













































































































































Автор: Васильев В.И.
Теги: автоматика системы автоматического управления и регулирования интеллектуальная техника технология управления оборудование систем управления техническая кибернетика информационные технологии вычислительная техника обработка данных кибернетика микропроцессоры машиностроение интеллектуальные системы
ISBN: 978-5-94275-667-3
Год: 2013




D
D
ДЛЯ ВУЗОВ
В.И. Васильев
ИНТЕЛЛЕКТУАЛЬНЫЕ
СИСТЕМЫ
ЗАЩИТЫ ИНФОРМАЦИИ
Издание второе, исправленное
Допущено Учебно-методическим объединением
по образованию в области информационной
безопасности в качестве учебного пособия для
студентов высших учебных заведений,
обучающихся по специализациям специальности
«Комплексное обеспечение информационной
безопасности автоматизированных систем»
МОСКВА
«МАШИНОСТРОЕНИЕ»
2013
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ 5
ГЛАВА 1. ОСНОВЫ ПОСТРОЕНИЯ ИНТЕЛЛЕКТУАЛЬ-
НЫХ СИСТЕМ ЗАЩИТЫ ИНФОРМАЦИИ 9
1.1. Системные принципы защиты информации 9
1.2. Интегрированные системы защиты информации 12
1.3. Интеллектуализация систем защиты информации 20
Контрольные вопросы 33
ГЛАВА 2. БИОМЕТРИЧЕСКИЕ СИСТЕМЫ
ИДЕНТИФИКАЦИИ ЛИЧНОСТИ 34
2.1. Биометрические технологии: классификация,
сравнительные характеристики 34
2.2. Постановка задачи распознавания образов.
Построение решающего правила 45
2.3. Нейросетевые алгоритмы биометрической
идентификации 52
2.4. Нейросетевая реализация биометрических систем
идентификации с криптозащитой 61
2.5. Биометрические системы идентификации на основе
нечетких экстракторов 67
Контрольные вопросы 73
ГЛАВА 3. НЕЙРОСЕТЕВЫЕ СИСТЕМЫ ОБНАРУЖЕНИЯ
АТАК 74
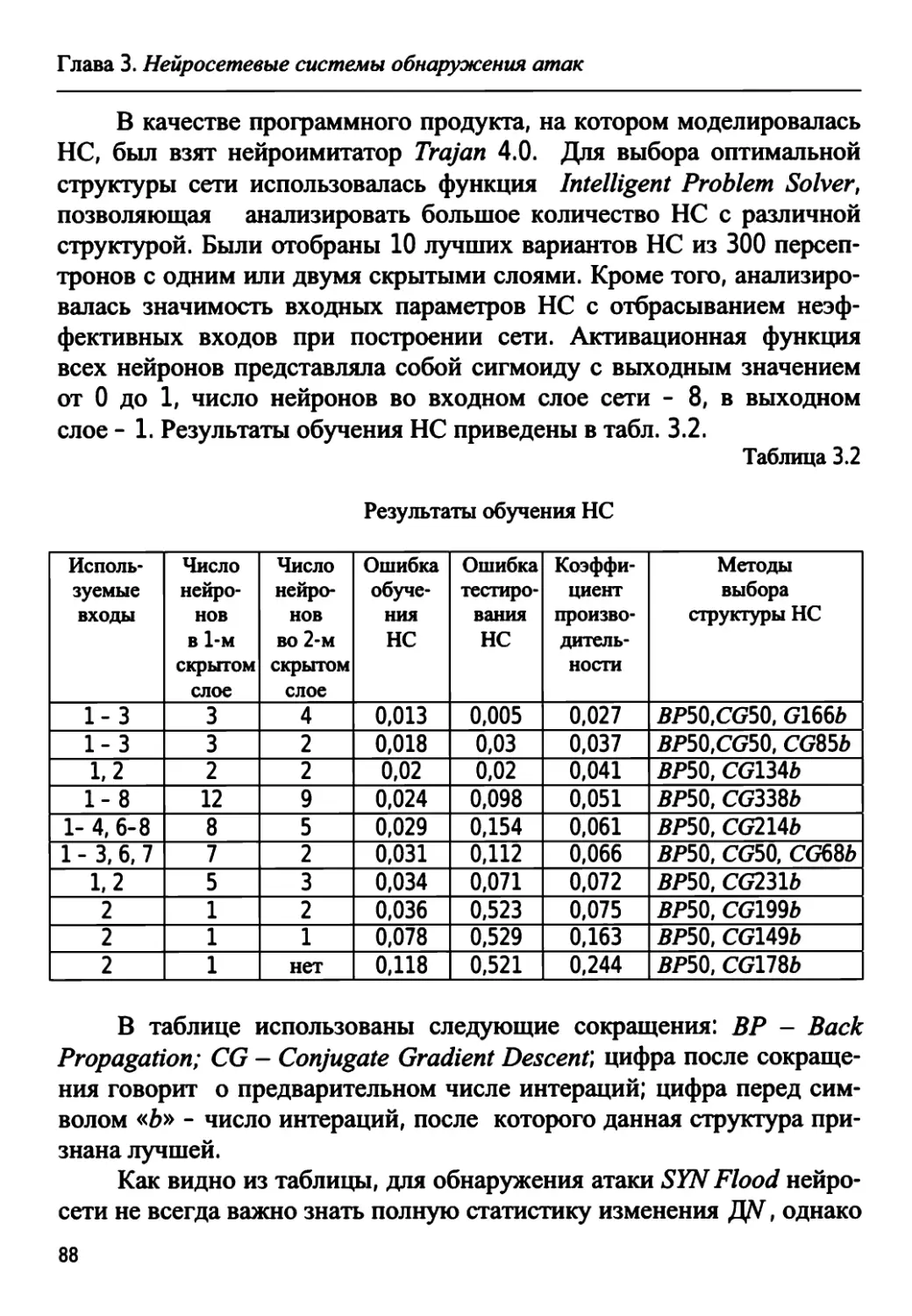
3.1. Актуальность проблемы, пути ее решения 74
3.2. Нейросетевые СОА на основе сигнатурного анализа ... 81
3.2.1. Обнаружение атаки SYN Flood 82
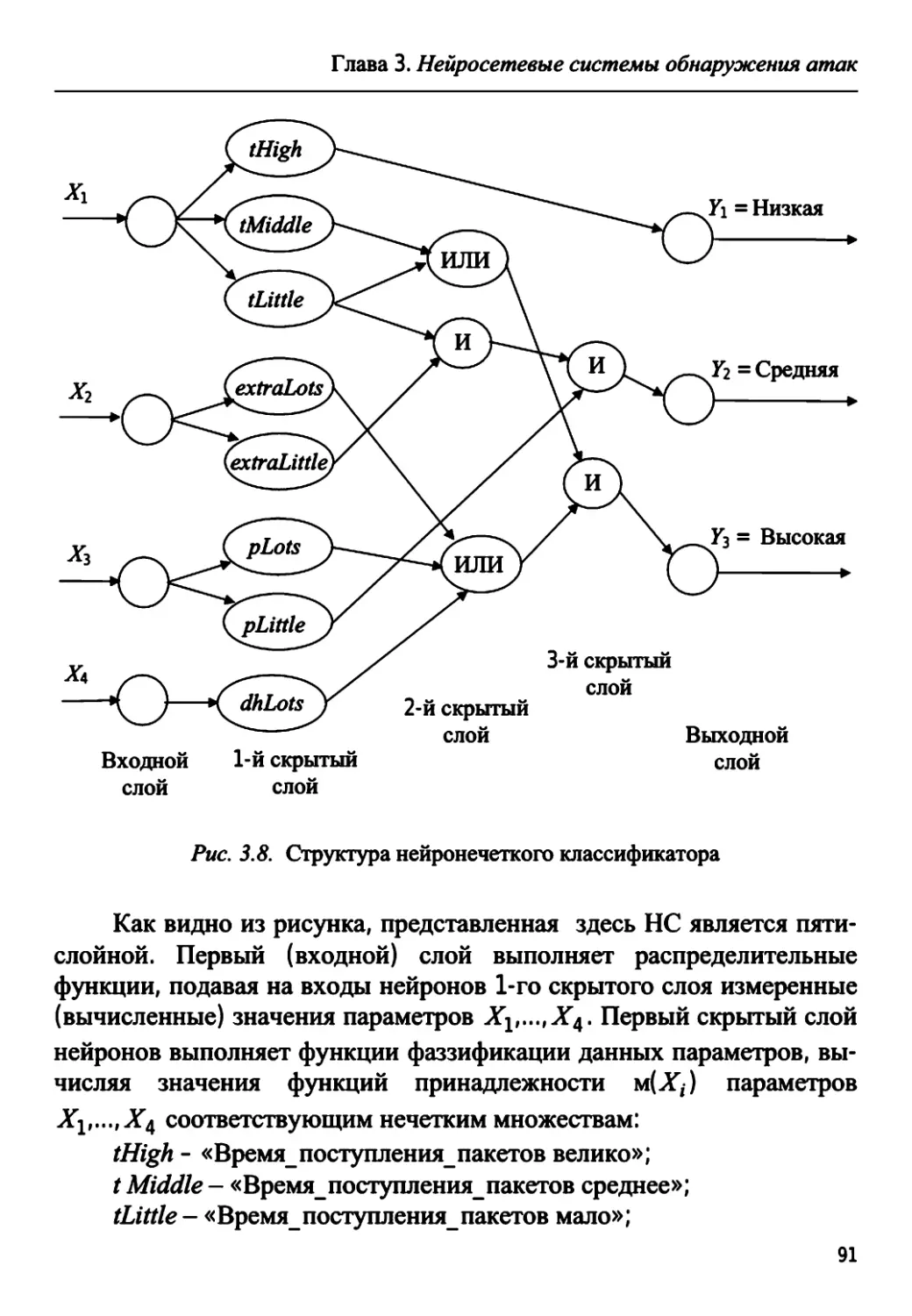
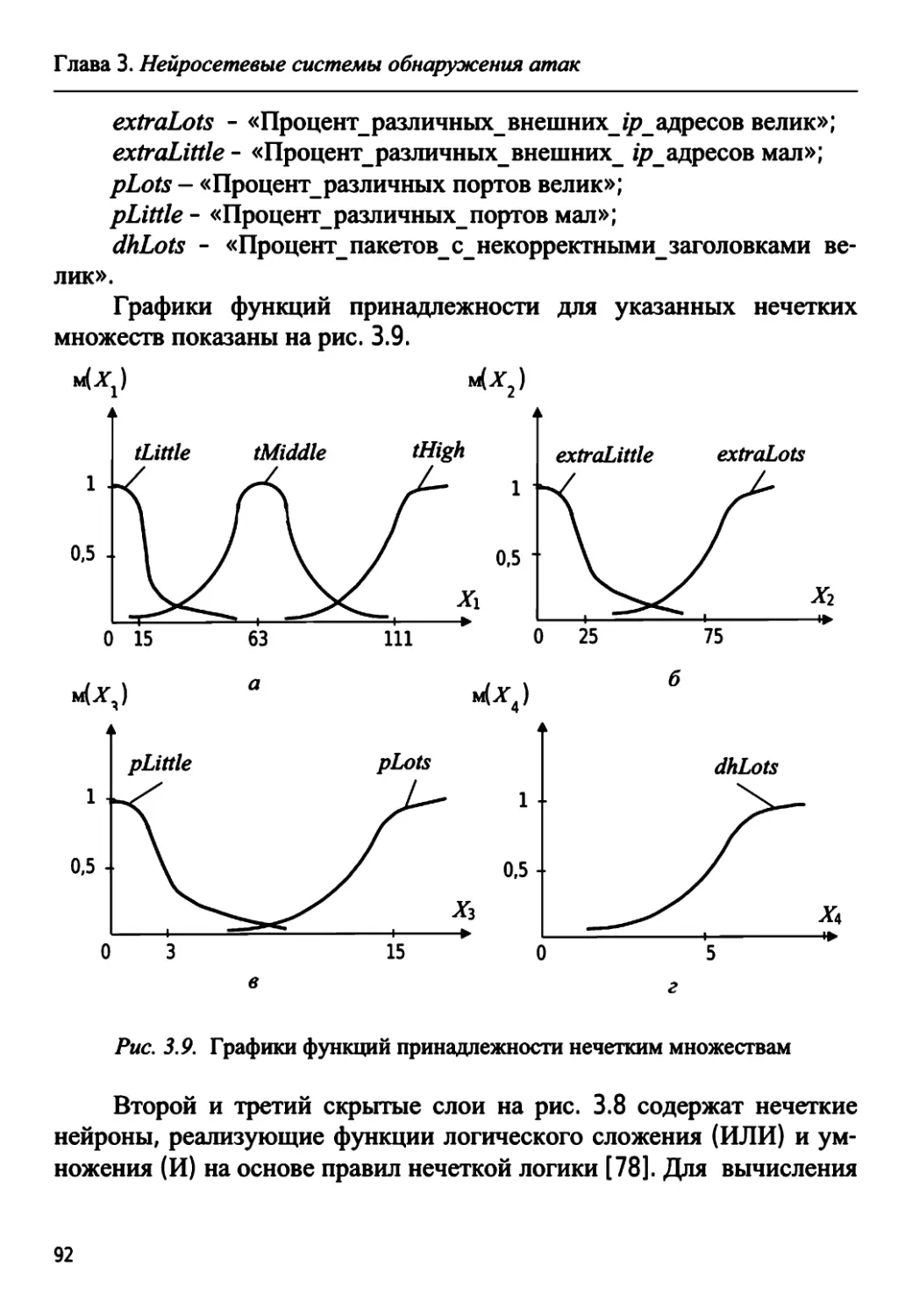
3.2.2. Построение нейронечеткого классификатора 89
3.2.3. Обнаружение сетевых атак с помощью
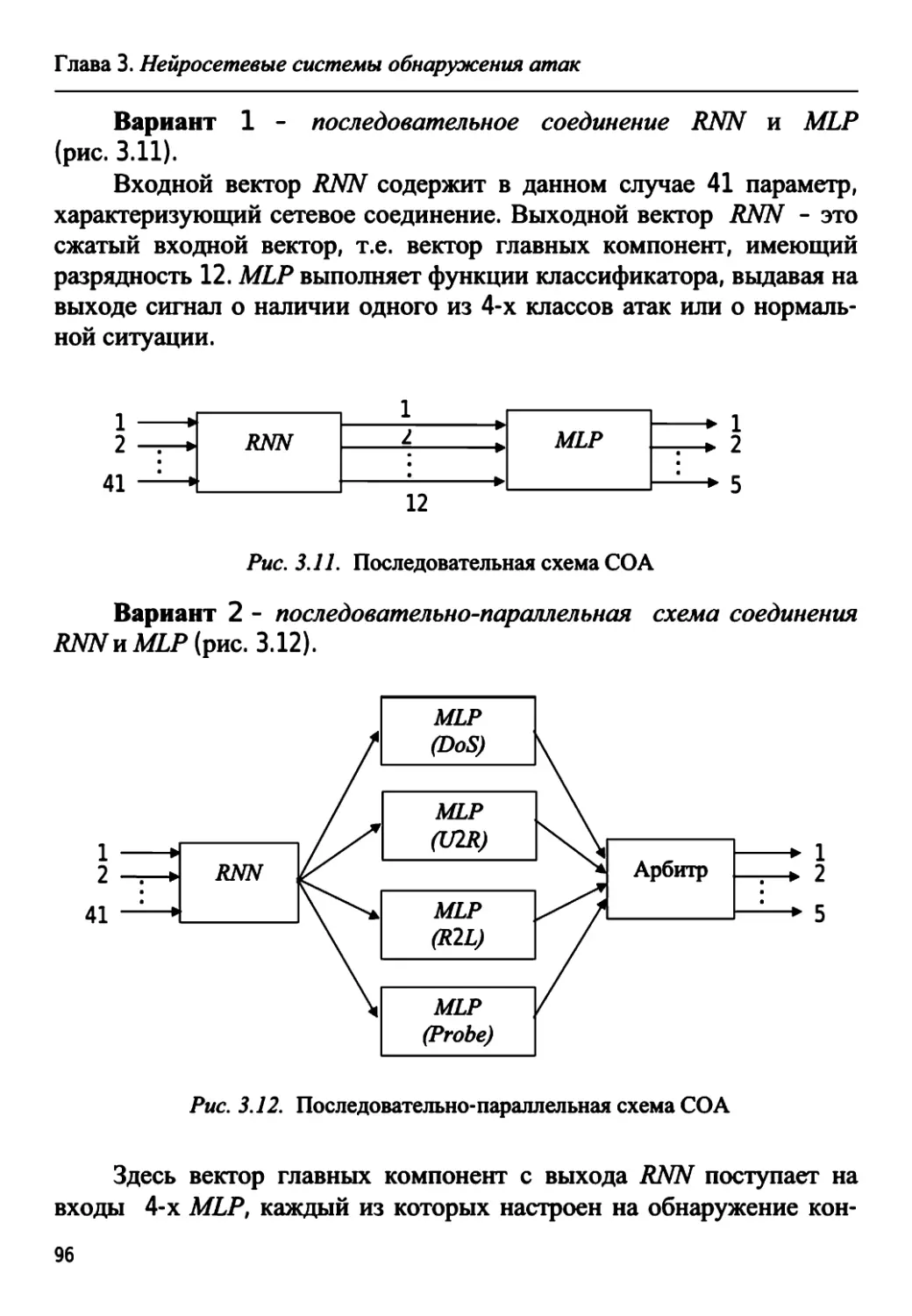
модулярной НС 94
3.3. Обнаружение аномалий с помощью НС.
Интегрированные системы обнаружения атак 99
Контрольные вопросы 111
Оглавление
ГЛАВА 4. ИНТЕЛЛЕКТУАЛЬНЫЕ СИСТЕМЫ ЗАЩИТЫ
ИНФОРМАЦИИ НА ОСНОВЕ МЕХАНИЗМОВ
ИСКУССТВЕННЫХ ИММУННЫХ СИСТЕМ 112
4.1. Роль и место искусственных иммунных систем
в задачах защиты информации 112
4.2. Естественная иммунная система: механизмы
функционирования 115
4.3. Обнаружение аномалий процесса на основе
механизмов иммунной системы 119
4.4. Практические примеры реализации систем
обнаружения аномалий на основе технологий искусственных
иммунных систем 126
4.5. Системы антивирусной защиты на основе
искусственных иммунных систем 133
Контрольные вопросы 137
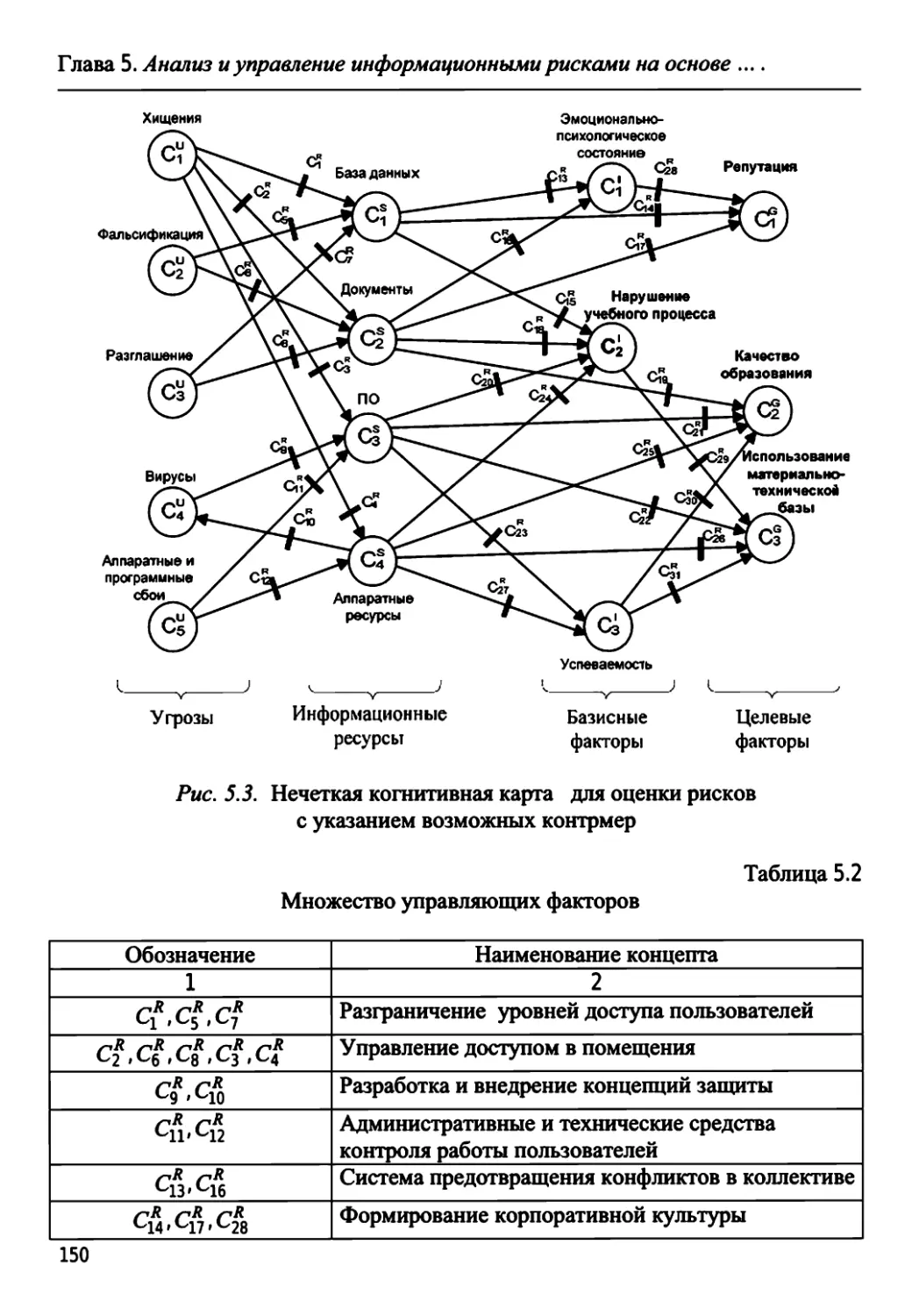
ГЛАВА 5. АНАЛИЗ И УПРАВЛЕНИЕ ИНФОРМАЦИОН-
НЫМИ РИСКАМИ НА ОСНОВЕ НЕЧЕТКИХ
КОГНИТИВНЫХ МОДЕЛЕЙ 138
5.1. Состояние вопроса 138
5.2. Методика когнитивного моделирования сложных
систем 141
5.3. Анализ информационных рисков с помощью
нечетких когнитивных карт 145
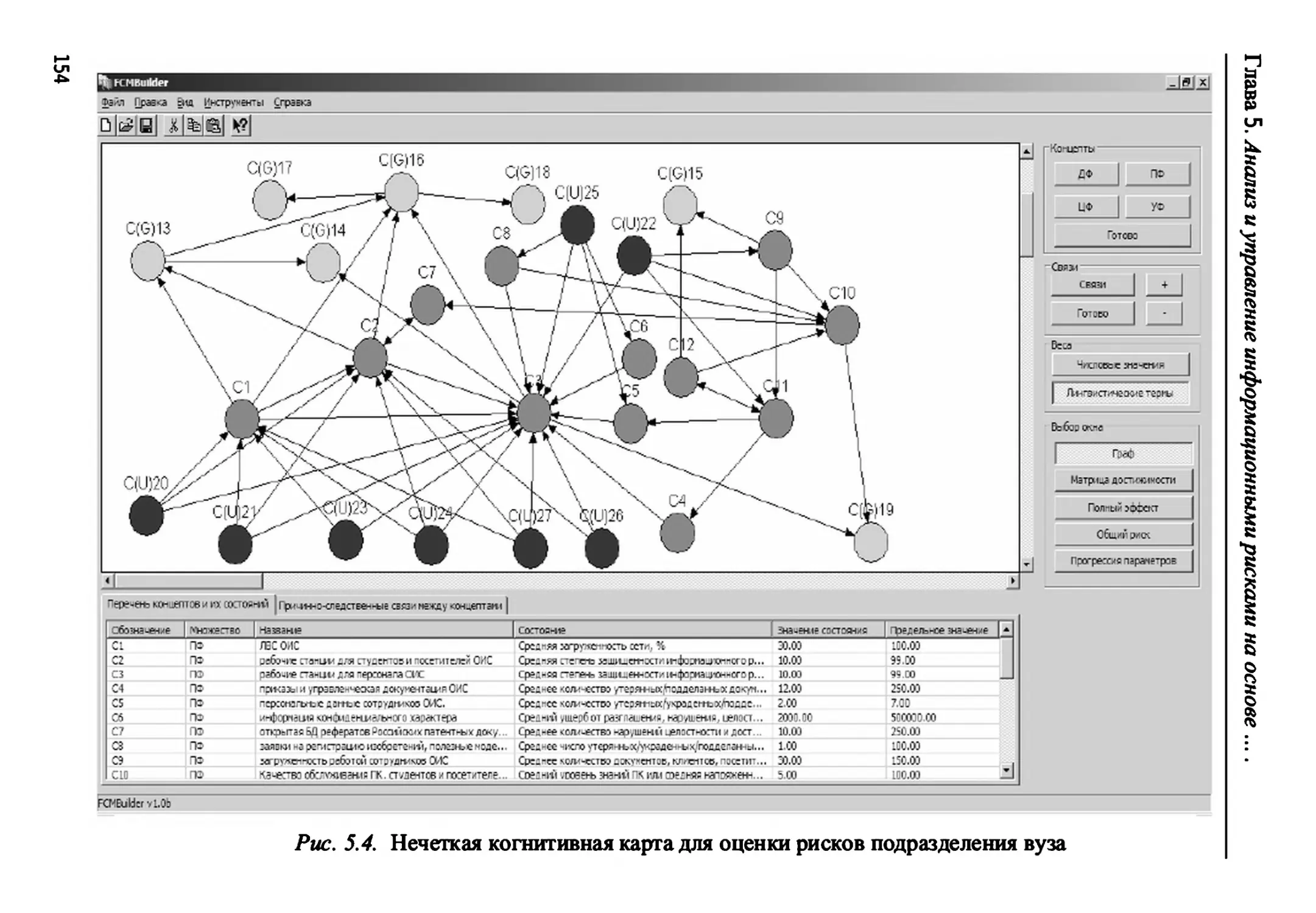
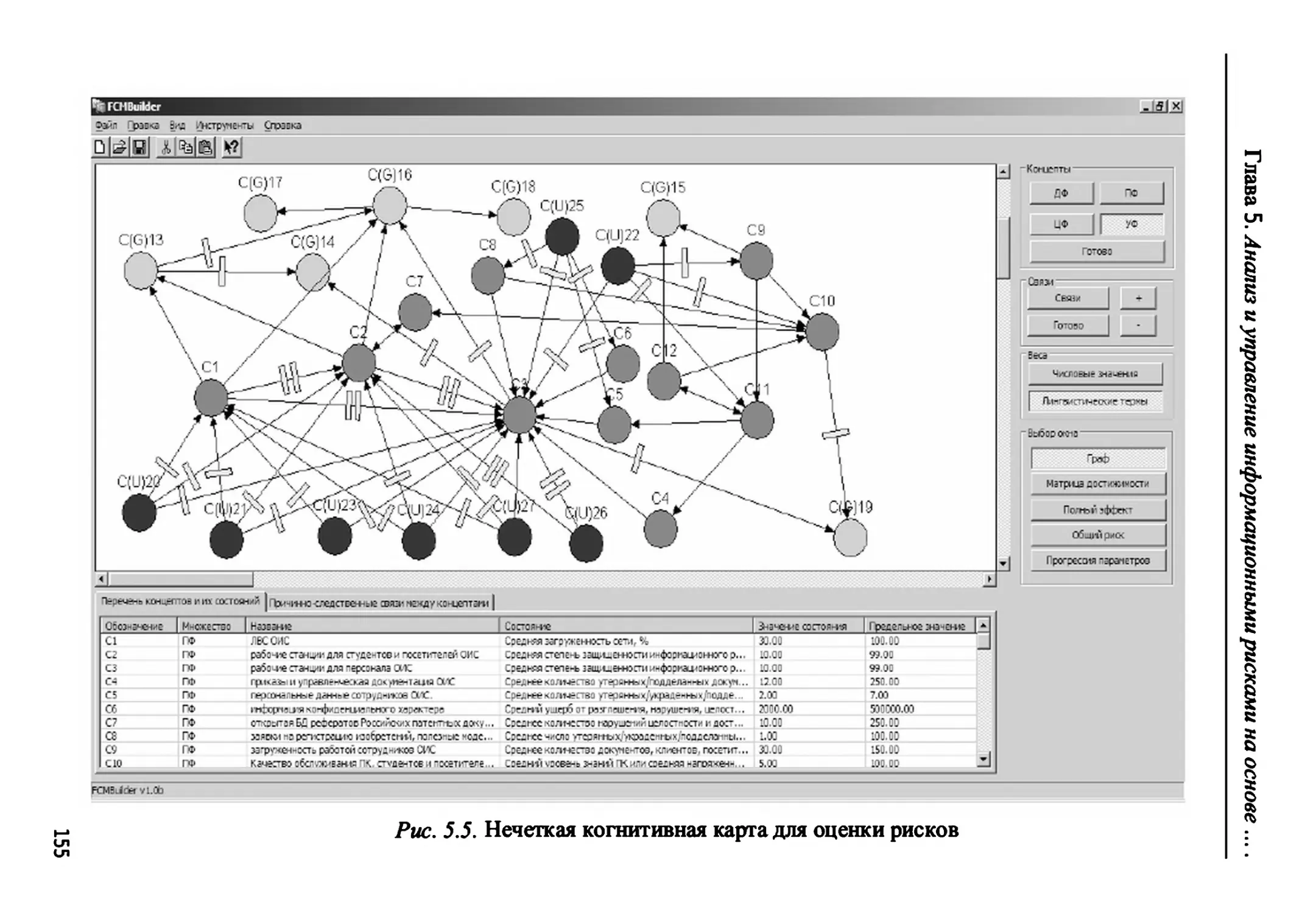
5.4. Инструментальное средство анализа и управления
информационными рисками 152
Контрольные вопросы 157
ЗАКЛЮЧЕНИЕ 158
СПИСОК СОКРАЩЕНИЙ 160
СПИСОК ЛИТЕРАТУРЫ 161
4
Введение
Миссия обеспечения
информационной безопасности
трудна, во многих случаях
невыполнима, но всегда
благородна
В. А. Галатенко
Я пришел к выводу, что наилучшими
экспертами в области безопасности
являются люди, исследующие
несовершенства защитных мер
Б. Шнайер «Секреты и ложь»
ВВЕДЕНИЕ
Современный мир - мир информационных технологий. Инфор-
мация сегодня является самым ценным и востребованным товаром.
Жизнь практически любой организации (предприятия, государствен-
ного учреждения, учебного заведения, банка и т.д.) в значительной
степени зависит от того, насколько эффективно и устойчиво функ-
ционирует ее информационная система, насколько надежно защище-
ны ее информационные ресурсы по отношению к действию возмож-
ных внешних и внутренних угроз.
Спектр угроз информационной безопасности сегодня значитель-
но расширился - это не только возможность получения несанкциони-
рованного доступа к секретной или конфиденциальной информации,
хакерские атаки или вирусы, но и тщательно спланированные компь-
ютерные преступления с целью материальной наживы или нанесения
материального и морального ущерба частным лицам и организациям,
кибертерроризм, подготовка к широкомасштабным информационным
войнам. Все больший удельный вес (по различным оценкам, до 60 -
70 %) приобретают внутренние угрозы, связанные с действиями так
называемых «инсайдеров» - штатных сотрудников организации,
умышленно или ошибочно превышающих свои полномочия при ра-
боте с информацией, следствием чего является ее утечка, несанкцио-
нированная модификация или уничтожение. Повсеместное использо-
вание Интернета в качестве глобальной сети, объединяющей сотни
5
Введение
миллионов компьютеров и пользователей по всему миру, лишь усу-
губляет ситуацию, поскольку получить доступ к ресурсам любого
(даже защищенного) компьютера, подключенного к Интернету, тео-
ретически можно с любого другого компьютера, расположенного в
сети.
Сложность решения проблемы информационной безопасности
состоит и в том, что лица, принимающие решения (руководители
высшего звена, специалисты по защите информации, системные ад-
министраторы, рядовые пользователи), вынуждены действовать в ус-
ловиях наличия факторов неопределенности, связанных с неточно-
стью и недостоверностью исходных данных, неполнотой знаний о
рассматриваемом объекте, неоднозначностью принимаемых решений
(известный специалист в области искусственного интеллекта
А. С. Нариньяни назвал эти факторы НЕ-факторами [1]). Попытки ав-
томатизации отдельных функций защиты информации с помощью
соответствующих программно-аппаратных средств (системы обнару-
жения атак, межсетевые экраны, сканеры уязвимости и т.п.) в целом
являются довольно ограниченными и, в силу указанных выше при-
чин, не позволяют решать поставленные задачи в полном объеме.
Возможный выход из сложившейся ситуации состоит в приме-
нении известного в кибернетике принципа «необходимого разнообра-
зия» У. Р. Эшби [2], суть которого заключается в том, что для ус-
пешного функционирования системы сложность ее управляющей
части (т.е. многообразие выполняемых ею функций и методов их реа-
лизации) должна соответствовать сложности управляемого объекта и
той среды, в которой он функционирует. Применительно к сфере
информационной безопасности, это означает, что защита должна
быть адекватна нападению, т.е. используемые средства защиты ин-
формации должны обеспечить своевременное обнаружение и досто-
верное распознавание различных видов угроз с учетом возможного
места и характера их проявления, квалификации злоумышленника,
потенциальных уязвимостей информационной системы и т.д., а также
предотвращение или локализацию воздействия этих угроз на защи-
щаемую информацию в условиях действия указанных выше факторов
неопределенности.
В последние годы большое внимание специалистов привлекает
направление, связанное с интеллектуализацией систем защиты ин-
6
Введение
формации, т.е. с наделением их такими функциями, которые обычно
выполняет высококвалифицированный оператор (эксперт), привлекая
для этого свои профессиональные знания и опыт. Решаемые им зада-
чи в процессе выполнения этих функций относятся к классу плохо-
формализуемых (неструктурированных) задач, составляющих пред-
мет изучения и применения методов искусственного интеллекта.
Существуют различные определения искусственного интеллекта
(ИИ). По мнению профессора Массачусетского технологического ин-
ститута (США) Марвина Мински, одного из пионеров ИИ, искусст-
венный интеллект (англ. - Artificial Intelligence) - это «наука, которая
позволяет машинам делать такие вещи, которые при их выполнении
людьми требуют интеллекта». Известный французский ученый Жан
Луи Лорьер в своей книге [3] дает более развернутое определение:
искусственный интеллект - это «область исследований, в которой
главным желанием исследователей является стремление понять, как
система обработки информации, будь то человек или машина - спо-
собна воспринимать, анализировать, передавать и обобщать то, чему
ее обучают, и с помощью этих данных исследовать конкретные си-
туации и находить решения задач».
Область исследований искусственного интеллекта чрезвычайно
широка и охватывает такие направления /методы, как:
• искусственные нейронные сети (НС);
• системы на основе нечеткой логики (НЛ);
• генетические алгоритмы (ГА);
• экспертные системы (ЭС);
• мультиагентные системы (MAC);
• искусственные иммунные системы (ИИС).
Не останавливаясь подробно на содержании указанных направ-
лений (более детальную информацию читатель может найти, напри-
мер, в [3 - 10]), рассмотрим ниже лишь те из задач, относящиеся к
области защиты информации (естественно, это далеко не полный их
перечень!), которые эффективно решаются с помощью указанных ме-
тодов для обеспечения эффективной защиты информации в условиях
неопределенности. Поскольку затронутая проблема является очень
обширной, авторы были вынуждены ограничиться рассмотрением
лишь некоторых «узловых точек» этой проблемы, с целью привлечь
7
Введение
внимание читателя к данной проблематике и пробудить в нем интерес
к более глубокому ее изучению. В основу пособия положен анализ
большого числа источников, на которые по тексту сделаны ссылки,
включая труды общепризнанных авторов в области ИИ, а также со-
временные научные публикации, в том числе принадлежащие автору.
Изложение сопровождается большим числом примеров (часть из ко-
торых носит оригинальный характер), иллюстрирующих особенно-
сти реализации соответствующих методов ИИ в системах защиты
информации.
Для того чтобы не перегружать основной текст множеством оп-
ределений, автор рекомендует читателям обратиться к
ГОСТ Р 50922-2006 «Защита информации. Основные термины и оп-
ределения» (см. также [11]).
Учебное пособие предназначено для слушателей и студентов,
обучающихся по специализации специальности «Комплексное обес-
печение информационной безопасности автоматизированных сис-
тем», а также преподавателям при проведении лекционных и индиви-
дуальных занятий по курсу «Искусственный интеллект в системах
защиты информации». Материалы, изложенные в пособии, могут
быть также полезны аспирантам, научным работникам и специали-
стам при проведении научных исследований и в практической работе.
8
Глава 1. Основы построения интеллектуальных систем защиты информации
ГЛАВА 1. ОСНОВЫ ПОСТРОЕНИЯ ИНТЕЛЛЕКТУАЛЬНЫХ
СИСТЕМ ЗАЩИТЫ ИНФОРМАЦИИ
L1. Системные принципы защиты информации
Под термином информационная безопасность (ИБ) понимается
отсутствие недопустимого риска, связанного с причинением прямого
или косвенного имущественного (финансового) ущерба предприятию
(организации), который вызван нарушением конфиденциальности,
целостности и доступности информации.
Сегодня состояние ИБ становится одним из рейтинговых пока-
зателей, отражающих надежность и устойчивость работы предпри-
ятия. Обеспечение ИБ предполагает проведение организационных
(административных), технических, юридических и других мероприя-
тий, направленных на предупреждение, отражение, ликвидацию все-
возможных видов угроз функционированию информационной струк-
туры предприятия, минимизацию или поддержание на некотором до-
пустимом уровне рисков, а также минимизацию возможного ущерба,
возникшего при реализации этих задач. При этом под угрозой ин-
формационной безопасности понимается наличие потенциальной
возможности использования некоторой информации или воздействия
на эту информацию, ведущей к прямому или косвенному ущербу для
предприятия.
С целью обеспечения заданного уровня ИБ на предприятии соз-
дается комплексная система защиты информации, в основу построе-
ния которой закладываются следующие системные принципы [12,
13]:
• принцип системного подхода - предполагает необходимость
учета всех взаимосвязанных, взаимодействующих и изменяющихся
во времени компонентов, условий и факторов, существенных для
обеспечения безопасного функционирования информационной сис-
темы (ИС);
• принцип комплексности - означает согласованное примене-
ние разнородных средств и мероприятий для обеспечения безопасно-
сти всей совокупности информации, подлежащей защите, по отноше-
нию ко всему спектру угроз;
9
Глава 1. Основы построения интеллектуальных систем защиты информации
• принцип адекватности - принимаемые решения должны вы-
бираться таким образом, чтобы обеспечить необходимый уровень ИБ
при минимальных затратах на создание механизмов защиты и обес-
печение их правильного функционирования;
• принцип адаптивности - система защиты информации
должна строиться с учетом возможного изменения конфигурации се-
ти, числа пользователей и степени конфиденциальности и ценности
информации. При этом введение каждого нового элемента сети или
изменение действующих условий не должно снижать достигнутого
уровня защищенности ИС;
• принцип неопределенности - должна обеспечиваться эффек-
тивная защита информации в условиях неопределенности действия
угроз, влияния человеческого фактора, отсутствия формальных мате-
матических моделей для описания информационных процессов и
технологий и т.д.;
• принцип непрерывности - защита информации представляет
собой непрерывный целенаправленный процесс, предполагающий
принятие соответствующих мер на всех этапах жизненного цикла ИС.
