список положительны* npHM^oZt
пользуемый для удаления любых стишком спещкгшзнрованных пшотез-кандиэТтовТетвер:
тьш н пятый параметрь, - это обновленные списки пшотез и положительных примеров
ответственно. Шестой параметр - это список допустимых подстановок переменных для
специализации понятии. Дм специализации путем подстановки константы вместо
переменной следует знать допустимые значения каждого компонента вектора признаков Эти
значения необходимо передавать с помощью шестого параметра предиката process.
В рассматриваемом примере векторов [Size, Color, Shape] список типов может иметь
вид [[small, medium, large], [red, blue, green], [ball, brick, cube]]. Заметим, что
позиция каждого подсписка соответствует компоненту вектора признаков, в котором
непользуются значения этого списка. Например, первый подсписок определяет допустимые
значения первого компонента вектора признаков.
Реализацию этого алгоритма предлагается осуществить в качестве упражнения. Для
ориентировки приведем результаты работы нашей реализация.
?- general_to_specif ic( [ [ ]],[], [ [small,medium, large] ,
tred,blue,green],
[ball, brick, cube]]).
= I[_0, 1, 211
Цедите пример: positive([small, red, ball])
"' [[-О. _1. _2]]
r - [[small, red, ballj'
"едите пример: negative![large, green, cube]).
£ = ([small, _89, _90] , [_79, red, _80] . I_69. _70, ball] J
= [[small, red^ ball]]
ведите пример: negative([small, blue, brick]),
p [1-79, red, _80],[_69, _70, ball)J
- [[small, red, ball]] u ,, , ,
уедите пример: positive![small, green, ball]).
P ; _69, _70, ball]] ^ . 1in
- [[small, green, ball], [small, red, ball!!
aea 14. Введение в PROLOG
14.8.2. Алгоритм исключения кандидата
- ппитм исключения кандидата, описанный в подразделе 9.2.2, предс^.
Полный алгоритм исклгс' ных алгоритмов поиска. Его ядром тоже яв»
„собой комбинац^дв^одно^нр^ ^ ^^ ^^ аргуыент __ ^ »*
ется предикат ргос.в= , ^ „-.„р.,™ ~ " — " "
ет собой комбинацию двух од ^.^ mmf арГументов. Первый аргумент —
предикат ргосе^мви^ _ Q и s _ эт0 множсстаа максимально „6щих
„.... пример, в™Рн"ст1х гипотез соответственно. Четвертый и пятый аргументы с„„"
„ максимально к нкр гны ги ^^ Шестой ^„^ претт «
ветствуют обновленные'^™«ок для специализации векторов признаков. °
^-ГГ^рГеровпредикат process выползет о6о6ще„ие множества s
„antaee конкретных обобщений с целью покрытия этого примера. Затем „з S исключав
ся любые чрезмерно „бобшеиные элементы. Кроме того, из множества G тоже утияи
Гее элементы не обеспечивающие покрытия этого обучающего примера. Интересно отме-
тшь что элемент S является чрезмерно общим, если не существует покрывающих его эле-
ментов G Дело в том, что множество G содержит такие гипотезы-кандидаты, которые, с
одной стороны, являются максимально общими, а с другой — не покрывают
отрицательных примеров. Для удаления гипотез используется предикат delete.
При поступлении отрицательного примера предикат process выполняет
специализацию всех гипотез в G, чтобы исключить этот пример. При этом из S удаляются все
кандидаты, покрывающие этот отрицательный пример. Как указывалось выше,
специализация векторов признаков сводится к замене переменных константами. Для этого
требуется передать список допустимых подстановок в качестве шестого аргумента
предиката process. Определение предиката process имеет следующий вид.
process (negativednstance) , G, S, Updated_G, Updated_S, Types) :-
delete(X, S, covers(X, Instance), Updated_S),
specialize_set(G, Spec_G, Instance, Types),
delete (X, Spec_G, (member (Y, Spec_G) , more_general (Y, X)),
Pruned_G),
deletelX, Pruned_G, (member(Y, Updated_S) , not (covers (X, Y))),
Updated_G).
process (positive (Instance) , G, [], Updated_G, [Instance], _):-
%Инициализация s
deletelX, G, not (covers (X, Instance)), Updated_G) .
process (positive (instance), G, s, 0pdated_G, Updated_S, _) :-
deletelX, G, not (covers (X, Instance)), Updated G) ,
generalize_set(S, Gen_s, Instance)
P™eS)etX' Gen"S' (member<Y. Gen_s), more_general(X, YD,
deletelUpda™s7S' n°t<<member<Y. Updated.G), coverslY, X))),
process(Input, G, P, G, p, )._
S£,SS:iir~-H^Slvibnstance, ™«o
пример negativednstance):.) nl
Предикат generalize 4ei- „, ' . run»
тез-кандидатов с пел,,», „„.ГГ.! "f 0Л|«" обобщение всех элементов множен»
т™а версии, опрГГнГв'™ ;6ГГШеГ° ПР"МСРа- ЕГ0 PCM™M ° """"«"п "
программе поиска от частного к общему. В качеств-.
Часть V,. языки и технологии программирования дая искусственного инт**""
-„м он получает множество гипотез-кандидатов и ш»-г,
„йиализаиии этих гипотез, исключающие („е покрьтаютГЛг^ Макс"мальн0 °6и™>
--„имание „а использование предикатаЬадо£ Г^ГаГе^ГаГ^
4Decialize_set([], []._,_).
'^ЕиЖ"1'' SPeCiaU-(HVPOthesis, instance, Types,.
Updated_head = []),
specialize_set(Rest, Updated_rest, Instance, Types) ■-
append (Updated_head, 0pdated_rest, Updated_H) .
specialize_set([Hypothesis|Rest), [HypothesislUpdated rest!
Instance, Types) :-
not (covers (Hypothesis, Instance) ) ,
specialize_set(Rest, Updated_rest, Instance, Types).
Предикат specialize находит среди элементов вектора признаков тот, который
является переменной. Он связывает эту переменную с константой, выбираемой им из
списка допустимых значений таким образом, чтобы она не соответствовала обучающему
примеру. Напомним, что предикат specialize_set вызывает предикат specialize
с помощью предиката bagof для получения всех специализаций. При однократном
вызове предиката specialize он лишь подставляет константу вместо первой
переменной. Использование предиката bagof обеспечивает получение всех специализаций.
specialize( [Prop|_J , [Inst_prop|_] , [Instance_values[_j ) :-
var(Prop),
member (Prop, Instance_values) , Prop \= Inst_prop.
specialize! [_|Tail] , [_| Inst_tail) , IjTypesJ):-
specialize(Tail, Inst_tail, Types).
Определения предикатов generalize. mOre_general, covers и delete
совпадают с соответствующими определениями этих предикатов в программе поиска от
частного к общему. Предикат candidate_elim реализует цикл верхнего уровня, выводит
текущие значения множеств G н S, а также вызывает предикат process.
candidate_elim( [G] , [S], _) :-
covers(G, S), covers(S, G),
wite( 'целевое понятие: '), write(G) ,nl.
candidate elim(G, s. Types) :- _ ,,^ „„._„
«ite(.G:.),wrice(G),„T,write('S='),write(S), nl, write, •ьзе.ите
пример: '),
read(lnstance), _ ,
Process (Instance, G, S, Updated_G, UpdatedLS, Types) ,
candidate_elim(Opdated_G, Updated_S, Types).
В заключение этого раздела представим результаты трассировки ГФ££££
«"» кандидата. Обратите внимание на инициализацию множеств G и S, а также список
Допустимых подстановок. , , д
?- candidates, [[_._._]). П, Г Г—". -"»-■ ^ ' '"*'
blue, green),
tball, brick, cube])).
sr'J-0' -1. -2)1
1<*. Введение в PROLOG
667
G= [[_n< -*' -
S= [(small, red, ball]] green, cube]).
Введите пример: negaivel [large, g^7b (_?^ _?^ ^^
G= [(small, -96, »' . '- '
s= [[small, red, Ьа11Л Ыце_ brick] ) .
введите пример: negative!I baU])
G= [(_86, red, _87J , '», _
S= [[small, red, ball u en, ball]).
Введите пример: positive![small, g
G= [[_76, _77, ball]]
S= [[small, -351, Ьа1Ш re ball]).
Введите пример: .«"«"f '„ ^n]
target concept is: [_76, _".
yes
14.8.3. Реализация обучения на основе пояснения на языке PROLOG
В этом разделе будет описана реализация на языке PROLOG алгоритма обучения на
основе пояснения, изложенного в подразделе 9.4.2. Наша реализация основывается на
алгоритме prolog_ebg. предложенном в работе [Kedar-Cabelli и McCarty, 1987], и
иллюстрирует возможности унификации в языке PROLOG. Несмотря на то что на многих
языках достаточно сложно реализовать алгоритм обучения на основе пояснения, его
версия на PROLOG очень проста.
Этот алгоритм не строит структуру пояснения и не поддерживает отдельные
множества для подстановок обобщения и специализации, как это описано в разделе 9.4. В нем
дерево доказательства для обучающих примеров и обобщенное дерево доказательства
строятся одновременно.
В этом примере будут использованы деревья доказательств, аналогичные применяемым
в оболочке exshell (подраздел 14.7.2). При выявлении факта в системе prolog_ebg
этот факт возвращается как лист дерева доказательства. Доказательство конъюнкции целей
представляет собой конъюнкцию доказательств каждой из них. Доказательство цели,
требующее построения цепочки правил, представляется в виде (Goal :- Proof), г*
Proof связывается с деревом доказательства для предпосылок этих правил.
Ядром алгоритма является предикат prolog_ebg. Ои зависит от четырех
аргументов. Первый из них— это целевое утверждение, доказываемое с помощью обучающего
примера. Второй — обобщение цели. Если теория описания области определения
допускает доказательство конкретной цели, то третий и четвертый аргументы связываются с
деревом доказательства для цели и его обобщения. В частиости, прн реализации пример»
>п подраздела 9.5.2 нужно вызвать предикат prolog.ebg со следующими аргументами.
РГо1од_еЬд(сир(оВД1,, cup(X), Proo£ _ GenJroof)_
ДслегГГоб™!™ "а ЯЗЫКе PR0L0G представлена теория описания области опре-
рь рго1о^УеЬаГпаПРИМеР " ПОДР^ла 9.4.2. При успешном завершении Ф*№
™Гств,:9к^„ьГ„:;г.9Л7.о£ и Gen^r°°f ^°»ины с деревьями
подразделе 14.7 2 ОснпГ„ 9 ~~ Э™ Простая вариация метаинтерпретатора, 0<№ат'\.Ф
"«я выполняется парГеГьноТиГ С°"0ИТ В *>"■ ™ разрешение ^ И * ^
раллсльно. Еще од„„ интересный аспект алгоритма связан с исп°
ЧаСТЬ"'ЯЗЫКИИТеХН0Л0™^РограММироваииЯдлЯискуоствениогоИНтая"»^
^этого правила со значении из ^^^—^Z
prolog_ebg(A, GenA, A, GenA) :- clause (A, true)
prolog_ebg((A, В), (GenA,GenB), (AProof,BProof)'
(GenAProof.GenBProof)) :- ., Г0ОГ) '
prolog_ebg{A, GenA, AProof, GenAProof) ,
prolog_ebg(B, GenB, BProof, GenBProof)
prolog_ebg(A, GenA, (a :- Proof), (GenA :- GenProof > ) ■-
clause(GenA, GenB), " *
duplicate((GenA :- GenB), (A :- B) ) ,
prolog_ebg(B, GenB, Proof, GenProof).
Предикат duplicate основывается иа использовании предикатов assert и
retract для создания копии выражения PROLOG с новыми переменными.
duplicate(Old, New) :- assert('$marker'(Old) ) ,
retract ('$marker'(New)).
Предикат extract^support возвращает последовательность операционных узлов
наивысшего уровня согласно определению предиката operational. Он реализует
рекурсивный проход по дереву. Рекурсия прекращается при обнаружении узла в дереве
доказательства, квалифицируемого как операционный.
extract_support (Proof, Proof) :- operational (Proof) .
extract_support { (A :- _), A) :- operational (A) .
extract_support( {AProof, BProof), (A, B) ) :-
extract_support(AProof, A) ,
extract_support(BProof, B).
extract_support ( (__ :- Proof), B) :- extract_support (Proof, B) .
Последним компонентом алгоритма является построение изученного правила на
основе предикатов prolog_ebg и extract_support.
ebgfGOal, Gen„goal, (Gen_goal :- Premise)) :-
prolog_ebg(Goal, Gen_goal, _, Gen_proof) ,
extract_support(Gen_proof, Premise) .
Проиллюстрируем выполнение этих предикатов на примере изучения структурных
определений чашки из подраздела 9.5.2 [Mitchell н др., 1986]. Сначала опишем теорию
предметной области чашек и других физических объектов. Эта теория включает
следующие правила.
CUP(X) :- liftable(X), holds_liciuid(X) .
holds_liquid(Z) :- part(Z, W), concave (W), points_up (W) .
liftable(Y) :- light(Y), part(Y, handle).
light(A) :- small (A) .
aight(A):~ made_of(A, feathers).
Обучаемой системе также дается следующий пример, о котором известно, что
°Ь]1 —чашка.
smaU(ob:jl) .
»rt(c,b;jl, handle) .
owns(bob, objl)
'4. Введение в PROLOG
669
J).
J).
p.i-tlobil. bottom),
psrtlobjl, bowl).
points,up(bowl).
concave(bowl)•
C° с пом^ю ^ -P—" 0ПРСЯСЛ"М ПРСД"КЭТЫ' К°таРЫС т"° "СП°ЛЬ-
зовать в правиле.
operational(small (->)
operational(part(_.
operational (owns (_,
operational(points_up )).
operational(concave(_)).
З.„уск алгоритма для этого примера иллюстрирует поведение эти, предикатов.
?-prolo3_eb3,cup,objl), cup(X). Proof. Genjroor).
X = _0,
Proof = CUp(objl) :-
((liftable(objl) :-
I (light(objl) •.-
smalHobjl)), part(ob:l, handle))),
(bolds_licraid(objl) :-
(part(objl, bowl),
concave(bowl) , points_up(bowl) ) ) )
Gen_prooof = cup(_0) :-
((liftable(_0) :-
(llight(_0) :-
small(_0)),
part(„0, handle))),
(holds_lieruidl_0) :-
(part(J), _106),
concave(_106),
points_up(_106))))
Если предикату extract_support передать обобщенное дерево доказательства,
полученное после выполнения предиката prolog_ebg, то он возвратит операционные
узлы дерева доказательства, упорядоченные слева направо.
?- extract_support((cup( 0) :-
mutable (_01 :-
KlightTj) !-
small(_0)),
part(_0, handle))),
(holds_liquia(_0) :-
(part(_0,_106), concave|_106)
_0= 0, 10nntrUPI-1O6)l)l»'Premise),
po1nt::u;,!irllTJ,'part,-°'handie".p«t<-°.j>. ««.«ui.
И, наконец, предикат eba исппп^„„
нового правда на„ен„веПРе9д:г„:0у;^;:;;:;ныо выше ,1роцсдуры для
?-=вЬа(сир(оЬП), cupoc,, Ruie).
пострче»»»
,в = сир(_0) :-
,1 snail<_<». part(_0,handle)),part(
^„«.UPCUO,,
,_110), concave(_ll
").
14.9Д)бработка естествениого^змкяня PROLOG
14.9.1. Семантические представления для обработки
естественного языка
Благодаря встроенным возможностям поиска и проверки соответствия шаблонам
язык PROLOG органично подходит для решения задач обработки естественного языка
Грамматику естественного языка можно описать на PROLOG напрямую, как это будет
сделано при описании контекстно-независимой и контекстно-зависимой грамматик в
подразделе М.9.2. На PROLOG легко создать и семантические представления, в чем мы
сможем убедиться при описании падежных фреймов в этом разделе. Семантические
представления также можно реализовать либо с помощью теории предикатов первого
порядка, либо на основе метаинтерпретатора для другого представления, как было
предложено в подразделе 14.7.4. И, наконец, семантический вывод, в том числе объединение,
ограничение и наследование в концептуальных графах можно напрямую описать на
языке PROLOG, в чем читатель сможет убедиться, прочитав подраздел 14.9.3.
Как известно нз раздела 6.2, концептуальные графы можно преобразовать в
выражения теории предикатов, а значит, напрямую описать на языке PROLOG. Имена узлов
концептуальных отношений становятся при этом именами предикатов, а арность
отношения определяет количество аргументов. Каждый предикат PROLOG, как и каждый
концептуальный граф, представляет одно предложение.
Концептуальные графы, представленные на рис. 6.11. на языке PROLOG можно
описать следующим образом.
bird(X), flies(X) .
а°Э(Х), color (X, Y) , brown(Y).
child(X), parents(X, Y, Z) , £ather(Y), mother(Z).
Здесь X, Y и z — переменные, связанные с соответствующими объектами. Как было
Указано в разделе 14.6. к параметрам можно добавить информацию о типах. С помощью
вариации предикатов isa можно также определить иерархию типов.
Падежные фреймы, введенные в подразделе 13.3.2, тоже очень легко построить на
«икс PROLOG. С каждым глаголом связывается список семантических отношении.
сРеди ннх могут быть агенты, инструменты и объекты. Ниже будут рассмотрены прпмс-
Р" ДДя глаголов give (давать) и bit, (кусать). Например, глагол „,« "^"^""^
"Лежащим, дополи „нем и непрямым дополнением. Очевидным примером ре^з ци.
*™ ^уктур является английское предложение "John g,veS Магу the took ««*
£? книгу,. Применяемые по умолчанию значения »°- J^^rLl Z
fP'HMe. связав „х с соответствующими неременным,.. Hd"P""P'^7ee№ (зубы) -
<«*•»> можно определить используемый по умолчанию и «с*-" ^^™ши
«оатъ, что и„струмс„т для кусания (foe*) принадлежит а, ент, Пал
т этих двух глаголов moot иметь следующий вид.
Ver»(3ive,
Ihuman (Subject),
670 ЧаСТЬ"'Я~~^ ГЛаВаИ.Вввденивврношс
671
>
agent (Subject give).
human (1по_оЬт) I 1 ■
verb(bite,
[animate (Sub:ect),
agent (Subject, Action),
act of_biting (Action)
object (Object, Action),
animate (Object),
instrument (teeth Action
part_o£ (teeth. Subject) ] )•
„т„..кшппвание предоставляет широкие возможности для построения
JrrSST^cKHX «.«ний. Д-ее „a PROLOG будут „острое™
Дивные анализаторы, а затем к ним будут добавлены семантические ограничен,,,.
14.9.2. Рекурсивный анализатор на языке PROLOG
Рассмотрим приведенное ниже подмножество правил грамматики английского языка.
Эта правша являются непроцедурными, поскольку просто определяют отношения
между частями речи. С помощью этого подмножества правил можно определить
корректность многих простых предложений.
Sentence<->NounPhrase VerbPhrase,
NounPhrase<r-*Noun,
NounPhrasetriArticle Noun,
VerbPhrase*^* Verb,
VerbPhrasetriVerb Nounphrase.
Добавим к этим правилам грамматики небольшой словарь.
Агп'с/е(а),
Arhde(fhe),
Noun(man).
Noun(dog},
Verb[likes).
Verb(bites).
На рис. 14.9 показано дерево грамматического разбора предложения "The man t*>
the dog , в котором связь and соответствует конъюнкции в правилах грамматики. Л1
правила естественным образом описываются на PROLOG. Например, предложение sen-
рукц^Г "to Г""" К°НСТРУКЦИЯ "°™Phrase, за которой следует глагольная коне
sentence(Start,End)
Каждое правило на PROLOG
- nounphrase!Start, Rest), verbphrase(Rest
End)'
зависит от
двух параметров, первый из
которых
приставляет собой ПОСледоват™, „„ " ' "арчмефои, перт" '„«гЯ*»"
некоторая шШШ^^"т ' *°Р» ™ Правило "P-P^U*
должен соответствовать в™ Д0П>'СТИМ0Й частью речи. Оставшийся суффи" ,.
твовать второму параметру, поскольку анализ предложений вь.по»
Часть и. языки и технологии программирован™ для искусственного ии1***"
ся слева направо. Если правило описания предложения „»«
параметр предиката sentence представляет собой оста? " Утешно, то второй
„ученную после разбора фраз nounphrase н verbnh УЮСЯ часть пРеДложения, по-
собой корректное предложение, то в остатке получается^' ^°Л" СПИС0К ПРедставл*"
ной „ именной конструкции определяются две альтеоня™?"""lсписок [' ■ Д™ глаголь-
упашвные формы описания.
I Sentence ,
Рис. 14.9.
Дерево грамматического разбора
И/ИЛИ для предложения "The man bites the dog "
Для простоты само предложение тоже описывается в виде списка [the, man,
bites, the, dog]. Список разделяется на составляющие и передается различным
грамматическим правилам для проверки синтаксической корректности. Обратите внимание
на то, как выполняется проверка соответствия шаблонам для списка в вопросительном
предложении. Сначала отбрасывается голова списка или голова со вторым элементом, а
предикату передается оставшаяся часть списка и т.д. Предикат utterance в качестве
параметра получает подлежащий анализу список и вызывает правило sentence. При этом
второй параметр правила инициализируется пустым списком [ ]. Полная грамматика
определяется следующим образом.
utterance(X) :- sentence(X, [ ])■
sentence (Start, End) ■- nounphraselStart, Rest), verbphrasefRest,
End) .
nounphrase( [Noun | End) , End) : - noun (Noun) .
nounphrase ((Article, Noun | End], End) :- article (Article) ,
noun(Noun).
nounphrase(Rest, End).
^rbphrase([Verb|End] , End) :- verb (Verb) .
'«rephrase! [Verb I Rest], End) : - verb(Verb) ,
artlcle(a)
«ticle(th .
n°un(man)
"°un(dog)
,Ver»(likes)
Verb(bites) .
Т«"Ч>ь можно проверять корректность построения конкретны* предложений.
iterance ( [the, man, bites, the, dog])■
"*■ Введение в PROLOG
673
h-ii-^s the]) •
Iterance![the. man, bites.
'„статор может также преложить возможные варианты слов для „^
предложеншш.
,_ utterance([the, man, like.. X)) .
X = man
X = dog
no
И наконец этот же код можно использовать для построения множества всех предл„.
жени'й Грректно сконструированных в рамках данных правил граыматикн и ограни^,
ного словаря.
?- utterance(X).
[man, likes]
[man, bites]
man, likes, man]
[man, likes, dog]
и т.д.
Если пользователь продолжает запрашивать решения, то в результате он получит все
возможные корректно сконструированные предложения, которые могут быть
сгенерированы на основе заданных правил грамматики и словаря. Заметим, что PROLOG
выполняет поиск в глубину слева направо.
Правила грамматики — это спецификация корректных конструкций выражений в данном
подмножестве легитимных предложений английского языка. Код на языке PROLOG
представляет этот набор логических спецификаций. Интерпретатору передаются запросы об этом
наборе. Таким образом, ответом является функция от спецификации и заданного вопроса.
В этом состоит основное преимущество вычислений на языке, который сам представляет
собой систему доказательства теорем на основе спецификаций. Более подробная информация о
PROLOG как системе доказательства теорем приводится в главе 12.
Предьшущий пример можно естественным образом расширить, добавив к нему
условия согласованности форм существительного и глагола. Тогда для каждого элемента
словаря необходимо указать форму этого слова в единственном н множественном числе,
а для предикатов nounphrase н verbphrase ввести дополнительный параметр,
отражающий числовую форму number данной фр^ы в этом е существнтель„ос а
кГтеГГИСЛе Д0ЛЖН° бЫТЬ СМЗано с ™™™м " Форме единственного числа,
пая ВыщеТеГ„я3аВИСВМ0СТЬ с^стае««» повышает мощность грамматики. Прнве »
екетГ а „™1 ИЗУ" контекс™°-незавнс„мую грамматику. Теперь построим кон
теГна, „ифорГииТ™?^ " ИЬШе ™°LOG (раздел 13.2^В ней сохраняется
ДификГщ^с^язеа°чХ0ДИМаЯ *" ПР0КРК" соответствия формы числа. Такая
utterances, ,. mJ^T^^^^
sentence(Start, End) * J} '
verbphrase (Rest ^/TP ase (Start, Rest, Number),
' bnd. Number).
K0«-
nounphrase([Noun|EndJ, End, Number)
nounphrase {[Article, NounlEnd] EnH '« n°Un(N°un, Number)
article{Article, Number) d' Number) :-noun(Noun
verbphrase([Verb|End], End, Number) •
verbphrase ([Verb | Rest], End Numb ' "~ verb{Verb, Number).
nounphrase (Rest, End, _) ' verb(Verb, Number)
noun(Noun, Number),
articlefa, singular,.
article{these, plural).
article(the, singular).
article{the, plural).
noun(man, singular),
noun(men, plural).
noun{dog, singular).
noun(dogs, plural).
verb(likes, singular).
verb(like, plural).
verbfbites, singular),
verb{bite, plural).
Теперь снова протестируем предложения.
?- utterance ([the, men, like, the doa] )
yes '
?- utterance ([the, men, likes, the, dog])
no
глагш 7illl ГГ "°ЛУЧеН 01рВДаТеЛЬНЬ1Й °™«- ^скольку существительное men „
глагол Ukes не согласуются по числу. Если в качестве целевого утверждения ввести
?- utterance([the, men|X]).,
то этот предикат с помощью параметра X вернет все глагольные конструкции,
дополняющие фразу "the men...", в которых числовая форма существительных н глаголов будет
согласована. '
В рассмотренном примере взятые из словаря параметры обеспечивают дополшггельную
информацию о значениях слов в предложении. Обобщая этот подход, можно построить
мощный грамматический анализатор естественного языка. В словарь можно включать все новую и
новую информацию о членах предложения, создавая базу знаний о значениях слов
английского языка. Например, люди являются одушевленными н социальными объектами, а собаки —
одушевленными и несоциальными. Тогда можно добавить новые правила типа "Сощгальные
екты не кусают одушевленных несоциальных существ". Это позволит исключить предло-
ения типа [the, man, bites, the, dog J. Если же несоциальный объект больше не
егся одушевленным, то его, конечно же, могут съесть в ресторане.
МАЗ. Рекурсивный анализатор на основе семантических сетей
Теперь расширим множество контекстно-зависимых правил грамматики, включив в
его условия семантической согласованности. Это можно сделать, определив для падеж-
нЫх фреймов глаголов соответствующие семантические описания подлежащил и допол-
аений. Затем ограничим полученные подграфы семантических сетей, обеспечив их
взаимную согласованность. Это достигается с помощью таких операций над графами, как
"Уединение н ограничение. Они выполняются для каждой части графа, возвращаемой в
Качсстве дерева разбора.
14. Введение в PROLOG
675
пимматнки. Заметим, что предикат самого верхнего
Сначала представим "Pf""^предложение, а граф предложения Sentence <ТЩ
utterance возврашает не про. ' (nounphrase и verbphrase) в;"3511
Прея»™ --^ГогрГе^ соответствующих графов,
предикат j oin л>
uttera„ce<X sentence graph,^-raphb
S8nt,=tart' End,' sentence_graph> :-
sentence (Start, ™a subject_graph) ,
nounphrase Start, Res predicate_graph) ,
verbphrase (Rest g Predicate_graph, Sentence_graph)
„„ЖЖГ^: fd „hrase.graph, s-
article (Article),
noun (Noun, Noun_phrase_graph) .
verbphrase ([Verb | End], End, Verbjhrase.graph) :-
verblVerb, Verb_phrase_graph) .
verbphrase ([Verb | Rest], End, Verb_phrase_graph) :-
verb(Verb, Verb_graph) ,
nounphrase (Rest, End, Noun_phrase_graph) ,
join! [object (Noun_phrase_graph) ] , Verb_graph,
Verb_phrase_graph) .
Опишем предикаты для выполнения операций ограничения и объединения графов.
На самом деле они представляют собой метапреднкаты, поскольку оперируют другими
структурами PROLOG. Их можно рассматривать как утилиты, реализующие ограничения
для объединяемых фрагментов семантических сетей.
join(X, X, X).
join!A, В, С) :-
isframe(A), isframe(B), !,
join_frames(A, в. С, not_joined).
join(A, В, С) :-
isframe(A), is_slot((B), !,
join_slot_to_£rame(B, A, C).
join(A, в. С) :-
isframe(в), is_slot(A), !,
join_slot_to_£rame(A, в с)
join(A, в, С) s-
is_slot(A), is_slot(B) i
J°in_slots(A, B, c).
(своПй™а1КпТ,п:'01ПдГ£?аГПе3 РекУРсивно проверяет соответствие каждой ячейк»
« к™ ^ I*"5™"46™3" ""*»"■ Предикат join_slot_to_£rame полу-
.«^ s;ч п?и фрейм и находит -э™ ^мг ячей№ ст.-
с Учетом иерархии т„пов *' Р *""" 1°™-^°^ проверяет соответствие двух
join_frames(ГА 1 ш
i°^-^tij^.A°.cOK, :-
. . ^injramesm с n' I ' DI ' 0K> ■'~
3w*-£»««т.»:A;°vk)- '■■
ячеек
join_slot_to_£rame(A, [B | c], [D | c] ) : -
join_slots(A, B, D).
join_slot_to_frame(A, [B | c) , [B | D)) :-
join_slot_to_frame(A, C, D).
join_slots(A, B, D) :-
functor(A, FA, _) , functor(B, FB, _) ,
match_with_inheritance(FA, FB, FN),
argd, A, Value_a) , arg(l, B, Value_b),
join(Value_a, Value_b, New_value) ,
D =.. [FN | [New_value]].
isframe![_ | _] ) .
isframe![ ]).
is_slot(A) :- £unctor(A, _, 1),
И, наконец, создадим словарь, представляющий собой иерархию иерархий, и опишем
падежные фреймы для глаголов. В рассматриваемом примере будем использовать простую
иерархию, в которой перечислены все корректные специализации. Третьим аргументом
предиката match_with_inheritance является общая специализация первых двух. Более
жизненная реализация должна содержать граф иерархий, на котором выполняется поиск общих
специализаций. Предлагаем читателю выполнить это в качестве упражнения.
match_with_inheritance(X, X, X).
match_with_inheritance(dog, animate, dog).
match_with_inheritance(animate, dog, dog).
match_with_inheritance(man, animate, man).
match_with_inheritance (animate, man, man),
article(a) .
article(the).
nounffido, [dog(fido)]).
nounfman, [man(X)]).
nountdog, [dog(X)]).
verbflikes, [actionf [liking(X) ] ) , agent ( [animate (X) ]) ,
object (animate(Y)))]).
verblbites, [action!(biting(Y)]), agent([dog(X) ]) ,
object (animate (Z) ] ) ] ) .
Теперь проанализируем несколько предложений и выведем граф Sentence_graph.
?- utterance ( [the, man, likes, the, dog], X).
X= [action! Iliking(_54)J) , agent ([man(_23) ]) , object ([dog(_52) ]) J .
?- utterance![fido, likes, the, man], X).
X= (action! [liking(_62)l ) , agent ( [dog(fido) ]) ,
object ([man(_70)])].
?- utterance!(the, man, bites, fido), Z) .
no
В первом предложении утверждается, что некоторый человек, имя которого
неизвестно, любит безымянную собаку. Последнее предчожение, несмотря на свою
синтаксическую корректность, не удовлетворяет семантическим ограничениям, поскольку
агентом глагола bites должна быть собака. Во втором предложении конкретная собака Фидо
любит безымянного человека. В последнем примере проверим, может ли Фи» укусить
безымянного человека.
'- utterance! (fido, bites, the, man], X).
x= [action((biting<_12>]>. agent ([dog (fido) ]) , ob-
]ect([man(_17)]) ] .
]4. Введение в PROLOG
677
™„ иожно оасширять во многих интересных направлениях, в ча„,
добавить к «£""« «общения нужно вьючить в граф прад^**»»-
^зГГи,— „о"^ иметь несколько значений^ допустимых толькоТрТ^
дС—рых обших требований к предложению. Дополнительные примерь, ^
дятся в перечне упражнении.
J4.10. Резюме и дополнительная литература
В таких традиционных языках программирования, как FORTRAN и С, логика описа
ния задачи и управление выполнением алгоритма решения неразрывно связаны друг с
другом. Программа на таком языке— это просто последовательность действий, выпол
няемых для получения ответа. Такие языки называются процедурными (procedural)
В PROLOG логика описания задачи отделена от ее выполнения. Как следует нз глав 5-7
на это существует множество причин.
Не стоит и говорить, что PROLOG еще не достиг состояния полного совершенства
Однако уже сейчас можно показать, что логическое программирование, реализуемое на
языке PROLOG, обладает некоторыми преимуществами непроцедурной семантики.
Рассмотрим пример декларативной природы PROLOG. Возьмем предикат append
append([ 1, L, L).
append([X|TJ , L, [X|NL]) :- append(T, L, Nb) .
Он является непроцедурным элементом, поскольку определяет отношения между
списками, а не набор операций по их обьедннению. Следовательно, различные запросы
могут приводить к вычислению различных аспектов этого отношения. Чтобы лучше
понять предикат append, можно провести трассировку процесса объединения двух
списков. Вот пример запроса н ответа.
?- append!(а, Ь, с], [d, ej , Y)
У - la, b, с, d, e)
че^пГ'1™ ПРеДНКаТа 3PPend He РекУРс«вно по хвосту, поскольку конкретные зна-
доЗьио" пТ* Я0СТИГаЮ™ после ушного завершения рекурсивного вызова. Сле-
ГхТГ, L МВеРШеН1М "дивного вызова X располагается в голове списка
след'Хи^ ;~r Не0бМДИМ° 3аП™" » <™ PR0L0G- P™"M
1. append([ J, l, L)
2. append![X|T], L, [X|nl])
append![a, b
try match 1
match 2,
td, e]
match 1, l is [d el If
yes N is [a, e], [XJNL i"[cB°™ P"™6^"'■ У"
yes, ML is [c, d, el rx m . ' d' el
yes, NL is [b, c, d, e] Ж 1.lsrlb- =■ *. el
y= [a, b, c, a, e], yes '^ 1S [a' b' =■ d. el
В большинстве алгоритмов PROLOG папане™ „„.,
"входные" и "выходные", поскольку в большинстве Z - М°ЖН° РаЗЯСЛИТЬ "а
при вызове предиката некоторые параметр"™быГГ" ПрСДПОЯага™' ™
Но это не обязательно так. На самом делГпарГГы в PROLOgT'6 " ^"^ ""'
входные и выходные. Код на PROLOG — это ™™ fKULOG вообц1е не делятся на
верждений или описание логики ситуации В частГсГГТ"^™* """""^ ^
отношение между тремя списками при котоппм 1^-Р PPend 3№" такое
вставки первого в начало второго Р ^""" С"Ж0К ЯВЛЯется Результатом
ванГрЗГЛаЮрг1ГВа1Ъ ЭТ° ™"' -*»•*»» Разные варианты „спользо-
?- append![а, Ь], [с], [а, Ь, с]),
yes
append![а], [с], [а, Ь, с]).
с] , [a, b, cl) .
по
?- appendix, [b, cl
X = [а]
?- appendix, Y, [a, b, c])
X = [ 1
Y = [a, b, c]
X =
Y =
X =
Y =
X =
Y =
[a]
[b.
[a,
[c]
(a,
[ ]
c]
b]
b.
В последнем запросе PROLOG возвращает все списки X и Y, которые в результате
конкатенации дают список [ а, b, с ] — всего четыре пары списков. Как было указано
выше, append — это описание логики отношения между тремя списками. Результат
работы ннтерпретатора зависит от запроса.
Решение задач на основе множества спецификаций корректных отношений в данной
предметной области в сочетании с работой системы доказательства теорем связано со
многими интересными н важными аспектами. Такое средство находит свое применение в столь
разнообразных областях знаний, как понимание естественного языка, обработка баз дан-
Иы*, написание компиляторов и машинное обучение. Работу интерпретатора PROLOG
нельзя до конца осмыслить без осознания понятий из области доказательства теорем
резолюции, особенно процесса опровержения хорновских дизъюнктов, описанного в главе 12.
PROLOG — это язык программирования общего назначения. В связи с
ограниченностью объема книги в этой главе были опущены его многочисленные важные аспекты.
Любознательному читателю автор рекомендует познакомиться со многими
замечательна 14. Введение в PROLOG
679
rrlnrksin и Mellish, 1984]. [Maier и Warren, 1988], rSter,.
ными книгами, в том ™^*^, 1993]. [Lucas. 1996] „ли [Ross. ,989]. i **»
Shapiro, 1986J,[0'Keefe. 1«М« • при„енеиие языка PROLOG eo „Г*
[King, I9911. [Gazdar » « ''^ '^„„„го интеллекта,
важных приложениях теор pR0LOG. а твкже предложения по созданию алггт.
ГГкоГпраС и"в доказательств при разработке экспертных систем „„„^
[Sterling и shapi"m'f6jcc „ваются вопросы построения таких представлений искус
^оГГ:"Гсе1нт„ческ„е сети, фреймы и объекты [WalKer „ др„ ^
[М Средс187представления языка PROLOG настолько органично подходят для решения
задач понГа! естественного языка, что PROLOG часто „спользукгг для модел„рова„щ
X языков Первый интерпретатор PROLOG был разработай для анализа фра„цузСК0Г0
языка на основе грамматики .метаморфоз (metamorphosis grammar) [Colmerauer, 1975].
В [Pereira и Warren. 1980] создана грамматика определенных дизъюнктов (definite clause
grammar) Свой вклад в развитие этой области исследований внесли работы [Dahl, 1977]
pahl и McCord, 1983], [McCord, 1982], [McCord, 1986], [Sowa, 1984], [Walker и др., 1987].
Интеллектуальные корни языка PROLOG уходят к теоретическим принципам
использования логики для описания задач. В этой области автор особенно рекомендует книга
[Kowalski, 1979о, 19796].
Неослабевающий интерес вызывают и другие, отличные от PROLOG, среды
логического программирования. К ним относятся параллельные языки логического
программирования [Shapiro, 1987]. В [Nadathur н Tong, 1999] описан Lambda-PROLOG — язык
логического программирования более высокого уровня. В работе [Hill и Lloyd, 1994]
предложен язык Goedel, а в [Somogyi и др., 1995] — язык Mercury. Goedel и Mercury — две
относительно новые среды декларативного логического программирования.
14.11. Упражнения
1. Создайте на языке PROLOG реляционную базу данных. Представьте кортежи данных >
виде фактов, а ограничения— в виде правил. В качестве примеров можно рассмотреть
базу данных товаров в универмаге или записей о сотрудниках в отделе кадров.
2. Напишите на языке PROLOG программу, решающую задачу Вирта "I am my own
grandfather (Я - мой собственный дедушка) (глава 2, упражнение 12).
' гооГ!Гэт"а PR°L0G пР01?аммУ проверки принадлежности элемента списку. Что
Х обоТ;, „""Г"6" "е пРииад»аи" списку? Дополните эту спецификацию га-
ким образом, чтобы „на позволяла разбивать список „а элементы
ГМС™^Г„„Тк0отПРО-'ТаММУиП1дие(Ва9' ЗеСкоторойпередаетс.;;
возвращает пS ГГ" тЖ" С°Держать "Меряющиеся элементы), г *
5. На„„шите „/р^ад МИ0ЖеС1В° б" повторяющихся элементов),
(список в списке счи™ рограммУ вычисления количества элементов в я»
™мов в списке (вычис^нГ"™ ЭЛемеитам>- Разработайте программу по*
можно воигальзовати.. „... количссггаа элементов во всех подсписка-
"сколькими метапрсдикатами типа atom О .
6. Напишите на PROLOG код программы, решающей задачу перевозки человека волка,
козы и капусты.
6.1. Выполните этот код и постройте граф поиска.
6.2. Измените порядок следования правил для получения альтернативных путей решения.
6.3. Используйте оболочку, описанную в этой главе, для реализации поиска в ширину.
6.4. Опишите полезные для данной задачи эвристики.
6.5. Постройте решение иа основе эвристического поиска.
7. Выполните задания 6.1-6.5 из упражнения 6 для следующей задачи.
Три миссионера и три каннибала стоят иа берегу реки и хотят переправиться через
нее. У берега находится лодка, в которую могут поместиться только два человека, и
ни одна из групп ие умеет плавать. Если на одном из берегов реки миссионеров
окажется больше, чем каннибалов, то каннибалы превратятся в миссионеров. Требуется
найти последовательность перемещений всех людей через реку, ие влекущую за
собой никаких превращений.
8. Воспользуйтесь своей программой для решения модифицированной задачи
миссионера и каннибала. Например, решите эту же задачу для 4 миссионеров и 4
каннибалов, если лодка может перевезти только двух человек. Решите эту же задачу для
случая, если в лодке помещается трн человека Постарайтесь обобщить решение на
целый класс задач миссионера и каннибала
9. Напишите программу иа PROLOG для решения полной задачи хода конем 8x8.
Используйте при этом архитектуру продукционной системы, предложенную в этой
главе и главе 5. Выполните задания 6.1-6.5 из упражнения 6.
10. Выполните задания 6.1-6.5 из упражнения 6 для задачи о кувшинах с водой.
Есть два кувшина, содержащие 3 и 5 литров воды соответственно. Их можно заполнять,
опорожнять и сливать воду id одного в другой до тех пор, пока один из них не окажется
полным или пустым. Выработайте последовательность действий, при которой в большем
кувшине окажется 4 литра воды. (Совет: используйте только целые числа.)
11. Воспользуйтесь алгоритмом path для решения задачи хода конем в этой главе.
Перепишите его вызов в рекурсивной форме вида
pathlX, Y) :- pachlX, И), move(W, V).
Выполните трассировку и опишите результаты.
12. Напишите программу передачи значений на верхний уровень дерева или графа игры.
Используйте при этом:
а) минимаксный подход;
б) отсечение дерева альфа-бета;
в) оба подхода для игры в "крестики-иолики".
13. Напишите иа PROLOG программу реализации процесса поиска для алгоритма
финансового консультанта, описанного в главах 2-5. Воспользуйтесь архитектурой
продукционной системы. Чтобы сделать программу интереснее, добавьте несколько правил.
14. Допишите код для системы планирования из раздела 14.5. Рк^"^
требующую нового множества перемещений, добавив такие фигуры, как пирамида
или сфера.
14. Введение в PROLOG
681
, ^ „ланнровщнк на основе поиска в ширину для примера из разд
'5' дХ^тоТ^Р'™? соогвехстзуюшне эвристики. Можно ли опреде^
ГТ^^ГшиЧ»-»» ^>WWy' П°ЛОбНУЮ ТРСУГОЛЬН0Й та^'«е. Ис,,
16. Создайте для nw* „^„„я успешных последовательностей перемещений
ivihe ее для сохрин1'",,л
17 СоГайте .шиши набор предикатов АТД для приоритетной очереди из раздела ^
|8 Гешгэуйте проверку соответствия типов, позволяющую предотвратить аномалИ10
вида append(nil, б, б).
,9 Действительно ли процедура конкатенации разностных списков выполняется за лн-
' нейное время (раздел 14.6)? Поясните.
20 Создайте базу данных товаров из подраздела 14.6.2. Реализуйте проверку соответст.
вия типов для набора из шести запросов на множестве этих кортежей данных.
П Дополните определение языка PROLOG в PROLOG (раздел 14.7), включив в wn
оператор отсечения и операции логического II и ИЛИ.
22 Добавьте новые правила к оболочке exshell. Добавьте новые подсистемы для вы.
явления неисправностей коробки передач или тормозов.
23. Создайте базу знаний доя новой предметной области оболочки exshell.
24. Работа оболочки ex-shell завершается неудачно, если предложенное целевое
утверждение нельзя доказать с помощью существующей базы правил. Дополните
оболочку exshell таким образом, чтобы при невозможности доказательства цели она
вызывала эту цель как запрос PROLOG. Добавление этой возможности потребует
изменения предикатов solve и build_proof.
25. Оболочка exshell позволяет пользователю отвечать на запросы, вводя степень
доверия или запросы why и how. Дополните эту оболочку таким образом, чтобы
пользователь мог вводить ответы у для истинных запросов нп — для ложных. Эти
ответы должны соответствовать степеням доверия 100 и -100.
26. Вспомшгге концептуальные графы, используемые для описания "мира собак" в
разделе 6.2. Опишите эти графы на PROLOG. Разработайте правила PROLOG дм
операций restrict, join и simplify. Совет: создайте список предложений,
конъюнкция которых составляет граф. Тогда операции на графах будут соответствовал,
операциям управления списками.
27. Реализуйте систему на основе фреймов с наследованием, поддерживающую определение
трех видов ячеек: свойств класса, наследуемых подклассами свойств, наследуемых
экземплярами данного класса, но не его подклассами, и ненаследуемых свойств класс*
Опишите преимущества и проблемы, связанные с таким разграничением.
*1™2Т™Т " °6Ш£Г0 К ЧаСТНОМ? ■ пространстве версий с использован»*-
чГГеГпеГ <РПДМ 9ЛЛ)- С™н™"3ация вектора признаков выполняете.*
Z^Z"T К°Н™нтам«- Поскольку для этого требуется указать ал£
люстрирует необхол.,1 Следующее определение цели верхнего И**"
^L^Z«Lmmmmm *» усмотренного примера. 0«*£
« »««ь Форму шарГ брусГГи™^" б0ЛЬШ"М"' КраСНЫМИ' СИНИМ" '""'
run_general :-
general_to_specific([ [_, _,_)], []
[[small, medium, large], [red, blue! green), [ball, brick,
cube]]).
29. реализуйте теорию описания предметной области для примера из главы 9. Запустит»
этот пример с помощью команды prolog_ebg.
30. Дополните определение предиката ebg таким образом, чтобы после построения
нового правила оно добавлялось в логическую базу данных и могло использоваться в
последующих запросах. Проверьте производительность полученной системы с
помощью теории достаточно богатой предметной области. Такую теорию можно
построить самостоятельно либо дополнить теорию из примера с чашками, добавив
в нее описание различных типов чашек, например, чашек без ручки.
31. В главе 15 приводится реализация алгоритма ID3 из главы 12 на языке LISP.
Создайте с ее помощью реализацию этого алгоритма на языке PROLOG. He пытайтесь при
этом просто перевести код LISP на PROLOG. Эти языки различны и, подобно
естественным языкам, для описания одних и тех же объектов требуют различных идиом.
Придерживайтесь стиля PROLOG.
32. Постройте на PROLOG ATN-анализатор из подраздела 13-2.4. Добавьте вопросы
who и what.
33. Напишите на PROLOG код для подмножества правил грамматики английского языка
(раздел 14.9). Добавьте к рассмотренному примеру:
а) прилагательные и наречия для модификации глаголов и существительных;
б) вводные фразы (можно ли сделать это с помощью рекурсивного вызова?);
в) сложные предложения (два предложения, объединенные операцией конъюнкции)-
34. Описанный в этой главе простой анализатор естественного языка допускает
грамматически корректные предложения, которые могут иметь недопустимое значение,
в частности "The man bites the dog" (Человек кусает собаку). Такие предложения
можно исключить из грамматики, добавив в нее данные о семантической
допустимости. Разработайте на PROLOG небольшую семантическую сеть, позволяющую
рассуждать о некоторых аспектах возможной итерпретации грамматических правил
английского языка.
35. Переработайте анализатор на основе семантических сетей ю подраздела 13.3.2.
обеспечив более богатое представление класса иерархий. Перепищите определение
предиката match_with_inhericance. чтобы вместо перечисления синих
специализаций двух элементов он вычислял такие специализации с помощью поиска по
иерархии типов.
'4. Введение в PROLOG
683
Введение в LISP
—...Заглавие этой песни называется "Пуговки для сюртуков"
— Вы хотите сказать — песня так называется? — спросила Алиса,
стараясь заинтересоваться песней.
— Нет, ты не понимаешь, —- ответил нетерпеливо Рыцарь. — Это заглавие так
называется. А песня называется "Древний старичок ".
— Мне надо было спросить: это у песни такое заглавие? — поправилась Алиса.
-Да чет, заглавие совсем другое "С горем пополам"! Но это она только так называется/
— А песня эта какая ? — спросила Алиса в полной растерянности.
— Я как раз собирался тебе об этом сказать.
— Льюис Кэррол (Lewis Carroll), Алиса в Зазеркалье
Старайтесь в сложном видеть простоту.
— Лао Тзу (Lao Tzu)
15.0. Введение
За более чем сорокалетнюю историю своего существования LISP зарекомендовал себя в
качестве хорошего языка программирования задач искусственного интеллекта. Изначально
разработанный для символьных вычислений, за время своего развития LISP был расширен и
модифицирован в соответствии с новыми потребностями приложений искусственного
интеллекта. LISP — это императивный язык (imperative language). Его программы описывают, как
выполнить алгоритм. Этим он отличается от декларативных языков (declarative language),
программы которых представляют собой определения отношений и ограничений в
предметной области задачи. Однако, в отличие от таких традиционных императивных языков, как
FORTRAN или C++, LISP — еще и функционапьный язык (functional language): его синтаксис
и семантика продиктованы математической теорией рекурсивных функций. Мощь
функционального программирования в сочетании с богатым набором таких высокоуровневых средств
построения символьных структур данных, как предикаты, фреймы, сети и объекты,
обеспечили популярность LISP в сообществе ИИ. LISP широко используется как язык реализации
средств и моделей искусственного интеллекта, особенно среди исследователей.
Высокоуровневая функциональность и богатая среда разработки сделали его идеальным языком для
построения и тестирования прототипов систем.
В этой главе кратко описаны синтаксис и семантика диалекта Common LISP. При
"ом особое внимание уделено средствам языка, используемым для программирования
^ач искусственного интеллекта; рассказано о применении списков для создания сим-
„„, а также реализации интерпретаторов и алгоритмов поиска дл,
вольных стру^л^"^™ ПР одятся примеры программ „а языке LISP, в™.
управления этими "Р^Т™ £„„„, с„стем проверки соответствия шаблонам; с„с
чаюшие реализацию механ,зэкспертных систем, основанные на правилах, ал
«мы доказательства теорем, . снт„рованного моделирования. Мы, конечно „'
горитмы для обучения и оо ^ usp ^ тсматнке посвящено много замеча
сможем дать «ет^Ткото „„мешены в конце данной главы. В этой книге
«льных книг, ссьшк"".ковании LISP для реализации языков представления и №
15.1.1-TSPMcpaTKHii обзор _____
15.1.1. Символьные выражения как синтаксическая основа LISP
Синтаксическими элементами языка программирования LISP являются
символьные выражения (symbolic expression), которые также называют s-выраокеният
(s-expression) В виде s-выражений представляются и программы, и данные, s-выраженис
представляет собой либо атом (atom), либо список (list). Атомы LISP— это базовые
синтаксические единицы языка, включающие числа и символы. Символьные атомы
состоят из букв, цифр и следующих иеалфавитно-цифровых символов.
Приведем несколько примеров атомов LISP.
3.1416
100
х
hyphenated-name
*some-global*
nil
Список— это последовательность атомов или других списков, разделенных
пробелами и заключенных в скобки. Вот несколько примеров списков.
(12 3 4)
(torn mary John Joyce)
(а (Ь с) (а (е f)))
( )
Заметим, что элементами списков могут быть другие списки. При этом глубина
вложенности может быть произвольной, что позволяет создавать символьные структур"
~ РМЫ " СЛ°ЖН0Ст ПуСГОЙ спис°к <> «грает особую роль при построен»
2еТ„™ГК " УПРаВЛеШШ НШ' У иего *™ «» специальное имя -nil; -U '
Сш „к ™ё в°ыч$;-ЫРаЖГИе' К°ТОр0е ^-Ременио является и атомом, и а**»
(on Ыоск-1 представления выражений из теории предикатов.
(likes bill x)
<ana (likeS george kate, ....
atel (llkes bill merry) )
boo Часть \l\ a '
зыки и технологии программирования для искусственного *
ЭГОТ синтаксис позволяет представить выражения теории предикатов в описанном в
зтой главе алгоритме унификации. Следующие два примера демонстрирую г способы
использования списков для реализации структур данных, необходимых в приложениях баз
данных. В подразделе 15.1.5 описана реализация простой системы изалечення данных на
основе этих представлении.
,(2467 (lovelace ada) programmer) (3592 (babbage charles)
computer-designer))
((key-1 value-1) (key-2 value-2) (key-3 value-3))
Важным свойством LISP является использование одинакового синтаксиса для
представления не только данных, но и программ. Например, списки
(• 7 9)
(- (+ 3 4) 7)
можно интерпретировать как арифметические выражения в префиксной форме записи.
LISP обрабатывает эти выражения именно так: (*7 9) означает произведение 7 на 9.
Если на компьютере установлен LISP, то пользователь может вести интерактивный
диалог с его интерпретатором. Интерпретатор выводит приглашение (в качестве примера в
этой книге используется символ >), считывает введенные пользователем данные,
пытается оценить их и в случае успеха выводит результат. Например,
> (* 7 9)
63
>
Здесь пользователь ввел выражение (* 7 9), а интерпретатор выдал результат
63 — значение, связанное с этим выражением. После этого LISP выводит следующее
приглашение и ожидает ввода пользователя. Такой цикл называется циклом чтения-
оценки-печати (read-eval-print loop) и составляет основу интерпретатора LISP.
Получив список, интерпретатор LISP пытается проанализировать его первый элемент
как имя функции, а остальные элементы — как ее аргументы. Так, s-выраженне ( f x
У) эквивалентно более традиционной математической записи f(x, у). Выводимое LISP
значение является результатом применения этой функции к ее аргументам. Выражения
LISP, которые могут быть осмысленно оценены, называются формами (form). Если
пользователь вводит выражение, которое нельзя корректно оценить, то LISP выводит
сообщение об ошибке и позволяет пользователю выполнить трассировку и внести
исправления. Вот пример сеанса работы с интерпретатором LISP.
( +
<♦
(-
(«
<=
(>
14 5
12 3 4
(+ 3
(+ 2
(+ 2
(* 5
4)
5)
3)
6)
7)
<-
5)
< +
(а Ь с)
r°r: invalia
7
4
(/
5))
21
function
7)))
а
» 15. Введение в LISP
687
примеров аргументы сами являются списками. „апр„Ме
.„™„.т композицию функции и в данном ел™.
ят" ot,„ ЧИта«-
"результат" выделено
ДЛятоГО|
в нескольких из этих "Р""^^ композ„цию фуикц,
3 *> I' ^^""-ияЗи4".Слово>
Хп^ер^' ™)ZZ ' ' """" аРГУМеНТа ПеРВДаеТСЯ " 5"ВЫРаЖе"Ие '*
341,3 Pa)'!!^'S»™' оценивает ее аргументы, а затем пр„„еняст ф
11lT„t«MeIм выражен™, к оценке аргумент. Если -р^е™™^
задаваемую первым neKVDClffl„o применяет это правило для их оценивания т.
T^U»"»"S» вызовов функций произвольной глубиГ'вГо
„«„Г ™ по Урчанию LISP оценивает все объекты. При этом используется c„Ce°
ГСчнсла соответствуют сами себе. Например, если интерпретатору передать значение
Гто LISP вернет результат 5. С символами, например х, могут быть связаны выражевш,
Пи. оценивании связанных символов возвращается результат связывания. Связанные сим.
волы могут появляться в результате вызова функции (подраздел 15.1.2). Если
символ не
связан, то при его оценке выдается сообщение об ошибке.
Например, оценивая выражение (+ (*2 3) (*3 5) ), LISP сначала оценивает аргумен-
ты (*2 3) и (*3 5). Для первого аргумента LISP оценивает его параметры 2 и 3,
возвращая соответствующие им арифметические значения. Эти
значения перемножаются и в результате дают число 6.
Аналогично результатом оценки выражения (*3 5) является 15.
Затем эти результаты передаются функции сложения более
высокого уровня, при оценивании которой возвращается 21.
Диаграмма выполнения этих операций показана на рис. 15.1.
Помимо арифметических операций LISP включает
множество функций работы со списками. К ним относятся функции
построения и комбинирования списков, доступа к элементам
списков н проверки различных свойств. Например, функция list
5 принимает любое количество аргументов и строит на их основе
список. Функция nth получает в качестве аргументов число и
список и возвращает указанный элемент этого списка.
Нумерация элементов списка начинается с нуля. Вот примеры
использования этих и других функций работы со списками.
(+(•2 3| (.3 5)1
Рис. 15.1. Древовидная диа-
грамма оценивания
простой функции LISP
> (list 12 3 4
(12 3 4 5)
а Ь
5)
> (nth О
а
> (nth 2
3
> (nth 2
(с 3)
> (length
4
> (member
nil
> (null (
с d))
(list 12 3 4
' ((a 1) (b 2)
' (а Ь с d))
^ 'U
<<= 3) (d 4)))
2 3 4 5))
))
Основнвд^з"™ C0 cnHCKa«« более подробно будут описаны в подраздел'15'1
раздела можно изложить в виде следующего определения.
688 ^:^™7™^^г^ир0Ва„иЯ для искусств^нс^^
ОПРЕДЕЛЕНИЕ
S-ВЫРАЖЕНИЕ
s-выражсине можно рекурсивно определить следующим образом.
1. Атом — это s-выражение.
2. Eoi«s„s2 s„- s-выражения, то s-выражением является и список (s,,s2 s„).
Список — это неатомарное s-выражение.
Форма- это подлежащее оцениванию s-выражение. Если это список, то первый
элемент обрабатывается как имя функции, а последующие оцениваются для
получения ее аргументов.
Оценивание выражений выполняется следующим образом.
Если s-выражение — число, то возвращается значение этого числа.
Если s-выражение — атомарный символ, возвращается связанное с ним значение.
Если этот символ не связан, возвращается сообщение об ошибке.
Если s-выражеиие — это список, оцениваются все его аргументы, кроме первого, а к
полученному результату применяется функция, определяемая первым аргументом.
В LISP в виде s-выражений представляются и программы, н данные. Это не только
упрощает синтаксис языка, но и в сочетании с возможностью управления оценкой
s-выражеиий упрощает написание программ, обрабатывающих в качестве данных другие
программы. Это облегчает реализацию интерпретаторов на LISP.
15.1.2. Управление оцениванием в LISP: функции quote и eval
В нескольких примерах из предыдущего раздела перед списками аргументов
располагался символ одинарных кавычек '. Этот символ, который также может быть
представлен функцией cruote, представляет собой специальную функцию, которая не оценивает
свои аргументы, а предотвращает их оценивание. Зачастую это делается для того, чтобы
аргументы обрабатывались как данные, а не как оцениваемая форма.
Оценивая s-выражения, LISP сначала старается оценить все аргументы. Если
интерпретатору передается выражение (nth 0 (а Ь с d) ), то он сначала пытается
оценить аргумент (а Ь с d). Эта попытка приведет к ошибке, поскольку а — первый
элемент этого s-выражения — не является функцией LISP. Чтобы предотвратить это,
следует воспользоваться встроенной функцией quote. Она зависит от одного аргумента
и возвращает этот аргумент без его оценки. Например,
> (quote (a b с))
(a b с)
> (quote (+13))
(+ 1 3)
Поскольку функция quote используется довольно часто, то в USP допускается ее
сокращенное обозначение в виде символа '. Поэтому предыдущие примеры можно пе-
реписать в следующем виде.
" '(а Ь с)
(а Ь с)
> '< + 1 3)
(+ 1 3)
и 15. Введение в LISP
689
. auote используется для предотвращен™ оценивания аргуме
В целом, функция ^eJ не как формы, а как данные. В рассмотренных ран^
сс„„ они должны обрабатывать тктх деиствни функция ^ote не ^ »«
примерах "«п^иевия прост,^ ^^ значениям„. Рассмотрим результат „рнм "
скольку числа всегда ™"" вызовах функции list.
ния функции quote в следуют
=, (list (♦ 12) (+ 3 4))
13 ?! „ .,♦ 1 2) ■<♦ 3 4))
> (list '(+1^1 >
((+ 12) (+3 4))
, гуситы ие квотированы, поэтому они оцениваются и передают.
Т^юТГГсогГн»используемой „о умолчанию схеме. Во втором ™
Г 8 ФГГпЬ предотвращает оценку, и в качестве аргументов функции list переда-
ФУ"К ,мГ5 ыр1ТнГи хотя ( + 1 2) - это осмысленная форма LISP, Функщи
Го1е предотвращает ее оценивание. Возможность предотвратить оценивание про-
ГмГи вращаться с - как с данными - важное свойство LISP.
В дополнение к функции quote LISP также предоставляет в распоряжение пользователя
функцию eval, позволяющую оценить s-выражение. Она зависит от одного аргумента, пред,
отвляющего собой s-выражение. Этот аргумент оценивается как обычный аргумент функции.
Однако результат снова оценивается, и в качестве значения выражения eval возвращается
окончательный результат. Вот примеры применения функций eval и quote.
> (quote ( + 2 3))
(+ 2 3)
> (eval (quote (+23))) .-функция eval отменяет результат выполнения
5
;функции quote
?> (list '* 2 5) ;строится оцениваемое s-выражение
(* 2 5)
> (eval (list '* 2 5)) .-строится и оценивается выражение
10
Функция eval, по существу, обеспечивает обычное оценивание s-выражений. Благодаря
функциям quote и eval существенно упрощается разработка метаинтерпретаторов
(meta-interpreter)— вариаций стандартного интерпретатора LISP, определяющих
альтернативные или дополнительные возможности этого языка программирования. Эта важная
методология программирования иллюстрируется на примере "инфиксного интерпретатора" в
разделе 15.7 и разработки оболочки экспертной системы в разделе 15.10.
15.1.3. Программирование на LISP: создание новых функций
Диалект Common LISP включает большое количество встроенных функций, в том
числе следующие.
• Полный спектр арифметических функций поддержки целочисленной, вешеств»
^ ной, комплексной арифметики и работы с рациональными числами,
азнообразные функции организации циклов и управления программой,
ункции работы со списками и другимн структурами данных.
Функции ввода-вывода.
искусственного инталя^
. формы для контроля оценивания функций.
. функции управления средой н операционной системой.
Вес функции LISP невозможно перечислить в одной главе. Более подробная
информация о иих содержится в специальной литературе по LISP «фооная пшрор
Программированне в LISP сводится к определению новых функций и построению
„рограмм на основе богатого спектра встроенных и пользовательских функциГновые
функции определяются с помощью функции defun, имя которой представляет собой
сокращение фразы define fnnct.on". После определения функции ее можно использовать
так же, как и любую другую встроенную функцию языка.
Предположим, что требуется определить функцию square, зависящую от одного ар-
гумента и возводящую его в квадрат. Эту функцию в LISP можно определить
следующим образом.
(defun square (х)
(* хх)}
Первым аргументом функции defun является имя определяемой функции,
вторым — список ее формальных параметров, которые должны быть символьными
атомами. Остальные аргументы — это нуль или s-выражения, составляющие тело новой
функции, т.е. код LISP, определяющий ее поведение. Как и все функции LISP, defun
возвращает значение, представляющее собой просто имя новой функции.
Важным результатом работы функции defun является побочный эффект, состоящий
в создании новой функции и добавлении ее в среду LISP. В рассмотренном примере
определяется функция square, зависящая от одного аргумента и возвращающая результат
умножения этого аргумента на себя. После определения функции ее необходимо
вызывать с тем же числом аргументов или фактических параметров. При вызове функции
фактические параметры связываются с формальными, и тело функции оценивается с
учетом этого связывания. Например, при вызове (square 5) значение 5 связывается
с формальным параметром х в теле определения. Оценивая тело (* х х), LISP сначала
оценивает аргументы функции. Поскольку в этом вызове параметр х связан со значением
5, то оценивается выражение ( * 5 5).
Более строго синтаксис выражения defun имеет вид.
(defun <имя функцию (<формальные параметра) <тело функции>)
В этом определении описания элементов формы заключены в угловые скобки <>. Это
обозначение будет использовано и далее. Заметим, что формальные параметры функции
defun представляются в виде списка.
Вновь определенную функцию можно использовать так же, как и любую другую
встроенную функцию Предположим, что необходимо вычислить длину гипотенузы
прямоугольного треугольника, зная длины двух его других сторон. Эту функцию можно
определить на основе теоремы Пифагора, используя определенную ранее функцию
square, а также встроенную функцию sqrt. Следующий пример кода снабжен
подробивши комментариями. LISP поддерживает однострочные комментарии, т.е.
игнорирует весь текст, начиная с первого символа ;, и до конца строки.
(defun к .- , 1 -длина гипотенузы равна
(загГГТ8" <Х У ;"°Р™ квадратному из сушь,
isqrt (+ (square x) -квадратов двух других сторон,
(square у)))) '
!s> 15. Введение в LISP
691
типичен поскольку большинство программ LISP cocm
Э„т пример довольно^т 'выполняющнх отдельные хорошо определен™" Щ
относительно .«больших фу ^ пспользуются для реализации функциГ, ««й-
дачи. После "пределе™ **_ писаи0 поведение самого высокого урови,е ■*-
сокого уровня до тех пир,
ША Управление программой в LISP: условия и предикаты
г 1ЧР тоже основывается иа оценивании функций УПп=„
Г1ГР: >Гье Ф"7м- Н^,мер, рассмотрим следующее определение ф^
Гыч"ГиС модуля Заметим, что в LISP имеется встроенная функция abs, вычисли
шая абсолютное значение числа).
((>= х 0) х))) ;в противном случае возвращается х
В этом примере используется функция cond, реализующая ветвление. Аргументам
этой функции является множество пар условие-действие (condition/action pair).
(cond {<условие1> <дейстиие!>)
(<условие2> <действие2>) '
' ' ' ,, I
1<условиеп> <деиствиеп>м [
Условие и действие могут быть произвольными s-выражениями, при этом каждая
пара заключается в скобки. Подобно функции def un cond не оценивает все свои
аргументы. Она оценивает условия по порядку до тех пор, пока одно из них не возвратит
значение, отличное от nil. В этом случае оценивается соответствующее действие, и
полученный результат возвращается в качестве значения выражения cond. Ни одно из других
действий и ни одно из последующих условий не оцениваются. Если все условия
возвращают значение ni 1, то и функция cond возвращает nil.
Приведем альтернативное определение функции absolute-value.
(defun absolute-value (x)
(cond ((< x 0) (- x)) ;если х меньше 0, вернуть -х
^ x'^ ;в противном случае возвращается х
В этой версии учитывается тот факт, что второе условие (>= х 0) — всегда
истинно, если первое условие ложно. Атом t в последнем условии оператора cond- этом
атом LlbP, который соответствует значению "истина". Его оценка всегда совпадает с с*
в" ГГ"' След0ватель™' "беднее действие выполняется только в том случае, сел»
колТ'п'Г"6 УСЛ°ВЮ1 В0»Равдют ™"ение nil. Эта конструкция очень полезна,
поучавес„IГ" №Ь ДеЙПВИе' ™"°™емое оператором cond по умолчанию в г»
случае, если все предыдущие условия „е выполняются
оцени ГеТеГ" ™ В ^"^ уСЛ°вий оператора cond можно использовать «**
-н„е ("истина" или ■ W?B Z ~ "° ФуНКЦНЯ' в™Р™ающМ **"££« *■
которому свойству Ha„S ЗДВИСИМ0С™ от того, удовлетворяют ли ее параметр
'Равнения вида - > „ I и 0Чевидиым» примерами предикатов являются опер
=■ Вот некоторые примеры арифметических предикатов в U
, (= 9 (+ « 5))
> (>= " 4»
> (< 8 (+4 2))
nil
> (oddP 3> .-проверка четности аргумента
l l .проверка, является ли аргумент числом
> (numberp nil)
nil
> ,zer°P 0) .-проверка равенства аргумента нулю
> (plusp 10) проверка строгой положительности аргумента
> (plusp -2)
nil
Заметим, что в этих примерах предикаты возвращают значения с или nil. а не
"истина" н "ложь". Вообще, в LISP значение предиката nil соответствует логическому
значению "ложь", а любое отличное от него значение (не обязательно с) обозначает
"истина". Примером функции, использующей это свойство, является предикат member.
