/









































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































Автор: Гонсалес Р. Вудс Р.
Теги: цифровая обработка сигналов компьютерные науки компьютерные технологии цифровая обработка изображений
ISBN: 5-94836-028-8
Год: 2005




Текст
м
циф
И Р
ровой обработки
Р. ГОНСАЛЕС, Р. ВУДС
Цифровая
обработка
изображений
Перевод с английского
под редакцией П. А. Чочиа
ТЕХНОСФЕРА
Москва
2005
Р. Гонсалес, Р. Вудс
Цифровая обработка изображений
Москва:
Техносфера, 2005. - 1072 с. ISBN 5-94836-028-8
Монография раскрывает базовые понятия и методологию компьютерной
обработки изображений, дает основы для дальнейшего изучения этой много-
гранной и быстро развивающейся области. Книга является одним из наиболее
популярных, известных в мире и полных учебников в области теории и методов
цифровой обработки видеоинформации. Многие из приведенных в ней алго-
ритмов реализованы в широко известных пакетах компьютерной обработки
изображений.
Рассмотрены все основные направления обработки и анализа изображений,
включая основы теории восприятия и регистрации видеоинформации, методы
фильтрации, вейвлет-преобразования, улучшения, восстановления и сжатия
черно-белых и цветных изображений. Обсуждаются также вопросы сегмента-
ции, распознавания образов, описания и представления деталей, морфологи-
ческого анализа изображения. Все разделы сопровождаются большим количест-
вом примеров и иллюстраций.
Книга рассчитана на научных работников и профессиональных программис-
тов. специалистов по компьютерному дизайну, студентов и преподавателей.
Книга постоянно занимает первое место в рейтинге продаж Amazon.com и ши-
роко используется разработчиками и дизайнерами.
Digital Image
Processing
Second fcdition
Rafael C. Gonzalez
Richard E. Woods
Cnxr Saddle Knrr. Хи» kro C~-J3h
© 2002. Authorized translation from the English language edition,
entitled DIGITAL IMAGE PROCESSING, 2ND EDITION by GONZALEZ,
RAFAEL C.; WOODS, RICHARD E., published by Pearson Education, Inc,
publishing as Prentice Hall.
© 2005, ЗАО «РИЦ «Техносфера» перевод на русский язык,
оригинал-макет, оформление.
ISBN 5-94836-028-8
ISBN 0-201-18075-8 (англ.)
СОДЕРЖАНИЕ
Предисловие научного редактора перевода......................12
Предисловие к английскому изданию ...........................15
Благодарности ...............................................19
Об авторах ..................................................20
ГЛАВА 1. ВВЕДЕНИЕ ................................................23
1.1. Что такое цифровая обработка изображений? ...................23
1.2. Истоки цифровой обработки изображений .......................26
1.3. Примеры областей применения цифровой обработки изображений...31
1.3.1. Формирование изображений с помошью гамма-лучей ..........33
1.3.2. Рентгеновские изображения ...............................35
1.3.3. Изображения в ультрафиолетовом диапазоне ................37
1.3.4. Изображения в видимом и инфракрасном диапазонах ..........38
1.3.5. Изображения в микроволновом диапазоне ...................48
1.3.6. Изображения в диапазоне радиоволн .......................48
1.3.7. Примеры, иллюстрирующие другие способы
формирования изображений........................................49
1.4. Основные стадии цифровой обработки изображений ..............56
1.5. Компоненты системы обработки изображений ....................60
Заключение........................................................64
Ссылки и литература для дальнейшего изучения .....................65
ГЛАВА 2. ОСНОВЫ ЦИФРОВОГО ПРЕДСТАВЛЕНИЯ ИЗОБРАЖЕНИЙ ..73
Введение .........................................................73
2.1. Элементы зрительного восприятия .............................74
2.1.1. Строение человеческого глаза.............................74
2.1.2. Формирование изображения в глазу ........................78
2.1.3. Яркостная адаптация и контрастная чувствительность ......79
2.2. Свет и электромагнитный спектр ..............................85
2.3. Считывание и регистрация изображения ........................89
2.3.1. Регистрация изображения с помощью одиночного сенсора ....90
2.3.2. Регистрация изображения с помощью линейки сенсоров.......92
2.3.3. Регистрация изображения с помошью матрицы сенсоров ......94
2.3.4. Простая модель формирования изображения .................96
2.4. Дискретизация и квантование изображения .....................98
2.4.1. Основные понятия, используемые при дискретизации и квантовании 99
2.4.2. Представление цифрового изображения ....................102
2.4.3. Пространственное и яркостное разрешения ................105
2.4.4. Эффекты муара и наложения спектров......................112
2.4.5. Увеличение и уменьшение цифровых изображений............114
2.5. Некоторые фундаментальные отношения между пикселями ........117
2.5.1. Соседи отдельного элемента .............................117
2.5.2. Смежность, связность, области и границы.................118
2.5.3. Меры расстояния ........................................120
2.5.4. Поэлементные операции над изображениями.................122
2.6. Линейные и нелинейные преобразования .......................123
Заключение.......................................................123
Ссылки и литература для дальнейшего изучения ....................124
4 Содержание
Задачи ..........................................................125
ГЛАВА 3. ПРОСТРАНСТВЕННЫЕ МЕТОДЫ УЛУЧШЕНИЯ
ИЗОБРАЖЕНИЙ......................................................131
Введение ........................................................131
3.1. Предпосылки ................................................132
3.2. Некоторые основные градационные преобразования .............135
3.2.1. Преобразование изображения в негатив....................135
3.2.2. Логарифмическое преобразование .........................137
3.2.3. Степенные преобразования................................138
3.2.4. Кусочно-линейные функции преобразований.................143
3.3. Видоизменение гистограммы ..................................148
3.3.1. Эквализация гистограммы ................................150
3.3.2. Приведение гистограммы (задание гистограммы) ...........158
3.3.3. Локальное улучшение.....................................167
3.3.4. Использование гистограммных статистик для
улучшения изображения .........................................169
3.4. Улучшение на основе арифметико-логических операций .........175
3.4.1. Вычитание изображений ..................................177
3.4.2. Усреднение изображений..................................180
3.5. Основы пространственной фильтрации .........................185
3.6. Сглаживающие пространственные фильтры ......................189
3.6.1. Линейные сглаживающие фильтры ..........................190
3.6.2. Фильтры, основанные на порядковых статистиках ..........194
3.7. Пространственные фильтры повышения резкости ................196
3.7.1. Основы .................................................197
3.7.2. Улучшение изображений с использованием вторых производных:
лапласиан .....................................................200
3.7.3. Улучшение изображений с использованием первых производных:
градиент ......................................................209
3.8. Комбинирование методов пространственного улучшения .........213
Заключение.......................................................219
Ссылки и литература для дальнейшего изучения ....................219
Задачи ..........................................................220
ГЛАВА 4 ЧАСТОТНЫЕ МЕТОДЫ УЛУЧШЕНИЯ ИЗОБРАЖЕНИЯ ..................228
4.1. Предварительные замечания ..................................229
4.2. Введение в фурье-анализ. Преобразование Фурье и частотная область ..231
4.2.1. Одномерное преобразование Фурье и его обращение ........231
4.2.2. Двумерное ДПФ и его обращение ..........................238
4.2.3. Фильтрация в частотной области .........................242
4.2.4. Соответствие между фильтрацией в пространственной области
и фильтрацией в частотной области..............................249
4.3. Сглаживающие частотные фильтры .............................257
4.3.1. Идеальные фильтры низких частот ........................257
4.3.2. Фильтры низких частот Баттерворта ......................265
4.3.3. Гауссовы фильтры низких частот .........................268
4.3.4. Дополнительные примеры низкочастотной фильтрации .......269
4.4. Частотные фильтры повышения резкости .......................273
4.4.1. Идеальные фильтры высоких частот .......................274
4.4.2. Фильтры высоких частот Баттерворта .....................277
6 Содержание
4.4.3. Гауссовы фильтры высоких частот .........................278
4.4.4. Лапласиан в частотной области ..........................279
4.4.5. Нерезкое маскирование, высокочастотная фильтрация
с подъемом частотной характеристики,
фильтрация с усилением высоких частот .........................284
4.5. Гомоморфная фильтрация .................................... 289
4.6. Вопросы реализации .........................................293
4.6.1. Некоторые дополнительные свойства двумерного
преобразования Фурье ...........................................293
4.6.2. Вычисление обратного преобразования Фурье
при помощи алгоритма прямого преобразования ....................298
4.6.3. Еще раз о периодичности: необходимость дополнения нулями.300
4.6.4. Свертка и теоремы о корреляции .........................309
4.6.5. Перечень свойств двумерного преобразования Фурье .......314
4.6.6. Быстрое преобразование Фурье ...........................317
4.6.7. Некоторые замечания по поводу конструирования фильтров .321
Заключение.......................................................322
Библиографические замечания......................................323
Задачи ..........................................................324
ГЛАВА 5. ВОССТАНОВЛЕНИЕ ИЗОБРАЖЕНИЙ .............................331
5.1. Модель процесса искажения/восстановления изображения .......332
5.2. Модели шума ................................................333
5.2.1. Пространственные и частотные свойства шума .............334
5.2.2. Функции плотности распределения вероятностей для
некоторых важных типов шума ...................................334
5.2.3. Периодический шум ......................................341
5.2.4. Построение оценок для параметров шума ..................343
5.3. Подавление шумов — пространственная фильтрация .............345
5.3.1. Усредняющие фильтры.....................................346
5.3.2. Фильтры, основанные на порядковых статистиках ..........349
5.3.3. Адаптивные фильтры .....................................355
5.4. Подавление периодического шума — частотная фильтрация ......364
5.4.1. Режекторные фильтры ....................................364
5.4.2. Полосовые фильтры ......................................366
5.4.3. Узкополосные фильтры ...................................367
5.4.4. Оптимальная узкополосная фильтрация ....................371
5.5. Линейные трансляционно-инвариантные искажения ..............377
5.6. Оценка искажающей функции ..................................382
5.6.1. Оценка на основе визуального анализа изображения .......382
5.6.2. Оценка на основе эксперимента ..........................383
5.6.3. Оценка на основе моделирования .........................384
5.7. Инверсная фильтрация .......................................388
5.8. Фильтрация методом минимизации
среднего квадратического отклонения (винеровская фильтрация) ....390
5.9. Фильтрация методом минимизации
сглаживающего функционала со связью..............................395
5.10. Среднегеометрический фильтр ...............................402
5.11. Геометрические преобразования..............................402
5.11.1. Пространственные преобразования .........................403
Содержание
5.11.2. Интерполяция значений яркости............................406
Заключение.......................................................410
Библиографические замечания......................................412
Задачи ..........................................................414
ГЛАВА 6. ОБРАБОТКА ЦВЕТНЫХ ИЗОБРАЖЕНИЙ ..........................420
Введение ........................................................420
6.1. Основы теории цвета.........................................421
6.2. Цветовые модели ............................................426
6.2.1. Цветовая модель RGB ....................................427
6.2.2. Цветовые модели CMY и CMYK ........................... 431
6.2.3. Цветовая модель HS1 ....................................432
6.3. Обработка изображений в псевдоцветах .......................439
6.3.1. Квантование по яркости .................................439
6.3.2. Преобразование яркости в цвет ..........................443
6.4. Основы обработки цветных изображений........................445
6.5. Цветовые преобразования ....................................447
6.5.1. Постановка задачи ......................................447
6.5.2. Цветовое дополнение ....................................482
6.5.3. Вырезание цветового диапазона...........................483
6.5.4. Яркостная и цветовая коррекция .........................485
6.5.5. Обработка гистограмм ...................................489
6.6. Сглаживание и повышение резкости ...........................490
6.6.1. Сглаживание цветных изображений ........................491
6.6.2. Повышение резкости цветных изображений .................493
6.7. Цветовая сегментация........................................493
6.7.1. Сегментация в цветовом пространстве HSI ................493
6.7.2. Сегментация в цветовом пространстве RGB ................495
6.7.3. Обнаружение контуров на цветных изображениях ...........498
6.8. Шум на цветных изображениях ................................501
6.9. Сжатие цветных изображений..................................502
Заключение.......................................................503
Библиографические замечания......................................504
Задачи ..........................................................505
ГЛАВА 7. ВЕЙВЛЕТЫ И КРАТНОМАСПГГАБНАЯ ОБРАБОТКА .................511
Введение ........................................................511
7.1. Предпосылки ................................................512
7.1.1. Пирамиды изображений ...................................514
7.1.2. Субполосное кодирование.................................519
7.1.3. Преобразование Хаара ...................................530
7.2. Кратномасштабное разложение.................................533
7.2.1. Разложения в ряды ......................................534
7.2.2. Масштабирующие функции .................................537
7.2.3. Вейвлет-функции.........................................543
7.3. Одномерные вейвлет-преобразования...........................547
7.3.1. Разложение в вейвлет-ряды...............................548
7.3.2. Дискретное вейвлет-преобразование ......................551
7.3.3. Интегральное вейвлет-преобразование ....................553
7.4. Быстрое вейвлет-преобразование..............................557
7.5. Двумерные вейвлет-преобразования ...........................567
8 Содержание
7.6. Вейвлет-пакеты ............................................577
Заключение......................................................590
Библиографические замечания.....................................590
Задачи .........................................................592
ГЛАВА 8. СЖАТИЕ ИЗОБРАЖЕНИЙ ....................................598
Введение .......................................................598
8.1. Основы.....................................................600
8.1.1. Кодовая избыточность ..................................601
8.1.2. Межэлементная избыточность ............................605
8.1.3. В изуальная избыточность ..............................609
8.1.4. Критерии верности воспроизведения .....................612
8.2. Модели сжатия изображений .................................614
8.2.1. Кодер и декодер источника .............................615
8.2.2. Кодер и декодер канала ................................617
8.3. Элементы теории информации.................................619
8.3.1. Измерение информации ..................................619
8.3.2. Канал передачи информации .............................620
8.3.3. Основные теоремы кодирования ..........................627
8.3.4. Применение теории информации ..........................637
8.4. Сжатие без потерь .........................................641
8.4.1. Неравномерное кодирование .............................642
8.4.2. LZW кодирование .......................................649
8.4.3. Кодирование битовых плоскостей ........................653
8.4.4. Кодирование без потерь с предсказанием ................663
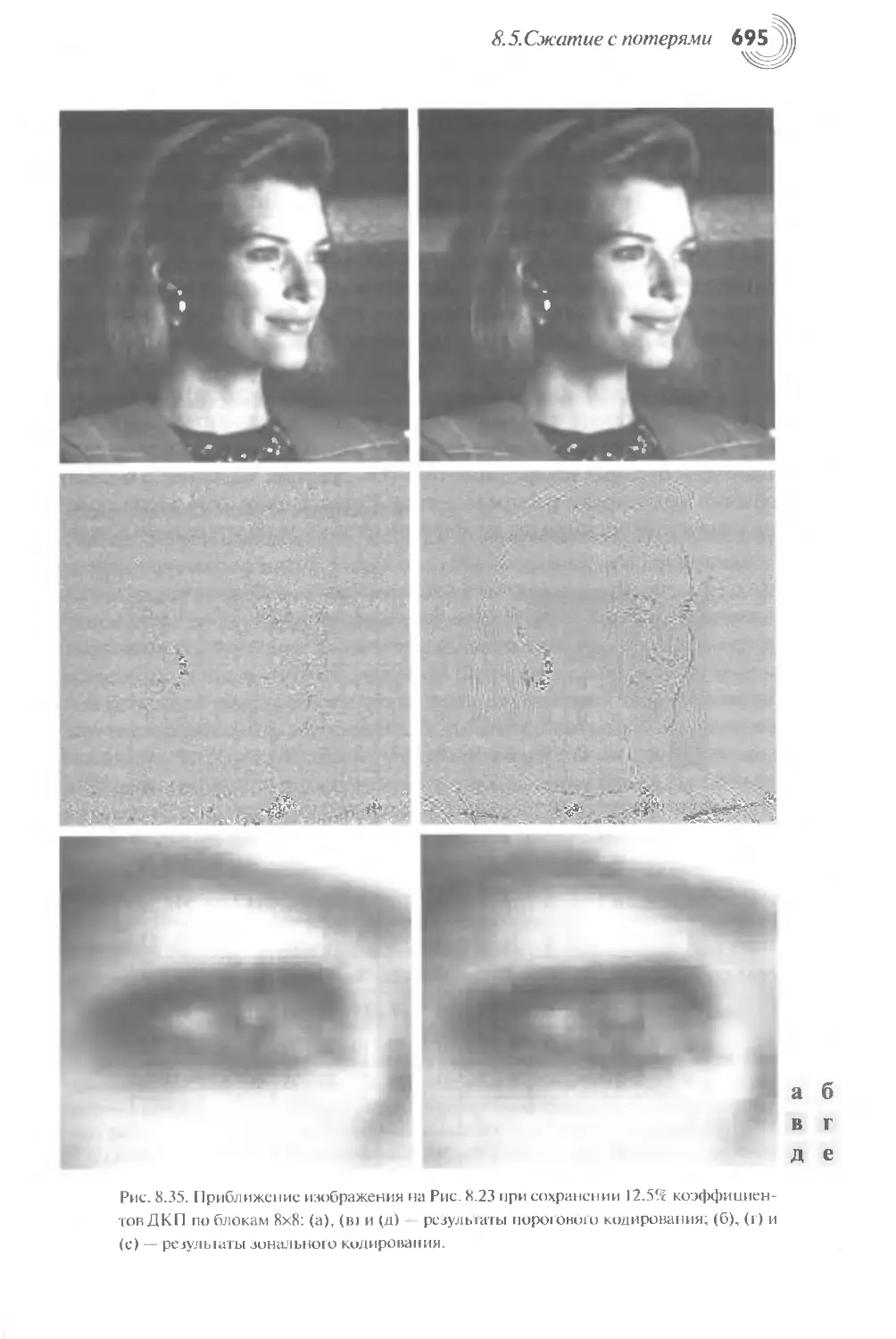
8.5. Сжатие с потерями .........................................667
8.5.1. Кодирование с предсказанием ...........................667
8.5.2. Трансформационное кодирование..........................681
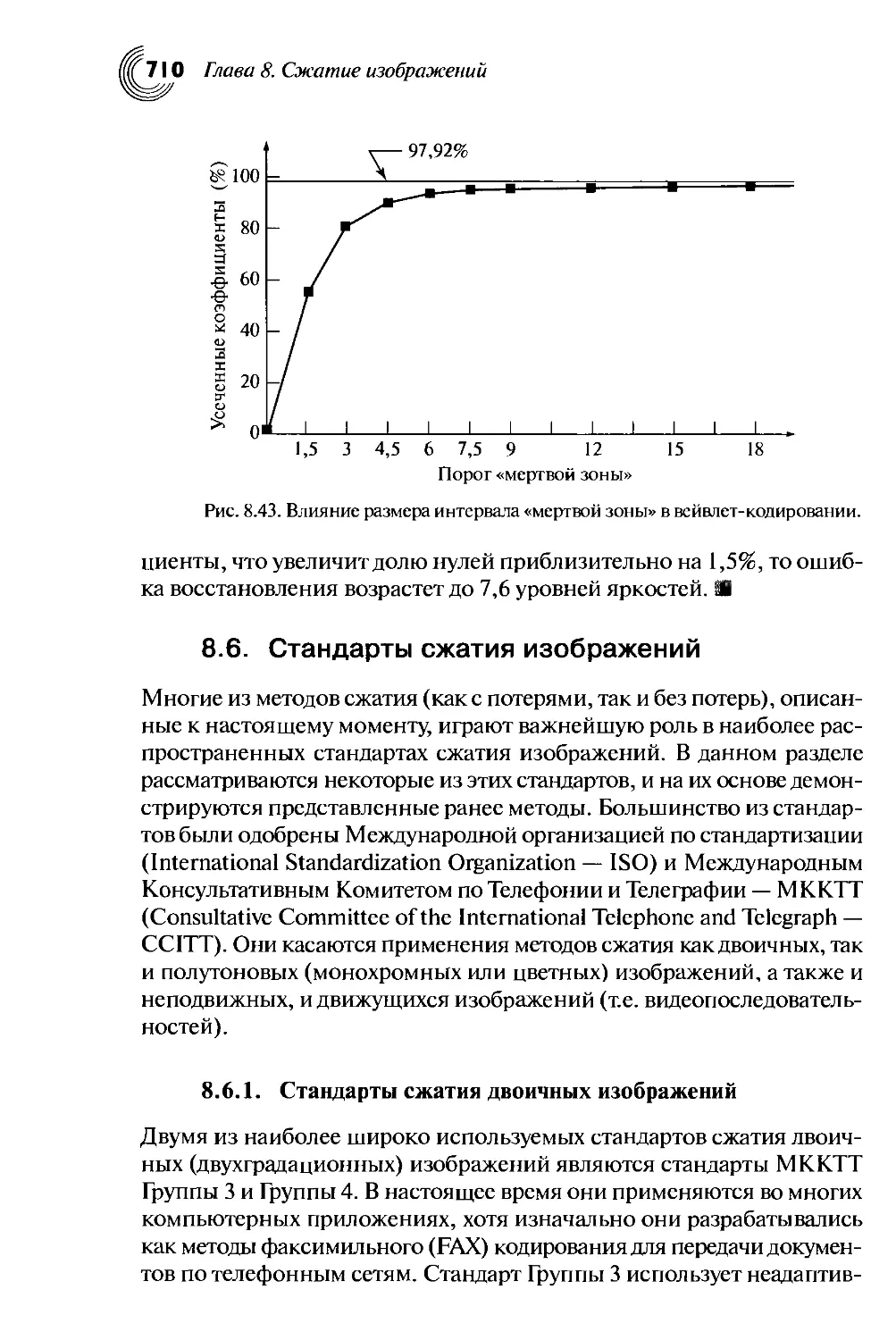
8.5.3. Вейвлет-кодирование ...................................700
8.6. Стандарты сжатия изображений ..............................710
8.6.1. Стандарты сжатия двоичных изображений .................710
8.6.2. Стандарты сжатия полутоновых неподвижных изображений...717
8.6.3. Телевизионные стандарты сжатия ..........................733
Заключение......................................................737
Ссылки и литература для дальнейшего изучения ...................738
Задачи .........................................................740
ГЛАВА 9. МОРФОЛОГИЧЕСКАЯ ОБРАБОТКА ИЗОБРАЖЕНИЙ .................747
Введение .......................................................747
9.1. Начальные сведения ........................................748
9.1.1. Некоторые базовые понятия теории множеств ......... 748
9.1.2. Логические операции над двоичными изображениями .......751
9.2. Дилатация и эрозия ........................................753
9.2.1. Дилатация .............................................753
9.2.2. Эрозия ................................................756
9.3. Размыкание и замыкание ....................................759
9.4. Преобразование «Успех / Неудача» ..........................765
9.5. Некоторые основные морфологические алгоритмы ..............767
9.5.1. Выделение границ ......................................768
9.5.2. Заполнение областей ...................................769
9.5.3. Выделение связных компонент ...........................771
10 Содержание
9.5.4. Выпуклая оболочка......................................774
9.5.5. Утончение .............................................777
9.5.6. Утолщение .............................................778
9.5.7. Построение остова .....................................780
9.5.8. Усечение ..............................................783
9.5.9. Сводная таблица морфологических операций...............786
9.6. Расширение морфологических алгоритмов
на полутоновые изображения .....................................789
9.6.1. Дилатация .............................................790
9.6.2. Эрозия ................................................791
9.6.3. Размыкание и замыкание ................................793
9.6.4. Некоторые приложения полутоновой морфологии ...........797
Заключение......................................................802
Ссылки и литература для дальнейшего изучения ...................802
Задачи .........................................................803
ГЛАВА 10. СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ ..............................812
Введение .......................................................812
10.1. Обнаружение разрывов яркости .............................813
10.1.1. Обнаружение точек.......................................814
10.1.2. Обнаружение линий ......................................816
10.1.3. Обнаружение перепадов ..................................819
10.2. Связывание контуров и нахождение границ...................836
10.2.1. Локальная обработка ....................................837
10.2.2. Глобальный анализ с помощью преобразования Хафа ........839
10.2.3. Глобальный анализ с помощью методов теории графов.......845
10.3. Пороговая обработка.......................................850
10.3.1. Обоснование ............................................851
10.3.2. Роль освещения .........................................853
10.3.3. Обработка с глобальным порогом .........................855
10.3.4. Обработка с адаптивным порогом .........................858
10.3.5. Обработка с оптимальными глобальным и адаптивным порогами .. .861
10.3.6. Использование характеристик границы для улучшения
гистограммы и локальной пороговой обработки....................868
10.3.7. Пороги, основанные на нескольких переменных ............872
10.4. Сегментация на отдельные области .........................874
10.4.1. Исходная постановка ....................................874
10.4.2. Выращивание областей ...................................875
10.4.3. Разделение и слияние областей ..........................879
10.5. Сегментация по морфологическим водоразделам ..............881
10.5.1. Основные концепции......................................882
10.5.2. Построение перегородок .................................885
10.5.3. Алгоритм сегментации по водоразделам....................888
10.5.4. Использование маркеров .................................891
10.6. Использование движения при сегментации ...................893
10.6.1. Пространственные методы ................................894
10.6.2. Частотные методы .......................................898
Заключение......................................................904
Ссылки и литература для дальнейшего изучения ...................904
Задачи .........................................................907
Содержание I I
ГЛАВА 11. ПРЕДСТАВЛЕНИЕ И ОПИСАНИЕ..............................917
Введение .......................................................917
11.1. Представление ............................................918
11.1.1. Цепные коды ............................................918
11.1.2. Аппроксимация ломаной линией............................920
11.1.3. Сигнатуры ..............................................923
11.1.4. Сегменты границы .......................................925
11.1.5. Остовы областей ........................................927
11.2. Дескрипторы границ .......................................931
11.2.1. Некоторые простые дескрипторы ..........................931
11.2.2. Нумерация фигур ........................................932
11.2.3. Фурье-дескрипторы ......................................935
11.2.4. Статистические характеристики...........................939
11.3. Дескрипторы областей .....................................941
11.3.1. Некоторые простые дескрипторы ..........................941
11.3.2. Топологические дескрипторы .............................942
11.3.3. Текстурные дескрипторы .................................947
11.3.4. Моменты двумерных функций ..............................957
11.4. Использование главных компонент для описания .............961
11.5. Реляционные дескрипторы ..................................971
Заключение......................................................976
Ссылки и литература для дальнейшего изучения ...................976
Задачи .........................................................978
ГЛАВА 12. РАСПОЗНАВАНИЕ ОБЪЕКТОВ ...............................983
Введение ...................................................... 983
12.1. Образы и классы образов ..................................983
12.2. Распознавание на основе методов теории решений ...........989
12.2.1. Сопоставление ..........................................990
12.2.2. Статистически оптимальные классификаторы ...............998
12.2.3. Нейронные сети ........................................1009
Алгоритмы обучения.............................................1014
Многослойные нейронные сети без обратной связи ................1019
12.3. Структурные методы распознавания ........................1036
12.3.1. Сопоставление номеров фигур ...........................1037
12.3.2. Сопоставление строк символов ..........................1039
12.3.3. Синтаксическое распознавание строк символов............1041
12.3.4. Синтаксическое распознавание деревьев ..................1048
Заключение.....................................................1060
Ссылки и литература для дальнейшего изучения ...................1061
Задачи .........................................................1061
Предметный указатель...........................................1067
Предисловие научного редактора перевода
Использование видеоинформации в современном мире стремитель-
но возрастает. Здесь и различные системы мониторинга, наблюде-
ния, технического зрения, видеотелефонии, регистрирующие и пере-
дающие огромные объемы видеоданных, и различные автономные
системы (роботы), принимающие решение на основе анализа видео-
информации, и персонализированное телевизионное вещание, и по-
лиграфия со значительно возросшим объемом иллюстраций в печат-
ной продукции, и медицина, и Интернет, и многие другие направления.
При этом наряду со значительным повышением уровня развития тех-
ники, весьма существенную роль играют методы обработки видеоин-
формации. Они обеспечивают улучшение изображений для их на-
илучшего визуального восприятия человеком, сжатие видеоданных для
хранения и передачи по каналам связи, а также анализ, распознава-
ние и интерпретацию зрительных образов для принятия решения и уп-
равления поведением автономных технических систем.
Монография известных американских специалистов в области
цифровой обработки изображений Р. Гонсалеса и Р. Вудса является вве-
дением в теорию и методы компьютерной обработки изображений, да-
ет основы для дальнейшего изучения этой многогранной и быстро раз-
вивающейся области. В книге излагаются основы теории и методов
преобразования и анализа видеоинформации, и она является одним
из наиболее известных и распространенных за рубежом учебников
в данной области науки. Многие алгоритмы, которые в ней приведе-
ны, реализованы в различных широко используемых пакетах ком-
пьютерного редактирования изображений. В США данная книга вы-
шла уже вторым изданием (первое появилось в 1992 г.). Перед этим
было два издания книги с тем же названием, написанной Гонсалесом
и Винцем (в 1977 г. и в 1987 г.).
Круг рассматриваемых в книге вопросов достаточно широк. Изуча-
ются все основные направления обработки и анализа изображений,
включая основы теории восприятия и регистрации видеоинформации,
основные методы фильтрации и вейвлет-преобразования, методы
улучшения, восстановления и сжатия черно-белых и цветных изо-
бражений; также обсуждаются вопросы сегментации, распознавания
образов, описания и представления деталей, морфологического ана-
лиза изображения. При этом необходимо отметить, что некоторые
из вопросов, например, вопросы вейвлет-преобразования изображе-
Предисловие научного редактора перевода 13
ний или теоретики-информационные подходы к кодированию изо-
бражений до настоящего момента были опубликованы на русском язы-
ке лишь в виде отдельных разрозненных статей. Без сомнения, про-
веденные в книге рассмотрения не являются исчерпывающими
в каждом из отдельных вопросов, однако они дают достаточно хоро-
шее представление о сущности проблем и о наиболее распростра-
ненных способах их решения.
Все разделы книги содержат достаточно подробные обсуждения,
приведено большое количество примеров и обработанных изображе-
ний, иллюстрирующих рассматриваемые методы. Оригинал книги
сопровождается Интернет-сайтом (англоязычным), расположенным
по адресу http://www.imageprocessingbook.com/index_dip2e.htm. На нем
представлены вспомогательные и дополнительные материалы, ре-
шения предложенных авторами задач, методические материалы по со-
ставлению учебных планов, а также база данных, содержащая многие
из приведенных в книге иллюстраций.
Материал книги излагается на вполне доступном уровне.
Предполагается, что читатель имеет математическую подготовку
в объеме первых курсов технических вузов и знаком с основами
математического анализа, линейной алгебры, теории вероятностей
и математической статистики, а также владеет минимальными
навыками программирования.
Данная монография создавалась авторами как введение в основные
понятия и методы цифровой обработки изображений, дающее основы
для последующего углубленного изучения проблематики обработки
изображений, а также проведения самостоятельных исследований в
этой области. В качестве стиля изложения авторы выбрали
постепенный переход от простого к сложному и снабдили материал
большим количеством задач, приведенных в конце каждой главы.
Эти качества, вместе с полнотой охвата и достаточной подробностью
рассмотрения изучаемых вопросов, позволяют рекомендовать эту
книгу в качестве основы для построения учебного курса по теории и
методам цифровой обработки изображений для студентов
соответствующих специальностей. Данная книга будет полезна
широкому кругу читателей: профессионалам в области анализа и
переработки видеоинформации, студентам и аспирантам,
специализирующимся в области информатики, а также всем
интересующимся вопросами компьютерной обработки и анализа
неподвижных изображений и видеопоследовательностей.
Следуя стилю авторов, мы сочли уместным привести список
наиболее важных книг, изданных на русском языке, связанных
с проблематикой обработки изображений. Данный список помещен
Предисловие научного редактора перевода
в конце Главы 1 вслед за аналогичным списком монографий,
рекомендованных авторами. К сожалению, в нашей стране в последние
годы заметно ощущается недостаток учебной литературы, отражающей
как фундаментальные основы, так и изменения, происходящие
в области цифровой обработки видеоинформации. Мы надеемся, что
книга Р. Гонсалеса и Р. Вудса сможет восполнить возникший
в отечественной учебной литературе дефицит книг из области теории
и методов обработки изображений.
В русском издании устранены многие неточности и опечатки: как
те, которые были отмечены авторами, так и те, которые встретились
при переводе. При переводе книги пришлось столкнуться с рядом
трудностей, прежде всего терминологического характера. Кроме того,
встречались неотмеченные авторами опечатки, неточности
в формулировках, а иногда и прямые ошибки. Переводчиками была
проделана большая работа по проверке значительной части
формулировок, алгоритмов и выкладок. Насколько было возможно,
переводчики старались сохранить стиль оригинала; однако книга
написана авторами не строго формально, в результате чего в некоторых
местах для достижения большей точности и ясности изложения
приходилось несколько отклоняться от текста оригинала. В тех случаях,
когда, по мнению переводчиков, полезным являлось дать некоторые
разъяснения, были написаны дополнительные примечания.
Нумерация всех примечаний сделана сплошная по главам: т.е. по
умолчанию ссылка указывает на примечание внутри той же самой
главы.
Перевод книги выполнен канд. техн, наук Л. И. Рубановым (вводная
часть, гл. 1, 2, 9—12), канд. физ.-мат. наук Д.В. Сушко (гл. 4—7) и
канд. техн, наук П.А. Чочиа (гл. 3, 8).
П.А. Чочиа
Предисловие к английскому изданию
Если что-то удается читать без усилий, значит
больших усилий стоило это написать.
Энрике Хардиел Понсела
Настоящее издание является результатом наиболее глубокой переработ-
ки книги «Цифровая обработка изображений» с тех пор, как она впер-
вые была издана в 1977 г. При подготовке этого издания, как и при
подготовке предыдущих (Гонсалес и Уинтц, 1977 г. и 1978 г.; Гонсалес
и Вудс, 1992 г.), мы ориентировались прежде всего на студентов и пре-
подавателей. Поэтому, как и прежде, основные цели этой книги — слу-
жить введением в основные понятия и методы цифровой обработки изо-
бражений, а также создать основу для последующего изучения и
проведения самостоятельных исследований в этой области. С учетом
этих целей мы вновь сконцентрировались на материале, который счи-
таем фундаментальным и применимым не только для решения узкоспе-
циальных задач. Уровень математической сложности книги остался в рам-
ках программы колледжа высшей ступени или первого курса университета
и предполагает начальную подготовку в области математического
анализа, линейной алгебры, теории вероятности и математической
статистики, а также элементов компьютерного программирования.
На нынешнее издание в значительной степени повлияло недавно
проведенное издательством Прентис-Холл исследование рынка, при
котором была выявлена необходимость:
1) более глубокой мотивировки во вступительной главе касательно
областей возможного применения цифровой обработки изображений;
2) упрощения и сокращения материала вводных глав для скорей-
шего проникновения в суть обсуждаемого предмета;
3) более наглядного изложения ряда тем, таких как преобразова-
ния и восстановление изображений;
4) выделения в самостоятельные главы вопросов, относящихся
к обработке цветных изображений, применению вейвлет-анализа1
и морфологии изображений;
1 В математической литературе для перевода термина «вейвлет» (wavelet) использу-
ется также термин «всплеск» — Прим, перев.
Предисловие к английскому изданию
5) расширения обзора сопутствующих проблем в конце каждой
главы.
Переработка книги, предпринятая в этом издании, отражает на-
ше желание соблюсти разумный баланс между строгостью изложения
и стремлением учесть конъюнктурные соображения, а также замеча-
ния и предложения студентов, читателей и коллег, высказанные со вре-
мени выхода последнего издания. Наиболее важные изменения, сде-
ланные в книге, перечислены ниже.
Глава 1 написана целиком заново. Проблемы, составляющие со-
временную трактовку предмета книги, рассматриваются на приме-
рах из тех областей, в которых используется цифровая обработка
изображений. Не претендуя на исчерпывающую полноту, приведен-
ные примеры не оставят у читателя сомнений в широте использова-
ния методов цифровой обработки изображений. Глава 2 также явля-
ется новой. Основной упор в изложении делается на способы
получения цифровых изображений и тесно связанные с этим поня-
тия квантования, дискретизации, ступенчатости, муара, а также про-
блемы, связанные с изменением масштаба изображения. Форма из-
ложения и включенный в эти две первые главы новый материал
непосредственно обращены к первому и второму из вышеперечислен-
ных требований рынка.
Главы с 3 по 6 охватывают те же понятия, что и Главы 3—5 в пре-
дыдущем издании книги, однако область рассмотрения расширена и
форма подачи материала полностью отличается. В предыдущем изда-
нии Глава 3 была посвящена исключительно преобразованиям изоб-
ражений. Одно из важных изменений, сделанных в книге, — то, что
теперь преобразования изображений вводятся в рассмотрение по ме-
ре их необходимости. Это позволило начать обсуждение методов об-
работки изображений намного раньше, что также согласуется с ры-
ночной конъюнктурой. Улучшению изображений в настоящем
издании посвящено две главы (3 и 4), в отличие от единственной Гла-
вы 4 в прежнем издании. Эта новая организация материала не озна-
чает, что улучшение изображений более важно, чем другие обсужда-
емые области. Скорее, мы выбрали такой путь, чтобы с одинаковой
полнотой изложить методы пространственной обработки изображе-
ний (Глава 3), а также ввести в рассмотрение преобразование Фурье,
частотное представление и фильтрацию изображений (Глава 4). Вво-
дя эти понятия в контексте улучшения изображений (тема, особо
привлекательная для начинающих), мы стремились повысить на-
глядность изложения и учесть тем самым третье из перечисленных тре-
бований рынка. Такая организация книги также предоставляет пре-
Предисловие к английскому изданию
подавателям больше свободы при выборе объема изучаемого матери-
ала, относящегося к частотному представлению изображений.
[лава 5 также была полностью переписана в более наглядной фор-
ме. В предыдущих изданиях книги эта тема излагалась на основе тео-
рии матриц. Несмотря на элегантность и единообразие такой формы
изложения, она оказалась трудной для восприятия, особенно для сту-
дентов младших курсов. Новая форма изложения по существу основы-
вается на тех же позициях, но не опирается на линейную алгебру
и потому воспринимается легче, отчасти благодаря большому количе-
ству новых примеров. Эта простота достигнута ценой потери единст-
ва подхода, в том смысле, что в прежней трактовке большое число ре-
зультатов в области восстановления изображений могло быть получено
из единой базовой формулировки. С другой стороны, однако, мы уве-
рены, что читатели (в особенности начинающие) найдут эту новую
трактовку более привлекательной и понятной. Кроме того, как указы-
вается ниже, изложение материала в прежней форме оставлено на до-
полняющем книгу узле сети Интернет, и к нему легко могут обра-
титься читатели, предпочитающие изложение с позиций теории матриц.
Глава 6, связанная с обработкой цветных изображений, являет-
ся новой. Интерес к этой области за последние несколько лет зна-
чительно вырос в связи с растущим использованием цифровых изо-
бражений в Интернете. Материал по этой тематике существенно
расширен по сравнению с прежними изданиями книги. Также новой
является Глава 7, касающаяся обработки изображений на основе
вейвлет-анализа. Помимо многочисленных применений в области об-
работки сигналов, интерес к этому вопросу вызван потребностью
в более совершенных методах сжатия изображений, что в свою оче-
редь диктуется ростом числа изображений, передаваемых по теле-
коммуникационным сетям и хранящихся в сети Интернет. В [лаву 8,
посвященную сжатию изображений, были внесены изменения, учи-
тывающие новые стандарты и методы компрессии, но основная ее
структура осталась той же, что и в прежних изданиях. В эту главу
перенесены из прежней Главы 3 некоторые виды преобразований
изображений, применяемые в основном в алгоритмах сжатия.
Глава 9, посвященная морфологии изображений, является новой. Ос-
новой для нее послужил значительно расширенный материал, ранее из-
лагавшийся в одном разделе в главе о представлении и описании изо-
бражений. [лава 10, где рассматривается сегментация изображений,
сохранила прежнюю структуру, но дополнена многочисленными новы-
ми примерами и новым разделом о сегментации по водоразделам, [ла-
ва 11, в которой обсуждается представление и описание изображений,
несколько сокращена за счет материала, перенесенного теперь в [лаву 9.
18 Предисловие к английскому изданию
Добавлены новые примеры, и из прежней 1лавы 3 сюда перенесено
преобразование Хотеллинга (описание с помошью главных компо-
нент). [лава 12, посвященная распознаванию объектов, сокращена за счет
удаления тематики, связанной с анализом изображений на основе зна-
ний, поскольку сегодня она очень подробно рассмотрена во многих
книгах, на которые мы ссылаемся в Главах 1 и 12. Опыт, накопленный
со времени последнего издания, показывает, что новое сокращенное об-
суждение задачи распознавания объектов является тем самым местом,
где логично поставить точку в книге «Цифровая обработка изображений».
Хотя книга содержит в себе весь необходимый материал, мы ос-
новали дополняющий ее сайт в Интернет {http://www.prenhall.com/gon-
zalezwoods), цель которого — помочь в использовании книги. На стра-
ницах этого сайта приводится большое число обучающих и
вспомогательных материалов как для студентов, которым преподает-
ся соответствующий курс, так и для самообразования. Также там со-
держится необходимый подготовительный материал, в частности, по
теории вероятности, математической статистике и линейной алгеб-
ре, который излагается на элементарном уровне и с применением
тех же обозначений, что и в книге. Даны также подробные решения
ко многим из предлагаемых в книге упражнений. Для преподавателей
предлагаются планы лекций, материалы для демонстраций и лабора-
торных работ, разнообразные коллекции изображений (в том числе
и большинство из приведенных в книге изображений). Кроме того, на
этом сайте хранятся изъятые из книги части прежних ее изданий, ко-
торые преподаватель может при желании получить по сети и исполь-
зовать в учебном процессе. Если эта книга принимается в качестве ос-
новы для учебного курса, с сайта можно загрузить детальное
руководство с примерами учебных планов, методическими указани-
ями к проведению лабораторных работ, а также решениями упражне-
ний из книги.
Настоящее издание книги «Цифровая обработка изображений» от-
ражает значительный прогресс, достигнутый в этой области за послед-
нее десятилетие. Как обычно для подобных проектов, прогресс про-
должается и после окончания работы над рукописью. Одна из причин,
по которым прежние редакции этой книги были так хорошо приня-
ты во всем мире, — то, что они в первую очередь акцентировались на
фундаментальных концепциях. Такой подход является одной из по-
пыток указать устойчивые ориентиры в стремительно развивающей-
ся совокупности знаний. Мы старались соблюсти тот же принцип
при подготовке этого издания книги.
PC. Г.
Р.Э.В.
Благодарности
Мы в неоплатном долгу перед множеством лиц, как из академичес-
ких кругов, так и из промышленности и правительства, которые вне-
сли большой вклад в это издание книги. Их помощь была столь важ-
ной и разносторонней, что нам трудно выделить их как-то иначе,
чем просто перечислить в алфавитном порядке. В частности, мы глу-
боко признательны за те многочисленные советы по улучшению фор-
мы изложения и содержания книги, которые предложили наши кол-
леги Монги А. Абиди, Уильям Е. Бласс, Рамиро Джордан, Йонг Мин
Ким, Брайан Морс, Эндрю Олдройд, Али М. Реза, Эдгардо
Фелипе Риверон и Хосе Руиз Шульклопер.
Многие лица и организации оказали нам ценную помощь во вре-
мя написания настоящего издания. Мы перечисляем их опять-таки по ал-
фавиту. Мы особо признательны Стиву Эддинсу и Наоми Фернан-
дес из компании The MathWorks, предоставившим нам пакет программ
MATLAB и оказавшим помощь в его использовании, что позволило по-
строить и уточнить многие примеры и экспериментальные результаты,
включенные в настоящее издание. Значительная доля использованных
в нем новых изображений (а в некоторых случаях — их история и объ-
яснение) поступили к нам благодаря усилиям лиц, чей вклад воисти-
ну неоценим, среди которых, в частности: Серж Бехер, Мелисса
Д. Байнд, Джеймс Бланкеншип, Уве Боос, Эрнесто Брибиеска, Дра-
гана Брзакович, Майкл Е. Кейси, Д.Р. Кейт, Майкл У. Дэвидсон,
Томас Р. Гест, Лалит Гупта, Жонг Хе, Роджер Хиди, Хуан Херрера,
Джон М. Хьюдек, Майкл 1урвиц, Крис Й. Йохансен, Ронда Найтон,
Эшли Мохамед, А. Моррис, Кертис С. Обер, Джозеф Е. Пассенте, Дэ-
вид Р. Пикенс, Майкл Робинсон, Барретт А. Шефер, Майкл Шаффер,
Пит Сайтс, Салли Стоу, Крейг Уотсон и Дэвид К. Уи. Мы также при-
знательны другим лицам и организациям, упоминающимся в подпи-
сях ко многим фотографиям, за любезное разрешение использовать
в книге предоставленные ими материалы.
Сотрудники издательства Прентис-Холл Том Роббинс, Роуз Кер-
нан, Элис Дворкин, Винс О’Брайен, Джоди Мак-Доннел и
Хитер Скотт заслуживают особой благодарности за их стремление
к совершенству во всем при выпуске этого издания книги. Их
творческие способности, помощь и терпение были действительно
неоценимыми.
Р.С.Г.
Р.Э.В.
Об авторах
Рафаэл С. Гонсалес
Р. С. Гонсалес получил степень бакалавра в университете шт. Майами
в 1965 г, а затем степени магистра и доктора философии по электротех-
нике в университете шт. Флорида (г. Гейнсвилл) в 1967 г. и 1970 г.
соответственно. В 1970 г. он поступил на работу на факультет элек-
тронной и компьютерной техники университета шт. Теннеси (UTK)
в г. Ноксвилл, где последовательно получил звания адьюнкт-профессо-
ра(1973 е), профессора(1978 е) ипрофессорас особыми заслугами (1984 г).
С 1994 г. по 1997 г. он был президентом факультета, а в настоящее вре-
мя является почетным профессором UTK в отставке.
Гонсалес был основателем двух лабораторий UTK: Лаборатории
анализа изображений и образов и Лаборатории робототехники и ма-
шинного зрения. Он также основал в 1982 г. компанию Perceptics
Corporation и вплоть до 1992 г. был ее президентом. В течение трех по-
следних лет этого периода он являлся сотрудником Westinghouse
Corporation, которая приобрела компанию Perceptics в 1989 г.
Под руководством Гонсалеса компания Perceptics достигла боль-
ших успехов в обработке изображений, машинном зрении и техноло-
гии запоминающих устройств на основе лазерных дисков. За первое
десятилетие своей работы компания Perceptics внедрила ряд нова-
торских изделий, в том числе: первую в мире коммерческую систему
машинного зрения для автоматического чтения номерных знаков
транспортных средств; ряд крупномасштабных систем обработки
и хранения изображений, которые применяются на шести различных
заводах ВМФ США при контроле реактивных двигателей ракет «Трай-
дент-2» для подводных лодок; семейство плат обработки изображений
для модернизации компьютеров «Макинтош», занимающее передо-
вые позиции на рынке; а также линейку запоминающих устройств на
базе лазерных дисков терабайтной емкости.
Р. С. Гонсалес часто привлекается промышленными предприяти-
ями и правительством в качестве консультанта в области распознава-
ния образов, обработки изображений и обучающихся машин. Его
академические заслуги в этих областях отмечены в 1977 г. премией тех-
нического факультета UTK за высокие достижения; в 1978 г. преми-
ей ректора UTK для ученых-исследователей; в 1980 г. — премией им.
М.Е. Брукса как выдающийся профессор и почетным званием профес-
сора Magnavox Engineering. В 1981 г. он становится профессором IBM
в университете шт. Теннеси, а в 1984 г. получил там звание профессора
Об авторах
с особыми заслугами. Он отмечен званием выдающегося выпускни-
ка университета шт. Майами (1985 г.), премией научного общества «фи-
каппа-фи» (1986 г.) и премией им. Натана В. Догерти университета
шт. Теннеси за высокие достижения в области техники (1992 г.).
Среди наград за промышленные достижения — премия выдающе-
муся инженеру IEEE 1987 г. за коммерческие разработки в Теннеси;
Национальная премия им. Альберта Роуза 1988 г. за успехи в создании
коммерческих систем обработки изображений; премия Б. Отто Уил и
за достижения в переносе технологий; звание «предприниматель го-
да» агентства Купере и Либранд в 1989 г.; премия выдающемуся ин-
женеру IEEE 1992 г. (по Округу 3); и Национальная премия 1993 г. за
развитие технологии Ассоциации по автоматизированной обработке
изображений.
Гонсалес является автором и соавтором свыше 100 технических ста-
тей, двух монографий и четырех учебников в области распознавания
образов, обработки изображений и робототехники. Его книгами поль-
зуются в более чем 500 университетах и исследовательских институ-
тах по всему миру. Он включен в престижные справочники «Кто есть
кто в Америке», «Кто есть кто в технике», «Кто есть кто в мире», а так-
же еще в 10 национальных и международных биографических переч-
ней. Он совладелец двух патентов США и член редколлегий научных
журналов «Труды по теории систем» (IEEE Transactions on Systems),
«Человек и кибернетика» (Man and Cybernetics), Международного
журнала по вычислительной технике и информатике (International
Journal of Computer and Information Sciences). Он является членом
IEEE и состоит в многочисленных профессиональных и почетных об-
ществах (в том числе «тау-бета-пи», «фи-каппа-фи», «эта-каппа-ню»
и «сигма-кси»),
Ричард Э. Вудс
Ричард Э. Вудс получил степени бакалавра, магистра и доктора
философии по электротехнике в университете шт. Теннеси (г. Нок-
свилл). Его профессиональный опыт охватывает широкий диапазон
от предпринимательской деятельности до исполнения более тради-
ционных обязанностей в академической, консультативной, прави-
тельственной и промышленной сферах. Недавно он основал рабо-
тающую в области высоких технологий компанию MedData
Interactive, которая специализируется на разработке портативных
компьютерных систем медицинского назначения. Он также явля-
ется соучредителем и вице-президентом компании Perceptics
Corporation, отвечая в ней за разработку многих видов продукции для
Об авторах
количественного анализа изображений и автономного принятия
решений.
До работы в компаниях Perceptics и MedData д-р Вудс был доцен-
том по электротехнике и вычислительной технике в университете Тен-
неси, а еще раньше — инженером по компьютеризации в компании
Union Carbide Corporation. В качестве консультанта он привлекался
к разработке ряда процессоров специального назначения для много-
численных космических и военных ведомств, включая агентство
NASA, Центр управления баллистическими ракетами и Национальную
лабораторию Оук Ридж (Oak Ridge).
Д-Р Вудс опубликовал множество статей по цифровой обработке
сигналов и состоит в ряде профессиональных обществ, включая «тау-
бета-пи», «фи-каппа-фи» и IEEE. В 1986 г. он был признан выдающим-
ся выпускником университета шт. Теннеси.
ГЛАВА 1
ВВЕДЕНИЕ
Лучше один раз увидеть, чем тысячу раз услышать.
Пословица
Интерес к методам цифровой обработки изображений произрастает
из двух основных областей ее применения, которыми являются повы-
шение качества изображений для улучшения его визуального вос-
приятия человеком и обработка изображений для их хранения, пере-
дачи и представления в автономных системах машинного зрения. Эта
глава преследует несколько целей: (1) определить границы области, на-
зываемой «обработка изображений»; (2) нарисовать историческую
перспективу развития этой области; (3) дать представление о современ-
ном состоянии предмета, рассмотрев несколько важнейших областей,
где применяется обработка изображений; (4) кратко обсудить основ-
ные подходы, используемые в цифровой обработке изображений;
(5) дать общее представление о компонентах типичной многоцеле-
вой системы обработки изображений; и (6) указать книги и периоди-
ческие издания, в которых публикуются работы по тематике обработки
изображений.
1.1. Что такое цифровая обработка изображений?
Изображение можно определить как двумерную функцию/(х, у), где
хну — координаты в пространстве (конкретно, на плоскости), и зна-
чение/которой в любой точке, задаваемой парой координат (х, у), на-
зывается интенсивностью или уровнем серого^ изображения в этой
точке. Если величины х, у и/принимают конечное число дискретных
значений, то говорят о цифровом изображении. Цифровой обработкой
изображений называется обработка цифровых изображений с помощью
цифровых вычислительных машин (компьютеров). Заметим, что ци-
фровое изображение состоит из конечного числа элементов, каждый
из которых расположен в конкретном месте и принимает определен-
ное значение. Эти элементы называются элементами изображения
1 В отечественной литературе для этого понятия широко распространен термин яр-
кость, который мы и будем использовать во всех случаях, когда это не приводит к не-
доразумениям. — Прим, перев.
или пикселями^. Чаще всего для элементов цифрового изображения ис-
пользуется термин «пиксель». Более строгие формальные определения
будут даны в Главе 2.
Зрение является наиболее совершенным из наших органов чувств,
поэтому неудивительно, что зрительные образы играют важнейшую
роль в человеческом восприятии. Однако, в отличие от людей, спо-
собных воспринимать электромагнитное излучение лишь в види-
мом диапазоне, машинная обработка изображений охватывает прак-
тически весь электромагнитный спектр от гамма-излучения до
радиоволн. Обрабатываемые изображения могут порождаться таки-
ми источниками, которые для человека непривычно связывать с на-
блюдаемыми изображениями. Таковы, например, ультразвуковые
изображения; изображения, получаемые в электронной микроско-
пии или генерируемые компьютером. Таким образом, цифровая об-
работка изображений охватывает широкие и разнообразные области
применения.
Не существует общепринятой точки зрения, где заканчивается
обработка изображений и начинаются другие смежные области, на-
пример, анализ изображений и машинное зрение. Иногда разграни-
чение делается здесь по тому принципу, что обработка изображений
определяется как дисциплина, в которой на входе и на выходе процес-
са присутствуют изображения. Мы убеждены, что такое вычленение
является ограниченным и отчасти искусственным. Например, в рам-
ках этого определения даже такая тривиальная задача, как определе-
ние средней интенсивности по полю изображения (при решении ко-
торой ищется единственное число), не может рассматриваться как
операция обработки изображения. С другой стороны, существуют
такие области, как машинное зрение, где конечной целью является
компьютерная имитация человеческого зрения, включая обучение,
способность к умозаключениям и действиям на основе наблюдае-
мой информации. Эта область сама по себе образует лишь одно из на-
правлений искусственного интеллекта, целью которого является ими-
тация интеллектуальной деятельности человека. Искусственный
интеллект находится еще на начальной стадии своего развития, при-
чем следует отметить, что прогресс идет значительно медленнее, чем
первоначально ожидалось. Область, связанная с анализом изобра-
жений (иначе называемая «понимание» или «интерпретация» изоб-
2 Слово pixel образовано от английского словосочетания «picture element» (элемент
изображения). В англоязычной литературе также широко употребляется сокращен-
ное написание pel. — Прим, перев.
1.1. Что такое цифровая обработка изображений ?
ражений) занимает промежуточное положение между обработкой
изображений и машинным зрением.
Во всем диапазоне от обработки изображений до машинного
зрения нет четких границ, тем не менее, можно различать в нем
компьютеризованные процессы низкого, среднего и высокого уров-
ня. Процессы низкого уровня касаются только примитивных опера-
ций типа предобработки с целью уменьшения шума, повышения
контраста или улучшения резкости изображений. Для низкоуровне-
вых процессов характерен тот факт, что на входе и на выходе присут-
ствуют изображения. Обработка изображений на среднем уровне
охватывает такие задачи, как сегментация (разделение изображе-
ния на области или выделение на нем объектов), описание объектов
и сжатие их в удобную для компьютерной обработки форму, а также
классификация (распознавание) отдельных объектов. Для процессов
среднего уровня характерно наличие изображений только на входе,
на выход же поступают признаки и атрибуты, извлекаемые из этих изо-
бражений (например, границы областей, линии контуров, отличитель-
ные признаки конкретных объектов). Наконец, высокоуровневая
обработка включает в себя «осмысление» набора распознанных объ-
ектов, как это делается в анализе изображений, и, в пределе, осуще-
ствление познавательных функций, которые принято связывать со
зрением.
Исходя из вышеприведенного замечания, мы видим, что естествен-
ным этапом перехода от обработки изображений к их анализу высту-
пает распознавание отдельных областей или объектов на изображении.
Таким образом, то, что в этой книге называется «цифровой обработ-
кой изображений», включает процессы с изображениями на входе
и на выходе, а также процессы извлечения признаков из изображений,
вплоть до (или включая) распознавание индивидуальных объектов. В ка-
честве простой иллюстрации, разъясняющей указанные понятия, рас-
смотрим область автоматизированного анализа печатного или руко-
писного текста. В сферу цифровой обработки изображений, которая
рассматривается в данной книге, входят процессы получения изобра-
жения области, содержащей этот текст, предварительной обработки по-
лученного изображения, выделения (сегментации) отдельных сим-
волов текста, описания символов в подходящей для компьютерной
обработки форме и, наконец, распознавания этих символов. Что ка-
сается осмысления содержимого страницы, то оно может быть отне-
сено уже к сфере анализа изображений или даже машинного зрения,
в зависимости от уровня сложности, который подразумевается за сло-
вом «осмысление». Как мы вскоре увидим, определенная таким об-
разом цифровая обработка изображений успешно применяется в ши-
Глава 1. Введение
роком круге областей, важных с социально-экономической точки
зрения. Концепции, развиваемые в последующих главах, служат
основой для методов, которые используются в этих прикладных
областях.
1.2. Истоки цифровой обработки изображений
Одно из первых применений цифровых изображений было опробова-
но в газетном деле для передачи иллюстраций по трансокеанскому под-
водному кабелю между Лондоном и Нью-Йорком. В начале 1920-х го-
дов была внедрена система «Бартлейн» для передачи изображений по
кабелю, что позволило уменьшить время доставки иллюстраций через
Атлантику с обычной недельной задержки до менее чем трех часов. С по-
мощью специального печатающего оборудования осуществлялось коди-
рование исходного изображения для передачи по кабелю и последующее
восстановление этого изображения на приемной стороне. На Рис. 1.1 по-
казано изображение, переданное таким образом и распечатанное затем
на телеграфном буквопечатающем аппарате со специальным шрифтом,
имитирующим различные уровни почернения.
Ряд начальных проблем, связанных с улучшением визуального
качества этих первых цифровых изображений, относился к выбору про-
цедуры печати и распределению уровней интенсивности. Способ пе-
чати, использованный для получения Рис. 1.1, в конце 1921 г. был от-
вергнут в пользу технологии фотографической репродукции с
использованием перфоленты, формируемой телеграфным аппаратом
на приемной стороне линии. На Рис. 1.2 показано изображение, по-
лученное таким способом. Улучшения по сравнению с Рис. 1.1 очевид-
Рис. 1.1. Цифровое изображение, полученное в 1921 г. с кодовой ленты на те-
леграфном аппарате с особым шрифтом. [McFarlane3]
3 Список литературы в конце книги расположен в алфавитном порядке по фамилии
первого автора.
1.2. Истоки цифровой обработки изображений
Рис. 1.2. Цифровое изображение, полученное в 1922 г. с использованием пер-
фоленты после прохождения сигнала через Атлантику дважды. Видны некоторые де-
фекты. [McFarlane]
ны как в отношении качества передачи полутонов, так и в простран-
ственном разрешении.
Ранние системы «Барглейн» были способны кодировать изображе-
ния с помощью пяти градаций яркости. В 1929 г. эти возможности бы-
ли увеличены до 15 градаций. На Рис. 1.3 приведено типичное изоб-
ражение, которое могло быть получено с помощью оборудования,
использующего 15 градаций яркости. За этот период были внедрены си-
стемы, в которых фотопластинка экспонировалась с помощью световых
лучей, модулируемых закодированной на перфоленте информацией,
что позволило значительно улучшить процесс репродукции.
Хотя в вышеприведенных примерах фигурируют цифровые изоб-
ражения, их нельзя рассматривать как результат цифровой обработ-
Рис. 1.3. Неретушированная фотография генералов Першинга и Фоша, пере-
даннаяв 1929 г. по кабелю из Лондона в Нью-Йорке помощью 15-градационного обо-
рудования. [McFarlane]
ки изображений в контексте нашего определения, коль скоро при их
получении не использовались компьютеры. Таким образом, история
цифровой обработки изображений тесно связана с развитием цифро-
вой вычислительной техники. В самом деле, для цифровых изображе-
ний требуется такая большая память и вычислительная мощность,
что прогресс в области цифровой обработки изображений в значитель-
ной степени определяется развитием компьютеров и вспомогательных
технологий для хранения, отображения и передачи данных.
Идея компьютера восходит к абаку, изобретенному на полуострове
Малая Азия более 5000 лет назад. Ближе к нашим дням, в последние два
столетия делались продвижения, заложившие основу для появления
компьютеров. Однако принципы того, что мы называем современным ци-
фровым компьютером, были заложены всего лишь в 1940-х годах, ког-
да Джон фон Нейман ввел в рассмотрение два ключевых понятия: (1) рав-
ноправное хранение в памяти и данных, и программ; и (2) условный
переход в программе. Эти две идеи заложены в фундамент центрально-
го процессора, который является сердцем современных компьютеров.
Вслед за фон Нейманом был целый ряд ключевых продвижений, кото-
рые привели к появлению компьютеров, достаточно мощных для исполь-
зования при цифровой обработке изображений. Кратко перечислим
эти достижения: (1) изобретение транзистора компанией Bell Laboratories
в 1948 г.; (2) изобретение в 1950-х и 1960-х гг. языков программирова-
ния высокого уровня КОБОЛ (COBOL, Common Business-Oriented
Language — Общий язык программирования, ориентированный на биз-
нес) и ФОРТРАН (FORTRAN, Formula Translator — Транслятор формул);
(3) изобретение интегральной микросхемы компанией Texas Instraments
в 1958г.; (4) разработка операционных систем в начале 1960-х гг.; (5) вы-
ход на рынок персонального компьютера IBM в 1981 г.; и (6) последо-
вательная миниатюризация электронных компонентов, начиная с по-
явления больших интегральных схем (БИС) в конце 1970-х гг., затем
сверхбольших интегральных схем (СБИС) в 1980-х гг., вплоть до сего-
дняшних ультраболыпих интегральных схем (УБИС). Одновременно
с перечисленными продвижениями шло развитие в области запомина-
ющих устройств и систем отображения, наличие которых необходимо для
цифровой обработки изображений.
Первые компьютеры с мощностью, достаточной для выполнения ос-
мысленных задач цифровой обработки изображений, появились в нача-
ле 1960-х гг. Рождение того, что мы сегодня называем цифровой обра-
боткой изображений, прослеживается с момента возникновения таких
машин и появления программ изучения космоса. Параллельный прогресс
в этих двух областях привел в действие мощный потенциал идей циф-
ровой обработки изображений. Работы по использованию вычисли-
1.2. Истоки цифровой обработки изображений 29
тельной техники для улучшения визуального качества изображений,
получаемых с помощью беспилотных космических аппаратов, были
развернуты в Лаборатории реактивного движения в Пасадене, шт. Ка-
лифорния, в 1964 г., когда переданные космическим аппаратом «Рейнд-
жер-7» изображения лунной поверхности были подвергнуты компьютер-
ной обработке для исправления различных искажений, обусловленных
конструкцией бортовой телевизионной камеры. На Рис. 1.4 приведено
изображение Луны, полученное «Рейнджером-7» 31 июля 1964 г. в 9 час.
9 мин. восточно-американского времени (EDT), приблизительно за
17 мин. до его удара о лунную поверхность (на фотографии видны мет-
ки так называемой ризо-маркировки, применяемой для коррекции гео-
метрических искажений; эта техника обсуждается подробнее в 1лаве 5).
Это было первое изображение Луны, полученное американским косми-
ческим аппаратом4. Опыт, накопленный при обработке первых косми-
ческих изображений, послужил основой для разработки усовершенст-
вованных методов восстановления и улучшения изображений. Эти
методы позже применялись при обработке изображений, получен-
ных в ходе полетов к Луне космических аппаратов «Сервейер», поле-
тов аппаратов «Маринер» по пролетной траектории вблизи Марса,
пилотируемых полетов космических кораблей «Аполлон» на Луну и т.д.
Рис. 1.4. Изображение лунной поверхности, переданное космическим аппара-
том «Рейнджер-7» 31 июля 1964 к (Снимок предоставлен Агентством NASA).
4 Напомним, что первые космические снимки лунной поверхности (в том числе
обратной стороны Луны) были сделаны советской автоматической межпланетной
станцией «Луна-3» в 1959 г. — Прим, перев.
Глава 1. Введение
Параллельно с космическими исследованиями, в конце 1960-х—на-
чале 1970-х гг. методы цифровой обработки изображений начали при-
меняться в медицине, дистанционном исследовании земных ресурсов,
астрономии. В начале 1970-х гг. была изобретена рентгеновская вычис-
лительная томография, кратко называемая также компьютерной томо-
графией (КТ), что стало важнейшим событием в области применения
обработки изображений для медицинской диагностики. При компью-
терной томографии набор детекторов излучения и рентгеновский ис-
точник располагаются на кольце, внутрь которого помещается иссле-
дуемый объект (те. пациент), и кольцо вращается вокруг объекта.
Проходящее через объект рентгеновское излучение улавливается детек-
торами, находящимися на противоположной стороне кольца; этот
процесс повторяется по мере вращения источника. Томография состо-
ит из алгоритмов, которые на основе использования данных от детек-
торов строят изображения «сечения» объекта в плоскости кольца. При
движении объекта вдоль оси кольца создается набор таких сечений, ко-
торые в совокупности образуют трехмерное представление внутренне-
го строения объекта. Томографию независимо друг от друга предложи-
ли сэр Годфри Н. Хаунсфилд и проф. Ален М. Кормак, которые в 1979 г.
были удостоены за это изобретение Нобелевской премии по медици-
не. Интересно отметить, что рентгеновские лучи были открыты в 1895 г.
Вильгельмом Конрадом Рентгеном, получившим за это Нобелевскую пре-
мию по физике в 1901 г. Эти два открытия, которые разделяет почти 100
лет, привели к одному из наиболее массовых сегодняшних применений
цифровой обработки изображений.
С 1960-х гг. до настоящего времени область применения обработки
изображений значительно расширилась. Помимо медицинских и косми-
ческих приложений, методы цифровой обработки изображений сего-
дня используются в широком круге областей. Компьютеризированные
процедуры применяются для облегчения восприятия рентгеновских
и иных изображений в промышленности, медицине и биологии путем по-
вышения контраста или цветового кодирования различных уровней ин-
тенсивности (представления изображений в псевдоцветах). Аналогичные
методы применяются в географии для изучения картины загрязнений ок-
ружающей среды по данным аэрофотосъемки и космическим снимкам.
Методы улучшения и восстановления изображений применяются при об-
работке некачественных изображений утраченных объектов или трудно-
воспроизводимых экспериментальных результатов. Например, в архео-
логии с помощью методов цифровой обработки изображений удалось по
имеющимся нечетким фотографиям успешно восстановить первона-
чальный вид раритетов, которые со времени съемки были утрачены или
повреждены. В физике и смежных областях компьютерная обработка яв-
ляется обычным способом улучшения качества изображений, получае-
мых в ходе экспериментов, как, например, в электронной микроскопии
или физике высокотемпературной плазмы. Аналогичные примеры успеш-
ного применения технологий обработки изображений можно найти в ас-
трономии, биологии, медицинской радиологии, промышленности,
в оборонной и правоохранительной сфере.
Приведенные примеры относились к случаям, когда результаты обра-
ботки предназначены для восприятия человеком. Другая крупная область
применения методов обработки изображений, упоминавшаяся в начале этой
главы, — это решение задач, связанных с машинным восприятием изоб-
ражений. В этом случае в центре внимания находятся процедуры, извле-
кающие из изображения некоторую информацию и представляющие ее в
форме, подходящей для компьютерной обработки. Часто эта информация
весьма мало похожа на визуальные признаки, используемые людьми при
интерпретации содержимого изображения. Примерами информации та-
кого рода, часто применяемой при машинном восприятии изображений,
могут быть статистические моменты, коэффициенты преобразования Фу-
рье, значения многомерного расстояния и т.д. Типичными задачами машин-
ного восприятия, в которых интенсивно используются методы обработки
изображений, являются автоматическое распознавание символов, систе-
мы машинного зрения для автоматизации сборки и контроля продукции,
задачи опознавания «свой—чужой» для военных объектов, автоматическая
обработка отпечатков пальцев, проверка анализов крови и результатов
рентгеновских исследований, компьютерная обработка аэрофотосним-
ков и спутниковых изображений с целью прогнозирования погоды и эко-
логического мониторинга. Продолжаюшееся уменьшение соотношения це-
на/производительность современных компьютеров, рост пропускной
способности сетей телекоммуникаций и развитие Интернета создали бес-
прецедентные возможности для дальнейшего расширения сферы циф-
ровой обработки изображений. Некоторые из прикладных областей рас-
сматриваются в следующем разделе.
1.3. Примеры областей применения цифровой
обработки изображений
Сегодня в технике нет почти ни одной области, которую в той или иной
мере не затрагивала бы цифровая обработка изображений. Наше обсуж-
дение коснется лишь сравнительно небольшого числа таких приклад-
ных областей, однако, несмотря на вынужденную ограниченность ма-
териала, у читателя не должно остаться сомнений в широте и важности
применения обработки изображений. В этом разделе демонстриру-
ются многочисленные прикладные области, в каждой из которых по-
вседневно используются методы цифровой обработки изображений,
описываемые в последующих главах. Многие из приведенных здесь
изображений впоследствии упоминаются во встречающихся в книге
примерах. Все эти изображения являются цифровыми.
Области применения цифровой обработки изображений столь разно-
образны, что попытка охватить их во всей широте требует какой-то сис-
темы изложения. Один из простейших способов — классификация при-
кладных областей в соответствии с видами источников, формирующих
соответствующие изображения (например, оптические, рентгеновские
и т.д.). Главным источником энергии для формирования применяемых се-
годня изображений является электромагнитное излучение. Среди других
важных энергетических источников, которые могут создавать изображе-
ния, упомянем акустические и ультразвуковые (механические) колебания,
а также электронные пучки, применяемые в электронной микроскопии.
Кроме того, имеется целый класс синтетических (искусственных) изоб-
ражений, которые синтезируются компьютерными программами и исполь-
зуются для моделирования и визуализации. В этом разделе мы кратко об-
судим, как регистрируются изображения этих многочисленных категорий
и каковы области их применения. Методы преобразования изображений
в цифровую форму будут рассмотрены в следующей главе.
Наиболее привычны изображения, создаваемые электромагнит-
ным излучением, особенно в видимом спектре или в рентгенов-
ском диапазоне. Электромагнитные волны можно трактовать как
распространяющиеся синусоидальные колебания определенной ча-
стоты, а можно — как поток частиц, движущихся со скоростью све-
та. Каждая такая частица обладает определенной энергией, но нуле-
вой массой, и называется квантом излучения (фотоном). Если
расположить диапазоны излучения в порядке убывания энергии фо-
тона, то получим изображенный на Рис. 1.5 спектр, простирающий-
ся от гамма-лучей (обладающих максимальной энергией) до радио-
Энергия фотона (электрон-вольт)
106 105 104 103 102 101 КГ1 10° 10‘2 10“3 IO** IQ-S 10-б 10-7 10-8 10-9
Рис. 1.5. Спектр электромагнитного излучения в порядке убывания энергии
фотона.
волн. Плавное изменение окраски интервалов диапазона на этом
рисунке призвано подчеркнуть тот факт, что спектр электромагнит-
ного излучения не разграничен строго, а имеет смысл говорить скорее
о плавном переходе одного участка диапазона в другой.
1.3.1. Формирование изображений с помощью
гамма-лучей
Изображения, полученные с помощью гамма-излучения, исполь-
зуются главным образом в медицинской радиологии и астрономиче-
ских наблюдениях. В медицинской радиологии применяется подход,
при котором пациенту вводится радиоактивный изотоп, распад ко-
торого сопровождается гамма-излучением. Это излучение регистри-
руется детекторами гамма-излучения, сигналы которых и использу-
ются для формирования изображения. На Рис. 1.6(a) приведен
полный снимок скелета, полученный с помощью гамма-лучей опи-
санным образом. Изображения такого вида используются для обна-
ружения участков различных патологий костей, в частности, при
инфекционных или онкологических заболеваниях. Рис. 1.6(6) демон-
стрирует другой важный вид медицинских радиологических изобра-
жений, получаемых методом позитронной эмиссионной томографии
(ПЭТ). Используется тот же принцип, что и при рентгеновской то-
мографии, кратко описанный в Разделе 1.2, однако вместо исполь-
зования внешнего источника рентгеновского излучения пациент
принимает радиоактивный изотоп, распад которого сопровождает-
ся позитронным излучением. При встрече позитрона с электроном
они аннигилируют с выделением двух гамма-квантов. Это гамма-из-
лучение регистрируется, и формируется томографическое изображе-
ние в соответствии с основными принципами томографии. Приве-
денное на Рис. 1.6(6) изображение представляет собой один кадр из
последовательности изображений, которые в совокупности дают
трехмерное представление тела пациента. На этом кадре хорошо
видны небольшие белые скопления — опухоли в мозге и в легком
пациента.
Около 15 тыс. лет назад в созвездии Лебедя произошел взрыв
сверхновой, что привело к образованию расширяющегося облака га-
за сверхвысокой температуры, которое получило название Петли Ле-
бедя. Столкновение этого облака с окружающими газовыми облака-
ми порождает излучение широкого спектра, которое в видимом
диапазоне дает эффектную цветовую картину. На Рис. 1,6(в) приведе-
но изображение Петли Лебедя в диапазоне гамма-излучения. В отли-
чие от примеров, показанных на Рис. 1.6(а, б), это изображение бы-
2 А-223
Глава 1. Введение
ло получено с использованием естественного излучения изображае-
мого объекта. Наконец, на Рис. 1.6(г) демонстрируется изображение
гамма-излучения из клапана ядерного реактора. В левой нижней
части изображения видна область сильной радиации.
Рис. 1.6. Примеры изображений, полученных с помощью гамма-лучей, (а) Сни-
мок скелета, (б) ПЭТ-изображение. (в) Петля Лебедя, (г) Гамма-излучение из клапа-
на реактора (яркое пятно). (Изображения предоставили: (а) Компания G.E. Medical
Systems; (б) Д-р Майкл Е. Кейси, компания CTI PET Systems; (в) Агентство NASA;
(г) Профессора Жонг Хе и Дэвид К. Уи, университет шт. Мичиган).
1.3.2. Рентгеновские изображения
Рентгеновские лучи — один из самых старых источников электро-
магнитного излучения, используемых для получения изображений. Хо-
рошо известно применение рентгеновских лучей для медицинской ди-
агностики, однако они также широко используются в промышленности
и других областях, в частности, астрономии. Рентгеновское излучение
для формирования изображений в медицине и промышленности ге-
нерируется с помощью рентгеновской трубки — вакуумного прибора
с катодом и анодом. Катод находится в нагретом состоянии, вследст-
вие чего испускает свободные электроны, которые с высокой скоро-
стью летят к положительно заряженному аноду. При соударении эле-
ктронов с ядрами атомов материала анода выделяется энергия в форме
рентгеновского излучения. Энергия рентгеновских лучей, от кото-
рой зависит их проникающая способность, регулируется изменением
приложенного к аноду напряжения, а интенсивность излучения (ко-
личество рентгеновских лучей) регулируется изменением тока, прохо-
дящего через нить накала катода. На Рис. 1.7(a) показан хорошо зна-
комый рентгеновский снимок грудной клетки, получаемый при
помещении пациента между рентгеновской трубкой и чувствительной
к рентгеновскому излучению пленкой. При прохождении рентгенов-
ских лучей через тело пациента, их интенсивность изменяется в зави-
симости от степени поглощения вдоль конкретной траектории, и окон-
чательный уровень энергии фиксируется на рентгеновской пленке,
экспонируя ее почти так же, как лучи света формируют изображение
на фотопленке. В цифровой рентгенографии применяются два спосо-
ба получения цифровых изображений: (1) дискретизация (оцифров-
ка) обычных рентгеновских пленок; или (2) непосредственная реги-
страция прошедших через тело пациента рентгеновских лучей
устройством, преобразующим рентгеновское излучение в световое
(например, с помощью фосфоресцирующего экрана). Полученный све-
товой сигнал затем считывается с помощью цифровой системы, рабо-
тающей в оптическом диапазоне. Вопросы дискретизации изображений
подробно рассматриваются в Главе 2.
Другое важное применение рентгеновских изображений — ангио-
графия, которая является одним из видов контрастной рентгенографии.
Эта процедура используется для получения изображений кровеносных
сосудов; такие изображения называются ангиограммами. В артерию
или вену в паховой области вводится катетер (тонкая гибкая трубка),
который продвигается вдоль сосуда, пока не достигнет обследуемой зо-
ны. Затем через катетер впрыскивается контрастное вещество, хорошо
Глава 1. Введение
Рис. 1.7. Примеры рентгеновских изображений, (а) Рентгенограмма груд-
ной клетки, (б) Ангиограмма аорты, (в) Компьютерная томограмма головы, (г) Пе-
чатные платы, (д) Петля Лебедя. (Изображения предоставили: (а, в) д-р Дэвид
Р. Пикенс, Департамент радиологии медицинского центра университета Вандер-
билта; (б) д-р Томас Р. Гест, Отделение анатомии медицинской школы университе-
та шт. Мичиган; (г) Джозеф Е. Пассенте, компания Lixi, Inc.; (д) Агентство NASA).
1.3. Примеры областей применения цифровой обработки изображений
поглощающее рентгеновские лучи. Благодаря этому усиливается кон-
траст рентгеновского изображения кровеносных сосудов, что позволя-
ет врачу-радиологу видеть аномалии кровоснабжения или места заку-
порки сосудов. На Рис. 1.7(6) демонстрируется ангиограмма аорты, на
которой виден катетер, введенный через крупный кровеносный сосуд
внизу слева. Обратим внимание на высокий контраст изображения
крупного сосуда в направлении потока контрастного вещества к почкам,
которые тоже видны на изображении. Как описано в 1лаве 3, в ангио-
графии широко используется цифровая обработка изображений, в ча-
стности, вычитание изображений с целью дальнейшего повышения
контраста исследуемых кровеносных сосудов.
Возможно, самое известное применение рентгеновских лучей для
формирования изображений в медицине — это компьютерная томо-
графия. Благодаря высокому разрешению и возможности трехмер-
ного представления, компьютерная томография с момента своего
первого появления в начале 1970-х гг. произвела революцию в меди-
цине. Как отмечалось в Разделе 1.2, каждое КТ-изображение переда-
ет поперечный срез тела пациента. При продольном перемещении
пациента формируется множество таких срезов, которые в совокуп-
ности образуют трехмерное представление внутреннего строения те-
ла с продольным разрешением, пропорциональным количеству сре-
зов. На Рис. 1.7(b) показано изображение типичного среза, получаемого
при компьютерной томографии головы.
Аналогичная технология используется и в промышленном производ-
стве, хотя там обычно применяется рентгеновское излучение с большей
энергией. На Рис. 1.7(г) приведено рентгеновское изображение печат-
ной платы радиоэлектронного прибора. Подобные изображения, буду-
чи лишь одним из сотен возможных промышленных применений рент-
геновских изображений, используются для контроля печатных плат на
наличие дефектов, таких как отсутствие деталей или разрывы контакт-
ных дорожек. Промышленная компьютерная томография применима,
когда детали проницаемы для рентгеновских лучей, что очевидно в слу-
чае пластмассовых узлов, но возможна даже и при контроле крупных из-
делий вроде твердотопливных реактивных двигателей. На Рис.1.7(д)
показан пример применения рентгеновских изображений в астроно-
мии. Здесь изображена та же Петля Лебедя, что и на Рис. 1.6(в), но на этот
раз в диапазоне рентгеновского излучения.
1.3.3. Изображения в ультрафиолетовом диапазоне
Ультрафиолетовый «свет» находит разнообразные применения, в ча-
стности, в литографии, производственном контроле, микроскопии, ла-
зерной технике, биологических и астрономических наблюдениях. Мы
проиллюстрируем использование изображений ультрафиолетового
диапазона на примерах из области микроскопии и астрономии.
Ультрафиолетовое освещение используется во флуоресцентной мик-
роскопии — одном из наиболее быстро развивающихся направлений ми-
кроскопии. Явление флуоресценции было открыто в середине XIX в.,
когда впервые было замечено, что минерал флуорит (плавиковый шпат)
излучает свет при направлении на него ультрафиолетового излучения.
Сами по себе ультрафиолетовые лучи невидимы, но при столкновении фо-
тона ультрафиолетового излучения с электроном атома флуоресцентно-
го материала, электрон переходит на более высокий энергетический уро-
вень. Последующее возвращение возбужденного электрона на нижний
уровень сопровождается излучением фотона с меньшей энергией, что
соответствует видимому (ближе к красному) диапазону спектра. Принцип
работы флуоресцентного микроскопа заключается в облучении подготов-
ленного препарата ярким активизирующим освещением и последующем
выделении значительно более слабого флуоресцентного свечения. Таким
образом, глаз наблюдателя или другой детектор будет воспринимать толь-
ко вторичное излучение. Свечение флуоресцирующих участков должно на-
блюдаться на темном фоне, чтобы обеспечивался достаточный для их
обнаружения контраст. Чем темнее фон, изготовленный из нефлуоресци-
рующего материала, тем выше эффективность прибора.
Флуоресцентная микроскопия — прекрасный метод исследова-
ния материалов, обладающих флуоресцирующими свойствами,—
либо в естественной форме (первичная флуоресценция), либо в ре-
зультате обработки флуоресцирующими химикатами (вторичная
флуоресценция). Рис. 1.8(а, б) демонстрируют типичные возможно-
сти флуоресцентной микроскопии. На Рис. 1.8(a) показан получен-
ный с помощью флуоресцентного микроскопа снимок здорового
зерна, а на Рис. 1.8(6) — снимок зерна, зараженного головней — за-
болеванием зерновых и бобовых культур, трав, а также луковичных рас-
тений, вызываемым более чем 700 видами паразитических грибков.
Особенно опасна головня злаковых культур, поскольку зерновые —
один из важнейших источников пищи людей. В качестве иллюстра-
ции другой области применения, на Рис. 1.8(b) показано изображе-
ние Петли Лебедя в высокочастотной полосе ультрафиолетового
диапазона.
1.3.4. Изображения в видимом и инфракрасном диапазонах
Учитывая, что видимый диапазон электромагнитного спектра для нас
наиболее привычен, неудивительно, что область использования изо-
1.3. Примеры областей применения цифровой обработки изображений
Рис. 1.8. Примеры изображений в ультрафиолетовом диапазоне, (а) Нормаль-
ное зерно, (б) Зерно, зараженное головней, (в) Петля Лебедя. (Изображения предо-
ставили: (а, б) д-р Майкл У. Дэвидсон, университет шт. Флорида; (в) Агентство
NASA).
Сражений этого диапазона оказывается намного шире, чем всех осталь-
ных вместе взятых. Инфракрасные изображения часто используются
совместно с видимыми, поэтому для иллюстрации мы объединили
оба эти диапазона в одном разделе. В нижеследующем обсуждении
Глава I. Введение
в качестве примеров областей использования будут обсуждаться:
световая микроскопия, астрономия, дистанционное зондирование,
промышленность и правоохранительная деятельность.
На Рис. 1.9 показано несколько примеров изображений, полу-
ченных с помощью оптического микроскопа. Диапазон примеров
Рис. 1.9. Примеры изображений в оптической микроскопии, (а) Таксол (про-
тивораковый препарат), увеличение 250х. (б) Холестерин, увеличение 40х. (в) Мик-
ропроцессор, увеличение 60х. (г) Тонкая пленка окиси никеля, увеличение бООх. (д)
Поверхность музыкального компакт-диска, увеличение 1750х. (е) Органический
сверхпроводящий материал, увеличение 450х. (Изображения предоставил д-р Майкл
У. Дэвидсон, университет шт. Флорида)
1.3. Примеры областей применения цифровой обработки изображений
простирается от фармацевтики и микроскопических методов произ-
водственного контроля до определения характеристик материалов. Да-
же в пределах одной микроскопии множество возможных прикладных
областей слишком обширно, чтобы его детально описать. Несложно
вообразить варианты обработки, которые могут потребоваться в приме-
нении к таким изображениям, от улучшения их визуального качества до
проведения различных измерений.
Еще одна важная область обработки видимых изображений —
дистанционное зондирование земной поверхности, охватывающее
обычно несколько зон в видимом и инфракрасном диапазонах спек-
тра. В Таблице 1.1 перечислены такие тематические зоны, в которых
осуществляет зондирование спутник LANDSAT, запущенный Агент-
ством NASA. Главная задача LANDSAT состоит в получении и пере-
даче изображений Земли из космоса с целью глобального экологиче-
ского мониторинга. Интервалы спектра представлены длинами волн
в микронах (мкм); напомним, что 1 мкм = 10'6 м (длины волн, отве-
чающих различным диапазонам электромагнитного спектра, подроб-
но обсуждаются в Главе 2). Обратим внимание на указанные в таблице
характеристики и назначение каждой из тематических зон.
Таблица 1.1. Тематические зоны американского спутника LANDSAT.
№ Наименование Длины волн, (мкм) Характеристики и назначение
1 Видимый синий цвет 0,45-0,52 Максимальная фильтрация влаги
2 Видимый зеленый цвет 0,52-0,60 Измерение плотности растительного покрова
3 Видимый красный цвет 0,63-0,69 Различение формы растительности
4 Ближнее ИК излучение 0,76-0,90 Съемка побережий и распределения биомассы
5 Средний ИК диапазон 1,55-1,75 Содержание влаги в почве и растительности
6 Тепловое ИК излучение 10,4-12,5 Влажность почвы и температурная карта
7 Средний ИК диапазон 2,08-2,35 Поиск полезных ископаемых
Чтобы получить начальное представление о возможностях таких
многозональных изображений, взглянем на Рис. 1.10, где приведено по
одному изображению для каждой из зон таблицы. Изображен район
г. Вашингтона, округ Колумбия; видны здания, дороги, участки рас-
тительности и протекающая через город крупная река Потомак. Изо-
бражения населенных пунктов часто (и давно) используются для оцен-
ки роста численности населения, динамики загрязнений и прочих
Глава 1. Введение
Г 2 3 Рис. 1.10. Полученные со спутника LANDSAT изображения г. Вашингтон,
15 6 7 ОКРУГ Колумбия. Номера снимков соответствуют номерам тематических зон в
Табл. 1.1. (Изображения предоставлены Агентством NASA).
факторов, вредно влияющих на экологию. Примечательна разница
между видимым и инфракрасным изображениями на этих снимках.
Обратим, например, внимание, насколько хорошо выделяется река на
фоне берегов в изображениях, соответствующих 4-й и 5-й зонам.
Наблюдение за погодой и составление прогнозов также является
важным применением многозональных спутниковых изображений.
Рис. 1.11. Мультиспектральное изображение урагана Эндрю, полученное
геостационарным спутником GEOS американской метеорологической службы NOAA.
(Изображение предоставлено службой NOAA).
Например, на Рис. 1.11 приводится изображение урагана, получен-
ное спутником Национальной океанографической и атмосферной
службы США (NOAA) с помощью датчиков, работающих в види-
мом и инфракрасном диапазонах. На этом снимке хорошо виден
так называемый «глаз» урагана (соответствует центру циклона).
Рис. 1.12 и 1.13 демонстрируют применение инфракрасных изоб-
ражений. Эти снимки были получены инфракрасной системой реги-
страции изображений, установленной на спутнике DMSP, запущен-
ном по оборонно-метеорологической программе службы NOAA,
и представляют собой фрагменты обширного набора данных «Ночные
огни Земли» — глобального реестра населенных пунктов. Устройство
регистрации инфракрасных изображений у этого спутника работает
в диапазоне длин волн 10,0—13,4 мкм и обладает уникальной способ-
ностью фиксировать находящиеся на земной поверхности слабые ис-
точники ближнего инфракрасного излучения, в том числе города,
поселки, деревни, газовые факелы и пожары. Даже не будучи специ-
алистом в обработке изображений, легко представить себе компьютер-
ную программу, которая использовала бы такие изображения для оцен-
ки относительной доли электроэнергии, потребляемой в различных
районах Земли.
Важной областью применения изображений, регистрируемых в ви-
димом диапазоне, является автоматический контроль выпускаемой
продукции. На Рис. 1.14 даны несколько примеров такого примене-
ния. Рис. 1.14(a) демонстрирует плату контроллера дисковода
CD-ROM. Для подобных изделий типичной задачей обработки изо-
бражений может быть контроль наличия всех компонентов (на данном
примере черный квадрат в правой верхней части изображения демон-
стрирует отсутствие микросхемы). На Рис. 1.14(6) показана упаковка
таблеток. Здесь задача состоит в компьютерном визуальном контро-
ле отсутствия пустых мест в упаковке. Рис. 1.14(в) иллюстрирует при-
мер обработки изображений для выявления недостаточно заполнен-
ных бутылок на производственной линии. На Рис. 1.14(г) показана
прозрачная пластмассовая деталь с недопустимым содержанием пу-
зырьков воздуха. Обнаружение подобных аномалий составляет важ-
ную область промышленного контроля различных материалов, напри-
мер, тканей и дерева. На Рис. 1.14(д) изображен пакет кукурузных
хлопьев, проходящий контроль по цвету и наличию брака в виде отдель-
ных подгоревших хлопьев. Наконец, на Рис. 1.14(e) показано изобра-
жение внутриглазного имплантата (вживляемого в глаз искусственно-
го хрусталика) при специальном структурированном освещении. Эта
технология применяется для простоты визуального обнаружения пло-
ских деформаций имплантата. Следы в положениях «1 час» и «5 часов»
Глава 1. Введение
Рис. 1.12. Инфракрасные спутниковые изображения американского континен-
та. Для наглядности рядом приведена небольшая карта. (Изображения предоставле-
ны службой NOAA).
1.3. Примеры областей применения цифровой обработки изображений
<
Рис. 1.13. Инфракрасные спутниковые изображения населенных регионов на
других континентах. Для наглядности рядом приведена небольшая карта. (Изобра-
жения предоставлены службой NOAA).
(по аналогии с часовым циферблатом) — повреждения, оставленные
пинцетом, а большинство других мелких пятнышек на изображении со-
зданы пылинками и остатками материала. Цель данного вида контроля
состоит в автоматическом обнаружении бракованныхили поврежденных
имплантатов перед упаковкой готовой продукции.
В качестве заключительной иллюстрации обработки изображений
видимого спектра рассмотрим Рис. 1.15. На Рис. 1.15(a) изображен от-
печаток большого пальца. Изображения отпечатков пальцев в массо-
вом порядке подвергаются компьютерной обработке как с целью их
улучшения, так и для поиска признаков, помогающих автоматически
выбирать из базы данных похожие отпечатки. На Рис. 1.15(6) приве,-
Глава 1. Введение
Рис. 1.14. Некоторые примеры промышленной продукции, часто контроли-
руемой с помощью цифровой обработки оптических изображений, (а) Печатная
плата контроллера, (б) Упаковка таблеток, (в) Бутылки, (г) Пузырьки в изделии из
прозрачной пластмассы, (д) Кукурузные хлопья, (е) Изображение искусственного
хрусталика. (Изображение (е) предоставил Пит Сайтс, Perceptics Corporation).
Рис. 1.15. Некоторые дополнительные примеры обработки изображений ви-
димого спектра, (а) Отпечаток пальца, (б) Бумажная купюра, (в, г) Автоматическое
чтение номерных знаков. (Изображения предоставили: (а) Национальный институт
стандартов и технологии США; (в, г) д-р Хуан Херрера, Perceptics Corporation).
дено изображение бумажной купюры. Цифровая обработка таких
изображений находит применение при автоматическом подсчете на-
личности и в правоохранительной деятельности, для чтения номе-
ров купюр с целью их прослеживания и идентификации. Два изобра-
жения транспортных средств, показанные на Рис. 1.15(в, г), являются
примерами автоматического чтения регистрационных номеров. Свет-
лые прямоугольники указывают области, в которых система обработ-
ки изображений опознала номер транспортного средства, а в черных
прямоугольниках выводятся результаты автоматического распознава-
ния этой системой содержимого номера. Чтение автомобильных но-
меров и другие применения автоматического распознавания символов
широко используются для контроля дорожного движения и надзора
правоохранительных органов.
1.3.5. Изображения в микроволновом диапазоне
Изображения микроволнового диапазона применяются главным
образом в радиолокации. Уникальным качеством радиолокации яв-
ляется возможность получения изображения любого района неза-
висимо от условий освещения и погоды. Микроволновое излуче-
ние некоторых диапазонов способно проникать даже сквозь облака,
растительность, лед и сухой песок. Во многих случаях радиолока-
ция остается единственным способом исследования труднодос-
тупных районов Земли. Применяемый для получения изображе-
ния радиолокатор работает аналогично фотоаппарату со вспышкой,
в том смысле, что он использует собственный источник освещения
(микроволновые импульсы), которое направляется на снимаемый
участок поверхности. Роль объектива фотоаппарата в радиолока-
торе играет антенна, сигнал от которой проходит через компьютер-
ную систему, осуществляющую регистрацию и обработку изобра-
жения. Радиолокационное изображение отображает распределение
интенсивностей отраженной энергии микроволнового диапазона,
которую уловила антенна локатора.
На Рис. 1.16 показано полученное из космоса радиолокационное
изображение труднодоступного горного массива в юго-восточном
Тибете, приблизительно в 90 км к востоку от г. Лхаса. В правом верх-
нем углу видна широкая долина реки Лхаса, населенная тибетскими
фермерами, разводящими яков; в этой долине расположена дер. Мен-
ба. Высота гор в этом районе достигает 5800 м над уровнем моря, а дно
долины располагается на высоте около 4300 м. Обратим внимание на
четкость изображения и качество воспроизведения деталей, независи-
мо от облаков и других атмосферных неоднородностей, которые обыч-
но мешают получить изображение сходного качества в оптическом
диапазоне.
1.3.6. Изображения в диапазоне радиоволн
Как и в случае изображений, получаемых на противоположной сто-
роне электромагнитного спектра (гамма-лучи), основными областя-
ми применения изображений в диапазоне радиоволн выступают ме-
1.3. Примеры областей применения цифровой обработки изображений
Рис. 1.16. Космическое радиолокационное изображение горного массива на
юго-востоке Тибета. (Изображение предоставлено Агентством NASA).
дицина и астрономия. В медицине радиоволны используются для по-
лучения изображений методом ядерного магнитного резонанса (ЯМР).
По этой технологии пациента помещают в сильное магнитное поле,
и через его тело пропускают радиоволны в форме коротких импуль-
сов. В ответ на каждый такой импульс ткани тела пациента реагиру-
ют, излучая свои радиоволновые сигналы. Сила этих сигналов и
места их возникновения определяются компьютерной системой об-
работки, генерирующей двумерное изображение среза тела пациента.
С помощью ЯМР можно получить срез вдоль любой плоскости. На
Рис. 1.17 показаны ЯМР-изображения человеческого коленного
сустава и позвоночника.
Крайний снимок справа на Рис. 1.18 демонстрирует изображе-
ние пульсара Крабовидной туманности в диапазоне радиоволн.
Интересно сравнить его с приведенными на этом рисунке изоб-
ражениями того же района, полученными в других обсуждавших-
ся ранее диапазонах электромагнитного спектра. Заметим, что
каждое изображение дает свой, совершенно отличающийся вид
этого пульсара.
1.3.7. Примеры, иллюстрирующие другие способы
формирования изображений
Хотя чаще всего используются изображения, полученные в электро-
магнитном спектре, существует ряд других важных способов форми-
Глава 1. Введение
Рис. 1.17. ЯМР-изображения человеческого (а) колена и (б) позвоночника.
(Изображения предоставили: (а) д-р Томас Р. Гест, Отделение анатомии медицинской
школы университета шт. Мичиган; (б) д-р Дэвид Р. Пикенс, Департамент радиоло-
гии медицинского центра университета Вандербилта).
рования изображений. В частности, в этом разделе мы обсудим акус-
тические изображения, электронную микроскопию и искусственные
изображения, синтезированные с помощью компьютеров.
Построение изображений с помощью звуковых волн находит при-
менение в геологических изысканиях, промышленности и медицине.
В геологии используются звуковые колебания с частотами у нижней
границы звукового спектра (до сотен герц), а в других областях для по-
лучения изображений применяются ультразвуковые колебания с ча-
стотами порядка мегагерц (миллионов герц). Наиболее важные ком-
мерческие применения обработки изображений в геологии касаются
поисков нефти и других полезных ископаемых. При формировании
изображения, несущего информацию о земных недрах, один из основ-
ных методов состоит в использовании тяжелого грузовика и большой
плоской стальной платформы. Грузовик давит на землю через платфор-
Рис. 1.18. Изображения пульсара Крабовидной туманности (находится в центре
снимков) в различных диапазонах электромагнитного спектра. (Изображения пре-
доставлены Агентством NASA).
радиоволновое
1.3. Примеры областей применения цифровой обработки изображений
му и одновременно является источником вибраций в спектре частот
до 100 Гц. Мощность и скорость распространения отраженных звуко-
вых волн определяется геологическим составом грунта под поверхно-
стью. В результате компьютерного анализа этих звуковых колебаний
строится цифровое изображение.
В морской геологии для получения изображений в звуковом ди-
апазоне обычно используют источник энергии в виде пары пневмо-
пушек, буксируемых позади судна. Отраженные звуковые волны де-
тектируются гидрофонами, помещенными внутрь кабелей, которые
либо также буксируются судами, либо укладываются на океанское дно
или вертикально подвешиваются к буям. Пневмопушки поочередно
выстреливают, создавая импульс давления порядка 150 атмосфер.
Картина отраженных звуковых волн в совокупности с постоянным
движением судна (что дает продольную составляющую) использу-
ются для формирования трехмерной карты состава земной коры под
дном океана.
На Рис. 1.19 изображено поперечное сечение известной трехмер-
ной модели, на которой проверяются характеристики алгоритмов по-
строения изображений по данным сейсморазведки. Стрелка указыва-
ет на углеводородный пласт (место залегания нефти и/или газа).
Указываемое место выглядит ярче окружающих пластов, поскольку из-
менения плотности в этом месте оказываются выше. Анализ изобра-
жений при сейсморазведке состоит в поиске подобных «ярких пятен»,
соответствующих вероятным нефтяным и газовым месторождени-
ям. Вышележащие пласты также выделяются своей яркостью, одна-
ко в этих случаях изменения яркости в поперечном направлении не
Рис. 1.19. Поперечное сечение модели данных сейсморазведки. Стрелкой
указан пласт углеводородов (место залегания нефти и/или газа). (Изображение пре-
доставил д-р Кертис С. Обер, Sandia National Laboratories).
столь сильны. Многие алгоритмы реконструкции данных сейсмораз-
ведки испытывают трудности при обнаружении отмеченной области
именно из-за ошибок, возникающих в вышележащих областях.
Хотя ультразвуковые изображения широко используются в про-
мышленности, наиболее известно применение этой технологии в ме-
дицине, особенно в акушерстве, где изображения еще не рожден-
ных детей изучаются на предмет отсутствия аномалий их развития.
Дополнительным результатом такого исследования является оп-
ределение пола будущего ребенка. Ультразвуковые изображения
формируются следующим образом:
1. Ультразвуковая система (состоящая из компьютера, ультразвуко-
вого зонда с излучателем и приемником, и дисплея) передает в тело
ультразвуковые импульсы высокой частоты (от 1 до 5 МГц).
2. Звуковые волны проходят сквозь тело пациента, и на границах
между тканями (например, между жидкостью и мягкой тканью, мягкой
тканью и костью скелета) происходит частичное отражение. Часть зву-
ковых волн отражается обратно в сторону зонда, часть волн затухает,
а остальные распространяются дальше, пока не достигнут следующей
границы раздела и снова частично отразятся, и т.д.
3. Отраженные волны улавливаются приемником зонда и переда-
ются в компьютер.
4. Исходя из времени прихода каждого эхо-сигнала и известной
скорости звука в тканях (1500 м/с), компьютер вычисляет расстояние
от зонда до соответствующей границы ткани или внутреннего органа.
5. Вычисленные расстояния и интенсивности принятых отраженных
сигналов выводятся на дисплее в виде двумерного изображения.
В типичных ультразвуковых исследованиях ежесекундно генери-
руются и принимаются миллионы звуковых импульсов и эхо-сигна-
лов. Зонд можно двигать вдоль поверхности тела и наклонять, полу-
чая изображения в различных проекциях. На Рис. 1.20 приводятся
несколько примеров таких изображений.
Мы продолжим обсуждение других способов получения изображе-
ний на примерах из электронной микроскопии. Электронный микро-
скоп действует аналогично оптическому, с той разницей, что вместо
световых лучей для получения изображения исследуемого объекта
применяется сфокусированный пучок электронов. Работа электрон-
ного микроскопа складывается из следующих основных шагов. Источ-
ник испускает поток электронов, которые движутся с ускорением в на-
правлении исследуемого образца благодаря приложенному
положительному напряжению. С помощью металлических щелевых
диафрагм и магнитных линз этот поток ограничивается и фокусиру-
ется, образуя тонкий пучок, сфокусированный на образце. Внутри об-
Рис. 1.20. Примеры ультразвуковых изображений, (а) Ребенок, (б) Ребенок
в другой проекции, (в) Щитовидная железа, (г) Мышечные слои с заметным повреж-
дением. (Изображения предоставила группа по ультразвуку компании Siemens Medical
Systems, Inc.).
лучаемого образца происходит взаимодействие, оказывающее влияние
на прохождение пучка электронов, эффект от которого обнаружива-
ется и преобразуется в изображение аналогично тому, как свет отра-
жается или поглощается объектами наблюдаемой сцены. Перечис-
ленные основные шаги имеют место во всех электронных микроскопах
независимо от их типа.
Принцип работы трансмиссионного электронного микроскопа (ТЭМ)
во многом аналогичен проектору слайдов. Проектор направляет (пе-
редает) пучок света на слайд; при проходе этого пучка сквозь слайд свет
претерпевает изменения в соответствии с содержимым слайда. После
этого пучок света проецируется на экран, формируя увеличенное изо-
бражение слайда. ТЭМ работает точно так же, за исключением того,
что сквозь образец, играющий роль слайда, направляется пучок эле-
ктронов. Часть пучка, прошедшая сквозь исследуемый образец, про-
ецируется на экран из фосфоресцирующего материала. Взаимодейст-
вие электронов с этим материалом приводит к появлению света и,
следовательно, видимого изображения. С другой стороны, сканирую-
Глава 1. Введение
щий электронный микроскоп (СЭМ) в действительности осуществля-
ет сканирование образца электронным пучком, и результат взаимодей-
ствия электронного пучка с каждой точкой поверхности образца ото-
бражается в виде пятнышка на фосфоресцирующем экране. Полное
изображение формируется путем растрового сканирования образца
электронным пучком аналогично телевизионной развертке. Отра-
женные электроны при попадании на фосфоресцирующий экран созда-
ют на нем видимое изображение. СЭМ лучше подходят для объемных
образцов, тогда как для ТЭМ необходим очень тонкий образец.
Электронные микроскопы способны дать очень большое увеличе-
ние. Если в оптической микроскопии кратность увеличения ограниче-
на приблизительно 1000х, то в электронной микроскопии достигается
увеличение 10000х и более. На Рис. 1.21 показаны полученные с по-
мощью СЭМ два изображения образцов с дефектами, возникшими
вследствие температурных перегрузок.
Завершим обсуждение различных способов формирования изоб-
ражений, кратко рассмотрев изображения, полученные не от какого-
то физического объекта или явления, а сгенерированные компьютером.
Примечательным примером изображений, синтезированных с помо-
щью компьютеров, являются фракталы [Lu, 1997]. По существу, фрак-
талы представляют собой не что иное, как повторяющееся воспроизве-
дение некоторого исходного образа по определенным математическим
правилам. Например, мозаика из квадратных элементов является од-
Рис. 1.21. (а) Изображение поврежденной при перегреве вольфрамовой ни-
ти накаливания, полученное на СЭМ при увеличении 250х. (б) СЭМ-изображение
вышедшей из строя интегральной микросхемы при увеличении 2500х. Белая нить —
это полоса окисла, возникшая при тепловом разрушении. (Изображения предоста-
вили: (а) Майкл Шаффер, факультет геологии университета шт. Орегон, г. Юджин;
(б) д-р Джон М. Хьюдек, университет Мак-Мастер, г. Гамильтон, шт. Онтарио, Ка-
нада).
1.3. Примеры областей применения цифровой обработки изображений
ним из простейших способов генерации фрактальных изображений.
Квадрат можно разделить на четыре квадратные подобласти, каждую
из которых, в свою очередь, можно разбить снова на четыре более мел-
ких квадрата, и так далее. В зависимости от сложности правил запол-
нения каждой квадратной подобласти, таким способом могут быть по-
лучены некоторые красивые мозаичные изображения. Разумеется,
геометрия может быть произвольной. Например, фрактальное изоб-
ражение может вырастать из одной центральной точки — такой при-
мер изображен на Рис. 1.22(a). Рис. 1.22(6) демонстрирует другое
фрактальное изображение («лунный ландшафт»), являющееся ин-
тересной аналогией некоторых космических снимков, приведенных
в качестве иллюстрации в предыдущих разделах.
Фрактальные изображения, при всей их художественности, несут
в себе элементы математического описания процесса «выращивания»
изображения из его более мелких элементов в соответствии с некото-
рыми правилами. Иногда они находят применение в качестве слу-
Рис. 1.22. (а, б) Фрактальные изображения, (в, г) Изображения, построенные
по трехмерным компьютерным моделям показанных объектов. (Изображения пре-
доставили: (а, б) Мелисса Д. Байнд, Swarthmore College; (в, г) Агентство NASA).
Глава 1. Введение
чайных текстур. Более систематический подход к генерации изобра-
жений с помощью компьютеров состоит в построении трехмерных мо-
делей объектов. Именно эта важная область, находящаяся на стыке об-
работки изображений и компьютерной графики, является основой для
построения множества систем трехмерной визуализации (например,
авиационных тренажеров). Рис. 1.22(в, г) демонстрируют примеры
изображений, синтезированных с помощью компьютерных программ.
Поскольку объекты моделировались как трехмерные, с помощью пло-
ской проекции трехмерного объема можно построить изображения
этих объектов в любом ракурсе. Изображения подобного вида исполь-
зуются в медицинском образовании, а также как основа для реше-
ния других прикладных задач, например, в криминалистике, судебной
медицине, или для создания спецэффектов.
1.4. Основные стадии цифровой обработки
изображений
Было бы полезно разделить изложенный в последующих главах ма-
териал на две большие категории, упомянутые в Разделе 1.1: методы,
в которых на входе и на выходе имеются изображения, и методы, где
на вход поступают изображения, а на выходе возникают признаки
и атрибуты, выделенные на основании этих изображений. Такая ор-
ганизация материала книги сведена в схему, изображенную на Рис. 1.23.
Эта схема не подразумевает, что к изображению применяется каждый
из описанных процессов, напротив, целью было донести принципы
всех методов обработки, который могут применяться к изображени-
ям в различных целях и, возможно, с различными получаемыми ре-
зультатами. Проводимое в данном разделе обсуждение можно рас-
сматривать как краткий обзор материала, представленного в остальной
части книги.
Регистрация изображения — первый из процессов, показанных на
Рис. 1.23. Обсуждение, проведенное в Разделе 1.3, дает некоторые
подсказки относительно возможных источников цифровых изобра-
жений, однако значительно более подробно эта тема рассматривает-
ся в Главе 2, где также вводится ряд базовых понятий, относящихся
к цифровым изображениям и используемых далее на протяжении
всей книги. Заметим, что регистрация изображения может оказаться
предельно простой, как в случае, когда исходное изображение уже
представлено в цифровой форме. В общем случае стадия регистра-
ции изображения включает некоторую предобработку, например,
масштабирован ие.
1.4. Основные стадии цифровой обработки изображений
На выходе этих процессов в общем случае получается изображение
Рис. 1.23. Основные стадии цифровой обработки изображений.
Улучшение изображения входит в число наиболее простых и впечат-
ляющих областей цифровой обработки изображений. По существу, за
методами улучшения изображений стоит идея выявления плохо раз-
личимых деталей или просто подчеркивания интересующих характе-
ристик на исходном изображении. Известным примером улучшения
является усиление контраста изображения, потому что в результате
«оно выглядит лучше». Важно иметь в виду, что улучшение качества —
весьма субъективная область в обработке изображений. Этой теме
посвящены две главы, но не потому, что улучшение изображений
важнее других изложенных в книге тем, а поскольку мы используем эту
тему для представления читателю той методики, которой будем при-
держиваться и в последующих главах. Так, вместо изложения в специ-
альной главе всех предварительных начальных сведений с позиций ма-
тематики, мы вводим ряд необходимых математических понятий,
иллюстрируя их применительно к улучшению изображений. При та-
ком подходе читатель будет знакомиться с этими понятиями в контек-
сте обработки изображений. Хорошим примером этого является фу-
рье-преобразование, которое вводится в Главе 4, но данный принцип
используется также и в других главах книги.
Восстановление изображений — это область, также связанная с по-
вышением визуального качества изображения, однако, в отличие от
собственно улучшения, критерии которого субъективны, восстанов-
ление изображения является объективным в том смысле, что методы
восстановления изображений опираются на математические или ве-
роятностные модели искажений изображения. Напротив, улучшение
изображений основано на субъективных предпочтениях человеческого
восприятия, которые связаны с тем, что именно считается «хорошим»
результатом улучшения.
Обработка цветных изображений приобрела особую важность в свя-
зи со значительным расширением использования цветных изобра-
жений в Интернет. В Главе 5 излагается ряд фундаментальных поня-
тий, относящихся к цветовым моделям и основным видам цифровых
преобразований цветов. Цвет также используется в последующих главах
как основа для выделения из изображения некоторых интересующих
признаков.
Вейвлеты образуют фундамент для представления изображений
с несколькими степенями разрешения одновременно. В частности, этот
аппарат используется в книге применительно к сжатию данных изо-
бражения, а также для построения пирамидального представления,
при котором изображение поэтапно разбивается на все более мелкие
фрагменты.
Сжатие, как следует из самого названия, относится к методам
уменьшения объема памяти, необходимого для хранения изображения,
или сужения полосы пропускания канала, требуемой для его переда-
чи. Хотя техника запоминающих устройств за последнее десятилетие
была значительно усовершенствована, этого нельзя сказать в отноше-
нии пропускной способности линий связи. Это особенно справедли-
во по отношению к информации в Интернет, где изобразительная
составляющая является существенным элементом содержимого. Со
сжатием изображений знакомо (возможно, не отдавая себе в этом от-
чета) большинство пользователей компьютеров, встречающих в име-
нах графических файлов определенные расширения; например, jpg ис-
пользуется в стандарте сжатия изображений, разработанном
Объединенной группой экспертов по фотографии (Joint Photographic
Experts Group — JPEG).
Морфологическая обработка связана с инструментами для извлече-
ния таких компонент изображения, которые могут быть полезны для
представления и описания формы. Приведенный в этой главе матери-
ал дает основы перехода от процессов, имеющих на выходе изображе-
ние, к процессам, имеющим на выходе атрибуты изображения, как это
указывалось в Разделе 1.L
Сегментация разделяет изображение на составные части или объ-
екты. В целом автоматическая сегментация принадлежит к числу са-
мых трудных задач цифровой обработки изображений. Излишне по-
1.4. Основные стадии цифровой обработки изображений
дробная сегментация уводит процесс решения задачи обработки изо-
бражения на сложный путь, если требуется идентифицировать объ-
екты по отдельности. С другой стороны, недостаточно подробная
или же ошибочная сегментация почти неизбежно приведет к воз-
никновению ошибок на финальной стадии обработки. В общем, чем
точнее сегментация, тем больше шансов на успех при распознавании.
Представление и описание почти всегда следуют непосредственно
за этапом сегментации, на выходе которого обычно имеются лишь не-
обработанные данные о пикселях, которые либо образуют границу
области (т.е. дается множество пикселей, отделяющих одну область
изображения от другой), либо представляют все точки самих областей.
В обоих случаях необходимо преобразовать данные в форму, пригод-
ную для компьютерной обработки. Первое решение, которое следует
принять, — должны ли эти данные представляться в форме границ
областей или областей целиком. Представление границами подходит
для тех случаев, когда в центре внимания находятся внешние характе-
ристики формы областей, например, углы и изгибы. Представление об-
ластями более уместно, если акцент делается на внутренних свойствах
объектов, например, текстуре или форме скелета. В некоторых прило-
жениях эти представления дополняют друг друга. Выбор способа пред-
ставления — лишь часть принятия решения по преобразованию «сы-
рых» пиксельных данных в подходящую для дальнейшей компьютерной
обработки форму. Должен быть еще указан метод описания данных, при
котором бы выдвигались на передний план интересующие признаки. По-
строение описания, иначе называемое выбором признаков, связано с вы-
делением атрибутов, которые бы выражали интересующую количест-
венную информацию или бы могли служить основой для различения
классов объектов.
Распознавание представляет собой процесс, который присваивает не-
которому объекту идентификатор (например, «транспортное средство»)
на основании его описателей. Как подробно разъяснялось в Разде-
ле 1.1, мы считаем, что сфера цифровой обработки изображений закан-
чивается разработкой методов распознавания отдельных объектов.
До настоящего момента ничего не говорилось о необходимости
априорных знаний, или, в терминах Рис. 1.23, о взаимосвязи между ба-
зой знаний и модулями обработки. На самом деле, знание о проблем-
ной области, т.е. база знаний, некоторым образом закодировано вну-
три самой системы обработки изображений. Это знание может быть
очень простым, как детальное указание участков изображения, где
должна находиться интересующая информация, что позволит огра-
ничить область ее поиска. База знаний может быть и очень сложной,
как, например, взаимосвязанный список всех наиболее вероятных де-
Глава 1. Введение
фектов в задаче контроля материалов, либо база данных спутниковых
изображений некоторого района с высоким разрешением в приклад-
ных задачах обнаружения изменений, происходящих в этом районе. По-
мимо того, что база знаний руководит работой каждого модуля обра-
ботки, она также управляет взаимодействием между модулями. Эта
отличительная особенность показана на Рис. 1.23 с помощью двунаправ-
ленных стрелок между обрабатывающими модулями и базой знаний,
в отличие от однонаправленных стрелок, которые связывают модули
обработки друг с другом.
Хотя мы не обсуждаем в этом месте задачу визуализации изобра-
жений, важно иметь в виду, что на выходе любой из показанных на
Рис. 1.23 стадий может выполняться отображение результатов обра-
ботки. Отметим также, что не во всех прикладных задачах обработки
изображений требуется вся сложность взаимодействия, подразумева-
емого Рис. 1.23. На самом деле, в ряде случаев даже не все эти моду-
ли необходимы. Например, улучшение изображений для визуальной
интерпретации человеком редко нуждается в использовании каких-
либо других стадий из числа показанных на Рис. 1.23. В общем слу-
чае, однако, чем выше сложность задачи обработки изображений,
тем большее число процессов требуется привлекать для решения
этой задачи.
1.5. Компоненты системы обработки изображений
Еще в середине 1980-х гг. большинство поступающих на рынок образцов
систем обработки изображений были относительно крупными перифе-
рийными устройствами, которые соединялись со столь же основательны-
ми компьютерами. Позднее — в конце 1980-х — начале 1990-х гг. — на
рынке произошел переход к аппаратуре обработки изображений в ви-
де одиночной платы, конструктивно совместимой с какой-либо из
ставших стандартом магистралей, и пригодной для установки в инду-
стриальные и персональные компьютеры. Наряду со снижением сто-
имости такой аппаратуры, рынок также стал катализатором для возник-
новения значительного числа новых компаний, ориентированных на
разработку программного обеспечения специально для обработки
изображений.
Хотя для массовой обработки изображений большого размера
(например, спутниковых) еще производятся крупные системы циф-
ровой обработки, общая тенденция направлена в сторону миниатюри-
зации и оснащения обычных малых компьютеров специализированным
оборудованием для решения задач обработки изображений. На Рис. 1.24
изображены основные компоненты, из которых состоит типичная
1.5. Компоненты системы обработки изображений
Сеть
Подсистема
отображения
Компьютер
Подсистема
массовой памяти
Подсистема вьщачи
твердой копии
Специализированные
устройства дли
обработки
изображений
Программы
для обработки
изображений
Подсистема
регистрации
изображений
и
Проблемная область
Рис. 1.24. Компоненты универсальной системы обработки изображений.
универсальная система цифровой обработки изображений, а ниже по
очереди обсуждаются функций каждого из ее компонентов.
Что касается регистрации, то для получения цифровых изображе-
ний в общем случае необходимы два элемента. Первый из них — это
чувствительный элемент (сенсор), т.е. физическое устройство, обла-
дающее чувствительностью к тому виду излучаемой объектом энер-
гии, который мы хотим отобразить. Второй элемент, цифровой пре-
образователь, представляет собой устройство, преобразующее
аналоговый выходной сигнал чувствительного элемента в цифровую
форму5. Например, в цифровой видеокамере элементы светочувстви-
тельной матрицы вырабатывают электрический сигнал, пропорцио-
нальный силе света. Цифровой преобразователь трансформирует эти сиг-
5 Здесь необходимо отметить, что для преобразования непрерывного сигнала в ци-
фровую форму необходимы два, вообще говоря, независимых процесса: дискрети-
зация, т.е. пространственное разложение непрерывного сигнала на некоторое чис-
ло отсчетов, и квантование — перевод непрерывного диапазона значений отсчетов
в конечный набор значений. — Прим, перев.
налы в цифровые данные. Более подробно эта тема рассматривается
в Главе 2.
Специализированные устройства для обработки изображений обыч-
но включают вышеупомянутый цифровой преобразователь, а также
оборудование, с помощью которого выполняются другие элементар-
ные операции, как, например, арифметико-логическое устройство
(АЛУ), которое позволяет выполнять арифметические и логические
операции параллельно для всего изображения. Один из вариантов
использования АЛУ — локальное усреднение изображений одновре-
менно с оцифровкой — может быть полезен для снижения уровня
шума. Оборудование такого типа иногда называют подсистемой пре-
добработки (или препроцессором)', ее отличительной характеристикой
является высокая скорость работы. Иначе говоря, этот блок выполня-
ет функции обработки данных, требующие высокой производитель-
ности (например, оцифровка и усреднение видеоизображений со
скоростью 25 кадров в секунду), с чем не справляется типичный
управляющий компьютер системы.
Под компьютером в системе обработки изображений подразу-
мевается универсальная ЭВМ в диапазоне от обычного персональ-
ного компьютера (ПК) до суперкомпьютера. В специализирован-
ных приложениях для достижения требуемой производительности
иногда используются компьютеры специальной конструкции, одна-
ко мы рассматриваем здесь именно универсальную систему обработ-
ки изображений. В таких системах практически любой хорошо ос-
нащенный ПК пригоден для решения задач обработки изображений,
не требующих работы в реальном масштабе времени.
Программное обеспечение для обработки изображений состоит из
специализированных модулей, выполняющих конкретные опера-
ции. В развитых пакетах программ имеются также средства, позво-
ляющие пользователю самостоятельно разрабатывать программы,
которые, как минимум, запускают в работу специализированные
модули системы. Более сложные программные пакеты позволяют со-
четать вызов этих модулей с обычными операторами какого-либо из
универсальных языков программирования.
Наличие массовой памяти большого объема обязательно для прак-
тических задач обработки изображений. Для хранения изображения
размером 1024 х 1024 пикселя, в котором яркость каждого пикселя
представляется 8-битовой величиной, необходим один мегабайт па-
мяти, если не используются средства сжатия изображений. При рабо-
те с тысячами или даже миллионами изображений наличие достаточ-
ной внешней памяти в системе обработки изображений может
оказаться проблематичным. Цифровые запоминающие устройства
1.5. Компоненты системы обработки изображений 63
для задач обработки изображений делятся на три основные категории:
(1) временная память для краткосрочного использования в ходе обра-
ботки, (2) внешняя память, обладающая относительно коротким вре-
менем обращения, и (3) архивная память, для которой характерны
редкие обращения. Емкость запоминающих устройств измеряется
в байтах (8 бит), килобайтах (тысяча байтов), мегабайтах (миллион
байтов), гигабайтах (миллиард байтов) и терабайтах (триллион байтов)6.
Одним из вариантов реализации временной памяти может быть
оперативная память компьютера. Другой вариант состоит в использо-
вании специальных плат, называемых буферами кадров, которые хра-
нят одно или более изображений, обеспечивая высокую скорость чте-
ния/записи, обычно соответствующую частоте кадров видеосигнала
(например, 25 кадр/с). Этот способ позволяет практически мгновен-
но выполнять увеличение изображения, либо сдвигать его в верти-
кальном (прокрутка) или горизонтальном (панорамирование) направ-
лениях. Буферы кадров обычно расположены в показанном на рисунке
блоке «Специализированные устройства для обработки изображе-
ний». Внешняя память, как правило, представлена накопителями на
магнитных или оптических дисках и характеризуется частыми обра-
щениями к хранящейся информации; т.е. важнейшим для нее являет-
ся фактор быстродействия. Напротив, обращение к архивной памяти
за информацией происходит редко, но требуется очень большая ем-
кость памяти. В запоминающих устройствах, используемых в качест-
ве архивной памяти, в качестве носителей информации обычно при-
меняются магнитные ленты и оптические диски внутри многодисковых
хранилищ с автоматической установкой и сменой дисков («jukebox»).
Графические дисплеи, используемые в настоящее время, в основ-
ном оснащаются электронно-лучевыми трубками по типу телевизи-
онных, предпочтительно с плоским экраном. Сигнал на монитор по-
дается с платы отображения (видеоадаптера), входящей в состав
компьютера. В редких случаях к системе отображения предъявляют-
ся такие требования, которым не отвечают встроенные видеоадапте-
ры современных компьютеров. Иногда необходим стереоскопический
режим отображения; это может достигаться с помощью закрепляемой
на голове гарнитуры с двумя малогабаритными дисплеями, встроен-
ными в оправу, похожую на защитные очки, в которые и смотрит
пользователь.
6 Зачастую, при выражении емкости памяти в байтах, коэффициент увеличения
при переходе в каждый следующий класс принимается равным 2* * 10=Ю24, а не
103= 1000, что, впрочем, здесь несущественно. — Прим, перев.
К числу устройств получения твердых копий относятся лазерные
и струйные принтеры, устройства термопечати, пленочные фотокаме-
ры и цифровые устройства, например оптические диски7. Макси-
мальное разрешение достигается при выводе на пленку, однако для
письменных и печатных материалов более естественным носителем яв-
ляется бумага. Для показав ходе презентаций, изображения выводят-
ся на прозрачную пленку или цифровой носитель (если используется
подключаемый к компьютеру проектор). Последний вариант постепен-
но становится общепринятым стандартом презентации изображений.
Соединение с телекоммуникационной сетью уже стало почти подра-
зумеваемой функцией в любой сегодняшней компьютерной системе.
Учитывая большие объемы данных, связанные с задачами обработки изо-
бражений, важнейшим фактором для передачи изображений является
пропускная способность сети. В локальных сетях и на выделенных ка-
налах телекоммуникации трудностей обычно не возникает, однако об-
мен информацией с удаленными пунктами через Интернет далеко не
всегда оказывается столь же эффективным. К счастью, в результате
развития оптоволоконных сетей и других технологий широкополосной
связи положение в этой сфере быстро исправляется.
Заключение
Главной целью материала этой главы было показать в исторической
перспективе истоки возникновения цифровой обработки изображе-
ний и, что более важно, нынешние и будущие возможности примене-
ния этой технологии. Хотя эти вопросы невозможно исчерпывающе
рассмотреть в пределах одной главы, у читателя должно остаться яс-
ное ощущение широты области практических применений цифровой
обработки изображений. Поскольку последующие главы книги посвя-
щены теории и приложениям обработки изображений, мы привели
большое число примеров, чтобы более четко представлять перспекти-
вы и пользу от применения таких методов. Закончив изучение послед-
ней главы книги, читатель должен прийти к такому уровню понима-
ния предмета, который является фундаментом для большинства работ,
ныне проводимых в этой области.
7 Оптические диски, вообще говоря, относятся к устройствам хранения информа-
ции. — Прим, перев.
Ссылки и литература для дальнейшего изучения 65
Ссылки и литература для дальнейшего изучения
В конце последующих глав даются относящиеся к конкретным темам каж-
дой из этих глав ссылки на общий список литературы, приведенный в кон-
це книги. Однако в этой главе использованадругая форма, чтобы собрать
в одном месте всю совокупность научных журналов, публикующих ма-
териалы по обработке изображений и смежным вопросам. Приводится
также список книг, по которым читатель легко может представить себе ис-
торическую и современную перспективу деятельности в этой области. Та-
ким образом, приводимый в этой главе список литературных источни-
ков следует рассматривать как доступный путеводитель по изданной
литературе в области обработки изображений.
К числу наиболее важных реферируемых журналов, публикую-
щих статьи по обработке изображений и смежным вопросам, относят-
ся: IEEE Transactions on Image Processing; IEEE Transactions on Pattern
Analysis and Machine Intelligence; Computer Vision, Graphics, and Image
Processing (до 1991 г.); Computer Vision and Image Understanding; IEEE
Transactions on Systems, Man and Cybernetics; Artificial Intelligence; Pattern
Recognition; Pattern Recognition Letters; Journal of the Optical Society of
America (до 1984 г.); Journal of the Optical Society of America—A: Optics, Image
Science and Vision; Optical Engineering; Applied Optics— Information Processing;
IEEE Transactions on Medical Imaging; Journal of Electronic Imaging; IEEE
Transactions on Information Theory; IEEE Transactions on Communications;
IEEE Transactions on Acoustics, Speech and Signal Processing; Proceedings of
the IEEE; а также выпуски журнала IEEE Transactions on Computers до
1980 г. Также представляют интерес публикации Международного
общества по оптической технике (SPIE).
Следующие книги, перечисленные в обратном хронологическом по-
рядке (и с уклоном в сторону более свежих публикаций), содержат
материал, дополняющий наш взгляд на цифровую обработку изобра-
жений. Эти книги дают общую картину обсуждаемой области за послед-
ние 30 лет и были выбраны так, чтобы представить разнообразие суще-
ствующих трактовок. В списке присутствуют и учебники, излагающие
фундаментальный материал, и руководства по применению опреде-
ленных методов, и, наконец, научные монографии, представляющие
достигнутый уровень исследований в этой области.
Duda R.O., Hart Р.Е., Stork, D.G. [2001]. Pattern Classification, 2nd ed., John
Wiley & Sons, NY.
3 A-223
Pratt W. К. [2001]. Digital Image Processing, 3rded., John Wiley & Sons, NY.
[Имеется перевод 1-го издания: Прэтт У. Цифровая обработка изо-
бражений. — М.: Мир, 1982. Кн. 1 и 2]
Ritter G.X., Wilson, J.N. [2001]. Handbook of Computer Vision Algorithms in
Image Algebra, CRC Press, Boca Raton, FL.
Shapiro L.G., Stockman G.C. [2001]. Computer Vision, Prentice Hall, Upper
Saddle River, NJ.
Dougherty E.R. (ed.) [2000]. Random Processes for Image and Signal
Processing, IEEE Press, NY.
Etienne E.K., Nachtegael M. (eds.). [2000]. Fuzgy Techniques in Image
Processing, Springer-Verlag, NY.
Goutsias J, Vincent L., Bloomberg D.S. (eds.). [2000]. Mathematical
Morphology and Its Applications to Image and Signal Processing, Kluwer
Academic Publishers, Boston, MA.
Mallot A.H. [2000]. Computational Vision, The MIT Press, Cambridge, MA.
Marchand-Maillet S., Sharaiha, YM. [2000]. Binary Digital Image Processing:
A Discrete Approach, Academic Press, NY.
Mitra S.K., Sicuranza G.L. (eds.) [2000]. Nonlinear Image Processing,
Academic Press, NY.
Edelman S. [1999]. Representation and Recognition in Vision, The MIT Press,
Cambridge, MA.
Lillesand T.M., Kiefer R.W. [1999]. Remote Sensing and Image Interpretation,
John Wiley & Sons, NY.
Mather P.M. [1999]. Computer Processing of Remotely Sensed Images: An
Introduction, John Wiley & Sons, NY.
Petrou M., Bosdogianni P. [1999]. Image Processing: The Fundamentals,
John Wiley & Sons, UK.
Russ, J.C. [1999]. The Image Processing Handbook, 3rd ed., CRC Press,
Boca Raton, FL.
Smirnov A. [1999]. Processing of Multidimensional Signals, Springer-Verlag, NY.
Sonka M., Hlavac V, Boyle R. [1999]. Image Processing, Analysis, and
Computer Vision, PWS Publishing, NY.
Umbaugh S.E. [1998]. Computer Vision and Image Processing: A Practical
Approach Using CVIPtools, Prentice Hall, Upper Saddle River, NJ.
Haskell B.G., Netravali A.N. [1997]. Digital Pictures: Representation,
Compression, and Standards, Perseus Publishing, NY.
Jahne B. [1997]. Digital Image Processing: Concepts, Algorithms, and Scientific
Applications, Springer-Verlag, NY.
Castleman K.R. [1996]. Digital Image Processing, 2nd ed., Prentice Hall,
Upper Saddle River, NJ.
Geladi P., Grahn H. [1996]. Multivariate Image Analysis, John Wiley &
Sons, NY.
Bracewell R.N. [1995]. Two-Dimensional Imaging, Prentice Hall, Upper
Saddle River, NJ.
Sid-Ahmed M.A. [1995]. Image Processing: Theory, Algorithms, and
Architectures, McGraw-Hill, NY.
Jain R., Rangachar K., Schunk B. [1995]. Computer Vision, McGraw-Hill, NY
MiticheA. [1994]. Computational Analysis of Visual Motion, Perseus Publishing, NY
Baxes G.A. [1994]. Digital Image Processing: Principles and Applications,
John Wiley & Sons, NY.
Gonzalez R.C., Woods R.E. [1992]. Digital Image Processing, Addison-
Wesley, Reading, MA.
Haralick R.M., Shapiro L.G. [1992]. Computer and Robot Vision, vols. 1 & 2,
Addison-Wesley, Reading, MA.
Pratt W.K. [1991] Digital Image Processing, 2nd ed., Wiley-Interscience,
NY. [Имеется перевод 1 -го издания: Прэтт У. Цифровая обработка
изображении. — М.: Мир, 1982. Кн. 1 и 2]
Lim J.S. [1990]. Two-Dimensional Signal and Image Processing, Prentice
Hall, Upper Saddle River, NJ.
Jain A.K. [1989]. Fundamentals of Digital Image Processing, Prentice Hall,
Upper Saddle River, NJ.
Schalkoff R.J. [1989]. Digital Image Processing and Computer Vision, John
Wiley & Sons, NY.
Giardina C.R., Dougherty E.R. [1988]. Morphological Methods in Image
and Signal Processing, Prentice Hall, Upper Saddle River, NJ.
Levine M.D. [1985]. Vision in Man and Machine, McGraw-Hill, NY.
Sena J. [1982]. Image Analysis and Mathematical Morphology, Academic Press, NY
Глава 1. Введение
Ballard D.H., Brown С.М. [1982]. Computer Vision, Prentice Hall, Upper
Saddle River, NJ.
FuK.S. [1982]. Syntactic Pattern Recognition and Applications, Prentice Hall,
Upper Saddle River, NJ. [Имеется перевод более ранней книги: Фу К.
Структурные методы в распознавании образов. — М.: Мир, 1977.]
Nevada R. [1982]. Machine Perception, Prentice Hall, Upper Saddle River, NJ.
Pavlidis T. [1982]. Algorithms for Graphics and Image Processing, Computer
Science Press, Rockville, MD.
Rosenfeld R., KakA.C. Digital Picture Processing, 2nded., vols. 1 &2,
Academic Press, NY.
Hall E.L. [1979]. Computer Image Processing and Recognition, Academic
Press, NY.
Gonzalez R.C., Thomason M.G. [1978]. Syntactic Pattern Recognition: An
Introduction, Addison-Wesley, Reading, MA.
Andrews H.C., Hunt B.R. [1977]. Digital Image Restoration, Prentice Hall,
Upper Saddle River, NJ.
Pavlidis T. [1977]. Structural Pattern Recognition, Springer-Verlag, NY, 1977.
Tou J.T., Gonzalez R.C. [1974]. Pattern Recognition Principles, Addison-
Wesley, Reading, MA, 1974.
Andrews H.C. [1970]. Computer Techniques in Image Processing, Academic
Press, NY.
Литература, добавленная при переводе
Ниже приводится список литературы по вопросам цифровой обработ-
ки изображений, который, по мнению переводчиков, будет способ-
ствовать расширению кругозора читателя данной книги. С сожалени-
ем следует отметить, что в нашей стране не существует каких-либо
специализированных периодических изданий, посвященных рас-
сматриваемой проблеме. К числу периодических изданий, в которых
регулярно публикуются научные работы по данной тематике, отно-
сятся журналы Автометрия, Исследование Земли из Космоса и Кибер-
нетика. Международной академической издательской компанией
Наука/Интерпериодика издается журнал «Pattern Recognition and
Image Analysis» (ISSN 1054-6618), который, к сожалению, выпускается
только на английском языке. Большинство современных результатов
публикуется в трудах различных научных конференций, симпозиумов,
ведомственных изданий, или же в виде сборников статей, издаваемых
Ссылки и литература для дальнейшего изучения
институтами Российской Академии наук или иными научными и
учебными учреждениями. Из их числа без сомнения следует отме-
тить такие сборники как Иконика и Цифровая оптика, издававшие-
ся Институтом проблем передачи информации РАН, а также сборни-
ки Вопросы кибернетики, издаваемые Научным Советом по комплексной
проблеме «Кибернетика» РАН.
Ранее (до начала 1990 г.) издавался перевод ежемесячного журна-
ла Труды института инженеров по электротехнике и радиоэлектрони-
ке (ТИИЭР), в котором с достаточной регулярностью появлялись как
отдельные статьи, так и тематические выпуски, посвященные обработ-
ке изображений. Без сомнения, особого внимания заслуживают
следующие тематические выпуски ТИИЭР:
Сокращение избыточности. — ТИИЭР, 1967, т. 55, № 3.
Цифровая обработка изображений. — ТИИЭР, 1972, т. 60, № 7.
Распознавание образов и обработка изображений. — ТИИЭР, 1979, т. 67, № 10.
Цифровое кодирование. — ТИИЭР, 1980, т. 68, № 7.
Обработка изображений. — ТИИЭР, 1981, т. 69, № 5.
Системы видеосвязи. — ТИИЭР, 1985, т. 73, № 4 и № 5.
Из числа изданных на русском языке книг, представляющих интерес
при изучении вопросов цифровой обработки изображений (как ориги-
нальных, так и переводных изданий), можно рекомендовать следующие.
Ахмед Н., Рао К.Р. Ортогональные преобразования при обработке циф-
ровых сигналов. — М.: Связь, 1980.
Александров В.В., Горский Н.Д. Представление и обработка изображений:
Рекурсивный подход. —Л.: Наука, 1985.
Бейтс Р., Мак-Доннелл М. Восстановление и реконструкция изобра-
жений. — М.: Мир, 1989.
БендатДж., ПирсолА. Прикладной анализ случайных данных. — М.: Мир,
1989.
Бонгард М.М. Проблема узнавания. — М.: Наука, 1967.
Быстрые алгоритмы в цифровой обработке изображений: Преобразова-
ния и медианные фильтры / Хуанг ТС., Эклунд Дж.-О., Нуссбаумер
ГДж. и др. / Ред. Хуанг ТС. — М.: Радио и связь, 1984.
Василенко Г.И., Тараторин А.М. Восстановление изображений. —
М.: Радио и связь, 1986.
Введение в цифровую фильтрацию / Ред. Богнер Р., Константинидис А. —
М.: Мир, 1976.
Витгих В.А., Сергеев В.В., Сойфер В.А. Обработка изображений в авто-
матизированных системах научных исследований. — М.: Наука, 1982.
Голд Б., Рэйдер Ч. Цифровая обработка сигналов. — М.: Сов. радио, 1973.
Горелик А.Л., Скрипкин В.А. Методы распознавания: Учебное пособие. —
М.: Высшая школа, 1989.
Тренандер У Лекции по теории образов. — М.: Мир. т. 1: Синтез образов. —
1979. т. 2: Анализ образов. — 1981. т. 3: Регулярные структуры. — 1983.
Даджион Д., Мерсеро Р. Цифровая обработка многомерных сигналов. —
М.: Мир, 1988.
Добеши И. Десять лекций по вейвлетам. — Ижевск: НИЦ «Регулярная
и хаотическая динамика» ,2001.
Дуда R, Харт П. Распознавание образов и анализ сцен. — М.: Мир, 1976.
Жуков А.И. Метод Фурье в вычислительной математике. — М.: Наука, 1992.
Завалишин Н.В., Мучник И.Б. Модели зрительного восприятия и алго-
ритмы анализа изображений. — М.: Наука, 1974.
Ковалевский В.А. Методы оптимальных решений в распознавании изо-
бражений. — М.: Наука, 1976.
Кодирование и обработка изображений / Ред. Лебедев Д. С., Зяблов В. В. —
М.: Наука, 1988.
Коды с обнаружением и исправлением ошибок. — М.: ИЛ, 1956.
Лебедев Д.С., Цуккерман И.И. Телевидение и теория информации.
М,—Л.: Энергия, 1965.
Марр Д. Зрение. Информационный подход к изучению представления и об-
работки зрительных образов. — М.: Радио и связь, 1987.
Методы компьютерной обработки изображений / Ред. Сойфер. В.А. —
М.: Физматлит, 2001.
Методы передачи изображений. Сокращение избыточности / Прэтт
УК., Сакрисон Д.Д., Мусман Х.Г.Д. и др. / Ред. Прэтт УК. — М.:
Радио и связь, 1983.
Методы сжатия данных / Ватолин Д., Ратушняк А., Смирнов М.,
ГОкин В. — М.: Диалог-МИФИ, 2002 (См. также http://compres-
sion.graphicon.ru/).
Ссылки и литература для дальнейшего изучения
Минский М., Пейперт С. Персептроны. — М.: Мир, 1971.
Нильсон Н. Искусственный интеллект. Методы поиска решений. —
М.: Мир, 1973.
Нильсон Н. Обучающиеся машины. — М.: Мир, 1967.
Обработка изображений и цифровая фильтрация. / Ред. Хуанг Т. — М.:
Мир, 1979.
Обработка изображений при помощи цифровых вычислительных машин /
Ред. Эндрюс Г., Инло Л. — М.: Мир, 1973. (См. также ТИИЭР,
1972, т. 60, № 7).
Оппенгейм А.В., Шафер Р.В. Цифровая обработка сигналов. —
М.: Связь, 1979.
Осовский С. Нейронные сети для обработки информации. — М.: Финансы
и статистика, 2002.
Павлидис Т. Алгоритмы машинной графики и обработки изображений. — М.:
Радио и связь, 1986.
Применение цифровой обработки сигналов / Ред. Оппенгейм Э. — М.:
Мир, 1980.
ПрэттУ. Цифровая обработка изображений. — М.: Мир, 1982. Кн. 1 и 2.
Психология машинного зрения / Ред. Уинстон П. — М.: Мир, 1978.
Рабинер Л., Гоулд Б. Теория и применение цифровой обработки
сигналов. — М.: Мир, 1978.
Распознавание образов при помощи цифровых вычислительных
машин / Ред. Хармон Л. — М.: Мир, 1974. (См. также ТИИЭР,
1972, т. 60, № 10).
Реконструкция изображений / Ред. Старк Г. — М.: Мир, 1992.
Розенблатт Ф. Принципы нейродинамики. Персептрон и теория механиз-
мов мозга. — М.: Мир, 1966.
Розенфельд А. Распознавание и обработка изображений с помощью
вычислительных машин. — М.: Мир, 1972.
Столниц Э., ДеРоуз Т, Салезин Д. Вейвлеты в компьютерной графике.
Теория и приложения. — Ижевск: НИЦ «Регулярная и хаотическая
динамика». 2002.
Теория информации и ее приложения. — М.: Физматгиз, 1959.
Тихонов А.Н., Арсенин В.Я. Методы решения некорректных задач. —
М.: Наука, 1979.
Ту Дж., Гонсалес Р. Принципы распознавания образов. — М.: Мир, 1978.
Ульман Ш. Принципы восприятия подвижных объектов. — М.: Радио и
связь, 1983.
Фу К. Последовательные методы в распознавании образов и обучении
машин. — М.: Наука, 1979.
Фу К. Структурные методы в распознавании образов. — М.: Мир, 1977.
Фукунага К. Введение в статистическую теорию распознавания образов. —
М.: Наука, 1979.
Хорн Б.К.П. Зрение роботов. — М.: Мир, 1989.
Хэмминг Р.В. Теория кодирования и теория информации. — М.: Радио и
связь, 1983.
Цифровая обработка изображений в информационных системах: Учебное
пособие / ГрузманИ.С., КиричукВ.С. идр. — Новосибирск, НГТУ,
2002.
Цифровая обработка телевизионных и компьютерных изображений
/ДворковичА.В., ДворковичВ.П., ЗубаревЮ.Б. идр. — М.: Меж-
дународный центр научной и технической информации, 1997.
Цифровое кодирование телевизионных изображений / Цуккерман И.И.,
Кац Б.М., Лебедев Д.С. идр. — М.: Радио и связь, 1981.
Чисар И., Кёрнер Я. Теория информации: теоремы кодирования для
дискретных систем без памяти. — М.: Мир, 1985.
Чуи К. Введение в вейвлеты. — М.: Наука, 2001.
Шашлов БА Цвет и цветовоспроизведение. — М.: М1АП «Мир книги», 1995.
Эндрюс Г. Применение вычислительных машин для обработки изоб-
ражений. — М.: Энергия, 1977.
Яншин В. В. Анализ и обработка изображений: принципы и алгоритмы. —
М.: Машиностроение, 1994.
Ярославский Л.П. Введение в цифровую обработку изображений. — М.:
Сов. радио, 1979.
Ярославский Л.П. Цифровая обработка сигналов в оптике и голографии:
Введение в цифровую оптику. — М.: Радио и связь, 1987.
ГЛАВА 2
ОСНОВЫ
ЦИФРОВОГО
ПРЕДСТАВЛЕНИЯ
ИЗОБРАЖЕНИЙ
Желающий добиться успеха должен задавать
правильные предварительные вопросы.
Аристотель
Введение
Цель этой главы — ввести основные понятия и обозначения, относя-
щиеся к цифровым изображениям и используемые на протяжении
всей книги. В Разделе 2.1 кратко описывается действие зрительной си-
стемы человека, включая механизмы формирования изображения
глазом и возможности зрения в плане яркостной адаптации и контра-
стной чувствительности. В Разделе 2.2 обсуждается свет и другие со-
ставляющие электромагнитного спектра, а также их характеристики
в отношении формирования изображений. Раздел 2.3 посвящен обсуж-
дению различных чувствительных элементов и способов регистра-
ции цифровых изображений. В Разделе 2.4 вводятся понятия равно-
мерной пространственной дискретизации изображений и квантования
по яркости. Кроме того, в этом разделе обсуждаются вопросы представ-
ления цифровых изображений и то, как на них сказываются измене-
ния частоты дискретизации и количества уровней квантования. Рас-
смотрены некоторые важные явления, связанные с дискретизацией,
а также технология увеличения и уменьшения изображений. В Разде-
ле 2.5 рассматриваются некоторые фундаментальные взаимосвязи
между пикселями, которые также повсеместно используются в кни-
ге. Наконец, в Разделе 2.6 определены условия линейности преобра-
зований. Как там отмечено, именно линейные преобразования игра-
ют центральную роль в построении методов обработки изображений.
2.1. Элементы зрительного восприятия
Хотя цифровая обработка изображений как прикладная дисциплина
строится на основе математических и вероятностных формулировок,
человеческая интуиция и анализ играют центральную роль при выбо-
ре того или иного метода среди других, и этот выбор часто соверша-
ется на основе субъективного визуального оценивания. Поэтому пер-
вым шагом нашего путешествия по этой книге будет приобретение
элементарных знаний о зрительном восприятии человека. Понимая
сложность и широту этой темы, мы сможем охватить лишь самые на-
чальные аспекты изучения зрения человека. В частности, мы опи-
шем физические механизмы и параметры, связанные с процессом
формирования изображения в глазу. Нам также интересно рассмотреть
физические ограничения человеческого зрения с точки зрения факто-
ров, учитываемых при работе с цифровыми изображениями. Поэтому
такие вопросы, как соотношение человеческого и электронного зре-
ния по разрешающей способности и способности глаза адаптиро-
ваться к изменениям освещенности, представляют не только познава-
тельный интерес, но и важны в практическом плане.
2.1.1. Строение человеческого глаза
На Рис. 2.1 в упрощенном виде показано горизонтальное сечение че-
ловеческого глаза. Глаз имеет почти сферическую форму со средним
диаметром около 20 мм. Глаз окружен тремя оболочками: роговица со
склерой образуют внешнюю оболочку, под которой последовательно
расположены сосудистая оболочка (хороидея) и нейроглиальная обо-
лочка (сетчатка). Роговица — это плотная прозрачная ткань, закры-
вающая переднюю поверхность глаза. Продолжением ее является
склера — непрозрачная оболочка, закрывающая остальную часть оп-
тической сферы глаза.
Хороидея расположена непосредственно под склерой. В этой обо-
лочке проходит сеть кровеносных сосудов, обеспечивающих питание
глаза. Даже незначительное повреждение хороидеи, часто кажущее-
ся неопасным, может привести к серьезному нарушению зрения из-
за воспаления, препятствующего нормальному кровотоку. Поверх-
ностный слой хороидеи сильно пигментирован, что снижает
интенсивность попадающего через склеру внешнего света, мешающе-
го восприятию из-за его отражения и рассеяния внутри оптической
сферы. Передняя область (зубчатая линия) хороидеи непосредствен-
но вплетена в цилиарное тело и радужную оболочку (или радужку). От-
верстие в центре радужной оболочки (зрачок) может сужаться или
2.1. Элементы зрительного восприятия
расширяться, регулируя тем самым количество попадающего через ро-
говицу света. Диаметр зрачка может изменяться в пределах от 2 до 8 мм.
От цвета пигмента на передней поверхности радужки зависит цвет
глаза человека, а пигмент на задней поверхности радужки имеет
черный цвет, что также снижает внутреннее рассеяние света.
Хрусталик {хрусталиковая линза), состоящий из наружной капсу-
лы и внутрихрусталикового вещества, закреплен внутри глаза с помо-
щью передней и задней порций волокон ресничного пояска хруста-
лика, которые проходят между отростками цилиарного тела и
вплетаются в зубчатую линию хороидеи. Капсула и внутрихрустали-
ковое вещество состоят из коллагеновых волокон и содержат от 60%
до 70% воды, около 6% жиров и больше белков, чем любые другие тка-
ни глаза. Внутрихрусталиковое вещество имеет слабо-желтую пиг-
ментацию, которая с возрастом усиливается. Ускоренное помутнение
вещества хрусталика, связанное с нарушением его питания, приводит
к заболеванию, называемому катарактой, при котором ухудшается цве-
товое восприятие и острота зрения. В видимом диапазоне спектра хру-
сталик поглощает около 8% света, и практически не пропускает более
коротковолновое излучение. Свет инфракрасного и ультрафиолетово-
го диапазонов существенно поглощается белком хрусталика, и при
высокой интенсивности может привести к необратимому нарушению
зрения.
Самая внутренняя оболочка глаза — сетчатка — выстилает изнут-
ри задний отдел глаза. При правильной оптической фокусировке гла-
за свет от наружного объекта проецируется в виде изображения на сет-
чатку. Зрительное восприятие образов становится возможным
благодаря распределению дискретных светочувствительных клеток
(рецепторов) по внутренней поверхности сетчатки. Существуют рецеп-
торы двух видов — колбочки и палочки. В глазу насчитывается от 6 до
7 миллионов колбочек, которые обладают высокой чувствительнос-
тью к спектральным составляющим света и располагаются преимуще-
ственно в центральной области сетчатки, называемой желтым пят-
ном. В центре желтого пятна имеется так называемая центральная
ямка — область наибольшей остроты зрения. Человек различает мел-
кие детали изображения в основном благодаря колбочкам, посколь-
ку каждая из них соединена с отдельным нервным окончанием. На-
ружные мышцы глаза обеспечивают вращение глазного яблока так,
чтобы изображение интересующего объекта попадало в область жел-
того пятна. Колбочки обеспечивают фотопическое зрение, или зрение
в ярком свете.
Количество палочек в глазу намного больше: по поверхности сет-
чатки их распределено от 75 до 150 миллионов. Большая, чем у кол-
бочек, область распределения и тот факт, что к одному нервному
окончанию присоединено сразу несколько палочек (в среднем около
10), уменьшают возможности различения деталей с помощью этих
рецепторов. Палочки позволяют сформировать общую картину все-
го поля зрения. Они наиболее чувствительны при низких уровнях ос-
вещенности и не участвуют в обеспечении функций цветного зре-
ния. Например, предметы, имеющие яркую окраску при дневном
свете, при сумеречном освещении выглядят как лишенные цветов
образы, поскольку возбуждаются только палочки. Это явление изве-
стно как скотопическое (или сумеречное) зрение.
2.1. Элементы зрительного восприятия
Рис. 2.2. Распределение палочек и колбочек по сетчатке.
Рис. 2.2 иллюстрирует зависимость плотности распределения па-
лочек и колбочек по сетчатке в зависимости от величины угла между
зрительной осью и линией, проведенной из центра хрусталика до сет-
чатки. Изображено горизонтальное сечение правого глаза в месте вы-
хода зрительного нерва. Отсутствие рецепторов в этой области приво-
дит к появлению так называемого слепого пятна (см. Рис. 2.1). В
остальной области сетчатки распределение рецепторов центрально
симметрично относительно центра желтого пятна.
Из Рис. 2.2 видно, что максимальная плотность колбочек наблюда-
ется в центре сетчатки (в центральной ямке), а плотность палочек воз-
растает от этой точки приблизительно до угла в 20, после чего плавно
снижается вплоть до периферии сетчатки.
Центральная ямка представляет собой углубление круглой формы
в сетчатке, с диаметром около 1,5 мм. В контексте дальнейшего обсуж-
дения более естественно говорить о прямоугольных массивах чувст-
вительных элементов. В несколько вольной интерпретации можно
рассматривать центральную ямку как квадратный массив чувстви-
тельных элементов на площади 1,5 ммх 1,5 мм. Плотность колбочек
в этой области сетчатки приблизительно равна 150 тыс. на 1 мм2, сле-
довательно, общее количество колбочек в области наибольшей остро-
ты зрения составляет около 337 тыс. элементов. Если рассуждать толь-
ко в терминах разрешающей способности, то широко применяемые в
современной технике светочувствительные матрицы среднего разре-
шения на основе приборов с зарядовой связью (ПЗС) содержат такое
же количество чувствительных элементов при площади кристалла не
Глава 2. Основы цифрового представления изображений
более 5 мм х 5 мм. Однако дальнейшее сравнение было бы непродук-
тивным, поскольку не учитывает способность человека объединять зре-
ние с интеллектом и опытом. В дальнейшем будем просто иметь в ви-
ду, что глаз человека по своей разрешающей способности вполне
сопоставим с современными электронными устройствами получения
изображений.
2.1.2. Формирование изображения в глазу
Основное отличие хрусталика глаза от жесткой оптической линзы со-
стоит в возможности изменения его оптической силы за счет некото-
рой вариации его формы (кривизны). Как видно из Рис. 2.1, радиус
кривизны передней поверхности капсулы хрусталика больше, чем
задней. Изменение формы хрусталика осуществляется путем натя-
жения или ослабления передней и задней порций волокон реснично-
го пояска. Для фокусировки зрения на удаленном предмете реснич-
ная мышца расслабляется, хороидея сжимается, натягивая при этом
волокна ресничного пояска, в результате чего хрусталик приобретает
уплощенную форму. Наоборот, для фокусировки на близкорасполо-
женном предмете ресничная мышца сокращается, что приводит к ос-
лаблению натяжения волокон ресничного пояска и округлению хру-
сталика, т.е. к увеличению его преломляющей способности.
При изменении преломляющей способности хрусталика с мини-
мального значения до максимального, его фокусное расстояние изме-
няется соответственно от 17 мм (при фокусировке на дальние предме-
ты) до 14 мм (при фокусировке на близкие предметы). При
рассмотрении предметов на удалении более 3 м преломляющая способ-
ность хрусталика минимальна, при разглядывании близкорасполо-
женных предметов преломляющая способность хрусталика макси-
мальна. На основе этих данных легко вычислить размеры изображения
некоторого объекта на сетчатке. Например, на Рис. 2.3 наблюдатель
видит дерево высотой 15 м с расстояния 100 м. Обозначая h высоту изо-
Рис. 2.3. Схематическое изображение глаза, наблюдающего дерево (точка С
— оптический центр хрусталика).
2.1. Элементы зрительного восприятия
Сражения дерева на сетчатке (в мм), получаем пропорцию 15/100=7?/17,
откуда Л=2,55 мм. Как указывалось в Разделе 2.1.1, проецирующе-
еся на сетчатку изображение воспринимается главным образом об-
ластью желтого пятна. Расположенные в ней рецепторы возбуж-
даются в соответствии с интенсивностью падающего света, что
приводит к преобразованию энергии светового излучения в электри-
ческие нервные импульсы, которые в конечном счете декодируют-
ся в мозге человека.
2.1.3. Яркостная адаптация и контрастная
чувствительность
Поскольку цифровые изображения воспроизводятся как дискретное
множество элементов с различной яркостью, способность глаза раз-
личать отличающиеся уровни яркости необходимо учитывать при
представлении результатов обработки изображений. Зрительная сис-
тема человека способна адаптироваться к огромному, порядка 1010, ди-
апазону значений яркости — от порога чувствительности скотопиче-
ского зрения до предела ослепляющего блеска. Эксперименты со всей
очевидностью показывают, что субъективная яркость (т.е. яркость,
как она воспринимается зрительной системой человека) является ло-
гарифмической функцией от физической яркости света, попадаю-
щего в глаз. На Рис. 2.4 изображен график этой зависимости субъек-
Рис. 2.4. Диапазон субъективно воспринимаемой яркости и конкретный уро-
вень адаптации.
тивной яркости от истинной яркости. Длинная сплошная кривая
представляет диапазон яркостей, в котором способна адаптировать-
ся зрительная система. При использовании одного фотопического
зрения этот диапазон составляет около 106. Постепенный переход от
скотопического зрения к фотопическому происходит в диапазоне
приблизительно от 0,003 до 0,3 кд/м2 (т.е. от —2,5 до —0,5 по логариф-
мической шкале), что показано в виде двух ветвей кривой адаптации
в этом диапазоне яркостей.
Для правильной интерпретации столь впечатляющего динамиче-
ского диапазона, изображенного на Рис. 2.4, важно понимать, что
зрительная система не способна работать во всем этом диапазоне од-
новременно. Вместо этого она охватывает такой большой диапазон за
счет изменения общей чувствительности. Это явление известно какя/>
костная адаптация. Общий диапазон одновременно различаемых
уровней яркости относительно мал по сравнению со всем диапазоном
адаптации. Для любого данного набора внешних условий текущий
уровень чувствительности зрительной системы, называемый уровнем
яркостной адаптации, соответствует некоторой яркости, например, точ-
ке Ва на Рис. 2.4. Короткая кривая, пересекающая основной график,
представляет диапазон субъективной яркости, которую способен вос-
принимать глаз при адаптации к указанному уровню. Этот диапазон
достаточно ограничен: все уровни яркости ниже Вь субъективно вос-
принимаются зрением как черное и, значит, неразличимы. Верхняя
(пунктирная) часть этой кривой реально не ограничена, но теряет
смысл при большой длине, поскольку при повышении яркости просто
повышается уровень адаптации Ва.
Способность зрения различать изменения яркости при данном
уровне адаптации также представляет значительный интерес. Класси-
ческий эксперимент для определения способности зрительной систе-
мы человека различать разные уровни яркости состоит в том, что ис-
пытуемый смотрит на плоский равномерно освещенный экран
достаточно больших размеров, такой, что он занимает все поле зрения.
Как правило, это рассеиватель из матового стекла, освещаемый со сто-
роны, противоположной наблюдателю, световым источником, яр-
кость /которого можно регулировать. На это равномерное поле на-
кладывается добавочная яркость А/ в форме кратковременной
вспышки в области круглой формы, расположенной в центре равно-
мерно освещенного экрана, как изображено на Рис. 2.5.
Если приращение А/недостаточно велико (неразличимо), испы-
туемый говорит «нет», указывая тем самым на отсутствие видимых из-
менений. По мере увеличения А/ в какой-то момент он начнет гово-
рить «да», подтверждая тем самым восприятие изменений яркости.
2.1. Элементы зрительного восприятия
Рис. 2.5. Постановка простого эксперимента для определения характеристик
контрастной чувствительности.
Наконец, при достаточно большом значении А/испытуемый станет го-
ворить «да» на каждую вспышку. Величина А/с /1, где А/с — величина
приращения яркости, различимая в 50% случаев на фоне яркости I, на-
зывается отношением Вебера. Малое значение А/с / I означает, что
различаются очень малые относительные изменения яркости, т.е.
имеет место «высокая» контрастная чувствительность. Наоборот,
большое значение А/с / / означает, что требуется большое относитель-
ное изменение яркости, чтобы его заметить; это говорит о «низкой»
контрастной чувствительности.
График зависимости величины log(A/c / Г) от log / имеет общую фор-
му, изображенную на Рис. 2.6. Эта кривая показывает, что низкая
контрастная чувствительность (т.е. большое отношение Вебера) наблю-
дается при малых уровнях яркости, и контрастная чувствительность за-
метно возрастает (т.е. отношение Вебера уменьшается) при увеличении
фоновой яркости. Наличие двух ветвей кривой отражает тот факт, что при
малых уровнях яркости зрение осуществляется благодаря действию па-
Рис. 2.6. Типичная зависимость отношения Вебера как функции яркости
лочек, тогда как при больших уровнях яркости (которым соответству-
ет высокая контрастная чувствительность) зрительные функции вы-
полняют колбочки сетчатки.
Если поддерживать фоновую яркость постоянной, а яркость до-
бавочного источника варьировать не вспышками, а ступенчатым
изменением яркости от неотличимого до заметного всегда, то типич-
ный наблюдатель способен различить всего 10—20 различаю-
щихся ступеней яркости. Грубо говоря, этот результат относит-
ся к числу различных уровней яркости, которые человек способен
различить в произвольной точке монохромного изображения. Это не
означает, что изображение может быть представлено таким неболь-
шим числом градаций яркости, так как по мере движения взгляда по
изображению меняется среднее значение яркости фона, что позво-
ляет обнаруживать различные множества относительных изменений
яркости для каждого нового уровня адаптации. Конечным следстви-
ем является способность глаза различать яркости в намного более ши-
роком общем диапазоне. В действительности, как мы покажем в Раз-
деле 2.4.3, глаз способен обнаруживать нежелательные ложные
контуры в монохромных изображениях, общий диапазон яркостей
которых представляется значительно большим количеством, чем 20
уровней.
Известны два явления, ясно доказывающие, что воспринимаемая
яркость не является простой функцией истинной яркости. Первое
основывается на том факте, что вблизи границ соседних областей с от-
личающимися, но постоянными яркостями зрение человека склонно
«подчеркивать» яркостные перепады, как бы добавляя несуществую-
щие выбросы яркости, что убедительно демонстрирует пример на
Рис. 2.7(a). Хотя яркость каждой из полос постоянна, мы, кроме дей-
ствительно ступенчатого изменения яркости, видим характерные вы-
бросы вблизи краев полос (Рис. 2.7(6)). Эти полосы с кажущимися из-
менениями яркости на краях называются полосами Маха в честь Эрнста
Маха, впервые описавшего этот феномен в 1865 г.
Второе явление, называемое одновременным контрастом, связано
с тем фактом, что воспринимаемая яркость некоторой области не оп-
ределяется просто ее яркостью, как показывает Рис. 2.8. Здесь все
центральные квадраты имеют в точности одинаковую яркость, одна-
ко зрительно воспринимаются тем более темными, чем светлее фон.
Еще более знакомым примером является лист бумаги, который кажет-
ся белым, когда он лежит на столе, но может показаться совершен-
но черным, если им закрывать глаза, глядя на яркое небо.
Другими примерами феноменов человеческого зрительного вос-
приятия являются оптические иллюзии, в которых глаз восполняет не-
2.1. Элементы зрительного восприятия
Воспринимаемая
яркость
V. Истинная яркость
,а
б
Рис. 2.7. Пример, показывающий, что воспринимаемая яркость не является про-
сто функцией от истинной яркости. Взаимное положение по вертикали двух графиков
на рис. (б) несущественно и выбрано для большей наглядности.
Рис. 2.8. Примеры одновременного контраста. Яркость всех центральных
квадратов одинакова, но они кажутся все темнее, чем светлее становится фон.
существующую информацию или ошибочно воспринимает геоме-
трические свойства объектов. Некоторые примеры оптических ил-
люзий изображены на Рис. 2.9. На Рис. 2.9(a) ясно видны очертания
квадрата, вопреки тому факту, что на изображении отсутствуют ли-
нии, определяющие такую фигуру. Аналогичный эффект, на этот раз
в виде круга, виден на Рис. 2.9(6); заметим, как всего нескольких ли-
ний достаточно для получения иллюзии полного круга. Два горизон-
тальных отрезка на Рис. 2.9(b) имеют одинаковую длину, но один ка-
жется короче другого. Наконец, все проведенные под углом 45° линии
на Рис. 2.9(г) параллельны и расположены на одинаковых расстояни-
ях друг от друга. Однако штриховка создает иллюзию, что эти линии
далеки от параллельности. Оптические иллюзии относятся к числу не
вполне понятных характеристик зрительной системы человека.
Рис. 2.9. Некоторые хорошо известные оптические иллюзии.
2.2. Свет и электромагнитный спектр
2.2. Свет и электромагнитный спектр
Электромагнитный спектр был кратко представлен в Разделе 1.3; те-
перь мы рассмотрим эту тему более подробно. В 1666 г. сэр Исаак
Ньютон открыл, что при прохождении луча солнечного света сквозь
стеклянную призму возникает световой пучок, который имеет не бе-
лый цвет, а состоит из непрерывного цветового спектра, цвет которо-
го меняется от фиолетового на одном конце до красного на другом. Как
видно из Рис. 2.10, диапазон цветов, которые мы воспринимаем как
видимый свет, составляет очень малую часть спектра электромагнит-
ного излучения. На одном конце этого спектра находятся радиовол-
ны, длина которых в миллиарды раз превышает длины волн видимо-
го света, а на другом конце — гамма-лучи, длина волны которых в
миллионы раз меньше длины световых волн. Компоненты электро-
магнитного спектра можно выражать в терминах длины волны, час-
тоты колебаний или энергии. Длина волны (X) и частота (v) связаны
соотношением
Х = -, (2.2-1)
v
где с — скорость света (2,998-108 м/с). Энергия составляющей элект-
ромагнитного спектра определяется выражением
E = hv, (2.2-2)
где h — постоянная Планка. Длина волны измеряется в метрах, но столь
же часто в качестве единиц измерения употребляются микрон
(1 мкм = 10‘6 м) и нанометр (1 нм = 10*9 м). Частота измеряется в гер-
цах (Гц); 1 Гц соответствует колебанию с частотой один период в се-
кунду. Общеупотребительной единицей измерения энергии фотонов
является электрон-вольт (эВ).
Электромагнитные волны можно трактовать как распространяю-
щиеся синусоидальные колебания с длиной волны X (Рис. 2.11), а
можно — как поток частиц с нулевой массой, движущихся со скоро-
стью света. Каждая такая частица не имеет массы, но обладает опре-
деленной энергией и называется квантом излучения (фотоном). Из
соотношения (2.2-2) видно, что энергия пропорциональна частоте, по-
этому электромагнитные колебания более высокой частоты (т.е. с
более короткой длиной волны) обладают большей энергией фотона.
Таким образом, радиоволны характеризуются малой энергией фо-
тона, у микроволн энергия больше, у инфракрасного излучения еще
Энергия одного фотона (эВ)
106 105 104 103 102 101 1 10’1 10’2 10’3 10’4 10’5 10’6 10’7 10’8 10’9
Sa-
53
§
1021 1О20 1019 1018 1017 1016 1015 1014 1013 1012 1011 1О10 109 108 107 106 105
_1______I_______I________I_______I_______I________I______I_______I________I_______I_______I________I______I_______I________I________L—
Длина волны (м)
10’12 10’11 1О'10 10’9 10’8 10’7 10’6 10’5 10’4 10’3 10'2 10’1 1 101 102 103
________I_______I________I_______I_______I_____I_________I_______I________I_______I_______I_____I_________I_______I________I_____।
а
о
5)
г
фиолетовое Фиолетовый Синий Голубой Зеленый Желтый Оранжевый Красный излучение
s:
о
§
Чз
В
§
1
§
а
излучение
Рис. 2.10. Спектр электромагнитных колебаний. Видимый спектр показан в растянутом виде, но следует подчеркнуть, что он
занимает весьма узкий участок всего электромагнитного спектра.
2.2. Свет и электромагнитный спектр
Рис. 2.11. Графическое представление длины волны колебаний.
этому электромагнитные колебания более высокой частоты (т.е. с
более короткой длиной волны) обладают большей энергией фотона.
Таким образом, радиоволны характеризуются малой энергией фо-
тона, у микроволн энергия больше, у инфракрасного излучения еще
больше, далее энергия фотона последовательно возрастает для диапа-
зонов видимого спектра, ультрафиолетового излучения, рентгеновских
лучей и, наконец, гамма-лучей, обладающих самой большой энергией.
Именно по этой причине гамма-излучение так опасно для живых ор-
ганизмов.
Свет является особым видом электромагнитного излучения, ко-
торое воспринимается человеческим глазом. Видимый (цветовой)
спектр приведен на Рис. 2.10 в растянутом виде только для сведения;
более подробно цвет рассматривается в Главе 6. Этот видимый диа-
пазон электромагнитного спектра охватывает длину волны прибли-
зительно от 0,43 мкм (фиолетовыйцвет) до 0,79 мкм (красный цвет).
Для удобства цветовой спектр делят на семь широких полос (цветов):
фиолетовый, синий, голубой, зеленый, желтый, оранжевый и крас-
ный; но это разграничение не резкое, а, скорее, один цвет плавно пе-
реходит в другой, как показано на Рис. 2.10, подобно любой другой
составляюшей электромагнитного спектра.
Различаемые зрением человека цвета предметов определяются ха-
рактером света, отраженного от этих предметов. Тело, которое отра-
жает свет приблизительно одинаково во всем видимом диапазоне
волн, представляется наблюдателю белым, тогда как тело, отражаю-
щее свет в каком-то ограниченном диапазоне длин волн, восприни-
мается с некоторым цветовым оттенком. Например, зеленый предмет
в основном отражает свет с длинами волн 500—570 нм, поглощая боль-
шинство энергии в других интервалах длин волн.
Свет, лишенный цветовой окраски, называется ахроматическим или
монохроматическим. Единственным параметром такого освещения
является его интенсивность, или яркость. Для описания монохрома-
тической яркости также используется термин уровень серого, посколь-
ку яркость изменяется от черного до белого, с промежуточными серы-
ми оттенками. Длины волн электромагнитного излучения для
хроматического света, как уже отмечалось, находятся в интервале
приблизительно от 0,43 мкм до 0,79 мкм. Хроматические источники
света характеризуются тремя основными величинами: энергетическим
потоком, световым потоком и (субъективной) яркостью. Энергетиче-
ский поток — это общее количество энергии, излучаемой источником
света, обычно измеряемое в ваттах (Вт). Световой поток, измеряе-
мый в люменах (лм), характеризует количество энергии, которое на-
блюдатель воспринимает от светового источника. Например, световой
источник, работающий в дальнем инфракрасном диапазоне, может да-
вать значительный энергетический поток, но наблюдатель его прак-
тически не ощущает, так что световой поток такого источника почти
нулевой. Наконец, как уже обсуждалось в Разделе 2.1, яркость описы-
вает субъективное восприятие света и практически не поддается изме-
рению. Она олицетворяет понятие интенсивности в ахроматическом
случае и является одним из ключевых факторов при описании цвето-
вого ощущения.
Продолжая обсуждение Рис. 2.10, заметим, что коротковолновая
сторона спектра электромагнитного излучения представлена гамма-
и рентгеновскими лучами. Мы уже обсуждали в Разделе 1.3.1 важность
использования изображений в гамма-лучах для медицины, астроно-
мии и ядерной энергетики. Жесткое (с высокой энергией) рентгенов-
ское излучение используется для получения изображений в промы-
шленности. Для получения рентгеновских изображений грудной
клетки используется верхний (коротковолновый) участок диапазона
мягкого рентгеновского излучения, а в стоматологии применяется
нижний участок этого диапазона (с меньшей энергией). Мягкие рент-
геновские лучи плавно переходят в ближний ультрафиолетовый ди-
апазон, длинноволновый участок которого, в свою очередь — в види-
мый спектр. Двигаясь дальше в сторону увеличения длин волн, мы
встретим инфракрасный диапазон, в котором излучается тепло, что де-
лает его полезным для получения изображений на основе тепловой кар-
тины объекта. Участок инфракрасного диапазона, соседствующий с ви-
димым спектром, называется ближним инфракрасным диапазоном, а
противоположный участок — дальним инфракрасным диапазоном. По-
следний плавно переходит в микроволновый диапазон, хорошо изве-
стный благодаря кухонным микроволновым печам, но также исполь-
зуемый во многих других целях, в том числе, для связи и радиолокации.
Наконец, в диапазоне радиоволн осуществляется теле- и радиовеща-
ние, а в области высоких энергий этого диапазона проводятся астро-
номические наблюдения радиосигналов, испускаемых некоторыми зве-
здными телами. Примеры изображений для большинства
перечисленных диапазонов излучения были приведены в Разделе 1.3.
2.3. Считывание и регистрация изображения
В принципе, если сконструировать чувствительный элемент, спо-
собный обнаруживать излучаемую энергию в некотором диапазоне
электромагнитного спектра, то можно получить интересующее изо-
бражение этого диапазона. Однако важно заметить, что длина элек-
тромагнитных волн, используемых для «наблюдения» некоторого
объекта, должна быть меньше его размера. Например, размер моле-
кулы воды равен порядка 10"10 м, поэтому для исследования этих
молекул необходимо применять источник излучения в диапазонах уль-
трафиолетового или мягкого рентгеновского излучения. Подобные ог-
раничения, наряду с физическими свойствами материала, из которо-
го изготовлен чувствительный элемент, определяют физические
пределы возможностей сенсоров, применяемых для регистрации изо-
бражений, в частности, оптических, инфракрасных или других.
Хотя подавляющее большинство получаемых цифровых изображе-
ний основано на энергии излучения электромагнитных волн, это не
единственный способ генерации изображений. Например, как гово-
рилось в Разделе 1.3.7, отраженные от объектов звуковые волны мо-
гут использоваться для построения ультразвуковых изображений.
Другие важные источники цифровых изображений — электронные
пучки, применяемые в электронной микроскопии, и компьютерный
синтез, используемый для визуализации и в компьютерной графике.
2.3. Считывание и регистрация изображения
Изображение, которое мы рассматриваем, есть двумерное отображе-
ние наблюдаемой сцены (какправило, двух- или трехмерной), возни-
кающее как результат регистрации лучистой энергии, исходящей из на-
блюдаемой сцены, с помощью некоторого устройства — сенсора (или
совокупности сенсоров одновременно). Мы предполагаем, что реги-
стрируемый сенсором сигнал возникает в результате взаимодействия
источника «освещения» с элементами изображаемой «сцены» в усло-
виях эффектов отражения и поглощения энергии этого источника. Мы
берем слова освещение и сцена в кавычки, чтобы подчеркнуть тот факт,
что они носят значительно более общий характер, чем в привычной
ситуации, когда источник видимого света освещает обычную трехмер-
ную бытовую сцену. Например, освещение не только может порождать-
ся источником другого диапазона электромагнитного излучения, на-
пример, радиолокационным, инфракрасным или рентгеновским, но
и происходить из менее традиционных источников, например, ульт-
развукового или даже виртуального, синтезированного компьютерной
программой. В роли элементов сцены могут выступать знакомые пред-
меты, но вполне могут быть и молекулы, структуры подземных плас-
тов или мозг человека. Можно также представить себе изображения
только самих источников, например, снимки Солнца или звезд. В
зависимости от природы источника и особенностей сцены, энергия
освещения отражается от объектов сцены или проходит сквозь них.
Примером первого вида может быть свет, отраженный от поверхно-
сти предметов. Второй вид взаимодействия имеет место, например,
при пропускании рентгеновских лучей через тело пациента для полу-
чения диагностического рентгеновского снимка на пленке.
Энергия излучаемая, отражаемая, или пропускаемая элементами
сцены, фиксируется с помощью специального устройства регистрации,
чувствительного к излучаемой сценой энергии. В некоторых при-
кладных задачах отраженная или проходящая энергия направляется на
фотопреобразователь (например, экран, покрытый фосфором или
другим фосфоресцирующим материалом), который преобразует эту
энергию в видимый свет. Такой подход обычен для электронной мик-
роскопии и иногда также применяется при регистрации изображений
в гамма-лучах.
На Рис. 2.12 изображены три основные схемы размещения чувст-
вительных элементов (сенсоров), которые используются для преобра-
зования энергии «освещения» в цифровое изображение. Сама идея пре-
образования очень проста: падающая энергия преобразуется в
напряжение благодаря сочетанию материала, обладающего чувстви-
тельностью к интересующему виду излучения, и приложенной к нему
электрической энергии. В ответ на энергию внешнего излучения такой
чувствительный элемент выдает сигнал выходного напряжения, который
затем преобразуется в цифровую форму. В этом разделе мы рассмотрим
основные способы получения и регистрации изображений, а вопросы
дискретизации и квантования изображений обсуждаются в Разде-
ле 2.4.
2.3.1. Регистрация изображения с помощью
одиночного сенсора
На Рис. 2.12(a) показаны компоненты одиночного сенсора (чувстви-
тельного элемента). Вероятно, наиболее известным сенсором такого
типа является фотодиод, изготовленный из полупроводникового ма-
териала (кремния), напряжение выходного сигнала которого пропор-
ционально освещенности. Установка фильтра перед чувствительным
элементом обеспечивает избирательность сенсора. Например, если ус-
тановить перед сенсором зеленый стеклянный фильтр, то выходной
сигнал будет выше для зеленого участка видимого спектра, чем для всех
остальных.
2.3. Считывание и регистрация изображения
Энергия излучения
Фильтр
Чувствительный материал
1Сигнал выходного напряжения
Корпус
Приложенная -
электроэнергия
' F
Рис. 2.12. (а) Одиночный чувствительный элемент, (б) Линейка чувствитель-
ных элементов, (в) Матрица чувствительных элементов.
а
б
в
Для получения двумерного изображения с помощью одиночного
сенсора необходимо обеспечить его перемещение в двух взаимно пер-
пендикулярных направлениях (по осям хиу) относительно регистри-
руемой области. На Рис. 2.13 изображена конструкция, применяемая
в прецизионных сканерах, где пленочный негатив закрепляется на ба-
рабане, вращение которого обеспечивает перемещение по одной оси.
Одиночный сенсор закреплен на ходовом винте, вращение которого
приводит к линейной подаче в перпендикулярном направлении. По-
скольку механическим перемещением можно управлять с большой
точностью, такой способ позволяет регистрировать изображения с
высоким разрешением при небольших затратах (но медленно). Дру-
гой вид механической конструкции аналогичного назначения — это
Негатив на пленке
строка изображения; регистрация всего
изображения происходит за полный ход
сенсора слева направо.
Рис. 2.13. Перемещение одиночного сенсора при регистрации двумерного
изображения.
планшет, по которому чувствительный элемент линейно передвига-
ется в двух направлениях. Такие устройства с последовательным ме-
ханическим сканированием всего поля изображения (как барабан-
ные, так и планшетные) иногда называют микроденситометрами.
При другом способе получения изображения с помощью одиноч-
ного сенсора используется лазерный источник света, конструктивно
совмещенный с сенсором. Механическая развертка осуществляется с
помощью движения зеркал, направляющих луч источника на скани-
руемый плоский объект и возвращающих отраженный луч на чувст-
вительный элемент. Та же конструкция может применяться для регист-
рации изображений с помощью линеек и матриц чувствительных
элементов, что обсуждается в следующих двух параграфах.
2.3.2. Регистрация изображения с помощью
линейки сенсоров
Более часто, чем одиночный сенсор, для считывания изображений ис-
пользуется одномерный массив сенсоров, обычно располагаемых
вдоль прямой, как это показано на Рис. 2.12(6). Такая линейка обес-
печивает одновременную регистрацию элементов изображения в од-
ном направлении (условно говоря, по строке), а перемещение всей ли-
нейки в перпендикулярном направлении позволяет получить все
строки изображения (Рис. 2.14(a)). Подобная конструкция применя-
ется в большинстве планшетных сканеров. Удается изготавливать ли-
нейки, состоящие из 4000 и более расположенных в ряд чувствитель-
ных элементов. Расположение сенсоров в ряд широко используется при
аэрофотосъемке, когда система регистрации устанавливается на само-
2.3. Считывание и регистрация изображения
Рис. 2.14. (а) Считывание изображения с помощью линейки сенсоров, (б) Счи-
тывание изображения с помощью кольцеобразного набора сенсоров.
а
б
лете, летящем с постоянной скоростью и на неизменной высоте над
интересующим районом. Одномерные линейки сенсоров, чувстви-
тельных к излучениям в различных участках электромагнитного спе-
ктра, располагаются перпендикулярно направлению полета. В каждый
момент времени линейка сенсоров регистрирует одну строку изобра-
жения, а движение всей системы в перпендикулярном направлении
позволяет заполнить второе измерение двумерного изображения. Для
проекции сканируемой области на линейку сенсоров применяются
линзы или другие фокусирующие устройства.
Кольцеобразные наборы сенсоров применяются в медицине и про-
мышленности для получения изображений поперечного сечения
(«срезов») трехмерных объектов, как показано на Рис. 2.14(6). Враща-
ющийся рентгеновский источник освещает объект, а расположенные
на противоположной стороне кольца детекторы рентгеновского излу-
чения улавливают энергию рентгеновских лучей, прошедших сквозь
объект. Таков основной принцип получения изображений в компью-
терной томографии (КТ), ранее упоминавшейся в Разделах 1.2 и 1.3.2.
Важно отметить, что выходные сигналы сенсоров подлежат обработ-
ке с помощью алгоритмов реконструкции, задача которых состоит в пре-
образовании регистрируемых данных в осмысленные изображения
поперечных срезов. Другими словами, изображение среза не может
быть получено простой регистрацией принимаемых сигналов одновре-
менно с движением источника, а необходима значительная по объе-
му вычислений обработка этих первичных данных. Трехмерное пред-
ставление исследуемого объекта, состоящее из серии последовательных
срезов, полученных с некоторым шагом, генерируется путем пере-
мещения объекта в направлении, перпендикулярном к плоскости
кольца. Существуют и другие способы регистрации изображений с ис-
пользованием принципа КТ, но на базе иных физических процессов,
в частности, получение изображений методом ядерного магнитного ре-
зонанса (ЯМР) и позитронной эмиссионной томографии (ПЭТ). В них
используются источники освещения и чувствительные элементы дру-
гих типов, отличается и вид получаемых изображений, но принципи-
ально эти способы регистрации изображений в значительной степени
основаны на базовой схеме, показанной на Рис. 2.14(6).
2.3.3. Регистрация изображения с помощью
матрицы сенсоров
На Рис. 2. 12(b) изображено расположение отдельных сенсоров в фор-
ме двумерного массива (матрицы). Многочисленные электромагнит-
ные и некоторые ультразвуковые устройства ввода данных сегодняш-
них систем обработки изображений используют именно матрицу
сенсоров. Такая же конструкция находится внутри подавляющего
числа цифровых камер, в которых типичным чувствительным эле-
ментом является матрица на основе приборов с зарядовой связью
2.3. Считывание и регистрация изображения
(ПЗС), которые выпускаются в виде монолитной конструкции, объ-
единяющей 4000x4000 элементов (и более) с широким диапазоном чув-
ствительных свойств. ПЗС-матрицы широко используются в цифро-
вых фото- и видеокамерах, а также других светочувствительных
приборах. Ответная реакция каждого элемента пропорциональна ин-
тегралу световой энергии, попадающей на поверхность этого элемен-
та за время экспозиции; это свойство используется в астрономии и дру-
гих приложениях, где требуется получать изображения с низким
уровнем шума. Уменьшение шума достигается за счет того, что чувст-
вительным элементам дают возможность интегрировать принимаемый
световой сигнал в течение минут или даже часов (подробнее способ по-
нижения уровня шума путем интегрирования обсуждается в Главе 3).
Коль скоро изображенная на Рис. 2.15(в) матрица сенсоров двумерна,
ее главное достоинство состоит в том, что можно считать сразу все изо-
бражение, если сфокусировать на поверхности матрицы отвечающий
ему пространственный поток лучистой энергии. Легко видеть, что в та-
ком случае отпадает необходимость в механическом перемещении
сенсоров, как это было в рассмотренных выше случаях одиночного
сенсора или линейки таких сенсоров.
Источник освещения
(энергии)
к 4-
Плоскость изображения
Г Л
Объект сцены
±f
4г
Система
формирования
изображения
Цифровое изображение
на выходе
а
б
Рис. 2.15. Процесс регистрации цифрового изображения (пример), (а) Источ-
ник энергии («освещения»), (б) Элемент сцены, (в) Система формирования изобра-
жения. (г) Проекция сцены на плоскость изображения, (д) Оцифрованное изобра-
жение.
Рис. 2.15 иллюстрирует главный способ использования матриц
сенсоров. Здесь показано, что энергия, излучаемая источником осве-
щения, отражается от объекта сцены (но, как отмечалось в начале
этого раздела, энергия также может и проникать сквозь объекты сце-
ны). Первая функция, выполняемая системой формирования изобра-
жения (Рис. 2.15(b)), состоит в том, чтобы собрать поступающую
энергию и сфокусировать ее на плоскости изображения. Если для ос-
вещения используется источник видимого света, то на входе системы
формирования изображения имеется объектив, который проецирует
наблюдаемую сцену на плоскость изображения (Рис. 2.15(г)). Совме-
щенная с этой плоскостью чувствительная матрица генерирует на-
бор выходных сигналов, каждый из которых пропорционален ин-
тегралу световой энергии, принятой соответствующим сенсором.
С помощью цифровой и аналоговой электроники эти выходные сиг-
налы поочередно преобразуются в комплексный видеосигнал. Тот
факт, что регистрация двумерного сигнала осуществляется дискретно
расположенными в пространстве сенсорами, обеспечивает простран-
ственную дискретизацию сигнала; квантование его осуществляется в сле-
дующем блоке системы формирования изображения. На выходе ее по-
лучается цифровое изображение, схематически показанное на
Рис. 2.15(д). Преобразование изображения в цифровую форму является
темой Раздела 2.4.
2.3.4. Простая модель формирования изображения
Как уже говорилось в Разделе 1.1, мы будем рассматривать изображе-
ние как двумерную функцию вида f (х, у). Значение функции f в точ-
ке с пространственными координатами (х, у) является положительной
скалярной величиной, физический смысл которой определяется ис-
точником изображения. Большинство рассматриваемых в этой кни-
ге изображений являются монохромными (черно-белыми), и их зна-
чения находятся в некотором диапазоне яркостей, как об этом
говорилось в Разделе 2.2. Если изображение генерируется в результа-
те физического процесса, его значения пропорциональны энергии
излучения некоторого физического источника, например, энергии эле-
ктромагнитных колебаний, вследствие чего функция f (х, у) должна
быть ненулевой и конечной, т.е.
0</(х,у)<оо. (2.3-1)
Функцию f (х, у) можно характеризовать двумя компонентами:
(1) величиной светового потока, который падает на наблюдаемую
2.3. Считывание и регистрация изображения
сцену от источника, и (2) относительной долей светового потока, от-
раженного от объектов этой сцены. Мы будем называть эти компонен-
ты освещенностью и коэффициентом отражения, обозначая их соответ-
ственно i (х, у) и г (х, у). Произведение этих функций дает функцию
изображения:
/(л,у) = г(х,у)г(л,у), (2.3-2)
где
0<г(л,у)<°° (2.3-3)
и
0<г(л,у)<1. (2.3-4)
Соотношение (2.3-4) указывает, что коэффициент отражения может
меняться в пределах от 0 (полное поглощение) до 1 (полное отражение).
Природа функции i(x, у) зависит от источника освещения, тогда как
функция г (х, у) определяется свойствами объектов изображаемой сце-
ны. Примечательно, что приведенные выражения в равной мере при-
менимы также и к изображениям, сформированным в проходящем ос-
вещении (сквозь наблюдаемый объект), как, например, при рентгене
грудной клетки. В подобном случае в качестве функции г (х, у) мы име-
ем дело с коэффициентом пропускания вместо коэффициента отражения,
но пределы ее изменения будут те же, что и в (2.3-4), и функция изоб-
ражения формируется по той же модели — как произведение (2.3-2).
Пример 2.1: Некоторые типичные значения освещенности и коэф-
фициента отражения.
Значения, указанные в соотношениях (2.3-3) и (2.3-4), представля-
ют собой теоретические границы. Ниже приводятся средние числовые
значения, иллюстрирующие типичный интервал изменения функции
i(x, у) для видимого света. В ясный день солнце создает на земной по-
верхности освещенность 90000 лм/м2 и выше, а в пасмурную погоду
эта величина падает до 10000 лм/м2. Безоблачной ночью в полнолуние
освещенность земной поверхности составляет около 0,1 лм/м2. В ти-
пичных служебных помещениях поддерживается уровень освещенно-
сти порядка 1000 лм/м2. Типичные значения коэффициента отраже-
ния (т.е. функции г (х, у)) составляют: 0,01 для черного бархата; 0,65
для нержавеющей стали; 0,80 для поверхности стены, окрашенной в
4 А-223
ровный белый цвет; 0,90 для посеребренной металлической поверхно-
сти; и 0,93 для снега.
В соответствии со сказанным в Разделе 2.2, значение интенсивно-
сти черно-белого изображения в произвольной точке с координатами
(хо, Уо)мы называем уровнем серого (f) или яркостью изображения в этой
точке, т.е.
^ = f(x0,y0).
(2.3-5)
Из соотношений (2.3-2) — (2.3-4) видно, что £ лежит в некотором
интервале
Лтип - - Лпах •
Теоретически, к границам этого интервала предъявляются толь-
ко те требования, чтобы £min было положительно, а Zmax — конечно.
На практике £min = zmin rmin, a £max = zmax rmax. С учетом вышепри-
веденных типичных значений освещенности в служебных помещени-
ях и коэффициента отражения, можно ожидать типичных пределов
Zmin = Ю и £тах ~ 1000 для изображений, наблюдаемых в помещениях
в отсутствие дополнительного освещения.
Интервал [Tmin, £max] называется диапазоном яркостей. На прак-
тике его обычно сдвигают по числовой оси, получая интервал [0, L— 1],
края которого принимаются за уровень черного (( = 0) и уровень бе-
лого (J = £—1). Все промежуточные значения в этом интервале соот-
ветствуют некоторым оттенкам серого при изменении от черного до
белого.
2.4. Дискретизация и квантование изображения
Из сказанного в предыдущем разделе ясно, что несмотря на много-
численные возможные способы регистрации изображений, задача
всегда одна и та же: сформировать цифровое изображение на осно-
ве данных, воспринимаемых чувствительными элементами. От боль-
шинства сенсоров поступает аналоговый выходной сигнал в форме
непрерывно меняющегося напряжения, форма и амплитуда которо-
го связаны с регистрируемым физическим явлением. Чтобы полу-
чить цифровое изображение, необходимо преобразовать непрерыв-
но поступающий сигнал в цифровую форму. Эта операция включает
в себя два процесса — дискретизацию и квантование.
2.4. Дискретизация и квантование изображения
2.4.1. Основные понятия, используемые при
дискретизации и квантовании
Главный принцип, лежащий в основе дискретизации и квантования
изображений, проиллюстрирован на Рис. 2.16. Здесь (Рис. 2.16(a))
приведено исходное изображение f (х, у), которое мы хотим преоб-
разовать в цифровую форму. Изображение непрерывно по коор-
динатам х и у, а также по амплитуде. Чтобы преобразовать эту
функцию в цифровую форму, необходимо представить ее отсчета-
Дискретизация
Рис. 2.16. Формирование цифрового изображения, (а) Непрерывное изобра-
жение. (б) Профиль вдоль линии сканирования между точками А и В на непрерыв-
ном изображении, который используется для иллюстрации понятий дискретизации
и квантования, (в) Дискретизация и квантование, (г) Цифровое представление стро-
ки изображения.
а б
в г
ми по обеим координатам и по амплитуде. Представление коор-
динат в виде конечного множества отсчетов называется дискрети-
зацией, а представление амплитуды значениями из конечного
множества — квантованием.
Изображенная на Рис. 2.16(6) одномерная функция пред-
ставляет собой график изменения значений яркости непрерыв-
ного изображения вдоль отрезка АВ на Рис. 2.16(a). Случайные
отклонения на графике вызваны наличием шумов в изображении.
Чтобы дискретизовать эту функцию, разобьем отрезок АВ на
равные интервалы, как показано засечками на Рис. 2.16(b) вни-
зу. Значения в выбранных точках отсчета представлены неболь-
шими квадратиками на графике функции. Построенный набор
значений в точках дискретизации описывает функцию в виде
совокупности ее дискретных отсчетов, однако сами эти значения
пока еще охватывают весь непрерывный диапазон яркостей (по
вертикали). Чтобы построить цифровую функцию, диапазон яр-
костей также необходимо преобразовать в дискретные величины
(проквантовать). Справа на Рис. 2.16(b) изображена шкала яр-
костей, разбитая на восемь дискретных уровней от черного до бе-
лого. Квантование непрерывных значений яркости в точках дис-
кретизации осуществляется простым сопоставлением каждому
отсчету одного из восьми дискретных уровней — того, к которо-
му ближе найденное значение яркости. В результате совмест-
ных операций дискретизации и квантования возникает отвечаю-
щий одной строке изображения дискретный набор цифровых
отсчетов, показанный на Рис. 2.16(г). Выполняя такую процеду-
ру построчно, с верхней по нижнюю строки, получаем двумерное
цифровое изображение.
Выполнение дискретизации описанным выше способом пред-
полагает, что нам доступно непрерывное по обеим координатам
и по яркости изображение. На практике, однако, способ оцифров-
ки определяется конструкцией сенсорного устройства, применя-
емого для регистрации изображения. Если изображение форми-
руется одиночным сенсором в сочетании с механическим его
перемещением (Рис. 2.13), выходной сигнал сенсора квантуется,
как описано выше, а дискретизация определяется выбором шагов
механического перемещения сенсора в процессе сбора данных. Ме-
ханическое перемещение может выполняться с очень высокой
точностью, так что в принципе почти нет пределов для уменьше-
ния шага дискретизации, однако на практике пределом является
несовершенство оптической системы, применяемой для фокуси-
ровки светового пятна на чувствительном элементе, точность ко-
торой оказывается хуже, чем достигаемая точность механического
перемещения сенсора.
Если для формирования изображения используется линейка сен-
соров, то число сенсоров в ней определяет предел дискретизации изо-
бражения по одному направлению. Механическим перемещением
в другом направлении можно управлять и с более высокой точнос-
тью, но нет особого смысла пытаться повышать частоту дискретиза-
ции в одном направлении, коль скоро в другом направлении она
жестко ограничена. Выходные сигналы всех элементов линейки под-
вергаются однотипному квантованию, в результате чего строится
цифровое изображение.
В случае регистрации изображения с помощью матрицы сенсо-
ров механического перемещения нет, и пределы дискретизации изо-
бражения по обоим направлениям определяются числом сенсоров
в матрице. Квантование их выходных сигналов осуществляется так
же, как и раньше. Рис. 2.17 иллюстрирует этой случай. На Рис. 2.17(a)
показано непрерывное изображение, спроецированное на плоскость
сенсорной матрицы, а Рис. 2.17(6) демонстрирует то же изображение
после дискретизации и квантования. Ясно, что качество получаемо-
го представления в большой степени зависит от числа отсчетов в раз-
биении и числа уровней квантования. Однако, как мы увидим в Раз-
деле 2.4.3, при выборе значений этих количественных параметров
важно учитывать содержательное наполнение изображения.
Рис. 2.17. (а) Проекция непрерывного изображения на матрицу чувствитель-
ных элементов, (б) Результат дискретизации и квантования изображения.
2.4.2. Представление цифрового изображения
В результате операций дискретизации и квантования возникает мат-
рица действительных чисел. В данной книге используются два ос-
новных способа представления цифровых изображений. Предполо-
жим, что в результате дискретизации изображения f (х, у) получена
матрица из М строк и Nстолбцов. Координаты (х, у) становятся теперь
дискретными значениями. Для ясности обозначений и большего удоб-
ства мы будем использовать для этих дискретных координат цело-
численные значения, принимая за начало координат левый верхний
угол изображения, где (х, у) = (0, 0). Следующим значением коорди-
нат вдоль первой строки изображения будет точка (х, у) = (0,1). Важ-
но иметь в виду, что обозначение (0, 1) используется лишь для ука-
зания на второй отсчет в первой строке, и не означает, что это
фактические значения физических координат точек дискретиза-
ции. Рис. 2.18 иллюстрирует принятое во всей этой книге соглашение
о системе координат.
С использованием введенных обозначений мы можем компакт-
но записать полное цифровое изображение размерами Л/х 7V в форме
следующей матрицы:
— Начало координат
0 1 2 3 • • • • JV-1
0 ----¥---Ф---¥---¥---¥--if—<f---y---т---?----► у
1 к- © 9 • 9 9 9
2 । Н 9 9 © 9 9 © © • 9
3 9 9 © 9 9 9 © 9 9 9
• 1 >- 9 9 9 9 9 9 Й 9 9 9
9 9 • © ® 9 9 9 9 9
1 к е 9 9 9 9 Й 9 • 9
9 9 9 9 © 9 9 9 9 9
1 1- © © 9 © ® 9 9 9 9
9 9 » 9 9 9 9 9 ©
мл © 9 9 9 9 Один пиксель © 9 9 9 9 f(X,y)
Рис. 2.18. Система координат для представления цифровых изображений,
принятая в этой книге.
2.4. Дискретизация и квантование изображения
/(0,0) /(0,1) • • /(0Л-1)
/(*,?) = /(1,0) /(1,1) • • /(1Л-1) . (2.4-1)
/(М-1,0) /(М-1,1) • • /(М-1Л-1)
Правая часть этого равенства есть по определению цифровое изо-
бражение. Каждый элемент этой матрицы называется элементом изо-
бражения или пикселем. Далее повсюду будут употребляться термины изо-
бражение и пиксель для указания на цифровое изображение и его
элементы.
В ряде случаев для обозначения цифрового изображения и его
элементов бывает полезно использовать более традиционную мат-
ричную запись:
fl0,0 °0,1
аЛ/-1,0 аМ~1,1 " aM~4,N-\
Ясно, что ay =f (х = z, у =j) =f (i,j), поэтому матрицы (2.4-1) и
(2.4-2) идентичны.
Иногда может быть полезно выражать операции дискретизации
и квантования в более формальных математических терминах. Пусть Z
и R обозначают соответственно множества целых и действительных чи-
сел. Процесс дискретизации можно рассматривать как разбиение пло-
скости ху на сеть, координаты центра каждой ячейки которой суть эле-
менты декартова произведения Z2, т.е. множества всех пар (zt, Zj), где Zj
MZj — элементы множества Z. Следовательно,/(х, у) — цифровое изоб-
ражение, если (х, у) суть целочисленные пары из Z2, и функция/при-
писывает каждой паре координат (х, у) конкретное значение яркости, т.е.
действительное число из множества R. Такое сопоставление, осуществ-
ляемое функцией/ очевидно, отвечает описанному выше процессу дис-
кретизации. Если (как обычно в этой и последующих главах) значения
яркости также целочисленные, и вместо множества R используется Z, тог-
да цифровое изображение становится двумерной цифровой функцией,
у которой как обе координаты, так и значения — целые числа.
Для выполнения процесса оцифровки изображения необходимо
принять решения относительно значений MhN.'a также числа уров-
ней (градаций) яркости L, разрешенных для каждого пикселя. Для М
и N не существует специальных требований помимо того, что они
должны быть положительными целочисленными значениями. Одна-
ко значение L, по соображениям удобства построения оборудования
для обработки, хранения и дискретизации, обычно выбирают равным
целочисленной степени двойки:
L = 2k .
(2.4-3)
Мы предполагаем, что дискретные уровни яркости расположены с по-
стоянным шагом (т.е. используется равномерное квантование) и при-
нимают целые значения в интервале [О, L—1]. Иногда интервал зна-
чений яркости называют динамическим диапазоном изображения, и мы
будем говорить об изображениях, интервал яркостей которых занима-
ет значительную часть всего диапазона уровней серого, как об изоб-
ражениях с большим динамическим диапазоном. Если заметная до-
ля пикселей обладает таким свойством, изображение имеет высокий
контраст. Наоборот, изображение с малым динамическим диапазоном
обычно выглядит тусклым, размытым и серым. Более подробно эта
тема обсуждается в Разделе 3.3.
Общее количество битов Ь, необходимое для хранения цифрового
изображения, определяется по формуле
b = M*Nxk. (2.4-4)
В случае квадратного изображения М= N,n это равенство приобре-
тает вид
b = N2k. (2.4-5)
В Таблице 2.1 приводится число бит, необходимых для хранения ква-
дратных изображений при различных значениях N и к. Количество
градаций яркости, соответствующее каждому значению к, указано
в скобках. Если пиксели изображения могут принимать 2к значений
яркости, то такое изображение часто называют «^-битным»; напри-
мер, изображение с возможными 256 градациями яркости называют
восьмибитным. Из таблицы видно, что для хранения 8-битных изобра-
жений размерами 1024x1024 и более элементов требуется существенный
объем памяти.
Таблица 2.1. Число бит для хранения изображения при различных значениях N и к.
N\k 1(Z=2) 2(Z=4) 3(/.=8) 4(Т=16) 8(/.=256)
32 1.024 2.048 3.072 4.096 8.192
64 4.096 8.192 12.288 16.384 32.768
128 16.384 32.768 49.152 65.536 131.072
256 65.536 131.072 196.608 262.144 524.288
512 262.144 524.288 786.432 1.048.576 2.097.152
1024 1.048.576 2.097.152 3.145.728 4.194.304 8.388.608
2048 4.194.304 8.388.608 12.582.912 16.777.216 33.554.432
4096 16.777.216 33.554.432 50.331.648 67.108.864 134.217.728
8192 67.108.864 134.217.728 201.326.592 268.435.456 536.870.912
2.4.3. Пространственное и яркостное разрешения
Дискретизация является главным фактором, определяющим простран-
ственное разрешение изображения. По существу, пространственное
разрешение — это размер мельчайших различимых деталей на изоб-
ражении. Предположим, что построен чертеж, состоящий из верти-
кальных линий с шириной W, разделенных промежутками также с ши-
риной W. Парой линий будем называть одну линию с примыкающим
с одной стороны промежутком. Таким образом, ширина пары линий
составляет 2W, и на единице длины размещается 1 /2 W таких пар.
Широко используемое определение разрешения состоит именно в ука-
зании максимального числа различимых пар линий на единицу длины;
например, 100 пар линий на миллиметр.
Яркостным (или полутоновым) разрешением, аналогично, называ-
ется мельчайшее различимое изменение яркости, но, как отмечалось
в Разделе 2.1.3, процесс измерения различимых уровней яркости яв-
ляется в высшей степени субъективным. Если при дискретизации
изображений имеется относительно большая свобода действий при вы-
боре числа отсчетов (т.е. частоты дискретизации), то при выборе чис-
ла градаций яркости приходится в значительной степени учитывать
особенности аппаратуры; по этим причинам число градаций обычно
выбирается равным степени 2. Наиболее частым решением является
выбор 8-битного представления (256 градаций яркости), но в некото-
рых приложениях используется 16 бит, если необходимо иметь более точ-
ное представление полутонов. Иногда можно встретить системы, в ко-
торых квантование уровней яркости изображения проводится с 10 или
12 битами точности, но это скорее исключение, чем правило.
Если нет необходимости измерять реальное пространственное
разрешение и достигаемую степень детализации исходной сцены, то
изображение, имеющее размеры M*N пикселей и точность L градаций,
часто называют изображением с пространственным разрешением
MxNпикселей и яркостным разрешением L градаций. Мы иногда бу-
дем пользоваться такой терминологией в последующем обсуждении,
указывая на реальный размер различимых деталей только в том случае,
если это необходимо для ясности.
Пример 2.2: Типичные эффекты при изменении числа отсчетов в
цифровом изображении.
Е На Рис. 2.19 слева приведено изображение размерами 1024x1024 пик-
селей, яркость элементов которого представлена 8 битами. Остальные
изображения на этом рисунке получены в результате «прорежива-
ния» изображения 1024x1024, которое осуществляется путем отбрасы-
вания соответствующего количества строк и столбцов исходного изо-
бражения. Например, изображение размером 512x512 получается
путем удаления строк и столбцов через один в изображении 1024x1024;
изображение размером 256x256 — путем удаления строк и столбцов
через один в изображении 512x512, и т.д. Число допустимых градаций
яркости сохраняется равным 256.
Данные изображения демонстрируют пропорциональные изме-
нения размеров при различной частоте дискретизации, однако это
затрудняет наблюдение эффектов, вызванных уменьшением простран-
ственного разрешения. Самый простой способ облегчить сопоставле-
ние — увеличить все прореженные изображения до размеров исход-
ного (1024x1024) путем дублирования строк и столбцов пикселей.
Результаты такой операции приведены на Рис. 2.20(6—е). Рис. 2.20(a)
совпадает с исходным изображением 1024x1024 (Рис. 2.19) и повторен
здесь для удобства сравнения.
Сравнивая Рис. 2.20(a) с изображением 512x512 (Рис. 2.20(6)) мож-
но заметить, что их практически невозможно различить. Потеря сте-
пени детализации слишком мала, чтобы ее можно было увидеть на пе-
чатной странице при том масштабе, как эти изображения приведены.
Следующее изображение размерами 256x256 (Рис. 2.20(b)) демонст-
рирует очень слабую ступенчатость на границах между лепестками
цветка и черным фоном. Начинает также проявляться слегка более вы-
раженная зернистость по всему полю изображения. Эти эффекты ста-
Рис. 2.19. 8-битное изображение 1024x1024, последовательно прореженное
до размеров 32x32 при сохранении числа градаций 256.
новятся еще более заметными в изображении размерами 128x128
(Рис. 2.20(г)) и совершенно отчетливы в изображениях 64x64 и 32x32,
показанных на Рис. 2.20(д) и (е) соответственно.
Пример 2.3: Типичные эффекты при изменении числа градаций яр-
кости в цифровом изображении.
В этом примере мы сохраняем число отсчетов дискретизации посто-
янным, но постепенно уменьшаем число уровней квантования с 256
до 2, двигаясь по степеням 2. На Рис. 2.21(a) показан полученный
методом проекционной КТ рентгеновский снимок размерами 452x374
пикселей с 256 градациями яркости (к = 8). Подобные изображения
получаются при закреплении рентгеновского источника в некотором
положении, что дает двумерное изображение в нужном направлении.
Проекционные КТ-изображения используются для настройки параме
тров компьютерного томографа, например, угла наклона, количества
срезов и диапазона.
Изображения на Рис. 2.21(6—з) были получены путем уменьшения
числа бит представления сА = 7доЛ=1, при сохранении постоян-
ного пространственного разрешения 452x374 пикселей. Изображения
с 256,128 и 64 градациями яркости оказываются визуально неотличи-
мыми и в равной мере применимыми. Однако, на 32-градационном
изображении (Рис. 2.21 (г)) появляются почти незаметные мелкие
рубчатые структуры в области плавных изменений полутонов, в част-
ности, в области мозга. Этот эффект, вызванный использованием не-
достаточного числа градаций яркости в областях плавных переходов
полутонов, называется появлением ложных контуров, поскольку эти
а б в
Рис. 2.20. (а) 8-битное изображение 1024x1024. (б) Изображение 512x512, уве-
г ДР
личенное до размеров
1024x1024 дублированием строк и столбцов.
(в)—(е) Изобра-
жения размерами 256x256, 128x128, 64x64 и 32x32, также увеличенные до размеров
1024x1024.
линии напоминают контурные линии горизонталей на топографи-
ческой карте. Ложные контуры становятся отчетливо видны на изо-
бражениях, представленных с равномерным разбиением всего ярко-
стного диапазона на 16 градаций и менее, как видно из Рис. 2.21(д—з).
В качестве очень грубого эмпирического правила можно считать,
что минимальные пространственное и яркостное разрешение, при
котором цифровое изображение будет относительно свободным от
дефектов типа ложных контуров и ступенчатости, составляет около
256x256 пикселей с 64 градациями яркости.
Результаты, показанные на Примерах 2.2 и 2.3, иллюстрируют
влияние независимого изменения значений /Vи к на качество изоб-
ражения. Но это дает лишь частичный ответ на вопрос о влиянии N
и к на свойства цифровых изображений, поскольку мы пока не рас-
сматривали возможные взаимосвязи между этими двумя параметра-
ми. В ранних исследованиях [H uang, 1965] делалась попытка измерить
экспериментально, как влияет на качество изображения одновремен-
а б
в г
Рис. 2.21. (а) Изображение размерами 452x374 пикселей с 256 градациями яр-
кости. (б)—(г) Изображения того же пространственного разрешения, представленные
с 128, 64 и 32 градациями яркости.
ное изменение значений Nи к. Эксперимент состоял из набора субъ-
ективных тестов, в которых использовались изображения, подобные
приведенным на Рис. 2.22. Женское лицо относится к классу изобра-
жении с относительно малым содержанием деталей, снимок толпы, на-
против, содержит большое число деталей, а изображение киноопера-
тора занимает промежуточное положение по степени наличия деталей.
Рис. 2.21. (д)—(з) Изображения, представленные с 16, 8, 4 и 2 градациями яр-
кости. (Исходное изображение предоставил д-р Дэвид Р. Пикенс, Департамент ра-
диологии медицинского центра университета Вандербилта).
Генерировался набор изображений указанных трех классов для
различных значений N и к, после чего наблюдателю предлагалось
упорядочить их в соответствии с субъективно ощущаемым качест-
вом. Результаты эксперимента представлялись в форме так называе-
мых кривых равного предпочтения на плоскости Nk (Рис. 2.23 демон-
стрирует типичные образцы кривых равного предпочтения для
изображений, приведенных на Рис. 2.22). Каждая точка на плоскости
Nk соответствует изображению со значениями параметров Nnk, рав-
ными координатам этой точки. Точки, лежащие на кривой равного
предпочтения, соответствуют изображениям одинакового субъектив-
но воспринимаемого качества. В описываемых экспериментах бы-
ло обнаружено, что кривые равного предпочтения имеют тенденцию
к смещению вправо и вверх, однако форма их для каждого из трех рас-
сматриваемых классов изображений отличается и в целом подоб-
на изображенной на Рис. 2.23. В целом результаты не являются не-
ожиданными, поскольку сдвиг кривой вправо и вверх означает
просто увеличение значений Nn к, что неминуемо ведет к повышению
качества изображения.
В контексте нашего обсуждения наиболее важным представляет-
ся тот факт, что кривые равного предпочтения приобретают все более
вертикальную форму по мере увеличения степени детализации изо-
бражения. Такой результат наводит на мысль, что для изображений
с большим количеством деталей может оказаться достаточным лишь
небольшое число градаций яркости. Например, приведенная на
Рис. 2.23 кривая равного предпочтения для изображения толпы поч-
ти вертикальна. Это показывает, что для фиксированного значения N
воспринимаемое качество изображения такого типа почти не зависит
от числа использованных 1радаций яркости (в показанном на Рис. 2.23
диапазоне). Интересно также отметить, что для других двух типов
изображений визуальное качество остается одинаковым в некоторых
интервалах, где пространственное разрешение увеличивается при од-
новременном уменьшении числа градаций яркости. Наиболее веро-
ятная причина такого результата состоит в том, что при уменьшении
Рис. 2.22. (а) Изображение с малым числом деталей, (б) Изображение со сред- а б В
ним уровнем детализации, (в) Изображение с относительно большим количеством
деталей. (Изображение (б) предоставлено Массачусетским технологическим инсти-
тутом).
N
Рис. 2.23. Образцы кривых равного предпочтения для трех типов изображе-
ний, показанных на Рис. 2.22.
к повышается видимый контраст изображения, а этот эффект часто
субъективно воспринимается человеком как улучшение качества
изображения.
2.4.4. Эффекты муара и наложения спектров
Как подробнее обсуждается в Главе 4, функции с конечной площадью
под графиком ее абсолютного значения могут быть представлены в ви-
де суперпозиции синусов и косинусов различных частот. При этом ком-
поненты с наибольшей частотой определяют «высокочастотный со-
став» данной функции. Предположим, что эта граничная частота
конечна, а функция определена на всей оси (такие функции называ-
ют функциями с ограниченным спектром). В этом случае теорема отсче-
тов Шеннона2 [Bracewel, 1995] гласит, что функция может быть точ-
но восстановлена (т.е. найдено ее значение для любого аргумента) по
значениям функции в точках отсчета, взятых с частотой не менее чем
удвоенная граничная частота. Если используется недостаточная час-
тота отсчетов, то восстановление функции происходит с ошибкой.
Применительно к изображениям, частота дискретизации равна чис-
лу отсчетов на единицу длины (по обоим пространственным на-
2 В русскоязычной литературе она известна также как теорема Котельникова. —
Прим, перев.
правлениям). При недостаточно высокой частоте дискретизации
возникает явление наложения спектров, которое приводит к искаже-
нию дискретного изображения. Эти искажения проявляются в фор-
ме дополнительных частотных составляющих, которые называются
разностными частотами.
Оказывается, что за исключением обсуждаемого чуть ниже особо-
го случая, на практике невозможно выполнить условия теоремы отсче-
тов, поскольку мы можем работать только с выборочными данными
конечной длины. Можно искусственно преобразовать функцию, за-
данную на конечном интервале, в функцию, определенную на всей оси,
умножая последнюю на «функцию окна», которая равна 1 на этом
интервале и 0 во всех остальных точках. К несчастью, такая функция
окна сама состоит из частотных составляющих с неограниченной ча-
стотой. Таким образом, сам факт ограничения длины интервала, на ко-
тором задана функция, не позволяет ей быть функцией с ограничен-
ным спектром, что приводит к нарушению ключевого условия теоремы
отсчетов. Основной метод борьбы с эффектом наложения спектров со-
стоит в ослаблении высокочастотных составляющих изображения
путем его сглаживания (расфокусировки) перед дискретизацией (сгла-
живание подробно обсуждается в Главе 4). Тем не менее, в дискретных
изображениях всегда присутствует эффект наложения спектров, ко-
торый при определенных условиях принимает характер так называе-
мого муара\ обсуждаемого ниже.
Существует важный особый случай, когда функция, определенная
на всей числовой оси, может тем не менее точно задаваться своими от-
счетами на конечном интервале, не нарушая при этом условия теоре-
мы отсчетов. Если функция является периодической, то эти отсчеты
нужно брать с частотой, которая в два раза или более превышает ча-
стоту высшей частотной составляющей спектра3 4. Функция может
быть точно восстановлена по значениям в этих точках отсчета при ус-
ловии, что длина всего интервала точек отсчета в точности равна це-
лому числу периодов функции. Этот специальный случай позволяет
нам живо проиллюстрировать эффект муара. На Рис. 2.24 показаны два
одинаковых периодических узора из расположенных на равном рас-
стоянии вертикальных линий, которые повернуты друг относительно
друга и затем наложены путем поэлементного перемножения яркос-
3 Слово «муар» возникло в сфере ткацкого производства и происходит от слова
mohair — названия ткани из шерсти ангорских коз.
4 Периодическая функция с ограниченным спектром — это тригонометрический по-
лином,— Прим, перев.
Рис. 2.24. Иллюстрация эффекта муара.
тей двух соответствующих изображений. Эффект муара, вызванный не-
совпадением периодов, виден на Рис. 2.24 в форме плоской интерфе-
ренционной волны (похожей на кровлю из гофрированного железа),
идущей в вертикальном направлении. Похожие эффекты могут так-
же возникать при оцифровке изображения (например, при помощи
сканера) с печатной страницы, на которой оно состоит из периодиче-
ски расположенных точек.
2.4.5. Увеличение и уменьшение цифровых изображений
Мы завершим обсуждение операций дискретизации и квантования изо-
бражений кратким рассмотрением способов увеличения и уменьше-
ния цифровых изображений. Эта тема связана с дискретизацией и
квантованием, поскольку увеличение может рассматриваться как по-
вышение частоты дискретизации, а уменьшение — как понижение этой
частоты. Главное отличие обсуждаемых операций от дискретизации и
квантования исходного непрерывного изображения состоит в том,
что они применяются к цифровому, т.е. ранее уже дискретизированно-
му изображению.
Для увеличения необходимы два шага: создание новой матрицы
пикселей и затем присвоение этим новым пикселям определенных зна-
чений яркости. Начнем с простого примера. Предположим, что име-
ется изображение размерами 500x500 пикселей, которое мы хотим
увеличить в 1,5 раза, до размеров 750x750 пикселей. По идее, простей-
2.4. Дискретизация и квантование изображения I 15
ший способ визуально наблюдать увеличение — это наложить на ис-
ходное изображение воображаемую сетку размерами 750x750 элемен-
тов. Очевидно, что шаг сетки будет меньше одного пикселя исходно-
го изображения. Чтобы присвоить значение яркости любому элементу
наложенного изображения, найдем ближайший к нему пиксель исход-
ного изображения и припишем его яркость данному элементу сетки.
Проделав аналогичную операцию для всех элементов сетки, получим
искомое увеличенное изображение. Такой способ присвоения значе-
ний яркости называется интерполяцией по ближайшему соседу. (Вопро-
сы соседства пикселей изображения рассматриваются в следующем раз-
деле этой главы).
Метод дублирования пикселей, который использовался для постро-
ения изображений Рис. 2.20(6—е), является частным случаем интер-
поляции по ближайшему соседу, который имеет место при увеличении
изображения в целое число раз. Например, для увеличения изображе-
ния вдвое мы вначале дублируем каждый столбец, получая тем самым
изображение с удвоенным горизонтальным размером. Затем дублиру-
ется каждая строка, чтобы вдвое увеличить вертикальный размер изо-
бражения. Чтобы увеличить изображение в любое целое число раз (в
3 раза, 4 раза и т.д.), применяется аналогичная процедура, в которой
строки и столбцы дублируются столько раз, сколько требуется для
получения изображения необходимых размеров. Здесь назначение
одинаковой яркости каждому пикселю в дублируемой группе предо-
пределено тем фактом, что все они в точности соответствуют одному
и тому же элементу исходного изображения. Хотя увеличение с интер-
поляцией по ближайшему соседу выполняется быстро, оно имеет ту
нежелательную особенность, что может приводить к заметной ступен-
чатости, особенно при большой кратности увеличения. Хорошим
примером этого эффекта могут служить Рис. 2.20(д) и (е). Немного бо-
лее сложным способом присвоения яркостей элементам увеличен-
ного изображения является билинейная интерполяция, в которой исполь-
зуются четыре ближайшие соседа данной точки. Пусть (х', у') —
координаты точки на увеличенном изображении (которую можно
представить себе как точку ранее упоминавшейся наложенной сетки).
Обозначим v(x', у') приписываемый этой точке уровень яркости. В слу-
чае билинейной интерполяции он задается соотношением
v(x', у') ~ ах' + by' + сх'у' + d , (2.4-6)
где коэффициенты a,b,c,d находятся из системы четырех линейных
уравнений с четырьмя неизвестными, выписанной для четырех бли-
жайших соседей точки (х', у').
Уменьшение изображений осуществляется способами, аналогич-
ными вышеизложенным для увеличения, но вместо операции дуб-
лирования строк и столбцов пикселей используются операции выбра-
сывания строк и столбцов. Например, для уменьшения изображения
в два раза выбрасываются строки и столбцы через один. Для иллюст-
рации принципов уменьшения изображения в нецелое число раз мы
можем воспользоваться той же аналогией с наложенной на исходное
изображение сеткой, с той разницей, что шаг сетки теперь оказыва-
ется больше размера исходного пикселя. Для назначения яркости
элементам уменьшенного изображения применяются те же методы, а
именно интерполяция по ближайшему соседу или билинейная интер-
поляция. Чтобы снизить риск появления эффектов, связанных с на-
ложением частот, рекомендуется перед уменьшением слегка сгладить
изображение. Сглаживание цифровых изображений описывается в
Главах 3 и 4.
Для интерполяции может использоваться большее число соседей,
что позволяет аппроксимировать дискретные точки поверхностью
более сложного вида; обычно это приводит к получению более глад-
ких результирующих изображений. Это соображение оказывается ис-
ключительно важным при генерации изображений в трехмерной ком-
пьютерной графике [Watt, 1993] и при обработке медицинских
изображений [Lehmann et al., 1999], однако ввиду повышенной вычис-
лительной сложности применение такого подхода в универсальных си-
стемах обработки изображений редко бывает оправданным, и обыч-
но для операций увеличения и уменьшения ограничиваются
билинейной интерполяцией.
Пример 2.4: Увеличение изображений с помощью билинейной интер-
поляции.
На Рис. 2.25 в верхнем ряду снова повторены изображения
Рис. 2.20(г—е). Как уже говорилось, эти изображения размерами
128x128, 64x64 и 32x32 были увеличены до исходных размеров
1024x1024 пикселей с помощью интерполяции по ближайшему сосе-
ду. Те же результаты, но с использованием билинейной интерполяции,
показаны в нижнем ряду на Рис. 2.25. Общее улучшение визуального
качества несомненно, особенно в случаях 128x128 и 64x64. Изображе-
ние размерами 32x32 выглядит несколько размытым при увеличении
до размеров 1024x1024, однако надо учитывать, что здесь коэффици-
ент увеличения составляет 32. Несмотря на это, показанный на
Рис. 2.25(e) результат билинейной интерполяции довольно хорошо пе-
редает форму исходного изображения, что совершенно терялось на
Рис. 2.25(b).
2.5. Некоторые фундаментальные отношения
между пикселями
В этом разделе мы рассмотрим некоторые важные взаимосвязи меж-
ду элементами цифрового изображения. Как указывалось выше, мы
будем обозначать изображение в виде функции/(х, у). Ссылаясь в
пределах этого раздела на конкретные пиксели, мы будем пользо-
ваться строчными буквами, например,/? и q.
2.5.1. Соседи отдельного элемента
У элемента изображения р с координатами (х, у) имеются четыре со-
седа по вертикали и горизонтали, координаты которых даются выра-
жениями
(х +1, у), (х -1, у), (х, у +1), (х, у -1).
Рис. 2.25. Верхний ряд: изображения размерами 128x128, 64x64 и 32x32 эле- а б В
мента, увеличенные до размеров 1024x1024 пикселей с помощью интерполяции по г j е
ближайи 1ему соседу. Нижний ряд: то же, но с использованием билинейной интерпо-
ляции.
Это множество пикселей называется четверкой соседей р и обознача-
ется Каждый его элемент находится на единичном расстоянии
от (х, у); если же точка (х, у) лежит на краю изображения, то некото-
рые из соседей оказываются за пределами изображения.
Четыре соседа р по диагонали имеют координаты
(х +1, у +1), (х +1, у -1), (х -1, у +1), (х -1, у -1)
и обозначаются Np(p). Вместе с четверкой соседей эти точки образу-
ют так называемую восьмерку соседей, обозначаемую Л^(р). Каки вы-
ше, некоторые точки множеств Np(p) и N$(p) могут оказаться за пре-
делами изображения, если точка (х, у) лежит на его краю.
2.5.2. Смежность, связность, области и границы
Отношение смежности между элементами изображения является
фундаментальным понятием, которое упрощает определение большо-
го числа других понятий, связанных с цифровыми изображениями,
например, областей и границ. Чтобы установить, что два элемента изо-
бражения являются смежными, необходимо, чтобы они были сосе-
дями и их уровни яркости удовлетворяли заданному критерию сход-
ства (скажем, были равны друг другу). Например, в бинарном
изображении, яркость элементов которого может принимать только
два значения 0 и 1, два пикселя могут входить в четверку соседей
друг друга, но считаются смежными только в том случае, если их
значения совпадают.
Пусть V— множество значений яркости, используемое при опре-
делении понятия смежности. В бинарном изображении V= {1}, если
смежными считаются соседние пиксели с единичным значением яр-
кости. Для полутоновых изображений идея та же, но множество V
обычно состоит из большего числа элементов. Например, при опре-
делении понятия смежности для пикселей с диапазоном возможных
значений яркости от 0 до 255 множество Vможет быть любым подмно-
жеством этих 256 значений. Мы будем рассматривать три вида смеж-
ности:
1) 4-смежность. Два пикселя р и q со значениями из множества V
являются 4-смежными, если q входит в множество ЛДд);
2) ^-смежность. Два пикселяр и q со значениями из множества V
являются 8-смежными, если q входит в множество N$(p);
3) т-смежностъ (смешанная). Два пикселя р и q со значениями из
множества Кявляются m-смежными, если:
а) элемент q входит в множество или
б) элемент q входит в множество Nptp) и множество
TV4(p) п A4G7) не содержит элементов изображения со значением яр-
кости из множества V.
Смешанная смежность представляет собой модификацию 8-смеж-
ности с целью исключения неоднозначности, часто возникающей
при использовании 8-смежности в чистом виде. Рассмотрим, напри-
мер, изображенную на Рис. 2.26(a) конфигурацию пикселей при
V= {1}. Три элемента в верхней части Рис. 2.26(6) демонстрируют не-
однозначную 8-смежность, как указано пунктирными линиями. Эта
неоднозначность устраняется при использовании /«-смежности, что
иллюстрирует Рис. 2.26(b). Два подмножества пикселей 5) и 6'2 назы-
ваются смежными, если некоторый пиксель из 5| является смежным
с некоторым пикселем из $2- В этом и последующих определениях под
смежностью подразумевается некоторый фиксированный ее вид, т.е.
4-, 8- или /«-смежность.
Дискретным путем (или кривой) от пикселя р с координатами (х, у)
до пикселя q с координатами (s, t) называется неповторяюшаяся по-
следовательность пикселей с координатами
(x(),y0),(x1,y1),...,(x„,y„),
где (х0, у0) = (х, у), (хп, уп) = (s, t) и пиксели (xz, yz) и (xz.b ум) являют-
ся смежными при 1 < i < п. В этом случае п называется длиной пути. Ес-
ли (xq, уо) = (хп, уп), то путь называется замкнутым. Можно определить
4-, 8- или т-путъ в соответствии с заданным типом смежности. На-
пример, на Рис. 2.26(6) изображено два 8-пути между правым верхним
и правым нижним элементами, а на Рис. 2.26(b) показан /«-путь. За-
метим, что он является однозначным, в отличие от 8-путей.
Пусть S — некоторое подмножество элементов изображения. Два
его элемента pv.q называются связными в S, если между ними суще-
ствует путь, целиком состоящий из элементов подмножества S. Для лю-
бого пикселя р из S множество всех пикселей, связных с ним в 5, на-
зывается связной компонентой (или компонентой связности) S. Если
0 11 0 О
0 10 О г О О 1. о
0 0 1 о о '1 о о '1 а б а
Рис. 2.26. (а) Конфигурация пикселей, (б) Элементы, являющиеся 8-смеж-
ными между собой (показано пунктиром), (в) Отношения /и-смежности.
множество 5 содержит только одну компоненту связности, оно назы-
вается связным множеством.
Пусть R — подмножество элементов изображения. Будем называть
его областью, если R — связное множество. Границей области R (так-
же называемой замкнутым контуром или краем) назовем множество
пикселей этой области, у которых один или более соседей не являют-
ся элементами R. Если подмножество R есть все изображение (кото-
рое, напомним, является прямоугольной матрицей элементов), то его
граница по определению состоит из элементов первого столбца и пер-
вой строки, а также элементов последнего столбца и последней стро-
ки. Такое доопределение необходимо, поскольку у этих элементов
нет соседей за пределами изображения. Обычно, говоря об области,
имеется в виду подмножество всего изображения, а элементы на гра-
нице области, которые совпадают с краем изображения, безусловно
включаются в состав границы этой области.
При обсуждении областей и границ часто возникает понятие кон-
тура. Между контуром (в общем случае незамкнутым) и границей
существует принципиальная разница. Граница конечной области все-
гда образует замкнутый путь (Задача 2.14) и поэтому является «глобаль-
ным» понятием. Контуры же, как подробно обсуждается в Главе 10, со-
стоят из пикселей, на которых значения производной яркости
превышают заранее заданный порог. Поэтому по самой своей идее кон-
тур является «локальным» понятием, основанным на мере непрерыв-
ности уровня яркости в некоторой точке. Контурные точки могут со-
единяться, образуя сегменты контуров, и эти сегменты иногда
соединяются подобно границам, но такой случай имеет место не все-
гда. Единственным исключением, когда контура и границы соответ-
ствуют друг другу, являются бинарные изображения. В зависимости от
используемых вида связности и оператора выделения контуров (эти
операторы рассматриваются в Главе 10), выделение контуров в бинар-
ной области дает результаты, совпадающие с границей этой области.
Ограничимся здесь этим изложением на интуитивном уровне и, по-
ка мы не достигли Главы 10, будем понимать контуры как разрывы яр-
кости, а границы — как замкнутые пути.
2.5.3. Меры расстояния
Пусть элементы изображения p,qv.z имеют координаты (х, у), (s, t)
и (v, w) соответственно. Функция D называется функцией расстояния
или метрикой, если:
a) D(p, q) > 0, причем D(p, q) = 0 тогда и только тогда, когдар = q~,
б) D(p, q) = D(q,p);
в) D(p, z) < D(p, q) + D(q, z).
Евклидово расстояние (метрика Lq) между элементами pwq определя-
ется следующим образом:
£
De{p,q) = [(х - s)2 + (у - О2 ]г .
(2.5-1)
При такой метрике пиксели, находящиеся на расстоянии не более г от
заданной точки (х, у), образуют круг радиуса г с центром в этой точке.
Расстояние (метрика £,) между элементами pwq определяется
следующим образом:
D^p,q) = |x-s| + |y - .
(2.5-2)
В этом случае пиксели, находящиеся на расстоянии Z>4, меньшем или рав-
ном г, от заданной точки (х, у), образуют повернутый на 45° квадрат с цен-
тром в этой точке. Например, пиксели с расстоянием D4 < 2 от централь-
ной точки образуют следующие замкнутые линии равных расстояний:
2
2 1 2
2 10 12
2 1 2
2
Пиксели с расстоянием = 1 являются четверкой соседей для эле-
мента (х, у).
Расстояние (метрика между элементами pwq определяет-
ся следующим образом:
£>8(p,g) = max(|x-s|,|y-r|). (2.5-3)
В этом случае пиксели, находящиеся на расстоянии Z>8, меньшем или
равном г, от заданной точки (х, у), образуют квадрат с центром в этой
точке. Например, пиксели с расстоянием Z>8 < 2 от центральной точ-
ки образуют следующие замкнутые линии равных расстояний:
2 2 2 2 2
2 1112
2 10 12
2 1112
2 2 2 2 2
Пиксели с расстоянием Dg = 1 являются восьмеркой соседей для эле-
мента^, у).
Заметим, что расстояния Z>4 и Z>8 между двумя элементамир и q не
зависят от каких-либо путей, которые могли существовать между эти-
ми пикселями, поскольку в определении этих расстояний участвуют
только координаты элементов. Однако, если мы выбираем в качест-
ве меры /«-смежность, то расстояние Dm между двумя элементами
изображения определяется как длина кратчайшего m-пути между эти-
ми элементами. В этом случае расстояние между пикселями будет за-
висеть от значений всех пикселей вдоль этого пути, равно как и от зна-
чений их соседей. Например, рассмотрим следующую конфигурацию
пикселей, и пусть элементы р, р2 ир4 имеют значение 1, а элементы р\
и Р2 могут принимать значения 0 или 1:
Р3Р4
Р] Р2
Р
Предположим, что рассматривается смежность пикселей со значе-
нием 1, т.е. V={ 1}. Если оба элементар\ ир% имеют значения 0, то дли-
на кратчайшего /и-пути (т.е. расстояние Dm) междур и р4 равна 2. Ес-
ли значение р\ равно 1, то элементы р и р2 больше не являются
/«-смежными (см. определение отношения /«-смежности), и длина
кратчайшего /«-пути становится равной 3 (этот путь проходит через точ-
ки р, Р\,р2, Рц)- Аналогичные рассуждения имеют место в том случае,
если значениер$ равно 1 (а значениерх равно 0). В этом случае длина
кратчайшего /«-пути также равна 3. Наконец, если оба пикселя р\ и р%
имеют единичные значения, то длина кратчайшего /«-пути между р и
р4 станет равной 4. В таком случае путь проходит через последователь-
ность точек р, Р\,р2, Рз, Рц-
2.5.4. Поэлементные операции над изображениями
В последующем многократно упоминаются операции, выполняемые
над изображениями, например, деление одного изображения на дру-
гое. В определении (2.4-2) изображение было представлено в форме
матрицы. Известно, что операция деления матриц в общем случае не
определена. Однако, говоря об операции типа «деления одного изо-
бражения на другое», мы на самом деле подразумеваем, что деление
выполняется для соответственных элементов двух изображений. Та-
ким образом, если, например,/идсуть цифровые изображения, то зна-
чение первого элемента изображения, получаемого «делением»/на^,
равно результату от деления значения первого пикселя/на значение
первого пикселя g; разумеется, в предположении, что все элементы g
имеют ненулевые значения. Прочие арифметические и логические опе-
рации определяются аналогичным образом и выполняются над соот-
ветственными элементами участвующих в операции изображений.
2.6. Линейные и нелинейные преобразования
Пусть И— оператор, входом и выходом которого являются изображе-
ния. Говорят, что оператор Нлинейный, если для любых двух изобра-
жений /и g, и любых двух скалярных значений а и Ъ справедливо ра-
венство
H(af +bg) = аН (f) + bH (g). (2.6-1)
Другими словами, результат применения линейного оператора к ли-
нейной комбинации двух изображений (т.е. к их сумме с предваритель-
ным умножением соответственно на коэффициенты а и Ь) идентичен
линейной комбинации результатов применения такого оператора к
этим изображениям по отдельности. Например, оператор, функция ко-
торого состоит в вычислении суммы К изображений, есть линейный
оператор. А оператор, вычисляющий модуль разности двух изображе-
ний, линейным не является. По определению, оператор, для которо-
го нарушается условие (2.6-1), является нелинейным оператором.
Линейные операторы исключительно важны для обработки изоб-
ражений, поскольку они опираются на значительную совокупность хо-
рошо изученных теоретических и практических результатов. Нелиней-
ные операторы, хотя иногда и приводят к лучшим результатам, не
всегда предсказуемы и по большей части недостаточно исследованы
теоретически.
Заключение
Изложенный в этой главе материал в первую очередь содержит под-
готовительную информацию, необходимую для последующих обсуж-
дений. Рассмотрение зрительной системы человека дает, хотя и крат-
кое, начальное представление о способностях глаза воспринимать
изобразительную информацию. Рассмотрение электромагнитного
спектра и света служит базой для понимания происхождения многих
изображений, приведенных в книге. Модель изображения, предложен-
ная в Разделе 2.3.4, используется далее в Главе 4 как основа для мето-
да улучшения изображения, называемого гомоморфной фильтрацией,
а также в Главе 10 для объяснения влияния освещения на форму гис-
тограммы изображения.
Принципы дискретизации, представленные в Разделе 2.4, объяс-
няют природу многих явлений, часто встречающихся в практике оци-
фровки изображений. Эти идеи можно развить еще дальше, вооружив-
шись хотя бы основами анализа частотного состава изображения.
Подробное обсуждение частотной области анализа и обработки изо-
бражений проводится в Главе 4. Представление о дискретизации и
эффектах наложения частот также важны в контексте ввода и регис-
трации изображений.
Введенные в Разделе 2.5 понятия служат фундаментом для пост-
роения методов обработки изображений на основе локальной окрест-
ности пикселей. Как показано в следующей главе и в Главе 5, методы
локальной обработки находятся в центре многих процедур улучшения
и восстановления изображений. Насколько это возможно, в коммер-
ческих системах обработки изображений предпочтение отдается ме-
тодам обработки в локальной окрестности, прежде всего благодаря вы-
сокой скорости выполнения операций и простоте аппаратной
реализации. Наконец, понятие линейного оператора и связанные с ним
теоретическая и концептуальная мощь будут интенсивно использовать-
ся на протяжении трех следующих глав.
Ссылки и литература для дальнейшего изучения
Дополнительный материал к Разделу 2.1 по строению человеческого
глаза можно найти в книгах [Atchison, Smith, 2000] и [Oyster, 1999], а
дальнейшие сведения о зрительном восприятии почерпнуть в моно-
графиях [Regan, 2000] и [Gordon, 1997]. Интерес также представляют
книги [Born, Wolf, 1999], [Hubei, 1988] и ставшая уже классикой
[Comsweet, 1970].
Книга [Bom, Wolf, 1999] может служить основным справочным
руководством, в котором свет рассматривается с позиций электромаг-
нитной теории. Подробности распространения энергии электромаг-
нитных волн обсуждаются в [Felsen, Marcuvitz, 1994].
Тема регистрации изображений необычайно широка и очень бы-
стро развивается. Прекрасным источником информации об оптиче-
ских сенсорах и других чувствительных элементах для регистрации изо-
бражений являются публикации Международного общества по
оптической технике (SPIE). Примерами типичных изданий SPIE по
этой тематике могут служить книги [Blouke et al., 2001], [Hoover, Doty,
1996], и [Freeman, 1987].
Представленная в Разделе 2.3.4 модель изображения взята из ста-
тьи [Oppenheim, Schafer, Stockham, 1968]. Приведенные в этом разде-
ле значения освещенности и коэффициента отражения взяты из спра-
вочника [IES Lighting Handbook, 2000]. Дополнительный материал по
дискретизации изображений и некоторым связанным с ней эффектам
можно найти в [Bracewell, 1995]. Упомянутые в Разделе 2.4.3 ранние экс-
перименты по изучению зависимости воспринимаемого качества изо-
бражения от дискретизации и квантования описаны в [Huang, 1965].
Вопрос об уменьшении частоты дискретизации и числа уровней кван-
тования при минимальном ухудшении качества изображения по-
прежнему представляет интерес, как показывает статья [Papamarkos,
Atsalakis, 2000]. Дополнительные сведения об уменьшении и увеличе-
нии изображений можно найти в работах [Sid-Ahmed, 1995], [Unseret
al., 1995], [Umbaugh, 1998] и [Lehmann et al., 1999]. В качестве допол-
нительного материала по теме Раздела 2.5 рекомендуются книги
[Rosenfeld, Как, 1982], [Marchand-Maillet, Sharaiha, 2000] и [Ritter,
Wilson, 2001]. Дальнейшие сведения о линейных системах примени-
тельно к обработке изображений можно найти в монографии
[Castleman, 1996].
Задачи5
*2.1 Используя материал Раздела 2.1 и рассуждая чисто геометри-
чески, оцените наименьший диаметр напечатанной точки,
различаемой глазом, если страница рассматривается с рассто-
яния 0,2 м. Для простоты предполагайте, что зрительная сис-
тема не воспринимает точку, если размеры ее изображения на
центральной ямке меньше диаметра одного рецептора (колбоч-
ки) в этой области сетчатки. Считайте, что центральная ямка
имеет форму квадрата со стороной 1,5 мм и колбочки равно-
мерно распределены на этой площади с промежутками, равны-
ми размеру рецептора.
2.2 Когда Вы входите в темный кинозал с улицы, проходит неко-
торое время, прежде чем Вы станете видеть достаточно хоро-
шо, чтобы найти свободное место. Какой из объяснявшихся
в Разделе 2.1 процессов происходит в это время в зрительной
системе?
5 Подробные решения задач, отмеченных звездочкой, приводятся на посвященном
книге сайте в Интернете http://www.prenhall.com/gonzalezwoods. Там же можно найти
темы предлагаемых проектов, основанных на материале данной главы.
Глава 2. Основы цифрового представления изображений
*2.3 Переменный ток является частью электромагнитного спектра,
хотя это явно не отражено на Рис. 2.10. Частота промышлен-
ного тока в США равна 60 Гц. Какова длина волны в киломе-
трах для этой составляющей спектра?
2.4 Перед Вами поставлена задача разработать входную часть си-
стемы обработки изображений для исследования формы кле-
ток, бактерий, вирусов и белков. В данном случае эта входная
часть должна состоять из одного или нескольких источников
освещения и отвечающих им устройств регистрации изображе-
ний (камер). Каждая из упомянутых категорий характеризует-
ся размером особей 50 мкм, 1 мкм, 0,1 мкм и 0,01 мкм соответ-
ственно.
(а) Можно ли в этой задаче обеспечить формирование изоб-
ражений с помощью одного набора из источника и каме-
ры? Если да, то укажите диапазон длин волн источника
освещения и вид необходимого устройства регистрации
(например, цветная фотокамера, камера ближнего инфра-
красного диапазона и т.д.).
(б) Если нет, то какие виды источников освещения и устройств
регистрации Вы бы порекомендовали? (Указывайте виды
источников и камер так же, как и в части (а)). Используй-
те минимально необходимое для решения задачи число источ-
ников освещения и устройств регистрации.
2.5 ПЗС-камера оснащена матрицей размерами 7x7 мм, состоящей
из 1024x1024 элементов. На эту матрицу проецируется изобра-
жение плоской квадратной области, находящейся на расстоя-
нии 0,5 м. Сколько пар линий на миллиметр в указанной об-
ласти способна различить такая камера? Камера оборудована
объективом с фокусным расстоянием 35 мм.
{Подсказка'. Используйте геометрическую модель формиро-
вания изображения, аналогичную изображенной на Рис 2.3, в
которой вместо фокусного расстояния глаза участвовало бы фо-
кусное расстояние объектива).
*2.6 Для автозавода разрабатывается автоматизированная систе-
ма, управляющая размещением декоративных элементов на
бамперах ограниченной серии спортивных автомобилей. Эти
элементы должны сочетаться по цвету с автомобилем, поэто-
му сборочный робот должен знать цвет конкретного автомоби-
ля для правильного выбора декоративных элементов. Модели
выпускаются только четырех цветов: синего, зеленого, красно-
го и белого. Вам поручено предложить решение на основе си-
стемы технического зрения. Как бы Вы предложили решить
2.7
2.8
*2.9
2.10
проблему автоматического определения цвета автомобиля,
считая стоимость наиболее важным соображением при выбо-
ре компонентов такой системы?