В [14, 15] в качестве важных методологических принципов, от-
носящихся к процессу изучения сложных проблем защиты информа-
ции и практической реализации результатов этого изучения, отмеча-
ются следующие принципы:
• построение адекватных моделей изучаемых систем и про-
цессов - необходима разработка методов, позволяющих адекватно
моделировать системы и процессы, существенно зависящие от воз-
действия случайных и труднопредсказуемых факторов. Попытки мо-
делирования таких систем с использованием традиционных методов
часто приводят к тому, что создаваемые модели оказываются неаде-
кватными моделируемым системам. Возможный выход из сложивше-
гося положения заключается в применении методов теории нечетких
множеств, лингвистических переменных (нестандартной математи-
ки), неформального оценивания, неформального поиска оптимальных
решений;
• унификация разрабатываемых решений - требуется разра-
ботка некоторой унифицированной концепции построения сложных
систем, позволяющей представить решение проблемной ситуации
10
Глава 1. Основы построения интеллектуальных систем защиты информации
«объект - среда - цели» в виде последовательности самостоятельных,
относительно независимых проектных задач (этапов) и, в конечном
итоге, свести решение задачи проектирования к выбору типовых и
стандартных проектных решений;
• максимальная структуризация изучаемых систем и разра-
батываемых решений - предполагает декомпозицию сложной сис-
темы и элементов ее среды на отдельные составляющие (компонен-
ты), взаимодействующие друг с другом, анализ которых позволяет в
конечном итоге сформировать такую архитектуру разрабатываемой
системы, которая наилучшим образом удовлетворяет всей совокупно-
сти условий проектирования, эксплуатации и усовершенствования;
• радикальная эволюция в реализации разработанных пред-
ложений - суть этого принципа, сформулированного академиком
В. М. Глушковым еще в 70-х годах прошлого столетия, заключается
в том, что необходимо стремиться к радикальным совершенствовани-
ям, связанным с кардинальными улучшениями архитектуры систем и
процессов их организации и обеспечения функционирования, однако,
с учетом практических соображений, реализовывать их следует по-
степенно, эволюционным путем.
Очевидно, что список перечисленных выше принципов можно
продолжить (хотя, как было замечено в дискуссии на одной из науч-
ных конференций, «... более трех принципов - это уже беспринцип-
ность»). Тем не менее, главный вывод, вытекающий из существа этих
принципов, состоит в следующем. Современная система защиты ин-
формации (СЗИ) - это сложная, динамическая, развивающаяся чело-
веко-машинная система, неотделимая от объекта защиты -
информационной системы предприятия (организации) и призванная
обеспечить его нормальное и устойчивое функционирование в усло-
виях действия возможных внутренних и внешних угроз. Эти угрозы
характеризуются существенной неопределенностью, что требует ис-
пользования для их описания, а равно, и для построения соответст-
вующих алгоритмов принятия решений в СЗИ, адекватных этим уг-
розам, математических моделей и методов искусственного интеллек-
та. Конкретная реализация этих моделей, методов и алгоритмов опре-
деляется характером угроз, спецификой решаемых задач по защите
информации, требованиями к уровню защищенности ИС.
11
Глава 1. Основы построения интеллектуальных систем защиты информации
1.2. Интегрированные системы защиты информации
Поскольку проблема обеспечения ИБ является комплексной и
многоплановой, то для ее решения обычно используется широкий
спектр различных по своей природе средств и мероприятий.
Различают следующие уровни обеспечения ИБ [16]:
• нормативно-законодательный;
• административный;
• процедурный;
• программно-технический.
На нормативно-законодательном уровне разрабатываются за-
конодательные меры обеспечения ИБ, регулирующие информацион-
ные отношения между различными субъектами (юридическими и фи-
зическими лицами) в пределах страны. В нашей стране в данной об-
ласти в течение последних лет приняты к исполнению «Доктрина ин-
формационной безопасности», Федеральные законы «Об информа-
ции, информационных технологиях и защите информации», «О госу-
дарственной тайне», «О коммерческой тайне», «О персональных
данных» и др. К числу нормативных документов, действующих в на-
стоящее время в Российской Федерации и определяющих норматив-
но-техническую базу в области ИБ, относятся такие национальные
стандарты (разработанные на основе соответствующих международ-
ных стандартов), как ГОСТ Р ИСО/МЭК 15408, 17799, 27001, 13335
[17].
К административному уровню ИБ относятся действия общего
характера, предпринимаемые руководством предприятия. Главная
цель административного уровня - сформировать программу работ в
области ИБ и обеспечить ее выполнение, выделяя необходимые ре-
сурсы и контролируя состояние дел. Основой этой программы явля-
ется политика безопасности, которая строится на основе анализа рис-
ков и отражает принятый подход к защите информационных ресурсов
предприятия.
На процедурном уровне ИБ применяются главным образом орга-
низационные меры безопасности, ориентированные на людей, а не на
технические средства. К данным мерам относятся: управление персо-
налом; физическая защита; поддержание работоспособности инфор-
12
Глава 1. Основы построения интеллектуальных систем защиты информации
мационной системы; реагирование на нарушения режима безопасно-
сти; планирование восстановительных работ (в случае возникновения
серьезных аварий). В качестве нормативно-методической базы ИБ
здесь выступают так называемые специализированные политики ИБ
(по конкретным аспектам ИБ), правила и процедуры ИБ, инструкции
администраторам и пользователям ИС.
И наконец, программно-технический уровень ИБ - это уровень,
на котором реализуются различные программно-технические меры,
направленные на контроль работоспособности оборудования и про-
граммного обеспечения. Поскольку из общего числа угроз в послед-
ние годы все больший удельный вес занимают внутренние угрозы со
стороны персонала, по отношению к которым процедурные меры не
дают большого эффекта, именно на программно-технические меры
возлагаются большие надежды в силу, прежде всего, большого раз-
нообразия выполняемых ими функций и способов их реализации.
Одним из центральных понятий для программно-технического
уровня является понятие сервиса (функции безопасности) . Наиболее
распространенными сервисами безопасности являются:
• идентификация и аутентификация;
• управление доступом;
• протоколирование и аудит;
• шифрование;
• контроль целостности;
• экранирование;
• анализ защищенности;
• обеспечение отказоустойчивости;
• обеспечение безопасного восстановления;
• туннелирование;
• управление.
Не вдаваясь в подробности относительно содержания каждого
из перечисленных сервисов (подробную информацию по этому во-
просу можно найти, например, в [16]), отметим лишь, что некоторые
1 Предполагается, что основные функции, выполняемые информационной
системой, относятся к ее основным сервисам. Сервисы безопасности относятся
к группе вспомогательных сервисов (функций) системы.
13
Глава 1. Основы построения интеллектуальных систем защиты информации
из этих сервисов будут детально рассмотрены в последующих главах
данного пособия, выступая в качестве «площадки» для реализации
соответствующих функций защиты с помощью методов искусствен-
ного интеллекта.
Необходимым условием эффективного функционирования ком-
плексной СЗИ является согласованная работа всех ее подсистем
(средств защиты информации) в соответствии с политикой безопас-
ности и нормативно-методическими документами, принятыми на
предприятии. Организационно, в составе СЗИ, помимо подсистем
управления защитой (ПСУх, ..., ПСУ#), образующих исполнитель-
ный уровень управления СЗИ и реализующих управление указанны-
ми выше сервисами безопасности для отдельных элементов объекта
защиты (303i, ..., ЭОЗд), в системе выделяются два дополнительных,
вышестоящих по иерархии уровня управления (рис. 1.1) - уровень ко-
ординации работы подсистем и уровень планирования СЗИ в целом.
Подобные системы, обладающие многоуровневой иерархической ор-
ганизацией, относятся к классу интегрированных систем защиты
информации.
ЦелиЗИ
11 псщ
1
1
f
псп2
i 1
| ПСК1
1 \
i
7
1
1
г
I
■ • ■
псщ |
i
пск2
i
\ | ПСУ1
1 1
i
г
ч
• • •
i
J
г
k
ПСКлг | 1
1 т
^ 1
ПСУ2
I
| |~ 303i
<—
1
i
^
■ ■ ■
у
i
7
i
ПСУ* |
i
эоз2
4 . . . 4
1
i
г
i
■ ЭОЗл | 1
Уровень
планирования
Уровень
координации
Исполнительный
уровень
Объект защиты
информации
Рис. 1.1. Схема иерархической организации СЗИ
14
Глава 1. Основы построения интеллектуальных систем защиты информации
Уровень координации данной системы, называемый также
«ядром» СЗИ, реализует функции координированного управления
работой подсистем защиты и включает в себя ряд подсистем управ-
ления (IlCKi,..., ПСКд/), обеспечивающих [15]:
• включение в работу компонентов (подсистем) СЗИ при по-
ступлении запросов на обработку защищаемых данных;
• управление работой СЗИ в процессе обработки защищаемых
данных;
• организацию и обеспечение проверок правильности функ-
ционирования СЗИ;
• блокирование несанкционированного доступа (НСД) к защи-
щаемым базам данных;
• обеспечение реагирования на сигналы о несанкционирован-
ных действиях;
• ведение протоколов СЗИ и др.
На уровень планирования СЗИ, также состоящий из нескольких
подсистем планирования (ПСЩ, ..., ПСПх,), возлагаются функции
контроля состояния безопасности информационной системы. Здесь
выполняются такие важные функции, как:
• контроль текущего уровня защищенности ИС;
• слежение за опасными ситуациями (непредвиденными об-
стоятельствами) ;
• анализ причин, которые привели к их возникновению, и уст-
ранение последствий;
• прогноз развития ситуаций;
• анализ рисков;
• перераспределение ресурсов (задача выбора оптимального на-
бора средств защиты) при изменении состава ИС или характеристик
среды.
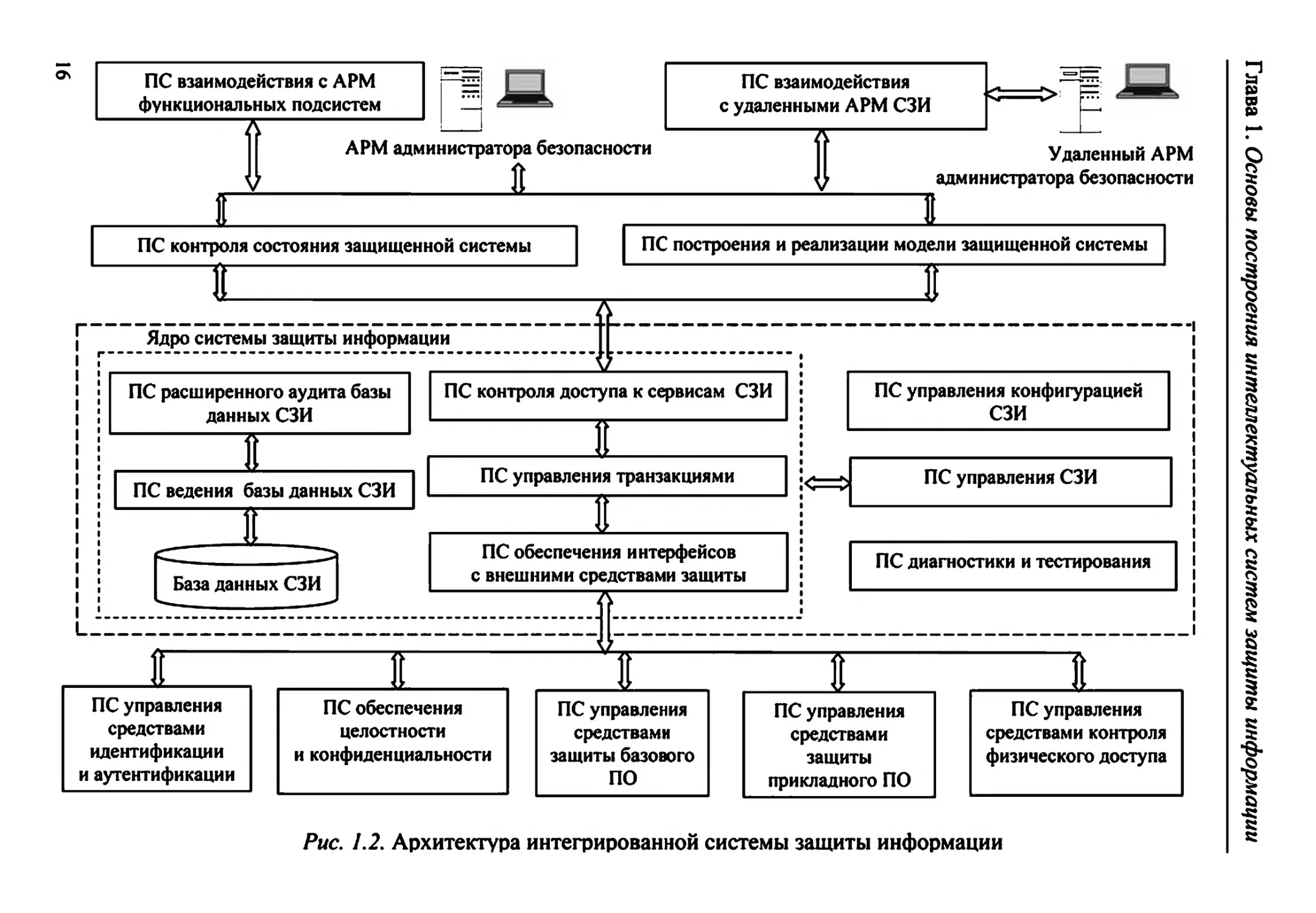
Развернутый вариант построения интегрированной СЗИ (в [13]
данная архитектура предложена в качестве типовой для построения
СЗИ в распределенных информационных системах) приведен на
рис. 1.2.
15
ПС взаимодействия с АРМ
функциональных подсистем
i
ПС взаимодействия
с удаленными АРМ СЗИ
АРМ администратора безопасности
Я
F
Удаленный АРМ
администратора безопасности
ПС контроля состояния защищенной системы
ПС построения и реализации модели защищенной системы
п
1
Ядро системы защиты информации
ПС расширенного аудита базы
данных СЗИ
i
ПС контроля доступа к сервисам СЗИ
п
ПС ведения базы данных СЗИ
—~г
ПС управления транзакциями
I База данных СЗИ I
ПС обеспечения интерфейсов
с внешними средствами защиты
fi
ПС управления конфигурацией
СЗИ
ПС управления СЗИ
ПС диагностики и тестирования
ПС управления
средствами
идентификации
и аутентификации
ПС обеспечения
целостности
и конфиденциальности
ПС управления
средствами
защиты базового
ПО
ПС управления
средствами
защиты
прикладного ПО
1
ПС управления
средствами контроля
физического доступа
Рис. 1.2. Архитектура интегрированной системы защиты информации
Глава 1. Основы построения интеллектуальных систем защиты информации
В этой системе для реализации функций управления базо-
выми сервисами безопасности используются следующие подсисте-
мы (ПС):
• ПС управления средствами идентификации и аутентифика-
ции - обеспечивает управление сервисами идентификации и аутен-
тификации, реализуемыми в СЗИ, включая средства идентификации
и аутентификации базового или прикладного программного обеспе-
чения (ПО);
• ПС обеспечения целостности и конфиденциальности - реали-
зует функции: управления доступом к ресурсам информационной
системы; управления сервисами контроля и восстановления целост-
ности, а также криптографических преобразований;
• ПС управления средствами защиты базового ПО - реализует
функции: интерпретации команд СЗИ в команды управления средст-
вами защиты базового ПО; прием и обработку сообщений о событиях
от средств защиты базового ПО;
• ПС управления средствами защиты прикладного ПО - реали-
зует функции: интерпретации команд СЗИ в команды управления
средствами защиты прикладного ПО; прием и обработку сообщений
о событиях от средств защиты прикладного ПО;
• ПС управления средствами контроля физического доступа -
реализует функции: интерпретации команд СЗИ в команды управле-
ния средствами контроля физического доступа; прием и обработку
сообщений от средств контроля физического доступа.
Для координации взаимодействия различных подсистем в
составе СЗИ используются следующие подсистемы:
• ПС контроля доступа к сервисам СЗИ - реализует функции
генерации сеансовых ключей при подключении к серверу СЗИ, кон-
троля полномочий администраторов на выполнение команд управле-
ния процессом защиты и ведения базы данных (БД) полномочий ад-
министраторов;
• ПС управления транзакциями - реализует функции поддержки
транзакционной модели выполнения команд СЗИ - команда считает-
ся выполненной, если выполнены все составляющие ее операции; в
противном случае система должна быть возвращена в исходное со-
стояние;
17
Глава 1. Основы построения интеллектуальных систем защиты информации
• ПС ведения базы данных СЗИ - реализует функции: интерпре-
тации команд СЗИ в команды управления данными; поддержки эф-
фективного функционирования БД СЗИ; резервирования и восста-
новления БД СЗИ после сбоев;
• ПС расширенного аудита базы данных СЗИ - реализует
функции: визуального построения и выполнения сложных запросов
по БД СЗИ (аудит модели системы, аудит журнала событий); пред-
ставления результатов запросов в удобной для администратора фор-
ме, анализ БД СЗИ с целью выявления «узких» мест в защите или по-
пыток несанкционированного доступа;
• ПС обеспечения интерфейсов с внешними средствами защи-
ты - реализует функции: установления связи с активными подсисте-
мами управления средствами контроля физического доступа, средст-
вами контроля целостности и криптографической защиты, средства-
ми защиты базового и прикладного ПО; предоставления сервисов
подходящей подсистемы управления в зависимости от команды, по-
лученной от подсистемы построения и реализации модели защищен-
ной системы;
• ПС управления СЗИ - реализует функции управления и кон-
троля за функционированием ядра СЗИ;
• подсистема управления конфигурацией СЗИ - реализует
функцию ведения внутренней БД, определяющей текущую структуру
активных средств защиты, правил разграничения доступа к ресурсам
СЗИ, настройки параметров функционирования других подсистем
СЗИ;
• ПС диагностики и тестирования - обеспечивает: контроль (и
при необходимости, восстановление) целостности программных
средств СЗИ, локализацию ошибок при сбоях и отказах; тестирование
и диагностику при старте системы, при восстановлениях после сбоев
и по запросу администратора безопасности.
Для централизованного управления защищенной системой с
помощью администраторов безопасности СЗИ используются:
• автоматизированное рабочее место (АРМ) администратора
СЗИ - реализует функции: предоставления графического интерфей-
са; выдачи визуальных или звуковых предупреждений о событиях,
имеющих критическое влияние на безопасность системы;
18
Глава 1. Основы построения интеллектуальных систем защиты информации
• ПС взаимодействия с удаленными АРМ - реализует функции:
предоставления сервисов СЗИ для удаленного использования; защи-
ты информации между СЗИ и удаленным АРМ (в том числе с исполь-
зованием криптографических методов);
• ПС взаимодействия с АРМ функциональных подсистем - реа-
лизует функцию управления потоком информации между СЗИ и АРМ
функциональных подсистем (АРМ администратора БД, АРМ админи-
стратора программно-технического комплекса, АРМ администратора
телекоммуникаций и сетей);
• ПС контроля состояния защищенной системы - реализует
функции: ведения журнала событий; отслеживания и обработки кри-
тичных событий; предоставления средств управления правилами от-
слеживания событий для отдельных подсистем информационной сис-
темы;
• ПС построения и реализации модели защищенной системы -
реализует функции: автоматизированного построения модели защи-
щенной системы, т.е. создания структуры объектов защиты, субъек-
тов информационной деятельности и правил разграничения доступа
для данной защищенной системы; ведения классификаторов типов
объектов, субъектов, режимов доступа и полномочий субъектов; ве-
дения классификаторов событий.
Заметим, что, по-существу, все реализованные в данной СЗИ
функции управления, а именно: управление сервисами безопасности,
координация их взаимодействия, осуществление контроля функцио-
нирования защищенной информационной системы, - являются со-
ставляющими одной общей задачи - реализации политики безопасно-
сти. Обеспечение и контроль безопасности представляют собой
комбинацию технических и административных мер. По данным зару-
бежных источников, администратор безопасности на техническую
работу, связанную с управлением программами и другими средства-
ми контроля доступа, защитой портов и т.д., тратит более 60 % своего
рабочего времени и только оставшиеся 40 % уходит на решение ад-
министративных задач (разработка документов, связанных с защитой
ИС, процедур проверки системы защиты и т.д.) [13]. Увеличение ко-
личества рабочих станций и использование программных средств,
включающих большое количество разнообразных компонентов, - все
19
Глава 1. Основы построения интеллектуальных систем защиты информации
это приводит к такой ситуации, когда администратор безопасности
уже физически оказывается не в состоянии оперативно анализировать
огромный объем сведений, содержащихся в журнале регистрации со-
бытий СЗИ. Это особенно важно в условиях, когда на повестку дня
ставится задача реализации упреждающей стратегии защиты, в со-
ответствии с которой необходимо обеспечить требуемый уровень
защищенности ИС в условиях воздействия на нее не только уже из-
вестных (т.е. ранее проявлявшихся) или наиболее опасных угроз, но
и от всех потенциально возможных (в том числе априорно неизвест-
ных) угроз на ИС.
Таким образом, несмотря на очевидные преимущества интегри-
рованных СЗИ - возможность централизованного управления рабо-
той всех подсистем практически с одного пульта (консоли), коорди-
нация и контроль правильности функционирования этих подсистем,
минимизация избыточности (устранение дублирования функций), уп-
рощение механизмов оценки ситуаций и принятия решений, им при-
сущ ряд недостатков. В качестве таких недостатков можно отметить,
прежде всего, их недостаточную гибкость (возможные ошибочные
реакции при появлении неизвестных угроз, затруднения при оценке
сложных ситуаций, снижение оперативности принятия решений при
большом числе дестабилизирующих факторов - так называемое
«проклятие размерности»), повышенная нагрузка на администратора
безопасности, возможные «нестыковки» механизмов защиты (алго-
ритмов реализации сервисов безопасности) при использовании тех-
нических решений различных фирм-производителей и т.д.
Подобные затруднения в значительной степени теряют свою
остроту в связи с появлением нового класса СЗИ - адаптивных ин-
тегрированных (интеллектуальных) систем защиты информации,
идея построения которых представлена ниже.
1.3. Интеллектуализация систем защиты информации
Под интеллектуализацией СЗИ будем понимать повышение ее
интеллектуальных возможностей с целью обеспечения высокого
уровня её автономности, адаптивности и надежности в условиях не-
определенности. Это предполагает передачу компьютеру максималь-
но возможного количества функций по сбору, обработке информации
20
Глава 1. Основы построения интеллектуальных систем защиты информации
и принятию решений для того, чтобы помочь пользователям и адми-
нистраторам системы получить более объективную оценку событий,
происходящих на объекте (в системе), и принять правильные и свое-
временные решения. В качестве средства борьбы с неопределенно-
стью (НЕ-факторами) в данном случае выступают методы и техноло-
гии искусственного интеллекта.
Заметим, что в отношении точного определения ИИ, его воз-
можностей и перспектив в последние годы не прекращаются споры.
Так, известный специалист в области ИИ Джордж Ф. Люггер в своей
книге [4] пишет: «Проблема определения искусственного интеллекта
сводится к проблеме определения интеллекта вообще: является ли он
чем-то единым, или этот термин объединяет набор разрозненных
способностей? В какой мере интеллект можно создать, а в какой он
существует априори? Что именно происходит при таком создании?...
Можно ли судить о наличии интеллекта только по наблюдаемому по-
ведению, или же требуется свидетельство наличия некого скрытого
механизма? Как представляются знания в нервных тканях живых су-
ществ, и как можно применить это в проектировании интеллектуаль-
ных устройств? ... И более того, необходимо ли создавать интеллек-
туальную компьютерную программу по образу и подобию человече-
ского разума, или же достаточно строго «инженерного» подхода?...
На эти вопросы ответа пока не найдено, но все они помогли сформи-
ровать задачи и методологии, составляющие основу современного
ИИ. Отчасти, привлекательность искусственного интеллекта в том и
состоит, что он является оригинальным и мощным орудием для ис-
следования именно этих проблем. ИИ представляет средство и испы-
тательную модель для теорий интеллекта: такие теории могут быть
переформулированы на языке компьютерных программ, а затем ис-
пытаны при их выполнении».
Термин «интеллектуальная система» также пока не получил об-
щепринятого определения. Как правило, считается, что интеллекту-
альная система характеризуется наличием одного или нескольких из
перечисленных ниже свойств:
• адаптивность;
• способность к обучению и самообучению;
• совершение «правильных действий»;
21
Глава 1. Основы построения интеллектуальных систем защиты информации
• ориентированность на определенную цель;
• использование знаний в процессе обучения и функциониро-
вания.
Для наглядности представим интеллектуальную систему в виде
некоторой «интеллектуальной машины» (рис. 1.3), формирующей ре-
зультат решения задачи (действие) на основе анализа и обработки
поступающей входной информации (восприятие) с помощью опреде-
ленной системы правил (знаний) [18].
-И Понимание
Осознание/
Мотивация
L _
Планирование
Логические
датчики
Восприятие
о
Логические
приводы
Л / \
' )—Н Действие J
Рис. 1.3. Структура интеллектуальной машины
Логические датчики (сенсоры) и логические приводы (исполни-
тельные механизмы) здесь играют роль интерфейса с внешней средой
(взаимодействующим объектом). В блоке понимания осуществляется
сравнение текущего состояния объекта с целью (т.е. его желаемым
состоянием), после чего производится планирование, т.е. принятие
решения о выполнении некоторых действий, для уменьшения этого
рассогласования при заданных ограничениях. Блок осозна-
ния/мотивации выполняет функцию слежения за пониманием и пла-
нированием. В случае, если машина не может понять полученные с
помощью логических датчиков данные, осознание/мотивация может
приспособить (изменить) знания и сделать полученные данные более
доступными для понимания. Таким образом, можно выделить два ос-
новных режима работы интеллектуальной системы (машины) - ре-
жим решения поставленной задачи и режим обучения/самообучения.
22
Глава 1. Основы построения интеллектуальных систем защиты информации
Под обучением понимается способность системы улучшать
свое поведение в будущем, основываясь на экспериментальной ин-
формации, полученной в прошлом о результатах взаимодействия с
объектом/окружающей средой. Самообучение - это обучение без
внешней корректировки, т.е. без указаний «учителя».
Подводя краткий итог сказанному, процитируем получившее
широкое распространение на практике определение [19]: интеллек-
туальная система - это такая система, которая «способна понимать,
делать выводы и обучаться в отношении процессов, возмущений и
условий своего функционирования. Эта система накапливает свои
знания и опыт, используя их для улучшения своих качественных ха-
рактеристик».
Необходимым признаком интеллектуальной системы является
наличие базы знаний, содержащей сведения (факты), модели и прави-
ла, позволяющие уточнить поставленную перед системой задачу и
выбрать рациональный способ ее решения. Именно поэтому об ин-
теллектуальных системах говорят как о системах, основанных на
знаниях (англ. - Knowledge-Based Systems). Для обеспечения свойст-
ва интеллектуальности системы необходимо придерживаться сле-
дующих принципов её структурной организации [20]:
1) наличие тесного информационного взаимодействия с реаль-
ным внешним миром и использование специально организованных
информационных каналов связи;
2) принципиальная открытость системы для повышения интел-
лектуальности и совершенствования собственного поведения;
3) наличие механизмов прогноза изменений внешнего мира и
собственного поведения системы в динамически меняющемся внеш-
нем мире;
4) наличие многоуровневой иерархической структуры, постро-
енной в соответствии с правилом: повышение интеллектуальности и
снижение требований к точности моделей по мере повышения ранга
иерархии (и наоборот);
5) сохраняемость функционирования (возможно, с некоторой
потерей качества или эффективности) при разрыве связей или потере
управляющих воздействий от внешних уровней иерархии в системе.
23
Глава 1. Основы построения интеллектуальных систем защиты информации
Системы, организованные и функционирующие в соответствии
со всеми пятью перечисленными принципами, называются система-
ми, интеллектуальными «в большом».
Как видно из этого определения, система, интеллектуальная «в
большом», должна иметь многоуровневую иерархическую структу-
ру. Наиболее полно указанным выше требованиям удовлетворяет
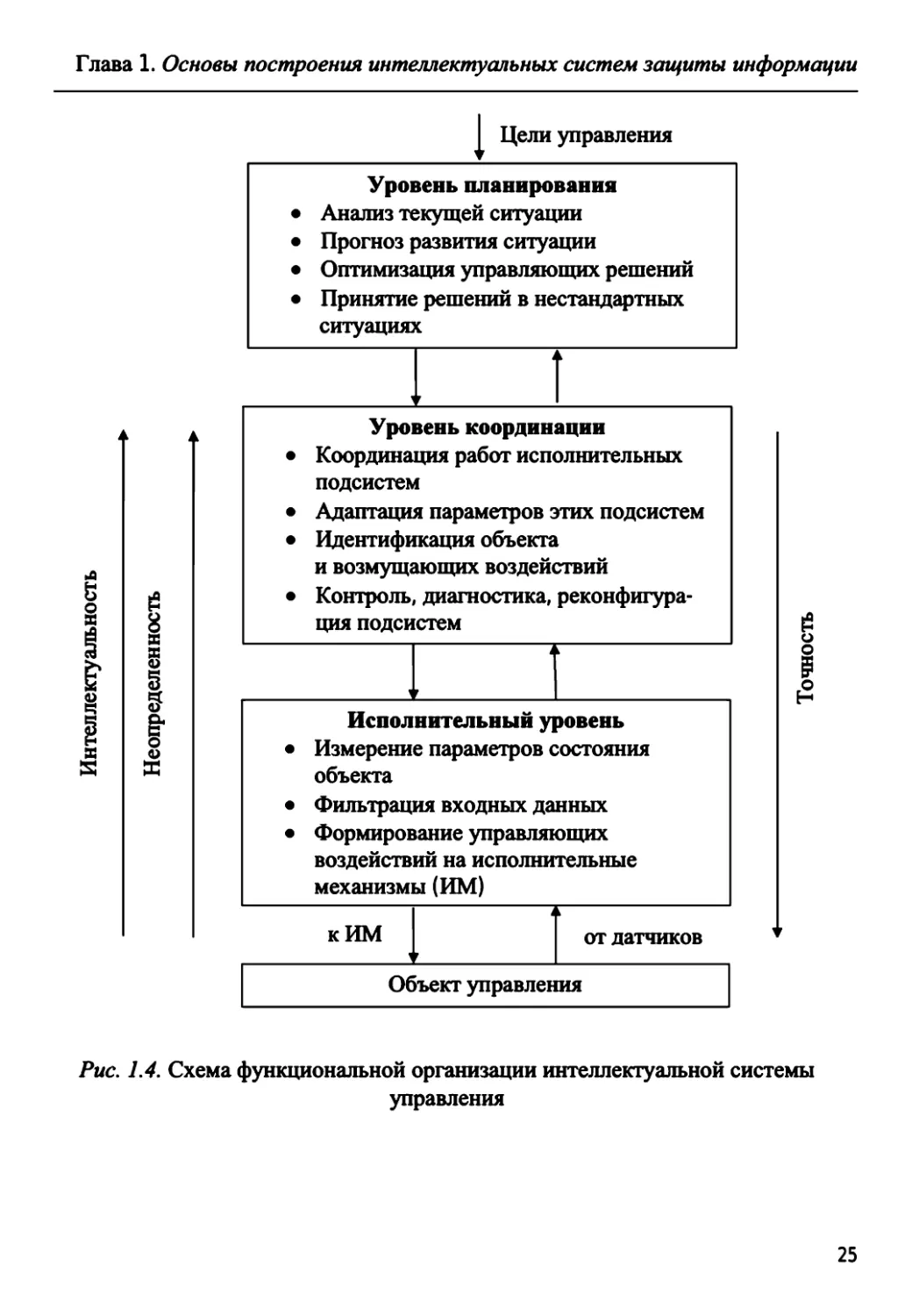
трехуровневая система управления, включающая в себя:
• исполнительный уровень;
• уровень координации (тактический уровень);
• уровень планирования (стратегический уровень).
Основные функции, реализуемые на данных уровнях управления ин-
теллектуальной системы, показаны на рис. 1.4.
Заметим, что хотя приведенные на рис. 1.1 и рис. 1.4 иерархиче-
ские структуры внешне очень похожи (более того, на каждом из 3-х
уровней как первой, так и второй системы решаются сходные по со-
держанию задачи), они используют совершенно различный подход к
достижению цели управления. В первом случае (интегрированная
СЗИ на рис. 1.1) основной упор делается на применение традицион-
ных методов, «жестко» запрограммированных алгоритмов или (на
верхних уровнях иерархии) участие оператора в процессе принятия
решений; главной целью является обеспечение согласованной работы
всех подсистем, как единого целого, для поддержания заданного
уровня защищенности информационной системы (объекта защиты).
Во втором случае (интеллектуальная система на рис. 1.4) главное
внимание уделяется достижению поставленных целей ЗИ за счет по-
вышения эффективности процессов обработки информации и приня-
тия решений на каждом из уровней управления (а значит, и в системе
в целом) на основе применения интеллектуальных технологий, апри-
орно ориентированных для работы в условиях неполноты и нечетко-
сти исходных данных, неопределенности внешних возмущений и
среды функционирования объекта.
24
Глава 1. Основы построения интеллектуальных систем защиты информации
Цели управления
8
8
S
S
I
8
§
о
Уровень планирования
Анализ текущей ситуации
Прогноз развития ситуации
Оптимизация управляющих решений
Принятие решений в нестандартных
ситуациях
Уровень координации
Координация работ исполнительных
подсистем
Адаптация параметров этих подсистем
Идентификация объекта
и возмущающих воздействий
Контроль, диагностика, реконфигура-
ция подсистем
Исполнительный уровень
Измерение параметров состояния
объекта
Фильтрация входных данных
Формирование управляющих
воздействий на исполнительные
механизмы (ИМ)
к ИМ
от датчиков
I
е2
Объект управления
Рис. 1.4. Схема функциональной организации интеллектуальной системы
управления
25
Глава 1. Основы построения интеллектуальных систем защиты информации
Заметим, что в соответствии с 4-м из перечисленных выше
принципов, называемым также принципом Саридиса, или принципом
IPDI [Increasing Precision - Decreasing Intelligence), по мере продви-
жения к верхним уровням иерархии системы должен повышаться
удельный вес ее интеллектуальных функций при одновременном
снижении требований к точности их реализации. И наоборот, чем
ниже по иерархии уровень управления, т.е. чем конкретнее решаемая
задача, тем меньше знаний (и тем больше конкретных данных) тре-
буется для ее решения.
Разумеется, степень интеллектуальности каждого из уровней
управления может существенно различаться в зависимости от назна-
чения системы и специфики решаемых с её помощью задач. На прак-
тике возможно построение таких интеллектуальных систем, которые
не удовлетворяют всем перечисленным выше пяти принципам, одна-
ко используют в процессе своего функционирования знания (напри-
мер, в виде правил или в виде обученной на основе эксперименталь-
ных данных нейронной сети) как средство преодоления неопределен-
ности информационной среды. Такие системы принято называть сис-
темами, интеллектуальными «в малом».
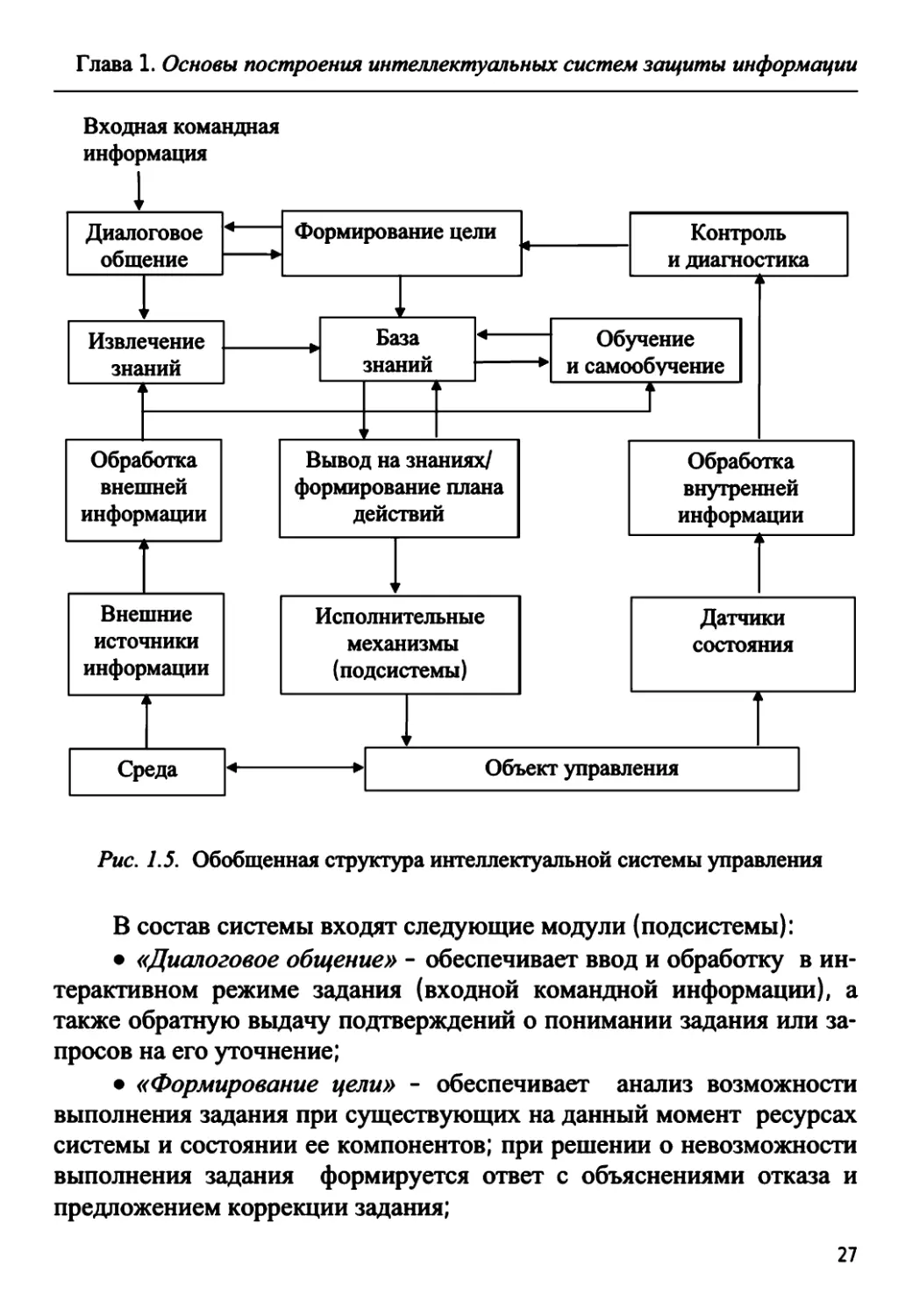
Для реализации представленных на рис. 1.4 функций управления
можно воспользоваться структурной схемой интеллектуальной сис-
темы управления, приведенной на рис. 1.5 [21]. В общем случае дан-
ная система получает задание от оператора (администратора систе-
мы), однако возможен вариант ее автономной работы без вмешатель-
ства оператора по заложенному при настройке критерию цели.
26
Глава 1. Основы построения интеллектуальных систем защиты информации
Входная командная
информация
1
Диалоговое
| общение
1
г
Извлечение
знаний
i
к
Обработка
внешней
информации
1 3
\ '
Внешние
источники
информации
i
к
1 г*
Ср
еда
Формирование цели
▼
База
знаний
\
А
г
^
Вывод на знаниях/
формирование плана
действий
v
Исполнительные
механизмы
(подсистемы)
L
у
Контроль I
и диагностика |
Обучение
и самообучение
t
А
Обработка
внутренней
информации
Датчики
состояния
А
\JKJl
>см уиуавл
СПИЛ
Рис. 1.5. Обобщенная структура интеллектуальной системы управления
В состав системы входят следующие модули (подсистемы):
• «Диалоговое общение» - обеспечивает ввод и обработку в ин-
терактивном режиме задания (входной командной информации), а
также обратную выдачу подтверждений о понимании задания или за-
просов на его уточнение;
• «Формирование цели» - обеспечивает анализ возможности
выполнения задания при существующих на данный момент ресурсах
системы и состоянии ее компонентов; при решении о невозможности
выполнения задания формируется ответ с объяснениями отказа и
предложением коррекции задания;
27
Глава 1. Основы построения интеллектуальных систем защиты информации
• «База знаний» (БЗ) - содержит формализованное в рамках
выбранного метода и языка представления знаний описание объекта,
его среды и правила, необходимые для выполнения поставленного
задания;
• «Извлечение знаний» - обеспечивает формирование знаний о
внешней среде путем интеграции полученной внешней информации и
корректирующей (уточняющей) информации от оператора;
• «Обучение и самообучение» - обеспечивает накопление до-
полнительных знаний о проблеме в режиме «с учителем» и «без учи-
теля» (т.е. автономно);
• «Вывод на знаниях/формирование плана действий» - осущест-
вляет обработку цели и знаний о среде и проблеме для прогнозиро-
вания и формирования управляющих воздействий, подаваемых на
исполнительные механизмы (подсистемы) объекта;
• «Обработка внешней и внутренней информации» - произво-
дит оценку изменения текущего состояния среды и объекта управле-
ния на основании информации, полученной от различных устройств
(сенсоров), связывающих систему с внешней средой (внешние источ-
ники информации), и от датчиков состояния объекта и системы;
• «Контроль и диагностика» - обрабатывает полученную внут-
реннюю информацию об изменениях состояния объекта и системы с
целью выработки контрольной информации, позволяющей анализи-
ровать возможность выполнения задания, поставленного перед сис-
темой.