Он зависит от двух аргументов, причем второй аргумент обязательно должен быть
списком. Первый аргумент — это элемент списка, определяемого вторым аргументом.
Предикат member возвращает суффикс второго аргумента, начальным элементом которого
является первый аргумент. Если первый аргумент не является элементом списка,
предикат member возвращает результат nil. Например,
> (member 3 '(12345))
(3 4 5)
Такое соглашение дает следующее преимущество. Предикат возвращает значение,
которое в случае истинности условия может использоваться для дальнейшей обработки.
Кроме того, при таком соглашении в качестве условия в форме cond можно выбирать
любую функцию LISP.
Форму if, зависящую от трех аргументов, можно использовать как альтернативу
Функции cond. Первым параметром является само условие. Если результатом проверки
условия является ненулевое значение, то оценивается второй аргумент функции if н
возвращается результат этой оценки. В противном случае возвращается результат оценки
третьего аргумента. При бинарном ветвлении конструкция if в целом обеспечивает
более прозрачный и изящный код, чем функция cond. Например, с помощью формы if
Функцию absolute-value можно определить следующим образом.
'defun absolute-value (x)
(i£ (< х 0) (- х) х))
Помимо функций if и cond. в LISP содержится обширный набор управляющих кон-
«РУКций, в том числе итеративных, таких как циклы do и while. Хотя эти функции
°чень полезны и обеспечивают программисту широкие возможности управления про-
Т'ммой, они здесь ие будут обсуждаться. Эту информацию читатель сможет нантя в
епецпализнроваиной литературе по LISP.
15. Введение в LISP
693
,. „пеяств управления программой в LISP свята1>
Одно из наиболее "««^"^ог и not. Функция not зависит от "н° С *■
кованием -"-^иГс "е« аргумент равен nil, и nil ^ в п° ^ ар-
гумента и возврашает ^""зависеть от любого числа параметров. Они вед^ "°Ч
случае. Функции and и or и у шк операторы. Однако важно nomL "
точ„о так же, как и со***™*^ ^ ^^ оцтке (conditional evaluation) """^
чт0 функции and и or о оценивает ее аргументы слева направо. Процесс „.
При обработке ♦Ч"^^^ значе„„е nil, или после оценки после^?"
ШаОТ^ГршеГ ^Торма and возврашает значение последнего оц*^
гумента. По ™ep"0 Рненул Joe значение возвращается только в том случае, если!
:= ф"оГ ньТоГнуля. Аналогично аргументы формы or oueHHBa^^
яо^—^левого значения, которое и возвращается в качестве результата НеК0ТОрь1
к, Г«в Z функций могут оставаться неоцененными, что иллюстрируется „а прим^ ,
штатом print. Помимо вывода значения своего аргумента, в некоторых диалектах Щр I
функши print по завершении работы возвращает значение nil. |
> (and (oddp 2) (print "второй оператор был оценен"))
"Nana (oddp 3) (print "второй оператор был оценен")) ;
второй оператор был оценен 1
> (or (oddp 3) (print -второй оператор был оценен")) |
t '
> (or (oddp 2) (print "второй оператор был оценен"))
второй оператор был оценен
Поскольку в первом выражении результатом оценки (oddp 2) является nil,
функция and просто возвращает значение nil без оценивания формы print. Во втором
выражении результатом оценки (oddp 3) является t, и форма and оценивает выражение
print. Аналогично можно проанализировать работу функции or. Поведение эли
функций очень важно понимать. Дело в том, что их аргументами могут быть формы,
оценка которых связана с получением побочных эффектов, подобных функции print.
Условный анализ логических функций позволяет управлять процессом выполнения
программы LISP. Например, форму or можно использовать для получения альтернативных
решений и проверки их до тех пор, пока одно нз них ие даст отличный от нуля результат.
15.1.5. Функции, списки и символьные вычисления
В предыдущих разделах был рассмотрен синтаксис LISP и введено несколько полезных
Sra. 0НИ приыенялись <™ Р^ния простых арифметических задач, однако истин»
Z 1 пп^Г"™ " символьаь« вычислениях. Они основываются иа использовании сш-
^ZZTT" ИРУКГуР ДаННЫХ лю6ой с»«н°™. состоящих из символьных и чнсло-
~ д^Г?етаС03ДаНИИ Ф°РМ т ™~«™ «-и. Простоту обработки «м-*-»
^ ^n^M™0™ П0ПроеН™ абстракттчьи ттшов'данных a LISP»P>
вьтога1™^ ™aZZ„ ^ ^ давления базой данньгх. В нашем приложении бу№
писи заданы 2^аГ Т™' ""«Р-ЩИ-и информацию о сотрудниках. В по*»
э™ записи прТа™Гл ' ™ Н0Мер с«РУД»ика.
™™я имя, зар^ТиТб™ * -^ °П"СК0В- пеРв"ми тремя элементами котор"*»
Фуи^п, «остуГ ™^"" "°МеР- С П°М°™Ю ^™" nth МОЖ"° °Vw*
пию получения поляим™Г Записн- Например, определим следующую ФУ
(defun name-field (record)
(nth 0 record))
Приведем пример ее использования.
, (name-field '((da Lovelace) 45000.00 338519)1
(Ada Lovelace)
дналог^шо можно определить фушо^, „олучения доступа к полям зарплаты и
табельного номера salary-field и number-field соответственно. Поскольку имя- это тоже
список, состоящий из двух элементов (собственно имя и фамилия), целесообразно определить
функцию, которая на основе параметра name вычисляет либо имя, либо фамилию.
(defun first-name (name)
(nth 0 name) )
Вот пример ее использования.
> (first-name (name-field '((Ada Lovelace) 45000.00 338519)))
Ada
Помимо доступа к отдельным полям записи необходимо реализовать функции
создания и модификации записей. Они определяются с помощью встроенной функции LISP
list. Функция list получает произвольное число аргументов, оценивает их и
возвращает список, содержащий значения параметров в качестве своих элементов. Например,
> (list 12 3 4)
(12 3 4)
> (list '(Ada Lovelace) 45000.00 338519)
((Ada Lovelace) 45000.00 338519)
Как видно из второго примера, функцию list можно использовать для определения
конструктора записей в базе данных.
(defun build-record (name salary emp-number)
(list name salary emp-number))
Вот пример ее использования.
> (build-record '(Alan Turing) 50000.00 135772)
((Alan Turing) 50000.00 135772)
Теперь с помощью функций доступа и build-record можно создать функцию,
возвращающую модифицированную копию записи. Например,
(defun replace-salary-field (record new-salary)
(build-record (name-field record)
new-salary
(number-field record))) т™сла, слллп nm
> (replace-salary-field '((Ada Lovelace) 45000.00 338519) 50000.00)
((Ada Lovelace) 50000.00 338519)
Заметим, что эта функция на самом деле не обновляет саму запись, а создает ее
модифицированную копию. Эту обновленную версию записи можио сохрани^ связи,<* с
глобальной переменной с помощью функции setf (подраздел 15.1.S1 Хотяв LIM-cy
"кствуот формы, позволяющие модифицировать конкретный элемент сп-^ = «сход-
«* структуре"^ создания копии,, хороший стиль.тр=ФО - «и ^
"х использования, поэтому в этой книге они не упоминаются, ecu t
,а 15. Введение в LISP
695
.-mvKTVPbi, их модификация выполняется с пок,„
„я„е слишком большие структуры, по„ои1Ь|о
пользуютс структур"' , ,„яи „бстоактиый тип данных т..
создания новой к шепр||ме|
„здания новой копии ^^мерах 6ь1Л создай абстрактный тип данных дл» 0б
•рассмотренных выше^пример созданы рю|Шчные функци„ доа№ .*.
„„формации о сотрудниках. В э™ £икац„,, При этом программисту не приходи^'
„"„там структуры данныхи^а м » используемых для реализации записей базы „ !
ботиться о ремьнои ^высокоуровневого кода, а также делает этот код ^
"о^упным для "он,,ма"'"" ""„ТнтелТекта требуют обработкибольших объемов з„а„,„-,
Приложения искусственн ^ ^ описания этих зианни структуры данных, в „
0 предметной области. и™° ' кт< достаточио сложны. Поэтому человеку „роще
стности объекты и сеиан ^ их СМЫСлового значения, а не конкретного синиц,
обрабатывать эти знания в Р^ ПоЭтому методология построения абстрактных ти-
сиса их внутреннего пред разработке приложений искусственного интеллекта,
пов данных играет важную р^^ определять новые функции, он является идеальный
язГГ^-тро^.аборактнь.хтииовданных. :
15.1.6. Списки как рекурсивные структуры |
В предыдущем разделе для реализации доступа к полям записей простой базы данных
сохрудннков^пользовались функции nth и list. Поскольку все записи о сотрудниках ,
Гли фиксированную длину (состояли из трех элементов), то этих двух функции было
достаточно Однако для выполнения операций иад списками неизвестной длины, в
частности для реализации поиска на неуказанном числе записей этого мало. Для выполнен™
такой операции необходимо иметь возможность сканировать список итеративно или
рекурсивно завершая проход при выполнении некоторых условий (т.е. при нахождении
нужной записи) или после просмотра всего списка. В этом разделе вводятся операции со
списками, причем для определения функций обработки списков используется рекурсия.
Основными функциями доступа к компонентам списков являются саг и cdr. Первая из
них зависит от одного аргумента, который сам является списком, и возвращает его первын
элемент. Функция cdr тоже зависит от одного аргумента, который должен быть списком, i
возвращает этот же список после удаления его первого элемента. Например, так.
;Заметим, что список квотирован
> (саг '(а Ь с))
а
> (cdr '(а Ь с))
(Ь с)
> (саг '((а Ы icdlll
(а Ь)
> (cdr ■((а Ь) (с d)>>
((с d))
> (car (cdr '(а Ь с d)))
b
;первый элемент списка может
быть списком
|ИЙ»
Функции саг и cdr основаны „а рекурсивном подходе к выполнению °ПЧ>»""
списочными структурами. Операции над каждым элементом списка выполняются
дующим образом.
1. Если список пуст, операция завершается.
2. В противном случае обрабатывается этот элемент и осуществляется переход
дующему элементу списка.
: СЛ'~
По этой схеме можно определить множество полезных .W, - „
„ример. язык Common L.SP включает предикат шешЬеГопг^Т '" СШЖ На"
^орого s-выражения списку, и length, позволяющиеi „Z я^Г™ ^и™шои1«п" «="
бренные версии этих функций, ф^ ^_^"б£Г"" ^^ ^
ргументов- произвольного в-вьгоа^енияисписка^-Т^о'Т «~» « «Ч»
% 5.вырзжеиие „е является элементом списка my list в „^ ВШВр™П'
извращать список, содержащей это s-вьшажение Z^'^Z^T °" ^
(defun my-member (element my-list)
(cond ({null my-list) nil) .э„рмрн. UQ
((equal element (car my-list,"ту^Г"^" ™H°" C™CKa
; элемент найден
(t (my-member element (cdr my-list)))))
;шаг рекурсии
Вот пример использования функции my-member.
> (my-member 4 '(123456))
(4 5 6)
> (my-member 5 '(abed))
nil
Аналогично определим собственные версии функций length и nth.
(defun my-length (my-list)
(cond ((null my-list) 0)
(t (+ (my-length (cdr my-list) ) 1))))
(defun my-nth (n my-list)
(cond ((zerop n) (car my-list)) .-функция zerop проверяет
.•равенство нулю
(t (my-nth (-n 1) (cdr my-list) ))) )
; своего аргумента
Интересно отметить, что приведенные примеры использования функций саг и cdr в
то же время иллюстрируют историю развития LISP. Ранние версии языка содержали ие
так много встроенных функций, как диалект Common LISP. Программистам приходилось
самим определять функции проверки принадлежности элемента списку, вычисления
Длины списка и т.д. Со временем наиболее общие из этих функций вошли в стандарт
языка. Common LISP — легко расширяемый язык. Он позволяет легко создавать и
использовать собственные библиотеки повторно используемых функций.
Помимо саг и cdr LISP содержит множество функций построения списков. Одна из
них— iist, зависящая от произвольного числа аргументов, представляющих собой
s-выражеиия. Функция оцешшает их и возвращает список результатов (подраздел 15.1.1).
Более примитивным конструктором списков можно считать функцию cons, параметрами кото-
Рой являются два s-выражения. Эта параметры оцениваются, и возвращается список, первым
элементом которого является значение первого аргумента, а хвостом - значение второго.
> (cons 1 '(234))
II 2 3 4)
Means ' (а Ь) ' (с d e))
"а Ь) с d е)
Функцию cons можно считать обратным преобразованием для *™*«" °££
«°»ьку результатом применен,* функции саг к значен™, возвращаемо» фасцией cons.
Часть VI. Языки „ технологии программирования для искусственного
„„телпе*"1 Гла|» 15. Введение в LISP
697
ент cons. Аналогично результатом применения фущ-,,,
всегда ^^о^рмой cons, всегда является второй аргумент этой ф^ С* к
ГТГГ.ГГв! 42 3 4,1)
J(<:dr (=onsl M2 3 4)))
12 3 ^ „пимес использования функции cons. Для этого определим функт
Приведе», ггр мер "С _ ^^ ^^ числовой ^^ g^UH»
filter-negatives, пар * значения. Функция f Uter-пеЛ ^"*
ДГ:Го"ГГмсГГ,:ска. Если первый элемент -п*™.^
РТ, Гнкиия в°зврашает результат фильтрации отрицательных элементов хвоста ел!
Гопредё"Zxo функцией cdr. Если первый элемент списка положителен, „„ ^
ZZZ результат фильтрации отрицательных чисел хвоста.
„defun filter-negatives (number-Ust)
(cond ((null number-list) ml)
;yCnOB"e,(pIuspBtcar number-list)) (cons (car number-list)
(filter-negatives
(cdr number-list))))
(t (filter-negatives (cdr number-list)))))
Вот пример вызова этой функции.
> (filter-negatives '(1-12-23 -4))
(1 2 3)
Это типичный пример использования функции cons в рекурсивных функциях над
списками. Функции саг и cdr делят список на части и "управляют" рекурсией, a cons
формирует результат по мере "развертывания" рекурсии. Еще один пример
использования функции cons — переопределение встроенной функции append.
(defun my-append (listl list2)
(cond ((null listl) list2)
(t (cons (car listl) (my-append (cdr listl) list2)))l)
Проиллюстрируем вызов этой функции.
> (my-append Ml 2 3) '(456))
(12 3 4 5 6)
Заметим, что по такой же рекурсивной схеме строятся определения функций да-
append, my-length и my-member. В каждом из этих определений для удаления
элемента из списка используется функция cdr. ^ о6еспечивает возможность реки»*»-
ГГ1ГР0Че1Ш0Г° СПИСКа Рек»сня завершается, если список пуст. В процессе £
7Zl,^T C°nS mW™^ решение. Эта схема зачастую называется с
льзуется для получения хвоста списка.
15 хо!,Гженные списки' струкгуры - рекур£«я c«-cdr
■««но понимать раллич1Г^аРРеП'1 °Р«™™№иы для объединения небольших с*
Е Межд>' ш™"- При вызове функщш cons ее параметрами «^
ЧЭСТЬ V' ЯЭЫШ И ТеХН0Л0™и программирования для искусственного и**»
nflW4
™я списка. Первый из них становится первым элемеит™, „„
^аетсписок, членами -^я^яГмеГГ^™^^^-6"'1
, (cons Ml 2) '(3 4))
((1 2) 3 4)
I (append '(12) '(3 4))
(12 3 4)
Списки (1 2 3 4) и ((1 2) 3 4) имеют принципиально разную структуру Это
различие можно отобразить графически. Уста„„в„8 изоморфизм между сгшсЗ и
деревьями. Простейший способ построения соответствия между списками „ деревьями -
создание для каждого списка узла без метки, потомками которого являются элементы
этого списка. Jto правило рекурсивно применяется ко
всем элементам списка, которые сами являются списка- А д
ми. Атомарные элементы становятся листовыми узлами А \\ /\\
дерева. При таком построении два указанных выше спи- / \ \\ Д \\
ска генерируют деревья различной структуры (рис. 15.2). ,234 (234
Этот пример иллюстрирует широкие возможности
списков по представлению данных. В частности, их можно ис- " 34' (С 2)34)
пользовать как средство представления любой древовидной Рж- '5-2 Представление стаях
структуры, в том числе дерева поиска или дерева граммам- * """' дере"ьа ды о^Р^е-
r f , lcu If ния различии в их структуре
ческого разбора (рис. 15.1). Кроме того, вложенные списки
обеспечивают возможность иерархического
структурирования сложных данных. В примере с записями о сотрудниках из подраздела 15.1.4 поле имени
само является списком, состоящим из собственно имени и фамилии. Этот список можно
рассматривать как единую сущность, а можно получать доступ к каждому его компоненту.
Простой схемы cdr-рекурсин, описанной в предыдущем разделе, недостаточно для
реализации всех операций над вложенными списками, поскольку в ней не различаются
списочные и атомарные элементы. Например, допустим, что функция length,
определенная в подразделе 15.1.6, применяется к иерархической списочной структуре.
> (length '((12) 3 (1 (4 (5)))))
3
Функция length возвращает значение 3. поскольку список состоит из 3 элементов: (1
2), 3 и (1 (4 (5))). Это, конечно, правильно, и такое поведение функщш корректно.
С другой стороны, если требуется подсчитать количество атомов в списке,
необходимо определить другую схему рекурсии, которая при сканировании элементов списка
будет "вскрывать" неатомарные элементы списка и рекурсивно выполнять операции по
подсчету атомов. Эту функцию можно определить так.
(defun count-atoms (my-list)
(cond ((null my-list) 0)
((atom my-list) 1)
(t (+ (count-atoms (car my-list)}
-•вскрываем элемент , , , , > >
(count-atoms (cdr щу-list) ) ) ) П
-'сканируем список
> (count-atoms '((1 2) 3 (((4 5 (6))))))
■^ „,.„„ r-ar-cdr Помимо рекурсивного прохода по
Это определение- пример рекурсии «r c°r- ^рскУрсЛЮ „о перво-
™"ску с помощью формы cdr, функция count-atoms аьи
„ с помошью формы саг. Затем функция ♦ ком6„„Ир
му элементу. п°^аеМ°1и1Г0твета. Рек7Р«« завершается при достижении атоМа *•
"^льтата ври Ф°Р^ОВ*"И„ож"о сматривать как добавление второто иэ„ерс **
S» «иска. Такуго схему «•>* Hj-^ „заглу6ление.. .„^ „3 элементов* «
„ростоис^-рек-урс^обесп iength „ count atoms, представление*
сТавнители^мь. вызов» J-ун^ ^^ car.cdr „ рекурсивного ^
[ИЙ В ПОД!»"""'-
„, „огасия (tength((1 2)3(1(4(5))»)
Линейная, или «1Г-Р.КУРСИЯ
(Iength{3 (1(4(5)))))
(length((l(4(5)))))
(lenglh(l)
Рекурсия по дереву, или car-cdr-рекурсия: (count-atoms{(1 2)3(1(4(5)))))
(count-atoms(12)) (count-atoms(3(l{4(5)))))
(count-aloms(2))
(count-atoms((1(4(5)))))
(count-atoms(1(4(5)))) 0
1 (count-atoms((4(5))))
+
(count-atoms(4(5))J °
(counl-atoms((5))t
(count-aloms(5))
p"c IS-З.Диаграч.
мы линейной и древовидной схемы рекурсии
Еше одним примером использования рекурсии car-cdr является определение
ф^книи «^°"а ™ - °Д"ого аргуме„та. пр^дставГ^о cZ Г пи
Произвольных структур, „ возвращает неиерархнческий список, состоящий из те" «с
5„мов расположенных в том же порядке. Обпатите ,«„,„„„ „ Г
а1омо»,р ,.,._„,._„,,„,. t «■«••"ир.иите внимание на аналогию определений
функций flatten и count-atoms. В обеих функциях для разбиения списков и
управления рекурсией используется схема car-cdr. рекурсия прекращается при достижении
ну„евого или атомарного элемента, и для построения ответа по результатам рекурсивных
вызовов в обоих случаях применяется вторая функция (append или+).
Mefun flatten (1st)
(cond ((null 1st) nil)
((atom 1st) (list 1st))
(t (append (flatten (car 1st)) (flatten (cdr 1st))))))
Вот пример вызова функции flatten.
> (flatten '(a (be) (((d) e f))))
(a b с d e f)
> (flatten '(a b c) ) ; этот список уд-е не содержит иерархии
(а Ь с)
> (flatten ' (1 (2 3) (4 (5 6) 7)) )
(12 3 4 5 6 7)
Рекурсия car-cdr является основой реализации процедуры унификации в разделе 15.6.
15.1.8. Связывание переменных с помошью функции set
Язык LISP строится иа теории рекурсивных функции. Ранние его версии могут
служить примером функционального или прикладного языка программирования. Важным
аспектом чисто функциональных языков является отсутствие побочных эффектов в
результате выполнения функций. Это означает, что возвращаемое функцией значение
зависит только от определения функции и фактических параметров при ее вызове. Хотя LISP
основывается на математических функциях, можно определить формы, нарушающие это
свойство. Рассмотрим следующие команды LISP
> (f 4)
(f 4)
(f 4)
Заметим, что f не является полноценной функцией, поскольку ее результат
определяете» не только фактическим параметром: различные вызовы с параметром 4 возвращают
Разные значения. Дело в том, что при выполнении этой функции создается побочный
эФфект, который сказывается на се поведении при последующих вызовах. Функция f
Реализована с помощью встроенной в LISP функции set.
fdefun £ (X)
<set 'inc (+ inc 1))
(+ x inc))
Функция set зависит от двух аргументов. Результатам оценивания первого должен
"■""ггься символ, а вторым параметром может быть произвольное s-выражение. Функция
s« оценива<,т второй аргумент и присваивает полученное значение символу, опоеде-
,а15. Введение в USP
701
_ 2ат в рассмотренном примере значение пере„С|„,„.
энному первом aw—^л„юРызова ^ , 0,, то при „oc^inc
„ШШИал„з,1Ровать"УЛ« 6 вмичиватьсяна1.
зовах значение этогопара'Р ^^ функцн„ set o6„aTej]bHo
результатом оценивай ' являстся „росто квотированный символ. Поскп
символ. Зачастую^п рвь м пара етр^ ^ ^ ^ ^^ ш,ЬТСрнативн^«о»ь.
КУ ™м ^Tta пТи ««зове которой первый параметр не оценивается. Для „^
з^й ^KU""u^s4etgP необходимо, чтобы ее первый параметр был символом. Ha„pt
м:;aГeГюШ-Ф°p»»в,,EaлcкIнь,' I
> (set 'x 0) I
О
> (setq x 0) I
0 Хотя использование функции set позволяет создавать в LISP объекты, не являющие,
г» чистыми функциями в строго математическом смысле, возможность связывания
значения с переменной глобального окружения - очень полезное свойство. Многие задачи
поогоаммирования наиболее естественно реализовать на основе определения объектов,:
состояние которых сохраняется между вызовами функции. Классическим примером та- \
ких объектов является начальное число, используемое генератором случайных чисел.'
Его значение изменяется н сохраняется при каждом вызове функции. Аналогично в сие-:
теме управления базой данных (в частности, описанной в подразделе 15.1.3) естественно '.
хранить базу данных, связав ее с переменной в глобальной среде.
Таким образом, существует два способа присваивания значения символу: явный— с по-1
мощью функцип set или setq, и неявный, когда при вызове функции фактические
параметры вызова связываются с формальными параметрами в определении функции. В
рассмотренных выше примерах все переменные в теле функции были либо связанными (bound variable)
либо свободными (free variable). Связанная переменная — это переменная, используемая в
качестве формального параметра в определении функции, а свободная переменная встречается в
теле функции, но не является формальным параметром. При вызове функции все связи
переменной в глобальной среде сохраняются, а сама связанная переменная ассоциируется с
фактическим параметром. После завершения выполнения функции исходные связи
восстанавливаются. Поэтому присваивание значений связанной переменной в теле функции не влияет на
глобальные связи этой переменной. Это видно из следующего примера.
> (defun foo (x)
(setq х (+ х 1)) ,-инкрементирование связанной переменной х
;возврат значения
foo
> (setq у 1)
1
> (Еоо у)
2
.■значение у не изменилось
^Тпер";™ Гв на™е этог° "■ - ^кцн"f леременнайя "££
«екныевонредеГнГи^ б0ДН°Й- КаК ясно "3 этого "Р™"**' "
функции— прямой источник побочных эффектов.
'02 Часть VI я " -^ - ~ """"
■ "ки и технологии программирования для искусственного и
Интересной альтернативой для формы set или я^г, „„„ „. « *
' „„,-f Что . ч- к ■ boL или setq является обобщенная функция
„усваивания setf. Эта функция не присваивает значения символу, а оценивает свой
первый аргумент с целью получения адреса в памятт, и помещает по этому адресу
значение второго аргумента. Прн связывании значения с символом футчкция setf веде^ себя
аналогично setq.
> (setq x 0)
О
> (setf x 0)
О
Однако, поскольку функцию sett можно вызвать для любой формы описания
местоположения в памяти, она допускает более общую семантику. Например, если первым
параметром функции setf является вызов функции саг, то setf заменяет первый
элемент списка. Если первым аргументом функции setf является вызов cdr, то заменяется
хвост этого списка. Например, так.
> (setf х ' (а Ь с) ) ;х связывается со списком
(а Ь с)
> х ; значение х - это список
(а Ь с)
> (setf (car x) 1) .-результат вызова функции саг для х соответствует
1
/адресу в памяти
> х ; функция setf изменила значение первого элемента х
(1 Ь с)
> (setf (cdr x) '(2 3))
(2 3)
> х ; теперь у х изменился хвост
(1 2 3)
Функцию setf можно вызывать для большинства форм LISP, соответствующих адресу
в памяти. В качестве первого параметра могут выступать символы и функции, в частности,
car, cdr и nth. Таким образом, функция setf обеспечивает большую гибкость при
создании структур данных LISP, управлении ими и даже замене их компонентов.
15.1.9. Определение локальных переменны)! с помощью функции let
санкция let — это еще одна полезная форма явного управления связыванием
переменных. Она позволяет создавать локальные переменные. В качестве примера использования
функции let рассмотрим функцию вычисления корней квадратного уравнения. «>ункция
quad-roots зависит от трех параметров а. Ь и с уравнения ах:+Ьх+с=0 и возвращает
список, состоящий из двух корней этого уравнения. Корни вычисляются по формуле
Y_-b±i/b'-4ac
2а
Например, так.
(quad-roots 12 1)
1-1,0 -1,0)
* (quad-roots 16 8)
1-2,0 -4,01
Гла°а 15. Введение в LISP
703
При вычислении значения
функдии quad-roots значение выражения
Япяжений эффективности и элегантности это значение мо*
используй дважды Из сообр^ ^ ^^^ переменной „, вычисления обоих J"
вычислить один раз и С»Р^\, ф^кции quad-roots может иметь такой вид. ""Р"
„ей. Поэтому исходная pea»03" *
(^unauad-!rt=-lt<abc,
temp) (* <! а) )
Ь)
temp) (* 2
а))))
(setcj temp (sqrt (
(list (/ (+ I-
(/ (- (- b)
Заметим что при такой реализации предполагается отсутствие мнимых корней ура,.
„енГгГьггка вычислить квадратный корень из о^ицаюльного числа приведет?*
™иому завершению функции sqrt с кодом ошибки. Модификация кода е цеяью &
™ботки этой ситуации не имеет прямого отношения к рассматриваемому вопросу.
Хотя с учетом этого исключения код функции корректен, оценивание тела приведи
побочному эффекту установки значения переменной temp в глобальном окружении.
> (quad-roots-1 12 1)
(-1,0 -1,0)
> temp
0.0
Более предпочтительно сделать переменную temp локальной для функции quad-
roots и исключить этот побочный эффект. Для этого можно использовать блок let.
Вот синтаксис этого выражения,
(let (<локальные-леременньге>) <выражения>)
Элементы списка (<локальные-переменные>) — это либо символьные атомы либо
пары вида
(<символ> <выражение>)
При оценивании формы (или блока) let устанавливается локальное окружение,
состоящее из всех символов списка (<локальные-переменные>). Если некоторый символ
является первым элементом пары, то второй элемент оценивается, и результат оценки
связывается с этим символом. Символы, не включенные в пары, связываются со
значением nil. Если некоторые из этих символов уже связаны в глобальном окружении, те
глобальные связи сохраняются и восстанавливаются при выходе из блока let.
После установки этих локальных связей задаваемые вторым параметром формы 1st
<шраженш> по порядку оцениваются в этом окружении. При выходе '""
возвращается значение последнего выражения, оцененного в этом блоке,
поведение блока let можно проиллюстрировать на следующем примере.
> (setcj a 0)
0
> 4et ((a 3) Ь)
(setq b 4)
(+ а Ы)
1 блока let
ERROR
is not bound at top level.
Часть VI. языки и технологии программирования для искусственного и
В этом примере до выполнения блока let переменна, » „
„е связана на верхнем уровне окружения. ПриТце" "В2И 1 " ? ™4WmM °' а Ь ~
"„„ением 3, а Ь- с nil. функция setq прнсвайкГпГ *°PM"let * св™<™ ™
I оператор let возвращает значение суммы а"по лТ^Ген ЗНа,-Н"С * "^ ~
в0сстаиавлнваются предыдущие значения переменныхаи Г.Г Ра0°™ Ф°рМ" let
^с переменной Ь. ременных а и ь. в том числе несвязанный сга-
С помощью оператора let функцию quad-roots u„m„ „„
„их побочных эффектов. ^ r°°ts можно Ревизовать без глобаль-
(defun quad-roots-2 (a b с)
(let (temp)
(seta; temp (sqrt (- (* b b) (* 4 a c)))l
(list (/ ( + (- b) temp) (« 2 a))
(/ (- (- b) temp) (♦ 2 a)))))
Переменную temp можно также связать при ее обьявлении в операторе let Это
обеспечит более согласованную реализацию функции quad-roots. В этой
окончательной версии знаменатель формулы 2а тоже вычисляется однократно и сохраняется в
локальной переменной denom.
(defun quad-roots-3 (а Ь с)
(let ((temp (sqrt (- (* b b) (* 4 а с))))
(denom (* 2 a)))
(list (/ (+ (- b) temp} denom)
(/ (- (- b) temp) denom))))
Помимо устранения побочных эффектов версия quad-roots-З наиболее
эффективна среди всех реализаций, поскольку в ней отсутствуют повторные вычисления
одинаковых значений.
15.1.10. Типы данных в Common LISP
Язык LISP включает большое количество встроенных типов данных. К ним относятся
целые числа, числа с плавающей точкой, строки и символы. В LISP также содержатся
такие структур1фованные типы, как массивы, хэш-таблицы, множества и структуры.
Со всеми этими типами связаны соответствующие операции и предикаты проверки
принадлежности объектов данному типу. Например, для списков поддерживаются функции
идентификации объекта как списка listp, определения пустоты списка null, а также
конструкторы и функции доступа list, nth, car и cdr.
Однако в отличие от таких строго типизированных языков, гак С или Pascal, в которых
проверка типов всех выражений может быть сделана до начала выполнения программы, в
LISP типы относятся к объектам данных, а не к переменным. Любой символ LISP можно
связать с любым объектом. При этом программист получает возможности типизации, ие
ограничивая гибкость работы с объектами различных или даже неизвестных типов.
Например, любой объект можно связать с любой переменной во время выполнения программы.
^ позволяет определять такие структуры данных, как фреймы, без пшшой спецификации
™пов хранящихся в них значений. Для поддержки этой гибкости в LISP реализована прс-
»4>ка соответствия топов во время выполнения программы. Таким образом, если связать
именную с символом и попытаться некорректно использовать это значение во время
"ыполнения
программы, интерпретатор LISP выдаст ошибку
Лава 15. Введение в LISP
> (setq x 'a)
' (t X 2) > is not a valid argument to +.
> > Error: a is not a
-. > While executing: +
rvr оеализовывать свои собственные функции проверки соотвеТСт.
Пользователи могут реал пользовательских предикатов. Это позволяет once
в„я типов на основе ^«"""^„ваннем типов. Ре~
делять ошибки, связанные^ ^^ описание возможностей LISP. Автор лишь ста.
Этот раздел не пглтии, ^ KHbIM11 свойствами языка, которые будут использо-
вГяХ"' <™ « " МГОР"™°В "СК^СТВСНН0™ "™™™- К э™„
свойствам относятся следующие.
1 Естественная поддержка абстрактных типов данных.
■> Использование списков для создания символьных структур данных.
3 Использование функции cond и рекурсии для управления программой.
4. Рекурсивна» природа списочных структур и рекурсивные схемы управления „мл.
5. Использование функций quote и eval для управления оцениванием форм.
6. Использование функций set и let для управления связыванием переменных и
побочными эффектами.
В оставшейся части этой главы эти идеи использованы для иллюстрации решения
задач искусственного интеллекта на языке LISP, в том числе для реализации алгоритмов
поиска и проверки соответствия шаблонам.
15.2. Поиск в LISP: функциональный подход к
решению задачи переправы человека, волка, козы
и капусты
Чтобы продемонстрировать возможности программного решения задач искусственного
интеллекта на языке USP, вернемся к задаче перевозки человека, волка, козы и капусты.
Человеку требуется переправиться через реку и перевезти с собой волка, козу я капусту-
На берегу реки находится лодка, которой должен управлять человек. Лодка одновреЖ"™
может перевозить не более двух пассажиров (включая лодочника). Если волк останется яа се-
регу с козой, то он се съест. Если коза останется на берегу с капустой, то она ужгчтояог"
путлу. Требуется выработать последовательность переправки через реку таким образом, "
бы все четыре пассажира были доставлены в пелоети и сохранности на другой берег реки
Решение этой задачи на языке PROLOG было описано в разделе 14.3. При программ"*
ЕГ ЯЗЫК ШР "°"« -олняется в том же простив. Но наряду со «В*£
ной аналотен с решением на Ркш г\г- у г _.„«..ое-т ЛуиШ"1
нтную ориентСко это™ язы1 L Пр0ГраМММЯ Р™»™™» ™ LISP **"£%*«•'
Для предотвращения uZo^ZT^^^ ЗДССЬ "сп0^еГСЯ "*"
Ядром программы IZZSZ: С"ИСИ' П0ССЩ— «"» , м11Ра как #*
рактный тип данных Вз * ФУ"""™, определяющих состояния мнРа тПро
граммных компонентов б^Г"* ВНуГренисе представление состояний ^ „^
к выс™ого уровня. Состояния представляются в вид
„з четырех элементов, в которых каждый компонент обозначает местоположение человека,
волка, козы и капусты соответственно. Так СПисок (е w а,ггмеегоположсн"е человека,
„ром человек (первый элемент) и коза (третгГэлеменГ) „™ 3W,aCT СОСГО"""е- «J» ^
. 8Ролк и капуста - „а западном. ^J^^^^Z^Z^Z
3Т ™П1£Я™ГЯаоК°ГТР Mk-et"« « —Ре ФуХи д~ £aler
slde. wolf-side, goat-slde и cabbage-side. Параметром конструктора является
местоиоложени человека, волка, козь, „ капусты. Эта функция воэвращ«г ™„е.
Параметрами функции доступа является состояние, а возвращаемым значением - местопо-
ложение объекта. Эти функции можно определить так.
(defun make-state (f w g с) (list f w g с) )
(defun farmer-side (state)
(nth 0 state))
(defun wolf-side (state)
(nth 1 state))
(defun goat-side (state)
(nth 2 state))
(defun cabbage-side (state)
(nth 3 state))
Оставшаяся часть программы основывается на этих функциях. В частности, они
применяются для реализации четырех возможных действий человека: переправы через реку
в одиночку или с одним из пассажиров.
При каждом переходе в новое состояние функции доступа используются для
разделения состояния на его компоненты. Функция opposite (которая вскоре будет
определена), задает новое местоположение объектов, пересекающих реку, а функция make-
state— трансформирует его в новое состояние. Например, функцию farmer-
takes-self можно определить так.
(defun farmer-takes-self (state)
(make-state (opposite (farmer-side state))
(wolf-side state)
(goat-side state)
(cabbage-side state)))
Заметим, что эта функция возвращает новое состояние без учета его безопасности.
Состояние является небезопасным, если человек оставит на берегл- козу с капустой или
волка с козой. Программа должна найти путь решения, не допускающий "опасных"
состояний. Проверку состояния на его "безопасность" можно проводить на многих этапах
выполнения программы. Мы будем выполнять ее в функциях перемещения с помощью
формы safe, которая вскоре будет определена. Вот пример ее использования.
> (safe ■(« w w w)) ,• состояние безопасно, возвращается без изменений
(w w w w)
> (safe • (е w w e)> ,-волк съест козу, вернуть nil
nil
> (safe • („ „ е е)) ;коза съест капусту, вернуть ml
Функция safe используется в каждой функции перехода для фильтрации опасных
' ^ ьа£е "сиолы}с11л •ч.лйоюпасному" состоянию, возвращает
состояний. Так. любой переход, приводящий к He6tMnatHl"f „поверяет
"С это состояние а значение nil. Рекурсивный алгоритм вычисления пути проверяет
и состояние, а значение пи- -f „^пасывает это состояние. Таким обра-
обращаемое значение, и. если оно равно niLorfPываег ^.^
зом функция safe обеспечивает реализацию проверки уело г-
ia 15. Введение в LISP
707
еоехода Этот стиль используется при созданш, „
ности "^Я^7Лу»™»« safe ЧеТЫРе Ф°РМЫ "еРеХ0Да М0ЖН° °Пре*к^
онных систем.
дуюшим образом.
(defun fanner-takes-selt^ (£а lde state) ,
(safe (make-state 1ВД (wol£-side state)
(goat-side state)
(cabbage-side state))))
i.,i/Q=-wolf (state)
(defun far»er-take « e sfcate) (wolf_side state) ,
'«nd ((egUa saffTmake-state (opposite (farmer-side state))
(opposite (wolf-side stat
(goat-side state)
(cabbage-side state)))
(t nil)))
'^опПе^Т^гтег-Йе^^е, (goat-side state,,
(safe (make-state (opposite (farmer-side state))
(wolf-side state)
(opposite (goat-side state))
(cabbage-side state))))
(t nil)))
(defun farmer-takes-cabbage (state)
(cond ((equal (farmer-side state) (cabbage-side state))
(safe (make-state (opposite (farmer-side state))
(wolf-side state,
(goat-side state)
(opposite (cabbage-side
state)))))
(t nil)))
Заметим, что трн последние функции перехода включают проверку условия для
определения, находятся ли человек и его предполагаемый пассажир на одном и том же берег)
реки. Если нет, то эти функции возвращают nil. В функциях перехода использую»
представленные выше формы обработки состояний, а также функция opposite,
возвращающая местоположение, противоположное текущему.
defun opposite (side)
(cond ((equal side 'e) 'w)
((equal side 'w) 'e)))
В LISP существует множество различных предикатов для проверки равенств»- №»
более простои - eg - возвращает значение "истина" только в том случае, если его ^
■агенты соответствуют одному „ тому же объекту, т.е. указывают на одну « ту *
е ^„1 М СЛ°ЖНЫМ ЯВЛЯется предика/ефаа!, для истинности которог»
его аргументы должны 6„Tb синтаксически идентичными.
ysetq |1 -(1 2 3))
а(Гз?|2',123>'
=• (equal |1 |2)
* leq |1 |2)
> (setq |3 |1)
(1 2 3)
> (eq |1 |3>
t
функция safe определена „а основе формы cond. Это позволяет проверить два
"опасных условия: человек расположен „а противоположном берегу от вол™"
ловек находится „а противоположном берегу от козы „ капусты.!™ состояние безопасно
функция safe возвращает его неизменным, в противном случае она возвращала
(defun safe (state)
(cond ((and (equal (goat-side state, (wolf-side state,)
;волк съест козу п
(not (equal (farmer-side state) (wolf-side state)))) nil)
( (and (equal (goat-side state) (cabbage-side state))
<~~± , . ,c . ;коза съест капусту
(not (equal (farmer-side state) (goat-side state)))) nil,
(t state,,)
Функция path реализует поиск с возвратами в пространстве состояний. Ее
аргументами являются исходное и целевое состояния. Сначала проверяется равенство этих
состояний. Если они равны, то поиск завершается успешно. Если эти состояния не равны,
функция path генерирует все четыре соседних состояния на графе состояний и
рекурсивно вызывает сама себя для каждого из них, пытаясь найти путь к цели. Это
определение на LISP можно записать так.
(defun path (state goal)
(cond ((equal state goal) 'success)
(t (or (path (farmer-takes-self state) goal)
(path (farmer-takes-wolf state) goal)
(path (farmer-takes-goat state) goal)
(path (farmer-takes-cabbage state) goal))),)
Эта версия функции path представляет собой простой перевод рекурсивного
алгоритма поиска пути с "человеческого" языка на LISP. Она содержит несколько ошибок,
которые необходимо устранить. Однако эта версия отражает основную структуру алгоритма,
поэтому до начала устранения ошибок ее следует проанализировать подробнее. Первый
оператор cond служит для проверки успешного завершения алгоритма поиска. При
соответствии исходного состояния целевому equal state goal рекурсия прекращается и
возвращается атом success. В противном случае функция path генерирует 4 дочерних
Узла на графе поиска, а затем вызывает сама себя для каждого из эпгх узлов.
Обратггте внимание на использование формы or для управления оцениванием
аргументов. Напомним что функция or оценивает свои аргументы до тех пор. пока один из них не
возвращает значение, отличное от nil. В этом случае вызов функции or прекращается,
остальные се аргументы не оцениваются, а результатом считается это ненулевое значение.
Таким образом функция or не только используется как логический оператор, но и обеспе-
1нвает способ управления ветвлением в пространстве поиска. Здесь применяется форма or,
а не cond, поскольку проверяемое и возвращаемое ненулевое значение совпадают.
Неудобство это™ определения состоит в том, что Функция ."^/"Хч^гГдот"
значение nil, если переход невозможен или ведет к "опасному состоянию. Чтооы пг*дот-
аратить генерацию узла^отокгкт, для состоя»" nil. необходимо '"-"nil
™ «кущее состояние нулевым. Если да. то функш» path должна возвращать m 1.
г 709
1 л<"ва 15. Введение в USP
, „ебуюшим решения при реализации фу„Кции
Еше одним вопросом требую нствс поиска. Через несколько Шагов'8>
„„явление потенциальны циклов р ^^ с6я самого q »p^
и^тнои выше функции path _ 6есконечныи ЦИЮ1 мс иде,„^
другой. Следователь»^ ^гор" ^ „ред твращения тако„ с„туаци„^
Униями, которые J ^™та параМетр been-list,представляющий СПи» V
„«, path нужно доб».т тр ревд)СИВИОМ вызове функции path дл» »*.
„осешенных состоянии, up e g „ добавляться в список been-1 ist. „ ° Ч-
Дли»,
т«ещ.
С™"И" Тгв,«ГэтоТсшГе'тек'^состояиия можно использовать Пр^£*
ГеГв°о^овоеопределе„иефу„кциираЕЬ.
и, i=rate aoal been-list)
(defun path (state g"a
(C°f 'iritate^oal) (reverse (cons state been-list)))
((equal state goal, ^ .tesc #.equal))
'^or^th.fSer-taKes-selt state, goal
(cons state been-list))
(path (farmer-takes-vrol£ state) goal
(cons state been-list))
(path (£armer-takes-goat state) goal
(cons state been-list))
(path (farmer-takes-cabbage state) goal
(cons state been-list)))) ) )
Здесь member — это встроенная функция Common LISP, которая ведет себя так к,
как и пользовательская функция my-member, определенная выше в этой главе.
Единственным различием между этими функциями является включение в список аргументов
параметра : test # 'equal. В отличие от "доморощенной" функции
my-member,такая форма позволяет программисту указать функцию, которая будет использоваться дм
проверки принадлежности элемента списку. Это повышает гибкость функции, но не
играет существенной роли в настоящем обсуждении.
Вместо того, чтобы возвращать атомарное значение success, лучше передавать и
функции найденный путь решения. Поскольку последовательность состояний в пути
решения уже содержится в списке been-list, список возвращается в новой
функции. Поскольку этот список построен в обратном порядке (начальное состояние
является его последним элементом), ои сначала обращается (перестраивается в обратно»
порядке с использованием встроенной функции LISP reverse).
И, наконец, поскольку параметр been-lisp желательно скрыть от
пользователя,целесообразно создать вызывающую функцию верхнего уровня, параметрами которой
будут являться начальное и целевое состояние. Она будут вызывать функцию path со
течением параметра been-list равным nil
различия между ними очень тонки но поз
тивным и процедурным стилями программное^ птч^шУть разницу между дсклара-
Состояния в версии PROLOG пткдетавляют
0 в LISP задаются с помощью списка Эти два пГ "Ш0ШЬЮ "Рахата state (e, е, е, е).
ческими вариациями друг друга Представление c^Z"T, т тТ™ '"™mC" СИН™СИ-
сштакенсом списков, но и функциями доступа и пег, определяется не только
тип данных "состояние". В версии PROLOG с Ч>еходов' описывающими абстрактный
рГГеХГть^
Jc^.™^
использует встроенный алгоритм поХ Х^Г"Z """^ ' ™ ^ " PR0LOG
а8 pR0L0G -неявно. Поскольку PROLOG сГитГнаТ™' " ^ Жшт "ВН0'
годах доказательства теорем, „агщеанные „ „Т™™"^™"™ прщсгашен™ » -
описание предметной области задачи В 2 алго™Т '™°Ш"Ш " ^"^^
прямую. Обратной стороной мед.и -л^^^^^^Г^*
„ого встроенными стратегиями вывода PROLOG. Кроме того, TJ npZ^l
"доваеют формализм гфедставления и стратег™ поиска, воженные ?1*£П^
очередь, LISP допускает большую гибкость в представлении и свободу действии
программиста. Однако здесь программисту приходится явно реатизовывать стратегию поиска. ^^
15.3. Функции и абстракции высшего порядка
(defun solve-£wgc (state goal) (path state goal nil))
Давайте сравним версии программ решения задачи перевозки человека, волка,
[ПУСТЫ uam„~, _ .._ . .„„ Г_ v . г*г\ лпН
козы»
_ Человека, ■< в
капусты написанные „a LISP „ raoL5ol^^«"m PROLOG описан
разделе М.З,. Программа „a LISP не только решает ту^ке задачу, но и выполняет^
м той „,tP0CIPal,CTBe С0СТ°ЯНШг ™ и веР»я ™ PROLOG. Это служит "ОД™^
ZZ „" ' ™ К01,«^^»ация задачи в пространстве состояний не завис «^
лизании программы поиска в этом пространстве. Поскольку обе программы вь,по»
г много
поиск в „дном и том же пространстве состояннй, эти реализации имевэт »
Часть VI. Языки и технологии программирования для искусствен
Одним из главных преимуществ LISP и других функциональных языков
программирования является возможность определения функций, параметрами которых являются
другие функции, а также функций, возвращающих функцию в качестве результата- Такие
функции называются функциями высшего порядка (higher-order functions) и составляют
важное средство реализации процедурной абстракции.
й версии 15.3.1. Отображения и фильтры
Фшьтр (filter) — это функция, проверяющая элементы списка на предмет
соответствия некоторому условию и удаляющая "отбракованные" элементы. Примером фильтра
является описанная выше в этой главе функция filter-negatives. Отображения
(тар) — выполняют некоторые действия над списком объектов данных и возвращают
список результатов. Эту идею можно развить и ввести понятия обобщенных
отображений и фильтров, получающих в качестве параметров списки и функции н проверяющих
применимость функций к элементам списков.
В качестве примера рассмотрим упомянутую в подразделе 15.1.6 функцию filter-
negatives. Ей в качестве параметра передается числовой список, а в результате ее
выполнения возвращается этот же список, но без отрицательных элементов- Аналогично
можно определить фуикцию-фильтр для удаления четных чисел из списка.
(defun filter-evens (number-list)
;условие останова
(cond ((null number-list) nil)
( (oddp (car number-list) )
эинтв*9'
Глава 15. Введение в LISP
711
(cons (car "umber-list, (£ilt™-
^^nslcdrnu^er-Hst),,,,
, „„„чаются друг от друга только именем лреюкап
Поскольку эти Ф^"™'1'0'"" ов"списка. логично объединить их в ётнш\ "*«"*■
' *Ж — преД-г-фкльтр "»> Ф*^
ТлатьТпоиошью формы LISP f uncall, параметрами к„т0рой „„
^Г^ГГва^ьностьар^нтоа.ккоторь.мзтафуикцияи^^^.
m^:„TI сГатьТпоИошьЮ формь, LISP f^™^ к„ТОрой ,
ся функции .
*•-,.. v mst-of-elements test)
,(d1^a^nUll:^o^^,s,nU,ment
(,t^^u^VtntBt!,,'£ilter
rdr list-of-elements) test)))
,t (filter (cdr list-of-elements) test))))
Функция filter проверяет условие test для первого элемента списка. Еслик
зультат проверки отличен от nil, он добавляется к результату фильтрации хвоста спя»
с помощью функции cons. В противном случае возвращается отфильтрованный хщ
списка При использовании этой функции ей можно передавать в качестве параметр,
различные предикаты. Тогда она будет решать разные задачи фильтрации.
> (filter -(13-95-2 -7 6) #'plusp) ,-Фильтрация
;отрицательных чисел
(13 5 6)
> (filter '(12345678 9) #'evenp) ;Фильтрация всех
; нечетных чисел
(2 4 6 8)
> (filter ' (1 a b 3 с 4 7 d) It'numberp)
(13 4 7) ; Фильтрация нечисловых
; элементов списка
При передаче функции в качестве параметра, как в приведенном примере, перед ее (ше-
нем нужно указывать # ', а не просто символ '. Это делается для того, чтобы интерпретатор
LISP мог соответствующим образом обрабатывать этот аргумент. В частности, при передаче
функции в качестве параметра в Common LISP сохраняются все связи ее свободных переме»
ных (если таковые существуют). Такое сочетание определения функции со связыванием
свободных переменных называется лексическим замыканием (lexical closure). Флаг #' уведом»
ет интерпретатор LISP о необходимости построен™ лексического замыкания и передачи его«
функцию. Более строго funcall определяется следующим образом,
(funcall <функция> <арг, > < apr2 > ... < арг„ >)
В этом определении <фу„щт>-ую функция LISP, а <арг>>. . ■ «W f!
или более аргументов функции. Результат оценивания funcall совпадает с резу»«"°"
вызова функции <футцт>^ есди указаиные 1юредаются ей в качестве фа«*
ческих параметров.
Функция apply и,™,,, задачу, что „ funcall, но ее аргументы *»*«££
лава-rwo ■> и„п ~ J — j""a^y, iiu н tuncaii, но си api>i«^«"- <- Rw
иТогТсах П ""** ^ ад"™'«* синтаксическое отличие между фун"*»» <
Фун^и al^T" М°Жет ВЫбиратъ °™У » Функш«5 по своему усмог-»"'
^ZZZZ»^™" EVa1' "^ "* ^позволяют пользовател.
Функции. Различие между ними состоит в том, что параметрами ФУ
Часть VI. Языки и технологии программирования для искусственного
являются оцениваемые s-выражсния, а функциям яг,г,1
ция „ ее параметры. Вот примерь, использован™ ™ Ф^Г*" ПСРслаюкя ™« ФУ"-
> (funcall #'plus2 3)
5
> (apply #'plus*(2 3))
5
> (eval '(plus 2 3))
5
> (funcall tt'ear '(a b c))
a
> (apply «'car ' ((a b C) ) )
a
Еще одним важным классом функций высшего порядка являются отображения т е фуик-
ции, применяющие заданнуто функцию ко веем элементам списка. На основе гГсаП ™ж-
„„ определить простую функцию-отображение map-simple, возвращающую список
результатов применения некоторого функционала ко всем элементам исходного списка,
(defun map-simple (func list)
(cond ((null list) nil)
(<t (cons (funcall func (car list))
(map-simple func (cdr list))))))
> (map-simple #'1+ '(1 2 3 4 5 6))
(234567)
> (map-simple #'listp (1 2 (3 4) 5 (6 7 8)))
(nil nil t nil t)
Это упрощенная версия встроенной в LISP функции mapcar. допускающая
использование нескольких списков аргументов. Тогда к соответствующим элементам
нескольких списков можно применять функции нескольких аргументов.
> (mapcar #'1+'(1 2 3 4 5 6)) ;та же оункция, что и map-simple
(234567)
>(mapcar #'+'(12 3 4) '(5 6 7 8))
(6 8 10 12)
> (mapcar #'max'(3917) '(2568))
(3 9 6 8)
Функция mapcar — лишь одна из многих встроенных функций-отображений в LISP,
а значит, одна из многих функций высшего порядка.
15.3.2. Функциональные аргументы и лямбда-выражения
В предыдущих примерах аргументы-функции передавались по имени и применялись к
другим аргументам. Для этого функции-аргументы нужно было определять заранее в
глобальной среде. Однако зачастую желательно передавать в качестве параметра само
определение функции, не определяя се глобально. Осуществить это позволяют мшбда-еыражашя.
Выражение lambda позволяет отделить определение функции от ее имени. Истоки
лямбда-выражений связаны с,чшбда-исчислеишм (lambda-calculus)- натеюттескои моделью
вычислений обеспечивающей (среди всего прочего) особенно четкое разграничение между
объектом и его именем. Синтаксис лямбда-выраженля аналогичен определении фунвдш
defun, однако имя функции здесь заменяется ключевым словом lambda.
Глава 15. Введение в LISP
713
„„_,„етры>) <темо>)
,, mbda 1<фориальнае-парачетр
„спользотать вместо имени функции в СПСШ(.
Лямбда-вьфажен.и, можно ^^ ^^ тело лямбда-вьфаже„„ГпФ''К1''%
funcall или apply- ^" п" |етрам„ funcall. Как и при использований Т'^
аргументы будут связ сиг[ параметров должны совпадать. HanpHK,,.™"1»*.
количества формальных и Ф ср,
> (funcall f.l«W. (x) <***" 4)
16
„.п^ртгя со значением 4, а затем оценивается тРпп
Здкь „ер— х связь -^ с ^ числа ^ Привед^* ^д,
^ЛеГо^!! лям6да-выраже„„Г, в функциях funcall и aPPl, *-*
> (адЛу.М1«Ма (ху, С (*хх) У)) '(2 3),
> (funcall «'(lambda (x) (append x x) ) ' (а Ь с) )
^(fuLall #Мlambda (xl x2> (append (reverse xl) x2)) ■ ,a b c)
'Id e f)>
(с Ь а d е f)
Лямбда-выражения можно использовать и в функциях высшего порядка наподебщ
mapcar вместо имени глобально определенной функции. Вот пример.
>(mapcar «'(lambda (x) (* х х) ) ' (1 2 3 4 5) )
(1 4 9 16 25)
> (mapcar «'(lambda (x) (* х 2)) '(12345))
(2468 10)
> (mapcar «'(lambda (x) (and (> x 0) (< х 10))) '(1 24 5 -9 8 231)
(t nil t nil t nil)
Если бы не существовало лямбда-выражений, программисту пришлось бы определять
все функции в глобальной среде с помощью функции def un, даже если они подлежат
однократному использованию. Лямбда-выражения освобождают программиста от такой
необходимости. Чтобы возвести в квадрат все элементы списка, достаточно передать
лямбда-форму функции mapcar. Это иллюстрируют приведенные выше примеры. При
этом не нужно заранее определять функцию возведения в квадрат.
15.4. Стратегии поиска в LISP
Функции высшего порядка являются мощным средством процедурной абстракции. В этом
разделе приемы абстрагирования будут применяться для реализации общих алгоритм» »«'
в главах 3 п 4. Для У"Г-
И closed.
open»
ка в ширину, глубину и "жадного" алгоритма поиска, описанных в i
ния поиском в пространстве состояний будут использованы списки open и с
15.4.1. Поиск в ширину и в глубину
качПГГ™ аЛГ0РИ™а "°ИСКа " ШИР"»У базируется на использовании списка
Гые пеое^Г^и™0 (°ЧереДИ)' Спнск" °Р™ и closed определяются как г
ать нТиоТзоГ' ™ ОТЬ НеСК0ЛЬК° »Р"™<- Во-первых, мы хотнм продев
использование глобальных структур в ШР. Во вторых, целесообразно Ч
714 Часть VI. Языки и тахноиогии программирования для искусственного *****
какглоба»'
;монстриь*
программное решение „a LISP с программой на
основная задача этой программы — решатъ nvo6™ ™LOG. В-третьих, поскольку
следует определить глобально. И, наконец списки П°ИСка' то пространство поиска
глобальными переменными, поскольку они'моги о*™^ " °losed разумно объявить
образность использования локальных и гл бальных "ГГ ^^ * ЦеЛ0М ЦСЛСС°-
лизании конкретного языка программирован^7П* Р * 3аВИСНТ °Т деталей реа"
^отся слева и справа c'hJL^T^^
следующим образом. 3ткЦИИ П0ИСКа в ШИРИНУ мо*»° определить
(defun breadth-first ( )
(cond ((null *open*) nil)
(t (let ((state (car *open*)))
( cond ((equal state *goal*) 'success)
(t (setq *closed* (cons state "closed'))
(setq *open* (append (cdx *open*)
(generate-descendants state *moves*)>)
(breadth-first)))))))
(defun run-breadth (start goal)
(setq *open* (list start))
(setq *closed* nil)
(setq *goal* goal)
(breadth-first))
В этой реализации проверяется наличие элементов в списке *ореп*. Если список
пуст, то алгоритм возврашает значение nil, означающее неудачное завершение
алгоритма. В противном случае проверяется первый элемент списка *ореп*. Если он
соответствует целевому узлу, то алгоритм завершается и возвращает значение success.
В противном случае для получения потомков текущего состояния вызывается функция
generate-descendants, узлы-потомки добавляются в список *ореп*, и функция
breadth-first рекурсивно вызывает сама себя. Функция run-breadth— это
процедура нннцнализации, в которой задаются исходные значения переменных *ореп*.
*closed* и *goal*. Функции generate-descendants в качестве параметров
передаются состояние state и список функций *moves*, генерирующих переходы. В
задаче перевозки человека, волка, козы и капусты с учетом определений переходов из
раздела 15.2 список *moves* имеет вид.
(setq "moves*
'(farmer-takes-self fanner-takes-wolf farmer-takes-goat
farmer-takes-cabbage) )
Функция generate-descendants зависит от состояния и возврашает список его
потомков. Помимо генерации списка потомков она предотвращает дублирование
элементов в этом списке и исключает узлы, уже „рискующие в списке орег или
•closed». Кроме состояния функции generate-descendants ^*™H°
переходов. Это могут быть имена уже определенных функции ™ »-^Sft£
ДР..сохранения резитов "^^^^Х^^^
let. Определение функции generate-descenuau
(defun generate-descendants (state moves)
(cond ((null moves) nil) state))
" ^es^eneUte-aescenaants state (cdr.oves,,,,
Глава 15. Введение в LISP
(cond (,nUll Child) rest)
, (member child rest :test # equal, rest)
„ember child -open* :test # equal) ra
(„ember child -closed* :test #•equal) r
L /„„,,. ,-hild rest) ))))))
(t
(cons child res
При вызове функции member используется дополнительны,, „„
».еГа1 который впервые упоминался в разделе 15.2. Функция member „03BeSt
, „льзГателю задавать любую процедуру проверки наличия элемент* „ с„„СКе **,
Z можно „спользовать предикаты любой сложности и семантики. Од„ако*" Ч
Гбуе, обязательного задания такой функции: по умолчанию используется пред,,,* »•
При использовании этого предиката два объект считаются идентичными, если о ,?
„,,мают одно „ то же местоположение в памяти. Мы используем более слабую ф 'У*
сравнена equal, в которой два обьекта считаются равным,,, если они „неют ^ '»
же значение. Поскольку глобальная переменная -moves* связывается с соответсти?
ш„м набором функций переходов, то описанный алгоритм поиска можно применять д!
поиска в ширину на любом графе состояний.
Единственной проблемой этой реализации является невозможность вывода спив,
состояний, расположенных вдоль пути решения от начала и до конца. Хотя при заверще
н,ш алгоритма все ведущие к цели состояния содержатся в списке -closed*, в нем
также находятся все остальные состояния, пройденные на предыдущих уровнях по„щ
Чтобы решить эту проблему, для каждого состояния нужно записывать и его предка
Когда текущее состояние будет соответствовать целевому, информацию о предки
можно будет использовать для построения пути от целевого состояния к исходному. Эта
расширенная версия поиска в ширину начинается с определения абстрактного типа
данных записи состояния.
(defun build-record (state parent) (list state parent) )
(defun get-state (state-tuple) (nth 0 state-tuple))
(defun get-parent (state-tuple) (nth 1 state-tuple))
(defun retrieve-by-state (state list)
(cond ((null list) nil)
((equal state (get-state (car list))) (car list))
(t (retrieve-by-state state (cdr list)))))
Функция build-record строит пару (<состояткхпредок>). Функции get-state и
get-parent обеспечивают доступ к соответствующим полям записи. Функция retrieve-
by-state получает в качестве параметров состояние и список записей состояния, а
возвращает запись, поле состояния которой соответствует данному состоянию.
Функция build-solution использует форму retrieve-by-state для
восстановления рошпельского состояния и построения списка состояний, ведущих к целевому. При ини-
циализащш списка -open* родительским состоянием для начального является nil. ФУ»'»
a-solution прекращает свою работу после перехода к нулевому состоянию.
(defun build-solution (State)
(cond ((null state) nil)
state'-closed-n ) П ) ^"^"^«оп (get-parent (retrieve-by-s»te
Остальная часть алгоритма аналогична реализации поиска в ширину из раздел» 32
(setT-o^f11 <Sta" WD
' etQ °pen* dist (buila-r6
Часть VI. Языки и техН0Л0гии программирования для искусственного инт^
(aetq "closed* nil)
(setq *goal* goal)
(breadth-first) )
(defun breadth-first ( )
(cond ((null -open*) nil)
(t (let ((state (car *open*)>)
(setq -closed* (cons state -closed*))
(t (setq -open* (append (cdr «opm'l
*™maest:endMta ,get-st*te ■««•>
(breadth-first)))))))
(defun generate-descendants (state moves)
(cond ((null moves) nil)
(t (let ((child (funcall (car moves) state))
"' aenerate-descendants state (cdr moves) )) )
(cond ((null child) rest)
((retrieve-by-state child rest) rest)
((retrieve-by-state child -open-) rest)
((retrieve-by-state child -closed*) rest)
(t (cons (build-record child state) rest)))))))
Поиск в глубину можно обеспечить путем модификации процедуры поиска в ширину
и реализации списка open в виде стека. Для этого нужно всего лишь изменить порядок
следования аргументов функции append.
15.4.2. "Жадный" алгоритм поиска
"Жадный" алгоритм поиска можно реализовать с помощью простой модификации
поиска в ширину. Вместе с каждым состоянием нужно сохранять его эвристическую
оценку. Затем кортежи -open* следует отсортировать по этой оценке. Для записей
состояний потребуются типы данных, основанные на типах данных из реализации
алгоритма поиска в ширину.
(defun build-record (state parent depth weight)
(list state parent depth weight))
(defun get-state (state-tuple) (nth 0 state-tuple))
(defun get-parent (state-tuple) (nth 1 state-tuple))
(defun get-depth (state-tuple) (nth 2 state-tuple))
(defun get-weight (state- tuple) (nth 3 state-tuple))
(defun retrieve-by-state (state list)
(cond ((null list) nil)
((equal state (get-state (car list))) (car list))
(t (retrieve-by-state state (cdr list)))))
Функции best-first „ generate-descendants определены следующим образом.
(defun best-first ( )
(cond ((null -open*) nil)
(t (let ((state (car -open4)))
'closed-) )
\::ii ^'.jr^-t.. •*»>*' <ь-«
-goal*))
(t (setq "open*
Глава 15. Введение в LISP
717
A
(cdr :
^sh,;
(insert-by-**1^ . __
.geerate-desceca-ws <get-s
(+ 1 (get-depth state])
(cdr 'open")))
,deru= S^"-, saves) nil)
(co== '■<- ,, v,-7d (funcall (car soves) state))
11 '^J Cerate-descendants state depth
— .IrSe^-stati'c^ld rest, rest,
retrieve-by-state child -open-, rest)
((retrieve-by-state child -c-csed*) rest)
(- (cezis (b'jild-record child state depth
(+ depth (heuristic child)), rest)))))))
рдадашш отличием прошэд поиска best-first от breadth-first „^
~ использование функции insert-by-.e-gr.t хтя сортировки записей спев
эвристическим весам и вычисление глуоины поиска и этих весов с помою*
.«««jgenerate-descendasts.
Ди завершена» процедуры поиска best-rtrst требуется определить футлю
inserc-by-weighr. Она получает в качестве параметра не сортированный сшюжзг.
шкей состожний и вставляет нх гю одному в соответствующие позиции списка *opet\
При этом также требуется с учетом специфики задачи определить функцию heuristic
Ее параметром является состояние, хтя которого вычисляется эвристический вес с во.
»ошыо гаобазьвой переменной -goal*. Определить эти функции читателю предагает-
153. Проверка соответствия шаблонам LISP
Проверка соответствия шаблонам — это важная методология искусственного ншез-
аекта, которая уже была описана в главах, посвященных языку PROLOG и продуждвое-
ным системам. В этом разделе будет представлена реализация рекурсивной процедуры
проверяя соответствия шаблонам и рассмотрено ее использование для построеши фуш-
цнн извлечения информации по шаблону из простой базы данных.
Ялром системы восстановления информации служит функция natch, параметрами ю-
торой являются два ^выражения, а возвращаемым значением — t. если эти выражен»
соответствуют друг другу. При этом оба выражения должны иметь одинаковую структур)'
также содержать идентичные атомы в соотаетствующих позициях. Функция mat^*^
«ает жпольэованве в s-выражениях переменных, обозначенных символом ?■ Перепала*
соответствуют любому s-выражению (списку или атому,, но не сохраняют свюыв^™пян
Ч« подвой унификации. Ниже приводятся примеры требуемого поведен."'Jy№^
natch. Эти примеры напоминают соответствующие примеры на языке Р»01-*"".^
«14, поскольку функция mtch на самом деле является упрошенной вегкж* а**"
>™*"™»"- положенного в основу языка PROLOG, а также многих друг"* С»^Г,>
с™™™ интеллекта, основанных на шаблонах. В разделе 15.6 функция match будя
поавоценной пмт^»,»^. ^„пекия воз*"—
• ДО полвоцеаной реализации алгоритма унификации за счет добавления
™ использования имен переменных и возвращения списка связей.