Предположим, что плоская область с центром в точке (х0, у0)
освещена источником света, обеспечивающим распределение
освещенности по следующему закону:
., . „ -Г(х-хо)2+(у-уо)21
i(x, у) = Ke L J .
Примем для простоты, что коэффициент отражения поверхно-
сти постоянен и равен 1, а К = 255. Предполагая, что получа-
емое изображение квантуется с яркостным разрешением к бит,
а глаз способен ощущать границу лишь при разности величи-
ны яркости соседних пикселей от 8 и выше, определить, при
каком значении к станут заметны ложные контуры.
Нарисуйте вид изображения в Задаче 2.7 при к = 2.
Общепринятой единицей измерения скорости передачи циф-
ровых данных является бод', по определению, 1 бод соответст-
вует скорости передачи 1 бит/с. В общем случае информация
передается пакетами, состоящими из стартового бита, байта ин-
формации (8 бит) и стопового бита. Опираясь на эти факты, от-
ветьте:
(а) Сколько минут займет передача изображения размерами
1024x1024 элементов с 256 градациями яркости с помо-
щью модема, обеспечивающего скорость передачи 56 Кбод
(1 Кбод = 1000 бод)?
(б) Каково будет время при скорости 750 Кбод, типичной для
соединения по телефонной линии в режиме DSL (цифро-
вая абонентская линия)?
В телевидении высокой четкости (ТВЧ) изображения с верти-
кальным разрешением 1125 строк генерируются в режиме че-
ресстрочной развертки, т.е. когда на экран с интервалом 1/60 с
по очереди выводятся два поля (полукадра), состоящие соот-
ветственно из четных и нечетных строк каждого кадра. Отно-
шение ширины изображения к высоте равно 16:9. Тот факт, что
изображение формируется из отдельных горизонтальных строк,
определяет разрешение по вертикали. Предположим, что со-
здано устройство для записи программ ТВЧ в виде последова-
тельности цифровых изображений каждого кадра, и в этом ус-
тройстве разрешение по горизонтали (вдоль телевизионной
строки) пропорционально вертикальному разрешению (в со-
ответствии с отношением сторон экрана). Каждый пиксель
цветного изображения представляется 24 битами яркости — по
8 бит для красного, зеленого и синего изображений, в совокуп-
ности образующих цветное изображение. Сколько бит займет
запись двухчасовой программы ТВЧ с помощью такого устрой-
ства?
*2.11 Рассмотрим на изображении два подмножества 5) и $2, пока-
занные на рисунке. Считая К={1}, определите, являются ли
эти два подмножества (а) 4-смежными, (б) 8-смежными или (в)
/«-смежными.
S2
о :’b''b''o'”o';'b'”o”T''i": о
1 ; 0 0 1 0 0 1 0 0 1
1 I 0 0 1 Oil 1 0 0 ! О
0 0 1 110 0 1 11
*2.12 Составьте алгоритм для преобразования 8-пути, имеющего
толщину в один пиксель, в 4-путь.
2.13 Составьте алгоритм для преобразования /и-пути, имеющего
толщину в один пиксель, в 4-путь.
2.14 Докажите, что граница области, как она определена в Разде-
ле 2.5.2, представляет собой замкнутый путь.
*2.15 Для показанного ниже участка изображения:
(а) Считая К={0, 1}, вычислите длины кратчайших 4-, 8-, и
/«-путей между элементами pvtq. Если какой-то из путей
между этими двумя точками не существует, то объясните по-
чему.
(б) Повторите тоже для Р={1, 2}.
3 1 2 Ito)
2 2 0 2
12 11
(Р)1 0 1 2
*2.16 (а) Сформулируйте условия, при которых расстояние Л4 меж-
ду двумя точками рнц равно длине кратчайшего 4-пути
между этими точками.
(б) Является ли этот путь единственным?
2.17 Решите Задачу 2.16 для расстояния Л8.
Задачи
2.18 В следующей главе мы познакомимся с операторами, функция
которых состоит в вычислении суммы значений пикселей в пре-
делах малой подобласти изображения У Докажите, что такие
операторы являются линейными.
2.19 Медианой £ множества чисел называется такой его элемент, ко-
торый больше или равен половине элементов этого множест-
ва и меньше или равен другой половине элементов. Например,
медианой множества чисел {2, 3, 8, 20, 21, 25, 31} является
число 20. Докажите, что оператор, вычисляющий медиану зна-
чений пикселей в пределах малой подобласти изображения 5,
является нелинейным.
2.20 Завод изготовляет миниатюрные квадратики из полупрозрач-
ного полимера. Жесткие требования качества вынуждают про-
водить стопроцентный визуальный контроль, требующий боль-
ших затрат. Проверка осуществляется в полуавтоматическом
режиме: на каждом посту контроля роботизированный меха-
низм помещает каждый квадратик между источником света и
оптической системой, проецирующей увеличенное изображе-
ние квадратика на экран размерами 80x80 мм, занимая всю его
площадь. Дефекты выглядят как круглые темные пятна, и в
функции контролера входит, используя нанесенную на экран
шкалу, вести отбраковку образцов, в которых встречается хо-
тя бы одно такое темное пятно диаметром 0,8 мм и более. Ме-
неджер убежден, что если удастся найти способ полностью
автоматизировать процесс контроля, это приведет к увеличе-
нию прибыли на 50% и поможет ему подняться в корпоратив-
ной иерархии. После изучения вопроса он решает оснастить
каждый пост контроля ПЗС-телекамерой, подключенной к
промышленной системе обработки изображений, которая бы
обнаруживала пятна, измеряла их диаметр и активировала ме-
ханизм отбраковки, как это раньше делал контролер. Менед-
жеру удается найти на рынке систему, способную выполнить
все эти действия, если дефект минимального размера будет
занимать на цифровом изображении область не менее чем 2x2
пикселя. Вас нанимают в качестве консультанта, чтобы по-
мочь правильно выбрать тип камеры и объектива среди се-
рийно выпускаемых изделий. Доступны объективы с фокусным
расстоянием от 25 мм до 200 мм (с шагом 25 мм) и ПЗС-каме-
ры с разрешением 512x512,1024x1024 или 2048x2048 пикселей,
у которых каждый сенсор имеет форму квадрата размером
8x8 мкм, а расстояние между соседними сенсорами равно
2 мкм. В этой прикладной задаче камеры обходятся намного до-
5 А-223
Глава 2. Основы цифрового представления изображений
роже объективов, поэтому следует выбрать камеру минималь-
но необходимого разрешения, используя соответствующий
объектив. Сформулируйте в письменном виде свои рекомен-
дации, обосновав их с помощью достаточно подробного ана-
лиза. Используйте ту же геометрическую модель формирова-
ния изображения, что и в Задаче 2.5.
ГЛАВА 3
ПРОСТРАНСТВЕННЫЕ
МЕТОДЫ
УЛУЧШЕНИЯ
ИЗОБРАЖЕНИЙ
Вся разница в том, что именно мы хотим увидеть:
темное на светлом или светлое на темном.
Дэвид Линдсей
Введение
Главная цель улучшения заключается в такой обработке изображе-
ния, чтобы результат оказался более подходящим с точки зрения кон-
кретного применения. Слово конкретное является здесь важным, по-
скольку оно с самого начала устанавливает, что методы, обсуждаемые
в настоящей главе, в значительной степени проблемно ориентирова-
ны. Так, например, метод, являющийся весьма полезным для улучше-
ния рентгеновских изображений, не обязательно окажется наилучшим
для обработки снимков Марса, переданных космическим аппаратом.
Однако, безотносительно к применяемым методам, улучшение изо-
бражений является одной из наиболее интересных и привлекательных
с позиции визуального анализа областей обработки изображений.
Множество подходов к улучшению изображений распадается на две
большие категории: методы обработки в пространственной области
(пространственные методы) и методы обработки в частотной облас-
ти (частотные методы). Термин пространственная область относится
к плоскости изображения как таковой, и данная категория объединя-
ет подходы, основанные на прямом манипулировании пикселями
изображения. Методы обработки в частотной области основывают-
ся на модификации сигнала, формируемого путем применения к изо-
бражению преобразования Фурье. Пространственные методы рас-
сматриваются в настоящей главе, а улучшение с применением
частотных методов обсуждается в Главе 4. Наряду с этим не являются
бесполезными и технологии, базирующиеся на различных комбина-
циях методов из данных двух категорий. Заметим также, что многие
132 Глава 3. Пространственные методы улучшения изображений
из основных методов, предлагаемых в данной главе в контексте улуч-
шения, используются также в последующих главах для других разно-
образных применений обработки изображений.
Общей теории улучшения изображений не существует. Когда изо-
бражение обрабатывается для визуальной интерпретации, наблюдатель
является окончательным судьей того, насколько хорошо действует
конкретный метод. Визуальное оценивание качества изображения
есть крайне субъективный процесс, делающий тем самым понятие
«хорошего изображения» некоторым неуловимым эталоном, с помо-
щью которого необходимо сравнивать эффективность алгоритма.
Когда целью является обработка изображения для машинного воспри-
ятия, задача оценивания несколько проще. Например, в задаче распоз-
навания символов наилучшим (оставляя в стороне другие вопросы, та-
кие как вычислительные требования) будет тот метод обработки
изображений, который дает более точные результаты машинного рас-
познавания. Тем не менее, даже в ситуации, когда проблема позволя-
ет установить четкие критерии качества, обычно требуется определен-
ное количество попыток тестирования, пока будет выбран конкретный
подход к улучшению изображений.
3.1. Предпосылки
Как указано выше, термин пространственная область относится к мно-
жеству пикселей, составляющих изображение. Пространственные
методы суть процедуры, оперирующие непосредственно значения-
ми этих пикселей. Процессы пространственной обработки описыва-
ются уравнением
g(x,y) = T[/(x,y)], (3.1-1)
где f(x, у) — входное изображение, g(x, у) — обработанное изобра-
жение, а Т~ оператор над/, определенный в некоторой окрестно-
сти точки (х, у). Более того, Тможет оперировать над последователь-
ностью входных изображений, например, выполняя поэлементное
суммирование К изображений для уменьшения шума, как обсуж-
дается в Разделе 3.4.2.
Главный подход в определении окрестности вокруг точки (х, у)
заключается в использовании квадратной или прямоугольной об-
ласти — подмножества изображения, центрированного в точке
(х, у), как показано на Рис. 3.1. Центр данного подмножества пе-
редвигается от пикселя к пикселю, начиная, скажем, с верхнего ле-
вого угла. Оператор Твыполняется в каждой точке (х, у), давая в ре-
3.1. Предпосылки
Начало
координат
— у)
Изображение fix, у)
х
Рис. 3.1. Окрестность 3x3 вокруг точки (х, у) изображения.
зультате выходное значение g для данной точки. Процесс исполь-
зует только пиксели внутри области изображения, ограниченной не-
которой окрестностью. Квадратные или прямоугольные массивы яв-
ляются, безусловно, наиболее распространенными из-за простоты
их реализации, хотя иногда применяются окрестности другой фор-
мы, например, приближающиеся к кругу.
Простейшая форма оператора Тдостигается в случае, когда ок-
рестность имеет размеры 1x1 (т.е. один пиксель). В этом случае g за-
висит только от значения/в точке (х, у), и Тстановится функцией
градационного преобразования (также называемой функцией преобра-
зования интенсивностей или функцией отображения) вида
s = T(r), (3.1-2)
где, для простоты обозначения, г и 5 суть переменные, обозначающие,
соответственно, значения яркостей изображений fix, у) и g(x, у) в каж-
дой точке (х, у). Например, если Т(г) имеет вид, показанный на
Рис. 3.2(a), то эффект от такого преобразования выразится в получе-
нии изображения более высокого контраста по сравнению с оригина-
лом, а также в затемнении пикселей со значениями меньшими т и по-
вышении яркостей пикселей со значениями большими т на исходном
изображении. В этом методе, известном как усиление контраста, зна-
чения г меньшие т при приближении к уровню черного сжимаются
с помощью функции преобразования во все более узкий диапазон 5.
Обратный эффект имеет место для значений г, больших т. В пре-
Глава 3. Пространственные методы улучшения изображений
Темное —► Светлое Темное Светлое
Рис. 3.2. Градационное преобразование для улучшения контраста.
дельном случае, показанном на Рис. 3.2(6), Г(г) дает в результате двух-
градационное (бинарное) изображение. Отображение такой формы на-
зывают пороговой функцией. С помощью градационных преобразова-
ний могут быть построены некоторые довольно простые, но
действенные методы обработки изображений. Поскольку результат
улучшения каждого элемента изображения зависит только от яркос-
ти этого же элемента, методы данной категории часто относят к про-
цедурам поэлементной обработки.
Увеличение размеров окрестности приводит к значительно боль-
шей гибкости. Принцип заключается в том, что для нахождения зна-
чения g в некоторой точке (х, у), используются значения функции
/внутри некоторой окрестности заранее заданной формы, окружа-
ющей точку (х, у). Один из основных подходов в такой постанов-
ке базируется на использовании так называемых масок (также упо-
минаемых как фильтры, ядра, шаблоны или окнаУ). Чаще всего маска
представляет собой небольшой (скажем, 3x3 элемента) двумерный
массив, подобный представленному на Рис. 3.2, значения коэффи-
циентов маски внутри которого определяют существо процесса,
например, повышение резкости изображения. Методы улучшения,
базирующиеся на таком подходе, часто относят к обработке по ма-
ске или фильтрации по маске. Эти концепции обсуждаются в Раз-
деле 3.5.
1 Для масок небольшого размера часто используется термин окрестность. — Прим,
перев.
3.2.Некоторые основные градационные преобразования
3.2. Некоторые основные градационные
преобразования
Мы начинаем изучение методов улучшения изображений с обсужде-
ния функций градационного преобразования. Они относятся к чис-
лу простейших из всех методов улучшения изображений. Значения
пикселей до и после обработки будут обозначаться символами г и 5 со-
ответственно. Как указано в предыдущем разделе, эти величины свя-
заны выражением видал = 7(г), где Тявляется преобразованием, ото-
бражающим значение пикселя г в значение пикселя л. Поскольку мы
имеем дело с дискретным (квантованным) представлением, значе-
ния функции преобразования, как правило, хранятся в одномерном
массиве, и отображение из г в л осуществляется по таблице. В случае
8-битного представления таблица преобразования, содержащая зна-
чения Т, будет состоять из 256 элементов.
В качестве введения в градационные преобразования рассмотрим
Рис. 3.3, на котором показаны три основных типа преобразований, ча-
сто используемых для улучшения изображений: линейное (негатив
и тождественное преобразование), логарифмическое (логарифм и об-
ратный логарифм), и степенное (и-ая степень и корень и-ой степени).
Тождественное преобразование является тривиальным случаем, при
котором яркости на выходе идентичны яркостям на входе. Оно при-
ведено на графике только для полноты рассмотрения.
3.2.1. Преобразование изображения в негатив
Преобразование изображения в негатив с яркостями в диапазоне
[О, L — 1] осуществляется с использованием негативного преобразо-
вания, показанного на Рис. 3.3, и определяемого выражением
л = £-1-г. (3.2-1)
Подобный переворот уровней яркости изображения создает эквивалент
фотографического негатива. Этот тип обработки особенно подходит для
усиления белых или серых деталей на фоне темных областей изобра-
жения, особенно когда темные области имеют преобладающие разме-
ры. Пример показан на Рис. 3.4. На исходном изображении представ-
лена цифровая рентгенограмма молочной железы, демонстрирующая
небольшое поражение. Несмотря на тот факт, что визуальное содержа-
ние на обоих изображениях является одним и тем же, заметим, насколь-
ко проще в данном случае анализировать молочную железу на негатив-
ном изображении.
Яркость на входе, г
Рис. 3.3. Некоторые основные функции градационных преобразований, ис-
пользуемых для улучшения изображений.
Рис. 3.4. (а) Исходный вид рентгенограммы молочной железы, (б) Негативное
изображение, полученное применением негативного преобразования по формуле
(3.2-1). (Предоставлено компанией G.E. Medical Systems)
3.2.Некоторые основные градационные преобразования 137л
3.2.2. Логарифмическое преобразование
Общий вид логарифмического преобразования, показанного на
Рис. 3.3, выражается формулой
5 = clog(l + г), (3.2-2)
где с — константа и предполагается, что г > 0. Форма логарифмичес-
кой кривой на Рис. 3.3 показывает, что данное преобразование отоб-
ражает узкий диапазон малых значений яркостей на исходном изобра-
жении в более широкий диапазон выходных значений. Для больших
значений входного сигнала верно противоположное утверждение. Мы
предлагаем использовать этот тип преобразования для растяжения
диапазона значений темных пикселей на изображении с одновремен-
ным сжатием диапазона значений ярких пикселей. Наоборот, при ис-
пользовании обратного логарифмического преобразования происхо-
дит растяжение диапазона ярких пикселей и сжатие диапазона темных
пикселей.
Любая кривая, имеющая общий вид, близкий к показанной на
Рис. 3.3 логарифмической функции, будет осуществлять такое растя-
жение/сжатие диапазонов яркости на изображении. На самом деле для
этих целей значительно более универсальными, чем логарифмичес-
кие, являются степенные преобразования, обсуждаемые в следующем
разделе. Несмотря на это, логарифмическая функция имеет важную
особенность, позволяя сжимать динамический диапазон изображе-
ний, имеющих большие вариации в значениях пикселей. Классиче-
ским примером, в котором значения пикселей имеют большой дина-
мический диапазон, является спектр Фурье, обсуждаемый в Главе 4.
В данный момент нас интересуют лишь свойства спектра как изоб-
ражения. Спектр, значения которого изменяются в диапазоне от 0 до
106 или более, не является чем-то необычным. Если обработка подоб-
ной совокупности значений не представляет проблемы для компью-
тера, то система воспроизведения изображений обычно не способна
правильно отобразить столь большой диапазон значений интенсив-
ности. Результирующий эффект таков, что при обычном воспроизве-
дении спектра Фурье значительное число деталей теряется.
В качестве иллюстрации логарифмического преобразования, на
Рис. 3.5(a) приведено изображение спектра Фурье, имеющего значе-
ния в диапазоне от Одо 1,5-106. Если масштабировать эти значения ли-
нейно для отображения в 8-битной системе воспроизведения, то на-
иболее яркие пиксели будут доминировать над слабыми (и зачастую
важными) значениями спектра. Эффект такого доминирования ярко
Глава 3. Пространственные методы улучшения изображений
Рис. 3.5. (а) Спектр Фурье, (б) Результат применения логарифмического пре-
образования по формуле (3.2-2) с с = 1.
иллюстрирует Рис. 3.5(a), на котором только весьма малая область
изображения не воспринимается как черная. Если же вместо подоб-
ного способа воспроизведения мы сначала применим к значениям
спектра преобразование по формуле (3.2-2) (с с = 1 в данном случае),
тогда диапазон значений результата будет от 0 до 6,2, что намного
удобнее. На Рис. 3.5(6) показан результат линейного масштабирова-
ния нового диапазона и отображения спектра на том же самом 8-бит-
ном устройстве воспроизведения. Из этих иллюстраций становится
очевидным богатство видимых деталей на втором изображении по
сравнению с непосредственным воспроизведением. Большинство
спектров Фурье, демонстрируемых в публикациях по обработке изо-
бражений, масштабируются именно таким способом.
3.2.3. Степенные преобразования
Степенные преобразования имеют вид
s = cr'1,
(3.2-3)
где с и у являются положительными константами. Иногда уравнение
(3.2-3) записывается в виде 5 = с(г + е)"/ для того, чтобы ввести сме-
щение, т.е. измеримый (ненулевой) выход, когда на входе ноль. Впро-
чем, смещения возникают при калибровке устройстве воспроизведе-
ния, и поэтому в уравнении (3.2-3) они обычно игнорируются.
Графики зависимостей 5 от г при различных значениях /показаны на
Рис. 3.6. Так же как в случае логарифмического преобразования, кри-
3.2.Некоторые основные градационные преобразования
вые степенных зависимостей при малых у отображают узкий диапа-
зон малых входных значений в широкий диапазон выходных значе-
ний, при этом для больших входных значений верно обратное утверж-
дение. Однако, в отличие от логарифмических функций, здесь
возникает целое семейство кривых возможного преобразования, по-
лучаемых простым изменением параметра у. Как и следовало ожидать,
на Рис. 3.6 видно, что кривые, полученные со значениями у > 1 дают
прямо противоположный эффект по сравнению с теми, которые по-
лучены при у < 1. Наконец отметим, что уравнение (3.2-3) приводит-
ся к тождественному преобразованию при с = у = 1.
Амплитудная характеристика многих устройств, используемых
для ввода, печати или визуализации изображений, соответствует сте-
пенному закону. По традиции, показатель степени в уравнении сте-
пенного преобразования называют гамма, и именно поэтому символ
у использован в уравнении (3.2-3). Процедура, используемая для
коррекции такой степенной характеристики, называется гамма-кор-
рекцией. Например, устройства с электронно-лучевой трубкой (ЭЛТ)
Рис. 3.6. Графики уравнения 5 = СГУ, для различных значений у (С = 1 во всех
случаях).
Глава 3. Пространственные методы улучшения изображений
имеют степенную зависимость яркости от напряжения с показателем
степени в диапазоне от 1,8 до 2,5. Обращая внимание на кривую для
у = 2,5 на Рис. 3.6, можно видеть, что подобная система отображения
будет иметь тенденцию к воспроизведению изображений темнее,
чем они есть на самом деле. Этот эффект иллюстрируется на Рис. 3.7.
На Рис. 3.7(a) показан простой полутоновой линейный клин, пода-
ющийся на вход монитора с ЭЛТ. Как и ожидалось, изображение на
экране реального монитора оказывается темнее, чем должно быть
на экране идеального монитора, что и видно на Рис. 3.7(6).
Необходимость применения гамма-коррекции очевидна. Все, что
требуется для компенсации — это произвести предобработку визуа-
лизируемого изображения с помощью преобразования 5 = г1/2-5 = /).4
прежде, чем оно поступит на вход монитора. Результат показан на
Изображение на экране монитора
Изображение на экране монитора
Рис. 3.7. (а) Полутоновое изображение с линейным клином, (б) Отклик мо-
нитора на линейный клин, (в) Клин, подвергнутый гамма-коррекции, (г) Результат
на экране монитора.
3.2.Некоторые основные градационные преобразования
Рис. 3.7(c). При воспроизведении на том же мониторе, такая гамма-
коррекция обеспечивает вывод, визуально близкий к оригинально-
му изображению, как и показано на Рис. 3.7(г). Аналогичные иссле-
дования должны быть применены и по отношению к другим
устройствам для работы с изображениями, таким как сканеры и прин-
теры. Единственным различием между ними должно быть значение
гамма, зависящее от конкретного устройства [Poynton, 1996].
Гамма-коррекция необходима, если требуется точное воспроизве-
дение изображения на экране компьютера. Изображения, которые
не откорректированы правильно, могут выглядеть или как выбелен-
ные, или, что более вероятно, как слишком темные. Правильное вос-
произведение цветов также требует некоторых знаний о гамма-коррек-
ции, поскольку подобное преобразование меняет не только яркость,
но также соотношения между красным, зеленым и синим цветами.
В последние годы гамма-коррекция становится более важной, по-
скольку увеличивается коммерческое использование цифровых изо-
бражений в Интернете. Зачастую изображения, размещенные на по-
пулярных сайтах в Интернете, рассматриваются миллионами людей,
большинство из которых имеет различные мониторы или их наст-
ройки. Некоторые компьютерные системы даже включают в себя
встроенную частичную гамма-коррекцию. К тому же, используемые
в настоящее время стандарты изображений не содержат исходного
значения гамма, с которым изображение формировалось, усложняя тем
самым получение правильного результата. Имея подобные ограниче-
ния, разумным подходом, при хранении изображений на сайте в Ин-
тернете, является их предобработка со значением гамма, отражающим
«средние» параметры мониторов и компьютерных систем.
Пример 3.1. Улучшение контрастов с помощью степенных
преобразований.
В дополнение к возможностям гамма-коррекции, степенные пре-
образования полезны для универсального управления контрастом.
На Рис. 3.8(a) показан снимок, полученный с помощью ЯМР-томо-
графа (основанного на эффекте ядерного магнитного резонанса). На
нем изображена грудная часть позвоночника человека, имеющего пе-
релом со смещением и поражением позвоночного столба. Перелом ви-
ден вблизи центра позвоночника на расстоянии одной четверти от верх-
него края снимка. Поскольку изображение преимущественно темное,
желательно осуществить растяжение уровней яркости. Это может
быть достигнуто с помощью степенного преобразования с дробным
(меньшим единицы) показателем степени. Оставшиеся три изображе-
ния получены путем обработки изображения Рис. 3.8(a) степенным
Глава 3. Пространственные методы улучшения изображений
преобразованием по формуле (3.2-3). Значения гамма для изображе-
ний (б), (в) и (г) равны, соответственно, 0,6, 0,4 и 0,3 (значение с рав-
но 1 во всех случаях). Можно заметить, что с уменьшением значения
Рис. 3.8. (а) Снимок позвоночника человека с переломом; изображение полу-
чено с помощью ЯМР-томографа. (б — г) Результаты преобразований по формуле
(3.2-3) с с = 1 и у = 0,6, 0,4 и 0,3 соответственно. (Исходное изображение предоста-
вил д-р Дэвид Пикенс, Отделение радиологии и рентгенологии Медицинского цен-
тра Университета Вандербильта).
3.2.Некоторые основные градационные преобразования
гамма от 0,6 до 0,4 становится видимым все большее количество де-
талей. Дальнейшее уменьшение гамма до 0,3 несколько усиливает де-
тали фона, но снижает контраст до уровня, когда изображение при-
обретает вид «вылинявшего», что особенно заметно на фоновых
участках. Сравнивая все изображения, можно видеть, что наилучший
результат в смысле оценки контраста и различимости деталей дости-
гается при у= 0,4. Значение у= 0,3 можно считать пределом, ниже ко-
торого контраст данного конкретного изображения уменьшается до не-
приемлемого уровня.!!
Пример 3.2. Другая иллюстрация степенного преобразования.
Проблема с изображением на Рис. 3.9(a) противоположна той, ко-
торая была с изображением на Рис. 3.8(a). В данном случае требует-
ся улучшить изображение, которое выглядит «вылинявшим», что
указывает на необходимость понижения яркости. Это может быть
достигнуто с помощью преобразования по формуле (3.2-3) со значе-
ниями у больше 1. Результаты обработки изображения Рис. 3.9(a) при
у= 3,0, 4,0 и 5,0 показаны на Рис. 3.9(б-г). Подходящие результаты
достигаются при значениях гамма 3,0 и 4,0, причем последний вари-
ант выглядит более предпочтительным, поскольку имеет больший кон-
траст. На изображении, полученном при у= 5,0, имеются слишком
темные области, на которых часть деталей утеряна. Такие темные
области можно наблюдать в левом верхнем квадранте, слева от основ-
ной дороги.И
3.2.4. Кусочно-линейные функции преобразований
Подходом, дополняющим методы, рассмотренные в предыдущих
трех разделах, является использование кусочно-линейных функций.
Главное преимущество кусочно-линейных функций по сравнению
с вышерассмотренными состоит в том, что их форма может быть
сколь угодно сложной. На самом деле, как будет скоро показано,
практическая реализация некоторых важных преобразований может
быть осуществлена только с помощью кусочно-линейных функций.
Основной недостаток кусочно-линейных функций заключается в том,
что для их описания необходимо задавать значительно большее ко-
личество параметров.
Усиление контраста
Одним из простейших случаев использования кусочно-линейных
функций является преобразование, усиливающее контрасты. Низ-
кий контраст изображений может быть следствием плохого освеще-
Глава 3. Пространственные методы улучшения изображений
Рис. 3.9. (а) Аэрофотоснимок, (б) — (г) Результаты преобразования по форму-
ле (3.2-3) с с — 1 и у= 3,0, 4,0 и 5,0 соответственно. (Исходное изображение предо-
ставлено Агентством NASA).
ния, излишне большого динамического диапазона сенсора, или даже
неверно установленной диафрагмы объектива при съемке. Усиление
контраста достигается увеличением динамического диапазона ярко-
стей на обрабатываемом изображении.
На Рис. 3.10(a) показано типичное преобразование, используе-
мое для усиления контрастов. Положения точек (rj, .s ,) и зада-
ют вид функции преобразования. Если rj =5, иг2 = s2, преобразова-
ние становится тождественным, не вносящим изменения в значения
яркостей. Если rj = r2, sj = 0 и ,s2 = L — 1, преобразование превраща-
ется в пороговую функцию, которая в результате дает бинарное изо-
бражение, как это показано на Рис. 3.2(6). Промежуточные значения
(г,, л)) и (r2, .s2) обеспечивают различные степени растяжения уровней
3.2.Некоторые основные градационные преобразования
Рис. 3.10. Усиление контраста, (а) Вид функции преобразования, (б) Исход-
ное малоконтрастное изображение, (в) Результат усиления контраста, (г) Результат
порогового преобразования. (Исходное изображение предоставил д-р Роджер Хиди,
Факультет биологических исследований Австралийского национального универси-
тета, Канберра, Австралия).
яркости на результирующем изображении, меняя тем самым его кон-
траст. Вообще говоря, условия Г] < г, и .s , < 5] означают, что функция
является однозначной и монотонно возрастающей2 *. Это условие обес-
печивает сохранение правильной последовательности уровней ярко-
сти, предотвращая тем самым появление ложных деталей на обрабо-
танном изображении.
2 На самом деле для этого требуется соблюдение строгих неравенств: и -' | < s I
Прим, перев.
' 146 Глава 3. Пространственные методы улучшения изображений
На Рис. 3.10(6) представлено исходное малоконтрастное 8-бито-
вое изображение. На Рис. 3.10(в) показан результат усиления контра-
ста, полученный при (гь = (rmin, 0) и (r2, s2) = (rmax, L - 1), где rmin
и rmax, соответственно, означают минимальную и максимальную яр-
кости на изображении. Таким образом, функция преобразования ли-
нейно растягивает исходный диапазон яркостей в полный диапазон
[0, L — 1 ]. Наконец, на Рис. 3.10(г) показан результат порогового пре-
образования с Г] = г2 = т, где т — среднее значение яркостей на изо-
бражении. В качестве исходного изображения в этом примере ис-
пользован снимок цветочной пыльцы, полученный сканирующим
электронным микроскопом с увеличением в 700 раз.
Вырезание диапазона яркостей
Зачастую желательно выделить какой-то конкретный диапазон яр-
костей на изображении. В практических применениях может потре-
боваться улучшение контраста отдельных деталей, таких как участ-
ков воды на спутниковых изображениях или дефектов изделий на
рентгеновских снимках. Существуют различные способы вырезания
уровней яркости, однако большинство из них являются вариация-
ми двух следующих подходов. Первый подход состоит в отображе-
нии всех тех уровней, которые представляют интерес, некоторой од-
ной большой яркостью, а всех остальных уровней — другой (низкой).
Такое преобразование, показанное функцией на Рис. 3.11(a), дает
в результате бинарное изображение. Второй подход, основанный на
преобразовании с функцией на Рис. 3.11 (б), повышает яркость точек
из выбранного диапазона, но сохраняет яркости фона и остальных
точек изображения. На Рис. 3.11(в) представлено исходное полуто-
новое изображение, а на Рис. 3.11 (г) — результат преобразования,
использующего функцию на Рис. 3.11(a). Легко построить дальней-
шие разновидности двух преобразований, проиллюстрированных на
Рис. 3.11.
Вырезание битовых плоскостей
Вместо выделения диапазонов яркостей, может оказаться полезным вы-
деление информации о вкладе тех или иных битов в общее изображе-
ние. Пусть каждый пиксель изображения представлен 8 битами. В этом
случае все изображение можно представить себе в виде восьми бито-
вых плоскостей, ранжированных от плоскости 0 с наименее значащи-
ми битами до плоскости 7 с наиболее значащими. В терминах 8-бито-
вых байтов плоскость 0 содержит все младшие биты, а плоскость 7 —
все старшие биты из составляющих изображение байтов. На Рис. 3.12
иллюстрируется это представление, а на Рис. 3.14 представлены все
3.2.Некоторые основные градационные преобразования
Рис. 3.11. (а) Данное преобразование выделяет диапазон яркостей [А, В ] и при-
водит остальные значения к уровню константы, (б) Данное преобразование выделя-
ет диапазон яркостей {А, В] , но сохраняет все остальные уровни, (в) Исходное по-
лутоновое изображение, (г) Результат преобразования с использованием функции (а).
Один
8-битовый байт
(наиболее значимая)
Битовая плоскость О
(наименее значимая)
Битовая плоскость 7
Рис. 3.12. Представление 8-битового изображения в виде набора битовых
плоскостей.
Глава 3. Пространственные методы улучшения изображений
Рис. 3.13. 8-битовое фрактальное изображение. (Фракталы — это образы, ге-
нерируемые с помощью математических выражений). (Предоставила Мелисса Байнд,
Свартморский колледж, Свартмор, шт. Пенсильвания).
битовые плоскости изображения, показанного на Рис. 3.13. Можно за-
метить, что старшие биты (главным образом первые четыре) содержат
основную часть визуально значимых данных. Остальные битовые пло-
скости дают вклад в более тонкие детали изображения. Разделение ци-
фрового изображения на битовые плоскости полезно для анализа отно-
сительной информативности, которую несет каждый бит изображения,
что позволяет оценить необходимое число битов, требуемое для кван-
тования каждого пикселя. Такая декомпозиция полезна при сжатии
изображений, что обсуждается в Главе 8.
На основе извлечения битовых плоскостей из 8-битового изобра-
жения нетрудно показать, что (бинарное) изображение битовой пло-
скости 7 может быть получено обработкой исходного изображения по-
роговым градационным преобразованием, которое (1) отображает все
уровни изображения от 0 до 127 в некоторый один (например, 0);
и (2) отображает все уровни от 128 до 255 в другой (например, 255). Би-
нарное изображение для битовой плоскости 7 на Рис. 3.14 было полу-
чено именно таким образом. Формирование функций градационно-
го преобразования для получения остальных битовых плоскостей
оставим в качестве упражнения (Задача 3.3).
3.3. Видоизменение гистограммы
Гистограммой цифрового изображения с уровнями яркости в диапазо-
не [0, L — 1] называется дискретная функция A(rfc) = пк, где есть £-ый
уровень яркости, а пк — число пикселей на изображении, имеющих яр-
3.3. Видоизменение гистограмм
Рис. 3.14. Восемь битовых плоскостей изображения на Рис. 3.13. В нижнем пра-
вом углу каждого изображения нанесен номер, идентифицирующий битовую плос-
кость.
кость гк. Общей практикой является нормализация гистограммы путем
деления каждого из ее значений на общее число пикселей в изображе-
нии, обозначаемое п. Тем самым, значения нормализованной гисто-
граммы будут р(гк) = пк/п для к=0, l,...,L — 1. Вообще говоря, р(гк) есть
оценка вероятности появления пикселя3 со значением яркости гк. Заме-
тим, что сумма всех значений нормализованной гистограммы равна
единице.
Гистограммы являются основой для многочисленных методов про-
странственной обработки. Как показано в настоящем разделе,
3 При условии некоррелированости значений яркостей пикселей. — Прим, перев.
' 150 Глава 3. Пространственные методы улучшения изображений
видоизменение гистограммы (гистограммная обработка) может быть ус-
пешно использовано для улучшения изображений. В последующих
разделах мы увидим, что кроме получения полезной статистики об изо-
бражении, содержащаяся в гистограмме информация также весьма по-
лезна и в других задачах, таких как сжатие и сегментация изображений.
1истограммы достаточно просты как для программного вычисления, так
и для аппаратной реализации, что делает их удобным инструментом для
обработки изображений в реальном времени.
В качестве знакомства с ролью гистограммы в улучшении изображе-
ний, рассмотрим Рис. 3.15, на котором приведен тот же снимок пыльцы,
что и на Рис. 3.10, но показанный здесь в четырех вариантах яркостных ха-
рактеристик: темном, светлом, низкоконтрастном и высококонтраст-
ном. На правой части рисунка приведены гистограммы, соответствующие
этим изображениям. По горизонтальной оси каждого графика отложены
значения уровней яркости гк. По вертикальной оси — значения гистограм-
мы А(г^) = пк (илир(гк) = п^/п, если они нормализованы). Тем самым, эти
графики суть попросту зависимости А(г^) = пк от гк илиp{r^) = njjn от гк.
Легко видеть, что на гистограмме темного изображения ненуле-
вые уровни сконцентрированы в области низких (темных) значений
диапазона яркостей. Аналогично, значимые уровни гистограммы яр-
кого изображения смещены к верхней части диапазона. Изображе-
ние с низким контрастом имеет узкую гистограмму, расположенную
вблизи центра диапазона яркостей. Для одноцветного изображе-
ния это означает вялый, «вылинявший» серый вид. Наконец видно,
что ненулевые уровни гистограммы высококонтрастного изображе-
ния покрывают широкую часть диапазона яркостей, а также, что рас-
пределение значений пикселей не слишком отличается от равномер-
ного, за исключением небольшого числа пиков, возвышающихся над
остальными значениями. Интуитивно можно сделать вывод, что
изображение, распределение значений элементов которого близко
к равномерному и занимает весь диапазон возможных значений
яркостей, будет выглядеть высококонтрастным и будет содержать
большое количество полутонов. Вскоре будет показано, что, осно-
вываясь только на информации, содержащейся в гистограмме исход-
ного изображения, можно построить функцию преобразования, ко-
торая позволит автоматически добиваться такого эффекта.
3.3.1. Эквализация гистограммы
Для простоты сначала рассмотрим непрерывные функции. Предпола-
гается, что значения г, отражающие яркость элементов изображения,
распределены непрерывно в диапазоне [0,1 ], при этом значение г = О
Рис. 3.15. Четыре основных типа изображения: темное, светлое, низкоконт-
растное и высококонтрастное. (Исходное изображение предоставил д-р Роджер Хи-
ди, Факультет биологических исследований Австралийского национального уни-
верситета, Канберра, Австралия).
Высококонтрастное изображение
.sW...I)l-4llhWl!H ......
a 6
Глава 3. Пространственные методы улучшения изображений
соответствует черному, а г = 1 — белому Позже будет осуществлен пе-
реход к дискретному представлению, а интервал значений будет рас-
ширен до [О, L — 1].
Для любого г, удовлетворяющего вышеуказанным условиям, рас-
сматривается преобразование вида
s = T(r) 0<г<1,
(3.3-1)
которое для любого пикселя, имеющего значение г, дает значение
5. По причинам, которые станут очевидны ниже, мы предполагаем,
что функция преобразования Т(г) удовлетворяет следующим усло-
виям:
(а) Т(г) является однозначной и монотонно возрастающей на интер-
вале 0 < г < 1;
(б) 0 < Т(г) < 1 при 0 < г < 1.
В условии (а) требование однозначности функции Т(г) необходимо для
существования обратного преобразования, а требование монотонно-
сти — для сохранения порядка изменения яркостей от черного к бе-
лому на выходном изображении4. Функция преобразования, не явля-
ющаяся монотонно возрастающей, может привести к появлению на
выходном изображении интервалов яркости с инвертированными
значениями. Хотя в некоторых случаях подобные эффекты и Moiyr ока-
заться желаемыми, такие функции выходят за рамки настоящего рас-
смотрения. Наконец, условие (б) означает, что допустимый диапазон
выходных значений сигнала совпадает с диапазоном входных значе-
ний. На Рис. 3.16 показан пример функции преобразования, которая
удовлетворяет поставленным выше условиям. Обратное преобразова-
ние из .s b г будет следующим:
г = Т 1 (,s)
0<5<1.
(3.3-2)
Можно показать (Задача 3.8), что даже если Т(г) удовлетворяет усло-
виям (а) и (б), результирующая функция Tx(s) может быть неодно-
значной5.
4 Заметим, что условия строгой монотонности непрерывной функции прямого пре-
образования достаточно для существования и монотонности обратного преобразо-
вания. — Прим, перев.
5 По-видимому, говоря о монотонно возрастающей функции, авторы подразумева-
ют неубывающую функцию, иначе данная задача не имеет решения. — Прим, перев.
.S'
Рис. 3.16. Однозначная и монотонно возрастающая функция градационного
преобразования.
Уровни яркости на изображении могут рассматриваться как зна-
чения случайной величины в интервале [0,1]. Одной из важнейших ха-
рактеристик случайной величины является плотность распределения
вероятностей. Пусть рг(г) и ps(s) означают плотности распределения ве-
роятностей случайных переменных г и s, соответственно, где индекс
при р означает, что рг(г) и ps(s) являются разными функциями. Из
элементарной теории вероятностей следует, что еслирг(г) и Г(г) изве-
стны и удовлетворяют условию (а), то плотность распределения веро-
ятностей ps(s) значений преобразованного сигнала л может быть по-
лучена с помощью простой формулы:
ps(s) = pr(r)
dr
ds
(3.3-3)
Таким образом, плотность распределения вероятностей значений пре-
образованного сигнала л задается плотностью распределения вероят-
ностей значений яркостей входного изображения и выбранной функ-
цией преобразования.
В обработке изображений особую важность имеет следующая
функция:
г
s = T(r) = J pr(w)dw, (3.3-4)
О
где w — переменная интегрирования. Правая часть уравнения (3.3-4)
есть не что иное, как функция распределения случайной переменной
г. Поскольку плотность распределения вероятностей всегда положи-
тельна, а интеграл функции есть площадь под графиком функции, еле-
Глава 3. Пространственные методы улучшения изображений
довательно, данная функция преобразования является однозначно
определенной и монотонно возрастающей6, и, тем самым, удовле-
творяет условию (а). Аналогично, поскольку интеграл плотности рас-
пределения вероятностей случайной величины при изменении г в ди-
апазоне [0,1] также находится в диапазоне [0,1 ], то условие (б) также
выполняется.
Зная функцию преобразования Т(г), плотность распределения ве-
роятностей ps(s) находится из уравнения (3.3-3). Из дифференциаль-
ного исчисления известно, что производная определенного интегра-
ла по его верхнему пределу равна подынтегральному выражению
в точке верхнего предела (правило Лейбница). Другими словами,
ds _dT(r) _ d
dr dr dr
r
0
= Pr(r).
(3.3-5)
Подставляя этот результат для dr/ds в уравнение (3.3-3), и предпола-
гая, что все значения плотности вероятностей больше нуля, получа-
ем в результате:
dr
PS(s) = Pr(r) — = pr(r)
ds
Pr(f)
Q<s<l.
(3.3-6)
Таким образом, мы получили, что ps(s) есть равномерная плотность
распределения вероятностей на отрезке [0, 1], равная нулю вне дан-
ного интервала. Попросту говоря, было продемонстрировано, что вы-
полнение градационного преобразования согласно функции, задан-
ной уравнением (3.3-4), приводит к получению некоторой случайной
величины s, характеризующейся равномерной плотностью распреде-
ления вероятностей. Здесь важно заметить, что хотя Г(г), как это сле-
дует из (3.3-4), зависит отpr(f), результирующая плотность распреде-
ления вероятностей ps(s), как следует из (3.3-6), всегда является
равномерной, независимо от формы рг(.г).
В случае дискретных значений, вместо плотностей распределе-
ния вероятностей и интегралов мы имеем дело с вероятностями кон-
кретных значений и суммами. Вероятность появления пикселя со
значением яркости гр приблизительно равна
6 Плотность распределения вероятностей неотрицательна, а значит функция преоб-
разования — неубывающая функция. По-видимому, подобные неточности потребо-
вались авторам, чтобы обойти стороной появление особых точек функций при по-
следующих вычислениях. — Прим, перев.
3.3. Видоизменение гистограмм 155
n(r) = ”L £ = 0,l,2,...,Z-l, (3.3-7)
п
где, как говорилось в начале настоящего раздела, п есть общее число
пикселей на изображении, пк — число точек яркости r^, a L — макси-
мально допустимое число уровней яркости на изображении. Дискрет-
ным аналогом функции преобразования, задаваемой уравнением
(3.3-4), будет
sk=T<rk)= Ц— & = 0,1, 2,...,£-1. (3.3-8)
j=0 j=o п
Таким образом, обработанное (выходное) изображение получается
отображением каждого пикселя входного изображения, имеющего яр-
кость Г£, в соответствующий элемент выходного изображения со зна-
чением^, согласно уравнению (3.3-8). Как указывалось ранее, зави-
симость рг(г^) от называется гистограммой. Преобразование
(отображение), задаваемое уравнением (3.3-8), называется эквали-
зацией или линеаризацией гистограммы. Нетрудно показать (Задача 3.9),
что преобразование по формуле (3.3-8) удовлетворяет условиям (а)
и (б), которые были ранее сформулированы в настоящем разделе.
В отличие от непрерывного случая, невозможно в общем виде до-
казать, что дискретное преобразование может дать в результате неко-
торый дискретный эквивалент равномерной плотности распределения
вероятностей, которой должна соответствовать равномерная гистограм-
ма. Однако, как будет вскоре показано, преобразование по формуле
(3.3-8) направлено на растяжение гистограммы входного изображения
таким образом, что значения элементов эквализованного изображе-
ния будут перекрывать более широкий диапазон уровней яркостей.
Ранее в настоящем разделе обсуждались многие преимущества
изображения, уровни яркости которого покрывают весь диапазон
возможных значений. Рассмотренный только что метод, кроме того,
что формирует изображение, близкое к выдвинутому критерию, обла-
дает дополнительным преимуществом в том, что является полностью
«автоматическим». Иными словами, получая на вход изображение,
процедура эквализации гистограммы сводится к выполнению пре-
образования по формуле (3.3-8), что базируется лишь на информации,
которая может быть извлечена непосредственно из обрабатываемого
изображения без указания каких-либо дополнительных параметров.
Стоит также отметить простоту вычислений, которая требуется для ре-
ализации этого метода.
156 Глава 3. Пространственные методы улучшения изображений
Обратное преобразование из л в г определяется следующей фор-
мулой:
rk=T~\sk) k=0,l,2,...,L-l. (3.3-9)
Может быть показано (Задача 3.9), что обратное преобразование по
формуле (3.3-9) удовлетворяет условиям (а) и (б), сформулирован-
ным ранее в настоящем разделе, только в том случае, если ни один из
уровней яркостей гк, к = 0, 1, 2, ...,£— 1, исходного изображения не
утерян. Хотя обратное преобразование и не используется при эквали-
зации гистограммы, оно играет центральную роль в схеме приведения
гистограмм, рассматриваемой в следующем разделе. Также там будут
обсуждены детали реализации методов гистограммной обработки.
Пример 3.3. Эквализация гистограммы.
j На рисунках 3.17(a) представлены те же четыре изображения, что
и на рисунке 3.15, а на рисунках 3.17(6) — результаты выполнения пре-
образований эквализации гистограммы по каждому из этих изобра-
жений. Первые три результата демонстрируют значительное улуч-
шение. Как и ожидалось, на четвертом изображении эквализация
гистограммы не приводит к появлению заметной визуальной разни-
цы, поскольку гистограмма данного изображения изначально зани-
мала весь диапазон значений яркости. Графики функций, по которым
производились преобразования изображений из 3.17(a) в 3.17(6),
представлены на Рис. 3.18. Эти функции были получены по форму-
ле (3.3-8) на основе гистограмм, показанных на Рис. 3.15(6). Заметим,
что график преобразования (4) близок к линейной форме, опять-та-
ки показывая этим, что уровни яркости на четвертом изображении
близки к равномерному распределению. Как и ожидалось, эффект от
преобразования эквализации гистограммы на таком изображении
незначителен.
Гистограммы изображений после эквализации представлены на
Рис. 3.17(b). Интересно отметить, что хотя все эти гистограммы
и различаются, тем не менее, эквализованные изображения вы-
глядят весьма похоже. Это не является неожиданным, поскольку
разница между изображениями в левой колонке заключается толь-
ко в их контрастах, а не в содержании. Другими словами, посколь-
ку изображения имеют одно и то же содержание, то увеличения кон-
траста, получаемого путем эквализации гистограммы, достаточно,
чтобы компенсировать разницы в яркостях и сделать результирую-
щие изображения визуально неотличимыми. На этом примере
с изображениями в левой колонке, имеющими значительные раз-
Рис. 3.17. (а) Изображения из рисунка 3.15. (б) Результаты эквализации гис-
тограммы. (в) Гистограммы изображений после обработки.
а б в
Глава 3. Пространственные методы улучшения изображений
Рис. 3.18. Функции преобразований (1) — (4) были получены на основе гис-
тограмм изображений на Рис. 3.17(a) с помощью уравнения (3.3-8).
ницы в контрастах, иллюстрируются возможности преобразова-
ния эквализации гистограммы как адаптивного инструмента улуч-
шения изображений.
3.3.2. Приведение гистограммы (задание гистограммы)
Как обсуждалось выше, эквализация гистограммы автоматически на-
ходит функцию преобразования, которая стремится сформировать
выходное изображение с равномерной гистограммой. В случае необ-
ходимости автоматического улучшения, это является хорошим подхо-
дом, поскольку результаты этого метода предсказуемы и он прост в ре-
ализации. В настоящем разделе мы покажем, что в некоторых случаях
улучшение, основанное на модели равномерной гистограммы, не яв-
ляется наилучшим подходом. В частности, иногда полезно задать
иную желаемую форму гистограммы для обрабатываемого изображе-
ния. Метод, позволяющий получить обработанное изображение с за-
даваемой формой гистограммы, называется методом приведения гис-
тограммы или задания гистограммы.
Разработка метода
Вернемся ненадолго к непрерывному представлению яркостей г и z
(рассматриваемые непрерывные случайные переменные), которые
обозначают уровни яркостей входного и выходного (обработанного)
3.3. Видоизменение гистограмм I
изображений, и пусть р/r) и pz{z) соответственно означают их непре-
рывные плотности распределения вероятностей. Значения дг(г) мы мо-
жем оценить по исходному изображению, в то время какpz(z) являет-
ся задаваемой плотностью распределения вероятностей, которую
должно иметь выходное изображение.
Пусть 5 — случайная переменная со следующими свойствами:
г
s = T(r) = \pr(w)dw, (3.3-10)
о
где w — переменная интегрирования. Это выражение есть не что иное,
как непрерывная форма эквализации гистограммы — повторение
уравнения (3.3-4). Предположим также, что z — еще одна случайная
переменная со свойством
z
G(z) = jpz(t)dt=s, (3.3-11)
о
где t — переменная интегрирования. Из этих двух уравнений следует, что
G(z) — T(f), а значит, £ должно подчиняться следующему условию:
г = 6-1(5) = 6-1[Т(г)]. (3.3-12)
Преобразование Т(г) может быть получено из уравнения (3.3-10)
сразу, как толькорг(с) оценена по входному изображению. Подобным
образом может быть получена функция преобразования G(z), по-
скольку задана pz(z).
Предполагая, что G!(z) существует и удовлетворяет условиям (а)
и (б) предыдущего раздела, из уравнений (3.3-10) — (3.3-12) следует, что
изображение с заданной плотностью распределения вероятностей мо-
жет быть получено из исходного изображения с помощью следующей
процедуры: (1) Получение функции преобразования Т(г) с помощью
уравнения (3.3-10). (2) Получение функции преобразования G(z) с по-
мощью уравнения (3.3-11). (3) Вычисление обратной функции преоб-
разования G'^z). (4) Получение выходного изображения путем приме-
нения уравнения (3.3-12) ко всем пикселям входного изображения.
Результатом такой процедуры будет изображение, уровни яркости z ко-
торого имеют заданную плотность распределения вероятностей pz(z).
Хотя только что описанная процедура в принципе понятна, на
практике достаточно редко удается получить аналитические выраже-
ния для Г(г) и G1. К счастью, в случае дискретных величин эта зада-
ча значительно упрощается. Издержки остаются теми же, что и в слу-
Глава 3. Пространственные методы улучшения изображений
чае эквализации гистограммы, когда достижимым является только
некоторое приближение к желаемой гистограмме.
Дискретная формулировка уравнения (3.3-10) задана уравнением
(3.3-8), которое мы здесь повторяем для удобства:
к к
*=o,i,2,...,l-i, (3.3-13)
где п есть общее число пикселей на изображении, п, — число точек яр-
кости tj, a L — число уровней яркости. Подобным образом, дискрет-
ная формулировка уравнения (3.3-11) получается из заданной гисто-
граммы pz(z), i = 0, 1, 2,..., L — 1, и имеет вид
к
vk=G(zk) = ^Pz^i) = sk £=0,1,2,...,£-1. (3.3-14)
/=0
Как и в непрерывном случае, ищется значение z, которое удовлетво-
ряет этому уравнению. Переменная vk была добавлена сюда только для
ясности последующих рассуждений. Наконец, дискретный вариант
уравнения (3.3-12) записывается в виде
z.k=G~x\T(rk)\ к =0,1,2,..., £-1, (3.3-15)
или, с учетом уравнения (3.3-13),
zk=G~x(sk) £ =0,1,2,...,£-1. (3.3-16)
Уравнения (3.3-13) — (3.3-16) являются основой для реализации алго-
ритма приведения гистограмм дискретных изображений. Уравнение
(3.3-13) базируется на гистограмме исходного изображения и являет-
ся отображением его уровней яркостей в соответствующие промежу-
точные значения sk. Уравнение (3.3-14) на основании заданной гисто-
граммы pz(z) задает функцию преобразования G. Наконец, уравнение
(3.3-15) или его эквивалент (3.3-15) дает (приближенные) значения яр-
костей результирующего изображения с заданной гистограммой. Пер-
вые два уравнения могут быть легко реализованы, поскольку все зна-
чения известны. Реализация уравнения (3.3-16) также понятна, но, тем
не менее, заслуживает дополнительного пояснения.
Реализация
Для начала мы отметим следующее: (1) Каждый набор значений яр-
костей {ту}, {sy} и {Zj},j = 0,1, 2,..., £ — 1, является одномерным масси-
3.3. Видоизменение гистограмм
вом размерами £х 1. (2) Все отображения из г в ли из л в z задаются про-
стыми табличными преобразованиями между заданным значением
пикселя и этими массивами. (3) Каждый из элементов этих массивов,
например s^, содержит два необходимых информационных элемента:
индекс к, указывающий на позицию элемента в массиве, и л — значе-
ние, соответствующее этой позиции. (4) Мы рассматриваем только це-
лые значения пикселей. Например, для 8-битового изображения
L = 256, а значит, значения в каждом из вышеупомянутых массивов есть
целые числа в диапазоне от 0 до 255. Это означает, что теперь мы име-
ем дело с целыми значениями яркостей в интервале [О, L — 1], вмес-
то нормализованного интервала [0, 1], который мы рассматривали
ранее для упрощения разработки гистограммных методов.
Для того чтобы увидеть, как метод приведения гистограммы мо-
жет быть реализован в действительности, рассмотрим Рис. 3.19(a),
Рис. 3.19. (а) Графическая интерпретация отображения гк в через Т(г).
(б) Отображение Zq в соответствующее ему значение vq через 6'(z). (в) Обратное ото-
бражение в соответствующее ему значение Zk-
6 А-223
' 162 Глава 3. Пространственные методы улучшения изображений
временно игнорируя показанную связь между этим рисунком и ри-
сунком 3.19(b). На Рис. 3.19(a) показана дискретная функция гипо-
тетического преобразования л = Г(г), полученного на основе анали-
за заданного изображения. Первый уровень яркости q исходного
изображения отображается в уровень q, второй — г-} — в s^, &-ый уро-
вень гк — в sk и так далее (важным моментом здесь является упоря-
доченное соответствие между этими значениями). Каждое значение
^вычисляется предварительно с помощью уравнения (3.3-13), так, что
процесс отображения использует исходное значение пикселя г в каче-
стве индекса в массиве, чтобы получить соответствующее результиру-
ющее значение s. Этот процесс чрезвычайно прост, поскольку мы
имеем дело с целыми числами. Например, л — образ для 8-битового
значения 127 будет находиться в позиции 128 массива Ц-} (напом-
ним, что элементы массива нумеруются с 0), содержащего всего 256
позиций. Если мы остановимся на этом шаге и заменим значение
пикселя на только что полученное, то результатом, в соответствии
с уравнением (3.3-8), будет эквализованное изображение.
Чтобы реализовать приведение гистограммы к заданной, мы долж-
ны сделать еще один шаг. Кривая на Рис. 3.19(6) является гипотети-
ческой функцией преобразования G, полученной из заданной гисто-
граммы pz(z) с помощью уравнения (3.3-14). Для любого zq эта функция
дает соответствующее значение vq. Такое отображение показано стрел-
ками на Рис. 3.19(6). Наоборот, взяв любое значение vq, можно най-
ти соответствующее значение Zq с помощью обратного преобразова-
ния 6s1. На рисунке это означает, что нужно изменить направления
стрелок на обратные, чтобы отобразить vq в zq. Однако, согласно урав-
нению (3.3-14), v = 5 для одинаковых индексов, а значит, такой под-
ход может быть использован для нахождения искомого значение zk, со-
ответствующего промежуточному значению sk, которое было
определено из уравнения sk = Т(гк). Эта идея продемонстрирована на
Рис. 3.19(b).
Изначально значений z не существует (напомним, что эти значе-
ния как раз и являются целью процедуры приведения гистограмм),
а значит для того, чтобы найти z из s, следует использовать какую-то
итеративную схему. Поскольку мы имеем дело с целыми значениями,
этот процесс несложен. Как видно из уравнения (3.3-14), vk = sk, сле-
довательно, z должны удовлетворять уравнению G(zk) = или
(G(zk) — sk) ~ 0. Таким образом все, что требуется сделать чтобы оп-
ределить значение zk, соответствующее sk, сводится к итеративному
поиску по значениям £для всех к = 0, 1, 2,..., L — 1. Это то же самое,
что и уравнение (3.3-16), только нам не нужно находить обратную
функцию к G, поскольку используются итерации по Z- Так как иско-
3.3. Видоизменение гистограмм 163
мые величины являются целыми, то ближайшим значением, которое
можно выбрать для удовлетворения уравнению (G(^) — sk) = 0, явля-
ется zk = Z* для каждого к, где z* есть наименьшее целое в интервале
[О, £—1], такое, что
(G(z)-sk)>$ £=0,1,2,..., Z-1. (3.3-17)
Вышесказанное иллюстрируется рисунком 3.19(b). Для очередного
значения sk необходимо начинать с z* = 0 и увеличивать значение z*
на единицу до того момента, когда станет выполняться неравенство
(3.3-17); эта точка и есть искомое zk = Z*. Повторение этой операции
для всех значений к позволяет получить все требуемые значения ото-
бражений из s в z, что и является реализацией уравнения (3.3-16). На
практике не нужно начинать каждый раз с z* = 0, поскольку извест-
но, что значения заявляются монотонно возрастающими. Следователь-
но, для очередного к = к + 1 можно начинать с точки z* — zk и затем
увеличивать значения.
Алгоритм приведения гистограмм, который был только что изло-
жен, может быть подытожен в следующем виде:
1. Получить гистограмму исходного изображения.
2. С помощью уравнения (3.3-13) вычислить значения отображений
rk в sk'
3. На основе заданных значенийpz(z) с помощью уравнения (3.3-14)
вычислить функцию преобразования G.
4. Итеративным путем с использованием неравенства (3.3-17) вычис-
лить значения zk для каждого sk.
5. Для каждого пикселя исходного изображения, имеющего значе-
ние гк, отобразить гк в соответствующее значение sk, а затем ото-
бразить sk в результирующее значение zk- Для отображений исполь-
зовать (табличные) значения, предварительно вычисленные на
шагах (2) и (4).
Заметим, что на этапе (5) для каждого пикселя на изображении ис-
пользуются два последовательных шага отображений, причем первое из
них есть не что иное, как эквализация гистограммы. Если эквализация
гистограммы как таковая не требуется, то, очевидно, можно объединить
эти два преобразования в одно и таким образом получить преимущест-
во за счет сокращения одного промежуточного шага.
В конце мы еще раз отметим, что даже для дискретного случая не-
обходимо, чтобы обратное преобразование G1 удовлетворяло усло-
виям (1) и (2) предыдущего раздела. Нетрудно показать (Задача 3.9),
Глава 3. Пространственные методы улучшения изображений
что единственным способом гарантировать однозначность и монотон-
ность (7-1 будет требование, чтобы преобразование G являлось стро-
го монотонно возрастающим, а это, в свою очередь, означает, что ни
одно из значений задаваемой гистограммыдг(г,-) в уравнении (3.3-14)
не должно быть равно нулю.
Пример 3.4. Сравнение эквализации гистограммы и приведения ги-
стограммы.
На Рис. 3.20(a) показан снимок спутника Марса — Фобоса, сделан-
ный космической станцией Mars Global Surveyor (NASA), а на Рис. 3.20(6)
представлена его гистограмма. На изображении преобладают большие
темные области, приводящие к тому, что точки на изображении концен-
трируются вблизи темного края шкалы яркостей, что приводит к появ-
лению на гистограмме пика вблизи нуля. На первый взгляд кажется, что
эквализация гистограммы будет хорошим способом улучшения изоб-
ражения, таким, что детали в темных областях ст анут более видимыми.
Далее будет продемонстрировано, что это не так.
На рисунках 3.21 (а) и (б) представлен результат преобразования эк-
вализации гистограммы (уравнения (3.3-8) или (3.3-13)), получен-
ный по гистограмме на Рис. 3.20(6). Наиболее характерной деталью
данной функции преобразования является то, насколько возрос уро-
вень черного — от 0 до почти 190. Причина заключается в том, что боль-
шинство значений пикселей входного изображения сконцентрирова-
но вблизи нулевых уровней гистограммы. Эффект применения данного
а б
Рис. 3.20 (а, б), (а) Снимок спутника Марса — Фобоса, сделанный космиче-
ской станцией Mars Global Surveyor (NASA), (б) Его гистограмма. (Исходный снимок
предоставлен Агентством NASA).
Входные значения яркостей
Рис. 3.21. (а) Функция преобразования эквализации гистограммы, (б) Эква-
лизованное изображение (хорошо виден эффект осветления), (в) Гистограмма изо-
бражения (б).
а .6
в
преобразования к входному изображению с целью эквализации гис-
тограммы сводится к тому, что очень узкий интервал темных пиксе-
лей отображается в верхнюю часть яркостного диапазона выходного
изображения. Поскольку большая часть пикселей входного изображе-
ния имеет значения как раз в этом интервале, следовало бы ожидать,
что результатом будет светлое изображение, выглядящее как
«вылинявшее». Как видно по изображению на Рис. 3.21(6), именно так
и происходит. Гистограмма обработанного изображения представле-
на на Рис. 3.21(b). Заметим, насколько все уровни яркости смещены
в верхнюю половину диапазона.
Поскольку проблемы с функцией преобразования на Рис. 3.21(a)
были вызваны высокой концентрацией значений пикселей исходно-
го изображения вблизи нуля, разумным подходом было бы модифи-
цировать гистограмму таким образом, чтобы избежать этого обстоя-
тельства. Так, на Рис. 3.22(a) показана искусственно заданная функция,
которая сохраняет основную форму исходной гистограммы, но име-
ет сглаженный переход уровней в темной области шкалы яркостей. Рав-
Глава 3. Пространственные методы улучшения изображений
Входные значения яркостей
Рис. 3.22. (а) Заданная форма гистограммы, (б) Кривая (1) получена с помо-
щью уравнения (3.3-14) из гистограммы (а); кривая (2) получена итеративным путем,
который обсуждался в связи с неравенством (3.3-17). (в) Улучшение изображения при
использовании кривой (2). (г) Гистограмма изображения (в).
номерная дискретизация этой функции на 256 значений и будет не-
обходимой заданной гистограммой. Функция преобразования G(z),
полученная на основе этой гистограммы с помощью уравнения (3.3-14),
показана графиком (1) на Рис. 3.22(6). Аналогично, обратное преобра-
зование G“i(s) из уравнения (3.3-16), полученное итеративным путем,
обсуждавшимся в связи с неравенством (3.3-17), показано графиком (2)
3.3. Видоизменение гистограмм
на Рис. 3.22(6). Изображение на Рис. 3.22(b) было получено примене-
нием преобразования (2) к значениям пикселей эквализованного изо-
бражения на Рис. 3.21(6). При сравнении этих двух изображений ста-
новится очевидным преимущество улучшения изображения по методу
задания гистограммы по сравнению с эквализацией гистограммы. Ин-
тересно отметить, что сравнительно небольших изменений исходной
гистограммы было достаточно, чтобы получить значительное улуч-
шение результатов. Гистограмма изображения на Рис. 3.22(b) показа-
на на Рис. 3.22(г). Наиболее характерной особенностью данной гисто-
граммы является то, что ее начальные значения сдвинулись влево —
к более темным значениям шкалы яркостей, что и являлось целью.И
Хотя к настоящему моменту это уже должно быть очевидно, в кон-
це данного раздела имеет смысл еще раз подчеркнуть, что метод зада-
ния гистограммы в большинстве случаев является процессом проб
и ошибок. Можно использовать руководства, составленные на основе
встречавшихся проблем, как это было сделано в предыдущем примере.
Временами могут встречаться случаи, когда можно сформулировать, как
именно должна выглядеть «средняя» гистограмма, и использовать ее как
задаваемую гистограмму. В таких случаях метод приведения гистограм-
мы становится достаточно простым. Но, вообще говоря, не существу-
ет общих правил по выбору гистограммы, и следует раз за разом при-
бегать к анализу в каждой из задач улучшения изображений.
3.3.3. Локальное улучшение
Рассмотренные в предыдущих двух разделах методы гистограммной об-
работки являлись глобальными, что означало построение функции
преобразования на основе анализа яркостного содержания всего изо-
бражения. Хотя такой глобальный подход и пригоден для улучшения
в целом, существуют случаи, когда приходится улучшать детали посред-
ством анализа малых областей изображения. Связано это с тем, что чис-
ло пикселей в таких областях мало и не может оказывать заметного вли-
яния на глобальную гистограмму, форма которой не обязательно
соответствует необходимому локальному улучшению. Решение со-
стоит в разработке функции преобразования, основанной на распре-
делении яркостей (или других характеристик) по окрестности каждо-
го элемента изображения. Несмотря на то, что рассмотрение методов
обработки, основанных на анализе окрестностей, является задачей Раз-
дела 3.5, мы рассматриваем локальную гистограммную обработку
здесь по причинам простоты и целостности. Читателю будет нетруд-
но проследить ход рассуждений.
Глава 3. Пространственные методы улучшения изображений
Описанные ранее методы гистограммной обработки могут быть
легко применены и к локальному улучшению. Процедура состоит в том,
что задается форма квадратной или прямоугольной окрестности вокруг
обрабатываемого элемента и затем центр этой области передвигается
от точки к точке. Для каждого нового положения окрестности подсчи-
тывается гистограмма по входящим в нее точкам и находится функция
преобразования эквализации или приведения гистограммы. Наконец,
эта функция используется для отображения уровня яркости централь-
ного элемента окрестности. Затем центр окрестности перемещается на
соседний пиксель и процедура повторяется. Поскольку при перемеще-
нии от точки к точке меняется только один столбец или строка окре-
стности, то становится возможным обновление гистограммы, получен-
ной на предыдущем шаге, путем добавления новых данных (Задача
3.11). Такой подход имеет очевидные преимущества по сравнению с вы-
числением гистограммы заново по всем точкам окрестности, при ее сме-
щении всего на один элемент. Другим подходом, применяемым ино-
гда для уменьшения количества вычислений, является использование
непересекающихся областей7, но такой метод обычно приводит к по-
явлению нежелательного эффекта шахматного поля.
Пример 3.5. Улучшение с использованием локальных гистограмм.
На рисунке 3.23(a) представлено изображение, слегка сглаженное
для уменьшения влияния шума (по вопросу сглаживания см. раздел
3.6.1). Результат глобальной эквализации гистограммы показан на
а<„ б *. Рис. 3.23. (а) Исходное изображение, (б) Результат глобальной эквализации ги-
стограммы. (в) Результат локальной эквализации гистограммы по окрестности 7x7
элементов вокруг каждого пикселя.
7 При этом одна и та же функция преобразования, построенная на основе анализа об-
ласти, применяется ко всем пикселям данной области. — Прим, перев.
3.3. Видоизменение гистограмм
Рис. 3.23(6). Как это часто случается при применении данного ме-
тода к изображениям с ровными, но зашумленными областями,
Рис. 3.23(6) демонстрирует значительное усиление шума при доста-
точно слабом усилении общих контрастов. Как легко видеть, ника-
ких новых структурных элементов в результате применения данно-
го метода не появилось. Тем не менее, локальная эквализация
гистограммы по окрестности 7x7 элементов (Рис. 3.23(c)) выявляет
существование маленьких квадратиков внутри больших темных ква-
дратов. Эти маленькие квадратики слишком близки по яркости
к большим квадратам, а их площадь слишком мала чтобы заметно по-
влиять на форму преобразования глобальной эквализации. Заме-
тим также, что шум на Рис. 3.23(c) стал гораздо мельче, что также яв-
ляется результатом локальной обработки по достаточно малой
окрестности.
3.3.4. Использование гистограммных статистик для
улучшения изображения
Вместо непосредственного использования гистограммы изображе-
ния, для его улучшения можно использовать некоторые статистиче-
ские параметры, получаемые из гистограммы. Пусть г обозначает дис-
кретную случайную переменную, представляющую квантованное
значение яркости в диапазоне [О, L — 1], и пустьр(г,) — значение нор-
мализованной гистограммы, соответствующее z-ому отсчету г. Как
уже говорилось ранее в настоящей главе, д(г,) может рассматривать-
ся как оценка вероятности появления уровня яркости г,. Центральный
момент порядка п случайной величины г есть
£-1
Нй(г)= (3.3-18)
<=о
где т — математическое ожидание г (т.е. средний уровень яркости):
£-1
m=^riP(ri) (3.3-19)
/=о
Из уравнений (3.3-18) и (3.3-19) следует, что Цо = 1, а щ = 0. Второй
момент равен
£-1
Н2(г)= (3.3-20)
/=0
170 Глава 3. Пространственные методы улучшения изображений
Это выражение есть не что иное, как дисперсия г, которая традици-
онно обозначается сг2(г). Стандартное отклонение ст есть квадратный
корень из дисперсии. Мы вернемся к моментам случайных величин
в Главе 11 в связи с вопросами описания изображений. Примени-
тельно к улучшению нас в основном будут интересовать математиче-
ское ожидание, как мера среднего уровня яркости на изображении,
а также дисперсия (или стандартное отклонение), как мера среднего
контраста.
В задаче улучшения используются, как правило, два типа измерения
среднего и дисперсии. Глобальные среднее и дисперсия измеряются по
всему изображению и обычно применяются для общего выравнивания
интенсивности и контраста изображения в целом. Намного более эффек-
тивным является применение этих двух оценок в методах локального
улучшения, где локальные среднее и дисперсия используются как базис
для проведения изменений, зависящих от характеристик области за-
данной формы вокруг каждого элемента изображения.
Пусть (х, у) — координаты элемента изображения, a Sxy означает
окрестность (подмножество изображения) заданных размеров с цен-
тром в (х, у). На основе уравнения (3.3-19) среднее значение mg*, пик-
селей в Sxy может быть вычислено по следующей формуле:
(3.3-21)
(.S,Об Sxy
где rs t — значение пикселя в точке с координатами (s, /) внутри ок-
рестности, a p(rs t) — значение нормализованной гистограммы по
окрестности, соответствующее данной яркости. Аналогичным об-
разом из уравнения (3.3-20) дисперсия яркостей пикселей в
равна
°9 = ТЗ'^^ху)2Р(^- (3.3-22)
UOeSxy
Локальное среднее есть показатель средней яркости по окрестности
S^, дисперсия (или стандартное отклонение) есть показатель кон-
траста по той же окрестности.
Важным аспектом обработки изображений при использовании
значений локальных среднего и дисперсии является гибкость, кото-
рая позволяет разрабатывать простые, но мощные методы улучшения,
основанные на статистических измерениях, имеющих близкое и пред-
сказуемое соответствие виду самого изображения. Эти особенности бу-
дут проиллюстрированы с помощью следующего примера.
i
Пример 3.6. Улучшение, основанное на локальных статистиках.
Я На рисунке 3.24 представлен снимок, полученный сканирующим
электронным микроскопом, на котором изображена вольфрамовая
нить накала, намотанная на держатель. И нить и держатель достаточ-
но хорошо видны. Однако в правой части снимка имеется еще одна
нить, которая значительно темнее, и ее форму, а также остальные де-
тали не так легко разглядеть. Локальное улучшение с изменением
контраста является идеальным подходом для решения подобных за-
дач, когда одна часть изображения вполне приемлема, в то время как
другие части могут содержать скрытые интересующие детали.
В данном частном случае задача состоит в улучшении темных об-
ластей при сохранении светлых областей по возможности неизменны-
ми, поскольку они не требуют улучшения. Можно использовать кон-
цепции, изложенные в данном разделе, чтобы построить метод
улучшения, позволяющий различить светлые и темные участки, а за-
тем улучшить только темные области. Критерий того, является ли об-
ласть, к которой относится точка (х, у), темной или светлой, основан
на сравнении уровня локального среднего тs со средним значением
яркости на изображении, называемым глобальным средним, и обозна-
чаемым MG. Это последнее значение может быть получено путем рас-
Рис. 3.24. Снимок вольфрамовой нити накала, намотанной вокруг держате-
ля, полученный сканирующим электронным микроскопом; увеличение приблизи-
тельно 130х. (Исходное изображение предоставил Майкл Шаффер, Факультет гео-
логических наук Орегонского университета, Юджин).
Глава 3. Пространственные методы улучшения изображений
ширения окрестности S на все изображение8. Таким образом, возни-
кает первый элемент схемы улучшения: пиксель в точке (х, у) являет-
ся кандидатом на обработку, если k$MG (здесь к$< 1). Посколь-
ку интерес представляет улучшение областей, имеющих низкий
контраст, то также необходим критерий для оценки контраста, с тем,
чтобы отнести область к кандидатам на улучшение и по данному при-
знаку. Таким образом, пиксель в точке (х, у) является кандидатом на
улучшение, если gs < k2DG, где DG есть глобальное стандартное от-
клонение, а к2 — положительная константа. Значение этой констан-
ты должно быть больше единицы, если требуется улучшение светлых
областей, и меньше единицы для темных областей. Наконец, необхо-
димо задать нижний уровень контраста для обрабатываемых областей,
иначе процедура будет пытаться улучшать даже области постоянной
яркости, на которых стандартное отклонение равно нулю. Тем са-
мым, задается также нижний предел для локального стандартного от-
клонения к\ такой, чтобы k\DG< g^ , причем к\ < к2. Если пиксель рас-
положен в точке (х, у), которая удовлетворяет всем
вышеперечисленным условиям, необходимым для локального улуч-
шения, то его обработка сводится к умножению значения пикселя
на заданную константу Е. При этом его яркость возрастает (или умень-
шается) относительно остальной части изображения. Значения осталь-
ных пикселей, не удовлетворяющих условиям улучшения, остаются без
изменения.
Краткое изложение метода улучшения сводится к следующему.
ПустьДх, у) есть значение пикселя в точке (х, у), и пустьg(x, у) есть зна-
чение того же пикселя, полученное в результате улучшения. Тогда
g<X,y)
E f(x,y) если ms^<k0MG и ^£^<05
f (х,у) в противном случае
Здесь, как указывалось ранее, Е, к$, к\ и к2 являются заданными па-
раметрами; MG — глобальное среднее, a.DG — глобальное стандартное
отклонение.
Как правило, подбор подходящих параметров требует определен-
ного количества экспериментов, чтобы «почувствовать» конкретное
изображение или класс изображений. В качестве рекомендуемых зна-
чений можно указать следующие: Е=4,0, к$ = 0,4, к\ = 0,02 и к2 = 0,4.
Относительно низкое значение 4,0 для Е было выбрано по следующей
8 Заметим, что значение Mq совпадает со значением т, подсчитываемым по форму-
ле (3.3-19). — Прим, перев.
причине. Когда Еумножается на значение яркости элемента (который
является темным, посколькуДх, у) мало), то результат E-flx, у) по-преж-
нему должен быть темным, чтобы сохранить визуальный баланс ярко-
стей на изображении. Значение fcg было выбрано равным 0,4, по-
скольку очевидно, что темные области, требуемые улучшения,
определенно должны быть темнее, чем половина значения глобально-
го среднего. Похожие рассуждения и анализ позволяют выбрать зна-
чения для параметров к\ и &2- Подбор всех этих констант в целом не
является трудной задачей, но их выбор определенно должен быть
предварен логическим анализом имеющейся проблемы улучшения. На-
конец, размеры локальной окрестности должны выбираться как мож-
но меньшими для того, чтобы сохранить детали и уменьшить объем вы-
числений. В приведенных примерах мы выбирали маленькую
локальную окрестность (3x3 пикселя).
На Рис. 3.25(a) показаны значения т^. для всех точек (х, у). По-
скольку значения являются средними значениями пикселей в ок-
рестностях 3x3 с центрами в точках (х, у), то результат весьма похож
на слегка расфокусированное исходное изображение. Изображение на
Рис. 3.25(6) составлено из значений стандартных отклонений .
Аналогично, можно составить изображение из значений коэффици-
ентов, на которые необходимо умножитьДх, у), чтобы получитьg(x, у).
Поскольку эти значения могут быть либо 1 либо Е, то изображение бу-
дет являться двоичным, как и показано на Рис. 3.25(b). Темные обла-
Рис. 3.25. (а) Изображение, сформированное из локальных средних значений, д б д
полученных обработкой изображения на Рис. 3.24 по формуле (3.3-21). (б) Изобра-
жение, сформированное из локальных стандартных отклонений, полученных обра-
боткой изображения на Рис. 3.24 по формуле (3.3-22). (в) Изображение, сформиро-
ванное из множителей, используемых процедурой улучшения; результат показан на
Рис. 3.26.
Глава 3. Пространственные методы улучшения изображении
Рис. 3.26. Улучшенное изображение. Сравните с изображением на Рис. 3.24.
В частности, обратите внимание на улучшение деталей в правой части изображения.
сти соответствуют значению 1, а светлые — Е. Таким образом, каждая
из светлых точек на Рис. 3.25(b) означает пару тех координат (х, у), где
процедура улучшения будет умножать fix, у) на Е, ч тобы получить
новое значение пикселя. Темные точки отражают координаты, где
значения пикселей меняться не будут.
Улучшенное изображение, полученное вышеописанным алгорит-
мом, представлено на Рис. 3.26. Сравнивая это изображение с исход-
ным на Рис. 3.24, легко видеть появление новых деталей в правой ча-
сти изображения. Стоит отмстить, что та часть изображения, которая
не подвергалась улучшению (светлые области), осталась по большей
части неизменной. Наряду с этим необходимо отметить появление не-
большого количества мелких ярких пятен в тенях, где витки пересе-
кают стержень держателя, а также вокруг границ между нитью нака-
ла и фоном. Эти нежелательные артефакты возникли из-за алгоритма
улучшения. Другими словами, точки, проявившиеся как яркие пятна,
удовлетворяли критерию улучшения, поэтому их значения были ум-
ножены на коэффициент Е. Появление артефактов является опреде-
ленным недостатком только что описанного метода из-за нелинейно-
сти преобразования, осуществлявшего обработку9. Ключевым местом
9 Точнее говоря, из-за разрывности сформированной функции градационного пре-
образования, возникающей в точке k0MG. — Прим, перев.
здесь, однако, является то, что изображение приобрело более прият-
ный вид, поскольку процедура улучшения выявила интересующие
детали.
Нетрудно представить то множество ситуаций, в которых может
быть применен рассмотренный только что алгоритм локального улуч-
шения изображений, равно как и возможные варианты его видоизме-
нения или расширения. И
3.4. Улучшение на основе арифметико-
логических операций
В применении к изображениям, арифметико-логические операции яв-
ляются поэлементными преобразованиями над двумя или более изо-
бражениями (за исключением операции NOT, которая выполняется над
одним изображением). Например, разность двух изображений дает но-
вое изображение, значение элемента с координатами (х, у) которого
есть разность значений элементов двух изображений в той же самой
точке. В зависимости от используемого аппаратного и программного
обеспечения, действительный механизм, осуществляющий арифме-
тико-логические операции, может быть реализован как в виде после-
довательной схемы, когда в единицу времени обрабатывается лишь
один элемент, так и в виде параллельной схемы, когда все операции
выполняются одновременно. Логические операции аналогичным об-
разом выполняются поэлементно^. Достаточной будет реализация
операций AND, OR и NOT, поскольку они образуют функционально пол-
ный класс. Другими словами, любая другая логическая операция мо-
жет быть получена с использованием только этих трех основных опе-
раций. При выполнении логических операций над полутоновыми
изображениями значения элементов обрабатываются как строки дво-
ичных значений. Например, выполнение операции NOT над 8-бито-
вым черным пикселем (строка из восьми нулей) приведет к получению
белого пикселя (строка из восьми единиц). Промежуточные значения
преобразуются похожим образом, изменяя нули на единицы и на-
оборот. В этом случае логическая операция NOT выполняет туже са-
мую операцию, что и негативное преобразование по формуле (3.2-1).
1° Напомним, что в случае двоичных переменных а и Ь, операция cANDb Даст в ре-
зультате 1 только тогда, когда и а и b равны 1; во всех остальных случаях в результа-
те будет 0. Аналогично, aOR6 будет равно 0 только когда обе переменные равны 0, ина-
че результат будет равен 1. Наконец, если а равно 1, то NOT(c) будет равно 0,
и наоборот.
Глава 3. Пространственные методы улучшения изображении
а б в
где
Рис. 3.27. (а) Исходное изображение, (б) Изображение-маска AND. (в) Резуль-
тат операции AND изображений (а) и (б), (г) Исходное изображение, (д) Изображе-
ние-маска OR. (е) Результат операции OR изображений (д) и (е).
Операции AND и OR используются для маскирования, то есть для вы-
деления части изображения, как это показано на Рис. 3.27. На масках
AND и OR белое означает двоичную единицу, а черное — двоичный
ноль. Маскирование иногда имеет отношение к обработке по области
интереса. С точки зрения задачи улучшения, маскирование в основ-
ном используется для изолирования области обработки. Это делает-
ся, чтобы выделить данную область и отличить ее от остальной части
изображения. Логические операции также часто используются в мор-
фологических преобразованиях, которые обсуждаются в Главе 9.
Из четырех арифметических операций наиболее часто используемы-
ми для улучшения изображений являются вычитание и сложение (имен-
но в таком порядке). Деление двух изображений рассматривается как
умножение одного изображения на обратные значения другого. Поми-
мо очевидной операции умножения изображения на константу с целью
увеличения среднего уровня его яркости, умножение изображений на-
ходит применение в задаче улучшения в первую очередь как операция
маскирования, которая является более обшей, чем логические маски,
обсуждавшиеся в предыдущем абзаце. Другими словами, умножение од-
ного изображения на другое может более универсально использовать-
ся для коррекции уровня яркости, чем двоичные маски. В Разделе 3.8
приводится пример того, насколько полезными инструментами могут
являться подобные операции маскирования. В оставшейся части дан-
ного раздела будут рассмотрены и проиллюстрированы методы, осно-
ванные на применении операций вычитания и сложения для улучше-
ния изображений. Другие применения умножения изображений
рассматриваются в Главе 5 в контексте восстановления изображений.
3.4.1. Вычитание изображений
Разность двух изображений Дх, у) и h(x, у), выражаемая формулой
g(x,y) = f(x,y)-h(x,y), (3.4-1)
получается вычислением разностей между парами значений всех соот-
ветствующих пикселей изображений fwh. Иллюстрируя эту концеп-
цию, ненадолго вернемся к разделу 3.2.4, где было показано, что стар-
шие битовые плоскости изображения содержат основную часть
видимых деталей, в то время как младшие плоскости несут информа-
цию о мелких (как правило, незаметных) деталях. На Рис. 3.28(a) по-
казано фрактальное изображение, использовавшееся ранее для иллю-
страции концепции битовых плоскостей. На Рис. 3.28(6) представлен
результат удаления (обнуления) четырех младших битовых плоско-
стей исходного изображения. Визуально изображения очень близки, за
исключением небольшого уменьшения общего контраста вследствие
меньших изменений значений яркостей на изображении (б). Поэле-
ментная разность этих двух изображений показана на Рис. 3.28(b). От-
личия в значениях элементов столь малы, что при 8-битовом воспро-
изведении разностное изображение выглядит почти абсолютно черным.
Чтобы увидеть детали необходимо выполнить преобразование усиле-
ния контраста, подобное рассмотренным в Разделах 3.2 и 3.3. Для кон-
кретного примера была выбрана эквализация гистограммы, однако
подходящее степенное преобразование также может с успехом решить
эту задачу. Результат показан на Рис. 3.28(г). Это очень показательный
пример для оценки эффекта обнуления младших битовых плоскостей.
Пример 3.7. Использование вычитания изображений в рентгеногра-
фии с использованием масок.
Одним из наиболее отработанных и успешных направлений ис-
пользования разностного изображения является область медицин-
Глава 3. Пространственные методы улучшения изображений
Рис. 3.28. (а) Исходное фрактальное изображение, (б) Результат обнуления че-
тырех младших битовых плоскостей, (в) Разность изображений (а) и (б), (г) Эквали-
зация гистограммы изображения (в). (Исходное изображение предоставила Мелис-
са Байнд, Свартморский колледж, Свартмор, шт. Пенсильвания).
ской интроскопии, называемая рентгенографией с использованием
масок. В этом случае маска h(x, у) в уравнении 3.4-1 есть рентгенов-
ское изображение части тела пациента, зарегистрированное телека-
мерой с дополнительным усилением, размешенной напротив рент-
геновского источника (вместо традиционной рентгеновской пленки).
Данный метод предполагает введение контрастного вещества в си-
стему кровообращения пациента. Первоначально, в качестве изоб-
ражения h(x, у), регистрируется серия изображений интересующего
участка тела пациента, затем вводится контрастное вещество и реги-
стрируется серия новых изображений — уже в качестве изображения
fix, у). Результирующий эффект вычитания маски h(x, у) из изобра-
жения fix, у) заключается в том, что детали, различающиеся на изо-
бражениях Дх, у) и h(x, у), на выходном изображении приобретают
повышенный контраст. Поскольку изображение может регистриро-
ваться телекамерой, то эта процедура, в сущности, позволяет полу-
чить фильм, показывающий, как контрастное вещество распростра-
няется по различным артериям в наблюдаемой области.
На Рис. 3.29(a) представлено рентгеновское изображение верхней ча-
сти головы пациента до ввода в систему кровообращения контрастно-
го йодистого вещества. Во время съемки камера была установлена вы-
ше головы пациента и была направлена вниз. Яркое пятно в нижней трети
снимка есть центр позвоночного столба, и может служить точкой при-
вязки. На Рис. 3.29(6) показана разность между изображением, получен-
ным через некоторое время после введения контрастного вещества в си-
стему кровообращения, и маской на Рис. 3.29(a). Яркие пути артерий
с контрастным веществом на Рис. 3.29(6) видны значительно лучше.
Общий фон изображения стал значительно темнее, чем на Рис. 3.29(a),
поскольку разность между областями с малыми изменениями также
мала, и на разностном изображении они стали выглядеть как темный фон.
Заметим, например, что спинной мозг, яркий на Рис. 3.29(a), в резуль-
тате вычитания на Рис. 3.29(6) выглядит достаточно темным.И
Прежде, чем завершить данный раздел, уместно сделать несколь-
ко комментариев. На практике большинство изображений представ-
Рис. 3.29. Улучшение путем вычитания изображений, (а) Изображение-мас-
ка. (б) Разность изображения, полученного после введения контрастного вещества
в систему кровообращения, и маски (а).
180 Глава 3. Пространственные методы улучшения изображений
ляются в виде 8-битового сигнала (даже 24-битовые цветные изобра-
жения состоят из трех независимых 8-битовых каналов). Тем самым,
значения изображений не могут выходить за диапазон [0, 255]. На
разностном же изображении значения меняются от —255 до 255, а зна-
чит, для воспроизведения результатов требуется некоторый вариант
масштабирования. Имеются два основных варианта масштабирования
разностного изображения. Один состоит в прибавлении ко всем зна-
чениям константы 255 и последующем делении на 2. В результате все
значения окажутся внутри диапазона от 0 до 255, но нет уверенности,
что они будут занимать весь этот диапазон. Данный метод является бы-
стрым и простым в реализации, но его недостатки заключаются в том,
что может оказаться задействованным не весь диапазон значений,
а также в усечении разностных значений при делении на 2, что озна-
чает некоторую потерю точности.
Если необходима более высокая точность и полное покрытие
диапазона 8 бит, то может использоваться иной подход. Сначала
находится минимум разности (как правило, эта величина отрица-
тельная), и полученное значение вычитается из значений всех элемен-
тов разностного изображения (тем самым на модифицированном
изображении минимальное значение будет равно 0). Затем все элемен-
ты полученного изображения приводятся в интервал [0, 255] умноже-
нием на значение 255/Мах, где Мах — максимальное значение эле-
ментов модифицированного изображения. Однако очевидно, что
такой подход несколько более сложен и трудоемок в реализации.
Заканчивая данное обсуждение, заметим, что вычитание изображе-
ний находит важное применение в области сегментации: таким спосо-
бом можно обнаруживать возникающие изменения наблюдаемой сце-
ны (данный вопрос рассматривается в Главе 10). По сути дела, методы
сегментации имеют целью разделение изображения на области по ка-
кому-то конкретному критерию. Вычитание изображений может быть
использовано при сегментации, когда в качестве критерия выбрано на-
хождение «отличий» на изображениях. Например, при прослеживании
(сегментации) движущихся объектов на последовательности изображе-
ний, вычитание позволяет удалить все неподвижные составляющие изо-
бражения. То, что остается, есть движущиеся элементы плюс шум.
3.4.2. Усреднение изображений
Рассмотрим зашумленное изображениеg(x, у), формируемое прибав-
лением шума Т](х, у) к исходному изображениюf(x, у), то есть
g(x,y) = f(x,y)+r\(x,y),
(3.4-2)
3.4. Улучшение на основе арифметико-логических операций
где предполагается, что значения шума в каждой точке (х, у) являют-
ся некоррелированными11 и имеют нулевое среднее значение. Це-
лью нижеследующей процедуры является уменьшение уровня шума пу-
тем суммирования серии зашумленных изображений {gj(x, у)}.
Если шум удовлетворяет только что сформулированным услови-
ям, то можно показать следующее (Задача 3.15). Пусть изображение
g(x,y) получено усреднением К изображений gt{x, у), отличающихся
лишь шумом цг(х, у),
I к
g(x,y)=—^gi(x,y), (3.4-3)
Л • !
z=l
откуда следует, что
E{g{x,y)} = f(x,y) (3.4-4)
и
Gg(x,y) ’ (3.4-5)
где E{g(x,y)} есть математическое ожидание g , а и —
дисперсии g и fj, все в точке (х, у). Стандартное отклонение в каж-
дой точке усредненного изображения будет
1
Г77аП(х,у) •
Gg(.X,y)
(3.4-6)
Как следует из уравнений (3.4-5) и (3.4-6), при увеличении К величи-
на отклонения (уровень шума) значения элемента в каждой точке
(х, у) уменьшается. Поскольку E{g(x,y)} = f(x,y), это означает, что
g(x, у) приближается к/(х, у) с увеличением числа суммируемых зашум-
ленных изображений. На практике изображения gf(x, у) могут быть по-
лучены в процессе накопления (очевидно, они должны являться сов-
мещенными), чтобы уменьшить влияние расфокусировки или других
искажений на выходном изображении.
11 Вспомним, что дисперсия случайной переменной х со средним т определяется как
Е{(х - т)2}, где £{} есть математическое ожидание аргумента. Ковариация двух слу-
чайных переменных х,- и у, определяется как Е{(х, - т,)(у/ - nij)}. Если переменные не-
коррелированы, их ковариация равна 0.
(Tl82 Глава 3. Пространственные методы улучшения изображений
Пример 3.8. Уменьшение шума путем усреднения изображений.
Е Усреднение изображений находит важное применение в астроно-
мии, где обычным является получение изображений при очень малом
уровне освещенности, и, как следствие, высоком уровне шума датчи-
ка, что зачастую делает отдельные снимки почти бесполезными для
анализа. На Рис. 3.30(a) представлен снимокдвойной галактики NGC
3314, полученный широкоугольной камерой Космического телеско-
па Хаббл (NASA). Галактика NGC 3314 находится на расстоянии око-
ло 140 миллионов световых лет от Земли, в созвездии Гидра, распо-
ложенном в южном полушарии. Яркие звезды, образующие форму
спирали возле центра передней галактики, сформированы недавно из
межзвездного газа и пыли. На Рис. 3.30(6) показано то же самое изо-
бражение, но искаженное некоррелированным гауссовским шумом
со средним ноль и стандартным отклонением 64 градации яркости.
Изображение выглядит бесполезным для практического использова-
ния. На изображениях Рис. 3.30(b) — (е) представлены результаты
усреднения 8,16, 64, и 128 изображений соответственно. Можно ви-
деть, что результат, полученный с К= 128, визуально весьма близок
к оригиналу.
С помощью рисунка 3.31 можно лучше понять, насколько умень-
шение шума зависит от увеличения К. На данном рисунке представ-
лены изображения разностей между оригиналом (Рис. 3.30(a)) и каж-
дым из усредненных изображений Рис. 3.30(b) — (е). Также на этом
рисунке представлены гистограммы соответствующих разностных
изображений. Как обычно, по вертикальной оси отложено число то-
чек (в диапазоне [0, 2-Ю4]). По горизонтальной оси отложены уров-
ни яркости в диапазоне [0, 255]. Из гистограмм видно, что и среднее
и дисперсия разностных изображений уменьшаются с увеличением К.
Эффект уменьшения значения среднего на разностном изображении
можно также наблюдать в левой колонке Рис. 3.31, где изображения
становятся темнее с увеличением К12.
Сложение является дискретным аналогом непрерывного инте-
грирования. В астрономических обсерваториях процесс, эквива-
лентный только что описанному методу, состоит в использовании ин-
тегрирующих свойств ПЗС (приборов с зарядовой связью) или
12 Поскольку шум, который наносился на изображения, имел нулевое среднее, то раз-
ностные изображения формально должны иметь одинаковое среднее равное нулю (т.е.
нулевую среднюю яркость), а их гистограммы быть центрированными в точке 0.
Ниже авторы поясняют, почему приведенные изображения и гистограммы выглядят
иначе. — Прим, перев.
Рис. 3.30. (а) Снимок пары галактик NGC 3314. (б) Изображение, искажен-
ное аддитивным гауссовским шумом со средним ноль и стандартным отклонением
64 градации яркости, (в)—(е) Результаты усреднения К= 8,16,64 и 128 зашумленных
изображений. (Исходное изображение предоставлено Агентством NASA).
Глава 3. Пространственные методы улучшения изображении
а б
Рис. 3 31. Сверху вниз: разностные изображения между Рис. 3.30(a) и четырь-
мя изображениями Рис. З.ЗО(в) — (е) и соответствующие им гистограммы.
3.5. Основы пространственной фильтрации
аналогичных сенсоров путем увеличения времени экспозиции, од-
нако результат этого аналогичен только что описанной процедуре.
Дополнительное уменьшение уровня шума можно достичь путем ох-
лаждения сенсоров.I
Как и в случае вычитания изображений, сложение двух или бо-
лее 8-битовых изображений требует специальных действий при ото-
бражении на 8-битовом устройстве. Значения суммы К 8-битовых
изображений находятся в диапазоне от 0 до 255-К. В этом случае мас-
штабирование значений обратно в диапазон 8 бит заключается в де-
лении результата на К. Некоторая точность, конечно, будет потеря-
на, но это неизбежно, если устройство отображения ограничено
8 битами.
В конкретных реализациях иногда приходится оперировать отри-
цательными значениями элементов изображений. Только что рассмо-
тренный пример, фактически, требовал именно таких действий, по-
скольку гауссовские случайные переменные с нулевым средним
и ненулевой дисперсией принимают как положительные, так и от-
рицательные значения. Изображения, приведенные в примере, бы-
ли масштабированы с помощью второго метода градационного пре-
образования, рассмотренного в конце предыдущего раздела. То есть
на усредненном изображении было найдено значение минимума,
которое затем было вычтено из значений элементов. Затем значения
элементов были приведены в диапазон [0,255] умножением их на ве-
личину 255/Мах, где Мах — максимальное значение элементов13.
3.5. Основы пространственной фильтрации
Как уже говорилось в Разделе 3.1, некоторые локальные преобразова-
ния оперируют одновременно как со значениями пикселей в окрест-
ности, так и с соответствующими им значениями некоторой матрицы,
имеющей те же размеры, что и окрестность. Такую матрицу называ-
ют фильтром, маской, ядром, шаблоном или окном, причем первые три
термина являются наиболее распространенными. Значения элемен-
тов матрицы принято называть коэффициентами.
Вообще говоря, фильтрация тесно связана с применением преоб-
разования Фурье и обработкой сигналов в частотной области. Этот
13 По-видимому, приведенные на Рис. 3.31 изображения подверглись несколько
другому преобразованию, так как иначе гистограммы всех изображений были бы рас-
тянуты на весь диапазон [0, 255] и выглядели бы одинаково. — Прим, перев.
Глава 3. Пространственные методы улучшения изображений
вопрос будет рассматриваться ниже в Главе 4. В данной же главе нас
интересуют операции фильтрации, которые выполняются непосред-
ственно над элементами изображения. Для подобных операций ис-
пользуется термин пространственная фильтрация, в отличие от более
традиционной фильтрации в частотной области.
Схема пространственной фильтрации иллюстрируется на Рис. 3.32.
Процесс основан на простом перемещении маски фильтра от точки
Рис. 3.32. Схема пространственной фильтрации. Увеличенные рисунки пред-
ставляют маску 3x3 и фрагмент изображения непосредственно под ней; для нагляд-
ности фрагмент изображения показан несколько смещенным относительно маски.
3.5. Основы пространственной фильтрации 187
к точке изображения; в каждой точке (х, у) отклик фильтра вычисляет-
ся с использованием предварительно заданных связей. В случае линей-
ной пространственной фильтрации (касательно линейности см. Раз-
дел 2.6) отклик задается суммой произведений коэффициентов фильтра
на соответствующие значения пикселей в области, покрытой маской
фильтра. Для маски 3x3 элемента, показанной на Рис. 3.32, результат (от-
клик) R линейной фильтрации в точке (х, у) изображения составит
R = w(-l,-l)/(x -1,у -1) +М -1,0)/(х -1, у) +...
+щ(0,0)/(х,у) +... +w(l,0)/(x +1, У) +w(U)/(x +1, у +1),
что, как видно, есть сумма произведений коэффициентов маски на зна-
чения пикселей непосредственно под маской. В частности заметим,
что коэффициент w(0,0) стоит при значенииДх, у), указывая тем са-
мым, что маска центрирована в точке (х, у). В случае маски размера-
ми тхп будем полагать, что т = 2а + 1 и и = 2й + 1, где а и b суть не-
отрицательные целые. Это означает, что в дальнейшем будут
рассматриваться маски нечетных размеров, причем наименьшей бу-
дет маска 3x3 элемента (маска размерами 1x1 элемент будет исклю-
чена как тривиальная).
Фильтрация изображения/, имеющего размеры MxN, с помощью
фильтра размерами /ихи задается выражением общего вида:
а Ь
g(x,y)= У У w(s,t)f(x+s,y+t), (3.5-1)
s=-a t=-b
где, как следует из предыдущего абзаца, а — (т — 1 )/2 и b = (п — 1)/2.
При фильтрации всего изображения данная формула должна быть
вычислена для всех сочетаний х = 0, \,2,...,М— 1 иу = 0, 1,2,...,JV— 1.
Это означает, что все элементы изображения будут обработаны по за-
данной маске!4. Легко проверить, что при т = п = 3 данная формула
сводится к формуле, приведенной в предыдущем абзаце.
Как будет рассмотрено в Главе 4, процедура линейной фильтрации,
задаваемая уравнением (3.5-1), в частотной области аналогична
операции свертки. По этой причине линейную пространственную
фильтрацию часто называют «сверткой маски с изображением». Ана-
14 Следует отметить, что для точек, расположенных вблизи краев изображения (на рас-
стоянии менее а от края по оси х или/и менее b по оси у), данная маска будет выхо-
дить за пределы изображения, что, вообще говоря, требует специального учета дан-
ного обстоятельства. Этот вопрос рассматривается ниже. — Прим, перев.
Глава 3. Пространственные методы улучшения изображений
логично, маску фильтра иногда называют маской свертки или ядром
свертки.
В случае, когда интерес представляет только значение отклика R
по маске ntxn в точке (х, у), а не схема реализации маски свертки, ино-
гда используют следующее выражение:
R = wxzx+w2z2 + +wmnzmn = Ywizi > (3-5-2)
/=1
где Wj суть коэффициенты маски, z.j — значения пикселей, соответст-
вующих данным коэффициентам, а тп — общее число коэффициен-
тов в маске. Для маски 3x3, представленной на Рис. 3.33, отклик в точ-
ке (х, у) изображения будет
9
R = WXZX + W2Z2 + • • •+ w9?9 = • (3.5-3)
Z=1
Специальное внимание, уделяемое данной простой формуле, объяс-
няется тем, что она часто встречается в литературе по обработке изо-
бражений.
Нелинейные пространственные фильтры также работают по окре-
стности, причем механизм перемещения маски по изображению тот
же, что был только что обрисован. Схема действий операции нелиней-
ной фильтрации зачастую зависит от значений элементов анализиру-
емой окрестности, и не обязательно должна использовать коэффици-
енты линейной комбинации, как это было в формулах (3.5-1) и (3.5-2).
Как будет показано в Разделе 3.6.2, подавление шума может быть,
например, эффективно осуществлено при помощи нелинейного филь-
тра, основная функция которого заключается в вычислении медианы
значений элементов анализируемой окрестности. Вычисление меди-
W1 W2 w3
w5
w7 W9
Рис. 3.33. Другой вариант представления часто используемой маски фильтра
по окрестности 3x3 элемента.
3.6. Сглаживающие пространственные фильтры 189
аны является нелинейной операцией, так же как и вычисление дис-
персии, использовавшейся в Разделе 3.3.4.
Важным вопросом при реализации операций пространственной
фильтрации по окрестности является рассмотрение ситуации, когда
центр фильтра приближается к границам изображения. Для просто-
ты рассмотрим квадратную маску размерами пхп. Когда эта маска на-
ходится на расстоянии (п — 1 )/2 элемента от границы изображения,
то как минимум одна сторона маски будет находиться на его краю. Ес-
ли же центр маски приближается к границе, то одна или несколько
строк или столбцов маски будут находиться вне изображения. Суще-
ствуют несколько способов учесть это обстоятельство. Простейший
способ состоит в ограничении перемещения центра маски по изоб-
ражению — не ближе, чем (и — 1 )/2 элементов от края. Результирую-
щее изображение после фильтрации будет по размерам меньше ори-
гинала, зато все его точки будут обработаны полной маской. Если
результат должен иметь те же размеры, что и оригинал, то обычно ис-
пользуется подход, при котором для фильтрации используется толь-
ко та часть маски, которая полностью находится внутри изображения.
При этом возле границ изображения образуется полоса точек, кото-
рые обрабатываются только частью маски фильтра. Другие подходы
предусматривают расширение изображения за его границы добав-
лением строк и столбцов из нулей (или других постоянных значений),
или же повторением строк и столбцов. После обработки добавленные
строки и столбцы удаляются. Это позволяет сохранить размеры об-
работанного изображения равными размерам исходного, однако зна-
чения элементов, использовавшихся для расширения, будут оказы-
вать влияние на значения элементов изображения внутри аналогичной
полосы, которая тем шире, чем больше размеры маски. Единствен-
ный способ получить достоверный результат сводится к тому, чтобы
согласиться с получением результирующего изображения с меньши-
ми размерами путем ограничения перемещения центра маски — не
ближе, чем на (и — 1 )/2 элементов от границ исходного изображения.
3.6. Сглаживающие пространственные фильтры
Сглаживающие фильтры применяются для расфокусировки изобра-
жения и подавления шума. Расфокусировка может применяться как
предварительный шаг обработки изображения, например, для удале-
ния мелких деталей перед обнаружением больших объектов, или же
для устранения разрывов в линиях или деталях. Для подавления шу-
мов может использоваться расфокусировка с применением как линей-
ной, так и нелинейной фильтрации.
' 190 Глава 3. Пространственные методы улучшения изображений
3.6.1. Линейные сглаживающие фильтры
Выход (отклик) простейшего линейного сглаживающего пространст-
венного фильтра есть среднее значение элементов по окрестности, по-
крытой маской фильтра. Такие фильтры иногда называют усредняющи-
ми или сглаживающими фильтрами. По причинам, изложенным
в Главе 4, их также называют низкочастотными фильтрами.
Идея применения сглаживающих фильтров достаточно ясна. За-
меной исходных значений элементов изображения на средние значе-
ния по маске фильтра достигается уменьшение «резких» переходов
уровней яркости. Поскольку случайный шум как раз характеризует-
ся резкими скачками яркости, наиболее очевидным применением
сглаживания является подавление шума. Однако контуры, которые
обычно представляют интерес на изображении, также характеризуют-
ся резкими перепадами яркостей, поэтому негативной стороной при-
менения сглаживающих фильтров является расфокусировка контуров.
Другим применением такой процедуры может быть сглаживание лож-
ных контуров, которые возникают при преобразованиях с недостаточ-
ным числом уровней яркости, как это обсуждалось в Разделе 2.4.3. Глав-
ное использование сглаживающих фильтров состоит в подавлении
«несущественных» деталей на изображении. Под «несущественны-
ми» здесь понимаются совокупности пикселей, которые малы по
сравнению с размерами маски фильтра. Это последнее применение бу-
дет проиллюстрировано ниже. На Рис. 3.34 показаны два сглаживаю-
щих фильтра по окрестности 3x3. Первый из них дает обычное сред-
нее значение по маске. Подстановкой коэффициентов маски
в уравнение (3.5-3) получим:
yi=l
ный множитель перед каждой из масок равен единице, деленной на сумму значений
коэффициентов, как это необходимо для нормировки.
что как раз и дает среднее значение яркостей по окрестности 3x3. За-
метим, что коэффициенты фильтра указаны как единицы, вместо 1/9.
Причина в том, что такой вариант является более эффективным при
компьютерных вычислениях. По окончании процесса суммирования
полученное значение делится на 9. Маска размерами /мхи будет иметь
нормировочный коэффициент, равный 1/иги. Такой пространственный
фильтр, все коэффициенты которого одинаковы, иногда называют
однородным усредняющим фильтром.
Вторая маска, представленная на Рис. 3.34(6), несколько более ин-
тересна. Эта маска дает так называемое взвешенное среднее; этот термин
применяется, чтобы показать, что значения элементов умножаются на
разные коэффициенты, что позволяет присвоить им как бы разные
«важности» (веса) по сравнению с другими. В маске на Рис. 3.34(6) ко-
эффициент в центре маски имеет самое большее значение (вес), тем са-
мым давая соответствующему элементу большую важность при вычис-
лении среднего. Значения остальных коэффициентов в маске
уменьшаются по мере удаления от центра маски. Диагональные члены,
по сравнению с ортогональными, расположены от центра дальше, и та-
ким образом «весят» меньше, чем ближайшие соседи центрального
элемента. Основная стратегия присвоения центральному пикселю на-
ибольшего веса, а остальным — обратно пропорционально их рассто-
янию, имеет целью уменьшение расфокусировки при сглаживании.
Можно было бы выбрать и другие значения коэффициентов маски для
достижения поставленной цели, но сумма коэффициентов, приведен-
ных на Рис. 3.34(6) равна 16, что удобно при компьютерной реализации,
поскольку это степень двойки. Следует заметить, что на практике до-
статочно трудно заметить разницу между изображениями, сглаженны-
ми фильтрами по одной из масок на Рис. 3.34 или какими-то другими,
аналогичными по конструкции, поскольку размеры области, покрыва-
емые маской при фильтрации одного элемента, очень малы.
Как следует из уравнения (3.5-1), общая формула фильтрации изо-
бражения размерами Л/xTV фильтром взвешенного среднего по окре-
стности тх.п (тип — нечетные) задается выражением
а b
X X w(s,t)f(x+s,y+t)
g(x,y) = ^=-at-^a---------------. (3.6-1)
у
s=-a t=—b
Параметры в этом уравнении такие же, как были определены для
уравнения (3.5-1). Каки ранее, подразумевается, что полная фильт-
Глава 3. Пространственные методы улучшения изображений
рация изображения достигается применением формулы (3.6-1) ко
всем парам х = 0, 1, 2,..., М — 1 и у = 0, 1, 2,..., N — 1. Знаменатель
в (3.6-1) есть сумма всех коэффициентов маски, следовательно явля-
ется константой и требует вычисления лишь один раз. Как правило,
такое масштабирование применяется сразу ко всем точкам изображе-
ния по окончании процесса фильтрации.
Пример 3.9. Сглаживание изображения по маскам различных размеров.
Зависимость эффекта сглаживания от размера фильтра проиллюс-
трирована на Рис. 3.35, где представлено исходное изображение и ре-
зультаты сглаживания усредняющим фильтром с квадратной окрест-
ностью размерами п = 3, 5, 9, 15, и 35 элементов. Главные результаты
а а а а а а а 3.
!а б в1'
г д г
Рис. 3.35. (а) Исходное изображение размерами 500x500 элементов, (б)—(е) Ре-
зультаты сглаживания усредняющим фильтром с квадратной маской размерами п = 3,
5, 9, 15, и 35. Черные квадратики в верхней части имеют размеры 3, 5, 9, 15, 25, 35,
45, и 55 пикселей соответственно и расположены на расстоянии в 25 пикселей друг
от друга. Буквы внизу изменяются в размерах от 10 до 24 пунктов, с увеличением каж-
дый раз на 2 пункта; размер самой большой буквы — 60 пунктов. Вертикальные по-
лосы имеют 5 пикселей в ширину и 100 пикселей в высоту; расстояния между ними —
20 пикселей. Диаметр кружков — 25 пикселей, и расположены они на расстоянии 15
пикселей друг от друга; их уровни яркостей изменяются от 0% до 100% черного с ша-
гом 20%. Общий фон изображения — 10% черного. Прямоугольники с шумом име-
ют размеры 50x120 пикселей.
этого эксперимента таковы. При п = 3 можно заметить легкую расфо-
кусировку на всем изображении, однако, как и следовало ожидать, бо-
лее всего искажены мелкие детали, имеющие размеры, близкие к раз-
мерам фильтра. На изображениях, сглаженных по окрестностям 3x3
и 5x5, уже видна значительная расфокусировка на маленькой букве «а»
и на мелкозернистом шуме. Заметно заглажены выступающие края
букв, а также серые кружочки. Положительным результатом можно
считать то, что шум стал значительно менее выраженным. Небольшое
увеличение размеров окрестности сглаживания (больше п = 5) не
приводит к сильным изменениям результатов. Но при п = 9 можно ви-
деть уже значительно более сильную расфокусировку, и 20-процентный
черный кружочек уже не так сильно отличаются от фона, как на пре-
дыдущих трех изображениях, тем самым иллюстрируя эффект смеши-
вания, являющийся результатом расфокусировки. Также видно значи-
тельно более сильное сглаживание зашумленных прямоугольников.
Результаты сд = 15 и 35 следует считать предельными по отношению
к размерам объектов на изображении. Такое чрезмерное сглаживание
используется в основном для удаления с изображения мелких объек-
тов. Например, три маленьких квадрата, два круга и большинство из
зашумленных прямоугольников на Рис. 3.35(e) неотличимы от фона.
На этом изображении стал сильно заметен темный бордюр, который
является следствием расширения изображения перед операцией сгла-
живания нулями (т.е. черным фоном) и последующего обрезания кра-
ев. Этот эффект проявляется на всех изображениях, но наиболее за-
метен на изображении, сглаженном фильтром самого большого
размера.®
Как было замечено ранее, важным применением пространствен-
ного сглаживания является расфокусировка изображения, позволяю-
щая создать грубый образ объектов, которые могут представлять ин-
терес. При этом интенсивность мелких объектов смешивается с фоном,
в то время как большие объекты остаются в виде пятен и могут быть
легко обнаружены. Размеры объектов, которые будут смешиваться
с фоном, приблизительно совпадают с размерами маски сглаживаю-
щего фильтра. В качестве примера рассмотрим изображение на
Рис. 3.36(a), полученное телескопом «Хаббл» с орбиты Земли. Ре-
зультат применения усредняющего фильтра с маской 15x15 элементов
показан на Рис. 3.36(6). Можно видеть, что многие из объектов или ока-
зались смешаны с фоном, или же их яркость значительно уменьши-
лась. Обычно после такого сглаживания следует операция разделения
по порогу, позволяющая убрать объекты малой интенсивности. Резуль-
тат применения пороговой операции к изображению на Рис. 3.36(6)
7 А-223
Глава 3. Пространственные методы улучшения изображений
$ Й Рис. 3.36. (а) Изображение, полученное космическим телескопом «Хаббл»,
(б) Изображение, обработанное сглаживающей маской размерами 15x15 элемен-
тов. (в) Результат применения порогового обнаружения к изображению (б). (Ис-
ходное изображение предоставлено Агентством NASA).
с уровнем порога в 25% от наибольшей яркости, показан на Рис. 3.36(b).
Сравнивая это изображение с исходным, можно сделать вывод, что по-
лученный результат был бы приемлемым с позиции поиска самых
больших и ярких объектов.
3.6.2. Фильтры, основанные на порядковых
статистиках
Фильтры, основанные на порядковых статистиках, относятся к клас-
су нелинейных пространственных фильтров. Отклик такого фильтра
определяется предварительным упорядочиванием (ранжированием)
значений пикселей, покрываемых маской фильтра, и последующим
выбором значения, находящегося на определенной позиции упоря-
доченной последовательности (т.е. имеющего определенный ранг).
Собственно фильтрация сводится к замещению исходного значения
пикселя (в центре маски) на полученное значение отклика фильтра.
Наиболее известен медианный фильтр, который, как следует из назва-
ния, заменяет значение пикселя на значение медианы распределения
яркостей всех пикселей в окрестности (включая и исходный). Меди-
анные фильтры весьма популярны потому, что для определенных ти-
пов случайных шумов они демонстрируют отличные возможности по-
давления шума при значительно меньшем эффекте расфокусировки,
чем у линейных сглаживающих фильтров с аналогичными размера-
ми. В частности, медианные фильтры эффективны при фильтрации
импульсных шумов, иногда называемых шумами «соль и перец», кото-
рые выглядят как наложение на изображение случайных черных и бе-
лых точек.
Медиана набора чисел есть такое число что половина чисел из
набора меньше или равны а другая половина — больше или равны
Чтобы выполнить медианную фильтрацию для элемента изображе-
ния, необходимо сначала упорядочить по возрастанию значения пик-
селей внутри окрестности, затем найти значение медианы, и, наконец,
присвоить полученное значение обрабатываемому элементу. Так, для
окрестности 3x3 элементов медианой будет пятое значение по вели-
чине, для окрестности 5x5 — тринадцатое значение, и так далее. Ес-
ли несколько элементов в окрестности имеют одинаковые значения,
эти значения будут сгруппированы. Например, пусть в окрестности 3x3
элементы имеют следующие значения: (10,20,20,20,15,20,20,25,100).
После упорядочивания они будут расположены следующим образом:
(10, 15, 20,20,20,20, 20, 25,100), а следовательно медианой будет зна-
чение 20. Можно сказать, что основная функция медианного фильт-
ра заключается в замене отличающегося от фона значения пикселя на
другое, более близкое его соседям. На самом деле, изолированные
темные или светлые (по сравнению с окружающим фоном) кластеры,
имеющие площадь не более чем и2/2 (половина площади маски филь-
тра), будут удалены медианным фильтром с маской размерами ихи.
В данном случае «удалены» означает, что значения пикселей в соответ-
ствующих точках будут заменены на значения медиан по окрестностям.
Кластеры больших размеров искажаются значительно меньше.
Хотя медианный фильтр значительно более распространен в обра-
ботке изображений, чем остальные виды фильтров, основанные на по-
рядковых статистиках, тем не менее он не является единственным. Ме-
диана представляет собой 50-й процентиль упорядоченного набора
чисел, но, как следует из основ статистики, упорядочивание предостав-
ляет много других возможностей. Например, использование 100-го
процентиля приводит к так называемому фильтру максимума, который
полезен при поиске на изображении наиболее ярких точек по отно-
шению к окружающему фону. Отклик фильтра максимума по окрест-
ности 3x3 задается выражениемR = max{^ I k = 1,2,..., 9}. Процентиль
0 является фильтром минимума, используемым для поиска противопо-
ложных значений. Медианный фильтр, а также фильтры максимума
и минимума более детально рассмотрены в Главе 5.
Пример 3.10. Использование медианной фильтрации для подавления
шума.
На Рис. 3.37(a) представлен рентгеновский снимок монтажной пла-
ты, сильно искаженный импульсным шумом. Чтобы проиллюстри-
ровать преимущество медианной фильтрации по сравнению с усред-
няющим фильтром, на Рис. 3.37(6) показан результат обработки
Глава 3. Пространственные методы улучшения изображений
Я б В Рис. 3.37. (а) Рентгеновский снимок монтажной платы, искаженный импульс-
ным шумом. (б) Подавление шума усредняющим фильтром по окрестности 3x3. (в) По-
давление шума медианным фильтром по окрестности 3x3. (Исходное изображение
предоставил Джозеф Пасенте, компания Lixi, Inc.).
зашумленного изображения усредняющим фильтром по окрестности
3x3, а на Рис. 3.37(b) — результат медианной фильтрации по окрестно-
сти 3x3. На изображении, обработанном усредняющим фильтром, уро-
вень шумов стал ниже, но ценою заметной расфокусировки. При этом
совершенно очевидно преимущество медианного фильтра во всех от-
ношениях. Вообще, медианная фильтрация намного больше подходит
для удаления импульсного шума, чем усредняющая фильтрация. Ей
3.7. Пространственные фильтры повышения
резкости
Главная цель повышения резкости заключается в том, чтобы под-
черкнуть мелкие детали изображения или улучшить те детали, кото-
рые оказались расфокусированы вследствие ошибок или несовер-
шенства самого метода съемки. Повышение резкости изображений
используется достаточно широко — от электронной печати и медицин-
ской интроскопии до технического контроля в промышленности и си-
стем автоматического наведения в военной сфере.
В предыдущем разделе мы видели, что расфокусировка изображе-
ния может быть достигнута пространственной операцией усредне-
ния значений точек по окрестности. Поскольку усреднение аналогич-
но интегрированию, то логично придти к выводу, что повышение
резкости, будучи явлением, обратным по отношению к расфокусиров-
ке, может быть достигнуто пространственным дифференцированием.
Это действительно так, и в настоящем разделе будут обсуждаться раз-
личные способы задания и использования операторов повышения
резкости путем численного дифференцирования. С принципиальной
точки зрения, величина отклика оператора производной в точке изо-
3.7. Пространственные фильтры повышения резкости
бражения пропорциональна степени разрывности изображения в дан-
ной точке. Таким образом, дифференцирование изображения позво-
ляет усилить перепады и другие разрывы (например, шумы) и не под-
черкивать области с медленными изменениями уровней яркостей.
3.7.1. Основы
В последующих двух разделах будут рассмотрены фильтры повышения
резкости, основанные на первой и второй производных. Однако преж-
де, чем перейти к непосредственному обсуждению, необходимо оста-
новиться на некоторых фундаментальных свойствах этих производных
в контексте цифровых методов. Для простоты изложения остановим-
ся на одномерных производных. В частности, представляет интерес по-
ведение этих производных на областях постоянной яркости (плоские
области), в начале и в конце разрывов (разрывы в виде ступенек и уча-
стков изменения яркости — склонов), а также на протяжении самих
склонов. Эти типы разрывов могут использоваться для описания шу-
мовых всплесков, линий и контуров на изображении. Также важным
является поведение производной на протяжении перехода от начала
до окончания указанных особенностей.
Производные дискретной функции определяются в терминах раз-
ностей. Эти разности можно задать различными способами, однако мы
будем руководствоваться следующим. Первая производная должна
быть: (1) равной нулю на плоских участках (областях с постоянным
уровнем яркости); (2) ненулевой в начале и в конце ступеньки или
склона яркости; (3) ненулевой на склонах яркости. Аналогично, вто-
рая производная должна быть: (1) равной нулю на плоских участках;
(2) ненулевой в начале и в конце ступеньки или склона яркости; (3) рав-
ной нулю на склонах постоянной крутизны. Так как мы оперируем ог-
раниченными численными значениями, максимальное значение из-
менения яркости также конечно, а кратчайшее расстояние, на котором
это изменение может происходить, есть расстояние между соседними
пикселями.
Первая производная одномерной функции f(x) определяется как
разность значений соседних элементов:
|^ = /(х + 1)-/(х).
дх
Здесь использована запись в виде частной производной для того, что-
бы сохранить те же обозначения в случае двух переменныхf(x, у), где
придется иметь дело с частными производными по двум пространст-
198 Глава 3. Пространственные методы улучшения изображений
венным осям. Использование частной производной не меняет суще-
ства рассмотрения.
Аналогично, вторая производная определяется как разность сосед-
них значений первой производной:
^Z=/(x+l)+/(x-l)-2/(x).
Эх
Легко проверить, что оба данных определения удовлетворяют сфор-
мулированным ранее условиям касательно производных первого и
второго порядков. Чтобы увидеть это, а также подчеркнуть основные
сходства и различия между производными первого и второго по-
рядков в контексте обработки изображений, рассмотрим пример на
Рис. 3.38.
На Рис. 3.38(a) показано простое изображение, содержащее не-
сколько сплошных объектов15, линию и отдельную шумовую точку. На
Рис. 3.38(6) представлен горизонтальный профиль яркости (по стро-
ке развертки), проходящий через центр изображения и шумовую точ-
ку. Этот профиль, являющийся одномерной функцией, будет исполь-
зоваться для последующих иллюстраций. На Рис. 3.38(b) показана
упрощенная дискретная схема профиля. Она содержит минимальное
количество точек, требуемое для анализа поведения первой и второй
производных вблизи отдельной точки, линии, склона и контура объ-
екта. На приведенной упрощенной схеме склон занимает четыре пик-
селя, отдельная точка — один пиксель, толщина линии — три пиксе-
ля, а ступенька яркости расположена между соседними пикселями.
Число уровней яркости также сокращено до восьми.
Рассмотрим поведение первой и второй производных при движе-
нии вдоль профиля слева направо. Для начала отметим, что первая
производная не равна нулю на протяжении всего склона, в то время
как вторая производная не равна нулю лишь в начале и конце скло-
на. Поскольку границы объектов на изображении соответствуют
именно такому типу переходов, можно сделать вывод, что первая про-
изводная дает в результате «толстые» контуры, а вторая — значитель-
но более тонкие. Следующей является отдельная точка. На ней (и ря-
дом) отклик второй производной оказывается значительно сильнее
отклика первой производной16. Это не должно быть неожиданным —
15 Они выглядят как светлые фрагменты геометрических фигур. — Прим, перев.
16 Здесь пока речь идет об абсолютной величине отклика производной. — Прим, перев.
3.7. Пространственные фильтры повышения резкости
Склон
Отдельная точка
Тонкая Ступенька
; линия
; Плоский
! участок / \
Строка
изображения
Первая
производная
Вторая
производная
|5|5|4|3|2|1|010|0|6|0|0|0|0|113|1101010101717 17 | 7 | • | •
I I I I I I I I I I I I I I I I I I I I I I I
-1 -1-1 -1 -1 0 0 6 -6 0 0 0 1 2 -2-1 0 0 0 7 0 0 0
I I I I I I I I I I I I I I I I I I I I I I I
-1 0 0 0 0 1 0 6-126 0011 -4 11007 -7 00
а б
в
Рис. 3.38. (а) Простое изображение, (б) Одномерный горизонтальный профиль,
проходящий через центр изображения и отдельную шумовую точку, (в) Схематичное
дискретное изображение профиля (для простоты точки соединены пунктирными
линиями).
в задаче подчеркивания резких переходов вторая производная по
сравнению с первой является намного более действенной, а значит
следует ожидать, что усиление мелких деталей (включая шум) при по-
мощи второй производной будет значительно более сильным, чем при
помощи первой производной. Тонкая линия (в данной проекции) так-
же представляет собой мелкую деталь, и можно увидеть ту же разни-
цу между двумя производными. Но даже если бы максимальная яр-
кость на линии совпадала с яркостью отдельной точки, отклик второй
производной на точке был бы все равно больше17. Наконец, на сту-
17 Это справедливо для двумерного случая. В рассматриваемом одномерном случае
(см. численные значения сигнала) это связано с тем, что по сравнению с точкой ли-
ния имеет более «размытые» края. — Прим, перев.
(Г 200 Глава 3. Пространственные методы улучшения изображений
пеньке отклики обеих производных совпадают (в большинстве слу-
чаев, когда ступенька несколько расфокусирована, отклик второй
производной будет слабее). Можно заметить, что значения второй
производной имеют колебания из положительных значений в отри-
цательные. На изображении это выглядит как двойная линия. Этот
эффект «двойных контуров» возникнет в качестве существенной
помехи в Главе 10, где производные будут использоваться для обна-
ружения контуров. Также интересно, что если амплитуда тонкой
линии совпадает с величиной перепада, то отклик второй произ-
водной на линии будет больше, чем на перепаде.
В заключение, сравнивая отклики первой и второй производных,
можно отметить следующее. (1) Первая производная обычно дает в ре-
зультате более толстые контуры. (2) Вторая производная дает больший
по величине отклик на мелкие детали — как на отдельных точках,
так и на тонких линиях. (3) Отклик на ступеньку у первой производ-
ной как правило выше, чем у второй. (4) На наклонных контурах вто-
рая производная дает двойной отклик. Касательно второй производ-
ной можно также отметить, что при одинаковых амплитудах изменения
сигнала, она дает более сильный отклик на линии, чем на ступеньке,
а на отдельной точке — более сильный, чем на линии.
В большинстве приложений методов улучшения изображений вто-
рая производная оказывается более предпочтительной, чем первая, бла-
годаря большему усилению мелких деталей. По этой причине, и что-
бы упростить дальнейшее развитие подхода, вначале мы уделим
внимание применению второй производной в методах улучшения
изображений. Методы же, основанные на первой производной, будут
рассмотрены в разделе 3.7.3. Хотя в применении к обработке изобра-
жений первая производная используется в основном для выделения
контуров, тем не менее она находит применение и в задачах улучше-
ния; в Разделе 3.8 будет показано, что в объединении со второй про-
изводной удается получить достаточно выразительные результаты.
3.7.2. Улучшение изображений с использованием
вторых производных: лапласиан
В данном разделе мы рассмотрим применение двумерной второй
производной в задачах улучшения изображений. Подход сводится
к выбору дискретной формулировки второй производной и к по-
следующему построению маски фильтра, основанной на данной
формулировке. Рассматриваться будут изотропные фильтры, отклик
которых не зависит от направления неоднородностей на обрабаты-
ваемом изображении. Другими словами, изотропные фильтры явля-
3.7. Пространственные фильтры повышения резкости
ются инвариантными к повороту, в том смысле, что поворот изобра-
жения и последующее применение фильтра дает тот же результат, что
и первоначальное применение фильтра с последующим поворотом
результата18.
Разработка метода
Можно показать ([Rosenfeld и Как, 1982]), что простейшим изотроп-
ным оператором, основанным на производных, является лапласиан
(оператор Лапласа), который в случае функции двух переменныхfix, у)
определяется как
V2/=37 + ^/ (3.7-1)
Эх2 Эу2
Поскольку производные любого порядка являются линейными операто-
рами, то значит и лапласиан является линейным оператором.
Чтобы применить данное уравнение в цифровой обработке изо-
бражений, его необходимо выразить в дискретном виде. Существу-
ет несколько способов задать лапласиан в дискретном виде на осно-
ве значений соседних пикселей. Однако каким бы ни было
определение, оно должно удовлетворять тем свойствам, которые
были изложены в Разделе 3.7.1. Нижеследующее определение дис-
кретной второй производной является одним из наиболее часто ис-
пользуемых. Принимая во внимание, что теперь имеются две пере-
менные, для частной второй производной по х будет использоваться
следующая формула:
^4 = Дх +1, у) +Дх -1, у) -2Дх, у) (3.7-2)
Эх
и, аналогично для производной по у:
Э2Г
—у = /(х,у+1)+/(х,у-1)-2/(х,у). (3.7-3)
0у2
Дискретная формулировка двумерного лапласиана, заданного уравне-
нием (3.7-1), получается объединением этих двух составляющих:
1R В применении кдискретному сигналу это утверждение верно лишь настолько, на-
сколько точными можно считать операцию поворота и круговую симметрию масок
фильтров. — Прим, перев.
Глава 3. Пространственные методы улучшения изображений
V2f = № +1,У) + Дх-1,у)+Дх,у+1) + Дх,у— 1)]- 4/(х, у). (3.7-4)
Это уравнение может быть реализовано с помощью маски, представ-
ленной на Рис. 3.39(a), которая дает изотропный результат для пово-
ротов на углы, кратные 90°. Способы реализации описаны при обсуж-
дении уравнения (3.5-1) и иллюстрируются в Разделе 3.6.1 для
линейных сглаживающих фильтров. Здесь попросту используются
другие значения коэффициентов.
Диагональные направления могут быть включены в формулу дис-
кретного лапласиана (3.7-4) добавлением еще двух членов — по одно-
му для каждого из диагональных направлени й. Вид каждого из них та-
кой же, как в уравнении (3.7-2) или (3.7-3), но указываются координаты
точек, расположенных по диагоналям. Поскольку каждая диагональ-
ная добавка включает член — 2Дх, у), то суммарный вычитаемый из сум-
мы член составит —8/(х, у). Маска, соответствующая такому новому оп-
ределению, представлена на Рис. 3.39(6). Такая маска является
изотропной для поворотов на углы, кратные 45°. Две оставшиеся ма-
ски, показанные на Рис. 3.39, также часто используются на практике.
Они основаны на определении лапласиана, являющегося «негатив-
ным» по отношению к тому, который уже был рассмотрен. По сущест-
> е
A JL
0 1 0
1 -4 1
0 1 0
1 1 1
1 -8 1
1 1 1
0 -1 0
-1 4 -1
0 -1 0
-1 -1 -1
-1 8 -1
-1 -1 -1
Рис. 3.39. (а) Маска фильтра, используемая для реализации дискретного ла-
пласиана согласно уравнению (3.7-4). (б) Маска, используемая для реализации рас-
ширения этого уравнения путем добавления диагональных членов, (в) и (г) Две дру-
гие реализации лапласиана.
3.7. Пространственные фильтры повышения резкости
ву они дают идентичный результат, но различие в знаке должно учиты-
ваться при комбинации — операцией сложения или вычитания — изо-
бражения, отфильтрованного лапласианом, с другим изображением.
Поскольку оператор Лапласа по сути является второй производной,
его применение подчеркивает разрывы уровней яркостей на изобра-
жении и подавляет области со слабыми изменениями яркостей. Это
приводит к получению изображения, содержащего сероватые линии
на месте контуров и других разрывов, наложенные на темный фон без
особенностей. Но фон можно «восстановить», сохранив при этом эф-
фект повышения резкости, достигаемый лапласианом. Для этого до-
статочно сложить исходное изображение и лапласиан. Как было ска-
зано в предыдущем абзаце, при этом необходимо помнить, какое из
определений лапласиана было использовано. Если использовалось
определение, использующее отрицательные центральные коэффи-
циенты, тогда для получения эффекта повышения резкости, изобра-
жение-лапласиан следует вычитать, а не прибавлять. Таким обра-
зом, обобщенный алгоритм использования лапласиана для улучшения
изображений сводится к следующему:
g(*,y)=
/(x,y)-V2/(x,y), если w(0,0)<0
f{x,y) + V2/(x,y), если w(0.0)>0
(3.7-5)
Здесь w(0,0) — значение центрального коэффициента маски лапласи-
ана. Применение этого уравнения иллюстрируется нижеследующим
примером.
Пример 3.11. Повышение резкости изображения с помощью лапласиана.
5 На Рис. 3.40(a) представлено изображение Северного полюса Луны.
На Рис. 3.40(6) показан результат фильтрации данного изображе-
ния лапласианом с маской на Рис. 3.39(6). Поскольку изображение-
лапласиан содержит как положительные, так и отрицательные зна-
чения, то для градационной коррекции такого сигнала может
применяться подход, изложенный в Разделе 3.4.1. Иногда, чтобы из-
бежать проблем с отрицательными значениями сигнала, отобража-
ют значение его модуля; однако такое преобразование в некоторых
случаях приводит к возникновению двойных линий, что может
сбить с толку.
Изображение, представленное на Рис. 3.40(b), было подвергнуто
градационной коррекции способом, изложенным в Разделе 3.4.1.
Видно, что основными деталями данного изображения являются
контуры и резкие перепады яркости различного уровня. Фон, ранее
черный, теперь, вследствие градационной коррекции, стал серым. Та-
Глава 3. Пространственные методы улучшения изображений
Рис. 3.40. (а) Изображение Северного полюса Луны, (б) Изображение, филь-
трованное лапласианом (неотрицательные значения сигнала), (в) Изображение-ла-
пласиан, подвергнутое градационной коррекции перед воспроизведением, (г) Изо-
бражение, улучшенное с помощью уравнения (3.7-5). (Исходное изображение
предоставлено Агентством NASA).
кое сероватое проявление фона является типичным для правильно от-
корректированных изображений-лапласианов. Наконец, на
Рис. 3.40(f) показан результат, полученный с использованием урав-
нения (3.7-5). Детали на этом изображении видны значительно более
чистыми и резкими, чем на исходном изображении. Добавление ис-
ходного изображения к лапласиану восстановило общий диапазон из-
менения яркостей на изображении, а лапласиан усилил контрасты
в местах яркостных разрывов. Конечным результатом стало изобра-
жение, на котором мелкие детали улучшены, а фоновые полутона
отлично сохранены. Результаты, подобные данному, позволили ме-
тодам улучшения, основанным на лапласиане, стать основным инст-
рументом, часто используемым для повышения резкости цифровых
изображений. Я
Упрощения
В предыдущем примере уравнение (3.7-5) было реализовано в два эта-
па: как первоначальное вычисление изображения, фильтрованного
лапласианом, и последующее вычитание его из исходного изображе-
ния. Это было сделано с целью обучения, чтобы проиллюстрировать
каждый шаг процедуры. На практике действия, описываемые уравне-
нием (3.7-5), обычно выполняют за один проход при использовании
единой маски. Коэффициенты такой единой маски легко получаются
подстановкой уравнения (3.7-4) в первую строку уравнения (3.7-5)
g(x, y)=f(x,y)~ [/(х +1, у) + f(x -1, у)+f(x, у +1)+
+f(x, у -1)]+4/(х, у) = 5f(x, у)- [/(х +1, у)+ /(х-1, у)+ (3-7'6)
+/(х,у+1)+/(х,у-1)].
Это уравнение может быть реализовано с помощью маски, показан-
ной на Рис. 3.41(a). Маска, показанная на Рис. 3.41(6), должна исполь-
зоваться, если в вычисление лапласиана включаются диагональные со-
седние элементы. Идентичные маски получатся, если во вторую строку
уравнения (3.7-5) подставить со знаком минус уравнение (3.7-4).
Пример 3.12. Улучшение изображения при использовании составной
маски лапласиана.
Результаты, получающиеся с применением маски, содержащей ди-
агональные элементы, обычно являются более резкими, чем с приме-
нением первичной маски на Рис. 3.41(a). Эта особенность проиллюс-
трирована изображениями на Рис. 3.41(г) и Рис. 3.41(д), где представлены
результаты фильтрации лапласианом с использованием масок
Рис. 3.41(a) и Рис. 3.41(6), соответственно. Сравнивая изображения
после фильтрации с оригиналом, представленным на Рис. 3.41(b), мож-
но заметить, что обе маски дают заметное улучшение, но результаты с ма-
ской на Рис. 3.41(6) выглядят более резкими. Исходное изображение на
Рис. 3.41 (в) есть снимок поврежденной при перегреве вольфрамовой ни-
ти накала, полученный сканирующим электронным микроскопом при
приблизительно 250-кратном увеличении. *
Глава 3. Пространственные методы улучшения изображений
Рис. 3.41. (а) Составная маска лапласиана, (б) Вторая составная маска, (в) Изо-
бражение, полученное сканирующим электронным микроскопом, (г) и (д) Резуль-
таты фильтрации с масками (а) и (б). Заметим, насколько (д) является более резким,
чем (г). (Исходное изображение предоставил Майкл Шаффер, Факультет геологиче-
ских наук Орегонского университета, Юджин).
Поскольку лапласиан является линейным оператором, то можно
было получить те же составные маски на Рис. 3.41(a) и Рис. 3.41(6) на-
прямую из уравнения (3.7-5), которое определено как разность (сум-
ма) двух линейных процессов. То есть,/(х, у) может быть представле-
но как исходное изображение, обработанное фильтром с маской,
имеющей единицу в центре и все остальные нули. Второй член урав-
нения — то же самое изображение, обработанное одной из масок ла-
пласиана на Рис. 3.39. Благодаря линейности, результат, полученный
с помощью уравнения (3.7-5) с единичной маской и одной из масок
лапласиана, будет тем же, что и результат, полученный составной ма-
ской, построенной как разность (сумма) единичной маски и маски ла-
пласиана.
3.7. Пространственные фильтры повышения резкости
Нерезкое маскирование и фильтрация с подъемом высоких частот
Процедура, много лет использующаяся в полиграфии для повышения
резкости изображений, заключается в вычитании из изображения его
расфокусированной копии. Эта процедура, называемая нерезким ма-
скированием, выражается формулой
А(х,у) = /(х,у)-7(х,у), (3.7-7)
где fs(x, у) обозначает изображение_с повышенной резкостью, получен-
ное нерезким маскированием, a f (х,у) — расфокусированная копия
исходного изображения/и, у). Нерезкое маскирование ведет свое на-
чало из фотографии, где для получения более резкого отпечатка на не-
гатив накладывался расфокусированный позитив, и экспозиция осу-
ществлялась через полученный двухслойный оригинал.
Некоторым обобщением нерезкого маскирования является филь-
трация с подъемом высоких частот. Процедура фильтрации с подъ-
емом высоких частот, формирующая изображение^, задается фор-
мулой
/ъь(х>У) = <(х,У)-7(х,у), (3.7-8)
где А > 1, a f , как и раньше, расфокусированная копия/. Это урав-
нение может быть записано в виде
/ьъ(^У) = (Л -1)/(х,у) +/(х,у) -f(x,у). (3.7-9)
Используя уравнение (3.7-7), получим
/ьь(*>.У)=(Л -!)/(x,y) + fs(x,y) (3.7-10)
как формулу для вычисления результата фильтрации изображения
с подъемом высоких частот.
Уравнения (3.7-8) и (3.7-10), вообще говоря, не определяют жест-
ко способ получения резкого изображения. Можно выбрать исполь-
зование лапласиана, тогда fs(x, у) может быть получено из уравнения
(3.7-5). В этом случае уравнение (3.7-10) будет иметь вид
с / \ j4/’(x,y)-V2/(x,y), если и(0,0)<0 .
ЫА'Э’)=<! _ • (3.7-Н)
[ Af(x, у) + V2/(x, у), если и(0,0) > 0
Здесь, как и ранее, w(0,0) есть значение центрального коэффициента
маски лапласиана. Фильтрация с подъемом высоких частот также мо-
Глава 3. Пространственные методы улучшения изображений
жет быть реализована за один проход при использовании одной из двух
масок, показанных на Рис. 3.42. Заметим, что при Л = 1 фильтрация
с подъемом высоких частот становится «стандартным» повышением
резкости с помощью лапласиана. При увеличении >4 больше 1, эффект
увеличения резкости становится все меньше и меньше. В конце кон-
цов, при достаточно больших Л, результат фильтрации изображения
с подъемом высоких частот будет приблизительно совпадать с резуль-
татом умножения исходного изображения на константу.
Пример 3.13. Улучшение изображения при помощи фильтра, усилива-
ющего высокие частоты.
Одним из типичных приложений фильтрации изображения с подъ-
емом высоких частот является случай, когда исходное изображение
темнее, чем это требуется. Варьированием коэффициента усиления
высоких частот обычно удается добиться общего увеличения яркос-
ти изображения и получить желаемый результат. Рисунок 3.43 иллю-
стрирует как раз такое применение метода. Часть (а) данного рисун-
ка есть более темный вариант изображения на Рис. 3.41(c). На
Рис. 3.43(6) показано изображение-лапласиан, полученное при исполь-
зовании маски на Рис. 3.42(6) с А = 0. Изображение на Рис. 3.43(b) бы-
ло получено при той же маске, но с А = 1. Как и ожидалось, изобра-
жение стало более резким, но все еще остается столь же темным, что
и исходное. Наконец, на Рис. 3.43(г) показан результат при Л = 1,7. Этот
результат намного более приемлем, поскольку увеличен средний уро-
вень яркости, а следовательно изображение стало более светлым и ес-
тественным.
быть реализован при использовании любой из этих масок с Л > 1.
Рис. 3.43. (а) То же изображение, что и на Рис. 3.41(b), но более темное, (б) ла-
пласиан изображения (а), полученный при использовании маски Рис. 3.42(6) с А = 0.
(в) Изображение, улучшенное наложением лапласиана с маской Рис. 3.42(6) иА = 1.
(г) То же, что и (в), но с А = 1,7.
3.7.3. Улучшение изображений с использованием
первых производных: градиент
В обработке изображений первые производные реализуются через
модуль градиента. Для функции fix, у) градиент/в точке (х, у) опре-
деляется как двумерный вектор-столбец
Vf =
Gx
Gy
дх
ду
(3.7-12)
Глава 3. Пространственные методы улучшения изображений
Модуль этого вектора определяется следующим образом:
Компоненты вектора градиента являются линейными операторами, но
модуль вектора, очевидно, нет, поскольку он выражается через опера-
ции возведения в квадрат и извлечения квадратного корня. С другой
стороны, частные производные в уравнении (3.7-12) не являются ин-
вариантными к повороту (изотропными), но модуль вектора градиен-
та таковым является. Хотя это и не является строго правильным, мо-
дуль вектора градиента часто называют градиентом. Следуя этой
традиции, мы также будем использовать этот термин в последующих
обсуждениях, явно ссылаясь на вектор или его амплитуду только в тех
случаях, когда возможна неясность.
Объем вычислений, необходимый для обработки всего изображения
оператором (3.7-13), достаточно велик, поэтому частой практикой яв-
ляется приближение значения модуля градиента суммой модулей отдель-
ных компонентов, вместо квадратов и квадратных корней:
V/-|Gx| + |Gy|. (3.7-14)
Это уравнение проще в вычислениях, оно все еще сохраняет относи-
тельные изменения в уровнях яркостей, но свойство изотропности
пропадает. Однако, как и в случае лапласиана, свойства изотропнос-
ти для определяемого в следующем абзаце дискретного градиента со-
храняются только для ограниченного набора угловых приращений,
который зависит от масок, используемых для приближения производ-
ных. Как оказывается, маски, наиболее часто используемые для при-
ближения градиента, дают те же результаты только для углов, кратных
90°. Эти результаты не зависят от того, какое уравнение используется —
(3.7-13) или (3.7-14), так что при использовании более простого урав-
нения (3.7-14) ничего существенного не теряется.
Аналогично лапласиану, первоначально будут определены дис-
кретные приближения приведенных выше уравнений, а затем уже по
ним будут сформированы соответствующие маски фильтров. Чтобы
упростить последующие рассуждения, для указания точек в окрест-
ности 3x3 будут использоваться обозначения, показанные на
Рис. 3.44(a). Так, например, центральная точка обозначает/^, у),
Zi обозначает/(х— 1, у— 1), и так далее. Как отмечено в Разделе 3.7.1,
простейшими приближениями первой производной, которые удов-
3.7. Пространственные фильтры повышения резкости
Рис. 3.44. Область изображения размерами 3x3 элемента (^i,...,^> — значения
яркости соответствующих пикселей под маской) и маски, используемые для вычис-
ления градиента в точке, отмеченной z5. Суммы коэффициентов по каждой из масок
равны нулю.
летворяют сформулированным в том же разделе условиям, являют-
ся следующие: Gx = (г8 - z$) nGy = (z$ — Zs). Два других определения,
предложенные Робертсом [Roberts, 1965] в ранних исследованиях
по цифровой обработке изображений, используют перекрестные
направления:
Gx=(z9-z5) и б^=и8-г6).
(3.7-15)
Если выбрать уравнение (3.7-13), то градиент будет вычисляться по сле-
дующей формуле:
Vf = [(z9-z5)2 + (z8-z6)2]l/2. (3.7-16)
Если используются абсолютные значения, тогда, подставляя уравне-
ния (3.7-15) в (3.7-14), получим следующее приближение к значени-
ям градиента:
V/^|z9-75| + k8-^|-
(3.7-17)
2 Глава 3. Пространственные методы улучшения изображений
Это уравнение может быть реализовано с помощью двух масок, показан-
ных на Рис. 3.44(6) и (в). Эти маски называют перекрестным градиентным
оператором Робертса. Однако маски четного размера реализовывать не-
удобно. Наименьшая маска фильтра, которая нас интересует, имеет раз-
меры 3x3. Приближением, использующим абсолютные значения для
той же самой точки z§, но уже по маске 3x3, будет:
V/«|(z7 + 2z8 + z9)~(zi + 2z2 + z3)|+ (3 718)
+|(^3 + 2^6 + Z9)~ (Z\ + 2^4 + Z7)|.
Разность между значениями пикселей в третьей и первой строках ок-
рестности 3x3 приближает значение производной по направлению х,
а разность между значениями пикселей в третьем и первом столбцах
приближает значение производной по направлению у. Маски, пред-
ставленные на Рис. 3.44(г) и (д), называют оператором Собела (Sobel).
Они могут использоваться для реализации уравнения (3.7-18) с помо-
щью того же алгоритма, что и уравнение (3.5-1). Использование весо-
вых коэффициентов со значением 2 основано на стремлении при-
своить центральным (в строках и столбцах) точкам большей
значимости, и тем самым достичь большей гладкости (этот вопрос
детально будет рассмотрен в Главе 10). Заметим, что суммы коэффи-
циентов каждой из масок равны 0, и это означает, что на участках
изображения с постоянным уровнем яркости отклик любого из при-
веденных операторов будет равен 0, как и должно быть у оператора,
соответствующего первой производной.
Пример 3.14. Применение градиента для улучшения контуров.
О Градиент часто используется в техническом контроле для того,
чтобы помочь человеку обнаружить дефекты, или, что является бо-
лее общим, как предварительная обработка в автоматизированном
контроле. Об этом будет говориться в Главах 10 и 11. Однако представ-
ляется полезным рассмотреть некоторый простой пример прямо сей-
час, чтобы показать, как может быть использован градиент для улуч-
шения видимости дефектов и для удаления слабо меняющихся
характеристик фона. В данном конкретном примере улучшение ис-
пользуется в качества шага предварительной обработки для последу-
ющего автоматического контроля, а не для визуального анализа.
На Рис. 3.45(a) показано оптическое изображение контактной лин-
зы, освещенной специальной световой установкой, предназначенной
для подчеркивания неточностей. В данном случае можно заметить два
дефекта на краях (они видны на окружности в позициях «4 и 5 ча-
сов»), На Рис. 3.45(6) показан градиент, подсчитанный по формуле
3.8. Комбинирование методов пространственного улучшения
Рис. 3.45. (а) Оптическое изображение контактной линзы (дефекты видны на
краях окружности в позициях «4 и 5 часов»), (б) Градиент, полученный оператором
Собела. (Исходное изображение предоставил Пит Сайтс, Perceptics Corporation).
(3.7-14) с масками оператора Собела, показанными на Рис. 3.44(г) и (д).
Дефекты краев видны как на изображении 3.45(a) так и на 3.45(6), но
преимуществом второго изображения является то, что удалены слабо
меняющиеся изменения яркостей, тем самым упрощена задача авто-
матического контроля. Заметим также, что градиентная обработка
подчеркивает мелкие дефекты, которые нелегко заметить на полуто-
новом изображении (такими дефектами могут быть чужеродные вкрап-
ления, воздушные карманы в держателе, а также неточности мениска
линзы). Способность подчеркнуть мелкие неоднородности на ровном
сером поле есть еще одна важная характеристика градиента. К"
3.8. Комбинирование методов
пространственного улучшения
За некоторыми исключениями, как, например, в случае комбина-
ции сглаживания с рассмотренным в Разделе 3.6.1 пороговым пре-
образованием, до настоящего момента внимание уделялось лишь
каждому из методов улучшения по отдельности. Однако при реше-
нии конкретных задач для достижения приемлемых результатов мо-
жет потребоваться применение нескольких дополняющих друг дру-
га методов улучшения. В данном разделе на отдельных примерах
будет проиллюстрировано, как скомбинировать отдельные подхо-
ды, разработанные в настоящей главе, для решения более сложной
задачи улучшения.
214 Глава 3. Пространственные методы улучшения изображений
Изображение на Рис. 3.46(a) есть полный снимок скелета, полу-
ченный с помощью гамма-лучей (см. Раздел 1.3.1), использующий-
ся для обнаружения таких заболеваний, как костные инфекции и опу-
холи. Целью является улучшение данного изображения путем
повышения его резкости и более подробного выявления деталей ске-
лета. Малый динамический диапазон уровней яркости и высокое со-
держание шума делают это изображение трудным для улучшения.
Стратегия состоит в использовании лапласиана для выделения мел-
ких деталей, и градиента для улучшения выступающих краев. По
причинам, которые будут объяснены ниже, сглаженная копия гради-
ентного изображения будет использоваться для маскирования ла-
пласиана (касательно маскирования см. Раздел 3.4). В конце, для
увеличения динамического диапазона яркостей, будет использовать-
ся градационное преобразование.
На Рис. 3.46(6) показан лапласиан, полученный фильтрацией ис-
ходного изображения с использованием маски на Рис. 3.39(f). Для луч-
шего воспроизведения это изображение было подвергнуто градацион-
ной коррекции, такой же, как и изображение на Рис. 3.40. Более
резкое изображение можно получить прямо сейчас простым сложени-
ем изображений на Рис. 3.46(a) и (б), что будет являться реализацией
второй строки уравнения (3.7-5), поскольку использовалась маска с по-
ложительным центральным коэффициентом. Уже 1лядя на уровень шу-
мов на изображении (б) можно ожидать, что сложение изображений
Рис. 3.46(a) и (б) приведет к получению более резкого, но весьма за-
шумленного изображения, что и подтверждается результатом, пока-
занным на Рис. 3.46(b). Уменьшить уровень шума можно было бы с по-
мощью медианного фильтра. Однако медианная фильтрация является
нелинейной операцией, способной удалить детали изображения, что
неприемлемо при обработке медицинских изображений.
Альтернативным подходом является использование маски, форми-
руемой путем сглаживания градиента исходного изображения. Это
нетрудно пояснить на основании свойств первой и второй производ-
ных, рассмотренных в Разделе 3.7.1. Лапласиан, будучи оператором вто-
рой производной, имеет то несомненное преимущество, что являет-
ся прекрасным способом улучшения мелких деталей. Однако из-за
этого он усиливает шум в значительно большей степени, чем гради-
ент. Этот шум более неприятен на гладких областях, где он весьма за-
метен. Градиент, по сравнению с лапласианом, дает более сильный от-
клик в областях со значительными изменениями яркости (на
яркостных переходах и ступеньках). Отклик градиента на шум и мел-
кие детали слабее, чем у лапласиана, и к тому же в дальнейшем может
быть снижен путем сглаживания градиента усредняющим фильтром.
3.8. Комбинирование методов пространственного улучшения
Рис. 3.46. (а) Полный снимок скелета, полученный с помощью гамма-лучей,
(б) Применение оператора лапласиана к изображению (а), (в) Повышение резкости
сложением изображений (а) и (б), (г) Применение оператора Собела к изображению
(а).
Глава 3. Пространственные методы улучшения изображений
Рис. 3.46. (д) Изображение (г), сглаженное усредняющим фильтром по окре-
стности 5x5. (е) Изображение-маска, полученное перемножением изображений (в)
и (д).(ж) Изображение с повышенной резкостью, полученное сложением изображе-
ний (а) и (е). (з) Конечный результат, полученный из изображения (ж) градационной
коррекцией по степенному закону. Сравните изображения (ж) и (з) с исходным изо-
бражением (а). (Исходное изображение предоставлено компанией G.E. Medical
Systems).
3.8. Комбинирование методов пространственного улучшения 217
Тем самым, идея сводится к сглаживанию градиента и умножению его
на изображение-лапласиан. В этом контексте можно рассматривать
градиент как изображение-маску. Их произведение позволит сохра-
нить детали в областях изменения яркости и подавить шум на отно-
сительно плоских участках. Этот процесс может быть грубо пред-
ставлен как объединение лучших качеств лапласиана и градиента.
Результат произведения прибавляется к исходному изображению,
чтобы получить окончательное изображение с повышенной резкос-
тью, и даже может использоваться как вариант фильтрации с подъе-
мом высоких частот.
На Рис. 3.46(г) показан градиент, полученный фильтрацией ис-
ходного изображения оператором Собела по формуле (3.7-14). Ком-
поненты Gx и Gy были получены с использованием масок, показан-
ных на Рис. 3.44(г) и (д) соответственно. Как и следовало ожидать из
рассуждений Раздела 3.7.1, контуры на этом изображении выделяют-
ся значительно сильнее, чем на изображении-лапласиане. Сглажен-
ное градиентное изображение, представленное на Рис. 3.46(д), бы-
ло получено с использованием усредняющего фильтра размерами
5x5. Оба градиентных изображения перед воспроизведением были
подвергнуты тому же градационному преобразованию, что и изобра-
жение-лапласиан. Поскольку на градиентном изображении наи-
меньшее допустимое значение равно 0, фон на этом изображении ос-
тается черным, а не серым, как в случае лапласиана на Рис. 3.46(6).
Тот факт, что изображения на Рис. 3.46(г) и (д) выглядят значитель-
но более яркими, чем изображение на Рис. 3.46(6), является очевид-
ным следствием того, что на изображении со значительным содер-
жанием контуров, градиент, как правило, имеет более высокие
значения, чем лапласиан.
Результат перемножения лапласиана и сглаженного градиента по-
казан на Рис. 3.46(e). Заметно преобладание резких контуров и отно-
сительное снижение уровня наблюдаемого шума, что и являлось ос-
новной целью маскирования лапласиана сглаженным градиентным
изображением. Прибавление полученного произведения к исходно-
му изображению дает в результате изображение с повышенной резко-
стью, показанное на Рис. 3.46(ж). Значительное повышение резкос-
ти деталей по сравнению с исходным изображением заметно на
большей части д анного изображения, включая ребра, позвоночник, таз
и череп. Такое улучшение недостижимо при использовании одного
только лапласиана или градиента.
Только что рассмотренная процедура повышения резкости не
влияет в заметной степени на динамический диапазон яркостей изо-
бражения. Таким образом, финальный шаг в данной задаче улучше-
218 Глава 3. Пространственные методы улучшения изображений
ния состоит в увеличении динамического диапазона полученного
результата. Как было детально рассмотрено в Разделах 3.2 и 3.3, су-
ществует множество функций градационной коррекции, которые
позволяют достичь этой цели. По результатам Раздела 3.3.2 известно,
что эквализация гистограммы вероятно не даст хорошие результаты
на изображениях, распределение яркости которых сдвинуто в об-
ласть черного, как на изображениях из данного примера. Решением
могло бы стать задание гистограммы, однако общий черный фон
изображения, с которым приходится иметь дело, заставляет сделать
выбор в пользу степенного преобразования. Так как требуется растя-
жение уровней яркостей, то, следовательно, значение ув уравнении
(3.2-3) должно быть меньше 1. Несколько экспериментов с различ-
ными значениями параметров позволяют получить окончательный ре-
зультат, показанный на Рис. 3.46(з), при у= 0,5 и с = 1. Сравнение дан-
ного изображения с изображением на Рис. 3.46(ж) показывает, что
стало заметным значительно большее число деталей. Участки вбли-
зи запястий, кистей рук, лодыжек и ступней являются тому хороши-
ми примерами. Структура костей скелета, включая кости рук и ног,
также стала более отчетливой. На исходном изображении весьма сла-
бо видны контуры тела и мягкие ткани. «Вытаскивание» подобных де-
талей с помощью растяжения динамического диапазона яркостей
усиливает также и шум, но, тем не менее, можно отметить, что на
Рис. 3.46(з) имеется значительное визуальное улучшение исходного
изображения.
Только что рассмотренный подход показателен как пример ис-
пользования взаимосвязанных процедур для получения конечного
результата, недостижимого с помощью какого-то одного метода. По-
следовательность применения процедур зависит от задачи. Конеч-
ным пользователем класса изображений, к которому относится рас-
смотренное в настоящем разделе изображение, скорее всего является
врач-рентгенолог. По причинам, которые выходят за рамки нашего рас-
смотрения, врачи не любят при диагностике основываться на резуль-
татах улучшения изображений. Тем не менее, улучшенные изобра-
жения весьма полезны в выявлении деталей, которые могут оказаться
ключевыми для последующего анализа исходного изображения или по-
следовательности изображений. В других же областях результаты улуч-
шения изображений могут действительно стать конечным продук-
том. Примеры можно найти в полиграфии, в системах контроля
продукции на основе анализа изображений, в судебной медицине,
в микроскопии, в системах слежения, а также во многих других обла-
стях, где главной целью улучшения является получение изображения
с более высоким содержанием видимых деталей.
Заключение
Материалы данной главы представляют типичные методы простран-
ственной обработки, обычно используемые на практике для улучше-
ния изображений. Эта область обработки изображений динамично раз-
вивается, так что и в профессиональных изданиях, и в анонсах новой
продукции регулярно появляются описания новых методов. По этой
причине вопросы, включенные в данную главу, были выбраны по
своей фундаментальной значимости как основа для понимания совре-
менного состояния методов улучшения и проведения дальнейших
исследований в этой области. Кроме вопросов улучшения, в данной
главе преследовались цели знакомства с рядом понятий, такими как
фильтрация с использованием пространственных масок, которые бу-
дут широко использованы в оставшейся части книги. В следующей гла-
ве вопросы улучшения будут рассмотрены с другой точки зрения —
с позиции фильтрации в частотной области. На основе изложенного
в этих двух главах, у читателя возникнет твердое понимание термино-
логии, а также некоторых, наиболее важных методов, используемых
в обработке изображений. Тот факт, что эти методы изложены в кон-
тексте улучшения изображений, поможет яснее понять, какой эффект
они оказывают на изображение.
Ссылки и литература для дальнейшего изучения
Материалы Раздела 3.1 взяты из [Gonzalez, 1986]. Дополнительный ма-
териал по Разделу 3.2 можно найти в [Schowengerdt, 1983], [Poyton,
1996] и [Russ, 1999]. Касательно оптимизации воспроизведения изо-
бражений см. [Tsujii et al., 1998]. Ранние ссылки на гистограммную об-
работку: [Hummel, 1974], [Gonzalez, Fittes, 1977] и [Woods, Gonzalez,
1981]. В работе [Stark, 2000] сделано интересное обобщение эквали-
зации гистограммы для адаптивного улучшения контраста. Другие
подходы к улучшению контраста проиллюстрированы в [Centeno,
Haertel, 1997] и [Cheng, Xu, 2000]. По поводу улучшения, базирующе-
гося на идеальной модели изображения, см. [Highnam, Brady, 1997].
Расширение локальной эквализации гистограммы рассмотрено
в [Caselles et al., 1999] и [Zhu et al., 1999]. Использование локальных
статистик для улучшения изображений рассмотрено в [Narendra,
Fitch, 1981]. В статье [Kim et al., 1997] представлен интересный под-
ход, в котором для улучшения изображения комбинируются гради-
ент и локальные статистики.
Разность изображений (Раздел 3.4.1) является общим средством,
широко применяемым для обнаружения изменений. Как уже отмена-
^ 220 Глава 3. Пространственные методы улучшения изображений
лось, одним из важных приложений метода разностей является рентге-
нография с использованием масок, в которой серьезную проблему со-
ставляет подвижность пациента, поскольку из-за движения изображе-
ние размазывается. Проблеме движения в применении к методу
разностей уделялось большое внимание уже сравнительно давно, как по-
казано в обзорной статье [Meijering et al., 1999]. Метод снижения шума
с помощью усреднения изображения (Раздел 3.4.2) был предложен
в [Kohler, Howell, 1963]. Касательно ожидаемых значений среднего и дис-
персии суммы случайных переменных см. [Peebles, 1993].
В качестве дополнительного чтения по вопросам линейной простран-
ственной фильтрации и ее применения рекомендуются работы
[Umbaugh,1998], [Jain, 1989], и [Rosenfeld, Как, 1982]; в них также рассма-
триваются ранговые фильтры. В статье [Wilburn, 1998] рассматриваются
обобщения фильтров, основанных на порядковых статистиках. В книге
[Pitas, Venetsanopoulos, 1990] также рассматриваются медианный и дру-
гие нелинейные пространственные фильтры. Специальный выпуск жур-
нала [IEEE Transactions in Image Processing, 1996] посвящен вопросу нели-
нейной обработки изображений. Материалы по вопросам фильтрации
с подъемом высоких частот взяты из [Schowengerdt, 1983]. Многие из
пространственных фильтров, которые были приведены в настоящей гла-
ве, будут вновь рассмотрены в связи с вопросами восстановления изоб-
ражений (Глава 5) и обнаружения контуров (Глава 10).
Задачи
3.1 Экспоненты вида е-аг2 с положительной константой приме-
нимы для построения гладкой функции градационной кор-
рекции. Начните с этой базовой функции и найдите функции
преобразования, вид которых, показан на графиках. Указанные
константы являются входными параметрами, и должны вхо-
дить в формулу предлагаемых Вами преобразований. (Для уп-
рощения решения, на третьей кривой Lq не является требуемым
параметром).
3.2 *(а) Найдите непрерывную функцию, реализующую преобра-
зование усиления контраста, показанное графиком на
Рис. 3.2.(а). Кроме параметра т Ваша функция должна
включать параметр Е для управления наклоном функции
при переходе от низких значений яркости к высоким. Ва-
ша функция должна быть нормализована так, что ее мини-
мальное и максимальное значения должны быть равны 0 и
1 соответственно.
(б) Найдите семейство преобразований как функции параме-
тра Е для фиксированного значения т = L/2, где L — чис-
ло уровней яркости на изображении.
(в) Чему равно наименьшее значение Е, при котором Ваша
функция в действительности будет выполнять преобразо-
вание, показанное на Рис. 3.2(6)? Другими словами, Ваша
функция не обязана быть ей идентичной, а просто должна
давать те же результаты в получении бинарного изображе-
ния. Предположите, что изображение является 8-битовым
и пусть т = 128. Также пусть С есть наименьшее положи-
тельное число, представимое в используемом компьютере.
3.3 Предложите набор функций градационных преобразований,
позволяющих получить все отдельные битовые плоскости
8-битового одноцветного изображения. (Например, функция
преобразования с параметрами Т(г) = 0 для г в диапазоне
[0,127] и Т(г) = 255 для гв диапазоне [128, 256] дает изображе-
ние 7-й битовой плоскости.)
3.4 *(а) К какому эффекту на гистограмме приведет обнуление
младшей битовой плоскости изображения?
(б) Как будет выглядеть гистограмма, если, наоборот, обнулить
старшую битовую плоскость изображения?
*3.5 Объясните, почему операция эквализации гистограммы в дис-
кретном виде не приводит, вообще говоря, к равномерной гис-
тограмме.
3.6 Предположим, что дискретное изображение было подвергну-
то операции эквализации гистограммы. Покажите, что вто-
рой проход операции эквализации гистограммы даст в точно-
сти тот же результат, что уже был получен после первого
прохода.
*3.7 В некоторых приложениях предполагается, что гистограмма
входного изображения описывается гауссовской плотностью
распределения вероятностей вида
222 Глава 3. Пространственные методы улучшения изображений
(г-т)2
Рг(г) = -гГ=~е 2°2 >
у2ла
где т и о суть значения среднего и стандартного отклонения
гауссовской плотности распределения вероятностей. Данное
приближение позволяет значениям тиа являться мерами
среднего уровня яркости и контраста такого изображения. Ка-
кой должна быть функция преобразования для эквализации ги-
стограммы такого изображения?
*3.8 Считая значения непрерывными, покажите на примере, что
возможен случай, при котором функция преобразования, за-
даваемая уравнением (3.3-4), удовлетворяет условиям (а) и (б)
Раздела 3.3.1, но обратная к ней функция может являться не-
однозначной19?
3.9 (а) Покажите, что функция дискретного преобразования, за-
даваемая уравнением (3.3-8) для эквализации гистограммы,
удовлетворяет условиям (а) и (б) Раздела 3.3.1.
(б) Покажите на примере, что для обратного преобразования,
задаваемого уравнением (3.3-9), это, вообще говоря, не
выполняется.
(в) Покажите, что обратное преобразование, задаваемое урав-
нением (3.3-9), удовлетворяет условиям (а) и (б) Разде-
ла 3.3.1, если ни один из уровней яркости гр,
к = 0, 1,..., L — 1, не пропущен.
3.10 Плотность распределения вероятностей р/r) значений элемен-
тов изображения имеет вид, показанный первым графиком на ри-
сунке. Необходимо преобразовать уровни яркостей изображения
так, чтобы плотность распределения вероятностей преобра-
19 Заметим, что условия строгой монотонности непрерывной функции прямого пре-
образования достаточно для существования и монотонности обратного преобразо-
вания. — Прим, перев.
зованного изображения имела вид, показанный на втором гра-
фике. Предполагая значения непрерывными, найдите преобра-
зование (в терминах г и z), решающее поставленную задачу.
*3.11 Предложите алгоритм обновления локальной гистограммы
при передвижении окрестности на один элемент (см. метод ло-
кального улучшения в Разделе 3.3.3).
3.12 Два изображения, fix, у) и g(x, у), имеют гистограммы hjVi hg.
Найдите условия, при которых можно выразить через и hg ги-
стограммы результатов следующих преобразований:
(а)/(х,у) +g(x,y)
(б) fix, у) - g(x, у)
(в)Жу)х^(х,у)
(г) f(x, у) / g(x, у)
Объясните, как вычислить гистограммы ддя каждого из случаев.
3.13 Рассмотрите два 8-битовых изображения (а) и (б), уровни яр-
костей которых занимают весь диапазон значений от 0 до 255.
(а) Обдумайте влияние эффекта ограничения при многократ-
ном вычитании изображения (б) из изображения (а).
(б) Изменится ли результат, если поменять изображения мес-
тами?
*3.14 Вычитание изображений часто используется в промышлен-
ности для выявления отсутствующих компонентов при сбор-
ке изделий. Подход состоит в том, что запоминается эталонное
изображение, соответствующее правильной сборке; это изоб-
ражение затем вычитается из изображений поступающих ана-
логичных изделий. В идеале, если новое изделие собрано пра-
вильно, разница должна быть равна нулю. Разностное
изображение ддя изделий с отсутствующими компонентами бу-
дет ненулевой в тех областях, где они отличаются от эталонно-
го изображения. С Вашей точки зрения, какие условия долж-
ны выполняться на практике для такого способа работы?
3.15 Докажите верность равенств (3.4-4) и (3.4-5).
3.16 В одном из промышленных приложений рентгеновская съем-
ка используется для контроля внутренней части некоторой
сложной отливки. Целью является обнаружение пустот в отлив-
ке, которые обычно выглядят как маленькие пятна на изобра-
жении. Однако, из-за особенностей материала отливки и уров-
ня энергии рентгеновских лучей, возникает высокий уровень
шума, часто затрудняющий процесс контроля. В качестве ре-
шения проблемы используется усреднение серии изображе-
ний для подавления шума и тем самым улучшения видимых
контрастов. При вычислении среднего важно максимально
224 Глава 3. Пространственные методы улучшения изображений
уменьшить число изображений, чтобы сократить общее время
экспозиции, в течение которого деталь должна оставаться не-
подвижной. После многочисленных экспериментов было вы-
яснено, что достаточным является уменьшение дисперсии шу-
ма в 10 раз. Если устройство ввода изображений работает с
частотой 30 кадров в секунду, как долго отливка должна оста-
ваться неподвижной при съемке, чтобы достичь требуемого
уменьшения дисперсии шума? Считайте шум некоррелиро-
ванным и имеющим нулевое среднее.
3.17 Реализация линейных пространственных фильтров требует
перемещения центра маски по изображению и вычисления, для
каждого из положений маски, суммы произведений коэффи-
циентов маски на значения соответствующих пикселей (см. Раз-
дел 3.5). В случае низкочастотной фильтрации все коэффи-
циенты равны 1, и можно использовать однородный усредняющий
фильтр или алгоритм скользящего среднего, основанный на том,
что при переходе от точки к точке обновляется только часть вы-
числяемых элементов.
*(а) Сформулируйте такой алгоритм для фильтра размерами
ихи, демонстрирующий характер взаимосвязи вычисле-
ний с последовательностью сканирования, использующей-
ся при передвижении маски по изображению.
(б) Отношение числа операций, требуемых для реализации
метода «в лоб» к числу операций, используемых алгоритмом
скользящего среднего называется эффективностью алгорит-
ма. Подсчитайте эффективность алгоритма для данного
случая и изобразите ее в виде графика зависимости от п для
п > 1. Коэффициент 1/и2 является общим для обоих случа-
ев, и поэтому не должен приниматься во внимание. Счи-
тайте, что изображение окружено бордюром из нулей до-
статочной ширины, чтобы не учитывать влияние граничных
эффектов при вычислениях.
3.18 Исследуйте предельные эффекты многократного применения
низкочастотного сглаживающего фильтра размерами 3x3 к дис-
кретному изображению. Можете игнорировать влияние границ
изображения.
3.19 *(а) В Разделе 3.6.2 утверждалось, что изолированные темные
или светлые (по отношению к фону) кластеры, с числом
пикселей меньшим половины площади медианного филь-
тра, будут при фильтрации удалены (заменены на значение
медианы по окружающему фону). Объясните, почему это
так, предполагая, что фильтр имеет размеры пхп, где п — не-
четное число.
(б) Рассмотрим изображение, содержащее различные наборы
кластеров. Предположим, что все точки кластера или свет-
лее, или темнее, чем фон (но не в одном и том же класте-
ре), а также что площадь каждого из кластеров меньше чем
«2/2. При каких условиях относительно п один или больше
кластеров перестанут быть изолированными в смысле, ука-
занном в части (а)?
*3.20 (а) Разработайте алгоритм для вычисления медианы по окре-
стности размерами пхп.
(б) Предложите способ обновления значения медианы при
передвижении центра окрестности от точки к точке.
3.21 (а) В задаче распознавания символов, страницы текста редуци-
руются в двоичную форму с помощью функции порогового
преобразования, показанной на Рис. 3.2(6). Затем применя-
ется процедура утоньшения линий до размера в один пиксель,
которые можно рассматривать как двоичные единицы на
нулевом фоне. Ввиду наличия шума, процесс бинаризации
и утоньшения приводит к возникновению разрывов в лини-
ях размерами от 1 до 3 элементов. Один из способов «реста-
врирования» разрывов состоит в сглаживании бинарного
изображения усредняющей маской, что позволяет с помощью
ненулевых пикселей построить «мостики» через разрывы.
Определите минимальный (нечетный) размер усредняющей
маски, при котором решается данная задача.
(б) После устранения разрывов желательно преобразовать изо-
бражение пороговой операцией обратно в бинарную фор-
му. Продолжая ответ к задаче (а), скажите, каково должно
быть максимальное значение порога, которое не приведет
вновь к возникновению разрывов между линиями?
*3.22 Три приведенных ниже изображения были сглажены квадрат-
ной усредняющей маской размерами п = 23, 25 и 45 соответст-
8 А-223
Глава 3. Пространственные методы улучшения изображений
венно. Вертикальные полоски в левой нижней части изобра-
жений (а) и (в) расфокусированы, но между ними видно чет-
кое разделение. Однако на изображении (б) полоски слились,
несмотря на то, что размер усредняющей маски значительно
меньше, чем на изображении (в). Объясните этот эффект.
3.23 Рассмотрим задачу, подобную показанной на Рис. 3.36, в ко-
торой требовалось удалить объекты, укладывающиеся в ква-
драт размерами qxq пикселей. Предположим, желательно
уменьшить среднюю яркость таких объектов до уровня од-
ной десятой (или более) от первоначального уровня их ярко-
сти. Тогда подобные объекты по яркости будут близки к фо-
ну и могут быть удалены пороговым преобразованием. Укажите
минимальной (нечетный) размер усредняющей маски, кото-
рая будет обеспечивать желаемое снижение уровня яркости за
один проход.
3.24 К исходному изображению применяется усредняющая маска
для подавления шума, а затем маска лапласиана для улучше-
ния мелких деталей. Изменится ли результат, если поменять
очередность этих операций?
*3.25 Покажите, что операция лапласиана, заданная уравнением
(3.7-1), является изотропной (инвариантной к повороту). Вам
потребуются следующие уравнения, связывающие координа-
ты точки при повороте осей на угол 0:
x = x'cos0-y'sin0
у = x'sin 0+у'cos 0,
где (х, у) значения координат до поворота, а (х', у') — по-
сле поворота.
3.26 Задайте маску размерами 3x3 для выполнения за один проход
операции нерезкого маскирования.
*3.27 Покажите, что вычитание лапласиана из изображения про-
порционально нерезкому маскированию. Используйте опре-
деление лапласиана, заданное уравнением (3.7-4).
3.28 (а) Покажите, что вычисление модуля градиента согласно
уравнению (3.7-13) является изотропной операцией (см. За-
дачу 3.25).
(б) Покажите, что свойство изотропности в общем случае на-
рушается, если вычислять градиент согласно уравнению
(3.7-14).
3.29 Для долговременного (круглосуточно в течение 30 дней) кон-
троля одной и той же сцены используется ПЗС-камера. Циф-
ровые изображения фиксируются и передаются в центр обра-
ботки каждые 5 минут. Освещение сцены меняется с дневно-
го на искусственное, но так, что сцена всегда освещена и все-
гда можно сделать снимок. Поскольку уровень освещения
достаточен настолько, что яркости объектов сцены всегда ос-
таются на линейном участке характеристики камеры, было
принято решение отказаться от использования какого-либо ме-
ханизма компенсации освещенности в самой камере. Наобо-
рот, было принято решение использовать цифровые методы
постобработки, и таким путем осуществить нормализацию —
приведение изображений к некоторому постоянному уровню
освещения. Предложите способ решения этой задачи. Вы сво-
бодны в выборе любых желаемых методов, но ясно формули-
руйте все предположения, которые Вам потребуются для дости-
жения цели.
ГЛАВА 4
ЧАСТОТНЫЕ
МЕТОДЫ
УЛУЧШЕНИЯ
ИЗОБРАЖЕНИЯ
Улучшать: увеличивать значимость, ценность или привлекательность.
Частота: величина, выражающая число повторений одной и той же последо-
вательности значений периодической функции в единицу времени.
Толковый словарь Вебстера
Несмотря на значительные усилия, затраченные в предыдущей гла-
ве на изучение пространственных методов улучшения изображе-
ний, для всестороннего понимания предмета необходимо также,
как минимум, практическое представление о том, как использовать
преобразование Фурье для обработки изображений в частотной об-
ласти. Для глубокого понимания этих вопросов не обязательно ста-
новиться специалистом в области обработки сигналов. Ключ к ус-
пеху в том, чтобы сосредоточиться на основных принципах и их
связи с цифровой обработкой изображений. Для того чтобы сде-
лать более понятной систему обозначений, являющуюся обычно
источником трудностей для начинающих, мы в этой главе обраща-
ем особое внимание на связь характеристик изображения с исполь-
зуемыми при их определении математическими инструментами.
Первоочередная цель этой главы — помочь читателю овладеть базо-
выми знаниями в области фурье-анализа и его применении для
улучшения изображений. Позднее, в Главах 5,8, 10 и 11, мы обсудим
другие применения преобразования Фурье.
Мы начнем обсуждение с краткого обзора истории возникновения
фурье-анализа и того воздействия, которое он оказал на математику,
естественные науки и технику. Затем мы дадим определение преобра-
зования Фурье, введем понятие частотной области и соответствующие
обозначения, а также выясним причины, по которым эти инстру-
менты оказываются столь полезными для улучшения изображений.
Последующие разделы аналогичны разделам Главы 3, в которых об-
суждались методы пространственного сглаживания и повышения
4.1. Предварительные замечания
резкости, за исключением того, что теперь фильтрация осуществляет-
ся в частотной области. После обсуждения других способов улучше-
ния изображений с помощью преобразования Фурье, мы завершаем
главу рассмотрением вопросов, связанных с реализацией этого преоб-
разования в контексте обработки изображений.
4.1. Предварительные замечания
Французский математик Жан Батист Жозеф Фурье родился в 1768 г.
в городе Осер на полпути из Парижа в Дижон. Главное научное дости-
жение Фурье, благодаря которому он остался в памяти потомков,
было схематически изложено им в мемуарах 1807 г. и полностью опуб-
ликовано в 1822 г в его книге «Аналитическая теория тепла» (La
Theorie Analitique de la Chaleur). Спустя 55 лет эта книга была переве-
дена на английский Фрименом (см. [Freeman, 1878]). Результат Фу-
рье, относящийся к предмету рассмотрения настоящей главы, состо-
ит, по существу, в том, что любая функция, периодически
воспроизводящая свои значения, может быть представлена в виде
суммы синусов и/или косинусов различных частот, умноженных на не-
которые коэффициенты (теперь эта сумма носит название ряд Фурье).
Сложность поведения функции при этом не имеет значения. Если
только функция является периодической и удовлетворяет необреме-
нительным математическим условиям, она может быть представлена
в виде вышеуказанной суммы. В настоящее время это утверждение яв-
ляется общепризнанным, однако в момент своего появления это бы-
ла революционная идея, на «привыкание» к которой математикам
всего мира потребовалось более века. В то время оплотом математи-
ческого мышления было понятие регулярности функций. С таких
позиций идея о том, что сложная функция может быть представлена
в виде суммы простых (синусов и косинусов), казалась далеко не оче-
видной (Рис. 4.1). Поэтому не удивительно, что идеи Фурье в этом от-
ношении были встречены скептически.
Когда функция не является периодической (но площадь под ее гра-
фиком конечна1), она может быть выражена в виде интеграла от си-
нусов и/или косинусов, умноженных на некоторую весовую функцию.
В таком случае мы имеем дело с преобразованием Фурье, которое в боль-
шинстве практических задач оказывается даже более полезным, чем
ряд Фурье. Оба представления обладают важной характерной осо-
бенностью. Функция, заданная как рядом, так и преобразованием
1 Точнее, конечна площадь под графиком ее модуля. — Прим, перев.
230 Глава 4. Частотные методы улучшения изображения
ЖШШШШ
лллллллллллл
Рис. 4.1. Нижняя функция является суммой четырех расположенных над ней
функций. Высказанная в 1807 г. идея Фурье о том, что периодическая функ-
ция может быть представлена в виде суммы синусов и косинусов с весами, бы-
ла встречена скептически.
Фурье, может быть полностью, без потери информации, восстановле-
на (реконструирована) при помощи некоторой процедуры обращения.
Это свойство является одним из наиболее важных свойств рассматри-
ваемых представлений, поскольку оно позволяет работать в «фурье-об-
ласти», а затем вернуться в исходную область определения функции
без потери какой-либо информации.
В конечном счете, именно эффективность применения аппарата
рядов и преобразования Фурье для решения практических задач пре-
вратила его в фундаментальный инструмент, широко используемый
и изучаемый. Первоначально идеи Фурье были применены для реше-
ния задачи о распространении тепла. Это дало возможность предста-
вить дифференциальные уравнения, описывающие тепловой поток,
в таком виде, который позволил впервые получить их решения. На
протяжении последнего века, и особенно в последние 50 лет, идеи Фу-
рье привели к расцвету целых научных дисциплин и даже промыш-
ленных отраслей. Наступление эпохи ЭВМ и открытие алгоритма
быстрого преобразования Фурье (БПФ) в конце 50-х годов (или не-
много позднее) произвели революцию в области обработки сигналов.
Эти две основные технологии впервые сделали возможным обработ-
ку и интерпретацию огромной совокупности сигналов исключитель-
ной важности в разных сферах человеческой деятельности от меди-
цинской диагностики до новейших средств электронной связи.
Поскольку мы будем иметь дело только с функциями (изображе-
ниями) конечной протяженности, нас будет интересовать именно
преобразование Фурье. Материал следующего раздела знакомит чи-
тателя с преобразованием Фурье и частотной областью. Показано,
что методы фурье-анализа дают ясные по смыслу и практичные
способы изучения и реализации совокупности подходов для улучше-
ния изображений. В некоторых случаях эти подходы аналогичны под-
ходам, развитым в Главе 3, в других случаях они являются дополни-
тельными по отношению к последним.
4.2. Введение в фурье-анализ.
Преобразование Фурье и частотная
область
Этот раздел знакомит читателя с преобразованием Фурье в прост-
ранствах одного и двух измерений. Упор сделан на дискретный вари-
ант преобразования и некоторые его свойства.
4.2.1. Одномерное преобразование Фурье и его обращение
Прямое фуръе-преобразование (фуръе-образ) F(u) непрерывной функ-
ции одной переменной f(x) определяется равенством
F(u) = J f(x)e~i2nuxdx,
(4.2-1)
где z — мнимая единица (z2 = — 1). Наоборот, по заданному фурье-пре-
образованию F(zz) можно получить исходную функцию f(x) при помо-
щи обратного преобразования Фурье:
/(х)= j F(u)el2mxdu.
(4.2-2)
Глава 4. Частотные методы улучшения изображения
Эти преобразования составляют пару преобразований Фурье, а входя-
щие в них функции образуют фуръе-пару. Обратим внимание на тот
упомянутый в предыдущем разделе важный факт, что зная фурье-об-
раз можно получить исходную функцию. Указанные преобразова-
ния можно легко распространить на функции двух переменных:
F{u,v) = J J f{x,y)e ^^^^dxdy
и, аналогично, для обратного преобразования
f(x,y) = J J F(w,v)e/27r^v+L-’4(yU(yv_
(4.2-3)
(4-2-4)
Поскольку нас интересуют дискретные функции, мы не будем здесь
подробно останавливаться на этих равенствах2. Однако в ряде случа-
ев для читателя может оказаться проще оперировать этими формула-
ми, чем их дискретными аналогами, при доказательстве свойств дву-
мерного преобразования Фурье.
Фурье-преобразование дискретной функции одной переменной
f(x), х = 0, 1,2,..., М— 1, задается равенством
, Л/-1
F{u) = ~S f{x)e~i2nux/M , «=0,1,2,...,М-1. (4.2-5)
М
Это {прямое) дискретное преобразование Фурье (ДПФ) лежит в основе
всех рассмотрений настоящей главы. Как и ранее, по заданному фу-
рье-преобразованию F{u) можно восстановить исходную функцию при
помощи обратного ДПФ:
М-1
f(x)= X F(u)ei2nux/M , х=0,1,2,...,М-1. (4.2-6)
и=0
2 Более распространенной является другая форма определения преобразования Фурье,
в которой показатель экспоненты не содержит множителя 2л. При этом в формуле об-
ращения возникает дополнительный нормировочный множитель, равный (2 л)1 в од-
номерном случае и (2л)-2 в двумерном. — Прим, перев.
Множитель 1/М иногда ставится в формуле, определяющей обрат-
ное, а не прямое, преобразование Фурье. Реже оба равенства содержат
множитель 1 / 4м . Местоположение множителя не имеет значения.
Единственное требование при использовании двух множителей состо-
ит в том, что их произведение должно равняться 1 /М. При всей своей
важности, приведенные формулы являются, в действительности,
очень простыми3.
Вычисление фурье-преобразования F(u) по формуле (4.2-5) осу-
ществляется следующим образом. Вначале мы подставляем значе-
ние и = 0 в показатель экспоненты и производим суммирование по
всем значениям переменной х. Затем мы подставляем в экспоненту
значение и = 1 и снова производим суммирование по всем значени-
ям переменной х. Для получения полного фурье-образа мы повто-
ряем этот процесс для всех Мзначений переменной и. Вычисление
дискретного преобразования Фурье, таким образом, требует М 2
сложений и умножений (уменьшение числа необходимых опера-
ций является важным вопросом, который обсуждается в Разделе 4.6).
Как и исходная функция f(x), фурье-образ является дискретной ве-
личиной и содержит то же число компонент (элементов). Аналогич-
ные замечания следует отнести и к вычислению обратного преобра-
зования Фурье.
Важная особенность дискретных преобразований заключается
в том, что, в отличие от непрерывного случая, здесь нет необходимос-
ти заботиться о существовании ДПФ и обратного к нему. Дискретное
преобразование Фурье и его обращение всегда существуют. Чтобы убе-
диться в этом, достаточно подставить одно из двух равенств (4.2-5), (4.2-
6) в другое и использовать ортогональность экспоненциальных членов
(Задача 4.1). Полученное в результате тождество указывает на сущест-
3 Полезно сразу обратить внимание начинающего читателя на следующее обстоятельст-
во. Формула (4.2-5) позволяет определить фурье-образ F(u) не только для указанных зна-
чений переменной и , но и для всех остальных целых значений. При этом функция Г(и)
оказывается периодической с периодом M(F(u+M) = F(u)), и любые Мподряд взятых зна-
чений содержат всю информацию о фурье-образе. В этом случае суммирование в форму-
ле (4.2-6) можно вести по любому периоду длины М, т.е. от и0 до и0 + М, где и(1 — любое
целое число.
Аналогично, формула (4.2-6) имеет смысл для всех целых значений переменной х. При
этом определяемая ею функция целого аргумента совпадает с периодическим (с пери-
одом М) продолжением исходной функции/}*) на все целые значения аргумента. Ес-
ли с самого начала периодически продолжить функцию/}*) на все целые значения ар-
гумента, то и в формуле (4.2-5) суммирование можно вести по любому периоду длины
М, т.е. от*о до*о + М, где*о—любое целое число. Подробнее вопросы, связанные с пе-
риодизацией, рассматриваются автором в Разделе 4.6. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
вование обеих функций4. Разумеется, вопрос о том, что происходит
в случае, когда функция f(x) принимает бесконечное число значений,
остается открытым. Однако в этой книге мы будем иметь дело исклю-
чительно с конечными величинами. Сказанное выше прямо примени-
мо к функциям двух (и более) переменных. Таким образом, в цифро-
вой обработки изображений нет проблемы существования дискретного
преобразования и обратного к нему.
Понятие частотной области, несколько раз упоминавшееся в этой
и предыдущей главах, прямо следует из формулы Эйлера:
е'е = cos 6+z sin6. (4.2-7)
Подставляя это выражение в (4.2-5) и используя четность косину-
са (cos(—6) = cos(6)) и нечетность синуса (sin(—6) = — sin(6)), по-
лучаем
। М-1
F(u) =— У f(x)[cos2iwx/M-ism2iwx/M],
м
и = 0,1,2,..., (М-1). (4.2-8)
Таким образом, мы видим, что каждый элемент фурье-преобразова-
ния (т.е. значение F(u) для каждого значения и) состоит из суммы по
всем значениям функции f(x). Значения функции/(х), в свою оче-
редь, умножаются на синусы и косинусы разных частот. Область зна-
чений переменной и, на которой принимает свои значения функция
F(u), естественно назвать частотной областью, поскольку значение пе-
ременной и определяет частоты слагаемых, составляющих преобра-
зование. (Значения переменной х также влияют на частоты, но по-
скольку по этой переменной производится суммирование, это
влияние одинаково для всех значений переменной и.) Каждый из М
элементов функции F(u) называется частотной компонентой пре-
образования. Использование терминов частотная область и час-
тотные компоненты по существу не отличается от использования
терминов временная область и временные компоненты, которыми мы
будем обозначать область определения и значения функцииДх) в слу-
чае, когда х — временная переменная.
4 В действительности существование с очевидностью следует из конечности соответ-
ствующих сумм. Предлагаемое вычисление позволяет убедиться, что данные преоб-
разования являются обратными по отношению друг к другу. — Прим, перев.
Полезная аналогия возникает при сравнении преобразования
Фурье со стеклянной призмой. Призма представляет собой физи-
ческий прибор, который разлагает свет на различные цвета в зави-
симости от длины (частоты) электромагнитных волн его составля-
ющих. Преобразование Фурье можно представлять себе как своего
рода «математическую призму», которая также разлагает функцию
на различные составляющие в зависимости от ее «частотного содер-
жания». Рассматривая свет, мы говорим о его спектральном соста-
ве. Аналогично, преобразование Фурье позволяет нам описать
функцию с помощью совокупности составляющих ее частот. Это
и есть та глубокая идея, которая лежит в основе методов линейной
фильтрации.
Из равенства (4.2-5) или (4.2-8) видно, что элементы фурье-обра-
за в общем случае являются комплексными величинами. Как и в слу-
чае комплексных чисел, значения F(u) удобно иногда выражать в по-
лярных координатах:
F(u)^F(u)\e~^u\ (4.2-9)
где величины
|F(«)|=[jR2(h) + /2(«)]1/2 (4.2-10)
называются модулем или спектром фурье-преобразования, а вели-
чины
0(«) = arctg
R(u)
(4.2-11)
называются фазой или фазовым спектром преобразования. В форму-
лах (4.2-10) и (4.2-11) величины R(u) и Дм) обозначают действитель-
ную и мнимую части величины Дм), соответственно. При обсужде-
нии круга вопросов, связанных с улучшением изображений, нас
в первую очередь будут интересовать свойства спектра. Другой вели-
чиной, также используемой ниже в этой главе, является энергетиче-
ский спектр, определяемый как квадрат фурье-спектра:
Р(м) =| F{ и) |2=R2 (и)+11 (и). (4.2-12)
Наряду с термином энергетический спектр используется также тер-
мин спектральная плотность.
Глава 4. Частотные методы улучшения изображения
Пример 4.1. Фурье-спектры двух простых одномерных функций.
Перед тем как двигаться дальше, полезно рассмотреть простой одно-
мерный пример ДПФ. На рисунках 4.2(a) и (б) показаны функция и ее
фурье-спектр, соответственно. И функцияДх), и ее фурье-образ Дм) яв-
ляются дискретными, однако на графиках точки соединены между собой
для улучшения зрительного восприятия. В обсуждаемом примере М = 1024,
А= 1, и А'— всего лишь 8 точек. Заметим также, что центр спектра нахо-
дится в точке м = 0. Как показано в следующем параграфе, это достигает-
ся умножением функцииДх) на (— 1)х перед вычислением преобразова-
ния. На следующей паре рисунков (в) и (г) изображены функция
и фурье-спектр для случая К = 16 точек. Отметим следующие важные
свойства: (1) при увеличении вдвое площади под кривой в пространствен-
ной области высота спектра удваивается; (2) при увеличении вдвое разме-
ра носителя функции количество нулей спектра в заданном интервале
удваивается. Эта характерная взаимосвязь функций, образующих фурье-
fix)
Кточек
I---------- М точек ----------1
Рис. 4.2. (а) Дискретная М— точечная функция и (б) ее фурье-спектр. (в) Дис-
кретная функция с удвоенным числом ненулевых значений и (г) ее фурье-
спектр.
А
пару, наиболее полезна при интерпретации результатов обработки изоб-
ражений в частотной области.!!
Пусть теперь функцияfix),х = 0,1,2,..., М— 1, входящая в дискрет-
ное преобразование (4.2-5), является последовательностью отсчетов сво-
его непрерывного аналога. Важно иметь в виду, что эти отсчеты не обя-
заны всегда соответствовать целым значениям х в интервале [О, М— 1].
Они выбираются в точках, наход ящихся на равных расстояниях друг от
друга, причем положение первой точки произвольно. Эта первая (про-
извольно расположенная) точка последовательности обычно обозна-
чается xq. При этом первый отсчет (первое значение дискретной функ-
ции) есть/(х0). Следующий отсчет, взятый на заданном расстоянии Ах
от первого, есть/(х0 + Ах), А-ый отсчет есть/(х0 + А Ах), и, наконец, по-
следний отсчет есть/(х() + (М— 1)Ах). Таким образом, выражение/(А) по-
нимается в дискретном случае как более короткая запись выражения
/(х0 + кЛх). При этом используемая до сих пор запись fix) означает
/(х) = /(х0+хДх), (4.2-13)
когда мы имеем дело с дискретными переменными. Переменная и до-
пускает похожее толкование, с той лишь разницей, что последователь-
ность частот всегда начинается с нуля. Таким образом, переменная и
принимает последовательно значения 0, Дм, 2Дм,...,(Л/—1) Дм. Далее,
запись Дм) понимается как
£(м) = ДмДм), м=0,1,2,...,(М-1). (4.2-14)
Такая короткая форма значительно упрощает запись и облегчает по-
нимание.
Величины Дх и Дм обратно пропорциональны,
Л/Ах ’
(4.2-15)
что неудивительно, принимая во внимание взаимосвязь функции и ее
фурье-преобразования, которая проиллюстрирована на Рис. 4.2. Эта
зависимость оказывается полезной в случае, когда интерес представ-
ляют линейные размеры деталей обрабатываемого изображения. На-
пример, в приложениях, связанных с электронной микроскопией,
соседние отсчеты изображения мотуг находиться на расстоянии 1 ми-
крон, и некоторые частотные характеристики (такие как амплитуды
частотных составляющих) могут иметь отношение к внутренней
Глава 4. Частотные методы улучшения изображения
структуре исследуемого образца. При изложении большей части по-
следующего материала в этой книге мы используем переменные х и и,
не связывая их с конкретным выбором дискретных данных или дру-
гими соображениями измерительного характера.
4.2.2. Двумерное ДПФ и его обращение
Дискретное прямое и обратное преобразования Фурье допускают не-
посредственное обобщение на двумерный случай. Прямое дискрет-
ное фурье-преобразование функции/(х,у) (изображения) размерами
Л/xW задается равенством
< M-\N-\
F(u,v) = (4 2-16)
MN x=o
Как и в одномерном случае, это выражение должно быть вычисле-
но для всех и = 0, 1, 2, ..., М— 1 и также для всех v = 0, 1, 2, ..., N— 1.
Аналогично, по заданному фурье-преобразованию F(u,v), мы можем
получить f(x,y) при помощи обратного преобразования Фурье, зада-
ваемого выражением
M-1N—1
f{x,y) = У У F^y^^/M+vy/^ ,
и=0 г=0
(4.2-17)
гдех = О, 1, 2,..., М— 1 и у = 0, 1,2,..., N— 1. Равенства (4.2-16) и (4.2-
17) составляют пару двумерных дискретных преобразований Фурье (ДПФ)
(прямое и обратное). Переменные миг называются переменными пре-
образования или частотными переменными, переменные х и у — про-
странственными переменными или переменными изображения. Как
и в одномерном случае, положение множителя 1/Л/Ане имеет значе-
ния. Он может быть отнесен в обратное преобразование или разделен
на два равных сомножителя \/Jmn в прямом и обратном преобра-
зованиях5.
5 Как и в одномерном случае (см. прим. 3), формула (4.2-16) позволяет определить фурье-
образ F(u,v) для всех целых значений и и г; при этом функция F(u.y) является двукратно
периодической с периодами Ми N (F(u+M,v+N) = F(u,v)). Вся информация о фурье-об-
разе содержится в любом (МхЛ^-прямоугольнике, при этом прямоугольник и = 0,1,2,...,
М— 1; г = 0,1, 2,..., N—1 иногда называют основным. — Прим, перев.
4.2. Преобразование Фурье и частотная область
Фурье-спектр, фаза и энергетический спектр определяются также,
как и в предыдущем параграфе:
|F(m,v)|=[k2(m,v) + /2(m,v)] /2, (4.2-18)
<|)(M,v) = arctg
Z(m,v)
(4.2-19)
и
Р(и, v)=| F(u, v) |2=R2 (u, v)+12 (u,v), (4.2-20)
где величины R(u,v) и I{u,v) обозначают действительную и мнимую ча-
сти величины F(u,v) соответственно.
Обычной практикой стало умножение исходной функции (изо-
бражения) на (—1)х +>’ перед вычислением фурье-преобразования. Ис-
пользуя свойства экспонент, нетрудно показать (см. Раздел 4.6),
что
d[f(x,y)(-l)x+y] = F(u-M/2,v-N/2), (4.2-21)
где 3[-1 обозначает преобразование Фурье своего аргумента6. Это ра-
венство означает, что начало координат для фурье-преобразования
функции f(x,y)(— 1)* + у (т.е. та точка, где значение этого преобразо-
вания равно Д0,0)) находится в точке с координатами и = M/2, v = N/2.
Другими словами, умножение функцииДх,у) на величину (— 1 +>’ при-
водит к сдвигу начала координат для ее образа F(u,v) в точку с частот-
ными координатами (M/2, N/2), которая является центром прямо-
угольной области размером (MxN), занимаемой двумерным
дискретным фурье-преобразованием. Мы будем говорить об этой об-
ласти в частотном пространстве как о частотном прямоугольнике. Он
простирается от и = 0 до и = М— 1 и от г = 0 до v = N— 1 (напомним, что
переменные миг целые). Для того чтобы обеспечить целочисленность
6 Для того чтобы равенство (4.2-21) можно было понимать буквально, помимо чет-
ности чисел М и N необходимо предполагать, что фурье-преобразование F(u,v) оп-
ределено для всех целых значений и и г (см. прим. 5). В противном случае вместо опе-
раций вычитания в правой части (4.2-21) следовало бы использовать операции
вычитания по модулю М и по модулю N. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
координат после сдвига, будем требовать, чтобы числа Л/ и N был и чет-
ными. При компьютерной реализации преобразования Фурье, индек-
сы принимают значения7 от и = 1 до и = М и от v = I до v = TV. Под-
линный центр фурье-образа тогда находится в точке и = (Л//2)+1
hv = (7V/2)+1.
Как следует из формулы (4.2-16), значение преобразования в точке
(м,т) = (0,0) равно
F(0,0) =
1
MN
M-1N-1
X Х^’^’
х=0 у=0
(4.2-22)
т.е. среднему значению функции /(х,у). Другими словами, если/(х,у) —
изображение, то значение фурье-преобразования в начале координат
равно среднему значению яркости на изображении. Поскольку нача-
лу координат отвечают нулевые частоты, величину F(0,0) иногда на-
зывают постоянной (de) составляющей спектра. Эта терминология
происходит из электротехники, где «de» обозначает постоянный ток8
(т.е. ток нулевой частоты).
Если функция f(x,y) вещественная9, то ее фурье-преобразова-
ние обладает симметрией по отношению к операции комплексно-
го сопряжения, а именно
F(m,v) = F*(-m,-v),
(4.2-23)
где «*» означает обычное комплексное сопряжение. Отсюда сле-
дует равенство
|F(m,v)| = |F(-m,-v)|,
(4.2-24)
которое говорит о том, что спектр фурье-преобразования симме-
тричен. Как показано в следующем параграфе, эти свойства сим-
метрии и рассмотренная выше операция центрирования, сущест-
венно облегчает описание центрально-симметричных частотных
фильтров.
7 В том случае, если индексацию массивов принято начинать с номера 1. — Прим,
перев.
8 От английского «direct current» — постоянный ток. — Прим, перев.
9 Условие вещественности функции, выполнение которого неявно предполагалось,
не является обязательным, но в задачах, связанных с обработкой изображений, это
условие выполняется. — Прим, перев.
Наконец, как и в одномерном случае, мы имеем следующие со-
отношения между отсчетами в
области:
пространственной и частотной
Дп =
1
Л/Дх
(4.2-25)
и
Ду = ——
NAy
(4.2-26)
Входящие в эти формулы переменные имеют тот же смысл, что и в од-
номерном случае (см. Раздел 4.2.1).
Пример 4.2. Центрированный спектр простой двумерной функции.
На Рис. 4.3(a) представлен белый прямоугольник размерами 20x40
пикселей, наложенный на черный фон размерами 512x512 пикселей.
Для того чтобы центрировать спектр, изображение было умножено на
(— 1)х +>’ перед вычислением фурье-преобразования. Полученный ре-
Рис. 4.3. (а) Изображение белого прямоугольника 20x40 на черном фоне раз-
мерами 512x512 пикселей, (б) Центрированный спектр Фурье представлен по-
сле применения логарифмического преобразования (3.2-2). Сравните с Рис. 4.2.
Глава 4. Частотные методы улучшения изображения
зультат (спектр изображения) представлен на Рис. 4.3(6). (Обратите
внимание на расположение осей и начала координат на каждом из ри-
сунков; в дальнейшем, при исследовании всех изображений и соот-
ветствующих им спектров Фурье, мы будем придерживаться именно
такого расположения.) Расстояние между нулями спектра в направ-
лении оси и на Рис. 4.3(6) ровно вдвое превышает соответствующее
расстояние в направлении оси v. Это отвечает обратному (1/2) отно-
шению длин сторон прямоугольника на изображении. Для улучшения
зрительного восприятия полутонов, спектр был предварительно (до
воспроизведения) подвергнут логарифмическому преобразованию
(3.2-2). В этом преобразовании для уменьшения общей яркости ис-
пользовалось значение с = 0,5. Большинство представленных в этой
главе спектров Фурье подвергнуто аналогичному логарифмическому
преобразованию.
4.2.3. Фильтрация в частотной области
Как отмечалось в двух последних параграфах, частотная область представ-
ляет собой ничто иное как пространство, в котором принимают значе-
ния переменные (м,г) фурье-преобразования. В этом параграфе мы при-
дадим этому понятию тот смысл, который оно несет в обработке
изображений.
Некоторые основные свойства частотной области
Мы начали с того наблюдения, что, в соответствии с (4.2-16), каждый
элемент фурье-образа F(u,v) содержит все отсчеты функции/(х,у), ум-
ноженные на значения экспоненциальных членов. Поэтому обычно,
за исключением тривиальных случаев, невозможно установить пря-
мое соответствие между характерными деталями изображения и его
образа. Однако некоторые общие утверждения относительно взаи-
мосвязи частотных составляющих фурье-образа и пространственных
характеристик изображения могут быть сделаны. Например, по-
скольку частота прямо связана со скоростью изменения сигнала, то
интуитивно ясно, что частоты в фурье-преобразовании связаны с ва-
риацией яркости на изображении. В предыдущем параграфе было
показано, что наиболее медленно меняющаяся (постоянная) частот-
ная составляющая (и = v = 0) совпадает со средней яркостью изобра-
жения. Низкие частоты, отвечающие точкам вблизи начала координат
фурье-преобразования, соответствуют медленно меняющимся компо-
нентам изображения. На изображении комнаты, например, они мо-
iyr соответствовать плавным изменениям яркости стен и пола. По
мере удаления от начала координат, более высокие частоты начинают
соответствовать все более и более быстрым изменениям яркости, ко-
торые суть границы объектов и другие детали изображения, характе-
ризуемые резкими изменениями яркости, такие как шум.
Пример 4.3. Изображение и его фуръе-спектр, демонстрирующие не-
которые важные свойства.
Поясняющий пример поможет читателю лучше понять суть выше-
сказанного. На Рис. 4.4(a) представлено увеличенное примерно в 2500
раз изображение интегральной схемы, полученное при помощи ска-
нирующего электронного микроскопа. Помимо собственно пред-
ставляющей интерес конструкции, мы видим две характерные дета-
ли. Это — резкие контуры деталей, проходящие под углом примерно
±45°, и пара белых оксидных пятен, выступивших наружу в резуль-
тате неудачно проведенной термической обработки. В фурье-спект-
ре на Рис. 4.4(6) хорошо видны диагональные составляющие, которые
отвечают упомянутым контурам. При внимательном рассматрива-
л
Рис. 4.4. (а) Изображение поврежденной интегральной схемы, полученное при
помощи сканирующего электронного микроскопа, (б) Фурье-спектр (а). (Исход-
ное изображение предоставил д-р Д. М. Хьюдек, Brockhouse Institute for Material
Research, университет Мак-Мастер, г. Гамильтон, шт. Онтарио, Канада.)
Глава 4. Частотные методы улучшения изображения
нии области, расположенной вдоль вертикальной оси, можно заме-
тить частотную составляющую, слегка повернутую против часовой
стрелки. Наличие этой составляющей обусловлено контурами оксид-
ных пятен. Обратим внимание на то, как угол поворота этой частот-
ной составляющей, связан с отклонением длинного белого пятна от
горизонтали. Обратим также внимание на положение нулей этой
частотной составляющей, связанное с малым поперечным разме-
ром оксидных пятен.
Приведенный пример дает образчик того, какие типы связей во-
обще могут быть установлены между частотной и пространственной
областью. На протяжении всей этой главы мы высвечиваем тот факт,
что даже такие очевидные типы связей вместе с упомянутой выше за-
висимостью между частотными составляющими и скоростью изме-
нения яркости на изображении могут приводить ко многим очень
полезным для улучшения изображений результатам.Я
Основы фильтрации в частотной области
Процедура фильтрации в частотной области проста и состоит из сле-
дующих шагов:
1. Исходное изображение умножается на (—1)* +у, чтобы его фурье-
преобразование оказалось, в соответствии с (4.2-21), центриро-
ванным;
2. Вычисляется прямое ДПФ F(u,v) изображения, полученного после
шага 1;
3. Функция F(u,v) умножается на функцию фильтра H(u,v);
4. Вычисляется обратное ДПФ от результата шага 3;
5. Выделяется вещественная часть результата шага 4;
6. Результат шага 5 умножается на (—1)* + у.
Причина, по которой множитель H(u,v) называется фильтром (час-
то используется также термин передаточная функция фильтра) состо-
ит в том, что он подавляет некоторые частоты преобразования, ос-
тавляя при этом другие без изменения. Аналогия с повседневной
жизнью возникает при рассмотрении сетчатого фильтра, который про-
пускает некоторые предметы и не пропускает другие в строгом соот-
ветствии с их размерами.
Пусть/(х,у) обозначает входное изображение после шага 1, и пусть
F(u,v) есть его фурье-образ. Тогда фурье-образ выходного изображе-
ния определяется выражением
G(u, v) = Щи, v)F(u, v).
(4.2-27)
4.2. Преобразование Фурье и частотная область 245
Умножение функций двух переменных Н и F осуществляется поэле-
ментно. Это означает, что первый элемент функции Н умножает-
ся на первый элемент функции F, второй элемент функции Н— на
второй элемент функции F, и т.д. В общем случае компоненты филь-
тра //являются комплексными величинами, но фильтры, рассматри-
ваемые в этой книге, обычно являются действительными. В этом
случае и действительная, и мнимая части функции / умножаются на
одну и ту же действительную функцию фильтра Н. Такие фильтры на-
зываются фильтрами нулевого фазового сдвига. Как и следует из назва-
ния, эти фильтры не меняют фазу фурье-преобразования. Это вид-
но из (4.2-19), если учесть, что общий для действительной и мнимой
части множитель сокращается.
Фильтрованное изображение получается вычислением обратного
преобразования Фурье от фурье-образа G(u,v):
Фильтрованное изображение = [G(u, v)]. (4.2-28)
Искомое изображение получается выделением действительной части
из последнего результата и умножения на (— 1)х + у, чтобы скомпенси-
ровать эффект от умножения входного изображения на ту же величи-
ну. Обратное фурье-преобразование в общем случае является ком-
плексным. Однако в случае вещественного входного изображения
и вещественной передаточной функции фильтра мнимые части всех
значений обратного фурье-преобразования должны равняться нулю.
Однако на практике значения обратного фурье-преобразования, как
правило, содержат паразитную мнимую составляющую, что связано
с ошибками округления при вычислениях. Этой составляющей необ-
ходимо пренебречь.
Только что описанная процедура фильтрации схематически ото-
бражена на Рис. 4.5 в несколько более общем виде, включающем
стадии предварительной и заключительной обработки. Помимо ум-
ножения на (—1) х+у, такая обработка может включать обрезание
входного изображения так, чтобы его размеры приняли ближайшие
четные значения по отношению к исходным (это необходимо для пра-
вильного центрирования фурье-преобразования), яркостное мас-
штабирование, преобразование формата входных данных в формат
с плавающей точкой и преобразование формата выходных данных в 8-
битовые целые. Возможны многоступенчатые процедуры фильтрации,
а также разнообразные операции предварительной и заключительной
обработки. Существуют многочисленные варианты данной основной
схемы. Важно помнить, что метод фильтрации основан на некотором
изменении фурье-образа изображения посредством передаточной
Глава 4. Частотные методы улучшения изображения
fix, у) g{x,y)
Входное
изображение
Улучшенное
изображение
Рис. 4.5. Основные этапы фильтрации в частотной области.
функции фильтра, и последующем обращении результата для полу-
чения обработанного выходного изображения.
Некоторые основные фильтры и их свойства
К настоящему моменту мы заложили основы фильтрации в частотной
области. Следующим логичным шагом является рассмотрение неко-
торых характерных фильтров и их воздействия на изображения. Про-
веденное ранее обсуждение формулы (4.2-22) идеально подводит нас
к рассмотрению простейшего примера. Предположим, что мы хотим
обратить в нуль среднее значение на изображении. В соответствии
с (4.2-22) это среднее значение задается величиной Е(0,0). Если мы об-
нулим этот член в частотной области и осуществим обратное преоб-
разование, то среднее значение полученного изображения будет рав-
но нулю. В предположении, что изображение было предварительно
отцентрировано так, как это обсуждалось в связи с (4.2-21), мы можем
осуществить такую операцию умножением всех значений F(u, у) на сле-
дующую функцию фильтра:
H(u,v)
О,
1,
при (и,v) = (М/2,#/2);
в другом случае.
(4.2-29)
Все действие такого фильтра сведется к тому, что значение Е(0,0) будет
обращено в нуль, а остальные частотные компоненты фурье-преобра-
зования останутся незатронутыми, что и требуется. Обработанное изо-
бражение (с нулевым средним) затем может быть получено, как пока-
зывает (4.2-28), обратным фурье-преобразованием функции
Н(и,у) F(u,v). Как было определено ранее, и действительная, и мнимая
часть функции F(u,v) умножается на функцию фильтра H(u,v).
Рассмотренный только что фильтр называется фильтр-пробка,
поскольку он представляет собой постоянную функцию с вырезом (ды-
рой) в начале координат10. Результат обработки изображения, пред-
ставленного на Рис. 4.4(a), данным фильтром показан на Рис. 4.6.
Отметим падение общей яркости в результате принудительного обну-
ления среднего значения; отметим также побочный результат, состо-
ящий в выделении контуров. (В действительности среднее значение
яркости выводимого на экран изображения не может равняться нулю,
поскольку для этого некоторые элементы изображения должны быть
отрицательными, а монитор не может оперировать с отрицательны-
ми величинами. Рисунок 4.6 представлен стандартным образом, при
котором наименьшее отрицательное значение соответствует нулю,
или черному, а остальные значения увеличены с учетом этого.) Как по-
казано в Разделе 5.4.3, узкополосные режекторные фильтры исклю-
чительно полезны, когда удается идентифицировать пространствен-
ные эффекты на изображении, вызываемые локализованными
компонентами частотного представления.
Низкие частоты фурье-преобразования отвечают за возникновение
превалирующих значений яркости на гладких участках изображения,
Рис. 4.6. Результат фильтрации изображения Рис. 4.4(a) с помощью фильтра-
пробки, который обнуляет член F(0,0) фурье-преобразования.
111В оригинале употреблен принятый термин «notch filter», от английского «notch» —
вырез, прорезь. Фильтр-пробка является простейшим примером узкополосного ре-
жекторного фильтра. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
в то время как высокие частоты ответственны за такие детали, как кон-
туры и шум. Эти представления подробно обсуждаются в последующих
параграфах, но будет поучительно дополнить наш пример с фильт-
ром-пробкой примерами фильтров следующих двух видов. Фильтр,
который ослабляет высокие частоты, одновременно пропуская низкие,
называется низкочастотным фильтром. Фильтр, обладающий противо-
положными свойствами, называется, соответственно, высокочастот-
ным фильтром. Можно ожидать, что, после применения низкочастот-
ной фильтрации, изображение, по сравнению с исходным, содержит
меньше резких деталей, поскольку высокие частоты подавлены. Ана-
логично, после применения высокочастотной фильтрации, на изобра-
жении уменьшаются изменения яркости в пределах больших гладких
областей и выделяются переходные зоны быстрого изменения яркос-
ти (те. контуры). Такое изображение выглядит более резким.
Рисунок 4.7 иллюстрирует влияние низкочастотной и высоко-
частотной фильтраций на изображение на Рис. 4.4(a). В левой части
рисунка показаны фильтры, а в правой — результаты фильтрации с ис-
Рис. 4.7. (а) Двумерная передаточная функция фильтра низких частот, (б) Ре-
зультат низкочастотной фильтрации изображения Рис. 4.4(a). (в) Двумерная
передаточная функция фильтра высоких частот, (г) Результат высокочастот-
ной фильтрации изображения Рис. 4.4(a).
пользованием процедуры, схематически представленной на Рис. 4.5.
Оба представленных фильтра H(u,v) являются центрально симметрич-
ными. После совмещения начала координат фильтров с центром ча-
стотного прямоугольника, они умножаются на центрированное фу-
рье-преобразование F(w,v) так, как было намечено при обсуждении
формул (4.2-27), (4.2-28) и Рис. 4.5. Взятие действительной части от
каждого из результатов и умножение их на (—1)х +>’, дает изображе-
ния в правой части рисунка. Как и ожидалось, изображение на
Рис. 4.7(6) является размытым, а на Рис. 4.7(г) — резким, с малым
уровнем яркостей внутри гладких областей вследствие обнуления чле-
на F(0,0). Это типично для результатов высокочастотной фильтрации,
и потому часто выполняется процедура, состоящая в добавлении
к фильтру некоторой постоянной с тем, чтобы составляющая F(0,0)
не уничтожалась полностью. Результат такой процедуры представлен
на Рис. 4.8. Улучшение по сравнению с Рис. 4.7(г) очевидно.
4.2.4. Соответствие между фильтрацией в
пространственной области и фильтрацией в
частотной области
В предыдущей главе мы подошли к различным видам пространствен-
ных фильтров, основываясь на интуитивных соображениях и/или на
математических конструкциях, таких как лапласиан. В этом пара-
графе мы установим прямую связь между некоторыми из этих филь-
тров и их аналогами в частотном пространстве.
Рис. 4.8. Результат высокочастотной фильтрации изображения Рис. 4.4(a) с ис-
пользованием фильтра на Рис. 4.7(b), измененного путем добавления к его пе-
редаточной функции константы, равной половине высоты фильтра. Срав-
ните с Рис. 4.4(a).
Тлава 4. Частотные методы улучшения изображения
Наиболее важная взаимосвязь пространственной и частотной
областей фильтрации устанавливается известным результатом, нося-
щим название теорема о свертке. Читатель уже знаком с основными
понятиями и техникой вычисления свертки в пространственной об-
ласти, которые были введены и проиллюстрированы в Разделе 3.5.
В основе операции свертки лежит процедура, при которой мы двига-
ем некоторую маску по изображению от элемента к элементу и для
каждого элемента вычисляем некоторую заранее определенную вели-
чину. Формально дискретная свертка двух функцийДх,у) и h(x,y) раз-
мерами MyN определяется выражением
M-XN-1
/Ос,у)*/г(х,у) = —— £ У f (m,ri)h(x-m,y-n) (4.2-30)
и обозначается символом flx,y)*h(x,у). С точностью до множителя
\/MN, знаков минус и пределов суммирования в правой части это вы-
ражение совпадает по форме с (3.5-1). Знаки минус, в частности, оз-
начают, что функция зеркально отражается относительно начала от-
счета, что характерно для определения свертки. Равенство (4.2-30)
означает ничто иное, как выполнение следующей последовательно-
сти действий: (1) зеркальное отображение одной из функций относи-
тельно начала координат; (2) сдвиг этой функции по отношению к дру-
гой на величины (х,у); и (3) вычисление суммы произведений по всем
значениям тип для всех значений сдвигов (х,у)11. Эти сдвиги суть це-
лые приращения аргументов, которые прекращаются, когда функции
перестают перекрываться.
Если F(w,y) и H(u,v) обозначают соответственно фурье-образы
функций Дх,у) и й(х,у), то одна половина теоремы о свертке утверж-
дает, что функции Дх,у)*/г(х,у) и F(u,v)H(u,v) образуют фурье-пару.
Это может быть формально записано в виде
/(х,у)*й(х,у)<=> Е(м,у)Я(м,у). (4.2-31)
Двойная стрелка указывает на то, что выражение слева (пространствен -
ная свертка) может быть получено применением обратного преобразо-
11 Для того чтобы придать строгий смысл правой части (4.2-30), нужно продлить функ-
цию h(x,y), определенную первоначально в прямоугольнике [0,Л/— l]x[0,./V— 1] до дву-
кратно периодической функции (с периодами Л/и N) на всем дискретном простран-
стве. Операция зеркального отображения применяется к продленной таким образом
функции и означает в данном контексте замену h(x,y) на h(—x,—y). — Прим, перев.
вания Фурье к выражению справа (произведению F(u,v)H(u,v) в частот-
ной области) и, обратно, выражение справа может быть получено при-
менением прямого преобразования Фурье к выражению слева. Сходный
результат заключается в том, что свертка в частотной области приводит
к умножению в пространственной области и наоборот, т.е.
/(х, y)h(x, у)« F(u, у) * Н(и, у).
(4.2-32)
Эти два результата составляют теорему о свертке. Важно осознать, что
их формулировка не содержит ничего трудного. Мы уже поняли, что
представляет собой операция свертки. Другая операция — умноже-
ние — есть поэлементное умножение двух функций.
Чтобы довести до конца рассмотрение связей между пространствен-
ной и частотной областями, нам потребуется еще одно понятие. Импульс-
ная функция^ (или импульс) с интенсивностью А, локализованная в точ-
ке с координатами (х0,у0), для которой мы будем использовать
обозначение Л8(х—х0, у—ур), определяется выражением
У У Дх,у)Л8(х-х0,у-у0) = ЛДх0,у0).
х=0 у=0
На словах это означает, что суммирование любой функции у(х,у), ум-
ноженной на импульс, дает значение этой функции в точке лока-
лизации импульса, умноженное на амплитуду импульса. Понятно,
что суммирование ведется по всей области определения функции.
Отметим, что импульсная функция Л8(х—х0, у—у0) также является
изображением размера MxN. Оно состоит из нулей за исключени-
ем точки с координатами (х0,у0), в которой значение изображения
равно А.
Подставив в качестве функции f или h в (4.2-30) импульсную
функцию, и используя ее определение (4.2-33), мы можем заклю-
чить, после несложных вычислений, что свертка12 13 функции с им-
пульсной функцией «копирует» значение первой в точке локализации
последней. Это свойство импульсной функции называется свойством
отсеивания. Особую важность в настоящий момент представляет слу-
12 Широко распространен также термин Ъ-функция. — Прим. ред. перев.
13 Речь здесь идет, конечно, не о свертке, а о сумме произведения некоторой функции
s{x, у) на функцию 8(х-х0, у-у0) (аналогичной сумме в левой части (4.2-34)), которая
равна ,s(x0, у0). Сверткой функции s(x, у) с 8-функцией является функция .s(x-xfl, у-у о),
те. операция свертки с 8-функцией приводит к сдвигу. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
чай единичной импульсной функции, локализованной в начале ко-
ординат, которая обозначается 8(х, у). В этом случае
M-1N-1
У У s(x,y)8(x,y) = 5(0,0). (4.2-34)
х=0 у=0
Вооруженные этими нехитрыми средствами, мы теперь готовы уста-
новить наиболее интересную и полезную связь между фильтрацией
в пространственной области и фильтрацией в частотной области. Вы-
числим фурье-образ единичного импульса в начале координат (т.е.
и = 0, v = 0) по формуле (4.2-16):
F\u,v) = —— У У b(x,y)e'i2n(ax/M+vy/N) = ^-~. (4.2-35)
MN
Вторая часть этого равенства следует из (4.2-34). Таким образом, мы ви-
дим, что фурье-образ единичного импульса в начале координат простран-
ственной области представляет собой вещественную постоянную функ-
цию (вещественность означает, что фаза равна нулю). Если бы импульс
был локализован где-нибудь в другом месте, фурье-образ имел бы ком-
плексные компоненты. Амплитуда осталась бы без изменений, а смеще-
ние импульса привело бы к появлению ненулевой фазы фурье-образа.
Предположим теперь, что/(х,у) = 8(х,у) и вычислим свертку (4.2-30).
Имеем
/(х,у)*й(х,у) = —— У У S(m,n)h(x-m,y-n)= —— h(x,y), (4.2-36)
MN£o%) MN
причем последняя часть равенства следует из (4.2-33), поскольку т ип
являются переменными суммирования. Объединяя (4.2-35) и (4.2-
36) с (4.2-31), получаем
f(x,y)*h(x,y)<^ F(u,v)H(u,v) ;
8(x,y)*h(x,y)<^> #[8(м,у)]Я(м,у); (4.2-37)
й(х,у)<=> Я(м,у).
Используя исключительно свойства импульсной функции и теорему
о свертке, мы установили, что фильтры в пространственной и частот-
ной областях образуют фурье-пару. Таким образом, по заданному в ча-
стотной области фильтру мы можем получить соответствующий фильтр
в пространственной области, применив к первому обратное преобра-
зование Фурье. Верно также и противоположное.
Отметим, что все функции в предыдущем рассмотрении имели
один и тот же размер My.N. Поэтому на практике задание фильтра в ча-
стотной области и последующее вычисление эквивалентного ему про-
странственного фильтра того же размера при помощи обратного пре-
образования Фурье не облегчает решение задачи с вычислительной
точки зрения. Как будет показано в Разделе 4.6, при одинаковом раз-
мере фильтров осуществление фильтрации в частотной области обес-
печивает, как правило, большую эффективность вычислений. Однако
в пространственной области используются фильтры намного меньше-
го размера, которые, в основном, и являются предметом нашего инте-
реса. Всякий раз когда это возможно, имеет смысл осуществлять филь-
трацию в пространственной области с использованием фильтров (масок)
малого размера. С другой стороны, фильтрация в частотной области поч-
ти всегда оказывается более наглядной. Равенства (4.2-37) показывают,
что мы можем задать фильтр в частотной области, вычислить его про-
образ, а затем использовать полученный пространственный фильтр
как ориентир для построения пространственного фильтра (маски)
меньшего размера (более строгие подходы обсуждаются в Разделе 4.6.7).
Сказанное проиллюстрировано ниже. Во время обсуждения следует по-
мнить, что поскольку прямое и обратное преобразования Фурье явля-
ются линейными операциями (Задача 4.2), то последующие рассужде-
ния относятся только к линейной фильтрации.
Фильтры, основанные на гауссовой функции, исключительно
важны, поскольку как прямое, так и обратное фурье-преобразования
этой функции также являются гауссовыми функциями. Кроме того
форма такого фильтра определяется всего двумя параметрами. Для уп-
рощения записи мы ограничимся рассмотрением одномерного слу-
чая. Двумерный случай обсуждается ниже в этой главе.
Пусть Н(и) — частотная передаточная функция гауссова фильтра,
которая задается равенством
Н(и) = Ае-иг^\ (4.2-38)
где ст— гауссово среднеквадратичное отклонение. Можно показать (За-
дача 4.4), что соответствующий фильтр в пространственной области
задается равенством
h(x) = л/2лоЛе-2л2°2х2 . (4.2-39)
Эти равенства важны по двум причинам. (1) Они задают фурье-пару, в ко-
торой каждая из функций является гауссовой и вещественной. Это за-
метно облегчает анализ, поскольку мы не должны иметь дело с комплекс-
Глава 4. Частотные методы улучшения изображения
ними числами. Кроме того, гауссовы функции наглядны и удобны при
вычислениях. (2) Они показывают, что если функция Н(и) имеет широ-
кий профиль (большое значение о), то функция h(x) имеет узкий, и на-
оборот В предельном случае, когда сг стремится к бесконечности, функ-
ция Н(и) стремится к постоянной функции, а функция h(x) стремится
к импульсной функции. Иными словами, ширины функций находят-
ся в обратном отношении друг к другу. Это в точности тот тип взаимо-
связи, который мы наблюдали в Разделе 4.2 в связи с обсуждением
Рис. 4.2 и 4.3. Эти два свойства, которые могут быть легко обоснованы
аналитически, помогают лучше понять особенности процедуры филь-
трации как в пространственной, так и в частотной области.
График гауссова фильтра в частотной области показан на Рис. 4.9(a).
По форме фильтра Н(и) читатель узнает в нем фильтр низких частот.
Соответствующий фильтр низких частот в пространственной облас-
ти представлен на Рис. 4.9(b). Интерес для нас представляет общая
форма фильтра h(x), которую мы хотели бы использовать как ориен-
тир для определения коэффициентов меньшего по размерам фильт-
ра в пространственной области. Бросающееся в глаза сходство двух
фильтров состоит в том, что все их значения, в обоих пространствах,
положительны. Таким образом мы приходим к заключению, что низ-
кочастотная фильтрация в пространственной области может быть
осуществлена при помощи маски, целиком состоящей из положитель-
ных коэффициентов, так как это делалось в Разделе 3.6.1. Две маски
из этого раздела показаны для справки на Рис. 4.9(b). Другая важная
особенность низкочастотной фильтрации связана с рассмотренным
в предыдущем абзаце свойством (2). Чем более узким в частотной
области является фильтр, тем сильнее он подавляет высокие частоты,
что выражается в дальнейшей расфокусировке изображения. Это эк-
вивалентно использованию более широкого фильтра в пространствен-
ной области, что демонстрирует Пример 3.9.
На основе гауссовых функций, задаваемых (4.2-38), могут быть по-
строены и более сложные фильтры. Например, мы можем построить
высокочастотный фильтр из двух гауссовых функций следующим об-
разом:
Н(и) = Ае~и2 /2<т1 -Ве~и2 /2о2 , (4.2-40)
где А>В и CTj > сг2- Соответствующий фильтр в пространственной об-
ласти имеет вид
/г(х) = л/^О]Ле~2к2°2х2-J^KOj^-27120^*2 . (4.2-41)
Рис. 4.9. (а) Гауссов низкочастотный фильтр в частотной области,
(б) Гауссов высокочастотный фильтр в частотной области, (в) Соответствую-
щий низкочастотный фильтр в пространственной области, (г) Соответствую-
щий высокочастотный фильтр в пространственной области. Представлен-
ные маски используются в Главе 3 для низкочастотной и высокочастотной
фильтрации.
Графики этих двух функций представлены на Рис 4.9(6) и (г), соответ-
ственно. Мы снова обращаем внимание на взаимообратное отноше-
ние ширины профилей, но наиболее важная особенность здесь за-
ключается в том, что фильтр в пространственной области принимает
как положительные, таки отрицательные значения. Интересно, что од-
нажды превратившись в отрицательное, значение никогда больше не
становится положительным. Две маски, использованные нами для
высокочастотной фильтрации в 1лаве 3, показаны на Рис. 4.9(г). Внеш-
нее сходство пространственной кривой и этих фильтров несомненно.
В Главе 3 мы устанавливали вид низкочастотных и высокочастот-
ных фильтров исключительно на основе анализа в пространственной
области. Важно отметить, что мы можем прийти к базовым формам всех
представленных на Рис. 4.9 масок пространственных фильтров мало-
256 Глава 4. Частотные методы улучшения изображения
го размера альтернативным путем, который открывает перед нами
только что развитый метод анализа в частотной области. Хотя разви-
тие метода потребовало от нас значительных усилий, читатель может
не сомневаться, что настоящее понимание фильтрации в частотной об-
ласти невозможно без того фундамента, который был нами заложен.
Вопрос, часто возникающий на данном этапе развития наших ме-
тодов, относится к проблеме сложности вычислений. Почему частот-
ная область? Что может быть сделано (хотя бы отчасти) в простран-
ственной области с использованием небольших пространственных
масок? Основной ответ состоит из двух частей. Во-первых, как мы ви-
дели, анализ в частотной области привносит значительное число на-
водящих соображений относительно того, как выбирать фильтр. Вто-
рая часть ответа зависит от размера пространственных масок и обычно
проистекает из сопоставления способов реализации.
Контрольной задачей, часто используемой с этой целью, является
вычисление свертки, которое может быть реализовано как непосред-
ственно в пространственной области, так и с использованием перехо-
да в частотную область. Пространственная свертка двух функций за-
дается формулой (4.2-30) и, как следует из теоремы о свертке, может
быть получена вычислением обратного фурье-преобразования от про-
изведения фурье-образов этих двух функций. Предположим, что мы
программно реализовали оба подхода на одном и том же компьютере
(используя для перехода в частотную область и обратно алгоритм бы-
строго преобразования Фурье (БПФ), обсуждаемый в Разделе 4.6.6).
Мы обнаружим, что вычисления, реализованные с использованием пе-
рехода в частотную область, осуществляются быстрее даже для удиви-
тельно малых значений Ми 2V. Например, сравнение, которое провел
Брайем [Brigham, 1988} показывает, что в одномерном случае БПФ под-
ход оказывается быстрее, если число точек превышает 32. Хотя послед-
нее число и зависит от сторонних факторов, таких как используемые
компьютер и алгоритм, оно заведомо меньше тех чисел, с которыми мы
сталкиваемся при обработке изображений.
Можно смотреть на частотное пространство как на «лаборато-
рию», в которой соответствие между изображением и его частотным
содержимым является полезным инструментом исследования. Мно-
гочисленные примеры, приведенные ниже в этой главе, показывают,
что некоторые задачи по улучшению изображений, прямое решение
которых в пространственной области исключительно сложно или да-
же невозможно, становятся почти тривиальными в частотной обла-
сти. Однажды выбрав некоторый характерный фильтр посредством
экспериментирования в частотной области, мы впоследствии обыч-
но осуществляем реализацию соответствующего метода в простран-
4.3. Сглаживающие частотные фильтры
ственной области. Таким образом, наш подход состоит в отыскании
небольшой пространственной маски, которая бы отражала в глав-
ном «сущность» выбранной передаточной функции фильтра в прост-
ранственной области, как это объяснялось при обсуждении Рис. 4.9.
Более строгий подход состоит в конструировании двумерных цифро-
вых фильтров на основе математических и статистических критериев.
К этому вопросу мы вернемся в Разделе 4.6.7.
4.3. Сглаживающие частотные фильтры
Как отмечалось в Разделе 4.2.3, контуры и другие резкие перепады
яркости на изображении (например, связанные с шумом) вносят
значительный вклад в высокочастотную часть его фурье-преобразо-
вания. Следовательно, сглаживание («размывание») достигается в ча-
стотной области ослаблением высокочастотных компонент опреде-
ленного диапазона фурье-образа данного изображения.
Наша базовая «модель» фильтрации в частотной области задается ра-
венством (4.2-27), которое мы приведем здесь еще раз для удобства:
G(u,v) = H(u,v)F(u,v), (4.3-1)
где F(u,v) — фурье-образ изображения, которое подлежит сглажива-
нию. Цель состоит в выборе передаточной функции которая
ослабит высокочастотные компоненты F(u,v) и сформирует функ-
цию G(u,v). Все методы фильтрации, применяемые в этом разделе, це-
ликом основаны на описанной в Разделе 4.2.3 схеме, включая ис-
пользование фильтров нулевого фазового сдвига.
Мы рассматриваем три вида низкочастотных фильтров: идеальный
фильтр, фильтр Баттерворта и гауссов фильтр. Эти три фильтра покры-
вают диапазон от очень резких фильтров (идеальный), до очень гладких
фильтров (гауссов). Фильтр Баттерворта характеризуется параметром, ко-
торый называется порядком фильтра. При малых значениях этого пара-
метра он имеет гладкую форму, похожую на форму гауссова фильтра. При
больших значениях фильтр Баттерворта приближается по форме к иде-
альному фильтру. Таким образом, фильтр Баттерворта может рас-
сматриваться как переходный между двумя «крайностями».
4.3.1. Идеальные фильтры низких частот
Самый простой фильтр низких частот, который можно представить, —
это фильтр, который обрезает все высокочастотные составляющие фу-
рье-образа, находящиеся на большем расстоянии от начала коорди-
9 А-223
Глава 4. Частотные методы улучшения изображения
нат (центрированного) преобразования, чем некоторое заданное рас-
стояние Dq. Такой фильтр называется двумерным (2D) идеальным низ-
кочастотным фильтром (идеальным фильтром низких частот, ИФНЧ),
и имеет передаточную функцию
Т при D(u, v) < Do ;
H(u,v) = < (4.3-2)
[О при D(u,v) >D0 ,
где Dq — заданная неотрицательная величина, a D(u,v) обознача-
ет расстояние от точки (н,у) до начала координат (центра час-
тотного прямоугольника). Если рассматриваемое изображение
имеет размер MxN, то, как мы знаем, тот же размер имеет его
фурье-образ. Следовательно центр частотного прямоугольника
находится в точке (u,v) = (M/2, N/2), поскольку фурье-преобра-
зование было центрировано, как обсуждалось в связи с равенст-
вом (4.2-21). В таком случае расстояние от произвольной точки
(н,г) до центра (начала координат) фурье-преобразования задает-
ся формулой
D(u,v)=[(u-M/2)2 + (v-N/2)2]1/2. (4.3-3)
На Рис. 4.10(a) дано трехмерное изображение в перспективе графи-
ка H(u,v) как функции и и у, а на Рис. 4.10(6) функция H(u,v) представ-
лена как изображение. Название идеальный фильтр указывает на то,
что все частоты внутри круга радиуса Dq проходят без изменения, в то
время как все частоты вне круга подавляются полностью. Рассматри-
ваемые в этой главе низкочастотные фильтры обладают централь-
ной симметрией относительно начала координат. Это значит, что од-
Н(и, v)
Рис. 4.10. (а) Изображение в перспективе графика передаточной функции
идеального низкочастотного фильтра, (б) Представление фильтра в виде изо-
бражения. (в) Радиальный профиль фильтра.
ного радиального профиля, т.е. функции расстояния от начала коор-
динат, достаточно для того, чтобы задать фильтр (см. Рис. 4. 10(b)). Пол-
ная передаточная функция фильтра получается вращением профиля
на 360° вокруг начала координат.
Та точка профиля радиального низкочастотного фильтра, в кото-
рой совершается переход от значений H(u,v) = 1 к значениям H(u,v) = 0
называется частотой среза. В случае, показанном на Рис. 4.10, напри-
мер, частота среза равна Do. Резкое обрезание частот, присущее иде-
альному низкочастотному фильтру, не может быть осуществлено в эле-
ктронных устройствах, хотя, конечно, может быть реализовано при
компьютерных вычислениях. Эффекты, возникающие на цифровом
изображении при использовании таких «нефизических» фильтров,
обсуждаются ниже в этом параграфе.
Сравнивая представленные в этом разделе низкочастотные филь-
тры, мы исследуем их поведение как функцию одинаковых частот
среза. Один из способов ввести эталонный набор положений обреза-
ющих частот состоит в том, чтобы определить круги, в которых заклю-
чена заданная часть полной энергии изображения РТ. Полная энер-
гия определена как сумма компонент энергетического спектра во
всех точках (i/,v), и = 0, 1, 2,...,М— 1 и у = 0, 1, 2,...,7V— 1, т.е.
Л/-1ЛМ
Pr=££P(«,v), (4-3-4)
и=0 v=0
где величины P(w,v) определены формулой (4.2-20). Частота г(а) оп-
ределяется как радиус круга с центром в центре частотного прямоуголь-
ника, содержащего а процентов энергии спектра, т.е.
«=100 ££Р(ц,т)/Рг
(4.3-5)
и V
причем суммирование в последней формуле идет по значениям (i/,v),
лежашим внутри круга или на его границе.
Пример 4.4. Энергия изображения как функция расстояния от цен-
тра ДПФ.
На Рис. 4.11(a) показан тестовый пример рисунка 3.35, который
мы использовали для демонстрации эффекта пространственного сгла-
живания. Фурье-спектр этого изображения показан на Рис. 4.11(6). На-
ложенные на спектр круги имеют радиусы 5,15, 30, 80 и 230 пикселей
(круг радиуса 5 едва виден). В этих кругах заключено а процентов энер-
гии изображения, а = 92,0, 94,6, 96,4, 98,0, и 99,5%, соответственно.
Глава 4. Частотные методы улучшения изображения
Рис. 4.11 (а) Изображение размерами 500x500 пикселей и (б) его фурье-спектр.
Наложенные круги имеют радиусы 5,15, 30, 80 и 230 и заключают в себе 92,0,
94,6, 96,4, 98,0, и 99,5% процентов энергии изображения, соответственно.
Спектр убывает весьма быстро, 92% полной энергии заключено в от-
носительно малом круге радиуса 5.
На Рис. 4.12 показаны результаты применения идеального низко-
частотного фильтра с частотами среза, равными значению радиусов
на Рис. 4.11(6). Результат на Рис. 4.12(6) практически совершенно
бесполезен, если только задача сглаживания не состоит в устранении
всех деталей изображения, за исключением пятен, представляющих
большие объекты. Очень сильное размывание на этом изображении
ясно указывает, что большая часть информации о резких деталях на
картинке содержится в 8% энергии, отсеченной фильтром. По мере
увеличения радиуса фильтра, все меньшая и меньшая часть энергии
подлежит отсечению, что выражается в уменьшении степени размы-
вания. Отметим, что для изображений на Рис. 4.12(b)—(д) характерен
«звон» w (выражающийся в появлении ложных контуров вокруг кон-
туров реальных), структура которого становится тоньше по мере
уменьшения энергии отсекаемой высокочастотной составляющей.
Звон хорошо заметен даже на изображении, из которого удалено
лишь 2% полной энергии. Обсуждаемое явление, как будет вскоре объ-
яснено, характерно для идеальных фильтров. Наконец, тщательное
14 Термин «звон» происходит из электро- и радиотехники, где им обозначают весь-
ма близкое явление. Рассматриваемое явление соответствует тому, что в математике
называется «явлением Гиббса». Последний термин также используется в обработке
изображений. — Прим, перев.
4.3. Сглаживающие частотные фильтры
а а Я а а Ю i а а а а а 3 3 а
а 6
в г
Д е
Рис. 4.12. (а) Исходное изображение, (б)—(е) Результаты фильтрации идеаль-
ными низкочастотными фильтрами с частотой среза 5, 15, 30, 80 и 230 (соот-
ветствующие круги на Рис. 4.11(6)). Фильтры отсекают 8,0,5,4, 3,6,2,0, и 0,5%
полной энергии, соответственно.
Глава 4. Частотные методы улучшения изображения
рассмотрение результата для а = 99,5% демонстрирует очень неболь-
шое размывание в областях, содержащих шум, притом что в осталь-
ном это изображение весьма близко к оригиналу. Это показывает,
что в рассматриваемом частном случае верхние 0,5% энергии спект-
ра содержат малое количество контурной информации.