В основе функционирования интеллектуальной системы
(см. рис. 1.5) используется идея ситуационного управления [22],
суть которого заключается в выборе управленческих решений с уче-
том сложившейся ситуации из некоторого набора допустимых (типо-
вых, стандартных) управляющих воздействий. Под текущей ситуа-
цией (С) при этом понимается совокупность текущего состояния
объекта (вектор состояния X) и его внешней среды (вектор возмуще-
ний F):
C=<X,F>. (1.1)
28
Глава 1. Основы построения интеллектуальных систем защиты информации
Полная ситуация (S) включает в себя, помимо текущей ситуации С,
также цель управления G:
S=<C,G>. (1.2)
В частном случае, цель управления G может быть представлена в ви-
де некоторой целевой ситуации Cg, к которой должна быть приведе-
на имеющаяся текущая ситуация:
S=<C,Gg>. (1.3)
Полагая, что текущая ситуация С принадлежит некоторому
классу Q\ а целевая (заданная) ситуация Cg - классу Q\ будем ис-
кать такое управление (вектор управляющих воздействий U), которое
принадлежит множеству допустимых управлений С1и и обеспечивает
требуемое преобразование одного класса ситуаций в другой:
CeQ Uen" )Gg€g". (1-4)
Таким образом, ситуационное управление выступает как ото-
бражение
(e',e")->Uentt, (1.5)
сопоставляющее паре «текущая ситуация - целевая ситуация» тре-
буемый результат - управление U. Другими словами, проблема вы-
бора управляющих воздействий сводится к адекватной оценке со-
стояния объекта и среды (что не всегда легко сделать в условиях фак-
торов неопределенности), отнесению соответствующей текущей си-
туации к одному из типовых классов и выбору такого управления (из
определенного набора альтернатив), которое приводит к достиже-
нию поставленной цели управления (целевой ситуации).
Очевидно, что перечисленные выше положения, касающиеся
общих принципов построения интеллектуальных систем, имеют уни-
версальный характер и в полной мере относятся к таким сложным
29
Глава 1. Основы построения интеллектуальных систем защиты информации
объектам управления, какими являются объекты защиты информа-
ции. Вместе с тем, на пути создания интеллектуальных систем защи-
ты информации пока имеется много нерешенных проблем, характер-
ных для данной предметной области (существует даже официально
утвержденный INFOSEC список «трудных проблем» в области ИБ
[23]).
Как отмечается в [24] (учитывая важность высказанных сообра-
жений, процитируем их практически полностью), «... основные не-
достатки традиционных СЗИ определяются сложившимися жестки-
ми принципами построения архитектуры и заключаются в практиче-
ской неспособности противодействовать современному информаци-
онному оружию. В современных СЗИ в основном применяются обо-
ронительные или наступательные стратегии защиты, которые пред-
назначены только для блокировки всех известных и наиболее опас-
ных потенциальных способов специальных программно-технических
воздействий (СПТВ), осуществляемых противником ... для нанесения
ущерба информационным ресурсам автоматизированной системы
(АС). Эти стратегии являются изначально проигрышными, так как не
позволяют СЗИ АС успешно противодействовать всем потенциаль-
ным способам СПТВ, следовательно, для решения этой проблемы не-
обходимо использовать в СЗИ АС исключительно упреждающую
стратегию защиты, в основе которой должна быть способность пол-
ной адаптации к любым изменениям условий функционирования АС,
вызванным применением противником информационного оружия.
Постоянная разработка новых методов и средств СПТВ и на-
блюдаемая в последнее время тенденция к постоянному росту коли-
чества случаев успешной реализации СПТВ требуют принципиально
новых подходов к обеспечению безопасности в АС.
Этим обусловлена актуальность создания теории интеллекту-
ального обеспечения безопасности информации АС. В рамках созда-
ния данной теории необходимо комплексное решение ряда функцио-
нальных научных проблем, направленных на исследование и разра-
ботку новых теоретических моделей и методов для создания на их
основе нового поколения интеллектуальных отечественных СЗИ:
Термин «автоматизированная система» используется здесь и ниже как синоним термина
«информационная система».
30
Глава 1. Основы построения интеллектуальных систем защиты информации
• разработка аксиоматической модели угроз безопасности ин-
формации;
• создание математической теории идентификации СПТВ на
АС;
• создание новых математических моделей систем разграниче-
ния доступа, соответствующих информационным процессам в АС;
• создание методологии построения адаптивных СЗИ АС;
• создание методологии построения систем поддержки приня-
тия решений при обеспечении ЗИ в АС;
• разработка замкнутой системы метрологических критериев
оценивания защищенности информации АС;
• создание общей теории информационных рисков;
• создание методологии обеспечения собственной безопасности
СЗИ АС.
Решение указанных фундаментальных научных проблем по-
зволит создавать новые интеллектуальные СЗИ, основным преиму-
ществом которых будет способность предотвращения, обнаружения и
нейтрализации, использования методов и средств СПТВ, имеющих
априорную параметрическую и сигнальную неопределенность.
Основные требования, которым должна удовлетворять пер-
спективная интеллектуальная СЗИ:
• способность обнаруживать априорно неизвестные СПТВ;
• автоматизированная поддержка принятия решений о проти-
водействии СПТВ;
• способность автоматического оценивания изменения уровня
защищенности АС от СПТВ при изменении условий функциониро-
вания;
• автоматизированная поддержка принятия решений о перерас-
пределении ресурсов СЗИ АС;
• автоматическое изменение своих свойств и параметров в за-
висимости от изменения условий среды функционирования, на осно-
ве накопления и использования информации о ней;
• способность к дезинформации нападающей стороны об ис-
тинных свойствах и параметрах АС;
• способность к снижению нецелевой нагрузки на комплекс
средств автоматизации АС;
31
Глава 1. Основы построения интеллектуальных систем защиты информации
• автоматическое воздействие на ресурсы нападающей стороны
(время, вычислительные и коммуникационные ресурсы).
Исходя из вышеизложенного, архитектура перспективной ин-
теллектуальной СЗИ АС должна включать в себя следующие функ-
циональные компоненты:
• подсистему обнаружения СПТВ;
• подсистему накопления данных;
• подсистему анализа защищенности;
• подсистему адаптации СЗИ;
• подсистему активного противодействия СПТВ»3.
Данной тематике в последнее время уделяется большое внима-
ние в специальной литературе. Так, вопросам интеллектуального
противодействия информационному нападению в корпоративных
информационно-вычислительных сетях посвящена монография [25],
в которой предлагается использовать для этих целей аппарат обучае-
мых М-сетей, генетические алгоритмы оптимизации, концепцию «ис-
кусственной жизни». Общая концепция построения модели адаптив-
ной системы защиты информации, реализуемой на основе биосис-
темной аналогии с использованием интеллектуальных механизмов
нейронных сетей и нечеткой логики, рассмотрена в учебном пособии
[26]. Конструктивные подходы, связанные с построением моделей
комплексной оценки угроз безопасности информации, анализом ин-
формационных рисков, построением систем обнаружения атак и сис-
тем поддержки принятия решений по управлению ЗИ с использова-
нием методов искусственного интеллекта, рассматриваются в работах
[27 - 36] и др. Разработке методов и алгоритмов управления защитой
информации в корпоративных информационных системах с исполь-
зованием интеллектуальных технологий посвящена докторская дис-
сертация И. В. Машкиной [37].
Вместе с тем, в силу широты и многоплановости проблемы соз-
дания интеллектуальных СЗИ, ограничимся ниже рассмотрением
лишь отдельных частных аспектов (задач) в рамках решения этой
проблемы, связанных с построением ряда ключевых функциональных
подсистем СЗИ с применением методов искусственного интеллекта.
3 Конец цитаты.
32
Глава 1. Основы построения интеллектуальных систем защиты информации
Контрольные вопросы
1. Сформулируйте основные системные принципы защиты ин-
формации.
2. Перечислите основные уровни обеспечения информационной
безопасности. Какие задачи решаются на этих уровнях?
3. Какие базовые подсистемы входят в состав интегрированной
системы защиты информации?
4. Что понимается под интеллектуализацией систем защиты
информации? Перечислите основные принципы структурной органи-
зации интеллектуальной системы.
5. Каковы основные направления развития интеллектуальных
систем защиты информации?
33
Глава 2. Биометрические системы идентификации личности
ГЛАВА 2. БИОМЕТРИЧЕСКИЕ СИСТЕМЫ
ИДЕНТИФИКАЦИИ ЛИЧНОСТИ
2.L Биометрические технологии: классификация,
сравнительные характеристики
Под биометрией (англ. - Biometrics), применительно к сфере
информационной безопасности, понимается область знаний, пред-
ставляющая методы автоматической идентификации и подтвержде-
ния личности человека по его физиологическим и поведенческим ха-
рактеристикам. Сегодня этой теме посвящено большое количество
публикаций (см., например, [38 - 43]). Подробная информация для
специалистов и непрофессионалов выставлена на Российском био-
метрическом портале http://www.biometrics.org.
С помощью биометрических методов (средств) предприятия пы-
таются сегодня защитить данные, здания, системы. Рынок распозна-
вания особенностей человеческого тела переживает настоящий бум
(говорят даже о «биометрической революции»). По данным исследо-
вания ведущей в данной области консалтинговой компании Interna-
tional Biometrics Group, в 2009 г. мировой оборот биометрических
средств достиг уже 3,4 млрд дол. К 2014 г., как утверждают аналити-
ки, эта цифра должна возрасти до 9,4 млрд дол., что соответствует
годовому росту в 30 %.
Ещё в 90-х гг. прошлого столетия биометрические системы ис-
пользовались главным образом для защиты военных секретов и особо
важной коммерческой информации. В наши дни биометрическими
системами доступа оборудовали аэропорты, крупные торговые цен-
тры, офисы многих компаний. Повышенный спрос стимулировал ис-
следования в этой области, что, в свою очередь, привело к появлению
новых устройств и новых технологий. На рынке биометрических
продуктов, наряду с устоявшимися лидерами - Identix, Digital
Persona, Precise Biometrics, Visionics, Ethentica, BioScript, Secugen, Ac-
Sys Biometrics, появились мощные корпорации, не специализировав-
шиеся ранее в области биометрии - Sony, Panasonic, LG, Compaq и
др.
34
Глава 2. Биометрические системы идентификации личности
Обычно при классификации биометрических технологий выде-
ляют две группы биометрических систем по типу используемых био-
метрических признаков.
Первая группа систем использует статические биометрические
признаки, полученные человеком с рождения и практически не изме-
няющиеся во времени. К таким признакам относятся:
• отпечатки пальцев;
• радужная оболочка глаза;
• изображение лица;
• геометрия кисти руки;
• рисунок пальцев руки;
• ДНК и др.
Вторая группа систем использует для идентификации динамиче-
ские биометрические признаки, подверженные изменениям во време-
ни и отражающие такие индивидуальные особенности каждого чело-
века, как:
• рукописный почерк (подпись);
• голос;
• манера работать на клавиатуре и др.
Каждый из этих признаков имеет свои достоинства и недостат-
ки. Преимуществом использования статических биометрических при-
знаков является их относительная независимость от психофизическо-
го состояния личности, малые затраты на реализацию алгоритмов
распознавания и, как следствие, возможность организации биометри-
ческой идентификации больших потоков людей. Не случайно, наи-
большее распространение на практике получили биометрические ме-
тоды, относящиеся именно к этой (первой) группе и основанные на
использовании первых 3-х из упомянутых выше признаков (распо-
знавание по отпечаткам пальцев, радужной оболочке глаза и особен-
ностям геометрии лица). Недостатком статической биометрии явля-
ется статичность (фиксированность) используемых биометрических
признаков, вследствие чего появляется соблазн их подделки (подме-
ны), требование наличия специального считывающего оборудования.
В отличие от методов первой группы, методы динамической
биометрии обеспечивают большую вариантность (так, подпись или
парольную фразу всегда легко сменить); они легко реализуются про-
35
Глава 2. Биометрические системы идентификации личности
граммным путем, с использованием стандартных периферийных уст-
ройств компьютера. Данные обстоятельства делают динамическую
биометрию более предпочтительной для аутентификации / идентифи-
кации личности при удаленном доступе пользователя. Основной не-
достаток динамических методов - влияние на работу биометрической
системы психофизического состояния личности (усталость, испуг,
воздействие лекарственных препаратов).
По данным International Biometrics Group на 2003 г. (рис. 2.1),
52 % биометрических решений составляют системы распознавания
отпечатков пальцев [41]. Согласно результатам различных исследо-
ваний, население охотнее всего воспринимает данный метод распо-
знавания: отпечатки пальцев сканируются быстро и удобно, проверка
не требует много времени и больших затрат. Распознавание особен-
ностей геометрии лица используется лишь в 11,4 % случаев. На рас-
познавание радужной оболочки глаза приходится 7,3 % биометриче-
ского рынка, несмотря на то, что этот метод считается потенциально
наиболее точным.
Распознавание
по геометрии
лица (11,4%)
Распознавание
по отпечаткам
пальцев (52,0 %)
Распознавание по геометрии
руки (10,0%)
Распознавание по радужной
оболочке глаза (7,3 %)
Распознавание
по голосу (4,1 %)
Распознавание
подписи (2,4 %)
ПО посредник
(middleware) (12,4 %)
Распознавание
по клавиатурному
почерку (0,3 %)
Рис. 2.1. Распределение сегментов биометрического рынка на 2003 г.
(см. сайт http //bre.ru/Security/20234.html)
36
Глава 2. Биометрические системы идентификации личности
Заметим, что именно цифровое изображение лица сегодня при-
знано обязательным во всех странах для паспортно-визовых докумен-
тов нового поколения (биометрических паспортов) , тогда как два
других параметра - отпечатки пальцев и изображение радужной
оболочки глаза - считаются дополнительными, и каждое государство
может включать их в биометрические паспорта по своему усмотре-
нию. Интересно, что именно по инициативе России была принята по-
правка к международному стандарту в области биометрии
(ISO/IEC 19794-5), суть которой заключается во включении трехмер-
ного цифрового изображения лица, наряду с обычной двухмерной
фотографией, в формат данных, предназначаемый для хранения, об-
мена и использования при автоматическом распознавании личности.
Трехмерная (3D) фотография - новейшая биометрическая техноло-
гия, созданная отечественными разработчиками (фирма А4 Vision).
Трехмерное фото, занимая всего 5 Кбайт, может быть записано в
биометрический паспорт, оно увеличивает точность идентификации
личности и повышает надежность автоматической сверки докумен-
тов. Эксперты отмечают, что уровень распознавания трехмерной фо-
тографии составляет более 90 %, тогда как у двухмерного изображе-
ния этот показатель редко превышает 50 % [42].
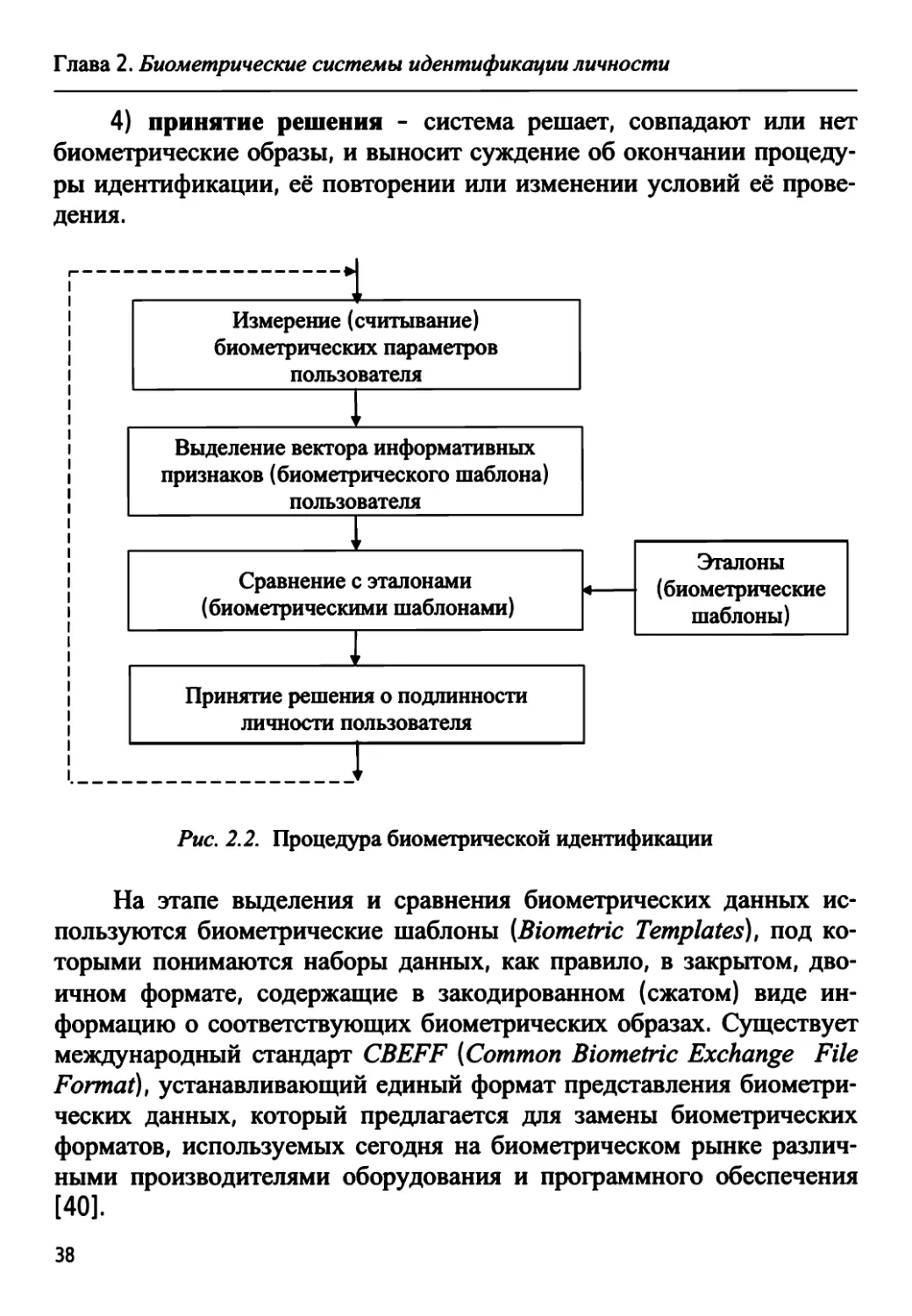
В основе функционирования любой биометрической системы
лежит цепочка следующих действий (рис. 2.2):
1) запись - считываются с помощью сканера биометрические
данные пользователя;
2) выделение - из представленных биометрических данных из-
влекается уникальная информация (в виде вектора информативных
признаков или короткого идентификационного кода, длиной до 1000
бит), которая и будет представлять собой биометрический «образ»
конкретного человека;
3) сравнение - производится сравнение представленного био-
метрического образа с одним или большим числом эталонов (шабло-
нов), хранящихся в базе данных системы;
1В России первые биометрические паспорта начали выдаваться с 2006 г.
37
Глава 2. Биометрические системы идентификации личности
4) принятие решения - система решает, совпадают или нет
биометрические образы, и выносит суждение об окончании процеду-
ры идентификации, её повторении или изменении условий её прове-
дения.
1
| Измерение (считывание)
| биометрических параметров
i пользователя
Выделение вектора информативных
признаков (биометрического шаблона)
пользователя
Сравнение с эталонами
(биометрическими шаблонами)
i Принятие решения о подлинности
{ личности пользователя
!_„' "Л
Рис. 2.2. Процедура биометрической идентификации
На этапе выделения и сравнения биометрических данных ис-
пользуются биометрические шаблоны (Biometric Templates), под ко-
торыми понимаются наборы данных, как правило, в закрытом, дво-
ичном формате, содержащие в закодированном (сжатом) виде ин-
формацию о соответствующих биометрических образах. Существует
международный стандарт CBEFF (Common Biometric Exchange File
Format), устанавливающий единый формат представления биометри-
ческих данных, который предлагается для замены биометрических
форматов, используемых сегодня на биометрическом рынке различ-
ными производителями оборудования и программного обеспечения
[40].
4
Эталоны
(биометрические
шаблоны)
38
Глава 2. Биометрические системы идентификации личности
Различают два возможных режима работы биометрической сис-
темы - верификация («сравнение одного с одним») и идентифика-
ция («сравнение одного с многими»).
В режиме верификации пользователь предъявляет системе свои
биометрические данные («биометрику»), объявляя тем самым ей,
«кто он такой». Задача системы в данном случае - проверить «прав-
дивость» полученной информации, т.е. сверить соответствие полу-
ченных биометрических данных с записанным ранее шаблоном (эта-
лоном) заявленного индивидуума.
В режиме идентификации пользователь также предъявляет сис-
теме свою биометрику, однако задача системы меняется - необходи-
мо принять решение, принадлежит ли пользователь к числу извест-
ных ей индивидуумов, и если принадлежит, то - кто он? В этом слу-
чае измеренные биометрические данные сравниваются с базой дан-
ных ранее записанных шаблонов всех «известных» системе людей.
Очевидно, что в реальных условиях применения биометриче-
ские системы сталкиваются с рядом проблем, одна из которых заклю-
чается в необходимости обеспечения высокой надежности распозна-
вания личности. Сложность решения этой проблемы заключается в
том, что:
а) сама процедура биометрической идентификации / верифика-
ции имеет вероятностный характер, поскольку сами измеряемые
биометрические данные подвержены влиянию большого числа фак-
торов неопределенности, а значит, сохраняется определенная вероят-
ность «не признать своего» и «признать своего чужим»;
б) биометрическая система должна быть защищена от созна-
тельного обмана, т.е. возможности подмены объекта биометрическо-
го сканирования;
в) приобретает особую остроту вопрос о сохранности собранной
биометрической информации (речь идет не только о возможности её
взлома и т.д., но и о том, что любой биокод, например, состояние ра-
дужной оболочки глаза или вен руки, несет в себе много информации
о состоянии здоровья конкретного человека и т.д., что может быть
использовано в противоправных целях).
2 Фактически здесь и ниже речь идет об аутентификации пользователя.
39
Глава 2. Биометрические системы идентификации личности
Для сравнительной оценки эффективности различных биомет-
рических технологий можно воспользоваться табл. 2.1 [38]. В столб-
цах этой таблицы указаны основные критерии, которым должна отве-
чать в той или иной степени любая биометрическая технология, а
также качественные значения этих критериев для различных техноло-
гий (рассматриваются только технологии распознавания по изобра-
жению лица - двухмерная (2D) и трехмерная (3D) фотография, по от-
печатку пальца и по радужной оболочке глаза).
Таблица 2.1
Характеристики биометрических технологий
Гч%ч,ч->ххКритерий
Технология4"**--^
По изображе-
нию лица:
2/>фото
3/)-фото
По отпечатку
пальца
По радужной
оболочке глаза
Измеримость
X
X
п
п
Устойчивость
к окружаю-
щей среде
П
X
П
X
Устойчивость
к подделке
П
О
П
П
Точность
распознавания
П
X
X
X
П - плохая; X - хорошая; О - отличная
Рассмотрим подробнее каждый из приведенных критериев.
1. Измеримость. Биометрический признак (параметр) должен
быть легко измерим. Измеримость можно количественно оценить ве-
личиной 1 - FER, где FER (Failure to Enroll) - доля индивидуумов,
которые не смогли пройти регистрацию (система не смогла построить
биометрический шаблон), и средним временем распознавания (Rec-
ognition Time). Под временем распознавания подразумевается либо
время верификации, либо время идентификации - в зависимости от
режима, в котором работает система. FER включает в себя случаи,
когда у индивидуумов нужные биометрические данные отсутствуют,
но главным образом случаи, когда по тем или иным причинам изме-
рение этих данных для данного человека на данном сканере затруд-
нено.
40
Глава 2. Биометрические системы идентификации личности
Так, например, для распознавания по радужной оболочке глаза
требуется ее изображение высокого разрешения, что приводит к оп-
ределенным затруднениям, связанным с необходимостью точного по-
зиционирования глаза по отношению к сканирующему устройству.
Распознавание многих групп людей по отпечаткам пальцев за-
труднено, особенно это касается работников физического труда, лю-
дей со слабо выраженными папиллярными узорами и дефектами ко-
жи, пожилых людей с сухой кожей. Методы распознавания по изо-
бражению лица - бесконтактные и потому обладают высокой изме-
римостью биометрического признака.
2. Устойчивость к окружающей среде. Биометрическая техно-
логия должна быть устойчива к изменению окружающей среды. Экс-
плуатационные качества различных технологий в значительной сте-
пени зависят от окружающих условий и могут терять стабильность
при изменении этих условий. Так, сканеры отпечатков пальцев, как
правило, быстро загрязняются. В этом случае качество работы падает,
а для распознавания лица по двухмерной фотографии большое значе-
ние имеет распределение внешней освещенности.
3. Устойчивость к подделке. Биометрическая система должна
быть устойчивой к различного рода подделкам (несанкционирован-
ному доступу). Систему распознавания по двухмерному изображе-
нию лица легко обмануть, предъявив ей фотографию «правильного»
человека из числа «знакомых» системе. Украсть изображение чужой
оболочки глаза, конечно, сложнее, чем фотографию лица, но если это
сделано, то систему также можно обмануть фотографическим изо-
бражением «нужного» глаза, распечатанным с высоким разрешением
или нанесенным на контактную линзу.
Для получения несанкционированного доступа по отпечатку
пальца, в принципе, можно снять отпечатки пальцев «нужного» ин-
дивидуума, оставленные на любой поверхности, оцифровать их и
обработать полученное изображение на компьютере, после чего изго-
товить «фальшивый» палец либо накладку на него (классический
пример, часто цитируемый в литературе, - японский криптограф Цу-
тому Мацумото с группой своих студентов из университета Иокога-
мы показал, как легко в лабораторных условиях изготовить фальши-
вые отпечатки пальцев, с помощью которых можно обмануть практи-
41
Глава 2. Биометрические системы идентификации личности
чески любую современную систему биометрической аутентифика-
ции).
Наиболее устойчивой к подделке является технология распозна-
вания по трехмерному изображению лица. Для того чтобы обмануть
такую систему, потребовалось бы изготовить точную твердотельную
маску лица, повторяющую во всех деталях его геометрию, что на
практике представляется затруднительным.
4. Точность распознавания. Для оценки точности работы био-
метрической системы обычно используются следующие показатели:
- FAR (False Acceptance Rate) - вероятность ложного распозна-
вания, когда система предоставляет доступ незарегистрированному
пользователю;
- FRR (False Rejection Rate) - вероятность ложного отказа в дос-
тупе, когда система не распознает «знакомого» ей субъекта и соот-
ветственно признает его за «чужого».
В теории статистических решений значения FRR и FAR принято
называть соответственно ошибками 1-го и 2-го рода.
На практике любую биометрическую систему можно настроить
на разную степень «бдительности», т.е. на разное значение вероятно-
сти ложного распознавания FAR. Но уменьшение FAR всегда приво-
дит к уменьшению чувствительности системы и увеличению вероят-
ности ложного отказа (нераспознавания) FRR. Таким образом, чем
«бдительнее» настроена система на непропускание «чужих», тем она
менее чувствительна, а значит, хуже пропускает «своих». В совре-
менных системах значения FAR составляют доли процента, значения
FRR - несколько процентов (2 ... 5 %).
Как показывают исследования, конкретные показатели точности
системы сильно варьируются в зависимости от производителя и ме-
тодики тестирования, однако важно, что три из указанных в табл. 2.1
технологий распознавания - по трехмерному изображению лица, по
отпечатку пальца и по радужной оболочке глаза - обладают сравни-
мой точностью.
При этом распознавание по двухмерному изображению лица
существенно уступает по точности перечисленным технологиям, так
же как и другие, не представленные в табл. 2.1, биометрические тех-
нологии (распознавание по геометрии руки, по голосу и др.). С дру-
42
Глава 2. Биометрические системы идентификации личности
гой стороны, следует отметить, что двухмерное изображение лица
наиболее удобно для визуального сравнения оператором.
Заметим также, что при использовании биометрической системы
в режиме идентификации («сравнение одного со многими») точность
распознавания многократно ухудшается по сравнению с режимом ве-
рификации («сравнение одного с одним»). Так, например, если при
FRR, равном 1,3 %, лучший пальцевый сканер в режиме верификации
обеспечивает FAR, равный 0,001 % (один шанс из ста тысяч), то в
режиме идентификации при том же FRR и базе данных в 100 чело-
век FAR уже оставляет 0,1 %, а при базе данных в 1000 человек - 1 %
(т.е. один шанс из ста), что уже недопустимо для большинства при-
ложений [38].
Для повышения точности распознавания в режиме идентифика-
ции целесообразно использование одновременно нескольких био-
метрических технологий. Данное перспективное направление в био-
метрии базируется на концепции построения многофакторных био-
метрических (мультибиометрических) систем идентификации
(AMIS, Automated Multimodal Biometric Identification Systems). Так, из-
вестная российская компания BioLink предлагает на рынке для при-
менения в правоохранительной практике многофакторную биомет-
рическую систему [44], интегрирующую следующие технологии
распознавания:
• по отпечаткам пальцев;
• по изображению лица;
• по голосу;
• по почерку.
Интеграция указанных биометрических технологий предполага-
ет два аспекта - технический и алгоритмический. Технически инте-
грация заключается в объединении нескольких программно-
аппаратных комплексов единым интерфейсом, что в достаточной
степени решается путем стандартизации. В качестве базовых модулей
биометрического программного обеспечения в состав системы при
этом включены:
• библиотека Biolink SDK (Россия) сравнения и экспертной об-
работки отпечатков пальцев;
43
Глава 2. Биометрические системы идентификации личности
• библиотека Neirotechnologia VeriLook 2.0 SDK (Литва) иден-
тификации лица;
• библиотека ПТ FaceDetection SDK (Россия) обнаружения и
межкадрового прослеживания лиц в видеопотоке;
• библиотека Trawl SDK (Россия) идентификации абонента в
телефонном канале.
С алгоритмической точки зрения, интеграция биометрических
технологий представляет собой достаточно сложную прикладную ма-
тематическую задачу принятия решения об идентичности наборов
биометрических образов, для решения которых использовались мето-
ды статистической теории принятия решений.
При создании многофакторной биометрической системы учи-
тывалось, что биометрическая идентификация сама по себе является
затратной вычислительной процедурой, вследствие чего в состав про-
граммно-аппаратного комплекса потребовалось включить высоко-
производительный сервер и специально оборудованные АРМ био-
метриста, т.е. биометрическая система разрабатывалась как клиент-
сервер приложение.
В целом, внедрение такой многофакторной биометрической сис-
темы позволяет значительно повысить качество процессов распозна-
вания личности, обеспечивая:
- уменьшение вероятностей ошибок 1-го и 2-го рода;
- снижение требований к квалификации операторов (экспертов);
- охват большей части населения, по сравнению с любой одно-
факторной системой;
- возможность ведения единого репозитория (хранилища) био-
метрических данных за счет интеграции различных биометрических
банков.
44
Глава 2. Биометрические системы идентификации личности
2.2. Постановка задачи распознавания образов.
Построение решающего правила
Вернемся еще раз к базовым функциям, лежащим в основе лю-
бой биометрической системы (см. рис. 2.2). При этом преднамеренно
не будем останавливаться на функциях измерения биометрических
параметров пользователя и построения его идентификатора (биомет-
рического шаблона), считая, что данные функции очень специфичны
и привязаны к конкретным биометрическим признакам человека
(изображение лица, отпечаток пальца и т.д.). Подробную информа-
цию по данному вопросу можно найти, например, в [39, 45, 46].
Инвариантную часть биометрической системы занимают моду-
ли, ответственные за функции распознавания и принятия решений.
Будем полагать, что биометрический образ пользователя представлен
некоторым вектором V = (V\, Vi,.. Ут) информативных признаков,
используемых для идентификации. Тогда задача распознавания
личности сводится к отнесению данного вектора к одному из клас-
сов, «известных» системе. В случае успешной классификации, систе-
ма «узнает» пользователя и производит предопределенное админист-
ратором действие: разрешает доступ к информационным ресурсам,
открывает дверь в охраняемое помещение и т.д.
Начальным этапом построения системы распознавания личности
является этап обучения [47]. На этом этапе осуществляется:
• формирование словаря классов - для системы идентификации
личности классами являются ее пользователи. При этом система
формирует (обновляет) свой словарь классов в то время, когда поль-
зователь проходит регистрацию и создает его уникальный идентифи-
кационный номер (ID) или метку класса;
• выполнение обучающих наблюдений - обновив словарь клас-
сов, система уже «знает» о существовании нового пользователя
(класса), но «не знает» его параметров. Для получения данной ин-
формации система несколько раз (от одного до R раз) измеряет инте-
ресующие ее параметры. Например, в случае распознавания человека
по кисти руки, пользователь несколько раз предъявляет руку для
«обучения» системы. При этом внутри распознающего устройства
формируется (обновляется) так называемая матрица данных, или
45
Глава 2. Биометрические системы идентификации личности
обучающая выборка. Строками этой матрицы являются векторы при-
знаков, а первым столбцом - метка класса. Совокупность матриц для
всех классов, известных системе распознавания, составляет её об-
щую базу данных. Именно из нее извлекается информация для опти-
мизации пространства признаков; именно с этого момента система
способна «узнать» пользователя;
• построение эталонов классов - для получения эталонных
описаний классов, хранящихся в архиве системы, используются раз-
личные методы: статистические, структурные, логические, нейросе-
тевые и т.д. Простейшим примером эталонного описания класса яв-
ляется вектор признаков, каждый компонент которого представляет
собой среднее значение измерений соответствующего признака.
В основе большинства алгоритмов, используемых на этапе соб-
ственно распознавания введенного биометрического образа, заложе-
ны следующие подходы: сравнение с эталоном, дискриминантный и
синтаксический (или лингвистический) подходы [46 - 48].
1. Метод сравнения с эталоном. Распознавание в данном слу-
чае сводится к прямому сопоставлению распознаваемого объекта,
представленного в виде вектора признаков V, с эталонами классов,
представленными в виде соответствующих векторов признаков
Vy,(y =l,2,...,Af). Решение о принадлежности распознаваемого объ-
екта тому или иному классу принимается путем сравнения некоторой
меры близости (или сходства) распознаваемого объекта с каждым
классом. При этом, если выбранная мера близости данного объекта и
некоторого класса превышает меру близости этого объекта со всеми
остальными классами и превышает некоторое заданное число г, то
принимается решение о принадлежности объекта к данному классу.
Если мера близости не превышает число г ни для какого класса, то
принимается решение о том, что в базе данных системы распознава-
ния не существует класс, к которому принадлежит распознаваемый
объект. Варьируя число г, можно регулировать «строгость» системы
идентификации. В теории систем распознавания это число называют
порогом принятия решения.
3 Последний подход представляется методологически наиболее сложным и в силу этого ниже
рассматриваться не будет.
46
Глава 2. Биометрические системы идентификации личности
В качестве меры близости могут быть использованы:
• коэффициент парной корреляции;
• вероятностные оценки на основе метода Байеса;
• мера близости Хемминга;
• евклидово расстояние, и др.
Вычисляя меры близости объекта ко всем известным классам и
применяя экстремум, получим систему идентификации, а вычисляя
меру близости между неизвестным системе вектором признаков и
эталонным описанием класса, который определен введенным паролем
(ID), получаем систему верификации.
2. Дискриминантный подход, разработанный в теории стати-
стических решений, является универсальным и включает в себя метод
сравнения с эталоном как частный случай.
Суть данного подхода состоит в следующем. Будем полагать,
что каждому вектору V = (Vi,V2,..Vm) соответствует определенная
точка в т-мерном пространстве признаков. Если имеется М классов
распознаваемых объектов - QiiQi^^Qm* то каждому классу
Q:, (j = 1,2,.. М) в этом пространстве будет соответствовать некото-
рая область (как правило, компактная, т.е. значения признаков одного
пользователя отличаются лишь разбросом). Таким образом, про-
странство признаков по числу классов разбивается на М областей.
Если удастся построить такие разделяющие (дискриминантные)
функции F/tV), (/ = 1, 2, ..., N), которые являлись бы границами для
указанных областей, то по величине или по знаку этих функций мож-
но было бы судить о принадлежности вектора признаков V той или
иной области (а следовательно, объекта - тому или иному классу).
Правило, которое позволяет на основе имеющейся (в том числе апри-
орной) информации о компонентах вектора признаков V и вычислен-
ных значениях функции Ff(V), (i = 1, 2, ..., N) принять решение о
принадлежности распознаваемого объекта конкретному классу из
числа известных («свой») или отсутствии такового («чужой»), назы-
вается решающим правилом. Общая схема процесса распознавания на
основе дискриминантного подхода приведена на рис. 2.3.
47
Глава 2. Биометрические системы идентификации личности
Объект
|(образ)
Построение
вектора
признаков
1 ►
V
►
►
W)
F2(V)
FW(V)
fr
^
| ►
Решающее
правило
Рис. 2.5. Схема процесса распознавания на основе
дискриминантного подхода
Понятно, что построение «точных» разделяющих функций
представляет собой достаточно сложную, а часто и неразрешимую
задачу. На практике ограничиваются построением приближенных
(аппроксимирующих) выражений для разделяющих функций. При
этом возможны следующие ситуации:
а) классы распознаваемых объектов линейно разделимы, т.е. раз-
деляющие функции принимают линейный вид
Fi(y)=twijVj^Cil (2.1)
7=1
где Wy и С, - некоторые постоянные коэффициенты, а разделение
классов 6l'62'-''6m осуществляется с помощью подобранных соот-
ветствующим образом М гиперплоскостей.
В простейшем случае (для т = 2) задача синтеза решающего
правила сводится к проведению на плоскости прямых, наилучшим
образом разделяющих классы распознаваемых объектов «Свой 1»,
«Свой 2», «Чужой» (рис. 2.4, а)]
б) классы распознаваемых объектов разделимы с использовани-
ем нелинейных разделяющих функций. Например, в качестве разде-
ляющих функций можно принять полиномиальные функции вида
48
Глава 2. Биометрические системы идентификации личности
F,(V)=£(»^ (2.2)
у=1 J J
где W\:', Wy ', W\j и С/ - постоянные коэффициенты, подбираемые
таким образом, чтобы обеспечить разделение упомянутых классов в
т-мерном пространстве признаков с помощью нелинейных гиперпо-
верхностей (пример для т = 2 приведен на рис. 2.4, б);
в) классы распознаваемых объектов «точно» не разделимы, т.е.
пересекаются (рис. 2.4, в). В этом самом сложном (однако наиболее
характерном для практики) случае, при любом выборе разделяющих
функций и решающего правила существует вероятность «неузнава-
ния» распознаваемого объекта FRR (ошибка 1-го рода) и вероятность
«неправильного распознавания» FAR (ошибка 2-го рода). На ошибки
распознавания влияет также связанное с помехами (шумами измере-
ний) искажение информации, содержащейся в самом векторе призна-
ков V.
Выходом в данной ситуации является учет стохастической при-
роды вектора V, который можно рассматривать как значение
/w-мерной случайной величины о, распределение которой описывает
статистическую изменчивость биометрических параметров пользова-
теля и характеризуется плотностью /?(V). Соответственно распреде-
ление векторов биометрических признаков «своих» (Qj) и «чужих»
(£^) пользователей будет характеризоваться плотностями p(VIQj) и
р{У IQk) • При этом задача заключается в построении на основе ста-
тистического материала, полученного в процессе обучения, разде-
ляющих функций
Fj (V) = p(Qj IV),(j=X2,..,M), (2.3)
где p(QjlV) - условная вероятность того, что неизвестный объект
(пользователь) относится к классу QJt если ему соответствует век-
тор V.