, .^ССЬ- (likes bin wiM) . (liiMB biu ^^
> =atcb' (likes bill «inel•(likes biu ^^^
Г Cfflatcb-(likes bill ?).,iikes ьш ^^
^ (match-(likes ? жше)-(likes bill o,,
; г.еремгнньге з обсгас
." Загаженхях
> (=atch- (likes bill 7)-(lites biu (pro.cs .^ srail,_aiii
; (=atcb- (likes ?>•(likes bin vine))
nil
функция match используется для определения форнь, „- ^л.г.
которой являются два s-выражения. Первый аргумеГ-^о"^^ ' ""P2*""3*
natcnes возвращает перечень элементов списка, соответсгв™,™* первому аргументу
В приведенном ниже примере футшщя get-^tches испорете Гнз1^Гз1
пнеен из оазы данных сотрудников, описанной выше в этой паве
Поскольку база данных велика н содержит относительно сложные s-выражения ее
целесоооразно связать с глобальной переменной «database* в нсгюльзоватГэту
переменную в качестве аргумента функции get-etches. Это существенно повышает чи-
табельиостъ примеров.
> [setq ^database' '(((Lovelace ada) 50000.00 1234)
((taring aZ.au) 45000.00 3927)
((shelley eary) 35000.00 2850)
{(vonJfeuaann John) 40000.00 7955)
t(siaon herbert) 5CG0O.QC 1374)
{ lisccarthy join) 46CQ0.C1? 2?£4!
(Irassell bertrandf 35CI: .: lz-
•database*
> (get-matches '((turing alan) 450C0.00 3927) «database'
((turing alar.) 45000.00 3927)
> (get-matches * (? 5000C.0C ?) *database») ;все сосрулники
с зарплатой 50С00
(((lovelace ada.) 50000.00 1234) ((si=o=. herbert) 5G00C.CC 1374))
> (get-matches '((? John) ? ?) *database*) ,-все сотрудники
с именем ichn
(({vonNeumann John) 40000.00 7955) ((accartfcy John) 48000. 0C 28641)
Функция get-matches реализована рекурсивно. Это обеспечивает поиск злемен-
тов, соответств>-юшкх первом}- аргументу (шаблону). Все элементы базы данных
соответствующие этому шаблону, объединяются с помощью функции cons н перелаются в
качестве результата. Определение функции get-matches имеет следутоший энл
((defun get-matches (pattern database)
(cond ((null database) ( 1) .СМГМ1С:МК .чайленс.
((match pattern (car database)) J*^™™ * Р«*»«~
(сопГ( car database) (get-aatches pattern
(cdr database)))) , . .,...
(t (get-^tches pattern (cdr database)))))
718
Часть VI. Языки и технологии программирова,
ния для искусе
.ценного
„нтел"-*
Глава 15. Введение в USP
. „,..„ „мяется функция match. Она представляет собой п„.
Основой даннои^«ь.^^^5.выражения с першенньщи р" **at„,
ределяюший. ""-«^ TO даа списка соответствуют друг другу в Фйиад,
^tch основана «^^^ствуют их головы и хвое™. Поэтому дл, реаяизацГ^
■** ^SSr^STSL. car-cdr. Рекурсия завершается, «*„%£*-
алгоритма примененарекурс ^^ д. ^ ^^ «нн № ^
^™ аГоТГпиГм Если оба аро-ента представляют собой один „ тот « аГчТ
мекноиатомом.ншис^^ ^_ атомарную переменную ? (соответствую,, J !,нл«
один из
шаблонов представляет собой атомарную переменную 1 (соответствующе |
вольно- шаблону), то рекурсия завершается успешно. В противном случае прове^
^Гэавершаегся с отрицательным результатом. Заметим, что если один ю ща6 ««•
л^ переменной, то второй необязательно должен быть атомарным, поскольку перемер
мс-Гсоо^етсгвовать s-выражениям произвольной сложности. *•
Поскольку обработка условий завершеиия очень сложна, то в реализации фу^
match используется функция match-atom, зависящая от двух аргументов, хот, j,
один из которых является атомом. Она и проверяет соответствие шаблонам. Поскольку
сложность реализации процедуры скрыта в функции match-atom, структура рекурси,
car-cdr в функции match выглядит более наглядно.
(defun match (patternl pattern2)
(cond (or (atom patteml) (atom pattern2)) ; один из шаблонов - атоа
(match-atom patteml pattern2)) ;вызов match-atom,
;в противном случае
(t (and (match (car patternl) (car pattern2))
; проверка соответствия car и
(match (cdr patternl) (cdr pattern2) ) ) ) ) )
;cdr
Прн реализации функции match-atom учитывается тот факт, что при вызове этой
функции один из ее аргументов — атом. Благодаря этому предположению упрощается
проверка соответствия шаблонов друг другу, поскольку требуется лишь удостовериться,
что оба они представляют собой одни и тот же атом (возможно, переменную). Эта
функция завершается неудачей, если шаблоны представляют собой различные атомы, либо
одни из них является неатомарным. Если первая проверка завершается неудачей, то
соответствие шаблону может быть достигнуто, только если один из шаблонов является
переменной. Эта проверка и составляет заключительную часть определения функции. И,
наконец, функция variable-p предназначена для проверки того, является ли шаблон
переменной. Обработка переменных как экземпляров абстрактного типа данных упроша-
ег дальнейшее расширение функции (например, распространение этой функции на
именованные переменные подобно тому, как это было реализовано в языке PROLOG).
((defun match-atom (patteml pattern2)
(or (equal patternl pattern2) ;шаблоны совпадают, или
variaMe-p patternl) ;один из них является переменной-
(variable-p pattern2)))
(defun variable-p (x) (equal x •?))
^^УР^дд^Функция унификации
зво^юш^^чаГв^Т РеКУРСИВНЬ1Й ^ОР-™ проверю, соответствия i_
Чать в шаб,юны неименованные переменные. Расширим эту простую
720 Часть VI. Языки и
„У до реализации полного алгоритма унификации описание
пускает использование именованных переменных о& * ГтК 2 фУ"ктя uni f У Д°-
связанных переменных, соответствующих данному fi* 8Ы,от<ениях и возвращает список
павляет основу систем вывода, которые 6vavr „„„of™"0"5'' Эв Ф>™ия унификации со-
Как и в разделе 15.5. будем P^^Z^^TIT"^"^
переменные или списочные структуры В полном алг рсдоташмюшие собой константы,
отличаться друг от друга своими именами Имено«!,иц0РИ™е уш^"шт" переменные могут
„пдесписков (var <шИ» ,Где шИ-это какпг^Г ПерСМенные 'тог™° представлять в
пустимыхпеременнькяшшотся (var х) I,™»- ™,'атомаРнь,и™«вол.Примерамидо-
W Параметрами функции unify являюте, ™ К" Ы" newstate>'
с„б„йРи набор подстановок <с.язГ„ГГреМ „Г™-~™ ранению между
ве функции это множество будет пустым (ппГр" ""^ """ п£рвом вш°-
yentLo, функция uni£y А^^™=£^—?
х„д„мых для соответствия шаблону. Если соответствия не найдены, то ф\™ unTf v
возвращает символ failed. Значение nil используется д,хя обозначен,* пустогомно
жества подстановок, т.е. соответствий, не требующих никаких подстановок Вот приме-
ры использования функции unify. v
> (unify' (P a (var x) ) ■ (р а Ь) ( )) возвращает подстановку
(((var X) . Ы) ;ЬЛЛ" ПеРе*е"»°*
; (var X)
> (unify' (p (var у) Ь) - (Р a (var х) ) ( )) ;переменные в обоих
,- шаблонах
(((var X) . b) {(var у) .а))
> (unify' (P (varx)l'(p (q a (vary))) { )); переменная, связанна»
; с более
(((var х) q a (var у)))
;СЛОЖНЫМ шабЛОНОМ
> (unify (р а) ' (р а) ( ) )
nil
> (unify '(Pa) '(q a) ( ) )
failed
Обратите внимание на использование в этих вызовах символа ., например, в
выражении ((var х) . Ь). Это обозначение будет обсуждаться после описания функции
unify. В ней, подобно системе проверю, соответствия шаблонам из раздела 155.
используется схема рекурсии car-cdr.
(defun unify (patternl pattem2 substitution-list)
(cond ((equal substitution-list 'failed) 'failed)
((varp patternl) (match-var patternl pateern2
substitution-list)) .проВерка на наличие переыенной
((varp pattern2) (match-var pattern2 patternl
substitution-list))
,<iSiconf UequPa?"rnl pattern2, „bsti™-!-,
(t 'failed)))
( (is-constant-p pattern2) '«"^ 2)
(t (unify (cdr patteml) (cdr pattern-,
mil означает, что
;подстановки не требуются
возвращает атом
failed, означающий
неудачное завершение
технологии программирования для искусственного
Интел*
глааа 15. Введение в LISP
(uni£y (car pattern!) I car patter^,
substitution-list)))))
r——-** —-reтся—nP„ вЫПОЛНе-ко
УТГмФСГдинТГшЛонов является переменной, вызывается фу,^ TOtch
Затем, если ид™ „mbctkv и возможное добавление новых связанных net». '
°о Гяет „а»™« «и™"- "Р" падении констант список подстаиовки в0зВращаегся »
™3ш. в противном случае возвращается значение taxied.
Последним элементом оператора cond является декомпозиция задачи по дереву
снн Сначала проводится унификация первых элементов с помощью связанных перемещу
из списка подстановки substitution-list. Результат передается в качестве третьего!
гумента функции unify для унификации хвостов списков шаблонов. Это позволяет исло!
зовать подстановки переменных, сделанные при проверке соответствия первых элементов,
проверять вхождение этих переменных в оставшейся часта обоих шаблонов.
Вот пример определения функции match-var.
(defun match-var (var pattern substitution-list) \
(cond ((equal var pattern) substitution-list)
{t (let ((binding (get-binding var substitution-list)))
(cond (binding (unify (get-binding-value binding) pattern
substitution-list) )
( (occursp var pattern) 'failed)
(t (add-substitution var pattern substitution-list)))))))
Эта функция сначала проверяет соответствие переменной шаблону. При
самоунификации переменной подстановки не требуются, поэтому список substitution-list
возвращается неизменным.
Если параметры var и pattern не совпадают, выполняется проверка связанности
переменной. Если переменная связана, то функция unify рекурсивно вызывается для проверю)
соответствия значений указанному шаблону pattern. Заметим, что значение связанной
переменной может быть константой, переменной или шаблоном произвольной сложности.
Поэтому для завершения проверки требуется вызов полного алгоритма унификации. I
Если переменная var не связана ни с какими значениями, вызывается функция ос- (
cursp, с помощью которой проверяется наличие var в шаблоне pattern. Проверю
вхождения (occurs check) необходимо выполнять для предотвращения попыток
унификации переменной с содержащим ее шаблоном, которые могут привести к появлению
циклов. Например, если переменная (var х) связана с выражением (р (var x)l.™
любая попытка применена этих подстановок к шаблону приведет к бесконечному U№
лу. Если в шаблоне pattern встречается фрагмент var. функция match-var
возвращает значение £aUed. В противном случае новая пара подстановки добавляется в
список substitution-list с помощью функции add.substitution.
опиеанм Г,,"" У " match-™r составляют основу алгоритма унификации. Ни*'
д й„t °CCUrSP (вь,™™™шая проход по дереву шаблона в поисках «и*
ет"ГZT "еР™-ной,, varp и is-constant-p (проверяющая, -к* «£
» «ноже™поГанГГ" KOHC™TOf,)' 3"™ ^ "™ функции обраС-
722 часть VI. Языки и технологии программирования для искусственного интолл""
Pattern)) nil)
(defun occursp (var pattern)
(cond ((equal var pattern) t)
((or (varp pattern\ <,„
(t (or ,ocoLspevar \а1;ТЛ1Т^
(defunis-oon^t-SpPISeIrPatte™"!!»
(atom item))
(defun varp (item)
(and (listp item)
(equal (length item) 2)
(equal (car item) 'var)))
Множества подстановок можно ппедставитк г ™„
данных, известного под названием ас!о"™21ZZZ"ТТ ' "^ ™™
(a-lisf). Работа с такими структурами, ла„Г„Z К0 <assoclall<>" "sl> »™ <-<™«™
, \. ■ ^ >. • , . F-y,vlJ'tJdM« данных положена в основу (Ьункиий ялл-
substitutions, get-binding и binding-value. Ас«,ш,ат„вный спГо"- 1
список записей данных «ли пар ЫЮч-мачение (key/data). Первый элемент к^ой зал!
си - это ключ для ее восстановления, а оставшаяся часть записи содержит дЗс ZI
рые могут представлять собой либо список значений, либо отдельны! атом. Извлечение
данных осуществляется с помощью функции assoc. параметрами которой являются
ключ и ассоциативный список, а возвращаемым значением - первый элемент
ассоциативного списка, соответствующий данному ключу. При вызове функции assoc можно
дополнительно указать третий аргумент, означающий тип проверки, используемой для
сравнения ключей. По умолчанию для проверки в Common LISP используется функция
eql, согласно которой равенство двух аргументов означает, что они указывают на один
и тот же объект (т.е. занимают одну и ту же область памяти или принимают одинаковое
числовое значение). При реализации множеств подстановок будем использовать менее
жесткий тест equal, проверяющий синтаксическое соответствие аргументов
(идентичность имен). Приведем примеры использования функции assoc.
>
(3
>
(d
>
(с
(assoc
с)
(assoc
е f)
(assoc
. 3)
3 '
'd
'с
( (1 a)
' ((a b
' ( (a .
(2
c)
1)
b)
(b
(b
(3 c)
с d e)
. 2) (
(4 d)))
(d e f) (c d e))
с . 3) (d
. 4)) :
: test
test #
if 'equal)
'equal)
Заметим, что функция assoc возвращает всю запись, соответствующую указанному
ключу. Данные из этого списка можно извлечь с помощью функции cdr. Заметим также,
что в последнем вызове элементами а-списка являются не списки, а структуры,
получившие название точечных пар (dotted pair), например (а . 1).
Точечная пара — это базовый конструктор в LISP. Она является результатом
объединения двух s-выражений. Обозначение списка, используемое в этой главе. —
это лишь один из вариантов точечных пар. Например, при вызове (cons 1 nil)
"а самом деле возвращается значение (1 . nil), что эквивалентно (1).
Аналогично список (1 2 3) можно записать в виде точечных пар (1 . (2 . (3
"И) ) ). Хотя на самом деле функция cons создает точечные пары, списочные
обозначения гораздо понятнее, а потому предпочтительнее.
При объединении двух атомов результат всегда зшзисьгвается в ооозначе»^ точеч
** 1Мр. Хвост точсчн/й „арЬ1 _ это ее второй момент, а не список, содержащий
Рой атом. Например,
Глава 15. Введение в LISP
723
(cons
a • Ь)_
{car
(cdr '
•b)
. b)>
. b))
ценным образом входят в состав ассоциативных с„
*" ' Lr„e ключа для извлечен™ другого атома), а та»1 (ки»
Точечные пары «^ ^ ^^ „,„,„„
***'*»
bill) (hobbies music skiing movies)
одиГатом используется = каче"-~^шнх ты с парамн ат -^ --™« „,,
няютс, в ДР^^; *:Гп„нТместо переменной зачастую подстав^етсТо ^ *
^ГчеГыТпары нередко встречаются в ассоциативных списках, возВр^
^"'TatToTeVmrnonLISP определена функция aeons, аргументам,,^
Наряду с ass ассоц„атнвный список, а возвращаемым значением .-Г!**
—,2'сГок, nU элемент которого - это результат объеди^
данных. Например,
> {aeons 'a 1 nil)
{(а . Ш
Заметим, что если в функцию aeons передаются два атома, то в ассоциативный cm-
сок добавляется их объединение.
> (aeons 'pets ' (erfflia jack Clyde)
'((name . bill) (hobbies music skiing movies)
(job . programmer)) )
((pets emma jack clyde) (name
(job . programmer))
Элементами ассоциативного списка могут быть точечные пары н списки.
Ассоциативные списки обеспечивают удобный способ реализации различных таблиц
и других простых схем извлечения данных. При реализации алгоритма унификации
ассоциативные списки используются для представления множеств подстановок: ключи
соответствуют переменным, а данные — нх значениям. Данные могут представлять собой
простую переменную, константу либо более сложную структуру.
С помощью ассоциативных списков функции работы со множеством подсташ»
можно определить следующим образом.
(defun get-binding (var substitution-list)
(assoc var substitution-list :test #'equal))
deZ J"-bi"din9-value (binding) (cdr binding) )
icetun acid-substitution (var pattern substitution-list)
(aeons var pattern substitution-list) )
деле 15*П Реа"ШаЦИЯ аЛГ°рнТма У™Ф"кации завершена. Она будет использован» >Р
« п 4^„РяеоГаЦИН ПР0СТОГ° ™-Р"Р-хораРдля языка PROLOG и в р«*
роения оболочки экспертной системы.
~^^^P£IgIgPMj_BHeflpeHHbie языки^
№»»иеотр«°ает'11ГТеРПреТаТ01'а1-15Р называется циклом read-eval-Pr^
-_____J^^~ по чтению, оцениванию и выводЯ^.
24 ЧaOTЬVI■Яз"»ит6xнoлorииnporpaммиpoвaниядляиcкyccтввннoгoИ«^e,
выражении, введенных пользователем, фуниш.
де 15.1.4, составляет основу интерпретатора LISP г 0"P«M«""M » подразде-
print можно напнеать на самом языке LISP Be п°и°Щью цикл read-eval-
упрошенная версия этого цикла. Упрощение состп?1™™" примеРс 6УД« разработана
хотя LISP обеспечивает средства, необходимые для е" " °ТСугствии обработки ошибок.
Для создания цикла read-eval-print в реализации-
read и print. Первая нз них не зависит от ™0ЛИуеМСЯ "Ч™ Функциями LISP
s-выражение, введенное с клавиатуры, функция JMM"p0B и "««раивет следующее
оценивает его и выводит результат в стандартный™ 3аВИ™Т °Т 0ДН0Г° аРгУмента'
бится также функция terpri, не зависящая от aorvMeLT™3' Пр" ЭТ°М "аМ понад°-
поТОк символ новой строки newline По ™,„„, выводящая в стандартный
^значеннепП. Цикл read-^p^^™ *>™ te^i возвра-
, , р lnc Рсализуется как вложенное s-выраженис
(print (eval (read)))
При этом сначала оценивается .-выражение самого глубокого уровня вложенности
(read). Возвращаемое этой функцией значение (следующее введенное поГовГл™
s-выражение) передается функции eval для оценки, результат которой в свою очередь
передается функции print и выводится на зкран. В завершение цикла выводите,
приглашение, а с помощью функции terpri после отображения результатов выводится
символ newline, н цикл рекурсивно повторяется. Таким образом, окончательно
определение цикла read-eval-print имеет вил.
(defun my-read-eval-print ( ) ;не зависит от аргументов
(print':)
(print (eval (read)))
(terpri)
(my-read-eval-print))
Этот цикл можно использовать "поверх" встроенного интерпретатора.
> (my-read-eval-print)
: (+ 1 2)
3
;вывод приглашения :
:цикл read-eval-print
;вывод символа newline
;повтор цикла
;новое приглашение
Из этого примера видно, что функции, подобные quote и eval, обеспечивают
программисту на LISP широкие возможности управления обработкой функций. Поскольку
программы и данные LISP представляются в виде s-выражений, можно написать
[программу, выполняющую любые действия над выражениями LISP до нх оценки. В этом состоит
преимущество LISP как процедурного языка представления: произвольный код LISP
можно хранить, модифицировать и оценивать при необходимости. Это свойство также
упрощает написание специализированных интерпретаторов, расширяющих или модифицирующих
поведение встроенного интерпретатора LISP. Эта возможность положена в основу многих
экспертных систем, написанных на языке LISP, считывающих запросы пользователя и
отвечающих на инх в соответствии с результатам., анализа базы »»
Примером реализации подобного сп^^ £"4*^»^
*ег служить модификация цикла my;read^L „ноЛ СИСге.ме обозначений. Работа
арифметические выражения в инфиксной, а не "Р^"™ ^ ВН1ШЗЫК на мод„ф„-
такого интерпретатора показана на следующем примере (оорат
цированное приглашение inf ix->*-
Глав:
«15. Введение в USP
in£ix-> (1 * 2)
infix-» (' " 2)
5 _ 1П ..цикл должен допускать вложенные выражен,,,,
infix-> ((5 + 2) * I
14 А„к.сныГ, интерпретатор обрабатывает только арифметические вЫра.
В целях простоты инфиксны .„„остить, ограничив его возможности обработай бинар.
жения. Можно его дополнитель > ^ выражени„ в скобки. Это позволяет избежать нсоб-
„ыхоперащшитребовашкм тсхнологай грамматического разбора и не требует
ходимости применения оол интерлретатор допускает вложенные выражения произ-
учета приоритета операции- при ■ арифметических операций.
*омопгфш*«*ш^^УЬ V rePad.eval_prlnt, добавив ф
Модифицируем разработан» J форму перед их передачей
:;РаТ^Г„1ГГпрХнШзтой;ункци„ может „меть такой вид.
(defun simple-in-to-pre (exp) элемент (символ операции)
(list (nth 1 exp) :с£ановится первым
(nth 0 exp) '; первый операнд
(nth 2 exp) ; второй операнд
Функцию simple-in-to-pre удобно применять для преобразования простых
выражений Однако с ее помощью не удастся корректно обработать вложенные выражения,
в которых операнды сами являются инфиксными выражениями. Для решения этой
проблемы операнды необходимо транслировать в префиксную форму. Рекурсия завершается
проверкой типа аргумента: если он представляет собой число, то оно возвращается
неизменным. Полная версия транслятора из инфиксной в префиксную форму имеет вид.
(defun in-to-pre (exp)
(cond {(пшпЬегр exp) exp)
(t (list (nth 1 exp)
(in-to-pre (nth 0 exp))
(in-to-pre (nth 2 exp))))))
С помощью этого транслятора можно модифицировать цикл read-eval-print и
обеспечить интерпретацию инфиксных выражений. Например, так.
(defun in-eval ( )
(print 'infix->)
(print (eval (in-to-pre (read))))
(terpri)
(in-eval))
фикнгГфГ10 таК0Г° Интер1третатоРа можно обрабатывать бинарные выражения в №
> (in-eval)
infix->(2 4- 2)
in£ix->((3 * 4)
7
5)
тик!.ГсГГ„ПаРр1ере Ш ШР Реиию"» ™°Ь'« -ж - язык инфиксной ар*";
кольку наряду с символьными вычислениями (списочными структурам» «
' технол°™и программирования для искусственного интеллеи*
Ауякии-ми их обработки) LISP поддерживает управ,,
*fLISF ™Р«Д° легче, чем „а многих друг,,, Й^ТТ °ЦеНКОЙ' ™ Р«*п. т ,„
,епэдологи.о программирования задач „скусств ^ "Ример илл^Д^4"
„с .е^ингшеш^скои австращт ^ ^™ Интелу, лолу^^ »
скусствениого интеллекта зачастуто =^ечаЮтс, с "ац, С''°П) При »-,*
,а заД"""' ИЛИ ТребУ-СМ^ ш ее Рсш<™ "Р°Ф™«а7лиш1К°ГДа "С М°™= «<™™Теа
„нгвистическои абстракции базовый язык „р "Г™ ""»" в I—и подход,
LISP) применяется.для реализации спеццал„з„ро,а„„0Т0 "ь, Р„ Г™ (" ДаНИ™ ч™.
Ый может быть более эффективным для решения к"™™ ОУР°'"ПОГО "»«. ■»»-
фидеистическая абстракция означает использованиГГ™ ЫаССа адач ТеР™"
„„„ другого языка программирования, а не решения самой затГТ "ЫКа ДЛЯ реал№
ле 14.6, PROLOG тоже позволяет программисту создавать ™Г П°гааВ0 " ра№-
Преимушества метаинтерпретаторов с точки зрения лоддеожки Р"рПэторы *™Уровия.
„з сложных предметных областей обсуждались также во введение™"щ™"* '**"
1^8. Логическое программировашк^наятмкеLISP
В качестве примера металингвистической абстракции разработаем на LISP интерпре
гатор для задач логического программирования, используя для этого алгоритм унифика-
щи из раздела 15.6. Подобно логическим программам на языке PROLOG логические
программы в данном случае тоже состоят из баз данных фактов и правил из области
исчисления предикатов. Интерпретатор обрабатывает запросы (или цели) за счет их
унификации с элементами логической базы данных. Если цель унифицируется с одним
простым фактом, процесс завершается успешно. Решением в этом случае является
множество связанных переменных, сгенерированное в процессе проверки соответствия. Если
цель соответствует голове правила, интерпретатор рекурсивно пытается соответствовать
предпосылке правила, используя при этом метод поиска в глубину и связанные
переменные, сгенерированные в процессе проверки. В случае успеха интерпретатор выводит
исходную цель, в которой переменные заменены соответствующими значениями.
Для простоты этот интерпретатор поддерживает конъюнктивные йети и импликации,
операторы or и not в нем ие определены, как не определены и арифметические опера-
иии, операторы ввода-вывода и другие встроенные в PROLOG предикаты. Мы не
пытаемся реализовать полную версию PROLOG и отследить все особенности °™"J™£
ствие оператора отсечения „с позво.ляет корректно обрабатывать РДО"" ■*££
™. Тем „е мРс„ее предлагаемая оболочка пллю» основи * я»™
логического программирования. Читатель может добавить к ннтер ре
ленные свойства в качестве интересного упражнения.
15.8.1. Простой язык логического программирования
погтмммироми'» полдержива
Предлагаемый интерпретатор для задач логического "Р" г^^ в полном исчяс-
« *орновские выражения - подмножество выраженш . v ^ ^^ в0К1Ю„кти„-
ле«"и предикатов. Корректно определенные Фор,7 " твяой «рм - ™ с™"13
ны* выражений и правил, написанных в стиле USE• " элеменгы и»™"™*""
^ злемеитом которого является имя предиката- «та переченные или другие
умеита.. п ..._ — ..nrvr выступать кони
'■ Введение a LISP
„„. Аункции unify, переменные будек,
„срс«ен«°йРаССМ.Н
Mikes biU music'
'onblOCi'UaUatherrobert))
(friend biii ^ ^ список, первым элементом которого явл,
Кончонктивное «'Р^ппостые термы или конъюнктивные выражения *с*
»„ and,. последую^»" Р er peter david),
ш* (=«"« davlf !«* у)) <likes <var z) !var y)))
Й llikes ^"ЦГЦ Ы«*-1 block-2) (on block-2 taile)))
'СиГГв.р-ется в синтаксически ясноГ, форме, что у„р0Щает ее ^
распознавание. „.„«яв»
(rule if <предпосылка> then
,»« <™*«»w>- эт0 ™6° """""г; ™ кон™"™ное Пред„„жен|1
о0даЧ™еГ- всегда простое предложение. Приведем несколько примеров „pa„„.
<™iT7f(and (lil— <«rx) (var z> )
1 (likes (var y) Ivar z, I ,
then (friend (var x) (yar y) ) )
(rule if (and (size (var x) small)
(color (var x) red)
(smell (var x) fragrant))
then (kind (var x) rose) )
Логическая база данных — это список фактов и правил, связанных с глобальной пера»
ной «assertions*. Приведем пример базы данных об отношениях симпатии, основам»
на вызове функции setq (можно было бы воспользоваться и функцией def var).
(setq 'assertions*
' {(likes george beer)
(likes george kate)
(likes george kids)
(likes bill kids)
(likes bill music)
(likes bill pizza)
(likes bill wine)
(rule
if (and (likes (var x) (var z))
(likes (var y) (var z) ) )
then (friend (var x) (var y) ) ) ) )
На верхнем уровне интерпретатора используется функция logic-shell, к»*
считывает целевые выражения „ пытается удовлетворить их иа основе *>«*»*>
анньГГ0" С ПереМеНН°Й '«Bert-ione*. При работе с приведенной *
<-=*, &££££ — —ировать следуй -
Hloglc-shell)
? Hikes bill (var xll ;ВЫВ0Д пРи™ашения ?
х»> .-успешно выполненные запросы выводите»
■'с подстановка™
Ча"ь\".Язы^и7
технологии программирования для искусственного
(1ikes bill kids)
(likes bill music)
(likes bill pizza)
(likes bill wine)
?(likes george kate)
(likes george kate)
?,likes george taxes) ;если запрос „е выполнен „
;возвоап,„.„ ™>олнен, ничего не
возвращается
ifriend bill george) :ю (and(liken him i,„ ,
?(£riend bill roy, ,.roy не <££rZ£B*£Llli*- 9eo^e kids,,
;не выполнен е Знании' запР°с
?(friend bill (var x))
(friend bill george) ;из (and (likes bill kw,,M.b
(friend bill bill) ,из ,ar,d(likes bin w? n I" 3e°rge ki<is) >
}ё£ Sil 55! .5 ,Ж= Й ™---■ *»^..
ifriend bill bill, ^ <£&£ SS Sine^^fbSi^n ''
?quit
bye
>
Прежде чем переходить к обсуждению реализации интерпретатора для решения задач
логического программирования, рассмотрим тип данных потока stream.
15.8.2. Потоки и их обработка
Как видно из предыдущего примера, даже небольшая база данных требует сложной
обработки. Необходимо не только определять выполнение или невыполнение целевого
выражения, но и находить в базе данных подстановки, обеспечивающие истинность
целевого выражения.
Одному целевому выражению могут соответствовать различные факты, а значит,
и разные множества подстановок. При использовании конъюнкции целей необходимо
удовлетворить всем конъюнктам, а также обеспечить согласованность связанных пере-
менных. Аналогично при обработке правил необходимо, чтобы подстановки,
сформированные в процессе проверки соответствия заключения правила целевому выражению,
были внесены в левую часть правила. Необходимость управления различными
множествами подстановок — основной источник сложности интерпретатора. Эту проблему
помогают решить потоки. Они позволяют сконцентрировать внимание на изменении
последовательности подстановок-кандидатов в рамках ограничений, определяемых
логической базой данных.
Поток (stream) — это последовательность объектов данных. Наиболее типичным
примером обработки потоков является обычная интерактивная программа. Поступающие
с клавиатуры данные рассматриваются как бесконечная последовательность символов,
а программа считывает и обрабатывает текущий символ из потока ввода. Обработка
потоков _ это обобщение этой идеи: потоки не обязательно создаются пользователям^Их
могут генерировать и модифицировать функции. Генератор (generator) - эге' Ф^и*
создающая непрерывный поток объектов данных. «««*. »~''Г\^.Шс с
-полняет „скорое преобразование над "^—^Z^Z—
^ючает некоторые элементы из потока по условиям, заданным некоп р i
г,гава 15. Введение в LISP
729
„„е механизмом вывода, можно представить в виде
Решения, возвращаемыемеха ^^ целевое нерадение следует °* *»•
лнч„ых подстановок переме» ^ з[ИнА используются № модифи^**.
знаний. Ограничения-о;^ДоГк-канд11Датов и получения результата. Рассмотри? »
PCK„fl базой данных из предыдущего раздела. С точки
Воспользуемся логи* ^ шршенш можно рассматривать как ф„лЬ1р ^е,"«
потоков каждый конью множество подстановок переменных в поток»
гока множеств «^^^ «,„„, а результат сверяете, с базой з^
((I) При отсутствии соответствия множество подстановок исключаете,
I „з потока. Если же соответствие найдено, создаются новые ыноже
I ства подстановок за счет добавления новых связанных переменных
' к исходному множеству,
(likesbill(varzl) Ha prIC 154 п0казана обработка потока подстановок с
помощью этого конъюнктивного целевого выражения. Сначала поток
подстановок-кандидатов содержит только пустое множество под.
становок. Ои расширяется после появления первого соответствии
(((van), s предложения множеству элементов базы данных. После исключе-
((varz). music) ния подстановок, не удовлетворяющих второму конъюнкту
(likes george (var z)), в потоке остается одно множество
подстановок. Результирующий поток ( ( ( (var z) . kids))) со-
((varz).wine)) держит единственную подстановку переменной, обеспечивающую
I соответствие обеих подцелей базе знаний.
I Как видно из этого примера, одна цель н единственное
множество подстановок позволяют сгенерировать несколько новых
(likesgeorge varz I
множеств подстановок, по одному для каждого соответствия
базе знаний. Кроме того, с помощью целевого утверждения
можно исключить множество подстановок из потока, если со-
((((varz).kids))) ответствие ие найдено. Поток множеств подстановок может
Рис 15.4 Фильтрация РасшиРяться н сужаться в процессе обработки последователь-
потока'подстановок н°с™ к™ыонктов.
переменных в соот- ^ основе обработки потоков лежат функции создания, расшн-
ветствт с тнъюнк- Рения " доступа к элементам потока. Простой набор функций
обдай четей работки потоков можно определить на основе списков и
стандартных операций над ними
^тиГсопз'-зСгеГ.еГ"* "**«* -емент-
; возвращает першй fnT^ Stream) (cons element stream))
«Mun head-streTutre^ Г"
; возвращает пот» I, ' (car "«am) )
(defun tail-str ' ,™ к°торого удалей первый элемент
■• возвращает значение"! 'Cdr str«>m) )
Mefun combine-streams (streaml -t„ ,
1 ,cond (lempty-stream-p streak ™2)
«= <с«ш- streaTUU^)
(=ombinelstream3ream №««1>
«^JTnstream"
Хотя реализация потоков в виде списков не об
вых типов данных, такое определение позволяетТосмоГ" "** 803™»™™й потоко-
НЙЯ обработки потоков. Во многих задачах, в частно °? "а Пр01ТаммУ < ™чки зре-
дм задач логического программирования „з раздела И s'7" С°ЗЛаНИИ ™«Рпр™тора
„ое средство организации и упрощения кода. В ши'к«?Ю "РО-раммнсту мощ-
раничения списочной реализации потоков а также п o6cW>™ra некоторые ог-
„ использованию потоков при оценивании с задержкой Ша™"Ы ^«рнативный подход
15.8.3. Интерпретатор для задач логического пр„граммирования
на основе потоков ' н«ммирования
Реализуем интерпретатор с помощью функции logic-shell, которая является vn
рощенным вариантом цикла read-eval-print, описанного в разделе 15 7 После вы
вода приглашения ? эта функция считывает следующее введенное пользователем
s-выражение и связывает его с символом goal. Если целевое утверждение oral
соответствует значению quit, функция завершает работу. В противном случае она вызывает
функцию solve для генерации потока множеств подстановок, удовлетворяющих
данному целевому утверждению. Этот поток передается в функцию print-solutions, которая
выводит целевое утверждение с каждой из найденных подстановок Затем функция
рекурсивно вызывает сама себя. Вот определение функции logic-shell,
(defun logic-shell ( )
(print '? )
(let ((goal (read)))
(cond ((equal goal 'cfuit) 'bye)
(t (print-solutions goal (solve goal nil))
(terpri)
(logic-shell)))))
Основой интерпретатора является функция solve. Она получает целевое
утверждение и набор подстановок и находит все решения, согласованные с содержимым базы
знаний. Эти решения возвращаются как поток множеств подстановок. Если соответствия
«е найдены, функция solve возвращает пустой поток. С точки зрения обработки
потоков функция solve является источником (source), или генератором (generator), потока
решений. Вот ее определение,
(defun solve (goal substitutions)
(declare (special «assertions*))
(if (conjunctive-goal-p goal)
<f ilter-through-conj-goals (body »°»^ cream,,)
(cons-stream substitutions (make еп.р«
(infer goal substitutions «assertions )))
•assertions* является еле-
Ключевое слово special означает, что переменная ымтьет со средой.
-"«"Мой (special), или глобальной (global), и будет динамичен,
!а 15. Введение в LISP
731
„i„e (Во многих современных версиях LISP nKl
.«оп.рой.ь—«?Ф5МГЯ° "^
ни. special не ^6УетсЯ> является ли цель конъюнктивной. Если да, то
"фикция solve «"■'*^nj. goals, выполняющая описанную , .Л»*
дая функш* ""е^^оеу1вер™еннедоа1неконъюнкг„в„о,вь1зываетеяРф0*
лс 15.8.2 фильтрат» Ьсли ц выполняющая разрешение цели с помощью базы знаний
„,«. определенная ю^,fc ^ nj.go»le вызывается для тела К0НЪ10_
Функция "^ет „„люнетов, из которой удален оператор and) и потом „
(«- послг:г:ь:-нГг:™о „о*™*», р^™™ ее Ра6отЫ zz
Приведем определение функции filter tn «
,lfun filter-through-con,-goals (goals substitution-stream,
(if (null goals)
substitution-stream
(filter-through-conj-goals (cdr goals) ^ ^
(filter-through-goal (car goals) substitution-stream))))
Если список целей пуст, функция завершает работу и возвращает поток
substitution-stream без изменений. В противном случае вызывается функция filter-
through-goal для фильтрации потока подстановок на основе первого целевого
выражения в списке. Результат ее работы передается вызываемой рекурсивно функции
filter-through-conj-goals для обработки оставшейся части списка целей. Таким
образом поток передается по списку целей слева направо, расширяясь и сужаясь при
обработке каждого целевого утверждения.
Функция filter-through-goal зависит от одного параметра (целевого
утверждения), который используется в качестве фильтра для потока подстановок. Такая
фильтрация выполняется с помощью вызова функции solve, параметрами которой
являются целевое утверждение н первое множество подстановок в потоке. Результатом
вызова этой функции является поток подстановок, полученный в результате проверки
соответствия целевого утверждения базе знаний. Этот поток может быть пустым, если
целевому утверждению не удовлетворяет ни одна из подстановок в потоке, либо содержать
несколько наборов подстановок, представляющих альтернативные значения переменных.
Полученный поток объединяется с результатом фильтрации хвоста входного потока.
(de£Kf£f^rthrOUSh"g0al (sMl substitution-stream)
(if empty-stream-p substitution-stream)
(make-empty-stream)
(combine-streams
(глЛ S1il (head-stream substitution-stream))
subsH^^rOU*-SOal goal (tail-stream
substitution-stream)))))
с™"^*^" "^«-through-con:-goals поток множеств^-
Йт^^^П^Г^™0"" ЦСлевь« ^ерждений, а функция fin*
°ь.з»в функции sot* Г" ЭТ°Т П°Т0К *" Каж^й конкретной цели. ГекуТ»»» "'
Если ко„ьЮИИИвные це„ТпТГРеШеН"е Цели «"* ™го наб0ра "^".ы о*
fHter-througn-COn77 бра6аТЬ,ва^я в функции solve с помощью «**
«ниой „„же фу„Кции 1п£<Л„ S' т0 «дельные цели разрешаются с помощью опр
' °Торая пмУчает целевое утверждение и набор поде""
732 ЧастьМ.Языкии
биологиипротраммироВания д,я искусставнногоинтел**
вок, а возвращает все решения, найденные в базе знаний Tn„ r
infer- это база знаний логических выраженнй п„„ ™Р"м«Р Мэ функции
Z solve ей передается база зианХТвяз/н^Т'гТ" '- ^ '" ФУ"К'
.assertions*. Функция infer последовательно вып1н - «' псрсмс""™
свер9я соответствие целевого утверждения каждом* Z П°ИСК " 6ше зншиП kb'
"^кая рекурсивная реализация функции^^бе—ГГ""" ""^
ствен„ый интерпретатору PROLOG и многим оболоч Гэкс" " Т СВ°"
проверяется, не пуста ли база знаний *Ь, н, ^^Гр^Г^Г^^
«.ном случае первый элемент базы знаний kb связывается с символом assertion
с помощью блока let . Этот блок аналогичен блоку let, но прн этом гарантированно
оценивает исходные значения локальных переменных в последовательно вложенных
контекстах, т.е. обеспечивает порядок связывания и видимость предыдущих переменных
В нем также определяется переменная match. Если assertion- это правило
переменная match инициализируется подстановкой, требуемой для унификации цели с
заключением этого правила. Если же assertion — это факт, переменная match
инициализируется подстановкой, требуемой для унификации assertion с целевым
утверждением. После унификации цели с первым элементом базы знаний функция infer
проверяет, удалась ли она. Если соответствие не найдено, она рекурсивно вызывает сама
себя, пытаясь разрешить целевое утверждение с помощью оставшейся части базы
знаний. Если же унификация завершилась успешно, a assertion — это правило, функция
infer вызывает функцию solve для предпосылки этого правила, причем множество
подстановок связывается с переменной match. Функция combine-stream объединяет
полученный поток решений с потоком, построенным функцией infer при обработке
оставшейся части базы знаний. Если assertion — не правило, значит, это факт. Тогда
функция infer добавляет решение, связанное с переменной match, к решению,
полученному при обработке оставшейся части базы знаний. На этом поиск прекращается.
Приведем определение функции infer.
(defun infer (goal substitutions kb)
(if (null kb)
(make-empty-stream)
(let* ((assertion (rename-variables (carkb)))
(match (if (rulep assertion)
(unify goal (conclusion assertion) substitutions)
(unify goal assertion substitutions))))
(if (equal match 'failed)
(infer goal substitutions (cdr kb) )
(if (rulep assertion)
(combine-streams
(solve (premise assertion) matcn)
(infer goal substitutions (cdr kb)))
(cons-stream match (infer goal substitutions
(cdr kb))))))))
Перед связыванием первого " ™^^e^'%£ZZ
передается в функцию «name-variables где каждо, ^> шш< в
Уникальное имя. Это позволяет предотврати™^конфликт^имен жду р^ ^
«■ом утверждении и базе знаний. В "cn"™'~"^„ сочную от (var x)
Фрагмент (var x), его нужно обрабатывать как. п Р^н»> переименования
8 описании правила или факта. Решить згу проблему проще . н
Глава 15. Введение в LISP
733
- „ гоисвоения им уникальных имен. Определение ,
.сех пер— в ** f^'^o в конце этого раздела. "* Фу*.
Z ra^e-variables будет Wro ^ р Залач логического пр0Гр
" На этом ре—"» ^'^^высокоуровневая функш». которая генериру^
ванн, завершен, Итак. «^шия1ШВ( решения для целевого утверждения, получе^'
тожеств полстаново,^™-; fllter-through-con3-goals разр^
использованием базы знани , ^ ^^ Ц£ЛЬ вь1ступает в качестве *,
»ныонк™ные цеп., слева нпр»^ ^^ )Тверждение „е принимает з„гче1Г
ди потока решен.ш-кандидатов^ ^^ ^^ подсгановок функция ^«о*
истина" с учетом iмм ^ подсган0вки из потока. Если целевое утверждение^
ChriC ™ Функши, solve вызывает функцию infer для генерации „„Тои
™ ТХ^метворяюших целевому утверждению с учетом базы знаний. Пол*
„ГгеаМ пенный интерпретатор для заданного целевого утверждения „ах0дтвсе
но PROLUU. полу ^ сммн[ше перемеНные из имеющейся базы знании.
УТ™оТоХеле™ть функции доступа к элементам базы знаний, управления подга.
новками и вывода решения. Параметрами функции print-solutions являются ц№.
вое утверждение и поток подстановок. Для каждого множества подстановок в потоке зга
функция вывода целевое утверждение, в котором переменные заменены их значения»,
из этого множества.
{defun print-solutions (goal substitution-stream)
(cond ((empty-stream-p substitution-stream) nil)
(t (print (apply-substitutions goal (head-stream
substitution-stream) ))
(terpri)
(print-solutions goal (tail-stream
substitution-stream) ))) )
Замена переменных значениями из множеств подстановок осуществляется с
помощью функции apply-substitutions, выполняющей рекурсивный проход по дереву
шаблона. Если шаблон является константой, он возвращается без изменении. Если же это
переменная, функция apply-substitutions рекурсивно вызывает сама себя для
данного значения. Заметим, что связанное значение может быть либо константой, либо
переменной, либо шаблоном любой сложности.
(defun apply substitutions (pattern substitution-list)
(cond (ds-constant-p pattern) pattern)
<(varp pattern)
(let ((binding (get-binding pattern substitution-list)))
(cond (binding (apply-substitutions (get-binding-value
binding)
,,. substitution-list))
(f ( Pattern))))
(a^ly"S,Y,;SfStitUtions «=ar Ctteml substitution-!^
^^^^ (apply substltutions (^^J^ substituti0„-Ust))l"
целевому ут^вдетГ^Т^Г" Переменны<; ■> базе знаний до проверки их coow^j
"«ей. Например, целевое «™ ДИМ° дга предотвращен™ нежелательных к°*"
^знаний J ,*"»» (р a ,var х) ) должно соответствовать ***
ограничена одним выражен»-' "0СК0ЛЬКУ область видимости каждой переменной («
№М'0днако Ч» унификации это соответствие ие требуете»'
Алия и"ен можно предотвратить за счет присвоения ,см,„„й „.
£ в основу схемы переименован, M0-J поло^^ ^^ГЗГшР
genSym не зависящую от аргументов. При каждом ^ZZ.„Z™Z^cZ
вол. состоящий из числа с префиксом # : G. Например, уникальный сим
у (gensym)
#:G4
у (gensym)
#:G5
> (gensym)
#:G6
>
В процессе переименования имя каждой переменной в выражении заменяется результатом
вызова функции gensym. Функция rename-variables выполняет необходимую
инициализацию (описанную ниже) и вызывает функцию rename-rec для рекурсивного
выполнения подстановок в шаблоне. Когда встречается переменная, вызывается функция rename.
возвращающая ее новое имя. Чтобы при нескольких вхождениях в шаблон одной и той же
переменной ей было присвоено одно имя. при каждом переименовании переменной ее имя
помешается в ассоциативный список, связанный со специальной переменной *name-list*.
Благодаря объявлению этой переменной как специальной все ссылки иа нее являются
динамическими, и irx можно использовать в различных функциях. Так. при каждом обращении к
переменной *name-list* в функции rename мы получаем доступ к экземпляру этой
переменной, объявленному в функции rename-variables. При первом вызове для данного
выражения функция rename-variables инициализирует переменную "name-list*
значением nil. Приведем определения этих функций.
(defun rename-variables (assertion)
(declare (special *name-list") )
(setq *name-list* nil)
(rename-rec assertion) )
(defun rename-rec (exp)
(declare (special *name-list*))
(cond ( (is-constant-p exp) exp)
((varp exp) (rename exp)) тИМП
(t (cons (rename-rec (car exp))(rename-rec (cdr exp))))))
(defun rename (var)
^t'^-^.cWTT.^^'-n—U.t. .est^al),
''^setT™!^" (aeons var na.e -„a^e-lisf, .na-ne, , , >
Функции доступа к компонентам правил и целевых утверждений не гребутот допол-
нительных пояснений.
(defun premise (rule) (nth 2 rule))
(defun conclusion (rule) (nth 4 rule))
(defun rulep (pattern)
(and (llstp pattern) .
(equal (nth 0 pattern)'rule)))
(defun conjunctive-goal-p (goal)
(and (llstp goal)
(equal (car goal)'and))1
(defun body (goal) (cdr goal))
Глава 15. Введение в USP
735
,5.9. Поток^иоиениван^ ___
■ " lociic-shell было показано, что испол*.
При описании реализации <зi лот f Однак0 рсалшация потоков 0 ^анис
поп^об-гч^н»»»™^^^ с потоками. В частное™, ттокая p^J*
„с обеспечивает всех воз, ет обрабатъ1вать потоки данных большой длины.
достаточно эффективна и не элементы необходимо обрабатывать ло п.
ПР" TT^SSU» ФУ— В оболочке loBic-sheU ^
ДаЧ" полноТу и ребору базы знаний для каждого промежуточного целевого у^.
В0Д'"я Чтобы сформировать первое решение для цели высокого уровня, протри
кюта. Чтобы сфоР ий. Даже если нам требуется лишь первое реЩе„№
:ГГсХ прСо" а°:маСдолРж„а выполнить понек во всем пространстве реш/ни, £
1ло предпочти^ьнее реализовать эту функцию таким образом, чтобы поиск первого
пшеиня осуществлялся только в определенной части пространства, а нахождение ос
тальных решений было отложено до нужного момента.
Вторая проблема-невозможность обработки потоков сколь угодно большой длины.
Хотя эта проблема в программе logic-shell не возникает, с ней приходится стали,,
ваться при решении многих важных задач. Предположим, что нужно написать функцию,
возвращающую поток из первых л нечетных чисел Фибоначчи. Для этого можно
использовать генератор потока чисел Фибоначчи, фильтр для удаления нз него четных чисел и
функцию для накопления полученных решений в списке нз п элементов (рис. 15.5).
К сожалению, длина потока чисел Фибоначчи неизвестна, поскольку неясно, сколько
чисел потребуется для получения первых п нечетных чисел.
Поэтому лучше создать генератор, выдающий числа Фибоначчи по одному и
пропускающий их через фильтр до тех пор, пока не будут получены первые п нечетных чисел. Такой
подход более близок интуитивному представлению об оценке потоков, чем используемый при
их списочной реализации. Будем называть его оцениванием с задержкой (delayed evaluation).
Вместо того, чтобы генерировать весь поток решений, функция-генератор должна
находить первый элемент потока и приостанавливать свое выполнение до тех пор, пока не
потребуется следующий элемент. Когда программе требуется следующий элемент,
работа генератора продолжается. Он находит очередной элемент и снова приостанавливает
оценивание оставшейся части потока. Тогда поток будет состоять не из всего списка
чисел, а лишь из двух компонентов — первого элемента и элемента, на котором процесс
генерации был приостановлен (рис. 15.6).
Для оценивания с задержкой воспользуемся замыканием функции (function closure).
Замыкание включает функцию н все ее связанные переменные в текущей среде. Такое
замыкание можно связать с переменной илн передать его в качестве параметра и обраба-
„еГЬ*?0М°ЩЬК> ФУ"КЦИИ £unCa11' П° суЩ^ву, замыкание "замораживает" выпол-
£vutchУ" Т Д° НУЖН0Г0 момента' Замыкание можно создать с помощью формы LISP
function. Например, рассмотрим следующую запись на LISP.
> (setq v 10)
10
*<еомр1ЬЕО-ьЁх1САГг?п=™^°зиге <£uncti°n (lambda ( ) v))) >
>o«un=an (!с1о^ГеГ **28641Е>
Накапливает первые л
чисел из потока
Рис. 15.5. Потоковая
реализация программы поиска первых
п нечетных чисел Фибоначчи
Поток на основе списка, содержащий неопределенное число элементов
Поток с отложенным оцениванием хвостовой части содержит только два элемента,
но может включать любое число элементов
(е1 . <отложенное оценивание хвостовой части потока>)
Рис. 15.6. Реализация потоков на основе списков и оценивания с задержкой
Изначально функция setq связывает переменную v со значением 10 в глобальной
среде. В блоке let переменная v локально связывается со значением 20 и создается
замыкание функции, возвращающей это значение переменной v. Интересно отметить, что
при выходе из блока let это связанное значение переменной v не исчезает, поскольку
оно сохраняется в замыкании функции, связанном с переменной f_closure. Однако
это лексическое связывание не имеет отношения к глобальному связыванию переменной
v- Следовательно если оценить это замыкание, будет возвращено значение 20
локальной перемеииой v хотя глобальная переменная v по прежнему принимает значение 10.
Эта реализация потоков основана на паре функций delay и force. Первая нз них
"олучает в качестве параметра выражение и „с оценивает его. а ВОТВР™"^
Функция force получает замыкание в качестве аргумента и запускает его с помощью
Функции funcall. Приведем определения этих функции.
jdefmacro delay (exp) '(£
efun force (function-closure)
(funcall function-closure)
(function (lambda 0. exp)))
г"ава 15. Введение в USP
737
,„.uu riSP, получившей название макроса fm,
функция delay- - ГГР 2£i функции defun, скольку о'пред^
Э^ фикцию нельзя о"Р*л^т свои аргу„енты до выполнена тела. Макросы «*£
Zm образом формы оценивают над оцсииваннем параметров. Макрос „Прсд .
чивают программистам полны*if ^ ^ выполнении аргументы „е оцениваю*!
отстся с помощью формы ае связьшаются с формальными параметрами, и '
а „сходные выражения при в ^ оцениваиия называется "«^роамра,
макроса оценивается дважды.^р ^ ^^ пмученной формы.
(macro-expansion), а второй с ^_^ ^ ^^ еще одну форму LISp _ обра1ную ^
Чтобы определить макр ^^ предотвращает анализ параметров, но д„.
вь^ку V Эта форма, подооФ, ^^ выраже„нй. Любой элемент s-выражения,
пускает оценивание вы»Р асположенный после запятой, оценивается, и его
SSSirr^^^n.B-p™., 2 3,„еоц,и.
^Г^^1Г»^--»1.е-е"н™^«е"»е" (+ 2 3,. Полется
вьграТениГ (function (lambda () (+ 2 3 ))). Оно снова оценивается, и воэвра-
шается замыкание функции.
Если позднее передать это замыкание в функцию force, то будет оцениваться выражение
(lambda О (+2 3)). Это функция, ие зависящая от аргументов, тело которой
соответствует значению 5. С помощью функций force н delay можно реализовать потоки на
основе оценки с задержкой. Перепишем функцию cons-stream в виде макроса, зависящего
от двух аргументов. Этот макрос должен присоединять значение первого к оценке второго.
При этом второй аргумент оценивается с задержкой и может возвращать поток любой длины.
Определим функцию tail-stream, оценивающую хвост потока.
(defmacro cons-stream (exp stream) ■ (cons, exp (delay, stream)))
(defun tail-stream (stream) (force (cdr stream) ) )
Переопределим также в виде макроса функцию combine-streams. Она должна
получать два аргумента, но ие оценивать нх. В этом макросе для создания замыкания
второго потока используется функция delay. Полученный результат вместе с первым
потоком передается в функцию comb-f, аналогичную определенной ранее функции
combine-streams. Однако, если первый поток оказывается пустым, то новая функция
оценивает второй поток. Если первый поток не пуст, выполняется рекурсивный вызов
функции comb-f с помощью обновленной веренн cons-stream. Прн этом рекурс™'
ный вызов в замыкании "замораживается" для дальнейшей оценки.
(defmacro combine-streams (streaml stream2)
(comb-f ,streaml (delay ,stream2))>
(defun comb-f ,5treaml streLi)
(if (empty-stream-p streaml)
(force stream2)
lCOTcomhT, <head-st«am streaml)
(comb-£ (tail-stream streaml) stream2)>))
str^re:"™""" K верСИЯМ *" ^ad-stream, n»W^
ков на „скове о„Г„„ва„иГ"Р " ""^^ 15-82. получим полную реализации
м ппаапня С ЗадерЖКОЙ,
Эти функции можно использовать для решения задачи получения первых п нечетных
чиссл Фибоначчи. Функция f ibonacci-stream возвращаТпоток всех чисел Фибо
наччИ. Заметим, что это бесконечная рекурсивная функция. Бесконечный цикл
предотвращается за счет оценивания с задержкой, поскольку следующий элемент вычисляется
только в случае необходимости. Функция filter-odds получает поток целых чисел и
исключает из него четные элементы, функция accumulate получает поток и число п
и возвращает список, состоящий из первых п элементов потока,
(defun fibonacci-stream (fibonacci-1 fibonacci-2)
(cons-stream (+ £ibonacci-l fibonacci-2)
(fibonacci-stream fibonacci-2 (+ fibonacci-1 fibonacci-2))))
(defun filter-odds (stream)
(cond Mevenp (head-stream stream) ) (filter-odds (tail-stream
stream)))
(t (cons-stream (head-stream stream) (filter-odds
(tail-stream stream))))))
((defun accumulate-into-list (n stream)
(cond ((zerop n) nil)
(t (cons (head-stream stream) (accumulate-into-list
(- n 1)(tail-stream stream))))))
Для получения списка первых 25 нечетных чисел Фибоначчи можно воспользоваться
следующим вызовом.
(accumulate-into-list 25 (filter-odds (fibonacci-stream 0 1)))
Эти функции работы с потоками можно использовать в определении интерпретатора для
решения задач логического программирования из раздела 15.8. Это позволит в некоторых
случаях повысить его эффективность. Предположим, необходимо модифицировать функцию
print-solutions, чтобы она выводила не все решения, а лишь первое га них, и ожидала
дополнительного запроса пользователя. Если потоки реализованы в виде списков, то перед
выводом первого решения необходимо иайти их все. При оценивании с задержкой первое
решение можно найти отдельно, а затем при желании вычислять остальные решения.
В следующем разделе интерпретатор для решения задач логического
программирования будет модифицирован в оболочку экспертной системы. Однако сначала будут
введены две дополнительные функции работы с потоками, используемые впоследствии в
реализации оболочки. В разделе 15.3 были представлены обобщенные функции
отображения и фильтрации списков. Эти функции map-simple и filter можно
модифицировать для работы с потоками. В следуюшем разделе будут использоваться функции
filter-stream н map-stream. Их реализацию предлагается разработать читателю
в качестве упражнения.
15.10. Оболочка экспертной системы на LISP
Оболочка экспертной системы, разрабатываемая в этом разделе, является
обобщением механизма обратного вывода, описанного в разделе 15.8. Основные «"ификац™
сводятся к использованию факторов достоверности для управления "^^ес "ы
Рассуждениями, возможности обращения к пользователю для "^ГГ^Г^ГсГ
Фактов и использованию рабочей памяти для хранения ответов пользователя. Эта обо-
лочка экспертной системы называется lisp-shell.
Г"ава 15. Введение в LISP
739
15101 Реализация факторов достоверности
15 „„„„статор для решения задач логического программ.
Разработай в-*>п*%£££ т КОТОрЫх целевое уткряя^ £*£
ния возврашал """^Связанные переменные, не обеепечнва.ощне согласование
„сдуег из базы знании-/- ^ ^ удалш1|СЬ ,„ потока, л1,бо воо6ще ^ осп,
целевого >™P«eH"" ' инзации рассуждений с факторами достоверное™ „рость,е £
решались. Однако при реши ^J^ значе„„ями из диапазона от -1 до +1. Ис-
тинные значения заменяю содержагь „е только связанные переменные, обесиечи
Поэтому поток paui агь степень доверия, с которой каждое решение сле™„
Т'^ГиГсХ'^оТболочка lisp-she!! должна обрабатывать «^
Ю ™^ постановок а потоки пар, состоящих из множества подстановки и числа, „ред.
множеств подстаново • „елевого утверждения при данной подстановке.
^еТ—^уем как абстрак-тньш тип данных. Для управления подстановку
„ ф1"™с^верР„ости"используем функции subst-reccrd, subst-list и subst_
^f Пепвая из нил строит пару, состоящую из множества подстановок „ фактора достоверно-
с™ вторая возвращает множество связанных переменных для этой пары, а третья - фаИор
достоверности Записи будут представлены как точечные пары вида «„,„„
подстановка. <фатюр достоверное). Приведем определения этих функций.
,. Возвращает список связанных переменных на основе пары
'■ подстановка-фактор достоверности.
'(defun subst-list (substitutions)
(car substitutions))
;Возврашает фактор достоверности на основе пары подстановка-фактор
; достоверности.
(defun subst-cf (substitutions)
(cdr substitutions))
,-Формирует пару множество подстановки-фактор достоверности,
(defun subst-record (substitutions cf)
(cons substitutions cf))
Правила и факты в базе знании тоже связаны с фактором достоверности. Факты
представляются точечными парами (<утвержденне> . <фактор достоверности), где
<утверждение> — это положительный литерал, а <фактор достоверности — мера
его определенности. Правила записываются в формате (rule if <предпосьта>
then <заключение> <фактор достоверностн>). Приведем пример правила из
предметной области описания цветов,
(rule
if (and (rose (var x) ) (color (var x) red))
then (kind (var x) american-beauty) 1)
Определим функции для обработки правил и фактов
;Возвращает предпосылку правила.
Idetun premise (rule)
(nth 2 rule))
(de?unPcma8I за*люч™ие правила
laetun conclusion (rule)
(nth 4 rule))
^р^;!с*тхгтоверности -p»-™ •
740 4aCTbV' ЯЗЫКИ И гех"°"°™„ программирования дли искусственного интел^
(nth 5 rule))
■Проверяет, является ли данный шаблон правилом
(defun rulep (pattern)
(and (listp pattern)
(equal (nth 0 pattern) 'rule)))
;Возвращает часть факта, являющуюся шаблоном
(defun fact-pattern (fact)
(car fact))
,.возвращает фактор достоверности факта,
(defun fact-cf (fact)
(cdr fact))
С помошью этах функций можно реализовать интерпретатор правил путем модификации
интерпретатора для решения задач логического программирования из раздела 15.8.
15.10.2. Архитектура оболочки lisp-shell
Основу оболочки lisp-shell составляет функция solve. Она не возвращает
поток решения напрямую, а сначала пропускает его через фильтр, удаляющий любые
подстановки, фактор достоверности которых ниже, чем 0,2. Таким образом удаляются
результаты с невысокой степенью доверия.
(defun solve (goal substitutions)
(filter-stream
(if (conjunctive-goal-p goal)
(filter-through-conj-goals
(cdr (body goal))
(solve (car (body goal)) substitutions))
(solve-simple-goal goal substitutions))
#' (lambda (x) (<0.2 (subst-cf x)))))
Это определение мало отличается от определения функции solve в оболочке
logic-shell. Эта функция по-прежнему содержит условный оператор, выделяющий
простые и конъюнктивные цели. Различие состоит в использовании обобщенного
фильтра filter-stream, удаляющего любые решения, фактор достоверности которых
оказывается ниже заданного значения. Эта проверка реализуется с помошью лямбда-
выражения. Второе отличие состоит в использовании функции solve-simple-goal
вместо формы infer. Обработка простых целей усложняется за счет возможности
запросов к пользователю.
(defun solve-simple-goal (goal substitutions)
(declare (special 'assertions*))
(declare (special *case-specific-data*) )
(or (told goal substitutions *case-specific-data*)
(infer goal substitutions *assertions*)
(ask-for goal substitutions}))
В этой функции для поочередного использования трех различных стратеги применяется
Форма or. Сначала вызывается функция told, проверяющая, было ли данное целевое
утверждение уже разрешено пользователем в ответ на предыдущий запрос: Ответы патьэов*«.™
связываются с глобальной .«ременной •cas.-specif ic-data* 0>«^told^««.
Р"--эТОтсписоквпоис^™^^
Hsp-shel 1 не запрашивает дважды одну „ ту же информацию. Если целевое утверждение
глава 15. Введение в LISP
741
lve_simple-g°al пытается вывести это vr»
. списке or**» « -*»; «К« 'assertions'. И. наконец, если зто не у£*
ждеи* с помощью правил « 6м ^^^ пользователю запрос „а получение ииформ;
вызывается функция
цш. Эти функш» 0Пре"!°я "d-solve-print изменился мало. В „его лишь т.
Цикл верхнего уровня rea „case-specif ic-data* значением nil „Г"
оператор "™«^^П^»»«-- ^"""^ ™ """ ПеР"°М ""»« ^
разрешением нового ««»> £ множество подстановок, а пара, состоЯЩад "
solve ей "^;олс J0B0K „ фактора достоверности cf. принимающего значение
пустого множеству> ^ „mtml. Оно лишь включается для согласованно^
с^итаксиГи заменяется реальным фактором достоверности, введенным пользователем
или полученным» базы знании.
^^cS^Peclil-case-specific-aata*,,
(seta *case-specific-data* ( ))
(prinl -lisp-shell» ) .-P""1 не выводит новую строку
(let ((goal (read)))
(terpri) ,
(cond ((equal goal 'quit) bye)
(t (print-solutions goal (solve goal (subst-record nil 0)))
(terpri)
(lisp-shell)))))
Функция filter-through-conj-goals не меняется, а функция filter-
through-goal должна вычислять фактор достоверности конъюнктивного выражения
как минимум соответствующих факторов-конъюнктов. Для этого первый элемент потока
substituion-stream связывается с символом subs в блоке let. Затем вызывается
функция solve для данного целевого утверждения goal и множества подстановок.
Результат передается в обобщенную функцию отображения map-stream, которая
получает поток пар подстановок, возвращаемых функцией solve, и пересчитывает их факторы
достоверности. Приведем определения этих функций.
(defun filter-through-conj-goals (goals substitution-stream)
(if (null goals)
substitution-stream
(filter-through-corrj-goals (cdr goals)
(filter-through-goal (car goals) substitution-stream))))
(defun filter-through-goal (goal substitution-stream)
(if (empty-stream-p substitution-stream)
(make-empty-stream)
(let ((subs (head-stream substitution-stream)))
(combine-streams
(map-stream (solve goal subs)
Lr?*^ <X) (subst-record (subst-list x)
Imin (subst-cf x)
(subst-cf subs)))))
substih,^0"*"9031 9Ml (tail-stream
substitution-stream))))))
Определение функции ;„<= ru Xo"
общая структура этойТ изменяется с учетом факторов достоверное»
"«•ЙГ.Й" ^ветствует ее версии, написанной для интерпр^.
^^^™^Ф5™^^ь,чисмстся £aicrop достовери0сти решении^
ЧаСТ" *ЯЗЫШ " тех"°"°™и программирования для искусственного »«*«<**
„ове факторов достоверности правил и степени соответствия решений предпосылкам
прав„л. Функцш, solve-rule вызывает функцию solve для'иахо™ н„, всех реше
„,,й „а основе предпосылок правил и использует функцию map-stre" Z вь чисГсн!
результирующего фактора достоверности для заключения этого правила
{defun infer {goal substitutions kb)
(if (null kb)
(make-empty-stream)
(let* ((assertion (rename-variables (car kb) ) )
(match (if (rulep assertion)
(unify goal conclusion assertion)
(subst-list substitutions))
(unify goal assertion (subst-list
substitutions)))))
(if (equal match 'failed)
(infer goal substitutions (cdr kb) )
{if (rulep assertion)
(combine-streams
(solve-rule assertion (subst-record match
(subst-cf substitutions)))
(infer goal substitutions (cdr kb)))
(cons-stream (subst-record match
(fact-cf assertion))
(infer goal substitutions (cdr kb))))))))
((defun solve-rule (rule substitutions)
(map-stream (solve (premise rule) substitutions)
#' (lambda (x) (subst-record
(subst-list x)
(* (subst-cf x) (rule-cf rule))))))
И, наконец, с учетом факторов достоверности модифицируется функция print-
solutions.
(defun print-solutions (goal substitution-stream)
(cond {{empty-stream-p substitution-stream) nil)
(t (print (apply-substitutions goal (subst-list
(head-stream substitution-stream))))
(write-string "cf =")
(prinl (subst-cf (head-stream substitution-stream)))
(terpri)
(print-solutions goal (tail-stream
substitution-stream)))))
Остальные функции, в том числе apply-substitutions и функции доступа
к компонентам правил н целевых утверждений, остаются неизменными. Их определения
приведены в разделе 15.8.
Для реализации оболочки lisp-shell остается определить функции ask-for и
told, обрабатывающие взаимодействие с пользователем. Они определяются достаточно
просто, однако читатель должен понимать, что при их описании сделаны некоторые
упрощающие предположения. В частности, в ответ на запросы можно вводить лишь
значения у «ли п. соответствующие значениям фактора достоверности 1 и -I. Пользователь
* может дать недостоверный ответ на запрос. Функция ask-rec выводит запрос и
считает ответ. Эти действия повторяются до тех пор. пока пользователь не о^уш
-■ Читатель может дополнить функцию ask-rec таким образом, чтобы принимались
глава15. Введение в LISP
, л0 i (Этот диапазон, конечно же, выбран щ»
-А, значен» из *—»- ^ок<0 выбирать другие диапазоны.)