Из приведенного примера понятно, что идеальные фильтры низ-
ких частот не имеют большого практического значения. Однако, по-
скольку такие фильтры могуг быть реализованы на компьютере, их изу-
чение полезно в рамках развития наших общих представлений о методах
фильтрации. Кроме того, как показывает дальнейшее обсуждение, по-
пытки объяснить появление звона для ИФН Ч в пространственной облас-
ти, позволяют достичь некоторого дополнительного понимания К.
Возникающие при использовании ИФНЧ эффекты размывания
и появления ложных контуров могут быть объяснены при помощи те-
оремы о свертке, которая обсуждалась в Разделе 4.2.4. Исходное изо-
бражение f(x,y) и сглаженное изображение g(x,y), получаемое после
фильтрации, связаны в частотной области соотношением
G(u, v) = И (и, v)F(u, v),
где, как и ранее, H(u,v) — передаточная функция фильтра, а Ри G —
фурье-преобразования двух упомянутых изображений. Теорема
о свертке говорит о том, что соответствующая процедура в простран-
ственной области может быть записана в виде
g(x,y) = h(x,y)*f(x,y),
где h(x,y) — обратное преобразование Фурье от функции H(u,v).
Ключ к пониманию размывания в процессе свертки лежит в при-
роде функции h(x,y). Например, идеальный низкочастотный фильтр
радиуса 5, вызвавший столь большое размывание в предыдущем при-
мере, показан на Рис. 4.13(a). На этом рисунке представлена функция
H(u,v) в частотной области. Пространственная функция h(x,y) для
этого фильтра была получена стандартным образом: (1) функция
H(u,v) была умножена на (-1 )“+г для центрирования; (2) затем было
произведено обратное ДПФ; (3) вещественная часть обратного ДПФ
была умножена на (-l)x+j. Полученный результат представлен на
Рис. 4.13(6).
Мы видим, что фильтр обладает двумя главными отличительны-
ми признаками: расположенной в центре доминирующей составля-
ющей и расположенными вокруг нее круговыми концентрическими
4.3. Сглаживающие частотные фильтры
Рис. 4.13. (а) ИФНЧ радиуса 5 в частотной области, (б) Соответствующий
фильтр в пространственной области (обратите внимание на концентрические
кольца), (в) Пять импульсов в пространственной области (пять ярких точек),
(г) Свертка (б) и (в) в пространственной области.
составляющими. Размывание главным образом обусловлено централь-
ной составляющей. Наблюдаемое при применении идеальных филь-
тров появление ложных контуров главным образом обусловлено кру-
говыми концентрическими составляющими. Как радиус центральной
264 Глава 4. Частотные методы улучшения изображения
компоненты, так и число кругов на единицу длины по направлению
от центра обратно пропорциональны значению частоты среза идеаль-
ного фильтра. 1рафик в правом верхнем углу рисунка представляет со-
бой профиль яркости вдоль горизонтальной прямой, проходящей
через центр фильтра в пространственной области. Проведенная на
графике ось соответствует нулевой амплитуде, и мы видим, таким об-
разом, что пространственный фильтр принимает и отрицательные
значения. Обычно это не приводит к серьезным осложнениям, по-
скольку при вычислении свертки доминирующую роль играет боль-
шая центральная компонента. Однако после фильтрации изображе-
ние может иметь отрицательные значения, и потому обычно требуется
процедура градационной коррекции.
Предположим теперь, что f(x,y) представляет собой простое изо-
бражение, состоящее из пяти ярких точек (пикселей), как показано
на Рис. 4.13(b). Эти точки могут рассматриваться как импульсные
функции, амплитуда которых определяется яркостью точек. В этом
случае, как указывалось15 в Разделе 4.2.4, операция свертки функций
h(x,y) и f(x,y) сводится к линейной суперпозиции сдвигов функции h,
при которых ее центр оказывается в точках локализации каждого из
импульсов. Соответствующий результат приведен на Рис. 4.13(г). Из
сказанного становится понятно, почему в результате свертки функ-
ции f(x,y) с передаточной функцией фильтра h(x,y) точки исходного
изображении оказываются размытыми. Также становится понятно
и происхождение звона. В действительности эффект в рассматрива-
емом случае настолько велик, что в результате интерференции коле-
баний яркости, сопутствующих каждому из импульсов, возникают за-
метные искажения. Приведенные соображения можно распространить
на более сложные изображения, если рассматривать каждую точку как
импульсную функцию с амплитудой, пропорциональной яркости
данной точки. График в левом нижнем углу рисунка представляет
собой профиль яркости вдоль диагонали, проходящей через центр
отфильтрованного изображения.
Обратная зависимость между шириной функции Н(и,у) и шири-
ной функции h(x,y) (с учетом только что рассмотренного механизма
свертки) дает математическое объяснение того, почему размывание
и звон усиливаются при уменьшении ширины используемого филь-
тра в частотной области. К этому моменту читатель уже должен при-
выкнуть к такому взаимообратному поведению. В следующих двух па-
раграфах мы покажем, что сглаживание может быть достигнуто при
15 См., также, прим 13. — Прим, перев.
4.3. Сглаживающие частотные фильтры
небольшом уровне возникающего звона или вовсе без него, что и яв-
ляется нашей главной целью.
4.3.2. Фильтры низких частот Баттерворта
Передаточная функция низкочастотного фильтра Баттерворта (БФНЧ)
порядка п с частотой среза на расстоянии Dq от начала координат за-
дается формулой
H(u,v) =-------------z-, (4.3-6)
1+[Шт)/Л0]2”
где расстояние D(u,v) задано формулой (4.3-3). Трехмерное перспектив-
ное изображение, полутоновое изображение и радиальные профили пе-
редаточной функции БФНЧ представлены на Рис. 4.14.
В отличие от ИФНЧ, передаточная функция БФНЧ не имеет раз-
рыва, который устанавливает точную границу между пропускаемыми
и обрезаемыми частотами. Для фильтров с гладкой передаточной
функцией обычной практикой является определение местоположе-
ния обрезающих частот как множества точек, в которых значения
функции H(u,v) становятся меньше некоторой части ее максимально-
го значения. В случае функции, заданной (4.3-6), H(u,v) = 0,5 (мень-
ше 50% максимального значения, равного 1) при D(u,v) = Dq.
Пример 4.5. Низкочастотная фильтрация Баттерворта.
На Рис. 4.15 представлены результаты применения БФНЧ, задан-
ных по формуле (4.3-6) с п = 2, значения частоты среза Dq которых рав-
ны значениям радиуса кругов, показанных на Рис. 4.11 (б). В отличие
от представленных на Рис. 4.12 результатов, относящихся к случаю
Я(«, v)
1
Я(и, v)
Рис. 4.14. (а) Перспективное изображение передаточной функции низкочас-
тотного фильтра Баттерворта, (б) Полутоновое изображение фильтра, (в) Ра-
диальные профили фильтров порядка от 1 до 4.
Глава 4. Частотные методы улучшения изображения
Рис. 4.15. (а) Исходное изображение, (б)—(е) Результаты фильтрации БФНЧ
порядка 2 с частотами среза 5, 15, 30, 80 и 230, соответствующими Рис. 4.11(6).
Сравните с Рис. 4.12.
4.3. Сглаживающие частотные фильтры
ИФНЧ, мы видим здесь плавное уменьшение степени размывания при
увеличении частоты среза. Более того, ни на одном из обработанных
при помощи этого конкретного БФНЧ изображения звон не заметен,
что объясняется свойственным фильтру гладким переходом между
низкими и высокими частотами .
При использовании фильтра Баттерворта порядка 1 звон не воз-
никает. Обычно звон является незаметным для фильтров порядка 2,
но может стать значительным при использовании фильтров более вы-
сокого порядка. Рис. 4.16 дает возможность провести интересное
сравнение представлений БФНЧ различных порядков (с частотой
среза равной 5) в пространственной области. На рисунке представ-
лены также профили яркости соответствующих фильтров вдоль го-
ризонтальной прямой, проходящей через их центр. Для получения
этих фильтров была использована та же процедура, что и для полу-
чения фильтра на Рис. 4.13(6). Для того чтобы облегчить визуальное
сравнение, изображения на Рис. 4.16 были дополнительно улучше-
ны с помощью гамма-коррекции (см. (3.2-3)), которая позволила
сильнее выделить компоненты изображения, находящиеся вдали
от начала координат. БФНЧ порядка 1 (Рис. 4.16(a)) не имеет ни кон-
центрических колец, ни отрицательных значений. Фильтр порядка 2
имеет слабые кольца и небольшие отрицательные значения, но они
выражены заведомо менее отчетливо, чем в случае ИФНЧ. Как по-
казывают оставшиеся изображения, для БФНЧ более высоких по-
Рис. 4.16. (а)—(г) Представления БФНЧ порядка 1,2, 5 и 20 в пространствен-
ной области и соответствующие профили яркости, проходящие через центр
фильтров (частота среза всех фильтров равна 5). Обратите внимание на воз-
растание звона по мере увеличения порядка фильтра.
Глава 4. Частотные методы улучшения изображения
рядков звон (кольца и отрицательные значения) становится значи-
тельным. Фильтр Баттерворта порядка 20 уже демонстрирует свой-
ства ИФНЧ, в чем можно убедиться сравнивая Рис. 4.16(г)
и Рис. 4.13(6). В пределе оба фильтра становятся идентичными. Во-
обще, БФНЧ порядка 2 дает пример хорошего компромисса между
эффективностью низкочастотной фильтрации и приемлемым уров-
нем звона.
4.3.3. Гауссовы фильтры низких частот
Гауссовы фильтры низких частот (ГФНЧ) для одномерного случая
были введены в Разделе 4.2.4, где они использовались для того, что-
бы установить некоторые важные взаимосвязи между пространст-
венной и частотной областями. В двумерном случае эти фильтры за-
даются формулой
Н(и, v) = e-^,2(“’vV2o2, (4.3-7)
где D(u,v) — расстояние (4.3-3) от начала координат фурье-образа, ко-
торый мы считаем сдвинутым в центр частотного прямоугольника с по-
мощью описанной в Разделе 4.2.3 процедуры. В отличие от Разде-
ла 4.2.4, мы опускаем константу перед выражением, задающим фильтр,
чтобы сохранить единообразие с остальными фильтрами, рассматри-
ваемыми в настоящем разделе, которые в начале координат прини-
мают значение 1. Как и раньше, о задает ширину гауссовой кривой.
Обозначив о = Dq, мы можем переписать выражение для фильтра в бо-
лее привычном для данного раздела виде
Н(и,г) = e-D2(u,v)/2Dl, (4.3-8)
где Dq — частота среза. Когда D(u,v) = Dq, значение передаточной
функции фильтра падает до 0,607 от своего максимального значения.
Как показано в Разделе 4.2.4, обратное фурье-преобразование от
гауссовой функции снова есть гауссова функция. В Разделе 4.2.4 мы
уже видели, что это свойство оказывается весьма полезным при ис-
следованиях. Для обсуждаемого сейчас круга вопросов это свойство
означает также, что пространственный гауссов фильтр, полученный
применением обратного преобразования Фурье к (4.3-7) или (4.3-8),
будет положительным и не будет иметь концентрических колец (звон
будет отсутствовать). Трехмерное перспективное изображение, полу-
тоновое изображение и радиальные профили передаточной функ-
ции ГФНЧ представлены на Рис. 4.17.
H(u, v)
I
Рис. 4.17. (а) Перспективное изображение передаточной функции ГФНЧ.
(б) Полутоновое изображение фильтра, (в) Радиальные профили фильтров для
различных значений
Пример 4.6. Низкочастотная гауссова фильтрация.
? На Рис. 4.18 представлены результаты применения ГФНЧ, заданных
формулой (4.3-8), к изображению на Рис. 4.18(a). Значения частот среза
Dq равнялись значениям радиуса кругов, показанных на Рис. 4.11(6). Как
и в случае БФНЧ, мы отмечаем плавное уменьшение степени размыва-
ния при увеличении частоты среза. Применение ГФНЧ дает меньшее по
сравнению с БФНЧ порядка 2 сглаживание при одинаковом значении ча-
стоты среза, что можно увидеть, например, при сравнении Рис. 4.15(b)
и Рис. 4. 18(b). Этого и следовало ожидать, поскольку профиль ГФНЧ не
такой «сжатый», как профиль БФНЧ порядка 2. Однако в целом резуль-
таты вполне сопоставимы, и, кроме того, в случае ГФНЧ мы гарантиро-
ванны от появления звона. Это свойство важно на практике, особенно в тех
ситуациях, когда артефакты любого рода недопустимы (например, при об-
работке медицинских изображений). В тех случаях когда требуется жест-
ко контролировать переходную зону от низких частот к высоким около
частоты среза, БФНЧ предоставляют более подходящий выбор. Платой
за этот дополнительный контроль над формой фильтра является необхо-
димость считаться с возможностью появления звона > .
4.3.4. Дополнительные примеры низкочастотной
фильтрации
В рассмотренных до сих пор примерах низкочастотной фильтрации мы
имели дело с изображениями хорошего качества, и нашей целью бы-
ло продемонстрировать и сравнить возникающие в результате филь-
трации эффекты. Здесь мы дадим несколько примеров практическо-
го применения низкочастотной фильтрации. Первый пример относится
к области машинного восприятия и связан с распознаванием текста,
второй связан с полиграфией и издательским делом, третий — с обра-
боткой аэрофотоснимков и изображений, полученных со спутников.
Глава 4. Частотные методы улучшения изображения
Рис. 4.18. (а) Исходное изображение, (б)—(е) Результаты фильтрации гауссо-
вым низкочастотным фильтром с частотами среза 5, 15, 30, 80 и 230, соответ-
ствующими Рис. 4.11(6). Сравнитес Рис. 4.12 и Рис. 4.15.
а а а а а а а а
4.3. Сглаживающие частотные фильтры
На Рис. 4.19 приведен образец текста плохого разрешения. Мы
сталкиваемся с текстом подобного рода в тех случаях, когда имеем де-
ло, например, с передачей сообщений по факсу, с материалами, по-
лученными в результате копирования или с архивными записями.
Как текст плохого качества, этот конкретный образец не содержит до-
полнительно проблемных участков, в виде пятен, складок и разрывов.
Увеличенный фрагмент на Рис. 4.19(a) показывает, что буквы в до-
кументе из-за недостаточного разрешения искажены, и многие из
них разорваны. Хотя человеческое зрение без труда ликвидирует об-
разовавшиеся пробелы, автоматические системы сталкиваются с се-
рьезными трудностями при распознавании разорванных символов. Для
решения этой проблемы наиболее часто используется подход, заклю-
чающийся в сглаживании исходного изображения, позволяющем пере-
крыть небольшие разрывы. Рис. 4.19(6) показывает, насколько хорошо
мы можем восстановить знаки с помощью простой процедуры, исполь-
зующей гауссов низкочастотный фильтр с частотой среза Dq = 80.
Размер изображений равен 444x508 пикселей.
Низкочастотная фильтрация является одним из основных инстру-
ментов в полиграфии и издательском деле, где она используется в мно-
гочисленных процедурах предобработки, включая нерезкое маскирова-
ние, как это обсуждалось в Разделе 3.7.2. Другое применение
низкочастотной фильтрации — «косметическая» обработка, предшеству-
ющая печати. Рис. 4.20 демонстрирует применение низкочастотной филь-
трации для получения более гладкого и приятного для глаза изображения
Historically, certain computer
programs were written using
only two digits rather than
four to define the applicable
year. Accordingly, the
company's software may
recognize a date using "00"
as 1900 rather than the yjeair
2000.
Historically, certain computer
programs were written using
only two digits rather than
four to define the applicable
year. Accordingly, the
company's software may
recognize a date using "00"
as 1900 rather than the vieair
2000.
C ci
Рис. 4.19. (а) Образец текста плохого разрешения (обратите внимание на раз-
рывы букв в увеличенном фрагменте), (б) Результат фильтрации с примене-
нием ГФНЧ (разорванные сегменты оказались соединены).
Глава 4. Частотные методы улучшения изображения
Рис. 4.20. (а) Исходное изображение (1028x732 пикселя), (б) Результат филь-
трации с применением ГФНЧ, Do = 100. (в) Результат фильтрации с приме-
нением ГФНЧ, Dq = 80. Обратите внимание на значительное снижение рез-
кости морщин в увеличенных фрагментах (б) и (в).
из резкого оригинала. В случае человеческого лица, типичной задачей яв-
ляется понижение резкости тонких линий и небольших пятен на коже. На
увеличенных фрагментах Рис. 4.20(6) и (в) хорошо видно значительное
снижение резкости морщин вокруг глаз. В действительности, сглаженные
изображения выглядят вполне привлекательно и приятно для глаза.
На Рис. 4.21 показаны результаты применения к одному и тому же
изображению двух процедур низкочастотной фильтрации, пресле-
Рис.4.21. (а) Изображение с заметными линиями, появившимися в результа-
те сканирования, (б) Результат, полученный при помощи ГФНЧ с Dq = 30.
(в) Результат, полученный при помощи ГФНЧ с Do = 10. (Исходное изобра-
жение предоставлено NOAA).
довивших совершенно различные цели. На Рис. 4.21(a) показан фраг-
мент панорамы размерами 588x600 элементов, на котором изображе-
на часть Мексиканского залива (темные участки) и Флориды (свет-
лые участки), полученной со спутника NOAA при помощи радиометра
высокого разрешения. Обратите внимание на горизонтальные ли-
нии, совпадающие с направлением движения сенсоров. (Появление
границ между большими участками водной поверхности связано с кон-
турными токами.) Данный фрагмент представляет собой типичный
пример изображений, формируемых сканерами с линейками сенсо-
ров, широко используемыми в дистанционном зондировании. По
причинам, выходящим за рамки настоящего обсуждения, характери-
стики сенсоров различаются, в результате чего возникают отчетливые
линии в направлении сканирования. Низкочастотная фильтрация
является грубым, но простым способом уменьшить визуальный эф-
фект, обусловленный наличием этих линий, что показано на
Рис. 4.21(6) (более действенный подход будет рассмотрен в Главе 5).
Это изображение было получено при использовании гауссова низко-
частотного фильтра с Dq = 30. Достигнутое уменьшение обсуждаемо-
го эффекта может упростить обнаружение таких характерных деталей
как границы раздела океанических течений. Рис.4.21 (в) представля-
ет результат применения значительно более сильного гауссова низко-
частотного фильтра (Dq = 10). Здесь цель обработки состояла в том,
чтобы стереть как можно больше деталей, оставив узнаваемыми лишь
большие характерные части изображения. Между прочим, фильтра-
ция такого типа бывает частью этапа предварительной обработки в си-
стемах анализа изображений, ориентированных на поиск объектов
в банке данных изображений. Примером таких объектов могут служить
озера заданного размера (такие как озеро Окичоби в юго-восточной
части полуострова Флорида, которое на Рис. 4.21(b) выглядит как
почти круглая темная область). Низкочастотная фильтрация помога-
ет упростить анализ за счет сглаживания изображения на участках с де-
талями, имеюшими размеры меньше интересующих.
4.4. Частотные фильтры повышения резкости
В предыдущем разделе было показано, что изображение может быть
сглажено путем подавления высокочастотных составляющих его фу-
рье-преобразования. Поскольку контуры и другие скачкообразные из-
менения яркости связаны с высокочастотными составляющими, по-
вышение резкости изображения может быть достигнуто в частотной
области при помощи процедуры высокочастотной фильтрации, кото-
рая наоборот, подавляет низкочастотные составляющие и не затрата-
вает высокочастотную часть фурье-преобразования. Как и в Разде-
ле 4.3, мы рассматриваем центрально-симметричные фильтры нуле-
вого фазового сдвига. Все обсуждаемые в этом разделе методы филь-
трации основаны на схеме, описанной в Разделе 4.2.3.
Поскольку рассматриваемые в этом разделе фильтры предназна-
чены для выполнения операции, в точности противоположной той,
которую осуществляли рассмотренные в предыдущем разделе низко-
частотные фильтры, то передаточная функция обсуждаемых высоко-
частотных фильтров может быть получена при помощи следующего
соотношения:
Hhp(u,v) = l-Hip(u,v), (4.4-1)
где H\p(u,v) обозначает передаточную функцию соответствующего
низкочастотного фильтра. Таким образом, частоты, ослабляемые низ-
кочастотным фильтром, пропускаются высокочастотным фильтром,
и наоборот.
В этом разделе мы рассматриваем идеальные высокочастотные
фильтры, высокочастотные фильтры Баттерворта и гауссовы высоко-
частотные фильтры. Как и в предыдущем разделе, мы изучаем свой-
ства этих фильтров как в частотной, так и в пространственной обла-
стях. На Рис. 4.22 представлены трехмерные и полутоновые
изображения, а также профили типичных фильтров каждого из пе-
речисленных видов. Как и ранее, мы видим, что фильтр Баттервор-
та занимает промежуточное положение между разрывным идеальным
фильтром и совершенно гладким гауссовым фильтром. Рис. 4.23 да-
ет представление о поведении этих фильтров в пространственной
области. Напомним, что для получения пространственного пред-
ставления фильтра, заданного в частотной области, необходимо:
(1) умножить функцию фильтра H(u,v) на (—1)" + v для центрирова-
ния; (2) вычислить обратное ДПФ; (3) умножить действительную
часть обратного ДПФ на (—1)*+у. Важные особенности приведенных
рисунков обсуждаются в следующих параграфах.
4.4.1. Идеальные фильтры высоких частот
Двумерные идеальные высокочастотные фильтры (идеальные фильтры
высоких частот, ИФВЧ) определяются формулой
H(u,v) =
О при£)(г/,г)<П0;
1 при D(u,v) > Dq ,
(4.4-2)
H(u, v)
l.Ot
D(u, v)
Рис. 4.22. Верхний ряд: перспективное изображение, полутоновое изобра-
жение и профиль типичного идеального высокочастотного фильтра. Средний
и нижний ряды: та же последовательность для типичных высокочастотных
фильтров Баттерворта и Гаусса.
ж зг>
где Dq — частота среза, равная расстоянию от центра частотного пря-
моугольника, а величина D(u,v) задается формулой (4.3-3). Это пря-
мо следует из (4.4-1) и (4.3-2). Как и следовало ожидать, действие
этого фильтра противоположно действию идеального низкочастотно-
го фильтра в том смысле, что он обнуляет все частоты, попадающие
внутрь круга радиуса Dq, одновременно пропуская без ослабления
все частоты, лежащие вне круга. Как и в случае идеального низкочас-
тотного фильтра, ИФВЧ не может быть реализован при помощи элек-
тронных устройств. Однако поскольку он может быть реализован в ком-
пьютере, мы рассмотрим его для полноты. Наше обсуждение будет
кратким.
Глава 4. Частотные методы улучшения изображения
Исходя из соотношения (4.4-1), которое связывает фильтры высо-
ких и низких частот, мы вправе ожидать, что ИФВЧ обладают такими
же свойствами в отношении звона, как и ИФНЧ (см. Рис. 4.23(a)). Это
ясно демонстрирует Рис. 4.24, который состоит из результатов обра-
ботки исходного изображения, представленного на Рис. 4.11(a), при по-
мощи различных ИФВЧ со значениями частоты среза Dq = 15, 30, и 80
пикселей, соответственно. Звон на Рис. 4.24(a) настолько велик, что
он привел к деформированию и утолщению границ объектов (посмо-
трите, например, на большую букву «а»). Границы трех верхних кру-
гов почти не видны, поскольку их контраст мал по сравнению с кон-
трастами других объектов на изображении (яркость этих трех объектов
гораздо ближе к яркости фона, что приводит к меньшей величине
разрывов). Если посмотреть на размер «пятна» на изображении ИФВЧ
(см. Рис. 4.23(a)) и вспомнить, что фильтрация в пространственной об-
ласти есть свертка фильтра с изображением, то это поможет объяснить,
почему маленькие объекты и линии выглядят как почти целиком бе-
лые. Посмотрите, в частности, на три маленьких квадрата в верхнем
ряду и на тонкие вертикальные полосы. Ситуация до некоторой сте-
пени улучшается в случае Dq = 30. Деформация контуров все еще до-
статочно очевидна, но теперь мы начинаем видеть фильтрацию на
маленьких объектах. Уже хорошо знакомое обратное отношение меж-
ду шириной фильтра в частотной и пространственной области гово-
Рис. 4.23. Представление в пространственной области типичных высокочас-
тотных фильтров: (а) идеальный фильтр, (б) фильтр Баттерворта, (в) гауссов
фильтр; внизу представлены соответствующие им профили яркости.
Рис. 4.24. Результаты применения к изображению на Рис. 4.11(a) идеальных а б В
фильтров высоких частот с £>0 = 15, 30 и 80, соответственно. Вызванные зво-
ном проблемы вполне очевидны на рисунках (а) и (б).
рит о том, что размер пят на этого фильтра меньше, чем размер пятна
фильтра с Dq — 15. Результат для = 80 близок к тому, как должен вы-
глядеть результат высокочастотной фильтрации. Контуры здесь го-
раздо более ровные и меньше искажены, и маленькие объекты от-
фильтрованы надлежащим образом.
4.4.2. Фильтры высоких частот Баттерворта
Передаточная функция высокочастотного фильтра Баттерворта
(БФВЧ) порядка п с частотой среза на расстоянии Dq от начала коор-
динат задается формулой
Я(щт) = —-----------(4.4-3)
1+[£>O/Z>(«,v)]2"
где расстояние D(u,v) вычисляется согласно (4.3-3). Формула (4.4-3)
прямо следует из (4.4-1) и (4.3-6). На Рис. 4.22 в среднем ряду пред-
ставлено изображение и профиль передаточной функции БФНЧ.
Как и в случае низкочастотных фильтров, мы вправе ожидать от
высокочастотных фильтров Баттерворта более гладкого поведения по
сравнению с ИФВЧ. Результаты применения БФНЧ порядка 2 с часто-
тами среза Dq, принимающими те же значения, что и на Рис. 4.24, пред-
ставлены на Рис. 4.25. Искажения границ объектов существенно мень-
ше, чем на Рис. 4.24, даже для наименьшего значения частоты среза.
Поскольку размеры центрального пятна для ИФВЧ и БФВЧ близки (см.
Рис. 4.23(a) и (б)), работа двух фильтров по маленьким объектам при-
водит к сопоставимым результатам. Переход к более высоким значени-
ям частоты среза для БФВЧ совершается гораздо более плавно.
Глава 4. Частотные методы улучшения изображения
а б V Рис. 4.25. Результаты высокочастотной фильтрации изображения на Рис. 4.11 (а)
с использованием БФВЧ порядка 2 с £>0 = 15.30 и 80, соответственно. Эти ре-
зультаты существенно более гладкие, чем полученные с применением ИФВЧ.
4.4,3. Гауссовы фильтры высоких частот
Передаточная функция гауссова фильтра высоких частот (ГФВЧ) с ча-
стотой среза, расположенной на расстоянии Do от начала координат, за-
дается формулой
Я(ц,т)=:1-е-р2(“’1’>/2ро,
(4.4-4)
где расстояние D(u,v) вычисляется согласно (4.3-3). Эта формула
прямо следует из (4.4-1) и (4.3-8). На Рис. 4.22 в нижнем ряду пред-
ставлены изображение и профиль передаточной функции ГФНЧ.
Придерживаясь того же формата, как при обсуждении БФНЧ, мы
приводим на Рис. 4.26 заслуживающие сравнения результаты, посчи-
танные с использованием ГФНЧ. Как и следовало ожидать, получен-
а б в Рис. 4.26. Результаты высокочастотной фильтрации изображения на Рис. 4.11 (а)
с использованием ГФВЧ с £>0 = 15, 30 и 80, соответственно. Сравните с Рис. 4.24
и 4.25.
ные изображения являются более гладкими, чем при использовании
предыдущих двух фильтров. Гауссов фильтр дает хорошее качество
фильтрации даже для маленьких объектов и тонких полос.
Как обсуждалось в Разделе 4.2.4, высокочастотные фильтры
можно построить как разность низкочастотных гауссовых фильт-
ров. Такие разностные фильтры содержат большее число параме-
тров, и потому позволяют лучше управлять формой фильтра. Од-
нако, для практической деятельности обычно оказывается вполне
достаточно фильтра (4.4-4), и его вид проще для проведения экс-
периментов.
4.4.4. Лапласиан в частотной области
Можно показать, что
ах
(4.4-5)
Из этого простого выражения следует, что
= (ш)2 F(u, г) + (zv)2 F(u, v) =
(4.4-6)
Э2/(х,у) Э2/(х,у)
Эх2 Эу2
= -(w2 + v2)T(w,v)-
Выражение в квадратных скобках в левой части (4.4-6) представляет
собой лапласиан функции fix,у), определенный формулой (3.7-1).
Таким образом, мы имеем важный результат
5"[v2/(x,y)] = -(и2 + v2)F(w, г), (4.4-7)
который означает, что вычисление лапласиана можно осуществить
в частотной области с помощью фильтра16
Н(и, г) = —(z/2 + г2). (4.4-8)
16 Приведенные выше формулы относятся к случаю непрерывных функций, и выпол-
няют роль наводящих соображений. Мы видим, что оператору Лапласа в простран-
ственной области (в непрерывном случае) отвечает оператор умножения на —(ц2 + v2).
Поэтому для построения дискретного аналога оператора Лапласа в пространствен-
ной области можно использовать аналогичный оператор умножения в частотной
области, что и делается далее. Необходимо сразу предупредить неискушенного чи-
280 Глава 4. Частотные методы улучшения изображения
Как всегда в этой главе, мы предполагаем, что начато координат ддя функ-
ции F(u,v) находится в центре частотного прямоугольника, что достига-
ется умножением функцииДх,у) на (— 1)х+у перед вычислением ее фу-
рье-преобразования. Как уже обсуждалось ранее, если f (и F) имеют
размеры M*.N, то в результате такого умножения центр преобразования
(т.е. (и, г) = (0,0)) попадает в точку (M/2, N/2) частотного прямоугольни-
ка. Центр передаточной функции фильтра также должен быть сдвинут:
Щи, v) = - [(« - М /2)2 + (г- N /2)2 ]. (4.4-9)
Результат применения (дискретного) оператора Лапласа, заданного
в частотной области, (частотного фильтра Лапласа) получается посред-
ством вычисления обратного преобразования Фурье от функции17
H(u,v)F(u,v):
V2f(x, у) = tf"1 £ [(«- М / 2)2 + (г- N /2)2 ] F(u, v)} (4.4-10)
Обратно, операция вычисления лапласиана в пространственной об-
ласти по формуле (3.7-1) с последующим преобразованием Фурье
эквивалентна умножению F(u,v) на H(u,v). Сказанное может быть за-
писано в уже знакомом нам виде18
\72f(x,y)^-^(u-M/2)2 + (v-N/2)2^F(u,v). (4.4-11)
тателя, что полученный таким образом дискретный «частотный» оператор Лапласа
отличается от дискретного «пространственного» оператора, определенного в преды-
дущей главе (например, при помощи (3.7-4)).
Отметим, кроме того, неточность в формулах (4.4-5)—(4.4-8), связанную с непра-
вильной нормировкой. Для того чтобы эти формулы были согласованы с формула-
ми раздела 4.2, определяющими непрерывное преобразование Фурье в одномерном
и двумерном случаях, правую часть формулы (4.4-5) нужно умножить на (2л)", а пра-
вые части остальных - на (2л)2. При другом определении преобразования Фурье (см.
прим. 2) эти нормировочные множители отсутствуют, и формулы выглядят так, как
в тексте. Указанная неточность не сказывается по существу на дальнейшем изложе-
нии. — Прим, перев.
17 Это равенство является, по сути, определением. Оно задает действие «частотного»
оператора Лапласа (фильтра Лапласа) на функцию в дискретном случае.
В написанном виде равенство не согласуется с формулами (4.2-25) и (4.2-26). Для то-
го чтобы восстановить согласование, необходимо либо умножить правую часть ра-
венства на (2л)2. либо умножить правые части формул (4.2-25) и (4.2-26) на 2л (см.,
также, предыдущее прим.). Как и выше, допущенная неточность не является прин-
ципиальной. — Прим, перев.
'8 Это утверждение в непрерывном случае выражается равенством (4.4-6). В дискретном
случае оно является прямым следствием определения (4.4-10). — Прим, перев.
Пространственное представление передаточной функции фильтра
Лапласа, для получения которой нужно применить обратное преобра-
зование Фурье к функции (4.4-9), обладает рядом интересных свойств,
что демонстрирует Рис. 4.27. На Рис. 4.27(a) показано трехмерное изо-
бражение в перспективе функции (4.4-9). Центр функции находится
в точке {М/1, N/2), значение функции в вершине купола равно нулю.
Все остальные значения функции отрицательны. На Рис. 4.27(6) функ-
ция H(u,v) представлена в виде полутонового изображения, также
центрированного. На Рис. 4.27(b) приведено изображение лапласиа-
на в пространственной области, которое получено последовательно ум-
ножением H(u,v) на (-1)" + v, вычислением обратного фурье-преобра-
зования и умножением действительной части последнего на (-1У+у.
На Рис. 4.27(г) показан увеличенный фрагмент центральной части
Рис. 4.27. (а) Трехмерное изображение лапласиана в частотной области, (б) По-
лутоновое изображение (а), (в) Лапласиан в пространственной области, по-
лученный с применением обратного ДПФ к (б), (г) Увеличенный централь-
ный фрагмент (в), (д) Профиль яркости, проходящий через центр фрагмента
(г), (е) Маска лапласиана, использованная в'Разделе 3.7.
Глава 4. Частотные методы улучшения изображения
Рис. 4.17(b). На Рис. 4.27(д) построен профиль, проходящий через
центр выделенного фрагмента. Наконец, на Рис. 4.27(e) приведена
маска, которая была использована в Разделе 3.7 при реализации дис-
кретного оператора Лапласа в пространственной области, заданного
в виде (3.7-4). Форма профиля, образуемого значениями в централь-
ной строке этой маски, повторяет в общих чертах форму профиля на
Рис. 4.27(д) (отрицательное значение расположено между двумя поло-
жительными, меньшими по амплитуде). Интересно отметить, что ес-
ли бы мы начинали с определенного в этом параграфе частотного
фильтра Лапласа, то это в итоге привело бы нас к пространственным
маскам, подобным представленным на Рис. 3.39(a).
Как и ранее (см. (3.7-5)), для получения улучшенного изображе-
ния д(х, у), мы вычитаем лапласиан (изображение, полученное с ис-
пользованием частотного фильтра Лапласа) из оригинала:
g(x,y) = f(x,y)-V2f(x,y). (4.4-12)
Лапласиан вычитается (а не прибавляется) из оригинала, что связано со
знаком минус в (4.4-8). Это согласуется с правилом, которое задается фор-
мулой (3.7-5) в пространственной области. К тому же заключению мож-
но прийти, если заметить, что значение центрального пика на Рис. 4.27(д)
отрицательно, а значения в ближайших точках положительны.
Как и при работе в пространственной области, где мы обрабаты-
вали изображение при помощи одной маски, обработку в частотной
области можно полностью осуществить, используя один фильтр, за-
данный следующим образом:
7/(w,v) = 1+[(w-71//2)2 + (v-^/2)2].
В таком случае искомое изображение получается при помощи един-
ственного обратного преобразования:
g(x, у) = £-1+ ((ы _ м / 2)2 + (V- N / 2)2 )] F(u, V) | (4.4-13)
Для того чтобы получить правильный результат при реализации по-
следней формулы, необходимо позаботиться о масштабировании
фильтра, поскольку квадраты переменных могут быть больше единицы
на несколько порядков.
Пример 4.7. Применение лапласиана в частотной области.
Рис. 4.28(a) повторяет Рис. 3.40(a). На Рис. 4.28(6) показан резуль-
тат частотной фильтрации изображения с использованием (4.4-10). Ре-
4.4. Частотные фильтры повышения резкости
зультат нуждается в градационной коррекции, что характерно для
изображений, полученных в результате применения фильтра Лапла-
са, который принимает как положительные, так и отрицательные
значения сопоставимые по абсолютной величине. На Рис. 4.28(b)
приведен результат градационной коррекции, осуществленной (исклю-
чительно в целях улучшения визуального восприятия) таким образом,
Рис. 4.28. (а) Изображение северного полюса Луны, (б) Изображение, полу-
ченное из (а) при помощи фильтра Лапласа, (в) То же после масштабирования,
(г) Изображение, полученное из (а) с использованием (4.4-12). (Исходное
изображение предоставлено Агентством NASA.)
Глава 4. Частотные методы улучшения изображения
чтобы наибольшему (по величине) отрицательному значению отвеча-
ло нулевое значение яркости, а наибольшему положительному значе-
нию отвечало максимально возможное значение яркости (255 в нашем
случае). Наконец, на Рис. 4.28(г) представлен результат улучшения изо-
бражения, полученный с использованием (4.4-12). Как и следовало
ожидать для случая применения лапласиана, очевидно увеличение рез-
кости мелких деталей на изображении. Только что представленный ряд
изображений следует сравнить с изображениями на Рис. 3.40, кото-
рые получены в результате такой же последовательности шагов, но вы-
полненных с использованием исключительно пространственных ме-
тодов. С точки зрения практических применений, результаты
одинаковы. R
4.4.5. Нерезкое маскирование, высокочастотная
фильтрация с подъемом частотной характеристики,
фильтрация с усилением высоких частот
Все изображения, полученные как результат фильтрации в Разде-
лах 4.4.1—4.4.3, имеют одно общее свойство: среднее значение яркос-
ти фона на них близко к нулю. Это связано с тем обстоятельством, что
высокочастотные фильтры, которые были применены для обработки
этих изображений, уничтожают постоянную составляющую (нуле-
вую компоненту) их фурье-преобразования (см. обсуждение этого яв-
ления в Разделе 4.2.3). Как обсуждалось в Разделе 3.7.2, чтобы изме-
нить такое положение, можно добавить к результату фильтрации
некоторую долю исходного изображения в качестве подложки. На са-
мом деле, именно это и имеет место, когда при использовании лапла-
сиана мы прибавляем все изображение к результату фильтрации. В ря-
де случаев выгодно увеличить вклад, привносимый исходным
изображением в итоговый результат фильтрации. Такой подход носит
название высокочастотной фильтрации с подъемом частотной харак-
теристики и является обобщением метода нерезкого маскирования.
Соответствующие идеи были представлены в Разделе 3.7.2. Мы повто-
ряем их здесь, используя частотную концепцию и соответствующие обо-
значения.
Нерезкое маскирование состоит в формировании резкого изобра-
жения путем вычитания из оригинала его сглаженной копии. В час-
тотных терминах это означает, что имеет место высокочастотная
фильтрация, которая достигается вычитанием из изображения
результата его низкочастотной фильтрации, т.е.
/hp (х, у)=/(х, у) - /1Р (х, у).
(4.4-14)
4.4. Частотные фильтры повышения резкости
Обобщая последнее выражение путем умножения входящей в него
функции f(x,y) на некоторую постоянную А > 1, мы приходим к вы-
сокочастотной фильтрации с подъемом частотной характеристики:
/hb (х, У) = 4f(x’ У) - Лр (х, У) • (4.4-15)
Таким образом, фильтрация с подъемом частотной характеристики
предоставляет нам возможность увеличить вклад, вносимый исходным
изображением в конечный результат обработки. Последнее равенст-
во может быть записано в виде
/hb (х,у) = (А - 1)/(х, у)+f(x, у) - /1р (х, у). (4.4-16)
Теперь, используя (4.4-14), получаем
/hb(x,y) = (Л-1)/(х,у)+fhp(x,y). (4.4-17)
Полученное выражение показывает, что основу обсуждаемого мето-
да фильтрации составляет высокочастотная, а не низкочастотная
фильтрация. Когда Л = 0, высокочастотная фильтрация с подъемом
частотной характеристики сводится к обычной высокочастотной
фильтрации. Если значение Л превышает 1, вклад исходного изобра-
жения становится более заметным.
Из (4.4-14) следует, что Ehp(H,v) = F(u,v) — Fip(u,v). Но поскольку
/)p(«,v)= Hip(u,v)F(u,v), где Др есть передаточная функция низкочастот-
ного фильтра, то нерезкое маскирование может быть осуществлено непо-
средственно в частотной области с использованием составного фильтра
Hhp(u,v) = l-HXp(u,v). (4.4-18)
Заметим, что последнее согласуется с (4.4-1). Аналогично, фильтра-
ция с подъемом частотной характеристики может быть осуществлена при
помощи составного фильтра
Hhb(u,v) = (A-\)+Hbp(u,v) (4.4-19)
с Л > 119. Процедура включает умножение этого фильтра на (центри-
рованное) фурье-преобразование входного изображения и затем вы-
19 Последнее равенство показывает, что обсуждаемый метод отличается от обычной
высокочастотной фильтрации тем, что передаточная функция (частотная характери-
стика) фильтра сдвигается вверх (поднимается) на величину (А — 1) > 0. Отсюда
и происходит название метода. — Прим, перев.
286 Глава 4. Частотные методы улучшения изображения
числение обратного преобразования Фурье от произведения. Умно-
жение действительной части полученного результата на (—I )л + ^да-
ет изображение, являющееся результатом фильтрации с подъемом
частотной характеристики, в пространственной области.
Пример 4.8. Высокочастотная фильтрация с подъемом частотной
характеристики.
Ч На Рис. 4.29 представлена та же последовательность изображений,
что и на Рис. 3.43, но теперь обработка производилась в частотной
области. Рис. 4.29(a) представляет собой исходное изображение,
Рис. 4.29(6) — результат высокочастотной фильтрации. Для того, что-
бы результаты данного примера можно было сравнивать с аналогич-
ными результатами на Рис. 3.43, мы использовали для высокочастот-
ной фильтрации лапласиан, вычисленный в соответствии с (4.4.-10).
Мы предпочли не использовать составной фильтр, чтобы упрос-
тить градационную коррекцию.
Изображение на Рис. 4.29(b) получено с использованием выраже-
ния (4.4-17), в котором А = 2,0. Как и на Рис. 3.43(b), изображение
здесь более резкое, но все еще слишком темное. Изображение на
Рис. 4.29(г) получено при А = 2,7, что означает умножение исходно-
го изображения на величину 1,7 перед вычитанием лапласиана. Как
и в случае Рис. 3.43, этот результат оказывается лучше. Однако
Рис. 4.29(г) не такой резкий, как Рис. 3.43(г). Причина заключается
в том, что используемый «частотный» лапласиан ближе к «прост-
ранственному» лапласиану с маской без диагональных элементов
(см. Рис. 4.27(e)). Как мы видели на примере Рис. 3.41, использова-
ние маски с диагональными элементами приводит к немного более
резким результатам. Эта разница обычно не заметна в тех случаях, ког-
да детали на изображении малы (как в примере со снимком Луны),
но она становится очевидной для изображений, содержащих детали
большего размера .
Иногда при обработке изображения выгодно усилить его высо-
кочастотную составляющую. В этом случае мы умножаем передаточ-
ную функцию высокочастотного фильтра на некоторую константу
и добавляем другую константу с тем, чтобы фильтрация не приво-
дила к уничтожению нулевой частотной компоненты. Такая проце-
дура фильтрации называется фильтрацией с усилением высоких час-
тот. Передаточная функция соответствующего фильтра задается
выражением
(и, v) = a+bHhp (и, v),
(4.4-20)
Рис. 4.29. То же, что на Рис. 3.43, но с использованием обработки в частотной
области, (а) Исходное изображение, (б) Лапласиан (а), (в) Изображение, по-
лученное с использованием (4.4-17), Л = 2,0. (г) То же, что (в), но с Л = 2,7. (Ис-
ходное изображение предоставил Майкл Шеффер, факультет геологии, уни-
верситет шт. Орегон, г. Юджин.)
где а > 0 и b > а. Характерные значения а находятся в диапазоне от 0,25
до 0,50, а характерные значения b — в диапазоне от 1,5 до 2,5. Сравни-
вая последнее равенство с (4.4-17), мы видим, что фильтрация с усиле-
нием высоких частот сводится к фильтрации с подъемом частотной ха-
рактеристики в случае, когда а = (А — 1) и Z> = 1. В случае b > I происходит
усиление высоких частот, откуда и происходит название метода.
Пример 4.9. Фильтрация с усилением высоких частот.
На Рис 4.30(a) представлен рентгеновский снимок грудной клетки
с узким диапазоном изменения яркости. Нашей главной целью явля-
ется повышение резкости этого изображения. Поскольку рентгенов-
ские лучи не могут быть сфокусированы также, как фокусируются при
помощи линз световые лучи, то рентгеновские снимки, как правило,
Глава 4. Частотные методы улучшения изображения
Рис. 4.30. (а) Рентгеновский снимок грудной клетки, (б) Результат высокоча-
стотной фильтрации с использованием фильтра Баттерворта, (в) Результат
фильтрации с усилением высоких частот, (г) Результат применения метода эк-
вализации гистограммы к (в). (Исходное изображение предоставил д-р. Томас
Р. Гест, отделение анатомии медицинской школы университета шт. Мичиган).
выглядят слегка расплывчато. Поскольку в нашем конкретном случае
яркость изображения в целом сдвинута в темную область, мы также
используем связанную с этим возможность и дадим пример того, как
обработка в пространственной области может дополнять обработку
в частотную области.
На Рис. 4.30(6) представлен результат высокочастотной фильтра-
ции с использованием фильтра Баттерворта порядка 2 с частотой сре-
за Dq, равной 5% вертикального размера изображения. Результат
фильтрации не слишком сильно зависит от последнего параметра, по-
скольку радиус фильтра не настолько мал, чтобы пропускать частоты,
близкие к нулевым. Как и можно было ожидать, полученное после
фильтрации изображение маловыразительно, на нем лишь едва вид-
ны основные контуры оригинала. Изображение на Рис. 4.30(b) демон-
стрирует преимущества фильтрации с усилением высоких частот (с
а = 0,5 и b = 2,0 в данном случае). Хотя изображение по-прежнему тем-
ное, общий яркостной тон, обусловленный низкочастотными со-
ставляющими, сохранен.
4.5. Гомоморфная фильтрация
Как указано в Разделе 3.3, изображение, характеризующееся узким
диапазоном яркости, является идеальным кандидатом для обработки
с помощью метода эквализации гистограммы. Как показывает
Рис. 4.30(г), применение этого метода оказалось целесообразным для
дальнейшего улучшения нашего изображения. Обратите внимание на
проявление костной структуры и других деталей, которые просто не
видны на других трех изображениях. Шум на результирующем изоб-
ражении немного увеличился, но это типично для рентгеновских
изображений при растяжении диапазона их яркостей. Результат, по-
лученный при совместном использовании фильтрации с усилением
высоких частот и эквализации гистограммы, превосходит по качест-
ву тот, который может быть получен при использовании каждого из
методов по отдельности .
4.5. Гомоморфная фильтрация
Модель формирования изображения, с которой мы познакомились
в Разделе 2.3.4, может быть использована для развития еще одного ме-
тода обработки в частотной области, направленного на улучшение изо-
бражения путем одновременного сжатия яркостного диапазона и уси-
ления контраста. Согласно обсуждению в Разделе 2.3.4, изображенис/(х,у)
может быть представлено в виде произведения освещенности и коэф-
фициента отражения:
/(х,у) = /(х,у)г(х,у). (4.5-1)
Равенство (4.5-1) не дает непосредственной возможности работать с ча-
стотными составляющими освещенности и коэффициента отражения
по отдельности, поскольку преобразование Фурье произведения не
равно произведению преобразований Фурье сомножителей; другими
словами,
Рассмотрим, однако, величину20
z(x, у) = In Дх, у) = In i(x, у) + In г (х, у). (4.5-2)
20 К логарифмированию изображений нужно подходить с некоторой осторожностью,
хотя бы потому, что некоторые элементы изображения могут обращаться в нуль. —
Прим, перев.
10 А-223
Глава 4. Частотные методы улучшения изображения
Тогда
5{г(х,у)}=5{1п/(х,у)}= ${lnz(x,y)]+${lnr(x,y)} (4.5-3)
или
Z(u,v) = Ff(u,v)+Fr(u,v), (4.5-4)
где Fj(u,v) и Fr(u,v) — фурье-образы функций In i(x,y) и In г(х,у), соот-
ветственно.
Подвергнем функцию Z(u,v) процедуре фильтрации с помощью
фильтра H(u,v). Тогда, в соответствии с (4.2-27),
S(u,г) = Щи, v)Z(u, г) = Щи, v)Fj(u, г) +Щи, v)Fr{u, г), (4.5-5)
где S(u,v) — фурье-образ результата. В пространственной области
имеем
= (45_6)
= Г1{Н(и^МУ^-1{Н(и,у)Рг(и,у)}.
Если обозначить
i'(x,y) = 2Г1 {Щи, v)Fj(u, v)} (4.5-7)
и
r'(x,y) = £-1 {H(u, v)Fr(u,v)}, <4-5’8)
то равенство (4.5-6) можно переписать в виде
s(x,y)=i'(x,y)+r'(x,y). (4.5-9)
Наконец, поскольку функция z(x,y) была получена в результате лога-
рифмирования исходного изображения fix,у), то обратная операция
(потенцирование) позволяет получить искомое обработанное изобра-
жение, обозначаемое g(x,y). Итак
g(x,y)=es^x’y^ =е1 (х’у) ег(х’у) =Щх,у)Щх,у), (4.5-10)
где
4.5. Гомоморфная фильтрация
iG(x,y)=e‘'(x'y) (4.5-11)
и
r0(x,y) = er('x’y'> (4.5-12)
суть освещенность и коэффициент отражения искомого изображения.
Метод обработки изображений, основанный на использовании из-
ложенной выше идеи, схематически представлен на Рис. 4.31. Он яв-
ляется частным случаем метода, применяемого для анализа так назы-
ваемых гомоморфных систем. В нашем частном случае ключевым
моментом рассматриваемого подхода является разложение изображе-
ния на составляющие, связанные с освещенностью и коэффициентом
отражения, в виде (4.3-4). После этого гомоморфный фильтр H(u,v) дей-
ствует на каждую из полученных составляющих по отдельности, так
как показывает (4.5-5).
Составляющая изображения, связанная с освещенностью, обычно
характеризуется медленными изменениями в пространственной об-
ласти, в то время как составляющая, обусловленная коэффициентом от-
ражения, склонна к резким изменениям, особенно в местах соедине-
ния разнородных объектов. Такое поведение позволяет ассоциировать
низкочастотную составляющую преобразования Фурье от логарифма
изображения с освещенностью, а высокочастотную — с коэффициен-
том отражения. Хотя такие ассоциации правильны лишь в грубом при-
ближении, они могут быть полезны при обработке изображений.
Использование гомоморфного фильтра предоставляет возмож-
ность в значительной степени контролировать каждую из означен-
ных составляющих. Для этого требуется задать передаточную функцию
H(u,v) так, чтобы фильтр по-разному воздействовал на низкочастот-
ные и высокочастотные составляющие фурье-преобразования. На
Рис. 4.32 показан профиль такого фильтра. В том случае, если параме-
тры /£ и уд выбраны так, что yL< 1 и yjj> 1, то показанный на Рис. 4.32
фильтр будет ослаблять вклад, вносимый низкими частотами (освещен-
ностью), и усиливать вклад, вносимый высокими частотами (коэффи-
циентом отражения). Конечный результат заключается в одновремен-
ном сжатии динамического диапазона и усилении контраста.
Рис. 4.31. Метод гомоморфной фильтрации для обработки изображений.
Глава 4. Частотные методы улучшения изображения
Рис. 4.32. Профиль центрально-симметричной передаточной функции филь-
тра. D(u,v) — расстояние от начала координат до центра частотного прямо-
угольника.
Для аппроксимации кривой, показанной на Рис. 4.32, можно
использовать любые из основных видов высокочастотных фильтров,
обсуждаемых в предыдущем разделе. Например, использование
модифицированного гауссова высокочастотного фильтра дает
H(u,v) = (yH-yL ) 1-е ct-l)2(u,v)/1)^)
+ yL, (4.5-13)
где D2(w,v) задается формулой (4.3-3), а константа с введена для того,
чтобы контролировать крутизну наклона передаточной функции
фильтра в переходной области между у£ и ун. Фильтр данного вида по-
хож на фильтр усиления высоких частот, который мы обсуждали в
конце Раздела 4.4.
Пример 4.10. Улучшение изображения при помощи гомоморфной филь-
трации.
Рис. 4.33 иллюстрирует типичный результат гомоморфной фильт-
рации. Исходное изображение представлено на Рис. 4.33(a). На фо-
не ярких наружных стен детали внутреннего помещения на изобра-
жении едва различимы. На Рис. 4.33(6) представлен результат
обработки изображения с использованием гомоморфного фильтра,
форма передаточной функции которого имеет вид графика на Рис. 4.32
со значениями yL = 0,5 и уц = 2,0. Уменьшение динамического диа-
пазона для ярких областей с одновременным усилением контраста поз-
волило выявить детали внутреннего помещения и сбалансировать
яркость наружных стен. Обработанное изображение также является
более резким R.
4.6. Вопросы реализации
В этом разделе мы обсудим вопросы, касающиеся реализации преоб-
разования Фурье. Мы начнем с краткого изложения некоторых допол-
нительных свойств двумерного преобразования Фурье и завершим рас-
смотрение сжатым обзором быстрого преобразования Фурье (БПФ).
4.6.1. Некоторые дополнительные свойства двумерного
преобразования Фурье
Сдвиг
Пара преобразований Фурье обладает следующими трансляционными
свойствами (свойствами по отношению к сдвигам):
fix^y^^/M+voy/N) F{u_Uq V_Vq} (4.6-!)
и
/(х-х0,у-у0)<=> F(u,v)e l21^uox/M+voy/N), (4.6-2)
где, как и в выражении (4.2-31), двойная стрелка использована для
обозначения того, что соответствующие функции образуют фурье-
пару. При и0 = М/2 и v0 = N/2 отсюда следует
Рис. 4.33. (а) Исходное изображение, (б) Изображение, обработанное при
помощи гомоморфной фильтрации (обратите внимание на детали внутренне-
го помещения). ([Stockham].)
Глава 4. Частотные методы улучшения изображения
ei2n(u0x/M+v0y/N) =ет(х+у) _
В этом случае выражение (4.6-1) превращается в выражение
/(х,у)(-1)х+^ « F(u-М /2, v- N/2) (4.6-3)
и, аналогично,
f(x - М / 2, у - N / 2)<=> F(u, v)(— l)"+v. (4.6-4)
Мы видим, что выражение (4.6-3) совпадает с выражением (4.2-21), ко-
торое мы использовали для центрирования фурье-преобразования. По-
следние две формулы относятся к случаю, когда переменные иии при-
нимают значения в диапазонах [О, М— 1] и [О, N— 1], соответственно. При
компьютерной реализации21 эти переменные будут принимать значе-
ния от к = 1 до М и от v =1 до N, при этом реальный центр фурье-пре-
образования будет находиться в точке и = М/2+1, v = N/2+1.
Дистрибутивность и изменение масштаба
Из определения преобразования Фурье следует, что
5[/lU,y)+/2(x,y)]=5[/i(x,y)]+5[/2U,y)]> (4-6-5)
и, вообще говоря, что
5[/lU,y)/2(x,y)]^5[/i(x,y)]5[/2(x,y)]. (4.6-6)
Иными словами, преобразование Фурье обладает свойством дистри-
бутивности по отношению к сложению, но не обладает этим свойст-
вом по отношению к умножению. Сказанное справедливо и по отно-
шению к обратному преобразованию Фурье. Аналогично, если а и b —
две постоянные, то
af(x,y)<^aF(u,v} (4.6-7)
и
f(ax,by)<^^—F(u/a,v/b), аЬД). (4.6-8)
|oZ>| 4 7
21 См. прим. 7. — Прим, перев.
Поворот
Введем полярные координаты
x = rcosO, y=rsinO, i/=cocos(p, v=cosin<p,
и обозначим черезДг,0) и f(co,tp) функции/и F, рассматриваемые
как функции полярных координат, соответственно. Прямая подста-
новка в формулы, определяющие преобразования Фурье, дает
/(г,е+е0)«г(со,ф+е0). (4.6-9)
Это выражение показывает, что поворот функции /(х,у) на угол Оо
приводит к повороту функции F(u,v) на тот же угол. Аналогично, при
повороте функции F(u,v) функция fix,у) поворачивается на тот же
угол.
Периодичность и симметрия относительно сопряжения
Дискретное фурье-преобразование обладает следующими свойства-
22
ми периодичности .
F(u, v) = F(u + M,v) = F(u, v+N) = F(u + M,v+N). (4.6-10)
Обратное фурье-преобразование также периодично
f{x, у) = f(x+М,у) = f(x,y+N)=f(x+М ,у+ N). (4.6-11)
Мы уже встречались в Разделе 4.2 со свойством симметрии относитель-
но операции комплексного сопряжения. Выпишем его здесь еще раз
для удобства
F(u,v)=F*(—u,—v). (4.6-12)
Отсюда следует, что спектр центрально симметричен относительно
начала координат:
|F(m,v)| =|Г(-и,-v)|. (4.6-13)
Справедливость всех приведенных равенств прямо следует из опре-
деления преобразований Фурье (4.2-16) и (4.2-17).
22 См., также, прим. 3 и прим. 5. — Прим, перев.
Важная роль свойства периодичности иллюстрируется примером
на Рис. 4.34(a), на котором изображен спектр одномерного фурье-пре-
образования F(u) (см. (4.2-5) и (4.2-10)). Согласно (4.6-10)
F(u) = F(u+M), откуда следует, что |Ди)| = \F(u +Л/)|. Кроме того, в со-
ответствии с (4.6-13), |Ди)| = |Г(—и)|. Свойство периодичности озна-
чает, что функция F(u) имеет период длины М, а свойство симметрии
относительно комплексного сопряжения приводит к тому, что спектр
является центрально-симметричным относительно начала координат.
Все это отражено на Рис. 4.34(a). Из рисунка и предшествующих ком-
ментариев ясно, что значения спектра преобразования в точках от
(M/2) + 1 до М — 1 равны соответствующим значениям в точках по-
ловины периода слева от начала координат. Поскольку дискретное пре-
образование Фурье было определено первоначально для значений и
в интервале [0, М— 1 ], то в результате мы получим в этом интервале две
расположенные «навстречу друг другу» половины периода. Все что не-
обходимо, чтобы получить в указанном интервале изображение одно-
го полного периода, — это сдвинуть начало координат преобразова-
1Д«)1
1Л«)|
а б
г
о
-М/1
в- Один период
Рис. 4.34. (а) Фурье-спектр, представляющий собой две половины периода «на-
встречу друг другу» на интервале [0, М— 1]. (б) Сдвинутый фурье-спектр, пред-
ставляющий полный период на том же интервале, (в) Фурье-спектр изобра-
жения, демонстрирующий те же свойства, что и (а), но для двумерного случая,
(г) Центрированный фурье-спектр.
М/1
Один период
4.6. Вопросы реализации
ния в точку и = М/2, как показано на Рис. 4.34(6). Для этого, в соот-
ветствии с (4.6-3), мы умножаем/(х) на множитель (—1)х.
Аналогично можно рассмотреть и двумерные спектры. На
Рис. 4.34(b) и (г) показано, как выглядит типичный спектр до и после
центрирования (показан только один период). Начало координат для
спектра на Рис. 4.34(b) находится в левом верхнем углу, и четыре дву-
мерные периодические составляющие распространяются «навстречу
друг другу» от четырех углов по направлению к центру, где находит-
ся самая высокочастотная составляющая спектра. В противополож-
ность этому, начало координат (нулевая частотная компонента) цен-
трированного спектра, полученного с использованием (4.6-3),
находится на Рис. 4.34(г) в центре, и центрально-симметричный
спектр распространяется от центра по направлению к краям.
Рис. 4.34(г) ясно демонстрирует, что центрирование преобразования
не только удобно с точки зрения визуализации, но, как уже отмеча-
лось неоднократно в этой главе, упрощает процедуру фильтрации.
Разделение переменных
Дискретное преобразование Фурье (4.2-16) можно записать так, что
переменные окажутся разделены:
, М-1 , N-1
/7(1/^) = — e-ilTiux/M £ j~^y)e-i27^y/N =
М х=0 N у=0
-12тмх / М
х=и
=77 X И*.*
где
F{x,v) = ^f{x,y)e~i^vy/N.
N y=Q
(4.6-14)
(4.6-15)
При каждом значении х (и при у = 0,1,2,..., N— 1) последнее выраже-
ние является полным одномерным фурье-преобразованием. Други-
ми словами, F(x,v) есть фурье-преобразование одной строки функции
fix,у). При изменении х от 0 до М— 1, мы получаем фурье-преобразо-
вания по всем строкам функции fix,у). Чтобы получить полное дву-
мерное преобразование, мы должны менять значения переменной и
в (4.6-14) диапазоне от 0 до М— 1. Нетрудно сообразить, что это вле-
чет вычисление одномерного преобразования по каждому столбцу
функции Fix,v). Полученный результат весьма важен. Он говорит о том,
что для вычисления двумерного преобразования можно сначала вы-
Глава 4. Частотные методы улучшения изображения
числить одномерные преобразования по каждой строке исходного
изображения, а затем вычислить одномерные преобразования по
каждому столбцу полученного промежуточного результата. Результат
остается в силе и при изменении порядка вычислений: сначала по
столбцам, затем по строкам. Предложенный метод вычисления схе-
матически изображен на Рис. 4.35.
Такой же метод применим и для вычисления двумерного обратно-
го преобразования Фурье. Сначала мы вычисляем обратное преобра-
зование по каждой строке функции F(u,v), а затем вычисляем обрат-
ное преобразование по каждому столбцу полученного промежуточного
результата. Как показано в следующем параграфе, обратное преобра-
зование может быть реализовано при помощи алгоритма прямого
преобразования Фурье.
4.6.2. Вычисление обратного преобразования Фурье
при помощи алгоритма прямого преобразования
Как было отмечено в предыдущем параграфе, двумерное преобразо-
вание Фурье может быть вычислено посредством одномерных пре-
образований. Одномерные преобразования Фурье (прямое и обрат-
ное) были определены в Разделе 4.2.1. Для удобства приведем здесь
соответствующие равенства:
1 М-1
F(u) = —Y f(x)e~i2nux/M , и = 0,1,2,...,М-1 (4.6-16)
М
и
М-1
f(x)=£ F(u)ei2nux/M , х=0,1,2,...,1И-1. (4.6-17)
и=0
Одномерные Одномерные
преобразования преобразования
по строкам по столбцам
Рис. 4.35 Вычисление двумерного преобразования Фурье с помощью после-
довательности одномерных преобразований.
Взяв комплексное сопряжение от обеих частей (4.6-17) и поделив их
на М, получим
, , м-1
—f*(x)=— У Ffu)e~i2mx^M . (4.6-18)
М М£о
Сравнивая последнее равенство с (4.6-16), мы видим, что правая
часть (4.6-18) имеет вид прямого преобразования Фурье. Поэтому
подстановка F (и) в некоторый алгоритм, предназначенный для вы-
числения прямого преобразования, дает величину f (х)/М. Взяв ком-
плексное сопряжение и умножив на М, получим искомую величину
Дх). Такие же рассуждения в случае двух переменных дают:
1 1 М-I N-1
—/*(V) = — У У F^u^-t2^ux/M^y/N) , (4.6_19)
MN MN
причем правая часть последнего равенства имеет вид прямого дву-
мерного преобразования Фурье. В том случае, когда функция fix) или
fix,у) является вещественной (т.е. изображением), операцию ком-
плексного сопряжения в левой части (4.6-19) можно опустить. В этом
случае мы просто берем действительную часть результата, игно-
рируя паразитные мнимые составляющие, которые в большинст-
ве случаев появляются при вычислении преобразования Фурье.
Вычисление двумерного преобразования с помощью последова-
тельности одномерных часто может стать источником ошибок, в том
случае когда развитая только что техника применяется для вычисле-
ния обратного преобразования. При реализации намеченной в пре-
дыдущем параграфе процедуры равенство (4.6-18) не должно сби-
вать с толку. Именно, при использовании одномерного алгоритма
для вычисления двумерного обратного преобразования мы не долж-
ны производить операцию комплексного сопряжения после обра-
ботки каждой строки или столбца. Вместо этого мы должны рассма-
тривать функцию F (u,v) в качестве функцииfix,у) в прямой двумерной
процедуре, представленной на Рис. 4.35. Для получения правильно-
го значения обратного фурье-преобразования/(х,у) необходимо осу-
ществить комплексное сопряжение (или отделение действительной
части в подходящем случае) полученного результата и умножить его
на 1/MN. Мы подчеркиваем, что предшествующие замечания, каса-
ющиеся констант Мн N, основаны на таком определении дискретно-
го преобразования Фурье, в котором эти константы отнесены в пря-
мое преобразование. Как указывалось в Разделах 4.2.1 и 4.2.2, нередко
встречаются и другие способы распределения этих констант между
Глава 4. Частотные методы улучшения изображения
прямым и обратным преобразованиями. Поэтому, чтобы избежать
ошибок в нормировке, необходимо проявлять осторожность с распо-
ложением этих констант при вычислении обратного преобразова-
ния, если они распределены некоторым отличным от принятого
в этой книге образом.
4.6.3. Еще раз о периодичности: необходимость
дополнения нулями
В Разделе 4.2 на основе теоремы о свертке было показано, что умно-
жение в частотной области эквивалентно свертке в пространственной
области, и наоборот. Работая с преобразованием Фурье в случае дис-
кретных переменных, мы должны помнить о периодичности различ-
ных функций, участвующих в преобразованиях (см. Раздел 4.6.1). Та-
кая периодичность, возможно не вполне понятная интуитивно,
является побочным математическим результатом, связанным со спо-
собом определения дискретного преобразования Фурье23. Итак, пе-
риодичность является неотъемлемой частью метода и не может быть
проигнорирована.
Важная роль, которую играет периодичность, проиллюстриро-
вана на Рис. 4.36. На этом рисунке в левой колонке показан процесс
вычисления свертки с использованием одномерного варианта равен-
ства (4.2-30)24:
. м-Л
f(x)*h(x) =— V f(m)h(x-т). (4.6-20)
23 Точнее сказать, только при переходе к рассмотрению периодических функций
(последовательностей) в дискретном случае удается корректно определить такие
операции как, например, сдвиг и свертка и сохранить те свойства этих операций от-
носительно дискретного преобразования Фурье (рассмотренные выше в этом разде-
ле), которыми они обладали в непрерывном случае. — Прим, перев.
24 Операция свертки, о которой идет речь в данном абзаце и процесс вычисления ко-
торой подробно представлен в левой колонке на Рис. 4.36, отличается от той сверт-
ки, которая рассматривалась до сих пор (и процесс вычисления которой представ-
лен в колонке справа). Отличие состоит в том, что теперь при расширении области
определения функции (которое необходимо, чтобы использовать (4.6-20)) мы доопре-
деляем ее всюду (при всех целых значениях аргумента) нулями, а не продолжаем пе-
риодически, как раньше. Фактически мы имеем дело с другим определением дискрет-
ной свертки. Такое определение свертки, в отличие от использовавшегося ранее,
прямо соответствует операции свертки в непрерывном случае. Это определение яв-
ляется более адекватным в ряде задач, например, если мы хотим построить прибли-
4.6. Вопросы реализации
fim)
О 200 400
fim)
О 200 400
h(rn)
2 —
h(m)
2
т
О 200 400
О 200 400
h(-m)
О 200 400
h{x-m)
h(x-m)
--х~-
0 200 400
/(x)*g(x)
О 200 400 600 800
О 200 400
0100 300
—-I I*-
\ Основной период (диапазон
значений аргумента сверт-
ки, вычисленной с исполь-
зованием ДПФ)
а б
В Jh
Л е
& 8
Ж 3
и к
т
т
Рис. 4.36. Слева: свертка двух дискретных функций. Справа: свертка тех же
функций с учетом периодизации, подразумеваемой при использовании аппа-
рата ДПФ. Обратите внимание (график (к)) на то, как значения в смежных пе-
риодах искажают результат свертки.
жение для свертки двух непрерывных функций по дискретному набору их значений.
Однако при таком определении теорема о свертке перестает быть справедливой. Это
сразу становится ясно, если обратить внимание на то обстоятельство, что получае-
мая дискретная свертка не является пери одической. Тем самым для вьиисления та-
кой свертки нельзя прямо использовать известный нам метод, основанный на пере-
ходе в частотное пространство с использованием ДПФ. Основной вопрос,
рассматриваемый в этом параграфе, как раз и состоит в том, как модифицировать этот
метод, чтобы он стал применим и в этом случае. — Прим, перев.
302 Глава 4. Частотные методы улучшения изображения
Используем представившуюся здесь возможность, чтобы детальнее
рассмотреть процесс свертки. Вместо того, чтобы вести изложение
в общем виде, мы, для простоты, зададимся конкретными значени-
ями длины и высоты функций. На Рис. 4.36(a) и (б) представлены две
функции, к которым мы хотим применить операцию свертки. Каж-
дая функция содержит 400 отсчетов. Первый шаг состоит в зеркаль-
ном отображении одной из функций относительно начала коорди-
нат. В нашем случае это было сделано со второй функцией, результат
отображения h(—т) показан на Рис. 4.36(b). Следующий шаг состо-
ит в сдвиге функции h(—т) по отношению к функции/!/и). Для это-
го мы прибавляем постоянную х к аргументу функции h и получа-
ем функцию h(x— т), представленную на Рис. 4.36(г). Заметим, что
на последнем рисунке представлена функция лишь для одного зна-
чения сдвига. Этот простой шаг часто является источником проблем
для начинающих. Полезно твердо запомнить, что именно здесь за-
ключается существо операции свертки. Иначе говоря, для осуществ-
ления операции свертки мы зеркально отображаем одну из функций
и сдвигаем ее относительно другой. Для каждого сдвига (для каждо-
го значения х) производится полное суммирование в соответствии
с (4.6-20). Это суммирование есть не что иное, как сложение произ-
ведений/и h при заданном значении сдвига. Сдвиги х принимают
все значения, необходимые для того, чтобы полностью перемес-
тить h относительно/. На Рис 4.36(д) представлен результат вычис-
лений в соответствии с формулой (4.6-20) при каждом значении х.
В нашем случае для полного перемещения функции h(x—т) относи-
тельно функции/ переменная х должна принять все значения в ди-
апазоне от 0 до 799. Функция на Рис 4.36(д) — свертка двух функций.
Необходимо твердо понимать, что аргументом свертки является пе-
ременная х.
На основании рассмотренной в Разделе 4.2 теоремы о свертке
(см. (4.2-31)), мы вправе ожидать, что в точности такой же результат
может быть получен при вычислении обратного преобразования Фу-
рье от произведения Г\и)Н(и). Однако, из обсуждения связанных с пе-
риодичностью вопросов, которое имело место ранее в этом разделе,
нам известно, что дискретное преобразование Фурье автоматически
воспринимает входящие в него функции как периодические. Иными
словами, использование ДПФ позволяет нам осуществить свертку
в частотной области, но функции при этом рассматриваются как пе-
риодические, с периодом, равным размеру первоначальной области
определения функций.
Мы можем изучить последствия, к которым приводит такая пери-
одичность, при помощи графиков в правой колонке на Рис. 4.36.
4.6. Вопросы реализации
Функция на Рис. 4.36(e) получена в результате периодического про-
должения изображенной на Рис. 4.36(a) функции на все (целые) зна-
чения аргумента (доопределенные части показаны пунктиром). Ана-
логично получены функции на Рис 4.36 от (ж) до (и). Для вычисления
свертки мы снова сдвигаем функцию h(x—m) относительно функции
f(m). Как и ранее, мы изменяем значение х в таких пределах, чтобы
обеспечить полное перемещение функции h(x—m) относительно функ-
ции f. Теперь однако, в результате осуществленного для функций
в правой колонке Рис 4.36 периодического продолжения, функции
h(x—ni) (при различных значениях х) приобретают ряд дополнитель-
ных ненулевых значений в точках основного периода (0,1,...,Л/—1). На-
пример, прих = 0 (см. Рис. 4.36(з)) мы видим, что ненулевая часть пер-
вого периода продолжения функции h(x—m) вправо лежит в основном
периоде функции/(где график функции показан сплошной линией).
По мере того как функция h(x—m) сдвигается вправо (значение х
возрастает), эта ненулевая часть также сдвигается вправо и выхо-
дит из основного периода, но заменяется аналогичной ненулевой ча-
стью, соответствующей продолжению Щх—т) влево. В результате на
интервале [0,100] свертка имеет постоянное значение, как показано
на Рис. 4.36(к). Значения свертки на интервале [100,400] правиль-
ные, однако дальше значения начинают периодически повторяться.
Это приводит к потере «хвоста» функции свертки, что можно видеть
при сравнении графика на Рис. 4.36(д) и части графика, нарисован-
ного сплошной линией, на Рис. 4.36(к).
В частотной области процедура состояла бы в вычислении фу-
рье-преобразований от функций на Рис. 4.36(a) и (б). В соответствии
с теоремой о свертке, полученные фурье-преобразования были бы пе-
ремножены, и к произведению было бы применено обратное преоб-
разование Фурье. В результате мы получили бы 400 отсчетов, состав-
ляющих свертку, показанную сплошной линией на Рис. 4.36(к). Этот
простой пример показывает, что без адекватного учета свойства пери-
одичности вычисление свертки с помощью преобразования Фурье
приведет к неправильным результатам. Получаемый массив будет
содержать неверные данные в начале, часть данных в конце будет от-
25
сутствовать.
Эта проблема допускает простое решение. Предположим, что
функции/и h состоят из А и Z? точек, соответственно. Дополним каж-
25 Здесь и далее точнее, наверное, было бы говорить о том, что получаемые резуль-
таты отличаются от результатов вычисления по-другому определенной свертки (см.
прим. 24). — Прим, перев.
Глава 4. Частотные методы улучшения изображения
дую из функций нулями так, чтобы в результате они были определе-
ны в одном и том же основном периоде длины Р:
feM =
I °,
0<х< Л-1;
А<х<Р;
(4.6-21)
ge(x) =
g(x),
О,
0<х<В-1;
В<х<Р.
(4.6-22)
После этого полученные таким способом расширенные, или дополнен-
ные нулями, функции продолжим периодически (с периодом Р). Мож-
но показать [Brigham, 1988], что до тех пор пока Р < А + В — 1, отдель-
ные периоды свертки будут перекрываться26 27. Мы уже видели на Рис. 4.36
последствия, к которым приводит этот эффект. Соответствующие
ошибки часто называют ошибками перекрытия. При Р = А + В — 1 эти
периоды будут соседствовать между собой. При Р > А + В — 1 периоды
будут отделены друг от друга, причем расстояние между ними будет рав-
но разности величин Р и А + В — 1.
Результат, полученный после дополнения нулями функций на
Рис. 4.36(a) и (б), представлен на Рис. 4.37(a) и (б). В этом случае мы
выбрали Р=А + В — 1 = 799, поэтому мы уверены, что периоды сверт-
ки будут соседствовать между собой. Придерживаясь описанной выше
процедуры, мы придем к свертке, график которой представлен на
Рис. 4.37(д). В одном периоде полученный результат совпадает с резуль-
татом на Рис. 4.36(д), который мы считаем правильным. Таким обра-
зом, если бы мы хотели вычислить свертку с помощью перехода в ча-
стотную область, нам следовало бы (1) получить фурье-образы двух
дополненных нулями последовательностей (по 800 точек в каждой); (2)
перемножить эти фурье-образы; и (3) вычислить обратное преобразо-
вание Фурье. В результате мы получили бы правильную свертку (раз-
мером в 800 точек), показанную в одном периоде на Рис. 4.37(д) сплош-
„27
нои линиеи .
26 При вычислении свертки будут перекрываться относящиеся к соседним периодам
области, в которых функции не обращаются в нуль. — Прим, перев.
27 Подчеркнем лишний раз, что результат носит общий характер. При дополнении
функций нулями в основном периоде P(JP> А + В— 1), результат вычисления сверт-
ки, при определении которой используется периодизация (это вычисление может быть
осуществлено при помощи ДПФ), совпадает в основном периоде с результатом вы-
числения свертки, при определении которой мы продолжаем функции нулем на
множество всех целых значений аргумента (ср. прим. 24). — Прим, перев.
4.6. Вопросы реализации
fe(m)
О 200 400 600 800
he(m)
2
О 200 400 600 800
----------1--------1---------i---------t------------
0 200 400 600 800
he(-m)
H----------------------
Основной период (диапазон
значений аргумента свертки,
вычисленной с использова-
нием ДПФ)
Рис. 4.37. Результат вычисления свертки для функций, дополненных нулями.
Сравните Рис. 4.37(д) и Рис. 4.36(д).
Глава 4. Частотные методы улучшения изображения
Для распространения представленной концепции на двумерные
функции нужно следовать той же цепочки рассуждений. Пусть мы име-
ем два изображения/(х,у) и h(x,y) размерами Ах В и CxD, соответствен-
но. Каки в одномерном случае, нужно рассматривать эти массивы как
периодические с некоторыми периодами Р в направлении х и Q в на-
правлении у. Выбор
Р>А+С-\
и
Q>B+C-A
(4.6-23)
(4.6-24)
позволяет избежать ошибок перекрытия при вычислении двумерной
свертки. Дополнение нулями функций Дх,у) и h(x,y) в основном пе-
риоде осуществляется следующим образом:
и 0<у<В-1;
или B<y<Q,
(4.6-25)
и
h(x,y), 0<х<С-1 и 0<у<£)-1;
О, С<х<Р или D<y<Q.
(4.6-26)
Обсуждаемая процедура расширения (дополнения изображения ну-
лями) играет важную роль в процессе фильтрации. При реализации
любого из рассмотренных в этой главе методов фильтрации в час-
тотной области, мы умножаем фурье-образ обрабатываемого изобра-
жения на передаточную функцию соответствующего фильтра. Как мы
знаем из теоремы о свертке, это эквивалентно свертке изображения
с образом данного фильтра в пространственной области. Поэтому
в случае, если изображение не дополнено нулями надлежащим обра-
зом, результаты будут неверны. Проиллюстрируем сказанное с помо-
щью Рис. 4.38, где для простоты полагается, что функции— ква-
дратные изображения одинакового размера, причем функция h —
обратное ДПФ фильтра H(u,v). На Рис. 4.38(a) показано, каким бу-
дет результат фильтрации, если не дополнить изображения нулями.
Это — характерный результат, который мы получим, если вычислим
преобразование Фурье исходного изображения (не дополняя его ну-
лями), умножим его на передаточную функцию фильтра (также не до-
полненную нулями) и вычислим обратное преобразование Фурье.
4.6. Вопросы реализации
Правильно расширенное
(дополненное нулями)
изображение
Результат фильтрации в частотной
области без правильного дополне-
ния нулями входных изображений
Р
Верные данные
-------------Q--------------Н
Результат фильтрации в частотной
области с правильным дополнени-
ем нулями входных изображений
Р=А+С-1
Q=B+D-l
Рис. 4.38. К вопросу о необходимости дополнения изображений нулями,
(а) Результат применения двумерной свертки без дополнения нулями, (б) Пра-
вильное дополнение нулями, (в) Правильный результат свертки.
Изображение на выходе будет иметь размеры АхВ, равные размерам
входного изображения, и будет находиться в левом верхнем квадра-
те на Рис. 4.38(a). Как и в одномерном случае, начальная пригранич-
ная область изображения (показанная на рисунке серым цветом) бу-
дет содержать неверные данные, что обусловлено периодичностью,
а данные в области продолжения будут отсутствовать. В результате
Глава 4. Частотные методы улучшения изображения
правильного дополнения нулями исходного изображения и функции
фильтра, как показано на Рис. 4.38(6), мы получим верно отфильт-
рованное изображение размером Рх Q, представленное на Рис. 4.38(b).
Это изображение вдвое больше исходного по каждому из направ-
лений, и потому содержит в четыре раза больше элементов. Однако,
обычно из этого большего изображения вырезают лишь область инте-
реса, отбрасывая все остальное.
Важно отметить, что для использования описанного выше под-
хода необходимо частотную передаточную функцию фильтра ум-
ножить на (—1)“+\ обратить ее, дополнить нулями полученное про-
странственное изображение и, применив к результату прямое
преобразование Фурье, вернуться назад в частотную область. Все дру-
гие аспекты фильтрации, которые мы обсуждали в Разделе 4.2.3,
остаются неизменны. Заметим также, что значения обратного фурье-
преобразования функции фильтра содержат как действительную,
так и мнимую части. Хотя амплитуда мнимой части значений филь-
тров, с которыми мы имеем дело, обычно на много порядков мень-
ше амплитуды действительной части, вообще говоря нехорошо пре-
небрегать мнимой составляющей на этапе промежуточных
вычислений. Поэтому перед формированием расширенного филь-
тра в частотной области с помощью вычисления прямого преобра-
зования Фурье, дополняются нулями обе части (как действительная,
так и мнимая).
На Рис. 4.39 показано расширенное (дополненное нулями) пред-
ставление в пространственной области идеального низкочастотного
Рис. 4.39. Расширенный (дополненный нулями) низкочастотный фильтр в про-
странственной области (показана только действительная часть).
4.6. Вопросы реализации
фильтра, использованного для получения изображения на Рис. 4.12(b)
(показана только действительная часть). Дополненная нулями об-
ласть видна как черная. Идеальный низкочастотный фильтр был вы-
бран для иллюстрации потому, что его «структура» в пространственной
области наиболее заметна. Представленное расширение имело ми-
нимальный необходимый размер, что, в случае когда и изображение,
и фильтр представляют собой квадраты одинаковой величины, озна-
чает просто увеличение размеров вдвое по каждому из направлений.
На Рис. 4.40 представлен результат фильтрации с использовани-
ем только что рассмотренного подхода, основанного на дополнении
функций нулями. Легко понять, каким образом свертка фильтра на
Рис. 4.39 с расширенным вариантом изображения на Рис. 4.12(a)
приведет к формированию изображения на Рис. 4.40. Очевидно так-
же, что в данном случае полученное изображение на три четверти
состоит из бесполезной информации, а потому обрезав его до разме-
ров исходного, мы получим искомый результат фильтрации. При
этом мы можем быть уверены в отсутствии ошибок перекрытия.
4.6.4. Свертка и теоремы о корреляции
Свертка функций была введена в Разделе 4.2.4, а вопросы, связанные
с вычислением свертки, дополнительно обсуждались в деталях в Раз-
деле 4.6.3. Повторим здесь кратко основные моменты, что будет спо-
собствовать сопоставлению свертки со схожим объектом, называемым
Рис. 4.40. Результат фильтрации с использованием процедуры дополнения ну-
лями. Изображение обычно обрезается до размеров исходного, поскольку об-
ласть вне границ исходного изображения содержит мало полезной информации
Глава 4. Частотные методы улучшения изображения
корреляционной функцией. Дискретная свертка двух функций fix,у)
и h(x,y) размера MxN, обозначаемая как/(х,у)*Л(х,у), определяется вы-
ражением
. Л/-1ЛМ
fix,y)*h(x,y) = —- У У f(m,n)h(x-m,y-n). (4.6-27)
MN >Zo„=o
Из материала Раздела 4.2.4 нам известно, что теорема о свертке свя-
зывает две функции и два их фурье-преобразования следующими со-
отношениями:
fix, у) * Ых, у) <=> F(u, v)H(u,v) (4.6-28)
и
f(x,y)h(x,у) <=> F(u, г) * H(u, v). (4.6-29)
Корреляция (корреляционная функция) двух функций fix,у) и h(x,y)
определяется следующим выражением:
। M-1N-1
f(x,y)°hix,y) = -—-^ f*im,n)h(x+m,y+n), (4.6-30)
MN ^0п=0
где f* — обозначает функцию, комплексно-сопряженную функции f
Обычно мы имеем дело с действительными функциями (изображени-
ями), в этом случае f =f. Выражение, определяющее корреляцию, от-
личается от выражения (4.6-27), определяющего свертку, только ком-
плексным сопряжением и заменой «плюсов» на «минусы» во всех
членах под знаком суммы. Последнее означает, что функция h не
отображается зеркально относительно начала координат. Во всем ос-
тальном вычисление корреляционной функции идентично вычис-
лению свертки, включая необходимость расширения области опреде-
ления (дополнения нулями)28.
28 При определении корреляции, как и в случае свертки, можно, в принципе, сразу
продолжать функции периодически, а не дополнять их предварительно нулями. При
этом мы получим другую корреляционную функцию (ср. прим. 24), для которой, ко-
нечно, также будет справедлива сформулированная ниже в тексте теорема о корре-
ляции. Однако использование такой корреляционной функции в рассматриваемой
автором далее задаче совмещения, да и в ряде других задач, совершенно не адекват-
но. Поэтому при определении корреляции требование предварительно дополнять
функции нулями представляется вполне оправданным. — Прим. ред. перев.
4.6. Вопросы реализации
С учетом сходства между сверткой и корреляцией не удивительно,
что имеет место теорема о корреляции, аналогичная теореме о свертке.
Пусть F(u,v) и H(u,v) обозначают фурье-образы функцийДх,у) и h(x,y),
соответственно. Первая половина теоремы констатирует, что корреля-
ция в пространственной области /(х,у)°й(х,у) и произведение
F *(и, v)H(u,v) образуют фурье-пару. Этот результат, который можно за-
писать в виде
f(x, у) о h(x, у) <^F* (и, v)H(u, v), (4.6-31)
означает, что корреляционная функция в пространственной области
может быть получена как результат обратного преобразования Фурье,
примененного к произведению F *(u,v)H(u,v), где F* — комплексно-
сопряженная к /’функция. Аналогично, вычисление корреляционной
функции в частотной области сводится к умножению в пространст-
венной области, т.е.
/* (x,y)h(x,y) <=> F(u, г) о H(u,v). (4.6-32)
Эти два утверждения составляют содержание теоремы о корреляции.
При этом предполагается, что все функции правильно дополнены
нулями.
Как нам известно, свертка является связующим звеном между
процедурами фильтрации в пространственной и частотной областях.
Основная задача, при решении которой используется корреляция, —
это задача совмещения. Изображение/(х,у), участвующее в совмеще-
нии, состоит из некоторых объектов или областей. Если мы хотим
определить, содержит ли изображение/конкретный интересующий
нас объект (область), то мы формируем отдельное изображение h(x,y)
этого объекта (области) (обычно это изображение называется этало-
ном) и вычисляем корреляционную функцию изображения и этало-
на. Тогда, если данное изображение содержит объект (область), сов-
мещаемый с эталоном, то корреляция двух функций будет иметь
максимум, расположенный там, где обнаружено соответствие между
эталоном h и изображением f При решении большинства практи-
ческих задач совмещения необходимы процедуры предобработки,
такие как масштабирование и выравнивание, однако главная часть
процесса состоит в вычислении корреляции.
В заключение сделаем следующее замечание относительно терми-
нологии. Для того чтобы подчеркнуть то обстоятельство, что корре-
ляция вычисляется между различными изображениями, вместо тер-
мина корреляция часто используется термин взаимная корреляция.
Глава 4. Частотные методы улучшения изображения
В противоположность этому, когда речь идет о корреляции между
одинаковыми изображениями, используют термин автокорреляция.
В последнем случае имеет место теорема об автокорреляции, которая
прямо следует из (4.6-31):
f(x,y)°f(x,y)«|7W)|2 - (4.6-33)
При получении выражения в правой части, мы учли то обстоятельст-
во, что квадрат модуля комплексного числа равен произведению это-
го числа на число, комплексно-сопряженное ему. Этот результат озна-
чает, что фурье-преобразование пространственной автокорреляционной
функции представляет собой энергетический спектр, определенный
формулой (4.2.-20). Аналогично
|/(х,у)|2 « F(u,v)°F(u,v). (4.6-34)
Пример 4.11. Корреляция изображений.
На Рис. 4.41 приведен простой пример решения задачи совмеще-
ния с помощью вычисления корреляции. На Рис. 4.41(a) представле-
но изображение, а на Рис. 4.41(6) — эталон. Изображение и эталон
имеют размеры 256x256 и 38x42, соответственно. В этом случае
А = В =256, С = 38 и D = 42. Отсюда минимальные размеры функций
после дополнения нулями равны Р = А + С — 1 = 293 и
Q = В + D — 1 = 297. Мы выбрали равные размеры этих функций
298x298. Дополненные нулями изображения показаны на Рис. 4.41(b)
и (г). Их корреляционная функция представлена на Рис. 4.41(д) как
изображение. В соответствии с (4.6-31), корреляционная функция
была получена в результате вычисления фурье-образов изображений,
дополненных нулями, взятия комплексного сопряжения от одного из
фурье-образов (для этого мы выбрали эталон), перемножения двух по-
лученных образов и вычисления обратного ДПФ. Вопрос о том, как
выглядел бы результат на Рис. 4.41(д), если бы мы взяли комплекс-
ное сопряжение от другого фурье-образа, оставлен читателю в каче-
стве упражнения (Задача 4.23).
Рис. 4.41 (д) показывает, что, как и следовало ожидать, корреляци-
онная функция принимает наибольшее значение в точке, отвечающей
такому положению эталона, при котором буквы «Т» на нем и на изо-
бражении точно совмещены. Важно иметь в виду, что, как и в случае
свертки, аргументами корреляционной функции в пространствен-
ной области являются сдвиги. Точка в левом верхнем углу изображе-
ния на Рис. 4.41(д), например, соответствует нулевому сдвигу одной
4.6. Вопросы реализации
Рис. 4.41. (а) Изображение, (б) Эталон, (в) и (г) Изображения, дополненные
нулями, (д) Корреляционная функция, представленная в виде изображения,
(е) Горизонтальный профиль яркости, проходящий через точку с наибольшим
значением на рис. (д); показана точка, для которой имеет место наилучшее
совпадение.
Глава 4. Частотные методы улучшения изображения
функции по отношению к другой. Значение каждого элемента изоб-
ражения на Рис. 4.41(д) есть значение корреляционной функции для
одного определенного значения сдвига, т.е. для одной заданной пары
значений (х,у) в (4.6-30). Отметим также, что корреляционная функ-
ция имеет те же размеры, что и расширенные изображения. Наконец,
на Рис. 4.41(e) представлен профиль яркости, проходящий в горизон-
тальном направлении через ту точку на Рис. 4.41(д), в которой корре-
ляционная функция принимает максимальное значение. Этот рису-
нок еще раз подтверждает, что наивысший пик корреляционной
функции расположен в той точке, которая отвечает лучшему совпа-
дению эталона и изображения.
4.6.5. Перечень свойств двумерного преобразования Фурье
Все рассмотренные в этой главе свойства преобразования Фурье све-
дены в Таблицу 4.1. Знаком «|» отмечены те из них, применение ко-
Таблица 4.1. Перечень некоторых основных свойств двумерного преобразо-
вания Фурье.
Свойство Выражение(я)
, M-1N-1
Преобразование Фурье
M-1N-1
Обратное преобразование f{x,y) = X YF^ei2K(UX/M+VylN)
Фурье u=0 v=0
Представление в полярных
координатах F(«,v)=|F(M,v)|e ^u’v}
Спектр |/'(м,г)|=р?2(м,г)+/2(м,г)] ,
/?=Re(F), Z=Im(F)
Фаза ф(м,г)=аг^Г~^Л
Энергетический спектр Р(м,г)=|Г(м,г)|2
> M-lN-l
Среднее значение /(x,y)=F(0,0)=— X X f(x,y) x=0 y=0
4.6. Вопросы реализации
Свойство Выражение(я)
Сдвиг /(x,y)e'2’t(‘^/M+’’oy/7V)«F(K-KO,v-vo) f(x-x^y-y^F{u,v)e-i2^/M+v^/N) При х0=и0=М/2 и yo = Vo=N/2 получаем /(х,у)(-1)*+>Ъ F(u-M/2,v-N/2) /(x-.M72,y-.lV/2)«F(«,v)(-l)u+v
Симметрия относительно комплексного сопряжения |F(«,v)|=|F(-«,-v)| |F(m,v)|=|F(-m,-v)|
Дифференцирование29 —(Х,У) <^(iu)n F(u,v) Эх" (_«)"/(x,y)«^^ Эи"
Лапласиан30 V2/(x,y)<=> -(м2+v2)F(m,v)
Дистрибутивность ?[/1(х,у)+/2(^,17)]=?[/1(^>17)]+?[/2(х>17)1
Масштабирование af(x,y)<^>aF(u,v), f(ax,by)^-^—F(u/a,v/b),ab^O. |aZ>|
Поворот x=rcosO y=rsinO u=cocos<p v=o>sin<p /(r,O+Oo)<=> F(co,<p+O0)
Периодичность F(u, v)=F(u+M, v)=F(u, v+N)=F(u+M, v+N) f(x, y)=f(x+M, у) =/(x, у +/V) =/(x +M, у +ЛГ)
Разделение переменных См. (4.6-14) и (4.6-15). Разделение переменных оз- начает, что для вычисления двумерного преобра- зования можно сначала вычислить одномерные преобразования по каждой строке изображения, а затем вычислить одномерные преобразования по каждому столбцу полученного промежуточного результата. Изменение порядка вычислений (сна- чала по столбцам, затем по строкам) приводит к тому же результату.
29 Выражение справа от двойной стрелки в первом соотношении нужно умножить на
нормировочный множитель (2л)", а во втором — на (2л)-", см., также, прим. 16. —
Прим, перев.
30 Выражение справа от двойной стрелки нужно умножить на нормировочный мно-
житель (2л)2, см., прим. 16 и прим. 17. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
Свойство Выражение(я)
Вычисление обратного преобразования Фурье при помощи алгоритма для прямого преобразования MN Равенство означает, что подстановка функции F*(и,v) в предназначенный для вычисления прямого преоб- разования алгоритм (в правую часть приведенного равенства), дает величину f *(x,y)/MN. Взяв ком- плексное сопряжение и умножив результат на MN, получим искомое обратное преобразование.
Свертка-!- 1 M-UV-1 f(x,y)*h(x,y)=—— У У f (m,ri)h(x-т,у-п) MN Л
Корреляция-!- J Л/-1Л-1 f(x,y)°h(x,y)=—— У у/*(/и,п)й(х+/и,у+п) мп т=0„=()
Теорема о свертке-!- f(x,y)*h(x,y) <^>F(u,v)H(u,v) f(x,y)h(x,y) <=>F(u,v)*H(u,v)
Теорема о корреляции-!- f(x,y)oh(x,y) c^F*(u,v)H(u,v) f* (x,y)h(x,y) <=> F(u,v)
Некоторые примеры фурье-преобразований:
Импульсная (б-)функция 8(x,y)<=>!
Гауссова функция A2w2e-21lV^+y^ « Ae~(M/2<?
Прямоугольная функция rectL,/) |« ab^(^^ble-in(ua+vb} (ma) (mb)
Косинус cos(2ra/0x+2nv0y)<=> <=v i [б(и+Ми0, v+Nvq )+5(и - Muq , v - Nvq ) ]
Синус sin(2nM0x+2nv0y) <=> <=> [5(и + Ми0, v + M’()) - 8(u - Ми0, v - Nvq ) ]
торых требует дополнения функций нулями во избежание неверных
результатов. Как обычно, двойные стрелки используются для обозна-
чения того, что выражения образуют фурье-пару Это означает, что вы-
ражение справа от двойной стрелки может быть получено применени-
ем прямого преобразования Фурье к выражению слева; выражение
слева может быть получено применением обратного преобразования
Фурье к выражению справа.
4.6. Вопросы реализации 317
4.6.6. Быстрое преобразование Фурье
Как указывалось в Разделе 4.1, одной из главных причин, способст-
вующих превращению ДПФ в важнейший инструмент обработки
сигналов, стало создание алгоритма быстрого преобразования Фурье
(БПФ). Прямое вычисление одномерного преобразования Фурье с ис-
пользованием выражения (4.2-5) для массива, состоящего из М то-
чек, требует порядка Л/2 операций умножения/сложения. То же вы-
числение, проводимое с использованием БПФ, требует порядка
Мlog2 М. Если, например, М = 1024, то при вычислении «в лоб» по-
требуется приблизительно 106 операций, в то время как при вычис-
лении с использованием БПФ потребуется приблизительно 104 опе-
раций. Это означает увеличение скорости вычислений в 100 раз.
Если такой выигрыш в скорости не кажется значительным, то вооб-
разите, что решение некоторой задачи может быть получено за один
год, а не за 100 лет. Именно здесь пролегает грань между возможным
и практически невозможным. И более того, с увеличением объема
данных возрастает выигрыш в скорости. Если, например, М = 8192
(213), то скорость вычислений возрастает в 600 раз. Числа подобно-
го рода являются мощным стимулом для изучения того, как работа-
ет БПФ алгоритм. В этом параграфе мы получим фундаментальное
разложение для ДПФ, которое приведет нас к БПФ алгоритму. Мы
сосредоточим внимание на БПФ для случая одной переменной. Как
указано в Разделе 4.6.1, двумерное преобразование Фурье может
быть получено путем последовательного вычисления одномерных
преобразований.
В основе развиваемого в этом параграфе БПФ алгоритма лежит так
называемый метод последовательного удвоения. Для удобства обозна-
чений мы запишем (4.2-5) в виде
< М-1
F(u)=— £ , (4.6-35)
где
WM=e~i2^M, (4.6-36)
а относительно числа М предполагается, что оно является степенью
двойки, т.е. представимо в виде
М=2п,
(4.6-37)
Глава 4. Частотные методы улучшения изображения
причем п — целое положительное число. Отсюда следует, что Мпред-
ставимо в виде
М = 2К,
(4.6-38)
где К — также целое положительное число. Подставив (4.6-38)
в (4.6-35), получим
х=0 (4.6-39)
2LAx=0 А х=0
х=0
Используя (4.6-36) нетрудно показать, что (В^к)2^ = (И-^)"*, поэто-
му (4.6-39) может быть переписано в виде
Г(“’Ц
1X +1 Х/(2х+1)ИГ
Л х=0 А х=0
Положив по определению
И
(4.6-40)
^even(M)=4 X f(2x)W^, для w = 0,l,2,...,K-l (4.6-41)
х=0
^odd(w)=—V/(2x+l)»^, для и = 0Д,2,...,К-1, (4.6-42)
К х=0
мы сможем записать (4.6-40) в виде
F(«) = |[/7even(«)+ ' (4.6-43)
Кроме того, поскольку (В^)“+м= (WM)U и (В^д/)"+м= то
F(U+K) = ||4ven(«)- ^odd («)^2К ] • (4.6-44)
При внимательном анализе выражения (4.6-41)— (4.6-44) обнаружи-
вают ряд интересных свойств. Как показывают выражения (4.6-43)
4.6. Вопросы реализации 319
и (4.6-44), Л/-точечное преобразование может быть вычислено с по-
мощью разложения исходного выражения на две части. Для вычис-
ления первой половины массива F(u) нужно вычислить два (М/2)-то-
чечных преобразования, заданных формулами (4.6-41) и (4.6-42).
Подстановка полученных значений Fevcn(u) и Fodd(u) в (4.6-43) дает F(u)
для и = 0,1,2,...,(Л//2— 1). Вторая половина массива прямо получает-
ся при подстановке этих значений в (4.6-44) без дополнительного
вычисления преобразований.
Для того чтобы понять последствия применения такой процедуры
с вычислительной точки зрения, обозначим через т(п) и а(п) соответ-
ственно число комплексных умножений и сложений, необходимых для
ее выполнения. Каки ранее, полное число отсчетов равно 2й, где п —
положительное целое число. Предположим сначала, что п = 1. Двух-
точечное преобразование требует вычисления значения ДО); затем
значение F( 1) может быть получено из (4.6-44). Для получения ДО) сна-
чала нужно вычислить Feven(0) и Дхи(О). Поскольку в данном случае
К= 1, то выражения (4.6-41) и (4.6-42) представляют собой одноточеч-
ные преобразования. Поскольку фурье-преобразование единствен-
ного отсчета есть сам этот отсчет, то для получения EeVen(0) и Д>аа(0)
не требуются ни умножения, ни сложения. Одно умножение Fodd(0) на
W2° и одно сложение дает ДО) по формуле (4.6-43). Затем Д1) полу-
чается по формуле (4.6-44) при помощи еще одного сложения (вычи-
тание рассматривается как операция аналогичная сложению). По-
скольку величина Дхм(0)^2° Уже была сосчитана ранее, то полное
число операций, необходимое для вычисления двухточечного пре-
образования, состоит из /л(1) = 1 умножений и й(1) = 2 сложений.
Пусть теперь п = 2. В соответствии с предыдущими результата-
ми, 4-точечное преобразование может быть разделено на две части.
Первая половина Ди) требует вычисления двух двухточечных пре-
образований, задаваемых формулами (4.6-41) и (4.6-42) с К = 2.
Вычисление двухточечного преобразования требует т(1) умноже-
ний и Д1) сложений, таким образом вычисление по двум указанным
формулам потребует всего 2/и(1) умножений и 2<з( 1) сложений. Еще
два сложения и умножения необходимы для получения ДО) и Д1)
по формуле (4.6-43). Поскольку величины F^iujW^ для и = {0,1}
уже были посчитаны, еще два сложения дадут Д2) и ДЗ). Таким об-
разом, полное число операций т(2) = 2т( 1 )+2 и а(2) = 2Д 1)+4.
Когда л = 3, вычисление EeVen(0)и Даа(0) сводится к вычислению
двух 4-точечных преобразований. Это требует 2т(2) умножений и 2Д 2)
сложений. Для полного завершения вычислений необходимо еще че-
тыре умножения и восемь сложений. Таким образом, полное число
операций /и(3) = 2т(2) +4 и ДЗ) = 2а(2) +8.
Глава 4. Частотные методы улучшения изображения
Продолжая рассуждать подобным образом, мы придем к следую-
щим рекуррентным выражениям для числа операций, необходимых
для вычисления БПФ при любом положительном значении п:
т(п) = 2т(п-1) + 2п 1, п>\
(4.6-45)
и
а(п) = 2а(п-1)+2п, л>1; (4.6-46)
кроме того т(0) = 0, с(0) ~ 0, поскольку одноточечное преобразова-
ние не требует ни умножений, ни сложений.
Формулы (4.6-41)—(4.6-44) лежат в основе БПФ алгоритма с после-
довательным удвоением. Это название связано с методом вычисления
двухточечного преобразования на основе двух одноточечных, 4-точеч-
ного — на основе двух двухточечных и т.д., для любого М, равного це-
лой степени 2. В качестве упражнения (Задача 4.25) мы предлагаем
читателю показать, что
и
т(п) = Л/log2 М
(4.6-47)
3 а(п) = М log 2 М.
(4.6-48)
Преимущество в скорости, которое дает БПФ алгоритм по сравнению
с прямым методом вычисления одномерного ДПФ, определяется вы-
ражением
М
С(М) =—-----=—^—.
Aflog2Af log2 Л/
(4.6-49)
Поскольку предполагается, что М = 2", то (4.6-49) можно переписать
в терминах гг.
С{п) = — .
п
(4.6-50)
График соответствующей функции представлен на Рис. 4.42. Как отме-
чалось ранее, преимущество в скорости быстро возрастает с ростом чис-
ла п. Например, при п = 15 (32768 отсчетов), БПФ превосходит в скоро-
4.6. Вопросы реализации
п
Рис. 4.42. Преимущество в скорости, которое дает БПФ алгоритм по сравне-
нию с прямым методом при вычислении одномерного ДПФ. Обратите вни-
мание на быстрый рост преимущества в скорости как функции от п.
сти прямой метод вычисления почти в 2200 раз. Поэтому можно ожидать,
что на одном и том же компьютере вычисления с помощью БПФ будут
совершаться почти в 2200раз быстрее, чем вычисления прямым методом.
Детальному рассмотрению БПФ посвящено так много прекрасных
работ (см., например [Brigham, 1988]), что мы не будем более останав-
ливаться на этом вопросе. Фактически все полные пакеты программ
для обработки сигналов и изображений включают в себя реализа-
цию обобщенного БПФ алгоритма, который может также оперировать
с количеством отсчетов, не равным целой степени 2 (за счет вычисли-
тельной эффективности). Бесплатные БПФ программы также легко
доступны, в основном через Интернет.
4.6.7. Некоторые замечания по поводу конструирования
фильтров
Все рассмотренные в этой главе фильтры задаются в аналитическом
виде. Для того чтобы использовать такие фильтры, следует брать зна-
чения соответствующего выражения в нужных точках (м,г). В резуль-
тате получается функция фильтра H(u,v). Во всех рассмотренных при-
мерах эта функция умножалась на (центрированное) ДПФ исходного
11 А-223
322 Глава 4. Частотные методы улучшения изображения
изображения, после чего вычислялось обратное ДПФ. Все прямые
и обратные преобразования Фурье, встречающиеся в этой главе, бы-
ли вычислены при помощи БПФ алгоритма с использованием мето-
дов, представленных схемой на Рис. 4.35 и в Разделе 4.6.2.
При рассмотрении в этой главе методов фильтрации в частотной
области, мы намеренно сосредоточили внимание на основных прин-
ципах, чтобы стала яснее суть используемых методов. Лучшего пути для
этого, чем избранный нами способ изложения, мы не знаем. Матери-
ал главы может рассматриваться как фундамент для конструирования
фильтров. Другими словами, если мы хотим подобрать фильтр для не-
которой конкретной задачи, то частотные методы будут тем идеальным
инструментом, который даст возможность экспериментировать быст-
ро и с полным контролем над параметрами фильтра.
Когда для конкретного приложения уже найден фильтр, часто воз-
никает вопрос о реализации соответствующей фильтрации непосредст-
венно в пространственной области с использованием встроенных про-
грамм и/или аппаратных средств. В работе [Petrou, Bosdogianni, 1999]
представлена подходящая связь между двумерными пространственны-
ми фильтрами и соответствующими цифровыми фильтрами. По пово-
ду разработки двумерных цифровых фильтров см. [Lu, Antoniou, 1992].
Заключение
Представленный в настоящей главе материал, вместе с материалом
Главы 3, закладывает всеобъемлющие основы для улучшения изобра-
жений. В настоящий момент читателю, несомненно, ясно, что улучше-
ние изображений как область знаний представляет собой в действи-
тельности набор опробованных на практике средств для получения
удовлетворительных результатов в конкретных приложениях. Большая
часть используемых методов имеет под собой хорошее математичес-
кое или статистическое обоснование, но их использование строго
проблемно-ориентированно. Другими словами, улучшение изобра-
жений больше искусство, чем наука, понятие «должным образом улуч-
шенного» изображения в высшей мере субъективно. В Главе 5 мы рас-
пространим некоторые развитые в этой и предыдущей главе
математические концепции на область восстановления изображений.
В отличие от рассмотренных до сих пор методов улучшения изображе-
ний, методы восстановления основаны в большей степени на объектив-
ных критериях, чем на субъективных. По существу методы восстанов-
ления значительно лучше структурированы.
Другой главной задачей этой главы было развитие аппарата
преобразований Фурье. Хотя это было сделано в контексте улучше-
ния изображений, разработанные методы являются совершенно об-
щими, что видно на различных примерах использования ДПФ в по-
следующих главах.
Библиографические замечания
В качестве дополнительного чтения по вопросам, затрагиваемым в Раз-
деле 4.1, мы рекомендуем [Hubbard, 1998]. Книги [Bracewell, 2000]
и [Bracewell, 1995] могут служить хорошим введением в теорию непре-
рывного преобразования Фурье и его обобщения на двумерный слу-
чай для обработки изображений. Две упомянутые книги, а также
[Lim, 1990], [Castleman, 1996], [Petrou, Bosdogianni, 1999] и [Brigham,
1988] содержат исчерпывающее изложение вопросов, составляющих
основу всех рассмотрений Раздела 4.2.
В качестве дополнительного чтения по материалу Разделов 4.3
и 4.4 см. [Castleman, 1996], [Pratt, 1991] и [Hall, 1979]. По-прежнему
представляет интерес вопрос о том, как эффективно управлять воз-
никающими в результате фильтрации артефактами (такими как звон);
по этому поводу см. [Baker, Reeves, 2000]. По вопросам нерезкого ма-
скирования и высокочастотной фильтрации с подъемом частотной ха-
рактеристики см. [Schowengerdt, 1983]. При изложении материала, от-
носящегося к гомоморфной фильтрации, мы основываемся на работе
[Stockham, 1972]; см., также, книги [Oppenheim, Schafer, 1975] и [Pitas,
Venetsanopoulos, 1990]. В работе [Brinkmanetai., 1998] методы нерез-
кого маскирования и гомоморфной фильтрации скомбинированы
для улучшения магнитно-резонансных изображений. Вопросы кон-
струирования цифровых фильтров (Раздел 4.6.7) на основе представ-
ленного в этой главе частотного подхода рассмотрены в [Lu, Antoniou,
1992] и [Petrou, Bosdogianni, 1999].
Как указано в Разделе 4.1, открытие быстрого преобразования
Фурье (Раздел 4.6.6) стало тем краеугольным камнем, на котором
держится популярность ДПФ как главного инструмента для обра-
ботки сигналов. Наше изложение БПФ в Разделе 4.6.6 основано
на работе [Cooley, Tuckey, 1965] и на книге [Brigham, 1988], которая
также содержит обсуждение ряда вопросов реализации БПФ, вклю-
чая рассмотрение других оснований, отличных от 2. Честь откры-
тия быстрого преобразование Фурье часто приписывают Кули и
Тьюки [Cooley, Tuckey, 1965]. Однако с открытием БПФ связана
интересная история, достойная того, чтобы упомянуть здесь о ней.
В ответ на статью Кули и Тьюки, Радник опубликовал работу
[Rudnick, 1966], в которой утверждал, что он использует аналогич-
ную технику, с числом операций также пропорциональным Мlog 2 Л/,
Глава 4. Частотные методы улучшения изображения
которая основана на методе, изложенном в работе Даниэльсона и
Ланцоша [Danielson, Lanczos, 1942]. Эти авторы, в свою очередь,
ссылались на Рунге [Runge, 1903, 1904] как на первоисточник. Две
последние работы вместе с лекциями Рунге и Кёнига [Runge, Kenig,
1924] содержат изложение всех существенных вопросов, относящих-
ся к вычислению БПФ. Похожие методы рассматривались также в
работах [Yates, 1937], [Stumpff, 1939], [Good, 1958] и [Thomas, 1963].
В работе [Cooley, Lewis, Welch, 1967a] приведены исторический об-
зор и интересное сравнение результатов, предшествующих работе
Кули и Тьюки 1965 г.
Задачи
*4.1 Покажите, что F(u) иДх) в формулах (4.2-5) и (4.2-6) образуют
фурье-пару. Для этого подставьтеДх) в виде (4.2-6) в формулу
(4.2-5) и убедитесь, что при этом она превращается в тождест-
во. Повторите вычисления, подставляя F(u) в виде (4.2-5) в фор-
мулу (4.2-6). Вам потребуется следующее свойство ортогональ-
ности для экспонент:
м-1
у ei2nrx/ Мg-/2raoc/ М _
х=0
М, если г = и;
0, в противном случае.
4.2 Покажите, что преобразование Фурье и обратное преобра-
зование суть линейные операции (относительно линейнос-
ти см. Раздел 2.6).
4.3 Пусть F(u,v) — ДПФ изображения fix,у). Из обсуждения в
Разделе 4.2.3 нам известно, что умножение F(u,v) на функцию
фильтра Н(и, г) и вычисление обратного преобразования Фу-
рье изменит вид изображения в соответствии с характером ис-
пользуемого фильтра. Пусть H(u,v) = А, где А — некоторая по-
ложительная константа. Используя теорему о свертке,
объясните математически, почему элементы изображения в
пространственной области умножаются на ту же самую кон-
станту.
*4.4 Передаточная функция гауссова низкочастотного фильтра в ча-
стотной области имеет вид
H(u,v) = Ae^u2+v2'>/2c2 .
Покажите, что соответствующий фильтр в пространственной
области имеет вид
к(х,у) = А1пс1е-'1^х1+У1л).
{Указание’, для упрощения вычислений рассматривайте пере-
менные как непрерывные31.)
4.5 Равенство (4.4-1) показывает, что высокочастотный фильтр
имеет передаточную функцию
ЯЬр(«,г) = 1-Я1р(«,г),
где Др(н,г) — передаточная функция соответствующего низко-
частотного фильтра. Используя результат Задачи 4.4, укажите,
какой вид в пространственной области имеет гауссов фильтр вы-
соких частот.
4.6 *(а) Докажите справедливость равенства (4.2-21).
(б) Докажите справедливость равенств (4.6-1) и (4.6-2).
4.7 Каково происхождение почти периодических ярких точек на
горизонтальной оси в спектре на Рис. 4.11(6)?
*4.8 Каждый из пространственных фильтров на Рис. 4.23 имеет
сильный пик в начале координат. Объясните происхождение
этих пиков.
4.9 Рассмотрим представленные изображения. Изображение спра-
ва получено следующим образом, (а) Изображение слева ум-
ножено на (— 1)х+у; (б) вычислено ДПФ; (в) взято комплекс-
ное сопряжение фурье-образа; (г) вычислено обратное ДПФ;
(д) вещественная часть полученного результата умножена на
(_1)х+у Объясните (математически), почему полученное изо-
бражение выглядит так, как на рисунке справа.
d . I. р I а • I • а
31 В дискретном случае это, строго говоря, неверно. Значения дискретного преобра-
зованя Фурье отсчетов непрерывной гауссовой функции h{x,y) отличается от отсче-
тов непрерывной гауссовой функции H(u,v). Однако для дискретных массивов боль-
шого размера это отличие мало по величине. — Прим, перев.
Глава 4. Частотные методы улучшения изображения
4.10 Покажите, что если передаточная функция фильтра H(u,v) ве-
щественная и центрально-симметричная, то и соответствую-
щий пространственный фильтр h(x,y) также вещественный и
центрально-симметричный.
*4.11 Докажите теорему о свертке. Для простоты ограничьтесь слу-
чаем непрерывных функций одной переменной.
4.12 Рассмотрим представленные изображения. Изображение спра-
ва получено в результате низкочастотной фильтрации с помо-
щью гауссова фильтра низких частот и последующего приме-
нения к результату высокочастотной фильтрации с помощью
гауссова фильтра высоких частот. Размер изображений
420x344, и Dq = 25 для каждого из фильтров.
(а) Рассмотрим рисунок справа. Объясните, почему централь-
ная часть кольца выглядит как сплошная яркая область, в
то время как превалирующая часть изображения после
фильтрации состоит из контуров вдоль внешней границы
объектов (например, костей пальцев и запястья) с темны-
ми областями посередине. Другими словами, разве не сле-
дует ожидать потемнения области постоянной яркости
внутри кольца в результате высокочастотной фильтрации,
коль скоро высокочастотные фильтры уничтожают посто-
янную составляющую изображения?
(б) Как Вы думаете, изменится ли результат, если поменять по-
рядок применения фильтров на противоположный.
Исходное изображение предоставил д-р. Томас Р. Гест, отделение анатомии ме-
дицинской школы университета шт. Мичиган.
4.13 Пусть дано изображение размерами MxN, и проводится экс-
перимент, состоящий в последовательном применении к изо-
бражению процедур низкочастотной фильтрации с исполь-
зованием одного и того же гауссова фильтра низких частот с
заданной частотой среза Dq. Ошибкой округления можно пре-
небречь. Пусть £mjn — наименьшее положительное число,
представимое в вычислительной машине, на которой прово-
дится эксперимент.
*(а) Обозначим через К число произведенных в эксперименте
процедур фильтрации. Можете ли Вы предсказать, без
проведения эксперимента, каков будет его результат (изо-
бражение) при достаточно большом значении К!
(б) Получите выражение для минимального значения К, га-
рантирующего получение предсказанного результата.
4.14 Предположим, что Вы сформировали низкочастотный прост-
ранственный фильтр, действие которого в каждой точке (х,у)
сводится к усреднению значений в четырех ближайших к ней
точках, исключая ее саму.
(а) Найдите эквивалентный фильтр в частотной области.
(б) Покажите, что это действительно низкочастотный фильтр.
*4.15 Основной метод, используемый для приближенного вычис-
ления производной в дискретном случае (Раздел 3.7), вклю-
чает вычисление разности f(x + 1, у) — f(x,y).
(а) Найдите передаточную функцию фильтра H(u,v) для осуще-
ствления эквивалентной операции в частотной области.
(б) Покажите, что фильтр H(u,v) есть фильтр высоких частот.
4.16 Рассмотрим представленную последовательность изображений.
Изображение слева представляет собой фрагмент рентгенов-
ского снимка промышленной печатной платы. Следующие
за ним изображения суть результаты 1-кратного, 10-кратного
и 100-кратного повторения процедуры фильтрации с исполь-
зованием гауссова высокочастотного фильтра с Dq = 30. Раз-
мер изображений — 330x334, диапазон яркости — 8 бит на эле-
мент. Перед воспроизведением изображения были подвергнуты
масштабированию, но это не сказывается на постановке задачи,
(а) Вид изображений наводит на мысль, что после некоторо-
го количества повторений результаты перестают меняться.
Исходное изображение предоставил Джозеф Е. Пассенте, Lixi, Inc.
Глава 4. Частотные методы улучшения изображения
Установите, имеет ли в действительности это место в рас-
сматриваемом случае. Ошибкой округления можно прене-
бречь. Пусть fcmin обозначает наименьшее положитель-
ное число, представимое в вычислительной машине, на
котормой проводится предлагаемый эксперимент.
(б) Если при решении части (а) задачи установлено, что из-
менения прекратятся после некоторого числа итераций,
то найдите минимальное значение этого числа.
4.17 Как показывает Рис. 4.17, совместное использование проце-
дур фильтрации с усилением высоких частот и эквализации ги-
стограммы является эффективным методом повышения рез-
кости и улучшения контраста.
(а) Подумайте, влияет ли порядок процедур на окончательный
результат.
(б) Если порядок процедур важен, то дайте обоснованный от-
вет, какую процедуру использовать вначале.
*4.18 Можно ли использовать преобразование Фурье для вычисле-
ния (хотя бы частичного) модуля градиента (см. Раздел 3.7.3)?
Если да, то укажите способ. Если нет, то объясните почему.
4.19 В Разделе 4.4.4 мы начали с определения лапласиана и полу-
чили фильтр для осуществления эквивалентной операции в ча-
стотной области. Начните с маски для дискретного приближе-
ния лапласиана на Рис. 4.27(e) и получите фильтр в частотной
области, реализующий это приближение.
4.20 Используя передаточную функцию высокочастотного фильтра
Баттерворта порядка п, сконструируйте гомоморфный фильтр.
Этот фильтр должен иметь характерную форму, показанную на
Рис. 4.32, и содержать те же параметры, что и на рисунке.
*4.21 Необходимость дополнения нулями изображения при филь-
трации в частотной области детально обсуждалась в Разде-
ле 4.6.3. В разделе указывалось, что нули должны быть добав-
Исходное изображение предоставлено Агентством NASA.
лены в конец строк и столбцов изображения (см. следующее
изображение слева). Как Вы думаете, изменится ли результат,
если вместо этого мы окружим изображение состоящим из
нулей бордюром (см. изображение справа), не изменив об-
щего числа нулей. Объясните.
4.22 Два представленных фурье-спектра являются спектрами одно-
го и того же изображения. Спектр слева соответствует исход-
ному изображению, а спектр справа получен после дополне-
ния нулями изображения.
(а) Объясните разницу в общем уровне яркости.
(б) Объясните значительный рост уровня сигнала вдоль вер-
тикальной и горизонтальной осей в спектре справа.
4.23 Показанная на Рис. 4.41(д) корреляционная функция была
вычислена с помощью перехода в частотную область в соот-
ветствии с (4.6-31). При вычислении мы применили опера-
цию комплексного сопряжения к фурье-образу эталона на
Рис. 4.41(г). Опишите в общих чертах, как выглядел бы
Рис. 4.41(д), если бы вместо этого мы применили операцию
комплексного сопряжения к фурье-образу изображения.
4.24 Еще относительно Рис. 4.41. Опишите в общих чертах, как
выглядела бы корреляционная функция (Рис. 4.41(д)), ес-
ли бы буквы UTK отстояли всего на один пиксель от
(а) левой границы изображения;
(б) правой границы изображения;
(в) верхней границы изображения;
(г) нижней границы изображения.
В случаях (а) и (б) предполагайте, что центры букв лежат на го-
ризонтальной линии, проходящей через центр изображения.
В случаях (в) и (г) центр буквы Т лежит на вертикальной ли-
нии, проходящей через центр изображения.
Глава 4. Частотные методы улучшения изображения
*4.25 Докажите справедливость равенств (4.6-47) и (4.6-48). (Указа-
ние: используйте метод математической индукции.)
4.26 Предположим, что Вы имеете набор изображений, получен-
ных в результате астрономических наблюдений. Каждое изо-
бражение состоит из множества ярких широко разбросанных
точек, соответствующих звездам в малонаселенной части Все-
ленной. Проблема заключается в том, что звезды едва разли-
чимы на фоне дополнительного освещения, возникающего в
результате рассеяния света в атмосфере. Исходя из модели, со-
гласно которой изображения представляют собой суперпози-
цию постоянной яркостной составляющей и множества им-
пульсов, предложите основанную на гомоморфной фильтрации
процедуру для выявления составляющих изображения, кото-
рые непосредственно связаны со звездами.
4.27 Опытному медицинскому эксперту поручено просмотреть не-
которую группу изображений, полученных при помощи эле-
ктронного микроскопа. Для того чтобы облегчить себе задачу,
эксперт решает воспользоваться методами цифровой обра-
ботки изображений. С этой целью он исследует ряд характер-
ных изображений и сталкивается со следующими трудностя-
ми. (1) Наличие на изображениях отдельных ярких точек, не
представляющих интерес. (2) Недостаточная резкость изобра-
жений. (3) Недостаточный уровень контрастности некоторых
изображений. И, наконец, (4) сдвиг среднего уровня яркости,
который для корректного проведения некоторых измерений
яркости должен принимать значение V. Эксперт хочет преодо-
леть эти трудности и затем выделить белым все точки изобра-
жения, яркость которых находится в диапазоне от Ц до 1^, со-
хранив яркость всех остальных точек без изменения.
Предложите последовательность шагов обработки, придержи-
ваясь которой эксперт достигнет поставленных целей. Вы мо-
жете использовать как методы Главы 3, так и методы Главы 4.
ГЛАВА 5
ВОССТАНОВЛЕНИЕ
ИЗОБРАЖЕНИЙ
Вещи, которые мы созерцаем, сами по себе не таковы, как мы их созерцаем...
Каковы предметы сами по себе и обособленно от восприимчивости нашей
чувственности, нам совершенно неизвестно. Мы не знаем ничего,
кроме свойственного нам способа воспринимать их.
Эммануил Кант
Как и при улучшении изображений, конечной целью восстановле-
ния является повышение качества изображения в некотором заранее
предопределенном смысле. Несмотря на пересечение областей при-
менения методов обоих классов, улучшение изображений является в
большей степени субъективной процедурой, в то время как процесс
восстановления имеет в основном объективный характер. При восста-
новлении делается попытка реконструировать или воссоздать изоб-
ражение, которое было до этого искажено, используя априорную ин-
формацию о явлении, которое вызвало ухудшение изображения.
Поэтому методы восстановления основаны на моделировании про-
цессов искажения и применении обратных процедур для воссоздания
исходного изображения.
Этот подход обычно включает разработку критериев качества, ко-
торые дают возможность объективно оценить полученный резуль-
тат. Напротив, методы улучшения изображений в основном пред-
ставляют собой эвристические процедуры, предназначенные для
такого воздействия на изображение, которое позволит затем исполь-
зовать преимущества, связанные с психофизическими особенностя-
ми зрительной системы человека. Например, процедура усиления
контраста рассматривается как метод улучшения, поскольку в ре-
зультате ее применения изображение, в первую очередь, становится
более приятным для глаза, тогда как процедура обработки смазанно-
го изображения, основанная на применении обратного оператора, рас-
сматривается как метод восстановления.
Материал этой главы носит сугубо вводный характер. Задача вос-
становления рассматривается лишь с момента получения уже ис-
каженного цифрового изображения; поэтому вопросы, касающие-
ся природы искажений, вносимых чувствительными элементами,
цифровыми преобразователями и воспроизводящими устройст-
332 Глава 5. Восстановление изображений
вами, затрагиваются лишь поверхностно. Эти вопросы, несмотря
на их важность в общем контексте применения методов восстанов-
ления изображений, находятся за рамками настоящего обсуждения.
Как и в Главах 3 и 4, некоторые методы восстановления удобно фор-
мулируются в пространственной области, в то время как для форму-
лировки других больше подходит частотная область. Например, про-
странственная обработка применима в случае, когда единственным
источником искажений является аддитивный шум. С другой стороны,
задача восстановления смазанных изображений, например, трудно
поддается решению в пространственной области с использованием ма-
сок малого размера. В этом случае правильным подходом является
использование частотных фильтров, полученных на основе различных
критериев оптимальности; такие фильтры учитывают также и наличие
шума. Также как и в Главе 4 (см. комментарий в Разделе 4.6.7), неко-
торый фильтр восстановления, решающий конкретную задачу в час-
тотной области, часто используется в качестве основы для построения
другого фильтра, более удобного для реализации вычислительных
процедур, использующих программно-аппаратные средства.
5.1. Модель процесса искажения/
восстановления изображения
Как показано на Рис. 5.1, принятая в этой главе модель процесса ис-
кажения предполагает действие некоторого искажающего оператора Н
на исходное изображение f(x,y), что после добавления аддитивного
шума дает искаженное изображение g (х,у). Задача восстановления со-
стоит в построении некоторого приближения f(x,y) исходного изо-
бражения по заданному (искаженному) изображению g (х,у), некото-
рой информации относительно искажающего оператора Н, и
некоторой информации относительно аддитивного шумац (х,у). Мы
хотим, чтобы наше приближение было как можно ближе к исходно-
му изображению, и, в принципе, чем больше мы знаем об операторе
Я и о функции г], тем ближе будет функция f(x,y) к функции f(x,y).
В основе подхода, применяемого на протяжении большей части гла-
вы, лежит использование операторов (фильтров), восстанавливающих
изображение.
В Разделе 5.5 будет показано, что если Н— линейный трансляци-
онно-инвариантный оператор, то искаженное изображение может
быть представлено в пространственной области в виде
g(x,y) = A(x,y)*/(x,y)+r|(x,y), (5.1-1)
Восстанавлива- I
ющий оператор С^>/(*,>’)
(фильтр) I
/г(х, у)
ИСКАЖЕНИЕ
Рис. 5.1. Модель процесса искажения/восстановления изображения.
ВОССТАНОВЛЕНИЕ
где h (х,у) — функция, представляющая искажающий оператор в про-
странственной области1, а символ «*» используется для обозначения
свертки, как и в Главе 4. Из материала Разделов 4.2.4 и 4.6.4 нам из-
вестно, что свертка в пространственной области эквивалентна умно-
жению в частотной области, поэтому задающее модель равенство
(5.1-1) может быть эквивалентным образом записано в частотной об-
ласти:
G(u,v) = H(u,v)F(u,v) +N(u,v), (5-1-2)
где обозначенные заглавными буквами функции суть фурье-образы
соответствующих функций в (5.1-1). Эти два равенства составляют ос-
нову для большей части материала настоящей главы.
В следующих трех разделах предполагается, что Я — тождествен-
ный оператор, и мы имеем дело только с искажениями, вызванными
наличием шума. Начиная с Раздела 5.6, мы рассматриваем рад важ-
ных искажающих операторов и некоторые методы восстановления при
наличии как искажающего оператора Н, так и шума ц.
5.2. Модели шума
Основные источники шума на цифровом изображении — это сам про-
цесс его получения (оцифровки), а также процесс передачи. Работа сен-
соров зависит от различных факторов, таких как внешние условия
в процессе видеосъемки и качество сенсоров. Например, в процессе по-
лучения изображения с помощью фотокамеры с ПЗС матрицей, основ-
ными факторами, влияющими на величину шума, являются уровень
освещенности и температура сенсоров. В процессе передачи изобра-
жения могут искажаться помехами, возникающими в каналах связи.
1 Функция h (х,у) называется ядром оператора Н. — Прим, перев.
Глава 5. Восстановление изображений
Например, при передаче изображения с использованием беспровод-
ной связи, оно может быть искажено в результате разряда молнии или
других возмущений в атмосфере.
5.2.1. Пространственные и частотные свойства шума
Для дальнейшего рассмотрения важными являются параметры, опре-
деляющие пространственные характеристики шума, а также вопрос,
коррелирует ли шум с изображением. Под частотными характеристи-
ками понимаются свойства спектра шума в смысле преобразования
Фурье (в отличие от электромагнитного спектра). Например шум,
спектр которого является постоянной величиной, называется обыч-
но белым шумом. Происхождение этого термина связано с физически-
ми свойствами белого света, который содержит практически все ча-
стоты видимого спектра в равных пропорциях. Исходя из
рассмотрения Главы 4, легко показать, что фурье-спектр функции, со-
держащей все частоты в равных пропорциях, является постоянной ве-
личиной.
За исключением периодического в пространстве шума (Раз-
дел 5.2.3), в этой главе мы предполагаем, что шум не зависит от
пространственных координат и не коррелирует с самим изображе-
нием (т.е. между значениями элементов изображения и значениями
шумовой составляющей нет корреляции). Хотя в ряде случаев такие
предположения по меньшей мере не вполне справедливы (примером
чего могут служить изображения, полученные в ситуации с неболь-
шим числом квантов, например, рентгеновские и ЯМР изображения),
трудности, возникающие при рассмотрении пространственно-зави-
симого и коррелированного шума, лежат за пределами нашего обсуж-
дения.
5.2.2. Функции плотности распределения вероятностей для
некоторых важных типов шума
В рамках сделанных в предыдущем параграфе предположений, мы
будем иметь дело с описанием поведения шума в пространственной об-
ласти, которое основано на статистических свойствах значений ярко-
сти компоненты шума в модели на Рис. 5.1. Эти значения яркости
могут рассматриваться как случайные величины, характеризующиеся
функцией плотности распределения вероятностей. Ниже даны приме-
ры функций плотности распределения вероятностей, которые наибо-
лее часто встречаются в приложениях, связанных с обработкой изоб-
ражений.
Гауссов шум
Математическая простота, характерная для работы с моделями гауссова
шума (также называемого нормальным шумом) как в пространствен-
ной, так и в частотной области, обусловила широкое распростране-
ние этих моделей на практике. На самом деле эта простота оказыва-
ется столь привлекательной, что зачастую гауссовы модели
используются даже в тех ситуациях, когда их применение оправда-
но, в лучшем случае, лишь частично.
Функция плотности распределения вероятностей гауссовой слу-
чайной величины z задается выражением
/>а)=~С(^)2/2°2, (5.2-1)
где z представляет собой значение яркости, ц — среднее значение слу-
чайной величины z, о — ее среднеквадратическое отклонение. Квад-
рат среднеквадратического отклонения о называется дисперсией ве-
личины z- 1рафик этой функции представлен на Рис. 5.2 (а). Когда
плотность распределения случайной величины z описывается функ-
цией (5.2-1), то приблизительно 70% ее значений попадают в диа-
пазон [(ц—о), (ц+о)], и примерно 95% — в диапазон [(ц—2о), (ц+2о)].
Шум Релея
Функция плотности распределения вероятностей шума Релея задается
выражением
p(z) = -
-(z-a)e 1Ь при ^>а;
b
(5.2-2)
0
при z<a.
Среднее и дисперсия для этого распределения имеют вид
ц = а + Л/лЛ/4,
и
.2_£(4-я)
, —-------
4
(5.2-3)
(5.2-4)
График плотности распределения вероятностей шума Релея пред-
ставлен на Рис. 5.2 (б). Обратите внимание на местоположение нача-
ла координат и на то обстоятельство, что график имеет асимметрия-
Глава 5. Восстановление изображений
p(z) P(z)
P(z)
P(z)
Pb
Равномерное
распределение
Pa
Импульсное
распределение
® °
в !
л e
a b
Рис. 5.2. Некоторые важные функции плотности распределения вероятностей.
ную (перекошенную вправо) форму. Распределение Релея бывает по-
лезно для приближения асимметричных гистограмм.
Шум Эрланга (гамма шум)
Функция плотности распределения вероятностей шума Эрланга
задается выражением
p(z) =-
abpb-i
------e~az при z > 0 ;
(6-1)!
О приг<0,
(5.2-5)
где а > О, b — положительное целое число и символ «!» обозначает
факториал. Среднее и дисперсия для этого распределения имеют вид
b
а
(5.2-6)
и
.2 _ 6
(5.2-7)
На Рис. 5.2 (в) представлен график плотности этого распределения.
Выражение (5.2-5) часто называют гамма распределением, хотя, стро-
го говоря, это название относится к распределению более общего
вида, когда Ь не является целым, а в знаменателе стоит гамма-функ-
ция Г(6). Рассматриваемый частный случай правильнее называть рас-
пределением Эрланга.
Экспоненциальный шум
Функция плотности распределения вероятностей экспоненциального
шума задается выражением
p{z)=-
ae~az при z>0;
О приг<0,
(5.2-8)
где а > 0. Среднее и дисперсия для этого распределения имеют вид
1
ц=-
а
(5.2-9)
и
338 Глава 5. Восстановление изображений
2 1 ° =-2’ а (5.2-10)
Заметим, что это распределение является частным случаем рас-
пределения Эрланга с b = 1. На Рис. 5.2 (г) представлен график плот-
ности этого распределения.
Равномерный шум
Функция плотности распределения вероятностей равномерного шу-
ма задается выражением
. . при a<z<b; p(z)=\b-a 0 в остальных случаях (5.2-11)
Среднее значение для этого распределения равно
а+Ь ц = > 2 (5.2-12)
а дисперсия
с2_(Ь-а)2 12 (5.2-13)
На Рис. 5.2 (д) представлен график плотности этого распределения.
Импульсный шум
Функция плотности распределения вероятностей (биполярного)
2
импульсного шума задается выражением^
Ра при z=a; p(z)=- Pb ivpviz=b; 0 в остальных случаях. (5.2-14)
2 Это выражение для самой вероятности Р (z). Плотность распределения вероятнос-
тей может быть записана в виде Ра8 (z — о) + Р/,8 (z—b), где 8 (•) — 8-функция.
Как правило, процесс добавления импульсного шума к изображению состоит в том,
что значение яркости каждой точки изображения с вероятностью Ps — Ра + Pb < 1 за-
меняется на случайное значение шума. Поэтому для биполярного импульсного шу-
Если b > а, то пиксель с яркостью b выглядит как светлая точка на изо-
бражении. Пиксель с яркостью а выглядит, наоборот, как темная точ-
ка. Если одно из значений вероятности (Ра или Рь) равно нулю, то им-
пульсный шум называется униполярным. Если ни одна из вероятностей
не равна нулю, и в особенности если они приблизительно равны по
величине, импульсный шум походит на крупицы соли и перца, слу-
чайно рассыпанные по изображению. По этой причине импульсный
шум называют также шумом типа «соль и перец». Мы будем использовать
оба названия как взаимозаменяемые* 3.
Значения импульсов шума могут быть как положительные, так
и отрицательные. При оцифровке изображения обычно происходит
масштабирование (и ограничение) значений яркости. Поскольку ве-
личина связанных с импульсным шумом искажений как правило ве-
лика по сравнению с величиной полезного сигнала, импульсный шум
после оцифровки принимает экстремальные значения, что соответ-
ствует появлению абсолютно черных и белых точек на изображении.
Поэтому обычно предполагается, что значения а и b являются «интен-
сивными» в том смысле, что они равны минимальному и максималь-
ному значениям, которые в принципе могут присутствовать в оци-
фрованном изображении. В результате отрицательные импульсы
выглядят как черные точки на изображении (перец). По тем же при-
чинам положительные импульсы выглядят как белые точки (соль). Для
8-битовых изображений это означает, что а = 0 (черное) и b = 255 (бе-
лое). На Рис. 5.2 (е) представлен график распределения вероятностей
значений импульсного шума.
Рассмотренные распределения в совокупности представляют со-
бой набор средств, которые позволяют моделировать искажения, свя-
занные с широким диапазоном встречающихся на практике шумов.
Так например, гауссов шум возникает на изображении в результате воз-
действия таких факторов, как шум в электронных цепях, а шум сен-
соров — из-за недостатка освещения и/или высокой температуры. Рас-
пределение Релея полезно при моделировании шума, который
возникает на снимках, снятых с большого расстояния. Экспоненци-
альное и гамма распределения отвечают шуму на изображениях, по-
лучаемых с использованием лазеров. С импульсным шумом мы стал-
ма, например, яркость изображения с вероятностью Ра заменяется на значение а, с
вероятностью Рь — на значение Ъ и с вероятностью (1 — Ps) остается неизменной. —
Прим, перев.
3 Английский термин «соль и перец» (salt-and-pepper) практически не употребляет-
ся в русскоязычной литературе. — Прим, перев.
Глава 5. Восстановление изображений
киваемся в ситуациях, когда в процессе получения изображения
имеют место быстрые переходные процессы, такие как неправиль-
ная коммутация. Равномерное распределение, пожалуй, в наимень-
шей степени подходит для описания встречающихся на практике
явлений. Однако это распределение весьма полезно как основа для
создания различных генераторов случайных чисел, используемых
при моделировании | Peebles, 1993].
Пример 5.1. Простые изображения с шумом и их гистограммы.
На Рис. 5.3 представлено тестовое изображение, весьма подходя-
щее для иллюстрации только что рассмотренных моделей шума. Изо-
бражение удобно тем, что оно состоит из простых областей постоян-
ной яркости, которая принимает всего три значения и при этом
охватывает весь диапазон от черного до почти белого. Это упрощает
визуальный анализ свойств различных шумовых составляющих, до-
бавляемых к изображению.
На Рис. 5.4 представлены изображения, полученные в результате
добавления к тестовому изображению шумов тех шести типов, кото-
рые обсуждались выше. Под каждым изображением приведена гис-
тограмма, посчитанная по этому изображению. Параметры шума бы-
ли подобраны в каждом отдельном случае таким образом, чтобы части
гистограммы, соответствующие трем уровням яркости на тестовом
изображении, начали сливаться. При этом шум хорошо заметен, но
не затеняет основную структуру тестового изображения.
При сравнении гистограмм на Рис. 5.4 с функциями плотности рас-
пределения вероятностей на Рис. 5.2 мы убеждаемся в том, что они со-
Рис. 5.3. Тестовое изображение, используемое при иллюстрации свойств шу-
мов, распределенных в соответствии с функциями на Рис. 5.2.
Гауссов шум
Релеевский шум
Гамма шум
Рис. 5.4. Изображения и гистограммы, полученные в результате добавления га- ? б В
уссова, релеевского, гамма, экспоненциального, равномерного и импульсного • ц е
шума к изображению на Рис. 5.3.
ответствуют друг другу. В примере с импульсным шумом, на гистограм-
ме имеется дополнительный пик в «белом» конце диапазона, посколь-
ку составляющие шума принимают значения яркости, соответст-
вующие абсолютно черным и абсолютно белым точкам, а наиболее
яркая часть тестового изображения (внутри круга) является светло-се-
рой. За исключением небольшого различия в общем уровне яркости,
первые пять изображений на Рис. 5.4 визуально мало различимы, хо-
тя их гистограммы существенно отличаются друг от друга. Только
внешний вид изображения, искаженного импульсным шумом, указы-
вает на тип шума, который привел к искажению.
5.2.3. Периодический шум
Причиной появления периодического шума обычно являются эле-
ктрические или электромеханические помехи во время получения
изображения. Периодический шум является тем единственным ви-
дом пространственно-зависимого шума, который мы будем рассма-
Глава 5. Восстановление изображений
Экспоненциальный шум
Равномерный шум
Импульсный шум
Рис. 5.4 (продолжение). Изображения и гистограммы, полученные в резуль-
тате добавления гауссова, релеевского, гамма, экспоненциального, равномер-
ного и импульсного шума к изображению на Рис. 5.3.
Ж 3 и
к л м
тривать в этой главе. Как обсуждалось в Разделе 5.4, такой шум мо-
жет быть существенно уменьшен при помощи частотной фильтрации.
Рассмотрим, например, изображение на Рис. 5.5 (а). Это изображе-
ние сильно искажено пространственным синусоидальным шумом
различных частот. Преобразование Фурье синусоиды в чистом виде
представляет собой пару сопряженных импульсов, расположенных
в центрально-симметричных точках частотной области, которые от-
вечают частотам синусоидальной волны (см. Таблицу 4.1). Поэтому
если амплитуды синусоидальных волн в пространственной области
достаточно велики, можно ожидать, что в спектре изображения бу-
дут видны пары импульсов, по одной для каждой синусоидальной вол-
ны в исходном изображении. Рис. 5.5 (б) показывает, что это имеет
место в действительности, причем в данном случае соответствующие
импульсы расположены приблизительно на окружности, что связа-
но с конкретным набором значений частот. В разделе 5.4 этот и дру-
гие примеры периодического шума будут рассмотрены значительно
подробнее.
Рис. 5.5. (а) Изображение, искаженное синусоидальным шумом, (б) Спектр
(каждая пара сопряженных импульсов соответствует одной синусоидальной
волне). (Изображение предоставлено Агентством NASA.)
о»»
5.2.4. Построение оценок для параметров шума
Оценка параметров периодического шума обычно осуществляется
путем анализа фурье-спектра изображения. Как указано в предыду-
щем параграфе, периодический шум приводит к появлению пиков
в частотной области, которые часто обнаруживаются даже при ви-
зуальном анализе. Другой подход состоит в том, чтобы попытать-
ся сделать вывод о периодичности шумовых составляющих прямо
на основе исходного изображения, однако это приводит к успеху
лишь в простейших случаях. Анализ в автоматическом режиме воз-
можен в тех ситуациях, когда шумовые пики ярко выражены, или ког-
да имеется некоторая информация общего характера относительно
месторасположения соответствующих частотных составляющих.
Параметры функции плотности распределения вероятностей шу-
ма могут быть частично известны исходя из технических характери-
стик сенсоров, однако часто необходимо оценить эти параметры для
конкретной системы, использованной при получении изображения.
Если эта система находится в вашем распоряжении, то один из про-
стых способов изучения ее характеристик, связанных с шумом, заклю-
чается в том, чтобы получить набор изображений однородных тесто-
вых объектов. В случае оптической системы, например, таким
объектом будет являться большая сплошная равномерно освещенная
серая область. Полученные таким путем изображения обычно доста-
точно хорошо характеризуют шум системы.
В тех случаях, когда доступны только изображения, ранее сфор-
мированные системой (а сама система недоступна), рассмотрение не-
больших участков изображения примерно постоянной яркости час-
то дает возможность оценить параметры функции плотности
распределения вероятностей шума. Например, на Рис. 5.6 показаны
вертикальные полосы, вырезанные из тех изображений на Рис. 5.4,
которые отвечают гауссову, релеевскому и равномерному шуму. Пред-
ставленные гистограммы посчитаны на основе данных, отвечающих
этим небольшим полосам. Гистограммам на Рис. 5.6 соответствуют
средние (из трех) части гистограмм на Рис. 5.4 (г), (д) и (л). Сравне-
ние показывает, что вид гистограмм на Рис. 5.6 весьма близок к ви-
ду соответствующих частей гистограмм на Рис. 5.4. Высота гистограмм
различается из-за масштабирования, но их форма, без сомнения,
одинакова.
Естественно использовать данные, отвечающие небольшим уча-
сткам изображения, для вычисления среднего значения и дисперсии
яркости. Обозначим через 5 фрагмент изображения (например, по-
лосу). Приближение для интересующих нас величин может быть по-
лучено на основе простых статистических формул
•г. о в
Рис. 5.6. Гистотраммы, посчитанные по небольшим полосам (показаны в ви-
де вставок) изображений на Рис. 5.4, содержащих (а) гауссов, (б) релеевский
и (в) равномерный шум.
5.3. Подавление шумов — пространственная фильтрация
Н= X УМ (5.2-15)
z-yS
И
О2 = у (zz-H)2p(Zi>, (5.2-16)
Zi&S
где Zi — значения яркости элементов части изображения S, ap(zi) —
соответствующие нормализованные значения гистограммы.
Вид гистограммы определяет, какая из функций плотности рас-
пределения вероятностей является наиболее подходящей. Если фор-
ма гистограммы приблизительно гауссова, то все что необходимо —
это определить среднее и дисперсию, поскольку гауссова функция
плотности распределения полностью определяется этими двумя па-
раметрами. Для распределений других типов, которые обсуждались
в Разделе 5.2.2, мы рассматриваем выражения для среднего и диспер-
сии как уравнения для параметров а, b и, разрешая уравнения, нахо-
дим параметры распределения. Обработка импульсного шума осуще-
ствляется по-другому, поскольку в этом случае требуется оценить
фактическую вероятность появления черных и белых точек на изо-
бражении. Для получения такой оценки необходимо, чтобы были вид-
ны как черные, так и белые точки. Таким образом для вычисления ги-
стограммы пригодна только такая область изображения, в которой
значения яркости лежат в средней части диапазона и относительно
постоянны. Высоты пиков, соответствующих черным и белым точ-
кам, дают оценку вероятностей Ра и Рь в (5.2-14)4.
5.3. Подавление шумов — пространственная
фильтрация
Когда искажение изображения обусловлено исключительно наличием
шума, равенства (5.1-1) и (5.1-2) приобретают вид
g(x,y)=f(x,y)+i\(x,y) (5.3-1)
и
G(u,v) = F(u,v)+N(u,v). (5.3-2)
4 См., также, прим. 2. — Прим, перев.
Слагаемое, описывающее шум, неизвестно, поэтому просто вы-
честь его из функции g (х,у) или G (u,v) невозможно. Обычно в слу-
чае периодического шума спектр G (u,v) дает возможность оценить
величину N (u,v), как было указано в Разделе 5.2.3. Тогда в целях по-
строения приближения исходного изображения, величина N (u,v)
может быть вычтена из функции G (u,v). Однако этот случай явля-
ется скорее исключением, чем правилом.
В тех ситуациях, когда на изображении присутствует только адди-
тивный шум, пространственная фильтрация является лучшим из воз-
можных методов восстановления. Этот метод детально обсуждался
в Разделах 3.5 и 3.6 как метод улучшения изображений. В подобном
случае процедуры улучшения и восстановления становятся практи-
чески неразличимыми. За исключением вычислительной процедуры,
характерной для использования некоторого особого фильтра, меха-
низм применения всех нижеследующих фильтров в точности такой,
как обсуждалось в Разделе 3.5.
5.3.1. Усредняющие фильтры
В этом параграфе мы кратко обсудим пространственные фильтры
для подавления шумов, введенные в Разделе 3.6, и построим неко-
торые другие фильтры, эффективность которых во многих случа-
ях превосходит эффективность фильтров, рассмотренных в этом
разделе.
Фильтр, основанный на вычислении среднего арифметического
Такой фильтр, называемый среднеарифметическим, является про-
стейшим среди усредняющих фильтров. Пусть Sxy обозначает
прямоугольную окрестность (множество координат точек изобра-
жения) размерами тхп с центром в точке (х,у). Процедура фильт-
рации предполагает вычисление среднего арифметического значения
искаженного изображенияg(x,у) по окрестности Sxy. Значение вос-
становленного изображения f в произвольной точке (х,у)
представляет собой среднее арифметическое значений в точ-
ках, принадлежащих окрестности S^. Другими словами
f(x,y) = — У g(s,t). (5.3-3)
W/2(5,0eSv
Эта операция может быть реализована в виде свертки с маской, все ко-
эффициенты которой равны \/тп. Как указывалось в Разделе 3.6.1, ус-
редняющий фильтр просто сглаживает локальные вариации яркости
5.3. Подавление шумов — пространственная фильтрация
на изображении. Уменьшение шума происходит в результате этого
сглаживания.
Фильтр, основанный на вычислении среднего геометрического
Изображение, восстановленное с использованием среднегеометрического
фильтра, задается выражением
7(х,У) = Г П
g(s, f) тп .
(5-3-4)
Здесь значение восстановленного изображения в каждой точке (х,у)
является корнем степени тп из произведения значений в точках ок-
рестности SXy. Как показывает Пример 5.2, применение среднегео-
метрического фильтра приводит к сглаживанию, сравнимому с тем,
которое достигается при использовании среднеарифметического
фильтра, но при этом теряется меньше деталей изображения.
Фильтр, основанный на вычислении среднего гармонического
Результат обработки с применением среднегармонического фильтра
дается выражением
f(x,y) =----(5.3-5)
у —
Среднегармонический фильтр хорошо работает в случае униполяр-
ного «белого» импульсного шума (т.е. когда значение шума соответ-
ствует появлению белых точек на изображении), но не работает в слу-
чае униполярного «черного» импульсного шума (когда значение
шума соответствует появлению черных точек). Этот фильтр также хо-
рошо работает для других типов шума, таких как гауссов шум.
Фильтр, основанный на вычислении среднего контрагармонического
Обработка с применением операции среднего контрагармонического
описывается выражением:
I ЛЧл.ОС'+1
(s,t)eSrv
f(x,y)=~?-------------------
У g(s,t)Q
(5.3-6)
где Q называется порядком фильтра. Этот фильтр хорошо приспособ-
лен для уменьшения или почти полного устранения импульсного шу-
ма. При положительных значениях Q фильтр устраняет «черную»
часть импульсного шума. При отрицательных значениях Q фильтр
устраняет «белую» часть импульсного шума. Обе части шума не мо-
гут быть устранены одновременно. Заметим, что контрагармоничес-
кий фильтр при Q = 0 сводится к среднеарифметическому фильтру,
а при Q = — 1 сводится к среднегармоническому фильтру.
Пример 5.2. Восстановление с помощью усредняющих фильтров.
На Рис. 5.7 (а) приведен рентгеновский снимок монтажной платы, а на
Рис. 5.7 (б) приведено то же изображение, но искаженное путем добав-
ления гауссова шума с нулевым средним и дисперсией 400. Для изобра-
жения такого типа данный уровень шума является значительным. На
Рис. 5.7 (в) и (г) представлены результаты фильтрации изображения
с шумом при использовании среднеарифметического и среднегеомет-
рического фильтров размерами 3x3. Хотя оба фильтра дали приемлемый
результат в плане уменьшения шума на изображении, применение
среднегеометрического фильтра привело к меньшему размыванию
изображения, чем применение среднеарифметического фильтра. На-
пример, штырьки разъема в верхней части изображения выглядят на
Рис. 5.7 (г) намного более резкими, чем на Рис. 5.7 (в). Это справедливо
и для других частей изображения (см. Задачу 5.1).
На Рис. 5.8 (а) представлено изображение той же платы, но иска-
женное униполярным «черным» импульсным шумом с вероятнос-
тью 0,1. Аналогично, на Рис. 5.8 (б) представлено изображение, ис-
каженное униполярным «белым» импульсным шумом с той же
вероятностью. На Рис. 5.8 (в) представлен результат фильтрации изо-
бражения на Рис. 5.8 (а) с использованием контрагармонического
фильтра порядка Q = 1,5, а на Рис. 5.8 (г) представлен результат филь-
трации изображения на Рис. 5.8 (б) с использованием аналогичного
фильтра порядка Q= — 1,5. В обоих случаях применение фильтров да-
ло хороший результат в плане уменьшения шума. Результаты работы
фильтра положительного порядка лучше в фоновой области, издерж-
ки выражаются в размывании темных областей. Обратное имеет ме-
сто для фильтра отрицательного порядка.
Вообще среднеарифметические и среднегеометрические фильтры
(особенно последние) подходят для фильтрации случайных шумов ти-
па гауссова или равномерного. Контрагармонические фильтры подхо-
дят для фильтрации импульсного шума, но их применение затруднено
тем, что необходимо заранее знать, является ли шум «черным» или «бе-
лым», поскольку необходимо выбрать правильный знак порядка филь-
5.3. Подавление шумов — пространственная фильтрация
Рис. 5.7. (а) Рентгеновский снимок, (б) Изображение, искаженное аддитив-
ным гауссовым шумом, (в) Результат фильтрации с использованием средне-
арифметического фильтра размерами 3x3. (г) Результат фильтрации с исполь-
зованием среднегеометрического фильтра тех же размеров. (Исходное
изображение предоставил Джозеф Е. Пассенте, Lixi, Inc.)
тра Q. Как показывает Рис. 5.9, неправильный выбора знака может при-
вести к катастрофическим результатам. Некоторые из фильтров, рассма-
триваемых в следующем параграфе, свободны от этого недостатка. В
5.3.2. Фильтры, основанные на порядковых статистиках
Фильтры, основанные на порядковых статистиках, были введены
в Разделе 3.6.2. В этом параграфе мы расширим рамки обсуждения
и введем дополнительно еще некоторые фильтры подобного рода.
Как отмечалось в Разделе 3.6.2, фильтры, основанные на порядковых
Глава 5. Восстановление изображений
Рис. 5.8. (а) Изображение, искаженное униполярным «черным» импульсным
шумом с вероятностью 0,1. (б) Изображение, искаженное униполярным «бе-
лым» импульсным шумом с той же вероятностью, (в) Результат фильтрации
изображения (а) с использованием 3x3 контрагармонического фильтра поряд-
ка Q = 1,5. (г) Результат фильтрации изображения (б) с использованием ана-
логичного фильтра порядка Q = —1,5.
статистиках, представляют собой пространственные фильтры, вы-
числение отклика которых требует предварительного упорядочивания
(ранжирования) значений пикселей, заключенных внутри обраба-
тываемой фильтром области изображения. Отклик фильтра в любой
точке определяется по результатам упорядочивания.
Медианные фильтры
Наиболее известным из фильтров, основанных на порядковых стати-
стиках, является медианный фильтр. Действие этого фильтра, как еле-
5.3. Подавление шумов —
Рис. 5.9. Результаты неправильного выбора знака порядков для контрагармо-
нических фильтров, (а) Результат фильтрации изображения Рис. 5.8 (а) с ис-
пользованием контрагармонического фильтра размерами 3x3 порядка Q = — 1,5.
(б) Результат фильтрации изображения Рис. 5.8 (б) с Q = 1,5.
дует из его названия, состоит в замене значения в точке изображения
на медиану значений яркости в окрестности этой точки:
/(х,у)= med {g(.v,/)}.
(5, tyeS'xy
(5.3-7)
При вычислении медианы значение в самой точке (т.е. в центре окре-
стности) также учитывается. Широкая популярность медианных филь-
тров обусловлена тем, что они прекрасно приспособлены для подавле-
ния некоторых видов случайных шумов, и при этом приводят к меньшему
размыванию по сравнению с линейными сглаживающими фильтрами
того же размера. Медианные фильтры особенно эффективны при нали-
чии как биполярного, так и униполярного импульсного шума. На самом
деле, как показывает Пример 5.3, применение медианных фильтров
дает отличные результаты для изображений, которые искажены шу-
мом этого типа. Процедура вычисления медианы и реализация медиан-
ной фильтрации детально обсуждались в Разделе 3.6.2.
Фильтры, основанные на выборе максимального и минимального значения
Хотя медианные фильтры, безусловно, принадлежат к числу наибо-
лее часто используемых в обработке изображений фильтров, основан-
ных на порядковых статистиках, это отнюдь не единственный пример
таких фильтров. Медиана представляет собой 50-ый процентиль упо-
рядоченного набора чисел, однако использование иных статистиче-
ских характеристик предоставляет много других возможностей. На-
пример, использование 100-го процентиля приводит к фильтру, ос-
нованному на выборе максимального значения (или фильтру мак-
симума), который задается выражением
/(х,у)= max {g(V)}.
(V)e.Sxv
(5.3-8)
Такой фильтр полезен при обнаружении наиболее ярких точек на
изображении. Кроме того, поскольку униполярный «черный» им-
пульсный шум принимает минимальные значения, применение
этого фильтра приводит к уменьшению такого шума, так как в про-
цессе фильтрации из окрестности Sxy выбирается максимальное
значение.
Использование 0-го процентиля приводит к фильтру, основанному
на выборе минимального значения (или фильтру минимума)'.
f(x,y)= min {g(V)}.
(s^S^
(5.3-9)
Такой фильтр полезен при обнаружении наиболее темных точек на
изображении. Кроме того, применение этого фильтра приводит
к уменьшению униполярного «белого» импульсного шума вследст-
вие операции выбора минимума.
Филыпр срединной точки
Применение фильтра срединной точки заключается просто в вычис-
лении среднего между максимальным и минимальным значениями
в соответствующей окрестности:
f(x,y) = - max {g(V)}+ min {g(s,O}
(5.3-10)
Отметим, что этот фильтр объединяет в себе методы порядковых ста-
тистик и усреднения. Этот фильтр лучше всего работает при наличии
таких случайно распределенных шумов, как гауссов или равномерный.
Фильтр, основанный на вычислении усеченного среднего
Предположим, что мы удалили d/l наименьших и d/2 наибольших зна-
чений яркости из множества всех значений функции g (s,t) в окрест-
ности S^. Пусть gr (s,f) представляет собой оставшиеся элементы изо-
бражения, количество которых равно (тп — d). Фильтр, действие
5.3. Подавление шумов — пространственная фильтрация
которого заключается в усреднении оставшихся значений, называется
фильтром усеченного среднего:
f(x,y) = ——— X SrM, (5.3-11)
mn-d№&<y
причем значение d может изменяться в диапазоне от 0 до тп — 1. В слу-
чае d= 0, фильтр усеченного среднего сводится к среднеарифметиче-
скому фильтру, который рассматривался в предыдущем параграфе.
В случае <7/2 = (тп — 1 )/2, фильтр превращается в медианный фильтр.
Использование фильтра усеченного среднего с другими значения-
ми d полезно в тех случаях, когда мы имеем дело с несколькими ви-
дами шума одновременно, например с комбинацией импульсного
и гауссова шума.
Пример 5.3. Восстановление с помощью фильтров, основанных на по-
рядковых статистиках.
На Рис. 5.10 (а) представлено изображение платы, искаженное би-
полярным импульсным шумом с вероятностями Ра = Рь = 0,1. На
Рис. 5.10 (б) представлен результат обработки с использованием ме-
дианного фильтра размерами 3x3. Улучшение изображения по срав-
нению с изображением на Рис. 5.10 (а) весьма значительное, однако
по-прежнему можно видеть остатки шума в некотором количестве то-
чек. Второй проход (по изображению на Рис. 5.10 (б)) медианным
фильтром удаляет большинство этих точек, оставляя лишь едва замет-
ную их часть. Последние удаляются при третьем проходе. Эти ре-
зультаты наглядно демонстрируют силу медианной фильтрации при
обработке изображений, содержащих шум типа импульсного. Следу-
ет иметь в виду, что повторные применения медианной фильтрации
приводят к размыванию изображения, поэтому желательно, чтобы чис-
ло проходов было как можно меньше.
На Рис. 5.11 (а) представлен результат применения фильтра мак-
симума к изображению на Рис. 5.8 (а), искаженному униполярным
«черным» импульсным шумом. Фильтрация дала разумный в смыс-
ле устранения шума результат, однако необходимо отметить, что не-
которые темные точки на границах темных объектов также оказа-
лись удалены (эти точки приобрели значения яркости из светлой
части диапазона). На Рис. 5.11 (б) представлен результат применения
фильтра минимума к изображению на Рис. 5.8 (б). В рассматриваемом
частном случае результат работы фильтра минимума по устранению
шума лучше, чем аналогичный результат для фильтра максимума, но
фильтр минимума удалил ряд белых точек около границ светлых объ-
12 А-223
Глава 5. Восстановление изображений
Рис. 5.10. (а) Изображение, искаженное биполярным импульсным шумом с ве-
роятностями Ра = Рь = 0,1. (б) Результат обработки с использованием медиан-
ного фильтра размерами 3x3. (в) Результат обработки (6) с использованием то-
го же фильтра, (г) Результат обработки (в) с использованием того же фильтра.
ектов. Вследствие этого светлые объекты стали меньше по размерам,
а некоторые темные объекты (как, например, штырьки разъема в верх-
ней части изображения) стали больше, поскольку белые точки вокруг
этих объектов заменились на темные.
Продемонстрируем теперь работу фильтра усеченного среднего.
На Рис. 5.12 (а) представлено изображение платы, искаженное в дан-
ном случае добавлением равномерного шума с нулевым средним и дис-
персией 800. На это изображение с высоким уровнем шумовых иска-
жений далее накладывается биполярный импульсный шум
с вероятностями Ра = Рь = 0,1, что, как видно на Рис. 5.12 (б), еще силь-
нее ухудшает его. При таком высоком уровне шума нужно использо-
5.3. Подавление шумов — пространственная фильтрация
Рис. 5.11. (а) Результат фильтрации изображения на Рис. 5.8 (а) с использова-
нием фильтра максимума размерами 3x3. (б) Результат фильтрации изобра-
жения на Рис. 5.8 (б) с использованием фильтра минимума тех же размеров.
вать фильтры большого размера. На Рис. 5.12 (в)— (с) представлены ре-
зультаты фильтрации, полученные с помощью среднеарифметическо-
го, среднегеометрического, медианного и усеченного среднего (с d= 5)
фильтров размерами 5x5. Как и следовало ожидать, применение сред-
неарифметического и среднегеометрического фильтров (особенно по
шеднс! о) не дало хороших результатов, что объясняется присутстви-
ем нт н.ульсного шума. Результаты, полученные с применением
медианного фильтра и фильтра усеченного среднего, намного лучше,
причем фильтр усеченного среднего привел к несколько большему
уменьшению шума. Обратите внимание, например, что четыре штырь-
ка разъема в верхней левой части изображения, полученного в ре-
зультате применения фильтра усеченного среднего, выглядят несколь-
ко более гладко. Это не удивительно, поскольку при больших
значениях d фильтр усеченного среднего по своему действию при-
ближается к медианному фильтру, но все еще сохраняет свои сглажи-
вающие способности.
5.3.3. Адаптивные фильтры
Рассмотренные до сих пор фильтры обладали одной общей особен-
ностью. Зафиксировав однажды какой-нибудь из этих фильтров, мы
в дальнейшем применяли его к изображению без учета того, как свой-
ства изображения меняются от точки к точке. В этом параграфе мы по-
знакомимся с двумя простыми адаптивными фильтрами, поведение
которых изменяется в зависимости от статистических свойств изоб-
Глава 5. Восстановление изображений
а б
в г
д е
Рис. 5.12. (а) Изображение, искаженное аддитивным равномерным шумом,
(б) Изображение, дополнительно искаженное биполярным импульсным шу-
мом. Результат фильтрации изображения (б) применением фильтров разме-
рами 5x5: (в) среднеарифметического фильтра; (г) среднегеометрического
фильтра (д) медианного фильтра; и (е) фильтра усеченного среднего с d = 5.
5.3. Подавление шумов — пространственная фильтрация 357
ражения внутри области действия фильтра, которая определяется
прямоугольной тхп окрестностью Sxy. Как показывает дальнейшее об-
суждение, возможности адаптивных фильтров превосходят возможно-
сти фильтров, которые были рассмотрены до сих пор. Платой за усо-
вершенствование методов фильтрации является увеличение сложности
фильтров. Будем иметь в виду, что мы по-прежнему находимся в си-
туации, когда искаженное изображение представляет собой сумму
исходного изображения и шума. Никакие другие виды искажений до
сих пор не рассматривались.
Адаптивные локальные фильтры подавления шума
Простейшими характеристиками случайной величины являются ее
среднее значение и дисперсия. Эти параметры естественно взять за ос-
нову при создании адаптивного фильтра, поскольку их величины тес-
но связаны с внешним видом изображения. Среднее значение дает ме-
ру средней яркости той области, по которой оно вычисляется,
а дисперсия дает меру среднего отклонения в этой области.
Наш фильтр должен действовать в окрестности Sxy. Отклик фильт-
ра в некоторой точке (х,у), которая является центром этой окрестнос-
ти, должен определяться четырьмя величинами: (а) значением изобра-
жения с шумом в точке (х,у); (б) дисперсией о2^ шума, превращающего
исходное изображениеДх,у) в искаженное изображение g(x,у); (в) ло-
кальным средним mf по значениям в окрестности Sxy; и (г) локальной
дисперсией ст2/ по значениям в окрестности Sxy. Мы хотим, чтобы по-
ведение фильтра определялось следующими условиями.
1. Если дисперсия шума о2^ равна нулю, то отклик фильтра должен
быть равен значению g(x,y). Это отвечает тривиальному случаю
нулевого шума, когда#(х,у) равно fix,у).
2. Если локальная дисперсия о2/ много больше о2^, то значение от-
клика фильтра должно быть порядка g (х,у). Большое значение
локальной дисперсии обычно связано с наличием контуров, кото-
рые должны быть сохранены.
3. Если обе дисперсии принимают значения одного порядка, то от-
клик фильтра должен быть равен среднему арифметическому зна-
чений в окрестности Sxy. Условие выполнено в том случае, когда
статистические характеристики данной локальной области и изо-
бражения в целом совпадают, и локальный шум должен быть
уменьшен, для чего используется простое усреднение.
Адаптивный фильтр, удовлетворяющий перечисленным условиям,
может быть задан следующим выражением:
f(x,y) = g(x,y) —£-[g(x,y) - mL ]. (5.3-12)
Единственной величиной, которая должна быть заранее известна или
оценена, является полная дисперсия шума о2^. Остальные входящие
в формулу величины вычисляются ддя каждой точки (х,у) по значени-
ям элементов изображения в окрестности с центром в этой точке.
В формуле (5.3-12) неявно предполагается, что о2^ < су2/. Поскольку мы
рассматриваем модели аддитивного и трансляционно-инвариантного
шума, такое предположение является оправданным, так как множест-
во элементов в окрестности является подмножеством элементов
изображения. Однако нам редко известна точная информация о значе-
нии о2л. Поэтому при реализации формулы (5.3-12) нужно предусмо-
треть дополнительную проверку условия о2^ < су2/ с тем, чтобы при
нарушении этого условия использовать в формуле (5.3-12) значение 1
вместо величины соответствующего отношения. В результате метод
фильтрации становится нелинейным. Однако такой подход предот-
вращает появление бессмысленных результатов (т.е. отрицательных
значений яркости при некоторых значениях mj), обусловленных недо-
статком информации о дисперсии шума на изображен и и. Другой под-
ход может состоять в том, чтобы допустить появление отрицательных
значений, но затем изменить шкалу яркости. Такой подход приведет
к уменьшению динамического диапазона изображения.
Пример 5.4. Восстановление с помощью адаптивных фильтров ло-
кального уменьшения шума.
На Рис. 5.13 (а) представлено изображение платы, на этот раз искажен-
ное добавлением гауссова шума с нулевым средним и дисперсией 1000.
Такой уровень шума приводит к значительным искажениям, что со-
здает, однако, идеальное тестовое изображение для сравнения рабо-
чих характеристик фильтров. На Рис. 5.13 (б) представлен результат об-
работки изображения с шумом при помощи среднеарифметического
фильтра размерами 7x7. Шум на изображен и и удалось сгладить ценой
значительного размывания. Это же имеет место и для изображения на
Рис. 5.13 (в), где представлен результат обработки при помощи сред-
негеометрического фильтра тех же размеров 7x7. Различия между по-
следними двумя изображениями аналогичны тем, которые обсужда-
лись при рассмотрении Примера 5.2; увеличилась лишь степень
размывания.
На Рис. 5.13 (г) представлен результат применения адаптивного
фильтра (5.3-12) размерами 7x7 при о2^ = 1000. Этот результат значи-
5.3. Подавление шумов — пространственная фильтрация
Рис. 5.13. (а) Изображение, искаженное аддитивным гауссовым шумом с ну-
левым средним и дисперсией 1000. (б) Результат обработки с использовани-
ем среднеарифметического фильтра, (в) Результат обработки с использовани-
ем среднегеометрического фильтра, (г) Результат обработки с использованием
адаптивного фильтра уменьшения шума. Размеры всех фильтров равны 7x7.
тельно лучше двух предыдущих. Общее уменьшение шума, которое до-
стигается при использовании адаптивного фильтра, сравнимо с умень-
шением шума при использовании среднеарифметического и средне-
геометрического фильтров. Однако изображение, получаемое после
обработки с помощью адаптивного фильтра, является намного более
резким. Например, штырьки разъема в верхней части изображения пла-
ты выглядят на Рис. 5.13 (г) намного более резкими. Другие характер-
ные детали, такие как отверстия или восемь ножек элемента схемы в ле-
вом нижнем углу изображения, видны на Рис. 5.13 (г) значительно более
отчетливо. Эти результаты являются типичным примером того, чего
можно достичь, используя адаптивные фильтры. Как было отмечено
в начале параграфа, платой за улучшение рабочих характеристик филь-
тров является увеличение их сложности.
При получении представленных выше результатов мы использова-
2
ли значение <г^, которое в точности соответствует значению диспер-
сии шума. Если эта величина заранее неизвестна и используемая д ля нее
оценка слишком занижена, то в результате обработки мы получим изо-
бражение, которое очень похоже на исходное (до обработки) изобра-
жение, поскольку коррекция будет меньше, чем ей следовало бы быть.
Использование завышенной оценки приведет к тому, что отношение
дисперсий в (5.3-12) будет обрезаться на уровне 1 для большего, чем сле-
довало бы, числа точек. Для таких точек отклик фильтра будет равен зна-
чению локального среднего5. При другом подходе к реализации алго-
ритма — когда допускаются отрицательные значения (т.е. обрезание
отсутствует), а в конце производится изменение шкалы яркости — ре-
зультатом использования слишком завышенной оценки станет, как
указывалось выше, сокращение динамического диапазона.
Адаптивные медианные фильтры
Рассмотренные в Разделе 5.3.2 медианные фильтры хорошо работа-
ют до тех пор, пока пространственная плотность импульсного шу-
ма невелика (эмпирическое правило-PawPb не превышают 0,2).
В этом параграфе показано, что адаптивная медианная фильтрация
помогает справиться с импульсным шумом, вероятности которого
превышают указанные значения. Дополнительное преимущество
адаптивного медианного фильтра состоит в том, что такой фильтр
«старается сохранить детали» в областях, искаженных не импульсным
шумом. Обычный медианный фильтр таким свойством не обладает.
Подобно всем рассмотренным до сих пор фильтрам, адаптивный
медианный фильтр осуществляет обработку в прямоугольной окре-
стности Syy. Однако, в отличие от этих фильтров, адаптивный меди-
анный фильтр изменяет (увеличивает) размеры окрестности Sxy во
время работы в соответствии с приведенными ниже условиями. Бу-
дем помнить о том, что отклик фильтра представляет собой единст-
венное число, замещающее значение элемента изображения в той
точке (xj>), которая является центром окрестности Sxy в текущий момент.
5 Те. будет совпадать с откликом среднеарифметического фильтра. В других точках
отклик фильтра также будет ближе, чем следовало бы, к среднеарифметическому зна-
чению, что в конечном счете приведет к излишнему размазыванию изображения. —
Прим, перев.
5.3. Подавление шумов — пространственная фильтрация
Введем следующие обозначения:
zmin — минимальное значение яркости в Sxy;
Zmax — максимальное значение яркости в Sxy;
Zmed — медиана значений яркости в Sxy,
Zxy — значение яркости в точке (х,у);
5тах — максимальный допустимый размер Sxy.
Алгоритм адаптивной медианной фильтрации состоит из двух вет-
вей, обозначенных ниже как ветвь А и ветвь Б, и его действие за-
ключается в следующем.
Ветвь A. Al — £med — linin’
^2 — <rned — ^max’
если Al > 0 и А2 < 0, перейти к ветви Б;
иначе увеличить размер окрестности;
если размер окрестности < 5тах повторить ветвь А;
иначе результат равен z^-
ВеТВЬ Б. Bl Z.xy ^min’
— ZXy ~ ?max’
если Bl > 0 и В2 < 0, результат равен zx>);
иначе результат равен zmed-
Для понимания того, как работает этот алгоритм, необходимо
помнить, что его применение преследует три основные цели: уда-
лить биполярный импульсный шум, обеспечить сглаживание шумов
других типов, а также свести к минимуму такие искажения, как чрез-
мерное утончение или утолщение границ объектов. Значения zmjn
и zmax воспринимаются алгоритмом статистически как значения «им-
пульсных» составляющих шума, даже если они не равны наименьше-
му и наибольшему возможным значениям яркости на изображении.
С учетом последнего замечания мы видим, что ветвь А алго-
ритма преследует цель определить, является ли медиана zmed импуль-
сом («черным» или «белым») или нет. Если условие ^rain<Zrned<'^max
выполнено, то в силу указанных в предыдущем абзаце причин zmed
не может быть импульсом. В этом случае мы переходим к ветви Б
и проверяем, является ли импульсом значение zx>) в той точке, ко-
торая отвечает центру окрестности (напомним, что мы строим от-
клик фильтра в этой точке). Если условия В1 >0 и В2<0 выполнены,
то ^min^xy ^max’ и значение zxy не является импульсным по тем же
причинам, что и выше. В этом случае алгоритм дает на выходе не-
измененное значение zxy- Сохранение значений в таких точках
«промежуточного уровня» яркости минимизирует искажения, вно-
симые обработкой изображения. Если одно из условий В\ > О
и 2?2 < О нарушено, то либо z^ = zmjn, либо z^ = zmax. В обоих слу-
чаях значение является экстремальным, и алгоритм дает на выхо-
де значение медианы zme<}, которое, как следует из результатов ра-
боты ветви А, не является значением импульсного шума. Последняя
операция соответствует действию обычного медианного фильтра.
Отличие заключается в том, что обычный медианный фильтр заме-
няет значение в каждой точке на значение медианы по соответст-
вующей окрестности. Это приводит к излишним искажениям де-
талей на изображении.
Продолжим далее объяснение работы алгоритма и предположим,
что вычисленная при работе ветви А медиана является импульсом (т.е.
нарушено условие перехода к ветви Б). В таком случае алгоритм пред-
полагает увеличение размеров окрестности и повторение вычислений
по ветви А. Процесс повторяется до тех пор, пока либо не будет най-
дена медиана, отличная от импульса, либо размеры окрестности не до-
стигнут максимального допустимого размера. В последнем случае
алгоритм дает на выходе значение zXy- При этом нет гарантий того, что
это значение не является импульсным. Чем меньше вероятности шу-
ма Ра и/или Рь, или чем больше максимальный допустимый размер ок-
рестности 5тах, тем меньше вероятность такого преждевременного (без
перехода к ветви Б) выхода из алгоритма. Это утверждение выглядит
очень правдоподобно. Естественно ожидать, что при увеличении
плотности импульсов будет необходимо использовать окрестность
большего размера для устранения шумовых пиков.
После получения значения обрабатываемого элемента изображе-
ния, центр окрестности смещается в позицию следующего элемента.
Алгоритм инициализируется вновь и применяется к пикселям внут-
ри окрестности Sxy, находящейся в новом положении. В Задаче 3.20
требовалось разработать алгоритм обновления значения медианы
при передвижении центра окрестности от точки к точке и тем самым
уменьшить объем необходимых вычислений.
Пример 5.5. Восстановление с помощью адаптивного медианного
фильтра.
На Рис. 5.14 (а) представлено изображение монтажной платы, ис-
каженное биполярным импульсным шумом с вероятностями
Pa=Pb= 0,25; уровень шума здесь в 2,5 раза выше, чем на Рис. 5.10 (а).
Шум настолько велик, что мешает разглядеть большую часть деталей
на изображении. Чтобы получить образец для сравнения, мы снача-
ла отфильтровали изображение, используя наименьший медианный
Рис. 5.14. (а) Изображение, искаженное биполярным импульсным шумом с
вероятностями Ра = Рь = 0,25. (б) Результат обработки с использованием ме-
дианного фильтра размерами 7x7. (в) Результат адаптивной медианной филь-
трации с 5тах = 7.
фильтр, необходимый для удаления наиболее явных следов импульс-
ного шума. Для этого потребовался медианный фильтр размерами 7x7.
Результат фильтрации представлен на Рис. 5.14 (б). Хотя шум уда-
лось эффективно устранить, однако фильтрация привела к значи-
тельным искажениям деталей на изображении. Например, некоторые
штырьки разъема в верхней части изображения выглядят деформиро-
ванными или разорванными. Другие детали изображения искажены
аналогичным образом.
На Рис. 5.14 (в) представлен результат применения адаптивного ме-
дианного фильтра с = 7. Степень устранения шума такая же, как
в случае медианного фильтра. Од нако улучшение по сравнению с Рис. 5.14
(б) весьма значительно в том, что касается сохранения резкости и пра-
вильного воспроизведения деталей. Штырьки разъема менее деформи-
рованы, некоторые другие характерные детали, которые после восста-
новления с помощью медианного фильтра были плохо различимы или
искажены, выглядят на Рис. 5.14 (в) более резко и лучше опознаются.
В качестве двух примечательных примеров можно указать небольшие бе-
лые отверстия, разбросанные по поверхности платы, и элемент схемы
с восемью ножками в левом нижнем углу изображения.
Принимая во внимание высокий уровень шума на Рис. 5.14 (а), ре-
зультат работы адаптивного алгоритма может быть признан вполне хо-
рошим. Выбор максимального допустимого размера окрестности в ал-
горитме зависит от конкретного приложения, однако разумную оценку
этого параметра можно получить, экспериментируя предварительно
с обычными медианными фильтрами различных размеров. Эти
эксперименты позволят также оценить, каких результатов можно
ожидать от применения адаптивного алгоритма.
Глава 5. Восстановление изображений
5.4. Подавление периодического
шума — частотная фильтрация
В Главе 4 мы обсуждали фильтры низких и высоких частот в качест-
ве основного средства улучшения изображений. В этом разделе мы об-
судим более специализированные полосовые, режекторные, узкопо-
лосные и узкополосные режекторные фильтры как средства для
уменьшения или устранения периодического шума.
5.4.1. Режекторные фильтры
Режекторные фильтры удаляют или ослабляют частоты в кольцевой
полосе вокруг начала координат преобразования Фурье. Переда-
точная функция идеального режекторного фильтра задается выра-
жением
1 при D(u,v) <D0------;
H(u,v)=lO
W ' W
при D0-—<D(u,v)<D0+ — ;
(5-4-1)
1 при D(u, v) >D0+—,
где D (u,v) — расстояние (4.3-3), измеряемое от центра частотного пря-
моугольника, W — ширина кольца, a Dq — радиус окружности, про-
ходящей через его середину.
Аналогично, передаточная функция режекторного фильтра
Баттерворта порядка п задается выражением
Я(«,т)=—
1+
1
D(u,v)W
D2(u,v)-D2
(5-4-2)
а передаточная функция режекторного гауссова фильтра задается вы-
ражением
г -|2
1 02(ц>у)-до
H(u,v) = l-e 2L J
(5.4-3)
На Рис. 5.15 представлены трехмерные перспективные изображения
этих фильтров.
5.4.Подавление периодического шума
Рис. 5.15. Трехмерные перспективные изображения режекторных фильтров: а б В
(а) идеальный фильтр; (б) фильтр Баттерворта порядка 1;(в) гауссов фильтр.
Пример 5.6. Использованиережекторных фильтров для устранения
периодического шума.
На Рис. 5.16 (а), который повторяет Рис. 5.5 (а), представлено изо-
бражение, сильно искаженное синусоидальным шумом различных
частот. На Рис. 5.16 (б), где представлен фурье-спектр этого изобра-
жения, хорошо видны частотные компоненты шума в виде пар сим-
метричных ярких точек. В рассматриваемом примере эти компонен-
ты лежат приблизительно на окружности с центром в начале координат
Рис. 5.16. (а) Изображение, искаженное синусоидальным шумом, (б) Спектр (а),
(в) Режекторный фильтр Баттерворта (белым показаны точки со значением 1).
(г) Результат фильтрации. (Изображение предоставлено Агентством NASA.)
Глава 5. Восстановление изображений
частотного пространства, и, таким образом, использование цент-
рально-симметричного режекторного фильтра представляется впол-
не оправданным. На Рис. 5.16 (в) представлен режекторный фильтр
Баттерворта порядка 4, радиус и ширина которого выбраны так, что-
бы шумовые импульсы полностью попадали в соответствующую об-
ласть. Поскольку, вообще говоря, желательно удалять как можно
меньшую часть фурье-преобразования, обычно используемые режек-
торные фильтры являются крутыми и узкими. Результат фильтрации
изображения на Рис. 5.16 (а) с помощью выбранного фильтра пред-
ставлен на Рис. 5.16 (г). Улучшение изображения вполне очевидно. Ис-
пользованный простой метод фильтрации позволил эффективно вос-
становить даже мелкие детали и текстуры на изображении. Стоит
отметить также, что прямой подход, основанный на фильтрации в про-
странственной области с использованием масок небольшого разме-
ра, не позволяет достичь подобного результата.
5.4.2. Полосовые фильтры
Полосовые фильтры осуществляют операцию, противоположную ре-
жекторным фильтрам. В Разделе 4.4 было показано, как передаточная
функция высокочастотного фильтра может быть получена из переда-
точной функции соответствующего низкочастотного фильтра при
помощи (4.4-1). Аналогично, передаточная функция 7/bp (w,г) поло-
сового фильтра может быть получена из передаточной функции со-
ответствующего режекторного фильтра при помощи выражения
#bP(">v) = 1-#br(".v)- (5.4-4)
Вывод выражений для полосовых фильтров, которые соответствуют
режекторным фильтрам (5.4-1)— (5.4-3), оставлен читателю в качест-
ве упражнения (Задача 5.12).
Пример 5.7. Полосовая фильтрация для выделения шумовой состав-
ляющей изображения.
Полосовая фильтрация обычно не используется для улучшения
изображений непосредственно, поскольку, как правило, в результа-
те ее применения слишком большая часть деталей оказывается уда-
лена. Однако полосовая фильтрация оказывается весьма полезной
для отделения тех компонентов, которые обусловлены частотными со-
ставляющими в выбранном д иапазоне. Рис. 5.17 иллюстрирует сказан-
ное. Изображение на этом рисунке получено следующим образом:
(1) при помощи (5.4-4) был получен полосовой фильтр, соответству-
Рис. 5.17. Шумовая составляющая изображения на Рис. 5.16 (а), полученная
при помощи полосовой фильтрации.
ющий режекторному фильтру, использованному в предыдущем при-
мере; и (2) изображение на Рис. 5.16 (а) было отфильтровано при по-
мощи полученного полосового фильтра. Все детали изображения ока-
зались потеряны, однако оставшаяся информация весьма полезна,
поскольку понятно, что восстановленная таким методом шумовая
составляющая очень близка к шумовой составляющей, вызвавшей
искажение изображения на Рис. 5.16 (а). Другими словами, полосовая
фильтрация позволила выделить шумовую составляющую изображе-
ния. Это полезно, поскольку упрощает процедуру анализа шума, ко-
торая теперь может быть осуществлена в достаточной мере независи-
мо от содержательной части изображения.
5.4.3. Узкополосные фильтры
Узкополосные (пропускающие) фильтры и узкополосные режекторные
фильтры соответственно пропускают или не пропускают частоты в
определенных окрестностях своих центральных частот. На Рис. 5.18
представлены трехмерные изображения узкополосных режектор-
ных фильтров (идеального фильтра, фильтра Баттерворта и гауссо-
ва фильтра). Из свойств симметрии преобразования Фурье следует,
что для получения осмысленных (т.е. вещественных) результатов
фильтрации любой фильтр должны быть симметричен относитель-
но начала координат (центра частотного прямоугольника). Поэтому
узкополосные фильтры должны иметь вид симметричных относитель-
но начала координат пар. Единственным исключением является сим-
Глава 5. Восстановление изображений
метричный узкополосный фильтр с центральной частотой в начале ко-
ординат. Хотя для иллюстрации на Рис. 5.18 мы ограничились филь-
трами, состоящими только из одной пары, количество таких пар для
узкополосных фильтров, используемых на практике, может быть про-
извольным. Также произвольной (например, прямоугольной) может
быть и форма окрестностей, в которых узкополосный фильтр подав-
ляет (пропускает) частотные составляющие.
Передаточная функция идеального узкополосного режекторного
фильтра радиуса Dq с центрами в точке (uq,vq) и, в силу симметрии,
в точке (—uq,—vq) задается выражением
0
1
Я(ы,т) = -
при, Dr (и, г) < Dq или D2 (u,v) < Dq ;
в остальных случаях,
(5.4-5)
где
D{(u, v) = [(u-M/2-u0)2 + (v-7V/2-v0)2] 1 , (5.4-6)
и
Z>2(«,v) = [(«-M/2+«0)2 + (v-7V/2+v0)2]1/2- (5.4-7)
Как обычно, в соответствии с принятой в Разделе 4.2.3 схемой мето-
да фильтрации, предполагается, что центр частотного прямоугольни-
а
б и
Рис. 5.18. Трехмерные перспективные изображения узкополосныхрежектор-
ных фильтров: (а) идеальный фильтр; (б) фильтр Баттерворта порядка 2; (в) га-
уссов фильтр.
ка находится в точке с координатами (Mfl, N/2). Поэтому значения
(u0,v0) отсчитываются от этого центра частотного прямоугольника.
Передаточная функция узкополосного режекторного фильтра
Баттерворта порядка п задается выражением
H(u,v) =
(5.4-8)
где функции (u,v) и Z>2 (u’v) задаются, соответственно, выражени-
ями (5.4-6) и (5.4-7). Передаточная функция гауссова узкополосного
режекторного фильтра имеет вид
Ip О[(и,у)1>2(и,у)
2
H(u,v) = \-e
(5.4-9)
Интересно отметить, что в случае uq = vq = 0, последние три фильтра
превращаются в фильтры высоких частот.
Узкополосные фильтры, которые пропускают, а не подавляют ча-
стоты в окрестностях некоторых своих центральных частот, могут
быть получены тем же способом, что и полосовые фильтры в преды-
дущем параграфе. Поскольку действие таких фильтров строго проти-
воположно действию узкополосных режекторных фильтров, заданных
формулами (5.4-5), (5.4-8) и (5.4-9), то их передаточные функции мо-
гут быть заданы выражением
Япр(«,т) = 1-Япг(«,р), (5.4-10)
где /7пр (u,v) — передаточная функция узкополосного (пропускающе-
го) фильтра, соответствующего узкополосному режекторному фильт-
ру с передаточной функцией Hnr (u,v). В качестве упражнения (Зада-
ча 5.13) мы предлагаем читателю получить выражения для узкополосных
(пропускающих) фильтров, которые соответствуют рассмотренным
выше узкополосным режекторным фильтрам, и установить, что в слу-
чае и0 = v0 = 0, они превращаются в низкочастотные фильтры.
Пример 5.8. Удаление периодического шума с помощью узкополосной
фильтрации.
На Рис. 5.19 (а) представлено то же изображение, что и на Рис. 4.21 (а).
При обсуждении в Разделе 4.3.4 результатов низкочастотной фильтра-
ции этого изображения было отмечено, что существует лучший способ
Глава 5. Восстановление изображений
Рис. 5.19. (а) Полученное со спутника изображение шт. Флорида и Мексикан-
ского залива (обратите внимание на горизонтальные линии, являющиеся ар-
тефактами системы сканирования), (б) Спектр изображения (а), (в) Узкопо-
лосный фильтр, (г) Результат узкополосной фильтрации с использованием
фильтра (в), который содержит лишь шумовую составляющую, (д) Результат
узкополосной режекторной фильтрации. (Исходное изображение предостав-
лено NOAA).
уменьшить артефакты в виде горизонтальных линий, вызванных осо-
бенностями системы сканирования. Представленный ниже подход,
основанный на использовании узкополосных фильтров, позволяет
уменьшить шум на изображении не приводя при этом к заметному
сглаживанию. За исключением тех случаев, когда по указанным в Раз-
деле 4.3 причинам необходимо осуществить сглаживание изображе-
ния, использование узкополосной фильтрации предпочтительно, если
только удается подобрать подходящий фильтр.
Непосредственное рассмотрение картины шума на Рис. 5.19 (а),
состоящего из почти горизонтальных линий, позволяет предполо-
жить, что частотная составляющая шума локализована вдоль верти-
кальной оси координат в частотной области. Однако при рассмот-
рении спектра на Рис. 5.19 (б) становится ясно, что влияние шума
не достаточно для появления в частотной области хорошо заметной
шумовой составляющей вдоль вертикальной оси. Для того чтобы со-
ставить представление о том, какой вклад вносит шум в изображе-
ние, мы построим простой идеальный узкополосный фильтр, про-
пускающий лишь частоты вблизи вертикальной оси координат
в частотном пространстве, как показано на Рис. 5.19 (в). Изображе-
ние шумовой составляющей в пространственной области (полу-
ченное как результат фильтрации с использованием указанного уз-
кополосного фильтра) представлено на Рис. 5.19 (г). Эта картина
шума хорошо соответствует картине шума на Рис. 5.19 (а). Постро-
ив, таким образом, подходящий узкополосный фильтр, который
с разумной степенью точности выделяет шумовую составляющую,
мы можем получить соответствующий ему узкополосный режек-
торный фильтр по формуле (5.4-10.). Результат обработки изобра-
жения при помощи этого узкополосного режекторного фильтра
представлен на Рис. 5.19 (д). Это последнее изображение содержит
значительно меньше шума (заметных горизонтальных линий), чем
исходное изображение.
5.4.4. Оптимальная узкополосная фильтрация
Помехи на изображении не часто имеют ясно выраженную структу-
ру. Изображения, полученные при помощи электрооптических при-
боров, которые используются, например, при аэрофотосъемке или
съемке из космоса, иногда бывают искажены в результате интерферен-
ции и усиления сигналов низкого уровня в электронном тракте этих
приборов. В результате на изображении возникают заметные двумер-
ные периодические помехи более сложной структуры, чем рассмотрен-
ные до сих пор.
Глава 5. Восстановление изображений
Пример периодических искажений такого рода представлен на
Рис. 5.20 (а), который содержит цифровое изображение поверхности
Марса, полученное космическим аппаратом Mariner 6. Структура по-
мех на этом изображении довольно похожа на аналогичную структу-
ру на Рис. 5.16 (а), однако сами помехи значительно менее различи-
мы и, следовательно, труднее поддаются обнаружению в частотной
области. На Рис. 5.20 (б) представлен фурье-спектр рассматривае-
мого изображения. Появление похожих по форме на звезды частот-
ных компонент связано с интерференцией. Наличие в спектре не-
скольких центрально-симметрично локализованных пар частотных
составляющих свидетельствует о том, что помехи содержат более чем
одну периодическую компоненту.
Когда помехи содержат несколько составляющих, рассмот-
ренные в предыдущих параграфах методы не всегда применимы,
поскольку их использование может привести к потери слишком
большого количества информации на изображении в процессе филь-
трации (что особенно нежелательно, когда изображения являются
уникальными и/или их получение связано с большими материаль-
ными затратами). Кроме того, как правило, частотные составляю-
щие помех не являются узко локализованными вблизи некоторых от-
дельных точек в частотной области. Напротив, каждой такой
составляющей обычно отвечает достаточно широкая область в час-
тотном пространстве, которая содержит соответствующую инфор-
мацию. Нахождение этих областей обычными методами фурье-ана-
Рис. 5.20. (а) Изображение поверхности Марса, полученное с космического
аппарата Mariner 6. (б) Фурье-спектр, указывающий на наличие периодиче-
ских помех. (Исходное изображение предоставлено Агентством NASA.)
5.4.Подавление периодического шума — частотная фильтрация
лиза далеко не всегда является простой задачей. Альтернативные
методы фильтрации, позволяющие уменьшить эффекты, связан-
ные с такими помехами, весьма полезны во многих прикладных зада-
чах. Обсуждаемый ниже метод является оптимальным, в том смысле,
что он минимизирует значения локальной дисперсии восстанов-
ленного изображения.
Метод состоит в том, чтобы сначала получить в виде отдельного
изображения основной вклад, привносимый помехой, а затем вы-
честь из исходного искаженного изображения некоторую непостоян-
ную весовую долю полученного изображения помехи. Хотя мы разо-
вьем наш метод в рамках конкретного приложения, используемый
нами подход является достаточно общим и применим в других зада-
чах восстановления, когда приход ится иметь дело с периодическими
помехами сложной структуры.
Первый шаг состоит в выделении основных частотных составля-
ющих помехи. Это может быть осуществлено при помощи узкополос-
ного фильтра Н («,у), который пропускает частоты в окрестностях
каждого связанного с помехой пика. Коль скоро фильтр Н (u,v) вы-
бран таким образом, чтобы пропускать только связанные с помехой
частотные компоненты, то, как следует из рассмотрений в Разде-
лах 5.4.2 и 5.4.3, фурье-преобразование шумовой составляющей (по-
мехи) дается выражением
N(u,v)=H(u,v)G(u,v), (5.4-11)
где, как обычно, G (и,у) обозначает фурье-преобразование искажен-
ного изображения.
Построение фильтра Н («,у) требует принятия важного решения
о том, является ли каждый конкретный пик в частотной области шу-
мовым пиком (т.е. пиком, связанным с помехой), или нет. По этой при-
чине узкополосный фильтр подбирается, как правило, интерактивно
на основе визуального анализа спектра изображения G (u,v). После то-
го, как конкретный фильтр выбран, соответствующее изображение
шума (помех) в пространственной области может быть получено сле-
дующим образом:
n(x,y) = ^] {H(u,v)G(u,v)}. (5.4-12)
Мы исходим из предположения, что искаженное изображение# (х,у)
получается из неискаженного изображения f (х,у) прибавлением по-
мехи т|(х,у). Поэтому, если бы мы точно знали функцию т](х,у), то
получение функции fix,у) представляло бы собой простейшую зада-
Глава 5. Восстановление изображений
чу, заключающуюся в вычитании ц(х,у) изДх,у), как указывалось вы-
ше в настоящей главе. Проблема, разумеется, состоит в том, что филь-
трация обычно позволяет получить лишь некоторое приближение
к функции, определяющей связанную с помехой составную часть
изображения. Эффект, связанный с отличием построенного прибли-
жения ц(х,у) от реально существующей помехи, может быть уменьшен,
если при построении приближения для неискаженного изображе-
ния Дх,у) мы вычтем из искаженного изображения g(x,у) некоторую
взвешенную долю функции ц(х,у):
7(x,y) = g(x,y)-w(x,y)T](x,y), (5.4-13)
где, как и ранее, f(x,y) обозначает приближение для Дх,у), a w(x,y) —
подлежащая определению функция. Функция w(x,y) называется весо-
вой функцией или функцией модуляции, и задача метода состоит в та-
ком выборе этой функции, чтобы результат оказался в некотором
смысле оптимальным. Один из критериев выбора функции w(x,y) за-
ключается в том, чтобы величина локальной дисперсии получаемо-
го f(x,y) приближения по заданной окрестности принимала мини-
мальное значение в каждой точке (х,у).
Рассмотрим окрестность некоторой точки (х.у) размерами
(2а + 1)х(26 + 1). Локальная дисперсия функции f(x,y) в точке с ко-
ординатами (х,у) может быть получена следующим образом:
т 1 а b г ~ — "|2
° (Х’У> (20+1)(2>+~1)д£^[/(Х+Я’У+,)~ ’ (5'4-14)
где /(х,у) — среднее значение функции f по окрестности, т.е.
/(х,у) =------------ У У, f (x+s,y+t). (5.4-15)
(2a + l)(2Z>+l) ^a£bJ 1 7
При обработке точек на границе или около нее можно рассматривать
неполные окрестности.
Подставляя (5.4-13) в (5.4-14), получаем
। а Ь
(2О + 1)(2(, + 1) ^1=_ь 0 4 16)
_____________ 2
-w(x+s, у+/)п(х+S, у + /) ] - [g(x, у)- М<Х, у)Т] (X, у) ] } .
5.4. Подавление периодического шума — частотная фильтрация
Предположим, что функция w (х,у) практически постоянна в преде-
лах окрестности, т.е.
w(x+5,y+/) = w(x,y) (5.4-17)
при — а < s < а и — b < ж < Ь. При этом в окрестности будет иметь место
равенство
и’(х,у)т|(х,у) = w(x,y)r](x,y). (5.4-18)
С учетом двух последних формул (5.4-16) принимает вид
о2(х,у) =------------х У У flg(x+s,y+/)-
(2п+1)(26+1) (54_19)
-w(xt.v,y t /)T|(x t s,y+ /)| [g(x,y)- w(x,y)r| (x,y)]}2.
Для того чтобы найти функцию w (х,у), на которой реализуется экс-
тремум (минимум) функционала о2 (х,у), заданного формулой (5.4-19),
нужно решить уравнение6
Эо2(х,у)_0 (5.4-20)
<)w(x,y)
относительно w (х,у). Искомое решение имеет вид
w(x>y)=g(x>jjn(x>y)-g(x>y)n(x>y) (5 4_21)
т]2(х,у)-т]2(х,у)
Для того чтобы получить восстановленное изображение /(х,у),
нужно вычислить функцию w (х,у) по (5.4-21), а затем использо-
вать (5.4-13). Поскольку мы предполагаем, что функция w (х,у) яв-
ляется постоянной в пределах окрестности, то нет необходимости вы-
числять значения этой функции для всех точек изображения. Вместо
этого можно вычислить по одному значению w (х,у) в некоторой точ-
ке каждого из непересекающихся его фрагментов (предпочтитель-
но в центральной точке фрагмента), а затем использовать это зна-
6 Это, по существу, уравнение Эйлера (необходимое условие экстремума) для функ-
ционала (5.4-19), т.е. условие обращения в нуль его вариации. Координаты (х,у)
можно рассматривать в этом уравнении как параметры. — Прим, перев.
Глава 5. Восстановление изображений
Рис. 5.21. Фурье-спектр (не центрированный) изображения, представленно-
го на Рис. 5.20 (а). (Изображение предоставлено NASA.)
чение при обработке всех точек изображения, содержащихся в этом
фрагменте.
Пример 5.9. Восстановление с помощью оптимальной узкополос-
ной фильтрации.
Рис. 5.21—5.23 иллюстрируют процесс применения описанной вы-
ше техники восстановления к изображению на Рис. 5.20 (а). Это изо-
бражение имеет размеры 512x512 пикселей, и параметры, определя-
ющие размеры окрестности в процедуре оптимизации, были выбраны
Рис. 5.22. (а) Фурье-спектр N (u,v), и (б) соответствующее изображение помех (шу-
мовой составляющей) т] (х,у). (Изображение предоставлено NASA.)
Рис. 5.23. Восстановленное изображение. (Изображение предоставлено NASA.)
следующим образом: а=6=15. На Рис. 5.21 представлен фурье-спектр
искаженного изображения. В этом конкретном случае спектр не
подвергался процедуре центрирования, поэтому начало координат
w= v О находится в левом верхнемуглу изображения на Рис. 5.21. На
Рис. 5.22 (а) представлен спектр шума N(u,v), т.е. на изображении при-
сутствуют лишь те пики, которые связаны с шумовой составляющей.
На Рис. 5.22 (б) представлено изображение помех ц(х,у), которое
получено вычислением обратного преобразования Фурье от функ-
ции N(u,v). Обратите внимание на сходство структуры этого изобра-
жения, и структуры шумовой составляющей на Рис. 5.20 (а). Нако-
нец, на Рис. 5.23 представлен результат восстановления, полученный
с использованием выражения (5.4-13). Периодическая помеха прак-
тически устранена.
5.5. Линейные трансляционно-инвариантные
искажения
Искажающее преобразование на Рис. 5.1, которому подвергается
функция Дх,у) на этапе, предшествующем восстановлению, может
быть записано в виде
#(х,у) = Я[/(х,у)]+т](х,у). (5.5-1)
Временно предположим, что ц(х,у)=0, так что^(х,у)=//[/(х,у)]. Как бы-
ло определено в Разделе 2.6, оператор //является линейным, если
H[ttfi(x,y)+bf2(x,y)]=aH[fl(x,y)]+bH [/2(*,У)1 (5.5-2)
Глава 5. Восстановление изображений
где ачЬ — любые скаляры, a /j (х,у) nfi (х,у) — две любые функции
(два любых изображения). В случае а = b = 1, равенство (5.5-2) при-
нимает вид
Н [/1 (х, У)+fi (х,у)]= Н [/} (х,у) ]+Н [/2 (х,у )]. (5.5-3)
Выражаемое равенством (5.5-3) свойство называется свойством ад-
дитивности. Это свойство просто означает, что если Н—линейный
оператор, то результат его действия на сумму двух функций равен
сумме результатов его действия на каждую из этих функций.
В случае/2 (х,у) = 0, равенство (5.5-2) принимает вид
ff[«/l(x,y)]=a^[/1(x,y)]. (5.5-4)
Выражаемое равенством (5.5-4) свойство называется свойством одно-
родности. Это свойство означает, что результат действия оператора на
произведение константы на функцию равен произведению этой кон-
станты на результат действия оператора на функцию. Таким образом,
линейный оператор обладает как свойством аддитивности, так и свой-
ством однородности.
Оператор, действующий по правилу# (х,у) = //[/(х,у)1, называет-
ся трансляционно-инвариантным (или пространственно-инвариант-
ным) , если для любой функции f (х,у) и для любых чисел а и 0 выпол-
няется равенство
Я[/(х-а,у-р)]=#(х-о,у-0). (5.5-5)
В соответствии с данным определением, действие оператора в точке
не зависит от местоположения этой точки в пространстве.
Небольшое видоизменение формы записи7 определения (4.2-33)
дискретной импульсной функции, дает возможность выразить функ-
цию/(х,у) в терминах непрерывной импульсной функции (8-функции):
f(x,y)= J J/(ot,p)8(x-a,y-p)daJp . (5.5-6)
7 Для того чтобы упростить изложение материала, автору удобно перейти к рассмо-
трению непрерывного случая, что не изменяет существа дела. Такой переход осуще-
ствляется заменой дискретных переменных на непрерывные, конечные суммы заме-
няются на соответствующие интегралы, а дискретная 8-функция (символ
Кронекера) — на непрерывную 8-функцию. Обратные замены позволяют вернуть-
ся к дискретному случаю. — Прим, перев.
5.5. Линейные трансляционно-инвариантные искажения
Последнее равенство является, по существу, определением 8-функции
(единичной импульсной функции), локализованной в точке с коор-
динатами (х,у).
Снова временно предположим, что т] (х,у) = 0. Тогда подстановка
(5.5-6) в (5.5-1) дает
#(х,у) = Я[/(х,у)]=Я
J J /(o,P)8(x-a,y-P)Jadp
(5.5-7)
Пусть Н— линейный оператор. Поскольку свойство аддитивности рас-
пространяется на интегралы, то
(5.5-8)
-f-OO-f-OO ' '
g(x,y) = J j Я[/(а,Р)8(х-а,у-Р)]с/а/7р .
Используя свойство однородности и учитывая, что f (а,Р) не зависит
от х и у, получаем
g(x,y) = J |/(<х,Р)Я[8(х-а,у-Р)]с/а/7р . (5.5-9)
Функция под знаком интеграла в правой части последнего равенства
й(х,о,у, р) = Я[8(х-а,у-р)] (5.5-10)
называется импульсным откликом (импульсной характеристикой} или
ядром оператора Н. Таким образом, функция h (х,а,у,Р) представля-
ет собой результат действия (отклик) оператора Н на 8-функцию,
локализованную в точке с координатами (х j>). В оптике, когда импульс
соответствует светящейся точке, функцию h (х,а,у,Р) обычно назы-
вают функцией рассеяния точки (ФРТ). Происхождение термина
связано с тем обстоятельством, что любая реальная оптическая сис-
тема до некоторой степени размывает (рассеивает) светящуюся точ-
ку, причем величина рассеивания определяется качеством оптичес-
кой системы.
Подставив (5.5-10) в (5.5-9), мы получим выражение
#(*,>') = J J /(«. Р)й(х,о,у, Р)Jadp,
(5.5-11)
Глава 5. Восстановление изображений
которое называется интегралом Фредгольма первого рода. В последнем
выражении заключен фундаментальный результат, лежащий в ос-
нове теории линейных систем. Этот результат устанавливает, что ес-
ли известен отклик системы на импульсную функцию, то отклик
системы на любую функцию f (а,Р) может быть вычислен на основе
(5.5-11). Другими словами, любая линейная система Я полностью ха-
рактеризуется своим импульсным откликом (ядром соответствующе-
го оператора).
Если оператор Н является трансляционно-инвариантным, то из
(5.5-5)следует, что
Н [8(х - а,у - Р)]= h(x - а,у - Р). (5.5-12)
Выражение (5.5-11) в этом случае принимает вид
g(x,y) = J j Да, Р)й(х-а,у-Р)^аф . (5.5-13)
Это выражение называется непрерывной сверткой, и является анало-
гом дискретной свертки (4.2-30) для случая непрерывных переменных.
Выражение (5.5-13) показывает, что зная ядро линейного оператора
можно вычислить результату его действия на любую функцию/. Этот
результат просто представляет собой свертку ядра с соответствую-
щей функцией.
При наличии ад дитивного шума выражение, определяющее линей-
ную модель искажений (см. (5.5-11)), принимает вид
g(x,y) = J J Да, Р)й(х, а, у, Р)daф+т](х,у). (5.5-14)
Если оператор Я трансляционно-инвариантный, то (5.5-14) записы-
вается в виде
g(x,y) = J J Да, Р)й(х-а,у-Р)б?аф+т](х,у). (5.5-15)
Значения описывающего шум слагаемого ц(х,у) являются случайны-
ми величинами, которые предполагаются не зависящими отточки про-
странства. Используя привычные обозначения для свертки, можно пе-
реписать (5.5-15) как
g{x,y) = h(x,y)*f{x,y}+T\{x,y), (5.5-16)
5.5. Линейные трансляционно-инвариантные искажения
или, используя теорему о свертке, перейти в частотную область,
что дает
G(u, v) = Н(и, v)F(u, у) + N(u, v). (5.5-17)
Последние два выражения суть выражения (5.5-1) и (5.5-2). Напом-
ним, что умножение понимается как поэлементное.
Итак, проведенное рассмотрение показывает, что воздействие ли-
нейной трансляционно-инвариантной искажающей системы с ад-
дитивным шумом может быть смоделировано в пространственной
области как свертка искажающей функции (ядра искажающего опе-
ратора) с изображением и последующее прибавление аддитивного
шума. На основе теоремы о свертке (см. Разделы 4.2.4 и 4.6.4) то же
воздействие может быть выражено в частотной области как произве-
дение фурье-преобразований изображения и искажающей функции
с последующим прибавлением фурье-преобразования шума. Для пе-
рехода в частотную область мы используем рассмотренный в Разде-
ле 4.6 алгоритм БПФ. Будем иметь в виду также, что применение
дискретного преобразования Фурье требует дополнения функций
нулями, как это объяснялось в Разделе 4.6.3.
Линейные трансляционно-инвариантные модели могут быть ис-
пользованы для приближенного описания многих типов искажений.
Преимущество такого подхода заключается в том, что огромное ко-
личество используемых в линейной теории методов и средств стано-
вится применимо для решения задач восстановления изображений.
Хотя нелинейные и трансляционно-неинвариантные методы являют-
ся более общими (и обычно более точными), но их использование ча-
сто приводит к непреодолимым или очень трудно решаемым чис-
ленными методами проблемам. Рассмотрения настоящей главы
сосредоточены на линейных трансляционно-инвариантных методах.
Поскольку искажение представляет собой результат свертки, то для
восстановления необходимо найти такой фильтр, применение кото-
рого приводило бы к обратному процессу. Поэтому для обозначения
линейного процесса восстановления часто используется термин рекон-
струкция (деконволюция^) изображений. Аналогично, фильтры, ис-
пользуемые для восстановления часто называются реконструирую-
щими фильтрами.
8 Процесс, обратный свертке («convolution»), по-английски называется «deconvolu-
tion» — деконволюция. В дальнейшем мы предпочитаем вместо этого термина исполь-
зовать термин реконструкция. — Прим, перев.
Глава 5. Восстановление изображений
5.6. Оценка искажающей функции
Существуют три основных способа оценки искажающей функции
(ядра искажающего оператора) для последующего ее использования
при восстановлении изображений: (1) визуальный анализ, (2) экспе-
римент и (3) математическое моделирование. Вследствие того, что ис-
тинная искажающая функция нечасто бывает известна полностью,
процесс восстановления изображения с использованием приближе-
ния искажающей функции, полученного некоторым образом, иногда
называют реконструкцией «вслепую».
5.6.1. Оценка на основе визуального анализа изображения
Предположим, что имеется искаженное изображение, но информация
об искажающей функции И отсутствует. Один из способов оценить эту
функцию состоит в выделении информации непосредственно из изо-
бражения. Например, если изображение является размытым, мы мо-
жем рассмотреть его небольшой фрагмент, содержащий простую струк-
туру, такую как часть некоторого объекта и фон. Для того чтобы
уменьшить влияние шума на наши наблюдения, следует выбрать ту об-
ласть изображения, которая содержит полезный сигнал большой амп-
литуды. Используя яркости объекта и фона, мы приблизительно мо-
жем построить неразмытое изображение тех же размеров и с теми же
особенностями, что и рассматриваемая часть исходного изображе-
ния. Обозначим рассматриваемую часть изображения как^ (х,у) и по-
строенное изображение (которое в действительности представляет
собой наше приближение для части неискаженного изображения в рас-
сматриваемой области) как /5(х,у) . Далее, предполагая, что влия-
ние шума пренебрежимо мало в силу нашего выбора области с боль-
шим полезным сигналом, на основании (5.5-17) имеем
Я>,т) = §^. (5.6-1)
^,v)
Исходя из свойств функции Hs (m,v), мы теперь можем сделать выво-
ды о свойствах полной искажающей функции если использо-
вать тот факт, что искажения предполагаются трансляционно-инва-
риантными. Предположим, например, что радиальный профиль
функции Hs (m,v) оказался той же формы, что и соответствующий
профиль низкочастотного фильтра Баттерворта. Это может быть ис-
пользовано для построения функции H(u,v) той же самой формы, но
большего размера.
5.6.2. Оценка на основе эксперимента
Если оборудование, аналогичное тому, которое использовалось при по-
лучении изображения, доступно, то, в принципе, возможно получить
точную оценку искажающей функции. Сначала необходимо так подо-
брать параметры системы, чтобы искажения на получаемых с ее помо-
щью изображениях, похожих по сценарию на подлежащее восстанов-
лению изображение, как можно лучше соответствовали искажениям
на этом изображении. Далее идея состоит в том, чтобы сформиро-
вать импульсный отклик (ядро искажающего оператора), для чего
нужно получить изображение импульса (маленькой яркой точки), ис-
пользуя систему с подобранными значениями параметров. Как было
отмечено в Разделе 5.5, линейная трансляционно-инвариантная сис-
тема полностью характеризуется своим импульсным откликом.
Импульс симулируется яркой световой точкой. Чтобы уменьшить
влияние шума, яркость должна быть как можно больше. Затем, учи-
тывая, что фурье-преобразование импульса есть константа, из (5.5-17)
получаем
Я(«,у)=^^, (5.6-2)
А
где, как и раньше, G (u,v) — фурье-преобразование полученного изо-
бражения, А — константа, описывающая величину яркости импуль-
са. На Рис. 5.24 приведен соответствующий пример.
Рис. 5.24. Оценка искажающей функции с помощью импульса, (а) Световой
импульс (показан с увеличением), (б) Изображение (искаженного) импульса.
Глава 5. Восстановление изображений
5.6.3. Оценка на основе моделирования
Моделирование искажений используется уже в течение многих лет, так
как оно позволяет проникнуть в суть задачи восстановления изобра-
жений. В некоторых случаях модель позволяет даже учесть внешние
условия, которые вызывают искажения. Например, в основе предло-
женной в работе [Hufnagel, Stanley, 1964] модели искажений лежит учет
таких физических свойств атмосферы, как турбулентность. Эта модель
имеет следующий знакомый вид:
Я(1/,г)=е-Л<ы2+г2>5/6, (5.6-3)
где константа к описывает турбулентные свойства атмосферы. С точ-
ностью до коэффициента 5/6 в показателе экспоненты, это выраже-
ние совпадает по форме с выражением для гауссова низкочастотного
фильтра, который рассматривался в Разделе 4.3.3. В действительнос-
ти ГФНЧ иногда используются для моделирования умеренной одно-
родной расфокусировки. На Рис. 5.25 представлены примеры, полу-
ченные в результате имитации расфокусировки изображения
с использованием выражения (5.6-3), в котором параметр к принимал
значения к = 0,0025 (случай сильной турбулентности), к = 0,001 (уме-
ренная турбулентность) и к = 0,00025 (слабая турбулентность). Разме-
ры изображений — 480x480 пикселей9.
Другим важным аспектом моделирования является построение
математической модели непосредственно из основных принципов.
В качестве иллюстрации мы детально рассмотрим случай, когда раз-
мывание (смазывание) возникает в результате равномерного поступа-
тельного движения изображения сцены относительно регистрирую-
щей системы в процессе фотосъемки. Предположим, что изображение
f{x,y) участвует в плоском движении и что функции хр(0 и Го(О опре-
деляют закон движения10 в направлениях х и у соответственно. Пол-
ная экспозиция в любой точке записывающего носителя (скажем,
пленки или матрицы сенсоров) определяется как интеграл по време-
ни (т.е. по времени, в течение которого открыт затвор регистрирую-
щей системы) от величины мгновенной экспозиции.
9 Кроме того, при генерации изображений был добавлен небольшой по величине ад-
дитивный шум (см. Пример 5.15), который практически незаметен, но играет важную
роль в рассматриваемых ниже процедурах восстановления. — Прим, перев.
10 Заметим, что эти функции описывают закон движения изображения сцены, кото-
рое возникает в поле кадра регистрирующей системы, а не само движение сцены в
пространстве. — Прим, перев.
5.6. Оценка искажающей функции
Рис. 5.25. Результаты моделирования турбулентности атмосферы, (а) Турбу-
лентность пренебрежимо мала, (б) Сильная турбулентность, к = 0,0025. (в) Уме-
ренная турбулентность, к = 0,001. (г) Слабая турбулентность, к = 0,00025.
(Исходное изображение предоставлено NASA.)
Предположим, что затвор системы открывается и закрывается
мгновенно и что, за исключением эффектов, связанных с движением,
процесс регистрации изображения является идеальным. Тогда, если
Т— время экспозиции, то
т
g(x,y)=f (x-XQ(t),y-yQ(t))dt, (5.6-4)
о
где g (х,у) — смазанное изображение.
В соответствии с (4.2-3), фурье-преобразование (5.6-4) имеет вид
13 А-223
Глава 5. Восстановление изображений
G(u,v) = J J g(x,y)e ll^ux+vy^dxdy =
-в»-в» Г Т 1
= J J J/(x-x0(Z),y-y0(Z))JZ e-'^^+^dxdy.
_оо_<х,|_0
(5.6-5)
Изменение порядка интегрирования позволяет записать (5.6-5) в виде
Т -В-4-О
G(w,v) = j J J f (х~хъ(1),у-yo(t)y)e~'27^ux+vy^dxdy dt. (5.6-6)
oL~°0-°°
Член внутри квадратных скобок представляет собой фурье-преобразова-
ние сдвинутой функции/^ — х0(/), у—Jo(0)- Используя (4.6-2), имеем
т
G(u, v) = J F(u, v) )dt =
0 (5.6-7)
т
=F(u, v) J (О+ХУо(О )dt,
0
причем второе равенство имеет место, поскольку функция F (u,v) не
зависит от переменной t.
Положив по определению
т
H(u,v) = Je-'M^oW+vToW)^, (5 6 8)
О
мы можем переписать (5.6-7) в стандартном виде
G(u,v) = H(u,v)F(u,v). (5.6-9)
Если функции %о(О и у0(/), определяющие закон движения изобра-
жения, известны, то передаточная функция H(u,v) может быть полу-
чена прямо из (5.6-8). Предположим, например, что рассматривае-
мое изображение участвует в равномерном поступательном движении
только в х-направлении со скоростью, которая определяется выра-
жением %о(О — at/T. За время экспозиции Т изображение смещает-
ся на общее расстояние а. Полагая в (5.6-8) у$(1) = 0, имеем
5.6. Оценка искажающей функции
Т Т
Щи, v) = J e~i2mx^ dt = J e-'^a>/Tdt =
О О (5.6-10)
= -^— sm(Ttua)e~l™a.
пиа
Легко заметить, что //обращается в нуль в точках и = п/а, где п — це-
лое. Если бы мы также рассмотрели равномерное движение в направ-
лении у видаур (/) = bt/T, то получили бы для искажающей функции
следующее выражение:
Щи,у) =-----—---sin(n(wo+v6))e гл<ий+1^).
n(ua+vb)
Пример 5.10. Размывание (смазывание) изображения в результате
движения.
23 На Рис. 5.26 представлен результат применения к изображению
искажающего оператора с ядром (5.6-11). Представленное на Рис. 5.26
(б) смазанное изображение получено в результате вычисления фу-
рье-преобразования изображения на Рис. 5.26 (а), умножения этого
преобразования на искажающую функцию вида (5.6-11) и вычисления
обратного преобразования. Размеры изображений составляют 688x688
пикселей; параметры в (5.6-11) выбирались следующим образом:
Рис. 5.26. (а) Исходное изображение, (б) Результат смазывания изображения
с использованием искажающей функции вида (5.6-11) со значением параме-
тров а = b = 0,1 и Т= 1.
Глава 5. Восстановление изображений
a=b=O, 1 и Г= 1. Ряд непростых вопросов, возникающих в процессе вос-
становления исходного изображения по его искаженному аналогу,
особенно при наличии шума, обсуждаются в Разделах 5.8 и5.9.
5.7. Инверсная фильтрация
В этом разделе мы сделаем первый шаг в решении задачи восстанов-
ления изображений, искаженных оператором Н, ядро (искажающая
функция) которого задано или определено с помощью методов, рас-
смотренных в предыдущем разделе. Простейшим способом восстанов-
ления является инверсная фильтрация, которая предполагает получе-
ние оценки F(u,v) фурье-преобразования исходного изображения
делением фурье-преобразования искаженного изображения на час-
тотное представление искажающей функции:
F(M,v) = -^^-. (5.7-1)
Я(щг)
Деление в (5.7-1) понимается как поэлементное. Подставив в (5.7-1)
выражение для G (u,v) из (5.5-17), получим
F(u,v) = F(u,v) + ?^ (5.7-2)
Последнее выражение представляет интерес. Из него видно, что да-
же зная искажающую функцию, невозможно точно восстановить не-
искаженное изображение (обратное фурье-преобразование функции
F(w,v)), поскольку функция N (и,г) является фурье-преобразовани-
ем случайной величины и неизвестна. Имеется и еще одна проблема.
Если функция Н (w,v) принимает нулевые или близкие к нулевым
значения, то вклад второго слагаемого в правой части (5.7-2) может
стать доминирующим. Как вскоре будет видно, эта ситуация часто ре-
ализуется на практике.
Один из способов обойти указанную проблему состоит в том, что-
бы ограничить частоты фильтра значениями вблизи начала коорди-
нат11. Как нам известно (см. (4.2-22)), значение Я (0,0) равно средне-
му значению функции h (%,у) и обычно является наибольшим
11 Т.е. считать, что правая часть (5.7-1) обращается в нуль вне некоторой области вбли-
зи начала координат. Можно, например, умножить эту правую часть на передаточную
функцию некоторого идеального низкочастотного фильтра. — Прим, перев.
5.7. Инверсная фильтрация 389
значением И (u,v) в частотной области. Поэтому ограничиваясь рас-
смотрением частот вблизи начала координат, мы уменьшаем вероят-
ность встретить нулевое значение. Следующий пример служит иллю-
страцией рассмотренного метода.
Пример 5.11. Инверсная фильтрация.
Представленное на Рис. 5.25 (б) изображение, искаженное турбу-
лентностью атмосферы, было восстановлено при помощи инверс-
ной фильтрации на основе (5.7-1) с использованием функции, явля-
ющейся обратной к функции, вызвавшей расфокусировку этого
изображения. В данном случае искажающая функция была равна
со значением параметра к = 0,0025. Константы М/1 и N/1 определя-
ют сдвиг, который центрирует функцию в частотной области так,
чтобы она соответствовала центрированному фурье-преобразованию
изображения, как уже многократно обсуждалось в предыдущей гла-
ве. В данном случае М = N= 480. Искажающая функция не обраща-
ется в нуль, поэтому проблема деления на нуль не возникает. Одна-
ко несмотря на это, значения искажающей функции становятся при
больших частотах настолько малыми, что результат полной инверс-
ной фильтрации (представленный на Рис. 5.27 (а)) совершенно бес-
полезен. Причины столь скверного результата были выяснены при об-
суждении равенства (5.7-2).
На Рис. 5.27 (б)— (г) представлены результаты восстановления, полу-
ченные при обрезании значений отношения G(u,v)/H(u,v) вне кру-
гов с радиусами 40, 70 и 85 отсчетов, соответственно. Обрезание осу-
ществлялось путем умножения этого отношения на передаточную
функцию низкочастотного фильтра Баттерворта порядка 10, что обес-
печило быстрое (но гладкое) убывание в переходной зоне требуемо-
го радиуса. Радиусы порядка 70 обеспечивают получение результатов
наилучшего качества (см. Рис 5.27 (в)). При меньших значениях ра-
диуса восстановленное изображение остается расфокусированным, что
и показывает изображение на Рис. 5.27 (б), полученное при значении
радиуса 40. Увеличение значения радиуса свыше 70 приводит к зна-
чительному ухудшению получаемого изображения, как это видно на
изображении на Рис. 5.27 (г), полученном при значении радиуса 85.
Шум явно доминирует на изображении, и его содержательная часть
едва видна из-за шумовой «завесы». При дальнейшем увеличении
значения радиуса мы получаем изображения, все более и более похо-
жие на Рис. 5.27 (а).
Глава 5. Восстановление изображений
Рис. 5.27. Восстановление изображения Рис. 5.25 (б) по формуле (5.7-1).
(а) Результат применения полного фильтра; результаты применения фильтра,
обрезанного: (б) вне круга радиуса 40; (в) вне круга радиуса 70; и (г) вне кру-
га радиуса 85.
Результаты приведенного примера свидетельствуют о слабых воз-
можностях метода инверсной фильтрации вообше. Основной темой
следующих разделов является вопрос о том, как можно улучшить
этот метод.
5.8. Фильтрация методом минимизации
среднего квадратического отклонения
(винеровская фильтрация)
Рассмотренный в предыдущем разделе метод инверсной фильтрации
не обеспечивает корректной работы по отношению к шуму. В насто-
5.8. Винеровская фильтрация
ящем разделе мы рассмотрим метод, соединяющий в себе учет свойств
искажающей функции и статистических свойств шума в процессе
восстановления. Метод основан на рассмотрении изображений и шу-
ма как случайных процессов, и задача ставится следующим образом:
найти такую оценку f для неискаженного изображения f, чтобы
среднеквадратическое отклонение этих величин друг от друга было ми-
нимальным. Среднеквадратическое отклонение е задается формулой
(5.8-1)
где £{•} обозначает математическое ожидание своего аргумента. Пред-
полагается, что выполнены следующие условия: (1) шум и неискажен-
ное изображение не коррелированы между собой; (2) либо шум, ли-
бо неискаженное изображение имеют нулевое среднее значение;
(3) оценка линейно зависит от искаженного изображения. При выпол-
нении этих условий минимум среднеквадратического отклонения
(5.8-1) достигается на функции, которая задается в частотной облас-
ти выражением
F(w,v)
Н (u,v)Sf(u,v)
Sf(u,v)\H(u,v)\2 +5n(w,v) ,
___________________________
J#(w,y)|2 +Sri(u,v)/Sf(u,v)
' ____________\H(u,v)\2
H(u,v) |Щи,y)|2 + S^(u,v)/Sf(u,v)
G(u,v) =
G(u,v) = (5.8-2)
G(u, v),
причем последнее равенство имеет место в силу того, что произведе-
ние комплексного числа на комплексно-сопряженное равно квадра-
ту модуля. Приведенный результат был получен Н. Винером [N. Wiener,
1942], и метод известен как оптимальная фильтрация по Винеру.
Фильтр, представленный выражением внутри скобок, часто называ-
ют фильтром минимального среднеквадратического отклонения или ви-
неровским фильтром. В конце главы приведены ссылки на источники,
в которых можно найти подробный вывод выражения для винеров-
ского фильтра. Отметим, что, как видно из первой строки (5.8-2),
проблема нулей в спектре искажающей функции при использова-
нии винеровского фильтра не возникает, за исключением тех случа-
ев, когда функции Н (и,у) и 5^ (w,v) обращаются в некоторых точках
в нуль одновременно.
В формуле (5.8-2) использованы следующие обозначения:
Н (u,v) — искажающая функция (ее частотное представление);
И* (w,v) — комплексное сопряжение H(u,v);
\Н (i/,v)|2 = Н* (u,v)H (w,v);
'S'n (w,v) = |7V(w,v)|2 — энергетический спектр шума (см. (4.2-30));
Sf(u,v) = |F(w,v)|2 — энергетический спектр неискаженного изобра-
жения.
Как и ранее, G (i/,v) — фурье-преобразование искаженного изоб-
ражения. Восстановленное изображение в пространственной облас-
ти получается применением обратного преобразования Фурье к оцен-
ке F(u, v). Отметим, что если шум равен нулю, то его энергетический
спектр обращается в нуль, и винеровская фильтрация в этом случае
сводится к инверсной фильтрации.
Когда мы имеем дело с белым шумом, спектр которого |N(и,v)|2
является постоянной функцией, происходят соответствующие
упрощения. Однако, спектр неискаженного изображения редко
бывает известен. В тех случаях, когда спектры шума и неискажен-
ного изображения неизвестны и не могут быть оценены, часто ис-
пользуется подход, состоящий в аппроксимации выражения (5.8-2)
выражением
F(w,v) =
1 |Я(щу)|2
Я(и,т)|я(ы,т)|2 + Я
X
G(i/,v),
(5.8-3)
где К— определенная константа. В приводимых ниже примерах филь-
трации используется именно это последнее выражение.
Пример 5.12. Сравнение инверсной фильтрации и винеровской филь-
трации.
Рис. 5.28 демонстрирует преимущества винеровской фильтра-
ции по сравнению с инверсной фильтрацией. На Рис. 5.28 (а) вос-
произведен представленный на Рис. 5.27 (а) результат восстанов-
ления с использованием полного инверсного фильтра. Аналогично,
на Рис. 5.28 (б) воспроизведен представленный на Рис. 5.27 (в) ре-
зультат восстановления с использованием инверсного фильтра,
обрезанного на высоких частотах. Эти результаты повторены здесь
для удобства сравнения. На Рис. 5.28 (в) представлен результат, по-
лученный при помощи винеровской фильтрации на основе (5.8-3)
с искажающей функцией из Примера 5.11. Значение К было подо-
брано так, чтобы обеспечить наилучшее качество восстановле-
ния. В этом примере очевидно преимущество винеровской филь-
трации по сравнению с инверсной фильтрацией. Сравнивая
Рис. 5.25 (а) и 5.28 (в), мы видим, что винеровская фильтрация поз-
воляет получить результат, очень близкий по виду к исходному изо-
бражению.
Пример 5ЛЗ. Дальнейшие сравнения винеровской фильтрации.
• В верхнем ряду на Рис. 5.29 представлены, слева направо, следу-
ющие изображения: (1) смазанное изображение Рис. 5.26 (б), силь-
но искаженное дополнительно аддитивным гауссовым шумом с ну-
левым средним и дисперсией 650; (2) результат его восстановления
с помощью инверсной фильтрации; (3) результат восстановления
с помощью винеровской фильтрации. Мы использовали винеров-
ский фильтр из (5.8-3) с искажающей функцией Примера 5.10 и со
значением К, подобранным так, чтобы обеспечить получение воз-
можно лучшего результата. Отметим, что шум на изображении, ко-
торое получено методом инверсной фильтрации, очень велик,
и имеет ярко выраженную диагональную структуру в направлению
смазывания. Результат фильтрации по Винеру никоим образом
нельзя признать идеальным, но он дает некоторое представление
о содержании изображения. Текст на изображении читается, хотя и
не без труда.
В среднем ряду на Рис. 5.29 представлена та же последовательность
изображений, но отвечающая шуму с дисперсией, уменьшенной на
один порядок. Это уменьшение не дало заметного эффекта в случае
инверсной фильтрации, но результат винеровской фильтрации за-
Рис. 5.28. Сравнение инверсной фильтрации и винеровской фильтрации, а б В
(а) Результат восстановления с использованием полного инверсного фильт-
ра. (б) Результат восстановления с использованием инверсного обрезанного
фильтра, (в) Результат винеровской фильтрации.
а б В Рис. 5.29. (а) Изображение, смазанное в результате движения и дополнитель-
g но искаженное аддитивным шумом, (б) Результат инверсной фильтрации.
(в) Результат винеровской фильтрации, (г)— (е) Те же изображения, но диспер-
Ф 3 сия шума на порядок меньше по величине, (ж)—(и) Те же изображения, но дис-
персия шума уменьшена на пять порядков по величине по отношению к (а).
Обратите внимание на рисунок (з), где несмазанное изображение проступа-
ет через шумовую «завесу».
метно улучшился. Читать текст теперь значительно легче. Для изоб-
ражений нижнего ряда на Рис 5.29 дисперсия шума была уменьшена
по величине более чем на пять порядков по сравнению с изображе-
ниями верхнего ряда. На самом деле, изображение на Рис. 5.29 (ж) уже
не содержит заметного на глаз шума. В этом случае результат инверс-
ной фильтрации представляет интерес. Шум все еще хорошо заметен,
но текст можно видеть через шумовую «завесу». Это хорошая иллю-
страция к тому, что было сказано при обсуждении формулы (5.7-2).
Другими словами, из рассмотрения изображения на Рис. 5.29 (з) яс-
но, что инверсный фильтр вполне в состоянии существенно уменьшить
степень размывания. Шум, однако, по-прежнему превалирует на изо-
бражении. Если бы мы могли «заглянуть за шумовую завесу» на
Рис. 5.29 (б) и (д), то мы также обнаружили бы незначительную сте-
пень размывания. Результат винеровской фильтрации на Рис. 5.29
(и) превосходен и весьма близок к исходному изображению на Рис. 5.26
(а). Результаты подобного рода показательны в плане того, чего мож-
но достичь с помощью винеровской фильтрации в том случае, когда
возможно построение хорошей оценки для искажающей функции.
5.9. Фильтрация методом минимизации
сглаживающего функционала со связью
Проблема, заключающаяся в необходимости иметь некоторую ин-
формацию относительно искажающей функции, является общей
для всех рассматриваемых в этой главе методов восстановления.
Применение винеровской фильтрации связано с дополнительной
трудностью, состоящей в том, что энергетические спектры неис-
каженного изображения и шума также должны быть известны.
В предыдущем разделе было показано, что использование при-
ближения (5.8-3) позволяет получать отличные результаты. Одна-
ко использование константы в качестве оценки для отношения
энергетических спектров не всегда приводит к удовлетворительно-
му решению задачи.
Применение метода, рассматриваемого в этом разделе, требует
только знания среднего значения и дисперсии шума. Это является важ-
ным преимуществом метода, поскольку, как показано в Разделе 5.2.4,
обычно можно оценить указанные величины на основе заданного
искаженного изображения. Другое отличие состоит в том, что вине-
ровская фильтрация основана на минимизации в смысле некоторо-
го статистического критерия и, следовательно, является оптимальной
в некотором среднестатистическом смысле. Метод, рассматриваемый
в настоящем разделе, обладает тем замечательным свойством, что поз-
воляет получить оптимальный результат для каждого конкретного изо-
бражения, к которому он применяется. Конечно, важно понимать, что
тот критерий, по отношению к которому результат является опти-
мальным с теоретической точки зрения, не связан с механизмом зри-
тельного восприятия. Поэтому выбор в пользу того или иного мето-
да почти всегда будет определяться (по крайней мере частично) на ос-
нове визуальной оценки получаемых результатов.
Используя определение свертки (4.2-30), мы можем записать
(5.5-16) в матрично-векторном виде следующим образом:
g = Hf + ?. (5.9-1)
Пусть, например, изображение g (х,у) имеет размеры Mx.N. Тогда мы
можем сформировать вектор g таким образом, чтобы первые Nего эле-
ментов были равны значениям в первой строке изображения g (х,у),
следующие ^элементов были равны значениям во второй строке, и т.д.
Полученный вектор будет иметь размер MN. Аналогично формируют-
ся векторы f и т], которые в результате имеют те же размеры. Далее, ма-
трица Н имеет размеры MNxMN. Ее элементы задаются значениями h
в свертке (4.2-30).
Естественно предположить, что задача восстановления может
быть таким способом сведена к задаче линейной алгебры. К сожале-
нию, дело обстоит не так просто. Предположим, для примера, что мы
работаем с изображениями средних размеров; пусть, для определен-
ности, M=N=5\2. Тогда векторы в формуле (5.9-1) будут иметь раз-
меры 262144, а матрица Н будет иметь размеры 262144x262144. Рабо-
та с векторами и матрицами подобных размеров представляет собой
далеко не простую задачу. Дело дополнительно осложняется тем,
что матрица Н очень чувствительна к шумам12 (что, учитывая опыт,
приобретенный нами в предыдущих двух параграфах при рассмотре-
нии влияния шума на результаты восстановления, не должно пока-
заться удивительным). Несмотря на это, формулировка задачи вос-
становления в матричном виде облегчает построение методов
восстановления.
Корни метода восстановления, составляющего предмет настояще-
го раздела, лежат в области матричного анализа. Мы не будем полно-
стью обосновывать этот метод, но приведем в конце главы ссылки на
работы, в которых содержится детальный его вывод. Главной пробле-
мой является чувствительность задачи по отношению к шуму. Один
из способов преодоления этой трудности состоит в регуляризации за-
12 Матрица Н является плохо определенной (т.е. ее определитель близок или даже ра-
вен нулю), вследствие чего соответствующая линейная задача является в высшей сте-
пени некорректной. Ее решение в обычном смысле может вообще не существовать,
и даже если оно существует, то является очень неустойчивым по отношению к шу-
му Т). Решение подобных задач на практике является делом исключительной трудно-
сти. — Прим, перев.
дачи, которая достигается заменой исходной задачи на задачу на-
хождения экстремума (минимума) некоторого сглаживающего функ-
ционала13. В качестве такого функционала С[/] можно использовать
квадрат нормы уже знакомого нам лапласиана,
С[Л=£ X(V2/(x,y)J, (5.9-2)
х=0 у=0
с дополнительным ограничением (связью) вида
k-Hf||2=M2. (5.9-3)
где ||w||2=w2w —евклидова норма вектора, a f —искомая оценка не-
искаженного изображения. Оператор Лапласа V2 определен выражени-
ем (3.7-1). Напомним, что если w — «-компонентный вектор, то
w7w = ,
k=l
где wk — к-ая координата вектора.
Решение оптимизационной задачи (5.9-2) с условием (5.9-3) в ча-
стотной области дается выражением
F(w,v) =
Н (и, г)
|Я(и,г)|2+у|Р(и,г)|2
С(ы, г),
(5.9-4)
где параметр у (параметр регуляризации) должен быть выбран таким
образом, чтобы выполнялось условие (5.9-3), а функция Р (u,v) есть
фурье-преобразование функции
О
Р(х,у)= -1
О
-1 О
4 -1
-1 О
(5.9-5)
13 Эта идея лежит в основе общего подхода к решению некорректных задач, который
был предложен и развит школой А. Н. Тихонова. Такой подход называется тихонов-
ским методом регуляризации, и рассматриваемый ниже метод является его весьма ча-
стным случаем. В связи со сказанным мы далее будем называть этот метод фильтра-
ции, основанный на минимизации сглаживающего функционала со связью,
фильтрацией по Тихонову. — Прим, перев.
т.е. той функции, с помощью которой в Разделе 3.7.2 был определен опе-
ратор Лапласа14. Как уже отмечалось выше, важно помнить о том, что
функция р (х,у), равно как и все остальные функции в пространствен-
ной области, должны быть правильно дополнены нулями перед вычис-
лением их фурье-преобразования для использования в (5.9-4). Вопрос
о дополнении нулями подробно рассматривался в Разделе 4.6.3. Обра-
тим внимание, что при обращении параметра регуляризации у в нуль
выражение (5.9-4) сводится к инверсной фильтрации.
Пример 5.14. Сравнение винеровской фильтрации и фильтрации по
Тихонову.
Л На Рис. 5.30 представлены результаты восстановления изображе-
ний на Рис. 5.29 (а), (г) и (ж) с помощью фильтрации по Тихонову.
Значения параметра у подбирались вручную так, чтобы обеспечить на-
илучшее визуальное качество восстановления. Тот же метод выбора
параметров был использован для получения результатов фильтрации по
Винеру, которые были представлены на Рис. 5.29 (в), (е), (и). Сравни-
вая между собой фильтрации по Тихонову и по Винеру, можно отметить,
что первая дала несколько лучшие результаты в случаях большого и сред-
него по величине шума, притом что обе дали практически одинаковые
результаты в случае низкого шума. То, что фильтрация по Тихонову ока-
залась лучше фильтрации по Винеру в случае подбора значений пара-
метров вручную, не является неожиданностью. Дело в том, что пара-
метр регуляризации у в (5.9-4) является числом, в то время как
В Рис. 5.30. Результаты фильтрации по Тихонову. Сравните (а), (б) и (в) с результа-
тами винеровской фильтрации на Рис. 5.29 (в), (е) и (и), соответственно.
14 Можно, в принципе, использовать и функцию // (u,v) = — (и2 + v2), которая в
соответствии с Разделом 4.4.4 определяет «частотный» оператор Лапласа. — Прим,
перев.
параметр Къ (5.8-3) является, по сути, значением постоянной функции,
используемой для приближения отношения двух неизвестных функций
в частотной области, которое редко является постоянным. Поэтому ес-
тественно ожидать, что результат, основанный на подборе параметра у
«вручную» даст более точную оценку неискаженного изображения. И
Как показывает приведенный пример, значения параметра регу-
ляризации у можно перебирать в интерактивном режиме до тех пор,
пока приемлемый результат не будет получен. Однако, если мы хотим
получить оптимальное решение, то значение параметра должно быть
выбрано так, чтобы выполнялось условие связи (5.9-3). Ниже приве-
дена итеративная процедура такого выбора.
Определим вектор невязки г следующим образом:
r = g-Hf. (5.9-6)
Поскольку решение F(u,v) (и соответствующий вектор f ), опреде-
ляемое по (5.9-4), есть функция параметра у, вектор невязки г также
зависит от этого параметра. Можно показать (см. [Hunt, 1973]), что
функционал невязки
ф(у) = ггг = ||г||1 2 3 (5.9-7)
является монотонной функцией параметра у. Мы хотели бы так вы-
брать параметр у, чтобы выполнялось условие
(5-9-8)
где коэффициент а задает приемлемую точность выполнения условия
связи. В случае а = 0 имеет место ||г||2 = ||т]||2, и, ввиду (5.9-6), условие
(5.9-3) выполняется точно.
Поскольку функционал невязки ф (у) является монотонной
функцией параметра регуляризации, нахождение искомого зна-
чения у не представляет трудности. Один из алгоритмов состоит
в следующем.
1. Задать начальное значение у.
2. Вычислить ||г||2.
3. Если условие (5.9-8) выполняется, то цель достигнута. В против-
ном случае увеличить значение у, если ||г||2 < ||т]||2 — а, или умень-
шить его, если ||г||2 > ||т]||2 + а, и повторить шаг 2, используя новую
оценку, пересчитанную по (5.9-4) с новым значением у.