49
Глава 2. Биометрические системы идентификации личности
V2
Разделяющая функция F\(M)
Разделяющая функция F2(V)
Vi
V2
Разделяющая функция F (V)
Vi
V2
ч*
Рис. 2.4. Разделение плоскости признаков на классы
50
Глава 2. Биометрические системы идентификации личности
Если плотности распределения вектора р(У IQj), (/ = 1, 2, ...,
А/) заранее неизвестны, то разделяющие функции Ft (V) могут быть
заданы в явном виде с использованием М параметров-весов:
Fi(V)=Fi(V,W1,W2 WM), (2-4)
а построение решающего правила сводится к выбору вида функ-
ций ^J(V) и подбору параметров-весов, такому, чтобы гиперповерх-
ности f)-(V) с приемлемой точностью могли выделить в т-мерном
пространстве биометрических признаков М классов «своих» пользо-
вателей, исключая «чужих».
В случае, если параметры распределения р(УIQj) известны,
целесообразно использовать параметрические методы, когда гипер-
поверхности Fj(V) строятся на основе данных обучающей выборки
[49]. В качестве решающих правил при этом могут использоваться
различные критерии, связанные с риском принятия решения:
• критерий Байеса - правило, в соответствии с которым стра-
тегия принятия решения выбирается таким образом, чтобы обеспе-
чить минимум среднего риска;
• минимаксный критерий - такой, который минимизирует мак-
симально возможное значение среднего риска;
• критерий Неймана-Пирсона, основанный на минимизации
ошибок распознавания.
Заметим, что качество решающего правила в значительной мере
зависит от степени соответствия реальных и использованных в Ft(\J)
параметров распределения. При отсутствии (или малом объеме) ста-
тистических данных, задачу оценки параметров распределения и
принятия решения можно решать с использованием так называемых
«субъективных вероятностей», назначаемых экспертами, и привлече-
нием аппарата теории нечетких множеств и лингвистических пере-
менных [5, 8].
Общие недостатки существующих биометрических методов
идентификации личности:
• качество распознавания (принятия решений) в значительной
степени зависит от качества измеряемых биометрических данных;
51
Глава 2. Биометрические системы идентификации личности
• имеет место значительный разброс показателей качества сис-
темы, поскольку существующие биометрические системы ориентиро-
ваны, как правило, на абстрактного среднестатистического пользова-
теля;
• высокий процент ошибок в условиях воздействия факторов
неопределенности, зависимость показателей точности распознавания
от числа пользователей системы;
• значительное усложнение алгоритмов распознавания (приня-
тия решений) при использовании многофакторной биометрической
идентификации;
• не до конца решены вопросы аттестации (оценки соответст-
вия) и сертификации средств биометрической идентификации поль-
зователей.
Указанные недостатки в значительной степени нивелируются
при построении нейросетевых биометрических систем идентифика-
ции, использующих механизмы настройки (адаптации) на конкретно-
го пользователя путем обучения (или самообучения) сети на множе-
стве полученных биометрических данных в реальных условиях экс-
плуатации [45, 50 - 53].
2.3. Нейросетевые алгоритмы
биометрической идентификации
Нейронные сети (НС) занимают важное место при решении за-
дач обеспечения информационной безопасности в силу следующих
своих преимуществ:
• возможность воспроизведения с любой точностью сколь
угодно сложных нелинейных зависимостей (за что их часто называют
«универсальными аппроксиматорами»);
• способность к обучению и самообучению (настройка НС на
решение определенной задачи производится на серии «примеров» из
обучающей выборки, причем на обучающую выборку не накладыва-
ются какие-либо ограничения);
• способность к обобщению (т.е. опыт, полученный сетью в
процессе обучения на конечном числе образов, можно успешно рас-
пространить на другие, в том числе неизвестные ей образы);
52
Глава 2. Биометрические системы идентификации личности
• потенциально высокая помехо- и отказоустойчивость (так, в
случае постепенного выхода из строя до 50 % составляющих ее эле-
ментов, НС может сохранить приемлемую работоспособность);
• в силу параллельной природы НС, ее архитектура естествен-
ным образом реализуется на параллельных вычислительных средст-
вах.
Система распознавания образов, построенная на основе НС, в
общем случае состоит из двух частей (рис. 2.5): подсистемы извлече-
ния информативных (инвариантных) признаков и нейросетевого
классификатора, выполняющего функцию решающего правила [6].
Входной
образ X
Извлечение
£>] информативных
признаков
Вектор
признаков
V
НС-классификатор
(решающее правило)
Выходной
вектор Y
Рис. 2.5. Блок-схема системы распознавания образов на основе НС
На первом этапе производится преобразование координат вход-
ного вектора (образа) X с целью выделения из него информативных
признаков, которые описывают наиболее существенную информа-
цию, содержащуюся в наборе входных данных (наблюдений), и при
этом инвариантны к трансформациям входного сигнала, связанным с
изменением положения распознаваемого объекта (сдвиг, вращение,
изменения масштаба, ракурса и т.п.). Это преобразование переводит
входной образ - точку X в ^-мерном пространстве входных данных -
в точку V в /n-мерном пространстве признаков. Поскольку m<q, то
данное преобразование можно рассматривать как операцию снижения
размерности (т.е. сжатия данных), упрощающую задачу классифика-
ции. Сама классификация представляет собой преобразование, кото-
рое отображает точку (вектор) V в один из классов Л/-мерного про-
странства решений (где М - количество выделяемых классов). Раз-
мерность выходного вектора Y при этом можно принять равной М,
если предположить, чтоу-я компонента вектора Y принимает значе-
53
Глава 2. Биометрические системы идентификации личности
ние 1 только в том случае, если вектор признаков V принадлежит
«известному» классу Qj; остальные компоненты вектора Y при этом
принимают нулевые значения.
Обобщенная блок-схема нейросетевой системы биометрической
идентификации личности, приведенная на рис. 2.6, отражает еле
дующие основные этапы обработки информации [50]:
• измерение биометрических данных пользователя с помощью
сенсоров (входных преобразователей);
• извлечение информативных (инвариантных) биометрических
признаков;
• построение нейросетевого биометрического эталона пользо
вателя;
• реализация решающего правила на основе НС.
«Входной
образ»
Измерение
0| биометрических
данных
Повтор
Обучение
1
1 *
Сырые» биометрические
данные (X)
Извлечение
информативных
признаков
Аутентификация
Вектор признаков V
Правила
обучения
и настройки
ы.
Решающее
правило
Биометрические
эталоны
з?
Принятие решения
Рис. 2.6. Обобщенная блок-схема нейросетевой системы биометрической
идентификации
54
Глава 2. Биометрические системы идентификации личности
Следует отметить, что первые два блока обработки информации
работают по одним и тем же алгоритмам, независимо от режима ра-
боты самой биометрической системы. Режим работы системы (обу-
чение или идентификация/аутентификация) определяет совокупность
операций, осуществляемых далее с выделенными векторами инфор-
мативных признаков пользователей V(r' = (V^ , V\ /•••* Vm )T •
В режиме обучения векторы признаков V , (г = 1, 2, .., R) по-
ступают в блок правил обучения и настройки, который формирует
биометрические эталоны пользователей (классов). Поскольку био-
метрические образы пользователей обладают существенной изменчи-
востью, для формирования биометрических эталонов требуется не-
сколько примеров реализации каждого образа.
В режиме идентификации (аутентификации) вектор признаков
V, полученный из предъявленного образа, сравнивается решающим
правилом с биометрическим эталоном. Если предъявленный вектор
оказывается близок к биометрическому эталону, принимается поло-
жительное аутентификационное решение. При значительных отли-
чиях предъявленного вектора и его биометрического эталона прини-
мается решение об отказе пользователю в аутентификации. В ряде
случаев пользователю может быть предоставлена попытка повторной
аутентификации.
Остановимся подробнее на процедуре построения и обучения
НС, используемой в качестве решающего правила и биометрического
эталона личности.
На рис. 2.7 приведен пример наиболее распространенной схе-
мы НС - многослойного персептрона.
Данная сеть содержит три слоя нейронов: входной слой, на кото-
рый подаются компоненты вектора признаков V - выполняет чисто
распределительные функции; скрытый слой - осуществляет нели-
нейное преобразование координат Vi,V2,.--,Vm в некоторые величины
ZlfZ2,...,Z^ - выходы нейронов скрытого слоя; выходной слой -
формирует вектор выходных реакций Y, состоит из М нейронов (по
числу распознаваемых классов Q±, Q2,..., QM).
55
Глава 2. Биометрические системы идентификации личности
Ц2)>
Рис. 2.7. Структурная схема трехслойного персептрона
Нейроны скрытого и выходного слоев описываются уравнения-
ми
Z/=/(Ivt#^), / = 1,2,...ЛГ;
/=0
(2.5)
N
,(2)
YJ=f(^fZl)f j = l2,..M,
(2.6)
/=о
где /(•)- нелинейная функция активации нейрона; {щ } и {wl'} -
матрицы весов синаптических связей; Vq = +1 и Z0 = +1 - постоян-
ные входы (смещения). Варианты задания функций активации
у = f(x) в виде пороговой (логической) и сигмоидной функции при-
ведены на рис. 2.8, а, б.
56
Глава 2. Биометрические системы идентификации личности
J
1
0
У=Лх)
►
i
1
0.5
0
У=Лх)
w
Рис. 2.8. Способы задания функции активизации: а - пороговая функция;
б - сигмоидная функция
Допустим, что имеется некоторая обучающая выборка
{(V(1\D(1)),(V(2),D(2)) (У(*\0(Л))},составленная из пар веюгоров
(V , D(r)), где V(r) и D - соответственно входной вектор и вектор
желаемых выходных реакций сети в r-м обучающем примере;
R - число таких примеров в обучающей выборке. Заметим, что число
обучающих примеров должно быть не меньше числа распознаваемых
классов (R>M), т.е. в обучающую выборку должно входить по
крайней мере по одному представителю (вектору признаков) каждого
из распознаваемых классов Q, Qi,..., Qm •
Цель обучения НС состоит в том, чтобы при предъявлении на
входы сети вектора признаков V, принадлежащего некоторому классу
Qj, выходной сигнал НС (т.е вектор Y) указывал (в принятой коди-
ровке) номер класса Qj. Процесс обучения сводится к выбору таких
значений весов w,/ , wL ', которые минимизируют суммарную квад-
ратическую ошибку сети
E=t lU>Jr) -Yjr))2,
(2.7)
где Yj и Dj - фактическое и желаемое значения у'-го выхода сети
для r-го примера из обучающей выборки. Наиболее простым (но не
самым лучшим) является градиентный алгоритм обучения НС, в со-
57
Глава 2. Биометрические системы идентификации личности
ответствии с которым настройка весов сети осуществляется по пра-
вилу
42'U+1) = ^W-6.^|, (2'8)
дЕ дЕ * к г
где —7ТТ-, —т^т- - частные производные ошибки обучения Е по ве-
dw)? dw\f}
сам wl7(1),wj2), (i = 0, 1 m; / = О, 1 N; j = 1, 2 M);
& = 0, 1, 2, ... - дискретное время (шаг обучения). Качество обучения
считается приемлемым, если ошибка обучения принимает достаточно
малые значения (2? = 10" ...10" ). Заметим, что поскольку в процессе
обучения НС «запомнила» биометрические образы всех предъявлен-
ных ей представителей М классов пользователей, то обученная НС
одновременно с решающим правилом выполняет функцию хранения
(памяти) соответствующих биометрических эталонов (см. рис. 2.6).
Доказано, что персептрон с одним скрытым слоем (см. рис. 2.7)
и пороговой функцией активацией нейронов (см. рис. 2.8, а) способен
за конечное число шагов решить задачу разделения М произвольных
классов Qj. j = 1,2,..М с помощью Мразделяющих гиперплоскостей
в т-мерном пространстве признаков Vi,V2,.~,Vm в том случае, если
эти классы представлены выпуклыми ограниченными областями4.
Ошибка такого разделения зависит только от степени пересечения
классов. Безошибочное разделение возможно только в случае полно-
стью непересекающихся классов (см. рис. 2.4, я). При использовании
сигмоидной функции активации (см. рис. 2.8, б) и двух скрытых сло-
ев, с помощью персептрона возможно формирование с заданной по-
грешностью любых выпуклых областей в пространстве признаков, а
4 Область называется выпуклой, если для любых двух ее точек соединяющий их отрезок так-
же целиком лежит в этой области.
58
Глава 2. Биометрические системы идентификации личности
при добавлении третьего скрытого слоя - областей любой сложности,
в том числе и невыпуклой формы [53].
Основные сложности, возникающие при обучении НС:
• наличие локальных минимумов целевой функции Е - приво-
дит к «зависанию» процесса поиска в «ловушках» («лакунах»);
• шум во входных данных - приводит к изменению направле-
ния поиска, и в конечном итоге, к существенному его замедлению;
• ошибки классификации - возникают вследствие близости
(пересечения) соседних классов образов;
• «проклятие размерности» - при увеличении числа настраи-
ваемых весов, вычислительные затраты на поиск растут экспоненци-
ально.
На сегодня известно более сотни различных алгоритмов обуче-
ния НС, ставящих своей целью в той или иной мере справиться с
указанными выше сложностями. Одним из способов сокращения
времени обучения НС является применение «быстрых» алгоритмов
обучения, основанных на процедуре вычисления весов сети с предва-
рительной декорреляцией (ортогонализацией) ее входных данных
[50].
Помимо многослойных персептронов, в настоящее время ведут-
ся активные исследования по применению ряда других архитектур
НС для решения задач биометрической идентификации [45, 53]. К
числу таких представляющих интерес архитектур НС относятся:
• модулярные НС (Modular neural networks);
• машины опорных векторов (Vector Support Machines);
• сверточные НС (Convolutional networks)]
• вейвлет-сети (Wavelet networks);
• ассоциативные НС (Associative networks);
• самоорганизующиеся карты Кохонена (Self-organizing maps,
SOM)\
• радиально-базисные сети (Radial-Basis Function networks,
RBFN);
• сигма-пи НС (У- P neural networks), и др.
Информацию об особенностях построения и организации про-
цесса обучения этих сетей можно найти, например, в [6, 54].
59
Глава 2. Биометрические системы идентификации личности
Перечень первоочередных задач, привлекающих внимание раз-
работчиков в области создания современных и перспективных био-
метрических систем идентификации личности, включает в себя такие
задачи, как [52]:
• разработка эффективных нейросетевых алгоритмов сжатия и
восстановления изображений с целью использования для представле-
ния биометрических признаков в биометрических чипах и базах дан-
ных биометрических изображений;
• разработка нейросетевых алгоритмов оценки качества изо-
бражений в системах биометрической идентификации личности;
• разработка нейросетевых алгоритмов биометрической иден-
тификации по дактилоскопическим отпечаткам;
• разработка нейросетевых алгоритмов биометрической иден-
тификации личности по радужной оболочке глаза;
• разработка нейросетевых алгоритмов объединения информа-
ции из нескольких различных систем биометрической идентифика-
ции;
• разработка методики количественной оценки интеллектуаль-
ности биометрических систем идентификации личности;
• разработка нейросетевых алгоритмов идентификации лично-
сти с управлением ошибками 1-го и 2-го рода;
• разработка методов анализа криптостойкости (надежности)
биометрических систем идентификации личности, включая разработ-
ку методов решения обратных задач для основных биометрических
признаков;
• разработка моделей угроз для биометрических систем иден-
тификации личности, в том числе анализ специфических типов атак
на биометрические системы идентификации личности и методов про-
тиводействия им;
• исследование перспективных методов защиты информации в
комплексах с биометрическими системами идентификации личности.
Поскольку требования к качеству работы биометрических сис-
тем идентификации личности постоянно возрастают, настоятельной
становится реализация этих систем с аппаратной поддержкой вычис-
лений. Уже в настоящее время за рубежом выпускаются системы
биометрической идентификации личности по изображению лица на
60
Глава 2. Биометрические системы идентификации личности
базе нейронов ZISC фирмы IBM. Значительные перспективы откры-
ваются в связи с построением нейросетевых биометрических систем
идентификации личности на базе программируемых логических ин-
тегральных схем (ПЛИС). Очевидно, что в ближайшие годы число
подобных систем с аппаратной поддержкой вычислений будет только
расти.
2.4. Нейросетевая реализация биометрических систем
идентификации с криптозащитой
Как уже отмечалось выше, при реализации решающего правила
на основе НС необходимость в хранении в явной форме биометриче-
ских эталонов (шаблонов) отпадает, поскольку сама НС в данном
случае берет на себя функцию распределенной памяти. Информация
о биометрических эталонах записывается в НС в виде значений весов
ее связей, настраиваемых в процессе обучения сети (иногда даже го-
ворят о «голографической» памяти НС). То обстоятельство, что био-
метрические образы легальных пользователей (эталоны) оказываются
«спрятанными» внутри сети, является положительным фактором с
точки зрения обеспечения анонимности биометрической защиты.
Каждый человек обладает уникальными статическими и динамиче-
скими биометрическими признаками, а значит, конкретные значения
весов НС, обученной с учетом значений этих признаков, также уни-
кальны.
Удобства использования нейросетевых биометрических систем
и достаточно высокий уровень предоставляемой ими защиты делают
их перспективными для применения в открытых и слабо защищенных
информационных пространствах (малые офисы, домашние и пере-
носные компьютеры). В то же время, потенциальный злоумышленник
(хакер) может попытаться «обойти» систему биометрической иден-
тификации, предъявляя информационной системе сразу «нужный»
вектор выходов НС-классификатора Y = (0 0 ... 1... 0)г, в котором
единица на определенной (i-й) позиции должна указывать на принад-
лежность пользователя (в данном случае, нелегального) к /-му классу
«своих» (легальных) пользователей. Данный тип атаки на биометри-
ческую систему получил название атаки на «последний бит» ре-
шающего правила [55]. Таким образом, использование биометриче-
61
Глава 2. Биометрические системы идентификации личности
ских систем в открытых и слабо защищенных информационных про-
странствах становится проблематичным, особенно в случае необхо-
димости приема, обработки и передачи конфиденциальной информа-
ции.
Наиболее надежными в этом случае оказываются криптографи-
ческие системы, существенно превосходящие по уровню предостав-
ляемой ими защиты любые биометрические системы. Однако, серьез-
ным недостатком криптографических систем является проблема на-
дежного хранения и правильного использования секретных крипто-
графических ключей.
Выходом из создавшейся ситуации стало появление нового
класса биометрических систем идентификации/аутентификации лич-
ности с криптографической защитой информации, или биометриче-
ских криптосистем [55 - 57]. С 1 апреля 2007 г. в России действует
национальный стандарт ГОСТ Р 52633-2006 «Защита информации.
Техника защиты информации. Требования к средствам высоконадеж-
ной биометрической аутентификации», устанавливающий требования
к реализации таких систем на базе больших и сверхбольших нейрон-
ных сетей [58]. Актуальность принятия данного стандарта, распро-
страняющегося только на средства высоконадежной биометрической
аутентификации с вероятностью ошибочного пропуска «чужого» (т.е.
ошибки 2-го рода) не более 10" , связана прежде всего с введением
мировым сообществом паспортно-визовых документов (паспортов)
нового поколения, ориентированных на автоматизацию процедуры
биометрической идентификации личности.
Блок-схема построения высоконадежной биометрической сис-
темы аутентификации с нейросетевым преобразованием биометриче-
ских параметров пользователя в код ключа доступа (криптографиче-
ский ключ) приведена на рис. 2.9.
62
Глава 2. Биометрические системы идентификации личности
Биометри-
ческий
образ
на физиче-
ском
уровне
Первичное
преобразо-
вание фи-
зического
образа
в элек-
тронный
Вычисление
вектора
контроли-
руемых
биопара-
метров
Преобра-
зователь
вектора
биопара-
метров
в ключ
(пароль)
—V
Криптогра-
фическая
аутентифи-
кация
по ключу
(паролю)
Да
Нет
Код ключа (пароля)
Рис. 2.9. Блок-схема высоконадежной системы
биометрической аутентификации
В соответствии с данной схемой, после измерения первичных
биометрических данных осуществляется вычисление вектора контро-
лируемых биопараметров большой размерности (например, в виде
коэффициентов ряда Фурье при аутентификации пользователя по ди-
намике воспроизведения голосового или рукописного пароля). Пре-
образователь «биометрия - код» представляет собой заранее обучен-
ную НС с большим числом входов и выходов, преобразующую неод-
нозначный (размытый) вектор входных биопараметрических пара-
метров «Свой» в однозначный код криптографического ключа (длин-
ного пароля) и преобразующую любой иной случайный вектор вход-
ных данных («Чужой») в случайный «белый шум» на выходах сети.
Безопасное решение «Да/Нет» («Свой/Чужой») принимается
криптопротоколом. Атаковать правильно построенный криптопрото-
кол бессмысленно, подобрать длинный код ключа (например, ключ
длиной 256 бит) также практически невозможно. В итоге, выполнен-
ная по технологии ГОСТ Р 52633-2006 система биометрической за-
щиты становится защищенной от множества атак и, самое главное, от
атаки на «последний бит» решающего правила.
Таким образом, применение данной технологии позволяет соз-
давать высоконадежные системы биометрической защиты, обеспечи-
вающие возможность работы пользователей с конфиденциальной ин-
формацией в открытых и слабо защищенных информационных про-
странствах и обладающие такими преимуществами, как:
63
Глава 2. Биометрические системы идентификации личности
а) быстрое и однозначное получение криптографического клю-
ча легальным пользователям по его размытому биометрическому об-
разу;
б) существенное снижение вероятности случайного или пред-
намеренного получения по биометрическим данным криптографиче-
ского ключа нелегальным пользователем;
в) исключение необходимости защищенного хранения как само-
го ключа, так и любых программных или аппаратных средств его по-
лучения (алгоритм, программа, устройство).
Общая схема процедуры обучения нейросетевого преобразова-
теля векторов биометрических параметров в код ключа (пароль) при-
ведена на рис. 2.10.
векторов «Свой»> ►
#2 примеров ^*ч >
векторов «Чужой»/
Нейронная
сеть
А
ю
——**1
1юч (пароль;
Случайные
^^ состояния выходов
г
Автомат
обучения
«белый шум»
Ключ
(пароль)
Рис. 2.10. Схема процедуры обучения преобразователя «биометрия - код»
Для обучения используются N\ примеров входных образов
«Свой» и Ni примеров входных образов «Чужой». Алгоритм обуче-
ния НС и реализующий его автомат при этом могут быть любыми,
однако время обучения и потребляемые вычислительные ресурсы
должны быть приемлемы для потребителей (так, время обучения НС
не должно превышать нескольких минут).
В настоящее время работы в области создания биометрических
криптосистем находятся в стадии экспериментальных исследований
(см., например, [56]). В [57] на основе предварительно проведенных
исследований сформулированы общие рекомендации по выбору
64
Глава 2. Биометрические системы идентификации личности
структуры НС, обеспечивающих выполнение требований
ГОСТ Р 52633-2006 к указанным системам. Согласно этим рекомен-
дациям, синтезируемая НС должна иметь следующие характеристи-
ки:
• размерность векторов входных данных - не менее 30;
• размерность векторов выходных данных - не менее 64;
• размерность выходных данных не должна зависеть от раз-
мерности входных данных;
• сеть должна быть способной генерировать произвольно за-
данный выходной образ (ключ) по заданному «учебному» образу
(вектору биометрических параметров);
• правильность реакции сети на предъявленные входные дан-
ные должна быть в пределах ошибок 1-го и 2-го рода, соответствую-
щих используемому типу биометрической системы аутентификации;
• структура и все программно-аппаратные компоненты не
должны позволять без больших трудозатрат определять закодирован-
ный в сети ключ пользователя.
Поиск конфигураций НС, удовлетворяющих перечисленным
требованиям, позволил выделить в качестве базового класс гибрид-
ных (модульных) НС с последовательными связями, в которых пер-
вый скрытый слой реализуется на основе самоорганизующейся карты
Кохонена, а выходной слой представляет собой обычный однослой-
ный персептрон (рис. 2.11).
При выборе данной архитектуры важную роль сыграла особен-
ность карты Кохонена, заключающаяся в ее способности к сжатию
(кластеризации) входных данных, в результате чего образующие кла-
стер большие группы однородных данных представляются одним
нейроном (или небольшой группой нейронов). Еще одним преимуще-
ством карты Кохонена является высокая скорость самообучения, ко-
торая более чем в 1000 раз превышает скорость обучения персептро-
на при той же размерности входных данных. Значительный уровень
сжатия (локализации) входных данных, реализуемых в слое Кохоне-
на, позволяет использовать в качестве выходного слоя НС простой
однослойный персептрон, обучаемый на выработку произвольного
ключа необходимой размерности (64 ... 256 бит).
65
Глава 2. Биометрические системы идентификации личности
PQ
&
Б
s
X
о
I
ю
a
Входной
слой
| Выходной слой
Кохонена i (персептрон)
Рис. 2.11. Структура гибридной нейронной сети
Одной из актуальных проблем при создании и внедрении высо-
конадежных биометрических систем аутентификации является про-
блема их тестирования и сертификации. Для решения этой проблемы
необходимо создание больших баз биометрических образов (двух-
мерных и трехмерных изображений лица, отпечатков пальцев, руко-
писных и голосовых образов и т.д.), что приобретает особые трудно-
сти в связи с прогнозом бурного роста сферы применения дистанци-
онной биометрии во всем мире.
66
Глава 2. Биометрические системы идентификации личности
2.5. Биометрические системы идентификации
на основе нечетких экстракторов
Отметим, что рассмотренный выше подход к построению био-
метрических криптографических систем не является единственно
возможным. На Западе в последние 10 - 15 лет было предложено
большое число различных по своему исполнению методов крипто-
графической защиты биометрических данных (Biometric Template
Protection). К числу этих методов относятся такие, как:
• Helper Data Scheme;
• Biotoken;
• Pseudonymous Identifier;
• Cancelable Biometrics;
• Biometric Encryption;
• Fuzzy Vault;
• Fuzzy Extractors и др.
Общую характеристику этих методов можно найти в [59 - 61].
Естественное желание обобщить эти методы, выработать общую
платформу для их реализации в высоконадежных биометрических
системах привело к созданию нового международного стандарта
ISO/ IEC 24745:2011 «Information Technology - Security Techniques -
Biometric authentification context» («Информационные технологии -
Методы обеспечения безопасности - Защита биометрической инфор-
мации») [62]. Работа над данным стандартом началась в 2006 г. и за-
вершилась его опубликованием в 2011 г. Стандарт описывает и рег-
ламентирует в частности следующие процедуры:
- анализ угроз и средств противодействия им, актуальных для
различных биометрических систем;
- требования к защищенности данных, позволяющих установить
соответствие между биометрической и конкретной личностью;
- моделирование биометрических систем с учетом различных
сценариев хранения и сравнения результатов измерений;
- обеспечение конфиденциальности в процессе обработки био-
метрической информации.
67
Глава 2. Биометрические системы идентификации личности
В качестве базовой архитектуры, используемой при построении
биометрических криптографических систем, в стандарте
ISO/IEC 24745 рассматривается архитектура, приведенная на
рис. 2.12.
Здесь X - вектор «сырых» биометрических данных (параметров
пользователя), подлежащих определенным преобразованиям на этапе
регистрации с целью выделения вектора информативных признаков V
(биометрического шаблона) пользователя. В качестве дополнитель-
ных данных компоненты вектора V могут включать в себя какие-
либо дополнительно запрашиваемые сведения о регистрируемом
пользователе (фамилия, И.О., дата и место рождения и т.п.). Далее
осуществляется кодирование полученного вектора V с использовани-
ем той или иной криптографической процедуры, результатом приме-
нения которой являются значения секретного ключа R, а также от-
крытого (общедоступного) ключа Р. Оба этих значения хранятся не-
зависимо друг от друга, в раздельных базах данных (БД).
Регистрация Хранение
Дополнительные данные
S я
I S
Форми-
рование
кода
иден-
тифи-
кации
БД
БД
•о
Верификация
Дополнительные данные
R'
равнение
Принимаемое
решение
Вос-
произ-
ведение
кода
иден-
тифика-
тора
Рис. 2.12. Архитектура биометрической криптографической системы
На этапе верификации (аутентификации) по вновь предъявлен-
ным системе биометрическим данным (вектор X'), а также запрошен-
ным (при необходимости) дополнительным данным о пользователе, и
известной информации об открытом ключе Р производится воспроиз-
ведение (восстановление) секретного ключа R\ Если значение R1 сов-
68
Глава 2. Биометрические системы идентификации личности
падает со значением R, то пользователь признается легитимным, в
противном случае он получает отказ в допуске (т.е. считается «чу-
жим»).
Рассмотрим один из достаточно широко известных методов
криптографической защиты биометрических данных, предложенный
в 2004 г. и получивший название метода нечетких экстракторов
(Fuzzy Extractors) [63 - 65]. Суть данного метода заключается в том,
что он позволяет извлечь случайную равномерно распределенную по-
следовательность символов (секретный ключ) из первоначальных
биометрических данных и далее однозначно восстанавливает ее из
любых входных данных, достаточно схожих с первоначальными. Для
воспроизведения секретного ключа при этом требуются дополни-
тельные открытые данные (Helper Data), соответствующие этому
ключу, которые хранятся в памяти. Преобразователь «биометрия -
код» (нечеткий экстрактор) позволяет получать только один секрет-
ный ключ для каждого пользователя, причем заранее неизвестно, ка-
кой именно ключ получится на выходе, однако качество выходной
ключевой последовательности удовлетворяет всем требованиям,
предъявляемым к качеству криптографических ключей.
Общая схема построения нечеткого экстрактора приведена на
рис. 2.13.
Регистрация
Входные
данные V
Секретный
ключ/?
^
Открытый
ключР
>
Зашумленные
входные данные
р
S
Верификация
Rep
R
"Ч
S
Рис. 2.13. Схема построения нечеткого экстрактора
Блоки, представленные на рисунке, выполняют следующие
функции:
• Gen (от англ. Generation) - генерация защищенного биомет-
рического шаблона пользователя, включающая в себя формирование
ключей J? иРпо предъявленным системе биометрическим данным;
69
Глава 2. Биометрические системы идентификации личности
• Rep (от англ. Reproduction) - воспроизведение секретного
ключа R1 по известному открытому ключу для зашумленных (иска-
женных, неполных) входных данных.
Корректность процедуры восстановления секретного ключа R
зависит от фактических различий между векторами признаков дан-
ных V и V, участвующих соответственно на этапах регистрации и
верификации данных. Доказано [63], что если |V-V|<A, где
А- достаточно малая величина, то R = R\ т.е. восстановленный ключ
R* совпадает с ключом R, полученным при первоначальной регистра-
ции пользователя. Данное обстоятельство объясняется тем, что сам
механизм построения нечеткого экстрактора основан на использова-
нии корректирующих кодов с обнаружением и исправлением ошибок,
например, кода Рида-Соломона. Особенностью предложенной проце-
дуры является то, что секретный ключ R не запоминается - в качестве
носителя такой информации выступают реальные биометрические
данные пользователя, которые в совокупности с ранее зарегистриро-
ванным и хранимым в БД открытым ключом позволяют восстановить
ключ R и таким образом установить легитимность пользователя.
В качестве необходимого шага при построении нечетких экс-
тракторов используется еще одна логическая конструкция, называе-
мая безопасным скетчем (SS, Secure Sketch, от англ. sketch - эскиз,
образец). Назначение этого скетча - обеспечить точное восстановле-
ние исходного вектора биометрических признаков V из вектора за-
шумленных входных данных V. Соответствующая процедура восста-
новления выглядит следующим образом. На этапе регистрации для
первоначальных входных данных (вектор V) формируется безопас-
ный скетч S - битовая последовательность, также имеющая равно-
мерное распределение символов (рис. 2.14). Далее, на этапе верифи-
кации при заданном S и зашумленных данных V (при условии, что
эти данные достаточно близки к V), производится восстановление
(Reconstruction, Rec) вектора V.
70
Глава 2. Биометрические системы идентификации личности
Регистрация Верификация
Зашумленные r Y
V'~V
5
-v
?
Rec
V
>v
S
данные V
s
ss
Скетч 5
S
Puc. 2.14. Схема построения безопасного скетча
Указанный скетч является безопасным в том смысле, что он сам
по себе не раскрывает информацию о векторе биометрических при-
знаков V. Таким образом, вместо запоминания входных данных V,
опасаясь, что последующее их чтение будет зашумлено или скомпро-
метировано, достаточно запомнить только скетч 5. В отличие от не-
четкого экстрактора, который гарантирует получение секретного
ключа с равномерным распределением символов, безопасный скетч
обеспечивает точное воспроизведение первоначальных входных дан-
ных, не обеспечивая равномерности их распределения (что и не тре-
буется). В целом, использование безопасного скетча и нечеткого экс-
трактора позволяет восстановить исходный биометрический шаблон
пользователя (V) и его секретный ключ (R) из искаженных (зашум-
ленных) данных V, используя для этого общедоступную (открытую)
информацию - скетч S и открытый ключ Р.
На рис. 2.15 представлена схема построения нечеткого экстрак-
тора на основе объединения 2-х конструкций - безопасного скетча
(SS) и так называемого «сильного» экстрактора (Strong Extractor, Ext),
работающего с восстановленными входными данными V.
Согласно данной схеме, на этапе регистрации пользователя по
его предъявленным биометрическим данным (вектор V) формируют-
ся скетч S = SS (V), выступающий в данном случае в качестве откры-
того ключа, и секретный ключ R =Ext (V). Чтобы воспроизвести сек-
ретный ключ R на этапе верификации, используя для этого зашум-
ленные входные данные (V'~V) и скетч 5, необходимо вначале вос-
пользоваться операцией восстановления входных данных V =Rec (V,
S), а уже затем с помощью сильного экстрактора Ext получить R.
71
Глава 2. Биометрические системы идентификации личности
Регистрация Верификация
V-V
5*
S
S
V
S
Rec
Ext
V
R
данные V
s
'Ч
s
SS
Ext
S
s
R
s
Рис. 2.15. Схема построения нечеткого экстрактора
Особенности практической реализации биометрических крипто-
систем, построенных на основе математического аппарата нечетких
экстракторов с учетом специфики конкретных биометрических при-
знаков (отпечатки пальцев, радужная оболочка глаза, лицо человека и
др.) исследуются в работах многих авторов (см., например [64 - 66]).
Заметим, что качество нечетких экстракторов во многом определяет-
ся качеством применяемых в них корректирующих кодов, обнаружи-
вающих и исправляющих ошибки, поэтому выбор эффективного ме-
тода кодирования и параметров этих кодов занимает в данном случае
одно из центральных мест.
В силу своих очевидных преимуществ, рассмотренный выше
метод построения биометрических криптографических систем полу-
чает все более широкое распространение в различных областях,
включая разработку биометрических идентификационных схем циф-
ровой подписи (Biometric Identity Based Signature (FIBS)), протоколов
биометрической аутентификации и распределения ключей и т.п., рас-
сматриваемых в качестве альтернативы традиционным криптосисте-
мам с инфраструктурой открытых ключей (Public Key Infrastruture).
72
Глава 2. Биометрические системы идентификации личности
Контрольные вопросы
1. Дайте определение биометрической системы идентификации
личности. Какие биометрические признаки используются при по-
строении биометрических систем?
2. Перечислите основные этапы реализации процедуры биомет-
рической идентификации. Какие трудности возникают при решении
задачи надежного распознавания личности?
3. Каковы преимущества построения многофакторных биомет-
рических (мультибиометрических) систем идентификации личности?
4. Какие методы распознавания личности имеют наиболее ши-
рокое распространение на практике? В чем заключаются преимуще-
ства нейросетевых алгоритмов биометрической идентификации?
5. Как решается задача построения нейросетевой биометриче-
ской системы идентификации? Охарактеризуйте основные этапы ре-
шения данной задачи.
6. В чем заключается идея построения нейросетевых биометри-
ческих систем идентификации с криптозащитой?
7. В чем суть построения биометрических систем идентифика-
ции на основе нечетких экстракторов? Какие преимущества дает
применение данного метода?
73
Глава 3. Нейросетевые системы обнаружения атак
ГЛАВА 3. НЕЙРОСЕТЕВЫЕ СИСТЕМЫ
ОБНАРУЖЕНИЯ АТАК
3.1. Актуальность проблемы, пути ее решения
Несмотря на существование разнообразных механизмов защиты
информации (системы аутентификации и разграничения доступа, ан-
тишпионские и антивирусные программы, межсетевые экраны, раз-
личные криптографические протоколы и т.п.), статистика последних
лет свидетельствует о резком росте числа преступлений, связанных с
нарушением конфиденциальности, целостности и доступности ин-
формации.
По данным аналитической компании Ernst & Young, в 2003 г.
было осуществлено проникновение со стороны злоумышленников в
компьютерные сети 45 % европейских компаний, при этом причиной
этого взлома в подавляющем большинстве случаев стала незащищен-
ность сетей передачи данных. Согласно данным компании Yankee
Group, потери от взлома систем защиты являются наивысшими для
банковского сектора, где средний уровень потерь в 2003 г. составил
от 3,24 до 4,1 млн долларов.
Согласно данным отчета компании Symantec об интернет-
угрозах, в 2008 г. было выявлено 2,7 млн новых, ранее неизвестных
компьютерных атак [67]. При этом свыше 90 % своих угроз зло-
умышленники направили на похищение конфиденциальной инфор-
мации, автоматизируя этот процесс и отыскивая общие признаки сра-
зу для целого класса уязвимостей. Около 63 % выявленных уязвимо-
стей нацелены на веб-приложения (из них 95 % приходится на уязви-
мости клиентских систем и только 5 % - на уязвимости серверов).
Большинство веб-атак направлено на известные уязвимости веб-
браузеров и других популярных клиентских веб-приложений. Отме-
чено, что на исправление каждой установленной уязвимости веб-
сайта в среднем уходит 60 дней, что, по мнению экспертов, дает
большие преимущества злоумышленникам.
В 2008 г. Symantec выявила резкое увеличение числа бот-сетей,
т.е. сетей, включающих в себя в среднем от 10 тыс. до 100 тыс. ком-
пьютеров по всему миру, зараженных вредоносной программой, с
помощью которой злоумышленники (хакеры) могут удаленно управ-
74
Глава 3. Нейросетевые системы обнаружения атак
лять этими машинами без ведома пользователей. Подобные системы,
действуя эшелонированными порядками и привлекая необходимые
ресурсы, могут быстро и надолго блокировать веб-ресурсы государ-
ственных органов власти, финансово-кредитных учреждений, круп-
ных корпораций и т.д. Ежедневное количество активных бот-
инфицированных (зомбированных) компьютеров в 2008 г. составило
более 75 тыс., что на 31 % больше по сравнению с 2007 г. По мнению
аналитиков фирмы Trend Micro, общее число таких компьютеров в
мире только с января по ноябрь 2008 г. составило 34,3 млн, т.е. прак-
тически каждый пятый компьютер, подключенный к Интернету, вхо-
дил в хакерские бот-сети.
Согласно результатам исследования, проведенного в США спе-
циалистами ITRC (Identity Theft Resource Center), в 2008 г. было заре-
гистрировано также существенное увеличение (на 47 %) числа утечек
конфиденциальных данных, связанных с негативными действиями
инсайдеров [67]. При этом отмечается, что реальное количество уте-
чек намного больше, чем было зарегистрировано (более подробную
информацию о статистике утечек и наиболее крупных утечках кон-
фиденциальной информации можно найти, например, на сайте:
http://www. infowatch.ru/threats_and_risfo/risks_analysis).
По данным организации Privacy Rights Clearinghouse, с 2005 г.
по настоящее время только в США в общей сложности было ском-
прометировано (похищено, предано гласности) более 250 млн запи-
сей конфиденциальных данных, большая часть из которых представ-
ляет собой персональные данные. Совокупный ущерб от таких уте-
чек информации исчисляется сотнями миллионов долларов.
Таким образом, налицо резкое ухудшение общей ситуации в ми-
ре в области информационной (и, прежде всего, сетевой) безопасно-
сти. Отсюда понятен тот интерес и те надежды, которые связываются
с развитием относительно нового направления в сфере защиты ин-
формации - систем обнаружения атак, или систем обнаружения
вторжений (Intrusion Detection Systems, IDS). Под системами обна-
ружения атак (СОА) при этом понимаются системы, собирающие
информацию из различных точек защищаемой компьютерной систе-
мы (вычислительной сети) и анализирующие эту информацию с це-
лью выявления как попыток нарушения, так и реальных нарушений
защиты (вторжений) [68].
75
Глава 3. Нейросетевые системы обнаружения атак
Атака - это событие, при котором злоумышленник (хакер, ви-
рус, инсайдер) пытается получить несанкционированный доступ к
информационным ресурсам системы (сети) или нарушить её нор-
мальное функционирование. Любая атака на систему может быть вы-
явлена в ходе анализа сетевого трафика или системных ресурсов
(журналы регистрации событий, системные файлы и т.д.). Соответст-
венно системы обнаружения атак делятся на СОА сетевого уровня
(Network Intrusion Detection Systems, NIDS) и СОА системного уров-
ня, или СОА на базе хоста (Host Intrusion Detection Systems, HIDS).