^,„„. В ДРУГ"- ЧГ"£££ можно ли задать вопрос пользователю по „оводу ^
%ун«ш» askable <#>«%«■ ВВОДИтся глобальный список -askables-. ^
и„го ue.ie.oro У™еР"еяЮ'п^й сисгемы может определить, для каких целевых уп*.
„омошью *Р^етр "^пользователю, а какие должны вывоштгься только из ^
«ени^ допустимы запрос" К" ^ ^ ,лементов в глобальном списке .case.
знаний. Фуниш» со*а Е™„ запросы, на которые пользователь уже отвечал. Ее ра.
specific-data-, содер*^ infer с учетом того, что в списке -case-
jllDaIXM аналогична определ т Приведем определения этих функций.
specific-da"* хранятся тольк Ф
* /m»l substitutions)
(defun ask-for (goal sf ables,))
(declare (special askaD data,, ,
(declare (special case sp
(lf l^Mojeri (^substitutions goal (subst-list
substitutions)») есдаегу)1)
,,setg -case-specific-data- (cons (subst-record query
result) j,»-,* * ,
•case-specifxc-data ) )
(cons-stream (subst-record (subst-list substitutions)
result)
(make-empty-stream})) ) )
{defun ask-rec (query)
Iprinl query)
(write-string *>*)
(lee ((answer (read}))
(cond ((equal answer 'y) 1)
((equal answer ' n) - 1)
(t (print "введите у или п"}
(terpri)
(ask-rec query)))})
(defun askable (goal askables)
(cond ((null askables) nil) _ .
((not (equal (unify goal (car askables} ( )> 'failed))
(t (askable goal (cdr askables} ) ) ) )
(defun told (goal substitutions case-specific-data)
(cond ((null case-specific-data) (make-empty-stream))
(t (combine-streams
(use-fact goal (car case-specific-data)
substitutions) \]))})
(told goal substitutions (cdr case-specific-data) J
На этом реализация оболочки экспертной системы на основе LISP завеРше|Л 1^5
дующем разделе эта оболочка будет использована для построения простой эксперт»
системы классификации.
15.10.3. Классификация с использованием оболочки lisp-sbeU
Хт^эта^Г Неб0ЛЬШУю ^пертную систему для классификации я*Р^"*^
Хотя эта система не претендует на полноту с точки зрения ботаники, она иллюстр^
Часть VI. Языки и технологии программирования для искусственного к
основные свойства экспертных систем. База званий связана с двумя глобальными перс-
менными: -assertions* и -askables*. С первой из них связана база данных .гравия
и фактов, а со второй - список целевых утверждений, по которым можно задавать
вопросы пользователю. Используемая в этом примере 6aia знаний строится с помощью
двух вызовов функции setq.
(setq *asserticns*' (
{rule
if (and (size (var x) tall) (woody (var x) ))
then (tree (var x)) .9)
(rule
if (and (size (var x) small) (woody (var x)))
then (bush (var x)) .9}
(rule
if (and (tree (var x) ) (evergreen (var x) ) (color (var x)
blue))
then (kind (var x) spruce) .8)
(rule
if (and (tree (var x) ) (evergreen (var x)) (color (var x)
green})
then (kind (var x) pine) .9)
(rule
if (and (tree (var x) ) (deciduous (var x)) (bears (var x)
fruit))
then (fruit-tree (var x)} 1)
(rule
if (and (fruit-tree (var x) ) (color fruiz red, ues-e i—nz.
sweet) )
then (kind (var x) apple-tree) .9)
(rule
if (and (fruit-tree (var x) ) (color fruit yellow! (taste
fruit sour)}
then (kind (var x) lemon-tree) .8)
(rule
if (and (bush (var x)) (flowering (var x. > ■ ^nonry (var x) ))
then (rose (var x)) 1)
(rule
if (and (rose (var x) ) (color (var .-., _ = -
then (kind (var x) american-beauty) 1)))
(setq "askables*'(
(size (var x) (var y))
(woody (var x))
(soft (var x))
(color (var x) (var y) )
(evergreen (var x))
(thorny (var x) )
(deciduous (var x))
(bears (var x) (var y) )
(taste (var x) (var y))
(flowering (var x))})
Приведем пример работ, систем, с зтой <*"5е^^Т£^Г
<^.lm, порядок обработки правил, измене™ *"и^и5воГО ,твер«еш«.
"ость удаления подстановок, не обеспечивающих истинность не
Глава 15. Введение в LISP
lisp-sbellXkind tree-1 (var x) )
(Size tree-1 tall) >y
(woody tree-1] >У
(evergreen tree-1) >У
(color tree-1 blue) >n
color tree-1 green) >y
(kind tree-1 pine) c£ 0.81
(deciduous tree-1) >n
(size tree-1 small) >n
lisp-shell>tkind bush-2 (var x) )
(size bush-2 tall) >n
(size bush-2 small) >y
(woody bush-2) >y
(flowering bush-2) >y
(thorny bush-2) >y
(color bush-2 red) >y
(kind bush-2 american-beauty) cf 0.9
lisp-shell>(kind tree-3 (var x) )
(size tree-3 tall) >y
(woody tree-3) >y
(evergreen tree-3) > n
(deciduous tree-3) >y
(bears tree-3 fruit) >y
(color fruit red) >n
(color fruit yellow) >y
(taste fruit sour) >y
(kind tree-3 lemon-tree) cf 0 72
(size tree-3 small) >n
lisp-shell>quit
bye
В этом примере можно заметить несколько аномалий. Например, система задает
пользователю вопрос о том, является ли дерево низким, хотя уже сообщалось, что оио высокое.
В другом случае пользователю задается вопрос о том, является ли дерево лиственным, хотя
°"1Ге ""Р^РИмвано как вечнозеленое. Это типичные примеры поведения экспертной
■wZ- Г6 ЗНаШЙ Не аиЧРжится никакой информации о взаимосвязи поняпш
•веГГ™. " -^?К"Й" (опРеделя«'ьк литералами tall и snail) или "лиственный" и
шлГпг!,™ (deClduous " evergreen). С точки зрения базы знаний это лишь шабло-
рякГя ^ г^Гп*"™1"- ПОСКОЛЬКУ П0ИСК вьшолняется полным перебором, то про*-
SS SC*" ТОГ0 ™6Ы СНСТега Демонстрировала более глубокие знания, в Ш
^о^^Г°^Ю"И™ОШе™м^°нятиями. Например, можно наяи»-
™и= <n£2£££ SmaU сотап<™У« not tall. В рассматриваемом пример
"♦^SST П0С№1ЬКУ В СИСТеме 1-Р-ь'п не Р—*- 0ЮРа-
налагается реализовать его в качестве упражнения.
^~~^122££1£££^1н_^насЛеДо1вание в LISP_^
Кк ««ействТпредбс^7ле1ГоСТаВЛеНа Реал1™«ия семантических сетей иа «U««"S£
_______J^™"*™h «»"™ческ„е сети обеспечивают базис для Р"воо6Р
ЧаСТЬ "' "3W" " ТЗД0Л0™" программировании для искусственного интел"^
„ых систем вывода. Мы не будем обсуждать все
внимание на основном подходе к построению cZT^^ вар"анты' а сконцентрируем
сков свойств (property lis,). После их использовав 1"^'™'''"'''" С помощыо cn"-
ческой сети будет введена функция для пС1„„„ определения простои ссмаити-
этом разделе идеи являются" вГьГи'сГн Z D™7 ^^ "™— "
методологии программирована, описаиной в разделеТ5Т 0бЬе1т",0Рисн™РО'™''оП
LISP — это Удобный язык для послегавп^и— ™ л. ' ' г
„аитические сети. Списки *JZZ£?£Z££" ""*"*'"' ВКЛЮЧШ "'
тов произвольной сложности. Эти обьект" мо-Т ДаНИЯ »™™™"''« "бъек-
вающими простоту ссылок и опГделенГвзГм^ ? CB"al"" C "Me"aM"' °бсс'":""-
ле все структурьГданных USr"S^ Z^^^Lf"™ "* ^ ~
указателей, которое изоморфно структуре графоГ Ч**™™-™ » виде цепочек
Например, граф с метками можно представить с помощью ассоциативного списка
Каждый узел - это элемент ассоциативного списка, в котором все иТхоГщие из "Го
узла дуги хранятся в разделе данных в виде другого ассоциативного спис^ути onZ
вак-тся с помощью элемента ассоциативного списка, ключом которого являетГимя
дуги, а данными - узел назначения. При таком представлении для поиска узла назначения
некоторой дуги выбранного узла можно использовать встроенные функции работы с
ассоциативными спнеками. Например, маркированный направленный граф, показанный на
рис. 15.7, можно представить с помощью ассоциативного списка вида
((а (1 . Ы)
(Ь (2 . с))
(с (2 . Ь) (3
Рис 15.7. Простой маркированный направленный граф
Такой подход положен в основу многих сетевых реализаций. Однако семантические
сети можно реализовать и на основе списков свойств (property list).
По существу, списки свойств — это встроенное средство LISP, позволяющее
связывать символы с именованными отношениями. При нспользоваинн списков свойств
объектам в глобальной среде можно напрямую сопоставить именованные атрибуты (без
применения функции setq). Такие связи с символом рассматриваются не как значения,
а как дополнительный компонент — список свойств.
Для управления списками свойств используются функции get, setf, remprop и
Plist. Функция get вида
(get <символ> <имя-свойства>)
позволяет получить свойство объекта <сшю<м> по его имени. Например, если для
символа rose свойство color принимает значение red, а свойство smell— значение
sweet, значит, функция get будет вести себя следующим образом,
(get
(get
'rose 'smell)
Г"ава 15. Введение в USP 747
(get 'rose 'party <•
nil что прн „опытке получить значение несуществ
Ю последнего вызова видна ^^ функция get возвращает значение nil Г°
свойства (отсутствующего в ^ Q птюшыо функции setf, имеющей сКлую
Свойства связываются с
синтаксис.
1 , „вляется обобщением функции setq. Первый аргумент фу„Кц„и set£
За функция ЯВМ^Я 0Ь0 0 списка форм. Функция setf использует не з„аче.
берется из большого.^ V^ в ^^ ^ включены функци„ саг „ ^ ^
„ие формы, а место н^ ^^ ^^ аргумента в указанное место. Например,
Т se" Tf нагошу с другими функциями работы со списками можно использовать
^Гд^ГсГсковвТлобальной среде. Это видно из следующего примера.
? (setq х'(а Ь с d e))
(а Ь с d е)
? (setf (nth 2 х) 3)
3
? х
(а Ь 3 d el
Функция setf наряду с функцией get используется для изменения значений
свойств. Например, свойства розы можно определить следующим образом.
> (setf (get 'rose 'color) 'red)
red
> (setf (get 'rose 'smell) 'sweet)
sweet
Параметрами функции remprop, удаляющей именованное свойство, являются
символ и имя свойства. Например,
> (get 'rose 'color)
red
> (remprop 'rose 'color)
color
> (get 'rose 'color)
nil
Функция plist получает в качестве аргумента символ и возвращает список я»
свойств. Например,
>Jset£ (get 'rose 'color) .red)
sweet" ^ 'r°Se 'Smell> '«•*)
> (Plist 'rose)
(smell sweet color red)
приСмГсТдую™Г1™1Г4В™0СтаТ0ЧН0 ПР0СТ0 Р^™вать семантическую с^
видов птиц, показанной „а рис uTrlf8" ""Р^™ описание оемаитическ
V с 14./, Отношение isa определяет связи наследован1
" программирования для искусственного и
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
(setf
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
get
'animal 'covering) •skin)
'bird 'covering) 'feathers)
'bird 'travel) 'flies)
'bird 'isa) 'animal)
'fish 'isa) 'animal)
'fish 'travel) 'swim)
'ostrich 'isa) 'bird)
'ostrich 'travel) 'walk)
'penguin 'isa) 'bird)
'penguin 'travel) 'walk)
'penguin 'color) 'brown)
'opus 'isa) 'penguin)
'canary 'isa) 'bird)
'canary 'color) 'yellow)
'canary 'sound) 'sing)
'tweety 'isa) 'canary)
'tweety 'color) 'white)
'robin ' isa) 'bird)
'robin 'sound) 'sings)
'robin 'color) 'red)
В этом представлении семантической сети уже определена иерархия наследования.
Если выполнить поиск по связи isa, то можно определить родительский объект по
заданному свойству. Для нахождения родительских объектов используется поиск в
глубину, который прекращается прн нахождении экземпляра заданного свойства. Такой
подход обычно используется во многих коммерческих системах. В качестве стратегии
поиска можно также использовать поиск в ширину.
Функция inherit-get— это вариация функции get, которая сначала пытается
получить свойство данного символа. Если это свойство отсутствует, функция inherit-get
вызывает функцию get-from-parents для реализации поиска. Первым параметром функции
get-from-parents является либо один родительский объект, либо список таких объектов,
а вторым параметром— имя свойства. Если параметр parents принимает значение nil,
поиск завершается неудачно. Если родительским объектом является атом, для него
вызывается функция inherit-get для получения свойства самого родительского объекта либо
продолжения поиска. Если в качестве параметра указан список родителей, функция get-from-
parents рекурсивно вьвывает сама себя для головы и хвоста этого списка. Функция
прохода по дереву inherit-get определяется следующим образом.
(defun inherit-get (object property)
{or (get object property)
(get-from-parents (get object 'isa) property)))
(defun get-from-parents (parents property)
(cond ((null parents) nil)
((atom parents) (inherit-get parents property))
(t (or (get-from-parents (car parents) Property
(get-from-parents (cdr parents) property)))))
15.12. Объектно-ориентированное программирование
с использованием CLOS
Несмотря „а МНОГоЧисле„„ь,е ^^^^^Z^Z^^
некоторые задачи лучше решать в терминах объектов, состояв!
Г 749
'"ава 15. Введение в LISP
„fiu4H0 относятся задачи моделирования. Представьте
временем. К такому типу °™™ 6 а большого здания. Если рассматриЛ, *
„^грамму. «оделирУ«ш>™ «^£, *ю мсжду собой объектов (комнаты?^ ^
еТсТГмукаккшожествовза„Моде„ств) ||даии TeMnepaTypbl и сост^**
™. ^-^Го ач" упростить. Объектно-ориснтированные вь£ *
друга, то задачу «°^° зн задач„, при котором задача разбивается на „1"'
держнаак^т такой подх^Р объектов. Она обладает состояние», КОТор0е ^
ЮШ,М0ДС" ГЛен «^множеством функции, определяющих их поведение. По ^
Г:Хкгноокованное программирование позволяет решать задачи „у^
ству, объектно ори у области. Такой модельный метод решения задач естестве.,
ГМТб"о:оГд^'^сствениого интеллекта. Это эффективная методов
ГотаХованш, предоставляющая мощные средства для решения сложных задач.
Р Мъектно-орнентированное профаммнрование поддерживают многие языки, в т„м
числе Smalltalk C++, Java и Common LISP Object System (CLOS). На первый взгляд Lisp
уходит корнями в функциональное программирование, а ооъектная ориентация с созда-
нием объектов, сохраняющих со временем свое состояние, не вписывается в его
исходную концепцию. Однако многие средства языка, в том числе динамическая проверка
соответствия типов и возможность динамического создания и разрушения объектов, деда-
ют его идеальной основой для создания объектно-ориентированного языка. LISP лежит в
основе мнопгх ранних объектно-ориентированных языков, таких как Flavors, KEE и
ART. После разработки стандарта Common LISP сообщество его почитателей
предложило систему CLOS как средство объектно-ориентированного программирования на LISP.
Чтобы называться объектно-ориентированным, язык программирования должен
обеспечивать три возможности: инкапсуляцию (encapsulation), полиморфизм (polymorphism) и
наследование (inheritance). Определим эти возможности более детально и опишем, как их
поддерживает система CLOS.
1. Инкапсуляция, Все современные языки программирования позволяют создавать
сложные структуры данных, в которых элементарные (атомарные) элементы
объединяются в одну структуру. Объектно-ориентированная инкапсуляция — это
сочетание в одной структуре элементов данных и процедур для их обработки. Такие
структуры называются классами (class). Например, рассмотренные в разделе 14.2
абстрактные типы данных вполне обоснованно можно считать классами. В таю»
объектно-орнентированиых языках, как Smalltalk, инкапсуляция процедур (или
методов) в определении объекта реализуется явно. В CLOS принят другой подход.
Ла возможность реализуется за счет проверки соответствия типов. Здесь
поддерживаются методы, получившие название родовых функций (generic function). Ой»
меняТ™ ™ПЫ СВ0ИХ "Ч-^Чк» и тем самым гарантируют, что их можно при-
ватТкаЛГ0 " ЭюемпляРам энного класса объектов Это можно рассматри-
вать как логическую связь методов со своими объектами.
' -Г ^ТмоТ*"" ПР°'™ШЛ0 °Т *"* К0РИСЙ: "Той 5
онадемонет-т РФ ~ Ф°Рма". Функция считается полиморфной,
НаноГ^n„PSZ™°e П0ВеДШИе В «-«и-осгн от типов своих аргу^
<** графичес™ " „Г " ПОЛИМ°РФ»ь.х функций и их важной роли да»' *
массе определить мет ^' '"^Р^ния этих объектов естественно в ^
висимости от нзобпаж»." Т КаЖДЫЙ мет°Д Д°лжен работать по-разномул
бралаем0" Ф«ОТ.ы), однако им, у всех одно. Для каждого ов»
а«ь VI. Языки и технологии программирования №я искусственного »«*""*'
т. в такой системе будет существовать метод draw. Это гораздо проще, чем
определять отдельные функции draw-square, draw-circle и т.д. Система CLOS
П0ДДоРГ„В^ГЛИМ°РФИЗМ ™ СЧСТ МеХаИШЮ Р0Д°ВЫ* ФУ»"»* по-гденис кото-
рых определяется типами их аргументов R ппик,РпР ,. \L a
F , H^MtHioe. в примере с графическим редактором
можно определить функцию draw, включающую код для изображения всех
определенных в программе фигур. При оценивании будет проверен тип аргумента и
автоматически выполнен соответствующий код.
3. Наследование. Наследование - это механизм для поддержки языком
программирования абстрактных классов. Оио позволяет определить общие классы и задать структуру и
поведение их специализаций. Так, класс деревьев tree может описывать свойства
сосен, тополей, дубов н других видов деревьев. В разделе 15.11 был построен алгоритм
наследования для семантических сетей. Он шиюстрирует простоту реализации
наследования с помощью встроенных в LISP структур данных. Система CLOS обеспечивает
более робастный н выразительный встроенный алгоритм наследования.
15.12.1. Определение классов и экземпляров в CLOS
Базовой структурой данных в CLOS являются классы. Класс — это описание
множества экземпляров объектов. Классы определяются с помощью макроса defclass,
имеющего следующий синтаксис.
(defclass <имя-класса> (<имя-суперкласса>*)
(<спецификатор-элемента>*) )
Здесь <имя-класса> — это символ, за которым следует список прямых суперклассов,
т.е. непосредственных предков данного класса в иерархии наследования. Этот список
может быть пустым. За списком родительских классов следует список (возможно,
пустой) спецификаторов элементов. Спецификатор элемента — это либо имя элемента, либо
список, состоящий из имени элемента и одного или нескольких параметров.
Спецификатор-элемента ::= имя-элемента\ (имя-элемента [параметр])
Например, можно определить класс прямоугольников rectangle, сегментами
которого являются длина length и ширина width.
> (defclass rectangle О
(length width))
#<standard-class rectangle>
Функция make-instance позволяет создавать экземпляры класса. Ее параметром
является имя класса а возвращаемым значением - его экземпляр. В экземплярах класса
хранятся реальные данные. Символ rect можно связать с экземпляром класса
rectangle с помощью функций make-instance и setq.
> (setq rect (make-instance 'rectangle))
*<rectangle #x286ACl>
,.„ „.,..«. необязательно. Они имеют еле-
Параметры элементов в определении класса задавая• »«*"™\
ДУющий синтаксис (где символ | означает альтернативные варианты).
-РамеТр !!= =га^г <r^^^!^uLMffllcw |
.__ -,..,„-,М'нкции-чтения> |
:accessor
<имя-функцич-
г"ава 15. Введение в LISP
751
allocation <тт-разхетения> \
•initarg <имя> |
•initform <форма>
ГО^Г„ВаЧФГГ — "параметры элемент обеспечивают»^
7Z "определяет ■» Ф>™™' возвращающей значение данного элемента £
^Сетного э^Гтяра. Юлюч : writer задает им» функции записи элемента. ь£
ТсГзог определяет фикцию, «™Р» МОЖеТ ""рваться *™ считывания
значение элемента или изменения его значения (с помощью функции s.tq). В следующем
понмере определяется класс прямоугольников rectangle, элементам,, которого ява».
1» длина length и ширина width с функциями доступа get-length и get-
width соответственно. Связав символ rect с экземпляром класса прямоугольник™ с
помощью функции make-instance, воспользуемся функцией доступа get-length
для присваивания с помощью функции setg элементу length значения 10. Для
считывания этого значения снова воспользуемся функцией доступа.
> (defclass rectangle (}
((length :accessor get-length)
(width :accessor get-width)))
#<standard-class rectangie>
> (setq rect (make-instance 'rectangle))
Streccangle #x289159>
> (secf (get-length rect) 10)
10
> (get-ler.gth rect)
10
Помимо функций доступа для обращения к элементам класса можно использовать
функцию-примитив slot-value. Она определена для всех элементов. Ее параметром
является экземпляр класса и имя элемента, а возвращаемым значением — значение этого
элемента. Эту функцию можно использовать совместно с setq для изменения значения
элемента. Например, функцию slot-value можно применить для получения значения
элемента width экземпляра rect.
> (setf (slot-value rect 'width) 5)
> (slot-value rect 'width)
B03MoZT™aU°Cati°n опРеделяет размещение элемента в памяти. Существует»»
^мшГэТРаЗМеШеШИ :instan« и -lass. В первом случае система CLOS
п^ь!Т„ольТГЫоКЛаССа №H0 ™ КаЖЛ°™ экземпляра, а во втором - все экзем-
= d« ГТзХниТ " Т0Т Же ЭЛеМе«- Ес™ в к^стве тнпа размещения вь,бр*
-» отражанэГ 1ДаНН0Г° MeM£™ >™ *™ экземпляров совпадают, а его из»*
ния = instance экземпляра класса. По умолчанию используется тип разме*
Ключ :initarg позволяет теа^тт. „i-ся ФУ""'
■шеи make-instance лл аргумент, который будет использоваться ч>
»одиф„ц„ровать 0 ~" адани" «сального значения элемента. Например, м°
leg» и „idth егоэвемгГроТ'" reCtangle' инициализируя значения элемент
аСТЬУ' ЯЭЫКИ " Техно™™и программирован™ для искусственного инте"**"
, (defclass rectangle ()
((length :accessor get-length -inif»,- • ■
(width : accessor get-width -inii-»;Carg. lnit-length)
s<standard-class rectangle» -lnit«g init-width)) )
>(setq rect (make-instance 'rectanr,i= . •
■init-width 50)) rectangle 'imt-length 100
#<rectangle #x28D081>
> (get-length rect)
100
> (get-width rect
50
Ключ :initform позволяет задавать форму оценивав,™ ™,
Ф^-*^-апсед„сле„ияГч2„Г^^
написать rrporpa.4i.ry, запрагшшающую у пользова-п-™ ,т„„ например, можно
земплярапрямоутольника. Это ««^Г^£^^ ™ "^ ~
> (defun read-value (query) (print query) (read) )
read-value
> (defclass rectangle ()
((length .accessor get-length :initform
(read-value "введите длину"))
(width : accessor get-width :initform (read-value
"введите ширину") ) ) )
S<standard-class rectangle>
> (setq rect (make-instance 'rectangle)}
"введите длину" 100
"введите ширину" 50
#<rectangle #x290461>
> (get-length rect)
100
> (get-width rect)
50
15.12.2. Определение родовых функций и методов
Родовая функция — это функция, поведение которой зависит от типа ее аргументов.
В CLOS родовые функции содержат множество методов (method), индексированных по
типу аргументов. Вызов родовой функции аналогичен вызову обычной функции. Просто
прн ее вызове реализуется метод, связанный с данным типом аргументов.
При выборе метода родовой функции используется структура иерархии классов. Если
не существует метода, определенного напрямую для аргумента данного класса,
используется метод, связанный с -ближайшим" предком в дереве иерархии. Родовые функшш
обеспечивают основные преимущества классического объектно-ориентированного
подала н передачи сообщений, включая наследование и перегрузку. Однако по дух) они
г°Раздо ближе к парадигме функционального программирования, составляющей основу
USP- Например, родовые функции можно использовать наряду с такими конструкциями
высокого уровня языка LISP, как mapcar иди funcall.
л вдовые фу„кци„ определяются с помощью функций defgenenc или ctefmethoa-
Ф^ии» defgeneric позволяет определять родов.™ функцию и несколы*™»
п°«°Щью одной формы. Функция defmethod определяет отдельные «года, которые
Гла " " " ^
6315. Введение в LISP
rL0S объединяет в общую родовую функцию. Приведем упроще
затем система CLUb оиьсд
синтаксис функции def gene ^ ^^ <описание-иетода>*)
(defgeneric иш-ФУ"«f^^d специалиэщ'оваииый-ля^да-сшсок форма)
<описание-«етода> . • ^. ^ тшются 11МЯ функции, лямбда-список ее аргумед
Параметрит функции « о п^) опнСаний методов. В описании метода спещ,а
тов и последовательность I» ^ Личный лямбда-список из определения функции, в ко-
литроваиный-лямбда-cmico ^ ^^ заменен парой (символ уточненный-параметр) в
тором формальный ™Р^ а уточненный параметр - класс аргумента. Если т.
которой символ - этоi, v^ по мотанию его типом считается t _ наиболее об-
раметр метода не сод р з Tmi t Moiyr быть связаны с любым объектом. Ко-
ший класс в иераряш^LL■_J™ лямбда-списка должно совпадать с числом аргу-
ГГнГГб" ГвТ~с,е£generic Эта функция создает обобщенную фун Д
меСГто! заменяют любую существующую родовую функцию.
ТГчесГ примера использования родовой функции можно определить классы прямо-
угольника и окружности и реализовать в них соответствующие методы вычисления площади.
^fuengS^ccessor get-length ;initarg init length,
(width accessor get-width :imtarg imt-wldth) ) )
(defclass circle {) _ ,
((radius accessor get-radius : initarg inrt-radrus) ) )
(defgeneric area (shape)
(method ((shape rectangle))
(* (get-length shape)
(get-width shape)))
(:method ((shape circle))
(* (get-radius shape) (get-radius shape) pi) ) )
(setq rect (make-instance 'rectangle 'init-length 10 'init-width 5))
(setq circ (make-instance 'circle 'init-radius 7))
Функцию area теперь можно использовать для вычисления площади любой фигуры-
> (area rect)
50
> (area circ)
153.93804002589985
Методы определяются с помощью функции defmethod, синтаксис которой
напоминает синтаксис функции defun. Однако здесь для объявления класса, к которому
принадлежат аргументы, используется специализированный лямбда-список. Если при
отделении функции с помощью defmethod не существует родовой функции с таким им
нем, она создается. Если же родовая функция с таким нмеием уже существует, то новь
метод добавляется к ней. Например, к приведенному выше определению можно добав.
класс квадратов square,
(defclass square ()
(defmethod aSeuSaSf"Side ЛП±Ь"3 ^-side, > »
<* «set-sfde'shapel "*"""
b[9et-side shape)))
'square 'init-side 6))
ide shape)
side sh
tsetq sqr (make-instance
7M ЧаСТЬVl'ЯЗЫ№ " тех"-°гии программирования для искусственного *****
функция defmethod не изменяет существовавши, ™
нкя площадей фигур, а лишь добавляет новый «^кро^Гф""'' "" "'
> (area sqr)
36
> (area rect)
50
> (area circ)
153.93804002589985
15.12.3. Наследование в CLOS
Язык CLOS поддерживает множественное наеледованне. Наряду с гибкой схемой
представления данных множественное наследование таит опасность возникновения
аномалий, связанных с наследованием элементов и методов. Если для двух предков
определен один н тот же метод, то важно знать, какой нз них наследуется. Возможные
неоднозначности устраняются в CLOS за счет определения списка приоритетности классов
(class precedence), в котором упорядочиваются все классы иерархии.
При определении класса с помощью функции defclass все его прямые предки
упорядочиваются слева направо. На основе этой информации система CLOS определяет
порядок всех классов в иерархии наследования, на базе которого формируется список
приоритетности классов. Список приоритетности классов удовлетворяет двум правилам.
1. Любой прямой родительский класс предшествует любому более дальнему предку.
2. Порядок приоритетности непосредственных родительских классов соответствует
их указанию при вызове функции defclass слева направо.
Система CLOS строит список приоритетности классов для любого объекта путем
топологической сортировки его родительских классов согласно следующему алгоритму.
Пусть С — это класс, для которого требуется определить список приоритетности.
1. Пусть Sc — это множество, состоящее из С и всех его суперклассов.
2. Для каждого класса с нз Sc определяется множество упорядоченных пар
Яс = «с, с,), (с„е,), (с„с,)...(с„_„ с„)},
где с, ...,с„— прямые предки класса с в порядке их перечимения в опредечении
defclass. Заметим, что для каждого множества Я, определен глобальный порядок.
3. Пусть Я— это объединение множеств Я„ составленных для всех элементов S,.
Оно может быть, а может н не быть частично упорядоченным. Если оно не является
частично упорядоченным, то иерархия ие согласована, и алгоритм это определит.
4. Выполняется топологическая сортировка элементов Я следующим образом.
4.1. Строится пустой список приоритетности Р.
4.2. Находится класс в Я. не имеющий предков. Он добавляется,>*"»^ "
удаляется из множества S„ а все содержащие его пары У*™»»££ ^™
S, содержится несколько классов, „е имеющих "Р*"™*^™™"
них, прямой производный класс которого расположен а.и« в-го к концу
кущей версии списка Р.
„™ mih-т не будут исчерпаны все элемен-
4.3. Пункты 4.1 и 4.2 повторяются до тех пор. пока не о>дут |
ты из Я, не имеющие предков.
,а 15. Введение в LISP
755
«-пи, S не пусто, значит, иерархия не согласована. В ней могут содеоз^.
Поскок no^HHb«Bpr=rZ
ГассГсГоГ^рГГ™ — используется . системе С^р/ГС
„«г^твания элементов и выборе методов.
При вХе «"ода. применяемого при данном вызове родовой фун1щн„,
CLOS „ач, а находит все подходящие методы. Метод считаетсяподходяшим дд, J
„7го вызова родовой функции, если каждый специализированны*.параметр метода «,
гласуется с типом соответствующего аргумента в вызове родовой функции. Специалкш.
рованный параметр согласован с аргументом, еслн ои соответствует классу этого аргу-
мента или массу одного из его предков.
Затем система CLOS сортирует все подходящие методы с учетом списков приоритетности
аргументов. Путем сравнения спешилизированных параметров слева направо определяется,
какой из двух методов должен стоять первым. Если первая пара соответствующих
специализированных параметров совпадает, система CLOS сравнивает вторую пару. Этот процесс
продолжается до тех пор, пока не будет найдена пара различающихся специализированных
параметров. Среди них более специализированным считается метод, параметр которого находится
левее в списке приоритетности соответствующего аргумента. После сорпгровки всех
подходящих методов по умолчанию применяется наиболее спешташгаированный метод для данных
аргументов. Более подробно эта процедура описана в работе [Steele, 1990].
15.12.4. Пример: моделирование термостата
Объектно-ориентированный подход к программированию, обеспечивающий
естественный способ организации больших н сложных программ, в равной степени применим
и для разработки баз знаний. Помимо преимуществ наследования классов для представ,
ления классифицированных знаний, принципы передачи сообщений в объектно-
ориентированных системах упрощают представление взаимодействия компонентов.
В качестве простого примера рассмотрим задачу моделирования системы парового
отопления для небольшого офисного здания. Эту проблему можно естественны»!
образом огшсать в терминах взаимодействия компонентов, например, так.
В каждом офисе есть термостат, включающий и выключающий систему обогрева офиа
Ов работает независимо от термостатов в других офисах.
Бойлер для теплоцентрали включается и выключается по требованию, поступающем)' из офис»
Когда нагрузи на бойлер возрастает, может потребоваться некоторое время для геяераит
нужного объема аара.
б^тГиГ Т™ ПереЛаЮТ в сисге"У Ри™<= требования. Например, угловые комнат» '
ХГяТГстТс^ГГиа^' ЧЕМ ВНУГРе"Н"е- ВН"'е П°МеШеН'И
Объем пара, капаемый системой в каждый офис, зависит от общих требован.* к системе
ДелиР^тГГси" мыТ K0T0P№ Необ*°Д««° Ч»™ во внимание ч*£
До сложнее Объект!" C3M°M деле взаимодействие между компонента»»' гор
пировать внимаГ и, РИеетИР0МНН°е «Ржавление позволяет разработчику «о**
_J___J^^™^ конкретного класса объектов. Термостат можно пГ«
Частью языки и твх„ологии программирования тя искусстввнного *****
ставить температурой, до которой он нагревает воду а -г,™.
изменение температуры. 3' ldioKe скоростью его реакции на
Теплоцентраль можно охарактеризовать в терминах и,,™.
кот„рое она может производить, количества то^™~^м"°Г° *°ШЧК™™*<
вре„еи„. затрачиваемого на выполнение поступиl^Z^T* "^^
скорости потребления воды. ' к сисгемс требовании, а также
Комната характеризуется объемом, теплопотерями через стены и окна, количество* тепла,
„„ступающего из соседних комнат и скоростью поступления тепла в ко^ату^ГиатсГ
База зиаини должна описывать информацию, хранящуюся в клаЛ ^mTSet
mostat. экземплярами которых являются объекты room-322 и thermostat-211 со-
ответственио.
Взаимодействие между компонентами описываете, в терминах передачи сообщений
между объектами. Например, при изменении температуры в комнате передается
сообщение экземпляру класса thermostat. Если эта температура достаточно низка, термостат
после некоторой задержки должен выточиться. При этом объекту теплоцентрали
передается сообщение с запросом большего количества тепла. При этом теплоцентраль
потребляет больше топлива или, если она уже функционирует на пределе своих возможностей,
некоторая часть тепла, передаваемого в другие комнаты, перенаправляется в ответ на
новое требование. Это может привести к включению других термостатов и т.д.
Такое моделирование позволяет проверить работоспособность системы в
экстремальных ситуациях, оценить потери тепла и эффективность самой системы обогрева.
Полученную модель можно использовать для диагностики неисправностей в системе н
выявления их симптомов. Например, если есть основания считать, что проблемы с
обогревом вызваны неисправностью теплотрассы, можно ввестн в модель соответствующие
характеристики и проверить свои предположения в модельном режиме.
Основу реашгзацин этой модели составляет набор определений классов. Класс
термостатов имеет один элемент— setting. Для каждого экземпляра он инициализируется
значением 65 с помощью функции initform Для класса thermostat определен
производный класс heater-thermostat для управления радиаторами (в противовес
кондиционерам воздуха). Единственный элемент этого класса связывается с экземпляром класса
heater. Заметим, что элемент класса heater имеет тип размещения : class. Это
означает, что термостаты в разных комнатах управляют общим на все здание радиатором.
(defclass thermostat О
((setting :initform 65
:accessor thenn-setting] ))
(defclass heater-thermostat (thermostat)
((heater :allocation :class
:initarg heater-obj)))
,, „., /„„ „,„ off) которое изначально принимает
Класс heater обладает состоянием (on или o.t). кот t** „__-_ „сект
значение off, и характеризуется ==■ £^i™*^
(defclass heater О
((state .-initform 'off
raccessor heater-state)
(location .-initarg lec1
(rooms-heated)))
Глава 15, Введение в LISP
757
„.„.кгтся temperature, принимающий начально.. ,
ваюшнй имя комнаты.
(defclaee room О
((temperature ;initform 65
:accessor room-temp)
(thermostat :inltarg therm
:acceasor room-thermostat)
(name :initarg name
;ассевиог room-name)))
Иерархия описанных классов приводится на рис. 15.$
Claw: thermostat
rooms-heated
Class: heater-thermoBtet
Рис. !5,8. Иерархия классов в модели термостата
При моделировании поведения термостата используются конкретные экземпляры
этих классов. Реализуем систему, состоящую из одной комнаты, одного нагревателя н
одною термостата,
i.etf lltL^l^l 'r^-^'tano. 'heater -loc 'office))
(setf room-325 (make-instance 'room
them (make-instance 'heater-thermostat
heater-obj office-heater)
name 'room-325))
tf l0lOt-v',luG °££lce-heater 'rooms-heated) (list room-325))
««ting. МеГл Г«ГеТГСЯ М"°аШ" cha"9e-temp, check-temp и chan^
«иводит сообщение полиов^ уСТИ1ащ",ш« "<"><* значение температурь, в комна*
■■У»» ли пш1^Г~Г " "ПЫ"е1 М"ОД ^eck-temp, чтобь, проверит,^
-Р«остата „ „ЩЫ11^Г01 ^J'0' » "™W chance-setting изменяет устан^
•"■■мнературв „ ком,штс vc„,, _temp' «ояопирующий функцию термостат».
'"«: о включении. Н.фшиГом "Рмостата, он передаст обогревателю сообш
«•лучас передастся сообщение об отключении.
мироаания для искусственного
интолл'
к
Class, standard-object
I Class: thermostat
Class, heater-thermostat
setting: 65
instance: office-heater
rooms-heated: (,)
instance, room-325
temperature: 65
name: room-325
Рис. 15.9. Экземпляры классов в модели термостата с исходными значениями и
нием типа размещения элементов
(defmethod change-temp ((place room) temp-change)
(let ( (new-temp (+ (room-temp place) temp-change) ) )
(setf (room-temp place) new-temp)
(terpri)
(prinl "температура в")
(prinl (room-name place))
(prinl "составляет*)
(prinl new-temp)
(terpri)
(check-temp place)) )
(defmethod change-setting ((room room) new-setting)
((let ((therm (room-thermostat room)))
(setf (therm-setting therm) new-setting)
(prinl "изменение установки термостата в")
(prinl (room-name room))
(prinl "на")
(prinl new-setting)
(terpri)
(check-temp room)))
(defmethod check-temp ((room room))
(let* ((therm (room-thermostat room))
(heater (slot-value therm 'heater))) „^n
(cond ((> (therm-setting therm) (room-temp room
luu"u ll (send-heater heater -on))
(t (send-heater heater 'off)))))
Глв8а 15. Введение a LISP
M
, heater управляют состоянием обогревателя и изменением тем
Методы классадЬ "^ метода send-heater являются экземпляр обогрев!
туры в комнатах. Аргумент нис Если новым состоянием является on .
имение, переда-^--;»Тофсвателя. в противном случае вызываете £*
вается метод turn-on включения обогревателя вызывается метод П»ПГ
"Г—Гя—турывкомна^на, градус,
«defmethoo- send-heater , «heater heater, new-state,
'Са1огГаПес1иа1 (heater-state heater, 'off,
(turn-on heater))
heat-rooms (slot-value heater 'rooms-heated) l),
(off (if (equal (heater-state heater) 'on)
(turn-off heater)))))
(defmethod turn-on ((heater heater))
(setf (heater-state heater) 'on)
(prinl "включение обогревателя в")
(prinl (slot-value heater 'location))
(terpri))
(defmethod turn-off ((heater heater))
(setf (heater-state heater) 'off)
(prinl "отключение обогревателя в")
(prinl (slot-value heater 'location))
(terpri))
(defun heat-rooms (rooms amount)
(cond ((null rooms) nil)
(t (change-temp (car rooms) amount)
(heat-rooms (cdr rooms) amount) ) ) )
Приведем пример работы модели.
> (change-temp room-325 5)
"температура в "room-325" составляет "60
"включение обогревателя в "office
"температура в "room-325" составляет "61
"температура в "room-325" составляет "62
"температура в "room-325" составляет "63
"температура в "room-325" составляет "64
температура в "room-325" составляет "65
отключение обогревателя в "office
nil
> (change-setting room-325 70)
-"п™::—г»- сост „ляет.66
"температура в "room-325- ™СТавляет "67
-температура в «room-325- С°СТаВляет "68
•температура в -room-325- =°CT«™^ "69
пО™е„ие обогревателя в^оШсТ "70
Х5ДЗ. Обучение в ШР^алхогжгмП»
В это„ разделе будет описана реализация алгоритма ID3 „з раздела 9 Я Согласно
этому алгоритму „а основе множества обучающих примеров строятся деревья решений"
обеспечивающие классификацию объекта по его свойствам. Каждый внутренни" узел
дерева решении отвечает за одно из свойств объекта-кандидата и использует его значе-
ние для выбора следующей ветви дерева. В процессе прохода по дереву проверяются
различные свойства. Эта процедура продолжается до тех пор, пока не будет достигнут
один из листов дерева, означающий класс, к которому относится данный объект В
алгоритме ID3 для упорядочения тестов и построения (почти) оптимального дерева решений
используется функция выбора тестов, построенная на основе теории информации.
В алгоритме ID3 задействованы сложные структуры данных, в том числе объекты,
свойства, множества и деревья решений. Основу его реализации составляет набор
определений структур — агрегатных типов данных, аналогичных записям в языке Pascal или
структурам в С. С помощью функции defstruct в Common LISP можно определить
тип данных как набор именованных элементов. Форма defstruct строит функции,
необходимые для создания и управления объектами данного типа.
Наряду с использованием структур для определения типов данных при реализации
алгоритма будут использованы такие функции высокого уровня, как mapcar. Как стало ясно прн
реализации оболочки экспертной системы, использование отображений и фильтров для
выполнения функций над списками объектов обеспечивает большую прозрачность подхода к
программированию на основе потоков данных по сравнению с другими принципами
программирования. Возможность обработки функций как данных и построения замыканий
функций — краеугольный камень стиля программирования на языке LISP.
15.13.1. Определение структур с помощью функции defstruct
С помощью функции defstruct можно определить новый тип данных (data t>pe)
сотрудников — employee.
(defstruct employee
name
address
serial-number
department
salary)
Здесь employee - это имя типа, name, address, serial-number, department
» salary- „мена его элементов. При оценивании формы defstruct не создается
никаких экземпляров записей о сотрудниках. Определяются лишь тип " Ф*»™^
ходимые для создания и давления его элементами. Параметрам, >&£*»*»1,^
являются символ, который гневится именем нового типа, и «"^£Г*££
ров элементов. В данном случае 5 элементов ^^^^ТТ»
элементов позволяют также определять различные свойства элементов,
""формацию для инициализации [Steele, 1990]. результатам. Рассмотрим
Оценивание формы defstruct приводит к нескольким ре .
""» примера следующее определение.
Глава 15. Введение в LISP
(defstruct <имя типа>
<имя элемента Х>
<имя элемента 2>
<имя элемента п>)
Эта Форма определяет функцию, имя которой формируется по принципу make-<lu„,
J" Z позволяет создавать экземпляры данного типа. Например, „осле о„ред,ления
^уктуры employee с объектом этого типа можно связать имя ne„-employee.
(setq new-employee (make-employee))
Имена элементов можно использовать в качестве ключей при создании функции. С щ
помощью элементам экземпляров можно присваивать начальные значения. Например, так.
(setq new-employee
(make-employee
■.name ' (Doe Jane)
:address "1234 Main, Randolph, Vt"
:serial-number 98765
:department 'Sales
:salary 4500.00))
При оценивании функции def struct <имя muna> становится названием типа
данных. Это имя можно использовать в функции typep для проверки принадлежности
объекта к некоторому типу. Например, так.
> (typep new-employee 'employee)
t
Более того, def struct определяет функцию <гшя muna>-p, которую тоже можно
использовать для проверки принадлежности объекта к данному типу.
> (employee-p new-employee)
t
> (employee-p '(Doe Jane))
nil
И, наконец, def struct определяет функции доступа к каждому элементу
структуры. Их имена формируются по схеме
<илш типа> <имя элемента>
В рассматриваемом примере доступ к значениям различных элементов объекта new-
employee можно получить следующим образом.
> (employee-name new-employee)
(Doe Jane)
-IpTm0^8^1^8 "«"-employee)
1234 Mam, Randolph vt-
^(employee-department new-employee,
«ioT^-*31"* ■»-«"Ployee,
> (setf (employee-sala„
salary new-employee) 5000.00)
i программирования для искусственного и
5000.0
> (employee-salary new-employee)
5000.0
Таким образом, с помощью структур можно onD
па к объекту данного типа в одной и той же форме /,1^/,рСДИКать1 " Функции досту-
ключевую роль при реализации алгоритма ID3. ' "Чгамення будут играть
На основе множества примеров, относяпшуг» „ .
строит дерево, позволяющее корректно™ ™и^пЛ ™ ЮИССМ' ^Р1™ Ш3
Осокой вероятностью) n^eZTol^X^ZZT Т """"^ " (С
обучающие примерь, были представлень^таблнчиТйТвме?"™ ' В РИДЫ""
свойств „их значений д.* какого примера. Ш™! Т™ л'^ГпрГГГГк
свойств обучающих примеров, используемых для прогнозирования крТдГ™™ риска
В данном разделе мы снова обратимся к этой задаче ия кредитного риска.
Таблицы - это лишь один из способов представления примеров. В более общем
случае нх можно рассматривать как объекты, обладающие различными свойствами
Сдерем несколько предположений о представлении объектов. Для каждого свойства
определим функцию, зависящую от одного аргумента и применяемую для получения значения
этого свойства. Например, если объект credit-prof ile-1 связан с первым примером
нз табл. 9.1, a history — функция, возвращающая значение кредитной нсторни, то при
вызове этой функции для указанного объекта будет получен следующий результат.
> (history credit-profile-1)
bad
Аналогично зададим функции для других свойств кредитного профиля.
> (debt credit-profile-1)
high
> (collateral credit-profile-1)
none
> (income credit-profile-1)
0-to-15k
> (risk credit-profile-1)
high
Выберем представление для базы знаний из данного примера. Представим объекты в
виде ассоциативных списков, в которых ключами являются имена свойств, а данными —
соответствующие значения. В частности, первый пример из табл. 9.1 можно представить
в виде ассоциативного списка.
((risk.high) (history .bad) (debt .high) (collateral.none)
(income.0-15k, )
Для определения примеров из табл. 9.1 в виде структур воспользуемся функцией
defstruct. Полный набор обучающих примеров представ™ в виде списка
ассоциативных списков и свяжем этот список с именем examples.
MUr^sT^high) (history . bad) (debt . high) (collateral . none,
'income . 0-15k)) ....
(,risk . high) (history . unknown) (debt . high)
collateral . none) (income . 15k-35k)l
<nsk . moderate) (history . unknown) (debt . low;
'collateral . none)(income . 15k-35k))
Г"ава 15. Введение в LISP
763
((risk
(incccie
((risk
(income
((risk
(income
((risk
^own) (debt . low» (collates
^Known. (debt . low» (collateral .
^own) (debt . l°w) (collateral . adequate
bad, (debt . low» (collateral . none)
high» (history
0-15X))
'low) (history
over-35k))
'low) (history
0ver-35W)
high) (history
(income . 0-15k>) 4torv . »>="' '" „r, .,
-Ilateraf^^r.^.over-SSK),
low) (history
over-3510)
high) (history -
•££», (history . .ood, (debt . high, «collateral
■ l5k-35kl) good, (debt . high) (collateral . none)
■ none)
none)
(inccene
((risk .
(inccene
((risk -
(incccie
((risk .
(income
((risk
(inccene
((risk
(inccene
bad, (debt . low)
-35k))
'good) (debt . low) (collateral
gocd) (debt . high) (collateral
. good) (debt . high) (collateral
. none)
adequate)
none)
none)
low) (history •
. over-35W )
high) (history
. 15У.-35Ю)))
bad) (debt . high) (collateral . none)
„»™„uu пишется определение риска для новых примеров,
в„^ГДГ:==сеИ:^..иЮЧеНиеМ з_ риска.
low) (collateral . none)
(setq test-instance
'((history . good) (debt . —...
(income . I5k-35k)))
Определим свойства для такого представления объектов.
(defun history (object)
(cdr (assoc 'history object :test ff'equal)))
(defun debt (object)
(cdr (assoc 'debt object :test S'equal)))
(defun collateral (object)
(cdr (assoc 'collateral object :CesC #'equal)))
(defun income (object)
(cdr (assoc 'income object :tesC #'equal)))
(defun risk (object)
(cdr (assoc 'risk object :test t'equal)))
Свойство property — это функция, определенная над объектами. Такие фуикш»
ставляются в виде элементов структуры, включающей другую полезную информацию-
(defstruct property
(defstruct property
name
test
values)
Элемент test экземпляра property связан с функцией, возврашаюшей значен^
свойства, name - это имя свойства. Оно включается исключительно для УД060^,^
зователя. Элемент values- зто список всех значений, которые могут возвр^
функцией test. Требование заблаговременного определения диапазона значении ев
ства значительно упрощает реализацию.
[ aecision-tree
Деревья решении можно определить с помощью следующей структуры.
(defstruct decision-tree
test-name
test
branches)
(defstruct leaf
values)
Таким образом, дерево поиска является экземпляром структуры de
или leaf. Структура leaf состоит из одного элемента value, определяющего кла"сс
объекта. Экземпляры типа decision-tree представляют внутренние узлы дерева.
Их элементами являются test, test-name и множество ветвей branches. Функция
test зависит от одного аргумента— объекта— и возвращает значение свойства. При
классификации объекта с помощью f uncall вьвывается функция test. Возвращаемое
ею значение применяется для выбора ветви дерева. Имя этого свойства задает элемент
test-name. Этот элемент облегчает пользователю контроль дерева решений. При
выполнении программы он не играет никакой существенной роли. Элемент branches —
это ассоциативный список поддеревьев. Ключами являются возможные значения,
возвращаемые функцией test, а данными — сами поддеревья.
Например, дерево на рис. 9.13 соответствует следующему набору вложенных
структур. Обозначение #S применяется при реализации ввода-вывода в Common LISP. Оно
означает, что данное s-выражение представляет структуру.
#S(decision-tree
:test-name income
:test #<Compiled-function income #x3525CE>
:branches
((0-15k . #S(leaf rvalue high)!
(I5k-35k .
#S(decision-tree
:test-name history
:test #<Compiled-function history #x3514D6>
:branches
((good . #S(leaf :value moderate))
(bad . #S(leaf :value high))
(unknown .
#S(decision-tree
:test-name debt
test #<Compiled-function debt *хЗо!А.ь>
branches
((high . #S(leaf ivaluehign))
(low-#S(leaf :value moderate))))))))
(over-35k .
#S(decision-tree :test-narae
history
:test #<Co...d-fun.. history
#x3514D6>
-branches
((good . «Sdeaf .-value
low))
(bad . SSUeaf : value
moderate))
(unknown . SStleaf
:value low)))))»)
r"aea 15. Введение в USP
™ов по существу представляет собой лишь множес1в
Хотя набор обуюоших пр.шер ^ ^^^и. включающей элементы друад
объектов, будем рассматривать^ определи», структуру example-f rame Me
информации, используемом
дуюшим образом.
«Jefstruct example-frame
instances
properties
classifier
size
information)
_ СШ1С0К объектов, для которых известно, к какому классу
Здесь instances НСПОЛЬЗук>тся в качестве обучающего множества дл,
■"" oTU „«иные используются в ка-.^.^ ~~ j -.- .....~т^,в,, дл,
они принадлежат^ти д^^ Элемент" properties - это список объектов типа
„Lira свойства, которые можно использовать при проходе узлов
property, вклюмаюшив свойства^ ^ ^^ ^ property 0н предгав
построения
дерева. Элемент classii изучить алгоритм ЮЗ. Поскольку известно,
^■е^ее^ж^ «»• - -фор— —»—■
каким классам mFi *д- -i„P..eHT size задает количество примеров в списке
качестве еше одного свойства, .элемент ьи« ->■" г г
fnsta^ces a information - это содержимое данного множества примеров.
Значения size'* information определяются из примеров. Поскольку их вычисление
г определенное время, а эти данные используются многократно, имеет смысл
занимает с
сохранить их в отдельных элементах.
Напомним, что алгоритм ЮЗ строит деревья решении рекурсивно. Для каждого
экземпляра структуры example-frame выбирается свойство, которое используется дл»
разбиения обучающего множества на непересекающиеся подмножества. Каждое
подмножество содержит все экземпляры, для которых данное свойство принимает одно и
то же значение. Выбранное свойство используется в качестве теста для данного узла
дерева. Для каждого подмножества в этом разбиении алгоритм ID3 рекурсивно строит
поддерево с учетом остальных свойств. Алгоритм прекращает свою работу, если
оставшееся множество примеров принадлежит к одному и тому же классу. Для него с
дается лист дерева.
Определим структуру partition, которая разбивает множество примеров на
подмножества с использованием заданного свойства.
tdefstruct partition
test-name
test
components
info-gain)
Элемент test экземпляра структуры partition связан со свойством. "сп0'^
мым для создания разбиения, test-name— это имя теста включенное для удоост»
пользователя. Элемент components связывается с подмножествами разбиения. В да»
ной реализации components - это ассоциативный список. Ключами являются раз*
■ш: значения выбранного свойства, а данными- экземпляр структуры example
менТния тесТз 9а1П~1п£° ота™« » информацию, получаемую в результате W
стг!™ еТат^ "Г"™ ^ ДСрСва П™°6н° ^мектам size и 1»""^
ЗгГпьз^ ГШ°е ЭТ0Т 3MMem со***" вычисляемое значение, **«*£,
766 частью. Языки „ технологии программироаани0 ^ искусствв„„ого Интеле
15.13.2. Алгоритм ID3
Основу реализации алгоритма ШЗ составляет рекурсивная функция построения
дерева build-tree, параметром которой является структура example-f rame.
(defun build-tree (training-frame)
(cond
; Вариант 1: пустое множество примеров
((null (example-frame-instances training-frame))
(make-leaf :value "невозможно классифицировать: нет
примеров") )
; Вариант 2: использованы все тесты
((null (example-frame-properties training-frame))
(make-leaf ivalue (list-classes training-frame)))
; Вариант З: все примеры принадлежат одному классу
((zerop (example-frame-information training-frame))
(make-leaf rvalue (funcall
(property-test (example-frame-classifier
training-frame))
(car (example-frame-instances training-frame)))))
; Вариант 4: выбор теста и рекурсивный вызов
(t (let ((part (choose-partition (gen-partitions
training-frame))))
(make-decision-tree
:test-name (partition-test-name parti
:test (partition-test part)
-.branches (mapcar #* (lambda (x)
(cons (car x) (build-tree (cdr x))))
(partition-components part)))))))
С помощью конструкции cond функция build-tree анализирует четыре
возможных случая. В первом случае структура training-frame не содержит обучающих
примеров. Такая ситуация может встретиться в том случае, если множество обучающих
примеров алгоритма'шЗ неполно - в нем отсутствуют экземпляры с указанным
значением данного свойства. В этом случае создается лист, содержащий сообщение
"невозможно классифицировать: нет примеров . _ ,«.„.;.,
Второму случаю соответствует ситуация, когда элемент свойств структуры tram-
inq-f Гаше пуст. При рекурсивном построении дерева решений после ""Р""™»
оно удал™ из списка свойств данного экземпляра example- *™ *"» "^
ревьев. Если множество примеров не согласовано, список ^_^£££££
построения однозначной -*^
ся лист, значением которого является список всех классов. щ.
обучающие примеры. vcneara(!e завершение построения ветви дерева. Если
Третья ситуация представляет успешное^заверш ^" TO, M34XV.
содержимое элемента -^^"^^"ссТ^но опреле^оо >ифч»ш.
все примеры принадлежат одному и тому я к. . i „ вшвращаетсд дне-
по Шеннону, приведенному в разделе 1231 А™Р^.^лзссх
товой узел, значение которого соответствует f^™"* ^ в четвертом случае для по-
В первых трех случаях построение дерева "^^^^ ф>жц1и build-tree.
строения поддеревьев текущего узла рек» свойств генерирует список всех
Функция gen-partitions с учетом тестов' "«*™ ch0ose-partiticr. выбирает
возможных разбиении множества примеров-МО™»' сПс
Глава 15. Введение в USP
- „ci После связывания в блоке let полученного разбиения с
„.„более информативный тест ^ которому соответствует использован,
переменной part строится ^е* „т'branches связывается с ассоциативным сп„ском
„ый для разбиения тест, а эле branches соответствует значение теста, а дан.
поддеревьев. Каждому ключу ^ построенное в процессе рекурсивного вьпова
„ые представляют собой дерев р^ ^^ components структуры part уже „ред.
функции build-tree. -^ ключтн которого являются значения свойств а
ставляет собой ассоциативны t'r!me построение поддеревьев выполняется с п'с-
данными- эюем™Р" еХп^0ЛЯЮЩей применить функцию build-tree к каждому
мощью функции mapcar, позволя™^ '
объекту данных ассоциативного^^ ^ ^^ аргумента training-f rame-
функция gen_p* £rame_ „ возвращает все разбиения соответствующего под-
объекта типа ехшпР1® пм6нение создается с использованием некоторого свойст-
множества примеров. Каждое^аз^ gen.partitions вызывает функцию parti -
ва из списка propert _ ' экземпляр example-frame и выбранное свойст-
t^x^^=^s на °Чзначеиий этого свойства- з~-•
™° помощью функции mapcar формируется разбиение для каждого элемента списка
свойств экземпляра training-frame.
(Idefun gen-partitions (training-frame)
" Spear #■ (lambda (x) (partition training-frame x) )
(example-frame-properties training-frame) ) )
функция choose-partition просматривает список возможных разбиений и вы-
бирает из ннх наиболее информативное.
(defun choose-partition (candidates)
(cond ((null candidates) nil)
((= (list-length candidates) 1) (car candidates))
(t (let ((best (choose-partition (cdr candidates))))
(if (> (partition-info-gain (car candidates) )
(partition-info-gain best))
(car candidates)
best)))))
Самой сложной функцией при реализации алгоритма ID3 является функция р
tion. Она получает в качестве параметров экземпляр exapmle-f rame и неко р
свойство property, а возвращает экземпляр структуры разбиения.
((defun partition (root-frame property) .,)
(let ((parts (mapcar #' (lambda (x) (cons x (make-example-frame)
(property-values property) ) ) ) ,*
(dolist (instance (example-frame-instances root-frame)
(push instance (example-frame-instances .
(cdr (assoc (funcall (property-test property) instan
parts)))))
(mapcar #'(lambda (x)
(let ({frame (cdr x)) )
(setf (example-frame-properties frame) eS
(remove property (example-frame-prope
root-frame) ) )
(setf (example-frame-classifier frame)
(example-frame-classifier root-frame)
768 часть VI. Языки и технологии программирования для искусственного интеЛ""'
(SEtf <eeriPle-frame-sl2e frame)
Гга^пГ"1 '^^—instances
ISet(c!S'le"f/me-in£™ti» frame)
(compute-information
(example-frame-instances frame)
part^ ame"ClaSSi£ier «>°t-frame) > > > >
(make-partition
: test-name (property-name property)
:test (property-test property)
:components parts
:info-gain (compute-info-gain root-frame parts))))
В функции partition сначала в блоке let определяется локальная переменная
parts. Она инициализируется ассоциативным списком, ключами которого являются все
возможные значения свойства, используемого для теста, а данными— поддеревья
разбиения. Это делается с помощью макроса dolist, который связывает с каждым
элементом списка локальную переменную и оценивает ее. Пока элементами списка являются
пустые экземпляры структуры example-frame, элементы, соответствующие каждой
подзадаче, связываются со значением nil. С помощью формы dolist функция
partition помещает каждый элемент root-frame а соответствующий элемент
поддерева переменной parts. При этом используется макрос LISP push, модифицирующий
список за счет добавления нового первого элемента. В отличие от cons функция push
постоянно добавляет новые элементы в список.
Этот фрагмент кода отвечает за разбиение множества root-frame. По завершении
работы функции dolist переменная parts представляет ассоциативный список, в
котором каждый ключ является значением свойства, а каждый элемент данных —
множеством примеров, для которых выбранное свойство принимает данное значение. С
помощью функции mapcar пополняется информация о каждом подмножестве примеров
переменной parts. При этом соответствующие значения присваиваются элементам
properties, classifier, size и information. Затем строится экземпляр
структуры partition, элемент components которой связывается с переменной parts.
Во второй ветви функции build-tree для создания листового узла при
неоднозначной классификации используется функция list-classes. В ней для перечисления
классов, которым соответствует список примеров, применяется цикл do. В этом цикле
список classes инициализируется всеми значениями классификатора из training-
frame. Если в списке training-frame содержится элемент, принадлежащий некото-
Рому классу, то этот класс добавляется в список classes-present,
(defun list-classes (training-frame)
(do . , ■
((classes (property-values (example-frame-ciassif ier
training-frame) )
(classifier {pSpe/rty^st (example-frame-classifier
training-frame))) ты накапливаются в локальной
classes-present) 'Hedyjl
переменкой ^^ ^ ^^
((null classes) classes-present)
г"ава 15. Введение в LISP
769
(if (member (car classes) (example-frame-instancas
""^"^ТГ^а <xy> (вда.1 x №11 classi£iery))
(push (car classes) classes-present))))
Остальные функции используются для извлечения из примеров необходимой „нф
мациГфуirUpute-inforrnation определяет информационное содержи
сп.Та примеров. Она вычисляет количество примеров для каждого класса и Д0ЛЕ0
дого^асса во всем множестве обучающих примеров. Если предположить, чт0 эта „0Ля
соответствует вероятности принадлежности объекта данному классу, то можно „^
лить информативность примеров но определению Шеннона.
(detun compute-information (examples classifier) I
(let ((class-count
(mapcar #'(lambda (x) IcOnsxO)) (property-values
classifier)))
(size 0))
; вычисление количества примеров для каждого класса
(dolist (instance examples)
(incf size)
(incf (cdr (assoc (funcall (property-test classifier)
instance)
class-count))))
; вычисление информативности примеров
(sum #'(lambda (x) (if (= (cdr x) 0) 0
(* -i ;
(/ (cdr x) size)
(log (/ (cdr x) size) 2))))
class-count)))
Функция compute-info-gain вычисляет прирост информации для данного
разбиения путем вычитания взвешенного среднего информацни компонентов из
соответствующего значения, полученного для родительских примеров.
(defun compute-info-gain (root parts)
(- (example-frame-information root)
(sum #• (lambda (x) (* (example-f rame-inf ormation (cdrx))
(/ (example-frame-size (cdr x) )
(example-frame-size root))))
Parts)))
Функция sum вычисляет значения, получаемые в результате применения функции f
ко всем элементам списка list-of-rmmbers.
(defun sum (f list-of-numbers)
(apply ■ + (mapcar £ list-of-numbers)))
На этом реализация функции build-tree завершена. Осталось реализовать фуяк-
trL Г К0Т°РаЯ "а °СН0Ве ДеРева Реш<=»"й. построенного функцией buiW-
дерев; ЭтаТет Ю,аСС"фика«'"0 данного объекта путем рекурсивного прохода °
» При эт„мФГкТ ДОгаТОЧН° ПР0СТа- Ее мнение завершается по Достижен»" »
цируемого объектТ" ^ """Ч»™» значение соответствующего свойства классФ»
*z^П; вы,:"фУ ;°ил„тный ряультат испм"^тся ■ качестве ключа т
770 Частью Языки и технологии программирования для искусственного ИНТ*»"*»
(defun classify (instance tree)
(if (leaf-p tree)
(leaf-value tree)
(classify instance
(cdr (assoc (funcall {decision-tree-test tree) instance)
(decision-tree-branches tree)) ) )))
Теперь вызовем функцию build-tree для примера из табл. 9.1. Свяжем символ
tests со списком определений свойств для кредитной истории, долга, поручительства и
дохода, а символ classifier — со значением риска для данного примера. С помощью
этих определений примеры из таблицы можно связать с экземпляром example-frame.
(setq tests
(list (make-property
:name 'history
:test «'history
:values '(good bad unknown))
(make-property
:name 'debt
:test #'debt
:values '(high low))
(make-property
:name 'collateral
:test #'collateral
rvalues '(none adequate))
(make-property
:name 'income
:test #'income
rvalues '(0-to-15k 15k-to-35k over-35k))))
(setq classifier
(make-property
:name 'risk
:test #'risk
rvalues '(high moderate low)))
(setq credit-examples
(make-example-frame
:instances examples
:properties tests
rclassifier classifier
rsize (list-length examples)
rinformation (compute-information examples class)))
На основе этих определений можно построить деревья решений и использовать их
для классификации примеров по их кредитному риску-
> (setq credit-tree (build-tree credit-examples)>
#S(decision-tree
:test-name income
rtest #<Compiled-function income #x352?CE>
:branches
(<0-to-15k , #S(leaf :valuehign))
(15k-to-35k .
#S(decision-tree
глава 15. Введение в LISP
771
. -яте history
test"^C«4>iled-£unCti°n hlSt0ry #«514D6>
br^aood . #S(leaf :value moderate))
(bad . #Sdeaf :value high))
(unknown .
#S(decision-tree
: test-name debt
:test #<Compiled-function debt « •>,
.branches ,х3^Юь
(((high . #S(leaf :value high),
(low . #S(lea£ :value "
moderate))))))))
(over-35k .
#S(decision-tree :test-name
history
: test #<Compiled-function
history #x...6>
: branches
((good . #S(lea£ :valoe
low) )
(bad . #S(leaf :value
moderate) )
(unknown . #S(lea£
:value low)))))))
>(classify '((history . good) (debt . low (collateral . none)
(income . 15k-to-35k))
credit-tree) moderate
15.14. Резюме и дополнительная литература
И PROLOG и LISP основаны иа формальной математической модели вычислил*
PROLOG— на логике и методах доказательства теорем, a LISP — на теории рекур»
них функций. Указанное свойство выделяет эти языки из множества более
традиционных языков программирования, структура которых определяется архитектурой испо»
с™„айТк7ЬооСРеД™' Унасл«°»ав синтаксис и семантику от математических Р*"
В то »„р„ " „„0G "0ЛУ™ также их выразительную мошь н ясность.
JL ZZT °L0C~ б°Лее новый » *™ двух языков - остался бл,*<
-и™ ГнкиТнТ" К°РНЯМ' USP "азв™ся "~i что его уже нельзя «в*
ски«,*Гк ~Г'М ЯЗЬ'К0М "РО-Р^-иро-ан™. Прежде всего он стал щ£*
"°»огий. К „имТ,ММ1'Р0ВаНШ'' п°^Р*™ающи„ полный спектр современн^.
рапные ™„ы дан!* *Унк™ональное и прикладное программирован" .
ориентированное пп„ °6работка П°токов, оценивание с задержкой и 00
Преимуше^0П,Р°? "Р0ВаНИе' г,азо» *
временных методов т,™""'" " ™М' что m* Her0 разработан широкий Д»»»' >
гопрограммирова Р^аммирования, расширяющих базовую модель ФУ^соз»»»11"
Ручных си™оль„ь1Л1СРедСТВа в ««етании с возможностями списков по,,
Рованиянаизр.Вэтой"™^ Даиных составляют основу современного пр
главе авторы пытались проиллюстрировать этот стиль.