Для увеличения скорости сходимости можно использовать более
продвинутые методы, например метод касательных Ньютона.
Для того чтобы использовать данный алгоритм, необходимы ве-
личины ||г||2 и ||т]||2. Для вычисления ||г||2 заметим, что из (5.9-6) сле-
дует равенство
R(u, v) = G(u, v) - H(u, v)F(u, v), (5.9-9)
и функция г (х,у) может быть получена вычислением обратного фу-
рье-преобразования от функции R (u,v). Далее,
||г||2= X X г2(х’У)- (5.9-10)
х=0 у=0
Вычисление ||т]|| 2 приводит к интересному результату. Прежде
всего рассмотрим дисперсию шума полного изображения, которая
равна
°n=^X X (nu,j)-™n) , (5.9-11)
х=0 у=0
где
. Л/-1N -1
^=^1 Хп(^) (5.9-12)
х=0 у=0
есть среднее значение шума. Сравнивая два последних выражения
с выражением для ||т]||2, которое имеет тот же вид, что и (5.9-10), мы
видим, что
||т]||2 = МУ{о2 + щ2). (5.9-13)
Это очень важный результат, который показывает, что для реализации
оптимального алгоритма восстановления нам достаточно знать лишь
среднее значение и дисперсию шума. Эти величины не трудно оценить
(см. Раздел 5.2.4) в предположении, что значения шума и изображения
не коррелированны. Это предположение является основным для всех
рассматриваемых в настоящей главе методов.
Пример 5.15. Итеративная оптимальная фильтрация по Тихонову.
На Рис. 5.31 (а) представлен результат восстановления изображения
на Рис. 5.25 (б), полученный с помощью оптимального алгоритма
Рис. 5.31. (а) Результат восстановления изображения на Рис. 5.25 (б) с помо-
щью итеративной оптимальной фильтрации по Тихонову, использующей пра-
вильные значения параметров шума, (б) Аналогичный результат, получен-
ный при неправильных значениях параметров шума.
фильтрации на основе только что рассмотренной итеративной проце-
дуры. Начальное значение у было равно 10“5, величина изменения
значений у в итеративной процедуре была равна 10-6, а значение ко-
эффициента а равнялось 0,25. Параметры шума в алгоритме восстанов-
ления выбирались такими же, как и при генерации изображения на
Рис. 5.25 (б) (шум имел нулевое среднее и дисперсию 10-5). Результат
восстановления столь же хорош, что и результат на Рис. 5.28 (в), для по-
лучения которого была использована винеровская фильтрация, а пара-
метр ^подбирался вручную так, чтобы обеспечить наилучший в визу-
альном смысле результат. Изображение на Рис. 5.31 (б) демонстрирует,
что может случиться при использовании неправильных оценок для
параметров шума. В данном случае считалось, что дисперсия шума
равна 102, а среднее значение по-прежнему равно нулю. Результат
восстановления расфокусирован заметно более сильно. И
Как было сказано в начале этого раздела, важно понимать, что оп-
тимальное в смысле минимизации сглаживающего функционала со
связью восстановление не обязательно является «лучшим» в смысле
визуального качества. В зависимости от природы и величины иска-
жений и шума, разные факторы влияют на вид окончательного резуль-
тата, получаемого с помощью итеративного алгоритма построения оп-
тимальной оценки. Вообще, фильтры для восстановления, которые
строятся в автоматическом режиме, дают результаты хуже, чем филь-
тры, параметры которых настраиваются вручную под конкретное
изображение. Это относится, в частности, и к рассмотренному филь-
тру, который полностью задается одним числовым параметром.
5.10. Среднегеометрический фильтр
Рассмотренный в Разделе 5.8 винеровский фильтр можно несколько
обобщить. Это обобщение приводит к так называемому среднегеоме-
трическому фильтру.
F{u,v) =
Н (и, у)
J^(«,V)|2
(5.10-1)
где а и Р — положительные вещественные константы. Среднегеометриче-
ский фильтр представляет собой произведение двух выражении в скобках,
которые, соответственно, возводятся в степени а и 1 — а.
При а = 1 этот фильтр сводится к инверсному фильтру. При а = 0
фильтр превращается в так называемый параметрический винеровский
фильтр, который сводится к обычному винеровскому фильтру при (3=1.
При а = I /2 фильтр представляет собой произведение двух величин, воз-
веденных в одинаковую степень 1 /2, т.е. является средним геометриче-
ским этих величин, откуда и происходит название фильтра. При а = 1/2
и Р = 1 этот фильтр известен как фильтр эквализации спектра. При
Р = 1, по мере убывания а (и а < 1/2), работа фильтра все больше напо-
минает работу инверсного фильтра. Выражение (5.10-1) весьма полез-
но, поскольку с его помощью в рамках одного выражения в действитель-
ности удается описать целое семейство фильтров.
5.11. Геометрические преобразования
Мы завершим эту главу кратким обсуждением того, как геометриче-
ские преобразования используются при восстановлении изображений.
В отличие от рассмотренных до сих пор методов, геометрические
преобразования изменяют пространственные взаимосвязи между
пикселями на изображении. Геометрические преобразования часто на-
зывают преобразованиями резинового холста, поскольку их можно
представить себе как процесс распечатки изображения на холсте из ре-
зины и дальнейшей растягивание этого холста в соответствии с опре-
деленными правилами.
С точки зрения цифровой обработки изображений геометричес-
кие преобразования состоят из следующих двух основных операций:
5.11. Геометрические преобразования
(1) пространственное преобразование, в результате которого происхо-
дит изменение расположения точек изображения в плоскости; и (2)
интерполяция значений яркости, при которой происходит присвое-
ние значений яркости точкам изображения, подвергнутого прост-
ранственному преобразованию. В следующих параграфах мы рас-
смотрим основные идеи, лежащие в основе концепции геометрических
преобразований, а также их применение в контексте восстановле-
ния изображений.
5.11.1. Пространственные преобразования
Предположим, что изображение/с координатами пикселей (х,у) под-
вергается геометрической деформации, в результате чего формирует-
ся изображение g с координатами пикселей (х',у'). Такое преобразо-
вание может быть записано следующим образом:
х' = г(х,у) (5.11-1)
и
y=s(x,y), (5.11-2)
где функции г (х,у) и s (х,у) определяют пространственное преоб-
разование, в результате которого формируется геометрически ис-
каженное (деформированное) изображение15 g (х',У). Например, ес-
ли г(х,у) = х/2 и .v(x,y) = у/2, то «искажение» сводится к уменьшению
размеров изображения f (х,у) вдвое по каждому из направлений.
Если функции г (х,у) и s (х,у) заданы аналитически, то теоретиче-
ски представляется возможным восстановление изображения f(x,y)
по деформированному изображению g (х',у') путем применения об-
ратного преобразования. На практике, однако, в общем случае невоз-
можно целиком описать процесс геометрических искажений на всей
плоскости изображения при помощи единственной пары аналитиче-
ских выражений для функций г (х,у) и s (х,у). Метод, наиболее часто
используемый для преодоления указанной трудности, заключается
в том, чтобы выразить изменения пространственного положения
15 Отметим, что при формировании искаженного (деформированного) изображения
необходимо использовать преобразование координат, обратное по отношению к
преобразованию, заданному формулами (5.11-1) и (5.11-2). Написанное преобразо-
вание необходимо в процессе восстановления. — Прим, перев.
Глава 5. Восстановление изображений
пикселей при помощи узловых точек, которые представляют собой та-
кое подмножество пикселей, положение которых на исходном (дефор-
мированном) и искомом (недеформированном) изображениях точно
известно.
На Рис. 5.32 представлены четырехугольные области на дефор-
мированном и соответствующем недеформированном изображениях.
Вершины четырехугольников являются соответствующими узловыми
точками. Предположим, что процесс деформации внутри четырехуголь-
ных областей можно промоделировать с помощью пары простых би-
линейных выражений следующего вида:
г(х,у) = с\Х+с2У+суху +с4 (5.11-3)
и
s(x,y)^c5x+c6y+c7xy+c8. (5.11-4)
Тогда, с учетом (5.11 -1) и (5.11-2), имеем
х'=С1Х + с2У+с3ху+с4 (5.11-5)
и
У = с5х+с6у+с7ху+с8. (5.11-6)
Поскольку полное число узловых точек равно восьми, последние урав-
нения могут быть разрешены относительно коэффициентов q, z = 1,2,...,8.
Эти коэффициенты задают модель геометрических преобразований для
Рис. 5.32. Узловые точки на двух участках изображений и их соответствие.
5.11. Геометрические преобразования 405
всех точек внутри четырехугольной области, отвечающей узловым точ-
кам, использовавшимся при определении коэффициентов. В целом
необходимо иметь множество узловых точек, достаточное для того, что-
бы полностью покрыть изображение набором соответствующих четы-
рехугольников. При этом каждому четырехугольнику отвечает свой
собственный набор коэффициентов.
Как только коэффициенты получены, дальнейшая процедура вос-
становления изображения не представляет трудности. Для того что-
бы найти значение неискаженного изображения в произвольной точ-
ке (хр,уо), необходимо знать положение ее образа на искаженном
изображении. Подставив (хо,уд) в выражения (5.11-5) и (5.11-6), мы
получим искомые координаты Если значение неискажен-
ного изображения в точке (хр,Уо) равно/(хр,ур), а значение искажен-
ного изображения в точке (хр^ур'), которая является образом точ-
ки (хр,ур) при пространственном преобразовании, равно# (хр',ур'), то
для получения значения восстановленного изображения достаточно
положить /(хр,ур) = #(хр,ур). Например, чтобы получить значение
/(0,0), мы подставляем (х,у) = (0,0) в уравнения (5.11-5) и (5.11-6) и
получаем из них пару координат (х',у'). Затем мы полагаем
/(0,0) = #(х', у'), где (х',у') — только что полученные координаты. Да-
лее, мы подставляем (х,у) = (0,1) в уравнения (5.11-5) и (5.11-6), по-
лучаем другую пару (х',у') и полагаем /(0,1) = #(х',у/ для этой пары
координат. Процесс повторяется пиксель за пикселем и строка за
строкой до тех пор, пока весь искомый массив, размеры которого не
превосходят размеры изображения g, не будет получен. Вычисления,
производимые в другом порядке (по столбцам, а не по строкам) при-
водят к тому же результату. Необходимо, конечно, организовать про-
цедуру, позволяющую по заданному положению пикселя найти соот-
ветствующие ему четырехугольные области, чтобы обеспечить
использование правильных коэффициентов в процессе вычисления.
Для выбора системы узловых точек существуют различные мето-
дики, которые ориентированы на конкретные приложения. Так, не-
которые системы формирования изображений обладают характер-
ными особенностями, имеющими физическую природу, такими как
специфические элементы конструкции самого сенсора. В результате
прямо на изображении в процессе его формирования возникает мно-
жество точек с известными координатами (эти точки называют опор-
ными, или точками ризо-маркировки). Если в дальнейшем такое изо-
бражение подвергается некоторой процедуре деформации (например,
в процессе воспроизведения или реконструкции), то его геометрия мо-
жет быть затем исправлена с использованием только что рассмот-
ренного метода.
5.11.2. Интерполяция значений яркости
Рассмотренный в предыдущем параграфе метод позволяет сделать
шаг на пути построения восстановленного изображения в точках с це-
лыми значениями координат (х,у). Однако, в зависимости от значе-
ний коэффициентов сь выражения (5. J J -5) и (5. J1 -6) могут давать не-
целые значения для координатУ и/. Поскольку функцияg, задающая
изображение, является дискретной, ее значения определены только
для целых значений координат. Поэтому нецелые значения х' иу' со-
ответствуют такой точке в плоскости изображения g, где значение
яркости не определено. Поэтому возникает необходимость делать
некоторые умозаключения относительно того, чему должны равнять-
ся значения яркости в таких точках, исходя из значений яркости в точ-
ках с целыми координатами. Используемый для этого метод называ-
ется интерполяцией значений яркости.
Простейший способ интерполяции значений яркости основан на
методе приближения «по ближайшему соседу». Этот метод, называ-
емый также интерполяцией нулевого порядка, проиллюстрирован на
Рис. 5.33. На этом рисунке показано (J) отображение точки с целы-
ми координатами (х,у) в точку с нецелыми координатами с исполь-
зованием (5.11-5) и (5.11-6); (2) нахождение ближайшей к (У,/) со-
седней точки с целыми координатами; и (3) присвоение значения
яркости в этой соседней точке элементу изображения, расположен-
ному в точке (х,у).
Хотя интерполяция по ближайшему соседу проста в реализации, она
имеет тот недостаток, что ее применение часто приводит к появлению
нежелательных артефактов, например, таких как зубчатость конту-
ров на изображениях высокого разрешения. Более гладкие результа-
ты могут быть получены с помощью более изощренной техники, та-
Рис. 5.33. Интерполяция значений яркости методом приближения по ближай-
шему соседу
5.11. Геометрические преобразования
кой как кубическая интерполяция типа свертки16. При этом получение
гладкой оценки искомого значения яркости в некоторой точке пред-
полагает построение поверхности типа sin (z)/z так, чтобы она прохо-
дила через большое число соседних точек (скажем, 16). Типичными об-
ластями, в которых требуется применение гладкой аппроксимации,
являются трехмерная графика [Watt, 1993] и обработка медицинских
изображений [Lehman et al., 1999]. Платой за использование более
гладких методов аппроксимации является возрастающая сложность
вычислений. Подходящим универсальным методом, применяемым
при неспециальной обработке, является метод билинейной интерпо-
ляции, в котором используются значения яркости в четырех ближай-
ших соседних точках. Этот метод достаточно прост. Нам известно зна-
чение яркости в каждой из четырех точек с целыми координатами,
ближайших к точке (У,/) с нецелыми координатами. Поэтому иско-
мое значение яркости в точке с координатами (х',у'), которое мы
обозначим v (х',уг), может быть получено по известным значениям яр-
кости в четырех соседних точках с помощью выражения
v(x',y')=ax'+by'+cx'y'+d, (5.11-7)
где четыре коэффициента в правой части последнего выражения лег-
ко могут быть определены из системы четырех уравнений с четырь-
мя неизвестными, для получения которой нужно последовательно
подставить в (5.11-7) координаты и известные значения яркостей
каждой из четырех соседних точек. После того как коэффициенты най-
дены, легко определить значение v (х',у')17, которое присваивается точ-
ке (х,у), являющейся прообразом точки (У,у') относительно рассма-
16 Речь, по-видимому, идет об аппроксимации с помощью кубических В-сплайнов. —
Прим, перев.
17 По поводу приведенного метода интерполяции нужно заметить следующее. Он на-
зывается билинейным, потому что построенная с его помощью функция яркости (вну-
три области интерполирования) является линейной функцией относительно каждой
из своих переменных при любом фиксированном значении другой. Суть метода со-
стоит в том, чтобы получить искомое приближение в результате последовательного
применения процедур одномерной линейной интерполяции. Именно, мы хотим по-
строить оценку значения яркости г в точке (Vу'). Пусть (х(|',у(|') — ближайшая сосед-
няя точка, значения координат которой являются целыми и не превосходят значе-
ний координат (У,у'), т.е. xqz< У и у0' < у. Если обозначить xf = xq + l,yi' = yo' + L
то координаты четырех ближайших к точке (V,y') соседних точек примут вид: (х(',у('),
(х0',у\), (Х]',уо') и (xf,yi'). Обозначим известные значения яркости в этих точках
v00> v01> VIO и vn> соответственно. Применим теперь процедуру одномерной линей-
ной интерполяции по горизонтали, чтобы найти оценки для значений яркости в
триваемого пространственного преобразования. Рис. 5.33 позволяет
легко представить себе описанную процедуру. Единственное ее отли-
чие от процедуры интерполяции по ближайшему соседу состоит в том,
что вместо того чтобы использовать в качестве значения в точке (х',у')
значение в ближайшей соседней точке, мы получаем значение в этой
точке в результате интерполяции. Затем, как обычно, мы присваива-
ем полученное значение точке (х,у).
Пример 5.16. Геометрические преобразования.
На Рис. 5.34 (а) представлено изображение, на котором выбраны 25
равномерно расположенных узловых точек (эти точки выделены белым,
чтобы их было хорошо видно), а на Рис. 5.34 (б) представлено другое
расположение этих узловых точек, которое вместе с первым порожда-
ет пространственное преобразование. Как мы знаем, это преобразова-
ние полностью задается выражениями (5.11 -5) и (5.11-6), коэффици-
енты в которых определяются координатами соответствующих узлов
в плоскостях недеформированного и деформированного изображе-
ний. Как только коэффициенты найдены, мы получаем модель, кото-
рая может быть использована как для деформации изображения (в де-
монстрационных целях), так и для восстановления изображения,
предварительно деформированного под действием геометрического
преобразования, которое определяется этими коэффициентами.
Предположим, что мы хотим деформировать изображение на
Рис. 5.34 (а). Для этого нужно подставить значения координат каж-
дой точки (хо ,Уо ) плоскости деформированного изображения в фор-
мулы, обратные18 к (5.11-5) и (5.11-6), и получить координаты (х0,у0)
соответствующей точки исходного изображения, которые затем ок-
руглить до ближайших целых значений. Значение деформированно-
точках и после чего, опять применяя одномерную линейную интерпо-
ляцию, на этот раз по вертикали, найдем искомое значение яркости в точке (х'.у’у
Окончательный результат всей процедуры имеет вид:
Изменение порядка применения процедур интерполяции (сначала по вертикали,
затем по горизонтали) не меняет окончательного результата, что легко видеть из
приведенной формулы. Кроме того очевидно, что эта формула приводится к виду
(5.11-7) и дает правильные значения для яркости четырех соседних точек. — Прим,
перев.
18 Здесь речь, фактически, идет об использовании преобразования (У,у) —> (х,у),
обратного по отношения к преобразованию (5.11-1), (5.11-2) — см. прим. 15. —
Прим, перев.
5.11. Геометрические преобразования
Рис. 5.34. (а) Изображение с узловыми точками, (б) Узловые точки после де-
формации. (в) Деформированное изображение с использованием интерполя-
ции по ближайшему соседу, (г) Восстановленное изображение. ^Деформи-
рованное изображение с использованием билинейной интерполяции,
(е) Восстановленное изображение.
го изображения в точке (х0',у0') получим, полагая# (х0',у0') =/(х0,у0).
Можно также использовать интерполяцию значений яркости/в ок-
рестности точки (х0,у0). Фактически мы используем процедуру, рас-
смотренную при обсуждении выражений (5.11-5) и (5.11-6), только
применяем ее в обратную сторону.
На Рис. 5.34 (в) представлен результат деформации изображения
на Рис. 5.34 (а), полученный только что рассмотренным способом с ис-
пользованием приближения по ближайшему соседу. Заметим, что
возникшие на изображении искажения довольно сильны. Если счи-
тать это изображение заданным, то можно использовать для его вос-
становления метод, состоящий из процедуры, рассмотренной при
обсуждении выражений (5.11 -5) и (5.11-6), дополненной одним из спо-
собов интерполяции, рассмотренных в настоящем параграфе. Ре-
зультат восстановления представлен на Рис. 5.34 (г). Мы опять исполь-
зовали интерполяцию по ближайшему соседу. Отметим, что результат
коррекции является приемлемым, однако допущено значительное
число ошибок в значениях яркости, в особенности вдоль границ се-
рой и черной областей. На Рис. 5.34 (д) и (е) представлены результа-
ты такой же последовательности экспериментов, но с использовани-
ем билинейной интерполяции. Улучшения особенно заметно
в пограничной между серой и черной областями зоне.
Только что рассмотренное изображение столь регулярно и прини-
мает такое малое число значений вблизи резко очерченных границ об-
ластей, что практически любая деформация вызывает значительные ис-
кажения. Когда изображение имеет более сложную структуру,
геометрические искажения становятся менее заметными. Рассмот-
рим, например, Рис. 5.35. На Рис. 5.35 (б) представлен результат дефор-
мации изображения на Рис. 5.35 (а), полученный тем же самым геоме-
трическим преобразованием, что и изображение на Рис. 5.34 (д).
Искажения на Рис. 5.35 (б) почти не заметны, в то время как различия
между изображениями на Рис. 5.35 (а) и (б) далеко не так малы, что вид-
но по изображению на Рис. 5.35 (в), которое представляет собой раз-
ность двух названных изображений. Просто вследствие изменчивого
характера исходного изображения эти различия не так заметны на
глаз. Наконец, на Рис. 5.35 (г) представлен результат коррекции гео-
метрических искажений. С практической точки зрения качество это-
го изображения совпадает с качеством оригинала. 5*
Заключение
Главные результаты этой главы получены в предположении, что про-
цесс искажений может быть представлен в виде некоторой линейной
Рис. 5.35. (а) Изображение перед деформацией, (б) Деформированное изоб-
ражение; параметры деформации те же, что и для изображения на Рис. 5.34 (д).
(в) Разность между (а) и (б), (г) Восстановленное изображение.
трансляционно-инвариантной процедуры и последующего добавле-
ния аддитивного шума, не коррелированного с исходным изображе-
нием. Даже в тех случаях, когда эти предположения не полностью вы-
полнены, часто бывает возможно получить полезные результаты
с помощью методов, развитых в предыдущих разделах.
В основе некоторых из методов восстановления, полученных
в этой главе, лежат различные критерии оптимальности. Слово «оп-
тимальный» в данном контексте имеет строго математический смысл,
и не имеет отношения к оптимальности в смысле зрительного воспри-
ятия. По сути, отсутствие достаточного понимания процессов зритель-
ного восприятия мешает сформулировать общую задачу восстановле-
ния таким образом, чтобы она учитывала возможности и особенности
зрения наблюдателя. С точностью до отмеченного недостатка, преиму-
щество представленной в этой главе концепции заключается в том, что
она позволяет выработать фундаментальные методы, которые твер-
до обоснованы с научной точки зрения и характеризуются коррект-
ным предсказуемым поведением.
Как и в Главах 3 и 4, некоторые задачи восстановления, такие, на-
пример, как задача уменьшения случайного шума, решаются в про-
странственной области с использованием небольших масок. Частот-
ная область оказалась идеально приспособленной для уменьшения
периодического шума и для моделирования некоторых важных типов
искажений, таких как смазывание изображения, обусловленное дви-
жением в процессе съемки. Мы также установили, что частотная об-
ласть удобна при разработке ряда методов фильтрации, используемых
для восстановления, таких как винеровская фильтрация и фильтра-
ция по Тихонову.
Как указывалось в Главе 4, частотное пространство предоставля-
ет солидную и удобную с точки зрения использования нашей инту-
иции основу для проведения экспериментов. После того как для
конкретной задачи найден подходящий метод решения (фильтр в ча-
стотной области), его реализация обычно осуществляется путем
конструирования некоторого цифрового фильтра (в пространст-
венной области), который приблизительно соответствует построен-
ному в частотной области решению, но значительно быстрее рабо-
тает на компьютере или на некотором специальном оборудовании.
Вопросы конструирования цифровых фильтров лежат Далеко за пре-
делами рассматриваемых в этой книге вопросов; литературные ссыл-
ки, имеющие отношение к данной проблеме даны в следующем па-
раграфе.
Библиографические замечания
В качестве дополнительного чтения по поводу представленной в Раз-
деле 5.1 линейной модели искажений рекомендуются [Castleman,
1996] и [Pratt, 1991]. В книге [Peebles, 1993] рассматриваются вопро-
сы, связанные с функциями плотности распределения вероятностей
шума и их свойствами (Раздел 5.2). Книга [Papoulis, 1991] содержит бо-
лее полное и детальное изложение этих вопросов на более высоком
уровне. В качестве литературы по материалу Раздела 5.3 можно реко-
мендовать [Umbaugh, 1998], [Boie, Сох, 1992], [Hwang, Haddad, 1995],
[Wilburn, 1998] и [Eng, Ma, 2001]. Рассмотренные в Разделе 5.3 адап-
тивные фильтры естественно вписываются в общую теорию адап-
тивных фильтров, хорошим введением в которую является книга
[Hayrin, 1996]. Фильтры Раздела 5.4 являются прямым обобщением
фильтров из Главы 4. В качестве дополнительного чтения по матери-
алу Раздела 5.5 см. [Rosenfeld, Как, 1982] и [Pratt, 1991].
Вопросы оценки искажающей функции (Раздел 5.6) и сегодня
представляют значительный интерес. Некоторые из давно известных
методов оценки искажающей функции описаны в [Andrews, Hunt,
1977], [Rosenfeld, Как, 1982], [Bates, McDonnell, 1986] и [Stark, 1987].
Поскольку искажающая функция редко бывает известна точно, в по-
следние годы был предложен целый ряд методов, в которых особое зна-
чение придается определенным аспектам восстановления. Напри-
мер, в работах [German, Reynolds, 1992] и [Hum, Jennison, 1996] особое
внимание уделено вопросам сохранения резких перепадов значений
яркости для повышения резкости изображения, в то время как основ-
ной целью в работе [Boyd, Meloche, 1998] является восстановление мел-
ких объектов на искаженных изображениях. В качестве примеров ра-
боты со смазанными изображениями укажем [Yitzhaky et al., 1998],
[Harikumar, Bresler, 1999], [Mesarovix, 2000] и [Giannakis, Heath, 2000].
Вопросы восстановления последовательностей изображений также
представляет значительный интерес, и книга [Kokaram, 1998] может
служить хорошим введением в эту область.
Методы фильтрации, рассмотренные в Разделах 5.7—5.9, обсужда-
ются и исследуются с различных точек зрения во многих книгах и ста-
тьях по обработке изображений. Существуют два основных методо-
логических подхода к разработке таких фильтров. Один из них,
основанный на общей формулировке задачи в виде задачи линейной
алгебры (в матричном виде), представлен в работе [Andrews, Hunt,
1977]. Этот подход характеризуется общностью и элегантностью, но
недостаточно нагляден и потому труден для начинающих. Подходы,
основанные на работе непосредственно в частотной области (такой
подход мы использовали в этой главе), обычно более просты для тех,
кто впервые сталкивается с задачами восстановления, но они не об-
ладают математической строгостью матричного подхода. Оба подхо-
да приводят к одинаковым результатам, но, как показывает наш об-
ширный опыт преподавания этого материала, студенты, впервые
знакомящиеся с данной областью, предпочитают последний подход.
В качестве литературы, которая дополняет материал Разделов 5.7—5.10
и устраняет пробелы в нем, мы рекомендуем [Castleman, 1996],
[Umbaugh, 1998] и [Petrou, Bosdogianni, 1999]. В последней работе ус-
танавливается также красивая связь между двумерными фильтрами в
частотной области и соответствующими цифровыми фильтрами. По
поводу конструирования цифровых фильтров см. [Lu, Antoniou, 1992].
Хотя этот вопрос и не затрагивался нами в настоящей главе, вопро-
сы реконструкции в компьютерной томографии также иногда рассма-
триваются в рамках задачи восстановления. Хорошим введением в эту
область является работа [Как, Slaney, 2001]. Для дальнейшего чтения
по материалу Раздела 5.11 см. [Sonka et al., 1999]. Представляют ин-
терес также статьи [Unser et al., 1995] и [Carey et al., 1999].
Задачи
*5.1 Белые полосы на представленном тестовом изображении име-
ют ширину 7 пикселей и высоту 210 пикселей. Расстояние
между полосами составляет 17 пикселей. Как будет выглядеть
это изображение после применения
(а) Среднеарифметического фильтра размерами 3x3?
(б) Среднеарифметического фильтра размерами 7x7?
(в) Среднеарифметического фильтра размерами 9x9?
Замечание'. Эта и следующие задачи, связанные с фильтрацией
этого изображения, могут показаться несколько утомительны-
ми. Однако они стоят того, чтобы потратить усилия на их ре-
шение, поскольку способствуют выработке настоящего по-
нимания того, как действуют соответствующие фильтры. После
того как Вам будет ясно, как именно конкретный фильтр ви-
доизменяет данное изображение, Ваш ответ может представ-
лять собой короткое словесное описание результата. Напри-
мер, «результирующее изображение будет состоять из
вертикальных полос шириной 3 пикселя и высотой 206 пик-
селей». Не забудьте описать изменение формы полос, такое как
округление углов. Эффекты, возникающие на краях, где ма-
ски лишь частично накладываются на изображение, можно не
принимать во внимание.
5.2 Решите задачу 5.1 для случая среднегеометрического фильтра.
*5.3 Решите задачу 5.1 для случая среднегармонического фильтра.
5.4 Решите задачу 5.1 для случая среднего контрагармоническо-
го фильтра с Q = 1.
*5.5 Решите задачу 5.1 для случая среднего контрагармоническо-
го фильтра с Q = — 1.
5.6 Решите задачу 5.1 для случая медианного фильтра.
*5.7 Решите задачу 5.1 для случая фильтра максимума.
5.8 Решите задачу 5.1 для случая фильтра минимума.
*5.9 Решите задачу 5.1 для случая фильтра срединной точки.
5.10 Два приведенных ниже изображения суть соответственно
фрагменты правых верхних частей изображений на Рис. 5.7 (в)
и (г). Таким образом, изображение слева представляет собой
результат применения среднеарифметического фильтра разме-
рами 3x3, а изображение справа — результат применения сред-
негеометрического фильтра тех же размеров.
*(а) Объясните, почему изображение, полученное с помощью
среднегеометрического фильтра менее размыто. Указание'.
Для начала проанализируйте действие фильтров на одно-
мерный профиль типа ступеньки (см. пример профиля
типа ступеньки на Рис. 3.38).
(б) Объясните, почему толщина черных деталей на правом
изображении больше.
5.11 Относительно заданного выражением (5.3-6) контрагармони-
ческого фильтра.
(а) Объясните, почему фильтр эффективно устраняет «чер-
ный» униполярный импульсный шум при положительном
значении параметра Q.
(б) Объясните, почему фильтр эффективно устраняет «бе-
лый» униполярный импульсный шум при отрицатель-
ном значении параметра Q.
(в) Объясните, почему фильтр дает плохие результаты (такие
как на Рис. 5.9), если знак параметра Q выбран неверно.
(г) Рассмотрите поведение фильтра при Q = — 1.
(д) Рассмотрите поведение фильтра (при положительных и от-
рицательных значениях Q) в областях постоянной яркости.
*5.12 Получите выражения для полосовых фильтров, соответствую-
щих режекторным фильтрам (5.4-1)— (5.4-3).
5.13 Получите выражения для узкополосных фильтров, соответст-
вующих узкополосным режекторным фильтрам, рассмотрен-
ным в Разделе 5.4.3. Покажите, что при и0 = т0 = 0 они превра-
щаются в низкочастотные фильтры.
*5.14 Покажите, что фурье-преобразование двумерной функции
синус
f(x,y) = A sin(uqX + voy)
представляет собой пару комплексно-сопряженных 5-функций
F(u,v) = -i^
я “б
5 и—— ,v-
2л
vo «о v()'l
— -5 и+— ,v+ —
2л J 2л 2л ?
Указание: Используйте непрерывное преобразование Фурье в
виде (4.2-3) и выразите синус в виде разности экспонент.
5.15 Выведите формулу (5.4-21) из формулы (5.4-19).
*5.16 Рассмотрим линейную трансляционно-инвариантную искажа-
ющую систему с искажающей функцией (ядром) вида
,, „ R4 -((х-а)2+(у-Р)2)
й(х-а,у-р) = е v Л
Предположим, что на вход системы подается изображение,
состоящее из прямой линии бесконечно малой ширины, ко-
торое задается выражением f(x,y) = &(х—а), где 5 есть 5-функ-
ция. Какое изображение g (х,у) получится на выходе, если
шум отсутствует?
5.17 Во время съемки изображение в течение времени Т\ участву-
ет в равномерном прямолинейном движении в вертикальном
направлении. Затем движение на время Г2 меняет направле-
ние на горизонтальное. Предполагая, что время изменения
направления движения пренебрежимо мало и затвор системы
открывается и закрывается мгновенно, найдите выражение
для искажающей функции
*5.18 Рассмотрите вопрос о смазывании изображения в результате
прямолинейного равноускоренного движения вдоль оси х.
Предполагая, что изображение в начальный момент t = 0 по-
5.19
*5.20
коилось, а затем двигалось равноускоренно, (/) = в те-
чение времени Т, найдите искажающую функцию Н (и, г).
Можно предполагать, что затвор системы открывается и закры-
вается мгновенно.
Космический аппарат предназначен для передачи изображений
поверхности планеты по мере ее приближения в процессе при-
земления. На последнем этапе приземления один из двигате-
лей малой тяги вышел из строя, что привело к быстрому вра-
щению аппарата вокруг вертикальной оси. Изображения,
полученные во время последних двух секунд перед приземле-
нием, оказались смазанными в результате этого кругового дви-
жения. Камера закреплена на нижней части космического ап-
парата вдоль его вертикальной оси и направлена вниз. По
счастью, ось вращения аппарата совпадает с оптической осью
камеры, таким образом изображения смазаны в результате
движения, которое представляет собой равномерное вращение.
За время съемки одного кадра аппарат поворачивается на угол
л/8 радиан. Модельные предположения относительно процес-
са съемки состоят в том, что она осуществляется при помощи
камеры с идеальным затвором, который открыт только во вре-
мя поворота на угол л/8 радиан. Вертикальным сдвигом каме-
ры за время экспозиции можно пренебречь. Разработайте ме-
тод решения задачи восстановления.
Изображение на рисунке ниже представляет собой размытую
двумерную проекцию объемной реконструкции сердца. Изве-
стно, что каждая из пересекающихся нитей в правой нижней
части рисунка имела до размывания ширину 3 пикселя, дли-
ну 30 пикселей и значение яркости, равное 255. Сформулируй-
те последовательность действий, при помощи которой можно
14 А-223
Изображение предоставлено компанией G. Е. Medical System.
418 Глава 5. Восстановление изображений
определить искажающую функцию Н (и,v) на основе данной
информации.
5.21 Геометрия некоторой рентгеновской системы формирования
изображений приводит к искажениям, которые могут быть
смоделированы как свертка неискаженного изображения с
центрально-симметричной функцией в пространственной об-
ласти
й(г) = |^(г2-о2 е-г2/2а2 ,
где г2 = х2 + у2. Покажите, что в частотной области искажаю-
щая функция имеет вид
Н(м,г) = -\/2лО (и2 + V2 ^e-2K2o2(u2+v2)
*5.22 Используя передаточную функцию Задачи 5.21, найдите вы-
ражение для винеровского фильтра в предположении, что от-
ношение энергетических спектров шума и неискаженного
изображения постоянно.
5.23 Используя передаточную функцию Задачи 5.21, найдите окон-
чательное выражение для тихоновского фильтра.
5.24 Предполагая, что модель на Рис. 5.1 является линейной и
трансляционно-инвариантной, покажите, что энергетичес-
кий спектр изображения на выходе задается выражением
| G(u, г) |2 =| Н(и, г) |21 F(u, г) |2 +1 N(u, v) |2.
Используйте (5.5-17) и (4.2-20).
5.25 В работе [Cannon, 1974] был предложен восстановительный
фильтр R (u,v), удовлетворяющий условию
IF (и, v) I2 -I R(u, v) I21 G(u, v) I2,
и обосновано предположение об усилении энергетического
спектра восстановленного изображения I F{u, г) |2 так, чтобы
он стал равным энергетическому спектру исходного изображе-
ния [F(w,v)|2.
(а) Выразите R (м,г) через [F (м,г)|2, \Н (м,г)|2 и (м,г)|2.
Указание'. Используйте модель на Рис. 5.1, формулу (5.5-17)
и ответ Задачи 5.24.
(б) Представьте результат (а) в виде, аналогичном виду фор-
мулы (5.8-2).
Задачи
5.26 Работая на большом телескопе астроном замечает, что полу-
чаемые изображения слегка расфокусированы. Изготовитель
сообщает астроному, что работа телескопа отвечает техниче-
ским требованиям. Линзы телескопа фокусируют изображение
на ПЗС матрицу, и затем изображение оцифровывается при по-
мощи электроники телескопа. Невозможно попытаться улуч-
шить ситуацию путем проведения лабораторных эксперимен-
тов с линзами и сенсорами из-за размера и веса составных
частей телескопа. Астроном, наслышанный о Ваших успехах
в области обработки изображений, просит Вас помочь найти
подходящий метод цифровой обработки с целью небольшого
повышения резкости изображений. Как бы Вы приступили к
решению этой проблемы, с учетом того, что единственный
доступный Вам тип изображений — это изображение звезд?
5.27 Профессор археологии, занимающийся исследованиями во-
просов денежного обращения времен Римской империи, не-
давно узнал, что четыре римские монеты, играющие ключевую
роль в его исследованиях, зарегистрированы в каталоге Бри-
танского музея в Лондоне. Посетив музей, профессор с сожа-
лением узнает, что эти монеты недавно были украдены. Даль-
нейшие расспросы показали, что музей хранит фотографии
всех своих экспонатов. К несчастью, фотографии интересую-
щих профессора монет нечеткие (размыты), поэтому дати-
ровка и другие надписи маленького размера не читаются. Раз-
мывание вызвано тем, что в процессе съемки объект не
находился в фокусе камеры. Вас, как специалиста по обработ-
ке изображений и друга профессора, просят оказать любезность
и установить, можно ли с помощью компьютерной обработ-
ки восстановить изображение так, чтобы профессор смог про-
читать интересующие его надписи. Вам сообщили, что та ка-
мера, с помощью которой производилась съемка монет,
по-прежнему доступна, так же, как и другие образцы монет то-
го же периода. Предложите последовательность шагов для ре-
шения этой задачи.
5.28 Предположим, что при определении пространственного пре-
образования и процедуры интерполяции значений яркости в
Разделе 5.11 вместо четырехугольных областей используются
треугольные области. Как в этом случае будут выглядеть вы-
ражения, аналогичные (5.11-5), (5.11-6) и (5.11-7)?
ГЛАВА 6
ОБРАБОТКА
ЦВЕТНЫХ
ИЗОБРАЖЕНИЙ
Только после долгих лет подготовки молодой художник имеет право
прикоснуться к цвету — не как к средству описания,
а как к средству самовыражения.
Анри Матисс
Долгое время я ограничивал себя лишь одним
цветом — в качестве дисциплины.
Пабло Пикасссо
Введение
Использование цвета в обработке изображений обусловлено двумя ос-
новными причинами. Во-первых, цвет является тем важным при-
знаком, который часто облегчает распознавание и выделение объек-
та на изображении. Во-вторых, человек в состоянии различать тысячи
различных оттенков цвета, и всего лишь порядка двух десятков оттен-
ков серого. Второе обстоятельство особенно важно при визуальном (т.е.
выполняемом непосредственно человеком) анализе изображений.
Обработку цветных изображений можно условно разделить на
две основные области: обработку изображений в натуральных цве-
тах и обработку изображений в псевдоцветах. В первом случае рас-
сматриваемые изображения обычно формируются цветными устрой-
ствами регистрации изображения, такими как цветная телевизионная
камера или цветной сканер. Во втором случае задача состоит в при-
своении цветов некоторым значениям интенсивности монохромно-
го сигнала или некоторым диапазонам изменения его интенсивнос-
ти. До последнего времени цифровая обработка цветных изображений
осуществлялась, по большей части, на уровне псевдоцветов. За послед-
нее десятилетие, однако, цветные устройства ввода и аппаратные
средства обработки цветных изображений стали вполне доступны по
ценам. Как результат, в настоящее время техника обработки изобра-
жений в натуральных цветах используется в широком диапазоне при-
ложений, включая издательские системы, системы визуализации и Ин-
тернет.
Из последующих обсуждений станет ясно, что некоторые методы
обработки полутоновых изображений, развитые в предыдущих главах,
непосредственно применимы и к цветным изображениям. Другие же
методы должны быть переформулированы и согласованы со свойст-
вами цветового пространства, которое строится далее в этой главе.
Описанные в настоящей главе методы далеко не являются исчерпы-
вающими; они иллюстрируют разнообразие методов, применимых в
обработке цветных изображений.
6.1. Основы теории цвета
Хотя процесс восприятия и интерпретации цвета человеческим моз-
гом представляет собой не до конца исследованное психофизиологи-
ческое явление, физическая природа цвета может быть точно описа-
на на основе экспериментальных и теоретических результатов.
В 1666 г. сэр Исаак Ньютон обнаружил, что при прохождении лу-
ча солнечного света через стеклянную призму выходящий поток лу-
чей не является белым, но состоит из непрерывного спектра цветов,
простирающихся от фиолетового цвета на одном конце до красного
на другом. Как показывает Рис. 6.1, спектр белого света (видимый) мо-
жет быть разделен на шесть широких цветовых диапазонов: фиолето-
вый, синий, зеленый, желтый, оранжевый и красный1. При рассмо-
трении полного спектра на Рис. 6.2 видно, что ни один цветовой
диапазон не имеет ярко выраженных границ; вместо этого каждый цвет
плавно переходит в другой.
Цвет, воспринимаемый человеком и некоторыми другими жи-
вотными как цвет объекта, определяется, по существу, характером
отраженного от объекта света. Как показано на Рис. 6.2, видимый свет
составляет относительно узкую часть всего диапазона длин волн электро-
магнитного спектра. Тело, которое равномерно отражает свет во всем
видимом диапазоне длин волн, выглядит для наблюдателя как бе-
лое. Однако тело, которое отражает свет преимущественно в некото-
ром ограниченном диапазоне видимого спектра, приобретает неко-
торый цвет. Так например, объект зеленого цвета отражает главным
образом свет с длиной волны в диапазоне от 500 до 570 нм и поглоща-
ет большую часть энергии в диапазонах других длин волн.
1 Деление спектра белого света на спектральные цвета достаточно условно. Напри-
мер, иногда говорят о пяти цветах, объединяя красно-оранжевый или сине-фиоле-
товый участки спектра, или же о семи цветах, когда между зеленым и синим выде-
ляется голубой участок спектра. — Прим, перев.
[Г422 Глава 6. Обработка цветных изображений
Важную роль в науке о цвете играет выбор параметров, характери-
зующих свет. Когда свет является ахроматическим (неокрашенным),
в роли единственной такой характеристики выступает интенсивность.
Ахроматический свет — это то, что видит зритель на экране черно-бе-
лого телевизора, и именно такой свет был до сих пор неявной состав-
ной частью всех наших рассмотрений, связанных с обработкой изо-
бражений. Определенный в Главе 2 и многократно использованный
впоследствии термин яркость (полутоновая яркость или уровень се-
рого) обозначает количественную меру интенсивности, которая при-
нимает значения в диапазоне от черного до белого, с промежуточны-
ми серыми оттенками.
Хроматический (окрашенный) свет охватывает диапазон элект-
ромагнитного спектра приблизительно от 400 нм до 700 нм. Хромати-
ческие источники света характеризуются тремя основными величина-
ми: потоком лучистой энергии, световым потоком и светлотой. Поток
лучистой энергии, обычно измеряемый в ваттах (вт), — это общее ко-
личество энергии, излучаемой источником света в единицу времени.
Световой поток, измеряемый в люменах (лм), — это поток лучистой
энергии, оцениваемой по зрительному ощущению. Например, свето-
вой источник, работающий в дальнем инфракрасном диапазоне, мо-
жет давать значительный поток энергии, но наблюдатель его практи-
чески не ощущает, так что световой поток такого источника почти
равен нулю. Наконец, как уже обсуждалось в Разделе 2.1, светлота яв-
ляется субъективной характеристикой, которая практически не под-
дается измерению. Она отражает уровень зрительного ощущения,
производимого интенсивностью (т.е. световым потоком), и является
одним из ключевых параметров для описания цветового восприятия.
Как указано в Разделе 2.1.1, рецепторами глаза, отвечающими за вос-
приятие цветов, являются колбочки. В результате всесторонних экспе-
риментов было установлено, что все 6-7 миллионов колбочек челове-
ческого глаза могут быть разделены по их восприимчивости к
спектральному составу света на три основные группы, которые прибли-
зительно соответствуют чувствительности к красному, зеленому и си-
нему цветам. Примерно 65% всех колбочек воспринимают красный свет,
33% колбочек воспринимают зеленый свет, и только 2% воспринима-
ют синий цвет (однако эти колбочки являются наиболее чувствитель-
ными). На Рис. 6.3 представлены экспериментальные кривые спектраль-
ной чувствительности колбочек каждой из трех групп для среднего
нормального глаза. Вследствие таких спектральных характеристик че-
ловеческий глаз воспринимает цвета как различные сочетания так на-
зываемых первичных основных цветов', красного (R), зеленого (G) и си-
него (В). В 1931 г. Международная комиссия по освещению (МКО)
разработала стандартный набор монохроматических первичных ос-
новных цветов: синий — с длиной волны 435,8 нм, зеленый — 546,1 нм
и красный — 700 нм. Этот стандарт был установлен до того, как в 1965 г.
стали доступны представленные на Рис. 6.3 кривые спектральной чув-
ствительности. Поэтому стандарт МКО лишь приблизительно соответ-
ствует экспериментальным данным. Как показывают Рис. 6.2 и 6.3,
никакой монохроматический цвет в отдельности не может быть назван
красным, зеленым или синим. Кроме того, важно понимать, что нали-
чие стандартного набора монохроматических первичных основных
цветов не означает, что все цвета спектра могут быть получены на ос-
нове этих фиксированных RGB цветов. Использование термина «основ-
ные» часто приводит к тому заблуждению, что все видимые цвета могут
быть воспроизведены при смешении основных первичных цветов в
различных пропорциях. Как вскоре будет видно, такое утверждение не
верно, за исключением того случая, когда длина волны основных цве-
тов также может изменяться. В этом последнем случае, однако, мы уже
не будем иметь трех стандартных первичных основных цветов.
Первичные основные цвета могут складываться, что дает вторич-
ные основные цвета: пурпурный (красный плюс синий), голубой (зе-
леный плюс синий) и желтый (красный плюс зеленый). Смешение трех
первичных основных цветов, или вторичного основного цвета и про-
тивоположного ему первичного, в правильных пропорциях дает бе-
лый цвет. Результат такого смешения представлен на Рис. 6.4 (а), где
также показаны три первичных основных цвета и их сочетания, даю-
щие вторичные основные цвета.
Важно различать первичные основные цвета световых источников
и первичные основные цвета красителей (светофильтров). В последнем
случае первичный основной цвет определяется как цвет красителя, ко-
торый поглощает, или вычитает, некоторый один первичный основ-
ной цвет светового источника и отражает либо пропускает два оставших-
ся. Поэтому для красителей первичными основными цветами являются
пурпурный, голубой и желтый, а вторичными — красный, зеленый и си-
ний. Эти цвета показаны на Рис. 6.4 (б). Правильная комбинация трех
первичных основных цветов красителей или вторичного основного
цвета и противоположного ему первичного дает черный цвет.
Цветное телевидение дает пример аддитивного цветовоспроиз-
ведения (т.е. основанного на сложении первичных основных цветов
световых источников). Внутренняя поверхность многих цветных ки-
нескопов составлена из большого числа триад — расположенных тре-
угольником точек люминофоров. При возбуждении электронным
лучом каждая точка триады способна излучать свет одного из первич-
ных основных цветов. Интенсивность свечения красного люминофо-
Глава 6. Обработка цветных изображений
ра модулируется с помощью расположенной внутри кинескопа эле-
ктронной пушки, которая генерирует импульсы в соответствии с
энергией, измеренной телекамерой в красном диапазоне. Управление
излучением зеленого и синего люминофоров осуществляется анало-
гично, с использованием своих электронных пушек. Эффект, наблю-
даемый на экране телевизионного приемника, состоит в том, что три
первичных основных цвета от каждого люминофора смешиваются и
воспринимаются чувствительными к цветам колбочками глаза как пол-
ноценное цветное изображение. Смена изображений со скоростью
тридцать кадров в секунду2 делает иллюзию непрерывного воспроиз-
ведения цветного изображения на экране полной.
Параметрами, обычно используемыми для различения цветов, яв-
ляются светлота, цветовой тон и насыщенность. Как указывалось ра-
нее в этом параграфе, светлота связана со зрительным ощущением ин-
тенсивности в цветовом случае. Цветовой тон характеризует
доминирующий цвет, воспринимаемый наблюдателем, причем боль-
шинство цветовых тонов в своем восприятии эквивалентны тому или
иному спектральному цвету (см. Рис. 6.5). Таким образом, когда мы на-
зываем некоторый объект красным, оранжевым или желтым, мы тем
самым обозначаем его цветовой тон. Насыщенность цвета связана с его
относительной белизной, или с количеством белого цвета в нем. Спе-
ктрально чистые (монохроматические) цвета являются полностью на-
сыщенными. Такие цвета как розовый (смесь красного и белого) или
бледно-лиловый (смесь фиолетового и белого) менее насыщены, при-
чем величина насыщенности цвета обратно пропорциональна коли-
честву белого цвета в смеси.
Цветовой тон и насыщенность вместе называются цветностью, и
поэтому цвет может быть охарактеризован своей светлотой и цветно-
стью. Величины красного, зеленого и синего, необходимые для полу-
чения некоторого конкретного цвета, называются координатами цве-
та и обозначаются соответственно X, Y и Z. Часто при описании
цвета светлота не представляет интереса, и в таком случае цветовой
тон и насыщенность можно выразить в координатах цветности, ко-
торые определяются как
х =----,
X+Y+Z
(6-1-1)
2 Такая частота кадров используется в стандарте NTSC; в стандарте SECAM, распро-
страненном в России, используется кадровая развертка с частотой 25 кадров (или 50 по-
лукадров) в секунду. — Прим, перев.
6.1. Основы теории
(6.1-2)
Y
У=--------,
X + Y + Z
Z (6.1-3)
Z —-------.
JT + r+Z
Из приведенных выражений видно, что3
x+y+Z=l. (6.1-4)
Для любой длины волны в диапазоне видимого спектра соответству-
ющие координаты цвета могут быть найдены непосредственно при по-
мощи кривых или таблиц, которые были составлены на основе обшир-
ного экспериментального материала [Poynton, 1996]. Отметим также
более ранние работы [Walsh, 1958], [Kiver, 1965].
Другой способ задавать цвета основан на использовании диаграм-
мы цветностей МКО (см. Рис. 6.5), на которой вся совокупность цве-
тов представлена как функция х (красной) и у (зеленой) координат
цветности. Для любых значений координат х и у соответствующее зна-
чение z (синей) координаты цветности может быть получено из выра-
жения (6.1-4): z=l-(x+y). Например, точка, отмеченная на Рис. 6.5 как
зеленая, содержит приблизительно 62% зеленого и 25% красного. Из
(6.1-4) следует, что содержание синего равно приблизительно 13%.
Вдоль границы диаграммы цветностей, имеющей форму языка,
расположены различные цвета спектра — от фиолетового с длиной вол-
ны 380 нм до красного с длиной волны 780 нм. Эти чистые (монохро-
матические) цвета показаны в спектре на Рис. 6.2. Любая точка, рас-
положенная не на границе, а внутри диаграммы, представляет
некоторую смесь цветов. Точка равной энергии на Рис. 6.5 соответст-
вует равным долям трех первичных основных цветов; она представ-
ляет опорный белый цвет стандарта МКО. Любая точка, располо-
женная на границе диаграммы цветностей, имеет максимальную
цветовую насыщенность. По мере того как точка смещается от грани-
цы к точке равной энергии, соответствующий ей цвет содержит в
своем составе все большую долю белого и становится все менее насы-
щенным. Цветовая насыщенность точки равной энергии равна нулю.
3 Для обозначения координат цветности мы используем общепринятые обозначения
х, у, z- Не следует путать их с обозначениями (х, у) для пространственных координат,
которые используются в этой и других частях книги.
(Г426 Глава 6. Обработка цветных изображений
Диаграмма цветности полезна при рассмотрении процедуры сме-
шения цветов, поскольку отрезок, соединяющий любые две точки ди-
аграммы, определяет всевозможные различные цвета, которые могут
быть получены при смешении двух данных цветов. Рассмотрим, на-
пример, отрезок, который соединяет точки, отмеченные на Рис. 6.5
как красная и зеленая. Точки, представляющие смесь этих цветов, бу-
дут лежать на рассматриваемом отрезке. Если в смеси больше крас-
ного, чем зеленого, то новому цвету такой смеси будет соответство-
вать точка, находящаяся ближе к красной точке. Аналогично, отрезок,
проведенный от точки равной энергии к любой точке границы диа-
граммы, определяет все оттенки выбранного цвета.
Рассмотренная процедура непосредственно обобщается на случай
смешения трех цветов. Для того чтобы определить диапазон цветов,
которые могут быть получены комбинацией трех любых заданных
цветов, нужно просто соединить между собой отрезками соответст-
вующие точки на диаграмме цветности. В результате получится тре-
угольник, и все цвета, соответствующие точкам внутри этого треуголь-
ника, могут быть получены как различные комбинации трех
первоначальных цветов. Никакой треугольник с вершинами в трех точ-
ках с неизменными цветами не может включать весь диапазон цветов
на Рис. 6.5. Это геометрическое наблюдение подтверждает сделанное
выше замечание о том, что не все цвета могут быть получены с помо-
щью трех фиксированных первичных основных цветов.
Треугольник на Рис. 6.6 представляет типичный для RGB монито-
ров диапазон воспроизводимых цветов (называемый цветовым охва-
том). Область сложной формы внутри этого треугольника представ-
ляет цветовой охват современных печатающих устройств высокого
качества. Граница области охвата для печатающих устройств имеет
сложную форму, потому что в процессе цветной печати одновремен-
но используются аддитивные и субтрактивные процедуры смешения
цветов. Управлять таким процессом намного труднее, чем процессом
воспроизведения цветов на экране монитора, основанном на смеше-
нии трех очень хорошо контролируемых первичных основных цветов.
6.2. Цветовые модели
Назначение цветовой модели (называемой также цветовым простран-
ством или системой цветов) состоит в том, чтобы сделать возможным
описание цветов некоторым стандартным, общепринятым образом.
По существу, цветовая модель определяет некоторую систему коор-
динат и подпространство внутри этой системы, в котором каждый цвет
представляется единственной точкой.
6.2. Цветовые модели
Большинство современных цветовых моделей ориентированы ли-
бо на устройства цветовоспроизведения (например, цветные монито-
ры или принтеры), либо на определенные прикладные задачи (такие
как создание цветной графики в анимации), когда работа с цветом яв-
ляется непосредственной целью. Аппаратно-ориентированными цве-
товыми моделями, наиболее часто используемыми на практике, явля-
ются модель RGB для цветных мониторов и широкого класса цветных
видеокамер, модели CMY и CMYK для цветных принтеров и модель
HSI4, которая хорошо соответствует цветовосприятию человека. По-
следняя модель обладает также тем преимуществом, что она разделя-
ет цветовую и яркостную (полутоновую) информацию на изображении
и поэтому дает возможность применять многие из полутоновых мето-
дов обработки изображений, развитых в этой книге. В настоящее вре-
мя используется множество различных цветовых моделей; это обуслов-
лено тем, что наука о цвете представляет собой широкую область,
включающую многочисленные приложения. Хотелось бы остановить-
ся здесь на некоторых из этих моделей, поскольку они интересны и ин-
формативны. Однако, чтобы не выходить за рамки задач настоящей
книги, мы ограничимся рассмотрением лишь вышеперечисленных
моделей, которые играют ведущую роль в обработке изображений.
Овладев материалом этой главы, читатель не будет иметь трудностей
в понимании других используемых цветовых моделей.
6.2.1. Цветовая модель RGB
В RGB модели каждый цвет представляется красным, зеленым и си-
ним первичными основными цветами (компонентами). В основе мо-
дели лежит декартова система координат. Цветовое пространство
представляет собой куб, показанный на Рис. 6.7. Точки, отвечающие
красному, зеленому и синему цветам, расположены в трех вершинах
куба, лежащих на координатных осях. Голубой, пурпурный и желтый
цвета расположены в трех других вершинах куба. Черный цвет нахо-
дится в начале координат, а белый — в наиболее удаленной от нача-
ла координат вершине. В рассматриваемой модели оттенки серого цве-
4 Названия цветовых моделей представляют собой английские аббревиатуры: RGB —
Red (красный), Green (зеленый), Blue (синий); CMY— Cyan (голубой), Magenta (пур-
пурный), Yellow (желтый); CMYK — Cyan (голубой), Magenta (пурпурный), Yellow
(желтый), ЫасК (черный); HSI — Hue (цветовой тон), Saturation (насыщенность),
Intensity (интенсивность). Последнюю модель иногда называют также BHS моде-
лью — Brightness (яркость), Hue (цветовой тон), Saturation (насыщенность). — Прим,
перев.
V428 Глава 6. Обработка цветных изображений
та (точки с равными RGB значениями) лежат на диагонали, соединя-
ющей черную и белую вершины. Различные цвета в этой модели
представляют собой точки на поверхности или внутри куба и опреде-
ляются вектором, проведенным в данную точку из начала координат.
Для удобства предполагается, что все значения цвета нормированы та-
ким образом, чтобы куб на Рис. 6.7 был единичным кубом, т.е. все зна-
чения R,GvlB лежат в диапазоне [0,1].
Представляемые в цветовой модели RGB изображения состоят
из трех отдельных изображений-компонент, по одному для каждого
первичного основного цвета. При воспроизведении RGB монито-
ром эти три изображения смешиваются на люминесцируюшем экра-
не и образуют составное цветное изображение. Число битов, исполь-
зуемых для представления каждого пикселя в RGB пространстве,
называется глубиной цвета. Рассмотрим RGB изображение, в котором
каждая из компонент — красная, зеленая и синяя — является 8-бито-
вой. В таком случае говорят, что каждый цветной RGB пиксель (т.е.
триплет значений (R, G, В)) имеет глубину 24 бита (три цветовые пло-
скости умножить на число битов на каждую плоскость); для такого изо-
бражения часто используется термин полноцветное изображение.
Суммарное число всевозможных цветов в 24-битовом RGB изображе-
нии составляет (28)3 = 16777216. На Рис. 6.8 изображен 24-битовый
цветовой куб RGB, соответствующий схеме на Рис. 6.7.
Пример 6.1. Формирование скрытых граней и сечения цветового
куба RGB.
™ На Рис. 6.8 показан сплошной куб, который составлен из
(28)3 = 16777216 указанных выше цветов. Удобным способом просмо-
тра этих цветов является формирование цветных плоскостей (граней
и сечений данного куба). Это достигается фиксированием одного из
трех цветов и изменением двух оставшихся. Например, сечение, про-
ходящее через центр куба и параллельное плоскости GB на Рис. 6.8 и
6.7, представляет собой плоскость (127, G, В), G, В = 0,1,2,..., 255. Здесь,
вместо нормализованных значений в диапазоне [0, 1], удобных с ма-
тематической точки зрения, мы использовали реальные значения пик-
селей, поскольку именно последние используются в компьютере для
формирования цветов. Рис. 6.9 (а) показывает, что если три отдельные
компоненты подать на цветной монитор, то в результате получится
цветное изображение сечения куба. Заметим, что компоненты явля-
ются полутоновыми (черно-белыми) изображениями, причем значе-
ние 0 соответствует черному, а 255 — белому. На Рис. 6.9 (б) представ-
лены те грани цветового куба, которые не видны на Рис. 6.8;
изображения сформированы аналогичным образом.
6.2. Цветовые модели
Интересно отметить, что процесс формирования (регистрации)
цветного изображения является, по существу, обратным к показанно-
му на Рис. 6.9 процессу. Цветное изображение может быть получено
с помощью трех фильтров: красного, зеленого и синего. Снимая цвет-
ную сцену на черно-белую фотокамеру, оснащенную одним из этих
фильтров, мы получаем в результате полутоновое (монохромное) изо-
бражение, яркость которого пропорциональна интенсивности света,
проходящего через фильтр. Повторение этой процедуры с каждым из
фильтров дает три монохромных изображения, которые являются
RGB компонентами изображения цветной сцены. На практике, ис-
пользование цветных RGB сенсоров дает возможность объединить весь
процесс в одном устройстве. Показанная на Рис. 6.9 (а) процедура вос-
произведения этих трех RGB компонент даст цветное RGB изобра-
жение исходной сцены.
Хотя высококачественные графические адаптеры и мониторы
обеспечивают хорошее воспроизведение цветов 24-битовых RGB
изображений, многие используемые в настоящее время системы ог-
раничены количеством цветов, равным 256. Кроме того, существует
целый ряд приложений, в которых имеет смысл использовать не бо-
лее сотни, а то и меньшее количество цветов. Хорошим примером здесь
могут служить методы обработки изображений в псевдоцветах, кото-
рые обсуждаются в Разделе 6.3. Также желательно иметь подмноже-
ство цветов, которые бы воспроизводились точно во всех используе-
мых графических системах вне зависимости от их особенностей.
Такое подмножество цветов называется палитрой фиксированных RGB
цветов5 или набором цветов, одинаково воспроизводимых всеми си-
стемами. Применительно к интернет-приложениям это подмножест-
во цветов называется палитрой фиксированных Web цветов или набо-
ром цветов, одинаково воспроизводимых всеми программами
просмотра интернет- сайтов.
Если исходить из предположения, что 256 цветов — это тот мини-
мальный набор цветов, которые точно воспроизводятся любым гра-
фическим устройством, то полезно иметь общепринятый стандарт
записи этих цветов. Известно, что сорок из этих 256 цветов воспро-
изводятся различными операционными системами по-разному; при
этом остается 216 цветов, которые являются общими для большинст-
ва систем. Эти 216 цветов стали de facto стандартом фиксированных
цветов, особенно для интернет-приложений. Они используются все-
5 В оригинале — safe RGB colors. — Прим, перев.
Глава 6. Обработка цветных изображений
гда, когда требуется, чтобы воспроизводимые цвета выглядели оди-
наково для большинства пользователей.
Обратим внимание, что 216 = (6)3, а значит, каждый из рассмат-
риваемых 216 вариантов цвета можно формировать по-прежнему из
трех RGB компонент, но каждая из которых может принимать лишь
6 возможных значений: 0, 51, 102, 153, 204 или 255. Обычно указан-
ные значения выражают в шестнадцатеричной системе счисления, как
показано в Таблице 6.1. Напомним, что шестнадцатеричные цифры
0, 1, 2,..., 9, А, В, С, D, Е, F соответствуют десятичным числам 0, 1,
2,..., 9, 10, 11, 12, 13, 14, 15. Напомним также, что (0)j6=(0000)2 и
(F)i6=(l 111)з- Таким образом, например, (FF) ^=(255) ю=(11111111)г,
и видно, что двузначное шестнадцатеричное число соответствует
восьмизначному двоичному, т.е. одному байту.
Поскольку для формирования RGB цвета требуется три числа,
каждый цвет из палитры фиксированных цветов задается тремя дву-
значными шестнадцатеричными числами из Таблицы 6.1. Например,
чистому красному цвету отвечает FF0000. Значения 000000 и FFFFFF
отвечают черному и белому цветам, соответственно. Те же результа-
ты получаются, конечно, и при использовании более привычной де-
сятичной системы счисления. Например, самый яркий красный цвет
имеет компоненты R = 255 (FF) и G = В = 0.
На Рис. 6.10 (а) изображена палитра 216 фиксированных цветов,
которые расположены в порядке убывания RGB значений. Первый
квадрат в верхнем левом массиве имеет значение FFFFFF (белый
цвет), второй квадрат справа от него имеет значение FFFFCC, третий
квадрат — FFFF99 и так далее для первой строки массива. Значения
во второй строке того же массива равны FFCCFF, FFCCCC, FFCC99
и т.д. Последний квадрат этого массива имеет значение FF0000 (са-
мый яркий красный цвет). Второй массив справа от только что рас-
смотренного начинается со значения CCFFFF, а его значения изме-
няются аналогично, как и значения оставшихся четырех массивов.
Последний (нижний правый) квадрат последнего массива имеет зна-
чение 000000 (черный цвет). Важно отметить, что палитра из 216 фик-
Таблица 6.1. Допустимые значения RGB компонент в палитре фиксированных
цветов.
Система счисления Значения RGB компонент
Шестнадцатеричная 0 33 66 99 сс FF
Десятичная 0 51 102 153 204 255
6.2. Цветовые модели
сированных цветов включает далеко не все возможные оттенки 8-би-
тового серого цвета. На Рис. 6.10 (б) показаны коды шестнадцати
равноотстоящих оттенков серого цвета в RGB модели. Некоторые
из этих значений не принадлежат множеству фиксированных цветов,
но большинство графических систем воспроизводит их ближайшим
(не серым) цветом правильной интенсивности. Серые цвета из пали-
тры фиксированных цветов вида (КККККККК)^ K=Q,3, 6, 9, С, F,
выделены на Рис. 6.10 (б) подчеркиванием.
На Рис. 6.11 представлен RGB куб фиксированных цветов. Как
видно из Рис. 6.10 (а), он состоит из 216 допустимых цветов (которые
изображены маленькими кубиками), причем каждый слой содержит
36 цветов. Совмещая его с 24-битовым кубом, показанным на Рис. 6.8,
можно сказать, что каждый маленький кубик, имеющий единствен-
ное значение, соответствует множеству попадающих в него цветов
24-битового RGB пространства.
6.2.2. Цветовые модели CMY и CMYK
Как указано в Разделе 6.1, голубой, пурпурный и желтый цвета явля-
ются вторичными основными цветами световых источников или,
альтернативно, первичными основными цветами красителей. На-
пример, если поверхность, покрытая голубой краской, освещается бе-
лым светом, то красный свет от такой поверхности не отражается. Та-
ким образом, голубой краситель вычитает красный свет из отражаемого
белого, который сам по себе состоит из одинаковых количеств крас-
ного, зеленого и синего света.
Большинство устройств для нанесения цветных красителей на
бумагу, такие как цветные принтеры и копировальные устройства, ли-
бо требуют представления входных данных в виде CMY, либо осуще-
ствляют преобразование данных из RGB в CMY Это преобразование
выполняется с помощью следующей простой операции
(6.2-1)
где снова предполагается, что все значения цвета нормированы так,
чтобы они находились в диапазоне [0,1]. Выражение (6.2-1) показы-
вает, что свет, отраженный от поверхности чисто голубого цвета, не со-
держит красного (поскольку в этом выражении С = 1 - R). Аналогич-
но, поверхность чисто пурпурного цвета не отражает зеленого, а
Глава 6. Обработка цветных изображений
поверхность чисто желтого цвета — синего. Кроме того, как видно из
(6.2-1), набор значений RGB может быть легко получен из значений
CMYвычитанием их из единицы. Как указывалось выше, цветовая мо-
дель CMY используется в процессе получения печатных копий, по-
этому обратный переход от CMYк RGB, вообще говоря, не представ-
ляет большого практического интереса.
В соответствии с Рис. 6.4, взятые в равном количестве первичные
основные цвета красителей — голубой, пурпурный и желтый — долж-
ны давать черный цвет. На практике, смешение этих цветов в процес-
се печати приводит к появлению черного цвета, который выглядит ос-
ветленным по сравнению с оригиналом. Поэтому для получения при
печати чистого черного цвета (который зачастую доминирует), цве-
товая модель CMY расширяется до модели CMYK, содержащей чет-
вертый основной цвет — черный. Таким образом, когда издатели го-
ворят о четырехцветной печати, они имеют в виду три основных цвета
модели CMY плюс черный цвет.
6.2.3. Цветовая модель HSI
Как мы видели, создание цветов в RGB и CMY моделях, а также пе-
реход из одной модели в другую являются простыми процедурами. Как
отмечалось ранее, эти цветовые системы идеально приспособлены для
аппаратной реализации. Кроме того, система RGB удачно согласова-
на со зрительной системой человека в том смысле, что человеческий
глаз восприимчив к красному, зеленому и синему — первичным ос-
новным цветам. К сожалению, цветовые системы RGB, CMY и дру-
гие подобные плохо приспособлены для описания цветов таким обра-
зом, как это свойственно человеку. Например, описывая цвет
автомобиля, человек не говорит о процентном содержании в нем
каждого из основных цветов. Более того, рассматривая цветное изо-
бражение мы не думаем о том, что оно составлено из трех отдельных
изображений — по одному для каждого первичного основного цвета.
Глядя на окрашенный объект, человек описывает его с помощью
цвета (цветового тона), насыщенности и светлоты. Напомним, что, как
это обсуждалось в Разделе 6.1, цветовой тон является характеристи-
кой, которая описывает собственно цвет (чистый желтый, оранжевый,
красный и т.д.), тогда как насыщенность дает меру того, в какой сте-
пени некоторый чистый цвет разбавлен белым. Светлота является
субъективной характеристикой, которая практически не поддается из-
мерению. Она соответствует понятию интенсивности (полутоновой
яркости) в ахроматическом случае и является одним из ключевых
параметров для описания цветового восприятия. Как известно, интен-
сивность (яркость) — основная характеристика монохромных (полу-
тоновых) изображений. Эта величина может быть измерена и легко
поддается интерпретации. В модели, которая носит название цвето-
вая модель HSI (цветовой тон, насыщенность, интенсивность) и к
рассмотрению которой мы приступаем, яркостная информация (ин-
тенсивность) отделена от цветовой информации (цветовой тон, насы-
щенность). В результате модель HSI представляет собой идеальное
средство для построения алгоритмов обработки изображений, по-
скольку в основе модели лежит естественное и интуитивно близкое че-
ловеку описание цвета, а ведь именно человек, в конечном счете, яв-
ляется и разработчиком, и пользователем этих алгоритмов. Можно
подвести итог и сказать, что модель RGB идеальна для создания цвет-
ных изображений (как при их регистрации цветной камерой, так и при
воспроизведении на экране монитора), но весьма ограничена в том,
что касается описания цвета. Последующий материал предоставляет
очень эффективный способ такого описания.
Как обсуждалось в Примере 6.1, цветное RGB изображение может
рассматриваться как совокупность трех полутоновых изображений, яр-
кость которых соответствует интенсивности красного, зеленого и си-
него цветов. Поэтому неудивительно, что существует возможность вы-
делить интенсивность из цветного RGB изображения. Это становится
достаточно ясно, если взять изображенный на Рис. 6.7 цветовой куб
и расположить его так, чтобы «черная» вершина (0, 0, 0) находилась
внизу, а «белая» вершина — прямо над ней, как показано на Рис. 6.12
(а). Как указывалось при обсуждении Рис. 6.7, все оттенки серого
цвета (которым отвечают определенные полутоновые яркости) рас-
положены вдоль прямой (оси интенсивности), соединяющей чер-
ную и белую вершины. Для показанного на Рис. 6.12 расположения,
эта ось является вертикальной. Таким образом, для того чтобы опре-
делить интенсивность (яркость) любой точки цветового куба на
Рис. 6.12, нужно провести плоскость перпендикулярно оси интенсив-
ности так, чтобы она проходила через данную точку. Пересечение
проведенной плоскости с осью интенсивности даст точку с искомым
значением интенсивности (яркости) в диапазоне [0, 1]. Можно так-
же заметить, что насыщенность цвета возрастает при увеличении
расстояния точки от оси интенсивности. Действительно, очевидно, что
цветовая насыщенность точек на оси интенсивности равна нулю, по-
скольку все эти точки являются серыми.
Для того чтобы понять, как определить цветовой тон для заданной
RGB точки, рассмотрим Рис. 6.12 (б). На этом рисунке изображена
плоскость, которая определяется тремя точками (черной, белой и го-
лубой). Поскольку плоскость содержит черную и белую точки, то она
434 Глава 6. Обработка цветных изображений
содержит и всю ось интенсивности. Более того, ясно, что все точки пло-
скости, которые принадлежат треугольнику, образованному осью ин-
тенсивности и отрезками пересечения плоскости с гранями куба (этот
треугольник выделен на Рис 6.12 (б) серым цветом), имеют одинако-
вый цветовой тон (в данном случае голубой). К такому выводу мож-
но прийти, если вспомнить (см. Раздел 6.1), что все цвета, порожда-
емые тремя любыми цветами, лежат в треугольнике, вершины которого
суть точки цветового куба, отвечающие этим цветам. Если двумя точ-
ками из трех являются черная и белая точки, а третья точка отвечает
некоторому цвету, то все точки треугольника будут иметь одинаковый
цветовой тон, поскольку черная и белая составляющие не могут его
изменить. (Разумеется, интенсивность и насыщенность точек в тре-
угольнике будет различаться.) Поворачивая рассматриваемую плос-
кость вокруг вертикальной оси интенсивности, мы будем получать раз-
личные цветовые тона. Проведенное концептуальное рассмотрение
приводит нас к выводу о том, что необходимые для построения про-
странства HSI значения цветового тона, насыщенности и интенсив-
ности могут быть получены из цветовых координат модели RGB. Та-
ким образом, если придать приведенным выше рассуждениям вид
точных геометрических формул, мы получим возможность преобра-
зовать RGB пространство в HSI пространство.
При выбранном на Рис. 6.12 расположении RGB куба простран-
ство HSI представляется множеством цветовых плоскостей, перпен-
дикулярных вертикальной оси интенсивности. В зависимости от по-
ложения точки пересечения этих плоскостей с осью интенсивности
сечение куба плоскостью может иметь треугольную или шестиуголь-
ную форму. Это легче представить себе, если смотреть на куб сверху
вниз вдоль оси интенсивности, как показано на Рис. 6.13 (а). В пред-
ставленной плоскости сечения мы видим, что первичные основные
цвета расположены под углом 120° друг относительно друга. Вторич-
ные основные цвета находятся под углом 60° относительно первич-
ных цветов. Это означает, что вторичные основные цвета также рас-
положены под углом 120° друг относительно друга. На Рис. 6.13 (б)
представлено сечение той же шестиугольной формы вместе с произ-
вольной цветовой точкой (показана на рисунке черной). Цветовой тон
этой точки определяется углом между направлениями из центра ше-
стиугольника на данную точку и на некоторую опорную точку. В ка-
честве опорной обычно (хотя и не всегда) выбирается точка пересе-
чения плоскости с осью, соответствующей красному цвету. Значение
угла отсчитывается против часовой стрелки. Насыщенность задается
длиной вектора, проведенного из центра в данную точку (т.е. рассто-
янием от вертикальной оси). Отметим, что центр является точкой
6.2. Цветовые модели
пересечения данной цветовой плоскости и вертикальной оси интен-
сивности. Таким образом, пространство HSI составляется из цвето-
вых областей в плоскостях, перпендикулярных вертикальной оси ин-
тенсивности. Положение точки в цветовой области характеризуется
длиной вектора, проведенного в эту точку из центра соответствующе-
го сечения, и углом, образуемым этим вектором с красной осью. В
принципе, при задании цветовой области можно использовать шес-
тиугольник, как это было сделано выше, треугольник или даже круг,
как это показано на Рис. 6.13 (в) и (г). Конкретный выбор формы об-
ласти в действительности не имеет значения, поскольку любая область
указанного вида может быть отображена на любую из двух других
при помощи геометрического преобразования. На Рис. 6.14 пред-
ставлены две HSI модели, в основе одной из которых лежат цветовые
треугольники, а другой — круги.
Преобразование цветов из системы RGB в систему HSI
Цветовой тон Ндля каждого пикселя, заданного в RGB формате изо-
бражения, определяется по формуле
0 при2?<(7,
360 - 0 при2?>(7,
(6.2-2)
где
0 = arccos-
\(R-G)2+(R-B)(G-B}^/2
Насыщенность 5 дается выражением
5 = 1-----------[niin(/?, G, В) 1.
(R + G+B)l j
Наконец, интенсивность /дается выражением
I = ^R+G+B).
(6.2-3)
(6.2-4)
Формулы написаны в предположении, что RGB координаты норми-
рованы так, чтобы их значения лежали в диапазоне [0,1 ], и угол 0 от-
считывается от красной оси пространства HSI, как показано на
Глава 6. Обработка цветных изображений
Рис. 6.13. Цветовой тон может быть нормирован таким образом, что-
бы его значения попадали в диапазон [0, 1]. Для этого нужно значе-
ния Н, получаемые по формуле (6.2-2), поделить на 360°. Значения двух
других HSI компонент автоматически попадают в этот диапазон при
условии, что RGB значения лежат в интервале [0, 1].
Формулы (6.2-2)- (6.2-4) могут быть выведены из геометрических
соображений на основе Рис. 6.12 и 6.13. Этот вывод является утоми-
тельным и не добавляет ничего существенного к проведенному рас-
смотрению. Интересующийся читатель может найти доказательство
этих формул, так же, как и нижеследующих формул обратного преоб-
разования из HSI в RGB, по приведенным литературным ссылкам или
на веб-сайте книги.
Преобразование цветов из системы HSI в систему RGB
Теперь, по заданным значениям HSI в интервале [0, 1] мы хотим най-
ти соответствующие RGB значения в том же интервале. Для этого, в
зависимости от значения Н, необходимо использовать различные
формулы. В области изменения цветового тона существуют три раз-
личных сектора величиной в 120°, которые разделены направления-
ми на первичные основные цвета (см. Рис. 6.13). Прежде всего мы ум-
ножаем величину Н на 360°, чтобы восстановить исходный диапазон
изменений цветового тона [0, 360°].
RGсектор (0° < Н< 120°). Если значение //находится в этом сек-
торе, то RGB координаты определяются по формулам
В = /(1-5), (6.2-5)
и
5 cos Я
cos(60° - Я)
С = 3/-(/?+Б).
(6.2-6)
(6.2-7)
GBсектор (120° < Я< 240°). Если значение Я находится в этом сек-
торе, то мы сначала вычитаем из него 120°:
Я = Я-120°.
После этого RGB координаты определяются по формулам
/?=/(!-5),
(6.2-8)
(6.2-9)
6.2. Цветовые модели
и
G = I
5 cos И
cos(60° - Н)
B = 3I-(R+G)
(6.2-10)
(6.2-11)
BR сектор (240° < Н< 360°). Наконец, если значение //находится в
этом секторе, то мы вычитаем из него 240°:
Я = Я-240' .
(6.2-12)
Затем RGB координаты определяются по формулам
G = /(l-5), (6.2-13)
и
В = 1
1 5 cos Н
cos(60° - Я)
R = 3I-(G+B).
(6.2-14)
(6.2-15)
Использование этих формул для обработки изображений обсуждает-
ся в ряде последующих разделов.
Пример 6.2. Значения HSI, соответствующие изображению цвето-
вого куба RGB.
На Рис. 6.15 представлены изображения цветового тона, насыщен-
ности и интенсивности, соответствующие изображению цветового ку-
ба RGB на Рис. 6.8. Изображение на Рис. 6.15 (а) является изображе-
нием цветового тона. Наиболее примечательная особенность этого
изображения — это разрыв значений вдоль диагонали передней (крас-
ной) грани куба. Для того чтобы понять причину этого разрыва, об-
ратимся к Рис. 6.8, нарисуем диагональ, соединяющую красную и
белую вершины куба, и выберем точку на середине этой диагонали.
Рассмотрим замкнутый путь на поверхности куба, который начина-
ется из этой точки, проходит последовательно через желтую, зеленую,
голубую, синюю и пурпурную вершины и возвращается обратно в
исходную красную точку. В соответствии с Рис. 6.13, значения цвето-
438 Глава 6. Обработка цветных изображений
вого тона вдоль этого пути должны возрастать от 0° до 360° (т.е. от на-
ибольшего до наименьшего возможного значения цветового тона).
Именно это и демонстрирует Рис. 6.15 (а), поскольку на этом полу-
тоновом рисунке наименьшему значению соответствует черный цвет,
а наибольшему — белый. В действительности изначально цветовой тон
принимал значения в диапазоне [0, 1], но для воспроизведения изо-
бражение цветового тона было подвергнуто масштабному преобразо-
ванию так, чтобы его значения оказались в диапазоне [0, 255].
Представленное на Рис. 6.15 (б) изображение насыщенности де-
монстрирует постепенное уменьшение значений в направлении белой
вершины RGB куба. Это показывает, что по мере приближения к бе-
лому, цвет становится все менее и менее насыщенным. Наконец, зна-
чение каждой точки изображения интенсивности, которое представ-
лено на Рис. 6.15 (в), есть среднее значений RGB компонент в
соответствующей точке изображения куба на Рис. 6.8.
Работа с HSI изображениями
Остановимся теперь кратко на некоторых простых методах работы с
изображениями, которые заданы своими HSI компонентами. Это
позволит лучше познакомиться с этими компонентами и будет спо-
собствовать более глубокому пониманию цветовой модели HSI. На
Рис. 6.16 (а) представлено изображение, составленное из первичных
и вторичных основных RGB цветов. На Рис. 6.16 (б)-6.16 (г) представ-
лены H,Sn / компоненты этого изображения. Эти изображения бы-
ли получены с использованием формул (6.2-2)- (6.2-4). Напомним, что,
согласно проведенному выше в этом параграфе рассмотрению, зна-
чение яркости на Рис. 6.16 (б) соответствует углу. Например, посколь-
ку красный цвет соответствует углу 0°, то области красного цвета на
Рис. 6.16 (а) отвечает черная область на изображении цветового тона.
Аналогично, яркость на Рис. 6.16 (в) соответствует насыщенности
(значения которой, для воспроизведения, растянуты на диапазон
[0, 255]), а значение яркости на Рис. 6.16 (г) равно интенсивности.
Чтобы изменить отдельный цвет некоторой области RGB изобра-
жения, мы изменяем значения в соответствующей области изображе-
ния цветового тона на Рис. 6.16 (б). Затем мы преобразуем новые
значения цветового тона Ни оставленные без изменений значения на-
сыщенности 5и интенсивности /обратно в RGB систему так, как это
было объяснено при рассмотрении формул (6.2-5)- (6.2-15). Чтобы из-
менить насыщенность (чистоту цвета) в некоторой области, мы дей-
ствуем подобным же образом, за исключением того, что теперь мы из-
меняем значения в компоненте насыщенности HSJ пространства.
Аналогично можно изменить и среднюю интенсивность любой обла-
6.3. Обработка изображений в псевдоцветах
сти. Разумеется, эти изменения могут быть осуществлены одновремен-
но. Например, изображение на Рис. 6.17 (а) было получено из изоб-
ражения на Рис. 6.16 (б) путем изменения значений в точках, соответ-
ствующих синей и зеленой областям; новые значения в этих точках
полагались равными нулю. На Рис. 6.17 (б) насыщенность голубой об-
ласти была уменьшена вдвое по сравнению с первоначальным значе-
нием насыщенности на Рис. 6.16 (в). На Рис. 6.17 (в) интенсивность
белой области в центре была уменьшена вдвое по сравнению с интен-
сивностью на Рис. 6.16 (г). Результат обратного преобразования в си-
стему RGB модифицированного таким образом HSI изображения
представлен на Рис. 6.17 (г). Как и следовало ожидать, внешние час-
ти всех кругов имеют теперь красный цвет, насыщенность цвета го-
лубой области уменьшилась, а центральная область из белой превра-
тилась в серую. Хотя полученные результаты элементарны, они
демонстрируют те возможности, которые предоставляет HSI модель
в части независимого контроля над цветовым тоном, насыщенностью
и интенсивностью — привычными характеристиками, используемы-
ми при описании цвета.
6.3. Обработка изображений в псевдоцветах
Обработка изображения в псевдоцветах (называемых также ложными
цветами) подразумевает присвоение цветов пикселям полутонового
изображения на основе некоторого определенного правила. Термин
псевдоцвета, или ложные цвета, используется для того, чтобы отли-
чать цветные изображения, полученные в результате присвоения цве-
тов точкам монохромного изображения, от изображений в натураль-
ных цветах, задача обработки которых будет обсуждаться начиная с
Раздела 6.4. Основное применение псевдоцветов — это визуализация
и интерпретация человеком той информации, которая содержится в
полутоновых изображениях или видеопоследовательностях. Как уже
отмечалось в начале настоящей главы, основным стимулом к исполь-
зованию псевдоцветов является то обстоятельство, что человек спо-
собен различать тысячи оттенков цвета и только около двух десятков
оттенков серого.
6.3.1. Квантование по яркости
Метод квантования по яркости (иногда называемый квантованием
по оптической плотности) и цветового кодирования (т.е. присвоения
пикселям тех или иных цветов в качестве уровней квантования) яв-
ляется одним из простейших примеров обработки изображения в
440 Глава 6. Обработка цветных изображений
псевдоцветах. Если рассматривать изображение как поверхность в
трехмерном пространстве (яркость отвечает третей пространственной
координате), то обсуждаемый метод можно представлять себе как
метод, основанный на проведении плоскостей, параллельных коор-
динатной плоскости изображения. Каждая такая плоскость «разреза-
ет» поверхность по области пересечения. На Рис. 6.18 представлен при-
мер, в котором секущая плоскость f (х, у) = lf используется для
разделения образованной изображением поверхности на два уровня.
Присвоим каждой из сторон показанной на Рис. 6.18 плоскости свой
цвет, и будем кодировать пиксели, которым отвечают точки поверхно-
сти, лежащие выше плоскости, одним цветом, а пиксели, которым от-
вечают точки поверхности, лежащие ниже плоскости, — другим. Точ-
кам, которые соответствуют пересечению плоскости с поверхностью,
можно присвоить любой из двух выбранных цветов. В результате мы по-
лучим двухцветное изображение, видом которого можно управлять,
двигая секущую плоскость вверх и вниз вдоль оси яркости.
В общем случае рассматриваемый метод может быть сформулиро-
ван следующим образом. Пусть яркость принимает значения в диапа-
зоне [0, L - 1], уровень /0 соответствует черному (f(x, у) = 0), а уро-
вень 1р_[ — белому (f(x, у) = L - 1). Предположим, что ^плоскостям,
перпендикулярным оси яркости, соответствуют уровни /р /2,..., /р, при-
чем 0 < Р < L - 1. Таким образом, Р плоскостей делят весь диапазон
яркости на Р+ 1 интервал Ej, ...., VP+2- Сопоставление цвета зна-
чению яркости осуществляется по правилу
f(x,y) = ck, если f(x,y)e Vk , (6.3-1)
где ck — цвет, соответствующий k-му интервалу яркости Ук, который
определяется секущими плоскостями при l = k- 1 и / = к.
Концепция секущих плоскостей полезна, главным образом, для
геометрической интерпретации метода квантования по яркости.
Рис. 6.19 иллюстрирует альтернативный способ определения того же
преобразования, которое ранее было определено с помощью Рис. 6.18.
Преобразование входного значения яркости в один из двух цветов, в
зависимости от того, превышает это значение данную величину /,
или нет, осуществляется при помощи представленной на Рис. 6.19
функции преобразования. Если используется большее число уровней,
то функция преобразования имеет ступенчатую форму.
Пример 6.3. Квантование по яркости.
э Простой практический пример использование квантования по яр-
кости представлен на рис. 6.20. Изображение на Рис. 6.20 (а) представ-
6.3. Обработка изображений в псевдоцветах
ляет собой монохромное изображение фантома щитовидной железы
(радиационного тестового образца), а изображение на Рис. 6.20 (б) —
результат квантования по яркости этого изображения на восемь цве-
тов. Области, которые на монохромном изображении выглядят как об-
ласти постоянной яркости, в действительности таковыми не являют-
ся, что показывают различия в цвете на квантованном изображении.
На монохромном изображении левая доля, например, имеет туск-
лый серый цвет, и заметить изменения яркости в этой области изоб-
ражения достаточно трудно. На цветном изображении, напротив,
четко выделяются восемь различных областей постоянной яркости,
по одной для каждого использованного цвета. Й
В предыдущем простом примере яркость была разделена на диапа-
зоны, которым были поставлены в соответствие различные цвета без
учета того, какую информацию несут значения яркости на конкретном
изображении. В этом случае интерес представляло лишь выделение об-
ластей с различными уровнями яркости, которые составляли изобра-
жение. Квантование по яркости играет гораздо более значимую и по-
лезную роль в том случае, если выбор диапазонов яркости на
изображении основан на физических характеристиках изображаемых
объектов. Так например, на Рис. 6.21 (а) представлено рентгеновское
изображение сварного шва (горизонтальная темная область), кото-
рый содержит несколько трещин и каверн (яркие белые прожилки, про-
ходящие горизонтально по центру изображения). Известно, что если
сварной шов содержит каверну или трещину, то полная интенсив-
ность потока рентгеновских лучей, проходящих через объект, приво-
дит к насыщению детектора, находящегося по другую сторону от объ-
екта (см. Раздел 2.3). Таким образом, 8-битовое изображение на выходе
такой системы содержит значения 255, что автоматически указывает
на дефект сварного шва. Если контроль качества сварного шва осуще-
ствляется человеком на основе просмотра изображения (такая проце-
дура контроля широко распространена по сей день), то простое цве-
товое кодирование, которое присваивает один цвет значению 255 и
другой цвет всем остальным значениям, может значительно облег-
чить работу эксперта. На Рис. 6.21 (б) показан результат такого коди-
рования. Без дополнительных объяснений ясно, что вероятность экс-
пертной ошибки будет меньше в том случае, если изображение
представлено в таком виде, как на Рис. 6.21 (б), а не на Рис. 6.21 (а). Дру-
гими словами, когда интерес представляют точно известные значения
яркости, квантование по яркости является простым, но мощным сред-
ством визуализации, особенно если речь идет о большом числе изоб-
ражений. Следующий пример значительно более сложный.
442 Глава 6. Обработка цветных изображений
Пример 6.4. Использование цвета для изображения количества
осадков.
Измерение количества осадков, особенно в тропических областях
Земли, представляет интерес в разнообразных приложениях, связан-
ных с изучением окружающей среды. Получение точных данных с ис-
пользованием приборов наземного базирования является непростым
и дорогостоящим делом, а получение полной картины осадков еще бо-
лее затруднено, поскольку значительное количество осадков выпада-
ет над океанами. Один из возможных способов получения полной кар-
тины осадков связан с использованием спутников. Спутник TRMM
(Tropical Rainfall Measuring Mission — Программа измерения количе-
ства осадков в тропических областях), в числе прочего, оснащен тре-
мя устройствами, разработанными для слежения за осадками: специ-
альным радаром, микроволновым сканером и сканером видимого и
инфракрасного диапазонов. (По поводу регистрации изображений раз-
личной природы см. Разделы 1.3 и 2.3.)
Результатом обработки данных со спутника являются оценки сред-
него количества осадков в исследуемой области за определенный пери-
од времени. Имея такие оценки, нетрудно построить полутоновое изо-
бражение, элементы которого соответствуют областям земной
поверхности (размер этих областей определяется разрешением исполь-
зуемых устройств регистрации данных), а значения элементов соответ-
ствуют количеству осадков. Такое изображение представлено на Рис. 6.22
(а), причем обследуемые спутником области находятся в чуть более свет-
лой горизонтальной полосе, занимающей среднюю треть картинки (тро-
пические области). В данном конкретном примере представлено сред-
немесячное количество осадков (в дюймах) за трехлетний период.
Визуальный анализ этой картины осадков представляет весьма труд-
ную, если не сказать невыполнимую, задачу. Предположим, однако,
что мы кодируем уровни яркости от 0 до 255 с помощью цветов, как по-
казано на Рис. 6.22 (б). Синие оттенки цвета означают малое количест-
во осадков, а красные — большое. Заметим, что шкала оканчивается чи-
стым красным цветом, который отвечает количеству осадков,
превышающему 20 дюймов. На Рис. 6.22 (в) показан результат цветово-
го кодирования исходного полутонового изображения с использовани-
ем приведенной цветовой шкалы. Как показывает это изображение, а
также увеличенное изображение области на Рис. 6.22 (г), представление
результатов таким способом существенно облегчает их интерпретацию.
Помимо того, что полученные с помощью спутников результаты обес-
печивают построение полной карты осадков земной поверхности, они
также позволяют метеорологам с большей, чем ранее, точностью кали-
бровать устройства слежения за осадками наземного базирования.
6.3. Обработка изображений в псевдоцветах
6.3.2. Преобразование яркости в цвет
Существуют другие преобразования, более общего вида, примене-
ние которых позволяет достичь более разнообразных результатов по
сравнению с простым методом квантования по яркости, рассмот-
ренным в предыдущем разделе. Один из таких методов, привлекатель-
ный с практической точки зрения, представлен на Рис. 6.23. Основ-
ная идея, лежащая в основе этого метода, состоит в том, чтобы
осуществить три независимых преобразования значений яркости для
каждого пикселя входного изображения. Затем три полученных изо-
бражения подаются в красный, зеленый и синий каналы цветного мо-
нитора. В результате формируется составное изображение, цветовое
содержание которого определяется природой используемых функ-
ций преобразования. Отметим, что эти преобразования затрагивают
лишь значения яркости изображения и не зависят от положения точ-
ки на изображении.
Частным случаем только что описанной методики является метод,
рассмотренный в предыдущем параграфе. В нем для формирования
цветов используются кусочно-постоянные функции (см. Рис. 6.19).
Метод, обсуждаемый в настоящем параграфе, может использовать
гладкие и нелинейные функции, что, естественно, придает всей ме-
тодике значительную гибкость.
Пример 6.5. Использование псевдоцветов для обнаружения взрывча-
тых веществ в багаже.
На Рис. 6.24 (а) представлены два монохромных изображения, по-
лученные с помощью используемой в аэропортах рентгеновской ска-
нирующей системы контроля багажа. Багаж на изображении слева со-
держит обычные предметы. Багаж на изображении справа содержит
те же предметы, а также некоторый блок, имитирующий пластиковую
взрывчатку. Цель данного примера состоит в том, чтобы проиллюст-
рировать использование метода преобразования яркости в цвет для ре-
ализации различных вариантов контроля.
На Рис. 6.25 изображены используемые функции преобразова-
ний. Эти синусоидальные функции содержат области вблизи макси-
мумов, в которых их значения относительно постоянны, а также об-
ласти вблизи минимумов, где их значения быстро изменяются.
Изменяя фазу и частоту каждой из синусоидальных функций, мож-
но добиться выделения (цветом) некоторых диапазонов значений
полутоновой яркости. Например, если фазы и частоты всех синусо-
ид совпадают, то изображение на выходе также будет монохромным.
Небольшие различия в фазах между тремя функциями преобразова-
^444 Глава 6. Обработка цветных изображений
ния приводят к незначительным изменениям для тех пикселей, яркость
которых соответствует положениям максимумов синусоид, особенно
если синусоиды имеют широкие профили (низкие частоты). Пиксе-
ли, яркость которых соответствует крутым участкам синусоид, при-
обретают намного более ярко выраженную цветовую окраску. Причи-
на этого в том, что в результате сдвига фаз между синусоидами их
амплитуды в этих областях заметно различаются.
Представленное на Рис. 6.24 (б) изображение получено с исполь-
зованием функций преобразования, изображенных на Рис. 6.25 (а), где
также показаны диапазоны яркости, которые соответствуют взрывча-
тому веществу, сумке с вещами и фону. Заметим, что хотя взрывчатое
вещество и фон достаточно сильно различаются по яркости, они ока-
зались изображены почти одинаковым цветом. Это произошло из-за
периодичности синусоидальных функций. Представленное на Рис. 6.24
(в) изображение получено с использованием функций преобразова-
ния, изображенных на Рис. 6.25 (б). В этом случае преобразование дей-
ствует почти одинаково в диапазонах яркости, соответствующих
взрывчатому веществу и сумке с вещами. Поэтому этим диапазонам
был присвоен, по существу, один и тот же цвет. Отметим, что такое ото-
бражение позволяет наблюдателю «видеть» сквозь взрывчатое веще-
ство. Отображение для фона практически не изменилось по сравне-
нию с Рис. 6.24 (б), соответственно почти не изменился и цвет фона.
Подход, схематически представленный на Рис. 6.23, предполагает ра-
боту с одним монохромным изображением. Однако часто интерес пред-
ставляет объединение нескольких монохромных изображений в одно со-
ставное цветное изображение, как показано на Рис. 6.26. Такой подход
(он проиллюстрирован Примером 6.6 ниже) используется при обра-
ботке спектрозональных изображений, когда различные сенсоры фор-
мируют отдельные монохромные изображения, каждое в своем спект-
ральном диапазоне. В качестве указанной на Рис. 6.26 дополнительной
обработки могут выступать такие процедуры, как цветовая коррекция
(см. Раздел 6.5.4), объединение изображений и выбор трех изображений
для воспроизведения на основе информации о приборных функциях сен-
соров, использованных при формировании изображений.
Пример 6.6. Цветовое кодирование спектрозоналъных изображений.
— На Рис. 6.27 (а)- (г) представлены полученные со спутника четы-
ре изображения г. Вашингтона, которые включают часть реки Пото-
мак. Первые три изображения получены в видимых красном, зеленом
и синем диапазонах, а четвертое — в ближнем инфракрасном диапа-
зоне (см. Таблицу 1.1 и Рис. 1.10). На Рис. 6.27 (д) представлено изо-
6.4. Основы обработки цветных изображений 445
бражение в натуральных цветах, полученное при объединении первых
трех изображений в RGB изображение. Изображения густонаселен-
ных областей в натуральных цветах с трудом поддаются интерпрета-
ции, но одной из примечательных особенностей этого изображения
является изменение цвета в различных частях реки Потомак. Изоб-
ражение на Рис. 6.27 (е) представляет несколько больший интерес. Это
изображение было получено заменой красной компоненты изображе-
ния на Рис. 6.27 (д) на изображение в ближнем инфракрасном диапа-
зоне. Из Таблицы 1.1 нам известно, что этот диапазон очень чувстви-
телен к наличию биомассы в сцене. Рис. 6.27 (е) достаточно ясно
демонстрирует различие между биомассой (красное) и объектами
сцены искусственного происхождения, которые состоят в основном
из бетона и асфальта и выглядят на изображении голубоватыми.
Только что продемонстрированный вид обработки весьма полезен
при визуализации представляющих интерес событий, особенно когда эти
события находятся за пределами нашего чувственного восприятия.
Рис. 6.28 прекрасно иллюстрирует сказанное. На этом рисунке представ-
лены изображения спутника Юпитера Ио в псевдоцветах, полученные
объединением нескольких спектрозональных изображений с косми-
ческого аппарата Galileo. Некоторые из компонент получены в невиди-
мых диапазонах спектра. Однако понимание того, как физические и хи-
мические процессы могут влиять на результаты измерений, дает
возможность соединить отдельные изображения в поддающуюся интер-
претации карту в условных цветах. Один из способов объединения на-
блюдаемых данных, представленных в виде изображений, может быть
основан на том, как эти данные отображают различия в химическом со-
ставе поверхности или изменения отражательных свойств поверхнос-
ти по отношению к солнечному свету. Например, на изображении в
условных цветах на Рис. 6.28 (б) ярко-красный цвет соответствует веще-
ству, которое недавно было выброшено на поверхность из активных
вулканов Ио, а окружающий желтый цвет представляет более старые сер-
ные отложения. Это изображение позволяет намного легче отследить ука-
занные свойства, чем это было бы возможно при исследовании каждой
из компонент, составляющих изображение, по отдельности.
6.4. Основы обработки цветных изображений
В этом разделе мы приступаем к изучению методов, применимых при
обработке изображений в натуральных цветах, или просто цветных изо-
бражений. Хотя набор рассматриваемых в последующих разделах ме-
тодов далеко не является исчерпывающим, эти методы служат иллю-
страцией того, как следует обращаться с такими изображениями при
Глава 6. Обработка цветных изображений
решении различных задач их обработки. Используемые при обработ-
ке цветных изображений подходы распадаются на две основные кате-
гории. Подходы первой категории предполагают, что каждая цветовая
компонента изображения обрабатывается отдельно, а затем результи-
рующее цветное изображение составляется из компонент, обработан-
ных по отдельности. Для подходов второй категории характерна непо-
средственная работа с цветными пикселями. Поскольку цветное
изображение содержит, как минимум, три составные части, то значе-
ние цветного пикселя представляет собой вектор. В RGB модели, на-
пример, значение пикселя изображения может рассматриваться как
вектор, проведенный из начала координат в соответствующую точку
цветового пространства (см. Рис. 6.7).
Пусть с есть произвольный вектор в цветовом пространстве RGB:
(6.4-1)
Это выражение показывает, что компонентами вектора с являются
RGB координаты точки в цветовом пространстве. Запись
с(х,у) =
cR(x,y)
cG(x,y)
св(х,у)
R(x,y)
G(x,y)
R(x,y)
(6.4-2)
отражает тот факт, что компоненты вектора с зависят от пространст-
венных координат (х, у). Для изображения размерами Mx.Nсущест-
вуют MNтаких векторов с(х, у), х=0, 1, 2,..., Л/-1,у=0,1, 2,..., N-1.
Важно ясно отдавать себе отчет в том, что выражение (6.4-2) описы-
вает вектор, компоненты которого являются функциями пространст-
венных переменных х и у. Это обстоятельство часто является источни-
ком недоразумений, которых можно избежать, если сконцентрироваться
на том, что наш интерес лежит в области пространственных методов об-
работки. А именно, нас интересуют неоднородные методы обработки
изображений, т.е. зависящие от пространственных координат хиу. Тот
факт, что пиксели изображения являются цветными, приводит в про-
стейшем случае к тому, что мы имеем возможность обрабатывать неза-
висимо каждую цветовую компоненту изображения, используя обыч-
ные методы обработки полутоновых изображений. Однако получаемые
таким способом результаты не всегда совпадают с результатами обработ-
6.5. Цветовые преобразования
ки, выполняемой непосредственно в цветовом векторном пространст-
ве; в этом случае требуется разработка новых подходов.
Для того чтобы методы покомпонентной обработки и векторной об-
работки были эквивалентны, необходимо выполнение двух условий. Во-
первых, метод должен быть применим как к векторам, так и к скаля-
рам. Во-вторых, операции над каждой компонентой вектора не должны
зависеть от других компонент. В качестве иллюстрации на Рис. 6.29 по-
казана процедура обработки полутонового и цветного изображений
по пространственной окрестности. Допустим, что эта процедура состо-
ит в усреднении по окрестности. Для полутонового изображения на
Рис. 6.29 (а) процедура усреднения будет заключаться в суммировании
значений яркости всех пикселей в заданной окрестности и делении по-
лученного значения на полное число таких пикселей. Для RGB изоб-
ражения на Рис. 6.29 (б) процедура усреднения будет заключаться в сум-
мировании всех векторов, отвечающих точкам заданной окрестности,
и делении полученного вектора на полное число векторов в окрестно-
сти. Но каждая компонента усредненного вектора равна среднему по
окрестности от значений изображения этой компоненты. Поэтому тот
же самый результат будет получен, если выполнить усреднение отдель-
но по каждой компоненте и затем из усредненных компонент сформи-
ровать искомый вектор. Более детальное рассмотрение приведено в по-
следующих разделах. Мы также рассмотрим методы, для которых два
указанных подхода дают различные результаты.
6.5. Цветовые преобразования
Предметом рассматриваемых в настоящем разделе методов, называ-
емых в совокупности цветовыми преобразованиями, является обра-
ботка компонент цветного изображения в рамках одной отдельно
взятой цветовой модели. Это отличает данные преобразования от
преобразований координат цвета при переходе из одной цветовой
модели в другую (таких как рассмотренные в Разделе 6.2.3 преобра-
зования цветов из модели RGB в модель HSI и обратно).
6.5.1. Постановка задачи
Как и для рассмотренных в Главе 3 методов преобразования полуто-
новых изображений, мы задаем преобразование цветных изображе-
ний следующим выражением:
g(x,y) = T[/(x,y)],
(6.5-1)
(Г448 Глава 6. Обработка цветных изображений
vp.cf(x, у) — цветное изображение на входе, g (х, у) — преобразован-
ное, или обработанное, цветное изображение на выходе и Г—дейст-
вующий на изображение/оператор обработки по пространственной
окрестности точки (х, у). Принципиальное отличие этого выражения
от выражения (3.1-1) заключается в интерпретации последнего. Теперь
значение пикселя представляет собой трехмерный или многомер-
ный вектор, т.е. набор из трех или более координат того цветового про-
странства, которое используется для представления изображения (см.
Рис. 6.29 (б)).
Так же как и при определении основных преобразований яркос-
ти для полутоновых изображений в Разделе 3.2, мы в этом разделе ог-
раничимся рассмотрением цветовых преобразований вида
s,-=7}(г1,Г2,...,^), 1=1,2,...,л, (6.5-2)
где, для упрощения записи, переменные г,- и л,- используются для обо-
значения цветовых компонент изображений/(х, у) и g (х, у) в произ-
вольной точке (х, у), п обозначает число цветовых компонент, а
{7), Тп} — множество функций преобразования или цветового
отображения, которые, действуя на величины г,-, дают величины л,-. За-
метим, что вся совокупность п функций преобразования 7} определя-
ет единственное отображение Тв выражении (6.5-1). Значение п оп-
ределяется цветовым пространством, выбранным для описания
пикселей изображений/и g. Например, если используется цветовое
пространство RGB, то п = 3 и переменные Г], и гз обозначают крас-
ную, зеленую и синюю компоненты входного изображения. Для цве-
товых пространств CMYK и HSI имеем, соответственно, п = 4 и п = 3.
В верхней части Рис. 6.30 представлено цветное изображение ва-
зы с клубникой и чашки кофе. Это изображение высокого разреше-
ния было получено в результате сканирования цветного негатива
большого формата (10 см.х 12,5см.). Во втором ряду на этом рисунке
изображены компоненты исходного CMYK изображения, получен-
ного в результате сканирования. На этих изображениях в каждой из
цветовых компонент CMYK модели черному соответствует значе-
ние 0, а белому — значение 1. Таким образом, мы видим, что цвет клуб-
ники состоит из большого количества пурпурного и желтого цветов,
так как соответствующие клубнике области являются наиболее ярки-
ми на изображениях, отвечающих этим двум CMYK компонентам.
Черный цвет присутствует в малом количестве и в основном ограни-
чен изображением кофе и теней в вазе с клубникой. В третьем ряду
представлены результаты преобразования цветов из системы CMYK
в систему RGB, из которых видно, что цвет клубники состоит из боль-
Рис. 6.1. Разложение белого света на спектральные составляющие при прохож-
дении через призму. (Изображение предоставлено General Electric Со., Lamp
Business Division).
Рис. 6.2. Длины волн видимой части электромагнитного спектра. (Изображе-
ние предоставлено General Electric Со., Lamp Business Division).
Рис. 6.3. Кривые спектральной чувствительности колбочек человеческого гла-
за (зависимость относительного коэффициента поглощения от длины волны).
15 А-223
СМЕШЕНИЕ ИСТОЧНИКОВ СВЕТА
(Аддитивные первичные основные цвета)
ЗЕЛЕНЫЙ
СМЕШЕНИЕ КРАСИТЕЛЕЙ
(Субтрактивные первичные основные цвета)
ЖЕЛТЫЙ
а
б
ПЕРВИЧНЫЕ И ВТОРИЧНЫЕ ОСНОВНЫЕ ЦВЕТА
СВЕТОВЫХ ИСТОЧНИКОВ И КРАСИТЕЛЕЙ
Рис. 6.4. Первичные и вторичные основные цвета световых источников и
красителей. (Изображение предоставлено General Electric Со., Lamp Business
Division).
Рис. 6.5. Диаграмма цветностей. (Изображение предоставлено General Electric
Со., Lamp Business Division)
Глава 6. Обработка цветных изображений
Рис. 6.6. Типичный цветовой охват цветного монитора (треугольная область)
и цветного печатающего устройства (область сложной формы).
Рис. 6.7. Схематическое изображение цветового куба RGB. Точки на главной
диагонали представляют оттенки серого цвета: от черного цвета в начале ко-
ординат до белого цвета в точке (1,1,1).
Рис. 6.8. 24-битовый цветовой куб RGB.
Красный
Рис. 6.9. (а) Формирование RGB изображения сечения цветового куба плос-
костью (127, G, В), (б) Три скрытые грани цветового куба на Рис. 6.8.
Глава 6. Обработка цветных изображений
000000
Рис. 6.10. (а) Палитра фиксированных RGB цветов, (б) 16 равноотстоящих от-
тенков серого цвета RGB модели (серые цвета, входящие в палитру фиксиро-
ванных цветов, выделены подчеркиванием).
Рис. 6.11. RGB куб фиксированных цветов.
Рис. 6.12. Концептуальные взаимосвязи между цветовыми моделями RGB и
HSL
Рис. 6.13. Цветовой тон и насыщенность в цветовой модели HS1. Конец
вектора на рисунках соответствует произвольной точке цветового прост-
ранства. Угол, отсчитываемый от красной оси, определяет цветовой тон, а
длина вектора — насыщенность. Интенсивность всех цветов в любой из изо-
браженных плоскостей задается положением этой плоскости относительно вер-
тикальной оси интенсивности.
Синий Пурпурный Красный
а б
в.д-
Рис. 6.14. Цветовая модель HSI, в основе которой лежат (а) цветовые треуголь-
ники и (б) цветовые круги. Треугольники и круги перпендикулярны вертикаль-
ной оси интенсивности.
Рис. 6.15. HSI компоненты изображения цветового куба на Рис. 6.8: (а) цве- а б В
товой тон, (б) насыщенность и (в) интенсивность.
Рис. 6.16. (a) RGB изображение и компоненты соответствующего HSI изобра-
жения: (б) цветовой тон, (в) насыщенность и (г) интенсивность
Рис. 6.17. (а)- (в) Изображения модифицированных HSI компонент, (г) Резуль-
тирующее RGB изображение. (Исходные изображения HSI компонент пред-
ставлены на Рис. 6.16.)
Рис. 6.18. Геометрическое объяснение метода квантования по яркости
<2
----------1-----------I-
/, £-1
Яркость
Рис. 6.19. Альтернативный способ определения метода квантования по яр-
кости.
Рис. 6.20. (а) Монохромное изображение фантома щитовидной железы, (б) Ре-
зультат квантования по яркости (по плотности) на восемь цветов. (Исходное
изображение предоставил др. Дж. Л. Бланкеншип, Instrumentation and Controls
Division, Oak Ridge National Laboratory).
Глава 6. Обработка цветных изображений
а б
Рис. 6.21. Монохромное рентгеновское изображение сварного шва. (б) Резуль-
тат цветового кодирования. (Исходное изображение предоставлено компани-
ей Х-ТЕК Systems. Ltd.)
Я б Рис. 6.22. (а) Полутоновое изображение, яркость которого (в выделенной
в j, чуть более светлой полосе) соответствует среднемесячному количеству осад-
ков. (б) Шкала соответствия цветов и значений яркости. (в) Изображение, по-
лученное в результате цветового кодирования, (г) Увеличенное изображение
части Южной Америки. (Изображения предоставлены NASA.)
Рис. 6.23. Функциональная блок-схема формирования изображения в псев-
доцветах. Величины/л,/с и fB подаются в качестве входных сигналов соот-
ветственно в красный, зеленый и синий каналы цветного RGB монитора.
Рис. 6.24. Обработка в псевдоцветах с использованием представленных на
Рис. 6.25 преобразований яркости в цвет. (Исходное изображение предоста-
вил др. М. Гурвиц, Вестенхауз.)
Глава 6. Обработка цветных изображений
а 5
Л-1
Красный
Л-1
Зеленый
Л-1
Синий
Взрывчатое Сумка Фон
Яркость
вещество с вещами
Яркость
вещество с вещами
Рис. 6.25. Функции преобразований, использованные для получения изобра-
жений на Рис. 6.24.
fKO,y')
Рис. 6.26. Метод формирования псевдоцветов при наличии нескольких мо-
нохромных изображений.
Рис. 6.27. (а) - (г) Изображения в диапазонах 1-4 на Рис. 1.10 (см. Таблицу 1.1).
(д) Цветное изображение, полученное при использовании изображений (а),
(б) и (в) в качестве красной, зеленой и синей компонент RGB изображе-
ния. (е) Изображение, полученное аналогично, с той разницей, что в ка-
честве красной компоненты использовано изображение (г) в ближнем ин-
фракрасном диапазоне. (Исходное спектрозональное изображение предоставлено
NASA.)
а б
в г
Д е
Глава 6. Обработка цветных изображений
а
б
Рис. 6.28. (а) Изображение спутника Юпитера Ио в условных цветах, (б) Круп-
ный план. (Изображения предоставлены NASA.)
(<у)
Пространственная _/
маска
а б
Полутоновое
изображение
Рис. 6.29. Пространственные маски для полутоновых и цветных RGB изобра-
жений.
Цветное изображение
Голубой (С) Пурпурный (М) Желтый (Y)
Черный (К)
Красный (R) Зеленый (G) Синий (В)
Цветовой тон (Н) Насыщенность (S) Интенсивность (I)
Рис. 6.30. Цветное изображение и его компоненты, соответствующие различ-
ным цветовым пространствам. (Исходное изображение предоставлено MedData
Interactive.)
16 А-223
Глава 6. Обработка цветных изображений
Рис. 6.31. Изменение интенсивности изображения при помощи цветовых
преобразований, (а) Исходное изображение, (б) Результат увеличения его ин-
тенсивности на 30% {к = 0,7). (в)- (д) Функции преобразования для моделей
RGB, CMYи HSL (Исходное изображение предоставлено MedData Interactive.)
Рис. 6.32. Дополнительные цвета на цветовом круге
Рис. 6.33. Цветовое дополнение, (а) Исходное изображение, (б) Функции
преобразования цветового дополнения, (в) 1 (истовое дополнение изображе-
ния (а), посчитанное на основе функций преобразования RGB модели, (г) При-
ближение для RGB изображения цветового преобразования, посчитанное на
основе функций преобразования HSI модели.
Рис. 6.34. Преобразование, которое вырезает диапазон красных цветов внут-
ри (а) куба в RGB пространстве с длиной грани W= 0,2549 и с центром в точ-
ке (0,6863, 0,1608,0,1922), и (б) сферы в RGB пространстве радиусом Rq = 0,1765
и центром в той же точке. Цвет пикселей, значения которых лежат вне дан-
ных куба или шара, установлен равным (0,5, 0,5, 0,5).
Темное изображение Результат коррекции
Рис. 6.35. Яркостная коррекция для малоконтрастного, светлого и темного
цветных изображений. При одинаковом изменении красной, зеленой и синей
компонент цветовой тон изображения не изменяется.
Исходное/скорректированное изображение
Рис. 6.36. Цветовая коррекция для CMYK изображений.
Глава 6. Обработка цветных изображений
a 6
в г
Histogram before processing
(median=0.36)
Histogram after processing
|lh (median=0.5)
Рис. 6.37. Эквализация гистограммы (с последующей коррекцией насыщен-
ности) в цветовом пространстве HSI.
Рис. 6.38. (a) RGB изображение. Компоненты изображения: (б) красная,
(в) зеленая и (г) синяя.
Рис. 6.39. HSI компоненты цветного RGB изображения на Рис. 6.38 (а), а б, В
(а) Цветовой тон. (б) Насыщенность, (в) Интенсивность.
Рис. 6.40. Сглаживание изображения с помощью усредняющей маски разме-
рами 5x5. (а) Результат независимой обработки каждой из RGB компонент
изображения, (б) Результат обработки компоненты интенсивности в HSI
пространстве с последующим переходом в RGB пространство, (в) Разность
между этими двумя результатами.
а б в
Рис. 6.41. Повышение резкости изображения с помощью лапласиана, (а) Ре-
зультат независимой обработки каждой RGB компоненты, (б) Результат об-
работки компоненты интенсивности и последующего перехода в RGB прост-
ранство. (в) Разность двух результатов.
а..б в
а б
в г
Д е
F з
Рис. 6.42. Сегментация изображений в пространстве HSI. (а) Исходное изо-
бражение. (б) Цветовой тон. (в) Насыщенность, (г) Интенсивность, (д) Дво-
ичная маска насыщенности (черное соответствует значению 0). (е) Произве-
дение изображений (б) и (д). (ж) Гистограмма значений яркости
изображения (е). (з) Результат сегментации изображения (а).
Глава 6. Обработка цветных изображений
Рис. 6.43. Три способа выделения областей данных для сегментации в цвето-
вом пространстве RGB с использованием: (а) шара, (б) эллипсоида и (в) па-
раллелепипеда.
а
б
Рис. 6.44. Сегментация в пространстве RGB. (а) Исходное изображение; цве-
та, представляющие интерес, расположены внутри прямоугольника, (б) Резуль-
тат сегментации в цветовом пространстве RGB. Сравните этот результат с
результатом, представленным на Рис. 6.42 (з).
Рис. 6.45. (а) (в) Изображения R,GnB компонент и (г) соответствующее RGB
изображение, (д)- (ж) Изображения R.G и В компонент и (з) соответствую-
щее RGB изображение.
Рис. 6.46. (a) RGB изображение, (б) Градиент, посчитанный в цветовом
векторном пространстве RGB. (в) Градиент, посчитанный как сумма гради-
ентов отдельных цветовых компонент, (г) Разность изображений (б) и (в).
Глава 6. Обработка цветных изображений
Я б В Рис. 6.47. Изображения градиентов компонент цветного изображения на
Рис. 6.46 (а). Градиенты: (а) красной компоненты, (б) зеленой компоненты и
(в) синей компоненты. Изображение на Рис. 6.46 (в) получено в результате сло-
жения этих изображений и масштабирования.
а б
в г
Рис. 6.48. (а)- (в) Красная, зеленая и синяя компоненты изображения, иска-
женные аддитивным гауссовым шумом с нулевым средним и дисперсией 800.
(г) Соответствующее RGB изображение. (Сравните изображение на рисунке (г)
с изображением на Рис. 6.46 (а).)
Рис. 6.49. HSI компоненты цветного изображения с шумом на Рис. 6.48 (г), (а) Цве- а б В
товой тон. (б) Насыщенность, (в) Интенсивность.
Рис. 6.50. (а) Цветное RGB изображение, зеленая компонента которого иска-
жена биполярным импульсным шумом, (б) Компонента цветового тона соот-
ветствующего HSI изображения, (в) Компонента насыщенности, (г) Компо-
нента интенсивности.
Рис. 6.51. Сжатие цветного изображения, (а) Исходное RGB изображение,
(б) Результат последовательного сжатия и восстановления изображения (а).
Цвет
К задаче 6.6
К задаче 6.6
К задаче 6.15
Красный Зелёный Синий
Пурпурный Голубой Жёлтый
Белый Чёрный
Глава 6. Обработка цветных изображений
К задаче 6.16
Зелёный Красный
Синий Зелёный
К задаче 6.25
6.5. Цветовые преобразования
шого количества красного, и содержит зеленый и синий цвета в очень
небольшом (но все же в некотором) количестве. В последнем ряду на
Рис. 6.30 представлены HS1 компоненты исходного изображения, ко-
торые вычислялись по формулам (6.2-2)- (6.2-4). Как и следовало ожи-
дать, компонента интенсивности представляет собой полутоновое изо-
бражение оригинала. Далее, цвет клубники является наиболее
насыщенным среди всех цветов изображения, т.е. он менее остальных
цветов разбавлен белым цветом; этот цвет обладает самой большой на-
сыщенностью. Отметим, наконец, определенную трудность в интерпре-
тации компоненты цветового тона, которая обусловлена сочетанием
следующих факторов: (1) значение цветового тона в модели HSI претер-
певает разрыв в тех точках, которым соответствуют углы 0° и 360°, и
(2) для цветовых точек с нулевой насыщенностью (т.е. белых, черных и
серых) значение цветового тона не определено. Разрыв цветового тона
наиболее заметен на области, соответствующей клубнике. В точках
этой области изображение цветового тона принимает значения, близ-
кие как к черному (0), так и белому (1). В результате мы имеем область
с непредсказуемо чередующимися высококонтрастными значениями яр-
кости, которые представляют единственный цвет — красный.
Любой из представленных на Рис. 6.30 наборов цветовых компо-
нент может быть использован в преобразовании (6.5-2). Теоретичес-
ки, в рамках каждой из цветовых моделей может быть осуществлено
любое преобразование. На практике, однако, некоторые операции луч-
ше приспособлены для реализации в рамках той или иной модели. При
принятии решения относительно того, в каком цветовом простран-
стве реализовывать данное преобразование, необходимо учитывать за-
траты на переход от одного цветового представления в другое. Пред-
положим, например, что мы хотим изменить интенсивность
изображения на Рис. 6.30 с помощью преобразования
g(x,y) = kf(x,y), (6.5-3)
где 0 < к < 1. В цветовом пространстве HSI этого можно достичь при
помощи простого преобразования
s3=kr3, (6.5-4)
причем 5| = Г] и 52 = г2. Изменению подлежит только компонента ин-
тенсивности. В цветовом пространстве RGB изменению должны быть
подвергнуты все три компоненты:
Sj =krt, i = 1,2,3. (6.5-5)
17 А-223
Глава 6. Обработка цветных изображений
Пространство CMY требует применения похожего набора линейных
преобразований:
si=kri+(\-k), /=1,2,3. (6.5-6)
Хотя в модели HSI преобразование осуществляется с помощью мень-
шего числа операций, вычисления, необходимые для перехода из
пространства RGB или CMY (К) в пространство HSI, не просто ни-
велируют (в данном конкретном случае) это преимущество, но и де-
лают такой способ вычисления совершенно неэффективным. Вы-
числительная сложность перехода в пространство HSI значительно
превосходит сложность самого преобразования. Результат преобразо-
вания, однако, не зависит от выбранной для его реализации цветовой
системы. На Рис. 6.31 (б) представлен результат применения любого
из рассматриваемых преобразований (6.5-4)- (6.5-6) со значением
к = 0,7 к изображению на Рис. 6.31 (а), которое является увеличенной
копией цветного изображения на Рис. 6.30. Графики соответствующих
функций преобразования изображены на Рис. 6.31 (в) - (д).
Важно отметить, что преобразование каждой из компонент цве-
тового пространства по формулам (6.5-4)- (6.5-6) зависит только от
одной этой компоненты. Например, красная компонента 5| на выхо-
де, в соответствии с (6.5-5), зависит только от красной компоненты Г|
на входе и не зависит от зеленой {г^} и синей (/3) компонент на вхо-
де. Преобразования такого типа относятся к числу наиболее простых
и часто используемых средств цветовой обработки и могут быть осу-
ществлены независимо для каждой отдельной цветовой компоненты,
о чем уже шла речь ранее в нашем обсуждении. В оставшейся части
этого раздела мы рассмотрим несколько преобразований такого ро-
да и обсудим случаи, когда функции преобразования зависят от всех
цветовых компонент входного изображения, и поэтому такое преоб-
разование не может быть осуществлено отдельно по каждой цветовой
компоненте.
6.5,2. Цветовое дополнение
Цвета, расположенные друг напротив друга на изображенном на
Рис. 6.32 цветовом круге^, называются дополнительными цветами.
Наш интерес к цветовому дополнению, т.е. к переходу отданных цве-
6 Это понятие появилось в XVII веке и восходит к сэру Исааку Ньютону, который впер-
вые соединил концы видимого спектра и образовал цветовой круг.
6.5. Цветовые преобразования
тов к соответствующим дополнительным цветам, связан с тем об-
стоятельством, что эта операция аналогична преобразованию полу-
тонового изображения в негатив (см. Раздел 3.2.1). Как и в полутоно-
вом случае, цветовое дополнение полезно для выявления деталей
внутри темных областей цветного изображения, особенно когда раз-
меры областей заметно превосходят размеры деталей.
Пример 6.7. Вычисление цветового дополнения.
Я На Рис. 6.33 (а) и (в) представлены цветное изображение Рис. 6.30
и его цветовое дополнение. График функций преобразования, ис-
пользованных для вычисления цветового дополнения в системе RGB,
показан на левом верхнем графике Рис. 6.33 (б). Эти функции совпа-
дают с определенной в Разделе 3.2.1 функцией преобразования полу-
тонового изображения в негатив. Заметим, что вычисленное цветовое
дополнение напоминает обычный цветной негатив, получаемый на
цветной фотопленке. Красные цвета на исходном изображении в
цветовом дополнении оказались замененными на голубые. Там, где ис-
ходное изображение белое, его цветовое дополнение — черное, и т.д.
Каждый цвет на изображении цветового дополнения может быть
предсказан по цвету на исходном изображении с помощью цветово-
го круга на Рис. 6.32. Каждая из функций преобразования RGB ком-
понент, используемая при вычислении цветового дополнения, зави-
сит только от соответствующей компоненты входного изображения.
В отличие от преобразования интенсивности на Рис. 6.31, функ-
ции преобразования в пространстве RGB для цветового дополнения
не имеют простого аналога в пространстве HSI. В качестве упражне-
ния (см. Задачу 6.18) читателю предлагается показать, что компо-
нента насыщенности ддя цветового дополнения не может быть вычис-
лена только на основе насыщенности исходного изображения. На
Рис. 6.33 (г) представлено приближение для цветового дополнения,
полученное с использованием показанных на Рис. 6.33 (б) функций
преобразования для цветового тона, насыщенности и интенсивнос-
ти (Н, S, I). Заметим, что компонента насыщенности не претерпева-
ет изменений; этим и обусловлена некоторая разница между изобра-
жениями на Рис. 6.33 (в) и (г).
6.5.3. Вырезание цветового диапазона
Вырезание определенного диапазона цветов на изображении приме-
няется для выделения некоторых объектов из их окружения. Основная
идея заключается в том, чтобы либо (1) воспроизвести интересующие
цвета так, чтобы они выступали на общем фоне, либо (2) использовать
Глава 6. Обработка цветных изображений
определяемые цветом области в качестве маски при дальнейшей об-
работке. Наиболее простой подход состоит в том, чтобы обобщить
рассмотренный в Разделе 3.2.4 метод вырезания яркостного диапазо-
на. Однако поскольку значение цветного пикселя представляет собой
«-мерный вектор, функции преобразования для вырезания цветово-
го диапазона являются более сложными, чем аналогичные функции для
вырезания яркостного диапазона. В действительности, интересую-
щие нас преобразования превосходят по сложности все цветовые пре-
образования, рассмотренные до сих пор. Это связано с тем, что при лю-
бом применяемом на практике методе вырезания цветового диапазона
каждая цветовая компонента преобразованного пикселя зависит от всех
п цветовых компонент исходного пикселя.
Один из простейших способов «разделить» цветное изображение
состоит в том, чтобы отобразить все цвета, лежащие вне области ин-
тереса, в некоторый нейтральный, не бросающийся в глаза цвет. Ес-
ли представляющие интерес цвета заключены в некотором кубе (или
гиперкубе при «>3) с длиной ребра Wn с центром в точке (оц aj,..., ап)
цветового пространства, которая соответствует некоторому заданно-
му цвету-прототипу, то совокупность необходимых функций преоб-
разования задается выражением
0,5,
W
если |г,-о,|> —
1 J J ' 2
ДЛЯ любого 1< J<n ;
i = \,2...n. (6.5-7)
tj, в остальных случаях
Эти преобразования выделяют цвета вокруг заданного, заменяя все ос-
тальные на цвет средней точки используемого цветового пространст-
ва (произвольно выбранный нейтральный цвет). В случае цветового
пространства RGB подходящей точкой является середина отрезка
серых цветов, т.е. цвет (0,5, 0,5, 0,5).
Если для задания цветовой области, представляющей интерес,
используется сфера, то формула (6.5-7) принимает вид
0,5, если У (г,- -а,)2 > R?;
% 1 1 i = \,2...n. (6.5-8)
fj, в остальных случаях;
Здесь 7?0 — радиус ограничивающей цвет сферы (или гиперсферы при
п > 3), а (оц ап) ~~ координаты центра сферы в цветовом прост-
ранстве, определяющие цвет-прототип. В других полезных модифи-
6.5. Цветовые преобразования
кациях формул (6.5-7) и (6.5-8) используются несколько цветов-про-
тотипов, а интенсивности цветов, лежащих вне области интереса,
уменьшаются — вместо замены этих цветов на некоторый нейтраль-
ный цвет.
Пример 6.8. Вырезание цветового диапазона.
Преобразования (6.5-7) и (6.5-8) могут быть использованы для вы-
деления областей, отвечающих съедобным частям клубники, на
Рис. 6.30 из остального фона: чашки, вазы, кофе и поверхности сто-
ла. На Рис. 6.34 (а) и (б) приведены результаты применения обоих пре-
образований. В обоих случаях красный цвет-прототип с RGB коор-
динатами (0,6863,0,1608, 0,1922) выбирался как доминирующий цвет
клубники; значения Wu Rq выбирались таким образом, чтобы нали-
чие светлых областей на изображении не приводило к нежелательно-
му расширению области интереса. Подходящие значения — W= 0,2549
и Rq = 0,1765 — были подобраны экспериментально. Отметим, что пре-
образование вида (6.5-8), основанное на использовании сферы, при-
водит к несколько лучшему результату, в том смысле, что выделенным
оказывается большее количество красных областей, отвечающих
клубнике. Сфера радиусом 0,1765 не содержит целиком куба с длиной
грани 0,2549, но и сама не содержится целиком в этом кубе.
6.5.4. Яркостная и цветовая коррекция
Цветовые преобразования осуществимы на большинстве из персональ-
ных компьютеров. В соединении с цифровыми фотокамерами, план-
шетными сканерами и цветными струйными принтерами они превра-
щают персональный компьютер в цифровую фотолабораторию, которая
позволяет осуществлять выравнивание яркости и цветовую коррек-
цию (две операции, составляющие основу любой системы высокока-
чественной цветной репродукции) без применения традиционных
средств химической обработки, используемых в обычной фотолабо-
ратории. Хотя яркостная и цветовая коррекции полезны в различных
областях обработки изображений, в центре нашего обсуждения будет
находиться их наиболее распространенное применение — улучшение
фотографий и цветное репродуцирование.
В этом параграфе эффективность преобразований оценивается
исключительно по результатам печати. При разработке и совершен-
ствовании этих преобразований оценка осуществляется с использо-
ванием монитора, поэтому необходимо обеспечить высокую степень
цветового соответствия между используемыми мониторами и воз-
можными устройствами вывода. В действительности, монитор должен
Глава 6. Обработка цветных изображений
точно воспроизводить цвета исходного изображения, представленно-
го в цифровом формате, равно как и окончательные цвета изображе-
ния в том виде, как они появятся на печати. Наилучшим образом это
достигается при использовании не зависящей от устройства цветовой
модели, которая связывает между собой цветовые охваты (см. Раз-
дел 6.1) мониторов, устройств вывода, а также других используемых
устройств. Успех такого подхода определяется как качеством цвето-
вых профилей, используемых для отображения каждого из устройств
в цветовую модель, так и моделью как таковой. В роли такой модели
во многих системах управления цветом выступает МКО (CIE) модель
L*aibi, называемая также моделью CIELAB ([CIE, 1978]. [Robertson,
1977]). Цветовые координаты в модели L*a*b* задаются следующими
выражениями:
£* = 116й-----16,
(6.5-9)
а* = 500
£* = 200
(6.5-10)
(6.5-11)
где
й(?) = <
7,787^+16/116,
если q > Q 008856,
если q <0.008856,
(6.5-12)
а величины Хц/, Ywh Zwпредставляют собой координаты опорного
белого цвета. В качестве такового обычно используется белый свет, от-
раженный идеальной диффузной поверхностью, освещенной источ-
ником 7)65 стандарта МКО (которому на диаграмме цветностей МКО
Рис. 6.5 соответствуют координаты цветности х = 0,3127 иу = 0,3290).
Цветовое пространство L*a*b* является колориметрическим (т.е. оди-
наково воспринимаемые цвета имеют одинаковые цветовые коор-
динаты), равноконтрастным (т.е. равным изменениям координат
цветности соответствуют равные изменения в ощущении цвета — см.
классическую работу Мак-Адама [MacAdams, 1942]) и независящим от
устройства. Хотя это цветовое пространство не может быть отобра-
6.5. Цветовые преобразования 487
жено напрямую (для отображения на экране или при печати необхо-
дим переход в другое цветовое пространство), его цветовой охват
включает весь видимый спектр и позволяет точно представить цвета
любых мониторов, принтеров и других устройств ввода-вывода. По-
добно системе HSI, система L*a*b* превосходно разделяет интенсив-
ность (которая представлена яркостью L*) и цветность (которая пред-
ставлена двумя цветоразностями: а* — красный минус зеленый и Ь* —
зеленый минус синий). Это свойство делает систему L*a*b* весьма
удобной как для улучшения изображений (тональной и цветовой кор-
рекции), так и для их сжатия7.
Главное преимущество калиброванных систем обработки изоб-
ражений состоит в том, что они позволяют осуществлять яркостную
и цветовую коррекции в интерактивном режиме независимо, т.е. в ви-
де двух последовательных операций. Вначале обычно производится
коррекция яркостного диапазона изображения, а затем устраняется
цветовой дисбаланс, такой как недостаточная или избыточная на-
сыщенность цветов. Яркостной диапазон цветного изображения свя-
зан с общим распределением интенсивности его цветов. Как и в мо-
нохромном случае, часто желательно распределить значения
интенсивности цветного изображения равномерно между наиболее
светлыми и наиболее темными значениями. В приводимых ниже
примерах рассматриваются различные цветовые преобразования, ис-
пользуемые для яркостной и цветовой коррекции.
Пример 6.9. Яркостная коррекция.
й Преобразования для изменения яркости изображения обычно вы-
бираются интерактивно. Задача — так подобрать яркость и контраст
изображения, чтобы обеспечить максимальную детализацию изобра-
жения в нужном диапазоне интенсивностей. При этом сами цвета на
изображении не изменяются. В пространствах RGB и CMY(К) это оз-
начает использование одной и той же функции преобразования для
каждой их трех (или четырех) цветовых компонент; в цветовом про-
странстве HSI преобразованию подвергается только компонента ин-
тенсивности.
На Рис. 6.35 представлены типичные преобразования, использу-
емые для коррекции трех основных типов яркостного дисбаланса.
7 Исследования показывают, что при использовании модели L*a*b* достигается на-
ивысшая степень разделения яркостной и цветовой информации по сравнению с дру-
гими цветовыми системами, такими как CIELUV, YIQ, YUV, YCC и XYZ [Kasson,
Plouffe, 1992].
(Г488 Глава 6. Обработка цветных изображений
когда изображение имеет низкий контраст, является слишком свет-
лым, или слишком темным. S-образная кривая в верхнем ряду на
этом рисунке идеально подходит для усиления контраста (ср. Рис. 3.2
(а)). Центральная точка этой кривой располагается таким образом, что-
бы значения в светлых и темных областях становились соответствен-
но еще более светлыми и темными. (Кривая, обратная по отношению
к рассматриваемой, может быть использована для уменьшения кон-
траста.) Преобразования во втором и третьем ряду на рисунке осуще-
ствляют коррекцию светлого и темного изображений и напоминают
степенные преобразования на Рис. 3.6. Хотя в действительности
функции преобразования, как и цветовые компоненты, являются
дискретными, принято изображать их и работать с ними как с непре-
рывными функциями; при этом обычно они составлены из кусочно-
линейных функций или (для более гладких отображений) из полино-
мов более высокого порядка. Заметим, что тип яркостного дисбаланса
для изображений на Рис. 6.35 виден непосредственно, однако его
также можно определить исходя из гистограмм значений цветовых
компонент изображения.
Пример 6.10. Цветовая коррекция.
После того как яркостные свойства изображения правильно откор-
ректированы, можно приступать к устранению цветового дисбалан-
са. Хотя объективно наличие цветового дисбаланса может быть уста-
новлено путем анализа на изображении какого-нибудь участка
известного цвета с помощью колориметра, однако в том случае, ког-
да на изображении имеются белые области, где значения RGB или
CMY (К) компонент должны быть равны между собой, возможна и до-
статочно точная визуальная оценка. Как можно видеть на Рис. 6.36,
оттенки кожи также являются прекрасным объектом для визуальных
оценок цвета, поскольку человеческое зрение крайне чувствительно
по отношению к цвету кожи. Яркие цвета, такие как ярко-красный
цвет, не слишком полезны, когда речь идет о визуальном оценивании
качества цветопередачи.
Существуют различные способы коррекции, применяемые при на-
личии цветового дисбаланса. При изменении цветовых компонент изо-
бражения важно понимать, что каждое действие влияет на весь цве-
товой баланс на изображении. Другими словами, восприятие каждого
цвета зависит от всех окружающих его цветов. Тем не менее, чтобы
предсказать, как одна цветовая компонента влияет на остальные,
можно использовать цветовой круг, представленный на Рис. 6.32. Ос-
новываясь на этом цветовом круге можно, например, прийти к заклю-
чению, что относительное количество некоторого цвета на изображе-
6.5. Цветовые преобразования
нии может быть увеличено, если уменьшить количество противопо-
ложного (дополнительного) цвета. Аналогично, это количество уве-
личивается при одновременном увеличении доли двух цветов, смеж-
ных с рассматриваемым цветом, или при одновременном уменьшении
доли двух цветов, смежных с дополнительным по отношению к рас-
сматриваемому цвету. Предположим, например, что на RGB изобра-
жении наблюдается избыток пурпурного цвета. Количество пурпур-
ного может быть уменьшено путем (1) одновременного уменьшения
красного и синего или (2) увеличением зеленого.
На Рис. 6.36 представлены преобразования, использованные для
коррекции простых CMYK изображений, цветовой баланс которых
был предварительно нарушен. Отметим, что на рисунке изображены
функции преобразования, необходимые для коррекции изображе-
ний (при формировании изображений с нарушенным цветовым ба-
лансом были использованы обратные к ним функции). Все вмести эти
изображения напоминают калейдоскоп отпечатков, полученных в
фотолаборатории, и могут быть полезны как атлас возможных иска-
жений в процессе цветной печати. Заметим, например, что переизбы-
ток красного цвета может быть вызван избытком пурпурного (со-
гласно левому изображению в нижнем ряду) или недостатком голубого
(как показывает крайне правое изображение во втором ряду).
6.5.5. Обработка гистограмм
В отличие от интерактивных методов обработки предыдущего пара-
графа, преобразования, рассмотренные в Разделе 3.3 и основанные на
обработке гистограмм значений яркости, могут применяться к цвет-
ным изображениям в автоматическом режиме. Напомним, что целью
преобразования эквализации гистограммы является получение изо-
бражения с равномерной гистограммой значений яркости. В случае
монохромных изображений эффективность метода эквализации ги-
стограмм была продемонстрирована (см. Рис. 3.17) для темных, свет-
лых и занимающих промежуточное положение изображений. Одна-
ко поскольку цветные изображения состоят из нескольких компонент,
то для того чтобы приспособить полутоновую технику для обработки
более чем одной компоненты и/или гистограммы, необходимо спе-
циальное рассмотрение. Очевидно, выравнивание гистограммы каж-
дой компоненты цветного изображения по отдельности является оп-
рометчивым подходом и может приводить к появлению неверных
цветов. Более логичный подход заключается в однородном растяже-
нии значений интенсивности цветов, не меняющем сами цвета (т.е.
значения цветового тона). Следующий пример показывает, что цве-
(Г490 Глава 6. Обработка цветных изображений
товое пространство HSI идеально приспособлено для реализации та-
кого подхода.
Пример 6.11. Эквализация гистограммы в цветовом пространстве
HSI.
Я На Рис. 6.37 (а) изображена вращающаяся стойка для специй с на-
ходящимися на ней графинчиками и солонками. Значения интенсив-
ности этого изображения занимают весь (нормализованный) диапа-
зон возможных значений [0, 1]. Как можно видеть по гистограмме
значений интенсивности до обработки (см. Рис. 6.37 (б)), изображе-
ние содержит большое количество темных цветов, что сдвигает меди-
ану в область меньших значений до уровня 0,36. Применение мето-
да эквализации гистограммы к компоненте интенсивности, без
изменения компонент цветового тона и насыщенности, дает изобра-
жение, представленное на Рис. 6.37 (в). Заметим, что изображение в
целом выглядит значительно более ярким, и что теперь стали видны
некоторые формы и текстура деревянного стола, на котором распо-
ложена стойка для специй. На Рис. 6.37 (б) представлена гистограм-
ма значений интенсивности этого нового изображения, а также функ-
ция преобразования интенсивности, использованная при эквализации
(см. формулу (3.3-8)).
Хотя использованный метод эквализации интенсивности не изме-
нил значения цветового тона и насыщенности изображения, он силь-
но повлиял на цветовосприятие изображения в целом. Отметим, в ча-
стности, что оказались утеряны переливы цвета, характерные для
масла и уксуса в графинчиках. Частично это удается скомпенсировать
последующим увеличением значений компоненты насыщенности
изображения с помощью функции преобразования, показанной на
Рис. 6.37 (б). Соответствующий результат приведен на Рис. 6.37 (г). Та-
кой тип коррекции часто используется при работе с компонентой
интенсивности в пространстве HSI, поскольку изменения в интенсив-
ности обычно влияют на то, как выглядят цвета на изображении.
6.6. Сглаживание и повышение резкости
В предыдущем разделе мы рассматривали преобразования цветных
изображений, при которых значение каждого пикселя изменялось
независимо от значений соседних пикселей. Наш следующий шаг
состоит в выходе за рамки таких преобразований и рассмотрении
преобразований, при которых значение каждого пикселя изображе-
ния изменяется в соответствии с характеристиками окружающих
пикселей. В настоящем разделе основные принципы такого рода ло-
6.6. Сглаживание и повышение резкости
калькой обработки рассматриваются на примерах сглаживания и по-
вышения резкости цветных изображений.
6.6.1. Сглаживание цветных изображений
В соответствии с проведенным в Разделе 3.6 обсуждением и
Рис. 6.29 (а), процедура сглаживания полутонового изображения мо-
жет рассматриваться как операция пространственной фильтрации, при
которой все коэффициенты фильтрующей маски равны по единице.
По мере того как маска перемещается по сглаживаемому изображе-
нию, значение каждого пикселя заменяется средним значением пик-
селей в окрестности, определяемой маской. Как показывает Рис. 6.29
(б), данная концепция легко распространяется на цветные изображе-
ния. Основная разница состоит в том, что вместо скалярных значений
яркости мы должны оперировать с компонентами векторов вида
(6.4-2).
Пусть Sxy обозначает совокупность координат, определяемых не-
которой окрестностью с центром в точке (х, у) в плоскости цветного
RGB изображения. Среднее значение трехкомпонентного вектора
RGB по этой окрестности равно
с(х,у)=-^ У с(х,у). (6.6-1)
К (x,yySn.
Из выражения (6.4-2) и свойств векторного сложения следует, что
с(х,у) =
У R(^y)
1 X G(x,y)
i У
л (xjfcSxy
(6.6-2)
Мы видим, что компоненты полученного среднего вектора представ-
ляют собой значения скалярных изображений, которые могут быть вы-
числены независимым сглаживанием каждой цветовой компоненты
исходного RGB изображения с использованием определенной «полу-
тоновой» процедуры обработки по окрестности. Таким образом, мы
приходим к заключению, что сглаживание методом усреднения по ок-
492 Глава 6. Обработка цветных изображений
рестности может быть осуществлено отдельно в каждой цветовой
плоскости (по каждой цветовой компоненте). При этом получаемый
результат совпадает с результатом векторного усреднения, выполня-
емого в RGB пространстве.
Пример 6.12. Сглаживание цветного изображения с помощью усред-
нения по окрестности.
Я Рассмотрим цветное изображение, представленное на Рис. 6.38 (а).
Красная, зеленая и синяя цветовые плоскости изображены на
Рис. 6.38 (б)- (г). На Рис. 6.39 (а)- (в) представлены HSI компонен-
ты этого изображения. Согласно сказанному выше, сглаживание RGB
изображения на Рис. 6.38 можно осуществить при помощи рассмот-
ренной в Разделе 3.6 усредняющей полутоновой маски размерами 5x5.
Для этого нужно сгладить каждую из RGB цветовых плоскостей не-
зависимо, а затем объединить результаты обработки в отдельных пло-
скостях для получения искомого сглаженного цветного изображе-
ния. Посчитанное таким образом изображение представлено на
Рис. 6.40 (а). Отметим, что оно выглядит так, как и можно было ожи-
дать исходя из нашего рассмотрения и примеров Раздела 3.6.
В Разделе 6.2 отмечалось, что важным преимуществом цветовой
модели HSI является то, что в ней происходит разделение интенсив-
ности (которая тесно связана с полутоновой яркостью) и цветовой ин-
формации. Это делает данную модель удобной для применения мно-
гих методов полутоновой обработки и наводит на мысль о том, что
может оказаться более эффективным осуществлять сглаживание толь-
ко компоненты интенсивности HSI представления, которое изобра-
жено на Рис. 6.39. Для того чтобы продемонстрировать достоинства
и/или последствия такого подхода, осуществим теперь сглаживание
только компоненты интенсивности (оставив без изменений компо-
ненты цветового тона и насыщенности), а для воспроизведения пре-
образуем полученный результат обратно в RGB изображение. Сгла-
женное изображение представлено на Рис. 6.40 (б). Заметим, что это
изображение весьма близко к изображению на Рис. 6.40 (а), но, как
показывает изображение их разности на Рис. 6.40 (в), не совпадает с
ним тождественно. Причина этого в том, что цвет среднего двух пик-
селей разных цветов представляет собой смесь этих цветов и не сов-
падает ни с одним из исходных цветов. Точки изображения на Рис. 6.40
(б), полученного сглаживанием только компоненты интенсивности,
сохраняют исходный цветовой тон и насыщенность, т.е. сохраняют
свой исходный цвет. В заключение отметим, что различие между ре-
зультатами сглаживания, полученными разными методами, будет
возрастать при увеличении размера сглаживающей маски.
6.6.2. Повышение резкости цветных изображений
В этом параграфе мы рассмотрим повышение резкости изображения
при помощи лапласиана (см. Раздел 3.7.2). Из векторного анализа нам
известно, что лапласиан вектора определяется как вектор, компо-
ненты которого равны лапласиану от каждой отдельной скалярной
компоненты входного вектора. В цветовом пространстве RGB ла-
пласиан вектора с вида (6.4-2) равен
V2/?(x,y)
V2 [с(х,у)]= V2G(x,y)
у2В(х,у)
(6.6-3)
Это означает, что вычисление лапласиана цветного изображения мо-
жет быть осуществлено путем вычисления лапласиана отдельно для
каждой компоненты изображения.
Пример 6.13. Повышение резкости с помощью лапласиана.
Изображение на Рис. 6.41 (а) было получено применением форму-
лы (3.7-6) к отдельным изображениям RGB компонент на Рис. 6.38 и
объединением результатов, что и дало искомое цветное изображе-
ние повышенной резкости. На Рис. 6.41 (б) представлен похожий ре-
зультат повышения резкости, основанный на использовании изобра-
женных на Рис. 6.39 HSI компонент. Для получения этого результата
вычислялся лапласиан только от компоненты интенсивности, а зна-
чения цветового тона и насыщенности не изменялись. Разность меж-
ду RGB и HSI результатами представлена на Рис. 6.41 (в). Различие ре-
зультатов обусловлено теми же причинами, что и в Примере 6.12.
6.7. Цветовая сегментация
Под сегментацией вообще понимается процесс разбиения изобра-
жения на отдельные области. Хотя сегментация является предметом
рассмотрения Главы 10, мы кратко обсудим цветовую сегментацию
здесь для целостности изложения. У читателя не должно возникнуть
трудностей в понимании нижеследующего материала.
6.7.1. Сегментация в цветовом пространстве HSI
Если мы хотим отсегментировать изображение на основе цвета, и,
кроме того, хотим иметь возможность выполнять эту операцию от-
494 Глава 6. Обработка цветных изображений
дельно по компонентам, то первое, что естественно приходит в го-
лову, — это использовать пространство HS1, поскольку в этом про-
странстве основная информация о цвете содержится в компоненте
цветового тона. Компонента насыщенности обычно используется
для формирования маски, позволяющей в дальнейшем выделить об-
ласти интереса в компоненте цветового тона. Компонента интенсив-
ности при сегментации цветных изображений используется реже,
так как она не несет цветовой информации. Ниже приводится типич-
ный пример того, как осуществляется сегментация в цветовом про-
странстве HSI.
Пример 6.14. Сегментация в пространстве HSI.
Предположим, что перед нами стоит задача выделения области
красноватого оттенка в левой нижней части изображения на Рис. 6.42
(а). Хотя это изображение является изображением в условных цветах,
его можно обрабатывать (сегментировать) как обычное цветное изо-
бражение. На Рис. 6.42 (б)- (г) представлены изображения его HSI ком-
понент. Сравнение Рис. 6.42 (а) и (б) показывает, что в интересующей
нас области цветовой тон принимает относительно высокие значения;
это указывает на то, что соответствующие цвета сдвинуты в пурпур-
но-синюю область красного цвета (см. Рис. 6.13). На Рис. 6.42 (д)
представлена двоичная маска, сформированная в результате приме-
нения процедуры порогового разделения к изображению насыщен-
ности, причем величина порога выбиралось равной 10% от максималь-
ного значения насыщенности. Любому пикселю, значение
насыщенности которого превышало пороговое, присваивалось зна-
чение 1 (белое). Всем остальным пикселям было присвоено значение 0
(черное).
На Рис. 6.42 (е) показано произведение двоичной маски и изоб-
ражения цветового тона, а на Рис. 6.42 (ж) — гистограмма этого про-
изведения (отметим, что яркость произведения принимает значе-
ния в диапазоне [0, 1J). Из гистограммы видно, что большие по
величине значения (которые представляют для нас интерес) сгруп-
пированы в крайнем правом конце яркостного диапазона вблизи
значения 1,0. Применение процедуры порогового разделения (со
значением порога 0,9) к изображению произведения на Рис. 6.42 (е)
дает двоичное изображение, которое представлено на Рис. 6.42 (з). По-
ложение белых точек указывает те места исходного изображения,
цвет которых имеет интересующий нас красноватый оттенок. Полу-
ченный результат сегментации далек от идеального: на исходном
изображении остались точки, про которые без сомнения можно ска-
зать, что они имеют красноватый оттенок, но которые не были опо-
знаны использованным методом сегментации8. Эксперименты, од-
нако, показывают, что области, отмеченные на Рис. 6.42 (з) белым,
представляют собой практически лучший результат по идентифика-
ции областей красноватого оттенка, которого можно достичь с помо-
щью рассмотренного метода. Метод сегментации, рассматриваемый
в следующем параграфе, позволяет получать значительно лучшие
результаты.
6.7.2. Сегментация в цветовом пространстве RGB
Несмотря на то, что работа в пространстве HSI, как неоднократно ука-
зывалось в настоящей главе, лучше отвечает нашим интуитивным
представлениям, тем не менее сегментация является той областью,
в которой более хорошие результаты обычно достигаются при рабо-
те в цветовом пространстве RGB. Предлагаемый метод достаточно
ясен. Предположим, что нашей задачей является сегментация объ-
ектов на RGB изображении, цвет которых лежит в некотором опре-
деленном диапазоне. Для некоторой выборки векторов в цветовом
пространстве, репрезентативной по отношению к интересующим
нас цветам, мы получаем оценку «среднего» цвета, подлежащего вы-
делению. Пусть вектор a RGB пространства обозначает этот средний
цвет. Задача сегментации заключается в том, чтобы классифициро-
вать каждый пиксель данного изображения в соответствии с тем,
попадает ли его цвет в заданный диапазон или нет. Для того чтобы
производить такое сопоставление, необходимо иметь в цветовом
пространстве некоторую меру сходства. Простейшей такой мерой
является евклидово расстояние. Пусть z — произвольная точка в
RGB пространстве. Будем говорить, что точка z сходна по цвету с точ-
кой а, если расстояние между ними не превышает некоторого задан-
ного порогового значения Dq. Евклидово расстояние между точками z
и а дается выражением
8 Как указано в Разделе 6.2.3, точки со значениями цветового тона как вблизи 1, так
и вблизи 0 имеют очень близкие оттенки цвета (в нашем случае красного, посколь-
ку в качестве нулевого уровня цветового тона был выбран именно красный цвет). Из-
за этого при пороговом выборе точек с большим значением цветового тона, точки
близкого цвета с малым значением (вблизи 0) пропали. Вообще, поскольку значения
цветового тона распределены на окружности, то правильнее осуществлять не поро-
говое разделение, а выделение точек внутри некоторой дуги окружности. Отметим
также, что в практических задачах полезно выбирать нулевую точку на участке дуги
с наиболее редко встречающимися цветами. — Прим, перев.
Глава 6. Обработка цветных изображений
Z>(z,a)=||z-а||=F(z-a)r(z- а)12 =
i (6.7-1)
=[(*/?-aR? + (*G - °g)2 + (^5 - ] 2,
где нижние индексы R, Gvi В используются для обозначения RGB
компонент векторов а и г. Геометрическое место точек, таких что
D (z, а) < £>о, представляет собой шар радиуса D§, показанный на
Рис. 6.43 (а). Точки, лежащие внутри или на поверхности шара удов-
летворяют заданному цветовому критерию; точки вне шара — не удов-
летворяют. Если присвоить двум множествам точек на изображении два
различных значения, скажем 1 (белое) и 2 (черное), то получится дво-
ичное изображение, представляющее собой результат сегментации.
Полезным обобщением (6.7-1) является расстояние, задаваемое вы-
ражением вида
Z>(z,a) = ^(z-a)rC-1(z-a)J 2, (6.7-2)
где С — ковариационная матрица9, посчитанная по выборке векторов
цветового пространства, репрезентативной по отношению к подлежа-
щему выделению цвету. Геометрическое место точек, таких что D
(z, а) < Г>о, представляет собой эллипсоид в трехмерном пространстве (см.
Рис. 6.43 (б)), важное свойство которого состоите том, что направление
его главной оси совпадает с направлением наибольшего разброса дан-
ных выборки. Если С = I, т.е. ковариационная матрица равна единич-
ной матрице размерами 3x3, то (6.7-2) сводится к (6.7-1). Процесс сег-
ментации осуществляется так же, как описано в предыдущем абзаце.
Расстояние является положительно определенной функцией. Это
дает возможность использовать не само расстояние, а его квадрат,
что позволяет избежать операции извлечения квадратного корня при
вычислениях. Однако даже в этом случае при изображениях обычных
размеров реализация (6.7-1) или (6.7-2) требует большого объема вы-
числений. Компромисс заключается в том, чтобы использовать пря-
моугольный параллелепипед, который изображен на Рис. 6.43 (в).
При таком подходе предполагается, что центр параллелепипеда нахо-
дится в точке а, а размеры параллелепипеда в направлении каждой из
осей в цветовом пространстве выбираются пропорциональными сред-
9 Вопрос вычисления ковариационной матрицы для совокупности векторов деталь-
но рассматривается в Разделе 11.4.
неквадратическому отклонению значений цветовых координат, соот-
ветствующих этой оси, в выборке. Вычисление срсднсквадратичсских
отклонений по заданной выборке векторов в цветовом пространстве
осуществляется только один раз.
Как и в формализме, основанном на использовании расстояния,
сегментация для произвольной точки цветового пространства сводит-
ся к решению вопроса о том, лежит ли эта точка внутри или на поверх-
ности параллелепипеда, или нет. Однако для параллелепипеда этот во-
прос с вычислительной точки зрения является существенно более
простым, чем для областей, имеющих сферическую или эллипсоидаль-
ную формы. Отметим, что приведенное рассмотрение представляет со-
бой обобщение метода, который обсуждался в Разделе 6.5.3 в связи с
вырезанием цветового диапазона.
Пример 6.15. Цветовая сегментация изображения в пространстве
RGB.
Прямоугольная область, показанная на Рис. 6.44 (а), содержит вы-
борку цветов красноватого оттенка, которые мы хотим выделить на дан-
ном цветном изображении. Это та же задача, которая решалась в При-
мере 6.14 с использованием компоненты цветового тона, но теперь для
ее решения применятся подход, основанный на использовании цве-
тового пространства RGB. При таком подходе по совокупности цве-
товых векторов, заключенных в прямоугольной области на Рис. 6.44
(а), вычислялся средний цветовой вектор а, после чего вычислялись
среднеквадратические отклонения для значений красной, зеленой и
синей цветовых координат векторов этой совокупности. Центр парал-
лелепипеда располагался в точке а, а размеры параллелепипеда в на-
правлении каждой из осей в RGB пространстве выбирались так, что-
бы они в 1,25 раза превосходили среднеквадратическое отклонение
данных, соответствующих этой оси. Пусть, например, среднеквадра-
тическое отклонение значений красной компоненты в выборке было
равно Тогда точкам параллелепипеда отвечали значения коорди-
нат от(aR - I,25g^) до (aR + 1,25иЛ) по оси/?, гдеaR — значение крас-
ной компоненты среднего вектора а. Далее, каждому пикселю цветно-
го изображения присваивалось одно значение (белое), если значение
этого пикселя лежало внутри или на поверхности параллелепипеда, и
другое значение (черное) в противном случае. Полученный результат
представлен на Рис. 6.44 (б). Обратим внимание на то, насколько рас-
пространилась область, выделенная на основе выборки цветовых век-
торов, заключенных в прямоугольнике. Сравнение Рис. 6.44 (б) и
Рис. 6.42 (з) показывает, что сегментация в цветовом пространстве
RGB позволила получить результаты, существенно более точные в
Глава 6. Обработка цветных изображений
том смысле, что они гораздо лучше отвечают тому, что мы бы опреде-
лили как точки красноватого оттенка на исходном изображении.
6.7.3. Обнаружение контуров на цветных изображениях
Как будет обсуждаться в Главе 10, важным инструментом для сег-
ментации изображений является обнаружение контуров. Основанный
на использовании контуров метод сегментации подробно рассматри-
вается в Разделе 10.1.3. В настоящем параграфе нас интересует вопрос
о том, чем отличается прямое вычисление контуров в цветовом век-
торном пространстве от вычисления контуров с помощью покомпо-
нентной обработки.
В Разделе 3.7.3, в связи с задачей улучшения изображений, мы по-
знакомились с методом обнаружения контуров, основанным на ис-
пользовании градиента. К сожалению, операция взятия градиента, в
том виде как она была введена в Разделе 3.7.3, не определена для век-
торных величин. Отсюда немедленно следует, что вычисление гради-
ента по изображениям отдельных компонент и использование полу-
ченных результатов для формирования цветного изображения
приводит к неверным окончательным результатам. Следующий про-
стой пример поможет нам понять, почему это происходит.
Рассмотрим представленные на Рис. 6.45 (г) и (з) два цветных изо-
бражения размерами МхМ (М—нечетное число), каждое из которых со-
стоит из трех компонент, изображенных соответственно на Рис. 6.45 (а)-
(в) и (д)- (ж). Если, например, мы вычислим градиент для изображений
каждой отдельной компоненты, а затем сложим результаты и сформи-
руем два соответствующих изображения градиента, то значения гради-
ентавточке [ (М + 1)/2, (М + 1)/2] будут одинаковы в обоих случаях. Од-
нако интуитивно следовало бы ожидать, что градиент в этой точке
должен быть больше для изображения на Рис. 6.45 (г), поскольку гра-
ницы на изображениях всех его составляющих R,Gu В проходят в од-
ном направлении, в то время как для изображения на Рис. 6.45 (з) в од-
ном направлении проходят только две из трех таких границ. Этот простой
пример показывает, что обработка, производимая отдельно в трех цве-
товых плоскостях, и последующее формирование составного изображе-
ния градиента может приводить к ошибочным результатам. Если зада-
ча состоит только в нахождении контуров, то основанный на такой
покомпонентной обработке метод обычно дает приемлемые результа-
ты. Однако для задач, в которых вопросы точности имеют первостепен-
ное значение, очевидно требуется такое новое определение градиента,
которое было бы применимо к векторным величинам. Далее мы рассмо-
трим метод, предложенный в этой связи Ди Зензо [Di Zenzo, 1986].
Перед нами стоит задача определить вектор градиента (его величи-
ну и направление) для векторной функции с (х, у) вида (6.4-2) в любой
точке (х, у). Как мы уже упоминали, введенная в Разделе 3.7.3 опера-
ция вычисления градиента применима к скалярной функции f (х, у) и
не применима к векторным функциям. Ниже приведен один из возмож-
ных способов обобщения понятия градиента на векторные функции.
Напомним, что для скалярной функции f (х, у) градиент представляет
собой вектор, направление которого совпадает с направлением наиболь-
шей скорости изменения функции f в точке с координатами (х, у).
Пусть г, g и b — единичные векторы в направлении осей R,Gvi В
цветового пространства RGB. Определим следующие два вектора
dR ЭС Э5К
11=--ГН----gH----1)
дх дх дх
и
dR dG дВ
v =—гн--gn---b.
Эу Эу Эу
(6.7-3)
(6.7-4)
Определим величины g^, gyy и gxy через скалярные произведения этих
векторов следующим образом:
т dR 2 dG 2 дв 2
Клл -U « = « « = дх + дх + дх (6.7-5)
т dR 2 dG 2 дБ 2
у,,.; = v v V v= + — + — (6.7-6)
°УУ ду ду ду
и
т dRdR dGdG дВдВ
y дх ду дх ду дх Эу
(6.7-7)
He будем забывать, что величины R,Gv\ В,а следовательно и величи-
ны g^ gyy и gxy являются функциями переменных х и у. Можно пока-
зать [Di Zenzo, 1986], что угол 0, в направлении которого скорость из-
менения функции с (х, у) максимальна, удовлетворяет уравнению
tg20 = ^^L,
(g>xx ~&уу)
(6.7-8)
Глава 6. Обработка цветных изображений
а величина скорости изменения в точке (х, у) в направлении угла 6 да-
ется выражением
1
^(е)=||[(5«+^)+(5хх-^)СО52е+2^81п20]р <6-7'9>
Поскольку tg (а) = tg (а ± л), то если 60 является решением уравнения
(6.7-8), то и Од ±л/2 является решением этого уравнения. Более того,
так как F(6) = F(Q + л), то величину Fдостаточно вычислить только
для значений 6 из полуоткрытого интервала [0, л). Тот факт, что урав-
нение (6.7-8) имеет два решения, отличающиеся на 90°, означает, что
это уравнение связывает с каждой точкой (х, у) пару взаимно перпен-
дикулярных направлений. Величина скорости изменения F макси-
мальна вдоль одного из них, и минимальна вдоль другого. Подробный
вывод приведенных результатов занимает много места, и его воспро-
изведение здесь мало что добавило бы в плане понимания главной рас-
сматриваемой нами задачи. Читатель может найти интересующие его
детали в работе [Di Zenzo, 1986]. Частные производные, необходимые
при реализации (6.7-5)- (6.7-7), могут быть вычислены, например, с
помощью рассмотренных в Разделе 3.7.3 операторов Собела.
Пример 6.16. Обнаружение контуров в цветовом векторном прост-
ранстве.
На Рис. 6.46 (а) представлено цветное изображение, а на
Рис. 6.46 (б) — его градиент, полученный с помощью только что рас-
смотренного векторного метода. На Рис. 6.46 (в) представлено изоб-
ражение, которое было получено в результате вычисления градиента
от каждой RGB компоненты исходного изображения и последую-
щего формирования изображения составного градиента путем сложе-
ния соответствующих значений трех полученных компонент в каж-
дой точке (х, у). Изображение градиента на Рис. 6.46 (б), полученное
векторным методом, содержит более подробные детали контуров,
чем аналогичное изображение на Рис. 6.46 (в), полученное в резуль-
тате покомпонентной обработки. В качестве примера обратим внима-
ние на мелкие детали в области правого глаза на портрете. Изображе-
ние на Рис. 6.46 (г) представляет собой разность двух изображений
градиента. Важно отметить, что оба подхода дают приемлемые резуль-
таты. Вопрос о том, стоят ли дополнительные детали на Рис. 6.46 (б)
затраченных на их вычисление дополнительных усилий (по сравне-
нию с реализацией операторов Собела, которые были использованы
для вычисления градиента в отдельных цветовых плоскостях), может
быть решен только исходя из требований конкретной задачи. На
6.8. Шум на цветных изображениях
Рис. 6.47 представлены изображения градиента каждой из трех ком-
понент исходного изображения, которые, после сложения и масшта-
бирования, дали изображения на Рис. 6.46 (в).
6.8. Шум на цветных изображениях
Рассмотренные в Разделе 5.2 модели шума применимы и к цветным
изображениям. Обычно шум на цветном изображении имеет одина-
ковые характеристики в каждом цветовом канале, но иногда шум
влияет на разные цветовые каналы по-разному. Такое возможно, на-
пример, в случае неисправности электроники одного из каналов. Од-
нако чаще различия в уровне шума вызываются различиями в отно-
сительном уровне освещенности каждого из цветовых каналов.
Например, установка режекторного фильтра, ослабляющего крас-
ную часть спектра, при съемке на ПЗС камеру уменьшит интенсив-
ность освещения красных сенсоров. Поскольку шум ПЗС сенсоров
увеличивается при низком уровне освещенности, то уровень шума
красной компоненты цветного RGB изображения будет в этом слу-
чае превосходить уровень шума двух других компонент.
Пример 6.17. Иллюстрация эффектов, сопутствующих преобразо-
ванию RGB изображений с шумом в систему HSI.
В этом примере мы кратко рассмотрим шум на цветных изображе-
ниях и остановимся на том, как преобразуется шум при переходе из
одной цветовой модели в другую. На Рис. 6.48 (а)- (в) представлены
три компоненты RGB изображения, искаженные гауссовым шумом,
а на Рис. 6.48 (г) представлено соответствующее цветное изображение.
Отметим, что подобного рода мелкозернистый шум заметен на цвет-
ном изображении в меньшей степени, чем на монохромном изобра-
жении. На Рис. 6.49 (а)- (в) представлены результаты преобразования
RGB изображения на Рис. 6.48 (г) в цветовую систему HSI. Сравни-
те эти результаты с изображениями HSI компонент исходного изоб-
ражения (см. Рис. 6.39) и обратите внимание, как сильно искажены
компоненты цветового тона и насыщенности для изображения с шу-
мом. Это связано с нелинейностью функций арккосинуса и миниму-
ма, входящих в формулы преобразования (6.2-2) и (6.2-3). С другой сто-
роны, изображение интенсивности на Рис. 6.49 (в) является несколько
более гладким по сравнению со всеми тремя изображениями RGB ком-
понент. Это объясняется тем, что в соответствии с формулой (6.2-4)
компонента интенсивности представляет собой среднее значение
RGB компонент. (Напомним, что усреднение уменьшает случайный
шум на изображении, как это обсуждалось в Разделе 3.4.2.)
Глава 6. Обработка цветных изображений
В том случае, когда лишь одна из RGB компонент искажена шу-
мом, преобразование в цветовую модель HSI приводит к распростра-
нению шума на все HSI компоненты. Это продемонстрировано на
Рис. 6.50. На Рис. 6.50 (а) представлено RGB изображение, зеленая
компонента которого искажена биполярным импульсным шумом,
причем вероятности импульсов обеих полярностей равны 0,05. Пред-
ставленные на Рис. 6.50 (б) - (г) изображения HS1 компонент на-
глядно показывают, что шум одной зеленой компоненты RGB изоб-
ражения распространяется на все компоненты HS1 изображения.
Это, разумеется, не является неожиданностью, поскольку для вы-
числения каждой из HSI компонент используются все RGB компо-
ненты, что и показывают формулы Раздела 6.2.3.
Подобно другим рассмотренным выше методам, фильтрация цвет-
ных изображений может осуществляться на основе покомпонентной об-
работки или прямо в цветовом векторном пространстве, в зависимос-
ти от выбранного метода. Например, уменьшение шума при помощи
усредняющего фильтра — это метод, рассмотренный в Разделе 6.6.1. ко-
торый, как нам известно, дает одинаковые результаты как при непосред-
ственном применении в цветовом векторном пространстве, так и в слу-
чае, когда каждая цветовая компонента изображения обрабатывается
отдельно. Другие фильтры, однако, не обладают подобным свойством.
Примером таких фильтров я вляются фильтры, основанные на порядко-
вых статистиках, которые рассматривались в Разделе 5.3.2. Например,
для применения медианного фильтра в цветовом векторном простран-
стве необходимо определить способ упорядочивания векторов, так что-
бы медиана имела смысл. Тогда как для скаляров дело обстоит очень про-
сто, в случае векторов упорядочивание представляет собой значительно
более сложный процесс, рассмотрение которого выходит за рамки на-
шего обсуждения. Хорошим руководством по вопросам упорядочива-
ния векторов и построению фильтров, основанных на таком упорядо-
чивании, может служить книга [Plataniotis, Venetsanopoulos, 2000].
6.9. Сжатие цветных изображений
Поскольку число битов, необходимых для представления цвета, обыч-
но в три или четыре раза превосходит число битов, используемое для
представления полутонов, то центральную роль при хранении и пе-
редаче цветных изображений играет сжатие данных. Что касается
рассмотренных в предыдущих параграфах RGB. CMY (К) и HS1 изо-
бражений, то в роли данных, подлежащих сжатию, выступают значе-
ния компонент каждой точки цветного изображения (например, крас-
Заключение
ная, зеленая и синяя компоненты пикселей RGB изображения); имен-
но посредством этих значений передается цветовая информация.
Сжатие представляет собой процесс уменьшения или устранения
избыточных и/или несущественных данных. Хотя сжатие изображе-
ний является предметом рассмотрения Главы 8, ниже мы кратко про-
демонстрируем основную идею на примере цветного изображения.
Пример 6.18. Пример сжатия цветного изображения.
На Рис. 6.51 (а) приведено 24-битовое цветное RGB изображение
цветков ириса; для представления каждого из значений красной, зеле-
ной и синей компонент используется по 8 битов. Изображение на
Рис. 6.51 (б) было восстановлено из сжатой копии изображения (а) и яв-
ляется, по существу, приближением изображения (а), полученным в ре-
зультате последовательного применения процедур сжатия и восстанов-
ления. Хотя сжатое изображения не может быть воспроизведено
непосредственно — перед выводом на цветной монитор изображение
должно быть восстановлено, — оно содержит всего 1 бит данных (и сле-
довательно, 1 бит информации для хранения) на каждые 230 битов дан-
ных исходного изображения. Если предположить, что сжатое изображе-
ние может быть передано, скажем через Интернет, за одну минуту, то
передача исходного изображения потребовала бы почти четырех часов.
Конечно, для визуализации переданные данные необходимо восстано-
вить, но эта операция может быть выполнена за время порядка секунды.
При формировании изображения на Рис. 6.51 (б) был использован ал-
горитм сжатия, основанный на недавно предложенном стандарте
JPEG 2000, который подробно рассматривается в Разделе 8.6.2. Отметим,
что восстановленное изображение является слегка размытым, что харак-
терно для многих методов сжатия с потерями. Этот эффект может быть
уменьшен или устранен при изменении степени сжатия, «и
Заключение
Материал этой главы представляет собой введение в обработку цвет-
ных изображений, и круг рассматриваемых вопросов был выбран та-
ким образом, чтобы выработать у читателя твердое понимание основ
тех методов, которые используются в этой области обработки изоб-
ражений. Наша трактовка теории цвета и цветовых моделей должна
рассматриваться как изложение основополагающего материала для той
сферы, которая сама по себе является обширной технической обла-
стью с большим количеством приложений. В частности, мы уделили
большое внимание цветовым моделям, которые, как нам кажется,
не просто полезны в цифровой обработке изображений, но дают аб-
504 Глава 6. Обработка цветных изображений
солютно необходимый инструмент для дальнейшего изучения во-
просов, связанных с обработкой цветных изображений. Рассмотрение
методов обработки изображений в псевдопветах и в натуральных цве-
тах, которые основаны на работе с отдельными компонентами, уста-
навливает связь с методами обработки полутоновых изображений, ко-
торые детально изучались в Главах 3-5.
При рассмотрении материала, посвященного цветовым векторным
пространствам, мы отходим от тех методов, которые были изучены на-
ми ранее, и особо подчеркиваем некоторые важные различия между
методами обработки в полутонах и в цвете. Существуют многочислен-
ные способы прямой обработки цветовых векторов, которые включа-
ют такие операции как медианная фильтрация, адаптивная фильтра-
ции, морфологическая фильтрация, восстановление, сжатие и многие
другие. Эти операции не эквивалентны цветовой обработке, выпол-
няемой отдельно для каждой компоненты цветного изображения. В
приведенных ниже ссылках указаны работы, которые содержат даль-
нейшие результаты в этой области.
Наша трактовка шума на цветных изображениях также показыва-
ет, что векторная природа задачи и то обстоятельство, что цветное
изображение может быть стандартным образом преобразовано из од-
ного цветового пространства в другое, имеют важные последствия в за-
даче уменьшения шума на таких изображениях. В некоторых случаях
фильтрацию шума можно осуществить с помощью покомпонентной
обработки. В других случаях, например при медианной фильтрации,
для работы с пикселями цветного изображения требуется предпринять
специальные меры, которые учитывали бы то обстоятельство, что зна-
чения пикселей представляют собой векторные величины.
Хотя сегментация изображений является предметом рассмотрения
Главы 10, а сжатие изображений — Главы 8, мы предварительно рас-
смотрели их здесь в контексте обработки цветных изображений для
того, чтобы обеспечить связность изложения. Как будет ясно из по-
следующих обсуждений, многие из развиваемых в этих главах мето-
дов применимы к материалу настоящей главы.
Библиографические замечания
В качестве наиболее полного источника информации, касающейся на-
укиоцвете, можно рекомендовать [Malacara, 2001J. По поводу физи-
ологии цветовосприятия см. [Gegenfurtner, Sharpe, 1999]. Эти две ра-
боты вместе с более ранними книгами [Walsh, 1958] и [Kiver, 1965]
содержат богатый дополнительный материал к Разделу 6.1. В качест-
ве дальнейшего чтения по цветовым моделям (Раздел 6.2) см. [Fortner,
Задачи
Meyer, 1997], [Poynton, 1996] и [Fairchild, 1998]. Подробный вывод
формул преобразования для HSI модели (Раздел 6.2.3) можно найти
в работе [Smith, 1978] или на веб-сайте книги. Тема псевдоцветов
(Раздел 6.3) тесно связана с общей проблемой визуализации данных.
Основы использования псевдоцветов хорошо изложены в работе
[Wolff, Yaeger, 1993]. Также представляет интерес книга [Thorell, Smith,
1990]. По поводу векторного представления цветовых данных (Раз-
дел 6.4) см. [Plataniotis, Venetsanopoulos, 2000].
Ссылками к Разделу 6.5 являются [Benson, 1985], [Robertson, 1977]
и [CIE, 1978]; см. также классическую работу [MacAdam, 1942]. Из-
ложение материала, относящегося к вопросам фильтрации цветных
изображений (Раздел 6.6), основано на введенном в Разделе 6.4 век-
торном формализме и нашем рассмотрении вопросов пространст-
венной фильтрации в Главе 3. Вопросы сегментации цветных изобра-
жений (Раздел 6.7) были предметом пристального внимания на
протяжении последних десяти лет. Статьи [Liu, Yang, 1994] и
[Shafarenko et al., 1998] дают представление о работах в этой области.
Представляет интерес также и специальный выпуск {IEEE Transactions
on Image Processing, 1997]. Изложение вопросов обнаружения конту-
ров на цветном изображении (Раздел 6.7.3) взято из работы [Di Zenzo,
1986]. Книга [Plataniotis, Venetsanopoulos, 2000] хороша тем, что в ней
собраны различные подходы к проблеме сегментации цветных изо-
бражений. Изложение в Разделе 6.8 основывается на введенных в
Разделе 5.2 моделях шума. Ссылки по поводу сжатия изображений
(Раздел 6.9) приведены в конце Главы 8.
Задачи
6.1 Укажите процентное содержание красного (X), зеленого (Г) и
синего (Z) света, необходимое для получения цвета, который
отмечен на Рис. 6.5 как «теплый белый».
*6.2 Рассмотрите два цвета С] и cj с координатами (х,, у0 и (х3, У2)
на диаграмме цветностей на Рис. 6.5. Выведите общее выраже-
ние (или выражения) для вычисления относительного процент-
ного содержания цветов cq и с^ в смеси, составляющей неко-
торый заданный цвет, про который известно, что он лежит на
отрезке, соединяющем эти два цвета.
6.3 Рассмотрите три цвета q, С2ИС3 с координатами (xi, yq),
(Х2, уз) и (х3, уз) на диаграмме цветностей на Рис. 6.5. Выве-
дите общее выражение (или выражения) для вычисления от-
носительного процентного содержания цветов С[, с^ и с3 в
смеси, составляющей некоторый заданный цвет, про который
Глава 6. Обработка цветных изображений
известно, что он лежит внутри треугольника с вершинами в
точках С], С2 и су
*6.4 В задаче автоматизированной сборки три типа деталей долж-
ны различаться по цвету, чтобы их было проще идентифици-
ровать. Однако предназначенная для регистрации изображе-
ний TV камера является монохромной. Предложите способ,
который позволил бы использовать такую камеру для обнару-
жения трех различных цветов.
6.5 Простое RGB изображение имеет такие горизонтальные про-
фили интенсивности своих R, G и В компонент, как пред-
ставлено ниже на диаграммах. Какой цвет отвечает среднему
столбцу этого изображения?
*6.6 Опишите в общих чертах, как будут выглядеть на монохромном
мониторе RGB компоненты представленного ниже изображения.
Все цвета на изображении имеют максимальную интенсивность
и насыщенность. При решении задачи, рассматривайте бордюр
как часть изображения (бордюр имеет средний серый цвет).
6.7 Сколько существует различных опенков серого цвета в та-
ком RGB пространстве, в котором каждая цветовая компонен-
та представляет собой 8-битовое изображение?
6.8 Рассмотрите цветовой куб RGB, представленный на Рис. 6.8,
и ответьте на следующие вопросы.
*(а) Опишите, как изменяется яркость на изображениях пер-
вичных цветов R, G и В, которые составляют переднюю
грань цветового куба.
(б) Предположим, что мы заменили каждый цвет в RGB ку-
бе на соответствующий CMY цвет и воспроизводим полу-
ченный новый куб на RGB мониторе. Укажите, какие цве-
та будут иметь восемь вершин куба на экране.
(в) Что можно сказать о насыщенности цветов, которые рас-
положены вдоль ребер цветового куба RGB?
6.9 (а) Опишите в общих чертах, как будут выглядеть на моно-
хромном мониторе CMY компоненты изображения из За-
дачи 6.6.
(б) Опишите изображение, которое получится, если подать
эти CMY компоненты соответственно на красный, зеленый
и синий входные каналы цветного монитора.
*6.10 Выведите выражение (6.5-6) для функции преобразования
интенсивности в CMYпространстве из выражения (6.5-5) для
соответствующей функции в RGB пространстве.
6.11 Рассмотрите полный набор из 216 фиксированных цветов,
представленный на Рис. 6.10 (а). Присвойте каждой ячейке но-
Задачи
5071
*6.12
6.13
*6.14
6.15
6.16
мера (строки и столбца) согласно ее местоположению, так
чтобы левой верхней ячейке отвечала пара (1,1), а нижней
правой — (12,18). В какой ячейке будет находиться
(а) наиболее насыщенный зеленый цвет?
(б) наиболее насыщенный синий цвет?
Опишите в общих чертах, как будут выглядеть на монохром-
ном мониторе HSI компоненты изображения из Задачи 6.6.
Предложите метод получения цветного изображения, сходно-
го с изображением видимой части электромагнитного спект-
ра на Рис. 6.2. Заметим, что диапазон начинается с темно-
фиолетового цвета в левой части и заканчивается чистым
красным цветам справа. (Указание: используйте цветовую мо-
дель HSI.)
Предложите метод формирования цветного варианта изобра-
жения, представленного на Рис. 6.13 (в) в виде диаграммы. От-
вет дайте в виде блок-схемы. Считайте значение интенсивно-
сти постоянным и заданным. (Указание: используйте цветовую
модель HSL)
Рассмотрите следующее изображение, составленное из сплош-
ных цветных квадратов. Используйте при решении задачи яр-
костную шкалу, состоящую из восьми градаций от 0 до 7, в ко-
торой 0 соответствует черному, а 7 — белому. Пусть изображение
преобразуется в цветовое пространство HSL Отвечая на постав-
ленные ниже вопросы, используйте при описании яркости
определенные числа в том случае, когда это возможно. В про-
тивном случае пользуйтесь выражениями типа «равный по
яркости», «более светлый» или «более темный». Если невоз-
можно описать яркость ни одним из указанных способов, то
объясните почему.
(а) Опишите изображение цветового тона.
(б) Опишите изображение насыщенности.
(в) Опишите изображение интенсивности.
Следующие 8-битовые изображения суть (слева направо) изо-
бражения H,Si\ ! компонент с Рис. 6.16. Значения яркости ком-
понент указаны числами на рисунках. Ответьте на поставлен-
ные ниже вопросы и обоснуйте Ваш ответ в каждом отдельном
случае. Если исходя из имеющейся информации, дать ответ на
вопрос невозможно, то сформулируйте точно причину этого.
*(а) Найдите значения яркости для всех областей на изображе-
нии цветового тона.
*(б) Найдите значения яркости для всех областей на изображе-
нии насыщенности.
Глава 6. Обработка цветных изображений
*(в) Найдите значения яркости для всех областей на изображе-
нии интенсивности.
6.17 Следующие вопросы связаны с Рис. 6.27.
(а) Почему изображение на Рис. 6.27 (е) окрашено преимуще-
ственно в красные тона?
(б) Предложите способ, позволяющий в автоматическом ре-
жиме закрасить воду на Рис. 6.27 в ярко-синий цвет.
(в) Предложите способ, позволяющий в автоматическом ре-
жиме закрасить на изображении объекты преимуществен-
но искусственного происхождения в ярко-желтый цвет.
{Указание', воспользуйтесь изображением на Рис. 6.27 (е).)
*6.18 Покажите, что компонента насыщенности для цветового до-
полнения некоторого цветного изображения не может быть вы-
числена только на основе компоненты насыщенности исход-
ного изображения.
6.19 Объясните вид представленной на Рис. 6.33 (б) функции пре-
образования для компоненты цветового тона, которая ис-
пользуется при вычислении приближенного цветового допол-
нения в цветовой модели HSI.
*6.20 Выведите функции преобразования, которые нужно исполь-
зовать в модели CMY для получения цветового дополнения.
6.21 Опишите общий вид функций преобразования в цветовом
пространстве RGB для устранения излишнего контраста на
изображениях.
*6.22 Предположим, что монитор и принтер некоторой системы обра-
ботки изображений имеют неправильную калибровку. Изобра-
жение, цвета которого на мониторе кажутся сбалансированны-
ми, при печати приобретает желтоватый оттенок. Опишите общие
преобразования, которые могут устранить этот дисбаланс.
6.23 Вычислите цветовые координаты в модели L*a*b* для изобра-
жения из Задачи 6.6, полагая, что
0,588
0,29
0
0,179 0,183
0,606 0,105
0,068 1,021
R
G
В
Это матричное равенство определяет значение цветовых коор-
динат света, испускаемого цветными TV люминофорами стан-
дарта NTSC (National Television Standards Committee — На-
циональный комитет по телевизионным стандартам) при
освещении стандартным источником D65 [Benson, 1985].
Задачи
*6.24 Как бы Вы реализовали для цветных изображений метод, ана-
логичный методу приведения (задания) гистограммы для по-
лутоновых изображений из Раздела 3.3.2?
6.25 Рассмотрим следующее цветное RGB изображение размерами
500x500, состоящее из квадратов чисто красного, зеленого и си-
него цветов.
(а) Выполним следующую последовательность действий. Пре-
образуем изображение в систему HSI, сгладим компонен-
ту цветового тона при помощи усредняющей маски разме-
рами 25x25 и перейдем обратно в систему RGB. Как будет
выглядеть полученный результат?
(б) А если сгладить компоненту насыщенности?
6.26 Покажите, что выражение (6.7-2) сводится к выражению
(6.7-1), если С = I, т.е. является единичной матрицей.
6.27 *(а) В связи с рассмотрением в Разделе 6.7.2, сформулируйте (в
виде блок-схемы) алгоритм для определения того, находит-
ся ли цветовой вектор (точка) z внутри куба с центром в точ-
ке а и длиной стороны И< Алгоритм не должен включать
вычисление расстояний.
(б) Если стороны куба направлены вдоль координатных осей,
то в этом случае алгоритм может быть реализован на осно-
ве обработки отдельных компонент в цветовом простран-
стве. Как бы Вы это сделали?
6.28 Опишите поверхность в RGB пространстве, которая задается
уравнением
1
£>(z,a) = pz-a)rC-1(z-a)]2 = Л0,
где Dq — некоторая ненулевая постоянная. Считайте, что а = 0 и
8
С= 0
0 0
1 0
0 1
0
6.29 Данная задача связана с материалом Раздела 6.7.3. Может по-
казаться, что при определении градиента RGB изображения в
точке (х, у) естественно было бы поступить следующим обра-
зом: вычислить вектор градиента (см. Раздел 3.7.3) от каждой
компоненты изображения и определить вектор градиента цвет-
ного изображения как векторную сумму полученных градиен-
Глава 6. Обработка цветных изображений
тов трех отдельных компонент. К сожалению, такой метод
может временами давать ошибочные результаты. А именно,
цветное изображение с четко определенными контурами мо-
жет, в случае использования этого метода, иметь нулевой гра-
диент. Приведите соответствующий пример. (Указание: для
простоты считайте, что одна из цветовых компонент изобра-
жения имеет постоянное значение.)
ГЛАВА 7
ВЕЙВЛЕТЫ И
КРАТНОМАСШТАБНАЯ
ОБРАБОТКА
Контролер все это время внимательно ее разглядывал —
сначала в телескоп, потом в микроскоп и,
наконец, в театральный бинокль.
Льюис Кэррол, Алиса в Зазеркалье.
Введение
Хотя преобразование Фурье является основой трансформационных
методов обработки изображений еще с конца 1950-х годов, примене-
ние более современного преобразования, называемого вейвлет-пре-
образованием упрощает сжатие, передачу и анализ многих изображе-
ний. В отличие от преобразования Фурье, базисными функциями
которого являются гармонические функции, вейвлет-преобразования
основаны на разложении по малым волнам, называемым вейвлетами^,
изменяющейся частоты и ограниченным во времени (в пространст-
ве). Такое разложение для изображения можно сравнить с нотной
записью музыкального произведения, которая указывает музыканту
не только какую ноту (частоту) взять, но и в какой момент это следу-
ет сделать. В противоположность этому обычное преобразование Фу-
рье содержит только частотную информацию (ноты); временная
информация теряется в процессе преобразования.
В 1987г. впервые было продемонстрировано [Mallat, 1987], что
вейвлеты могут быть положены в основу нового мощного метода об-
работки и анализа сигналов, получившего название кратномасштаб-
ный анализ. Эта теория сводит воедино методы из разных областей, та-
кие как субполосное кодирование из теории обработки сигналов,
1 Термин вейвлет (от английского -wavelet — маленькая, небольшая в смысле продол-
жительности волна), утвердился в русской литературе, относящейся к областям об-
работки информации, сигналов и изображений. В математической литературе полу-
чил распространение предложенный К. И. Осколковым термин всплеск. — Прим,
перев.
Глава 7. Вейвлеты и кратномасштабная обработка
квадратурную зеркальную фильтрацию из теории распознавания
речи и пирамидальную обработку изображений. Как следует из ее
названия, кратномасштабная теория имеет дело с представлением
и анализом сигналов (или изображений) в различных масштабах, т.е.
при различных разрешениях2. Преимущество такого подхода оче-
видно — характерные детали, которые могут оставаться незаметными
при одном разрешении, легко могут быть обнаружены при другом.
Хотя до конца 1980-х годов интерес научного сообщества к кратно-
масштабной теории был весьма ограничен, в настоящий момент уже
трудно уследить за всеми статьями, докладами и книгами, посвящен-
ными данному предмету.
Настоящая глава посвящена изучению преобразований, основан-
ных на вейвлетах, с точки зрения кратномасштабного анализа. Хотя
эти преобразования могут быть введены и другими способами, такой
подход упрощает как математическую, так и физическую трактовку.
Мы начнем с краткого рассмотрения тех методов обработки изобра-
жений, которые, в числе других, предопределили появление кратно-
масштабной теории. Наша цель состоит в том, чтобы привести основ-
ные концепции теории в контексте обработки изображений, а заодно
дать небольшой исторический обзор методов и их приложений.
Большая часть главы посвящена разработке «кратномасштабного ин-
струментария» для представления и обработки изображений. Полез-
ность этого набора средств демонстрируется на разнообразных
примерах, от кодирования изображений до устранения шума и об-
наружения контуров. В следующей главе будет рассматриваться при-
менение вейвлетов для сжатия изображений — приложение, в котором
они нашли широкое применение.
7.1. Предпосылки
Когда мы смотрим на изображение, мы обычно видим связанные об-
ласти одинаковой структуры и яркости, которые, объединяясь, обра-
зуют объекты на изображении. Если эти объекты имеют маленький
размер или низкий контраст, то мы как правило изучаем их при вы-
2 Следуя установившейся традиции, для перевода английского multiresolution (мно-
жественное разрешение) мы везде используем прилагательное кратномасштаб-
ный. Следует иметь в виду, что в действительности разные масштабы (разреше-
ния), о которых идет речь, являются кратными по отношению друг к другу, т.е.
связаны целой степенью некоторого масштабного фактора, который в большинстве
случаев равен 2. — Прим, перев.
соком разрешении; если же они имеют большой размер или высокий
контраст, то вполне достаточно и поверхностного осмотра. Когда на
изображении одновременно присутствуют как большие, так малень-
кие объекты (или как низкоконтрастные, так и высококонтрастные
объекты), то полезным может оказаться анализ такого изображе-
ния в разных масштабах (при различных разрешениях). Это и есть
основная мотивировка для использования кратномасштабной
обработки.
С математической точки зрения изображение представляет со-
бой двумерный массив значений яркости с локально зависимыми
статистиками, что обусловлено различным сочетанием характерных
резких деталей, таких как контуры и контрастные однородные обла-
сти. Как демонстрирует изображение на Рис. 7.1, которое будет еше
неоднократно рассматриваться в этом разделе, даже статистики пер-
вого порядка значительно изменяются при переходе от одной части изо-
бражения к другой, что мешает применению ко всему изображению
одной простой статистической модели.
Рис. 7.1. Обычное изображение и локальные гистограммы отдельных его
фрагментов.
18 А-223
7.1.1. Пирамиды изображений
Мощной, но концептуально простой структурой для представления
изображений в более чем одном масштабе является пирамида изобра-
жений [Burt, Adelson, 1983]. Разработанная первоначально для приме-
нения в задачах машинного зрения и сжатия изображений, пирами-
да изображений представляет собой набор изображений в
уменьшающемся масштабе, организованный в форме пирамиды. Как
видно из Рис. 7.2 (а), основу пирамиды составляет подлежащее обра-
ботке изображение высокого разрешения; вершина пирамиды со-
стоит из приближения низкого разрешения. По мере движения вверх
по пирамиде масштаб (размеры и разрешение) уменьшаются. Если
нижний уровень J имеет размеры 2/х2-/ или NxN, где J= log 2А, то про-
межуточный уровеньj имеет размеры 2J х 2/, где 0 <j < J. Целиком за-
полненная пирамида состоит из J + 1 уровней от 2Jx2J до 2°х2°, но в
большинстве случаев пирамида усекается до Р + 1 уровней, где j —
J—P,..., J—2, J— 1, J и 1 < Р< J. Таким образом мы обычно ограничи-
ваемся Р приближениями исходного изображения в уменьшенном мас-
штабе; приближение размерами 1x1, т.е. одноточечное, не слишком
информативно для описания исходного изображения размерами, на-
пример, 512x512 элементов. Полное число элементов на Р + 1 уров-
нях пирамиды для Р > 0 составляет
N2
1 1
4|+42
4'J
— N2
3
На Рис. 7.2 (б) показана простая блок-схема для построения пи-
рамиды изображений. Приближение (J—1)-го уровня на выходе блок-
схемы позволяет сформировать пирамиды приближений, содержащие
один или более уровней приближения исходного изображения. До-
ступными при этом являются как исходное изображение, лежащее в
основании пирамиды, таки Рприближений уменьшенного масшта-
ба, которые могут использоваться самостоятельно. Разность с пред-
сказанием j-го уровня на выходе схемы на Рис. 7.2 (б) используется для
построения пирамиды разностей с предсказаниями. На уровне J— Рта-
кие пирамиды содержат приближение исходного изображения само-
го мелкого масштаба, а на других уровнях — информацию, необхо-
димую для построения приближений более крупного масштаба.
Информация на у-ом уровне представляет собой разность между
приближением у-го уровня соответствующей пирамиды приближе-
ний и оценкой этого приближения, которая вычисляется на основе
приближения (/ — 1)-го уровня. Эта разность может быть закодиро-
Входное
изображение
уровня j
Прореживающая
выборка
Разность с
предсказанием
уровня j б
Рис. 7.2. (а) Структура пирамиды изображений и (б) блок-схема процедуры ее
формирования.
вана и, в силу этого, может храниться и передаваться более эффек-
тивно, чем сами приближения.
Как показывает блок-схема на Рис. 7.2 (б), пирамиды приближе-
ний и разностей с предсказаниями вычисляются итеративным обра-
зом. Для построения (Р+ 1)-го уровня пирамиды нужно Рраз выпол-
нить операции, представленные на блок-схеме. Во время первой
итерации (первого прохода) j = J,n исходное изображение размера-
ми 2Jx2J рассматривается как входное изображение J-го уровня. На
выходе мы получаем приближение (J— \)-го уровня и разность с пред-
сказанием J-го уровня. Во время проходов у =./— 1, J — 2,..., J — Р+ 1
(именно в таком порядке) полученное на предыдущей итерации при-
ближение (j — 1)-го уровня выполняет роль входного изображения.
Каждый проход состоит из следующих последовательных шагов.
1. Вычисление приближения уменьшенного масштаба для входно-
го изображения. Этот шаг состоит в фильтрации входного изобра-
жения и прореживающей выборке3 с фактором 2. Можно использо-
вать различные виды фильтрации, такие как усреднение по
окрестности, что дает пирамиду средних значений, гауссову низкоча-
стотную фильтрацию, что дает гауссову пирамиду, или не использо-
вать фильтрацию вовсе, что дает пирамиду прореженных значений.
Качество получаемого приближения, обозначенного на блок-схеме
Рис. 7.2 (б) как приближение (/' — \)-го уровня, зависит от используе-
мого фильтра. При отсутствии фильтрации, на изображениях верх-
них уровней пирамиды может проявиться ступенчатость контуров,
поскольку выбранные пиксели могут оказаться плохими представи-
телями тех областей, из которых они выбраны.
2. Сгущающая выборка (снова с фактором 2) для полученного на
первом шаге изображения и интерполяция. В результате мы полу-
чаем предсказание, которое представляет собой изображение того
же масштаба, что и изображение на входе. Вид интерполяционного
фильтра, используемого для построения значений яркости в тех точ-
ках, которые являются промежуточными по отношению кточ-
кам изображения на выходе шага 1, определяет то, насколько точ-
но предсказанное изображение будет аппроксимировать исходное
изображение на входе шага 1. Если интерполяционный фильтр
отсутствует4, то предсказание представляет собой просто сгу-
щенную копию изображения на выходе шага 1, и могут проявить-
ся связанные с дублированием пикселей ступенчатые эффекты.
3. Вычисление разности между предсказанием шага 2 и входным изо-
бражением шага 1. Эта разность, обозначенная на блок-схеме
Рис. 7.2 (б) как разность с предсказанием]-го уровня, можетвдаль-
нейшем быть использована для последовательного восстановле-
ния исходного изображения (см. Пример 7.1). Пирамида разностей
с предсказаниями (в отсутствие посторонних ошибок, например,
ошибок квантования) позволяет точно построить соответствую-
щую пирамиду приближений, включая исходное изображение.
3 Прореживающая выборка или просто прореживание (downsampling) с фактором 2 есть
операция, которая заключается в отбрасывании каждого второго отсчета. Обратная
операция называется сгущающей выборкой или сгущением (upsampling) и состоит в
добавлении нового отсчета между каждыми двумя старыми. По умолчанию предпо-
лагается, что значения добавленных отсчетов равны нулю. — Прим, перев.
4 Точнее, используется простейший метод интерполяции по ближайшему соседу,
т.е., фактически, значения яркости в промежуточных точках дублируют значения в
соседних точках. — Прим, перев.
7.1. Предпосылки 517
Проделав Р раз описанную выше процедуру, мы получим Р + 1
уровень двух тесно связанных между собой пирамид: пирамиды при-
ближений и пирамиды разностей с предсказаниями. Изображения, яв-
ляющиеся приближениями (J — 1)-го уровня, составляют пирамиду
приближений; изображения, представляющие собой разности с пред-
сказанием j -го уровня, составляют пирамиду разностей с предсказани-
ями. Если построение пирамиды разностей с предсказаниями не тре-
буется, то шаги 2 и 3, вместе со сгущающей выборкой и процедурами
интерполяции и суммирования на Рис. 7.2 (б), можно опустить.
Пример 7.1. Гауссова пирамида и пирамида лапласианов.
И На Рис. 7.3 представлены две возможные пирамиды (приближений
и разностей с предсказаниями) для изображения с вазой на Рис. 7.1.
Пирамида приближений на Рис. 7.3 (а) является гауссовой. Фильт-
рация осуществлялась в пространственной области при помощи низ-
кочастотного гауссова фильтра с маской 5x5, подобного тем, что
изображены на Рис. 4.9 (в) Раздела 4.2.4. Как можно видеть, получен-
ная пирамида состоит из исходного изображения (в основании пи-
рамиды), и трех приближений уменьшенных масштабов размерами
256x256,128x128 и 64x64. Таким образом Р= 3, и пирамида была усе-
чена до четырех уровней — с номерами 9, 8, 7 и 6 — из возможных
log 2 (512) + 1 или 10 уровней. Обратим внимание на уменьшение де-
тализации, которое сопровождает уменьшение масштаба изображений
в пирамиде. Приближение 6-го уровня (т.е. размерами 64x64), напри-
мер, позволяет обнаружить местонахождение оконного проема, но не
стебли растения. Вообще, уровни пирамиды мелких масштабов мо-
гут быть использованы для анализа структур большого размера или
содержания изображения в целом; изображения крупных масштабов
подходят для анализа особенностей отдельных объектов. Такая стра-
тегия анализа, состоящая в постепенном переходе от грубого просмо-
тра к точному рассмотрению, особенно полезна при распознавании
образов.
Пирамида лапласианов на Рис. 7.3 (б) содержит разности с пред-
сказаниями, необходимые для вычисления дополняющей ее гауссо-
вой пирамиды на Рис. 7.3 (а). Чтобы построить гауссову пирамиду, сна-
чала берется изображение размерами 64x64, являюшееся
приближением 6-го уровня в пирамиде лапласианов, с помощью сгу-
щающей выборки и интерполяции предсказывается приближение
7-го уровня гауссовой пирамиды (размерами 128x128), и прибавляет-
ся разность с предсказанием 7-го уровня пирамиды лапласианов. За-
тем эта процедура повторяется по отношению к последовательно вы-
числяемым приближениям до получения исходного изображения
Рис. 7.3. Две пирамиды изображений и их гистограммы: (а) гауссова пирами-
да (приближений) и (б) пирамида лапласианов (разностей с предсказаниями).
размерами 512x512. Обратим внимание на то обстоятельство, что ги-
стограмма изображений разности с предсказаниями в пирамиде ла-
пласианов имеет ярко выраженный пик вблизи нуля. В отличие от изо-
бражений, составляющих соответствующую гауссову пирамиду, эти
изображения могут быть сильно сжаты путем присваивания кодов
меньшей длины наиболее вероятным значениям (см. метод неравно-
мерного кодирования в Разделе 8.1.1). В заключение отметим, что
разности с предсказаниями на Рис. 7.3 (б) проградуированы таким об-
разом, чтобы сделать заметными меньшие по величине ошибки пред-
сказания; однако соответствующая гистограмма посчитана на осно-
ве результатов до градуировки, при этом значение 128 отвечает нулевой
ошибке.
7.1. Предпосылки
7.1.2. Субполосное кодирование
Другим важным методом, используемым при обработке изображений
и связанным с кратномасштабной теорией, является субполосное ко-
дирование. Этот метод был первоначально разработан для сжатия ре-
чевых сигналов и изображений. В субполосном кодировании изобра-
жение разлагается на несколько составляющих с ограниченным
диапазоном частот, которые могут быть снова собраны воедино, что
позволит точно (без искажений) восстановить исходное изображение.
Каждая составляющая называется субдиапазоном и формируется в ре-
зультате применения полосовой фильтрации к входному изображению.
Поскольку полоса частот субдиапазонов уже, чем у исходного изоб-
ражения, применение к ним прореживающей выборки не приводит
к потере информации. Восстановление исходного изображения дости-
гается при помощи сгущающей выборки, фильтрации и сложения
отдельных субдиапазонов.
На Рис. 7.4 (а) представлена блок-схема двухканальной системы
субполосного кодирования и декодирования. На вход системы пода-
ется сигнал, представляющий собой последовательность х(п),
и = 0,±1,±2,..., которая может рассматриваться как последовательность
отсчетов одномерной функции времени с полосой ограниченной ши-
рины (с ограниченным спектром). Последовательность х(п) на выхо-
де системы формируется путем разложения сигналах(и) на составля-
ющие Уо(и) и У|(«) с помощью фильтров анализа Hq(h) и h\(n) и
Рис. 7.4. (а) Двухканальный блок фильтров для субполосного кодирования
и декодирования одномерного сигнала и (б) спектры его фильтров анализа.
последующего объединения с помощью фильтров синтеза gQ(n) ng|(«).
Фильтры анализа /?о(и) и й](л) представляют собой цифровые филь-
тры с полосой пропускания вдвое меньшей, чем полоса исходного сиг-
нала; идеализированные передаточные функции Hq и Я] фильтров та-
кого рода представлены на Рис. 7.4 (б). Фильтр Hq представляет собой
низкочастотный фильтр, сигнал на выходе которого является (низко-
частотным) приближением исходного сигнала х(и). Фильтр Нх пред-
ставляет собой высокочастотный фильтр, сигнал на выходе которо-
го является высокочастотной или детальной частью исходного сигнала
х(п). Фильтрация всегда осуществляется во временной области и
представляет собой свертку входного сигнала с импульсной характе-
ристикой соответствующего фильтра (ядром) в пространственной
области, т.е. с его импульсным откликом (откликом на импульсную
функцию единичной амплитуды — 8(и)). Мы хотим так выбрать филь-
тры й0(и), й|(и), go(w) и£1(л) (или, что равносильно, Hq, H\,GqH G|),
чтобы исходный сигнал мог быть правильно восстановлен, т.е. чтобы
х(п) = х(п).
Идеальным средством для изучения систем с дискретным временем,
таких как представленная на Рис. 7.4 (а) система, является Z-преоб-
разование, которое может рассматриваться как обобщение дискрет-
ного преобразования Фурье. Z-преобразование последовательности
х(п), п = 0, ±1, ±2,..., имеет вид
X(z) = Yx(n)z'n, (7.1-1)
где z — комплексная переменная5. (Если в качестве переменной z
подставить e'w, то (7.1 -1) превратится в дискретное преобразование Фу-
рье последовательностих(п)). Наш интерес к Z-преобразованию оп-
ределяется его свойствами по отношению к изменению частоты дис-
кретизации. Прореживающая выборка с фактором 2 во временной
области отвечает в Z-области следующей операции
5 Рассматриваемое преобразование ставит в соответствие последовательности х (и)
формальный ряд X(z) вида (7.1-1), который часто называют символом данной после-
довательности. Если переменная z принимает значения на круге единичного ради-
уса в комплексной плоскости, z — е iv>, то этот ряд превращается в ряд Фурье
.Если последователь! юстьДи) суммируема с квадратом, т.е.
то он определяет 2л-периодическую интегрируемую с квадратом на периоде функ-
цию Дсо). Обратно, любая такая функция определяет последовательностьх(и), чле-
нами которой являются коэффициенты ее разложения в ряд Фурье. Функцию Х(а)
естественно интерпретировать как спектр последовательности х(п). — Прим, перев.
7.1. Предпосылки
х^п(п)^х(2п) « ^downU)=|[^^'/2)+^(-Z1/2)]5 (7.1-2)
где двойная стрелка указывает на то, что выражения слева и спра-
ва от нее образуют Z-napy. Аналогично, сгушаюшая выборка, снова
с фактором 2, определяет следующую Z-napy:
up, ч Jat(w/2) л = 0,±2,±4,...;
X v(n) = <
[О и = ±1,±3,±5,...;
Xup = X(z2). (7.1-3)
Если обозначить через х(п) последовательность, которая получается
в результате последовательного применения к последовательнос-
ти х(п) прореживающей выборки и сгущающей выборки, то совмест-
ное использование (7.1-2) и (7.1-3) дает
X(z) = i[X(z) + X(-3], (7.1-4)
причем .£(«) = Z~l[X (^)] . Член Х(—z) в (7.1-4) является Z-преобразо-
ванием последовательности, которая представляет собой результат мо-
дуляции или сдвига спектра6 последовательности х(п). Обратное Z-npe-
образование Х(—z) имеет вид
Z[Х(-г)]=(-1)пх(и). (7.1-5)
После этого краткого введения в теорию Z-преобразования вер-
немся к рассмотрению представленной на Рис. 7.4 (а) системы субпо-
лосного кодирования и декодирования. В соответствии с (7.1-4) мы
можем записать для сигнала на выходе системы
ха)=|(70и)[Я0а)Хи)+Я0(-г)А'(-г)]+
1 (7.1-6)
где, например, сигнал на выходе фильтра/?о(и) на Рис. 7.4 (а) опреде-
ляется Z-парой вида
6 В случае z = езамена z —> — z, очевидно, эквивалентна замене со —> со + л, т.е. при-
водит к сдвигу спектра последовательности. — Прим, перев.
hQ{n)*x(n) = ^hQ(n-k)x(k) <=> H0(z)X(z)- (7.1-7)
к
Как и в случае преобразования Фурье, свертка во временной (или про-
странственной) области эквивалентна умножению в Z-области. Пе-
регруппировывая члены в (7.1-6), мы получаем выражение
* (*) = Ч [яо UXW + Я, (zX7j (г) ]ВД+
2 (7.1-8)
+|[Я0 (-№(г) + Нх (-zYh (z) ]*(-z),
причем второе слагаемое в правой части, которое появилось в ре-
зультате последовательного применения прореживающей выборки
и сгущающей выборки, приводит к эффектам наложения спектров, по-
скольку, в силу того что оно содержит зависимость от —z, представляет
собой результат сдвига спектров.
Точное восстановление исходного сигнала означает, что х(и) = л(л)
и X (z) = X (z) Поэтому потребуем выполнения следующих условий:
Яо (-z)G0 (z) + Нх (~z)G\ (z) = 0, (7.1 -9)
Я0(г)Я0 (z)+Я] (zX7, (z)=2. (7.1-10)
Условие (7.1-9) обеспечивает обращение в нуль второго слагаемого в
правой части (7.1-8) и, тем самым, устраняет эффекты наложения
спектров7. Первое слагаемое в (7.1-8) при выполнении условия (7.1-10)
7 Самый простой способ исключить наложение спектров и добиться выполнения ус-
ловий (7.1-9) и (7.1-10) состоит в том, чтобы использовать идеальные фильтры:
й0(со) = 1, при |со| < л/2, и й0(со) = 0, при л/2 < |со| < л, h] (со) = 1 — йо(со), g0(co) = 2й(1(со)
и £i(k>) = 2й,(со). С учетом примечания 6 выполнение нужных условий очевидно.
Кроме того, из общих соображений ясно, что поскольку данные фильтры анализа пол-
ностью разделяют частоты спектра пополам (области частот, где их передаточные
функции не обращаются в нуль, перекрываются), то эффект наложения спектров не
возникает. Проблема, однако, состоит втом, что коэффициенты ядер (импульсныхха-
рактеристик) этих фильтров в пространственной области очень медленно (лишь как
и-1) убывают на бесконечности. Причиной такого медленного убывания являются
разрывы передаточных функций фильтров в частотной области. Поэтому такие филь-
тры не пригодны для практического использования. Для того чтобы обеспечить бо-
леебыстрое убывание коэффициентов, нужно использовать фильтры с большей глад-
костью в частотной области. Это приведет к тому, что области частот, где передаточные
функции фильтров не обращаются в нуль, начнут перекрываться (см., например,
сводится к X(z), т.е. это условие препятствует искажению амплитуды
сигнала. Оба условия можно объединить в одно матричное выражение
[<70(г) qU)]H,„U) = [2 0], (7.1-11)
где матрица модуляции анализа Hw(z) равна
HmU) =
Я0(г)
Нх (г)
Я0(-г)
#i(-z)
(7.1-12)
Предполагая, что матрица Hw(z) неособенная, т.е. существует обрат-
ная матрица (которая является одновременно и левой, и правой об-
ратной матрицей), мы можем транспонировать (7.1-11) и умножить
полученное равенство слева на матрицу (нг(г)) Это дает
GOU)1 2 Г Я1(-г)
_Й(*)] det(HwU))L-^0(-^)J’
(7.1-13)
где det(Hw(z)) — детерминант матрицы Hw(z).
Выражения (7.1-9)— (7.1-13) обнаруживают ряд важных свойств
блоков фильтров точного восстановления. Матричное равенство
(7.1-13), например, показывает, чтобДД есть функция Д/—г), вто вре-
мя как Gq(z) есть функция Н\(—z). Фильтры анализа и синтеза явля-
ются перекрестно-модулированными^, т.е. фильтры, расположенные
друг напротив друга по диагонали в блок-схеме на Рис. 7.4 (а), функ-
ционально связаны между собой в Z-пространстве преобразованием,
состоящим в замене z —> —Z- Для фильтров с конечной импульсной ха-
рактеристикой9 (КИХ-фильтров) детерминант матрицы модуляции
Рис. 7.4 (б)) и может возникнуть эффект наложения спектров, препятствующий точ-
ному восстановлению. Дальнейшее рассмотрение в тексте связано с разрешением
указанной проблемы. А именно, рассматривается вопрос о нахождении гладких (в ча-
стотной области) фильтров точного восстановления. - Прим, перев.)
8 Это утверждение, вообще говоря, необоснованное, поскольку множитель в правой
части (7.1-13) содержит детерминант матрицы модуляции анализа Н,„(г) в знаменате-
ле. В случае КИХ-фильтров (см. далее в тексте) утверждение справедливо с точностью
до сдвига фильтров в пространственной (временной) области. — Прим, перев.
9 Фильтр h называется фильтром с конечной импульсной характеристикой, если
лишь конечное число значений h(n) отлично от нуля. Такой фильтр полностью зада-
ется своими значениями в целых точках некоторого конечного интервала, число
этих точек называется длиной фильтра. КИХ-фильтры представляют наибольший
практический интерес. — Прим, перев.
представляет собой чистое запаздывание, т.е. det(Hw(z)) = аг_(2Л+1)
(см., например, [Vetterli, Kovacevic, 1995]). Множительz~(2fc+l) мож-
но не принимать во внимание, поскольку он лишь приводит к сдви-
гу в пространственной области, изменяющему общее запаздывание
фильтра. Таким образом, точный вид перекрестной модуляции зависит
от значения а. Игнорируя запаздывание, полагая а = 2 и применяя
обратное Z-преобразование к (7.1-13), мы получаем
g0(«)=(-D"A1(«);
й(л)=(-1)и+Ч(«)-
(7.1-14)
Если положить а = —2, то результирующие выражения имеют обрат-
ные знаки:
g0(«)=(-i)"+1/2i(«);
gl(«)=(-l)"/20(«).
(7.1-15)
Таким образом КИХ-фильтры синтеза являются перекрестно-моду-
лированными копиями соответствующих КИХ-фильтров анализа,
причем знак одного (и только одного) из них изменен на противопо-
ложный.
Выражения (7.1 -9)— (7.1-13) позволяют также установить, что филь-
тры анализа и синтеза являются биортогональными. Для этого обозна-
чим через P(z) произведение передаточных функций низкочастотных
фильтров анализа и синтеза. Выразив Gq(z) из (7.1-13), имеем
2
P(z)-G0(z)H0(z) = и ^H0(z)Hx(-z).
det(Hw(z))
(7.1-16)
Поскольку det(Hw(z)) = — det(Hw(—z)), то произведение Gx(z)Hx(z)
может быть выражено аналогично
-2
Gx(z)Hx(z) = . ( Я0(-г)Я!(г)= Р(-г).
det(Hw(^))
(7.1-17)
Так как G| (г) Я] (г) = Р(-г)= С0(-г)Я0(-г), то равенство (7.1-10) при-
нимает вид
Сои)Яои)+Со(-г)Яо(-г)=2.
(7.1-18)
Взяв обратное Z-преобразование, имеем
к к
где, как всегда, импульсная функция б(л) равна 1 при п = 0, и равна О
для остальных значений п. Члены, отвечающие нечетным значениям
л, сокращаются, что дает окончательно10
Ygo(k)ho(2n-k) = {go(k),ho(2n-k)}=8(n). (7.1-19)
к
Начиная с равенств (7.1 -9) и (7.1 -10) и выражая (70 и Hq через Gx и Нх,
можно аналогично показать, что
^1(/с),й1(2л-/:)) = 5(л);
(^ЦМ)=0; (7.1-20).
[gx{k),hQ{2n-k))^.
Равенства (7.1 -19) и (7.1 -20) можно записать в следующем общем виде
^•(2«-/f),gy(/f)) = 6(z-j)6(«), i,j = {0,1}. (7.1-21)
Блоки фильтров, удовлетворяющие этим условиям, называются биорто-
гональными. Более того, для того чтобы некоторый двухканальный блок
фильтров с вещественными коэффициентами осуществлял субполосное
кодирование с точным восстановлением, импульсные характеристики
(ядра) его фильтров анализа и синтеза должны удовлетворять условиям
биортогональности (7.1-21). Примерами биортогональных КИФ-филь-
тров являются семейство биортогональных сплайнов [Cohen, Daubechies,
Feauveau, 1992] и семейство биортогональных койфлетов (вейвлетов
Койфмана) [Tain, Wells, 1995].
В Таблице 7.1 даны три общих решения уравнений (7.1 -9) и (7.1 -10).
Несмотря на то что каждое из них удовлетворяет условиям биортого-
нальности, все они получены по-разному и определяют единственные
в своем роде классы фильтров точного восстановления. Для каждого
10 Скалярное произведение последовательностей х{п) и у(п) определяется выражени-
ем {х,у) = E„X"(/i)y{n), где знак * означает комплексное сопряжение. Если последова-
тельности х(п) и у(п) вещественные, то (х. у} = (у, х).
класса один «фильтр-прототип» конструируется исходя из конкрет-
ных условий, а оставшиеся три фильтра определяются этим прототи-
пом. В колонках 1 и 2 Таблицы 7.1 представлены классические резуль-
таты работ по блокам фильтров, а именно квадратурные зеркальные
фильтры (КЗФ) [Croisier, Estaban, Galand, 1976] и сопряженные квад-
ратурные фильтры (СКФ) [Smith, Barnwell, 1986]. Фильтры в третьей
колонке, которые впоследствии будут использованы при разработке
быстрого вейвлет-преобразования (см. Раздел 7.4), называются орто-
нормированными фильтрами. Помимо условия биортогональности,
они удовлетворяют условию
{gi(n),gj(n + 2m)} = 8(.i-J)8(m), z,j={O,l}, (7.1-22)
которое представляет собой условие того, что блок фильтров точно-
го восстановления является ортонормированным11. Заметим, что в вы-
ражение для фильтра G\(z) в четвертой строке величина 2Кпредстав-
ляет собой длину каждого из фильтров. Видно, что фильтр G\ связан
с низкочастотным фильтром синтеза Gq операциями модуляции (см.
(7.1-5)), обращения времени и сдвига12 (нечетного). Взяв обратное
Z-преобразование от соответствующих выражений в последней колон-
ке Таблицы 7.1, мы получим
Таблица 7.1
Фильтр КЗФ СКФ Ортонорм ирован н ые
яо(г) Hq(z)~ Hq(-z) = 2 H0(z)H0(z~l) + +tf0(-z)//0(-r')=2 GoU’*)
r'z/oi-r1) С^Г1)
G0(z) W Hv(z~l) <7oU)<7o(^')+ +G0(-z)G'0(-z”l)=2
G,(z) -Ho(-Z) zH0(-z) -z Go(-Z )
11 Отметим, что существуют СКФ блоки фильтров точного восстановления, которые
также являются ортонормированными. — Прим, перев.
12 Z-пары для операций обращения времени и сдвига имеют видх(—п) <^> Д'!?1)
и х{п k) I -1), соответственно.
(л) = £,(-«), / = {0,1},
где Ло, h ।, go и g| суть импульсные характеристики (ядра) заданных ор-
тонормированных фильтров. Примеры включают фильтры Смита и
Барнвелла [Smith, Barnwell, 1984], фильтры Добегли [Daubechies, 1988]
и фильтры Вайданатана и Хоанга [Vaidyanathan, Hoang, 1988].
Одномерные фильтры из Таблицы 7.1 могут быть использованы
при обработке двумерных изображений как двумерные разделимые
фильтры. Как видно из схемы на Рис. 7.5, фильтрация осуществля-
ется раздельно, сначала по столбцам (т.е. в вертикальном направле-
нии), затем по строкам (т.е. в горизонтальном направлении). Более
того, прореживающая выборка осуществляется в два этапа, причем
первый раз перед второй операцией фильтрации — чтобы уменьшить
общее количество необходимых вычислений. Получаемые на выхо-
де результаты фильтрации называются субдиапазонами изображения.
Субдиапазон, обозначенный на Рис. 7.5 как а(т,п), называется суб-
диапазоном приближения, а субдиапазоны, обозначенные как
d v(m,n), d и(т,п) и dD(m,n), называются субдиапазонами верти-
кальных, горизонтальных и диагональных деталей, соответствен-
но. Каждый из этих субдиапазонов в свою очередь может быть раз-
делен на четыре меньших субдиапазона, которые могут быть
разделены еще раз, и т.д.
Столбцы
Рис. 7.5. Двумерный четырехканальный блок фильтров для субполосного ко-
дирования изображений.
Пример 7.2. Четырехканальное субполосное кодирование изобра-
жения на Рис. 7.1.
На Рис. 7.6 изображены импульсные характеристики четырех ор-
тонормированных фильтров Добеши, которые имеют по 8 отличных
от нуля коэффициентов. Коэффициенты низкочастотного фильт-
ра Ьц(п) для 0 < п < 7 равны —0,01059740, 0,03288301, 0,03084138,
-0,18703481, -0,02798376, 0,63088076, 0,71484657 и 0,23037781
[Daubechies, 1992]. Коэффициенты остальных ортонормированных
фильтров могут быть вычислены с помощью (7.1 -23). Заметим, что пе-
рекрестная модуляция фильтров анализа и синтеза видна прямо из
Рис. 7.6. С помощью вычислений нетрудно проверить, что фильтры
являются и биортогональными (удовлетворяют (7.1-21)), и ортонор-
мированными (удовлетворяют (7.1-22)). Кроме того, они удовлетво-
ряют условиям (7.1 -9) и (7.1 -10) и обеспечивают точное восстановление
исходного сигнала.
На Рис. 7.7 представлено четырехканальное разложение изображе-
ния с вазой на Рис. 7.1 размерами 512x512 с использованием представ-
ленных на Рис. 7.6 фильтров. Каждое из четырех изображений на этом
рисунке представляет субдиапазон размерами 256x256. Расположе-
Рис. 7.6. Импульсные характеристики четырех 8-элементных ортонормиро-
ванных фильтров Добеши.
ние субдиапазонов, начиная от верхнего левого по часовой стрелке, сле-
дующее: субдиапазон приближения а, субдиапазон горизонтальных де-
талей d11, субдиапазон диагональных деталей dD и субдиапазон верти-
кальных деталей dv. Значения яркости всех субдиапазонов, за
исключением субдиапазона приближения в верхнем левом углу, было
подвергнуто градационному преобразованию для того, чтобы сделать
их внутреннюю структуру более заметной. Обратим внимание на ар-
тефакты характерной геометрической структуры в субдиапазонах d,!
и dv, появление которых связано с наложением спектров в результа-
те применения прореживающей выборки к области изображения на
Рис. 7.1 с едва заметной сеткой от комаров на окне. При восстановле-
нии исходного изображения по субдиапазонам с помощью фильтров
Рис. 7.7. Разложение изображения с вазой на Рис. 7.1 на четыре субдиапазо-
на с помощью системы субполосного кодирования на Рис. 7.5.
синтезаgo(n) и g[ (п) эффект наложения спектров будет уничтожен в со-
ответствии с (7.1-9). Для осуществления процедуры восстановления не-
обходимо использовать блок фильтров, который, грубо говоря, явля-
ется зеркальным отражением системы на Рис. 7.5. В этом новом блоке
фильтры h^n), i= {0,1}, заменяются на отвечающие им фильтры gt{n),
прореживающие выборки заменяются на сгущающие и добавляется
процедура суммирования.
7.1.3. Преобразование Хаара
Третьим и последним используемым при обработке изображений ме-
тодом, который связан с кратномасштабной теорией, является пре-
образование Хаара [Haar, 1910]. В контексте настоящей главы значи-
мость этого преобразования обусловлена тем, что его базисные
функции образуют первую и простейшую из известных систему орто-
нормированных вейвлетов. Эти вейвлеты будут использованы в ряде
примеров далее.
Преобразование Хаара является разделимым и может быть запи-
сано в матричном виде следующим образом
THFH7,
(7.1-24)
где F — матрица изображения, Н — матрица преобразования, Т — ре-
зультат преобразования (все матрицы размерами NxN), а Тозначает
операцию транспонирования матрицы. Матрица преобразование Ха-
ара состоит из базисных функций Хаара ЛДг). Эти функции опреде-
лены на непрерывном замкнутом интервале z 6 [0,1] при
к = 0, 1, 2, ..., N — 1, где N = 2п. Для любого индекса к из указанного
множества определим индексы pviq, 0<р<п—1,^ = 0, 1 при р = 0 и
1 < q < 2 Р при р Ф 0 так, чтобы выполнялось равенство к = 2 Р + q — 1.
Тогда базисные функции Хаара суть
Mz) = Wz) = ~/=’ ге[0,1],
yjN
(7.1-25)
и
fyc(Z) hpq(z)
при(#-1)/2р <z<(q-0,5)/2p;
при(<7-0,5)/2р <z<q/2p;
в остальных случаях, ze [0,1].
(7.1-26)
Строка с номером i матрицы преобразования Хаара Н состоит из
значений функции ht(z), взятых в точках £=0//V, l/N, 2/N, ... гл,
(N — 1)/jV. При N = 4, например, индексы k,q,vtp принимают
значения
к р_£
ООО
1 0 1
2 1 1
3 1 2
и 4x4 матрица преобразования Н4 имеет вид
1 1 1
1 -1 -1
-л/2 О О
О л/2 —л/2
(7.1-27)
Аналогично, 2x2 матрица преобразования Щ имеет вид
1
1
(7.1-28)
Ее базисные функции определяют блок КИХ-фильтров, имеющих
лишь пару отличных от нуля коэффициентов (коэффициенты соот-
ветствующих фильтров анализа hn(n) и/ц(п) суть элементы первой и
второй строки матрицы Щ, соответственно). При этом низкочастот-
ный фильтр анализа удовлетворяет условию на СКФ фильтр-прото-
тип13 в первой строке второго столбца Таблицы 7.1.
13 Высокочастотный фильтр анализа также удовлетворяет соответствующему усло-
вию на СКФ-фильтры с точностью до тривиальной замены знака. Выбрав фильтры
синтеза надлежащим образом (т.е. в соответствии с приведенными в Таблице 7.1 ус-
ловиями, но изменив знак высокочастотного фильтра синтеза), мы получим простей-
ший блок ортонормированных СКФ-фильтров точного восстановления, причем
каждый фильтр блока будет КИХ-фильтром всего лишь с двумя ненулевыми коэф-
фициентами. Этот пример является иллюстрацией того факта, что каждый орто-
нормированный базис вейвлетов, связанный с кратномасштабным анализом (в дан-
ном случае в роли такого базиса выступает базис Хаара) дает начало паре СКФ в схеме
субполосной фильтрации с точным восстановлением. — Прим, перев.
Пример 7.3. Дискретное вейвлет-преобразование на основе функций
Хаара.
На Рис. 7.8 (а) представлено кратномасштабное разложение изоб-
ражения на Рис. 7.1 с использованием базисных функций Хаара
а
б в г
Рис. 7.8 (а) Дискретное вейвлет-преобразование с использованием базисных
функций Хаара. Приведены локальные гистограммы полученных компонент,
(б)— (г) Несколько различных приближений (размерами 64x64, 128x128 и
256x256), которые могут быть получены на основе изображения (а).
7.2. Кратномасштабное разложение
(7.1-25) и (7.1 -26). Соответствующий математический аппарат разви-
вается нами ниже в настоящей главе. В отличие от пирамидальной
структуры на Рис. 7.3, это представление, называемое дискретным
вейвлет-преобразованием, состоит из того же числа пикселей, что и ис-
ходное изображение. Кроме того, данное представление обладает
следующими свойствами.
1. Его локальные статистики мало изменяются и могут быть легко
промоделированы (см. Рис. 7.8 (а)).
2. Значения большого количества элементов преобразования близ-
ки к нулю, что делает его отличным кандидатом для применения
процедуры сжатия.
3. Преобразование дает возможность восстанавливать как грубые, так
и детальные приближения исходного изображения; изображения
на Рис. 7.8 (б)— (г) восстановлены из частей изображения Рис. 7.8 (а).
При работе с базами данных эти свойства облегчают пользовате-
лю в процессе поиска доступ к уменьшенным копиям изображений
низкого качества, и дают возможность получить недостающие данные,
необходимые для полного восстановления изображения, на более
поздней сталии.
В заключение отметим, что изображение на Рис. 7.8 (а) имеет
большое сходство как с результатом субполосного кодирования на
Рис. 7.7, так и с пирамидой лапласианов на Рис. 7.3 (б). Как и в двух
упомянутых случаях, значения яркости частей изображения на
Рис. 7.8 (а) были подвергнуты градационному преобразованию с тем,
чтобы сделать их внутреннюю структуру более заметной. Изображе-
ния на Рис. 7.8 (б)— (г), являющиеся приближениями исходного
изображения, имеют размеры 64x64, 128x128 и 256x256. Возможно
также идеальное восстановление оригинала размерами 512x512.
7.2. Кратномасштабное разложение.
В предыдущем разделе мы рассмотрели три хорошо известных мето-
да обработки изображений, которые сыграли важную роль в развитии
уникальной математической теории, называемой кратномасштабным
анализом (КМА). В КМА использование масштабирующей функции
позволяет построить последовательность приближений для некоторой
функции или изображения, причем каждое приближение отличает-
ся от соседнего масштабным фактором 2. Для кодирования информа-
ции, описывающей разность между соседними приближениями,
используются дополнительные функции, называемые вейвлетами.
7.2.1. Разложения в ряды
Функцию (сигнал)Дх) часто проше анализировать, если представить
ее в виде линейной комбинации функций из некоторой системы
функций разложения {<рДх)}
/(х) = £«£(()£ (х), (7.2-1)
к
где индекс суммирования к принимает конечное или бесконечное
множество целых значений14, вешественные числа называются
коэффициентами разложения, а сами функции <рЛ принимают вещест-
венные значения и называются функциями разложения. Если разложе-
ние единственно, т.е. для любой заданной функции Дх) существует
единственный набор коэффициентов о.д. такой, что выполнено (7.2-1),
то функции <рк(х) называются базисными функциями, а все множество
функций разложения {<рДх)} называется базисом в том классе функ-
ций, которые могут быть представлены таким образом. Представимые
в виде (7.2-1) функции образуют пространство функций, которое назы-
вается замыканием линейной оболочки функций {<рДх)} или пространством,
натянутым на систему функций {<рДх)}, и обозначается
l/ = Span{(pA.(x)}. (7.2-2)
к
ЗаписьДх) е Vозначает, что функцияДх) принадлежит замыканию ли-
нейной оболочки функций {(рДх)} и может быть записана в виде (7.2-1).
Для любого пространства функций Vи соответствующей системы
функций разложения {<рДх)} существует двойственная система функ-
ций {ф^(х)}, которая может быть использована для вычисления коэф-
фициентов разложения в (7.2-1) любой функцииДх). Эти коэффи-
циенты вычисляются как скалярные произведения15 двойственных
функций ф^(х) и функцииДх), а именно
ак = {f(x),qk(x)}=]/(х)фд(х)б/х, (7.2-3)
14 Обычно термин «линейная комбинация» употребляется лишь в том случае, если
сумма в правой части (7.2-1) конечная, а в случае бесконечного числа слагаемых
принято говорить о разложении в ряд. — Прим, перев.
15 Скалярное произведение двух вещественно- или комплекснозначных функцииДх)
и Дх) задается выражением ,7(х),х(л))=//(х)х‘(ОЛ . Если функция/(х) вещественная,
TOg*(x) =Дх) И ,/(.r),KU)z=J/(.r)XU)dl.
7.2. Кратномасштабное разложение
где символ * означает операцию комплексного сопряжения16. В зави-
симости от свойств системы функций разложения, можно выделить три
различных случая, которые проиллюстрированы в Задаче 7.10 в конце
главы на примере векторов в двумерном евклидовом пространстве.
Случай 1. Система функций {<р^(х)} образует в пространстве Vор-
тонормированный базис, т.е.
0
<
1
(<р7(лс),<рА.(дс))=5уЛ =
j=k.
(7.2-4)
В этом случае двойственная система функций совпадает с исходным
ортонормированным базисом, ф^.(х) = ф^(х), и формула (7.2-3) при-
нимает вид
ак = (/W,(p^(x)).
(7.2-5)
Коэффициенты вычисляются как скалярные произведения базис-
ных функций и функцииДх).
Случай 2. Система функций {<р^(х)} не является ортогональной,
т.е. некоторые из условий
= J*k,
(7.2-6)
нарушаются, но образует в пространстве Vбазис Рисса17. Тогда двой-
ственная система функций {фДх)} также образует базис Рисса, и вместе
они образуют так называемую биортогональную систему, что означает
выполнение условий
(<ру(х),ф*(х)) = 8Л = <!
j*k;
j = k.
(7.2-7)
16 В любом из трех рассматриваемых ниже случаев (т.е. когда система функций раз-
ложения образует ортонормированный базис, базис Рисса или фрейм) приведенное
утверждение справедливо. — Прим, перев.
17 Базис в гильбертовом пространстве называется базисом Рисса, если он является бе-
зусловным, т.е. порядок, в котором производится суммирование в (7.2-1), не имеет
значения. Базис Рисса может быть охарактеризован следующим требованием: суще-
ствуют/! > 0, В < “ такие, что для любой функцииДх) выполнено приводимое ниже
в тексте условие (7.2-8). Базисы Рисса — следующие после ортонормированных «хо-
рошие» базисы. Отметим, что 1) в конечномерном пространстве любой базис явля-
ется базисом Рисса и 2) если А = В = 1, то базис Рисса является ортонормированным
базисом. — Прим, перев.
\
536 Глава 7. Вейвлеты и кратномасштабная обработка
Коэффициенты и.к вычисляются по формуле (7.2-3).
Случай 3. Система функций {срДх)}, участвующих в разложении
(7.2-1), не является базисом, т.е. существует более одного набора ко-
эффициентов разложения для функпийДх) е V. В этом случае го-
ворят, что система функций разложения является переполненной или
избыточной. Если существуют константы А > О, В < °° такие, что для
всех функций f(x) е Vвыполнено условиеIS * * 18 *
Л||/(х)||2 <Х|</(х),(р*(х))|2 < В||/(х)||2, (7.2-8)
то функции разложения образуют фрейм^. В этом случае система
двойственных функций также переполнена и образует двойственный
фрейм1®. Разделив неравенство (7.2-8) на квадрат нормы функцииДх),
мы видим, что константы АмВ ограничивают сумму квадратов моду-
лей коэффициентов разложения нормированной функции. Для вы-
числения коэффициентов разложения можно использовать форму-
лы21, аналогичные (7.2-3) и (7.2-5). Если границы фрейма равны,
А = В, то фрейм называется жестким фреймом, и можно показать
[Daubechies, 1992], что в этом случае
f(x) = 4 X (x))ipk (х).
A L
(7.2-9)
С точностью до множителя А ~1, который является «мерой избыточ-
ности» фрейма, последнее выражение совпадает по форме с выраже-
нием, которое можно получить, подставив выражение (7.2-5) (для
ортонормированных базисов) в разложение (7.2-1)22.
IS Норма функцииf(x) определяется как квадратный корень из скалярного произве-
дения функции на себя и обозначается символом |]/(глс)||.
19 Константы А и В называются границами фрейма. Заметим также, что при опре-
делении фрейма прямо не требуется, чтобы множество {ср*} было переполнен-
ным, требуется только выполнение приведенного условия. Однако если множест-
во не переполнено, т.е. функции образуют базис, то фрейм превращается в базис
Рисса (ср. прим. 17) и мы попадаем в ситуацию, рассмотренную в Случае 2. -
Прим, перев.
20 Границами двойственного фрейма I'M 1 являются константы В 1 и/f L — Прим, перев.
21 Формулы разложения имеют вид .Ф* = / = Х J -<М)Ч>‘. — Прим, перев.
22 То обстоятельство, что выражение (7.2-9) весьма похоже на разложение функции
по ортонормированному базису, не должно вводить в заблуждение. Даже жесткие
фреймы не являются ортонормированными базисами, что показывает пример (в) из
7.2. Кратномасштабное разложение
7.2.2. Масштабирующие функции
Рассмотрим теперь систему функций разложения, которая состоит из
целых сдвигов и двоичных изменений масштаба (т.е. двоичных сжа-
тий и растяжений с сохранением нормы) некоторой заданной веще-
ственной квадратично-интегрируемой функции ф(х). Таким образом,
мы рассматриваем систему функций {фуДх)} вида
<р7 Л =2у/2<р(2УА7-А;),
(7.2-10)
где j, к е Z и ф(х) е £2(R).23 Здесь индекс к определяет положение
функции фуДх) на оси х, индекс j — ширину функции фуДх) вдоль
оси х, а множитель 2т72 регулирует высоту (амплитуду) функции.
Функция ф(х) называется масштабирующей функцией. Надлежащий вы-
бор функции ф(х) позволяет добиться того, что пространство измери-
мых квадратично-интегрируемых функций £2(R) оказывается натя-
нутым на систему функций {фуДх)} (т.е. замыкание линейной
оболочки системы функций {ф7Дх)} совпадает с £2(R)).
Если мы ограничимся рассмотрением какого-нибудь одного фик-
сированного значениями (7.2-10), скажем j =j0, то получаемая в резуль-
тате система функций разложения {фуп Дх)} будет подмножеством всей
системы функций {фуДх)}. Замыкание линейной оболочки такой си-
стемы не совпадает со всем пространством L 2 (R), а является некоторым
его подпространством. Используя систему обозначений предыдущего
параграфа, это подпространство можно определить выражением
К7о =8рап{фУоЛ(х)}. (7.2-11)
к
Таким образом, подпространство Vj — это пространство, натянутое на
функции фупДх) при различных значениях к. Если функцияДх) е ,
то она может быть записана в виде
/(х) = ^алфУоЛ(х). (7.2-12)
к
Задачи 7.10. Однако если жесткий фрейм состоит из нормированных функций
({(рф ||(pj = 1) и его границы А = В = 1, то такой фрейм является ортонормирован-
ным базисом. — Прим, перев.
23 Здесь R — множество вещественных чисел, 1 — множество целых чисел, a £2(R)
обозначает пространство измеримых интегрируемых с квадратом функций на дейст-
вительной оси.
538 Глава 7. Вейвлеты и кратномасштабная обработка
В общем случае обозначим через ^подпространство, натянутое на си-
стему функций24 {фуДх)} при любом фиксированном j и всех к\
Py=Span{(pyA.(x)}.
(7.2-13)
Как будет видно из следующего примера, при увеличении j возраста-
ет размер подпространства Vj, так что в него попадают более быстро
меняющиеся функции (описывающие мелкие детали). Это является
следствием того, что при увеличении значения j функции фуДх), ис-
пользуемые для представления функций из соответствующего подпро-
странства, становятся уже и разделяются на меньших расстояниях по
оси х.
Пример 7.4. Масштабирующая функция Хаара.
Рассмотрим масштабирующую функцию Хаара, которая пред-
ставляет собой характеристическую функцию полуинтервала [0,1)
[Haar, 1910]:
Ф(х) = -
1 0<х<1;
0 в остальных случаях
(7.2-14)
На Рис. 7.9 (а)— (г) представлены четыре функции из системы функ-
ций разложения, которая может быть получена подстановкой в вы-
ражение (7.2-10) масштабирующей функции, имеющей вид прямо-
угольного импульса. Заметим, что при j = 1 функции разложения
являются более узкими и расположены ближе друг к другу, чем
аналогичные функции при j = 0.
На Рис. 7.9 (д) представлена функция из подпространства Кр Эта
функция не принадлежит подпространству И(), поскольку функции раз-
ложения для подпространства Ко (см. Рис. 7.9 (а) и (б)) слишком гру-
бы для представления данной функции с их помощью. Для этого не-
обходимо использовать функции разложения более крупного масштаба
(высокого разрешения), такие как функции, представленные на
Рис. 7.9 (в) и (г). Как показано на Рис. 7.9 (д), использование послед-
них позволяет получить представление интересующей функции в виде
разложения, состоящего из трех слагаемых:
24 Ниже эту систему функций автор часто называет масштабирующими функциями
у-го масштаба (или подпространства Vj), что не должно вызывать недоразумений. —
Прим, перев.
7.2. Кратномасштабное разложение
Ф1,о(*)=^<р(2х) Ф1, i(x)=x/2q>(2x-l)
1
О
Рис. 7.9. Масштабирующие функции системы Хаара в подпространствах и Ир
а б
• г
Д е
/(х)=0,5ф10(х)+фи(л:)-0,25ф14(л:).
Завершая обсуждение примера, заметим, что на Рис. 7.9 (е) пред-
ставлено разложение функции Фо.о(х) по функциям разложения под-
пространства V]. Аналогично можно поступить с любой функцией раз-
ложения подпространства Ир, если воспользоваться формулой
Ф°Л № = ^<Р1,2Н*) + W
Таким образом, если функцияДх) является элементом подпростран-
ства Ир, то она является также и элементом подпространства К|. При-
чина этого в том, что все функции разложения подпространства Ир яв-
ляются элементами подпространства V\. На математическом языке
указанный факт означает, что подпространство вложено в под-
пространство К| (эквивалентные формулировки: Pg само является
подпространством К], содержит (включает) Рд) и записывается в виде
M-i
Простая масштабирующая функция из приведенного примера
удовлетворяет четырем основным условиям кратномасштабного
анализа [Mallat, 1989а].
КМА Условие 1. Масштабирующая функция и ее целые сдвиги орто-
гональны.
В случае функции Хаара это условие очевидно выполнено. Дейст-
вительно, во всех точках, где значение функции Хаара равно едини-
це, значение любой функции, полученной из нее сдвигом на целую
величину, равно нулю. Поэтому равно нулю и их скалярное произве-
дение. Говорят, что масштабирующая функция Хаара есть функция
с компактным носителем. Это означает, что функция обращается в нуль
вне некоторого конечного интервала, являющегося носителем25. Раз-
мер носителя функции Хаара равен единице; функция обращается
в нуль вне полуоткрытого интервала [0,1). Следует отметить, что до-
биться выполнения рассматриваемого условия ортогональности
труднее в случае, когда размер носителя масштабирующей функции
становится больше единицы.
КМА Условие 2. Подпространства, натянутые на систему масшта-
бирующих функций при низком разрешении (в мелком масштабе), содер-
жатся в подпространствах, натянутых на систему масштабирую-
щих функций при более высоком разрешении (в более крупном масштабе).