Модель действий злоумышленника при реализации сетевой ата-
ки (т.е. с использованием средств удаленного доступа) включает в се-
бя в общем случае следующие этапы (рис. 3.1) [69]:
1) сбор общей информации об объекте атаки, в том числе све-
дений:
• о сети и ее топологии;
• о хостах и используемых средствах защиты;
• об администраторах и пользователях;
• о потенциально уязвимых ресурсах;
2) несанкционированный доступ (НСД) к компьютерам объекта
атаки (с целью реализации угроз нарушения конфиденциальности,
целостности и доступности информации на уровне отдельных хостов
или всей системы в целом);
3) сокрытие следов и долговременное присутствие злоумыш-
ленника в объекте атаки (системе).
Сбор информации
об объекте атаки
*>
НСД к компонентам
объекта атаки
i ^,
Сокрытие следов
и долговременное
присутствие
Рис. 3.1. Модель действий злоумышленника
76
Глава 3. Нейросетевые системы обнаружения атак
Типовая архитектура СОА на сетевом уровне, приведенная на
рис. 3.2, содержит следующие модули (компоненты) [70, 71]:
• сенсоры (датчики) - занимаются сбором событий, представ-
ляющих интерес с точки зрения безопасности информационной сис-
темы;
• выявление атак (детекторы) - отвечает за анализ собранной
информации, обеспечивает обнаружение атак;
• хранение данных (аудит) - обеспечивается хранение собран-
ной информации, результатов анализа и критериев обнаружения для
детального расследования имевших место инцидентов;
• управление (менеджер СОА) - управляет всеми потоками
информации в СОА, режимами сбора и анализа информации, а также
реакциями на обнаруженные атаки;
• консоль - представляет администратору интерфейс взаимо-
действия с СОА.
Параметры
активности
Информационная
система
Контрмеры, действия
«и Уведс
[аружения
Выявление атак
(детекторы)
Г"
пение
Хранение данных
(аудит)
Запись уведомления
сигналов тревог
Настройка
Управление
(менеджер СОА)
—Г"
Реакция,
обслуживание
Управление
Рис. 3.2. Архитектура системы обнаружения атак
77
Глава 3. Нейросетевые системы обнаружения атак
Количество используемых в СОА сенсоров различно и зависит
от специфики защищаемой системы. В зависимости от места сбора
данных, характеризующих те или иные параметры активности ин-
формационной системы, различают:
• сенсоры приложений - собирают данные о работе ПО защи-
щаемой системы;
• сенсоры хоста - контролируют работу рабочей станции за-
щищаемой системы;
• сенсоры (датчики) сети - осуществляют сбор данных для
оценки сетевого трафика;
• межсетевые сенсоры - содержат характеристики данных,
циркулирующих между сетями.
Модуль выявления атак включает в себя некоторое количество
детекторов, в функции которых входит непосредственное обнаруже-
ние атак, основываясь на определенных критериях обнаружения. В
качестве базовых методов, используемых для решения этой задачи,
обычно выделяют два основных направления:
1) методы сигнатурного анализа (или методы обнаружения зло-
употреблений);
2) методы обнаружения аномалий.
Рассмотрим вкратце суть каждого из этих направлений.
Методы сигнатурного анализа. В основе данных методов ис-
пользуется допущение о том, что каждую атаку можно описать с по-
мощью определенного набора правил или с помощью некоторой
формальной модели, представляющей собой символьную строку, се-
мантическое выражение на том или ином языке и т.п. Обнаружение
атак (злоупотреблений) при этом сводится к сравнению текущих дей-
ствий пользователя или входящего/исходящего трафика с известными
шаблонами (сигнатурами) атак, хранящимися в специализированной
базе знаний. Например, большое число ГСР-соединений с различ-
ными портами указывает на то, что кто-то занимается сканированием
ГСР-портов. Другой пример сетевой атаки - атака SYN Flood, когда
злоумышленник забрасывает веб-сервер большим числом TCP SYN-
пакетов (которые инициализируют соединение), оставляя жертву в
ожидании огромного количества соединений и вызывая тем самым
отказ в обслуживании (Denial of Service, DoS) легального пользовате-
78
Глава 3. Нейросетевые системы обнаружения атак
ля. База знаний современных СОА, основанных на анализе сигнатур,
как правило, достаточно обширна (так, с помощью сетевого монито-
ринга Real Secure обеспечивается обнаружение до 700 сценариев
атак).
Достоинства методов, основанных на сигнатурном анализе:
• высокая эффективность при обнаружении известных атак;
• незначительное количество «ложных тревог» {false negative).
Недостатки данных методов:
• обнаруживаются только известные атаки;
• необходимо постоянно пополнять базу знаний сигнатурами
новых атак, поскольку в противном случае возникает потенциальная
опасность «пропуска атаки» [falsepositive)]
• в силу заведомой избыточности (попытки запомнить и учесть
все возможные, ранее наблюдаемые виды атак), применение данной
технологии требует больших вычислительных затрат - до 50 % сете-
вого трафика.
Методы обнаружения аномалий. Суть данных методов за-
ключается в том, что СОА обладает некоторым набором знаний о
нормальном (штатном) поведении пользователя или характере сете-
вых подключений. Предполагается, что достаточно долго отслеживая
действия конкретного пользователя или трафик сети, можно соста-
вить их профиль, т.е. образ (модель) нормального функционирования
информационной системы при выполнении штатных технологиче-
ских операций. Любые отклонения от этого профиля расцениваются
как аномальное поведение системы. После обнаружения этой ано-
малии и оценки степени ее опасности принимается решение о том,
является ли она следствием атаки или данное отклонение допустимо.
При построении профиля пользователя или сетевого трафика
должны приниматься во внимание такие показатели, как:
• среднее число записей аудита, обрабатываемых для элемента
защищаемой системы в единицу времени;
• распределение различных типов действий, связанных с дос-
тупом к файлам, операциями ввода-вывода и т.п., в записях аудита;
• относительная частота регистрации в системе (логинов) из
каждого физического места нахождения пользователя;
79
Глава 3. Нейросетевые системы обнаружения атак
• количество файлов, к которым обращается пользователь в
данный интервал времени;
• число неудачных попыток входа в систему и т.п.
Достоинства методов обнаружения аномалий:
• они позволяют обнаруживать новые типы атак, сигнатуры
для которых еще не разработаны;
• они не нуждаются в обновлении сигнатур и правил обнару-
жения атак;
• они могут быть всегда адаптированы под конкретного поль-
зователя, учитывая его индивидуальные поведенческие характери-
стики.
Недостатки данных методов:
• требуют длительного и качественного обучения;
• пока слишком медленны в работе и требуют больших вычис-
лительных затрат;
• в силу нечеткости самого определения аномального поведе-
ния, они часто приводят к ошибкам 1-го рода (т.е. к «ложным трево-
гам», когда аномальное поведение еще не является атакой, а система
признает его за атаку).
Заметим, что данное направление в целом пока остается менее
изученным и еще не получило такого широкого распространения, как
сигнатурные методы. Хотя следует отметить, что в последние годы
проявляется все больший интерес к построению комбинированных
СОА, совмещающих в себе преимущества двух указанных выше на-
правлений обнаружения атак (поиск сигнатур и обнаружение анома-
лий).
Подобные возможности, в частности, предоставляются при ис-
пользовании для анализа атак перспективных нейросетевых техноло-
гий [27, 29, 51, 71-77]. Этому способствуют такие преимущества НС,
как:
• способность изучать характеристики умышленных атак;
• возможность динамического реагирования на различные воз-
действия, в том числе ранее неизвестные;
• возможность обнаружения ранее неизвестных атак и в даль-
нейшем классификации их;
80
Глава 3. Нейросетевые системы обнаружения атак
• возможность анализа неполных и искаженных данных,
фильтрации данных;
• возможность параллельной (многопроцессорной) обработки
данных.
3.2. Нейросетевые СОА на основе сигнатурного анализа
Как уже отмечалось, работа большинства современных систем
обнаружения атак сетевого уровня строится на использовании раз-
личных методов поиска сигнатур атак, т.е. специфических призна-
ков (индикаторов) того, что передача сетевого трафика осуществля-
ется в рамках той или иной атаки на информационную систему. Про-
цесс обработки информации в СОА при этом включает в себя сле-
дующие этапы (рис. 3.3) [71]:
1) определение перечня признаков (параметров);
2) предварительная обработка параметров;
3) распознавание атак (классификация).
Сетевой трафик
Определение полного
перечня параметров
/
Предварительная
обработка
1 2
т
Классификатор
1 12| . . . Г7
Результат классификации
Рис. 3.3. Схема процесса обработки информации в СОА
81
Глава 3. Нейросетевые системы обнаружения атак
На первом этапе осуществляется захват трафика сети [feature se-
lection). Сбор необходимых данных производится с помощью специ-
ального программного модуля - сниффера пакетов, который перехва-
тывает все пакеты, приходящие по протоколу TCP, и осуществляет
их фильтрацию. В качестве первичных признаков (параметров), ха-
рактеризующих анализируемый трафик, в данном случае выступают
значения полей заголовков сетевых пакетов.
Второй этап (feature preprocessing) связан с выделением (на базе
входных данных) наиболее существенных параметров, характери-
зующих активность сети и представленных в такой форме, в которой
они наиболее эффективно могут использоваться для их последующей
обработки с помощью классификатора.
Третий этап (classification) заключается в обнаружении и распо-
знавании атак. Использование НС на данном этапе является более
предпочтительным по сравнению с классическими СОА, осуществ-
ляющими простое сравнение данных заголовков пакетов с известны-
ми сигнатурами атак, поскольку НС всегда пытается определить, на-
сколько похожи признаки текущей сетевой активности на образцы
атак из обучающей выборки. В силу способности НС к обобщению,
при достаточном объеме и представительности обучающей выборки
НС может экстраполировать свои знания об известных видах сетевых
атак на неизвестные виды. Решающую роль в данном случае играет
выбор архитектуры НС, адекватной поставленной задаче обнаруже-
ния атак.
Остановимся более подробно на различных вариантах постанов-
ки и решения данной задачи.
3.2.1. Обнаружение атаки SYN Flood. Данная атака относится
к классу атак типа «отказ в обслуживании», т.е. основной её целью
является не попытка модифицировать или похитить конфиденциаль-
ную информацию, а блокировать работу сервера. Это также может
нанести значительный ущерб, так как несвоевременное представле-
ние информации может повлечь за собой принятие неправильного
решения или простои в работе предприятия.
На рис. 3.4 показаны временные диаграммы смены состояний
сервера, соответственно, для нормальной ситуации (а) и во время
атаки (б).
82
Глава 3. Нейросетевые системы обнаружения атак
Цифрами по оси 5, показаны состояния сервера: 1 - исходное
состояние, ожидание сервером запроса от клиента; 2 - получение от
клиента ГСР-пакета с установленным флагом C-SYN] 3 - ответ серве-
ра клиенту (ГСР-пакет с флагом С-АСК), запрос сервера (посылка
TCP- пакета с установленным флагом S-SYN), ожидание от клиента
ответа (ГСР-пакет с флагом S-AСК)\ 4 - получение от клиента
ГСР-пакета с флагом S-ACK] 5 - сеанс установлен.
S, S,
5 L
4 I
3
2 J-
1
5 J.
4 1
3 1
2 I
1 J-
-► t
Ожидание
< ^
-> t
Рис. 3.4. Диаграммы смены состояний сервера
Отличие состояния атаки от нормальной работы в том, что после
перехода в состояние 3 клиент не посылает пакет с флагом S-ACK,
что заставляет сервер ждать некоторое время. Учитывая, что на об-
работку каждого запроса от клиента выделяется часть ресурсов ком-
пьютера (например, оперативной памяти), большое количество за-
просов может привести к нехватке свободных ресурсов сервера, в ре-
зультате чего он уже будет неспособен выполнять свои функции.
Трудность борьбы с данной атакой заключается в необходимо-
сти быстрого её обнаружения на начальной стадии, до того как у
сервера закончатся свободные ресурсы.
Признаком атаки является резкое увеличение числа соединений
за небольшой промежуток времени, соответствующее состоянию 3,
как это показано на диаграмме рис. 3.5, а (здесь N - число одновре-
менных соединений на момент времени t). Поэтому для анализа в ка-
честве исходных данных можно использовать разность ДМ между
числом соединений, соответствующих состояниям 3 и 5. Нетрудно
заметить, что в начальной стадии атаки происходит резкое увеличе-
ние величины ДЛГ, что не характерно для нормальной работы клиен-
тов с сервером.
83
Глава 3. Нейросетевые системы обнаружения атак
N
соединения, соответст-
вующие состояниям 3
соединения, соответст-
вующие состояниям 5
Рис. 3.5. Диаграммы числа одновременных соединений сервера с клиентами:
а - состояние атаки; б - нормальное состояние
Существующие методы обнаружения данной атаки основаны на
сравнении величины ДМ с заранее установленным фиксированным
порогом (например, атакой считается выполнение условия ДМ > 100)
либо на сравнении отношений значений ДМ в предыдущие моменты
времени с определенной заданной величиной (т.е. атакой считается
возрастание текущего значения ДМ, например, в пять раз).
Эти методы имеют свои недостатки. Вышеуказанные пороговые
величины должны выбираться в каждом конкретном случае, для каж-
дого сервера они могут принимать различные значения. Не существу-
ет точных пороговых значений, которые однозначно соответствовали
бы атаке и нормальному состоянию. Кроме того, эти пороги зависят
от времени - например, дневная статистика работы с сервером замет-
но отличается от ночной. Поэтому необходима непрерывная под-
стройка под текущие параметры, характеризующие работу сервера,
что практически неосуществимо при данных методах.
Учитывая указанные выше достоинства НС, и прежде всего, их
способность к обучению на множестве изменяющихся входных дан-
ных, покажем возможность применения НС для обнаружения атаки
типа SYN Flood [27]. Задача обнаружения атаки может быть сформу-
лирована в данном случае следующим образом: на основе сведений о
текущем и предыдущих значениях параметра ДМ и сравнении их с
84
Глава 3. Нейросетевые системы обнаружения атак
эталонными диаграммами (см. рис. 3.5, а и б), НС должна выдать ре-
зультат, свидетельствующий о наличии или отсутствии атаки.
Исходные данные для анализа будем получать через некоторый
промежуток времени, условно называемый тактом. Для анализа на-
личия атак воспользуемся схемой НС, приведенной на рис. 3.6, где
MLP - многослойный персептрон (Multi-Layer Perceptron)] z~ -
элемент временной задержки на один такт.
w
1
1
г
С-1!
1
[
t
Г*-1
^—
t
1
Z
п
г
-1
—
1
2
3
7
8
MLP
Y
Рис. 3.6. Структурная схема НС
Здесь на входы персептрона подаются данные о состоянии сер-
вера: на первый вход подается текущее значение ДМ, на второй вход
- его предыдущее значение, на третий - значение ДМ, задержанное
на два такта и т.д. (для определенности число входов персептрона
здесь принято равным восьми). Выход НС принимается равным «1»,
если обнаружена атака, и «О» в противном случае.
В соответствии с рис. 3.5, построим графики зависимостей ДМ
от времени t для нормального состояния и состояния атаки
(рис. 3.7, а, б).
85
Глава 3. Нейросетевые системы обнаружения атак
ьы
а б
Рис. 3.7. Диаграмма изменения ДМ во времени
для нормального состояния (а) и состояния атаки (б)
В качестве исходных данных для обучения НС использовались
характерные njxrb, отмеченные на графиках зависимостей Д/У(/) на
рис. 3.7. В табл. 3.1 приведены числовые значения ДМ > отражающие
примерную статистику работы сервера (первые 11 строк составляют
обучающую выборку, последние 4 строки - тестовую выборку, для
проверки правильности работы сети).
Таблица 3.1
Исходные данные для обучения НС
№
Вход 1
Вход 2
ВходЗ
1
2
3
4
5
6
7
8
9
10
11
0
1000
10
60
0
-150
0
9
350
1000
350
0
0
8
55
20
-140
-20
10
250
950
400
0
0
6
45
40
-100
-80
15
180
800
450
1
2
3
4
100
20
10000
-50
90
0
0
-40
80
0
0
100
Вход 4
Вход 5
Вход 6
Вход 7
Вход 8
Признак
атаки
Данные для обучения
0
0
4
40
60
-80
-100
18
140
600
500
0
0
2
30
50
-20
-140
20
60
500
600
0
0
1
20
40
0
-150
25
40
450
800
0
0
0
10
25
30
-135
30
20
400
950
0
0
0
10
10
40
-100
40
0
350
1000
0
1
0
0
0
0
0
0
1
1
1
Данные для проверки
70
0
0
80
60
0
0
30
50
0
0
20
40
0
0
10
0
0
0
10
0
0
1
о
86
Глава 3. Нейросетевые системы обнаружения атак
Здесь первый пример соответствует точке 1 (см. рис. 3.7, а, б).
Он характеризует стабильную ситуацию: ни одного соединения не
установлено и нет запросов на новые соединения или число запросов
равно числу установленных соединений. Это говорит об отсутствии
атаки.
Второй пример характеризует резкое поступление большого
числа запросов, которое должно соответствовать атаке (точка 2 на
рис. 3.7, б).
Данные третьего примера характеризуют нормальную работу
сервера (точка 2 на рис. 3.7, я). Четвертый пример аналогичен пре-
дыдущему, но уже с учетом большой загруженности сервера, харак-
теристики которого, тем не менее, считаются нормальными для дан-
ного сервера.
Пятый пример соответствует точке 3 на рис. 3.7, а - число за-
просов на соединение равно числу установленных соединений, что
говорит об отсутствии атаки.
Данные шестого примера говорят о том, что новых запросов на
соединение сервер не получает, поэтому он работает только с уже ус-
тановленными соединениями (точка 4 на рис. 3.7, а). Этот пример од-
нозначно указывает на отсутствие атаки.
Дальнейшее поступление относительно небольшого количества
новых запросов характеризует седьмой пример (точка 5 на
рис. 3.7, а).
Для улучшения способности НС распознавать атаки было до-
бавлено несколько дополнительных примеров. Так, восьмой пример
показывает постепенное установление соединений со всеми клиента-
ми (по своему смыслу он аналогичен пятому примеру). Данные девя-
того и десятого примеров, в отличие от четвертого примера, уже счи-
таются недопустимыми, что говорит о наличии атаки.
И наконец, если система противодействия атакам по каким-либо
причинам не смогла защитить сервер, т.е. число запросов на соеди-
нение все еще недопустимо большое, необходимо продолжать выда-
вать сообщение об атаке - это описано в примере № 11.
Для проверки способности НС обнаруживать атаки было созда-
но несколько тестовых примеров, соответствующих как нормальному
состоянию, так и атаке (см. табл. 3.1).
87
Глава 3. Нейросетевые системы обнаружения атак
В качестве программного продукта, на котором моделировалась
НС, был взят нейроимитатор Trajan 4.0. Для выбора оптимальной
структуры сети использовалась функция Intelligent Problem Solver,
позволяющая анализировать большое количество НС с различной
структурой. Были отобраны 10 лучших вариантов НС из 300 персеп-
тронов с одним или двумя скрытыми слоями. Кроме того, анализиро-
валась значимость входных параметров НС с отбрасыванием неэф-
фективных входов при построении сети. Активационная функция
всех нейронов представляла собой сигмоиду с выходным значением
от 0 до 1, число нейронов во входном слое сети - 8, в выходном
слое - 1. Результаты обучения НС приведены в табл. 3.2.
Таблица 3.2
Результаты обучения НС
Исполь-
зуемые
входы
1-3
1-3
1,2
1-8
1- 4, 6-8
1 - 3, б, 7
1.2
2
2
2
Число
нейро-
нов
в 1-м
скрытом
слое
3
3
2
12
8
7
5
1
1
1
Число
нейро-
нов
во 2-м
скрытом
слое
4
2
2
9
5
2
3
2
1
нет
Ошибка
обуче-
ния
НС
0,013
0,018
0,02
0,024
0,029
0,031
0,034
0,036
0,078
0,118
Ошибка
тестиро-
вания
НС
0,005
0,03
0,02
0.098
0,154
0,112
0,071
0,523
0,529
0,521
Коэффи-
циент
произво-
дитель-
ности
0,027
0,037
0,041
0,051
0,061
0,066
0,072
0,075
0,163
0,244
Методы 1
выбора
структуры НС
BP50.CG50, G1666
^O.CGSO, CG856
BP5Q, CG1346
BP5Q, CG3386
BP5Q, CCflUb
ВР50, CG50, CG6Bb\
BP5Q, CGJilb
ВРЬЪ, CG199&
BP50, CG№b
BP5Q, сеть
В таблице использованы следующие сокращения: ВР - Back
Propagation; CG - Conjugate Gradient Descent) цифра после сокраще-
ния говорит о предварительном числе интераций; цифра перед сим-
волом «6» - число интераций, после которого данная структура при-
знана лучшей.
Как видно из таблицы, для обнаружения атаки SYN Flood нейро-
сети не всегда важно знать полную статистику изменения Д/V, однако
88
Глава 3. Нейросетевые системы обнаружения атак
при слишком малом объеме обрабатываемой информации возникает
большая ошибка на тестовой выборке (см. последние три структуры
сети в табл. 3.2). Наилучший результат достигается при анализе те-
кущего значения ДМ и двух предыдущих (первые две структуры в
табл. 3.2). Это говорит о том, что чрезмерно большое количество
входных данных «запутывает» сеть; вместе с тем, для улучшения
способности распознавать атаку необходимо увеличить количество
вариантов для обучения.
В табл. 3.2 также приведены значения коэффициента производи-
тельности НС, который необходимо учитывать при практической
реализации СОА.
Полученные результаты свидетельствуют об эффективности
применения НС для обнаружения атак методом анализа сигнатур.
Существует большое количество атак, механизмы реализации кото-
рых аналогичны атаке SYN Flood, но отличаются смыслом исходных
данных (в качестве которых могут выступать файлы, сведения о заре-
гистрированных в системе пользователях и др.). Поэтому описанная
выше методика может быть с успехом применена для обнаружения и
этих атак.
3.2.2. Построение нейронечеткого классификатора. Другой
возможный подход к обнаружению DDoS атак типа SYN Flood, осно-
ванный на применении математического аппарата нечетких нейрон-
ных сетей, рассмотрен в [77]. Суть данного подхода состоит в сле-
дующем.
Предполагается, что на входы классификатора (см. рис. 3.3) по-
ступают некоторые параметры, характеризующие поступающую на
сервер очередь пакетов данных. Существенными для анализа в дан-
ном случае являются такие параметры, как ГСР-флаги (SYN),
/Р-адреса отправителя и получателя, направленные пакеты (входящие
или исходящие), время поступления пакета, порт получателя. Необ-
ходимо также учитывать корректность заголовков, поскольку посту-
пление большого количества пакетов с некорректными заголовками
является одним из признаков атаки. Таким образом, вектор входных
параметров классификатора, составленный на основе результатов
анализа входящего трафика, будет включать в себя следующие пере-
менные:
89
Глава 3. Нейросетевые системы обнаружения атак
Х\ - среднее время поступления одного пакета;
Xi - процент пакетов с различными внешними /Р-адресами;
Хз - процент пакетов с различными внешними портами;
X* - процент пакетов с некорректными заголовками.
Выходом классификатора является параметр Y, определяемый
как «степень уверенности в атаке». Система правил (продукций), свя-
зывающих указанные выше параметры сетевого трафика Х\, Х^ Х^, Х^
и степень уверенности в атаке У, задается экспертами и принимает
следующий вид:
1. ЕСЛИ Время_поступления_пакетов = «мало» И
Процент_различных_внешних_*/?_адресов = «мал» И
Процент_различных_портов = «мал», ТО
Степень_ уверенности_ в_атаке = «средняя»;
2. ЕСЛИ (Время_поступления_пакетов =«мало» ИЛИ
Время_поступления_пакетов = «среднее») И
(Процент_различных_внешних_ф_адресов = «велик» ИЛИ
Процент_различных_портов = «велик» ИЛИ
Процент_пакетов_с_некорректными_заголовками = «велик»), ТО
Степень_уверенности_в_атаке = «высокая»;
3. ЕСЛИ Время_поступления_пакетов = «велико», ТО
Степень_ уверенности_ в_атаке = «низкая».
Структура нейронечеткого классификатора, реализующего про-
цедуру нечеткого логического вывода для данной системы правил,
приведена на рис. 3.8.
90
Глава 3. Нейросетевые системы обнаружения атак
Xi
Y\ = Низкая
tLittle
Хг
Yi = Средняя
Хг
ХА
Входной
слой
pLots V-^.
pLittley
dhLots J
1-й скрытый
слои
// х / \s~-?3 = Высокая
' 3-й скрытый
слои
2-й скрытый
слой Выходной
слой
Рис. 3.8. Структура нейронечеткого классификатора
Как видно из рисунка, представленная здесь НС является пяти-
слойной. Первый (входной) слой выполняет распределительные
функции, подавая на входы нейронов 1-го скрытого слоя измеренные
(вычисленные) значения параметров Xlt...,XA. Первый скрытый слой
нейронов выполняет функции фаззификации данных параметров, вы-
числяя значения функций принадлежности м^) параметров
А^,..., Х^ соответствующим нечетким множествам:
(High - «Время_поступления_пакетов велико»;
t Middle - «Время_поступления_пакетов среднее»;
tLittle- «Время_поступления_пакетов мало»;
91
Глава 3. Нейросетевые системы обнаружения атак
extraLots - «Процент_различных_внешних_*р_адресов велик»;
extraLittle - «Процент_различных_внешних_ /р_адресов мал»;
pLots - «Процент_различных портов велик»;
pLittle - «Процент_различных_портов мал»;
dhLots - «Процент_пакетов_с_некорректными_заголовками ве-
лик».
Графики функций принадлежности для указанных нечетких
множеств показаны на рис. 3.9.
мЦ) м(*2)
i
1.
0,5 -
i
tLittle
<
L
tMiddle
LL
tHigh
Xi
=H ►
0 15
▲
1
0,5 "
extraLittle
-\
K,
extraLots
/"
Хг
—• »■
Рис. 3.9. Графики функций принадлежности нечетким множествам
Второй и третий скрытые слои на рис. 3.8 содержат нечеткие
нейроны, реализующие функции логического сложения (ИЛИ) и ум-
ножения (И) на основе правил нечеткой логики [78]. Для вычисления
92
Глава 3. Нейросетевые системы обнаружения атак
значения выхода 1-го ИЛИ-нейрона в случае входного вектора с 3-мя
компонентами Xj.Xj.Xk можно воспользоваться формулой
Sl = W^ + WjiXj + У»ЫХк + WnXiWflXj + WaXiWUX - WaXiWjiXjWuXk, (3.1)
где Wjj,Wy/,W0 - настраиваемые веса синаптических связей, связы-
вающих /-й,у-й и к-й нейроны 1-го скрытого слоя с /-м нейроном 2-го
скрытого слоя; xitX:,xk - выходы /-го, у-го и к-го нейронов 1-го
скрытого слоя.
Для /1-го 2-хвходового И-нейрона значение выхода zn вычисля-
ется по формуле
zn = (W/ц +*/ "Щп*№тп +хт-™тпхт)' (3-2)
где jc/ и хт - выходы /-го и т-го нейронов предыдущего (2-го скры-
того) слоя; w/„, и^ - веса связей от 1-го и т-го нейронов 2-го скры-
того слоя к w-му нейрону 3-го скрытого слоя.
Нейроны выходного слоя - это классические нейроны с сигмо-
идной функцией активации, веса синаптических связей которых так-
же настраиваются в процессе обучения. Предполагается, что выходы
У[,12#1з определяют значения функций принадлежности для кон-
кретных термов (нечетких множеств) лингвистической переменной
Степень_уверенности_в_атаке = {низкая; средняя; высокая}.
Особенности реализации алгоритма обучения для показанной на
рис. 3.8 нейронечеткой (гибридной) сети рассмотрены в [77]. Данный
алгоритм обучения является модификацией известного метода обуче-
ния «с учителем» на основе обратного распространения ошибки, с
учетом того обстоятельства, что нейроны в каждом слое рассматри-
ваемой НС имеют различные функции активации. Заметим, что каче-
ство работы системы обнаружения атак существенно зависит от пол-
ноты и репрезентативности (представительности) обучающей выбор-
ки, которая, в свою очередь, может формироваться двумя способами:
1) путем сбора статистики для реальных проявлений атаки в се-
ти (что, конечно же, весьма затруднительно в силу ограниченности
самого числа подобных атак применительно к данному конкретному
серверу);
2) путем моделирования (имитации) атак на сервер.
93
Глава 3. Нейросетевые системы обнаружения атак
Последний способ представляется более предпочтительным, однако
вопрос об эффективности применения обученной СОА в реальных
условиях эксплуатации остается открытым.
3.2.3. Обнаружение сетевых атак с помощью модулярной НС.
Важным достоинством НС является возможность обнаружения с по-
мощью одной и той же сети различных типов атак. В качестве репре-
зентативной обучающей выборки при этом часто используется набор
данных KDD Сир 99 - специально созданная база данных для тести-
рования нейросетевых СОА, содержащая около 5 млн записей о со-
единениях [79]. Каждая запись в этой базе представляет собой неко-
торый образ сетевого соединения. Соединение - это последователь-
ность TCP- пакетов за некоторое конечное время, моменты начала и
завершения которого четко определены, в течение которого данные
передаются от /Р-адреса источника на /Р-адрес приемника (и в об-
ратном направлении), используя определенный протокол. Отдельная
запись содержит около 100 байт, включает 41 параметр сетевого тра-
фика и промаркирована как «атака» или «не атака». Например, 1-й
параметр определяет длительность соединения, 2-й указывает ис-
пользуемый протокол, 3-й - целевую службу и т.д.
Всего в базе данных KDD Сир 99 представлено 22 типа атак.
При этом все атаки делятся на 4 основных класса:
1) атака DoS - «отказ в обслуживании», характеризуется гене-
рацией большого объема трафика, что приводит к перегрузке и бло-
кированию сервера;
2) атака U2R - предполагает получение зарегистрированным
пользователем привилегий локального суперпользователя (админист-
ратора);
3) атака R2L - характеризуется получением доступа незареги-
стрированного пользователя к компьютеру со стороны удаленной
машины;
4) атака Probe - заключается в сканировании портов с целью
получения конфиденциальной информации.
Выходные значения классификатора (см. рис. 3.3) при этом со-
ответствуют 4-м классам атак и «нормальному» состоянию сети.
Задача построения нейросетевой СОА в классе модулярных (ан-
самблевых) НС рассматривается в [71, 80]. Под модулярностью по-
94
Глава 3. Нейросетевые системы обнаружения атак
нимается разбиение сложной вычислительной задачи на несколько
небольших и относительно простых задач, которые решаются от-
дельными модулями системы. Далее на основании выводов, получен-
ных с помощью отдельных модулей, формируется общее (интеграль-
ное) решение, отличающееся от указанных локальных решений.
Первый важный вопрос, который необходимо решить при по-
строении модулярной НС - какие параметры входного вектора явля-
ются наиболее существенными (значимыми) для успешного обнару-
жения атак? Для решения этой задачи могут быть использованы ре-
циркуляционные НС (Recirculation Neural Networks, RNN). Они имеют
вид многослойного персептрона (Multi-Layer Perceptron, MLP), кото-
рый осуществляет линейное или нелинейное сжатие входных данных
через «узкое горлышко» в скрытом слое (п < т), выделяя таким обра-
зом главные компоненты входного вектора X = (Х\, Х2,.~, Хт)Т
(рис. 3.10). Цель обучения НС: п -> min при условии Х-Х <е, где
е допустимая погрешность аппроксимации вектора X.
Входной Скрытый Выходной
слой слой слой
RNN
Рис. 3.10. Схема выделения главных компонент
Комбинируя рециркуляционные сети и многослойные персеп-
троны, можно получить различные архитектуры СОА.
95
Глава 3. Нейросетевые системы обнаружения атак
Вариант 1 - последовательное соединение RNN и MLP
(рис. 3.11).
Входной вектор RNN содержит в данном случае 41 параметр,
характеризующий сетевое соединение. Выходной вектор RNN - это
сжатый входной вектор, т.е. вектор главных компонент, имеющий
разрядность 12. MLP выполняет функции классификатора, выдавая на
выходе сигнал о наличии одного из 4-х классов атак или о нормаль-
ной ситуации.
1
2
41
Е
—-—»
RNN
1
1
•
►
MLP
—:—►
12
Рис. 3.11. Последовательная схема СОА
Вариант 2 - последовательно-параллельная схема соединения
RNNnMLP (рис. 3.12).
1
2
41
»
—■—»
RNN
MLP
(DoS)
MLP
(U2R)
MLP
(R2L)
MLP
(Probe)
Арбитр
^
—■—►
Рис. 3.12. Последовательно-параллельная схема СОА
Здесь вектор главных компонент с выхода RNN поступает на
входы 4-х MLP, каждый из которых настроен на обнаружение кон-
96
Глава 3. Нейросетевые системы обнаружения атак
кретных типов атак внутри определенного класса. Арбитр, также
реализованный на MLP, анализирует сигналы, поступающие с выхо-
дов MLP, и принимает окончательное решение о принадлежности
атаки тому или иному классу или указывает, что состояние сети явля-
ется нормальным.
Вариант 3 - дальнейшая трансформация схемы модулярной
СОА (рис. 3.13).
Эксперт
1
2 »Г
1 • J
1 PL
| »
>
—н
RNN
MLP
Эксперт
и —
] /WW
1—r-
Эксперт
] MLP
/WW [
! [
MLP [
Арбитр
I 1
-^-* 2
-^ 5
Рис. 3.13. Комбинированная схема построения СОА
Здесь в качестве экспертов выступают модели СОА, рассмот-
ренные в варианте 1 (см. рис. 3.11). Обучение каждого эксперта про-
изводится на отдельном множестве данных, причем вектор главных
компонент, выделенный с помощью собственной RNN, может иметь
свою размерность и свой состав. Данные для обучения последующего
эксперта формируются с учетом обучения предыдущих экспертов.
Алгоритм, используемый для такого обучения, называется алгорит-
мом подкрепления с фильтрацией (Boosting by Filtering).
В каждом из рассмотренных вариантов (см. рис. 3.11 - 3.13) для
обучения и тестирования НС использовалась база данных
KDD Сир 99. При оценке эффективности СОА рассматривались 3
основных показателя [80]:
- доля обнаруживаемых атак (т.е. число атак, обнаруженных
системой, к общему количеству атак в базе данных);
97
Глава 3. Нейросетевые системы обнаружения атак
• доля распознанных атак (т.е. количество распознанных атак
для отдельных клиентов, отнесенное к общему количеству таких
атак);
- число ложных срабатываний системы (т.е. число нормальных
состояний сети, ошибочно классифицированных как атаки, к общему
количеству записей в базе данных).
Результаты тестирования СО А (вариант 1) приведены в
табл. 3.3.
Таблица 3.3
Результаты тестирования СОА
Класс атаки
DoS
U1R
R2L
Probe
Всего
391458
52
1126
4107
Обнаружено, %
99,99
92,31
98,85
99,68
Распознано, %
94.71
80.77
58,44
99,37
Нормальное состояние
Normal
97277
-
52,25
Как видно из таблицы, наилучшие результаты получены для
атак класса DoS и Probe (почти однозначная распознаваемость). Не-
сколько хуже определяются атаки U2R и R2L (распознаваемость - со-
ответственно 80,77 % и 58,44 %). Кроме того, существует довольно
высокий процент ложных срабатываний системы.
Сводные данные по каждому из вариантов построения СОА
приведены в табл. 3.4.
Таблица 3.4
Результаты оценки эффективности СОА
Вариант
СОА
Вариант 1
Вариант 2
Вариант 3
Обнаружено
атак,%
99,98
99,80
99,95
Распознано
атак, %
94,65
94,61
94,70
Ложные
срабатывания,
%
47,75
13.77
12,90
Общая доля
распознанных
состояний, %
86,30
92,97
93,21
98
Глава 3. Нейросетевые системы обнаружения атак
Таким образом, вариант 3 характеризуется наиболее высокой
точностью (93,21 %) и наименьшим числом ложных срабатываний
(12,9 %), что позволяет сделать вывод о возможности его успешного
применения для работы с большими наборами данных сложной
структуры.
В то же время, следует отметить, что всем рассмотренным выше
системам в той или иной степени присущи известные недостатки ме-
тодов сигнатурного анализа: неспособность определять новые, еще не
описанные в базе знаний СОА атаки; возможность обойти такую сис-
тему, изменяя методику атаки (например, порядок выполнения опе-
раций); резкое увеличение потребных системных ресурсов при рас-
ширении базы сигнатур и др. Отсюда понятен интерес к интеграции
указанных методов обнаружения атак с другими перспективными ме-
тодами и, в первую очередь, с методами обнаружения аномалий сете-
вого трафика или действий пользователей компьютерных сетей.
3.3. Обнаружение аномалий с помощью НС.
Интегрированные системы обнаружения атак
Методы и средства обнаружения аномалий в последние годы за-
нимают видное место в различных федеральных и целевых програм-
мах в области защиты информации. Так, например, в разработанном
Научно-техническим советом НАТО списке из 11 важнейших задач
исследований на 2002 - 2007 гг. три первые были ориентированы на
разработку аппаратных и аппаратно-программных средств обнаруже-
ния аномалий вычислительных процессов в современных и перспек-
тивных распределенных вычислительных системах на основе прото-
колов TCP/IP [81].
Как уже отмечалось, под аномалией понимается любое откло-
нение от нормальной (допустимой) модели объекта: действий пользо-
вателя (на системном уровне) или сетевой активности (на сетевом
уровне). Но тут возникают вопросы:
1. Что понимать под допустимой моделью данного объекта, ко-
торая однозначно характеризует наличие либо отсутствие атаки?
2. Как построить допустимую модель объекта?
Рассмотрим формальную постановку задачи обнаружения ано-
малий. Обозначим через D множество входных данных, обрабаты-
99
Глава 3. Нейросетевые системы обнаружения атак
ваемых информационной системой за определенное ограниченное
время работы Г. Поскольку это время Т ограничено, то множество
входных данных D конечно. Разобьем данное множество D на два
подмножества А и В - данные, которые считаются аномалией, или
атакой (множество А), и данные, которые считаются безопасными
для системы (множество В). Очевидно, что
A^D,B^D,AnB = 0,AvB = D. (3.3)
В отличие от сигнатурных систем обнаружения атак, база зна-
ний которых содержит сведения о различных атаках (элементы мно-
жества А), в базу знаний систем, анализирующих аномалии, должны
помещаться все элементы множества В.
Множество В, в свою очередь, можно разбить на подмножества
Bi,...,Bn, характеризующие отдельные стороны поведения объекта
(действий пользователя, сетевой активности), которые также называ-
ются шаблонами допустимой модели
п (3.4)
1=1
В идеальном случае, если точно формализована допустимая мо-
дель объекта (действий пользователя, сетевой активности) и данная
модель полностью реализована в базе знаний СОА, то теоретически
вероятности появления ошибок 1-го и 2-го рода могут быть снижены
до нуля. В то же время, реализация данного метода сталкивается с ре-
альными ограничениями, связанными со сложностью функциониро-
вания современных информационных систем, что приводит к недос-
таточно полной и точной формализации элементов множества В.
Поскольку практически невозможно создать такую универсаль-
ную систему обнаружения аномалий, которая бы учитывала всевоз-
можные вариации санкционированной деятельности различных поль-
зователей (сетевой активности), задача может решаться следующими
путями:
1) вместо анализа санкционированного поведения многих
пользователей (трафиков сети) может быть смоделировано поведение
индивидуальных пользователей (сетевого трафика) в конкретной сис-
теме;
100
Глава 3. Нейросетевые системы обнаружения атак
2) ручное описание возможных вариантов нормального пове-
дения пользователя (трафика) системы можно заменить рассмотрени-
ем шаблонов такого поведения в виде серии примеров санкциониро-
ванной (безопасной) деятельности.
Нетрудно заметить, что перечисленные обстоятельства являются
предпосылкой к построению нейросетевых систем обнаружения ано-
малий, размещенных на конкретном сервере или рабочей станции и
адаптируемых на основе реальных (изменяющихся) входных данных
к особенностям поведения индивидуального пользователя (трафика
сети). Рассмотрим подробнее примеры построения таких систем.
В [82, 83] предложен конструктивный подход к созданию ней-
росетевой системы обнаружения аномалий, основанный на построе-
нии комплексной модели действий пользователя. Эта модель состоит
из интерактивной и сеансовой частей, которые учитывают соответст-
венно динамические и статистические свойства поведения пользова-
теля.