"="■ И- Языки и технолог программирования для искусственного и
^Хо^=^
того, можно порекомендовать такие учебники ™ „„„„ iJ"=c"=. i»w|. лроме
,т »,,[.„ mora га т, учеоники по программированию на LISP, как
[Touretzky, 1990], [Hasemer и Domingue, 1989]. [Graham, 1993] и (Graham 1995]
Многие книги посвящены применению языка LISP для разработки 'систем решения
задач искусственного интеллекта. Так, [Forbus и аеИеег. 1993] содержит описание реТ
„изацнн известных алгоритмов ИИ „a LISP и является незаменимым пособием для
специалистов по практической реализации методов искусственного интеллекта. Кроме того
существует множество книг, посвященных общим проблемам искусственного интеллекта
и их решению иа основе LISP. К ним относятся [Noyes, 1992) и [Tanimolo 1990]
15.15. Упражнения
1. Метод Ньютона нахождения квадратного корня из числа предполагает вычисление
значения корня и проверку его точности. Если найденное решение не обладает
требуемой точностью, вычисляется новая оценка, и процесс повторяется. Псевдокод
этой процедуры имеет следующий вид.
function root-by-newtons-method (х, tolerance)
guess := 1;
repeat
guess := 1/2(guess + x/guess)
until absolute-value(x - guess * guess) < tolerance
Напишите на LISP рекурсивную функцию вычисления квадратных корней по методу
Ньютона.
2. а. Напишите на LISP рекурсивную функцию обращения элементов списка (не
используя встроенную функцию reverse). Оцените сложность реализации. Можно ли
реализовать обращение списка за линейное время?
б. Напишите на LISP рекурсивную функцию, получающую вложенный список
произвольной длины и выводящую зеркальный образ этого списка. В частности,
функция должна демонстрировать такое поведение.
> (mirror '((a b) (с (d е))) )
(((е d) с) (Ь а))
3. Напишите на LISP генератор случайных чисел. Эта функция датжна поддерживать
глобальную переменную seed и возвращать разные случайные числа при каждом вызове.
Описание алгоритма генерации случайных чисел найдите в специальной литературе.
4. Напишите функции initialize, push, top, pop и list-stack,
поддерживающие глобальный стек. Оин должны вести c-fi« """•«« образом.
> (initialize)
nil
> (push 'foo)
f oo
> (push 'bar)
bar
> (top)
bar
> (list-stack)
Глава 15. Введение в USP 773
(bar
fool
(pop)
(list-stack)
(£00)
1 £00) „вставить с помощью списков, не содержащих повторяй,,,
5. Множества можно пред реализацию операций объединения, nenejT'
-Ме"ТОВНГо"и-оп, intersection и difference. (He п„^">
"J::--„ШРзерс.м„з™хфУнКЦии,
6Z* ^ен Ханоя основана „а следующей легенде,
я^дальневосточном монастыре существует головоломка, состоящая из трех брщл,
™™х иг лок и 64 золотых дисков различного размера. Изначально диски бь*
Л, на одну щлу и упорядочены по уменьшению размера. Монахи „ыИЮ1с<
„ертГстить все диски на другую нглу по следующим правилам.
6.1. Диски можно перемещать только по одному.
6.2. Ни один диск не может располагаться поверх диска меньшего размера.
Согласно легенде, когда эта задача будет решена, наступит конец света.
Напишите на LISP программу для решения этой задачи. Для простоты (и чтобы про-
грамма завершила свою работу еще при вашей жизни), не пытайтесь решить полную
задачу о 64 дисках. Попробуйте рассмотреть 3 или 4 диска.
7. Напишите компилятор для оценки арифметических выражений вида
(оператор операнд! операнд2),
где оператор — это +, -, * или /, а операндами являются числа или вложенные
выражения. Примером допустимого выражения является (*(+ 3 6) (- 7 9)). Допустим,
что целевая машина поддерживает инструкции:
(move value register)
(add register-1 register-2)
(subtract register-1 register-2)
(times register-1 register-2)
(divide register-1 register-2) " \
Результаты всех арифметических операций присваиваются аргументу, хранящему»
в первом регистре. Для проСтоть, количество регистров считайте неограничен»»
Компилятор должен получать арифметическое выражение и возвращать список)»
заиньгх машинных операций.
8'Р^е^аЛГОРИ1М П°ИСКа В ГЛ^ с возвратами (аналогичный использован**;
нГГач!' "Р" РеШен™ ™a™ переправы человека, волка, козы и капусть.) ff> P»
ния задачи миссионера и каннибала. Задача формулируется следующим образом.
IT. ТС^Г" КаИИИбШИ ™ЯТ На 6^ Р- и хотят переправиться ^,
ни одна ш ™пп °„Д СЯ Л°ДКа' ° KOT<W'° могут поместиться только два чел
^ольшеУПчПеГка:::ГаВаТЬ- ЕС™ m вд»™ - &"ег0В реК" МИСГтре>
"и™ последователь "' Т° ка>™б<">ь. превратятся в миссионеров У ,,
6»" никаких „ре"р~ пЧ*«щен„й всех людей через реку, ие влекушу*
»■ Разуйте алгоритм „0ИСЕа в „^ ^ ^^ ^^ q кув[динах - .опой-
" Техноло™и программирования для искусственного
Имеются два кувшина емкостью 3 и 5 литров водь, соответственно. Их можно заполнять,
опорожнять и сливать воду из одного в другой до тех пор, пока один из иих не окажется
полным или пустым. Выработайте последовательность действий, при которой в большем
кувшине окажется 4 литра вода. (Совет: используйте только целые числа.)
10. Реализуйте функции build-solution и eliminate-duplicates для
алгоритма поиска в ширину из раздела 15.3.
11. Используйте разработанный в упражнении 10 алгоритм поиска в ширину для
решения следующих задач.
11.1. Задача переправы человека, волка, козы и капусты (см. раздел 15.2).
11.2. Задача миссионера и каннибала (см. упражнение 8).
11.3. Задача о двух кувшинах (см. упражнение 9).
Сравните полученные результаты с результатами работы алгоритма поиска в
глубину. Различия должны особенно четко проявиться в задаче о двух кувшинах. Почему?
12. Завершите реализацию "жадного" алгоритма поиска из подраздела 15.3.3.
Используйте его с учетом соответствующих эвристик для решения каждой из трех задач,
перечисленных в упражнении П.
13. Напишите на LISP программу решения задачи о 8 ферзях. (Задача состоит в
нахождении на шахматной доске такой позиции для 8 ферзей, чтобы оии ие могли побить
друг друга за 1 ход. Следовательно, никакие два ферзя не должны располагаться в
одном ряду, столбце или на одной диагонали.)
14. Напишите на LISP программу решения полной версии задачи о ходе конем для
доски 8x8.
15. Реализацни алгоритмов поиска в ширину, в глубину и "жадного" алгоритма с
использованием списков open и closed очень близки друг другу. Они различаются
только реализацией списка open. Напишите общую функцию поиска, реализующую
любой из трех алгоритмов поиска, определив функцию поддержки списка open в
качестве параметра.
16. Перепишите функцию print-solution из реализации интерпретатора для
решения задач логического программирования таким образом, чтобы она выводила
первое решение и ожидала запроса пользователя (например, символ возврата каретки)
для вывода второго решения.
17. Модифицируйте интерпретатор для решения задач логического программирования
таким образом, чтобы он поддерживал операторы or и not. Дизъюнктивное
выражение должно принимать значение "истина", если таксе значение принимает хотя бы
один из дизъюнктов. При обработке дизъюнктивных выражений интерпретатор
должен возвращать объединение всех решений, возвращаемых дизъюнктами. Отрицание
реализовать несколько сложнее, поскольку отрицание цели истинно только в том
случае, если целевое утверждение принимает значение "ложь". Поэтому для
отрицания цели нельзя возвращать никаких связанных переменных. Это результат
предположения о замкнутости мира, описанного в разделе 12.3.
18. Реализуйте общие функции отображения и фильтрации map-stream и filter-
stream, описанные в разделе 15.8.
19. Перепишите программу решения задачи поиска первых п нечетных чисел Ф,«5онач-
чи с использованием общего фильтра потока filter-stream вместо функции
глава 15. Введение в LISP
, Ашгаотйте ее такт образом, чтобы программа В(и.
£ilcer.oddS. *£$&. *»™ -ова ™™™ "р°^«у С2>
первые л четных чис,=л ^ фи6оначчи.
„ия квадратов P СН11Я задач логического программирования on
20. Дополните интерпрета р^^ выводнть сообщения непосредственно пользоваГ"
рами LISP write. J дикцию solve так, чтобы она проверяла, явп. *■
^":c=r*rs* --- ^—-- .^^
целевое У1веР*да „ содержащий исходное множество подстановок
шоо write и верните поток, •.яг
и^, язык логического программирования, включив в него арифметически О0е
21. дополните,. ы. логичi ^ ^ ^ ^ и в з^ражиеими 20, сначала моднфИВДр*£
Г« solve для выявления лих операторов до вызова функции infer. Если вы.
^Гсодержтг оператор сравнения, замените все переменные их значен,»»,, й 0Ц£.
Ге "то выражение. Если результатом оценивания будет nil, функция solve mm>
возвратить пустой поток. В противном случае оиа возвращает поток, содержащий
исходное множество подстановок. Будем предполагать, что выражения не содержат щ.
связанных переменных. В качестве более сложного упражнения определите оператор =
как функцию (подобно оператору is в PROLOG), присваивающую значение несвищ.
ной переменкой и выполняющую проверку равенства, если все элементы связаны.
22. Используйте разработанные в упражнении 21 арифметические операторы в
интерпретаторе для решения задач лопгческого программирования для решения задачи
консультанта по финансовым вопросам из главы 2.
23. Выберите задачу (например, диагностики автомобилей или классификации видов
животных) и решите ее с помощью оболочки lisp-shell.
24. Модифицируйте оболочку экспертной системы из раздела 15.10 таким образом,
чтобы в качестве ответов пользователя допускались не только значения у и п.
Например, пользователь может задать связанные переменные для целевого утверждения
Для этого нужно изменить функцию ask-f or и связанные с ней функции и
позволить пользователю вводить шаблоны, соответствующие целевому утверждению.
В случае соответствия нужно запрашивать у пользователя коэффициент достоверности.
25. Дополните оболочку lisp-shell оператором not. В качестве примера
обрабояиотрицания цели с использованием рассуждений с неопределенностью используйте материи
главы 7 и оболочку экспертной системы из главы 14, написанную на языке PROLOG.
Ж язьгГ1™ А™"анализат°Р (Р^л Н.З) для некоторого подмножества аншш«»ге
11' в кгГГ ' М°ДеЯЬ "3 РаЗДела 15'12 ™™«У охлаждения, понижающую темпера*
ФбГеит7* °На ПРеВЫШаеТ 3аЛаинм ™™™e- Для каждой комиать, вреди*
от17бС Г'™0™' ЧТОбЫ "епе«ь "агреванилТохлаждения комнаты *«*
к ооъема и изолированности
8' cS " СИ™Ме СЦВ « дл, другой предметной области, например Д* *
МПрИме»™-оритл, ЮЗ для решения друг» задачи, выбранной по своему^»*
ЧаСТЬ "' ЯЗЫКИ И Техноло™« программирования для искусственного ин*
Часть VII
Эпилог
Потенциал компьютерных наук (при его полном изучении и реализации) поставит нас
на более высокую ступень знания о мире. Компьютерные науки помогут нам достичь
более глубокого понимания интепектуальных процессов. Они углубят наши знания о
процессах обучения, мышяаиа и анализа. Мы сможем построить модели и
концептуальные средства для развития науки о познании. Подобно доминирующей роли физики
в нашем веке при изучении природы материи и начала вселенной, сегодня на первый
план выступает изучение интеллектуальной вселенной идей, структур знаний и языка
По моему мнению, это приведет к существенны.» улучшениям, которые в корне
изменят нашу жизнь... Мне кажется, недачек тот час. когда мы поймем принципы
организации знаний иуправления ими...
— Дж. Хопкрофт (J. Hopcroft),
лекция по случаю вручения премии Тьюринга. 1987
Что такое мышление ? Нематериальная субстанция.
Что такое материя? Этого никогда не осмыслить...
— Гомер Симпсон (Homer Simpson)
Мы научимся, когда поймем, что это важно.
— Эрл Уивер (Weaver)
Рассуждения о природе интеллекта
Хотя в этой книге затрагивается множество философских аспектов искусственного
интеллекта, основное внимание сосредоточено на инженерных технологиях,
используемых для построения интеллектуальных артефактов на основе компьютера. В заключение
книги мы вернемся к более сложным вопросам философских основ искусственного
интеллекта, постараемся еще раз переосмыслить возможности науки о познании на основе
методологии Ш1, а также обсудить будущие направления развития этой дисциплины.
Как неоднократно отмечалось ранее, исследования человеческого познания и
способов решения задач человеком внесли существенный вклад в теорию искусственного
интеллекта и разработку его программного обеспечения. В свою очередь, работы в области
ИИ обеспечили возможность построения моделей и экспериментальную проверку науч-
.„ многих дисциплинах, в том числе биологии, лингвд
ных ^""^чение мы обсудим такие темы, как ограниченное «■»<ЪЧ
™" ПЮ"Т „чес^о овеществлена процессов мышления и роль кул Р «*%„
МЖН°СТЬ tS« знаний. Эя вопросы приводят к таким новым научн^'8 «Ч
ншп'интерпре™' шость моделей или природа и возможности ФнЛ(Ч
ским <Чю6юШ' ,втора привел его к междисциплинарному подходу 0fk ""«i
^"ХГ'о^сГиИ с исследованиями психологов, лиигз^^
а^ролологов, эпистемологов и специалистов в других областях, иэучаЮЩ1к в *Ч
проблем человеческого мышления. °*р
Тоадиционно работы в области искусственного интеллекта основывал™,, нагцп
„ ф1зР,ГскоГ. символьной системе [Newell и Simon, 1976]. В рамках этого по™^
разработаны сложные структуры данных и стратегии поиска, которые, в своюо"
привели к получению множества важных результатов. Были созданы системы, обли
шие элементами интеллектуального поведения, и выявлены миогне компоненты, с«Г
ляюшие интеллект человека. Важно отметить, что большинство результатов, основа^
на этих ранних подходах, были ограничены предположениями, вытекающими из фи.
софии рационализма. Согласно рационалистской традиции сам интеллект рассматащ
ется как процесс логических рассуждений и решения научных задач, основанный ш
прямом, эмпирическом подходе к пониманию вселенной. Этот философский рацио»
лизм слишком ограничивает развитие искусственного интеллекта на современном этак
В книге представлено множество более современных разработок, в том числе
альтернативные модели обучения, агентно-орнеитированные и распределенные системы реш-
ния задач, подходы, связанные с овеществлением интеллекта, а также исследования по
реализации эволюционных вычислений и искусственной жизни. Эти подходы к пони»
нию интеллекта обеспечивают необходимые альтернативы идеям рационалистского [«■
дукционизма. Биологические и социальные модели интеллекта показали, что
человеческий разум во многом является продуктом нашего тела и ощущений. Он связан с
культурными „ социальными традициями, навеян произведениями искусства, нашим опьгам
Г„„е ™»0КРУЖаЮЩИХ ЛЮдаЙ' Создавая мет°™ и компьютерные модели таких ело»»
?Zmln^TmaZr аДаПТация ««".росетевых структур человеческого мозга, «-
^^"аг"1"новых=резу"' ~~
обласг!СЕ?лГГоцеТЛЛеКГ' П°Д°бн0 самим компьютерным наукам. - довольно но»
современных компью™"™ ФШИКИ ти би0™™и измеряется столетиями, то вир*
интегрировать различи?,?* "^ исчисля"ся десятками лет. В главе 16 мы постара*
систем. Автор „и™""' П0ДХ0ДЫ " ИИ в единую „ауку создания интеллекту^
луг к возмож1юсти еоз'ля„„ "^ те™ол°™, философия и жизненное кредо пр
н»м использовании позво^"™'? ^Ф™» и экспериментов, которые при «&
щ««х систем, в этой глаГ ЩЫ" П0НЯТЬ o6™«e принципы построения «***«.
2 э™стемологических™21 С2а1рива1отс« предложенные в главе 1 традиция-л
™« кригикам (Хотя*ог0иСеИОив, ИИ' *° бается не для того, чтобы дать Д « „f
лью-нсслед„8атьи J°™c из « нападок все еще требуют ответа), а с позитив»»'
"'"'"Ч™ Развития этой науки
Искусственный
интеллект
как эмпирическая
проблема
Теория вычислительных систем — дисциплина эмпирическая. Можно было бы назвать
ее экспериментальной наукой, но, подобно астрономии, экономике и геологии, некоторые
из ее оригинальных форм испытаний и наблюдений невозможно втиснуть в узкий
стереотип экспериментального метода. Тем не менее это эксперименты. Конструирование
каждого нового компьютера — это эксперимент. Сам факт создания машины ставит
вопрос перед природой; и мы получаем ответ на него, наблюдая за машиной в действии,
анализируя ее всеми доступными способами. Каждая новая программа — это
эксперимент. Она ставит вопрос природе, и ее поведение дает нам ключи к разгадке. Ни машины,
ни программы не являются "черными ящиками", это творения наших рук,
спроектированные как аппаратно, так и программно; мы можем снять крышку и загушуть внутрь.
Мы можем соотнести их структуру с поведением и извлечь множество уроков из одного-
единственного эксперимента.
— Ньюэлл (A. Newell) и Саймон (Н.А. Simon),
лекция по случаю вручения премии Тьюринга, 1976
Изучение мысгящих машин дает нам больше знаний о мозге, чем самоанализ.
Западный человек воплощает себя в устройствах.
- Уильям С. Берроуз (William Burroughs), Завтрак нагишом
Где то знание, что утеряно в информации?
— Т.С. Элиот (T.S. Eliot), хоры из поэмы "Скача"
16.0. Введение
Для многих люден наиболее удивительным аспектом работы в сфере искусственного
интеллекта является степень, в которой ИИ, да и большая часть теории вычислительных
систем, оказывается эмпирической дисциплиной. Этот аспект удивителен, поскольку
большинство рассматривает эти области в терминах своего математического или
инженерного образования Пунктуальным математикам свойственно желание применить к
аи-из. С ™^„Сст7нГало бы 'разумными". К „ссчастыо, а может. „ ^>
систем, KOTOpf °^" ешн,). сложность интеллектуальных программ „ иеопредс„Р. '
(в «'»'с"м0"" ОТихТОвзГ„молействию с миром природы и человеческой деятельности '
„ость, присущая их в ^ ^^ маТематяческой или чисто инженерной точек зрен"
лают невозможным ^^ ^^ „ссяедования „скуеетвеиного интеллект, ,0
„™ а™ 'и сделать их неотъемлемой частью теории ннпкнектупъных с,,^
ЕсеоПп diligent systems), то в процессе конструирования, использования „ a„Mll3
аоХгов должны применять смесь из аналитических и эмпирических методов. С эд
Гки зрения каждая программа ИИ должна рассматриваться как эксперимент: он став*,
вопрос перед природой, и ответ на него - это результат выполнения программы. ОтВД1к
™™оды на заложенные конструкторские и программные принципы формирует „аще
понимание формализма, закономерностей и самой сути мышления.
В отличие от многих традиционных наук, изучающих человеческое познание, разра-
ботчики разумных компьютерных систем могут исследовать внутренние механизмы сво-
их "подопытных". Они могут останавливать выполнение программы, изучать ее
внутреннее состояние и как угодно модифицировать ее структуру. Как отметили Ньюэлл и
Саймон, устройство компьютеров и компьютерных программ предопределяет их потен-
циальное поведение, возможность всестороннего исследования, и доступность для
понимания. Сила компьютеров как инструментов для изучения интеллекта проистекает нз
этой двойственности. Соответствующим образом запрограммированные компьютеры
способны достигнуть высокой степени сложности как в семантике, так и в поведении.
Такие системы естественно охарактеризовать в терминах физиологии. Кроме того,
можно исследовать их внутренние состояния, что в большинстве случаев не могут
осуществить ученые, занимающиеся разумными формами жизни.
К счастью для работ в сфере ИИ, равно как и для становления теории
интеллектуальных систем, современные физиологические методы, в особенности относящиеся к
нейрофизиологии, пролили свет на многие аспекты человеческого мышления. Например,
сегодня мы знаем, что функция человеческого интеллекта не цельна и однородна. Она.
скорее, является модульной и распределенной. Достоинства этого подхода проявляют!
в работе органов чувств, например, сетчатки глаза которая умеет фильтровать и
предварительно обрабатывать визуальную информацию. Точно так же обучение нельзя назвать
однородной, гомогенной способностью. Скорее, оио является функцией множества раз-
^онТнГ™' КаЖДаЯ И3 К°ТОрЫХ адаптирована для специфических целей. Магнтно-
~ изоУпКааНИРОИН',е' ПЮ'"Р°™- эмиссионная томография и другие методы №
=£S££S£sr"и точную"вну,ре
бле™Zl:„о от и" ШСШТа6аМ НауК"' НетбХ0*™° ■*■»«"■ »—ь,е философские £
систем;0^"™"™;:8 Г«°™и, «ли вопрос о том, как интеллект^
предметом изучения hcioJ™ пробтемы варьируются от вопроса о том,
~ " ^меиГоГгГпТеГоТ™ Д° б°Лее ГЛУб°КИХ' "С ^
вопросы о том что такое " ° Физической символьной системе. Далее ^
ситься с узлами Конн™,„.!ИМВОЛ В "'"вольной системе, и как символы могут
™«а, выРаже„„„ГвТ° СК°Й М°ДеЛН- Усматривается вопрос о роли Р* t
°°Учающ„хся программ в„ ИНДуктивн°го порога и представленного в °°".ь"\укЛ-
Р П»-. Возникает вопрос, как соотнести это с недостаточной ^
цГинГпГод^^^ » звол.0-
„ения. внедрения агентов и социологических гГреГоХк "зХГэГ«
дискуссии о философских вопросах будет предложена эпистемология в духе
конструктивизма, которая естественным образом согласуется с предложенным подходом к
рассмотрению ИИ как науки, так и эмпирической проблемы.
Итак, в этой заключительной главе мы вновь возвращаемся к вопросу, поставленному в
главе U что такое интеллект? Поддается ли ои формализации? Как построить системы
проявляющие это свойство? Каким образом искусственный и человеческий интеллект
вписываются в более широкий контекст теории интеллектуальных систем? В разделе 16.1
рассматривается пересмотренное определение искусственного интеллекта. Оно
свидетельствует о следующем. Хотя работа в области ИИ и основана на гипотезе о физической
символьной системе Ньюэлла и Саймоиа, сегодня набор ее средств и методов значительно
расширился. Эта область покрывает гораздо более широкий круг вопросов. Анализируются
альтернативные подходы к вопросу об интеллекте. Они рассматриваются и как средства
проектирования интеллектуальных устройств, и как составные части теории
интеллектуальных систем. В разделе 16.2 основное внимание читателя будет сконцентрировано на
использовании методов современной когнитивной психологии, иеиросетевых вычислений и
эпистемологии для лучшего понимания области искусственного интеллекта.
Наконец, в разделе 16.3 обсуждаются задачи, стоящие сегодня как перед практиками
ИИ, так и перед специалистами по формированию понятий. Хотя традиционные подходы
к ИИ зачастую обвиняют в рационалистском редукционизме, новые междисциплинарные
методы тоже нередко страдают подобными недостатками. Например, разработчики
генетических алгоритмов и исследователи искусственной жизни определяют интеллект с
точки зрения дарвинизма: "Разумно то, что выживает". Знание в сложном мире
внедренных агентов часто сводится к формуле "знаю, как сделать", а не к "знаю, что делаю". Но
для ученых ответы требуют пояснений, их не устраивает одна лишь "успешность" или
"выживаемость" моделей. В этой заключительной главе мы обсудим будущее ИИ,
сформулировав насущные для создания вычислительной теории интеллекта вопросы, и
придем к выводу, что эмпирическая методология является важным, если не наилучшим
орудием для исследования природы интеллекта.
16.1. Искусственный интеллект: пересмотренное
определение __
16.1.1. Интеллект и гипотеза о физической символьной системе
Основываясь иа материале предыдущих 15 глав, можно сформулировать
пересмотренное определение искусственного интеллекта.
ИИ- это дисциплина, исследующая закономерности, лежащие в основе
разумного поведения, путел, построения и изучения артефактов, предо-
пределяющих эти закономерности.
Согласно этому определению искусственный интеллект в ««степени п^Д™
собой теорию закономерностей, лежаших в основе интеллекта и в батьки ~ »^™
методологию создания и исследования всевозможных молелен, на которые зта теория опира
Глава 16. Искусственный интеллект как эмпирическая проблема 781
™, я„ из научного метода проектирования и проведения экс﹄,
№, эпгг вывод «""""^"^гоЯ модели и постановки дальней™* экспер*^!"'
№В с целью ^^к" класть ИИ, бросает вызов многовековому ф££*
Однако это определение, к 0н0 даег людям, которые жаждут понимания!™
"УмР^-^^Та^Р^ой человека,, альтернативу религии, су^
возможно, является главн ч> ^^ времсщ| ,ши поискам а в ™1
^"ПГз^—^н— [Ряво*19891'Еош наука- нсм^С:
открытых ™eJ^T„ внесла какой-то вклад в человеческие знания, то он подтвер^
КуСС™еН pZT- это не мистический эфир, пронизывающ™ люден „ ангелов, а, с№рй,
"TZfe прГцшов и законов, которые можно постичь и применить в конструиро,^;
"^ ™1ьТмашин. Необходимо отметить, что наше пересмотренное определение,,,
%£££££*. оно определяет роль искусственного ингуше™ а изучении пр„р0ДЬ1.
ФТ™ИРЩсГ°г^авенетвующий подход к искусственному интеллекту включал „о-
стооение Формальных моделей и соответствующих им механизмов рассуждений, оснс
ванных на переборе. Ведущим принципом ранней методологии искусственного Интел-
лекта являлась гипотеза о физической символьной системе (physical symbol system),
впервые сформулированная Ньюэллом н Саймоном [Newell и Simon. 1976]. Эта гипотеза
гласит следующее.
Физическая система проявляет разумное в широком смысле поведение
тогда и только тогда, когда она является физической символьной системой.
Достаточность означает, что разумность может быть достигнута
каждой правильно организованной физической символьной системой.
Необходимость означает, что каждый агент, проявляющий разумность в
общепринятом смысле, должен являться физической символьной системой.
Необходимое условие этой гипотезы требует, чтобы любой разумный агент,
будь-то человек, инотанетянин или компьютер, достигал разумного
поведения путей физической реализации операций над ашвольными структурами.
Разумное в широком смысле поведение (general intelligent action) означает
действия, характерные для поведения человека. Физически ограниченная
система ведет себя соответственно своим целям, приспосабливаясь к
требованиям окружающей среды.
Ньюэлл и Саймон собрали аргументы в пользу необходимого н достаточного услов»»
[Newell „ Stmon, 1976]-. [Newell, 1981]; [Simon, 1981]. В последующие годы специалист*
в области ИИ и когнитологни исследовали территорию очерченную этой гипотезой.
Гипотеза о физической символьной системе привела к трем важнейшим прин^
—яГ ття~Ю СИМВМ0В " символьных систем в качестве среде* ^
следов н"Г; РаЗРаб°™ мем«»«°в перебора, в особенности эвристического, даИ
тивной П п°тснциальных умозаключений таких систем; отвлеки" п(>ннз*
сГвольГ сТ7""' MeeiM B ВВД* ^««сложение о том, что правильно постр
средГреалт,™" :анМ°Жет "^^ «™™« » широко- ™ЫС№ ""**" «""
ру1вн жсГ1кГНеЦ' С ЭТ0Й ТОЧКИ 3Р»н* "И становится эмпирической» °
Различные сторонние ■ГВаемь,е "««», непользуктгея для обозначении или ^
"оронние объекты. Как вербальные знаки в естественном языке, сим*- .
Часть»
1И10Т „ли ссылаются на конкретные вещи в мире разумного агента. Например для этих обь-
^„-ссылочных связей можно предложить некоторый варнак сем™ <« р^ ™зГ
С точки зрения символьных систем использование символов в ИИ уходит далеко за
пределы такой семантику Символами здесь представляются все формы знаний, опыта
понятии н причинности. Все подобные конструктивные работы опираются на тот факт,
что символы вместе со своей семантикой могут использоваться для построения
формальных систем. Оин определяют язык представления (representation language) Эта
возможность формализовать символьные модели принципиальна для моделирования
интеллекта как выполняемой компьютерной программы. В этой книге было детально изучено
несколько представлений, в том числе предикатное исчисление, семантические сети,
сценарии, концептуальные графы, фреймы и объекты.
Математика формальных систем позволяет говорить о таких вещах, как
непротиворечивость, полнота н сложность, а также обсуждать организацию знаний.
Эволюция формализмов представления позволяет установить более сложные (широкие)
семантические отношения. Например, системы наследования формируют семантическую
теорию таксономического знания и его роли в интеллекте. Формально определяя
наследование классов, такие языки облегчают построение интеллектуальных программ и
предоставляют удобно тестируемые модели организации возможных категорий интеллекта-
Схемы представления и их использование в формальных рассуждениях тесно связаны с
понятием поиска. Поиск — это поочередная проверка узлов в априори семантически
описанной сети представления на предмет нахождения решения задачи или подзадач, выявления
симметрии задачи и тому подобного (в зависимости от рассматриваемого аспекта).
Представление н поиск связаны, поскольку соотнесение задачи с конкретным
представлением определяет априорное пространство поиска. Действительно решение многих
задач можно значительно усложнить, а то и вовсе сделать невозможным, неудачно
выбрав язык представления. Последующее обсуждение индуктивного порога в этой главе
проиллюстрирует эту точку зрения.
Вьфазительным и часто цитируемым примером связи между поиском и
представлением, а также трудности выбора удобного представления является задача размещения
костей домино на усеченной шахматной доске. Допустим, имеется шахматная доска и
набор костей домино, причем каждая закрывает ровно две клетки на доске. Положим
также, что у доски не хватает нескольких клеток — на рис. 16-1 отсутствуют верхний
левый н нижний правый уголки.
•
•
Рис 16.1. Усеченна, шах-чатна, доска с Лп:« "<-« '^
костью домино
Глава 16. Искусственный интеллект как эмпирическая
783
Задача состов^м.чтобы^^^
клетки. Можно попытаться Ре ' поиска, который являстся "та "ос
геЙ' ^ "Гд^е'Гдс- в в^е просто,, матрицы, игнорирующим"^
СЛТГГн —™сс„6=„иост,, как цвет поля. Сложность подобного поиска^.'
,'поятна Для эффективного решения необходимо применение эвристических %
т?до: S мерДможФ„! отсечь частные решения, которые оставляют изолирован^
дельныТклетк". Можно также начать с решения задачи для досок меньшего р^"
таких как 2x2. 3x3. и постараться расширить решение до ситуации 8x8.
Опираясь на более сложное представление, можно получить изящное решение. ^
этого нужно учесть тот факт, что каждая кость должна одновременно покрывать белую „
черную клетки. На усеченной доске 32 черные клетки, но лишь 30 белых, следовательно
требуемое размещение невозможно. Таким образом, в системах, основанных на сим-
вольных рассуждениях, возникает серьезный вопрос: существуют ли представления,
позволяющие оперировать знаниями с такой степенью гибкости и творческого подхода?
Как может конкретное представление изменять свою структуру по мере появления новых
сведений о предметной области?
Эвристика — это третий важный компонент символьного ИИ после представления и
поиска. Эвристика — это механизм организации поиска среди альтернатив,
предлагаемых конкретным представлением. Эвристики разрабатываются для преодоления
сложности полного перебора, являющейся непреодолимым барьером на пути получения
полезных решений многих классов интересных задач. В компьютерной среде, как и в
человеческом обществе, интеллект нуждается в обоснованном решении "что делать дальше".
На протяжении истории развития ИИ эвристики принимали множество форм.
Такие ранние методы решения задач, как метод поиска экстремума (hill climbing) в
шашечной программе (см. главу 4) или анализ целей и средств (means-ends analysis) в
обобщенной системе решения задач General Problem Solver (см. главу 12), пришли в ПН
из других дисциплин, таких как исследование операций (operations research), и
постепенно выросли до обшепрнменимых методов решения задач ИИ. Характеристики поиска,
включая допустшюсть (admissibility), монотонность (monotonicity) и осведомленность
(informedness), являются важными результатами этих ранних работ. Подобные методы
часто называют слабыми (weak methods). Слабые методы были разработаны как
универсальные стратегии поиска, рассчитанные на применение в целых классах предметна
ооластеи [Newell and S.mon, 1972], [Ernst и Newell, 1969]. Эти методы и их
характеристики рассмотрены в главах 3, 4, 5 и 12.
ИИВс™^' ? " 8 Представлены «™«ые методы (strong methods) для решения зада'
ний „с"Т„У™ ЭКСПерТНЫХ СИСгем на °™°™ продукционных правил, расе)*'
™«е сиГоГнГ г" (model-based reasoning),, примеров (case-based reason,» •
тоГфокус Гют (s>™bol-based learning) В отличие от слабых, сильные £
-стн,Сь У"д1ГШ'е "а ""♦Ч»-™- -ецифнчиой ДЛЯ каждой предметно« *
толь, лежат в оХТкс^Т* °Р™°в «™ интегральное исчисление. Оптыш^
усвоением :
пгнпоа -,, t"""j» ыш интегральное иичи^и-п»— — м
а«В вТ„ХЬ1ХнГ"' " Г"Х П™ К РеШеНИЮ 'Тств"^
х мет°лах особое значение придается количеств.
адачи, обучению и пополнению знаний, их синтакс
неопределенностью, а также вопросам о качестве з
сиением знаний. В сильны, „ ' У подходов к решение —- и,.
необходим для „ешетГ ДИ осо6ое значение придается количеству^
представлен,,,». ^"Т..МЧК 0бУчению и пополнению знаний, их синтаксич
Почему до сих пор ие существует действительно интеллектуальных
символьных систем ■"ылектуалшыж
Характеристика интеллекта как физической гииппт„ -
реканий. Большую их часть легко olep^T "а-моГГ С""еМЫ "^^ "ШШ° №
„ обоснования fprnnnHin-i "Т™)™. рассмотрев вопросы семантического значс-
* uLfZZZjZ^™ ЦеПШЙ СИМВ0Л0В " '"™>™ых систем. Вопрос
смысла , конечно, тоже оьет по идее интеллект* »alf п™„,„,
пп!сллекта как поиска в предварительно интепппети-
пованных символьных структурах Понятие гмиг™ „ ™ |~«"н""=льно ингерпрети
Р с т... „„ «.„„» .,,.„, понятие смысла в традиционном ИИ развито весьма
слабо. Тем не менее искушение сдвинуться в сторону более "математизированной"
семантики^ например, теории возможных миров (possible worlds), предается ошибочным.
Такой метод уходит корнями к рационалистской идее подмены гибкого
эволюционирующего интеллекта материализованного агента миром ясных, четко определенных идей.
Обоснование смысла- это проблема, которая всегда путала планы как
приверженцев, так н критиков искусственного интеллекта, а также когнитологов. Проблема
обоснования сводится к следующему: как символы могут иметь смысл? В работе [Searle. 1980]
она рассматривается на примере так называемой "китайской комнаты". Автор помещает
себя в комнату, предназначенную для перевода китайских предложений на английский.
Ему передают набор китайских иероглифов, а он отыскивает значение иероглифов в
большом каталоге и передает на выход соответствующий набор английских символов.
Автор заявляет, что даже без знания китайского языка его "систему" можно
рассматривать как машину — переводчик с китайского на английский.
Но здесь возникает одна проблема. Любой специалист, работающий в области
машинного перевода или понимания естественных языков (см. главу 13), может возразить, что
"переводчик", слепо сопоставляющий один набор символов с другим, выдает результат
очень низкого качества. Более того, возможности текущего поколения интеллектуальных
систем по "осмысленной" интерпретации набора символов весьма ограничены. Проблема
слишком бедной опорной семантики распространяется н на вычислительно реализованные
сенсорные модальности, будь то визуальные, кинестетические или вербальные.
Что касается понимания естественного языка, Лакофф и Джонсон [Lakoff и Johnson,
1999] возражают, что способность создавать, использовать, обменивать и
интерпретировать осмысленные символы является следствием интеграции человека в изменяющуюся
социальную среду. Благодаря ей возникли человеческие способности выживания,
эволюционирования и продолжения рода. Она сделала возможными рассуждения по аналогии,
юмор, музыку и искусство. Современные средства и методы искусственного интеллекта и
впрямь весьма далеки от способности кодировать и использовать эквивалентные по
"смыслу" системы.
Прямым следствием бедной семантики является го, что методология поиска в
традиционном ИИ рассматривает лишь предварительно интерпрепфованные состояния и их
контексты. Это означает что создатель программы ИИ связывает с используемыми
символами семантический смысл. Поэтому интеллектуальные системы, включая системы
обучения и понимания естественного языка, могут строить лишь некую вычисляемую
Функцию в этой интерпретации. Таким образом, большая часть систем ИИ очень
ограничена в возможности построения новых смысловых ассоциации по мере изучения окру-
Жающего мира [Lewis и Luger, 2000].
Вследствие стесненных возможностей семантического ^™Р^"*»"*™*-
чительиые успехи связаны с разработкой приложений, в которых можно**£™?™
« от чересчур широкого контекств и в то же врем, описать ««™™"ЗиХ™
"И задачи спомошью заранее интерпретируемых символьных систем. Большая их часть
Глава 16. Искусственный интеллект как эмпирическая
785
згой книге Но и такие системы не поддерживают множественна „
„оминалась в этой книг ст аосстанавливать работоспособность после сбоя
i4'raU'""' " ТниГвсей недолгой истории искусственного интеллекта изучались различ.
* "Р0™гипотезы о физической символьной системе Были разработаны альтера .
„ыс варианты илоте ^ ^ ^^^ главах этои „,„„, символьная с
тивы этому подходу вмможные средства реализации интеллектуальной системы
"°"СК"" ™ьГе"модели основанные на работе органического мозга, а также на процес:
Гбиолоой эГлюции. предоставляют альтернативную базу для понимание
™ „ тепминах научно познаваемых и эмпирически воспроизводимых процессов
^Г^сяГтГэтогоГаздела посвящена обсуждению этих подходов.
16.1.2. Коннекционнстские, или нейросетевые,
вычислительные системы
Существенной альтернативой гипотезе о физической символьной системе являются
исследования в области нейронных сетей и других, заимствованных из биологии,
вычислительных моделей. Нейронные сети, например, являются физически реализуемыми
вычислительными моделями познания, не основанными на предварительно
интерпретированных символах, которыми точно описывается предметная область. Поскольку знания в
нейронной сети распределены по всей ее структуре, зачастую сложно (а то и
невозможно) соотнести конкретные понятия с отдельными узлами или весовыми коэффициентами.
Фактически любая часть сети может служить для представления разных понятий.
Следовательно, нейронные сети являются хорошим контрпримером, по крайней мере, условию
гипотезы о физических символьных системах.
Нейронные сети и генетические алгоритмы сместили акцент исследований ИИ с
проблем символьного представления и стратегий формальных рассуждений на проблемы
обучения и адаптации. Нейронные сети, подобно человеческим существам и животным,
умеют адаптироваться к миру. Структура нейронной сети формируется ие только при ее
разработке, но и при обучении. Интеллект, основанный на нейронной сети, ие требует
переведения мира иа язык символьной модели. Скорее, сеть формируется при
взаимодействии с миром, который отражается в неявной форме опыта. Этот подход внес
значительный вклад в наше понимание интеллекта. Он дал правдоподобное описание
механизмов, лежащих в основе физической реализации процессов мышления; более
жизнеспособную модель обучения и развития; демонстрацию возможности путем простой
локальной адаптации сформировать сложную систему реагирующую на реальные явле-
иа„Г„ТГЩНОе °РУДИе ""* ко™"™™ой теории нейронных систем (neuroscience).
множестве.^Г°ДаРЯ СВ°еЙ М1,огогРа™°™ иейроииые сетн помогают ответить на
Ш В™ ЬГГ еЖаЩ"Х ЗЭ пРаделами впечатляющих возможностей символьного
™ .пр дстГвГ 7р0С0В касается проблемы пер«еп«ии- пр',рода ие "Г
дикатного " Гя Не Pf0Ty НаШеГ0 В°СПР'™ » -ИД* набора точных формул j£
образов из хаоса сеГ„""Р1ННЬ1е Се™ ^спечивают модель выделения "осмысленных
в из хаоса сенсорных стимулов.
«ли аналогичные симвоГГ ПреДставле""я нейронные сети часто более устойчпвы^
сеть может эфф=к™ГГас"1СИтеМЫ' Со™—УК""™ образом обученная нейрон*
»еческ„кгУв4ият,,е осГ2ГР°Ва1Ъ Н°ВЫе "^.e данные, проявляя подобное^
нескольких нейронов серьезе "' ™ СТР°Г0Й логак^ а иа "схожести". Аналогично пота
Это является следствием(избыто П0Шт" "* "^бдительность большой нейронной
чности, часто присущей сетевым моделям.
ЭПИЛ»Г
Наверное, самым притягательным аспектом >гал»>...
со6иость обучаться. Вместо noerpoaTS^Z^ "*" "M"X C"°'
м благодаря гибкости своей структурьГо™ZL™ °Т М"Ра "'Т'""
rj JHbl могут адаптироваться на основе опыта Они ие
„олько строят модель, сколько сами формирую™ под влиянием мира. ОбучсГявГ™
од„„„ из главных аспектов интеллекта. И именно и, проблемы обучения вырастают
наиболее сложные вопросы, связанные с нейросетевыми вычислительными системами.
Почему мы до сих пор не создали мозг
Недавние исследования в когнитивной теории нейронных систем [Squ.re и
Kosslyn, 1998], [Gazzamga, 2000] представляют новый аспект в понимании когнитивной
архитектуры человеческого мозга. В этом разделе мь. кратко ознакомимся с некоторыми
открытиями в этой области, проведя параллель между ними и искусственным
интеллектом. Эти вопросы будут рассмотрены с трех позиций: иа уровне, во-первых, нейрона, во-
вторых, нейронной архитектуры и, в-третьих, когнитивного представления проблемы
кодирования (encoding).
На уровне отдельного нейрона Шепард [Shephard, 1998] и Карлсон [Carlson, 1994]
определяют множество различных типов нейронной архитектуры, построенной из
клеток, каждая из которых выполняет специализированную функцию и играет свою роль в
большей системе. Они выделяют клетки рецепторов наподобие клеток кожи, которые
передают входную информацию другим скоплениям клеток, внутренним нейронам,
основная задача которых сводится к передаче информации внутри скоплении клеток, и
моторным нейронам, формирующим выход системы.
Нейронная активность имеет электрическую природу. Состояние возбуждения или
покоя определяется характером ионных потоков в нейрон и из него. У типичного
нейрона потенциал покоя составляет приблизительно -70 мВ. Когда клетка активна, окончание
аксона выделяет определенные вещества. Эти химические вещества, называемые
медиаторами (neurotransmitters), взаимодействуют с постсинаптической мембраной, обычно
вливаясь в иу-жиые рецепторы и возбуждая тем самым дальнейшие ионные токи. Потоки
ионов, достигая критического уровня, около -50 мВ, формируют потенииш
возбуждения (action potential) — триггерный механизм, однозначно определяющий степень
возбуждения клетки. Таким образом, нейроны сообщаются, обмениваясь
последовательностями двоичных кодов.
Существует два вида постсинаптических изменений, вызванных достижением
потенциала возбуждения: тормозящие (inhibitory), наблюдаемые в основном в межненрониых
структурах клеток, и возбуждающие (excitatory). Такие положительные и отрицательные
потенциалы постоянно генерируются в синапсах дендритной системы. Когда
результирующее влияние всех этих событий изменяет потенциалы мембран соответствующих
нейронов от -70 мВ до примерно -50 мВ, пороговое значение превышается, и вновь
инициируются ионные токи в аксонах этих клеток.
На уровне нейронной архитектуры в коре головного мозга (тонком слое,
покрывающем полушария мозга) содержится приблизительно 1010 нейронов. Большая часть коры
имеет складчатую форму, что увеличивает ее площадь поверхности. С точки зрения
вычислительной системы необходимо учитывать не только количество синапсов, но и
нагрузочные способно™ но входу и выходу. Шепард [Shephard, 1998] примерно
оценивает оба этих параметра числом f_ н£Йр0„иых и компьютерных систем, суще-
Кроме различии в клетках и архитектура.* mnVu ,.,,,,_„.„
ствует более глубокая проблема когнитивного представления. Мы, к примеру, совершен
Глава 16. Искусственный интеллект как эмпирическая проблема
787
г. ,„*. как в коре кодируются даже простейшие воспоминания, и^
-^.Г =ГлГ lo о том, как нервная система кодируй
Д^7Г1У1ЭеГсГ:ГГ~ГКОТОрЫМ ст_я исследователи „
„esnt „ого и вычислительного толка, касается роли врожденного знания в оṄ„„.
МоГо ли провести эффективное обучение "с нуля", без начального знания основываясь
ГскГит^ьно „a ouZ или же должен присутствовать „екни индуктивный порот? Опыт
разработки обучающихся программ предполагает необходимость какого-либо начального
знания обычно выражающегося в форме индуктивного порога Оказалось, что способность
нейронных сетей строить осмысленное обобщение на основе обучающего множества
зависит от числа нейронов, топологии сети и специфики алгоритмов обучения. Совокупность
этих факторов составляет индуктивный порог, играющий не менее важную роль, чем в
любом символьном представлении. Например, находится все больше подтверждений тому,
что дети наследуют совокупность "аппаратно прошитых" когнитивных предпосылок
(порогов), благодаря которым возможно обучение в таких областях, как язык и
интуитивное понимание законов природы. Представление врожденных порогов в нейронных сетях
сегодня является областью активных исследований [Elman и др., 1996].
Вопрос о врожденных порогах отходит на второй план, если обратить внимание на
более сложные проблемы обучения. Предположим, нужно разработать вычислительную
модель научного открытия и смоделировать переход Коперника от геоцентрического к
гелиоцентрическому взгляду на устройство вселенной. Для этого требуется представить
в компьютерной программе теории Коперника и Птолемея. Хотя эти взгляды можно
представить в качестве активационных схем нейронной сети, такие сети ничего ие
скажут о них, как о теориях. Человек предпочитает получать объяснения вроде: "Коперник
был озадачен сложностью системы Птолемея и предпочел более простую модель, в
которой планеты вращаются вокруг Солнца". Подобные объяснения требуют символьного
выражения. Очевидно, нейронные сети должны обеспечивать символьное обоснование.
В конце концов, человеческий мозг — это нейронная сеть, но она неплохо умеет
обращаться с символами. И тем ие менее символьное обоснование в нейронных сетях —
важная, но все еще открытая проблема.
Еще одной проблемой является роль развития в обучении Дети не могут просто
учиться на доступных данных. Их способность к обучению в конкретных областях
проявляется на четко определенных стадиях развития [Karmiloff-Smith, 1992]. Возникает
любопытный вопрос: является ли этот факт всецело следствием человеческой биологии,
теТЛ0" „0ТРаЖаеТ ИеКИе "Р™"™1™™ необходимые ограничения на способность ин
ви™^™!^ 3аКОНОМеРио™ окружающего мира? Могут ли подобные стадии раз;
ВозГжГли "7НИЗМОМ <™ Р^ния задачи общения на более простые подзадача
венГйТ! в:г "Гхои;Тоствеино втата °^™те™й ™ р№ие искусст'
Примене„„Г™йп„„„ И°СН0В0Й "* обучения в сложном мире?
ные п^блемь п ед „" "овГЙ "" Г^ пР-™-ких задач ставит дополнит.» ■
лают их такими привл к «льн '" ""* СВ°ЙС™ нейронных сетей, которые Д
точности „л„ „"ГГсГд "о0™ —™Роваться, устойчивость к .Д«
практического применения П данных>' одновременно создают препятствия для
ся, их поведение сложнее предсказав рЙр0НИЬ,е се™ обучаются, а ие программирУ
редсказать. Существует несколько общих принципов про
тироваиия сетей, которые вели бы себя тчкимм nfi™,
Однако сложно объяснить, почему нейрГГ 7ГТ " ^""^ пРедме™й °*™™-
Обычно такие объяснения принимают вил каких ™ iT™ * опРеделеяномУ в"»оду.
^перечисленные проблемы являю™ nPeZ^
Возникает вопрос, так ли уж различаются в км,.™,, "с™Д°вании.
„нстские сети и символьные системы И^ Ених^ " ютиат «°™™°-
в них Достаточно много общего В обоих
подходах процесс мышления" сводите» к вычислительным операциям ™еющнмфГ
дамеитальиые и формальные ограничения, такие как описанная в^Ге2™ипэтеГа Чео-
ча-Тьюринга Church-Turing) [Luser 19941 Оба „„„„„, гипотеза Чср-
6 '""Б". i"4j. uoa подхода предлагают модель разума,
применимую в практических задачах. Более того, оба подхода отвергают философию
дуализма и помещают истоки разума в структуру и функцию физических устройств
Мы верим, что согласование этих двух очень разных подходов неизбежно.
Исключительным вкладом в науку стало бы построение теории преобразования символьного
представления в конфигурацию сети, н. в свою очередь, влияния на ее дальнейшую адаптацию. Такая
теория помогла бы во многих исследованиях, например, интеграции в единую
интеллектуальную систему иейросетевого восприятия и систем рассуждения на основе знаний. Тем не менее
в ближайшее время у приверженцев обоих взглядов будет достаточно работы, и мы ие видим
никаких причин, мешающих им сосуществовать. Для тех же, кого смущает подобная
противоречивость двух моделей интеллекта, приведем пример из физики, в которой свет иногда
удобнее рассматривать как волну, а иногда — как поток частиц.
16.1.3. Агенты, интелле1ст и эволюция
Агентные вычисления и модульные теории познания ставят перед исследователями
систем ИИ интересные вопросы. Одна нз известных школ когнитологии полагает, что разум
формируется из наборов специализированных функциональных элементов [Minsky, 1995],
[Fodor, 1983]. Все модули имеют четкую специализацию и используют широкий диапазон
врожденных структур и функций, от "аппаратно прошитого" решения задач до индуктивного
порога. Это связано с разнообразием проблем, которыми они как практические агенты
должны заниматься. В этом есть смысл: как можно обучить нейронную сеть заниматься и
перцепцией, и двигательными функциями, и запоминанием, и логическими рассуждениями?
Модульные теории интеллекта предоставляют базу для поиска ответа на этот вопрос, а также
направление дальнейшего исследования таких вопросов, как природа индуктивного порога в
отдельных модулях или механизмы модульного взаимодействия.
Генетические и эволюционные вычислительные модели обеспечивают новые
захватывающие подходы к пониманию как человеческого, так и искусственного разума.
Демонстрируя возможность рассмотрения разумного поведения как совокупности работы
большого числа ограниченных независимых агентов, теория генетических и
эволюционных вычислений решает проблему представления сложного разума в виде результата
взаимодействия относительно простых структур.
В работе [Holland, 1995] приведен пример, в котором механизмы обеспечения хле&м
большого города (например Нью-Йорка) демонстрируют процесс возникновения
интеллекта в агеТкой системе Вряд ли можно написать централизованны,, планировщик,
который™ ваХ жителей Нью-Йорка привычным им P^T—ZZ
6а. Да и неудачный эксперимент коммунистического мир. по М,^""^^ГХ
иого управления явно показ. о,рани—™-™-^ "^.Гсла-
тические сложности написания алгоритма такого центра..^
Глава 16. Искусственный интеллект как эмпирическая
789
скоординированные*^^
о п„™еб„о?тях города в хлебе. Ои всего лишь старается оптимизировать возможно^
свое™ бизнеса. Решение глобальной проблемы складывается из коллективной де,тель.
ности таких независимых локальных агентов.
Темонстрируя. как целенаправленное, устойчивое к флуктуацшш и почти опт»ма„ь.
ное поведение может складываться из взаимодействия отдельных локальных агентов, эти
модели дают еще один ответ иа старый философский вопрос о происхождении разума.
Главный урок эволюционных подходов к интеллекту состоит в том, что цельный
интеллект может возникнуть и возникает из взаимодействия множества простых, отдельных,
локальных, овеществленных агентских интеллектов.
Вторая главная особенность эволюционных моделей заключается в том, что они
опираются на дарвиновски принцип естественного отбора как иа основной механизм, формирующий
поведение отдельных агентов. Возвращаясь к примеру с булочниками, трудно утверждать, что
каждый отдельный пекарь ведет себя "глобально оптимальным" образом. Источник такой
оптимальности— не централизованный проект, а простой факт. Булочники, которые плохо
удовлетворяют нужды своих покупателей, разоряются. Путем неустанных, многократных
селективных воздействий отдельные булочники приходят к модели поведения, которая
обеспечивает как их собственное выживание, так и общественную полезность.
Комбинация распределенной, агентской архитектуры и адаптивных воздействий
естественного отбора — мощная модель эволюции и работы разума. Эволюционные
психологи [Cosmides и Tooby, 1992, 1994], [Barkow и др., 1992] разработали модель
формирования врожденной структуры и индуктивного порога человеческого мозга в процессе
естественного отбора. Основа эволюциоииой психологии — это рассмотрение разума как
модульной системы взаимодействующих специализнроваиных агентов. В эволюционной
психологии ум часто сравнивают со швейцарским иожом — нвбором
специализированных инструментов, предназначенных для решения различных задач. Появляется все
больше свидетельств тому, что человеческий интеллект действительно в высокой
степени является модульной системой. В [Fodor, 1983] приводятся философские доводы в
пользу модульной структуры интеллекта. Минский [Minsky, 1985] исследовал различные
применения теорий модульности в сфере искусственного интеллекта. Такая архитектура
имеет важное значение для теорий эволюции интеллекта. Сложно представить себе, как
эволюция могла сформировать цельную систему такой сложности, как человеческий
Гял,1Д„РУ1Г ""Т пРавдоп°»°"™ выглядит тот факт, что эволюция в течение
ГаГяьнье „аГк°„Т УСПеГ° С*°Р™Р°в"ь отдельные, специализированные позна-
м™н,ГыГ™и °На бЫ М°ГЛа работать на« комбинациями модулей, формирУ»
p^~zz::a^z^:rинформащ,ей - <—*• —°ш,,е в
Теории нейоон„„о сло*ные задачи познания [Mithen, 1996].
отвечГза ГптГю Г""™ ^^ 19921 """зывиот. как эти же процессы могут
описывают ад^™цГне"ро™ГЙ "ерВИ°Й ™™Ы- Мода™ нейР°™0Г° ^'"""с*
вет „а воздействн^ешней Г '"^ ' ТерМННах ДаР8ина: » "Р°«ессе сеЛеКЦ"" ' яб-
жние других. В отличие от г Вроисходит Умение одних цепочек в мозге н осла»
информацию нз обучающих ""ВОт'Шх мет°Д°в обучения, которые пытаются выдел*
рии нейронной селекции пасс ННЫХ " ИСПОЛЬЗОВать ее для построения модели мира,
нейронов и их взаимоПейт,„Ма?ИваЮТ в™ян"е селективных воздействий на популя"
Действие. Эдедьщн (Edelman, 1992, С. 81] утверждает:
Рассматривая изучение мозга как науку о noiiraim„ „„
инструктивным процессом. Здесь „е пМ„„ГГ' nWtpa3yMCMM' ™> "°™а„„£ ™ является
как ее нет в эволюционных или имм™„ьк п„3 "'"Jf*»™""»» пересылки информации,
л или иммунных процессах. Напротив, познание селективно
Агентиые технологии предоставляют также „одели социального взаимодействия
Используя агентные подходы, экономисты построили „„формативные (если не пс_ю
прогнозирующие) модели экономических рынков. Агенттше технологии оказывают в е
возрастающее влияние иа построение распределенных компьютерных систем, разработ-
ку средств поиска в Internet и проектирование сред совместной разработки
Наконец, агентиые модели оказали немалое влияние на теорию сознания Например
Даниэль Дэннетт [Dennett, 1991] рассматривает функцию и структуру сознания,
отталкиваясь от агеитнои архитектуры интеллекта. Он начинает с замечания, что вопрос о
местоположении сознания в мозге или разуме некорректен. Напротив, его множественная
теория сознания (multiple draft theory of consciousness) основана на рассмотрении
сознания во взаимодействии агентов в распределенной архитектуре интеллекта. Во время
перцепции, управления двигательными функциями, решения задач, обучения и другой
психической активности формируются объединения взаимодействующих агентов. Эти
сочетания очень динамичны и изменяются в зависимости от потребностей в различных
ситуациях. Сознание, по Дэннету, служит связующим механизмом этих объединений
агентов, оно поддерживает взаимодействие агентов. Совокупность агентов становится
основой когнитивной обработки данных.
Ограничения агентного представления интеллекта
Развитие эволюционного подхода привело к возникновению новых вопросов.
Например, еще предстоит понять весь путь эволюции высокоуровневых познавательных
способностей языка. Подобно попыткам палеонтологов реконструировать эволюцию видов,
отслеживание развития этих высокоуровневых проблем связано с большим объемом
кропотливой роботы. Необходимо перечислить все агенты, лежащие в основе
архитектуры разума, и отследить их эволюцию во времени.
Важная проблема для агентских теорий — объяснение взаимодействий между
модулями. Хотя модель ума как "швейцарского ножа" полезна для интуитивного понимания,
модули, из которых состоит интеллект, не так независимы, как лезвия перочинного
ножика. Разум демонстрирует широкие, весьма изменчивые взаимодействия между
когнитивными областями: мы можем говорить о вещах, которые видим, что выявляет
взаимодействие между визуальным и лингвистическим модулями. Мы можем сооружать
здания, служащие специфичным социальным целям, что свидетельствует о взаимодействии
между технической и социальной сторонами интеллекта. Поэты могут строить метафоры
для описания зрительных сцен, демонстрирующие гибкое взаимодействие между
визуальным и тактильным модулями. Исследование представлении и "Р™их™л"
возможными эти межмодульные взаимодействия, является областью текущих
исследований [Karmiloff-Smitn, 1992], [Mithen. 1996]. [Lakoff., ^^«"L ^ K0M.
Все важнее становятся практические применения агентиых технологии. Используя ком
асе важнее становятся прльш JL 0 сюдать сложные системы, для кото-
иъютер„ос моделирование „а основе ^™в;3°е„-за этого ранее были недоступны
рых не существует -"«^-"^7^Ссания некого спектра явле-
Для изучения. Методы моделирования применится дм еН1и сложными
прений, например, адаптации человеческой им^"™С""!™кс^тют. метеоролога.,. Во-
цессами, включая ускорение ™^™12^™^"™« ^ да ""»
■Люсь, представления и вычислительной реализации. »и v
Глава 16. Искусственный интеллект как эмпирическая п.
791
,,,„ таких моделей, опр.
,т«нление исследовании в построении предс-к.
.„ределяют."^"ЫотерноП аппаратуры. Я^^Щ
.«аний.алгор.ггмовидажеразрабс. с вторыми предстоит иметь дело агентным aDv,1T„
Дррт,епракт„чес^о„р„сь^ Ро ^ ^^ g >*£.
турам, включают протоколы "« 0 проблеме в целом или о том, 1а ° "'
лТкальные агенты имеют ограни*ниы ^ ^ сущсствуст жс ■**»,
знаниями уже могут обладать другие ^ нтир0 ванные подзадачи и p^Z.m
==р6==>«э™"™~—~™ 3SS
ЛТожГГ„СХГ^°Г:н^ аспект эволюционной теории интеллект эд
возможнсГь описать ручные виды психической деятельности единой моделью воз.
ГоГнГпорадка ю хаоса. Краткий обзор, проведенный в этом разделе, позволяет
вшёлить работы, использующие зволюционную теорию для моделирования ряда лро.
шесов- от эволюции интеллекта до конструирования экономических и социальных
моделей поведения. Есть нечто чрезвычайно привлекательное в той идее, что эволюцион-
ные процессы, описываемые теорией Дарвина, могут объяснить разумное поведение во
многих масштабах: от взаимодействия индивидуальных нейронов до формирования мо.
лекулярной структуры мозга или функционирования экономических рынков и
социальных систем. Оказывается, интеллект подобен фрактальной структуре, где одни и те же
процессы действуют в любых масштабах и во всей системе в целом.
Далее будут рассмотрены психологические и философские аспекты человеческого
мышления, которые повлияли иа создание, разработку и применение теории искусствен-
нпгп инт-pnnpirra
ного интеллекта.
16.2. Теория интеллектуальных систем ^^
Основная группа исследователей искусственного интеллекта сосредоточила свою
деятельность на понимании человеческого разума совсем не случайно. Люди
обеспечивают прототипы и примеры интеллектуальных действий. Поэтому разработчики
искусственного интеллекта редко игнорируют "человеческий" подход хотя обычно и не ставят
перед собой цели заставить программы действовать по примеру людей. Так, в приложе-
юих компьютерной диагностики программы зачастую моделируют рассуждения людей-
SZf™* B соответ"вУ">Щ=й области. А главное понимание человеческо-
С~~ ГВаТЬШаЮЩаЯ И ВСе СЩе 0ТКР™ научная проблема.
(scieacePonMeIen™?Jrara (С°8Ш"те SCience>' или теория интеллектуальных систем
теР Огша о rBetmS) [LU6er'1994L В°ЗН™ с изобретением цифрового комп*
ки'ихсТисокн ч„„^°сМАНаЛ0СЬ' ЧТ° У ЭТ0Й Д-"ипли„ы были свои предшественг*
теоретиков, таких какТ АрИстотеля- Де"арта и Буля и включает многих современны
моделей, а также Джон ГТ'- МаК-Кашюк " Питтс, основоположники нейросете»"
венной жизни. Эти иссл™ " е'Ша" ~ 0ДИН из пеРвых защитников концепции искус
<™>ить эксперименты, 0T»2Z "^ ШутЛ ЛИШЬ Tor^ к°™а ВОЗННКЛа B03M°*H,rS-
нием компьютеров. Наконец? "' 1е0Рстите«их соображениях, а точнее, с поя
«°рия интеллекта?". МожнГ° М°ЖИ° Задать """Р0^ "Существует ли всеобъемлющ
тем помочь в создании И(2™™° СПрОСИТЬ; "Может ли теория интеллектуальных
В иижеследующих,, Кусственн°г° разума?",
«олотия „ социология n™Z„BmT'X!: 6УДСТ Ра«"азаио о том, как психология, **»
и на исследования в сфере ИИ.
Часть
\\\.ЭО»0
16.2.1. Ограничения психологии
Ранние когнитологнческие исследования Kara™- „
Такие системы учились играть в простые ^Гг^Г"" """"'^ МИ 4e"°BCK°M'
тий [Feigenbaum н Feldman, 1963], [Newell и S тш ,эт7rV' "To^T" тУЧСШК "°"Я-
над системой Logic Theorist (см. раздел 12 ,7ЙГзлл t^ "' '' В "*"*"* Ра6°™
числительные подходы со стратегиями поиска ™ и»? № Т™ ™" "*
I "" Минска, применяемыми человеком Исходными пан-
„ыми для „их служили протоком "мь^ей вщ*~ (lhink.aloud _ J^'ZZ,
СВГ "Гоемы И0""" °*Т™ Ре« задачи, например, доказательств^
иибудь теоремьтНьюэлл и Саймон сравнили эти протоколы с поведением компьютерной
программы, работающей над той же задачей. Исследователи обнаружили поразительную
схожесть и интересные отличия, как в задачах, так и в субъектах исследования
Эти раиние проекты позволили создать методологию, применяемую в когнитологии в
последующие десятилетия.
l.Ha основе данных, полученных от людей, решающих определенный класс
проблем, строится схема представления и соответствующая стратегия поиска для
решения задачи.
2. Отслеживается поведение компьютерной модели, решающей такую проблему.
3. Ведется наблюдение за людьми, работающими над решением задач, и
отслеживаются измеряемые параметры их процесса решения, а именно: протоколы "мыслей
вслух", движения глаз, записи промежуточных результатов.
4. Решения человека и компьютера сравниваются н анализируются.
5. Компьютерная модель пересматривается для следующего цикла экспериментов.
Эта эмпирическая методика описана в лекции Ньюэлла и Саймона, прочитанной по
случаю вручения премии Тьюринга. Ее фрагмент был выбран в качестве эпиграфа к этой
главе. Важным аспектом когнитологии является использование экспериментов для
подтверждения работоспособности архитектуры решателя, будь то продукционная система,
сеть связей или архитектура, основанная иа взаимодействии распределенных агентов.
В последние годы к этим понятиям добавилось принципиально новое измерение.
Теперь в процессе решения задач можно "разбирать" и изучать не только программы, но и
людей, и другие формы жизни. Множество новых технологий получения изображений
пополнили набор средств, применяемых для изучения активности коры мозга. К этим
технологиям относится магнитная энцефалография (magnetoencephalography — MEG).
которая регистрирует магнитные поля, создаваемые группами нейронов. В отличие от
электрического магнитное поле не искажается костями и кожей черепа, следовательно,
можно получить более четкое его изображение.
Другая технология- поттропная эмиссионная томография (positron ermssion
tomography-PET) В кровеносный сосуд впрыскивается радиоактивное вешество. обычно 0 .Когда
определенная область мозга возбуждена, чувствительными детекторами реп,стрнруется
большее количество радиоактивного агента, чем в состоянии покоя этой o&iac™ мозгаХрав-
нение изображений возбужденных и находящихся в покое областей .юмогает обнаруж,шать
ПТ=т==^^^
от более стандартного метода, основанного на «дерт
Глава 16. Искусственный интеллект как эмпирическая щ
793
MUR) Подобно методу PET. в этом подходе для выявления ,
№епа,с '—'^пользуется сравнение изображений возбужденных „ ^
„иональнои локалимии
ш„хся в покос областей м _ функц„й мозга сделали программные ал1-о„ити
Д-ьвеншнй вклад-ло— ^ФУ* ^ ^^ ^^ ^ ?
разработанные Барака ^ ^ ^ свтиы с псречнслснныМн выше МПа '
[Tang и ДР.. 1'*^,шип, появись возможность получить сложные образцы ш ;
Благодаря этим „сел Д ^ ycipof|CTB ^ п0ЛученИя изображений „ервной С(]
Ма' ""Z важньГшаг в исследованиях, поскольку такие показатели, как движения гяаз
темы. Это »"""" свюа1Ш с исследуемыми схемами возбуждения нейронов.
"ТульЗн д «них исследований в ко—он теории нейронных систем (Sq»ire„
kIZm [Staphs. 1»«J. [Gazzaniga,2O00] значительно улучшили понимание
лХжной'составляющей в интеллектуальной деятельности. Хотя анализ „ критика
таких результатов выходит за пределы рассмотрения данной книги, коснемся нескольких
важных вопросов.
. В области восприятия и внимания существует проблема связывания (binding
problem). Такие исследователи, как Энн Трисмэи [Triesman, 1993, 1998], отмечают, что
представление восприятия зависит от распределенных нейронных кодов,
отвечающих за сопоставление частей и качеств объектов, и ставят вопрос о том, какие
механизмы "связывают" информацию, относящуюся к конкретному объекту, и
позволяют отличать этот объект от других.
• В области визуального поиска рассматривается вопрос о том, какие нейронные меха-
низмы обеспечивают восприятие объектов, входящих в большие, сложные сцены-
Некоторые эксперименты показывают, что фильтрация информации о незначительных
объектах играет важную роль в определении целей поиска [Luck, 1998J. Вопрос о том,
как мы "учимся" видеть, исследуется в работе [Sagi и Таппе, 1998].