Подпространства, содержащие функции высокого разрешения,
с необходимостью содержат также все функции более низкого разре-
шения, как показано на Рис. 7.10. Таким образом,
V_^ С"-сИ2 cPLj сИ0 сЦ сК2 (7.2-15)
Более того, подпространства удовлетворяют тому естественному ус-
ловию, что еслиДх) е Ру, то/(2х) е Vj+ То обстоятельство, что мас-
штабирующая функция Хаара удовлетворяет рассматриваемому усло-
вию, не следует воспринимать как признак того, что любая функция
25 Напомним, что носителем функции/называется замыкание множества тех точек,
гдеДх) Ф 0. Если носительf— ограниченное множество, то функция f называется фи-
нитной. — Прим, перев.
7.2. Кратномасштабное разложение
Рис. 7.10. Вложенные функциональные пространства, порождаемые масшта-
бирующей функцией.
с размером носителя, не превосходящим единицы, также автомати-
чески удовлетворяет этому условию. В качестве упражнения мы пред-
лагаем читателю убедиться в том, что похожая на функцию Хаара
простая функция вида
1
0
(р(х) = -
0,25<х<0,75,
в остальных случаях
не является корректной масштабирующей функцией кратномасштаб-
ного анализа (см. Задачу 7.11).
КМА Условие 3. Единственной функцией, принадлежащей одновремен-
но всем подпространствам Vj, является функция Дх) = 0.
Если мы рассмотрим самую грубую из систем функций разложе-
ния (т.е. при j = —°°), то единственной представимой функцией будет
функция, не содержашая никакой информации. Итак,
И_={0}.
(7.2-16)
КМА Условие 4. Любая функция может быть представлена с произ-
вольной точностью.
Хотя разложение (подобное тому, которое имело место для функ-
ции на Рис. 7.9 (д)) для некоторой конкретной функцииДх) при лю-
бом заданном масштабе j может оказаться невозможным, все измери-
мые квадратично-интегрируемые функции оказываются представимы
в пределе) —> +°о. Таким образом26,
26 Обычно условие 3 записывают в виде Q Vj= 10), а условие 4—в виде
Прим, перев. 7е 2
={Z2(R)}. (7.2-17)
При выполнении указанных условий, функции разложения подпро-
странства Vj могут быть выражены в виде суммы с весами функций раз-
ложения подпространства Ру+|. Используя (7.2-12), мы можем записать
<P;,*W=Xa«(Pj+U(x)’
п
где мы, для ясности, изменили индекс суммирования. Подставив
Фу+1Дх) ввиде (7.2-10) и заменив обозначение коэффициентов ап на
Лф(и), преобразуем последнее равенство к виду
(Р7Л^ = ХЛФ^2(7+1)/2(р^27+1х-л)-
п
Поскольку ф(х) = фо о(х), то положив индексыj и к равными нулю, по-
лучим простейшее выражение
ф(х) = £Лф(и)л/2ф(2х-и). (7.2-18)
п
Коэффициенты Лф(и) в этом рекурсивном равенстве называются мас-
штабными коэффициентами для масштабирующей функции., при этом
вся последовательность /гф называется масштабной (двухмасштаб-
ной) или уточняющей последовательностью^ для масштабирующей
функции. В литературе часто используются обозначения h(n) или Иц(п),
но так как мы уже использовали их ранее для обозначения фильтров
анализа при обсуждении субполосного кодирования, то, во избежа-
ние недоразумений, не будем ими пользоваться. Равенство (7.2-18) иг-
рает фундаментальную роль в кратномасштабном анализе и называ-
ется уравнением КМА, масштабным равенством или уточняющим
равенством^. Утверждается, что функции разложения любого подпро-
странства могу быть построены из своих копий удвоенного разре-
шения, т.е. из функций разложения соседнего подпространства более
27 При этом функцию ^<р(ю) - ,пявляющуюся спектром последователь-
ности называют масштабирующим фильтром или уточняющей маской. — Прим, перев.
28 Обычно масштабным называют само равенство (7.2-18), а равенство, которое получа-
ется из него переходом к образам Фурье, Ф(ш) = Н(р(ш/2)Ф(С1)/2), называют уточняю-
щим. - Прим, перев.
7.2. Кратномасштабное разложение
крупного масштаба. Центральное пространство Ц) может быть выбра-
но произвольно.
Пример 7.5. Масштабные коэффициенты для функции Хаара.
Масштабные коэффициенты для заданной (7.2-14) функции Хаара
равны /^,(0)=/^(1)=1/л/2 и представляют собой первую строку матри-
цы Н2 в (7.1-28). Таким образом,
ф(х) = х/2ф(2х) ]+ л/2ф(2х-1) J.
Это разложение было проиллюстрировано графически для функ-
ции ФО’ОС*)на Рис. 7.9 (е), где члены в квадратных скобках являются,
как нетрудно видеть, функциями ф] о(х) и Ф1,1(*)- После дополни-
тельного упрощения мы получаем ф(х) = ф(2х) + ф(2х — I). И
7.2.3. Вейвлет-функции
Если задана масштабирующая функция, удовлетворяющая КМ А ус-
ловиям предыдущего параграфа, мы можем определить такую вейвлет-
функцию^ у(х), что система функций, состоящих из целых сдвигов
и двоичных изменений масштаба функции у(х), порождает разность
между двумя смежными КМА подпространствами Vj и J^+1. Данная си-
туация проиллюстрирована графически на Рис. 7.11. Мы определяем
систему вейвлетов
уу л(х) = 2>/2у(2>х- к), (7.2-19)
и каждое из пространств Wj на рисунке оказывается натянутым на под-
систему {удДх)} при к е Z. Как и ранее, мы записываем
И7.—Span {у Jk(x)}, (7.2-20)
к
и, если f (х) g Wj, то
/(х) = £аАуjk(x). (7.2-21)
29 Эту функцию называют также базовым или материнским вейвлетом — Прим,
перев.
Глава 7. Вейвлеты и кратномасштабная обработка
Рис. 7.11. Взаимосвязь функциональных пространств, порождаемых масшта-
бирующей функцией и вейвлет-функцией.
Подпространства на Рис. 7.11, порождаемые масштабирующей
функцией и вейвлет-функцией, связаны между собой соотношением
Гу+|=ГуФИ<, (7.2-22)
где символ Ф обозначает прямую сумму пространств (аналог объеди-
нения множеств). Подпространство По является ортогональным до-
полнением подпространства ^д° подпространства ^+ь причем все
элементы подпространства Vj ортогональны к элементам подпрост-
ранства Wj. Таким образом,
(ФуЛ(х),ууу(х))=0 (7.2-23)
для всех значений j, k, / g Z.
Теперь мы можем представить пространство измеримых квадра-
тично-интегрируемых функций в виде
£2(К)=К0ФИл0ФИл1Ф... , (7.2-24)
ИЛИ
£2(В) = И ФИО ФИ^Ф..., (7.2-25)
или даже
£2(К)=...ФИС2ФИС1ФИ0)ФИ0ФИл2Ф... , (7.2-26)
причем зависимость от масштабирующей функции исключена из по-
следнего представления, которое, таким образом, определяется толь-
ко в терминах вейвлетов. Заметим, что если функция Дх) принадле-
7.2. Кратномасштабное разложение
жит подпространству но не принадлежит подпространству Vq, то
разложение, основанное на (7.2-24). содержит две части: первая часть
есть приближение f(x) масштабирующими функциями подпростран-
ства Ко; вторая часть из подпространства Ир при этом связана с вейв-
летами и содержит разность этого приближения и самой функции.
Выражения (7.2-24)— (7.2-26) можно обобщить следующим образом:
£2(К)^оФ^®^+1®..„ (7.2-27)
где7о — произвольный начальный масштаб.
Поскольку вейвлет-пространство Wj принадлежит пространст-
ву Vj+i, натянутому на масштабирующие функции следующего более
крупного масштаба (см. Рис. 7.11), любая вейвлет-функция, подоб-
но масштабирующей функции, может быть выражена в виде суммы
с весами масштабирующих функций этого увеличенного масштаба.
Значит, можно записать
V(x) = ^Av(«)V2(p(2x-«), (7.2-28)
п
где коэффициенты hy(n) называются масштабными коэффициентами
для вейвлет-функции, ahy — масштабной или уточняющей последова-
тельностью для вейвлетов (в литературе часто используется обозначе-
ние Л](л)). Используя ортогональность вейвлетов, а также то обсто-
ятельство, что вейвлеты порождают ортогональное дополнение
соответствующих пространств, которые изображены на Рис. 7.11,
можно показать (см., например, [Burrus, Gopinath, Guo, 1998]), что
масштабные коэффициенты h^(n) и hfp(n) связаны соотношением
/1^) = (-1)^(1-и). (7.2-29)
Обратим внимание на сходство этого выражения и выражения (7.1-23),
которое определяет взаимосвязь импульсных характеристик орто-
нормированных фильтров анализа и синтеза в схеме субполосного ко-
дирования.
Пример 7.6. Масштабные коэффициенты для вейвлет-функции
Хаара.
В предыдущем примере было установлено, что ненулевые члены
масштабной последовательности для функции Хаара равны
/fy(0)=/fy(l)=l/>51. Используя (7.2-29), мы получаем, что ненулевые
члены масштабной последовательности для вейвлет-функции Хаара
19А-223
равны Лч,(0)=(-1)°/^(1-0)=1/л^ и Лч,(1)=(-1)1 1)=-i/yfl. Заметим,
что эти коэффициенты соответствуют второй строке матрицы Щ
в (7.1 -28). Подставив эти значения в (7.2-28), мы получаем функцию
у(х) = ф(2х) — ф(2х — 1), график которой представлен на Рис. 7.12 (а).
Таким образом, вейвлет-функция Хаара имеет вид
1, 0<х<0,5;
у(х)=(-1,
0,5<х<1;
в остальных случаях.
(7.2-30)
О
Используя (7.2-19), мы теперь можем построить всю систему вейвле-
тов Хаара, состоящую из целых сдвигов и двоичных изменений мас-
штаба функции у(х). Графики двух вейвлетов из этой системы. УоДх)
и \|/] 0(х), представлены на Рис. 7.12 (б) и (в), соответственно. Отме-
тим, что вейвлету] о(х) из пространства уже, чем вейвлет у02(х)
из пространства И/о; он может быть использован для представления
более тонких деталей.
На Рис. 7.12 (г) представлена функция из подпространства
которая не принадлежит подпространству Vq. Эта функция уже рас-
сматривалась в примере ранее (см. Рис. 7.9 (д)). Несмотря на то, что
эта функция не может быть точно представлена в подпространст-
ве Vq, формула (7.2-22) показывает, что она может быть представле-
на с использованием функций разложения подпространств Vq и Wq.
Результат имеет вид
f(x)=fa(x)+fd(x).
где
г 3V2 V2
fa W =—Г Ф0,0 (*)-------<Р0,2 (*)
Ц о
И
-V2 V2
fdM=~r~ Vo.oW-
4 о
Здесь слагаемое fa(x) представляет собой приближение функцииДх)
масштабирующими функциями подпространства Vq, в то время как
слагаемое Д/(х) представляет собой разность f(x) — fa(x), выражен-
ную в виде суммы вейвлетов подпространства Ир. Полученное раз-
7.3. Одномерные вейвлепг-преобразования
Рис. 7.12. Вейвлеты Хаара в подпространствах и И^.
ложение, части которого представлены на Рис. 7.12 (д) и (е), анало-
гично разложению функции Дх) с помощью низкочастотного и вы-
сокочастотного фильтров. Приближение fa(x) вобрало в себя низ-
кие частоты функции Дх) (оно состоит из средних значений
функции Дх) в целых интервалах), в то время как высокочастотная
(детальная) составляющая содержится в части/Дх).
7.3. Одномерные вейвлет-преобразования
Теперь мы в состоянии рассмотреть несколько тесно связанных меж-
ду собой вейвлет-преобразований: разложение в вейвлет-ряды, дискрет-
ное вейвлет-преобразование и интегральное (непрерывное) вейвлет-пре-
образование. В фурье-анализе аналогами этих преобразований
548 Глава 7. Вейвлеты и кратномасштабная обработка
являются, соответственно, разложение в ряд Фурье, дискретное фу-
рье-преобразование и интегральное (непрерывное) фурье-преобразо-
вание. В Разделе 7.4 мы рассмотрим эффективный с вычислительной
точки зрения способ реализации дискретного вейвлет-преобразования,
который называется быстрым вейвлет-преобразованием.
1.3А. Разложение в вейвлет-ряды
Мы начнем с рассмотрения разложения функции Дх) g L2(Z) в
вейвлет-ряд, отвечающий вейвлет-функции у(х) и масштабирую-
щей функции ф(х). В соответствии с (7.2-27) мы можем записать
/(%) = Х9о (*)Ф/Ол(*)+ ,(&)Vyfc(x), (7.3-1)
k J=Jo k
где значениеj0 определяет произвольный начальный масштаб, а ко-
эффициенты Cj (к) и dj (к) суть переобозначенные коэффициенты
разложения из (^7.2-12) и (7.2-21). Коэффициенты cJo(k) обычно назы-
ваются коэффициентами приближения или масштабными коэффициен-
тами, а коэффициенты dj(k) — коэффициентами деталей или вейвлет-
коэффициентами. Использование таких названий оправдано
следующими обстоятельствами. Первое слагаемое в правой части
(7.3-1) дает приближение функции Дх) в масштабе Д, выраженное
посредством соответствующих масштабирующих функций (за ис-
ключением того случая, когдаДх) 6 Vj и первое слагаемое совпадает
с самой функцией). Второе слагаемое в правой части (7.3-1) соответ-
ствует более крупным масштабам j > и добавляет к приближению
«высокоразрешающую часть» — сумму вейвлетов, что обеспечивает
возрастаюшую, по мере роста J, детализацию. Если система функ-
ций разложения образует ортонормированный базис или жесткий
фрейм, коэффициенты разложения вычисляются на основе формул
(7.2-5) или (7.2-9) следующим образом30:
90 (V = (/М’Ф/оЛ М) = jfM(Pjo^(x)dx
dj{k) = (/(х),fc(x)) = J7(x)vy fc(x)dx.
(7-3-2)
(7.3-3)
30 Автор ограничивается рассмотрением случая вещественных функций разложе-
ния. — Прим, перев.
7.3. Одномерные вейвлет-преобразования 549
Если функции разложения являются частью биортогонального бази-
са, то (р - и у - функции в соответствующих членах этих выражений
должны быть заменены на двойственные ф-иУ - функции.
Пример 7.7. Разложение функции у =х2 в вейвлет-ряд по системе
Хаара.
Рассмотрим простую функцию
х2 0<х<1;
О в остальных случаях,
график которой представлен на Рис. 7.13 (а). Используя (7.3-2) и
(7.3-3), мы можем получить для коэффициентов разложения этой
функции по вейвлетам Хаара с начальным масштабом = 0 (см.
(7.2-14) и (7.2-30)) следующие значения:
1 1 3
с0 (0) = ]х2ф00 (х) dx=jx 2dx =
0 о 3
1
0
1 0,5 1 ]
г/о(О) = p2y0.0W^= J x2dx-j x2dx=—;
0 0 0,5 4
1 0,25 0,5 fT
<У](0) = jx2yi ()(x)dx= J x2\lldx- j x2\lldx=---------------;
0 О 0,25 32
i/](l) = |х2у]\(x)dx= J x2\[2dx- J x241dx=-
0 0,5 0,75
Зд/2
32 ’
Подставляя полученные значения в (7.3-1), мы получаем начальную
часть разложения в вейвлет-ряд
Й1=ИО©%
V2 =И] =У0 ©% ©щ
а б
в г
Д е
Рис. 7.13. Разложение функции у = х2 в вейвлет-ряд по системе вейвлетов
Хаара.
В первом члене этого ряда коэффициент сц(0) используется для фор-
мирования приближения подлежащей разложению функции в
подпространстве Ио. Это приближение показано на Рис. 7.13 (б) и
представляет собой среднее значение исходной функции. Во втором
члене коэффициент t4)(0) используется для уточнения этого прибли-
жения с помощью добавления деталей из подпространства Wq. Добав-
ляемые детали и результирующее приближение в пространстве V\
представлены на Рис. 7.13 (в) и (г), соответственно. Для добавления
деталей из подпространства W\ на следующем уровне используются
коэффициенты dx(О') и d\( Г). Эти дополнительные детали представле-
ны на Рис. 7.13 (д), а на Рис. 7.13 (е) представлено результирующее при-
ближение в пространстве Заметим, что последнее приближение на-
чинает напоминать исходную функцию. По мере того как масштаб
увеличивается (добавляются детали все более высокого уровня), при-
7.3. Одномерные вейвлет-преобразования
ближение становится все более точным и совпадает с исходной функ-
цией в пределеj —>
7.3.2. Дискретное вейвлет-преобразование
Подобно разложению в ряд Фурье, рассмотренное в предыдущем па-
раграфе разложение в вейвлет-ряд ставит в соответствие функции
непрерывного аргумента некоторую последовательность коэффици-
ентов. В том случае, когда подлежащая разложению функция являет-
ся последовательностью чисел, таких как отсчеты непрерывной функ-
цииДх), получаемая последовательность коэффициентов называется
дискретным вейвлет-преобразованием (ДВП) функцииДх). В этом
случае определяемое формулами (7.3-1)— (7.3-3) разложение в ряд
превращается в пару ДВП преобразований
И'фО’оЛ) = ~^£Лх)<Р; fcW>
у] М v и
(7-3-5)
yjM
(7.3-6)
при/>70, и
/(%) = -7=ХИф(7°Л)Ф7ол(%)+-7=Х (7-3-7)
k M J=J0 k
В этих формулах функцииДх), фуо, &(х) и суть функции дискрет-
ной переменной х= 0, 1,2,..., М— 1. Например,Дх) =Дхо + хДх) для
некоторых значенийХо, Дх, их = 0, 1, 2,..., М- 1. Обычно полагают
7о = 0 и выбирают число М так, чтобы оно было степенью двойки
(т.е. М = 2J); при этом суммирование производится по значениям
х = 0, 1, 2,..., М- 1,7= 0, 1, 2,..., J- 1, и к = 0, 1, 2,..., 2J - 1. Для си-
стемы Хаара дискретные аналоги масштабирующих функций и вейв-
лет-функций (т.е. базисных функций), участвующих в преобразова-
нии, соответствуют строкам Л/хЛ/ матрицы преобразования Хаара из
Раздела 7.1.3. Само преобразование состоит из Мкоэффициентов, ми-
нимальный масштаб равен нулю, а максимальный равен 7- 1. По при-
чинам, указанным в Разделе 7.3.1 и проиллюстрированным на При-
мере 7.6, определяемые формулами (7.3-5) и (7.3-6) коэффициенты
обычно называются коэффициентами приближения и коэффициентами
деталей.
552 Глава 7. Вейвлеты и кратномасштабная обработка
Коэффициенты W^Q^k) и И^О’Л) в формулах (7.3-5)— (7.3-6)
соответствуют коэффициентам разложения су- (к) и dj(k) функции Дх)
в вейвлет-ряд, которое было рассмотрено в предыдущем параграфе. (Та-
кая смена обозначений не является обязательной, но приводит к стан-
дартной системе записи, используемой при рассмотрении интеграль-
ного вейвлет-преобразования, которое еше предстоит нам в следующем
параграфе.) Заметим, что интегрирование, используемое при разложе-
нии в вейвлет-ряд, заменилось суммированием, и нормировочный мно-
житель 1/у[М , напоминающий аналогичный множитель ДПФ в Раз-
деле 4.2.1, добавился в выражения как для прямого, так и обратного
преобразования. Этот множитель может быть также отнесен в прямое
или обратное преобразование целиком (как \/М). В заключение необ-
ходимо напомнить, что формулы (7.3-5)— (7.3-7) справедливы только
для ортонормированных базисов и жестких фреймов. Для биортогональ-
ных базисов функции <р и у в формулах (7.3-5) и (7.3-6) должны быть
заменены на двойственные функции ф и у, соответственно.
Пример 7.8. Вычисление одномерного дискретного вейвлет-преобра-
зования.
Проиллюстрируем использование формул (7.3-5)— (7.3-7) на при-
мере дискретной функции, состоящей из четырех элементов:ДО) = 1,
Д1) = 4,Д2) =-3 иДЗ) = 0. Поскольку Л/= 4, J= 2, то. приД = 0, сум-
мирование производится по х = 0, 1,2, 3 и к = 0 приj = 0, или к = 0,1
при j = 1. Мы будем использовать систему вейвлетов Хаара и пред-
полагать, что отсчеты функцииДх) распределены по носителю мас-
штабирующей функции, который представляет собой отрезок [0,1].
Подставляя отсчеты в (7.3-5), находим
1 з 1
И^р(О,О) = - X/(x)<Po,oW = t[11 + 41-3-1 + O-1 ]= 1,
V— Л
х=0
поскольку Фо,о(%) = 1 прих = 0, 1,2, 3. Заметим, что мы использова-
ли равномерно распределенные в пространстве отсчеты масштабиру-
ющей функции Хаара при j = 0 и к = 0. Значения отсчетов соответст-
вуют первой строке матрицы преобразования Хаара Н4 из Раздела 7.1.3.
Далее, используя (7.3-6) и значения аналогично расположенных в про-
странстве отсчетов функций ф)Дх), которые соответствуют строкам 2,
3 и 4 матрицы Н4, мы получаем
%(0,0) = -[11 + 41-3 (-1)4-0-(-1)>4,
7.3. Одномерные вейвлет-преобразования
^v(l,0) = |[lj2 + 4-(-j2)-30+0-0] = -l,5j2,
^(l,l) = |[l-0+40-3-j2 + 0-(-72)] = -l,572.
Таким образом, дискретное вейвлет-преобразование по системе вейв-
летов Хаара нашей простой функции, состоящей из четырех отсчетов,
есть{15 4, -\,5у/2}, причем коэффициенты приведены в по-
рядке их вычисления.
Выражение (7.3-7) позволяет нам восстановить исходную функ-
цию по ее вейвлет-преобразованию. В развернутом виде мы имеем дня
х = 0, 1,2,3
/(х)=^[^р(О,О)фО1О(х) + ^(О,О)уо<о(х)+
+И^(1,0)у10(х) + И^(1,1)уЬ1(х)].
При х = 0, например,
/(0) = |[ll+41-l,5-(j2)-l,5j2 0] = l.
При вычислении обратного преобразования, также как и при вычис-
лении прямого, мы используем равномерно распределенные в прост-
ранстве отсчеты масштабирующей функции и вейвлетов.
Четырехточечное ДВП предыдущего примера служит иллюстраци-
ей двухмасштабного (j = {0,1}) разложения функции f (х). Исходное
предположение состояло в том, что начальный масштаб равен нулю.
Возможно, однако, использование и других начальных масштабов.
В качестве упражнения (Задача 7.16) мы предлагаем читателю получить
одномасштабное преобразование {2,5-/2, -1,5л/2, -1,5^/Т, -1,5^/Т},
которое соответствует начальному масштабу, равному 1. Таким обра-
зом, выражения (7.3-5) и (7.3-6) определяют семейство преобразова-
ний, различающихся начальным масштабому0.
7.3.3. Интегральное вейвлет-преобразование
Естественным обобщением дискретного вейвлет-преобразования яв-
ляется интегральное {непрерывное) вейвлет-преобразование (ИВП). Это
преобразование отображает непрерывную функцию одной перемен-
554 Глава 7. Вейвлеты и кратномасштабная обработка
ной в функцию двух непрерывных переменных — сдвига и сжатия (рас-
тяжения), содержащую сильно избыточную информацию. Получае-
мая функция допускает удобную интерпретацию и полезна при час-
тотно-временном анализе. Хотя наши интересы лежат в области
дискретных функций (изображений), мы дня полноты рассмотрим
здесь ивп.
Интегральное вейвлет-преобразование непрерывной квадратич-
но-интегрируемой функцииДх) относительно вещественнозначного
базового вейвлета у(х) задается формулой
^(5,?) = J /(x)vSiT(x)rfx,
(7.3-8)
где
1 (х-т')
(7.3-9)
и параметры s > 0, т называются, соответственно, параметрами мас-
штаба и сдвига. Исходная функцияДх) может быть восстановлена по
заданной функции ИДДа,т) с помощью формулы обратного интег-
рального вейвлет-преобразования'.
2 W ЧЛт(х)
/(*) = — j j ИД,(5,т)-^—dTds,
V 0
где
(7.3-10)
(7.3-11)
и Ч'(и) — фурье-преобразование функции у(х). Выражения (7.3-8)-
(7.3-11) определяют обратимое преобразование, если выполнено так
называемое условие допустимости < <=о [Grossman, Morlet, 1984].
В большинстве случаев это условие означает просто, что *Р(0) = 0
и Ч'(и) —> 0 при и —> оо достаточно быстро, дня того чтобы обеспечить
Написанные выше выражения напоминают свои дискретные ана-
логи — выражения (7.2-19), (7.3-1), (7.3-3), (7.3-6) и (7.3-7). Следует
отметить их следующие сходные черты:
7.3. Одномерные вейвлет-преобразования
1. Непрерывный параметр сдвига т играет ту же роль, что и целый па-
раметр сдвига к.
2. Непрерывный параметр масштаба л связан с двоичным параметром
масштаба И обратной зависимостью, поскольку в выражении
(7.3-9) он входит в знаменатель: у((х - т)/х). Таким образом, вейв-
леты, используемые в интегральном преобразовании, сжимаются
при 0 < s < 1 и растягиваются при s > 1. В этом смысле понятие мас-
штаба для вейвлета и наше обычное понятие частоты находятся в
«обратном отношении».
3. Интегральное преобразование аналогично разложению в вейвлет-
ряд (см. (7.3-1)), или дискретному вейвлет-преобразованию (см.
(7.3-6)), в которых начальный масштаб----сю.
4. Подобно дискретному преобразованию, интегральное преобразо-
вание может рассматриваться как множество коэффициентов
{РКуО,!)}, величины которых дают количественную «меру сходства»
функцииДх) с функциями из множества базисных функций {у s т(х)}.
В непрерывном случае, однако, оба множества бесконечны. По-
скольку функции у 5 т(х) являются вещественнозначными, т.е.
yVT(x) = то каждый из коэффициентов в (7.3-8) представ-
ляет собой скалярное произведение (Дх),у 5Дх)) функцийДх) и у 5 т(х).
Пример 7.9. Одномерное интегральное вейвлет-преобразование.
И Вейвлет «мексиканская шляпа» вида
у(х) =
(1-х2)е“х2/2
(7.3-12)
получил такое название из-за своей характерной формы (см. Рис. 7.14 (а)).
Он пропорционален второй производной от гауссовой функции плотно-
сти распределения, имеет нулевое среднее и очень быстро убывает при
|х | —»°°. Хотя этот вейвлет удовлетворяет условию допустимости, тем не
менее не существует связанной с ним масштабирующей функции, и при
вычислении преобразования нельзя использовать ортогональность. На-
иболее примечательными свойствами этого вейвлета является его
симметрия, а также то, что он задается явной формулой (7.3-12).
Непрерывная одномерная функция на Рис. 7.14 (а) представляет
собой сумму двух вейвлетов «мексиканская шляпа»:
/(*) = Vljo(x) + V6,8O<x)-
Фурье-спектр этой функции, представленный на Рис. 7.14 (б), обна-
руживает тесную связь между масштабом вейвлета и его частотным ди-
а б
в г
100
Рис. 7.14. Интегральное вейвлет-преобразование ((в) и (г)) и фурье-спектр (б)
одномерной непрерывной функции (а).
О 10 t 80 100
апазоном. Спектр состоит из двух частотных диапазонов, которые
соответствуют двум всплескам гауссова типа, составляющим функцию.
На Рис. 7.14 (в) представлена часть (1<л<10ит<100) ИВП функ-
ции на Рис. 7.14 (а), построенной на основе вейвлета «мексикан-
ская шляпа». В отличие от фурье-спектра, ИВП содержит одновре-
менно как пространственную, так и частотную информацию.
Заметим, например, что при s = 1, преобразование достигает макси-
мума в точке т = 10, которая отвечает положению в пространстве со-
ставляющей части Vl,io(x) функции fix). Поскольку значение преоб-
разования определяет объективную «меру сходства» функции Дх) и
того вейвлета, для которого оно посчитано, легко понять, как преоб-
разование может быть использовано для нахождения характерных де-
талей. Нужно просто подобрать вейвлет так, чтобы он соответство-
7.4. Быстрое вейвлет-преобразование
вал по форме интересующей детали. Аналогичные наблюдения мо-
гут быть сделаны на основе полутонового изображения ИВП на
Рис. 7.14 (г), где абсолютная величина преобразования | \Уф(л,т) |
представлена в виде яркости соответствующей точки. Отметим еще
раз, что интегральное вейвлет-преобразование превращает одно-
мерную функцию в двумерную.
7.4. Быстрое вейвлет-преобразование
Быстрое вейвлет-преобразование (ВВП) представляет собой эффектив-
ный метод реализации вычислений дискретного вейвлет-преобразо-
вания (ДВП), который использует взаимосвязь между коэффициен-
тами ДВП соседних масштабов. Метод ВВП, называемый также
иерархическим алгоритмом31 Малла [Mallat, 1989а, б], напоминает
рассмотренную в Разделе 7.1.2 схему двухканального субполосного
кодирования.
Рассмотрим снова масштабное равенство кратномасштабного
анализа
ф(х) = ^Аф(л)д/2ф(2х-л). (7.4-1)
Изменим масштаб по переменной х в 2/ раз, осуществим сдвиг на ве-
личину к и сделаем замену переменной суммирования т = 2к + п
Это дает
ф(27 х - Л) = У hq(n)y!2 ф(2(27 х - к) - п) =
п (7.4-2)
= уЛф(д1-2£)л/2ф(27+1х-д1).
т
Заметим, что члены уточняющей последовательности Аф могут рассма-
триваться как весовые коэффициенты в разложении функции ф(27х -
к) в сумму масштабирующих функций (J + 1 )-го масштаба. Та же по-
следовательность действий, примененная к формуле (7.2-28), дает
аналогичный результат для вейвлета ф(27х-Л):
ф(27 х - к) = У hy(m-2к) >/2 ф(27+| х- т), (7.4-3)
т
31 В оригинале herringbone algorithm, что означает дословно «елочный алгоритм». —
Прим, перев.
где уточняющая последовательность АфДля масштабирующей функ-
ции в (7.4-2) заменяется уточняющей последовательностью для вейв-
летов в(7.4-3).
Теперь рассмотрим выражения (7.3-5) и (7.3-6) из Раздела 7.3.3, ко-
торые определяют дискретное вейвлет-преобразование. Подставляя
определение вейвлетов (7.2-19) в (7.3-6), получаем выражение
Ж (j,A) = ^LX/W27/2V(27x-A:),
yJM х
(7.4-4)
которое, после замены функций у (2j'x - к) на их выражения в правой
части(7.4-3), принимает вид
^(М) = 7=
V м
Х/(х)2у/2ГХ\(/”-2Л)^<Р(27+'х-/”)1- <7’4'5)
х Lт
Изменение порядка суммирования и простые подобные преобразо-
вания теперь дают
т
~-£/(х)2<у+,)/2Ф(2-'+,х-л1)
\'М г
(7.4-6)
причем величина в квадратных скобках идентична величине в правой
части (7.3-5) при j'q =/ + 1. Чтобы убедиться в этом, достаточно под-
ставить (7.2-10) в (7.3-5) и положить/0 равным/+ 1. Таким образом,
мы можем записать
WyU^) = ^h^m-2k)Wqti + \,т) (7.4-7)
и констатировать, что коэффициенты деталей ДВП масштаба / вы-
ражаются через коэффициенты приближения масштаба (/ + 1). На-
чиная с (7.4-2) и (7.3-5), мы выводим таким же образом аналогичное
выражение, связывающее коэффициенты приближения ДВП двух
соседних масштабов:
(7.4-8)
Равенства (7.4-7) и (7.4-8) обнаруживают замечательную взаимосвязь
между коэффициентами ДВП соседних масштабов. Сопоставляя эти
равенства с формулой (7.1-7), мы видим, что и коэффициенты при-
ближения W^(/, к), и коэффициенты деталей И^/, к) масштаба j мо-
гут быть вычислены исходя из коэффициентов приближе-
7.4. Быстрое вейвлет-преобразование
ния W^j + 1, к) масштаба (/ + 1) с помощью операций свертки и про-
реживающей выборки. А именно, достаточно вычислить свертки ко-
эффициентов W^(J + 1 ,к) с обращенными во времени уточняющими
последовательностями для масштабирующей функции Аф(-л) и для
вейвлетов и оставить лишь члены с четными номерами. На
Рис. 7.15 эта процедура вычисления коэффициентов представлена
в виде блок-схемы. Заметим, что она совпадает с блоком анализа
представленной на Рис. 7.4 системы двухканального субполосного
кодирования и декодирования при Ар(л) = Аф(-л) и Л](л) = Аф(-л).
Поэтому мы можем записать
^ф(/Л)=Аф(-л)*^ 0 + 1,«)| (7.4-9)
• Т т tfl—
и
^U,k)=^-n)*W(j+\,n)\ (7.4-10)
т Т Т ifi—
где свертки вычисляются в моменты времени п = 2к при к > 0. Вы-
числение сверток для неотрицательных четных значений индек-
сов эквивалентно фильтрации и прореживающей выборке с фак-
тором 2.
В заключение нашего обсуждения ВВП, отметим, что блок филь-
тров на Рис. 7.15 может использоваться как базовый элемент итера-
тивной многоступенчатой структуры ддя вычисления ВВП коэффи-
циентов в двух или более последовательных масштабах. На
Рис. 7.16 (а), например, представлен двухступенчатый блок фильтров
для вычисления коэффициентов в двух наиболее крупных масшта-
бах преобразования. Предполагается, что коэффициенты самого
крупного масштабы суть отсчеты исходной функции. Таким образом,
Wq(J,n) =f(x), где J— самый крупный масштаб. (Это означает, в со-
ответствии с Разделом 7.2.2, чтоДх) g Vj, т.е. Vj — то масштабирую-
щее пространство, которому принадлежит функция Дх).) Первый
блок фильтров на Рис. 7.16 (а) раскладывает исходную функцию на
Рис. 7.15. Блок анализа БВП.
Иф(7, и)
Рис. 7.16. (а) Двухступенчатый или двухмасштабный БВП блок анализа и
(б) его свойства в отношении разделения частот.
низкочастотную составляющую (приближение), которая соответст-
вует коэффициентам 1,и), и высокочастотную (детальную) со-
ставляющую, которая соответствует коэффициентам Wy(J - 1,л).
Это изображено графически на Рис. 7.16 (б), где масштабирующее
пространство Vj разложено в подпространство вейвлетов Wj _ । и
масштабирующее пространство ]. Спектр исходной функции
оказывается разложенным на два частотных полудиапазона. Вто-
рой блок фильтров на Рис. 7.16 (а) раскладывает подпространст-
во ] на подпространства 2 и 2, коэффициенты ДВП рав-
ны соответственно ^(J - 2,п) и - 2,п). При этом нижний
частотный полудиапазон в свою очередь раскладывается на два ча-
стотных полудиапазона.
Двухступенчатый блок фильтров на Рис. 7.16 легко продолжить
так, чтобы получить разложение на любое число масштабов. Блок
фильтров третей ступени, например, будет оперировать с коэффи-
циентами W^(J-2,n) и разлагать подпространство Vj_ 2 на подпро-
странства Wj_ з и Vj _ з , что отвечает разложению нижней четвер-
7.4. Быстрое вейвлет-преобразование
ти спектра исходного сигнала на частотные полудиапазоны. В обыч-
ной ситуации мы берем 2J отсчетов функцииДх) и используем Р бло-
ков фильтров (таких как на Рис. 7.15), чтобы получить P-масштаб-
ное ВВП в масштабах J - 1,1-2, ..., J - Р. Коэффициенты для
наиболее крупного масштаба!- 1 вычисляются вначале, для наибо-
лее мелкого масштаба J- Р — в конце. Если частота дискретизации
функцииДх) порядка частоты Найквиста, что обычно и имеет мес-
то, то отсчеты функции являются хорошим приближением для ко-
эффициентов того масштаба, разрешение которого соответствует
шагу дискретизации. Эти отсчеты могут быть использованы на вхо-
де алгоритма в качестве начальных масштабных коэффициентов
(коэффициентов приближения) высокого разрешения. Другими
словами, вейвлет-коэффициенты (коэффициенты деталей) в масшта-
бе, который определяется шагом дискретизации, не нужны. Масшта-
бирующие функции самого крупного масштабы ведут себя в форму-
лах (7.3-5) и (7.3-6) подобно 8-функциям, что позволяет использовать
отсчетыДл) в качестве приближения 1-го масштаба или масштабных
коэффициентов на входе первого двухканального блока фильтров
[Odegard, Gopinath, Burrus, 1992].
Пример 7.10. Вычисление одномерного быстрого вейвлет-преобра-
зования.
Для иллюстрации представленной концепции рассмотрим дис-
кретную функпиюДл) = {1,4, -3,0} из Примера 7.8. Как и в том при-
мере, мы снова вычислим преобразование относительно масштаби-
рующих функций и вейвлетов Хаара. Теперь, однако, мы не будем
непосредственно использовать функции разложения, как это было
сделано в Примере 7.8, а воспользуемся уточняющими последователь-
ностями из Примеров 7.5 и 7.6:
и
Л<р(«) =
1/V2
О
л = 0,1,
в остальных случаях,
(7.4-11)
1/V2
Щп)= -1/V2
л = 0,
л = 1,
в остальных случаях.
(7.4-12)
О
Эти функции используются при построении блока фильтров БВП;
они определяют коэффициенты фильтров.
Поскольку посчитанное в Примере 7.8 ДВП состояло из элемен-
тов {^(0,0), ^(0,0), ^(1,0), ^(1,1)}, мы вычислим соответству-
ющее БВП для масштабов / = {0,1}. Итак, J = 2 (всего имеется 2J = 22
отсчетов) и Р = 2 (мы работаем с масштабами /-1=2-1=1и/-
Р= 2 - 2 = 0). Для вычисления преобразования будет использован двух-
ступенчатый блок фильтров, показанный на Рис. 7.16 (а). На Рис. 7.17
представлены последовательности, получаемые в результате приме-
нения операций свертки и прореживающей выборки, которые со-
ставляют БВП. На вход самого левого блока фильтров подается функ-
ция /(л). Чтобы вычислить коэффициенты ^(1, к), которые
появляются в конце верхней ветви на Рис. 7.17, сначала вычисляет-
ся свертка функции f[n) с функцией Как было объяснено в Раз-
деле 4.6.3, для этого нужно отразить одну из функций относительно
начала координат, сдвинуть ее относительно другой и вычислить сум-
му значений произведения двух этих функций во всех точках. Для по-
следовательностей {1, 4, -3, 0} и {-\/&, 1/V2} это дает результат
{-1 / у!1, -3/ л/2, T/yfl, -3/ ^2,0}, причем второй член соответствует зна-
чению индекса к = 2п = 0. (На Рис. 7.17 подчеркнутые элементы от-
вечают отрицательным значениям индекса, т.е. п < 0.) После проре-
живающей выборки (т.е. после удержания только членов, отвечающих
четным значениям индекса) мы имеем И/Ч/(1Д) = {-3/л/2, -З/л/2) при
{-1А/2 , -З/л/2, 7/л/2, -З/л/2, 0}
{25, 1,-1.5)
Рис. 7.17. Вычисление двухмасштабного быстрого вейвлет-преобразования по-
следовательности {1,4, -3, 0) с использованием уточняющих последователь-
ностей для масштабирующей функции и вейвлетов Хаара
7.4. Быстрое вейвлет-<
к= {0,1}. Альтернативный способ вычисления состоит в использова-
нии выражения (7.4-9):
=^,(-">*WV<2.n)|/i_2Jfct20=M-„>*Z<«>|ri=aJtJta0=
Здесь мы подставили индекс 2к вместо индекса п в свертку и исполь-
зовали индекс / как индекс суммирования. Из всей суммы остается
лишь два слагаемых, поскольку лишь два члена обращенной во вре-
мени масштабной последовательности для вейвлетов h{-n) отличны
от нуля. При к = 0, мы получаем Wy(1,0) = -3/^2 , а при к = 1 полу-
чаем И\Д1,1) = -3/>/2. Таким образом, после фильтрации и прорежива-
ющей выборки мы имеем последовательность {-3/Ф2, -3/^2} , что сов-
падает с полученным ранее результатом. Остальные операции свертки
и прореживающей выборки осуществляются аналогично.
Имеется возможность построить столь же эффективную проце-
дуру для восстановления функции Дх) по ДВП/БВП коэффициен-
там приближения W^{j,k) и деталей W^{j,k), что, впрочем, и следо-
вало ожидать. Эта процедура, называемая обратное быстрое
вейвлет-преобразование {обратное ВВП), использует уточняющие
последовательности прямого преобразования и коэффициенты при-
ближения и деталей масштаба / для получения коэффициентов при-
ближения масштаба j + 1. Памятуя о сходстве блока анализа для
ВВП на Рис. 7.15 и блока анализа в схеме двухканального субполос-
ного кодирования и декодирования на Рис. 7.4 (а), мы легко можем
предположить, какой вид имеет блок фильтров синтеза для обратно-
го ВВП. На Рис. 7.18 представлена структура такого блока, идентич-
ного блоку синтеза на Рис. 7.4 (а). Условия (7.1-23) Раздела 7.1.2
Иф(7+1, п)
Ряс. 7.18. Блок фильтров синтеза обратного БВП
определяют подходящие фильтры синтеза. Как отмечено в указан-
ном разделе, для точного восстановления (в случае ортонормирован-
ных квадратурных фильтров) требуется выполнение условия
gj(n) = hj(-n), при / = {0,1}. Таким образом, фильтры синтеза долж-
ны быть обращенными во времени копиями фильтров анализа, и на-
оборот. Поскольку фильтрами анализа для БВП являются последо-
вательности Ар(я) = h<p(-n) и АД») = hy(-n) (см. Рис. 7.15), то
фильтрами синтеза для обратного БВП должны быть последова-
тельности g0(n) = h0(-n) = hqfn) ng\(n) = h\(-ri) = h^(n). Следует, од-
нако, напомнить, что возможно также использование биортого-
нальных фильтров анализа и синтеза, которые не являются
обращенными во времени копиями друг друга. Биортогональные
фильтры анализа и синтеза являются перекрестно-модулированными
(см. (7.1-14и (7.1-15)).
Блок фильтров синтеза обратного БВП реализует вычисления
^(J+ l,k) = k(p(k)^^(J,k)+^(k)* ^“P(J,A)|^O, (7.4-13)
где 1KUP обозначает применение сгущающей выборки с фактором 2
(т.е. добавление нулей между коэффициентами W, в результате че-
го полное число коэффициентов увеличивается вдвое). Для полу-
чения коэффициентов приближения более крупного масштаба
предварительно «сгущенные» коэффициенты сворачиваются с по-
следовательностями hq(ri) и hy(n) и складываются. При этом, в сущ-
ности, формируется более точное приближение функции Дх), бо-
лее подробное и с более высоким разрешением. Как и в случае
прямого БВП, описанная операция обратного БВП может приме-
няться повторно. На Рис. 7.19 изображена структура двухступенча-
того (двухмасштабного) блока фильтров обратного БВП. Такая
Рис. 7.19. Двухступенчатый или двухмасштабный блок синтеза обратного БВП.
7.4. Быстрое вейвлет
процедура вычисления коэффициентов может быть распростра-
нена на любое число масштабов, что гарантирует точное восста-
новление функцииДх).
Пример 7.11. Вычисление одномерного обратного быстрого вейвлет-
преобразования.
Процесс вычисления обратного быстрого вейвлет-преобразования яв-
ляется «зеркальным отражением» процесса вычисления прямого пре-
образования. Для рассмотренной в Примере 7.10 последовательности
этот процесс изображен на Рис. 7.20. Прежде всего, к коэффициентам
приближения и деталей уровня (масштаба) 0 применяется сгущающая
выборка, что дает соответственно {1,0} и {4,0}. Свертка с фильтрами
/?о(л) = Мл> =61^61 и gi(«)=Av(n) = {l/^,-l/•&} с последующим сло-
жением дает И/(р(1,п) = {5/>Д,-3/ у!1}. Тем самым получено приближение
уровня 1 на Рис. 7.20, совпадающее с приближением того же уровня на
Рис. 7.17. Аналогично с помощью второго блока фильтров синтеза (в
правой части на Рис. 7.20) строится вся последовательностьДл).
Завершим наше рассмотрение быстрого вейвлет-преобразования
обсуждением некоторых различий между БВП и БПФ, касающихся,
в первую очередь, их вычислительной сложности. Для вычисления
БВП последовательности размером M=2Jтребуется порядка О(М) ма-
тематических операций. Это означает, что число необходимых опера-
ций умножения и сложения с плавающей точкой (для использую-
щей блоки фильтров процедуры) линейно зависит от размера
последовательности. Это предпочтительно по сравнению с БПФ,
которое требует О(М log/W) операций.
(-3/V2, о, -з/А 0)
Рис. 7.20. Вычисление двухмасштабного обратного быстрого вейвлет-преобра-
зования (1,4,-1,5-72,-1,5-72) последовательности с использованием уточняющих
последовательностей для масштабирующей функции и вейвлетов Хаара.
Второе различие связано с базисными функциями преобразования.
В то время как базисные функции преобразования Фурье (т.е. синусо-
идальные функции) гарантируют существование БПФ алгоритма, су-
ществование БВП алгоритма зависит как от наличия масштабирующей
функции для используемой системы вейвлетов, так и от ортогональ-
ности (или биортогональности) системы масштабирующих функций
и соответствующих вейвлетов. Так, для заданного формулой (7.3-12)
вейвлета «мексиканская шляпа» не существует подходящей масшта-
бирующей функции, и вычисления для этой системы не могут быть осу-
ществлены с помощью БВП. Другими словами, для вейвлета «мекси-
канская шляпа» невозможно построить блок фильтров, типа
представленного на Рис. 7.15, который бы удовлетворял основопола-
гающему требованию БВП метода.
Наконец отметим, что хотя временная и частотная области часто
рассматриваются как различные пространства, тем не менее они меж-
ду собой неразрывно связаны. При попытке анализировать функцию
одновременно во временной и частотной областях мы сталкиваемся со
следующей проблемой. Если нам необходима точная временная инфор-
мация, то мы обязаны допустить некоторую неопределенность в час-
тотной информации, и наоборот. Это есть принцип неопределенности
Гайзенберга в приложении к задачам обработки информации. Для то-
го чтобы графически проиллюстрировать этот принцип, нужно схема-
тически рассматривать каждую базисную функцию, используемую
для представления всех остальных функций, как элемент покрытия
в частотно-временной плоскости. Элемент покрытия, называемый
также ячейкой Гайзенберга, показывает, где сконцентрирована энергия
базисной функции. Ортонормированные базисные функции характе-
ризуются тем, что их ячейки не пересекаются.
На Рис. 7.21 изображены частотно-временные покрытия для сле-
дующих базисов: (а) базис 8-функций (во временной области), (б) ба-
зис синусоидальных функций (БПФ базис) и (в) БВП базис. Заметим,
что обычный временной базис точно указывает момент времени, ког-
да произошло событие, но не дает никакой частотной информации.
С другой стороны, БПФ базис точно указывает частотные составляю-
щие события, которое происходит внутри длительного интервала вре-
мени, но не обеспечивает вовсе разрешения по времени. Временное
и частотное разрешение БВП ячеек различно, но их площади одина-
ковы. Это значит, что каждая из них представляет одинаковую часть
частотно-временной плоскости. При низких частотах ячейки имеют
малую высоту (т.е. имеют высокое частотное разрешение или меньшую
неопределенность по частоте), но большую ширину (что соответству-
ет низкому временному разрешению или большую неопределенность
7.5. Двумерные вейвлет-преобразования
Рис. 7.21 Частотно-временньте покрытия для (а) временного, (б) БПФ и
(в) БВП базисов функций.
во времени). При высоких частотах ширина ячеек меньше (что отве-
чает более высокому временному разрешению), а высота — больше (что
означает меньшее частотное разрешение). Рассмотренное фундамен-
тальное различие между БПФ и БВП отмечалось во введении к на-
стоящей главе и играет важную роль при анализе нестационарных
процессов, когда частоты изменяются во времени.
7.5. Двумерные вейвлет-преобразования
Рассмотренные в предыдущем разделе одномерные вейвлет-преобра-
зования нетрудно обобщить на двумерные функции (изображения).
В двумерном случае необходимо иметь двумерную масштабирую-
щую функцию ф(х,у) и три двумерных вейвлет-функции уя(х,у),
и ф/}(х,у). Каждая функция представляет собой произведение
одномерной масштабирующей функции ср и соответствующей вейв-
лет-функции у. Если исключить те произведения, которые приводят
к «одномерным результатам» типа ф(х)у(х), то оставшиеся образуют
разделимую масштабирующую функцию
ф(х,у)=ф(х)ф(у) (7.5-1)
и разделимые «направленные» вейвлет-функции
уя(х,у) = у(х)ф(у), (7.5-2)
УИ(х,у)=ф(х)у(у), (7.5-3)
V/)(*,_y) = V(*)V(j;)- (7-5-4)
Эти вейвлеты измеряют вариации значений функции — изменения яр-
кости для изображений — по разным направлениям: измеряет
вариации вдоль столбцов (связанные, например, с горизонтальны-
ми краями объектов), — вдоль строк (вертикальные края) и
вдоль диагоналей. Диагональная чувствительность является естест-
венным следствием свойства разделимости, выраженного формула-
ми (7.5-1)- (7.5-4); она не приводит к увеличению вычислительной
сложности рассматриваемого в этом разделе двумерного преобразо-
вания.
Если заданы двумерные разделимые масштабирующая функция и
вейвлет-функции, то дальнейшее обобщение одномерного БВП на дву-
мерный случай не представляет труда. Прежде всего определим семей-
ство базисных функций с помощью операций сдвигов и изменений
масштаба:
^jmn(x,y) = 2jх- m,2j у-п), (7.5-5)
Ч/у/пп(хЭ') = 2-/^2у'(2-/х-/7г,2-/у-л), i={H,V,D}, (7.5-6)
причем верхний индекс i служит для идентификации направленных
вейвлетов, заданных формулами (7.5-2)- (7.5-4), и принимает значе-
ния Н, ИилиЕ). После этого определим дискретное вей влет-преобра-
зование функции f(x,y) размерами Л/x/V следующим образом:
] Л/-1Л-1
^(7oA»)=-t==£ (7-5-7)
>jMN х=0 >!=()
। M-AN-X
Wy(j,m,n) = -r=Y X /(х’У^ут.п(х’У^ i={H,V,D}. (7.5-8)
Ч MN Л=о >=0
Как и в одномерном случае,/о — произвольный начальный масштаб,
и коэффициенты Иф(/0,/и,я) определяют приближение функцииДху)
в масштабе/(). Коэффициенты Wy(J,m,n) определяют горизонтальные,
вертикальные и диагональные детали для масштабов j >j'q. Обычно мы
полагаем Jq =0 и выбираем N = М = 2J, так что j = 0, 1, 2.J - 1 и
т, п = 0, 1, 2,..., 2-7-1. Исходная функция f(x,y) может быть восста-
новлена по заданным коэффициентам и в (7.5-7) и (7.5-8) при
помощи обратного дискретного вейвлет-преобразования
7.5. Двумерные вейвлет
f(x'y}= (/0,/и,л)(р7пЛ)Л(х,у)+
v Mly m n
(7.5-9)
+77777 X X EE^(-/>>«)v;,m,w(-^)-
V MIV i=H V Dj=j0 m n
Как и одномерное дискретное вейвлет-преобразование, двумер-
ное ДВП может быть реализовано с помощью операций фильтрации
и прореживающей выборки. Поскольку используемые масштабиру-
ющая функция и вейвлет-функции являются разделимыми, то снача-
ла вычисляется одномерное БВП по строкам от функцииДх,у), а за-
тем вычисляется одномерное БВП по столбцам от полученного
результата. На Рис. 7.22 (а) представлена блок-схема такой процеду-
ры. Заметим, что как и в случае своего одномерного аналога на Рис. 7.15,
для получения коэффициентов приближения и деталей в масштабе /,
двумерное БВП оперирует с коэффициентами приближения мас-
штаба/ + 1. В двумерном случае, однако, мы имеем дело с тремя на-
борами коэффициентов деталей — горизонтальным, вертикальным
и диагональным.
Одномасштабный блок фильтров на Рис. 7.22 (а) может применять-
ся повторно (для чего коэффициенты приближения на выходе этого
блока фильтров нужно подать на вход такого же следующего блока
фильтров), результатом чего будет Р-масштаб ное преобразование с
масштабами/ = J-l, J-2,..., J-Р. Как и в одномерном случае, изо-
бражениеДх,у) используется в качестве коэффициентов Wq(J,m,ri) на
входе. Сверткой строк изображения с последовательностями Аф(-л)
и hy(-n) и прореживанием столбцов полученного результата мы по-
лучаем две части изображения с уменьшенным вдвое разрешением по
горизонтали. Высокочастотная или детальная часть характеризует
высокочастотную в вертикальном направлении составляющую изо-
бражения. Низкочастотная часть или приближение содержит инфор-
мацию о низких в вертикальном направлении частотах. К обеим ча-
стям изображения затем применяется процедура фильтрации по
столбцам и прореживание. Это дает на выходе четыре изображения (че-
тыре части исходного изображения), — Иф, и —каждое
вдвое меньших линейных размеров, чем исходное. Эти изображе-
ния, показанные в центре Рис. 7.22 (б), представляют собой резуль-
тат применения прореживающей выборки с фактором 2 по обоим
направлениям к массиву, элементами которого являются скалярные
произведения изображения /(х,у) и двумерных масштабирующих
функций и вейвлет-функций соответствующего масштаба. Две итера-
у
И$Л tn, п)
Строки
И^р(у+1, т, п)
у
а
б
В
И^(у, т, п)
И'фО, т, п)
н
Wyij, т, п)
Строки
Wv(j+l,m,n)
Рис. 7.22. Двумерное быстрое вейвлет-преобразование: (а) блок фильтров
анализа; (б) получаемое разложение; (в) блок фильтров синтеза.
7.5. Двумерные вейвлет
ции такой процедуры дают двухмасштабное разложение, показан-
ное справа на Рис. 7.22 (б).
На Рис. 7.22 (в) представлен блок фильтров синтеза, который слу-
жит для обращения рассмотренной выше процедуры. Как и следовало
ожидать, алгоритм восстановления в двумерном случае аналогичен ал-
горитму восстановления в одномерном случае. Каждая итерация заклю-
чается в применении к четырем частям изображения (приближению
и трем детальным частям) масштаба/операций сгущающей выборки
и свертки с двумя одномерными фильтрами, один из которых действует
на столбцы, а другой на строки. Сложение полученных таким образом ре-
зультатов дает приближение масштаба j + 1, после чего процедура повто-
ряется до тех пор, пока исходное изображение ни будет восстановлено.
Рис. 7.23. Трехмасштабное БВП.
Пример 7.12. Вычисление быстрого вейвлет-преобразования.
Рассмотрим двумерное БВП, показанное на Рис. 7.23. Здесь мы име-
ем последовательность разложений для смоделированного на компью-
тере изображения размерами 128x128, которое представлено на
Рис. 7.23 (а). Для получения результатов использовался блок фильт-
ров, схема которого изображена на Рис. 7.22 (а), причем в качестве од-
номерных фильтров были использованы симметричные фильтры
(симлеты), представленные на Рис. 7.24 (а) и (б). На Рис. 7.23 (б), (в)
и (г) представлены результаты разложения. Входными данными для
блока фильтров первого разложения (на Рис. 7.23 (б)) является исход-
ное изображение, представляющее собой набор синусоидальных им-
пульсов на черном фоне. Входными данными для всех последующих
разложений является приближение , т.е. верхняя левая часть изо-
бражения предыдущего разложения. Результатом каждого разложения
являются четыре изображения вдвое меньших линейных размеров, рас-
положенные в указанном на Рис. 7.22 (б) порядке, которые подменя-
ют то входное изображение, из которого они получены. Обратите
внимание на характерную ориентацию изображений детальных состав-
ляющих и в каждом масштабе.
Использованные в предыдущем примере фильтры разложения
принадлежат хорошо известному семейству симметричных вейвлетов,
называемых для краткости симлетами. Хотя симлеты не являются
идеально симметричными, они сконструированы так, чтобы при за-
данном компактном носителе обладать минимально возможной асим-
метрией и наибольшим возможным числом обращающихся в нуль мо-
ментов32 [Daubechies, 1992]. На Рис. 7.24 (д) и (е) представлены
одномерные симлеты четвертого порядка (т.е. вейвлет и масштабиру-
ющая функция). На Рис. 7.24 (а)- (г) представлены соответствую-
щие фильтры разложения и восстановления. Коэффициенты низко-
частотного фильтра восстановленияgp(п) = й^(п) равны 0,0322, -0.0126,
-0,0992, 0,2979, 0,8037, 0,4976 и -0,0758 при 0 < п < 7. Коэффициен-
ты остальных ортогональных фильтров могут быть получены с помо-
щью (7.1 -23). На Рис. 7.24 (ж) представлено перспективное изображе-
ние вейвлета уя(х,у). Оно служит для иллюстрации того, как в
32 К-ый момент вейвлета v(x) определяется как ">(*) = J Наличие нулевых мо-
ментов тесно связано с гладкостью масштабирующей функции и вейвлет-функции,
а также с возможностью представления их в виде полиномов. Симлет порядка N
имеет N обращающихся в нуль моментов.
7.5. Двумерные вейвлет-преобразования
v(x)
Рис. 7.24. Симметричные вейвлеты (симлеты) четвертого порядка: (а)-(б) филь-
тры разложения; (в)- (г) фильтры восстановления; (д) одномерная вейвлет-
функция; (е) одномерная масштабирующая функция; и (ж) один из трех дву-
мерных вейвлетов уД(х,у).
результате комбинации одномерных масштабирующей функции и
вейвлет-функций формируется двумерный разделимый вейвлет.
В заключение параграфа приведем два примера, иллюстрирую-
щие полезность вейвлетов при обработке изображений. Как и при
использовании фурье-анализа, основу подхода составляют
1. Вычисление двумерного вейвлет-преобразования изображения.
2. Изменение полученного преобразования.
3. Вычисление обратного преобразования.
Рис. 7.25. Изменение коэффициентов ДВП для обнаружения границ объ-
ектов: (а) и (в) двухмасштабные разложения, определенные коэффициен-
ты которых обращены в нуль; (б) и (г) соответствующие результаты восста-
новления.
7.5. Двумерные вейвлет-преобразования 575
Поскольку используемые уточняющие последовательности для
масштабирующей функции и вейвлетов представляют собой низко-
частотные и высокочастотные фильтры, то большинству методов
обработки данных, основанных на фурье-анализе, соответствуют
аналогичные методы, основанные на вейвлет-анализе.
Пример 7.13. Обнаружение границ объектов на основе вейвлет-анализа.
Рис. 7.25 служит простой иллюстрацией сказанного. На Рис. 7.25 (а)
составляющая приближения самого мелкого масштаба, представлен-
ного на Рис. 7.23 (в) дискретного вейвлет-преобразования, удалена
путем обращения в нуль ее значений. Как видно на Рис. 7.25 (б), вы-
числение обратного преобразования с использованием этих изменен-
ных коэффициентов приводит к выделению контуров на восстановлен-
ном таким образом изображении. Это позволяет обнаружить
месторасположение границ объектов на исходном изображении, несмо-
тря на то, что яркость вблизи этих границ изменяется относительно
плавно, по синусоидальному закону. Если обратить в нуль также гори-
зонтальную детальную составляющую, — см. Рис. 7.25 (в) и (г) — то мож-
но добиться выделения вертикальных границ объектов.
Пример 7.14. Устранение шума на основе вейвлет-анализа.
В качестве второго примера рассмотрим представленное на
Рис. 7.26(a) магнитно-резонансное изображение (магнитно-резонанс-
ную томограмму, МРТ) головного мозга. Рассмотрение фоновой час-
ти изображения позволяет заключить, что изображение равномерно ис-
кажено некоторым аддитивным или мультипликативным белым
шумом. Основанный на вейвлет-анализе общий метод устранения
шума (т.е. подавления шумовой составляющей) состоит в следующем.
1. Выбирается система вейвлетов (например, система Хаара, систе-
ма симлетов, и т.п.), а также количество масштабов или уровней Р
разложения. Затем вычисляется БВП изображения с шумом.
2. Коэффициенты деталей подвергаются пороговому преобразова-
нию. Это означает выбор некоторого значения порога и примене-
ние порогового преобразования к коэффициентам деталей в мас-
штабах от J-1 до Р. При этом можно использовать как жесткое
пороговое преобразование, так и мягкое пороговое преобразование. При
жестком пороговом преобразовании приравниваются нулю те
значения элементов, которые меньше порога по абсолютной ве-
личине. При мягком пороговом преобразовании первоначально
приравниваются нулю значения элементов, меньшие порога по аб-
солютной величине, а затем к оставшимся ненулевым элементам
Глава 7. Вейвлеты и кратномасштабная обработка
Рис. 7.26. Устранения шума путем изменения коэффициентов ДВП: (а) МРТ
изображение головного мозга (с шумом); (б), (в) и (д) изображения, восста-
новленные после различных пороговых преобразований коэффициентовде-
талей; (г) и (е) информация, удаленная в процессе восстановления изображе-
ний (в) и (д). (Исходное изображение предоставлено медицинским центром
университета Вандербилдта.)
1.6. Вейвлет-пакеты 577
применяется градационное преобразование, сдвигающее диапа-
зон их значений к нулю. Мягкое пороговое преобразование поз-
воляет избежать разрыва значений вблизи порога, которое харак-
терно для жесткого преобразования.
3. Осуществляется обратное вейвлет-преобразование, используя ис-
ходные коэффициенты приближения уровня J- Р и измененные
коэффициенты деталей уровней от J- Р до J- 1.
На Рис. 7.26 (б) представлен результат применения описанного ме-
тода с использованием системы симлетов четвертого порядка, двух
масштабов (т.е. Р= 2) и глобального порога равного 94,9093. Отметим
уменьшение шума и соответствующую потерю качества на границах
объектов. Эта потеря качества изображения контурных деталей зна-
чительно меньше на Рис. 7.26 (в), который получен обнулением ко-
эффициентов деталей только в разложении наиболее крупного мас-
штаба (но не коэффициентов деталей в разложении мелкого масштаба)
и последующим восстановлением. На этом изображении фоновый
шум устранен практически полностью, а контура (границы объектов)
лишь слегка размазаны. На Рис. 7.26 (г) представлена та информация,
которая оказалась потеряна в процессе устранения шума. Это изоб-
ражение было получено с помощью обратного БВП, которое приме-
нялось к разложению, все коэффициенты которого были обнулены,
за исключением коэффициентов деталей самого крупного масштаба.
Как нетрудно видеть, последнее изображение содержит большую
часть шума исходного изображения и некоторую контурную инфор-
мацию. На Рис. 7.26 (д) и (е) представлена похожая пара изображе-
ний, причем затрагивались все коэффициенты деталей всех масшта-
бов. А именно, изображение на Рис. 7.26 (д) представляет собой
результат ДВП восстановления, в котором были обнулены значения
всех коэффициентов деталей на обоих уровнях. Изображение на
Рис. 7.26 (е) является результатом восстановления, в котором были ос-
тавлены только коэффициенты деталей (т.е. коэффициенты прибли-
жения мелкого масштаба были удалены). Обратите внимание на су-
щественное увеличение количества контурной информации на
Рис. 7.26 (е) и соответствующее понижение качества восстановления
контуров на Рис 7.26 (д).
7.6. Вейвлет-пакеты
Быстрое вейвлет-преобразование дает разложение функции в ряд ча-
стотных диапазонов, величины которых находятся в логарифмичес-
ком отношении. Таким образом, низкие частоты объединены в узкие
20 А-223
диапазоны, а высокие частоты — в широкие диапазоны. Это стано-
вится очевидно, если посмотреть на частотно-временную плоскость
на Рис. 7.21 (в). Указанное свойство характеризует так называемые
Q-постоянные фильтры. Желание иметь больший контроль над разби-
ением частотно-временной плоскости (например, получить мень-
шие диапазоны в области высоких частот), приводит к обобщению
БВП и созданию более гибкой конструкции, называемой вейвлет-па-
кеты [Coifman, Wickerhauser, 1992]. Ценой такого обобщения являет-
ся возрастание вычислительной сложности с О(Л/) для БВП до
O(MlogA/).
Рассмотрим снова двухмасштабный блок фильтров на Рис. 7.16 (а),
но разложение изобразим в виде двоичного дерева. На Рис. 7.27 (а) по-
казана структура дерева и привязка соответствующих масштабных ко-
эффициентов и вейвлет-коэффициентов БВП (см. Рис. 7.16 (а)) к уз-
лам этого дерева. Корневой узел дерева отвечает коэффициентам
приближения наиболее крупного масштаба, которые представляют со-
бой отсчеты исходной функции, а листья дерева отвечают коэффици-
ентам приближения и деталей на выходе преобразования. Единствен-
ный промежуточный узел W^{J - 1,п), который представляет собой
приближение после фильтрации первого уровня, в обязательном по-
рядке снова подвергается фильтрации второго уровня и превращает-
ся в два листа на выходе. Заметим, что коэффициенты в каждом узле
суть коэффициенты того линейного разложения, которое порожда-
ет ограниченные по частоте «части» корневого узла ftp). Поскольку лю-
бая такая часть есть элемент известного масштабирующего подпро-
странства или подпространства вейвлетов (см. Разделы 7.2.2 и 7.2.3),
мы можем сменить обозначения для коэффициентов преобразования
на Рис. 7.27 (а) на обозначения для соответствующих подпространств.
В результате мы получим представленное на Рис. 7.27 (б) дерево
подпространств анализа.
Представленная концепция проиллюстрирована далее на Рис. 7.28,
где изображены трехмасштабный блок анализа, дерево анализа и со-
Рис. 7.27. Дерево (а) коэффициентов и (б) анализа для двухмасштабного БВП
блока анализа на Рис. 7.16.
1.6. Вейвлет-пакеты
Рис. 7.28. Трехмасштабный БВП блок фильтров: (а) блок-схема; (б) дерево про-
странств разложения (анализа); (в) спектральные характеристики разложения.
ответствующий спектр частот. В отличие от Рис. 7.16 (а), на блок-схе-
ме Рис. 7.28 (а) использованы обозначения, похожие на обозначения
для дерева анализа на Рис. 7.28 (б) и для спектра на Рис. 7.28 (в). Так,
в результате применения верхнего левого фильтра и последующего про-
реживания получаются величины W^J- 1,п), отмеченные символом
Wj-i, который также используется для обозначения соответствую-
щего подпространства вейвлетов. Это подпространство соответст-
вует верхнему правому листу сопутствующего дерева анализа, а так-
же самому правому (самому широкому) частотному диапазону
соответствующего спектра.
Деревья анализа являются компактным и информативным спо-
собом представления кратномасштабных вейвлет-преобразований.
Их легко рисовать, они занимают меньше места, чем соответствую-
щие им блок-схемы, и позволяют относительно легко заметить эф-
фективные разложения. Трехмасштабное дерево анализа на Рис. 7.28(6)
показывает, например, что существуют следующие три возможных раз-
ложения:
Глава 7. Вейвлеты и кратномасштабная обработка
К/=И,_1©^_1; (7.6-1)
Vj=Vj-2®^j-2®^j-X^ (7-6-2)
Vj =Vj_3 ®Wj_3 ®Wj_2 ®Wj_x . (7.6-3)
Эти разложения соответствуют одно-, двух- и трехмасштабному
БВП разложениям Раздела 7.4 и могут быть получены из выражения
(7.2-27) Раздела 7.2.3 подстановкой в него/0 = J-Рпри Р = {1, 2, 3}.
В общем случае Р-масштабное дерево БВП анализа содержит Р
различных разложений.
Деревья анализа являются также эффективным средством пред-
ставления вейвлет-пакетов, которые суть ничто иное как обычные
вейвлет-преобразования с повторной фильтрацией деталей. Так, трех-
масштабное дерево анализа для БВП на Рис. 7.28 (б) превращается в трех-
масштабное дерево анализа для вейвлет-пакета на Рис. 7.29. Обратим
внимание на появление дополнительных нижних индексов. Когда
некоторый узел помечен парой нижних индексов, то первый нижний
индекс в паре определяет масштаб БВП узла-родителя, от которого
происходит данный узел. Второй индекс в паре, который представля-
ет собой строку из символов Л и D переменной длины, определяет путь
от узла-родителя до данного узла. При этом символ А означает исполь-
зование низкочастотного фильтра (фильтра приближения), а сим-
вол D — высокочастотного фильтра (фильтра деталей). Например,
подпространство Wj_x DA получено «пропусканием» БВП коэффи-
циентов масштаба/- 1 (т.е. родителя Wj_x на Рис. 7.29) через допол-
нительный фильтр деталей (что дает Wj_x D) и, после этого, через до-
полнительный фильтр приближения (что дает окончательно ^/-|,£>л)-
На Рис. 7.30 (а) и (б) представлены блок фильтров и спектральные ха-
Wj.x,AA Wj-X'AD Wja,DA Wja,DD
Рис. 7.29. Полное дерево анализа для трехмасштабного вейвлет-пакета.
Vj-I ^J-3 Wj-2' A ^J-2,D
7.6. Вейвлет-пакеты
|W(co)|
----------------------:------Vj------------------------------
’ Vj_j *T* Wj-i "
" K/-2 ИТ-2 И7/-!, Л И9-1, D "
Рис. 7.30. (а) Блок фильтров и (б) спектральные характеристики разложения
вейвлет-пакета, отвечающего полному трехмасштабному дереву анализа.
рактеристики разложения, отвечающие дереву анализа на Рис. 7.29.
Обратим внимание на равномерное расположение частотных диапа-
зонов, характерное для полного пакета разложений.
Использование вейвлет-пакета, соответствующего трехмасштаб-
ному дереву на Рис. 7.29, дает разложение, число частей (и связанных
с ними частотно-временных ячеек) которого почти втрое превосхо-
дит число частей разложения, получаемого в результате обычного
вейвлет-преобразования, соответствующего трехмасштабному БВП
дереву. Напомним, что при обычном БВП мы разлагаем, фильтруем
и прореживаем только низкочастотные составляющие. При этом воз-
никает определенная логарифмическая зависимость между величи-
нами частотных диапазонов. Поэтому, в то время как трехмасштабное
дерево анализа БВП предполагает наличие трех возможных разложе-
ний (см. (7.6-1)- (7.6-3)), дерево анализа вейвлет-пакета на Рис. 7.29
приводит к 26 различным разложениям. Например, пространство
(а следовательно и функция/(и)) может быть выражена в виде
Vj =Vj-3®^j-3®^j-2,a®wJ-LD®
(7.6-4)
®WJ-l,AA ® Wj-1, AD ® WJ -\,DA ® WJ -A.DD ,
причем соответствующее разложение спектра показано на Рис. 7.30(6),
или в виде
Vj =Vj_1®^j_lD®^J_KAA®^J^AD , (7.6-5)
соответствующее разложение спектра показано на Рис. 7.31. Обратим
внимание на различия между этим последним спектром, спектром раз-
ложения с использованием полного вейвлет-пакета на Рис. 7.30 (б),
и спектром трехмасштабного БВП разложения на Рис. 7.28 (в). В об-
щем случае Р-масштабные преобразования на основе вейвлет-пакетов
(и отвечающее им дерево анализа, состоящее из Р + 1 уровня) дают
возможность получить различные разложения в количестве
D(P + \) = [Л(Р)]2 + 1,
где D(l) = I. При таком большом числе допустимых разложений,
преобразования, основанные на применении пакетов, позволяют
лучше контролировать процесс разделения спектра подлежащей раз-
ложению функции на части. Конечно, платой за это является увели-
чение вычислительной сложности (сравните блоки фильтров на
Рис. 7.28 (а) и 7.30 (а)).
Рис. 7.31. Спектр разложения по формуле (7.6-5).
7.6. Вейвлет-пакеты
Рис. 7.32. Первое двумерное БВП разложение: (а) спектр и (б) дерево подпро-
странств анализа.
а •
Рассмотрим теперь двумерный четырехполосный блок фильтров
на Рис. 7.22 (а). Как указывалось в Разделе 7.5, он делит Wv(j + 1.т.п)
приближение на четыре части: И^(у,т,п), W^(j,ni,n), и
W^(j,m,n). Как и в одномерном случае, повторение процесса приво-
дит к формированию Р-масштабного преобразования с масштабами
j = J-\,J- 2,..., J-Р, причем Wq(J,m,n) =f(m,ri). Разложение спект-
ра после первой итерации (т.е. при j + 1 = /в блок-схеме на Рис. 7.22(a))
показано на Рис. 7.32 (а). Отметим, что частотная плоскость оказы-
вается разделенной на четыре равные по площади составные части.
Низкочастотная четверть диапазона в центре соответствует коэффи-
циентам преобразования H^p(J- 1,т,п) и масштабирующему простран-
ству Vj_ ]. Это полностью согласуется с одномерным случаем. В дву-
мерном случае, однако, мы имеем три (вместо одного) подпространства
вейвлетов. Они обозначаются как и отвечают коэф-
фициентам И^(/-1,/и,«)> и Htf(JНа Рис. 7.32
Рис. 7.33. Полное дерево анализа для трехмасштабного вейвлет-пакета. По-
казана лишь часть дерева.
(б) представлено соответствующее одномасштабное четверичное де-
рево анализа БВП. Обратим внимание на использованные верхние
индексы, которые связывают обозначения для подпространств вейв-
летов и обозначения для отвечающих им коэффициентов преобразо-
вания.
На Рис. 7.33 представлена часть полного трехмасштабного двумер-
ного дерева анализа для вейвлет-пакетов. Как и в одномерном случае
на Рис. 7.29, первый из нижних индексов для каждого узла, опреде-
ляет масштаб обычного БВП узла-родителя, от которого происходит
данный узел. Второй индекс — строка из символов Л, H,V,viD пере-
менной длины — определяет путь от узла-родителя до рассматривае-
мого узла. Например, узел, отмеченный как W^_x VD, получен следую-
щим образом. Сначала коэффициенты горизонтальных деталей
двумерного БВП масштаба/- 1 (т.е. узла-родителя на Рис. 7.33) под-
вергаются фильтрации с использованием блока фильтров вертикаль-
ных деталей, что дает W^_x v. Затем полученные коэффициенты под-
вергаются фильтрации с использованием блока фильтров диагональных
деталей, что дает окончательно WjH_x VD. Дерево анализа для двумерных
Р-масштабных вейвлет-пакетов дает возможность построить различные
разложения в количестве
а б Рис. 7.34. (а) Изображение отпечатка пальца и (б) его трехмасштабное разло-
жение с использованием полного вейвлет-пакета. (Исходное изображение
предоставлено Национальным институтом стандартов и технологий.)
7.6. Вейвлет -пакеты
D(P + 1) = [D(P)]4 + 1, (7.6-7)
где D(l) = 1. Таким образом, полное число различных разложений,
которые можно получить из трехмасштабного дерева на Рис. 7.33
равно 83522.
Пример 7.15. Разложения с помощью двумерных вейвлет-пакетов.
Каждое отдельное дерево для вейвлет-пакетов предоставляет мно-
гочисленные возможности для разложения. В действительности чис-
ло возможных разложений часто бывает так велико, что не имеет
смысла, и даже невозможно перебирать или исследовать каждое из
них в отдельности. Поэтому весьма желательно иметь эффективный
алгоритм нахождения разложений, оптимальных по отношению к не-
которым критериям, связанным с конкретными приложениями.
Как будет видно, во многих случаях применим классический крите-
рий, основанный на вычислении некоторой функции стоимости,
который хорошо приспособлен для алгоритмов поиска по двоичным
и четверичным деревьям.
Рассмотрим задачу сжатия изображения отпечатка пальца на Рис. 7.34
(а). Использование деревьев анализа для трехмасштабных вейвлет-па-
кетов дает 83522 (см. (7.6-7)) потенциальных разложений, которые мо-
гут быть использованы на начальном этапе процедуры сжатия. На
Рис. 7.34 (б) представлено одно из таких разложений — разложение с ис-
пользованием полного вейвлет-пакета, дерево которого, подобно дере-
ву на Рис. 7.33, содержит 64 листа. При этом листья дерева соответст-
вуют полученным в результате разложения частям изображения, набор
8x8 которых составляет изображение Рис. 7.34 (б). Однако вероятность
того, что это конкретное разложение, состоящее из 64 частей, являет-
ся в некотором роде оптимальным для целей сжатия, относительно не-
велика. В отсутствие подходящего критерия мы не можем ни подтвер-
дить, ни опровергнуть оптимальность выбранного разложения.
Один из подходящих критериев выбора разложения для сжатия
изображения на Рис. 7.34 (а) может быть получен при рассмотрении
функции стоимости (функционала)
= (7.6-8)
Л7/,/7
Этот функционал может использоваться в качестве меры информаци-
онного содержания функции/, в случае, когда она является разностью
изображения и его приближения более мелкого масштаба. Если зна-
(Г586 Глава 7. Вейвлеты и кратномасштабная обработка
чение функционала £(/) мало, то это означает, что такая функция/со-
держит малое количество информации (например, большое число ну-
левых значений), и, значит, допускает более высокую степень сжатия.
Большое значение функционала, наоборот, указывает на то, что такая
функция содержит много ненулевых значений. В большинстве схем
трансформационного сжатия используется процедура усечения или по-
рогового преобразования, при которой малые по величине коэффи-
циенты заменяются нулевыми значениями. Поэтому использование
функции стоимости, минимизация которой максимизирует число
значений, близких к нулевым, приводит к разумному (с точки зрения
задачи сжатия) критерию выбора «лучшего» разложения.
Только что рассмотренную функцию стоимости просто вычис-
лять и легко использовать в стандартных процедурах оптимизации по
деревьям. Алгоритм оптимизации должен минимизировать значение
этой функции для листьев возможных деревьев анализа. Предпочте-
ние должно быть отдано тому дереву, значение функционала листь-
ев которого минимально, поскольку соответствующее разложение
имеет максимальное число близких к нулю коэффициентов, что
приводит к большей степени сжатия. Функция стоимости (7.6-8)
локальна в том смысле, что она может быть представлена в виде сум-
мы своих значений, вычисленных отдельно для частей (узлов), состав-
ляющих изображение. При этом вычисление значения функции
стоимости для каждого узла требует только той информации, которая
содержится в данном узле. Поэтому нетрудно предложить следующий
эффективный алгоритм для нахождения решений, минимизирующих
значение функционала.
Чтобы построить оптимальное дерево анализа, для каждого из уз-
лов, начиная от корня и двигаясь вниз уровень за уровнем до дости-
жения листьев, необходимо выполнить следующие действия:
1. Подсчитать значение функционала ЕР для данного узла, (рассма-
тривая его как узел-родитель), а также значения функционала для
его четырех узлов-потомков ЕА, Е//, Еуи Ер. Для разложений, ос-
нованных на использовании двумерных вейвлет-пакетов, узлу-ро-
дителю отвечает двумерный массив коэффициентов приближе-
ния или деталей, а узлам-потомкам — полученные в результате
фильтрации этого массива коэффициенты приближения и коэф-
фициенты горизонтальных, вертикальных и диагональных деталей.
2. Если суммарное значение функционала для узлов-потомков
меньше значения функционала для узла-родителя, т.е. Ед +
+ Ец + Еу+ Ер < ЕР, то присоединить потомков к строящемуся де-
реву анализа. Если суммарное значение функционала для узлов-
7.6. Вейвлет-пакеты
шш
Рис. 7.35. Оптимальное разложение изображения отпечатка пальца на
Рис. 7.34(a) с помощью вейвлет-пакета.
потомков больше или равно значению функционала для узла-ро-
дителя, то отсечь потомков и оставить только родителя; данный узел
будет являться листом оптимального дерева анализа.
Рис. 7.36. Оптимальное дерево анализа, соответствующее разложению с по-
мощью вейвлет-пакета, который показан на Рис. 7.35.
(Г588 Глава 7. Вейвлеты и кратномасштабная обработка
Представленный алгоритм можно использовать для (1) усечения
деревьев вейвлет-пакетов или (2) конструирования процедур вычисле-
ния оптимальных деревьев с самого начала. В последнем случае несу-
щественные потомки, исходящие из тех узлов, которые удаляются на вто-
ром шаге алгоритма, вычисляться не будут. На Рис. 7.35 представлено
оптимальное разложение, полученное в результате применения рас-
смотренного алгоритма с функционалом (7.6-8) к изображению на
Рис. 7.34 (а). Соответствующее дерево анализа представлено на Рис. 7.36.
Отметим, что многие части представленного на Рис. 7.34 (б) полного раз-
ложения на 64 составляющие объединены, а соответствующие ветви
представленного на Рис. 7.33 полного дерева анализа с 64 листьями
отсечены. Кроме того, значения яркости тех частей изображения на
Рис. 7.35, которые не были подвергнуты процедуре дальнейшего разло-
жения, являются почти постоянными и лежат в середине яркостного ди-
апазона. Все части изображения на этом рисунке (за исключением при-
ближения) были подвергнуты градационному преобразованию так,
чтобы яркость 128 соответствовала нулевому значению коэффициентов.
Как видно из рисунка, эти части изображения содержат малое количе-
ство информации, а значит их дальнейшее разложение не приведет к
уменьшению общего значения функционала.
Представленный пример связан с практической задачей, которую
удалось решить с применением вейвлетов. В настоящее время Феде-
ральное бюро расследований (ФБР), обладающее огромной базой
данных отпечатков пальцев, установило вейвлет-ориентированный на-
циональный стандарт оцифровки и сжатия дактилоскопических изо-
бражений [FBI, 1993]. Использование биортогональных вейвлетов
позволило достичь в этом стандарте типичного коэффициента сжа-
тия 1:15. Преимущества вейвлет-ориентированного сжатия изобра-
жений по сравнению с более традиционными JPEG-подходами изу-
чаются в следующей главе.
Фильтры разложения, использованные в Примере 7.15 (и входящие
в стандарт ФБР), являются частью широко известного семейства вейв-
летов, называемого биортогональными вейвлетами Коэна—Добеши—
Фово [Cohen, Daubechies, Feauveau, 1992]. Масштабирующая функция
и вейвлет-функция этого семейства симметричны и имеют одинако-
вые размеры. Благодаря этим свойствам вейвлеты семейства Коэна-
Добеши-Фово входят в число наиболее широко используемых биор-
тогональных вейвлетов. На Рис. 7.37 (д)~ (з) представлены
двойственные пары масштабирующих функций и вейвлет-функций,
которые определяют биортогональные базисы. Значения коэффици-
ентов низкочастотного фильтра анализа Лр(л): 0, 0,0019, -0,0019, -
7.6. Вейвлет-пакеты
Рис. 7.37. Представительбиортогонального семейства вейвлетов Коэна—До-
беши—Фово: (а) и (б) коэффициенты фильтров анализа; (в) и (г) коэффици-
енты фильтров синтеза; (д)- (з) двойственные пары масштабирующих функ-
ций и вейвлет-функций.
0,017,0,0119, 0.0497, -0,0773, -0,0941,0,4208, 0,8259. 0,4208, -0,0941,
-0,0773, 0,0497, 0,0119, -0,017, -0,0019и0,0010при 0<п< 17. Значе-
ния коэффициентов высокочастотного фильтра анализа h[(n): 0,0, 0,
0,0144, -0,0145, -0,0787, 0,0404, 0,4178, -0,7589, 0,4178, 0,0404,
-0,0787, -0,0145, 0,0144, 0, 0, 0 и 0 при 0 < п < 17. Коэффициенты со-
ответствующих биортогональных фильтров синтеза могут быть вычис-
лены по формуле (7.1-15): go(ri) = (-1)п + lh\(n) и(п) = (-1) nho(n),
т.е. фильтры синтеза являются перекрестно-модулированными копи-
ями фильтров анализа. Для того чтобы фильтры имели одинаковую
длину, были добавлены нулевые коэффициенты.
Заключение
Материал настоящей главы закладывает прочные математические ос-
новы для понимания той роли, которую играют вейвлет-методы и крат-
номасштабный анализ в обработке изображений, и открывает возмож-
ности для овладения этими методами. Вейвлеты и
вейвлет-преобразования являются сравнительно новыми средствами
обработки изображений, причем круг задач, для решения которых
они применяются, стремительно расширяется. В силу известного
сходства с преобразованием Фурье, многие методы Главы 4 находят свой
аналог среди методов вейвлет-анализа. Неполный список приложений,
которые допускают подход с позиций вейвлет-анализа, включает за-
дачи сопоставления, регистрации, сегментации, подавления шумов,
улучшения, сжатия, морфологического анализа и вычислительной
томографии. Поскольку не представляется возможным охватить все эти
приложения в рамках одной главы, темы для обсуждения были выбра-
ны исходя из их значимости для понимания основных идей и подго-
товки читателя кдальнейшему изучению данной области. В Главе 8 бу-
дет рассмотрено применение вейвлетов в задаче сжатия изображений.
Библиографические замечания
Существует много хороших работ, посвященных вейвлетам и их при-
ложениям. Некоторые из них были использованы нами при написа-
нии основных разделов настоящей главы. При изложении мате-
риала Раздела 7.1.2, посвященного субполосному кодированию
и цифровой фильтрации, мы следовали книге [Vetterli, Kovacevic,
19951, а при рассмотрении в Разделах 7.2 и 7.4 кратномасштабного раз-
ложения и быстрого вейвлет преобразования — придерживались из-
ложения этих вопросов в [Burrus, Gopinath, Guo, 1998]. Ссылки на ра-
боты, ставшие основой для остального материала главы, приведены
Библиографические замечания
в тексте. Экспериментальная часть и многие примеры вычислялись
с использованием средств вейвлет-анализа, входящих в состав паке-
та Matlab [Misiti, Misiti, Oppenheim, Poggi, 1996].
История вейвлет-анализа описана в книге [Habbard, 1998]. Ранние про-
тотипы вейвлетов появились одновременно в различных областях и собраны
воедино в работе [Mallat, 1987]. Эта работа заложила математические основы
теории вейвлетов. Многое из истории вейвлетов можно почерпнуть из работ
Мейера [Meyer, 1987,1990,1992а, б, 1993], Малла [Mallat, 1987,1989а-в, 1998]
иДобеши [Daubechies, 1988,1990,1992, 1993, 1996]. Большой интерес к
вейвлетам был в немалой степени стимулирован работами последней.
Книга Добеши [Daubechies, 1992], посвященная математической те-
ории вейвлетов, является классической.
По поводу применения вейвлетов в обработке изображений мы от-
сылаем читателя к посвященным этой тематике работам общего харак-
тера, таким как [Castleman, 1996], и многочисленным специальным ра-
ботам, некоторые из которых представляют собой доклады на
конференциях. Среди работ, относящихся к этой последней категории,
упомянем [Rosenfeld, 1984], [Prasad, Iyengar, 1997] и [Topiwala, 1998].
Следующие современные работы могут послужить отправными пунк-
тами дальнейших исследований применения вейвлетов в различных
прикладных задачах обработки изображений, в том числе: регистра-
ция изображений — [Thdvenaz. Unser, 2000]; классификация на осно-
ве текстур — [Chang, Kuo, 1995], и [Unser, 1995]; применение вейвле-
тов для морфологического анализа — [Heijmans, Goutsias, 2000];
восстановление изображений — [Banham et. al., 1994], [Wang, Zhang,
Pan, 1995] и [Banham, Kastaggelos, 1996]; улучшение изображений — [Xu
et. al., 1994] и [Chang, Yu, Vetterli, 2000]; вычислительная томография
— [Delaney, Bresler, 1995] и [Westenberg, Roerdink, 2000]; описание изо-
бражений и задача сопоставления — [Lee, Sun, Chen, 1995], [Liang, Kuo,
1999], [Wang, Lee, Toraichi, 1999] и [You. Bhattacharya, 2000]. По пово-
ду наиболее важного применения вейвлетов для сжатия изображений
см., например, [Antonini et. al., 1992], [Wei et. al., 1998], а также книгу
[Topiwala, 1998]. Наконец, имеется ряд специальных выпусков журна-
лов, посвященных вейвлетам. Упомянем специальный выпуск \IEEE
Transactions on Information Theory, 1992], посвященный вейвлет-преоб-
разованиям и кратномасштабному анализу сигналов, специальный
выпуск [IEEE Transactions on Signal Processing, 1993], посвященный
вейвлетам и обработке сигналов, а также специальный выпуск [IEEE
Transactions on Pattern Analysis and Machine Intelligence, 1989], где от-
дельный раздел посвящен кратномасштабным представлениям.
Хотя материал настоящей главы концентрируется на основопола-
гающих вопросах вейвлет-анализа и его применения в области обра-
ботки изображений, значительный интерес представляют вопросы
конструирования самих систем вейвлетов. Заинтересованного чита-
теля мы отсылаем к работам [Battle, 1987, 1988], [Daubechies, 1988,
1992], | Cohen, Daubechies, 1992], [Meyer. 1990]. [Mallat, 1989 (6)].
[Unser, Aldroubi, Eden, 1993] и [Gruchenig, Madych, 1992]. Данный спи-
сок не является исчерпывающим, но может быть использован в ка-
честве отправного пункта для дальнейшего чтения. Имеет смысл об-
ратить внимание также на список литературы по субполосному
кодированию и блокам фильтров, имеющейся в [Strang, Nguyen,
1996] и [Vetterli, Kovacevic, 1995], а также на ссылки, приведенные
в тексте главы в связи с рассматриваемыми примерами.
Задачи
7.1 Придумайте систему декодирования пирамиды разностей с
предсказанием, которая формируется системой кодирования
на Рис. 7.2 (б), и нарисуйте ее блок-схему. Предполагайте, что
система кодирования не вносит ошибок квантования.
*7.2 Постройте полностью заселенную пирамиду приближений и
соответствующую пирамиду разностей с предсказанием для
изображения
1 2 3 4
5 6 7 8
/(х,у)=
9 10 11 12
13 14 15 16
В процедуре фильтрации на Рис. 7.2 (б) используйте усредне-
ние по окрестности 2x2 и предполагайте, что процедура интер-
поляции отсутствует.
*7.3 Пусть задано изображение размерами 2Jx2J. Меньшее или
большее количество данных потребуется для представления пи-
рамиды этого изображения, состоящей из J + 1 уровня? Чему
равен коэффициент сжатия или растяжения?
7.4 Докажите, что следующие фильтры из Таблицы 7.1 образуют
блоки фильтров точного восстановления:
*(а) квадратурные зеркальные фильтры (КЗФ);
(б) ортонормированные фильтры.
7.5 Какими фильтрами являются квадратурные зеркальные филь-
тры: биортогон ал ьны ми, ортогональными, или могут являть-
ся как теми так и другими?
Задачи 593
7.6 Вычислите коэффициенты фильтров синтеза Добеши g0(n) и
gi(n) в Примере 7.2. Используя (7.1-22), убедитесь, что эти
фильтры являются ортонормированными (ограничьтесь рас-
смотрением только значения т = 0).
*7.7 Нарисуйте блок-схему двумерного четырехканального блока
фильтров субполосного декодирования для восстановления
входного изображения х(т,п) в блок-схеме на Рис. 7.5.
7.8 Выпишите матрицу преобразования Хаара для случая N= 8.
7.9 (а) Вычислите преобразование Хаара для следующего изобра-
жения размерами 2x2:
[6 2.
(б) Обратное преобразование Хаара имеет вид F = Н-1Т(Н-1)^,
где Т — преобразование Хаара, Н-1 — матрица, обратная
к матрице преобразования Хаара и Т означает операцию
транспонирования. Найдите матрицу Н2-1 для матрицы
преобразования Н2 и вычислите обратное преобразова-
ние Хаара от результата пункта (а).
7.10 Вычислите коэффициенты разложения двумерного векто-
ра [3,2] г относительно следующих базисов (фреймов) и выпи-
шите соответствующие разложения.
*(а) Базис из двух векторов в R2 ф0=[1/д/2,1/^]Г и
Ф1=[1/л/2,-1/Л1г.
(б) Базис в R2 фо =11,0]г, фо =[1,1]г и двойственный к нему
базис фо = [1,- 1]г, Ф1 = Ю,1]Г .
(в) Фрейм из трех векторов в R2 фо = [1,0]г, ф] = [—1/2, л/з/2]г ,
Ф2 =[-1/2,-д/з/2]г и двойственный к нему фрейм
Ф, =2ф, /3 , i= {0,1,2}.
Указание: используйте скалярное произведение евклидового
пространства.
7.11 Покажите, что масштабирующая функция
1
0
<р(х) =
0,25 <х< 0,75,
в остальных случаях
не удовлетворяет второму условию кратномасштабного анализа.
7.12 Выразите масштабирующее пространство И3 через масшта-
бирующую функцию <р(х). Используя определение (7.2-14)
для масштабирующей функции Хаара, выразите масштабиру-
ющие функции Хаара пространства Из для сдвигов к — {0,1,2}.
Глава 7. Вейвлеты и кратномасштабная обработка
*7.13 Напишите выражение для вейвлета узз(х) системы вейвлетов
Хаара. Выразите вейвлет у3з(х) через масштабирующую функ-
цию Хаара.
7.14 Предположим, что функцияДх) принадлежит масштабирую-
щему пространству системы Хаара, т.е.Дх) е Vy Используя
(7.2-22), выразите пространство И3 в виде прямой суммы мас-
штабирующего пространства Vq и необходимых пространств
вейвлетов. Предполагая, что функция Дх) обращается в нуль
вне отрезка [0,1], укажите масштабирующие функции и вейв-
леты, входящие в разложение Дх), основанное на получен-
ном Вами выражении.
Время
7.15 Вычислите первые четыре члена разложения функции из При-
мера 7.7 в вейвлет-ряд с начальным масштабомJq — 1. Выпи-
шите полученное разложение, используя соответствующие
масштабирующие функции и вейвлеты. Сравните Ваш ре-
зультат с результатом Примера 7.7, в котором был выбран на-
чальный масштаб ]q = 0.
7.16 Заданное формулами (7.3-5) и (7.3-6) ДВП зависит от выбора
начального масштаба/0.
(а) Вычислите одномерное ДВП функции Ди) = {1,4, 3, 0},
0 < и < 3, из Примера 7.8 с начальным масштабом Д = 1
(вместо Уо = 0).
(б) Используйте результат (а) для вычисления значенияД 1) по
значениям преобразования.
*7.17 Какие заключения относительно одномерной функции позво-
ляет сделать ее интегральное вейвлет-преобразование, пред-
ставленное ниже на рисунке?
7.18 (а) Интегральное (непрерывное) вейвлет-преобразование в
Задаче 7.17 было сформировано на компьютере. Функция,
к которой применялось преобразование, была предвари-
тельно дискретизована, т.е. преобразование применялось к
отсчетам функции с некоторым шагом. Что же непрерыв-
Задачи
ного в этом преобразовании, т.е. что отличает его от дискрет-
ного вейвлет-преобразования той же функции?
*(б) При каких условиях использование ДВП предпочтительнее
использования ИВП? Существуют ли случаи, когда ис-
пользование ИВП предпочтительнее использования ДВП?
*7.19 Нарисуйте схему блока фильтров БВП, необходимого для вы-
числения преобразования в Задаче 7.16. Напишите последо-
вательности на входах и выходах всех элементов схемы.
7.20 Вычислительная сложность быстрого вейвлет-преобразова-
ния для М-точечного массива равна О(М), т.е. число необхо-
димых операций пропорционально М. Чем определяется ко-
эффициент пропорциональности?
7.21 *(а) Если на вход трехмасштабного блока фильтров на
Рис. 7.28(a) подать масштабирующую функцию Хаара
<р(и) — 1 при и = 0, 1,..., 7, и равную 0 в остальных случаях,
то каков будет результат преобразования при использова-
нии системы вейвлетов Хаара?
(б) Каков будет результат преобразования, если подать на вход
вейвлет-функцию Хаара у(и) = {1,1, 1,1,-1,—1,-1,—1} при
и = 0, 1,..., 7.
(в) Какой последовательности на входе отвечает преобразова-
ние {0, 0, 0, 0, 0, 0, В, 0} с ненулевым коэффициентом
И^(2,2) = В.
*7.22 Двумерное быстрое вейвлет-преобразование имеет много об-
щего с рассмотренной в Разделе 7.2.1 пирамидой изображений.
Чем они похожи? Имея трехмасштабное вей влет-преобразо-
вание, представленное на Рис. 7.8 (а), как бы Вы построили со-
ответствующую пирамиду приближений? Сколько уровней
имела бы эта пирамида?
7.23 Вычислите двумерное вейвлет-преобразование по системе
вейвлетов Хаара для изображения размерами 2x2 из Зада-
чи 7.9. Нарисуйте схему требуемого блока фильтров и напиши-
те массивы на входах и выходах всех элементов схемы.
*7.24 В случае фурье-преобразования
/(х -х0,у - )« Е(«,г)е-/2л(^ / M+vy"'N}
сдвиг не меняет изображение спектра|/(iz,v)|. Установите свой-
ства вейвлет-преобразования по отношению к сдвигу, ис-
пользуя приведенную ниже последовательность изображе-
ний. Самое левое изображение состоит из двух белых
квадратов в центре (размерами 32x32) на сером фоне (разме-
596 Глава 7. Вейвлеты и кратномасштабная обработка
рами 128x128). Второе слева изображение является одномас-
штабным вейвлет-преобразованием по системе вейвлетов Ха-
ара. Третье изображение представляет собой вейвлет-преоб-
разование изображения, полученного в результате сдвига
исходного на 32 элемента вправо и вниз. Наконец четвертое
(самое правое) изображение — вейвлет-преобразование изо-
бражения, полученного в результате сдвига исходного на 1 эле-
мент вправо и вниз.
7.25 В приведенной ниже таблице нарисованы вейвлеты и масшта-
бирующие функции Хаара для четырехмасштабного быстро-
го вейвлет-преобразования. Нарисуйте дополнительные ба-
зисные функции, необходимые для трехмасштабного
разложения с использованием полного вейвлет-пакета. При-
ведите явные выражения для этих функций или выражения,
с помощью которых их можно определить.
7.26 Используя вейвлеты Хаара, найдите для функцииДл) = 0,25,
п = 0, 1, 2....15, пакетное разложение с минимальным коли-
чеством информации. Используйте в качестве функции сто-
имости функционал вида
£[/(«)]= £/21«)1п(/2(л))
п
7.27
Нарисуйте оптимальное дерево и напишите в узлах найденные
значения функционала.
Ниже представлено разложение изображения с вазой на
Рис. 7.1 с помощью вейвлет-пакета.
(а) Нарисуйте соответствующее дерево анализа этого разложе-
ния, подпишите узлы, используя обозначения соответст-
вующих масштабирующих пространств и пространств
вейвлетов.
(б) Нарисуйте и подпишите частотные диапазоны разложения.
ГЛАВА 8
СЖАТИЕ
ИЗОБРАЖЕНИЙ
Жизнь коротка, а информация бесконечна... Сокращение есть неизбежное зло, и
задача того, кто этим занимается, состоит в достижении наилучшего в том,
что хотя и является по существу плохим, все же лучше, чем ничего.
Олдос Хаксли
Введение
Каждый день огромное количество информации запоминается, преобра-
зуется и передается в цифровом виде. Фирмы снабжают через Интернет
своих деловых партнеров, инвесторов и потенциальных покупателей го-
довыми отчетами, каталогами и информацией о товарах. Ввод и просле-
живание распоряжений — две основные электронные банковские опера-
ции — могут выполняться в комфортных условиях прямо из дома. Как часть
правительственной программы информатизации в США сформирован
полный каталог (а также средства для его поддержания и хранения) Биб-
лиотеки Конгресса — самой большой в мире библиотеки, доступной по
сети Интернет. Вот-вот станет реальностью составление индивидуаль-
ной программы кабельного телевидения по заказу пользователей. По-
скольку значительная часть передаваемых данных при этом является по
сушеству графической или видеоинформацией, требования к устройст-
вам хранения (см. Раздел 2.4.2) и средствам связи становятся огромны-
ми. Таким образом, значительный практический и коммерческий инте-
рес приобретают средства сжатия данных для их передачи или хранения.
Сжатие изображений ориентировано на решение проблемы сокра-
щения объема данных, требуемого для представления цифрового изо-
бражения. Основой такого процесса сокращения является удаление из-
быточных данных. С математической точки зрения это равнозначно
преобразованию некоторого двумерного массива данных в статисти-
чески некоррелированный массив1. Такое преобразование сжатия
1 Заметим, что если набор данных является коррелированным, то, значит, имеются
статистические взаимосвязи между его элементами, следовательно его можно сокра-
тить. — Прим, перев.
Введение
применяется к исходному изображению перед тем как его сохранить
или передать. Впоследствии сжатое изображение распаковывается и
восстанавливается исходное изображение или некоторое его при-
ближение.
Интерес к проблеме сжатия изображений возник более 35 лет
назад. Первоначальное внимание исследователей было обращено к
вопросам разработки аналоговых методов сокращения полосы час-
тот видеосигнала — подход, называемый сжатием полосы пропуска-
ния. Появление вычислительной техники и последующие разработ-
ки в области интегральных микросхем привели к смещению интереса
от аналоговых методов к цифровым алгоритмам сжатия. Принятие от-
носительно недавно нескольких ключевых международных стандар-
тов сжатия изображений наглядно продемонстрировало значитель-
ный рост данной области — от теоретических разработок, начатых в
1940-х годах К. Шенноном и другими учеными, которые первыми
сформулировали вероятностный подход к информации, ее представ-
лению, передаче и сжатию, до практического применения этих тео-
ретических результатов.
В настоящее время сжатие изображений может рассматриваться как
«технология расширения возможностей». В дополнение к вышеупо-
мянутым областям применения, сжатие изображений является есте-
ственным способом поддержания увеличивающегося разрешения со-
временных устройств ввода изображений, а также все возрастающей
сложности широковещательных телевизионных стандартов. Более то-
го, сжатие изображений играет существенную роль во многих разно-
образных и важных применениях, таких как видеоконференции, дис-
танционное зондирование (использование изображений, получаемых
со спутников, для прогноза погоды и изучения земных ресурсов),
формирование изображений документов, медицинские изображения,
факсимильная передача (факс), управление беспилотными летатель-
ными аппаратами в военных, космических, или других опасных обла-
стях. Короче говоря, наблюдается все возрастающее число областей,
взаимосвязанных с эффективной обработкой, запоминанием, хра-
нением и передачей двоичных (бинарных), полутоновых черно-белых
и цветных изображений.
В настоящей главе рассматриваются теоретические и практичес-
кие аспекты сжатия изображений. Разделы 8.1-8.3 являются введени-
ем и составляют теоретические основы данной дисциплины. В Раз-
деле 8.1 рассматривается избыточность данных, которая может
использоваться алгоритмами сжатия изображений. В Разделе 8.2 на ос-
нове модели вводится система понятий, используемых в общей про-
цедуре сжатия—восстановления. В Разделе 8.3 в деталях рассматрива-
ются основные понятия теории информации и их роль в определении
фундаментальных пределов представления информации.
Разделы 8.4—8.6 посвящены практической стороне вопроса сжа-
тия изображений, включая как важнейшие используемые методы,
так и принятые стандарты, которые стимулировали расширение ра-
мок и способствовали признанию данной дисциплины. Методы под-
разделяются на две большие категории: методы сжатия без потерь и ме-
тоды сжатия с потерями. Раздел 8.4 посвящен методам первой группы,
которые, в частности, полезны при архивации изображений. Эти ме-
тоды гарантируют сжатие и восстановление изображений без какого
бы то ни было искажения информации. В Разделе 8.5 описываются ме-
тоды второй группы, позволяющие достичь более высокого уровня со-
кращения данных, но не обеспечивающие абсолютно точного воспро-
изведения исходного изображения. Сжатие изображений с потерями
находит применение в таких областях как широковещательное теле-
видение, видеоконференции и факсимильные передачи, в которых не-
которое количество ошибок является приемлемым компромиссом,
позволяющим повысить степень сжатия. Наконец, Раздел 8.6 посвя-
щен рассмотрению существующих и предлагаемых стандартов сжатия
изображений.
8.1. Основы
Термин сжатие данных означает уменьшение объема данных, исполь-
зуемого для представления определенного количества информации.
При этом между понятиями данные и информация должны быть про-
ведены четкие различия. Они не являются синонимами. Данные фак-
тически являются тем средством, с помошью которых информация пе-
редается, и для представления одного и того же количества
информации может быть использовано различное количество данных.
Это имеет место, например, в том случае, когда два разных человека,
один — многословный, а другой — точный и лаконичный, рассказы-
вают одну и ту же историю. В этом случае информацией являются фак-
ты, о которых идет речь, а слова — данными, использующимися для
изложения информации. Если два рассказчика используют разное
количество слов, то возникают два варианта одной истории, и по
крайней мере один из них будет содержать несущественные данные.
Это означает, что такой вариант содержит данные (т.е. слова), которые
либо несут несущественную информацию, либо являются повторени-
ем уже известного. В этом случае говорят об избыточности данных.
Избыточность данных является центральным понятием цифрово-
го сжатия данных. Это не абстрактное понятие, а измеримая матема-
тическая категория. Пусть и j и и2 означают число элементов — носи-
телей информации — в двух наборах данных, представляющих одну
и те же информацию. Тогда относительная избыточность данных Яр
первого набора (характеризуемого значением «]) по отношению ко
второму набору может быть определена как
*0 = 1-4-
(8.1-1)
где величина CR, обычно называемая коэффициентом сжатия, есть
, _«]
R~
«2
(8.1-2)
В случае, когда п2 = гц, получим: CR = 1 и Яр — 0, что говорит о том,
что первый способ представления информации не содержит из-
быточных данных по сравнению со вторым. Если и2 « п\->то Cr ~> 00
и Яр —> 1, что означает значительное сжатие и высокую избыточность
данных первого набора по отношению ко второму. Наконец, если
п2»П],тоСЛ—Яр—> —оо, и значит, что второй набор содержит мно-
го избыточных данных по сравнению с первым. Как правило, такое уве-
личение количества данных является нежелательным. Вообще, значе-
ния CR и Яр находятся внутри открытых интервалов (0, °°) и (—°°, 1),
соответственно. На практике, коэффициент сжатия, такой как 10
(или 10:1), означает, что первый набор данных (в среднем) содержит
10 единиц хранения информации (скажем, бит) на каждую одну еди-
ницу второго (то есть сжатого) набора данных. Соответствующее
этому значение избыточности 0,9 и означает, что 90% данных первого
набора являются избыточными.
В задаче цифрового сжатия изображений различаются и могут
быть использованы три основных вида избыточности данных: кодовая
избыточность, межэлементная избыточность, и визуальная избыточ-
ность. Сжатие данных достигается в том случае, когда сокращается или
устраняется избыточность одного или нескольких из вышеуказанных
видов.
8.1.1. Кодовая избыточность
В Главе 3 был рассмотрен метод улучшения изображения с помошью
обработки гистограммы в предположении, что значения яркости на
изображении являются случайными величинами. Было показано, что
значительная доля информации о виде изображения может быть по-
лучена на основе анализа гистограммы его значений яркости. В насто-
ящем разделе мы используем похожий формализм, чтобы показать,
как гистограмма значений яркости изображения используется для по-
строения кодов2, уменьшающих требуемое количество данных для
представления изображения.
Предположим опять, что дискретная случайная переменная гк,
распределенная в интервале [0, 1], представляет значение яркости
изображения, и что каждое значение гк появляется с вероятностью
Ptkrk). Как и в Главе 3,
pr(rk)J± k = 0,l,2,...,L-l, (8.1-3)
п
где L — общее число уровней яркости, пк — число пикселей, име-
ющих значение яркости к, а и — общее число элементов в изобра-
жении. Если число битов, используемых для представления каждо-
го из значений гк, равно 1(гк), то среднее число битов, требуемых для
представления значения одного элемента, равно
£-1
А:р — 51 ((fy)Pr(rk)•
£=0
(8.1-4)
Итак, средняя длина всех кодовых слов, присвоенных различным зна-
чениям яркостей, определяется как сумма произведений числа битов,
используемых для представления каждого из уровней яркостей, на ве-
роятность появления этого уровня яркости. Таким образом, общее
число битов, требуемое для кодирования изображения размерами
MyN, составит M-N-Lcp.
Представление уровня яркости изображения обычным /«-бито-
вым двоичным кодом3 упрощает правую часть уравнения (8.1 -4). По-
2 Код есть система символов (букв, чисел, битов и т.д.), используемых для представ-
ления совокупности информации или набора событий. Любая часть информации или
отдельное событие представляются последовательностью кодовых символов, называ-
емых вместе кодовым словом. Число символов в каждом кодовом слове есть его дли-
на. Один из самых знаменитых кодов — код, использованный Полем Ревером (Paul
Revere) 18 апреля 1775 года. Фраза «один, если по суше, два, если по морю» («one if
by land, two if by sea») использовалась для задания кода, согласно которому одна или
две вспышки света означали, двигаются ли британцы морем или сушей.
3 В случае обычного (или прямого) двоичного кода каждому информационному эле-
менту или событию (например, значению яркости) присваивается одно из 2т значе-
ний m-битовой двоичной последовательности.
скольку вместо l(rk) подставляется т, а сумма рг(гк) по всем 0 < к < L — 1
равна 1, то Lcp = т.
Пример 8.1 Простое объяснение неравномерного кодирования.
Изображение имеет 8 уровней яркости, распределение вероятнос-
тей которых представлено в Таблице 8.1. Если для представления воз-
можных 8 уровней используется простой 3-битовый двоичный код
(см. колонки Код 1 и в Таблице 8.1), то Lcp = 3 битам, посколь-
ку = 3 битам для всех гк. Если используется Код 2 из Таблицы 8.1,
то среднее число битов, необходимых для кодирования изображения,
уменьшится до следующей величины:
7
6ср = р2 (Гк )Рг ('к) =2(0,19) + 2(0,25) + 2(0,21) +
к=0
+ 3(0,16)+4(0,08) + 5(0,06) + 6(0,03) + 6(0,02) = 2,7 битов
Таблица 8.1 Пример неравномерного кодирования.
Гк Рг(гк) Код 1 h(rk) Код 2 h(rk)
'0 = ° 0,19 000 3 11 2
И = 1/7 0,25 001 3 01 2
''2 = 2/7 0.21 010 3 10 2
''3 = 3/7 0,16 011 3 001 3
'-4 = 4/7 0,08 100 3 0001 4
'-5 = 5/7 0,06 101 3 00001 5
''6 = 6/7 0,03 по 3 000001 6
'7 = 1 0,02 111 3 000000 6
Согласно формуле (8.1-2), результирующий коэффициент сжатия Сл
равен 3/2,7 или 1,11. Таким образом, при использовании Кода 1 око-
ло 10% данных (по сравнению с Кодом 2) являются избыточными. Точ-
ный уровень избыточности может быть вычислен согласно (8.1-1):
RD=\—L = o,O99.
D 1,11
На Рисунке 8.1 проиллюстрирован принцип, лежащий в основе сжа-
тия, достигаемого при использовании Кода 2. Сплошной линией по-
казана гистограмма изображения (зависимостьр^г^) от гк), а пунктир-
ной — число используемых битов Z2(ty). Поскольку с уменьшением р^гк)
значение 12(гк) возрастает, то наиболее короткие кодовые слова в Ко-
604 Глава 8. Сжатие изображений
Рис. 8.1. Графическое представление принципа, лежащего в основе сжатия дан-
ных с помощью неравномерного кодирования.
де 2 присвоены наиболее часто встречающимся уровням яркости на
изображении.
Как видно из предыдущего примера, присвоение кодовых слов
с меньшим числом битов более вероятным значениям яркости, и на-
оборот, более длинных кодовых слов менее вероятным значениям,
позволяет достичь сжатия данных. Такой подход называют неравномер-
ным кодированием. Если значения яркости изображения кодируются
некоторым способом, требующим большего числа символов, чем это
строго необходимо (т.е. код не минимизирует уравнение (8.1-4)), то го-
ворят, что изображение имеет кодовую избыточность. Вообще, кодо-
вая избыточность возникает всегда, когда при выборе кодовых слов,
присваиваемых событиям (например, значениям яркости), знания
о вероятностях событий не используется в полной мере. Когда значе-
ния яркости изображения представляются обычным или прямым дво-
ичным кодом, это происходит почти всегда. Основанием для возник-
новения кодовой избыточности в этом случае является то, что
изображения, как правило, состоят из объектов, имеющих регулярную,
в некотором смысле предсказуемую морфологию (форму) и отража-
тельные свойства поверхности, причем размеры объектов на изобра-
жении обычно намного превышают размеры пикселей. Прямым след-
ствием этого является тот факт, что на большинстве изображений
определенные значения яркости оказываются более вероятными, чем
другие (т. е. гистограммы большинства изображений не являются рав-
номерными). Обычное двоичное кодирование значений яркости та-
ких изображений присваивает кодовые слова одинаковой длины как
более вероятным, так и менее вероятным значениям. В результате не
обеспечивается минимизация уравнения (8.1 -4) и появляется кодовая
избыточность.
8.1.2. Межэлементная избыточность
Рассмотрим изображения, представленные на Рис. 8.2(a) и (б). Как
показывают Рис. 8.2(b) и (г), эти изображения имеют почти одина-
ковые гистограммы. Заметим, что обе гистограммы содержат по
три явных пика. Это показывает, что на изображении имеются три
доминирующих диапазона яркостей. Поскольку яркости на изоб-
ражениях не являются равновероятными, то для сокращения кодо-
вой избыточности, возникающей при прямом или обычном двоич-
ном кодировании значений пикселей, можно воспользоваться
неравномерным кодированием. Такой процесс кодирования, одна-
ко, не приведет к изменению корреляционных зависимостей меж-
ду элементами изображения. Другими словами, кодирование, ис-
пользуемое для представления значений яркости, не может изменить
корреляции между пикселями, которая является следствием струк-
турных или геометрических взаимосвязей между объектами на изо-
бражении.
Графики на Рис. 8.2(д) и (е) суть соответствующие коэффициенты
автокорреляции у, вычисленные вдоль одной строки каждого изобра-
жения. Эти коэффициенты были получены с помощью нормализован-
ного варианта уравнения (4.6-30):
у(Ди) = ^^, (8.1-5)
Л(0)
где
1 Л-1-Дл
Л(Дл) = —--- У /(х,у)Дх,у+Дл). (8.1-6)
у=0
Нормировочный коэффициент в (8.1-6) учитывает изменение чис-
ла элементов суммирования, которое зависит от значения Ди. Конеч-
но, значение Ди должно быть строго меньше числа элементов W в стро-
ке. Значение переменной х есть номер строки, используемой для
вычислений. Обратим внимание на существенные различия между
графиками на Рис. 8.2(д) и (е), которые могут быть качественно свя-
заны со структурами изображений (а) и (б). Эта связь особенно за-
метна на Рис. 8.2(e), где высокая корреляция между значениями
Глава 8. Сжатие изображений
пикселей, отстоящих на 45 и 90 отсчетов, может быть прямо связа-
на с расстояниями между вертикально ориентированными спичка-
ми на Рис. 8.2(6). Кроме того, сильно коррелированными оказыва-
Рг* 102
1.6г
0 128 гк 225
102
Рис. 8.2. Два изображения, гистограммы значений их яркости и нормализо-
ванные коэффициенты автокорреляции вдоль одной из строк.
0 128 Гк 225
ются значения смежных пикселей: при Ди = 1, у = 0,9922 для изоб-
ражения (а) и у = 0,9928 для изображения (б). Эти значения явля-
ются типичными для большинства правильно оцифрованных теле-
визионных изображений.
Приведенный пример отражает другую важную форму избыточно-
сти данных, которая напрямую связана с межэлементными связями
внутри изображения. Поскольку значение любого элемента изображе-
ния может быть достаточно точно предсказано по значениям его со-
седей, то информация, содержащаяся в отдельном элементе, оказы-
вается относительно малой. Большая часть вклада отдельного элемента
в изображение является избыточной; она может быть угадана на ос-
нове значений соседних элементов. Для отражения подобной межэ-
лементной связи были введены различные термины, такие как прост-
ранственная избыточность, геометрическая избыточность и
внутрикадровая избыточность. Объединяя их все, мы будем использо-
вать термин межэлементная избыточность.
Для уменьшения межэлементной избыточности в изображении,
двумерный массив пикселей, обычно используемый для наблюдения
и интерпретации, должен быть преобразован в некоторый более ра-
циональный (но обычно «не визуальный») формат. Например, для
представления изображения может быть использована разность меж-
ду соседними элементами. Преобразования такого типа (которые ус-
траняют межэлементную избыточность) классифицируются как ото-
бражения. Если из преобразованного набора данных может быть
восстановлено исходное изображение, то в таком случае говорят об
обратимом отображении.
Пример 8.2 Простое пояснение к кодированию длин серий.
На Рисунке 8.3 показана простая процедура отображения. На
Рис. 8.3(a) изображен участок монтажной схемы электронного устрой-
ства, оцифрованный с разрешением приблизительно 13 линий/мм.
(330 dpi). На Рис. 8.3(6) данное изображение представлено в двухгра-
дационном варианте, а график на Рис. 8.3(b) показывает профиль яр-
кости вдоль некоторой строки изображения и уровень порога бинари-
зации (см. Раздел 3.1). Поскольку на двухградационном изображении
содержится много областей с постоянными значениями, то более эф-
фективным представлением может являться преобразование значений
элементов вдоль строки f (х, 0),/(х, 1),...,/(х, 7V — 1) в набор следую-
щих пар: (g],Wi), (g2,w2), •••’ здесьg, означает значение яркости на от-
резке (серии) /, a Wj — длину данной серии. Другими словами, бина-
ризованное изображение, преобразованное в набор значений и длин
серий постоянной яркости (т.е. в не визуальную форму), может быть
Глава 8. Сжатие изображений
ЯЯ яяя яя л и ЯЯ ft И ГТ. ГТ
IC04
ОТЛТЦ Ц Ц и и ц LTU U'U U и
¥
ЛППЛЛ,
>~~1С
ТЛТЕППТ
ti ви м и и иди и и и и
ТГОТГЕГ
пппл
ЛШ1ДЛ
ИПЛПП ППП ЛП.ГШЛП пн
IC04
Г Строка 100: (1, 63) (0, 87) (1, 37) (0, 5) (1, 4) (0, 556) (1, 62) (0, 210)
Рис. 8.3. Иллюстрация к кодированию длин серий, (а) Исходное изображение,
(б) Бинаризованное изображение с отмеченной строкой номер 100. (в) Про-
филь строки и порог бинаризации, (г) Код длин серий.
представлено более экономно, чем в виде двумерного массива двоич-
ных элементов.
На Рис. 8.3(г) представлены данные кодирования длин серий, со-
ответствующие бинаризации строки, профиль которой показан на
Рис. 8.3(b). Для представления 1024 бит исходных двухградационных
данных оказалось достаточно всего 88 бит. В целом же, весь приведен-
ный фрагмент размерами 1024x343 элемента может быть представлен
в виде 12166 серий. На запись одной серии использовалось 11 бит, та-
ким образом результирующий коэффициент сжатия и соответствующая
относительная избыточность составляют:
г 1024-3431 ... и „ 1
Ср =-----------= 2,63 и Л/)-1------—0,62.
R 12166-11 2,63
8.1.3. Визуальная избыточность
В Разделе 2.1 отмечалось, что воспринимаемая глазом яркость зависит
не только от количества света, исходящего из рассматриваемой облас-
ти, но и от других факторов. Так, например, на области с постоянной
яркостью могут возникать кажущиеся изменения яркости (полосы Ма-
ха). Дело в том, что чувствительность глаза по отношению к визуальной
информации различна в разных условиях4. При обычном визуальном
восприятии часть информации оказывается менее важной, чем другая.
Такую информацию называют визуально избыточной5. Она может быть
удалена без заметного ухудшения визуального качества изображения.
Такая визуальная избыточность не удивительна хотя бы потому, что
при восприятии информации на изображении глаз человека не в со-
стоянии оценивать значения пикселей количественно. Вообще, гля-
дя на изображение, наблюдатель отыскивает на нем особенности и
отличия, такие как контуры или текстурные области, и подсознатель-
но объединяет их в узнаваемые группы. Затем мозг соотносит эти
группы с имеющимися априорными знаниями, завершая тем самым
процесс интерпретации изображения.
Визуальная избыточность принципиально отличается от других ви-
дов избыточности, рассмотренных ранее. В отличие от кодовой или ме-
жэлементной избыточности, визуальная избыточность связана с ре-
альной и количественно измеримой зрительной информацией. Ее
удаление возможно лишь постольку, поскольку такая информация
не является существенной (не воспринимается) при обычном визуаль-
ном восприятии. Важнейшей операцией при оцифровке зрительной
информации, основанной на указанном явлении, является квантова-
4 По-видимому, авторы имеют в виду проявление некоторых зрительных явлений, ос-
нованных на психофизических свойствах зрения, таких как контрастная чувствитель-
ность, пространственно-частотные характеристики глаза, одновременный контраст,
а также некоторых других; часть из них рассмотрена в Главе 2. — Прим, перев.
5 В оригинале использован термин «психовизуальная избыточность» (psychovisual ге-
dunduncy). Мы будем использовать принятый в русскоязычной литературе термин ви-
зуальная избыточность, однако следует понимать, что эта избыточность связана с пси-
хофизическими свойствами зрения. — Прим, перев.
21 А-223
Глава 8. Сжатие изображений
ние изображения. Как уже обсуждалось в Разделе 2.4, квантование оз-
начает отображение широкого (и, вообще говоря, непрерывного) ди-
апазона входных значений в ограниченный набор выходных значений6.
Поскольку данная операция необратима (происходит потеря визу-
альной информации), то квантование является сжатием с потерями.
Пример 8.3. Сжатие посредством квантования.
Рассмотрим изображения на Рис. 8.4. На Рис. 8.4(a) представлено
черно-белое изображение с 256 возможными градациями яркости.
На Рис. 8.4(6) показано то же самое изображение после равномерно-
го квантования на 16 уровней (4 бита). Полученный в результате ко-
эффициент сжатия равен 2:1. Заметим, как это уже обсуждалось в Раз-
деле 2.4, что на гладких областях исходного изображения появились
ложные контуры; это обычный видимый эффект слишком грубого
представления уровней яркостей изображения.
Рис. 8.4. (а) Исходное изображение, (б) Равномерное квантование на 16 уров-
ней. (в) Метод модифицированного квантования яркости на 16 уровней.
6 Следует отметить, что одним из важнейших способов сокращения объема изобра-
жения (т.е. его сжатия) является выбор оптимальных параметров как яркостного, так
и пространственного разрешений. Превышение параметров дискретизации и кван-
тования сверх различимых глазом значений приведет лишь к увеличению объема изо-
бражения без улучшения его визуального качества. — Прим, перев.
Можно отметить значительное улучшение изображения на
Рис. 8.4(b), ставшее возможным при использовании квантования, ос-
нованного на особенностях зрительной системы человека. Несмотря
на то, что коэффициент сжатия при втором способе квантования так-
же равен 2:1, ложные контуры значительно ослаблены; однако при
этом появилась некоторая дополнительная, хотя и мало заметная зер-
нистость. Для получения данного результата был использован так на-
зываемый метод модифицированного квантования яркости (МКЯ). Он
учитывает свойственную глазу чувствительность к контурам и разру-
шает ложные контуры путем прибавления к значению каждого элемен-
та перед его квантованием небольшой квазислучайной величины, ге-
нерируемой на основании значений младших битов соседних
элементов7. Поскольку младшие биты, как правило, достаточно слу-
чайны (см. битовые плоскости в Разделе 3.2.4), это эквивалентно до-
бавлению некоторого уровня случайности, зависящего от локальных
характеристик изображения, и тем самым приводит к разрушению
четкости возникающих перепадов, выглядящих как ложные контуры.
Данный метод поясняется Таблицей 8.2. Значение суммы — изна-
чально равное нулю — формируется путем сложения текущего 8-би-
тового значения яркости и четырех младших разрядов ранее полу-
ченной суммы. Однако если старшие четыре разряда значения элемента
уже были равны 11112 , то перенос единицы из младших разрядов
в старшие блокируется8. Четыре старших бита полученной суммы
используются в качестве результата квантования (кодирования) зна-
чения элемента.
Таблица 8.2. Иллюстрация метода модифицированного квантования яркости
(МКЯ).
Элемент Значение яркости Сумма МКЯ Код
1 — 1 — 0000 0000 —
i 01101100 ОНО 1100 оно
i + 1 10001011 10010111 1001
i + 2 10000111 1000 1110 1000
i + 3 11110100 1111 0100 1111
7 Как видно из дальнейшего, суть метода состоит в переносе остатка яркости, возни-
кающего при квантовании текущего элемента, в следующий элемент:
f (х, у) —fo(x, у) + Д/(х, у — I). Здесь Д f (х, у) =Дх, у) — fq(x. у) есть разница значения
f предыдущего элемента (аналогичной суммы) и его квантованного значения fq. —
Прим, перев.
8 Иначе это вызовет ложный скачок яркости из белого в черное. Заметим также, что
данный алгоритм рассматривается для варианта квантования на 16 уровней. — Прим,
перев.
Подход, использованный в методе модифицированного кванто-
вания яркости, широко используется многими процедурами квантова-
ния, оперирующими непосредственно со значениями яркостей элемен-
тов сжимаемых изображений. Зачастую они осуществляют
одновременное уменьшение как пространственного, так и яркостно-
го разрешения изображения. Влияние эффекта квантования в виде
появляющихся ложных контуров или других похожих эффектов тре-
бует применения эвристических методов их компенсации. Так, обыч-
ная чересстрочная развертка 2:1, применяемая в системах широкове-
щательного телевидения, есть тоже форма квантования, при котором
чередующиеся соседние кадры позволяют уменьшить скорость скани-
рования при сравнительно небольшом снижении воспринимаемого ка-
чества изображения.
8.1.4. Критерии верности воспроизведения
Как отмечалось ранее, сокращение визуальной избыточности влечет
потерю реальной количественной визуальной информации. Посколь-
ку при этом может быть также утеряна и представляющая интерес
информация, то весьма желательно иметь средства количественных
оценок характера и величины потерь информации. В основу такого оп-
ределения могут быть положены как объективные, так и субъективные
критерии верности (точности) воспроизведения.
Если степень потери информации может быть выражена как функ-
ция исходного (входного) изображения и сжатого, азатем восстанов-
ленного (выходного) изображения, то такой подход называют объек-
тивным критерием верности воспроизведения. Хорошим примером
здесь является критерий среднеквадратического отклонения (СКО)
разности выходного и входного изображений. Пусть Дх, у) означает
входное изображение, a f(x,y) — его приближение, получаемое в ре-
зультате операций сжатия и последующего восстановления. Для лю-
бых хи у ошибка (невязка) е(х, у) для элементов изображений Дх, у)
и /(х,у) определяется как
е(х,у) = f(x.y)-f(x,y), (8.1-7)
а величина полной невязки двух изображений равна
М-lN-l 2
Кх,У)|| = X X [/(х^)-жу)] ,
х=0 у=0
8.1. Основы
где размеры изображения равны My.N. Величина среднеквадратическо-
го отклонения еск0 разности изображений Дх, у) и /(х,у) будет равна:
^ско
1 Af-IA'-I 2
х=0 у=0
(8.1-8)
Другим близким объективным критерием верности воспроизведения
является отношение сигнал—шум сжатого — восстановленного изоб-
ражения. Если с помощью простой перестановки членов в выражении
(8.1-7) рассматривать изображение f(x,y) как сумму исходного изо-
бражения Дх, у) и шума е(х, у), то средний квадрат отношения сиг-
нал-шум выходного изображения, обозначаемый SNRCK, будет равен
М-1 N-1
tff(x,yy
--------------j- (8Л-9)
х=0 у=0
Отношение сигнал—шум, обозначаемое SNR, получается извлечением
квадратного корня из правой части выражения (8.1-9).
Хотя объективные критерии верности воспроизведения предо-
ставляют простой и удобный механизм оценки информационных по-
терь, все-таки большинство восстановленных изображений, в конце
концов, рассматриваются человеком. Следовательно, определение
качества изображения с помощью субъективного оценивания часто яв-
ляется предпочтительным. Это может быть достигнуто путем показа
«типичного» восстановленного изображения группе наблюдателей
(экспертов) и усреднения их оценок. Оценивание может произво-
диться как с использованием абсолютной шкалы оценок, так и путем
попарного сравнения изображенийДх, у) и /(х,у). В Таблице 8.3 при-
веден один из возможных вариантов абсолютной шкалы оценивания.
Попарные сравнения с использованием такой шкалы могут быть
сформированы, например, в виде набора следующих чисел: {—3, —2,
-1,0,1,2.3}, отражающего, соответственно, субъективные оценки рей-
тинга: {значительно хуже, хуже, слегка хуже, одинаково, слегка лучше,
лучше, значительно лучше]. В любом случае эти оценки основаны на
субъективных критериях верности воспроизведения.
Пример 8.4. Сравнение оценок качества изображений.
Оценки среднеквадратических отклонений (8.1 -8) изображений на
Рис. 8.4(6) и (в) от оригинала (а) составляют 6,93 и 6,78 градаций яр-
кости. Аналогичные оценки отношений сигнал—шум (SNR) равны
Глава 8. Сжатие изображений
Таблица 8.3. Шкала оценок качества изображений. (Организация по исследо-
ванию классификаций в телевидении [Frendendall, Behrend]).
Значение Оценка Описание
1 Отлично Изображение чрезвычайно высокого качества, настолько хорошо, насколько только возможно.
2 Хорошо Изображение высокого качества, оставляющее приятное впечатление. Искажения не наблюдаются.
3 Приемлемо Изображение приемлемого качества. Искажения не наблюдаются.
4 Плохо Изображение плохого качества; кажется, что его можно улучшить. Наблюдаются некоторые искажения.
5 Очень плохо Очень плохое, но возможное для наблюдения изображение. Наблюдаются многочисленные искажения.
соответственно 10,25 и 10,39. Хотя эти значения весьма близки, субъ-
ективные оценки визуального качества двух вышеуказанных изобра-
жений составляют «плохо» для изображения на Рис. 8.4(6) и «прием-
лемо» для изображения на Рис. 8.4(b).
8.2. Модели сжатия изображений
В Разделе 8.1 мы рассматривали по отдельности методики сокраще-
ния объема данных, требуемого для представления изображения. Од-
нако при формировании реальных систем сжатия изображений они
обычно используются совместно. В настоящем разделе исследуются
глобальные характеристики таких систем, и строится общая модель для
их рассмотрения.
Как видно из Рис. 8.5, система сжатия содержит два принципиаль-
но разных структурных блока: кодер и декодер^. Исходное изображе-
ние f(x, у) подается на кодер, который преобразует входные данные
в набор символов. После передачи по каналу кодированные данные по-
ступают на декодер, где создается восстановленное изображение
f(x,y). Вообще, изображение f(x.y) может быть точной копией изо-
9 Употребление терминов кодер и декодер обусловлено влиянием теории информа-
ции (которая будет рассматриваться в Разделе 8.3) на область сжатия изображений.
8.2. Модели сжатия изображений 61
Кодер
Декодер
Рис. 8.5. Общая модель системы сжатия.
бражения/(х, у), а может таковой и не быть. В первом случае мы име-
ем систему кодирования без потерь, а во втором — систему кодирова-
ния с потерями, и при этом на восстановленном изображении будут
наблюдаться некоторые искажения.
Как кодер, так и декодер, показанные на Рис. 8.5, состоят из двух
достаточно независимых блоков. Кодер содержит кодер источника, ко-
торый устраняет избыточность источника (входного сигнала), и ко-
дер канала, который увеличивает помехоустойчивость сигнала на вы-
ходе кодера канала. Как легко предположить, декодер содержит
декодер канала, за которым следует декодер источника. Если канал меж-
ду кодером и декодером является каналом без помех (т.е. в нем не воз-
никает ошибок), то кодер канала и декодер канала могут отсутство-
вать, и тогда колер и декодер будут содержать, соответственно, только
кодер источника и декодер источника.
8.2.1. Кодер и декодер источника
Кодер источника отвечает за сокращение или устранение возможных
видов избыточности на входном изображении: кодовой, межэлемент-
ной и визуальной. Конкретные приложения и связанные с ними кри-
терии верности заставляют выбирать тот или иной способ кодирова-
ния, являющийся наилучшим в данном случае. Обычно, процедура
кодирования представляется в виде последовательности из трех неза-
висимых операций (стадий). Как видно на Рис. 8.6(a), каждая из опе-
Канал
Кодер источника
Канал
Декодер источника
Рис. 8.6. (а) Модель кодера источника, (б) Модель декодера источника.
&
б
раций предназначена для сокращения одного из типов избыточнос-
ти, рассмотренных в Разделе 8.1. На Рис. 8.6(6) показан соответству-
ющий декодер источника.
На первой стадии процесса кодирования источника преобразова-
тель превращает входные данные, т.е. изображение, в формат (обыч-
но не визуальный), предназначенный для сокращения межэлемент-
ной избыточности входного изображения. Как правило, данная
операция обратима, и, в принципе, может как сокращать, так и уве-
личивать объем данных, требуемый для представления изображения.
Кодирование длин серий (Разделы 8.1.2 и 8.4.3) является примером
преобразования, которое прямо приводит к сокращению объема дан-
ных на данной начальной стадии общей процедуры кодирования ис-
точника10. Представление изображения с помощью набора коэффи-
циентов преобразования (Раздел 8.5.2) является примером
противоположной ситуации. В этом случае преобразователь превра-
щает изображение в некоторый массив коэффициентов с опреде-
ленными статистическими характеристиками, благодаря чему ме-
жэлементная избыточность может быть удалена на более поздней
стадии процедуры кодирования.
Вторая стадия, или блок квантователя на Рис. 8.6(a), уменьшает
точность выхода преобразователя в соответствии с некоторым пред-
варительно заданным критерием верности. На этой стадии сокраща-
ется визуальная избыточность входного изображения. Как отмеча-
лось в Разделе 8.1.3, эта операция является необратимой, а значит
должна быть пропущена, если требуется сжатие без потерь.
На третьей и последней стадии процедуры кодирования источ-
ника, кодер символов генерирует равномерный или неравномерный код
для представления выхода квантователя и формирует соответствую-
щий коду выход. Термин кодер символов позволяет отличать эту опе-
рацию от процедуры кодирования источника в целом. В большинст-
ве случаев для представления преобразованных и квантованных
значений данных используется неравномерный код. Он приписыва-
ет самые короткие кодовые слова наиболее часто встречающимся
значениям и тем самым сокращает кодовую избыточность. Данная опе-
рация, конечно же, является обратимой. Таким образом, можно ска-
зать, что по завершении стадии кодирования символов, входное изо-
10 Необходимо заметить, что это происходит не всегда, а только в случае, если сиг-
нал изображения состоит из сравнительно длинных последовательностей одинако-
вых значений. В иных случаях это может привести к прямо противоположному ре-
зультату, т.е. увеличению общего объема данных. — Прим, перев.
8.2. Модели сжатия изображений 6
бражение претерпевает полную процедуру сокращения каждого из
трех типов избыточности, рассмотренных в Разделе 8.1.
Хотя на Рис. 8.6(a) процесс кодирования источника показан в ви-
де трех последовательных стадий, тем не менее, не в каждой системе сжа-
тия требуется использование их всех. Например, напомним, что в слу-
чае сжатия без потерь должен быть исключен блок квантователя. Кроме
того, некоторые методы сжатия строятся так, что в них объединяются
блоки, показанные на Рис. 8.6(a) как самостоятельные. Например, в си-
стемах сжатия с предсказанием, которые будут рассматриваться в Разде-
ле 8.5.1, преобразователь и квантователь часто представляются в виде
единого блока, выполняющего обе операции одновременно.
Схема декодера источника, представленная на Рис. 8.6(6), включа-
ет лишь два блока: блок декодера символов и блок обратного преобра-
зователя. Эти блоки осуществляют операции, обратные тем операци-
ям, которые выполнялись в кодере источника блоками кодера символов
и преобразователя, причем в обратном порядке. Поскольку операция
квантования необратима, то блок «обратного квантователя» на
Рис. 8.6(6) отсутствует1 *.
8.2.2. Кодер и декодер канала
Когда канал передачи на Рис. 8.5 является каналом с шумом, т.е. в нем
возможно возникновение ошибок, важную роль в общем процессе ко-
дирования-декодирования играют кодер и декодер канала. Для
уменьшения влияния шума канала, к исходным закодированным
данным регулируемым образом добавляется некоторая избыточная ин-
формация. Поскольку данные на выходе кодера источника имеют ма-
лую избыточность, то в отсутствие такой «регулируемой избыточности»
передаваемые данные были бы крайне чувствительны к помехам.
Один из наиболее фундаментальных и полезных способов кодиро-
вания канала был разработан Р.В. Хэммингом [Hamming, 1950]. Он ос-
нован на добавлении к передаваемым данным некоторого числа битов,
гарантирующих, что допустимые кодовые слова будут различаться не
менее чем в заданном числе позиций (двоичных разрядов, битов).
Хэмминг показал, например, что если 4-битовое кодовое слово расши-
рить тремя дополнительными битами (проверочными символами) так,
11 Иногда, тем не менее, подобная операция может присутствовать (см., например,
Рис. 8.47), но в подобных случаях, как правило, она означает обратное отображение
полученного кода в соответствующее значение уровня квантования. — Прим, перев.
чтобы расстояние12 между любыми двумя допустимыми кодовыми
словами стало не менее чем 3, то любые единичные ошибки (в любой
одной позиции любого слова) могут быть обнаружены и исправлены.
Добавление большего числа проверочных битов позволяет обнаружи-
вать и исправлять ошибки в нескольких позициях одновременно.
Рассмотрим 7-битовый код Хэмминга, состоящий из кодовых слов
avmah^hyh^hyhffi-j, ассоциированный с множеством 4-битовых дво-
ичных чисел Z>3Z>2Z>iZ>0:
й] = by® Ь2® ь^ Л3-^3
й2 -Ьу ©6] ®bq /25 = ^2
й4 =Z>2 ©Й] ®bq hf> = b\
й7 = Ь$,
(8.2-1)
где знак © означает операцию исключающего ИЛИ. Заметим, что
биты h\, й2 и й4 суть биты четности для наборов битов й3й2йо, Ьу/Ь\Ьц
и соответственно. (Напомним, что двоичная строка является
четной, если содержит четное число битов со значением 1).
При декодировании декодер канала должен проверить на четность
битовые позиции полученного расширенного кодового слова. Это
осуществляется следующими операциями:
q ®hy®hy®hq
с2 = й2 ©й3 ©/^ ©й7
с4 = h^®hy®h(i®h1
(8.2-2)
В результате формируется проверочное слово c4c2q, которое в случае от-
сутствия ошибок будет равно нулю. При возникновении одиночной
ошибки сформированное двоичное число c4c2q укажет номер пози-
ции, в которой произошла ошибка. Для ее исправления необходимо
значение бита в данной позиции изменить на противоположное. Затем
из исправленного расширенного кодового слова извлекается исходное
кодовое слово, которое в данном случае будет состоять из битов Л3Й5Й5Л7.
12 Расстояние между двумя кодовыми словами определяется как число разрядов,
которые нужно изменить в одном кодовом слове, чтобы получить другое кодовое сло-
во. Например, расстояние между кодовыми словами 101101 и 011101 равно 2. Мини-
мальное кодовое расстояние определяется как наименьшее расстояние между любы-
ми парами кодовых слов в коде.
8.3. Элементы теории информации
Пример 8.5. Кодирование по Хэммингу.
Рассмотрим передачу 4-битовых значений яркости, например, по-
лученных с помощью алгоритма модифицированного квантования
яркости (МКЛ) — см. Таблицу 8.2, по каналу связи с шумом. Ошиб-
ка в единственном бите может привести к изменению правильного зна-
чения сигнала на 128 градаций яркости13. Для повышения устойчиво-
сти к шуму и чтобы обеспечить обнаружение и устранение одиночных
ошибок, кодер канала может использовать код Хэмминга, что потре-
бует некоторого увеличения избыточности. Согласно уравнениям
(8.2-1), после кодирования по Хэммингу первое значение МКЯ из
Таблицы 8.2 будет равно 11001102. Поскольку код Хэмминга увеличи-
вает число бит, необходимых для передачи значения МКЯ, с 4 до 7, то
коэффициент сжатия 2:1, который был ранее достигнут за счет исполь-
зования метода МКЯ, уменьшится до 8/7 или 1,14:1. Такое уменьше-
ние результирующего коэффициента сжатия есть та цена, которую
приходится платить за повышение помехозащищенности.
8.3. Элементы теории информации
В Разделе 8.1 было представлено несколько путей уменьшения объе-
ма данных, требуемых для представления изображения. Естественно
возникает следующий вопрос: насколько много данных в действи-
тельности необходимо для представления изображения? Другими
словами, существует ли минимальное количество данных, которых до-
статочных для полного описания изображения без потери информа-
ции? Теория информации дает математическую основу для ответа на
этот и близкие ему вопросы.
8.3.1. Измерение информации
Фундаментальная предпосылка теории информации заключается в том,
что источник информации может быть описан как вероятностный
процесс, который может быть измеряй естественным образом. В со-
ответствии с этим предположением говорят, что случайное событие Е,
появляющееся с вероятностью Р(Е), содержит
13 Заметим, что процедура восстановления сжатого 4-битового значения МКЯ сво-
дится к умножению полученного числа на 16. Например, если значение МКЯ было
равно 11102= 1^10»то восстановленное значение должно быть равно 14-16 = 224. Ес-
ли же старший бит в результате ошибки был передан как 0, то восстановленное зна-
чение будет равно 96, что составляет ошибку в 128 градаций. — Прим, перев.
/(£) = log-^- = -logP(£) (8.3-1)
P(E)
единиц информации. Значение 1(E) часто называют количеством ин-
формации в событии Е. Вообще говоря, приписываемое событию Еко-
личество информации тем больше, чем меньше вероятность Е. Если
Р(Е) = 1 (то есть событие возникает всегда), то 1(E) = 0 и данному со-
бытию не приписывают никакой информации. Это означает, что ес-
ли нет никакой неопределенности, связанной с событием, то сообще-
ние о том, что данное событие произошло, не несет никакой
информации. Однако, если Р(Е) = 0,99, то сообщение о том, что Епро-
изошло, уже передает некоторое небольшое количество информации.
Сообщение же, что Е не произошло, передает существенно больше
информации, поскольку это событие значительно реже.
Основание логарифма в (8.3-1) задает единицу измерения количе-
ства информации14. Если используется основание т, то говорят о еди-
ницах измерения по основанию т. Когда основание равно 2, единица
информации называется бит. Заметим, что если Р(Е) = 1/2, то
1(E) = —log21/2, или одному биту. Таким образом, бит есть количество
информации, передаваемое сообщением о том, что произошло одно из
двух возможных равновероятных событий. Простой пример сообще-
ния такого рода — сообщение о результате подбрасывания монеты.
8.3.2. Канал передачи информации
Когда информация передается между источником и получателем инфор-
мации, то говорят, что источник информации соединен с получателем
каналом передачи информации (или просто каналом). Канал есть некото-
рая физическая среда, соединяющая источник с получателем. Это мо-
жет быть телефонная линия, среда распространения электромагнитных
волн, или проводник в компьютере. На Рис. 8.7 представлена простая
Источник информации > Канал ► Получатель информации
Ансамбль сообщений (A, z) Ансамбль сообщений (В, v)
Л={«7} G=1%J B={bk}
z=[P(at), Р(а2),..., P(aj)]J v=[P(b\), P(b2),... , P(bK)]'
Рис. 8.7. Простая система передачи информации.
14 Если основание логарифма явно не задается, это означает, что результат справед-
лив при любых основаниях и соответствующих единицах информации.
‘О
8.3. Элементы теории информации
математическая модель системы передачи информации. Здесь представ-
ляющим интерес параметром является пропускная способность системы,
определяемая как возможность системы передавать сообщения.
Предположим, что источник информации на Рис. 8.7 генерирует слу-
чайную последовательность символов из конечного или счетного набо-
ра возможных символов, т.е. выход источника есть дискретная случайная
величина. Набор исходных символов {oj, 02,---, aj} называют алфавитом
источника А, а элементы набора ар — символами или буквами. Вероятность
того, что источник порождает символ о,, равна Р(а-), причем
(8-3-2)
7=1
Для описания совокупности вероятностей символов источника {P(oi),
Р(а2),..., P(aj)} обычно используется J-мерный вектор вероятностей
z= [P(oi), Р(а2),..., P(aj)]T. Тем самым источник информации полно-
стью описывается конечным ансамблем сообщений (A, z).
В соответствий со сделанными предположениями и формулой
(8.3-1), количество информации, передаваемое источником при по-
рождении одного символа оу, будет равно /(оу) = —log Р(оу). Если по-
рождаются к символов источника, то, согласно закону больших чисел,
при достаточно больших/; символ о,- будет появляться на выходе (в сред-
нем) kP(aj) раз. Тем самым среднее количество информации, переда-
ваемое посредством к символов источника, составит величину
-кР(а{) log Р(ах) - кР(а2 )\ogP(a2)-...-kP(aJ)logP(aJ) =
J
= -k^P(aj)logP(aj).
7=1
Среднее количество информации, приходящейся на один символ
источника и обозначаемое Н(г), равно
7
Я(г) = -^Р(Оу)ЮёЛоу). (8.3-3)
7=1
Эту величину называют энтропией или неопределенностью источника15.
Она определяет среднее количество информации (в системе единиц
с основанием т), получаемой при наблюдении одного символа источ-
15 Формулу (8.3-3) также называют формулой Шеннона.
ника. Когда эта величина больше, то связанная с источником неопре-
деленность, а значит, и количество информации, больше. Когда сим-
волы источника равновероятны, задаваемая уравнением (8.3-3) энт-
ропия, или неопределенность, принимает максимальное значение, и
тогда источник передает максимально возможное среднее количест-
во информации на один символ.
Построив модель источника информации, мы можем легко опреде-
лить переходные характеристики канала. Поскольку мы предполагали,
что на вход канала на Рис. 8.7 поступает дискретная случайная величи-
на, то на выходе канала мы также будем иметь дискретную случайную
величину. Подобно случайной величине на входе, случайная величина
на выходе принимает значения из конечного или счетного набора сим-
волов bp}, называемого алфавитом канала В. Вероятность со-
бытия, состоящего в том, что к получателю поступит символ bk, рав-
на P(bk). Конечный ансамбль {В, v), где v = [ЛА), Р(ЬК)]Т.
полностью описывает выход канала, и тем самым информацию, посту-
пающую к получателю.
Вероятность Р{Ь0 выхода данного канала и распределение веро-
ятностей источника z связаны следующим выражением16:
J
P(.bk) = ^iP(,bk\aj)P(aj), (8.3-4)
7=1
где P(bk\aj) есть условная вероятность, т.е. вероятность получить на
выходе символ bk, при том условии, что на вход был подан символ aj.
Если условные вероятности, входящие в выражение (8.3-4), записать
в виде матрицы Q размерами К kJ, так что
Q= ЛА|«1) АШ) • • Pd^aj)' , (8.3-5)
%1«1) Л^|о2) P(bK\aj)
16 Один из основных законов теории вероятностей гласит, что если D — произвольное
событие и С|, С2,..., С, —набор из t попарно несовместных событий, таких что
Р(С1)+Р(С2)+...+Р(С,)=1, то вероятность события D равна P(D)=P(D\C}P(C}+ ...+
8.3. Элементы теории информации 6231)
тогда распределение вероятностей выходных символов канала может
быть записано в матричной форме:
v = Qz. (8.3-6)
Матрицу Q с элементами qkj = P(b^aj) называют матрицей переходных
вероятностей канала, или, в сокращенном виде, матрицей канала.
Чтобы определить пропускную способность канала с прямой ма-
трицей переходов Q, сначала необходимо вычислить энтропию источ-
ника информации в предположении, что получатель наблюдает на
выходе некоторый символ bk. Для любого наблюдаемого bk уравнение
(8.3-4) задает распределение вероятностей на множестве символов
источника, так что для каждого bk имеется своя условная энтропия, обо-
значаемая H(z\bk). С помощью последовательности шагов, использо-
вавшихся при выводе уравнения (8.3-3), условная энтропия может
быть записана в следующем виде:
J
H(z\bk) = -^ P(aj\bk)logP(aj\bk), (8.3-7)
7=1
где P(aj\bk) есть вероятность того, что источником был передан
символ aj, при условии, что получатель принял символ bk. Ожида-
емое (среднее) значение для данного выражения по всем bk будет
равно:
к
H(z\y) = ^H(z\bk)P(bk), (8.3-8)
k=l
которое, после подстановки уравнения (8.3-7) для H($bk) и несложных
подобных преобразований17 может быть записано в следующем виде:
J к
tf(z|v) = -££ P(aj,bk)\ogP(aj\bk). (8.3-9)
j=lk=l
Здесь P{aj,bk) есть совместная вероятность ау и bk, т.е. вероятность того,
что был передан символ оу, и был получен символ bk.
Величину //(z|v) называют условной энтропией или неопределенно-
стью величины z относительно величины v. Она представляет среднее
17 Здесь использована формула совместной вероятности двух событий С и D:
P(C,D) = = P(D)P(C[D).
количество информации на один символ источника, при условии на-
блюдения конкретного выходного символа. Поскольку //(z) — сред-
нее количество информации на один символ без предположения о ре-
зультирующем выходном символе, то разность между Mz) и 7/(zjv)
есть среднее количество информации, получаемое при наблюдении од-
ного выходного символа. Эта разность, обозначаемая /(z,v) и называ-
емая средней взаимной информацией z и v, равна
/(z,v) = /7(z)-/7(z|v). (8.3-10)
Подставляя выражения (8.3-3) и (8.3-9) для H(z) и 7/(z|v) в (8.3-10),
и вспоминая, что P{aj) = Р(а]ф\) + Р(йу|/>2) + ... + P{aj\bK). получаем
J К Р(а bi }
(8.3-11)
j=lk=l t\aj)t\bk)
после дальнейших преобразований это выражение может быть пере-
писано в виде
/(Z,v) = £ £ P(aj)qkJ\og-r------. (8.3-12)
/=И=1 £рЦ)<7л/
г=1
Таким образом, среднее количество информации, получаемое при
наблюдении одного символа на выходе канала, зависит от распреде-
ления вероятностей источника (вектора z) и матрицы канала Q. Ми-
нимальное возможное значение /(z,v) равно нулю и достигается тог-
да, когда входные и выходные символы оказываются статистически
независимыми, т.е. в случае, когда P{aj,bk) = P{aj)P{bk)\ при этом ло-
гарифмические члены в правой части (8.3-11) равны нулю для всех зна-
чений/и к. Максимальное значение /(z,v) по всем возможным выбо-
рам распределения z источника есть пропускная способность С канала,
описываемого матрицей канала Q. Таким образом
C = max[/(z,v)], (8.3-13)
Z
где максимум берется по всем возможным распределениям символов на
входе. Пропускная способность канала определяет максимальную скорость
(в системе единиц измерения информации по основанию т на символ ис-
точника), при которой информация может достоверно передаваться по ка-
8.3. Элементы теории информации 625
налу. Более того, пропускная способность канала не зависит от порожда-
ющего распределения источника (т.е. от того, как собственно канал исполь-
зуется), а зависит лишь от условных вероятностей qkj, которые определя-
ют собственно канал.
Пример 8.6. Двоичный случай.
Рассмотрим двоичный источник информации с исходным алфа-
витом А = {а], о2} = {0,1}. Вероятности порождения символов aj и а2
источником равны Л«1) = Pbs и P(ai) = l~ Pbs = Pbs’ соответственно.
Согласно (8.3-3), энтропия источника равна
Н (z) = -PbS log2 log2 Pbs.
Посколькуг= [P(Gi), Р(аг)1Г= [Pbs3 — pbs] to//(z) зависит от един-
ственного параметра pbs, и правая часть уравнения называется двоич-
ной функцией энтропии, и обозначается //bs(). Так, например, есть
функция —гlog2 t-t log2 t. На Рис. 8.8(a) показан график //bs(pbs) для
0 <pbs < 1. Заметим, что функция //bs принимает свое максимальное
значение (равное 1 биту) при рь& = 1/2. Для всех остальных значений
источник дает менее 1 бита информации.
Теперь предположим, что информация должна передаваться по
двоичному информационному каналу с шумом, и пусть вероятность
ошибки при передаче любого символа равна ре. Такой канал называ-
ется двоичным симметричным каналом (ДСК) и определяется следую-
щей матрицей канала:
1-Ре Ре = Ре Ре
Ре 1— Ре _ _ Ре Ре
Для каждого поступающего на вход символа ДСК порождает один
символ bj из алфавита канала В = ,/>2} = {0,1}. Вероятности полу-
чения на выходе символов Ь\ и />2 могут быть определены из (8.3-6):
v = Qz =
Ре
Ре
Ре Pbs _ PePbs PePbs
PelPbsJ № PePbs
Поскольку v= [P0i),P(b^\1 = [P(0), /XI)]7,следовательно, вероятность
того, что на выходе будет символ 0, равна реРъ& + РеPbs,a вероятность
того, что на выходе будет символ 1, равна Pepbfi + РеРь&
Теперь из (8.3-12) может быть вычислена средняя взаимная инфор-
мация для ДСК. Раскрывая знаки суммирований в этом уравнении, и
собирая вместе соответствующие члены, получим в результате:
Глава 8. Сжатие изображений
Рис. 8.8. Три функции двоичной информации: (а) Двоичная функция энтро-
пии. (б) Средняя взаимная информация двоичного симметричного канала
(ДСК). (в) Пропускная способность ДСК.
/(z,v) = /7bs(pbspe+pbspe)-ITbs(pe),
где //bs(-) есть двоичная функция энтропии, показанная на Рис. 8.8(a).
Если значение ошибки канала ре фиксировано, то /(z,v) = 0 при
Pte — 0 ир^ = 1. Более того, /(z,v) принимает максимальное значение, ког-
да символы двоичного источника равновероятны. На Рис. 8.8(6) пока-
зана зависимость /(z,v) от при фиксированном значении ошибки
канала ре.
8.3. Элементы теории информации 627
Согласно уравнению (8.3-13), пропускная способность ДСК опре-
деляется как максимум средней взаимной информации по всем порож-
дающим распределениям источника. На Рис. 8.8(6) приведен график
/(z,v) для всех возможных распределений двоичного источника (т.е. для
О <pi,s < 1, или для всех значений otz= [0,1]гдог = [ 1,0]Т). Можно ви-
деть, что для любогоре максимум /(z,v) достигается при pbs = 1/2. Это
значение /?bs соответствует вектору распределений символов двоично-
го источника z = [1/2,1/2]т. При этом значение /(z,v) будет равно
1 — Таким образом, пропускная способность ДСК, изображен-
ная на Рис. 8.8(b) равна:
С = '-Ны(ре).
Заметим, что если в канале нет ошибок (ре = 0), равно как если ошиб-
ка имеется всегда (ре = 1), пропускная способность канала достигает сво-
его максимального значения, равного 1 бит/символ. В обоих случаях воз-
можна максимальная передача информации, поскольку выход канала
абсолютно предсказуем. Однако, еслире = 1/2, то выход канала полно-
стью непредсказуем и передача информации через него невозможна.
8.3.3. Основные теоремы кодирования
Общие математические принципы, изложенные в Разделе 8.3.2, бази-
руются на модели системы передачи информации, схема которой
приведена на Рис. 8.7, и состоящей из источника информации, кана-
ла и получателя. В данном разделе в эту схему будет добавлена систе-
ма связи, и будут рассмотрены три основные теоремы кодирования,
или представления, информации. Как показано на Рис. 8.9, систе-
ма связи размещена между источником и получателем, и состоит из
кодера и декодера, соединенных каналом связи.
Терема кодирования для канала без шума
Когда и информационный канал, и система связи свободны от оши-
бок, то основная роль последней должна сводиться к представлению
Рис. 8.9. Модель системы передачи информации.
источника в максимально компактной форме. При этих условиях те-
орема кодирования для канала без шума, также называемая первой те-
оремой Шеннона [Shannon, 1948], определяет минимально достижимую
среднюю длину кодового слова на символ источника.
Источник информации с конечным ансамблем сообщений (A, z)
и статистически независимыми символами источника, называется
источником без памяти. Если выходом источника является не один сим-
вол, а последовательность из п символов алфавита, то можно счи-
тать, что выход источника принимает одно из возможных значений,
обозначаемых ос,-, из полного набора возможных последовательностей
в и элементов: А'={а1,а2,—,(Ху}. Другими словами, каждый блок ос,-,
называемый блоковой случайной переменной, состоит из п символов
алфавита Л. (Обозначение А' позволяет отличать набор блоков от на-
бора символов алфавита Л.) Вероятность отдельного блока ос,- равна
Р(а,-) и связана с вероятностями отдельных символов следующим
соотношением:
Р(а,) = Р(о,- )P(ai2 )-P(aJ, (8.3-14)
где индексы zb /2,,..., in используются для указания п символов алфа-
вита Л, составляющих блок ос,-. Как и ранее, вектор z' (штрих означа-
ет, что используется блоковая случайная переменная) обозначает
совокупное распределение вероятностей {P(oci),/>(cc2),...,P(aj")},
и энтропия источника равна
Jn
H(z') = -^P(ai)\ogP(ai).
i=l
Подставляя (8.3-14) для Р(ос,-) и упрощая выражение, получим:
Щт.') = пН(т.).
(8.3-15)
Таким образом, энтропия блокового источника информации без па-
мяти (который порождает блоки случайных символов) в п раз больше,
чем энтропия соответствующего источника одиночных символов. Та-
кой источник называют п-кратным расширением источника одиноч-
ных символов (нерасширенного источника). Заметим, что однократ-
ным расширением источника является нерасширенный источник как
таковой.
Поскольку количество информации на выходе источника ос,- есть
log[l/P(a,)], разумным представляется кодирование ос, с помощью
кодовых слов длины /(ос,-), где /-целое число, такое что
8.3. Элементы теории
log—Ц- </(ocz)< log-—J—+1. (8.3-16)
Р(аг) Р(а,)
Интуиция подсказывает, что выход источника ocz- должен быть пред-
ставлен кодовым словом, длина которого есть ближайшее целое, пре-
вышающее количество информации18 в ocz. Умножение (8.3-16) на
Р(а,) и суммирование по всем /, дает
Jn Jn Jn
ХР(а/)1оё7^^ХР(С(/)/(с(/)<ХР(с(/)|оё777т+1’
г=1 Z=1 /=]
ИЛИ
Н(т.')< Ц.р< (8.3-17)
где означает среднюю длину кодового слова, которое соответст-
вует и-кратному расширению нерасширенного источника, то есть
4p = £P(az)/(az). (8.3-18)
г=1
Разделив (8.3-17) на п, и учитывая, что H(z')/n = Н(г), получим нера-
венство:
£сп 1
//(z)<-^<//(z)+ -,
п И
(8.3-19)
которое превращается в предельном случае в равенство:
lim
п—
Ар
п
= H(z).
(8.3-20)
Неравенство (8.3-19) устанавливает первую теорему Шеннона для ис-
точников без памяти, которая утверждает, что, кодируя источник бес-
конечнократного расширения, можно достичь значения L'cp /п сколь
угодно близкого к энтропии источника //(z). Несмотря на то, что мы
основывались на предположении о статистической независимости
символов источника, полученный результат может быть легко распро-
18 Построение однозначно декодируемого кода, удовлетворяющего данным усло-
вия, является самостоятельной задачей.
странен на более общий случай, когда появление символа источника
cij может зависеть от конечного числа предшествующих символов. Та-
кие типы источников (называемые марковскими источниками) обыч-
но используются для моделирования межэлементных связей на изо-
бражении. Поскольку Н(г) является точной нижней гранью для
выражения Аср /п (это выражение, согласно (8.3-20), стремится кН(г)
при увеличении и), то эффективность т| любой стратегии кодирования
может быть выражена следующей формулой:
Я(г)
у/
(8.3-21)
Пример 8.7. Кодирование с расширением.
Источник информации без памяти с алфавитом А = {aj, 02}
имеет вероятности символов Pta^) = 2/3 и Р(а2) = 1/3. Согласно
(8.3-3), энтропия этого источника равна 0,918 бит/символ. Если
символы О] и й2 представлены однобитовыми кодовыми словами
0 и 1, то Еср — 1 бит/символ и результирующая эффективность коди-
рования равна ц = 10,918/1, или 0,918.
В Таблице 8.4 содержатся и только что рассмотренный код, и аль-
тернативный способ кодирования, основанный на двукратном расши-
рении источника. В нижней части таблицы приведены четыре блоко-
вых символа (ai,a2,«3,04), соответствующих второму варианту. Как
следует из (8.3-14), их вероятности равны 4/9, 2/9, 2/9 и 1/9. Соглас-
но (8.3-18), средняя длина кодового слова при этом будет равна
17/9 =1,89 бит/символ. Энтропия при двукратном расширении источ-
ника равна удвоенной энтропии нерасширенного источника, т.е.
1,83 бит/символ, так что эффективность при втором варианте коди-
Таблица 8.4. Пример кодирования с расширением.
ai Символы источника Р(ч) (8.3-14) /(а,) (8.3-1) (8.3-16) Кодовое слово Длина кодового слова
Однократное расширение
а. «1 2/3 0,59 1 0 1
а2 «2 1/3 1,58 2 1 1
Двукратное расширение
а. а\а\ 4/9 1,17 2 0 1
а2 а\а2 2/9 2,17 3 10 2
а3 а2а1 2/9 2,17 3 по 3
а4 1/9 3,17 4 111 3
8.3. Элементы теории информации 631 J
рования составит т] = 1,83/1,89 = 0,97. Это несколько лучше, чем эф-
фективность нерасширенного источника, которая равна 0,92. Как
легко видеть, кодирование двукратного расширения источника сокра-
щает среднее число битов кодовой последовательности на один сим-
вол источника с 1 бит/символ до 1,89/2 = 0,94 бит/символ.
Теорема кодирования для канала с шумом
Если канал, изображенный на Рис. 8.9 является каналом с шумом
(т.е. в нем возможны ошибки), то интерес смещается от задачи пред-
ставления информации максимально компактным способом к зада-
че ее кодирования таким образом, чтобы достичь максимально возмож-
ной надежности связи. Вопрос, который естественно возникает, звучит
следующим образом: насколько можно уменьшить ошибки, возника-
ющие в канале?
Пример 8.8. Двоичный канал с шумом.
Предположим, что ДСК имеет вероятность ошибкире = 0,01 (т.е. 99%
всех символов источника передаются через канал правильно). Простой
способ увеличения надежности связи заключается в повторении каж-
дого сообщения или каждого двоичного символа несколько раз. На-
пример, предположим, что вместо передачи одного символа 0 или 1,
используется кодовое сообщение 000 или 111. Вероятность того, что
во время передачи трехсимвольного сообщения не возникнет ошиб-
ки, равна (1 —pjp, или . Вероятность одной ошибки будет Зрер^,
двух — Зр1~ре, а вероятность трех ошибок составит . Поскольку ве-
роятность ошибки при передаче одного символа составляет менее
50%, то получаемое сообщение может быть декодировано методом го-
лосования трех полученных символов. Вероятность неверного деко-
дирования трехсимвольного кодового слова равна сумме вероятнос-
тей ошибок в двух символах и в трех символах, т.е. ЗреД,+рЗ Еслиже
в слове нет ошибок, или всего одна ошибка, то оно будет декодиро-
вано верно. Таким образом, для ре = 0,01 вероятность ошибки при
передаче уменьшилась до значения 0,0003.
Расширяя только что описанную схему повторения, можно до-
стичь сколь угодно малой результирующей ошибки передачи. В об-
щем случае, это осуществляется кодированием л-кратного расшире-
ния источника при использовании Л'-символьной кодовой
последовательности длины г, где Kr>Jn. Ключевым вопросом при
таком подходе является выбор в качестве допустимых кодовых слов
только некоторого числа ср из Кг возможных кодовых последователь-
ностей, а также формулировка решающего правила, оптимизирую-
(^632 Глава 8. Сжатие изображений
щего вероятность правильного декодирования. В предыдущем при-
мере, повторение каждого символа источника три раза эквивалент-
но кодированию нерасширенного двоичного источника, использу-
ющего лишь два из 23 = 8 возможных кодовых слов. Два допустимых
кода — это ООО и 111. Если на декодер поступает какой-то другой (не-
допустимый) код, то выход определяется голосованием по большин-
ству из трех кодовых битов.
Источник информации без памяти порождает информацию со
скоростью (в единицах информации на символ), равной энтропии
источника Н(г). В случае л-кратного расширения, источник порожда-
ет информацию со скоростью Н(^)/п единиц информации на символ.
Если информация кодируется так, как в предыдущем примере, то
максимальная скорость кодированной информации равна (log<p)/r, и
она достигается в случае, когда все ф допустимые кодовые слова рав-
новероятны. В таком случае говорят, что код размера ф и длиной бло-
ка г имеет скорость кода
R = - logtp (8.3-22)
г
единиц информации на символ. Вторая теорема Шеннона [Shannon,
1948], также называемая теоремой кодирования для канала с шумом, ут-
верждает следующее. Для любого R<C, где С есть пропускная способ-
ность канала без памяти , существует код длины г, где г— целое, име-
ющий скорость R, такую, что вероятность ошибки блокового
декодирования не превышает любого наперед заданного е из интерва-
ла 0 < е < 1. Таким образом, вероятность ошибки можно сделать сколь
угодно малой, при условии, что скорость кодовых сообщений меньше
или равна пропускной способности канала.
Теорема кодирования источника (о взаимосвязи скорости и искажения)
Теоремы, рассмотренные к настоящему моменту, устанавливают
фундаментальные пределы безошибочной связи как по надежным,
так и по ненадежным каналам. В данном разделе мы вернемся к слу-
чаю канала без ошибок, но в целом процесс передачи информации мо-
жет быть не точным. Главной задачей системы связи в такой постанов-
ке является «сжатие информации», возможно, за счет некоторого ее
искажения. В большинстве случаев средняя ошибка, вносимая сжа-
19 Канал без памяти это такой канал, в котором реакция канала на текущий входной
символ не зависит от его реакции на предыдущие входные символы.
8.3. Элементы теории
тием, ограничивается некоторым максимально допустимым уровнем
D. Мы хотим найти наименьшую допустимую скорость как функцию
заданного критерия точности, при которой информация может быть
передана от источника к получателю. Решением этой конкретной про-
блемы занимается раздел теории информации, называемый теория
взаимосвязи скорости и искажения.
Пусть источник информации и выход декодера на Рис. 8.9 опре-
делены конечными ансамблями (A, z) и (В, z) соответственно. Пред-
полагается, что канал на Рис. 8.9 является каналом без ошибок, так что
матрица канала Q, которая связывает z с v согласно (8.3-6), может
рассматриваться как определяющая только сам процесс кодирова-
ния-декодирования. Поскольку процесс кодирования—декодирова-
ния является детерминированным, Q описывает некоторый модель-
ный канал без памяти, имитирующий эффект сжатия и восстановления
информации. Всякий раз, когда источник порождает исходный сим-
вол Oj, последний представляется некоторым кодовым символом, ко-
торый в результате декодируется в выходной символ bk с вероятностью
<7^-(см. Раздел 8.3.2).
Постановка задачи кодирования источника, при которой средняя
величина искажения не должна превышать уровня D, требует спосо-
ба количественной оценки величины искажения для любого выхода
источника. Для простого случая нерасширенного источника может
быть использована неотрицательная функция стоимости р( aj, bk),
называемая мерой искажения, определяющая величину «штрафа», воз-
никающего в случае, когда выход источника aj воспроизводится на вы-
ходе декодера как bk. Выход источника является случайной величиной,
поэтому искажение также является случайной величиной, среднее
значение J(Q) которой равно
J к j к
= <8-3-23)
у=1Л=1 у=]Л=1
Запись J(Q) подчеркивает, что среднее искажение есть функция про-
цедуры кодирования—декодирования, которая (как уже отмечалось ра-
нее) моделируется матрицей канала Q. Конкретная процедура коди-
рования-декодирования называется D-точной тогда и только тогда,
когда среднее искажение J(Q) меньше или равно D. Таким образом,
набор D-точных процедур кодирования—декодирования может быть
записан в виде:
(8.3-24)
Глава 8. Сжатие изображений
Поскольку каждая процедура кодирования—декодирования определя-
ется матрицей канала Q, то средняя информация, получаемая при
наблюдении единичного выхода декодера, может быть посчитана со-
гласно (8.3-12). Следовательно, мы можем определить наименьшую до-
пустимую скорость как функцию искажения выражением
/?(£))= min [/(z,v)], (8.3-25)
QsQp
т.е. как минимальное значение (8.3-12) на множестве всех £)-точных
кодов. Заметим, что /(z, v) зависит от значений вероятностей в векто-
ре z и элементов матрицы Q, а минимум в правой части (8.3-25) берет-
ся по Q. Если D = 0, то R(D) меньше или равно энтропии источника,
т.е. /?(0) < И (г).
Уравнение (8.3-25) определяет минимально возможную скорость
как функцию искажения, при которой информация от источника мо-
жет быть доставлена получателю при условии, что среднее искажение
меньше или равно D. Чтобы вычислить эту скорость, т.е. /?(£)), нуж-
но минимизировать значение /(z, v), задаваемое (8.3-12), путем выбо-
ра подходящей матрицы Q (или qkj) при условии выполнения следу-
ющих ограничений:
^>0, (8.3-26)
к
(8.3-27)
Л=1
и
d(Q) = D. (8.3-28)
Формулы (8.3-26) и (8.3-27) выражают основные свойства матрицы ка-
нала Q: ее элементы должны быть неотрицательными и, поскольку лю-
бому входному символу должен соответствовать какой-то выход, сум-
ма элементов по любому столбцу матрицы Q должна быть равна 1.
Уравнение (8.3-28) показывает, что минимальная скорость достигает-
ся при максимально допустимом искажении.
Пример 8.9. Вычисление скорости как функции искажения для дво-
ичного источника без памяти.
И Рассмотрим двоичный источник без памяти с равновероятными
символами источника {0, 1} и простой мерой искажения
8.3. Элементы теории информации
^aj,bk) = \-?>ik,
где §у£ — единичная дельта-функция. Поскольку p(fly, Ьк) = 1 если
Oj^ bk и 0 в остальных случаях, то каждая ошибка кодирования—деко-
дирования считается за одну единицу искажения. Для нахождения
R(D) может быть использовано вариационное исчисление, а именно
метод Лагранжа нахождения условного экстремума. Рассмотрим функ-
цию Лагранжа
J к
J(Q) = Z(z, v) - £ qkj -\iJ+xd(Q).
/=1 k=\
которая дополнительно зависит от множителей Лагранжа ц,, щ,..., Pj+i-
Приравняем ее производные по переменным qkj к нулю (т.е. dJ/dqkj = 0),
и решим систему, состоящую из полученных JKуравнений вместе с J+1
уравнениями связей (8.3-27) и (8.3-28), для неизвестных qkj и
Р1, Ц),..., Pj+i- Если полученные значения qkj неотрицательны, т.е.
удовлетворяют (8.3-26), это означает, что найдено верное решение. Для
определенной выше пары источника и искажения, получим следую-
щие 7 уравнений (с 7-ю неизвестными):
29ц =(Ф 1+912)ехр{2|Щ} 2922 = (921 + 922)ехР{2Р2 }
2912 =(9ц +912)ехР{2Р1 +Рз} 2921= (921 + 922)ехР{2Р2+Рз }
911+921 =1 912 + 922 = 1
921 +912 =2Е).
Последовательность алгебраических преобразований приводит к сле-
дующим результатам:
912 = 921 = 911 = 922 = 1“
111=112 = ^72(1-Я) p3=logj^,
так что
Г1-£) D 1
Q =
D 1-D
Поскольку было задано, что символы источника равновероятны, то
максимальное возможное искажение равно 1/2. Таким образом
0< D< 1/2 и элементы матрицы Q соответствуют (8.3-12) для всех D.
Взаимная информация, связанная с Q и ранее определенным двоич-
ным источником, вычисляется с использованием (8.3-12). Однако за-
метив сходство матрицы Q и матрицы двоичного симметричного ка-
нала, можно сразу написать:
/(z,v) = l-//bs(D).
Это следует из результата Примера 8.6 при подстановке/^ = 1/2 ире = D
в выражение /(z, v) = H^ip^Pg + р^ре) ~Hbs (ре). Скорость как функ-
ция искажения может быть получена прямо из (8.3-25):
R(D)= min [l-//bs(£))] = l-//bs(£)).
<XQ/>
Последнее упрощение основано на том обстоятельстве, что для заданно-
го D разность 1 - Hb& (D) принимает единственное значение, по умолча-
нию являющееся минимумом. Результирующая функция показана графи-
ком на Рис. 8.10; эта форма типична для большинства графиков скорости
как функции искажения. Отметим точку максимума D, обозначенную Д11ах.
такую, что R(D) = 0 для всех D > Dmax. Кроме того, R(D) всегда положи-
тельна, монотонно убывает, и выпукла вниз на отрезке (0, Отах).
Для простых источников и мер искажения, скорость как функция
искажения может быть вычислена аналитически, как и в предыдущем
примере. Более того, когда аналитические методы не работают, то
могут использоваться сходящиеся итеративные алгоритмы, удобные
Рис. 8.10. Скорость как функция искажения для двоичного симметричного
источника.
8.3. Элементы теории
для численной реализации на компьютерах. После того, как вычисле-
на R(D) (для любого источника без памяти и односимвольной меры ис-
кажения20), теорема кодирования источника утверждает, что для лю-
бого е > 0 существует такой код длины г и скорости R < R(D) + е, что
среднее искажение на символ удовлетворяет условию J(Q) < D + е. Важ-
ное практическое следствие данной теоремы и теоремы кодирования
для канала с шумом состоит в том, что выход источника может быть
восстановлен декодером с произвольно малой вероятностью ошибки,
при условии, что канал имеет пропускную способность С > R(D) + е.
Этот последний результат известен как теорема о передаче информации.
8.3.4. Применение теории информации
Теория информации предоставляет основные средства, необходимые
для прямого представления и количественной обработки информации.
В данном разделе рассматривается применение этих средств в конкрет-
ных задачах сжатия изображений. Поскольку фундаментальная посыл-
ка теории информации состоит в том, что формирование информации
может быть представлено в виде вероятностного процесса, в первую
очередь будет рассмотрена статистическая модель процесса формиро-
вания изображения.
Пример 8.10. Вычисление энтропии изображения.
Рассмотрим вопрос оценивания информационного содержания
(т.е. энтропии) простого 8-битового изображения:
21 21 21 95 169 243 243 243
21 21 21 95 169 243 243 243
21 21 21 95 169 243 243 243
21 21 21 95 169 243 243 243
Один относительно простой подход состоит в том, что можно
предположить некоторую конкретную модель источника и вычис-
лить энтропию изображения, базируясь на этой модели. Например,
можно предположить, что изображение было получено воображаемым
«8-битовым полутоновым источником», который последовательно
порождает статистически независимые пиксели согласно какому-то
заранее заданному вероятностному закону. При этом необходимо,
20 Мера искажения является односимвольной, если искажение, связанное с блоком
символов, есть сумма искажений для каждого из символов блока.
чтобы символы источника являлись уровнями яркости, а алфавит ис-
точника состоял из 256 возможных символов. Если вероятности сим-
волов известны, то среднее информационное содержание изображе-
ния (энтропия) каждого элемента изображения может быть вычислена
напрямую с помощью выражения (8.3-3). Например, в случае равно-
мерной плотности вероятностей, символы источника равновероятны
и источник характеризуется энтропией 8 бит/элемент. То есть коли-
чество информации на символ источника (элемент изображения) со-
ставляет 8 бит. Тогда полная энтропия приведенного выше изображе-
ния составит 256 битов. Это конкретное изображение есть только
одно из возможных 28х4х8 = 2256 (~1077) равновероятных изображений
размерами 4x8 пикселей, которые могут быть порождены выбран-
ным источником.
Альтернативным подходом к оцениванию информационного со-
держания может быть создание модели источника, основанной на
относительной частоте появления уровней яркостей рассматриваемо-
го изображения. То есть наблюдаемое изображение может быть интер-
претировано как образец последовательного процесса работы источ-
ника значений яркостей, которым оно было создано. Поскольку
наблюдаемое изображение является единственным индикатором по-
ведения источника, то разумным будет использование гистограммы яр-
костей полученного изображения для моделирования порождающе-
го распределения источника символов:
Оценка энтропии источника, называемая оценкой первого порядка.
Уровень яркости Число Вероятность
21 12 3/8
95 4 1/8
169 4 1/8
243 12 3/8
может быть вычислена с помощью (8.3-3). Для данного примера оцен-
ка первого порядка составит 1,81 бит/элемент. Таким образом, энтро-
пия источника составит приблизительно 1,81 бит/элемент, а всего
изображения — 58 битов.
Более точные оценки энтропии источника значений яркостей,
который породил данное изображение, могут быть рассчитаны путем
исследования относительной частоты появления блоков пикселей на
изображении, где под блоком понимается группа соседних пикселей.
При увеличении размера блока до бесконечности, оценка прибли-
жается к истинной энтропии источника. (Этот результат может быть
получен с помощью процедуры, применявшейся для доказательства
8.3. Элементы теории
теоремы кодирования без шума в Разделе 8.3.3.)- Таким образом, пред-
полагая, что у данного изображения строки последовательно сцепле-
ны одна за другой, а конец сцеплен с началом, можно вычислить от-
носительные частоты пар пикселей (т.е. двукратное расширение
источника):
Пары яркостей Число Вероятность
(21,21) 8 1/4
(21,95) 4 1/8
(95, 169) 4 1/8
(169, 243) 4 1/8
(243, 243) 8 1/4
(243, 21) 4 1/8
Полученная оценка энтропии (опять-таки, при помощи (8.3-3)) со-
ставляет 2,5/2 = 1,25 бит/элемент, где деление на 2 является следстви-
ем рассмотрения двух пикселей одновременно. Эта оценка называет-
ся оценкой второго порядка энтропии источника, поскольку она получена
вычислением относительных частот двухэлементных блоков. Хотя
оценки третьего, четвертого, и более высоких порядков обеспечили бы
еще лучшее приближение энтропии источника, сходимость этих оце-
нок к истинной энтропии источника медленная, а их вычисление слож-
но. Например, обычное 8-битовое изображение содержит 28х2 = 65536
возможных пар значений, относительные частоты которых должны
быть определены. Если рассматриваются блоки из 5 элементов, то чис-
ло возможных групп из пяти значений составит 28х5, или ~1012. И
Хотя нахождение истинной энтропии изображения достаточно за-
труднительно, тем не менее, оценки, подобные рассмотренным в пре-
дыдущих примерах, помогают в понимании возможностей сжатия изо-
бражений. Например, оценка первого порядка энтропии дает нижнюю
границу для сжатия, которого можно достичь применением одного
только кода переменной длины. (Вспомним из Раздела 8.1.1, что коды
переменной длины используются для сокращения кодовой избыточно-
сти.) Кроме того, различия между оценками энтропии первого и более
высоких порядков указывают на наличие или отсутствие межэлемент-
ной избыточности; т.е. они показывают, являются ли элементы изобра-
жения статистически независимыми. Если элементы оказываются ста-
тистически независимы (что означает отсутствие межэлементной
избыточности), то тогда оценки высоких порядков энтропии эквивалент-
ны оценкам первого порядка, а значит, неравномерное кодирование
обеспечивает оптимальное сжатие. Для изображения, рассмотренного
Глава 8. Сжатие изображений
в предыдущем примере, численная разность между оценками энтропии
первого и второго порядков показывает, что может быть построено та-
кое отображение, которое позволит дополнительно сократить пред-
ставление изображения на 1,81 — 1,25 = 0,56 бит/элемент.
Пример 8.11. Применение отображения для уменьшения энтропии.
И Рассмотрим отображение элементов изображения, приведенного в
предыдущем примере, которое представляет изображение следую-
щим образом:
21 0 0 74 74 74 0 0
21 0 0 74 74 74 0 0
21 0 0 74 74 74 0 0
21 0 0 74 74 74 0 0
Сформированный здесь разностный массив получен воспроизве-
дением первого столбца исходного изображения и использованием зна-
чений разностей соседних столбцов для остальных элементов. На-
пример, второй элемент в первой строке получен как (21 — 21) = 0.
Статистика разностного изображения следующая:
Яркость или разность яркостей Число Вероятность
0 16 1/2
21 4 1/8
74 12 3/8
Если теперь рассматривать полученный массив как порожденный
«разностным источником», то для определения оценки первого поряд-
ка энтропии можно опять воспользоваться формулой (8.3-3). Резуль-
татом будет 1,41 бит/элемент. Это означает, что если кодировать по-
лученное разностное изображение способом неравномерного
кодирования, исходное изображение может быть представлено с по-
мощью 1,41 бит/элемент, или около 46 битов. Это значение больше,
чем оценка второго порядка энтропии, полученная в предыдущем
примере и равная 1,25 бит/элемент. Тем самым ясно, что может быть
найден более эффективный способ отображения.
Предыдущие примеры показывают, что оценка первого порядка эн-
тропии изображения не обязательно является минимальной скоростью
кода изображения. Причина заключается в том, что, как правило, зна-
чения элементов изображения не являются статистически независи-
8.4. Сжатие без потерь
мыми. Процедура минимизации фактической энтропии изображения
(какотмечено в Разделе 8.2) называется кодированием источника. При
условии отсутствия ошибок эта процедура объединяет две операции —
отображение и кодирование символов. Если же допустимо возникнове-
ние ошибок, то в нее также включается еще и этап квантования.
С применением средств теории информации может также решать-
ся и несколько более сложная задача — сжатие изображения с поте-
рями. В этом случае, однако, важнейшим результатом является теоре-
ма кодирования источника. Как показано в Разделе 8.3.3, эта теорема
утверждает, что любой источник без памяти может быть закодирован
при помощи кода, имеющего скорость R < R(D), такого, что среднее
искажение на символ не превышает D. Чтобы правильно применить
этот результат к сжатию изображений с потерями, требуется разработ-
ка подходящей модели источника, выбор адекватной меры искажений,
а также вычисление соответствующей скорости как функции искаже-
ний R(D). Первый шаг этой процедуры уже был рассмотрен. На вто-
ром шаге возможен подход на основе использования объективного кри-
терия качества из Раздела 8.1.4. Заключительный шаг касается
отыскания матрицы Q, элементы которой минимизируют выраже-
ние (8.3-12) при ограничениях, накладываемых условиями (8.3-24)
— (8.3-28). К сожалению, данная задача особенно трудна, и может быть
решена лишь в небольшом числе практических случаев. Одним из
таковых является случай, когда изображение представляет собой га-
уссову случайную величину, а мера искажения есть функция средне-
квадратической ошибки. Тогда оптимальный кодер должен преобра-
зовать изображение по методу главных компонент (см. Раздел 11.4) и
представить каждую компоненту с одинаковой среднеквадратической
ошибкой [Davisson, 1972].
8.4. Сжатие без потерь
Во многих приложениях сжатие без потерь является единственно до-
пустимым способом сокращения объема данных. Одним из таких
приложений является архивация медицинских или деловых докумен-
тов, сжатие с потерями которых обычно запрещено по закону. Другим
является обработка спутниковых изображений, где как применение,
так и стоимость получения исходных данных делают сжатие нежела-
тельным. Еще одним направлением является цифровая рентгеноло-
гия, в которой потеря информации может ухудшить точность диа-
гностики. В этих и других областях потребность в сжатии изображений
без потерь объясняется конкретным использованием рассматриваемых
изображений.
22 Л-223
В настоящем разделе внимание будет сконцентрировано на исполь-
зуемых в настоящее время методах сжатия без потерь. Такие методы
обычно обеспечивают степень сжатия в 2-10 раз. Более того, они рав-
но применимы и к полутоновым и к двоичным изображениям. Как от-
мечалось в Разделе 8.2, алгоритмы сжатия без потерь обычно состоят
из двух достаточно независимых операций: (1) разработка альтерна-
тивного представления изображения, в котором уменьшена межэле-
ментная избыточность, и (2) кодирование полученных данных для
устранения кодовой избыточности. Эти шаги соответствуют операци-
ям отображения и символьного кодирования модели источника, ко-
торая рассматривалась при обсуждении Рис. 8.6.
8.4.1. Неравномерное кодирование
Наиболее простым подходом к сжатию изображений без потерь явля-
ется сокращение только кодовой избыточности. Как правило, кодо-
вая избыточность присутствует при любом обычном двоичном коди-
ровании значений элементов изображения. Как уже отмечалось в
Разделе 8.1.1, она может быть устранена кодированием уровней ярко-
сти при условии минимизации среднего числа бит. необходимого для
представления значения одного элемента (8.1-4). Чтобы достичь это-
го, требуется разработка неравномерного кода, который наиболее ве-
роятным уровням яркости присваивает самые короткие кодовые ком-
бинации. Ниже исследуются несколько оптимальных и почти
оптимальных методов построения таких кодов, которые формулиру-
ются на теоретико-информационном уровне. Заметим, что наделе сим-
волами источника могут быть как значения яркостей изображения, так
и выходы операций их отображения (разности значений элементов,
длины серий и т.д.).
Кодирование Хаффмана
Самый известный метод сокращения кодовой избыточности был
предложен Хаффманом [Huffman, 1952]. При независимом кодирова-
нии символов источника информации, коды Хаффмана обеспечивают
наименьшее число кодовых символов (битов) на символ источника.
В терминах теоремы кодирования без шума (Раздел 8.3.3), результат
является оптимальным для фиксированного значения п, при усло-
вии, что символы источника кодируются по отдельности.
Первым шагом в подходе Хаффмана является построение серии
(множества уровней) редуцированных источников путем упорядочи-
вания вероятностей рассматриваемых символов и «склеивания» сим-
волов с наименьшими вероятностями в один символ, который будет
8.4. Сжатие без потерь
‘•ёЭ
Исходный источник Редуцированный источник
Символ Вероятность 1 2 3 4
«2 0.4 0.4 0.4 0.4 -►0.6
аь 0.3 0.3 0.3 0.3- 0.4
а\ 0.1 0.1 г* °-2-г ► 0.3-1
04 0.1 0.1- 0.1J
оз 0.06—т— 0.04—1 -*• 0.1J
05
Рис. 8.11. Модификации источника по Хаффману.
замещать их в редуцированном источнике следующего уровня. Этот
процесс иллюстрируется на Рис. 8.11 для двоичного кодирования
(аналогично могут быть построены .^-символьные коды Хаффмана).
В двух левых колонках гипотетический набор символов источника и
их вероятности упорядочены сверху вниз в порядке убывания вероят-
ностей. Для формирования первой редукции источника, символы с на-
именьшими вероятностями — в данном случае 0,06 и 0,04 — объеди-
няются в некоторый «составной символ» с суммарной вероятностью
0,1. Этот составной символ и связанная с ним вероятность помеща-
ются в список символов редуцированного источника, который опять
упорядочивается в порядке убывания значений полученных вероят-
ностей. Этот процесс повторяется до тех пор, пока не образуется мо-
дифицированный источник всего лишь с двумя оставшимися симво-
лами (самая правая колонка на рисунке).
Второй шаг в процедуре кодирования по Хаффману состоит в ко-
дировании каждого из модифицированных источников, начиная с
источника с наименьшим числом символов (т.е. правого на Рис. 8.11),
и возвращаясь обратно к исходному источнику. Для источника с дву-
мя символами наименьшим двоичным кодом являются, конечно,
символы 0 и 1. Как показано на Рис. 8.12, эти символы приписывают-
ся символам источника справа (выбор символов произволен — изме-
нение 0 на 1 и наоборот даст абсолютно тот же результат). Поскольку
символ текущего модифицированного источника, имеющий вероят-
ность 0,6, был получен объединением двух символов предыдущего
модифицированного источника, то кодовый бит 0, выбранный для дан-
ного варианта, приписывается каждому из двух соответствующих
символов предыдущего источника, затем эти коды произвольным об-
разом дополняются символами 0 и 1, для отличия их друг от друга. Эта
операция затем повторяется для модифицированных источников всех
остальных уровней, пока не будет достигнут уровень исходного источ-
ника. Результирующий код приведен в самой левой колонке (Код) на
Рис. 8.12. Средняя длина этого кода составит:
Исходный источник Редуцированный источник
Символ Вероят-ть Код 1 2 3 4
02 0.4 1 0.4 1 0.4 1 0.4 1 ।—0.6 0
Об 0.3 00 0.3 00 0.3 00 0.3 004 0.4 1
а\ 0.1 011 0.1 011 1-0.2 ОЮ^л-О.З 01-4
04 0.1 0100 0.1 010 М 0.1 0114
оз 0.06 01010*7- -0.1 0101-4
05 0.04 010114
Рис. 8.12. Процедура построения кода Хаффмана.
£ср = 0,4-1 + 0,3-2 + 0,1-3 + 0,1-4 +-0,06-5 + 0,04-5 = 2,2 бита/символ.
Поскольку энтропия источника равна 2,14 бита/символ, то, согласно
(8,3-21), эффективность кода Хаффмана составит 0,973.
Процедура Хаффмана строит оптимальный код для набора симво-
лов и их вероятностей при условии, что символы кодируются по отдель-
ности. После того, как код построен, процесс кодирования/декоди-
рования осуществляется простым табличным преобразованием. Код
Хаффмана является мгновенным однозначно декодируемым блоковым
кодом. Он называется блоковым кодом, поскольку каждый символ ис-
точника отображается в фиксированную последовательность кодовых
символов. Он является мгновенным, потому что каждое кодовое сло-
во в строке кодовых символов может быть декодировано независимо
от последующих символов. Он является однозначно декодируемым, т.к.
любая строка из кодовых символов может быть декодирована единст-
венным образом. Таким образом, любая строка кодированных по
Хаффману символов может декодироваться анализом отдельных сим-
волов в строке слева направо. Для двоичного кода, представленного
на Рис. 8.12, анализ слева направо показывает, что в закодированной
строке 010100111100 первым правильным кодовым словом является
01010, которое есть код для символа о3. Следующим правильным ко-
довым словом является 011, что соответствует символу О]. Продолжая
эти действия, получим декодированное сообщение в виде атр^а^.
Почти оптимальные неравномерные коды
Построение двоичного оптимального кода Хаффмана является нетри-
виальной задачей, когда нужно кодировать большое число символов.
Для общего случая / исходных символов необходимо построить J — 2
редукций источника (см. Рис. 8.11) и выполнить/— 2 присвоения ко-
да (см. Рис. 8.12). Так, построение оптимального кода Хаффмана для
изображения с 256 уровнями яркостей, требует 254 редукции источ-
ника и 254 присвоения кода. Ввиду вычислительной сложности этой
задачи, иногда приходится жертвовать кодовой эффективностью для
упрощения кодовой конструкции.
В Таблице 8.5 приведены четыре неравномерных кода, обеспечи-
вающих такой компромисс. Заметим, что средняя длина кода Хафф-
мана (см. последнюю строку таблицы) меньше, чем у других приведен-
ных кодов. Простой двоичный код имеет максимальную среднюю
длину. Вдобавок, скорость кода в 4,05 бита/символ, достигаемая по ме-
тоду Хаффмана, приближается к границе энтропии, равной 4,0 би-
та/символ, подсчитанной по формуле (8.3-3) и приведенной внизу
таблицы. Хотя ни один из оставшихся кодов, приведенных в Табли-
це 8.5, не достигает эффективности кода Хаффмана, все они являют-
ся более простыми для построения. Подобно коду Хаффмана, они
Таблица 8.5. Неравномерные коды.
Исходный символ Вероятность Двоичный код Хаффман Урезанный Хаффман В2-код Двоичный сдвиг Сдвиговый Хаффман
Блок 1
°1 0.2 00000 10 11 соо 000 10
°2 0.1 00001 110 ОН С01 001 И
°3 0.1 00010 111 0000 сю 010 110
°4 0.06 00011 0101 0101 СИ 011 100
°5 0.05 00100 00000 00010 соосоо 100 101
°6 0.05 00101 00001 00011 С00С01 101 1110
°7 0.05 00110 00010 00100 соосю но 1111
Блок 2
°8 0.04 00111 00011 00101 соосн 111000 010
Oq 0.04 01000 00110 00110 СО 1 соо 111001 он
°10 0.04 01001 00111 00111 С01С01 111010 оно
°11 0.04 01010 00100 01000 С01С10 111011 0100
°12 0.03 01011 01001 01001 С01С11 111100 0101
°13 0.03 01100 01110 100000 сюсоо 111101 01110
°14 0.03 01101 ОНИ 100001 С10С01 111110 они
Блок 3
°15 0.03 01110 01100 100010 С10С10 111111000 0010
°16 0.02 01111 010000 100011 С10С11 111111001 ООН
«17 0.02 10000 010001 100100 спсоо ИННОЮ 00110
«18 0.02 10001 001010 100101 С11С01 111111011 00100
«19 0.02 10010 001011 100110 сисю 111111100 00101
«20 0.02 10011 011010 100111 С11С11 111111101 001110
«21 0.01 10100 011011 101000 соосоосоо 111111110 001111
Энтропия 4.0
Средняя длина кода 5.0 4.05 4.24 4.65 4.59 4.13
Глава 8. Сжатие изображений
присваивают самые короткие кодовые слова наиболее вероятным
символам источника.
Столбец 5 Таблицы 8.5 соответствует простой модификации основ-
ного метода кодирования Хаффмана, называемой урезанное кодирова-
ние Хаффмана. Урезанный код Хаффмана строится только для наибо-
лее вероятных v символов источника, где 0 < < J. Для представления
остальных (относительно редких) символов источника используется
код префикса, сопровождаемый кодом постоянной длины. В Табли-
це 8.5 значение было выбрано равным 12, а префиксом являлось 13-е
кодовое слово кода Хаффмана. Тем самым «символ префикс-кола» был
включен как 13-й (и последний) символ модифицированного кодово-
го источника с вероятностью, равной сумме вероятностей оставших-
ся символов с 0^3 Д° °21- Эти 9 символов затем кодировались при ис-
пользовании кода префикса, который оказался равным 102, и
4-битового двоичного кода, равного индексу символа минус 13.
В столбце 6 Таблицы 8.5 приведен второй близкий к оптимально-
му неравномерный код, известный как В-код. Он близок к оптималь-
ному, когда вероятности символов источника подчиняются степенно-
му закону вида
P(aj) = cj ₽, с =
J ’
7=0
(8.4-1)
с некоторой положительной константой р. Например, распределе-
ние длин серий в двоичном представлении типичного машинописно-
го текстового документа близко экспоненциальному. Как видно из Таб-
лицы 8.5, кодовое слово составлено из битов продолжения,
обозначенных С, и информационных битов, которые являются дво-
ичными числами. Единственной задачей битов продолжения являет-
ся разделение отдельных кодовых слов; для этого значения битов про-
должения меняются с 0 на 1 и наоборот для каждого кодового слова
в строке. В-код, представленный в Таблице 8.5, называется В2-кодом
потому, что за каждым битом продолжения идут два информационных
бита. Последовательность В2-кодов, соответствующих исходной стро-
ке символов о1]О2°7, будет выглядеть следующим образом:
001 010 101 000 010 или 101 110 001 100 НО, в зависимости оттого, вы-
брано ли значение первого бита продолжения равным 0 или 1.
Два оставшихся неравномерных кода в Таблице 8.5 относятся к
сдвиговым кодам. Сдвиговый код формируется последовательнос-
тью следующих операций: (1) упорядочиванием исходных символов
в порядке убывания их вероятностей, (2) разделением общего числа
8.4. Сжатие без потерь
символов на блоки равных размеров, (3) кодированием символов вну-
три одного блока и повторением набора полученных кодов для всех ос-
тальных блоков, (4) добавление специальных символов сдвига вверх
и/или сдвига вниз для идентификации каждого из блоков. Всякий раз,
когда декодер распознает символы сдвига, он перемещается на соот-
ветствующее число блоков вверх или вниз по отношению к опорно-
му блоку.
Чтобы сформировать 3-битовый двоичный сдвиговый код, ис-
пользованный в колонке 7 Таблицы 8.5, исходные символы (в коли-
честве 21) первоначально были расположены в порядке убывания их
вероятностей и разделены на три блока по 7 символов. Затем симво-
лы верхнего блока (at — а7) — он рассматривается как опорный блок —
кодируются двоичным кодом со значениями от ООО до 110. Восьмой
двоичный код (111), не входящий в опорный блок, используется как
один символ сдвига вверх и идентифицирует оставшиеся блоки (в
данном случае символ сдвига вниз не используется). Символы в остав-
шихся двух блоках кодируются с помощью одного или двух символов
сдвига в комбинации с двоичным кодом, построенным для опорного
блока и распространенным на остальные блоки. Например, символ ис-
точника будет закодирован как 111 111 100.
Сдвиговый код Хаффмана в колонке 8 Таблицы 8.5 формируется
похожим образом. Принципиальная разница заключается в присво-
ении вероятности сдвиговому символу еще до кодирования опорно-
го блока по Хаффману. Как правило, значение вероятности сдвигово-
го символа подсчитывается как сумма вероятностей всех символов вне
опорного блока, а код сдвигового символа определяется на основе
тех же концепций, что и префикс-код в урезанном коде Хаффмана. В
данном случае сумма подсчитывается по исходным символам — о21
и составляет 0,39. Таким образом символ сдвига оказывается наибо-
лее вероятным символом и ему приписывается одно из кратчайших ко-
довых слов кода Хаффмана (0).
Арифметическое кодирование
В отличие от рассмотренных ранее неравномерных кодов, арифмети-
ческое кодирование создает неблоковые коды. В арифметическом ко-
дировании, история которого может быть прослежена вплоть до ра-
бот Элайеса (Elias, см. [Abramson, 1963]), не существует однозначного
соответствия между символами источника и кодовыми словами. Вме-
сто этого, вся последовательность символов источника (т.е. все сооб-
щение) соотнесена с одним арифметическим кодовым словом. Само
по себе кодовое слово задает интервал вещественных чисел между 0 и 1.
С увеличением числа символов в сообщении, интервал, необходи-
мый для их представления, уменьшается, а число единиц информации
(скажем, битов), требуемых для представления интервала, увеличива-
ется. Каждый символ в сообщении уменьшает размер интервала в со-
ответствии с вероятностью своего появления. Поскольку метод не
требует, как, например, подход Хаффмана, чтобы каждый исходный
символ отображался в целое число кодовых слов (т.е. чтобы символы
кодировались по одному), он достигает (в теории) границы, установ-
ленной теоремой кодирования без шума (см. Раздел 8.3.3).
На Рис. 8.13 проиллюстрирован основной процесс арифметичес-
кого кодирования. Здесь кодируется сообщение из пяти символов, по-
рожденное четырехсимвольным источником: й]й2Яз°4°5- В начале
процесса кодирования предполагается, что сообщение занимает весь
полуоткрытый интервал [0, 1). Этот интервал изначально делится на
четыре отрезка пропорционально вероятностям символов источника,
которые приведены в Таблице 8.6. Символу ах, например, соответст-
вует подинтервал [0, 0,2). Поскольку это первый символ кодируемо-
го сообщения, то значит, интервал оставшейся части сообщения
(O2«3fl4fls) будет сужен до [0, 0,2). На Рис. 8.13 полученный интервал
растянут на полную высоту рисунка, и приведенные значения на его
концах соответствуют значениям суженого диапазона. Затем суже-
ный диапазон также делится на отрезки, пропорционально вероятно-
стям символов источника, и процесс повторяется со следующим сим-
волом сообщения. Таким образом, символ й2 сузит подинтервал до
[0,04, 0,08), й3 — до [0,056, 0,072) и т.д. Последний символ сообщения,
который должен быть зарезервирован для специального индикатора
окончания сообщения, сужает диапазон до [0,06752, 0,0688). Конеч-
но, любое число в этом подинтервале — например, 0,068 — может
быть использовано для представления сообщения.
Рис. 8.13. Процедура арифметического кодирования
Таблица 8.6. Пример арифметического кодирования.
Символ источника Вероятность Исходный подинтервал
°1 0,2 [0.0. 0,2)
а1 0.2 [0,2, 0.4)
а3 0.4 [0.4. 0.8)
°4 0,2 [0,8, 1,0)
Сообщение из пяти символов, приведенное на Рис. 8.13, после
арифметического кодирования требует для записи всего трех деся-
тичных цифр. Это соответствует 3/5 или 0,6 десятичных знаков на
символ источника и весьма близко энтропии источника, которая, со-
гласно (8.3-3), составляет 0,58 десятичных знаков (десятичных единиц)
на символ. При увеличении длины кодируемой последовательности,
результирующий арифметический код приближается к границе, уста-
навливаемой теоремой кодирования без шума. На практике два фак-
тора мешают кодовым характеристикам приблизиться к данной гра-
нице вплотную: (1) необходимость включения некоторого символа
окончания, позволяющего отделять одну кодовую последователь-
ность от другой, и (2) использование арифметики конечной точнос-
ти. Для преодоления последней проблемы, при практической реали-
зации арифметического кодирования применяются стратегии
масштабирования и округления [Langdon, Rissanen, 1981]. Согласно
стратегии масштабирования, каждый подинтервал перед разбиением
его на отрезки, пропорциональные вероятностям символов, растяги-
вается до диапазона [0, 1). Стратегия округления гарантирует, что ог-
раничения. связанные с конечной точностью вычислений, не препят-
ствуют точному представлению кодовых подинтервалов.
8.4.2. LZW кодирование
Рассмотрев основные методы сокращения кодовой избыточности,
перейдем к рассмотрению одного из нескольких методов сжатия без
потерь, который также направлен на сокращение межэлементной из-
быточности изображения. Метод, называемый метолом кодирования
Лемпеля-Зива-Уэлша (Lempel-Ziv-Welch, LZW), отображает после-
довательности символов источника различной длины на равномерный
код, причем не требует априорного знания вероятностей появления ко-
дируемых символов. Вспомним из Раздела 8.3.3 утверждение первой
теоремы Шеннона о том, что «-кратное расширение источника без па-
мяти может быть кодировано с меньшим средним числом битов на сим-
вол источника, чем сам нерасширенный источник. Несмотря на тот
факт, что метод LZW-сжатия должен быть лицензирован согласно
патенту США№ 4,558,302, он интегрирован во многие широко исполь-
зуемые файловые форматы изображений, включая GIF (graphic inter-
change format), TIFF (tagged image file format), а также PDF (portable doc-
umentformat).
Концептуально LZW-кодирование является очень простым21 22
[Welch, 1984]. При запуске процесса кодирования строится начало
кодовой книги или «словарь», содержащий лишь кодируемые симво-
лы источника. Для 8-битового монохромного изображения словарь
имеет размеры в 256 слов и отображает значения яркостей 0, 1,2,..., 255.
Кодер последовательно анализирует символы источника (т.е. значения
пикселей), и при появлении отсутствующей в словаре серии, она по-
мещается в определяемую алгоритмом (следующую свободную) пози-
цию словаря. Если первые два пикселя изображения, например, бы-
ли белыми (255-255), эта серия может быть приписана позиции 256,
являющейся следующей свободной после зарезервированных для
уровней яркостей позиций с 0 по 255. В следующий раз, когда встре-
тится серия из двух белых пикселей, для их представления будет ис-
пользовано кодовое слово 256, как адрес позиции, содержащей серию
255-255. В случае 9-битового словаря, содержащего 512 кодовых слов,
исходные 8+8 = 16 битов, требуемые для представления двух пиксе-
лей, будут заменены одним 9-битовым кодовым словом. Ясно, что до-
пустимый размер словаря является важнейшим параметром. Если он
слишком мал, то обнаружение совпадающих серий яркостей будет
маловероятна; если слишком велик, то размер кодового слова будет
22
ухудшать характеристики сжатия .
21 Метод кодирования LZWбазируется на том, что кодовая книга формируется в про-
цессе кодирования последовательности символов источника (т.е. пикселей), и яв-
ляется индивидуальной для каждого сеанса. Каждое слово кодовой книги отобра-
жает серию из одного или нескольких символов источника. Формирование кода и
его запись в кодовую последовательность происходят лишь тогда, когда при поступ-
лении очередного символа источника образуется новая серия, не присутствующая
в кодовой книге, а значит, не отображаемая ни одним из имеющихся кодовых слов.
При этом в кодовую последовательность записывается код предыдущей, ранее уже
известной серии, и осуществляется пополнение кодовой книги новой серией. За-
тем кодер начинает анализировать следующую последовательность символов, на-
чиная с того, на котором оборвалась предыдущая серия. Перед началом кодирова-
ния строится короткая тривиальная и заранее известная кодовая книга, а алгоритм
ее пополнения дает возможность и кодеру и декодеру строить одинаковые кодовые
книги и передавать по каналу лишь уже известные к настоящему моменту кодовые
слова. — Прим, перев.
22 В практических реализациях алгоритма LZW размер кодового слова изменяется (воз-
растает) в процессе кодирования. — Прим, перев.
8.4. Сжатие без потерь
Пример 8.12. Пример LZW-кодирования.
Рассмотрим следующее 8-битовое изображение размерами 4x4, со-
держащее вертикальный контур:
39 39 126 126
39 39 126 126
39 39 126 126
39 39 126 126
В Таблице 8.12 описываются шаги, используемые при кодировании его
16 пикселей. Подготавливается словарь на 512 кодовых слов:
Позиция в словаре Содержание (серия)
0 0
1 1
255 255
256 —
511 —
В начальный момент позиции с 256 по 511 еще не используются.
При кодировании пиксели изображения обрабатываются слева на-
право и сверху вниз. Осуществляется катенация (присоединение) каж-
дого следующего значения яркости с имеющейся на данный момент се-
рией, называемой «распознанная серия», которая приведена в позиции
1 Таблицы 8.7. Как можно увидеть, вначале эта переменная обнулена
или пуста. Словарь просматривается на обнаружение совпадения с
каждой очередной серией, и если таковая обнаруживается, что и отме-
чено в первой строке таблицы, то серия заменятся кодом (номером по-
зиции) совпадающей и распознанной (т.е. имеющейся в словаре) серии,
что отмечено в первой колонке второй строки. При этом еще не порож-
дается никакого кода и не происходит обновления словаря. Если же сов-
падения серии и словаря не обнаруживается (что отмечено во второй
строке таблицы), то номер позиции распознанной к настоящему мо-
менту серии (39) подается на выход в качестве очередного кода; теку-
щая нераспознанная серия пополняет словарь, а состояние распо-
знанной серии инициируется последним поступившим символом.
Последние две колонки таблицы описывают коды и серии яркостей,
которые последовательно добавляются к словарю при кодировании все-
го изображения размерами 4x4 элемента. Добавляются девять допол-
нительных кодовых слов. По завершении кодирования словарь со-
Глава 8. Сжатие изображений
Таблица 8.7. Пример LZW кодирования.
Распознанная серия Обрабатываемый пиксель Выход кодера Позиция кодового слова в словаре Входы словаря
39
39 39 39 256 39-39
39 126 39 257 39-126
126 126 126 258 126-126
126 39 126 259 126-39
39 39
39-39 126 256 260 39-39-126
126 126
126-126 39 258 261 126-126-39
39 39
39-39 126
39-39-126 126 260 262 39-39-126-126
126 39
126-39 39 259 263 126-39-39
39 126
39-126 126 257 264 39-126-126
126 126
держит 265 кодовых слов; при этом LZWa.n горитм успешно обнаружил
несколько повторяющихся серий яркостей, что позволило ему сокра-
тить исходное 128-битовое изображение до 90-битового изображения
(т.е. до 10 кодов из 9 битов). Кодовая последовательность на выходе об-
разуется при чтении третьей колонки (Выход кодера) сверху вниз. Ре-
зультирующий коэффициент сжатия равен 1,42:1.
Уникальным качеством только что продемонстрированного LZW
кодирования является то, что кодовая книга (словарь) создается в про-
цессе кодирования данных. Примечательно, что LZW-декодер стро-
ит идентичный словарь восстановления, если он декодирует поток
данных синхронно с кодером. Пользователю предлагается в качест-
ве упражнения (см. Задачу 8.16) декодировать выход, полученный в
предыдущем примере, и восстановить кодовую книгу. Хотя в дан-
ном примере это и не требуется, тем не менее, большинство практи-
ческих приложений предусматривают стратегию действий при пере-
полнении словаря. Простым решением является очистка, или
инициализация, словаря при его заполнении, и затем продолжение
кодирования с чистым словарем. Более сложным вариантом может
быть слежение за характеристиками сжатия и очистка словаря, если
он становится недоступен или работа замедляется. В качестве альтер-
нативы можно прослеживать и временно удалять наименее часто ис-
пользуемые входы словаря, и восстанавливать их, если потребуется.
8.4.3. Кодирование битовых плоскостей
Другим эффективным подходом к сокращению межэлементной избы-
точности является обработка битовых плоскостей изображения по
отдельности. Метод, называемый кодирование битовых плоскостей,
основан на концепции предварительного разложения многоградаци-
онного изображения (черно-белого или цветного) на серию двоичных
изображений, и последующего кодирования каждого из них при по-
мощи одного или нескольких хорошо известных алгоритмов сжатия
двоичных изображений. Ниже рассматриваются наиболее известные
подходы к разложению и анализируются некоторые из широко исполь-
зуемых методов сжатия.
Разложение на битовые плоскости
Уровни яркости w-битового черно-белого изображения могут быть
представлены в форме полинома с основанием 2:
^12^' +ат-22т~2 +-+щ2х +а02°. (8.4-2)
Основанный на этом свойстве простой метод разложения многогра-
дационного изображения на множество двоичных изображений за-
ключается в разделении т коэффициентов полинома на т однобито-
вых битовых плоскостей. Как уже отмечалось в Главе 3, плоскость
нулевого порядка образуется выделением битов (или коэффициентов)
каждого элемента, а битовая плоскость порядка (т — 1) — выделе-
нием битов ат\. Вообще, каждая битовая плоскость нумеруется от
О до т — 1 и формируется установкой значений ее элементов равным
значениям соответствующих битов или полиномиальных коэффици-
ентов элементов исходного изображения. Недостаток, присущий
данному подходу, состоит в том, что малые изменения яркостей мо-
гут существенно влиять на сложность битовых плоскостей. Так, если
пиксель со значением 127 (011111112) изменит значение на 128
(100000002), то во всех битовых плоскостях произойдет переход с 1 на
О (или с 0 на 1). Например, поскольку старшие биты двух двоичных
кодов для 127 и 128 различаются, то пиксель 7-ой битовой плоскости,
имевший первоначальное значение 0, изменит значение на 1.
Альтернативным подходом к разложению, который уменьшает
эффект переноса битов при малых изменениях яркостей, является
представление изображения в виде w-битового кода Грея. Соответ-
Глава 8. Сжатие изображений
ствующий код Грея, записываемый в видс^П1_|...^|^о, может быть вы-
числен по коэффициентам полинома (8.4-2) следующим образом:
gi =а,- ®й;+| 0<i<m-2
(8.4-3)
Sm-l am-l.
Здесь знак Ф означает операцию исключительного ИЛИ. Этот код23
имеет то уникальное свойство, что идущие друг за другом кодовые сло-
ва различаются только в одной битовой позиции. Таким образом, ма-
лые изменения яркости с меньшей вероятностью будут воздействовать
на все т битовых плоскостей. Например, если происходит переход с
уровня 127 на уровень 128, то переход с 0 на 1 возникнет только в 7-й
битовой плоскости, поскольку коды Грея для 127 и 128 равны 110000002
и 01ОООООО2 соответственно.
Пример 8.13. Кодирование битовых плоскостей.
£ На Рис. 8.14(a) и (б) представлены изображения размерами
1024x1024, используемые для иллюстрации методов сжатия, описан-
ных в оставшейся части данного раздела. Полутоновое (многограда-
Рис. 8.14. Изображения размерами 1024x1024 элемента: (а) полутоновое 8-би-
товое изображение, (б) двоичное изображение.
23 Обратим внимание читателя, что полученный код 1рся^т_.|...Х|А’о не может интер-
претироваться в виде набора коэффициентов какого-то полинома, и значения его би-
тов не могут быть подставлены в формулу (8.4-2) вместо коэффициентов а,и_| —
Прим, перев.
8.4. Сжатие без потерь
Рис. 8.15. Четыре старших битовых плоскости изображения на Рис. 8.14(a): ле-
вый столбец — двоичный код, правый столбец — код Грея.
Глава 8. Сжатие изображений
Бит 3
Бит 2
Бит 1
Бит О
Рис. 8.16. Четыре младших битовых плоскости изображения на Рис. 8.14(a):
левый столбец — двоичный код, правый столбец — код Грея.
8.4. Сжатие без потерь 657
ционное) изображение ребенка было получено ПЗС камерой высоко-
го разрешения. Двоичное (двухградационное) изображение текста
документа на право владения, подготовленного президентом США Эн-
дрю Джексоном в 1796 г., было оцифровано на планшетном сканере.
На Рис. 8.15 и 8.16 изображение ребенка представлено в виде восьми
двоичных битовых плоскостей, а также в виде восьми битовых плос-
костей кода Грея. Заметим, что битовые плоскости высоких порядков
являются значительно менее сложными, чем их дополнения низких по-
рядков; то есть они содержат протяженные области с меньшим коли-
чеством деталей или случайных изменений. Кроме того, битовые пло-
скости кода Грея, являются менее сложными, чем соответствующие
двоичные битовые плоскости. К
Кодирование областей постоянства
Простым, но эффективным методом сжатия двоичных изображений
или битовых плоскостей, является использование специальных кодовых
слов для идентификации больших областей, состоящих из соседствую-
щих единиц или нулей. Согласно одному из таких подходов, называе-
мому кодирование областей постоянства (КОП), изображение разбива-
ется на блоки размерами pxq пикселей, которые классифицируются как
целиком белые, целиком черные, или смешанной яркости. Затем наи-
более вероятной или часто встречающейся категории присваивается
1 -битовое кодовое слово 0, а остальные две категории получают 2-бито-
вые коды 10 и 11. Сжатие достигается за счет того, что pq битов, которые
в обычном случае необходимы для представления области произвольных
значений, заменяются 1- или 2-битовым кодовым словом, указывающим
на область постоянства. Конечно же, код, присваиваемый категории
областей смешанной яркости, используется в качестве префикса, за ко-
торым следует набор изpq битов, содержащихся в блоке.
При сжатии текстовых документов, которые преимущественно
являются белыми, может использоваться несколько более простой
подход, состоящий в том, что белые блоки кодируются кодом 0, а все
остальные (включая целиком черные) блоки — кодом 1, за которым
следует набор битов в блоке. Преимущество такого подхода, называ-
емого пропуском белых блоков (ПББ), возникает за счет предполагае-
мых структурных свойств сжимаемого изображения. Если же и встре-
тится небольшое количество целиком черных блоков, то они будут
отнесены к группе блоков смешанной яркости; тем самым 1-битовое
кодовое слово будет использоваться только для наиболее вероятных
белых блоков. Очень эффективной модификацией данного способа яв-
ляется выбор размеров блока равным 1хд. При этом полностью белые
строки кодируются колом 0, а все остальные строки — кодом префик-
Глава 8. Сжатие изображений
са 1, за которым следует обычная ПББ кодовая последовательность24.
Другой подход состоит в применении итеративного подхода, соглас-
но которому двоичное изображение или битовая плоскость разбива-
ется на последовательность все уменьшающихся двумерных подбло-
ков. Целиком белые блоки получают код 0, а все остальные делятся на
подблоки с префиксом 1 и колируются аналогичным образом. Таким
образом, если подблок является целиком белым, то он представляет-
ся префиксом 1, указывающим, что это подблок первого уровня, за ко-
торым следует 0, указывающий, что подблок белый. Если же подблок
не является целиком белым, то процесс разбиения продолжается до тех
пор, пока не будет достигнут заданный порог, после чего подблок ко-
дируется либо кодом 0, если он целиком белый, либо кодом 1, за ко-
торым следует изображение подблока.
Одномерное кодирование длин серий
Эффективной альтернативой кодированию областей постоянства, яв-
ляется представление каждой строки изображения или битовой пло-
скости последовательностью длин, которая описывает протяжение
соседних черных или белых пикселей. Этот метод, относящийся к ко-
дированию длин серий (КДС), был разработан в 1950-х годах и вместе со
своим двумерных расширением стал стандартным способом сжатия в
факсимильном (ФАКС) кодировании. Основная идея состоит в том, что
при сканировании строки слева направо обнаруживаются непрерыв-
ные серии из нулей или единиц, которые затем кодируются кодом их
длины; кроме того, устанавливаются соглашения об определении зна-
чения каждой серии. Наиболее частыми способами задания значения
серии являются следующие: (1) задавать значение первой серии каж-
дой строки, или (2) постановить, что каждая строка начинается с бе-
лой серии, однако допустить, что ее длина может быть нулевой.
Хотя кодирование длин серий само по себе является весьма эф-
фективным способом сжатия изображений (см. пример в Разделе 8.1.2),
обычно можно дополнительно повысить степень сжатия путем нерав-
номерного кодирования самих значений длин серий. К тому же, дли-
ны черных и белых серий могут кодироваться по отдельности, исполь-
зуя разные неравномерные коды, каждый их которых оптимизирован
по своей статистике. Например, допуская, что символ aj представляет
черную серию длины j, можно оценить вероятность того, что символ aj
24 Здесь в явном виде используется тот факт, что текстовые документы представля -
ют собой горизонтальные строки символов, разделенные белыми интервалами. —
Прим, перев.
может быть порожден гипотетическим источником длин черных серий,
путем деления числа черных серий длины j изображения на общее чис-
ло черных серий. Оценка энтропии этого источника длин черных серий,
обозначаемая Я(), получается подстановкой этих вероятностей в (8.3-3).
Аналогичным образом можно подсчитать энтропию источника длин бе-
лых серий, обозначаемую//|. Приближенное значение общей энтропии
изображения, кодированного длинами серий, составит
"дс~Ог’ (8.4-4)
г0+ь1
где Lq и £] означают средние значения длин черных и белых серий.
Формула (8.4-4) дает оценку среднего числа битов на пиксель, требу-
емых для сжатия двоичного изображения кодом длин серий.
Двумерное кодирование длин серий
Концепции одномерного кодирования длин серий легко расширя-
ются на построение различных вариантов двумерного кодирования.
Одним из наиболее известных способов является кодирование относи-
тельных адресов (КОА), основанное на отслеживании двоичных пере-
ходов, которые начинают и заканчивают каждую серию из черных
или белых элементов. Рис. 8.17(a) иллюстрирует одну из реализаций
такого подхода. Пусть ес есть расстояние от текущего перехода с до пре-
дыдущего перехода е (противоположного знака) на той же строке, а сс'
есть расстояние от с до первого аналогичного (т.е. того же знака) пе-
рехода на предыдущей строке после е, который обозначается с'. Если
Предыдущая строка *"1 с’ -4 _ сс
I |[ Of II ll II 1 1 J О 1 1! 1
1 1 1 Г >, " . г
(| 1 _ ' J
Текущая строка — ес - Текущий О?
переход
1 Измеренное Расстояние Код । Диапазон Код h(d)
расстояние расстояний
сс' 0 0 1-4 0 хх
। ес или сс'(слева) 1 100 5-20 10 хххх
сс'(справа) 1 101 I 21-84 110 хххххх
ес d(d> 1) 111 h(d) 85-340 1110 хххххххх
сс'(с'слева) d(d> 1) \\00h(d) 341-364 11110 ххххххххх а
сс’(с'справа) d(d> 1) 1101 h(d) 1365-5460 111110 хххххххххх б
Рис. 8.17. Иллюстрация кодирования относительных адресов (КОА).
ес < сс', то кодируемое КОА расстояние d будет равно ес, если сс' < ес,
то d устанавливается равным сс'.
Подобно кодированию длин серий, кодирование относительных
адресов также требует принятия соглашения об определении значений
серий. Кроме того, для корректной работы на границах изображе-
ния, предполагается наличие фиктивных переходов в начале и конце
каждой строки, равно как и фиктивной предваряющей начальной
строки (скажем, целиком белой). Наконец, поскольку для большин-
ства реальных изображений распределение вероятностей КОА рассто-
яний является неравномерным (см. Раздел 8.1.1), заключительным
шагом процесса КОА будет кодирование выбранного (т.е. кратчайше-
го) КОА расстояния d с помощью подходящего неравномерного ко-
да. Как показано на Рис. 8.17(6), может быть использован код, подоб-
ный В।-коду. Наименьшим расстояниям присваиваются кратчайшие
кодовые слова, а все остальные расстояния кодируются с использова-
нием префиксов. Код префикса устанавливает диапазон ддя значения
d, а следующее за ним значение (обозначенное ххх...х на Рис. 8.17(6)) —
смещение d относительно начальной границы диапазона. Если ес и сс'
равны +8 и +4, как показано на 8.17(a), то правильный КОА код бу-
дет 1100011. Наконец, если d = 0, то с находится непосредственно
под с', тогда как если d = 1, то декодер имеет возможность выбрать бли-
жайшую точку перехода, поскольку код 100 не различает, указывает-
ся ли смещение относительно текущей или предыдущей строки.
Прослеживание и кодирование контуров
Кодирование относительных адресов — всего лишь один из возмож-
ных подходов для представления яркостных переходов, формирующих
контуры на двоичном изображении. Другим подходом является пред-
ставление каждого контура с помощью набора граничных точек, или
одной граничной точкой и набором направляющих. Последний метод
иногда называют прямым прослеживание контуров. В данном разделе
будет рассмотрен еще один метод, называемый дифференциальное
кодирование с предсказанием (ДКП), который отражает важнейшие
характеристики обоих подходов. Он представляет собой построчную
процедуру прослеживания контуров.
В дифференциальном кодировании с предсказанием передний и зад-
ний контуры каждого объекта изображения (см. Рис. 8.18) прослежи-
ваются одновременно, чтобы сформировать последовательность пар
(Д', Д"). Величина Д' означает разность между координатами передне-
го контура соседних строк, а Д" — разность между протяженностью
объекта на соседних строках. Эти разности, а также специальные сооб-
щения, указывающие на начало нового контура (сообщение начало но-
Рис. 8.18. Параметры алгоритма дифференциального кодирования с пред-
сказанием (ДКП).
вого контура) и окончание старого контура (сообщение замыкание кон-
тура), описывают каждый объект. Если А" заменяется разностью меж-
ду координатами задних контуров объекта на соседних строках, обозна-
чаемой А'", то метод называется двойным дельта кодированием (ДДК).
Сообщения о начале и замыкании контура позволяют парам (Д', А")
или (Д', Д'"), порожденным на какой-то одной строке изображения,
быть правильно связанными с соответствующими парами на преды-
дущей и последующей строках. Без этих сообщений декодер не смог
бы связать одну пару разностей с другой, или правильно разместить
контур на изображении. Чтобы избежать кодирования координат
столбца и строки в каждом сообщении о начале и замыкании конту-
ра, часто используют отдельный код, позволяющий идентифицировать
строки, вообще не содержащие точек объектов. Финальным шагом как
ДКП-, так и ДДК-кодирования является кодирование значений Д', А"
или Д'", а также координат начала и замыкания контуров подходящим
неравномерным кодом.
Пример 8.14. Сравнение методов сжатия двоичных изображений.
Заканчивая настоящий раздел, сравним вышеописанные методы
сжатия двоичных изображений. Методы сравниваются путем сжатия
изображений на Рис. 8.14. Итоговые скорости кодов и коэффициен-
ты сжатия представлены в Таблицах 8.8 и 8.9. Отметим, что результа-
ты для длин серий в методе КДС, а также для расстояний в методах
ДКП и ДДК, приведены с учетом сжатия, достижимого при последу-
ющем неравномерном кодировании (см. Разделе 8.4.1). Для этого вы-
числялись и использовались оценки первого порядка энтропии (см.
Раздел 8.3.4).
Результаты, представленные в Таблицах 8.8 и 8.9, демонстрируют, что
все методы способны сокращать некоторое количество межэлемент-
ной избыточности. То есть, результирующие кодовые скорости оказы-
Таблица 8.8. Результаты сжатия без потерь изображения на Рис. 8.14(a) мето-
дом кодирования битовых плоскостей (прочерк в графе таблицы означает
отсутствие сжатия, и скорость кода равна 1,00): Н = 6,82 бита/пиксель.
Метод Скорость кодирования битовых плоскостей (бит/пиксель) Скорость кода Коэффиц сжати
7 6 5 4 3 2 1 0
Кодирование двоичных битовых плоскостей
КОП (4 х 4) 0,14 0,24 0,60 0,79 0,99 — — — 5,75 1,4:1
КДС 0,09 0,19 0,51 0,68 0,87 1,00 1,00 1,00 5,33 1,5:1
ДКП 0,07 0,18 0,79 — — — — — 6,04 1,3:1
ДДК 0,07 0,18 0,79 — — — — — 6,03 1,3:1
КОД 0,06 0,15 0,62 0,91 - — — — 5,71 1,4:1
Кодирование битовых плоскостей кода Грея
КОП (4 х 4) 0,14 0,18 0,48 0,40 0,61 0,98 — — 4,80 1,7:1
КДС 0,09 0,13 0,40 0,33 0,51 0,85 1,00 1,00 4,29 1,9:1
ДКП 0,07 0,12 0,61 0,40 0,82 — — — 5,02 1,6:1
ДДК 0,07 0,11 0,61 0,40 0,81 — — — 5,00 1.6:1
КОА 0,06 0,10 0,49 0,31 0,62 — — — 4,58 1,7:1
Таблица 8.9. Результаты сжатия без потерь двоичного изображения на
Рис. 8.14(6): Н = 0,55 бита/пиксель.
ПББ (1x8) ПББ (4x4) КДС ДКП ДДК КОА
Скорость кода (бит/пиксель) 0,48 0,39 0,32 0,23 0,22 0,23
Коэффициент сжатия 2,1:1 2,6:1 3,1:1 4,4:1 4,7:1 4,4:1
ваются ниже, чем оценка первого порядка энтропии каждого изображе-
ния. Метод кодирования длин серий оказывается наилучшим при коди-
ровании многоградационного изображения с помощью битовых плос-
костей, в то время как двумерные методы, такие как ДКП, ДДК и КОД,
обеспечивают более хорошее сжатие двухградационного изображения.
Более того, относительно простая процедура использования кода Грея
при сжатии изображения на Рис. 8.14(a), позволяет улучшить достига-
емую эффективность кодирования приблизительно на 1 бит/пиксель. На-
конец, заметим, что все пять методов сжатия смогли сжать полутоновое
изображение только с коэффициентами сжатия от 1 до 2, в то время как
при сжатии двоичного изображения на Рис. 8.14(6) им удалось достичь
коэффициентов сжатия от 2 до 5. Как видно из Таблицы 8.8, причина раз-
8.4. Сжатие без потерь
ницы в эффективности заключается в том, что все алгоритмы оказались
неспособными сжать изображения младших порядков при кодирова-
нии изображения по битовым плоскостям. Прочерком в графах табли-
цы обозначены те случаи, когда применение алгоритма сжатия приводи-
ло к увеличению объема данных. В таких случаях для представления
битовой плоскости использовались несжатые данные, и, следовательно,
к скорости кода добавлялась величина 1 бит/пиксель.
8.4.4. Кодирование без потерь с предсказанием
Вернемся теперь к вопросу сжатия без потерь, не требующему разло-
жения изображения на отдельные битовые плоскости. Общий подход,
называемый кодированием без потерь с предсказанием, основан на ус-
транении межэлементной избыточности близко расположенных пик-
селей путем выделения и кодирования только новой информации, со-
держащейся в каждом пикселе. Новая информация, содержащаяся в
пикселе, определяется как разность между истинным и предсказанным
значениями пикселя. На Рис. 8.19 представлены основные элементы
системы кодирования без потерь с предсказанием. Система состоит из
кодера и декодера, причем каждый содержит одинаковый предсказа-
тель. Когда очередной элемент входного изображения, обозначае-
мый fn, поступает на вход кодера, предсказатель генерирует оценку его
значения, основанную на значениях некоторого количества предыду-
щих элементов. Затем выход предсказателя округляется до ближайше-
го целого, обозначаемого fn , и используется для получения разности,
или ошибки предсказания
<8.4-5)
Рис. 8.19. Модель кодирования без потерь с предсказанием: (а) кодер; (б) де- а
кодер. б
которая затем кодируется с помощью неравномерного кода (кодером
символов), и тем самым формируется очередной элемент сжатого по-
тока данных. Декодер на Рис. 8.19(6) восстанавливает значение еп из
полученной кодовой последовательности и выполняет обратную опе-
рацию:
Л=7„+е„. (8.4-6)
Для формирования предсказываемого значения f„ могут ис-
пользоваться различные локальные, глобальные или адаптивные
методы (см. Раздел 8.5.1). Однако в большинстве случаев предска-
зание формируется как линейная комбинация т предыдущих эле-
ментов:
= round
in
1=1
(8.4-7)
где т — порядок линейного предсказания, а, — коэффициенты пред-
сказания (z = 1,а операция round[] означает округление до бли-
жайшего целого. При растровом сканировании индекс п нумерует
выходы предсказателя в соответствии с моментами их появления. То
есть, fn, fn и еп в уравнениях (8.4-5) — (8.4-7) могут быть заменены на
обозначения/(0, /(/) и e(t), где t означает дискретное время. В прин-
ципе, п может являться индексом как в пространстве координат, так
и во времени (номер кадра в случае временной последовательности изо-
бражений). Для одномерного линейного кодирования с предсказани-
ем выражение (8.4-7) может быть переписано в виде
/И
f(x,y) = round £a,/(x,y-z)
Lz=i
(8.4-8)
где каждая зависимая переменная теперь выражается исключитель-
но как функция пространственных координатх и у. Согласно (8.4-8)
одномерное линейное предсказание есть функция значений преды-
дущих элементов одной текущей обрабатываемой строки. В случае
двумерного кодирования с предсказанием, величина предсказания
будет, вообще говоря, являться функцией всех предыдущих эле-
ментов, полученных к настоящему моменту при последовательном
сканировании слева направо и сверху вниз. В трехмерном случае бу-
дут также добавляться значения пикселей из предыдущих кадров. Для
8.4. Сжатие без потерь
первых т элементов каждой строки выражение (8.4-8) не определе-
но, поэтому эти элементы должны кодироваться каким-то другим
способом (например, кодом Хаффмана), и рассматриваться как из-
держки процесса кодирования с предсказанием. Эти комментарии
имеют отношение также и к случаям двумерного или трехмерного
кодирования.
Пример 8.15. Кодирование с предсказанием.
Рассмотрим кодирование полутонового изображения на Рис. 8.14(a)
с помощью простого линейного предсказателя первого порядка:
f(x,y) = round [a/(x.j-l)]. (8.4-9)
Рис. 8.20. (а) Изображение ошибки предсказания, полученной из (8.4-9).
(б) Гистограмма уровней яркости исходного изображения, (в) Гистограмма оши-
бок предсказания.
Предсказатель такого общего вида называется предсказателем по пре-
дыдущему элементу, и соответствующая процедура кодирования назы-
вается дифференциальным кодированием, или кодированием по предыду-
щему элементу. На Рис. 8.20(a) показано в виде изображения значение
(сигнал) ошибки предсказания, получаемое из (8.4-9) при а = 1. На
этом изображении значение яркости 128 соответствует нулевой ошиб-
ке предсказания, а отличные от нуля положительные и отрицательные
ошибки предсказания усилены в 8 раз и изображаются, соответст-
венно, более яркими или более темными оттенками. Среднее значе-
ние данного изображения составляет 128,02, что соответствует сред-
ней ошибке предсказания в 0,02 уровня яркостей.
На Рис. 8.20(6) и (в) представлены гистограмма уровней яркостей
исходного изображения (приведенного на Рис. 8.14(a)), а также гис-
тограмма ошибок предсказания, полученных по формуле (8.4-9). За-
метим, что дисперсия ошибок предсказания на Рис. 8.20(b) много
меньше дисперсии уровней яркостей исходного изображения. Более
того, оценка первого порядка энтропии сигнала ошибки предсказания
также значительно меньше, чем соответствующая оценка энтропии ис-
ходного изображения (3,96 бит/пиксель против 6,81 бит/пиксель).
Это уменьшение энтропии отражает сокращение значительной степе-
ни избыточности при помощи процесса кодирования с предсказани-
ем, несмотря на то, что согласно (8.4-5) для точного представления по-
следовательности ошибок предсказания /и-битового изображения
требуются (т + 1) - битовые числа. Хотя для кодирования данной по-
следовательности ошибок предсказания может быть использована
любая из рассмотренных в Разделе 8.4.1 процедур неравномерного
кодирования, результирующий коэффициент сжатия будет ограничен
величиной приблизительно 8/3,96, или около 2:1. Вообще, оценка мак-
симального сжатия любого варианта кодирования без потерь с пред-
сказанием может быть получена делением среднего числа битов, ис-
пользуемого для представления значения одного пикселя, на оценку
первого порядка энтропии сигнала ошибки предсказания. И
Предыдущий пример показывает, что величина сжатия, достига-
емая при кодировании без потерь с предсказанием, прямо связана с
уменьшением энтропии, происходящем благодаря отображению вход-
ного изображения в последовательность ошибок предсказания. По-
скольку в процессе предсказания и вычисления разности удаляется зна-
чительная доля межэлементной избыточности, распределение
вероятностей ошибок предсказания имеет резкий пик в нуле и ха-
рактеризуется относительно малой дисперсией (по сравнению с рас-
пределением яркостей входного изображения). Плотность распреде-
ления вероятностей ошибки предсказателя часто моделируют рас-
пределением Лапласа с нулевым средним:
-л/2|е|
Pe(e) = -U—е °е , (8.4-10)
д/2ое
где се — величина стандартного отклонения е.
8.5. Сжатие с потерями
В отличие от изложенного в предыдущем разделе подхода к кодиро-
ванию без потерь, кодирование с потерями основано на выборе балан-
са между точностью восстановления изображения и степенью его
сжатия. Если допустить появление искажений в конечном результа-
те кодирования (которые могут быть, а могут и не быть заметными),
то возможно значительное увеличение коэффициента сжатия. Факти-
чески, многие методы сжатия с потерями могут вполне узнаваемо
восстанавливать одноцветные изображения из данных, сжатых с ко-
эффициентами более чем 100:1, а также воспроизводить фактически
неотличимые от оригинала изображения при коэффициентах сжа-
тия от 10:1 до 50:1. В то же время методы сжатия без потерь редко до-
стигают коэффициентов лучших, чем 3:1. Как показано в Разделе 8.2,
принципиальная разница между структурными схемами этих двух
подходов заключается в наличии или отсутствии блока квантования
на Рис. 8.6.
8.5.1. Кодирование с предсказанием
В настоящем разделе в модель кодирования, введенную в Разделе
8.4.4, будет добавлен квантователь и проведен поиск компромисса
между точностью восстановления и степенью сжатия. Как видно из
Рис. 8.21, между кодером символов и точкой, в которой формирует-
ся ошибка предсказания, помещается квантователь, который берет на
себя функцию определения ближайшего целого от величины, получа-
емой на выходе кодера без ошибок. Он отображает ошибку предска-
зания в ограниченный набор (квантованных) значений сигнала на
выходе ёп, величина разности между которыми (т.е. точность кванто-
вания) определяет степень сжатия и величину искажения, возникаю-
щего в результате такого кодирования.
Для адаптации модели к введению блока квантователя, безошибоч-
ный кодер на Рис. 8.19(a) должен быть изменен так, чтобы предска-
Глава 8. Сжатие изображений
Входное
изображение
Сжатое
изображение
а Рис. 8.21. Модель кодирования с потерями с предсказанием: (а) кодер, (б) де-
й кодер.
зания, генерируемые кодером и декодером, были идентичными. Как
видно на Рис. 8.21(a), это достигается помешением кодера с потеря-
ми в цепь обратной связи предсказателя, где его вход, обозначаемый
fn, формируется как функция от предыдущего предсказания и теку-
щей ошибки квантования. Таким образом,
fn ёп + /п, (8.5-1)
где fn та же, что была определена в формуле (8.4-7) в Разделе 8.4.4. Схе-
ма с обратной связью предотвращает накопление ошибки на выходе
кодера. Как видно из Рис. 8.21 (б), выход декодера также задается фор-
мулой (8.5-1).
Пример 8Л6. Дельта-модуляция.
Дельта-модуляция (ДМ) является простым, но хорошо известным
способом кодирования с потерями, в котором предсказатель и кван-
тователь определяются следующим образом:
fn = «Л-1 (8-5’2)
и
+£ для еп > О,
—£ в остальных случаях
(8.5-3)
8.5.Сжатие с потерями 669
где а — коэффициент предсказания (обычно меньше 1), а £ — поло-
жительная константа. Выход квантователя ёп, может быть представ-
лен единственным битом (см. Рис. 8.22(a)), так что кодер символов на
Рис. 8.21(a) может использовать 1-битовый равномерный код. Ре-
зультирующая скорость ДМ-кода составит 1 бит/пиксель.
На Рис. 8.22(b) иллюстрируется механизм дельта-модуляции; в
таблице приведены значения сигналов при сжатии и восстановлении
следующей входной последовательности: {14,15, 14, 15, 13, 15,15, 14,
20, 26, 27, 28, 27, 27, 29, 37, 47, 62, 75, 77, 78, 79, 80, 81, 81, 82, 82} при
а = 1 и £ — 6,5. Процесс начинается с передачи неискаженного зна-
чения первого элемента декодеру. При начальных условиях /0 = /0 = 14
установленных как на стороне кодера, так и на стороне декодера, ос-
тальные значения на выходе могут быть определены повторными вы-
числениями по формулам (8.5-2), (8.4-5), (8.5-3) и (8.5-1). Так, при п = 1
получим: Д =1-14 = 14, ej = 15 — 14=1, ё] =+6,5 (потому, чтоej > 0),
у = 6,5 +14 = 20,5, и результирующая ошибка восстановления соста-
вит (15 — 20,5), или —5,5 уровней яркости.
Вход Кодер Декодер Ошибка
п f f е ё f / f [/-/]
0 14 — 14.0 — 14.0 0.0
1 15 14.0 1.0 6.5 20.5 14.0 20.5 -5.5
2 14 20.5 -6.5 -6.5 14.0 20.5 14.0 0.0
3 15 14.0 1.0 6.5 20.5 14.0 20.5 -5.5
14 29 20.5 8.5 6.5 27.0 20.5 27.0 2.0
15 37 27.0 10.0 6.5 33.5 27.0 33.5 3.5
16 47 33.5 13.5 6.5 40.0 33.5 40.0 7.0
17 62 40.0 22.0 6.5 46.5 40.0 46.5 15.5
18 75 46.5 28.5 6.5 53.0 46.5 53.0 22.0
19 77 53.0 24.0 6.5 59.6 53.0 59-6 17.5
Рис. 8.22. Пример дельта-модуляции.