Интерактивная модель используется для выявления аномаль-
ной деятельности во время работы пользователя. Для каждого поль-
зователя информационной системы строится и обучается НС таким
образом, чтобы спрогнозировать его последующие действия (коман-
ды) на основе предыдущих (рис. 3.14).
г
1—|—' Ct-l
ct-m
Рис. 3.14. Интерактивная модель действий пользователя
101
НС
Y,
Глава 3. Нейросетевые системы обнаружения атак
При этом результат работы НС (в качестве которой использует-
ся многослойный персептрон) в момент времени t определяется зави-
симостью
Yt=F(Xt), Xt=(ct_i c,_Jr, (3.5)
где F() - нелинейное преобразование, осуществляемое НС; с, - /-я
команда сеанса; т - количество предыдущих команд, на основе ко-
торых происходит прогнозирование следующей команды Yt = ct.
Сеансовая модель предназначена для выявления нехарактерной
деятельности пользователя за сеанс в целом, используя для этого ста-
тистический набор данных. Обученная НС в данном случае определя-
ет, насколько активность пользователя соответствует ранее постро-
енной модели его действий. В качестве входных данных НС при реа-
лизации сеансовой модели выступают:
с, - количество команд за i'-й сеанс;
о, - результаты работы интерактивной модели (процентное со-
отношение правильно спрогнозированных команд);
ht - номер компьютера;
dt - продолжительность /-го сеанса;
st - время начала /-го сеанса, (/ = 1, 2, ..., N).
Таким образом, выход НС для сеансовой модели определяется соот-
ношением
Yt=F(Xt), Х(=(с(,о(,к(^,*()Т, (З.б)
где i - условный номер сеанса; F() - нелинейное преобразование,
осуществляемое НС по отношению к указанным выше переменным
cit О/, A,-, d;, s(. При этом ожидаемый выход НС может принимать
два значения: 1 - для нормального поведения пользователя и 0 - для
аномального поведения, т.е. НС работает в качестве классификатора.
Предполагается, что для каждого сеанса работы пользователя созда-
ется отдельный аудит-файл, в котором записывается информация в
следующем формате:
время запуска команды/идентификатор команды/название ко-
манды/ флаг начала или завершения.
102
Глава 3. Нейросетевые системы обнаружения атак
При кодировании команд важно обеспечить, чтобы одинаковым
командам соответствовали одинаковые значения. С этой целью для
интерактивной части комплексной модели на основе собранной ин-
формации для каждого пользователя строится алфавит команд, т.е.
набор команд, которые вводились пользователем на протяжении ука-
занного периода времени. Далее каждой команде присваивается соот-
ветствующий десятичный номер, который впоследствии используется
при преобразовании аудит-файлов в последовательности команд. В
результате, для каждого пользователя составляется следующий на-
бор данных
Ц.}> i = U„...tf; 7 = 1,2,...,^-, (3.7)
где С;
десятичный номер введенной у-и команды в /-м сеансе;
Ng - общее количество команд в i-м сеансе; N- количество сеансов.
На рис. 3.15 приведен пример последовательности команд, вво-
димых пользователем за один сеанс.
О 50 100 150
Номер команды в последовательности
200
Рис. 3.15. Временная последовательность команд пользователя
Для сеансовой части комплексной модели на основании информации,
содержащейся в аудит-файлах, получается следующий набор данных
103
Глава 3. Нейросетевые системы обнаружения атак
Необходимо отметить, что точность прогнозирования команд
пользователя с помощью интерактивной модели, представленной на
рис. 3.14, существенно зависит от выбора числа т учитываемых пре-
дыдущих команд, т.е. от размера «временного окна». Если число т
слишком мало, то прогноз будет недостаточно обоснован; если т -
очень велико, то на результат прогноза будут оказывать влияние не
самые актуальные данные. Проведенный в [83] анализ автокорреля-
ционных кривых для последовательностей команд, введенных раз-
личными пользователями, показал, что для эффективного прогнози-
рования поведения пользователя достаточно учитывать не более
восьми его предыдущих команд. Недостающие входные данные из
(3.8), необходимые для качественного обучения сеансовой модели,
при этом могут быть получены путем статистического моделирова-
ния на базе располагаемого набора фактических данных о работе сис-
темы.
Возможности использования НС для обнаружения аномалий се-
тевого трафика исследуются в [84, 85]. Разработанное авторами про-
граммное обеспечение (макет системы выявления аномалий) позво-
ляет решать следующие задачи:
1) перехват сетевого трафика сегмента сети Ethernet,
2) декодирование содержания пакетов стека протоколов TCP/IP
(рассматриваются протоколы ARP, IP, TCP, UDP)\
3) формирование на основе декодированных заголовков пакетов
векторов статистических показателей;
4) формирование профилей штатного сетевого трафика путем
кластеризации векторов с применением нейронных сетей адаптивно-
го резонанса ART1M)
5) выявление аномальной сетевой активности на основе фикса-
ции выхода векторов показателей за пределы сформированных при
обучении кластеров;
6) сбор статистической информации о функционировании про-
граммных компонентов макета.
Для перехвата пакетов используются функции библиотеки
ЫВРСАР (применяются кадры, циркулирующие в сегменте сети, ко-
торые записываются в выходной буфер соответствующего модуля
ПО. Каждый кадр сопровождается заголовком, содержащим дату,
время и длину кадра).
104
Глава 3. Нейросетевые системы обнаружения атак
Модуль декодирования формирует вектор показателей, который
записывает в свой буфер. В качестве параметров принимается адрес
подсети, анализ пакетов которой требуется произвести, а также раз-
решенные номера портов TCP и UDP соответствий MAC и
/Р-адресов. Координаты результирующего вектора представляют со-
бой флаги пакетов и статистические значения, которые получаются
путем усреднения значений параметров пакетов в заданном времен-
ном окне (в экспериментах размер окна принимается равным 8 с).
Всего вектор статистических показателей включал в себя 20 ко-
ординат:
I - 3. Количество входящих (исходящих, внутрисетевых)
/Р-пакетов в единицу времени;
4-6. Количество входящих (исходящих, внутрисетевых)
ГСР-пакетов в единицу времени;
7-9. Количество входящих (исходящих, внутрисетевых)
[/DP-пакетов в единицу времени;
10. Количество опросов неразрешенных портов UDP в единицу
времени;
II - 12. Количество завершенных (ещё незавершенных) запро-
сов по протоколу UDP в единицу времени;
13. Количество незавершенных запросов по протоколу UDP,
тайм-аут ответа на которые истек, в единицу времени;
14 - 15. Количество опросов портов (разрешенных портов) TCP
в единицу времени;
16 - 18. Количество соединений TCP, находящихся в состоянии
установления - SYNSEND (в открытом состоянии - ESTABLISHED, в
состоянии закрытия - FINEDD) в единицу времени;
19. Отношение количества опросов разрешенных портов прото-
кола TCP к количеству опросов всех портов этого протокола;
20. Отношение количества открываемых соединений TCP к об-
щему количеству соединений.
С использованием разработанного ПО, реализующего нейросе-
тевую систему обнаружения аномалий, были проведены специальные
эксперименты с целью определения эквивалентности нейросетевого и
сигнатурного методов анализа. Суть экспериментов заключалась в
следующем. Для экспериментально полученного трафика корпора-
тивной сети, с помощью свободно распространяемого сигнатурного
105
Глава 3. Нейросетевые системы обнаружения атак
анализатора Snort была произведена локализация атак, обнаруженных
в этом трафике, т.е. были выяснены конкретные номера пакетов, со-
держащих данные атаки. Далее, путем исключения компьютерных
атак из экспериментального трафика, был получен «чистый» трафик,
на котором с помощью описанной выше технологии была обучена
соответствующая НС. После этого была произведена обработка ис-
ходного экспериментального трафика с использованием обученной
НС, с фиксацией номеров пакетов, отнесенных к аномальным, и
сравнение выделенных номеров пакетов с атаками, выданными сиг-
натурным анализатором.
По результатам экспериментов были сделаны следующие важ-
ные выводы [86]:
1. Обученные на «чистом» трафике НС оказались неспособны-
ми распознавать атаки в исходном трафике, обнаруживаемые сигна-
турным анализатором. При этом при нестрогой классификации (па-
раметр близости достаточно мал) зафиксирована неприемлемая
ошибка пропуска атак, а при строгой классификации (параметр бли-
зости достаточно велик) - неприемлемая ошибка ложных тревог.
2. НС не является альтернативой сигнатурному анализатору и
должна применяться как дополнение к нему для выявления распреде-
ленных во времени атак, существенно искажающих статистические
свойства сетевого трафика корпоративной сети.
3. Принципы использования НС в данном контексте, включая
подбор признакового пространства, должны стать предметом даль-
нейших исследований. В частности, следует проверить гипотезу о
формировании входных векторов НС не на основе статистических
показателей корпоративного трафика в целом, а например, по каждой
сессии TCP в отдельности.
Проблема создания интегрированных СО А, основанных на ком-
бинированном применении методов сигнатурного анализа и обнару-
жении аномалий, обсуждается во многих работах (см., например, [29,
32, 70, 74 - 76, 75]). Так, в [74] решается задача сравнительного ана-
лиза эффективности 2-х альтернативных методов построения интег-
рированных СОА: 1) сигнатурная система обнаружения атак допол-
няется некоторым множеством шаблонов безопасных действий поль-
зователя; 2) система обнаружения аномалий дополняется «уточняю-
106
Глава 3. Нейросетевые системы обнаружения атак
щими» сигнатурами атак. Результаты выполненных теоретических
исследований показывают, что:
1) добавление множества шаблонов безопасных действий поль-
зователя при использовании в качестве базового метода поиска сиг-
натур не приводит к изменению вероятности появления ошибки 2-го
рода («пропуск атаки»);
2) увеличение числа уточняющих шаблонов безопасных дейст-
вий пользователя при использовании метода поиска сигнатур с «не-
точным» описанием атак приводит к уменьшению вероятности появ-
ления ошибки 1-го рода («ложная атака»);
3) добавление множества «уточняющих сигнатур» при исполь-
зовании в качестве базового метода обнаружения аномалий не приво-
дит к изменению вероятности появления ошибки 1-го рода;
4) увеличение числа «уточняющих» сигнатур при использова-
нии метода обнаружения аномалий с «неточными» описаниями шаб-
лонов безопасных действий пользователя приводит к уменьшению
вероятности появления ошибки 2-го рода.
На основании проведенного анализа в [29, 74] предложена сле-
дующая архитектура перспективной интегрированной СОА
(рис. 3.16). При этом предполагается, что наиболее актуальным ас-
пектом обнаружения атак является обнаружение атак на уровне сис-
темных приложений. Обеспечение устойчивости к атакам на более
низких уровнях модели OSI сегодня успешно реализуется сущест-
вующими системами защиты (термины «устойчивая» операционная
система и «устойчивый» сервер здесь используются именно в этом
смысле).
Специфика рассматриваемого комбинированного метода обна-
ружения атак заключается в том, что на НС возлагается задача распо-
знавания входных данных и отнесения их к одному из п = К +1 воз-
можных классов. К классам атак либо классу безопасных данных.
Сравнительный анализ характеристик различных типов НС показал,
что наилучшие результаты обработки данных могут быть получены
при использовании гибридной нейронной сети встречного распро-
странения (Counter-propagation network). Эта сеть представляет собой
последовательное соединение 2-х слоев (не считая входного) - слоя
Кохонена и слоя Гроссберга [б, 54] (рис. 3.17).
107
Глава 3. Нейросетевые системы обнаружения атак
Нейросетевой модуль
проверки данных
прикладного уровня
Безопасный
запрос
пользователя
Устойчивая
операционная
система
Ответ
информацион-
ной системы
Устойчивый
сервер
ИС
Рис. 3.16. Структура интегрированной нейросетевой системы
обнаружения атак
- YK
Входной
слой
Слой
Кохонена
Слой
Гроссберга
Рис. 3.17. Структура сети встречного распространения
Обучение гибридной сети осуществляется в два этапа. На пер-
вом этапе обучается слой Кохонена. В данном случае используется
алгоритм обучения «без учителя», по принципу «Победитель получа-
ет всё». Суть данного алгоритма заключается в настройке весов
Ь*у }# связывающих компоненты входного вектора Х\,„.,Хт с ней-
ронами слоя Кохонена, таким образом, чтобы для данного входного
108
Глава 3. Нейросетевые системы обнаружения атак
вектора только один нейрон данного слоя выдавал на выходе логиче-
скую единицу («нейрон-победитель»), а все остальные нейроны вы-
давали ноль. В итоге, после завершения процесса обучения слой Ко-
хонена выполняет функцию распознавания, т.е. выдает заключение о
принадлежности входного вектора X тому или иному классу (класте-
ру), характеризующемуся признаками наличия или отсутствия атаки.
На втором этапе производится настройка весов связей {wy/ }
слоя Гроссберга. Данный слой обучается «с учителем» и служит для
того, чтобы полученную случайную картину выходов слоя Кохонена
(поскольку использовалось обучение без учителя) преобразовать в
желаемую картину расположения выходов нейросетевого классифи-
катора. При этом изменяются не все веса, а только те, которые связа-
ны с нейронами-победителями слоя Кохонена.
Достоинством сети встречного распространения является ее
способность к обобщению. В процессе обучения НС входные векто-
ры ассоциируются с соответствующими выходными векторами, при-
чем обобщающая способность сети позволяет получать правильный
выход даже в случае неполного или искаженного входного вектора.
В качестве базовой платформы для реализации программного
модуля прототипа интегрированной нейросетевой СОА был выбран
wwv-сервер Apache 1.3, функционирующий на основе операционной
системы Linux Red Hat 7.1. Обмен между пользователем и WWW-
сервером осуществлялся посредством сложного протокола приклад-
ного уровня HTTP (Hyper Text Transfer Protocol) l.L В целях упро-
щения задачи построения прототипа СОА было принято, что для
обеспечения безопасности информационной системы необходимо
контролировать допустимость значений переменных CGI и Cookie,
т.е. переменных, обработка которых может привести к нештатной
ситуации в системе (т.е. к «взлому»).
Для построения и обучения НС использовался нейросимулятор
SNNS [Stuttgart Neural Network Simulator) 4.2. Число входов НС при-
нималось равным т = 4 • 9 = 36 (т.е. каждая из 9-ти контролируемых
переменных может принимать одно из 4-х возможных значений -
цифра, латинская буква, буква кириллицы, печатный символ). Коли-
чество выходов сети для упрощения принималось равным единице
(т.е. на выходе сети получается «1» для безопасной работы пользова-
109
Глава 3. Нейросетевые системы обнаружения атак
теля, и «О» - в случае атаки). Фактически использовалась более гиб-
кая логика работы сети:
Y > 0,7 - «отсутствие атаки»;
Y < 0,3 - «атака»;
0,3 < Y < 0,7- ошибочное решение (ошибки 1-го или 2-го рода).
После обучения разработанный прототип СОА подвергся тести-
рованию. Для этого www-сервер - «жертва» был атакован с помощью
сканеров уязвимостей различных типов (Nessus, Nikto, XSpider, Retina,
ISS Internet Scanner, N-Stealth HTTP). Для сравнения, помимо нейро-
сетевой СОА, были протестированы методом сканирования распро-
страненные системы обнаружения атак Snort и Real Secure Network
Sensor. Результаты сканирования СОА с использованием 3-х из пере-
численных выше сканеров уязвимости приведены в табл. 3.5.
Таблица 3.5
Сравнительная таблица результатов сканирования СОА
Характеристики
СОА
Об-
щее
число
атак
Число
правильно
распо-
знанных
атак
Вероят-
ность
ошибки
2-го
рода
Общее
число
безопас-
ных за-
просов
Число
ложных
сраба-
тываний
Вероят-
ность
ошибки
1-го
рода
Сканирование Nessus
Нейросетевая
СОА
Real Secure
Network Sensor
Snort
1247
1247
1247
1149
732
821
0,08
0,41
0.34
132
132
132
7
3
24
0,05
0,02
0,18
Сканирование Nikto
Нейросетевая
СОА
Real Secure
Network Sensor
Snort
3125
3125
3125
2986
1029
936
0,04
0,67
0,70
83
83
83
8
2
13
0,10
0,02
0,16
Сканирование XSpider
Нейросетевая
СОА
Real Secure
Network Sensor
Snort
732
732
732
707
632
598
0,03
0,14
0,18
62
62
62
12
3
5
0,19
0,05
0,08
110
Глава 3. Нейросетевые системы обнаружения атак
Как видно из таблицы, разработанная нейросетевая СОА с ис-
пользованием комбинированного метода обнаружения атак обеспе-
чивает снижение в 4-5 раз вероятности принятия ошибочных реше-
ний по сравнению с классическими СОА.
Дальнейшее повышение эффективности применения нейросете-
вых СОА предполагает проведение дополнительных исследований в
таких направлениях, как:
- разработка теоретических основ построения интеллектуальных
СОА (включая создание систем обнаружения аномалий на основе
теории инвариантов [81]);
- сбор и непрерывный анализ статистики о сетевом трафике и
действиях пользователей, с целью выявления скрытых закономерно-
стей (Data Mining) и предпосылок к возникновению угроз;
- интеграция СОА с другими системами защиты информации
(межсетевые экраны, антивирусные системы), с целью обеспечения
гибкого реагирования и активного противодействия атакам в режиме
реального времени;
- обнаружение распределенных и скоординированных во време-
ни и пространстве атак (таких, как массированные DDoS-эгаки на
корпоративные сети);
- создание СОА, обладающих свойствами адаптации, самоорга-
низации и эволюционного обучения на основе аналогий с организма-
ми в живой природе.
Контрольные вопросы
1. Что понимается под типовой архитектурой системы обнару-
жения атак? Какие основные подсистемы входят в ее состав?
2. Назовите основные методы обнаружения атак, а также их
достоинства и недостатки.
3. Как решается задача построения нейросетевой системы обна-
ружения атак на основе метода сигнатурного анализа? Приведите
примеры решения данной задачи.
4. В чем заключаются особенности решения задачи обнаруже-
ния аномалий с помощью нейронных сетей?
5. Что понимается под интегрированной нейросетевой систе-
мой обнаружения атак? Какие преимущества дает применение таких
систем?
ill
Глава 4. Интеллектуальные системы защиты информации на основе...
ГЛАВА 4. ИНТЕЛЛЕКТУАЛЬНЫЕ СИСТЕМЫ ЗАЩИТЫ
ИНФОРМАЦИИ НА ОСНОВЕ МЕХАНИЗМОВ
ИСКУССТВЕННЫХ ИММУННЫХ СИСТЕМ
4.1. Роль и место искусственных иммунных систем
в задачах защиты информации
В последние годы резко возрос интерес со стороны специали-
стов по защите информации к новому направлению исследований в
области искусственного интеллекта - искусственным иммунным
системам (Artificial Immune Systems, AIS). Данной тематике посвяще-
но большое число публикаций [10, 86 - 92]. Появились новые терми-
ны и понятия - «иммунокомпьютинг», «иммунокомпьютер», «имму-
ночип». Первый международный семинар «Методы, основанные на
принципах иммунной системы», был проведен в 1996 г. в Японии, а
уже в 2002 г. в Великобритании состоялась первая международная
конференция по искусственным иммунным системам ICARIS (Interna-
tional Conference on Artificial Immune Systems). Чем же данное научное
направление привлекает внимание ученых и специалистов?
Дело в том, что за миллионы лет эволюции Природа создала и
довела до совершенства такую уникальную биологическую систему
защиты, присущую человеку (а также другим позвоночным), какой
является иммунная система. Отличительной чертой этой системы яв-
ляется наличие врожденного, а также приобретенного в течение жиз-
ни организма иммунитета - способности к выявлению и отторже-
нию чужеродных тел, пытающихся укорениться в организме. Факти-
чески, иммунная система обладает не только собственной распреде-
ленной памятью, она также способна обучаться и самообучаться,
распознавать и принимать решения относительно того, как «спра-
виться» с теми или иными инородными телами - патогенами (вред-
ными бактериями, вирусами, грибками и т.д.), даже если они ранее
не встречались на Земле. Перечисленные свойства иммунной систе-
мы позволяют специалистам называть ее «вторым мозгом».
112
Глава 4. Интеллектуальные системы защиты информации на основе...
Первые разработки по иммунным системам появились еще в се-
редине 70-х годов XX века, но действительно масштабные работы по
созданию и применению в различных областях деятельности (и, пре-
жде всего, в области защиты информации) искусственных иммунных
систем, в той или иной степени копирующих механизмы поведения
своего биологического прототипа, начались совсем недавно, в конце
90-х годов. Сегодня алгоритмы искусственных иммунных систем на-
ходят применение при решении таких задач, как:
• обнаружение вторжений (атак, аномалий) в компьютерных
системах;
• распознавание новых видов компьютерных вирусов;
• управление инцидентами информационной безопасности;
• защита от спама;
• индексирование содержимого корпоративных сетей;
• обнаружение неавторизованных устройств или пользовате-
лей;
• выявление ошибок на клиентских местах и серверах, и т.д.
Известны примеры успешного применения искусственных им-
мунных систем в задачах интеллектуального анализа данных (Data
Mining), машинного обучения (Machine Learning), управления движе-
нием мобильных роботов, мониторинга и диагностики состояния
сложных технических объектов и производств [10, 86, 90].
Многие специалисты отмечают очевидную параллель между ис-
кусственными иммунными системами (ИИС) и искусственными ней-
ронными сетями (ИНС) [87]. И те и другие способны обучаться, ведя
наблюдение за динамикой и изменением статистических характери-
стик окружающей среды, обладают ассоциативной памятью, требуют
для своей работы первоначальной настройки и подгонки параметров.
Вместе с тем, между ИИС и ИНС имеется и ряд существенных отли-
чий, в силу различного характера самих имитируемых систем - им-
мунной и нервной системы. Основные отличия ИИС и ИНС приведе-
ны в табл. 4.1.
из
Глава 4. Интеллектуальные системы защиты информации на основе...
Таблица 4.1
Отличительные свойства ИИС и ИНС
Искусственная иммунная система
Базовые элементы - лимфоциты и ан-
титела
Количество элементов не является
строго фиксированным, их положение
изменяется динамически
Характерны самоорганизация и эво-
люция поведения
Взаимодействие между элементами не
имеет постоянного характера и может
динамически изменяться
Отсутствует централизованное управ-
ление
Искусственная нейронная сеть
Базовые элементы - искусственные
нейроны
Количество нейронов и их местополо-
жение фиксировано
Поведение сети во многом зависит
от принятого алгоритма
Взаимодействие между нейронами
постоянно и задается
при подключении
Используется единый механизм
настройки весов связей
Как видно из приведенной таблицы, концепция и принципы по-
строения ИИС заметно отличаются от концепции и принципов по-
строения ИНС, прежде всего, за счет большего разнообразия (измен-
чивости) механизмов иммунной защиты, поскольку и цель, постав-
ленная перед ИИС, является чрезвычайно сложной - обеспечить са-
мосохранение (выживаемость) наблюдаемой системы в условиях аг-
рессивной (враждебной) внешней среды.
Прежде чем перейти к рассмотрению способов построения ИИС
и решаемых с их помощью задач, остановимся вкратце (с существен-
ными упрощениями) на тех механизмах и алгоритмах, которые со-
ставляют основу функционирования естественной (биологической)
иммунной системы [10, 87, 89].
114
Глава 4. Интеллектуальные системы защиты информации на основе...
4.2. Естественная иммунная система: механизмы
функционирования
Как уже отмечалось, главной целью иммунной системы являет-
ся предохранение человека от воздействия опасных для него инород-
ных тел (патогенов). Защита организма многослойна и включает в се-
бя, прежде всего, физический барьер (т.е. кожный покров, слизистые
оболочки и т.п.), за ним следует биохимический барьер (пот, слезы,
слюна, кислотность, температура, делающая невозможной существо-
вание проникших извне чужеродных микроорганизмов, и многое дру-
гое), и наконец, последний рубеж защиты составляют клетки и ткани
иммунной системы.
Согласно современным представлениям, в основе функциониро-
вания иммунной системы человека лежит принцип сравнения некото-
рых «шаблонов» с попавшими внутрь организма телами и выявления
между ними различий. В качестве базовых механизмов защиты при
этом используются механизмы врожденного и приобретенного имму-
нитета. Врожденный иммунитет обладает малой специфичностью
и основан на пожирании и разрушении инородных тел макрофагами и
лейкоцитами. На данном этапе распознаются и уничтожаются только
известные болезнетворные микроорганизмы, знания о которых при-
обретены иммунной системой в процессе эволюции. Приобретенный
иммунитет отвечает за распознавание специфических «чужих», т.е.
не известных системе заранее молекул (антигенов), и связан с актив-
ностью лимфоцитов - клеток, выполняющих роль упомянутых выше
шаблонов. Общее число лимфоцитов в организме человека составля-
ет около 2 10 ; по клеточной массе иммунная система человека
сравнима с головным мозгом. Лимфоциты разносятся организмом че-
рез лимфатические узлы, постоянно перемещаясь и контролируя та-
ким образом организм в целом, а не отдельные его участки. Каждый
тип лимфоцитов отвечает за обнаружение какого-то ограниченного
числа антигенов.
Различают две основные группы лимфоцитов: В-лимфоциты и
Т-лимфоциты. В-лимфоциты вырабатывают антитела - особые белки
из класса иммуноглобулинов, которые связываются с антигенами и
подготавливают их к последующему разрушению. Для успешной pa-
ns
Глава 4. Интеллектуальные системы защиты информации на основе...
боты иммунная система должна генерировать огромное число разно-
образных антител, способных связаться с любой молекулой.
Г-лимфоциты, как и Я-лимфоциты, первоначально зарождаются в
спинном мозге, после чего попадают в тимус - среду, богатую собст-
венными антигенами организма. Г-лимфоциты не порождают свобод-
ные антитела. Существует несколько типов Г-лимфоцитов: Г-хелперы
- клетки, распознающие чужеродные тела, и Г-киллеры - клетки,
уничтожающие опознанные хелперами антигены.
Важным механизмом иммунной системы является отрицатель-
ный отбор (или негативная селекция). Суть этого процесса (рис. 4.1)
состоит в том, что располагающиеся в большом количестве в тимусе
71-лимфоциты взаимодействуют с каждым из собственных антигенов
и если Г-лимфоцит «узнал» собственный антиген, т.е. отреагировал
на него так, словно это чужеродная клетка, то такой лимфоцит уда-
ляется. Таким образом, лимфоциты «учатся» не реагировать на соб-
ственные клетки, чтобы в будущем распознавать только чужеродные
антигены. Таким образом, благодаря негативной селекции создаются
«шаблоны», содержащие ту информацию, которая внутри организма
отсутствует, и если какое-то тело подходит под данный шаблон, зна-
чит, оно явно «чужое».
«Зародышевые»
Т-лимфоциты
Иммунокомпетентные
лимфоциты
Рис. 4.1. Механизм отрицательного отбора
116
Глава 4. Интеллектуальные системы защиты информации на основе...
Другим, не менее важным механизмом иммунного ответа, ле-
жащим в основе поведения иммунной системы, является механизм
клональной селекции (рис. 4.2). Согласно этого механизма, если ка-
кой-либо из ^-лимфоцитов обнаружил определенный антиген, то
сразу же активизируется процесс клонирования соответствующих
лимфоцитов. Чем больше антигенов данного типа попало в организм,
тем больше образуется соответствующих ^-лимфоцитов, которые
вырабатывают антитела, ответственные за уничтожение данных анти-
генов. Высокая степень сродства лимфоцита и антигена повышает
интенсивность его клонирования и снижает интенсивность мутаций
лимфоцитов. Лимфоциты с наибольшей степенью сродства сохраня-
ются в виде долгоживущих клеток памяти {М). Срок жизни осталь-
ных лимфоцитов невелик. Таким образом, клональная селекция обес-
печивает своеобразный естественный отбор 5-лимфоцитов (и соот-
ветствующих им антител): выживают лишь те, что максимально под-
ходят под данный антиген.
В-лимфоцит ( Х( <^ Ячейки памяти
( д( (( (==5> ( д( (л Клонирование, мутация
Антигены V_^A\C:^ х—чу* /~\/7
Антитело v_y>\ Ч_У\\
Рис. 4.2. Механизм клональной селекции
Очевидно, что более подробное ознакомление с механизмами
иммунной системы требует обращения к специальной литературе
(см., например, обстоятельную монографию [10]). Вместе с тем, от-
метим еще раз те перспективные свойства данной системы, которые
являются ориентиром при создании компьютерных иммунных систем
[10, с. 22-23, 218]:
117
Глава 4. Интеллектуальные системы защиты информации на основе...
• Распознавание. Иммунная система способна распознавать и
классифицировать различные молекулярные структуры и избира-
тельно на них реагировать. Распознавание своего и чужого является
одной из основных задач, решаемых иммунной системой.
• Разнообразие. Иммунная система использует комбинаторный
механизм (генетически обусловленный процесс) для образования
множества различных конфигураций лимфоцитов, с тем чтобы гаран-
тировать, что хотя бы один лимфоцит из всей совокупности сможет
провзаимодействовать с любым наперед заданным (известным или
неизвестным) антителом.
• Обучение. Иммунная система оценивает структуру конкретно-
го антигена, используя его случайные контакты с составляющими эту
систему клетками. Обучение состоит в изменении концентрации
лимфоцитов, которое происходит при первичном ответе (в результате
первого контакта с антигеном). Способность иммунной системы к
обучению заложена, главным образом, в механизме пополнения кло-
нов, приводящим к образованию новых иммунокомпетентных клеток
с учетом текущего состояния системы.
• Память. Используя кратковременные и долгосрочные меха-
низмы иммунной памяти, иммунная система поддерживает идеаль-
ный баланс между экономией ресурсов и исполнением функции за
счет сохранения минимально необходимой, но достаточной памяти о
предыдущих контактах с антигеном.
• Распределенный поиск. По своей сути, иммунная система -
это распределенная система. Клетки иммунной системы, главным об-
разом лимфоциты, непрерывно рециркулируют через кровь, лимфу,
лимфоидные органы и остальные ткани. В случае встречи с антиге-
ном они осуществляют специфический иммунный ответ.
• Саморегуляция. Иммунная система обладает свойством само-
регуляции. Центрального органа, контролирующего функции иммун-
ной системы, не существует. В зависимости от способа проникнове-
ния в организм и других свойств антигена, регуляция иммунного от-
вета может быть как локальной, так и системной.
• Пороговый механизм. Иммунный ответ и размножение имму-
нокомпетентных клеток происходят лишь после преодоления некото-
рого порога, зависящего от силы химических связей.
118
Глава 4. Интеллектуальные системы защиты информации на основе...
• Совместная стимуляция. Активация В-лимфоцитов жестко
регулируется при помощи дополнительного стимулирующего сигна-
ла. Второй сигнал (от хелперных Г-лимфоцитов) помогает обеспечи-
вать толерантность и проводит различие между серьезной угрозой и
«ложным звонком» (т.е. опасными и неопасными антигенами).
• Динамическая защита. Иммунная система не только обна-
руживает и удаляет из организма антигены, но и участвует в процес-
сах самоподдержания организма в условиях динамически изменяю-
щейся внешней среды путем взаимодействий между лимфоцитами и
антителами. Таким образом, иммунная система обладает методологи-
ей решения динамических, а не статических задач в условиях неиз-
вестного и враждебного окружения.
Перейдем теперь непосредственно к решению задач компьютер-
ной безопасности с использованием принципов искусственных им-
мунных систем.
4.3. Обнаружение аномалий процесса на основе механизмов
иммунной системы
Процедура обнаружения аномального поведения информацион-
ной системы в данном случае также включает в себя следующие эта-
пы [93]:
1) сбор исходных данных о работе системы;
2) анализ собранных данных;
3) обнаружение атаки;
4) реагирование на выявленную атаку.
На этапе сбора исходных данных предполагается, что все воз-
можные варианты поведения системы можно разделить на две груп-
пы: нормальное поведение системы (соответствует работе системы в
штатном режиме) и аномальное поведение (может соответствовать
атаке, вторжению или просто неправильной работе системы). В каче-
стве исходных данных, используемых для анализа поведения систе-
мы, можно выбрать запись последовательностей системных вызо-
вов, выполняемых различными приложениями. Подобный подход
справедлив, в частности, и для операционной системы Windows.
119
Глава 4. Интеллектуальные системы защиты информации на основе...
В [94] при проведении экспериментов учитывались 133 систем-
ных вызова. Каждый вызов кодировался целым числом (рис. 4.3), а
сбор данных осуществлялся путем непрерывного наблюдения за ак-
тивностью каждого приложения.
Cancel Remove Device
Cancel Stop Device
Close File
Write File
1
2
3
133
Рис. 4.3. Способ кодирования системных вызовов
На рис. 4.4, а - б приведены графики активности программ sv-
chost.exe и explorer.exe. Как видно из данного рисунка, каждое при-
ложение проявляет свойственную лишь ему активность. При дли-
тельном наблюдении, в активности приложения можно обнаружить
повторения, что позволяет судить о том, что при нормальной работе
та или иная программа осуществляет конечное число различных по-
следовательностей системных вызовов.
- •
nil
1 1
II
1 III Hi
О 20GO 40СО ЮЛ ЮМ 10ЛО ШО UCC0 1ЕШ) 18QQ0 О 2СС0 4ССС 6Q0O ЗОЮ КХГО 1200О 14СС0 I6CC0
а б
Рис. 4.4. Графики активности процессов {а- svchost.exe, б- explorer.exe)
120
Глава 4. Интеллектуальные системы защиты информации на основе...
При построении системы обнаружения аномалий за основу мо-
жет быть принят следующий метод:
а) записывается последовательность системных вызовов за не-
который интервал времени;
б) выбирается размер скользящего временного окна / и сдвиг
временного окна А;
в) создается набор шаблонов - строк длины /, который описыва-
ет нормальное поведение системы (рис. 4.5).
На рисунке принят размер окна / = 6, а размер сдвига А = 1. Ис-
пользуя описанный метод, можно составить адекватную модель по-
ведения информационной системы.
51
4 27 3 4 4
Т~|
Набор шаблонов (профилей):
51 4 27 3 4 4
4 27 3 4 4 3
Рис. 4.5. Формирование набора шаблонов для описания нормального
поведения системы
На этапе обнаружения атаки используется алгоритм отрица-
тельного отбора, суть которого заключается в следующем [10]. Обо-
значим через S набор шаблонов нормальной активности, полученных
в результате наблюдения за системными вызовами. Сгенерируем слу-
чайным образом набор детекторов R, т.е. строк длины /, каждая из
которых не совпадает ни с одной из строк в S (рис. 4.6). В алгоритме
отрицательного отбора используется принцип частичного г- совпаде-
ния. Считается, что две строки г - совпадают, если образующие их
символы (числа) идентичны в г или более смежных, т.е. следующих
друг за другом позициях, где величина г выбирается в зависимости от
решаемой задачи.
121
(/ = 6;Л= 1)
Глава 4. Интеллектуальные системы защиты информации на основе...
Пусть, например, г - 4. Тогда случайным образом сгенериро-
ванная строка Rx = (21 4 27 13 35 4) совпадает с шаблоном нор-
мальной активности S\ = (1 4 27 13 35 7), поскольку они содер-
жат одинаковые числа во 2-й, 3-й, 4-й и 5-й позициях, поэтому данная
строка уничтожается, не попадая в искомый набор детекторов R. Во-
обще, количество одинаковых значений в смежных позициях двух
шаблонов называется аффинностью этих шаблонов. Таким образом,
в набор детекторов R попадают только те случайно сгенерированные
строки (шаблоны) длины /, аффинность которых по сравнению со
всеми шаблонами нормальной активности меньше заданного поро-
га г.
Шаблоны нормальной активности (5)
Строки, сгенерированные
с помощью генератора
случайных чисел
Да I
I
Уничтожение кандидата в детекторы
Рис. 4.6. Схема алгоритма отрицательного отбора
На практике элементы множества кандидатов в детекторы соз-
даются последовательно и продолжают генерироваться до тех пор,
пока не будет достигнуто необходимое для решения конкретной за-
дачи число детекторов. Для оценки этого числа воспользуемся сле-
дующими обозначениями:
NRq - число строк-кандидатов в детекторы, сформированных
алгоритмом генерации;
NR - число детекторов, оставшихся после удаления строк, сов-
падающих с шаблонами нормальной активности;
Ns - число шаблонов нормальной активности;
Рм - вероятность r-совпадения двух случайно сгенерированных
строк;
122
Глава 4. Интеллектуальные системы защиты информации на основе...
/ = (1-^л/) s - вероятность того, что случайная строка не
совпадет с одним из Ns шаблонов нормальной активности;
Pf - вероятность того, что оставшиеся NR детекторов не смогут
обнаружить атаку.
В случае, если Рм достаточно мала, a Ns и NR достаточно ве-
лики, можно записать:
f = (\-PMfs- (4.1)
NR=NR0.f, (4.2)
Pf-Q-PM)"*-*-*""*- (43)
Отсюда получаем:
\nPf (4.4)
NR=~
и, соответственно:
Nro =
_Nr_ lnPf (4.5)
Формула (4.5) определяет число строк-кандидатов в детекторы, кото-
рые необходимо сгенерировать с помощью алгоритма, в функции от
вероятности пропуска атаки Pf, числа шаблонов нормальной актив-
ности Ns и вероятности совпадения двух случайных строк Рм. Для
вычисления вероятности Рм, в свою очередь, можно воспользоваться
формулой
г (/-гХт-Р (4.6)
т
где /я - количество символов алфавита, т.е. диапазон значений чисел,
записываемых на каждой позиции (в рассмотренном выше случае,
т = 133); / - длина строки; г - число идентичных значений в смеж-
ных позициях, учитываемых при проверке выполнения условия
r-совпадения строк.
123
Глава 4. Интеллектуальные системы защиты информации на основе...
Для уменьшения вычислительных затрат на генерацию детекто-
ров, в принципе, можно воспользоваться различными подходами, на-
пример, методом, основанным на применении генетических алгорит-
мов [95].
Следующим этапом после сбора исходных данных о нормальном
поведении системы, т.е. составления множества ^-шаблонов «своих»,
и формирования набора детекторов Л-шаблонов «чужих», является
непосредственное наблюдение (мониторинг) за работой приложения
в режиме реального времени, с целью обнаружения возможных ано-
малий в поведении процесса. Для этого осуществляется непрерывное
сравнение поступающих в систему шаблонов (профилей) активности
с детекторами из R. Если имеет место r-совпадение, то это указывает
на аномалию (рис. 4.7).
Набор детекторов (R)
Шаблоны, посту-
пающие во время
мониторинга
Нет
Обнаружена аномалия
(атака)
Переход
к следующему
шаблону
Рис. 4.7. Схема алгоритма обнаружения аномалий
Таким образом, общая схема работы системы обнаружения ано-
малий, основанной на использовании механизмов иммунной системы,
принимает следующий вид (рис. 4.8). Здесь показаны два основных
режима работы системы: режим обучения (режим off-line), связанный
с накоплением и анализом большого объема исходных данных о по-
ведении системы и, вследствие этого, являющийся достаточно за-
тратным по времени; и оперативный режим (режим on-line), заклю-
чающийся в мониторинге текущей активности в работе с приложе-
ниями с целью выявления возникающих аномалий.
124
Глава 4. Интеллектуальные системы защиты информации на основе...
Режим обучения Оперативный режим
Сбор исходных данных
о нормальном поведении
системы
\
г
Первичная обработка
и кодирование данных
Создание набора
детекторов «чужих»
Мониторинг текущих
данных о поведении
| системы
s
г
Первичная обработка
и кодирование данных
т
Проверка условий
совпадения с детекторами
\
1 при совладей
Выработка сигнала
тревоги
(обнаружения аномалии)
Рис. 4.8. Схема работы системы обнаружения аномалий
Как отмечается в [10], особенностью рассмотренного выше под-
хода к решению задачи обнаружения аномалий, основанного на ис-
пользовании алгоритма отрицательного отбора, является то, что он
направлен на поиск отклонений от нормы, а не на поиск тех или иных
конкретных аномалий. Другими словами, данный метод не проверяет
новые шаблоны данных на соответствие какому-либо классу нару-
шений, а отмечает, что эти шаблоны являются новыми по отношению
к нормальным. В большинстве случаев мониторинга систем, обнару-
жение постепенных изменений в шаблоне данных является более
важной задачей, чем обнаружение ложных или измененных данных,
поэтому описанный вероятностный алгоритм является полезной аль-
тернативой существующим подходам. Используемый в данном слу-
чае набор случайно сгенерированных детекторов может периодиче-
ски обновляться путем создания новых детекторов, по мере измене-
ния нормы поведения информационной системы при ее старении или
модернизации.