• Работы [Gilbert, 1992, 1998] посвящены гибкости восприятия. Из них следует, что
видимая человеком картина не отражает точные физические характеристики
сцены. Она значительно зависит от процессов, с помощью которых мозг пытается
интерпретировать эту картину.
• В [Ivry. 1998] рассматривается вопрос о том, каким образом кора мозга кодирует и
индексирует соотносящуюся во времени информацию, включая интерпретацию
ощущений и двигательную активность.
• Стрессовые гормоны, вырабатываемые в состояниях эмоционального возбу*№
ния, влияют на процессы памяти [Cahill и McGaugh 1998] Это соотносится с про-
лёнГзн»0™0"""'"' (eroundi"S>: почему мысли, слова, ощушення имеют оемьк-
е"ГГZT* В КаК°М СМЫСЛ= «"грусть в вещах", вер,*
" »:*°сН™:еС1<Ие «*™ Речи основаны на важных организационн»»
-миТГинт: ГеЮс~оЛеДОМН^ ' °бЛаС™ НеЙ»ОННЫХ СНСТСМ %шГ "
отпивается вопрос о "Г""™ [М1ег,1дР" 1998Ь В У^гыщ». ^Ш,
остаются в кореТозга """""""•«кие и семантические составляв
пади^Зв^у"'" °ПределенномУ «"ку, и какие нейрофизиологи^
IKuhl, 1993. 1998]. у пР0чессу? Этой проблеме посвяшены Р"
794 "
щнх. Крнгичны ли фазы развития для формирования интеллекта'' Эти же вопоосы
рассматриваются в [Karmiloff-Smi.h. 1992], [Gazzanlga. 2СЮ0] и под„ 16 12
Практическая работа в сфере искусственного интеллекта „е требует обширных
познании в вышеперечисленных и смежных нейронных и психологических облТсГ. Но
такие знания могут помочь в разработке интеллектуальных устройств, а также в
определении места исследовании ИИ в контексте общей теорин интеллектуальных систем
Наконец, синтез психологии, нейрофизиологии и компьютерных наук- по-настоящему
увлекательная задача. Но она требует детальной проработки эпистемологами что будет
нашей следующей темой для обсуждения.
16.2.2. Вопросы эпистемологии
Если не знаешь, куда идешь, придешь не туда, куда хочешь...
— приписывается Йоги Берра (Yogi Вегга)
Развитие искусственного интеллекта происходило в процессе решения множества
важных задач и вопросов. Понимание естественных языков, планирование, рассуждения
в условиях неопределенности и машинное обучение — все это типичные проблемы,
которые отражают важные аспекты разумного поведения. Интеллектуальные системы,
работающие в этих предметных областях, требуют знания целей и опыта в контексте
конкретной социальной ситуации. Для этого в программе, которую человек пытается
наделить "разумом", необходимо обеспечить возможность формирования понятий.
Процесс формирования понятий отражает как семантику, поддерживающую
использование символов, так и структуру применяемых символов. Задача состоит в том, чтобы
найти и использовать инвариантности, присущие данной предметной области. Термин
"инвариант" используется для описания регулярностей или значимых, пригодных для
использования, аспектов сложных рабочих сред. В данном рассмотрении термины
символы и символьные системы используются в широком смысле. Они включают широкий
спектр понятий: от четко определенных символов Ньюэла н Саймона [Newell н
Simon, 1976] до узлов и сетевой архитектуры систем связей, а также эволюционирующих
структур генетики и искусственной жизни.
Хотя рассматриваемые ниже вопросы характерны для большей части работ в сфере НИ.
остановимся на проблемах машинного обучения. Это обусловлено тремя причинами.
Во-первых, довольно глубокое изучение хотя бы одной ключевой предметной
области искусственного интеллекта даст читателю более полное и точное представление о
последних достижениях ИИ. Во-вторых, успехи в машинном обучении, а особенно в
нейронных сетях генетических алгоритмах и других эволюционных подходах,
потенциально способны совершить революцию в сфере ИИ. Наконец, обучение- это одна го
наиболее увлекательных областей исследований в искусственном интеллекте.
Несмотря на прогресс, обучение остается одной из наиболее трудных проблем,
встающих перед исследователями ИИ. Далее мы обсудим три вопроса, сдерживающих
сегодня продвижение в этой сфере: во-первых, ><^7^.*^
and overtiming), во-вторых, роль индуктивного порога (,nduc.,ve b.asl в обученш ^в-
третьих. dunJJ лирика (empiricist dilemma), или понимание эволюции без ограни-
Глава 16. Искусственный интеллект как эмпирическая пробле,
795
заимосвязаны. Присущий многим алгоритм^
чений Последние лве "Р"6"™",,, рационалистической проблемы. Порог опреде^
;^й порог явяя^-в"Р^™е;аРемся, зачастую зависит от того, чему J4^
киданиями. т.е. то, чему *»<>£ мь1 ие располагаем априорными Догадками 0"">'
Гея.ЕстьиДРУ^;Р;б;^0ИнаблюЛать в исследованиях, посвященных искус^
зультате. Это, например. "ожн , ^ „ да0 будет pa6oTaTbi как а '.,,?*
"""Гй^еТра ^S к Р-Д-У). ™- -°Р- »*"• НСТ! Э™ ™ы булут за^"
„у^в следукш™ разлеле.
Проблема обобщения ^ представления разнообразных моделей обучен»,
"РТ Гн^ионистскнх и эволюционных), зачастую были слишком неестест
(символьных, коннеш^ ^^ ^^ содарЖ!ши всего несколько узлов ил„ одщ
„енны. Напр. "^' ^ы )ИЯЛ поскольку основные законы обучения мо*«„
скрытый сл№ ;нтекете нескольких нейронов или слоев. Но стоит помнить, то
Г^^ГаГиейро^ые сети обычно значительно больше, н проблема масштаб,
l^Tmem значение. Например, для обучения с обратным распространением ошибки
тоебуется большое количество обучающих примеров, а для решения сколько-нибудь
тактически интересных задач нужны большие сети. Многие исследователи ([Nechl-
Nielsen 1990]; [Zurada, 1992], [Freeman и Scapura, 1991]) работали над проблемой выбора
оптимального'числа входных данных, соотношения между числом входных параметров
и узлов в скрытом слое, определением количества проходов процесса обучения,
достаточного для обеспечения сходимости. Здесь мы только констатировали, что эти
проблемы сложные, важные и в большинстве случаев открытые.
Количество и качество обучающих данных важны для любого обучающего
алгоритма. Без обширных исходных знаний о предметной области алгоритм обучения может не
справиться с выделением образов при получении зашумленных, недостаточных или даже
испорченных данных.
Смежная проблема — вопрос "достаточности" в обучении. В каких случаях алгоритмы
можно назвать достаточно пригодными для выделения важных границ или инвариантов
предметной области задачи? Приберечь ли запас входных данных для тестирования
алгоритма? Отвечает ли количество имеющихся данных требуемому качеству обучения?
Должно быть, суждение о "достаточности" является в большей степени эвристическим или да*
эстетическим: мы, люди, часто рассматриваем алгоритмы как "достаточно хорошие".
Проиллюстрируем проблему обобщения на примере используя метод обратного
распространения ошибки для нахождения функции по набору заданных точек (Р"0'^
Линии вокруг этого набора представляют фу« ^
найденные алгоритмом обучения. Напомним,
по завершении обучения алгоритму нео X ^
предоставлять новые входные данные, ч
верить качество обучения. ^, и-
Функция f, представляет довольно vn^t^
проксимацию методом наименьших „щуЮ
Дальнейшее обучение системы может дать Ф^„ 0
™1ТыНа6°Р """"*' дат^ » т„и h KCT°PM выглядит как достаточно 'W> ^„о
атрмаш"РУ»Щие ф,щии три проксимация набора данных. Но все же ^ ^,
соответствует заданным точкам. Дальнем
(oye^nine.) сети. Одной нз сильных 1^^^^
ошибки является то, что в предметных областях и„™ „„. - распространением
с z „„»„,,„ ^ ^яя многих приложении оно дает эффективные
обобщения, т.е. агшроксимации функций, которые привлекают обучающие данные^
рекпю обрабатывают новые. Тем не менее обнаружить точку, в к^рой сеть переход ю
"недообучеиного в переобученное состание,- „дача нетривиальная. Наш>но думать,
что можно построить сеть, или вообще какой-либо обучающий инструмент, снабдить его
"сырыми данными, а затем отойти в сторону н наблюдать за тем, как он вырабатывает
самые эффективные и полезные обобщения, применимые к новым подобным проблемам
Подведем итог, возвращая вопрос обобшения в коитекст его эпистемологии Когда
решатель задач формирует и применяет обобщения в процессе решения он создает
инварианты или даже системы инвариантов в области задача-решение. Таким образом
качество и четкость таких обобщений могут быть необходимой основой для успешного
осуществления проекта. Исследования в области обобщения задачи и процесса ее
решения продолжаются.
Индуктивный порог: рационалистское априори
Методы автоматического обучения, рассмотренные в главах 9-11, и, следовательно,
большая часть методов ИИ отражают индуктивные пороги, присущие их создателям.
Проблема индуктивных порогов в том, что получаемые в результате представления и
стратегии поиска дают средство кодирования в уже интерпретированном мире. Они
редко могут предоставить механизмы для исследования наших интерпреташш, рождения
новых взглядов или отслеживания и изменения неэффективных перспектив. Такие
неявные предпосылки приводят к ловушке рационалистской эпистемологии, когда
исследуемую среду можно увидеть лишь так, как мы ожидаем или научены ее видеть.
Роль индуктивного порога должна быть явной в каждом обучающем алгоритме.
(Альтернативное утверждение гласит, что незнание индуктивного порога вовсе не
означает того, что он не существует и не влияет критически иа параметры обучения.) В
символьном обучении индуктивные пороги обычно очевидны, например, использование
семантической сети для концептуального обучения. В обучающем алгоритме Уинстона
[Winston, 1975a] пороги включают представление в виде конъюнктивных связей и
использование "попаданий близ цели" для коррекции наложенных иа систему ограничении.
Подобные пороги используются при реализации поиска в пространстве версий
(раздел 9.1), построении деревьев решений в алгоритме LD3 (раздел 9.3) или даже
правилах Meta-DENDRAL (раздел 9.5).
Как упоминалось в главах 10 и 11, многие аспекты стратегий коииекционнстского и
генетического обучения также предполагают наличие индуктивных порогов. Например,
ограничения персептрониых сетей привели к появлению скрытых слоев. Уместен вопрос
о том. какой вклад вносят скрытые узлы в получение решения. Одна из функции
скрытых узлов состоит в том, что они добавляют новые измерения в пространство
представлений. На простом примере из подраздела 10.3.3 было видно, что данные в задаче
"исключающего ИЛИ" не были лииейно разделимы в двухмерном пространстве. Однако
получаемые в процессе обучения весовые коэффициенты добавляют к "Р"™™
«ие одно измерение В трехмерном пространстве точки можно разделить двухмерной
плоскостью. Выходной сюй этой сети можно рассматривать как перееттюн. „а.одяшин
плоскость в трехмерном пространстве.
Глава 16. Искусственный интеллект как эмпирическая про&
797
„r„e из "различных" парадигм обучения использУ10т ,„
Стоит отметить, что мн° Примером подобной ситуации является Взак»">
неявно) обшие инду™ »«£» CLUSTEP72 (раздел 9.5), персешроном (разде^ »*
между кластеризацией в си ^ ^^ ветрсчное распространи »
сетями прототипов (раме юшей обучение без учителя с коррекцией вес»
формации в дуально" сети и /6учением с учителем в слое Гроссберга, й0 „"* "°
выходу в слое Ко»«ена " ^;с^анеиием ош„6ки.
подобно обучению с обр смжи во многих важиых аспекгах. фаетически даде
Рассмотренные СР д я ДОПОлиением к методу аппроксимации функций, в леГ
^ТлСеТ, пьГемея классифицировать наборы данных; во втором строи» ^
ТпГодно начно отделяют кластеры данных друг от друга. Это можно иаблю„ать;
Z «емын персептроном алгоритм классификации „а основе шшШыьнщ
^яиняТаходит также параметры, задающие линейное разделение.
Тжё задачи обобщения „ли построения функции можно рассматривать с разл„ч„щ
позиций Например, статистические методы используются для обнаружения корремц,»
данных Итеративный вариант рядов Тейлора позволяет аппроксимировать большинство
функций Алгоритмы полиномиальной аппроксимации на протяжении более столепя
используются для аппроксимации функций по заданным точкам.
Итак, результат обучения (символьного, коннекционнстского или эволюционного) во мко-
том определяется принятыми предположениями о характере решения. Принимая в расчет лот
синергетический эффект в процессе разработки вычислительных решателей задач, зачастую
можно улучшить шансы на успех и более осмысленно интерпретировать результаты.
Дилемма эмпирика
Если в сегодняшних подходах к машинному обучению, особенно обучению с учителем,
главную роль играет индуктивный порог, то обучение без учителя, которое используется во
многих генетических и эволюционных подходах, сталкивается с противоположной
проблемой, которую иногда называют диделшой эмпирика. В таких подходах считается, что
решения сложатся сами на основе эволюционирующих альтернатив, в процессе "выживания"
наиболее подходящих особей популящш. Это мощный метод, особенно в контексте
параллельных и распределенных средств поиска. Но возникает вопрос: откуда можно узнать, то
система пришла к правильному решению, если мы ие зиали, куда идем?
Давным-давно Платон сформулировал эту проблему словами Меиона из знаменитого
диалога:
■Но каким же образом. Сократ, ты будешь искать вещь, не зная даже, что она такое? Какую в
™Т™* ВеШеЙ ГОбс>*шь ™ "Радметом исследован™? Или, если в лучшем случае™
аТ0ЛЮ"тс" ™ **• <™«» ™ узнаешь, что она именно то, чего ты не зналГ
"обесГГоГЛеД°ГЯеЙ П°™Р*^ слова Меиона [Mi.chel., 1997) и ^
«к„ н^ ™,Т "^ " Ш^т Wolpert, ""'ready, 1995i' 3mKt"^
У-ГГГ;:с~ямД°Ле Ра~стского априорного знания для придав
™™"»™::Хн1ТТЯ МН°ЖеСТВ0 Удельных разработок в обуне^ *
"Лелях или минГн " 1 УЧеН"И- ПрИмеРом мУ*<ит создание сетей, основа^
Р™ ли сложные ZZ^''^ К°Т0,'№ МОЖИО Р-сматрнвать в качестве «*
притяжен™, ИССЛ№вв*Иа"™°стей. Наблюдая, как данные "выстраиваются «
Фактически исследователи „оказали [Siegelman и Sonag, 1991) что рекуррентные
сети полны в смысле вычислений, т.е. эквивалентны классу м.шии ТьюрГигГ^Гэквива-
лентность обобщает более ранние результаты. Колмогоров [Kolmogol, 1957) „оказал
что для каждой непрерывной функции существует нейронная сеть, ревизующая «Л£
числение. Также было показано, что сеть обратного распространения ошибки с одним
™РТ^еГп^дТс,^аППР0КСИМИР°ВаТЬ ЛЮ6УЮ «™Р=Р"=ную на компакте функцию
[Necht-N.elsen, 1989). В разделе 11.3 было указано, что фон Нейман построил полные, ио
Тьюрингу, конечные автоматы. Таким образом, сети связей и конечные автоматы
оказались еще двумя классами алгоритмов, способных аппроксимировать практически любую
функцию. Кроме того, индуктивные пороги применимы к обучению без учителя а также
к эволюционным моделям; пороги представлений применимы к построению узлов сетей
и геномов, а алгоритмические пороги — к механизмам поиска, подкрепления и селекции.
Что в таком случае могут нам предложить коннекциоиистские, генетические или
эволюционные конечные автоматы в их разнообразных формах?
1. Одна из наиболее привлекательных черт нейросетевого обучения — это
возможность адаптации на основе входных данных или примеров. Таким образом, хотя их
архитектуры точно проектируются, они обучаются на примерах, обобщая данные в
конкретной предметной области. Но возникает вопрос о том, хватает ли данных и
достаточно они ли "чисты", чтобы не исказить результат решения. И может ли это
знать конструктор?
2. Генетические алгоритмы также обеспечивают мощный и гибкий механизм поиска
в пространстве параметров задачи. Генетический поиск управляется как
мутациями, так и спецнатьнымн операторами (например, скрещивания или инверсии),
которые сохраняют важные аспекты родительской информации для последующих
поколений. Каким образом проектировщик программы может найти и сохранить в
нужной мере компромисс между разнообразием и постоянством?
3. Генетические алгоритмы н коннекциоиистские архитектуры можно рассматривать
как примеры параллельной и асинхронной обработки. Но действительно ли они
обеспечивают результаты, недостижимые в последовательном программировании?
4. Хотя иейросетевые и социологические корни ие имеют принципиального
значения для многих современных практиков коннекциоиистского и генетического
обучения, эти методы отражают многие важные стороны естественного оттэора и
эволюции. В главе 10 были рассмотрены модели обучения с уменьшением
ошибки — персептронные сети, сети с обратным распространением ошибки и
модели Хсбба. В подразделе 10.3.4 описаны сети Хопфнлда, предназначенные
для решения задач ассоциативной памяти. Разнообразные эволюционные модели
рассматривались в главе 11.
5. И, наконец все методики обучения являются эмпирическими средствами.
Достаточно ли мощны и выразительны эти средства, чтобы по мере выявления инвари-
антностеи нашего мира ставить дальнейшие вопросы о природе восприятия, обу-
чения и понимания?
В следующем разделе будет обоснован вывод о том, что констр>зсги.истска>.зшвгге-
«ология, объединенная с экспериментальными »™^\™*»^^™™
интеллекта, предлагает средства и технологии для дальнейшего построения и „Белова-
ння теории интеллектуальных систем.
Глава 16. Искусственный интеллект как эмпирическая проблема
799
При-реннесконстру-сг-вис™».
v Теории, как сети: кто их закидывает v л
- Л. Витггснштейн
(L.Wi
»о«„.
'"««litem
я»)
"Т'ЛМ «78]% терминах Пиагета (Wage.), мы аса,штруем <„,^.
[von Glasesfeld,19W " „, с нашим текущим пониманием „ „тп™»
—" d, "н. ж понимание к ■•требованиям" явления. Р"С№*
'Tone™— часто используют термин схемы (schemata) для обозначен., а„,
™£™ используемых в организации опытного знания о внешнем мире, э™
^Гн-^ован убр^нского психолога Бартлетта [ВаШе... 1932, и корня^
ГЦософию Канта. С этой точки зрения наблюдение не пассивно и нейтрально, а №
ется активным и интерпретирующим.
Воспринятая информация (кантовское апостериорное знание) никогда не
вписывается точно в заранее составленные схемы. Поэтому пороги, основанные на схемах
и используемые субъектом для организации опытных знаний, должны быть
модифицированы, расширены или же заменены. Необходимость приспособления, вызванная
неудачными взаимодействиями с окружающей средой, служит двигателем процесса
когнитивного уравновешивания. Таким образом, конструктивистская эпистемология
является основой когнитивной эволюции и уточнения- Важным следствием теории
конструктивизма является то, что интерпретация любой ситуации подразумевает
применение понятий и категорий наблюдателя.
Когда Пиагет [Piaget, 1954. 1970] предложил конструктивистский подход к
пониманию, он назвал его генетической эпистемологией (genetic epistemology). Несоответствие
между схемой и реальным миром создает когнитивное противоречие, которое вынуждает
пересматривать схему. Исправление схемы, приспособление приводит к непрерывному
развитию понимания в сторону равновесия (equilibration).
Пересмотр схемы и движение к равновесию— это врожденная
предрасположенность, а также средство приспособления к устройству общества и окружающего мира. В
пересмотре схем объединяются обе эти силы, отражающие присущую нам склонность к
выживанию. Модификация схем априори запрограммирована нашей генетикой и в то же
время является апостериорной функцией общества и мира. Это результат нашего
воплощения в пространстве и времени.
Здесь наблюдается слияние эмпирической н рационалистической традиций- №
материализованный объект человек может воспринимать не больше, чем воспр«н» -
"""Г"" ЧУ8СТВ- Благодаея приспособлению он выживает, изучая обшие Щ»
Гредь 2? МИР" В0ОТР™ определяется нашими ожиданиям.,, которые,г<*£
лГвь4:г;;:г:Р~ртатием' °—»■»«*>»™«могу16ыть
ром"™™::;РеМ° °С°ЗНаеТ СХемЫ- обеспечивающие его взаимодействие <£
-»все~е ™ энаГ П™™°™ И "Рождении в науке и в обш «*
"ого равновесия с "ш "* СМЫСЛа' 0ни формирую™ за счет достижения "»г
Почему конг™,Л°М' ^ "е В пР°"ессе сознательного мышления. .,
проблем искусстве^ ТСКаЯ «"«емология особенно полезна ирИ "^"" ,
Н0Г° и™™екта? Автор считает, что конструктивизм п°«°г
80° "~ ^Гэп^0'
рассмотреннн проблемы эпистемологического доступа (epistemological access).
Более столетия в психологии идет борьба между двумя направлениями: позитивистами,
которые предлагают исследовать феномен разума, отталкиваясь от обозримого
физического поведения, и сторонниками более феноменологического подхода
который позволяет использовать описания от первых лиц. Это разногласие существует
поскольку оба подхода требуют некоторых предположений или толкований По
сравнению с физическими объектами, которые считаются непосредственно
наблюдаемыми, умственные состояния и поведение субъекта четко охарактеризовать
крайне сложно. Автор полагает, что противоречие между прямым подходом к
физическим явлениям и непрямым к ментальным является иллюзорным.
Конструктивистский анализ показывает, что никакое опытное знание о предмете ие возможно без
применения некоторых схем для организации этого опыта. В научных
исследованиях это подразумевает, что всякий доступ к явлениям мира происходит посредством
построения моделей, приближений и уточнений.
16.2.3. Внедренный исполнитель и экзистенциальный разум
Символьные рассуждения, нейросетевые вычисления и разнообразные формы
эволюционных стратегий являются главенствующими подходами в современном изучении ИИ.
Тем не менее, как было отмечено в предыдущем разделе, для обеспечения более высокой
эффективности эти подходы должны принимать в расчет ограничения мира, согласно
которым весь "интеллект" является овеществленным.
Теории внедренного и овеществленного действия утверждают, что интеллект не
является результатом управления моделями, построенными разумом- Его лучше
всего рассматривать в терминах действий, предпринимаемых помешенным в мир
агентом. В качестве метафоры для лучшего понимания разницы между двумя подходами
в работе (Suchman, 1987] предлагается сравнение между европейскими методами
навигации и менее формальными методами, практикуемыми полинезийскими
островитянами. Европейские навигационные методы требуют постоянного отслеживания
местонахождения корабля в каждый момент путешествия. Для этого штурманы
полагаются на обширные, детальные географические модели. Полинезийские
навигаторы, напротив, не пользуются картами и другими средствами определения своего
местонахождения. Они используют звезды, ветры и течения, чтобы продолжать
движение к своей цели, импровизируя маршрут, который непосредственно зависит
от обстоятельств их путешествия. Не полагаясь на модели мира, островитяне
рассчитывают на свое взаимодействие с ним и достигают своей цели с помощью
надежного и гибкого метода.
Теории внедренного действия утверждают, что интеллект ие нужно рассматривать
как процесс построения и использования моделей мира. Это, скорее, менее
структурированный процесс выполнения действий в этом мире и реагирования на результат. Этот
подход акцентирует внимание на способности чувственного восприятия окружающего
мира, целенаправленных действиях, в также непрерывной и быстрой реакции на
изменения, происходящие в нем. В этом подходе чувства, посредством которых человек
внедряется в этот мир имеют большее значение, нежели процессы рассуждения о них.
Важнее способность действовать, а не способность объяснять эти действия^
Влияние твкой точки зрения на сети связей и агентские подходы оч ™но_Шо
состоит в отказе от обших символьных методов в пользу процессов адаптации и обучения.
Глава 16. Искусственный интеллект как эмпирическая лробле!
801
генной жизни [Lang.on. 1995). должно быть, самый яркий „„
Работы . области "°*«™е""°х пол вл„яннем теории внедренного дейст.™. С' "Р"-
„ рисслелованиГ^вьшолн ннь,хп л ехнике ^ Брукса ^^ ^,ы
" -^ "Тм^пТие 1 Ль-са и Люгера ,l*w» и Ln^OOO]. ^^
Мак-Гонигла [Мс*^ оши6кой начинать работы в сфере ИИ с реализации вЫс„ "
ил„ утверждают, что от^ в модСЛ1фуемом разуме. Этот акцент на лог„чссГ
уровневых «^"ХвечТство неверной дорогой, отвлек внимание от фундамент*
рассуждениях повел чел мют тту ввеДрЯТЬся в мир и деиетвовать в нем „ро
„ых "Р0^0"'*0™ „нению Брукса, нужно начинать с проектирования и исследован^
„.ныв #°^"° „, С0зданий. действующих на уровне насекомых. Они „„•,„„.
небольших простых р ^ ^ ^^ поведен1ш как Прость1х, так и сложных ^^
ляг изучить проце . ^ Брукс „ его кодлегн пыгаются
Построив множество так р6mffi сяожного робота C0G
Гт^Р^^Гд^гГГпособностеГ, человека.
несмо™ на это теория внедренного действия также повлияла на символьные подхо-
„н «ИИ Например! работы в области реактивного планирования [Benson, 1995), [Benson
и Nilsson 1995] [Klein нлр, 2000] отвергают традиционные методы планирования,
поедполагаюшие разработку полного и определенного плана, который проведет агента
пГвсему пути от стартовой точки и до желаемой цели. Такие планы редко срабатывают
нужным образом, потому что на пути может возникнуть слишком много ошибок и
непредвиденных проблем. Напротив, системы реактивного планирования работают
циклами. За построением частичного плана следует его выполнение, а затем ситуации
переоценивается для построения нового плана.
Конструктивистские теории и теории внедренного действия подтверждают
многие идеи философии экзистенциализма. Экзистенциалисты считают, что человек
проявляет себя посредством своих действий в окружающем мире. То, во что люди
верят (или утверждают, что верят), куда менее важно, чем то, что они совершают в
критических ситуациях. Этот акцент весьма важен в ИИ. Исследователи постепенно
поняли, что интеллектуальные программы необходимо помешать прямо в
предметную область, а не лелеять в лаборатории. В этом причина роста интереса к
робототехнике и проблеме восприятия, а также к сети Internet. В последнее время ведутс
активные работы по созданию Web-агеитов, или "софтботов", — программ, которые
выходят в сеть и совершают полезные интеллектуальные действия. Сеть привлею
тельна для разработчиков ИИ прежде всего тем. что она может предложить!»11^
лектуальным программам мир, куда более сложный, чем построенный в ла6ор"ь
рии. Этот мир. сравнимый по сложности с природой и обществом, могут пасе
интеллектуальные агенты, не имеющие тел, но способные чувствовать и леи"
вать. как в физическом мире. в
По мнению автора, теории внедренного действия будут оказывать все в<"Рас«"*а.
сияние „а искусственный интеллект, заставляя исследователей уделять больше вням
атТнтГв В°"Р0СаМ- КМ ВаЖН0С1Ь °«шествле„ия „ обоснования для интеллекту"
ZZj^T™ У™ТЫВа1Ъ ВЛШШИе социального, культурного и «о*»"*
тП^ЖТ» "а СП0С°6 "ЛИЯНИЯ ™P* "а рост н эвопюцию внедрен*^
1Ъ l lUkoff и ionnson, 1999] „К и
препяГ^ГсГго^нГнГ^™ °СН0ВНЫе ™Р°™- ™°?кК КЗК СПОСОби^>Ь-
ных систем. УСИЛИЯМ специалистов в построении теории инте*
16.3. Искусственный интеллект: текущие задачи
и будущие направления
Как геометр, напрягший все старанья.
Чтобы измерить круг, схватить умом
Искомого не может основанья.
Таков был я при новом диве том...
— Данте (Dame), Рай
Хотя использование методик ИИ для решения практических задач
продемонстрировало его полезность, проблема их применения для построения полной теории интеллекта
сложна, н работа над ней продолжается. В этом заключительном разделе мы вернемся к
вопросам, которые привели автора к изучению проблем искусственного интеллекта и
написанию этой книги: возможно ли дать формальное математическое описание процессов,
формирующих интеллект?
Вычислительное описание интеллекта возникло с появлением абстрактных
определений вычислительных устройств. В 1930-1950-х гг. эту проблему начали исследовать
Тьюринг, Пост, Марков и Черч — все они работали над формальными системами для
описания вычислений. Целью этого исследования было не просто определить, что
подразумевать под вычислениями, но и установить рамки их применимости. Наиболее
изученным формальным описанием является универсальная машина Тьюринга [Turing, 1950],
хотя правила вывода Поста, лежащие в основе продукционных систем, тоже вносят
важный вклад в развитие этой области знаний. Модель Черча [Church, 1941], основанная на
частично рекурсивных функциях, привела к созданию современных высокоуровневых
функциональных языков, таких как Scheme и Standard ML.
Теоретики доказали, что все эти формализмы эквивалентны по своей мощности:
любая функция, вычисляемая при одном подходе, вычисляется и при остальных. На самом
деле можно показать, что универсальная машина Тьюринга эквивалента любому
современному вычислительному устройству. Исходя из этих фактов, был выдвинут тезис Чер-
ча-Тьюринга о том, что невозможно создать модель вычислительного устройства, более
мощного, чем уже известные модели. Установив эквивалентность вычислительных
моделей, мы обретаем свободу в выборе средств их технической реализации: можно
строить машины иа основе электронных ламп, кремния, протоплазмы или консервных банок.
Автоматизированное проектирование в одной реализации можно рассматривать как
эквивалент других механизмов. Это делает еще более важным эмпирический метод,
поскольку исследователь может экспериментировать над системой, реализованной одними
средствами, чтобы понять систему, реализованную иными.
Хотя, возможно, универсальная машина Тьюринга и Поста чересчур универсальна.
Парадокс состоит в том, что для реализации интеллекта может потребоваться менее
мощный вычислительный механизм с большим упором на управление. В работе
[Levesque и Brachman, 1985] высказано предположение, что для реализации
человеческого интеллекта могут потребоваться вычислительно более эффективные (хотя н
менее впечатляющие) представления, в том числе основанные на использовании хориов-
ских дизъюнктов для представления рассуждений н сужении фактического знания до
основных литералов. Агентские н эволюционные модели интеллекта также разделяют
подобную идеологию.
Глава 16- Искусственный интеллект как эмпирическая проблема
803
„„„■и с формальной эквивалентностью вычислительны, >
Еще один аспект, связанный ч■ т взаим0отношения мозга и тела. По 1 >'
лей _ это вопрос дуализма "лк фы задавались вопросом взаимол!"4
,, ,1И1£П,ации мозга со на»«^юма да о1рнцания матер]1адьного су *^<
объяснения, от полного мар ^ когиитологические исследования отвергают к*"4
вплоть до тштяъс™ матер„адьион модели разума, основанной на физической Г
з„а„ский дуализ», в п° у ^^ форшльном 0 исании вычислительных o^
„изадии, или конкретизаш представлении и "реализации" знаний и nil
над этими символами эквив—«и ^Р^д^^^^ ^^^ q "«^
ове1цествленных « деляхЛсп« т. ^ ^ ^^ ^ Дливоо,»
"К ГеГ—"т множество вопросов, связанных с эпистемолог„ческ11нв
принципами организации интеллекта как физической системы. Отметим некоторые ва*.
иые проблемы.
1 Проблема представления. Ньюэлл и Саймон выдвинули гипотезу о том, что ф„.
зическая символьная система и поиск являются необходимой и достаточной харак.
теристикой интеллекта (см. раздел 16.1). Опровергают ли успехи нейронных сетей,
генетических и эволюционных подходов к интеллекту гипотезу о физической сим-
вольной системе, или же они сами являются символьными системами?
Вывод о том, что физическая символьная система представляет собой достаточную
модель интеллекта, привел ко многим впечатляющим и полезным результатам в
современной науке о мышлении. Исследования показали, что можно реализовать
физическую символьную систему, которая будет проявлять разумное поведение.
Достаточность гипотезы позволяет строить и тестировать символьные модем
многих аспектов поведения человека ([Pylyshyn, 1984], [Posner, 1989]). Нотеоркяо
том, что физическая символьная система и поиск необходимы для разумного
поведения, остается под вопросом [Searle, 1980], [Weizenbaum, 1976], [Winograd и
Flores, 1986], [Dreyfus и Dreyfus, 1985], [Penrose, 1989].
2. Роль овеществления в позиании. Одним из главных предположений гипотезы о
физической символьной системе является то, что физическая реализация
символьной системы не влияет на ее функционирование. Значение имеет лишь формальная
структура. Это ставится под сомнение многими исследователями [Searle, 1980],
[Johnson, 1987], [Agre и Chapman, 1987], [Brooks 1989] [Varela н др., 1933],
которые утверждают, что разумные действия в мире требуют физического воплошо»
которое позволяет агенту объединяться с миром. Архитектура сегодняшних кои-
2Г доп>™»« такой степени внедрен™, ограничивая взаимодействие^
^™мТ„„° И"ТеЛЛе1Сга С М"Р0М "осиными устройствами ввода-вывода- В*
о1чн7о7гТЫ' Т° РеШ'ШЦИЯ МаШинио™ Р«У«а требует интерфейса, весь>«
иичн„го от предлагаемого современными компьютерами.
' ^аСиГчГГ' ТР«°™о упор в ИИ делался на разум отд*^
«зга (спос бГГ ИНТеЛЛеИа- Предполагается, что изучение принципов?
нимание ™к°0ВвТ'РОааИНЯ " Мащ™У™роваиия знаниями) обеспечит полис^
в^в„о„™етео " е Иа' Н° М0ЖИ° ^ерждать, что знание лучше Р-*-^
™см важных^™'° ИСаИН°И В 1Edelm^. 1992], общество само являете»
__ С0Ставш"<"«'<* интеллекта. Возможно, понимание социально^
—■ ТлГэгг^1^
Часть VII."
текста знания и человеческого поведения ие менее важно для теории интеллекта,
чем понимание процессов отдельного разума (мозга).
4. Природа интерпретации. Большинство вычислительных моделей работают с
-заранее интерпретированной предметной областью, т.е. существует неявная
априорная привязка разработчиков к контексту интерпретации. Из-за этой привязки
система ограничена в изменении целей, контекстов, представлений по мере решения
задачи. Кроме того, сегодня делается слишком мало попыток осветить процесс
построения интерпретации человеком.
Позиция Тарскиана (Tarskian), который рассматривает семантическое
приспособление как отображение множества символов иа множество объектов, безусловно,
слишком слаба и ие объясняет, например, тот факт, что одна предметная область
может иметь разные интерпретации в свете различных практических целей.
Лингвисты пытаются устранить ограничения такой семантики, добавляя к ней теорию
прагматики [Austin, 1962] (раздел 13.1). К этим вопросам в последнее время часто
обращаются исследователи в области анализа связной речи, поскольку здесь
важную роль играет применение символов в контексте. Однако проблема гораздо
шире — она сводится к изучению преимуществ и недостатков ссылочных средств в
целом [Lave, 1988], [Grosz и Sidner, 1990].
В традиции семиотики, основанной Пирсом [Peirse, 1958] и продолженной в
работах [Есо, 1976], [Grice, 1975], [Seboek, 1985], принимается более радикальный
подход к языку. Здесь символьные выражения рассматриваются в более широком
контексте знаков и знаковых интерпретаций. Это предполагает, что значение символа
может быть понято лишь в контексте его интерпретации и взаимодействия с
окружающей средой.
5. Неопределенность представлений. Гипотеза Андерсона о неопределенности
представлений [Anderson, 1978] гласит принципиально невозможно определить,
какая схема представления наилучшим образом аппроксимирует решение задачи
человеком в контексте его опыта и навыков. Эта гипотеза основывается иа том
факте, что всякая схема представления неразрывно связана с большей
вычислительной архитектурой и со стратегиями поиска. Детальный анализ человеческого
опыта показывает, что иногда невозможно управлять процессом решения в
степени, достаточной для определения представления, или же установить
представление, которое бы однозначно определяло процесс. Как и принцип неопределенности
в физике, где процесс измерения влияет иа исследуемое явление, это соображение
важно при проектировании моделей интеллекта, но оно, как будет показано ниже,
не ограничивает их применимости.
Такие же замечания могут быть адресованы к самой вычислительной модели, где
индуктивные пороги символов и поиска в контексте гипотезы Черча-Тьюринга все
же накладывают ограничения на систему. Мысль о необходимости построения
некой оптимальной схемы представления вполне может оказаться осколком мечты
рационалиста, в то время как ученому нужна лишь модель, достаточно
качественная для рассмотрения эмпирических вопросов. Доказательством качества модели
является ее способность интерпретировать, предсказывать и адаптироваться.
6 Необходимость построения ошибочных вычислительных моделей. Поппер
[Popper 1959] и другие утверждают, что научные теории должны ошибаться.
Следовательно должны существовать обстоятельства, при которых модель не .может
16. Искусственный интеллект как эмпирическая проблема
805
ГГ—"Ж:.^—™-» —- «222*
следовал"- физической символьной системе, а также агента
Край"» ^Гмо^ннтеАлекта «ожег привести к тому, что их бУХ^
^SSi Следовательно, их применимость в качестве ^
"удТо^чениой. Те же замечания можно «««ьпо поводу предположив
2„о» нолоп.ческой традиции (п. 7). Некоторые структуры данных ИИ, так* ^
септические сети, тоже настолько общи, что ими можно смоделировать пра^,.
Гески все что поддается описанию, или, как в универсальной машнне Тьюрвд,
любую вычислимую функцию. Таким образом, если исследователю ИИ или когни-
толшу задать вопрос о том, при каких условиях его модель интеллекта не будет
работать, он затруднится ответить.
7. Ограничения научного метода. Некоторые исследователи [Winograd и Flo-
res. 1986]. [Weizenbaum. 1976) утверждают, что наиболее важные аспекты интеллекта
в принципе невозможно смоделировать, а в особенности с помощью символьного
представления. Эти аспекты включают обучение, понимание естественного языка и
речь. Эти вопросы корнями уходят глубоко в феноменологическую традицию.
Например, замечания Винограда (Winograd) н Флореза (Flores) основываются на
проблемах, поднятых в феноменологии [Husserl, 1970], [Heidegger, 1962].
Многие положения современной теории ИИ берут начало в работах Карнапз
(Сагпар), Фреге (Frege), Лейбница (Leibniz), а также Гоббса (Hobbes), Лоиа
(Locke;. Гумма (Ниш) и Аристотеля. В этой традиции утверждается, что
интеллектуальные процессы отвечают законам природы н в принципе постижимы.
Хайдеггер (Heidegger) и его последователи представили альтернативный подход i
пониманию интеллекта- Для Хайдеттера рефлексивная осведомленность свойственна
миру овеществленного опыта. Приверженцы этой точки зрения, включая Винограда,
Флореса и Дрейфуса (Dreyfus), говорят, что понимание личностью каких-либо
аспектов основывается на их практическом "использовании" в повседневной жизни. По
существу, мир представляет собой контекст социально организованных ролей и
целей. Эта среда и функционирование человека в ней не объясняются соотношениями в
теоремами. Это поток, который сам себя формирует и непрерывно модифицирует В
дашментальном смысле в мире эволюционирующих норм н неявных целей челом-
несши опыт -это знание не объекта, а. скорее, способа действия. Человек по сво-
Z^ZnT*" Т*"* &-1ЬШуЮ "^ с"*»> знания и разумного поведен*.
форме языка, будь то формального или естественного
^иZИoнaTlI0нЧ,tУp5PeH,,"• В°-ПерВЫХ- ка" 4>и™» чисто ртцнони-я*.
~иос7„ТГ Р*ШЮИ"™ °^"»ает позицию, что всякая человече^
иие, отводя важ^к Г Б°'ишИНС™ вдумчивых людей ставят это под «*£
'ваконеп-то') Сам Г„ "'м°™*м. самоутверждению и обязательствам Л ■
*• ™ требует отт^™Г"Г "П°ЧеМУ " "С ^^ П°6У^*«*
ческой деятельное™ „ иоса ■ • Существует множество разновидностей
К™- "«одяших за „ределы досягаемости научного метода. *»
Часть*. ЭП'
i*^
рые играют важную роль в сознательном взаимодействии людей. Их невозможно
воспроизвести в машинах.
И все же научная традиция, состоящая в изучении данных, построении моделей,
постановке экспериментов и проверке результатов с уточнением модели
дальнейших экспериментов, дала человечеству высокий уровень понимания, объяснения и
способности предсказывать. Научный метод - ношный инструмент для
улучшения понимания человека. Тем не менее в этом подходе остается множество
подводных камней.
Во-первых, ученые не должны путать модель с моделируемым явлением. Модель
позволяет постепенно аппроксимировать феномен, но всегда имеется "остаток",
который нельзя объяснить эмпирически. В этом смысле неоднозначность
представления не является проблемой. Модель используется для исследования,
объяснения н предсказания, и если она выполняет эти функции, то это — удачная
модель [Kuhn, 1962]. В самом деле разные модели могут успешно пояснять разные
аспекты одного явления, например, волновая и корпускулярная теории света.
Более того, когда исследователи утверждают, что некоторые аспекты интеллекта
находятся за рамками методов научной традиции, само это утверждение можно
проверить лишь с помощью этой традиции. Научный метод — единственный
инструмент, с помощью которого можно объяснить, в каком смысле вопросы могут
быть за пределами текущего понимания человека. Всякая логически
последовательная точка зрения, даже точка зрения феномен' - . ш. должна
соотноситься с текущими представлениями об с' она всего
лишь устанавливает границы, в которых (реномен ■-'
jhn вопросы необходимо рассматривать для сохранения логической связности н развития
ИИ. Для того чтобы понять процесс решения задач, обучение и язык, необходимо осмыслить
представления и знания на уровне философии. Исследователям предстоит решать
аристотелевское противоречие между теорией и практикой, жить между наукой и искусством.
Ученые создают инструменты. Все наши представления, алгоритмы и языки — это
инструменты для проектирования и построения механизмов, проявляющих разумное
поведение. Посредством эксперимента можно исследовать как их вычислительную
адекватность для решения задач, так и наше собственное понимание явления интеллекта.
Мы наследники традиции Гоббса. Лейбница. Декарта. Бэббиджа. Тьюринга и других, о
чьем вкладе в науку было рассказано в главе 1 Инженерия, наука и философия; природа щей.
знаний и опыта; могущество и пределы формализма и механизма - это ограничения, с
которыми необходимо считаться и с учетом которых нужно продолжать исследования.
16.4. Резюме и дополнительная литература
Для получения дополнительной информации ч1
ками, приведенными в конце г.завы 1. К ним стен '
[Winograd и Flores. 1986]. Вопросы когнитолопш , —. . , -':.
[Newell и Simon. 1972), [Posner. 1989]. [Luger, 1994], (Ballard. 1997J, (Franklin. 1995].
[Jeannerod. 1997], [Elman и др.. 1996]
В работах [Haugeland. 1981. 1997], [Dennett. 1978). [Smith. 1996] описаны
философские корни теории интеллектуальных систем Книга [Anderson, 1990] по когнитивной
Глава 16. Искусственный интеллект как эмпирическая проб/
807
„нет ценные примеры моделей обработки информации, в „ с
,рГыпТ984]. [Anderson. 1978] приводится детальное описание „„огих приНЦип^
ых вопросов когиитологии, включая рассмотрение неопределенности представ,^'
[Tnnett1991J методы когнитологии применяются для исследовании структурь, ""-В
Z Также можно порекомендовать книги по научному методу; [Р °^-
ZhJml] [Bechtel, 1988), [Hempel. 1965], [Laka.os, 1976], [Quine, 1963]. "^ 19»l
Наконец в [Lakoff и Johnson, 1999] предложены возможные ответы на вопрос обо
„ования. В книге [Clark, 1997] описаны важные аспекты овеществленное™ интеллект!'
Описание модели Брукса [Brooks, 1991o] для решения задачи внедренного робота мо*»
найти в работах [McGonigle, 1990, 1998] и [Lewis н Luger, 2000]. *"°
Предлагаем читателям адреса двух известных научных групп.
The American Association for Artificial Intelligence
445 Burgess Drive
Menlo Park, CA 94025
Computer Professionals for Social Responsibility
P.O. Box 717
Palo Alto, CA 94301
Библиография
АЬе1МАНМ1т'1рт™П.9385: S'mC"m m" 1теГрГеШоп "f Computer Programs. Cambridge,
Ackley D. H., Hinton G^E. and Sejnowski T. J. A learning algorithm for Bohmann machines.
Cognitive Science 9,1985.
Ackley D. H., Littman M. Interactions between learning and evolution. In Langton et al
(1992), 1992. 6
Adler M. R„ Davis А. В., Weihmayer R. and Worrest R. W. Conflict resolution strategies for
nonhierarchical distributed agents. Distributed Artificial Intelligence, Vol. 112. San
Francisco: Morgan Kaufmann, 1989.
Agre P. and Chapman D. Ptngi: an implementation of a theory of activity. Proceedings of the
Sixth National Conference on Artificial Intelligence, pp. 268-272. CA: Morgan
Kaufmann, 1987.
Aho A. V. and Ullman J. D. Principles of Compiler Design. Reading, MA: Addison-Wesley, 1977.
Allen J. Natural Language Understanding. Menlo Park, CA: Benjamin/Cummings, 1987.
Allen J. Natural Language Understanding, 2nd ed. Menlo Park, CA Benjamin/Cummings, 1995.
Allen J., Hendler J. and Tate A. Readings in Planning. Los Altos, CA: Morgan Kaufmann, 1990.
Alty J. L. and Coombs M. J. Expert Systems: Concepts and Examples. Manchester NCC
Publications, 1984.
Anderson J. A., Silverstein J. W., Ritz, S. A. and Jones R. S. Distinctive features, categorical
perception and probability learning: Some applications of a neural model. Psychological
Review, 84: 413^»51, 1977.
Anderson J. R. Arguments concerning representations for mental imagery. Psychological
Review, 85: 249-277, 1978.
Anderson J. R. Acquisition of cognitive skill. Psychological Review, 89: 369^406, 1982.
Anderson J. R. Acquisition of proof skills in geometry. In Michalski et al. (1983e), 1983a.
Anderson J. R. 77ie Architecture of Cognition. Cambridge, MA: Harvard University Press, 19834.
Anderson J. R. Cognitive Psychology and its Implications. New York; W. H. Freeman. 1990.
Anderson J. R. and Bower G. H. Human Associative Memory. Hillsdale, NJ: Erlbaum. 1973.
Andrews P. An Introduction to Mathematical Logic and Type Theory: To Truth Through
Proof. New York: Academic Press, 1986.
Smalltalk^: Tutorial and Programming Handbook. Los Angeles: Digitalk. 1986.
Appelt D. Planning English Sentences. London: Cambridge University Press. 1985.
Arbib M. Simple self-reproducing universal automata. Information and Control 9:177-189. 1966.
, л w ed Papers of John Von Neumann on Computing ani
мргау W. and Burk-s A-Wj ^^ I987. <4^
Пеон. Cambn ■ ^ applicalion of agnostic pac-learning
T1-9Q San Francisco: ivioig*1
PP: . ., . .„ n„ Thins with Words. Cambridge MA: Harvard University Press
„, L How,oDoThinSsw,,h Words.cw™^. ™-™Ч^ ,9щ
Bach E and Harm, R.. ed. №/«««* */W theory. New York: Holt, ш^
Winsion. 196S.
Bachant J and McDermon l.RI revised: Four years m the trenches. Al Magaztne 5(3), щ
n i ,. т r,„, вго«.гат»шк fe liberated from the Von Neumann style? A functional style aeJ
8 la,gZaZro\ra,ns, Con^unicat.ons of the ACM, 21(8): 613-641. 1978. *
Ballard D. An introduction to Natural Computation. Cambridge, MA: MIT Press, 1997.
Balzer R Erman L. U. London P. E. and Williams С HEARSAY III: A domain independent
framework for expert systems. Proceedings AAAI. 1980.
Bareiss E. R., Porter, B. W. and Weir С. С. Protos: An exemplar-based learning apprentice
International loumal of Man-Machine Studies, 29: 549-561, 1988.
Barker V.E. and O'Connor D.E. Expert Systems for configuration al DIGITAL: XCOli ani
Beyond. Communications of the ACM, 32(3): 298-318, 1989.
Barkow J. H, Cosmides L. and Tooby J. Tile Adapted Mittd. New York: Oxford Univ. Press, 1992.
Barr A. and Feigenbaum E., ed. Handbook of Artificial Intelligence. Los Altos, CA: William
Kaufman, 1989.
BartlettF. Remembering. London: Cambridge University Press, 1932.
BatesonG. Mind and Nature: A Necessary Unity. New York: Dutton, 1979.
Bechtel W. Philosophy of Mind. Hillsdale, NJ: Lawrence Erlbaum, 1988.
Bellman R E. Dynamic Programming. Princeton, NJ: Princeton University Press, 1956.
Benson S. Action Model Learning and Action Execution in a Reactive Agent. Proceedings of
the International Joint Conference on Artificial Intelligence (IJCAI-95), 1995.
Benson S and Nilsson N. Reacting. Planning and Learning in an Autonomous Agent. Machine
STw '4'Bdited by K-Furakawa'D-Michie and s- M»gg|Mon- °xford: clar
Вагш'шТтГ rdla;PJetra S- Wla Pletra V" G'»et< J., Laffeny J., Mercer R., B№»
ЫпЛ6^: S>Ste'"M Machi"e translation. Human Language Technology
M^SfltC W°rkshop °n Speech and Natural ,an8uage' San Ma,£0'
BeX»,oiaS0NavaGkpA'pFrpy,fI;GarableEB- K™kk>B- Kurien:;Т'!Гвх
Design oftkeren^ ' '" B" Raja" K- Duquette N.. Smith B. and Will***j
AerospaceЪ£^?^£^«™*'»<*«>*fi ™,0,,o,^ Proceedings of "* С№
BB™aX^^Rre"ro-Dy',a",iCP^™ ™,Be,mont, MA. Athena. I^;;7,
в'*ор С H Neural w / / S°hmg '" semantically rich domains. Cog. Set. 1.
^^orbforPa„em Region. Oxford'oxford University Press, 19*
ВЫ11ш8е1,^55-77Л97ГС'/0" *"*"" '" — *""»" "°^ А"'"™1
Bledsoe W. W. Non-resolution theorem proving. Artificial Intelligence, 9, 1977.
Bobrow D. G. Dimensions of representation. In Bobrow and Collins (1975), 1975.
Bobrow D. G. and Collins A., ed. Representation and Understanding. NY: Academic Press, 1975.
Bobrow D. G, and Winograd T. An overview of K.RL. a knowledge representation language.
Cognitive Science 1(1). 1977.
Bond A. H. and Gasser L., ed. Readings in Distributed Artificial Intelligence. San Francisco-
Morgan Kaufmann, 1988.
Boole G. The Mathematical Analysis of Logic. Cambridge: Macmillan, Barclay & Macmillan, 1847.
Boole G. An Investigation of the Laws of Thought. London: Walton & Maberly, 1854.
Boyer R. S. and Moore J. S. A Computational Logic. New York; Academic Press, 1979.
Brachman R. J. On the epistemological status of semantic networb. In Brachman and
Levesque (1985), 1979.
Brachman R. J. / lied about the trees. Al Magazine 6(3), 1985.
Brachman R. J. and Levesque H. I. Readings in Knowledge Representation. Los Altos, CA:
Morgan Kaufmann, 1985.
Brachman R. I., Fikes R. E. and Levesque H. J. KRYPTON: A functional approach to
knowledge representation. In Brachman and Levesque (1985), 1985.
Brachman R. J., Levesque H. J. and Reiter R-, ed. Proceedings of the First International
Conference on Principles of Knowledge Representation and Reasoning. Los Altos. CA:
Morgan Kaufmann, 1990.
Breiman L., Friedman J., Olsen R. and Stone C. Classification and Regression Trees.
Monterey. CA: Wadsworth, 1984.
Brodie M. L., Mylopoulos J. and Schmidt J. W. On Conceptual Modeling. New York:
Springer-Verlag, 1984-
Brooks R. A. A robust layered control system for a mobile robot. IEEE Journal of Robotics and
Automation. 4: 14-23, 1986.
Brooks R. A. A hardware retargetable distribiaed layered architecture for mobile robot
control. Proceedings IEEE Robotics and Automation, pp. 106-110. Raliegh. NC. 1987.
Brooks R. A. A robot that walks: Emergent behaviors from a carefully evolved network. Neural
Computation 1(2): 253-262. 1989.
Brooks R. A. Intelligence witlwut reason. Proceedings of UCAI-91. pp. 569-595. San Mateo,
CA: Morgan Kaufmann. 1991a.
Brooks R. A. Challenges for complete creature architectures. In Meyer and Wilson, 1991.
Brooks R. and Stein L. Building brains for bodies. Autonomous Robots. 1: 7-25. 1994.
Brown }. S. and Burton R. R Diagnostic models for procedural bugs in basic mathematical
skills. Cognitive Science, 2. 1978.
Brown J. S. and VanLehn K. Repair theory: A generative theory of bugs in procedural skills.
Cognitive Science, 4: 379-126. 19S0.
Brown J S Burton R R and deKleer J. Pedagogical, natural language and knowledge
engineering techniques m SOPHIE. In Sleeman and Brown (10821. 1182.
Библиография
811
о ii в Kant E and Martin N. Programming Expen Sys,e„,s ,„ -
BroMS,on L., Fan-еП^. Kant E.^ramm.^ ^.^ МД; «^.^ ^ OP^
and Hayes-Roth (1978), 19 «s.
„ ,- л Sh„,<liffe E H ed. Rule-Based Expert Systems: The MYCIN £,„„ .
Bundy A Computer Moving of Mathematical Reasoning. New York: Academlc Press 198J
о л л Я,» /«м of explicit plans to guide inductive proofs. Lusk R. and Overbeek R , ,,
^■^gsofC^E9.№Ul-120,NewYork:SpnngerVerIag,1988. ' <«*
Bundv A Byrd L.. Luger G„ Mellish С Milne R. and Palmer M. Solving mechanics probiem
ustgmeTa-level inference. Proceedings of UCAI-I979, pp. 1017-1027, 1979. '*
Bundy A and Welham R. Using meta-level inference for selective application of mulibk
rewrite rules in algebraic manipulation. Artificial Intelligence, 16: 189-212, 1981.
Burks A. W. Theory of Self Reproducing Automata. University of Illinois Press, 1966.
Burks A. W. Essays on Cellular Automata. University of Illinois Press, 1970.
Burkks A. W. Von Neumann's self-reproducing automata. In Aspray and Burks (1987), 1987.
Burmeister В., Haddadi A. and Matylis G. Applications of multi-agent systems in traffic and
transportation. ШЕЕ Transactions in Software Engineering, 144(1): 51-60, 1997.
Burstall R. M. and Darlington J. A. A transformational system for developing recursive
programs. JACM, 24 (January), 1977.
Burstein M. Concept formation by incremental analogical reasoning and debugging. In
Michalskietal. (1986).
Busuoic M. and Griffiths D. Cooperating intelligent agents for service management in
communications networks. Proceedings of 1993 Workshop on Cooperating Knowledge
Based Systems, University of Keele, UK, 213-226, 1994.
Butler M„ ed. Frankenstein, or The Modem Prometheus: the 1818 text by Mary Shelly. New
York: Oxford University Press, 1998.
Cahill L. and McGaugh J. L. Modulation of memory storage. In Squire and Kosslyn (1998), 1998.
Carbonell J.G. Learning by analogy: Formulating and generalizing plans from P°*
experience. In Michalskietal. (1983), 1983.
С^аиШопТ"шТ^ат1°№ А ЛеогУ "f reconstructive problem solving and expertise
a'"u,"MlnMichalskietal. (1986) 1986
'^Mtatbe,^ %f2 »« Mi^« T.M. An overview of machine learn.* '»
5-9,1999. "Chw ka™»S «id natural language. Machine Learning.
1977 M.A. Cogmir* pmcasa Ui Comprelu,nsim Hjyisdale. NJ: &«"
Gordon & Breach, 19б'Г" тЛ Pr°sra""'""S for Mechanical Translation. Ne*
1^°>"
Chang С L. and Lee P.C. T. Symbolic Loglc and Mechanical Theorem Proving. New York:
Academic Press, 1973. *
Charniak E. Toward a model of children's story comprehension. Report No. TR-266, Al
Laboratory, MIT, 1972.
Charniak E. Statistical Language Learning. Cambridge, MA: МГГ Press, 1993.
Charniak E.. Hendrickson C. Jacobson N. and Perkowitz M. Equations for part-of-speech
tagging. Proceedings of the Eleventh National Conference on Artificial Intelligence
Menlo Park, CA; AAAI/MIT Press, 1993.
Charniak E. and McDermott D. /mroduclion to Artificial Intelligence. Readme MA' Addison-
Wesley, 1985.
Charniak E„ Riesbeck С. К., McDermott, D. V. and Meehan J. R. Artificial Intelligence
Programming, 2nd ed. Hillsdale, NJ: Erlbaum, 1987.
Charniak E. and Shimony S. Probabilistic semantics for cost based abduction. Proceedings of
the Eighth National Conference on Artificial Intelligence, pp. 106-111. Menlo Park, CA:
AAAI Press/ МГТ Press, 1990.
Charniak E. and Wilks Y. Computational Semantics. Amsterdam: North-Holland. 1976.
Chen L. and Sycara K. Webmaie: A personal agent for browsing and searching. Proceedings of
Second International Conference on Autonomous Agents (Agents 98), 199S.
Chomsky N. Aspects of the Theory of Syntax. Cambridge, MA: MIT Press, 1965.
Chorafas D. N. Knowledge Engineering. New York: Van Nostrand Reinhold. 1990.
Chung K. T. and Wu С. Н. Dynamic scheduling with intelligent agents. Metra Application
Note 105. Palo Alto: Metra, 1997.
Church A. The calculi of lambda-conversion. Annals of Mathematical Studies. Vol. 6.
Princeton: Princeton University Press, 1941.
Churchland P. S. Neurophilosophy: Toward a Unified Science of the Mind/Brain. Cambridge.
MA: MIT Press, 1986.
Clancy W. J. The advantages of abstract control knowledge in expert system design. AAAI-3.1983.
Clancy W. J. Heuristic Classification. Artificial Intelligence, 27: 289-350. 1985.
Clancy W. J. and Shortliffe E. H. Introduction: Medical artificial intelligence programs. In
Clancy and Shortliffe (19845), 1984a.
Clancy W. J. and Shortliffe E. H.. ed. Readings in Medical Artificial Intelligence: the First
Decade. Reading, MA: Addison-Wesley, 19845.
Clark A. Being There: Putting Brain. Body, and World Together Again. Cambridge, MA: МГГ
Press, 1977.
Clocksin W. F. and Mellish С S. Prog, in PROLOG. 2nd ed. New York: Springer-Verlag. 19S4.
Codd E. F. Cellular Automata. New York: Academic Press, 1968.
Codd E. F. Private communication to J. R. Koza- In Koza (1992). 1992.
Cohen P. R. and Feigenbaum E. А. Пе Handbook of Artificial Intelligence. Vol. 3. Los Altos.
CA: William Kaufmann, 1982.
Cole R. A., ed. Sun-ey of the Slate of the An in Human Lang"*!' Technology. New York:
Cambridge University Press, 1997.
Cole P. and Morgan J. L., ed. Studies in Syntax. Vol. 3. New York: Academic Press, 197b.
Библиография
813
, п Шяп M R Retrial lime from semantic memory: JOUma|
^^^SetL 8: 24^7.1969^
Aix-MarseiMe П. 197 ■ ^^ p Un $умте Je Co„„
C0^Zleeu^Zl Research Report, Croupe Intelligence Artificielle, UniCfe£
TZT^DZoZltsu'E^rtSysten.. New York: Academic Press. 1984
Cortnen T. H.. Uta» С E. and Rives, R. J. Introduce» to Algcri,!,*,. Cambridge, МД;
MIT Press, 1990.
Cosmides L. and Tooby 1- Cognitive adaptations for social exchange. In Barkow e, al. (1992), 1992
Costnides L. and Tooby I. Origins of down specificity: the evolution of Лпс„Ъло,
organization. In Hirschfeld and Gelman (1994), 1994.
Cotton S Bundy A. and Walsh T. Automatic invention of mteger sequences. Proceedings of
the AAAI-20OO, Cambridge: MIT Press, 2000.
Crick F. H. and Asanuma С Certain aspects of the anatomy and physiology of the cerebral
cortex. In McClelland et al. (19S6), 1986.
Crutchfield J. P. and Mitchell M. The Evolution of Emergent Computation. Working Paper 94-
03-012. Santa Fe Institute, 1995.
Culosky M. R., Fikes. R. E.. Engelmore R. S„ Genesereth M. R., Mark W. S„ Gruber T,
Tenenbaum J.M. and Weber C.J. PACT: An experiment in integrating concurrent
engineering systems. IEEE Transactions on Computers, 26(1): 28-37, 1993.
Dahl V. Un Systeme Deductif dInterrogation de Banques de Donnes en Espagnol. PhD thesis,
Universite Aix-Marseille, 1977.
Dahl V. and McCord M. C. Treating Coordination in Logic Grammars. American Journal of
Computational Linguistics, 9: 69-91,1983.
Dallier J. H. Logic for Computer Science: Foundations of Automatic Theorem Proving. New
York: Harper & Row, 1986.
Darr T. P. and Birmingham W. P. An attribute-space representation and algorithm fat
concurrent engineering. AEDAM 10(1): 21-35, 1996.
Davis E. Representations ofCemmonsense Knowledge. Los Altos, CA: Morgan Kaufmann, 1990.
Davis L. Applying Adaptive Algorithms to Epistatic Domains. Proceedings of the International
Joint Conference on Artificial Intelligence, pp. 162-164, 1985.
Davis R. Applications of meta level know/edge to the construction, maintenance, and use 4
large knowledge bases. In Davis and Lenat (1982), 1982.
^Мс^-ЩиШ13' K"OWled^based Ъ»™ I" Artificial Intelligence. New York:
DaVi(1992a)nd19H92mSCher W' M0dd-b™d Zoning: Trouble Shooting. In Hamscher et al.
Davis R-, Shrobe H-, Hamscher W., Wieckert К 4hiri«„ \я j г, ,- „
Description of Structure ana Fu7c,"n P™cSn« o? J N ,'• °ТГ, " ""
ArtincialIn,elligence.Me„loPark,CalifoJrA^;i|re° ^82 * СаЛтю °"
^^n^XtinS
deKI?,rTpe,"«"f/r Td 4Uan^aUvc bowtedje of classical mechanics. Technical Report
AI-TR-352, Al Laboratory, MIT, 1975.
deKleer J. Local methods for localizing faults in electronic circuits (MIT Al Memo 394)
Cambridge, MA: MIT, 1976.
deKleer J. Choices without backtracking. Proceedings of the Fourth National Conference on
Artificial Intelligence, Austin, TX, pp. 79-84. Menlo Park, CA: AAAI Press, 1984.
deKleer J. An assumption based truth maintenance system. Artificial Intelligence, 28. 1986.
deKleer J. and Williams B.C. Diagnosing midtiple faults. Artificial Intelligence 32(1)' 92-130
1987.
deKleer J- and Williams В. С Diagnosis with beltavioral modes. Proceedings of the
International Joint Conference on Artificial Intelligence, pp. 13124-13330. Cambridge
MA: MIT Press, 1989.
Dempster A. P. A generalization ofBayesian inference. Journal of the Royal Statistical Society.
30 (Series B): 1-38, 1968.
Dennett D. C. Brainstorms: Philosophical Essaxs on Mind and Psychology. Montgomery. AL:
Bradford, 1978.
Dennett D. C. Elbow Room: The Varieties of Free Will Worth Wanting. London: Cambridge
University Press, 1984.
Dennett D. C. The Intentional Stance. Cambridge MA: MIT Press, 1987.
Dennett D. С Consciousness Explained. Boston: Little, Brown. 1991.
Dennett D. С Darwin's Dangerous Idea: Evolution and tlie Meanings of Life. New York:
Simon & Schuster, 1995.
Dietterich T. G. Learning at the knowledge level. Machine Learning, 1(3): 287-316. 1986.
Dietterich T. G. and Michalski R. S. Inductive learning of structural descriptions: Evaluation
criteria and comparative review of selected methods- Proceedings UCAI 6. 1981.
Dietterich T. G. and Michalski R. S. Leam'mg to predict sequences. In Michalski et al. (1986), 1986.
Doorenbos R , Etzioni. O. and Weld D. A scalable comparison shopping agent for the world
wide web. Proceedings of the First International Conference on Autonomous Agents
(Agents 97), pp. 39^18, 1997.
Doyle J. A truth maintenance svstem. Artificial Intelligence. 12, 1979.
Doyle J. Some theories of reasoned assumptions: An essay in rational psychology. Tech.
Report CS-83-125. Pittsburgh-. Carnegie Mellon Umverstty, 1983.
rv_ i ^ . j j i л тич Pm.-mlint"i nf the Second International Workshop on Non-
Dressier O. An extended basic ATMS. Proceedings ot me jk».i ■»* cLh™.,ii
Monotonic Reasoning, pp. 143-163. Edited by Remfrank. deKleer. Omterg and Sandew.ll.
Lecture Notes in Artificial Intelligence 346. Heidelberg: Spnnger-Verlag, I9SS.
Библиография
815
-rwfiKS S. Mind Over Machine. New York: Macmillan/The Freely ...
Dud. R О Hart P. E.. Konolige K. and Reboh R. A computer-based consuls, for „.^
exploration. SRI International. 19796.
DurfeeE H and Lesser V. Negotiating task decomposition and allocatton using panial ,
1*IS. Debuted Ar.if.cal Intelligence: Vol П. Gasser. L and Huhns. M. ed Sa„
Francisco: Moraan Kaufmann, 229-244. 1989.
Durkin I. Expert Systems: Design and Development. New York: Macmillan. 1994.
Eco. Urnberto A theory of Semiotics. Bloomington. Indiana: University of Indiana Press, 1976.
Edelman G. M. BrigluAir, Brilliant Fire: On the Matter of the Mind. New York: Basic Books, 1992.
Elrnan I. L. Bates E. A., Johnson M. A.. Karmiloff-Smith A., Parisi D. and Plnnkett K.
Rethinking Innateness: A Connectionist Perspective on Development. Cambridge, MA:
МГГ Press, 1996.
Engelmore R. and Morgan Т., ed. Blackboard Systems, London: Addison-Wesley, 1988.
Erman L. D., Hayes-Roth F„ Lesser V. and Reddy D. The HEARSA У11 speech understanding
system: Integrating knowledge to resolve uncertainty. Computing Surveys, 12(2): 213-
253,1980.
Erman L. D., London P. E. and Fickas S. F. Vie design and an example use of HEARSAY 111
In Proceedings UCAI 7, 1981.
Ernst G. W. and Newell A. GPS: A Case Study in Generality and Problem Solving. New York:
Academic Press, 1969.
Etherington D. W. and Reiter R. On inheritance hierarchies with exceptions. Proceedings
AAAI-83,pp. 104-108. 1983.
Euler L. The seven bridges of Konigsberg. In Newman (1956), 1735.
Evans T. G. A lieurisne program to solve geometric analogy problems. In Minsky (1968), 1968.