На Рис. 8.22(6) графически показаны данные, представленные в
таблице на Рис. 8.22(b). Здесь показан входной сигнал (/„) и выход де-
кодера ( /„). Заметим, что на участке быстрого изменения входного сиг-
нала от п = 14 до 19, где £ оказывается слишком малым для отслежи-
вания больших изменений на входе, возникает искажение, называемое
перегрузка по крутизне. Кроме того, на участке от п = 0 до 7, где £ ока-
зывается слишком велико для отражения малых изменений на входе
или относительно плавных участков, возникает шум гранулярности. На
большинстве изображений эти два явления приводят к размыванию
контуров и появлению областей с высокой зернистостью или шумом
(т.е. к искажению гладких объектов).
Искажения, отмеченные в предыдущем примере, являются об-
щими для всех видов кодирования с потерями с предсказанием.
Насколько велики эти искажения, зависит от выбранных методов
квантования и предсказания в целом. Несмотря на взаимосвязи
между ними, обычно предсказатель рассчитывается в предположе-
нии отсутствия ошибок квантования, а квантователь — исходя из ус-
ловия минимизации своих собственных ошибок. Таким образом, и
предсказатель и квантователь рассчитываются независимо друг от
друга.
Оптимальные предсказатели
Оптимальные предсказатели, использующиеся в большинстве приме-
няемых кодеров с предсказанием, минимизируют средний квадрат
ошибки предсказания кодера:
Е(е2} = £(1/„-/„]2}, (8.5-4)
где £{•} — математическое ожидание, при условии, что
fn ~ + fn ~ еп + ffl — fn (8.5-5)
и
w
Л = (8-5-б)
/=1
Таким образом, критерий оптимизации выбирается так, чтобы мини-
мизировать средний квадрат ошибки предсказания, ошибка кванто-
вания считается пренебрежимо малой (~ е), а предсказание пред-
ставляет собой линейную комбинацию значений т предыдущих
элементов25. Эти ограничения не являются строго необходимыми,
но они значительно упрощают анализ, и, в то же время, позволяют
уменьшить вычислительную сложность предсказателя. Получаемый
в результате подход к кодированию с предсказанием известен как
дифференциальная импульсно-кодовая модуляция (ДИКМ).
При таких условиях проблема построения оптимального предска-
зателя сводится к относительно простой задаче выбора т коэффици-
ентов предсказателя, которые будут минимизировать следующее вы-
ражение:
£{е2} = £-
fn ~ ^ifn-\
/=|
(8.5-7)
Дифференцируя уравнение (8.5-7) по каждому из коэффициентов,
приравнивая значения производных к нулю, и решая получающуюся
систему уравнений при условии, что^, имеет нулевое среднее и дис-
2
Персию о , получим
cc = R 'г,
(8.5-8)
где R 1 является обратной матрицей следующей матрицы автокорре-
ляции размерами тхт:
\E{fn_Jn_x} E{fnAfn_2\ ... E{fnAfn^}
E{f„_2fn_x}
R= ...
(8.5-9)
E{f„_mfnA} E{fn_mfn_2} ... E{fn^fn^
а г и а являются /и-элементными векторами:
(8.5-10)
25 Вообще говоря, для не гауссова сигнала (изображения) оптимальный предсказа-
тель является нелинейной функцией значений элементов, участвующих в формиро-
вании оценки.
Глава 8. Сжатие изображений
Таким образом, для любого входного изображения, коэффициенты,
которые минимизируют (8.5-7), могут быть определены с помощью
последовательности элементарных матричных операций. Более того, ко-
эффициенты зависят лишь от значений автокорреляций пикселей на ис-
ходном изображении. Дисперсия ошибки предсказания, возникающая
при использовании этих оптимальных коэффициентов, будет равна
т
о2 = °2 - = о2 - X E{fnfn-№i • (8.5-11)
i=l
Хотя основанный на уравнении (8.5-8) способ вычислений достаточ-
но прост, практическое вычисление значений автокорреляций, необ-
ходимых для формирования R и г настолько затруднительно, что ча-
стные предсказания (те, в которых коэффициенты предсказания
вычисляются для изображения индивидуально) почти никогда не
применяются. В большинстве случаев выбирается набор общих ко-
эффициентов, вычисляемый путем оценивания некоторой простой мо-
дели изображения и подстановки соответствующих значений автокор-
реляции в (8.5-9) и (8.5-10). Так, в случае, если предполагается
двумерный Марковский источник (см. Раздел 8.3.3) с разделимой ав-
токорреляционной функцией
E{f(x,y)f(x-i,y -j)} = о2р(р^ (8-5-12)
и обобщенным линейным предсказателем четвертого порядка
/(x,y) = a1/(x,y-l) + a2/^-bj-l)+ (g 513)
+а3/(х-1,у) + а4/(х- 1,у+1),
то результирующие оптимальные коэффициенты [Jain, 1989] будут
равны
«1=Рл а2=~РуРл a3=Pv «4=°, (8.5-14)
где p/j — горизонтальный, a pv — вертикальный коэффициенты кор-
реляции рассматриваемого изображения.
Наконец, обычно требуется, чтобы сумма коэффициентов предска-
зания в (8.5-6) была меньше или равна единице, т.е.
£а,<1. (8.5-15)
<=1
8.5. Сжатие с потерями
Это ограничение накладывается для того, чтобы гарантировать, что
значение на выходе предсказателя будет оставаться внутри допусти-
мого диапазона уровней яркостей, а также, чтобы уменьшить влия-
ние шумов передачи, воздействие которых обычно проявляется на вос-
становленном изображении в виде горизонтальных полос. Важно
также уменьшить чувствительность ДИ КМ декодера по отношению
к входному шуму, потому что единственная помеха (при определен-
ных условиях) может распространяться на весь последующий выход.
Это означает, что выход декодера может оказаться неустойчивым.
Введение дополнительного ограничения в (8.5-15) — что сумма долж-
на быть строго меньше единицы — позволяет уменьшить продолжи-
тельность влияния шума на входе декодера до нескольких выходных
значений.
Пример 8.17. Сравнение методов предсказания.
Рассмотрим ошибки предсказания, возникающие при ДИ КМ ко-
дировании полутонового изображения на Рис. 8.23, в предположении
нулевой ошибки квантования и при использовании каждого из сле-
дующих четырех предсказателей:
/(х,у) = 0,97/(х,у-1);
(8.5-16)
f (х, у) = 0,5/(х, у -1) + 0,5/( х - L у); (8.5-17)
f(x,у) = 0,75/(х,у-1) + 0,75/(х-1у) -0,5/(х- I, у-1); (8.5-18)
Рис. 8.23. Полутоновое монохромное изображение размерами 512x512 пикселей
23 А-223
Глава 8. Сжатие изображений
f(x,y) =
0,97f(x,y-l) если АЛ < Av;
’ ’ (8.5-19)
0,97/(х-1,у) в остальных случаях,
где АЛ = |/(х-1, у) —f{x—1, у—1 )| и Av = |/(х, у-1) -f(x-1, у-1 )| оз-
начают вертикальный и горизонтальный градиенты в точке (х, у).
В формулах (8.5-16) — (8.5-18) задан достаточно устойчивый набор ко-
эффициентов а,-, обеспечивающий удовлетворительные характерис-
тики в широком диапазоне изображений. Адаптивный предсказа-
тель в (8.5-19) предназначен для улучшения передачи контуров. Он
измеряет локальные характеристики изображения по направлени-
ям (АЛ и Av) и выбирает предсказатель, соответствующий измеренной
оценке.
Рис. 8.24. Сравнение четырех методов линейного предсказания
На Рис. 8.24(a) — (г) в виде изображений показаны ошибки пред-
сказаний, возникающие при использовании формул (8.5-16) — (8.5-19).
Как видно, заметность ошибки уменьшается с увеличением порядка
предсказания26. Стандартные отклонения ошибок предсказания да-
ют близкие результаты: они равны, соответственно, 4,9, 3,7, 3,3 и 4,1
уровня яркости.
Оптимальное квантование
Ступенчатая функция квантования t = q(s), показанная на Рис. 8.25,
является нечетной функцией s, т.е. q(—s) = —q(s); таким образом, она
полностью задается набором из L/2 пар значений s,- и ti для первого
квадранта на графике. Эти точки разрывов задают скачки функции и
называются пороговыми уровнями (s,) и уровнями квантования (/,) кван-
тователя. Обычно полагают, что входное значение л отображается в уро-
вень квантования /2, если л находится в полуинтервале [sy, л,-+|) при s,-> О,
и, соответственно, (л,-, sj+1] при s, < 0.
Проблема построения квантователя заключается в выборе наи-
лучших значений s,- и для конкретного критерия оптимизации и
плотности распределения вероятностей p(s). Если критерием оптими-
26 Предсказатели, использующие более трех или четырех предыдущих пикселей,
при существенном усложнении предсказателя дают незначительное улучшение ха-
рактеристик сжатия [Habibi, 1971 j.
зации, который может быть как статистической, так и визуальной27 ме-
рой, является минимизация среднего квадрата ошибки квантования
(т.е. E{(.s — /f)2}), а также, если p(s) является четной функцией, услови-
ями минимальной ошибки [Мах, 1960] являются:
Г' (5-/,)р(5)Л = 0 (/ = 1,2,...,£/2), (8.5-20)
JS; I
0
Ь + ^+1
2
оо
/=0;
/ = 1,2,....
(8.5-21)
И
5_f=-5,
(8.5-22)
Уравнение (8.5-20) показывает, что оптимальные уровни квантования
являются точками центров тяжестей областей подр(л) по каждому из
интервалов квантования, разделенных пороговыми уровнями, а урав-
нение (8.5-21) — что пороговые уровни должны располагаться посе-
редине между уровнями квантования. Условия (8.5-22) являются след-
ствием того, что q — нечетная функция. Таким образом, для любого
L и p(s), такие пары s, и для которых выполняются уравнения
(8.5-20) — (8.5-22), являются оптимальными в смысле среднеквадри-
тической ошибки. Соответствующий квантователь называется £-уров-
невым квантователем Ллойда—Макса.
Таблица 8.10. Квантователь Ллойда—Макса для плотности распределения
вероятностей Лапласа с единичной дисперсией.
Уровни i 2 4 8
si si •i si t,
1 со 0,707 1,102 0,395 0,504 0,222
2 ОО 1,810 1,181 0,785
3 2,285 1,576
4 CO 2,994
0 1,414 1,087 0,731
27 Касательно визуальных (в оригинале психовизуальных — Прим, перев ) мер см.
[Netravali, 1977] и [Limb, Rubinstein, 1978].
В таблице 8.10 приведены пороговые уровни и уровни квантования 2-,
4-, и 8-уровневого квантователя Ллойда—Макса для функции плотно-
сти распределения вероятностей Лапласа с единичной дисперсией
(8.4.10). Эти значения были получены численным методом [Paez,
Glisson, 1972], поскольку получение точного, или явного, решения
уравнений (8.5-20) — (8.5-22) для большинства нетривиальных p(s)
достаточно затруднительно. Три представленных квантователя обеспе-
чивают фиксированные скорости кода, равные, соответственно, 1, 2 и
3 битам/пиксель. Поскольку Таблица 8.10 была построена для распре-
деления с единичной дисперсией, то значения пороговых уровней и
уровней квантования ддя случаев о Ф 0 получаются простым умноже-
нием табулированных значений на величину стандартного отклонения
имеющегося распределения плотности вероятностей. В последнем ря-
ду таблицы приведены размеры шага в оптимального равномерного
квантователя, который одновременно удовлетворяет уравнениям
(8.5-20) — (8.5-22), а также дополнительным ограничениям
Ц ~ 'i-1 = si ~ 5i-l = 0 • (8.5-23)
Если в кодере с потерями с предсказанием (Рис. 8.21(a)) использует-
ся кодер символов, порождающий неравномерный код, то при одной
и той же выходной точности оптимальный равномерный квантователь
с шагом размера 6 обеспечит более низкую скорость кода (для плот-
ности распределения вероятностей Лапласа), чем равномерно коди-
рованный выход квантователя Ллойда—Макса [O’Neil, 1971].
Как квантователь Ллойда—Макса, так и оптимальный равномер-
ный квантователь не являются адаптивными, и гораздо лучший резуль-
тат можно получить, адаптируя уровни квантования в соответствии с
изменениями локальных характеристик изображения. Теоретически,
области с плавными изменениями яркости могут квантоваться на бо-
лее мелкие уровни, тогда как области быстрых изменений — на более
грубые. Такой подход одновременно сокращает как шум гранулярно-
сти, так и перегрузку по крутизне, требуя при этом минимальное уве-
личение кодовой скорости. Однако такой компромисс значительно уве-
личивает сложность квантователя.
Пример 8.18. Иллюстрация процессов квантования и восстановления.
На Рис. 8.26(a), (в) и (д) представлены восстановленные изображе-
ния, полученные комбинацией 2-, 4-, или 8-уровневого квантовате-
ля Ллойда—Макса и двумерного предсказателя (8.5-18). Параметры
квантователей определялись путем умножения табличных значений
пороговых уровней и уровней квантования для квантователя Ллой-
Глава 8. Сжатие изображений
Рис. 8.26. Результаты ДИКМ кодирования с потерями изображения на Рис. 8.23:
(а) 1,0; (б) 1,125; (в) 2,0; (г) 2,125; (д) 3,0; (е) 3,125 бита/пиксель.
да—Макса (см. Таблицу 8.10) на стандартное отклонение некванто-
ванной ошибки двумерного предсказания, приведенное в предыду-
щем примере (т.е. 3,3 уровня яркости). Обратите внимание, что кон-
туры на декодированных изображениях размыты из-за перегрузки
по крутизне. Этот эффект сильно заметен на Рис. 8.26(a), где ис-
пользовался двухуровневый квантователь, но уже проявляется мень-
ше на Рис. 8.26(b) и (д), которые получены с помощью 4- и 8-уров-
невых квантователей. На Рис. 8.27(a), (в) и (д) показаны усиленные
разности между исходным (на Рис. 8.23) и полученными декодиро-
ванными изображениями.
Для получения декодированных изображений на Рис. 8.26(6), (г)
и (е), ошибки которых показаны на Рис. 8.27(6), (г) и (е), использо-
вался метод адаптивного квантования, в котором для каждого блока
из 16 элементов выбирался наилучший (в смысле среднего квадрата
ошибки) из четырех возможных квантователей. Эти четыре квантова-
теля являются варантами масштабирования ранее описанного опти-
мального квантователя Ллойда—Макса. Масштабные коэффициенты
были 0,5, 1,0, 1,75. и 2,5. Поскольку для указания номера выбранно-
го квантователя к каждому блоку добавлялся 2-битовый дополни-
тельный код, то накладные расходы составили 0,125 бита/пиксель. Об-
ратите внимание на значительное уменьшение видимых ошибок,
достигнутое благодаря незначительному увеличению скорости кода.
В Таблице 8.11 приведены значения стандартных отклонений оши-
бок (8.1 -8) разностных изображений на Рис. 8.27(a) — (е) всех четырех
вариантов вышеприведенных предсказателей (8.5-16) — (8.5-19) при
различных комбинациях предсказателя и квантователя. Заметим, что
с точки зрения среднего квадрата ошибки, двухуровневый адаптивный
квантователь дает столь же хорошие результаты, что и четырехуровне-
вый неадаптивный. Более того, четырехуровневый адаптивный кван-
тователь дает лучшие результаты, чем восьмиуровневый неадаптивный.
Вообще, численные результаты показывают, что тенденции измене-
Таблица 8.11. Значения стандартных отклонений ошибок при ДИКМ коди-
ровании с потерями.
Предсказатель Квантователь Ллойда—Макса Адаптивный квантователь
2 уровня 4 уровня 8 уровней 2 уровня 4 уровня 8 уровней
Ф. (8.5-16) 30,88 6,86 4,08 7,49 3,22 1,55
Ф. (8.5-17) 14,59 6,94 4,09 7,53 2,49 1,12
Ф. (8.5-18) 9,90 4,30 2,31 4,61 1.70 0,76
Ф. (8.5-19) 38,18 9,25 3,36 11,46 2,56 1,14
Сжатие 8,00:1 4,00:1 2,70:1 7,11:1 3,77:1 2,56:1
Рис. 8.27. Изображения усиленных в 8 раз ошибок ДИ КМ кодирования на
Рис. 8.26.
ния величины ошибки для предсказателей (8.5-16), (8.5-17) и (8.5-19)
совпадают с аналогичными характеристиками предсказателя (8.5-18).
В нижней строке таблицы приведена величина сжатия, достигаемая
каждым из рассмотренных методов. Заметим, что значительное умень-
шение стандартного отклонения ошибки, достигаемое адаптивным
квантователем, не приводит к существенному улучшению характе-
ристик сжатия.
8.5.2. Трансформационное кодирование
Методы кодирования с предсказанием, которые обсуждались в Разде-
ле 8.5.1, оперируют непосредственно со значениями элементов изо-
бражения, и тем самым являются пространственными методами. В
настоящем разделе будут рассматриваться методы сжатия, основанные
на модификации и сжатии результатов преобразования изображения,
так называемые методы трансформационного кодирования. Согласно
этому подходу, обратимое линейное преобразование (например, пре-
образование Фурье) используется для отображения изображения в
набор коэффициентов преобразования, которые затем квантуются и
кодируются. Для большинства реальных изображений значительное
число коэффициентов имеют малую величину, и могут быть достаточ-
но грубо квантованы (или полностью удалены) ценой небольшого
искажения изображения. Для преобразования данных изображения мо-
гут использоваться различные преобразования, включая дискретное
преобразование Фурье (ДПФ), рассмотренное в Главе 4.
На Рис. 8.28 показана схема обычной системы трансформацион-
ного кодирования. Кодер выполняет четыре достаточно понятные
операции: разбиение изображения на блоки, преобразование, кван-
тование и кодирование. Декодер выполняет обратную последователь-
ность операций (за исключением квантования). Первоначально изо-
бражение размерами NxN разбивается на (N/n)2 блоков размерами
пхп, которые затем и подвергаются преобразованиям. Целью процес-
Входное
изображение
(NxN)
Сжатое
изображение
Сжатое
изображение
Рис. 8.28. Система трансформационного кодирования: (а) кодер; (б) декодер, б
Восстановленное
изображение
а
са преобразования является декорреляция значений элементов в каж-
дом блоке, или уплотнение как можно большего количества инфор-
мации в наименьшее число коэффициентов преобразования. На эта-
пе квантования те коэффициенты, которые несут минимальную
информацию, удаляются или же квантуются грубо (они дают наи-
меньший вклад в качество восстанавливаемого блока). На заключи-
тельном этапе осуществляется кодирование квантованных коэффици-
ентов, как правило, с помощью неравномерных кодов. Все или
некоторые из указанных этапов могут быть адаптированы к содержи-
мому блока, т.е. к локальным характеристикам изображения; такой ва-
риант называют адаптивным трансформационным кодированием. В
противном случае говорят о не адаптивном трансформационном коди-
ровании.
Выбор преобразования
Системы трансформационного кодирования, основанные на раз-
личных дискретных двумерных преобразованиях, достаточно хорошо
исследованы и изучены. Выбор наилучшего преобразования для кон-
кретного приложения зависит от величины допустимой ошибки вос-
становления и от имеющихся вычислительных ресурсов. Сжатие же
возникает не во время преобразования, а на этапе квантования полу-
ченных коэффициентов.
Рассмотрим изображениеf(x, у) размерами NxN, прямое дискрет-
ное преобразование Т(и, г) которого может быть выражено в следую-
щем общем виде
/V-1/V-1
Т(и,у)= У У f(x,y)g(x,y,u,v) (8.5-24)
л=0 у=0
для w, у = 0. 1, 2...., N — 1. Аналогичным образом, изображение фх.у}
может быть получено по заданному Т(и, у) при помощи обратного пре-
образования
/v-1 ,v~i
/(х,у)= У У Т(и,у)Л(х,у,и,у) (8.5-25)
/7=0 v=()
длях, у = 0, I, 2,..., А — 1. Функции g(x, у, и, у) и h(x, у, и, у) в данных
уравнениях называются, соответственно, ядром прямого и ядром обрат-
ного преобразования. По причинам, которые будут ясны ниже, их так-
же называют базисными функциями или базисными изображениями.
Набор Т(и. у) для и. у = 0, 1, 2,..., N- 1 в уравнении (8.5-25) называ-
ют коэффициентами преобразования; они могут являться коэффициен-
8.5.Сжатие с потерями
тами разложения (см. Раздел 7.2.1) изображения/(х, у) по базисным
функциям h(x, у, и, v).
Ядро прямого преобразования в (8.5-24) называется разделимым, если
g(x,y, и, V) =g, (х, u)g2(y, v).
(8.5-26)
В случае, когда#] равноg2, уравнение (8.5-26) может быть записано в
виде
#(х, у, и, v) = #] (х, и)#] (у, v).
(8.5-27)
Аналогичные комментарии могут быть сделаны по отношению к яд-
ру обратного преобразования; для этого достаточно заменитьg(x, у, и, v)
най(х, у, и, v) в (8.5-26) и(8.5-27). Нетрудно показать, что двумерное
разделимое преобразование может быть вычислено с помощью соот-
ветствующих одномерных преобразований, выполняемых последова-
тельными проходами сначала по строкам, затем по столбцам, или же
в обратном порядке (см. Раздел 4.6.1).
Ядра прямого и обратного преобразований в (8.5-24) и (8.5-25)
определяют само преобразование, общую вычислительную слож-
ность, а также ошибки восстановления системы трансформацион-
ного кодирования, в которой это преобразование используется. На-
иболее известной парой ядер преобразования являются
g(x, у, и, V) = ^e-i2n(ux+vy)/N (8.5-28)
А2
и
/г(х,у,к, г) = е'2я("’с+1>’*/Л/, (8.5-29)
где / = V—Т. Подставляя эти ядра в (8.5-24) и (8.5-25), получим упро-
щенный вариант (в котором М= N) прямого и обратного дискретно-
го преобразования Фурье, введенного в Разделе 4.2.2.
Вычислительно более простое преобразование, также широко при-
меняемое в трансформационном кодировании и называемое преобра-
зованием Уолша-Адамара (ПУА), получается с помощью функцио-
нально идентичных ядер:
т-1
1 X L^(A7p,(«)+6,(y)p,(v) J
g(x,y,u,v) = h(x,y,u,v) =—(-1)'=л) (8.5-30)
N
Глава 8. Сжатие изображении
где N= 2т. Суммирование в показателе степени выполняется по мо-
дулю 2, и b^z) означает к-й бит (справа налево) в двоичном пред-
ставлении Z- Если, например,/л = 3иг = 6(1102),тоbQ(z) = 0,bx(z) = 1,
и b2(z) = 1. Значения р,(и) в (8.5-30) вычисляются следующим образом:
Ро(“) = Ьт_}(и)
P\(u) = bm_l(u)+bm_2(u)
Р2^ = Ьт-2^ + Ьт-2>(и>
(8.5-31)
Pm^U^b^uy + bQiu),
где суммирования, как отмечалось ранее, производятся по модулю 2.
Для вычисления рДг) используются аналогичные выражения.
В отличие от ядер ДПФ, которые являются суммами синусов и ко-
синусов (см. (8.5-28) и (8.5-29)), ядра преобразования Уолша—Адама-
ра состоят из чередующихся +1 и — 1, расположенных в шахматном по-
рядке. На Рис. 8.29 показано ядро для N= 4. Каждый блок состоит из
4x4 =16 элементов; белый цвет означает+1, а черный означает —1. Что-
бы сформировать левый верхний блок необходимо положить и = v = 0
и вычислить значения g(x, у, 0, 0) для х, у = 0, 1, 2, 3. Все значения в
этом случае равны +1. Второй блок в верхнем ряду есть набор значе-
Рис. 8.29. Базисные функции Уолша-Адамара для N= 4. Начало координат каж-
дого блока находится в его левом верхнем углу.
8.5.Сжатие с потерями
ний#(х, у, 0,1) днях, у = О, 1,2,3, и так далее. Как уже отмечалось, зна-
чимость преобразования Уолша-Адамара состоит в простоте реализа-
ции — значения всех элементов в его ядре равны или +1 или —1.
Одним из наиболее часто используемых преобразований для сжа-
тия изображений является дискретное косинусное преобразование (ДКП).
Оно получается путем подстановки в (8.5-24) и (8.5-25) следующих
(одинаковых) ядер:
g(x,y,u,v) = h(x,y,u,v) = a(«)a(v)cos
(2х +1 )ип
-------- cos
2N
(2у+ l)V7t
2/V
(8.5-32)
где
а(и) = -
для и = 0
VW
для u = l,2,...,7V-l
(8.5-33)
и аналогично для a(v). На Рис. 8.30 показаны базисные функции
g(x, у, и, v) для случая N= 4. Результаты представлены в том же фор-
мате, что и на Рис. 8.29, за исключением того, что значения g не яв-
ляются целыми. Более светлые уровни яркостей на Рис. 8.30 соот-
ветствуют большим значениям g.
Д* 0 1____2___3
IIII
MEAN
<ОЙ
SSSD
Рис. 8.30. Базисные функции дискретного косинусного преобразования для
/V — 4. Начало координат каждого блока находится в его левом верхнем углу.
Пример 8.19. Трансформационное кодирование с использованием ДПФ,
ПУЛ и ДКП, и усечением коэффициентов.
На Рис. 8.31(a), (в) и (д) показаны три приближения полутонового
изображения размерами 512x512 элементов (Рис. 8.23). Эти результа-
ты были получены разбиением исходного изображения на блоки раз-
мерами 8x8 элементов, представлением каждого блока при помощи од-
ного из рассмотренных преобразований (ДПФ, ПУА или ДКП),
обнулением (усечением) 50% наименьших по значениям коэффици-
ентов, и выполнением обратных преобразований над полученными
массивами.
Во всех случаях 32 остающихся коэффициента выбирались как
самые большие по значению. Если отвлечься от использования кван-
тования и кодирования, то этот процесс приводит к двукратному28 сжа-
тию исходного изображения. Во всяком случае заметим, что 32 удален-
ных коэффициента имели весьма малое влияние на качество
восстановленного изображения. Их устранение, тем не менее, приве-
ло к возникновению некоторых отклонений, которые в виде изобра-
жений представлены на Рис. 8.31(6), (г) и (е). Значения стандартных
отклонений ошибок составили, соответственно, 1,28, 0,86, и 0,68
уровней яркости.
Небольшие различия в стандартных отклонениях ошибок, приве-
денных в предыдущем примере, прямо связаны с энергией, или харак-
теристиками уплотнения информации примененных преобразова-
ний. В соответствии с (8.5-25), изображение/(х, у) размерами пхп
может быть представлено как функция своего двумерного преобразо-
вания Т(и, v):
п-1 п-1
f(x,y) = £ ^T(u,v)h(x,y,u,v) (8.5-34)
п=0 v=0
для х, у = 0, 1,2,..., л — 1. Заметим, что по сравнению с (8.5-25) здесь
произошла замена N на п, и теперьДх. у) рассматривается как блок
сжимаемого изображения. Поскольку ядро обратного преобразова-
ния h(x, у, и, v) в (8.5-34) зависит только от индексов х, у, и, v, а не
от значений/(х, у) или Т(и, v), то оно может рассматриваться как на-
28 Если удаляется половина коэффициентов именно по значению, а не по расположе-
нию в блоке, то необходимо также передавать дополнительную информацию о том.
какие именно коэффициенты были удалены (или остались, что эквивалентно), тем
самым коэффициен г сжатия будет несколько меньше 2. — Прим, перев.
Рис. 8.31. Приближения изображения на Рис. 8.23 при помощи преобразова-
ний с усечением коэффициентов: (а) Фурье, (в) Уолша- Адамара, (д) косинус-
ного, а также изображения соответствующих усиленных ошибок.
а б
в г
Д е
Глава 8. Сжатие изображений
бор базисных функций или базисных изображений для линейной ком-
бинации (8.5-34). Эта интерпретация станет яснее, если записать
(8.5-34) в виде
л-1 л-1
m=0v=0
(8.5-35)
где F есть матрица размерами лхл, содержащая значения элементов
блокаДх, у), а
A(0,0,u,v) й(0,1,и,г)
й(1,0,«,г)
••• й(0,л-1,ы,т)
HMV =
. (8.5-36)
й(л-1,0,«,г) й(и-1,1,цу) ••• й(л-1,л-1,цу)
Тогда F — матрица, содержащая значения элементов входного блока —
явно задается как линейная комбинация я2 матриц размерами лхл, т.е.
матриц HMV для и, v = 0, 1, 2,..., л — 1 в (8.5-36). Эти матрицы факти-
чески являются базисными изображениями (или функциями) разло-
жения (8.5-35); соответствующие значения Т(и, v) являются коэффи-
циентами разложения. Базисные изображения ПУА и ДКП для случая
л = 4 иллюстрируются на Рис. 8.29 и 8.30.
Зададим маскирующую функцию для коэффициентов преобразо-
вания:
0
1
Y(«,v) =
если T(u,v) удовлетворяет заданному критерию усечения
в остальных случаях
(8.5-37)
для и, v = 0, 1,2.п — 1. Приближение для F получается из усечен-
ной последовательности
л-1 п-1
F = '£^y(u,v)T(u.v)Huv,
и=0v=0
(8.5-38)
гдеу(«, v) предназначена для удаления тех базисных изображений, ко-
торые дают наименьший вклад в общую сумму в (8.5-35). Тогда сред-
ний квадрат ошибки между фрагментом F и его приближением будет
равен
еск
X X n«,v)HMV -XX y{u,v)T(u,v)Huv
u=Ov=O u=Ov=O
11л—1 n—I
X X T'ОИщ’П - Y(«’v)]
||m=Ov=O I
л-1 Л-1
= X ХаЛаз’)[1“Т(Ы’У)]’
w=Ov=O
(8.5-39)
где || F - F || есть норма матрицы (F - F), a °7(w,v) — дисперсия коэф-
фициентов 7(w, v) в точке (и, v). При получении последнего выраже-
ния в (8.5-39) использовано свойство ортогональности базисных изо-
бражений, а также предположение, что элементы F порождаются
случайным процессом с нулевым средним и известной ковариацией.
Таким образом, суммарный средний квадрат ошибки приближения ра-
вен сумме дисперсий коэффициентов отброшенных членов после-
довательностей (т.е. тех для которых y(w, v) = 0, а [1 — y(w, v)| в (8.5-39)
равно 1). Преобразования, которые перераспределяют или упаковы-
вают максимальное количество информации в наименьшее число ко-
эффициентов, обеспечивают наилучшее приближение элементов бло-
ка, и, как результат, дают наименьшую ошибку восстановления.
Наконец, согласно тем же предположениям, что привели к (8.5-39),
средний квадрат ошибки (Л/л)2 блоков на изображении размерами
/Vx/V совпадают. Следовательно, средний квадрат ошибки (являю-
щийся мерой средней ошибки) для изображения размерами NxN ра-
вен среднему квадрату ошибки отдельного блока.
Предыдущий пример показал, что ДКП обладает лучшей способ-
ностью к упаковке информации, по сравнению с ДПФ и ПУА. Хотя
эта ситуация справедлива для большинства реальных изображений, тем
не менее, оптимальным в смысле упаковки информации является
преобразование Карунена-Лоэва (ПКЛ будет рассматриваться в Гла-
ве 11), а не ДКП. То есть ПКЛ минимизирует средний квадрат ошиб-
ки в (8.5-39) для любого входного изображения и любого числа сохра-
няемых коэффициентов [Kramer, Mathews, 1956]29. Однако, поскольку
ПКЛ зависит от преобразуемых данных, то получение базисных изо-
бражений для каждого блока изображения является нетривиальной вы-
числительной задачей. По этой причине ПКЛ для сжатия изображе-
ний используется редко. Вместо этого обычно применяются такие
29 Оптимальность дополнительно обусловливается тем, что маскирующая функция
(8.5-37) выбирает коэффициенты ПКЛ с максимальной дисперсией.
Глава 8. Сжатие изображений
преобразования, как ДПФ, ПУА или ДКП, базисные изображения
которых фиксированы (т.е. не зависят от входных данных). Из преоб-
разований, не зависящих от входных данных, простейшими в реали-
зации являются не синусоидальные, а такие, например, как ПУА. С дру-
гой стороны, преобразования, основанные на гармонических функциях
(ДПФ, ДКП или аналогичные), лучше приближаются к оптималь-
ной упаковке информации, достигаемой ПКЛ.
Благодаря этому многие системы трансформационного кодирова-
ния основываются на ДКП, которое дает хороший компромисс между
степенью упаковки информации и вычислительной сложностью. До-
казательством того, что характеристики ДКП имеют большое практи-
ческое значение, является тот факт, что ДКП вошло в международный
стандарт систем трансформационного кодирования (см. Раздел 8.6). По
сравнению с другими подобными преобразованиями, ДКП обеспечи-
вает упаковку наибольшего количества информации в наименьшее
число коэффициентов30 (для большинства реальных изображений), а
также минимизирует эффект появления блочной структуры, называе-
мой блоковыми искажениями, проявляющейся в том, что на изображе-
нии становятся видны границы между соседними блоками. Последняя
особенность выгодно выделяет ДКП среди других синусоидальных
преобразований. Поскольку ДПФ характеризуется «-точечной перио-
дичностью (см. Раздел 4.6), то разрывы на границах блоков, показан-
ные на Рис. 8.32(a), приводят к появлению заметной высокочастотной
составляющей. При усечении или квантовании коэффициентов ДПФ,
приграничные элементы блоков из-за явления Гиббса31 принимают
неверные значения, что приводит к возникновению блоковых искаже-
ний. Таким образом, границы между соседними блоками становятся за-
метными из-за того, что приграничные элементы блоков принимают ис-
каженные значения. ДКП. представленное на Рис. 8.32(6), уменьшает
этот эффект, пот ому что его периодичность в 2п точек не приводит к раз-
рывам на границах блока. Преимуществом ДКП является также и то, что
оно реализовано в интегральных микросхемах.
^Ахмсдилр. [Ahmed et al., 1974| первыми заметили, что базисные изображения ПКЛ
для марковского источника первого порядка имеют близкое сходство с базисными
изображениями ДКП. Если корреляция между соседними пикселями приближает-
ся к единице, то базисные изображения зависимого от входных данных П КЛ совпа-
дают с базисными изображениями независимого от входных данных ДКП [Clarke,
1985|.
31 Это явление, описываемое во многих работах, посвященных анализу электриче-
ских цепей, возникает из-за того, что ряд Фурье не является равномерно сходящим-
ся вблизи разрывов. В точке разрыва ряд Фурье принимает среднее значение.
8.5.Сжатие с потерями
—I--------------1-------------1-------------1-------------к- 6
Рис. 8.32. Периодичность, присущая одномерным (а) ДПФ и (б) ДКП.
Выбор размеров блока
Другим важным фактором, от которого зависят ошибки трансформа-
ционного кодирования и вычислительная сложность, является размер
блока. В большинстве приложений изображения разбиваются таким
образом, что корреляция (избыточность) между соседними блоками
уменьшается до некоторого допустимого уровня, причем размер бло-
ка/? выбирается как целая степень двойки. Последнее условие позво-
ляет упростить вычисление преобразований по блокам (см. метод по-
следовательного удвоения в Разделе 4.6.6). Вообще, с увеличением
размера блока возрастает как степень сжатия, так и вычислительная
сложность. Наиболее часто используемыми являются размеры 8 х 8 и
16x16 элементов.
Пример 8.20. Влияние размера блока в трансформационном кодиро-
вании.
На Рис. 8.33 графически иллюстрируется влияние размера блока на
точность восстановления при трансформационном кодировании.
Данные, приведенные на графиках, были получены разбиением по-
лутонового изображения на Рис. 8.23 на блоки размерами и х и, где
п = 2, 4, 8, 16 и 32, вычислением преобразования по каждому блоку,
усечением 75% полученных коэффициентов, и выполнением обрат-
ного преобразования. Заметим, что кривые ПУА и ДКП становятся
почти горизонтальными при размерах блока больших 8x8, тогда как
ошибки восстановления ДПФ в этой области уменьшаются даже еще
более быстро. Экстраполируя эти кривые на большие значения п мож-
но предположить, что кривая ошибок восстановления ДПФ Пересе-
Глава 8. Сжатие изображений
Размер блока
Рис. 8.33. Зависимость ошибки восстановления от размеров блока.
чет кривую ПУА и приблизится к ДКП. Фактически эти данные сов-
падают с теоретическими и экспериментальными результатами, опуб-
ликованными в работах [Netravali, Limb, 1980J и f Pratt, 1991J для дву-
мерной Марковской модели источника.
При размерах блока 2x2 все три кривые совпадают. В этом случае
остается только один из четырех (25%) коэффициентов в каждом пре-
образованном массиве. Этот коэффициент во всех преобразованиях
является постоянной составляющей, так что обратное преобразование
попросту заменяет значения всех четырех пикселей блока их средним
значением (см. (4.2-22)). Этот эффект хорошо виден на Рис. 8.34(г),
где показан увеличенный фрагмент результата ДКП с блоками 2x2. За-
метим, что блоковые искажения, которые максимальны на данном изо-
бражении, уменьшаются при увеличении размеров блока до 4x4 и 8x8
на Рис. 8.34(д) и (е). Для сравнения, на Рис. 8.34(b) показан увеличен-
ный фрагмент исходного изображения. Кроме того, для сопоставле-
ния с результатами предыдущего примера, на Рис. 8.34(a) и (б) при-
ведено восстановленное изображение (после усечения 75%
коэффициентов) а также изображение получившихся ошибок.
Представление в двоичной форме
Ошибка восстановления, связанная с усечением разложений (8.5-38),
является функцией числа и относительной важности отбрасываемых
коэффициентов преобразования, а также точности, используемой
для представления значений сохраняемых коэффициентов. В больший-
8.5.Сжатие с потерями
Рис. 8.34. Приближение изображения на Рис. 8.23 при сохранении 25% коэффи-
циентов ДКП и различных размерах блока: (а) восстановленное изображение, блок
8x8; (б) усиленное изображение ошибок; (в) увеличенный фрагмент исходного
изображения; результат восстановления (в) с использованием (г) блока 2x2;
(д) блока 4x4; (е) блока 8x8.
Глава 8. Сжатие изображений
стве систем трансформационного кодирования выбор оставляемых ко-
эффициентов, т.е. построение маскирующей функции в (8.5-37), осу-
ществляется либо детерминировано на основе анализа дисперсии
значений коэффициентов по всем блокам (зональное кодирование),
либо адаптивно — выбором коэффициентов с максимальными значе-
ниями (пороговое кодирование). Весь процесс, включаюший усечение,
квантование и кодирование коэффициентов, обычно называют пред-
ставлением в двоичной форме.
Пример 8.21. Двоичное представление.
На Рис. 8.35(a) и (б) показаны два приближения изображения на
Рис. 8.23, в которых при ДКП преобразовании по блокам 8x8 были от-
брошены 87,5% коэффициентов. Первый результат был получен при-
менением порогового кодирования, оставляющего 8 самых больших
коэффициентов каждого блока, а второй — с помощью зонального ко-
дирования. В последнем случае каждый коэффициент ДКП рассма-
тривался как случайная величина, распределение которой определя-
лось по всему ансамблю блоков на изображении. Были найдены 8
распределений с максимальными дисперсиями (12,5% из 64 коэф-
фициентов блока 8x8), и в соответствии с их расположением была
сформирована маска, аналогичная у(и, г) в (8.5-38), использовавша-
яся для всех блоков. Обратите внимание, что при пороговом кодиро-
вании (Рис. 8.35(b)) разностное изображение содержит значительно
меньше ошибок, чем при зональном кодировании (Рис. 8.35(г)). На
Рис. 8.35(д) и (е) показаны увеличенные фрагменты восстановленных
изображений (а) и (б).
Реализация зонального кодирования
Зональное кодирование основано на концепции теории информа-
ции о количестве информации как мере неопределенности. Таким
образом, коэффициенты преобразования с максимальной дисперси-
ей содержат максимум информации, и, значит, должны сохраняться
в процессе кодирования. Сами же вариации могут быть вычислены ли-
бо напрямую из ансамбля (N/ri)2 массивов преобразованных блоков,
также как и в предыдущем примере, либо на основании принятой
модели изображения (скажем, Марковской автокорреляционной
функции). В любом случае, согласно (8.5-38), зональный отбор коэф-
фициентов может рассматриваться как умножение каждого коэффи-
циента Т(и, г) на соответствующие элементы зональной маски, которая
аналогична коэффициентам у(и, г), и содержит единицы в точках
максимальной дисперсии и нули во всех остальных точках. Обычно ко-
эффициенты с максимальной дисперсией располагаются вблизи на-
8.5.Сжатие с потерями
Рис. 8.35. Приближение изображения на Рис. 8.23 при сохранении 12.55? козффициен-
товДКП по блокам 8x8: (а), (в, и (д) резулыаты пороювою кодирования; (б), (г) и
(с) — резулыаты зональною кодирования.
чала координат преобразованного блока; типичный пример зональной
маски представлен ни Рис. 8.36(a).
Коэффициенты, остающиеся в процессе зонального отбора, долж-
ны быть проквантованы и закодированы, поэтому иногда зональная
маска изображается в виде массива чисел, каждое из которых означа-
ет число битов, отводимых для кодирования соответствующего коэф-
фициента (Рис. 8.36(6)). Коэффициентам при кодировании может
отводиться как равное, так и неравное число битов. В первом случае
коэффициенты, как правило, нормализуются по значению их стандарт-
ного отклонения, а затем равномерно квантуются. Во втором случае
для каждого коэффициента (или группы коэффициентов) строится от-
дельный квантователь, подобный оптимальному квантователю Ллой-
да—Макса. При построении квантователей, плотность распределения
значений нулевых коэффициентов (т.е. средних значений в блоках)
обычно моделируют распределением Рэлея, а плотность распределе-
ния значений оставшихся коэффициентов — распределением Лапла-
а б
в г
1 1 1 1 1 0 0 0 8 7 6 4 3 2 1 0
1 1 1 1 0 0 0 0 7 6 5 4 3 2 1 0
1 1 1 0 0 0 0 0 ь_ 5 4 3 3 1 1 0
1 1 0 0 0 0 0 0 4 4 3 3 2 1 0 0
1 0 0 0 0 0 0 0 3 3 3 2 1 1 0 0
0 0 0 и 0 0 0 0 2 2 1 1 1 0 0 0
0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
1 1 0 1 1 0 0 0 0 1 5 6 14 15 27 28
1 1 1 1 0 0 0 0 2 4 7 13 16 26 29 42
1 1 0 0 0 0 0 0 3 8 12 17 25 30 41 43
1 0 0 0 0 0 0 0 1 9 11 18 24 31 40 44 53
0 0 0 0 0 0 0 0 110 19 23 32 39 45 52 54
и 1 0 0 0 0 0 0 1 20 22 33 38 4б 51 55 60
0 0 0 0 0 0 0 0 1 21 34 37 47 50 56 59 61
0 0 0 0 0 0 0 0 351 36 48 49 57 58 62 63 J
Рис. 8.36. Типичные (а) зональная маска, (б) распределение битов по зонам,
(в) пороговая маска, (г) упорядочивание коэффициентов (зигзаг, или Z-yno-
рядочивание). Затенением отмечены позиции сохраняемых коэффициентов.
са или гауссовым распределением32. Число уровней квантования (а зна-
чит, число битов), отводимых каждому квантователю, выбирают про-
порциональным l°g2 °7 (n,v)- Такое распределение битов согласуется с
теорией взаимосвязи скорости и искажения (см. Раздел 8.3.3), кото-
рая гласит, что гауссова случайная переменная с дисперсией о , при
воспроизведении со средним квадратом ошибки меньше, чем D, не мо-
жет быть представлена менее чем l/2Iog2(o2/£>) битами (см. Задачу 8.11).
Интуитивный вывод таков, что информационное содержание гауссо-
вой случайной переменной пропорционально logger2//)). Таким обра-
зом, число битов, отводимое оставшимся коэффициентам в (8.5-38)
(которые в данном случае выбираются согласно критерию макси-
мальной дисперсии) должно быть пропорционально логарифму дис-
персии коэффициентов.
Реализация порогового кодирования
При зональном кодировании, для всех блоков обычно используется од-
на фиксированная маска. Пороговое кодирование, наоборот, являет-
ся по существу адаптивным, поскольку позиции сохраняемых коэф-
фициентов преобразования зависят от конкретного блока. Фактически,
пороговое кодирование является адаптивным подходом к трансфор-
мационному кодированию, которое благодаря своей вычислитель-
ной простоте, чаще всего и используется на практике. В его основе ле-
жит тот принцип, что в любом блоке коэффициенты преобразования,
имеющие наибольшую амплитуду, дают самый значительный вклад в
информационное содержание восстанавливаемого блока, что и было
продемонстрировано на последнем примере. Поскольку положения
самых больших коэффициентов от блока к блоку меняются, элемен-
ты у(м, v)T(u, v) упорядочиваются (предварительно заданным спосо-
бом) в одномерную последовательность, впоследствии кодируемую ко-
дом длин серий33. На Рис. 8.36(b) представлен пример типичной
пороговой маски для одного блока некоторого гипотетического изоб-
ражения. Эта маска позволяет проиллюстрировать процесс порогово-
32 Поскольку коэффициенты являются линейными комбинациями значений элемен-
тов в блоке (см. (8.5-24)), то центральная предельная теорема утверждает, что при уве-
личении размеров блока распределение значений коэффициентов стремится к гаус-
сову распределению. Этот результат неприменим к нулевому коэффициенту.
33 На самом деле смысл упорядочивания состоит в такой перегруппировке коэффи-
циентов, чтобы получить максимально длинные серии из ненулевых и нулевых ко-
эффициентов. Заметим также, что к настоящему моменту коэффициенты блоков уже
являются квантованными и кодированными по значениям уровней квантования. —
Прим, перев.
го кодирования, математически описываемого формулой (8.5-38).
После маскирования, двумерный массив из пхп коэффициентов пе-
реупорядочивается с помощью зигзаг упорядочивания (называемого
также Z-упорядочиванием). Зигзаг упорядочивание очевидно из
Рис. 8.34(г), где показана очередность, в которой выбираются коэф-
фициенты. Сформированный одномерный массив из л2 коэффици-
ентов содержит длинные серии постоянных кодов, во второй полови-
не — нулей, которые хорошо сжимаются кодированием длин серий.
Получаемая кодовая последовательность подвергается еще одному
этапу кодирования, уже с применением одного из алгоритмов нерав-
номерного кодирования, рассмотренных в Разделе 8.4.
Существует три основных способа разделения коэффициентов пре-
образования в блоке по порогу, или, иначе говоря, построения поро-
говой маскирующей функции в форме, заданной формулой (8.5-37):
(1) использование единого глобального порога, одинакового для всех
блоков; (2) использование индивидуальных порогов для каждого бло-
ка; (3) переменный порог, который может изменяться как функция по-
ложения коэффициента в блоке. В первом случае уровень сжатия мо-
жет меняться от изображения к изображению в зависимости от того,
сколько коэффициентов оказываются выше или ниже порога. Вто-
рой вариант, называемый кодированием N-наибольших, оставляет оди-
наковое количество коэффициентов в каждом блоке. Как результат, ско-
рость кода является постоянной и заранее известной. Третий метод, как
и первый, приводит к коду непостоянной скорости, но зато имеет то
преимущество, что позволяет объединить этапы квантования и разде-
ления по порогу, заменяя у (и, v)T(u, г) в (8.5-38) на
f (и, г) = round
T(«,v)
Z(u, г)
(8.5-40)
где Т(и, г) — результат квантования и разделения по порогу значения
Т(и, V), aZ(u, г) — элемент массива коэффициентов нормализации пре-
образования:
Z(0,0) Z(0,0)
Z(0,0)
Z(0,«-l)
z=
(8.5-41)
Z(«-l,0) Z(n-l,l) Z(n-l,n-l)
Перед тем, как нормализованные (квантованные и разделенные по по-
рогу) коэффициенты преобразования Т(и, г) могут быть подвергнуты
обратному преобразованию для восстановления блока изображения
Дх, у), они должны быть умножены на Z{u, г). Получаемый в резуль-
тате массив t(u,v) является приближением Т{и, г):
t {и, v)=f (и, v)Z(u, г).
(8.5-42)
Тем самым, обратное преобразование полученных значений t (и, г) даст
в результате приближение восстанавливаемого блока изображения.
На Рис. 8.37 графически изображена формула (8.5-40) для случая
Z(u, г) = с. Заметим, что T(u,v) принимает целое значение к при ус-
ловии
kc~<T(u,v)<kc+^.
Если Z(u, г) > 2Т(и, г), то Т(и,г) = 0 и коэффициент преобразования
оказывается усеченным или вычеркнутым. Когда коэффициент Т(и, г)
представляется неравномерным кодом, длина которого возрастает с
увеличением к, то число битов, отводимых на представление Т(и, г),
управляется изменением значения с. Т.е. элемент матрицы Z может мас-
штабироваться, обеспечивая тем самым многообразие уровней сжа-
тия. На Рис. 8.37(6) показаны значения типичного массива коэффи-
циентов нормализации. Этот массив значений, являющихся весовыми
множителями для коэффициентов преобразования в блоке, составлен-
Рис. 8.37. (а) Кривая квантования порогового кодирования (см. формулу
(8.5-40)). (б) Типичная матрица коэффициентов нормализации
16 И 10 16 24 40 [ 51 ' 61
12 12 14 19 Г 26 58 60 I 55
14 14 13 17 16 24 1 1 40 57 69 I 56 j. j
22 29 51 87 ! 80 62 j
18 22 37 56 68 109 103177]
24 35 55 64 81 104 113 । 92 к 1 I
49 64 78 87 г 103 121 120 101
72 92 95 l98 - "1 Г " 112 100 103 99 1 1 я К
ный на основе оценок визуального восприятия, широко использует-
ся в стандарте JPEG34.
Пример 8.22. Иллюстрация порогового кодирования.
На Рис. 8.38(a) и (б) показаны два варианта приближения полуто-
нового изображения на Рис. 8.23 методом порогового кодирования. Оба
изображения получены при использовании ДКП по блокам 8x8 и
массива коэффициентов нормализации, приведенного на Рис. 8.37(6).
Первый вариант, обеспечивающий коэффициент сжатия 34:1, был
получен прямым применением коэффициентов нормализации. Вто-
рой, на котором изображение сжато с коэффициентом 67:1, получен
с помощью масштабирования (предварительного умножения масси-
ва коэффициентов нормализации на 4). Для сравнения: среднее зна-
чение коэффициентов сжатия по всем методам сжатия без потерь,
рассмотренных в Разделе 8.4, составило лишь 2,62:1.
Различия между исходным изображением на Рис. 8.23 и восста-
новленными изображениями на Рис. 8.38(a) и (б), приведены на
Рис. 8.38(b) и (г). Соответствующие стандартные отклонения оши-
бок (см. (8.1-8)) составили 3,42 и 6,33 уровней яркостей. Характер
ошибок хорошо виден на Рис. 8.38(д) и (е), которые являются уве-
личенными фрагментами изображений на Рис. 8.38(a) и (б). Они
позволяют оценить в деталях разницу между восстановленными
изображениями.
8.5.3. Вейвлет-кодирование
Как и все методы трансформационного кодирования, рассмотренные
в предыдущем разделе, вейвлет-кодирование основано на той же
идее, что коэффициенты преобразования, осуществляющие декорре-
ляцию значений элементов на изображении, могут быть сжаты более
эффективно, чем исходные значения пикселей. Если базисные функ-
ции преобразования — в данном случае вейвлеты — упаковывают
большую часть зрительно важной информации в небольшое число ко-
эффициентов, то оставшиеся коэффициенты могут быть грубо кван-
тованы или обнулены с минимальными искажениями изображения.
На Рис. 8.39 показана типичная система вейвлет-кодирования.
Чтобы закодировать изображение размерами 27х27, выбираются
34 JPEG — аббревиатура от Joint Photographic Experts Group (Объединенная группа
экспертов по фотографии, созданная при Международной организации по стандар-
там (ISO) при сотрудничестве с МККТТ).
8.5.Сжатие с потерями
Рис. 8.38. Левая колонка: Приближение изображения на Рис. 8.23 при исполь-
зовании ДКП и массива коэффициентов нормализации на Рис. 8.37(6). Пра-
вая колонка: Аналогичные результаты для масштабированных в 4 раза коэф-
фициентов нормализации.
^702 Глава 8. Сжатие изображений
Рис. 8.39. Система вейвлет-кодирования: (а) кодер, (б) декодер.
вейвлет анализа v и минимальный уровень разложения (J — Р), ко-
торые используются для вычисления дискретного вейвлет-преоб-
разования. Если вейвлет имеет подходящую масштабирующую функ-
цию ср, то может применяться быстрое вейвлет-преобразование (см.
Разделы 7.4 и 7.5). В любом случае, вычисляемое преобразование
трансформирует значительную часть исходного изображения в гори-
зонтальные, вертикальные и диагональные коэффициенты разложе-
ния с нулевым средним и распределением, близким распределению
Лапласа. Вспомним изображение на Рис. 7.1 и чрезвычайно про-
стые статистики его вейвлет-преобразования на Рис. 7.8(a). По-
скольку многие из вычисленных коэффициентов несут малую зри-
тельную информацию, то они могут быть квантованы и сжаты для
уменьшения межкоэффициентной и кодовой избыточности. Более
того, при квантовании может учитываться корреляция местоположе-
ния на Руровнях разложения (межуровневые связи). На последнем
шаге кодирования символов может использоваться один или не-
сколько методов кодирования без потерь, из числа рассмотренных
в Разделе 8.4, таких как кодирование длин серий, коды Хаффмана,
арифметическое кодирование, или кодирование битовых плоско-
стей. Декодирование осуществляется инвертированием операций
кодирования — за исключением квантования, которое не является
обратимой операцией.
Принципиальное отличие системы вейвлет-кодирования на
Рис. 8.39 от системы трансформационного кодирования на
Рис. 8.28 состоит в отсутствии этапа формирования отдельных
блоков. Поскольку вейвлет-преобразование эффективно с точки
зрения вычислений, и одновременно с этим по существу локаль-
но (т.е. его базисные функции являются пространственно ограни-
ченными), то не требуется дополнительного разбиения исходно-
го изображения. Как будет видно на следующем примере,
отсутствие такого шага позволяет избавиться от блоковых искаже-
ний, характерных для методов, основанных на ДКП, при высоких
коэффициентах сжатия.
8.5.Сжатие с потерями 703
Пример 8.23. Сравнение способов кодирования, основанных на вейв-
лет-преобразовании и ДКП.
На Рис. 8.40 представлены два приближения полутонового изобра-
жения Рис. 8.23, полученные с помощью вейвлет-преобразования.
Изображение на Рис. 8.40(a) было восстановлено после сжатия 34:1,
а 8.40(6) — после сжатия 67:1. Поскольку эти значения совпадают с ко-
эффициентами сжатия в Примере 8.22, то изображения на
Рис. 8.40(a) — (е) могут сравниваться как качественно, так и количе-
ственно с изображениями на Рис. 8.38(a) — (е). Визуальное сравнение
показывает значительное сокращение ошибок при вейвлет-кодирова-
нии. Количественное сравнение показывает, что для изображения на
Рис. 8.40(a) стандартное отклонение ошибки составляет 2,29 уров-
ней яркости, по сравнению с 3,42 уровней яркости для изображения
на Рис. 8.38(a). Аналогичные оценки для изображений на Рис. 8.40(6)
и Рис. 8.38(6) составляют, соответственно, 6,33 и 2,96. Эти оценки
показывают преимущество результатов, основанных на вейвлет-коди-
ровании, для обоих уровней сжатия.
Кроме уменьшения ошибок восстановления при использованных
уровнях сжатия, вейвлет-кодирование — см. Рис. 8.40(д) и (е) — суще-
ственно улучшает (в субъективном смысле) визуальное качество изо-
бражения. Это хорошо видно на Рис. 8.40(e). Заметим полное отсут-
ствие блоковых искажений, доминирующих на аналогичном фрагменте
на Рис. 8.38(e), сжатым блочным вариантом трансформационного
кодирования.
При увеличении степени сжатия более чем 67:1, максимального
из использованных в предыдущих примерах, заметным становится
пропадание фактуры на платье женщины и размывание контуров
глаз. Оба эффекта видны на Рис. 8.41(a) и (б), являющихся результа-
тами восстановления изображения на Рис. 8.23, сжатого вейвлет-ко-
дированием с коэффициентами 108:1 и 167:1. Увеличение размыва-
ния особенно заметно на фрагментах, приведенных на Рис. 8.41 (д) и
(е). Стандартные отклонения ошибок составили 3,72 и 4,73 уровней
яркости. Субъективная оценка обоих изображений показывает их
очевидное преимущество перед результатом сжатия 67:1 на
Рис. 8.38(6), выполненного с помощью ДКП, стандартное отклоне-
ние ошибки которого 6,33 уровней яркости. Таким образом, при ко-
эффициенте сжатия более чем вдвое выше, уровень ошибки у изоб-
ражения, сжатого вейвлет-кодированием, на 25% ниже, чем у
изображения, сжатого с ДКП; к тому же, первое из них имеет несо-
мненное преимущество в качестве. Заканчивая обсуждение сжатия на
основе вейвлет-кодирования, сделаем краткий обзор основных фак-
Глава 8. Сжатие изображений
Рис. 8.40. (а), (в), (д) Результаты вейвлет-кодирования — сравните с резуль-
татами кодирования с применением ДКП на Рис. 8.38(a). (в), (д); и
(б), (г), (е) аналогичные результаты для сравнения с Рис. 8.38(6), (г), (е).
Рис. 8.41. (а), (в) (д) Результаты вейвлет-кодирования со сжатием 108:1; и
(б), (г), (е) аналогичные результаты при сжатии 167:1.
24 А-223
торов, влияющих на кодовую сложность, производительность и ошиб-
ки восстановления.
Выбор вейвлета
Вейвлеты, выбранные в качестве базиса прямого и обратного преоб-
разований (см. Рис. 8.39), влияют на все аспекты системы вейвлет-ко-
дирования, включая как структурную схему, так и производитель-
ность. От них прямо зависит вычислительная сложность
преобразований, и, косвенным образом, возможности системы в от-
ношении сжатия и восстановления изображений при приемлемом
уровне искажений. Если вейвлет-функция, задающая преобразование,
имеет сопутствующую масштабирующую функцию, то преобразова-
ние может быть реализовано как последовательность операций циф-
ровой фильтрации. При этом длины фильтров равны длинам уточня-
ющих последовательностей для вейвлет-функции и масштабирующей
функции. Характеристики сжатия и восстановления изображений с по-
мощью вейвлет-преобразования определяются возможностями по-
следнего упаковывать информацию в малое число коэффициентов
преобразования.
Наиболее широко используемыми системами функций разложе-
ния для сжатия на основе вейвлет-преобразования являются системы
вейвлетов Добеши и биортогональных вейвлетов. Цифровые фильт-
ры, отвечающие последней системе, обладают рядом полезных свойств,
таких как гладкость, относительно малая длина и некоторое число ну-
левых моментов (см. Раздел 7.5), которые важны для разложения и по-
следующего восстановления.
Пример 8.24. Вейвлет-базис в вейвлет-кодировании.
Рисунок 8.42 содержит четыре дискретных вейвлет-преобразования
изображения женщины на Рис. 8.23. Изображение на Рис. 8.42(a) по-
лучено с использованием вейвлетов Хаара в качестве функций разло-
жения (базисных функций), которые являются единственными раз-
рывными вейвлетами из рассматриваемых здесь. Изображение на
Рис. 8.42(6) получено с использованием вейвлетов Добеши, относя-
щихся к числу вейвлетов, наиболее популярных в обработке изобра-
жений. Изображения на Рис. 8.42(b) — с использованием симлетов
(симметричных вейвлетов), являющихся расширением вейвлетов До-
беши с дополнительной симметрией. Для изображения на Рис. 8.42(г)
применялись вейвлеты Коэна-Добеши-Фово, включенные сюда для
иллюстрации возможностей биортогональных вейвлетов. Как и ранее
на аналогичных примерах, чтобы повысить наглядность возникающих
структур, все изображения коэффициентов были подвергнуты масшта-
8.5. Сжатие с потерями
Рис. 8.42. Вейвлет-преобразование изображения на Рис. 8.23 с использовани-
ем: (а) вейвлетов Хаара, (б) вейвлетов Добеши, (в) симлетов, и (г) биортого-
нальных вейвлетов Коэна—Добеши—Фово.
б
г
бирующему градационному преобразованию, при котором значе-
нию 0 соответствует уровень яркости 128.
Как можно видеть из Таблицы 8.12, для преобразований, представ-
ленных на Рис. 8.42, число требуемых операций умножения и сложе-
ния на коэффициент (для каждого уровня разложения) увеличивает-
ся с 4 (для изображения на Рис. 8.42(a)) до 28 (для изображения на
Рис. 8.42(г)). Все четыре преобразования выполнялись с использова-
нием быстрого вейвлет-преобразования (т.е. блока фильтров). Заме-
тим, что способность к упаковке информации возрастает с увеличе-
нием вычислительной сложности (т.е. числа ненулевых
коэффициентов фильтров). При использовании вейвлетов Хаара и усе-
чении коэффициентов деталей на уровне значения 1,5, обнуляются
Таблица 8.12. Длины (количество ненулевых коэффициентов) фильтров вейв-
лет-преобразования и доля обнуляемых коэффициентов при усечении преоб-
разований на Рис. 8.42 на уровне 1.5.
Система вейвлетов Длины фильтров (масштабирующий + вейвлет) Обнуляемые коэффициенты
Хаара (см. Пример 7.10) 2+2 46%
Добеши (см. Рис. 7.6) 8+8 51%
Симлет (см. Рис.7.24) 8+8 51%
Биортогональные (см Рис.7.37) 17+11 55%
46% коэффициентов преобразования. При использовании более
сложных биортогональных вейвлетов, число обнуляемых коэффици-
ентов вырастает до 55%, увеличивая при этом потенциал сжатия
на 10%.
Выбор уровня разложения
Другим важным фактором, влияющим на вычислительную слож-
ность и уровень ошибок восстановления вейвлет-кодирования, яв-
ляется число уровней разложения преобразования. Поскольку P-мас-
штабное быстрое вейвлет-преобразование требует Р итераций блока
фильтров, число операций при вычислении прямого и обратного
преобразований возрастает с увеличением числа уровней разложения.
Более того, квантование коэффициентов уменьшающихся масшта-
бов, требующее большего числа уровней разложения, влияет на все
большую область восстанавливаемого изображения. Во многих при-
ложениях, таких как поиск по базе данных изображений или пере-
дача изображений для постепенного восстановления, число уровней
преобразования определяется разрешением хранимых или передава-
емых изображений, а также масштабом наименьшей из используе-
мых копий.
Пример 8.25. Уровни разложения в вейвлет-кодировании.
Таблица 8.13 иллюстрирует эффект влияния выбора уровня разло-
жения на результат кодирования изображения на Рис. 8.23 с фикси-
рованным глобальным порогом, равным 25. Как и в предыдущих
примерах использования вейвлет-кодирования, усечению подверга-
лись лишь детальные коэффициенты. В таблице приведены как до-
ли обнуляемых коэффициентов, так и результирующие стандарт-
ные отклонения ошибок восстановления. Заметим, что основное
сжатие происходит при начальных разложениях. При увеличении
числа уровней разложения больше трех, число обнуляемых коэффи-
циентов меняется мало.
8.5. Сжатие с потерями 709
Таблица 8.13. Влияние уровня разложения на вейвлет-кодирование изображе-
ния размерами 512x512, представленного на Рис. 8.23.
Масштабы и итерации блока фильтров Размеры изображения коэффициентов приближения Доля обнуляемых коэффициентов (%) СКО ошибки восстановления
1 256 х 256 75% 1,93
2 128 х 128 93% 2,69
3 64 х 64 97% 3,12
4 32 х 32 98% 3,25
5 16 х 16 98% 3,27
Расчет квантователя
Важнейшим фактором, влияющим на коэффициент сжатия и точ-
ность восстановления изображения в вейвлет-кодировании, являет-
ся квантование коэффициентов. Хотя чаще всего для разных уров-
ней применяются одинаковые квантователи, эффективность
квантования может быть заметно повышена одним из следующих спо-
собов: (1) введением увеличенного интервала квантования вокруг ну-
ля, называемого «мертвой зоной», или (2) согласование размеров ин-
тервалов квантования с масштабом. В любом случае выбранные
интервалы квантования должны быть переданы декодеру вместе с ко-
дированным потоком данных. Сами интервалы могут определяться
как эвристически, так и автоматически на основе анализа сжимае-
мого изображения. Например, глобальный порог для коэффициен-
тов может вычисляться как медиана модулей детальных коэффици-
ентов первого уровня, или же, как функция числа отбрасываемых
нулей и количества энергии, которое остается в восстанавливаемом
изображении.
Пример 8.26. Выбор интервала «мертвой зоны» в вейвлет-кодировании.
На Рис. 8.43 иллюстрируется влияние размера интервала «мертвой
зоны» на долю усекаемых детальных коэффициентов для трехуровне-
вого вейвлет-кодирования изображения женщины на Рис. 8.23. С
увеличение размера «мертвой зоны» число обнуляемых коэффициен-
тов также возрастает. Выше излома кривой (т.е. больше 4,5) прирост
мал; это является следствием того, что гистограмма детальных коэф-
фициентов имеет ярко выраженный пик вблизи нуля (см., например,
Рис. 7.8). Стандартные отклонения ошибок восстановления, соот-
ветствующие порогу «мертвой зоны» на Рис. 8.43, возрастают от 0 до
1,77 уровня яркости при пороге 4,5, и до 2,79 при пороге 18, где чис-
ло нулей достигает уже 96,43%. Если удалить все детальные коэффи-
Порог «мертвой зоны»
Рис. 8.43. Влияние размера интервала «мертвой зоны» в вейвлет-кодировании.
циенты, что увеличит долю нулей приблизительно на 1,5%, то ошиб-
ка восстановления возрастет до 7,6 уровней яркостей.
8.6. Стандарты сжатия изображений
Многие из методов сжатия (как с потерями, так и без потерь), описан-
ные к настоящему моменту, играют важнейшую роль в наиболее рас-
пространенных стандартах сжатия изображений. В данном разделе
рассматриваются некоторые из этих стандартов, и на их основе демон-
стрируются представленные ранее методы. Большинство из стандар-
тов были одобрены Международной организацией по стандартизации
(International Standardization Organization — ISO) и Международным
Консультативным Комитетом по Телефонии и Телеграфии — МККТТ
(Consultative Committee of the International Telephone and Telegraph —
CCITT). Они касаются применения методов сжатия как двоичных, так
и полутоновых (монохромных или цветных) изображений, а также и
неподвижных, и движущихся изображений (т.е. видеопоследователь-
ностей).
8.6.1. Стандарты сжатия двоичных изображений
Двумя из наиболее широко используемых стандартов сжатия двоич-
ных (двухградационных) изображений являются стандарты МККТТ
Группы 3 и Группы 4. В настоящее время они применяются во многих
компьютерных приложениях, хотя изначально они разрабатывались
как методы факсимильного (FAX) кодирования для передачи докумен-
тов по телефонным сетям. Стандарт Группы 3 использует неадаптив-
8.6. Стандарты сжатия изображений 711
ный метод одномерного кодирования длин серий, согласно которо-
му в каждой группе из К строк (А'= 2 или 4) все строки кроме первой
могут кодироваться двумерным образом. Стандарт Группы 4 являет-
ся модернизированным и несколько упрощенным вариантом стандар-
та Группы 3, допускающим лишь двумерное кодирование. Оба стан-
дарта используют один и тот же неадаптивный подход к двумерному
кодированию. Этот подход весьма близок к методу кодирования от-
носительных адресов (КОА), описанному в Разделе 8.4.3.
При разработке стандартов МККТТ были отобраны восемь пред-
ставительных тестовых документов, содержащих напечатанные и ру-
кописные тексты на нескольких языках, а также графические рисун-
ки. Изображения этих документов использовались как основа для
оценивания различных вариантов двоичного сжатия. Существующие
стандарты Группы 3 и Группы 4 позволяют сжимать их с коэффици-
ентом около 15:1. Поскольку стандарты Группы 3 и Группы 4 являют-
ся неадаптивными методами, то иногда они приводят к увеличению
объема данных (например, в случае полутоновых изображений). Что-
бы преодолеть эту и связанные с ней другие проблемы. Объединенная
группа по двоичным изображениям (Joint Bilevel Imaging Group —
JBIG), являющаяся объединенным комитетом при МККТТ и ISO,
адаптировала и предложила несколько других стандартов сжатия дво-
ичных изображений. Они включают JBIG1 — метод адаптивного
арифметического кодирования, обеспечивающий наилучшие резуль-
таты сжатия, как в среднем, так и в наихудшем случаях, а также JBIG2
(на данный момент окончательный вариант, представленный комите-
том), который позволяет достичь сжатия в 2—4 раз лучшего, чем JBIG1.
Эти стандарты могут быть использованы для сжатия как двоичных, так
и полутоновых изображений с разрешением по яркости до 6 битов на
пиксель (методом кодирования битовых плоскостей).
Одномерное сжатие
В одномерном методе сжатия МККТТ Группы 3 каждая строка изоб-
ражения35 кодируется последовательностью неравномерных кодов, ко-
торые отображают длины перемежающихся серий белых и черных
элементов при построчном сканировании слева направо. При этом бы-
вают два типа кодовых слов. Если длина серии меньше 63 элементов,
то используется код окончания из Таблицы 8.14, содержащей модифи-
цированный код Хаффмана. Если же длина серии превышает 63 эле-
35 Согласно стандарту, отдельные изображения называются страницами, а последо-
вательности изображений —документами.
Таблица 8.14. Коды окончания МККТТ.
Длина серии Кодовое слово Длина серии Кодовое слово
Белая серия Черная серия Белая серия Черная серия
0 00110101 0000110111 32 00011011 000001101010
1 000111 010 33 00010010 000001101011
2 0111 11 34 00010011 000011010010
3 1000 10 35 оооююо 000011010011
4 1011 он 36 00010101 000011010100
5 1100 ООН 37 00010110 000011010101
6 1110 0010 38 00010111 000011010110
7 1111 00011 39 00101000 000011010111
8 10011 000101 40 00101001 000001101100
9 10100 000100 41 00101010 000001101101
10 00111 0000100 42 00101011 000011011010
11 01000 0000101 43 00101100 000011011011
12 001000 0000111 44 00101101 000001010100
13 000011 00000100 45 00000100 000001010101
14 110100 00000111 46 00000101 000001010110
15 110101 000011000 47 00001010 000001010111
16 101010 0000010111 48 00001011 000001100100
17 101011 0000011000 49 01010010 000001100101
18 0100111 0000001000 50 01010011 000001010010
19 0001100 00001100111 51 01010100 000001010011
20 0001000 00001101000 52 01010101 000000100100
21 0010111 00001101100 53 00100100 000000110111
22 0000011 00000110111 54 00100101 000000111000
23 0000100 00000101000 55 01011000 000000100111
24 0101000 00000010111 56 01011001 000000101000
25 0101011 00000011000 57 01011010 000001011000
26 0010011 000011001010 58 01011011 000001011001
27 0100100 000011001011 59 01001010 000000101011
28 0011000 000011001100 60 01001011 000000101100
29 00000010 000011001101 61 00110010 000001011010
30 00000011 000001101000 62 00110011 000001100110
31 00011010 000001101001 63 00110100 000001100111
мента, то первоначально ставится максимально возможный код про-
должения (не превышающий длины серии) из Таблицы 8.15, за кото-
рым следует код окончания, соответствующий разности между дейст-
вительной длиной серии и значением кода продолжения. Стандарт
требует, чтобы каждая строка начиналась с серии белых точек, кото-
Таблица 8.15. Коды продолжения МККТТ.
Длина серии Кодовое слово Длина серии Кодовое слово
Белая серия Черная серия Белая серия Черная серия
64 ПОП 0000001111 960 011010100 0000001110011
128 10010 000011001000 1024 011010101 0000001110100
192 010111 000011001001 1088 011010110 0000001110101
256 0110111 000001011011 1152 011010111 0000001110110
320 00110110 000000110011 1216 011011000 0000001110111
384 00110111 000000110100 1280 011011001 0000001010010
448 01100100 000000110101 1344 011011010 0000001010011
512 01100101 0000001101100 1408 011011011 0000001010100
576 01101000 0000001101101 1472 010011000 0000001010101
640 01100111 0000001001010 1536 010011001 0000001011010
704 011001100 0000001001011 1600 010011010 0000001011011
768 011001101 0000001001100 1664 011000 0000001100100
832 011010010 0000001001101 1728 010011011 0000001100101
896 011010011 0000001110010
Кодовое слово Кодовое слово
1792 00000001000 2240 000000010110
1856 00000001100 2304 000000010111
1920 00000001101 2368 000000011100
1984 000000010010 2432 000000011101
2048 000000010011 2496 000000011110
2112 000000010100 2560 000000011111
2176 000000010101 КС 000000000001
рая может оказаться нулевой длины — в этом случае она будет пред-
ставлена кодовым словом 00110101. Наконец, для окончания каждой
строки, а также для начала нового изображения (страницы), исполь-
зуется уникальное кодовое слово конца строки (КС) со значением
000000000001. Конец последовательности изображений (документа)
обозначается шестью последовательными кодами КС.
Двумерное сжатие
Способ двумерного сжатия36, принятый стандартами МККТТ Груп-
пы 3 и Группы 4, основан на построчном сканировании, согласно ко-
36 Этот способ известен как модифицированный код выбора относительного адреса
элемента (modified Relative Element Address Designate code — «modified READ code»). —
Прим, перев.
fe4
Глава 8. Сжатие изображений
торому позиция каждого элемента изменения (т.е. элемента перехода
из черного в белое или из белого в черное) текущей кодируемой стро-
ки кодируется либо относительно позиции соответствующего эле-
мента изменения опорной строки (т.е. строки, расположенной непосред-
ственно над кодируемой строкой), либо относительно позиции
предыдущего элемента изменения в кодируемой строке. Опорной
строкой для первой строки каждого изображения является вообража-
емая белая строка.
На Рис. 8.44 показан алгоритм кодирования отдельной строки.
Начало процедуры состоит в нахождении нескольких элементов из-
менения: Ср, й|, о2, Ьх, и Ь2. Элемент изменения определяется как эле-
мент, значение которого отличается от значения предыдущего элемен-
та в той же строке. Наиболее важным элементом изменения является
элемент «о — опорный элемент. Его позиция определяется либо пред-
шествующим режимом кодирования (см. ниже), либо его значение ус-
танавливается на воображаемом белом элементе изменения, располо-
женном перед первым действительным элементом новой кодируемой
строки. Когда элемент найден, элемент «| определяется как следу-
ющий элемент изменения справа от о0 на той же строке, а элемент о2 —
как следующий элемент изменения справа от «|. Элемент Ь\ опреде-
ляется как следующий элемент изменения в опорной строке, распо-
ложенный справа от а0, и имеюший противоположный цвет по отно-
шению к ад, а элемент Ь2 — как следующий элемент изменения в
опорной строке справа от Ь\. Если любой из этих элементов не обна-
ружен, то он устанавливается на позиции воображаемого элемента, рас-
положенного справа от последнего элемента строки сканирования. На
Рис. 8.45 представлены две иллюстрации основных взаимосвязей
между различными элементами изменения.
После определения позиции текущего опорного элемента и связан-
ных с ним элементов изменения, выполняются две простые провер-
ки, на основании которых выбирается один из трех возможных режи-
мов кодирования: переходной режим, вертикальный режим или
горизонтальный режим. Первая проверка, соответствующая первой
точке ветвления в схеме на Рис. 8.44, сравнивает позиции Ь2 и а{. Вто-
рая проверка, соответствующая второй точке ветвления в схеме на
Рис. 8.44, определяет расстояние между позициями «| и Ь\ и сравни-
вает его со значением 3. В зависимости от результатов этих проверок
осуществляется переход на один из трех обведенных блоков на
Рис. 8.44, после чего выполняется соответствующая процедура коди-
рования. Затем для подготовки к следующему шагу итерации опреде-
ляется новая позиция опорного элемента согласно соответствующе-
му способу на блок-схеме.
8.6. Стандарты сжатия изображений 715
Начало новой
кодируемой строки
Рис. 8.44. Блок-схема МККТТ процедуры двумерного кодирования Запись
]</1 b11 означает абсолютную величину расстояния между элементами измене-
ния Я1 и Ь\.
Глава 8. Сжатие изображений
Опорная строка
Кодируемая строка
пжпипжп-' □
яд Следующий яд Я| Переходной
а0
режим
Вертикальный режим
Опорная строка ---р---| b\ />2
ПГТ ГТТТТПГ IT i Т Т*ТТТИ i con
□□□□□□□Dp
Кодируемая строка яд
«I "2
-aoai---------------------fl|«2------------I О Y
Горизонтальный режим
Рис. 8.45. Параметры МККТТ процедуры двумерного кодирования: (а) пере-
ходной режим, (б) горизонтальный и вертикальный режимы.
В Таблице 8.16 приведены особые коды, используемые для каждо-
го из трех возможных режимов кодирования. В переходном режиме,
в котором, в частности, исключен случай расположения «| непосред-
ственно под Ь2, требуется только кодовое слово переходного режима
0001. Как показано на Рис. 8.45(a), данный режим соответствует слу-
чаю, когда белые или черные серии опорной строки не перекрывают
текущую белую или черную серию на кодируемой строке. В горизон-
тальном режиме кодирования расстояния от до и от й] до с2
должны кодироваться в соответствии с кодами окончания и кодами
продолжения из Таблиц 8.14 и 8.15, которые следуют за кодовым сло-
вом горизонтального режима 001. Этот случай обозначен в Таблице 8.16
Таблица 8.16. Таблица двумерного кода МККТТ.
Режим кодирования Кодовое слово
Переходной 0001
Горизонтальный 001 + Л/(я0Я|) + Л/(Я|Я2)
Вертикальный
под Ь} 1
Я] на один элемент справа от 6] 011
Я| на два элемента справа от 000011
Я] на три элемента справа от bt 0000011
Я] на один элемент слева от t>t 010
Я] на два элемента слева от Ь\ 000010
Я] на три элемента слева от Л| 0000010
Расширение 0000001XXX
8.6. Стандарты сжатия изображений 717
как 001 + Л/(аоО|) + Л/(О|О2), где а^ау и а]О2 обозначают расстояния,
соответственно, от до О| и от «| до о2. Наконец, в вертикальном ре-
жиме кодирования одно из семи кодовых слов обозначает расстояние
между О] и Ь]. Параметры, связанные с горизонтальным и вертикаль-
ным режимами кодирования, представлены на Рис. 8.45(6). Кодовое
слово моды расширения, приведенное в нижней строке Таблицы 8.16,
используется для указания дополнительного режима факсимильного
кодирования. Так, например, код 0000001111 используется для нача-
ла режима передачи без сжатия.
Пример 8.27. Пример вертикального режима кодирования МККТТ.
Хотя на Рис. 8.45(6) приведены параметры и для вертикальной, и для
горизонтальной мод кодирования, однако рисунок по существу соот-
ветствует вертикальной моде кодирования. То есть, поскольку Ь2 рас-
положен справа от «1, то первая проверка (на переходной режим) на
Рис. 8.44 дает отрицательный результат. Вторая проверка, осуществ-
ляющая выбор между вертикальным и горизонтальным режимом,
указывает на то, что должен быть задействован вертикальный режим,
поскольку расстояние между и by меньше 3. Согласно Таблице 8.16,
должно быть выбрано кодовое слово 000010, указывающее, что «| на-
ходится на две позиции левее by. В качестве подготовки к следующей
итерации, перемещается в позицию а у. Я
8.6.2. Стандарты сжатия полутоновых неподвижных
изображений
МККТТ и ISO разработали несколько стандартов сжатия полутоно-
вых (многоградационных) изображений. Эти стандарты, находящи-
еся на различных стадиях утверждения, касаются алгоритмов сжатия
как монохромных (черно-белых), так и цветных изображений. В про-
тивоположность стандартам сжатия двоичных изображений, рассмо-
тренным в Разделе 8.6.1, стандарты сжатия полутоновых изображений
принципиально основываются только на методах сжатия с потерями
(см. Разделы 8.5.2 и 8.5.3). При разработке стандартов, комитеты
МККТТ и ISO запрашивали рекомендации по поводу алгоритмов у
большого числа исследовательских лабораторий, компаний и уни-
верситетов. Лучшие из числа алгоритмов, представленных на рассмо-
трение, были отобраны на основе критериев качества изображения и
характеристик сжатия. Итоговыми стандартами, отражающими совре-
менное положение технологии сжатия полутоновых изображений,
явились следующие: первоначальный стандарт JPEG основанный на
ДКП; недавно предложенный, основанный навейвлет-преобразова-
нии, стандарт JPEG 2000; а также стандарт JPEG-LS, сочетающий
схему безошибочного или почти безошибочного адаптивного предска-
зания с механизмом обнаружения плоских областей и кодированием
длин серий [ISO/IEC, 1999].'
JPEG
Одним из наиболее полных и популярных стандартов сжатия полуто-
новых неподвижных изображений является стандарт JPEG. Он опре-
деляет три различных режима кодирования: (1) режим последователь-
ного кодирования с потерями, основанный на ДКП и подходящий для
большинства применений; (2) расширенный режим кодирования, исполь-
зуемый для большего сжатия, для более высокой точности, или для по-
степенного воспроизведения; и (3) режим кодирования без потерь, га-
рантирующий точное восстановление информации после сжатия.
Чтобы быть совместимым со стандартом JPEG, продукт или система
должны обеспечивать поддержку режима последовательного коди-
рования. При этом точно не определяются ни формат файла, ни про-
странственное разрешение, ни модель цветового пространства.
В системе с последовательной обработкой (кодированием), часто на-
зываемой системой последовательной развертки, точность входных и вы-
ходных данных ограничена 8 битами, а точность квантованных коэф-
фициентов ДКП ограничена 11 битами. Сам процесс сжатия состоит из
трех последовательных шагов: вычисление ДКП, квантование и коди-
рование неравномерным кодом. Сначала изображение разбивается на
отдельные блоки размерами 8x8 элементов, которые обрабатываются по-
следовательно слева направо и сверху вниз. Обработка каждого блока
начинается со сдвига по яркости значений всех его 64 элементов, что до-
стигается вычитанием величины 2W~', где 2п — максимальное число
уровней яркости. Затем вычисляется двумерное дискретное косинусное
преобразование элементов блока. Полученные значения коэффициен-
тов квантуются в соответствии с формулой (8.5-40), переупорядочива-
ются зигзаг преобразованием согласно Рис. 8.36(д), и формируется од-
номерная последовательность квантованных коэффициентов.
Одномерный массив, полученный после зигзаг преобразования в
соответствии с Рис. 8.3б(д), упорядочивается по возрастанию прост-
ранственной частоты; при этом, как правило, возникают длинные
последовательности нулей, что эффективно используется процедурой
JPEG кодирования. В частности, ненулевые АС коэффициенты37 ко-
37 Согласно стандарту нулевой коэффициент обозначается DC, а остальные коэф-
фициенты — АС.
8.6. Стандарты сжатия изображений
Таблица 8.17. Категории кодирования JPEG коэффициентов.
Диапазон Категория DC Категория АС
разностей
0 0
-1. 1 1 1
-3,-2, 2,3 2 2
—7,...,—4, 4,...,7 3 3
—15,...,—8, 8,....15 4 4
-31,...,-16, 16,...,31 5 5
-63 -32, 32,...,63 6 6
-127,... ,-64, 64,...,127 7 7
-255,...-128, 128,...,255 8 8
-511 -256, 256 511 9 9
-1023,...,-512, 512,...,1023 А А
-2047,...,-1024, 1024,...,2047 В В
-4095....,-2048. 2048....,4095 С С
-8191 -4096, 4096,...,8191 D D
-16383 -8192, 8192,...,16383 Е Е
-32767,...,-16384, 16384,...,32767 F —
дируются неравномерным кодом, определяющим одновременно и
значение коэффициента и число предшествующих нулей. Текущий DC
коэффициент кодируется дифференциальным кодом как разность с DC
коэффициентом предыдущего блока. Таблицы38 8.17, 8.18 и 8.19 пред-
Таблица 8.18. Стандартные JPEG коды для DC коэффициентов (яркость).
Категория Основной код Длина Категория Основной код Длина
0 010 3 6 1110 10
1 ОН 4 7 11110 12
2 100 5 8 111110 14
3 00 5 9 1111110 16
4 101 7 А 11111110 18
5 110 8 В 111111110 20
38 Для сокращения записи в таблице 8.19 применены шестнадцатеричные числа. В
них первые 10 цифр совпадают с цифрами десятичных чисел, а последние 6 обозна-
чаются латинскими буквами от Одо F. Тем самым: А]6 = 1010, В = 11 ]0, С|6 = 12]0,
О16 = |3ю, Е|6= 14]0, F(6= 1510. - Прим, перев.
Глава 8. Сжатие изображений
Таблица 8.19. Стандартные JPEG коды для АС коэффициентов (яркость).
Длина серии/ категория Основной код Длина Длина серии/ категория Основной код Длина
0/0 1010 (=КБ) 4
0/1 00 3 8/1 11111010 9
0/2 01 4 8/2 111111111000000 17
0/3 100 6 8/3 1111111110110111 19
0/4 1011 8 8/4 1111111110111000 20
0/5 ПОЮ 10 8/5 1111111110111001 21
0/6 111000 12 8/6 1111111110111010 22
0/7 1111000 14 8/7 1111111110111011 23
0/8 1111110110 18 8/8 1111111110111100 24
0/9 1111111110000010 25 8/9 1111111110111101 25
0/А 1111111110000011 26 8/А 1111111110111110 26
1/1 1100 5 9/1 111111000 10
1/2 111001 8 9/2 1111111110111111 18
1/3 1111001 10 9/3 1111111111000000 19
1/4 111110110 13 9/4 1111111111000001 20
1/5 11111110110 16 9/5 1111111111000010 21
1/6 1111111110000100 22 9/6 1111111111000011 22
1/7 1111111110000101 23 9/7 1111111111000100 23
1/8 1111111110000110 24 9/8 1111111111000101 24
1/9 1111111110000111 25 9/9 1111111111000110 25
1/А 1111111110001000 26 9/А 1111111111000111 26
2/1 11011 6 А/1 111111001 10
2/2 11111000 10 А/2 1111111111001000 18
2/3 1111110111 13 А/3 1111111111001001 19
2/4 1111111110001001 20 А/4 1111111111001010 20
2/5 1111111110001010 21 А/5 1111111111001011 21
2/6 1111111110001011 22 А/6 1111111111001100 22
2/7 1111111110001100 23 А/7 1111111111001101 23
2/8 1111111110001101 24 А/8 1111111111001110 24
2/9 1111111110001110 25 А/9 1111111111001111 25
2/А 1111111110001111 26 А/А 1111111111010000 26
3/1 111010 7 В/1 111111010 10
3/2 111110111 11 В/2 1111111111010001 18
3/3 11111110111 14 В/3 1111111111010010 19
3/4 1111111110010000 20 В/4 1111111111010011 20
3/5 1111111110010001 21 В/5 1111111111010100 21
3/6 1111111110010010 22 В/6 1111111111010101 22
3/7 1111111110010011 23 В/7 1111111111010110 23
3/8 1111111110010100 24 В/8 1111111111010111 24
3/9 1111111110010101 25 В/9 1111111111011000 25
3/А 1111111110010110 26 В/А 1111111111011001 26
8.6. Стандарты сжатия изображений
Таблица 8.19 (продолжение). Стандартные JPEG коды для АС коэффициен-
тов (яркость).
Длина серии/ категория Основной код Длина Длина серии/ категория Основной код Длина
4/1 111011 7 С/1 1111111010 11
4/2 1111111000 12 С/2 1111111111011010 18
4/3 1111111110010111 19 С/3 1111111111011011 19
4/4 1111111110011000 20 С/4 1111111111011100 20
4/5 1111111110011001 21 С/5 1111111111011101 21
4/6 1111111110011010 22 С/6 1111111111011110 22
4/7 1111111110011011 23 С/7 1111111111011111 23
4/8 1111111110011100 24 С/8 1111111111100000 24
4/9 1111111110011101 25 С/9 1111111111100001 25
4/А 1111111110011110 26 С/А 1111111111100010 26
5/1 иною 8 D/1 11111111010 12
5/2 1111111001 12 D/2 1111111111100011 18
5/3 1111111110011111 19 D/3 1111111111100100 19
5/4 1111111110100000 20 D/4 1111111111100101 20
5/5 1111111110100001 21 D/5 1111111111100110 21
5/6 1111111110100010 22 D/6 1111111111100111 22
5/7 1111111110100011 23 D/7 1111111111101000 23
5/8 1111111110100100 24 D/8 1111111111101001 24
5/9 1111111110100101 25 D/9 1111111111101010 25
5/А 1111111110100110 26 D/A 1111111111101011 26
6/1 1111011 8 Е/1 111111110110 13
6/2 11111111000 13 Е/2 1111111111101100 18
6/3 1111111110100111 19 Е/3 1111111111101101 19
6/4 1111111110101000 20 Е/4 1111111111101110 20
6/5 1111111110101001 21 Е/5 1111111111101111 21
6/6 1111111110101010 22 Е/6 1111111111110000 22
6/7 1111111110101011 23 Е/7 1111111111110001 23
6/8 1111111110101100 24 Е/8 1111111111110010 24
6/9 1111111110101101 25 Е/9 1111111111110011 25
6/А 1111111110101110 26 Е/А 1111111111110100 26
7/1 11111001 9 F/0 111111110111 12
7/2 11111111001 13 F/1 1111111111110101 17
7/3 1111111110101111 19 F/2 1111111111110110 18
7/4 1111111110110000 20 F/3 1111111111110111 19
7/5 1111111110110001 21 F/4 1111111111111000 20
7/6 1111111110110010 22 F/5 1111111111111001 21
7/7 1111111110110011 23 F/6 1111111111111010 22
7/8 1111111110110100 24 F/7 1111111111111011 23
7/9 1111111110110101 25 F/8 1111111111111100 24
7/А 1111111110110110 26 F/9 1111111111111101 25
F/A 1111111111111110 26
ставляют составленные JPEG и задаваемые по умолчанию стандарт-
ные коды Хаффмана для яркостной составляющей. Рекомендованный
JPEG массив квантования яркостей представлен на Рис. 8.37(6) и мо-
жет быть масштабирован для получения множества уровней сжатия.
Хотя как для яркости, так и ддя цветности предусмотрены стандарт-
ные таблицы кодирования, а также проверенные шкалы квантова-
ния, тем не менее*, допускается построение пользовательских таблиц
и шкал, адаптированных к характеристикам сжимаемого изображения.
Пример 8.28. Последовательное кодирование и декодирование JPEG.
Рассмотрим сжатие и восстановление следующего блока из 8x8
элементов согласно стандарту последовательного кодирования JPEG:
52 55 61 66 70 61 64 73
63 59 66 90 109 85 69 72
62 59 68 ИЗ 144 104 66 73
63 58 71 122 154 106 70 69
67 61 68 104 126 88 68 70
79 65 60 70 77 68 58 75
85 71 64 59 55 61 65 83
87 79 69 68 65 76 78 94
Исходные значения пикселей могут иметь 256 или 28 возможных уров-
ней яркости, так что процесс кодирования начинается со сдвига ди-
апазона значений — вычитания из значений пикселей величины 27 или
128. В результате получится массив:
-76 -73 -67 -62 -58 -67 -64 -55
-65 -69 -62 -38 -19 -43 -59 -56
-66 -69 -60 -15 16 -24 -62 -55
-65 -70 -57 -6 26 -22 -58 -59
-61 -67 -60 -24 —2 -40 -60 -58
-49 -63 -68 -58 -51 -65 -70 -53
-43 -57 -64 -69 -73 -67 -63 -45
-41 -49 -59 -60 -63 -52 -50 -34
который, после прямого ДКП согласно (8.5-24) и (8.5-32) для N = 8,
будет иметь вид:
-415 -29 -62 25 55 -20 -1 3
7 -21 -62 9 11 —7 -6 6
-46 8 77 -25 -30 10 7 -5
8.6. Стандарты сжатия изображений
-50 13 35 -15 -9 6 0 3
11 -8 -13 —2 -1 1 —4 1
-10 1 3 -3 -1 0 2 -1
—4 -1 2 -1 2 -3 1 —2
-1 -1 -1 —2 -1 -1 0 -1
Если для квантования полученных данных используется рекомендо-
ванный JPEG массив нормализации, приведенный на Рис. 8.37(6), то
после масштабирования и усечения (то есть нормализации в соот-
ветствии с (8.5-40)), коэффициенты примут следующие значения:
-26 -3 -6 2 2 0 0 0
1 -2 -4 0 0 0 0 0
-3 1 5-1-1 0 0 0
—4 1 2 -1 0 0 0 0
10 0 0 0 0 0 0
00000000
00000000
00000000
где, например, DC коэффициент вычислен следующим образом:
f (0,0) = round
Т(0,0)
Z(0,0)
= round
-415
~16~
= -26.
Заметим, что процедура преобразования и нормализации дает значи-
тельное число нулевых коэффициентов. После того, как коэффици-
енты переупорядочены в соответствии с зигзаг преобразованием (см.
Рис. 8.36(д)), получится следующая одномерная последовательность
коэффициентов:
[-26-3 1—3—2—62—41—4 1150200—1 200000—1—1 КБ].
Предусмотрено специальное кодовое слово КБ, означающее конец
блока (см. код категории 0 и длиной серии 0 в Таблице 8.19 кодов
Хаффмана), указывающее, что все оставшиеся коэффициенты в пе-
реупорядоченной последовательности равны нулю.
Построение JPEG кода для переупорядоченной последователь-
ности коэффициентов начинается с вычисления разности между зна-
чениями DC коэффициентов в текущем и предыдущем (уже закоди-
рованном) блоках. Поскольку блок был взят нами из изображения
на Рис. 8.23, и известно, что DC коэффициент соседнеголевого, уже
преобразованного и закодированного, блока равен —17, получаемая
ДИ КМ разность будет (-26 - (-17)) = -9, которая попадает в катего-
рию 4 разностей DC в Таблице 8.17. Согласно стандартным кодам
Хаффмана для разностей из Таблицы 8.18, правильный основной код
будет 101 (3-битовый код). Однако суммарная длина полностью зако-
дированного коэффициента категории 4 составит 7 бит — оставшие-
ся 4 бита должны быть взяты из младших разрядов (МР) значения раз-
ности. В общем случае, для конкретной категории DC разностей
(скажем, категории К), дополнительно требуется К битов, которые
вычисляются или как К младших разрядов положительной разности,
или как К младших разрядов отрицательной разности минус 1. Для раз-
ницы —9 соответствующие значения МР составят (0111-1), или 0110,
и, таким образом, полное кодированное ДИКМ кодовое слово будет
1010110.
Ненулевые АС коэффициенты переупорядоченного массива коди-
руются аналогичным образом по Таблицам 8.17 и 8.19. Разница состо-
ит лишь в том, что выбор кодового слова кода Хаффмана для АС ко-
эффициента зависит как от категории амплитуды коэффициента, так
и от числа предшествующих нулей (см. колонку «Длина серии/кате-
гория» в Таблице 8.19). Окончательный код первого ненулевого АС ко-
эффициента переупорядоченного массива (—3) будет 0100. Первые 2
бита данного кода указывают, что коэффициент был из категории 2,
и что у него нет предшествующих нулевых коэффициентов (см. Таб-
лицу 8.17); последние 2 бита были получены процедурой добавления
МР, аналогичной изложенной выше для кода DC разностей. Продол-
жая подобным образом, полная кодовая последовательность пере-
упорядоченного массива будет выглядеть:
1010110 0100 001 0100 0101 100001 ОНО 100011 001 100011 001
001 100101 11100110 110110 ОНО 11110100 000 1010.
Пробелы между кодовыми словами поставлены здесь исключитель-
но для удобства чтения. Хотя это и не потребовалось в данном приме-
ре, таблица стандартных кодов Хаффмана содержит специальное кодо-
вое слово для серии длиной в 15 нулей, за которой опять идет 0 (см. длину
серии F и категорию 0 в таблице 8.19). Общее число битов, требуемых для
кодирования переупорядоченного массива (а значит, требуемых для ко-
дирования всех 8x8 элементов выбранного блока), составляет 92. Резуль-
тирующий коэффициент сжатия равен 512/92, или около 5,6/1.
При восстановлении сжатого JPEG блока декодер в первую очередь
должен из непрерывного потока битов воссоздать нормализованные
коэффициенты преобразования. Поскольку последовательность дво-
8.6. Стандарты сжатия
ичных кодов Хаффмана является мгновенной и однозначно декоди-
руемой (см. Раздел 8.4.1), этот шаг легко реализуется при помощи
табличного преобразования. Ниже приведен массив квантованных
коэффициентов, восстановленный из потока битов:
-26 -3 -6 2 2 О О О
1-2 -4 0 0 0 0 0
-315-1-1000
—4 1 2 -1 0 0 0 0
1 0 0 0 0 0 0 0
00000000
00000000
00000000
После умножения на коэффициенты нормализации согласно (8.5-42),
получим массив:
-416 -33 -60 32 48 0 0 0
12 -24 —56 0 0 0 0 0
-42 13 80 -24 -40 0 0 0
-56 17 44 —29 0 0 0 0
18 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
где, например, DC коэффициент получен следующим образом
Т(0.0) = f (0,0)Z(0,0) = -26 -16 = -416.
Полностью восстановленный блок получается после выполнения об-
ратного ДКП полученного массива согласно уравнениям (8.5-25) и
(8.5-32), что дает
-70 -64 -61 -64 -69 -66 -58 -50
-72 -73 -61 -39 -30 -40 -54 -59
-68 -78 -58 -9 13 -12 -48 -64
-59 -77 -57 0 22 -13 -51 -60
-54 -75 -64 -23 -13 -44 -63 -56
-52 -71 -72 -54 -54 -71 -71 -54
-45 -59 -70 -68 -67 -67 -61 -50
-35 -47 -61 -66 -60 -48 -44 -44
и обратного сдвига диапазона значений на +27 (т.е. +128). В результа-
те получаем:
58 64 67 64 59 62 70 78
56 55 67 89 98 88 74 69
60 50 70 119 141 116 80 64
69 51 71 128 149 115 77 68
74 53 64 105 115 84 65 72
76 57 56 74 75 57 57 74
83 69 59 60 61 61 67 78
93 81 67 62 69 80 84 84
Все отличия значений элементов исходного и восстановленного бло-
ков возникают вследствие самой природы сжатия с потерями, явля-
ющегося сутью JPEG процедур сжатия и восстановления. В данном
примере, ошибки восстановления находятся в диапазоне от —14 до +11
и распределены следующим образом:
-6 —9 -6 2 11 -1 -6 -5
7 4 -1 1 11 -3 -5 3
2 9 —2 -6 -3 -12 -14 9
-6 7 0 —4 -5 -9 —7 1
—7 8 4 -1 11 4 3 —2
3 8 4 —4 2 11 1 1
2 2 5 -1 -6 0 —2 5
-6 —2 2 6 —4 —4 -6 10
Среднеквадратическая ошибка отклонения, появившаяся в результа-
те всего процесса сжатия и восстановления, составляет приблизи-
тельно 5,9 уровней яркости. 1
Блок пикселей, восстанавливаемый в предыдущем примере, распо-
ложен почти в центре правого глаза снимка женщины на Рис. 8.38(a). За-
метим, что как в исходном, так и в восстановленном блоках имеется пик
значений яркости в пятом элементе четвертого ряда, что соответствует
блику на зрачке. Наличие такого локального пика и привело к заметно-
му увеличению среднеквадратической ошибки отклонения восстанов-
ленного блока по сравнению со средней ошибкой по всему восстанов-
ленному изображению. Фактически она оказалась вдвое выше, чем у
восстановленного изображения на Рис. 8.38(a), которое также было
сжато тем же JPEG алгоритмом последовательного кодирования. При-
чина в том, что многие блоки на исходном изображении попадают на уча-
8.6. Стандарты сжатия
стки с почти постоянным значением, и могут быть представлены с ма-
лыми ошибками. На Рис. 8.38(6) представлен еще один результат сжа-
тия изображения JPEG алгоритмом последовательного кодирования.
JPEG 2000
Стандарт JPEG 2000, хотя он еще окончательно формально не принят,
расширяет исходный стандарт JPEG, предоставляя большую гиб-
кость, как при сжатии полутоновых неподвижных изображений, так
и при доступе к самим сжатым данным. Так, например, отдельные ча-
сти изображения, сжатого по стандарту JPEG 2000, могут быть извле-
чены для передачи, хранения, воспроизведения или редактирования.
Сжатие по стандарту J PEG 2000 основано на методах вейвлет-коди-
рования, рассмотренных в Разделе 8.5.3. Квантование коэффициен-
тов осуществляется по-разному в разных масштабах и диапазонах
(полосах), а сами квантованные коэффициенты кодируются ариф-
метическим кодом как битовые плоскости (см. Раздел 8.4). Согласно
определениям стандарта [1SO/IEC, 2000], процедура кодирования
изображения состоит в следующем.
Первым шагом процедуры кодирования является сдвиг значения
среднего уровня яркости, осуществляемый вычитанием из неотрицатель-
ных значений отсчетов кодируемого изображения величины 2й-1, где п —
число битов в элементах изображения. Если изображение имеет более
одной компоненты — как, например, красная, зеленая и синяя компо-
ненты в случае цветного изображения — каждая компонента сдвигает-
ся независимо. Если компонент в точности три, то они дополнительно
могут быть декоррелированы с помощью линейного преобразования
компонент. Согласно стандарту, преобразование компонент может быть
обратимым (преобразование целых значений в целые, используемое в об-
ратимом вэйвлет-преобразовании 5-3 без потерь)3^, или необратимым (пре-
образование действительных значения в действительные, используе-
мое в необратимом вэйвлет-преобразовании 9-7 с потерями). Так,
необратимое преобразование компонент состоит в следующем:
Го(л,у) = О,299/о(х,у)+О,587/|(х,у)+О,144/2(х,у);
У| (х,У) = 16875/р (х, у) - 0,33126 7] (х, у) + 0,5 /2 (х, у); (8.6-1)
Г2 (х, у) = 0,5 /0 (х, у) - 0,41869/, (х, у) - 0,08131 /2 (х, у),
39 В обозначении вэйвлет-преобразования а-b число (а) означает количество коэф-
фициентов низкочастотного, а (Ь) — высокочастотного фильтров анализа. В стандар-
те приняты вэйвлет-преобразования 5-3 и 9-7. — Прим, перев.
ТТЛ Глава 8. Сжатие изображений
где 10, 7| и /2 — сдвинутые влево по оси яркости значения входных ком-
понент, a Yq, У] и К2 — соответственные значения декоррелирован-
ных компонент. Если входными компонентами являются красная,
зеленая и синяя составляющие цветного изображения, то формулы
(8.6-1) соответствуют цветовому преобразованию из пространства
RG'ff в пространство У' СЛСГ [Poynton, 1996]40 41 42. Цель преобразования
состоит в улучшении эффективности сжатия; компоненты У] и У2 яв-
ляются разностными изображениями, гистограммы которых имеют яр-
ко выраженные пики вблизи нуля.
После того, как изображение сдвинуто по уровням яркости и, воз-
можно, декоррелировано, как правило, оно разбивается на непересе-
кающиеся блоки — тайлы^. Тайлы представляют собой прямоуголь-
ные массивы пикселей, и содержат одинаковую относительную долю
всех компонент изображения. Тем самым, в процессе разбиения на об-
ласти создаются компоненты тайла (тайл-компоненты), которые мо-
гут выделяться и восстанавливаться независимо, при условии сущест-
вования простого механизма для доступа и/или управления этими
небольшими областями закодированного изображения.
Затем вычисляется одномерное дискретное вейвлет-преобразование
по строкам и по столбцам каждой компоненты тайла. Сжатие без потерь
(обратимое вэйвлет-преобразование 5-3) основано на использовании
коэффициентов уточняющих последовательностей для масштабирующей
функции и вейвлет-функции системы биортогональных вейвлетов [Le
Gall, Tabatabai, 1988]. Для нецелых значений коэффициентов преобразо-
вания задается процедура округления. В системах сжатия с потерями
(необратимое вэйвлет-преобразование 9-7) применяют коэффициенты
уточняющих последовательностей для масштабирующей функции и
вейвлет-функции системы вейвлетов, описанной в [Antonini, Barlaud,
Mathieu, Daubechies, 1992]. В каждом из случаев преобразование вычис-
ляется посредством быстрого вейвлет-преобразования, рассмотренного
в Разделе 7.4, или с помощью так называемой лифтинг^-схемы [Mallat,
40 Цветовое пространство RGIY есть вариант градационной коррекции линейного цве-
тового пространства АСЯ, рекомендованного МКО — Международной комиссией по
освещению (CIE — Commission Internationale de L’Eclairage). Y' есть яркость, a Cb и
Cr — две цветоразности (т.е. масштабированные значения ff - Y' и R' - Y').
41 В оригинале — tiles. - Прим, перев.
Данный раздел изобилует терминами, почерпнутыми из материалов, касающихся стан-
дарта кодирования JPEG 2000. Не для всех из них удалось подобрать удачный русско-
язычный термин. По тем или иным причинам часть терминов было решено оставить
в англоязычном произношении. — Прим, перев.
42 В оригинале — lifting. — Прим, перев.
1999]. Коэффициенты, необходимые для построения блока фильтров
анализа необратимого быстрого вэйвлет-преобразования (БВП) 9-7,
приведены в Таблице 8.20. Реализация альтернативной лифтинг-схемы
требует шести последовательных операций:
У(2л+1) = Х(2п +1) + а[ X (2л) + Х(2п + 2)],
Y(2n) = Х(2п)+р[У(2л -1) + У(2л + Г)],
У(2л +1) = У(2л +1) + у] У(2л) + У(2л + 2)],
У(2л) = У(2л) + 8[У(2л-1) + У(2л + 1)],
Y(2n + l) = -XY(2n+l)
Y(2n)=Y(2n)/К,
z0 — 3 < 2л +1 < /'] + 3:
z0 - 2 < 2л < z) + 2;
/0-1<2л + 1</1+1; (86 2)
Zq < 2л < Z|;
z’o <2л + 1<ф
Zq <2л</|.
Здесь А" есть преобразуемая тайл-компонента, У — результат преоб-
разования, a zq и Z] задают положение тайл-компоненты внутри ком-
поненты полного изображения. То есть, они являются индексами
первого отсчета преобразуемой строки или столбца тайл-компонен-
ты (z'q), и того отсчета, который следует непосредственно за послед-
ним отсчетом (z’i). Переменная л принимает значения в зависимос-
ти от значений z'q и г’|, а также от того, какая из шести операций
выполняется. Для л < г0 или л > q, А(л) получается симметричным про-
должением X', например, X(iq - 1) = АХ/’о + 1), A(zq - 2) = AVo + 2),
A(z’|) = X(i\ - 2), X(ii + 1) = А(/| - 3). Поокончании операций лифтин-
га значения Ус четными индексами будут совпадать с результатами на
выходе низкочастотного БВП фильтра анализа, а значения Ус нечет-
ными индексами — с результатами на выходе высокочастотного БВП
фильтра анализа. Параметры лифтинга составляют: ос=— 1,586134342,
р=-0,052980118, у=0,882911075, 8 = 0,433506852, а коэффициент
К= 1,230174105.
Таблица 8.20. Импульсные характеристики низкочастотного и высокочас-
тотного фильтров анализа для необратимого вейвлет-преобразования 9-7,
применяемого в случае сжатия с потерями.
Номера позиций фильтра Коэффициенты высокочастотного фильтра анализа Коэффициенты низкочастотного фильтра анализа
0 -1,115087052456994 0,6029490182363579
±1 0.5912717631142470 0,2668641184428723
±2 0,05754352622849957 -0,07822326652898785
±3 -0,09127176311424948 -0,01686411844287495
±4 0 0,02674875741080976
Глава 8. Сжатие изображений
Только что описанное преобразование дает в результате четыре со-
ставляющих — низкочастотное приближение тайл-компоненты, а так-
же ее вертикальные, горизонтальные и диагональные высокочастотные
детали. Повторное применение преобразования NL раз к полученным
на предыдущей итерации коэффициентам низкочастотного приближе-
ния, дает в результате /V/ -масштабное вейвлет-преобразование. Про-
странственное разрешение соседних масштабов различается вдвое,
причем самый крупный масштаб содержит наиболее точное прибли-
жение исходной тайл-компоненты. Как можно предположить из
Рис. 8.46, где приведена стандартная система обозначений для случая
Nl = 2, масштабное преобразование общего вида содержит + 1
составляющую часть, коэффициенты которых обозначаются а/,, где
b = NlLL, \HL, \LH, \HH. Стандарт не определяет число мас-
штабов, которые должны быть вычислены.
Когда компонента тайла обработана, общее число коэффициентов
преобразования равно числу отсчетов в исходной тайл-компоненте,
однако важная визуальная информация сосредоточена только в неболь-
шом числе коэффициентов. Для уменьшения числа битов, необходи-
мых для представления преобразования, коэффициент а^и, v) со-
ставляющей b разложения квантуется в величину q^u, v) при помощи
преобразования
a2££<W’ v)
«2///X«, V)
а\нн^ v)
1
Рис. 8.46. Система обозначений JPEG 2000 для коэффициентов двухмасштаб-
ного вейвлет-преобразования тайл-компоненты и число дополнительных би-
тов разложения.
8.6. Стандарты сжатия
qb(u,v) = sgn(ab(u,v))-
АЛ
(8.6-3)
где sgn( ) — знак числа, [•] — целая часть числа, а шаг квантования Аь
составляет
АЛ = 2кь~гь
21
(8.6-4)
Здесь Rb — номинальный динамический диапазон составляющей Ь, а £Ь
ить — число битов, отводимых на значения порядка и мантиссы ее ко-
эффициентов. Номинальный динамический диапазон составляющей
b есть сумма числа битов, используемых для представления исходно-
го изображения, и числа дополнительных битов разложения составля-
ющей Ь", число дополнительных битов приведено цифрами в кружоч-
ках на Рис. 8.46. Так, для составляющей b = \НН требуется 2
дополнительных бита разложения.
В случае сжатия без потерь, ть = 0, Rb = Eb, a Ab = 1. Для необра-
тимого сжатия в стандарте не указывается никакого конкретного ша-
га квантования. Вместо этого, число битов порядка и мантиссы долж-
но передаваться декодеру или вместе с каждой составляющей, и это
называется явным квантованием, или же только с составляющей NbLL,
что называется неявным квантованием. В последнем случае осталь-
ные составляющие квантуются с использованием значений парамет-
ров, вычисленных из параметров составляющей NbLL. Полагая, что
Го и т$ — число битов, отводимых для составляющей N/LL, параме-
тры для составляющей b вычисляются следующим образом:
. я (8.6-5)
eZ> = е0 + nsdb ~ ns“0 ’
где nsdb обозначает число уровней разложения составляющей от ис-
ходной тайл-компоненты изображения до составляющей Ь.
Финальными шагами процесса кодирования являются упаковка би-
тов коэффициентов^, арифметическое кодирование, формирование
слоев битового потока и образование пакетов. Коэффициенты каждой
трансформированной полосы тайл-компоненты размещаются в пря-
моугольных блоках, называемых кодовыми блоками, которые кодиру-
ются независимо по битовым плоскостям. Начиная с наиболее значащей
43 В оригинале — coefficient bit modeling. — Прим, перев.
битовой плоскости с ненулевым элементом, каждая битовая плоскость
обрабатывается за три прохода. Каждый бит из битовой плоскости ко-
дируется только на одном из трех проходах, называемых распростране-
ние значащего разряда, уточнение значения и подчистка^. Полученные ре-
зультаты затем арифметически кодируются и группируются вместе
с аналогичными проходами других кодовых блоков того же тайла, фор-
мируя слои&. Слой — объединение кодовых блоков тайла одного и то-
го же уровня разложения. Разделение на слои позволяет по отдельнос-
ти кодировать уровни разложения вейвлет-преобразования, обеспечивая
тем самым при декодировании необходимую масштабируемость по про-
странственному разрешению. Полученные слои в конце концов делят-
ся на пакеты, предоставляя дополнительную возможность выделения
пространственных областей интереса из общего кодового потока. Паке-
ты являются основными единицами закодированного потока данных.
В декодере JPEG 2000 описанные выше операции выполняются
в обратном порядке. Первоначально, на основании указываемого поль-
зователем интересующего фрагмента изображения и точности его вос-
произведения, осуществляется восстановление нужных полос соот-
ветствующих тайл-компонент. Для этого из общего потока данных
выбираются необходимые пакеты нужных слоев, восстанавливается би-
товый поток, осуществляется арифметическое декодирование и распа-
ковываются биты коэффициентов. Хотя кодер мог закодировать Мь би-
товых плоскостей конкретной полосы, пользователь, благодаря
особенностям вложенности кодового потока, может выбрать восстанов-
ление лишь части Nb битовых плоскостей. Это эквивалентно кванто-
ванию коэффициентов кодового блока с шагом размера 2Mh~Nh. Все
не распакованные биты обнуляются, и результирующие коэффициен-
ты, обозначаемые Qb{uyV), восстанавливаются следующим образом
[qb(u,v)+2Mb
0
Rgb^V) =
при ^(ы,т)>0;
при qb(u,v)<Q: (8.6-6)
при qb(u,v) = Q,
где Rqb(u,v) означает восстановленное значение коэффициента, а
Nb(u, v) — число декодируемых битовых плоскостей для qb(u,v)„ По-
44 В оригинале — significance propagation, magnitude refinement, и cleanup. — Прим, перев.
45 В оригинале — layers. — Прим, перев.
8.6. Стандарты сжатия
лученные значения коэффициентов затем подвергаются обратным
преобразованиям по столбцам и строкам, используя блок фильтров об-
ратного БВП, коэффициенты которого берутся из Таблицы 8.20 и
уравнения (7.1-15), или с помощью следующей лифтинг-операции
X(2n) = KY(2n),
Jf(2z? + 1) = (-1/А')-K(2w+1),
Х(2п) = Х(2п) - 8[ Х(2п-1) + Х(2п+1)],
Х(2п + \) = Х(2п+\)-у[Х(2п)+ Х(2п+2)],
Х(2п) = X(2ri) - р[ Х(2п -1) + Х(2п+1)],
Х(2п +1) = Х(2п +1) - ос[ Х(2п) + Х(2п+ 2)],
z0-3< 2п< /|+ 3
z'o-2<2w+l< /|+2
z'o-3<2«< /] + 3
z0 - 2 < 2 w+1 < Z| + 2
z‘o-l<2w< z’i + 1
z‘o<2w+l< z’j.
Параметры a, p, у, 8 и К здесь те же, что использовались для уравне-
ний (8.6-2). Если необходимо, осуществляется симметричное про-
должение значений коэффициентов Y(n) по строкам и столбцам. Фи-
нальными операциями декодирования являются сбор тайл-компонент,
обратное преобразование компонент (если требуется) и обратный
сдвиг значения среднего уровня яркости. В случае необратимого вэйв-
лет-преобразования 9-7, обратное преобразование компонент вычис-
ляется по формулам
/0(х,у) = Г0(х, у) + 1,402Г2(х,у);
/1(х,у) = Го(х,у)-О,34413Г1(х,у)-О,71414Г2(х,у); (8.6-8)
/2(х,у)=Г0(х,у) + 1,772У)(х,у),
после чего к полученным значениям прибавляется величина 2й-1, где
п — число битов в элементах изображения. Изображения на Рис. 8.40
и 8.41 Раздела 8.5.3, иллюстрирующие сжатие с коэффициентами от
34:1 до 167:1, были получены с помощью алгоритма JPEG 2000 сжа-
тия с потерями.
8.6.3. Телевизионные стандарты сжатия
Стандарты сжатия видеоданных (телевизионные стандарты) расши-
ряют трансформационные методы сжатия неподвижных изображений,
рассмотренные в предыдущем разделе, в смысле сокращения вре-
менной или межкадровой избыточностей. Хотя в настоящее время име-
ется целый ряд различных стандартов кодирования, тем не менее,
большинство из них основано на использовании похожих методов
сжатия видеоданных. В зависимости от предназначения, стандарты
группируются в две большие категории: (1) стандарты для видеокон-
ференций, и (2) мультимедийные стандарты.
Многие из стандартов для видеоконференций, включая Н.261 (на-
зываемый также РХ64), Н.262, Н.263, и Н.320, определены Междуна-
родным Союзом по Телекоммуникациям (International
Telecommunications Union — ITU), являющимся преемником Между-
народного Консультативного Комитета по Телеграфии и Телефонии
(МККТТ). Стандарт Н.261 предназначен для применения при скоро-
стях, соответствующих обычным телефонным линиям, и обеспечива-
ет передачу видеоданных по линиям Т146 с задержками не более 150 мс.
(при задержках более 150 мс. у наблюдателя частично теряется ощу-
щение визуальной обратной связи). Стандарт Н.263, наоборот, пред-
назначен для передачи видеоданных с очень низкими скоростями от
10 до 30 Кбит/сек., а стандарт Н.320, являющийся расширением Н.261,
разработан с учетом полосы пропускания Цифровых сетей с интегри-
рованными услугами47 (Integrated Services Digital Network — ISDN). В
каждом из стандартов используется схема кодирования на основе
дискретного косинусного преобразования (ДКП) с компенсацией
движения. Осуществить оценку движения по преобразованным дан-
ным затруднительно, поэтому данная операция осуществляется в про-
странственной области. Блоки пикселей, называемые макроблоками,
сравниваются с блоками предыдущего кадра, находится величина
смещения блока, обеспечивающая наименьшую ошибку предсказания,
которая и является параметром компенсации движения. Ошибка
предсказания затем трансформируется ДКП по блокам 8x8 пиксе-
лей, квантуется и кодируется для передачи или хранения.
Мультимедийные стандарты сжатия видеоданных для персонали-
зированного телевидения, цифровое широковещательное телевидение
высокой четкости (ТВЧ), а также обслуживание баз данных изображе-
ний/видео используют близкие методы оценки движения и кодиро-
вания. Три основных стандарта — MPEG-1, MPEG-2 и MPEG-4 бы-
ли разработаны Группой Экспертов по Движущимся Изображениям
(Moving Picture Experts Group — MPEG), действующей под эгидой
ISO и МККТТ. MPEG-1 является стандартом кодирования «развлека-
46 Понятие линии Т1 было введено Bell system для цифровой передачи голоса на ко-
роткие расстояния от 15 до 80 км. Линия Т1 позволяет мультиплексировать во вре-
мени, оцифровывать и кодировать методом импульсно-кодовой модуляции со ско-
ростью 1.544 Мбит/сек. сигналы двадцати четырех телефонных каналов.
47 Два ISDN «В»-канала обеспечивают удовлетворительную полосу пропускания
(т.е. 128 Кбит./с.) для передачи сжатых изображений размерами 320x240 с частотой
15 кадров в секунду.
8.6. Стандарты сжатия
тельного качества», предназначенного для записи и воспроизведе-
ния видеоданных на цифровые носители типа компакт-дисков
(CD-ROM); он обеспечивает скорость потока данных около 1,5 Мбит/с.
MPEG-2 ориентирован на приложения, требующие телевизионного
качества с уровнем между NTSC/PAL48 и CCIR 60149 при скорости пе-
редачи от 2 до 10 Мбит/с. —данный параметр соответствует диапазо-
ну кабельного телевидения и узкополосных систем спутникового ве-
щания. Целью как MPEG-1, так и MPEG-2 является обеспечение
эффективности передачи и хранения аудио- и видеоданных (АВ).
MPEG-4, с другой стороны, обеспечивает (1) повышение эффектив-
ности сжатия видеоданных; (2) интерактивность, основанную на со-
держании, например, объектно-ориентированный доступ к АВ-объ-
ектам, или эффективную интеграцию натурных и синтезированных
данных; (3) универсальный доступ, допускающий неустойчиво рабо-
тающее оборудование, возможность добавлять или удалять АВ-объек-
ты или менять масштабы разрешения объектов. Хотя подобные функ-
циональные возможности и приводят к необходимости сегментации
видеоданных на объекты произвольного вида, тем не менее, сегмен-
тация как таковая не является частью стандарта. Значительная часть
видеоданных (например, компьютерные игры) изготавливается и лег-
кодоступна в форме видео объектов. MPEG-4 нацелен на скорости пе-
редачи от 5 до 64 Кбит/с. для мобильных и Коммутируемых телефон-
ных сетей общего доступа (Public switched telephone network — PSTN),
а также на скорости до 4 Мбит/с. для передачи ТВ и фильмов. Кроме
того, он поддерживает передачу как с постоянной, так и с переменной
скоростями кодирования.
Также как и стандарты видеоконференций ITU, стандарты MPEG по-
строены на основе гибридной блоковой схемы ДИКМ/ДКП кодирова-
ния. На Рис. 8.47 показан типичный MPEG-кодер. Он использует избы-
точности как внутри кадра, так и между соседними кадрами, однообразие
движения между кадрами, а также психофизические свойства зритель-
ной системы человека. Входом кодера являются массивы 8x8 пиксе-
лей, называемые блоками изображения. Стандартами определены также
макроблоки размерами 2x2 блока изображения (т.е. массивы из 16x16
пикселей) и так называемые слайсы — наборы из последовательных не-
перекрывающихся макроблоков. Для цветного видео макроблок состо-
48 NTSC и PAL являются, соответственно, аббревиатурами National Television System
Committee и Phase Alternate Line. Оба являются композитными стандартами цветного
телевидения.
49 CCIR является аббревиатурой International Radio Consultive Committee.
Глава 8. Сжатие изображений
Рис. 8.47. Принципиальная схема ДИКМ/ДКП кодера для сжатия видео с ком-
пенсацией движения.
ит из четырех блоков яркости, обозначаемых от Y\ до Y4, и двух блоков
цветоразностей Q, и Сг. Напомним, что Q вычисляется как разность си-
него и яркости, а Сг — как разность красного и яркости. Поскольку раз-
решающая способность глаза в области цветового зрения значительно
ниже, чем в области черно-белого (т.е. яркостного) зрения, сигналы
цветоразностей обычно оцифровывают с вдвое более низким прост-
ранственным разрешением, чем сигнал яркости. Это приводит к соот-
ношению числа отсчетов между компонентами Y''.Cd:Cr равному 4:1:1.
Блоки основного потока данных, отмеченные серым цветом на
Рис. 8.47, аналогичны операциям преобразования, квантования и не-
равномерного кодирования JPEG-кодера. Принципиальная разни-
ца заключается во входных данных, которые могут являться либо
обычным блоком данных изображения, либо разностью между обыч-
ным блоком и его предсказанием, сделанным на основе предыдущего
и/или последующего кадров видеопоследовательности. Это приводит к
трем основным типам кодируемых кадров видеопоследовательности:
1. Опорный или независимый кадр (1-кадр). 1-кадр кодируется незави-
симо от всех как предыдущих, так и последующих кадров видео-
последовательности. Из всех трех возможных типов кадров он на-
иболее похож на JPEG-кодированное изображение. Более того, он
является точкой отсчета для построения последовательности из Р-
и М-кадров. Наличие 1-кадров обеспечивает произвольный доступ
к видеопоследовательности, легкость ее редактирования, а также
Заключение
защиту от распространения ошибок передачи. Как результат, все
стандарты требуют периодического вставления подобных кадров
в сжатый кодовый поток.
2. Предсказываемый кадр {Р-кадр). Р-кадр есть сжатая разность между
текущим кадром и его предсказанием, сделанным на основе преды-
дущего I- или Р-кадра. Разность формируется в блоке вычисления
разности на Рис. 8.47. Предсказание включает компенсацию движе-
ния, осуществляемую смещением декодированных макроблоков в
окрестности своей центральной точки, и вычислением меры корре-
ляции (например, суммы квадратов разностей значений пикселей
в предсказываемом изображении и сдвинутом макроблоке); эти
операции показаны в нижней части схемы на Рис. 8.47. В действи-
тельности процесс поиска оптимального предсказания часто про-
исходит на более точном уровне, чем размер одного элемента (на-
пример, возможно смещение макроблока на 1/4 элемента), что
требует осуществления интерполяции значений элементов до вычис-
ления меры корреляции. Найденный вектор движения затем коди-
руется неравномерным кодом и передается как часть общего коди-
рованного потока данных.
3. Двунаправленный кадр (В-кадр). В-кадр есть сжатая разность меж-
ду текущим кадром и его предсказанием, основанном на интерполя-
ции между предыдущим I- или Р-кадром и последующим Р-кадром.
Соответственно, декодер должен иметь доступ как к предшествующим
по времени, так и к будущим опорным кадрам. Для этого кодируемые
кадры перед передачей перестанавливаются, так, что на вход декоде-
ра они поступают в нужном для декодирования порядке; затем деко-
дер восстанавливает первоначальную очередность кадров.
Кодер, показанный на схеме Рис. 8.47, должен порождать поток би-
тов, соответствующий пропускной способности имеющегося канала
видеоданных. Для этого в схему введен контроллер скорости передачи,
который на основе оценки заполненности буфера выхода управляет зна-
чением параметров квантования. При заполнении буфера квантова-
ние становится более грубым, так, что в буфер поступает уменьшен-
ный битовый поток.
Заключение
Главные цели настоящей главы заключались в том, чтобы изложить те-
оретические основы сжатия цифровых изображений, а также опи-
сать наиболее распространенные методы сжатия, составляющие яд-
ро существующей на данный момент технологии. Хотя материал
25 А-223
представлен на вводном уровне, его глубина и широта достаточны
для того, чтобы стать основой для дальнейшего самостоятельного
изучения этой области. Приводимые ниже ссылки д ают только отправ-
ные точки для знакомства с огромным объемом литературы, посвящен-
ным сжатию изображений и смежным вопросам. В добавление к мно-
гочисленным применениям методов сжатия в обработке черно-белых
изображений, эти методы играют все более важную роль в архивном
хранении изображений документов, а также при передаче данных,
что следует из появления международных стандартов сжатия, рас-
смотренных в Разделе 8.6. Наряду с обработкой медицинских изобра-
жений, сжатие является одной из немногих областей обработки изо-
бражений, которые приобрели достаточно большую коммерческую
привлекательность, что гарантирует д альнейшее развитие имеющих-
ся широко распространенных стандартов.
Ссылки и литература для дальнейшего изучения
Вводный материал настоящей главы, изложенный в Разделах 8.1 и 8.2,
представляет теоретические основы сжатия изображений, и может
быть найден в том или ином виде в большинстве книг по обработке изо-
бражений, приведенных в конце Главы 1. Изложение материала Раз-
дела 8.1.3, касающегося вопросов улучшения квантования полуто-
нов, основано на работе [Bisignani, Richards, Whelan, 1966]. Для
получения дополнительной информации по вопросам зрительной
системы человека см. [Netravali, Limb, 1980], [Huang, 1966], [Schreiber,
Knapp, 1958], а также ссылки в конце Главы 2. Субъективные крите-
рии качества обсуждаются в [Behrend, 1960]. Коды, обнаруживающие
и исправляющие ошибки, рассматриваются в большинстве вводных
разделов монографий, посвященных теории переключательных схем
или теории конечных автоматов, а также в работах по теории инфор-
мации.
Материал Раздела 8.3 основан на нескольких прекрасных книгах
по теории информации: [Noteworthy, Abramson, 1963], [Blahut, 1987],
и [Berger, 1971 ]. Фундаментальные основы всего этого раздела были за-
ложены в классической работе К. Шеннона «Математическая тео-
рия связи» [Shannon, 1948], которую мы настоятельно рекомендуем чи-
тателю.
Описание методов кодирования без потерь, приведенные в Разде-
ле 8.4, по большей части основаны на оригинальных статьях, цитиро-
ванных в тексте, а также на указанных ниже работах. Рассматривае-
мые в них алгоритмы отражают положение дел в данной области, но
никоим образом ее не исчерпывают. Результаты, касающиеся LZW-ko-
дирования, восходят к работам [Ziv, Lempel, 1977, 1978]. Материалы
по арифметическому кодированию следуют разработкам | Witten, Neal,
Cleary, 1987]. Одно из наиболее важных применений арифметическо-
го кодирования приведено в работе [Pennebaker et al., 1988]. Дополни-
тельную информацию по вопросам кодирования битовых плоскостей
можно найти в работе (Schwartz, Barker, 1966], а также в пособии
[Rabbani, Jones, 1991], где, кроме того, рассматривается кодирование
с предсказанием без потерь. Впервые детали алгоритма пропуска бе-
лых блоков были опубликованы в работе (Huang, Tretiak, 1972]. Коди-
рование относительных адресов, а также дифференциальное кванто-
вание с предсказанием впервые были опубликованы, соответственно,
вработах [Yamazaki,Wikahara, Teramura, 1976] и [Huang, Tretiak, 1972].
Адаптивный предсказатель, описываемый уравнением (8.5-19) взят из
(Graham, 1958].
В Разделе 8.5 приведены материалы, касающиеся основных под-
ходов к сжатию с потерями. На этих способах основано множество дру-
гих методов, среди которых заслуживают внимание следующие. Гиб-
ридное кодирование [Habibi, 1974] — схема, комбинирующая одномерное
трансформационное кодирование и ДИ КМ для получения почти тех
же характеристик, что и двумерное сжатие при меньшем объеме вы-
числений. Субполосное кодирование [Waods, O’Neil, 1986], при котором
изображение преобразуется в набор изображений (с различающими-
ся пространственными характеристиками), которые могут быть коди-
рованы по-отдельности при помогли ДИ КМ-кодирования. Межкад-
ровое кодирование [Roese et al., 1977], в котором избыточность между
соседними кадрами видеопоследовательности сокращается на осно-
ве кодирования с предсказанием или трансформационного кодирова-
ния. Кроме того, с указанными методами связаны и многие другие ме-
тоды кодирования с потерями, которые, среди прочих, включают
следующие. Блоковое кодирование с ограничениями [Delp, Mitchell,
1979], в котором каждому из лхл блоков изображения соответствует
1-битовый квантователь. Векторное квантование [Linde et al., 1980], в
котором изображение раскладывается на векторы, содержащие пик-
сели, коэффициенты преобразования и т.д., которые, согласно кодо-
вой книге, сопоставляются с возможными векторами и кодируются с
целью обеспечить наилучшее соответствие. Наконец, иерархическое ко-
дирование [Knowlton, 1980], обычно приводящее к построению пира-
мидальной структуры набора данных, которая позволяет при после-
довательном доступе получать все лучшие и лучшие приближения
исходного изображения. Эти работы не обязательно повторяют ори-
гинальные разработки; они дают отправные точки для дополнитель-
ного изучения методов. Другими статьями и книгами, представляю-
Глава 8. Сжатие изображений
щими интерес, являются [Tasto, Wintz, 1971], [Gharavi, Tabatabai, 1988],
[Baylon, Lim, 1990], [Candy et al., 1971], [Jain, Jain, 1981], |Healy,
Mitchell, 1981], [Lerna, Mitchell, 1984], [LJdpikar, Raina, 1987], [Gray,
1984], [Equitz, 1989], [Sezan, et al., 1989], [Tanimoto, 1979], [Blume,
Fand, 1989], [Rabbani, Jones, 1991], [Storer, Reif, 1991]. Почти каждый
из номеров журнала IEEE Transactions on Image Processing содержит
различные статьи по сжатию неподвижных изображений или видео-
последовательностей, среди которых много статей по вейвлет-коди-
рованию, фрактальному сжатию, векторному квантованию, компен-
сации движения в видеопоследовательности. В качестве ссылок, а
также для дальнейшего изучения, см., например, [Boulgouris et al.,
2001], [Martin, Bell, 2001], [Chen, Wilson, 2000], [Hartenstein et al.,
2000], [Yang, Ramchandran, 2000], [Meyer et al., 2000].
Раздел 8.6 главным образом основывается на проектах и формаль-
ных стандартах ISO и МККТТ (CCITT). Эти документы доступны
через соответствующие организации, занимающиеся разработкой
этих стандартов, или через Американский национальный институт
стандартов (American National Standards Institute — ANSI)50. В качест-
ве дополнительных ссылок по стандартам сжатия можно указать
[Hunter, Robinson, 1980], [Ang et al., 1991], [Fox, 1991], [Pennebaker,
Mitchell, 1992], [Bhatt et al., 1997], [Sikora, 1997], [Bhaskaran,
Konstantinos, 1997], [Nganetal., 1999], [Weinberger et al., 2000], [Symes,
2001].
Проблеме сжатия изображений посвящено много обзорных статей.
Особого внимания заслуживают обзоры: [Netravali, Limb, 1980], [А. К.
Jain, 1981], специальный выпуск по системам передачи изображений
в журнале {IEEE Transactions on Communications, 1981], специальный вы-
пуск по кодированию графики в сборнике {Proceedings of IEEE, 1980],
специальный выпуск по системам коммуникации в сборнике
{Proceedings of IEEE, 1985], специальный выпуск по сжатию видео-
последовательностей в журнале {IEEE Transactions on Image Processing,
1994], а также специальный выпуск по векторному квантованию в
журнале {IEEE Transactions on Image Processing, 1996].
50 В настоящее время большинство из необходимой документации по стандартам сжа-
тия можно найти через Интернет. — Прим, перев.
Задачи
8.1 (а) Может ли процедура неравномерного кодирования сжать
изображение с эквализованной гистограммой, имеющее
2я уровней яркости? Поясните.
(б) Может ли такое изображение иметь межэлементную из-
быточность, которую можно было бы использовать для
сжатия данных?
8.2 Одна из процедур кодирования длин серий, описанная в Раз-
деле 8.1.2, включает (1) кодирование серий длиной 0 или 1 (не
обеих) и (2) присвоение специального кода началу каждой
строки с целью снижения эффекта ошибок при передаче. Од-
ной из возможных кодовых пар является (х^, гк), где хк и гк пред-
ставляют, соответственно, координату начала и длину А-й се-
рии. Код (0,0) используется для начала каждой новой строки,
(а) Выведите общее выражение для максимального числа се-
рий на строке изображения, требуемого для обеспечения
эффекта сжатия двоичного изображения размерами 2ях2я.
(б) Вычислите максимально допустимое значение для п = 10.
*8.3 Рассмотрите 8-элементную строку полутонового изображе-
ния, содержащую значения {12, 12, 13, 13, 10, 13, 57, 54}, кото-
рые равномерно квантованы с 6-битовой точностью. Сконст-
руируйте 3-битовый МКЯ код (см. Пример 8.3).
8.4 Вычислите среднеквадратическую ошибку и отношение сиг-
нал-шум для декодированного сигнала в задаче 8.3.
8.5 (а) Используйте код Хэмминга (7, 4) для кодирования МКЯ-
квантованных данных из Таблицы 8.2.
*(б) Определите, какой бит, если таковой есть, искажен в зако-
дированном по Хэммингу кодовом сообщении 1100111,
1100110 и 1100010. Каковы декодированные значения?
*8.6 Основание е единиц информации обычно называют натураль-
ным, а основание 10 единиц информации называют десятич-
ным. Вычислите коэффициенты преобразования, необходи-
мые для связи этих единиц информации с основанием 2
единицы информации (битом).
*8.7 Докажите, что для источника без памяти с q символами мак-
симальное значение энтропии составляет log q, которое до-
стигается тогда и только тогда, когда все символы источника
равновероятны. Указание', рассмотрите величину log q-H(z) и
воспользуйтесь неравенством logx<x- 1.
8.8 Вычислите различные вероятности, связанные с информацион-
ным каналом, в котором А = {0, 1}, В= {0, 1}, z = [0,75, 0,25] ^и
Глава 8. Сжатие изображений
2
3 3
1 9
10 10
Вычислите значения Р(а = 0), Р(а = 1), Р(Ь = 0), P{b = 1),
Р(Ь = 0|а = 0), P(b = 0|о = 1), Р{Ь = 1|о = 0), P(b = 1|а = 1),
Р(а = 0|6 = 0), Р(а = 0|6 = 1), Р(а = 1|6 = 0), Р(а = 1|6 = 1),
Р{а = 0, 6 = 0), Р(а = 0,b = 1), Р(а = 1, Ь = 0), и Р(а =1,6= 1).
*8.9 Рассмотрите двоичный источник и ДСК из примера в Разде-
ле 8.3.2 с pbs = 3,4 и ре = 1,3.
(а) Чему равна энтропия источника?
(б) Насколько становится меньше неопределенность на входе
канала, если известен выход?
(в) Как эта разница в неопределенности называется, и как она
численно связана со скоростью канала?
8.10 Двоичный канал со стиранием — это такой канал, в котором
существует конечная вероятность Р того, что передаваемый
символ не будет принят. Канал имеет три возможных состоя-
ния на выходе: 0, символ стерт (нет выходного символа) и 1.
Этим трем вариантам выхода соответствуют три строки матри-
цы двоичного канала со стиранием
Q=
1-Р
₽
о
о
₽
1-р
(а) Найдите скорость канала.
*(б) Что бы Вы предпочли: двоичный симметричный канал с ве-
роятностью ошибки 0,125, или канал со стиранием с веро-
ятностью стирания Р = 0,5?
8.11 Скорость как функция искажения для гауссова источника без
.. 2
памяти с произвольным средним и дисперсией ст по отноше-
нию к критерию среднеквадратической ошибки ([Berger, 1971])
равна
11 °2
2IOg«
при 0<Л<о2;
о
при D>o2.
*(а) Постройте график этой функции.
(б) Чему равно Лтах?
(с) Если допустимый уровень искажений составляет 75% дис-
персии источника, чему равно максимально возможное
сжатие, которое может быть достигнуто?
8.12 (а) Сколько кодов Хаффмана можно построить для трехсим-
вольного источника?
(б) Постройте их.
8.13 (а) Вычислите энтропию источника, вероятности символов
которого заданы в Таблице 8.1.
(б) Постройте код Хаффмана для источника символов и объ-
Символ Вероятность
а 0,2
е 0,3
i 0,1
о 0,2
и 0,1
! 0,1
ясните все различия между построенным кодом и Кодом 2
таблицы.
(в) Постройте наилучший В]-код для этого распределения.
(г) Постройте наилучший двухбитовый двоичный сдвиговый
код.
(д) Разделите набор символов на два блока по четыре и пост-
ройте наилучший сдвиговый код Хаффмана.
(е) Вычислите среднюю кодовую длину для каждого кода и
сравните ее с энтропией, вычисленной в части (а) задачи.
*8.14 Процесс арифметического декодирования является обратным
по отношению к процессу кодирования. Декодируйте сообще-
ние 0,23355, сформированное моделью кода
8.15 Используйте алгоритм кодирования LZW из Раздела 8.4.2 для
кодирования 7-битовой строки ASCII-кода «ааааааааааа».
*8.16 Разработайте алгоритм для декодирования LZW-кодированно-
го выхода в Примере 8.12. Поскольку словарь, который ис-
пользовался при кодировании, недоступен, кодовая книга
Глава 8. Сжатие изображений
должна быть воспроизведена к моменту окончания декоди-
рования.
8.17 (а) Постройте полный 4-битовый код Грэя.
(б) Создайте общую процедуру для преобразования числа,
представленного кодом Грэя, в его двоичный эквивалент,
и используйте его для декодирования последовательности
0111010100111.
8.18 Двоичное изображение размерами 64x64 элемента закодирова-
но при помощи одномерного ПББ-кода с блоками из четырех эле-
ментов. ПББ-код для одной строки изображения выглядел как
0110010000001000010010000000, где 0 представляет блок белых
элементов.
(а) Декодируйте эту строку.
(б) Постройте одномерную итеративную ПББ-пропедуру, ко-
торая начинается с поиска целиком белых строк (блок из
64 белых элементов) и делит пополам небелые интервалы,
пока не получатся блоки из четырех элементов.
(в) Используйте Ваш алгоритм для кодирования ранее декоди-
рованной строки. Должно получиться меньшее число битов.
8.19 *(а) Объясните, почему в алгоритме кодирования относитель-
ных адресов (КОА) в качестве с' используется первый аналогич-
ный переход на предыдущей строке после точки е.
(б) Можете ли Вы предложить другой способ?
8.20 Изображение, автокорреляционная функция которого задана
в форме (8.5-12) с рЛ = 0, кодируется при помощи ДИКМ-ко-
дера с использованием предсказателя второго порядка.
(а) Сформируйте автокорреляционную матрицу R и вектор г.
(б) Найдите оптимальные коэффициенты предсказания.
(в) Определите дисперсию ошибки предсказания, которая по-
лучится в результате использования оптимальных коэф-
фициентов.
*8.21 Найдите пороговые уровни и уровни квантования квантовате-
ля Ллойда—Макса для L = 4 и равномерной функции распре-
деления вероятностей
0 в остальных случаях.
8.22 Используйте алгоритм сжатия МККТТ Группы 4 для кодиро-
вания второй строки следующего сегмента из двух строк:
01100111001111111100001
11111110001110000111111
Предположите, что начальный опорный элемент а0 располо-
жен на первом элементе второй строки сегмента.
*8.23 (а) Выпишите все члены JPEG коэффициентов DC катего-
рии разностей 3.
(б) На основании Таблицы 8.18 вычислите их коды Хаффме-
на, используемые по умолчанию.
8.24 Рентгенолог из известного исследовательского центра одного
из госпиталей недавно посетил медицинскую конференцию, где
была представлена система, которая может передавать оцифро-
ванные рентгеновские изображения размерами 4096x4096,
12-бит, по стандартной телефонной линии класса Т1. Система
передает изображения в сжатом виде с использованием мето-
дики последовательных приближений. При этом на приемной
стороне сначала восстанавливается некоторое приближение
рентгеновского снимка, которое затем постепенно улучшает-
ся до точного воспроизведения. Передача данных, необходимых
для построения первого приближения, требует от 5 до 6 с вре-
мени. Улучшения происходят (в среднем) каждые 5 или 6 с в те-
чение следующей 1 минуты, при том, что первое улучшение яв-
ляется наиболее значительным, а последнее — наименее
заметным. Данная система произвела сильное впечатление на
врача, поскольку он может начать диагностику уже при воспро-
изведении первого приближения, и закончить ее к моменту
полного безошибочного воспроизведения рентгеновского изо-
бражения. Вернувшись в госпиталь, он подал в администрацию
госпиталя запрос на покупку. К сожалению, бюджет госпита-
ля был невелик, поскольку недавно был принят на работу мо-
лодой перспективный и целеустремленный выпускник элект-
ротехнического вуза. Чтобы удовлетворить пожелания
рентгенолога, администратор дал молодому инженеру задачу
разработать такую систему. Он полагал, что разработка и созда-
ние подобной системы собственными силами окажется дешев-
ле. Госпиталь располагал некоторыми из элементов такой си-
стемы, но передача несжатого рентгеновского изображения
занимала более 2 мин. Администратор попросил инженера под-
готовить исходную блок-схему возможной системы к собранию
персонала во второй половине дня. Имея лишь немного време-
ни и экземпляр данной книги, оставшийся после недавнего
обучения, инженер смог разработать концепцию системы, ко-
Глава 8. Сжатие изображений
торая удовлетворяла условиям на скорость передачи и связан-
ным с этим требованиям к сжатию. Составьте концептуаль-
ную блок-схему такой системы, точно определив, какие имен-
но методы сжатия Вы бы рекомендовали.
8.25 Покажите, что вейвлет-преобразование, основанное на приме-
нении лифтинг-схемы, определенной уравнениями (8.6-2),
эквивалентно применению обычного блока фильтров БВП с ко-
эффициентами, заданными в Таблице 8.20. Найдите значения
коэффициентов фильтров в терминах а, (3, у, 5 и К.
8.26 Вычислите величины шагов квантования отдельных составля-
ющих для JPEG 2000 кодированного изображения, в котором
используется неявное квантование, а на мантиссу и порядок от-
ведено 8 битов составляющей 2LL.
8.27 Изобразите блок-схему MPEG-декодера, парного кодеру, при-
веденному на Рис. 8.47.
ГЛАВА 9
МОРФОЛОГИЧЕСКАЯ
ОБРАБОТКА
ИЗОБРАЖЕНИЙ
Я рос столь похожим на брата чертами и телосложением,
что люди принимали меня за него, а его — за меня.
Генри Сэмбрук Лей, Песни Кокейна, «Близнецы»
Введение
Словом морфология обычно обозначают ту область биологии, которая
занимается формой и строением животных и растений. Мы будем
использовать здесь то же слово в контексте математической морфоло-
гии — инструмента для извлечения некоторых компонент изображе-
ния, полезных для его представления и описания, например, границ,
остовов и выпуклых оболочек. Интерес также представляют морфо-
логические методы, применяемые на этапах предварительной и заклю-
чительной обработки, например, морфологические фильтрация, утон-
чение и усечение.
В математической морфологии используется язык теории мно-
жеств. Морфология как таковая предлагает единый мощный подход
для многочисленных задач обработки изображений. Множествами
в математической морфологии представляются объекты на изображе-
нии. Например, множество всех черных пикселей двоичного (двух-
градационного — т.е. содержащего только элементы со значениями
О или 1) изображения является одним из вариантов его полного мор-
фологического описания. В двоичных изображениях обсуждаемые
множества являются подмножествами двумерного целочисленного
пространства Z2 (см. Раздел 2.4.2) с элементами в виде пар чисел, т.е.
двумерных векторов (х, у), координаты которых указывают на черный
(или белый, в зависимости от соглашения) пиксель изображения.
Полутоновые цифровые изображения могут быть описаны множест-
вами, состоящими из элементов пространства Z3. В этом случае две
координаты элемента множества указывают координаты пикселя, а
третья соответствует дискретному значению яркости. Множества в
пространствах более высокой размерности могут с помощью допол-
нительных координат описывать и другие характеристики изображе-
Глава 9. Морфологическая обработка изображении
ния, например его цветовые компоненты или закон изменения во вре-
мени.
В следующих разделах вводятся в рассмотрение и иллюстрируют-
ся некоторые важные понятия математической морфологии. Многие
из представленных идей допускают формулировку в терминах «-мер-
ного евклидова пространства Еп, однако мы прежде всего интересу-
емся двоичными изображениями, состоящими из элементов Z 2.
Обобщение описанных концепций для полутоновых изображений
рассматривается в Разделе 9.6.
С материала данной главы начинается переход от методов, скон-
центрированных исключительно на обработке изображений (по смыс-
лу определения в Разделе 1.1.1, когда и на входе, и на выходе процес-
са присутствуют изображения), к таким процессам, на вход которых
по-прежнему поступают изображения, но выходными результатами
являются некоторые атрибуты, извлекаемые из этих изображений. Та-
кие инструменты, как морфология и сопутствующие ей концепции,
играют роль краеугольного камня математических основ извлечения
«смысла» изображения. Развитию и применению других подходов
к такой проблеме посвящены оставшиеся главы книги.
9.1. Начальные сведения
В этом разделе мы введем в рассмотрение некоторые базовые поня-
тия теории множеств, которые будут служить основой для осталь-
ных разделов данной главы.
9.1.1. Некоторые базовые понятия теории множеств
Пусть Л — множество в пространстве Z2. Если а = (а\,а-2) есть элемент
А, то этот факт обозначается символической записью
ае Л. (9.1-1)
В противном случае, т.е. когда а не является элементом А, использу-
ется запись
аеА. (9.1-2)
Множество, не содержащее ни одного элемента, называется пустым
множеством и обозначается символом 0.
Множество задается путем перечисления его содержимого в фи-
гурных скобках: {•}. В этой главе мы будем заниматься множествами,
9.1. Начальные сведения
элементами которых являются координаты пикселей, представляющих
объекты или другие интересующие признаки на изображении. Напри-
мер, записывая выражение в форме С = {w| w = —d, de D}, мы под-
разумеваем, что множество С состоит из элементов w, которые стро-
ятся умножением на —1 обеих координат каждого элемента множества
D.
Если все элементы множества А являются также элементами дру-
гого множества В, то говорят, что А есть подмножество множества В,
что символически обозначается
Лев. (9.1-3)
Объединение двух множеств/! и В, которое обозначается
С=Лив, (9.1-4)
есть по определению множество всех элементов, принадлежащих ли-
бо множеству Л, либо множеству В, либо обоим множествам одновре-
менно. Аналогично, пересечение двух множеств Л и В, которое обозна-
чается
Л = ЛПв, (9.1-5)
есть по определению множество всех элементов, принадлежащих од-
новременно обоим множествам Ли В.
Два множества Л и в называются непересекающимися или взаимо-
исключающими, если у них нет общих элементов. В этом случае
Лпв=0. (9.1-6)
Дополнение множества Л есть множество элементов, не содержащих-
ся в Л:
Лс={гг|м>еЛ}. (9.1-7)
Разность двух множеств Ли В обозначается Л \ В и определяется сле-
дующим образом:
Л\в = {м>|гге A,weB}=A(-]Bc. (9.1-8)
Видно, что это множество состоит из элементов Л, которые не входят
в множество В. Рис. 9.1 иллюстрирует введенные выше понятия, где
Глава 9. Морфологическая обработка изображений
Рис. 9.1. (а) Два множества А и В. (б) Объединение множеств А и В. (в) Пере-
сечение множеств Д и В. (г) Дополнение множества Д. (д) Разность множеств
Лий.
на каждом из рисунков результат выполнения той или иной операции
над множествами показан темным цветом.
Нам потребуется определить еще два понятия, которые широко
используются в области морфологической обработки изображений, но
обычно не упоминаются в элементарных учебниках по теории мно-
жеств. Центральное отражение множества В, обозначаемое В, опре-
деляется следующим образом1:
В = {w\w = Ь& В} (9.1-9)
Параллельный перенос (или сдвиг) множества А в точку z = (Zj, 1т) обо-
значается (A)z и определяется по следующему правилу:
(A)z ={c|c = a+z, ае А }. (9.1-10)
Рис. 9.2 иллюстрирует два последних определения с использованием
множеств Л и Виз Рис. 9.1. Точки на рисунке указывают местополо-
жение начала координат для каждого из множеств.
Эта операция эквивалентна повороту множества В на 180г относительно начала ко-
ординат. — Прим перев.
Рис. 9.2. (а) Сдвиг множества Д в точку Z- (6) Центральное отражение множе-
ства В. (Использованы множества И и В из Рис. 9.1).
9.1.2. Логические операции над двоичными изображениями
Рассматриваемые в данной главе морфологические концепции при-
меняются в большинстве случаев к двоичным изображениям. Логиче-
ские операции, хотя и просты по существу, служат мощным дополне-
нием к алгоритмам обработки изображений на основе морфологии.
Логические операции были введены в рассмотрение в Разделе 3.4
применительно к маскированию. В последующем обсуждении нас
интересуют логические операции, в которых участвуют двоичные
пиксели и целые двоичные изображения.
Основными логическими операциями, используемыми в обра-
ботке изображений, являются AND (логическое умножение), OR (ло-
гическое сложение) и NOT (отрицание); свойства этих операций све-
дены в Таблицу 9.1. Эти три операции образуют функционально полный
класс, в том смысле, что любая другая логическая операция может быть
получена путем комбинирования только этих основных операций.
Логические операции выполняются поэлементно, т.е. над соответ-
ственными пикселями двух или более изображений (за исключением
операции NOT, применяемой к элементам одного изображения). По-
скольку результат перемножения двух двоичных переменных равен 1,
если только они обе равны 1, то и при логическом умножении двоич-
ных изображений результирующее изображение будет содержать еди-
ничные пиксели только в тех местах, где соответственные элементы
Таблица 9.1. Три основные логические операции.
р 9 р AND q (также р q) р OR q (также р + q) NOT(p) (также р)
0 0 0 0 1
0 1 0 1 1
1 0 0 1 0
1 1 1 1 0
Глава 9. Морфологическая обработка изображений
обоих исходных изображений одновременно имеют значения 1. На
Рис. 9.3 представлены различные примеры логических операций над
двоичными изображениями, где черное отвечает двоичной 1, а бе-
лое — 0. (В этой главе мы будем использовать оба варианта соглаше-
ния, иногда заменяя противоположным смысл двоичного значения —
темное или светлое — в зависимости от удобства в конкретной ситу-
ации). С помощью определений Таблицы 9.1 легко строятся прочие ло-
Рис. 9.3. Некоторые логические операции над двоичными изображениями.
В этом примере черное представляется двоичной единицей, а белое — нулем.
9.2. Дилатация и эрозия
гические операции. Например, операция XOR (исключающее ИЛИ)
дает в результате 1, когда любой из участвующих в ней пикселей име-
ет значение 1 (но не оба одновременно), и результат 0 в остальных слу-
чаях. Данная операция отличается от OR тем, что последняя дает еди-
ничный результат и когда хотя бы один из пикселей равен 1, и когда
оба равны 1. Аналогично, операция [NOT(>4)]AND(Z?) выбирает пик-
сели изображения В со значением 1, которым соответствуют пиксели
изображения А со значением 0.
Важно заметить, что описанные только что логические операции
взаимно однозначно соответствуют операциям над множествами, об-
суждавшимся в Разделе 9.1.1, с тем ограничением, что логические
операции могут применяться лишь к двоичным переменным, тогда как
операции над множествами применимы и в общем случае. Таким об-
разом, например, операция пересечения множеств сводится к логиче-
скому умножению, когда участвующие переменные двоичные. Такие
термины, как пересечение и AND (и даже соответствующие обозначе-
ния) в литературе часто подменяют друг друга, относясь и к общему
случаю, и к операциям над двоичными множествами, однако пра-
вильная интерпретация обычно ясна из контекста обсуждения.
9.2. Дилатация и эрозия
Мы начнем рассмотрение морфологических операций с детального
изучения двух операций: дилатации и эрозии. Эти операции имеют ос-
новополагающее значение для морфологической обработки изобра-
жений. По существу, многие из обсуждаемых в данной главе алгорит-
мов морфологической обработки основаны на этих двух базовых
операциях.
9.2.1. Дилатация
Пусть А и В-— множества из пространства Z2. Дилатация множества
А по множеству В (или относительно В) обозначается А ф В и опреде-
ляется как
A®B = {z\(B)zHA*0}.
(9.2-1)
В основе этого соотношения лежит получение центрального отраже-
ния множества В относительно его начала координат (которое для
краткости будем называть центром В) и затем сдвиг полученного мно-
жества в точку Z- При этом дилатация множества Л по В — это множе-
ство всех таких смещений z, при которых множества В п А совпадают
754 Глава 9. Морфологическая обработка изображений
по меньшей мере в одном элементе. Исходя из такой интерпретации,
соотношение (9.2-1) можно переписать в следующем виде2 3:
А® Я = {г|[(В)г М]сЛ} (9.2-2)
Множество Сбудем называть структурообразующим множеством или
3
примитивом дилатации, равно как и других описываемых ниже мор-
фологических операций.
Уравнение (9.2-1) представляет собой не единственное определе-
ние дилатации, встречающееся в современной литературе по морфо-
логии изображений (см. Задачи 9.10 и 9.11, где приводятся два отли-
чающихся, хотя и эквивалентных определения). Однако, приведенное
выше определение лучше других формулировок тем, что оно более на-
глядно, если рассматривать примитив В в качестве маски свертки.
Несмотря на то, что дилатация основана на операциях над множест-
вами, а свертка на арифметических операциях, основной процесс,
состоящий в «перевороте» множества Z? относительно его центра и за-
тем в последовательном «скольжении» по множеству Л (т.е. изображе-
нию), — по сути аналогичен процессу свертки, обсуждавшемуся в Раз-
делах 3.5 и 4.2.4.
На Рис. 9.4(a) приведено множество простой формы, а на
Рис. 9.4(6) изображен примитив и его центральное отражение (точ-
кой обозначен центр примитива). В данном случае сам примитив и
его отражение совпадают, поскольку данное структурообразующее
множество симметрично относительно центра. Пунктирной лини-
ей на Рис. 9.4(b) для сравнения показаны границы исходного мно-
жества, а сплошная линия соответствует тем предельным значени-
ям z, при выходе центра множества В за которые пересечение этого
множества с множеством А оказывается пустым. Следовательно,
множество всех точек, находящихся внутри обозначенной сплош-
ной линией границы, образует дилатацию А по В. На Рис. 9.4(г)
изображен примитив, построенный с таким расчетом, чтобы до-
биться большей дилатации в вертикальном направлении, чем по
горизонтали. Рис. 9.4(д) показывает результат дилатации по такому
примитиву.
2 Строго говоря, выписанное соотношение не эквивалентно определению (9.2-1), а
может рассматриваться лишь как его следствие, поскольку пустое множество также
является подмножеством любого множества. Авторы, очевидно, исходят из проти-
воположного. — Прим, перев.
3 В оригинале использован термин structuring element. — Прим, перев.
9.2. Дилатация и эрозия
7551
d
d
d/4
• 4/4
В=В
А ® В
4/8
4/8
d/2
d
4/4
В=В
d
d/2
А® В
а б в
d/8 4/8 ГД
Рис. 9.4. (а) Множество?! (б) Структурообразующее множество (примитив) ква-
дратной формы; точкой обозначен центр, (в) Результат дилатации А по В (за-
темненная область), (г) Примитив вытянутой формы, (д) Дилатация А по та-
кому примитиву.
Пример 9.1: Применение морфологической дилатации для перекры-
тия разрывов.
Одно из простейших применений дилатации — устранение разрывов
линий путем их перекрытия. На Рис. 9.5(a) показано изображение с ра-
зорванными символами, которое уже приводилось на Рис. 4.19 в свя-
зи с рассмотрением низкочастотной фильтрации. Известно, что макси-
мальная длина разрывов составляет два пикселя. На Рис. 9.5(6) показан
простой примитив, которым можно воспользоваться для устранения раз-
рывов. Результат дилатации исходного изображения по такому при-
митиву представлен на Рис. 9.5(b). Поверх разрывов образовались «мос-
тики». Одно из непосредственных преимуществ морфологического
подхода по сравнению с применявшимся в Главе 4 методом устранения
разрывов путем низкочастотной фильтрации состоит в том, что морфо-
логический метод сразу приводит к двоичному изображению. Напро-
Глава 9. Морфологическая обработка изображении
a bj
<
Historically, certain computer
programs were written using
only two digits rather than
four to define the applicable
year. Accordingly, the
company's software may
recognize a date using ”00"
as 1900 rather than the
2000. ,________
Historically, certain computer
programs were written using
only two digits rather than
four to define the applicable
year. Accordingly, the
company's software may
recognize a date using "ОО"
as 1900 rather than the Veer
2000. ._________ZZ
0 1 0
1 1 1
0 1 0
еа
Рис. 9.5. (а) Пример изображения текста с недостаточным разрешением и раз-
рывами букв (видны на увеличенном фрагменте), (б) Вид примитива, (в) Дила-
тация множества (а) по примитиву (б). Изолированные сегменты объединились.
тив, при низкочастотной фильтрации из исходного двоичного изобра-
жения вначале получается полутоновое, которое затем с помощью по-
роговой функции предстоит преобразовывать обратно в двоичное.
9.2.2. Эрозия
Для множеств А и В из пространства Z 2 эрозия А по В, обозначаемая
A G В, определяется как
Л©Я = {;:| (В\ с Л}. (9.2-3)
Иначе говоря, эрозия множества Л по примитиву В — это множество
всех таких точек z, при сдвиге в которые множество Б целиком содер-
жится в А. Как и в случае дилатации, уравнение (9.2-3) является не един-
ственным возможным определением эрозии (см. Задачи 9.12 и 9.13, где
приводятся два отличающихся, хотя и эквивалентных определения). Тем
не менее, формулировке (9.2-3) обычно отлается предпочтение при
практической реализации морфологических методов по тем же самым
причинам, о которых говорилось ранее в связи с соотношением (9.2-1).
Рис. 9.6 демонстрирует действия, аналогичные приведенным на
Рис. 9.4, нос применением эрозии вместо дилатации. Как и раньше,
9.2. Дилатация и эрозия
d/A
• t//4
В
1 1 ЗД/4 1 1
Д/8 ' d/%
d/A
d/2
• d
В
а б в
г д
Рис. 9.6. (а) Множество А. (б) Примитив в форме квадрата, (в) Результат эро-
зии А по В (затемненная область), (г) Примитив вытянутой формы, (д) Эро-
зия А по такому примитиву.
множество Л изображено на Рис. 9.6(b) пунктирной линией для на-
глядности сопоставления. Сплошная линия соответствует тем пре-
дельным значениям z, при сдвиге центра примитива В за которые пе-
рестает выполняться условие, требующее, чтобы В было
подмножеством множества А. Таким образом, геометрическое мес-
то точек внутри этой сплошной границы (т.е. затемненная область)
является результатом эрозии множества А по примитиву В. На
Рис. 9.6(г) изображен примитив вытянутой формы, а Рис. 9.6(д) де-
монстрирует результат эрозии множества Л по такому примитиву. За-
метим, что в результате эрозии исходное множество сжалось до го-
ризонтальной линии.
Дилатация и эрозия являются двойственными операциями по от-
ношению к теоретико-множественным операциям дополнения и цен-
трального отражения. Иначе говоря,
(А®В)С = АС®В. (9.2-4)
Проведем формальное доказательство этого факта, чтобы проиллю-
стрировать типичный способ проверки справедливости соотноше-
ний в морфологическом подходе. Начав с определения эрозии, имеем
758 Глава 9. Морфологическая обработка изображений
(Ле/?)с={;:|(Я)гсЛ}С.
Раз множество (B)z содержится в множестве А, то (B)z А Ас = 0 и пре-
дыдущее равенство принимает вид
(ле^)с={г|(в)гплс=0}с.
Но дополнением для множества z, удовлетворяющих условию
(B)z Г\АС = 0, является множество такихz, что (B)z('\АС^0. Поэтому
(А е В )с = |(5)г А Ас * 0 } Ас е в,
что и требовалось доказать (последний шаг следует из определения
(9.2-1)).
Пример 9.2: Применение морфологической эрозии для удаления со-
ставляющих изображения.
I Одно из простейших применений эрозии состоит в исключении
несущественных (по их размерам) деталей на двоичных изображе-
ниях. На Рис. 9.7(a) приведено двоичное изображение, состоящее из
квадратов с размерами сторон 1, 3, 5, 7, 9 и 15 пикселей. Предполо-
жим, что задача состоит в том, чтобы убрать все квадраты, кроме са-
мых больших. Это можно сделать путем применения к изображению
операции эрозии по примитиву несколько меньших размеров, чем
объекты, которые мы желаем сохранить. В этом примере выбран при-
митив с размерами 13x13 пикселей. Результат применения такой
эрозии к исходному изображению показан на Рис. 9.7(6). От самых
а б в Рис. 9.7. (а) Изображение, содержащее квадраты со сторонами 1, 3, 5, 7, 9 и 15
пикселей, (б) Результат эрозии изображения (а) по квадратному примитиву раз-
мерами 13x13 пикселей, заполненному единицами (в) Результат дилатации
изображения (б) по тому же примитиву.
9.3. Размыкание и замыкание 759
больших квадратов остались только фрагменты. Как видно из
Рис. 9.7(b), можно восстановить эти три квадрата до их исходных раз-
меров 15x15 путем дилатации полученного изображения по тому
же примитиву, что использовался при эрозии. (Вообще говоря, ди-
латация не позволяет полностью восстанавливать объекты после
эрозии; см. Задачу 9.18). Заметим, что в данном примере на всех трех
изображениях объекты представляются белыми пикселями, в отли-
чие от черных в предыдущем примере. Как уже отмечалось, на прак-
тике используются оба способа представления. Если не указано
иное, в общем случае действует соглашение, что «активные» пиксе-
ли примитива принимают те же двоичные значения, что и интере-
сующие объекты. Изложенные в этом примере идеи подготавлива-
ют основу для морфологической фильтрации, рассматриваемой
в следующем разделе.
9.3. Размыкание и замыкание
Как мы уже видели, дилатация приводит к расширению изображения,
а эрозия — к сжатию. В этом разделе рассматриваются еще две важ-
ные морфологические операции: размыкание и замыкание. В общем
случае размыкание^ сглаживает контуры объекта, обрывает узкие пе-
решейки и ликвидирует выступы небольшой ширины. Замыкание так-
же проявляет тенденцию к сглаживанию участков контуров, но, в от-
личие от размыкания, в общем случае «заливает» узкие разрывы и длинные
углубления малой ширины, а также ликвидирует небольшие отверстия
и заполняет промежутки контура.
Размыкание множества Л по примитиву Z? обозначается А ° В и оп-
ределяется равенством
AoB = (AQB)®B. (9.3-1)
Таким образом, размыкание множества Л по примитиву встроится как
эрозия Л по В, результат которой затем подвергается дилатации по то-
му же примитиву В.
Аналогично, замыкание множества Л по примитиву В обозначает-
ся Л • В и определяется как
А*В = (А®В)®В, (9.3-2)
4 В оригинале использованы термины opening (размыкание) и closing (замыкание). —
Прим, перев.
760 Глава 9. Морфологическая обработка изображений
то есть как дилатация множества Л по В, за которой следует эрозия по
тому же примитиву В.
Операция размыкания допускает простую геометрическую интер-
претацию (Рис. 9.8). Предположим, что примитив В имеет форму кру-
га. Тогда границу множества Л ° В образуют максимально близкие к гра-
нице А точки множества В при «обкатывании» примитивом В этой
границы изнутри. Это геометрическое свойство прилегания, прису-
щее операции размыкания, вытекает из теоретико-множественной
формулировки, согласно которой размыкание множества А по В стро-
ится как объединение всех параллельных переносов В, которые укла-
дываются в множество Л. Таким образом, операция размыкания мо-
жет быть выражена процессом «укладки» следующего вида:
A fi = u{(S)J(fi)z сЛ}, (9.3-3)
где и{•} обозначает объединение всех множеств внутри фигурных скобок.
Замыкание допускает сходную геометрическую интерпретацию, но
в этом случае примитив Б обкатывает границу А снаружи (Рис. 9.9). Ни-
же будет показано, что размыкание и замыкание являются двойствен-
ными операциями, так что обкатывание с противоположной стороны
границы {снаружи) не является чем-то удивительным. С геометриче-
ской точки зрения, точка w является элементом множества Л • В в том
и только в том случае, если (B)z Г\А^0 для любого сдвига (B)z, накры-
вающего точку w. Рис. 9.9 иллюстрирует основные геометрические
свойства замыкания.
Пример 9.3: Простая иллюстрация морфологических операций раз-
мыкания и замыкания.
Рис. 9.10 служит для дальнейшей иллюстрации операций замыка-
ния и размыкания. На Рис. 9.10(a) показано множество А, а на
а б в г
Рис. 9.8. (а) Примитив В. обкатывающий изнутри границу множества А.
(б) Примитив В; положение его центра указано точкой, (в) Жирная линия по-
казывает внешнюю границу размыкания, (г) Все множество, получаемое в ре-
зультате размыкания (показано темным цветом).
Рис. 9.9. (а) Примитив В, обкатывающий снаружи границу множества А.
(б) Жирная линия показывает внешнюю границу замыкания, (в) Все множе-
ство, получаемое в результате замыкания (показано темным цветом).
Рис. 9.10(6) — различные положения круглого примитива в ходе опе-
рации эрозии. В результате выполнения этой операции образуется
несвязная фигура, показанная на Рис. 9.10(в). Обратите внимание на
уничтожение мостика между двумя основными частями исходной
фигуры. Его ширина меньше диаметра примитива, т.е. данный при-
митив не может целиком поместиться в этой части множества Л, и, зна-
чит, условие в (9.2-3) нарушается. То же самое справедливо для двух ча-
стей с правой стороны объекта, и выступающие элементы, куда не
вмещается круг, также пропадают. Рис. 9.10(г) демонстрирует про-
цесс дилатации множества, полученного в результате эрозии, а на
Рис. 9.10(д) приведен конечный результат размыкания. Видно, что об-
ращенные наружу углы подверглись закруглению, тогда как обра-
щенных внутрь углов это не коснулось.
Аналогично, фигуры на Рис. 9.10(e) — (и) иллюстрируют результа-
ты замыкания множества А по тому же примитиву. Можно заметить, что
в этом случае закругляются внутренние углы, а внешние углы остают-
ся нетронутыми. Углубление, расположенное слева на границе множе-
ства Л, значительно уменьшилось в размерах, поскольку в нем снару-
жи не помещается используемый круглый примитив. Обратите также
внимание на сглаживание формы деталей в результате размыкания и за-
мыкания исходного множества А с помощью круглого примитива.
Так же, как в случае дилатации и эрозии, операции размыкания
и замыкания являются двойственными операциями по отношению
к теоретико-множественным операциям дополнения и центрального
отражения. Иначе говоря,
(А»В)С = АС °В.
(9.3-4)
Доказательство этого факта оставляем в качестве самостоятельного уп-
ражнения (Задача 9.14).
Глава 9. Морфологическая обработка изображений
Операция размыкания обладает следующими свойствами:
а) А с В является подмножеством А (т.е. вложенным изображением).
б) Если С есть подмножество D, то С ° В является подмножеством
D В.
в) (А°В)°В=А°В.
Аналогично, операция замыкания обладает следующими свойствами:
а) А является подмножеством (вложенным изображением) А • В.
б) Если С есть подмножество D, то С • В является подмножеством
/)•/?.
в)(Л«Я)» В = А» В.
АоВ=(АеВ)®в
*
б в
Г д
е *
з и
Рис. 9.10. Морфологические размыкание и замыкание Используется при-
митив в форме небольшого круга, показанного в различных положениях на ри-
сунках (б) и (г). Темная точка в центре круга указывает положение начала ко-
ординат примитива.
9.3. Размыкание и замыкание 763
Свойства «в» в обоих случаях означают, что многократные примене-
ния операций размыкания или замыкания к некоторому множеству не
оказывают никакого действия после того, как соответствующая опе-
рация выполнена в первый раз.
Пример 9.4: Применение операций размыкания и замыкания для мор-
фологической фильтрации.
Морфологические операции можно использовать для построения
фильтров, похожих по своему принципу на пространственные филь-
тры, рассматривавшиеся в Главе 3. На Рис. 9.11(a) приведено двоич-
Рис. 9.П. (а) Зашумленное изображение, (б) Использующийся примитив,
(в) Изображение после применения операции эрозии, (г) Результат размыка-
ния исходного изображения, (д) Дилатация размыкания, (е) Замыкание раз
мыкания. (Исходное изображение предоставлено Национальным институтом
стандартов и технологии США).
764 Глава 9. Морфологическая обработка изображении
ное изображение фрагмента отпечатка пальца, искаженное шумом, ко-
торый проявляется в виде присутствующих на темном фоне светлых
элементов, равно как и темных элементов на светлых полосах, со-
ставляющих отпечаток. Задача состоит в устранении шума при мини-
мальном искажении формы отпечатка. Для решения этой задачи мож-
но применить морфологический фильтр, выполняющий вначале
операцию размыкания, а затем — замыкания.
Используется примитив, изображенный на Рис. 9.11(6). Осталь-
ные части рисунка иллюстрируют последовательность шагов опера-
ции фильтрации. На Рис. 9.11 (в) показан результат эрозии множест-
ва Л по указанному примитиву. Шум в фоновой области изображения
полностью устраняется на этапе эрозии, входящем в состав операции
размыкания, поскольку в рассматриваемом примере физические раз-
меры всех составляющих шума меньше размеров примитива. Что ка-
сается шумовых компонент в виде темных пятен на отпечатке, то
они увеличились в размерах. Это объясняется тем, что такие компо-
ненты по существу являются внутренними границами области, и они
увеличиваются в размерах при выполнении операции эрозии. Такое
расширение нейтрализуется путем дилатации, что приводит к ре-
зультату, показанному на Рис. 9.11 (г). Видно, что шумовые составля-
ющие на полосах отпечатка пальпа уменьшились в размерах или пол-
ностью исчезли.
Две только что описанные операции вместе составляют опера-
цию размыкания множества Л по примитиву В. Из Рис. 9.11 (г) вид-
но, что результирующий эффект от размыкания состоит в устране-
нии практически всех шумовых составляющих как в фоновой
области, так и на самом отпечатке. Однако в результате этой опера-
ции появились ранее отсутствовавшие пропуски на полосах отпечат-
ка. Чтобы преодолеть этот нежелательный эффект, применим к ре-
зультату размыкания операцию дилатации, как показано на
Рис. 9.11 (д). В большинстве указанных промежутков целостность по-
лос восстановилась, однако сами полосы стали шире. Такое увели-
чение можно скомпенсировать эрозией. Результат, показанный на
Рис. 9.11(e), получен путем применения операции замыкания к ра-
нее построенному размыканию исходного множества, приведен-
ному на Рис. 9.11 (г). Этот конечный результат примечателен отсут-
ствием шумовых точек, хотя и имеет тот недостаток, что некоторые
из полос отпечатка пальца восстановлены не полностью, а содержат
разрывы. Этого можно было ожидать, поскольку в описываемую
процедуру не было заложено никаких условий для сохранения связ-
ности. Мы вновь вернемся к этому вопросу в Примере 9.8 и укажем
пути его решения в Разделе 11.1.5. 4
9.4. Преобразование «Успех / Неудача»
9.4. Преобразование «Успех / Неудача»
Морфологическое преобразование «успех / неудача»5 является основ-
ным инструментом для обнаружения объектов определенных размеров
и формы. Мы изложим его идею с помощью Рис. 9.12, где приведено
Рис. 9.12. (а) Множество А. (б) Окно Wи локальный фон области Л'по отно-
шению к W, (Щ\Л). (в) Дополнение множества/!. (г) Эрозия/1 по X. (д) Эро-
зия/F по (W\X). (е) Пересечение множеств (г) и (д), которое дает искомое по-
ложение начала координат X.
а б
в г
д
е
5 В оригинале использован термин hit-or-miss transform. — Прим, перев.
Глава 9. Морфологическая обработка изображений
множество?!, состоящее из трех фигур (подмножеств), обозначенных
X, YxxZ. Затемненные области на Рис. 9.12(a) — (в) указывают исход-
ные множества, тогда как темным цветом на Рис. 9.12(г) и (д) показа-
ны результаты выполнения морфологических операций. Задача со-
стоит в том, чтобы найти местоположение одной из фигур, скажем, X.
Пусть начало координат (центр) каждой из фигур находится в ее
центре тяжести. Опишем вокруг фигуры Xнесколько большее окно Ж
Локальный фон фигуры X по отношению к окну ^определяется как раз-
ностное множество (Ж\X), показанное на Рис. 9.12(6). На Рис. 9.12(b)
изображено дополнение множества А, которое понадобится позже.
Рис. 9.12(г) демонстрирует результат применения к Л операции эро-
зии с использованием X в качестве примитива (пунктирными лини-
ями для ясности показаны контуры исходных фигур). Напомним, что
результатом эрозии Л по % является множество таких положений на-
чала координат множества X, при которых X совпадает с некоторым
подмножеством Л. В другой интерпретации, множество Л О X можно
рассматривать как геометрическое место точек положения начала ко-
ординат X, для которых у X имеется эквивалент в Л (т.е. X «попадает»
в Л). Будем помнить, что обсуждаемое на Рис. 9.12 множество Л состо-
ит только из трех непересекающихся подмножеств X, YhZ.
На Рис. 9.12(д) показан результат применения к дополнению Л
операции эрозии с использованием множества локального фона (Ж\ X)
в качестве примитива. Внешняя область темного цвета на Рис. 9.12(д)
также является частью результата эрозии. Сопоставляя Рис. 9.12(г)
и (д), замечаем, что множество позиций точного местонахождения X
в множестве Л есть пересечение результата эрозии Л по Хи результата
эрозии Лс по (Ж\ X), как показано на Рис. 9.12(e). Эго пересечение да-
ет в точности искомое местоположение центра X. Другими словами,
если множество, состоящее из объекта X и его окрестности, обозна-
чить В, то вхождение (или набор вхождений) В в А, которое обознача-
ется А ® В, описывается множеством
л@в=(ле*)п[лсе(Ж\%)]. (9.4-1)
Эта нотация допускает некоторое обобщение, если рассмотреть мно-
жество В как В = (А?[, В?), где Bi — множество элементов В, относя-
щихся к интересующему объекту, а В2 есть множество элементов ок-
ружающего фона. Из предшествующего рассмотрения ясно, что В, = X
и В} = (W\X). С использованием таких обозначений равенство (9.4-1)
принимает вид
А®В = (А®В})П{АС®В2).
(9.4-2)
9.5. Некоторые основные морфологические алгоритмы 767
Таким образом, множество А ® В содержит все точки (положения
центра), в которых одновременно для В] имеется эквивалент в А, а для
В} — эквивалент в Ас (т.е. имеет место «успех»). Применяя определе-
ние разности множеств (9.1-8) и соотношение двойственности меж-
ду операциями эрозии и дилатации (9.2-4), можно переписать равен-
ство (9.4-2) в виде
>1®В = (ЛеВ1)\(>1©В2)- (9.4-3)
Запись в форме (9.4-2) все же отличается значительно большей нагляд-
ностью. Любое из трех вышеприведенных соотношений мы будем
называть морфологическим преобразованием «успех/неудача».
Мотивировка для совместного использования примитива В], свя-
занного с интересующим объектом, и примитива В2, связанного с фо-
ном, базируется на том соображении, что два или более объектов раз-
личимы только в том случае, если они образованы непересекаюшимися
множествами. Это гарантируется, если потребовать, чтобы вокруг
каждого объекта на изображении присутствовала область фона шири-
ной как минимум один пиксель. В некоторых прикладных задачах
интерес представляет обнаружение в исходном множестве заданных
эталонов, т.е. сочетаний единиц и нулей. В подобных случаях понятие
фона теряет смысл, и преобразование «успех / неудача» сводится
к обычной операции эрозии. Как уже указывалось, эрозия дает лишь
множество точек совпадения, однако в отсутствие дополнительного
требования к совпадению фона это позволяет обнаруживать изолиро-
ванные объекты. Такая упрощенная схема обнаружения эталонов
применяется в некоторых из алгоритмов, описываемых в следующем
разделе.
9.5. Некоторые основные морфологические
алгоритмы
Опираясь на результаты проведенного выше обсуждения, мы готовы
теперь рассмотреть некоторые практические применения морфологи-
ческих методов. При работе с двоичными изображениями морфоло-
гия в основном применяется для извлечения компонент изображения,
которые могут служить для представления и описания формы объек-
тов. В частности, мы рассмотрим морфологические алгоритмы выде-
ления границ, связных компонент, выпуклых оболочек и остовов об-
ластей. Будут также изложены некоторые методы, такие как
заполнение, утончение, утолщение областей и отсечение ветвей, ча-
сто используемые в сочетании с упомянутыми алгоритмами в качест-
Глава 9. Морфологическая обработка изображений
ве шагов предварительной или финальной обработки. В этом разде-
ле мы будем широко использовать небольшие модельные изображе-
ния, помогающие лучше понять механизм действия каждого описы-
ваемого морфологического процесса. Все эти изображения двоичные;
единицы соответствуют черным пикселям, а нули — белым.
9.5.1. Выделение границ
Граница множества?!, которую будем обозначать [)(/!), может быть вы-
делена путем выполнения сначала операции эрозии А по В, а затем по-
лучения разностного множества между А и результатом его эрозии, т.е.
Р(Л) = Л\(/1ев), (9.5-1)
где В — подходящий примитив.
Рис. 9.13 иллюстрирует механизм выделения границы. Здесь при-
ведены простой двоичный объект, примитив В и результат примене-
ния соотношения (9.5-1). Хотя показанный на Рис. 9.13(6) примитив
относится к числу наиболее часто используемых, он никоим образом
не является единственно возможным. Например, если использовать
заполненный единицами квадратный примитив размерами 5x5 пик-
селей, то это приведет к построению границы толщиной от 2 до 3
пикселей. Заметим, что когда центр примитива В находится на краях
множества, некоторые части примитива выходят за пределы изобра-
жения. Обычная трактовка таких ситуаций исходит из предположения,
что значения элементов за пределами изображения равны 0.
Пример 9.5: Выделение границы путем морфологической обработки.
Рис. 9.14 служит дальнейшей иллюстрацией использования уравне-
ния (9.5-1) с тем же примитивом, что и на Рис. 9.13(6). В этом приме-
а б
в г
Рис. 9.13. (а) Множество Л. (б) Примитив В. (в) Эрозия Л по В. (г) Граница, по-
лученная вычитанием из исходного множества Л результата операции эрозии.
9.5. Некоторые основные морфологические алгоритмы
Рис. 9.14. (а) Простое двоичное изображение; белым цветом представлены еди-
ницы. (б) Результат применения уравнения (9.5-1) с примитивом на Рис. 9.13(6).
ре двоичной единице отвечает белый цвет, а двоичному нулю — чер-
ный, поэтому пиксели примитива ^(которые являются единичными)
также считаются белыми. Благодаря применению такого примитива
В, выделяется граница толщиной в один пиксель, как показано на
Рис. 9.14(6). 4
9.5.2. Заполнение областей
Теперь мы изложим простой алгоритм заполнения области, основан-
ный на операциях дилатации, дополнения и пересечения множеств.
На Рис. 9.15 исходное множество?! состоит из граничных точек неко-
торой области, образующих 8-связный замкнутый путь. Задача со-
стоит в том, чтобы, начав с некоторой точки р внутри этой границы,
заполнить единичными значениями всю область6.
Если принять соглашение, что все точки, кроме граничных, име-
ют значения 0, то в качестве начального шага присвоим значение 1 точ-
ке р. К заполнению области единицами приведет следующая рекур-
рентная процедура:
Хк =(^_1®В)ПЖ к =1,2,3,..., (9.5-2)
6 Обратим внимание на то, что кроме условия замкнутости границы, данный алго-
ритм требует также знания хотя бы одной точки внутри границы. — Прим, перев.
26 А-22.1
Глава 9. Морфологическая обработка изображений
а б в
где
ж з и
Рис. 9.15. Заполнение области, (а) Множество А. (б) Дополнение множества
А. (в) Примитив В. (г) Начальная точка внутри заданной границы, (д) — (з) Ша-
ги применения уравнения (9.5-2). (и) Окончательный результат (объединение
множеств (а) и (з)).
где Xq =р, а В — симметричный примитив, показанный на Рис. 9.15(в).
Данный алгоритм останавливается на &-ом шаге итерации, когда
Хк = - 1- Объединение множеств^ и Я содержит границу области
вместе с ее внутренним заполнением.
При отсутствии дополнительного контроля, процесс дилатации
в уравнении (9.5-2) привел бы к заполнению единицами всего поля изо-
бражения. Однако взятие на каждом шаге пересечения с Ас ограничи-
вает результат операции только внутренностью интересующей обла-
сти. Это наш первый пример того, как можно ограничить
морфологическую обработку для достижения некоторого желаемого
свойства. В рассматриваемом приложении этот прием уместно на-
звать условной дилатацией. Остальные примитивы Рис. 9.15 иллюст-
рируют фазы применения уравнения (9.5-2). Хотя в этом примере
присутствует только одна область, ясно, что тот же принцип может при-
меняться для любого конечного числа таких подмножеств, при усло-
вии, что заданы начальные точки внутри каждого из них.
77IJ
9.5. Некоторые основные морфологические алгоритмы
Пример 9.6: Морфологическое заполнение областей.
На Рис. 9.16(a) приведено изображение, состоящее из белых кругов
с черными пятнами внутри. Подобное изображение могло быть полу-
чено в результате порогового преобразования изображения сцены,
в которой присутствуют полированные сферические объекты (на-
пример, подшипниковые шарики). Темные пятна внутри кругов мог-
ли возникнуть в результате отражений. Задача состоит в устранении
этих отражений путем заполнения светлых областей. На Рис. 9.16(a)
нанесена точка, выбранная внутри одного из кругов, а на Рис. 9.16(6)
показан результат заполнения соответствующей области. Наконец,
Рис. 9.16(b) демонстрирует результат заполнения всех таких областей.
Поскольку в данном случае необходимо знать, относятся ли черные
точки к фону изображения или являются внутренними точками обла-
сти, для полной автоматизации процедуры необходимо оснастить ал-
горитм дополнительным «интеллектом» (Задача 9.23).
9.5.3. Выделение связных компонент
Понятия связности и связных компонент были введены в рассмотре-
ние в Разделе 2.5.2. На практике выделение компонент связности в дво-
ичном изображении занимает центральное место во многих приклад-
ных задачах анализа изображений. Пусть Y — некоторая связная
компонента из множества А, содержащегося в изображении, и пред-
положим, что известна точка ре Y. Тогда все элементы компоненты
Yмогут быть получены с помощью следующего рекуррентного соот-
ношения:
Хк=(Хк^®В)Г)А к =1,2,3,... ,
(9.5-3)
Рис. 9.16. (а) Двоичное изображение (белая точка внутри одной из облас- а б В
тей — начальная точка для алгоритма заполнения областей), (б) Результат
заполнения этой области, (в) Результаты заполнения всех областей.
Глава 9. Морфологическая обработка изображений
где Xq =р, а В — подходящий примитив, например, изображенный на
Рис. 9.17(6). Если Xk = Xk_ j, то это говорит о сходимости алгоритма,
и мы принимаем Y= Xk.
Соотношение (9.5-3) по форме схоже с (9.5-2); единственное от-
личие состоит в использовании самого множества Л вместо его допол-
нения. Это отличие происходит оттого, что все разыскиваемые пик-
сели (т.е. элементы связной компоненты) имеют значения 1. Взятие
пересечения с множеством Л на каждом шаге итерации исключает из
результатов дилатации те положения центра, которые приходятся на
нулевые элементы. Механизм действия соотношения (9.5-3) проил-
люстрирован на Рис. 9.17. Заметим, что форма примитива предпола-
гает наличие 8-связности между пикселями одной связной компо-
ненты7. Как и для алгоритма заполнения областей, изложенный
результат применим также в случае любого конечного числа связных
компонент, из которых состоит множество Л, при условии, что внут-
ри каждой компоненты связности известна хотя бы одна точка.
а б в
г Д
Рис. 9.17. (а) Множество Л, на котором штриховкой отмечена начальная точ-
ка р (все темные точки имеют значение 1, однако отмечены отличным отр об-
разом, чтобы показать, что они еще не найдены данным алгоритмом), (б) Ис-
пользуемый примитив, (в) Результат первого шага итерации, (г) Результат
второго шага, (д) Окончательный результат.
7 Иначе говоря, области, соприкасающиеся по диагонали, включаются в одну ком-
поненту связности. — Прим, перев.
9.5. Некоторые основные морфологические алгоритмы
О
Пример 9.7: Применение алгоритма выделения связных компонент
для обнаружения инородных объектов в упакованных
пищевых продуктах.
Выделение связных компонент изображения часто применяется
для автоматического контроля. На Рис. 9.18(a) приведено рентгенов-
ское изображение куриного филе, в котором присутствуют фрагмен-
ты костей. Значительный интерес представляет задача обнаружения
подобных инородных объектов в ходе обработки пищевых продуктов,
до их упаковки и/или поставки. В данном конкретном случае благо-
даря слабой проницаемости костей для рентгеновских лучей соот-
ветствующие пиксели заметно отличаются по уровню яркости от фо-
на изображения, что делает выделение костных фрагментов из фона
Рис. 9.18. (а) Рентгеновское изображение куриного филе с фрагментами ко-
стей. (б) Двоичное изображение после порогового преобразования, (в) Резуль-
тат эрозии изображения по квадратному примитиву размерами 5x5, заполнен-
ному единицами, (г) Число пикселей в связных компонентах изображения (в).
(Изображение предоставлено компанией NTB Elektronische Geraete GmbH,
Diepholz, Германия; адрес в Интернете www.ntbxray.com).
Глава 9. Морфологическая обработка изображений
простой задачей, решаемой с помощью порогового преобразования
(пороговое преобразование было введено в Разделе 3.1 и более подроб-
но рассматривается в Разделе 10.3). В результате его применения по-
лучается двоичное изображение, показанное на Рис. 9.18(6).
Наиболее существенной характеристикой данного рисунка явля-
ется тот факт, что точки, оставшиеся после выполнения преобразова-
ния, сконцентрированы в виде объектов (костей), а не превратились
в отдельные несвязанные фрагменты. Мы можем оставить только
объекты «значительных» размеров, применив к полученному двоич-
ному изображению преобразование эрозии. В данном примере значи-
тельными признаются любые объекты, не исчезающие после эрозии
по заполненному единицами квадратному примитиву размерами 5x5
пикселей. Результат применения такого преобразования показан на
Рис. 9.18(b). Следующий шаг состоит в анализе размеров оставшихся
объектов, которые опознаются путем выделения связных компонент
на изображении. Результаты выделения сведены в таблицу на
Рис. 9.18(г). Видно, что всего имеется 15 компонент связности, четы-
ре из которых доминируют по площади. Этой информации достаточ-
но, чтобы сделать вывод о присутствии инородных объектов в исход-
ном изображении. При желании можно определить дальнейшие
характеристики объектов (например, форму), для чего используются
методы, описанные в Главе 11.
9.5.4. Выпуклая оболочка
Множество/! называется выпуклым^, если отрезок прямой, соединя-
ющий любые две точки А, целиком лежит внутри А. Выпуклая оболоч-
ка Н произвольного множества S — это наименьшее выпуклое мно-
жество, содержащее S. Разность множеств Н\Sназывается дефектом
выпуклости S. Как будет видно из подробного рассмотрения в Разде-
лах 11.1.4 и 11.3.2, выпуклая оболочка и дефект выпуклости полезны
для построения описания объектов. Здесь мы представим простой
8 Данное определение, строго говоря, относится к множествам, являющимся подмно-
жествами евклидова пространства, и не может быть прямо перенесено на дискрет-
ные множества (подмножества Z2). В основу определения выпуклости в дискретном
случае можно положить следующее верное для непрерывного случая основное свой-
ство: выпуклое множество совпадает со своей выпуклой оболочкой. Поэтому, если
вначале конструктивно определить выпуклую оболочку, как это делают авторы, то вы-
пуклыми можно затем объявить те множества, которые совпадают со своей выпук-
лой оболочкой. Отметим, что такое понятие выпуклости зависит от той процедуры,
которая используется для построения выпуклой оболочки. — Прим, перев.
9.5. Некоторые основные морфологические алгоритмы 775
морфологический алгоритм построения выпуклой оболочки С(А) ис-
ходного множества/1.
Обозначим В1, i= 1, 2, 3, 4 четыре примитива, показанные на
Рис. 9.19(a). Описываемая процедура состоит в применении рекуррент-
ного соотношения
М=(Л1 , ® В')иЛ / = 1,2,3,4 и Л = 1,2,3,... (9.5-4)
для Х^ = А. Пусть теперь D1 = Х'ход где индекс «сход» указывает на
момент сходимости, в том смысле, что Х'к = . Тогда выпуклая обо-
лочка А есть множество
4
C(/1) = U£'. (9.5-5)
/=1
Другими словами, процедура состоит в итеративном применении
к множеству Л преобразования «успех / неудача» по примитиву В1, объ-
единении с множеством Л, и повторении этих шагов (преобразования
и объединения) до тех пор, пока происходят изменения; результат
обозначается D1. Затем такие же действия повторяются с применени-
ем кА преобразования по примитиву В2, и так далее. Объединение че-
тырех полученных множеств D1 дает в результате выпуклую оболочку
для множества/!. Отметим, что здесь используется упрощенная реа-
лизация преобразования «успех / неудача», в которой не требуется
сравнивать фон, о чем уже шла речь в конце Раздела 9.4.
Рис. 9.19 иллюстрирует процедуру, задаваемую соотношениями
(9.5-4) и (9.5-5). На Рис. 9.19(a) показаны примитивы, используемые
для построения выпуклой оболочки. Начало координат каждого при-
митива находится в его центре. Знаки х на элементах примитивов
указывают, что значения этих пикселей не важны. Иначе говоря, эк-
вивалентом в множестве А для данного примитива признается такая
область с размерами 3x3 пикселя, значения в которой совпадают с кон-
фигурацией нулей (белое поле) и единиц (темное поле) в этом прими-
тиве, вне зависимости от значений пикселей на позициях, отмечен-
ных знаком х. Конкретно, для каждого примитива используется маска
с нулем в центре и тремя единицами вдоль одной из сторон квадрата,
а остальные пиксели не учитываются. С учетом обозначений на
Рис. 9.19(a), примитив В1 получается из Вповоротом на угол 90° по
часовой стрелке.
На Рис. 9.19(6) показано множество А, для которого требуется по-
строить выпуклую оболочку. Начиная с Xq = А после четырех итера-
ций применения соотношения (9.5-4) приходим к множеству, показан-
Глава 9. Морфологическая обработка изображений
а
б в г
Д е ж
з
Рис. 9.19. (а) Используемые примитивы, (б) Множество Л. (в)-(е) Результаты
сходимости процедуры для каждого из примитивов (а), (ж) Выпуклая оболоч-
ка. (з) Вклад каждого примитива в формирование выпуклой оболочки.
ному на Рис. 9.19(b). Затем полагаем X® =А и вновь с помощью
(9.5-4) приходим к множеству, показанному на Рис. 9.19(г) (в этом слу-
чае сходимость происходит уже за два шага). Следующие два резуль-
тата получаются аналогичным образом. В конце строится объедине-
ние множеств из Рис. 9.19(b), (г), (д) и (е), которое и является искомой
выпуклой оболочкой (Рис. 9.19(ж)). На Рис. 9.19(з) обозначен вклад,
который вносит в это составное множество каждый из применяв-
шихся примитивов.
Очевидный недостаток только что описанной процедуры состоит
в том, что построенная выпуклая оболочка может превысить размеры,
Рис. 9.20. Результат работы алгоритма выделения выпуклой оболочки с огра-
ничением роста области максимальными размерами исходного множества
по вертикали и горизонтали.
минимально необходимые для выполнения условия выпуклости. Про-
стой способ ослабить данный эффект состоит в ограничении роста об-
ласти, чтобы она не превышала вертикальный и горизонтальный раз-
меры исходного множества точек. Если наложить такое ограничение
на описанный алгоритм, то преобразованием множества на Рис. 9.19,
будет выпуклая оболочка, изображенная на Рис. 9.20. Для ограниче-
ния роста выпуклой оболочки в изображениях с большим числом де-
талей могут применяться граничные условия более сложного вида.
Например, можно дополнительно учитывать максимальные размеры
исходного множества в диагональных направлениях. Такое уточнение
границ выпуклой оболочки достигается ценой дополнительного услож-
нения алгоритма (и соответствующего увеличения вычислительной
сложности).
9.5.5. Утончение
Утончение множества?! по примитиву В, обозначаемое А ® В, можно
определить с помощью преобразования «успех / неудача»:
А® В = А\(А® В) = АГ\(А®В)С. (9.5-6)
Как и в предыдущем разделе, интерес представляет только поиск
в исходном множестве мест совпадения с конфигурацией пикселей
примитива, так что в преобразовании «успех / неудача» не участвует
окружающий фон. Более полезное выражение для симметричного
утончения множества Л основано на последовательности примитивов
{в}={в\в2,в3
(9-5-7)
Глава 9. Морфологическая обработка изображений
где В' получается из Вz l поворотом. На этой основе можно опреде-
лить операцию утончения по последовательности примитивов следу-
ющим образом:
А®{В}=((...((А®В1)®В2)...)®Вп). (9.5-8)
Процесс состоит в том, что на первом проходе производится утончение
множества Л по примитиву 51, затем полученный результат подверга-
ется утончению по примитиву Б2 за второй проход, и так далее вплоть
до л-го прохода с примитивом В ”. Весь этот процесс повторяется до
тех пор, пока наблюдаются изменения. Каждый шаг утончения выпол-
няется с помощью соотношения (9.5-6).
На Рис. 9.21(a) приведен набор примитивов, обычно применяемых
для утончения, а Рис. 9.21(6) демонстрирует пример множества Л, ко-
торое подвергается утончению с помощью описанной выше процеду-
ры. На Рис. 9.21(b) показан результат утончения после одного скани-
рующего прохода по множеству А с помощью примитива В *, а на
Рис. 9.21 (г) — (л) — результаты проходов с помошью других примити-
вов. Сходимость достигается после второго прохода с примитивом
В^. Рис. 9.21(л) демонстрирует результат утончения. В заключение, на
Рис. 9.21 (м) показан результат преобразования утонченного множе-
ства с учетом требования wi-связности (см. Раздел 2.5.2), чтобы исклю-
чить неоднозначность внутренних путей.
9.5.6. Утолщение
Утолщение представляет собой двойственную морфологическую опе-
рацию по отношению к утончению, определяемую выражением
ЛО5 = Ли(Л®Я), (9.5-9)
где В — подходящий примитив. Как и в случае утончения, утолщение
может определяться как последовательная операция:
Л©{5}=((...((Л©^)©52)...)©5”). (9.5-10)
Используемые для утолщения примитивы имеют ту же форму, что
и показанные на Рис. 9.21(a) для операции утончения, но единицы
и нули внутри примитивов меняются местами. Однако специальный
алгоритм утолщения редко реализуется на практике. Вместо этого
обычно применяется процедура, состоящая в утончении фона для
рассматриваемого множества, а затем берется дополнение полученно-
в5
в6
и
в*
А®В3 Л®й4 А®В3
а
б в г
д е ж
з и к
л м
Рис. 9.21. (а) Последовательность поворотов примитивов, используемых для
утончения, (б) Множество А. (в) Результат утончения по первому примитиву,
(г) — (и) Результаты утончения по следующим семи примитивам (при смене
7-го примитива на 8-й изменений не происходит), (к) Результат повторного
применения первого примитива (использование следующих двух примитивов
не приводит к изменениям), (л) Результат после сходимости алгоритма,
(м) Преобразование с учетом требования /и-связности.
го результата. Иными словами, для утолщения множества А сначала
строится множество С = А с, проводится его утончение, а затем стро-
ится Сс. Рис. 9.22 иллюстрирует такую процедуру.
В зависимости от вида исходного множества Л, описанная проце-
дура может привести к появлению отдельных изолированных точек,
как видно на Рис. 9.22(г). Поэтому вслед за таким методом утолшения
обычно применяется несложный шаг финальной обработки, цель ко-
торого состоит в удалении изолированных точек. На Рис. 9.22(b) мож-
но заметить, что фон после утончения образует границу для утолщен-
ного исходного множества. Это полезное качество не проявляется
при непосредственной реализации утолщения с помощью соотно-
Глава 9. Морфологическая обработка изображений
а б
в г
д
Рис. 9.22. (а) Множество Л. (б) Дополнение множества А. (в) Результат утонче-
ния дополнения А. (г) Утолщенное исходное множество, полученное как допол-
нение (в), (д) Окончательный результат после удаления изолированных точек.
шения (9.5-10), что является одной из главных причин, почему утол-
щение обычно осуществляется посредством утончения фона.
9.5.7. Построение остова
Как видно из Рис. 9.23, понятие остова 5'(Д) множества?! является про-
стым и интуитивно понятным. Опираясь на этот рисунок, можно сде-
лать следующие заключения:
а) Если точка z принадлежит 5(/1) и (£>)г — наибольший круг с цент-
ром в z, целиком содержащийся в А, то не существует круга
с большим диаметром (не обязательно с центром в точке z), кото-
рый бы включал в себя (D)z и при этом содержался в А. Такой круг
(D)z называется максимальным кругом.
б) Круг <JJ)Z касается границы множества А в двух или более различ-
ных точках.
Множество точек, образующих остов А, может быть выражено с ис-
пользованием операций эрозии и размыкания. Так, можно показать
([Serra, 1982]), что
К
5(Л)=и^(>»)
к=\
при
Sk(А) = (А е кВ) \((Л е кВ) В),
(9.5-11)
(9.5-12)
9.5. Некоторые основные морфологические алгоритмы
Рис. 9.23. (а) Множество А. (б) Различные положения максимальных кругов
с центрами на остове А. (в) Добавочные максимальные круги на других отрез-
ках остова Л. (г) Полный остов (показан пунктиром).
а б
в г
где В — примитив, а запись (А © кВ) обозначает к последовательных
применений операции эрозии к множеству Л:
(леАй)=((...(л©Б)е/?)е...)ей (9.5-13)
(операция © повторяется Л раз)9. Символ Къ (9.5-11) — номер послед-
него шага итерации перед превращением множества Л в пустое мно-
жество. Другими словами,
tf = max{A;|G4eCS)^0}. (9.5-14)
Формулы (9.5-11) и (9.5-12) утверждают, что остов ДЛ) можно по-
лучить объединением подмножеств остова Sp(A). Кроме того, можно
9 Полезно обратить внимание на тот факт, что 5ДЛ) есть то множество точек, кото-
рые не восстанавливаются операцией дилатации из множества (A Q {к + \)В). Это поз-
волит легко понять уравнение (9.5-15). — Прим, перев.
Глава 9. Морфологическая обработка изображений
показать, что множество А может быть восстановлено по этим подмно-
жествам с помощью уравнения
К
/1=U(S*G4)®^), (9.5-15)
л=о
где (5^(>4) © кВ) обозначает последовательное применение дилата-
ции к Sk(A) к раз, т.е.
(Sk(A)®kB) = ((...(Sk(A)® В)® В)®..}® В. (9.5-16)
Рис. 9.24. Реализация соотношений (9.5-11) — (9.5-15). Исходное изображение
находится слева вверху, а его морфологический остов — в четвертой колонке
внизу Восстановленное множество приведено в шестой колонке внизу
9.5. Некоторые основные морфологические алгоритмы 783
Пример 9.8: Построение остова простой фигуры.
Рис. 9.24 иллюстрирует описанный подход. В первой колонке свер-
ху вниз показаны исходное множество и результаты двух последова-
тельных применений к нему операции эрозии по примитиву В. Заме-
тим, что при следующем применении эрозии будет получено пустое
множество, поэтому в данном случае К = 2. Во второй колонке пока-
заны результаты применения к множеству из первой колонки опера-
ции размыкания по тому же примитиву В. Эти результаты легко объ-
ясняются характерным для операции размыкания свойством
прилегания, о котором говорилось в связи с Рис. 9.8. В третьей колон-
ке содержится просто разность множеств из первой и второй колонок.
Четвертая колонка содержит (сверху вниз) две части остова и окон-
чательный результат его построения. Этот финальный остов не только
толще, чем хотелось бы, но и не является связным, что более сущест-
венно. Такой результат вполне закономерен, поскольку в пред-
шествующем построении морфологического остова не было ничего,
что гарантировало бы связность. Морфологический подход приводит
к красивой формулировке в терминах эрозии и размыкания данного
множества. Однако если необходимо построить максимально тон-
кий, связный и максимально гладкий остов (что обычно и требуется
на практике), то приходится прибегать к эвристическим построени-
ям, например, подобным алгоритму из Раздела 11.1.5. В пятой ко-
лонке показаны множества 50(Л), 5](Л) © В и S2(A) © 2В =
(^(Л) © В) © В. Наконец, в шестой колонке показан процесс восста-
новления множества А, который, согласно уравнению (9.5-15), со-
стоит в объединении подвергнутых дилатации подмножеств остова из
пятой колонки.
9.5.8. Усечение
Методы усечения являются существенным дополнением алгоритмов
утончения и построения остова, поскольку эти алгоритмы склонны ос-
тавлять паразитные компоненты, которые необходимо «вычистить»
в ходе финальной обработки. Мы начнем обсуждение с задачи усече-
ния областей (или отсечения ложных ветвей), азатем выработаем в рам-
ках морфологического подхода решение, основанное на материале
предыдущих разделов. Таким образом, мы воспользуемся этой возмож-
ностью, чтобы проиллюстрировать, как приступать к решению постав-
ленной конкретной задачи путем комбинирования методов, рассмо-
тренных к данному моменту.
Общепринятый подход к задаче автоматического распознавания ру-
кописных знаков основан на анализе формы остова каждого симво-
Глава 9. Морфологическая обработка изображений
ла. Такие остовы часто характеризуются наличием паразитных «отро-
стков». Они могут возникать в результате операции эрозии из-за не-
однородностей линий, из которых состоит знак. Исходя из предполо-
жения, что длина паразитных составляющих не превышает известного
числа пикселей, мы построим морфологический метод для их устра-
нения.
На Рис. 9.25(a) приведен остов рукописной буквы «а». Паразитная
составляющая в левой верхней части символа является типичным
В\В2,В\&
(с поворотами на 90°)
а
г
е
(с поворотами на 90 )
Рис. 9.25. (а) Исходное изображение, (б) и (в) Примитивы для удаления кон-
цевых точек, (г) Результат трех циклов утончения (д) Концевые точки мно-
жества (г), (е) Дилатация концевых точек при условии принадлежности мно-
жеству (а), (ж) Изображение после усечения.
9.5. Некоторые основные морфологические алгоритмы 785
примером объекта, который хотелось бы удалить. Решение базирует-
ся на подавлении паразитной ветви путем последовательного удале-
ния ее концевой точки. Разумеется, при этом также сокращаются
(или пропадают) и другие ветви символа, однако, за неимением дру-
гой информации о структуре, в данном примере предполагается, что
удалению подлежит любая ветвь, состоящая из трех пикселей или ме-
нее. Желаемый результат достигается путем утончения множества Л с
помощью последовательности примитивов, построенных для обнару-
жения только концевых точек. Итак, пусть
Хх=А®{В}, (9.5-17)
где {В} обозначает последовательность примитивов, показанную на
Рис. 9.25(6) и (в) (операции с использованием последовательности при-
митивов рассматривались при обсуждении соотношения (9.5-7)). Эта
последовательность состоит из двух различных структур, каждая из ко-
торых путем последовательных поворотов на 90° образует четыре при-
митива, что в сумме дает 8 примитивов. Знак х на Рис. 9.25(6) обозна-
чает «несущественность», в том смысле, что не имеет значения, какой
пиксель оказывается в этой позиции — нулевой или единичный. В ли-
тературе по морфологическим методам сообщается о многочисленных
результатах, основанных на применении одиночного примитива, похо-
жего на показанный на Рис. 9.25(6), но с признаками несущественно-
сти во всем первом столбце. Это ошибочно: например, с помощью та-
кого примитива точка, расположенная в 8-й строке и 4-м столбце на
Рис. 9.25(a), была бы опознана как концевая и удалена, что привело
бы к разрыву штриха.
Трехкратное применение уравнения (9.5-17) к множеству Л при-
водит к показанному на Рис. 9.25(г) множеству У,. Дальнейшие ша-
ги состоит в «восстановлении» символа до его первоначального ви-
да, но без удаленных паразитных ветвей. Для этого сначала потребуется
построить множество состоящее из всех концевых точек Хх
(Рис. 9.25(д)):
8
У2 = и<%1®^)’ (9.5-18)
к=\
где Вк суть те же самые детекторы концевых точек, изображенные на
Рис. 9.25(6) и (в). На следующем шаге три раза выполняется дилата-
ция этих концевых точек по заполненному единицами квадратному
примитиву Я размерами 3x3 при одновременном использовании ис-
ходного множества Л в качестве ограничителя:
Глава 9. Морфологическая обработка изображении
У3=(У2©Я)П^. (9.5-19)
Как и в случаях заполнения областей и выделения связных компонент,
условная дилатация такого вида предотвращает появление единичных
пикселей за пределами области интереса, что подтверждает результат,
показанный на Рис. 9.25(e). Наконец, объединение множеств Xj иХ]
приводит к желаемому результату
%4 = %]U%3, (9.5-20)
приведенному на Рис. 9.25(ж).
В более сложных случаях применение уравнения (9.5-19) иногда за-
хватывает «кончики» некоторых паразитных ветвей, что случается,
если они находятся вблизи остова. Хотя соотношением (9.5-17) они
могли быть устранены, во время дилатации они захватываются снова,
поскольку их правомерно считать точками множества Л. Если только
это не привело к восстановлению паразитной составляющей целиком
(что является редким случаем, если длина таких составляющих мала
по сравнению с действительными штрихами), обнаружение и устра-
нение подобных артефактов не представляет трудностей, поскольку
они образуют несвязные области с исходным множеством.
В этом месте возникает естественная мысль, что должны сущест-
вовать более простые пути решения данной задачи. Например, мож-
но отслеживать все удаленные точки и присоединять обратно соответ-
ствующие точки ко всем концевым точкам, оставшимся после
применения шага (9.5-17). Такой вариант вполне действенен, но до-
стоинством приведенного выше построения является возможность
решения всей задачи целиком с помощью простых морфологичес-
ких конструкций. В практических ситуациях, когда доступен набор та-
ких инструментальных средств, это преимущество состоит в отсутст-
вии необходимости написания новых алгоритмов. Мы просто
комбинируем нужные морфологические функции, строя из них после-
довательность операций обработки.
9.5.9. Сводная таблица морфологических операций
В Таблице 9.2 приведены итоговые результаты обсуждения морфоло-
гических операций, представленных в предшествующих разделах, а на
Рис. 9.26 показаны основные виды примитивов, применяющихся в раз-
личных процессах морфологической обработки, которые были рассмо-
трены ранее. Числа, записанные римскими цифрами в скобках в тре-
тьей колонке таблицы, указывают номера примитивов на Рис. 9.26.
9.5. Некоторые основные морфологические алгоритмы
Таблица 9.2. Сводная таблица морфологических операций и их свойств.
Операция Уравнения Примечания (Римские цифры в скобках означают номера примитивов на Рис. 9.26).
Параллельный перенос (Л)г ={^1^=0+?, ае/1} Сдвиг центра (начала ко- ординат) множества А в точку Z-
Центральное отражение В = {w| w = -b, be В} Симметричное отражение всех элементов В относи- тельно начала координат.
Дополнение Ас = {w | е А } Множество точек, не вхо- дящих в А.
Разность Д\В = {и'|и'б/1.и'еВ}= Множество точек, принад- лежащих А, но не принад- лежащих В.
Дилатация ?lffiB = {?|(B)z ПА*0} «Расширение» границы множества А. (I)
Эрозия лев={г|(в)гсд} «Сужение» границы множества А. (I)
Размыкание А»В = (АеВ)ФВ Сглаживает контуры, раз- рывает узкие перешейки, убирает небольшие остров- ки и острые выступы. (I)
Замыкание А»В = (АФВ)еВ Сглаживает контуры, за- полняет узкие разрывы, уг- лубления, и небольшие от- верстия. (I)
Успех/неудача А®В=(А ®ВХ) П(АС ®В2)= =(Л О Вх) \ ( Множество координат то- чек, в которых одновре- менно для В] есть совпаде- ние в А, а для В2 - в Ас.
Выделение границы $(А) = А\(АеВ) Множество граничных то- чек множества А. (I)
Заполнение области Хк =(Хк_\®В)ЪАс-, Хо = р иЛ = 1,2,3,... Заполняет область множе- ства А, начиная с заданной внутренней точки р этой области. (II)
Выделение связной компоненты Хк ~(Хк В)Г\ А: Ха = р и к = 1,2,3,... Находит связную компо- ненту Yв множестве А, на- чиная с заданной точки р внутри Y. (I)
Выпуклая оболочка Xk=(Xk_x®Bi)}jA-J = \,23,A\ к = \.2,3,--\ Х‘п=А и£>'=Х'стп • • • > U 1.ЛМЦ Находит для множества А выпуклую оболочку С(А). Индекс «сход» соответству- ет сходимости, в том смыс- ле, что Х'к^Х'к r (III)
Глава 9. Морфологическая обработка изображений
Таблица 9.2 (продолжение). Сводная таблица морфологических операций и их
свойств.
Операция Уравнения Примечания (Римские цифры в скобках означают номера примитивов на Рис. 9.26).
Утончение А® В = А\(А® В) А®В = АП(А® В)с А® {В}= ((...((А® В1)®В2) ..)®Вп) {в}={в',в2,в3,...,вп] Делает множество А «тонь- ше». Первые два уравнения являются базовым опреде- лением утончения. Вторые два уравнения отвечают утончению по последова- тельности примитивов. Этот метод обычно применяется на практике. (IV)
Утолщение A®B = A\J(A®B) А®{В}=((...((А®В')®В2)...)®Вп) Делает множество/1 «толще» (см. выше замечание о по- следовательности примити- вов). Используются прими- тивы (IV), в которых нули заменяются единицами, а единицы - нулями.
Построение остова к 5(Л)=и^(Л) А=1 Sk(A) = (A®kB)\{{A®kB)oB} Восстановление множества А’, к А = UGW)ffifcB) *-о Находит остов 5(/1) множе- стваА Последнее уравнение показывает, что множество А может быть восстановлено по подмножествам остова 5ДЛ). В этих уравнениях значение /Г-номер шага ите- рации, после которого эро- зия множества А приводит к пустому множеству. Запись (А е кВ) обозначает к приме- нений подряд к множеству А операции эрозии по прими- тиву В. (I)
Усечение Xi = А®{В} 8 ^2 = U(^®ba) Ar-l X3 = (X2® H) nA Xj= Xi и х2 Х4 есть результат усечения множества А. Необходимо указать, сколько раз приме- няется первое уравнение для получения В двух первых уравнениях используются примитивы V; Н в третьем уравнении обозначает при- митив типа I.
9.6. Расширение алгоритмов на полутоновые изображения
1
II
2, 3,4
(с поворотами на 90°)
III
£' /=1,2,..., 8
(с поворотами на 45°)
IV
Б'/=1,2,3,4
(с поворотами на 90')
В' i=5, 6, 7, 8
(с поворотами на 90°)
Рис. 9.26. Пять основных типов примитивов, применяемых для двоичных
морфологических методов. Начало координат каждого примитива располо-
жено в его центре, и знаки х указывают, что значение пикселя на этой пози-
ции не принимается во внимание.
9.6. Расширение морфологических алгоритмов
на полутоновые изображения
В этом разделе мы распространим базовые морфологические опера-
ции дилатации, эрозии, размыкания и замыкания на полутоновые
изображения, а затем воспользуемся ими для построения несколь-
ких основных полутоновых морфологических алгоритмов. В частности,
будут предложены алгоритмы выделения границ с помощью операции
морфологического градиента и разделения на области на основе тек-
стурных признаков. Мы также обсудим алгоритмы сглаживания и по-
вышения резкости, которые часто бывают полезны на этапах предва-
рительной и окончательной обработки изображений.
В последующем рассмотрении будут участвовать цифровые изоб-
ражения, заданные функциями f(x, у) и b (х, у), где f(x, у) — исходное
изображение, а функция Ь(х, у) задает примитив, который сам явля-
ется изображением (с меньшими размерами). Предполагается, что
эти функции являются дискретными в том смысле, как это определя-
лось в Разделе 2.4.2, т.е. пары координат (х, у) берутся из множества
ZxZ(где Z — множество целых чисел), и функции/и b сопоставляют
каждой паре координат значение яркости в соответствующей точке —
действительное число из множества R. Если значения яркости также
целочисленные, то вместо R используется Z.
Глава 9. Морфологическая обработка изображений
9.6.1. Дилатация
Полутоновая дилатация/по b обозначается/© b и определяется как
(f®b)(s.t) =
r . , (9.6-1)
= max{/(5-x,r-y)+6(x,y)|(5-x,r-y)e Df-(x,y)e Dbf,
где Dj и Db — области определения изображений/и b соответствен-
но. Подчеркнем, что здесь /и b — функции, а не множества, как в слу-
чае двоичной морфологии.
Условие, что координаты (s — х) и (t — у) должны находиться в об-
ласти определения / ах иу — в области определения Ь, является ана-
логом условия в определении двоичной дилатации, которое требует,
чтобы два множества пересекались хотя бы в одном элементе. Заме-
тим также, что уравнение (9.6-1) по форме сходно с определением
двумерной свертки (4.2-30), с точностью до замены суммирования
операцией взятия максимума, а умножения — сложением.
Проиллюстрируем систему обозначений и механизм действия со-
отношения (9.6-1) на простом примере одномерных функций. В слу-
чае функций одной переменной уравнение (9.6-1) сводится к виду
(/®b)(s) = max{f(s-x) + b(x)\(s-x)eDj и хеЛ^}.
Вспомним из обсуждения свертки, что /(—х) получается зеркальным
отражением / (х) относительно начала координат на оси х. Как и в
случае свертки, функция f(s — х) означает сдвиг вправо, если s поло-
жительно, и влево, если s отрицательно. Требования, что значение
(s — х) должно находиться в области определения / а значение х — в
области определения Ь, означают, что/и b перекрываются. Как отме-
чалось выше, эти условия аналогичны требованию в определении
двоичной дилатации, что два множества должны пересекаться по
меньшей мере водном элементе. Наконец, в отличие от двоичного слу-
чая, сдвигу подвергается исходная функция/ а не примитив Ь. Соот-
ношение (9.6-1) можно переписать так, чтобы сдвиг претерпевала
функция b вместо/. Однако, если Db меньше, чем Df(a именно такой
случай почти всегда встречается на практике), форма записи (9.6-1) по-
рождает более простой закон формирования индексов, приводя в
итоге к тем же самым результатам. В принципе, движение / относи-
тельно b ничем не отличается от движения b относительно /. Факти-
чески, хотя приведенное соотношение и проще в реализации, меха-
низм действия полутоновой дилатации легче представить наглядно,
если считать, что функция b скользит вдоль функции /.
9.6. Расширение алгоритмов на полутоновые
Рис. 9.27. (а) Простая функция, (б) Примитив с высотой А. (в) Результаты ди-
латации для различных положений при движении b вдоль/. (г) Окончатель-
ный результат операции дилатации (сплошная линия).
На Рис. 9.27 приводится пример выполнения дилатации. Заме-
тим, что в каждом положении примитива значение дилатации в этой
точке есть максимум суммы f к b в интервале, охватываемом функ-
цией Ь. Применение дилатации к полутоновому изображению приво-
дит в целом к двоякому эффекту: (1) если все значения примитива по-
ложительные, то результирующее изображение становится ярче
исходного; (2) темные детали ослабляются или вообще пропадают, в
зависимости от соотношения их размеров и яркостей с параметрами
используемого при дилатации примитива.
9.6.2. Эрозия
Полутоновая эрозия/по b обозначается fQ b и определяется как
(/ez>)(v)=
= min^/(.s+x,Z+y)-Z>(x,y)|(5+x,/+y)e D^;(x,y)e Dby, (9.6-2)
где Dj и Db — области изображений f и b соответственно. Условия,
что координаты (s + х) и (t + у) должны находиться в области опреде-
792 Глава 9. Морфологическая обработка изображении
ления/, ах и у — в области определения h, аналогичны условиям в оп-
ределении двоичной эрозии, где примитив должен полностью нахо-
диться внутри исходного множества. Заметим, что по форме уравне-
ние (9.6-2) сходно с определением двумерной корреляции (4.6-30) с
точностью до замены суммирования операцией взятия минимума, а
умножения — вычитанием.
Проиллюстрируем механизм действия соотношения (9.6-2) на
простом примере одномерных функций. В случае функций одной пе-
ременной уравнение для эрозии сводится к виду
(/©6)(5) = min{/(5 + x)-6(x)|(.s + x)e£y и xeD^,}.
Как и в случае корреляции, функция f(s + х) означает сдвиг влево, ес-
ли s положительно, и вправо, если s отрицательно. Требования
(s + x)e Df и х е Л/, означают, что область определения b должна це-
ликом находиться внутри области определения сдвинутой функции f.
Как отмечалось выше, эти условия аналогичны требованию в опреде-
лении двоичной эрозии, где примитив не должен выходить за грани-
цу исходного множества.
Наконец, в отличие от двоичного случая, сдвигу подвергается ис-
ходная функция/, а не примитив Ь. Соотношение (9.6-2) можно пе-
реписать так, чтобы сдвиг претерпевала функция b вместо/, однако это
приведет к более сложным индексным выражениям. Поскольку дви-
жение f относительно b по существу ничем не отличается от движе-
ния b относительно /, используется форма записи (9.6-2) в силу тех
же причин, что были изложены выше при рассмотрении полутоновой
дилатации. На Рис. 9.28 показан результат применения к функции
на Рис. 9.27(a) операции эрозии по примитиву, показанному на
Рис. 9.27(6).
A-f(b/2\
Рис. 9.28. Результат эрозии функции, показанной на Рис. 9.27(a), по при-
митиву, представленному на Рис. 9.27(6).
9.6. Расширение алгоритмов на полутоновые изображения
Соотношение (9.6-2) показывает, что в основе операции эрозии ле-
жит выбор минимального значения (/— Ь) на интервале, определяе-
мом формой примитива. Применение эрозии к полутоновому изоб-
ражению приводит в целом к двоякому эффекту: (1) если все значения
примитива положительные, то результирующее изображение стано-
вится темнее исходного; (2) яркие детали исходного изображения,
площадь которых меньше площади примитива, ослабляются, при-
чем степень этого ослабления зависит от значений яркости элементов
изображения вокруг этих деталей, а также от формы и амплитудных
значений самого примитива.
Полутоновые операции дилатации и эрозии являются двойствен-
ными друг другу по отношению к дополнению и центральному отра-
жению функций, т.е.
(f Qb)c(s,t) = (fc®b)(s,f), (9.6-3)
где fc = -f (х,у) иЬ = Ь(-х,-у). В дальнейшем рассмотрении мы будем
пользоваться упрощенной системой обозначений, опуская аргумен-
ты всех функций, за исключением тех случаев, когда это необходимо
для ясности.
Пример 9.9: Иллюстрация действия операций дилатации и эрозии на
полутоновое изображение.
На Рис. 9.29(a) приведено полутоновое изображение с размерами
512x512 пикселей, а Рис. 9.29(6) демонстрирует результат дилатации
этого изображения по примитиву с плоской вершиной, имеюшему
форму параллелепипеда с размерами 5x5 пикселей и высотой в одну
градацию яркости. С учетом сказанного выше, можно ожидать, что бу-
дет получено более яркое изображение, чем исходное, и что неболь-
шие темные детали уменьшатся в размерах или исчезнут. Эти эффек-
ты ясно видны на Рис. 9.29(6). Изображение не только стало более
ярким, но и уменьшились размеры темных деталей, таких как нозд-
ри и спускающийся от ушей к шее ремень упряжи с бляшками.
Рис. 9.29(b) демонстрирует результат эрозии исходного изображения.
Заметны эффекты противоположного характера: изображение стало
темнее, и размеры небольших ярких деталей (например, бляшек на
ремне) уменьшились.
9.6.3. Размыкание и замыкание
Выражения для операций размыкания и замыкания в случае полуто-
новых изображений имеют такую же форму, как и в двоичном случае.
Глава 9. Морфологическая обработка изображений
Рис. 9.29. (а) Исходное изображение, (б) Результат дилатации, (в) Результат эро-
зии. (Изображения предоставил А. Моррис, компания Leica Cambridge, Ltd.)
Размыкание изображения f по примитиву b обозначается f Ьи оп-
ределяется следующим образом:
f°b=(feb)®b.
(9.6-4)
Как и в двоичном случае, размыкание состоит в эрозии/по Ь, после
чего к результату применяется дилатация опять-таки по Ь. Аналогич-
но, замыкание / по b обозначается / • b и определяется следующим
образом:
f»b = (f®b)Qb.
(9.6-5)
Полутоновые операции размыкания и замыкания являются двойствен-
ными друг другу по отношению к дополнению и центральному отра-
жению функций, т.е.
9.6. Расширение алгоритмов на полутоновые изображения 795J^
{f*b)c=fc°b. (9.6-6)
Поскольку fc =-f(x,y), уравнение (9.6-6) можно также записать в
виде -(/•/>) = (-/ ь).
Для операций размыкания и замыкания изображений имеется
простая геометрическая интерпретация. Рассмотрим функцию изоб-
ражения f (х, у) в объемной перспективе, подобно рельефной карте,
на которой оси х и у соответствуют обычным пространственным ко-
ординатам, а значения координат по третьей оси отвечают уровням яр-
кости в точках изображения. В таком представлении изображение
выглядит как дискретная поверхность, высота которой в любой точ-
ке (х, у) равна значению/при этих координатах. Пусть размыкание/
выполняется по сферическому примитиву Ь, который будем рассма-
тривать как «катящийся шарик». Тогда механизм размыкания функ-
ции/ по b можно геометрически интерпретировать как процесс обкат-
ки шариком всей нижней стороны поверхности. При этом огибающая
высших точек сферы и будет поверхностью, соответствующей раз-
мыканию исходного изображения.
Рис. 9.30 иллюстрирует описанный принцип. Для упрощения од-
на из строк развертки полутонового изображения показана на
Рис. 9.30(a) в виде непрерывной функции. На Рис. 9.30(6) показаны
различные положения шарика во время обкатки этой строки, а
Рис. 9.30(b) демонстрирует окончательный результат размыкания /
по b вдоль этой строки. Все пики, узкие по сравнению с диаметром сфе-
ры, снизились по амплитуде и сгладились. На практике операция раз-
мыкания обычно используется для устранения небольших (по сравне-
нию с размерами примитива) светлых деталей, при сохранении
практически неизменными общей яркости и крупных ярких деталей.
Выполняемая вначале эрозия удаляет мелкие детали, но также и де-
лает изображение более темным. Последующая дилатация увеличива-
ет общую яркость до прежнего уровня, но не восстанавливает детали,
удаленные при эрозии.
Рис. 9.30(г)и(д) иллюстрируют операцию замыкания / по Ь. Здесь
сфера обкатывает верхнюю сторону поверхности, и выступающие пи-
ки в основном сохраняют исходную форму (если расстояние между ни-
ми в самом узком месте превышает диаметр сферы). На практике
операция замыкания обычно используется для удаления темных де-
талей изображения, при сравнительно малых изменениях ярких дета-
лей. Выполняемая вначале дилатация удаляет темные детали и дела-
ет изображение светлее, а последующая эрозия уменьшает общую
яркость до прежнего уровня, но не восстанавливает детали, удаленные
при дилатации. Интересно сравнить Рис. 9.30 с Рис. 9.8 и 9.9.
Глава 9. Морфологическая обработка изображений
Рис. 9.30. (а) Строка развертки полутонового изображения, (б) Положе-
ния катящейся сферы при размыкании, (в) Результат размыкания, (г) По-
ложения катящейся сферы при замыкании, (д) Результат замыкания.
Полутоновая операция размыкания удовлетворяет следующим
свойствам:
а) (/ b) J/.
б) Если J /2 , то (/ о b) J (/2 Ь)
в) (/ Ь) О b = fo b .
Запись е J г обозначает, что область определения е является подмно-
жеством области определения г и при этом е (х, у)<г (х, у) для любой
точки (х, у) в области определения е.
Аналогично, полутоновая операция замыкания удовлетворяет сле-
дующим свойствам:
a)fJ(f'b).
б) Если/] J /2 , то (/ • b) J (/2 • Ь).
в) (f.b)*b=f*b.
а о
Рис. 9.31(a) Размыкание и (б) замыкание изображения, представленного на
Рис. 9.29(a). (Изображения предоставил А. Моррис, компания Leica Cambridge, Ltd.)
Эти равенства являются столь же полезными, как и их аналоги для дво-
ичного случая.
Пример 9.10: Иллюстрация полутоновых операций размыкания и за-
мыкания.
На Рис. 9.31(a) приведен результат размыкания изображения из
Рис. 9.29(a) потому же примитиву, что и ранее. Обратите внимание на
уменьшение размеров небольших ярких деталей при отсутствии ощу-
тимого влияния на более темные области. На Рис. 9.31(6) показан
результат замыкания того же изображения. Здесь можно отметить
уменьшенные размеры небольших темных деталей, в то время как
яркие участки изображения относительно мало изменились. К
9.6.4. Некоторые приложения полутоновой морфологии
Завершая рассмотрение морфологических методов, рассмотрим в об-
щих чертах различные области применения полутоновой морфологии.
(Касательно иллюстраций отметим, что все приведенные изображе-
ния, если не указано иное, имеют размеры 512x512 элементов и обра-
батываются с использованием примитива, обсуждавшегося в связи
с Рис. 9.29: квадрата размерами 5x5 элементов и значениями 1).
Морфологическое сглаживание
Один из возможных способов сглаживания состоит в выполнении
операций морфологического размыкания, а затем размыкания. Ито-
говый результат выполнения двух операций состоит в удалении или
ослаблении как темных, так и светлых артефактов и шума. На
Глава 9. Морфологическая обработка изображений
Рис. 9.32. Результат морфологического сглаживания изображения из Рис. 9.29(a).
(Изображение предоставил А. Моррис, компания Leica Cambridge, Ltd.)
Рис. 9.32 показан результат подобного сглаживания изображения
из Рис. 9.29(a).
Морфологический градиент
Помимо тех операций, которые рассматривались выше в связи с уда-
лением из изображения небольших темных и светлых артефактов,
дилатация и эрозия часто применяются для вычисления морфологиче-
ского градиента изображения, обозначаемого g:
g=(J®b)-(fQb). (9.6-7)
На Рис. 9.33 приведены результаты вычисления морфологического гра-
диента изображения, показанного ранее на Рис. 9.29(a). Как можно бы-
ло ожидать, морфологический градиент выделяет резкие перепады
яркости на исходном изображении. В отличие от вычисления гради-
ента с помощью методов, рассматривавшихся в Разделе 3.7.3, в полу-
чении морфологического градиента участвуют симметричные при-
митивы, для которых характерна меньшая зависимость результата от
направленности контуров.
Преобразование «столбик»
Морфологическое преобразование «столбик»10, обозначаемое А, оп-
ределяется уравнением
10 В оригинале использован термин top-hat transformation. — Прим, перев.
9.6. Расширение алгоритмов на полутоновые изображения
Рис. 9.33. Морфологический градиент изображения из Рис. 9.29(a). (Изобра-
жение предоставил А. Моррис, компания Leica Cambridge, Ltd.)
(9.6-8)
где, как и прежде, f — исходное изображение, а b — функция прими-
тива. Это преобразование, которое обязано своим названием приме-
няемой функции примитива в форме цилиндра или параллелепипе-
да с плоским верхом, оказывается полезным для подчеркивания
деталей на полутоновых изображениях. На Рис. 9.34 показаны ре-
зультаты применения данного преобразования к изображению из
Рис. 9.29(a). Обратите внимание на достигнутое усиление деталей в об-
ласти фона ниже лошадиной головы.
Рис. 9.34. Результат применения преобразования «столбик» к изображению из
Рис. 9.29(a). (Изображение предоставил А. Моррис, компания Leica Cambridge, Ltd )
Глава 9. Морфологическая обработка изображений
Текстурная сегментация
На Рис. 9.35(a) представлено простое полутоновое изображение, со-
стоящее из двух областей с различными текстурами. Правая часть
изображения содержит круглые пятна большего диаметра, чем те, ко-
торые находятся в левой части. Задача состоит в нахождении грани-
цы между этими двумя областями на основе их текстурных признаков.
Поскольку операция замыкания в общем случае приводит к уда-
лению темных деталей изображения, в данном конкретном примере
процедура может состоять в замыкании исходного изображения по
примитиву последовательно увеличивающихся размеров. Когда раз-
меры примитива становятся сопоставимыми с меньшими пятнами
на изображении, эти пятна исчезают, уступая место светлому фону.
В этот момент на изображении остаются только пятна больших раз-
меров и светлый фон в левой части и между ними. После этого выпол-
няется одиночная операция размыкания по примитиву, размеры ко-
торого превышают расстояние между оставшимися темными пятнами.
В результате светлые промежутки между пятнами будут заполнены тем-
ным фоном и исчезнут. Мы получим изображение, состоящее из свет-
лой области слева и темной области справа. После этого простое по-
роговое преобразование выделяет границу между двумя областями,
отличающимися по текстурным признакам. На Рис. 9.35(6) показан
участок полученной границы, наложенный на исходное изображе-
ние. Полезно проработать этот пример более подробно, воспользовав-
шись аналогией с шариком на Рис. 9.30.
Рис. 9.35. (а) Исходное изображение, (б) Изображение с показанной грани-
цей между областями, отличающимися по текстуре. (Изображения предо-
ставил А. Моррис, компания Leica Cambridge, Ltd.)
Гранулометрия
Гранулометрия — это область, которая занимается в основном изу-
чением распределения размеров частиц на сложных изображениях.
На Рис. 9.36(a) показан пример такого изображения, на котором при-
сутствуют светлые объекты трех различных размеров. Эти объекты
не только могут перекрываться, но и расположены слишком скучен-
но,'чтобы пытаться выделять отдельные частицы. Поскольку эти ча-
стицы светлее фона, для построения распределения частиц по раз-
меру можно применить следующий морфологический подход.
К исходному изображению применяется операция размыкания по
примитиву с увеличением размеров примитива на каждым шаге.
После каждого такого шага вычисляется разность между исходным
изображением и результатом размыкания. В конце вычисленные
значения разности нормализуются и используются для построения
гистограммы распределения размеров частиц. В основе данного
подхода лежит та идея, что операция размыкания по примитиву
некоторых конкретных размеров в наибольшей степени воздейст-
вует на те области исходного изображения, в которых содержатся
частицы аналогичных размеров. Поэтому мерой относительного чис-
ла частиц может быть вычисленная разность между исходным и обра-
ботанным изображениями. Рис. 9.36(6) демонстрирует полученное
в данном примере распределение размеров частиц. Данная гисто-
грамма указывает на наличие в исходном изображении частиц трех
преобладающих размеров. Описанный вид обработки также может
а б
Рис 9 36. (а) Исходное изображение, содержащее перекрывающиеся части-
цы. (б) Распределение размеров частиц. (Изображения предоставил А. Мор-
рис, компания Leica Cambridge, Ltd.)
27 А-223
Глава 9. Морфологическая обработка изображений
быть полезен для описания областей, в которых преобладают сим-
волы, напоминающие частицы.
Заключение
Представленные в этой главе морфологические понятия и методы
образуют мощный набор инструментов для выделения интересую-
щих признаков в изображении. Один из наиболее привлекательных ас-
пектов морфологических методов обработки изображений состоит
в их исчерпывающем теоретическом обосновании. С точки зрения ре-
ализации важным преимуществом является то, что и дилатация, и эро-
зия представляют собой примитивные операции, которые лежат в ос-
нове широкого класса морфологических алгоритмов. Как будет
показано в следующей главе, на базе морфологии могут быть разрабо-
таны процедуры сегментации изображений для широкого класса при-
ложений. Как обсуждается в Главе 11. морфологические методы игра-
ют важную роль в процедурах построения описаний изображений.
Ссылки и литература для дальнейшего изучения
Книга Серра [Serra, 1982] является фундаментальным источником по
морфологической обработке изображений. См. также работы [Serra,
1988], [Giardina, Dougherty, 1988] и [Haralick, Shapiro, 1992]. К числу
дополнительных более ранних источников, связанных с предметом рас-
смотрения, относятся статьи [Blum, 1967], [Lantiljoul, 1980], [Maragos,
1987] и [Haralick et al., 1987]. Обзор методов двоичной и полутоновой
морфологии проведен в работах [Basart, Gonzalez, 1992] и [Basart et al.,
1992]. Этот набор источников является достаточно широкой базой
для материала, изложенного в Разделах 9.1 — 9.4.
Важные вопросы, относящиеся к реализации морфологических ал-
горитмов, подобных рассмотренным в Разделах 9.5 и 9.6, обсуждаются
в статьях [Jones, Svalbe, 1994], [Park, Chin, 1995], [Sussner, Ritter, 1997],
[Anelli et al., 1998] и [Shaked, Bruckstein, 1998]. Современные работы
в области теории и приложений морфологической обработки изобра-
жений собраны в книге [Goutsias, Bloomberg 2000] и специальном вы-
пуске журнала «Распознавание образов» [Pattern Recognition, 2000].
См. также недавний обзор литературы, составленный А. Розенфель-
дом [Rosenfeld, 2000]. Кроме того, представляют интерес книги по
обработке двоичных изображений [Marchand-Maillet, Sharaiha, 2000]
и по алгебре изображений [Wilson, 2001].
Задачи
9.1 Обсуждаемые в этой книге цифровые изображения построены
на квадратной сетке пикселей, которые могут находиться в
отношениях 4-, 8- или дг-связности. Возможны, однако, и дру-
гие формы сетки. В частности, иногда применяется гексаго-
нальная сетка, в которой рассматривается 6-связность (см.
рисунок ниже).
(а) Как бы Вы преобразовали изображение с квадратной сет-
кой элементов в изображение с гексагональной сеткой?
(б) Рассмотрите и сравните инвариантность формы объектов к
повороту, в случае квадратной сетки и в случае гексагональ-
ной сетки.
(в) Могут ли на гексагональной сетке возникать неоднознач-
ные диагональные конфигурации, как в случае 8 связнос-
ти? (См. Раздел 2.5.2).
9.2 *(а) Для множеств А и В, представленных на Рис. 9.1(a), изоб-
разите множество (А П В) U (A U В)с.
(б) Приведите выражения для отмеченных темным цветом
множеств на трех следующих рисунках (для каждого ри-
сунка необходимо дать единое выражение независимо от
числа отмеченных областей):
Глава 9. Морфологическая обработка изображений
9.3 *(а) Предложите морфологический алгоритм для преобразо-
вания 8-связной двоичной границы в/и-связную (см. Раз-
дел 2.5.2). Вы можете предполагать, что граница имеет тол-
щину в 1 пиксель и состоит из одной компоненты
связности.
(б) Требует ли работа Вашего алгоритма выполнения более чем
одной итерации с каждым примитивом? Ответ объясните.
(в) Зависят ли характеристики алгоритма от порядка исполь-
зования примитивов? В случае отрицательного ответа до-
кажите это; в противном случае приведите контрпример,
иллюстрирующий зависимость Вашей процедуры от поряд-
ка применения примитивов.
9.4 Результат эрозии множества А по примитиву В является под-
множеством А до тех пор, пока начало координат В содержит-
ся в В. Приведите пример случая, когда результат эрозии лежит
вне множества А, полностью или частично.
9.5 Следующие четыре утверждения верны. Выдвиньте аргументы
в поддержку их правильности. Пункт (а) справедлив в общем
случае. Пункты (б) — (г) верны только для дискретных мно-
жеств. Чтобы показать правильность утверждений (б) — (г), на-
рисуйте квадратную дискретную сетку (подобную показанной
в Задаче 9.1) и приведите пример для каждого случая, исполь-
зуя множества точек на этой сетке. Указание: Используйте в
каждом случае минимально возможное число точек, при кото-
ром еще соблюдается проверяемое утверждение* *.
*(а) Эрозия выпуклого множества по выпуклому примитиву
приводит к получению выпуклого множества.
*(б) Результат дилатации выпуклого множества по выпуклому
примитиву не обязательно является выпуклым множеством.
(в) Точки выпуклого дискретного множества не всегда являют-
ся связными.
(г) Существует множество точек, в котором отрезки, соединя-
ющие всевозможные пары точек, принадлежат этому мно-
жеству, но оно не является выпуклым.
*9.6 Используя приведенное изображение, укажите, какой (или
какими) морфологической операцией и по какому примити-
ву получен каждый из рисунков (а) — (г). Укажите начало ко-
ординат каждого примитива. Пунктирные линии обозначают
11 См. также примечание 8. — Прим, перев.
границу исходного множества и приведены для сведения. Об-
ратите внимание, что в случае (г) все углы закруглены.
9.7 Пусть А — множество, показанное темным цветом на следую-
щем рисунке, а ниже него изображены четыре вида примити-
вов (черными точками обозначены их начала координат). Изо-
Глава 9. Морфологическая обработка изображений
бразите результаты выполнения следующих морфологичес-
ких операций:
(а) (ЛейШ2
(б) (А е В ') ф В 3
(в) (Лф В ‘) ф В3
(г) (А ф в3) е в2
*9.8 (а) Какой эффект ограничивает возможность повторной дила-
тации изображения, если не используется тривиальный
примитив, состоящий из единственной точки?
(б) Какое минимальное изображение может использоваться в
качестве начального в Вашем ответе на пункт (а) без нару-
шения правильности рассуждений?