125
Глава 4. Интеллектуальные системы защиты информации на основе...
4.4. Практические примеры реализации систем
обнаружения аномалий на основе технологий
искусственных иммунных систем
Базовая архитектура системы обнаружения аномалий (СОА),
построенной для одного сегмента сети с использованием изложенных
выше моделей функционирования иммунной системы, приведена на
рис. 4.9.
Вторичные СОА
Отрицательный
отбор
Рис. 4.9. Архитектура системы обнаружения аномалий на основе ИИС
126
Глава 4. Интеллектуальные системы защиты информации на основе...
Представленная система подразделяется на основную, которая
является некоторым аналогом спинного мозга, и вторичные - аналоги
лимфатических узлов [88]. В основной системе на базе ИИС имити-
руются два процесса - эволюция генной библиотеки и отрицатель-
ный отбор.
На этапе эволюции генной библиотеки происходит накопление
информации о характере аномалий сетевого трафика. Генная библио-
тека ИИС должна содержать данные о характерных свойствах паке-
тов - их количестве, длине, структуре, типичных ошибках и т.д., на
основании которых будут генерироваться детекторы (аналоги лимфо-
цитов). Начальные данные для формирования генной библиотеки
формируются исходя из особенностей применяемых сетевых прото-
колов, в частности их слабых с точки зрения защиты мест. В после-
дующем, при обнаружении детекторами аномальной активности в се-
ти, библиотека будет пополняться новыми «генами», соответствую-
щими данным аномалиям.
На следующем этапе путем произвольного комбинирования «ге-
нов» производится генерация пре-детекторов (аналоги «зародыше-
вых» лимфоцитов), которые затем с помощью алгоритма отрицатель-
ного отбора проверяются на совпадение (точнее, на несовпадение) с
профилями (шаблонами) нормального сетевого трафика. При этом
используются данные о характере сетевого трафика, формируемые
автоматическим профайлером, который осуществляет постоянный
анализ потока данных, поступающих от маршрутизатора, располо-
женного на входе в сетевой сегмент.
Используя алгоритм отрицательного отбора, далее создается та-
кой набор детекторов, с помощью которых можно обнаружить мак-
симальное число сетевых аномалий. Этот набор рассылается по узлам
сети, образующим вторичные СОА. При обнаружении аномалии про-
изводится клональная селекция - соответствующий ей детектор «кло-
нируется» и рассылается на все узлы. Окончательное решение о том,
происходит вторжение в сеть или нет, принимается на основании ин-
формации, полученной от нескольких узлов. Каждый узел, а также
основная СОА содержит еще один компонент - коммуникатор, опе-
рирующий таким параметром, как уровень риска. В случае, если на
каком-то узле замечена подозрительная активность, коммуникатор
поднимает свой уровень риска и отсылает соответствующее сообще-
127
Глава 4. Интеллектуальные системы защиты информации на основе...
ние коммуникаторам других узлов и основной СОА, и те также под-
нимают свои уровни риска. При появлении аномалий сразу на не-
скольких узлах в течение короткого промежутка времени этот уро-
вень быстро растет, и если будет достигнут определенный порог, ад-
министратор сети сразу получит сигнал тревоги.
Перечислим некоторые практические наработки в области по-
строения искусственных иммунных систем [87, 96].
1. Сетевая система обнаружения аномалийLisys -обеспечи-
вает контроль трафика TCP SYN. Система состоит из распределенных
детекторов размером 49 байт, контролирующих «data-path triple», т.е.
/Р-адреса источника и назначения, а также порты (рис. 4.10).
//?:20.20.20.5
port 21
datapath triple
- 4Z0.20.20 5,31.14.21.37, ftp)
Внутренний
Корпоративная сеть
/р:31 №1.37
port 17(Х)\^-'
Хост
Порог
активации
Уровень
регистрации
Значение
маски
Значение
детектора
Детектор
0100111010101110011011001 ... 1011010
immature memory activated ^matches
Рис. 4.10. Принцип действия искусственной иммунной системы
Сначала детекторы генерируются случайно, и в процессе работы
те из них, которые соответствуют нормальному трафику, постепенно
удаляются. Кроме того, детекторы имеют время жизни, и в итоге весь
их набор, кроме записанных в память, через некоторое время регене-
рируется. При таком подходе возможно появление незаполненных
мест в наборе, которое устраняется использованием масок переста-
новки, позволяющих повторно отобразить «data-path triple», заме-
128
Глава 4. Интеллектуальные системы защиты информации на основе...
ченное различными детекторами. Для уменьшения количества лож-
ных тревог используется порог активации, превышение которого
приводит к срабатыванию датчика. Этот порог активации является
общим на всю сеть.
В случае обнаружения необычных ГСР-связей, система посыла-
ет по e-mail предупреждение администратору. Если администратор
при этом ничего не предпринял, то соответствующий детектор, от-
реагировавший на подключение как на аномальное, исчезнет и боль-
ше не появится. Если аномалия подтверждена, то детектор станет ча-
стью набора и будет предупреждать пользователя всякий раз при об-
наружении подобного подключения.
2. Система Homeostasis Process (HP) - расширение к ядру
Linux, позволяющее обнаруживать необычное поведение прикладных
программ. Для обнаружения подобных аномалий прежде всего соз-
даются шаблоны (профили) системных вызовов, сделанных различ-
ными программами. На создание такого шаблона уходит некоторое
время, после чего программа может действовать самостоятельно, соз-
давая вначале задержки во времени для аномальных вызовов, а затем
и полностью устраняя эти процессы. Поскольку контролировать все
системные вызовы нерационально, система работает только с теми
системными вызовами, которые имеют полный доступ к ресурсам
компьютера.
3. Аналогичный проект сетевой системы STIDE (Sequence
Time - Delay Embedding) - призван помочь в обнаружении вторже-
ний, распознавая необычные эпизоды системных вызовов. В процессе
обучения STIDE формирует базу данных из всех уникальных, непре-
рывных системных вызовов и затем делит их на части заранее задан-
ной фиксированной длины. Во время работы STIDE сравнивает эпи-
зоды, полученные при новых трассировках, с уже имеющимися в базе
данных, и сообщает об обнаружении аномалии с указанием того,
сколько новых вызовов отличаются от нормы.
4. Исследовательский прототип системы активного аудита
информационной системы на основе технологии ИИС [95]. В ка-
честве базовой платформы для реализации системы выбрана опера-
ционная система Microsoft Windows и технология .NET компании Mi-
crosoft. Структура системы активного аудита приведена на рис. 4.11.
129
Глава 4. Интеллектуальные системы защиты информации на основе...
3-. I , L
Системный
l| сенсор п
У
'
1 База данных
системных
сенсоров
Журнал работы
системы
Фильтр
данных
w
Блок анализа
и обработки
данных
▼
Блок
реагирования
Статистический
1_| сенсор т
▼
База данных
статистических
сенсоров
т ►
Консоль
администратора
Рис. 4.11. Структура системы активного аудита с использованием
технологии ИИС
Здесь системные сенсоры предназначены для анализа парамет-
ров информационной системы и действий пользователей, а также
выдачи предупреждений для обработки в блоке анализа и обработки
данных о таких событиях, как попытки перебора паролей, монтирова-
ния носителей, вход/выход пользователя из системы и т.п. Стати-
стические сенсоры анализируют поведение каждого пользователя
системы. При этом для каждого пользователя создаются индивиду-
альные профили (шаблоны), в которые заносятся данные о типичном
поведении пользователя, собираемые в течение определенного пе-
риода времени. Фильтр данных предназначен для удаления из очере-
ди повторяющихся предупреждений для ускорения работы системы.
При реализации блока анализа и обработки данных использо-
вался алгоритм отрицательного отбора. Для ускорения процедуры
генерации детекторов применялся модифицированный метод с ис-
пользованием генетического алгоритма. В ходе экспериментов, для
оценки эффективности обнаружения атак системе предъявлялись ата-
ки, известные на момент создания профилей пользователей (общее
число - 5 атак), а также атаки, которые до этого не были известны
130
Глава 4. Интеллектуальные системы защиты информации на основе...
(общее число - 20 атак). Для увеличения базы атак была произведе-
на генерация дополнительных наборов атак на основе существующих
(общее число - 120 атак) с помощью генетических операций мутации
и кроссинговера. Тестирование проводилось при различных значени-
ях параметров Pf (вероятность того, что произошедшая атака не бу-
дет обнаружена) и г (числа символов, необходимых для выполнения
условия частичного совпадения шаблонов). На рис. 4.12 приведены
графики зависимости ошибок 1-го и 2-го рода при обнаружении атак
от параметра Pf (при / = 10, г = 3).
% обнаружения
ошибок
100
80
60
40
20
0
Ошибки
1-го рода
Ошибки
2-го рода
0,1
37
5
0,2
11
12
0,3
3
24
0,4
1
40
1
0,5
1
58
0,6
0
75
0,7
0
87
^ 2
0,8
0
99
0,9
0
100
Рис. 4.12. Графики зависимостей ошибок 1-го и 2-го рода
(соответственно, кривые 1 и 2) от вероятности не обнаружения атаки Pf
Как видно из рисунка, при снижении надежности обнаружения
атак (что вызвано уменьшением числа генерируемых детекторов
ИИС) вероятность реализации неизвестных атак увеличивается, од-
нако уменьшается вероятность ложных срабатываний системы, в ре-
зультате которых легальные действия пользователя принимаются за
атаку. Оптимальными значениями параметров искусственной иммун-
131
Глава 4. Интеллектуальные системы защиты информации на основе...
ной системы, при которых обеспечиваются минимальные значения
ошибок 1-го и 2-го рода, являются значения Pf = 0,2 ...0,3 и г = 3.
При этих значениях параметров разработанный прототип системы ак-
тивного аудита позволяет обнаруживать до 85 % атак, а число лож-
ных срабатываний не превышает 6 %.
При обнаружении атаки система активного аудита принимает
решение о способе ее нейтрализации. Соответствующее решение
принимается на основе алгоритма нечеткой логики, с учетом типа
объекта, подвергающегося угрозе, и условий выполнения атаки.
5. Сетевая иммунная система противодействия компьютер-
ным атакам, описанная в [96], обеспечивает решение следующих за-
дач:
- статистический анализ сетевого трафика для оценки состояния
защищенности сети;
- фильтрация (очистка) трафика при обнаружении аномалий в
сети;
- блокирование и предупреждение обнаруженных компьютер-
ных атак.
Реализация метода иммунного ответа доведена до соответст-
вующего аппаратно-программного решения. Система противодейст-
вия компьютерным атакам включает в себя централизованную «биб-
лиотеку генов», формирующую ограниченный набор векторов, харак-
теризующих потенциально чужеродные события, а также распреде-
ленную систему датчиков (сенсоров), выполняющих собственно об-
наружение и подавление информационно-технических воздействий и
обладающих обратной связью с «библиотекой генов». Достоинством
разработанного метода является принципиальная возможность про-
тиводействия ранее не известным компьютерным атакам. Как показа-
ли эксперименты, полнота обнаружения атак с помощью метода им-
мунного ответа достигала 95 % (для сравнения: при использовании
метода сигнатурного анализа этот показатель составил чуть более
50 %, а при использовании поведенческого блокиратора - около
80 %).
Известны и другие проекты создания компьютерных иммунных
систем, например, проект Computational Immunology for Fraud Detec-
tion (CIFD) (http://www.icsa.ac.uk/CIFD), целью которого является
разработка системы защиты информации на базе технологии ИИС
132
Глава 4. Интеллектуальные системы защиты информации на основе...
для почтовой службы Англии. Конструктивный подход к построению
иммунной мультиагентной системы управления инцидентами инфор-
мационной безопасности исследуется в [83].
4.5. Системы антивирусной защиты на основе искусственных
иммунных систем
Как отмечают специалисты, за последние десять - пятнадцать
лет резко возросло количество компьютерных вирусных атак, на-
правленных как на корпоративные сети, так и на индивидуальных
пользователей. Так, если в 1998 г., согласно данным лаборатории
AV-test.org, было зарегистрировано 1738 видов вредоносных про-
грамм, то только за первые 8 месяцев 2008 г. их было уже около
6 млн. По данным компании Trend Micro, в начале 2009 г. она реги-
стрировала уже около 855 новых видов угроз в час, а по прогнозам ее
специалистов, к 2015 г. каждый час будет фиксироваться уже
26,5 тысяч новых угроз [69]. Несмотря на огромные усилия конкури-
рующих между собой антивирусных фирм, убытки, приносимые ком-
пьютерными вирусами, составляют ежегодно сотни миллионов дол-
ларов.
В «Толковом словаре по информатике» дано следующее опреде-
ление вируса [97]: компьютерные вирусы - это класс программ,
способных к саморазмножению и самомодификации в работающей
вычислительной среде и вызывающих нежелательные для пользова-
теля действия. Эти действия могут выражаться в нарушении работы
программ, выводе на экран посторонних сообщений или изображе-
ний, порче записей, файлов, дисков, замедлении работы ЭВМ и т.п.
Большинство современных антивирусных пакетов использует
методы сигнатурного анализа для борьбы с вирусами. При этом неко-
торые разработчики, стремясь повысить эффективность своих про-
дуктов, выпускают по несколько обновлений сигнатурных баз дан-
ных каждый час. Однако частое обновление сигнатур и постоянное
сканирование компьютеров антивирусными системами в поиске вре-
доносных кодов приводит к снижению производительности защи-
щаемых информационных систем, поскольку антивирусы используют
значительные ресурсы оперативной памяти и время работы процес-
сора.
133
Глава 4. Интеллектуальные системы защиты информации на основе...
С целью отработки механизмов обнаружения новых и неизвест-
ных компьютерных вирусов в последние годы усиленное внимание
уделяется эвристическим методам. Так, используемая в составе анти-
вирусного пакета Norton Antivirus (фирмы Symantec) технология
Bloodhound Heuristic обеспечивает изучение структуры файлов, про-
граммную логику, инструкции, данные файлов и прочие атрибуты,
после чего на основе эвристических правил определяет вероятность
инфицирования. «Чистые» файлы беспрепятственно проходят через
этот фильтр, а подозрительные задерживаются. Утверждается, что
использование данной технологии позволяет автоматически опреде-
лить и обезвредить до 95 % всех новых и неизвестных вирусов [97].
Одним из перспективных направлений в области создания сис-
тем антивирусной защиты, обеспечивающих распознавание новых и
неизвестных вирусов и их эффективное подавление, является исполь-
зование технологий искусственных иммунных систем [10, 98]. Так,
уже в октябре 1997 г. фирмой IBMm конференции «Virus Bulletiri91»
(г. Сан-Франциско, США) был представлен действующий макет Им-
мунной системы киберпространства {Immune System for Cyberspace,
ISC). Общая структура алгоритмов антивирусной защиты, защищен-
ных рядом патентов и реализованных в составе данной системы, при-
ведена на рис. 4.13.
В соответствии с данной структурой, система ISC должна обес-
печивать выполнение следующих функций:
• обнаружение неизвестного вируса на компьютере пользовате-
ля;
• выделение образа (шаблона) вируса и отправка его централь-
ному компьютеру;
• автоматический анализ вируса и выработка предписания для
его распознавания и удаление с любой машины, подключенной к се-
ти;
• доставка предписания компьютеру пользователя, встраивание
в его антивирусные базы данных и запуск программы для обнаруже-
ния и удаления всех копий вируса;
• распространение антивирусного предписания в локальной се-
ти пользователя.
134
Глава 4. Интеллектуальные системы защиты информации на основе...
Детектирование аномального
поведения компьютера
В настоящее время
включено
в IBM Antivirus
Поиск известных вирусов
Если вирус неизвестен
Удаление вирусов
Если вирус известен
Захват базы неизвестного
вируса
Расщепление
программного
кода вируса
Анализ алгоритма
функционирования
вируса
Выделение сигнатуры
вируса
В настоящее время
включено
в Virus Lab
Добавление информации
на незаряженные
машины
Передача
сигнала на
незаряжен-
ные машины
Добавление сигнатуры
вируса в БД
Рис. 4.13. Структурная схема искусственной иммунной системы ISC
фирмы IBM
135
Глава 4. Интеллектуальные системы защиты информации на основе...
В 1999 г. известная американская корпорация RAND по заказу
Министерства обороны провела исследования в области выбора тех-
нологий, способных обеспечить необходимый уровень информаци-
онной безопасности национальной информационной инфраструктуры
США. В качестве наиболее перспективных технологий создания сис-
тем защиты информации нового поколения были выбраны техноло-
гии построения искусственных иммунных систем.
По сообщениям прессы, в Израиле в 2005 г. была разработана
иммунная система для компьютеров, позволяющая успешно бороться
с вирусными эпидемиями в Интернете. В основе данной системы ис-
пользуется идея создания в Интернете подсети, состоящей из «ком-
пьютеров-ловушек» (honey-pots). Эти компьютеры должны «замани-
вать» вирусы, автоматически их анализировать и распространять по
всей сети средства защиты. «Ловушки» должны быть связаны между
собой отдельными защищенными каналами. При обнаружении атаки
на одной из «ловушек» остальные будут моментально оповещены и
начнут работать как центры распространения обезвреживающего ко-
да.
Моделирование показало, что чем больше сеть, тем эффективнее
работает эта схема. Например, если в сети будет 50 тыс. узлов (ком-
пьютеров) и только 0,4 % из них «ловушки», то, как утверждают
разработчики, вирусы успеют захватить не более 5 % сети, а затем
будут остановлены иммунной системой. Для сети с 20 млн узлов при
этой же пропорции «ловушек» заражение составит всего 0,001 %.
И наконец, отметим еще одно важное обстоятельство. Результа-
ты теоретических исследований и проведенных вычислительных экс-
периментов [10, 91] показывают, что искусственные иммунные сис-
темы, вообще говоря, позволяют решать задачи сжатия, кластериза-
ции и защиты информации, распознавания образов, поиска оптимума
сложных функций и др. более эффективно, чем интеллектуальные
системы, построенные на основе нечеткой логики и нейронных сетей,
что свидетельствует о перспективности широкого применения им-
мунных систем в различных областях науки и техники.
136
Глава 4. Интеллектуальные системы защиты информации на основе...
Контрольные вопросы
1. Что понимается под искусственной иммунной системой? Чем
объясняется интерес к подобным системам?
2. Перечислите основные механизмы функционирования есте-
ственной иммунной системы человека. За счет чего обеспечивается
высокая эффективность ее функционирования?
3. Что понимается под алгоритмом отрицательного отбора? Ка-
кова процедура реализации этого алгоритма?
4. Как реализуется система обнаружения атак на основе меха-
низмов искусственной иммунной системы? Какие преимущества
обеспечивает использование данного подхода?
5. В чем состоит идея реализации систем антивирусной защиты
на основе искусственных иммунных систем? Почему данное направ-
ление считается перспективным?
137
Глава 5. Анализ и управление информационными рисками на основе ....
ГЛАВА 5. АНАЛИЗ И УПРАВЛЕНИЕ ИНФОРМАЦИОННЫМИ
РИСКАМИ НА ОСНОВЕ НЕЧЕТКИХ КОГНИТИВНЫХ
МОДЕЛЕЙ
5.1. Состояние вопроса
К настоящему времени сложилась общепринятая международ-
ная практика обеспечения режима информационной безопасности
(ИБ). Как правило, основные работы по обеспечению режима ИБ ор-
ганизации (предприятия) предполагают выполнение следующих эта-
пов [99]:
• определение политики информационной безопасности;
• установление границ, в которых предполагается поддержи-
вать режим ИБ;
t проведение оценки рисков;
• выбор контрмер противодействия угрозам и управление рис-
ками;
• выбор средств контроля и управления, обеспечивающих ре-
жим ИБ;
• сертификация системы управления ИБ на соответствие стан-
дартам безопасности (аудит ИБ).
Выработка концепции информационной безопасности органи-
зации предполагает, в первую очередь, анализ ее информационной
защищенности. В соответствии со стандартом ИСО/МЭК Р 17799,
задача определения уровня информационной безопасности любой ор-
ганизации сводится к анализу информационных рисков.
При анализе рисков необходимо рассматривать следующие ас-
пекты:
а) шкалы и критерии, по которым можно измерить риски;
б) оценку вероятностей событий;
в) технологии (методики) измерения рисков.
Риски можно оценивать по объективным либо субъективным
критериям. Субъективные критерии измеряются по качественной, на-
пример, 100-балльной или лингвистической («низкий», «средний»,
«высокий») шкале, поскольку:
138
Глава 5. Анализ и управление информационными рисками на основе ....
• оценка должна отражать субъективную точку зрения вла-
дельца информационных ресурсов;
• следует учитывать различные аспекты - не только техниче-
ские, но и организационные, психологические и т.д.
В силу того, что для получения «объективных» (физических) ве-
роятностей наступления определенных событий необходимо обрабо-
тать результаты большого числа наблюдений, имевших место в про-
шлом, при оценке рисков обычно используются так называемые
«субъективные» вероятности. Под субъективной вероятностью име-
ется в виду мера уверенности некоторого человека или группы людей
(экспертов) в том, что данное событие в действительности будет
иметь место. В современном понимании, субъективная вероятность
позволяет не только определить меру уверенности, но и увязывается с
системой предпочтений лица, принимающего решения (ЛПР), и в
конечном итоге, с функцией полезности (целевой функцией), отра-
жающей его предпочтения на множестве альтернатив.
В общем случае, риск R определяется как средний ожидаемый
потенциальный ущерб от реализации возможных угроз информаци-
онным ресурсам и представляет собой функцию трех фактор-
множеств:
R= f(U,M,G), (5.1)
где U - множество возможных угроз; М - множество уязвимостей
информационной системы; G - множество защищаемых ресурсов.
Таким образом, для того чтобы оценить уровень защищенности
информационной системы, необходимо проанализировать эти три
множества.
Для оценки угроз и уязвимостей применяются различные методы,
в основе которых используются:
• статистические данные;
• экспертные оценки;
• учет факторов, влияющих на уровни угроз и уязвимостей.
Классический подход, основанный на накоплении статистиче-
ских данных об имевших место происшествиях, анализе и классифи-
кации их причин, выявлении факторов, от которых они зависят, как
правило, оказывается в данном случае малоэффективным (прежде
всего, в силу недостаточной и недостоверной статистики о событиях
139
Глава 5. Анализ и управление информационными рисками на основе ....
в информационной системе). Поэтому наиболее распространенным в
настоящее время является подход, основанный на учете различных
факторов, влияющих на уровни угроз и уязвимостей, используя при
этом знания и опыт экспертов в данной предметной области.
Управление рисками предполагает использование одной из сле-
дующих стратегий [99]:
• уменьшение рисков - принимаются специальные контрмеры,
включающие в себя программно-технические и организационные ме-
ры защиты, с целью уменьшения ожидаемого потенциального ущерба
от воздействия угроз;
• устранение (уклонение) от рисков - исключаются те элемен-
ты или функции системы, для которых значение риска становится не-
допустимым. При этом система, возможно, перестанет выполнять не-
которые функции, опасные с точки зрения обеспечения её безопас-
ности;
• устранение уязвимостей - устраняются слабые с точки зре-
ния безопасности места системы путем улучшения защищенности ее
элементов, при сохранении ее функциональной целостности, с целью
снижения общего риска до приемлемых значений;
• принятие рисков - устранение уязвимостей или принятие ка-
ких-либо других мер по снижению рисков не производится. Такое
решение принимается обычно, если уровень рисков в системе счита-
ется допустимым, либо их устранение не представляется возможным
по объективным причинам;
• страхование рисков - в данном случае часть рисков берет на
себя страховая компания, обеспечивающая приемлемый уровень рис-
ка для систем.
Анализ построения комплексных систем защиты информации
различных организаций (предприятий, фирм) показывает, что суще-
ствующие международные и отечественные стандарты в области ИБ
и принятые в различных организациях корпоративные документы по
обеспечению ИБ не позволяют построить единую для всех организа-
ций универсальную методику управления рисками. В каждом част-
ном случае приходится адаптировать общую методику анализа и
управления рисками под конкретные нужды предприятия с учетом
140
Глава 5. Анализ и управление информационными рисками на основе ....
специфики его функционирования и характера выполняемых бизнес-
процессов.
Известные методики анализа и управления рисками (COBRA,
RiskWatch, RA2 art of risk, CRAMM, «АванГард», «Гриф», «Кондор» и
др.) не обладают достаточной наглядностью («прозрачностью»),
имеют, как правило, описательный характер и сводятся к формальной
проверке выполнения (или невыполнения) требований стандартов по
ИБ (ИСО/МЭК Р 17799, 27001, 13335 и др.) [17]. В данных методи-
ках недостаточно проработаны вопросы количественной оценки
ущерба, вызванного воздействием угроз на информационные ресур-
сы; не производится анализ чувствительности оценок ущерба по от-
ношению к основным дестабилизирующим факторам или уязвимо-
стям; не выявляются критичные факторы (угрозы, уязвимости), вно-
сящие наибольший вклад в величину потенциального ущерба; не
производится оценка эффективности принятых контрмер.
5.2. Методика когнитивного моделирования сложных систем
Решение данной проблемы, как показывают исследования, воз-
можно с использованием компьютерных средств когнитивного моде-
лирования [100 - 103]. Когнитивное моделирование имеет своей це-
лью использовать неполную, нечеткую или даже противоречивую
информацию об объекте исследования, располагаемую экспертами,
выявить наиболее существенные, значимые взаимосвязи, определить
«веса» факторов, влияющих на изучаемую проблему, в данном слу-
чае, проблему анализа рисков и построения эффективной системы
управления ИБ.
Рассмотренная ниже методика анализа рисков основана на по-
строении нечетких когнитивных карт, описывающих воздействие по-
тенциальных угроз на защищаемые ресурсы с оценкой возможного
ущерба (т.е. риска).
Под нечеткой когнитивной картой (НКК) понимается ориенти-
рованный граф K = (C,F,W), узлы которого представляют собой
концепты (факторы, процессы) Q,C2,...,CW еС, существенные для
понимания сути исследуемого объекта (проблемы), а дуги (связи)
графа i^,F2....,Fw eF не только отражают причинно-следственные
141
Глава 5. Анализ и управление информационными рисками на основе ....
связи между этими концептами, но и определяют степени влияния
(веса) W{CitCj) sW связываемых концептов [104, 105]. Предполага-
ется, что изменения состояния концептов (факторов) НКК описыва-
ются переменными состояния Х(, (/=1,2,...,л), которые в целях уп-
рощения, как правило, полагаются безразмерными и принимающими
значения в интервале [ - 1,1].
Влияние концептов друг на друга может быть как «положи-
тельным», когда увеличение (уменьшение) переменной Х{ приводит
к увеличению (уменьшению) переменной X,-, так и «отрицатель-
ным», когда увеличение (уменьшение) переменной Х{ приводит к
уменьшению (увеличению) переменной Xj. Для отображения степе-
ни влияния концептов используются нечеткие лингвистические пере-
менные, принимающие значения «мало», «средне», «сильно» и т.п.,
оцениваемые по числовой шкале [0,1].
В общем случае, состояние /-го концепта НКК описывается
уравнением вида
ir,(*+D=/( I WjtXjW+Xtik)), (5,2)
7=1
где Xt(k+\) и Xt(k) - значения переменной Х( на (£ + 1)-м и к-м
шаге соответственно, (А: = 1,2,...); W*- вес связи между концептами
С,- и С-■;/(•) - некоторая нелинейная функция, принимающая значе-
ния в интервале [0,1].
Выбирая те или иные управляющие воздействия, изменяющие
веса связей НКК и, как следствие, состояния концептов, можно
управлять состоянием исследуемого объекта в соответствии с задан-
ной целью управления, под которой понимается достижение требуе-
мого состояния объекта.
С помощью построенной НКК можно оценить влияние (эффект)
TJ С4
произвольного концепта С, на любой другой концепт С, . При этом
некоторый путь от концепта СУ к концепту С J (например, СУ—► cf
142
Глава 5. Анализ и управление информационными рисками на основе ....
—> С!т —> С: ) считается непрямым эффектом Тп(СУ —>Cj ). Если ве-
са причинно-следственных связей между концептами заданы, то для
определения непрямого эффекта T„(Q —>Су ) можно воспользовать-
ся формулой:
T„(Clf^Cf)=mm{W9h (5-3)
где {Wjj} - множество весов связей на пути между концептом С, и
концептом С: .
Полный эффект от воздействия С, на Су равен:
ПСУ^С?) =max {Th Т2 TN}\ (5.4)
тт с*
где Г/ - непрямой 1-й эффект между концептом С,- и концептом Cj ,
(/ = 1, 2,..., N); N- число непрямых эффектов.
Допустим, что схема воздействия некоторой угрозы на опреде-
ленный информационный ресурс принимает вид НКК, представлен-
ной на рис. 5.1, где концепт cf7 соответствует рассматриваемой уг-
розе; С\ - искомый информационный ресурс (целевой фактор);
С\ tCi,Ci - промежуточные факторы (концепты), отражающие це-
почку прохождения угрозы до информационного ресурса. Тогда, ис-
пользуя приведенные выше формулы (5.2) - (5.4), можно получить
тт с*
оценку влияния угрозы С( на информационный ресурс С\ .
Для этого необходимо выделить все непрямые эффекты между этими
концептами Тп(С\ —> С{ ). Как видно из рис. 5.1, таких непрямых
эффектов четыре: П(С? -+ С? -► Ср), Т2(С?^С? -+ С{ -+ QG),
Т3(С? -► С$^ С?), r4(Cf -+ Cf -+ С{ -► Ср). Тогда получаем:
Т\ =min {сильно, средне} = средне;
72 = min {сильно, средне, мало} = мало;
73 = min {средне, сильно} = средне;
Ть = min {средне, сильно, мало} = мало.
143
Глава 5. Анализ и управление информационными рисками на основе
Рис. 5.1. Определение влияния концепта Сх на концепт С\
Полный эффект влияния концепта С?\ на целевой фактор соста-
вит:
1\С¥ -> CXG) =max {Tlt Ть Т3, ТА} = средне.
Значение полного эффекта дает оценку вероятности реализации
угрозы и уязвимости защиты в отношении данной угрозы. Локальный
риск (ущерб) от действия угрозы Cf7 на у-й ресурс (целевой фак-
тор) С: при этом определится из следующей формулы:
fy = 7tC?-C?) rj, (5.5)
144
Глава 5. Анализ и управление информационными рисками на основе ....
где 7\ СУ —► С: ) - полный эффект от действия угрозы СУ нау-й
информационный ресурс; г,- ценность у-го ресурса.
Общий риск от действия множества угроз { С, } для рассматри-
ваемого объекта можно рассчитать по формуле:
R = I,VjRij, (5.6)
где Ry - ущерб, нанесенный i-й угрозой у-му ресурсу; vj - значимость
(вес)у-го ресурса, определяемая экспертно.
Выбирая множество средств (мер) защиты {С* }, т. е. изменяя
силу (вес) влияния концептов друг на друга, можно свести оценку
потенциального ущерба (риска) до приемлемого допустимого уровня.
5.3. Анализ информационных рисков
с помощью нечетких когнитивных карт
Рассмотрим основные аспекты решения задачи анализа и управ-
ления рисками на примере информационной системы высшего учеб-
ного заведения (вуза) [102].
Трудность проведения анализа рисков при определении уровня
информационной безопасности вуза заключается в сложности и не-
однозначности оценки ущерба, который понесет высшее учебное за-
ведение при реализации угроз его информационным ресурсам. Так,
помимо финансовых потерь, связанных с восстановлением ресурсов
после реализации угрозы, можно выделить потери нематериального
характера, существенные для жизнедеятельности вуза, такие как:
• ущерб репутации вуза;
• снижение качества образования;
• нарушение эмоционально-психологического состояния кол-
лектива;
• дезорганизация учебного процесса и прочих видов деятель-
ности вуза;
• снижение конкурентоспособности вуза на рынке образова-
тельных услуг.
145
Глава 5. Анализ и управление информационными рисками на основе ....
Перечисленные аспекты трудно поддаются формализации. В то
же время, учет данных факторов при построении формализованной
модели вуза как объекта защиты от информационных угроз, оказы-
вается возможным на основе технологий когнитивного моделирова-
ния с использованием аппарата НКК.
Для построения нечеткой когнитивной карты необходимо
проанализировать информационные потоки, циркулирующие в вузе;
определить информационные ресурсы, требующие защиты; выявить
основные угрозы информационной безопасности вуза; проанализиро-
вать уязвимости существующей системы защиты и сформулировать
виды возможного ущерба от реализации угроз информационной
безопасности. Исходя из этого, были выделены основные концепты
НКК, определяющие ситуацию информационной защиты в вузе. Все
концепты разделены на следующие четыре класса:
• множество дестабилизирующих факторов (угроз) {С, };
• информационные ресурсы {Ст}, нуждающиеся в защите (ба-
зы данных, документы, программное и аппаратное обеспечение, ноу-
хау и др.);
• базисные, или сенсорные концепты (индикаторы) {С/}, по
которым можно судить о тенденциях, происходящих в системе (мо-
рально-психологическое состояние коллектива, успеваемость студен-
тов, нарушения графика учебного процесса и др.);
• целевые факторы {С,- }, определяющие основной ущерб ор-
ганизации, изменение которых является существенным для успешно-
го функционирования вуза (качество образования, материально-
техническое состояние, имидж вуза и др.).
Направления и сила воздействия отдельных концептов друг на
друга (в виде значений лингвистических переменных «сила связи»
или весовых коэффициентов) определяются путем опроса экспертов.
Пример построения НКК, отражающей возможные потери вуза
от воздействия различных угроз на ее информационную систему,
приведен на рис. 5.2.
146
Глава 5. Анализ и управление информационными рисками на основе
Эмоционально-
психологическое состояние
Фальсификация
Разглашение
Репутация
Аппаратные
и программные сбои
Качество образования
Материально-
техническое состояние
Успеваемость
Рис. 5.2. Нечеткая когнитивная карта для определения ущерба вуза
Основные угрозы ИБ {С^7} определены здесь как хищение,
фальсификация, разглашение информации, внесение вирусов, выход
из строя ПО и компьютеров по техническим причинам (отказы, сбои).
Основные информационные ресурсы, нуждающиеся в защите,
{Csm} - базы данных (БД), документы, программное обеспечение
(ПО), аппаратные ресурсы.
В качестве целевых факторов {Cj }, характеризующих положе-
ние вуза на рынке образовательных услуг, определены:
- репутация (имидж) вуза;
- качество образования;
- материально-техническое состояние вуза.
147
Глава 5. Анализ и управление информационными рисками на основе ....
Базисные факторы (индикаторы) {с/} " эмоционально-
психологическое состояние коллектива, нарушения учебного процес-
са, успеваемость студентов.
Перечень концептов НКК и соответствующих им переменных
состояния^ приведены в табл. 5.1.
Таблица 5.1
Концепты НКК и их переменные состояния
Концепт
<?
сиг
с?
сЧ
с"
с?
rs
2
rs
3
с!
ci
с{
с[
с?
2
rG
3
Наименование концепта
Хищения
Фальсификация
Разглашение
Вирусы
Нарушение
работоспособности
Базы данных
Документы
Программное обеспечение
Аппаратные ресурсы
Эмоционально-
психологическое
состояние
Нарушения учебного
процесса
Успеваемость
Репутация
Качество образования
Материально-
техническое состояние
Переменные состояния
Среднее количество хищений, в ед.
времени
Среднее количество несанкциони-
рованных изменений, в ед. времени
Среднее количество разглашений, в
ед. времени
Среднее количество вирусных атак,
в ед. времени
Среднее количество отказов, в ед.
времени
Объем информации, содержащейся
в БД, Мбайт
Количество документов, ед.
Количество видов ПО, ед.
Количество работоспособных ком-
пьютеров и аппаратных средств, ед.
Время, необходимое на восстанов-
ление режима работы коллектива,
час.
Среднее время простоев, час.
Средний уровень знаний, в пяти-
балльной системе
Число негативных публикаций /
высказываний, ед.
Количество выпускников, работаю-
щих по специальности, %
Финансовые потери, связанные с
восстановлением ресурсов, %
148
Глава 5. Анализ и управление информационными рисками на основе ....
Допустим, что в качестве угрозы, воздействующей на информа-
ционные ресурсы вуза, рассматриваются вирусы (концепт С^), и
пусть уровень силы этой угрозы описывается лингвистической пере-
менной «сильно» (что соответствует интенсивной внешней вирусной
атаке). Тогда для уменьшения соответствующей составляющей риска
можно ввести такие блокирующие контрмеры, как разработка и вне-
дрение концепции антивирусной защиты (идентификация уязвимо-
стей, выбор стратегии антивирусной защиты, выбор антивирусной
программы, управление антивирусными программами) и установка
межсетевого экрана (МЭ) с соответствующей политикой ИБ для МЭ.
Это позволит снизить степень влияния концепта С$ на концепт Ci
(целевой фактор - качество образования) с «сильно» на «средне».
Таким образом, вводя в данную модель дополнительно множе-
ство управляющих факторов (контрмер) {Ст }, оказывающих изме-
нение в желаемом направлении весов связей НКК, можно оценить
эффективность различных мероприятий по управлению ИБ вуза.
Пример построения НКК с указанием возможных управляющих
факторов «защитных барьеров» {Ст } приведен на рис. 5.3. Наимено-
вания соответствующих концептов приведены в табл. 5.2. В принци-
пе, каждый управляющий концепт С* может быть представлен спи-
ском мероприятий, направленных на уменьшение силы влияния меж-
ду соответствующими концептами.
149
Глава 5. Анализ и управление информационными рисками на основе
Угрозы Информационные Базисные Целевые
ресурсы факторы факторы
Рис. 5.3. Нечеткая когнитивная карта для оценки рисков
с указанием возможных контрмер
Таблица 5.2
Множество управляющих факторов
Обозначение
1
•П1Л f^R /"^Л
L*i ,1^5 'W
/~lR /ПГЛ /ТЛ /~*R /~*R
С 2 ,Сб »Сз ,Сз ,С4
^Л siR
с11»с12
Чз'Чб
/^»Л s^R r^R
Ч4»Ч7'С28
Наименование концепта
2
Разграничение уровней доступа пользователей
Управление доступом в помещения
Разработка и внедрение концепций защиты
Административные и технические средства
контроля работы пользователей
Система предотвращения конфликтов в коллективе
Формирование корпоративной культуры
150
Глава 5. Анализ и управление информационными рисками на основе
Окончание табл. 5.2
1
ей
rR
с18
rR
С20
/"»Л r*R /nr**
С19'С21'С25
r*R r-Л
С22'С23
r»R г1** r>R
С24'С26'С27
f*iR /~*R /^R
c29'c30'c31
2
Резервное копирование
Организация процедуры хранения документов
Разработка и документирование механизма
восстановления после вирусных атак
Разработка процедур оперативного реагирования
на инциденты
Использование лицензионного ПО, разграничение
доступа
Техническая поддержка аппаратных ресурсов
Разработка мероприятий по повышению стабиль-
ности учебного процесса
Анализ соотношения полученных рисков и затрат на вводимые
мероприятия по их уменьшению позволяет определить механизмы
управления для определения достигнутого уровня защищенности
безопасности информационных ресурсов вуза, поддержания его не-
обходимого уровня и требуемых при этом затрат на безопасность.
Принятие решения о выборе необходимых контрмер должно
производиться при этом по критерию «эффективность - стоимость».
Возможны следующие постановки задачи выбора управляющих фак-
торов для снижения информационных рисков:
1) S^ —> min при R < Лдоп - минимизация затрат на мероприятия
по защите информации при обеспечении допустимого уровня риска;
2) Л—>min при S% ^Ядоп - минимизация риска при выделен-
ных (допустимых) затратах на реализацию контрмер.
Здесь R и 5£ - соответственно общий риск и суммарные затраты
на мероприятия (контрмеры) по защите информации; Ядои и 5Д0П -
допустимые значения риска и суммарных затрат.
Эффективность выбора управляющих факторов рассчитывается
по формуле
151
Глава 5. Анализ и управление информационными рисками на основе ....
r,_R-R' (5.7)
R '
где R - первоначальное значение риска; R1 - значение риска после
введения дополнительных контрмер.