Falkenhainer B. Explanation and theory formation. In Shrager and Langley (1990), 1990.
Falkenhainer В., Forbus K. D. and Centner D. The structure mapping engine: Algorithm and
examples. Artificial Intelligence, 41(1): 1-64, 1989.
Fass D. and Wilks Y. Preference semantics with ill-fonnedness and metaphor. American
Journal of Computational Linguistics IX, pp. 178-187 1983
''Tl^U^l Пе йтиШт °fverbai W"« »«*"<■"■ ln Feigenbaum and Feldr»»»
Feigenbaum E. A. and Feldman J., ed Compiaers caul Viought. New York: McGraw-Hill. 1963.
puter Challenge to the World. Reading, MA: Addison-Wesley. 1983.
Rkes R. E. and Nilsson N. J. STRIPS: A new approach to ,h. ,- •
,0 artificial intelligence. Artificial Intelligence, 1(2) \Ш "" ™" proving
Fikes R- E., Hart P. E. and Nilsson N. J Leammo „1a
Artificial Intelligence, 3(4): 251-288, 1972 """» generalized robot plans.
Fillmore С J. The case for case. In Bach and Harms (1968), 1968
Fischer K„ Muller J. P. and Pischel M. Cooperative ,m„,!„„ ,-
domain for DAI. Applied Arfifical 1п,еШВепСе, вд'ТТ "*' "" °№"'C'"''<'"
RShe2:^tm."1^ aCqUiMm ^ 'nmmMal ">""ptual clustering. Machine Uaming,
Fisher D. H„ Pazzani M. J. and Langley P. Concept Formation: Knowledge and Experience in
Unsupervtsed Learning. San Mateo, CA: Morgan Kaufmann Publishing. 1991.
Fodor J. A. The Modularity of Mind. Cambridge, MA: МГТ Press. 1983.
Forbus K. D. and deKleer J. Focusing the ATMS. Proceedings of the Se4enth National
Conference on Artificial Intelligence, pp. 193-198. Menlo Park. CA, 1988.
Forbus K. D. and deKleer J. Building Problem Solvers. Cambridge. MA: MIT Press. 1993.
Ford К. М. and Hayes P. J. Turing Test Considered Harmful. Proceedings of International Joint
Conference on Artificial Intelligence, Montreal, 1995.
Ford K. M., Glymour C. and Hayes P. J. Android Epistemology. Cambridge: МГГ Press. 1995.
Forgy С L. RETE: a fast algorithm for the many pattern/many object pattern match problem.
Artificial Intelligence, 19(1): 17-37, 1982.
Forney G. D., Jr. 77k Viterbi Algorithm. Proceedings of the IEEE (March), pp. 268-278. 1973.
Forrest S. Emergent Computation: Self-organizing, collective, and cooperative phenomena in
natural and artificial computing networks. PhysicaD, 42: 1-11, 1990.
Forrest S. and Mitchell M. Wliat makes a problem hard for a genetic algorithm? Some
anomalous results and their explanation. Machine Learning, 13: 285-319, 1993л.
Forrest S. and Mitchell M. Relative building block fitness and the building block hypothesis. In
L.D.Whitley (1993). 19936.
Franklin S. Artificial Minds. Cambridge, MA: МГТ Press. 1995.
Freeman J. A. and Skapura D. M. Neural Networks: Algorithms. Applications and
Programming Teclmiques. New York: Addison-Wesley. 1991.
Frege G. Begriffsschnft. eine der arithmetischen nachgebildete Formelsprache des reinen
Denkens. Halle: L. Niebert, 1879.
Frege G. Die Gnmdlagcn der Arithmetic. Breslau: W. Koeber. 1S84.
Frey B. J. Graphical Models for Machine Uaming and Digital Communication. Cambridge:
MIT Press, 1998.
Gadamer H. G. Philosophical Hermeneutics. Translated by D. E. Linge. Berkeley: University
of California Press. 1976.
Gallier J. H. Logic for Computer Science: Foundations of Automatic Theorem Proving. New
York: Harper and Row, 1986. .
Ganzinger H., Meyer С and Veanes M. 77, ^«^^^^^^ГГад
Proceedings of the Annual Symposium on Logic in Computer Science, pp. -4-34. !999.
Gardner M. Mathematical Games. Scientific American (October 1970).
Библиографий
817
i г „ Scientific American (February 1971).
^■::z:!tz,:^iT^ * <-»*. *-, ofNP_
оГГг^ and Ш5Юп N. Logical — «""»**" ""^'- ^ **, CA:
Morgan Kaufmann, 1987.
Genesereth M. R. The role of plans in intelligent teachmg system: In Sleeman and Brow,
(1982), 1982.
Gennari J H, Langley P. and Rsher D. Models of incremental concept formation. Artiflcia|
Intelligence. 40(1-3): 11-62, 1989.
Gentner D. Structure-mapping: A theoretical framework for analogy. Cognitive Science, 7:
155-170, 1983.
Giarratano J. and Riley G. Expert Systems: Principles and Programming. PWS-Kent
Publishing Co, 1989.
Gilbert С D. Plasticity in visula perception and physiology. In Squire and Kosslyn (1998), 1998.
Gilbert С D. Horizontal integration and conical dynamics. Neuron, 9: 1-13, 1992.
Ginsburg M. ed. Readings in Nonmonotonic Reasoning. San Francisco: Morgan Kaufrnann, 1987.
Glasgow В., Mandell A., Binney D., Gherari L. and Fisher D. MITA: An information extraction
approach to analysis of free-form text in life insurance applications. Proceedings of the
Ninth Conference oflnnovative Applications of Artificial Intelligence, pp. 992-999,1997.
Gluck M. and Corter J. Infonnalion, uncertainty and the utility of categories. Seventh Annual
Conference of the Cognitive Science Society in Irvine, Calif, 1985,
Glymour C, Ford K. and Hayes P. The Prehistory of Android Epistemology. In Glymour et al.
(19956), 19950.
Glymour C, Ford K. and Hayes P. Android Epistemology. Menlo Park, CA: AAAI Press, 19956.
Glymour С and Cooper G. F. Computation. Causation and Discovery. Cambridge: МГТ Press, 1999.
Goldberg A. and Robson D. Smalltalk 80: Vie Language and Its Implementation. Reading,
MA: Addison-Wesley, 1983.
Goldberg D E. Generic Algorithms in Search. Optimization and Machine Learning. Reading,
MA: Addison-Wesley, 1989.
Goldstine H. Я The Computer from Pascal to Von Neumann. Princeton. NJ: Princeton
University Press, 1972.
Goodman N. Fact. Fiction and Forecast, 4th ed. Cambridge, MA: Harvand University Press, 1954.
doping ип^^Гз^ ?982mPUter 8С!еПСе and lnf0m,ati°n '
Could SJ. Full House: The Spread of Excels from Plato to Danvin. NY: Harmony Bo*
818
БивпИОГраФ""
Graham P. On LISP: Advanced Techniques for Common I IIP с ,
Hall. 1993. ' common LISP. Englewood Cliffs. NJ: Prentice
Graham P. ANSI Common Lisp. Englewood Cliffs, NJ: Prentice Hall 1995
Grice H. P. Logic and conversation. In Cole and Morgan (1975), 1975
Grossberg S. Adaptive pattern classification and universal record;,,, I p ,„,, , л ,
Grossberg S. Studies of Mind and Brain: Neural Principles of Leamin, Perception
Development. Cogmtwn and Motor Control. Boston: Reidel Press. 1982 P""PU°"'
Grossberg S„ ed. Neural Nenvorks and Natural Imelligence. Cambridge, MA: MIT Press 1988
Grosz B. The representation and use of focus in dialogue understanding. PhD thesis.
University of California, Berkeley, 1977.
Grosz B. and Sidner С L. Plans for discourse. Intentions in Communications, Cohen P. R and
Pollack M. E. ed., pp. 417-444. Cambridge, MA: MIT Press, 1990.
Hall R. P. Computational approaches to analogical reasoning: A comparative analvsis 19(1)'
39-120, 1989. '*
Hammond K„ ed. Case Based Reasoning Works/юр. San Mateo, CA: Morgan Kaufmann. 1989.
Hamscher W., Console L. and deKleer J. Readings in Model-based Diagnosis. San Mateo:
Morgan Kaufmann, 1992.
Hanson J. E. and Crutchfield J. P. 1992. The Attractor-basin portrait of a cellular automaton.
Journal of Statistical Physics, 66(5/6): 1415-1462.
Harmon P. and King D. Expert Systems: Artificial Imelligence in Business. New York: Wiley, 1985.
Harmon P., Maus, R. and Morrissey W. Expert Svstems: Tools and Applications- New York:
Wiley, 1988.
Harris M. D. Introduction to Natural Language Processing. Englewood Cliffs NJ: Prentice
Hall, 1985.
Hasemer T. and Domingue I. Common LISP Programming for Artificial Intelligence. Reading,
MA: Addison-Wesley. 1989.
Haugeland J., ed. Mind Design: Philosophy, Psychology, Artificial Intelligence. Cambridge,
MA: MIT Press, 1981.
Haugeland J. Artificial Intelligence: tlie Very Idea. Cambridge/Bradford, MA: MIT Press, 1985.
Haugeland J., ed. Mind Design: Philosophy, Psychology, Artificial Intelligence, 2nd ed.
Cambridge, MA: МГТ Press, 1997.
Haussler D. Quantifying inductive bias: Al learning algorithms and Valiants learning
framework. Artificial Intelligence, 36:177-222, 1988.
Hayes P. J. Some problems and non-problems in representation theory. Proc. AISB Summer
Conference pp. 63-69, University of Sussex, 1974.
Hayes P. J. ft, defense of logic. Proceedings IJCAI-77, pp. 559-564, Cambndge. MA, 1977.
Hayes P. J. The logic of frames. In Metzing (1979). 1979.
Hayes-Roth B. Agents on stage: Advancing the state ^"'^'^МЛШ
Fourteenth International Joint Conference on Aruficial Imell,Se,«. Cambndge.
Press, 967-971, 1995.
Библиография
819
myJZ, and -^ъгжг' ,edmquefor**- -^
Communications of ше ли». ».
Hayes-Roth F„ Waterman D. and Una, D. Building Expert Systetns. Reading. MA; Addis^
Wesley 1984.
Hebb D О The Organimion of Bettor. New York: Wiley, 1949.
Hecht-Nielsen R. Neural analog processing. Pnx. SPIE. 360, pp. 180-189. Bel„ngham, ^
Hecht-Nielsen R. &U^"W^» »^*. Applied Opucs, 26: 4979-^984 (December 1987)'
Hecht-Nielsen R Theory of the backpropagation neural network. Proceedings of .,
"Гопа, Join. Conference on Neural Networks, I, pp. 593-611. New York: ffiE^
Press, 1989.
Hecht-Nielsen R. Neurocomputing. New York; Addison-Wesley, 1990.
Heidegger M. Being and Time. Translated by J. Masquarrie and E. Robinson. New York'
Harper & Row, 1962.
Heidorn G. E Augmented phrase structure grammar. In Schank and Nash-Webber (1975), 1975.
Helman P. and Veroff R. Intermediate Problem Solving and Data Structures: Walls and
Mirrors, Menlo Park, CA: Benjamin/Cummings, 1986.
Hempel C. G. Aspects of Scientific Explanation. New York: The Free Press, 1965.
Henderson Peter. Functional programming: Application and Implementation. Englewood
Cliffs, NJ; Prentice-Hall, 1980.
Hightower R. The Devore universal computer constructor. Presentation at the Third Workshop
on Artificial Life, Santa Fe. NM, 1992.
Hill P. A. and Lloyd J. W. 77i£ Goedel Progratnming Language. Cambridge, MA: MIT Press, 1994,
Hillis D. W. 77ie Connection Machine. Cambridge, MA: MIT Press, 1985.
Hinsley D., Hayes J. and Simon H. From words to equations: Meaning and representation in
algebra word problems. In Carpenter and Just (1977), 1977.
Hinton G. E. and Sejnowski T. J. Learning and relearning in Boltvnatm machines. In
McClelland et al. (1986), 1986.
Hinton G. E. and Sejnowski T. J. Neural network architectures for Al. Tutorial, AAAI
Conference, 1987.
Hirschfeld L. A. and Gelman S. A., ed. Mapping the Mind: Domain Specificity in Cognition
and Culture. Cambridge: Cambridge University Press, 1994.
H°bbL'!'R",™d M0°re RC- Fonnal Tories of the Commonsense World. Norwood, NJ:
Ablex, 1985.
Hodges A. Alan Turing: The Enigma. New York: Simon and Schuster, 1983.
Ho stadter D. Fluid Concepts and Creative Analogies, New York: Basic Books, 1995.
Ho and J. H. Adaptation in Natural and Artificial Systems. University of Michigan Press, 1975.
ltomL!:t™f: SP°'"a"T emerge"Ce ofself-rcplicating systems using «»»'»'
МЬпн Г a"df0nml^m^- Ь Lindenmayer and Rozenberg (1976), 1976.
^"«:^tr The ^^ **«««* ™°«'«"»<•« *r,*B
P <№( rule-based systems. In Michalski et al. (1986), 1986.
БиблиограФ1*'
Holland J. H. Hidden Order: How Adaptation Build, r„ ,
Wesley, 1995. P "" №"№ Complexity. Reading, MA: Addison-
Holland J.H.. Holyoak K.J, Nisbett R. E. and Thanard P p , ., .
Inference. Learning and Discovery. Cambridge, MA^lIT Press «8б"°"'' "" "'
Holowczak R. D. and Adam N. R. Information extracion-ha^ „ ,. •
classification for the global leeal mfnm„, multiple-category document
ConferenceonlnnovativeAp li aion rfZn'cTa.wTr" ^^^ °f *» ^
ft""""4b 01 Artiticial Intelligence, pp. 1013-1018, 1997.
Holyoak K. J. The pragmatics of analogical transfer The P™-hnl„,,„ f i - a
Motivation, 19: 59-87, 1985. Psychology of Learning and
Hopcroft IE and Unman J. p. introduction ,0 Automata Theory, Languages and
Computation. Rending, MA: Addison-Wesley, 1979. X""5" ""«
Hopfield J. J. Neural networks and physical systems whh emergen, collective computational
abilities. Proceedings of the National Academy of Sciences 79, 1982.
Hopfield J. J. Neural networks and physical systems with emergent collective computational
abilities. Proceedings of the National Academy of Sciences, 79: 2554-2558. 1984.
Horowitz E. and Sahni S. Fundamentals of Computer Algorithms. Rockville MJ> Computer
Science Press, 1978.
Hume D. An Inquiry Concerning Human Understanding. New York: Bobbs-Merrill, 1748.
Husserl E. The Crisis of European Sciences and Transcendental Phenomenology. Translated
by D. Carr. Evanston, IL: Northwestern University Press, 1970.
Husserl E. Ideas: General Introduction to Pure Phenomenology. New York: Collier, 1972.
Ignizio J. P. Introduction to Expert Systems: The Development and Implementation of Rule-
Based Expert Systems. New York: McGraw-Hill, 1991.
Ivry I. B. The representation of temporal information in perception and motor control. In
Squire and Kosslyn (1998), 1998.
Jackson P. Introduction to Expert Systems. Reading, MA: Addison-Wesley, 1986.
Jeannerod M. The Cognitive Neuroscience of Action. Oxford. Blackwell, 1997.
Jennings N. R. Controlling cooperative problem solving in industrial multi-agent systems using
joint intentions. Artificial Intelligence, 75: 195-240, 1995.
Jennings N.R and Wooldridge M. Agent Technology: Foundations, Applications, and
Markets. Jennings N. R. and Wooldridge M. ed. Berlin: Springer-Verlag, 1998.
Jennings N.R., Sycara K. P. and Wooldndge M. A roadnmp for agent researcl, and
development. Journal of Autonomous Agents and MultiAgent Systems. 1 (1): 7-36, 1998.
Johnson L. and Keravnou E. T. Expert Systems Technology: A Guide. Cambridge, MA: Abacus
Press, 1985.
Johnson M. The Body in the Mind: The Bodily Basis of Meaning. Imagination and Reason.
Chicago: University of Chicago Press, 1987.
Johnson W.L. and Soloway E. Proiur. B)te (April), 1985.
Johnson-Laird P. Mental Models. Cambridge, MA: Harvard University^. 19
Johnson-Laird P. N. The Conner and,,. Mind. Cambndge. MA Harvard Uni^ity Pre- .988.
Jordan M. (ed.) Learning in Graphical Mode.s. Boston: K.uwer Academ.c, 1999.
Библиография
821
сп d ibduclive Inference: Compulation, Philoso»!.
JZZZZ?*.*. *- -—'—Up- s^ «-, *
J^ZZs Crttiaue of Pure ~ — N-K. transU.or. New ^ si
Martin's Press. 17S1/I964.
blsri* A. 8^«"'^ * Л™**—'»' *»Ч>«™ ™ CoSni,i» Scince
Cambridge. MA: МГГ Press, 1992.
bto M. Mano.ios P. and Mo». JLS- l«d.> Computer-A.ded Reasonmg: ACa ^
Studies Boston: Klu»er Academic. 20UU.
Kautz H Se.ma„ B. and Shah M. The hidden web. AI Magazine 18(2): 27-35. 1997.
Kedar-CabelliST. Analogy-From a unified perspective An Шты'тЯ), 1988.
Kedar-Cabelli S T and McCam L T. Explanation based generalization as resolution theon*,
proving. Proceedings of the Fourth International Workshop on Machine Learning, 1987.
Keravnou E. T. and Johnson L Competent Expert Systems: A Case Smdy in Fault Diagnosis.
London: Kegan Paul. 1986.
King S. H. Knowledge Systems Through PROLOG. Oxford: Oxford University Press, 1991.
Klahr D.. Langley P. and Neches R.. ed. Production System Models of Learning and
Development. Cambridge. MA; MIT Press, 1987.
Klahr D. and Waterman D. A. Expert Systems: Techniques. Tools and Applications. Reading,
MA: Addison-Wesley. 1986.
Kfem W. B- Westenelt R. T. and Luger G. F. A general purpose intelligent control system for
panicle accelerators. Journal of intelligent & Fuzzy Systems. New York: John Wiley, 1999.
Klein W. В.. Stem С R.. Luger G. F. and Pless D. Teleo-reactive control for accelerator
beamline tuning. .Artificial Intelligence and Soft Computing: Proceedings of the LASTED
Internationa! Conference. Anaheim: LASTED/ACT A Press. 2000.
Kodratoff Y. and Michalski R. S.. ed. Machine Learning: An Artificial Intelligence Approach.
Vol. 3. Los Altos, CA: Morgan Kaufmann. 1990.
Kohonen T. Correlation matrix memories, IEEE Transactions Computers. 4: 353-359,1972.
KobonenT. Self-Organization and Associative Memory. Berlin: Springer-Verlag. 1984.
Roller D. and Pfeffer A. Object-oriented Bayesian networks. Proceeding of the ТЫпееШп
Annual Conference on Uncertainty in Artificial Intelligence San Francisco: Morgan
Kautmann, 1997.
Koller D./^Pfeffer A Probabilistic frame-based systems. Proceeding of the Fifteenth An»!
Conference on Uncertainty m Artificial Intelligence. San Francisco: Motgan Kaufmann. IW
^^L v N' ?° "* """«nation 0f continuous functions of manv variables by
2ЖЖЙ1.0("" ***** аЫ addil,on <m Russ,an)'
m°rZjat^'^"l РСШ'П SO,r" «-Pabilities through case based и*™**
SSSTiw** *""* Ыатао^ W-bhop on Machine Leanung. CA: №*•
fo'1fle С^Ва^Г/еГ'еШ1УГ " «" m™°": A P°">'M indentation. Pn****
R№onmS W«fahop. Los Altos, CA: Morgan Kaufmann. 19SS-.
БиблистИ»*
Kolodner J. L-. ed. Сше Based Reasoning Works/юр. San Mateo Гл u „ *_
C0l0dner J.L. improving Hutnan decision malg ,h^h ""^T^ ^
Magazine. 12(2): 52-68. 1991. S mrouSh case-based decision aidmg. Al
Kolodner J. L. Ca^ed Reasoning. San Mateo. CA: Morgan Kaufmanr, 1993
Korf R- E- Search. In Shapiro (19876). 1987.
Korf R. E. Artificial intelligence search algorithms In CRC H„v«™i, „r «, ■ u
Theory of Computation, Ml. Atallah, L Boca в£„ a- SS^. m^
^No^S-nT^ PKd" ^ **"'' ^ m " ™™h- ^ b«ffif« Systems.
Kosk°8B4^™8a' a"°Cia'^ mem°™ IEEE Transactions Systtms. Man & Cybernetics.
Kosoresow A. P. A fast-first cut protocol for agent coordination. Proceeding of the Eleven*
National Conference on Artificial Intelligence, pp. 237-242, Cambridge. MA: МП Press. 1993.
Kolon P. Reasoning about e\-idence in causal explanation. Proceedings of AAAI-8S
Cambridge. MA: AAAI Press/МГТ Press. 1988a.
Koton P. Integrating case-based and causal reasoning. Proceedings of me Tenth Annual
Conference of the Cognitive Science Society. Nonhdale. NJ: Erlbaum. 1988(5.
Kowalski R. Algorithm = Logic + Control. Communications of the ACM. 22:424-436.1979a.
KowalskiR- Logic for Problem Salving. Amsterdam; North-Holland. 19796.
Koza J. R. Generic evolution and co-evolution of 'computerprograms. InLangton et aL (1991), 1991.
Koza J. R. Genetic Programming: On the Programming of Computers by Means of Natural
Selection. Cambridge, KLA: MJT Press, 1992.
Koza J. R. Genetic Programming 11: Automatic Discovery of Reusable Programs. Cambridge.
MA: MIT Press. 1994.
Krulwich B. The BarginFinder agent: Comparison price shopping an the internet. Berts, and
other Internet Beasties. Williams, J- ed. 257-263. Indianapolis; MacmiUan. 19%.
Kuhl P. K. Innate predispositions and the effects of experience in speech perception: The
native language magna theory. Developmental Neurccogmrion Speech and Face
Processing in the First Year of Life. Boysson-Bardies В.. de Schonen S-. Jusczvk P..
McNeilage P. and Morton J. ed. pp. 259-274. Naherlands: Kluwer Academic 1993.
Kuhl P. K. Learning and representation in speech and language. In Squire and Kosslyn
(1998). 1998.
Kuhn T. S. Пе Structure of Scientific Revolutions. Chicago; University of Chicago Press. 1962.
Laird J.. Rosenbloom P. and Newll A Chunking in SOAR: Пе Anmomy of a Caw»/
Learning Mechanism. Machine Learning 1 (1). 1986a.
Laird J„ Rosenbloom P. and Ne»ell A. Vnhersa! Subgoaling and Oun^g: Пе auttmatic
Generation and Learning of Goal Hierarchies Dordrecht: Khmer. 19866.
Lalcoff G. Women. Fire and Dangerous Things. Chicago. University of Chicago Press. 1987.
Lakoff G. and Johnson M. Philosophy in the nesh. Ne* York: Basic Books. 1999.
Lakatos I. Proofs and Refutations: The Logic of МаЛешЛЫ Dixovef?. Carnbcdee
University Press. 1976.
Langley P. Elements ofMachtne Learning. San France Могил Kautmann. 199.-..
" ~^
Библиография
■е^ц
j u г J and Simon H. A. Bacon 5: The discover, of con,
Ungley F- Bradsh™ Seventh International Joint Conference on Artificial 1т1"Щ"
«so^Seve ^ j м ^.^ ^^4,
, , i Simon H A. and Bradshaw G. L. The search for r„0 ,
**£$Z& %Z£ - M*lski - al-(1986)'1986-
Lang.onC G. Studying artificial life with cellular automata. Physica D, 120-149, 1986
И» C.G. Л^сш/ i/jfc to» Й,/«/««« Wle Й. the Sciences of Coinpk
Reading, MA Addison-Wesley, 1989. * VI.
Langton С. С^И'и» «' "« «*< °fchaos: Fh"Se "•'"«"""« «'"' «»erse„,
Physica D., 42: 12-37,1990.
Langton С G. Artificial Ufe: An Overview. Cambridge, MA: MIT Press, 1995.
Langton С G, Taylor С Farmer J. D. and Rasmussen S. Artificial Life 11, SF1 Studies in л
Sciences of Complexity. Vol. 10. Reading, MA: Addison-Wesley, 1992. ""
Larkin J. H., McDermott J., Simon D. P. and Simon H. A. Models of competence in sok4
physics problems. Cognitive Science, 4, 1980.
Laskey K. and Mahoney S. Network fragments: Representing knowledge for constructing
probabilistic models. Proceedings of the Thirteenth Annual Conference on Uncertainty in
Artificial Intelligence. San Francisco: Morgan Kaufmann, 1997.
Lauritzen S. L. and Spiegelhalter D. J. Local computations with probabilities on graphical
structures and their application to expert systems. Journal of the Royal Statistical Society
В 50(2); 157-224, 1988.
Lave J. Cognition in Practice. Cambridge: Cambridge University Press, 1988.
Leake D. B. Constructing Explanations: A Content Theory. Northdale, NJ: Erlbaum, 1992.
Leake D. В., ed. Case-based Reasoning: Experiences, Lessons and Future Directions. Menlo
Park: AAAI Press, 1996.
Leibniz G. W. Philosophische Schriften. Berlin, 1887.
Lenat D. B. On automated scientific theory formation: a case study using the AM program.
Machine Intelligence. 9: 251-256, 1977.
Lenat D. В AM: an artificial intelligence approach to discovery in mathematics as heuristic
search. In Davis and Lenat (1982), 1982.
^"мю EimSK°: A Pmmm """ 'ear"s "ew '«'"•""'«• Artificial Intelligence, 21(1,2):
Una23№B'l98n4dBmWn JS- МУ Ш Ш Eurisk° °PP™r >° ™rk- Ar,ificial 1П,еШ8еПЛ
^^isiwi^ov- B""di"g urse Kiumkd"w **""•Read,n8, MA:
Len™„ J. d M Салпеу р Ыу Raccoon The ww(e д1ьит RecordS] ig68
bTv^Ie hTJ ' °- D' ^ "ШЬШЫ ***' '"* testbed. AI Magazine, 4(3). 1»
Intelligence^T'wsf " f""C,it"m> "PProach to knowledge representation
ificial
Levesque, H. J. A knowledge level account of ahd, r n
International Joint Conference on Artificial ImHli„. p«*eedmgS „f ше Eleventh
Morgan Kaufmann, 1989. Intelligence, pp. 1051-1067. San Mateo, CA:
Levesque H. J. and Brachman R. J. A fundamental tradeoff in b, tJ
reasoning (revised version). In Brachman and Levesque "m5)llts TepK5m""io" md
Lewis J. A. and Luger G. F. A constructivist model of rohm „ ' ' ,
Proceedings of the Twenty Second Annual Conference' UbrT"-'"'f *"™"ce' ln
Hillsdale, NJ: Erlbaum, 2000. ^-onterence of the Cognitive Science Society.
Lieberman H. Laizia: An agent that assists web browsim PmrmW „f ,., с
Internationa, Join, Conference on Artificial M^'^^S
Lifschitz V. Some Results on Circumscription. AAAI 1984, 1984
Lifschitz V. Pointwise Circumscription: Preliminary Report. Proceedings of the Fifrh National
Conference on Artificial Intelligence, pp. 406-110. Menlo Park, С A: AAAI Press, 1986.
Linde С Information structures in discourse. PhD thesis, Columbia University, 1974.
Lindenmayer A. and Rosenberg G.. ed. Automata, Languages, Development New York
North-Holland, 1976.
Lindsay R. K., Buchanan B. G, Feigenbaum E. A and Lederberg J. Applications of artificial
intelligence for organic chemistry: the DENDRAL project. New York: McGraw-Hill, 1980.
Ljunberg M. and Lucas A. The OASIS air traffic management system. Proceedings of the
Second Pacific Rim International Conference on AI (PRICAI-92), 1992.
Lloyd J. W. Foundations of Logic Programming. New York: Springer-Verlag, 1984.
Lovelace A. Notes upon LF. Menabrea 's sketch of the Analytical Engine invented by Charles
Babbage. In Morrison and Morrison (1961), 1961.
Loveland D. W. Automated Tlieorem Proving: a Logical Basis. New York: North-Holland. 1978.
Lucas R. Mastering PROLOG. London: UCL Press, 1996.
Luck S. J. Cognitive and neural mechanisms in visual search. In Squire and Kosslyn (1998). 1998.
Luger G. F. Formal analysis of problem solving behavior in Cognitive Psychology: Learning
and Problem Solving, Milton Keynes: Open University Press. 1978.
Luger G. F. Mathematical model building in the solution of mechanics problems: human
protocols and the MECHO trace. Cognitive Science, 5: 55-77, 1981.
Luger G. F. Cognitive Science: The Science of Intelligent Systems. San Diego and New York:
Academic Press. 1994.
Luger G. F. Computation <t Intelligence: Collected Readings. CA: AAAI Press/МГГ Press. 1995.
Luger G.F. and Bauer M. A. Transfer effects in isomorphic problem solvmg. Acta
Psychologia, 42, 1978. ... ,
Luger G. F, Wishar, J. G. and Bower T. G. R. Modelling the stages of.he tdentuy theory of
object-concept development in infancy. Perception, 13: 9/-113. i»t.
Machtey M. and Young P. An Introduction to the Genera, Theory of Algortduns. Amsterdam.
North-Holland. 1979.
MacUnnan B. J. ' Principles of Programnung ^uages: Design.
Implement- '"^ New York: Holt, Rmehar. & Winston, 1987.
Библиография
Evaluation, and
Implementation, 2nd ed. New York: t
825
Лв**,'"П^*М«-^ О-nbndg*. MA: MIT Pre». 1990.
-"''"' ,,__~t.„StatisticalPattern Recognition. PhD dissertancn ь_
ybta I ЯЮЮС- .4 Reumomd ^-*-в« -"' to ^Я*^*»" Eogfcuood СШЬ.эд.
Ри«вНЛ19Г
Чаан Z and Waldmger R- 7ir ioji:^ Basil for Computer Programming. Raamg, ^
Adasca-WesJey- 19S5-
Vfma, Z and Pno* A. 7ir Гламяв* big* °f Чеасте and Concurrem Spkm
Spec^caam. BoSa: Spriager-Verlag. 1992.
-• Ц,- c.D.«i Scnaae H. Foundations of Suaistical Natural Language Pmceamg.
Oamndge. MA: MIT Press. 1999.
Мжак М. A Лада? of Syntactic Recognition far Natural Language. Cambridge. MA: Iflr
Press. 198a
Maim А. AntorT^ia>arnla& National Academy of Sciences, USSR. 1954
Mxsfcal I. B. ilemcac A Seff-Waching Cognitive Architecture for Analogy-Mating mi
High-Levet Perception. PhD dissertation. Department of Computer Science. nana
lirvo». 1999.
Mn А. Cammummmol Learning Theory: An Introduction. Carnbridge: Сгшвпвш-
Сшая)№£. 1997.
^xmsi. The trmm. the mmnemait, and nothing but the truth: an indexed bibtiognamy to me
laermmre on от* mamtcnancc systems- Ai Magazine, 11(5): 7-25. 1990.
Mania» J. А ягшашге far episumic suues. New Directions for mteJliger* Tutoring Syaans
Gee. е&ХАТОАЯ Series F. Heidelberg: Springer- Veriag. 1991.
Mann» I. P. The* Maintenance Systems. In Shapiro S.C. ed- (1992). 1992-
il. and Skapro Я С Reasoumg m multiple belief spaces. Proceedings of *e tan*
DCA1 San Мает. CA: Morgan Kaufman. 1983.
M*^'** 2* Ьааашк- «Knagr daemon #r люсяюг translation, using laenmna
w«Z!^ baenukmal Conference on Machine Translation. 1961-
^D.uto^^Mi„^(];]iniMIIAlljbMclM4j3il!a
Coafe^'r0"*4''^ "* "»■*»■*- Proceedings of the T«lfrh ACM »"*
v-^*b7ZZ*T*m'"°ai La"*41ЪМУ COLT"-1999
^niin.1 'А*"**» of symbolic expressions and their computation by ■***
jfcc^TT^ 4)- ,96°
McCarthy I Л™"'T*camm""* Ь Minsk, (1968). pp. 403-418. 1968
iZ-lbZ^F*0" РПЫа" а '"Я*" oaell.gence. Proceedings UCA!-*- *
деСагшу J. Сптатесгфпоя — A farm of ш
13.1980.
ifcCarrby J- Applications of Oramncnpmm к Formmbjnt *■ с ,—j-j_
Artificial Inieffigence. 28: 89-116.198fc ™°« &-« S» и»нф.
irfcCannyJ andHayesPJ. Si» рВвдЩ ,„а. ^_ ^ . . .. . ,
intelligence. In Meltzer and Midne (1969X1969. * **n*am
processing. 2 vols. Cambridge. MA: МП Press. 1986. ^^ i—™—»
jfcCord M ^Daign of a PROLOG based maemme ттЛшит хаем. IWedmgsofme
Third глкпвгюпа! Logic Programming Conference. bsadoa. 1986.
McCulkx± W. S. and Phis W. A logical cakmlus of me idem i n i _ т., uemmy.
Bulletin of Mathematical Biophysics. 5:115-133.1943.
McDennoa D. Ло»^ and ocia«. Cbgaitiye Scene 2.71-10». 1978.
MeDermoo D. and Doyle 1. №ншпк logic I. Artificial tateKgeace. 13:14-72.19Я0.
McDermott I- Rl. The formative years. AI Magazine (яаашег 198Ц. 1981,
McDermotlJ-K/- А пае based configurer of compmersysems- Агш1сЫ aaeKgeax. 19.1982.
McDennotI J. aid Bacbaot J. Rl rensmed: Four years «I the trenches. AI Ma^ziBe. S3). 1984.
McGooigle B- Incrementing mteUigem systems by design. Proceediags of the Hrs:
Intematioml Conference on Smadarioa of Adaptive 8eh»ior ISAB-901.199a
McGooigle B. Autonomy m the irakmg: Getting robots to control themsehes. 1
Symposium on Autooomons Agents. Oxford: Oxford University Press. 1998.
McGra» K. L and HartHSOE-Brigs K. Knowledge AcquitiUm- Prmc&es and
Engiewod aifb. NJ: Ргеппсе-НаЛ. 1989.
Mead С Analog \ISI and Seural Systems. Reading. MA: .VirSsoo-Westey. 1989.
Mekzer В. зп& Midne D. Machine buemgence 4. Edmbargh: EdM»a^ Uiaveriiy Press. 1969-
Merleairfonn \L Phenomenology <jPmcptum-Utodoa: Rondedge4 KeganPad. 1962-
Memng D. ed. Frame Conceptions and Text Undersumdmg. ВегИп; Wiber i Grujaer aa^
Co. 1979.
Meyer J. A- and Wilson S- W. ed. From wdmats to mrimaa. Proceedings of the H^
Iraemaoonal Conference on Simolation of .Adaptive ВеЬагюг. Cambridge. MA: M..
Pres&Bradford Books. 1991.
MichaUb R S. CarboneU J-G. and Mhchefl T-M. ed. machine lemrnng An An^d:
IntelligenceAppraach.X<*. 1 Prio Aho.CVTioga. 1983
MichaUki R-S, CarboneU J. G- and МясвеП T.M. ed. ""
Intelligence Approach. Vol- 2 Los Alios. CA: Morgan Г
Michalski R. S and Stepp R-E. Learning from
Michalskieta! П983). 1983.
Mrch^ D- Tnol and error.Science Survey. P»t 2 Barnen S.A and McCtaren -V. ed- 129-
M5.Harmnor<lsv«»mlJK;Peiignm.l961. _^^^_ „. v^ ,<гх)
ir . j .^_ j-_^tK Fc«*ersfc Edaton* Iti^ Press. 19 4.
Miehie D_ ed. bperi Systems m me Mkro-eltcmmc Age. anmn.^
бибяиографмя
827
MWK Tofte M and Harper R. Definition of Standard ML. Cambridge. MA: MIT Press, 1990.
MNnerR andTofteM. Commentary on Standard ML. Cambndge. MA: МГГ Press, 1991.
MinskyM ed. &»»«*/»(Ь™«*" Processing. Cambridge, MA: MIT Press, 1968.
Minsky M A framework for representing knowledge. In Brachman and Levesque (1985), 1975.
Minsk? M in Psychology of Computer Vision by P. Winston. McGraw-Hill, 1975*.
Minsky M. The Society of Mind, New York: Simon and Schuster, 1985.
Minsky M. and Papert S. Perceptrons: An Introduction to Computational Geometry.
Cambridge, MA: MIT Press, 1969.
Minton S. Learning Search Control Knowledge. Dordrecht: Kiuwer Academic Publishers, 1988.
Mitchell M. Analogy-Making as Perception. Cambridge, МАЦ MIT Press, 1993.
Mitchell M. An Introduction to Genetic Algorithms. Cambridge, MA: The MIT Press, 1996.
Mitchell M„ Crulchfield J. and Das R. Evolving cellular automata with genetic algorithms: A
review of recent work. Proceedings of the First International Conference on Evolutionary
Computation and Its Applications. Moscow, Russia: Russian Academy of Sciences, 1996.
Mitchell Т. М. Version spaces: an approach to concept learning. Report No. STAN-CS-78-
711, Computer Science Dept., Stanford University, 1978.
Mitchell Т. М. An analysis of generalization as a search problem. Proceedings IJCAI, 6, 1979.
Mitchell T. M. 77te need for biases in learning generalizations. Technical Report CBM-TR-
177. Department of Computer Science, Rutgers University, New Brunswick, NJ, 1980.
Mitchell Т. М. Generalization as search. Artificial Intelligence, 18(2): 203-226, 1982.
Mitchell T. M. Machine Learning. New York: McGraw Hill, 1997.
Mitchell T. M., Utgoff P. E. and Banarji R. Learning by experimentation: Acquiring and
refining problem solving heuristics. In Michalski, Carbonell, and Mitchell (1983), 1983.
Mitchell T. M., Keller R. M. and Kedar-Cabelli S. T. Explanation-based generalization: A
unifying view. Machine Learning, 1(1): 47-80, 1986.
Mithen S. The Prehistory of the Mind. London: Thames & Hudson, 1996.
Mockler R. J. and Dologite D. G. An Introduction to Expert Systems, New York: Macmillan, 1992.
Moore 0. K. and Anderson S. B. Modem logic and tasks for experiments on problem solving
behavior. Journal of Psychology, 38: 151-160, 1954.
M°°LRceedin"rAAAI-82,'w8V" ^^ represen""io" and commonsense reasoning.
МО°75К94С198Г"Са' COmidemti°ns °" nonmonotonic logic. Artificial Intelligence, 25(1):
М0'^Л^;Гт1°- A'«-"-A- P <o NP, vol 1. Redwood City, CA:
Morns» P. and Morrison E., ed. Charles Babbage and His Calculating Machines. NY: Do*-
Mosiow D. J Machine t f r
Michalski «^.(«бзПдда''''1'''0" °f advke '""> « heuristic search procedure. И
828
Библиография
MUC-5, Proceedings of the Fifth Messag, „„,
^„fmann. 1994 essa» "nder. ....... .u„ICrence
- SVXlPm f~_ n„„. _ _
'• Artificial Intelligence,
Kaufmann, 1994. ge ""^standing Confa
Mycroft A. and O' Keefe R. A. A polymorphic „„
23:295-307,1984. ^^Wem for Prolog.
™«, San Francisco: Morgan
Mylopoulos J. and Levesque H. J. An overview „l t ,
d"84^ 1984- " *•""•H* Mentation n Br* M a.
Nadathur G. and Tong G. Realizing modularity ,'„ /
Logic Programming, 9, Cambridge, MA: MIT Pre" 1999°'°S' Ьш,а1 0f Functioml ™1
Nagel E. and Newman ]. R. GodeVs Proof. New York- New Y„ t „ ■
Nahm U.Y. and Mooney R.I. A JL^^^?™*>*»-™-
tZ£ рТ^Гт& °( ^ ^ " ^ fc
Neches R., Langley P. and Klahr D. Learnine develnm,.», „ j j
et al. (1987). 1987. development and production systems. In Klahr
Negoita С Expert Systems and Fuzzy Systems. Menlo Part CA: Benjaimr^rnmirrc 1985
Neves J. С F. M, Luger G. F. and Carvalho J. M. A formalism for vie«s in a log* data base
In Proceedings of the ACM Computer Science Conference. Cincinnati, OH. 1986.
Newell A. Physical symbol systems. In Norman (1981), 1981.
Newell A. The knowledge level. Artificial Intelligence, 18(1): 87-127,1982.
Newell A. Unified Theories of Cognition. Cambridge, MA: Harvard University Press. 1990.
Newell A., Rosenbloom P. S. and Laird J. E. Symbolic architectures for cognition. In Posner
(1989), 1989.
Newell A.. Shaw J. С and Simon HA. Elements of a theory of human problem solving.
Psychological Review. 65: 151-166, 1958.
Newell A and Simon H. 77ie logic theory machine. Ш Transactions of Information Theory. 2:
61-79, 1956.
Newell A. and Simon H. GPS: a program that simulates human thought. Lemende Automalen.
H. Billing ed. pp. 109-124. Munich: R. Oldenbourg KG, 1961.
Newell A. and Simon H. Empirical explorations with theUgic Theory Machine: a casesnuly
in heuristics. In Feigenbaum and Feldman (1963). 1963a.
Newel, A and Simon H GPS: a program tha, simulates human though,. In Feigenbaam and
Feldman (1963), 19636. ш Pmm'nr Hill W-
Newell A. and Simon H. Human Problem Solving.ВД**-.OA« ^
Newell A. and Simon H. Computer science as empfcal mauiry. symbols
Communications of the ACM, 19(3). Ш— ^ ^^ 1956.
Newman J. R. The World of Mathematics. W tv ■ Explanation. Proceedings
Ng H. T. and Moonev R. J. On the Role ^^ pp. W Menlo Park.
of the Eighth National Conference on Aruhca.
CA: AAAI Press/MIT Press, 1990. j()/,.,„,. W „e evohmon of
Nil H. P. Blackboard systems: The blackboard<mod^
blackboard architectures. AI Magazine, /(.I.
829
Библиография
PW*"*-™*™* New York McGnm-НШ, 1965.
N J Learning Machines- r*ew it**--
*tH ч J л*- ли **»* * Ля*!ов' /""*«e""-New York Мссь»-щ, 1И
^ N J л*** **«#w """*"■"■ Ра'° А"°-СА: Т|'°8а-198°
«, м N J Tdeo-Reacttve f'°Sr°™ f°r Ag"" СоП'Го1 J°Umal °f Artfaal ImehW
Search. ЫЭ9-158. 1994. ***
NUs» N. J- «(Ml Intelligence: A New Syndesis. San Francisco: Morgan Kaufmarm, щ
№<ЫЬе Y Kuwabara K-. Suda T. and Ishida T. Distributed channel allocation j, _,
• даА. Proceedings of the IEEE Globecom Conference. 12.2.1-12.2.7. 1993.
Nordbausen B. and Langley P An integrated approach to empirical discovery. In Shrage a]
Langley (1990), 1990.
Norman D. A. Mototy. knowledge and the answering of questions. CHIP Technical Report 25
Center for Human Information Processing, University of California, San Diego, 1972.
Norman D. A- Perspectives on Cognitive Science. Hillsdale. NJ: Erlbaum, 1981.
Norman D. A., Rumelhart D. E. and the LNR Research Group. Explorations in Cognition. Sa
Francisco: Freeman, 1975.
Novak G. S. Computer understanding of physics problems stated in natural language.
Proceedings ЦСА15.1977.
Noyes J. L Artificial Intelligence with Common USP: Fundamentals of Symbolic and Numeric
Computing. Lexington, MA: D. С Heath and Co. 1992.
O'KeefeR. The Craft of PROLOG. Cambridge, MA,- МГГ Press, 1990.
O'Leary D.D. M, Yates P. and McLaughlin T. Mapping sights and smells in the bntx
distinct chanisms to achieve a common goal. Cell 96: 255-269, 1999.
Oliver L M., Smith D. J. and Holland J. R. С A Study of Permutation Crossover Operatonm
the Traveling Salesman Problem. Proceedings of the Second International Conference o>
Genetic Algorithms, pp. 224-230. Hillsdale. NJ: Erlbaum & Assoc. 1987.
Oliveira E_ Fonseca J. M. and Steiger-Garcao A. MACIV: A DAI based resource manage**
rysum. Applied Artificial Intelligence, 11(6): 525-550, 1997.
Papen S. Mindstorms. New York. Basic Books. 1980.
Paul R Szoloviu P. ^ s^.^ w ^^ und ^ f ш ,-„«„ Й «*«J
rtoT'«°Ceedm8S °f те b«enutional Joint Conference on Artifirial W*T-»
Palo Alto: Morgan Kaufmann, 1981
^ii^SSey.'^T' ^^ "" С0тРШГ FrMm S°'""S- *""* ^
РаЛм£°££ч1С RTTg Ы *■""'*« *»»».• "«works of Plausible Ы*** V
iw i E Kaufmann, 1988
^^Ne"Y*CambndgeUn,versityPres,2C<*.
Pearlmnner B. A. and Parra LC Mai™, uUihocd ыш „^ nakm. A атю>,
С^споТм^^
Рейсе С. S. Collected Papers 1931-1958. Cambridge MA: Harvard University Pre**, 1958
Penrose R. The Emperor's New Mind. Oxford; Oxford University Press, 1989
Pereira L. M. and Warren D. H. D. Definite clause grammar, for language analysts- A
Perils D. Autocircumscription. Artificial Intelligence. 36: 223-236, 1988
Perriolai F-^«",pLl and Jermings N.J. Using archon: Panicle accelermor
Control. 11(6): 80-86, 1996.
Pfeffer A.. Koller D., Milch B. and Takusagawa K. SPOOK: A system for probabilistic object-
oriented knowledge representation. Proceedings of the Fifteenth Annual Conference on
Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann, 1999.
Piaget J. 77u? Construction of Reality in The Child. New York: Basic Books, 1954.
Piaget J. Structuralism. New York: Basic Books. 1970.
Pinker S. 77k Language Instinct. New York: William Morrow and Company. 1994.
Plato 77u? Collected Dialogues of Plato. Hamilton E and Caims H. ed. Princeton: Princeton
University Press, 1961.
Pless D., Luger G. and Stem C. A new object-oriented stochastic modeling language. Artificial
Intelligence and Soft Computing: Proceedings of the IASTED International Conference.
Anaheim: LASTED/ACT A Press. 2000.
Polya G. How to Solve It. Princeton, NJ: Princeton University Press. 1945.
Popper K- R. 77кг Logic of Scientific Discovery. London: Hutchinson. 1959.
Posner M. I. Foundations of Cognitive Science. Cambridge. MA: МП" Press, 1989
Post E. Formal reductions of the general combinatorial problem. American Journal of
Mathematics. 65: 197-268, 1943.
Poundstone W. The Recursive Universe: Cosmic Complexity and the Limits of Scsejmpc
Knowledge. New York: William Morrow and Company. 1985.
Pratt T. W. Programming Languages: Design and Implementation. Englewood Cuffs. N1:
Prentice-Hall. 1984.
Prerau D. S. Developing and Managing Expert Systems: Proven Techniques for Business and
Industry. Reading. MA: Addison-Wesley. 1990.
Pylyshyn Z W. What the minds eye tells the mind's brain: a critique of mental imagery.
Psychological Bulletin. 80: 1-24. 1973.
Pylyshyn Z W. The causal power of machines. Behavioral and Bram Sciences 3:442-444.1980.
Pylyshyn Z. W. Computation and Cognition: Toward a Foundation for Cognitive Science
Cambridge, MA: МП" Press, 1984.
Quilhan M. R. Word concepts A theory and simulation of some basic semantic capabilities. In
Brachman and Levesque (1985). 1967.
Quine W. V. O. From a Logical Point of View. ЪА ed. Ne« York: Harper Torchhxta. 1963.
Библиография
831
^,,-^П^з.
classification procedures and their application
"> Ле,
games.
Machine Learning, 1(1): 81-106, 1986л.
In Michalski e
j. R. Induction "fdeaSIO"n'concepl ,earning. In Michalski et al. (1986), 19866.
rrf crMs Proceedings AAAI 96. Menlo Park: AAA1 Press, Ш
' covering
0uinlan J. R. Baf'\oeranls for Machine Learning. San Francsco: Morgan Kaufman,,, зд
Quinlan J. R- C4.3- x^ ^ Psychology. Chicago, IL: University of Chicago Press, i99l '
Quinlan P. Connecltontsm fgrsemmtic information retrieval. In Minsky (1968), i9«
"XitsP^X *—*-~*—*»of ■» ffiEE « <* »*
1976' ™ с „„H Wane P Y. Diagnostic expert systems based on a
Re^re™aL|nU.of Man-Machine Studies, ,9(5): 437^60, 1983
ffiXSSa. —•"; 1989;1981) 1978
ReiterR on closed «arid databases. In Webber and N.lsson (1981), 1978.
Reiter R Ол шш,ш>,8 tv A/»"- In Brachman and Levesque (1985), 1985.
Reiter R. and Criscuolo G. On interacting defaults. Proceedings of the International Joint
Conference on Artificial Intelligence, 1981.
Reitraan W. R Cognition and Thought. New York: Wiley, 1965.
Rendell L. A general framework for induction and a study of selective induction. Machine
Learning, 1(2). 1986.
Rich E. and Knight K. Artificial Intelligence, 2nd ed. New York: McGraw-Hill, 1991.
Rissland E. L. Examples in legal reasoning: Legal hypotheticals. Proceedings of DCAI-83. an
Mateo, CA: Morgan Kaufmann, 1983.
Rissland E. L. and Ashley K. HYPO: A case-based system for trade secrets law. Proc mg ,
First International Conference on Artificial Intelligence and Law, 1987.
Roberts D. D. The Existential Graphs ofCliarles S. Pierce. The Hague: Mouton.
1973.
Robinson J. A. A machine-oriented logic based on the resolution prim
ACM, 12: 23-41,1965.
,ciple. Journal of the
Rochester N„ Holland J. H., Haibit L. H. and Duda W. L. Test on a cell asse"*^nfeld, ed.
actuation of the brain, using a large digital computer. In J. A. Anderson and
Neurocomputing: Foundations of Research. Cambridge, MA: MIT Press, 1988.
Rosen E. Principles of categorization. In Rosch and Lloyd (1978). 1978. ^g
Rosch E. and Lloyd В. В., ed. Cognition and Categorization, Hillsdale, NJ: Erlbaum, ^^
Rosenblatt F. The
perceptron: A probabilistic model for information
storage and org^
in the brain. Psychological Review, 65: 386-408, 1958.
Rosenblatt F. Principles ofNeurodynamics. New York: Spartan, 1962. ^ oj
RosenbloomP.S. and Newell A. The chunking of goal hierarchies: A g«'era,,ze
practice. In Michalski et al. (1986), 1986.
Rosenbloom P. S. and Newell A. Learning by chunking, a production system model of
practice. In Klahr et al. (1987), 1987. '
Rosenbloom P. S., Lehman J. F. and Laird J. E. Overview of Soar as a unified theory of
cognition: Spring 1993. Proceedings of the Fifteenth Annual Conference of the Counitive
Science Society. Hillsdale, NJ: Erlbaum, 1993.
Ross P. Advanced PROLOG. Reading, MA: Addison-Wesley, 1989.
Ross T. Fuzzy Logic with Engineering Applications. New York: McGraw-Hil 1, 1995.
Roussel P. PROLOG: Manuel de Reference et a"Utilisation. Groupe d'Intelligence Artificielle,
University d'Aix-Marseille, Luminy, France, 1975.
Rumelhart D. E., Lindsay P. H„ and Norman D. A. A process model for long-term memory. In
Tulving and Donaldson (1972), 1972.
Rumelhart D. E. and Norman D. A. Active semantic networks as a model of human memory
Proceedings IJCAI-3, 1973.
Rumelhart D. E., Hinton G. E. and Williams R. J. Learning internal representations bv error
propagation. In McClelland et al. (1986), 1986a.
Rumelhart D. E., McClelland J. L. and The PDP Research Group. Parallel Distributed
Processing. Vol. 1. Cambridge, MA; MIT Press, 19866.
Russell S. J. 77ie Use of Knowledge in Analogy and Induction. San Mateo, CA: Morgan
Kaufmann, 1989.
Russell S. J. and Norvig P. Artificial Intelligence. A Modem approach. Englewood Cliffs, NJ:
Prentice-Hall, 1995.
Sacerdotti E. D. Planning in a hierarchy of abstraction spaces. Artificial Intelligence. 5: 115-
135, 1974.
Sacerdotti E. D. The поп linear nature of plans. Proceedings UCAI4, 1975.
Sacerdotti E. D. A Structure of Plans and Behavior. New York: Elsevier, 1977.
Sagi D. and Tanne D. Perceptual learning: Learning to see. In Squire and Kosslyn (1998). 1998.
Samuel A. L. Some studies in machine learning using the game of checkers. ГВМ Journal of R & D,
3:211-229,1959.
Schank R. С Dynamic Memory: A Theory of Reminding and Learning in Computers and
People. London: Cambridge University Press, 1982.
Schank R. С and Abelson R. Scripts. Plans, Goals aiul Understanding. Hillsdale, NJ:
Erlbaum, 1977.
Schank R. С and Colby K. M.. ed. Computer Models of Tliought and Language. San
Francisco: Freeman, 1973.
Schank R. С and Nash-Webber B. L„ ed. Tlieoretical Issues in Natural Language Processing.
Association for Computational Linguistics, 1975.
Schank R. С and Rieger С J. Inference and the computer understanding of natural language.
Artificial Intelligence 5(4): 373-412, 1974.
Schank R. С and Riesbeck С. К., ed. Inside Computer Understanding: Fire Programs Plus
Miniatures. Hillsdale, N.J.: Erlbaum, 1981.
832
библи
Библиография
833
л r Holland О. and Bruten J. Ant-like agents for had
Schoondemoerd R., № Proceed,ngs of the First International с0„£> '•
л ,п Ле Velde W. Software agent foundation for dynamic ■
^TtrolcTaiZes ^ Artificial Intelligence, , 1(5) pp. 459^,^.'"'-*,
, „ м ,„H Ouan A. G. Enhancing performance of cooperating agents i„ . ,
s*'Z2?^»^«£Thirteenth Internationai Ь1- <*££
Artificial Intelligence, pp.
332-337,1993. ~'аде о»
SearleJ Speed, Acs. London: Cambridge University Press, 1969.
Searle J. R. Minds, brains and program. The Behavioral and Brain Sciences, 3: 417-424.1980.
Sebeok T. A. Contributions to the Doctrine of Signs. Lanham, MD: Univ, Press of America, 1985
StigsmckK. Algorithms. Reading, MA: Addison-Wesley, 1983.
Sejn°owski T. J. and Rosenberg С R. Parallel networks tltat learn to pronounce English ,m.
Complex Systems, 1: 145-168, 1987.
Selfridge 0. Pandemonium: A paradigm for learning. Symposium on the Mechanization ol
Thought. London: HMSO, 1959.
Selman B. and Levesque H. J. Abductive and Default Reasoning: A Computational Con.
Proceedings of the Eighth National Conference on Artificial Intelligence, pp. 343-34!.
Menlo Park, CA: AAAI Press/MIT Press, 1990.
SelzO. Uber die Cesetze des Ceordneten Denkverlaufs. Stuttgart: Spemann, 1913.
Selz 0. Zwr Psychologie des Produhiven Denkens und des lrrtwns. Bonn: Friedrich Cohen, 1922.
Shafer G. & Pearl J., ed. Readings in Uncertain Reasoning, Los Altos, CA: Morgan Kaufman
1990.
Shannon С A mathematical theory of communication. Bell System Technical Journal, 1948.
Shapiro E. Concurrent Prolog: Collected Papers, 2 vols. Cambridge, MA: MIT Press, 1987,
Shapiro S. C, ed. Encyclopedia of Artificial Intelligence. New York: Wiley-Interscience, 198!
Shapiro S. C. ed. Encyclopedia of Artificial Intelligence. New York: Wiley, 1992.
Shavlik J. W. and Dietterich T. G., ed. Readings in Machine Learning- San Mateo, CA
Morgan Kaufmann, 1990.
Shavlik J. W., Mooney R. j. and Towell G. G. Symbolic and neural learning algorithm»
experimental comparison. Machine Learning, 6(1)- 111-143, 1991.
Shephard G. M 77,e Synoptic Organization of,he Brain. New York: Oxford University Pre» «*
FoL7n V"g!ey P- Ы' C°">P«"«onal Models of Scientific Discovery and №•■
Shrob н Г' 'CA: Morgan Kaufmann' 199° 0i
ConferlncetnT^'j, А"ФсШ in,M^ce: Survey Talks from "•' ">
^tai H.:d 0:f; d : sTe'pp- 291-ш-san ма,ео: могСГ>
Report SYCONqTorm ,e"r"' "e'Works are "n"ersal computing devic*i
Siegler, ed. midrl! nV Г5еУ; RU'gerS СетеГ f0f SyS'emS and C° '
Siekmann T H . " ?ткт*: W>"» Develops. Hillsdale, NJ: Erlbaum, 1978. у
1957,о 1970 Vol I Г" °" ^ The A"'°'»*lion of Reasoning: Collet
•V°'-1-New York: Springer-Verlag, 1983,.
^ZllmXZ'tT у' f с"* АШОта"°П °fR«»°™i: Collected Papers from
1VJ/ to IV7U. Vol. II. New York: Springer-Verlag, 19836.
Simmons R. F. Storage and retrieval of aspects of meaning in directed graph structures.
Communications of the ACM, 9:211-216, 1966.
Simmons R.F. Semantic naworb: Their computation and use for understanding English
sentences. In Schank (1972), 1973.
Simon DP. and Simon H. A. Individual differences in solving physics problems. In Siegler
(1978), 1978.
Simon H. A. Decision making and administrative organization. Public AdministraUon Review
4: 16-31, 1944.
Simon H. A. The functional equivalence of problem solving skills Cognitive PsvchoIoEV 7-
268-288, 1975. '
Simon H. A. The Sciences of the Artificial, 2nd ed. Cambridge, MA: MIT Press, 1981.
Simon H. A. Why should machines learn? In Michalski et al. (1983), 1983.
Sims M. H. Empirical and analytic discovery in IL. Proceedings of the Fourth International
Workshop on Machine Learning. Los Altos, CA: Morgan Kaufmann, 1987.
Skinner J. M. and Luger G. F. A synergistic approach to reasoning for autonomous satellites.
Proceedings for NATO Conference of the Advisory Group for Aerospace Research and
Development, 1991.
Skinner J. M. and Luger G. F. An architecture for integrating reasoning paradigms. Principles
of Knowledge Representation and Reasoning. B. Nobel, С Rich and W. Swartout, ed. San
Mateo, CA: Morgan Kaufmann, 1992.
Skinner J. M. and Luger G. F. Contributions of a case-based reosoner to an integrated
reasoning system. Journal of Intelligent Systems. London: Freund. 1995.
Sleeman D. Assessing aspects of competence in basic algebra. In Sleeman and Brown (1982),
1982.
Sleeman D. and Smith M.J. Modelling students' problem solving. AI Journal, pp. 171-187.
1981.
Sleeman D. and Brown J. S. Intelligent Tutoring Systems. New York: Academic Press. 1982.
Smalllalk/V: Tutorial and Programming Handbook. Los Angeles: Digitalk. 1986.
Smart G. and Langeland-Knudsen J. The CRI Directory of Expert Systems. Oxford: Learned
Information (Europe) Ltd., 1986.
Smith В. С Prologue to reflection and semantics in a procedural language. In Brachman and
Levesque (1985). 1985.
Smith В. С On the Origin of Objects. Cambridge, MA: МГГ Press, 1996.
Smith R G and Baker J D. The dipmeler advisor system: a case smdy in commercial expert
system development. Proc. 8th IJCAI. pp. 122-129, 1983.
SmoliM S. W A View ofGoal-oricued Programming, Schlumberger-Doll Research Note. №.
Soderland S„ Fisher D„ Aseltine J. and Lehner, W. CRYSTAL- Inducing a conceptual
dictionan. Proceedings of the Fourteenth International Joint Conference on Artifiual
Intelligence. 1314-1319. 1995.
Библиография
835
о hn F Woolf В., Bonar J. and Johnson W. L. MENO-ll- „
S0'°Way r!;Xr«W'''lournalofCoropUterBaSedlnStrUCti0n' 10(1'2>. 1983.' A'-4/
^T nirhmt J and Jensen K. Assessing the maintainability of Xc .
^plgX problems of a very large rule base. Proceedings AAAI^>
CA- Morgan Kaufrnann, 1987. 4
Somogyi Z. Henderson, F. and Conway С Mercun: An efficient purely decl
programming language. Proceedings ot .he Austrian Computer Science Co^*
499-512,1995. ce'
Sowa J F. Conceptual Structures: Information Processing in Mind and Machine. Rca(li
MA: Addison-Wesley, 1984. &
Squire L. R. and Kosslyn S. M., ed. Findings and Current Opinion in Cognitive Neuroscienc j
Cambridge: MIT Press, 1998. e' \
Steele G. L. Common LISP: The Language, 2nd ed. Bedford, MA: Digital Press, 1990.
Stefik M., Bobrow D., Mittal S. and Conway L. Knowledge programming in LOOPS: Repo„
on an experimental course. Artificial Intelligence, 4(3), 1983.
Sterling L. and Shapiro E. The Art of Prolog: Advanced Programming Techniques. Cambridge
MA: MIT Press, 1986.
Stern С R. An Architecture for Diagnosis Employing Schema-based Abduction. РШ
dissertation, Department of Computer Science, University of New Mexico, 1996.
Stern С R. and Luger G. F. A model for abduaive problem solving based on explanation templates
and lazy evaluation. International Journal of Expert Systems, 5(3): 249-265,1992.
Stem С R. and Luger G. F. Abduction and abstraction in diagnosis: a schema-based account,
Situated Cognition: Expertise in Context Ford et al. ed. Cambridge, MA: МГГ Press, 1997.
Stubblefield W. A. Source Retrieval in Analogical Reasoning: An lnteractionist Approach.
PhD dissertation. Department of Computer Science, University of New Mexico, 1995.
Stubblefield W. A. and Luger G. F. Source Selection for Analogical Reasoning: An ЕтрШ
Approach. Proceedings: Thirteenth National Conference on Artificial Intelligence, 1996.
Stytz M. p. and Frieder O. Three dimensional medical imagery modalities: An onrm»
Critical Review of Biomedical Engineering, 18, 11-25, 1990.
^oLV'T mdSi«ta"d Actions: Tlte Problem of Human Machine Communicate
Cambridge: Cambridge University Press, 1987
зГТя \A C0mp'"erModd of Skill Acquisition. Cambridge, MA: MIT Press, 1975.
9П-44, \тШЧ '"PredW' Ьу "'e melhod °f temP°'*l differences. Machine Lean*l
^^PVxJZridnnarMteC'UreS for leami'^ Pining, and reactmg based*
cTnferenc :Uth;eLfr0?rammW?- ?™^& of tta Seventh tow»**
S"tton R s Dyna ^mltmm^ PP- 21&-224. San Francisco: Morgan Kaufrnann, №
Bulletin, 2: 16^]мТг^аГсЫ'ес,иге f°<- ''"ruing, planning, and reacting- SK*
<;,,..., n „ ^ Л*-М Press, 1991
SWonR.s.andBarto А п в ■ ,
S№ K„ Decker К ' P f°r""'em earning. Cambridge: MIT Press. 1998-
ШЕЕ Expert, ll(6),T9n9U6A-' Williams°" M. and Zeng D. Distributed intclW*' "*
Tang A. C, Pearlmutter B. A., and Zibulevsky M. Blind source separation of neuromagnelic
responses. Computational Neuroscience 1999, Proceedings published in Neurocomputing,
Tang A. C, Pearlmutter B. A., Zibulevsky M, Hely T. A., and Weisend M. A MEG study of
response latency and variability in the human visual system during a visual-motor
integration task. Advances in Neural Information Processing Systems: San Francisco:
Morgan Kaufrnann, 2000a.
Tang A. C, Phung D. and Pearlmutter B. A. Direct measurement of interhemispherical transfer
time (IH7T) for natural somatosensory stimulation during voluntary movement using
MEG and blind source separation. Society of Neuroscience Abstracts, 20005.
Takahashi K., Nishibe Y., Morihara I. and Hattori F. Intelligent pp.: Collecting slwp and senice
information with software agents. Applied Artificial Intelligence, 11(6): 489-500,1997.
Tanimoto S. L The Elements of Artificial Intelligence using Common USP. New York: W.H.
Freeman, 1990.
Tarski A. 77le semantic conception of truth and the foundations of semantics. Philos. and
Phenom. Res., 4: 341-376, 1944.
Tarski A. Logic, Semantics, Metamathemalics. London: Oxford University Press, 1956.
Tesauro G. J. TD-Gammon. a self-teaching backgammon program achieves master-level play.
Neural Computation, 6(2): 215-219, 1994-
Tesauro G. J. Temporal difference learning and TD-Gammon. Communications of the ACM,
38: 58-68, 1995.
Thagard P. Dimensions of analogy. In Helman (1988), 1988.
Touretzky D. S. 77ie Mathematics of Inlterilance Systems. Los Altos, CA: Morgan Kaufrnann, 1986.
Touretzky D. S. Conunon USP: A Gentle Imroduction to Symbolic Computation. Redwood
City, CA: Benjamin/Cummings, 1990.
TrappI R. and Petta P. Creating Personalities for Synthetic Actors. Berlin: Springer-Verlag, 1997.
Triesman A. The perception of features and objects. Attention: Selection. Awareness, and
Control: A Tribute to Donald Broadbent. Badderly A. and Weiskrantz L. ed, pp. 5-35.
Oxford: Clarendon Press, 1993.
Treisman A. The binding problem. In Squire and Kosslyn (1998), 1998.
Tulving E. and Donaldson W. Organization of Memory. New York: Academic Press. 1972.
Turing A. A. Computing machinery and intelligence. Mind, 59: 433^160, 1950.
Turner R, Logics for Artificial Intelligence. Chichester: Ellis Horwood, 1984.
Ullman J. D. Principles of Database Systems. Rockville, MD: Computer Science Press, 1982.
Urey H. С The Planets: Their Origin and Development. Yale University Press. 1952.
Utgoff P. E. Shift of bias in inductive concept learning. In Michalski et al. (1986). 1986.
Valiant L. G. A theory of the leamable. CACM, 27: 1134-1142, 1984.
van der Gaag L. C, ed. Special issue on Bayesian Belief Networks. AISB Quarterly. 94. 1996.
van Emden M. and Kowalski R. The semantics of predicate logic and a programming
language. Journal of the ACM, 23: 733-742, 1976.
VanLe T. Techniques of PROLOG Programming with Implementation of Logical Negation and
Quantified Goals. New York: Wiley, 1993.
Библиография
837
„ F and Rosch E. The Embodied Mind: Cognitive Sci
Var£la F. /.. "^ M* MIT Press, .993. <* «^
Expenence. Can* g ^ ^ p cwr£D.9s ад
Vcloso M-. Bbow"n8„tm 7ма8аг.пе, 2.(1): 29-36. 2000. "-«Ц,
v 7?;^чг«^'^'^^ыыи'-ргос^'п,55исА1*-'975.