9.9 (а) Какой эффект ограничивает возможность повторной эро-
зии изображения, если не используется тривиальный при-
митив, состоящий из единственной точки?
(б) Какое минимальное изображение может использоваться в
качестве начального в Вашем ответе на пункт (а) без нару-
шения правильности рассуждений?
*9.10 Альтернативное определение дилатации формулируется следу-
ющим образом:
A©2?={weZ2|w = «+Z> для некоторых аеАиЬеВ].
Покажите, что это определение эквивалентно определению
(9.2-1).
9.11 (а) Покажите, что определение из Задачи 9.10 эквивалентно
еще одному определению дилатации:
ЛФЯ= (J (А),,
ЬеВ
(данное выражение называют также суммой Минковского
двух множеств).
(б) Покажите, что выражение в пункте (а) также эквивалент-
но определению (9.2-1).
*9.12 Альтернативное определение эрозии формулируется следую-
щим образом:
АОB=[wgZ2\w + 6gA длялюбого
Покажите, что это определение эквивалентно определению
(9.2-3).
Задачи
9.13 (а) Покажите, что определение из Задачи 9.12 эквивалентно
еще одному определению эрозии:
Аев= П (А)_ь
be В
(при замене — b на b данное выражение называют также разно
стью Минковского двух множеств).
(б) Покажите, что выражение в пункте (а) также эквивалент-
но определению (9.2-3).
*9.14 Докажите правильность соотношения двойственности
(А* В)с ={АС В).
9.15 Докажите правильность следующих утверждений:
*(а ) А В является подмножеством А (т.е. вложенным изобра-
жением).
(б) Если С есть подмножество D,toC° В является подмноже-
ством D В.
(в) (А В) В=А В.
9.16 Докажите правильность следующих утверждений (предпола-
гая, что начало координат В содержится в множестве В, и что
утверждение Задачи 9.16(a) истинно):
(а) А является подмножеством (вложенным изображением)
А» В.
(б) Если С есть подмножество D, то С • В является подмноже-
ством D* В.
(в) (А* В)* В = А* В.
9.17 Обратитесь к показанным на рисунке изображению и прими-
тиву В. Нарисуйте вид множеств С, D, Ей F, получаемых при
Глава 9. Морфологическая обработка изображений
выполнении такой последовательности операций: С = A Q В\
D = С ® В, Е = D ® В, и F = Е Q В. Исходное множество А со-
держит все компоненты изображения, показанные белым цве-
том, исключая сам примитив. Заметим, что данная последова-
тельность операций представляет собой размыкание А по В,
после чего следует замыкание по В полученного результата. Вы
можете предполагать, что примитив В достаточно велик, что-
бы покрыть любую из шумовых составляющих.
*9.18 В примере, обсуждающем Рис. 9.7, демонстрируется, что ква-
драты, уцелевшие после операции эрозии, можно полностью
восстановить выполнением дилатации по тому же примитиву,
который использовался при эрозии. Эрозия, после которой
выполняется дилатация, вместе составляют операцию размы-
кания изображения, а, как известно, в общем случае размыка-
ние не приводит к тождественному восстановлению объек-
тов, к которым эта операция применяется. Объясните, почему
в показанном на Рис. 9.7 случае оказалось возможным полно-
стью восстановить оставшиеся квадраты.
9.19 (а) Изобразите результат выполнения преобразования «успех
/ неудача» для показанных ниже изображения и примити-
ва. Четко укажите выбранные Вами центр и границу при-
митива.
(б) Сравните полученный результат с результатом сопоставле-
ния корреляционным методом (Рис. 4.46), сформулируй-
те сходства и различия между ними.
Изображение Примитив
*9.20 Для описания объектов изображения, полученных в результа-
те утончения, полезно различать три их вида (озеро, залив и от-
резок), показанные наследующем рисунке. Разработайте мор-
фолого-логический алгоритм для различения этих трех типов
фигур. Исходными данными для алгоритма является изобра-
Задачи
Озеро
Залив Отрезок
жение одного из этих типов, а на выходе должно даваться его
название. Вы можете предполагать, что фигуры всегда имеют
толщину в 1 элемент и являются односвязными, но они могут
появляться в любой ориентации.
9.21 Опишите результаты, которых можно ожидать в каждом из
следующих случаев:
(а) Начальная точка в алгоритме заполнения области, опи-
санном в Разделе 9.5.2, выбирается на границе объекта.
(б) Начальная точка в алгоритме заполнения области выбира-
ется вне границ объекта.
(в) Изобразите, как будет выглядеть выпуклая оболочка фигу-
ры из Задачи 9.7, найденная по алгоритму, описанному в
Разделе 9.5.4. Считайте, что L = 3 пикселям.
9.22 (а) Опишите эффект от использования примитива из
Рис. 9.15(b) для выделения границ, вместо показанного на
Рис. 9.13(6).
(б) Какой эффект вызовет использование в алгоритме запол-
нения областей, основанном на соотношении (9.5-2), запол-
ненного единицами примитива размерами 3x3 вместо при-
митива из Рис. 9.15(b)?
9.23 Предложите полностью автоматический метод для примера, по-
казанного на Рис. 9.16. Это подразумевает выяснение, какие
черные точки относятся к фону, а какие содержатся внутри
кругов (т.е. входят в черные области внутри белых кругов).
Считайте, что белый цвет соответствует двоичной единице.
*9.24 Для алгоритма выделения связных компонент, описанного в
Разделе 9.5.3, требуется знать точку в каждой компоненте связ-
ности, чтобы выделить их все. Предположим, что имеется дво-
ичное изображение, содержащее произвольное заранее неиз-
вестное число связных компонент. Предложите автоматическую
Глава 9. Морфологическая обработка изображений
процедуру выделения связных компонент, предполагая, что
точки этих компонент имеют значения 1, а точки фона — 0.
9.25 Предположим, что в определении (9.6-1) изображение f(x,y)
и примитив b (х, у) оба имеют прямоугольную форму, с обла-
стями определения и Db вида ([Fx|, [/^q, /^2]) и
([/?х1, Bx2l, [fiji, Яуг!) соответственно. Это, например, означа-
ет, что замкнутые интервалы [f^j, /у2| и [/^q, Fy2\ суть диапа-
зоны изменения значений координатх и у на плоскости ху, где
определена функция f (х, у).
*(а) Предполагая, что (х, у) е Db, выведите выражения для ин-
тервалов, в которых могут изменяться переменные сдвига
.s и t, чтобы удовлетворялись условия в (9.6-1). Эти интерва-
лы на осях .s и t определяют прямоугольную область опре-
деления (/ф b){s, Г) на плоскости s t.
(б) Повторите то же самое для эрозии, определяемой в соот-
ветствии с (9.6-2).
9.26 На полутоновом изображении f (х, у) присутствуют неперекры-
вающиеся импульсы аддитивного шума. По форме каждый
импульс представляет собой небольшой цилиндр с радиусом г
И ВЫСОТОЙ a (/?mjn — ^max ’ -^min — а — -^тах)-
(а) Разработайте алгоритм морфологической фильтрации для
устранения шума на этом изображении.
(б) Повторите пункт (а) в предположении, что импульсы шу-
ма могут перекрываться, образуя группы, содержащие не бо-
лее четырех импульсов.
9.27 В прикладной задаче микроскопии на шаге предварительной
обработки ставится задача выделения одиночных круглых ча-
стиц среди набора таких частиц, которые могут перекрывать-
ся, образуя группы из двух или более частиц (см. пример изо-
бражения на рисунке). Считая, что диаметр всех частиц
Задачи 81
одинаков, предложите морфологический алгоритм для постро-
ения трех изображений, которые содержали бы соответствен-
но:
*(а) только частицы, касающиеся краев изображения;
(б) только перекрывающиеся частицы;
(в) только одиночные частицы.
9.28 Высокотехнологичное производственное предприятие получи-
ло правительственный заказ на изготовление прецизионных
шайб показанной на рисунке формы. По условиям контракта,
форма всех шайб должна контролироваться с помощью систе-
мы технического зрения. Контроль состоит в обнаружении
отклонений формы внутреннего и внешнего краев шайбы от
круглой. Вы можете предполагать, что: (1) имеется эталонное
изображение годной шайбы; и (2) используемые системы по-
зиционирования и регистрации изображений имеют доста-
точную точность, позволяющую не принимать во внимание
ошибки, вносимые из-за дискретизации и позиционирова-
ния. Вы приглашены в качестве консультанта для составления
спецификаций той части системы технического зрения, кото-
рая осуществляет контроль качества по изображению объекта.
Предложите решение на основе морфологических и/или логи-
ческих операций. Ответ следует дать в форме блок-схемы.
ГЛАВА 10
СЕГМЕНТАЦИЯ
ИЗОБРАЖЕНИЙ
Целое равно сумме его частей.
Евклид
Целое есть нечто большее, чем сумма его частей.
Макс Уертхеймер
Введение
Начиная с предыдущей главы, мы перешли от рассмотрения низко-
уровневых методов обработки изображений, на входе и на выходе ко-
торых присутствуют изображения, к изучению методов среднего и
высокого уровня, когда на вход подается изображение, а на выходе воз-
никают некоторые атрибуты, извлеченные из этого изображения (в том
смысле, как это описывалось в Разделе 1.1). Сегментация — следую-
щий важный шаг в этом направлении.
Сегментация подразделяет изображение на составляющие его об-
ласти или объекты. Та степень детализации, до которой доводится
такое разделение, зависит от решаемой задачи. Иначе говоря, сег-
ментацию следует прекратить, когда интересующие объекты оказыва-
ются изолированными. Например, в задаче автоматизированного
контроля сборки узлов радиоэлектронной аппаратуры интерес пред-
ставляет анализ изображений изготавливаемых изделий с целью вы-
явления определенных дефектов, таких как отсутствие компонентов
или разрыв контактных дорожек на плате. Поэтому не имеет смысла
проводить сегментацию мельче того уровня детализации, который
необходим для обнаружения подобных дефектов.
Сегментация изображений, не являющихся тривиальными, пред-
ставляет собой одну из самых сложных задач обработки изображений.
Конечный успех компьютерных процедур анализа изображений во
многом определяется точностью сегментации, по этой причине зна-
чительное внимание должно быть уделено повышению ее надежнос-
ти. В некоторых ситуациях, например в задачах технического кон-
троля, возможно хотя бы в некоторой степени управлять условиями
съемки. Опытный проектировщик системы обработки изображений
неизменно обращает внимание на подобные возможности. В других
10.1. Обнаружение разрывов яркости 813
прикладных задачах, например, в автономных системах наведения на
цель, разработчик не может контролировать окружающие условия, по-
этому обычный подход состоит в том, чтобы сосредоточиться на вы-
боре сенсоров такого вида, которые, скорее всего, будут усиливать сиг-
нал от интересующих объектов и одновременно ослаблять влияние
несущественных деталей изображения. Хорошим примером такого
подхода может служить съемка в инфракрасном диапазоне, исполь-
зуемая в военных целях для обнаружения объектов с мощным тепло-
вым излучением, например, боевой техники или движущихся войск.
Как правило, алгоритмы сегментации изображений основывают-
ся на одном из двух базовых свойств сигнала яркости: разрывности и
однородности. В первом случае подход состоит в разбиении изображе-
ния на основании резких изменений сигнала, таких как перепады яр-
кости на изображении. Вторая категория методов использует разбие-
ние изображения на области, однородные в смысле заранее выбранных
критериев. Примерами таких методов могут служить пороговая обра-
ботка, выращивание областей, слияние и разбиение областей.
В этой главе мы рассмотрим некоторые подходы в рамках двух ука-
занных категорий. Вначале будут рассматриваться методы, пригодные
для обнаружения разрывов яркости, например, точек, линий и пере-
падов. В частности, выделение контуров долгие годы являлось осно-
вой алгоритмов сегментации. Помимо обнаружения перепадов как та-
ковых, мы также рассмотрим методы связывания участков контуров
и «составления» из них границ областей. Вслед за выделением конту-
ров мы рассмотрим различные способы реализации пороговых пре-
образований. Пороговая обработка также является одним из фунда-
ментальных подходов к сегментации изображений, завоевавшим
значительную популярность, особенно в задачах, в которых важней-
шим фактором является быстродействие. После пороговых преобра-
зований будут изложены несколько подходов к сегментации, ориен-
тированных на выделение областей. Затем мы рассмотрим
морфологический подход к сегментации, названный сегментацией
по водоразделам. Этот подход особенно привлекателен, поскольку со-
четает в себе несколько положительных свойств методов сегментации,
изложенных в первой части данной главы. В заключение будет рассмо-
трено использование для сегментации изображений некоторых клю-
чевых особенностей, характеризующих движение объектов.
10.1 .Обнаружение разрывов яркости
В этом разделе мы изложим некоторые методы обнаружения трех ос-
новных видов разрывов яркости, встречающихся в цифровых изобра-
Глава 10. Сегментация изображений
жениях: точек, линий и перепадов. Наиболее общим способом поис-
ка разрывов является обработка изображения с помощью скользя-
щей маски, подобно тому, как описывалось в Разделе 3.5. Для пока-
занной на Рис. 10.1 маски размерами 3x3 элемента эта процедура
основана на вычислении линейной комбинации коэффициентов ма-
ски со значениями яркости элементов изображения, покрываемых
маской. Иначе говоря, по аналогии с формулой (3.5-3), при исполь-
зовании этой маски отклик в каждой точке изображения задается вы-
ражением
9
/? = W!Zi + w2Z2 + ..+w9z9 = '£wizi, (10.1-1)
7=1
где Zj — значение яркости пикселя, соответствующего коэффициен-
ту Wj маски. Как обычно, отклик маски приписывается позиции ее цен-
трального элемента. Детали выполнения операций с использованием
маски рассматривались в Разделе 3.5.
10.1.1. Обнаружение точек
В принципе, обнаружение отдельных изолированных точек на изоб-
ражении не представляет сложности. Воспользуемся маской, показан-
ной на Рис. 10.2(a), и будем считать, что в том пикселе, куда попада-
ет центр маски, обнаружена точка, если
(10.1-2)
где Т — неотрицательный порог, a R вычисляется в соответствии с
(10.1-1). Посуществу, вданной формуле измеряется взвешенная сум-
ма разностей значений центрального элемента и его соседей. Идея со-
стоит в том, что изолированная точка (т.е. расположенная в однород-
*1 W2 *3
И-4
И’7 H's Wg
Рис. 10.1. Общее представление маски размерами 3x3 элемента
10.1. Обнаружение разрывов яркости
-1 -1 -1
-1 8 -1
-1 -1 -1
-1 -1 -1
а
б в г
Рис. 10.2. (а) Маска для обнаружения точек, (б) Рентгеновское изображение
лопатки турбины с раковинами, (в) Результат обнаружения точек, (г) Резуль-
тат применения пороговой операции (10.1-2). (Исходное изображение предо-
ставлено компанией Х-ТЕК Systems Ltd.).
ной или почти однородной области точка, значение яркости которой
существенно отличается от окружающего фона) будет заметно от-
личаться по яркости от ближайших соседей, а значит, будет легко
обнаруживаться с помощью маски приведенного вида. Заметим, что
такая маска совпадает с маской, показанной на Рис. 3.39(г), приме-
нявшейся для одной из реализаций лапласиана. Однако в данном
случае цель состоит исключительно в обнаружении отдельных то-
чек, поэтому интерес представляют только достаточно большие раз-
личия (определяемые порогом 7), при которых точка может считать-
ся изолированной. Обратите внимание, что сумма коэффициентов
маски равна нулю, так что на областях постоянной яркости она бу-
дет давать нулевой отклик.
Пример 10.1: Обнаружение изолированных точек в изображении.
U Проиллюстрируем сегментацию изолированных точек изображения
с помощью Рис. 10.2(6), на котором показано рентгеновское изобра-
жение лопатки турбины реактивного двигателя с дефектом в виде ра-
ковины в правой верхней части. Внутри области раковины имеется оди-
ночный пиксель черного цвета. На Рис. 10.2(b) показан результат
Глава 10. Сегментация изображений
применения к исходному изображению маски для обнаружения точек,
а на Рис. 10.2(г) — результаты применения пороговой операции (10.1 -2)
со значением Т, равным 90% наибольшего по абсолютной величине
значения пикселей изображения на Рис. 10.2(b). (Вопрос выбора ве-
личины порога подробно обсуждается в Разделе 10.3). На финальном
изображении четко виден одиночный элемент (он был искусственно
увеличен, чтобы оставаться заметным на иллюстрации в книге). Дан-
ный способ обнаружения изолированных точек достаточно специ-
фичен, поскольку предполагается одноэлементный разрыв, вокруг
которого (в области маски детектора) располагается однородный фон.
Если такое условие не соблюдается, то для обнаружения разрывов
яркости более подходящими будут другие методы, рассматриваемые
ниже в данной главе.
10.1.2. Обнаружение линий
Следующим по уровню сложности является обнаружение линий.
Рассмотрим набор масок, показанный на Рис. 10.3. При скольже-
нии первой маски по изображению, наиболее сильный отклик будет
на горизонтальных линиях толщиной в один пиксель; причем, если
яркость фона одинакова, то отклик будет максимальным, когда ли-
ния проходит горизонтально через центр маски. Это легко прове-
рить на простом примере однородного поля со значениями элемен-
тов равными 1, содержащего горизонтальную линию из элементов с
отличающимся значением яркости (скажем, 5). Аналогичные экс-
перименты подтвердят, что вторая маска на Рис. 10.3 дает наиболь-
ший отклик на линиях, проходящих под углом +45°; третья — на
вертикальных линиях; четвертая — на проходящих под углом —45°. Эти
направления можно выявить и по тому признаку, что предпочти-
тельные направления каждой из масок характеризуются большими
значениями весовых коэффициентов (а именно, 2), чем любые дру-
гие направления. Обратите внимание, что сумма коэффициентов
Рис. 10.3. Маски для обнаружения линий
10.1. Обнаружение разрывов яркости 817
каждой маски равна нулю, так что они будут давать нулевой отклик
на областях постоянной яркости.
Обозначим через /?|, /?2> ^3 и ^4 отклики масок, показанных на
Рис. 10.3 (слева направо), где значения Rt вычисляются согласно со-
отношению (10.1-1). Будем считать, что изображение обрабатывает-
ся независимо с помощью каждой из этих масок. Если в некоторой точ-
ке изображения | Rt? | > | Rj | для всех j 1, то эта точка, скорее всего,
связана с линией, ориентированной вдоль направления маски /. На-
пример, если в какой-то точке изображения | /?| | > | Rj | для j = 2, 3, 4,
то эта точка, по-видимому, принадлежит горизонтальной линии. Аль-
тернативная задача может быть сформулирована в виде поиска линий,
идущих в заданном направлении. В таком случае можно обработать все
изображение с помощью маски для этого направления, применяя по-
роговое преобразование (10.1-2) к получаемому отклику. Другими
словами, если интерес представляют все линии в изображении, кото-
рые ориентированы по направлению данной маски, достаточно прой-
ти этой маской по всему изображению, сравнивая абсолютное значе-
ние результата с заданным порогом. Оставшиеся при этом точки
соответствуют наибольшим значениям отклика, которые в случае ли-
ний толщиной в один пиксель наиболее близки к направлению, оп-
ределяемому маской. Данную процедуру иллюстрирует следующий
пример.
Пример 10.2: Обнаружение линий заданного направления.
На Рис. 10.4(a) показано двоичное изображение шаблона, исполь-
зуемого при изготовлении выводов кристалла интегральной микросхе-
мы. Предположим, что мы хотим найти все линии, имеющие толщи-
ну в один пиксель и идущие под углом —45°. Воспользуемся для этой
цели последней маской из приведенных на Рис. 10.3. Абсолютное
значение результата обработки по указанной маске приводится на
Рис. 10.4(6). Видно, что все вертикальные и горизонтальные состав-
ляющие исходного изображения уничтожаются, а составляющие,
близкие к направлению —45°, дают наиболее сильный отклик. Чтобы
определить, какие из линий лучше соответствуют маске, выполняет-
ся обычная пороговая обработка полученного изображения. При ис-
пользовании значения порога, равного максимальному значению эле-
ментов этого изображения, будет получен результат, показанный на
Рис. 10.4(b). Выбор в качестве порога максимального значения хорош
для подобных задач, где исходное изображение двоичное, и мы ищем
точки, дающие наиболее сильный отклик. Белый цвет на Рис. 10.4(b)
имеют те точки, которые удовлетворяют критерию сравнения с поро-
гом. В данном случае описываемая процедура выделяет только те от-
Глава 10. Сегментация изображений
Рис. 10.4. Иллюстрация обнаружения линий, (а) Двоичное итображение шаб-
лона соединений, (б) Абсолютное значение результата, полученного после об-
работки по маске обнаружения линий под углом —45°. (в) Результат порого-
вой обработки изображения (б).
резки, которые имеют толшину в один пиксель и проходят под углом
—45° (другая линия с таким же направлением, расположенная в левой
верхней части изображения, исчезла, поскольку она имеет большую
толщину). На Рис. 10.4(b) видны изолированные точки, в которых
применяемая маска также дает сильный отклик. В исходном изобра-
жении эти точки и их ближайшие соседи расположены таким образом,
что отклик маски в данных отдельных точках1 также оказывается мак-
1 Данный эффект возникает из-за дискретизации, т.к. линии с углами наклона, близ-
кими к искомому, образуют расположенные под углом —45° небольшие отрезки дли-
ной 3 или более элементов. — Прим, перев.
10.1. Обнаружение разрывов яркости
симальным. Такие изолированные точки легко обнаруживаются с по-
мощью маски, показанной на Рис. 10.2(a), и затем удаляются. Их так-
же можно устранить с помощью операции морфологической эрозии,
которая рассматривалась в предыдующей главе.
10.1.3. Обнаружение перепадов
Хотя обнаружение точек и линий играет важную роль в любом рассмо-
трении задачи сегментации изображений, обнаружение перепадов
яркости является намного более общим подходом к нахождению ин-
терпретируемых разрывов на яркостной картине. В этом разделе мы
обсудим методы, в которых для обнаружения перепадов яркости на изо-
бражении применяются дискретные аналоги производных первого и
второго порядка. Эти производные уже рассматривались в Разделе 3.7
в контексте улучшения изображений. В данном разделе мы сосредо-
точимся на их свойствах применительно к нахождению перепадов
яркости. Для большей связности изложения некоторые из ранее вве-
денных понятий будут здесь кратко представлены снова.
Постановка задачи
Перепады яркости, как пространственные компоненты изображе-
ния, неформально были введены в рассмотрение в Разделе 3.7.1. В дан-
ном разделе мы немного ближе познакомимся с понятием перепада в
дискретном изображении. На интуитивном уровне, перепад — это
связное множество пикселей, лежащих на границе между двумя обла-
стями. В Разделе 2.5.2 уже приводилось некоторое объяснение разни-
цы между перепадом (контуром) и границей (замкнутым контуром).
По существу, как мы вскоре увидим, понятие перепада яркости явля-
ется «локальным», тогда как граница области, благодаря способу ее за-
дания, заключает в себе более глобальное представление. Корректное
определение «перепада» требует выбора способа измерения яркостных
переходов на изображении.
Мы начнем с интуитивной модели перепада, которая приведет
нас к формализму, позволяющему количественно измерять «значимые»
переходы яркости. Интуитивно ясно, что идеальный перепад облада-
ет свойствами модели, показанной на Рис. 10.5(a). В соответствии с
этой моделью, идеальный контурный перепад — это множество соеди-
ненных пикселей (в данном случае по вертикали), каждый из которых
расположен рядом с прямоугольным скачком яркости, как показыва-
ет горизонтальный профиль на рисунке.
На практике оптические ограничения, дискретизация, а также не-
совершенство других элементов системы регистрации изображений
Глава 10. Сегментация изображений
Модель идеального перепада
Модель наклонного перепада
Горизонтальный
профиль яркости
Горизонтальный
Я б профиль яркости
Рис. 10.5. (а) Модель идеального перепада яркости, (б) Модель наклонного пе-
репада яркости. Крутизна наклона обратно пропорциональна степени размы-
тости перепада.
приводят к получению размытых перепадов яркости. Причем сте-
пень расфокусировки определяется такими факторами, как качество
системы регистрации, шаг дискретизации и условия освещения, при
которых изображение было получено. В результате перепады яркос-
ти более точно моделируются наклонным профилем, подобным по-
казанному на Рис. 10.5(6). Крутизна наклонного участка обратно про-
порциональна степени расфокусировки перепада. В такой модели
уже больше нет тонкой траектории (шириной в один пиксель). Вме-
сто этого точкой перепада яркости теперь является любая точка, ле-
жащая на наклонном участке профиля, а сам перепад представляет со-
бой связное множество, образованное всеми такими точками.
«Ширина» такого перепада определяется длиной наклонного участка,
на котором осуществляется переход от начальной яркости к конечной.
Эта длина зависит от крутизны участка, которая, в свою очередь, оп-
ределяется степенью расфокусировки перепада. Такая зависимость
выглядит вполне осмысленно: размытые перепады выглядят широки-
ми, а резкие перепады — тонкими.
На Рис. 10.6(a) приведено изображение, участок которого крупным
планом был показан на Рис. 10.5(6). На Рис. 10.6(6) приведен горизон-
тальный профиль перепада яркости между двумя областями. На этом
рисунке также показаны первая и вторая производные такого профи-
ля яркости. При движении вдоль профиля слева направо первая про-
изводная имеет разрыв в начале и конце наклонного участка, посто-
10.1. Обнаружение разрывов яркости
Г1
Первая
производная
I
Вторая
производная
а б
Рис. 10.6. (а) Две области, разделенные вертикальным перепадом яркости,
(б) Горизонтальный профиль яркости вблизи перепада, а также первая и вто-
рая производные этой зависимости.
янное положительное значение на протяжении склона, и равна нулю
в областях постоянства яркости. Вторая производная положительна в
точке перехода от темного участка к наклонному, отрицательна в точ-
ке перехода от наклонного участка к светлому, и равна нулю на линей-
ном склоне и участках постоянной яркости. В случае обратного пере-
пада яркости (от светлого к темному) знаки производных на Рис. 10.6(6)
изменятся на противоположные.
Из проведенного рассмотрения можно заключить, что значение
первой производной может использоваться для обнаружения наличия
перепада яркости в каждой точке изображения (т.е. выяснения, нахо-
дится ли точка на наклонном участке). Аналогично, знак второй про-
изводной позволяет определить, лежит ли пиксель, находящийся на
перепаде, на темной или светлой его части. Обратим внимание на
822 Глава 10. Сегментация изображений
два дополнительных свойства второй производной вблизи перепада яр-
кости: (1) она дает два ненулевых (положительное и отрицательное)
значения для каждого перепада, что является нежелательным свойст-
вом; и (2) воображаемая прямая линия, соединяющая максимальные
положительное и отрицательное значения второй производной вбли-
зи перепада, пересекает нулевой уровень приблизительно в середине
перепада яркости. Это свойство пересечения нулевого уровня1 второй про-
изводной весьма полезно для локализации середины широких пере-
падов, как мы увидим позже в этом разделе. Наконец, отметим, что в
некоторых моделях перепада яркости используется наклонный учас-
ток с плавными переходами в начале и в конце (Задача 10.5). Тем не
менее, сделанные выше выводы остаются справедливыми и для тако-
го случая. Очевидно также, что в нашем рассмотрении использовались
локальные оценки, откуда и замечания о локальном свойстве перепа-
дов, сделанные в Разделе 2.5.2.
Хотя до сих пор наше рассмотрение ограничивалось горизонталь-
ным (одномерным) профилем яркости, те же соображения действуют
и для перепадов, имеющих любое другое направление на изображении.
Для этого достаточно рассмотреть профиль вдоль перпендикуляра к
направлению перепада яркости в интересующей точке, после чего
результаты интерпретируются так же, как описывалось выше.
Пример 10.3: Поведение первой и второй производных на перепаде
яркости с шумом.
На перепадах яркости, показанных на Рис. 10.5 и 10.6, шум отсут-
ствует. Приведенные в первом столбце на Рис. 10.7 увеличенные фраг-
менты изображений представляют собой четыре варианта перепада яр-
кости между черной областью слева и белой областью справа (важно
помнить, что весь такой переход от черного к белому представляет со-
бой один перепад). Верхнее изображение не содержит шума. Оставши-
еся три изображения этого столбца искажены аддитивным гауссовым
шумом с нулевым средним и стандартными отклонениями 0,1, 1,0 и
10,0 градаций яркости соответственно. График под каждым изображе-
нием показывает профиль яркости вдоль его строки.
Во втором столбце на Рис. 10.7 приведены изображения первых
производных соответствующих изображений слева (детали вычисле-
ния первой и второй производных изображения рассматриваются в сле-
дующем разделе). Рассмотрим, например, верхнее изображение вто-
рого столбца. Как уже говорилось в связи с Рис. 10.6(6), производная
2 В оригинале — zero-crossing. — Прим, перев.
10.1. Обнаружение разрывов яркости
Рис. 10.7. Первый столбец: изображения и профили яркости наклонного пе-
репада, искаженного гауссовым шумом со средним 0 и о = 0; 0,1; 1,0; и 10,0
градаций яркости соответственно. Второй столбец; изображения первой про-
изводной и их профили яркости. Третий столбец: изображения второй произ-
водной и их профили яркости.
824 Глава 10. Сегментация изображений
равна нулю в черной и белой областях постоянной яркости. На изо-
бражении первой производной им отвечают две области черного цве-
та. На наклонном участке первая производная есть константа, равная
его крутизне. Эта область на изображении производной имеет серый
цвет. По мере движения вниз по второму столбцу рисунка производ-
ные все больше отличаются от случая без шума. В самом деле, послед-
ний профиль этого столбца вообще трудно соотнести с линейным
перепадом3. Этот результат особенно интересен тем, что на исходных
изображениях в левом столбце шум почти незаметен. На последнем
изображении имеется легкая зернистость, но эти искажения почти не-
различимы. Данные примеры являются хорошей иллюстрацией чув-
ствительности производных к присутствию шума.
Как этого можно было ожидать, вторая производная оказывается
еще чувствительнее к шуму. Изображение второй производной для слу-
чая без шума приведено в правом верхнем углу. Тонкие черная и бе-
лая линии — это положительная и отрицательная составляющие, ко-
торые объяснялись при обсуждении Рис. 10.6. Средний уровень
яркости изображений вторых производных выбран так, что серый
фон соответствует нулевому значению. Можно заметить, что единст-
венное из зашумленных изображений вторых производных, которое
еще как-то напоминает случай без шума, — это при уровне шума со
стандартным отклонением 0,1 градации яркости. Другие два изобра-
жения вторых производных и их профили ясно иллюстрируют, что и
в самом деле трудно найти те два импульса (положительный и отри-
цательный), которые, согласно свойствам второй производной, явля-
ются истинными признаками начала и конца перепада.
Таким образом, важно помнить, что даже небольшой шум может
оказывать значительное воздействие на первую и вторую производные,
применяемые для обнаружения перепадов на изображениях. В част-
ности, в практических задачах, где возможно появление заметного шу-
ма, целесообразно рассмотреть вопрос о сглаживании изображения пе-
ред вычислением производных. I
На основе этого примера и предшествовавших ему рассуждений
можно придти к следующему заключению: чтобы с уверенностью
3 Приведенные во втором и третьем столбцах изображения (а значит, и графики) бы-
ли, очевидно, подвергнуты операции градационной коррекции, описанной в конце
раздела 3.4.1. Поэтому видна такая разница в средних контрастах верхнего и нижне-
го изображений во втором столбце, а также исчезли темная и светлая полоски в тре-
тьем столбце. — Прим. ред. перевода.
10.1. Обнаружение разрывов яркости
классифицировать точку как находящуюся на перепаде яркости, изме-
нение яркости, ассоциированное с данной точкой, должно быть су-
щественно большим, чем допустимое изменение яркости в точке фона.
Поскольку мы имеем дело с локальными вычислениями, способ опре-
деления того, какое значение является «существенным», а какое нет, со-
стоит в установлении порога. Итак, мы определяем точку изображения
карточку перепада. если ее двумерная производная первого порядка пре-
вышает некоторый заданный порог. Связное множество таких точек в со-
ответствии с заранее заданным критерием связности (см. Раздел 2.5.2)
есть по определению перепад яркостей. Протяженный перепад яркостей
называют контуром. Термин участок контура обычно используется,
когда протяженность перепада мала по сравнению с размерами изобра-
жения. Главная задача при сегментации состоит в том, чтобы собрать из
участков контура более длинные контуры, как это объясняется в Разде-
ле 10.2. Если опираться на поведение второй производной, можно дать
альтернативное определение точек перепада яркостей как точек пересе-
чения нулевого уровня второй производной изображения. При этом
определения перепада яркостей и контура остаются теми же. Важно от-
метить, что эти определения не гарантируют успешного отыскания кон-
туров в изображении, а лишь дают формальный способ для их поиска.
Каки в Главе 3, производные первого порядка в изображении вычис-
ляются с помощью градиента. Для получения производных второго
порядка применяется лапласиан.
Операторы градиента
Вычисление первой производной цифрового изображения основано
наразличныхдискретных приближениях двумерного градиента. По оп-
ределению, градиент изображения /(х, у) в точке (х, у) — это вектор
G.
df
дх
df
ду
(10.1-3)
Как известно из курса математического анализа, направление векто-
ра градиента совпадает с направлением максимальной скорости изме-
нения функции f в точке (х, у).
Важную роль при обнаружении контуров играет модуль этого век-
тора, который обозначается V/и равен
V/=|Vf|=^ + G?.
(10.1-4)
Глава 10. Сегментация изображений
Эта величина равна значению максимальной скорости изменения функ-
ции/в точке (х, у), причем максимум достигается в направлении векто-
ра Vf. Величину V/также часто (хотя и не вполне правильно) называют
градиентом. Мы будем следовать этой укоренившейся практике и исполь-
зовать этот термин для обеих целей, делая различия между вектором и
его модулем только в тех случаях, когда возможна путаница.
Направление вектора градиента также является важной характери-
стикой. Обозначим а(х, у) угол между направлением вектора Vf в точ-
ке (х, у) и осью х. Как известно из математического анализа,
( G "1
a(x,y) = arctg . (10.1-5)
Отсюда легко найти направление контура в точке (х, у), которое пер-
пендикулярно направлению вектора градиента в этой точке.
Вычисление градиента изображения состоит в получении величин
частных производных df/dx и df/dy для каждой точки. Пусть область
3x3, показанная на Рис. 10.8(a), представляет собой значения яркос-
ти в окрестности некоторого элемента изображения. Как говорилось
в Разделе 3.7.3, один из простейших способов нахождения первых
частных производных в точке z§ состоит в применении следующего пе-
рекрестного градиентного оператора Робертса'.
Gx=(z9-z5) (Ю.1-6)
и
Gy=^~Zb). (10.1-7)
Эти производные могут быть реализованы путем обработки всего изо-
бражения с помощью оператора, описываемого масками на Рис. 10.8(6)
и (в), используя представленную в Разделе 3.5 процедуру.
Реализация масок размерами 2x2 неудобна, так как у них нет чет-
ко выраженного центрального элемента. Метод, при котором исполь-
зуются маски 3x3, задается выражениями
Gx^(zt+z.^+z^)-{z\ +Z2+Z3) (10.1-8)
и
Gy = (*з +Z6 +г9 )-(zi +z4 +z7).
(10.1-9)
10.1. Обнаружение разрывов яркости
Маски оператора Робертса
а
б в
г д
е ж
Рис. 10.8. Окрестность 3x3 внутри изображения (переменные z, суть значения
яркости) и различные маски, применяемые для вычисления градиента в цен -
тральной точке окрестности.
В этих формулах разность между суммами по верхней и нижней стро-
кам окрестности 3x3 является приближенным значением производ-
ной по оси х, а разность между суммами по первому и последнему
столбцам этой окрестности — производной по оси у. Для реализации
этих формул используется оператор, описываемый масками на
Рис. 10.8(г) и (д), который называется оператором Превитта.
Небольшое видоизменение последних двух формул состоит в ис-
пользовании весового коэффициента 2 для средних элементов:
Gx = (^7 + 2^8+29 )-(?! +2?2 +Z3 ) (10.1-10)
И
828 Глава 10. Сегментация изображений
Gy =(^3+2Z6+&))-( Z1 +2z4+z7)- (10.1-11)
Это увеличенное значение используется для уменьшения эффек-
та сглаживания за счет придания большего веса средним точкам
(Задача 10.8). Для реализации двух последних выражений исполь-
зуются маски на Рис. 10.8(e) и (ж), отвечающие оператору Собела.
На практике для вычисления дискретных градиентов чаще всего ис-
пользуются операторы Превитта и Собела. Маски оператора Пре-
витта проще реализовать, чем маски оператора Собела, однако у по-
следнего оператора влияние шума угловых элементов несколько
меньше, что существенно при работе с производными. Отметим,
что у каждой из масок на Рис. 10.8 сумма коэффициентов равна ну-
лю, т.е. эти операторы будут давать нулевой отклик на областях по-
стоянной яркости, как и следовало ожидать от дифференциально-
го оператора.
Рассмотренные выше маски применяются для получения состав-
ляющих градиента Gx и Gy. Для вычисления величины градиента эти
составляющие необходимо использовать совместно, согласно (10.1-4).
Однако такая реализация требует вычисления квадратов и квадратных
корней. Часто используется подход, при котором величина градиен-
та вычисляется приближенно через абсолютные значения частных
производных:
V/-|Gj + |Gy|. (10.1-12)
С точки зрения сложности вычислений такое выражение выглядит
намного привлекательнее, и по-прежнему несет информацию об
изменениях яркости. Как уже говорилось в Разделе 3.7.3, это дости-
гается ценой потери изотропности (т.е. инвариантности в отношении
поворота) получаемых фильтров. Однако, если для вычисления ча-
стных производных Gx и Gy применяются маски типа Превитта и
Собела, то вопрос изотропности не возникает, так как эти маски
инвариантны лишь для поворотов на углы, кратные 90°. В случае вер-
тикальных и горизонтальных контуров вычисления градиента соглас-
но выражениям (10.1-4) и (10.1-12) будут давать одинаковые резуль-
таты (Задача 10.6).
Можно изменить приведенные на Рис. 10.8 маски 3x3 таким обра-
зом, чтобы они давали максимальный отклик для контуров, направ-
ленных диагонально. Эти дополнительные пары масок операторов
Превитта и Собела, предназначенных для обнаружения разрывов в ди-
агональных направлениях, показаны на Рис. 10.9.
10. J. Обнаружение разрывов яркости
а б
в г
Рис. 10.9. Маски операторов Превитта и Собеладля обнаружения диагональ-
ных контуров.
Пример 10.4: Иллюстрация градиента и его составляющих.
На Рис. 10.10 демонстрируются отклики двух составляющих гради-
ента, | Gx | и | Gy |, а также градиентное изображение, формируемое пу-
тем суммирования этих составляющих. На Рис. 10.10(6) и (в) хорошо
заметна направленность этих двух составляющих; в частности, обра-
тите внимание, насколько сильно выделяются элементы кровли, го-
ризонтальные швы кладки и горизонтальные отрезки окон на
Рис. 10.10(6). Напротив, на Рис. 10.10(b) выделены вертикальные со-
ставляющие, например, углы стен, вертикальные отрезки окон, вер-
тикальные швы кладки, а также фонарный столб справа на снимке.
Исходное изображение (размерами 1200x1600 пикселей) имеет
сравнительно высокое разрешение, поэтому при выбранном масшта-
бе съемки кирпичная кладка стен вносит существенный вклад в тек-
стуру (детальность) изображения. Для сегментации такая степень де-
тализации может быть излишне высокой, и одним из способов ее
снижения является сглаживание изображения. На Рис. 10.11 показа-
на та же последовательность изображений, что и на Рис. 10.10, но с
предварительным сглаживанием исходного изображения усредняющим
фильтром с окном 5x5. Как видно, сигнал, вносимый кирпичной
кладкой стен в отклики масок, существенно ослаблен, и в результате
основные контуры здания стали намного более заметными. Обрати-
те внимание, что усреднение привело к ослаблению величины откли-
ка на всех контурах. На Рис. 10.10 и 10.11 хорошо видно, что горизон-
тальная и вертикальная маски Собела дают примерно одинаковый
Глава 10. Сегментация изображений
Рис. 10.10. (а) Исходное изображение, (б) Составляющая градиента вдоль оси
х, | Gx | (в) Составляющая градиента вдоль оси у. | Gy |. (г) Изображение гра-
диента, | Gx | + | Gy |.
отклик на контурах, имеющих направления ±45°. Если важно подчерк-
нуть такие контуры диагональных направлений, то следует восполь-
зоваться одной из пар масок на Рис. 10.9. Абсолютные величины от-
кликов диагональных масок Собела показаны на Рис. 10.12, где хорошо
виден более сильный отклик на перепадах, ориентированных вдоль ди-
агональных направлений. Обе диагональные маски дают приблизитель-
но одинаковые отклики на горизонтальных и вертикальных контурах,
которые, как и можно было ожидать, слабее, чем отклики, получае-
мые горизонтальной и вертикальной масками Собела и показанные на
Рис. 10.10(6) и (в).
Лапласиан
Лапласиан двумерной функции f (х, у) представляет собой производ-
ную второго порядка, определяемую выражением
V2/=^Z+8V.
Эх2 Эу2
(10.1-13)
10.1. Обнаружение разрывов яркости
Рис. 10.11. Та же последовательность, что и на Рис. 10.10, но исходное изоб-
ражение предварительно сглажено с помощью усредняющего фильтра 5x5.
Дискретные приближения лапласиана рассматривались в Разделе 3.7.2.
Применительно к окрестностям 3x3, одной из двух форм, наиболее ча-
сто используемых на практике, является выражение
(10.1-14)
V2/-4z5 -(^2 +?4 + Zf> +Zg ),
Рис. 10.12. Обнаружение диагональных контуров (а) Результат использования
маски на Рис. 10.9(b). (б) Результат использования маски на Рис. 10.9(г). Ис-
ходным для обоих случаев являлось изображение на Рис. 10.11(a).
Глава 10. Сегментация изображений
где расположение переменных z, показано на Рис. 10.8(a). Дискретное
приближение с использованием диагональных соседних элементов
имеет вид
V2/ = 8^5 — (?1 + Zi + Z3 + <4 + ^6 + ^7 + ^8 + ^9 )• (Ю.1-15)
Для реализации этих двух уравнений применяются маски, показанные
на Рис. 10.13. По ним видно, что такие реализации уравнений (10.1-14)
и (10.1 -15) оказываются инвариантными к повороту на углы, кратные
90° и 45° соответственно.
Как правило, лапласиан в чистом виде для обнаружения контуров
не используется, что объясняется следующими причинами. Как про-
изводная второго порядка, лапласиан является излишне чувствитель-
ным к шуму (см. Рис. 10.7). Кроме того, использование модуля лапла-
сиана приводит к удвоению контуров (см. Рис. 10.6 и 10.7), что дает
нежелательный эффект и усложняет сегментацию. По этим причинам
роль лапласиана в задачах сегментации сводится к (1) использова-
нию его свойства пересечения нулевого уровня для локализации кон-
тура, как уже обсуждалось выше в данном разделе; или (2) вспомога-
тельному его использованию для выяснения, находится
рассматриваемый пиксель на темной или светлой стороне контура, о
чем будет говориться в Разделе 10.3.6.
В первом случае лапласиан в сочетании со сглаживанием приме-
няется для предварительного обнаружения контуров в точках пересе-
чения нулевого уровня. Рассмотрим функцию
h(r) = -e 2о2 , (10.1-16)
где г2 = х 2 + у 2, а о - стандартное отклонение. Свертка изображе-
ния с такой функцией приводит к его расфокусировке, причем степень
Рис. 10.13. Маски лапласиана, используемые для реализации формул (10.1-14)
и (10.1-15) соответственно.
10.1. Обнаружение разрывов яркости
расфокусировки определяется значением и. Лапласиан функции h
(вторая производная h по г) имеет вид
V2/?(r) = -
и4
_ г2
е 2с2 . (10.1-17)
Эту функцию обычно называют лапласианом гауссиана (ЛГ), так как
уравнение (10.1-16) задает гауссову функцию. На Рис. 10.14 показаны
трехмерный график, изображение и профиль ЛГ-функции. Там так-
же приведена маска 5x5, используемая для приближенного вычисле-
ния V2A. Такое приближение не является единственно возможным;
цель его — уловить сущность формы V2h, т.е. положительную состав-
ляющую в центре, окруженную областью отрицательных значений, ко-
торые возрастают по мере удаления от центра, вплоть до нулевого
значения за пределами окрестности. Кроме того, сумма коэффициен-
Рис. 10.14. Лапласиан гауссиана, (а) Трехмерный график, (б) Изображение (чер-
ный цвет представляет отрицательные значения, белый — положительные, а
серый — нулевую плоскость) (в) Поперечный профиль с отмеченными точ-
ками пересечения нулевого уровня, (г) Маска 5x5 для приближенного вычис-
ления зависимости (а).
0 0 -1 0 0
0 -1 -2 -1 0
-1 -2 16 -2 -1
0 -1 -2 -1 0
0 0 -1 0 0
28 А-223
(Г834 Глава 10. Сегментация изображений
тов должна равняться нулю, чтобы маска давала нулевой отклик на об-
ласти постоянной яркости. Маска столь малых размеров применима
только для изображений, практически свободных от шума. Из-за ха-
рактерной формы графика лапласиан гауссиана иногда называют
функцией вида мексиканская шляпа.
Поскольку взятие второй производной является линейной опера-
цией, свертка изображения с оператором V2/? эквивалентна тому, как
если бы изображение сначала сворачивалось с гауссовой сглаживаю-
щей функцией вида (10.1-16), а потом вычислялся лапласиан резуль-
тата. Итак, мы видим, что цель гауссовой функции в лапласиане гаус-
сиана состоит в сглаживании изображения, а цель лапласиана — найти
на изображении точки пересечения нулевого уровня, используемые для
локализации контуров. Сглаживание изображения снижает влияние
шума и, в принципе, противостоит повышенной шумовой чувствитель-
ности вторых производных в составе лапласиана. Как интересно от-
метить, проводившиеся в начале 1980-х нейрофизиологические экс-
перименты ([Ullman, 1981], [Marr, 1982]) с очевидностью показали, что
определенные аспекты зрения человека описываются математической
моделью в форме того же уравнения (10.1-17).
Пример 10.5: Поиск контуров с помощью пересечений нулевого уровня.
На Рис. 10.15(a) приведено изображение ангиограммы, обсуждав-
шееся в Разделе 1.3.2. Для сравнения, на Рис. 10.15(6) приведен гра-
диент этого изображения, полученный с помошью оператора Собе-
ла. На Рис. 10.15(b) показана двумерная гауссова функция со
стандартным отклонением 5 пикселей, которая использовалась при
получении маски пространственного сглаживания размерами 27x27.
Маска строилась путем равномерной дискретизации данной гауссо-
вой функции. Рис. 10.15(г) демонстрирует пространственную маску,
которая применялась для реализации уравнения (10.1-15). На
Рис. 10.15(д) показано изображение лапласиана гауссиана, являюще-
еся результатом применения Л Г-функции. Оно получено путем сгла-
живания исходного изображения с помощью гауссовой сглаживаю-
щей маски, а затем применения маски лапласиана (изображение
обрезано по краям для устранения краевых эффектов, вызванных
применением сглаживающей маски). Как отмечалось выше, ЛГ-
функция V2/? может вычисляться путем применения сначала гаусси-
ана (в), а потом лапласиана (г). Такой способ реализации обеспечи-
вает лучшее управление функцией сглаживания, и часто сводится к
двум отдельным маскам, которые оказываются значительно меньше,
чем единая составная маска, непосредственно реализующая форму-
лу (10.1-17). Составная маска обычно имеет большие размеры, по-
10.1. Обнаружение разрывов яркости
Рис. 10.15. (а) Исходное изображение, (б) Градиент Собела (приведен для
сравнения), (в) Гауссова функция пространственного сглаживания, (г) Мас-
ка лапласиана, (д) Лапласиан гауссиана (Л Г-изображение). (е) Результат по- g
роговой обработки ЛГ-изображения. (ж) Пересечения нулевого уровня. (Ис-
ходное изображение предоставил д-р Дэвид Р. Пикенс, Департамент в
радиологии медицинского центра университета Вандербилта). д е Ж
скольку должна воплощать собой функцию более сложной формы, ко-
торая показана на Рис. 10.14(a).
Полученное ЛГ-изображение, показанное на Рис. 10.15(д), ис-
пользовалось для нахождения положения контуров с помощью вычис-
ления точек пересечения нулевого уровня. Один из простых способов
836 Глава 10. Сегментация изображений
приближенного нахождения точек пересечения нулевого уровня со-
стоит в пороговой обработке Л Г-изображения, при которой все его по-
ложительные значения замещаются, скажем, белым цветом, а отри-
цательные — черным. Результат такого преобразования приведен на
Рис. 10.15(e). Точки пересечения нулевого уровня при этом оказыва-
ются между положительными и отрицательными значениями лапла-
сиана. Наконец, на Рис. 10.15(ж) отмечены точки пересечения нуле-
вого уровня, найденные путем такого приближенного оценивания. Они
были получены сканированием двоичного изображения (е) и фикса-
цией всех точек перехода от черного к белому и обратно.
Сравнение Рис. 10.15(6) и (ж) выявляет некоторые интересные и
важные отличия. Прежде всего, можно заметить, что контуры в изо-
бражении пересечений нулевого уровня тоньше, чем в градиентном
изображении. Таково положительное свойство метода пересечения
нулевого уровня. С другой стороны, как видно из Рис. 10.15(ж), в со-
став контуров, найденных с помощью данного метода, входят много-
численные замкнутые петли. Этот так называемый «эффект спагетти»
является одним из наиболее серьезных его недостатков. Другой круп-
ный недостаток кроется в самом отыскании точек пересечения нуле-
вого уровня, что является основой метода. Хотя в данном примере это
выглядело довольно естественно, в общем случае нахождение точек пе-
ресечения нулевого уровня представляет собой сложную задачу, реше-
ние которой часто требует применять значительно более сложные ме-
тоды для получения приемлемых результатов [Huertas, Medione, 1986].
Методы, основанные на пересечении нулевого уровня, представ-
ляют интерес благодаря их пониженной чувствительности к шуму и по-
тенциальной устойчивости в работе. Однако отмеченные выше недо-
статки являются существенным препятствием на пути практического
их применения. По этой причине в алгоритмах сегментации изобра-
жений все же чаще применяют методы нахождения контуров на осно-
ве различных градиентных операторов, чем с использованием пересе-
чений нулевого уровня.
10.2. Связывание контуров и нахождение границ
В идеале методы, рассмотренные в предыдущем разделе, должны вы-
делять в изображении только пиксели, лежащие на контурах. На прак-
тике это множество пикселей редко отображает контур достаточно точ-
но по причине шумов, разрывов контуров из-за неоднородности
освещения, а также прочих эффектов, нарушающих непрерывность яр-
костной картины. Поэтому алгоритмы обнаружения контуров обыч-
но дополняются процедурами связывания, чтобы сформировать из
множества контурных точек содержательные контуры. Для этой цели
существует несколько основных подходов.
10.2.1. Локальная обработка
Один из простейших подходов к связыванию точек контура состоит
в анализе характеристик пикселей в небольшой (скажем, 3x3 или 5x5)
окрестности каждой точки (х, у) изображения, которая была отмече-
на как контурная точка с помощью какого-либо из рассмотренных в
предыдущем разделе методов. Все точки, являющиеся сходными в
соответствии с некоторыми заранее заданными критериями, связы-
ваются и образуют контур, состоящий из пикселей, отвечающих этим
критериям.
При таком анализе используются следующие два основных пара-
метра для установления сходства пикселей контура: (1) величина от-
клика оператора градиента, определяющая значение пикселей конту-
ра; и (2) направление вектора градиента. Первый параметр задается
значением V/, определяемым согласно выражению (10.1-4) или
(10.1-12). Таким образом, пиксель контура, имеющий координаты
(*о, >’о) и расположенный внутри заданной окрестности точки (х, у),
считается сходным по модулю градиента с пикселем (х, у), если
|V/(x,y)-V/(x0,y0)|<£, (10.2-1)
где Е — заданный неотрицательный порог.
Направление (угол) вектора градиента задается выражением
(10.1-5). Пиксель контура с координатами (х0,ур), расположенный вну-
три заданной окрестности точки (х, у), считается сходным по направ-
лению градиента с пикселем (х, у), если
|а(х,у)-а(х0,у0)|<Л, (10.2-2)
где Л — заданный неотрицательный угловой порог. Как уже отмечалось
при обсуждении формулы (10.1 -5), направление контура в точке (х, у)
перпендикулярно направлению вектора градиента в этой точке.
Пиксель в заданной окрестности объединяется с центральным
пикселем (х, у), если выполнены критерии сходства и по величине, и
по направлению. Этот процесс повторяется в каждой точке изображе-
ния, с одновременным запоминанием найденных связанных пиксе-
лей при движении центра окрестности. Простой способ учета данных
состоит в том, что каждому множеству связываемых пикселей конту-
ра присваивается свое значение яркости.
Глава 10. Сегментация изображений
Пример 10.6: Связывание контурных точек на основе локальной обра-
ботки.
I Чтобы проиллюстрировать вышеизложенную процедуру, рассмот-
рим снимок автомобиля сзади. показанный на Рис. 10.16(a). Цель со-
стоит в отыскании прямоугольников, которые по своим размерам
могут являться подходящими кандидатами на роль номерного знака.
Такие прямоугольники могут формироваться на основе обнаружения
строго вертикальных и горизонтальных контуров. На Рис. 10.16(6) и
(в) показаны вертикальные и горизонтальные контуры, полученные
с помощью оператора Собела с масками горизонтального и вертикаль-
ного направлений. Рис. 10.16(г) иллюстрирует результаты связывания
всех точек, у которых одновременно значение градиента больше 25, а
направления градиента отличаются не более чем на 15°. Горизонталь-
ные линии были получены путем последовательного применения это-
го критерия к каждой строке изображения на Рис. 10.16(в). а вертикаль-
ные — путем последовательной обработки всех столбцов изображения
на Рис. 10.16(6). Дальнейшая обработка включала в себя связывание
Рис. 10.16 (а) Исходное изображение, (б) Составляющая Gy градиента, (в) Со-
ставляющая Gx градиента, (г) Результат связывания контуров. (Изображения
предоставлены компанией Perceptics Corporation).
10.2. Связывание контуров и нахождение границ
отрезков контура, разделенных небольшими пропусками, и удаление
изолированных коротких отрезков. Как видно из Рис. 10.16(г), прямо-
угольник, отвечающий номерному знаку, является одним из несколь-
ких прямоугольников, обнаруженных на этом изображении. Зная все
эти прямоугольники, нахождение номерного знака становится не-
сложной задачей (поскольку соотношение ширины и высоты номер-
ного знака в США равно 2 : 1). в
10.2.2. Глобальный анализ с помощью преобразования Хафа
В этом разделе точки связываются друг с другом путем предваритель-
ного выяснения, лежат ли они на некоторой кривой заданной формы.
В отличие от изложенного в Разделе 10.2.1 метода, который был осно-
ван на анализе локальной окрестности, здесь будут анализироваться
глобальные геометрические связи между элементами изображения.
Пусть задано п точек на изображении (плоскости). Предполо-
жим, что требуется найти подмножества этих точек, лежащие на пря-
мых линиях. Одно из возможных решений этой задачи состоит в том,
что вначале находятся все прямые, определяемые каждой парой то-
чек, и затем ищутся все подмножества точек, близких к конкретным
прямым. Трудности реализации такой процедуры вызываются необ-
ходимостью нахождения п(п— 1 )/2 ~ л2 прямых, а затем выполнения
(п)(п(п—1))/2 ~ л3 сравнений каждой точки со всеми прямыми. Вы-
числительная сложность данного подхода позволяет применить его
лишь в самых тривиальных прикладных задачах.
Хаф [Hough, 1962] предложил альтернативный подход (который
принято называть преобразованием Хафа). Возьмем точку (xf, у,) из за-
данного множества п точек и рассмотрим общее уравнение прямой на
плоскости в форме с угловым коэффициентом: у = ах + h. Очевидно,
что через точку (xz, у() проходит бесконечно много прямых, удовлетво-
ряющих уравнению = ах, + b при различных значениях а и Ь. Одна-
ко если переписать это уравнение в виде —Ь = —х, а + у, и рассмотреть
плоскость а Ь, называемую пространством параметров, то для задан-
ной пары {х,, у() получаем уравнение единственной прямой. Более то-
го, другой точке (Xj, yj) также соответствует своя прямая в простран-
стве параметров, и эти две прямые пересекаются в некоторой точке
{а'. Ь'), такой, что а' есть угловой коэффициент, а Ь' — точка пересе-
чения с осьюу прямой, проходящей через точки (х,, у,) и (ху, уф в пло-
скости ху. На самом деле, каждой точке прямой, проходящей через точ-
ки (х(, уф и (ху, уф, в пространстве параметров соответствует своя
прямая линия, причем все они пересекаются в точке (а', Ь'). Это ил-
люстрирует Рис. 10.17.
Глава 10. Сегментация изображений
а б
Рис. 10.17. (а) Плоскостьлу. (б) Пространство параметров.
Привлекательность преобразования Хафа с точки зрения вычис-
лений проистекает из возможности разбиения пространства параме-
тров на так называемые ячейки накопления, как показано на Рис. 10.18,
где (omax, flmin) и (^тах, ^min) — предполагаемые диапазоны возмож-
ных значений углового коэффициента и ординаты точки пересечения
прямой с осью у. В ячейке (р, q) накапливается значение А(р, q) для
прямоугольника в пространстве параметров, соответствующего точ-
ке (ар, bq). Первоначально значения во всех ячейках накопления
равны нулю. Затем для каждой точки (х,-, у,) из заданного множест-
ва п точек в плоскости изображения полагаем параметр а равным по-
очередно каждому дискретному значению ар в разрешенном интер-
вале на оси а и находим соответствующее ему значение Ь, решая
уравнение b = -х,а + у,. После этого найденное значение округляет-
Рис. 10.18. Разбиение плоскости параметров для применения преобразования
Хафа.
10.2. Связывание контуров и нахождение границ
ся до ближайшего дискретного значения bq на оси Ь. Если выбор зна-
чения ар приводит к допустимому решению bq, увеличиваем накоплен-
ное значение в соответствующей ячейке: А(р, q) = А(р, q) + 1. После вы-
полнения описанной процедуры для всех анализируемых точек (х,, у,-),
записанное в ячейке (р, q) значение А(р„ q) = Q означает, что в плос-
кости ху имеется Q точек, лежащих на прямой у = ОрХ + bq. Точность
попадания точек на эту прямую определяется размерами ячеек накоп-
ления на плоскости ab.
Заметим, что разбиение оси а на АГдискретных значений дает для
каждой точки (х,-,у,) АГзначений параметра Ь, соответствующих А'воз-
можным значениям а. Для п точек заданного множества данный ме-
тод требует выполнения пК вычислений. Таким образом, трудоем-
кость рассмотренной процедуры линейна по п, что намного меньше
количества вычислений, требуемых для указанного в начале этого
раздела прямого метода (если только К не оказывается сопостави-
мым с п по порядку величины).
Если прямая близка к вертикали, то использование уравнения
у = ах + b для ее представления затруднительно, поскольку при этом
угловой коэффициент стремится к бесконечности. Один из способов
обойти эту трудность состоит в представлении прямой с помощью
нормали:
xcos0 + y sin0 = p.
(10.2-3)
Рис. 10.19(a) дает геометрическую интерпретацию параметров, ис-
пользованных в уравнении (10.2-3). Такое представление использует-
ся при построении таблицы ячеек накопления точно так же, как и в
Рис. 10.19. (а) Представление прямой с помощью нормали (б) Разбиение
плоскости р0 на ячейки накопления.
Глава 10. Сегментация изображений
случае уравнения в форме с угловым коэффициентом. Однако, вме-
сто прямых линий, геометрические места точек, лежащих на одной пря-
мой, в плоскости рО представляют собой синусоидальные кривые.
Как и ранее, Q точек, лежащих на прямой xcos09 + ysinO^ = рр, порож-
дают в пространстве параметров Q синусоидальных кривых, пересе-
кающихся в точке (р^, 0^). Если последовательно придавать 0 всевоз-
можные дискретные значения и находить соответствующие им
значения р, будет выполнено Q приращений содержимого ячейки на-
копления Л(/>, q), отвечающей параметрам (рр, Qq). Рис. 10.19(6) иллю-
стрирует способ разбиения пространства параметров в этом случае.
Диапазон значений углов 0 составляет ±90°; угол измеряется по от-
ношению к оси х. Таким образом, в соответствии с Рис. 10.19(a), для
горизонтальной прямой 0 = 0°, а р будет равно координате точки ее пе-
ресечения с осью х. Аналогично, для вертикальной прямой р есть ко-
ордината точки ее пересечения с осью у, а 0 = 90° при р > 0 или
0 = —90° при р < 0.
Пример 10.7: Иллюстрация преобразования Хафа.
И Рис. 10.20 иллюстрирует выполнение преобразования Хафа, осно-
ванного на уравнении (10.2-3). На Рис. 10.20(a) показано изображение,
на котором отмечены пять точек. Для каждой из них построен образ (от-
резок синусоиды) в плоскости рО, как показано на Рис. 10.20(6). Диа-
пазон значений 0 составляет [—90°, ±90°], а диапазон значений р ра-
вен [-л/2Е>,л/2£>], где D — расстояние между углами изображения по
диагонали. Отметим, что каждая из синусоид имеет свою амплитуду и
фазу. Горизонтальная линия, полученная при отображении точки 1,
представляет собой синусоиду с нулевой амплитудой.
Свойство преобразования Хафа обнаруживать точки, лежащие на
одной прямой, демонстрирует Рис. 10.20(b). В точке, обозначенной Л,
пересекаются кривые, которые соответствуют точкам 1, 3 и 5 в плос-
кости ху исходного изображения. Координаты точки А показывают, что
упомянутые три точки лежат на прямой линии, проходящей через на-
чало координат (р = 0) под углом -45°. Аналогично, пересечение кри-
вых в точке В пространства параметров указывает, что точки 2, 3 и 4 ле-
жат на прямой, проходящей под углом 45° на расстоянии, равном
половине диагонали от начала координат (т.е. левого верхнего угла
изображения).
Наконец, Рис. 10.20(г) иллюстрирует тот факт, что используемое пре-
образование Хафа на левом и правом краях области значений в прост-
ранстве параметров ведет себя зеркально симметричным образом, как
показывают точки А, Ви Сна этом рисунке. Это свойство является след-
ствием того, как меняются знаки параметров 0 и р на границах ±90°. И
10.2. Связывание контуров и нахождение границ
Рис. 10.20. Иллюстрация преобразования Хафа. (Изображения предоставил
Д. Р. Кейт, компания Texas Instruments, Inc.).
а б
в г
Хотя до сих пор в центре внимания были прямые линии на изоб-
ражении, преобразование Хафа можно применить к любой функции
видаку, с) = 0, где v — вектор координат, ас — вектор коэффициен-
тов. Например, точки, лежашие на окружности
(х-С])2 + (у-с2)2 = с^, (10.2-4)
также могут обнаруживаться описанным выше методом. Основное
отличие состоит в увеличении числа параметров до трех (q, с2 и q3),
что приводит к трехмерному пространству параметров с кубическими
ячейками, накапливаемые значения в которых имеют вид А(р, q. г).
Процедура состоит в последовательном присваивании параметрам q
и с2 всех сочетаний допустимых дискретных значений, нахождением
для каждой пары значения с3, которое бы удовлетворяло уравнению
(10.2-4), и увеличением накопленного значения в ячейке, отвечаюшей
тройке (q, с2, q3). Ясно, что сложность преобразования Хафа про-
Глава 10. Сегментация изображений
порциональна числу координат и коэффициентов в данном функци-
ональном представлении4. Возможны дальнейшие обобщения преоб-
разования Хафа на случаи обнаружения кривых, не имеюших просто-
го аналитического представления, как в случае применения этого
преобразования к полутоновым изображениям. Некоторые ссылки, от-
носящиеся к подобным расширениям, приводятся в конце данной
главы.
Вернемся теперь к задаче связывания контуров. Подход, осно-
ванный на преобразовании Хафа, заключается в следующем:
1. Вычисляется модуль градиента изображения в каждой точке, ко-
торый подвергается пороговому преобразованию, в результате че-
го формируется двоичное изображение.
2. Выполняется разбиение (дискретизация) пространства параметров
рО на ячейки накопления.
3. Для всех ненулевых пикселей двоичного изображения, полученно-
го в п. 1, находятся образы в пространстве параметров рО и осуще-
ствляется процедура накопления5.
4. Анализируются накопленные значения и отыскиваются ячейки с
наибольшей концентрацией точек.
5. Исследуются отношения между пикселями изображения, отвеча-
ющих выбранным ячейкам накопления (в основном на предмет их
связности).
Понятие связности вданном случае обычно базируется на вычис-
лении расстояний между несвязными пикселями, обнаруженными
при обходе множества элементов изображения, соответствующего
данной ячейке накопления. Разрыв в некоторой точке считается зна-
чимым, если расстояние между этой точкой и ее ближайшим соседом
превышает заданный порог. (См. Раздел 2.5, где рассматриваются от-
ношения связности и соседства, а также меры расстояния).
Пример 10.8: Использование преобразования Хафа для связывания
контуров.
На Рис. 10.21(a) представлен инфракрасный снимок, полученный
при аэросъемке, на котором изображены два ангара и взлетно-поса-
4 Можно показать, что сложность преобразования Хафа пропорциональнапКргде
Р — число параметров, а К — число дискретных значений (одинаковое) для каждо-
го из параметров. — Прим. ред. перевода.
5 Данный пункт добавлен при переводе. — Прим. ред. перевода.
10.2. Связывание контуров и нахождение границ
Рис. 10.21. (а) Исходное инфракрасное изображение, (б) Градиентное изобра-
жение после порогового преобразования, (в) Преобразование Хафа. (г) Свя-
занные пиксели. (Изображения предоставил Д. Р. Кейт, компания Texas
Instruments, Inc.).
дочная полоса. Рис. 10.21(6) демонстрирует градиентное изображение
(после порогового преобразования), полученное с помощью операто-
ра Собела из Раздела 10.1.3. Обратите внимание на небольшие разры-
вы границ взлетно-посадочной полосы. На Рис. 10.21(b) приведены ре-
зультаты преобразования Хафа этого градиентного изображения. На
Рис. 10.21 (г) белым цветом показаны множества пикселей, связанные
с помощью следующего критерия: (1) они принадлежат одной из трех
ячеек с наибольшими накопленными значениями, и (2) длина разры-
вов не превышает пяти пикселей. Замечаем, что в результате связыва-
ния исчезли разрывы, бывшие на градиентном изображении.
10.2.3. Глобальный анализ с помощью методов теории
графов
В этом разделе мы рассмотрим глобальный подход к обнаружению и
связыванию контуров на основе представления отрезков контуров в
846 Глава 10. Сегментация изображении
виде графа и поиска на этом графе путей с наименьшей стоимостью,
которые соответствуют значимым контурам. Такое представление
позволяет построить метод, хорошо работающий в присутствии шу-
ма. Как этого можно было ожидать, такая процедура оказывается зна-
чительно более сложной и требующей большего времени обработки,
чем методы, рассмотренные до сих пор.
Начнем с ряда базовых определений. ГрафС = (М, U) представля-
ет собой непустое конечное множество вершин N вместе с множест-
вом U неупорядоченных пар различных элементов из N. Каждая па-
ра (л(-, rij) е U называется ребром^. Если ребру графа приписано
направление, такое ребро называется дугой. Граф, содержащий толь-
ко дуги, называют ориентированным. Если дуга направлена от вер-
шины к вершине «у, то вершина п, называется начальной вершиной ду-
ги (родителем), а «у — конечной вершиной дуги (потомком). Процесс
выявления потомков некоторой вершины называют ее расширением.
В каждом графе выделим единственную вершину, которую будем на-
зывать начальной или корневой, и множество вершин, называемых
концевыми (или целевыми) вершинами. Пусть каждой дуге (и,-, Иу) при-
писана некоторая стоимость с(п/, п^). Последовательность вершин
«1, П2,..., пр, в которой каждая вершина и, является потомком верши-
ны л,_|, будем называть/цтаел/6 7от Л| до/?д.. Стоимость всего пути по оп-
ределению равна
к
c = ^c(ni_x,ni). (10.2-5)
1=2
Для простоты последующих рассуждений определим элемент кон-
тура как границу между двумя пикселями pviq, являющимися 4-со-
седями (см. Раздел 2.5.1), как показано на Рис. 10.22. Элементы кон-
тура идентифицируются координатами точек р и q, иначе говоря,
элемент контура на Рис. 10.22 определяется парами (хр, yp)(xq, yq). В
соответствии с определением, данным в Разделе 10.1.3, контур есть по-
следовательность соединенных друг с другом элементов контура.
6 Из такой постановки следует, что все ребра являются однократными и отсутствуют
петли. Прим. ред. перевода.
7 Общепринятым является понятие маршрута, который определяется как последо-
вательность ребер, соединяющих пары вершин «| и «д в графе. Маршрут, в котором
все ребра различны, называется цепью, а в котором все вершины различны - простой
цепью, что, собственно, и представ л яст собой вводимый здесь путь. — Прим. ред.
перевода.
10.2. Связывание контуров и нахождение границ
Р»
Рис. 10.22. Элемент контура, находящийся между пикселями pnq.
Можно проиллюстрировать, как только что введенные понятия мо-
гут применяться к задаче обнаружения контуров; для этого восполь-
зуемся изображением 3x3, приведенным на Рис. 10.23(a). Номера по
периметру суть координаты изображения, а числа в квадратных скоб-
ках представляют значения яркости пикселей. Каждому элементу
контура, заданному пикселями pviq. припишем стоимость, которую
определим как
c(p,q) = H-[f(p)-f(q)\ (10.2-6)
где Н — максимальный уровень яркости в изображении (в данном слу-
чае 7), a f(p) и f (q) представляют собой значения яркости пикселей
р и q соответственно. По соглашению, точкар находится справа от на-
правления обхода элемента контура. Например, на Рис. 10.23(6) эле-
мент контура (1, 2)(2, 2) находится между точками (1, 2) и (2, 2). Ес-
ли проходить этот элемент слева направо, то точка р будет иметь
координаты (2, 2), а точка q — координаты (1,2); следовательно, сто-
имость элемента контура составит с(р, q) = 7 — [7 — 6] = 6. Это значе-
ние записано в рамке под элементом контура. Напротив, если прохо-
дить по тому же элементу влево, то точкой р будет точка (1, 2), а точкой
2
Рис. 10.23. (а) Область изображения размерами 3x3. (б) Элементы контура и а б В
их стоимости, (в) Контур, соответствующий пути с минимальной стоимостью
в графе, показанном на Рис. 10.24.
Глава 10. Сегментация изображений
Рис. 10.24. Граф для изображения на Рис. 10.23(a). Пунктирной линией выде-
лен путь минимальной стоимости.
q — (2, 2). В этом случае стоимость будет равна 8, как записано на
Рис. 10.23(6) в рамке над элементом контура. Для простоты рассуж-
дений предположим, что контуры начинаются в верхней строке изо-
бражения и заканчиваются в нижней, так что первый элемент конту-
ра может находиться только или между точками (1, 1) и (1, 2) или
между точками (1,2) и (1,3). Аналогично, последним элементом кон-
тура может быть или находящийся между точками (3, 1) и (3, 2), или
между точками (3, 2) и (3, 3). Напомним, что точкир и должны быть
4-соседями.
На Рис. 10.24 показан граф, относящийся к обсуждаемой задаче.
Каждая вершина графа (обозначенная прямоугольником) соответст-
вует какому-то элементу контура на Рис. 10.23. Между двумя верши-
нами имеется дуга, если соответствующие два элемента контура, бу-
дучи соединенными подряд, могут являться участком контура. Как и
на Рис. 10.23(6), стоимость каждого элемента контура, вычисленная
согласно (10.2-6), показана в рамке рядом с дугой, ведущей к соответ-
ствующей вершине. Целевые вершины графа, в которых может закон-
10.2. Связывание контуров и нахождение границ 849
читься контур, обозначены темным цветом. Существует множество раз-
личающихся по стоимости путей из начальной вершины в каждую из
целевых вершин. Путь минимальной стоимости (по всем целевым
вершинам) показан пунктирной линией; этому пути соответствует
контур, изображенный на Рис. 10.23(b).
Вообще говоря, задача отыскания на графе пути минимальной
стоимости является нетривиальной по вычислительной сложности, и
зачастую приходится жертвовать оптимальностью в пользу скорости
вычислений. Приводимый ниже алгоритм является представителем
класса процедур, в которых для уменьшения объема перебора ис-
пользуются различные эвристики. Пусть г(п) — оценка минималь-
ной стоимости пути из начальной вершины s в любую из целевых
вершин, при условии, что этот путь проходит через вершину п. Эту сто-
имость можно выразить в виде суммы оценки минимальной стоимо-
сти пути из s в п и опенки минимальной стоимости пути из и в целе-
вую вершину, т.е.
r(n) = g(n}+h(n}. (10.2-7)
Здесь в качествеg(n) можно выбрать стоимость найденного к этому мо-
менту минимального пути из s в п, а й(и) получают с использованием
любых имеющихся эвристических соображений (например, исходя из
стоимости пути, ведущего в текущую вершину, далее прослеживают-
ся только определенные вершины). Для проведения поиска на графе
с учетом оценки г(и) используется следующий алгоритм:
Шаг 1: Отметить начальную вершину как «открытую» и установить
g(s) = 0.
Шаг 2: Если не осталось ни одной «открытой» вершины, то аварий-
ное завершение; в противном случае продолжить выполнение.
Шаг 3: Отметить как «закрытую» ту из «открытых» вершин п, для
которой оценка г(и), вычисленная согласно (10.2-7), является мини-
мальной. В случае неоднозначности минимума выбор осуществля-
ется произвольно, но всегда в пользу целевой вершины, если тако-
вая есть.
Шаг 4: Если п является целевой вершиной, то завершение работы;
путь, являющийся решением, находится обратным прослеживанием
по ранее запомненным указателям. В противном случае продолжить
выполнение.
Шаг 5: Расширить вершину п, т.е. построить все выходящие из нее
дуги к вершинам-потомкам. Если таковых нет, то перейти к шагу 2.
Шаг 6: Если вершина-потомок nt еще не отмечена, то установить
Глава 10. Сегментация изображений
g(ni) = g(n) + c(n,ni).
отметить вершину и,- как «открытую» и запомнить указатель от нее об-
ратно к п. Перейти к шагу 2.
Шаг 1: Если вершина-потомок п, отмечена как «открытая» или
«закрытая», то обновить для нее значение стоимости минимального
пути из начальной вершины:
g'(ni) = min[g(n,-), g( п) +с( п. п/) ].
Пометить как «открытые» те из «закрытых» вершин-потомков п, для
которых значения g' при этом уменьшились, и переадресовать на вер-
шину п их прежние обратные указатели. Перейти к шагу 2.
Изложенный алгоритм не гарантирует нахождение пути мини-
мальной стоимости; его достоинством является быстродействие, до-
стигнутое благодаря использованию эвристик. Однако, если h(n) есть
нижняя граница стоимости минимального пути из вершины п в целе-
вую вершину, то данная процедура в самом деле приводит к нахожде-
нию оптимального пути до целевой вершины ([Hart et al., 1968]). Ес-
ли нет никакой эвристической информации (т.е. h = 0), эта процедура
сводится к алгоритму равных стоимостей [Dijkstra, 1959].
Пример 10.9: Нахождение контуров путем поиска на графе.
Л На Рис. 10.25 приведено зашумленное изображение очертаний хро-
мосомы, а также контур, найденный с помошью эвристического по-
иска на графе по описанному выше алгоритму. Контур (показанный
белой линией) наложен на исходное изображение. Заметим, что в
данном случае граница объекта и найденный контур приблизительно
совпадают. Для вычисления стоимости использовалось выражение
(10.2-6). Применяемая в каждой вершине графа эвристика состояла в
том, что в качестве продолжения находился и выбирался путь, явля-
ющийся оптимальным при длине цепи в пять дуг от текущей верши-
ны. Учитывая уровень шума, присутствующего в данном изображении,
подход, основанный на поиске по графу, приводит к достаточно точ-
ному результату.
10.3. Пороговая обработка
Пороговые преобразования занимают центральное место в приклад-
ных задачах сегментации изображений благодаря интуитивно понят-
ным свойствам и простоте реализации. Простое пороговое преобра-
10.3. Пороговая обработка 851
3
Рис. 10.25. Изображение зашумленного силуэта хромосомы; белой линией по-
казан контур, найденный путем поиска по графу.
зование в первый раз упоминалось в Разделе 3.1, и в последующих гла-
вах мы использовали его в самых различных обсуждениях. В этом
разделе дается более формальное определение порогового преобразо-
вания и на его основе строятся значительно более общие методы по-
роговой обработки, чем излагались до сих пор.
10.3.1. Обоснование
Предположим, что показанная на Рис. 10.26(a) гистограмма соответ-
ствует некоторому изображению f(x, у), содержащему светлые объек-
ты на темном фоне, так что яркости пикселей объекта и фона сосре-
доточены вблизи двух преобладающих значений. Очевидный способ
выделения объектов из окружающего фона состоит в выборе значения
порога Т, разграничивающего моды распределения яркостей. Тогда лю-
бая точка (х. у), в которой /(х, у) > Т, называется точкой объекта, а в
противном случае — точкой фона. Пороговое преобразование такого
вида было введено в Разделе 3.1.
Рис. 10.26(6) демонстрирует слегка обобщенный вариант этого
подхода для случая, когда гистограмма изображения характеризуется
наличием трех мод распределения (например, если на темном фоне
изображения имеются два вида светлых объектов). Здесь с помощью
Глава 10. Сегментация изображений
Рис. 10.26. Гистограммы яркости, допускающие разделение с помощью (а) оди-
ночного порога; (б) нескольких порогов.
многоуровневого порогового преобразования точка (х, у) классифициру-
ется как принадлежащая объекту одного класса, если /(х, у) > Т2, ес-
ли Т| </(х, у)<Т2 — объекту другого класса, и если /(х, у) < Т| — фо-
ну. Вообще говоря, задачи сегментации, требующие применения
нескольких порогов, лучше всего решаются с использованием мето-
дов выращивания областей, таких, как обсуждаются в Разделе 10.4.
С учетом обсуждения выше, пороговое преобразование может рас-
сматриваться как операция, при которой производится сравнение с
функцией Т, имеющей вид
T = T(x,y,p{x,y),f), (10.3-1)
где f— изображение, ар(х, у) обозначает некоторую локальную харак-
теристику точки (х,у) изображения, например, среднюю яркость в ок-
рестности с центром в этой точке. Изображение ^(х, у), получаемое в
результате порогового преобразования, определяется следующим об-
разом:
g(*,y) =
1, если/(х,у)>7’
0, если/(х,у)<Т.
(10.3-2)
Таким образом, пиксели, которым присвоено значение 1 (или иной
подходящий уровень яркости), соответствуют объектам, а пиксели
со значением 0 (или любым другим, отличным от значений объекта)
соответствуют фону.
Если значение Тзависит только отf, т.е. одинаково для всех точек
изображения, то такой порог называется глобальным. Если порог Тза-
висит от пространственных координат х и у, то он называется локаль-
ным или динамическим. Если Тзависит отр(х, у), то такой порог назы-
вается адаптивным.
10.3. Пороговая обработка 853
10.3.2. Роль освещения
В Разделе 2.3.4 рассматривалась упрощенная модель, в которой изо-
бражение f(x, у) формируется как произведение двух составляющих:
функции отражения г (х, у) и функции освещения/(х, у). Цель данно-
го раздела состоит в том, чтобы воспользоваться этой моделью для крат-
кого обсуждения влияния эффекта освещения на пороговую обра-
ботку, особенно в случае использования глобального порога.
Рассмотрим смоделированную на компьютере двумерную функцию
коэффициента отражения, которая показана на Рис. 10.27(a). Гисто-
грамма этой функции, приведенная на Рис. 10.27(6), носит четко вы-
раженный бимодальный характер и легко разделяется с помощью
одиночного глобального порога Т, расположенного во впадине меж-
ду пиками гистограммы. При умножении функции отражения из
Рис. 10.27(a) на функцию освещения, приведенную на Рис. 10.27(b),
будет получено изображение, показанное на Рис. 10.27(г), гистограм-
ма которого приводится на Рис. 10.27(д). Как можно заметить, преж-
няя глубокая впадина практически исчезла, что делает невозможной
сегментацию с помощью единого глобального порога. Хотя функция
отражения как таковая бывает известна достаточно редко, эта простая
иллюстрация показывает, что различный характер отражения света от
объектов и фона может позволять легко различать их визуально, од-
нако автоматическая сегментация изображения, полученного при
плохом (в данном случае — неравномерном) освещении, может ока-
заться весьма сложной задачей.
Причину, по которой гистограмма на Рис. 10.27(д) оказывается
столь сильно искаженной, можно объяснить с помощью обсуждения,
проведенного в Разделе 4.5. В соответствии с соотношением (4.5-1),
/(х,у) = /(х,у)г(х,у). (10.3-3)
Логарифмируя это равенство, приходим к сумме:
z(x,y) = ln/(х,у)=1ш(х,у)+1пг(х,у) =/'(х,у) +г'(х,у). (10.3-4)
Как известно из теории вероятностей [Papoulis, 1991], если /'(х, у) и
г '(х, у) — независимые случайные переменные, то гистограмма их сум-
мы z(x, у) получается сверткой гистограмм i'(x, у) и г'(х, у). Если бы
функция /(х, у) была константой, то f (х, у) также была бы константой,
и ее гистограмма представляла бы собой одиночный импульс (дель-
та-функцию). Свертка такой функции с гистограммой /(х, у) не ме-
няет форму гистограммы (вспомним из рассмотрения в Разделе 4.2.4,
Глава 10. Сегментация изображений
что свертка произвольной функции с дельта-функцией приводит к
сдвигу исходной функции на расстояние, равное координате локали-
зации дельта-функции). Но если функция Г(х, у) имеет более широ-
кую гистограмму (вследствие неравномерности освешения), то в про-
цессе свертки гистограмма г'(х, у) размывается, что приводит к
Рис. 10.27. (а) Смоделированная на компьютере двумерная функция коэффи-
циента отражения (б) Гистограмма функции коэффициента отражения,
(в) Смоделированная на компьютере функция освещения, (г) Произведение
(а) и (в), (д) Гистограмма полученного изображения.
10.3. Пороговая обработка 855
гистограмме функции z(x, у) совершенно отличающейся формы по
сравнению с гистограммой г'(х, у). Степень искажения зависит от
широты гистограммы i'(x, у), которая, в свою очередь, зависит от не-
равномерности функции освещения.
Мы рассматривали здесь логарифм f(x, у), а не саму функцию
изображения, поскольку это позволяет разделить осветительную и
отражательную составляющие, не меняя существа задачи. Такой под-
ход позволяет рассматривать формирование гистограммы как про-
цесс свертки, объясняя, почему ярко выраженная впадина на гисто-
грамме функции отражения претерпевает искажения при неудачном
освещении.
Когда имеется доступ к источнику освещения, на практике часто
применяют способ компенсации неравномерности освещения, со-
стоящий в том, что свет направляется на отражательную поверхность
ровного белого цвета. Это позволяет получить изображение
g(x. у) = ki(x, у), где к — зависящая от типа поверхности константа, а
i{x, у) — функция освещения. После этого любое изображение
/(х, у) = i(x, у) г(х, у), полученное с помощью той же самой функции
освещения, можно поделить nag(x, у), приходя тем самым к норми-
рованной функции h(x, у) =f(x, у)/g(x, у) = г(х, у)/к. Таким образом,
если функция г(х, у) допускает сегментацию с помощью единого по-
рога Т, то и функция h(x, у) может сегментироваться с помощью еди-
ного порога с величиной Т/к.
10.3.3. Обработка с глобальным порогом
С учетом обсуждения в Разделе 10.3.1, простейший из методов поро-
говой обработки состоит в разделении гистограммы изображения на
две части с помощью единого глобального порога Т, как показано на
Рис. 10.26(a). После этого сегментация осуществляется путем поэле-
ментного сканирования изображения, при этом каждый пиксель от-
мечается как относящийся к объекту или к фону, в зависимости от то-
го, превышает ли яркость этого пикселя значение порога Тили нет. Как
указывалось выше, успешность применения этого метода целиком
зависит оттого, насколько хорошо гистограмма поддается разделению.
Пример 10.10: Глобальная пороговая обработка.
Г На Рис. 10.28(a) приведено простое изображение, а на Рис. 10.28(6) —
его гистограмма. На Рис. 10.28(b) показан результат сегментации ис-
ходного изображения с помощью порога Т, расположенного посере-
дине между максимальным и минимальным уровнями яркости. Этот
порог позволяет достичь «чистой» сегментации, при которой устраня-
Глава 10. Сегментация изображений
б в
Рис. 10.28. (а) Исходное изображение, (б) Гистограмма изображения, (в) Ре-
зультат глобальной пороговой обработки со значением порога, равным полу-
сумме максимального и минимального значений яркости.
ются тени и остаются только сами объекты. В данном случае интересу-
ющие объекты темнее фона, поэтому все пиксели с яркостью <Тотме-
чаются черным цветом (0), а все пиксели с яркостью > Т— белым цве-
том (255). Основная цель преобразования состоит лишь в получении
двоичного изображения, поэтому в принципе выбор цвета объекта и фо-
на — черный или белый — может меняться на противоположный.
Успешного применения рассмотренного глобального порогового
преобразования следует ожидать только в хорошо контролируемых ус-
ловиях. Одной из таких областей, где это часто оказывается возмож-
ным, являются задачи технического контроля, где обычно можно уп-
равлять условиями освещения.'
В предыдущем примере порог выбирался эвристически, на осно-
вании визуального изучения гистограммы. Для автоматического вы-
бора значения порога Т может применяться следующий алгоритм:
10.3. Пороговая обработка
1. Выбирается некоторая начальная оценка значения порога Т.
2. Проводится сегментация изображения с помощью порога Т. В ре-
зультате образуются две группы пикселей: (?], состоящая из пик-
селей с яркостью больше Т, и G^^ состоящая из пикселей с яркос-
тью меньше или равной Т.
3. Вычисляются значения Ц] и Р2 средних яркостей пикселей по об-
ластям G] и С2 соответственно.
4. Вычисляется новое значение порога:
= +М2 )•
5. Повторяются шаги со 2-го по 4-й до тех пор, пока разница значе-
ний Т при соседних итерациях не окажется меньше значения на-
перед заданного параметра 7ф
Если есть основания полагать, что объект и фон занимают сравни-
мые площади в изображении, хорошим начальным приближением
для Тявляется средний уровень яркости изображения. Если занима-
емая объектами площадь мала по сравнению с площадью фоновой об-
ласти (или наоборот), то одна из групп пикселей будет доминировать
в гистограмме, и средняя яркость окажется не слишком хорошим на-
чальным приближением. В подобных случаях более подходящим на-
чальным значением Тявляется полусумма минимального и максималь-
ного значений яркости. Параметр Tq используется для остановки
алгоритма, когда изменения на каждой итерации становятся малы по
сравнению с заданным значением. Такие меры применяются, когда
важным соображением является скорость вычислений.
Пример 10.11: Сегментация изображения с помощью вычисленного
глобального порога.
На Рис. 10.29 демонстрируется пример сегментации по порогу, вы-
численному вышеописанным алгоритмом. На Рис. 10.29(a) приведено
исходное изображение, а на Рис. 10.29(6) — его гистограмма. Обрати-
те внимание на ярко выраженную впадину на гистограмме. В резуль-
тате применения итерационного алгоритма, начиная со среднего зна-
чения яркости и параметра Tq = 0, после трех итераций было найдено
значение порога 125,4. Результат сегментации исходного изображе-
ния с использованием порога Т = 125 приводится на Рис. 10.29(b).
Как и следовало ожидать, благодаря четко разделяющимся модам ги-
стограммы, сегментация объектов и фона оказывается весьма эффек-
тивной.
Глава 10. Сегментация изображений
Рис. 10.29. (а) Исходное изображение, (б) Гистограмма изображения, (в) Ре-
зультат сегментации с порогом, полученным итерационным метолом. (Исход-
ное изображение предоставлено Национальным институтом стандартов и
технологии США)
10.3.4. Обработка с адаптивным порогом
Как было продемонстрировано на Рис. 10.27, условия получения изо-
бражения, например, неравномерное освещение, могут превратить
хорошо разделяемую гистограмму в такую, которую невозможно эф-
10.3. Пороговая обработка
фективно разделить с помошью единого глобального порога. В подоб-
ных ситуациях применим подход, при котором исходное изображение
разбивается на подобласти, в каждой из которых для сегментации ис-
пользуется свое значение порога. Основные проблемы при таком под-
ходе — как разбить исходное изображение и как оценить порог для каж-
дой полученной области. Поскольку порог, применимый для каждого
пикселя, оказывается зависящим от характеристик подобласти изоб-
ражения, содержащей данный пиксель, такое пороговое преобразова-
ние является адаптивным. В качестве иллюстрации адаптивной поро-
говой обработки приведем нижеследующий простой пример. Более
полный пример будет рассмотрен в следующем разделе.
Пример 10.12: Адаптивная пороговая обработка.
На Рис. 10.30(a) показано то же изображение, что и на Рис. 10.27(г),
для которого мы уже пришли к выводу о невозможности его эффек-
тивной сегментации с помощью единого глобального порога. Дейст-
вительно, Рис. 10.30(6) демонстрирует, какой был бы результат сегмен-
Рис. 10.30. (а) Исходное изображение, (б) Результат обработки с глобальным
порогом, (в) Изображение, разбитое на области меньших размеров, (г) Резуль-
тат обработки с адаптивным порогом.
((860 Глава 10. Сегментация изображений
тации этого изображения с помощью глобального порога, вручную ус-
тановленного в точку, соответствующую впадине в гистограмме (см.
Рис. 10.27(д)). Один из возможных подходов для ослабления влияния
неравномерности освещения состоит в разбиении изображения на
подобласти меньших размеров, такие, что в пределах каждой из них
освещение остается приблизительно равномерным. На Рис. Ю.ЗО(в)
показано такое разбиение, при котором изображение делится на че-
тыре равные части, каждая из которых затем вновь разбивается на
четыре области.
Все подобласти, не содержащие границы между объектом и фоном,
характеризуются значениями дисперсии не более 75. Все подобласти,
через которые проходит граница объекта, имеют значения дисперсии
100 и выше. В каждой области со значением дисперсии более 100 сег-
ментация проводилась с порогом, вычисленным для этой области по
алгоритму из предыдущего раздела. За начальное значение Т во всех
случаях принималась полусумма максимального и минимального зна-
чений яркости в пределах подобласти. Все области, в которых значе-
ние дисперсии не превышало 75, обрабатывались как одно составное
изображение, сегментация которого осуществлялась с помощью еди-
ного порога, оценивавшегося по тому же алгоритму.
Результаты сегментации с помощью описанной процедуры приве-
дены на Рис. Ю.ЗО(г). За исключением двух подобластей, улучшение
по сравнению с Рис. 10.30(6) очевидно. В обеих подобластях, где сег-
ментация дала неверный результат, доля точек фона весьма мала, так
что соответствующие гистограммы оказались почти унимодальны-
ми. На Рис. 10.31 (а) показана верхняя из областей с неправильной сег-
ментацией на Рис. Ю.ЗО(в), а также область непосредственно над ней,
где сегментация была проведена правильно. Гистограмма области с пра-
вильной сегментацией имеет явную бимодальную форму, с ярко вы-
раженными пиками и впадиной между ними. Другая гистограмма яв-
ляется почти унимодальной в том смысле, что пик гистограммы,
соответствующий точкам фона, чрезвычайно мал8.
На Рис. 10.31 (г) представлено дальнейшее разбиение области, в ко-
торой наблюдалась ошибочная сегментация, на еще более мелкие по-
добласти. На Рис. 10.31(д) показана гистограмма левой верхней из
этих подобластей. В ней расположена граница между объектом и фо-
8 Рассмотренная ситуация является хорошим примером того, что использованный ал-
горитм итеративного вычисления порога сегментации не всегда лает верные резуль-
таты. Рекомендуем читателю самостоятельно подумать, в каких случаях и почему это
происходит. — Прим. ред. перевода.
10.3. Пороговая обработка
Рис. 10.31. (а) Подобласти с правильной и ошибочной сегментацией из
Рис. 10.30. (б — в) Соответствующие гистограммы, (г) Дальнейшее разбиение
области с ошибочной сегментацией, (д) Гистограмма маленькой подобласти
в левом верхнем углу, (е) Результат адаптивной сегментации изображения (г).
ном, поэтому ее гистограмма отчетливо бимодальна, так что область
легко поддается сегментации, как это видно из Рис. 10.31(e). На дан-
ном рисунке также показана сегментация всех остальных малых по-
добластей. Все они характеризуются гистограммами почти унимо-
дальной формы, причем значения средних яркостей оказываются
ближе к объекту, чем к фону, поэтому все эти подобласти классифи-
цируются как принадлежащие объекту. В качестве самостоятельного
упражнения оставляем читателю убедиться, что при разбиении всего
исходного изображения Рис. 10.30(a) на подобласти таких размеров,
как показаны на Рис. 10.31 (г), достигается значительно более точная
сегментация.
10.3.5. Обработка с оптимальными глобальным
и адаптивным порогами
В этом разделе мы рассмотрим метод нахождения порогов, миними-
зирующих среднюю ошибку сегментации. В качестве иллюстрации этот
Глава 10. Сегментация изображений
метод применяется к задаче, требующей решения нескольких важных
вопросов, часто возникающих при практическом использовании по-
роговой обработки.
Предположим, что изображение состоит только из областей с дву-
мя главными уровнями яркости (которые естественно трактовать как
«светлый» и «темный»). Пусть значения яркости обозначаются пере-
менной Z- Эти значения можно рассматривать как случайные величи-
ны, а их гистограмму — как оценку плотности распределения вероят-
ностей p(z). Общая плотность распределения вероятностей значений
элементов изображения представляет собой взвешенную сумму (смесь)
двух плотностей распределения вероятностей: для светлых и для тем-
ных областей. Кроме тою, веса в таком смешанном распределении про-
порциональны относительным площадям светлой и темной облас-
тей. Если плотности распределения вероятностей известны (или
основаны на гипотезе), то можно определить оптимальный (в смыс-
ле минимума ошибки) порог для сегментации изображения на две
области различной яркости.
На Рис. 10.32 показаны два графика плотностей распределения ве-
роятностей. Предположим, что график/?](z) соответствует яркостям
пикселей объектов, а график p2(z) — яркостям пикселей фона. Плот-
ность распределения вероятностей значений их смеси, описываю-
щая общую изменчивость яркости на изображении, имеет вид:
p(z) = P\P](z) +P2p2(z)- (10.3-5)
Здесь Р] и Р2 — априорные вероятности каждого из этих двух классов
пикселей. А именно, Р] есть вероятность того, что случайно взятый
пиксель принадлежит объекту; аналогично, Р2 — вероятность того, что
Рис. 10.32. Плотности распределения вероятностей значений яркости для
двух областей изображения.
10.3. Пороговая обработка
пиксель является фоновым. Предполагается, что любой пиксель изо-
бражения относится либо к объекту, либо к фону, так что
Р1 + Р2=1- (10.3-6)
Сегментация изображения осуществляется таким образом, что к клас-
су фоновых относятся пиксели, у которых значения яркости выше
уровня порога Т(см. Рис. 10.32). Все остальные пиксели считаются при-
надлежащими объектам. Наша основная цель состоит в выборе тако-
го порога Т, который минимизирует среднюю ошибку от принятия ре-
шения о принадлежности данного пикселя объекту или фону.
Как известно, вероятность того, что случайная переменная прини-
мает значение в интервале [а, Ь\, есть интеграл ее плотности распреде-
ления вероятностей по интервалу от а до Ь, который численно равен
площади под кривой плотности распределения вероятностей между эти-
ми пределами. Следовательно, вероятность того, что точка фона будет
ошибочно классифицирована как принадлежащая объекту, равна
Т
Е2(Т} = J p2(z}dz, (10.3-7)
что есть площадь под кривой p2(z) слева от порога. Аналогично, веро-
ятность того, что точка объекта будет ошибочно классифицирована как
принадлежащая фону, равна
оо
E^T^jp^dz, (10.3-8)
т
т.е. площади под кривой д/г) справа от Т. Тогда общая вероятность
ошибки составляет
Е(Т} = Р{ЕХ{Т) + Р2Е2(Т). (10.3-9)
Обратим внимание, что величины Е\ и Е2 суммируются с весами, со-
ответственно равными вероятностям появления пикселей объекта и
фона. Если вероятность появления точек фона и объекта одинакова,
то веса будут равны Р| = Р2 = 0,5.
Чтобы найти значение порога, при котором ошибка минимальна, не-
обходимо продифференцировать Е(Т) по Т(применяя формулу Нью-
тона-Лейбница) и приравнять результат нулю, после чего получаем:
Р{р^Т) = Р2р2 (Т).
(10.3-10)
864 Глава 10. Сегментация изображений
Решая это уравнение относительно Т, находим оптимальный порог. За-
метим, что если Р[ = Р2, то оптимальное значение порога находится
в точке пересечения кривыхp\(z) иP2(z) (см. Рис. 10.32).
Чтобы получить аналитическое выражение для Т, необходимо
знать уравнения обеих функций плотности распределения вероятно-
стей. На практике оценить эти функции плотности не всегда представ-
ляется возможным, и часто используется такой подход, когда в каче-
стве гипотезы принимаются такие функции плотности, параметры
которых можно сравнительно просто оценить. Одной из основных
функций, используемых таким способом, является гауссова функция
плотности, которая полностью задается двумя параметрами: средним
и дисперсией. В этом случае
(£-R)2
p(z) = е
2of
_(£-Й2)2
. Р2- е 2о22
\JlTtC52
(10.3-11)
где Ц1 и of суть среднее и дисперсия гауссова распределения одного
класса пикселей (скажем, принадлежащих объектам), а Ц2 и °? —
среднее и дисперсия для другого класса. Используя это уравнение
для решения (10.3-10) в общем виде, приходим к следующему резуль-
тату для значения порога Т:
АТ2 +ВТ+С = 0, (10.3-12)
где
A=G2-G2
(10.3-13)
С = 1^2°?-^O2 + 2g22g2 1п(о2^/с1^2 )•
Поскольку квадратное уравнение может иметь два решения, то в не-
которых случаях оптимальное решение будет достигаться при двух
значениях порога.
Если дисперсии распределений одинаковы, т.е. of = of = о2, то
порог только один:
2 Bi -иг И j
(10.3-14)
10.3. Пороговая обработка
Если, кроме того, Р\ = Р-±, то оптимальный порог равен среднему
арифметическому средних значений распределений. То же самое спра-
ведливо, если о = 0. Аналогичным образом можно найти оптимальный
порог для других известных распределений, например, рэлеевского или
логарифмически нормального распределения.
Вместо предположений об известном виде функции р(г) может
использоваться подход, основанный на минимизации среднеквадра-
тической ошибки, при котором по гистограмме изображения строит-
ся оценка распределения вероятностей значений яркости. Напри-
мер, средний квадрат ошибки между непрерывной плотностью
распределения вероятностей смеси р(г) и дискретной гистограммой
изображения /?Uzj равен
1 " 7
есркв = -Х[-Р^)_/г^/)] ’ (10.3-15)
где предполагается, что гистограмма состоит из п значений. Основная
задача оценивания полного распределения вероятностей состоит в
том, чтобы определить наличие или отсутствие преобладающих мод
в распределении. Например, наличие двух мод обычно указывает на
присутствие контуров на изображении (или в области, по которой
вычисляется распределение вероятностей).
В общем случае, аналитическое определение параметров, при ко-
торых достигается минимум среднеквадратической ошибки, пред-
ставляет собой непростую задачу. Даже в случае гауссова распределе-
ния непосредственные расчеты путем приравнивания нулю частных
производных приводят к системе трансцендентных уравнений, кото-
рые обычно удается решить только с помощью численных методов, на-
пример, метода сопряженных градиентов или метода Ньютона для
систем нелинейных уравнений.
Пример 10.13: Использование оптимальной пороговой обработки для
сегментации изображения.
Ниже излагается один из самых ранних (и, тем не менее, самых по-
учительных) примеров сегментации изображения путем пороговой
обработки с оптимальным порогом. Этот пример особенно интересен
тем, что он показывает, как можно добиться лучших результатов сег-
ментации, используя методы предварительной обработки, изложен-
ные при обсуждении методов улучшения изображений. Кроме того,
в этом примере также демонстрируется использование оценки ло-
кальной гистограммы и адаптивное пороговое преобразование. Общая
проблема состоит в том, чтобы автоматически выделять границы же-
29 А-223
Глава 10. Сегментация изображении
Рис. 10.33. Кардиоангиограмма до и после предварительной обработки. [Chow,
Капеко].
лудочков сердца на кардиоангиограммах (рентгеновских изображени-
ях сердца, получаемых с введением контрастирующего вещества).
Описываемый подход был разработан Чоу и Канеко [Chow, Капеко,
1972] для выделения границ левого желудочка сердца.
Перед сегментацией все изображения подвергались следующей
предварительной обработке. (1) Значение каждого пикселя преобра-
зовывалось с помощью логарифмической функции (см. Раздел 3.2.2),
чтобы компенсировать экспоненциальную зависимость радиоактив-
ного поглощения. (2) Изображение, полученное перед введением
контрастного вещества, вычиталось из каждого изображения, которые
были получены после введения контрастного вещества, что позволя-
ло убрать присутствующий на всех изображениях силуэт позвоночни-
ка (см. Раздел 3.4.1). (3) Для уменьшения случайного шума суммиро-
вались несколько ангиограмм (см. Раздел 3.4.2). На Рис. 10.33 показаны
исходная кардиоангиограмма и изображение, полученное после пред-
варительной обработки (объяснение областей, отмеченных^ и В, бу-
дет дано ниже).
Для вычисления оптимальных порогов каждое изображение после
предварительной обработки разбивалось на 49 областей по сетке 7x7
с 50% перекрытием соседних областей. Все исходные изображения в
этом примере имели размеры 256x256 пикселей, а каждая из 49 полу-
ченных перекрывающихся областей имела размеры 64x64 пикселей.
На Рис. 10.34(a) и (б) приведены гистограммы областей Л и В, отме-
ченных на Рис. 10.33(6). Заметим, что гистограмма области Л имеет яр-
ко выраженную бимодальную структуру, что указывает на присутст-
вие границы. Напротив, гистограмма области В является
унимодальной, что говорит об отсутствии в этом фрагменте двух за-
метно различающихся областей.
10.3. Пороговая обработка
Рис. 10.34. Гистограммы областей (а) А и (б) В, показанных на Рис. 10.33(6),
изображенные черными точками. [Chow, Капеко].
Темнее
Светлее
а б
После вычисления всех 49 гистограмм выполнялась проверка их би-
модальности, чтобы отсеять области с унимодальными гистограмма-
ми. Оставшиеся гистограммы затем приближались бимодальными
гауссовыми кривыми плотности (с уравнениями вида (10.3-11)), ис-
пользуя метод сопряженных градиентов для минимизации функции
ошибки, заданной уравнением (10.3-15). Кружочками и крестиками
на Рис. 10.34(a) показаны два найденных варианта аппроксимации ги-
стограммы, нанесенной черными точками. Затем с помощью соотно-
шений (10.3-12) и (10.3-13) находились оптимальные значения поро-
гов. Как уже было сказано, пороги назначались только для областей
с бимодальными гистограммами. Для унимодальных областей поро-
ги вычислялись путем интерполяции найденных оптимальных поро-
гов. После этого проводилась повторная интерполяция с использова-
нием значений ближайших порогов, так что в конце этой процедуры
каждой точке изображения был присвоен некоторый свой порог. В за-
ключение для каждого пикселя принималось двоичное решение в со-
ответствии с правилом
1,
0
f(x,y) = -
если/(х,у)>7^,,
в противном случае,
где — значение порога, приписанное точке (х, у) изображения
(отметим, что этот порог является адаптивным, поскольку его значе-
ние зависит от характеристик той области, в которую попадает точка
(х, у)). Затем границы объекта находились путем вычисления гради-
ента полученного двоичного изображения. На Рис. 10.35 показан ре-
Глава 10. Сегментация изображений
Рис. 10.35. Кардиоангиограмма с наложенными границами. [Chow, Капеко].
зультат наложения границ на исходное изображение. Учитывая слож-
ность и разнообразие обрабатываемых изображений, описанная про-
цедура сегментации дает прекрасные результаты. Я
10.3.6. Использование характеристик границы для
улучшения гистограммы и локальной
пороговой обработки
С учетом обсуждения, проводившегося на протяжении предшеству-
ющих пяти разделов, становится интуитивно ясно, что шансов на вы-
бор «хорошего» порога значительно больше, если пики на гистограм-
ме являются высокими, узкими, симметричными, а также разделены
глубокими впадинами. Один из возможных подходов к «улучшению»
формы гистограммы состоит в том, чтобы рассматривать в изображе-
нии только те пиксели, которые лежат вблизи перепадов между объ-
ектами и фоном, либо на самих перепадах. Непосредственное и оче-
видное улучшение заключается в том, гистограммы станут меньше
зависеть от относительных размеров объектов и областей фона. Напри-
мер, на гистограмме изображения, состоящего из маленького объек-
та на фоне с большой площадью (или наоборот), будет доминиро-
вать один большой пик, потому что имеется большое число пикселей
одного из видов. Рисунки 10.30 и 10.31 являются хорошей иллюстра-
цией того, как в таких случаях ухудшается качество сегментации.
Если учитывать только пиксели, лежащие на перепаде между объ-
ектом и фоном, или вблизи перепада, то в получаемой гистограмме бу-
дут присутствовать пики примерно равной высоты. К тому же веро-
ятность того, что любой из таких пикселей принадлежит объекту,
будет приблизительно равна вероятности его принадлежности фону,
что улучшает симметричность пиков гистограммы. Наконец, как бу-
10.3. Пороговая обработка 869
дет ясно из следующего абзаца, при использовании пикселей, удовле-
творяющих некоторым простым метрическим соотношениям, осно-
ванным на операторах градиента и лапласиана, наблюдается тенден-
ция к углублению впадины между пиками гистограммы.
Главная трудность при реализации описанного подхода состоит в
неявном предположении, что известны места перепадов между объ-
ектами и фоном. Ясно, что во время сегментации этих данных нет, по-
скольку нахождение границ между объектами и фоном как раз и яв-
ляется целью сегментации. Однако, как упоминалось в Разделе 10.1.3,
указание на то, находится ли некоторый пиксель на перепаде, можно
получить, вычисляя градиент в этой точке. Кроме того, с помощью ла-
пласиана можно получить информацию о том, лежит ли некоторый
пиксель на темной или светлой стороне перепада. На склоне перепа-
да среднее значение лапласиана равно нулю (см. Рис. 10.6), поэтому
на практике можно ожидать, что интервалы промежуточных значений
на гистограммах, которые строятся из пикселей, отбираемых по кри-
терию «градиент/лапласиан», будут заполнены слабо. Это и означает
наличие глубокой впадины — столь желательное свойство, обсуж-
давшееся выше.
Градиент V/ в произвольной точке (х, у) изображения задается
уравнением (10.1-4) или (10.1-12). Аналогично, лапласиан \72/задает-
ся уравнением (10.1-14) или (10.1-15). Эти две величины позволяют
сформировать трехградационное изображение следующим образом:
0, если Vf <Т
s(x,y) = - +, если ^f>T hV2/>0
(10.3-16)
-, если Vf>T hV2/<0,
где символы 0, + и — представляют любые три отличающихся уровня
яркости, Т— порог, а градиент и лапласиан вычисляются в каждой точ-
ке (х,у). Оператор (10.3-16) позволяет построить изображение s(x,y),
в котором: (1) все пиксели, не находящиеся на перепадах (о чем гово-
рит величина градиента V/, не превышающая порог 7), отмечены
символом 0; (2) все пиксели, расположенные на темной стороне пе-
репала, отмечены символом +; и (3) все пиксели, расположенные на
светлой стороне перепада, отмечены символом —. На Рис. 10.36 пока-
зан результат такой разметки изображения темного росчерка на свет-
лом фоне, полученный с помощью соотношения (10.3-16).
Данные, получаемые с помощью такой процедуры, можно ис-
пользовать для построения сегментированного двоичного изобра-
жения, в котором единичные пиксели соответствуют интересующим
00000000000000000—-оо*о*оооооооооооооооооооооооооооооооооооооооооооооо
000000000000000000000000000*000000*0000000«ОООООООООООООООООООООСООООо
000000000000000000000000-00000000000—000000-00**00**00000000000000000
000000000000000000000000000000000000000000000000000000000*000000000с00
00000000000000000000000000000000000000000000000000-0000-00000*00000000
0000000000000000000*00000000000000000000000000000000000000-00000*00000
000000с000000с00000000*000000000с000000000000000000000000000000-0-00*0
00000000-00000000000-00000000**000000000000000000000000000000000000000
00000000000000000000000000000000000*000*000000000000000000000000000-0-
0000000000000000000000000000000-000-0000000-0*000000000000000000000000
0000000000000000000000000000000000000000000000000000*00000*00000000000
000000000000000000000000000000000000000000000000000-0000-0000*00000000
000000000000000000000000000000000000000000000000000000000-00*000000000
000000000000000----—оооооооооооооооооооооооооооооооооооооооооооооооо
0000000000000............-ооооооооооооооооооооооооооооооооооооооооооо
000000000000—♦*»♦♦♦♦—000000000000000000000000000000000000000000000
0000000000--«***00* *«*--0000000000000000-——00000000000000000000000
0000000000—♦♦♦..»♦•*.♦♦—000000000000-—------—000000000000000000000
000000000-—♦ ♦♦♦——* — —0000000000— ♦♦♦♦♦♦♦♦—-0900000000000000000
00000000---* * --------0000000000——**•*♦♦♦—-00000000000000000
00000000---*«*—0-***-—--30000000—*«*«*•***»»•**—00000000000000000
00000009---♦.♦-00—♦♦.♦*♦—00000—----*•»»------»♦♦**. .-ОООООООООООООООС
00000000--»***—00—♦ ♦»о***-0000------ »• »- — --»♦♦♦♦ *.--0000000000000
00000000--» ООО--**00**♦—00-----• ♦—-09------♦ » ♦ » -00000000000
00000000-—♦♦*--000—♦♦♦♦♦♦*♦——-♦♦♦.*--00000000—♦♦♦♦♦.--0090000000
000000000—» » «--ООО—♦ *♦ ♦-♦ ♦ ♦ »----♦♦♦♦—---0000000000--*♦ .*- — -00000-
000000000—•♦.*—00—♦ ♦*♦—-+•♦.♦♦.** *---99000000000--»♦♦♦..♦- —
0000000000—♦♦♦—о—♦ »*•♦—— --------00000000000009-—♦♦*»♦».♦»*►»•
00000000000—• ------ * ------------900000000000000000---- > » .........
...................»♦♦*»♦—0000000000000000000000000000009-----------------
оооооооооооооо-—♦♦.»♦*•—-ооосоооооооооооооооооооорооооооооо........С
000000000000009---—-----00000000000000000000000000000000000000000000
ООООООООООООООООООООСООООООООООООООООООООООООООООООООООООООООООООООООО
ОООООООООООООООООООООООООООООООООООООООООООООООООООООООООООООоОООООООО
0000000000000000000000000000000000000000000000000000000000000000000000
----000-00000-0000-0000000000000000000000000000000000000000000000000
000-00000000--00-000000-------0000000-----------------9.........-.....
ооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооээ
оооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооооо
оооооооооооооооооооооооооооооооооооосоосоооооооооооооооооооооооооооосо
оооооооооооооооооооооооооооосооооооооооооооооооооооооооооооооооооооооо
0000000000000000000000000000000000000000000000000000000000000000000000
Рис. 10.36. Изображение рукописного росчерка, закодированное с помощью
соотношения (10.3-16). (Предоставлено IBM Corporation).
объектам, а нулевые — фону. При сканировании изображения в вер-
тикальном или горизонтальном направлении переход от светлого
фона к темному объекту должен характеризоваться появлением в
изображении s(x, у) символа —, за которым идет символ +. Область
объекта заполнена пикселями, которые отмечены символами 0 (или
+, если объект мал). Наконец, переход от объекта обратно к фону ха-
рактеризуется появлением символа +, после которого идет символ —.
Таким образом, горизонтальная или вертикальная линия сканирова-
ния, пересекающая темный объект на светлом фоне, имеет следую-
щую структуру:
(...) (-,+) (0 или +) (+,-) (...),
где (...) означает любую комбинацию символов +, — и 0. Внутри сред-
них скобок находятся точки объекта, которые в результирующем изо-
бражении отмечаются единицами. Остальные пиксели вдоль этой ли-
нии сканирования отмечаются нулями, за исключением всех других
последовательностей такого же вида, т.е. (О или +), ограниченные с двух
сторон парами (—,+) и (+,—). Наоборот, когда светлый объект распо-
ложен на темном фоне, знаки + и — в структуре линии сканирования
меняются местами.
10.3. Пороговая обработка
Пример 10.14: Сегментация изображения путем локальной пороговой
обработки.
На Рис. 10.37(a) показано изображение обычного банковского че-
ка с декоративным фоном, а на Рис. 10.38 — гистограмма значений гра-
диента для пикселей с величиной градиента больше 5. Видно, что на
этой гистограмме имеются две моды, которые расположены симмет-
рично, имеют приблизительно одинаковую высоту и разделены хоро-
шо различимой впадиной. Наконец, на Рис. 10.37(6) приведено сег-
ментированное изображение, полученное с помощью правил (10.3-16)
при значении порога Твблизи середины впадины. Двоичное изобра-
жение было получено на основе анализа последовательностей пиксе-
лей, как описано выше. Данный пример является иллюстрацией ло-
кальной пороговой обработки, как это определялось в уравнении
(10.3-1), поскольку значение Топределялось по гистограмме градиен-
та и лапласиана, которые являются локальными характеристиками .
а
б
Рис. 10.37. (а) Исходное изображение, (б) Результат сегментации изображения
посредством локальной пороговой обработки. (Изображения предоставле-
ны IBM Corporation).
9 Несмотря на то, что порог определяется по локальным характеристикам и исполь-
зуется локальная обработка, сам порог здесь является глобальным, поскольку он оди-
наков для всех пикселей изображения. — Прим. ред. перевода.
Величина градиента
Рис. 10.38. Гистограмма значений градиента для пикселей с величиной гради-
ента больше 5. (Изображение предоставлено IBM Corporation).
10.3.7. Пороги, основанные на нескольких переменных
До сих пор мы занимались пороговыми преобразованиями одно-
цветных полутоновых изображений. В некоторых случаях для полу-
чения изображений могут применяться сенсоры, позволяющие харак-
теризовать каждый элемент изображения более чем одной
переменной, что в свою очередь позволяет выполнятьл/ульшпснекли-
ралъную пороговую обработку. Как подробно обсуждалось в Разде-
ле 6.7, хорошим примером такого рода могут быть цветные изобра-
жения, в которых каждый пиксель характеризуется тремя значениями
RGB. В этом случае становится возможным построение трехмерной
«гистограммы». В основном процедура аналогична методу, применя-
емому в случае одной переменной. Например, для изображения с
тремя переменными (компонентами RGB), каждая из которых име-
ет 16 градаций, строится трехмерная (кубическая) сетка размерами
16x16x16. В каждую ячейку такого куба заносится число пикселей, у
которых значения цветовых составляющих соответствуют коорди-
натам данной ячейки. После этого значения в каждой ячейке делят-
ся на общее число пикселей изображения, чтобы получить нормиро-
ванную гистограмму.
Суть порогового преобразования теперь состоит в отыскании скоп-
лений точек (кластеров) в трехмерном пространстве. Например, пред-
положим, что в гистограмме найдены К значимых кластеров. Тогда дан-
ное изображение допускает сегментацию путем присвоения одного
произвольно выбранного значения (скажем, белого) тем пикселям, у
которых RGB-компоненты близки к одному из кластеров, и другого
значения (скажем, черного) всем остальным пикселям изображения.
Этот принцип легко распространяется на случай большего числа ком-
понент и, конечно, большего числа кластеров. Основную трудность при
10.3. Пороговая обработка
таком подходе представляет то, что сложность задачи кластеризации
быстро растет с увеличением числа переменных. Изложение методов
кластеризации можно найти, например, в книгах [Duda, Hart, Stork,
2001] и [Той, Gonzalez, 1974].
Пример 10.15: Мулыписпектральная пороговая обработка.
Е На Рис. 10.39(a) приведено изображение, являющееся монохромным
представлением цветной фотографии. Исходное цветное изображение
объединяло три 16-градационных RGB-компоненты. Шарф на сним-
ке — ярко-красного цвета, а лицо и волосы имели светлые цвета, от-
личающиеся по спектральным характеристикам от окна и других де-
талей фона.
Изображение на Рис. 10.39(6) было получено пороговым выде-
лением ячеек гистограммы вблизи одного из кластеров, соответст-
вующих цветовым тонам лица. Обратите внимание, что окно, ко-
торое на монохромном изображении близко по яркости к волосам,
пропадает при сегментации, потому что при использовании муль-
тиспектральных характеристик эти две области разделяются. Изо-
бражение на Рис. 10.39(b) было получено путем порогового выде-
ления кластера, расположенного вблизи оси красной компоненты.
В этом случае в результате сегментации выделяются только шарф
и часть цветка (который тоже красного цвета). При получении обо-
их результатов использовалось значение порога, равное размеру
ячейки гистограммы. Таким образом, любой пиксель, компоненты
которого не попадали в ячейку, где расположен центр интересую-
щего кластера, классифицировался как элемент фона (представлял-
ся черным цветом). Пиксели, которые по своим цветовым состав-
ляющим оказывались внутри этой ячейки, представлены белым
цветом.
Рис. 10.39. (а) Исходный цветной фотоснимок в виде монохромного изобра- а б В
жения. (б) Сегментация пикселей с цветами, близкими к цвету лица, (в) Сег-
ментация деталей красного цвета
Глава 10. Сегментация изображений
Как уже говорилось в Разделе 6.7, цветовая сегментация может
выполняться на основе любой из цветовых моделей, описанных в
Главе 6. Например, цветовой тон и насыщенность являются важными
характеристиками для многочисленных прикладных задач, в кото-
рых изображения применяются для автоматизированного контроля.
Эти характеристики оказываются особенно важными при попытках
имитировать деятельность человека, например, при контроле спело-
сти фруктов или качества промышленных товаров. Как отмечалось в
Главе 6, модель, основанная на характеристиках цветового тона, на-
сыщенности и интенсивности (HS1), идеально подходит для подобных
приложений, поскольку она тесно связана с восприятием цвета чело-
веком. Кроме того, особо привлекательным является подход, при ко-
тором сегментация осуществляется только на основании составляю-
щих цветового тона и насыщенности цветного сигнала, поскольку
это требует лишь двумерной кластеризации, что значительно проще,
чем, скажем, трехмерный анализ, необходимый для сегментации на ос-
нове RGB-компонент.
10.4. Сегментация на отдельные области
Конечной целью сегментации является разбиение изображения на об-
ласти. В Разделах 10.1 и 10.2 описывался подход к решению этой
проблемы, при котором границы между областями обнаруживаются
на основе разрывов яркости. В Разделе 10.3 сегментация осуществля-
лась с помощью пороговых преобразований, в которых значения по-
рогов определялись по распределению характеристик пикселей, та-
ких как значение яркости или цвет. В этом разделе рассматриваются
методы сегментации, основанные на непосредственном поиске самих
областей.
10.4.1. Исходная постановка
Обозначим через R область, занимаемую всем изображением. Сег-
ментацию можно рассматривать как процесс разбиения R на п подоб-
ластей Rj, таких, что
п
а) и^=Я.
7=1
б) Rj является связной областью, i = 1, 2,..., п.
в) Rj Г\ Rj = 0 для всех i, j = 1,2,..., л; i j.
г) P(Rj) = TRUE для i = 1, 2,..., л.
д) P(Rj и Rj) = FALSE для i j.
10.4. Сегментация на отдельные области
Здесь P(Rj) — некоторый логический предикат10, определенный на
точках множества Rj, а 0 — пустое множество.
Условие (а) означает, что сегментация должна быть полной, т.е. каж-
дый пиксельдолжен быть включен в какую-то область. Условие (б) тре-
бует, чтобы точки области были связными в некотором заранее задан-
ном смысле (понятие связности рассматривалось в Разделе 2.5.2).
Условие (в) показывает, что области не должны пересекаться. Условие
(г) касается свойств, которые должны соблюдаться для всех пикселей
одного сегмента, например, P(Rj) = TRUE, если все пиксели в R, име-
ют одно и то же значение яркости. Наконец, условие (д) означает,
что любые две области R, и Rj должны быть различными11 в смысле пре-
диката Р.
10.4.2. Выращивание областей
Как ясно из названия, выращивание областей представляет собой про-
цедуру, которая группирует пиксели или подобласти в более крупные
области по заранее заданным критериям. Основной подход состоит в
том, что вначале берется множество точек, играющих роль «центров
кристаллизации», а затем на них наращиваются области путем присо-
единения к каждому центру тех пикселей из числа соседей, которые
по своим свойствам близки к центру кристаллизации (например, име-
ют яркость или цвет в определенном диапазоне).
Выбор множества, состоящего из одной или более начальных то-
чек, часто может основываться на сути задачи, как будет показано в
Примере 10.16. При отсутствии априорной информации процедура со-
стоит в вычислении одного и того же набора свойств для каждого
пикселя. В конечном счете, эти свойства будут использоваться для от-
несения пикселя к той или иной области в процессе выращивания. Ес-
ли в результате вычислений обнаруживаются кластеры значений, то
пиксели, близкие по своим свойствам к центроидам таких класте-
ров, могут выбираться в качестве центров кристаллизации.
Выбор критериев сходства зависит не только от конкретной рас-
сматриваемой задачи, но и от вида имеющихся данных, из которых со-
стоит изображение. Например, задача анализа данных спутниковой
съемки земной поверхности существенно основана на использовании
1,1 То есть функция, принимающая только два значения, истинное (TRUE) и ложное
(FALSE). - Прим, перев.
11 Как правило, выполнения последнего условия требуют лишь для смежных (т.е. име-
ющих общую границу) областей. — Прим. ред. перевода.
876 Глава 10. Сегментация изображений
цвета, и она стала бы значительно труднее, вплоть до полной невоз-
можности ее решить, при отсутствии такой цветовой информации. Ес-
ли изображения монохромные, анализ областей проводится с исполь-
зованием дескрипторов, основанных на значениях яркости и
пространственных характеристиках (таких как текстура или статисти-
ческие моменты). Дескрипторы, применяемые для описания областей
изображения, обсуждаются в Главе 11.
Использование при выращивании областей одних лишь дескрип-
торов может привести к ошибочным результатам, если это делается в
отрыве от информации о смежности или связности областей. Напри-
мер, представим себе случайную схему расположения пикселей, при-
нимающих только три отличающихся значения яркости. Если строить
«области», группируя вместе пиксели с одинаковой яркостью и не
обращая внимания на их связность, то это приведет к сегментации, ли-
шенной смысла в контексте нашего обсуждения.
Другая проблема при выращивании областей состоит в том, что-
бы сформулировать правило остановки этого процесса. По идее, вы-
ращивание некоторой области следует прекратить, когда в изобра-
жении больше нет пикселей, удовлетворяющих критериям
присоединения к данной области. Такие критерии, как яркость, тек-
стура и цвет, являются по своей природе локальными и не учитывают
«историю» выращивания области. Мощность алгоритма выращивания
областей можно повысить за счет привлечения дополнительных кри-
териев, использующих, например, такие понятия, как размеры и фор-
ма выращиваемой области, а также сходство между пикселем-кан-
дидатом и пикселями, объединенными к данному моменту (скажем,
путем сравнения значений яркости нового кандидата и средней ярко-
сти уже выращенной области). Использование дескрипторов такого ти-
па основано на предположении, что имеется хотя бы грубая модель
ожидаемых результатов.
Пример 10.16: Применение метода выращивания областей при кон-
троле качества сварки.
На Рис. 10.40(a) приводится рентгеновское изображение сварного
шва (горизонтальная темная область), в котором имеются несколько
трещин и раковин (белые яркие полосы, идущие горизонтально по-
середине изображения). Мы хотим воспользоваться метолом выраши-
вания областей для сегментации участков изображения с дефектами
сварки. Эти выделенные признаки могут применяться в целях техни-
ческого контроля, включаться в базу хронологических данных, исполь-
зоваться для управления автоматическим сварочным оборудованием
и во многих других прикладных задачах.
10.4. Сегментация на отдельные области
Рис. 10.40. (а) Изображение сварного шва с дефектами, (б) Центры кристал-
лизации. (в) Результаты выращивания областей, (г) Границы дефектов, выде-
ленные при сегментации (показаны черным цветом). (Исходное изображение
предоставлено компанией Х-ТЕК Systems, Ltd.).
Первоочередной задачей является определение начальных точек для
выращивания. В данной конкретной задаче было установлено, что
пиксели в зоне дефектов сварки обычно имеют значения вблизи мак-
симально возможной яркости (в данном случае 255). Исходя из этой
информации, в качестве начальных точек выбирались все пиксели
со значениями 255. Выделенные таким способом точки исходного
изображения представлены на Рис. 10.40(6). Обратите внимание, что
многие из этих точек концентрируются вместе, образуя области кри-
сталлизации.
Следующий шаг состоит в выборе критериев выращивания обла-
стей. В данном конкретном примере были выбраны два критерия
присоединения пикселя к области: (1) Абсолютная величина разности
значений яркости добавляемых пикселей и начальной точки должны
быть меньше 65. Это число получено по гистограмме на Рис. 10.41 и
Глава 10. Сегментация изображений
Рис. 10.41. Гистограмма изображения на Рис. 10.40(a).
равно разности между значением 255 и положением ближайшей сле-
ва значительной впадины. Одновременно, эта точка отображает мак-
симальные значения яркости, достигаемые в темной области сварно-
го шва. (2) Чтобы быть включенным в какую-либо область, пиксель
должен быть 8-связанным по меньшей мере с одним пикселем из
этой области. Если обнаружено, что некоторый пиксель связан более
чем с одной областью, эти области сливаются в одну.
На Рис. 10.40(b) показаны области, полученные с помощью выше-
изложенных критериев, начиная с центров кристаллизации, которые
приведены на Рис. 10.40(6). При наложении границ этих областей на
исходное изображение (см. Рис. 10.40(г)) видно, что данная процеду-
ра выращивания областей действительно приводит к сегментации де-
фектов сварки с допустимой степенью точности. Интересно отме-
тить, что в данном случае не было необходимости указывать какие-то
правила остановки, поскольку критерии, использованные для выра-
щивания областей, оказались достаточными, чтобы изолировать об-
ласти с интересующими признаками.
При обсуждении Рис. 10.26(6) в Разделе 10.3.1 отмечалось, что за-
дачи с мультимодальными гистограммами в общем случае лучше ре-
шаются с помощью подходов, основанных на выращивании областей.
Гистограмма на Рис. 10.41 является прекрасным примером мультимо-
дальности. Эта гистограмма, а также результаты, полученные в При-
мере 10.16, подкрепляют утверждение о том, что даже в случае «хоро-
ших» гистограмм многоуровневая пороговая обработка является
сложной проблемой. По результатам этого примера интуитивно ясно.
10.4. Сегментация на отдельные области
что такую задачу невозможно эффективно решить, исходя только из
значений яркости. При решении данной задачи существенную роль иг-
рала связность.
10.4.3. Разделение и слияние областей
Описанная только что процедура выращивает области из множества
начальных точек, играющих роль центров кристаллизации. Альтерна-
тивный подход состоит в том, чтобы провести первичное разбиение
изображения на множество произвольных непересекающихся облас-
тей и в дальнейшем осуществлять слияние и/или разделение этих об-
ластей, стремясь выполнять условия, сформулированные в Разде-
ле 10.4.1. Ниже излагается итеративный алгоритм разделения —
слияния, который ориентирован на соблюдение этих ограничений.
Пусть вся область изображения обозначена R, и выбран предикат
Р. Один из подходов к сегментации R состоит в том, чтобы последо-
вательно разбивать ее на все более и более мелкие квадратные обла-
сти Rj, пока для каждой из них не будет выполняться условие
P(Rj) = TRUE. Работа начинается со всей области изображения. Ес-
ли P(R) = FALSE, изображение делится на четверти вертикальной и
горизонтальной прямыми, проходящими через середину. Если для
какой-то четверти предикат Р принимает значение FALSE, она ана-
логичным способом делится на более мелкие четверти, и так далее. Та-
кой метод разбиения удобно представлять в форме так называемого
квадродерева (т.е. дерева, у которого вершины, не являющиеся листь-
ями, имеют в точности четыре потомка), как показано на Рис. 10.42.
Отметим, что корень дерева соответствует целому изображению, а
каждая другая вершина — какой-то из подобластей. В данном случае
только область R^ подверглась дальнейшему разбиению.
Л2
«3 /?4! /?42
Л43 Я44
Рис. 10.42. (а) Изображение, разбитое на области, (б) Соответствующее ква-
дродерево.
880 Глава 10. Сегментация изображений
Если использовать только операцию разделения, то в окончатель-
ном разбиении изображения могут присутствовать соседние области
с одинаковыми свойствами. Этот недостаток можно устранить, при-
меняя наряду с разделением также операцию слияния. Для соблюде-
ния ограничений из Раздела 10.4.1 требуется, чтобы слиянию под-
вергались только соседние области, пиксели которых в совокупности
удовлетворяют предикату Р. Иначе говоря, две соседних области Rj и
Rk сливаются только в том случае, если P(Rj и R^) = TRUE.
Проведенное обсуждение можно кратко суммировать в виде про-
цедуры, на каждом шаге которой выполняются следующие действия:
1. Любая область Rj, для которой P(Rj) = FALSE, разделяется на че-
тыре не пересекающиеся четверти.
2. Любые две соседние области Rj и R^, для которых
P(Rj U Rk) = TRUE, объединяются в одну.
3. Если невозможно выполнить ни одной операции слияния или
разделения, то окончание процедуры.
Возможны различные варианты изложенной основной схемы. На-
пример, изображение вначале разбивается на множество блоков; даль-
нейшее разделение проводится как описано выше, но слияние допу-
скается только внутри группы из четырех блоков, являющихся
потомками в квадродереве и удовлетворяющих предикату Р. Когда
дальнейшее слияние такого вида оказывается невозможным, проце-
дура заканчивается однократным слиянием областей, для которых
соблюдаются условия вышеуказанного шага 2; при этом объединяе-
мые области уже могут быть различных размеров. Главное достоинст-
во такого подхода состоит в использовании одного и того же квадро-
дерева для разделения и слияния на всех шагах, кроме заключительного
шага слияния.
Пример 10.17: Разделение и слияние.
На Рис. 10.43(a) приведено простое изображение. Определим пре-
дикат Ртаким образом, что P(Rj) = TRUE, если не менее 80% пиксе-
лей в области Rj обладают свойством \zj~ т,\< 2<5h где Zj обозначает
значение яркости J-го пикселя этой области, дг, — среднюю яркость
по области, а о, — стандартное отклонение значений яркости в обла-
сти Rj. Если в результате выполнения такого условия оказывается
P(Rj) = TRUE, то значения всех пикселей области /?, устанавливают-
ся равными trij. В остальном разделение и слияние областей выполня-
ется с применением описанного ранее алгоритма. Результат примене-
ния такого метода к изображению на Рис. 10.43(a) показан на
10.5. Сегментация по морфологическим водоразделам
а б в
Рис. 10.43. (а) Исходное изображение, (б) Результат процедуры разделения и
слияния, (в) Результат пороговой обработки изображения (а).
Рис. 10.43(6). Видно, что сегментация проведена правильно. Изобра-
жение на Рис. 10.43(b) было получено путем пороговой обработки
исходного изображения со значением порога, находящимся посере-
дине между двумя главными пиками гистограммы. Видно, что в резуль-
тате порогового преобразования исчезли тени и черешок листа, что яв-
ляется ошибкой.
Использованные в предыдущем примере свойства, основанные
на среднем значении и стандартном отклонении яркости пикселей вну-
три некоторой области, представляют собой попытку количественно
охарактеризовать текстуру области (обсуждение текстуры проводит-
ся в Разделе 11.3.3). Идея сегментации по текстуре основана на исполь-
зовании количественных текстурных признаков для построения пре-
дикатов P(Rj). Иначе говоря, сегментация по текстуре может
осуществляться с помошью любого из рассмотренных в этом разделе
методов, если предикаты основаны на характеристиках текстуры.
10.5. Сегментация по морфологическим
водоразделам
До сих пор обсуждались способы сегментации, основанные на трех
главных подходах: (а) обнаружении разрывов, (б) пороговой обра-
ботке и (в) обработке областей. Каждый из этих подходов обнаружил
свои достоинства (например, скорость в случае глобального порого-
вого преобразования) и недостатки (в частности, необходимость по-
следующей обработки, например, связывания контуров для методов,
основанных на обнаружении разрывов яркости). В этом разделе будет
рассмотрен подход, основанный на идее так называемых морфологи-
ческих водоразделов. Как станет ясно из дальнейшего обсуждения, сег-
ментация по водоразделам заключает в себе многие концепции из
трех рассмотренных подходов и часто приводит к получению более ста-
882 Глава 10. Сегментация изображений
бильных результатов сегментации, в том числе к непрерывным грани-
цам выделяемых областей. Этот подход также предоставляет простую
схему, позволяющую включать в процесс сегментации добавочные
ограничения, берущиеся из базы знаний (см. Рис. 1.23).
10.5.1. Основные концепции
Понятие водораздела основано на представлении изображения как
трехмерной поверхности, заданной двумя пространственными коор-
динатами и уровнем яркости в качестве высоты поверхности (релье-
фа). В такой «топографической» интерпретации рассматриваются
точки12 трех видов: (а) точки локального минимума; (б) точки, нахо-
дящиеся на склоне, т.е. с которых вода скатывается в один и тот же ло-
кальный минимум; и (в) точки, находящиеся на гребне или пике, т.е.
с которых вода с равной вероятностью скатывается более чем в один
такой минимум. Применительно к конкретному локальному миниму-
му, набор точек, удовлетворяющих условию (б), называется бассейном
(или водосбором) этого минимума. Множества точек, удовлетворяю-
щих условию (в), образуют линии гребней на поверхности рельефа и
называются линиями водораздела.
Главная цель алгоритмов сегментации, основанных на введенных
понятиях, состоит в нахождении линий водораздела. Основная идея
метода выглядит просто. Предположим, что в каждом локальном ми-
нимуме проколото отверстие, после чего весь рельеф заполняется во-
дой, равномерно поступающей снизу через эти отверстия, так что
уровень воды всюду одинаков. Когда поднимающаяся вода в двух со-
седних бассейнах близка к тому, чтобы слиться вместе, в этом месте ста-
вится перегородка, препятствующая слиянию. В конце концов за-
полнение достигает фазы, когда над водой остаются видны только
верхушки перегородок. Эти перегородки, соответствующие линиям во-
доразделов, и образуют непрерывные границы, выделенные с помо-
щью алгоритма сегментации по водоразделам.
Дальнейшее объяснение изложенной идеи дается с помощью
Рис. 10.44. На Рис. 10.44(a) показано простое полутоновое изображе-
ние, представленное в виде рельефа на Рис. 10.44(6), где высота «гор»
12 Вообще говоря, следует различать точки трехмерной поверхности и точки коорди-
натной плоскости ху. Но поскольку между ними имеется взаимно однозначное со-
ответствие, а также в силу того, что из контекста всегда ясно, о чем идет речь, в обо-
их случаях будет использоваться просто термин точка. Аналогично, построенная
трехмерная поверхность также будет называться изображением. — Прим, перев.
10.5. Сегментация по морфологическим водоразделам
Рис. 10.44. (а) Исходное изображение, (б) Рельефное представление. (в)~
(г) Две стадии заполнения.
пропорциональна значениям яркости в точках исходного изображения.
Для наглядности на скатах нанесены тени, которые не следует путать
со значениями яркости; интерес представляет лишь объемное представ-
ление обшего рельефа. Во избежание выливания воды за пределы кра-
ев всей конструкции, вообразим, что все изображение по периметру об-
несено перегородкой, по высоте превышающей самую высокую гору,
т.е. максимально возможный уровень яркости изображения.
Предположим, что в каждом локальном минимуме (которые по-
казаны темными областями на Рис. 10.44(6)) проколото отверстие, по-
сле чего весь рельеф постепенно заполняется водой снизу через эти от-
верстия. На Рис. 10.44(b) показан первый этап такого заполнения,
когда «вола», показанная серым цветом, закрыла только области, со-
ответствующие наиболее темному фону изображения. На Рис. 10.44(г)
Глава 10. Сегментация изображений
Рис. 10.44(продолжение). (д) Результат дальнейшего заполнения, (е) Начало
слияния двух бассейнов (между ними строится короткая перегородка), (ж) Пе-
регородки большей длины, (з) Окончательные линии водоразделов (резуль-
тат сегментации). (Изображения предоставлены д-ром С. Бёше, СММ/Есо1е
des Mines de Paris).
и (д) видно, что теперь вода поднялась и начала заполнять, соответ-
ственно, левый и правый внутренние бассейны. По мере дальнейше-
го подъема воды в какой-то момент эти два бассейна должны будут
слиться; первые признаки этого показаны на Рис. 10.44(e) Здесь, во
избежание слияния правого и левого внутренних бассейнов при по-
вышении уровня воды, строится короткая перегородка, состоящая
из одиночных пикселей (построение перегородок подробно рассма-
тривается в следующем разделе). Это явление становится более выра-
женным по мере того, как вода продолжает подниматься, что демон-
стрирует Рис. 10.44(ж). На этом рисунке видна более длинная
10.5. Сегментация по морфологическим водоразделам
перегородка между бассейнами, а также еще одна перегородка в пра-
вой верхней части правого бассейна. Последняя была построена, что-
бы предотвратить слияние этого бассейна с областью, соответствую-
щей фону. Этот процесс продолжается до тех пор, пока уровень
заполнения водой не достигнет того, который соответствует максималь-
ной яркости в исходном изображении. Заключительный набор пере-
городок соответствует линиям водораздела, которые и представляют
собой искомый результат сегментации. Для рассматриваемого приме-
ра этот результат показан на Рис. 10.44(з) темной линией шириной в
один пиксель, наложенной на исходное изображение. Отметим то
важное свойство, что линии водоразделов образуют связный путь,
тем самым определяя непрерывные границы между областями.
Одним из важнейших применений сегментации по водоразделам
является выделение на фоне изображения однородных по яркости
объектов (в виде пятен). Области, характеризующиеся малыми вари-
ациями яркости, имеют малые значения градиента. Поэтому на прак-
тике часто встречается ситуация, когда метод сегментации по водораз-
делам применяется не к самому изображению, а к градиенту этого
изображения. В такой постановке локальные минимумы бассейнов хо-
рошо согласуются с малыми значениями градиента, что обычно соот-
ветствует интересующим объектам.
10.5.2. Построение перегородок
Перед тем, как двигаться дальше, рассмотрим способ построения перего-
родок вдоль линий водоразделов, требуемый для описанного алгоритма
сегментации. Построение перегородок основано на двоичных изобра-
жениях, которые являются подмножествами двумерного целочисленно-
го пространстваZ2 (см. Раздел 2.4.2). Простейший способ построения ли-
ний раздела для множеств, образованных двоичными точками, состоите
использовании морфологической дилатации (см. Раздел 9.2.1).
Начальные сведения о построении перегородок с помощью дила-
тации иллюстрирует Рис. 10.45. На Рис. 10.45(a) показаны участки
двух бассейнов на (л— 1)-ом шаге заполнения, а на Рис. 10.45(6) те же
участки на следующем, л-ом шаге. Происходит слияние этих двух
бассейнов, и, следовательно, должна быть построена перегородка,
препятствующая данному событию. Для согласования с системой
обозначений, которая будет принята далее, обозначим через Л/] и
множества точек, соответствующие локальным минимумам двух рас-
сматриваемых бассейнов. Через )(Л7|) и обозначим мно-
жества точек, покрытых водой в этих бассейнах на (л— 1 )-ом шаге за-
полнения. Эти два множества показаны черным цветом на Рис. 10.45(a).
Глава 10. Сегментация изображений
«♦
а
б
в
г
И Точки перегородки
Рис. 10.45. (а) Два частично заполненных бассейна на (и -1)-ом шаге запол-
нения. (б) д-ый шаг заполнения, при котором два бассейна сливаются вмес
те (для наглядности залитая водой область показана белым цветом, а не чер-
ным). (в) Примитив, используемый в операции дилатации, (г) Результаты
дилатации и построения перегородки.
10.5. Сегментация по морфологическим водоразделам
Пусть С[п— 1] — объединение двух последних множеств. На
Рис. 10.45(a) имеется две компоненты связности (о связности компо-
нент см. Раздел 2.5.2), а на Рис. 10.45(6) — только одна, охватывающая
две прежние компоненты связности (обозначены пунктирными лини-
ями). Тот факт, что две компоненты связности превратились в одну, ука-
зывает, что на л-ом шаге заполнения произошло слияние двух бассей-
нов в один. Обозначим через q образовавшуюся единую связную
компоненту. Заметим, что две компоненты, имевшиеся на шаге л—1,
можно выделить из множества q одной операцией И: q П С[л—1]. От-
метим также, что все точки, соответствующие отдельному бассейну, об-
разуют одну компоненту связности.
Допустим, к каждой компоненте связности на Рис. 10.45(a) при-
меняется операция дилатации по примитиву, показанному на
Рис. 10.45(b), с соблюдением двух условий: (1) применение дилатации
должно ограничиваться множеством q (это значит, что центр прими-
тива может располагаться только в точках q)\ и (2) дилатация не долж-
на выполняться в тех точках, где это приведет к слиянию обрабатыва-
емых множеств, так что они станут единой связной компонентой. Из
Рис. 10.45(г) видно, что при первом проходе дилатации границы каж-
дой из исходных компонент связности расширяются (показано свет-
ло-серым цветом). Заметим, что входе дилатации условие (1) соблю-
далось для всех точек, а условие (2) не применялось ни разу, так что
границы обеих областей раздвигались равномерно.
При втором проходе дилатации (показанном темно-серым цветом)
для некоторых точек соблюдалось условие (2), но нарушалось условие
(1), что привело к разрывности множества точек, добавляемых по пе-
риметру, как это видно из рисунка. Очевидно также, что единствен-
ными точками множества q, для которых выполнено условие (1) и не
выполнено условие (2), являются точки (перечеркнутые крест-на-
крест на Рис. 10.45(г)), образующие связную линию толщиной в один
пиксель. Эта линия и составляет искомую разделяющую перегород-
ку на л-ом шаге подъема уровня воды. Построение перегородки на этом
шаге завершается тем, что всем точкам найденной линии присваива-
ется значение яркости, превышающее максимальное в изображении.
Обычно высота всех перегородок принимается равной максимально
возможному уровню яркости, плюс единица. Это предотвращает воз-
можность слияния бассейнов поверх построенной перегородки в бу-
дущем, по мере дальнейшего подъема воды. Важно отметить, что пе-
регородки, построенные с применением данной процедуры и
являющиеся искомыми границами сегментации, представляют со-
бой связные компоненты. Иначе говоря, данный метод исключает
проблемы, связанные с появлением разрывов в линиях сегментации.
Глава 10. Сегментация изображений
Хотя приведенное описание процедуры основывается на простом
примере, точно такой же метод используется и в более сложных слу-
чаях; при этом используется тот же симметричный примитив разме-
рами 3x3, показанный на Рис. 10.45(b).
10.5.3. Алгоритм сегментации по водоразделам
Пусть Л/|, Л/2,..., — множества точек координатной плоскости,
соответствующие локальным минимумам поверхности g(x, у); как
указывалось в конце Раздела 10.5.1,g(x,у) обычно является градиент-
ным изображением. Обозначим через С(Л/() множество точек бассей-
на, отвечающего локальному минимуму М,- (напомним, что точки лю-
бого бассейна образуют компоненту связности). Обозначения min и
max будем использовать для указания наименьшего и наибольшего зна-
чений изображения g(x, у). Наконец, запись Т [и] означает множест-
во точек (s, t), для которых g(s, t) < п, т.е.
r[>] = {(V)|g(v)<4. (Ю.5-1)
С геометрической точки зрения, Т [и] есть множество точек, в кото-
рых поверхностьg(x, у) лежит ниже плоскости g(x, у) = п.
При заполнении рельефа водой уровень поднимается в виде цело-
численных дискретных приращений от п = min + 1 до п = max + 1. В про-
цессе подъема воды на любом шаге п алгоритму необходимо знать
число точек, лежащих ниже уровня воды. Вообразим, что все точки
множества Т\п\ (т.е. которые лежат ниже плоскости g{x, у) = п) отме-
чены черным цветом, а все остальные — белым. Тогда при произ-
вольном (л-ом) шаге подъема уровня воды, рассматриваемая трех-
мерная поверхность в проекции на плоскость ху может быть
представлена двоичным изображением, в котором черные точки со-
ответствуют точкам исходной функции, лежащим ниже плоскости
g(x,y) = п. Такая интерпретация весьма полезна для понимания после-
дующего изложения.
Пусть С„(Л/() обозначает множество точек бассейна с локальным
минимумом Mh которые оказались залитыми водой на шаге п. С уче-
том вышесказанного, Cn(Mf) можно рассматривать как двоичное изо-
бражение, задаваемое соотношением
С„(М,.)=С(Л/,)ПТ[л]. (10.5-2)
Другими словами, С„(Л/,) = 1 в тех точках (х, у), для которых одновре-
менно выполняется (х, у) е С(Л/,) и (х, у) е Т [л]; в остальных точках
10.5. Сегментация по морфологическим водоразделам
изображения = 0. Геометрическая интерпретация выражения в
правой части (10.5-2) понятна: с помошью операции пересечения на
л-ом шаге подъема уровня воды мы выделяем ту часть двоичного изо-
бражения Г|л], которая относится к локальному минимуму М,.
Пусть теперь С[л] — объединение залитых водой частей всех бас-
сейнов на шаге л:
R
СН=иСи(Ч)- (10.5-3)
/=1
Тогда C[max+1 ] есть объединение всех имеющихся бассейнов:
R
C[max + 1]=(JC(A/,). (10.5-4)
7=1
Можно показать (Задача 10.29), что при работе алгоритма никогда не
происходит удаления элементов из множеств C„(A/Z) и Т[л]; таким об-
разом, при увеличении п число элементов этих множеств либо возра-
стает, либо остается неизменным. Следовательно, С[п— 1] является
подмножеством С[л]. Согласно равенствам (10.5-2) и (10.5-3), С[л]
также является подмножеством Т[п], а значит, С[п—1] также есть под-
множество Т[л]. Отсюда следует важный результат: каждая компонен-
та связности множества С[л— 1 ] содержится ровно в одной связной ком-
поненте множества Т [л].
Алгоритм нахождения линий водораздела начинается с инициали-
зации C[min+1] = T[min+1]. После этого алгоритм выполняется ре-
куррентно, предполагая на л-ом шаге множество С [л—1] уже постро-
енным. Для получения множества С[л] из множества С[л-1 ]
применяется следующая процедура. Пусть Q[n] — множество компо-
нент связности множества Т [л]. Тогда для каждой связной компонен-
ты q е Q[n\ есть три возможности:
a) q Г) С[п— 1 ] — пустое множество;
б) q Г) С[л—1] содержит единственную компоненту связности множе-
ства С[л— 1];
в) q П С[л— 1] содержит более одной компоненты связности множества
С[л—1].
Способ построения С[л] по С[л—1] зависит от того, какое из этих трех
условий имеет место. Условие (а) означает, что встретился новый ло-
кальный минимум (начинается наполнение нового бассейна); в этом
случае для построения множества С[л] компонента q добавляется к
С[л— 1 ]. Условие (б) имеет место, когда q лежит внутри бассейна неко-
торого локального минимума; в этом случае для построения множе-
Глава 10. Сегментация изображений
ства С\п] компонента q также добавляется к С[л— 1 ]. Условие (в) возни-
кает, когда встретились точки гребня, разделяющего два или более бас-
сейна. В этом случае дальнейший подъем воды привел бы к слиянию этих
бассейнов, поэтому внутри связной компоненты q должна быть пост-
роена перегородка (или перегородки, если объединяется более двух
бассейнов), не позволяющая бассейнам слиться вместе. Как объясня-
лось в предыдущем разделе, перегородку толщиной в один пиксель
при необходимости можно построить, применяя к множеству q Г1, С[л— 1 ]
операцию дилатации по примитиву 3x3, заполненному единицами, и
затем ограничивая результат дилатации точками множества q.
Эффективность описанного алгоритма можно повысить, исполь-
зуя только те значения п, которые соответствуют уровням яркости,
встречающимся в изображенииg(x, у); эти значения, как и величины
min и max, можно определить по гистограмме изображения g(x, у).
Рис. 10.46. (а) Изображение пятен, (б) Градиент исходного изображения,
(в) Линии водоразделов, наложенные на градиентное изображение, (г) Линии
водоразделов, наложенные на исходное изображение. (Изображения предо-
ставлены д-ром С. Бёше, CMM/Ecole des Mines de Paris).
10.5. Сегментация по морфологическим водоразделам
Пример 10.18: Иллюстрация работы алгоритма сегментации по во-
доразделам.
Рассмотрим представленные на Рис. 10.46(a) и (б) исходное изоб-
ражение и его градиент. Применение описанного алгоритма к гради-
ентному изображению дает в результате линии водораздела, показан-
ные на Рис. 10.46(b) белым цветом поверх изображения градиента. На
Рис. 10.46(г) те же границы сегментов наложены на исходное изобра-
жение. Как отмечалось в начале этого раздела, получаемые при таком
методе сегментации границы областей обладают важным свойством:
они образуют связные линии.
10.5.4. Использование маркеров
Непосредственное применение алгоритма сегментации по водоразде-
лам в том виде, как описывалось в предыдущем разделе, обычно при-
водит к избыточной сегментации, вызванной шумом и другими локаль-
ными неровностями на градиентном изображении. Как видно из
Рис. 10.47, избыточная сегментация может быть настолько значи-
тельной, что сделает результат практически бесполезным. В данном
случае это означает огромное число областей, выделенных при сегмен-
тации. Практическое решение этой проблемы состоит в том, чтобы ог-
раничить допустимое число областей путем включения в состав про-
цедуры шага предварительной обработки, служащего для привнесения
добавочных знаний в процедуру сегментации.
Рис. 10.47. (а) Исходное изображение, (б) Результат применения алгоритма сег-
ментации по водоразделам к градиентному изображению, на котором хоро-
шо видна избыточная сегментация. (Изображения предоставлены д-ром С. Бё-
ше, CMM/Ecole des Mines de Paris).
Глава 10. Сегментация изображений
Подход, применяемый для управления избыточной сегментацией,
основан на идее маркеров. Маркер представляет собой связную ком-
поненту, принадлежащую изображению. Будем различать внутрен-
ние маркеры, относящиеся к интересующим объектам, и внешние мар-
керы, соответствующие фону. Процедура выбора маркера обычно
состоит из двух главных шагов: (1) предобработка, и (2) выработка кри-
териев, которым должны удовлетворять маркеры. Для иллюстрации
снова обратимся к изображению на Рис. 10.47(a). Одной из причин,
которые привели к результату с избыточной сегментацией, показан-
ному на Рис. 10.47(6), является наличие большого числа локальных ми-
нимумов. Принимая во внимание размеры соответствующих бассей-
нов, многие из этих минимумов в действительности отражают
несущественные детали. Как многократно указывалось ранее, эф-
фективным способом снижения влияния, которое оказывают мел-
кие пространственные детали изображения, является фильтрация
изображения с помощью сглаживающего фильтра. Такая схема пред-
варительной обработки пригодна и для данного случая.
Пусть внутренний маркер в данном случае определяется как об-
ласть, (1) окруженная точками с большей «высотой»; (2) такая, что ее
точки образуют компоненту связности; и (3) все точки которой име-
ют одинаковые значения яркости. Внутренние маркеры, найденные
на сглаженном изображении согласно такому определению, показа-
ны на Рис. 10.48 в виде светло-серых пятен. Затем к сглаженному изо-
бражению применяется вышеописанный алгоритм сегментации по во-
Рис. 10.48. (а) Сглаженное изображение с показанными внутренними (светло-
серые области) и внешними (линии водоразделов) маркерами. (6) Результаты
сегментации, на которых видно улучшение по сравнению с Рис. 10.47(6). (Изо-
бражения предоставлены д-ром С. Бёше, CMM/Ecole des Mines de Paris).
доразделам, с тем ограничением, что в качестве локальных миниму-
мов рассматриваются только внутренние маркеры. Рис. 10.48(a) демон-
стрирует полученные в результате линии водоразделов, которые по оп-
ределению являются внешними маркерами. Заметим, что точки вдоль
этих водоразделов являются хорошими кандидатами на роль фоновых,
поскольку проходят по самым высоким местам между соседними мар-
керами.
Внешние маркеры, показанные на Рис. 10.48(a), эффективно раз-
граничивают изображение на области, каждая из которых содержит
единственный внутренний маркер и часть фоновой области. После это-
го задача сводится к разделению каждой такой области на две: одиноч-
ный объект и окружающий его фон. Для решения этой упрощенной
задачи можно использовать многие методы сегментации, ранее рас-
смотренные в данной главе. В частности, можно просто применить тот
же алгоритм сегментации по водоразделам к каждой отдельной обла-
сти. Иначе говоря, получив градиент по всему сглаженному изобра-
жению (как на Рис. 10.46(6), мы затем ограничиваем применение ал-
горитма границами только одного «водосбора», внутри которого
находится маркер данной конкретной области. Полученные с приме-
нением такого подхода результаты приведены на Рис. 10.48(6). Улуч-
шение по сравнению с Рис. 10.47(6) очевидно.
Способ выбора маркеров может меняться от простейших процедур,
основанных на связности и значениях яркости, как было только что
продемонстрировано, до более сложных описаний, в которых участ-
вуют размеры, форма, местоположение, относительные расстояния,
текстурные признаки и т.д. (дескрипторы, применяемые для описания,
рассматриваются в Главе 11). Суть состоит в том, что применение
маркеров позволяет учесть априорные знания, имеющие отношение
к задаче сегментации. Напомним читателю, что в сегментации, как и
в еще более сложных задачах, повседневно решаемых человеческим
зрением, часто полезными являются априорные знания, среди кото-
рых одно из самых известных — это конкретные знания о задаче. Тот
факт, что метод сегментации по водоразделам предлагает каркас, в ко-
тором можно эффективно применять знания такого типа, является
важным достоинством этого метода.
10.6. Использование движения при сегментации
Движение — это мощный ключ, которым пользуются люди и мно-
гие животные для выделения интересующих объектов на фоне не-
существенных деталей. В прикладных задачах обработки изобра-
жений’движение возникает при относительном перемещении
Глава 10. Сегментация изображений
сенсорной системы и наблюдаемой сцены, например, в робототех-
нике, автономных навигационных системах, при анализе динами-
ческих сцен и др. В последующих разделах рассматривается ис-
пользование движения при сегментации, как в пространственной,
так и в частотной области.
10.6.1. Пространственные методы
Основной подход
Один из простейших подходов к обнаружению изменений в последо-
вательности изображений, произошедших между двумя кадрами
/(х, у, tj) и/(х, у, tj), полученными в моменты времени t, и tj соответст-
венно, состоит в поэлементном сравнении этих двух изображений.
Один из способов такого сравнения — построение разностного изо-
бражения. Предположим, что имеется опорное изображение, содер-
жащее только неподвижные компоненты. Сравнение этого изображе-
ния с последующим изображением той же сцены, но содержащим
движущийся объект, приведет к тому, что в разности двух изображе-
ний неподвижные составляющие взаимно уничтожатся, а ненулевые
значения останутся только в местах, соответствующих подвижным
компонентам изображений.
Разностное изображение между двумя изображениями, взятыми в
моменты времени и tj, можно определить следующим образом:
dij(x,y) = -
1, если \f(x,y,tj)-f(x,y,tj)\>T
0 в противном случае,
(10.6-1)
где Т — заданный порог. Заметим, что djj(x, у) принимает значение
1 в точке с пространственными координатами (х, у) только в том слу-
чае, если значения яркости в этой точке на двух изображениях от-
личаются достаточно существенно, что определяется заданным по-
рогом Т. Предполагается, что все изображения имеют одинаковые
размеры, поэтому диапазон координат (х, у) в (10.6-1) совпадает с
размерами исходных изображений, так что любое разностное изо-
бражение djj(x, у) имеет те же размеры, что и изображения в после-
довательности.
При обработке динамических изображений все единичные пиксе-
ли изображения djj(x, у) считаются результатом движения объекта. Та-
кой подход применим только в том случае, если оба изображения яв-
ляются пространственно совмещенными, а также, если флуктуации
яркости не выходят за границы, задаваемые порогом Т. На практике
10.6. Использование движения при сегментации 895Д
ненулевые элементы разности dt j (х, у) часто являются следствием
шума. Обычно такие элементы образуют небольшие изолированные
группы точек в разностном изображении; простой способ их удаления
состоит в том, что в изображении djj(x, у) находятся 4- или 8-связан-
ные области из единичных элементов, и области, содержащие мень-
ше заранее заданного числа элементов, удаляются. Хотя это и может
привести к пропуску малых и/или медленно движущихся объектов,
данный подход повышает шансы того, что оставшиеся ненулевые
элементы разностного изображения действительно возникли в ре-
зультате движения.
Накопленные разности
Возникновение в разностном изображении изолированных групп то-
чек, являюшихся следствием шума, представляет серьезное препятст-
вие выделению движущихся компонент из последовательности изо-
бражений. Хотя количество ложных составляющих удается уменьшить
с помощью порогового анализа связности, при такой фильтрации
также исчезают мелкие или медленно движущиеся объекты, как отме-
чалось выше. Один из способов решить такую проблему — это рассма-
тривать изменения каждого пикселя на протяжении нескольких кад-
ров, тем самым вводя в процесс обработки некоторую «память». Идея
состоит в том, чтобы игнорировать изменения, встречающиеся в по-
следовательности кадров лишь изредка, и которые поэтому могут
быть отнесены к случайному шуму.
Рассмотрим последовательность кадров изображения Дх, у, /|),
Дх,у, fix,у, tn) и пусть/(х,у, г() — опорное изображение. Накоп-
ленное разностное изображение (НРИ) формируется путем сравнения
опорного изображения с каждым следующим кадром последователь-
ности. Для каждого пикселя в накопленном разностном изображении
ведется счетчик, значение которого увеличивается всякий раз, когда
в этой точке наблюдается отличие кадра последовательности от опор-
ного изображения. Таким образом, при сравнении k-ro кадра с опор-
ным значение каждого пикселя накопленного изображения указыва-
ет число раз, когда яркость в этой точке отличалась от значения
соответствующего пикселя в опорном изображении. Отличие устанав-
ливается, например, согласно (10.6-1).
Часто оказывается полезным рассматривать три вида накопленных
разностных изображений: абсолютные, положительные и отрицатель-
ные НРИ. Эти виды НРИ определяются следующим образом. Обозна-
чим опорное изображение R(x, у) и, пусть к для простоты обозначает
момент времени t^, т.е. Дх, у, к) = ftx, у, tk); полагаем также, что
R(x, У) у, 1). Тогда для любого к > 1 значения элементов (кото-
Глава 10. Сегментация изображений
рые суть счетчики) НРИ упомянутых видов определяются в каждой точ-
ке (х, у) следующим образом:
4_Дх,у) + 1, если |/?(х,у)-/(х,уЛ)|>7'
А-1 (х> >’) в противном случае,
^-1(х,У)+1,
^(*,У) =
если (R(x,y)-f(x,y,k))> Т
в противном случае
и
(10.6-3)
Nk(x,y) = <
Л^_,(х,у)+1,
Nk_}(x,y)
если (R(x,y)-f(x,y,k))<-T
в противном случае,
(10.6-4)
где Ак(х, у), Рк(х, у) и Nk(x, у) обозначают, соответственно, абсолют-
ное, положительное и отрицательное Н РИ после обработки к изобра-
жений последовательности.
Начальные значения всех счетчиков берутся равными нулю. Заме-
тим также, что все НРИ имеют те же размеры, что и изображения по-
следовательности (как уже говорилось, последовательность состоит из
кадров с одинаковыми размерами).
Пример 10.19: Формирование абсолютного, положительного и от-
рицательного накопленных разностных изображений.
На Рис. 10.49 в виде яркостных изображений показаны НРИ трех ука-
занных видов ддя прямоугольного объекта размерами 75x50 пикселей,
который движется в направлении правого нижнего угла изображения
со скоростью 5л/2 пикселей за кадр. Размеры всех изображений со-
ставляют 256x256 пикселей. Для данного случая, когда яркость объ-
екта больше яркости фона, заметим следующее: (1) размеры области
ненулевых элементов положительного НРИ равны размерам движу-
щегося объекта; (2) положение этой области на положительном НРИ
совпадает с положением объекта в опорном кадре; (3) число ненуле-
вых точек в положительном НРИ перестает возрастать, когда объект
полностью сдвигается за пределы области, которую он занимал в
опорном кадре; (4) абсолютное НРИ состоит из объединения облас-
тей положительного и отрицательного НРИ; (5) направление и ско-
рость движения объекта можно определить по ненулевым областям в
абсолютном и отрицательном НРИ. Для обратного случая, когда яр-
кость объекта меньше яркости фона, эти утверждения справедливы при
замене слов «положительное НРИ» на «отрицательное НРИ».
Рис. 10.49. Накопленные разностные изображения прямоугольного объекта,
перемещающегося в направлении правого нижнего угла, (а) Абсолютное
НРИ. (б) Положительное НРИ. (в) Отрицательное НРИ.
Построение опорного изображения
Ключом к успеху тех методов, которые рассматривались в двух
последних разделах, является наличие опорного изображения, с ко-
торым производятся дальнейшие сравнения. Как отмечалось, для раз-
ности между двумя кадрами в последовательности динамических изо-
бражений характерно подавление всех неподвижных составляющих,
в результате чего остаются лишь те элементы изображения, которые
соответствуют движущимся объектам и шуму. Влияние шума можно
ослабить с помошью методов фильтрации, обсуждавшихся ранее, или
путем формирования накопленного разностного изображения, как
описано в предыдущем разделе.
На практике не всегда можно получить опорное изображение, состо-
ящее только из неподвижных элементов, и его приходится строить на ос-
новании набора изображений, содержащих один или более движущих-
ся объектов. В частности, такая потребность возникает в ситуациях,
относящихся к производственным сценам или к условиям, когда необ-
ходимо частое обновление. Опишем одну из возможных процедур пост-
роения опорного изображения. Вначале берем в качестве опорного пер-
вое изображение последовательности. Когда некоторая подвижная
составляющая целиком сдвинется за пределы своего положения в этом
опорном кадре, соответствующая фоновая область текущего кадра может
быть скопирована в то место опорного изображения, которое занимал дви-
жущийся объект. После того, как все движущиеся объекты полностью ос-
вободят свои первоначальные места, с помощью такой процедуры будет
построено опорное изображение, в котором присутствуют только непо-
движные компоненты. Как указывалось в предыдущем разделе, смеше-
ние объекта устанавливается путем наблюдения за изменениями в поло-
жительном НРИ для тех объектов, яркость которых выше фона, и в
отрицательном НРИ для объектов, яркость которых ниже фона.
30 Л223
Глава 10. Сегментация изображений
Пример 10.20: Построение опорного изображения.
На Рис. 10.50(a) и (б) приведены два изображения перекрестка с ин-
тенсивным движением. Первое изображение рассматривается как
опорное, а второе представляет ту же сцену спустя некоторое время.
Цель состоит в том, чтобы убрать из опорного изображения крупные
движущиеся объекты, создав тем самым статичное изображение. Хо-
тя в изображении присутствуют и другие, более мелкие движущиеся
объекты, главная динамическая составляющая — это автомобиль,
проезжающий через перекресток слева направо. Для наглядности ос-
тановимся на этом объекте. Наблюдая за изменениями в положи-
тельном и отрицательном НРИ, можно определить начальное поло-
жение движущегося объекта, как объяснялось ранее. После того, как
выявлена область, первоначально занимаемая этим объектом, его
можно удалить из изображения. Из кадра последовательности, на ко-
тором положительное или отрицательное НРИ перестало меняться,
можно скопировать область, ранее занятую объектом, в то же место
опорного изображения. Тем самым фон изображения в этом месте
будет восстановлен. Если проделать то же самое для всех движущих-
ся объектов, то в результате получим опорное изображение, состоящее
только из статичных компонент; с ним и будем сравнивать последу-
ющие кадры для выявления движения, как это разъяснялось в двух пре-
дыдущих разделах. Результат удаления автомобиля, движущегося впра-
во, демонстрируется на Рис. 10.50(b).
10.6.2. Частотные методы
В этом разделе мы рассмотрим задачу нахождения оценок движения
на основе преобразования Фурье. Рассмотрим последовательность
f(x,y, f), t = 0,1,..., К— 1, состоящую из А'цифровых изображений раз-
мерами MxN, полученных неподвижной камерой. При изложении
Рис. 10.50. Построение статичного опорного изображения, (а) — (б) Два кад-
ра из последовательности, (в) Движущийся вправо автомобиль убран из кад-
ра (а) путем восстановления фона из соответствующей области изображения
(б). [Jain, Jain].
10.6. Использование движения при сегментации
метода сначала будем предполагать, что все кадры имеют равномер-
ный фон с нулевой яркостью, а объект представлен одиночным пик-
селем единичной яркости, движущимся с постоянной скоростью.
Спроецируем плоскость изображения первого кадра (Г = 0) на осьх, что
эквивалентно суммированию яркостей пикселей по строкам. В резуль-
тате такой операции получим одномерный массив из Мзначений, из
которых все равны нулю, кроме того, на которое проецируется объект.
Умножая все элементы массива на ехр(/2ла|хА0, х =0, 1,2,..., М— 1, и
складывая результаты, получим сумму, равную ехр(/2ла|Х'Дг), где
(х', /) — координаты объекта в данный момент времени, — поло-
жительное целое число, а А/ — промежуток времени между соседни-
ми кадрами.
Предположим, что во втором кадре (t = 1) объект передвинулся в
точку с координатами (х'+1, у'), т.е. на один пиксель вдоль оси х. По-
вторяя ту же процедуру проецирования, получим сумму, равную
ехр[/2ла|(х'+1)Дг]. Если объект продолжает двигаться в том же на-
правлении и с той же скоростью 1 пиксель за кадр, то в любой цело-
численный момент времени результат будет равен exp|z2ra7j(x'+r)Af],
что по формуле Эйлера можно выразить в виде
e'lTOjU+OAz =СО8[2ла1(х,+ 0Дг]+/ втртгоДх'+ОДг] (10.6-5)
ддя г = 0, 1,..., К— 1. Другими словами, описанная процедура дает в ре-
зультате комплексную синусоиду с частотой а(. Если за время между
кадрами объект сдвигается вдоль оси х на vj пикселей, то синусоида
будет иметь частоту У|а ,. Поскольку t меняется с целым шагом от 0 до
К—1, то, ограничивая а\ только целочисленными значениями, полу-
чим комплексную синусоиду, дискретное преобразование Фурье ко-
торой будет иметь два пика: один на частоте V|Oj, а другой на частоте
К— V|O|. Последний появляется вследствие симметрии ДПФ, о чем го-
ворилось в Разделе 4.6, и может не приниматься во внимание. Итак,
в спектре Фурье имеется пик на частоте У|О|. Таким образом, при де-
лении этой частоты на О| получим у,, т.е. составляющую скорости по
оси х в пикселях на кадр (частота кадров предполагается известной).
Аналогичными рассуждениями можно получить значение у2 — со-
ставляющую скорости движения объекта вдоль оси у.
Если в последовательности изображений не происходит никако-
го движения, то всем кадрам соответствуют одинаковые экспоненци-
альные члены временной последовательности, фурье-преобразова-
ние которой будет состоять из одиночного пика при частоте 0 (т.е.
только члена с постоянной составляющей). Поскольку все до сих пор
рассмотренные операции являются линейными, то в общем случае,
Глава 10. Сегментация изображений
когда имеется один или более объектов любой формы, движущихся от-
носительно произвольного неподвижного фона, в результате фурье-
преобразования получим пик в нуле, отвечающий статическим ком-
понентам изображения, и пики в точках, координаты которых
пропорциональны скоростям движения объектов.
Эти идеи в сжатом виде можно изложить следующим образом.
Для последовательности из К цифровых изображений размерами Mx.N
взвешенная сумма проекций на ось х в любой целочисленный мо-
мент времени равна
Л/-17V-1
gx(f,<2])= У, X /(х,у,Г)е'27М1хЛ/ /=0,1,...,А'-1. (10.6-6)
х=0 >=()
Аналогично, сумма проекций на ось у равна
ЛЧМ-1
gy(f,fl2)=XX/^)e/2^ t-0,l,...,K-1, (Ю.6-7)
>=() х=0
где, как уже отмечалось, а, и а2 ~ положительные целые числа. При-
меняя одномерное преобразование Фурье к функциям (10.6-6) и
(10.6-7), соответственно получаем:
1 А-1
Gx(ux,ai) = —^igx(t,al)e~'2jzuil/K ut = 0,1,..., К-1 (10.6-8)
К г=0
и
i К-1
Су(и2,а2) = -^^2)е-12^/к д2 = 0,1,...,^-1. (10.6-9)
А t=0
На практике для вычисления этих преобразований используется ал-
горитм БПФ, как описано в Разделе 4.6.
Связь между частотой и скоростью устанавливается следующими
соотношениями:
^1=0]^ (10.6-10)
и
и2 -a2v2 .
(10.6-11)
10.6. Использование движения при сегментации
В этих формулах скорость измеряется в единицах пикселей за время
всей последовательности. Например, значение = 10 интерпретиру-
ется как сдвиг на 10 пикселей за время К кадров. Если кадры снима-
ются через равные интервалы, то реальная физическая скорость объ-
екта зависит от частоты кадров и расстояния между пикселями. Так,
при V] = 10, К= 30, частоте кадров, равной 2 изображениям в секун-
ду, и шаге пикселей, соответствующем расстоянию 0,5 м, реальная фи-
зическая скорость в направлении оси х оказывается равной
V] = (10 пикселей)(0,5 м/пиксель)(2 кадра/с) / (30 кадров) = 1/3 м/с.
Для нахождения знака составляющей скорости в направлении оси
х вычислим выражения
и
Посколькуизменяется по синусоидальному закону, можно показать,
что 51х и будут иметь одинаковые знаки в любой момент времени
п, если составляющая скорости vf (вдоль осих) положительна. Наобо-
рот, разные знаки 51х и показывают, что эта компонента отрица-
тельна. Если какая-либо из величин А|Х и принимает нулевое зна-
чение, то рассматривается следующий ближайший момент времени
t = п ± А/. Аналогичным способом определяется и знак составляющей
по оси у (для скорости V2)-
Пример 10.21: Нахождение малых движущихся объектов с помощью
частотных методов.
Рисунки 10.51 — 10.54 демонстрируют эффективность изложенно-
го выше подхода. На Рис. 10.51 приведено одно изображение из после-
довательности 32 кадров, полученных путем добавления белого шума
к опорному изображению, снятому спутником LANDSAT. На эту по-
следовательность был наложен интересующий объект, движущийся со
скоростью 0,5 пикселя на кадр вдоль оси х и 1 пиксель на кадр —
вдоль оси у. Этот объект, обведенный кружком на Рис. 10.52, имеет га-
Глава 10. Сегментация изображений
Рис. 10.51. Кадр, полученный со спутника LANDSAT. [Cowart, Snyder, RuedgerJ.
уссово распределение яркости на малой площади (9 пикселей) и труд-
но различим глазом. Результаты вычисления величин (10.6-8) и (10.6-9)
при <71 = 6 и 02 = 4 показаны на Рис. 10.53 и 10.54, соответственно. Пик
Рис. 10.52. Двумерный график яркости изображения на Рис. 10.51, на котором
интересующий объект обведен кружком. [Rajala, Riddle, Snyder].
Рис. 10.53. Спектр согласно (10.6-8), на котором виден пик при М] = 3. [Rajala,
Riddle, Snyder].
при Wj = 3 на Рис. 10.53 дает, согласно соотношению (10.6-10), значе-
ние Vj = 0,5. Аналогично, пик при д2 = 4 на Рис. 10.54 дает, согласно
соотношению (10.6-11), значение v2 = 1,0.
Рис. 10.54. Спектр согласно (10.6-9), на котором виден пик при иг = 4. [Rajala,
Riddle, Snyder].
Глава 10. Сегментация изображений
Правила выбора значений и а2 можно объяснить с помошью ри-
сунков 10.53 и 10.54. Предположим, например, что вместо а2 = 4 мы
использовали бы значение а2 = 15. В этом случае, поскольку v2 = 1,0,
пики на Рис. 10.54 находились бы в точках д2 = 15 и w2 = 17, что в ре-
зультате привело бы к значительной ошибке, связанной с наложени-
ем спектров. Как отмечалось в Разделе 2.4.4, причиной таких ошибок
является недостаточная частота дискретизации (применительно к
данному рассмотрению — слишком малое число кадров, поскольку
диапазон для и зависит от К). Поскольку и = av, одна из возможнос-
тей состоит в выборе в качестве а ближайшего целочисленного зна-
чения к величине а = umax/vmax, где wmax — максимальная частота, оп-
ределяемая величиной К, a vmax — максимальная ожидаемая скорость
объекта.
Заключение
Сегментация изображения является важным предварительным шагом
большинства задач автоматического распознавания зрительных обра-
зов и анализа сцен. Как показывают представленные в этой главе
примеры, выбор того или иного метода сегментации диктуется по
большей части специфическими особенностями рассматриваемой за-
дачи. Хотя набор методов, изложенных в этой главе, далеко не исчер-
пывающий, они являются характерными представителями техники сег-
ментации, обычно применяемой на практике. Приводимые ниже
ссылки могут использоваться как основа для дальнейшего изучения
данной темы.
Ссылки и литература для дальнейшего изучения
Благодаря центральной роли, которую играет сегментация при авто-
матической обработке изображений, тема сегментации представлена
в большинстве книг, связанных с обработкой изображений, анализом
сцен и машинным зрением. В качестве книг, которые можно рекомен-
довать для дополнительного изучения материала, изложенного в дан-
ной главе, укажем следующие: [Shapiro, Stockman, 2001], [Sonka et
al., 1999], [Petrou, Bosdogianni, 1999] и [Umbaugh, 1998].
Работы, в которых рассматривается применение масок для на-
хождения разрывов яркости (Раздел 10.1), имеют долгую историю. За
эти годы было предложено большое число масок: [Roberts, 1965],
[Prewitt, 1970], [Kirsh, 1971], [Robinson, 1976], [Frei, Chen, 1977] и
[Canny, 1986]. В обзорной статье [Fram, Deutsch, 1975] исследуется
большое число масок и дается оценка их характеристик. Вопрос о ка-
’O
Ссылки и литература для дальнейшего изучения
честве масок, особенно в плане обнаружения контуров, по-прежнему
вызывает значительный интерес, примером чему могут служить рабо-
ты [Qian, Huang, 1996], [Wang et al., 1996], [Heath et al., 1997, 1998] и
[Ando, 2000]. В большинстве прикладных задач, где используются
многодиапазонные сенсоры, все более популярным становится обна-
ружение контуров на цветных изображениях. См., например, работы
[Salinas, Abidi, Gonzalez, 1996], [Zugaj, Lattuati, 1998], [Mirmehdi,
Petrou, 2000] и [Plataniotis, Venetsanopoulos, 2000]. В настоящее время
также вызывает интерес взаимосвязь между характеристиками изоб-
ражения и качеством работы масок; укажем как пример работу [Ziou,
2001 ]. Наше изложение в этой главе свойств лапласиана в отношении
пересечения нулевого уровня основано на статье [Marr, Hildredth,
1980] и книге [Marr, 1982]. См. также статью [Clark, 1989] по поводу про-
верки правильности контуров, найденных с помощью алгоритма пе-
ресечения нулевого уровня (отдельные исправления к этой статье бы-
ли даны в работе [Piech, 1990]). Как отмечалось в Разделе 10.1,
использование пересечения нулевого уровня лапласиана гауссиана
является важным подходом, характеристики которого в настоящее
время активно изучаются ([Gunn, 1998, 1999]).
Преобразование Хафа [Hough, 1962] за последнее десятилетие
проявило себя как метод обнаружения кривых и глобальных связей
между пикселями. В течение этого времени были предложены много-
численные обобщения базового преобразования, рассмотренного в
этой главе. Например, в работе [Lo. Tsai, 1995] рассматривается под-
ход к обнаружению толстых линий, работы [Guil et al., 1995, 1997] ка-
саются быстрой реализации преобразования Хафа и методов обнару-
жения элементарных кривых. Дальнейшие обобщения для
обнаружения эллиптических дуг обсуждаются в [Daul et al., 1998], а в
работе [Shapiro, 1996] рассматривается применение преобразования Ха-
фа к полутоновым изображениям. Алгоритм, представленный в Раз-
деле 10.2.3, основан на работах [Martelli, 1972, 1976]. Дополнительный
материал по эвристическому поиску на графе см. в книгах [Nilsson,
1980], [Sonkaet al., 1999] и в статье [LImeyama, 1988].
Как отмечалось в начале Раздела 10.3, методы пороговой обра-
ботки завоевали значительную популярность ввиду простоты реали-
зации. Неудивительно, что эта тематика широко представлена в ли-
тературе. Хорошую предварительную оценку этих публикаций можно
получить из обзорных статей [Sahooetal., 1988] и [Leeetal., 1990]. В Раз-
деле 10.3.2 были потрачены определенные усилия при рассмотрении
влияния освещения на результаты порогового преобразования; су-
ществующие подходы к этой проблеме демонстрируются в работах
[Perez, Gonzalez, 1987], [Parker, 1991], [Murase, Nayar, 1994], [Bischsel,
906 Глава 10. Сегментация изображений
1998] и [Drew et al., 1999]. Дополнительный материал к Разделам 10.3.3
и 10.3.4 приводится в книге [Jain et al., 1995]. Обсуждаемая в Разде-
ле 10.3.5 давняя работа [Chow, Kaneko, 1972] все еще остается образ-
цом в плане иллюстрации важных аспектов решения задачи сегмен-
тации на основе пороговых преобразований. По существу, то же самое
можно сказать о материале, представленном в Разделе 10.3.6 (на ос-
нове статьи [White, Rohrer, 1983]), где для решения сложной задачи сег-
ментации используется сочетание порогового преобразования, гради-
ента и лапласиана. Интересно сравнить фундаментальное сходство в
плане возможностей сегментации между этими двумя статьями и ра-
ботами в области пороговых преобразований, проделанными почти 20
лет спустя ([Cheriet et al., 1998], [Sauvola, Pietikainen, 2000]). См. так-
же статьи [Liang et al., 2000] и [Chan et al., 2000], где излагаются аль-
тернативные подходы к задаче обнаружения границ в изображениях,
сходные по своей идее с тем, который разрабатывали Чоу и Кане ко.
Давний обзор по теме сегментации на основе областей содержит-
ся в статье [Fu, Mui, 1981]. Работы [Haddon, Воусе, 1990] и [Pavlidis,
Liow, 1990] относятся к числу первых попыток объединить для целей
сегментации характеристики областей и границ. Интересен также бо-
лее поздний подход к выращиванию областей, предложенный в ста-
тье [Hojjatoleslami, Kittier, 1998]. Современное состояние основных кон-
цепций, связанных с сегментацией на основе областей, излагается в
книгах [Shapiro, Stockman, 2001] и [Sonka et al., 1999].
Как было показано в Разделе 10.5, мощную идею представляет
собой сегментация по водоразделам. Ранними работами по этой теме
были книга [Serra, 1988], а также работы [Beucher, 1990] и [Beucher,
Meyer, 1992]. В статье [Baccar et al., 1996] рассматривается сегмента-
ция на основе морфологических водоразделов и слияния данных.
Прогресс в этой области, достигнутый немногим больше, чем за де-
сятилетие, демонстрирует специальный выпуск журнала [Pattern
Recognition, 2000], целиком посвященный данной теме. Как указыва-
лось в Разделе 10.5, одной из основных трудностей при использовании
водоразделов является избыточная сегментация. Существующие под-
ходы к решению этой проблемы демонстрируют статьи [Najmanand,
Schmitt, 1996], [Haris et al., 1998] и [Bleau, Leon, 2000]. В статье [Bieniek,
Moga, 2000] обсуждается алгоритм сегментации по водоразделам, ос-
нованный на компонентах связности.
Материал Раздела 10.6.1 взят из статьи [Jain, R., 1981]. См. также кни-
гу [Jain, Kasturi, Schunck, 1995]. Материал Раздела 10.6.2 взят из статьи
[Rajala, Riddle, Snyder, 1983]. См. также статьи [Shariat, Price, 1990] и
[Cumani et al., 1991]. В книгах [Shapiro, Stockman, 2001] и [Sonka et al.,
1999] приводится дополнительный материал по оцениванию движения.
Задачи
*10.1 Двоичное изображение содержит прямые линии, ориенти-
рованные горизонтально, вертикально и под углами 45° и
—45°. Приведите набор масок 3x3 для обнаружения в этих ли-
ниях разрывов шириной в один пиксель. Считайте, что линии
имеют яркость 1, а фон — 0.
10.2 Предложите метод обнаружения промежутков длиной от 1 до
L пикселей на отрезках прямых в двоичном изображении.
Считайте, что ширина линий составляет 1 пиксель. Предла-
гаемый метод должен основываться на анализе связности для
восьмерки соседей, а не попытках построения масок для об-
наружения разрывов.
10.3 Ответьте по Рис. 10.4 на следующие вопросы.
*(а) Некоторые из линий, соединяющих центральный эле-
мент с контактными площадками, на Рис. 10.4(6) превра-
тились в одиночные линии, а другие стали двойными ли-
ниями. Объясните, почему.
(б) Как бы Вы подошли к задаче удаления тех компонент на
Рис. 10.4(b), которые не являются частями прямых, иду-
щих под углом —45°?
10.4 Рассмотрите горизонтальный профиль яркости через сере-
дину двоичного изображения, которое содержит идущий вер-
тикально ступенчатый перепад в центре изображения. Нари-
суйте вид профиля после сглаживания этого изображения
усредняющей маской ихи, коэффициенты которой равны
1/и 2. Для простоты предполагайте, что сглаженное изображе-
ние промасштабировано по яркости так, что слева от перепа-
да яркость равна 0, а справа 1. Считайте также, что размеры ма-
ски значительно меньше размеров изображения, так что
краевые эффекты не затрагивают область перепада в середи-
не профиля яркости.
*10.5 Предположим, что вместо модели линейного перепада, при-
веденной на Рис. 10.6, применяется модель, показанная на ри-
Изображение
L
Горизон-
тальный
профиль
Глава 10. Сегментация изображений
сунке ниже. Нарисуйте вид градиента и лапласиана для каж-
дого из профилей.
10.6 Используя Рис. 10.8, ответьте на следующие вопросы.
(а) Предположим, что для получения составляющих Gx и Gy
используются маски Собела. Покажите, что в этом случае вы-
числение градиента по формулам (10.1 -4) и (10.1 -12) приве-
дет к идентичным результатам, если контуры ориентирова-
ны в горизонтальном и вертикальном направлениях.
(б) Покажите, что то же самое справедливо и для масок Пре-
витта.
*10.7 Покажите, что маски Собела и Превитта дают при вычисле-
нии градиента изотропный результат только для горизонталь-
ных и вертикальных контуров, а также для проходящих под уг-
лами ±45°.
10.8 Результаты, достигаемые одиночным проходом по изображе-
нию с использованием некоторых двумерных масок, также мо-
гут быть получены двумя проходами с использованием од-
номерных масок. Например, тот же результат, что и при
обработке сглаживающей маской 3x3 с коэффициентами 1 /9,
можно получить одиночным проходом по изображению с ма-
ской [1 I 1 ], а затем одиночным проходом с маской
т
1 .
1
Окончательный результат получается затем масштабирова-
нием по яркости с коэффициентом 1 /9. Покажите, что маски
Собела (Рис. 10.8) можно реализовать однократным проходом
с дифференцирующей маской вида [—101] (или такой же транс-
понированной), а затем проходом со сглаживающей маской ви-
да [1 2 1] (или такой же транспонированной).
*10.9 Для измерения градиентов контуров, ориентированных в
восьми главных направлениях компаса (С, СВ, В, ЮВ, Ю,
ЮЗ, 3, СЗ), строятся так называемые компасные градиент-
ные операторы размерами 3x3. Приведите вид каждого из
этих восьми операторов, используя значения коэффициен-
тов 0, 1 или —1. Укажите для каждой маски направление
градиента, учитывая, что оно перпендикулярно направлению
перепада.
10.10 Прямоугольник в центре изображения, приведенного на ри-
сунке, имеет размеры тхп пикселей.
Задачи
(а) Нарисуйте вид градиента этого изображения, используя
приближение, даваемое соотношением (10.1-12). Считай-
те, что составляющие Gx и Gy получаются с помощью опе-
раторов Собела. Укажите на градиентном изображении
все различные значения пикселей.
(б) Нарисуйте гистограмму направлений перепадов, вычис-
ленных с помощью соотношения (10.1 -5). Укажите точные
значения высот всех пиков гистограммы.
(в) Нарисуйте вид лапласиана этого изображения при ис-
пользовании приближения, даваемого соотношением
(10.1-14). Укажите на изображении лапласиана все раз-
личные значения пикселей.
10.11 Для уравнения (10.1-17):
*(а ) Покажите, что среднее значение оператора Лапласа рав-
но нулю.
(б) Докажите, что среднее значение любого изображения по-
сле свертки с этим оператором также равно нулю.
(в) Будет ли в общем случае справедливо утверждение (б) для
приближений лапласиана, заданных соотношениями
(10.1-14) и (10.1-15)? Ответ объясните.
10.12 Обратитесь к Рис. 10.15.
(а) Объясните, почему перепады на Рис. 10.15(ж) образуют за-
мкнутые контуры.
(б) Всегда ли метод нахождения контуров с помощью пересе-
чения нулевого уровня будет давать в результате замкну-
тые контура? Ответ обоснуйте.
*10.13 Используя материал Раздела 10.2.2:
(а) Объясните, почему в результате преобразования Хафа на
Рис. 10.20(6) точка 1 отображается в прямую.
(б) Только ли эта точка будет давать такой результат преобра-
зования?
(в) Объясните зеркальную симметричность точек пересечения
кривых с правой и левой границами области на Рис. 10.20(f).
10.14 Используя материал Раздела 10.2.2:
(а) Разработайте общую процедуру построения представления
прямой с помощью нормали по уравнению в форме с уг-
ловым коэффициентом, у = ах + Ь.
(б) Найдите представление прямой у = —2х + I с помощью
нормали.
10.15 Важной областью применения методов сегментации изобра-
жений является обработка снимков, полученных с помощью
пузырьковых камер. Эти изображения регистрируются в ходе
экспериментов в физике высоких энергий, когда пучками ча-
стиц с известными свойствами бомбардируются известные
ядра. Типичное событие на снимке состоит из треков входящих
частиц, один из которых в случае соударения с ядром разветв-
ляется на треки вторичных частиц, испускаемых в точке соуда-
рения. Предложите метод сегментации изображения для обна-
ружения всех треков, состоящих не менее чем из 100 пикселей
и наклоненных к горизонтали под одним из следующих углов:
±25°, ±50° и ±75°. Допустимая ошибка при оценке угла любо-
го из этих направлений не должна превышать ±5°. Чтобы трек
считался достоверным, его длина должна быть не менее 100
пикселей при наличии не более трех разрывов, каждый длиной
до 10 пикселей. Предполагается, что изображения прошли
предварительную обработку, в результате чего они преобразо-
ваны в двоичные, и все треки всюду имеют ширину 1 пик-
сель, кроме, быть может, точки соударения. Предлагаемая
процедура должна быть в состоянии различать треки одинако-
вого направления, но исходящие из разных точек. (Подсказка'.
Стройте решение на основе преобразования Хафа).
*10.16 Обратитесь к Рис. 10.22 и 10.24.
(а) Проведите на Рис. 10.22 всевозможные контуры, задава-
емые графом на Рис. 10.24.
(б) Вычислите стоимость пути с минимальной стоимостью.
10.17 Найдите для приведенного фрагмента изображения контур, со-
ответствующий пути с минимальной стоимостью. В квадрат-
ных скобках указаны значения яркости пикселей, а числа
снаружи изображения суть пространственные координаты.
Предполагается, что контур начинается в первом столбце, а
кончается в последнем.
__________2__________3.....
11 • • •
[2] [1] [0]
2
[i] [71
3 •
[6] [8] [2]
*10.18 Два приведенных ниже изображения совершенно разные,
хотя их гистограммы идентичны. Предположим, что каждое
изображение сглажено с помощью сглаживающей маски 3x3.
(а) Будут ли гистограммы по-прежнему одинаковы после
сглаживания?
(б) В случае отрицательного ответа нарисуйте обе гистограммы.
10.19 Рассмотрим не содержащее шума изображение размерами
WxTV, у которого первые JV/2 столбцов имеют яркость LA, а ос-
тальные — яркость LB, причем LB< LA. Гистограмма этого изо-
бражения состоит только из двух пиков одинаковой высоты,
один в точке ЬА, другой в точке Lв. Сегментация такого изо-
бражения на две половины, исходя из величины яркости, яв-
ляется тривиальной задачей, решаемой с помощью одного
глобального порога, располагающегося между точками LaviLb.
Предположим, однако, что изображение умножается на полу-
тоновой клин, значения которого плавно меняются от 0 сле-
ва до К справа, где К > LA. Как будет выглядеть гистограмма
полученного нового изображения? Ясно отметьте и опишите
различные участки этой гистограммы.
10.20 Обратитесь к алгоритму нахождения величины порога, пред-
ложенному в Разделе 10.3.3. Пусть имеется задача, в которой
гистограмма является бимодальной и, более того, форма мод
приближенно описывается гауссовыми кривыми вида
/2а, и ^е-(г-т2)2/2с2 . ПреДПОЛЭГЭЯ, ЧТО /И] < УКЯ-
Глава 10. Сегментация изображений
жите требования, которым должны удовлетворять параметры
этих кривых, чтобы после сходимости алгоритма выполнялись
следующие условия:
*(а) Значение порога равно (т} + /и2) / 2.
*(б) Порог находится слева от .
(в) Порог находится в интервале (т} + /и2) / 2 < Г< /и2.
Если какое-то из трех условий невозможно, укажите это и
обоснуйте свой ответ.
10.21 Известно, что освещение некоторой сцены описывается
функцией пространственных координат i(x, у) с уравнением
/(х, у) = А
-b\(x-N/2)2+(y-N !2)2~\
1 + е L J
где константы имеют значения Л = 0,5 и В = 10-4, а значения
функции измеряются в походящих нормализованных единицах.
Цифровое изображение сцены, обозначенноеДх, у), имеет раз-
меры AWV(7V = 1000). Известно, что любой фрагмент изобра-
жения Дх, у), размеры которого превышают 10x10 пикселей, до-
пускает правильную сегментацию, если при получении
изображения размах функции освещения между любыми двумя
точками этого фрагмента не превосходит 0,1 единицы измере-
ния. Также известно, что значения порогов, используемых для
сегментации при соблюдении описанных условий, можно по-
лучить по алгоритму, описанному в Разделе 10.3.3. Предложи-
те адаптивный метод для пороговой обработки данного изоб-
ражения. Не требуется, чтобы все фрагменты были одинаковых
размеров, однако в каждом месте изображения необходимо
использовать область с максимально возможными размерами.
*10.22 Предположим, что некоторое изображение имеет плотность
распределения вероятностей значений яркости, показанную
на рисунке ниже, гдеР] (г) соответствует объектам, ap2(z) — фо-
ну. Предполагая, что Р] = Pi, найдите оптимальный порог
между пикселями объекта и фона.
о
1
2
3
Задачи
10.23
На рисунке ниже приведен вид функции Рэлея плотности рас-
пределения вероятностей и ее типичный график. Такая функ-
ция хорошо подходит для приближенного описания гисто-
грамм с перекосом, наподобие показанной на Рис. 10.29.
Воспользуйтесь рэлеевской плотностью распределения веро-
ятностей для формулировки задачи с бимодальным распреде-
лением двух категорий пикселей, подобно тому, как это дела-
лось в Задаче 10.22. Выразите значение оптимального порога
через априорные вероятности категорий и параметры распре-
деления Рэлея. Длинные «хвосты» двух функций плотности
должны идти навстречу друг другу, как показано на Рис. 10.29.
P(z)=-
*10.24
10.25
*10.26
Выведите из равенства (10.3-10) соотношения (10.3-12) и
(10.3-13).
Выведите равенство (10.3-14) из соотношений (10.3-12) и
(10.3-13).
На приводимом рисунке пиксели фона имеют среднее значе-
ние НО при стандартном отклонении 15. Пиксели объекта
имеют среднее значение 200 и стандартное отклонение 40.
Глава 10. Сегментация изображений
Предложите для такого изображения метод пороговой сег-
ментации, выделяющий объекты из фона. Четко сформули-
руйте предположения, которые сделаны при решении данной
задачи.
10.27 Предложите для изображения из Задачи 10.26 метод сегмен-
тации на основе выращивания областей. Четко сформули-
руйте предположения, которые сделаны при решении данной
задачи.
10.28 Выполните сегментацию приведенного ниже изображения с
помощью процедуры разделения и слияния, описанной в Раз-
деле 10.4.3. Используйте предикат следующего вида:
P(Rj) = TRUE, если все пиксели области R, имеют одинако-
вую яркость. Изобразите квадродерево, соответствующее Ва-
шей сегментации.
10.29 Обратитесь к материалу Раздела 10.5.3.
*(а) Покажите, что во время работы алгоритма сегментации
по водоразделам элементы множеств Сп(М^) и Т[п\ никог-
да не удаляются.
(б) Покажите, что с увеличением п число элементов в мно-
жествах и Т[п\ возрастает или остается неиз-
менным.
10.30 В Разделе 10.5 на примере было показано, что границы облас-
тей, выделенных с помощью алгоритма сегментации по водо-
разделам, образуют замкнутые петли. Выдвиньте аргументы в
подтверждение или опровержение того, что применение это-
го алгоритма всегда приводит к получению замкнутых границ
* 10.31 Дайте пошаговую реализацию процедуры построения перего-
родок для одномерного профиля яркости, показанного на
рисунке ниже. Для каждого шага процедуры нарисуйте попе-
речное сечение с указанием уровня «воды» и построенных
перегородок.
10.32 Как выглядело бы отрицательное НРИ на Рис. 10.49(b), если
бы в соотношении (10.6-4) сравнение производилось с Т, а не
с—Г?
10.33 Предполагая, что яркость движущегося объекта выше ярко-
сти фона, укажите, являются ли следующие высказывания
истинными или ложными. Ответ обоснуйте.
(а) Область ненулевых элементов в абсолютном НРИ уве-
личивается в размерах, пока объект продолжает дви-
гаться.
(б) Область ненулевых элементов в положительном НРИ все-
гда занимает одну и ту же площадь, независимо от движе-
ния, которое претерпевает объект.
(в) Область ненулевых элементов в отрицательном НРИ
увеличивается в размерах, пока объект продолжает дви-
гаться.
10.34 Предположим, что в Примере 10.21 отсутствует движение
вдоль оси х. Теперь объект движется лишь вдоль оси у со ско-
ростью 1 пиксель за кадр на протяжении 32 кадров, после че-
го мгновенно меняет направление на противоположное и
движется обратно с той же скоростью еще на протяжении 32
кадров. Как при таких условиях выглядели бы Рис. 10.53 и
10.54?
10.35 С помощью высокоскоростной съемки необходимо оценить
скорость полета пули. Выбран способ, в котором использует-
ся телевизионная камера и лампа-вспышка, освещающая сце-
ну в течение К секунд. Длина пули 2,5 см, диаметр 1 см, а ди-
апазон возможных скоростей составляет 750 ± 250 м/с. Оптика
камеры создает изображение размерами 256x256, на котором
пуля занимает 10% размера по горизонтали.
(а) Определите максимальное значение К, при котором рас-
фокусировка из-за движения не превышает 1 пикселя.
(б) Определите минимальную частоту съемки (число кадров
в секунду), необходимую, чтобы гарантировалось получе-
ние как минимум двух полных изображений пули во вре-
мя пролета ее в поле зрения камеры.
Глава 10. Сегментация изображений
(в) Предложите процедуру сегментации для автоматическо-
го выделения изображения пули в последовательности
кадров.
(г) Разработайте способ автоматического определения скоро-
сти полета пули.
ГЛАВА 11
ПРЕДСТАВЛЕНИЕ
И ОПИСАНИЕ
Сократ: Тогда, ради Зевса, слушай. Разве нам не приходилось уже много раз
соглашаться, что хорошо установленные имена подобны тем вещам,
которым они присвоены, и что имена — это изображения вещей?
Платон, «Кратил» (пер. Т.В. Васильевой)
Введение
После того, как выполнена сегментация изображения на области, на-
пример, с помощью методов, описанных в Главе 10, полученные со-
вокупности пикселей обычно описываются и представляются в фор-
ме, удобной для последующей компьютерной обработки. По существу,
при выборе способа представления областей возникает следующая
альтернатива: (1) область можно представить ее внешними характери-
стиками (т.е. границей) или (2) область можно представить внутрен-
ними характеристиками (т.е. совокупностью элементов изображения,
составляющих эту область). Однако выбор способа представления
является только частью задачи преобразования данных в форму, удоб-
ную для компьютерной обработки. Следующая задача состоит в том,
чтобы описать область, исходя из выбранного способа представления.
Например, область может быть представлена своей границей, а грани-
ца — описана с помощью таких характеристик, как длина границы, на-
правления прямых, соединяющих угловые точки, и число вогнутос-
тей границы.
Внешнее представление обычно выбирается в тех случаях, ког-
да основное внимание обращено на характеристики формы обла-
сти. Внутреннее представление выбирается, если интерес пред-
ставляют свойства самой области, например, цвет и текстура.
Иногда приходится использовать оба способа представления одно-
временно. В любом случае, выбранные для описания признаки
(дескрипторы) должны быть как можно менее чувствительными
к изменению размеров области и ее перемещению по полю изобра-
жения (сдвиг, поворот). За редким исключением, рассматривае-
мые в этой главе дескрипторы обладают всеми или некоторыми из
этих свойств.
Глава 11. Представление и описание
11.1. Представление
Методы сегментации, обсуждавшиеся в Главе 10, дают на выходе не-
обработанные данные в форме множества пикселей, расположенных
вдоль границы или внутри области. Хотя эти данные иногда непосред-
ственно используются для получения дескрипторов (например, при
определении текстурных признаков области), обычная практика со-
стоит в применении методов компактного представления данных
сегментации. Полученные компактные представления оказываются
значительно более эффективными для вычисления дескрипторов.
В этом разделе мы рассмотрим различные подходы к представлению
данных об областях.
11.1.1. Цепные коды
С помощью цепных кодов граница представляется в виде последова-
тельности соединенных отрезков, для которых указаны длина и на-
правление. Как правило, такое представление основывается на отрез-
ках с 4- или 8-связностью. Направление каждого отрезка кодируется
числом в соответствии со схемой нумерации, например, как изобра-
жено на Рис. 11.1.
Цифровые изображения обычно регистрируются и обрабатывают-
ся в виде сетки с одинаковым шагом дискретизации в направлениях
осей х и у, поэтому цепной код можно построить путем прослежива-
ния границы, скажем, по часовой стрелке, присваивая номера направ-
лений отрезкам, соединяющим каждую пару пикселей. В общем слу-
чае такой метод является неприемлемым по двум главным причинам:
(1) получаемая цепочка кодов оказывается слишком длинной,
и (2) любые малые возмущения вдоль границы области, вызванные на-
личием шума или несовершенством алгоритма сегментации, приво-
Рис. 11.1. Нумерация направлений для (а) 4-связного цепного кода и (б) 8-связ-
ного цепного кода.
11.1. Представление
дят к изменениям в кодовой последовательности, которые не связа-
ны с общей формой границы.
Чтобы обойти указанные проблемы, часто применяется подход, ис-
пользующий повторную дискретизацию границы с увеличенным ша-
гом сетки, как показано на Рис. 11.2(a). После этого в процессе обхо-
да границы строятся отрезки, соединяющие узлы укрупненной сетки,
выбираемые по признаку их близости к первоначальной границе, что
иллюстрирует Рис. 11.2(6). Полученная таким способом граница с по-
ниженным разрешением может затем представляться с помощью 4- или
8-кода, показанных на Рис. 1 1.2(b) и (г) соответственно. В качестве на-
чальной точки на Рис. 11.2(в, г) произвольно выбран левый верхний
Рис. 11.2. (а) Дискретная граница с наложенной укрупненной сеткой дискре-
тизации. (б) Результат новой дискретизации, (в) Цепной код с 4 направлени-
ями. (г) Цепной код с 8 направлениями.
920 Глава 11. Представление и описание
угол границы, а сама граница представляет собой кратчайший допу-
стимый 4-или 8-путь на сетке из Рис. 11.2(6). Граница на Рис. 11.2(b)
представляется цепным кодом 0033...01, а на Рис. 11.2(г) — кодом
0766... 12. Как и следовало ожидать, точность представления границы
полученным кодом определяется шагом дискретизации новой сетки.
Цепной код границы области зависит от начальной точки, но с по-
мощью простой процедуры его можно сделать инвариантным к ее
выбору. Для этого цепной код просто рассматривается как цикличе-
ская последовательность номеров направлений отрезков, и начальная
точка переопределяется таким образом, чтобы при начале отсчета с нее
получалась линейная запись, соответствующая целому числу наи-
меньшей величины. Цепной код также можно сделать инвариант-
ным относительно поворота, если вместо самого кода рассматривать
его первую разность, которая формируется путем вычитания значений
направления для всех пар соседних элементов кодовой последова-
тельности. Каждая разность вычисляется циклически (против часовой
стрелки), так что, например, для цепного кода с 4 направлениями
10103322 первая разность задается последовательностью 3133030. Ес-
ли и сам код трактовать как циклическую последовательность, то пер-
вый элемент разностной последовательности должен вычисляться
как циклическая разность последнего и первого элемента исходного
цепного кода, и тогда первой разности отвечает код 33133030. Норми-
ровка по размерам области может быть достигнута путем изменения
шага сетки, применяемой для новой дискретизации.
Упомянутые способы нормировки будут точными только в том
случае, если границы сами по себе инвариантны относительно пово-
рота и изменения масштаба, что редко достигается на практике. На-
пример, при дискретизации одного и того же объекта в двух различ-
ных ориентациях получаются, вообще говоря, границы отличающейся
формы, причем степень рассогласования тем больше, чем выше раз-
решение изображения. Этот эффект можно уменьшить, выбирая дли-
ну элементов цепи большей, чем расстояния между пикселями оци-
фрованного изображения, а также ориентируя сетку вторичной
дискретизации вдоль главных осей описываемого объекта, как это
рассматривается в Разделе 11.2.2, или вдоль его собственных осей,
как рассматривается в Разделе 11.4.
11.1.2. Аппроксимация ломаной линией
Дискретная граница может быть сколь угодно точно приближена ло-
маной линией. В случае замкнутой границы аппроксимация являет-
ся точной, когда число отрезков ломаной равно числу точек границы,
так что каждую пару соседних точек соединяет свой отрезок. На прак-
тике цель аппроксимации ломаной состоит в том, чтобы с помощью
как можно меньшего числа отрезков приблизить «самое существенное»
в форме границы. В общем случае эта задача нетривиальна и ее реше-
ние часто выливается в трудоемкие переборные схемы. Тем не менее,
существуют некоторые методы аппроксимации, которые характери-
зуются умеренной вычислительной сложностью и хорошо подходят для
цифровой обработки изображений.
Ломаные минимальной длины
Рассмотрение аппроксимации ломаной линией мы начнем с метода
нахождения ломаной минимальной длины. Эту процедуру легче всего объ-
яснить на примере. Предположим, что граница области заключена вну-
три множества соединенных в цепочку соседних элементов, как по-
казано на Рис. 11.3(a). Это позволяет рассматривать границу области
как резиновую ленту, находящуюся между двумя стенками, соответ-
ствующими внутренней и внешней границам указанной цепочки эле-
ментов. При стягивании ленты она примет форму, указанную на
Рис. 11.3(6), образуя многоугольник с минимальным периметром, от-
вечающий геометрической форме данной цепочки элементов. Если
каждый элемент заключает в себе единственную точку границы, то ве-
личина отклонения фактической границы от ее приближения резино-
вой лентой внутри любого элемента не превышает \fld, где d — ми-
нимальное расстояние между пикселями, т.е. шаг дискретизации при
получении исходного цифрового изображения. Это отклонение может
быть уменьшено вдвое, если принимать за опорную точку элемента
центр соответствующего ему пикселя.
Рис. 11.3. (а) Граница объекта, заключенная внутри цепочки элементов, (б) Ло-
маная минимальной длины.
И
922 Глава 11. Представление и описание
Методы слияния
Методы слияния основаны на применении к задаче кусочно-линейной
аппроксимации критерия средней ошибки или критерия другого ви-
да. Согласно одному из подходов происходит объединение точек вдоль
границы в одну прямую линию до тех пор, пока среднеквадратичес-
кое отклонение объединяемых точек от формируемой прямой не пре-
высит заранее заданный порог. После этого параметры прямой запо-
минаются и начинается новое объединение точек, сопровождающееся
построением новой прямой и новым накоплением ошибки отклоне-
ния. В результате повторения такой процедуры в конце будет постро-
ена ломаная, состоящая из соседних отрезков аппроксимирующих
прямых. Одним из главных недостатков описанного метода является
то, что вершины полученной ломаной линии не всегда совпадают с из-
гибами изначальной границы (например, с ее изломами), так как но-
вое звено ломаной не начинается до тех пор, пока величина отклоне-
ния предыдущего отрезка ломаной не превысит заданный порог.
Например, если при прослеживании длинного прямолинейного отрез-
ка границы встретится угол, то к этому отрезку будет добавлено еще
некоторое (зависящее от установленного порога) количество точек за
вершиной угла, прежде чем обнаружится превышение порога. Одна-
ко, этот недостаток можно уменьшить, применяя наряду со слияни-
ем обсуждаемые ниже методы разбиения.
Методы разбиения
Один из возможных подходов к разбиению отрезков границы состо-
ит в том, что отрезок последовательно разбивается на две части (т.е.
заменяется двумя новыми отрезками), до тех пор, пока не начнет
выполняться некоторый заданный критерий. Например, может быть
поставлено такое требование, чтобы максимум кратчайших рассто-
яний от отрезка прямой, соединяющей две точки границы, до проме-
жуточных точек границы не превышал установленного порога. Если
это условие нарушается, то максимально удаленная от отрезка точка
границы становится новой вершиной аппроксимирующей ломаной,
а первоначальный отрезок ломаной заменяется двумя новыми. Этот
метод обладает тем достоинством, что позволяет обнаруживать наи-
более заметные точки изгиба или излома на границе объекта. В каче-
стве примера на Рис. 11.4(a) изображена граница объекта, а Рис. 11.4(6)
демонстрирует этап дробления начального отрезка аппроксимации
этой границы, соединяющего ее наиболее удаленные друг от друга точ-
ки (сплошная линия). Точка с является наиболее удаленной (в смыс-
ле кратчайшего расстояния) от отрезка ab точкой верхнего участка гра-
ницы, а точка d — наиболее удаленной точкой нижнего участка
Рис. 11.4. (а) Исходная граница, (б) Разбиение границы на участки с помощью
угловых точек, (в) Добавление вершин, (г) Полученная ломаная.
границы. На Рис. 11.4(b) показан результат применения описанной
выше процедуры разбиения с порогом, равным одной четверти дли-
ны отрезка ab. Поскольку ни для одного из полученных отрезков
этот порог (максимум кратчайших расстояний от точек границы до
соответствующих отрезков) не превышен, процедура завершается
построением замкнутой ломаной линии, показанной на Рис. 11.4(г).
11.1.3. Сигнатуры
Сигнатура есть описание границы объекта с помощью одномерной
функции, которое может строиться различными способами. Один из
простейших состоит в построении зависимости расстояния от цент-
роида (т.е. от некоторой средней точки объекта, например, его цент-
ра тяжести) до границы объекта в виде функции угла, как иллюстри-
рует Рис. 11.5. Независимо от способа построения сигнатуры, основная
идея состоит в том, чтобы свести представление границы к одномер-
ной функции, которую предположительно описать легче, чем исход-
ную двумерную границу.
Сигнатуры, построенные описанным выше способом, инвари-
антны по отношению к параллельному переносу, однако зависят от по-
ворота и изменения масштаба. Инвариантность к повороту можно
получить, найдя способ выбора одной и той же начальной точки для
построения сигнатуры, независимо от ориентации фигуры. Один из
способов сделать это —выбирать в качестве начальной точку, макси-
мально удаленную от центроида, если такая точка оказывается един-
ственной и не зависящей от искажений, возникающих при поворотах
интересующих фигур. Другой способ может заключаться в выборе
924 Глава 11. Представление и описание
максимально удаленной от центроида точки на собственной оси фи-
гуры (см. Раздел 11.4). Такой метод требует большего объема вычис-
лений, но является и более устойчивым, поскольку направление соб-
ственной оси фигуры определяется с учетом всех точек ее контура. Еще
один способ основан на получении цепного кода границы и последу-
ющем применении метода, описанного в Разделе 11.1.1, полагая, что
кодирование является достаточно грубым, так что поворот не наруша-
ет его цикличности.
Если предполагать, что изменение масштаба производится одина-
ково по обеим осям и дискретизация по углу 0 является равномерной,
то масштабирование фигуры приводит к изменению амплитуды соот-
ветствующей сигнатуры. Этот результат можно пронормировать путем
масштабирования функций сигнатуры таким образом, чтобы они все-
гда охватывали один и тот же диапазон значений, например, [0, ^.До-
стоинством данного метода является простота, однако его потенци-
альный серьезный недостаток кроется в том, что масштабирование всей
функции зависит всего от двух значений — минимального и макси-
мального. Если в изображении присутствует шум, эта зависимость
может стать источником расхождений между объектами. Более ус-
тойчивый (но также требующий больших вычислений) метод состо-
ит в делении каждого углового отсчета на дисперсию функции, зада-
ющей сигнатуру, в предположении что эта дисперсия не нулевая (как
Рис. 11.5. Сигнатуры «угол — расстояние». В случае (a) r(0) = const. В случае
(б) сигнатура состоит из повторяющихся с периодом л/2 участков зависимо-
стей r(0) = A sec0 для 0 < 0 < л/4 и г(0) = yl-cosec0 для л/4 < 0 < л/2.
на Рис. 11.5(a)) и не столь мала, чтобы это вызывало вычислительные
трудности. Учет дисперсии приводит к переменному коэффициенту
масштабирования, который обратно пропорционален изменениям
размеров и действует аналогично автоматической регулировке усиле-
ния. Какой бы способ ни применялся, следует иметь в виду, что основ-
ная цель состоит в устранении зависимости от масштаба при сохране-
нии формы кривой в целом.
Конечно, зависимость расстояния от угла — не единственный спо-
соб построения сигнатуры. Например, другой способ состоит в обхо-
де точек границы с одновременным построением зависимости угла
между касательной к границе в текущей точке и фиксированной опор-
ной прямой от положения точки на границе. Сигнатура, получаемая та-
ким способом, имеет совершенно другой вид по сравнению с кривой
г(0), однако также несет информацию об основных характеристиках
формы объекта. Например, горизонтальные участки такой функции со-
ответствуют прямолинейным отрезкам границы области, поскольку
вдоль них угол наклона касательной постоянен. Вариантом данного ме-
тода является использование в качестве сигнатуры так называемой
функции плотности крутизны. Эта зависимость представляет собой
обычную гистограмму значений тангенса угла наклона. Поскольку ги-
стограмма является мерой концентрации значений, функция плотно-
сти крутизны дает большой отклик на участках границы с постоянны-
ми углами наклона касательной (т.е. прямолинейных или близких
к таковым) и характеризуется глубокими спадами на участках быстро-
го изменения угла наклона (т.е. в углах и местах резких изгибов).
11.1.4. Сегменты границы
Часто оказывается полезным разбиение границы на сегменты. При та-
кой декомпозиции уменьшается сложность границы и тем самым уп-
рощается процесс ее описания. Такой подход особенно привлекателен,
когда граница содержит одну или несколько хорошо выраженных во-
гнутостей, несущих информацию о форме объекта. В этом случае
мощным инструментом для устойчивой декомпозиции границы явля-
ется использование выпуклой оболочки области, находящейся внут-
ри границы.
Согласно определению из Раздела 9.5.4, выпуклая оболочка //про-
извольного множества 5 есть наименьшее выпуклое множество, со-
держащее 5. Разность множеств Н\ S называется дефектом выпукло-
сти D множества 5. Чтобы проиллюстрировать, как эти понятия
могут использоваться для разбиения границы на содержательные
сегменты, рассмотрим Рис. 11.6(a), на котором изображен объект
и описание
Рис. 11.6. (а) Область 5 и ее дефект выпуклости (отмечен темным цветом),
(б) Разбиение границы области.
(множество S) со своим дефектом выпуклости (области, закрашенные
темным цветом). Разбиение границы области осуществляется путем
обхода контура 5 и пометки точек входа в область дефекта выпукло-
сти и выхода из нее. На Рис. 11.6(6) показано местоположение этих
точек в рассматриваемом случае. Отметим, что результат такого раз-
биения в принципе не зависит от изменения размеров и ориентации
области.
На практике границы областей на дискретных изображениях час-
то являются неровными из-за шума, погрешностей дискретизации и от-
клонений при сегментации. В результате область дефекта выпуклости
содержит незначащие мелкие составляющие, случайно разбросанные
вдоль границы. Вместо того чтобы пытаться отсеять эти неровности
в ходе последующей обработки, общепринятый способ состоит в сгла-
живании границы перед ее разбиением. Для этого существует целый ряд
способов. При одном из них во время обхода границы координаты
каждого пикселя заменяются средними значениями координат к его со-
седей по границе. Этот способ справляется с небольшими неровнос-
тями, однако требует большого объема вычислений и трудно поддает-
ся контролю. При больших значениях к происходит излишнее
сглаживание, а малые значения к могут оказаться недостаточными на
некоторых участках границы. Более надежный способ состоит в том,
что перед нахождением дефекта выпуклости выполняется кусочно-
линейная аппроксимация границы, как описано в Разделе 11.1.2. Как
правило, границы интересующих объектов на дискретных изображе-
ниях аппроксимируются замкнутыми ломаными без самопересече-
ний, т.е. области являются простыми многоугольниками. Грэм и Яо
[Graham, Yao, 1983] предложили алгоритм построения выпуклой обо-
лочки таких многоугольников.
11.1. Представление
Понятия выпуклой оболочки и дефекта выпуклости оказываются
столь же полезными и для описания всей области, а не только ее гра-
ницы. Например, в основу описания области может быть положена ее
площадь, площадь дефекта выпуклости, число компонент дефекта вы-
пуклости, их относительное расположение и т.д. Напомним, что мор-
фологический алгоритм для построения выпуклой оболочки был опи-
сан в Разделе 9.5.4. В списке литературы для дальнейшего изучения в
конце данной главы содержатся ссылки на другие способы построения.
11.1.5. Остовы областей
Важным для практики является подход, в котором представление
формы плоской области строится путем сведения ее к графу. Такое со-
кращенное представление можно получить, выделяя остов этой об-
ласти с помощью алгоритма утончения (этот процесс иначе называ-
ют скелетонизацией). Процедуры утончения занимают центральное
место в широком классе прикладных задач обработки изображений,
от автоматического контроля печатных плат до подсчета волокон ас-
беста в воздушных фильтрах. В Разделе 9.5.7 мы уже рассматривали
построение остова с использованием морфологического подхода.
Однако, как отмечалось, в описанной там процедуре не было преду-
смотрено никаких условий сохранения связности остова. Ниже изла-
гается алгоритм, позволяющий исправить этот недостаток.
Остов области может быть построен с помощью преобразования
к главным осям (ПГО), предложенного Блюмом [Blum, 1967]. ПГО об-
ласти R с границей В выполняется следующим образом. Для каждой
Рис. 11.7. Срединные оси трех областей простой формы (показаны пунктиром)
и описание
чек больше одной, то говорится, что точкар лежит на срединной оси об-
ласти R (т.е. остове). Понятие «ближайшей» точки (и соответствующее
ему ПГО) зависит от определения расстояния (см. Раздел 2.5.3). На
Рис. 11.7 приводится несколько примеров, в которых используется ев-
клидово расстояние. Те же результаты были бы получены при исполь-
зовании максимальных кругов из Раздела 9.5.7.
ПГО области имеет наглядное объяснение, образно называемое «по-
жар в степи». Рассмотрим область изображения как степь, равномерно по-
крытую сухой травой, и предположим, что вся ее граница одновременно
загорается. Фронт пожара распространяется внутрь области, всюду с по-
стоянной скоростью. Результатом ПГО области будет множество точек,
куда фронт огня доходит одновременно более чем с одного направления.
Хотя ПГО области приводит к получению интуитивно приемлемо-
го остова, непосредственная реализация такого алгоритма требует боль-
шого объема вычислений, поскольку потенциально связана с вычисле-
нием расстояний от каждой внутренней точки области до всех точек
границы. Предложено большое число алгоритмов, позволяющих повы-
сить эффективность вычислений при построении результата ПГО об-
ласти. Как правило, в них используются алгоритмы утончения, в кото-
рых постепенно убираются точки контура области, при тех условиях, что
(1) они не являются концевыми точками, (2) после удаления область ос-
тается связной, и (3) это не приводит к излишней эрозии области.
В этом разделе мы изложим алгоритм утончения двоичных обла-
стей, предполагая, что точки области имеют значения 1, а точки фо-
на — 0. Метод состоит в последовательном применении двух основ-
ных шагов, которые применяются для точек контура данной области.
В соответствии с определением, данным в Разделе 2.5.2, контурной точ-
кой является любой единичный пиксель, среди восьмерки соседей
которого есть хотя бы один элемент с нулевым значением. С исполь-
зованием приведенных на Рис. 11.8 обозначений для восьмерки сосе-
дей, на первом шаге алгоритма контурная точка р\ помечается для
удаления, если выполнены следующие условия:
Рч Р2 Рз
Ps Р\ Р4
Pl Рб Р5
Рис. 11.8. Обозначения элементов окрестности в алгоритме утончения.
11.1.
О О 1
1 Р\ О
I О 1
Рис. 11.9. Иллюстрация условий (а) и (б) в (11.1-1). В данном случае N(p\) = 4
и T(Pl) = 3.
(a) 2</V(/?])<6
(б) Т(А) = 1
(в) р2 р4 р6 = 0
(г) р4р6-р8=0
(Н.1-1)
где N(p\) — число ненулевых соседей элемента/?], т.е.
М(Р\)-Р2 +Рз +--- + Р& +Р9 > (11.1-2)
a Т(р\) — число переходов 0—1 в упорядоченной последовательности
/?2,/?з, ,/’8,/’9,/’2- Например, на Рис. 11.9 MPi) = 4 и Т(р\) = 3.
На втором шаге условия (а) и (б) остаются теми же, а условия (в)
и (г) заменяются на
(Д) Рг РА Р8=° /]] I эх
(е) Р2 Рб ^=0 • * ‘ ’
Вначале к каждой точке границы рассматриваемой двоичной
области применяется шаг 1. Если нарушается хотя бы одно из усло-
вий (а)—(г), то значение соответствующего элемента не меняется.
При выполнении всех условий элемент помечается для удаления, но
само удаление не производится, пока не будут обработаны все точ-
ки границы. Такая задержка предотвращает изменение структуры
данных в процессе выполнения алгоритма. После того, как шаг 1 вы-
полнен для всех точек границы, отмеченные элементы удаляются
(значение изменяется на 0). После этого точно так же выполняет-
ся шаг 2 алгоритма.
Таким образом, одна итерация алгоритма утончения складывается
из (1) применения шага 1 ко всем точкам границы с пометкой канди-
датов на удаление; (2) удаления отмеченных точек; (3) применения
шага 2 с пометкой кандидатов на удаление среди оставшихся точек гра-
ницы; и (4) удаления отмеченных точек. Описанная процедура повто-
ряется до тех пор, пока не прекратится процесс удаления точек. При
31 \-аз
Глава 11. Представление и описание
этом алгоритм останавливается, приводя в результате к остову исход-
ной области.
Условие (а) нарушается, если среди восьмерки соседей контурной
точкир\ имеется только один единичный элемент или только один ну-
левой. Первое означает, что/?] является концевой точкой остова и, ра-
зумеется, не подлежит удалению. Удаление точкир\, имеющей семь еди-
ничных соседей, привело бы к эрозии внутрь региона. Условие (б) не
соблюдается для элементов, лежащих на линии толщиной в 1 пик-
сель, что препятствует разделению отрезков остова в ходе операции
утончения. Минимальный набор фоновых элементов в окрестности,
при котором одновременно выполняются условия (в) и (г), следующий:
(р4 = О или рь = 0) или (д2 = 0 и pg = 0). То есть, с учетом расположения
элементов в окрестности согласно Рис. 11.8, одновременно все четы-
ре условия (а) — (г) соблюдаются для граничных точек, находящихся
на нижней или правой границах, либо в левых верхних углах границы.
В любом из этих случаев точка/?] не является частью остова и подле-
жит удалению. Аналогично, условия (д) и (е) одновременно выполня-
ются для следующего минимального набора элементов фона в окрест-
ности: (р2 = 0 или р8 = 0) ил и (р4 = 0 «pg = 0). Это соответствует точкам
верхней или левой границ, а также правым нижним углам границы. За-
метим, что для точек в правых верхних углах границы р2 = 0 и р4 = 0.
т.е. условия (в) и (г) выполняются, так же как и условия (д) и (е). То же
самое справедливо для левых нижних углов границы, где pg = 0 npg = 0.
Пример 11.1: Остов области.
На Рис. 11.10 приведено сегментированное изображение бедренной
кости человека, на которое наложен вид остова данной области, пост-
роенного в соответствии с изложенным алгоритмом. По большей час-
ти этот остов совпадает с интуитивным представлением. Обратим вни-
мание на верхнюю головку кости, выглядящую как силуэт туловища
человека. На правом «плече» имеется двойная ветвь, которая, на первый
взгляд, должна была быть одинарной, как и слева. Заметим, однако,
что правое «плечо» несколько длиннее левого, что и явилось причиной
построения алгоритмом еще одной ветви1. Непредсказуемое поведе-
ние такого рода часто встречается у алгоритмов скелетонизапии.
1 Причина появления второй ветви, по-видимому, все же не в размере «плеча», а в на-
личии на правом контуре небольшого выступа (в продолжение аналогии с силуэтом —
в месте «локтя»). Этот эффект хорошо иллюстрируется на модельной области на
Рис. 11.7(6), где в середине прямоугольника из-за небольшого выступа на контуре воз-
никла дополнительная ветвь. — Прим. ред. перевода.
11.2. Дескрипторы границ
Рис. 11.10. Бедренная кость человека с наложенным остовом области.
11.2. Дескрипторы границ
В этом разделе будут рассмотрены некоторые подходы, применяе-
мые для описания границы области, а в Разделе 11.3 мы обратимся к
дескрипторам всей области. Ряд подходов, рассмотренных в Разде-
лах 11.4 и 11.5, в равной мере применимы и к границам, и к областям.
11.2.1. Некоторые простые дескрипторы
Одним из простейших дескрипторов границы является ее длина. Об-
щее число пикселей границы является грубым приближением ее дли-
ны. Для кривой, представленной цепным кодом с единичными шага-
ми дискретизации по обоим направлениям, сумма числа вертикальных,
горизонтальных и умноженных на \/2 диагональных составляющих,
дает точное значение длины границы.
Диаметр границы В определяется соотношением
Diam(Z?) = rna.x[z>( (Н.2-1)
где D — мера расстояния (см. Раздел 2.5.3), apt иpj суть точки грани-
цы. Полезными дескрипторами границы являются значение ее диа-
метра и направление отрезка, соединяющего две экстремальные точ-
ки, которые определяют диаметр (этот отрезок называется большой
осью границы). Малая ось границы определяется как отрезок, перпен-
дикулярный большой оси и имеющий такую (минимальную) длину,
что проведенный через концы обеих осей прямоугольник со сторо-
нами, параллельными этим осям, полностью содержит в себе всю
границу2. Упомянутый прямоугольник называется базовым прямо-
угольником, а отношение длины большой оси к длине малой — эксцен-
триситетом границы, величина которого также является полезным
дескриптором.
Кривизна определяется как скорость изменения угла наклона. В об-
щем случае трудно надежно измерить кривизну в некоторой точке
дискретной границы, потому что обычно на таких границах имеются
локальные «зазубрины». Тем не менее, часто оказывается полезным ис-
пользовать разность углов наклона соседних сегментов границы (ко-
торые приближены отрезками ломаной) в качестве дескриптора кри-
визны границы в точке пересечения этих отрезков. Например,
вершины границ наподобие показанных на Рис. 11.3(6) и 11.4(г) хо-
рошо согласуются со способом описания с помощью значений кри-
визны. Говорят, что вершинная точкар лежит в выпуклом сегменте, ес-
ли при обходе границы по часовой стрелке изменение угла наклона
в точке р отрицательно; в противном случае точка называется лежашей
в вогнутом сегменте. Описание с помощью кривизны в точке может
быть подвергнуто дальнейшему уточнению посредством ранжирова-
ния изменений крутизны. Например, точка/? может считаться частью
почти прямолинейного отрезка границы, если изменение крутизны не
превышает 10°, или же угловой точкой, если это изменение более 90°.
Однако, следует отметить, что такого рода дескрипторы необходимо
использовать с осторожностью, поскольку их интерпретация зави-
сит от длины отдельных сегментов по отношению к обшей длине
границы.
11.2.2. Нумерация фигур
Как объяснялось в Разделе 11.1.1, вид первой разности для представ-
ленной цепным кодом границы зависит от выбора начальной точки.
Номер фигуры такой границы строится на основе 4-направленного
кода по Рис. 11.1(a) и определяется как первая разность с минималь-
2 Не следует путать данное определение большой и малой осей с собственными ося-
ми, определение которых дается в Разделе 11.4.
Порядок 4
Порядок 6
0 0 3 2 2 1
3 0 3 3 0 3
0 3 3 0 3 3
Цепной код: 0 3 2 1
Разность: 3 3 3 3
Номер фигуры: 3 3 3 3
Порядок 8
Цепной код:
Разность:
Номер фигуры:
0 0 3 3 2 2 1 1
30303030
03030303
----1--
0 3 0 3 2 2 1 1
33133030
03033133
--1---1--
--1---1--
00032221
30033003
00330033
Рис. 11.11. Все возможные фигуры порядков 4, 6 и 8. Направления закодиро-
ваны согласно Рис. 11.1 (а), а точкой отмечено положение начальной точки.
ным численным значением. Порядком п номера фигуры по определе-
нию называется число цифр в его записи. Более того, для замкнутой
границы п — четное число, и его значение ограничивает число возмож-
ных различных фигур. На Рис. 11.11 приведены все возможные фигу-
ры 4-го, 6-го и 8-го порядков вместе с их представлениями в форме цеп-
ного кода, первой разности и номера фигуры. Заметим, что первая
разность вычисляется, считая цепной код циклической последователь-
ностью, как говорилось в Разделе 11.1.1. Хотя первая разность цепно-
го кода инвариантна относительно поворота, в обшем случае код гра-
ницы зависит от направления сетки дискретизации. Один из способов
стандартизовать ориентацию сетки состоит в совмещении ее направ-
лений со сторонами базового прямоугольника, рассмотренного в пре-
дыдущем разделе.
На практике, исходя из желаемого порядка фигуры, находят
прямоугольник порядкам, эксцентриситет которого (определение
дано в предыдущей главе) ближе всего соответствует базовому пря-
моугольнику фигуры, и затем используют этот прямоугольник для
построения сетки дискретизации. Например, при п = 12 все суще-
ствующие прямоугольники порядка 12 (т.е. с периметром, равным
12) суть 2x4, 3x3 и 1x5. Если ближайшим по значению эксцентри-
ситета к базовому прямоугольнику заданной границы является пря-
Глава 11. Представление и описание
моугольник 2x4, то строится выровненная по этому базовому пря-
моугольнику сетка 2x4 и затем применяется описанная в Разде-
ле 11.1.1 процедура построения цепного кода. Номер фигуры полу-
чается из первой разности этого кода. Хотя порядок получаемого
номера фигуры обычно равен п в силу выбора сетки дискретизации,
при обработке границ, на которых имеются вогнутости с размера-
ми, сравнимыми с шагом дискретизации, иногда получаются номе-
ра фигур большего, чем п порядка. В таких случаях уменьшают по-
рядок прямоугольника п, повторяя процедуру, пока не будет получен
номер фигуры, равный п.
Пример 11.2: Вычисление номеров фигур.
Пусть для границы, приведенной на Рис. 11.12(a), выбрано значе-
ние п = 18. Чтобы получить для нее номер фигуры, необходимо про-
а б
в г
Цепной код: 00003003223222 121 1
Разность: 3OOO31O33O13OO313O
Номер фигуры: OOO31O33O13OO313O3
Рис. 11.12. Шаги построения номера фигуры.
11.2. Дескрипторы границ
делать вышеописанную процедуру. Первый шаг состоит в нахожде-
нии базового прямоугольника, что иллюстрирует Рис. 11.12(6). Бли-
жайшим к нему по эксцентриситету среди прямоугольников поряд-
ка 18 является прямоугольник 3x6, поэтому строится сетка разбиения
базового прямоугольника, показанная на Рис. 1 1.12(b), и четыре на-
правления цепного кода ориентируются вдоль нее. Заключительный
шаг состоит в построении цепного кода и использовании его первой
разности для вычисления номера фигуры, как показано на
Рис. 11.12(г).
11.2.3. Фурье-дескрипторы
На Рис. 11.13 приведена АГ-точечная дискретная граница на плоско-
сти ху. Начиная с ее произвольной точки (х0, у0), будем обходить гра-
ницу, скажем, против часовой стрелки, и обозначим координаты
встречающихся точек границы (х0,у0), (xi,yi), (х^уД,---, (хк-ъУк~\).
Эти координаты можно записать в форме х(к) = хк и у(к) = ук. С ис-
пользованием таких обозначений границу можно представить в виде
последовательности координатных пар s(k) = [x(Z:), у(£)], где
к = 0, 1, 2,..., К—\. Далее, каждую пару координат можно рассматри-
вать как комплексное число, так что
Действительная ось
Рис. 11.13. Дискретная граница и ее представление в виде комплексной после-
довательности. Отмеченные точки (х0, >'о) и (Х], у ]) являются первыми двумя
точками последовательности (начальная точка выбрана произвольно).
936 Глава 11. Представление и описание
s(k) = x(k)+iy(k) (11.2-2)
для к = О, 1, 2,..., А"—1. Таким образом, х и у рассматриваются какдей-
ствительная и мнимая оси для последовательности комплексных чи-
сел. Несмотря на изменившийся способ интерпретации этой после-
довательности, сущность границы осталась прежней. Конечно, такое
представление имеет одно крупное преимущество: оно позволяет све-
сти двумерную задачу к одномерной.
Как мы видели в Разделе 4.2.1, дискретное преобразование Фурье
(ДПФ) конечной последовательности s(k) задается уравнением
1
а(и) =— У s(k)e~i2mik/ К
К .г.
(11.2-3)
для и = 0, 1,2,..., А"—1. Комплексные коэффициенты o(w) называют-
ся фурье-дескрипторами границы. Обратное преобразование Фурье,
примененное к этим коэффициентам, позволяет восстановить грани-
цу^):
АГ-1
s(k) = У o(u)e'2jtwA:/^
и=0
(П.2-4)
для к = 0, 1, 2,..., А"—1. Предположим, однако, что вместо всех коэф-
фициентов Фурье используются только первые Р из них. Это равно-
сильно тому, что в уравнении (11.2-4) принимается а(и) = 0 при и > Р— 1.
Результатом восстановления окажется следующее приближение s(k):
s(k) = ^a(u)el2mk К
и=0
(11.2-5)
для к = 0, 1,2,..., К— 1. Хотя при вычислении каждой компоненты ис-
пользуется лишь Р членов, к по-прежнему пробегает весь диапазон от
О до К— 1, т.е. в приближенной границе будет то же самое число точек,
хотя для восстановления их координат используется меньшее число
членов. Вспомним из рассмотрения фурье-преобразования в Главе 4,
что высокочастотные составляющие описывают мелкие детали, тог-
да как низкочастотные компоненты определяют общую форму грани-
цы. Следовательно, чем меньше Р, тем больше деталей границы теря-
ется. Это убедительно демонстрирует следующий пример.
11.2. Дескрипторы границ
Пример 11.3: Иллюстрация фурье-дескрипторов.
I На Рис. 11.14 изображена граница квадратной формы, состояшая из
К = 64 точек, а также результаты ее восстановления с помощью урав-
нения (11.2-5) при разных значениях Р. Обратите внимание, что лишь
начиная со значений Р около 8, восстановленная граница становит-
ся больше похожей на квадрат, чем на круг. Заметим также, насколь-
ко слабо остаются выраженными углы, пока Рне достигает значения
приблизительно 56, когда угловые точки начинают «выдаваться» из по-
следовательности. Наконец, при Р = 61 кривые начинают выпрямлять-
ся, и при добавлении еще одного коэффициента восстанавливается
почти точная копия оригинала. Итак, нескольких коэффициентов
низшего порядка достаточно для описания общей формы границы,
однако для точного восстановления резких деталей, например, углов
и прямолинейных участков, требуется значительно большее число
членов высокого порядка. Этот результат вполне понятен, если учесть
ту роль, которую играют в определении формы области низко- и вы-
сокочастотные составляющие.
Рис. 11.14. Примеры восстановления границы по фурье-дескрипторам. Робо-
значает число коэффициентов Фурье, использованных при восстановлении.
938 Глава 11. Представление и описание
Из предыдущего примера видно, что небольшого числа фурье-де-
скрипторов достаточно для описания границы по существу. Такое
свойство является ценным, поскольку эти коэффициенты несут ин-
формацию о форме, и, как мы увидим подробнее в (лаве 12, могут слу-
жить основой для различения границ по форме.
Выше неоднократно утверждалось, что дескрипторы должны
быть как можно менее чувствительными к параллельному перено-
су, повороту и изменению масштаба объектов. В тех случаях, когда
результат зависит от порядка обработки точек границы, ставится до-
полнительное требование, чтобы дескрипторы не зависели от выбо-
ра начальной точки. Фурье-дескрипторы сами по себе не инвариант-
ны к указанным геометрическим изменениям, однако измененные
дескрипторы могут быть получены несложными преобразованиями.
Например, применительно к повороту, вспомним из курса элемен-
тарного математического анализа, что поворот точки комплексной
плоскости на угол 0 относительно начала координат равносилен
умножению соответствующего числа на е/е. Выполнение этой опе-
рации для каждой точки s(k) приводит к повороту всей последова-
тельности на угол 0 относительно начала координат. Повернутая
последовательность s(k)e‘G характеризуется фурье-дескрипторами
следующего вида:
1 К-\
аг(и) = — s(k)e‘® ? к -а(и)е,в (11.2-6)
К к=0
для и = 0, 1,2,..., К— 1. Следовательно, поворот объекта приводит про-
сто к умножению всех коэффициентов на одинаковую мультиплика-
тивную константу е‘в.
В Таблице 11.1 приведены выражения для фурье-дескрипторов
последовательности точек границы s(k) после ее поворота, параллель-
ного переноса, изменения масштаба и смены начальной точки. Сим-
вол обозначает число ДЛ>, = Лл + iAy, поэтому запись st(k) = s(k) + Дх,.
соответствует последовательности, переопределенной путем параллель-
ного переноса:
s^£) = [x(£)+Aj-H[yU) + Aj . (11-2-7)
Другими словами, параллельный перенос состоит в прибавлении по-
стоянного смещения к координатам всех точек границы. Заметим,
что параллельный перенос не оказывает влияния на все дескрипторы,
кроме первого (и = 0), у которого значение дельта-функции б(ы) бу-
11.2. Дескрипторы границ
Таблица 11.1. Основные свойства дескрипторов Фурье.
Преобразование Граница Фурье-дескрипторы
Тождественное s(k) я(«)
Поворот sr(k)=s(k)eif> ar(u)=a(u)e'G
Параллельный перенос s'W=s(k)+Axy а1(и)=а(и)+Лху?>(и)
Изменение масштаба ss(k)=as(k) as(u)=aa(u)
Смена начальной точки sp(k)=s(k-k0) ar(u)=a(u)ei2nk^/K
дет ненулевым3. Наконец, выражение sp(k) = s(k — ко) означает пере-
определение последовательности в соответствии с уравнением
sp=x(k-ko)+iy(k-ko),
(11.2-8)
что попросту соответствует смене начальной точки последователь-
ности с к = 0 на к = Icq. Последняя строка таблицы показывает, что из-
менение начальной точки влияет на все дескрипторы по-разному, хо-
тя и известным способом, поскольку а(и) умножается на член,
зависящий от и.
11.2.4. Статистические характеристики
Форму участков границы (или кривых сигнатуры) можно количест-
венно описывать с помощью простых статистических характеристик,
таких как среднее, дисперсия и моменты более высокого порядка.
Чтобы увидеть, как это достигается, обратимся к Рис. 11.15(a), где по-
казан участок границы, и Рис. 11.15(6), на котором этот участок
представлен в виде одномерной функции g(r) свободной переменной
Рис. 11.15. (а) Участок границы, (б) Его представление одномерной функцией.
3 Вспомним из Главы 4, что преобразование Фурье от константы есть дельта-функ-
ция в начале координат, принимающая во всех остальных точках комплексной пло-
скости нулевые значения.
Глава 11. Представление и описание
г. Эта функция получается путем соединения двух крайних точек
границы отрезком, и последующим поворотом его до горизонталь-
ного положения. Координаты точек границы поворачиваются на
тот же угол.
Будем рассматривать амплитуду функции g как дискретную случай-
ную величину v и построим ее гистограмму р(г,), / = 0, I, 2,..., А— 1, где
А — число дискретных интервалов, на которые разбит диапазон амп-
литуд. Учитывая затем, что р(у,) есть оценка вероятности появления
значения vh аналогично определению (3.3-18) можно записать следу-
ющее выражение для центрального момента порядка п случайной ве-
личины V.
Л-1
Hn(v)= (11.2-9)
1=0
где
Л-1
(11.2-10)
i=0
Величина т есть среднее значение (математическое ожидание), а Ц2 —
дисперсия случайной величины г. В общем случае требуется лишь
несколько первых моментов, чтобы различать сигнатуры границ яв-
но отличающихся форм.