5.4. Инструментальное средство анализа и управления
информационными рисками
Для автоматизации рассмотренной процедуры анализа и работо-
способности рисками разработано программное средство Fuzzy Cog-
nitive Maps (FCM)Builder, позволяющее моделировать ситуацию за-
щиты информационных ресурсов того или иного подразделения (или
организации в целом) в среде Borland Delphi 7. Эта программа по-
зволяет построить граф НКК, задавать веса связей между концепта-
ми, рассчитывать значения полных эффектов 7({Cf } —► С, ) и рис-
ков с учетом значимости целевых факторов V}. Задавая ценность (ус-
ловную стоимость) целевых факторов, с помощью данной програм-
мы можно оценить локальные риски Ry и общий риск R и предста-
вить результаты расчета в виде соответствующих гистограмм.
На рис. 5.4 приведена нечеткая когнитивная карта для оценки
информационных рисков на примере одного из подразделений вуза
- отдела интеллектуальной собственности (ОИС) [102]. На рисунке
представлено рабочее поле, в котором производится построение
НКК. В него добавляются факторы (целевые, базисные, информаци-
онные ресурсы, дестабилизирующие, управляющие факторы), а так-
же задаются причинно-следственные связи между ними. Указанные
факторы представляют собой вершины графа - концепты НКК, а
связи между ними - его дуги. Входными характеристиками для вер-
шин графа являются:
а) тип фактора;
б) наименование фактора;
в) переменная состояния фактора;
г) начальное и предельное значения переменной состояния.
Дуги графа, выражающие количественную взаимосвязь кон-
цептов, характеризуются своими весами, заданными в виде значений
152
Глава 5. Анализ и управление информационными рисками на основе
лингвистической переменной («мало», «средне», «сильно»). По-
строение нечеткой когнитивной карты осуществляется по техноло-
гии «drag-and-drop», предоставляющей пользователю возможность
размещать объекты на форме, производить обмен данными между
разными объектами путем перемещения, что значительно упрощает
использование программы.
Перечень концептов для НКК на рис. 5.4 и на рис. 5.5 во мно-
гом совпадает с аналогичным перечнем для НКК на рис. 5.2 и
рис. 5.3 (см. табл. 5.1, 5.2), поэтому для сокращения места он здесь
не приводится.
Следующим этапом является расчет значений полных эффек-
тов для представленной НКК с целью оценки влияния дестабилизи-
рующих факторов на целевые факторы, после чего производится
расчет как отдельных составляющих информационных рисков, так и
общего риска для подразделения в целом.
Далее следует определение комплекса контрмер - мероприятий,
направленных на ликвидацию или уменьшение воздействия угроз ИБ.
Для этого в НКК вводится дополнительное множество управляющих
факторов CR ={C2q,—,C§j}, элементами которого являются указан-
ные контрмеры (рис. 5.5).
Заметим, что каждый управляющий фактор С* характеризует-
ся своей «эффективностью», под которой понимается степень влия-
ния данного фактора на силу связи между соответствующими сосед-
ними концептами. Информация об эффективности управляющих
факторов (контрмер) {С*} хранится в базе знаний FCM Builder в
виде специальной системы правил (продукций).
153
fc Н MBuider
•ойя !_раз<а гщ Инггро«гн-г| Сгрэээ
LA
•.: пдотга
Дф
П©
Цф
УФ
Готово
-i/xrcesc якчвх'р
Лигэист*«сюе тер»ъ
быбя •-•
ГОвФ
Матриц Д5~ <ч;|чссп1
Полный эбвскт
Сбит" рис*
Прсгресеие параметров I
Пере-енэ ксинептовм ихскговнй | Прии^о-сгедакн-ые свя** «гчху <он^етгп« |
Сбэвна-ение РКмаство названа
coros-i»?
| Ена-еже соаодаио
С1 ПФ ЛВСОИС Сред~яя
С2 ПЭ згбо-ссгаги^^-я-угегтозипссспислгйОИС Сргд-уя
::з ~»: рабэ-иег-а-ц!* дгя-фгснапаа'С Среднее
С1 1: пякзыиупрэБлгнчсскаягскууентатяОИС Среднее
С5 ПФ пср:с«злигзе astttse сотрудгкм» CVC Среднее
Сб Г» K-ij>cpieuta <01йм!1еш<&гьиог о хаз<ктера Средний
О п от»з>пасЫ^ферат:вРэса11:к<х патентных доку... Сре/
СЗ ПФ заязки-5|х-1п:за1С1Сс6рете-т, г-о.->£эьемоде... Среднее
С9 ПФ мгр>?да1-«хтьзе6этс»1 агэ>дг*\яв CMC Сргднее
_ II -=-f.~R- ГГ." "V-V.I-H С ! К n,lf~i-!CF..TC,-f--.-f-r- 1.0?:-1-11
| -ьдделэ-се -на-ечуе
:офч-<е огь:ст. i
;~c"eti ил11_сгг:ст/- и-4из»э jt?--cr op...
iaaui-.efHKT/" 1ьфэгиа4<ъ-сг;. p...
количество утезтнбК^одделзньхдок-^...
чоллчеегтю /геэя^а/учрэдегах/годде...
ущерб от раулаиешр, hepytuettiP, иелоет...
<ол<-ество -^рушгнй иелэст-огтн*дост...
-кто афр-н^хлчоаденнь^'пойсепонны...
чол.1чсство ccrcvHcmoD, wineiice, посетит...
TjoesH) a«Hjti пк wii зэегик напэяке*...
10.0D
10.00
12.0Э
2.00
2000.00
10.00
1.СО
Z0.0D
5.00
100.03
99. СО
99.00
2S0.OD
7.00
50СООО.СО
М0.00
::с.оэ
150.03
100.00
-I
Рис. 5.4. Нечеткая когнитивная карта для оценки рисков подразделения вуза
^iffjxj
©зйл Гравка Вид Лктруненть Сгоэзка
Р||3|Д| Ь\ЫШ\ *1
C(G)17
C(G)16
C(G)18 C(G)15
C(U)25
\*\ -KcrtjenTw-
П.|ягвистги«к»«е ngj*fct
BbMPON :
Граф
ыэтрш состюшности
Полъй J<W*KT
Общий риос
Прогрессия параметров |
ftepe*=wB концептов и»* соспхний |Пэичтв-слеаавежые связичехду KOHjemaw |
Сссз-з^еуь | Мняисгад | Наззаче
Сосор-ие
С2
сз
С5
Сб
С7
С8
С9
1 СЮ
ГФ
РФ
ГФ
п»
ГФ
ГФ
ГФ
ПФ
ГФ
.fc'.'..!.
рабоч* станции для студентов и посетителей оис
рабо^* станции для -ерсонзлэ эх.
гри<ёь>и упргвлс-м^к^а до<>п£нта41Я ОИС
персональное дгшве сотрудников at.
т£српви1якоч1»кпснивпьмго характере
откэмтая Б£ рсосратов Российских готсмтмых доку ...
мрски па pcntrpcuro гаобретемш, nonoim «оде...
загруженность работой сотрудников ОИС
Кё^гвэ асе- .х'эснt= ПК ГА'ае-тсб и чсоетитеге...
Сэедкяя загэуженчость сети, %
средняя стеле** защи^а-ности инфорпашоннэго р.. •
Соедквя стеле-ь згщ.1_еню:ти ;<нфээизи<окнэго р...
Среднееколмгетво ?тёрен*лх/-одаела1—«х доку»...
Среднее колмгетео утервк^х/ухраденкьх/лодде...
Средний ущерб от рэзгпешетя, нарушения, icnccr...
Среднее колмгетво nopy;j&in£u»roc-i:av и дог...
Среднее -.-ела утфЯ11их/укоадсп>ъх/поадслаппы..
Среднее ко лмес-эо доклче-тоз, kt.wob, посети-...
Соедини •.асег-з знажй ркили саёдьда нагоюзенн, .
| Значение сос-ор-ия | Гредегаюе енэ-еже
эо.оо
ю.оо
ю.оо
12.00
2.00
200О.СО
Ю.ОО
L0Q
3Q.O0
5.00
LO0.0O
99.00
99.00
250.00
7.00
Vf-.Yi.fil
25:::
юо.оо
150.00
юо.оо
:
FCMBJdervt.Ob
Рис. 5.5. Нечеткая когнитивная карта для оценки рисков
Глава 5. Анализ и управление информационными рисками на основе ....
Следующий шаг - это вычисление новых значений полных
эффектов от воздействия дестабилизирующих факторов на целевые
факторы НКК (см. рис. 5.5) и расчет информационных рисков с уче-
том введенных контрмер (рис. 5.6).
у !.■. ' "'Я
u!*iei *i*ielgl
у.с.
/? = 692175 у.е.
qo)w
'.;.• га
С(0)17
дога
у.е.
/?' = 296987 у.е.
С№)М
»>»»iMlii —-ilWHTMOm
*»*с* ■ мен» те»' 7ШГ> » м
1>Ч Hl'llir—I«41—|»ДИ
I Р>"с№1»
, I I I A
^Ш
JS- I
Puc. 5.6. Значения рисков до и после внедрения дополнительных мер
по защите информации
Как видно из рис. 5.6, показатель эффективности внедрения
контрмер (т.е. относительное уменьшение риска) для рассмотренного
примера составляет
Э =
R -Я' 692175-296987
R
692175
100% = 57 %.
В физическом выражении, величина риска уменьшилась более
чем в 2,3 раза (при суммарной стоимости использованного набора
контрмер 25987 у.е.), что позволяет говорить об эффективности кон-
кретных предложений по обеспечению требуемого уровня безопас-
ности подразделения вуза.
156
Глава 5. Анализ и управление информационными рисками на основе
Таким образом, изложенная выше методика оценки информа-
ционных рисков с использованием НКК и специально разработан-
ных для этого инструментальных программных средств (типа FCM
Builder) позволяет анализировать и прогнозировать состояние ин-
формационной безопасности организации (подразделения), выявить
критичные факторы, влияющие в наибольшей степени на состояние
защищенности её информационных ресурсов и определить степень
влияния угроз и уязвимостей на основные бизнес-процессы. Анализ
значений предсказанных рисков и изменения состояния целевых
факторов НКК позволяет выбрать адекватные меры защиты инфор-
мационных ресурсов, в соответствии с критерием «эффективность -
стоимость».
Контрольные вопросы
1. В чем заключается проблема анализа и управления инфор-
мационными рисками? Укажите основные пути решения данной про-
блемы.
2. Что понимается под когнитивным моделированием? Как
данный подход используется при решении задачи оценки рисков?
3. Дайте определение нечеткой когнитивной карты. Какие
группы концептов (факторов) выделяются при ее построении?
4. Приведите пример построения нечеткой когнитивной карты
для оценки ущерба от действия информационных угроз.
5. Каковы преимущества использования данного подхода для
анализа и управления рисками?
157
Заключение
ЗАКЛЮЧЕНИЕ
Подведем итог. Искусственный интеллект (а в современной
трактовке - вычислительный интеллект) занимает сегодня прочное
место при решении тех задач, где велико влияние факторов неопре-
деленности, а результат принятия решений в значительной степени
зависит от опыта, знаний и умений человека (оператора, эксперта).
Именно к такому классу плохоформализованных задач относятся за-
дачи защиты информации, для которых характерно отсутствие доста-
точно полной и достоверной информации об объекте защиты, его уг-
розах и уязвимостях, невозможность (и даже нецелесообразность)
получения сколько-нибудь точного математического описания иссле-
дуемого объекта и его среды. Как было показано выше, в данных ус-
ловиях методы искусственного интеллекта зачастую опережают клас-
сические подходы при решении многих задач защиты информации,
показывая свою высокую эффективность при реализации с помощью
современных средств вычислительной техники.
Очевидно, что рассмотренный выше круг задач, относящихся к
проблеме построения интеллектуальных систем защиты информации,
далеко не полон и не охватывает весь спектр направлений в данной
области исследований. Так, за пределами тематики данного учебного
пособия остались такие, не менее важные вопросы, как:
- построение защищенных компьютерных систем на основе
концепции проактивной безопасности;
- построение многоагентных систем защиты информации;
- построение интеллектуальных систем анализа уязвимостей
информационных систем;
- построение интеллектуальных систем криптографической за-
щиты информации;
- построение интеллектуальных систем физической защиты ин-
формации;
- построение интеллектуальных систем поддержки принятия
решений по выбору реального состава технических средств защиты
информации;
158
Заключение
- построение интеллектуальных систем поддержки принятия
решений по оперативному управлению защитой информации в ре-
альном времени; и многое другое.
Автор надеется, что читатель сможет найти интересующую его
информацию по перечисленным направлениям в специальной науч-
но-технической литературе (в том числе, в изданиях из приведенного
в конце пособия перечня источников). Главным мотивом при написа-
нии данного пособия было желание пробудить у читателя интерес к
изучению основ, а возможно, и к первым самостоятельным шагам в
рамках нового перспективного направления в области защиты ин-
формации - создания интеллектуальных систем защиты информации,
обеспечивающих современный уровень требований к защищенности
корпоративных информационных систем организаций (предприятий)
в условиях действия факторов неопределенности на основе примене-
ния интеллектуальных технологий обработки информации, управле-
ния и принятия решений.
159
Список сокращений
АРМ -
АС
БД -
БЗ
ГА
ЗИ
ИБ
ИИ
ИИС -
ИНС -
ИС
НКК -
НС
нсд -
по
сзи -
СОА -
сптв -
эс
автоматизированное рабочее место
автоматизированные системы
база данных
база знаний
генетический алгоритм
защита информации
информационная безопасность
искусственный интеллект
искусственные иммунные системы
искусственные нейронные сети
информационная система
нечеткие когнитивные карты
нейронные сети
несанкционированный доступ
программное обеспечение
система защиты информации
система обнаружения атак
специальные программно-технические воздействия
экспертная система
160
Список литературы
СПИСОК ЛИТЕРАТУРЫ
1. Нарииьяни А. С. Недоопределенность в системе представления и
обработки знаний // Изв. АН ССР. Техническая кибернетика. -
1986.-№5.-С.З-28.
2. Эшби, У. Р. Введение в кибернетику: пер. с англ. - 2-е изд. - М.:
КомКнига, 2005. - 432 с.
3. Лорьер Ж.-Л. Системы искусственного интеллекта: пер. с франц.
-М: Мир, 1991. -586 с.
4. Люггер Дж. Ф. Искусственный интеллект: стратегии и методы
решения сложных проблем: пер. с англ. - М.: Вильяме. 2003. -
864 с.
5. Ярушкина Н. Г. Основы теории нечетких и гибридных систем:
учеб. пособие. - М: Финансы и статистика, 2004. - 320 с.
6. Хайкин С. Нейронные сети: полный курс: пер. с англ. - 2-е изд. -
М.: Вильяме, 2006. - 1104 с.
7. Рутковский Л. Методы и технологии искусственного интеллекта:
пер. с польск. - М.: Горячая Линия-Телеком, 2010. - 520 с.
8. Леденева Т. М Системы искусственного интеллекта и принятия
решений: учеб. пособие для вузов / Т. М. Леденева, С. Л. Подваль-
ный, В. И. Васильев; Уфимск. гос. авиац. техн. ун-т., Воронеж,
гос. техн. ун-т. - Уфа: УГАТУ, 2005. - 206 с.
9. Васильев В. И. Интеллектуальные системы управления: теория и
практика: учеб. пособие для вузов / В. И. Васильев, Б. Г. Ильясов.
- М.: Радиотехника, 2009. - 392 с.
10. Искусственные иммунные системы и их применение /под ред.
Д. Дасгупты: пер. с англ. - М.: ФИЗМАТЛИТ, 2006. - 344 с.
11. Защита информации. Основные термины и определения по
ГОСТ Р 50922-2006 // Вестник компьютерных и информацион-
ных технологий. - 2009. - № 4. - С. 53-54; - № 5. - С. 54-55.
12. Вихорев С. Как оценить угрозы безопасности корпоративной ин-
формации ?/ С. Вихорев, А. Соколов//Connect. - 2000.- №12.
- 232 с.
13. Домарев В. В. Безопасность информационных технологий. Сис-
темный подход. - Киев: ТИД-ДС, 2004. - 992 с.
161
Список литературы
14. Герасименко В. А. Основы защиты информации / В. А. Гераси-
менко, А. А. Малюк. - М.: МИФИ, 1997. - 537 с.
15. Малюк А. А. Информационная безопасность: концептуальные и
методологические основы защиты информации: учеб. пособие
для вузов. - М.: Горячая Линия-Телеком, 2004. - 280 с.
16. Галатенко В. А. Основы информационной безопасности. Курс
лекций: учеб. пособие. - 2-е изд. - М.: Интернет-университет
информационных технологий - ИНТУИТ.РУ, 2004. - 264 с.
17. Галатенко В. А. Стандарты информационной безопасности. Курс
лекций: учеб. пособие. - 2-е изд. - М.: Интернет-университет
информационных технологий - ИНТУИТ.РУ, 2004. - 260 с.
18. Смурое В. А. Оценка интеллектуальности систем // Нейрокомпь-
ютеры: разработка, применение. - 2006. - № 8- 9. - С. 98- 104.
19. Handbook of Intelligent Control: Neural, Fuzzy and Adaptive Ap-
proaches (Eds.: D.A. White, D.A. Sofge); Van Nostrand Reinhold,
N.Y.,1992.-568p.
20. Захаров В. H. Интеллектуальные системы управления: основные
понятия и определения //Известия РАН. Теория и системы управ-
ления. - 1997. - № 3. - С. 138-145.
21. Станкевич Л. А. Интеллектуальные системы // Системный анализ
и принятие решений: словарь - справочник: учеб. пособие для
вузов /под ред. В. Н. Волковой, В. Н. Козлова. - М.: Высшая
школа, 2004.-С. 150-158.
22. Макаров И. М. Искусственный интеллект и интеллектуальные
системы управления / И. М. Макаров, В. М. Лохин, С. В. Манько,
И. П. Романов / под ред. И. М. Макарова. - М.: Наука, 2006. -
333 с.
23. INFOSECResearch Council Hard Problems List. [Электронный ре-
сурс]. - Режим доступа: http://www.infosec-reseach.org/
ocs_public/2005/1130-IRC-HPL-FINAL.pdf.
24. Бородакий Ю. В. Интеллектуальные системы обеспечения ин-
формационной безопасности: материалы конф. /VII Междунар.
науч.-практич. конф. «Информационная безопасность», Таганрог:
ТРТУ. - 2005. - № 4(48). - С. 65-69.
25. Гриняев С Н. Интеллектуальное противодействие информаци-
онному оружию / серия «Информационная Россия на пороге X11
века». - М.: СИНТЕГ, 1999. - 232 с.
162
Список литературы
26. Нестерук Ф. Г. Основы организации адаптивных систем защиты
информации: учеб. пособие / Ф. Г. Нестерук, Г. Ф. Нестерук,
Л. Г. Осовецкий. - СПб.: СПбГУ ИТМО, 2008.- 112 с. [Элек-
тронный ресурс]. - Режим доступа : http: // window.edu.ru/
window_ catalogt?p_ id=57893.
27. Васильев В. И. Применение нейронных сетей при обнаружении
атак на компьютеры в сети Интернет (на примере атаки
SY N FLOOD) / В. И. Васильев, А. Ф. Хафизов // Нейрокомпьюте-
ры: разработка, применение // Радиотехника. - 2001. - № 4 - 5.
-С. 108-114.
28. Васильев В. И, Интеллектуальная многоагентная система обна-
ружения атак / В. И. Васильев, К. В. Сафронов: материалы конф. /
V междунар. конф. «Проблемы управления и моделирования в
сложных системах», Самара, 17-21 июня 2003 г. - Самара: СНЦ
РАН, 2003. - С.354- 360.
29. Васильев В. И. Нейросетевые системы обнаружения атак на
WWW-сервер / В. И. Васильев, А. Ф. Хафизов // Вестник УГАТУ. -
2005. - б т. - № 1(12). - С. 116-120.
30. Машкина И. В. Система поддержки принятия решений по управ-
лению защитой информации / И. В. Машкина, В. И. Васильев,
Е. А. Рахимов // Безопасность информационных технологий. -
2006.-№2.-С. 62-67.
31. Машкина И. В. Проектирование системы защиты информации
объекта информатизации / И. В. Машкина, В. И. Васильев,
Е. А. Рахимов // Информационные технологии. - 2006. - № 10. -
С. 17-26.
32. Васильев В. И. Комплексный подход к построению интеллекту-
альной системы обнаружения атак / В. И. Васильев, Т. Р. Кашаев,
Л. А. Свечников // Системы управления и информационные тех-
нологии. - 2007. - № 2. - С. 76-81.
33. Машкина И. В. Концепция построения модели угроз в информа-
ционной среде объекта информатизации / И. В. Машкина,
В. И. Васильев, Е. А. Рахимов // Информационные технологии. -
2007.-№2.-С. 24-32.
163
Список литературы
34. Машкина И. В. Подход к разработке интеллектуальной системы
защиты информации / И. В. Машкина, В. И. Васильев // Инфор-
мационные технологии. - 2007. - № 6. - С. 2-6.
35. Dasgupta D. Computational Intelligence in Cyber Security, 2007. -
135 p. [Электронный ресурс]. - Режим доступа: http://ewh.ieee.
о rg/c mte/c i s/mtsc/i eeec i s/tu to r i al2007_Dasgupta_2007.pdf.
36. Hentea M. Intelligent System for Information Security Management:
Architecture and Design Issues // Issues in Information Science and
Information Technology. - V. 4. - 2007. - P. 29-43. [Электронный
ресурс]. - Режим доступа: http://procerdings. infor-
mingscience.org/lnSITE2007/IISITv4p029-043.Hent.387.pdf.
37. Машкина И. В. Управление защитой информации в сегменте
корпоративной информационной системы с применением интел-
лектуальных технологий: дис. ... докт. техн. наук: 05.13.19. -
Уфа, 2009.
38. Вакуленко А. Биометрические методы идентификации личности:
обоснованный выбор и внедрение /А. Вакуленко, А. Юхин //PC
Week/RE. - 2005. - № 29. - С. 15-16, 31.
39. Болл P.M. Руководство по биометрии/ Р. М. Болл, Дж. X. Кон-
нел, Ш. Панкантин Н. К. Ратха, Э. У. Сеньор: пер. с англ. - М.:
Техносфера, 2007. - 368 с.
40. Биометрические технологии /Электронная энциклопедия «Вики-
педия» [Электронный ресурс]. - Режим доступа:
http://ru.w ikipedia.org.
41. Задорожный В. Обзор биометрических технологий [Электрон-
ный ресурс]. - Режим доступа: http://www.bre.ru/security/
20234.html.
42. Современные биометрические системы безопасности [Элек-
тронный ресурс]. - Режим доступа: http://www /npo_inform.com
/press/sovrbio.
43. Система гражданской идентификации [Электронный ресурс]. -
Режим доступа: http://www /civilJdentification.info/mnenie_ zachi-
ta _dostupa.htm.
44. Умашев О. С. Реализация концепции многофакторной биометри-
ческой идентификации: материалы конф. /VI Междунар. биомет-
рическая конф. BIOMETRICS AIA 2007 LEGS «Паспортные и
правоохранительные системы 2007 [Электронный ресурс]. - Ре-
Список литературы
жим доступа: http://www.dancom.ru/rus/AIA/ Archive/RUVI
_Вiolink Solutions_M ultimodal Biometric Concept_ Short, doc.
45. Томашевич H. С. Обзор методов биометрической идентификации
личности по лицу // Нейрокомпьютеры: разработка, применение.
-2006.-№8-9.-С. 40-80.
46. Аралбаев Т. 3. Контроль и управление доступом в АСУ ТП на
основе биометрических характеристик пользователей /
Т. 3. Аралбаев, А. Г. Африн. - Уфа: Гилем, 2008. - 124 с.
47. Тельных, А. Идентификация личности. Как это делается? /
А. Тельных, А. Коган // Компьютерра. - 2009. - № 10 [Электрон-
ный ресурс]. - Режим доступа: http://offline.computerra.ru/
1999/288/2484.
48. Леонова А. Е. Распознавание образов // Системный анализ и при-
нятие решений: словарь-справочник: учеб. пособие для вузов /
под ред. В. Н. Волковой, В. Н. Козлова. - М.: Высшая школа,
2004. - С. 399-404.
49. Брюхомицкий Ю. А. Параметрическое обучение биометрических
систем контроля доступа / Ю. А. Брюхомицкий, М. Н. Казарин //
Вестник компьютерных и информационных технологий. - 2006. -
№2(20).-С.б-13.
50. Иванов А. И. Нейросетевые алгоритмы биометрической иденти-
фикации личности. - 15 кн. Сер. «Нейрокомпьютеры и их приме-
нение». - М.: Радиотехника, 2004. - 144 с.
51. Галушкин А. И. Нейрокомпьютеры в решении задач обеспечения
информационной безопасности // Нейрокомпьютеры: разработка,
применение. - 2005. - № 12. - С. 50-58.
52. Галушкин А. И. Биометрические системы идентификации лично-
сти: основные проблемы и тенденции разработок // Нейрокомпь-
ютеры: разработка, применение. - 2006. - № 8-9. - С. 6-11.
53. Брилюк Д. В. Распознавание человека по изображению лица ней-
росетевыми методами / Д. В. Брилюк, В. В. Старовойтов. -
Минск, 2002. - 54 с. [Электронный ресурс]. - Режим доступа:
http://neuroface.narod.ru/files/preprint_neuroface_part2.pdf.
165
Список литературы
54. Брюхомицкий Ю. А. Нейросетевые модели для систем информа-
ционной безопасности: учеб. пособие. - Таганрог: ТРТУ, 2005. -
160 с. [Электронный ресурс]. - Режим доступа:
http://window.edu.ru/window_catalog/pdf2txt7p_ id= 120498.
55. Фунтиков В. Основные преимущества высоконадежной, высоко-
интеллектуальной, анонимной биометрии тайных образов чело-
века / В. Фунтиков, А. Иванов, О. Ефимов // Современные тех-
нологии безопасности. - 2007. - № 4 [Электронный ресурс]. -
Режим доступа: http://daily.sec.ru/dailypblprnver.cfm? pid= 20715.
Бабенко Л. К. Перспективы развития биометрической крипто-
графии / Л. К. Бабенко, О. Б. Макаревич, Е. П. Тумоян: материа-
лы конф. /VII международ, научно-техн. конф. «Информацион-
ная безопасность»: Таганрог: ТРТУ, 2005. - № 4(48). -С. 191-199.
57. Брюхомицкий Ю. А. Оценка возможностей нейросетевой реализа-
ции биометрической криптосистемы [Электронный ресурс]. -
Режим доступа: http://www.contrteror.tsure.ru/site/ magazine 8/04-
11-Bruhomickiy/htm.
58. ГОСТ Р 52633-2006 «Защита информации. Техника защиты ин-
формации. Требования к средствам высоконадежной биометри-
ческой аутентификации» [Электронный ресурс]. - Режим досту-
па: http://faculty.ifmo.ru/csd/files/52633-2006.pdf.
59. Busch С. Biometrics and Security / NISNet - Winter School FINSE,
April 27, 2010. [Электронный ресурс]. - Режим доступа:
http://www.nisnet, no/filer/Finse 10/Biometrics_and_ Security^
Busch:pdf.
60. Cavoukian A.f Stoianov, A. Biometric Encryption Chapter from the
Encyclopedia of Biometrics [Электронный ресурс]. - Режим досту-
па: http:// www.ipc.on.ca/images/Resours/bio-encrypt-chp.pdf.
61. Куликова О. В. Биометрические криптографические системы и
их применение [Электронный ресурс]. - Режим доступа:
http://www. pvti.ru/ data/file/bit/bit_3_2009_10.pdf.
62. Busch С. ISO 24745 - Biometric Template Protection [Электронный
ресурс]. - Режим доступа: http://biometrics.nist.gov/cs_links/
ibpc2010/work||/ 4buschBJBPC-ISO24745-100305-2p.pdf.
166
Список литературы
63. DodisE., Ostrovsky R., Reyzin L. Fuzzy Extractors: How to Gener-
ate Strong Keys from Biometrics and Other Noisy Data //SI AM Jour-
nal on Computing, 38(1), Jan., 2008. - P.97-139 [Электронный ре-
сурс]. - Режим доступа: http://www.iacr.org/archive/ euro-
cry pt2004/30270518/D R S-ec2004-fi nal .pdf.
64. Shokrollahi J. Review of Fuzzy Extractors and Their Applications,
Goetingen, Sept. 2007 [Электронный ресурс]. - Режим доступа:
http://stohastic.math.uni-goetingen.de/biometrics2007/talks/ shokrol-
lahi.pdf.
65. Viet Triem long, V., Sibert ,H., Lecceur, J., Girault, M. Biometric
Fuzzy Extractors Made Practical: a Proposal Based on FingerCodes
[Электронный ресурс]. - Режим доступа: http://hal.archives-
ouvertes.fr/does/00/17/53/53/PDF/fuzzy_icb07_final.pdf.
66. F. Hernandez Alvarez, L. Hernandez Encinas and С Sanchez Avila.
Biometric Fuzzy Extractor Scheme for Iris Templates [Электронный
ресурс]. - Режим доступа:Ьйр:/^1д11а1.С515/е5/Ы151теат/
10261/15966/1/SA M3262.pdf.
67. Васильев, В. Состояние компьютерных угроз //PC Week/RE. -
2009.-№20.-С.16-17.
68. Корниенко А. А. Системы и методы обнаружения вторжений: со-
временное состояние и направления совершенствования /
А. А. Корниенко, И. М. Слюсаренко [Электронный ресурс]. - Ре-
жим доступа: http://www.citforum.ru/security/internet/ids_ over -
view/
69. Пржегорлинский В, К Характеристики защищенности от сете-
вых атак / В. Н. Пржегорлинский, В. В. Кратенко, В. А. Гончаров
// Information Security/Информационная безопасность. - 2005.
-№1.- С. 26-27.
70. Зегжда Д. П. Общая архитектура систем обнаружения вторже-
ний /Д. П. Зегжда, А. И. Бовт [Электронный ресурс]. - Режим
дocтyпa:http://www.ssl.stu.neva.ru/ssl/publications/magazine/2001/
4/4/ zegzhda.pdf.
71. Технологии обнаружения сетевых атак [Электронный ресурс]. -
Режим доступа: http://www.bstu.by/M)po/ru/uni/bstu/science/ ids/
167
Список литературы
72. Власов А. И. Нейросетевые методы и средства обнаружения атак
на сетевом уровне / А. И. Власов, С. В. Колосков, А. Е. Пакилев:
материалы конф.- Ч. 1. /V111 Международ, научно-технич. конф.
«Нейроинформатика». - М.: МИФИ, 2000. - С. 30-32.
73. Лиховидов В. Н. Нейроподобные адаптивные алгоритмы обнару-
жения атак в компьютерных сетях / В. Н. Лиховидов, П. Н.
Корнюшин: материалы конф. /VII Международ, научно-практич.
конф. «Информационная безопасность». - Таганрог: ТРТУ. -
2005.-№4(48).-С. 82-87.
74. Хафизов А. Ф. Нейросетевая система обнаружения атак на WWW-
сервер: дис. ... канд. техн. наук: 05.13.11.- Уфа, 2004. - 172 с.
75. Абрамов Е. С Разработка и исследование методов построения
систем обнаружения атак: дис. ... канд. техн. наук: 05.13.19. - Та-
ганрог, 2005. - 142 с.
76. Костин А. А. Модель и методика проектирования адаптивной
системы обнаружения компьютерных атак с использованием
нейросетевых средств: дис. ... канд. техн. наук: 05.13.19. - СПб.,
2006. - 108 с.
77. Слеповичев К К Обнаружение DDoS атак нечеткой нейронной
сетью / И. И. Слеповичев, П. В. Ирматов, М. С. Комарова, А. А.
Бежин // Известия Саратовского университета: серия «Математи-
ка. Механика. Информатика». - Т. 9. - 2009. - Вып. 3. - С. 84-89.
78. Нестерук Л. Г. Анализ нейросетевой элементной базы для по-
строения систем защиты информации / Л. Г. Нестерук,
Г. Ф. Нестерук, А. А. Молдовян // Вопросы защиты информации.
- 2007.-№1.-с. 32-38.
79. KDD Сир 1999 [HTVL] [Электронный ресурс]. - Режим доступа:
http://kdd.ics.edu/databases/kddcup99/kddcup99.html.
80. Ajiht A. Johnson, Th. Distributed Intrusion Detection System: Com-
putational Intelligence Approach [Электронный ресурс]. - Режим
доступа: http://www.softcomputing.net/hussein_chapter.pdf.
81. Беляев А. В. Современное состояние проблем обнаружения втор-
жений / А. В. Беляев, С. А. Петренко, А. В. Обухов // Защита ин-
формации, INSIDE. - 2009. - № 4. - С. 21-31.
82. Скакун С. В. Нейросетевая модель пользователей компьютерных
систем / С. В. Скакун, Н. Н. Куссуль // Кибернетика и вычисли-
тельная техника. - 2004. - Вып. 143. - С. 55-68.
168
Список литературы
83. Скакун С В. Математическое моделирование поведения пользо-
вателей компьютерных систем // Математичн1 машини i системи.
- 2005. - № 2. - С. 122-129 [Электронный ресурс]. - Режим дос-
тупа: http://www.immsp.kiev.ua/publications/articles/2005 /2005_2/
Skakun_02_2005.pdf.
84. Райх В. В. Макет системы выявления атак на основе обнаружения
аномалий сетевого трафика /В. В. Райх, И. Н. Синица,
С. М. Шарашкин [Электронный ресурс]. - Режим доступа:
http://lvk.cs. msu.su/files/mco2005/raih.pdf.
85. Корнеев, В. В. Интегрированные системы обнаружения атак /
В. В. Корнеев, В. В. Райх // Наукоемкие технологии. - 2006. - 7
т.-№11-12.-С. 62-73.
86. Tarakanov А. О. Immunocomputing : principles and applications/
A.O. Tarakanov, V.A. Skormin, S.P. Sokolova, Springer Verlag, New
York, 2003.
87. Яремчук С. Иммунная система для компьютера // Системный ад-
министратор. - 2004. - Вып. 11. - ноябрь. - С. 48-51 [Электрон-
ный ресурс]. - Режим доступа: http://av5/journals-magazines-
online/1/47/464.
88. Гвозденко А. Искусственные иммунные системы как средство се-
тевой самозащиты [Электронный ресурс]. - Режим доступа:
http://itc.ua/node/4270/
89. Анкудинов П. В. Искусственные иммунные системы - взгляд в
будущее / П. В. Анкудинов, В. П. Просихин, В. А. Яковлев // За-
щита информации. INSIDE. - 2005. - № 3. - С. 56-59.
90. Станкевич Л. А. Иммунологические системы: модели и приме-
нение: материалы конф. /IX Всеросс. научно-технич. конф. «Ней-
роинформатика - 2007». - М.: МИФИ, 2007. - С.98-105.
91. Tarakanov А. О. Immunocomputing for Intelligent Intrusion Detec-
tion// IEEE Computational Intelligence Magazine. - Vol. 3. - №2. -
2008.-P. 22-30.
92. Гладыш С В. Иммунокомпьютинг в управлении инцидентами
информационной безопасности // Штучный интеллект. - 2008. -
№ 1. - С. 123-130. [Электронный ресурс]. - Режим доступа:
http://www.nbuv.gov.ua/Portal/natural/ll/2008_l/JournalAI_2008_l/
Razdel3/00_G ladysh.pdf.
169
Список литературы
93. Корелов С. В. Обнаружение аномального поведения процесса на
основе системы вызовов/ С. В. Корелов, А. С. Пуртов,
Л. Ю. Ротков: материалы конф. /Научная конф. по радиофизике.
НГУ, 2006 [Электронный ресурс]. - Режим доступа: http://www.rf.
unn.ru/rus /sci/ books/06/doc/lll nfSys06.doc.
94. Kotov V. D., Vasilyev, V. I. Artificial Immune Systems Based Intru-
sion Detection System // Proceedings of the Second International Con-
ference on Security of Information and Networks (SIN'09), October
6-10, 2009. Famagusta, North Cyprus. - P. 207-212.
95. Катаев Т. P. Алгоритмы активного аудита информационной сис-
темы на основе технологии искусственных иммунных систем:
дис.... канд. техн. наук: 05.13.19. - Уфа, 2008. - 131 с.
96. Обухов А. В. Метод иммунного ответа на вторжения / А. В. Обу-
хов, С. А. Петренко, А. В. Беляев // Защита информации. INSIDE.
-2009.-№4.-С. 44-54.
97. Камалян А. Н. Интерактивный учебник «Компьютерные сети».
Лекция 4 - «Компьютерные преступления и средства защиты ин-
формации»/ А. Н. Камалян, К. Н. Назаренко, С. В. Ломакин,
С. М. Кусмагамбетов [Электронный ресурс]. - Режим доступа:
http://w ww. iomas.vsau.ru/uch_proz/ei/txt/internet/start/htm.
98. Гриняев С. О новом подходе к организации защиты от компью-
терных вирусов // Компьютерра. - 2002. - № 5 [Электронный ре-
сурс]. - Режим доступа: http://offline.computerra.ru/2002/430/
15920.
99. Петренко С. А. Управление информационными рисками. Эко-
номически оправданная безопасность / С. А. Петренко,
С. В. Симонов. - М.: ДМК Пресс, 2005. - 384 с.
100. Васильев В. И. Анализ и управление информационной безопас-
ностью вуза на основе когнитивного моделирования / В. И. Ва-
сильев, Р. Т. Кудрявцева // Системы управления и информаци-
онные технологии. - 2007. - № 1(27). - С. 74-81.
101. Гузаиров М. Б. Системный анализ информационных рисков с
применением нечетких когнитивных карт / М. Б. Гузаиров,
В. И. Васильев, Р. Т. Кудрявцева // Информационные техноло-
гии. - 5 т. - 2007. - № 4. - С. 42-48.
170
Список литературы
102. Кудрявцева Р. Т. Управление информационными рисками с ис-
пользованием технологий когнитивного моделирования (на
примере высшего учебного заведения): дис. ... канд. техн. наук:
05.13.19. - Уфа, 2008. - 142 с.
103. Свечников Л. А. Интеллектуальная система обнаружения атак на
основе имитационного моделирования с использованием нечет-
ких когнитивных карт: дис. ... канд. техн. наук: 05.13.19. - Уфа,
2010. - 127 с.
104. Максимов В. И. Когнитивные технологии для поддержки приня-
тия управленческих решений / В. И. Максимов, Е. К. Корно-
ушенко, С. В. Качаев // Технологии информационного общества-
98. - М.: ИЛУ РАН, 1999. - С. 11- 18.
105. Борисов В. В. Нечеткие модели и сети / В. В. Борисов,
В. В. Круглое, А. С. Федулов. - М.: Горячая Линия-Телеком,
2007. - 284 с.
171
УДК 681.5:004(07)
ББК 32.81:32.97я7
В19
Рецензенты:
кафедра программирования и вычислительной техники
(Башкирский государственный педагогический университет им. М. Акмуллы)
зав, кафедрой, д-р физ.-мат. наук профессор Р. М. Асадуллин;
д-р техн. наук, профессор Валеев С.С.,
д-р техн. наук, профессор Мельников А.В.
Васильев В* И.
В19 Интеллектуальные системы защиты информации: учеб. пособие/
В. И. Васильев. 2-е изд., испр. и доп. - М: Машиностроение,
2013.-172 с.
ISBN 978-5-94275-667-3
Рассмотрены основы построения интеллектуальных сис-
тем защиты информации в корпоративных информационных
системах. Особое внимание уделено построению биометриче-
ских систем идентификации личности, систем обнаружения и
предотвращения вторжений, анализа и управления информаци-
онными рисками. Изложены современные подходы к созданию
данного класса систем с использованием методов теории ней-
ронных сетей, искусственных иммунных систем, нечетких ког-
нитивных моделей.
Предназначено для студентов высших учебных заведений,
обучающихся по специализациям специальности «Комплекс-
ное обеспечение информационной безопасности автоматизиро-
ванных систем».
УДК 681.5:004(07)
ББК 32.81:32.97я7
ISBN 978-5-94275-667-3 ©Издательство «Машиностроение», 2013
©ВасильевВ. И.,2013
Учебное издание
ВАСИЛЬЕВ Владимир Иванович
ИНТЕЛЛЕКТУАЛЬНЫЕ СИСТЕМЫ
ЗАЩИТЫ ИНФОРМАЦИИ
Редактор ОЛ Соколова
Дизайнер Н.А. Свиридова
Корректор М.Я. Барская
Подписано к печати 03.12.2012. Формат 60x88 1/16.
Бумага офсетная. Гарнитура Times New Roman Суг.
Усл. печ. л. 10,53. Уч.-изд. л. 10,6.
ООО «Издательство «Машиностроение»,
107076, Москва, Стромынский пер., 4
www.mashin.ru
Отпечатано в ООО «Белый ветер»
115407, Москва, Нагатинская наб., 54, пом. 4.