IffRd./«-^''»*'«W''MWta''W-Cambnd8£'MA;MIT4lW
. • .' i г ,„, ЛпшкЬ for convolutional codes and an asymptotically optimum л. ',
^^^^^оп1п(ЬпШ.юпТТ^,Я-13(2):260-269^96Т^
von Glaserfeld E. An introduction to radical constructivism. The Invented Reality, Wau|
cd pp. i7_40. New York: Norton, 1978.
Walker A McCord M„ Sowa J. F. and Wilson W. G. Knowledge Systems and PROLOG: a
Logical Approach to Expert Systems and Natural Language Processing. Reading,^
Addison-Wesley, 1987.
Warren D. H. D. Generating conditional plaits and programs. Proc. AISB Sum*,
Conference, Edinburgh, pp. 334-354, 1976.
Wanen D. H. D. Logic programming and compiler writing. Software-Practice and Experieia.
10(11). 1980.
Warren D. H. D.. Pereira F. and Pereira L. M. User's Guide to DEC-Syslem 10 PR0WC
Occasional Paper 15. Department of Artificial Intelligence, University of Edinburgh, 1979.
Warren D. H. D., Pereira L. M. and Pereira F. PROLOG — the language and i»
implementation compared with LISP. Proceedings, Symposium on AI and Programming
Languages, S1G-PLAN Notices, 12:8,1977.
Waterman D. and Hayes-Roth F, Pattern Directed Inference Systems. New York: Academic
Press, 1978.
Waterman D. A. Machine Learning of Heuristics. Report No. STAN-CS-68-118, Compile
Science Dept, Stanford University, 1968.
Waterman D. A. A Guide to Expert Systems. Reading, MA: Addison-Wesley, 1986.
Watkins С J. С. Н. Learning from Delayed Rewards. PhD Thesis, Cambridge University, 1989.
Wavish P. and Graham M. A situated action approach to implementing characters in aMf*>
games. Appl.ed Artificial Intelligence, 10(1): 53-74 1996
Webber B.,.. and Nilsso„ N ; ы^ ^ ^^ ^.^ ^ ^ Tioga te 1981
KauflnM^f0"8"1 ° *' С°""""еГ ^'e™ """ *■""■• San МаК°' °* **
"^й:£ *••*»■*s and safir a- a ™™-b™d me,h°d%co0"""
Wmenbaum I г '""""""^'"г- ArtificUl Intelligence, 11(1-2): 145-172,1977.
-^u1c2rP°randHUmmR^- S» »«*«»= W.H.Freeman.«
WeldD.sX^rr" ''""-^"^.A.MagaZinei5(4,:.6-35..;us
Alius, CA: Morgan Kaufma'nn "Г "' Q""l'""'V€ Reasoning about Physical Sp
1™="18епсГ™п!7ег^оШ1„^г?,аКе5еаГС|1 Rep0rt 14' DePar'mem °' ^
WellmanM. P. ^mental concepts of qualitative probabilistic networks. Artificial
Intelligence, 44(3): 257-303, 1990.
Weyhrauch R. W. Prolegomena to a theory of mechanized formal reasoning. Artificial
Intelligence, 13(1, 2): 133-170, 1980.
Whitehead A.N. and Russell B. Principia Mathematica. 2nd ed. London- Cambridge
University Press, 1950.
Whitley L. D„ ed. Foundations of Genetic Algorithms 2. Los Altos, CA: Morgan Kaufmann, 1993.
Widrow B. and Hoff M. E. Adaptive switching circuits. I960 IRE WESTCON Convention
Record, pp. 96-104. New York, 1960.
Wilensky R. Common LISPCraft. Norton Press, 1986.
Wilks Y. A. Grammar, Meaning and the Machine Analysis of Language. London: Routledge &
Kegan Paul, 1972.
Williams В. С and Nayak P. P. Immobile robots: Al in the new millennium. AI Magazine
17(3): 17-34, 1996a.
Williams В. С and Nayak P. P. A model-based approach to reactive self-configuring systems.
Proceedings of the AAAI-96, pp. 971-978. Cambridge, MA: MIT Press. 1996.
Williams В. С and Nayak P. P. A reactive planner for a model-based executive. Proceedings
of the International Joint Conference on Artificial Intelligence, Cambridge. MA: MTT
Press, J 997.
Winograd T. Understanding Natural Language. New York: Academic Press, 1972.
Winograd T. A procedural model of language understanding. In Schank and Colby (1973), 1973.
Winograd T. Language as a Cognitive Process: Syntax. Reading, MA: Addison-Wesley, 1983.
Winograd T. and Flores F. Understanding Computers and Cognition. Norwood, N J.: Ablex. 1986.
Winston P. H. Learning structural descriptions from examples. In Winston (19756), 1915a.
Winston P. H., ed. The Psychology of Computer Vision. New York: McGraw-Hill, 19756.
Winston P. H. Learning by augmenting rules and accumulating censors. In Michalski et al.
(1986), 1986.
Winston P. H. Artificial Intelligence. 3rd ed. Reading, MA: Addison-Wesley. 1992.
Winston P. H., Binford Т.О., Katz B. and Lowry M. Learning physical descriptions from
functional definitions, examples and precedents. National Conference on Artificial
Intelligence in Washington, D. C. Morgan Kaufmann, pp. 433-439. 1983.
Winston P. H. and Horn B. K. P. USP. Reading, MA. Addison-Wesley. 19S4.
Winston P. H. and Prendergast K. A., ed. 77i£ Al Business. Cambridge. MA: MIT Press. 1984.
Wirth N. Algorithm + Data Strucmres = Programs. Englewood Cliffs, NJ: Prentice-Hall, 1976.
Wittgenstein L. Philosophical Investigations. New York: Macmillan. 1953,
Wolpert D. H. and Macreadv W. G. The No Free Lunch Tlieorems for Search. Technical
Report SFI-TR-95-02-010. Santa Fe. NM: The Santa Fe Institute. 1995.
Wolstencroft J. Restructuring, reminding and repair: WhatS missing from models of analogy.
AICOM. 2(2): 58-71. 1989.
Wooldridge M. Agent-based computing. Interoperable Communication Networks. 1( П: 71-97, 199S.
Wooldridge M. Reasoning about Rational Agents. Cambridge. MA: МГГ Press. 2000.
Библиография
839
W00ds W. Wlutts «• - "* nations for Setnantic Networks. ,n Brachman авд ^
(1985). 1985. Pammodulalion and set of support. Proceeding nf L
^^шГшо^О^г^, VersaiHes. NeW York: Spring,
Ш^шопШе^Reasoning. 33 Basic Research Problems. NJ: Prentice Hall, ,988
1 L. TkJfcW*.—' masoning. In Computers and Mathematics with ^
29(2): xi-xiv, 1995.
w„, I Overbeek R., Lusk E. and Boyle J. Лнита/л/ Reasoning: Introduce
ШВАрр1ШоТяп;^Ы Cliffs, NJ: Prentice-Hal., 1984.
Xiane Y Poole D. and Beddoes M. Multiply sectioned Bayestan networks and junction htl
}or large knowledge based systems. Compmiiomilnlelhgenoe 9(2): 171-220,199;Г
Xiang Y., Olesen K. G. and Jensen F. V. Practical issues in modeling large diagnostic №te.
with multiply sectioned Bayesian network. International Journal of Pattern Recoil*,
and Artificial Intelligence, 14(1): 59-71, 2000.
Yager R. R. and Zadeh L. A. Fuzzy Sets, Neural Networks and Soft Computing. New York-
Van Nostrand Reinhold, 1994.
Young R. M. Seriation by Children: An Artificial Intelligence Analysis of a Piagetian Task
Basel: Birkhauser, 1976.
Yuasa T. and Hagiya M. Introduction to Common LISP. Boston: Academic Press, 1986.
Zadeh L. Commonsense knowledge representation based on fuzzy logic. Computer, 16: 61-65,1983.
Zurada J. M. Introduction to Artificial Neural Systems. New York: West Publishing, 1992.
Библии
Алфавитный
указатель авторов
Abclson, IIS: 239; 599; 773
Ackley, 516
Adam, 598
Adlcr, 265
Agre, 49:221:226:804
Aho, 144; 189
Aiello, 215
Allen, 54:316:566:576; 585; 598
Ally, 321
Anderson. 54; 199:230:268:467; 481: 524; 805:807
Andews, 103
Appelt, 56
Arbib, 509
Ashly, 299
Auer, 432
Austin, 39:805
В
Baker, 45
Ballard, 481; 807
Balzer, 215
Bareiss, 299
Barker, 200
Barkow, 790
Ватт, 54; 322
Barllelt, 237; 800
Barto, 427; 429; 431:432
Bateson, 54
Becntel, SOS
Benson, J/6; 322; 511; 516; 802
Berger, 591
Bernard, 296
Bcrtsekas, 432
Birmingham. 264
Bishop, 482
Bledsoe. 54; 528; 557; 55S
Bobraw, 226; 268
Bond, 266
Boole, 33
Bower, 230; 268
Boyer. 44; 54; 559
Brachman. 104; 233; 26», 803
Brooks, 49; 54; 220; 221; 226; 255; 256; 25S; 268; 26*.
485; 510.802:804; SOS
Brown, 295; 522; 4/5
Brownston, 210,215
Buchanan, 45; 321; 341; 348; 406
Bundy, 44; 104; 553:559
Burks, 509; 5/6
Burmeisler. 265
Burelall, 35
Burton, 322
Busuoic, 265
ButUer,J0
Cahill, 794
Carbonell, 505:-152
Cardie, 597
Carlson, 787
Ceccaio,230
Chang, 103; 531:539.559
Chapman. 49, 221; 226; 804
Оштак, 146:241; 341; 599
Chen, 265
Chomsky. 574
Chorafas, 321
Chung. 264
Church, 607; 803
aancy.295
ОаЛ. 220; 222; 268; 802; 808
aocksin,607:6/0;6S0
Codd, 509
Colby, 54; 233
Cole. 599
Collins, 227; 268
СоЬгажа.606,680
Conn-ay, 4S4; 50S; 516
Coombs, 321
Cooper, .'55
Corera.264
Corkill.2/5.2/5
Cormen, 145
Cosmidcs. 790
Стоп. 50.416
Criscuolo, 55/. 566
Cratchficld, 4S5;511:5I3
Cutosk). 264
D
Dahlr»
Darlington, 35
Dm, 264
Dans, 50; 293; 322; 366; 415; 490
Dechter, 365
DeJong, 51; 407:409
deKJeer. 55; 269; 293; 319; 334; 335; 339; 366; 773
Dempster, 350
Dennett 54; 222; 268; 516; 791; 804; 807
Devis.269.322
Devon, 509
Dietlerich,411;432
Dologite, 321
Domingue, 773
Doorenbos, 265
Doyle, 329; 332; 334; 366
Dreyfus, 39,804
Dnuu6,364;366
Dmk,45;357
Durfee,26J
Dutin,45;54;321
E
ECO.S55
Edelman, 790,804
Bman, 481; 807
Engelraore, 215
Emm, 213; 215
Ernst, 522; 526; 784
Eukr, 32
Evans, 259
Falkenhainer, 413
Fass,599
ftigenbaura, 54; 322; 371; 432; 559- 793
Feldman, 432; 559; 793
ntes.3ll;407;S28
Fillmore, 233
Fischer, 265
Fisher, 300; 420; 432
^■3^^S8;599;804;806-807
"«tor, 789, 790 •"".«"
"■•»», 55; 773
Pont 37; 54; 55
*xgf.291;301
Forney, 587
Forest 5/5
Franklin, 481,807
Freeman, 481;7%
Frege, 34
Frey,4S2
Frieda, 79J
Oallier. 103
Ganzinger, 559
Garcy, /50; 181
Gasser,266
Gazdar, 599; 680
Gazzaniga, 747; 794
Geneserelh, 104; 338; 366; 559
Gennari, 42/
Gentner, 413
Giarratano, 321
Gilbert, 794
Ginsburg, 366
Glasgow, 598
Glymour, 354
Goldberg. 494; 515
Goodwin, 333
Gould. 506; 516
Graham, 265; 773
Grice, 39; 341; 805
Griffiths, 265
Grossberg, 459; 481
Grosz, 805
H
Hall, 412
Hammond, 303
Hamscher, 293; 322
Hanson, 513
Harbison-Briggs, 321
Harmon, 54; 228; 321
Harris, 599
Hasemer, 773
Haugeland, 54; 268; 807
Haussler, 405
Hayes, 37; 54; 308; 366; 607
Hayes-Roth, 54; 215; 265:321:516
Hebb, 437; 439:462; 481
Hecht-Nielsen, 436; 456; 459; 477; 481
Heidegger, 39; 806
Heidora, 576
Herman, 145
Hempel, 808
Henrion, 365
Hightower, 509; 516
№\\,680
Hillis, 52
Hinton, 481
Hobbs, 366
Hodges, 54
Hoff, 446
Hofstadter, 259
Holland, 259; 485; 492; 494; 497; 499; 515;<
Holowczak, 595
Holyoak, 432
Алфавитный указатель
Hopcroft, 574; 599
Hopbe\6,437;472;48l
Horowitz, 117:145
Hume, 401
Husserl. 39; 806
I
Ignizio, 321
Ivry, 794
J
Jeannerod, 481:807
Jennings, 221:226; 262; 264; 266
Johnson, 39; 54; 150.181; 226; 321- 785 79Л 802-
808
Johnson-Laird, 804
Jordan, 482
Josephson, 366
Jurafsky, 47; 54; 585; 588; 592; 599
К
KarmilotT-Smilh, 788; 791; 795
Kaufmann, 559
Kautz, 265
Kedar-Cabelli, 412; 432; 668
Keravnou, 321
King, 54; 228; 680
Klzbi,199;2l5;321;432
Klein, 49; 264; 318:511:802
Knight, 310
Kohonen, 436; 455; 457; 467; 481
Koller, 365
Kolmogorov, 799
Ko\o&ier,241;301;303;32l
Kondratoff. 55; 432
Korf, 131:181
Kosko,472;481
Kosoresow, 365
Kosslyn, 787; 794
Koton. 299
Kowalski, 52S; 547; 549; 606; 680
Koza. 485; 500; 501:504:515
Krulwich, 265
Kuhl, 794
Kuhn, S07; SOS
Kulikowski. 432
L
Lakatos, SOS
Lakoff, ,19; 54; 226; 417; J57; 7S5; 791; 802: SOS
Langeland-Knudsen, 321
Langley, 416; 432
Langton, 55; 485; 509; 516:802
Алфавитный указатель авторов
Larkin,/99
Laskey.365
Lauritzen, 363
Lave. 805
Leake. 302; 321
Lee, 103:531; 539;5S9
Leibniz, 32
Leiscrson, 145
Lenau 50; 415;4I6
Lesser, 213; 215; 263
Levesque, 104; 268; 269; 339,803
Lewis, 49; 54:226; 261; 262; 510; 785:802
Lieberman, 265
Ufschitz,j37;jJS;j66
Lindsay, 45; 322
Ljunberg, 264
Lloyd, 559,607
Lovelace, 33
Loveland. 559
Lucas. 264; 680
Luck, 79»
Luger, 25; 48; 49.54; 198:215; 226; 26J; 262; 269; 296;
300,302; 322; 432; 510,524; 785; 789. 792; 802;
SM;807
M
Machtey, 58
Macready, 798
Maes, 265; 269; 5J6
Magerman, 591
Mahoney, 365
Maier.650
Malpas.6«):6S0
Manna, 79; 103:319
Manning, 47:591:592; 599
Marcus, 47
Markov, 198
Marshall 26/
Martin, 47; 54; 405; 432; 585:588; 592; 599
Martins, 333:335:366
Maslerman. 230
McAllester, 333; 366; 559
McCarthy. S6:308; 337; 366.607; 647
McCarty, 668
McCord, 680
McCorduck.37/
Mc(Mlxh, 438:481
McDermott, 61:146:200:322:329
McGaugh, 794
McGonigle, S02;S0S
McGraw, 321
Mead, 481
McKish,599:607;61O.6S()
Merieau-Pomy, 39
Michalski. 55; 418; 432:500
Michie, 4 32
843
Miller, 794
Hkr&3.55;242;244;440;789;790
MM 51: 2» 2« Ж «':JS7' ** *"*""/;
«2; «5; 494; 504:511:513:515,669: 798
Milhen, 790: 791
Mockler, 321
Mooney, 5/; 341:407:409:598
Moore, ■«; Л; .«ft 366:524:559
Mora, 181
Morgan, 215
Morrison, 33
Mycroft, 64ft 643; 650
N
Nadathur, 6S0
Nahm,595
Nash-Webber, 233
Nayak.296;298;318;322
Nechl-Nielsen, 796:799
Negoita, 32/
Neves, 640
Newell, 42:43:52; 54, 71; 77; 145; 175; 199; 212; 215;
515:522; 524; 525; 526; 604; 778; 784- 793- 795 '
807
K& 341
Nil 215
Nilsson, 49; 54; 104; 136; 145; 174; 177; 181; 200-, 310.
311; 316; 338; 366; 440; 510; 511; 528- 545- 553- '
558:559:802
Nishibe,265
Nordbausen, 417
Norman, 230; 233; 807
Norvig, 314; 322
Noyes, 773
О
O'Connor, 2(Ю
ОщКес{е,б40-643\680
O'Leary, 795
Oliveira, 264
Oliver, 490
Papert, 275; 440
Parra, 794
l^\S4;,46;,74:,81;355;359;364 4U
Pearlmutter, 794 v,*"t
Peirse,505
Penrose, 752; 804
Penueli, 319
Pereira, 680
Perl, 361
Perlis, 338; 366
Pcrriolat, 26V
Pctta, 265
PfcfTer, 365
Piaget. 800
Pitts, 438; 481
Pless, 36.5
Polya, 149
Popper, 805; 808
Posner, 804; 807
Post, 198
Poundstone, 484; 507
Prerau, 321
Pylyshyn, 54; 804; 807
Quan, 264
Quillitui, 227; 230; 268
Quine, 808
Quinlan, 50; 392; 398; 399; 432; 439
R
Raphael, 230
Reddy, 213; 215
Reggia, 339
Reinfrank, 334; 366
Reiter, 329; 330; 366
Reitman, 230,259
Rich. 3/0
Rieger, 234
Riesbeck, 241; 599
Riley, 321
Rissland, 299
Rivest, 145
Roberts. 230
Robinson, 528; 540; 606
Rochester, 439
Rosch, 420; 457
Rosenberg, 452
Rosenblatt, 439; 481
Rosenbloom, 515
Ross, 345; 349; 366; 680
Roussel, 606
Rumelhart, 233; 446; 481
Russell, 34; 65; 77; 220; 314; 322; 412; 522; 523
Sacerdotti, 322; 528
Sagi, 794
Sahni, 117; 145
Samuel, 300; 302
Scapura, 796
Schank, 54; 233; 238; 239; 241; 599
Schoonderwoerd, 265
Schrooten, 265
Алфавитный указатель
Scr,utze.47;59/;592;599
Schwuuke, 264
Salk. 39,58; 599; 785; 804
Seboek, 805
Sedgewick, 145
Sejnowski, 452
Selfridge, 481
Selman, 340
Selz,230;26S
Staler, 366
Shannon, 396; 481
Shapiro, 55; 181:322; 333; 366; 504; 549; 560; 6t
Shavlik. 432; 453
Shcpbard, 787; 794
Shimony, 341
Shortliffe, 45; 327; 34У; 345
Shrager, 416; 432
Shrobe, 294
Sidner, 805
Siegelman, 799
Siekmann, 559
Simmons. 230; 233
Simon, 38; 42; 43; 52;54; 71; 77; 145; 175; 198;
219; 372; 522; 525; 775; 784; 793; 795; 807
Sims, 476
Skapura, 481
Skinner, 215; 300:322
Smart, 321
Smith, 45; 221; 599; 807
Smoliar, 522
Soderlruid, 598
Soloway, 200
Somogyi, 6S0
Sonlag, 799
Sowa, 250; 245; 254; 265; 576; 583; 594; 599; 6
Spiegelhalter, 363
Squire, 757; 794
Steele, 756; 761; 773
Stein, 255; 269
Stepp, 418
Sterling, 6S0
Stem, 296, 300; 302
Stubblefield, 300; 302:416; 432
Stytz, 795
Suchman, 801
Sussman, 57; 773
Sutton, 425; 427; 429; 431; 432
Sycara, 262; 264
T
Takahashi, 265
Tang, 794
Tammoto, 773
Tanne, 794
Tarski,35
Tesauro.429;437
Thagard,432
Tong.650
Tooby, 790
Touretzky,337; 366; 773
Trappl. 265
Triesman, 794
Tsitsiklis, 432
Turing, 36; 54:803
Turner, 253; 366
и
UUman, 144:189:574,593; 594; 599
Urey. 504
Utgoff,402
V
Valiant, 404
van de Velde, 265
van der Gaag, 366
van Emden, 547; 549
VanLe,6S0
VanLehn,322
Varela.504
Veloco,262;265
Veroff. 44; 54; 104; 145; 559
Viterbi, 5S7
von Glasesfeld, 800
w
Waldinger, 79; 103
Walker, 680
Warren, 607; 680
Waterman, 45; 54; 215; 274; 321
Watkins. 431; 432
Wavish.265
Weiss, 432
Weizeooaum. 54; 804; 806
Weld, 269; 376
Weyhrauch.366
Whitehead, 34; 65; 77; 22ft 522; 523
Widrow, 446
Willis, 54; 23ft 599
Williams, 296; 295; 318; 322
Winograd, 39; 47; 54:55; 265; 563; Я5:5S», 804;
806:807
Winston, SO; 146; 376; 407: 797
Wmh, 105
Wittgenstein. 39; 42ft 457
Worptn.795
WolstencrotV 412
Wcods, 237
Алфавитный указатель авторов
845
Wrtfe* 221.226.262 264 Y
W» U. 104. S2I: *ft «2; Я5; 5Х. SSS Yapf M
WnjKson. «9 Young. Я
ч/и. 264
X Z
Zodch. 2J7; 344. Л>6
Xjang..».';J«6 Zurada.*«;-<56U59;JS;; 7ЭД
846
Алфавитный указатель
Предметны
A
Abductive inference, 71; 552
Abstract data type. 609
Abstraction, 58
ABSTRIPS, 527
Absurd type. 249
Action potential, 787
Activation record, 189
Admissibility. 784
Agglomerative clustering, 417
a-list, 723
AM, программа, 415
Anonymous variable, 617
Answer extraction, 535
Antecedent, 74
ART, 750
Artificial life, 485
Association list, 723
Associationist theory, 227
ATN, 575
Atom, 686
Atomic sentence, 80
Attractor, 472
network, 437
Attribute, 593
Augmentation oflogic grammar, 576
Augmented
phrase structure, 576
transition network, 569; 575; 576
Autoassociative memory, 437; 468
Autoepistemic logic, 330
Automated reasoning, 520; 522
Autonomous system, 263
В
Backpropagalion, 436
Backtracking, 121
В ACON, программа. 416
Base-level category, 420
Bayesian belief network, 359
Beam search, 180
Belief network, 71;327
Best first search. 150
Bigram, 589
Binary resolution, 529
Binding problem, 794
Bound variable. 702
указатель
Branching factor, 208
Breadth-first search, 124
Bucket brigade algorithm, 495
С
C++, 60S; 750
C4.5, алгоритм, 399; 598
Candidate elimination, 381
Candide, программа, 591
Canonical formation rule, 252
Case frame, 233; 581
Case-based reasoning, 415; 784
Category
formation, 373
utility, 421
cdr-рекурсия, 698
Cellular automata, 505
Certainty factor, 164; 342
Chomsky hierarchy, 574
Clashing, 529
Class, 750
precedence, 755
Classifier system, 485:495
Clause form, 528
CLOS. 750
Closed world assumption, 547; 551:612
CLUSTER/2, система, 373; 401:418; 457
Clustering problem, 417
COB-WEB. система, 373; 420
Cognitive science, 524; 792
Competitive learning, 436
Complete proof procedure, 90
Concept, 375
learning, 373
Conceptual
clustering. 373; 417; 418
graph, 245
Condition/action pair, 692
Conditional
evaluation, 694
probability, 356
Confidence n>easure, 162
Conflict
resolution, 197
set, 197
Conjunction of disjuncis. 530
Conjunctive bias, 402
Conncctionist network, 371
Context-free
grammar, 573
language, 574
Context-sensitive language 574
Counterpropagation network, 456; 45V
C~PROLOG,610
Credit assignment, 390
Crossover, 487; 503
D
Data flow diagram, 594
Data-driven search, 118
Decision tree, 392,403
Declarative
language, 685
semantics, 609
Deductive closure, 411
Default logic, 330
Definite clause grammar, 680
Delayed evaluation, 736
Delta rule, 436; 446
Demodulation, 556
Demodulator, 556
Demon, 244
DENDRAL, система, 45; 406
Depth-fist search, 124
Detachment, 522
Difference
list, 645
table, 522
Directed acyclic graph, 114
Discrimination net, 432
Dotted pair, 723
DYNA-Q, алгоритм, 425
d-отделение, 361
E
EBL.-Ш
Elman, 788
Embedded panicle a, 514
Empiricist's dilemma, 795
Encapsulation, 750
Encoding scheme, 438
Entity-relationship diagram, 594
Evaluation, 79
Evolutionary
learning, 572
programming, 509
EVR1SKO, программа, 416
Exhaustive search, 69
Explanation structure 409
^amm-^^^4,S73;405;407;66!
Fact, 548:612
Factor, 536
Family resemblance theory, 420
Feasibility test, 526
Feature vector, 403; 662
Feedback network, 472
Feedforward network, 471
FIFO, структура данных, 624; 714
Filter, 711; 729
First-order predicate calculus, 86
Fitness
function, 484
proportionate selection, 486
Flat Concurrent PROLOG, 560
Flavors, 750
Flexible agent, 263
F-MRI, 793
Form, 687
FORTRAN, 678
Forward chaining, 118
Frame, 24l; 639
Free variable, 702
Function
closure, 736
grammar, 598
Functional
language, 685
magnetic resonance imaging, 793
Fuzzy
associative matrix, 346
set, 345
theory, 344
General Problem Solver, 44; 198; 220; 522; 526; 784
Generalized delta-rule, 441
Generator, 729
Generic function, 750
Genetic
algorithm, 485
epistemology, 800
learning, 372
Glider, 507
Goal regression, 408
Goal-directed strategy, 135
GOFAI, система, 40
Gradient descent learning, 446
Grammatical
marker, 598
trigram, 591
Gray coding, 492
Ground expression, 85
предметный **
H
Hamming distance, 468
HEARSAY-II, 213
Heteroasscciative memory, 437; 468
Heuristics, 69
Hierarchical
abstraction, 604
problem decomposition, 48
Higher-order function, 711
Hill climbing. 153
Horn clause. 403; 547; 612
calculus, 612
Hyperresolution, 536; 555
I
ЮЗ, алгоритм, 373; 387; 392; 394; 398; 401; 453- 591
598; 761; 797
IDA*, алгоритм. 181
IL, программа, 416
Imperative language, 685
Improper symbol, 78
Incremental parsing, 566
Induction, 372
Inductive bias, 372; 400; 795
Inference rule, 70; 89
Information
extraction system, 596
processing psychology, 524
Informedness, 784
Inheritance, 750
Interpolaiive memory, 468
Interpretation, 75
J
JASS.276
Java, SO; 60S; 750
Justification based truth maintenance system, 332
К
KEE, 750
Knowledge representation hypothesis, 221
к-коннектор, 134
L
Lambda-calculus, 713
Lambda-PROLOG, 680
Learning algorithm. 438
LEX. 388; 402; 411
Lexical closure, 712
Lexicon, 567
LIFO. структура данных, 622
Limitation on the number of disjuncts, 402
Предметный указатель
Linear associator, 437; 467
Link grammar, 597
LISP, 50; 276; 396; 416; 501; 606; 607; 685
логическая операция, 694
связывание переменных, 701
символьные вычисления, 694
List, 186; 615; 686
Literal, 529
Logic
program, 547
programming, 542; 547
Logical inference, 89
Logistic function, 445
M
Macro, 738
Macro-expansion, 738
Magnetoencephalography, 793
Majority vote, 512
Map. 7/7
function, 729
Marker, 247
Markov
assumption, 587
chain, 564
Matching process, 523
Maximally specific generalization, 383
Maximum likelihood density estimation, 417
Means-aids analysis, 220
Means-ends analysis, 522; 784
Mercury, 680
Meta-DENDRAL, 797
Meta-inierpreter, 609; 646; 690
Meta-linguistic abstraction, 647; 727
Metamorphosis grammar, 680
Meta-predicate, 609; 639
Modal logic, 253
Model-based reasoning, 784
Modus tollens, 91
Monotonicity, 784
Monte-Carlo, 486
Morphology. 564
Multiple draft theory of consciousness. 791
Mutation, 487; 503
Mutual information clustering, 589
MYCIN, система, 45; 650
N
NASA, 318
Natural deduction system, 557
NETtalk, система, 452
Network topology, 438
Neural network, 372
Neuroscience, 786
Neurotransmitter, 787
849
N-ply look-ahead, 171
Nuclear magnetic resonance, 794
Nucleus, .555
Numeric taxonomy, 4 и
Occurs check, 722
Operations research, 784
Operator table, 527
Order crossover. 490
Ouistar, 459
О
обучения на основе пояснения 668
семантических сетей, 657
создание
метаинтерпретаторов, 646
семантических сетей, 639
типы данных, 640
Property list, 747
PROSPECTOR, программа, 45
Queue, 609; 624
Q-обучение, 431
РАС-
нзучаемость, 404
обучение, 404
Paramodulation, 555
Parse tree, 568
Parsing, 565
Pascal, язык, 641; 705
Pattern, 58
Perception, 436\ 439
Permutation, 503
Phonology, 564
Phrase structure, 568
Physical symbol system, 782
hypothesis, 58
Planning, 527
Polymorphism, 750
Positive literal, 612
Positron emission tomography, 793
Posterior probability, 356
Pragmatics, 564
Predicate, 62; 692
calculus, 62
Predictability, 421
Predictiveness, 421
Prenex normal form, 532
Prior probability, 355
Priority queue, /55; 609; 624
Probability density function, 352
Probably approximately correct learning, 404
Procedural
attachment, 543
semantics, 547
Production, 197
system, 796
PR0^ 50- «* 276; 383; 520, 528; 606- 706
абстрактный тин данных, 622
множество, 625
очередь, 624
приоритетная очередь 624
стек, 622
проверка соответствия типов 642
реализация
R
Raw fitness, 503
Read-eval-print loop, 687
Reasoning over minimum model, 336
Recursively enumerable language, 574
Reduce, 557
Refraction, 211
Refutation, 528
complete, 539
Regular language, 574
Reinforcement learning, 71; 373
Relational database, 593
Replacement, 522
Representation language, 783
Reproduction, 503
Resolution, 77; 90; 92; 95; 606
inference rule, 91
proof procedure, 528
refutation, 533
system, 606
theorem prover, 522
Resolvent, 534
Reward function, 426
Rewrite rule, 567
Roulette wheel, 486
Satellite, 555
SCAVENGER, система, 416
Schema, 494
Schemata, 800
SCHEME, 605
Scheme, язык, 803
Science of intelligent systems, 780; 792
Script, 238
Self-organizing network, 458
Semantic
grammar, 598
interpretation, 565
network, 64; 229; 639
preference theory, 599
Предметный Y*a3i
1ате|1Ь
Semantics, 564
Sentential form, 567
Set, 625
of support, 522
s-exprcssion, 686
SHRDLU, 563
Sigmoid, 445
Similarity-based learning, 373; 405
Skolem
constant, 532
function, 93
Skolemizalion, 93; 532
Smalltalk, 750
Speech act theory, 39
Split, 557
SQL, 593
Stack, 609
Standard ML, язык, 803
State space
graph, 32
search, 32; 108
Step-size parameter, 427
Stream, 729
STRIPS. 407; 528
Strong method, 784
Structure mapping theory, 413
Subproblem list, 523
Substitution, 522
Subsumpdon architecture, 222; 255; 510
Supervised learning. 373; 381:415
Surface structure, 599
Symbol-based learning, 784
Symbolic expression, 686
Syntax, 564
Systematicity, 413
principle, 414
Systran, программа, 59/
s-выражение, 501; 686:689
m\,686
T
Table of connections, 526
Tail resursron, 695
Target, 375
Temporal difference learning. 426
rule. 428
Terminal, 142; 567
Theorem proving. 522
Theory of reference, 35
Top-down
derivation, 568
parser, S6S
Transformational grammar. 598
Transition network, 569
Tree,;;;
Tngram, 58Я
и
Unconditional probability, 355
Unit
clause, 541
preference, 522
Universal type, 249
Unsupervised learning, 373,415
V
Value function, 426
Variable quantifier, 81
Verb phrase, 142
Version space, 381
Search, 373; 380; 661
Vitebi algorithm, 587
w
Weak method, 520; 784
problem solver, 220
Well -formed formula, 74
William of Occam, 394
A
А*, алгоритм, 493
Абдуктивные рассуждения, 7}; 326.338
Абдуктнвный вывод, 327; 552
Абдукция
на основе стоимости, 341
Абстрактный
класс, 751
тип данных, 609; 622:696
Абстракция, 58
данных. 30
металингвистическая, 647; 727
Абсурдный тип. 249
Автоассоииативная память. 437:468:477
Автомат, конечный, 574
Автоматические рассуждения, 519; 522; 559
Автоматическое
доказательство теорем, 43; 369
программирование, 504
Автономная система, 263
Агент, 4ft 49; 222
гибкий, 263
кнтеллеггуальнын, 37/
Агентная
архитектура, 792
модель, 79/
Адаптивное планирование, 3/6
Аксиома гранив, J10
Аксон, 51
Апивацнакная функция, 445
Алгебре ограничений, 337
Предметный указатель
851
Алгорш*
A, 165
A», 165.493
C4.5, 399
CLUSTERS, 373
COB-WEB, 373
DYNA-Q, 425
ЮХ-^73-2392-394;398;453;588;591; 76h
797
IDA* 18!
LEX, 411
Meta-DENDRAL, 406
ШЕ,291;30Г
Вктерби, 557
возврата, 331
генетический, 481:485; 786
двухуровневого минимакса, 174
индукции,395
исключения кандидата, 381; 385; 391; 661; 666
исходящей звезды, 459
Кохонена,457
Маркова, 198
обобщения на основе объяснения, 407
обратного распространения, 448
обучения, 438
на основе подобия, 373
на основе пояснения, 668
персептрона, 441
с учителем Гроссберга, 456
Хебба без учителя, 463
Хебба с учителем, 466
отбора пропорционально критерию
качества, 486
победитель забирает все, 455
пожарной цепочки, 495
поиска
в пространстве версий, 373
в ширину, 714
допустимый, 165
жадный, 7}7
построения дерева решений (ЮЗ), 392
унификации, 103; 724
устранения противоречий, 335
хронологических возвратов, 331
Альфа-бета-усечение, 175
Анализ
естественного языка, 592.
лингвистический, 585
синтаксический, 564
целей и средств, 220; 522; 526; 784
Анализатор
на основе сети переходов, 573
сверху вниз, 568
Аналогия, 375; 412
Анонимная переменная, 617
Антецедент, 74
Апостериорная вероятность, 356
Априорная вероятность, 355
Арность, 79
Арх1ггсктура
Copycat, 255; 259
гибридная, 306
категориальная, 222; 255
категоризации, 510
классной доски, 213
а-список, 723
Ассоциативный список, 723; 724
Атом, 609; 686; 689
Атомарное высказывание, 80
Атрибут, 593
Аттрактор, 436; 437; 472; 513
Аттракторная сеть, 437
Аттракторный радиус, 471; 472
Ациклический
направленный граф, 360
ориентированный граф, 114
База знаний, 275
Базовая категория, 420
Байесовская сеть доверия, 327; 359
Байесовский
анализ, 355
подход,520
Безусловная вероятность, 355
Биграмма, 589
Бинарная резолюция, 529; 555
Бритва Оккама, 394
в
Вектор
весовых коэффициентов, 436
признаков, 403; 662
Вероятностная
семантика, 341
функция чувствительности, 352
Вершины-братья, 111
Весовой коэффициент, 438
Включение процедур, 543
Внедренная частица а, 514
Возврат с учетом зависимостей, 331
Воспроизводство, 503
Временная
логика, 365
разность, 426
Встроенный тип данных, 705
Входной сигнал, 437
Выбор свойств на основе теории информаци .
Выражение
k-CNF, 405
единичное, 541
396
852
Предметный указ'
,ате*ь
замкнутое, 85
категоризированное, 543
КНФ.488
конъюнктивное, 728
символьное, 686
функциональное, 79
хорновское, 547; 727
Высказывание, атомарное, 80
Вычислимость по Тьюрингу, 58
Вычислительная эффективность, 268
Генератор, 729
Генерация языковых конструкций, 584
Генетическая эпистемология, 800
Генетический
алгоритм, 52; 481; 484; 485; 786
оператор, 487
инвертирования, 488
мутации, 487
обмена, 488
упорядоченного скрещивания, 490
Генетическое
обучение, 372
программирование, 484; 501
Гетероассоциативная память, 437; 468
Гибкая сеть, 260
Гибкий агент, 263
Гибридная система, 303; 306
Гнперграф, 134
Гипердуга, 134
Гиперплоскость, 44}
Гиперрезолюция, 536; 555
Гипотеза, 383
Андерсона, 805
о представлении знаний, 221
о физической символьной системе, 52; 58; 778;
782
Черча-Тьюрннга, 789; 805
Глагольная конструкция, 142; 568
Головоломка
15,114
8,200
Грамматика, 574
контекстно-независимая, 573
метаморфоз, 650
определенных дизъюнктов, 680
падежная, 598
преобразований, 555; 598
связей, 591
семантическая, 598
фразовая структура, 568
функциональная, 598
Грамматическая триграмма, 591
Грамматический маркер, 598
Грамматическое пратто, 570
Гргф,64
ациклический
направленный, 360
ориентированный 114
№ИЛИ,Ш;2в5
и-вершина, 142
и-узел, 133
концептуальный, 222; 245; 581; 594
ориентированный, 110
отношения между вершинами, / / /
поведения задачи, 198
поиска, 283
пространства состояний, 66; 108
размеченный, ПО
состояний, 32
д
Двоичная арифметика, 34
Двунаправленная ассоциативная память (ДАЛ), 472
Двунаправленный поиск, 385
Дедуктивное замыкание, 411
Дедукция. 522
Декларативная семантика, 609
Декларативное программирование, 522
Декларативность, 685
Дельта-правило, 436; 446; 449
обобщенное, 441
Демодулятор. 556
Демодуляция, 556
Демон, 244
Дендрит, 51
Дерево, 111
грамматического разбора, 568; 573; 5SO
разбора, 565
решений, 392; 403
построение сверху вниз, 394
Диагностика, 274
Диаграмма
потоков данных, 594
сущность-связь. 594
Дизъюнкт, 74
Дизъюнктивная форма, 528
хорновская, 612
Дизъюнкция, 74
Дилемма эмпирика. 795; 798
Динамическое программирование. 429; 587
Днскриминантная
сеть.-«2
фикция, 442
Добавление повторяющихся элементов, 400
Доказательство
на основе опровержения. 612
теорем, 520; 522; 528
Допустимая эарнстика, 164
Допустимость, 7S4
Допустимый
Предметный указатель
853
алгоритм поиска, 165
путь, 113
Доступ к компонентам списка, о*>
Единичное
выражение, 541
предпочтение, 522
Естественная дедуктивная система, 55/
Естественный язык, 5/9; 561
Ж
153; 160:634
Жадный алгоритм поиска.
Задача
анализа естественного языка, 592
генерации языковых конструкций, 584
диагностики автомобиля, 287
из мира блоков, 637
индуктивных порогов, 403
индукции,372; 40]
интересной жизни, 537; 540
исключающего ИЛИ, 440; 454
классификации, 442
битовых строк, 400
эндшпилей, 398
кластеризации, 417; 459
коммивояжера, ИЗ; 116; 437; 489
о кеннгсбергских мостах, 32; 108
о кувшинах с водой, 65/
о миссионерах и каннибалах, 336; 681
обработки естественного языка, 671
обучения классификации, 441
определения частей речи, 585
оценки кредитного риска, 392
перевозки человека, волка, козы и капусты, 626;
706
планирования, 308; 311
размещения костей домино, 783
смертной собаки, 530
счастливого студента, 536
управления перевернутым маятником 345
финансового советника, 100; 139; 163
ханойских башен, 526
хода конем, 202; 618
Закон
де Моргана, 220; 548
исключения третьего 344
Замена, 522
Замкнутость предметной области 337
Замыкание функции, 736
Запись активации,189
Запрос SQL, 595
И
и-вершина, 138
Игра
-Жизнь", 505; 506
"крестики-нолики", ИЗ; 150;427
"ним", 170
"пятнашки", 114
Иерархическая
абстракция, 604
декомпозиция задачи, 48
Иерархия
обобщения понятий, 391
Хомского, 574; 599
Извлечение
знаний, 279
ответа, 535
Изучаемость, 404
Изучение понятий, 373
Именная конструкция, 142; 568
Императивность, 685
Импликация, 74; 523; 728
Индуктивное обучение, 373
Индуктивный порог, 370; 372; 373; 391,400; 43&
457; 795; 797
Индукция, 372; 373; 395
Инкапсуляция, 750
Инкрементальный
алгоритм обучения, 387
синтаксический разбор, 566
Интеллектуальный агент, 371; 373
Интерполятивная память, 468
Интерпретатор, 726
метауровия, 727
семантический, 580
Интерпретация, 75; 84; 274
Интерфейс взаимодействия с базой данных, 592
Инфиксный интерпретатор, 690; 726
Искусственная жизнь, 485; 508
Искусственный
интеллект, 27; 42; 781
распределенный, 262
нейрон,372; 437
Исследование операций, 784
Исходящая звезда, 459
Исчерпывающий поиск, 69
Исчисление
высказываний, 73; 522
символы, 74
предикатов, 62; 73; 77; 103; 727
алфавит, 78
первого порядка, 34; 86
символы, 80
пропозициональное, 296
Итерационное заглубление, 13!
К
Каноническая форма, 237
Каноническое правило формирования, 252
Категориальная архитектура, 222; 255
трехуровневая, 256
категоризация, 4/7
Категоризированное выражение, 543
Категория базового уровня, 420
Квантификация переменных, 85
Квантор
всеобщности, 81; 85
переменных, 81
существования, 81; 85
Китайская комната, 785
Класс, 750
NP-сложных задач, 181
абстрактный, 751
регулярных языков, 574
Классификатор, 400; 515
Классификация, 436
по минимальному расстоянию, 443
Классная доска, 213
Кластеризация взаимной информации, 589
Клеточный автомат, 481; 484; 505; 512
Ключ, 723; 752
КНФ, 488
Когнитология, 524; 792
Кодироваине
Грея, 492
сжимающее, 453
Композиция, 94
Конечный автомат, 574
Конкурентное обучение, 455
Конкурентный метод обучения, 436
Коннекшоннстская модель, 780
Конструктор, 705
Контекстно-зависимый язык, 574
Контекстно-независимая грамматика, 573; 575
Контекстно-независимое правило, 598
Контекстно-независимый язык, 574
Концевая вершина, 112
Концептуальная
кластеризация, 373; 417; 418
модель, 280
Концептуальное
отношение, 245
синтаксическое правило, 234
Концептуальный граф, 222; 230; 245; 581; 594
обобщение и специализация, 250
тип, 247
Концепция
d-отделенич, 360
Конъюнкт, 74; 729
Конъюнктивная нормальная форма. 455
Конъюнктивное выражение, 728
Конъюнктивный порог, 402
Конъюнкция, 74
Дизъюнктов, 530
Корень графа,//о
Корневой граф, Но
Корректность понятия, 404
Коэффициент
скорости обучения, 445
Критерий отбора, 484
Кусочно-линейная биполярная пороговая функция,
Л
Лексикон, 567
Лексическое замыкание, 772
Лингвистический анализ, 585
Линейная
ассоциативная память, 437
входная форма, 551
Линейный
ассоциатор, 467
кршернн качества, 5Й2
Литерал, 529
положительный, 612
Логика
умолчания, 330
хорновских дизъюнктов, 612
Логистическая функция, 445.449
Логическая
операция. 694
программа, 545; 606
система поддержки истинности, 335
Логический вывод, 59
Логическое
исчисление Буля, 34
программирование, 542; 547.609, 727
следствие, 74
Лучевой поиск, 180
Лямбда-выражение, 713
м
Магнитная звцефалография, 793
Мажоритарное голосование. 512
Макрорасширение, 738
Макрос, 738
defclass, 751
Максимально
конкретное обобщение, 383
общее понятие, 383
Максимальное правдоподобие,^;?
Максимальный общий подтип, 249
Маркер. 247
*,248
Марковская
модель, 58S
цепь, 564
855
Предметный указатель
Марковское предположение, 587
Массив. 705 ., ■,
^атнчсскаянодельан^гии.4/2
Машина Тьюринга, 448; 509,803
Машинное обучение, 373; JVJ, 4JJ
Медиатор. 787
Мера
доверия, 162; 164; 350
неопределенности, 326
правдоподобия, 350
Метазнание, 65
Метаинтерпретатор, 609; 646; 690
М* LISP, 647
Металингвистическая абстракция, 64/; ш
Метаплаиирование, 322
Метапредикат, 609; 639
Метод
фобучения,45/
ветвей н границ, 117
временных разностей, 426
встречного распространения, 457
градиентного спуска, 446; 449
грамматических триграмм, 591
дефаззификацни, 349
динамического программирования, 429
добавления повторяющихся элементов, 400
максимального правдоподобия, 417
миниыакса, 170
Монте-Карло. 429; 431; 486
неточных рассуждений на основе фактора
уверенности, 652
обратного распространения ошибки, 449
обучения по методу обратного распространения,
44!
основанный на знаниях, 273
поиска экстремума, 784
редукции целен, 317
сильный, 784
слабый, 784
триангуляции дерева клик, 364
центра тяжести, 349
цепочки, 523
Методология классной доски, 272
Механизм
вывода, 275
рассуждений
на основе множественной достоверности
335; 366
на основе опыта, 300
Минимальная модель мира, 337
Минимальный общий супертип, 249
Многозначная логика, 365; 612
Многослойный персептрон.440
Мис^ественная теория сознания 79}
"ножественное наследование 755
Множество, 622; 625; 705
поддержки, 522; 540
Модальная логика, 253; 365
Модель, 336
автоассоциативной памяти, 477
агентная, 791
внешней среды, 426
Гроссберга, 459
искусственной жизни, 437
классной доски, 186
коннекнионистская, 780
концептуальная, 280
концептуальной зависимости, 237
марковская, 564; 588
минимальная, 336
нейроподобная, 435
обоснования по аналогии, 412
обучения с подкреплением, 437
рассуждения, 325
стохастическая, 585
триграмм, 588
физиологическая, 481
Хебба, 437; 799
змерджентная, 370; 484
Модификатор отношений, 236
Моноид, 237
Монотонность, 784
Морфема, 564
Морфология, 564
Мультнагентнал система, 262
Мутация, 487; 503
н
Наиболее общий унификатор, 95
Накопительная кластеризация, 417
Наследование, 64; 750
множественное, 755
Научная деятельность, 476
Начальное состояние, 772
Нейрон, 57; 372; 435
искусственный, 437
Мак-Каллока-Питса, 436; 438
Нейронная
вычислительная модель, 51
сеть, 372; 435; 786
Нейрон-победитель, 437; 456
Нейроподобная модель, 435
Нейро-сим&ольная гибридная система, 481
Немонотонная система, 328
Немонотонные рассуждения, 327
Несобственный символ, 78
Нетерминальный символ, 573
Неточный вывод .
на основе фактора уверенности, 31
Нечеткая ассоциативная матрица, 346
Нечеткое множество, 344
Нормализованный критерий качества.
Нормальная дизъюнктивная форма,
Предметный у***
О
Обобщение. 370; 377; 380
максимально конкретное, 383
на основе объяснения, 407
Обобщенное дельта-правило, 44}
Обобщенный граф, 377
Оболочка
CUPS. 276
cxsheU,65fl
Обоснование
на основе опыта, 475
по аналогия, 4J2
Обработка естественного языка, 671
Обратная цепочка, 118
Обратное распространение ошибки, 436
Обучение, 50; 37}
без учителя, 373; 415; 456
генетическое, 372
индуктивное, 373
конкурентное, 455
машинное, 373; 391; 431
на основе
временных разностей, 426; 428
обратного распространения ошибки, 436
объяснения, 373; 374; 405; 407
подобия, 373:405
поиска, 391,400
пояснения, 661; 668
на уровне знаний,411
по аналогии, 303
по методу
градиентного спуска, 445
обратного раеггространення. 441; 448
с подкреплением, 71; 373; 424 4*7 49Л
с учителем, 373; 381; 415
синхронное. 463
эволюционное, 372
Общая стратегия вывода, 522
Общий подтип, 249
Объект. 750
Объектно-ориекпфованное
моделирование, 686
программирование. 749
Ограничение на количество дизъюнктов, 402
Однослойная нейронная сеть, 439
Оператор
cut, 549
unless, 329
генетический, 52
отсечения, 609; 620
разрешения, 52}
Операция, 388
а 74
Опорный объект, 418
Оппортунистический поиск, 2S9
Оппортунистическое планирование, 322
Предметный указатель
Опровержение, 528
разрешения, 528; 533
Ошимизаиия, 436
^^ЛфИаВДыйграф 7/0
?ГаСЧЯа1ыотвап^^ 469
Осведомленность. 784
Основное выражение, 85
Открепление, 522
Отношение
конткгпуальвое, 245
концептуальной зависимости, 234
"«ЖДУ вершинами графа, 77/
Отображение, 7/7
Оценивание
с задержкой, 736
функции, 79
Оценка плотности по методу максимального
правдоподобия, 477
Очередь, 725; 186.699;622; 714
приоритетная, 755; 624
п
Падежная грамматика, 598
Падежный фрейм. 233;581:671
Пакет организации памяти,237
Пара условие-действие, 692
Параметр
качества. 498
совести,456
шага, 427
Парамолутншия, 555
Парсинг, 744
Переменная, анонимная, 6/7
Перестановка, 503
Пегзсеггфон, 43&, 439; 798
многослойный, 440
атанер, 507
Планирование, 274; 527
адаптивное, 3J6
Планировщик. 274; 307
STRIPS, 263
Поведение, 750
Поверхностям структура, 599
Поверхность ошибки, 446
Погранична* частив. 514
Подсистема объяснений. 275
Подстановка. 94; 522
Подтип, 249
максимальный общий, 249
Подход ТЬтскра-Шафера. 350
Пожтронвм эмвесиояш томография. 793
Поиск, 42; 783
в Web. 592
в глубину, 72/: 124; 1Л>. 61l;63i; 706
пределы» глуби», 131
с возвратом- 631
857
, пространстве
юст. 373:3», 661 ,
716
двунаправленный, 385
лучевой,180
методом полного перебора, 69
на графе И/ИЛИ,/-W
на основе
данных, 118; 206
образца, 212
цели, 287
оппортунистический, 2S9
от общего к частному, 383; 406; 665
от цели, 118
от частного к общему. 382
по ключевым словам в Web, 596
с возвратом,95; 121
эвристический, 163
экстремума, 153
Полезность категории, 421
Полиморфизм, 750
Полиморфная функция, 750
Политика л, 426
Полный байесовский анализ, 355
Положительный литерал, 612
Помеха, 474
Понимание
естественного языка, 369; 519; 561
языка на основе шаблонов, 555
Понятие
-кандидат, 576
максимально общее, 383
Порог
индуктивный, 372; 400
конъюнктивный, 402
синтаксический, 402
Пороговая функция, 438
Построение
дерева решений сверху вниз, 394
опровержений, 528
списков, 697
Потенциал возбуждения, 787
Поток, 729
Правило, 197; 612
Meta-DENDRAL, 797
Вилроу-Хоффа, 446
временных разностей, 429
вывода, 70,89; 521; 567; 574
Демпстера, 35}
если..., то..., 275; 500
контекстно-независимое, 598
копирования, 250
логического вывода, 495
мажоритарного голосования, 512
модус поненс, 31; 77; 90
модус толленс, 91
обучения
Кохонсна, 456
на основе временных разностей, 428
объединения, 250
отделения, 107; 523; 529
перехода, 485
преобразования, .599
продукционное, 2Я2; 574; 784
резолюции, 77; 91; 92
рулетки, 456
специализации, 2.50
Правильно построенная формула, 74
Прагматика, 564
Предваренная нормальная форма, 532
Предикат, 62; 79; 685; 692
assert, 6/4
bagof, 633
consult, 614
eq,708
member, 616; 697
retract, 614
Предиктивность, 427
Предложение, 81; 568
Предположение о замкнутости
мира, 296; 328; 336; 547
пространства, 55/
Предпосылка, 74
Предсказуемость, 42У
Представление знаний, 42
иерархических, 559
Пренексная нормальная форма, 532
Приведение, 557
Принцип
бритвы Оккама, 340
Вильяма из Оккама, 394
Дарвина, 370
минимизации энергии, 477
обучения без учителя, 456
понимания языка на основе шаблонов, 585
разделения переменных, 614
резолюции, 90; 528; 534
систематичности, 414
Приоритет операций, 726
Приоритетная очередь, /55; 186; 609; 622; 624
Приоритетность классов, 755
Проблема
выделения кредита, 390
границ, 267; 308
исследования представления знаний, - ■*'
линейной разделимости, 436; 441
машинного обучения, 371
обобщения, 370
обоснования, 794
понимания естественного языка, 561
представления знания и поиска,-'
Предметный ука**
связывания, 794
формализации метазнаний, 65
эпистемологического Доступа, 801
Проверка
вхождения, 94; 722
соответствия
типов. 706; 750
шаблонам, 718
Прогнозирование, 274; 436
Программа
AM, 415
BACON, 416
Candide, 591
DENDRAL, /20; 406
Dipmeter Advisor, 45
EVRISKO, 416
Hacker, 50
!L,4/6
INTERNIST, 45
LEX, 388; 402
компоненты, 390
Logic Theorist (LT), 219; 522
PROSPECTOR, 45
SHRDLU, 47
STRIPS, 407
Systran, 591
WEBMATE, 265
XCON, 45
AM, 50
игры в шашки, 173; 300
логическая, 548; 606
на языке PROLOG, 611
Прогр аммирование
автоматическое, 504
генетическое, 484
декларативное, 522
динамическое, 587
логическое, 542; 547; 609; 727
объектно-ориентированное, 749
функциональное, 607; 685
эволюционное, 509
Продукционная
память, 497
система, 144; 186; 196; 2S2; 511; 708
на языке PROLOG, 626
Продукционное правило, 197; 574; 784
Продукция, 197
Проект NASA, 31S
Проектирование, 274
Пропозициональное исчисление, 296
Просодия, 564
Пространство
версий, 381
возможных действий, 308
понятий, 376
состояний, 112
задачи, 42
Прототип, 278
Процедура
аяьфа-бт->-сечення,77^
"'«еррезолюции, 536
Доказательства теорем, разрешающая. 528
миннмакса.Ш
полного доказательства, 90
Процедурная семантика, 547
Процедурный
метод ннтерггреташн правил, 290
язык, 67Я
Процесс
извлечения знаний, 279
проверки соответствия, 523
сколемизации, 532
триангуляции, 363
уменьшения различий, 526
Прямая цепочка, 118
Прямой процесс рассуждения, 252
Психология обработки информации 524
Путь
доггустнмый, 113
на графе, ПО
Разбор предложений. 568
на естественном языке, 598
Разделение переменных, 614
Различил между декларативным и процедурным
стилями программирования, 71!
Размеченный граф, ПО
Разностный список, 645
Распознавание образов, 436
Распределенная система, 435
Распределенный искусственный интеллект, 262
Рассуждения
абдуктивные, 338
байесовские, 355
на минимальных моделях, 336
на основе
модели, 292; 305: 7S4
проект NASA, 296; 318
<явю,299;305
правил, 304
немонотонные 327
Расширение логических грамматик, 576
Расширенная
грамматика фразовой структуры, 576
сеть переходов, 569
Расшепление, 557
рацтжашкнюпяеекм программная система, 40
Реализация памяти, 436
Регрессия цели.405
Регулярный язык,
574
Редактор базы знаний, 276
Редукция целей, 317
Предметный указатель
859
на основе семаетическнх сетей. 675
к 1S6; 187:618
Раярса* 196:615
car-сот. 699
Релядюняая база лавных. 59^
Рефраири.27/
Ревак» задач на основе еявбых методов, 220
г>ешеяк-гавдидат, *>. *£5
Решет зависимостей предпосылок, 335
Розовая футшв. >5(* ТУ
Роль- ЗУ. 2*1
C++, 50
Самовосщмнзвйзстео, 509
Слмоорганюапнв сети. 45S
Оморешнкаавя. 4М
Свтежвжг,555
Своисиоортовормя1ЫДСтн,#77
х°4
1.70!
К 564
вероятностная, 341
Семантическая
грвммвтнкв, 59£
внгерцроадт. 565
сеть, б* 229: 377; 520; 639:65& 746
Саяншчеодм вытчкусгатор. 580
Севтеицвалывя форма. 567
Сеть
NETttfc.4»
асидйминаыясобрвтнымиящ-дни.^т^
встречного реафостравенкж, 456;459
гибкая, 26D
L 7/. 327; 355
а. 457
!;78б
рострваово, 799
1.569; 574
,575
Ч*"^раоц>ос1рввеяня,47/
с обратными связями, 472
LJ72; 435; 4S3
обратного
Хоафвда. 437; 472. 477; 479: 799
Сигмслиальная функция, 445
Сильный метод, 273
решети проблем. 220
Символ. 7JC
1КТЮВД0СТИ, 79
несобственный, 75
нетерминальный. 573
Символьная модель, 436
Символьное
выражение. 656
исчисление. 30
обучение, 784
представление, 435
Символьные вычисления, 694
Символьный анализ. 564
Синапс 51; 439
Сннтакагкскнй
яя&та. 144.564:567
порог, 402
раэбор, 565
Синхронное обучение, 463
Система
Button. 321
CASEY. 299
CLUSTER/14/5; 457; 75№
COB-WEB. 420
DENDRAL. 45
Dipmeter. 120
exsheU. 650
Geneo] Problem Sober, 522
HEARSAY-П, 213
HEARSAY-Ш. 215
Livingstone, 296; 31S
Logic Theorist. 43
NLACSY>L\. 135
Meca-DEXDRAL, 5ft 322
MYCIN. 45; 26J; 292; 321; 650
NETtalk. 452
PROSPECTOR, 120; 357
PROTOS, 299
ROBOCUP. 263
SCAVENGER, 416
SHRDLU. 563
STRIPS, 311,528
Tdresias,50
автоматической классификации юрил***1*1
документов, 598
автономная, 263 ^
анашш меднплнеякх карточек папнеяя*-
гибридная, 306
доказательства на основе резолюции. 5
извлечения информации, 596
классификации. 485; 495
логического вывода, 496
м>ш.тиагентная. 262
на основе модели, 293
кенро-снмвольная п|брядная. 481
х.522
Предметный У**8*
немонотонная, 325
о6ъеетно-ор1гснт1(рованвая, 294
основанная на знаниях. 326
параллельном распределенной обработки. 435
поддержки истинности. 328; 331
с учетом обоснования, 332
поддержки страхования «они. 598
1гродукционная, 196; 511; 626; 708
прямого поиска, 2Я9
решения обших задач GPS, 526
с сильными методами, 303
формальная, 733
формальной логики, 32
экспертная, 37; 273; 520
Систематичность, 413
Сжолемгааиия. 93:531
Скоэемовская
константа, 532
функция. 93
Скрещивание. 457; 503
Скрытый стон, 453
Ствбын метод. 784
решения задач. 220:520
Слой нейронов. 435
Создание
конфликта. 529
локальных переменных. "Л?
Составной терм, 727
Состояние. 108: 750
Специализация. 377; 330
Список, 607; 615; 6S6; 6S9
open, 186
ассоциативный, 723
подзадач, 523
прнорктетнестй классов. 755
разностный. 645
свойств, 747
Способность к обученгоо, 369
Среднеквадрат1тческая ошибка, 447
Стек. 609; 622
Степень
вершины графа. /i*>
подобия. 302
Стохастическая модель, 5S5
Стратегия
поиска
от цели. 135
жстремума. 153
пропкшфовання о-го стоя. 171
Строгий индуктивный порог, 457
Структура. 7D5
обтленення. 409
Стжлфордская теория фактора уверенности. 342
Супертнп. 249
минимальный общий, 24$
Схема
кодирования, 435
^язгоо&юженяя, 500
Сценарий, 237-.23*
роль, 240
TR-лерево, 3/6
нстанвоста, 76
операций. 527
отэнчнй,522
связей, 526
треугольная.3/2
Тстео^кэатнввое гшннроввнме, 316
Теорема
Байеса,32?.356;357
о бесплатном сыре, 79S
Теория
пгпиштиггд" "|?7
Байеса, 71; 355
вероятностей, 344; 35t
внедренного действия, 802
возможных миров, 7S5
вычислимости. 36
графов. 32; 108
Дешктсра-Шафсра. 326
ннгеззектуазьных систем, 780; 792
ивформашви 396; 591
клеточных автоматов, 484
конпегоуаяьвойдаисивюстж. 23*237
концептуальных графов, 250
логического вывода. 89
ъ.3&0;415
птл.790
к сетей. 437; 7S5
нечетких множеств, 344
обоснования Демпстера-Шафера. Зл'
обучения Хебба.462
Пирса, 2»
поисо в ирииранивс состояний. 108
позутюрязка. 406
предикатов. 657
первого порядка. 521; 606; 612:671
(рнбаияявао корректного с кмяяхЛ
кровтвестыо РАСчйучеяи. 404
рекурсивных функшиа, 607:685
!*■•.•* ™
семантического оредгючтевна. У
семейного сходства. 420
сетей своей. 437
ссылок. 35
стрл-ктурнот отсорвжеяяя. 4/3
схематического учреждения. 2А
фактор3 \sepeHBCcriL 342
ферма-тьмых языков. 5!4
Терм. 7*
составное- -
861
Предметный указатель
%шменимости,.^
Тьюринга,-*5
Тип данных, 247
встроенный, 70.*
универсальный, 249
Топаюгаясетн,^
Точечная пара, 723
ТЕ^сформаононнал аналог. ^
Трансформация сверху вниз, Зов
Третий закон Keaiepa,5£W
Треугольная таблнпа, i/2
Триангуляция, #3
Триграмма, 555
грамматическая, 59!
Тьюринг, 36
Универсальная машина Тьюринга, 509
Универсальное ннстанцирование, 91
Универсальный тип, 249
Уникальность имен, 337
Унификация, 93; 94; 139; 530; 642; 644; 687; 701
Упорядоченное скрещивание, 490
Уровень активации нейрона, 438; 445
Ускорение обучения, 41 1
Условная
вероятность, 356
оценка, 694
Ф
Факт. 548; 612
Фактор, 536
ветвления, 121
пространства, 178
достоверности, 740
момента, 448
ybepMHQcm,I64;326;342
Факторизация выражений 536
Феноменология, 39
Физиологически модель, 45/
Фильтрация, 436
шума, 407
Фонема, 452
Фонология, 564
Форма, б§7; 689
и". 693
^^ие категор,^^
формула, атомарная, 80
Фразовая структура грамматики «,
фрейм. 241; 576; 639; 659; 685; 7QS' **
падежный, 581; 671
функциональная грамматика, 59s
функциональное
выражение, 79
магнитно-резонансное сканирован»
программирование, 607; 685 79i
функция
defun, 691
eval, 690
let, 703
list, 655
quote, 659
set, 701
setf,69S
вознаграждения, 426
высшего порядка, 711
дискримннантная, 442
доступа к компонентам списка, 696
отображения, 713; 729
полиморфная, 750
построения списков, 697
предикат, 692
принадлежности, 345
рекурсивная, 655
родовая, 750; 753
стоимости, 426
унификации, 721
фильтр, 711
ценности, 427
энергии, 437
сет, 472
X
Хвостовая рекурсия, 698
Хебб, 460
Хеммингов вектор, 468
Хорновская дизъюнктивная форма, 612
Хорновский дизъюнкт, 612
Хорновское выражеине, 403; 521; 547,
Хронологический возврат к поелыдушеМУ
состоянию, 331
Хэш-таблица, 70S
Ц
Целевое условие, 112
1Ькп,б93
чтения-оценки-печати, 687
Числовая таксономия, 4\7
Предмете
,ый<
Ш
Я
Шаблон, 58; 711; 718
предложений, 584
условий, 498
Шаговый множитель, 427
Эволюционная модель обучения, 437
Эволюционное
обучение, 372
программирование, 509
Эвристика, 43; 69; 149; 301; 784
допустимая, 164
Эвристический поиск, 153; 163; 18J; 376
Эдинбургский синтаксис, 607
Эквивалентность, 74
Экспертная система, 37; 45; 273; 520; 526
MYCIN, 292
общие задачи, 274
основанная на правилах, 282
основные модули, 275
подсистема объяснений, 275
Эмерджентная модель, 370,484
Эмерджентное
поведение, 435
решение задач, 22/
Эмерджентность. 258
Эмерджентные вычисления, 512
Эмпирическая дилемма, 370
Эффект горизонта, 174
Ядерный магнитный резонанс. 793
Ядро, 315; 555
Язык
C++, 608; 750
Common USP, 608; 685; 690; 697
встроенные типы данных, 705
встроенные функции, 690
глобальные переменные, 715
основные свойства, 706
C-PROLOG, 610
FORTRAN. 675
Goedd,650
Java, 750
KL-0№,268
KRU265
Umbda-PROLOG,6S0
USP, 396.416; 501; 607; 685
LOGO, 278
Mercury. 650
OPS, 200
Pascal, 641; 705
PROLOG, 186; 383; 528; 60&. 706
Scheme, 803
Smalltalk, 608
SQL, 593
SWM«, 335
естественный, 519; 561
инфиксной арифметики, 726
контекстно-зависимый, 574
гантисстяо-незавнеямый, 574
представления. 783
процедурный, 678
регулярный, 574
рек>тхивно-перечнслимын, 574
Фреге, 34
Предметный указатель
863
Научно-популярное издание
Джордж Ф. Люгер
Искусственный интеллект: стратегии и методы решения
сложных проблем, 4-е издание
Литературный редактор О.Ю. Белозовская
Верстка О.В. Линник
Художественный редактор С.А. Чернокозинский
Корректоры Л.А. Гордиенко, Т.А. Корзун, Л.В. Карою".
О.В. Мишушина, Л.В. Чернокозинская
Издательский дом "Вильяме".
101509, Москва, ул. Лесная, д. 43, стр. 1.
Изд. лиц. ЛР № 090230 от 23.06.99
Госкомитета РФ по печати.
Подписано в печать 23.06.2003. Формат 70X100/16.
Гарнитура Times. Печать офсетная.
Усл. печ. л. 69,66. Уч.-изд. л. 58,9.
Тираж 3500 экз. Заказ № 289.
Отпечатано с диапозитивов в ФГУП "Печатный двор"
телт Мин""ерства РФ по делам печати,
,071<?оСЩа™Я и Ч*дап1 массовых коммуникаций.
15 "0, Санкт-Петербург, Чкалова™! пр., 15.