Альтернативный подход состоит в рассмотрении самой функции
g(r) как гистограммы, для чего она нормируется до единичной площа-
ди. Другими словами, g(rz) теперь трактуется как вероятность4 появ-
ления значения rz. В этом случае г рассматривается как случайная ве-
личина с центральными моментами
К-\
1=0
(11.2-11)
где
4 Такая интерпретация возможна лишь при условии, что функция g(r) неотрица-
тельна, т.е. выбранный участок границы оказывается по одну сторону отрезка, соеди-
няющего крайние точки этого участка. Кроме того, использование получаемых зна-
чений моментов для сравнения форм кривых потребует нормировки не только
площади под кривой, но также и диапазона изменения значений г, о чем авторы упо-
минают ниже. — Прим. ред. перевода.
tf-1
m=
/=0
(11.2-12)
В этой записи К — число точек границы, а ц„(г) непосредственно свя-
зано с формой функцииg(r). Например, второй момент ц2(/') характе-
ризует разброс значений функции относительно среднего значения г,
а третий момент Цз(г) является характеристикой симметричности
кривой относительно среднего значения.
По существу, нам удалось свести задачу описания двумерной гра-
ницы к описанию одномерных функций. Хотя описание с помо-
щью моментов — далеко не самый распространенный метод, это не
единственные дескрипторы, которые могут применяться для такой
цели. Например, другой метод основан на вычислении спектра по-
средством одномерного дискретного преобразования Фурье и исполь-
зовании затем первых q составляющих спектра для описания функ-
ции g(r). Преимущество моментов перед другими методами
заключается в простоте реализации, а также в том, что они позволя-
ют «физически» интерпретировать форму границы. Из Рис. 11.15
ясно, что данный метод инвариантен к повороту объекта, а норми-
ровку по размерам можно при желании получить путем масштаби-
рования диапазона значений g и г.
11.3.Дескрипторы областей
В этом разделе мы рассмотрим различные подходы, применяемые
для описания областей изображения. Напомним, что общепринятая
практика состоит в использовании комбинированного описания,
включающего дескрипторы как границ, так и областей.
11.3.1. Некоторые простые дескрипторы
Площадь области определяется как число пикселей, которые в ней
содержатся. Периметр области есть длина ее границы. Хотя площадь
и периметр иногда и применяются в качестве дескрипторов, это отно-
сится преимущественно к тем случаям, когда размеры интересующих
областей не меняются. Чаще эти дескрипторы используются при вы-
числении меры компактности области, которая определяется как от-
ношение квадрата периметра к площади. Компактность является без-
размерной величиной (и поэтому инвариантна к однородным
изменениям масштаба), которая принимает минимальное значение для
области круглой формы. С точностью до погрешностей, возникающих
Глава 11. Представление и описание
при повороте дискретных областей, компактность также инвариант-
на к ориентации объекта.
К числу других простых дескрипторов, применяемых для описа-
ния областей, относятся среднее значение и медиана яркостей элемен-
тов области, а также число пикселей со значениями яркости больше
и меньше среднего значения.
Пример 11.4: Извлечение информации из изображения с помощью
вычисления площадей.
Даже такой простой дескриптор области, как нормированная пло-
щадь, может оказаться весьма полезным для извлечения информации
из изображений. Рассмотрим в качестве примера Рис. 11.16, где при -
ведено инфракрасное спутниковое изображение американского кон-
тинента. Как уже подробно рассказывалось в Разделе 1.3.4, подобные
изображения позволяют вести глобальный учет населенных пунк-
тов. Применяемые для регистрации таких изображений сенсоры чув-
ствительны к излучению в видимом и ближнем инфракрасном диа-
пазонах и позволяют фиксировать свет и огонь, в том числе
кратковременные вспышки. В таблице на рисунке приведены отно-
шения площади белого (освещенные области) по регионам к общей
освещенной площади во всех четырех регионах. Даже такие простые
измерения позволяют, например, получить относительные оценки
энергопотребления по регионам. Эти данные можно уточнить пу-
тем нормирования по отношению к площади суши в регионе, числен-
ности населения и т.д.
11.3.2. Топологические дескрипторы
Для глобального описания областей на плоскости изображения час-
то оказываются полезными их топологические свойства. В общих
чертах, топология изучает свойства фигур, на которые не влияют лю-
бые их деформации, если не происходит разрывов и склеек (как буд-
то плоскость изображения ведет себя аналогично листу резины). На-
пример, на Рис. 11.17 показана область с двумя отверстиями внутри.
Если в качестве топологического дескриптора использовать число
отверстий внутри области, то это свойство, очевидно, будет инвари-
антным относительно растяжения или поворота. Однако, вообще го-
воря, число таких отверстий будет меняться, если область складыва-
ется или разрывается. Заметим, что хотя при растяжении и меняются
расстояния между точками области, топологические свойства не за-
висят ни от понятия расстояния, ни от каких-либо других свойств, не-
явно основанных на измерении расстояний.
11.3. Дескрипторы областей
943
Номер региона (сверху вниз) Доля освещенной площади от всей освещенной площади
1 0,204
2 0,640
3 0,049
4 0,107
Рис. 11.16. Инфракрасные спутниковые изображения американского конти
нента ночью. (Предоставлены службой NOAA).
Глава 11. Представление и описание
Рис. 11.17. Область с двумя отверстиями.
Другое полезное для описания области топологическое свойст-
во — это число ее связных компонент. Определение компоненты связ-
ности области было дано в Разделе 2.5.2. На Рис. 11.18 изображена об-
ласть, состоящая из трех компонент связности (См. Раздел 9.5.3, где
рассматривался алгоритм выделения связных компонент).
Число отверстий Ни число связных компонент С некоторой фи-
гуры используются в определении ее числа Эйлера Е:
ECU.
(11.3-1)
Ч исло Эйлера также является топологическим свойством. Например,
показанные на Рис. 11.19 области характеризуются числами Эйлера О
и — 1 соответственно, поскольку область «А» состоит из одной связной
компоненты и содержит одно отверстие, а область «В» также состоит
из одной связной компоненты, однако содержит два отверстия.
Области, образованные отрезками прямых (такие области приня-
то называть многоугольными сетями), допускают особо простую интер-
претацию в терминах числа Эйлера. На Рис. 11.20 показан пример
многоугольной сети. Внутренние области таких многоугольных сетей
часто бывает важно классифицировать как грани или отверстия. Обо-
Рис. 11.18. Область, состоящая из трех компонент связности
11.3. Дескрипторы областей
Рис. 11.19. Области, для которых числа Эйлера равны 0 и — 1 соответственно.
значая V — число вершин сети, Q — число ее ребер, a F— число гра-
ней, выпишем следующее соотношение, называемое формулой Эйлера'.
V-Q+F=C-H.
(11.3-2)
С учетом определения (11.3-1), обе части этого равенства равны чис-
лу Эйлера:
V-Q+F = C-H = E.
(11.3-3)
У сети, показанной на Рис. 11.20, имеется 7 вершин, 11 ребер, 2 гра-
ни, 1 связная компонента и 3 отверстия; следовательно, число Эйле-
ра равно —2:
7-11 + 2=1-3 =-2.
Рис. 11.20. Область, содержащая многоугольную сеть.
Глава 11. Представление и описание
Топологические дескрипторы часто бывают полезными дополнитель-
ными признаками, характеризующими области представленной на
изображении сцены.
Пример 11.5: Использование связных компонент для выделения мак-
симально крупных признаков в сегментированном изо-
бражении.
На Рис. 11.21(a) приведено полученное со спутника LANDSAT Агент-
ства NASA 8-битовое изображение размерами 512x512 элементов, отно-
сящееся к району г. Вашингтон (округ Колумбия). Это конкретное изо-
бражение было получено в ближнем инфракрасном диапазоне (подробнее
Рис. 11.21. (а) Инфракрасное изображение окрестностей г. Вашингтон, округ
Колумбия, (б) Изображение после порогового преобразования (в) Наиболее
крупная компонента связности (б), (г) Остов области (в)
11.3. Дескрипторы областей
см. Рис. 1.10). Предположим, что мы хотим выделить область реки на ос-
нове только этого изображения (без использования других компонент
многозонального изображения, что упростило бы задачу). Поскольку реч-
ной поверхности на изображении соответствует относительно темная од-
нородная область, для ее выделения естественно попробовать применить
пороговое преобразование. На Рис. 11.21(6) показан результат примене-
ния такого преобразования с максимальным значением порога, при ко-
тором область реки еще остается связной. Этот порог был выбран вруч-
ную, чтобы наглядно показать, что в данном примере с помощью
порогового преобразования невозможно выделить на изображении толь-
ко реку, не захватив одновременно и части других областей. Цель этого
примера — показать, как можно использовать компоненты связности на
заключительной стадии сегментации.
В изображении на Рис. 11.21 (б) имеется 1591 связная компонента (при
выделении на основе отношения 8-связности) и число Эйлера для не-
го равно 1552, откуда можно заключить, что имеется 39 отверстий.
Рис. 11.21 (в) демонстрирует компоненту связности с наибольшим чис-
лом элементов (8479). Это и есть желаемый результат, который, как мы
уже знаем, невозможно получить просто сегментацией. Обратите вни-
мание на чистоту полученных данных. Если мы хотим провести неко-
торые измерения, например, длин всех рукавов и притоков реки, мож-
но для этого провести скелетонизацию найденной компоненты связности
(Рис. 11.21(г)); при этом длина каждой ветви остова области будет доволь-
но точным приближением длины соответствующего участка реки.
11.3.3. Текстурные дескрипторы
Одним из важных подходов к описанию областей является количест-
венное представление их текстурных признаков. Несмотря на отсут-
ствие формального определения текстуры, интуитивно ясно, что этот
дескриптор является мерой таких свойств области, как гладкость, ше-
роховатость и регулярность (на Рис. 11.22 даны несколько примеров).
В цифровой обработке изображений для описания текстуры области
применяются три основных подхода: статистический, структурный
и спектральный. Статистические методы позволяют охарактеризо-
вать текстуру области как гладкую, грубую, зернистую и т.д. Структур-
ные методы занимаются изучением взаимного положения простейших
составляющих изображения, как, например, при описании текстуры
из параллельных линий, проходящих с постоянным шагом. Спектраль-
ные методы основаны на свойствах Фурье-спектра и используются
прежде всего для обнаружения глобальной периодичности в изобра-
жении по имеющим большую энергию узким выбросам на спектре.
Глава 11. Представление и описание
Я б В Рис. 11.22. Белые квадраты отмечают (слева направо) области с гладкой, гру-
бой и периодичной текстурами. Приведены полученные с помощью оптиче-
ского микроскопа изображения сверхпроводника, человеческого холестери-
на и микропроцессора. (Изображения предоставил д-р Майкл У. Дэвидсон,
университет шт. Флорида).
Статистический подход
Один из простейших подходов, применяемых для описания тексту-
ры, состоит в использовании статистических характеристик, опре-
деляемых по гистограмме яркости всего изображения или его обла-
сти. Пусть z — случайная величина, соответствующая яркости
элементов изображения, ap(zi), 1 = 0, 1,2,..., L— 1 — ее гистограмма,
где L обозначает число различных уровней яркости. Согласно урав-
нению (3.3-18), центральный момент порядка п случайной величи-
ны г равен
Л-1
i=0
(11.3-4)
где т — среднее значение z (средняя яркость изображения):
Л-1
/=()
(11.3-5)
Из (11.3-4) видно, что Цо = 1 и |1] = 0. Для описания текстуры особен-
но важен второй момент, т.е. дисперсия а2(г) = РзСД- Она является ме-
11.3. Дескрипторы областей
рой яркостного контраста, что можно использовать для построения де-
скрипторов относительной гладкости. Например, величина
R=\------(11.3-6)
l + a2(z)
равна 0 для областей постоянной яркости (где дисперсия нулевая) и
приближается к 1 для больших значений <л2(г). Поскольку для полу-
тоновых изображений со значениями элементов, скажем, от 0 до 255,
значения дисперсии оказываются большими, для использования в
уравнении (11.3-6) целесообразно нормировать дисперсию до интер-
вала изменения [0,1], для чего необходимо поделить a2(z) на (L — I)2.
Значение стандартного отклонения a(z) также часто используется в ка-
честве характеристики текстуры, поскольку оно, как правило, явля-
ется более наглядным.
Третий момент
£-1
(11.3-7)
z=0
является характеристикой асимметрии гистограммы, а четвертый мо-
мент характеризует так называемый эксцесс, т.е. остроту распределе-
ния. Пятый и шестой моменты не так легко соотнести с формой гис-
тограммы, но они, тем не менее, обеспечивают дальнейшее
количественное разграничение текстурных составляющих. Среди про-
чих полезных характеристик текстуры, основанных на гистограмме,
отметим «однородность», задаваемую выражением
£-1
^ = Xp2Uz), (Н.3-8)
/=о
и среднюю энтропию, которая, как читатель помнит из основ теории
информации или нашего рассмотрения в Главе 8, определяется выра-
жением
£-1
e = -^P(z№%lP(ZiY (11.3-9)
/=о
Поскольку все значения р находятся в интервале [0,1 ], и их сумма рав-
на 1, то максимум величины {/достигается для изображения, все эле-
менты которого имеют одинаковую яркость (максимально однород-
ное), и уменьшается по мере роста яркостных различий. Энтропия
Глава П. Представление и описание
характеризует изменчивость яркости изображения; она, наоборот,
равна 0 для области постоянной яркости и максимальна в случае рав-
новероятных значений.
Пример 11.6: Характеристики текстуры, основанные на гисто-
грамме.
В Таблице 11.2 приведены значения описанных выше характерис-
тик для текстур трех видов, которые были отмечены на Рис. 11.22.
Значение среднего характеризует просто средний уровень яркости
каждой из областей и на самом деле дает лишь грубое представление
об интенсивности, а не о текстуре. Стандартное отклонение значитель-
но более информативно; цифры ясно показывают, что первая тексту-
ра характеризуется значительно меньшей изменчивостью, чем две
другие (т.е. является более гладкой). Грубая текстура резко выделяет-
ся по этой характеристике. Как и следовало ожидать, то же самое
справедливо для величины R, потому что она характеризует по суще-
ству то же, что и стандартное отклонение. Третий момент в общем слу-
чае оказывается полезным для определения степени симметрии гис-
тограммы: наблюдается ли на ней перекос влево (при отрицательном
значении момента) или вправо (при положительном значении). Это
дает грубое представление о «скошенности» распределения яркости
в сторону светлых или темных значений от среднего. Применитель-
но к описанию текстуры, информация, содержащаяся в третьем мо-
менте, оказывается полезной только при большой разнице значе-
ний этой характеристики. Глядя на характеристику равномерности,
можно вновь заключить, что первая область является более гладкой
(более равномерной, чем остальные), а наиболее случайной (наиме-
нее равномерной) оказывается область с грубой текстурой, что не
удивительно. Наконец, значения энтропии располагаются в обратном
порядке и приводят нас к тем же выводам, что и характеристика рав-
номерности. Область первого изображения характеризуется наимень-
шей вариабельностью яркости, а область с грубой текстурой являет-
ся самой изменчивой. Периодичная текстура занимает промежуточное
положение по обеим этим характеристикам.
Таблица 11.2. Характеристики текстуры для областей изображений из Рис. 11.22.
Текстура Среднее Стандартное отклонение R (норми- ровано) Третий момент Одно- родность Энтропия
Гладкая 82,64 11,79 0,002 -0,105 0,026 5,434
Грубая 143,56 74,63 0,079 -0,151 0,005 7,783
Периодичная 99,72 33,73 0,017 0,750 0,013 6,674
Текстурные характеристики, которые вычисляются только на ос-
новании гистограммы, страдают определенной ограниченностью, по-
скольку не несут никакой информации о взаимном расположении
элементов изображения. Один из способов учесть подобную инфор-
мацию при анализе текстуры состоит в том, чтобы рассматривать не
только распределение яркостей, но и местоположение пикселей с рав-
ными или близкими значениями яркости.
Пусть Р — оператор позиционирования и А — матрица порядка кхк,
составленная из элементов az/, каждый из которых показывает, сколь-
ко раз элемент с яркостью z,- встретился на определяемой оператором
Рпозиции относительно элемента с яркостью z.j, где 1 < i,j<k. Напри-
мер. рассмотрим следующее изображение с тремя уровнями яркости
*1 = 0, z2 = 1 и z-i = 2:
0 0 0 1 2
110 11
2 2 10 0
110 2 0
0 0 10 1
Если определить оператор позиционирования /’как «на один пик-
сель вправо и вниз», получаем следующую матрицу А порядка 3x3:
4
А= 2
2 1
3 2
2 0
0
где, например, элемент а,, (левый верхний) есть число раз, когда
пиксель с яркостью z\ = 0 оказывается правее и ниже пикселя с такой
же яркостью, а элемент a j 3 (правый верхний) — число раз, когда пик-
сель с яркостью Zj = 0 оказывается правее и ниже пикселя с яркостью
Z3 = 2. Порядок матрицы А определяется количеством различных гра-
даций яркости в исходном изображении. Поэтому перед применени-
ем методов, рассматриваемых в данном разделе, обычно проводят
вторичное квантование на меньшее число градаций яркости, чтобы раз-
меры матрицы А оставались в разумных пределах.
Пусть п — число пар элементов изображения, которые удовлетво-
ряют условиям оператора Р(это сумма всех элементов матрицы А; в вы-
шеприведенном примере п = 16). Если построить матрицу С путем де-
ления всех элементов А на п, то с, у будет оценкой вероятности того
события, что пара пикселей с взаимным расположением согласно
Глава 11. Представление и описание
правилу Р будет иметь значения (г,-, Такая матрица С называется яр-
костной матрицей смежности. Поскольку она зависит от Р, то присут-
ствие в изображении участков с заданной текстурой можно обнаружи-
вать, выбирая надлежащий оператор позиционирования. Например, в
упомянутом примере был использован оператор, обнаруживающий
полосы равной яркости, идущие под углом —45 . (Заметьте, что наиболь-
шим элементом матрицы А был а} । = 4, отчасти благодаря полоске пик-
селей с нулевой яркостью, которая проходит под углом —45 ). В более
общем виде, задача состоит в том, чтобы на основании анализа данной
матрицы С определить, к какой категории относится текстура облас-
ти, для которой была вычислена эта матрица. Для этой цели можно
предложить следующий набор полезных дескрипторов:
1. Максимум вероятности
тах(с,-).
ij
2. Момент порядка к разности элементов
i j
3. Обратный момент разности элементов Л-го порядка
i J
4. Однородность
I j
5. Энтропия
I j
Основная идея состоит в том, чтобы охарактеризовать «содержимое» ма-
трицы С посредством этих дескрипторов. Например, первый из перечис-
ленных дескрипторов указывает значение наиболее сильного отклика на
оператор Р. Второй дескриптор принимает относительно малые значе-
11.3. Дескрипторы областей
ния, если элементы С с большими значениями лежат вблизи главной ди-
агонали, поскольку там разности (/ — j) меньше. Третий дескриптор ве-
дет себя противоположным образом. Четвертый дескриптор оказывает-
ся минимальным, когда все элементы с,у равны. Пятый дескриптор,
как уже отмечалось, является мерой хаотичности, и наоборот, когда
значения всех элементов С равны, принимает максимальное значение.
Один из способов использования этих дескрипторов состоит в «обу-
чении» системы характерным значениям дескрипторов на выборке из
различных текстур. После этого неизвестная текстура интересующей
области определяется по тому, насколько вычисленные для нее дес-
крипторы близки к наборам значений для известных текстур, найден-
ным на этапе обучения и хранящимся в памяти системы. Порядок со-
поставления более подробно рассматривается в Главе 12.
Структурный подход
Как отмечалось в начале данного раздела, второй важный класс опи-
саний текстур основан на структурном подходе. Пусть имеется прави-
ло, записанное в форме S —> aS, которое указывает, что символ раз-
решается переписывать в виде aS (например, троекратное применение
такого правила дает строку символов aaaS). Если а символически
представляет круг (Рис. 11.23(a)), и строке ааа... придан смысл «после-
довательность кругов вправо от начальной точки», то применение
правила 5 —» aS приводит к построению текстуры, изображенной на
Рис. 11.23(6).
Рис. 11.23. (а) Базовый элемент текстуры, (б) Текстура, строящаяся примене-
нием правила 5 -> aS. (в) Двумерная текстура, сгенерированная с помощью
этого и других правил.
[f954 Глава 11. Представление и описание
Далее, добавим к этой схеме еще несколько новых правил: S—> ЬА,
А сА, А с, А bS, S^a. Здесь появление b интерпретируется как
«круг ниже», а с — как «круг слева». С помощью таких правил можно
построить символьную строку aaabccbaa, которой соответствует пост-
роенная из кругов матрица 3x3. Таким же образом могут генерировать-
ся и более крупные текстурные образы, например, как на Рис. 11 .23(b).
(Отметим, однако, что по этим правилам можно сгенерировать и
структуры, не являющиеся прямоугольными).
Основная идея вышеприведенного обсуждения состоит в том, что
из относительно простых базовых элементов текстуры можно форми-
ровать более сложные текстурные образы с помощью некоторых пра-
вил, ограничивающих возможное взаимное расположение этих базо-
вых элементов. Эти принципы лежат в основе реляционных
дескрипторов — темы, которую мы подробнее рассмотрим в Разде-
ле 11.5.
Спектральный подход
Как указывалось в Разделе 5.4, спектр Фурье идеально подходит для
описания направленности присутствующих в изображении периоди-
ческих или квазипериодических двумерных структур. Эти глобальные
текстурные образы легко различаются на спектре в виде импульсов с
высокой энергией, однако их весьма непросто обнаружить с помощью
пространственных методов обработки, которые являются локальны-
ми по своей природе.
Мы рассмотрим здесь следующие три свойства фурье-спектра,
полезных для описания текстуры. (1) Выступающие пики спектра
указывают главное направление текстурной составляющей. (2) Мес-
тоположение этих пиков на частотной плоскости дает основной про-
странственный период текстуры. (3) После устранения всех периоди-
ческих составляющих путем фильтрации, в изображении остаются
только непериодические компоненты, которые затем могут описывать-
ся с помощью статистических методов. Напомним, что амплитуда
спектра симметрична относительно начала координат, так что доста-
точно рассматривать только половину частотной плоскости. Таким об-
разом, в нашем анализе каждая периодическая компонента текстуры
связана только с одним пиком спектра, а не двумя.
Обнаружение и интерпретация вышеупомянутых спектральных
признаков часто упрощается при переходе к полярным координатам,
в которых спектральная функция выражается в виде S(r, 0), где г и 0 —
переменные этой системы координат. Для каждого угла 0 функция
S(r, 0) может рассматриваться как одномерная функция Se(r). Анало-
гично, для каждого значения частоты г, Sr(0) является одномерной
’О
11.3. Дескрипторы областей
функцией. Анализ функции 5е(г) при фиксированном 0 дает картину
поведения спектра (скажем, наличие пиков) по направлению радиу-
са из начала координат, а исследуя 5г(0)при фиксированном г, полу-
чаем поведение спектральной функции вдоль окружности с центром
в начале координат.
Более глобальное описание получается интегрированием этих
функций (которое в рассматриваемом дискретном случае заменяется
сум м ированием):
S(r)=^SQ(r) (11.3-10)
0=0
и
*о
5(0)= £ 5Д0), (11.3-11)
Г=1
где Rq — радиус круга с центром в начале координат.
Результатом вычислений по формулам (11.3-10) и (11.3-11) явля-
ется получение пары значений (5(г), 5(0)) для каждой точки спектра
с координатами (г, 0). Варьируя эти координаты, можно построить две
одномерные функции 5(г) и 5(0), описывающие текстуру всего изоб-
ражения или области интереса в терминах энергии спектра. После
этого уже можно вычислять те или иные дескрипторы самих этих
функций, количественно характеризующие поведение последних.
Для этих целей обычно используются такие дескрипторы, как среднее,
положение максимума и дисперсия, а также разность между средним
и максимальным значениями функции.
Пример 11.7: Спектральный анализ текстуры.
Рис. 11.24 иллюстрирует использование уравнений (11.3-10) и
(11.3-11) для глобального описания текстуры. На Рис. 11.24(a) приве-
дено изображение с периодической текстурой, а на Рис. 11.24(6) — его
спектр. Графики функций 5(г) и 5(0) показаны, соответственно, на
Рис. 11 .24(b) и (г). График 5(г) демонстрирует типичную зависимость,
с большой энергией вблизи начала координат и постепенным сниже-
нием значений по мере увеличения частоты. На графике 5(0) видны
выступающие пики с шагом 45°, которые четко соответствуют пери-
одичности текстурной составляющей изображения.
Чтобы проиллюстрировать, как по виду графика 5(0) можно раз-
личать два вида текстур, на Рис. 11.24(д) приведено другое изображе-
ние, текстура которого проявляется преимущественно в горизонталь-
Глава 11. Представление и описание
ном и вертикальном направлениях. Рис. 11.24(e) демонстрирует гра-
фик функции 5(0) для спектра этого изображения. Как и ожидалось,
на графике видны пики через 90°. Таким образом, можно различить
эти две текстуры, просто анализируя форму соответствующих им за-
висимостей 5(0). С
а б
в г
Д е
Рис. 11.24. (а) Изображение с периодической текстурой, (б) Спектр, (в) Гра-
фик функции S(r). (г) График функции 5(0). (д) Другое изображение с пери-
одической текстурой отличающегося вида, (е) График функции 5(0) для изо-
бражения (д). (Изображения предоставила д-р Драгана Брзакович, университет
шт. Теннеси).
11.3. Дескрипторы областей
11.3.4. Моменты двумерных функций
Момент порядка (р + q) двумерной непрерывной функцииДх, у) оп-
ределяется как
трд= J J xpyQ f{x,y)dxdy ( • - )
дляр, q = О, I, 2,... . Теорема единственности [Papoulis, 1991] утверж-
дает, что для любой кусочно-непрерывной функцииДх,^), принима-
ющей ненулевые значения только в конечной области плоскости ху,
существует момент любого порядка, и последовательность моментов
(трд) однозначно определяется функцией Дх, у). И наоборот, (трд)
однозначно определяет функциюДх, у)-
Центральные моменты определяются следующим образом:
Vpg= J J (x-xy\y-y)qj\x,y)dxdy, (11.3-13)
где
_ ffl|0 - W01
х — —— и у = —— .
woo w00
Если f(x,y) — дискретное изображение, то равенство (11.3-13) прини-
мает вид:
= X ^x~^P{y-yf f^yV (11.3-14)
X У
Выпишем выражения для центральных моментов до третьего поряд-
ка включительно:
Й00 = X X <* - *)° (J - )° = X X f(x> У)=тоо
X у X у
Н10 = X I?*- *)’<У- y)°f(x,y)= ~ ~<™оо )= °
х у ™00
Hoi =Х ^(x-x)0(y-yyf(x,y)=mQ]-—(mQQ)=0
X V
Ни =Х
X У
"’10"Ч)1
= шц--------=m1|-xm01 = m11-^m10
^00
Н20 = X £ (* - *)2 (-У - -У)0 Дх, у)=
х У
2wi20
= ™20----------- + —= т20-------—= ™20~ -X™IO
^00 "4)0 "’00
Ног = X XU-x)°(y-У)2Дх,У)= т02--eL= ШО2- ^ШО1
х у "’00
М21 = X Х<х“ х)\у-у)хДх,у)= m2i - 2xW], - Уш20+ 2x2w01
х У
Н12 = У У(х- х>*У^2ДХ’у) = т\2- 2Ут\ 1 - xmQ2 + 2у2ш10
х у
Изо = У X<х“х)3СУ"У)° Дх’У)=тзо~ ^хт20 + 2х2т}0
х у
Поз = У Х(х- *)0(У- У)3ДХ,У )= "’оз — 3У"’02+ 2^2"%1 ‘
X у
Если подытожить,
Моо=,"оо Н02 = "’02->’"’01
Ию=° g3O=wi3O-3xw2o+2^2"’io
Hoi=O ц03=ш03-Зрд102+2у2д101
jill^ll-xw’oi^l-pMlO 1Л21 = т21-2хтп-ут20+ 2х2т01
И20=т20~хт10 И12 = т\2~ 2JW11-хт02+ 2У2т10
Нормированные центральные моменты, обозначаемые T]w, определяются как
П =^~
Чоа ’ /п 1 к\
где
11.3. Дескрипторы
Y=
P+Q
2
(11.3-16)
+ 1
дляp + q = 2, 3,....
С использованием моментов второго и третьего порядков может
быть выведен следующий набор из семи инвариантных моментов5.
01 -Л20 +Л02 (11.3-17)
Фг =(т120 _ Лог)2 + 4т1п (11.3-18)
Фз =(Лзо _ Зт]12)2 +(3т|21 - Лоз )2 (11.3-19)
04 =(лзо +Л12 )2 +(Л21 +Лоз )2 (11.3-20)
05 =(ЛзО-ЗЛ12)(ЛзО+Л12)[(Лзо + Л12 )2_ 3(Л21 + ЛоЗ )2]+ + (ЗЛ21 _Лоз)(Л21 +Лоз)[3(Лзо+Л12 )2_ (П21+Л оз )2] (11.3-21)
06 =0120_Лог)[(Лзо +Л12)2- (Л21+Лоз )2]+ + 4Пц(Пзо+П12)(П21 +Лоз) (11.3-22)
07 =(ЗЛ21_Лоз)(ЛзО+Л12)[(ЛзО+Л12 )2_ 3(П21 + ЛоЗ )2]+ + (ЗЛ12-Лзо)(Л21 +Лоз)[3(Лзо+Л12 )2_ 0121 + ЛоЗ )2] • (11.3-23)
Этот набор моментов является инвариантным по отношению к парал-
лельному переносу, повороту и изменению масштаба.
Пример 11.8: Инварианты двумерных моментов.
На Рис. 11.25(a) приведено исходное изображение, которое затем бы-
ло уменьшено в два раза (Рис. 11.25(6)), зеркально отражено
(Рис. 11 .25(b)) и повернуто на угол 2° (Рис. 11.25(г)) и 45° (Рис. 11,25(д)).
Затем для каждого из этих изображений согласно соотношениям
5 При выводе этих результатов используются понятия, выходящие за рамки нашего об-
суждения, которые подробно рассмотрены в книге Белла [Bell, 1965] и статье Ху [Ни, 1962].
Инварианты моментов допускают обобщение и на «-мерный случай [Mamistvalov, 1998].
Глава 11. Представление и описание
Рис. 11.25. Изображения, на примере которых демонстрируются свойства
инвариантов моментов (см. Таблицу 11.3).
(11.3-17) — (11.3-23) были вычислены семь инвариантов двумерных мо-
ментов и результаты прологарифмированы, чтобы сузить динамиче-
ский диапазон. Полученные значения представлены в Таблице 11.3,
откуда видно, что результаты для преобразованных изображений при-
мерно согласуются с инвариантами, вычисленными для исходного
11.4. Использование главных компонент для описания 961
Таблица 11.3. Логарифмы инвариантов моментов для изображений из
Рис. 11.25(a)—(д).
Инвариант Исходное изображение Половинный размер Зеркальное отражение Поворот на 2° Поворот на 45°
ф1 6,249 6,226 6,919 6,253 6,318
ф2 17,180 16,954 19,955 17,270 16,803
фЗ 22,655 23,531 26,689 22,836 19,724
ф4 22,919 24,236 26,901 23,130 20,437
ф5 45,749 48,349 53,724 46,136 40,525
фб 31,830 32,916 37,134 32,068 29,315
ф7 45,589 48,343 53,590 46,017 40,470
изображения. Основной причиной наблюдаемых расхождений явля-
ется дискретный характер данных, что особенно проявляется в случае
поворота изображений.
11.4. Использование главных компонент для
описания
Материал этого раздела можно применять и для границ, и для обла-
стей. Кроме этого, на его основе можно описывать наборы изображе-
ний, которые пространственно совмещены в момент регистрации,
но имеют отличающиеся значения пикселей (как, например, три цве-
товые составляющие RGB в цветном изображении). Предположим, что
даны три такие цветовые компоненты. Эти изображения можно рас-
сматривать как единое целое, если считать вектором любую группу, со-
стоящую из трех соответственных пикселей в каждом из них. Напри-
мер, пусть X], х2 и хз ~ значения первого пикселя в каждом из трех
изображений соответственно. Эти три элемента можно записать
в форме вектор-столбца х размерности 3:
*1
х= х2
х3
Один такой вектор представляет один общий пиксель во всех трех
изображениях. Если изображения имеют размеры М х N, то после
представления аналогичным образом всех их пикселей получим
К = MNтрехмерных векторов. Если регистрируется не 3, а л совмещен-
ных изображений, векторы станут «-мерными:
32 А-223
962 Глава 11. Представление и описание
(11.4-1)
Всюду на протяжении этого раздела мы будем считать, что все векто-
ры являются вектор-столбцами (т.е. матрицами порядка «х I). Записы-
вая их в строке текста, будем использовать нотацию х = (х], х2, • • •, х„)Т,
где Тобозначает операцию транспонирования.
Будем считать эти векторы реализациями случайной величины, точ-
но так же, как это делалось при построении яркостной гистограммы.
Разница состоит только в том, что теперь вместо таких характеристик,
как среднее значение и дисперсия случайной величины, мы будем
говорить о векторе математического ожидания и ковариационной ма-
трице случайного вектора. Вектор математического ожидания для ге-
неральной совокупности определяется как
mx = ^{xj (П.4-2)
где Е{ } есть ожидаемое значение аргумента, а индекс обозначает, что
ш связан с генеральной совокупностью векторов х. Напомним, что
ожидаемое значение вектора или матрицы формируется как набор
независимых математических ожиданий их компонентов.
Ковариационная матрица для генеральной совокупности векторов
определяется как
Сх =£’{(x-mx)(x-mx)r }. (11.4-3)
Поскольку х есть «-мерный вектор, то (х — шх)(х — шх )^и Сх — мат-
рицы порядка п х п. Элемент с,- матрицы Сх есть дисперсия х,-, т.е. z-ой
компоненты векторов х генеральной совокупности, а элемент с,у ма-
трицы Сх есть ковариация6 компонент х,- и Xj этих векторов. Значения
матрицы Сх действительные и симметричны относительно главной ди-
агонали. Если компоненты х,- и Xj являются некоррелированными, то
значение их ковариации равно нулю и, следовательно, с,у = су, = 0. За-
6 Напомним, что дисперсия случайной величины х, имеющей среднее значение т,
определяется какЕ{(х — т)2}. Ковариация (второй смешанный момент) двух случай-
ных величин х, и Xj определяется как Е{(х, — — /Эту)}. Если эти величины явля-
ются некоррелированными, значение их ковариации равно 0.
11.4. Использование главных компонент для описания 963
метим, что все эти определения при п = 1 сводятся к хорошо знако-
мым одномерным эквивалентам.
На основании выборки К векторов из генеральной совокупности,
приближенная оценка вектора математического ожидания находит-
ся с помощью обычного усреднения:
ш
1 к
х = ~77 X Х£ ’
А к=\
(11.4-4)
Аналогично, раскрывая произведение (х — шх)(х — шх)Т и используя
равенства (11.4-2) и (11.4-4), получаем следующую выборочную оцен-
ку для ковариационной матрицы:
1 к
Сх=^ХхлхГ-тхтх (11.4-5)
кк=\
Пример 11.9: Вычисление вектора математического ожидания и
матрицы ковариации.
В качестве иллюстрации соотношений (11.4-4) и (11.4-5) рассмот-
рим четыре вектора xf = (0, 0, 0)г, х2 = (1, 0, 0)г, х3 = (1, 1, 0)^и
х4 = (1, 0, 1)Т, где, как уже говорилось, мы используем транспониро-
вание для более удобной записи вектор-столбцов в строке текста.
Применяя равенство (11.4-4), получаем следующий вектор математи-
ческого ожидания:
шх
3
1
1
Аналогичным образом, с помощью соотношения (11.4-5) вычисляем
следующую матрицу ковариации:
16
С
X
1 1
3 -1
-1 3
Все элементы на главной диагонали матрицы равны между собой; это
означает, что дисперсия всех компонент векторов генеральной совокуп-
ности одинакова. Кроме того, корреляция компонент и х2, как и X]
ихз, положительная, а корреляция компонентх2 и х3 отрицательная.
964 Глава 11. Представление и описание
Поскольку матрица Сх является действительной и симметричной,
то для нее всегда существует ортонормированный базис, состоящий
из п собственных векторов [Noble, Daniel, 1988]. Пусть е, и X,,,
i = 1, 2,..., п, — набор собственных векторов и соответствующие им соб-
ственные значения7 матрицы Сх, которые для удобства упорядочим по
убыванию, так что Ху< Xj+i для j = 1,2,..., п— 1. Образуем матрицу А из
собственных векторов Сх, располагая их по строкам таким образом,
чтобы в первой строке записывался вектор, которому отвечает наиболь-
шее собственное значение, а в последней — собственный вектор, со-
ответствующий наименьшему собственному значению.
Будем использовать А в качестве матрицы преобразования, кото-
рое отображает векторы х в векторы у по следующему закону:
у = А(х-шх). (11.4-6)
Это выражение называется преобразованием Хотеллинга, которое, как
мы скоро увидим, обладает рядом интересных и полезных свойств.
Нетрудно показать, что получаемые в результате такого преобра-
зования векторы у имеют нулевое математическое ожидание, т.е.
шу = £{у}=0. (11.4-7)
Из элементарной теории матриц следует, что ковариационная матри-
ца генеральной совокупности векторов у выражается через матрицы
А и Сх следующим образом:
Су=АСхАг (11.4-8)
Более того, учитывая способ построения матрицы А, ковариационная
матрица Су является диагональной, и элементы, находящиеся на глав-
ной диагонали, суть собственные значения матрицы Сх, т.е.
7 По определению, собственные векторы и собственные значения матрицы С поряд-
ка лхл удовлетворяют условиям Се,- = для i = 1,2,..., п.
11.4. Использование главных компонент для описания 965
Все элементы этой ковариационной матрицы, расположенные вне
главной диагонали, равны 0, поэтому компоненты векторов у являют-
ся некоррелированными.
Учитывая, что все Ху являются собственными значениями матри-
цы Сх, а элементы любой диагональной матрицы, находящиеся на ее
главной диагонали, — собственными значениями этой матрицы [Noble,
Daniel, 1988], делаем вывод, что матрицы Схи Су имеют совпадающий
набор собственных значений. В действительности, это же относится
и к их собственным векторам.
Другое важное свойство преобразования Хотеллинга связано с
восстановлением х по у. Поскольку строки матрицы А представляют
собой ортонормированные векторы, отсюда следует, что А-1 = Аг, и,
значит, любой вектор х может быть восстановлен по соответствующе-
му вектору у с помощью соотношения
х = А7у+тх. (11.4-10)
Предположим, однако, что вместо использования всех собственных
векторов Сх, строится матрица преобразования А^, состоящая лишь из
к собственных векторов, которым отвечают к наибольших собствен-
ных значений; т.е. матрица А^ имеет размеры кхп. Тогда векторы у бу-
дут иметь размерность к, и восстановление по формуле (11.4-10) пе-
рестанет быть точным (подобно тому, как это было в рассмотренной
в Разделе 11.2.3 процедуре описания границы с помощью части коэф-
фициентов Фурье).
С использованием матрицы восстанавливаться будет вектор
х = А^у + шх. (11.4-11)
Можно показать, что среднеквадратическая ошибка между х и х за-
дается выражением:
п к п
= (11.4-12)
7=1 /=1 J=k+\
Первое равенство в (11.4-12) указывает, что ошибка равна 0, если
к = п (т.е. когда в преобразовании используются все собственные век-
торы ковариационной матрицы). Коль скоро значения Ху в нашем
построении монотонно убывают (при увеличении j), из соотноше-
ния (11.4-12) также видно, что при заданном к ошибку можно мини-
мизировать, выбирая к собственных векторов, которым соответству-
Глава 11. Представление и описание
ют наибольшие собственные значения. Таким образом, Преобразова-
ние Хотеллинга оптимально в том смысле, что оно минимизирует
среднеквадратическую ошибку между векторами х и их приближени-
ями х. Учитывая лежащий в основе преобразования Хотеллинга
принцип использования собственных векторов, отвечающих наи-
большим собственным значениям, его также называют приведением
к главным компонентам.
Пример 11.10: Описание изображений с помощью главных компо-
нент.
На Рис. 11.26 приведены шесть изображений, зарегистрированных
6-диапазонным мультиспектральным сканером, работающим в диа-
Канал 1 Канал 2
Канал 3
Канал 4
Канал 5
Канал 6
Рис. 11.26. Шесть компонент мультиспектрального изображения, полученно-
го путем аэросъемки. (Изображения предоставлены Лабораторией приклад-
ного дистанционного зондирования, Университет Пердью).
11.4. Использование главных компонент для описания
Таблица 11.4. Диапазоны регистрируемых длин волн для каналов.
Номер канала Диапазон длин волн (мкм)
1 0,40-0,44
2 0,62-0,66
3 0,66-0,72
4 0,80-1,00
5 1,00-1,40
6 2,00-2,60
пазонах длин волн, перечисленных в Таблице 11.4. Рассматривая эти
изображения в соответствии с Рис. 11.27, из каждого набора их соот-
ветственных пикселей можно построить 6-мерный вектор
х = (X], Х2,..., xg)Т. В данном примере изображения имели разрешение
384x239, так что выборка состояла из 91776 векторов, по которым
рассчитывались вектор математического ожидания и ковариационная
матрица Сх. В Таблице 11.5 указаны вычисленные собственные зна-
чения этой матрицы. Обратите внимание на явное преобладание двух
первых собственных значений.
С помощью уравнения (11.4-6) были построены преобразован-
ные векторы у, соответствующие всем исходным векторам х. Из этих
Рис. 11.27. Построение вектора из соответственных пикселей шести изобра-
жений.
Глава 11. Представление и описание
Таблица 11.5. Собственные значения ковариационной матрицы, полученной
для набора изображений на Рис. 11.26.
I1 I2 I3 I4 1? X6
3210 931,4 118,5 83,88 64,00 13,40
векторов непосредственным обращением схемы на Рис. 11.27 были по-
лучены изображения каждой из главных компонент, показанные на
Рис. 11.28. Компоненты 1 — 6 суть изображения, построенные из всех
компонент преобразованных векторов у] — у6. Напомним изэлемен-
Компонента 1
Компонента 2
Компонента 3 Компонента 4
Компонента 5
Компонента 6
Рис. 11.28. Шесть изображений главных компонент, вычисленных по исход-
ным изображениям на Рис. 11.26. (Изображения предоставлены Лаборатори-
ей прикладного дистанционного зондирования, Университет Пердью).
11.4. Использование главных компонент для описания
тарной теории матриц, что, например, координата^ получается ум-
ножением первой строки матрицы А на вектор-столбец (х — шх)Г
В первой строке матрицы А стоит собственный вектор, отвечаю-
щий максимальному собственному значению ковариационной матри-
цы выборки, и это собственное значение равно дисперсии яркости пер-
вого преобразованного изображения. Следовательно, исходя из чисел,
приведенных в Таблице 11.5, это изображение должно иметь наи-
больший контраст. Именно это наблюдается на Рис. 11.28. Посколь-
ку первые два преобразованных изображения отвечают приблизи-
тельно за 94% общей дисперсии8, становится совершенно понятен
столь низкий контраст четырех изображений остальных главных ком-
понент. Таким образом, вместо того, чтобы сохранять на будущее все
шесть исходных изображений, возможно, достаточно хранить только
первые два преобразованных изображения вместе с вектором шх и
первыми двумя строками матрицы А, на основании чего впоследствии
можно будет достаточно точно восстановить исходные изображения.
Такая способность к сжатию данных, хотя и не столь впечатляющая
по сегодняшним меркам, является полезным побочным результатом
преобразования Хотеллинга. Применительно к описанию это означа-
ет, что содержимое шести изображений описывается двумя изображе-
ниями плюс вектор математического ожидания и первые две строки
матрицы преобразования. Та же аргументация остается в силе, если
вместо целых изображений мы бы рассматривали их области.
Пример 11.11: Использование главных компонент для описания гра-
ниц и областей одиночного изображения.
J Выше мы показали, как приведение к главным компонентам при-
меняется для преобразования набора изображений или их областей.
В этом примере иллюстрируется способ применения главных компо-
нент для описания границ и областей одиночного изображения. Ис-
пользуемый подход состоит в формировании двумерных векторов,
составленных из координат границы или области. Рассмотрим объект,
изображенный на Рис. 11.29(a). Если предполагается описывать всю
его область, то векторы формируются из координат всех пикселей
объекта; если же описывается граница — из координат точек грани-
цы области.
8 Для сопоставления амплитуд полученных компонент было бы правильнее сравни-
вать среднеквадратические отклонения. Такая оценка показывает, что первые две ком-
поненты составляют вместе лишь 73% суммы сигналов, что хотя и снижает заявлен-
ную точность, но не меняет общего вывода. — Прим. ред. перевода.
Глава 11. Представление и описание
Рис. 11.29. (а) Изображение объекта, (б) Объект с наложенными собственны-
ми векторами, (в) Объект, повернутый согласно уравнению (11.4-6). Обший
эффект состоит в ориентации объекта по собственным осям.
Полученные векторы рассматриваются затем как совокупность
реализаций двумерного случайного вектора. Другими словами, каж-
дый пиксель объекта рассматривается как двухкомпонентный век-
тор х = (о, Ь)Т, где а и b суть значения координат этого пикселя по осям
%! и %2- Эти векторы используются для вычисления вектора математи-
ческого ожидания и ковариационной матрицы данной совокупности
(т.е. объекта). Задача теперь значительно упрощается, поскольку мы
имеем дело всего лишь с векторами размерности 2.
Общий эффект от применения уравнения (11.4-6) равносилен пе-
реходу к новой системе координат, начало которой совпадает с цент-
роидом совокупности (точка с координатами вектора математическо-
го ожидания), а оси совпадают с направлениями собственных векторов
ковариационной матрицы С*, как показано на Рис. 11.29(6). Эта сис-
тема координат ясно демонстрирует, что преобразование (11.4-6) есть
поворот до совпадения с направлениями собственных векторов, как по-
казано на Рис. 11.29(b). Фактически, такое выравнивание в точности
является механизмом, который обеспечивает декорреляцию данных.
Более того, поскольку собственные значения оказываются на глав-
ной диагонали матрицы Су, каждое из X, есть дисперсия составляющей
у, вдоль направления собственного вектора ez. Эти два собственных век-
тора взаимно перпендикулярны, и координатные оси yf, по оче-
видным причинам иногда называют собственными осями.
11.5. Реляционные дескрипторы 971
Принцип ориентации двумерного объекта по направлениям глав-
ных собственных векторов ковариационной матрицы играет важную
роль в описании. Как отмечалось выше, описание должно быть мак-
симально независимым от изменений размеров, сдвига и поворота объ-
екта. Возможность ориентировать объект по его собственным осям пре-
доставляет надежный способ устранить влияние поворота.
Собственные значения ковариационной матрицы равны дисперсиям
вдоль собственных осей, что можно использовать для нормирования
объекта по размерам. Влияние параллельного переноса устраняется пу-
тем центрирования объекта относительно его вектора математическо-
го ожидания, как видно из уравнения (11.4-6). Следует учитывать и тот
факт, что метод описания, изложенный в данном разделе, одинаково
применим как для областей, так и для их границ.
11.5. Реляционные дескрипторы
В Разделе 11.3.3 мы рассматривали принцип использования правил
подстановки при построении описания текстуры. В данном разделе эта
идея получит развитие в связи с реляционными дескрипторами. Они
с равным успехом могут применяться для границ и для областей, и глав-
ная цель таких дескрипторов — зафиксировать в форме правил под-
становки элементарные конфигурации, которые повторяются на гра-
нице или внутри области.
Рассмотрим простую структуру в виде лестницы, показанную на
Рис. 11.30(a). Предположим, что в результате сегментации на изобра-
жении была выделена такая структура, и теперь мы хотим описать ее
некоторым формальным способом. Определив два непроизводных эле-
менте? а и Ь, как показано на рисунке, мы можем закодировать фи-
Рис. 11.30. (а) Простая ступенчатая структура, (б) Структура в закодирован-
ном виде.
9 В оригинале — primitive element. — Прим, перев.
гуру на Рис. 11.30(a) в форме, показанной на Рис. 11.30(6). Самым оче-
видным свойством закодированной структуры является чередование
элементов а и Ъ. Следовательно, простой способ символьного описа-
ния состоит в построении формальной рекурсивной зависимости, в ко-
торой участвовали бы эти базисные элементы. В частности, это мож-
но сделать с помощью следующих правил подстановки:
1. S^aA
2. A^bS
3. А —>b,
где S и А — переменные, а элементы а и Ъ — константы, соответству-
ющие введенным непроизводным элементам. Правило 1 указывает, что
так называемый начальный символ S разрешается заменять на непро-
изводный элемент а со следующей за ним переменной А. Эта перемен-
ная, в свою очередь, в соответствии с правилом 2 может заменяться на
b или сочетание Ъ и S. Последний вариант позволяет снова применить
правило 1 и повторить ту же процедуру. При замене А на Ъ по прави-
лу 3 процедура заканчивается, поскольку в выражении больше не ос-
тается переменных. Рис. 11.31 демонстрирует несколько примеров
порождения с помощью указанных правил, где под каждой из фигур
цифрами указана очередность применения правил 1,2 и 3. Связь меж-
ду а и b во всех случаях сохраняется, поскольку по этим правилам
вслед за непроизводным элементом а всегда должен появиться Ь.
Примечательно, что с помошью этих трех простых правил подста-
новки может порождаться (и, значит, описываться) бесконечно мно-
го «похожих» структур. Как будет показано в Главе 12, достоинство это-
го подхода состоит также в наличии веского теоретического
обоснования.
Поскольку строки символов являются одномерными структурами,
применение их для описания изображений требует построения подхо-
дящего метода, позволяющего свести двумерные пространственные
Рис. 11.31. Примеры порождения для системы правил 5—>аА, А—> bS нА —>Ь.
11.5. Реляционные дескрипторы 973
отношения к одномерной форме. Большинство применений строк
символов к описанию изображения базируется на идее выделения из ин-
тересующего объекта линии, составленной из соединенных друг с дру-
гом отрезков. Один из таких подходов основан на прослеживании кон-
тура объекта с кодированием результата отрезками заданного
направления и/или длины. Рис. 11.32 иллюстрирует такую процедуру.
Другой, в чем-то более общий, подход состоит в том, чтобы опи-
сывать фрагменты изображения (например, однородные области ма-
лого размера) направленными отрезками (см. Рис. 11.33(a)), которые
могут соединяться не только как начало одного — с концом другого,
но и другими способами, как показано на Рис. 11.33(6), где представ-
лены некоторые типовые операции, которые можно определить для
абстрактных непроизводных элементов. На Рис. 1 1.33(b) предлагает-
ся конкретный набор таких элементов, состоящий из отрезков четы-
рех направлений, а Рис. Н.ЗЗ(г) демонстрирует последовательные
шаги построения определенной фигуры, где обозначение (~d) ис-
пользуется для указания на непроизводный элемент d с противополож-
ным направлением. Заметим, что у каждой такой составной структу-
ры имеется одно начало и один конец. Искомым результатом является
последняя строка, которая описывает законченную структуру.
Описания в виде строк символов лучше всего подходят для прило-
жений, в которых способы соединения непроизводных элементов
могут быть выражены в терминах «конец с началом» или иным непре-
рывным способом. Иногда области, сходные по текстурным призна-
кам или другим дескрипторам, оказываются несмежными, и для опи-
сания таких ситуаций требуются особые способы. Здесь одним из
наиболее продуктивных подходов является использование деревьев в
качестве дескрипторов.
Рис. 11.32. Кодирование границы области с помощью направленных отрезков.
Граница
Начало
Конец
Конец
Начало
Конец
Начало •---------
c+(~d)
(a+b) * с
d+[c+(~d)]
Рис. 11.33. (а) Абстрактные непроизводные элементы, (б) Операции над эле-
ментами. (в) Конкретный набор непроизводных элементов, (г) Шаги постро-
ения некоторой структуры.
Дерево Тесть конечное множество, состоящее из одной или более
вершин, такое что:
(а) существует единственная вершина $, принимаемая за корень де-
рева, и
(б) остальные вершины разделяются на m непересекающихся мно-
жеств, каждое из которых в свою очередь является деревом, называ-
емым поддеревом дерева Т.
11.5. Реляционные дескрипторы
Рис. 11.34. Простое дерево с корнем $ и концевыми вершинами ху.
Концевые вершины графа — это набор вершин внизу дерева (кото-
рые также называются листъямй), взятых в фиксированном порядке
(слева направо). Например, изображенное на Рис. 11.34 дерево име-
ет корень $ и концевые вершины ху.
Вообще говоря, есть два вида существенной информации об эле-
ментах (вершинах) дерева: (1) информация о самой вершине, храня-
щаяся в виде некоторых параметров, описывающих эту вершину, и
(2) информация о связях вершины с ее соседями, хранимая в виде на-
бора указателей на эти соседние вершины. Применительно к описа-
нию изображений, первый вид информации определяет фрагмент
структуры изображения (например, часть области или границы), тог-
да как второй вид информации определяет физическую связь этого
фрагмента структуры с другими фрагментами (т.е. отношение между
ними). Например, объект на Рис. 11.35(a) можно представить в виде
дерева с помощью отношения «находиться внутри». Тогда, если за
корень дерева принять область, обозначенную на рисунке $, видно, что
на первом уровне сложности внутри $ находятся области a and с, что
дает две ветви, исходящие от корня, какпоказано на Рис. 11.35(6). На
следующем уровне появляется область Ь, находящаяся внутри а, а
также области d и е внутри с. Наконец, областью/, находящейся вну-
три е, завершается построение дерева.
Рис. 11.35. (а) Простая область, состоящая из вложенных подобластей,
(б) Представление в виде дерева, полученное с помощью отношения «нахо-
диться внутри».
Заключение
Представление и описание объектов или областей, выделенных при
сегментации изображения, составляют начальные этапы работы боль-
шинства автоматизированных процессов, в которых участвуют циф-
ровые изображения. Такие описания, например, являются входной ин-
формацией для методов распознавания объектов, обсуждаемых в
следующей главе. Как показывает изложенный выше набор методов
описания, выбор того или иного подхода определяется рассматрива-
емой задачей. Цель состоит в том, чтобы выбрать дескрипторы, спо-
собные «ухватить» существенные различия между объектами или клас-
сами объектов, и которые в то же время были бы максимально
независимыми от изменений таких факторов, как местоположение объ-
екта, его размер и ориентация.
Ссылки и литература для дальнейшего изучения
Рассмотренное в Разделе 11.1.1 представление границ области с помо-
щью цепного кода впервые было предложено Фрименом [Freeman,
1961, 1974]. Современное состояние исследований по цепным кодам
представлено в работах Брибиески [Bribiesca, 1999], который также рас-
пространил цепные коды на трехмерный случай [Bribiesca, 2000]. Пред-
ставление границ с помощью многоугольников (Раздел 11.1.2) вызыва-
ет значительный интерес ввиду простоты и продуктивности. Типичные
работы, проделанные в этой области за последнее десятилетие, рассма-
триваются в статьях [Bengtsoon, Eklundh, 1991] и [Sato, 1992]. В статье [Zhu,
Chirlian, 1995] представлен интересный подход к обнаружению точек из-
гиба при движении по кривой. По этой теме см. также статью [Hu, Yan,
1997]. Более поздние работы в этой области посвящены построению
инвариантного приближения ломаной линией [Voss, Suesse, 1997], ме-
тодам оценки производительности алгоритмов кусочно-линейной ап-
проксимации [Rosin, 1997], типовым методам реализации [Huang, Sun,
1999] и исследованию скорости вычислений [Davis, 1999].
Рассмотрение сигнатур (Раздел 11.1.3) проводится в книге [Ballard,
Brown, 1982] и статье [Gupta, Srinath, 1988]. Фундаментальные пост-
роения для нахождения выпуклой оболочки и дефекта выпуклости
(Раздел 11.1.4) проводятся в [Preparata, Shamos, 1985]. См. также ста-
тью [Liu-Yu, Antipolis, 1993]. В работе [Katzir et al., 1994] рассматрива-
ется обнаружение частично смыкающихся кривых. В статье [Zimmer
et al., 1997] рассматривается улучшенный алгоритм построения выпук-
лой оболочки, а статья [Latecki, Lakamper , 1999] обсуждает правило
выпуклости применительно к декомпозиции фигуры.
Алгоритм скелетонизации, рассмотренный в Разделе 11.1.5, ос-
нован на работе [Zhang, Suen, 1984]. Ряд полезных дополнительных за-
мечаний о свойствах и реализации этого алгоритма, приводятся в ста-
тье [Lu, Wang, 1986]. Статья [Jang, Chin, 1990] проводит интересную
связь между предметом рассмотрения Раздела 11.1.5 и морфологиче-
ским принципом утончения, представленным в Разделе 9.5.5. По по-
воду методов утончения в присутствии шума см. статьи [Shi, Wong, 1994]
и [Chen, Yu, 1996]. В работе [Shaked, Bruckstein, 1998] описывается ал-
горитм отсечения, полезный для удаления паразитных отростков ос-
това области. Быстрый алгоритм вычисления преобразования сре-
динной оси рассматривается в работах [Sahni, Jenq, 1992] и [Ferreira,
U bed а, 1999]. Представляет интерес обзорная статья [Loncaric, 1998],
касающаяся многих методов, обсуждаемых в Разделе 11.1.
В статье [Freeman, Shapira, 1975] дается алгоритм нахождения ба-
зового прямоугольника для замкнутой кривой, представленной с по-
мощью цепного кода (Раздел 11.2.1). Обсуждение номеров фигур в Раз-
деле 11.2.2 базируется на работах [Bribiesca, Guzman, 1980] и [Bribiesca,
1981]. В качестве дополнительного материала по фурье-дескрипторам
(Раздел 11.2.3) рекомендуются ранние работы [Zahn, Roskies, 1972] и
[Persoon, Fu, 1977]. См. также [Aguado et al., 1998] и [Sonkaet al., 1999].
В статье [Reddy, Chatteiji, 1996] обсуждается интересный подход, в
котором с помощью БПФ достигается инвариантность к параллель-
ному переносу, повороту и изменению масштаба. Материал Разде-
ла 11.2.4 базируется на элементарной теории вероятности (см., напри-
мер, [Peebles, 1993] и [Popoulis, 1991]).
В качестве дополнительной литературы по Разделу 11.3.2 см. кни-
ги [Rosenfeld, Как, 1982] и [Ballard, Brown, 1982]. Прекрасным введе-
нием в анализ текстуры (Раздел 11.3.3) является книга [Haralick,
Shapiro, 1992]. Ранний обзор по анализу текстуры приводится в ста-
тье [Wechsler, 1980]. Современные работы в этой области представле-
ны статьями [Murinoet al., 1998] и [Garcia, 1999], атакже монографи-
ей [Shapiro, Stockman, 2001].
Подход с использованием инвариантов для моментов, изложенный
в Разделе 11.3.4, взят из статьи [Ни, 1962]. См. также [Bell, 1965]. Что-
бы получить представление о диапазоне возможных приложений ин-
вариантов моментов, см. работы [Hall, 1979] о сравнении изображе-
ний и [Cheung, Teoh, 1999] об описании симметрии с помощью
моментов. Инварианты моментов для «-мерного случая обобщены в
работе [Mamistvalov, 1998].
Хотеллинг первым вывел и опубликовал метод преобразования дис-
кретных переменных в некоррелированные коэффициенты, названный
им методом главных компонент [Hotelling, 1933]. Эта статья демонстри-
33 А 223
рует глубокое понимание метода и заслуживает прочтения. Преобразо-
вание Хотеллинга было заново «открыто» в статье [Kramer, Mathews,
1956], а затем в [Huang, Schultheiss, 1963]. Главные компоненты все еще
остаются одним из основных инструментов описания изображений в
многочисленных прикладных задачах, примерами чего могут служить ра-
боты [Swets, Weng, 1996] и [Duda, Heart, Stork, 2001]. В качестве дополни-
тельных ссылок по материалу Раздела 11.5 укажем монографии [Gonzalez,
Thomason, 1978] и [Fu, 1982]. См. также книгу [Sonka et al., 1999].
Задачи
11.1 *(а) Покажите, что переопределение начальной точки цепно-
го кода, так чтобы получаемая последовательность цифр
образовывала наименьшее целое число, делает код не за-
висящим от выбора начальной точки на границе.
(б) Найдите начальную точку, которая нормализует цепной код
11076765543322.
11.2 (а) Покажите, что вычисление первой разности цепного ко-
да делает его инвариантным по отношению к повороту, как
говорится в Разделе 11.1.1.
(б) Вычислите первую разность кода 0101030303323232212111.
11.3 *(а) Покажите, что описанный в Разделе 11.1.2 метод аппрок-
симации замкнутой ломаной линией, построенной с помо-
щью резиновой ленты, приводит к многоугольнику с ми-
нимальным периметром.
(б) Покажите, что если каждая клетка соответствует пикселю
на границе, то максимально возможная ошибка аппрок-
симации в этой клетке составляет л/2d, где d — мини-
мальное расстояние между соседними пикселями по гори-
зонтали или по вертикали (т.е. шаг сетки дискретизации,
использованной для получения цифрового изображения).
11.4 *(а) Опишите, как повлияет на полученный прямоугольник вы-
бор нулевого порога для ошибки в методе слияния, рассмо-
тренном в Разделе 11.1.2.
(б) А как такой же порог повлияет на метод разбиения?
11.5 *(а) Постройте для границы квадратной формы график сигна-
туры при использовании метода угла наклона касательной
к контуру, описанного в Разделе 11.1.3.
(б) Повторите то же самое для функции плотности крутизны.
Предполагайте, что стороны квадрата параллельны осям
координат, и в качестве опорной прямой используется ось
х. Начните с угла, ближайшего к началу координат.
11.6 Найдите аналитические выражения для сигнатуры каждой из
следующих границ и постройте их графики.
*(а) Равносторонний треугольник
(б) Прямоугольник
(в) Эллипс
11.7 Нарисуйте срединные оси
*(а) круга
*(б) квадрата
(в) прямоугольника
(г) равностороннего треугольника.
11.8 Для каждого из показанных ниже рисунков
*(а) Опишите действия, выполняемые в точкер на первом ша-
ге алгоритма скелетонизации, описанного в Разделе 11.1.5.
(б) Повторите то же для второго шага алгоритма, предполагая,
что р = 1 во всех случаях.
как будет выглядеть показанная ниже фигура после выполне-
ния:
*(а) Одного прохода первого шага алгоритма?
(б) Одного прохода второго шага (для результата, полученно-
го на шаге 1, а не исходного изображения)?
11.10*(а) Каков будет порядок номера фигуры для изображенной ни-
же фигуры?
(б) Получите сам номер фигуры.
11.11 Рассмотренная в Разделе 11.2.3 процедура использования де-
скрипторов Фурье состоит в выражении координат точек
контура комплексными числами, вычислении ДПФ для этих
чисел и сохранении затем лишь части членов ДПФ в качест-
ве описателей формы границы. При выполнении обратного
ДПФ будет получено некоторое приближение исходного кон-
тура. Для какого класса форм контуров полученное ДПФ бу-
дет состоять из действительных чисел и как следует провес-
ти координатные оси на Рис. 11.13, чтобы получить этот
результат?
*11.12 Укажите наименьшее число дескрипторов — статистических мо-
ментов, необходимых, чтобы различать сигнатуры фигур, по-
казанных на Рис. 11.5.
11.13 Приведите пример двух границ различной формы, у которых
дескрипторы математического ожидания и третьего момента
были бы одинаковы, а вторые моменты — отличались.
* 11.14 Предложите набор дескрипторов, с помощью которых можно
было бы различать по форме символы 0, 1, 8, 9 и X. (Подсказ-
ка: Воспользуйтесь топологическими дескрипторами в соеди-
нении с выпуклой оболочкой).
11.15 Рассмотрите изображение шахматного поля, состоящего из
чередующихся белых и черных квадратов со стороной т. Ука-
жите оператор позиционирования, который бы порождал яр-
костную матрицу смежности диагонального вида.
11.16 Постройте яркостную матрицу смежности для изображения
5x5, содержащего шахматное поле из чередующихся единиц и
нулей, если оператор позиционирования допределен следую-
щим образом:
* (а) «на один пиксель вправо»,
(б) «на два пикселя вправо».
Предполагайте, что левый верхний элемент изображения име-
ет значение 0.
11.17 Докажите справедливость равенств (11.4-7), (11.4-8) и (11.4-9).
*11.18 В Примере 11.10 отмечалось, что достоверное восстановление
шести исходных изображений может быть выполнено с помо-
щью всего двух изображений главных компонент, которым от-
вечают наибольшие собственные значения. Какая при этом бу-
дет внесена среднеквадратическая ошибка? Выразите свой ответ
в процентах от максимально возможного значения ошибки.
11.19 Пусть дан набор изображений размерами 64x64 и предположим,
что ковариационная матрица в (11.4-9) оказывается единичной
матрицей. Какова будет среднеквадратическая ошибка при
восстановлении исходных изображений согласно уравнению
(11.4-11), если используется только половина от всех собствен-
ных векторов?
*11.20 При соблюдении каких условий можно ожидать, что введен-
ные в Разделе 11.2.1 главные оси границы будут совпадать с ее
собственными осями?
11.21 Предложите пространственное отношение и постройте соот-
ветствующее ему представление в виде дерева для шахматно-
го поля из черных и белых квадратов. Считайте, что левый
верхний элемент черный, и ему соответствует корень дерева. В
построенном дереве из каждой вершины должно исходить не
более двух ветвей.
*11.22 С Вами заключен контракт на проектирование системы обра-
ботки изображений для обнаружения дефектов внутри твердых
пластмассовых дисков. Диски обследуются с помощью рент-
геновской системы, дающей 8-битные изображения с разреше-
нием 512x512 элементов. При отсутствии дефектов изображе-
ние выглядит «чистым», характеризуясь средней яркостью 100
с дисперсией 400. Дефекты проявляются в виде округлых об-
ластей, внутри которых около 70% пикселей имеют отклоне-
ние по яркости до 50 градаций от среднего значения 100. Диск
считается дефектным, если такая область занимает площадь бо-
лее 20x20 элементов. Предложите систему, основанную на ана-
лизе текстуры.
11.23 Компания, фасующая в пластмассовые бутылки различные
промышленные химикаты, прослышала о Ваших успехах в ре-
шении задач анализа изображений и нанимает Вас для разра-
ботки метода обнаружения не до конца заполненных бутылок
во время их движения на конвейерной линии (см. рисунок). Бу-
тылка считается заполненной не до конца, если уровень жид-
кости ниже середины между началом сужения и низом горлыш-
ка. Хотя бутылки движутся, система регистрации изображений
оборудована лампой-вспышкой, что создает эффект непо-
Глава 11. Представление и описание
движного изображения, которое выглядит очень похоже на
показанный пример. Основываясь на уже изученном матери-
але, предложите решение для обнаружения дефектных буты-
лок. Четко сформулируйте все сделанные предположения, ко-
торые влияют на выбор предлагаемого решения.
11.24 Узнав о том, как Вы успешно справились с задачей обнаруже-
ния неполных бутылок, к Вам обращается компания, желаю-
щая автоматизировать подсчет пузырьков в определенных тех-
нологических процессах с целью контроля качества. Компания
уже решила проблему регистрации изображений и может по-
лучать 8-битные изображения с разрешением 700x700 элемен-
тов, подобных примеру на рисунке ниже. Изображение пред-
ставляет площадь 7 см2. Для каждого изображения компания
хочет решить две следующие задачи: (1) определить долю пло-
щади, занимаемой пузырьками, по отношению ко всей площа-
ди изображения; и (2) подсчитать число отдельных пузырьков.
Основываясь на уже изученном материале, предложите реше-
ние этих задач. В этом решении обязательно укажите мини-
мальные размеры пузырька, который сможет обнаруживаться
предлагаемой системой. Четко сформулируйте все сделанные
предположения, которые влияют на выбор Вашего решения.
ГЛАВА 12
РАСПОЗНАВАНИЕ
ОБЪЕКТОВ
Одно из самых интересных свойств мира — это то, что его можно
рассматривать как составленный из образов.
Образ — это по существу структура, которая характеризуется
в большей степени расположением ее элементов,
чем их внутренней природой.
Норберт Винер
Введение
Завершим наше изучение сферы цифровой обработки изображений
знакомством с методами распознавания объектов. Как отмечалось в
Разделе 1.1, мы включили в тематику цифровой обработки изображе-
ний распознавание отдельных областей изображения, которые в этой
главе и будем называть объектами или образами.
Излагаемые в данной главе методы распознавания образов делят-
ся на две основные категории: методы, основанные на теории реше-
ний, и структурные методы. Первая категория имеет дело с образами,
описанными с помощью количественных дескрипторов, таких как
длина, площадь, текстура. Вторая категория методов ориентирована
на образы, для описания которых лучше подходят качественные дес-
крипторы, например, реляционные, обсуждавшиеся в Разделе 11.5.
В распознавании образов центральную роль играет принцип «обу-
чения» на выборке известных образов. Далее рассматриваются и ил-
люстрируются методы обучения, применимые как в структурном под-
ходе, так и в теории решений.
12.1 .Образы и классы образов
Под образом^ подразумевается некоторая упорядоченная совокупность
дескрипторов, подобных рассмотренным в Главе 11. В литературе по
1 Выше авторы отождествили распознаваемые объекты (в нашем случае области изо-
бражения) и их образы (т.е. представления в виде совокупности дескрипторов). Та-
Глава 12. Распознавание объектов
распознаванию образов эти дескрипторы часто называют признаками.
Классом образов (или просто классом) называется совокупность обра-
зов, обладающих некоторыми общими свойствами. Будем обозна-
чать классы символами coj, со2,..., гДе W— число классов. Под ма-
шинным распознаванием образов понимаются методы, позволяющие
относить образы к тем или иным классам — автоматически или с ми-
нимальным вмешательством человека.
В практических задачах получили распространение три формы
упорядоченного представления признаков: в виде векторов признаков
(для количественных дескрипторов), в виде символьных строк, а так-
же в виде деревьев (строки и деревья применяются для структурных
описаний). Образы, представленные векторами признаков, обозна-
чаются жирными строчными буквами, например, х, у, z, и имеют
форму
(12.1-1)
где каждая из компонентхг-представляет z'-ый дескриптор, ап — об-
щее число дескрипторов, связанных с данным образом. Образы пред-
ставляются вектор-столбцами (т.е. матрицами порядка wxl) вида
(12.1-1) или в эквивалентной форме х = (xj,x2,...,x„)r, где Т— опера-
ция транспонирования. Читатель помнит эту запись, уже использовав-
шуюся нами в Разделе 11.4.
Содержательное наполнение компонент вектора признаков х за-
висит от применяемого подхода к описанию самого физического объ-
екта. Проиллюстрируем это на простом примере, который в то же
время позволит ощутить историю этого научного направления, иду-
щего от классификации результатов измерений. В ставшей классиче-
ской статье Фишера [Fisher, 1936] сообщалось об использовании но-
вого метода, получившего название дискриминантный анализ (мы
рассмотрим его в Разделе 12.2), для распознавания трех видов цветков
кое отождествление часто встречается в литературе по распознаванию образов. Сле-
дуя этой укоренившейся традиции, мы будем в дальнейшем использовать термин «объ-
ект» наравне с понятием «образ», не делая между ними принципиального различия.
Отметим, что переход от объекта к его образу в общем случае необратим, и само изо-
бражение в дальнейшем содержательно не используется. — Прим. ред. перевода.
*2
л Iris virginica
n Iris versicolor
° Iris setosa
A AA
A A
АЛЛА ДДД Д
ДА A
АЛЛА Д д
аала A a
£& А ДА
&A A &S A A
Д □
□ □ □ A
□ Д~п tzhA
□ В еЕЬ a
□ Ц 11111 i
ш □ □ □
□ m
В В □ ш
0.5
о
о
о Qdo о
1 2 3 4 5
Длина лепестка, см
Рис. 12.1. Три вида цветков ириса, описанные двумя измерениями.
ириса (Iris setosa, Iris virginica и Iris versicolor) по данным измерений дли-
ны и ширины их лепестков (Рис. 12.1). В нашей сегодняшней терми-
нологии каждый цветок описывается результатами двух измерений, что
приводит к двумерному вектору признаков вида
х2
(12.1-2)
где X] и х2 соответствуют длине и ширине лепестка соответственно.
В данном случае три класса, обозначенные ад, о>2 и отвечают раз-
новидностям setosa, virginica и versicolor соответственно.
Поскольку для лепестков характерна изменчивость по длине и
ширине, описывающие их векторы признаков варьируются не толь-
ко от класса к классу, но также в пределах одного и того же класса.
На Рис. 12.1 приведены результаты измерения длины и ширины
для нескольких экземпляров каждой из разновидностей ириса. По-
сле того, как выбран набор измеряемых величин (состоящий из
двух характеристик в рассматриваемом случае), компоненты векто-
ра признаков становятся исчерпывающим описанием каждого фи-
зического образца. Таким образом, в данном случае каждый цветок
становится точкой в двумерном евклидовом пространстве. Заме-
Глава 12. Распознавание объектов
тим также, что в данном примере класс Iris setosa оказывается доста-
точно обособленным от двух других классов по данным измерения
ширины и длины лепестков; однако столь же успешного отделе-
ния друг от друга разновидностей virginica и versicolor не наблюдает-
ся. Это явление является иллюстрацией классической проблемы
выбора признаков, которая проявляется в том, что в конкретном
приложении степень разделимости классов сильно зависит от вы-
бора дескрипторов. Этот вопрос будет подробнее рассматриваться
в Разделах 12.2 и 12.3.
Рис. 12.2 демонстрирует другой пример построения вектора при-
знаков. Здесь интересующими объектами являются различные фигу-
ры искаженной формы, типичный пример которых изображен на
Рис. 12.2(a). Если выбрать в качестве способа представления объекта
его сигнатуру (см. Раздел 11.1.3), мы будем получать одномерные сиг-
налы с формой, подобной показанной на Рис. 12.2(6). Предположим,
что каждую сигнатуру решено описывать как набор значений ее амп-
литуды, для чего с заданным шагом проводится дискретизация по уг-
лу 0, которая дает последовательность точек отсчета 0j, 02,..., 0„. Тог-
да векторы признаков можно формировать, присваивая их
компонентам значенияXj = г(0|),Х2 = г(02),---,хЛ = г(0Л). Этим векто-
рам соответствуют точки в «-мерном евклидовом пространстве, а
класс образов можно представить себе в виде «-мерного «облака» в этом
пространстве. Отметим, что в такой постановке задачи искажение
формы объекта можно трактовать как шум сигнатуры.
Вместо того чтобы использовать значения амплитуды сигнатуры
непосредственно, мы могли бы вычислять, скажем, первые « статис-
тических моментов для данной сигнатуры (см. Раздел 11.2.4), а затем
использовать эти дескрипторы в качестве компонент вектора при-
знаков. Как уже ясно, векторы признаков можно построить и многи-
ми другими способами; некоторые из них будут представлены в этой
главе. На данный момент важно отчетливо понять, что выбор дес-
Рис. 12.2. Искаженный объект и соответствующая ему сигнатура.
12.1. Образы и классы образов
крипторов, на которых базируются компоненты вектора признаков,
оказывает глубочайшее влияние на конечные характеристики систе-
мы распознавания, использующей этот вектор признаков.
Описанная выше техника построения векторов признаков приво-
дит к классам образов, характеризующихся количественной информа-
цией. Однако в ряде практических областей характеристики образов
лучше описываются структурными связями. Например, распознавание
отпечатков пальцев основывается на взаимосвязях признаков отпечат-
ка, называемых мелкими деталями1. Эти признаки играют роль не-
производных элементов (примитивов), которые вместе с их относитель-
ными размерами и расположением описывают свойства линий
отпечатка, такие как обрывы, ветвления, слияния и несвязные сег-
менты. Такие задачи распознавания, в которых принадлежность к
классу определяется не только данными количественных измерений
признаков, но и пространственными отношениями между признака-
ми, обычно лучше решаются с использованием структурных методов.
Этот подход был нами впервые рассмотрен в Разделе 11.5; кратко на-
помним его здесь применительно к дескрипторам образов.
На Рис. 12.3(a) представлен образ в виде простой ступенчатой
структуры. Такой объект, конечно, может быть дискретизован, и за-
тем из его отсчетов построен вектор признаков, аналогично тому, как
это делалось для объекта на Рис. 12.2. Однако при таком описании бы-
ла бы потеряна базовая структура, образуемая повторением двух про-
стых непроизводных элементов. Более содержательным способом
описания было бы определение примитивов а и b и формирование об-
раза в виде символьной строки w = ...abababab..., как это показано на
Рис. 12.3(6). Такое описание отражает структуру данного конкретно-
Рис. 12.3. (а) Ступенчатая структура, (б) Структура, закодированная с помо-
щью непроизводных элементов а и Ь, в форме символьной строки ...ababab....
г В оригинале — minutiae. — Прим, перев.
Глава 12. Распознавание объектов
го класса объектов, требуя, чтобы связь осуществлялась по принципу
«начало одного примитива с концом другого», причем с обязательным
чередованием символов. Построенная подобным образом конструк-
ция годится для ступенчатых структур произвольной длины, но исклю-
чает другие виды структур, которые могли бы быть построены из тех
же непроизводных элементов а и b в других сочетаниях.
Описания в форме символьных строк порождают адекватные обра-
зы для таких объектов, структура которых базируется на относительно не-
сложных способах соединения примитивов; такая связь обычно соответ-
ствует формам границ фигур. Для многих при кладных задач применяется
более мощный подход, основанный на описании с помощью деревьев,
который рассматривался в Разделе 11.5. По существу, большинство
иерархически упорядоченных схем приводят к древовидным структу-
рам. Например, на Рис. 12.4 представлено спутниковое изображение
плотно застроенной центральной части города и окружающих ее жилых
пригородов. Обозначим символом $ всю область изображения. Показан-
ное на Рис. 12.5 представление в виде дерева, обращенного корнем вверх,
было получено с помощью структурного отношения «состоять из». Итак,
корень дерева представляет изображение целиком. Следующий уровень
показывает, что изображение составлено из центральной части города и
Рис. 12.4. Спутниковое изображение плотно застроенного центра г. Вашинг-
тон (округ Колумбия) и окружающих жилых районов. (Изображение предо-
ставлено Агентством NASA).
12.2. Распознавание на основе методов теории решений
Изображение
Жилые дома
Центр города
Жилой район
Здания
Плотная Большие
застройка здания
Площади с
магазинами
Дороги
Редкая Небольшие Лесопарковая Однорядные С редкими
застройка строения зона перекрестками
Дороги
Многорядные С частыми Кольцевые
перекрестками
Рис. 12.5. Описание изображения на Рис. 12.4 в виде дерева.
жилой зоны, которая, в свою очередь, состоит из жилых домов, шоссей-
ных дорог и площадей с магазинами. Следующий уровень пред лагает даль-
нейшую детализацию описания для жилых зданий и шоссейных дорог.
Разбиение подобного вида может продолжаться вплоть до предела нашей
способности разграничивать отличающиеся области на изображении.
В последующих разделах мы познакомимся с методами распознава-
ния объектов, которые описаны всеми упомянутыми выше способами.
12.2. Распознавание на основе методов
теории решений
Подход к задачам распознавания образов с позиций теории решений
основан на использовании решающих (или дискриминантных) функций.
Пустьх= (xi,X2,-..,xn)T — «-мерный вектор признаков объекта, обсуж-
давшийся в Разделе 12.1. Основная задача распознавания в теории ре-
шений формулируется следующим образом. Предположим, что суще-
ствует W классов образов со, , со2 . (Ощ. Требуется найти W
дискриминантных функций (х), J2(x),..., <7щ(х), таких, что если об-
раз х принадлежит классу со,-, то
ф(х) >dj(x) /=1,2,...,Ж; jVz. (12.2-1)
Другими словами, незнакомый образ х относят к z-ому классу, если при
подстановке х во все дискриминантные функции наибольшее числен-
ное значение дает функция J,(x). В случае неоднозначности решение
принимается произвольным образом.
Глава 12. Распознавание объектов
Разделяющая поверхность между классами со,- и соу задается множе-
ством значений х, для которых с/,(х) = с^-(х), или, что то же самое, та-
кими х, для которых
d,(x)-dy(x) = 0.
(12.2-2)
Общепринятая практика состоит в том, чтобы описывать разделяю-
щую поверхность между двумя классами единой функцией
djj(x) = с/,(х) - dj(x) = 0. Тогда dy(x) > 0 для образов из класса со,- и
</,у(х) < 0 для образов из класса соу. Главная цель этого раздела состо-
ит в рассмотрении различных подходов, применяемых для отыскания
дискриминантных функций, удовлетворяющих неравенству (12.2-1).
12.2.1. Сопоставление
В методах распознавания, основанных на сопоставлении, каждый
класс представляется вектором признаков образа, являющегося про-
тотипом этого класса. Незнакомый образ приписывается к тому
классу, прототип которого оказывается ближайшим в смысле зара-
нее заданной метрики. Простейший подход состоит в использовании
классификатора, основанного на минимальном расстоянии, который,
как ясно из названия, вычисляет евклидовы расстояния между век-
тором признаков неизвестного объекта и каждым вектором прото-
типа. Решение о принадлежности объекта к определенному классу
принимается по наименьшему из таких расстояний. Мы также рас-
смотрим корреляционный подход, который формулируется непосред-
ственно в терминах изображений и поэтому вполне нагляден.
Классификатор по минимуму расстояния
Предположим, что прототип каждого класса определяется как вектор
математического ожидания образов из этого класса:
>1.2.-.»'. <12.2-3)
V j хе a j
где Nj — число векторов признаков объектов класса соу, и суммирова-
ние ведется по всем таким векторам. Как и прежде, W обозначает
число классов. Как уже отмечалось выше, один из способов отнести
неизвестный объект с вектором признаков х к какому-то классу состо-
ит в выборе того класса, прототип которого окажется ближайшим. При
использовании евклидова расстояния в качестве меры близости зада-
ча сводится к вычислению расстояния
12.2. Распознавание на основе
D/(x) = ||x-my|| j=\,2,...,W, (12.2-4)
где ||а|| = (а^а)'/2 — евклидова норма. После этого объект х относится
к тому классу со,, для которого расстояние Pz(x) оказывается наимень-
шим. Таким образом, в данной постановке минимальное расстояние
до прототипа означает наилучшее совпадение. Нетрудно показать
(Задача 12.2), что выбор кратчайшего расстояния эквивалентен вычис-
лению функций
J,(x) = xrm,-—m^ni, j=\,2,...,W (12.2-5)
и отнесению затем х к тому классу coz, для которого Jz(x) принимает на-
ибольшее численное значение. Такая формулировка согласуется с по-
нятием дискриминантной функции, определяемой согласно соотно-
шению (12.2-1).
Из уравнений (12.2-2) и (12.2-5) следует, что разделяющая поверх-
ность между классами coz- и со, в случае классификатора по минимуму
расстояния задается уравнением
dtj (х) = dt (х) - dj (х) = хг(ш, - niy) -1 (mz - шу) 7(mz - ) = 0. (12.2-6)
Заданная уравнением (12.2-6) поверхность представляет собой пер-
пендикуляр, проведенный через середину отрезка, соединяющего
точки mz- и Шу в пространстве признаков (см. Задачу 12.3). В случае п = 2
это есть линия, при п = 3 — плоскость, а при п > 3 называется гипер-
плоскостью.
Пример 12.1: Иллюстрация классификатора по минимуму рассто-
яния.
На Рис. 12.6 показаны два класса образов, выделенных из приме-
ров цветков ириса на Рис. 12.1. Для этих двух классов, Iris versicolor и
Irissetosa, обозначенных, соответственно, coj и о^, выборочные оцен-
ки векторов математического ожидания равны го, = (4,3; 1,3)ги
ш2 = (1,5; 0,3)7 Согласно уравнению (12.2-5), дискриминантные
функции имеют вид
(х) = хЛп! - mi= 4,3xj + 1,3х2 - 10,1
и
Глава 12. Распознавание объектов
Рис. 12.6. Разделяющая поверхность для классов Iris versicolor и Iris setosa в слу-
чае классификатора по минимуму расстояния. Кружок и квадратик черного
цвета указывают положения математических ожиданий обоих классов.
d2 (х) = x^m2 - m2 m2 = l,5xj + 0,Зх2 -1,17.
В соответствии с (12.2-6), уравнение разделяющей поверхности при-
нимает вид
d12(x) = d](x)-d2(x)=2,8xj +1,0х2-8,9 =0.
На Рис. 12.6 показан график этой разделяющей поверхности (об-
ратите внимание, что масштаб по координатным осям неодинаков).
Подстановка в ее уравнение любого вектора признаков объекта из
класса соj приводит к результату с/, 2(х) > 0, а из класса сд? — напротив,
к <7,2(х) < 0. Другими словами, чтобы определить, к какому из двух этих
классов принадлежит неизвестный образ, достаточно исследовать
знак функции с/]2(х).
Классификатор по минимуму расстояния хорошо работает в тех
практических задачах, где расстояния между точками математических
ожиданий классов велики по сравнению с диапазоном разброса объ-
ектов каждого класса. В Разделе 12.2.2 мы покажем, что оптимальные
(в смысле минимизации средних потерь от ошибок распознавания) ха-
рактеристики классификатора по минимуму расстояния достигают-
ся, когда распределение каждого класса имеет форму гиперсферы в
и-мерном пространстве признаков с центром в точке его математиче-
ского ожидания.
На практике редко встречаются случаи, когда одновременно и ма-
тематические ожидания классов далеко разнесены друг от друга, и
разброс объектов каждого класса достаточно мал; разве что сама при-
рода исходных данных находится под контролем проектировщика
системы. Прекрасным примером такого рода могут служить системы
автоматического чтения знаков стилизованного печатного шрифта, на-
пример, хорошо известного шрифта Е-13В, используемого Амери-
канской банковской ассоциацией3. Каквидно из Рис. 12.7, этот шрифт
Рис. 12.7. Набор символов шрифта Е-13В Американской банковской ассоци-
ации и соответствующие им формы сигналов.
3 Таким шрифтом, в частности, печатается код банка и номер счета на банковских че-
ках в США. — Прим, перев.
состоит из 14 символов, которые были специальным образом нарисо-
ваны на сетке 9x7 элементов, чтобы упростить их считывание. Эти зна-
ки обычно печатаются типографской краской, содержащей мелкий по-
рошкообразный магнитный материал. Перед считыванием документ
с краской попадает в магнитное поле, которое усиливает каждый сим-
вол, упрощая его выделение. Иначе говоря, задача сегментации реша-
ется с помощью искусственного подчеркивания ключевых характери-
стик каждого символа.
Символы обычно сканируются в горизонтальном направлении
магнитной читающей головкой с одиночным зазором, ширина ко-
торого много меньше ширины символа, а высота превышает высо-
ту символа. При прохождении головки над символом она выдает
одномерный электрический сигнал (сигнатуру), который нормиру-
ется так, чтобы его амплитуда была пропорциональна скорости убы-
вания или возрастания суммарной площади линий символа в зоне за-
зора головки. Например, рассмотрим на Рис. 12.7 форму сигнала,
связанного с цифрой 0. При движении головки слева направо сум-
марная площадь символа под зазором сначала увеличивается, что да-
ет положительную производную (положительную скорость измене-
ния площади). По мере того, как зазор головки выходит за левую
боковину цифры, площадь начинает уменьшаться, давая отрица-
тельную производную. Когда головка находится в средней зоне сим-
вола между боковинами, площадь остается примерно постоянной, что
соответствует нулевой производной. Такая же последовательность по-
вторяется при проходе головки над правой боковиной символа. Осо-
бое начертание шрифта гарантирует, что форма сигнала для каждо-
го знака отличается от других, и этим также обеспечивается то, что
и пики и нулевые значения сигнала попадают на вертикальные ли-
нии сетки, как это показано на Рис. 12.7. Особенностью шрифта
Е-1 ЗВ является то, что отсчеты сигнала только в этих точках дают до-
статочно информации для правильной классификации знаков. При-
менение магнитной краски помогает получать сигналы чистой фор-
мы с минимальным разбросом.
Классификатор по минимуму расстояния для такого приложения
можно построить достаточно просто. Запомним набор значений каж-
дого сигнала в точках, соответствующих сетке дискретизации, придав
этому набору смысл вектора прототипа Шу, у = 1,2,..., 14. При поступ-
лении неизвестного символа, подлежащего классификации, он ска-
нируется описанным выше способом и выходной сигнал дискретизу-
ется по той же сетке. Набор полученных значений образует вектор х,
после чего символ будет отнесен к тому классу, для которого вектор
прототипа максимизирует значение Jz-(x) в (12.2-5). Высокая скорость
классификации может быть достигнута с использованием аналоговых
схем, составленных из блоков резисторов (см. Задачу 12.4).
Корреляционное сопоставление
Теоретические основы корреляции изображений были изложены в
Разделе 4.6.4. Здесь мы воспользуемся корреляцией как средством
поиска эквивалентов эталона w(x, у) размерами JxK на изображении
f(x, у) размерами MxN; предполагается, что J<MvlK<N. Хотя кор-
реляционный подход можно излагать в векторной форме (см. Зада-
чу 12.5), однако более наглядным (и традиционным) вариантом явля-
ется непосредственное использование значений элементов
изображения или области.
В самой простой форме корреляция между изображениями f(x, у)
и w(x, у) задается выражением
с(х,у) = ,/)w(x + s,y+Z) (12.2-7)
5 t
для х = 0, 1, 2,..., М— 1, у = 0, 1, 2,..., N— 1, где суммирование ведется
по той области изображения, где w и /пересекаются. Сравнивая это вы-
ражение с уравнением (4.6-30), заметим, что здесь неявно предпола-
гается действительность значений всех функций и не используется кон-
станта MN. Причины этого в том, что мы собираемся пользоваться
нормированной функцией, в которой зависимость отданных разме-
ров будет скомпенсирована, а также в том, что определение (12.2-7) яв-
ляется общепринятым. Кроме того, в (12.2-7) используются перемен-
ные 5 и t, чтобы не путать их с т и п, которые в этой главе задействованы
для других целей.
Рис. 12.8 иллюстрирует процедуру корреляции в предположении,
что начало координат/находится в левом верхнем углу изображения,
а начало координат w — в центре эталона. Для одной точки (х, у) изо-
бражения / скажем, точки (х0, у0), применение формулы (12.2-7) да-
ет одно значение с(х0, у0). При изменении х и у эталон w скользит по
всему полю изображения, что дает в результате функцию с(х, у). По-
ложения максимумов функции с указывают те точки, где область w луч-
ше всего согласуется с изображением /. Заметим, что для значений х
и у вблизи краев изображения/точность теряется; величина ошибки
корреляции пропорциональна той доли площади эталона w, которая
выходит за границы изображения/. Это уже знакомая проблема кра-
ев, с которой мы много раз сталкивались в Главе 3.
Недостаток корреляционной функции, заданной уравнением
(12.2-7), состоит в ее чувствительности кизменениям амплитуд /и w.
Глава 12. Распознавание объектов
Рис. 12.8. Схема для получения значения корреляции/и w в точке (х0, у0).
Например, удвоение всех значений /приведет к увеличению вдвое
значений функции с(х, у). Чтобы преодолеть это затруднение, часто ис-
пользуется подход, при котором сопоставление осуществляется с по-
мощью коэффициента корреляции, определяемого выражением
££[/(VW(V)][w(x + s,y+O-w]
у(х,у) =
(12.2-8)
££[/0,0V(v)]2££Hx+.s,y+f)-w]2 >
st st
гдех = 0,1, 2,..., М— 1,у = 0,1, 2,..., N— 1, w — среднее значение пик-
селей в эталоне w (вычисляемое только один раз), / — среднее зна-
чение элементов изображения/в области, совпадающей с текущим по-
ложением w, а суммирование ведется по всем парам координат, общим
для fww. Коэффициент корреляции у(х, у) изменяется в диапазоне от
—1 до 1 и не зависит от изменения масштаба амплитуд /и и (см. За-
дачу 12.5).
Пример 12.2: Сопоставление объектов с помощью коэффициента
корреляции.
Рис. 12.9 иллюстрирует описанный принцип. На Рис. 12.9(a) при-
ведено изображение f(x, у), а на Рис. 12.9(6) — эталон w(x, у). Коэф-
Рис. 12.9. (а) Изображение, (б) Эталон, (в) Коэффициент корреляции между
(а) и (б). Заметим, что максимальная (самая яркая) точка массива (в) находит-
ся в позиции, где область (б) совпадает с буквой «D» на изображении (а).
фициент корреляции у(х, у) показан как изображение на Рис. 12.9(b).
Наибольшее (т.е. самое яркое) значение у(х, у) достигается в той точ-
ке, где найдено наилучшее совпадение /и ж
Хотя корреляционная функция может быть нормирована относи-
тельно изменений амплитуды путем перехода к коэффициенту корре-
ляции, достичь нормировки относительно поворота или изменения
размера не так просто. Нормировка относительно размеров связана с
пространственным масштабированием, что само по себе связано с
весьма трудоемкими вычислениями. Нормировка относительно пово-
рота является еще более трудной задачей. Если из изображенияf(x, у)
можно извлечь подсказку о величине поворота, то достаточно просто
повернуть эталон w(x, у) на тот же угол, чтобы направления осей изо-
бражения и эталона совпали. Однако если данные о повороте неизве-
стны, то для поиска наилучшего совпадения потребуется проанализи-
ровать всевозможные повороты эталона w(x, у). Такая процедура
трудно применима на практике, поэтому корреляция редко использу-
ется в тех случаях, когда возможен произвольный поворот распозна-
ваемого объекта.
В Разделе 4.6.4 мы отмечали, что корреляция также может вычис-
ляться в частотной области с помощью БПФ. Если размеры f и w
одинаковы, такой подход может оказаться более рациональным, чем
непосредственная реализация корреляционного метода в простран-
ственной области. Уравнение (12.2-7) применяется в тех случаях,
когда эталон w значительно меньше изображения/. Компромиссная
оценка, полученная Кэмпбеллом [Campbell, 1969], показывает, что ес-
Глава 12. Распознавание объектов
ли число ненулевых элементов w меньше 132 (что соответствует обла-
сти с размерами приблизительно 13x13), непосредственная реализа-
ция уравнения (12.2-7) оказывается более выгодной, чем подход с ис-
пользованием БПФ. Разумеется, это число зависит от компьютера и
применяемых алгоритмов, но оно указывает те приблизительные раз-
меры обекта, начиная с которых имеет смысл рассматривать частот-
ную область в качестве альтернативы. Реализация вычисления коэф-
фициента корреляции в частотной области заметно труднее, поэтому
обычно его вычисляют напрямую в пространственной области.
12.2.2. Статистически оптимальные классификаторы
В этом разделе излагается вероятностный подход к распознаванию. Как
и в большинстве областей, связанных с измерением и интерпретаци-
ей физических явлений, вероятностные подходы оказываются важны-
ми в задаче распознавания образов из-за случайностей, влияющих
на порождение классов образов. Как будет видно из дальнейшего рас-
смотрения, можно выработать такой метод классификации, который
будет оптимальным в том смысле, что при его использовании будет до-
стигаться наименьшая (в среднем) вероятность появления ошибок
классификации (см. Задачу 12.10).
Основы
Обозначим через p(coz | х) вероятность того, что поступивший образ х
принадлежит классу со,-. Если классификатор относит к классу (Оу об-
раз х, в действительности принадлежащий классу со,-, это приводит к
потерям, которые обозначаются Zzy. Поскольку образ х может принад-
лежать любому из рассматриваемых Ж классов, средняя величина по-
терь, связанных с отнесением х к классу (Оу, равна
/}(х)=Х£^Т’(“л1х). (12.2-9)
к=\
В теории решений эту величину часто называют (условный) средний риск
(или потери). Из элементарной теории вероятностей известно, что при
р(А) > 0 и р(В) > 0 справедливо равенство р(А | Б) = [р(Л) р(В | А)] / р(В).
С его использованием перепишем уравнение (12.2-9) в следующей
форме:
. w
i-j (х)=—— Lkj р (х | ык )Р (ык), (12.2-10)
к=\
12.2. Распознавание на основе методов теории решений
где р(х | со^) — функция плотности распределения вероятностей обра-
зов класса a Дсо^.) — вероятность появления образа из класса о^.
Поскольку множитель 1/р(х) положителен и одинаков для всех ту(х),
j = 1,2,..., Ж, его можно опустить в уравнении (12.2-10); при этом упо-
рядоченность значений функций лу(х) не изменится. Тогда выражение
для условных средних потерь (с точностью до постоянного множите-
ля) сводится к
W
г;(х) = ££^.р(х|^)Р(^). (12.2-11)
к=\
Классификатор имеет возможность отнести поданный неизвест-
ный образ к любому из Wклассов. Если он будет для каждого обра-
за х вычислять функции 7*1 (х), г2(х),-.-, ги/(х) и приписывать этот
образ к тому классу, для которого потери минимальны, то суммар-
ное значение средних потерь по всем решениям будет минимальным.
Такой классификатор, минимизирующий суммарную величину сред-
них потерь, называется байесовским классификатором. Итак, байесов-
ский классификатор относит неизвестный образ х к классу со,, если
rz-(x) < /у(х) для j = 1, 2,..., Ж; jV i. Последнее неравенство можно за-
писать в виде:
YLkiP<x\(i>k)P(Gik)< Z fW7’(xl%)/’H) (12.2-12)
k=l q=\
для всех j Ф i. Обычно величина потерь при правильном выборе класса
принимается нулевой, а потери при ошибочном решении считаются оди-
наковыми и составляют некоторую ненулевую величину, скажем, 1.
При таких условиях функция потерь принимает вид
А;=1-5/у, (12.2-13)
где 8jj = 1 при i =j и 8zy = 0 при I Ф j, то есть потери равны 1 при оши-
бочном выборе класса и 0 при правильном решении. Функцию 8zy на-
зывают симметричной или нулъ-единичной функцией потерь. Подстав-
ляя (12.2-13) в (12.2-11), получаем
W
ri <х> = X 0 “ Ч/ Мх । ак)р<®к) = Р( х>- Н Х1 «у)Р(соу). (12-2-14)
Z—I
Тогда байесовский классификатор приписывает образ х к классу coz, ес-
ли для всех j Ф i
р(х) - p(x I (Oz) P((DZ) < p( x) - p( XI (Dy) P(CDy)
(12.2-15)
или, что то же самое, если
P(x|(dz)P(cdz)> p(x|(Dy)P((Dy) 7= 1,2,...,Ж; /V i. (12.2-16)
С учетом обсуждения, которое привело к неравенству (12.2-1), мы
видим, что байесовский классификатор в случае нуль-единичной
функции потерь есть не что иное, как вычисление дискриминантных
функций вида
(/у(х) = р(х|(о/)Р((о/) J=l, 2,. ..,W, (12.2-17)
с отнесением образа х к тому классу со,, у которого значение дискри-
минантной функции Jz-(x) оказывается наибольшим.
Дискриминантные функции, заданные соотношениями (12.2-17),
являются оптимальными в том смысле, что они минимизируют вели-
чину средних потерь из-за ошибочной классификации. Однако для до-
стижения оптимальности должны быть известны как функции плот-
ности распределения вероятностей образов каждого класса, так и
вероятности появления каждого из классов. Последнее требование
обычно не создает трудностей. Например, если все классы являются
равновероятными, то = 1/W. Даже если это и не так, вероятно-
сти классов обычно можно оценить на основе априорных сведений о
задаче. Совершенно по-другому обстоит дело с оценкой функции
плотности распределения р(х | соД Если векторы признаков х являют-
ся «-мерными, то р(х | со^) есть функция п переменных, для оценки ко-
торой (в случае функции неизвестного вида) необходимы методы те-
ории вероятностей, описывающие многомерные случайные величины.
Эти методы трудно применить на практике, особенно в случаях недо-
статочно представительных выборок образов из каждого класса или не-
достаточно хороших форм функций плотностей распределения веро-
ятностей. По этим причинам при использовании байесовского
классификатора обычно исходят из предполагаемых аналитических вы-
ражений общего вида для различных функций плотности распределе-
ния вероятностей, оценивая затем их параметры по выборке образов
из каждого класса. Наиболее часто используется предположение о
том, что функция р(х | (о^) описывается гауссовой функцией плотно-
сти распределения вероятностей (т.е. класс имеет нормальное распре-
деление). Чем ближе предположения о функциях распределения к
действительности, тем точнее достигается минимум средних потерь в
результате использования байесовского классификатора.
Байесовский классификатор для классов с нормальным распределением
Для начала рассмотрим одномерную (и = 1) задачу распознавания об-
разов в случае двух классов (Ж= 2) с нормальными распределениями.
Пусть соответствующие гауссовы функции плотности распределения
вероятностей для каждого из классов характеризуются математически-
ми ожиданиями т.। и m2 и стандартными отклонениями О| и о2- Соглас-
но (12.2-17), байесовские дискриминантные функции имеют вид
(X-ffly)2
J,(x) = p(x|co,)P(co,) = ^=^e 2о> Р(со,) у=1,2, (12.2-18)
J J J yjlTtGj J
где образы представляют собой скалярную величину х. На Рис. 12.10
изображены графики функций плотности распределения вероятнос-
тей для этих двух классов. Разделяющая поверхность между классами
есть точка х0 такая, что d\ (хр) = ^2(хо)- Если указанные два класса яв-
ляются равновероятными, то P(coj) = Р(о>2)= 1/2 и координата точки
xq определяется из условияр(х01 со/) =р(х01 (02), что соответствует точ-
ке пересечения графиков функций плотности распределения вероят-
ностей, как показано на Рис. 12.10. Любой образ (т.е. точка), лежащий
правее xq, классифицируется как принадлежащий классу ОЭ], а распо-
ложенный левее х0 — классу (О2- Если вероятности появления образов
каждого класса неодинаковы, то точка х0 сдвигается влево, если
большую вероятность имеет класс ОЭ], и вправо, если более вероятным
является класс (02- Этого результата следовало ожидать, поскольку
данный классификатор стремится минимизировать потери от ошибоч-
ной классификации. Например, в предельном случае, если объекты
Рис. 12.10. Функции плотности распределения вероятностей для двух одно-
мерных классов. Точка х0 указывает положение разделяющей поверхности в
случае, когда классы равновероятны.
класса а>2 не встречаются вообще, то классификатор не совершит
ошибки, относя все образы к классу (Oj, т.е. считая х0 = -<*>.
В и-мерном случае гауссова функция плотности распределения
вероятностей векторову-го класса имеет вид
, 1 --(х-шД^СуЧх-пь)
^>=(2^1^ 2 ’ (12'2-‘9)
где каждая функция р(х | со,) полностью задается вектором математи-
ческого ожидания Шу и ковариационной матрицей Су, которые опре-
деляются как
my = Ej {х } (12.2-20)
и
Cj = Ej{(x-mj)(x-mj)T } (12.2-21)
где запись Ej{-} означает математическое ожидание значения аргу-
мента на образах из класса <о.-. В уравнении (12.2-19) л есть размерность
пространства признаков, а [Су | — определитель матрицы Су. Прибли-
жая математические ожидания Ej средними значениями, получаем
следующие оценки для вектора математического ожидания и ковари-
ационной матрицы:
т,= — У х (12.2-22)
J N-
J хе соу
И
С.=—У xx7-m,mf, (12.2-23)
J уу J J ’ ' '
J хе соу
где Nj — число образов из класса (Оу, на которых проводится суммиро-
вание. Ниже в этом разделе мы приведем пример использования этих
двух выражений.
Ковариационная матрица является симметрической и положитель-
но полуопределенной. Как объяснялось в Разделе 11.4, ее диагональные
элементы скк являются дисперсиями компонент хк вектора признаков,
а лежащие вне диагонали элементы с,к — ковариациями компонент Xj
и хк этого вектора. Если все недиагональные элементы матрицы кова-
риации нулевые, то многомерная гауссова функция распределения раз-
лагается на произведение одномерных гауссовых плотностей каждой
компоненты вектора х. Это происходит в том случае, если компонен-
ты Xj и Xfc этого вектора (т.е. признаки j и к) некоррелированы.
В соответствии с (12.2-17), байесовская дискриминантная функ-
ция для класса (о7 есть t^-(x) = р(х | (Оу)Р((Оу). Однако, учитывая экспо-
ненциальный вид гауссовой плотности распределения, удобнее иметь
дело с натуральным логарифмом этой функции. Другими словами, мы
будем использовать дискриминантные функции вида
Jy(x) = 1п[ Дх | ro/)P((Oy)J = In р(х|а)у)+ In (12.2-24)
Данное выражение эквивалентно (12.2-17) с точки зрения классифи-
кации, поскольку логарифм — монотонно возрастающая функция.
Иначе говоря, упорядоченность значений дискриминантных функций,
задаваемых уравнениями (12.2-17) и (12.2-24), будет одинаковой. Под-
ставляя уравнение (12.2-19) в (12.2-24), получаем:
с?у(х) = 1пР(о)7)-^1п2л-^1п|С7 |-^(х- ш7)тС71(х- m7)J. (12.2-25)
Член (и/2)1п2л одинаков для всех классов, так что его можно исклю-
чить из уравнения (12.2-25), которое тогда примет вид
J7.(x)=lnP(®;)-|ln|C7.|-
-|[(x-m7)7’C71(x-m7)] У=1,2,...,Ж.
(12.2-26)
Это уравнение байесовских дискриминантных функций для классов
с нормальным распределением при условии нуль-единичной функции
потерь.
Дискриминантные функции, заданные уравнениями (12.2-26),
определяют поверхности второго порядка, поскольку являются ква-
дратичными функциями в и-мерном пространстве, не содержащими
членов с компонентами векторах выше второй степени. Поэтому яс-
но, что для нормально распределенных образов байесовский класси-
фикатор строит между каждой парой классов разделяющую поверх-
ность второго порядка общего вида. Если генеральные совокупности
образов каждого класса в самом деле описываются нормальным рас-
пределением, то никакая другая поверхность не позволит получить
меньшую величину средних потерь от ошибочной классификации.
Глава 12. Распознавание объектов
Если ковариационные матрицы для всех классов одинаковы, т.е.
Cj= Сдляу =1, 2,..., W, то, раскрывая уравнение (12.2-26) и отбрасы-
вая все члены, не зависящие от j, получим
J7(x) = ln /’(и/)+х7С“|т/-^т/-7С“_|т/- у=1,2,...,Ж, (12.2-27)
т.е. линейные дискриминантные функции, которые задают разделя-
ющие гиперплоскости.
Если вдобавок С = I (где 1 — единичная матрица) и Р(со,) = 1 /Ждля
j = 1, 2,..., W(классы равновероятны), то
^(x^x^my-^mjinj y = l,2,...,FF. (12.2-28)
Эти уравнения задают дискриминантные функции для классификато-
ра по минимуму расстояния, и совпадают с ранее приведенными фор-
мулами (12.2-5). Таким образом, классификатор по минимуму рассто-
яния является оптимальным в байесовском смысле, если (1) классы
имеют нормальное распределение, (2) все ковариационные матрицы
единичные, и (3) все классы равновероятны. Удовлетворяющие пере-
численным требованиям нормально распределенные классы имеют в
л-мерном пространстве признаков форму одинаковых гиперсфер. Клас-
сификатор по минимуму расстояния строит разделяющую гиперпло-
скость для каждой пары классов, проходящую перпендикулярно через
середину отрезка, соединяющего центры этих двух классов. В двумер-
ном случае классы образуют области круглой формы, и разделяющие
поверхности имеют форму линий — перпендикуляров в серединах от-
резков, соединяющих центры каждой пары таких кругов.
Пример 12.3: Байесовский классификатор для трехмерных образов.
На Рис. 12.11 показан простой пример расположения двух классов
образов в трехмерном пространстве. Проиллюстрируем с помощью
этих образов технику реализации байесовского классификатора, пред-
полагая, что образы каждого класса являются выборкой из гауссова рас-
пределения.
Применяя равенство (12.2-22) к образам на Рис. 12.11, получаем:
ность (показана серым цветом).
Аналогично, применяя равенство (12.2-23) к этим двум классам, по-
лучаем их ковариационные матрицы, которые в данном случае оказы-
ваются одинаковыми:
Г3
С,=С2=— 1
' 2 16
1 1
3 -1
-1 3
1
Поскольку ковариационные матрицы одинаковы, байесовские дискри-
минантные функции определяются уравнениями (12.2-27). Если пред-
положить, что Р(<о1) = = УЪ то из (12.2-27) получаем:
г/,(х) = х7С ш.гС
jv 7 J 2 J J
где
8 4
4 8
Проведя в этих уравнениях матричные вычисления, получаем следу-
ющие дискриминантные функции:
dv(х) = 4х( -1,5 и d2 (х) = -4xj + 8х2 + 8х3 -5,5.
Уравнение разделяющей поверхности для этих двух классов имеет вид
Jj(x)- J2(x)=8xj -8х2 -8х3 +4 =0.
На Рис. 12.11 показано сечение единичного куба этой поверхностью,
которое демонстрирует, что классы эффективно разделяются, if
Одним из самых успешных применений байесовского классифи-
катора является его использование в задаче классификации данных
дистанционного зондирования, регистрируемых с помощью мульти-
спекгральных сканеров, установленных на борту самолета, спутника
или орбитальной станции. Учитывая большой объем изображений, по-
лучаемых с помощью такого оборудования, задача автоматического
анализа и классификации изображений вызывает значительный ин-
терес. Прикладные задачи дистанционного зондирования весьма раз-
нообразны и включают землепользование, прогнозирование урожая,
обнаружение заболеваний пищевых растений, наблюдение залесны-
ми ресурсами, мониторинг качества воздуха и воды, геологические ис-
следования, прогнозирование погоды, а также десятки других прило-
жений, важных для контроля окружающей среды. Ниже
рассматривается пример типичной прикладной задачи.
Пример 12.4: Классификация мультиспектральных данных с помо-
щью байесовского классификатора.
Как уже упоминалось в Разделах 1.3.4 и 11.4, мультиспектральный
сканер регистрирует энергию электромагнитного излучения в задан-
ных участках длин волн, например, 0,40—0,44,0,58—0,62, 0,66—0,72 и
0,80—1,00 мкм. Эти участки находятся в диапазонах фиолетового, зе-
леного, красного и инфракрасного излучения соответственно. При ска-
нировании земной поверхности в указанных диапазонах, регистриру-
ются четыре цифровых изображения — по одному для каждого
диапазона спектра. Сформированные изображения являются несме-
щенными (наложенными друг на друга), что иллюстрирует Рис. 12.12.
Следовательно, в точности, как это делалось в Разделе 11.4, каждая точ-
ка земной поверхности может быть представлена 4-компонентным век-
тором признаков вида х = (xj, х2, х3, х4)Т, где xt — яркость в фиолето-
вом участке спектра, х2 — в зеленом, и т.д. Если размеры изображений
*1
х2
хз
*4
Рис. 12.12. Построение вектора признаков из пикселей четырех цифровых изо-
бражений, зарегистрированных с помощью мультиспектрального сканера.
Спектральный
диапазон 4
Спектральный
диапазон 3
Спектральный
диапазон 2
Спектральный
диапазон 1
составляют 512x512 пикселей, то каждый комплект мультиспекграль-
ных изображений можно представить с помощью 262144 четырех-
мерных образов.
Как отмечалось выше, при построении байесовского классифи-
катора образов с гауссовым распределением требуется получить оцен-
ки вектора математического ожидания и ковариационной матрицы
для каждого класса. В прикладных задачах дистанционного зондиро-
вания эти оценки вычисляются путем сбора мультиспектральных дан-
ных для каждого интересующего вида областей, после чего полученная
выборка используется так же, как в предыдущем примере. На
Рис. 12.13(a) показано типичное изображение, полученное при аэро-
фотосъемке (приведена монохромная копия мультиспектрального
оригинала). В данном конкретном случае задача состояла в различении
поверхностей с отнесением их к классам водных, покрытых расти-
тельностью, или с голой почвой. Рис. 12.13(6) иллюстрирует результа-
ты машинной классификации с помощью гауссовско-байесовского
классификатора. Стрелками отмечены некоторые интересные осо-
бенности. Стрелка 1 указывает на угол поля, покрытого зеленой рас-
тительностью, а стрелка 2 — на реку. Стрелкой 3 обозначена неболь-
шая зеленая изгородь между двумя областями голой почвы. Стрелкой 4
указан приток реки, правильно распознанный системой. Стрелка 5
указывает на небольшой пруд, который почти неразличим на
Рис. 12.13(a). Сопоставление результатов компьютерного распозна-
вания с исходным изображением показывает, что классификация близ-
ка к тому, что получил бы человек в ходе визуального анализа.
Глава 12. Распознавание объектов
Рис. 12.13. (а) Мультиспектральное изображение, (б) Распечатка результатов
машинной классификации с помощью байесовского классификатора. (Изо-
бражения предоставлены Лабораторией прикладного дистанционного зонди-
рования, Университет Пердью).
Прежде чем завершить этот раздел, интересно отметить, что поэле-
ментная классификация пикселей изображения, описанная в послед-
нем примере, в действительности сегментирует изображение на обла-
сти, относящиеся к различным классам. Этот подход похож на
сегментацию путем порогового преобразования с несколькими пере-
менными, кратко рассмотренную в Разделе 10.3.7.
12.2.3. Нейронные сети
Методы, рассмотренные в двух последних разделах, основывались
на использовании выборочной совокупности образов для оце-
нивания статистических параметров каждого класса. Классифи-
катор по минимуму расстояния полностью задается векторами ма-
тематического ожидания всех классов. Аналогично, байесовский
классификатор для нормально распределенных совокупностей
образов полностью определяется векторами математического
ожидания и ковариационными матрицами каждого класса. Обра-
зы, принадлежащие к известным классам и используемые для
оценивания упомянутых параметров, называются обучающими,
а множество таких образов для каждого класса — обучающей вы-
боркой этого класса. Процесс, в ходе которого с помощью обуча-
ющей выборки строятся дискриминантные функции, называет-
ся обучением.
В двух рассмотренных выше подходах сущность обучения
проста. Обучающие образы каждого класса используются для
вычисления параметров дискриминантной функции, соответ-
ствующей этому классу. После того, как оценки необходимых па-
раметров получены, структура классификатора становится фик-
сированной, и его окончательное качество зависит лишь от того,
насколько хорошо реальные совокупности образов отвечают ста-
тистическим предположениям, изначально сделанным при вы-
воде используемого метода классификации.
В реальных задачах статистические свойства классов образов за-
частую неизвестны или не поддаются оценке (вспомним упоминав-
шиеся выше трудности работы с многомерными статистиками). На
практике для таких задач теории решений более эффективными ока-
зываются методы, в которых необходимые дискриминантные функ-
ции строятся непосредственно в ходе обучения. Это устраняет необ-
ходимость использовать предположения о функциях плотности
распределения вероятностей или о каких-то других вероятностных
параметрах рассматриваемых классов. В этом разделе мы обсудим
различные методы, отвечающие такому критерию.
34 А-223
Предпосылки
Главной особенностью излагаемого ниже материала является исполь-
зование большого числа простейших нелинейных вычислительных эле-
ментов (называемых нейронами), которые организованы в виде се-
тей, напоминающих предположительный способ соединения нейронов
в мозге человека. Применяемые модели известны под различными на-
званиями, в частности, нейронные сети, нейрокомпьютеры, модели па-
раллельной распределенной обработки, нейроморфные системы, многослой-
ные самонастраивающиеся сети и модели с межсоединениями. Здесь
мы будем придерживаться термина нейронные сети. Мы воспользуем-
ся этими сетями в качестве среды, в которой осуществляется адаптив-
ная настройка параметров дискриминантных функций путем после-
довательного предъявления обучающих выборок образов из различных
классов.
Интерес к нейронным сетям восходит к началу 40-х годов, чему
примером является работа Мак-Каллока и Питтса [McCulloch, Pitts,
1943]. Они предложили модель нейрона в виде двоичного порогово-
го устройства, а в качестве основы для моделирования нейронных
систем — стохастические алгоритмы, в которых происходят внезапные
переходы нейронов из состояния 0 в состояние 1 и наоборот. В после-
дующей работе Хебба [Hebb, 1949] на основе математических моделей
была сделана попытка ухватить концепцию обучения посредством
усиления или ослабления связи.
В середине 50-х — начале 60-х годов Розенблаттом был создан но-
вый класс так называемых обучающихся машин [Rosenblatt, 1959,1962],
что пробудило значительный интерес исследователей и инженеров к
теории распознавания образов. Причиной большого интереса к таким
машинам, названным персептронами, было построение математиче-
ских доказательств того факта, что при обучении персептрона с помо-
щью линейно разделимых обучающих выборок (т.е. выборок образов,
для которых разделяющей поверхностью может быть гиперплоскость)
сходимость крещению достигается за конечное число итеративных ша-
гов. Решение имеет вид набора коэффициентов уравнений гиперпло-
скостей, правильно разделяющих классы, представленные образами
из обучающей выборки.
К сожалению, те ожидания, которые последовали за открытием ка-
завшейся хорошо обоснованной теоретической модели обучения,
вскоре сменились разочарованием. Простой персептрон, как и неко-
торые его обобщения, были для того времени просто недостаточно
мощными для решения большинства практически важных задач рас-
познавания образов. Последующие попытки увеличить мощность ма-
шин, подобных персептрону, за счет рассмотрения нескольких слоев
таких устройств в принципе выглядели привлекательными, однако им
не хватало эффективных алгоритмов обучения, вроде тех, которые
вызвали интерес к самому персептрону. Состояние дел в области обу-
чающихся машин в середине 60-х годов было обрисовано Нильсоном
[Nilsson, 1965]. Несколькими годами позже Минский и Пейперт пред-
ставили обескураживающий анализ ограничений машин, подобных
персептрону [Minsky, Papert, 1969]. Такая точка зрения продержалась
до середины 80-х годов, о чем свидетельствует критический разбор Си-
мона [Simon, 1986]. В этой работе, первоначально опубликованной на
французском языке в 1984 г., Симон развенчал персептрон под загла-
вием «Рождение и смерть мифа».
Более поздние результаты в области разработки новых алгоритмов
обучения для многослойных персептронов, полученные Румельхартом,
Хинтоном и Уильямсом [Rumelhart, Hinton, Williams, 1986], сущест-
венно изменили положение дел. Предложенный ими основной метод,
который часто называют обобщенным дельта-правилом обучения по-
средством обратного распространения ошибки, предлагает эффектив-
ный способ обучения многослойных машин. Хотя для такого алгорит-
ма обучения не удается доказать конечную сходимость к правильному
решению, как это было сделано для однослойного персептрона, обоб-
щенное дельта-правило успешно было применено для решения боль-
шого числа задач, представляющих практический интерес. Благода-
ря этим успехам многослойные машины, подобные персептрону, стали
одной из главных моделей нейронных сетей, используемых в насто-
ящее время.
Персептрон для двух классов
В самой простой форме, при обучении персептрона строится линей-
ная дискриминантная функция, осуществляющая дихотомию двух
линейно разделимых обучающих выборок. Рис. 12.14(a) схематичес-
ки показывает модель персептрона в случае двух классов образов.
Выходной сигнал (реакция) этого элементарного устройства базиру-
ется на взвешенной сумме его входных сигналов, имеющей вид
п
J(x) = ^wz-x/+w„+i, (12.2-29)
Z=1
которая является линейной дискриминантной функцией по отноше-
нию к компонентам вектора признаков. Коэффициенты
Wj, i = 1, 2,..., п, п+1, называемые весами, изменяют (масштабируют)
входные сигналы перед тем, как они суммируются и подаются на по-
роговое устройство. В этом смысле веса аналогичны синапсам в нерв-
Векторы
признаков
X
если d(x)>0
если d(x)<0
Веса
Векторы
признаков
х
и
если X WiXi>-wn+i
i=i
если 2 w(-x,<-w„+1
i=l
Рис. 12.14. Два эквивалентных представления модели персептрона для двух
классов образов.
ной системе человека. Функцию, которая отображает результат сум-
мирования в конечный выходной сигнал устройства, иногда называ-
ют активирующей функцией.
Если J(x) > 0, пороговое устройство устанавливает на выходе пер-
септрона сигнал +1, указывающий, что объект х опознан как принад-
лежащий классу (0|; при J(x) < 0 на выходе устанавливается сигнал — 1.
Такой режим работы согласуется с замечанием, сделанным ранее при
обсуждении уравнения (12.2-2), об использовании единой дискри-
минантной функции в случае двух классов. Если J(x) = 0, то объект х
лежит на разделяющей поверхности между двумя классами, что явля-
ется условием неопределенности. Уравнение разделяющей поверх-
ности, реализуемой персептроном, получается приравниванием нулю
выражения (12.2-29):
п
d(x) = £wzxz + w„+1 = 0
/=1
(12.2-30)
или
W|X| + W}*! +... + wnx,n + wn+1 =0, (12.2-31)
что представляет собой уравнение гиперплоскости в «-мерном прост-
ранстве признаков. С геометрической точки зрения, первые п коэф-
фициентов задают направление гиперплоскости, а последний, свобод-
ный член wn+\, пропорционален расстоянию откачала координат до
гиперплоскости в перпендикулярном направлении. Следовательно,
при wn+\ = 0 разделяющая гиперплоскость проходит через начало ко-
ординат в пространстве признаков. Аналогично, если Wj = 0, гиперпло-
скость проходит параллельно координатной оси Xj.
Выходной сигнал порогового устройства на Рис. 12.14(a) зависит
от знака функции J(x). Вместо того чтобы исследовать знак всей функ-
ции, можно сравнивать член с суммой в правой части уравнения
(12.2-29) со свободным членом w„+1; в этом случае выходной сигнал
системы формируется в соответствии с законом
п
+1, если ^wzxz>-w„+1
/=1
п
-1, если ^wzxz<-w„+1.
i=\
(12.2-32)
Такая реализация эквивалентна модели, изображенной на Рис. 12.14(a),
и показана на Рис. 12.14(6). Единственное отличие состоит в том, что
пороговая функция смещается на величину -w„+i и константа боль-
ше не присутствует в числе входов сумматора. Мы вернемся к экви-
валентности этих двух построений позже в этом разделе — при обсуж-
дении вопросов реализации многослойных нейронных сетей.
При другом часто применяемом построении вектор признаков
расширяется посредством добавления к нему еще одной (и+1)-ой
компоненты, которая всегда равна 1, независимо от класса, к которо-
му принадлежит объект. Иначе говоря, строится расширенный вектор
признаков объекта у, такой что yi=xb i = 1,2,..., п; уп+j = 1. Тогда урав-
нение (12.2-29) примет вид
п+1
d(y)=Ywiyi = VfTy’
/=1
(12.2-33)
где у—(ур У2, Уп, 1)^ — расширенный вектор признаков, а
w=(wj, W2,..., wn, w„+1)r называется весовым вектором. Такая запись
обычно является более удобной с точки зрения обозначений. Однако
какая бы формулировка ни использовалась, главная задача всегда со-
стоит в нахождении вектора w по данной обучающей выборке образов
каждого из двух классов.
Алгоритмы обучения
Рассматриваемые ниже алгоритмы являются типичными представи-
телями многочисленных подходов к обучению персептрона, предло-
женных за годы исследования данного вопроса.
Линейно разделимые классы
Ниже излагается простой итерационный алгоритм получения весово-
го вектора, являющегося решением для двух линейно разделимых
обучающих выборок. Пусть имеются две обучающие выборки рас-
ширенных векторов признаков объектов, принадлежащих классам
(Oj и (02 соответственно, и пусть w( 1) — начальный весовой вектор, ко-
торый можно выбрать произвольно. Тогда на А+ом шаге итерации,
если у(А?) g coj и v/T(k)y(k) < 0, заменяем w(A) на
w(fc + l) = w(fc) + cy(fc), (12.2-34)
где с — положительный коэффициент коррекции. Напротив, если
y(k) е со2 и w^(A)y(A) > 0, заменяем w(A) на
v/(k + Y) = vf(k)-cy(k). (12.2-35)
В остальных случаях оставляем w(A) неизменным:
v/(Jc + l) = v/(k). (12.2-36)
Данный алгоритм вносит изменения в вектор w только в тех случаях,
когда рассматриваемый на А-ом шаге обработки обучающей последо-
вательности объект классифицируется ошибочно. Корректирующий
12.2. Распознавание на основе методов теории решений
коэффициент с считается положительным и в данном случае посто-
янным. Такой алгоритм иногда называют правилом постоянного коэф-
фициента коррекции.
Сходимость алгоритма наступает, когда обучающие выборки обо-
их классов целиком проходят через машину без единой ошибки. Ал-
горитм с постоянным коэффициентом коррекции сходится за конеч-
ное число шагов, если две используемые обучающие выборки
являются линейно разделимыми. Доказательство этого результата, ко-
торый называют теоремой о сходимости персептрона, можно найти
в книгах [Duda, Hart, Stork, 2001], [Той, Gonzalez, 1974] и [Nilsson,
1965].
Пример 12.5: Иллюстрация алгоритма обучения персептрона.
Ш Рассмотрим две обучающие выборки, представленные на
Рис. 12.15(a), каждая из которых состоит из двух образов. Описанный
алгоритм обучения должен завершиться успешно, так как эти две вы-
борки линейно разделимы. Прежде чем применять алгоритм, выпол-
ним расширение образов, в результате чего получаем обучающие вы-
борки{(0,0,I)7, (0,1,1)7} для класса ioj и{(1,0,1)г,(1,1,1)7} для класса
102- Полагая с = 1 и w(l) = О, будем предъявлять образы в порядке ни-
жеприведенной последовательности шагов:
0
0
0
1
w7(l)y(l) = [0,0,0 ]
=0
w(2) = w(l) + y(l) =
0
w7’(2)y(2) = [0,0,1] 1 =1
1
w(3) = w(2) =
1
w7(3)y(3) = [0,0,1] 0 =1
1
w(4) = w(3)-y(3) =
-1
0
0
1
wr(4)y(4) = [-1,0,0] 1 =-1
1
w(5)=w(4)=
-1
0
0
0
1
0
0
1
*a
*2
d(x)—~ 2x]+l=0
Q-
0
c>
0
O— *1
О e co]
О G C02
Рис. 12.15. (а) Образы из двух классов, (б) Разделяющая поверхность, постро-
енная в результате обучения.
где по причине ошибок классификации на первом и третьем шагах бы-
ли внесены изменения в весовой вектор, как предписывают рекуррент-
ные соотношения (12.2-34) и (12.2-35). Поскольку решение считает-
ся полученным только в том случае, когда ошибки классификации не
возникают при предъявлении обученному алгоритму всей выборки це-
ликом, то выборку необходимо предъявить снова. Процесс обучения
продолжается вышеописанным способом, считая у(5) = у(1), у(6) = у(2),
у(7) = у(3), у(8) = у(4) и так далее. Сходимость достигается при к = 14;
полученным решением является весовой вектор w(14) = (—2,0, I)7. Со-
ответствующая дискриминантная функция определяется уравнением
d(y) --2у, +1. Полагая х, = у,, возвращаемся к исходному простран-
ству признаков, где уравнение дискриминантной функции будет иметь
вид <7(х) = -2xi+l. Приравнивая дискриминантную функцию нулю,
получаем уравнение разделяющей поверхности, показанной на
Рис. 12.15(6). Л
Неразделимые классы
На практике линейно разделимые классы являются скорее редким
исключением, чем правилом. Поэтому в 60-х — 70-х годах значитель-
ные усилия исследователей были направлены на разработку мето-
дов, предназначенных для работы с неразделимыми классами объ-
ектов. С успехами последних продвижений в области обучения
нейронных сетей, многие из таких методов для неразделимых клас-
сов стали представлять лишь исторический интерес; однако один из
ранних методов имеет непосредственное отношение к теме обсуж-
дения: это дельта-правило в его первоначальной формулировке.
Данный метод обучения персептронов, известный как метод Уид-
роу—Хоффа или как дельта-правило наименьшего среднего квадрата,
на каждом шаге обучения минимизирует ошибку между фактичес-
кой и желаемой реакциями.
Рассмотрим целевую функцию
1 2
•/(w) = -(r-wry) , (12.2-37)
где г — желаемая реакция (т.е. г = +1, если расширенный вектор при-
знаков у объекта из обучающей выборки принадлежит классу (Oj, и
г = -1, если у принадлежит классу (02). Задача состоит в том, чтобы пу-
тем последовательных приращений корректировать весовой вектор w
в направлении, противоположном градиенту функции J(w), чтобы
найти минимум этой функции, который достигается при г = w7y; т.е.
минимум соответствует безошибочной классификации. Если обозна-
чить через w(A?) весовой вектор на А;-ом шаге итерации, то в общем ви-
де алгоритм градиентного спуска можно записать следующим образом:
w(k + 1) = v/(k)-a
dJ(yv)
3w
(12.2-38)
w=w(fc)
где w(k+1) — новое значение вектора w, а параметр а > 0 задает вели-
чину коррекции. Из уравнения (12.2-37) имеем
3J(w)
3w
= -(r-wry)y.
(12.2-39)
Подстановка этого результата в рекуррентное соотношение (12.2-38)
дает
v/(k +1) = v/(k) + а [г (k)- v/T(k)y (к)] у(к), (12.2-40)
причем начальный весовой вектор w(l) выбирается произвольно.
По определению, изменение («дельта») весового вектора есть век-
торная величина
Aw=w(fc+l)-w(fc), (12.2-41)
и мы можем записать уравнение (12.2-40) в форме алгоритма дельта-
коррекции:
Aw = ае(к)у(к),
(12.2-42)
где
e(k) = r(k)-wT(k)y(k) (12.2-43)
есть величина ошибки, допущенной при использовании весового век-
тора w(/c) для распознавания объекта у (к).
Равенство (12.2-43) указывает величину ошибки для весового век-
тора w(/c). Если мы заменим его на w(A;+1), оставляя объект тем же са-
мым, ошибка станет равной
е(к) = г(к) - wT(к+ 1)у( к). (12.2-44)
Тогда величина изменения ошибки составит
Ae(fc) = [r(fc)-wr(£+l)y(fc)]-[r(fc)-wr(fc)y(fc)]=
= - [ wr(& +1) - wT(k) j у(к)=-AwTy(k).
Но Aw = ае(/с)у(/с), поэтому
Ас = -ае(к)ут(к)у(к)=-а е(к) || у(к) ||2. (12.2-46)
Следовательно, при изменении весов происходит уменьшение ошиб-
ки с коэффициентом ос||у(А}||2. С предъявлением следующего образа
начнется новый цикл адаптации, в котором следующая ошибка умень-
шится с коэффициентом ос||у(А;+1)||2, и т.д.
От выбора параметра а зависит устойчивость и скорость сходимо-
сти алгоритма [Widrow, Stearns, 1985]. Для устойчивости алгоритма
необходимо, чтобы 0 < а < 2. На практике используется интервал
значений 0,1 < а < 1,0. Хотя доказательство этого факта здесь не при-
водится, алгоритм, определяемый уравнениями (12.2-40) или (12.2-42)
и (12.2-43), сходится к решению, минимизирующему средний квад-
рат ошибки на образах обучающей выборки. Если классы линейно раз-
делимы, то вышеописанный алгоритм не обязательно строит решение
в виде разделяющей гиперплоскости. Иначе говоря, решение, мини-
мизирующее средний квадрат ошибки, не обязательно является реше-
нием в смысле теоремы о сходимости персептрона. Такая неопреде-
ленность — цена за возможность применения алгоритма, который в
данной конкретной постановке сходится и для разделимых, и для не-
разделимых классов.
12.2. Распознавание на основе методов теории решений
Рассматривавшиеся до сих пор два алгоритма обучения персептро-
на могут быть распространены на случаи, когда имеется более двух
классов, а также используются нелинейные дискриминантные функ-
ции. Но, учитывая сделанные выше замечания исторического харак-
тера, нет особого смысла излагать здесь алгоритмы обучения для слу-
чая многих классов. Вместо этого мы рассмотрим обучение для
нескольких классов в контексте нейронных сетей.
Многослойные нейронные сети без обратной связи
В этом разделе мы сосредоточимся на построении дискриминант-
ных функций в задачах распознавания образов из нескольких классов.
Эти функции не зависят от того, разделимы классы или нет, и осно-
ваны на архитектурах, состоящих из слоев вычислительных элемен-
тов типа персептрона.
Базовая архитектура
Рис. 12.16 демонстрирует архитектуру рассматриваемой модели
нейронной сети. Она состоит из слоев, в которых находятся иден-
тичные по структуре вычислительные узлы (нейроны), организован-
ные таким образом, что выход каждого нейрона одного слоя соединя-
ется с входом каждого нейрона следующего слоя. Число нейронов в
первом слое, называемом слоем А, равно NA, оно часто выбирается рав-
ным размерности входных векторов-образов: NA = п. Число нейронов
выходного слоя, называемого слоем Q, обозначается Nq. Это число Nq
равно W, числу классов, образы которых данная нейронная сеть обу-
чена распознавать. Сеть распознает объект с вектором признаков х как
принадлежащий классу го,-, если на г-ом выходе сети присутствует «вы-
сокий» уровень, а на остальных выходах — «низкий», что разъясняет-
ся в дальнейшем.
Как показано на Рис. 12.16 в увеличенном фрагменте, каждый
нейрон имеет тот же вид, что и рассмотренная ранее модель персеп-
трона (см. Рис. 12.14), с тем исключением, что вместо активирующей
функции с разрывным пороговым преобразованием используется не-
прерывная сигмоидальная функция со «сглаженным порогом», по-
скольку для разработки обучающего правила необходима дифферен-
цируемость вдоль всех путей в нейронной сети. Следующая
сигмоидальная функция активации обладает требуемой дифференци-
руемостью:
(12'2’47>
' Веса
i p=l, 2, ...,NP
1 J=l,2,...,Nj
Класс coi
Входной
вектор
признаков
Веса wba
6=1,2, ...,NB
о=1,2, ...,Na
Веса Wjk
7=1,2,
k=l,2, ...,NK
Веса Wqp
q=l,2,...,NQ
/>=1,2, ...,NP
Веса waXj
o=l,2, ...,Na
i=l, 2,..., n
Класс а>2
Класс <оц/
Слой Р
Np узлов
Слой В
Np узлов
Слой К
Nk узлов
Слой Q
(выходной)
Nq-W узлов
Слой Л
Na узлов
Слой/
Nj узлов
Рис. 12.16. Модель многослойной нейронной сети без обратной связи. В увеличенном фрагменте показана базовая структура,
которую имеет каждый элементарный нейрон сети. Величина смещения 0у рассматривается как еще одна весовая компонента.
12.2. Распознавание на основе методов теории решений 1021
ще Ij, j= 1,2,..., Nj, — значение на входе активирующего элемента каж-
дого узла слоя /нейронной сети, Qj — величина смещения, а параметр
Оо определяет крутизну сигмоидальной функции.
На Рис. 12.17 приведен график функции (12.2-47), а также (пунктир-
ными линиями) показаны «высокий» и «низкий» уровни выходного
сигнала каждого узла. Итак, при использовании данной функции, зна-
чение уровня на выходе узла будет высоким при Ij > Qj и низким при Ij < бД
Как видно из Рис. 12.17, сигмоидальная функция активации всюду по-
ложительна и достигает своих предельных значений 0 и 1, когда значе-
ние на входе активирующего элемента равно минус или плюс бесконеч-
ности. По этой причине в качестве порогов нижнего и верхнего уровней
сигнала на выходе нейронов в модели на Рис. 12.16 выбираются значе-
ния вблизи 0 и 1, скажем, 0,05 и 0,95. В принципе, для разных слоев ней-
ронной сети или даже для разных узлов в одном слое могут применять-
ся активирующие функции различного вида, однако на практике обычно
во всей сети используют функции активации одинакового вида.
Показанное на Рис. 12.17 смещение 0у- аналогично весовому коэф-
фициенту w„+i рассмотренного ранее персептрона (см. Рис. 12.14(a)).
Эта функция со смещенным порогом может быть реализована по схе-
ме, аналогичной Рис. 12.14(a), при этом смещение Qj рассматривает-
ся как дополнительный коэффициент, на который умножается посто-
Рис. 12.17. Сигмоидальная функция активации, задаваемая уравнением
(12.2-47).
4 Точнее, высоким при Ij > бу + т(0о) и низким при Ij < бу — т(60), где [бу + т(60)] и
[бу — т(60)] — те значения I, при которых график функции (12.2-47) пересекает, со-
ответственно, линию «высокого» или «низкого» уровня выходного сигнала. — Прим,
ред. перевода.
янный единичный входной сигнал, одинаковый для всех узлов сети.
Следуя преобладающей в литературе системе обозначений, мы не по-
казываем отдельный постоянный входной сигнал +1 для всех узлов се-
ти на Рис. 12.16, а вместо этого считаем этот входной сигнал и моди-
фицирующий его вес Qj составной частью каждого узла нейронной сети.
Как видно на увеличенном фрагменте Рис. 12.16, для каждого из 7V/уз-
лов в слое / имеется по одному такому коэффициенту.
Входом для узла любого слоя сети на Рис. 12.16 является взвешен-
ная сумма выходных сигналов всех узлов предыдущего слоя. Пусть
слой К, предшествующий слою /сети (заметим, что на Рис. 12.16 не пред-
полагается никакой алфавитной упорядоченности), создает на входе ак-
тивирующего элемента каждого узла слоя / сигнал, обозначаемый If.
NK
Ij = LwJk°k (12.2-48)
к=\
для j= 1,2,..., Nj, где Nj— число узлов в слое /, N^— число узлов в слое
К, a Wj:к — веса, модифицирующие выходные сигналы Ок узлов слоя К
на входе узлов слоя /. Эти выходные сигналы слоя К имеют значения
Ok=hk(Ik), k=\,2,...,NK. (12.2-49)
Важно четко понимать систему индексных обозначений, фигуриру-
ющих в уравнении (12.2-48), поскольку мы будем пользоваться ей на про-
тяжении всей оставшейся части данного раздела. Прежде всего отметим,
что Ij, j = 1,2,..., Nj, обозначает сигнал на входе активирующего элемен-
та /го узла слоя /, т.е. /j есть сигнал на входе активирующего элемен-
та первого (верхнего) узла слоя /, 1^ — сигнал на входе активирующего
элемента второго узла слоя /, и т.д. У каждого узла в слое /имеется
входов, но каждый отдельный вход умножается на свой собственный ве-
совой коэффициент. Так, /Уд-входов первого узла в слое /взвешивают-
ся с коэффициентами W\k, k = 1,2,..., TV^; входы второго узла имеют ве-
са к= 1,2,..., N^, ит.д. Следовательно, для преобразования выходных
сигналов слоя К на входе слоя /требуется в общей сложности Njx NK
коэффициентов. Чтобы полностью описать узлы в слое /, необходимы
еще дополнительные Nj коэффициентов — смещений 0/.
Подстановка выражений (12.2-48) в уравнение (12.2-47) дает
Т ~ <12'2-50*
- YKjkOk+^j /6о
1 + е l*=1 >
Активирующую функцию данного вида мы будем использовать на
протяжении оставшейся части этого раздела.
Адаптация нейронов выходного слоя в ходе обучения не пред-
ставляет трудностей, поскольку желаемый выходной сигнал всех этих
узлов известен. Основная проблема при обучении многослойной се-
ти состоит в настройке весов так называемых скрытых слоев, т.е. всех
кроме выходного.
Обучение путем обратного распространения ошибки
Вначале сосредоточим внимание на выходном слое. Суммарный
квадрат ошибки между желаемыми реакциями rq узлов выходного
слоя Q и соответствующими фактическими реакциями Oq равен
EqA^%~0^- <12'2'51>
2«-1
где Nq — число узлов выходного слоя Q, а полусумма взята для
удобства последующего дифференцирования. Наша цель состоит в
разработке обучающего правила, подобного дельта-правилу, кото-
рое бы позволяло корректировать веса в каждом слое таким обра-
зом, чтобы заданная уравнением (12.2-51) функция ошибки стре-
милась к минимальному значению. Для получения такого
результата, как и ранее, будем корректировать веса пропорцио-
нально частной производной функции ошибки по этим весам. Дру-
гими словами,
Awqp=~a
™q
dWQP
(12.2-52)
где слой Р предшествует слою Q, и а — положительный коэффициент
коррекции. Таким образом, определение аналогично определе-
нию Aw в (12.2-42).
Функция ошибки Eq зависит от выходных сигналов Oq, а они, в
свою очередь, являются функциями входных сигналов Iq. Используя
правило дифференцирования сложной функции, вычисляем част-
ную производную Eq следующим образом:
Э£6 JEq dlq
^Wqp dig dwqp
(12.2-53)
С учетом (12.2-48),
1024 Глава 12. Распознавание объектов
a NP - = ~^— У wnnOп = О„. (12.2-54) dw dw . qp р р uwqp uwqp p=l
Подстановка выражений (12.2-53) и (12.2-54) в уравнение (12.2-52) да-
ет
dEo Ewqp = а ~ ор = aSqOp , (12.2-55) О1 q
где dE0 (12.2-56) dlq
Чтобы вычислить dEQ/dIq, воспользуемся формулой производной
сложной функции, выражая частную производную через скорость из-
менения Eq относительно Oq и скорость изменения Oq относительно
Iq. Иначе говоря,
ЭЕО дЕо дОо 5„ = *.= (12.2-57) 9 dlq dOq dlq
Из уравнения (12.2-51) следует, что
dE0 ^- = -^q-°q^ (12.2-58)
а из уравнения (12.2-49) имеем
—q- = —ho(Ia) = h'(Ia). (12.2-59) dig dlq q q 9 q
Подставляя (12.2-58) и (12.2-59) в (12.2-57), получаем
dq=(rq-Oq)hq(Iq), (12.2-60)
т.е. выражение, пропорциональное величине ошибки (rq — Oq). Под-
ставляя выражения (12.2-56) — (12.2-58) в уравнение (12.2-55), окон-
чательно получаем:
&Wqp = a(rq-Oq)hq(Iq)Op = aSqOp . (12.2-61)
После того, как задана функция hq(lq), все члены в (12.2-61) или ста-
новятся известными, или могут быть получены из наблюдения за се-
тью. Другими словами, предъявляя любой обучающий образ на вход
сети, мы знаем, какой должна быть желаемая реакция rq каждого вы-
ходного узла. Значения Oq на каждом выходном узле мы можем наблю-
дать, равно как и Iq (сигналы на входах активирующих элементов
слоя Q) и Ор (выходные сигналы узлов слоя Р). Таким образом, мы те-
перь знаем, как откорректировать веса на связях между предпослед-
ним и последним слоями нейронной сети.
Продолжим рассмотрение, двигаясь назад от выходного слоя. Про-
анализируем теперь, что происходит в слое Р. Действуя точно так же,
как описывалось выше, получаем:
AWpj = a(rp - Op)hp (Ip)Oj = abpOj , (12.2-62)
где составляющая ошибки имеет вид
Ър = <Гр-ОрУ1'рЦр). (12.2-63)
За исключением гр, все остальные члены в уравнениях (12.2-62) и
(12.2-63) либо известны, либо могут быть получены из наблюдения
за сетью. Член гр бессодержателен во внутреннем слое сети, так как
мы не знаем, какова должна быть реакция промежуточных узлов
по отношению к принадлежности образов к тому или иному клас-
су. Мы можем формулировать вид желаемой реакции г только на
выходах сети, где происходит окончательная классификация обра-
зов. Если бы мы имели эту информацию для внутренних узлов, то
дальнейшие слои стали бы ненужными. Таким образом, мы хо-
тим найти способ переформулирования на основании величин,
которые или известны, или могут быть получены из наблюдения
за сетью.
Возвращаясь к равенству (12.2-57), запишем составляющую ошиб-
ки для слоя Р в виде
5 = дЕР-_ дЕРд0Р
р dlp дОр dip
(12.2-64)
Член дОр/dip не доставляет трудностей. Как и ранее, он равен
dOp dhp(Ip)
dlp dip
= h'PkJp),
Глава 12. Распознавание объектов
т.е. известен при заданной функции hp, поскольку 1р можно наблюдать.
Членом, который порождает сигнал гр, является производная дЕр/<Юр,
поэтому ее необходимо выразить таким образом, чтобы она не со-
держала гр. Применяя правило дифференцирования сложной функ-
ции, перепишем эту производную следующим образом:
ЭГЛ a й .
—У ————= У ——------У w„nO„
д°Р &1ддОр дТ^ЭОр^ ?
= yG(j4
' nq
wqp = X\wqp '
. q=i
(12.2-66)
где последний шаг следует из (12.2-56). Подстановка выражений (12.2-65)
и (12.2-66) в уравнение (12.2-64) дает желаемое выражение для &р:
^p=h’p{Ip)^qWqp. (12.2-67)
9=1
Теперь параметр бр можно вычислить, так как все его члены извест-
ны. Итак, уравнения (12.2-62) и (12.2-67) образуют окончательное
обучающее правило для слоя Р. Уравнение (12.2-67) важно тем, что
в нем вычисляется через величины б? и wqp, которые были найде-
ны в слое, следующем за Р. После вычисления составляющей ошиб-
ки и весов для слоя Р, эти величины можно будет использовать ана-
логичным образом для нахождения ошибки и весов для слоя,
непосредственно предшествующего слою Р. Другими словами, мы на-
шли способ распространять ошибку назад по сети, начиная с ошиб-
ки в выходном слое.
Можно подытожить и обобщить изложенную процедуру обуче-
ния следующим образом. Для любого слоя J, которому непосредствен-
но предшествует слой К, вычисляются веса Wjk, модифицирующие
связи между этими слоями, с помощью уравнения
Awjlc-a8jOk. (12.2-68)
Если слой / является выходным, то бу вычисляется как
бу=(гу-Оу)/г;-(/у). (12.2-69)
Если слой /является внутренним, и следующим (в сторону выхода) яв-
ляется слой Р, тогда бу задается уравнениями
Np
8j=hW^PwJp (12.2-70)
для j = 1, 2,..., Nj. Применяя активирующую функцию вида (12.2-50)
с параметром 0О = 1, получаем
hjdj^Ojd-Oj), (12.2-71)
и тогда уравнения (12.2-69) и (12.2-70) приобретают следующий доста-
точно элегантный вид:
(12.2-72)
для выходного слоя, и
Np
(12.2-73)
д=1
для внутренних слоев. В обоих уравнениях (12.2-72) и (12.2-73)
Уравнения (12.2-68) — (12.2-70) вместе составляют обобщенное
дельта-правило обучения многослойной нейронной сети без обратной
связи, изображенной на Рис. 12.16. Процесс начинается с произволь-
ного набора весов в узлах сети (но не всех одинаковых). После этого
применение обобщенного дельта-правила на любом шаге итерации
складывается из двух основных этапов. На первом этапе на вход сети
предъявляется обучающий вектор признаков, и сигналы распростра-
няются по слоям вплоть до установления сигнала Oj на выходе каждо-
го узла. Затем реакции Oq узлов выходного уровня сравниваются с
желаемыми выходными сигналами rq, в результате чего строятся со-
ставляющие ошибок 8q. На втором этапе осуществляется обратный
проход по сети, при котором соответствующие сигналы ошибки пе-
редаются в каждый узел, что позволяет нужным образом откорректи-
ровать его веса. Эта процедура применяется и к смещениям 0у, кото-
рые, как говорилось выше, рассматриваются в качестве
дополнительных весовых коэффициентов, на которые умножается
единичный сигнал, подаваемый на вход сумматора каждого узла ней-
ронной сети.
Обычная практика состоит в том, чтобы прослеживать ошибки
сети, в том числе ошибки, связанные с конкретными образами. При
успешном сеансе обучения величина ошибки сети уменьшается по ме-
ре роста числа итераций, и процедура обучения сходится к устойчи-
вому набору весовых векторов, в котором, в случае дополнительного
обучения, наблюдаются лишь небольшие флуктуации. Для выяснения
того, что в процессе обучения некоторый образ классифицируется
правильно, необходимо проверить, что реакция узла выходного слоя,
сопоставляемого тому классу, к которому принадлежит данный образ,
имеет высокий уровень, а сигналы остальных узлов выходного слоя
имеют низкий уровень, как было определено выше.
После того, как обучение системы закончено, она применяется для
классификации неизвестных образов с использованием тех значений
параметров, которые были установлены в процессе обучения. В обыч-
ном режиме работы все линии обратной связи разрываются. После это-
го сигналы любого поступающего образа свободно распространяют-
ся по всем слоям, и образ классифицируется как принадлежащий
классу, который соответствует узлу с высоким уровнем на выходе,
при условии, что на выходах остальных узлов уровень сигнала низкий.
Если высокий уровень отмечается сразу на нескольких узлах выход-
ного слоя сети, или не обнаруживается ни на одном из узлов, то (по
выбору разработчика) либо объявляется об отказе от классификации,
либо принимается решение отнести объект к тому классу, на выход-
ном узле которого присутствует сигнал максимальной амплитуды.
Пример 12.6: Классификация формы фигуры с помощью нейронной сети.
Проиллюстрируем теперь процесс обучения нейронной сети (общий
вид которой представлен на Рис. 12.16) распознаванию фигур четы-
рех эталонных форм, изображенных на Рис. 12.18(a), вместе с искажен-
ными вариантами форм, примеры которых показаны на Рис. 12.16(6).
Векторы признаков объектов строились путем вычисления нор-
мированных сигнатур фигур (см. Раздел 11.1.3), после чего от каждой
сигнатуры брались 48 отсчетов через равные интервалы. Полученные
48-мерные вектора подавались на вход трехслойной нейронной сети
без обратной связи, показанной на Рис. 12.19. Число узлов в первом
слое сети было выбрано равным 48 — размерности исходного прост-
ранства признаков. Четыре нейрона в третьем (выходном) слое соот-
ветствуют числу распознаваемых классов, а число нейронов в сред-
нем слое было эвристически выбрано равным 26 (среднее
арифметическое числа узлов входного и выходного слоев). Для выбо-
ра числа узлов во внутренних слоях нейронной сети не существует из-
вестных правил, поэтому выбор обычно производится на основании
предшествующего опыта или делается произвольно, с последующим
уточнением по результатам эксперимента на экзаменационной выбор-
ке. Четыре узла выходного слоя в данном случае представляют четы-
ре класса Юу, j = 1, 2, 3, 4 (сверху вниз соответственно). После того,
Рис. 12.18. (а) Эталонные формы и (б) типичные искаженные фигуры, исполь-
зованные для обучения нейронной сети на Рис. 12.19. (Изображения предостав-
лены д-ром Лалит Гупта, кафедра ЕСЕ, Южный университет шт. Иллинойс).
как зафиксирована структура сети, необходимо выбрать вид активи-
рующих функций для всех узлов во всех слоях. Все эти функции ак-
тивации были выбраны согласно уравнению (12.2-50) при Оо = L, так
что, в соответствии с проведенным выше рассмотрением, примени-
мы уравнения (12.2-72) и (12.2-73).
Процесс обучения состоял из двух стадий. На первой стадии весам
были присвоены небольшие случайные начальные значения с нуле-
вым средним, после чего проводилось обучение сети на обучающей вы-
борке неискаженных образов, подобных приведенным на Рис. 12.18(a).
В ходе обучения контролировались выходные сигналы узлов послед-
него слоя. Обучение сети распознаванию фигур всех четырех классов
считалось законченным, когда для любого обучающего образа из клас-
са со,- реакции узлов выходного уровня составляли Oj > 0,95 и Од < 0,05
для <7=1,2,..., Nq, q Ф i. Другими словами, для любого образа из клас-
са со, соответствующий этому классу выходной узел должен был выда-
вать сигнал высокого (> 0,95) уровня, при этом выходные сигналы всех
прочих узлов выходного слоя должны были иметь низкий (< 0,05)
уровень.
Глава 12. Распознавание объектов
Рис. 12.19. Трехслойная нейронная сеть, использованная для распознавания
фигур на Рис. 12.18. (Изображение предоставлено д-ром Лалит Гупта, кафе-
дра ЕСЕ, Южный университет шт. Иллинойс).
На второй стадии обучения использовались искаженные образы, ко-
торые генерировались следующим образом. Каждый пиксель границы
эталонной фигуры (без искажений) с вероятностью R случайным об-
разом передвигался в положение одного из восьми соседних пикселей,
и с вероятностью V= 1 — R сохранял свои первоначальные координа-
ты. Тем самым уровень искажений возрастал с увеличением значения
R, которое можно трактовать как уровень шума сигнатуры. Были по-
строены две выборки зашумленных данных. В первой содержалось по
100 искаженных объектов из каждого класса, полученных при измене-
нии А от 0,1 до 0,6, что составило в общей сложности 400 образов.
Этот набор объектов, называемый экзаменационной выборкой, исполь-
зовался для оценки характеристик системы по результатам обучения.
Для обучения системы на зашумленных данных, было сформи-
ровано несколько выборок фигур с искажениями. Выборки обозна-
чаются символом Rt, значение которого численно равно R — уров-
ню искажений при генерации обучающих данных. Первая состояла
из 10 образцов каждого класса, сгенерированных при Rt = 0. В каче-
стве начальных весовых векторов на этой стадии обучения исполь-
зовались те, которые были найдены на первой стадии обучения (без
искажений), и системе давалась возможность провести их коррекцию
на обучающей последовательности, состоящей из нового набора
данных. Поскольку Rt = 0 означает отсутствие искажений, такое по-
вторное обучение было попросту продолжением ранее проведенно-
го обучения на эталонах. Затем с окончательными весами, получен-
ными при дообучении, работа нейронной сети испытывалась на
экзаменационной выборке; полученные результаты показаны на
Рис. 12.20 в форме кривой с пометкой Rt = 0,0. Вероятность ошибоч-
ной классификации оценивалась как отношение числа ошибочно рас-
познанных объектов к общему числу образов в экзаменационной
выборке, что является общепринятой характеристикой определе-
ния качества работы нейронной сети.
Уровень искажений экзаменационной выборки (R)
Рис. 12.20. Качество работы нейронной сети в зависимости от уровней искаже-
ний обучающей (R,) и экзаменационной (R) выборок. (Изображение предостав-
лено д-ром Лалит Гупта, кафедра ЕСЕ, Южный университет шт. Иллинойс).
После этого, начиная с весовых векторов, которые были найдены
в результате обучения на данных, построенных при Rt = 0, система сно-
ва обучалась, но уже на искаженных данных, сгенерированных при
Rt = 0,1, причем качество распознавания (с новыми весами) опять
определялось по полной экзаменационной выборке (кривая Rt = 0,1
на Рис. 12.20). Как видно из графика, качество заметно повысилось.
На этом же рисунке приведены результаты, полученные в дальнейшем
при повторении такой процедуры дообучения и перепроверки с вы-
борками Rt = 0,2; 0,3 и 0,4. Как и ожидалось, при правильном обуче-
нии системы вероятность ошибочной классификации объектов из
экзаменационной выборки уменьшается по мере роста значения Rt, по-
скольку обучение системы при этом производится на данных с более
высоким уровнем искажений. Единственным исключением на
Рис. 12.20 является результат, полученный при Rt = 0,4, причиной че-
го является малый объем выборки, использованной для обучения си-
стемы: при таком числе эталонных образов она оказывается неспособ-
ной эффективно адаптироваться к изменениям формы, которые
возникают при высоком уровне искажений. Эту гипотезу подтверж-
Уровень искажений экзаменационной выборки (А)
Рис. 12.21. Повышение качества распознавания для Rt = 0,4 при увеличении
объема обучающей выборки (для сравнения показан прежний график при
Аг = 0,3 из Рис. 12.20). (Изображение предоставлено д-ром Лалит Гупта, кафе-
дра ЕСЕ, Южный университет шт. Иллинойс).
дают результаты на Рис. 12.21, где показано, что при увеличении чис-
ла образов в обучающих выборках происходит снижение вероятнос-
ти ошибочной классификации. Для сравнения на Рис. 12.21 также
приведен график для Rt = 0,3 из Рис. 12.20.
Приведенные результаты показывают, что трехслойная нейронная
сеть способна обучаться распознаванию формы искаженных объектов
после умеренного дообучения. Уже после обучения на неискажен-
ных данных (Rt = 0,0 на Рис. 12.20) система достигает уровня правиль-
ного распознавания, близкого к 77%, при проверке на значительно ис-
каженных экзаменационных данных (Rt = 0,6 на Рис. 12.20).
Вероятность правильного распознавания на тех же данных возраста-
ет почти до 99%, если система дообучается на искаженных данных
(Rt = 0,3 и 0,4). Важно обратить внимание, что обучение системы
проводилось путем постепенного повышения ее мощности распозна-
вания с помощью систематического и плавного увеличения уровня ис-
кажений. Если природа искажений известна, такой метод идеально
подходит для улучшения сходимости и повышения устойчивости ней-
ронной сети в процессе ее обучения.
Сложность разделяющих поверхностей
Ранее отмечалось, что однослойный персептрон строит разделяю-
щую поверхность в форме гиперплоскости. Возникает естественный
вопрос: а какую форму имеет разделяющая поверхность, реализуемая
многослойной нейронной сетью, подобной модели на Рис. 12.16? В ни-
жеследующем рассмотрении демонстрируется, что трехслойная сеть
способна строить сколь угодно сложные разделяющие поверхности,
образованные пересекающимися гиперплоскостями.
Для начала рассмотрим двухслойную сеть с двумя входами, как по-
казано на Рис. 12.22(a). В случае двух входов все объекты являются дву-
мерными, и, следовательно, каждый узел первого слоя сети реализует
прямую в двумерном пространстве. Обозначим 1 и 0 соответственно вы-
сокий и низкий уровни выходного сигнала для каждого из этих двух уз-
лов. Будем считать, что выходной сигнал 1 показывает, что соответст-
вующий входной вектор лежит с положительной стороны разделяющей
прямой. На единственный узел второго слоя с узлов первого слоя мо-
гут поступать следующие комбинации выходных сигналов: (1,1), (1,0),
(0,1) и (0,0). Если определить две области — одну для класса Ю], лежа-
щую с положительной стороны от обеих прямых, и другую для класса
и>2, расположенную где-то еще, — выходной узел способен относить лю-
бой входной объект к одной из этих областей простым выполнением ло-
гической операции И. Иначе говоря, реакция выходного узла будет 1 (что
указывает на класс CD]), только когда оба выходных сигнала первого
Рис. 12.22. (а) Двухвходовая двухслойная нейронная сеть без обратной связи.
(б) и (в). Примеры разделяющих поверхностей, реализуемых такой сетью.
уровня одновременно равны 1. Вышеописанный узел нейронной сети
способен выполнять операцию И, если весовые коэффициенты на его
входах равны 1, а значение смещения 0у берется из полуоткрытого ин-
тервала (1,2]. Таким образом, если предположить, что реакции узлов пер-
вого слоя могут принимать только значения 0 или 1, то сигнал выход-
ного узла установится на высоком уровне (тем самым указывая на класс
со।) лишь в том случае, если сумма сигналов от первого слоя будет боль-
ше 1. Рисунки 12.22(6) и (в) демонстрируют, что показанная на
Рис. 12.22(a) сеть способна успешно разграничивать два класса образов,
не разделяющиеся одиночной линейной поверхностью.
Если число узлов первого слоя увеличить до трех, изображенная на
Рис. 12.22(a) сеть будет строить разделяющую поверхность, образован-
ную пересечением трех прямых. Требование, чтобы класс cdj распола-
гался с положительной стороны от всех трех линий, будет означать вы-
пуклую область, ограниченную тремя этими линиями. На самом деле,
простым увеличением числа узлов первого слоя двухслойной ней-
ронной сети, можно построить любую, сколь угодно сложную, от-
крытую или замкнутую выпуклую область.
Следующий логический шаг состоит в увеличении числа слоев до
трех. В этом случае, как и прежде, узлы первого слоя реализуют прямые.
Узлы второго слоя выполняют затем операции И, так чтобы построить
области из различных полуплоскостей, образуемых этими прямыми. Уз-
лы третьего слоя приписывают различные области к конкретным клас-
сам. Предположим, например, что класс СО) состоит из двух отдельных
областей, каждая из которых ограничена своим набором прямых. Тог-
да два узла второго слоя отвечают за области, относящиеся к одному и
тому же классу, а один из выходных узлов (в третьем слое) должен сиг-
нализировать о появлении объекта из этого класса, когда высокий уро-
вень имеется на выходе любого из упомянутых двух узлов второго слоя.
Обозначая высокий и низкий уровни на выходах узлов второго слоя 1
и 0 соответственно, такая схема работы выходных узлов эквивалентна
выполнению ими логической операции ИЛИ. Применительно к обсуж-
даемым узлам нейронной сети этого можно достичь, взяв значение
смещения 6у- из полуоткрытого интервала [0, 1). Тогда всякий раз, ког-
да установится высокий уровень на выходе по меньшей мере одного уз-
ла во втором слое, присоединенного с ненулевым весом к данному вы-
ходному узлу, на выходе последнего также появится высокий уровень,
указывая на принадлежность предъявленного образа к тому классу, ко-
торый соответствует этому узлу выходного слоя.
Рис. 12.23 суммирует итоги вышесказанного. Обратите внимание
на третью строку, иллюстрирующую, что сложность областей в простран-
стве решений, которые могут быть реализованы трехслойной нейронной
сетью, в принципе является неограниченной. На практике серьезные
трудности обычно вызывает построение второго слоя, который бы фор-
мировал набор правильных реакций для различных сочетаний конкрет-
ных классов. Причина этого в том, что разделяющие прямые не закан-
чиваются в местах пересечений, а неограниченно продолжаются, в
результате чего образы одного класса могут оказаться по обе стороны раз-
Структура сети Виды областей решений Решение проблемы «исключающего или» Классы с «зацепляющимися» областями Разделяющие поверхности наиболее общей формы
Однослойная Полу- пространство ®/@ ' (§)
Двухслойная Открытая или замкнутая выпуклая область
Трехслойная Произвольная (сложность ограничена числом узлов)
Рис. 12.23. Виды областей в пространстве решений, которые могут быть сфор-
мированы с помощью одно- или многослойных нейронных сетей без обрат-
ной связи при одном или двух скрытых слоях и двух входах. [Lippmann],
деляютцих прямых в пространстве признаков. Практически, на втором
слое могут возникнуть трудности при выяснении того, какие прямые (по-
луплоскости) должны быть включены в операцию И для данного клас-
са образов — или же это вообще невозможно сделать. Ссылка на пробле-
му «исключающего ИЛИ» в третьей колонке Рис. 12.23, относится к
тому факту, что в случае двоичных признаков в двумерном пространст-
ве существует всего четыре различных объекта. При этом если в класс ю ।
входят образы {(0,1), (1,0)},авкласса>2 — образы {(0,0), (1,1)},то функ-
ция принадлежности объектов к классам задается логической операци-
ей «исключающее ИЛИ», которая принимает единичное значение, толь-
ко тогда, когда любой один ее аргумент равен 1, и нулевое значение в
остальных случаях. Таким образом, значение 1 этой функции означает
принадлежность объекта к классу Wj, а значение 0 — к классу
Проведенное выше рассмотрение легко обобщается на случай п из-
мерений: вместо прямых мы имеем дело с гиперплоскостями. Одно-
слойная сеть реализует разделяющую поверхность в форме гиперпло-
скости, которая делит на две части все л-мерное пространство
признаков объектов. Двухслойная сеть строит произвольные выпук-
лые области, образованные пересекающимися гиперплоскостями.
Трехслойная сеть реализует разделяющие поверхности произвольной
сложности. В последних двух случаях достижимая сложность формы
областей определяется числом узлов каждого слоя. В случае одно-
слойной сети число классов ограничено двумя. В двух других случа-
ях число классов произвольно, поскольку число выходных узлов мож-
но выбрать в соответствии с решаемой задачей.
В этом месте возникает естественный вопрос: какой смысл имеет
изучение нейронных сетей с числом слоев более трех? Ведь трехслой-
ная сеть способна строить сколь угодно сложные разделяющие поверх-
ности. Ответ кроется в том методе, который применяется для обуче-
ния сети с использованием лишь трех слоев. Обучающее правило для
сети на Рис. 12.16 минимизирует показатель ошибки, но ничего не го-
ворит о том, как связывать группы гиперплоскостей с конкретными
узлами второго слоя трехслойной сети рассматриваемого вида. По
существу, проблема обмена числа слоев на число узлов в слое остает-
ся неизученной. На практике компромиссное решение обычно нахо-
дится методом проб и ошибок, либо по прошлому опыту решения за-
дач в данной проблемной области.
12.3. Структурные методы распознавания
Методы, обсуждавшиеся в Разделе 12.2, основывались на количествен-
ных характеристиках объектов и по большей части игнорировали
12.3. Структурные методы распознавания
структурные связи, присущие форме объектов. Рассматриваемые в
этом разделе структурные методы, напротив, нацелены на распозна-
вание образов именно за счет использования связей такого вида.
12.3.1. Сопоставление номеров фигур
Для сравнения границ областей, описанных в терминах номеров фи-
гур (см. Раздел 11.2.2), можно построить процедуру, аналогичную идее
минимума расстояния для векторов признаков, рассмотренной в Раз-
деле 12.1.1. С учетом обсуждения в Разделе 11.2.2, степень сходства к
формы границ двух областей определяется как наибольшее значение
порядка (т.е. числа цифр в записи номера фигуры), при котором их но-
мера фигур еще совпадают. Например, пусть avtb — номера фигур для
замкнутых границ, представленных цепными кодами с 4 направлени-
ями. Эти две формы имеют степень сходства к, если
Sj(a) = Sj(b) при j = 4,6,8,...,к
Sj(a)^Sj(b) при j = fc + 2,fc+4,...,
(12.3-1)
где функция 5 означает номер фигуры, а ее индекс равен значению по-
рядка номера фигуры. Расстояние между двумя формами а и b опре-
деляется как величина, обратная их степени сходства:
D(a,b) = — . (12.3-2)
к
Определенная так мера расстояния действительно удовлетворяет сле-
дующим свойствам:
D(a,b)> О
D(a,6) = 0 a-b
D(a,c) < max [D(a,b), D(b, с) ].
(12.3-3)
Для сопоставления форм можно использовать как значение к, так и D.
Если используется степень сходства, то чем больше значение к, тем бо-
лее похожими по форме являются границы областей (заметим, что для
идентичных фигур к равно бесконечности). При сравнении по мере
расстояния (12.3-2) имеет место обратная зависимость.
Пример 12.7: Использование номеров фигур для сравнения форм областей.
Предположим, что имеется фигура/, и мы хотим найти наиболее
похожую на нее среди набора других пяти фигур {а, Ь,с,с1м е); все
Глава 12. Распознавание объектов
фигуры приведены на Рис. 12.24(a). Эта задача аналогична той, ког-
да имеется пять образцов формы и требуется найти, к какому из них
ближе всего данная неизвестная фигура. Процедуру поиска можно
изобразить с помощью дерева сходства, показанного на Рис. 12.24(6).
Корень дерева соответствует наименьшей возможной степени сход-
ства, которая в данном примере равна 4. Предположим, что все
формы идентичны вплоть до порядка 8, за исключением фигуры а,
имеющей степень сходства с остальными фигурами, равную 6. Дви-
гаясь по дереву ниже, находим, что фигура d имеет по отношению
к остальным степень сходства 8, и так далее. Фигуры/и с однознач-
но согласуются друг с другом, имея более высокую степень сходст-
ва, чем любая другая пара фигур. Напротив, другую крайность об-
разует фигура а", если бы она была неизвестной фигурой, то все,
что можно было бы сказать с помощью такого метода — что а похо-
жа на все остальные фигуры со степенью сходства 6. Та же инфор-
оо 6 6 6 6 6
оо 8 8 10 8
оо 8 8 12
оо 8 8
00 8
00
Рис. 12.24. (а) Фигуры, (б) Гипотетическое дерево сходства, (в) Матрица сход-
ства. [Bribiesca, Guzman].
12.3. Структурные методы распознавания 1039
мация может быть компактно представлена в форме матрицы сход-
ства, показанной на Рис. 12.24(b).
12.3.2. Сопоставление строк символов
Предположим, что границы awb двух областей закодированы в виде
строк символов (см. Раздел 11.5), которые обозначены а\а2—ап и
b\b2...bm соответственно. Будем говорить о совпадении строк на fc-ой
позиции, если а^ = Ь^. Пусть а — общее число совпадений этих строк,
тогда число несовпадающих символов равно
Р = max(|a|,|Z>| )-а,
(12.3-4)
где | arg | обозначает длину аргумента, представленного символьной
строкой (т.е. число символов в ней). Можно показать, что Р = 0 тогда
и только тогда, когда представления а и b идентичны (см. Задачу 12.21).
Простой мерой сходстваanb является отношение
а а
Р max
(12.3-5)
Отсюда следует, что величина R равна бесконечности при полном
совпадении и нулю, когда соответственные символы а и b не совпа-
дают ни на одной позиции (в этом случае а = 0). Поскольку сравне-
ние выполняется посимвольно, с точки зрения уменьшения вычисле-
ний важен выбор начальной точки на каждой из границ. Любой способ,
позволяющий хотя бы приблизительно стандартизовать выбор на-
чальной точки, будет полезен, поскольку даст преимущество перед пол-
ным перебором всех положений начальной точки в одной из строк сим-
волов, с циклическим сдвигом последней и вычислением каждый раз
величины (12.3-5). Наибольшее значение R, найденное при перебо-
ре, дает наилучший вариант совпадения строк.
Пример 12.8: Иллюстрация сопоставления строк символов.
На Рис. 12.25(a) и (б) для объектов из двух классов показаны при-
меры границ, описания которых, полученные с помощью аппрокси-
мации ломаной линией (см. Раздел 11.1.2), приведены на Рис. 12.25(b)
и (г) соответственно. Из этих ломаных были построены строки сим-
волов путем вычисления внутреннего угла 0 между соседними звень-
ями ломаной при обходе ее по часовой стрелке. Значения угла коди-
ровались одним из восьми символов для каждого интервала в 45°, т.е.
af 0°< 0 < 45°; а2:45°< 0 < 90°;...; а8: 315°< 0 <360°.
Глава 12. Распознавание объектов
* $
в т
,'Д <
ж
Рис. 12.25. (а) и (б) Примеры границ объектов из двух различных классов; (в)
и (г) аппроксимация этих границ ломаными линиями; (д) - (ж) таблицы зна-
чений R. [Sze, Yang],
В таблице на Рис. 12.25(д) показаны результаты вычисления харак-
теристики R для шести объектов первого класса относительно друг дру-
га. В ячейках таблицы указаны значения R, а обозначение, напри-
мер, 1 .с указывает на третью строку символов для объекта из класса 1.
В таблице на Рис. 12.25(e) показаны результаты попарного сопостав-
ления строк для объектов второго класса. Наконец, в таблице на
Рис. 12.25(ж) приводятся значения R, полученные при сравнении
символьных строк, описывающих объекты из разных классов. Обра-
тите внимание, что здесь значения R значительно меньше, чем любые
значения в первых двух таблицах. Это указывает, что мера сходства R
12.3. Структурные методы распознавания
обладает хорошими дискриминантными свойствами для указанных
двух классов объектов. Например, если бы было неизвестно, к како-
му классу относится строка символов, обозначенная 1.а, то при срав-
нении ее с образцами строк класса 1 наименьшее полученное значение
характеристики R составило бы 4,7 (см. Рис. 12.25(д)). Напротив, при
сравнении с образцами класса 2, наибольшее значение Сравнялось бы
1,24 (см. Рис. 12.25(ж)). На этом основании был бы сделан вывод, что
строка 1 .а является объектом класса 1. Такой подход к классификации
аналогичен классификатору по минимуму расстояния, описанному в
Разделе 12.2.1.
12.3.3. Синтаксическое распознавание строк символов
Синтаксические методы5 предлагают единый методологический под-
ход к задачам распознавания структур. По сути, за синтаксическими
методами распознавания стоит простая идея: задается множество не-
производных элементов, из которых могут состоять образы (см. Раз-
дел 11.5), а также набор правил (в форме грамматики), управляющих
объединением этих элементов. После этого строится распознаватель
(иначе называемый автоматом), структура которого определяется
набором правил грамматики. Вначале мы рассмотрим грамматики
символьных строк и соответствующие им автоматы, а затем, в следу-
ющем разделе, распространим эти идеи на грамматики деревьев и ос-
нованные на них автоматы.
Грамматики строк символов
Пусть имеются два класса Wj и W2, объекты которых представляют собой
строки, составленные из непроизводных элементов с помощью методов,
рассмотренных в Разделе 11.5. Каждый непроизводный элемент можно
интерпретировать как разрешенный символ алфавита некоторой грам-
матики — набора правил синтаксиса (откуда и название «синтаксичес-
кие методы распознавания»), которые управляют построением предложе-
ний из символов этого алфавита. Множество (7 предложений, порождаемых
данной грамматикой, называется ее языком и обозначается L(G). Таким
образом, грамматика есть набор правил построения объектов одного
класса из заданного алфавита, предложения являются строками симво-
лов, представляющими образы, а язык — тот класс образов, который
может быть построен при помощью конкретной грамматики.
5 В отечественной литературе также используется термин лингвистические методы. —
Прим, перев.
35 Л-223
Рассмотрим две грамматики G\ и Gz, такие, что G) порождает толь-
ко предложения, соответствующие образам из класса CD], a G2 порож-
дает только предложения, соответствующие образам из класса <в2-
Коль скоро построены две грамматики с такими свойствами, то про-
цесс синтаксического распознавания образов становится, в принци-
пе, простым. А именно, для данного предложения, представляющего
неизвестный образ, задача состоит в том, чтобы решить, в каком из двух
языков этот образ задается синтаксически правильной последова-
тельностью. Если данная последовательность принадлежит £(Сц), мы
скажем, что образ относится к классу Юр Аналогично, образ будет
отнесен к классу <в2, если данная последовательность является допу-
стимой в £(G2). Если последовательность принадлежит обоим языкам,
то однозначная классификация невозможна. Предложения, недопу-
стимые в обоих языках, отбрасываются.
Если в задаче имеется более двух классов образов, классификация
на основе синтаксического подхода выполняется аналогично, за исклю-
чением того, что в процессе участвует большее число грамматик —
как минимум, по одной на каждый класс. В случае нескольких клас-
сов объект принадлежит к классу если его описание является пра-
вильным предложением только в языке L(Gj). Как и прежде, если со-
ответствующее предложение является допустимым более чем в одном
языке, принять однозначное решение о классификации невозможно.
Предложения, не разрешенные ни в одном из языков, отбрасываются.
Применительно к строкам символов, грамматика определяется
как четверка
G = (N,£,P,S), (12.3-6)
где: N— конечное множество переменных, называемых нетерминаль-
ными символами, Е — конечное множество констант, называемых тер-
минальными символами, Р — множество правил подстановки, называ-
емых продукциями, а символ S из множества А называется начальным
символом. Обязательное условие состоит в том, чтобы множества Nn
Е не пересекались. В последующем рассмотрении заглавными буква-
ми Л, В,..., S,... будем обозначать нетерминальные символы, а строч-
ными буквами а, Ь, с,... из начала алфавита — терминальные симво-
лы. Строчные буквы v, w, х, у, z из конца алфавита будут использоваться
для обозначения строк, состоящих исключительно из терминальных
символов. Греческими буквами а, Р, 0,... будем обозначать смешанные
строки, составленные из терминальных и нетерминальных симво-
лов. Пустое предложение (не состоящее ни из одного символа) обозна-
чается X. Наконец, если V— некоторое множество символов, то запись
12.3. Структурные методы распознавания
V* обозначает множество всех предложений, составленных из элемен-
тов множества V.
Грамматики символьных строк характеризуются формой продук-
ций. Для синтаксического распознавания образов особый интерес
представляют регулярные и контекстно-свободные грамматики^. Регу-
лярные грамматики основаны на продукциях, имеющих только вид
А —> аВ или А —э а, где A, Be Nnae Е, а знак (—>) означает разрешен-
ную подстановку. Контекстно-свободные грамматики используют
только продукции видаЛ —> а, где Ае /V и а е (7VU Е)*; иными сло-
вами, а может быть любой непустой строкой, состоящей из терминаль-
ных и нетерминальных символов.
Пример 12.9: Порождение класса объектов с помощью регулярной
грамматики строк символов.
Прежде чем двигаться дальше, полезно рассмотреть механизм по-
рождения класса объектов грамматикой. Предположим, что показан-
ный на Рис. 12.26(a) объект представляется своим остовом (после его
очистки), и для описания структуры этого и ему подобных остовов оп-
ределены непроизводные элементы, приведенные на Рис. 12.26(6).
Рассмотрим грамматику G = (N, Z,P,S) с множествами N= {А, В, S},
Е = {а, Ь, с} и Р = {5 —э аА, А —> ЬА, А —> ЬВ, В —> с}, где терминальные
символы а, Ь и с соответствуют непроизводным элементам, показан-
ным на Рис. 12.26(6). Как указывал ось выше, S— начальный символ,
из которого порождаются строки языка L(G). Например, в результа-
те применения сначала первой продукции, а затем два раза второй про-
дукции получаем строку символов S => аА => abA => abbA, где знаком
(=>) обозначен вывод символьных строк с помощью продукций из
множества Р, начиная с символа S. Первая продукция позволяет под-
ставить вместо S строку аА, а вторая — заменить А на ЬА. Коль скоро
в полученной строке abbA присутствует нетерминальный символ, опе-
рацию вывода можно продолжить. Например, применяя вторую про-
дукцию еще два раза, а затем по одному разу применяя третью и чет-
вертую продукции, получим строку abbbbbc, которой соответствует
структура, изображенная на Рис. 12.26(b). После применения четвер-
той продукции в строке не остается нетерминальных символов, поэто-
му на ней процедура вывода заканчивается. Правилами данной грам-
матики порождается язык L(G) = {abnc | n > 1}, где запись Ьп означает
6 В отечественной литературе для этих грамматик также употребляются названия,
соответственно, «автоматные» и «бесконтекстные», или «КС-грамматики». — Прим,
перев.
Рис. 12.26. (а) Объект, представленный своим остовом (отфильтрованным),
(б) Непроизводные элементы, (в) Структура, порождаемая регулярной грам-
матикой строк символов.
л-кратное повторение символа Ь. Другими словами, грамматика G
способна порождать только остовы с формой, показанной на
Рис. 12.26(b), но имеющие произвольную длину.
Использование семантики
В вышеприведенном примере предполагалось, что соединение не-
производных элементов происходит только в местах, отмеченных
жирными точками на Рис. 12.26(6). В более сложных ситуациях пра-
вила связи, число возможных применений той или иной продукции,
а также информация, относящаяся к другим факторам (например,
длина и направление непроизводных элементов), должны указывать-
ся в явном виде. Это достигается с помощью семантических правил, ко-
торые хранятся в показанной на Рис. 1.23 базе знаний. По существу, син-
таксис, заложенный в правила подстановки, определяет структуру
объекта, тогда как семантика обеспечивает его корректность. Напри-
мер, в языке программирования, таком как Си, выражение Л = D/Еяъ-
ляется синтаксически правильным, но семантически оно корректно
только при Е* 0.
Предположим, что к правилам подстановки рассмотренной в
предыдущем примере грамматики добавляется семантическая инфор-
мация в форме, указанной в Таблице 12.1. С помощью этой семан-
12.3. Структурные методы распознавания
Таблица 12.1. Пример семантической информации, приписанной к правилам
подстановки.
Продукция Семантическая информация
5—> аА Соединения с непроизводным элементом а выполняются только в отмеченных точках. Биссектриса угла между отрезками элемента а определяет направление этого элемента, которое обозначается 0. Длина каждого отрезка равна 3 см.
А^ЬА Соединения с непроизводным элементом b могут выполняться только в отмеченных концевых точках; не более одного соединения в каждой точке. Направление b должно совпадать с направлением элемента а. Длина элемента b составляет 0,25 см. Эту подстановку можно применять не более 10 раз.
А^ЬВ Направления непроизводных элементов а и b должны совпадать. Соединения могут выполняться только в отмеченных концевых точках; множественные соединения не допускаются.
Вс Направления непроизводных элементов с и а должны совпадать (направление с определяется аналогично а, т.е. биссектрисой угла). Соединения могут выполняться только в отмеченных концевых точках; множественные соединения не допускаются.
тической информации можно описать достаточно широкий, но в
то же время ограниченный (насколько это желательно), класс объ-
ектов, используя лишь несколько синтаксических правил. Например,
указание в Таблице 12.1 направления 6 устраняет необходимость
иметь непроизводные элементы всех возможных ориентаций. Ана-
логичным образом, требуя, чтобы все непроизводные элементы бы-
ли ориентированы в одном и том же направлении, мы исключаем бес-
содержательные конструкции, отличающиеся от типовой формы,
представленной на Рис. 12.26(a).
Автоматы как распознаватели строк символов
До сих пор демонстрировалось, как формальные грамматики порож-
дают образы. Далее мы рассмотрим задачу распознавания, которая со-
стоит в выяснении, принадлежит ли некоторый образ (предложение)
языку L(G), порождаемому грамматикой G. Основные принципы, ле-
жащие в основе синтаксических методов распознавания, можно про-
иллюстрировать на математических моделях вычислительных машин;
такие модели принято называть автоматами. На основании поступив-
шего на вход образа в виде строки символов автомат способен распоз-
нать, принадлежит ли этот образ тому языку, который соответствует
данному автомату. Здесь мы будем рассматривать только конечные ав-
томаты, которые являются распознавателями языков, порождаемых
регулярными грамматиками.
По определению, конечный автомат — это пятерка
Af=(Q,Z,8,q0,F), (12.3-7)
где Q — конечное непустое множество состояний автомата, Е — ко-
нечный входной алфавит, 8 — отображение множества QxE (множе-
ства упорядоченных пар, составленных из элементов множеств Q и Е)
в множество всех подмножеств Q, тем самым 8 есть функция, опреде-
ляющая (в зависимости от текущего символа входной строки) следу-
ющее состояние автомата, qG — начальное состояние, a F (подмноже-
ство Q) — множество заключительных состояний.
Пример 12.10: Простой автомат.
Рассмотрим автомат, определенный согласно (12.3-7), где
Q = {<7сь 91, 9г}, = {°, b},F= {<7q}, а отображение 8 действует по пра-
вилам 8(<?0, а) = {q2}, 8(?о, b} = {^}, 8(tfb а) = {q2}, 8(<?b b) = {q0},
8(q2, a) = {<?()} и 8(<72, b) = {<7| } Если, например, этот автомат находит-
ся в состоянии q(}, и на вход поступает символ а, то автомат переходит
в состояние q2. Аналогично, если затем поступает символ Ь, то авто-
мат переходит в состояние q^, и т.д. В данном случае начальное и за-
ключительное состояния совпадают.
На Рис. 12.27 показана диаграмма состояний рассмотренного авто-
мата. Она состоит из вершин, отвечающих каждому состоянию, и на-
правленных дуг, показывающих возможные переходы между состоя-
ниями. Заключительное состояние показано двойным кругом, а каждая
Рис. 12.27. Конечный автомат.
12.3. Структурные методы распознавания 1047
дуга помечена символом входного алфавита, при поступлении кото-
рого выполняется переход в состояние, куда направлена эта дуга. Как
уже сказано, в данном случае начальное и заключительное состояния
совпадают. Говорят, что автомат допускает или распознает строку тер-
минальных символов w, если, начав с состояния и по очереди по-
давая на вход символы w слева направо, после обработки последнего
символа w автомат оказывается в заключительном состоянии. На-
пример, показанный на Рис. 12.27 автомат распознает строку
w = abbabb, но отвергает строку w = aabab.
Между регулярными грамматиками и конечными автоматами име-
ется взаимно-однозначное соответствие. Это значит, что язык распоз-
нается конечным автоматом в том и только в том случае, если он по-
рожден регулярной грамматикой. Построение синтаксического
распознавателя строк символов, работающего на основе изложенных
принципов, состоит в формальной процедуре получения конечного ав-
томата из данной регулярной грамматики. Пусть грамматика обозна-
чена G = (N, Е, Р, Xq), где Xq = S, и предположим, что множество Nсо-
стоит из начального символа Xq и п добавочных нетерминальных
символов Ху Х2,..., Х„. Множество состояний Q конструируемого ав-
томата строится из п+2 состояний {<7о, qy..., q„, qn+\}, таких, что qt со-
ответствует А} для О < i < п, a qn+i — заключительное состояние. Вход-
ной алфавит совпадает с множеством терминальных символов
грамматики G. Отображение 8 строится из продукций G с помощью двух
нижеследующих правил; а именно, для любых i иj таких, что 0 < i < п
и 0 <J<n,
1. Если в множестве Р имеется правило X, —> aXj, то в множество
8(<yz-, а) включается qj.
2. Если в множестве Р имеется правило Л} —> а, то в множество 8(<yz-, а)
включается qn+y
Наоборот, если задан конечный автомат Aj= (Q, Е, 8, q0, F), то со-
ответствующая ему регулярная грамматика G = (N, Е, Р, Xq) строится
следующим образом: множество N составляется из элементов Q, в ка-
честве начального символа Xq принимается qG, а продукции грамма-
тики G получаются по правилам:
1. Если qj е 8(<7;-, о), то в множество Р включается правило А/ —> aXj.
2. Если в 8(<7;-, а) входит состояние из F, то в множество Р включает-
ся правило Xj —> а.
Множество терминальных символов Е одно и то же в обоих случаях.
Пример 12.11: Конечный автомат для распознавания образов на
Рис. 12.26.
Конечный автомат для грамматики, приведенной выше в связи с
Рис. 12.26, получается путем записи правил подстановки в виде
Xq —> аХ\, X] —> bXi, Х\ —> ЬХ2 и X2 —> с. После этого получаем автомат
Af= (Q, Е, 8, q0, F) с Q = {q0, qb q2, q3}, E = {a, b,c},F= {<y3} и отобра-
жением 8 таким, что 8(^0, а) = {<7i}, 8(<?i, b) = {q\, q2}, 6(q2, с) = {<73}- Для
полноты запишем 8(<?о, Ь) = 8(90, с) = 8(<7|, а) = 8(^j, с)= 6(q2, а)=
= 8(q2, b) = 0, где 0 — пустое множество, что указывает на невозмож-
ность таких переходов между состояниями для данного автомата.И
12.3.4. Синтаксическое распознавание деревьев
Аналогично тому, как это делалось выше для символьных строк, включим
теперь в область рассмотрения объекты, описанные в форме деревьев.
Предполагается, что интересующие области изображения или объекты
представлены древовидными описаниями с использованием подходя-
щих непроизводных элементов по типу рассмотренных в Разделе 11.5.
Грамматики деревьев
Грамматика деревьев определяется как пятерка
G' = (A,E,P,/-,S), (12.3-8)
где, как и прежде, Nn Е являются соответственно множествами нетер-
минальных и терминальных символов; S е N — начальный символ, ко-
торый в общем случае может быть деревом; Р — множество продук-
ций вида 7} —> Tj, где 7} и 7) суть деревья; а г — функция ранжирования,
определяющая возможные количества прямых потомков вершины
дерева, помеченной терминальным символом грамматики. Для наше-
го рассмотрения особенно важны расширяющие грамматики деревьев,
у которых продукции имеют вид
X -> к
Xt Х2 ... Хп
где Xi, Х2 ,...,Х„ — нетерминальные символы, ак—терминальный символ.
Пример 12.12: Простая грамматика деревьев.
Остов приведенной на Рис. 12.28(a) конструкции может порож-
даться с помощью грамматики деревьев, у которой множества симво-
12.3. Структурные методы распознавания
лов имеют вид N= {Х\, Х%, Х^, 5} и Z = {a,b, с, d, е}, где терминальные
символы соответствуют непроизводным элементам, показанным на
Рис. 12.28(6). Предполагая, что элементы, состоящие из отрезков,
могут соединяться по схеме «начало с концом», а соединение с окруж-
ностью возможно в любой ее точке, рассматриваемая грамматика бу-
дет иметь продукции следующего вида:
(1) S-> а
(2) X -> ।
X
(3)
(4) Х2 ।
X
(5) Х2 -> а
(6) Х2 —> е
X
(7) *3 -+а.
Функции ранжирования в этом случае равны г(о) = {0,1},
r(b) = r(d) = г(е) = {1} и г(с) — {2}. Ввод ограничения, в соответствии с ко-
торым продукции 2, 4 и 6 должны применяться одинаковое число раз,
обеспечивает порождение конструкций с ответвлениями равной длины,
подобных изображенной на Рис. 12.28(a). Если же ограничение требу-
ет лишь одинакового числа применений продукций 4 и 6, то порожда-
емые конструкции будут симметричны относительно вертикальной оси.
Семантическая информация аналогичного вида обсуждалась выше в
связи с Таблицей 12.1 и показанной на Рис. 1.23 базой знаний.
Рис. 12.28. (а) Объект и (б) непроизводные элементы, используемые для пред-
ставления его остова с помощью грамматики деревьев.
Автоматы на деревьях
В отличие от традиционного конечного автомата, который обрабаты-
вает входную строку символов последовательно слева направо (т.е.
посимвольно), автомат на деревьях должен начинать работу сразу со
всех листьев входного дерева одновременно, параллельно двигаясь в
сторону корня. Такой автомат, обрабатывающий дерево от листьев к
корню, определяется совокупностью
4=(е,Л{А|А;еХ}),
(12.3-9)
где Q — конечное множество состояний, Fez Q, — множество заклю-
чительных состояний, afk — отношение на 0"гх0, такое, что т есть
ранг символа к. Запись 0й обозначает декартово произведение Q са-
мо на себя т раз: 0й = Q х Q х Q х...х 0. Согласно определению де-
картова произведения, это выражение означает множество всех упо-
рядоченных наборов т элементов из 0. Например, если т = 3, то
03 = Q х 0 х 0 = {х, у, z | х е 0, у е 0, z е 0}. Напомним, что отноше-
ние R элементов множества Л к элементам множества В, есть подмно-
жество декартова произведения множеств Л и В, т.е. R с АхВ. Таким
образом, упомянутое выше отношение есть просто подмножество
множества 0"гх0.
Для расширяющей грамматики деревьев, G = (N, Е, P,r,S), мож-
но построить соответствующий ей автомат на деревьях, полагая 0 = N,
F={S} и для каждого символа а е Е определяя отношение fk такое, что
(Т|, Х2,..., Хт; X) является его элементом в том и только в том случае,
если среди правил подстановки грамматики G есть продукция
X -> к
*1 Х2 ... хт
Например, рассмотрим грамматику деревьев G = (N, Е, Р, г, S), у ко-
торой N = {5, X}, Е = {а, Ь, с, d}, множество продукций
и функции ранжирования г(а) = {0}, г(Ь) = {0}, г(с) = {1} и г(с!) = {2}. Со-
ответствующий автомат на деревьях, Af = (Q, F, {fk | к е Е}), строится
следующим образом. Полагаем Q~{S,X}, F = {5} и {fk | к е Е} =
~ {fa’fb’fc’fd}с отношениями следующего вида:
12.3. Структурные методы распознавания
как следует из продукции X —> а
4={(0;*)}. как следует из продукции X —> b
как следует из продукции X —> с
X
fd = {(X,$)} ’ как следует из продукции 5 —> d
X X.
Отношение fa интерпретируется следующим образом: вершине, поме-
ченной символом входного алфавита а, у которой нет потомков (от-
сюда символ 0 пустого множества), присваивается состояние X. Ана-
логично интерпретируется отношениеИнтерпретация отношения
fc состоит в том, что вершине, помеченной символом с, у которой
имеется один потомок с состоянием X, также присваивается состоя-
ние X. Отношение fd интерпретируется так, что вершине с пометкой
d и двумя потомками, каждый с состоянием X, присваивается состо-
яние S.
Чтобы продемонстрировать, как такой автомат на деревьях распоз-
нает деревья, которые порождает описанная выше грамматика, рас-
смотрим дерево, показанное на Рис. 12.29(a). Вначале автомат Af при-
сваивает состояния листьям дерева а и b посредством отношений fa и
fb соответственно. В данном случае обоим листьям присваивается со-
стояние X, как показано на Рис. 12.29(6). Теперь автомат поднимает-
ся на один уровень от каждого листа, что позволяет присвоить состо-
яние вершине с на основе отношения fc и состояний потомков этой
вершины. Присваивается опять-таки состояние X, как показано на
Рис. 12.29(b). Поднимаясь вверх по дереву еще на один уровень, авто-
мат встречает вершину d, у которой обоим потомкам присвоены со-
стояния, что позволяет применить отношение fd, требующее присво-
ить вершине d состояние S. Поскольку эта вершина является
последней, и состояние Sвходит в множество заключительных состо-
яний F, данный автомат распознает предложенное дерево, т.е. допу-
скает его в качестве правильного представителя языка приведенной вы-
ше грамматики деревьев. На Рис. 12.29(г) показано окончательное
представление последовательностей состояний, возникающих на пу-
тях от листьев к корню.
Глава 12. Распознавание объектов
а б
в t
Рис. 12.29. Этапы работы автомата на деревьях при обработке дерева от лис-
тьев к корню: (а) Исходное дерево, (б) Присвоение состояний концевым вер-
шинам (листьям), (в) Присвоение состояний промежуточным вершинам,
(г) Присвоение состояния корневой вершине дерева.
Пример 12.13: Применение грамматик на деревьях для опознавания со-
бытий на снимках, полученных с помощью пузырько-
вой камеры.
Снимки (изображения) с пузырьковых камер в большом количест-
ве регистрируются в ходе экспериментов в физике высоких энергий,
когда пучок элементарных частиц с определенными свойствами на-
правляется на мишень, материал которой содержит известные ядра.
Типичное событие состоит в соударении частицы с ядром и возник-
новении вторичных частиц, испускаемых в точке столкновения, тре-
ки (следы) которых регистрируются на изображении, как это видно на
Рис. 12.30. Треки частиц входного облучающего пучка представляют
собой параллельные горизонтальные линии. Обратите внимание на ес-
тественную древовидную структуру в центре фотографии, соответст-
вующую событию соударения.
За время обычного эксперимента снимаются сотни тысяч фото-
графий, многие из которых не содержат интересующих событий. Руч-
ной анализ и классификация таких снимков представляют собой тру-
доемкую и утомительную работу, чем и продиктована необходимость
применения методов автоматического распознавания событий.
12.3. Структурные методы распознавания
Рис. 12.30. Фотография, полученная с использованием пузырьковой камеры.
[Fu, Bhargava].
Можно построить грамматику деревьев G = (TV, X, Р, г, S), кото-
рая порождает деревья, соответствующие типичным событиям, воз-
никающим в водородной пузырьковой камере при попадании в нее
пучка положительно заряженных частиц. В этом случае N = {5, Х{, Х2},
X = {а, Ь} и непроизводные элементы имеют следующую интерпре-
тацию:
а: — выпуклая дуга
Ь: — вогнутая дуга.
Множество Р состоит из следующих продукций:
х2 -> ь
Функции ранжирования в этой грамматике имеют вид г(а)=
= {0, 1, 2, 4, 6} и г (Ь) = {0, 1}. Продукции с ветвлением представляют
число треков, выходящих из точки столкновения, это число является чет-
ным и обычно не превышает шести. На Рис. 12.31(a) изображена схема
столкновения в зафиксированном на Рис. 12.30 событии, разделенная
на выпуклые и вогнутые участки, а на Рис. 12.31(6) показано соответст-
вующее представление в виде дерева. Это дерево, как и возможные его
варианты, допускают порождение вышеприведенной грамматикой.
Автомат на деревьях, способный распознавать деревья описанного
вида, задается с помощью изложенной выше процедуры. Таким образом,
для построения автомата At = (Q, F, {ДI к е X}) полагаем Q = {5, Х\, Х2},
F= {5} и {fk | к& X} = {fa,fb}. Отношения определяются следующим об-
разом^ = {(5; S), (Xb Х2; S), (Хь Хъ Х2, Х2, S), (Хь ХЬХЬ Х2, Х2, Х2, S),
(Ху, X]), (0; Jf[)} nfb = {(Х2; Х2), (0; Х2)}. Доказательство того, что этот
автомат допускает показанное на Рис. 12.31(6) дерево, оставляем чита-
телю в качестве самостоятельного упражнения.
Обучение
Синтаксические методы распознавания, представленные выше, требу-
ют задания соответствующего автомата (распознавателя) для каждого
рассматриваемого класса объектов. В простых ситуациях нужные авто-
маты можно построить в результате аналитического рассмотрения за-
Рис. 12.31. (а) Кодированное представление события на Рис. 12.30. (б) Соот-
ветствующее представление в виде дерева. [Fu, BhargavaJ.
12.3. Структурные методы распознавания 1055^
дачи. В более сложных случаях может потребоваться специальный ал-
горитм обучения автоматов по выборке описаний объектов (те. символь-
ных строк или деревьев). Поскольку между описанными выше грамма-
тиками и автоматами имеется взаимно-однозначное соответствие,
задача обучения иногда ставится в терминах обучения грамматик непо-
средственно на примерах входных образов. Этот процесс обычно назы-
вают грамматическим выводом. Мы здесь остановимся на обучении ко-
нечных автоматов по выборке образов, представленных строками
символов. Среди ссылок в конце данной главы имеются указания на ме-
тоды обучения грамматик деревьев и автоматов на деревьях, равно как
и на другие синтаксические подходы к распознаванию образов.
Предположим, что все образы некоторого класса порождаются
неизвестной грамматикой Си имеется конечная выборка примеров 7?+
со следующим свойством:
Л+с{у|уе£(С)}. (12.3-10)
Такое множество 7?+, называемое выборкой правильных примеров, пред-
ставляет собой обычную обучающую выборку образов из класса, от-
вечающего грамматике G. Говорят, что такая выборка является струк-
турно полной, если каждое правило вывода грамматики G используется
для порождения по меньшей мере одного элемента множества 7?+.
Мы хотим обучить (т.е. синтезировать) конечный автомат Aj, который
бы допускал все строки символов из множества /?+ и, по возможнос-
ти, некоторые похожие на них.
Исходя из определения конечного автомата и соответствия меж-
ду Си Aj, можно заключить, что 7?+ с Е*, где Е* — множество всех строк,
состоящих из элементов Е. Пусть строка символов z е I* такова, что
zyv е А+ для некоторой строки w е Е*. Для целого положительного к
определим к-шлейф строки z относительно /?+ как множество
h(z,R+,к) = | zyv e R+, | w |<fc j>. (12.3-11)
Другими словами, /с-шлейф строки символов z представляет собой
множество строк w, обладающих двумя свойствами: (1) zyv е 7?+, и
(2) длина w не превосходит к.
Для конкретного значения к процедура обучения автомата
Af(R+, к) = (Q, Е, 8, q0, F) на выборке примеров 7?+ состоит в том, что
принимается
Q=[q\q = h(z,R+, к) длягеЕ*}
(12.3-12)
и, для каждого а е X,
&(q,a)={q'eQ\q' = h(za,R+,k) для q = h(z,R+,k)}. (12.3-13)
Помимо этого, полагаем
q0=h(k,R+,k) (12.3-14)
и
F = {q\qeQ,keq}, (12.3-15)
где к — пустая строка (строка, не содержащая ни одного символа). За-
метим, таким образом, что автомат Af(R+, к) в качестве состояний ис-
пользует подмножества множества всех ^-шлейфов, которые могут
быть построены из строк 7?+.
Пример 12.14: Вывод конечного автомата на основании выборки пра-
вильных примеров.
Предположим, что /?+ = {a, ab, abb} nk = 1. В соответствии с про-
веденным выше рассмотрением,
Z=k, /z(X,2?+,l) = -|w|Xwe Л+,| w |<1 {о}= Qq
Z = a, /z(a,2?+,l) = -^v|nwe7?+,| w |<1 {X,Z>}= qx
Z-ab, h(ab,R+,l)=[k,b] = qi
z = abb, h(abb,R+,\) = { X } = <?2 •
В данном случае остальные строки z. е X* дают строки символов zyv,
не входящие в R+, которые вызывают переход в четвертое состояние,
обозначаемое q0, которое соответствует условию, что h есть пустое мно-
жество. Таким образом, получаем четыре состояния qQ = {a}, q\ = {X, а},
<?2 = {X} и q0, которые образуют множество Q = {<?0, q}, q^, q0}. Хотя эти
состояния были получены в виде множеств символов (^-шлейфы), для
построения множества Q используются только их метки qQ, q\,... .
Следующий шаг состоит в построении функций переходов. Посколь-
ку Qo = h(k, R+, 1), отсюда следует
12.3. Структурные методы распознавания
8к0,п)=/г(Хд,Л+,1) =h(a,R+,i) =q}
и
?>(q0,b)=h(kb,R+,l)=h(b,R+, 1) =q0.
Аналогично, q\ = h(a, R+, 1) = h(ab, R+, 1), откуда следует
S(qi,a)=h(aa,R+,1) =h(aba,R+,1) =q0.
Кроме того, 8(<7i, b) o h(ab, R+, 1) = q^ и 8(<?i, b) 2 h(abb, R+, 1) = <72,
т.е. 8(^i, b) = {qj, q2\. Продолжая описанную процедуру, получаем
8(<?2,й)= S(?2> = S(?0, а)= 8(<?0, b) - q0. В множество заключитель-
ных состояний входят те состояния, у которых А:-шлейф содержит
пустую строку X. В данном случае q\ = {X, b} и <72 = {М, поэтому
F= kb Ql}-
Суммируя вышеприведенные результаты, полученный автомат
имеет вид
^U?+,1) = (G,Z,8,<7o,F),
где Q = k0, q\, q2, q®}, X = {a, b},F={qx, q2}, а функции перехода при-
ведены выше. На Рис. 12.32 показана диаграмма состояний такого ко-
нечного автомата. Этот автомат допускает строки символов вида
a, ab, abb,..., al/1, что согласуется с предложенной выборкой примеров.
Рис. 12.32. Диаграмма состояний конечного автомата, выведенного на осно-
вании выборки примеров А+ = {a, ab, abb}.
Приведенный выше пример показывает, что выбор значения па-
раметра к управляет поведением получаемого автомата. Следующие
свойства иллюстрируют зависимость ЛД7?+, к) от этого параметра.
Свойство 1. R+ с L[Af(R+, к)] для всех к > 0, где £[Лу( А+, к)] — язык,
допускаемый автоматом ЛД7?+, к).
Свойство 2. L[Af(R+, £)] = /?+, если к больше или равно максималь-
ной длине строки символов в множестве /?+; £[/1у(/?+, &)] = X*, если
£ = 0.
Свойство 3. L[Af(R+, к + 1)] с £[Л^(7?+, £)].
Свойство 1 гарантирует, что Aj(R+, к) будет, как минимум, допускать
строки из исходной выборки примеров R+. Если значение параметра к
больше или равно длине самой длинной строки в R+, то в соответствии
со Свойством 2 получаемый автомат будет допускать только строки из
обучающей выборки 2?+. Если к = 0, у автомата ЛД7?+, 0) будет единст-
венное состояние Qq = {£}, которое одновременно является начальным
и заключительным. Функции перехода будут иметь вид S(<7o, а) = q0
для а е X. Следовательно, язык L[Aj(R+, 0)] = X*, и автомат допускает
как пустую строку к, так и все строки, составленные из символов алфа-
вита X. Наконец, Свойство 3 показывает, что область охвата языка, до-
пускаемого автоматом Af(R+, к), сужается по мере увеличения к.
Эти три свойства позволяют управлять поведением автомата
Aj(R+, к), просто меняя значение параметра к. Если L[Aj(R+, к) ] пред-
ставляет собой гипотезу относительно языка £0, из которого была
получена выборка R+, и если значение к очень мало, то эта гипотеза
относительно языка £() будет давать возможность свободного вывода
большинства или даже всех символьных строк из X*. Однако, если к
равно максимальной длине строки в 7?+, вывод будет осторожным в том
смысле, что автомат Aj(R+, к) будет допускать только строки симво-
лов, содержащиеся в выборке 7?+. Рис. 12.33 графически иллюстриру-
ет эту концепцию.
Пример 12.15: Еще один пример вывода автомата по заданному мно-
жеству образов.
Рассмотрим множество R+ = {caaab, bbaab, caab, bbab, cab, bbb, cb}. Вы-
полняя для к = 1 ту же процедуру, что и в предыдущем примере, получим:
1. z = k, h(k,R+, l) = {0} = q0;
2. z = c, h(z,R+, l) = {b} = q}-,
3. z = ca, h(z, R+, 1) = {b} = qy
4. z = cb, h(z, R+, 1) = {£} = q0',
5. z. = caa, h(z, R+, 1) = {A} = qy
6. z = cab, h(z, R+, 1) = {£} = q0;
12.3. Структурные методы распознавания
L[Af(R^, 0)]
Рис. 12.33. Связь между значением параметра к и языком £|Лу(й+, £)]. Значе-
ние кт таково, что кт > /макс (максимальной длины строки символов из мно-
жества Л+).
7. z — сааа, 8. z — caab, 9. z— caaab, h(z,R+, l) = W = 9b h(z,R+, l) = {X}=90; h(z, R+, 1) = {X} = 9O;
10. z = b, h(z, R+, I) = {0} = 90;
11. z. = bb, h(z,R+, 1) = {*} = 9ь
2. z— bba, h(z,R+, l) = W=9b
3. z — bbb, h(z,R+, l) = {X} = 90;
4. z — bbaa, h(z, R+, 1) = {b} = 9b
5. z— bbab, h(z, R+, 1) = {X} = 90;
6. z — bbaab, h(z,R+, l) = {X} = 9o-
Автомат будет иметь вид
Л/и+,1) = (е,Х,8,?0,Р),
где Q = {<70, ^1, 9q}, Е = {a, b, с}, F= {90}, а возможные переходы по-
казаны в диаграмме состояний на Рис. 12.34. Чтобы распознавать-
ся этим автоматом, строка должна начинаться с символа а, b или
с, и заканчиваться символом Ь. Автомат Aj\R+, 1) также допуска-
ет строки с повторяющимися произвольное число раз символами
а, b или с.
a
Рис. 12.34. Диаграмма состояний автомата Af(R+, 1), выведенного по выбор-
ке примеров R+ = {caaab, bbaab, caab, bbab, cab, bbb, cb}.
Основное достоинство вышеописанного метода состоит в про-
стоте реализации. Такую процедуру синтеза автомата можно с мини-
мальными усилиями реализовать в форме компьютерной програм-
мы. Главный недостаток кроется в необходимости выбора надлежашего
значения параметра к, хотя эту задачу в некоторой степени упроща-
ют рассмотренные выше три свойства.
Заключение
Начиная с Главы 9, наше изучение цифровой обработки изображе-
ний переместилось с процессов, выходом которых являлись изобра-
жения, к процессам, выходом которых являются признаки изобра-
жений, в том смысле, как это описывалось в Разделе 1.1. Хотя
представленный в настоящей главе материал носит вводный харак-
тер, затронутые темы имеют фундаментальное значение для пони-
мания современного состояния проблемы распознавания объектов.
Как отмечалось в начале главы, распознавание объектов является ло-
гическим завершением этой книги. Чтобы двигаться дальше, нам по-
требовались бы понятия, выходящие за те границы рассмотрения, ко-
торые мы наметили в Разделе 1.4. В частности, следующим
логическим шагом должно было бы стать изучение методов анали-
за изображений, для чего потребовались бы понятия из области ис-
кусственного интеллекта.
Как уже отмечалось в Разделах 1.1 и 1.4, искусственный интеллект
и некоторые смежные области, в частности, анализ сцен и машинное
зрение, все еще пребывают на относительно ранних стадиях практи-
ческих разработок. Для решения задач анализа изображений сегодня
характерны эвристические подходы. Хотя эти подходы и в самом де-
ле разнообразны, однако большинство из них существенно опирает-
ся на методы, рассмотренные в данной книге.
Закончив изучение материала предшествующих двенадцати глав,
читатель теперь способен понимать основную проблематику сферы ци-
фровой обработки изображений, как с теоретической, так и с практи-
ческой точки зрения. На протяжении всего рассмотрения мы стара-
лись заложить твердую основу для дальнейшего изучения как
обсуждаемых, так и смежных областей. Учитывая специфический ха-
рактер многих задач обработки изображений, ясное понимание базо-
вых принципов существенно повышает шансы на успешное решение
этих задач.
Ссылки и литература для дальнейшего изучения
Подготовительный материал для Разделов 12.1 — 12.2.2 приводится в
книгах [Duda, Hart, Stork, 2001] и [Той, Gonzalez, 1974]. Также пред-
ставляет интерес обзор [Jain et al., 2000]. В книге [Principe et al., 1999]
дан хороший обзор нейронных сетей. Специальный выпуск журнала
{IEEE Trans. Image Processing, 1998] стоит сравнить с аналогичным
специальным выпуском, вышедшим десятью годами ранее ([IEEE
Computer, 1988]). Материал Раздела 12.2.3 носит вводный характер.
Фактически, рассматриваемая модель нейронной сети является лишь
одной из многочисленных моделей, предложенных за прошедшее
время. Тем не менее, эта модель является представительной и широ-
ко используется в обработке изображений. Пример с распознавани-
ем искаженных фигур является переделанным вариантом из статей
[Gupta et al., 1990,1994]. В работе [Gori, Scarselli, 1998] обсуждается во-
прос о мощности классификации, обеспечиваемой многослойными
нейронными сетями. Хорошим дополнительным источником по этой
теме служит статья [Ueda, 2000], где сообщается о подходе, основан-
ном на использовании линейных комбинаций нейронных сетей для
минимизации ошибки классификации.
В качестве дополнительного материала по Разделу 12.3.1 реко-
мендуется статья [Bribiesca, Guzman, 1980]. По поводу сопоставле-
ния строк символов см. работы [Sze, Yang, 1981], [Oommen, Loke,
1997] и [Gdalyahu, Weinshall, 1999]. По Разделам 12.3.3 и 12.3.4 реко-
мендуются книги [Gonzalez, Thomason, 1978], [Fu, 1982] и [Bunke,
Sanfeliu, 1990]. См. также работы [Tanaka, 1995], [Vailaya et al., 1998],
[Aizaka, Nakamura, 1999] и [Jonket al., 1999].
Задачи
12.1 (а) Вычислите дискриминантные функции классификатора no
минимуму расстояния для образов на Рис. 12.1. Необходи-
Глава 12. Распознавание объектов
мне векторы математического ожидания получите само-
стоятельно путем измерений и анализа данных на рисунке.
(б) Нарисуйте разделяющие поверхности, реализуемые дис-
криминантными функциями в (а).
*12.2 Покажите, что уравнения (12.2-4) и (12.2-5) реализуют одну и
ту же функцию с точки зрения классификации объектов.
12.3 Покажите, что поверхность, заданная уравнением (12.2-6),
есть гиперплоскость в и-мерном пространстве, перпендикуляр-
ная отрезку прямой, соединяющему точки mz- и Шу, и проходя-
щая через его середину.
*12.4 Покажите, как обсуждаемый в связи с Рис. 12.7 классифика-
тор по минимуму расстояния можно реализовать с помощью
Жблоков резисторов (где W— число классов), сумматоров по
числу блоков (для суммирования токов) и Ж-входовой схемы
выбора максимума, способной выбирать вход, через который
протекает максимальный ток.
12.5 Покажите, что коэффициент корреляции, определяемый со-
отношением (12.2-8), принимает значения в диапазоне [—1,1].
Подсказка: Выразите функцию у(х, у) в векторной форме.
*12.6 В результате эксперимента получаются двоичные изображе-
ния пятен эллиптической формы (см. рисунок ниже). Пят-
на бывают трех размеров, со средними значениями главных
осей эллипсов (1,3; 0,7), (1,0; 0,5) и (0,75; 0,25). Разброс
размеров этих осей составляет ±10% от указанных средних
значений. Разработайте систему обработки изображений,
которая бы отбрасывала неполные или перекрывающиеся
эллипсы, а затем классифицировала бы оставшиеся раз-
дельные эллипсы по трем указанным классам. Представь-
те решение в виде блок-схемы с указанием конкретных по-
дробностей работы каждого блока. Для решения задачи
классификации используйте классификатор по минимуму
расстояния, четко указав, как предполагается получать обу-
чающую выборку и как объекты из этой выборки будут ис-
пользоваться для обучения классификатора.
12.7 Следующие два класса образов имеют гауссовы распределения:
сор {(0, 0)г, (2, 0)г, (2, 2)г, (О, 2)г} и со2: {(4, 4)г, (6, 4)г, (6, 6)г,
(4, б)7}.
(а) Предполагая, что /э(со1) = ЛоД = 1 /2, получите уравнение
байесовской разделяющей поверхности между этими дву-
мя классами.
(б) Нарисуйте эту разделяющую поверхность.
*12.8 Решите Задачу 12.7 для следующих классов образов:
Ю1: {(-1, 0)г, (0, -1)г, (1, 0)г, (О, I)7} и со2: {(-2, О)7, (О, -2)г,
(2, 0)т, (О, 2)7}. Заметьте, что эти классы не являются линей-
но разделимыми.
12.9 Решите Задачу 12.6 с использованием байесовского классифи-
катора, предполагая, что распределения являются нормаль-
ными. Четко укажите, как предполагается получать обучающую
выборку и как объекты из этой выборки будут использовать-
ся для обучения классификатора.
*12.10 Байесовские дискриминантные функции ^(х) = р(х | со,)Р(со,),
j = 1, 2,..., И7 был и выведены с использованием нуль-единич-
ной функции потерь. Докажите, что эти дискриминантные
функции обеспечивают минимальную вероятность ошибки.
(Подсказка: Вероятность ошибкир(е) равна 1 — р{с), гдер{с) —
вероятность правильного распознавания. Если образ с векто-
ром признаков х принадлежит классу coz, то р(с | х) = 1 х).
Найдитер(с) и покажите, что она максимальна (т.е. р(е) мини-
мальна), когдар(х | coz)P(coz) принимает максимальное значение).
12.11 (а) Примените алгоритм персептрона к следующим классам
образов: со,: {(0, 0, 0)г, (1, 0, 0)г, (1, 0, 1)г, (1, 1, О)7} и
c^: {(0,0,1)г, (0,1,1)г, (0,1,0)г, (1,1,1)7}. Положите с = 1,
a w(l) = (—1, —2, —2, 0)г.
(б) Нарисуйте разделяющую поверхность, полученную в п. (а).
Укажите положительную сторону поверхности и облас-
ти, занимаемые классами.
*12.12 Алгоритм персептрона, задаваемый уравнениями (12.2-34) —
(12.2-36), можно выразить более компактно, умножая образы
класса ш2на — 1. При этом корректирующие шаги алгоритма
приобретают вид: w(£ + 1) = w(£), если v/T(k)y(k) > 0; и
w(k + 1) = v/(k) + cy(k) в противном случае. Это одна из несколь-
ких известных формулировок алгоритма обучения персептро-
на, которую можно вывести из общего уравнения градиентно-
го спуска
w(£ + l) = w(k)-c
9J(w,y)
3w
w=w(fc)
где с > 0, J(w, у) — целевая функция, и частная производная вы-
числяется в точке w = w(Zc). Покажите, что эту формулировку
алгоритма персептрона можно получить из общей процедуры
градиентного спуска, используя целевую функцию вида
J(w, У) = (|wry| — wry)/2, где | arg | абсолютное значение ар-
гумента. (Примечание: Частная производная wzy по w равна у).
12.13 Докажите, что алгоритм обучения персептрона, задаваемый
уравнениями (12.2-34) — (12.2-36), сходится за конечное чис-
ло шагов, если обучающие выборки классов являются линей-
но разделимыми. [Подсказка: Умножьте образы из класса ш2 на
—1 и введите в рассмотрение такой неотрицательный порог Т,
чтобы алгоритм обучения персептрона (со значением с = 1) вы-
ражался условиями w(£ + 1) = w(£), если v/T(k)y(k) > Т, и
w(k + 1) = v/(k) + y(k) в остальных случаях. Вам может потре-
боваться неравенство Коши — Шварца: ||а ||2||Ь||2>(агЬ)2].
*12.14 Укажите структуру и веса нейронной сети, которая бы дейст-
вовала в точности так же, как классификатор по минимуму рас-
стояния для двух классов образов в «-мерном пространстве.
12.15 Укажите структуру и веса нейронной сети, которая бы действо-
вала в точности так же, как байесовский классификатор для
двух классов образов в «-мерном пространстве. Считайте, что
классы подчиняются нормальным законам распределения с от-
личающимися математическими ожиданиями и одинаковыми ко-
вариационными матрицами.
*12.16 (а) При каких условиях нейронные сети, построенные в За-
дачах 12.14 и 12.15, будут идентичны?
(б) Можно ли получить конкретную нейронную сеть из п. (а),
применяя описанное в Разделе 12.2.3 обобщенное дельта-
правило для обучения многослойной нейронной сети без
обратной связи на достаточно большой выборке образов
из каждого класса?
12.17 Два класса в двумерном пространстве имеют такие распреде-
ления, что образы класса со] случайно распределены вдоль ок-
ружности радиуса г,, а образы класса со2 — вдоль концентри-
ческой окружности радиуса г2, где г2 = 2г,. Постройте структуру
нейронной сети с минимальным количеством слоев и узлов, ко-
торая бы правильно классифицировала образы из этих двух
классов.
*12.18 Решите Задачу 12.6 с помощью нейронной сети. Четко укажи-
те, как предполагается получать обучающую выборку и как
объекты из этой выборки будут использоваться для обучения
классификатора. Выберите наиболее простую конфигурацию
нейронной сети, которая, по Вашему мнению, подходит для ре-
шения задачи.
12.19 Покажите, что приведенное в (12.2-71) выражение
= Оу(1 — Оу), где hj'(Jj) = dh^ty/dlj, следует из уравнения
(12.2-50) при 0О = 1.
*12.20 Покажите, что мера расстояния D(A, Б) из определения (12.3-2)
удовлетворяет свойствам (12.3-3).
12.21 Покажите, что величина Р = max(|a|, |Z>|) — а из уравнения
(12.3-4) равна 0 тогда и только тогда, когда строки символов а
и b идентичны.
12.22 *(а) Постройте конечный автомат, распознающий строки ви-
да alfa.
(б) Получите из решения, найденного в п. (а), соответствую-
щую регулярную грамматику. (Не стройте грамматику не-
посредственно из условия задачи).
12.23 Постройте расширяющую грамматику деревьев, порождаю-
щую изображения в виде шахматного поля, состоящего из че-
редующихся нулевых и единичных элементов в обоих прост-
ранственных направлениях. Считайте, что левый верхний
элемент имеет значение 1, и все изображения заканчиваются
единичным элементом в левом нижнем углу.
*12.24 Воспользуйтесь обучающей процедурой в соответствии с урав-
нениями (12.3-12) — (12.3-15) для обучения конечного авто-
мата, способного распознавать строки вида alfa при п > 0. Нач-
ните с обучающей выборки примеров {aba, abba, abbba}. Если
это множество окажется недостаточным, чтобы алгоритм обна-
ружил повторяющийся символ Ь, добавляйте к выборке допол-
нительные примеры строк символов, пока это не произойдет.
12.25 Покажите, что автомат на деревьях, построенный в связи с
Рис. 12.30, допускает дерево, приведенное на Рис. 12.31(6).
12.26 Фабрика осуществляет массовое производство маленьких аме-
риканских флажков для спортивных мероприятий. Служба га-
рантии качества заметила, что в моменты пика производства
на некоторых печатных машинах случайным образом пропа-
дают от одной до трех звездочек и от одной до трех полосок.
Глава 12. Распознавание объектов
В остальном выпускаемые флаги не содержат дефектов. Хотя
брак и составляет малую долю общего объема производства, ди-
ректор фабрики хочет решить эту проблему и считает, что на-
иболее экономичным способом будет автоматизированный
контроль с использованием методов обработки изображений.
Основные технические данные производственного процесса
следующие. Флажки имеют размеры приблизительно
7,5 х 12,5 см и двигаются по производственной линии со ско-
ростью приблизительно 50 см/с в продольной ориентации (с до-
пустимым отклонением ±15°) с расстоянием между флажками
приблизительно 5 см. «Приблизительно» во всех случаях озна-
чает допустимое отклонение ±5%. Директор фабрики нанима-
ет Вас для проектирования системы обработки изображений к
каждой из производственных линий. Вам сказано, что оценка
предлагаемого подхода будет определяться с позиций его про-
стоты и стоимости. Разработайте полную систему, исходя из мо-
дели на Рис. 1.23. Представьте Ваш проект (включая допущения
и спецификации) в форме краткого (но ясного) письменного от-
чета, адресованного директору фабрики.
предметный указатель
Автокорреляция 312
Автомат конечный 1045-1046
Алфавит источника 621
Алфавит канала 622
Ангиография 35-37, 834
Базис в функциональном пространстве 534
Базис ортонормированный 535
Базис Рисса 535
Базисные функции 534
Биортогональная система функций 535
Биортогональных койфлетов семейство 525
Биортогональных сплайнов семейство 525
Битовая плоскость 146-148, 653-657
Вейвлет «мексиканская шляпа» 555
Вейвлет-кодирование 700-710
Вейвлет-кодирование, расчет квантователя 709
Вейвлет-пакеты трехмасштабные 580-582
Вейвлет-преобразование быстрое (БВП) 548
Вейвлет-преобразование быстрое, блок
фильтров Хаара 562
Вейвлет-преобразование быстрое, двумерное
567-571
Вейвлет-преобразование быстрое, одномерное
557-567
Вейвлет-преобразование быстрое,
представление в виде дерева 578
Вейвлет-преобразование дискретное 532-533
Вейвлет-преобразование интегральное 547,553-
557
Вейвлет-преобразование компонент 5-3
обратимое 727
Вейвлет-преобразование компонент 9-7
необратимое 727-733
Вейвлеты биортогональные Коэна-Добеши-
Фово 588-590
Вектор признаков 984
Видимый (цветовой) спектр 32, 85-89
Водораздел, линия 882
Водораздел, сегментация 881-893
Выпуклая оболочка 774-777, 787, 925-927
Вычитание изображений 177, 894-898
Гайзенберга ячейка 566
Гамма-коррекция 139-141
Гистограмма глобальная 148-150
Гистограмма локальная 167-169
Гистограмма цветного изображения 489
Гистограммные статистики 169-175
Глаз, строение 74-78
Гомоморфная система 291
Градиент 209-212,498, 825-826, 869
Градиент морфологический 798
Грамматика автоматная 1043
Грамматика деревьев 1048-1049
Грамматика символьных строк 1041-1044
Граница 120
Граница, декомпозиция 925
Граница, дескрипторы 931-941
Граница, морфологическое выделение 768, 787
Граница, нахождение 836-850
Граница, представление ломаной линией 920-
923
Декодер 614-617
Дельта кодирование двойное (ДДК) 661
Дельта-модуляция 668-670
Дерево анализа 578
Дерево двоичное 578
Дескриптор, главные компоненты 961-971. см.
также Преобразование Хотеллинга
Диапазон яркостей, вырезание 146
Дилатация 753, 787, 790
Динамический диапазон 104
Дискриминантная функция 989
Дифференциальная импульсно-кодовая
модуляция (ДИКМ) 671
Замыкание 759,787,794
Избыточность визуальная 609-612
Избыточность кодовая 600-605
Избыточность пространственная 605-609
Изображение акустическое 50-52
Изображение в гамма-лучах 33-34
Изображение инфракрасное 38-45, 845, 943, 946
Изображение магнитно-резонансное (ЯМР) 49,
94
Изображение многозональное
(мультиспекгральное) 41,444-445, 872-873,
1006-1008
Изображение мозаичное 54-55
Изображение опорное 897-898
Изображение полноцветное 428
Изображение радиолокационное 48
Изображение рентгеновское 35-37
Изображение ультразвуковое 52
Изображение ультрафиолетовое 37-38
Изображение фрактальное 54-56, 148, 178
Изображение, модель формирования 96-98,853
Изображение, система координат 102
Изображение, увеличение и уменьшение 114-
116
Импульсная функция 251, 378
Интенсивность 23, 87
Интерполяция 115-116, 403, 406-410
Интерполяция билинейная 115,407-408
Интерполяция кубическая типа свертки 407
Интерполяция нулевого порядка 115, 406
Информации количество 620
Информация взаимная 624
Искажающий оператор 332, 377, 382-388
Искажения блоковые 690
Искажения линейные 377-381
Искажения мера 633
Источник без памяти 628
Источник марковский 630
Источник, п—кратное расширение 628
Кадр двунаправленный (В-кадр) 737
Кадр опорный (независимый, 1-кадр) 736
Кадр предсказываемый (Р-кадр) 737
Канал без памяти 632
Канал двоичный симметричный 625- 627
Канала матрица 622
Качество изображения 108-112, 613-614
Квантование изображения 98-101, 439-440, 611,
675-677
Квантователь 616
Класс, порождение грамматикой 1043-1044
Классификатор байесовский 998-1008
Классификатор, корреляционное
сопоставление 995-998
Классификатор, минимум расстояния 990-995
Код блоковый 644
Код Грея 653-654
Код Лемпеля-Зива-Уэлша (LZW) 649-653
Код мгновенный 644
Код неравномерный 603-604, 642-649
Код однозначно декодируемый 644
Код сдвиговый 646-647
Код Хаффмана 642-644
Код цепной 918-920
Кодер 614-617
Колер символов 616
Кодирование арифметическое 647-649
Кодирование дифференциальное 666
Кодирование длин серий (КДС) 607-609,658-
660
Кодирование зональное 694-697
Кодирование контуров 660-661
Кодирование по Хэммингу 617-619
Кодирование пороговое 694, 697-700
Кодирование с предсказанием 663-681
Кодирование с расширением 630-631
Кодирование субполосное 519-530
Кодирование субполосное двухканальное 519-
520
Кодирование, двоичное представление 692-700
Кодирования источника теорема 632-634
Кодирования режим без потерь 718
Кодирования режим последовательный 718
Кодирования режим расширенный 718
Кодовое расстояние 618
Контрастная чувствительность 79-82
Контур ложный 107-108
Контур, направление 826
Контур, обнаружение 498-501. 825-828. 834-836,
869
Контур, понятие 120, 825
Контур, связывание 836-850
Контур, связывание методами теории графов
845-850
Контур, точка 928
Контур, участок 825
Контуры в цветовом пространстве 500-501
Корреляция взаимная 311
Корреляция изображений 995
Корреляция с эталоном 311
Коэффициент отражения, 97, 853
Коэффициент пропускания 97
Коэффициент сжатия 601
Кратномасштабное разложение 533-547
Кратномасштабный анализ (КМА) 511, 533
Кривые равного предпочтения 110-112
Лапласиан 200-207, 279, 397, 398, 830-832, 869
Лапласиан гауссиана 833
Лапласиан цветных изображений 493
Линия, обнаружение 816-819
Линия, представление границы ломаной 920-
923, 1039
Лифтинг-схема 728-729
Макроблок 734
Маска (ядро, шаблон, окно, окрестность) 134,
815,816, 827, 829, 832, 835
Маскирование изображения 176-179
Масштабирующая функция 533, 537
Масштабная (двухмасштабная)
последовательность 542
Метод последовательного удвоения 317
Нейронная сеть 1010, 1019-1036
Нейронная сеть для классификации по форме
1028-1033
Нейронная сеть, многослойная без обратной
связи 1019-1036
Нейронная сеть, обучение 1011, 1023-1028
Нейронная сеть, скрытые слои 1023
Нейронная сеть, сложность разделяющей
поверхности 1033-1036
Непроизводный элемент 971-975, 1041, 1049
Нерезкое маскирование 207, 284-289
Нумерация фигур 932-935, 1037-1039
Область временная 234
Область пространственная 131
Область частотная 131, 234
Область, выпуклая оболочка 925
Область, выращивание 875-878
Область, дескрипторы 941-961
Область, дефект выпуклости 926
Область, мера компактности 941
Область, морфологическое заполнение 769, 787
Область, разделение 879
Область, сегментация 874-875
Область, слияние 880
Область, текстура 947-956
Обучающая выборка 1009
Обучение 953, 1009, 1054-1060
Оператор градиентный 825-826, 869
Оператор Превитта 827
Оператор Робертса 211-212, 826
Оператор Собела 212-213, 215, 828
Опорные точки 405
Освещение 89, 853-855
Освещенность 97
Остов 780-781, 788, 927-930
Остов, морфологическое построение 780-783
Остов, представление 927-930
Отношение Вебера 81
Отображение 607, 640-641
Оценка искажений 383-388
Перегородка, построение 885-888
Перегрузка по крутизне 670
Перепад 819-825 см. также Контур
Перепад, обнаружение 825-836
Персептрон 1010-1019
Пиксель (элемент изображения) 24, 103, 117-122
Пирамида гауссова 516, 517-518
Пирамида изображений 514-518
Пирамида Лапласианов 517-518
Пирамида приближений 514
Пирамида разностей с предсказанием 515-517
Повышение резкости морфологическое 798
Повышение резкости см. Фильтры высоких
частот
Повышение резкости цветных изображений
490-493
Полосы Маха 82
Пороговая обработка адаптивная 852, 858-868
Пороговая обработка мультиспекгральная 872-
873
Пороговая обработка, оптимизация 861-868
Пороговая обработка, цветное изображение
872-873
Поток лучистой энергии 422
Предсказания ошибка 663
Представление изображения 59, 917-930
Представление изображения, инвариантность
917
Предметный указатель 1069
Представление изображения, остов 927-930
Представление изображения, сигнатура 923-925
Преобразование «столбик» 798-799
Преобразование «успех/неудача» 765-767, 787
Преобразование к главным компонентам 964-
966
Преобразование к главным осям 927
Преобразование Карунена-Лоэва (ПКЛ) 689
Преобразование косинусное дискретное (ДКП)
685-690
Преобразование Уолша-Адамара (ПУА) 683-690
Преобразование Хаара 530
Преобразование Хафа 839-845
Преобразование Хотеллинга 964-966
Преобразования цветовых координат 431 -437
Признак 59, 984-986
Примитив (структурообразующее множество)
754
Производная дискретной функции 197-200
Пропускная способность 621, 624
Прореживание изображения 106
Пространственная инвариантность 378
Псевдоцвета 439, 443-445
Разделяющая поверхность 990, 1033-1036
Разложение в вейвлет-ряды 547, 548-549
Размыкание 759, 787, 794
Разностное изображение 894-898
Разность с предсказанием 515
Разрешение пространственное 105-112
Разрешение яркостное 105-112
Разрыв яркости, обнаружение 813-814, 825-828
Распознавание объектов, методы
сопоставления 990-998
Распознавание объектов, методы теории
решений 989-1036
Распознавание объектов, синтаксические
методы 1041-1060
Распознавание объектов, структурные методы
1036-1060
Регистрация изображений 31-61, 89-96
Реконструкция изображения 381
Решающая функция 989
Свертка изображений 187-188, 250, 262, 310, 380
Световой поток 88,422
Связная компонента 119
Связная компонента, морфологическое
выделение 771-772, 787
Сглаживание 189-196, 834-835 см. также
Усреднение по окрестности, Фильтрация
Сглаживание морфологическое 797
Сглаживание цветных изображений 490-493
Сегментация в пространстве HSI493-495
Сегментация в пространстве RGB 495-498
Сегментация в пространственной области 894-
898
Сегментация в частотной области 898-903
Сегментация избыточная 891-893
Сегментация на основе выделения областей
874-881
Сегментация по гистограмме 852
Сегментация текстурная 800, 881,947-956
Сегментация цветных изображений 493-501
Сегментация, использование движения 893-904
Сжатие видеоданных, стандарты MPEG 734-737
Сжатие видеоданных, телевизионные
стандарты 733-737
Сжатие данных 600
Сжатие двоичных изображений 713-717
Сжатие двоичных изображений одномерное
711-713
Сжатие двоичных изображений, вертикальный
режим 714, 717
Сжатие двоичных изображений,
горизонтальный режим 714-717
Сжатие двоичных изображений, переходной
режим 714-716
Сжатие изображений с использованием
главных компонент 969
Сжатие изображений, стандарты МККТТ 710-
738
Сжатие посредством квантования 610-612
Сжатие цветных изображений 502-503
Сигнал-шум отношение 613
Сигнатура 923-925, 986
Симметричные вейвлеты (симлеты) 572-574
Синтаксическое распознавание деревьев 1048-
1060
Синтаксическое распознавание символьных
строк 1041- 1048
Скелетонизация см. Остов
Скорость как функция искажения 634
Скорость кода 632
Скотопическое зрение 76, 79-80
Слайс 735
Случайная переменная блоковая 628
Смазывание изображения 384-388, 393-395,
398-399
Собственные оси 970
Тайл-компонента 728
Текстура, морфологическая сегментация 800
Текстура, описание спектральное 954-956
Текстура, описание статистическое 948-953
Текстура, описание структурное 953-954
Текстура, энтропия 949, 950, 952
Теорема о корреляции 311
Теорема о свертке 250-251, 300, 310
Теорема об автокорреляции 312
Точка изолированная, обнаружение 814-815
Трансформационное кодирование 681-710
Узловые точки 404
Уровень квантования 675
Уровень пороговый 675
Уровень серого 23, 87, 98 см. также
Интенсивность
Усечение морфологическое 783-786, 788
Усиление контраста 133, 143-146
Усреднение по окрестности 190-191, 346,491-
492.829,831
Утолщение морфологическое 778-780, 788
Утончение морфологическое 777-778, 788
Фильтр адаптивный локальный 357-358
Фильтр винеровский (минимального
среднеквадратического отклонения) 390-395
Фильтр винеровский параметрический 402
Фильтр гауссов 253
Фильтр гауссов пространственный 268
Фильтр гомоморфный 291
Фильтр изотропный 200
Фильтр инверсный 388-390
Фильтр интерполяционный 516
Фильтр контрагармонический 347-348
Фильтр максимума 195, 351-352
Фильтр медианный 194-196, 350-351, 360-363
Фильтр минимума 195, 351-352
Фильтр нулевого фазового сдвига 245
Фильтр реконструирующий 381
Предметный указатель
Фильтр срединной точки 352
Фильтр среднеарифметический 346
Фильтр среднегармонический 347
Фильтр среднегеометрический 347, 402
Фильтр усеченного среднего 352-353
Фильтр частотный Лапласа 279-284
Фильтр эквализации спектра 402
Фильтр, передаточная функция 244
Фильтрация морфологическая 763
Фильтрация пространственная 185-218
Фильтрация пространственная линейная 187
Фильтрация пространственная нелинейная 188
Фильтрация пространственная, маска 185-189
Фильтрация Тихоновская 395-402
Фильтрация узкополосная 367-377
Фильтрация частотная 242-289, 364-377
Фильтр-пробка 247
Фильтры Q-постоянные 578
Фильтры биортогональные Коэна-Добеши-
Фово 588-590
Фильтры Вайданатана-Хоанга 527
Фильтры высоких частот 248, 274
Фильтры квадратурные зеркальные 526
Фильтры квадратурные сопряженные 526
Фильтры низких частот 257
Фильтры ортонормированные 526
Фильтры ортонормированные Добеши 528
Фильтры перекрестно-модулированные 523
Фильтры синтеза 520
Фильтры Смита-Барнвелла 527
Фотопическое зрение 76, 79-80
Фрейм 536
Функция модуляции 373
Функция окна 113
Функция пороговая 134, 144
Функция преобразования интенсивностей 133
Функция ранжирования 1048
Функция рассеяния точки 379
Фурье преобразование 231-242
Фурье преобразование быстрое (БПФ) 317-321
Фурье преобразование двумерное 232
Фурье преобразование двумерное, перечень
свойств 314-316
Фурье преобразование дискретное 232, 238,
685-690
Фурье преобразование обратное 231,232, 238,
298-299
Фурье преобразование одномерное 231
Фурье преобразование, постоянная
составляющая 240
Фурье преобразование, спектр 137-138, 235, 239
Фурье преобразование, фаза 235, 239
Фурье преобразование, энергетический спектр
235, 239
Фурье ряд 229
Хаара функции 530
Цвета глубина 428
Цвета дополнительные 482
Цвета основные 422-423
Цветности диаграмма 425
Цветности координаты 424-425
Цветность 424
Цветовая коррекция 485,488-489
Цветовая модель CIELAB 486
Цветовая модель CMY 431-432
Цветовая модель CMYK 432
Цветовая модель HSI 432-435
Цветовая модель L*a*b* см. Цветовая модельС1Е1ЛВ
Цветовая модель RGB 427-428
Цветовая модель колориметрическая 486
Цветовая модель равноконтрастная 486
Цветовая модель, не зависящая от устройства
486
Цветовая насыщенность 424
Цветовая система (цветовое пространство) см.
Цветовая модель
Цветового преобразования функции 448
Цветовое дополнение 482-483
Цветовой круг 482
Цветовой куб RGB 428, 431
Цветовой охват 426
Цветовой тон 424
Цветовые координаты 424
Цветовые профили 486
Цветовые стандарты МКО 422-423
Цепной код 918-920
Цифровой преобразователь 61
Частота дискретизации 112-113
Частота среза 259
Частотная область 131, 234, 242
Частотно-временная плоскость 566
Частотный прямоугольник 239
Чувствительный элемент (сенсор) 61, 90-96,
100-101 см. также Регистрация изображений
Шум белый 334
Шум гауссов 335
Шум гранулярности 670
Шум импульсный 194-196, 338-339
Шум импульсный биполярный 338-339
Шум импульсный униполярный 339
Шум на изображении 180-185, 333-345, 373,
501-502
Шум периодический 341-342
Шум равномерный 338
Шум равномерный аддитивный 356
Шум Релея 335-337
Шум экспоненциальный 337-338
Шум Эрланга (гамма шум) 337
Шум, оценка параметров 243-245
Экзаменационная выборка 1030-1033
Электромагнитный спектр 24, 32
Элемент изображения см. Пиксель
Энергетический спектр 235, 239
Энтропия изображения, вычисление 637-640
Энтропия источника 621, 638-639
Энтропия условная 623
Эрозия 756, 787, 791-792
Эффект муара 113-114
Эффект наложения спектров 112-114
Яркостная адаптация 79-83
Яркостная коррекция 485, 487-488
Яркость 87
Яркость субъективная 79-80
Ячейка накопления 840
Заявки на книги присылайте по адресу:
125319 Москва, а/я 594
Издательство «Техносфера»
e-mail: knigi@technosphera.ru
sales@technosphera.ru
факс: (095) 956 33 46
В заявке обязательно указывайте
свой почтовый адрес!
Подробная информация о книгах на сайте
http://www.technosphera.ru
Р. Гонсалес, Р. Вудс
Цифровая обработка изображений
Компьютерная верстка — С. В. Плетнев
Корректор — Л. Г. Циферова
Ответственный за выпуск — Л. Ф. Соловейчик
Формат 70x100/16. Печать офсетная.
Гарнитура Ньютон
Печ.л. 67. Тираж 2000 экз. Зак. А-223
Бумага офсет №1, плотность 65г/м2,
цветная вклейка — бумага мелованная, плотность 115г/м2
Издательство «Техносфера»
Москва, Лубянский проезд, дом 27/1
Диапозитивы изготовлены ООО «Европолиграфик»
Отпечатано в типографии ОАО ПИК «Идел-Пресс»
в полном соответствии с качеством
предоставленных диапозитивов.
420066, г. Казань, ул. Декабристов, 2.